KR20160046914A - 신규한 sez6 조절물질 및 사용방법 - Google Patents
신규한 sez6 조절물질 및 사용방법 Download PDFInfo
- Publication number
- KR20160046914A KR20160046914A KR1020167008239A KR20167008239A KR20160046914A KR 20160046914 A KR20160046914 A KR 20160046914A KR 1020167008239 A KR1020167008239 A KR 1020167008239A KR 20167008239 A KR20167008239 A KR 20167008239A KR 20160046914 A KR20160046914 A KR 20160046914A
- Authority
- KR
- South Korea
- Prior art keywords
- antibody
- sez6
- seq
- epitope
- residues
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 175
- 206010028980 Neoplasm Diseases 0.000 claims description 240
- 230000001225 therapeutic effect Effects 0.000 claims description 95
- 239000003795 chemical substances by application Substances 0.000 claims description 54
- 239000000611 antibody drug conjugate Substances 0.000 claims description 42
- 229940049595 antibody-drug conjugate Drugs 0.000 claims description 42
- 208000000587 small cell lung carcinoma Diseases 0.000 claims description 34
- 239000000562 conjugate Substances 0.000 claims description 33
- 238000000338 in vitro Methods 0.000 claims description 33
- 206010041067 Small cell lung cancer Diseases 0.000 claims description 32
- BASFCYQUMIYNBI-UHFFFAOYSA-N platinum Chemical compound [Pt] BASFCYQUMIYNBI-UHFFFAOYSA-N 0.000 claims description 32
- 125000000539 amino acid group Chemical group 0.000 claims description 25
- YUOCYTRGANSSRY-UHFFFAOYSA-N pyrrolo[2,3-i][1,2]benzodiazepine Chemical compound C1=CN=NC2=C3C=CN=C3C=CC2=C1 YUOCYTRGANSSRY-UHFFFAOYSA-N 0.000 claims description 24
- 208000024770 Thyroid neoplasm Diseases 0.000 claims description 19
- 229910052697 platinum Inorganic materials 0.000 claims description 16
- 238000003364 immunohistochemistry Methods 0.000 claims description 13
- 201000002510 thyroid cancer Diseases 0.000 claims description 12
- 108010044540 auristatin Proteins 0.000 claims description 10
- 210000001685 thyroid gland Anatomy 0.000 claims description 8
- 208000033781 Thyroid carcinoma Diseases 0.000 claims description 6
- 208000013077 thyroid gland carcinoma Diseases 0.000 claims description 6
- 208000020816 lung neoplasm Diseases 0.000 claims description 5
- 206010058467 Lung neoplasm malignant Diseases 0.000 claims description 2
- 101000864751 Homo sapiens Seizure protein 6 homolog Proteins 0.000 claims 8
- 102100030057 Seizure protein 6 homolog Human genes 0.000 claims 8
- 201000005202 lung cancer Diseases 0.000 claims 1
- 230000002062 proliferating effect Effects 0.000 abstract description 24
- 210000004027 cell Anatomy 0.000 description 248
- 108090000623 proteins and genes Proteins 0.000 description 149
- 230000027455 binding Effects 0.000 description 115
- 102000004169 proteins and genes Human genes 0.000 description 115
- 125000005647 linker group Chemical group 0.000 description 114
- 235000018102 proteins Nutrition 0.000 description 107
- 239000000126 substance Substances 0.000 description 102
- 230000001105 regulatory effect Effects 0.000 description 93
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 71
- 239000012634 fragment Substances 0.000 description 68
- 241000282414 Homo sapiens Species 0.000 description 67
- 206010057190 Respiratory tract infections Diseases 0.000 description 67
- 239000000427 antigen Substances 0.000 description 67
- 108091007433 antigens Proteins 0.000 description 67
- 102000036639 antigens Human genes 0.000 description 67
- 108090000765 processed proteins & peptides Proteins 0.000 description 65
- 208000035475 disorder Diseases 0.000 description 63
- 230000014509 gene expression Effects 0.000 description 62
- 125000003275 alpha amino acid group Chemical group 0.000 description 61
- 235000001014 amino acid Nutrition 0.000 description 59
- 201000011510 cancer Diseases 0.000 description 59
- 150000007523 nucleic acids Chemical group 0.000 description 57
- 229940024606 amino acid Drugs 0.000 description 54
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 53
- -1 Lgr6 Proteins 0.000 description 53
- 239000003814 drug Substances 0.000 description 53
- 150000001413 amino acids Chemical class 0.000 description 51
- 150000001875 compounds Chemical class 0.000 description 51
- 102000004196 processed proteins & peptides Human genes 0.000 description 50
- 239000002246 antineoplastic agent Substances 0.000 description 49
- 102000039446 nucleic acids Human genes 0.000 description 47
- 108020004707 nucleic acids Proteins 0.000 description 47
- 238000011282 treatment Methods 0.000 description 46
- 210000005102 tumor initiating cell Anatomy 0.000 description 45
- 229940079593 drug Drugs 0.000 description 42
- 229940127089 cytotoxic agent Drugs 0.000 description 39
- 238000001727 in vivo Methods 0.000 description 39
- 239000000463 material Substances 0.000 description 39
- 239000000203 mixture Substances 0.000 description 39
- 229920001184 polypeptide Polymers 0.000 description 39
- 239000011230 binding agent Substances 0.000 description 38
- 239000000523 sample Substances 0.000 description 36
- 108010029485 Protein Isoforms Proteins 0.000 description 35
- 102000001708 Protein Isoforms Human genes 0.000 description 35
- 125000001424 substituent group Chemical group 0.000 description 34
- 210000000130 stem cell Anatomy 0.000 description 32
- 230000000694 effects Effects 0.000 description 31
- 210000004881 tumor cell Anatomy 0.000 description 29
- 108020004414 DNA Proteins 0.000 description 28
- 150000001720 carbohydrates Chemical class 0.000 description 28
- 238000003556 assay Methods 0.000 description 27
- 102000004190 Enzymes Human genes 0.000 description 25
- 108090000790 Enzymes Proteins 0.000 description 25
- 238000004458 analytical method Methods 0.000 description 25
- 125000003118 aryl group Chemical group 0.000 description 25
- 231100000599 cytotoxic agent Toxicity 0.000 description 25
- 229940088598 enzyme Drugs 0.000 description 25
- 101000777370 Homo sapiens Coiled-coil domain-containing protein 6 Proteins 0.000 description 24
- 239000002254 cytotoxic agent Substances 0.000 description 24
- 229920006344 thermoplastic copolyester Polymers 0.000 description 24
- 210000001519 tissue Anatomy 0.000 description 24
- 231100000588 tumorigenic Toxicity 0.000 description 24
- 230000000381 tumorigenic effect Effects 0.000 description 24
- 238000012360 testing method Methods 0.000 description 23
- 125000005843 halogen group Chemical group 0.000 description 22
- 238000004519 manufacturing process Methods 0.000 description 22
- 125000000217 alkyl group Chemical group 0.000 description 21
- 230000001965 increasing effect Effects 0.000 description 20
- 108010016626 Dipeptides Proteins 0.000 description 19
- 206010027476 Metastases Diseases 0.000 description 19
- 125000003277 amino group Chemical group 0.000 description 19
- 230000009401 metastasis Effects 0.000 description 19
- 108060003951 Immunoglobulin Proteins 0.000 description 18
- 238000012217 deletion Methods 0.000 description 18
- 230000037430 deletion Effects 0.000 description 18
- 125000000524 functional group Chemical group 0.000 description 18
- 230000012010 growth Effects 0.000 description 18
- 102000018358 immunoglobulin Human genes 0.000 description 18
- 230000037396 body weight Effects 0.000 description 16
- 238000003745 diagnosis Methods 0.000 description 16
- 201000011519 neuroendocrine tumor Diseases 0.000 description 16
- 102000007399 Nuclear hormone receptor Human genes 0.000 description 15
- 108020005497 Nuclear hormone receptor Proteins 0.000 description 15
- 230000006870 function Effects 0.000 description 15
- 238000009396 hybridization Methods 0.000 description 15
- 238000002560 therapeutic procedure Methods 0.000 description 15
- UHOVQNZJYSORNB-UHFFFAOYSA-N Benzene Chemical compound C1=CC=CC=C1 UHOVQNZJYSORNB-UHFFFAOYSA-N 0.000 description 14
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 14
- 241001465754 Metazoa Species 0.000 description 14
- 230000000875 corresponding effect Effects 0.000 description 14
- 238000000684 flow cytometry Methods 0.000 description 14
- 230000035772 mutation Effects 0.000 description 14
- 230000001613 neoplastic effect Effects 0.000 description 14
- 210000002569 neuron Anatomy 0.000 description 14
- 230000009467 reduction Effects 0.000 description 14
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 13
- 241000699670 Mus sp. Species 0.000 description 13
- 239000005557 antagonist Substances 0.000 description 13
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 13
- 238000010790 dilution Methods 0.000 description 13
- 239000012895 dilution Substances 0.000 description 13
- 230000003993 interaction Effects 0.000 description 13
- 239000003446 ligand Substances 0.000 description 13
- 108020004999 messenger RNA Proteins 0.000 description 13
- 230000002829 reductive effect Effects 0.000 description 13
- 238000006467 substitution reaction Methods 0.000 description 13
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 description 12
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 12
- 241001529936 Murinae Species 0.000 description 12
- 241000699666 Mus <mouse, genus> Species 0.000 description 12
- 108091079223 SEZ6 family Proteins 0.000 description 12
- 102000041855 SEZ6 family Human genes 0.000 description 12
- 125000002947 alkylene group Chemical group 0.000 description 12
- 238000002648 combination therapy Methods 0.000 description 12
- 238000009472 formulation Methods 0.000 description 12
- 125000005842 heteroatom Chemical group 0.000 description 12
- 230000000955 neuroendocrine Effects 0.000 description 12
- 102000005962 receptors Human genes 0.000 description 12
- 108020003175 receptors Proteins 0.000 description 12
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 11
- 239000004472 Lysine Substances 0.000 description 11
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 11
- 230000004069 differentiation Effects 0.000 description 11
- 230000013595 glycosylation Effects 0.000 description 11
- 238000006206 glycosylation reaction Methods 0.000 description 11
- 210000004408 hybridoma Anatomy 0.000 description 11
- 230000002163 immunogen Effects 0.000 description 11
- 230000000670 limiting effect Effects 0.000 description 11
- 229960003646 lysine Drugs 0.000 description 11
- 231100001221 nontumorigenic Toxicity 0.000 description 11
- 238000001959 radiotherapy Methods 0.000 description 11
- 241000894007 species Species 0.000 description 11
- 239000000758 substrate Substances 0.000 description 11
- 206010010904 Convulsion Diseases 0.000 description 10
- RYGMFSIKBFXOCR-UHFFFAOYSA-N Copper Chemical compound [Cu] RYGMFSIKBFXOCR-UHFFFAOYSA-N 0.000 description 10
- 101100477420 Homo sapiens SEZ6 gene Proteins 0.000 description 10
- JUJWROOIHBZHMG-UHFFFAOYSA-N Pyridine Chemical compound C1=CC=NC=C1 JUJWROOIHBZHMG-UHFFFAOYSA-N 0.000 description 10
- 230000009471 action Effects 0.000 description 10
- 230000001413 cellular effect Effects 0.000 description 10
- 238000006243 chemical reaction Methods 0.000 description 10
- 239000003153 chemical reaction reagent Substances 0.000 description 10
- 230000007423 decrease Effects 0.000 description 10
- 238000001514 detection method Methods 0.000 description 10
- 238000010494 dissociation reaction Methods 0.000 description 10
- 230000005593 dissociations Effects 0.000 description 10
- 208000005017 glioblastoma Diseases 0.000 description 10
- 230000001976 improved effect Effects 0.000 description 10
- 239000003112 inhibitor Substances 0.000 description 10
- 230000004048 modification Effects 0.000 description 10
- 238000012986 modification Methods 0.000 description 10
- 230000002285 radioactive effect Effects 0.000 description 10
- 150000003384 small molecules Chemical class 0.000 description 10
- 239000013598 vector Substances 0.000 description 10
- 239000002253 acid Substances 0.000 description 9
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 9
- 238000003776 cleavage reaction Methods 0.000 description 9
- 230000021615 conjugation Effects 0.000 description 9
- 125000000623 heterocyclic group Chemical group 0.000 description 9
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 9
- 239000003550 marker Substances 0.000 description 9
- 239000003607 modifier Substances 0.000 description 9
- 238000012544 monitoring process Methods 0.000 description 9
- 230000003472 neutralizing effect Effects 0.000 description 9
- 229910052760 oxygen Inorganic materials 0.000 description 9
- 230000037361 pathway Effects 0.000 description 9
- 229920001223 polyethylene glycol Polymers 0.000 description 9
- 125000006239 protecting group Chemical group 0.000 description 9
- 229910052717 sulfur Inorganic materials 0.000 description 9
- 238000002054 transplantation Methods 0.000 description 9
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 8
- 239000002671 adjuvant Substances 0.000 description 8
- 125000006297 carbonyl amino group Chemical group [H]N([*:2])C([*:1])=O 0.000 description 8
- 231100000433 cytotoxic Toxicity 0.000 description 8
- 230000001472 cytotoxic effect Effects 0.000 description 8
- 239000000539 dimer Substances 0.000 description 8
- 201000010099 disease Diseases 0.000 description 8
- 238000005516 engineering process Methods 0.000 description 8
- 239000013604 expression vector Substances 0.000 description 8
- 230000002401 inhibitory effect Effects 0.000 description 8
- 229910052757 nitrogen Inorganic materials 0.000 description 8
- 230000000269 nucleophilic effect Effects 0.000 description 8
- 238000002823 phage display Methods 0.000 description 8
- 229920000642 polymer Polymers 0.000 description 8
- 230000003439 radiotherapeutic effect Effects 0.000 description 8
- 230000007017 scission Effects 0.000 description 8
- 231100000765 toxin Toxicity 0.000 description 8
- 108010087819 Fc receptors Proteins 0.000 description 7
- 102000009109 Fc receptors Human genes 0.000 description 7
- 208000002091 Febrile Seizures Diseases 0.000 description 7
- 101000984015 Homo sapiens Cadherin-1 Proteins 0.000 description 7
- 102000035195 Peptidases Human genes 0.000 description 7
- 108091005804 Peptidases Proteins 0.000 description 7
- 238000007792 addition Methods 0.000 description 7
- 230000000692 anti-sense effect Effects 0.000 description 7
- 238000013459 approach Methods 0.000 description 7
- 230000008901 benefit Effects 0.000 description 7
- 230000004663 cell proliferation Effects 0.000 description 7
- 230000004540 complement-dependent cytotoxicity Effects 0.000 description 7
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 7
- 229960002433 cysteine Drugs 0.000 description 7
- 235000018417 cysteine Nutrition 0.000 description 7
- XMYQHJDBLRZMLW-UHFFFAOYSA-N methanolamine Chemical compound NCO XMYQHJDBLRZMLW-UHFFFAOYSA-N 0.000 description 7
- 239000000178 monomer Substances 0.000 description 7
- 238000011275 oncology therapy Methods 0.000 description 7
- 239000000546 pharmaceutical excipient Substances 0.000 description 7
- 125000001997 phenyl group Chemical group [H]C1=C([H])C([H])=C(*)C([H])=C1[H] 0.000 description 7
- 125000000843 phenylene group Chemical group C1(=C(C=CC=C1)*)* 0.000 description 7
- 230000002265 prevention Effects 0.000 description 7
- 230000035755 proliferation Effects 0.000 description 7
- 238000012216 screening Methods 0.000 description 7
- 210000002966 serum Anatomy 0.000 description 7
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 7
- 230000004083 survival effect Effects 0.000 description 7
- 125000003396 thiol group Chemical group [H]S* 0.000 description 7
- 239000003053 toxin Substances 0.000 description 7
- 108700012359 toxins Proteins 0.000 description 7
- 230000004614 tumor growth Effects 0.000 description 7
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical group N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 6
- KXDHJXZQYSOELW-UHFFFAOYSA-N Carbamic acid Chemical group NC(O)=O KXDHJXZQYSOELW-UHFFFAOYSA-N 0.000 description 6
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 6
- KDLHZDBZIXYQEI-UHFFFAOYSA-N Palladium Chemical compound [Pd] KDLHZDBZIXYQEI-UHFFFAOYSA-N 0.000 description 6
- 108020004459 Small interfering RNA Proteins 0.000 description 6
- 239000002585 base Substances 0.000 description 6
- 230000004071 biological effect Effects 0.000 description 6
- 230000015572 biosynthetic process Effects 0.000 description 6
- 210000004556 brain Anatomy 0.000 description 6
- 230000002860 competitive effect Effects 0.000 description 6
- 238000011161 development Methods 0.000 description 6
- 230000018109 developmental process Effects 0.000 description 6
- 230000004927 fusion Effects 0.000 description 6
- 108020001507 fusion proteins Proteins 0.000 description 6
- 102000037865 fusion proteins Human genes 0.000 description 6
- 229940027941 immunoglobulin g Drugs 0.000 description 6
- 230000003834 intracellular effect Effects 0.000 description 6
- 230000008774 maternal effect Effects 0.000 description 6
- 239000002773 nucleotide Substances 0.000 description 6
- 125000003729 nucleotide group Chemical group 0.000 description 6
- 230000008569 process Effects 0.000 description 6
- 230000019491 signal transduction Effects 0.000 description 6
- 239000000725 suspension Substances 0.000 description 6
- 238000003786 synthesis reaction Methods 0.000 description 6
- 229940124597 therapeutic agent Drugs 0.000 description 6
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 6
- 125000003088 (fluoren-9-ylmethoxy)carbonyl group Chemical group 0.000 description 5
- 102100032912 CD44 antigen Human genes 0.000 description 5
- 102000005600 Cathepsins Human genes 0.000 description 5
- 108010084457 Cathepsins Proteins 0.000 description 5
- 102000053602 DNA Human genes 0.000 description 5
- 241000282412 Homo Species 0.000 description 5
- 101000868273 Homo sapiens CD44 antigen Proteins 0.000 description 5
- 101000610551 Homo sapiens Prominin-1 Proteins 0.000 description 5
- 244000046052 Phaseolus vulgaris Species 0.000 description 5
- 235000010627 Phaseolus vulgaris Nutrition 0.000 description 5
- 102100040120 Prominin-1 Human genes 0.000 description 5
- 241000700159 Rattus Species 0.000 description 5
- 230000004913 activation Effects 0.000 description 5
- 125000002252 acyl group Chemical group 0.000 description 5
- 230000008512 biological response Effects 0.000 description 5
- 210000004899 c-terminal region Anatomy 0.000 description 5
- 239000000969 carrier Substances 0.000 description 5
- 230000024245 cell differentiation Effects 0.000 description 5
- 238000012512 characterization method Methods 0.000 description 5
- 229960004316 cisplatin Drugs 0.000 description 5
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 5
- 238000012875 competitive assay Methods 0.000 description 5
- 230000000295 complement effect Effects 0.000 description 5
- 239000002299 complementary DNA Substances 0.000 description 5
- 230000001268 conjugating effect Effects 0.000 description 5
- 230000001086 cytosolic effect Effects 0.000 description 5
- 230000008030 elimination Effects 0.000 description 5
- 238000003379 elimination reaction Methods 0.000 description 5
- 230000002255 enzymatic effect Effects 0.000 description 5
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 5
- 230000003053 immunization Effects 0.000 description 5
- 230000000977 initiatory effect Effects 0.000 description 5
- 230000002452 interceptive effect Effects 0.000 description 5
- 230000007246 mechanism Effects 0.000 description 5
- 230000001404 mediated effect Effects 0.000 description 5
- 206010061289 metastatic neoplasm Diseases 0.000 description 5
- 125000000956 methoxy group Chemical group [H]C([H])([H])O* 0.000 description 5
- 108091070501 miRNA Proteins 0.000 description 5
- 102000040430 polynucleotide Human genes 0.000 description 5
- 108091033319 polynucleotide Proteins 0.000 description 5
- 239000002157 polynucleotide Substances 0.000 description 5
- 238000002360 preparation method Methods 0.000 description 5
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 5
- UMJSCPRVCHMLSP-UHFFFAOYSA-N pyridine Natural products COC1=CC=CN=C1 UMJSCPRVCHMLSP-UHFFFAOYSA-N 0.000 description 5
- 230000004044 response Effects 0.000 description 5
- 150000003839 salts Chemical class 0.000 description 5
- 239000007787 solid Substances 0.000 description 5
- 239000000243 solution Substances 0.000 description 5
- 238000011285 therapeutic regimen Methods 0.000 description 5
- 150000003573 thiols Chemical class 0.000 description 5
- 230000009261 transgenic effect Effects 0.000 description 5
- OGWKCGZFUXNPDA-UHFFFAOYSA-N vincristine Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(OC(C)=O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-UHFFFAOYSA-N 0.000 description 5
- 229960004528 vincristine Drugs 0.000 description 5
- OGWKCGZFUXNPDA-XQKSVPLYSA-N vincristine Chemical compound C([N@]1C[C@@H](C[C@]2(C(=O)OC)C=3C(=CC4=C([C@]56[C@H]([C@@]([C@H](OC(C)=O)[C@]7(CC)C=CCN([C@H]67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)C[C@@](C1)(O)CC)CC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-XQKSVPLYSA-N 0.000 description 5
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 4
- 206010063836 Atrioventricular septal defect Diseases 0.000 description 4
- 108010092160 Dactinomycin Proteins 0.000 description 4
- 238000002965 ELISA Methods 0.000 description 4
- 241000196324 Embryophyta Species 0.000 description 4
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 4
- ZHNUHDYFZUAESO-UHFFFAOYSA-N Formamide Chemical compound NC=O ZHNUHDYFZUAESO-UHFFFAOYSA-N 0.000 description 4
- 108010015899 Glycopeptides Proteins 0.000 description 4
- 102000002068 Glycopeptides Human genes 0.000 description 4
- 102100031573 Hematopoietic progenitor cell antigen CD34 Human genes 0.000 description 4
- 101000777663 Homo sapiens Hematopoietic progenitor cell antigen CD34 Proteins 0.000 description 4
- 101000884271 Homo sapiens Signal transducer CD24 Proteins 0.000 description 4
- OAKJQQAXSVQMHS-UHFFFAOYSA-N Hydrazine Chemical compound NN OAKJQQAXSVQMHS-UHFFFAOYSA-N 0.000 description 4
- 102100026120 IgG receptor FcRn large subunit p51 Human genes 0.000 description 4
- 101710177940 IgG receptor FcRn large subunit p51 Proteins 0.000 description 4
- 108700005091 Immunoglobulin Genes Proteins 0.000 description 4
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 4
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 4
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 4
- PEEHTFAAVSWFBL-UHFFFAOYSA-N Maleimide Chemical compound O=C1NC(=O)C=C1 PEEHTFAAVSWFBL-UHFFFAOYSA-N 0.000 description 4
- 102100039373 Membrane cofactor protein Human genes 0.000 description 4
- 206010052399 Neuroendocrine tumour Diseases 0.000 description 4
- 108091028043 Nucleic acid sequence Proteins 0.000 description 4
- 206010061535 Ovarian neoplasm Diseases 0.000 description 4
- 206010035226 Plasma cell myeloma Diseases 0.000 description 4
- RJKFOVLPORLFTN-LEKSSAKUSA-N Progesterone Chemical compound C1CC2=CC(=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H](C(=O)C)[C@@]1(C)CC2 RJKFOVLPORLFTN-LEKSSAKUSA-N 0.000 description 4
- 239000004365 Protease Substances 0.000 description 4
- 206010039491 Sarcoma Diseases 0.000 description 4
- 102100038081 Signal transducer CD24 Human genes 0.000 description 4
- RJURFGZVJUQBHK-UHFFFAOYSA-N actinomycin D Natural products CC1OC(=O)C(C(C)C)N(C)C(=O)CN(C)C(=O)C2CCCN2C(=O)C(C(C)C)NC(=O)C1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)NC4C(=O)NC(C(N5CCCC5C(=O)N(C)CC(=O)N(C)C(C(C)C)C(=O)OC4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-UHFFFAOYSA-N 0.000 description 4
- 239000013543 active substance Substances 0.000 description 4
- 230000002776 aggregation Effects 0.000 description 4
- 150000001299 aldehydes Chemical class 0.000 description 4
- 125000003342 alkenyl group Chemical group 0.000 description 4
- 150000001412 amines Chemical class 0.000 description 4
- 230000001093 anti-cancer Effects 0.000 description 4
- 229940041181 antineoplastic drug Drugs 0.000 description 4
- 238000004364 calculation method Methods 0.000 description 4
- 230000032823 cell division Effects 0.000 description 4
- 230000008859 change Effects 0.000 description 4
- 239000010949 copper Substances 0.000 description 4
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 4
- 239000000824 cytostatic agent Substances 0.000 description 4
- 238000002405 diagnostic procedure Methods 0.000 description 4
- 238000009826 distribution Methods 0.000 description 4
- 238000012377 drug delivery Methods 0.000 description 4
- 239000012636 effector Substances 0.000 description 4
- 238000001211 electron capture detection Methods 0.000 description 4
- 230000002124 endocrine Effects 0.000 description 4
- 229910052731 fluorine Inorganic materials 0.000 description 4
- OVBPIULPVIDEAO-LBPRGKRZSA-N folic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-LBPRGKRZSA-N 0.000 description 4
- 125000002485 formyl group Chemical group [H]C(*)=O 0.000 description 4
- 230000030279 gene silencing Effects 0.000 description 4
- 229960002989 glutamic acid Drugs 0.000 description 4
- 235000013922 glutamic acid Nutrition 0.000 description 4
- 239000004220 glutamic acid Substances 0.000 description 4
- 206010073071 hepatocellular carcinoma Diseases 0.000 description 4
- 125000004404 heteroalkyl group Chemical group 0.000 description 4
- 229910052739 hydrogen Inorganic materials 0.000 description 4
- 230000028993 immune response Effects 0.000 description 4
- 238000003018 immunoassay Methods 0.000 description 4
- 229940127121 immunoconjugate Drugs 0.000 description 4
- 229940072221 immunoglobulins Drugs 0.000 description 4
- 230000006872 improvement Effects 0.000 description 4
- 230000005764 inhibitory process Effects 0.000 description 4
- 239000007924 injection Substances 0.000 description 4
- 238000002347 injection Methods 0.000 description 4
- UWKQSNNFCGGAFS-XIFFEERXSA-N irinotecan Chemical compound C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 UWKQSNNFCGGAFS-XIFFEERXSA-N 0.000 description 4
- 208000037841 lung tumor Diseases 0.000 description 4
- 238000012423 maintenance Methods 0.000 description 4
- 210000004962 mammalian cell Anatomy 0.000 description 4
- 238000005259 measurement Methods 0.000 description 4
- 239000002679 microRNA Substances 0.000 description 4
- 238000002493 microarray Methods 0.000 description 4
- 235000013336 milk Nutrition 0.000 description 4
- 239000008267 milk Substances 0.000 description 4
- 210000004080 milk Anatomy 0.000 description 4
- 230000009826 neoplastic cell growth Effects 0.000 description 4
- 230000001537 neural effect Effects 0.000 description 4
- 230000007472 neurodevelopment Effects 0.000 description 4
- 208000016065 neuroendocrine neoplasm Diseases 0.000 description 4
- 208000002154 non-small cell lung carcinoma Diseases 0.000 description 4
- 230000036961 partial effect Effects 0.000 description 4
- 239000008194 pharmaceutical composition Substances 0.000 description 4
- 239000012071 phase Substances 0.000 description 4
- 238000003752 polymerase chain reaction Methods 0.000 description 4
- 238000004393 prognosis Methods 0.000 description 4
- 238000000746 purification Methods 0.000 description 4
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical compound C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 description 4
- 230000011664 signaling Effects 0.000 description 4
- 230000009870 specific binding Effects 0.000 description 4
- 238000010561 standard procedure Methods 0.000 description 4
- ZSJLQEPLLKMAKR-GKHCUFPYSA-N streptozocin Chemical compound O=NN(C)C(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O ZSJLQEPLLKMAKR-GKHCUFPYSA-N 0.000 description 4
- 229960001052 streptozocin Drugs 0.000 description 4
- 238000001356 surgical procedure Methods 0.000 description 4
- 230000002195 synergetic effect Effects 0.000 description 4
- 208000013076 thyroid tumor Diseases 0.000 description 4
- WYWHKKSPHMUBEB-UHFFFAOYSA-N tioguanine Chemical compound N1C(N)=NC(=S)C2=C1N=CN2 WYWHKKSPHMUBEB-UHFFFAOYSA-N 0.000 description 4
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 description 4
- 229910052720 vanadium Inorganic materials 0.000 description 4
- 125000004400 (C1-C12) alkyl group Chemical group 0.000 description 3
- HIXDQWDOVZUNNA-UHFFFAOYSA-N 2-(3,4-dimethoxyphenyl)-5-hydroxy-7-methoxychromen-4-one Chemical compound C=1C(OC)=CC(O)=C(C(C=2)=O)C=1OC=2C1=CC=C(OC)C(OC)=C1 HIXDQWDOVZUNNA-UHFFFAOYSA-N 0.000 description 3
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 description 3
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 3
- KXDHJXZQYSOELW-UHFFFAOYSA-M Carbamate Chemical compound NC([O-])=O KXDHJXZQYSOELW-UHFFFAOYSA-M 0.000 description 3
- 102100025473 Carcinoembryonic antigen-related cell adhesion molecule 6 Human genes 0.000 description 3
- 208000005623 Carcinogenesis Diseases 0.000 description 3
- 208000005443 Circulating Neoplastic Cells Diseases 0.000 description 3
- 108091026890 Coding region Proteins 0.000 description 3
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 3
- 102000004127 Cytokines Human genes 0.000 description 3
- 108090000695 Cytokines Proteins 0.000 description 3
- 229930189413 Esperamicin Natural products 0.000 description 3
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 3
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 3
- 101000914326 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 6 Proteins 0.000 description 3
- 101000961414 Homo sapiens Membrane cofactor protein Proteins 0.000 description 3
- 101000685296 Homo sapiens Seizure 6-like protein Proteins 0.000 description 3
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 3
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 3
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 3
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 3
- 102100029185 Low affinity immunoglobulin gamma Fc region receptor III-B Human genes 0.000 description 3
- 102000018697 Membrane Proteins Human genes 0.000 description 3
- 108010052285 Membrane Proteins Proteins 0.000 description 3
- 229930192392 Mitomycin Natural products 0.000 description 3
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 3
- 108700026244 Open Reading Frames Proteins 0.000 description 3
- 206010060862 Prostate cancer Diseases 0.000 description 3
- 108010076504 Protein Sorting Signals Proteins 0.000 description 3
- 238000010240 RT-PCR analysis Methods 0.000 description 3
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 3
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 3
- 101000980463 Treponema pallidum (strain Nichols) Chaperonin GroEL Proteins 0.000 description 3
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 3
- JXLYSJRDGCGARV-WWYNWVTFSA-N Vinblastine Natural products O=C(O[C@H]1[C@](O)(C(=O)OC)[C@@H]2N(C)c3c(cc(c(OC)c3)[C@]3(C(=O)OC)c4[nH]c5c(c4CCN4C[C@](O)(CC)C[C@H](C3)C4)cccc5)[C@@]32[C@H]2[C@@]1(CC)C=CCN2CC3)C JXLYSJRDGCGARV-WWYNWVTFSA-N 0.000 description 3
- 241000700605 Viruses Species 0.000 description 3
- 230000002159 abnormal effect Effects 0.000 description 3
- 238000001042 affinity chromatography Methods 0.000 description 3
- 230000009824 affinity maturation Effects 0.000 description 3
- 238000004220 aggregation Methods 0.000 description 3
- 229940100198 alkylating agent Drugs 0.000 description 3
- 239000002168 alkylating agent Substances 0.000 description 3
- 125000000304 alkynyl group Chemical group 0.000 description 3
- 239000004037 angiogenesis inhibitor Substances 0.000 description 3
- 230000003042 antagnostic effect Effects 0.000 description 3
- 239000003242 anti bacterial agent Substances 0.000 description 3
- 230000001028 anti-proliverative effect Effects 0.000 description 3
- 230000000259 anti-tumor effect Effects 0.000 description 3
- 229940088710 antibiotic agent Drugs 0.000 description 3
- 229960005261 aspartic acid Drugs 0.000 description 3
- 235000003704 aspartic acid Nutrition 0.000 description 3
- 230000002238 attenuated effect Effects 0.000 description 3
- VSRXQHXAPYXROS-UHFFFAOYSA-N azanide;cyclobutane-1,1-dicarboxylic acid;platinum(2+) Chemical compound [NH2-].[NH2-].[Pt+2].OC(=O)C1(C(O)=O)CCC1 VSRXQHXAPYXROS-UHFFFAOYSA-N 0.000 description 3
- 210000003719 b-lymphocyte Anatomy 0.000 description 3
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 3
- 229960002685 biotin Drugs 0.000 description 3
- 235000020958 biotin Nutrition 0.000 description 3
- 239000011616 biotin Substances 0.000 description 3
- 230000000903 blocking effect Effects 0.000 description 3
- 210000004369 blood Anatomy 0.000 description 3
- 239000008280 blood Substances 0.000 description 3
- 239000000872 buffer Substances 0.000 description 3
- 230000036952 cancer formation Effects 0.000 description 3
- 229940022399 cancer vaccine Drugs 0.000 description 3
- 238000009566 cancer vaccine Methods 0.000 description 3
- 229960004562 carboplatin Drugs 0.000 description 3
- 231100000504 carcinogenesis Toxicity 0.000 description 3
- 230000015556 catabolic process Effects 0.000 description 3
- 238000004113 cell culture Methods 0.000 description 3
- 238000007385 chemical modification Methods 0.000 description 3
- 239000003638 chemical reducing agent Substances 0.000 description 3
- 238000004587 chromatography analysis Methods 0.000 description 3
- 239000011651 chromium Substances 0.000 description 3
- 238000010367 cloning Methods 0.000 description 3
- 230000009137 competitive binding Effects 0.000 description 3
- 238000002591 computed tomography Methods 0.000 description 3
- 239000000356 contaminant Substances 0.000 description 3
- 238000011443 conventional therapy Methods 0.000 description 3
- 238000005859 coupling reaction Methods 0.000 description 3
- 229960004397 cyclophosphamide Drugs 0.000 description 3
- 230000006378 damage Effects 0.000 description 3
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 description 3
- 230000003247 decreasing effect Effects 0.000 description 3
- 238000006731 degradation reaction Methods 0.000 description 3
- 239000000032 diagnostic agent Substances 0.000 description 3
- 229940039227 diagnostic agent Drugs 0.000 description 3
- 229960004679 doxorubicin Drugs 0.000 description 3
- 239000003937 drug carrier Substances 0.000 description 3
- 239000003623 enhancer Substances 0.000 description 3
- 150000002148 esters Chemical class 0.000 description 3
- RTZKZFJDLAIYFH-UHFFFAOYSA-N ether Substances CCOCC RTZKZFJDLAIYFH-UHFFFAOYSA-N 0.000 description 3
- AEOCXXJPGCBFJA-UHFFFAOYSA-N ethionamide Chemical compound CCC1=CC(C(N)=S)=CC=N1 AEOCXXJPGCBFJA-UHFFFAOYSA-N 0.000 description 3
- VJJPUSNTGOMMGY-MRVIYFEKSA-N etoposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 VJJPUSNTGOMMGY-MRVIYFEKSA-N 0.000 description 3
- 230000001747 exhibiting effect Effects 0.000 description 3
- SDUQYLNIPVEERB-QPPQHZFASA-N gemcitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 SDUQYLNIPVEERB-QPPQHZFASA-N 0.000 description 3
- 230000002068 genetic effect Effects 0.000 description 3
- 150000004676 glycans Chemical class 0.000 description 3
- 208000014829 head and neck neoplasm Diseases 0.000 description 3
- 230000036541 health Effects 0.000 description 3
- 231100000844 hepatocellular carcinoma Toxicity 0.000 description 3
- 238000001794 hormone therapy Methods 0.000 description 3
- 150000002466 imines Chemical class 0.000 description 3
- 230000001900 immune effect Effects 0.000 description 3
- 210000000987 immune system Anatomy 0.000 description 3
- 238000002649 immunization Methods 0.000 description 3
- 230000001024 immunotherapeutic effect Effects 0.000 description 3
- 238000011065 in-situ storage Methods 0.000 description 3
- 230000006698 induction Effects 0.000 description 3
- 239000000543 intermediate Substances 0.000 description 3
- 230000000968 intestinal effect Effects 0.000 description 3
- 125000002183 isoquinolinyl group Chemical group C1(=NC=CC2=CC=CC=C12)* 0.000 description 3
- 210000003734 kidney Anatomy 0.000 description 3
- 230000002147 killing effect Effects 0.000 description 3
- 210000004185 liver Anatomy 0.000 description 3
- 230000033001 locomotion Effects 0.000 description 3
- 210000004072 lung Anatomy 0.000 description 3
- 210000003712 lysosome Anatomy 0.000 description 3
- 230000001868 lysosomic effect Effects 0.000 description 3
- 210000002540 macrophage Anatomy 0.000 description 3
- 238000009115 maintenance therapy Methods 0.000 description 3
- 238000007726 management method Methods 0.000 description 3
- 238000013507 mapping Methods 0.000 description 3
- GLVAUDGFNGKCSF-UHFFFAOYSA-N mercaptopurine Chemical compound S=C1NC=NC2=C1NC=N2 GLVAUDGFNGKCSF-UHFFFAOYSA-N 0.000 description 3
- 230000002503 metabolic effect Effects 0.000 description 3
- 230000001394 metastastic effect Effects 0.000 description 3
- 229960004857 mitomycin Drugs 0.000 description 3
- 238000001823 molecular biology technique Methods 0.000 description 3
- 238000010369 molecular cloning Methods 0.000 description 3
- 108010068617 neonatal Fc receptor Proteins 0.000 description 3
- 210000005170 neoplastic cell Anatomy 0.000 description 3
- 210000005036 nerve Anatomy 0.000 description 3
- 125000004433 nitrogen atom Chemical group N* 0.000 description 3
- 235000020660 omega-3 fatty acid Nutrition 0.000 description 3
- 210000001672 ovary Anatomy 0.000 description 3
- 208000008443 pancreatic carcinoma Diseases 0.000 description 3
- 229920001282 polysaccharide Polymers 0.000 description 3
- 239000005017 polysaccharide Substances 0.000 description 3
- NLKNQRATVPKPDG-UHFFFAOYSA-M potassium iodide Chemical compound [K+].[I-] NLKNQRATVPKPDG-UHFFFAOYSA-M 0.000 description 3
- 238000012545 processing Methods 0.000 description 3
- 239000000651 prodrug Substances 0.000 description 3
- 229940002612 prodrug Drugs 0.000 description 3
- 235000019833 protease Nutrition 0.000 description 3
- 238000011002 quantification Methods 0.000 description 3
- 108700006481 rat Sez6 Proteins 0.000 description 3
- 238000003259 recombinant expression Methods 0.000 description 3
- 229920006395 saturated elastomer Polymers 0.000 description 3
- 238000000926 separation method Methods 0.000 description 3
- 238000012163 sequencing technique Methods 0.000 description 3
- 125000006850 spacer group Chemical group 0.000 description 3
- 239000003381 stabilizer Substances 0.000 description 3
- 238000010186 staining Methods 0.000 description 3
- 208000024891 symptom Diseases 0.000 description 3
- 230000001988 toxicity Effects 0.000 description 3
- 231100000419 toxicity Toxicity 0.000 description 3
- 238000013518 transcription Methods 0.000 description 3
- 230000035897 transcription Effects 0.000 description 3
- 230000005740 tumor formation Effects 0.000 description 3
- 229960003048 vinblastine Drugs 0.000 description 3
- JXLYSJRDGCGARV-XQKSVPLYSA-N vincaleukoblastine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 JXLYSJRDGCGARV-XQKSVPLYSA-N 0.000 description 3
- 238000005406 washing Methods 0.000 description 3
- FLCQLSRLQIPNLM-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 2-acetylsulfanylacetate Chemical compound CC(=O)SCC(=O)ON1C(=O)CCC1=O FLCQLSRLQIPNLM-UHFFFAOYSA-N 0.000 description 2
- JWDFQMWEFLOOED-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 3-(pyridin-2-yldisulfanyl)propanoate Chemical compound O=C1CCC(=O)N1OC(=O)CCSSC1=CC=CC=N1 JWDFQMWEFLOOED-UHFFFAOYSA-N 0.000 description 2
- MFRNYXJJRJQHNW-DEMKXPNLSA-N (2s)-2-[[(2r,3r)-3-methoxy-3-[(2s)-1-[(3r,4s,5s)-3-methoxy-5-methyl-4-[methyl-[(2s)-3-methyl-2-[[(2s)-3-methyl-2-(methylamino)butanoyl]amino]butanoyl]amino]heptanoyl]pyrrolidin-2-yl]-2-methylpropanoyl]amino]-3-phenylpropanoic acid Chemical compound CN[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(=O)N(C)[C@@H]([C@@H](C)CC)[C@H](OC)CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MFRNYXJJRJQHNW-DEMKXPNLSA-N 0.000 description 2
- 125000004178 (C1-C4) alkyl group Chemical group 0.000 description 2
- FDKXTQMXEQVLRF-ZHACJKMWSA-N (E)-dacarbazine Chemical compound CN(C)\N=N\c1[nH]cnc1C(N)=O FDKXTQMXEQVLRF-ZHACJKMWSA-N 0.000 description 2
- IAKHMKGGTNLKSZ-INIZCTEOSA-N (S)-colchicine Chemical compound C1([C@@H](NC(C)=O)CC2)=CC(=O)C(OC)=CC=C1C1=C2C=C(OC)C(OC)=C1OC IAKHMKGGTNLKSZ-INIZCTEOSA-N 0.000 description 2
- LJCZNYWLQZZIOS-UHFFFAOYSA-N 2,2,2-trichlorethoxycarbonyl chloride Chemical compound ClC(=O)OCC(Cl)(Cl)Cl LJCZNYWLQZZIOS-UHFFFAOYSA-N 0.000 description 2
- 125000003903 2-propenyl group Chemical group [H]C([*])([H])C([H])=C([H])[H] 0.000 description 2
- VPFUWHKTPYPNGT-UHFFFAOYSA-N 3-(3,4-dihydroxyphenyl)-1-(5-hydroxy-2,2-dimethylchromen-6-yl)propan-1-one Chemical compound OC1=C2C=CC(C)(C)OC2=CC=C1C(=O)CCC1=CC=C(O)C(O)=C1 VPFUWHKTPYPNGT-UHFFFAOYSA-N 0.000 description 2
- 125000001963 4 membered heterocyclic group Chemical group 0.000 description 2
- AOJJSUZBOXZQNB-VTZDEGQISA-N 4'-epidoxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-VTZDEGQISA-N 0.000 description 2
- TVZGACDUOSZQKY-LBPRGKRZSA-N 4-aminofolic acid Chemical compound C1=NC2=NC(N)=NC(N)=C2N=C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 TVZGACDUOSZQKY-LBPRGKRZSA-N 0.000 description 2
- 125000002373 5 membered heterocyclic group Chemical group 0.000 description 2
- 125000004070 6 membered heterocyclic group Chemical group 0.000 description 2
- 125000003341 7 membered heterocyclic group Chemical group 0.000 description 2
- ZCYVEMRRCGMTRW-UHFFFAOYSA-N 7553-56-2 Chemical compound [I] ZCYVEMRRCGMTRW-UHFFFAOYSA-N 0.000 description 2
- 102100031585 ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Human genes 0.000 description 2
- DLFVBJFMPXGRIB-UHFFFAOYSA-N Acetamide Chemical compound CC(N)=O DLFVBJFMPXGRIB-UHFFFAOYSA-N 0.000 description 2
- 101000669426 Aspergillus restrictus Ribonuclease mitogillin Proteins 0.000 description 2
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 2
- 108090001008 Avidin Proteins 0.000 description 2
- NOWKCMXCCJGMRR-UHFFFAOYSA-N Aziridine Chemical compound C1CN1 NOWKCMXCCJGMRR-UHFFFAOYSA-N 0.000 description 2
- 102100024222 B-lymphocyte antigen CD19 Human genes 0.000 description 2
- 235000014469 Bacillus subtilis Nutrition 0.000 description 2
- LSNNMFCWUKXFEE-UHFFFAOYSA-M Bisulfite Chemical compound OS([O-])=O LSNNMFCWUKXFEE-UHFFFAOYSA-M 0.000 description 2
- 108010006654 Bleomycin Proteins 0.000 description 2
- 241000283690 Bos taurus Species 0.000 description 2
- 208000003174 Brain Neoplasms Diseases 0.000 description 2
- GAGWJHPBXLXJQN-UORFTKCHSA-N Capecitabine Chemical compound C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](C)O1 GAGWJHPBXLXJQN-UORFTKCHSA-N 0.000 description 2
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 2
- 201000009030 Carcinoma Diseases 0.000 description 2
- 108090000994 Catalytic RNA Proteins 0.000 description 2
- 102000053642 Catalytic RNA Human genes 0.000 description 2
- 108090000712 Cathepsin B Proteins 0.000 description 2
- 102000004225 Cathepsin B Human genes 0.000 description 2
- 102000000844 Cell Surface Receptors Human genes 0.000 description 2
- 108010001857 Cell Surface Receptors Proteins 0.000 description 2
- 206010008342 Cervix carcinoma Diseases 0.000 description 2
- 108090000317 Chymotrypsin Proteins 0.000 description 2
- 206010009944 Colon cancer Diseases 0.000 description 2
- 108020004635 Complementary DNA Proteins 0.000 description 2
- XZMCDFZZKTWFGF-UHFFFAOYSA-N Cyanamide Chemical compound NC#N XZMCDFZZKTWFGF-UHFFFAOYSA-N 0.000 description 2
- UHDGCWIWMRVCDJ-CCXZUQQUSA-N Cytarabine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 UHDGCWIWMRVCDJ-CCXZUQQUSA-N 0.000 description 2
- 102000016607 Diphtheria Toxin Human genes 0.000 description 2
- 108010053187 Diphtheria Toxin Proteins 0.000 description 2
- 102100024361 Disintegrin and metalloproteinase domain-containing protein 9 Human genes 0.000 description 2
- HTIJFSOGRVMCQR-UHFFFAOYSA-N Epirubicin Natural products COc1cccc2C(=O)c3c(O)c4CC(O)(CC(OC5CC(N)C(=O)C(C)O5)c4c(O)c3C(=O)c12)C(=O)CO HTIJFSOGRVMCQR-UHFFFAOYSA-N 0.000 description 2
- 108090000371 Esterases Proteins 0.000 description 2
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 2
- PXGOKWXKJXAPGV-UHFFFAOYSA-N Fluorine Chemical compound FF PXGOKWXKJXAPGV-UHFFFAOYSA-N 0.000 description 2
- GYHNNYVSQQEPJS-UHFFFAOYSA-N Gallium Chemical compound [Ga] GYHNNYVSQQEPJS-UHFFFAOYSA-N 0.000 description 2
- 108700004714 Gelonium multiflorum GEL Proteins 0.000 description 2
- 108010051815 Glutamyl endopeptidase Proteins 0.000 description 2
- 102000003886 Glycoproteins Human genes 0.000 description 2
- 108090000288 Glycoproteins Proteins 0.000 description 2
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 2
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 description 2
- 101710154606 Hemagglutinin Proteins 0.000 description 2
- 241000238631 Hexapoda Species 0.000 description 2
- 101000777636 Homo sapiens ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Proteins 0.000 description 2
- 101000980825 Homo sapiens B-lymphocyte antigen CD19 Proteins 0.000 description 2
- 101000832769 Homo sapiens Disintegrin and metalloproteinase domain-containing protein 9 Proteins 0.000 description 2
- 101000917858 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 description 2
- 101000917839 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-B Proteins 0.000 description 2
- 101000620365 Homo sapiens Protein TMEPAI Proteins 0.000 description 2
- 101000685293 Homo sapiens Seizure 6-like protein 2 Proteins 0.000 description 2
- MPBVHIBUJCELCL-UHFFFAOYSA-N Ibandronate Chemical compound CCCCCN(C)CCC(O)(P(O)(O)=O)P(O)(O)=O MPBVHIBUJCELCL-UHFFFAOYSA-N 0.000 description 2
- 206010061598 Immunodeficiency Diseases 0.000 description 2
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 description 2
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 description 2
- 108010002350 Interleukin-2 Proteins 0.000 description 2
- 102000000588 Interleukin-2 Human genes 0.000 description 2
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 2
- RHGKLRLOHDJJDR-BYPYZUCNSA-N L-citrulline Chemical compound NC(=O)NCCC[C@H]([NH3+])C([O-])=O RHGKLRLOHDJJDR-BYPYZUCNSA-N 0.000 description 2
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 2
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 2
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 2
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 2
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 2
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 2
- 241000124008 Mammalia Species 0.000 description 2
- VFKZTMPDYBFSTM-KVTDHHQDSA-N Mitobronitol Chemical compound BrC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CBr VFKZTMPDYBFSTM-KVTDHHQDSA-N 0.000 description 2
- ZOKXTWBITQBERF-AKLPVKDBSA-N Molybdenum Mo-99 Chemical compound [99Mo] ZOKXTWBITQBERF-AKLPVKDBSA-N 0.000 description 2
- 208000034578 Multiple myelomas Diseases 0.000 description 2
- 108010021466 Mutant Proteins Proteins 0.000 description 2
- 102000008300 Mutant Proteins Human genes 0.000 description 2
- OVBPIULPVIDEAO-UHFFFAOYSA-N N-Pteroyl-L-glutaminsaeure Natural products C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)NC(CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-UHFFFAOYSA-N 0.000 description 2
- RHGKLRLOHDJJDR-UHFFFAOYSA-N Ndelta-carbamoyl-DL-ornithine Natural products OC(=O)C(N)CCCNC(N)=O RHGKLRLOHDJJDR-UHFFFAOYSA-N 0.000 description 2
- 206010061309 Neoplasm progression Diseases 0.000 description 2
- 108091034117 Oligonucleotide Proteins 0.000 description 2
- 241000283973 Oryctolagus cuniculus Species 0.000 description 2
- 101710093908 Outer capsid protein VP4 Proteins 0.000 description 2
- 101710135467 Outer capsid protein sigma-1 Proteins 0.000 description 2
- 229930012538 Paclitaxel Natural products 0.000 description 2
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 2
- 108090000526 Papain Proteins 0.000 description 2
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 2
- 101710176177 Protein A56 Proteins 0.000 description 2
- 102100022429 Protein TMEPAI Human genes 0.000 description 2
- SMWDFEZZVXVKRB-UHFFFAOYSA-N Quinoline Chemical compound N1=CC=CC2=CC=CC=C21 SMWDFEZZVXVKRB-UHFFFAOYSA-N 0.000 description 2
- 108020004511 Recombinant DNA Proteins 0.000 description 2
- 108010083644 Ribonucleases Proteins 0.000 description 2
- 102000006382 Ribonucleases Human genes 0.000 description 2
- 241000283984 Rodentia Species 0.000 description 2
- 101150038281 SEZ6 gene Proteins 0.000 description 2
- 239000002262 Schiff base Substances 0.000 description 2
- 150000004753 Schiff bases Chemical class 0.000 description 2
- 238000012300 Sequence Analysis Methods 0.000 description 2
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 2
- 210000001744 T-lymphocyte Anatomy 0.000 description 2
- YZCKVEUIGOORGS-NJFSPNSNSA-N Tritium Chemical compound [3H] YZCKVEUIGOORGS-NJFSPNSNSA-N 0.000 description 2
- 108090000631 Trypsin Proteins 0.000 description 2
- 102000004142 Trypsin Human genes 0.000 description 2
- VGQOVCHZGQWAOI-UHFFFAOYSA-N UNPD55612 Natural products N1C(O)C2CC(C=CC(N)=O)=CN2C(=O)C2=CC=C(C)C(O)=C12 VGQOVCHZGQWAOI-UHFFFAOYSA-N 0.000 description 2
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 2
- 102000009524 Vascular Endothelial Growth Factor A Human genes 0.000 description 2
- 238000012452 Xenomouse strains Methods 0.000 description 2
- FHNFHKCVQCLJFQ-NJFSPNSNSA-N Xenon-133 Chemical compound [133Xe] FHNFHKCVQCLJFQ-NJFSPNSNSA-N 0.000 description 2
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 2
- IEDXPSOJFSVCKU-HOKPPMCLSA-N [4-[[(2S)-5-(carbamoylamino)-2-[[(2S)-2-[6-(2,5-dioxopyrrolidin-1-yl)hexanoylamino]-3-methylbutanoyl]amino]pentanoyl]amino]phenyl]methyl N-[(2S)-1-[[(2S)-1-[[(3R,4S,5S)-1-[(2S)-2-[(1R,2R)-3-[[(1S,2R)-1-hydroxy-1-phenylpropan-2-yl]amino]-1-methoxy-2-methyl-3-oxopropyl]pyrrolidin-1-yl]-3-methoxy-5-methyl-1-oxoheptan-4-yl]-methylamino]-3-methyl-1-oxobutan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]-N-methylcarbamate Chemical compound CC[C@H](C)[C@@H]([C@@H](CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C)[C@@H](O)c1ccccc1)OC)N(C)C(=O)[C@@H](NC(=O)[C@H](C(C)C)N(C)C(=O)OCc1ccc(NC(=O)[C@H](CCCNC(N)=O)NC(=O)[C@@H](NC(=O)CCCCCN2C(=O)CCC2=O)C(C)C)cc1)C(C)C IEDXPSOJFSVCKU-HOKPPMCLSA-N 0.000 description 2
- 230000021736 acetylation Effects 0.000 description 2
- 238000006640 acetylation reaction Methods 0.000 description 2
- 150000007513 acids Chemical class 0.000 description 2
- 229930183665 actinomycin Natural products 0.000 description 2
- RJURFGZVJUQBHK-IIXSONLDSA-N actinomycin D Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)N[C@@H]4C(=O)N[C@@H](C(N5CCC[C@H]5C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-IIXSONLDSA-N 0.000 description 2
- 239000004480 active ingredient Substances 0.000 description 2
- 229960000548 alemtuzumab Drugs 0.000 description 2
- 125000003545 alkoxy group Chemical group 0.000 description 2
- 229960003896 aminopterin Drugs 0.000 description 2
- 150000001450 anions Chemical class 0.000 description 2
- VGQOVCHZGQWAOI-HYUHUPJXSA-N anthramycin Chemical compound N1[C@@H](O)[C@@H]2CC(\C=C\C(N)=O)=CN2C(=O)C2=CC=C(C)C(O)=C12 VGQOVCHZGQWAOI-HYUHUPJXSA-N 0.000 description 2
- RJGDLRCDCYRQOQ-UHFFFAOYSA-N anthrone Chemical compound C1=CC=C2C(=O)C3=CC=CC=C3CC2=C1 RJGDLRCDCYRQOQ-UHFFFAOYSA-N 0.000 description 2
- 230000006907 apoptotic process Effects 0.000 description 2
- 125000000732 arylene group Chemical group 0.000 description 2
- 239000011324 bead Substances 0.000 description 2
- HSDAJNMJOMSNEV-UHFFFAOYSA-N benzyl chloroformate Chemical compound ClC(=O)OCC1=CC=CC=C1 HSDAJNMJOMSNEV-UHFFFAOYSA-N 0.000 description 2
- 229960000397 bevacizumab Drugs 0.000 description 2
- 238000002306 biochemical method Methods 0.000 description 2
- 229920000249 biocompatible polymer Polymers 0.000 description 2
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 2
- 239000007975 buffered saline Substances 0.000 description 2
- 239000002775 capsule Substances 0.000 description 2
- 235000014633 carbohydrates Nutrition 0.000 description 2
- 229910052799 carbon Inorganic materials 0.000 description 2
- CREMABGTGYGIQB-UHFFFAOYSA-N carbon carbon Chemical compound C.C CREMABGTGYGIQB-UHFFFAOYSA-N 0.000 description 2
- 239000011203 carbon fibre reinforced carbon Substances 0.000 description 2
- 230000008568 cell cell communication Effects 0.000 description 2
- 230000022534 cell killing Effects 0.000 description 2
- 230000005754 cellular signaling Effects 0.000 description 2
- 229960005395 cetuximab Drugs 0.000 description 2
- 239000002738 chelating agent Substances 0.000 description 2
- 229960002376 chymotrypsin Drugs 0.000 description 2
- 229960002173 citrulline Drugs 0.000 description 2
- 235000013477 citrulline Nutrition 0.000 description 2
- 230000005757 colony formation Effects 0.000 description 2
- 238000011970 concomitant therapy Methods 0.000 description 2
- 239000000599 controlled substance Substances 0.000 description 2
- 230000001276 controlling effect Effects 0.000 description 2
- 230000001054 cortical effect Effects 0.000 description 2
- 238000004132 cross linking Methods 0.000 description 2
- 125000004093 cyano group Chemical group *C#N 0.000 description 2
- 125000000753 cycloalkyl group Chemical group 0.000 description 2
- 229940104302 cytosine Drugs 0.000 description 2
- 230000001085 cytostatic effect Effects 0.000 description 2
- 230000003013 cytotoxicity Effects 0.000 description 2
- 231100000135 cytotoxicity Toxicity 0.000 description 2
- 239000002619 cytotoxin Substances 0.000 description 2
- GVJHHUAWPYXKBD-UHFFFAOYSA-N d-alpha-tocopherol Natural products OC1=C(C)C(C)=C2OC(CCCC(C)CCCC(C)CCCC(C)C)(C)CCC2=C1C GVJHHUAWPYXKBD-UHFFFAOYSA-N 0.000 description 2
- 229960000640 dactinomycin Drugs 0.000 description 2
- 229960000975 daunorubicin Drugs 0.000 description 2
- 230000034994 death Effects 0.000 description 2
- 231100000517 death Toxicity 0.000 description 2
- 238000004925 denaturation Methods 0.000 description 2
- 230000036425 denaturation Effects 0.000 description 2
- 230000000779 depleting effect Effects 0.000 description 2
- 238000009795 derivation Methods 0.000 description 2
- 239000003085 diluting agent Substances 0.000 description 2
- 238000011038 discontinuous diafiltration by volume reduction Methods 0.000 description 2
- VHJLVAABSRFDPM-QWWZWVQMSA-N dithiothreitol Chemical compound SC[C@@H](O)[C@H](O)CS VHJLVAABSRFDPM-QWWZWVQMSA-N 0.000 description 2
- AMRJKAQTDDKMCE-UHFFFAOYSA-N dolastatin Chemical compound CC(C)C(N(C)C)C(=O)NC(C(C)C)C(=O)N(C)C(C(C)C)C(OC)CC(=O)N1CCCC1C(OC)C(C)C(=O)NC(C=1SC=CN=1)CC1=CC=CC=C1 AMRJKAQTDDKMCE-UHFFFAOYSA-N 0.000 description 2
- 229930188854 dolastatin Natural products 0.000 description 2
- VLCYCQAOQCDTCN-UHFFFAOYSA-N eflornithine Chemical compound NCCCC(N)(C(F)F)C(O)=O VLCYCQAOQCDTCN-UHFFFAOYSA-N 0.000 description 2
- 210000001163 endosome Anatomy 0.000 description 2
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 description 2
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 description 2
- 229960001904 epirubicin Drugs 0.000 description 2
- 229930013356 epothilone Natural products 0.000 description 2
- 150000003883 epothilone derivatives Chemical class 0.000 description 2
- LJQQFQHBKUKHIS-WJHRIEJJSA-N esperamicin Chemical compound O1CC(NC(C)C)C(OC)CC1OC1C(O)C(NOC2OC(C)C(SC)C(O)C2)C(C)OC1OC1C(\C2=C/CSSSC)=C(NC(=O)OC)C(=O)C(OC3OC(C)C(O)C(OC(=O)C=4C(=CC(OC)=C(OC)C=4)NC(=O)C(=C)OC)C3)C2(O)C#C\C=C/C#C1 LJQQFQHBKUKHIS-WJHRIEJJSA-N 0.000 description 2
- 229960005420 etoposide Drugs 0.000 description 2
- 238000000605 extraction Methods 0.000 description 2
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 2
- 239000011737 fluorine Substances 0.000 description 2
- 229960000304 folic acid Drugs 0.000 description 2
- 235000019152 folic acid Nutrition 0.000 description 2
- 239000011724 folic acid Substances 0.000 description 2
- 229910052733 gallium Inorganic materials 0.000 description 2
- CHPZKNULDCNCBW-UHFFFAOYSA-N gallium nitrate Chemical compound [Ga+3].[O-][N+]([O-])=O.[O-][N+]([O-])=O.[O-][N+]([O-])=O CHPZKNULDCNCBW-UHFFFAOYSA-N 0.000 description 2
- BTCSSZJGUNDROE-UHFFFAOYSA-N gamma-aminobutyric acid Chemical compound NCCCC(O)=O BTCSSZJGUNDROE-UHFFFAOYSA-N 0.000 description 2
- 238000001502 gel electrophoresis Methods 0.000 description 2
- 229960005277 gemcitabine Drugs 0.000 description 2
- 229960000578 gemtuzumab Drugs 0.000 description 2
- 201000010536 head and neck cancer Diseases 0.000 description 2
- 210000001320 hippocampus Anatomy 0.000 description 2
- 229940088597 hormone Drugs 0.000 description 2
- 239000005556 hormone Substances 0.000 description 2
- 102000058162 human SEZ6L Human genes 0.000 description 2
- 238000006460 hydrolysis reaction Methods 0.000 description 2
- 229940015872 ibandronate Drugs 0.000 description 2
- 238000003384 imaging method Methods 0.000 description 2
- 230000000984 immunochemical effect Effects 0.000 description 2
- 230000005847 immunogenicity Effects 0.000 description 2
- 230000016784 immunoglobulin production Effects 0.000 description 2
- 239000000367 immunologic factor Substances 0.000 description 2
- 239000002955 immunomodulating agent Substances 0.000 description 2
- 238000009169 immunotherapy Methods 0.000 description 2
- 238000007901 in situ hybridization Methods 0.000 description 2
- 229910052738 indium Inorganic materials 0.000 description 2
- APFVFJFRJDLVQX-UHFFFAOYSA-N indium atom Chemical compound [In] APFVFJFRJDLVQX-UHFFFAOYSA-N 0.000 description 2
- 239000004615 ingredient Substances 0.000 description 2
- 229940079322 interferon Drugs 0.000 description 2
- 238000007912 intraperitoneal administration Methods 0.000 description 2
- 229910052740 iodine Inorganic materials 0.000 description 2
- 239000011630 iodine Substances 0.000 description 2
- 229960005386 ipilimumab Drugs 0.000 description 2
- 229960004768 irinotecan Drugs 0.000 description 2
- 229960003136 leucine Drugs 0.000 description 2
- 208000032839 leukemia Diseases 0.000 description 2
- 230000007774 longterm Effects 0.000 description 2
- 238000002595 magnetic resonance imaging Methods 0.000 description 2
- 230000014759 maintenance of location Effects 0.000 description 2
- 125000005439 maleimidyl group Chemical group C1(C=CC(N1*)=O)=O 0.000 description 2
- 230000036210 malignancy Effects 0.000 description 2
- 230000003211 malignant effect Effects 0.000 description 2
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 description 2
- 238000004949 mass spectrometry Methods 0.000 description 2
- 230000035800 maturation Effects 0.000 description 2
- 230000010534 mechanism of action Effects 0.000 description 2
- 201000001441 melanoma Diseases 0.000 description 2
- 239000012528 membrane Substances 0.000 description 2
- 229960001428 mercaptopurine Drugs 0.000 description 2
- 239000002207 metabolite Substances 0.000 description 2
- 229910052751 metal Inorganic materials 0.000 description 2
- 239000002184 metal Substances 0.000 description 2
- 229910021645 metal ion Inorganic materials 0.000 description 2
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 description 2
- 229960000485 methotrexate Drugs 0.000 description 2
- 229950002142 minretumomab Drugs 0.000 description 2
- 229960005485 mitobronitol Drugs 0.000 description 2
- 229960001156 mitoxantrone Drugs 0.000 description 2
- KKZJGLLVHKMTCM-UHFFFAOYSA-N mitoxantrone Chemical compound O=C1C2=C(O)C=CC(O)=C2C(=O)C2=C1C(NCCNCCO)=CC=C2NCCNCCO KKZJGLLVHKMTCM-UHFFFAOYSA-N 0.000 description 2
- 108010093470 monomethyl auristatin E Proteins 0.000 description 2
- 108010059074 monomethylauristatin F Proteins 0.000 description 2
- 230000000877 morphologic effect Effects 0.000 description 2
- 238000002703 mutagenesis Methods 0.000 description 2
- 231100000350 mutagenesis Toxicity 0.000 description 2
- 201000000050 myeloid neoplasm Diseases 0.000 description 2
- VLKZOEOYAKHREP-UHFFFAOYSA-N n-Hexane Chemical class CCCCCC VLKZOEOYAKHREP-UHFFFAOYSA-N 0.000 description 2
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 description 2
- 125000001624 naphthyl group Chemical group 0.000 description 2
- 201000002120 neuroendocrine carcinoma Diseases 0.000 description 2
- 229920001542 oligosaccharide Polymers 0.000 description 2
- 150000002482 oligosaccharides Chemical class 0.000 description 2
- 230000002018 overexpression Effects 0.000 description 2
- 229960001756 oxaliplatin Drugs 0.000 description 2
- DWAFYCQODLXJNR-BNTLRKBRSA-L oxaliplatin Chemical compound O1C(=O)C(=O)O[Pt]11N[C@@H]2CCCC[C@H]2N1 DWAFYCQODLXJNR-BNTLRKBRSA-L 0.000 description 2
- 238000007254 oxidation reaction Methods 0.000 description 2
- 230000001590 oxidative effect Effects 0.000 description 2
- 150000002923 oximes Chemical class 0.000 description 2
- 229960001592 paclitaxel Drugs 0.000 description 2
- 229910052763 palladium Inorganic materials 0.000 description 2
- 201000002528 pancreatic cancer Diseases 0.000 description 2
- 229960001972 panitumumab Drugs 0.000 description 2
- 229940055729 papain Drugs 0.000 description 2
- 235000019834 papain Nutrition 0.000 description 2
- 238000007911 parenteral administration Methods 0.000 description 2
- 239000000825 pharmaceutical preparation Substances 0.000 description 2
- 230000026731 phosphorylation Effects 0.000 description 2
- 238000006366 phosphorylation reaction Methods 0.000 description 2
- 230000000704 physical effect Effects 0.000 description 2
- 239000013612 plasmid Substances 0.000 description 2
- 238000002600 positron emission tomography Methods 0.000 description 2
- 230000004481 post-translational protein modification Effects 0.000 description 2
- 230000003389 potentiating effect Effects 0.000 description 2
- 239000002243 precursor Substances 0.000 description 2
- 230000003449 preventive effect Effects 0.000 description 2
- CPTBDICYNRMXFX-UHFFFAOYSA-N procarbazine Chemical compound CNNCC1=CC=C(C(=O)NC(C)C)C=C1 CPTBDICYNRMXFX-UHFFFAOYSA-N 0.000 description 2
- 229960000624 procarbazine Drugs 0.000 description 2
- 239000000047 product Substances 0.000 description 2
- 239000000186 progesterone Substances 0.000 description 2
- 229960003387 progesterone Drugs 0.000 description 2
- 230000001737 promoting effect Effects 0.000 description 2
- 238000011321 prophylaxis Methods 0.000 description 2
- AQHHHDLHHXJYJD-UHFFFAOYSA-N propranolol Chemical compound C1=CC=C2C(OCC(O)CNC(C)C)=CC=CC2=C1 AQHHHDLHHXJYJD-UHFFFAOYSA-N 0.000 description 2
- 210000002307 prostate Anatomy 0.000 description 2
- 229950010131 puromycin Drugs 0.000 description 2
- 239000001397 quillaja saponaria molina bark Substances 0.000 description 2
- 125000002943 quinolinyl group Chemical group N1=C(C=CC2=CC=CC=C12)* 0.000 description 2
- 238000003127 radioimmunoassay Methods 0.000 description 2
- 238000006722 reduction reaction Methods 0.000 description 2
- 230000008929 regeneration Effects 0.000 description 2
- 238000011069 regeneration method Methods 0.000 description 2
- 230000000754 repressing effect Effects 0.000 description 2
- 230000029058 respiratory gaseous exchange Effects 0.000 description 2
- 108091092562 ribozyme Proteins 0.000 description 2
- 125000006413 ring segment Chemical group 0.000 description 2
- 229960004641 rituximab Drugs 0.000 description 2
- 229930182490 saponin Natural products 0.000 description 2
- 235000017709 saponins Nutrition 0.000 description 2
- 150000007949 saponins Chemical class 0.000 description 2
- 208000011581 secondary neoplasm Diseases 0.000 description 2
- 230000003248 secreting effect Effects 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 2
- 239000007790 solid phase Substances 0.000 description 2
- 206010041823 squamous cell carcinoma Diseases 0.000 description 2
- 238000012409 standard PCR amplification Methods 0.000 description 2
- 210000002784 stomach Anatomy 0.000 description 2
- 239000003826 tablet Substances 0.000 description 2
- 230000008685 targeting Effects 0.000 description 2
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 2
- 229910052713 technetium Inorganic materials 0.000 description 2
- GKLVYJBZJHMRIY-UHFFFAOYSA-N technetium atom Chemical compound [Tc] GKLVYJBZJHMRIY-UHFFFAOYSA-N 0.000 description 2
- 125000000999 tert-butyl group Chemical group [H]C([H])([H])C(*)(C([H])([H])[H])C([H])([H])[H] 0.000 description 2
- 125000001981 tert-butyldimethylsilyl group Chemical group [H]C([H])([H])[Si]([H])(C([H])([H])[H])[*]C(C([H])([H])[H])(C([H])([H])[H])C([H])([H])[H] 0.000 description 2
- 125000000037 tert-butyldiphenylsilyl group Chemical group [H]C1=C([H])C([H])=C([H])C([H])=C1[Si]([H])([*]C(C([H])([H])[H])(C([H])([H])[H])C([H])([H])[H])C1=C([H])C([H])=C([H])C([H])=C1[H] 0.000 description 2
- 229910052716 thallium Inorganic materials 0.000 description 2
- BKVIYDNLLOSFOA-UHFFFAOYSA-N thallium Chemical compound [Tl] BKVIYDNLLOSFOA-UHFFFAOYSA-N 0.000 description 2
- SRVJKTDHMYAMHA-WUXMJOGZSA-N thioacetazone Chemical compound CC(=O)NC1=CC=C(\C=N\NC(N)=S)C=C1 SRVJKTDHMYAMHA-WUXMJOGZSA-N 0.000 description 2
- 150000003568 thioethers Chemical class 0.000 description 2
- UMGDCJDMYOKAJW-UHFFFAOYSA-N thiourea Chemical compound NC(N)=S UMGDCJDMYOKAJW-UHFFFAOYSA-N 0.000 description 2
- 229960003087 tioguanine Drugs 0.000 description 2
- 229960001295 tocopherol Drugs 0.000 description 2
- 229930003799 tocopherol Natural products 0.000 description 2
- 235000010384 tocopherol Nutrition 0.000 description 2
- 239000011732 tocopherol Substances 0.000 description 2
- 229960005267 tositumomab Drugs 0.000 description 2
- 230000002103 transcriptional effect Effects 0.000 description 2
- 238000001890 transfection Methods 0.000 description 2
- 238000011830 transgenic mouse model Methods 0.000 description 2
- 229960000575 trastuzumab Drugs 0.000 description 2
- 229910052722 tritium Inorganic materials 0.000 description 2
- 239000012588 trypsin Substances 0.000 description 2
- 229960001322 trypsin Drugs 0.000 description 2
- 230000005751 tumor progression Effects 0.000 description 2
- 238000000108 ultra-filtration Methods 0.000 description 2
- 241000701161 unidentified adenovirus Species 0.000 description 2
- 210000003932 urinary bladder Anatomy 0.000 description 2
- 229960005486 vaccine Drugs 0.000 description 2
- 210000003462 vein Anatomy 0.000 description 2
- 230000035899 viability Effects 0.000 description 2
- GBABOYUKABKIAF-IELIFDKJSA-N vinorelbine Chemical compound C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC GBABOYUKABKIAF-IELIFDKJSA-N 0.000 description 2
- 229960002066 vinorelbine Drugs 0.000 description 2
- 230000003612 virological effect Effects 0.000 description 2
- 229910052727 yttrium Inorganic materials 0.000 description 2
- 239000011701 zinc Substances 0.000 description 2
- GVJHHUAWPYXKBD-IEOSBIPESA-N α-tocopherol Chemical compound OC1=C(C)C(C)=C2O[C@@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1C GVJHHUAWPYXKBD-IEOSBIPESA-N 0.000 description 2
- NNJPGOLRFBJNIW-HNNXBMFYSA-N (-)-demecolcine Chemical compound C1=C(OC)C(=O)C=C2[C@@H](NC)CCC3=CC(OC)=C(OC)C(OC)=C3C2=C1 NNJPGOLRFBJNIW-HNNXBMFYSA-N 0.000 description 1
- GKSPIZSKQWTXQG-UHFFFAOYSA-N (2,5-dioxopyrrolidin-1-yl) 4-[1-(pyridin-2-yldisulfanyl)ethyl]benzoate Chemical compound C=1C=C(C(=O)ON2C(CCC2=O)=O)C=CC=1C(C)SSC1=CC=CC=N1 GKSPIZSKQWTXQG-UHFFFAOYSA-N 0.000 description 1
- DIGQNXIGRZPYDK-WKSCXVIASA-N (2R)-6-amino-2-[[2-[[(2S)-2-[[2-[[(2R)-2-[[(2S)-2-[[(2R,3S)-2-[[2-[[(2S)-2-[[2-[[(2S)-2-[[(2S)-2-[[(2R)-2-[[(2S,3S)-2-[[(2R)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[2-[[(2S)-2-[[(2R)-2-[[2-[[2-[[2-[(2-amino-1-hydroxyethylidene)amino]-3-carboxy-1-hydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1,5-dihydroxy-5-iminopentylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]hexanoic acid Chemical compound C[C@@H]([C@@H](C(=N[C@@H](CS)C(=N[C@@H](C)C(=N[C@@H](CO)C(=NCC(=N[C@@H](CCC(=N)O)C(=NC(CS)C(=N[C@H]([C@H](C)O)C(=N[C@H](CS)C(=N[C@H](CO)C(=NCC(=N[C@H](CS)C(=NCC(=N[C@H](CCCCN)C(=O)O)O)O)O)O)O)O)O)O)O)O)O)O)O)N=C([C@H](CS)N=C([C@H](CO)N=C([C@H](CO)N=C([C@H](C)N=C(CN=C([C@H](CO)N=C([C@H](CS)N=C(CN=C(C(CS)N=C(C(CC(=O)O)N=C(CN)O)O)O)O)O)O)O)O)O)O)O)O DIGQNXIGRZPYDK-WKSCXVIASA-N 0.000 description 1
- WDQLRUYAYXDIFW-RWKIJVEZSA-N (2r,3r,4s,5r,6r)-4-[(2s,3r,4s,5r,6r)-3,5-dihydroxy-4-[(2r,3r,4s,5s,6r)-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-6-[[(2r,3r,4s,5s,6r)-3,4,5-trihydroxy-6-(hydroxymethyl)oxan-2-yl]oxymethyl]oxan-2-yl]oxy-6-(hydroxymethyl)oxane-2,3,5-triol Chemical compound O[C@@H]1[C@@H](CO)O[C@@H](O)[C@H](O)[C@H]1O[C@H]1[C@H](O)[C@@H](O[C@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H](CO)O2)O)[C@H](O)[C@@H](CO[C@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H](CO)O2)O)O1 WDQLRUYAYXDIFW-RWKIJVEZSA-N 0.000 description 1
- URLVCROWVOSNPT-XOTOMLERSA-N (2s)-4-[(13r)-13-hydroxy-13-[(2r,5r)-5-[(2r,5r)-5-[(1r)-1-hydroxyundecyl]oxolan-2-yl]oxolan-2-yl]tridecyl]-2-methyl-2h-furan-5-one Chemical compound O1[C@@H]([C@H](O)CCCCCCCCCC)CC[C@@H]1[C@@H]1O[C@@H]([C@H](O)CCCCCCCCCCCCC=2C(O[C@@H](C)C=2)=O)CC1 URLVCROWVOSNPT-XOTOMLERSA-N 0.000 description 1
- CGMTUJFWROPELF-YPAAEMCBSA-N (3E,5S)-5-[(2S)-butan-2-yl]-3-(1-hydroxyethylidene)pyrrolidine-2,4-dione Chemical compound CC[C@H](C)[C@@H]1NC(=O)\C(=C(/C)O)C1=O CGMTUJFWROPELF-YPAAEMCBSA-N 0.000 description 1
- XMTVGVHOYSYOLF-CYXWZZGFSA-N (5S,8R,9S,10S,13S,14S,17S)-15,15,17-trihydroxy-10,13-dimethyl-2,4,5,6,7,8,9,11,12,14,16,17-dodecahydro-1H-cyclopenta[a]phenanthren-3-one Chemical compound OC1([C@@H]2[C@]([C@H](C1)O)(C)CC[C@H]1[C@H]2CC[C@H]2CC(=O)CC[C@]12C)O XMTVGVHOYSYOLF-CYXWZZGFSA-N 0.000 description 1
- XRBSKUSTLXISAB-XVVDYKMHSA-N (5r,6r,7r,8r)-8-hydroxy-7-(hydroxymethyl)-5-(3,4,5-trimethoxyphenyl)-5,6,7,8-tetrahydrobenzo[f][1,3]benzodioxole-6-carboxylic acid Chemical compound COC1=C(OC)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@H](O)[C@@H](CO)[C@@H]2C(O)=O)=C1 XRBSKUSTLXISAB-XVVDYKMHSA-N 0.000 description 1
- XRBSKUSTLXISAB-UHFFFAOYSA-N (7R,7'R,8R,8'R)-form-Podophyllic acid Natural products COC1=C(OC)C(OC)=CC(C2C3=CC=4OCOC=4C=C3C(O)C(CO)C2C(O)=O)=C1 XRBSKUSTLXISAB-UHFFFAOYSA-N 0.000 description 1
- AESVUZLWRXEGEX-DKCAWCKPSA-N (7S,9R)-7-[(2S,4R,5R,6R)-4-amino-5-hydroxy-6-methyloxan-2-yl]oxy-6,9,11-trihydroxy-9-(2-hydroxyacetyl)-4-methoxy-8,10-dihydro-7H-tetracene-5,12-dione iron(3+) Chemical compound [Fe+3].COc1cccc2C(=O)c3c(O)c4C[C@@](O)(C[C@H](O[C@@H]5C[C@@H](N)[C@@H](O)[C@@H](C)O5)c4c(O)c3C(=O)c12)C(=O)CO AESVUZLWRXEGEX-DKCAWCKPSA-N 0.000 description 1
- JXVAMODRWBNUSF-KZQKBALLSA-N (7s,9r,10r)-7-[(2r,4s,5s,6s)-5-[[(2s,4as,5as,7s,9s,9ar,10ar)-2,9-dimethyl-3-oxo-4,4a,5a,6,7,9,9a,10a-octahydrodipyrano[4,2-a:4',3'-e][1,4]dioxin-7-yl]oxy]-4-(dimethylamino)-6-methyloxan-2-yl]oxy-10-[(2s,4s,5s,6s)-4-(dimethylamino)-5-hydroxy-6-methyloxan-2 Chemical compound O([C@@H]1C2=C(O)C=3C(=O)C4=CC=CC(O)=C4C(=O)C=3C(O)=C2[C@@H](O[C@@H]2O[C@@H](C)[C@@H](O[C@@H]3O[C@@H](C)[C@H]4O[C@@H]5O[C@@H](C)C(=O)C[C@@H]5O[C@H]4C3)[C@H](C2)N(C)C)C[C@]1(O)CC)[C@H]1C[C@H](N(C)C)[C@H](O)[C@H](C)O1 JXVAMODRWBNUSF-KZQKBALLSA-N 0.000 description 1
- FPVKHBSQESCIEP-UHFFFAOYSA-N (8S)-3-(2-deoxy-beta-D-erythro-pentofuranosyl)-3,6,7,8-tetrahydroimidazo[4,5-d][1,3]diazepin-8-ol Natural products C1C(O)C(CO)OC1N1C(NC=NCC2O)=C2N=C1 FPVKHBSQESCIEP-UHFFFAOYSA-N 0.000 description 1
- 125000006652 (C3-C12) cycloalkyl group Chemical group 0.000 description 1
- 229920002818 (Hydroxyethyl)methacrylate Polymers 0.000 description 1
- WSEQXVZVJXJVFP-HXUWFJFHSA-N (R)-citalopram Chemical compound C1([C@@]2(C3=CC=C(C=C3CO2)C#N)CCCN(C)C)=CC=C(F)C=C1 WSEQXVZVJXJVFP-HXUWFJFHSA-N 0.000 description 1
- AGNGYMCLFWQVGX-AGFFZDDWSA-N (e)-1-[(2s)-2-amino-2-carboxyethoxy]-2-diazonioethenolate Chemical compound OC(=O)[C@@H](N)CO\C([O-])=C\[N+]#N AGNGYMCLFWQVGX-AGFFZDDWSA-N 0.000 description 1
- NWUYHJFMYQTDRP-UHFFFAOYSA-N 1,2-bis(ethenyl)benzene;1-ethenyl-2-ethylbenzene;styrene Chemical compound C=CC1=CC=CC=C1.CCC1=CC=CC=C1C=C.C=CC1=CC=CC=C1C=C NWUYHJFMYQTDRP-UHFFFAOYSA-N 0.000 description 1
- NKIJBSVPDYIEAT-UHFFFAOYSA-N 1,4,7,10-tetrazacyclododec-10-ene Chemical group C1CNCCN=CCNCCN1 NKIJBSVPDYIEAT-UHFFFAOYSA-N 0.000 description 1
- VSNHCAURESNICA-NJFSPNSNSA-N 1-oxidanylurea Chemical compound N[14C](=O)NO VSNHCAURESNICA-NJFSPNSNSA-N 0.000 description 1
- IIZPXYDJLKNOIY-JXPKJXOSSA-N 1-palmitoyl-2-arachidonoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCC\C=C/C\C=C/C\C=C/C\C=C/CCCCC IIZPXYDJLKNOIY-JXPKJXOSSA-N 0.000 description 1
- OGNSCSPNOLGXSM-UHFFFAOYSA-N 2,4-diaminobutyric acid Chemical compound NCCC(N)C(O)=O OGNSCSPNOLGXSM-UHFFFAOYSA-N 0.000 description 1
- UFBJCMHMOXMLKC-UHFFFAOYSA-N 2,4-dinitrophenol Chemical compound OC1=CC=C([N+]([O-])=O)C=C1[N+]([O-])=O UFBJCMHMOXMLKC-UHFFFAOYSA-N 0.000 description 1
- BOMZMNZEXMAQQW-UHFFFAOYSA-N 2,5,11-trimethyl-6h-pyrido[4,3-b]carbazol-2-ium-9-ol;acetate Chemical compound CC([O-])=O.C[N+]1=CC=C2C(C)=C(NC=3C4=CC(O)=CC=3)C4=C(C)C2=C1 BOMZMNZEXMAQQW-UHFFFAOYSA-N 0.000 description 1
- FUOOLUPWFVMBKG-UHFFFAOYSA-N 2-Aminoisobutyric acid Chemical compound CC(C)(N)C(O)=O FUOOLUPWFVMBKG-UHFFFAOYSA-N 0.000 description 1
- OTLLEIBWKHEHGU-UHFFFAOYSA-N 2-[5-[[5-(6-aminopurin-9-yl)-3,4-dihydroxyoxolan-2-yl]methoxy]-3,4-dihydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-3,5-dihydroxy-4-phosphonooxyhexanedioic acid Chemical compound C1=NC=2C(N)=NC=NC=2N1C(C(C1O)O)OC1COC1C(CO)OC(OC(C(O)C(OP(O)(O)=O)C(O)C(O)=O)C(O)=O)C(O)C1O OTLLEIBWKHEHGU-UHFFFAOYSA-N 0.000 description 1
- RTQWWZBSTRGEAV-PKHIMPSTSA-N 2-[[(2s)-2-[bis(carboxymethyl)amino]-3-[4-(methylcarbamoylamino)phenyl]propyl]-[2-[bis(carboxymethyl)amino]propyl]amino]acetic acid Chemical compound CNC(=O)NC1=CC=C(C[C@@H](CN(CC(C)N(CC(O)=O)CC(O)=O)CC(O)=O)N(CC(O)=O)CC(O)=O)C=C1 RTQWWZBSTRGEAV-PKHIMPSTSA-N 0.000 description 1
- QCXJFISCRQIYID-IAEPZHFASA-N 2-amino-1-n-[(3s,6s,7r,10s,16s)-3-[(2s)-butan-2-yl]-7,11,14-trimethyl-2,5,9,12,15-pentaoxo-10-propan-2-yl-8-oxa-1,4,11,14-tetrazabicyclo[14.3.0]nonadecan-6-yl]-4,6-dimethyl-3-oxo-9-n-[(3s,6s,7r,10s,16s)-7,11,14-trimethyl-2,5,9,12,15-pentaoxo-3,10-di(propa Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N=C2C(C(=O)N[C@@H]3C(=O)N[C@H](C(N4CCC[C@H]4C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]3C)=O)[C@@H](C)CC)=C(N)C(=O)C(C)=C2O2)C2=C(C)C=C1 QCXJFISCRQIYID-IAEPZHFASA-N 0.000 description 1
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 description 1
- DJQYYYCQOZMCRC-UHFFFAOYSA-N 2-aminopropane-1,3-dithiol Chemical compound SCC(N)CS DJQYYYCQOZMCRC-UHFFFAOYSA-N 0.000 description 1
- 125000002941 2-furyl group Chemical group O1C([*])=C([H])C([H])=C1[H] 0.000 description 1
- 125000000175 2-thienyl group Chemical group S1C([*])=C([H])C([H])=C1[H] 0.000 description 1
- NDMPLJNOPCLANR-UHFFFAOYSA-N 3,4-dihydroxy-15-(4-hydroxy-18-methoxycarbonyl-5,18-seco-ibogamin-18-yl)-16-methoxy-1-methyl-6,7-didehydro-aspidospermidine-3-carboxylic acid methyl ester Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 NDMPLJNOPCLANR-UHFFFAOYSA-N 0.000 description 1
- PWMYMKOUNYTVQN-UHFFFAOYSA-N 3-(8,8-diethyl-2-aza-8-germaspiro[4.5]decan-2-yl)-n,n-dimethylpropan-1-amine Chemical compound C1C[Ge](CC)(CC)CCC11CN(CCCN(C)C)CC1 PWMYMKOUNYTVQN-UHFFFAOYSA-N 0.000 description 1
- 125000004207 3-methoxyphenyl group Chemical group [H]C1=C([H])C(*)=C([H])C(OC([H])([H])[H])=C1[H] 0.000 description 1
- 125000004172 4-methoxyphenyl group Chemical group [H]C1=C([H])C(OC([H])([H])[H])=C([H])C([H])=C1* 0.000 description 1
- LGZKGOGODCLQHG-CYBMUJFWSA-N 5-[(2r)-2-hydroxy-2-(3,4,5-trimethoxyphenyl)ethyl]-2-methoxyphenol Chemical compound C1=C(O)C(OC)=CC=C1C[C@@H](O)C1=CC(OC)=C(OC)C(OC)=C1 LGZKGOGODCLQHG-CYBMUJFWSA-N 0.000 description 1
- VVIAGPKUTFNRDU-UHFFFAOYSA-N 6S-folinic acid Natural products C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)NC(CCC(O)=O)C(O)=O)C=C1 VVIAGPKUTFNRDU-UHFFFAOYSA-N 0.000 description 1
- CJIJXIFQYOPWTF-UHFFFAOYSA-N 7-hydroxycoumarin Natural products O1C(=O)C=CC2=CC(O)=CC=C21 CJIJXIFQYOPWTF-UHFFFAOYSA-N 0.000 description 1
- HBAQYPYDRFILMT-UHFFFAOYSA-N 8-[3-(1-cyclopropylpyrazol-4-yl)-1H-pyrazolo[4,3-d]pyrimidin-5-yl]-3-methyl-3,8-diazabicyclo[3.2.1]octan-2-one Chemical class C1(CC1)N1N=CC(=C1)C1=NNC2=C1N=C(N=C2)N1C2C(N(CC1CC2)C)=O HBAQYPYDRFILMT-UHFFFAOYSA-N 0.000 description 1
- ZGXJTSGNIOSYLO-UHFFFAOYSA-N 88755TAZ87 Chemical compound NCC(=O)CCC(O)=O ZGXJTSGNIOSYLO-UHFFFAOYSA-N 0.000 description 1
- HDZZVAMISRMYHH-UHFFFAOYSA-N 9beta-Ribofuranosyl-7-deazaadenin Natural products C1=CC=2C(N)=NC=NC=2N1C1OC(CO)C(O)C1O HDZZVAMISRMYHH-UHFFFAOYSA-N 0.000 description 1
- 101150092476 ABCA1 gene Proteins 0.000 description 1
- 208000030507 AIDS Diseases 0.000 description 1
- 108700005241 ATP Binding Cassette Transporter 1 Proteins 0.000 description 1
- 102100021501 ATP-binding cassette sub-family B member 5 Human genes 0.000 description 1
- 108010066676 Abrin Proteins 0.000 description 1
- 108010022752 Acetylcholinesterase Proteins 0.000 description 1
- 102000012440 Acetylcholinesterase Human genes 0.000 description 1
- 102100035990 Adenosine receptor A2a Human genes 0.000 description 1
- 102100032156 Adenylate cyclase type 9 Human genes 0.000 description 1
- 102100027211 Albumin Human genes 0.000 description 1
- 108010088751 Albumins Proteins 0.000 description 1
- 108020002663 Aldehyde Dehydrogenase Proteins 0.000 description 1
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 1
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 1
- 102100023635 Alpha-fetoprotein Human genes 0.000 description 1
- CEIZFXOZIQNICU-UHFFFAOYSA-N Alternaria alternata Crofton-weed toxin Natural products CCC(C)C1NC(=O)C(C(C)=O)=C1O CEIZFXOZIQNICU-UHFFFAOYSA-N 0.000 description 1
- QGZKDVFQNNGYKY-UHFFFAOYSA-O Ammonium Chemical compound [NH4+] QGZKDVFQNNGYKY-UHFFFAOYSA-O 0.000 description 1
- 102400000068 Angiostatin Human genes 0.000 description 1
- 108010079709 Angiostatins Proteins 0.000 description 1
- 102100031323 Anthrax toxin receptor 1 Human genes 0.000 description 1
- 108020000948 Antisense Oligonucleotides Proteins 0.000 description 1
- 108020005544 Antisense RNA Proteins 0.000 description 1
- 108091023037 Aptamer Proteins 0.000 description 1
- 241000219194 Arabidopsis Species 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- 102000014654 Aromatase Human genes 0.000 description 1
- 108010078554 Aromatase Proteins 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 206010003571 Astrocytoma Diseases 0.000 description 1
- 108091008875 B cell receptors Proteins 0.000 description 1
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 description 1
- MLDQJTXFUGDVEO-UHFFFAOYSA-N BAY-43-9006 Chemical compound C1=NC(C(=O)NC)=CC(OC=2C=CC(NC(=O)NC=3C=C(C(Cl)=CC=3)C(F)(F)F)=CC=2)=C1 MLDQJTXFUGDVEO-UHFFFAOYSA-N 0.000 description 1
- 102100037150 BMP and activin membrane-bound inhibitor homolog Human genes 0.000 description 1
- 241000193738 Bacillus anthracis Species 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- VGGGPCQERPFHOB-MCIONIFRSA-N Bestatin Chemical compound CC(C)C[C@H](C(O)=O)NC(=O)[C@@H](O)[C@H](N)CC1=CC=CC=C1 VGGGPCQERPFHOB-MCIONIFRSA-N 0.000 description 1
- 102100024775 Beta-1,4-mannosyl-glycoprotein 4-beta-N-acetylglucosaminyltransferase Human genes 0.000 description 1
- 108060000903 Beta-catenin Proteins 0.000 description 1
- 102000015735 Beta-catenin Human genes 0.000 description 1
- 102100026189 Beta-galactosidase Human genes 0.000 description 1
- 102100023995 Beta-nerve growth factor Human genes 0.000 description 1
- 229940122361 Bisphosphonate Drugs 0.000 description 1
- 108010049955 Bone Morphogenetic Protein 4 Proteins 0.000 description 1
- 102100024505 Bone morphogenetic protein 4 Human genes 0.000 description 1
- 206010006187 Breast cancer Diseases 0.000 description 1
- 208000026310 Breast neoplasm Diseases 0.000 description 1
- 102100022595 Broad substrate specificity ATP-binding cassette transporter ABCG2 Human genes 0.000 description 1
- 210000003771 C cell Anatomy 0.000 description 1
- 102100031650 C-X-C chemokine receptor type 4 Human genes 0.000 description 1
- 102100024210 CD166 antigen Human genes 0.000 description 1
- 102100038078 CD276 antigen Human genes 0.000 description 1
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 description 1
- 108050005493 CD3 protein, epsilon/gamma/delta subunit Proteins 0.000 description 1
- 102100037904 CD9 antigen Human genes 0.000 description 1
- 102100025659 Cadherin EGF LAG seven-pass G-type receptor 1 Human genes 0.000 description 1
- 102000055006 Calcitonin Human genes 0.000 description 1
- 108060001064 Calcitonin Proteins 0.000 description 1
- KLWPJMFMVPTNCC-UHFFFAOYSA-N Camptothecin Natural products CCC1(O)C(=O)OCC2=C1C=C3C4Nc5ccccc5C=C4CN3C2=O KLWPJMFMVPTNCC-UHFFFAOYSA-N 0.000 description 1
- 101710158575 Cap-specific mRNA (nucleoside-2'-O-)-methyltransferase Proteins 0.000 description 1
- GAGWJHPBXLXJQN-UHFFFAOYSA-N Capecitabine Natural products C1=C(F)C(NC(=O)OCCCCC)=NC(=O)N1C1C(O)C(O)C(C)O1 GAGWJHPBXLXJQN-UHFFFAOYSA-N 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- 208000017897 Carcinoma of esophagus Diseases 0.000 description 1
- 208000010667 Carcinoma of liver and intrahepatic biliary tract Diseases 0.000 description 1
- 208000001843 Carotid Body Tumor Diseases 0.000 description 1
- 208000037211 Carotid body tumour Diseases 0.000 description 1
- 102000014914 Carrier Proteins Human genes 0.000 description 1
- 108010078791 Carrier Proteins Proteins 0.000 description 1
- 241000701489 Cauliflower mosaic virus Species 0.000 description 1
- 102100035888 Caveolin-1 Human genes 0.000 description 1
- 102100038909 Caveolin-2 Human genes 0.000 description 1
- 241000282994 Cervidae Species 0.000 description 1
- 102000009016 Cholera Toxin Human genes 0.000 description 1
- 108010049048 Cholera Toxin Proteins 0.000 description 1
- 208000005243 Chondrosarcoma Diseases 0.000 description 1
- VYZAMTAEIAYCRO-UHFFFAOYSA-N Chromium Chemical compound [Cr] VYZAMTAEIAYCRO-UHFFFAOYSA-N 0.000 description 1
- 102100031162 Collagen alpha-1(XVIII) chain Human genes 0.000 description 1
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 1
- 108010078015 Complement C3b Proteins 0.000 description 1
- 108010077762 Complement C4b Proteins 0.000 description 1
- 108091035707 Consensus sequence Proteins 0.000 description 1
- 241000557626 Corvus corax Species 0.000 description 1
- 241000186216 Corynebacterium Species 0.000 description 1
- 239000004971 Cross linker Substances 0.000 description 1
- 108700032819 Croton tiglium crotin II Proteins 0.000 description 1
- 229930188224 Cryptophycin Natural products 0.000 description 1
- 206010011732 Cyst Diseases 0.000 description 1
- 102100032759 Cysteine-rich motor neuron 1 protein Human genes 0.000 description 1
- 101710112752 Cytotoxin Proteins 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- IGXWBGJHJZYPQS-SSDOTTSWSA-N D-Luciferin Chemical compound OC(=O)[C@H]1CSC(C=2SC3=CC=C(O)C=C3N=2)=N1 IGXWBGJHJZYPQS-SSDOTTSWSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- 230000005778 DNA damage Effects 0.000 description 1
- 231100000277 DNA damage Toxicity 0.000 description 1
- 239000012626 DNA minor groove binder Substances 0.000 description 1
- 230000008265 DNA repair mechanism Effects 0.000 description 1
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 1
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 1
- XPDXVDYUQZHFPV-UHFFFAOYSA-N Dansyl Chloride Chemical compound C1=CC=C2C(N(C)C)=CC=CC2=C1S(Cl)(=O)=O XPDXVDYUQZHFPV-UHFFFAOYSA-N 0.000 description 1
- WEAHRLBPCANXCN-UHFFFAOYSA-N Daunomycin Natural products CCC1(O)CC(OC2CC(N)C(O)C(C)O2)c3cc4C(=O)c5c(OC)cccc5C(=O)c4c(O)c3C1 WEAHRLBPCANXCN-UHFFFAOYSA-N 0.000 description 1
- 102100035784 Decorin Human genes 0.000 description 1
- 108090000738 Decorin Proteins 0.000 description 1
- CYCGRDQQIOGCKX-UHFFFAOYSA-N Dehydro-luciferin Natural products OC(=O)C1=CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 CYCGRDQQIOGCKX-UHFFFAOYSA-N 0.000 description 1
- NNJPGOLRFBJNIW-UHFFFAOYSA-N Demecolcine Natural products C1=C(OC)C(=O)C=C2C(NC)CCC3=CC(OC)=C(OC)C(OC)=C3C2=C1 NNJPGOLRFBJNIW-UHFFFAOYSA-N 0.000 description 1
- 108010008532 Deoxyribonuclease I Proteins 0.000 description 1
- 102100030012 Deoxyribonuclease-1 Human genes 0.000 description 1
- 108010002156 Depsipeptides Proteins 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 1
- 206010061819 Disease recurrence Diseases 0.000 description 1
- 206010059866 Drug resistance Diseases 0.000 description 1
- 229930193152 Dynemicin Natural products 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 101150028000 EED gene Proteins 0.000 description 1
- 238000012286 ELISA Assay Methods 0.000 description 1
- 102000012804 EPCAM Human genes 0.000 description 1
- 101150084967 EPCAM gene Proteins 0.000 description 1
- 101150076616 EPHA2 gene Proteins 0.000 description 1
- LVGKNOAMLMIIKO-UHFFFAOYSA-N Elaidinsaeure-aethylester Natural products CCCCCCCCC=CCCCCCCCC(=O)OCC LVGKNOAMLMIIKO-UHFFFAOYSA-N 0.000 description 1
- MBYXEBXZARTUSS-QLWBXOBMSA-N Emetamine Natural products O(C)c1c(OC)cc2c(c(C[C@@H]3[C@H](CC)CN4[C@H](c5c(cc(OC)c(OC)c5)CC4)C3)ncc2)c1 MBYXEBXZARTUSS-QLWBXOBMSA-N 0.000 description 1
- 102100037241 Endoglin Human genes 0.000 description 1
- 206010014759 Endometrial neoplasm Diseases 0.000 description 1
- 108010079505 Endostatins Proteins 0.000 description 1
- 241000792859 Enema Species 0.000 description 1
- 108010055211 EphA1 Receptor Proteins 0.000 description 1
- 102100030322 Ephrin type-A receptor 1 Human genes 0.000 description 1
- 102100030340 Ephrin type-A receptor 2 Human genes 0.000 description 1
- YQYJSBFKSSDGFO-UHFFFAOYSA-N Epihygromycin Natural products OC1C(O)C(C(=O)C)OC1OC(C(=C1)O)=CC=C1C=C(C)C(=O)NC1C(O)C(O)C2OCOC2C1O YQYJSBFKSSDGFO-UHFFFAOYSA-N 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- 108700024394 Exon Proteins 0.000 description 1
- 206010015866 Extravasation Diseases 0.000 description 1
- 108010021468 Fc gamma receptor IIA Proteins 0.000 description 1
- 108010008177 Fd immunoglobulins Proteins 0.000 description 1
- 102100039036 Feline leukemia virus subgroup C receptor-related protein 1 Human genes 0.000 description 1
- BJGNCJDXODQBOB-UHFFFAOYSA-N Fivefly Luciferin Natural products OC(=O)C1CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 BJGNCJDXODQBOB-UHFFFAOYSA-N 0.000 description 1
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 1
- 102100020997 Fractalkine Human genes 0.000 description 1
- 241000233866 Fungi Species 0.000 description 1
- 102100032523 G-protein coupled receptor family C group 5 member B Human genes 0.000 description 1
- 102100021337 Gap junction alpha-1 protein Human genes 0.000 description 1
- 239000001828 Gelatine Substances 0.000 description 1
- 108700023863 Gene Components Proteins 0.000 description 1
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 1
- 208000007569 Giant Cell Tumors Diseases 0.000 description 1
- 206010018338 Glioma Diseases 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- 102000053187 Glucuronidase Human genes 0.000 description 1
- 108010060309 Glucuronidase Proteins 0.000 description 1
- SXRSQZLOMIGNAQ-UHFFFAOYSA-N Glutaraldehyde Chemical compound O=CCCCC=O SXRSQZLOMIGNAQ-UHFFFAOYSA-N 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 239000005562 Glyphosate Substances 0.000 description 1
- 108010026389 Gramicidin Proteins 0.000 description 1
- 102000004269 Granulocyte Colony-Stimulating Factor Human genes 0.000 description 1
- 108010017080 Granulocyte Colony-Stimulating Factor Proteins 0.000 description 1
- 108010051696 Growth Hormone Proteins 0.000 description 1
- 208000031886 HIV Infections Diseases 0.000 description 1
- 208000037357 HIV infectious disease Diseases 0.000 description 1
- 102100030595 HLA class II histocompatibility antigen gamma chain Human genes 0.000 description 1
- 208000002250 Hematologic Neoplasms Diseases 0.000 description 1
- 208000032843 Hemorrhage Diseases 0.000 description 1
- HTTJABKRGRZYRN-UHFFFAOYSA-N Heparin Chemical compound OC1C(NC(=O)C)C(O)OC(COS(O)(=O)=O)C1OC1C(OS(O)(=O)=O)C(O)C(OC2C(C(OS(O)(=O)=O)C(OC3C(C(O)C(O)C(O3)C(O)=O)OS(O)(=O)=O)C(CO)O2)NS(O)(=O)=O)C(C(O)=O)O1 HTTJABKRGRZYRN-UHFFFAOYSA-N 0.000 description 1
- 206010073069 Hepatic cancer Diseases 0.000 description 1
- 101710121996 Hexon protein p72 Proteins 0.000 description 1
- 102100026122 High affinity immunoglobulin gamma Fc receptor I Human genes 0.000 description 1
- 102100023605 Homer protein homolog 2 Human genes 0.000 description 1
- 101000677872 Homo sapiens ATP-binding cassette sub-family B member 5 Proteins 0.000 description 1
- 101000783751 Homo sapiens Adenosine receptor A2a Proteins 0.000 description 1
- 101000775499 Homo sapiens Adenylate cyclase type 9 Proteins 0.000 description 1
- 101000796095 Homo sapiens Anthrax toxin receptor 1 Proteins 0.000 description 1
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 description 1
- 101000740070 Homo sapiens BMP and activin membrane-bound inhibitor homolog Proteins 0.000 description 1
- 101000922348 Homo sapiens C-X-C chemokine receptor type 4 Proteins 0.000 description 1
- 101000980840 Homo sapiens CD166 antigen Proteins 0.000 description 1
- 101000884279 Homo sapiens CD276 antigen Proteins 0.000 description 1
- 101000738354 Homo sapiens CD9 antigen Proteins 0.000 description 1
- 101000914155 Homo sapiens Cadherin EGF LAG seven-pass G-type receptor 1 Proteins 0.000 description 1
- 101000714537 Homo sapiens Cadherin-2 Proteins 0.000 description 1
- 101000868788 Homo sapiens Carboxypeptidase D Proteins 0.000 description 1
- 101000715467 Homo sapiens Caveolin-1 Proteins 0.000 description 1
- 101000740981 Homo sapiens Caveolin-2 Proteins 0.000 description 1
- 101000942095 Homo sapiens Cysteine-rich motor neuron 1 protein Proteins 0.000 description 1
- 101000881679 Homo sapiens Endoglin Proteins 0.000 description 1
- 101000866302 Homo sapiens Excitatory amino acid transporter 3 Proteins 0.000 description 1
- 101001029786 Homo sapiens Feline leukemia virus subgroup C receptor-related protein 1 Proteins 0.000 description 1
- 101000854520 Homo sapiens Fractalkine Proteins 0.000 description 1
- 101001014684 Homo sapiens G-protein coupled receptor family C group 5 member B Proteins 0.000 description 1
- 101000894966 Homo sapiens Gap junction alpha-1 protein Proteins 0.000 description 1
- 101001066129 Homo sapiens Glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 1
- 101001082627 Homo sapiens HLA class II histocompatibility antigen gamma chain Proteins 0.000 description 1
- 101000913074 Homo sapiens High affinity immunoglobulin gamma Fc receptor I Proteins 0.000 description 1
- 101001048464 Homo sapiens Homer protein homolog 2 Proteins 0.000 description 1
- 101001078133 Homo sapiens Integrin alpha-2 Proteins 0.000 description 1
- 101000994365 Homo sapiens Integrin alpha-6 Proteins 0.000 description 1
- 101000935043 Homo sapiens Integrin beta-1 Proteins 0.000 description 1
- 101000960952 Homo sapiens Interleukin-1 receptor accessory protein Proteins 0.000 description 1
- 101001076418 Homo sapiens Interleukin-1 receptor type 1 Proteins 0.000 description 1
- 101001050321 Homo sapiens Junctional adhesion molecule C Proteins 0.000 description 1
- 101001091205 Homo sapiens KiSS-1 receptor Proteins 0.000 description 1
- 101001043596 Homo sapiens Low-density lipoprotein receptor-related protein 3 Proteins 0.000 description 1
- 101001038507 Homo sapiens Ly6/PLAUR domain-containing protein 3 Proteins 0.000 description 1
- 101001065568 Homo sapiens Lymphocyte antigen 6E Proteins 0.000 description 1
- 101000628547 Homo sapiens Metalloreductase STEAP1 Proteins 0.000 description 1
- 101000946889 Homo sapiens Monocyte differentiation antigen CD14 Proteins 0.000 description 1
- 101001133056 Homo sapiens Mucin-1 Proteins 0.000 description 1
- 101000623901 Homo sapiens Mucin-16 Proteins 0.000 description 1
- 101000969763 Homo sapiens Myelin protein zero-like protein 1 Proteins 0.000 description 1
- 101001124388 Homo sapiens NPC intracellular cholesterol transporter 1 Proteins 0.000 description 1
- 101000581981 Homo sapiens Neural cell adhesion molecule 1 Proteins 0.000 description 1
- 101000601048 Homo sapiens Nidogen-2 Proteins 0.000 description 1
- 101000812677 Homo sapiens Nucleotide pyrophosphatase Proteins 0.000 description 1
- 101000720966 Homo sapiens Opsin-3 Proteins 0.000 description 1
- 101000605434 Homo sapiens Phospholipid phosphatase 2 Proteins 0.000 description 1
- 101000801640 Homo sapiens Phospholipid-transporting ATPase ABCA3 Proteins 0.000 description 1
- 101000841411 Homo sapiens Protein ecdysoneless homolog Proteins 0.000 description 1
- 101001134937 Homo sapiens Protocadherin alpha-10 Proteins 0.000 description 1
- 101001134801 Homo sapiens Protocadherin beta-2 Proteins 0.000 description 1
- 101000735377 Homo sapiens Protocadherin-7 Proteins 0.000 description 1
- 101001106420 Homo sapiens Reactive oxygen species modulator 1 Proteins 0.000 description 1
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 description 1
- 101000738771 Homo sapiens Receptor-type tyrosine-protein phosphatase C Proteins 0.000 description 1
- 101000651309 Homo sapiens Retinoic acid receptor responder protein 1 Proteins 0.000 description 1
- 101000650822 Homo sapiens Semaphorin-4B Proteins 0.000 description 1
- 101000693269 Homo sapiens Sphingosine 1-phosphate receptor 3 Proteins 0.000 description 1
- 101000648549 Homo sapiens Sushi domain-containing protein 4 Proteins 0.000 description 1
- 101000934346 Homo sapiens T-cell surface antigen CD2 Proteins 0.000 description 1
- 101000800116 Homo sapiens Thy-1 membrane glycoprotein Proteins 0.000 description 1
- 101000669460 Homo sapiens Toll-like receptor 5 Proteins 0.000 description 1
- 101001067250 Homo sapiens Transcription cofactor HES-6 Proteins 0.000 description 1
- 101000976959 Homo sapiens Transcription factor 4 Proteins 0.000 description 1
- 101000596771 Homo sapiens Transcription factor 7-like 2 Proteins 0.000 description 1
- 101000904724 Homo sapiens Transmembrane glycoprotein NMB Proteins 0.000 description 1
- 101000798702 Homo sapiens Transmembrane protease serine 4 Proteins 0.000 description 1
- 101000830596 Homo sapiens Tumor necrosis factor ligand superfamily member 15 Proteins 0.000 description 1
- 101000762128 Homo sapiens Tumor suppressor candidate 3 Proteins 0.000 description 1
- 101001135565 Homo sapiens Tyrosine-protein phosphatase non-receptor type 3 Proteins 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- 101100321817 Human parvovirus B19 (strain HV) 7.5K gene Proteins 0.000 description 1
- WOBHKFSMXKNTIM-UHFFFAOYSA-N Hydroxyethyl methacrylate Chemical compound CC(=C)C(=O)OCCO WOBHKFSMXKNTIM-UHFFFAOYSA-N 0.000 description 1
- 101710123134 Ice-binding protein Proteins 0.000 description 1
- 101710082837 Ice-structuring protein Proteins 0.000 description 1
- XDXDZDZNSLXDNA-TZNDIEGXSA-N Idarubicin Chemical compound C1[C@H](N)[C@H](O)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2C[C@@](O)(C(C)=O)C1 XDXDZDZNSLXDNA-TZNDIEGXSA-N 0.000 description 1
- XDXDZDZNSLXDNA-UHFFFAOYSA-N Idarubicin Natural products C1C(N)C(O)C(C)OC1OC1C2=C(O)C(C(=O)C3=CC=CC=C3C3=O)=C3C(O)=C2CC(O)(C(C)=O)C1 XDXDZDZNSLXDNA-UHFFFAOYSA-N 0.000 description 1
- 108010073807 IgG Receptors Proteins 0.000 description 1
- 102000013463 Immunoglobulin Light Chains Human genes 0.000 description 1
- 108010065825 Immunoglobulin Light Chains Proteins 0.000 description 1
- 206010061218 Inflammation Diseases 0.000 description 1
- 102100025305 Integrin alpha-2 Human genes 0.000 description 1
- 102100032816 Integrin alpha-6 Human genes 0.000 description 1
- 102100025304 Integrin beta-1 Human genes 0.000 description 1
- 108010002352 Interleukin-1 Proteins 0.000 description 1
- 102100039880 Interleukin-1 receptor accessory protein Human genes 0.000 description 1
- 102100026016 Interleukin-1 receptor type 1 Human genes 0.000 description 1
- 102000004889 Interleukin-6 Human genes 0.000 description 1
- 108090001005 Interleukin-6 Proteins 0.000 description 1
- 102100023429 Junctional adhesion molecule C Human genes 0.000 description 1
- 102100034845 KiSS-1 receptor Human genes 0.000 description 1
- AHLPHDHHMVZTML-BYPYZUCNSA-N L-Ornithine Chemical compound NCCC[C@H](N)C(O)=O AHLPHDHHMVZTML-BYPYZUCNSA-N 0.000 description 1
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 1
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- 125000000998 L-alanino group Chemical group [H]N([*])[C@](C([H])([H])[H])([H])C(=O)O[H] 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 1
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 1
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- 125000000174 L-prolyl group Chemical group [H]N1C([H])([H])C([H])([H])C([H])([H])[C@@]1([H])C(*)=O 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 1
- 239000005551 L01XE03 - Erlotinib Substances 0.000 description 1
- 239000005511 L01XE05 - Sorafenib Substances 0.000 description 1
- 239000002118 L01XE12 - Vandetanib Substances 0.000 description 1
- 239000002146 L01XE16 - Crizotinib Substances 0.000 description 1
- 239000002177 L01XE27 - Ibrutinib Substances 0.000 description 1
- 101150017554 LGR5 gene Proteins 0.000 description 1
- 102100038235 Large neutral amino acids transporter small subunit 2 Human genes 0.000 description 1
- 244000207740 Lemna minor Species 0.000 description 1
- 235000006439 Lemna minor Nutrition 0.000 description 1
- 229920001491 Lentinan Polymers 0.000 description 1
- NNJVILVZKWQKPM-UHFFFAOYSA-N Lidocaine Chemical compound CCN(CC)CC(=O)NC1=C(C)C=CC=C1C NNJVILVZKWQKPM-UHFFFAOYSA-N 0.000 description 1
- 206010024612 Lipoma Diseases 0.000 description 1
- 102100029204 Low affinity immunoglobulin gamma Fc region receptor II-a Human genes 0.000 description 1
- 102100029193 Low affinity immunoglobulin gamma Fc region receptor III-A Human genes 0.000 description 1
- 102100021917 Low-density lipoprotein receptor-related protein 3 Human genes 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- DDWFXDSYGUXRAY-UHFFFAOYSA-N Luciferin Natural products CCc1c(C)c(CC2NC(=O)C(=C2C=C)C)[nH]c1Cc3[nH]c4C(=C5/NC(CC(=O)O)C(C)C5CC(=O)O)CC(=O)c4c3C DDWFXDSYGUXRAY-UHFFFAOYSA-N 0.000 description 1
- 102100040281 Ly6/PLAUR domain-containing protein 3 Human genes 0.000 description 1
- 102100032131 Lymphocyte antigen 6E Human genes 0.000 description 1
- 238000012307 MRI technique Methods 0.000 description 1
- 241000282567 Macaca fascicularis Species 0.000 description 1
- 241000282560 Macaca mulatta Species 0.000 description 1
- 101710125418 Major capsid protein Proteins 0.000 description 1
- 206010026865 Mass Diseases 0.000 description 1
- 108010090306 Member 2 Subfamily G ATP Binding Cassette Transporter Proteins 0.000 description 1
- 102100026712 Metalloreductase STEAP1 Human genes 0.000 description 1
- 102000003792 Metallothionein Human genes 0.000 description 1
- 108090000157 Metallothionein Proteins 0.000 description 1
- 102100023174 Methionine aminopeptidase 2 Human genes 0.000 description 1
- 108090000192 Methionyl aminopeptidases Proteins 0.000 description 1
- 108091022875 Microtubule Proteins 0.000 description 1
- 102000029749 Microtubule Human genes 0.000 description 1
- 244000302512 Momordica charantia Species 0.000 description 1
- 235000009811 Momordica charantia Nutrition 0.000 description 1
- 102100035877 Monocyte differentiation antigen CD14 Human genes 0.000 description 1
- 102100034256 Mucin-1 Human genes 0.000 description 1
- 102100023123 Mucin-16 Human genes 0.000 description 1
- 241000699660 Mus musculus Species 0.000 description 1
- 101100058550 Mus musculus Bmi1 gene Proteins 0.000 description 1
- 101100477421 Mus musculus Sez6 gene Proteins 0.000 description 1
- 101100310657 Mus musculus Sox1 gene Proteins 0.000 description 1
- 102100021270 Myelin protein zero-like protein 1 Human genes 0.000 description 1
- 201000003793 Myelodysplastic syndrome Diseases 0.000 description 1
- 102000005717 Myeloma Proteins Human genes 0.000 description 1
- 108010045503 Myeloma Proteins Proteins 0.000 description 1
- OVRNDRQMDRJTHS-RTRLPJTCSA-N N-acetyl-D-glucosamine Chemical group CC(=O)N[C@H]1C(O)O[C@H](CO)[C@@H](O)[C@@H]1O OVRNDRQMDRJTHS-RTRLPJTCSA-N 0.000 description 1
- 102100023315 N-acetyllactosaminide beta-1,6-N-acetylglucosaminyl-transferase Human genes 0.000 description 1
- 108010056664 N-acetyllactosaminide beta-1,6-N-acetylglucosaminyltransferase Proteins 0.000 description 1
- 102100029565 NPC intracellular cholesterol transporter 1 Human genes 0.000 description 1
- 101150111783 NTRK1 gene Proteins 0.000 description 1
- 229930193140 Neomycin Natural products 0.000 description 1
- 108090000028 Neprilysin Proteins 0.000 description 1
- 102000003729 Neprilysin Human genes 0.000 description 1
- 108010025020 Nerve Growth Factor Proteins 0.000 description 1
- 108010088225 Nestin Proteins 0.000 description 1
- 102000008730 Nestin Human genes 0.000 description 1
- 102100027347 Neural cell adhesion molecule 1 Human genes 0.000 description 1
- 206010029260 Neuroblastoma Diseases 0.000 description 1
- 241000208125 Nicotiana Species 0.000 description 1
- 102100037371 Nidogen-2 Human genes 0.000 description 1
- KGTDRFCXGRULNK-UHFFFAOYSA-N Nogalamycin Natural products COC1C(OC)(C)C(OC)C(C)OC1OC1C2=C(O)C(C(=O)C3=C(O)C=C4C5(C)OC(C(C(C5O)N(C)C)O)OC4=C3C3=O)=C3C=C2C(C(=O)OC)C(C)(O)C1 KGTDRFCXGRULNK-UHFFFAOYSA-N 0.000 description 1
- 230000005913 Notch signaling pathway Effects 0.000 description 1
- 102100039306 Nucleotide pyrophosphatase Human genes 0.000 description 1
- 108020005187 Oligonucleotide Probes Proteins 0.000 description 1
- 102000004140 Oncostatin M Human genes 0.000 description 1
- 108090000630 Oncostatin M Proteins 0.000 description 1
- 102100025909 Opsin-3 Human genes 0.000 description 1
- AHLPHDHHMVZTML-UHFFFAOYSA-N Orn-delta-NH2 Natural products NCCCC(N)C(O)=O AHLPHDHHMVZTML-UHFFFAOYSA-N 0.000 description 1
- UTJLXEIPEHZYQJ-UHFFFAOYSA-N Ornithine Natural products OC(=O)C(C)CCCN UTJLXEIPEHZYQJ-UHFFFAOYSA-N 0.000 description 1
- 208000000035 Osteochondroma Diseases 0.000 description 1
- 101710160107 Outer membrane protein A Proteins 0.000 description 1
- 206010033128 Ovarian cancer Diseases 0.000 description 1
- 241000282579 Pan Species 0.000 description 1
- VREZDOWOLGNDPW-ALTGWBOUSA-N Pancratistatin Chemical compound C1=C2[C@H]3[C@@H](O)[C@H](O)[C@@H](O)[C@@H](O)[C@@H]3NC(=O)C2=C(O)C2=C1OCO2 VREZDOWOLGNDPW-ALTGWBOUSA-N 0.000 description 1
- VREZDOWOLGNDPW-MYVCAWNPSA-N Pancratistatin Natural products O=C1N[C@H]2[C@H](O)[C@H](O)[C@H](O)[C@H](O)[C@@H]2c2c1c(O)c1OCOc1c2 VREZDOWOLGNDPW-MYVCAWNPSA-N 0.000 description 1
- 108020002230 Pancreatic Ribonuclease Proteins 0.000 description 1
- 102000005891 Pancreatic ribonuclease Human genes 0.000 description 1
- 206010033701 Papillary thyroid cancer Diseases 0.000 description 1
- 206010033799 Paralysis Diseases 0.000 description 1
- 206010033963 Parathyroid tumour Diseases 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- CWRVKFFCRWGWCS-UHFFFAOYSA-N Pentrazole Chemical compound C1CCCCC2=NN=NN21 CWRVKFFCRWGWCS-UHFFFAOYSA-N 0.000 description 1
- 102000057297 Pepsin A Human genes 0.000 description 1
- 108090000284 Pepsin A Proteins 0.000 description 1
- 108091093037 Peptide nucleic acid Proteins 0.000 description 1
- RFCVXVPWSPOMFJ-STQMWFEESA-N Phe-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 RFCVXVPWSPOMFJ-STQMWFEESA-N 0.000 description 1
- 208000016012 Phenotypic abnormality Diseases 0.000 description 1
- 102100038120 Phospholipid phosphatase 2 Human genes 0.000 description 1
- 102100033616 Phospholipid-transporting ATPase ABCA1 Human genes 0.000 description 1
- 102100033623 Phospholipid-transporting ATPase ABCA3 Human genes 0.000 description 1
- 241000219506 Phytolacca Species 0.000 description 1
- 101100413173 Phytolacca americana PAP2 gene Proteins 0.000 description 1
- 241000235648 Pichia Species 0.000 description 1
- KMSKQZKKOZQFFG-HSUXVGOQSA-N Pirarubicin Chemical compound O([C@H]1[C@@H](N)C[C@@H](O[C@H]1C)O[C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1CCCCO1 KMSKQZKKOZQFFG-HSUXVGOQSA-N 0.000 description 1
- 208000007913 Pituitary Neoplasms Diseases 0.000 description 1
- 108010038512 Platelet-Derived Growth Factor Proteins 0.000 description 1
- 102000010780 Platelet-Derived Growth Factor Human genes 0.000 description 1
- 229920000805 Polyaspartic acid Polymers 0.000 description 1
- 239000002202 Polyethylene glycol Substances 0.000 description 1
- 239000004793 Polystyrene Substances 0.000 description 1
- 235000001855 Portulaca oleracea Nutrition 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- 102100024924 Protein kinase C alpha type Human genes 0.000 description 1
- 101710109947 Protein kinase C alpha type Proteins 0.000 description 1
- 102100033412 Protocadherin alpha-10 Human genes 0.000 description 1
- 102100033437 Protocadherin beta-2 Human genes 0.000 description 1
- 102100034941 Protocadherin-7 Human genes 0.000 description 1
- 241000589516 Pseudomonas Species 0.000 description 1
- 101000762949 Pseudomonas aeruginosa (strain ATCC 15692 / DSM 22644 / CIP 104116 / JCM 14847 / LMG 12228 / 1C / PRS 101 / PAO1) Exotoxin A Proteins 0.000 description 1
- 108020005067 RNA Splice Sites Proteins 0.000 description 1
- 108091008103 RNA aptamers Proteins 0.000 description 1
- 239000013614 RNA sample Substances 0.000 description 1
- 102100021423 Reactive oxygen species modulator 1 Human genes 0.000 description 1
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 description 1
- 102100037422 Receptor-type tyrosine-protein phosphatase C Human genes 0.000 description 1
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 1
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 1
- 102100027682 Retinoic acid receptor responder protein 1 Human genes 0.000 description 1
- OWPCHSCAPHNHAV-UHFFFAOYSA-N Rhizoxin Natural products C1C(O)C2(C)OC2C=CC(C)C(OC(=O)C2)CC2CC2OC2C(=O)OC1C(C)C(OC)C(C)=CC=CC(C)=CC1=COC(C)=N1 OWPCHSCAPHNHAV-UHFFFAOYSA-N 0.000 description 1
- AUVVAXYIELKVAI-UHFFFAOYSA-N SJ000285215 Natural products N1CCC2=CC(OC)=C(OC)C=C2C1CC1CC2C3=CC(OC)=C(OC)C=C3CCN2CC1CC AUVVAXYIELKVAI-UHFFFAOYSA-N 0.000 description 1
- 108091006780 SLC19A2 Proteins 0.000 description 1
- 102000012979 SLC1A1 Human genes 0.000 description 1
- 108091006930 SLC39A1 Proteins 0.000 description 1
- 102000016681 SLC4A Proteins Human genes 0.000 description 1
- 108091006267 SLC4A11 Proteins 0.000 description 1
- 108060007753 SLC6A14 Proteins 0.000 description 1
- 102000005032 SLC6A14 Human genes 0.000 description 1
- 108091006238 SLC7A8 Proteins 0.000 description 1
- 108010017324 STAT3 Transcription Factor Proteins 0.000 description 1
- 241000235070 Saccharomyces Species 0.000 description 1
- 240000003946 Saponaria officinalis Species 0.000 description 1
- 102100027717 Semaphorin-4B Human genes 0.000 description 1
- 206010070834 Sensitisation Diseases 0.000 description 1
- 229920002684 Sepharose Polymers 0.000 description 1
- 201000001880 Sexual dysfunction Diseases 0.000 description 1
- 102100024040 Signal transducer and activator of transcription 3 Human genes 0.000 description 1
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 1
- 108020004682 Single-Stranded DNA Proteins 0.000 description 1
- 229920000519 Sizofiran Polymers 0.000 description 1
- 208000000453 Skin Neoplasms Diseases 0.000 description 1
- 108091027967 Small hairpin RNA Proteins 0.000 description 1
- 208000021712 Soft tissue sarcoma Diseases 0.000 description 1
- 244000061456 Solanum tuberosum Species 0.000 description 1
- 235000002595 Solanum tuberosum Nutrition 0.000 description 1
- 102100038803 Somatotropin Human genes 0.000 description 1
- 102100025747 Sphingosine 1-phosphate receptor 3 Human genes 0.000 description 1
- 108010090804 Streptavidin Proteins 0.000 description 1
- 241000187747 Streptomyces Species 0.000 description 1
- ZSJLQEPLLKMAKR-UHFFFAOYSA-N Streptozotocin Natural products O=NN(C)C(=O)NC1C(O)OC(CO)C(O)C1O ZSJLQEPLLKMAKR-UHFFFAOYSA-N 0.000 description 1
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 1
- 102100028860 Sushi domain-containing protein 4 Human genes 0.000 description 1
- 108091008874 T cell receptors Proteins 0.000 description 1
- BXFOFFBJRFZBQZ-QYWOHJEZSA-N T-2 toxin Chemical compound C([C@@]12[C@]3(C)[C@H](OC(C)=O)[C@@H](O)[C@H]1O[C@H]1[C@]3(COC(C)=O)C[C@@H](C(=C1)C)OC(=O)CC(C)C)O2 BXFOFFBJRFZBQZ-QYWOHJEZSA-N 0.000 description 1
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 description 1
- 102100025237 T-cell surface antigen CD2 Human genes 0.000 description 1
- 101150057140 TACSTD1 gene Proteins 0.000 description 1
- CGMTUJFWROPELF-UHFFFAOYSA-N Tenuazonic acid Natural products CCC(C)C1NC(=O)C(=C(C)/O)C1=O CGMTUJFWROPELF-UHFFFAOYSA-N 0.000 description 1
- WDLRUFUQRNWCPK-UHFFFAOYSA-N Tetraxetan Chemical compound OC(=O)CN1CCN(CC(O)=O)CCN(CC(O)=O)CCN(CC(O)=O)CC1 WDLRUFUQRNWCPK-UHFFFAOYSA-N 0.000 description 1
- 102100030104 Thiamine transporter 1 Human genes 0.000 description 1
- GNVMUORYQLCPJZ-UHFFFAOYSA-M Thiocarbamate Chemical compound NC([S-])=O GNVMUORYQLCPJZ-UHFFFAOYSA-M 0.000 description 1
- FOCVUCIESVLUNU-UHFFFAOYSA-N Thiotepa Chemical compound C1CN1P(N1CC1)(=S)N1CC1 FOCVUCIESVLUNU-UHFFFAOYSA-N 0.000 description 1
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 1
- 239000004473 Threonine Substances 0.000 description 1
- 102100033523 Thy-1 membrane glycoprotein Human genes 0.000 description 1
- ATJFFYVFTNAWJD-UHFFFAOYSA-N Tin Chemical compound [Sn] ATJFFYVFTNAWJD-UHFFFAOYSA-N 0.000 description 1
- 102000003978 Tissue Plasminogen Activator Human genes 0.000 description 1
- 108090000373 Tissue Plasminogen Activator Proteins 0.000 description 1
- 241000723873 Tobacco mosaic virus Species 0.000 description 1
- 101710183280 Topoisomerase Proteins 0.000 description 1
- 101710120037 Toxin CcdB Proteins 0.000 description 1
- 102100034424 Transcription cofactor HES-6 Human genes 0.000 description 1
- 102100023489 Transcription factor 4 Human genes 0.000 description 1
- 108010033576 Transferrin Receptors Proteins 0.000 description 1
- 102100026144 Transferrin receptor protein 1 Human genes 0.000 description 1
- 102100033663 Transforming growth factor beta receptor type 3 Human genes 0.000 description 1
- 102100023935 Transmembrane glycoprotein NMB Human genes 0.000 description 1
- 102100032471 Transmembrane protease serine 4 Human genes 0.000 description 1
- UMILHIMHKXVDGH-UHFFFAOYSA-N Triethylene glycol diglycidyl ether Chemical compound C1OC1COCCOCCOCCOCC1CO1 UMILHIMHKXVDGH-UHFFFAOYSA-N 0.000 description 1
- WGLPBDUCMAPZCE-UHFFFAOYSA-N Trioxochromium Chemical compound O=[Cr](=O)=O WGLPBDUCMAPZCE-UHFFFAOYSA-N 0.000 description 1
- 235000021307 Triticum Nutrition 0.000 description 1
- 244000098338 Triticum aestivum Species 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 1
- 102100024587 Tumor necrosis factor ligand superfamily member 15 Human genes 0.000 description 1
- 102100031988 Tumor necrosis factor ligand superfamily member 6 Human genes 0.000 description 1
- 108050002568 Tumor necrosis factor ligand superfamily member 6 Proteins 0.000 description 1
- 102100024248 Tumor suppressor candidate 3 Human genes 0.000 description 1
- 108091005906 Type I transmembrane proteins Proteins 0.000 description 1
- 101710107540 Type-2 ice-structuring protein Proteins 0.000 description 1
- 102100033131 Tyrosine-protein phosphatase non-receptor type 3 Human genes 0.000 description 1
- GBOGMAARMMDZGR-UHFFFAOYSA-N UNPD149280 Natural products N1C(=O)C23OC(=O)C=CC(O)CCCC(C)CC=CC3C(O)C(=C)C(C)C2C1CC1=CC=CC=C1 GBOGMAARMMDZGR-UHFFFAOYSA-N 0.000 description 1
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 1
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 description 1
- 108010073929 Vascular Endothelial Growth Factor A Proteins 0.000 description 1
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 description 1
- 240000001866 Vernicia fordii Species 0.000 description 1
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 1
- 235000009754 Vitis X bourquina Nutrition 0.000 description 1
- 235000012333 Vitis X labruscana Nutrition 0.000 description 1
- 240000006365 Vitis vinifera Species 0.000 description 1
- 235000014787 Vitis vinifera Nutrition 0.000 description 1
- 240000008042 Zea mays Species 0.000 description 1
- 235000005824 Zea mays ssp. parviglumis Nutrition 0.000 description 1
- 235000002017 Zea mays subsp mays Nutrition 0.000 description 1
- 108010016200 Zinc Finger Protein GLI1 Proteins 0.000 description 1
- 108010088665 Zinc Finger Protein Gli2 Proteins 0.000 description 1
- 102100035535 Zinc finger protein GLI1 Human genes 0.000 description 1
- 102100035558 Zinc finger protein GLI2 Human genes 0.000 description 1
- 102100025452 Zinc transporter ZIP1 Human genes 0.000 description 1
- IFJUINDAXYAPTO-UUBSBJJBSA-N [(8r,9s,13s,14s,17s)-17-[2-[4-[4-[bis(2-chloroethyl)amino]phenyl]butanoyloxy]acetyl]oxy-13-methyl-6,7,8,9,11,12,14,15,16,17-decahydrocyclopenta[a]phenanthren-3-yl] benzoate Chemical compound C([C@@H]1[C@@H](C2=CC=3)CC[C@]4([C@H]1CC[C@@H]4OC(=O)COC(=O)CCCC=1C=CC(=CC=1)N(CCCl)CCCl)C)CC2=CC=3OC(=O)C1=CC=CC=C1 IFJUINDAXYAPTO-UUBSBJJBSA-N 0.000 description 1
- XZSRRNFBEIOBDA-CFNBKWCHSA-N [2-[(2s,4s)-4-[(2r,4s,5s,6s)-4-amino-5-hydroxy-6-methyloxan-2-yl]oxy-2,5,12-trihydroxy-7-methoxy-6,11-dioxo-3,4-dihydro-1h-tetracen-2-yl]-2-oxoethyl] 2,2-diethoxyacetate Chemical compound O([C@H]1C[C@](CC2=C(O)C=3C(=O)C4=CC=CC(OC)=C4C(=O)C=3C(O)=C21)(O)C(=O)COC(=O)C(OCC)OCC)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 XZSRRNFBEIOBDA-CFNBKWCHSA-N 0.000 description 1
- 229950005186 abagovomab Drugs 0.000 description 1
- 108010023617 abarelix Proteins 0.000 description 1
- AIWRTTMUVOZGPW-HSPKUQOVSA-N abarelix Chemical compound C([C@@H](C(=O)N[C@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCNC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N[C@H](C)C(N)=O)N(C)C(=O)[C@H](CO)NC(=O)[C@@H](CC=1C=NC=CC=1)NC(=O)[C@@H](CC=1C=CC(Cl)=CC=1)NC(=O)[C@@H](CC=1C=C2C=CC=CC2=CC=1)NC(C)=O)C1=CC=C(O)C=C1 AIWRTTMUVOZGPW-HSPKUQOVSA-N 0.000 description 1
- 229960002184 abarelix Drugs 0.000 description 1
- 206010000210 abortion Diseases 0.000 description 1
- 231100000176 abortion Toxicity 0.000 description 1
- ZOZKYEHVNDEUCO-XUTVFYLZSA-N aceglatone Chemical compound O1C(=O)[C@H](OC(C)=O)[C@@H]2OC(=O)[C@@H](OC(=O)C)[C@@H]21 ZOZKYEHVNDEUCO-XUTVFYLZSA-N 0.000 description 1
- 229950002684 aceglatone Drugs 0.000 description 1
- QUHYUSAHBDACNG-UHFFFAOYSA-N acerogenin 3 Natural products C1=CC(O)=CC=C1CCCCC(=O)CCC1=CC=C(O)C=C1 QUHYUSAHBDACNG-UHFFFAOYSA-N 0.000 description 1
- DHKHKXVYLBGOIT-UHFFFAOYSA-N acetaldehyde Diethyl Acetal Natural products CCOC(C)OCC DHKHKXVYLBGOIT-UHFFFAOYSA-N 0.000 description 1
- 150000001241 acetals Chemical class 0.000 description 1
- DPXJVFZANSGRMM-UHFFFAOYSA-N acetic acid;2,3,4,5,6-pentahydroxyhexanal;sodium Chemical compound [Na].CC(O)=O.OCC(O)C(O)C(O)C(O)C=O DPXJVFZANSGRMM-UHFFFAOYSA-N 0.000 description 1
- 125000002777 acetyl group Chemical group [H]C([H])([H])C(*)=O 0.000 description 1
- 229940022698 acetylcholinesterase Drugs 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 239000008186 active pharmaceutical agent Substances 0.000 description 1
- 125000004423 acyloxy group Chemical group 0.000 description 1
- 230000002730 additional effect Effects 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- 229950009084 adecatumumab Drugs 0.000 description 1
- 238000011360 adjunctive therapy Methods 0.000 description 1
- 210000004100 adrenal gland Anatomy 0.000 description 1
- 208000024447 adrenal gland neoplasm Diseases 0.000 description 1
- 229940009456 adriamycin Drugs 0.000 description 1
- 208000037842 advanced-stage tumor Diseases 0.000 description 1
- 239000000443 aerosol Substances 0.000 description 1
- 239000007801 affinity label Substances 0.000 description 1
- 238000005054 agglomeration Methods 0.000 description 1
- 229960003767 alanine Drugs 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- 238000012867 alanine scanning Methods 0.000 description 1
- 108700025316 aldesleukin Proteins 0.000 description 1
- 125000001931 aliphatic group Chemical group 0.000 description 1
- 229940045714 alkyl sulfonate alkylating agent Drugs 0.000 description 1
- 150000008052 alkyl sulfonates Chemical class 0.000 description 1
- 230000000172 allergic effect Effects 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 229950009106 altumomab Drugs 0.000 description 1
- WNROFYMDJYEPJX-UHFFFAOYSA-K aluminium hydroxide Chemical compound [OH-].[OH-].[OH-].[Al+3] WNROFYMDJYEPJX-UHFFFAOYSA-K 0.000 description 1
- 229950001537 amatuximab Drugs 0.000 description 1
- 230000009435 amidation Effects 0.000 description 1
- 238000007112 amidation reaction Methods 0.000 description 1
- 125000003368 amide group Chemical group 0.000 description 1
- 150000001408 amides Chemical class 0.000 description 1
- 229960002749 aminolevulinic acid Drugs 0.000 description 1
- STFSECMHVCFKFX-UHFFFAOYSA-N aminotin Chemical compound [Sn]N STFSECMHVCFKFX-UHFFFAOYSA-N 0.000 description 1
- 238000012870 ammonium sulfate precipitation Methods 0.000 description 1
- 229960001220 amsacrine Drugs 0.000 description 1
- XCPGHVQEEXUHNC-UHFFFAOYSA-N amsacrine Chemical compound COC1=CC(NS(C)(=O)=O)=CC=C1NC1=C(C=CC=C2)C2=NC2=CC=CC=C12 XCPGHVQEEXUHNC-UHFFFAOYSA-N 0.000 description 1
- 239000003098 androgen Substances 0.000 description 1
- 230000033115 angiogenesis Effects 0.000 description 1
- 239000003957 anion exchange resin Substances 0.000 description 1
- PYKYMHQGRFAEBM-UHFFFAOYSA-N anthraquinone Natural products CCC(=O)c1c(O)c2C(=O)C3C(C=CC=C3O)C(=O)c2cc1CC(=O)OC PYKYMHQGRFAEBM-UHFFFAOYSA-N 0.000 description 1
- 150000004056 anthraquinones Chemical class 0.000 description 1
- 230000002280 anti-androgenic effect Effects 0.000 description 1
- 230000006909 anti-apoptosis Effects 0.000 description 1
- 230000002424 anti-apoptotic effect Effects 0.000 description 1
- 229940046836 anti-estrogen Drugs 0.000 description 1
- 230000001833 anti-estrogenic effect Effects 0.000 description 1
- 230000000340 anti-metabolite Effects 0.000 description 1
- 230000002001 anti-metastasis Effects 0.000 description 1
- 230000001166 anti-perspirative effect Effects 0.000 description 1
- 230000002785 anti-thrombosis Effects 0.000 description 1
- 239000000051 antiandrogen Substances 0.000 description 1
- 229940030495 antiandrogen sex hormone and modulator of the genital system Drugs 0.000 description 1
- 230000009830 antibody antigen interaction Effects 0.000 description 1
- 210000000628 antibody-producing cell Anatomy 0.000 description 1
- 238000011319 anticancer therapy Methods 0.000 description 1
- 239000003146 anticoagulant agent Substances 0.000 description 1
- 230000000890 antigenic effect Effects 0.000 description 1
- 239000013059 antihormonal agent Substances 0.000 description 1
- 229940100197 antimetabolite Drugs 0.000 description 1
- 239000002256 antimetabolite Substances 0.000 description 1
- 239000003213 antiperspirant Substances 0.000 description 1
- 239000000074 antisense oligonucleotide Substances 0.000 description 1
- 238000012230 antisense oligonucleotides Methods 0.000 description 1
- 239000012736 aqueous medium Substances 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- 150000008209 arabinosides Chemical class 0.000 description 1
- 229950005725 arcitumomab Drugs 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 229960003121 arginine Drugs 0.000 description 1
- 235000009697 arginine Nutrition 0.000 description 1
- 239000003886 aromatase inhibitor Substances 0.000 description 1
- 229940046844 aromatase inhibitors Drugs 0.000 description 1
- 150000001491 aromatic compounds Chemical class 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- 238000009246 art therapy Methods 0.000 description 1
- 125000005418 aryl aryl group Chemical group 0.000 description 1
- 125000004104 aryloxy group Chemical group 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- FZCSTZYAHCUGEM-UHFFFAOYSA-N aspergillomarasmine B Natural products OC(=O)CNC(C(O)=O)CNC(C(O)=O)CC(O)=O FZCSTZYAHCUGEM-UHFFFAOYSA-N 0.000 description 1
- 210000001130 astrocyte Anatomy 0.000 description 1
- 208000010668 atopic eczema Diseases 0.000 description 1
- 230000003190 augmentative effect Effects 0.000 description 1
- 230000004009 axon guidance Effects 0.000 description 1
- 229950011321 azaserine Drugs 0.000 description 1
- 230000001580 bacterial effect Effects 0.000 description 1
- 229950007843 bavituximab Drugs 0.000 description 1
- 229950003269 bectumomab Drugs 0.000 description 1
- 230000006399 behavior Effects 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 108010087667 beta-1,4-mannosyl-glycoprotein beta-1,4-N-acetylglucosaminyltransferase Proteins 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- 150000001576 beta-amino acids Chemical class 0.000 description 1
- 108010079292 betaglycan Proteins 0.000 description 1
- 230000001588 bifunctional effect Effects 0.000 description 1
- 238000012575 bio-layer interferometry Methods 0.000 description 1
- 238000011325 biochemical measurement Methods 0.000 description 1
- 239000003124 biologic agent Substances 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 230000031018 biological processes and functions Effects 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 239000000090 biomarker Substances 0.000 description 1
- 238000001574 biopsy Methods 0.000 description 1
- 229950008548 bisantrene Drugs 0.000 description 1
- 229910052797 bismuth Inorganic materials 0.000 description 1
- JCXGWMGPZLAOME-UHFFFAOYSA-N bismuth atom Chemical compound [Bi] JCXGWMGPZLAOME-UHFFFAOYSA-N 0.000 description 1
- 150000004663 bisphosphonates Chemical class 0.000 description 1
- 229950002903 bivatuzumab Drugs 0.000 description 1
- 230000000740 bleeding effect Effects 0.000 description 1
- 229960001561 bleomycin Drugs 0.000 description 1
- 229960003008 blinatumomab Drugs 0.000 description 1
- 210000001124 body fluid Anatomy 0.000 description 1
- 239000010839 body fluid Substances 0.000 description 1
- 230000036760 body temperature Effects 0.000 description 1
- 210000001185 bone marrow Anatomy 0.000 description 1
- 150000005693 branched-chain amino acids Chemical class 0.000 description 1
- 210000000481 breast Anatomy 0.000 description 1
- 229960000455 brentuximab vedotin Drugs 0.000 description 1
- 229960005520 bryostatin Drugs 0.000 description 1
- MJQUEDHRCUIRLF-TVIXENOKSA-N bryostatin 1 Chemical compound C([C@@H]1CC(/[C@@H]([C@@](C(C)(C)/C=C/2)(O)O1)OC(=O)/C=C/C=C/CCC)=C\C(=O)OC)[C@H]([C@@H](C)O)OC(=O)C[C@H](O)C[C@@H](O1)C[C@H](OC(C)=O)C(C)(C)[C@]1(O)C[C@@H]1C\C(=C\C(=O)OC)C[C@H]\2O1 MJQUEDHRCUIRLF-TVIXENOKSA-N 0.000 description 1
- MUIWQCKLQMOUAT-AKUNNTHJSA-N bryostatin 20 Natural products COC(=O)C=C1C[C@@]2(C)C[C@]3(O)O[C@](C)(C[C@@H](O)CC(=O)O[C@](C)(C[C@@]4(C)O[C@](O)(CC5=CC(=O)O[C@]45C)C(C)(C)C=C[C@@](C)(C1)O2)[C@@H](C)O)C[C@H](OC(=O)C(C)(C)C)C3(C)C MUIWQCKLQMOUAT-AKUNNTHJSA-N 0.000 description 1
- 239000004067 bulking agent Substances 0.000 description 1
- 125000000484 butyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 108700002839 cactinomycin Proteins 0.000 description 1
- 229950009908 cactinomycin Drugs 0.000 description 1
- BBBFJLBPOGFECG-VJVYQDLKSA-N calcitonin Chemical compound N([C@H](C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N1[C@@H](CCC1)C(N)=O)C(C)C)C(=O)[C@@H]1CSSC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1 BBBFJLBPOGFECG-VJVYQDLKSA-N 0.000 description 1
- 229960004015 calcitonin Drugs 0.000 description 1
- 238000004422 calculation algorithm Methods 0.000 description 1
- 229940088954 camptosar Drugs 0.000 description 1
- 229940127093 camptothecin Drugs 0.000 description 1
- VSJKWCGYPAHWDS-FQEVSTJZSA-N camptothecin Chemical compound C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-FQEVSTJZSA-N 0.000 description 1
- 230000000711 cancerogenic effect Effects 0.000 description 1
- 229960004117 capecitabine Drugs 0.000 description 1
- 239000004202 carbamide Substances 0.000 description 1
- 125000005488 carboaryl group Chemical group 0.000 description 1
- 229910002091 carbon monoxide Inorganic materials 0.000 description 1
- 125000005587 carbonate group Chemical group 0.000 description 1
- 239000001768 carboxy methyl cellulose Substances 0.000 description 1
- 125000002843 carboxylic acid group Chemical group 0.000 description 1
- 231100000315 carcinogenic Toxicity 0.000 description 1
- 208000002458 carcinoid tumor Diseases 0.000 description 1
- 235000012730 carminic acid Nutrition 0.000 description 1
- XREUEWVEMYWFFA-CSKJXFQVSA-N carminomycin Chemical compound C1[C@H](N)[C@H](O)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=C(O)C=CC=C3C3=O)=C3C(O)=C2C[C@@](O)(C(C)=O)C1 XREUEWVEMYWFFA-CSKJXFQVSA-N 0.000 description 1
- 229930188550 carminomycin Natural products 0.000 description 1
- XREUEWVEMYWFFA-UHFFFAOYSA-N carminomycin I Natural products C1C(N)C(O)C(C)OC1OC1C2=C(O)C(C(=O)C3=C(O)C=CC=C3C3=O)=C3C(O)=C2CC(O)(C(C)=O)C1 XREUEWVEMYWFFA-UHFFFAOYSA-N 0.000 description 1
- 239000000679 carrageenan Substances 0.000 description 1
- 235000010418 carrageenan Nutrition 0.000 description 1
- 229920001525 carrageenan Polymers 0.000 description 1
- 229940113118 carrageenan Drugs 0.000 description 1
- 229950001725 carubicin Drugs 0.000 description 1
- 108010047060 carzinophilin Proteins 0.000 description 1
- 239000003729 cation exchange resin Substances 0.000 description 1
- 150000001768 cations Chemical class 0.000 description 1
- 229960000419 catumaxomab Drugs 0.000 description 1
- 230000001364 causal effect Effects 0.000 description 1
- CZTQZXZIADLWOZ-CRAIPNDOSA-N cefaloridine Chemical compound O=C([C@@H](NC(=O)CC=1SC=CC=1)[C@H]1SC2)N1C(C(=O)[O-])=C2C[N+]1=CC=CC=C1 CZTQZXZIADLWOZ-CRAIPNDOSA-N 0.000 description 1
- 210000005056 cell body Anatomy 0.000 description 1
- 230000022131 cell cycle Effects 0.000 description 1
- 230000030833 cell death Effects 0.000 description 1
- 230000010261 cell growth Effects 0.000 description 1
- 230000012292 cell migration Effects 0.000 description 1
- 239000002458 cell surface marker Substances 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 210000001638 cerebellum Anatomy 0.000 description 1
- 210000003710 cerebral cortex Anatomy 0.000 description 1
- 201000010881 cervical cancer Diseases 0.000 description 1
- 208000019065 cervical carcinoma Diseases 0.000 description 1
- 210000003679 cervix uteri Anatomy 0.000 description 1
- NDAYQJDHGXTBJL-MWWSRJDJSA-N chembl557217 Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](CC(C)C)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](CC(C)C)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](CC(C)C)NC(=O)[C@H](CC=3C4=CC=CC=C4NC=3)NC(=O)[C@@H](C(C)C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](C(C)C)NC(=O)[C@H](C)NC(=O)[C@H](NC(=O)CNC(=O)[C@@H](NC=O)C(C)C)CC(C)C)C(=O)NCCO)=CNC2=C1 NDAYQJDHGXTBJL-MWWSRJDJSA-N 0.000 description 1
- 239000013043 chemical agent Substances 0.000 description 1
- 239000002975 chemoattractant Substances 0.000 description 1
- 230000000973 chemotherapeutic effect Effects 0.000 description 1
- 238000002512 chemotherapy Methods 0.000 description 1
- 208000011654 childhood malignant neoplasm Diseases 0.000 description 1
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 1
- 229910052801 chlorine Inorganic materials 0.000 description 1
- 125000001309 chloro group Chemical group Cl* 0.000 description 1
- RCTYPNKXASFOBE-UHFFFAOYSA-M chloromercury Chemical compound [Hg]Cl RCTYPNKXASFOBE-UHFFFAOYSA-M 0.000 description 1
- 238000011098 chromatofocusing Methods 0.000 description 1
- 229910052804 chromium Inorganic materials 0.000 description 1
- 229910000423 chromium oxide Inorganic materials 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- GTZCVFVGUGFEME-HNQUOIGGSA-N cis-Aconitic acid Natural products OC(=O)C\C(C(O)=O)=C/C(O)=O GTZCVFVGUGFEME-HNQUOIGGSA-N 0.000 description 1
- GTZCVFVGUGFEME-IWQZZHSRSA-N cis-aconitic acid Chemical compound OC(=O)C\C(C(O)=O)=C\C(O)=O GTZCVFVGUGFEME-IWQZZHSRSA-N 0.000 description 1
- 229960001653 citalopram Drugs 0.000 description 1
- 229950006647 cixutumumab Drugs 0.000 description 1
- 210000000078 claw Anatomy 0.000 description 1
- 208000009060 clear cell adenocarcinoma Diseases 0.000 description 1
- 239000005515 coenzyme Substances 0.000 description 1
- 230000007278 cognition impairment Effects 0.000 description 1
- 229960001338 colchicine Drugs 0.000 description 1
- 210000001072 colon Anatomy 0.000 description 1
- 208000029742 colonic neoplasm Diseases 0.000 description 1
- 230000001332 colony forming effect Effects 0.000 description 1
- 239000013066 combination product Substances 0.000 description 1
- 229940127555 combination product Drugs 0.000 description 1
- 230000002301 combined effect Effects 0.000 description 1
- LGZKGOGODCLQHG-UHFFFAOYSA-N combretastatin Natural products C1=C(O)C(OC)=CC=C1CC(O)C1=CC(OC)=C(OC)C(OC)=C1 LGZKGOGODCLQHG-UHFFFAOYSA-N 0.000 description 1
- 230000000052 comparative effect Effects 0.000 description 1
- 230000006957 competitive inhibition Effects 0.000 description 1
- 230000024203 complement activation Effects 0.000 description 1
- 102000033815 complement binding proteins Human genes 0.000 description 1
- 108091009760 complement binding proteins Proteins 0.000 description 1
- 230000001010 compromised effect Effects 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 229950007276 conatumumab Drugs 0.000 description 1
- 230000003750 conditioning effect Effects 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 229920001577 copolymer Chemical group 0.000 description 1
- 229910052802 copper Inorganic materials 0.000 description 1
- 235000005822 corn Nutrition 0.000 description 1
- 239000007822 coupling agent Substances 0.000 description 1
- 229960005061 crizotinib Drugs 0.000 description 1
- KTEIFNKAUNYNJU-GFCCVEGCSA-N crizotinib Chemical compound O([C@H](C)C=1C(=C(F)C=CC=1Cl)Cl)C(C(=NC=1)N)=CC=1C(=C1)C=NN1C1CCNCC1 KTEIFNKAUNYNJU-GFCCVEGCSA-N 0.000 description 1
- 230000009260 cross reactivity Effects 0.000 description 1
- 210000004748 cultured cell Anatomy 0.000 description 1
- 238000005520 cutting process Methods 0.000 description 1
- ATDGTVJJHBUTRL-UHFFFAOYSA-N cyanogen bromide Chemical compound BrC#N ATDGTVJJHBUTRL-UHFFFAOYSA-N 0.000 description 1
- 208000031513 cyst Diseases 0.000 description 1
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 1
- 229960000684 cytarabine Drugs 0.000 description 1
- GBOGMAARMMDZGR-TYHYBEHESA-N cytochalasin B Chemical compound C([C@H]1[C@@H]2[C@@H](C([C@@H](O)[C@@H]3/C=C/C[C@H](C)CCC[C@@H](O)/C=C/C(=O)O[C@@]23C(=O)N1)=C)C)C1=CC=CC=C1 GBOGMAARMMDZGR-TYHYBEHESA-N 0.000 description 1
- GBOGMAARMMDZGR-JREHFAHYSA-N cytochalasin B Natural products C[C@H]1CCC[C@@H](O)C=CC(=O)O[C@@]23[C@H](C=CC1)[C@H](O)C(=C)[C@@H](C)[C@@H]2[C@H](Cc4ccccc4)NC3=O GBOGMAARMMDZGR-JREHFAHYSA-N 0.000 description 1
- 230000009089 cytolysis Effects 0.000 description 1
- 238000007822 cytometric assay Methods 0.000 description 1
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 1
- 229960003901 dacarbazine Drugs 0.000 description 1
- 229950007409 dacetuzumab Drugs 0.000 description 1
- 229960002482 dalotuzumab Drugs 0.000 description 1
- 229960002204 daratumumab Drugs 0.000 description 1
- 238000013480 data collection Methods 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 229960005052 demecolcine Drugs 0.000 description 1
- 210000001787 dendrite Anatomy 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 230000008021 deposition Effects 0.000 description 1
- 238000001212 derivatisation Methods 0.000 description 1
- URLVCROWVOSNPT-QTTMQESMSA-N desacetyluvaricin Natural products O=C1C(CCCCCCCCCCCC[C@@H](O)[C@H]2O[C@@H]([C@@H]3O[C@@H]([C@@H](O)CCCCCCCCCC)CC3)CC2)=C[C@H](C)O1 URLVCROWVOSNPT-QTTMQESMSA-N 0.000 description 1
- 230000018732 detection of tumor cell Effects 0.000 description 1
- 230000006866 deterioration Effects 0.000 description 1
- 229950003913 detorubicin Drugs 0.000 description 1
- 229950008962 detumomab Drugs 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- 238000000502 dialysis Methods 0.000 description 1
- WVYXNIXAMZOZFK-UHFFFAOYSA-N diaziquone Chemical compound O=C1C(NC(=O)OCC)=C(N2CC2)C(=O)C(NC(=O)OCC)=C1N1CC1 WVYXNIXAMZOZFK-UHFFFAOYSA-N 0.000 description 1
- 229950002389 diaziquone Drugs 0.000 description 1
- 235000014113 dietary fatty acids Nutrition 0.000 description 1
- 238000006471 dimerization reaction Methods 0.000 description 1
- 150000002019 disulfides Chemical class 0.000 description 1
- VSJKWCGYPAHWDS-UHFFFAOYSA-N dl-camptothecin Natural products C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)C5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-UHFFFAOYSA-N 0.000 description 1
- 239000003534 dna topoisomerase inhibitor Substances 0.000 description 1
- 239000002552 dosage form Substances 0.000 description 1
- 231100000673 dose–response relationship Toxicity 0.000 description 1
- 230000003828 downregulation Effects 0.000 description 1
- 229950009964 drozitumab Drugs 0.000 description 1
- 229940000406 drug candidate Drugs 0.000 description 1
- 239000003118 drug derivative Substances 0.000 description 1
- 229940126534 drug product Drugs 0.000 description 1
- 229940088679 drug related substance Drugs 0.000 description 1
- 238000002651 drug therapy Methods 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 229960005501 duocarmycin Drugs 0.000 description 1
- VQNATVDKACXKTF-XELLLNAOSA-N duocarmycin Chemical compound COC1=C(OC)C(OC)=C2NC(C(=O)N3C4=CC(=O)C5=C([C@@]64C[C@@H]6C3)C=C(N5)C(=O)OC)=CC2=C1 VQNATVDKACXKTF-XELLLNAOSA-N 0.000 description 1
- 229930184221 duocarmycin Natural products 0.000 description 1
- 229950011453 dusigitumab Drugs 0.000 description 1
- 229950000006 ecromeximab Drugs 0.000 description 1
- 230000002500 effect on skin Effects 0.000 description 1
- 229960002759 eflornithine Drugs 0.000 description 1
- 238000001962 electrophoresis Methods 0.000 description 1
- XOPYFXBZMVTEJF-PDACKIITSA-N eleutherobin Chemical compound C(/[C@H]1[C@H](C(=CC[C@@H]1C(C)C)C)C[C@@H]([C@@]1(C)O[C@@]2(C=C1)OC)OC(=O)\C=C\C=1N=CN(C)C=1)=C2\CO[C@@H]1OC[C@@H](O)[C@@H](O)[C@@H]1OC(C)=O XOPYFXBZMVTEJF-PDACKIITSA-N 0.000 description 1
- XOPYFXBZMVTEJF-UHFFFAOYSA-N eleutherobin Natural products C1=CC2(OC)OC1(C)C(OC(=O)C=CC=1N=CN(C)C=1)CC(C(=CCC1C(C)C)C)C1C=C2COC1OCC(O)C(O)C1OC(C)=O XOPYFXBZMVTEJF-UHFFFAOYSA-N 0.000 description 1
- 229950000549 elliptinium acetate Drugs 0.000 description 1
- 229960004137 elotuzumab Drugs 0.000 description 1
- AUVVAXYIELKVAI-CKBKHPSWSA-N emetine Chemical compound N1CCC2=CC(OC)=C(OC)C=C2[C@H]1C[C@H]1C[C@H]2C3=CC(OC)=C(OC)C=C3CCN2C[C@@H]1CC AUVVAXYIELKVAI-CKBKHPSWSA-N 0.000 description 1
- 229960002694 emetine Drugs 0.000 description 1
- AUVVAXYIELKVAI-UWBTVBNJSA-N emetine Natural products N1CCC2=CC(OC)=C(OC)C=C2[C@H]1C[C@H]1C[C@H]2C3=CC(OC)=C(OC)C=C3CCN2C[C@H]1CC AUVVAXYIELKVAI-UWBTVBNJSA-N 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 239000008393 encapsulating agent Substances 0.000 description 1
- 230000007368 endocrine function Effects 0.000 description 1
- 210000000750 endocrine system Anatomy 0.000 description 1
- 230000002357 endometrial effect Effects 0.000 description 1
- 210000004696 endometrium Anatomy 0.000 description 1
- 108010003914 endoproteinase Asp-N Proteins 0.000 description 1
- 210000002889 endothelial cell Anatomy 0.000 description 1
- 230000003511 endothelial effect Effects 0.000 description 1
- 239000002158 endotoxin Substances 0.000 description 1
- 239000007920 enema Substances 0.000 description 1
- 229940095399 enema Drugs 0.000 description 1
- JOZGNYDSEBIJDH-UHFFFAOYSA-N eniluracil Chemical compound O=C1NC=C(C#C)C(=O)N1 JOZGNYDSEBIJDH-UHFFFAOYSA-N 0.000 description 1
- 229950010213 eniluracil Drugs 0.000 description 1
- 229950010640 ensituximab Drugs 0.000 description 1
- 231100000655 enterotoxin Toxicity 0.000 description 1
- 229960004671 enzalutamide Drugs 0.000 description 1
- WXCXUHSOUPDCQV-UHFFFAOYSA-N enzalutamide Chemical compound C1=C(F)C(C(=O)NC)=CC=C1N1C(C)(C)C(=O)N(C=2C=C(C(C#N)=CC=2)C(F)(F)F)C1=S WXCXUHSOUPDCQV-UHFFFAOYSA-N 0.000 description 1
- 230000007071 enzymatic hydrolysis Effects 0.000 description 1
- 206010015037 epilepsy Diseases 0.000 description 1
- 230000001037 epileptic effect Effects 0.000 description 1
- 210000000981 epithelium Anatomy 0.000 description 1
- AAKJLRGGTJKAMG-UHFFFAOYSA-N erlotinib Chemical compound C=12C=C(OCCOC)C(OCCOC)=CC2=NC=NC=1NC1=CC=CC(C#C)=C1 AAKJLRGGTJKAMG-UHFFFAOYSA-N 0.000 description 1
- 229960001433 erlotinib Drugs 0.000 description 1
- 229950008579 ertumaxomab Drugs 0.000 description 1
- 210000003238 esophagus Anatomy 0.000 description 1
- 229940011871 estrogen Drugs 0.000 description 1
- 239000000262 estrogen Substances 0.000 description 1
- 239000000328 estrogen antagonist Substances 0.000 description 1
- 239000002834 estrogen receptor modulator Substances 0.000 description 1
- 229950009569 etaracizumab Drugs 0.000 description 1
- 238000012869 ethanol precipitation Methods 0.000 description 1
- 229960005542 ethidium bromide Drugs 0.000 description 1
- ZMMJGEGLRURXTF-UHFFFAOYSA-N ethidium bromide Chemical compound [Br-].C12=CC(N)=CC=C2C2=CC=C(N)C=C2[N+](CC)=C1C1=CC=CC=C1 ZMMJGEGLRURXTF-UHFFFAOYSA-N 0.000 description 1
- QSRLNKCNOLVZIR-KRWDZBQOSA-N ethyl (2s)-2-[[2-[4-[bis(2-chloroethyl)amino]phenyl]acetyl]amino]-4-methylsulfanylbutanoate Chemical compound CCOC(=O)[C@H](CCSC)NC(=O)CC1=CC=C(N(CCCl)CCCl)C=C1 QSRLNKCNOLVZIR-KRWDZBQOSA-N 0.000 description 1
- 125000001495 ethyl group Chemical group [H]C([H])([H])C([H])([H])* 0.000 description 1
- LVGKNOAMLMIIKO-QXMHVHEDSA-N ethyl oleate Chemical compound CCCCCCCC\C=C/CCCCCCCC(=O)OCC LVGKNOAMLMIIKO-QXMHVHEDSA-N 0.000 description 1
- 229940093471 ethyl oleate Drugs 0.000 description 1
- 229960005237 etoglucid Drugs 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 208000021045 exocrine pancreatic carcinoma Diseases 0.000 description 1
- 239000002095 exotoxin Substances 0.000 description 1
- 231100000776 exotoxin Toxicity 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 230000036251 extravasation Effects 0.000 description 1
- 229950009929 farletuzumab Drugs 0.000 description 1
- 229930195729 fatty acid Natural products 0.000 description 1
- 239000000194 fatty acid Substances 0.000 description 1
- 239000010685 fatty oil Substances 0.000 description 1
- 230000002349 favourable effect Effects 0.000 description 1
- 210000002950 fibroblast Anatomy 0.000 description 1
- 229950002846 ficlatuzumab Drugs 0.000 description 1
- 229950008085 figitumumab Drugs 0.000 description 1
- 239000012467 final product Substances 0.000 description 1
- 229950010320 flanvotumab Drugs 0.000 description 1
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 1
- 125000001153 fluoro group Chemical group F* 0.000 description 1
- 229960002949 fluorouracil Drugs 0.000 description 1
- JYEFSHLLTQIXIO-SMNQTINBSA-N folfiri regimen Chemical compound FC1=CNC(=O)NC1=O.C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1.C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 JYEFSHLLTQIXIO-SMNQTINBSA-N 0.000 description 1
- VVIAGPKUTFNRDU-ABLWVSNPSA-N folinic acid Chemical compound C1NC=2NC(N)=NC(=O)C=2N(C=O)C1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 VVIAGPKUTFNRDU-ABLWVSNPSA-N 0.000 description 1
- 235000008191 folinic acid Nutrition 0.000 description 1
- 239000011672 folinic acid Substances 0.000 description 1
- 230000022244 formylation Effects 0.000 description 1
- 238000006170 formylation reaction Methods 0.000 description 1
- 238000005194 fractionation Methods 0.000 description 1
- 210000005153 frontal cortex Anatomy 0.000 description 1
- 125000002446 fucosyl group Chemical group C1([C@@H](O)[C@H](O)[C@H](O)[C@@H](O1)C)* 0.000 description 1
- 229950002140 futuximab Drugs 0.000 description 1
- 229940044658 gallium nitrate Drugs 0.000 description 1
- 229960003692 gamma aminobutyric acid Drugs 0.000 description 1
- 229950004896 ganitumab Drugs 0.000 description 1
- 230000002496 gastric effect Effects 0.000 description 1
- 239000000499 gel Substances 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 229940020967 gemzar Drugs 0.000 description 1
- 102000034356 gene-regulatory proteins Human genes 0.000 description 1
- 108091006104 gene-regulatory proteins Proteins 0.000 description 1
- 210000004392 genitalia Anatomy 0.000 description 1
- 238000003205 genotyping method Methods 0.000 description 1
- 210000004602 germ cell Anatomy 0.000 description 1
- 229950002026 girentuximab Drugs 0.000 description 1
- 230000000762 glandular Effects 0.000 description 1
- 229950000918 glembatumumab Drugs 0.000 description 1
- 239000003862 glucocorticoid Substances 0.000 description 1
- 229930182478 glucoside Natural products 0.000 description 1
- 150000008131 glucosides Chemical class 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 229960002743 glutamine Drugs 0.000 description 1
- 235000004554 glutamine Nutrition 0.000 description 1
- 102000005396 glutamine synthetase Human genes 0.000 description 1
- 108020002326 glutamine synthetase Proteins 0.000 description 1
- 108020004445 glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 1
- 102000006602 glyceraldehyde-3-phosphate dehydrogenase Human genes 0.000 description 1
- 229960002449 glycine Drugs 0.000 description 1
- 229930182470 glycoside Natural products 0.000 description 1
- 229940097068 glyphosate Drugs 0.000 description 1
- XDDAORKBJWWYJS-UHFFFAOYSA-M glyphosate(1-) Chemical compound OP(O)(=O)CNCC([O-])=O XDDAORKBJWWYJS-UHFFFAOYSA-M 0.000 description 1
- 239000008187 granular material Substances 0.000 description 1
- 239000003102 growth factor Substances 0.000 description 1
- 239000000122 growth hormone Substances 0.000 description 1
- 150000004820 halides Chemical class 0.000 description 1
- 229910052736 halogen Inorganic materials 0.000 description 1
- 150000002367 halogens Chemical group 0.000 description 1
- 230000035876 healing Effects 0.000 description 1
- 210000002216 heart Anatomy 0.000 description 1
- 239000000185 hemagglutinin Substances 0.000 description 1
- 208000014951 hematologic disease Diseases 0.000 description 1
- 210000003958 hematopoietic stem cell Anatomy 0.000 description 1
- 229920000669 heparin Polymers 0.000 description 1
- 229960002897 heparin Drugs 0.000 description 1
- 125000004051 hexyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 229920006158 high molecular weight polymer Polymers 0.000 description 1
- 238000004128 high performance liquid chromatography Methods 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 229960002885 histidine Drugs 0.000 description 1
- 230000003054 hormonal effect Effects 0.000 description 1
- 102000047791 human ECD Human genes 0.000 description 1
- 102000047486 human GAPDH Human genes 0.000 description 1
- 102000056080 human SEZ6L2 Human genes 0.000 description 1
- 208000033519 human immunodeficiency virus infectious disease Diseases 0.000 description 1
- 239000003906 humectant Substances 0.000 description 1
- 150000007857 hydrazones Chemical class 0.000 description 1
- 125000004435 hydrogen atom Chemical group [H]* 0.000 description 1
- QAOWNCQODCNURD-UHFFFAOYSA-M hydrogensulfate Chemical class OS([O-])(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-M 0.000 description 1
- 230000007062 hydrolysis Effects 0.000 description 1
- WGCNASOHLSPBMP-UHFFFAOYSA-N hydroxyacetaldehyde Natural products OCC=O WGCNASOHLSPBMP-UHFFFAOYSA-N 0.000 description 1
- 238000012872 hydroxylapatite chromatography Methods 0.000 description 1
- 230000003463 hyperproliferative effect Effects 0.000 description 1
- 210000003016 hypothalamus Anatomy 0.000 description 1
- 229960001001 ibritumomab tiuxetan Drugs 0.000 description 1
- 229960001507 ibrutinib Drugs 0.000 description 1
- XYFPWWZEPKGCCK-GOSISDBHSA-N ibrutinib Chemical compound C1=2C(N)=NC=NC=2N([C@H]2CN(CCC2)C(=O)C=C)N=C1C(C=C1)=CC=C1OC1=CC=CC=C1 XYFPWWZEPKGCCK-GOSISDBHSA-N 0.000 description 1
- 229960000908 idarubicin Drugs 0.000 description 1
- 229950002200 igovomab Drugs 0.000 description 1
- 229950005646 imgatuzumab Drugs 0.000 description 1
- 150000002463 imidates Chemical class 0.000 description 1
- 150000003949 imides Chemical class 0.000 description 1
- 238000007654 immersion Methods 0.000 description 1
- 230000002519 immonomodulatory effect Effects 0.000 description 1
- 230000036737 immune function Effects 0.000 description 1
- 208000026278 immune system disease Diseases 0.000 description 1
- 238000003119 immunoblot Methods 0.000 description 1
- 238000013115 immunohistochemical detection Methods 0.000 description 1
- 230000002055 immunohistochemical effect Effects 0.000 description 1
- 238000011532 immunohistochemical staining Methods 0.000 description 1
- 230000001771 impaired effect Effects 0.000 description 1
- 238000012606 in vitro cell culture Methods 0.000 description 1
- 206010021654 increased appetite Diseases 0.000 description 1
- 239000000411 inducer Substances 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 230000002757 inflammatory effect Effects 0.000 description 1
- 230000004054 inflammatory process Effects 0.000 description 1
- 206010022000 influenza Diseases 0.000 description 1
- 238000011081 inoculation Methods 0.000 description 1
- 229910052500 inorganic mineral Inorganic materials 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 238000007689 inspection Methods 0.000 description 1
- 229940100601 interleukin-6 Drugs 0.000 description 1
- 230000006525 intracellular process Effects 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- 238000005342 ion exchange Methods 0.000 description 1
- 238000004255 ion exchange chromatography Methods 0.000 description 1
- 229950010939 iratumumab Drugs 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 1
- 229960000310 isoleucine Drugs 0.000 description 1
- 125000004551 isoquinolin-3-yl group Chemical group C1=NC(=CC2=CC=CC=C12)* 0.000 description 1
- 150000002540 isothiocyanates Chemical class 0.000 description 1
- 238000005304 joining Methods 0.000 description 1
- 150000002576 ketones Chemical class 0.000 description 1
- 108010045069 keyhole-limpet hemocyanin Proteins 0.000 description 1
- 210000003292 kidney cell Anatomy 0.000 description 1
- 238000011813 knockout mouse model Methods 0.000 description 1
- 229950000518 labetuzumab Drugs 0.000 description 1
- 201000003445 large cell neuroendocrine carcinoma Diseases 0.000 description 1
- 239000000787 lecithin Substances 0.000 description 1
- 235000010445 lecithin Nutrition 0.000 description 1
- 229940067606 lecithin Drugs 0.000 description 1
- 229940115286 lentinan Drugs 0.000 description 1
- 229960001691 leucovorin Drugs 0.000 description 1
- 229950002884 lexatumumab Drugs 0.000 description 1
- 229960004194 lidocaine Drugs 0.000 description 1
- 108020001756 ligand binding domains Proteins 0.000 description 1
- 238000007798 limiting dilution analysis Methods 0.000 description 1
- 229950002950 lintuzumab Drugs 0.000 description 1
- 206010024627 liposarcoma Diseases 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 201000007270 liver cancer Diseases 0.000 description 1
- 201000002250 liver carcinoma Diseases 0.000 description 1
- 208000014018 liver neoplasm Diseases 0.000 description 1
- 238000011068 loading method Methods 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- YROQEQPFUCPDCP-UHFFFAOYSA-N losoxantrone Chemical compound OCCNCCN1N=C2C3=CC=CC(O)=C3C(=O)C3=C2C1=CC=C3NCCNCCO YROQEQPFUCPDCP-UHFFFAOYSA-N 0.000 description 1
- 229950008745 losoxantrone Drugs 0.000 description 1
- 229950004563 lucatumumab Drugs 0.000 description 1
- HWYHZTIRURJOHG-UHFFFAOYSA-N luminol Chemical compound O=C1NNC(=O)C2=C1C(N)=CC=C2 HWYHZTIRURJOHG-UHFFFAOYSA-N 0.000 description 1
- 201000005296 lung carcinoma Diseases 0.000 description 1
- RVFGKBWWUQOIOU-NDEPHWFRSA-N lurtotecan Chemical compound O=C([C@]1(O)CC)OCC(C(N2CC3=4)=O)=C1C=C2C3=NC1=CC=2OCCOC=2C=C1C=4CN1CCN(C)CC1 RVFGKBWWUQOIOU-NDEPHWFRSA-N 0.000 description 1
- 229950002654 lurtotecan Drugs 0.000 description 1
- 210000004324 lymphatic system Anatomy 0.000 description 1
- 230000000527 lymphocytic effect Effects 0.000 description 1
- 239000006166 lysate Substances 0.000 description 1
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 229920002521 macromolecule Polymers 0.000 description 1
- 230000005291 magnetic effect Effects 0.000 description 1
- 208000030883 malignant astrocytoma Diseases 0.000 description 1
- 210000001161 mammalian embryo Anatomy 0.000 description 1
- MQXVYODZCMMZEM-ZYUZMQFOSA-N mannomustine Chemical compound ClCCNC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CNCCCl MQXVYODZCMMZEM-ZYUZMQFOSA-N 0.000 description 1
- 229950008612 mannomustine Drugs 0.000 description 1
- 229950001869 mapatumumab Drugs 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 229950008001 matuzumab Drugs 0.000 description 1
- 235000013372 meat Nutrition 0.000 description 1
- 239000002609 medium Substances 0.000 description 1
- 238000002844 melting Methods 0.000 description 1
- 230000008018 melting Effects 0.000 description 1
- 150000002739 metals Chemical class 0.000 description 1
- 238000003358 metastasis assay Methods 0.000 description 1
- 208000011645 metastatic carcinoma Diseases 0.000 description 1
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 description 1
- WSFSSNUMVMOOMR-NJFSPNSNSA-N methanone Chemical compound O=[14CH2] WSFSSNUMVMOOMR-NJFSPNSNSA-N 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 229960004452 methionine Drugs 0.000 description 1
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 1
- HPNSFSBZBAHARI-UHFFFAOYSA-N micophenolic acid Natural products OC1=C(CC=C(C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-UHFFFAOYSA-N 0.000 description 1
- 238000012775 microarray technology Methods 0.000 description 1
- 210000004688 microtubule Anatomy 0.000 description 1
- 230000005012 migration Effects 0.000 description 1
- 238000013508 migration Methods 0.000 description 1
- 229950003734 milatuzumab Drugs 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 235000010755 mineral Nutrition 0.000 description 1
- 239000011707 mineral Substances 0.000 description 1
- 230000002438 mitochondrial effect Effects 0.000 description 1
- MXWHMTNPTTVWDM-NXOFHUPFSA-N mitoguazone Chemical compound NC(N)=N\N=C(/C)\C=N\N=C(N)N MXWHMTNPTTVWDM-NXOFHUPFSA-N 0.000 description 1
- 229960003539 mitoguazone Drugs 0.000 description 1
- VFKZTMPDYBFSTM-GUCUJZIJSA-N mitolactol Chemical compound BrC[C@H](O)[C@@H](O)[C@@H](O)[C@H](O)CBr VFKZTMPDYBFSTM-GUCUJZIJSA-N 0.000 description 1
- 229950010913 mitolactol Drugs 0.000 description 1
- 230000011278 mitosis Effects 0.000 description 1
- 230000000394 mitotic effect Effects 0.000 description 1
- 229950003063 mitumomab Drugs 0.000 description 1
- 230000004879 molecular function Effects 0.000 description 1
- 125000004573 morpholin-4-yl group Chemical group N1(CCOCC1)* 0.000 description 1
- 210000003097 mucus Anatomy 0.000 description 1
- HPNSFSBZBAHARI-RUDMXATFSA-N mycophenolic acid Chemical compound OC1=C(C\C=C(/C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-RUDMXATFSA-N 0.000 description 1
- 229960000951 mycophenolic acid Drugs 0.000 description 1
- ZTLGJPIZUOVDMT-UHFFFAOYSA-N n,n-dichlorotriazin-4-amine Chemical compound ClN(Cl)C1=CC=NN=N1 ZTLGJPIZUOVDMT-UHFFFAOYSA-N 0.000 description 1
- NJSMWLQOCQIOPE-OCHFTUDZSA-N n-[(e)-[10-[(e)-(4,5-dihydro-1h-imidazol-2-ylhydrazinylidene)methyl]anthracen-9-yl]methylideneamino]-4,5-dihydro-1h-imidazol-2-amine Chemical compound N1CCN=C1N\N=C\C(C1=CC=CC=C11)=C(C=CC=C2)C2=C1\C=N\NC1=NCCN1 NJSMWLQOCQIOPE-OCHFTUDZSA-N 0.000 description 1
- OWIUPIRUAQMTTK-UHFFFAOYSA-M n-aminocarbamate Chemical compound NNC([O-])=O OWIUPIRUAQMTTK-UHFFFAOYSA-M 0.000 description 1
- 210000000822 natural killer cell Anatomy 0.000 description 1
- 229930014626 natural product Natural products 0.000 description 1
- 229940086322 navelbine Drugs 0.000 description 1
- 229960000513 necitumumab Drugs 0.000 description 1
- QZGIWPZCWHMVQL-UIYAJPBUSA-N neocarzinostatin chromophore Chemical compound O1[C@H](C)[C@H](O)[C@H](O)[C@@H](NC)[C@H]1O[C@@H]1C/2=C/C#C[C@H]3O[C@@]3([C@@H]3OC(=O)OC3)C#CC\2=C[C@H]1OC(=O)C1=C(O)C=CC2=C(C)C=C(OC)C=C12 QZGIWPZCWHMVQL-UIYAJPBUSA-N 0.000 description 1
- 229960004927 neomycin Drugs 0.000 description 1
- 230000030363 nerve development Effects 0.000 description 1
- 229940053128 nerve growth factor Drugs 0.000 description 1
- 210000000653 nervous system Anatomy 0.000 description 1
- 210000005055 nestin Anatomy 0.000 description 1
- 210000004412 neuroendocrine cell Anatomy 0.000 description 1
- 230000004766 neurogenesis Effects 0.000 description 1
- 230000001272 neurogenic effect Effects 0.000 description 1
- 210000000607 neurosecretory system Anatomy 0.000 description 1
- 239000002858 neurotransmitter agent Substances 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 238000006386 neutralization reaction Methods 0.000 description 1
- 210000000440 neutrophil Anatomy 0.000 description 1
- 229950010203 nimotuzumab Drugs 0.000 description 1
- 125000000449 nitro group Chemical group [O-][N+](*)=O 0.000 description 1
- QJGQUHMNIGDVPM-UHFFFAOYSA-N nitrogen group Chemical group [N] QJGQUHMNIGDVPM-UHFFFAOYSA-N 0.000 description 1
- KGTDRFCXGRULNK-JYOBTZKQSA-N nogalamycin Chemical compound CO[C@@H]1[C@@](OC)(C)[C@@H](OC)[C@H](C)O[C@H]1O[C@@H]1C2=C(O)C(C(=O)C3=C(O)C=C4[C@@]5(C)O[C@H]([C@H]([C@@H]([C@H]5O)N(C)C)O)OC4=C3C3=O)=C3C=C2[C@@H](C(=O)OC)[C@@](C)(O)C1 KGTDRFCXGRULNK-JYOBTZKQSA-N 0.000 description 1
- 229950009266 nogalamycin Drugs 0.000 description 1
- 230000009701 normal cell proliferation Effects 0.000 description 1
- 238000001668 nucleic acid synthesis Methods 0.000 description 1
- 238000011330 nucleic acid test Methods 0.000 description 1
- 239000012038 nucleophile Substances 0.000 description 1
- 238000011580 nude mouse model Methods 0.000 description 1
- 229960003347 obinutuzumab Drugs 0.000 description 1
- 229950009090 ocaratuzumab Drugs 0.000 description 1
- 229960002450 ofatumumab Drugs 0.000 description 1
- 239000003921 oil Substances 0.000 description 1
- 235000019198 oils Nutrition 0.000 description 1
- 239000002674 ointment Substances 0.000 description 1
- 229950008516 olaratumab Drugs 0.000 description 1
- 210000000956 olfactory bulb Anatomy 0.000 description 1
- 239000002751 oligonucleotide probe Substances 0.000 description 1
- 229950000846 onartuzumab Drugs 0.000 description 1
- 231100000590 oncogenic Toxicity 0.000 description 1
- 230000002246 oncogenic effect Effects 0.000 description 1
- 238000004204 optical analysis method Methods 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 229950007283 oregovomab Drugs 0.000 description 1
- 230000005305 organ development Effects 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 229960003104 ornithine Drugs 0.000 description 1
- 150000002905 orthoesters Chemical class 0.000 description 1
- 239000012285 osmium tetroxide Substances 0.000 description 1
- 229910000489 osmium tetroxide Inorganic materials 0.000 description 1
- 230000003204 osmotic effect Effects 0.000 description 1
- 201000008968 osteosarcoma Diseases 0.000 description 1
- 230000002611 ovarian Effects 0.000 description 1
- 230000016087 ovulation Effects 0.000 description 1
- 230000003647 oxidation Effects 0.000 description 1
- 239000003002 pH adjusting agent Substances 0.000 description 1
- VREZDOWOLGNDPW-UHFFFAOYSA-N pancratistatine Natural products C1=C2C3C(O)C(O)C(O)C(O)C3NC(=O)C2=C(O)C2=C1OCO2 VREZDOWOLGNDPW-UHFFFAOYSA-N 0.000 description 1
- 210000000496 pancreas Anatomy 0.000 description 1
- 239000012188 paraffin wax Substances 0.000 description 1
- 230000005298 paramagnetic effect Effects 0.000 description 1
- 244000052769 pathogen Species 0.000 description 1
- 230000008506 pathogenesis Effects 0.000 description 1
- 230000001717 pathogenic effect Effects 0.000 description 1
- 239000013610 patient sample Substances 0.000 description 1
- 229950010966 patritumab Drugs 0.000 description 1
- 238000000059 patterning Methods 0.000 description 1
- 230000006320 pegylation Effects 0.000 description 1
- 229960005570 pemtumomab Drugs 0.000 description 1
- 230000035515 penetration Effects 0.000 description 1
- 229960005152 pentetrazol Drugs 0.000 description 1
- 229960002340 pentostatin Drugs 0.000 description 1
- FPVKHBSQESCIEP-JQCXWYLXSA-N pentostatin Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(N=CNC[C@H]2O)=C2N=C1 FPVKHBSQESCIEP-JQCXWYLXSA-N 0.000 description 1
- 229940111202 pepsin Drugs 0.000 description 1
- 239000000813 peptide hormone Substances 0.000 description 1
- 230000007030 peptide scission Effects 0.000 description 1
- KHIWWQKSHDUIBK-UHFFFAOYSA-N periodic acid Chemical compound OI(=O)(=O)=O KHIWWQKSHDUIBK-UHFFFAOYSA-N 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 230000002688 persistence Effects 0.000 description 1
- 230000002085 persistent effect Effects 0.000 description 1
- 229940124531 pharmaceutical excipient Drugs 0.000 description 1
- 108010076042 phenomycin Proteins 0.000 description 1
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 1
- 229960005190 phenylalanine Drugs 0.000 description 1
- 108010073101 phenylalanylleucine Proteins 0.000 description 1
- 230000010399 physical interaction Effects 0.000 description 1
- 230000035479 physiological effects, processes and functions Effects 0.000 description 1
- OXNIZHLAWKMVMX-UHFFFAOYSA-N picric acid Chemical compound OC1=C([N+]([O-])=O)C=C([N+]([O-])=O)C=C1[N+]([O-])=O OXNIZHLAWKMVMX-UHFFFAOYSA-N 0.000 description 1
- 239000006187 pill Substances 0.000 description 1
- 229940126620 pintumomab Drugs 0.000 description 1
- 125000004193 piperazinyl group Chemical group 0.000 description 1
- 229960000952 pipobroman Drugs 0.000 description 1
- NJBFOOCLYDNZJN-UHFFFAOYSA-N pipobroman Chemical compound BrCCC(=O)N1CCN(C(=O)CCBr)CC1 NJBFOOCLYDNZJN-UHFFFAOYSA-N 0.000 description 1
- 229960001221 pirarubicin Drugs 0.000 description 1
- 208000010916 pituitary tumor Diseases 0.000 description 1
- 229940012957 plasmin Drugs 0.000 description 1
- 150000003057 platinum Chemical class 0.000 description 1
- 108700028325 pokeweed antiviral Proteins 0.000 description 1
- 229920001983 poloxamer Polymers 0.000 description 1
- 229920000747 poly(lactic acid) Polymers 0.000 description 1
- 229940065514 poly(lactide) Drugs 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 108010064470 polyaspartate Proteins 0.000 description 1
- 229920005862 polyol Polymers 0.000 description 1
- 150000003077 polyols Chemical class 0.000 description 1
- 229920002223 polystyrene Polymers 0.000 description 1
- 235000012015 potatoes Nutrition 0.000 description 1
- 239000000843 powder Substances 0.000 description 1
- 150000003141 primary amines Chemical class 0.000 description 1
- 229950009904 pritumumab Drugs 0.000 description 1
- 230000000750 progressive effect Effects 0.000 description 1
- 210000001176 projection neuron Anatomy 0.000 description 1
- 229940087463 proleukin Drugs 0.000 description 1
- 230000002035 prolonged effect Effects 0.000 description 1
- 229960003712 propranolol Drugs 0.000 description 1
- 125000001436 propyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 210000004129 prosencephalon Anatomy 0.000 description 1
- 201000001514 prostate carcinoma Diseases 0.000 description 1
- 235000019419 proteases Nutrition 0.000 description 1
- 230000001681 protective effect Effects 0.000 description 1
- 238000002818 protein evolution Methods 0.000 description 1
- 238000001742 protein purification Methods 0.000 description 1
- 230000017854 proteolysis Effects 0.000 description 1
- 230000002797 proteolythic effect Effects 0.000 description 1
- 229940024999 proteolytic enzymes for treatment of wounds and ulcers Drugs 0.000 description 1
- 230000002685 pulmonary effect Effects 0.000 description 1
- 201000001722 pulmonary large cell neuroendocrine carcinoma Diseases 0.000 description 1
- 150000003212 purines Chemical class 0.000 description 1
- 210000002763 pyramidal cell Anatomy 0.000 description 1
- 125000004076 pyridyl group Chemical group 0.000 description 1
- UOWVMDUEMSNCAV-WYENRQIDSA-N rachelmycin Chemical compound C1([C@]23C[C@@H]2CN1C(=O)C=1NC=2C(OC)=C(O)C4=C(C=2C=1)CCN4C(=O)C1=CC=2C=4CCN(C=4C(O)=C(C=2N1)OC)C(N)=O)=CC(=O)C1=C3C(C)=CN1 UOWVMDUEMSNCAV-WYENRQIDSA-N 0.000 description 1
- 229950011613 racotumomab Drugs 0.000 description 1
- 230000005855 radiation Effects 0.000 description 1
- 239000012857 radioactive material Substances 0.000 description 1
- 238000002601 radiography Methods 0.000 description 1
- 239000002287 radioligand Substances 0.000 description 1
- 229950011639 radretumab Drugs 0.000 description 1
- 102000016914 ras Proteins Human genes 0.000 description 1
- BMKDZUISNHGIBY-UHFFFAOYSA-N razoxane Chemical compound C1C(=O)NC(=O)CN1C(C)CN1CC(=O)NC(=O)C1 BMKDZUISNHGIBY-UHFFFAOYSA-N 0.000 description 1
- 229960000460 razoxane Drugs 0.000 description 1
- 230000007420 reactivation Effects 0.000 description 1
- 230000009257 reactivity Effects 0.000 description 1
- 230000008707 rearrangement Effects 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 206010038038 rectal cancer Diseases 0.000 description 1
- 208000020615 rectal carcinoma Diseases 0.000 description 1
- 208000016691 refractory malignant neoplasm Diseases 0.000 description 1
- 230000008439 repair process Effects 0.000 description 1
- 125000006853 reporter group Chemical group 0.000 description 1
- 230000008672 reprogramming Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 239000011347 resin Substances 0.000 description 1
- 229920005989 resin Polymers 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 210000001525 retina Anatomy 0.000 description 1
- 230000004254 retinal expression Effects 0.000 description 1
- 230000004243 retinal function Effects 0.000 description 1
- 238000004007 reversed phase HPLC Methods 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 201000009410 rhabdomyosarcoma Diseases 0.000 description 1
- OWPCHSCAPHNHAV-LMONGJCWSA-N rhizoxin Chemical compound C/C([C@H](OC)[C@@H](C)[C@@H]1C[C@H](O)[C@]2(C)O[C@@H]2/C=C/[C@@H](C)[C@]2([H])OC(=O)C[C@@](C2)(C[C@@H]2O[C@H]2C(=O)O1)[H])=C\C=C\C(\C)=C\C1=COC(C)=N1 OWPCHSCAPHNHAV-LMONGJCWSA-N 0.000 description 1
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 1
- 229950003238 rilotumumab Drugs 0.000 description 1
- 229950001808 robatumumab Drugs 0.000 description 1
- 229950004892 rodorubicin Drugs 0.000 description 1
- VHXNKPBCCMUMSW-FQEVSTJZSA-N rubitecan Chemical compound C1=CC([N+]([O-])=O)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 VHXNKPBCCMUMSW-FQEVSTJZSA-N 0.000 description 1
- 210000003296 saliva Anatomy 0.000 description 1
- 210000003079 salivary gland Anatomy 0.000 description 1
- 229930182947 sarcodictyin Natural products 0.000 description 1
- 229950007308 satumomab Drugs 0.000 description 1
- 238000009738 saturating Methods 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 230000011218 segmentation Effects 0.000 description 1
- 150000007659 semicarbazones Chemical class 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 230000008313 sensitization Effects 0.000 description 1
- 230000001235 sensitizing effect Effects 0.000 description 1
- 238000013207 serial dilution Methods 0.000 description 1
- 239000008159 sesame oil Substances 0.000 description 1
- 235000011803 sesame oil Nutrition 0.000 description 1
- 231100000872 sexual dysfunction Toxicity 0.000 description 1
- 229950008684 sibrotuzumab Drugs 0.000 description 1
- 239000000377 silicon dioxide Substances 0.000 description 1
- 229960003323 siltuximab Drugs 0.000 description 1
- 229950009513 simtuzumab Drugs 0.000 description 1
- 238000009097 single-agent therapy Methods 0.000 description 1
- 238000001542 size-exclusion chromatography Methods 0.000 description 1
- 229950001403 sizofiran Drugs 0.000 description 1
- 210000003491 skin Anatomy 0.000 description 1
- 201000000849 skin cancer Diseases 0.000 description 1
- 239000004055 small Interfering RNA Substances 0.000 description 1
- 235000019812 sodium carboxymethyl cellulose Nutrition 0.000 description 1
- 229920001027 sodium carboxymethylcellulose Polymers 0.000 description 1
- 239000001509 sodium citrate Substances 0.000 description 1
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 1
- 229950011267 solitomab Drugs 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 229960003787 sorafenib Drugs 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 201000011096 spinal cancer Diseases 0.000 description 1
- 210000000278 spinal cord Anatomy 0.000 description 1
- 208000014618 spinal cord cancer Diseases 0.000 description 1
- 229950006315 spirogermanium Drugs 0.000 description 1
- ICXJVZHDZFXYQC-UHFFFAOYSA-N spongistatin 1 Natural products OC1C(O2)(O)CC(O)C(C)C2CCCC=CC(O2)CC(O)CC2(O2)CC(OC)CC2CC(=O)C(C)C(OC(C)=O)C(C)C(=C)CC(O2)CC(C)(O)CC2(O2)CC(OC(C)=O)CC2CC(=O)OC2C(O)C(CC(=C)CC(O)C=CC(Cl)=C)OC1C2C ICXJVZHDZFXYQC-UHFFFAOYSA-N 0.000 description 1
- 230000007480 spreading Effects 0.000 description 1
- 238000003892 spreading Methods 0.000 description 1
- 208000017572 squamous cell neoplasm Diseases 0.000 description 1
- 102000009076 src-Family Kinases Human genes 0.000 description 1
- 108010087686 src-Family Kinases Proteins 0.000 description 1
- 230000010473 stable expression Effects 0.000 description 1
- 238000011255 standard chemotherapy Methods 0.000 description 1
- 239000007858 starting material Substances 0.000 description 1
- 238000007619 statistical method Methods 0.000 description 1
- 230000004936 stimulating effect Effects 0.000 description 1
- 125000001273 sulfonato group Chemical group [O-]S(*)(=O)=O 0.000 description 1
- 125000000472 sulfonyl group Chemical group *S(*)(=O)=O 0.000 description 1
- 239000011593 sulfur Substances 0.000 description 1
- 125000004434 sulfur atom Chemical group 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 239000000829 suppository Substances 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- 230000002459 sustained effect Effects 0.000 description 1
- 239000012730 sustained-release form Substances 0.000 description 1
- 239000006188 syrup Substances 0.000 description 1
- 235000020357 syrup Nutrition 0.000 description 1
- 238000007910 systemic administration Methods 0.000 description 1
- 229940037128 systemic glucocorticoids Drugs 0.000 description 1
- 210000001138 tear Anatomy 0.000 description 1
- 229950001289 tenatumomab Drugs 0.000 description 1
- NRUKOCRGYNPUPR-QBPJDGROSA-N teniposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@@H](OC[C@H]4O3)C=3SC=CC=3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 NRUKOCRGYNPUPR-QBPJDGROSA-N 0.000 description 1
- 229960001278 teniposide Drugs 0.000 description 1
- 229950010259 teprotumumab Drugs 0.000 description 1
- 210000001550 testis Anatomy 0.000 description 1
- GKCBAIGFKIBETG-UHFFFAOYSA-N tetracaine Chemical compound CCCCNC1=CC=C(C(=O)OCCN(C)C)C=C1 GKCBAIGFKIBETG-UHFFFAOYSA-N 0.000 description 1
- 229960002372 tetracaine Drugs 0.000 description 1
- 229940126622 therapeutic monoclonal antibody Drugs 0.000 description 1
- 125000000335 thiazolyl group Chemical group 0.000 description 1
- 150000007970 thio esters Chemical class 0.000 description 1
- CNHYKKNIIGEXAY-UHFFFAOYSA-N thiolan-2-imine Chemical compound N=C1CCCS1 CNHYKKNIIGEXAY-UHFFFAOYSA-N 0.000 description 1
- ATGUDZODTABURZ-UHFFFAOYSA-N thiolan-2-ylideneazanium;chloride Chemical compound Cl.N=C1CCCS1 ATGUDZODTABURZ-UHFFFAOYSA-N 0.000 description 1
- 229960001196 thiotepa Drugs 0.000 description 1
- 230000001732 thrombotic effect Effects 0.000 description 1
- 210000001541 thymus gland Anatomy 0.000 description 1
- 208000030045 thyroid gland papillary carcinoma Diseases 0.000 description 1
- 229950004742 tigatuzumab Drugs 0.000 description 1
- 230000008467 tissue growth Effects 0.000 description 1
- 229960000187 tissue plasminogen activator Drugs 0.000 description 1
- 238000011200 topical administration Methods 0.000 description 1
- 230000000699 topical effect Effects 0.000 description 1
- 229940044693 topoisomerase inhibitor Drugs 0.000 description 1
- 229960000303 topotecan Drugs 0.000 description 1
- UCFGDBYHRUNTLO-QHCPKHFHSA-N topotecan Chemical compound C1=C(O)C(CN(C)C)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 UCFGDBYHRUNTLO-QHCPKHFHSA-N 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 231100000041 toxicology testing Toxicity 0.000 description 1
- 238000012549 training Methods 0.000 description 1
- GTZCVFVGUGFEME-UHFFFAOYSA-N trans-aconitic acid Natural products OC(=O)CC(C(O)=O)=CC(O)=O GTZCVFVGUGFEME-UHFFFAOYSA-N 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 230000001296 transplacental effect Effects 0.000 description 1
- 230000032258 transport Effects 0.000 description 1
- 238000011269 treatment regimen Methods 0.000 description 1
- 150000003626 triacylglycerols Chemical class 0.000 description 1
- PXSOHRWMIRDKMP-UHFFFAOYSA-N triaziquone Chemical compound O=C1C(N2CC2)=C(N2CC2)C(=O)C=C1N1CC1 PXSOHRWMIRDKMP-UHFFFAOYSA-N 0.000 description 1
- 229960004560 triaziquone Drugs 0.000 description 1
- 238000009966 trimming Methods 0.000 description 1
- 229950010147 troxacitabine Drugs 0.000 description 1
- RXRGZNYSEHTMHC-BQBZGAKWSA-N troxacitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1O[C@@H](CO)OC1 RXRGZNYSEHTMHC-BQBZGAKWSA-N 0.000 description 1
- HDZZVAMISRMYHH-LITAXDCLSA-N tubercidin Chemical compound C1=CC=2C(N)=NC=NC=2N1[C@@H]1O[C@@H](CO)[C@H](O)[C@H]1O HDZZVAMISRMYHH-LITAXDCLSA-N 0.000 description 1
- 239000000439 tumor marker Substances 0.000 description 1
- 102000003390 tumor necrosis factor Human genes 0.000 description 1
- 208000017997 tumor of parathyroid gland Diseases 0.000 description 1
- 230000005760 tumorsuppression Effects 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- 229940121358 tyrosine kinase inhibitor Drugs 0.000 description 1
- 239000005483 tyrosine kinase inhibitor Substances 0.000 description 1
- 229950009811 ubenimex Drugs 0.000 description 1
- 229950004593 ublituximab Drugs 0.000 description 1
- 238000002604 ultrasonography Methods 0.000 description 1
- 238000009281 ultraviolet germicidal irradiation Methods 0.000 description 1
- ORHBXUUXSCNDEV-UHFFFAOYSA-N umbelliferone Chemical compound C1=CC(=O)OC2=CC(O)=CC=C21 ORHBXUUXSCNDEV-UHFFFAOYSA-N 0.000 description 1
- HFTAFOQKODTIJY-UHFFFAOYSA-N umbelliferone Natural products Cc1cc2C=CC(=O)Oc2cc1OCC=CC(C)(C)O HFTAFOQKODTIJY-UHFFFAOYSA-N 0.000 description 1
- 241000701447 unidentified baculovirus Species 0.000 description 1
- 241001515965 unidentified phage Species 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
- 150000003673 urethanes Chemical class 0.000 description 1
- 210000002700 urine Anatomy 0.000 description 1
- 206010046766 uterine cancer Diseases 0.000 description 1
- 208000012991 uterine carcinoma Diseases 0.000 description 1
- 239000004474 valine Substances 0.000 description 1
- LSGOVYNHVSXFFJ-UHFFFAOYSA-N vanadate(3-) Chemical compound [O-][V]([O-])([O-])=O LSGOVYNHVSXFFJ-UHFFFAOYSA-N 0.000 description 1
- 229960000241 vandetanib Drugs 0.000 description 1
- UHTHHESEBZOYNR-UHFFFAOYSA-N vandetanib Chemical compound COC1=CC(C(/N=CN2)=N/C=3C(=CC(Br)=CC=3)F)=C2C=C1OCC1CCN(C)CC1 UHTHHESEBZOYNR-UHFFFAOYSA-N 0.000 description 1
- 210000005166 vasculature Anatomy 0.000 description 1
- 239000003981 vehicle Substances 0.000 description 1
- 229950000815 veltuzumab Drugs 0.000 description 1
- 229960003862 vemurafenib Drugs 0.000 description 1
- GPXBXXGIAQBQNI-UHFFFAOYSA-N vemurafenib Chemical compound CCCS(=O)(=O)NC1=CC=C(F)C(C(=O)C=2C3=CC(=CN=C3NC=2)C=2C=CC(Cl)=CC=2)=C1F GPXBXXGIAQBQNI-UHFFFAOYSA-N 0.000 description 1
- 108700026220 vif Genes Proteins 0.000 description 1
- UGGWPQSBPIFKDZ-KOTLKJBCSA-N vindesine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(N)=O)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1N=C1[C]2C=CC=C1 UGGWPQSBPIFKDZ-KOTLKJBCSA-N 0.000 description 1
- 229960004355 vindesine Drugs 0.000 description 1
- CILBMBUYJCWATM-PYGJLNRPSA-N vinorelbine ditartrate Chemical compound OC(=O)[C@H](O)[C@@H](O)C(O)=O.OC(=O)[C@H](O)[C@@H](O)C(O)=O.C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC CILBMBUYJCWATM-PYGJLNRPSA-N 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
- 229950006959 vorsetuzumab Drugs 0.000 description 1
- 229950003511 votumumab Drugs 0.000 description 1
- 238000001262 western blot Methods 0.000 description 1
- 238000009736 wetting Methods 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
- 229940053867 xeloda Drugs 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
- 229950008250 zalutumumab Drugs 0.000 description 1
- 150000003751 zinc Chemical class 0.000 description 1
- UHVMMEOXYDMDKI-JKYCWFKZSA-L zinc;1-(5-cyanopyridin-2-yl)-3-[(1s,2s)-2-(6-fluoro-2-hydroxy-3-propanoylphenyl)cyclopropyl]urea;diacetate Chemical compound [Zn+2].CC([O-])=O.CC([O-])=O.CCC(=O)C1=CC=C(F)C([C@H]2[C@H](C2)NC(=O)NC=2N=CC(=CC=2)C#N)=C1O UHVMMEOXYDMDKI-JKYCWFKZSA-L 0.000 description 1
- 229950009268 zinostatin Drugs 0.000 description 1
- FBTUMDXHSRTGRV-ALTNURHMSA-N zorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(\C)=N\NC(=O)C=1C=CC=CC=1)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 FBTUMDXHSRTGRV-ALTNURHMSA-N 0.000 description 1
- 229960000641 zorubicin Drugs 0.000 description 1
- OFILNAORONITPV-ZUROAWGWSA-N ε-amanitin Chemical compound O=C1N[C@@H](CC(O)=O)C(=O)N2C[C@H](O)C[C@H]2C(=O)N[C@@H]([C@@H](C)[C@H](C)O)C(=O)N[C@@H](C2)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@H]1CS(=O)C1=C2C2=CC=C(O)C=C2N1 OFILNAORONITPV-ZUROAWGWSA-N 0.000 description 1
Images








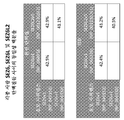











































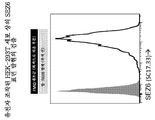


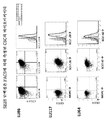

















Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
-
- A61K47/48561—
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
- A61K47/68035—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates the drug being a pyrrolobenzodiazepine
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6843—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a material from animals or humans
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6849—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a receptor, a cell surface antigen or a cell surface determinant
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P5/00—Drugs for disorders of the endocrine system
- A61P5/14—Drugs for disorders of the endocrine system of the thyroid hormones, e.g. T3, T4
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/574—Immunoassay; Biospecific binding assay; Materials therefor for cancer
- G01N33/57407—Specifically defined cancers
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/574—Immunoassay; Biospecific binding assay; Materials therefor for cancer
- G01N33/57407—Specifically defined cancers
- G01N33/57423—Specifically defined cancers of lung
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/33—Crossreactivity, e.g. for species or epitope, or lack of said crossreactivity
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/34—Identification of a linear epitope shorter than 20 amino acid residues or of a conformational epitope defined by amino acid residues
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/77—Internalization into the cell
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Engineering & Computer Science (AREA)
- Immunology (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Molecular Biology (AREA)
- Organic Chemistry (AREA)
- Hematology (AREA)
- Biomedical Technology (AREA)
- Urology & Nephrology (AREA)
- Biochemistry (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Cell Biology (AREA)
- Epidemiology (AREA)
- General Physics & Mathematics (AREA)
- Analytical Chemistry (AREA)
- Biotechnology (AREA)
- Hospice & Palliative Care (AREA)
- Pathology (AREA)
- Microbiology (AREA)
- Oncology (AREA)
- Food Science & Technology (AREA)
- Physics & Mathematics (AREA)
- Genetics & Genomics (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biophysics (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Zoology (AREA)
- Diabetes (AREA)
- Endocrinology (AREA)
- Peptides Or Proteins (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
Abstract
항체 및 이들의 유도체를 포함하는 신규한 조절물질 및 증식성 장애를 치료하기 위해 상기 조절물질을 사용하는 방법이 제공된다.
Description
상호 참조 출원
본 출원은, 2013년 8월 28일에 출원된 미국 가특허 출원 제61/871,289호의 우선권을 주장하고, 이의 전문은 본원에 참조로 인용된다.
서열목록
본 출원은, EFS-Web을 통해 ASCII 포맷으로 제출되었던 서열목록을 포함하고, 이의 전문은이 본원에 참조로 인용된다. 2014년 8월 27일에 생성된 상기 ASCII 사본은 "S69697 1130WO SEQL 082714 for filing"이라고 명명되고 462,073 바이트의 크기이다.
본 발명의 분야
본 출원은 일반적으로 신규한 화합물, 조성물 및 증식성 장애와 이들의 임의의 확대, 재발, 도짐 또는 전이를 진단, 예방, 치료 또는 개선하는데 있어서의 이들의 사용방법에 관한 것이다. 광범위한 양상에서, 본 발명은, 신생물 장애의 치료, 진단 또는 예방을 위한 항-SEZ6 항체 및 융합 작제물을 포함하는 발작 관련 6 상동체(seizure related 6 homolog, SEZ6) 조절물질의 용도에 관한 것이다. 본 발명의 선택된 실시형태는, 바람직하게는 종양 개시 세포 출현빈도의 감소를 포함하는 악성종양의 면역치료학적 치료를 위한, 항체 약물 접합체를 포함하는 상기 SEZ6 조절물질의 용도를 제공한다. 본 발명의 특히 바람직한 실시형태는, 특정 에피토프와 회합하는 조절물질, 및 갑상선 수질암, 소세포 폐암에 걸린 환자 개체군 및 백금계 제제의 치료 기준에 내성이 있는 환자와 같은 소정 환자 개체군을 치료하기 위한 개시된 조절물질의 용도를 포함한다.
줄기 및 전구 세포 분화 및 세포 증식은 기관형성 동안의 조직 성장 및 모든 살아있는 유기체들의 일생 동안의 대부분 조직들의 세포 교체와 수복(repair)을 지지하기 위해 협력해서 작용하는 정상적으로 계속 진행되는 과정들이다. 정상적으로 발생하는 사건들의 과정에서 세포 분화와 증식은 세포 운명 결정과 조직 구성을 유지하기 위해 일반적으로 균형을 맞추고 있는 수많은 인자들과 신호들에 의해 제어된다. 따라서, 크게 보아 세포 분열과 조직 성숙을 조절하는 것은 유기체의 필요에 따라 신호들을 적절하게 발생시키고 있는 이러한 제어된 미세환경(microenvironment)이다. 이와 관련하여 세포 증식과 분화는 손상되었거나 죽어가는 세포들의 교체에 또는 성장에 필요할 때에만 정상적으로 일어난다. 불행하게도, 세포 증식 및/또는 분화의 중단(disruption)은, 예를 들면, 각종 신호전달 화학물질들의 과소 또는 과다, 변경된 미세환경의 존재, 유전자 돌연변이들 또는 이들의 몇몇의 조합을 포함하는 무수한 인자들로부터 초래될 수 있다. 정상 세포 증식 및/또는 분화가 교란되거나 어떤 이유로든 중단되면 암과 같은 증식성 장애를 포함하는 질환이나 장애를 유도할 수 있다.
암의 종래 치료법들로는 화학치료요법, 방사선치료요법, 수술, 면역치료요법(예를 들면, 생물학적 반응 변형제(modifier), 백신 또는 표적 치료제) 또는 이들의 조합이 포함된다. 불행하게도, 소정 암들은 이러한 치료법들에 반응하지 않거나 최소한으로 반응한다. 예를 들면, 몇몇 환자들에서 종양은 선택된 치료요법의 일반적인 유효성에도 불구하고 종양을 비-반응성으로 만드는 유전자 돌연변이를 나타낸다. 게다가, 암의 유형 및 이것이 취한 형태에 따라 몇몇 이용가능한 치료법들, 예를 들면, 수술은 실행가능한 대안들이 아닐 수 있다. 현재 기준의 치유 치료제에 내재된 한계는 전에 치료를 받았고 이후 재발한 환자들을 치료하려고 할 때 특히 명백하다. 상기한 경우들에서 실패한 치료학적 용법과 이로 얻어진 환자 악화는 종종 결국에는 난치(incurable)로 판명되는 비교적 공격적인 질환을 나타내는 불응성(refractroy) 종양에 기여할 수 있다. 여러 해에 걸쳐 암의 진단과 치료에 커다란 개선들이 있었지만, 많은 고형 종양들의 전체적인 생존율은 기존 치료요법들이 도짐, 종양 재발 및 전이를 예방하지 못하고 있기 때문에 크게 변화되지 않았다. 따라서, 증식성 장애의 더욱 표적화된 그리고 강력한 치료요법들을 개발하려는 도전은 여전히 남아 있다.
본 발명의 요약
상기 목적 및 그 밖의 목적들은, 넓은 의미에서, SEZ6 관련 장애(예를 들면, 증식성 장애 또는 신생물 장애)의 치료에 사용될 수 있는 방법, 화합물, 조성물 및 제조 물품에 관한 본 발명에 의해 제공된다. 이러한 목적을 위해, 본 발명은 종양 세포 및/또는 암 줄기 세포를 효과적으로 표적화하며 광범하게 다양한 악성종양에 걸린 환자들을 치료하는데 사용될 수 있는 신규한 발작 관련 6 상동체(또는 SEZ6) 조절물질을 제공한다. 본원에 더욱 자세하게 논의될 것이지만, 적어도 2개의 천연 발생 SEZ6 이소형(isoform) 또는 변이체(variant)가 있으며 개시된 조절물질은 하나의 이소형 또는 다른 하나의 이소형 또는 둘 다를 포함하거나 선택적으로 회합할 수 있다. 게다가, 소정 실시형태들에서 개시된 SEZ6 조절물질은 하나 이상의 SEZ6 패밀리 구성원들(예를 들면, SEZ6L 또는 SEZ6L2)과 더 반응할 수 있거나, 다른 실시형태들에서는 오로지 SEZ6 이소형(들)과 회합하거나 반응하도록 생성되고 선택될 수 있다. 바람직한 실시형태들에서 본 발명은 더욱 구체적으로, 특히 바람직한 실시형태들에서는 하나 이상의 세포독성제 또는 치료학적 모이어티(therapeutic moiety), 예를 들면, 아우리스타틴, 아마니틴 및 피롤로벤조디아제핀에 회합되거나 접합되는 항체(즉, SEZ6의 적어도 하나의 이소형과 면역선택적으로 결합하거나, 반응하거나 또는 회합하는 항체)를 포함하는 단리된 SEZ6 조절물질에 관한 것이다. 게다가, 아래에 광범위하게 논의되는 바와 같이, 이러한 조절물질은 증식성 장애의 예방, 진단 또는 치료에 유용한 약제학적 조성물을 제공하는데 사용될 수 있다.
본 발명의 선택된 실시형태들에서, SEZ6 조절물질은, 단리된 형태이거나 또는 다른 모이어티들(예를 들면, Fc-SEZ6, PEG-SEZ6 또는 표적 모이어티와 회합된 SEZ6)과 융합되거나 회합된 SEZ6 폴리펩타이드 또는 이의 단편을 포함할 수 있다. 다른 선택된 실시형태들에서 SEZ6 조절물질은, 본 출원의 목적을 위하여, SEZ6을 인식하거나, 경쟁하거나, 상호작용하거나, 결합하거나 또는 회합하며 종양 개시 세포들을 포함하는 종양 세포들의 성장을 중화시키거나, 제거하거나, 감소시키거나, 감작화시키거나, 재프로그램화하거나, 억제하거나 또는 제어하는 임의의 작제물 또는 화합물을 의미하는 것으로 간주될 SEZ6 길항제들을 포함할 수 있다. 바람직한 실시형태들에서 본 발명의 SEZ6 조절물질은 종양 세포들의 생존, 재발, 재생 및/또는 전이를 전파시키거나, 유지하거나, 확대되거나, 증식하거나 또는 그렇지 않으면 촉진하는 종양 개시 세포들의 능력을 침묵시키거나, 중화하거나, 감소시키거나, 줄이거나, 고갈시키거나, 누그러지게 하거나, 감소시키거나, 재프로그램화하거나, 제거하거나, 또는 그렇지 않으면 억제하는 것으로 예상외로 발견된 항-SEZ6 항체, 또는 이들의 단편 또는 유도체를 포함한다. 특히 바람직한 실시형태들에서 상기 항체 또는 면역반응성 단편은 하나 이상의 항암제(예를 들면, 세포독성제)와 회합하거나, 또는 이에 접합될 수 있다.
상기 조절물질과 관련하여 적합한 항체는, 예를 들면, 폴리클로날 및 모노클로날 항체, 키메라, CDR 절편이식된, 사람화된 및 사람 항체 그리고 상기 각각의 면역반응성 단편 및/또는 변이체를 포함하는 여러 가지 형태들 중 어느 하나를 취할 수 있음을 알게 될 것이다. 바람직한 실시형태들에서는 사람화된 또는 완전한 사람 작제물과 같은 비교적 비-면역원성인 항체를 포함할 것이다. 물론, 본 개시의 관점에서 당해 분야의 숙련가라면 과도한 실험 없이 SEZ6 항체 조절물질의 중쇄 및 경쇄 가변 영역들과 회합하는 하나 이상의 상보성 결정 영역(complementarity determining region, CDR)을 용이하게 동정하며 이들 CDR을 사용하여 키메라, 사람화된 또는 CDR 절편이식된 항체를 조작처리하거나 제조할 수가 있을 것이다. 따라서, 소정 바람직한 실시형태들에서 SEZ6 조절물질은, 본원에 제시된 경쇄(도 10a) 또는 중쇄(도 10b) 연속 쇄 뮤린 가변 영역들(서열번호 20 내지 169)로부터 유도된 하나 이상의 CDR을 포함하는 항체를 포함한다. 또한, 사람 프레임워크를 가진 상기 CDR 절편이식된 가변 영역들과 이들의 변이체들도, 서열번호 170 내지 199를 포함하는 도 10에 나타낸다. 바람직한 실시형태들에서 이러한 항체들은 모노클로날 항체를 포함할 것이며, 더욱 더 바람직한 실시형태들에서는 키메라, CDR 절편이식된 또는 사람화된 항체를 포함할 것이다.
도 10a 및 도 10b에 제시된 아미노산 서열의 각각을 암호화하는 예시적인 핵산 서열은 첨부된 서열목록에 제시되어 있으며, 서열번호 220 내지 399를 포함한다. 이와 관련하여, 본 발명은 서열목록에 제시된 것들을 포함하는 개시된 항체 가변 영역 아미노산 서열들을 암호화하는 핵산 분자(및 관련 작제물, 벡터 및 숙주 세포)를 추가로 포함한다는 것도 알게 될 것이다.
더욱 구체적으로는, 선택된 실시형태들에서 적합한 SEZ6 조절물질은, 경쇄 가변 영역 및 중쇄 가변 영역을 갖는 항체를 포함할 수 있고, 여기서, 상기 경쇄 가변 영역은 서열번호 20, 서열번호 22, 서열번호 24, 서열번호 26, 서열번호 28, 서열번호 30, 서열번호 32, 서열번호 34, 서열번호 36, 서열번호 38, 서열번호 40, 서열번호 42, 서열번호 44, 서열번호 46, 서열번호 48, 서열번호 50, 서열번호 52, 서열번호 54, 서열번호 56, 서열번호 58, 서열번호 60, 서열번호 62, 서열번호 64, 서열번호 66, 서열번호 68, 서열번호 70, 서열번호 72, 서열번호 74, 서열번호 76, 서열번호 78, 서열번호 80, 서열번호 82, 서열번호 84, 서열번호 86, 서열번호 88, 서열번호 90, 서열번호 92, 서열번호 94, 서열번호 96, 서열번호 98, 서열번호 100, 서열번호 102, 서열번호 104, 서열번호 106, 서열번호 108, 서열번호 110, 서열번호 112, 서열번호 114, 서열번호 116, 서열번호 118, 서열번호 120, 서열번호 122, 서열번호 124, 서열번호 126, 서열번호 128, 서열번호 130, 서열번호 132, 서열번호 134, 서열번호 136, 서열번호 138, 서열번호 140, 서열번호 142, 서열번호 144, 서열번호 146, 서열번호 148, 서열번호 150, 서열번호 152, 서열번호 154, 서열번호 156, 서열번호 158, 서열번호 160, 서열번호 162 서열번호 164, 서열번호 166 및 서열번호 168에 제시된 아미노산 서열들로 이루어진 그룹으로부터 선택되는 아미노산 서열과 적어도 60%의 동일성을 갖는 아미노산 서열을 포함하며, 상기 중쇄 가변 영역은 서열번호 21, 서열번호 23, 서열번호 25, 서열번호 27, 서열번호 29, 서열번호 31, 서열번호 33, 서열번호 35, 서열번호 37, 서열번호 39, 서열번호 41, 서열번호 43, 서열번호 45, 서열번호 47, 서열번호 49, 서열번호 51 , 서열번호 53, 서열번호 55, 서열번호 57, 서열번호 59, 서열번호 61, 서열번호 63, 서열번호 65, 서열번호 67, 서열번호 69, 서열번호 71, 서열번호 73, 서열번호 75, 서열번호 77, 서열번호 79, 서열번호 81, 서열번호 83, 서열번호 85, 서열번호 87, 서열번호 89, 서열번호 91, 서열번호 93, 서열번호 95, 서열번호 97, 서열번호 99, 서열번호 101, 서열번호 103, 서열번호 105, 서열번호 107, 서열번호 109, 서열번호 111, 서열번호 113, 서열번호 115, 서열번호 117, 서열번호 119, 서열번호 121, 서열번호 123, 서열번호 125, 서열번호 127, 서열번호 129, 서열번호 131, 서열번호 133, 서열번호 135, 서열번호 137, 서열번호 139, 서열번호 141, 서열번호 143, 서열번호 145, 서열번호 147, 서열번호 149, 서열번호 151, 서열번호 153, 서열번호 155, 서열번호 157, 서열번호 159, 서열번호 161, 서열번호 163, 서열번호 165, 서열번호 167 및 서열번호 169에 제시된 아미노산 서열들로 이루어진 그룹으로부터 선택되는 아미노산 서열과 적어도 60%의 동일성을 갖는 아미노산 서열을 포함한다. 다른 바람직한 실시형태들에서 선택된 조절물질은 상기 언급된 뮤린 서열들과 65, 70, 75 또는 80%의 동일성을 포함하는 중쇄 및 경쇄 가변 영역을 포함할 것이다. 또 다른 실시형태들에서 상기 조절물질은 개시된 뮤린 서열들과 85, 90 또는 심지어 95%의 동일성을 포함하는 중쇄 및 경쇄 가변 영역을 포함할 것이다.
물론, 본원 개시의 관점에서 당해 분야의 숙련가들이라면 과도한 실험 없이 상기 언급된 중쇄 및 경쇄 가변 영역들의 각각과 회합된 CDR들을 용이하게 동정하며 이러한 CDR들을 사용하여 키메라, 사람화된 또는 CDR 절편이식된 항체를 조작처리하거나 제조할 수가 있을 것이다. 이와 관련하여 대상 중쇄 또는 경쇄 가변 영역 핵산 또는 아미노산 서열의 진입시 (통상적으로 사용되는 번호부여 시스템들 중 어느 하나에 따라) CDR 및 프레임워크 영역을 자동으로 명명하는 몇몇의 웹사이트 데이터베이스가 이용 가능하다. 이와 같이, 선택된 실시형태들에서 본 발명은 도 10a 또는 도 10b에 제시된 가변 영역 서열로부터 유도된 하나 이상의 CDR들을 포함하는 항-SEZ6 항체에 관한 것이다. 바람직한 실시형태들에서 이러한 항체는 모노클로날 항체를 포함할 것이며, 더욱 더 바람직한 실시형태들에서는 키메라, CDR 절편이식된 또는 사람화된 항체를 포함할 것이다. 아래에 더욱 상세하게 논의되는 바와 같이 또 다른 실시형태들은 하나 이상의 세포독성제와 접합되거나 회합된 이러한 항체를 포함할 것이다.
본 발명의 다른 양상은 SC17.1, SC17.2, SC17.3, SC17.4, SC17.8, SC17.9, SC17.10, SC17.11, SC17.14, SC17.15, SC17.16, SC17.17, SC17.18, SC17.19, SC17.22, SC17.24, SC17.27, SC17.28, SC17.29, SC17.30, SC17.32, SC17.34, SC17.35, SC17.36, SC17.38, SC17.39, SC17.40, SC17.41, SC17.42, SC17.45, SC17.46, SC17.47, SC17.49, SC17.50, SC17.53, SC17.54, SC17.56, SC17.57, SC17.59, SC17.61, SC17.63, SC17.71, SC17.72, SC17.74, SC17.76, SC17.77, SC17.79, SC17.81, SC17.82, SC17.84, SC17.85, SC17.87, SC17.89, SC17.90, SC17.91, SC17.93, SC17.95, SC17.97, SC17.99, SC17.102, SC17.114, SC17.115, SC17.120, SC17.121, SC17.122, SC17.140, SC17.151, SC17.156, SC17.161, SC17.166, SC17.187, SC17.191, SC17.193, SC17.199 및 SC17.200으로부터 수득하거나 유도된 조절물질을 포함한다.
또 다른 적합한 실시형태들에서 본 발명은 CDR 절편이식된 또는 사람화된 SEZ6 조절물질 hSC17.16, hSC17.17, hSC17.24, hSC17.28, SC17.34, hSC17.46, SC17.151, SC17.155, SC17.156, SC17.161 및 SC17.200을 포함할 것이다. 또 다른 실시형태들은 사람화된 항체를 포함하는 SEZ6 조절물질에 관한 것이고, 여기서, 상기 사람화된 항체는 경쇄 가변 영역과 중쇄 가변 영역을 포함하고, 여기서, 상기 경쇄 가변 영역은 서열번호 170, 서열번호 172, 서열번호 174, 서열번호 176, 서열번호 178, 서열번호 180, 서열번호 182, 서열번호 184, 서열번호 186, 서열번호 188 및 서열번호 190에 제시된 아미노산 서열들로 이루어진 그룹으로부터 선택되는 아미노산 서열과 적어도 60%의 동일성을 갖는 아미노산 서열을 포함하고, 상기 중쇄 가변 영역은 서열번호 171, 서열번호 173, 서열번호 175, 서열번호 177, 서열번호 179 및 서열번호 181, 서열번호 183, 서열번호 185, 서열번호 187, 서열번호 189 및 서열번호 191에 제시된 아미노산 서열들로 이루어진 그룹으로부터 선택되는 아미노산 서열과 적어도 60%의 동일성을 갖는 아미노산 서열을 포함한다. 또한, 경쇄(서열번호 192) 및 중쇄(서열번호 193, 서열번호 194, 서열번호 195, 서열번호 196, 서열번호 197, 서열번호 198 및 서열번호 199) 가변 영역들의 소정의 사람화된 변이체들도 본원의 교시에 따라 제공된다. 더욱이, 바로 앞에 상기한 바와 같이 예시된 사람화된 중쇄 및 경쇄 가변 영역들을 암호화하는 핵산 서열들은 본원에 첨부된 서열목록에 서열번호 370 내지 399로서 제시되어 있다.
상기 언급된 양상들 외에도, 본 발명의 다른 바람직한 실시형태들은 (단독으로 또는 다른 약제학적 활성제와의 조합으로) 증식성 장애를 치료하는데 특히 효과적일 수 있는 조절물질 접합체를 제공하기 위한 하나 이상의 약물들 또는 치료학적 모이어티들(예를 들면, 아우리스타틴, 아마니틴 및 피롤로벤조디아제핀)과 회합되거나 접합된 SEZ6 조절물질을 포함할 것이다. 더욱 일반적으로는, 일단 본 발명의 조절물질이 제조되어 선택되었으면 이들은 약제학적 활성 또는 진단학적 모이어티 또는 생체적합성 변형제와 연결되거나, 융합되거나, (예를 들면, 공유결합적으로 또는 비공유결합적으로) 접합되거나 그렇지 않으면 회합될 수 있다. 본원에 사용되는 용어 "접합체(conjugate)" 또는 "조절물질 접합체(modulator conjugate)"또는 "항체 접합체(antibody conjugate)"는 광범위하게 사용될 것이며 회합 방법에 관계없이 개시된 조절물질과 회합된 임의의 생물학적으로 활성이거나 검출가능한 분자 또는 약물을 의미하는 것으로 간주될 것이다. 이와 관련하여 상기 접합체들은, 개시된 조절물질에 더하여, 펩타이드, 폴리펩타이드, 단백질, 생체내에서 (in vivo ) 활성제로 대사되는 프로드럭(prodrug), 폴리머, 핵산 분자, 소분자, 결합제, 모방제, 합성 약물, 무기 분자, 유기 분자 및 방사성 동위원소를 포함할 수 있는 것으로 이해될 것이다. 더욱이, 상기 나타낸 바와 같이 선택된 약물 또는 치료학적 모이어티는 조절물질과 공유결합적으로 또는 비공유결합적으로 회합되거나, 또는 연결될 수 있으며, 적어도 부분적으로는, 접합을 달성하는데 사용된 방법에 따라 다양한 화학양론적 몰 비를 나타낸다.
본 발명의 특히 바람직한 양상은 증식성 장애의 진단 및/또는 치료에 사용될 수 있는 항체 조절물질 접합체 또는 항체-약물 접합체를 포함할 것이다. 이러한 접합체는 식 M-[L-D]n으로 표시될 수 있고, 여기서, M은 개시된 조절물질 또는 표적 결합 모이어티를 나타내고, L은 임의의 링커 또는 링커 단위이고, D는 적합한 약물 또는 프로드럭이며, n은 약 1 내지 약 20의 정수이다. 문맥에서 달리 지시하지 않는 한, 용어들 "항체-약물 접합체(antibody-drug conjugate)" 또는 "ADC" 또는 식 M-[L-D]n은 치료학적 및 진단학적 모이어티 둘 다를 포함하는 접합체를 포함하는 것으로 간주될 것임도 알게 될 것이다. 이러한 실시형태들에서 항체-약물 접합체 화합물은 전형적으로 조절물질 단위(M)로서의 항-SEZ6, 치료학적 또는 진단학적 모이어티(D), 및 임의로 약물과 항원 결합제를 연결시켜 주는 링커(L)를 포함할 것이다. 조절물질은 치료학적 또는 진단학적 모이어티에 직접적으로 또는 간접적으로 접합될 수 있다. 링커로 치료학적 또는 진단학적 모이어티에 연결된 조절물질은 "간접적으로 접합"되었다고 하는 반면 링커의 부재 하에 치료학적 또는 진단학적 모이어티에 연결된 항체는 "직접적으로 접합"되었다고 한다. 바람직한 실시형태에서, 항체는 상기한 바와 같은 중쇄 및 경쇄 가변 영역들로부터의 적어도 하나의 CDR을 포함하는 SEZ6 mAb이다.
이전에 진술한 바와 같이 본 발명의 한 양상은 SEZ6 폴리펩타이드의 암 줄기 세포와의 예상외의 회합을 포함할 수 있다. 따라서, 소정의 다른 실시형태들에서 본 발명은 대상체에게 투여시 종양 개시 세포의 출현빈도를 감소시키는 SEZ6 조절물질을 포함할 것이다. 바람직하게는 출현빈도의 감소는 시험관내 또는 생체내 한계 희석 분석법을 사용하여 측정될 것이다. 특히 바람직한 실시형태들에서 상기 분석법은 살아있는 사람 종양 세포들의 면역손상된 마우스로의 이식을 포함하는 생 체내 한계 희석 분석법을 사용하여 수행될 수 있다. 대안으로, 살아있는 사람 종양 세포들의 시험관내 콜로니 지지 조건으로의 한계 희석 침착을 포함하는 시험관 내 한계 희석 분석법을 사용하여 수행될 수 있다. 둘 중의 어느 한 경우에서, 출현빈도 감소의 분석, 계산 또는 정량은 바람직하게는 정확한 계산을 제공하기 위해 뿌아송(Poisson) 분포 통계학의 사용을 포함할 것이다. 상기 정량화 방법이 바람직하지만, 유동 세포분석법 또는 면역조직화학과 같은 다른, 덜 노동 집약적인 방법들도 원하는 값들을 제공하는데 사용될 수 있으며, 따라서, 본 발명의 범위 내에 속하는 것으로 명백히 고려될 수 있음을 이해할 수 있을 것이다. 이러한 경우들에서 출현빈도의 감소는 종양 개시 세포들에 대하여 농후하게 되는 것으로 알려진 종양 세포 표면 마커들의 유동 세포 분석이나 면역조직화학적 검출을 이용하여 측정될 수 있다.
이와 같이, 본 발명의 다른 바람직한 실시형태는 SEZ6 관련 장애 치료를 필요로 하는 대상체에게 치료학적 유효량의 SEZ6 조절물질을 투여하여 종양 개시 세포들의 출현빈도를 감소시킴을 포함하는, SEZ6 관련 장애를 치료하는 방법을 포함한다. 바람직하게는 SEZ6 관련 장애는 신생물 장애를 포함한다. 또한, 종양 개시 세포 출현빈도의 감소는 바람직하게는 시험관내 또는 생체내 한계 희석 분석을 사용하여 측정될 것이다.
이와 관련하여, 본 발명은, SEZ6 면역원들이 각종 신생물형성의 병인에 연루되어 있는 종양 영속화 세포(즉, 암 줄기 세포)에 연관되어 있다는 발견에 적어도 부분적으로 기초한다는 것을 알게 될 것이다. 더욱 구체적으로, 본 출원은 각종의 예시적인 SEZ6 조절물질의 투여로 종양 개시 세포들에 의한 종양원성 신호전달을 매개하거나, 감소시키거나, 고갈시키거나, 억제하거나 또는 제거할 수 있다(즉, 종양 개시 세포들의 출현빈도를 감소시킬 수가 있다)는 사실을 예상외로 증명한다. 이러한 감소된 신호전달은, 종양 개시 세포들의 고갈, 중화, 감소, 제거, 재프로그래밍 또는 침묵에 의한 것이든 또는 종양 세포 형태학(예를 들면, 분화 유도, 생태적 적소(niche) 파괴)을 변형시킨 것이든 간에, 결국 종양생성, 종양 유지, 확대 및/또는 전이와 재발을 억제함으로써 SEZ6 관련 장애의 더욱 효과적인 치료를 가능하게 한다.
상기 언급된 암 줄기 세포와의 회합 이외에도, SEZ6 이소형이 신경내분비 특성들을 포함하는 종양의 성장, 재발 또는 전이 잠재성과 관련되어 있을 수 있다는 증거가 있다. 본 발명의 목적을 위하여 이러한 종양들은 신경내분비 종양(예를 들면, 소세포 폐암 및 갑상선 수질암) 및 가성(pseudo) 신경내분비 종양을 포함할 것이다. 본원에 기술된 신규한 SEZ6 조절물질을 사용하여 상기 종양원성 세포의 증식을 중재함으로써, 하나 이상의 메커니즘(즉, 종양 개시 세포 감소 및 종양원성 경로 신호전달의 중단)에 의한 장애를 개선시키거나 치료하여 부가적이거나 상승작용적인 효과들을 제공할 수 있다. 또 다른 바람직한 실시형태들은 조절물질 매개된 항암제를 전달하기 위한 세포 표면 SEZ6의 세포 내재화를 이용할 수 있다. 이와 관련하여 본 발명은 (각종 종양을 포함하는) SEZ6 관련 장애를 치료하기 위해 임의의 특정한 작용 메커니즘에 한정되지 않지만 개시된 조절물질의 광범위한 용도를 포함한다는 것을 알게 될 것이다.
따라서, 다른 실시형태들에서 본 발명은 개시된 조절물질을 필요로 하는 대상체에서 내분비 특성들을 포함하는 종양, 예를 들면, 소세포 폐암 및 갑상선 수질암을 치료하기 위한 개시된 조절물질의 용도를 포함할 것이다. 물론 동일 조절물질은 이러한 동일한 종양들의 예방, 예후, 진단, 치료진단, 억제 또는 유지 치료요법에 사용될 수 있다.
개시된 조절물질은 소세포 폐암 또는 갑상선 수질암에 걸린 환자를 치료하는데 효과적임이 추가로 발견되었다. 더욱이, 아래에 보다 상세하게 논의되고 실시예에 제시된 바와 같이 본 발명의 항-SEZ6 항체 및 항체 약물 접합체는 치료 기준 백금계 제제(예를 들면, 카보플라스틴, 시스플라스틴 또는 옥살리플라틴)에 내성인 소세포 폐암의 형태들에 걸린 환자와 같은 특정 환자 개체군을 치료하는데 특히 효과적이다. 따라서, 선택된 실시형태들에서 본 발명은 SEZ6 조절물질을 투여하는 단계를 포함하는 백금 내성 소세포 폐암에 걸린 환자를 치료하는 방법을 포함한다.
본 발명의 다른 양상은 종양원성 경로들을 중단시킬 가능성이 있으면서 동시에 종양 개시 세포들을 침묵화하는 개시된 조절물질의 능력을 개발한다. 이러한 다중-활성 SEZ6 조절물질(예를 들면, SEZ6 길항제)은 치료 기준 항암제 또는 용적축소제와 조합하여 사용하는 경우에 특히 효과적인 것으로 증명될 수 있다. 따라서, 본 발명의 바람직한 실시형태들은 개시된 조절물질을 초기 치료 후 유지 치료요법을 위한 항-전이제로서 사용함을 포함한다. 또한, 둘 이상의 SEZ6 길항제(예를 들면, SEZ6 상의 2개의 구별되는 에피토프에 특이적으로 결합하는 항체)를 본 발명의 교시에 따라 조합하여 사용할 수 있다. 더욱이, 아래에 다소 상세하게 논의되는 바와 같이, 본 발명의 SEZ6 조절물질은 접합된 또는 비접합된 상태로, 그리고 임의로 감작제로서 각종 화학적 또는 생물학적 항암제들과 조합하여 사용될 수 있다.
따라서, 본 발명의 다른 바람직한 실시형태는 항암제로의 치료 대상체에게 SEZ6 조절물질을 투여하는 단계를 포함하는, 항암제로의 치료 대상체의 종양을 감작화시키는 방법을 포함한다. 다른 실시형태들은 치료 이후의 전이 또는 종양 재발의 감소를 필요로 하는 대상체에게 SEZ6 조절물질을 투여하는 단계를 포함하는, 치료 이후의 전이 또는 종양 재발을 감소시키는 방법을 포함한다. 본 발명의 특히 바람직한 양상에서 SEZ6 조절물질은 특히 시험관내 또는 생체내 한계 희석 분석법을 사용하여 측정되는 바와 같이 종양 개시 세포 출현빈도의 감소를 초래할 것이다.
본 발명의 더욱 일반적으로 바람직한 실시형태들은 대상체에게 SEZ6 조절물질을 투여하는 단계를 포함하는, SEZ6 관련 장애의 치료를 필요로 하는 대상체에서 SEZ6 관련 장애를 치료하는 방법을 포함한다. 특히 바람직한 실시형태들에서 SEZ6 조절물질은 항암제와 회합(예를 들면, 접합)될 것이다. 또 다른 실시형태들에서 SEZ6 조절물질은 세포의 표면 상에서 또는 표면 부근에서 SEZ6과 회합하거나 결합한 이후 내재화할 것이다. 또한, 신호전달 경로들의 중단 및 부수적인 이점을 포함하는, 본 발명의 이로운 양상들은 대상체 종양 조직이 정상의 인접한 조직과 비교하여 상승된 SEZ6 수준을 나타내거나 감소되거나 억압된 SEZ6 수준을 나타내는지에 관계없이 달성될 수 있다. 특히 바람직한 실시형태들은 정상 조직 또는 비-종양원성 세포들과 비교하여 종양원성 세포들 상에 상승된 SEZ6 수준을 나타내는 장애의 치료를 포함할 것이다.
다른 양상에서 본 발명은 치료학적 유효량의 적어도 하나의 내재화 SEZ6 조절물질을 투여하는 단계를 포함하는 신생물 장애에 걸린 대상체를 치료하는 방법을 포함할 것이다. 바람직한 실시형태들은 내재화 항체 조절물질의 투여를 포함할 것이고, 여기서, 다른 선택된 실시형태들에서는 내재화 항체 조절물질이 세포독성제와 접합되거나 또는 회합된다.
다른 실시형태들은 치료학적 유효량의 적어도 하나의 고갈화 SEZ6 조절물질을 투여하는 단계를 포함하는 SEZ6 관련 장애에 걸린 대상체를 치료하는 방법에 관한 것이다.
또 다른 실시형태에서 본 발명은 개시된 효과물질 또는 조절물질을 종양 덩어리의 적어도 일부분을 제거하도록 고안된 초기 절차(예를 들면, 화학치료요법제, 방사선 또는 수술) 이후의 기간에 걸쳐 투여하는 유지 치료요법의 방법을 제공한다. 이러한 치료학적 용법은 몇 주, 몇 달 또는 심지어 몇 년의 기간에 걸쳐 투여될 수 있고, SEZ6 조절물질이 전이 및/또는 종양 재발을 억제하는데 예방학적으로 작용할 수 있다. 또 다른 실시형태들에서 개시된 조절물질은 전이, 종양 유지 또는 재발을 예방하거나 저지하기 위한 공지의 용적축소 용법과 협력하여 투여될 수 있다.
본 발명의 SEZ6 조절물질은 SEZ6의 공지의 이소형(들) 또는 단백질의 단일 이소형과 반응하도록 생성 및 선택될 수 있거나, 역으로, SEZ6에 더하여 적어도 하나의 추가의 SEZ6 패밀리 구성원(예를 들면, SEZ6L 또는 SEZ6L2 및 이들의 이소형)과도 반응하거나 회합하는 범(pan)-SEZ6 조절물질을 포함할 수 있음을 추가로 이해할 수 있을 것이다. 더욱 구체적으로, 본원에 개시되어 있는 바와 같이 항체와 같은 바람직한 조절물질은 SEZ6에 의해서만 나타나는 도메인(또는 그 안의 에피토프)과 또는 둘 이상의 SEZ6 패밀리 구성원들에 걸쳐 적어도 어느 정도 보존된 도메인과 반응하도록 생성되고 선택될 수 있다.
또 다른 바람직한 실시형태들에서 조절물질은 SEZ6의 특정 에피토프, 부분, 모티프 또는 도메인에 회합하거나 결합할 것이다. 아래에 다소 상세하게 논의될 것인 바와 같이, SEZ6 이소형들은 둘 다 적어도 N-말단 도메인, 두 개의 교대하는 스시(Sushi)와 CUB 도메인들, 및 세 개의 추가의 직렬(tandem) 스시 도메인 반복부위를 포함하는 동일한 세포외 영역(도 1e 참조)을 포함한다. 또한, SEZ6 단백질은 막관통 도메인과 세포질 도메인을 포함한다. 따라서, 소정 실시형태들에서 조절물질은 SEZ6의 N-말단 도메인(즉, 성숙 단백질의 아미노산 1-335)과 또는 그 안의 에피토프에 결합하거나 회합할 것이다. 본 발명의 다른 양상은 SEZ6의 특정 스시 도메인에 위치한 특정 에피토프에 회합하거나 결합하는 조절물질을 포함한다. 이와 관련하여 상기 특정 조절물질은 스시 도메인 1(아미노산 336-395), 스시 도메인 2(아미노산 511-572), 스시 도메인 3(아미노산 690-748), 스시 도메인 4(아미노산 750-813) 또는 스시 도메인 5(아미노산 817-878)에 위치한 에피토프에 회합하거나 결합할 수 있다. 본 발명의 다른 양상은 SEZ6의 특정 CUB-유사 도메인에 위치한 특정 에피토프와 회합하거나 결합하는 조절물질을 포함한다. 이와 관련하여 상기 특정 조절물질은 CUB 도메인 1(아미노산 397-508) 또는 CUB 도메인 2(아미노산 574-685)에 위치한 에피토프에 회합하거나 결합할 수 있다. 추가의 실시형태들에서 본 발명의 항체는 SEZ6 상의 소정 에피토프에 결합할 수 있다.
한 실시형태에서, 본 발명은 SEZ6 단백질 상의 에피토프에 특이적으로 결합하는 단리된 항체를 제공하며, 여기서, 상기 에피토프는 (i) 잔기 R762, L764, Q777, I779, D781 및 Q782; (ii) 잔기 R342 및 K389 및 (iii) 잔기 T352, S353 및 H375로 이루어진 그룹으로부터 선택되는 아미노산 잔기를 포함한다.
다른 실시형태에서 본 발명은 치료학적 모이어티에 직접적으로 또는 간접적으로 접합된 항체를 포함하는 항체 약물 접합체를 제공하며, 여기서, 상기 항체는 SEZ6 단백질 상의 에피토프에 특이적으로 결합하고, 여기서, 상기 에피토프는 (i) 잔기 R762, L764, Q777, I779, D781 및 Q782; (ii) 잔기 R342 및 K389 및 (iii) 잔기 T352, S353 및 H375로 이루어진 그룹으로부터 선택되는 아미노산 잔기를 포함한다.
물론 상기 언급된 도메인들의 각각은 하나 이상의 에피토프를 포함할 수 있으며 하나 이상의 빈(bin)과 회합될 수 있음을 이해할 수 있을 것이다. 조절물질 또는 항체 "빈(bin)"에 관해서 SEZ6 항원은 단백질을 따라 위치한 특정 빈들을 정의할 수 있는 당해 분야에서 인정되어 있는 기술들을 사용하는 경쟁 항체 결합을 통해 분석되거나 맵핑될 수 있음을 이해할 수 있을 것이다. 본원에 더욱 상세하게 논의되며 아래에 실시예 9 및 실시예 10에서 나타나지만, 두 개의 항체가 (그 중 하나는 "표준 항체(reference antibody)", "빈 경계 항체(bin delineating antibody)" 또는 "경계 항체(delineating antibody)"라고 할 수 있음) 표적 항원에 결합하기 위해 서로 실질적으로 경쟁한다면 이들은 동일한 빈 내에 존재하는 것으로 간주될 수 있다. 이러한 경우들에서 양쪽 항체 둘 다가 항원에의 결합이 입체공간적으로나 또는 정전기학적으로 억제되거나 차단되도록 대상 항체 에피토프들은 동일하거나, 실질적으로 동일하거나, (이들이 몇 개 아미노산으로 구별되는 선형적인 의미에서나 형태적으로나 어느 쪽이든) 충분히 밀접한 것일 수 있다. 상기 정의된 빈들은 일반적으로 소정 SEZ6 도메인들과 회합될 수 있지만(예를 들면, 표준 항체는 특정 도메인에 포함되어 있는 에피토프와 결합할 것이다) 그 상관관계가 항상 정확한 것은 아니다(예를 들면, 하나의 도메인에 하나 이상의 빈이 있을 수 있거나 빈이 형태적으로 정의되어 하나 이상의 도메인을 포함할 수 있다). 당해 분야의 숙련가라면 SEZ6 도메인들과 경험적으로 결정된 빈들 사이의 관계를 용이하게 결정할 수 있음을 이해할 것이다.
본 발명에 관해서는 당해 분야에서 인정되고 있는 기술들을 사용하는 경쟁 결합 분석(예를 들면, ELISA, 표면 플라스몬 공명 또는 바이오-레이어 간섭분석법)으로 적어도 7개의 구별되는 빈들이 정의되었고, 이들의 각각은 다수의 항체 조절물질을 포함하는 것으로 밝혀졌다. 본원 개시의 목적을 위하여 7개의 빈들을 빈 A-F 및 빈 U로 명명하였다. 빈 A-F는 고유한 빈이며 이들 빈들 각각에 함유된 항체는 SEZ6 단백질에 결합하기 위해 서로 경쟁한다. 빈 U는 빈 A-F의 항체와는 경쟁하지 않지만 서로 결합하기 위해 경쟁할 수 있는 항체를 함유한다. 따라서, 선택된 실시형태들에서 본 발명은 빈 A, 빈 B, 빈 C, 빈 D, 빈 E, 빈 F, 및 빈 U로 이루어진 그룹으로부터 선택되는 빈에 존재하는 조절물질을 포함할 것이다. 다른 실시형태들에서 본 발명은 SC17.1, SC17.2, SC17.3, SC17.4, SC17.8, SC17.9, SC17.10, SC17.11, SC17.14, SC17.15, SC17.16, SC17.17, SC17.18, SC17.19, SC17.22, SC17.24, SC17.27, SC17.28, SC17.29, SC17.30, SC17.32, SC17.34, SC17.35, SC17.36, SC17.38, SC17.39, SC17.40, SC17.41, SC17.42, SC17.45, SC17.46, SC17.47, SC17.49, SC17.50, SC17.53, SC17.54, SC17.56, SC17.57, SC17.59, SC17.61, SC17.63, SC17.71, SC17.72, SC17.74, SC17.76, SC17.77, SC17.79, SC17.81, SC17.82, SC17.84, SC17.85, SC17.87, SC17.89, SC17.90, SC17.91, SC17.93, SC17.95, SC17.97, SC17.99, SC17.102, SC17.114, SC17.115, SC17.120, SC17.121, SC17.122, SC17.140, SC17.151, SC17.156, SC17.161, SC17.166, SC17.187, SC17.191, SC17.193, SC17.199 및 SC17.200으로 이루어진 그룹으로부터 선택되는 표준 항체에 의해 정의된 빈에 존재하는 조절물질을 포함한다. 또 다른 실시형태들에서 본 발명은 빈 A로부터의 조절물질, 빈 B로부터의 조절물질, 빈 C로부터의 조절물질, 빈 D로부터의 조절물질, 빈 E로부터의 조절물질, 빈 F로부터의 조절물질 또는 빈 U로부터의 조절물질을 포함할 것이다. 또 다른 바람직한 실시형태들은 표준 항체 조절물질 및 표준 항체와 경쟁하는 임의의 항체를 포함할 것이다.
개시된 조절물질의 맥락에서 사용될 때의 용어 "경쟁하다(compete)" 또는 "경쟁하는 항체(competing antibody)"는 표준 항체 또는 면역학적으로 기능하는 단편이 공통 항원에 대한 시험 항체의 특이 결합을 (예를 들면, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85% 또는 90% 이상) 실질적으로 예방하거나 억제하는 검정에 의해 측정된 항체 간의 결합 경쟁을 의미한다. 이러한 경쟁을 측정하는 적합한 방법은, 예를 들면, 바이오-레이어 간섭분석법, 표면 플라스몬 공명, 유동 세포분석법, 경쟁 ELISA 등과 같은 당업계에 알려진 기술을 포함한다.
선택된 실시형태들에서 본 발명은 SEZ6 및 적어도 하나의 다른 SEZ6 패밀리 구성원(예를 들면, SEZ6L 또는 SEZ6L2)과 회합하는 범-SEZ6 조절물질을 포함한다. 다른 선택된 실시형태들에서 본 발명은 하나 이상의 SEZ6 이소형과 면역특이적으로 회합하지만 임의의 다른 SEZ6 패밀리 구성원과는 면역특이적으로 회합하지 않는 SEZ6 조절물질을 포함한다. 또 다른 실시형태들에서 본 발명은 치료학적 유효량의 범-SEZ6 조절물질을 투여함을 포함하여 이를 필요로 하는 대상체를 치료하는 방법을 포함한다. 또 다른 실시형태들은 하나 이상의 SEZ6 이소형과 면역특이적으로 회합하지만 임의의 다른 SEZ6 패밀리 구성원과는 면역특이적으로 회합하지 않는 치료학적 유효량의 SEZ6 조절물질을 투여함을 포함하는 이를 필요로 하는 대상체를 치료하는 방법을 포함한다.
한 실시형태에서 본 발명은 치료학적 모이어티에 직접적으로 또는 간접적으로 접합된 항체를 포함하는 치료학적 유효량의 항체 약물 접합체를 투여함을 포함하는 암에 걸린 대상체를 치료하는 방법에 관한 것이고, 여기서, 상기 항체는 SEZ6 단백질 상의 에피토프에 특이적으로 결합하고, 여기서, 상기 에피토프는 (i) 잔기 R762, L764, Q777, I779, D781 및 Q782; (ii) 잔기 R342 및 K389 및 (iii) 잔기 T352, S353 및 H375로 이루어진 그룹으로부터 선택되는 아미노산 잔기를 포함한다. 바람직한 실시형태들에서 치료학적 모이어티는 아우리스타틴, 아마니틴 및 피롤로벤조디아제핀을 포함할 것이다. 몇몇 경우에 암에 걸린 대상체는 이전에 백금계 제제로 치료받았을 수 있다.
다른 실시형태에서 본 발명은 치료학적 모이어티에 직접적으로 또는 간접적으로 접합된 항체를 포함하는 치료학적 유효량의 항체 약물 접합체를 투여함을 포함하는 갑상선 수질암에 걸린 대상체를 치료하는 방법에 관한 것이다. 한 실시형태에서 갑상선 수질암에 걸린 대상체를 치료하는데 사용되는 항체 약물 접합체는, SEZ6 단백질 상의 에피토프에 특이적으로 결합하는 항체를 포함할 수 있고, 여기서, 상기 에피토프는 (i) 잔기 R762, L764, Q777, I779, D781 및 Q782; (ii) 잔기 R342 및 K389 및 (iii) 잔기 T352, S353 및 H375로 이루어진 그룹으로부터 선택되는 아미노산 잔기를 포함한다. 바람직한 실시형태들에서 치료학적 모이어티는 아우리스타틴, 아마니틴 및 피롤로벤조디아제핀을 포함할 수 있다.
추가의 실시형태에서 본 발명은 치료학적 모이어티에 직접적으로 또는 간접적으로 접합된 항체를 포함하는 치료학적 유효량의 항체 약물 접합체를 투여함을 포함하는 백금 내성 소세포 폐암에 걸린 대상체를 치료하는 방법에 관한 것이며, 여기서, 항체는 SEZ6 단백질 상의 에피토프에 특이적으로 결합하고, 여기서, 상기 에피토프는 (i) 잔기 R762, L764, Q777, I779, D781 및 Q782; (ii) 잔기 R342 및 K389 및 (iii) 잔기 T352, S353 및 H375로 이루어진 그룹으로부터 선택되는 아미노산 잔기를 포함한다. 바람직한 실시형태들에서 백금 내성 소세포 폐암에 걸린 환자는 이전에 백금계 제제로 치료받았을 수 있다. 다른 바람직한 실시형태들에서 치료학적 모이어티는 아우리스타틴, 아마니틴 및 피롤로벤조디아제핀을 포함할 것이다.
상기 논의된 치료학적 용도들을 능가하여 본 발명의 조절물질은 SEZ6 관련 장애와, 특히, 증식성 장애를 검출하거나, 진단하거나 또는 분류하는데 사용될 수 있음도 또한 이해할 수 있을 것이다. 몇몇의 실시형태들에서 상기 조절물질은 대상체에게 투여될 수 있으며 생체내 검출되거나 모니터링될 수 있다. 당해 분야의 숙련가라면 이러한 조절물질이 아래에 개시된 바와 같은 마커들 또는 리포터들로 표지되거나 회합될 수 있으며 다수의 표준 기술들(예를 들면, MRI, CAT 스캔 PET 스캔 등) 중 어느 하나를 이용하여 검출될 수 있음을 이해할 수 있을 것이다.
따라서, 몇몇의 실시형태들에서 본 발명은 SEZ6 조절물질을 투여하는 단계를 포함하는 이를 필요로 하는 대상체에서 SEZ6 관련 장애를 생체내 진단하거나, 검출하거나 또는 모니터링하는 방법을 포함할 것이다.
다른 경우들에서 조절물질은 당해 분야에서 인정되어 있는 절차들을 사용하는 시험관내 진단학적 세팅에 사용될 수 있다. 이와 같이, 바람직한 실시형태는: (a) 대상체로부터 종양 샘플을 제공하는 단계; (b) 상기 종양 샘플을 리포터로 표지된 항-SEZ6 항체에 노출시키는 단계(여기서, 상기 항-SEZ6 항체는 종양 샘플(예를 들면, 갑상선 수질암 종양 샘플, 소세포 폐암 종양 샘플 또는 백금 내성 소세포 폐암 종양 샘플)과 회합한다); 및 (c) 상기 종양 샘플과 회합된 리포터를 검출하는 단계를 포함하는, 대상체에서의 암(예를 들면, 갑상선 수질암 또는 백금 내성 소세포 폐암)을 진단하는 방법을 포함한다. 소정 실시형태들에서, 종양 샘플을 제공하는 단계는 종양 샘플을 항-SEZ6 항체에 노출시키는 단계 또는 상기 종양 샘플과 회합된 리포터를 검출하는 단계와는 별도로 수행될 수 있다. 일부 경우들에서 종양 샘플과 회합된 리포터는, 예를 들면, 면역조직화학을 사용하여 시험관내에서 검출될 것이다. 일부 경우들에서 종양 샘플은 SEZ6 단백질 상의 에피토프에 결합하는 항-SEZ6 항체에 노출될 것이며, 여기서, 상기 에피토프는 아미노산 잔기 R762, L764, Q777, I779, D781 및 Q782를 포함한다.
이러한 방법은 본 출원에 관련하여 쉽게 식별가능하며 자동 플레이트 판독기, 전용 리포터 시스템 등과 같은 일반적으로 이용가능한 시판용 과학기술을 사용하여 용이하게 이행될 수 있다. 선택된 실시형태들에서 SEZ6 조절물질은 샘플에 존재하는 종양 영속화 세포들과 회합할 것이다. 다른 바람직한 실시형태들에서 검출하거나 정량화하는 단계는 종양 개시 세포 출현빈도의 감소 및 이의 검출을 포함할 것이다. 더욱이, 한계 희석 분석을 상기 언급한 바와 같이 수행할 수 있으며 바람직하게는 뿌아송 분포 통계학의 사용을 이용하여 출현빈도 감소에 대해 정확한 계산을 제공할 수 있다.
유사한 맥락에서 본 발명은 또한 암과 같은 SEZ6 관련 장애의 진단 및 모니터링에 유용한 키트 또는 장치 및 관련 방법을 제공한다. 이를 위하여 본 발명은 바람직하게는 SEZ6 관련 장애를 치료하거나 진단하기 위해 SEZ6 조절물질을 포함하는 용기와 상기 SEZ6 조절물질을 사용하기 위한 교육 자료를 포함하는, SEZ6 관련 장애를 진단하거나 치료하는데에 유용한 제조 물품을 제공한다. 선택된 실시형태들에서 장치 및 관련 방법은 적어도 하나의 순환하는 종양 세포를 접촉시키는 단계를 포함할 것이다.
본 발명의 다른 바람직한 실시형태들은 또한 개시된 조절물질의 특성들을 형광 활성화 세포 분류(FACS) 또는 레이저 매개된 분할을 포함하는 유동 세포 분석과 같은 방법을 통해 종양 개시 세포들의 개체군 또는 부분모집단을 동정하거나, 특성평가하거나, 단리하거나, 분할하거나 또는 풍부하게 하는데 유용한 수단으로서 이용한다.
이와 같이, 본 발명의 다른 바람직한 실시형태는 종양 개시 세포들을 SEZ6 조절물질과 접촉시키는 단계를 포함하는 종양 개시 세포들의 개체군을 동정하거나, 단리하거나, 분할하거나 풍부하게 하는 방법에 관한 것이다.
상기한 것은 요약이며, 따라서, 필요에 따라 단순화한 것들, 일반화한 것들, 그리고 상세한 설명의 생략을 포함하고 있다; 그러므로, 당해 분야의 숙련가들이라면 요약은 설명적인 것일 뿐이며 어떤 식으로도 한정적인 것으로 의도되지 않음을 이해할 수 있을 것이다. 본원에 기술된 방법, 조성물 및/또는 장치 및/또는 대상 물질의 다른 양상들, 특징들, 그리고 이점들은 본원에 제시된 교시에서 명백해질 것이다. 요약은 선택된 개념들을 단순화한 형태로 소개하기 위해 제공된 것으로 아래의 상세한 설명에서 추가로 기술된다. 이러한 요약은 청구되는 대상 물질의 핵심 특징들 또는 본질적 특징들을 동정하기 위해 의도되지 않고, 특허청구되는 요지의 범위를 결정하는데 도움되는 자료로서 사용되도도록 의도되는 것도 아니다.
도 1a 내지 도 1e는 본원에 기술된 SEZ6 조절물질에 속하는 핵산 또는 아미노산 서열을 포함하는 SEZ6의 다양한 표현들이다. 도 1a 및 도 1b(서열번호 1 및 2)는, 각각 SEZ6 변이체 1 및 2를 암호화하는 개방 판독 프레임(open reading frame, ORF)(밑줄친 부분)을 포함하는 전장 mRNA 서열을 도시한다. 도 1c 및 도 1d(서열번호 3 및 4)는 각각 도 1a 및 도 1b에 표시된 ORF의 상응하는 아미노산 서열을 제공하고, 밑줄친 아미노산 잔기는 각 단백질 이소형의 예측된 막관통 걸침 도메인을 나타내고 굵게 밑줄친 아미노산 잔기(잔기 1-19)는 신호 펩타이드를 나타내며; 도 1e는 각 이소형의 세포질 말단들의 서열 차이를 예시하기 위한 2개의 단백질 이소형(서열번호 3 및 4)의 정렬을 도시한 것으로, 밑줄친 잔기들은 2개의 서열들간의 차이를 나타내며; 도 1f는 각종 도메인들의 위치를 예시하는 SEZ6 단백질의 세포외 영역의 도식적 표현을 제공한다.
도 2a 내지 도 2c는 SEZ6의 가장 가까운 사람 이소형과 레서스 원숭이, 사이노몰거스, 마우스 또는 래트 SEZ6 단백질들간의 단백질 수준에서의 동일성 백분율의 표로 만든 표시(도 2a); SEZ6 유전자들의 패밀리의 보고된 이소형들 각각에 대한 각종 cDNA 또는 단백질 서열 수탁번호들의 표로 만든 목록(도 2b); 그리고 사람 SEZ6, SEZ6L, 및 SEZ6L2 단백질의 가장 긴 이소형들간의 단백질 수준에서의 동일성 백분율(도 2c)을 제공한 것이다.
도 3a 내지 도 3c는 본원에 기술된 SEZ6 조절물질을 생성하거나 특성평가하는데에 사용된 면역원 또는 세포주의 생산에 관련된 핵산 또는 아미노산 서열들의 각종 표현들을 제공한다. 사람 SEZ6의 경우에 완전한 성숙 사람 SEZ6 단백질(도 3b; 서열번호 6)을 암호화하는 특정 cDNA 클론(도 3a; 서열번호 5)은 SEZ6 단백질에 대하여, 데이터베이스 기준 서열, NP_849191(서열번호 3)로부터의 공지의 차이들을 갖고서(도 3c) 시판용 cDNA 클론(BC146292; 서열번호 7)으로부터 작제되었다.
도 4a 및 도 4b는 CHO-S 세포들에서 Fc-SEZ6 작제물을 발현하고, 사람 IgG2 Fc 도메인에 융합된 사람 SEZ6의 ECD를 포함하는 단백질 면역원(도 4b; 서열번호 9)을 얻는데 사용된 cDNA(도 4a; 서열번호 8)를 제공한 것으로, 여기서 밑줄친 서열들은 사람 IgG2 Fc 도메인에 상응하고, 이중으로 밑줄친 서열들은 IgK 신호 펩타이드에 상응하며, 굵은 글자체의 아미노산은 hSEZ6 단편을 클로닝하는데에 사용된 제한 부위들에 의해 기여된 잔기에 해당한다.
도 5a 내지 도 5j는 본원에 기술된 SEZ6 조절물질을 생성하거나 특성평가하는데에 사용된 면역원 또는 세포주의 생산에 관련된 핵산 또는 아미노산 서열들의 각종 표현들을 제공하고, 여기서, 밑줄친 서열들은 예시되는 특정한 SEZ6 또는 SEZ6 패밀리 구성원에 대한 단백질의 ECD를 나타내며, 도면들은 성숙 뮤린 SEZ6(도 5a, 서열번호 10), 성숙 래트 SEZ6(도 5c, 서열번호 12), 성숙 사이노몰거스 SEZ6(도 5e, 서열번호 14), 사람 SEZ6L 단백질의 성숙 ECD(도 5g, 서열번호 16), 또는 사람 SEZ6L2 단백질의 성숙 ECD(도 5i, 서열번호 18)를 암호화하는 작제물의 cDNA 서열들, 또는 이들 cDNA 작제물에 의해 암호화된 상응하는 단백질들, 즉, 성숙 뮤린 SEZ6(도 5b, 서열번호 11), 성숙 래트 SEZ6(도 5d, 서열번호 13), 성숙 사이노몰거스 SEZ6(도 5f, 서열번호 15), 사람 SEZ6L 단백질의 성숙 ECD(도 5h, 서열번호 17), 또는 사람 SEZ6L2 단백질의 성숙 ECD(도 5j, 서열번호 19)를 포함한다.
도 6a 및 도 6b는 종양 세포 부분모집단들 또는 정상 조직들로부터 유도된 mRNA의 완전 전사체(SOLiD) 서열분석을 이용하여 측정된 각종 유전자들의 mRNA 발현 수준을 도시한다. 도 6a는 신경내분비 특징들을 가진 종양들과 관련된 유전자들의 표로 나타낸 표현이며; 도 6b는 정상 조직들 및 몇몇 폐암으로부터 유도된 비전통적인 이종이식편(NTX) 종양들에서의 SEZ6 mRNA 발현의 그래프 표현이다.
도 7a 내지 도 7f는 마이크로어레이를 이용하여 분석된 mRNA 발현 수준을 도시한다. 도 7a는 46개의 종양주와 2개의 정상 조직들에 대한 마이크로어레이 프로파일의 자율 집단화의 그래프 표현이고; 도 7b 및 도 7c는 신경내분비 표현형들(도 7b) 또는 노치(Notch) 신호전달 경로(도 7c)에 관련된 선택된 유전자들의 상대적 발현 수준에 상응하는 표준화 강도 값들의 표로 만든 표현들이고, 여기서, 그늘지지 않은 세포들 및 비교적 작은 숫자들은 발현이 거의 내지 전혀 없음을 가리키고 더 어두운 세포들 및 비교적 큰 숫자들은 더 높은 발현 수준을 가리키며; 도 7d는 qRT-PCR을 이용하여 측정되는 각종 종양들 및 대조군 조직들에서의 HES6 mRNA의 상대적 발현 수준을 보여주는 그래프 표현이고; 도 7e는 신경 운명을 향한 신경발생, 신경 연루, 또는 분화를 나타내는 선택된 유전자들의 상대적 발현 수준에 상당하는 표준화 강도 값들의 표로 만든 표시로, 그늘지지 않은 세포들은 발현이 거의 내지 전혀 없음을 가리키고 더 어두운 세포들은 더 높은 발현 수준을 가리키며; 도 7f는 각종 NTX 종양주들에서의 SEZ6의 상대적 발현에 상당하는 정상화 강도 값들의 그래프를 이용한 표시이다.
도 8a 및 도 8b는 정상 조직들 또는 벌크 신경내분비 NTX 종양들(도 8a) 및 다양한 다른 NTX 종양들(도 8b)로부터 단리된 다양한 RNA 샘플들에서 RT-PCR에 의해 측정되는 SEZ6 mRNA 전사물들의 상대적 발현 수준을 보여주는 그래프 표현이다.
도 9a 및 도 9b는 18개의 상이한 고형 종양 유형들 중 하나를 갖는 환자들로부터 완전 종양 피검물(회색 점) 또는 매칭된 정상 인접 조직(normal adjacent tissue, NAT; 백색 점)에서 RT-PCR에 의해 측정되는 사람 SEZ6의 절대적(도 9a) 또는 표준화된(도 9b) mRNA 발현 수준을 보여주는 그래프 표현들이다.
도 10a 내지 도 10b는 본원의 실시예들에서 기술된 바와 같이 단리, 클로닝 및 조작처리된 다수의 예시적인 뮤린 및 사람화된 SEZ6 조절물질의 경쇄(도 10a) 및 중쇄(도 10b) 가변 영역들의 연속적인 아미노산 서열을 제공한다. 상응하는핵산 서열은 첨부된 서열목록에 제시되어 있다. 도 10c는 사람화된 항체 SC17.200 및 SC17.200vL1의 경쇄 및 중쇄의 전장 아미노산 서열을 제시한다.
도 11은 본 발명의 예시적인 조절물질의 여러 가지 특성들을 제시한다. 도 11a는 표의 형식으로 나타낸 예시적인 SEZ6 조절물질의 생화학적 및 면역학적 특성들을 보여주며; 도 11b는 항체가 결합하는 도메인과 상기 항체의 시험관내 살해 검정에서의 효능 간의 상관관계를 제공한 것이다.
도 12a 및 도 12b는 전기화학발광 검정을 사용하여 측정된 SEZ6 단백질의 발현의 검출을 보여준다. 도 12a는 항-SEZ6 항체 SC17.33을 사용하여 사람 SEZ6 단백질(h293T-HuSEZ6)을 과다-발현하도록 조작처리된 HEK-293T 세포에서의 SEZ6 발현을 보여주고; 도 12b는 각종 NTX 종양 및 정상 조직 용해물에서의 사람 SEZ6의 상대적 단백질 발현을 보여준다.
도 13a 및 도 13b는 각종 항-SEZ6 항체를 사용하여 NTX 종양 세포들에서의 SEZ6 단백질 발현의 유동 세포분석에 의한 검출을 보여주고(도 13a); 반면, 도 13b는 각종 항-SEZ6 항체를 사용하여 NTG 부분모집단에 비교하여 CSC에서의 SEZ6 단백질의 증대된 발현을 보여준다(도 13b).
도 14a 및 도 14b는 SEZ6을 발현하는 CSC가, SEZ6을 발현하지 않는 CSC에 비교하여 증대된 종양원성(tumorigenictiy)을 나타냄을 보여준 것이다. 도 14a는 CD324(CSC의 마커) 및 SEZ6의 발현에 기초하여 폐 종양(LU37)에서의 세포들의 FACS에 의한 세포 분류를 보여주는 윤곽도이며; 도 14b는 면역손상된 마우스로의 이식 후 CD324+SEZ6+(흑색 원) 또는 CD324+SEZ6-(백색 원)인 종양 세포들의 성장의 그래프 표현이다. CD324와 SEZ6 둘 다를 발현하는 종양 세포들은 증대된 종양원성을 나타낸다.
도 15a 및 도 15b는, 각각, 개시된 조절물질이 세포독성 적재물들을 SEZ6을 발현하도록 조작처리된 세포들(도 15a) 및 시험관내에서 성장시킨 NTX 폐 종양(LU80, LU37 및 LU100)(도 15b)에 지시하는 표적화 모이어티들로서 효과적으로 사용될 수 있음을 예시하는 표 및 그래프한 표현을 제공하며, 여기서, 표준화된 상대 발광 단위(RLU)의 감소는 사포린 독소의 내재화를 통한 세포 살해를 나타낸다.
도 16은 면역조직화학(IHC)을 사용하여 측정된 각종 SCLC 및 갑상선 수질 종양에서의 SEZ6 발현의 정량화를 보여주며, 여기서, 도 16a는 NTX SCLC 종양에서의 SEZ6 발현을 보여주고, 도 16b는 SCLC 종양 마이크로어레이에서의 SEZ6 발현을 보여주며, 도 16c는 원발성 갑상선 수질 종양에서의 SEZ6 발현을 보여준다.
도 17a 내지 도 17b는 NTX 종양 세포들의 시험관내 및 생체내 성장을 저지하기 위한 접합된 항-SEZ6 마우스 항체의 능력을 도시한다. 도 17a는 SCLC(LU64) 및 OV(OV26) NTX 종양 세포주에 대해 항-SEZ6 ADC를 사용한 시험관내 살해 검정의 결과를 보여주고; 반면, 도 17b는 SCLC(LU86) 및 LCNEC(LU50) 종양들의 생체내 성장들에 대한 항-SEZ6 ADC들의 효과를 보여준다.
도 18a 내지 도 18d는 갑상선 세포주의 시험관내(도 18a) 및 생체내(도 18b) 성장을 저지하고; 4개의 SCLC 종양(LU80, LU64, LU111 및 LU117)의 생체내 성장을 저지하고 면역결핍 마우스에서 지속적인 소실(remission)(도 18c 및 18d)을 달성하는 접합된 사람화된 항-SEZ6 항체의 능력을 도시한다.
도 19는 옥살라플라틴-내성 세포주 LU124OXAHIp2 및 LU124OXAHIp3에 비교하여 모체(parental) 소세포 폐암(SCLC) 환자-유도된 이종이식편(PDX) 주, LU124p2에서의 옥살라플라틴의 용량 반응 곡선을 보여준다.
도 20은 모체 SCLC PDX 주 LU124p1 및 LU124p3에서, 및 옥살라플라틴-내성 세포주 LU124OXAHIp3에서의 SEZ6의 mRNA 발현을 보여준다.
도 21은 모체 SCLC PDX 주 LU124p3에서 및 옥살라플라틴-내성 세포주 LU124OXAHIp3에서의 SEZ6의 단백질 발현을 보여준다.
도 2a 내지 도 2c는 SEZ6의 가장 가까운 사람 이소형과 레서스 원숭이, 사이노몰거스, 마우스 또는 래트 SEZ6 단백질들간의 단백질 수준에서의 동일성 백분율의 표로 만든 표시(도 2a); SEZ6 유전자들의 패밀리의 보고된 이소형들 각각에 대한 각종 cDNA 또는 단백질 서열 수탁번호들의 표로 만든 목록(도 2b); 그리고 사람 SEZ6, SEZ6L, 및 SEZ6L2 단백질의 가장 긴 이소형들간의 단백질 수준에서의 동일성 백분율(도 2c)을 제공한 것이다.
도 3a 내지 도 3c는 본원에 기술된 SEZ6 조절물질을 생성하거나 특성평가하는데에 사용된 면역원 또는 세포주의 생산에 관련된 핵산 또는 아미노산 서열들의 각종 표현들을 제공한다. 사람 SEZ6의 경우에 완전한 성숙 사람 SEZ6 단백질(도 3b; 서열번호 6)을 암호화하는 특정 cDNA 클론(도 3a; 서열번호 5)은 SEZ6 단백질에 대하여, 데이터베이스 기준 서열, NP_849191(서열번호 3)로부터의 공지의 차이들을 갖고서(도 3c) 시판용 cDNA 클론(BC146292; 서열번호 7)으로부터 작제되었다.
도 4a 및 도 4b는 CHO-S 세포들에서 Fc-SEZ6 작제물을 발현하고, 사람 IgG2 Fc 도메인에 융합된 사람 SEZ6의 ECD를 포함하는 단백질 면역원(도 4b; 서열번호 9)을 얻는데 사용된 cDNA(도 4a; 서열번호 8)를 제공한 것으로, 여기서 밑줄친 서열들은 사람 IgG2 Fc 도메인에 상응하고, 이중으로 밑줄친 서열들은 IgK 신호 펩타이드에 상응하며, 굵은 글자체의 아미노산은 hSEZ6 단편을 클로닝하는데에 사용된 제한 부위들에 의해 기여된 잔기에 해당한다.
도 5a 내지 도 5j는 본원에 기술된 SEZ6 조절물질을 생성하거나 특성평가하는데에 사용된 면역원 또는 세포주의 생산에 관련된 핵산 또는 아미노산 서열들의 각종 표현들을 제공하고, 여기서, 밑줄친 서열들은 예시되는 특정한 SEZ6 또는 SEZ6 패밀리 구성원에 대한 단백질의 ECD를 나타내며, 도면들은 성숙 뮤린 SEZ6(도 5a, 서열번호 10), 성숙 래트 SEZ6(도 5c, 서열번호 12), 성숙 사이노몰거스 SEZ6(도 5e, 서열번호 14), 사람 SEZ6L 단백질의 성숙 ECD(도 5g, 서열번호 16), 또는 사람 SEZ6L2 단백질의 성숙 ECD(도 5i, 서열번호 18)를 암호화하는 작제물의 cDNA 서열들, 또는 이들 cDNA 작제물에 의해 암호화된 상응하는 단백질들, 즉, 성숙 뮤린 SEZ6(도 5b, 서열번호 11), 성숙 래트 SEZ6(도 5d, 서열번호 13), 성숙 사이노몰거스 SEZ6(도 5f, 서열번호 15), 사람 SEZ6L 단백질의 성숙 ECD(도 5h, 서열번호 17), 또는 사람 SEZ6L2 단백질의 성숙 ECD(도 5j, 서열번호 19)를 포함한다.
도 6a 및 도 6b는 종양 세포 부분모집단들 또는 정상 조직들로부터 유도된 mRNA의 완전 전사체(SOLiD) 서열분석을 이용하여 측정된 각종 유전자들의 mRNA 발현 수준을 도시한다. 도 6a는 신경내분비 특징들을 가진 종양들과 관련된 유전자들의 표로 나타낸 표현이며; 도 6b는 정상 조직들 및 몇몇 폐암으로부터 유도된 비전통적인 이종이식편(NTX) 종양들에서의 SEZ6 mRNA 발현의 그래프 표현이다.
도 7a 내지 도 7f는 마이크로어레이를 이용하여 분석된 mRNA 발현 수준을 도시한다. 도 7a는 46개의 종양주와 2개의 정상 조직들에 대한 마이크로어레이 프로파일의 자율 집단화의 그래프 표현이고; 도 7b 및 도 7c는 신경내분비 표현형들(도 7b) 또는 노치(Notch) 신호전달 경로(도 7c)에 관련된 선택된 유전자들의 상대적 발현 수준에 상응하는 표준화 강도 값들의 표로 만든 표현들이고, 여기서, 그늘지지 않은 세포들 및 비교적 작은 숫자들은 발현이 거의 내지 전혀 없음을 가리키고 더 어두운 세포들 및 비교적 큰 숫자들은 더 높은 발현 수준을 가리키며; 도 7d는 qRT-PCR을 이용하여 측정되는 각종 종양들 및 대조군 조직들에서의 HES6 mRNA의 상대적 발현 수준을 보여주는 그래프 표현이고; 도 7e는 신경 운명을 향한 신경발생, 신경 연루, 또는 분화를 나타내는 선택된 유전자들의 상대적 발현 수준에 상당하는 표준화 강도 값들의 표로 만든 표시로, 그늘지지 않은 세포들은 발현이 거의 내지 전혀 없음을 가리키고 더 어두운 세포들은 더 높은 발현 수준을 가리키며; 도 7f는 각종 NTX 종양주들에서의 SEZ6의 상대적 발현에 상당하는 정상화 강도 값들의 그래프를 이용한 표시이다.
도 8a 및 도 8b는 정상 조직들 또는 벌크 신경내분비 NTX 종양들(도 8a) 및 다양한 다른 NTX 종양들(도 8b)로부터 단리된 다양한 RNA 샘플들에서 RT-PCR에 의해 측정되는 SEZ6 mRNA 전사물들의 상대적 발현 수준을 보여주는 그래프 표현이다.
도 9a 및 도 9b는 18개의 상이한 고형 종양 유형들 중 하나를 갖는 환자들로부터 완전 종양 피검물(회색 점) 또는 매칭된 정상 인접 조직(normal adjacent tissue, NAT; 백색 점)에서 RT-PCR에 의해 측정되는 사람 SEZ6의 절대적(도 9a) 또는 표준화된(도 9b) mRNA 발현 수준을 보여주는 그래프 표현들이다.
도 10a 내지 도 10b는 본원의 실시예들에서 기술된 바와 같이 단리, 클로닝 및 조작처리된 다수의 예시적인 뮤린 및 사람화된 SEZ6 조절물질의 경쇄(도 10a) 및 중쇄(도 10b) 가변 영역들의 연속적인 아미노산 서열을 제공한다. 상응하는핵산 서열은 첨부된 서열목록에 제시되어 있다. 도 10c는 사람화된 항체 SC17.200 및 SC17.200vL1의 경쇄 및 중쇄의 전장 아미노산 서열을 제시한다.
도 11은 본 발명의 예시적인 조절물질의 여러 가지 특성들을 제시한다. 도 11a는 표의 형식으로 나타낸 예시적인 SEZ6 조절물질의 생화학적 및 면역학적 특성들을 보여주며; 도 11b는 항체가 결합하는 도메인과 상기 항체의 시험관내 살해 검정에서의 효능 간의 상관관계를 제공한 것이다.
도 12a 및 도 12b는 전기화학발광 검정을 사용하여 측정된 SEZ6 단백질의 발현의 검출을 보여준다. 도 12a는 항-SEZ6 항체 SC17.33을 사용하여 사람 SEZ6 단백질(h293T-HuSEZ6)을 과다-발현하도록 조작처리된 HEK-293T 세포에서의 SEZ6 발현을 보여주고; 도 12b는 각종 NTX 종양 및 정상 조직 용해물에서의 사람 SEZ6의 상대적 단백질 발현을 보여준다.
도 13a 및 도 13b는 각종 항-SEZ6 항체를 사용하여 NTX 종양 세포들에서의 SEZ6 단백질 발현의 유동 세포분석에 의한 검출을 보여주고(도 13a); 반면, 도 13b는 각종 항-SEZ6 항체를 사용하여 NTG 부분모집단에 비교하여 CSC에서의 SEZ6 단백질의 증대된 발현을 보여준다(도 13b).
도 14a 및 도 14b는 SEZ6을 발현하는 CSC가, SEZ6을 발현하지 않는 CSC에 비교하여 증대된 종양원성(tumorigenictiy)을 나타냄을 보여준 것이다. 도 14a는 CD324(CSC의 마커) 및 SEZ6의 발현에 기초하여 폐 종양(LU37)에서의 세포들의 FACS에 의한 세포 분류를 보여주는 윤곽도이며; 도 14b는 면역손상된 마우스로의 이식 후 CD324+SEZ6+(흑색 원) 또는 CD324+SEZ6-(백색 원)인 종양 세포들의 성장의 그래프 표현이다. CD324와 SEZ6 둘 다를 발현하는 종양 세포들은 증대된 종양원성을 나타낸다.
도 15a 및 도 15b는, 각각, 개시된 조절물질이 세포독성 적재물들을 SEZ6을 발현하도록 조작처리된 세포들(도 15a) 및 시험관내에서 성장시킨 NTX 폐 종양(LU80, LU37 및 LU100)(도 15b)에 지시하는 표적화 모이어티들로서 효과적으로 사용될 수 있음을 예시하는 표 및 그래프한 표현을 제공하며, 여기서, 표준화된 상대 발광 단위(RLU)의 감소는 사포린 독소의 내재화를 통한 세포 살해를 나타낸다.
도 16은 면역조직화학(IHC)을 사용하여 측정된 각종 SCLC 및 갑상선 수질 종양에서의 SEZ6 발현의 정량화를 보여주며, 여기서, 도 16a는 NTX SCLC 종양에서의 SEZ6 발현을 보여주고, 도 16b는 SCLC 종양 마이크로어레이에서의 SEZ6 발현을 보여주며, 도 16c는 원발성 갑상선 수질 종양에서의 SEZ6 발현을 보여준다.
도 17a 내지 도 17b는 NTX 종양 세포들의 시험관내 및 생체내 성장을 저지하기 위한 접합된 항-SEZ6 마우스 항체의 능력을 도시한다. 도 17a는 SCLC(LU64) 및 OV(OV26) NTX 종양 세포주에 대해 항-SEZ6 ADC를 사용한 시험관내 살해 검정의 결과를 보여주고; 반면, 도 17b는 SCLC(LU86) 및 LCNEC(LU50) 종양들의 생체내 성장들에 대한 항-SEZ6 ADC들의 효과를 보여준다.
도 18a 내지 도 18d는 갑상선 세포주의 시험관내(도 18a) 및 생체내(도 18b) 성장을 저지하고; 4개의 SCLC 종양(LU80, LU64, LU111 및 LU117)의 생체내 성장을 저지하고 면역결핍 마우스에서 지속적인 소실(remission)(도 18c 및 18d)을 달성하는 접합된 사람화된 항-SEZ6 항체의 능력을 도시한다.
도 19는 옥살라플라틴-내성 세포주 LU124OXAHIp2 및 LU124OXAHIp3에 비교하여 모체(parental) 소세포 폐암(SCLC) 환자-유도된 이종이식편(PDX) 주, LU124p2에서의 옥살라플라틴의 용량 반응 곡선을 보여준다.
도 20은 모체 SCLC PDX 주 LU124p1 및 LU124p3에서, 및 옥살라플라틴-내성 세포주 LU124OXAHIp3에서의 SEZ6의 mRNA 발현을 보여준다.
도 21은 모체 SCLC PDX 주 LU124p3에서 및 옥살라플라틴-내성 세포주 LU124OXAHIp3에서의 SEZ6의 단백질 발현을 보여준다.
I. 서론
본 발명은 여러 가지 다른 형태들로 구현될 수 있지만, 본원에 개시된 것은 이들의 특정의 예시적인 실시형태들로서 본 발명의 원리를 예시해 주는 것이다. 강조되어야 할 사실은 본 발명은 예시된 특정의 실시형태들에 한정되는 것이 아니라는 것이다. 더욱이, 본원에 사용된 임의의 항목 제목들은 구성상의 목적들만을 위한 것이며 기술된 대상을 한정하는 것으로 해석되어서는 안된다. 마지막으로, 본원 개시의 목적을 위하여 모든 동정되는 서열 수탁번호(sequence Accession number)들은 달리 언급되지 않는 한 NCBI Reference Sequence(RefSeq) 데이터베이스 및/또는 NCBI GenBank® 기록 서열 데이터베이스에서 찾아 볼 수 있다.
상기 언급한 바와 같이, 놀랍게도 SEZ6의 발현이 신생물 성장 및 증식성 장애, 특히 신경내분비 특징들을 가진 종양의 경우에서 연관되어 있으며, SEZ6 및 이의 변이체 또는 이소형은 관련 질환들의 치료에 이용될 수 있는 유용한 종양 마커를 제공하는 것으로 밝혀졌다. 더욱이, 본 출원에서 보여지는 바와 같이 세포 표면 SEZ6 단백질과 같은 SEZ6 마커들 또는 결정인자들이 암 줄기 세포(종양 영속화 세포로 알려져 있기도 함)에 연관이 있으며 이를 제거하거나 침묵시키는데 효과적으로 이용될 수 있다는 사실을 예상외로 발견하였다. 암 줄기 세포를 (예를 들면, 접합된 SEZ6 조절물질의 사용을 통해) 선택적으로 감소시키거나 제거할 수 있는 능력은 이러한 세포들이 일반적으로 많은 종래의 치료들에 내성인 것으로 알려져 있는 점에서 특히 놀라운 것이었다. 즉, 전통적인 치료 방법뿐만 아니라 더욱 최근의 표적화 치료 방법의 유효성은 이들 다양한 치료 방법에도 불구하고 암을 영속화할 수 있는 저항성 암 줄기 세포들의 존재 및/또는 출현으로 제한적인 경우가 많다. 또한, 암 줄기 세포와 연관된 결정인자들은 낮거나 일관성이 없는 발현, 종양원성 세포와의 회합 상태 유지 실패 또는 세포 표면에의 존재 실패 때문에 치료학적 표적들로는 불충분한 경우가 많다. 선행 기술의 교시들에 뚜렷하게 대조적이게도, 본원에 개시된 화합물과 방법은 이런 고유한 내성을 효과적으로 극복하여 상기 암 줄기 세포의 분화를 특이적으로 제거하거나, 고갈시키거나, 침묵시키거나 또는 촉진시킨 것이며 이에 의해 암 줄기 세포의 근원적인 종양 성장을 유지하거나 재유도할 수 있는 능력을 없애게 한다.
더욱 구체적으로, 본원에 개시된 것들과 같은 SEZ6 조절물질이 이를 필요로 하는 대상체에서 증식성 장애(예를 들면, 신생물 장애)의 예후, 진단, 치료진단, 치료 또는 예방에 유리하게 사용될 수 있음이 발견되었다. 따라서, 본 발명의 바람직한 실시형태들은, 특히 특정 도메인, 영역 또는 에피토프의 관점에서 또는 신경내분비 특징들과 개시된 조절물질과의 상호작용을 포함하는 암 줄기 세포 또는 종양의 맥락에서 아래에 광범하게 논의될 것이지만, 당해 분야의 숙련가들이라면 본 발명의 범위가 이러한 예시적인 실시형태들에 의하여 한정되는 것이 아님을 이해할 것이다. 오히려, 본 발명의 가장 광범위한 실시형태들 및 첨부된 특허청구범위는 폭넓고도 분명하게, 임의의 특정 작용 메커니즘이나 특이적으로 표적화된 종양, 세포 또는 분자 구성성분에 관계없이, SEZ6 조절물질(접합된 조절물질 포함)과 이들의, 신생물 또는 증식성 장애를 포함하는, 다양한 SEZ6 관련 또는 매개 장애의 예후, 진단, 치료진단, 치료 또는 예방에서의 용도에 관한 것이다.
이를 위하여, 그리고 본 출원에서 증명하고 있는 바와 같이, 개시된 SEZ6 조절물질이 증식성 또는 종양원성 세포들을 표적화하여 제거하거나 그렇지 않으면 무능력하게 만들며 SEZ6 관련 장애(예를 들면, 신생물)를 치료하는데 효과적으로 사용될 수 있음이 예상외로 발견되었다. 본원에 사용되는 바와 같이 "SEZ6 관련 장애(SEZ6 associated disorder)"는 질환 또는 장애의 경과 또는 병인 동안에 SEZ6 유전자 구성성분들 또는 발현의 표현형 또는 유전자형 이상으로 표시되거나, 진단되거나, 검출되거나 동정되는 (증식성 장애를 포함하는) 임의의 장애 또는 질환을 의미하는 것으로 간주될 것이다. 이와 관련하여 SEZ6 표현형 이상 또는 결정인자는, 예를 들면, SEZ6 단백질 발현의 상승하였거나 하강한 수준들, 소정의 정의할 수 있는 세포 개체군 상에서의 비정상적인 SEZ6 단백질 발현 또는 세포 생명주기의 부적절한 페이즈(phase) 또는 단계에서의 비정상적인 SEZ6 단백질 발현을 포함할 수 있다. 물론, SEZ6의 유전자형 결정인자(예를 들면, mRNA 전사 수준)의 유사한 발현 패턴들도 또한 SEZ6 관련 장애를 분류하거나 검출하는데에 사용될 수 있음도 알게 될 것이다.
본원에 사용되고 있는 용어 "결정인자(determinant)" 또는 "SEZ6 결정인자(SEZ6 determinant)"는 SEZ6 관련 질환 또는 장애에 걸린 조직, 세포 또는 세포 개체군 so에 또는 표면에서 동정되는 것들을 포함하는 특정한 세포, 세포 개체군 또는 조직과 확실히 연관이 있거나, 또는 그 속에 또는 표면에 특이적으로 발견되는 임의의 검출가능한 특성, 성질, 마커 또는 인자를 의미할 것이다. 선택된 바람직한 실시형태들에서 SEZ6 조절물질은 SEZ6 결정인자(예를 들면, 세포 표면 SEZ6 단백질 또는 SEZ6 mRNA)와 직접 회합하거나, 결합하거나 또는 반응함으로써 장애를 개선할 수 있다. 더욱 일반적으로 결정인자는 실제로는 형태학적이거나, 기능적이거나 또는 생화학적일 수 있으며 유전자형이거나 표현형일 수 있다. 다른 바람직한 실시형태들에서 결정인자는 특정 세포 종류(예를 들면, 암 줄기 세포)에 의해 또는 어떤 조건 하의 세포(예를 들면, 세포 주기의 특정 시점 동안 또는 특정한 생태적 적소의 세포)에 의해 차별적으로 또는 우선적으로 발현되는 (또는 그렇지 않은) 세포 표면 항원 또는 유전자 성분이다. 또 다른 바람직한 실시형태들에서 결정인자는 특정한 세포 또는 별개의 세포 개체군에서 다르게 (상향 또는 하향) 조절되는 유전자 또는 유전자 실체, 유전자의 물리적 구조와 화학적 조성에 대하여 차별적으로 변형되는 유전자 또는 차별적인 화학적 변형을 보여주는 유전자와 물리적으로 회합하는 단백질 또는 단백질들의 집합을 포함할 수 있다. 본원에서 고려되는 결정인자들은 구체적으로 양성 또는 음성으로 판단하며 그것의 존재(양성) 또는 부재(음성)에 의해 세포, 세포 부분모집단 또는 조직(예를 들면, 종양)을 표시할 수 있다.
유사한 맥락에서 본 발명의 "SEZ6 조절물질"은 폭넓게는 SEZ6 변이체 또는 이소형(또는 이의 특정 도메인, 부위 또는 에피토프) 또는 이의 유전자 성분을 인식하거나, 반응하거나, 경쟁하거나, 길항작용하거나, 상호작용하거나, 결합하거나, 작용하거나, 또는 회합하는 임의의 화합물을 포함한다. 이러한 상호작용들에 의해, SEZ6 조절물질은 종양원성 세포(예를 들면, 종양 영속화 세포 또는 암 줄기 세포)의 출현빈도, 활성, 재발, 전이 또는 이동을 유리하게 제거하거나, 감소시키거나 또는 완화할 수 있다. 본원에 개시된 예시적인 조절물질은 뉴클레오타이드, 올리고뉴클레오타이드, 폴리뉴클레오타이드, 펩타이드 또는 폴리펩타이드를 포함한다. 소정 바람직한 실시형태들에서 선택된 조절물질은 SEZ6 단백질 이소형 또는 이의 면역반응성 단편 또는 유도체에 대한 항체를 포함할 것이다. 상기 항체는 실제로는 길항작용적이거나 작용적일 수 있으며 임의로 치료제 또는 진단제와 접합되거나 회합될 수 있다. 게다가, 상기 항체 또는 항체 단편들은 고갈화, 중화 또는 내재화 항체를 포함할 수 있다. 다른 실시형태들에서, 본 발명의 범위 내의 조절물질은 SEZ6 이소형 또는 이의 반응 단편을 포함하는 SEZ6 작제물을 구성할 것이다. 상기 작제물은 융합 단백질을 포함할 수 있으며 면역글로불린 또는 생체반응조절물질과 같은 다른 폴리펩타이드로부터의 반응 도메인을 포함할 수가 있음을 알게 될 것이다. 또 다른 양상에서, SEZ6 조절물질은 유전체 수준에서 목적하는 효과들을 발휘하는 핵산 모이어티(예를 들면 miRNA, siRNA, shRNA, 안티센스 작제물 등)을 포함할 것이다. 본 발명의 교시들과 부합하는 또 다른 조절물질은 아래에 상세하게 논의될 것이다.
더욱 일반적으로 본 발명의 SEZ6 조절물질은 폭넓게는 세포 표면 SEZ6 단백질을 포함하는 SEZ6 결정인자(유전자형 또는 표현형)를 인식하거나, 반응하거나, 경쟁하거나, 길항작용하거나, 상호작용하거나, 결합하거나, 작용하거나, 또는 회합하는 임의의 화합물을 포함한다. 궁극적으로 선택되는 조절물질의 형태가 어느 것이든 대상체로 도입되기 전에 분리되어 정제된 상태가 바람직할 것이다. 이와 관련하여 용어 "단리된 SEZ6 조절물질(isolated SEZ6 modulator)" 또는 "단리된 SEZ6 항체(isolated SEZ6 antibody)"는 폭넓은 의미에서 그리고 표준 제약 실제에 따라 바람직하지 않은 오염물질(생물학적 약제 및 기타)이 실질적으로 없는 상태로 조절물질을 포함하는 임의의 제제 또는 조성물을 의미하는 것으로 해석될 것이다. 게다가 이들 제제들은 여러 가지의 당해 분야에서 인정되고 있는 기술들을 사용하여 원하는 대로 정제되어 제형화될 수 있다. 물론, 상기 "단리된(isolated)" 제제를 계획적으로 제형화하거나 원하는 대로 불활성 또는 활성 성분들과 조합하여 최종 산물의 상업적, 제조적 또는 치료적 양상들을 개선할 수 있으며 약제학적 조성물을 제공할 수 있음을 알게 될 것이다. 더욱 폭넓은 의미에서 똑같은 일반적인 고찰들을 "단리된" SEZ6 이소형 또는 변이체 또는 이것들을 암호화하는 "단리된" 핵산에도 적용할 수 있다.
더욱이, 놀랍게도 특정한 SEZ6 도메인, 모티프 또는 에피토프에 상호작용하거나, 회합하거나 결합하는 조절물질이 종양원성 세포들을 제거하는데에 및/또는 종양 성장 또는 전파에 대한 암 줄기 세포 효과를 침묵시키거나 약화시키는데에 특히 효과적이라는 사실도 발견되었다. 즉, 세포 표면에 가까운 도메인(예를 들면, 스시 또는 CUB-유사 도메인 중의 하나)과 반응하거나 회합하는 조절물질이 종양원성 세포들을 고갈시키거나 중화하는데에 효과적이기는 하지만, 세포 표면과 비교적 더욱 멀리 있는 도메인, 모티프 또는 부위에 회합하거나 결합하는 조절물질도 종양원성 세포들을 제거하거나, 중화하거나, 고갈시키거나 침묵시키는데에 역시 효과적이라는 사실이 발견된 것은 예상외의 일이었다. 이것은, 예를 들면, 세포독성제를 포함한 항-SEZ6 항체 약물 접합체와 같은 접합된 조절물질에 특히 해당한다.
본 발명은 명백히, 임의의 종류의 종양을 포함하는, 임의의 SEZ6 장애의 치료에서의 SEZ6 조절물질의 사용을 고려하고 있지만, 특히 바람직한 실시형태들에서 개시된 조절물질은 신경내분비 종양을 포함하는 신경내분비 특성(유전자형 또는 표현형)을 포함하는 종양을 예방하거나, 치료하거나 진단하는데에 사용될 수 있다. 진성의 또는 "전형적인 신경내분비 종양(canonical neuroendocrine tumor)"(NET)은 분산성 내분비계에서 발생하며 전형적으로는 아주 공격성이다. 신경내분비 종양은 신장, 비뇨생식기관(방광, 전립선, 난소, 자궁경부, 및 자궁내막), 위장관(위, 결장), 갑상선(갑상선 수질암), 및 폐(소세포 폐 암종 및 대세포 신경내분비 암종)에 발생한다. 게다가, 개시된 조절물질은 전형적인 신경내분비 종양들과 공통의 특성들을 유전자형으로나 표현형으로나 모방하거나, 포함하거나, 닮았거나 나타내는 가성의 신경내분비 종양(pNET)을 치료하거나, 예방하거나 진단하는데에 유리하게 사용될 수 있다. "가성 신경내분비 종양(Pseudo neuroendocrine tumor)"은 확산성 신경내분비계의 세포들 또는 종양원성 과정 동안 신경내분비 분화 캐스케이드가 비정상적으로 재활성화된 세포들에서 발생하는 종양이다. 이러한 pNET는 생물학적 활성 아민, 신경전달물질, 및 펩타이드 호르몬의 서브세트를 생성할 수 있는 능력을 포함하여 전통적으로 정의된 신경내분비 종양들과 소정 유전자형, 표현형 또는 생화학적 특성들을 흔히 공유한다. 따라서, 본 발명의 목적을 위하여 문구 "신경내분비 특징들을 포함하는 종양들(tumors comprising neuroendocrine features)" 또는 "신경내분비 특징들을 나타내는 종양들(tumors exhibiting neuroendocrine features)"은 문맥에 의해 달리 지시하지 않는 한 신경내분비 종양들과 가성 신경내분비 종양들 둘 다를 포함하는 것으로 간주될 것이다.
바람직한 실시형태들에서 개시된 조절물질은 소세포 폐암을 치료하는데 사용될 것이며, 특별히 바람직한 실시형태들에서는 이를 필요로 하는 대상체에서 백금 내성 소세포 폐암을 치료하는데 사용될 것이다. 본원에서 사용되고 당업계에 공지된 바와 같이, 용어 "백금 내성 소세포 폐암"은 카보플라틴, 시스플라틴 및/또는 옥살라플라틴과 같은 치료 기준 백금계 제제로의 치료에 대해 내성이거나 난치성인 대상체에서의 종양 또는 종양원성 소세포 폐암 세포의 존재를 의미한다. 이러한 상태는 표준 임상 절차를 사용하여 쉽게 진단되며, 이들의 인식은 당업계의 통상의 숙련된 임상의의 이해 범위내에 있다.
상기 일반적으로 논의된 종양들과의 회합 외에도, 선택된 종양 개시 세포들(TIC)과 SEZ6 결정인자들 간의 표현형 또는 유전자형 회합의 징후들도 존재한다. 이와 관련하여 선택된 TIC(예를 들면, 암 줄기 세포)는 정상 조직 및 비-종양원성 세포(NTG)와 비교하였을 때 SEZ6 단백질의 상승된 수준을 발현할 수 있는데, 이는 통틀어 전형적으로는 고형 종양의 대부분을 포함한다. 따라서, SEZ6 결정인자는 종양 관련 마커(또는 항원 또는 면역원)를 포함할 수 있으며 개시된 조절물질은 세포 표면 상의 또는 종양 미세환경에서의 단백질의 변화된 수준으로 인하여 TIC 및 관련 종양의 검출 및 억제를 위한 효과적인 제제를 제공할 수 있다. 따라서, 단백질과 회합하거나, 결합하거나 반응하는 면역반응 길항제 및 항체를 포함한 SEZ6 조절물질은 종양 개시 세포의 출현빈도를 효과적으로 감소시킬 수 있으며 이들 종양-개시 세포의 분화를 제거하는데, 고갈시키는데, 무력화하는데, 감소시키는데, 촉진하는데, 또는 그렇지 않으면 이들 종양-개시 세포가 환자에서 휴지 상태로 있고/있거나 종양 성장, 전이 또는 재발을 계속 자극할 수 있는 능력을 차단하거나 제한하는데에 유용할 수 있다. 이와 관련하여 당해 분야의 숙련가들이라면 본 발명은 더 나아가 SEZ6 조절물질, 및 종양 개시 세포의 출현빈도를 감소시키는데 있어서의 이들의 용도를 제공하는 것임을 이해할 것이다.
II. SEZ6 생리학
SEZ6(발작 관련 6 상동체로도 알려짐)은 원래 경련유발제 펜틸렌테트라졸로 치료된 마우스 대뇌 피질-유래 세포로부터 클로닝된 제I형 막관통 단백질이다(문헌 참조; Shimizu-Nishikawa, 1995; PMID: 7723619). 대표적인 SEZ6 단백질 이종상동체(ortholog)에는 사람(NP_849191; NP_001092105), 침팬지(XP_511368, NP_001139913), 마우스(NP_067261), 및 래트(NP_001099224)가 포함되지만, 이들에 한정되는 것은 아니다. 사람에서, SEZ6 유전자는 염색체 17q11.2 상에 위치한 51.1 kBp에 걸쳐 있는 17개의 엑손들로 이루어져 있다. 마지막 엑손 안쪽의 불과 16 염기쌍 떨어진 선택적 스플라이스 수용체 자리(alternate splice acceptor site)는 두 개의 가공처리 전사물들을 생성하는데, 대략 4210개 염기들의 전사물(NM_178860; 도 1a)과 대략 4194개 염기들의 전사물(NM_001098635, 도 1b)이다. 전자의 전사물은 994개 아미노산 단백질(NP_849191; 도 1c)을 암호화하는 반면, 후자는 993개 아미노산 단백질(NP_001092105; 도 1d)을 암호화한다. SEZ6의 이들 두 가지 단백질 이소형은 자신들의 세포외 도메인과 자신들의 막관통 도메인의 전역에서 전체적으로 100%의 동일성을 공유하며, 마지막의 열 개 아미노산 잔기들에서만 차이가 있을 뿐이다(도 1e). 제3의 스플라이스 변이체가 SEZ6의 분비형(Shimizu-Nishikawa, 1995; PMID: 7723619)을 생성하는 것으로 보고되었으나, NCBI 데이터베이스 유전자 페이지 목록 안에 관련된 RefSeqs에 포함되지 않았다. 본 발명의 조절물질은 스플라이스 변이체들의 어떠한 것에도 결합할 수 있다.
이소형의 생물학적 관련성은 불확실하나, 뮤린 SEZ6 녹아웃(knockout) 마우스의 뉴런들에서 이들의 발현이 회복되었을 때 막 단백질 대 수용성 단백질에 대한 정반대의 작용들을 시사한 한 가지 연구가 있었다(문헌 참조; Gunnersen et al. 2007, PMID: 18031681). SEZ6 단백질에 대한 교차 종 단백질 서열 동일성이 도 2a에 수록되어 있다. 사람 유전체에서는, 두 개의 밀접하게 관련된 유전자들, 즉, 발작 관련 6 상동체-유사(SEZ6L)와 발작 관련 6 상동체 유사-2(SEZ6L2)가 존재하는데, 이들 각각은 수많은 이소형을 암호화하는 다수의 스플라이스 변이체를 갖는다(도 2b). 사람들에서 이 패밀리의 SEZ6-유사 단백질의 구성원들 각각의 가장 긴 단백질에 대한 동일성 비율이 도 2c에 나타나 있다. 종합하면 SEZ6, SEZ6L 및 SEZ6L2는, 이들의 다양한 변이체들을 포함해서, 본 출원의 목적을 위하여 SEZ6 패밀리라고 부를 것이다. 본 발명의 SEZ6 조절물질은 SEZ6, SEZ6L 또는 SEZ6L2의 각각에 특이적인 조절물질을 포함한다. 또는, 본 발명의 조절물질은 SEZ6과 교차 반응할 수 있으며 SEZ6L 및/또는 SEZ6L2 중의 하나 또는 둘 다와 교차 반응할 수 있다.
성숙 SEZ6 단백질은 일련의 구조적 도메인들로 구성되어 있다: 세포질 도메인, 막관통 도메인 그리고 고유한 N-말단 도메인에 이어 두 개의 교대하는 스시와 CUB-유사 도메인, 및 세 개의 추가 직렬성 스시 도메인 반복부위들을 포함하는 세포외 도메인. SEZ6 항원의 두 가지 이소형이 존재하는데, 맨끝의 카복시 말단, 세포질 도메인에서만 차이가 있을 뿐이다.
도 1f는 SEZ6 단백질의 세포외 영역의 도식적 그림을 제공한 것으로, 스시와 CUB 도메인 및 N-말단 도메인의 일반적인 병치 상태를 예시한 것이다. 일반적으로, 도메인은 대체로 아미노산 잔기 336-395(스시 도메인 1), 397-508(CUB 도메인 1), 511-572(스시 도메인 2), 574-685(CUB 도메인 2), 690-748(스시 도메인 3), 750-813(스시 도메인 4), 817-878(스시 도메인 5)에서 발생하는 것으로 인지되고, N-말단 도메인은 대체로 아미노산 잔기 1-335에, 그리고 프롤린이 풍부한 잔기들의 구성 편중(compositional bias)은 대체로 아미노산 잔기 71-169에 있는 것으로 인지된다.
스시 반복부위들은 다른 사람 보체 조절성 단백질(즉, 보체 C3b/C4b 결합 부위)에서 발견되는 짧은 컨센서스 반복부위들과 유사하다. CUB-유사 도메인은, 패턴화, 신경돌기 경로유도(axon guidance), 염증, 그리고 종양 억제를 포함하지만 이들에 한정되지 않는, 보체 활성화 외에 수많은 생물학적 과정들에 참여하는 폭넓은 범위의 단백질들과 회합하는 다른 포유동물 보체 결합 단백질들에서 발견되는 CUB 도메인들과 유사하다(Bork and Beckman, 1993, PMID: 8510165). 스시 및 CUB 도메인 둘 다는 세포 밖에서 다른 단백질들의 결합에 연루된 SEZ6의 기능을 암시한다. CUB 도메인을 포함한 단백질들은 또한 세포 신호전달 경로들에 연루되어 왔으며, 이러한 기능과 모순되지 않게도, SEZ6 C-말단 세포질 도메인은 Asn-Pro-Thr-Tyr 모티프(서열번호 403)를 포함하고 있는데, 이것은 Src 티로신 키나제 패밀리 구성원들에 의한 인산화의 잠재적 표적이다. 만일 사실이면, 이는 Ras의 활성화로 이끄는 세포 신호전달 경로에 SEZ6을 연결할 수 있는 것이어서, SEZ6이 신경성장 수용체일 수 있음을 시사한다.
본원에 사용되는 용어들 "성숙 단백질(mature protein)" 또는 "성숙 폴리펩타이드(mature polypeptide)"는 세포 표면 발현에 앞서 절단될 수 있는 19개 아미노산의 신호 펩타이드 없이 생성된 SEZ6 단백질 형태(들)를 가리키는 것임을 주지한다. 달리 나타내지 않는 한 SEZ6 아미노산 번호부여(도메인, 부위, 에피토프 등에 대한)는 선도부위가 없는 성숙 단백질의 맥락 안에 있을 것이다.
SEZ6은 설치류의 신장, 간, 심장, 폐 및 흉선에서 낮은 수준으로 RT-PCR에 의해 검출가능하지만, 강한 단백질 발현은 뇌에서만 관찰되었을 뿐이고, 고환에서 상당한 수준으로 발현된다(Herbst and Nicklin, 1997, PMID: 9073173). SEZ6에 대한 폴리클로날 혈청을 사용하여, 발달하는 마우스 전뇌(前腦)의 13일째에 단백질 발현이 검출되었다. 발달하는 피질 판 및 피질판하 구조물의 유사분열 후의, 성숙하는 뉴런들에서 강한 염색이 검출되었다. 이 염색은 성체 뇌에서는 감소되는데, 여기서는 SEZ6 발현이 진행 중인 형태학적 유연성과 관련된 다른 뇌 부위들, 이를 테면 해마상 융기, 소뇌, 및 후각 망울에서 그리고 망막 및 척수의 뉴런들에서 검출될 수가 있다(Gunnersen et al., 2007, PMID: 18031681). 가장 밀집한 신호들은 뉴런 세포체들의 농도가 가장 높은 부위에서 발견된다. SEZ6의 광범한 망막 발현에도 불구하고, SEZ6의 부재 하에서의 망막 기능은 영향을 받지 않았다(Gunnersen et al., 2009, PMID: 19662096). SEZ6 염색 패턴은 신피질층들 및 해마상 융기의 출현과 밀접하게 관계가 있으며, 발달 동안의 이 유전자의 전뇌-특이적 역할을 암시하는 것이다. 사람 및 마우스에서 SEZ6은 신피질의 아주 특이적인 부위에서 차별적으로 발현되는 것으로 밝혀졌다(Gunnersen et al., 2007, 상기).
사람 SEZ6 유전자의 돌연변이들은 체온의 상승과 관련된 경련이며 어린이에서 발작의 가장 흔한 종류인, 열병성 발작(FS)에 관련되어 왔다(Yu et al., 2007, PMID:17086543). FS는 지속기간, 재발, 및 발작에 의해 영향을 받는 몸의 정도에 따라, 단순형 또는 복합형으로 분류될 수 있다. 중국 코호트에서, 15명의 건강한 대조군들에서는 SEZ6의 돌연변이가 전혀 발견되지 않았으나, FS를 가진 60명의 환자들 중 21명에서 돌연변이가 발견되었는데, 가장 흔한 돌연변이는 cDNA의 1435번 위치에서의 이형접합체의, 사이토신 삽입(프레임 이동 돌연변이)이었다. 돌연변이 발생은 복합형 FS를 가진 환자들에서 그리고 가족력이 실재하는 환자들에서 유의하게 더 높았다. 복합형 FS를 가진 어린이들은 생애의 나중에 발작을 일으킬 가능성이 80%이므로, 본 출원인은 SEZ6의 돌연변이들에 대하여 조사하는 것은 FS 재발 또는 간질 발생을 예측하는데 도움이 될 수 있다고 제안한다(Yu et al., 2007, 상기). 후속 연구들은 인과관계를 암시하는 적절한 힘을 가졌던 상기 연구의 범위, 관련성, 및 능력을 의문시하였으나, SEZ6이 발작 장애에서 역할을 할 수 있는 여러 유전자들 중 한 가지 유전자일 수 있음을 뒷받침하고 있다(Mulley et al., 2011, PMID: 21785725).
SEZ6의 특정한 분자 기능들은 여전히 불확실하다. 앞서 논의한 바와 같이, 상동성 및 서열 분석에 의해 동정된 단백질의 구조적 구성단위들에 대한 분석은 신호전달, 세포-세포 소통, 그리고 뉴런 발달에서의 가능한 역할을 시사하고 있다. 뇌의 회로를 구성하는 신호전달 연결망들을 형성하는 뉴런의 수상돌기 분지화 및 연결능력이 나타나며 외부로부터의 신호들 뿐만 아니라 신경 세포의 내재한 분자 프로그램들 둘 다에 의해서 특수화된다. 포유동물 전뇌에 있는 주(主) 뉴런인, 피라미드 뉴런들에서의 수상돌기 성장의 과정은, 고유한 형태들을 가진 뉴런들을 내놓는다 - 피라미드 세포체, 그리고 두 개의 구별되는, 복잡한 수상돌기 나무들로서: 하나는 세포체의 꼭대기에서 나오며 다른 하나는 바닥에서 나온다. Gunnersen 등(2007, 상기)은 SEZ6 무효 마우스들이 상기 뉴런들의 수상돌기 나무들에서 과다한 짧은 수상돌기들을 나타내지만, 주어진 뉴런이 연결하는 뉴런들의 범위인, 전체적인 수상돌기 영역에서는 전혀 증가를 보이지 않음을 밝혔다. 녹아웃 뉴런에서 막 결합형 SEZ6 이소형의 발현을 회복시키면 항-분지화 효과가 초래된다. 행동 시험들에서 SEZ6 무효 마우스들은 특이적 탐색, 운동, 및 인식 결함들을 보인다. 이들 데이터는 SEZ6이 발달 동안의 복잡한 수상돌기 수목의 다듬기 동안에 수상돌기 신장과 분지화 간의 필요한 균형의 달성에 중요함을 시사하는 것이다.
종합하여, 상기 연구들은 SEZ6 단백질이 신경 발달의 맥락에서 중요하며, 세포-세포 소통과 신호전달에서 아마 소정 역할을 할 것임을 강하게 시사하고 있다. 발달상의 신호전달 경로들의 부적절한 재활성화 또는 정상 신호전달 경로들의 조절이상은 종양들에서 흔히 관찰된다(Harris et al., 2012). 발달 프로그램들의 일부 재활성화를 나타내는 특징들을 공유하는 종양들의 한 집합이 신경내분비 표현형을 가진 종양들인데(Yao 2008; PMID: 18565894), 여기서는 각종 호르몬과 내분비 마커들이 발현되고/발현되거나 분비되며, 신경 운명을 향한 신경발생, 신경 연루, 또는 분화를 나타내는 각종 신경 마커들이 발현된다. 신경내분비 특징들을 가진 종양들은 가끔 폭넓은 범위의 원발성 위치들에서 발생하며, 이들의 철저한 분류는 의문의 여지가 있지만(Yao; PMID: 18565894; Klimstra 2010; PMID: 20664470; Kloppel, 2011; PMID: 22005112), 이들은 크게 네 종류들로 분류될 수 있다: 저등급 양성 카르시노이드, 악성 성질이 있는 저등급 고분화 신경내분비 종양, 신경내분비 및 상피 특징들이 혼합된 종양, 그리고 고등급 저분화 신경내분비 암종. 이러한 분류들 중에서, 소세포 폐암(SCLC)과 서브세트의 비-소세포 폐암(NSCLC)을 포함하는, 저분화 신경내분비 암종이 무서운 예후를 가진 암 종류들이다. SCLC는 기원이 기관지유래성이며 일부는 폐 신경내분비 세포들에서 발생하는 것으로 추정되어 왔다(Galluzzo and Bocchetta, 2011; PMID: 21504320). 이들 종양들의 기원의 세포 공급원이 무엇이든 간에, 이들은 저분화성의 내분비 표현형을 보여주고, 종종 고도의 증식적이고 공격적이며, 빈번히 신경 단백질들을 과다-발현함은 분명하다. 유사하게, 갑상선의 칼시토닌-분비 방여포 C 세포로부터 야기되는 특수한 신경내분비 종양 타입인 갑상선 수질암(MTC)은 이들의 성숙한 내분비 기능과 신경능 조직으로부터의 이들의 유래 둘 다와 일관되는 신경내분비 표현형을 보여준다(Cook et al., 2010; PMID: 20182588). 갑상선암의 단지 약 3-5%를 나타내기는 하지만, MTC는 모든 갑상선암 사망의 최대 14%를 초래하며, 표준 화학요법 또는 방사선 치료에 매우 반응하지 않고, 심지어 카보잔티닙 및 반데타닙과 같은 보다 최신의 분자 표적화된 티로신 키나제 억제제에도 그다지 반응하지 않으며, 단일요법에 불량하게 반응한다(Haddad, 2013; PMID: 24002516). 참담한 예후를 갖는 종양의 이러한 예를 고려해 볼 때, 이들 종양들에서 신경 발현 마커들의 결과로서의 상승은, 만약 그렇지 않으면 발달 동안에 신경계에 주로 한정되거나 제한적인 발현을 보여줄 수 있겠지만, 그 중 SEZ6이 한 본보기가 될 수 있고, 그러므로 신경내분비 표현형을 가진 종양의 고유한 치료학적 표적을 제공할 수 있다.
III. 암 줄기 세포
상기 언급한 대로 (유전자형 및/또는 표현형의) 비정상적인 SEZ6 발현이 각종의 종양원성 세포 부분모집단들과 연관이 있음이 발견된 것은 놀라운 일이었다. 이와 관련하여 본 발명은 이러한 세포들, 특히 종양 영속화 세포들을 표적화함으로써 신생물 장애의 치료, 관리 또는 예방을 촉진시키기에 특히 유용할 수 있는 SEZ6 조절물질을 제공한다. 따라서, 바람직한 실시형태들에서 (표현형 또는 유전자형의) SEZ6 결정인자의 조절물질은 본 발명의 교시에 따라 종양 개시 세포 출현빈도를 감소시킴으로써 증식성 장애의 치료 또는 관리를 촉진시키는데에 유리하게 사용될 수 있다.
본 출원의 목적을 위하여 용어 "종양 개시 세포(tumor initiating cell)"(TIC)는 "종양 영속화 세포(tumor perpetuating cell)"(TPC; 즉, 암 줄기 세포 또는 CSC)와 고도 증식성의 "종양 전구 세포(tumor progenitor cell)(TProg라고 함) 둘 다를 포함하는 것으로, 이 둘이 합쳐져 일반적으로는 벌크 종양 또는 덩어리의 고유한 부분모집단(즉, 0.1-40%)을 구성한다. 본원 개시의 목적을 위하여 용어들 "종양 영속화 세포(tumor perpetuating cell)"와 "암 줄기 세포(cancer stem cell)" 또는 "종양 줄기 세포(neoplastic stem cell)"는 같은 뜻이며 본원에서는 서로 바꾸어 사용될 수 있다. TPC는 적은 수의 단리된 세포들의 연속 이식(마우스들을 통한 두 번 이상의 통과들)에 의해 증명되는 바와 같이 TPC가 종양 내부에 존재하는 종양 세포들의 조성을 완전히 발생반복하여 무제한의 자기-재생 능력을 가질 수가 있는 반면, TProg는 무제한의 자기-재생 능력을 보여줄 수 없다는 점에서 TProg와 다르다.
당해 분야의 숙련가들이라면 적합한 세포 표면 마커들을 사용하는 형광-활성화 세포 분류(FACS)가, 적어도 부분적으로, 단일 세포들과 세포들의 덩어리들(즉 이중체들 등) 간을 구별할 수 있는 능력 때문에 고도의 농축된 암 줄기 세포 부분모집단을 (예를 들면, > 99.5% 순도로) 분리할 수 있는 신뢰할 수 있는 방법인 것을 이해할 것이다. 이러한 기술들을 사용하면 적은 세포 개수의 고도 정제된 TProg 세포들이 면역손상된 마우스로 이식되었을 때 이들은 1차 이식에서 종양 성장을 자극할 수가 있음이 밝혀졌다. 그러나, 정제된 TPC 부분모집단들과 달리 TProg에 의해 발생된 종양들은 표현형 세포 이질성에서 모체 종양들을 완전히 반영하지 못하며 후속 이식들에서 연속 종양원성을 재개시하기에는 명백히 비효과적이다. 이와 대조적으로, TPC 부분모집단들은 모체 종양들의 세포 이질성을 완전히 재구성하며 연속적으로 분리 및 이식될 때 종양들을 효과적으로 개시시킬 수가 있다. 따라서, 당해 분야의 숙련가들이라면 TPC와 TProg 간의 결정적인 차이가, 비록 둘 다는 1차 이식들에서 종양을 발생시킬 수 있지만, 적은 세포로 연속 이식시 이질성의 종양 성장을 영속적으로 자극할 수 있는 TPC의 고유한 능력임을 인식할 것이다. TPC의 특성을 밝힐 수 있는 다른 일반적인 접근방법은 세포 표면 마커들의 형태학과 검사, 전사 프로파일, 그리고 약물 반응 등을 포함하고 있지만 마커 발현은 배양 조건들에 따라 그리고 시험관내에서의 세포주 통과에 따라 변할 수 있다.
따라서, 본 발명의 목적을 위하여 종양 영속화 세포들은, 정상 조직에서 세포적 계층구조를 유지하는 정상 줄기 세포들과 마찬가지로, 바람직하게는 다계통 분화의 능력을 유지하면서도 무한히 자기-재생할 수 있는 능력으로 정의된다. 따라서 종양 영속화 세포들은 종양원성 자손(즉, 종양 개시 세포들: TPC와 TProg)과 비-종양원성(NTG) 자손 둘 다를 발생시킬 수 있다. 본원에 사용되는 바와 같이 "비-종양원성 세포(non-tumorigenic cell)"(NTG)는 종양 개시 세포들에서 발생하지만, 그 자신은 자기-재생하거나 종양을 포함하는 종양 세포들의 이질 계통들을 발생시킬 수 있는 능력을 갖지 않은 종양 세포를 가리킨다. 실험적으로, NTG 세포는 과도한 세포 수들을 이식하였을 때조차도, 마우스들에서 재현가능할 정도로 종양들을 형성하지는 못한다.
언급한 바와 같이, TProg는 마우스에서 종양을 발생시킬 수 있는 한정된 능력 때문에 종양 개시 세포(또는 TIC)로 분류되기도 한다. TProg는 TPC의 자손이며 전형적으로는 유한한 횟수의 비-자기-재생 세포 분열들을 할 수 있다. 게다가, TProg 세포는 초기 종양 전구 세포(ETP)와 후기 종양 전구 세포(LTP)로 더 나누어질 수 있는데, 그 각각은 표현형(예를 들면, 세포 표면 마커들)과 종양 세포 구성을 반복할 수 있는 다른 능력들로 구별될 수 있다. 이러한 기술적 차이들에도 불구하고, ETP와 LTP 둘 다는 이들이 적은 세포 개수로 이식하였을 때 종양들을 연속적으로 재구성할 능력이 일반적으로 떨어지며 전형적으로는 모체 종양의 이질성을 반영하지 못하는 점에서 TPC와 기능적으로 다르다. 상기의 차이점들에도 불구하고, 각종 TProg 개체군들은, 드물게, 정상적으로는 줄기 세포들에 속하는 자기-재생 능력들을 획득하여 그들 자신이 TPC (또는 CSC)가 될 수가 있음도 또한 밝혀졌다. 아무튼 종양-개시 세포들의 종류 둘 다는 단일 환자의 전형적인 종양 덩어리에 나타날 가능성이 있으며 본원에 개시된 조절물질로 치료하기가 쉽다. 즉, 개시된 조성물은 종양에 나타난 특별한 형태나 혼합비율에 관계없이 상기 SEZ6 양성 종양 개시 세포들의 출현빈도를 감소시키거나 항암제민감성을 변화시키는데 일반적으로 효과가 있다.
본 발명의 맥락에서, TPC는 종양의 대부분을 포함하는 TProg(ETP와 LTP 둘 다), NTG 세포 및 종양-침윤 비-TPC 유래 세포(예를 들면, 섬유아세포/스트로마, 내피 및 조혈 세포)보다 더욱 종양유발적이고, 비교적 더 침묵적이며 종종 더욱 항암제내성이다. 종래의 치료요법들과 용법들은, 대부분, 종양들의 크기를 감소할 뿐 아니라 빠르게 증식하는 세포들을 공격하도록 설계되었음을 고려하면, TPC는 더 빠르게 증식하는 TProg 및 그 밖의 벌크 종양 세포 개체군들보다 종래 치료요법들 및 용법들에 더욱 내성일 가능성이 있다. 더욱이, TPC는 자신들을 종래 치료요법들에 비교적 항암제내성이도록 만들어 주는 다른 특성들을 종종 발현하기도 하는데, 이를 테면, 다-약제 내성 운반체들의 발현 증가, DNA 수복 메커니즘들과 항-아폽토시스(세포자살사) 단백질들의 증대 등이다. 이러한 성질들은, 그 각각이 TPC의 약제 내성에 기여하는 것인데, 진행된 단계 종양을 가진 대부분 환자들에게 장기에 걸친 혜택을 보장할 수 있는 표준적인 종양학 치료학적 용법들의 실패의 중요한 이유이기도 하다; 즉, 계속되는 종양 성장과 재발을 자극하는 세포들(즉 TPC 또는 CSC)을 적절히 표적화하고 근절하지 못하는 중요한 이유이다.
많은 선행 기술의 치료들과 달리, 본 발명의 신규한 조성물은 선택된 조절물질의 형태나 특정 표적(예를 들면, 유전 물질, SEZ6 항체 또는 리간드 융합 작제물)에 관계없이 대상체에게 투여시 바람직하게는 종양 개시 세포들의 출현빈도를 감소시킨다. 상기 언급한 바와 같이, 종양 개시 세포 출현빈도의 감소는 a) 종양 개시 세포들의 제거, 고갈, 감작, 침묵화 또는 억제; b) 종양 개시 세포들의 성장, 확대 또는 재발을 통제함; c) 종양 개시 세포들의 개시, 전파, 유지, 또는 증식을 차단함; 또는 d) 다르게는 종양 개시 세포들의 생존, 재생 및/또는 전이를 방해함의 결과로서 일어날 수 있다. 소정 실시형태들에서, 종양 개시 세포들의 출현빈도의 감소는 하나 이상의 생리학적 경로들에서의 변화의 결과로 일어난다. 경로상의 변화는, 종양 개시 세포들의 감소 또는 제거에 의한 것이거나 또는 종양 환경 또는 다른 세포들에 영향을 미칠 수 있는 이들의 잠재력(예를 들면, 분화의 유도, 생태적 적소의 파괴)을 부분변화시키거나 또는 다르게는 이들의 능력을 간섭함에 의한 것이든 간에, 종양원성, 종양 유지 및/또는 전이와 재발을 억제함으로써 SEZ6 관련 장애의 더욱 효과적인 치료를 가능하게 한다.
종양 개시 세포들의 출현빈도 감소를 평가하는데 사용될 수 있는 당해 분야에서 인정되고 있는 방법 중에는 시험관내에서의 또는 생체내에서의 한계 희석 분석이 있는데, 이는 바람직하게는 생체내에서든 아니든 종양들을 발생시킬 수 있는 능력과 같은 미리 정의된 명확한 결과들에 대해 뿌아송 분포 통계학을 사용하는 또는 그 출현빈도를 평가하는 계수를 수반한다. 이러한 한계 희석 분석은 종양 개시 세포 출현빈도 감소를 계산하는 바람직한 방법을 포함하지만 다른 덜 힘든 방법도, 비록 약간 덜 정확하지만, 원하는 값들을 효과적으로 측정하는데 사용될 수 있으며 본원의 교시들에 완전히 적합한 것이다. 따라서, 당해 분야의 숙련가들이라면 이해할 수 있는 바와 같이, 잘 알려진 유동 세포분석 또는 면역조직화학적 수단을 통해 출현빈도 감소 값들을 측정하는 것도 또한 가능하다. 앞에 언급한 방법 모두에 대하여는, 예를 들면, 문헌[Dylla et al. 2008, PMID: 18560594 & Hoey et al. 2009, PMID: 19664991]을 참조하며; 그 각각은 그 전부가, 특히, 개시된 방법에 대해, 참조로 본원에 인용된다.
한계 희석 분석에 대하여, 종양 개시 세포 출현빈도의 시험관내 계수는 분획된 또는 분획되지 않은 사람 종양 세포들(예를 들면, 각각, 치료된 그리고 미치료된 종양들로부터의)을 콜로니 형성을 촉진하는 시험관내 성장 조건들에 놓음으로써 이루어질 수 있다. 이런 식으로, 콜로니 형성 세포들은 단순 집계 및 콜로니들의 특성평가로, 또는, 예를 들면, 사람 종양 세포들의 연속 희석으로 플레이트에 놓고, 도포 후 적어도 10일째의 콜로니 형성에 대한 각각의 웰을 양성 또는 음성의 어느 쪽으로 평가하는 단계로 이루어진 분석으로 계수될 수 있을 것이다. 생체내 한계 희석 실험들 또는 분석들은, 종양 개시 세포 출현빈도를 측정하는 능력면에서 일반적으로 더욱 정확한 것인데, 미치료된 대조군 또는 치료된 개체군들로부터 사람 종양 세포들의, 예를 들면, 연속 희석하의 면역손상 마우스로의 이식 그리고 이어서 이식 후 적어도 60일째의 종양 형성에 대한 각각의 마우스의 양성 또는 음성의 어느 쪽으로 평가하는 단계를 포함하고 있다. 시험관내 또는 생체내 한계 희석 분석에 의한 세포 출현빈도 값들의 도출은 바람직하게는 뿌아송 분포 통계학을 양성 및 음성 경우들의 알려진 출현빈도에 적용하여, 그것에 의해 양성 결과의 정의를 충족시키는 결과들에 대하여 출현빈도를 제공함으로써 이루어진다; 이 경우에는, 각각, 콜로니 또는 종양 형성.
종양 개시 세포 출현빈도를 계산하는데에 사용될 수 있는 본 발명에 적합한 다른 방법에 대하여는, 가장 흔한 것이 정량화할 수 있는 유동 세포분석 기술들 및 면역조직화학 염색 절차들을 포함한다. 비록 바로 위에 기술된 한계 희석 분석 기술만큼 정확하지 않다 하더라도, 이들 절차들은 훨씬 덜 노동 집약적이며 비교적 짧은 기간에 합리적인 값들을 제공해 준다. 따라서, 숙련가라면 종양 개시 세포들에 대하여 증대되는 것으로 알려진 당해 분야에서 인정되고 있는 세포 표면 단백질(예를 들면, 그 전부가 본원에 인용되어 있는 PCT 출원 제2012/031280호에 제시된 잠재적으로 적합한 마커)을 결합시켜 그것에 의해 각종 샘플들의 TIC 수준을 측정하는 하나 이상의 항체 또는 시약을 사용하는 유동 세포분석 세포 표면 마커 프로파일 측정을 이용할 수 있음을 이해할 것이다. 또 다른 적합한 방법에서 당해 분야의 숙련가라면 상기 세포들을 구별해 주는 것으로 생각되는 세포 표면 단백질들을 결합할 수 있는 하나 이상의 항체 또는 시약을 이용하는 면역조직화학에 의해서 동일반응계에서의(in situ)(예를 들면, 조직 구획에서의) TIC 출현빈도를 계수할 수 있을 것이다.
당해 분야의 숙련가들이라면 수많은 마커들(혹은 이들의 부재)이 각종 암 줄기 세포의 개체군과 연관이 있으며 종양 세포 부분모집단을 분리하거나 특성평가하는데에 사용되어 왔음을 인식할 것이다. 이와 관련하여 예시적인 암 줄기 세포 마커들은 OCT4, 나노그(Nanog), STAT3, EPCAM, CD24, CD34, NB84, TrkA, GD2, CD133, CD20, CD56, CD29, B7H3, CD46, 트랜스페린 수용체, JAM3, 카복시펩티다제 M, ADAM9, 옹코스타틴(oncostatin) M, Lgr5, Lgr6, CD324, CD325, 네스틴(nestin), Sox1, Bmi-1, eed, easyh1, easyh2, mf2, yy1, smarcA3, smarckA5, smarcD3, smarcE1, mllt3, FZD1, FZD2, FZD3, FZD4, FZD6, FZD7, FZD8, FZD9, FZD10, WNT2, WNT2B, WNT3, WNT5A, WNT10B, WNT16, AXIN1, BCL9, MYC, (TCF4) SLC7A8, IL1RAP, TEM8, TMPRSS4, MUC16, GPRC5B, SLC6A14, SLC4A11, PPAP2C, CAV1, CAV2, PTPN3, EPHA1, EPHA2, SLC1A1, CX3CL1, ADORA2A, MPZL1, FLJ10052, C4.4A, EDG3, RARRES1, TMEPAI, PTS, CEACAM6, NID2, STEAP, ABCA3, CRIM1, IL1R1, OPN3, DAF, MUC1, MCP, CPD, NMA, ADAM9, GJA1, SLC19A2, ABCA1, PCDH7, ADCY9, SLC39A1, NPC1, ENPP1, N33, GPNMB, LY6E, CELSR1, LRP3, C20orf52, TMEPAI, FLVCR, PCDHA10, GPR54, TGFBR3, SEMA4B, PCDHB2, ABCG2, CD166, AFP, BMP-4, β-카테닌, CD2, CD3, CD9, CD14, CD31, CD38, CD44, CD45, CD74, CD90, CXCR4, 데코린(decorin), EGFR, CD105, CD64, CD16, CD16a, CD16b, GLI1, GLI2, CD49b, 및 CD49f를 포함한다. 예를 들면, 각각이 참조로 본원에 인용된 문헌[Schulenburg et al., 2010, PMID: 20185329, U.S.P.N. 7,632,678 그리고 U.S.P.Ns. 2007/0292414, 2008/0175870, 2010/0275280, 2010/0162416 및 2011/0020221]을 참조한다. 게다가 상기 마커들 각각은 본 발명의 이중특이 또는 다중특이 항체의 맥락에서 이차 표적 항원으로 사용될 수 있음도 또한 이해할 것이다.
마찬가지로, 소정 종양 종류들의 암 줄기 세포들과 연관된 세포 표면 표현형들의 비제한적인 예에는 당해 분야에서 알려져 있는 다른 암 줄기 세포 표면 표현형들 뿐만 아니라 CD44hiCD24low, ALDH+, CD133+, CD123+, CD34+CD38-, CD44+CD24-, CD46hiCD324+CD66c-, CD133+CD34+CD10-CD19-, CD138-CD34-CD19+, CD133+RC2+, CD44+α2 β1 hiCD133+, CD44+CD24+ESA+, CD271+, ABCB5+가 포함된다. 예를 들면, 각각이 참조로 그 전체가 본원에 인용된 문헌[Schulenburg et al., 2010, 상기, Visvader et al., 2008, PMID: 18784658 및 U.S.P.N. 2008/0138313]을 참조한다. 당해 분야의 숙련가들이라면 바로 위에 예시된 것들과 같은 마커 표현형들을 표준의 유동 세포계측 분석 및 세포 분류 기술과 함께 사용하여 후속 분석을 위한 TIC 및/또는 TPC 세포들 또는 세포 개체군들을 특성평가하거나, 분리하거나, 정제하거나 또는 증대시킬 수 있음을 이해할 것이다. 본 발명에 관련하여 중요한 것으로 CD46, CD324 및, 임의로, CD66c는, 분석하고자 하는 종양 피검물들이 일차 환자 종양 피검물들인지 또는 환자-유래의 NTX 종양들인지 관계없이, 많은 사람 직장결장암("CR"), 유방암("BR"), 비-소세포 폐암(NSCLC), 소세포 폐암(SCLC), 췌장암("PA"), 멜라노마("Mel"), 난소암("OV"), 및 두경부암("HN") 종양 세포들의 표면에서 고도로 발현되거나 이질적으로 발현된다.
당해 분야에 알려진 상기 언급한 방법과 선택된 마커들의 임의의 것을 사용하면 본원의 교시에 따라 (세포독성제와 접합한 것들을 포함하는) 개시된 SEZ6 조절물질에 의해서 제공되는 TIC(또는 그 속의 TPC)의 출현빈도 감소를 정량화하는 것이 가능하다. 소정 경우들에서, 본 발명의 화합물은 (제거, 분화의 유도, 생태적 적소 파괴, 침묵화 등 상기 언급한 다양한 메커니즘들에 의해) TIC 또는 TPC의 출현빈도를 10%, 15%, 20%, 25%, 30% 또는 심지어 35%까지 감소시킬 수 있다. 다른 실시형태들에서, TIC 또는 TPC의 출현빈도 감소는 대략 40%, 45%, 50%, 55%, 60% 또는 65%일 수 있다. 소정 실시형태들에서, 개시된 화합물은 TIC 또는 TPC의 출현빈도를 70%, 75%, 80%, 85%, 90% 또는 심지어 95%까지 감소시킬 수 있다. 물론 TIC 또는 TPC의 출현빈도의 감소는 아마 종양의 종양원성, 지속, 재발 및 공격성의 상응하는 감소로 귀착될 것임도 이해될 것이다.
IV. SEZ6 조절물질
아무튼, 본 발명은 다수의 SEZ6 관련 악성종양 중 어느 하나를 포함하는 각종 장애의 진단, 치료진단, 치료 및/또는 예방을 위한, SEZ6 길항제를 포함하는, SEZ6 조절물질의 용도에 관한 것이다. 개시된 조절물질은 단독으로 또는 화학요법제 또는 면역요법제(예를 들면, 치료 항체) 또는 생체 반응 조절물질과 같은 폭넓게 다양한 항암 화합물과 함께 사용될 수 있다. 다른 선택된 실시형태들에서, 둘 이상의 구별되는 SEZ6 조절물질은 조합하여 사용되어 증대된 항-종양 효과를 제공할 수 있거나 또는 다중특이 작제물을 제조하는데에 사용될 수 있다.
소정 실시형태들에서, 본 발명의 SEZ6 조절물질은 뉴클레오타이드, 올리고뉴클레오타이드, 폴리뉴클레오타이드, 펩타이드 또는 폴리펩타이드를 포함할 것이다. 더욱 구체적으로, 본 발명의 예시적인 조절물질은 항체와 항원-결합 단편 또는 이들의 유도체, 단백질, 펩타이드, 글리코프로테인, 글리코펩타이드, 글리코리피드, 폴리사카라이드, 올리고사카라이드, 핵산, 안티센스 작제물, siRNA, miRNA, 생체유기 분자, 펩타이드모방체, 약제학적 활성제와 이들의 대사물질들, 전사 및 번역 통제 서열 등을 포함할 수 있다. 소정 실시형태들에서 조절물질은 수용성 SEZ6(sSEZ6) 또는, 예를 들어, SEZ6 융합 작제물(예를 들면, SEZ6-Fc, SEZ6-표적화 물질 등) 또는 SEZ6-접합체(예를 들면, SEZ6-PEG, SEZ6-세포독성제, SEZ6-brm 등)을 포함하는, 이들의 형태, 변이체, 유도체 또는 단편을 포함할 것이다. 또한, 다른 실시형태들에서, SEZ6 조절물질은 항체 또는 이들의 면역반응성 단편 또는 유도체를 포함하는 것임을 이해할 수 있을 것이다. 특히 바람직한 실시형태들에서 본 발명의 조절물질은 중화 항체 또는 이들의 유도체 또는 단편을 포함할 것이다. 다른 실시형태들에서 SEZ6 조절물질은 내재화 항체 또는 이들의 단편을 포함할 수 있다. 또 다른 실시형태들에서 SEZ6 조절물질은 고갈화 항체 또는 이들의 단편을 포함할 수 있다. 더욱이, 상기한 융합 작제물과 마찬가지로, 이들 항체 조절물질은 선택된 세포독성제, 폴리머, 생체 반응 조절물질(BRMs) 등과 접합되거나, 연결되거나 또는 그렇지 않으면 회합되어 다양한 (그리고 임의로 다수의) 작용 메커니즘을 가진 유도 면역요법을 제공할 수 있다. 상기 언급한 바와 같이 이러한 항체는 범-SEZ6 항체일 수 있으며 둘 이상의 SEZ6 패밀리 구성원들(예를 들면, 도 11a에 보여진 SEZ6과 SEZ6L)과 회합하거나 또는 SEZ6 이소형의 하나 또는 둘 다와 선택적으로 반응하는 면역특이적 항체일 수 있다. 또 다른 실시형태들에서 조절물질은 유전자 수준에서 작동할 수 있으며 SEZ6 결정인자의 유전자형 성분과 상호작용하거나 또는 회합하는 안티센스 작제물, siRNA, miRNA 등으로서 화합물을 포함할 수 있다.
또한 개시된 SEZ6 조절물질은, 예를 들면, SEZ6 조절물질의 형태, 임의의 회합 적재물 또는 투여용량 및 전달 방법에 따라, 선택된 경로들을 자극하거나 길항작용하거나 또는 특정 세포들을 제거하는 것을 포함한 다양한 메커니즘을 통해 TPC, 및/또는 회합된 종양을 포함하는, 종양 세포들의 성장, 전파 또는 생존을 고갈시키거나, 침묵시키거나, 중화하거나, 제거하거나 또는 억제할 수 있음도 이해될 것이다. 따라서, 본원에 개시된 바람직한 실시형태들은 종양 영속화 세포들과 같은 특정 종양 세포 부분집합들의 고갈, 억제 또는 침묵화에 관한 것이거나 또는 특정 에피토프 또는 도메인과 상호작용하는 조절물질에 관한 것이지만, 이러한 실시형태들은 단지 예시적인 것이며 결코 제한하는 것이 아님을 강조하여야 하겠다. 오히려, 첨부된 특허청구범위에 기재된 바와 같이, 본 발명은 폭넓게는 임의의 특정 메커니즘, 결합 부위 또는 표적 종양 세포 개체군에 관계없이 SEZ6 조절물질과 다양한 SEZ6 관련 장애의 치료, 관리 또는 예방에 있어서의 이들의 용도에 관한 것이다.
선택된 조절물질의 형태에 관계없이 선택된 화합물은 실제로 길항작용적일 수 있음이 이해될 것이다. 본원에 사용되는 바와 같이 "길항제(antagonist)"는 리간드에 대한 수용체의 결합이나 효소와의 기질과의 상호작용들을 포함하는, 특별한 또는 특정된 표적(예를 들면, SEZ6)의 활성을 중화하거나, 차단하거나, 억제하거나, 파기시키거나, 감소시키거나 또는 간섭할 수 있는 분자를 가리킨다. 이와 관련하여 본 발명의 SEZ6 길항제는 SEZ6 단백질 또는 이의 단편을 인식하거나, 반응하거나, 결합하거나, 화합하거나, 경쟁하거나, 회합하거나 또는 그렇지 않으면 상호작용하고 벌크 종양 또는 NTG 세포를 포함하는 종양 개시 세포 또는 그 밖의 종양 세포의 성장을 제거하거나, 침묵시키거나, 감소시키거나, 억제하거나, 방해하거나, 제한하거나 또는 통제하는 임의의 리간드, 폴리펩타이드, 펩타이드, 융합 단백질, 항체 또는 면역활성 단편 또는 이들의 유도체를 포함할 수 있음이 이해될 것이다. 적합한 길항제는 또한 SEZ6 유전자형 또는 표현형 결정인자를 인식하거나 또는 회합하는 소분자 억제물질, 앱타머, 안티센스 작제물, siRNA, miRNA 등, 수용체 또는 리간드 분자 그리고 이들의 유도체도 포함할 수 있는데, 그 결과 발현 패턴을 변화시키거나 또는 기질, 수용체 또는 리간드와의 결합 또는 상호작용을 봉쇄하는 것이다.
본원에 사용되는 바와 같이 길항제는 리간드로의 수용체의 결합 또는 효소와 기질들과의 상호작용을 포함하는 특별한 또는 특정된 단백질의 활성들을 중화하거나, 차단하거나, 억제하거나, 파기시키거나, 감소시키거나 또는 간섭할 수 있는 분자를 가리킨다. 더욱 일반적으로 본 발명의 길항제는 항체 및 항원-결합 단편 또는 이들의 유도체, 단백질, 펩타이드, 글리코프로테인, 글리코펩타이드, 글리코리피드, 폴리사카라이드, 올리고사카라이드, 핵산, 안티센스 작제물, siRNA, miRNA, 생체유기 분자, 펩타이드모방체, 약제학적 제제 및 이들의 대사물질, 전사 및 번역 통제 서열 등을 포함할 수 있다. 길항제는 또한 소분자 억제물질, 융합 단백질, 단백질에 특이적으로 결합함으로써 그것의 기질 표적에의 결합을 봉쇄하는 수용체 분자 및 유도체, 단백질의 길항제 변이체, 단백질에 대한 안티센스 분자, RNA 앱타머, 및 단백질에 대한 리보자임도 포함할 수 있다.
본원에 사용되고 둘 이상의 분자들 또는 화합물에 적용되고 있는 바와 같이, 용어들 "인식하다(recognizes)" 또는 "회합하다(associates)"는 한 분자가 다른 분자에 효과를 미치는 분자들의, 공유결합적으로 또는 비공유결합적으로, 반응, 결합, 특이 결합, 화합, 상호작용, 연결, 연관, 통합, 합체, 합병 또는 접합을 의미하는 것으로 간주될 것이다.
더욱이, 본원의 실시예들에 증명되는 바와 같이(예를 들면, 도 11 참조), 사람 SEZ6의 몇몇 조절물질은, 소정 경우들에서는, 사람 아닌 다른 종(예를 들면, 래트 또는 사이노몰거스 원숭이)으로부터의 SEZ6과 교차-반응할 수 있다. 다른 경우들에서 예시적인 조절물질은 사람 SEZ6의 하나 이상의 이소형에 특이적일 수 있으며 다른 종으로부터의 SEZ6 이종상동유전자들과 교차-반응성을 나타내지 않을 것이다. 물론, 본원의 교시들에 관련하여 이러한 실시형태들은 단일 종으로부터의 둘 이상의 SEZ6 패밀리 구성원들과 회합하는 범-SEZ6 항체 또는 SEZ6과 배타적으로 회합하는 항체를 포함할 수 있다.
아무튼, 그리고 아래에 더욱 상세하게 논의되는 바와 같이, 당해 분야의 숙련가들이라면 개시된 조절물질이 접합 또는 비접합 형태로 사용될 수 있음을 이해할 것이다. 즉, 조절물질은 약제학적 활성 화합물, 생체 반응 조절물질, 항암제, 세포독성제 또는 세포증식억제제, 진단학적 모이어티 또는 생체적합성 변형제와 (예를 들면 공유결합적으로 또는 비공유결합적으로) 회합하거나 또는 접합할 수 있다. 이와 관련하여 상기 접합체들은 펩타이드, 폴리펩타이드, 단백질, 융합 단백질, 핵산 분자, 소분자, 모방제, 합성 약물, 무기 분자, 유기 분자 및 방사성 동위원소를 포함할 수 있는 것임이 이해될 것이다. 게다가, 본원에 언급한 바와 같이 선택된 접합체는, 적어도 부분적으로는, 접합을 달성하기 위해 사용된 방법에 따라 여러 가지 몰 비율로 SEZ6 조절물질에 공유결합적으로 또는 비공유결합적으로 연결될 수 있다.
V. 조절물질 제조와 공급
A. 항체 조절물질
1. 개요
상기 언급한 바와 같이 본 발명의 특히 바람직한 실시형태들은 SEZ6의 하나 이상의 이소형과 선택적으로 회합하는 (그리고, 임의로, 다른 SEZ6 패밀리 구성원들과 교차-반응할 수 있는) 항체의 형태로 SEZ6 조절물질을 포함한다. 당해 분야의 통상의 숙련가들이라면, 예를 들면, 각각이 그 전체가 참조로 본원에 인용된 문헌[참조; Abbas et al., Cellular and Molecular Immunology, 6th ed., W.B. Saunders Company (2010) or Murphey et al., Janeway's Immunobiology, 8th ed., Garland Science (2011)]에 제시된 바와 같은 항체에 기초한 잘 다듬어진 지식을 이해할 것이다.
용어 "항체(antibody)"는 폴리클로날 항체, 멀티클론성 항체, 모노클로날 항체, 키메라 항체, 사람화된 및 영장류화 항체, 사람 항체, 재조합 제조 항체, 내부체(intrabody), 다중특이성 항체, 이중특이성 항체, 일가 항체, 다가 항체, 항-유전자형 항체, 돌연변이 단백질 및 이들의 변이체를 포함한 합성 항체; Fab 단편, F(ab') 단편, 단일-쇄 FvFc, 단일-쇄 Fv와 같은 항체 단편; 및 Fc 융합체와 그 밖의 변형체를 포함하는 이들의 유도체, 그리고 목적하는 생물학적 활성(즉, 항원 회합 또는 결합)을 나타내는 한 그 밖의 임의의 면역활성 분자를 포함한다. 게다가, 이 용어는 더 나아가 모든 종류의 항체(즉 IgA, IgD, IgE, IgG, 및 IgM) 및 모든 이소형(즉, IgG1, IgG2, IgG3, IgG4, IgA1, 및 IgA2) 뿐만 아니라 문맥상 달리 드러내지 않는 한 이들의 변이체들까지도 포함한다. 다른 종류들의 항체에 상응하는 중쇄 불변 도메인은, 각각, 상응하는 소문자 그리스 문자 α, δ, ε, γ 및 μ로 표시된다. 임의의 척추동물종 유래 항체의 경쇄는 이들의 불변 도메인의 아미노산 서열에 기초하여, 카파(κ) 및 람다(λ)로 불리우는, 두 개의 분명하게 구별되는 종류들 중의 하나에 할당될 수가 있다.
상기의 모든 항체가 본 발명의 범위 내에 있지만, IgG 클래스의 면역글로불린을 포함하는 바람직한 실시형태들이 오로지 예시의 목적으로 본원에서 다소 상세하게 논의될 것이다. 그러나, 상기 개시는 예시적인 조성물과 본 발명을 실시하는 방법을 단지 명시하는 것이며 본 발명의 범위나 본원에 첨부된 특허청구범위를 결코 한정하는 것이 아님이 이해될 것이다.
잘 알려져 있는 바와 같이, 경쇄(VL) 및 중쇄(VH) 부분 둘 다의 가변 도메인은 항원 인식 및 특이성을 결정지으며 경쇄(CL) 및 중쇄(CH1, CH2 또는 CH3)의 불변 도메인은 분비, 경태반성 이동(transplacental mobility), 순환 반감기, 보체 결합 등과 같은 중요한 생물학적 특성들을 부여하고 조절한다.
"가변(variable)" 영역은 경쇄과 중쇄 가변 도메인 둘 다에서 보통 상보성 결정 영역(CDR)이라고 부르는 세 개의 분절들로 나타나는 극가변 영역을 포함한다. CDR의 측면에 위치하는 가변 도메인의 더욱 고도의 보존적인 부분을 프레임워크 영역(FR)이라고 부른다. 예를 들면, 천연 발생 모노머성 면역글로불린 G(IgG) 항체에서, "Y"의 각각의 아암에 존재하는 여섯 개의 CDR은 짧은데, 항체가 수성 환경에서 삼차원 배열을 취할 때 항원 결합 부위를 형성하도록 특이적으로 배치되는 비연속적인 아미노산 서열들이다. 따라서, 각각의 천연 발생 IgG 항체는 Y의 각각의 아암의 아미노-말단에 근접한 두 개의 동일한 결합 부위를 포함한다.
CDR의 위치는 표준 기술들을 사용하여 당해 분야의 통상의 숙련가들에 의해서 쉽게 동정될 수가 있음이 이해될 것이다. 당해 분야의 사람들에게 또한 익숙한 것이기도 한 것이 Kabat et al.(1991, NIH Publication 91-3242, National Technical Information Service, Springfield, Va.)에서 기술된 번호부여 시스템이다. 이와 관련하여 Kabat 등은 임의의 항체에도 적용할 수 있는 가변 도메인 서열들에 대한 번호부여 시스템을 정의하였다. 당해 분야의 통상의 숙련가라면 이러한 "Kabat 번호부여(Kabat numbering)" 시스템을 임의의 가변 도메인 서열에도, 서열 그 자체 이상의 임의의 실험 데이터에 대한 의지 없이, 분명하게 할당할 수가 있다. 달리 지정하지 않는 한, 항체에서 특정 아미노산 잔기 위치들의 번호부여에 대한 언급들은 Kabat 번호부여 시스템에 따른 것이다.
따라서, Kabat에 따르면, VH에서, 잔기 31-35는 CDR1을 구성하고, 잔기 50-65는 CDR2를 구성하며, 95-102는 CDR3을 구성하는 한편, VL에서는, 잔기 24-34가 CDR1을 구성하고, 50-56은 CDR2를 구성하며, 89-97은 CDR3을 구성한다. 전후관계상, VH에서, FR1은 아미노산 1-30을 포함하는 가변 영역 도메인에 해당하고; FR2는 아미노산 36-49를 포함하는 가변 영역 도메인에 해당하고; FR3은 아미노산 66-94를 포함하는 가변 영역 도메인에 해당하며, FR4는 가변 영역의 아미노산 103에서부터 끝까지의 가변 영역 도메인에 해당한다. 경쇄에 대한 FR도 경쇄 가변 영역 CDR 각각에 의해 유사하게 분리되어 있다.
CDR은 항체마다 상당히 다르다는 사실을 주지한다(그리고 정의상 Kabat 컨센서스 서열들과의 상동성을 나타내지 않을 것이다). 게다가, 임의의 주어진 Kabat 자리 번호의 소정 개별 잔기들의 동일성은 종간(種間)의 또는 대립유전자의 갈라짐으로 인해 항체 쇄마다 다를 수 있다. 다른 방식의 번호부여가 문헌[참조; Chothia et al., J. Mol . Biol . 196:901-917 (1987) and MacCallum et al., J. Mol. Biol . 262:732-745 (1996)]에 기재되어 있지만, Kabat에서와 마찬가지로, FR 경계들은 상기한 바와 같이 각각의 CDR 말단에 의해 분리되어 있다. 또한, 문헌[참조; Chothia et al., Nature 342, pp. 877-883 (1989) and S. Dubel, ed., Handbook of Therapeutic Antibodies, 3rd ed., WILEY-VCH Verlag GmbH and Co. (2007)]을 참조하며, 여기서는 정의들이 서로에 대하여 비교할 때 중복되는 또는 부분집합의 아미노산 잔기들을 포함한다. 상기한 참고문헌들 각각은 전부 참조로 본원에 인용되며 상기 인용된 참고문헌들 각각에서 정의된 결합 부위 또는 CDR을 포함하는 아미노산 잔기들이 아래에 비교를 위하여 기재되어 있다.

보다 실제적으로 항체 서열에서 가변 영역 및 CDR은 (i) 상기 논의된 바와 같은 당업계에서 개발된 일반적인 규칙에 따라 또는 (ii) 알려진 가변 영역의 데이터베이스에 대해 서열들을 정렬함으로써 동정될 수 있다. 이러한 영역들을 동정하기 위한 방법은 문헌[참조; Kontermann and Dubel, eds., Antibody Engineering, Springer, New York, NY, 2001, and Dinarello et al., Current Protocols in Immunology, John Wiley and Sons Inc., Hoboken, NJ, 2000]에 기재되어 있다. 항체 서열의 예시적인 데이터베이스는 문헌[참조; Retter et al., Nucl. Acids Res., 33 (Database issue): D671 -D674 (2005)]에 기재된 바와 같이 "Abysis" 웹사이트 www.bioinf.org.uk/abs(영국 런던에 소재하는 유니버시티 컬리지 런던의 생화학 & 분자 생물학과의 A.C. Martin에 의해 유지됨) 및 VBASE2 웹사이트 www.vbase2.org에 기재되고 이를 통해 억세스할 수 있다. 이와 관련하여 Abysis 데이터베이스 웹사이트는 대상 중쇄 또는 경쇄 가변 영역 핵산 또는 아미노산 서열의 진입시 CDR 및 프레임워크 영역을 (통상적으로 사용되는 번호부여 시스템 중의 어느 것에 따라) 지동으로 명명하고 주석을 달 것이다. 게다가, Abysis 데이터베이스 웹사이트는 또한 본원의 교시에 따라 사용될 수 있는 CDR을 쉽게 동정하기 위해 개발된 일반적인 규칙들을 포함한다. 본 발명의 맥락에서 도 10a 또는 도 10b에 제시된 뮤린 가변 영역 아미노산 서열들 유래의 개시된 경쇄 및 중쇄 CDR들의 어느 것이라도 본원의 교시에 따라 화합시키거나 재배열하여 최적화된 항-SEZ6(예를 들면 사람화된, CDR 절편이식된 또는 키메라 항-hSEZ6) 항체를 제공할 수 있음을 이해할 수 있을 것이다. 즉, 도 10a 내지 도 10a(서열번호 20 내지 168, 짝수 번호)에 제시된 경쇄 가변 영역 아미노산 서열들 또는 도 10b(서열번호 21 내지 169, 홀수 번호)에 제시된 중쇄 가변 영역 아미노산 서열들로부터 유도된 하나 이상의 CDR은 SEZ6 조절물질에 그리고, 특히 바람직한 실시형태들에서는, 하나 이상의 SEZ6 이소형과 면역특이적으로 회합하는 CDR 절편이식된 또는 사람화된 항체에 삽입될 수 있다. 이러한 사람화된 조절물질의 경쇄(서열번호 170 내지 192, 짝수 번호) 및 중쇄(서열번호 171 내지 193, 홀수 번호 그리고 194 내지 199) 가변 영역 아미노산 서열의 예가 또한 도 10a 및 도 10b에 제시되어 있다.
hSC17.200vL1(서열번호 192)은 사람화된 경쇄 작제물 hSC17.200(서열번호 190)의 변이체이고, hSC17.155vH1 - vH6(서열번호 193 내지 198)은 SC17.90(서열번호 127)로부터 유도된 중쇄 작제물 hSC17.155(서열번호 184)의 변이체이며, hSC161vH1(서열번호 199)은 중쇄 작제물 hSC17.161(서열번호 189)의 변이체임을 주지한다. 아래에 더욱 상세하게 논의되겠지만 이들 변이체들은 모체 항체의 하나 이상의 생화학적 성질들을 최적화하도록 구성하여 시험된다. 예시적인 사람화된 항체, hSC17.200 및 hSC17.200vL1의 전장 아미노산 서열이 도 10c에 서열번호 400-402로서 제시되어 있다. 사람화된 항체 변이체 hSC17.200vL1은 사람화된 항체 hSC17.200로부터 유래하고 hSC17.200 항체와 공통의 HC를 공유한다. 따라서 hSC17.200의 전장 LC 및 HC는 각각 서열번호 400 및 401에 상응하고; hSC17.200vL1의 전장 LC 및 HC는 각각 서열번호 403 및 401에 상응한다.
종합하면 이들 신규한 아미노산 서열들은 본 발명에 따른 일흔 다섯개의 뮤린 유래 및 열 한개의 사람화된 예시적인 조절물질을 (보고된 변이체와 함께) 도시한 것이다. 더욱이, 도 10a 및 도 10b에 제시된 일흔 다섯개의 예시적인 뮤린 조절물질과 열 한개의 사람화된 조절물질 및 변이체들 각각의 상응하는 핵산 서열들은 본 출원의 서열목록(서열번호 220 내지 399)에 포함되어 있다.
도 10a 및 도 10b에서 주석이 달린 CDR은 Kabat 번호부여를 사용하여 정의된다. 그러나, 본원에서 논의되고 아래 실시예 8에서 입증된 바와 같이, 당해 기술 분야의 숙련가라면 도 10a 또는 도 10b에 제시된 각각의 중쇄 및 경쇄 서열에 대해 Chothia 등, MacCallum 등 또는 Abysis 또는 VBase 2와 같은 웹사이트 데이터베이스 중의 하나에 의해 정의된 바와 같은 CDR들을 쉽게 정의, 동정, 도출 및/또는 계수할 수 있을 것이다. 따라서, 상기 모든 명명법에 의해 정의된 CDR들을 포함하는 대상 CDR 및 항체의 각각은 본 발명의 범위 안에 명백히 포함된다. 더욱 폭넓게는, 용어들 "가변 영역 CDR 아미노산 잔기(variable region CDR amino acid residue)" 또는 더 간단하게 "CDR"은 상기 제시된 임의의 서열 또는 구조를 바탕으로 한 방법을 사용하여 동정되는 CDR 안의 아미노산을 포함한다.
본 출원에 논의된 임의의 중쇄 불변 영역 아미노산 위치에 대해서도, 번호부여는 보고된 바에 따르면 서열화된 첫번째 사람 IgG1이었던 골수종 단백질 Eu의 아미노산 서열을 설명하는 문헌[참조; Edelman et al., 1969, Proc, Natl. Acad. Sci. USA 63(1): 78-85]에 처음 기재된 Eu 인덱스에 따른다. 에델만(Edelman)의 Eu 인덱스는 Kabat 등, 1991 (supra.)에도 제시되어 있다. 따라서, 중쇄의 맥락에서 용어 "Kabat에 제시된 바와 같은 Eu 인덱스" 또는 "Kabat의 Eu 인덱스"는 Kabat 등, 1991 (supra.)에 제시된 바와 같이 에델만 등의 사람 IgG1 Eu 항체에 기초하는 잔기 번호부여 시스템을 가리킨다. 경쇄 불변 영역 아미노산 서열에 사용되는 번호부여 시스템도 유사하게 Kabat 1991에 제시되어 있다. 본 발명에 적합한 예시적인 카파 CL 및 IgG1 중쇄 불변 영역 아미노산 서열이 첨부된 서열목록에 서열번호 403 및 404로서 제시되어 있다. 당해 분야의 숙련가들이라면 개시된 불변 영역 서열들이 표준 분자 생물학 기술들을 사용하여 개시된 중쇄 및 경쇄 가변 영역과 결합하여 본 발명의 SEZ6 항체 및 ADC에 삽입될 수 있는 전장 항체를 제공할 수 있음을 알게 될 것이다.
아래에 실시예에서 제시된 바와 같이, 본 발명의 선택된 실시형태들은 SEZ6에 면역특이적으로 결합하는 뮤린 항체를 포함하며, 이것은 "소스" 항체 또는 "기준" 항체로 간주될 수 있다. 다른 실시형태들에서, 본 발명에 의해 고려되는 항체들은 소스 항체의 불변 영역 또는 에피토프-결합 아미노산 서열의 임의의 변형을 통해 이러한 "소스" 또는 "기준" 항체로부터 유도될 수 있다. 한 실시형태에서 소스 항체에서 선택된 아미노산이 결실, 돌연변이, 치환, 동화 또는 조합을 통행 변한다면 항체는 소스 항체로부터 "유도"된다. 또 다른 실시형태에서, "유도된" 항체는 소스 항체의 단편들(예를 들면, 하나 이상의 CDR 또는 전체 가변 영역)이 수락자 항체 서열과 조합되거나 이에 삽입되어 유도체 항체(예를 들면, 키메라, CDR 절편이식된 또는 사람화된 항체)를 제공하는 것이다. 이러한 "유도된"(예를 들면, 사람화된 또는 CDR-절편이식된) 항체는, 예를 들면, 결정인자에 대한 친화력을 개선시키거나; 세포 배양물에서의 생산과 수율을 개선시키거나; 생체내 면역형성성을 감소시키거나; 독성을 감소시키거나; 활성 모이어티의 접합을 촉진시키거나; 다중특이성 항체를 생성하는 것과 같은 다양한 이유로 표준 분자 생물학 기술들을 사용하여 생성할 수 있다. 이러한 항체들은 또한 화학적 수단 또는 번역후 변형에 의해 성숙 분자의 변형(예를 들면, 글리코실화 패턴 또는 페길화)를 통해 소스 항체로부터 유도될 수 있다. 본 발명의 "소스" 뮤린 항체의 예는 SC17.155, SC17.161 및 SC17.200이고 이러한 소스 항체로부터 유도되는 항체의 예는 hSC17.155, hSC17.155vH1-vH5(SC17.155로부터 유도); hSC17.161vL1(SC17.161로부터 유도) 및 hSC17.200vL1(hSC17.200으로부터 유도)이다.
2. 항체 조절물질 생성
a. 폴리클로날 항체
래빗, 마우스, 래트 등을 포함하는 각종 숙주 동물들에서의 폴리클로날 항체의 생성은 당해 분야에 잘 알려져 있다. 소정 실시형태들에서, 폴리클로날 항-SEZ6 항체-함유 혈청은 동물을 출혈시키거나 죽임으로써 얻어진다. 혈청은 동물로부터 얻어진 형태로 연구 목적으로 사용될 수 있거나, 대안으로, 항-SEZ6 항체를 부분적으로 또는 완전히 정제하여 면역글로불린 분획이나 균질 항체 제제물을 제공할 수 있다.
간단히 말해 선택된 동물을, 예를 들면, 선택된 이소형, 도메인 및/또는 펩타이드를 포함할 수 있는 SEZ6 면역원(예를 들면, 수용성 SEZ6 또는 sSEZ6), 또는 SEZ6 또는 이의 면역반응성 단편을 발현하는 살아있는 세포 또는 세포 제제물로 면역화시킨다. 접종된 종에 따라, 면역 반응을 증가시키는데 사용될 수 있는 당해 분야에 알려진 보조제들은 프로인트(Freund's) 보조제(완전 및 불완전형), 미네랄 젤, 예를 들면 수산화알루미늄, 표면 활성 물질, 예를 들면 리소레시틴, 플루로닉 폴리올, 다가음이온, 펩타이드, 오일 이멀션, 키홀 림핏 헤모사이아닌, 디니트로페놀, 및 BCG(칼메뜨-게랭 세균(bacille Calmette-Guerin))나 코리네박테리움 파르붐(corynebacterium parvum)과 같은 잠재적으로 유용한 사람 보조제들을 포함하지만, 이들에 한정되는 것은 아니다. 이러한 보조제들은 항원을 국소 저장장소(local deposit)에 격리함으로써 항원이 빨리 분산되는 것을 막을 수 있거나, 이들은 숙주를 자극하여 면역계의 대식세포들과 그 밖의 성분들에 화학주성적인 인자들을 분비하게 하는 물질들을 함유할 수 있다. 바람직하게는 면역화 일정에는 선택된 면역원을 미리 결정된 기간에 걸쳐 두 번 이상의 투여로 퍼뜨리는 것이 수반될 것이다.
도 1c 또는 도 1d에 나타낸 바와 같은 SEZ6 단백질의 아미노산 서열은 항체를 생성시키기 위한 SEZ6 단백질 특정 부위들을 선택하기 위하여 분석될 수가 있다. 예를 들면, SEZ6 아미노산 서열의 소수성 및 친수성 분석이 SEZ6 구조에서의 친수성 부위들을 동정하는데에 사용된다. 다른 부위들 및 도메인들 뿐만 아니라 면역형성 구조를 보여주는 SEZ6 단백질의 부위들은 당해 분야에 알려진 각종의 다른 방법, 이를 테면 Chou-Fasman, Garnier-Robson, Kyte-Doolittle, Eisenberg, Karplus-Schultz 또는 Jameson-Wolf 분석을 사용하여 쉽게 동정될 수가 있다. 평균 유연성 프로파일은 문헌[참조; Bhaskaran R., Ponnuswamy P. K., 1988, Int. J. Pept. Protein Res. 32:242-255]의 방법을 사용하여 생성될 수가 있다. 베타-회전(Beta-turn) 프로파일은 문헌[참조; Deleage, G., Roux B., 1987, Protein Engineering 1:289-294]의 방법을 사용하여 생성될 수가 있다. 따라서, 이러한 프로그램들이나 방법의 임의의 것에 의해 동정되는 각각의 SEZ6 부위, 도메인 또는 모티프는 본 발명의 범위 내에 있으며 원하는 성질들을 포함하는 조절물질을 야기하는 면역원들을 제공하기 위하여 단리되거나 조작처리될 수 있다. SEZ6 항체의 생성을 위한 바람직한 방법은 본원에 제공된 실시예들을 통해 더욱 예시된다. 면역원으로 사용하기 위한 단백질 또는 폴리펩타이드를 제조하기 위한 방법은 당해 분야에 잘 알려져 있다. 또한 당해 분야에 잘 알려진 것으로 BSA, KLH 또는 그 밖의 운반체 단백질과 같은, 운반체를 가진 단백질의 면역형성 접합체를 제조하기 위한 방법이 있다. 소정 경우들에서는, 예를 들면, 카보디아미드 시약을 사용하는 직접 접합이 사용된다; 다른 경우들에서는 결합 시약이 효과적이다. SEZ6 면역원의 투여는, 당해 분야에 이해되는 바와 같이, 적당한 기간의 주사 및 적당한 보조제의 사용으로 실시되는 경우가 많다. 면역화 일정 동안에, 항체의 역가들을 아래 실시예에서 기술된 대로 취하여 항체 형성의 타당성을 측정할 수가 있다.
b. 모노클로날 항체
게다가, 본 발명은 모노클로날 항체의 사용을 고려한다. 당해 분야에 알려져 있는 바와 같이, 용어 "모노클로날 항체(monoclonal antibody)" (또는 mAb)는 실질적으로 균일한 항체의 개체군으로부터 얻어진 항체를 가리키는 것으로, 즉, 개체군을 구성하는 개개의 항체는 미량으로 존재할 수 있는, 가능한 돌연변이(예를 들면, 천연 발생 돌연변이)을 제외하고는 동일하다. 소정 실시형태들에서, 그러한 모노클로날 항체는 항원과 결합하거나 회합하는 폴리펩타이드 서열을 포함하는 항체를 포함하는데, 여기서 항원-결합 폴리펩타이드 서열은 다수의 폴리펩타이드 서열로부터의 단일 표적 결합 폴리펩타이드 서열의 선택을 포함하는 과정에 의해 얻어진 것이었다.
더욱 일반적으로, 그리고 본원의 실시예 6에 예시되어 있는 바와 같이, 모노클로날 항체는 하이브리도마, 재조합 기술들, 파지 디스플레이 기술들, 유전자이식 동물(예를 들면, XenoMouse®) 또는 이들의 소정 조합을 포함하는 당해 분야에 알려진 폭넓게 다양한 기술들을 사용하여 제조될 수가 있다. 예를 들면, 각각 참조로 그 전체가 본원에 인용된 문헌[참조; An, Zhigiang (ed.) Therapeutic Monoclonal Antibodies: From Bench to Clinic, John Wiley and Sons, 1st ed. 2009; Shire et. al. (eds.) Current Trends in Monoclonal Antibody Development and Manufacturing, Springer Science + Business Media LLC, 1st ed. 2010; Harlow et al., Antibodies: A Laboratory Manual, Cold Spring Harbor Laboratory Press, 2nd ed. 1988; Hammerling, et al., in: Monoclonal Antibodies and T-Cell Hybridomas 563-681 (Elsevier, N.Y., 1981)]에서 더욱 상세하게 기술되어 있는 것과 같은 하이브리도마 및 당해 분야에서 인정되고 있는 생화학적, 유전공학적 기술들을 사용하여 모노클로날 항체를 제조할 수가 있다. 선택된 결합 서열을 더 변경시켜서, 예를 들면, 표적에 대한 친화력을 개선시키고, 표적 결합 서열을 사람화하고, 세포 배양물에서 이의 생성을 개선시키고, 생체내 이의 면역형성력을 감소시키고, 다중특이성 항체 등을 만들어 낼 수가 있으며 변경된 표적 결합 서열을 포함하는 항체도 본 발명의 항체임을 이해할 필요가 있다.
c. 키메라 항체
또 다른 실시형태에서, 본 발명의 항체는 적어도 두 개의 다른 종들이나 종류의 항체로부터의 공유결합에 의해 연결된 단백질 분절로부터 유도된 키메라 항체를 포함할 수 있다. 당해 분야에 알려져 있는 바와 같이, 용어 "키메라(chimeric)" 항체는 중쇄 및/또는 경쇄의 일부는 특정한 종 유래의 또는 특정한 항체 클래스 또는 서브클래스에 속하는 항체의 상응하는 서열과 동일하거나 상동성인 반면 쇄(들)의 나머지는, 항체가 목적하는 생물학적 활성을 나타내는 한, 또 다른 종 유래의 또는 또 다른 항체 클래스 또는 서브클래스에 속하는 항체 뿐만 아니라 이 항체의 단편들의 상응하는 서열들과 동일하거나 상동성인 작제물을 나타낸다(U.S. P.N. 제4,816,567호; 문헌[Morrison et al., Proc. Natl. Acad. Sci. USA, 81:6851-6855 (1984)] 참조).
한 실시형태에서, 본원의 교시들에 따른 키메라 항체는 뮤린 VH 및 VL 아미노산 서열 및 사람 유래의 불변 영역을 포함할 수 있다. 다른 적합한 실시형태들에서 본 발명의 키메라 항체는 아래 기술된 바와 같은 사람화된 항체를 포함할 수 있다. 또 다른 실시형태에서, 이른바 "CDR-절편이식된(CDR-grafted)" 항체, 이 항체는 특정한 종 유래의 또는 특정한 항체 클래스 또는 서브클래스에 속하는 하나 이상의 CDR을 포함하는 반면, 항체 쇄(들)의 나머지는 또 다른 종 유래의 또는 또 다른 항체 클래스 또는 서브클래스에 속하는 항체의 상응하는 서열과 동일하거나 상동성이다. 사람에서 사용하기 위해, 선택되는 설치류 CDR은 사람 항체 속으로 이식되어, 사람 항체의 하나 이상의 천연 발생 가변 영역 또는 CDR을 치환할 수 있다. 이러한 작제물은 일반적으로 충분한 세기의 조절물질 기능들(예를 들면, CDC(보체 의존성 세포독성), ADCC(항체-의존성 세포-매개 세포독성) 등)을 제공하면서 대상체에 의해 항체에 대한 원치않는 면역 반응들을 감소시켜 주는 이점들을 갖고 있다.
d. 사람화된 항체
CDR-절편이식된 항체와 유사한 것이 "사람화된(humanized)" 항체이다. 본원에 사용되는 바와 같이, 비사람(예를 들면, 뮤린) 항체의 "사람화된(humanized)" 형태는 하나 이상의 비사람 면역글로불린으로부터 유도된 최소한의 서열을 포함하는 키메라 항체이다. 한 실시형태에서, 사람화된 항체는 사람 면역글로불린(수용자 또는 수락자 항체)이며 여기서 수용자의 CDR로부터의 잔기들이 원하는 특이성, 친화력, 및/또는 능력을 갖는 마우스, 래트, 래빗, 또는 비사람 영장류와 같은 비사람 종(공여자 항체)의 CDR로부터의 잔기들로 치환된 것이다. 소정 바람직한 실시형태들에서, 사람 면역글로불린의 가변 도메인에 있는 하나 이상의 FR의 잔기들이 공여자 항체로부터의 상응하는 비사람 잔기들로 치환되어 절편이식된 CDR(들)의 적합한 삼차원 배열상태를 유지하게 도와주며 그 결과 친화력이 개선된다. 더욱이, 사람화된 항체는 수용자 항체에서나 공여자 항체에서나 발견되지 않는 잔기들을 포함하여, 예를 들면, 항체 성능을 더욱 다듬을 수 있다.
CDR 절편이식된 및 사람화된 항체는, 예를 들면, U.S.P.Ns. 제6,180,370호 및 제5,693,762호에 기술되어 있다. 사람화된 항체는 임의로 면역글로불린 Fc, 전형적으로는 사람 면역글로불린의 적어도 일부를 또한 포함할 수 있다. 더 자세한 사항들에 대해서는, 예를 들면, 문헌[Jones et al., Nature 321:522-525 (1986)]; 및 U.S.P.Ns. 제6,982,321호 및 제7,087,409호를 참조한다. 또 다른 방법으로, 예를 들면, U.S.P.N. 제2005/0008625호에 기술된 "인간공학(humaneering)"이라고 부르는 것이 있다. 아울러, 비사람 항체도 사람 T-세포 에피토프들의 특이 결실 또는 WO 제98/52976호 및 WO 제00/34317호에 개시된 방법에 의한 "비면역(deimmunization)"에 의하여 또한 변형될 수 있다. 상기 참고문헌들 각각은 그 전체가 본원에 인용되어 있다.
사람화된 항체는 또한 중쇄 또는 경쇄의 적어도 하나로부터 면역글로불린 가변 영역들의 전부 또는 일부를 암호화하는 핵산 서열들을 분리하고, 조작하며, 발현시키는 것과 같은 통상의 분자생물학 기술들을 사용하여 생물공학적으로 처리될 수 있다. 상기한 그런 출처들의 핵산뿐 아니라, 사람 생식선(germline) 서열들도, 예를 들면, 문헌[참조; Tomlinson, I. A. et al. (1992) J. Mol . Biol. 227:776-798; Cook, G. P. et al. (1995) Immunol . Today 16: 237-242; Chothia, D. et al. (1992) J. Mol . Biol . 227:799-817; and Tomlinson et al. (1995) EMBO J 14:4628-4638]에 개시된 바와 같이 이용가능하다. V-BASE 디렉토리(VBASE2 - Retter et al., Nucleic Acid Res. 33; 671-674, 2005)는 사람 면역글로불린 가변 영역 서열들의 종합 목록을 제공해 준다(Tomlinson, I. A. 등에 의해 자료수집. MRC Centre for Protein Engineering, Cambridge, UK). 컨센서스 사람 FR도 또한, 예를 들면, U.S.P.N. 제6,300,064호에 기술된 바와 같이 사용될 수가 있다.
선택된 실시형태들에서, 그리고 아래 실시예 8에서 상세히 설명된 바와 같이, 사람화된 항체 중쇄 또는 경쇄 가변 영역 아미노산 잔기들의 적어도 60%, 65%, 70%, 75%, 또는 80%가 수용자 FR 및 CDR 서열의 잔기들에 상응할 것이다. 다른 실시형태들에서는 사람화된 항체 가변 영역 잔기들의 적어도 85% 또는 90%가 수용자 FR 및 CDR 서열의 잔기들에 상응할 것이다. 더욱 바람직한 실시형태에서는, 사람화된 항체 가변 영역 잔기들의 95% 초과가 수용자 FR 및 CDR 서열의 잔기들에 상응할 것이다.
e. 사람 항체
또 다른 실시형태에서, 항체는 완전한 사람 항체를 포함할 수 있다. 용어 "사람 항체(human antibody)"는 사람에 의해 생성된 및/또는 사람 항체를 만들기 위한 기술들 중의 어느 것을 사용하여 만들어진 항체의 아미노산 서열에 상응하는 아미노산 서열을 가진 항체를 가리킨다.
사람 항체는 당해 분야에 알려진 각종 기술들을 사용하여 제조될 수가 있다. 한 가지 기술이 파지 디스플레이로서 (바람직하게는 사람) 항체의 라이브러리를 파지들 상에서 합성하고, 그 라이브러리를 관심 항원 또는 이의 항체-결합 부분으로 선별하며, 항원을 결합하는 파지를 분리하는 것인데, 이로부터 면역반응성 단편들을 얻을 수 있다. 이러한 라이브러리들을 제조하고 선별하는 방법은 당해 분야에 잘 알려져 있으며 파지 디스플레이 라이브러리들을 생성시키기 위한 키트들이 상업적으로 입수가능하다(예를 들면, Pharmacia Recombinant Phage Antibody System, 카탈로그 번호 27-9400-01; 및 Stratagene SurfZAPTM 파지 디스플레이 키트, 카탈로그 번호 240612). 또한 항체 디스플레이 라이브러리들을 생성시키고 선별하는데에 사용될 수 있는 다른 방법과 시약들도 있다(예를 들면, U.S.P.N. 제5,223,409호; PCT 공개 제WO 92/18619호, 제WO 91/17271호, 제WO 92/20791호, 제WO 92/15679호, 제WO 93/01288호, 제WO 92/01047호, 제WO 92/09690호; 및 문헌[Barbas et al., Proc. Natl. Acad. Sci. USA 88:7978-7982 (1991)] 참조).
한 실시형태에서, 재조합 사람 항체는 상기한 바와 같이 제조된 재조합체 조합 항체 라이브러리를 선별함으로써 분리될 수 있다. 한 실시형태에서, 라이브러리는 B-세포들로부터 단리된 mRNA로부터 제조된 사람 VL 및 VH cDNA들을 사용하여 생성된, scFv 파지 디스플레이 라이브러리이다.
실험된 일 없는 라이브러리들에 의해서 제조된 항체는 (천연이든 합성이든) 친화력이 그리 높지 않을 수가 있으나(약 106 내지 107 M-1의 Ka), 당해 분야에 기술된 바와 같이 이차 라이브러리들을 구성하여 재선별함으로써 친화력 성숙을 또한 시험관내에서 모방할 수가 있다. 예를 들면, 오류 유발성(error-prone) 폴리머라제를 사용하여 돌연변이를 시험관내에서 무작위로 도입할 수가 있다(Leung et al., Technique, 1: 11-15 (1989)에서 보고됨). 게다가, 친화력 성숙은 하나 이상의 CDR을 무작위로 돌연변이시킴으로써 실행될 수가 있는데, 예를 들면, 선택된 개개의 Fv 클론에서, 관심 CDR에 걸치는 무작위 서열을 가진 프라이머들을 갖는 PCR을 사용하여 더 높은 친화력의 클론들을 선별하는 것이다. 제WO 9607754호는 면역글로불린 경쇄의 CDR에서 돌연변이생성을 유도하여 경쇄 유전자들의 라이브러리를 만들 수 있는 방법을 기술하였다. 또 다른 효과적인 접근방법은 파지 디스플레이에 의해 선택된 VH 또는 VL 도메인들을 면역되지 않은 공여자들로부터 얻어진 천연 발생 V 도메인 변이체들의 모든 레퍼토리들과 재조합하여 문헌[참조; Marks et al., Biotechnol., 10: 779-783 (1992)]에 기술된 바와 같이 쇄 재셔플링(chain reshuffling) 몇 차례로 더 높은 친화력에 대해 선별하는 것이다. 이러한 기술을 통해 약 10-9 M 이하의 해리 상수 KD(koff/kon)를 가진 항체 및 항체 단편들을 생성할 수 있다.
다른 실시형태들에서, 자신들의 표면에 결합 쌍들을 발현하는 유핵 세포들(예를 들면, 이스트)을 포함하는 라이브러리를 이용하여 유사한 절차들을 사용할 수 있다. 예를 들면, U.S.P.N. 제7,700,302호와 U.S.S.N. 제12/404,059호를 참조한다. 한 실시형태에서, 사람 항체는 파지 라이브러리에서 선택되는데, 그 파지 라이브러리는 사람 항체를 발현한다(문헌 참조; Vaughan et al. Nature Biotechnology 14:309-314 (1996): Sheets et al. Proc . Natl . Acad . Sci . USA 95:6157-6162 (1998)). 다른 실시형태들에서, 사람 결합 쌍들은 이스트와 같은 유핵 세포들에서 만들어진 조합 항체 라이브러리들로부터 분리될 수 있다. 예를 들면, U.S.P.N. 제7,700,302호를 참조한다. 이러한 기술들은 유리하게는 많은 수의 후보 조절물질의 선별을 가능하게 하며 후보 서열들의 (예를 들면, 친화력 성숙 또는 재조합체 셔플링에 의한) 비교적 쉬운 조작을 제공해 준다.
사람 항체는 또한 사람 면역글로불린 유전자자리를 유전자이식 동물, 예를 들면, 마우스에 도입함으로써 만들어질 수가 있는데, 여기서 내생성 면역글로불린 유전자들이 부분적으로 또는 완전히 불활성화되어 사람 면역글로불린 유전자들이 도입된 것이다. 실험도전 중에, 사람 항체 생성이 관찰되는데, 이것은 유전자 재배열, 어셈블리, 및 항체 레퍼토리를 포함하는, 모든 점에서 사람에서 보여지는 것과 아주 유사한 것이다. 이러한 접근방법은, 예를 들면, U.S.P.Ns. 제5,545,807호; 제5,545,806호; 제5,569,825호; 제5,625,126호; 제5,633,425호; 제5,661,016호, 및 XenoMouse®과학기술에 대하여는 U.S.P.Ns. 제6,075,181호와 제6,150,584호; 및 문헌[참조; Lonberg and Huszar, Intern. Rev. Immunol. 13:65-93 (1995)]에 기술되어 있다. 대안으로, 표적 항원을 향한 항체를 생성하는 사람 B 림프구의 불멸화를 통해 사람 항체를 제조할 수 있다(이러한 B 림프구는 신생물 장애에 걸린 개인으로부터 회수될 수 있거나 또는 시험관내에서 면역화될 수 있다). 예를 들면, 문헌[참조; Cole et al., Monoclonal Antibodies and Cancer Therapy, Alan R. Liss, p. 77 (1985); Boerner et al., J. Immunol, 147 (l):86-95 (1991)]; 및 U.S.P.N. 제5,750,373호를 참조한다.
3. 추가의 처리
어떻게 얻어졌든 간에, 조절물질-생산 세포들(예를 들면, 하이브리도마, 이스트 콜로니 등)은 선택되고, 클로닝되며, 예를 들면, 활발한 성장, 높은 항체 생산 및, 아래에 더욱 상세하게 논의되는 바와 같이, 바람직한 항체 특성들을 포함하는 바람직한 특성들에 대해 더욱 선별될 수 있다. 하이브리도마는 공통유전자형 동물들에서 생체내에서, 면역계가 결핍된 동물들, 예를 들면, 누드 마우스에서, 또는 시험관내 세포 배양물에서 확장될 수가 있다. 각각이 하나의 구별되는 항체 종들을 생성하는, 하이브리도마 및/또는 콜로니를 선택, 클로닝 및 확장하는 방법은 당해 분야의 통상의 숙련가들에게는 잘 알려져 있다.
B. 재조합체 조절물질 제조
1. 개요
일단 공급원이 완전한 것이면 목적하는 SEZ6 조절물질을 암호화하는 DNA는 (예를 들면, 항체 중쇄 및 경쇄를 암호화하는 유전자에 특이적으로 결합할 수 있는 올리고뉴클레오타이드 탐침(probe)들을 사용함으로써) 종래의 절차들을 사용하여 용이하게 분리하고 서열화할 수 있다. 단리되고 서브클로닝된 하이브리도마 세포(또는 파지 또는 이스트 유래 콜로니)는 조절물질이 항체라면 그러한 DNA의 바람직한 공급원으로 작용할 수 있다. 원한다면, 핵산을 본원에 기술된 바와 같이 더 조작하여 융합 단백질, 또는 키메라, 사람화된 또는 완전한 사람 항체를 포함하는 약제들을 만들어 낼 수가 있다. 더욱 구체적으로, (변형될 수 있는) 단리된 DNA는 제조 항체를 위한 불변 및 가변 영역 서열들을 클로닝하는데에 사용될 수가 있다.
따라서, 예시적인 실시형태들에서 항체는 (문헌[참조; Al-Rubeai; An, and Shire et. al. all supra, and Sambrook J. & Russell D. Molecular Cloning: A Laboratory Manual, 3rd ed., Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y. (2000); Ausubel et al., Short Protocols in Molecular Biology: A Compendium of Methods from Current Protocols in Molecular Biology, Wiley, John & Sons, Inc. (2002)]에 제시된 바와 같은) 종래의 절차들을 사용하여, 재조합체로 제조될 수 있으며, 여기서 단리되고 서브클로닝된 하이브리도마 세포(또는 파지 또는 이스트 유래의 콜로니)는 핵산 분자의 바람직한 공급원으로 작용한다.
용어 "핵산 분자(nucleic acid molecule)"는, 본원에 사용되는 바와 같이, 단일-가닥이든 이중-가닥이든, DNA 분자와 RNA 분자 및 이들의 인위적인 변이체(예를 들면, 펩타이드 핵산)를 포함하는 것으로 간주된다. 핵산은 본 발명의 항체의 쇄 하나 또는 양쪽 쇄들, 또는 이들의 단편 또는 유도체를 암호화할 수 있다. 본 발명의 핵산 분자들은 또한 폴리펩타이드를 암호화하는 폴리뉴클레오타이드를 동정하거나, 분석하거나, 돌연변이시키거나 또는 증폭시키기 위한 혼성화(hybridization) 탐침, PCR 프라이머 또는 서열분석 프라이머로서 사용하기에 충분한 폴리뉴클레오타이드; 폴리뉴클레오타이드의 발현을 억제시키기 위한 안티-센스 핵산, 그리고 뿐만 아니라 상보적인 서열을 포함한다. 핵산은 임의의 길이도 될 수가 있다. 이들은, 예를 들면, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 75, 100, 125, 150, 175, 200, 250, 300, 350, 400, 450, 500, 750, 1,000, 1,500, 3,000, 5,000 또는 그 이상의 뉴클레오타이드의 길이일 수가 있고/있거나 하나 이상의 부가 서열, 예를 들면, 조절성 서열을 포함할 수가 있고/있거나 더 큰 핵산, 예를 들면, 벡터의 일부일 수가 있다. 이러한 핵산 서열들을 더 조작하여 키메라, 사람화된 또는 완전 사람 항체를 포함하는 조절물질을 만들어 낼 수가 있음이 이해될 것이다. 더욱 구체적으로, (변형될 수 있는) 단리된 핵산 분자들은 U.S.P.N. 제7,709,611호에 기술된 제조 항체를 위한 불변 및 가변 영역 서열들을 클로닝하는데에 사용될 수가 있다.
용어 "단리된 핵산(isolated nucleic acid)"은 핵산이 (i) 시험관내에서, 예를 들면 폴리머라제 쇄 반응(PCR)에 의해서 증폭되었거나, (ii) 클로닝에 의해서 재조합체로 제조되었거나, (iii) 예를 들면 절단반응 및 젤-전기영동 분획화에 의해서 정제되었거나, 또는 (iv) 예를 들면 화학적 합성에 의해서 합성된 것임을 의미한다. 단리된 핵산은 재조합 DNA 기술들에 의한 조작에 이용가능한 핵산이다.
항체의 원하는 면역반응 부분을 암호화하는 핵산의 공급원이 파지 디스플레이 기술, 이스트 라이브러리, 하이브리도마-기반 기술로부터 얻어지거나 유도된 것이든 또는 합성에 의한 것이든 간에, 본 발명은 항체 또는 항원-결합 단편 또는 이들의 유도체를 암호화하는 핵산 분자들 및 서열들을 포함한 것임을 이해할 필요가 있다. 게다가, 본 발명은 이러한 핵산 분자들을 포함하는 벡터 및 숙주 세포에 관한 것이다.
일단 VH 및 VL 세그먼트를 암호화하는 DNA 단편이 얻어지면, 이들 DNA 단편을, 예를 들면 표준 재조합 DNA 기술에 의해 더 조작하여 가변 영역 유전자들을 전장 항체 쇄 유전자로, Fab 단편 유전자로 또는 scFv 유전자로 전환시킬 수 있다. 이러한 조작에서, VL- 또는 VH-암호화 DNA 단편은 항체 불변 영역 또는 가요성 링커와 같은 또 다른 단백질을 암호화하는 또 다른 DNA 단편에 작동적으로 연결된다. 이러한 맥락으로 사용되는 용어 "작동적으로 연결된"은 두 개의 DNA 단편에 의해 암호화된 아미노산 서열이 프레임 안에 있도록 두 개의 DNA 단편이 결합됨을 의미한다.
VH 영역을 암호화하는 단리된 DNA는 VH-암호화 DNA를 중쇄 불변 영역(CH1, CH2 및 CH3)을 암호화하는 또 다른 DNA 분자에 작동적으로 연결시킴으로써 전장 중쇄 유전자로 전환될 수 있다. 사람 중쇄 불변 영역 유전자의 서열들은 당업계에 알려져 있으며(문헌 참조; 예를 들면, Kabat, E. A., et al. (1991) Sequences of Proteins of Immunological Interest, Fifth Edition, U.S. Department of Health and Human Services, NIH Publication No. 91-3242) 이러한 영역을 포함하는 DNA 단편들은 표준 PCR 증폭에 의해 수득될 수 있다. 중쇄 불변 영역은 IgG1, IgG2, IgG3, IgG4, IgA, IgE, IgM 또는 IgD 불변 영역일 수 있지만, 가장 바람직하게는 IgG1 또는 IgG4 불변 영역이다. 아래에 보다 상세하게 논의되는 바와 같이 본원의 교시와 양립하는 예시적인 IgG1 불변 영역이 첨부된 서열목록에 서열번호 403으로서 제시되어 있다. Fab 단편 중쇄 유전자에 대해, VH-암호화 DNA는 단지 중쇄 CH1 불변 영역을 암호화하는 또 다른 DNA 분자에 작동적으로 연결될 수 있다.
VL 영역을 암호화하는 단리된 DNA는 VL-암호화 DNA를 경쇄 불변 영역, CL을 암호화하는 또 다른 DNA 분자에 작동적으로 연결함으로써 전장 경쇄 유전자(뿐만 아니라 Fab 경쇄 유전자)로 전환될 수 있다. 사람 경쇄 불변 영역 유전자의 서열은 당업계에 알려져 있으며(문헌 참조; Kabat, E. A., et al. (1991) Sequences of Proteins of Immunological Interest, Fifth Edition, U.S. Department of Health and Human Services, NIH Publication No. 91-3242) 이러한 영역을 포함하는 DNA 단편은 표준 PCR 증폭에 의해 수득될 수 있다. 경쇄 불변 영역은 카파 또는 람다 불변 영역일 수 있지만, 가장 바람직하게는 카파 불변 영역이다. 이와 관련하여 예시적인 적합한 카파 경쇄 불변 영역이 첨부된 서열목록에 서열번호 404로서 제시되어 있다.
2. 혼성화 및 서열 동일성
언급한 바와 같이, 본 발명은 더 나아가 특정한 혼성화 조건 하에서 다른 핵산과 혼성화하는 핵산을 제공한다. 더욱 구체적으로 본 발명은 보통의 또는 고도의 엄중도 혼성화 조건 하에서 (예를 들면, 아래에 정의된 바와 같이), 본 발명의 핵산 분자와 혼성화하는 핵산 분자를 포함한다. 핵산의 혼성화 방법은 당해 분야에 잘 알려져 있다. 잘 알려진 바와 같이, 보통의 엄중한 혼성화 조건은 5x 염화나트륨/시트레이트산나트륨(SSC)을 함유하는 예비세척 용액, 0.5% SDS, 1.0 mM EDTA(pH 8.0), 약 50% 포름아미드의 혼성화 완충제, 6xSSC, 및 혼성화 온도 55℃(또는 약 50% 포름아미드를 함유하는 용액과 같은 다른 유사한 혼성화 용액은 혼성화 온도 42℃로), 그리고 0.5xSSC, 0.1% SDS에서 60℃의 세척 조건을 포함한다. 비교를 위하여 고도의 엄중한 혼성화 조건 하의 혼성화는 45℃에서 6xSSC에 의한 세척에 이어 68℃에서 0.1xSSC, 0.2% SDS에서의 한 번 이상의 세척을 포함한다. 더욱이, 당해 분야의 숙련가라면 서로에 대해 적어도 65%, 70%, 75%, 80%, 85%, 90%, 95%, 98% 또는 99%가 동일한 뉴클레오타이드 서열을 포함하는 핵산들이 전형적으로 서로에 혼성화된 상태를 유지하도록 혼성화 및/또는 세척 조건들을 조작하여 혼성화의 엄중도를 증가시키거나 감소시킬 수 있다.
본 발명은 또한 기술된 핵산 분자들과 "실질적으로 동일한(substantially identical)" 핵산 분자를 포함한다. 한 실시형태에서, 핵산 서열에 관련하여 용어 실질적으로 동일한이 의미하는 것은 적어도 약 65%, 70%, 75%, 80%, 85%, 또는 90% 서열 동일성을 나타내는 핵산 분자의 서열로서 해석될 수 있다. 다른 실시형태들에서, 핵산 분자는 기준 핵산 서열과 95% 또는 98% 서열 동일성을 나타낸다.
혼성화 조건들의 선택에 영향을 주는 기본 매개변수들 및 적당한 조건들을 궁리하는 지침은, 예를 들면, 문헌[침조; Sambrook, Fritsch, and Maniatis (1989, Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y., chapters 9 and 11; and Current Protocols in Molecular Biology, 1995, Ausubel et al., eds., John Wiley & Sons, Inc., sections 2.10 and 6.3-6.4)]에 의해 제시되어 있으며, 당해 분야의 통상의 숙련가들이, 예를 들면, 핵산의 길이 및/또는 염기 조성에 기초하여 용이하게 결정할 수가 있다.
폴리펩타이드의 서열 유사성은, 또한 서열 동일성이라고 부르기도 하는데, 전형적으로는 서열 분석 소프트웨어를 사용하여 측정된다. 단백질 분석 소프트웨어는 보존성 아미노산 치환을 포함하여, 여러 가지 치환, 결실, 및 그 밖의 변형에 할당된 유사성의 척도를 사용하여 유사한 서열들을 매치시킨다. 예를 들면, 서열 분석 도구 GCG(Accelrys Software Inc.)는 디폴트 매개변수들을 사용하여 서로 다른 종의 유기체들 유래의 상동 폴리펩타이드와 같은 가깝게 관련된 폴리펩타이드 간의 또는 야생형 단백질과 이의 돌연변이단백질 간의 서열 상동성 또는 서열 동일성을 측정하는데 이용될 수가 있는 "GAP" 및 "BEST-FIT"과 같은 프로그램들을 담고 있다. (예를 들면, GCG Version 6.1 or Durbin et. Al., Biological Sequence Analysis: Probabilistic models of proteins and nucleic acids., Cambridge Press (1998) 참조).
폴리펩타이드 서열은 또한 GCG Version 6.1의 한 프로그램인, 디폴트 또는 추천된 매개변수들을 사용하는 FASTA를 사용하여 비교될 수가 있다. FASTA(예를 들면, FASTA2 및 FASTA3)는 조회 및 탐색 서열들 간의 최대 중복 부위들의 정렬 및 서열 동일성 비율을 제공해 준다(상기 Pearson (2000)). 본 발명의 서열을 서로 다른 유기체들로부터의 많은 수의 서열들을 포함하고 있는 데이터베이스에 비교하는 또 다른 바람직한 알고리즘은 디폴트 매개변수들을 사용하는 컴퓨터 프로그램 BLAST, 특히 blastp 또는 tblastn이다. 예를 들면, 문헌(Altschul et al. (1990) J. Mol. Biol. 215: 403 410 and Altschul et al. (1997) Nucleic Acids Res. 25:3389 402)을 참조하며, 이들 각각이 본원에 참조로 인용되어 있다.
이와 관련하여 본 발명은 또한 항체 가변 영역 폴리펩타이드 서열(예를 들면, 공여자 경쇄 또는 중쇄 가변 영역, 수용자 경쇄 또는 중쇄 가변 영역 또는 결과로서 생기는 사람화된 작제물)에 대하여 "실질적으로 동일한" 폴리펩타이드를 암호화하는 핵산 분자를 포함한다. 이러한 폴리펩타이드에 적용되는 바와 같이, 용어 "실질적으로 동일성(substantial identity)" 또는 "실질적으로 동일한(substantially identical)"은 두 개의 펩타이드 서열이, 디폴트 갭 가중치들을 사용하는 GAP 또는 BEST-FIT 프로그램들에 의해서와 같이 최적으로 정렬되었을 때, 적어도 60% 또는 65% 서열 동일성을, 바람직하게는 적어도 70%, 75%, 80%, 85%, 또는 90% 서열 동일성을, 한층 더 바람직하게는 적어도 93%, 95%, 98% 또는 99% 서열 동일성을 공유함을 의미한다. 바람직하게는, 동일하지 않은 잔기 위치는 보존성 아미노산 치환만큼 차이가 있는 것이다. "보존성 아미노산 치환(conservative amino acid substitution)"은 아미노산 잔기가 화학적 성질들(예를 들면, 전하 또는 소수성)이 유사한 측쇄(R기)를 가진 또 다른 아미노산 잔기로 치환된 것이다. 일반적으로, 보존성 아미노산 치환은 단백질의 기능적 성질들을 실질적으로 변화시키지 않을 것이다. 둘 이상의 아미노산 서열이 보존성 치환만큼 서로 차이가 나는 경우들에서, 서열 동일성 비율 또는 유사성의 정도가 상향 조정되어 치환의 보존적 성질을 보정할 수 있다.
3. 발현
재조합 발현, 즉, RNA의 또는 RNA 및 단백질/펩타이드의 제조의 다양한 과정들은 예를 들면, 문헌[참조; Berger and Kimmel, Guide to Molecular Cloning Techniques, Methods in Enzymology volume 152 Academic Press, Inc., San Diego, Calif.; Sambrook et al., Molecular Cloning-A Laboratory Manual (3rd Ed.), Vol. 1-3, Cold Spring Harbor Laboratory, Cold Spring Harbor, N.Y., (2000); and Current Protocols in Molecular Biology, F. M. Ausubel et al., eds., Current Protocols, a joint venture between Greene Publishing Associates, Inc. and John Wiley & Sons, Inc., (supplemented through 2006)]에 제시된 바와 같이 잘 알려져 있다.
중요한 몇몇 용어들에 "발현 통제 서열(expression control sequence)"이 포함되는데, 이것은 유전자의 전사 또는 mRNA의 번역을 조절하는 프로모터, 라이보솜 결합 부위, 인핸서 및 그 밖의 통제 요소들을 포함한다. 잘 알려져 있는 바와 같이, "프로모터(promoter)" 또는 "프로모터 부위(promoter region)"는 일반적으로 발현하고자 하는 핵산 서열의 상류(5')에 위치하고 RNA-폴리머라제를 위한 인식 및 결합 부위를 제공함으로써 서열의 발현을 통제하는 핵산 서열에 관련된 것이다.
본 발명에 따른 적합한 예시적인 프로모터에는 SP6, T3 및 T7 폴리머라제를 위한 프로모터, 사람 U6 RNA 프로모터, CMV 프로모터, 및 한 부분 또는 여러 부분이 예를 들면 사람 GAPDH(글리세르알데히드-3-포스페이트 데하이드로게나제)와 같은 다른 세포성 단백질들의 유전자들의 프로모터의 한 부분 또는 여러 부분에 융합된, 그리고 추가의 인트론(들)을 포함하거나 포함하지 않은 이들의 인위적인 혼성체 프로모터(예를 들면 CMV)가 포함된다.
소정 실시형태들에서, 핵산 분자는 핵산의 발현을 통제하는, 프로모터가 있는 적합한 벡터에 존재할 수 있다. 잘 알려진 용어 "벡터(vector)"는 핵산을 위한 임의의 중간 운반체를 구성한 것으로 상기 핵산이 예를 들면, 무핵 세포 및/또는 유핵 세포들 속으로 도입되는 것을 가능하게 하며, 적합한 경우에는, 유전체 속으로 통합되는 것을 가능하게 해준다. 포유동물 세포들을 형질전환하는 방법은 당해 분야에 잘 알려져 있다. 예를 들면, U.S.P.Ns. 제4,399,216호, 제4,912,040호, 제4,740,461호, 및 제4,959,455호를 참조한다. 벡터는 프로모터에 작동적으로 연결된, 본 발명의 항체(예를 들면, 완전 항체, 항체의 중쇄 또는 경쇄, 항체의 VH 또는 VL, 또는 이들의 일부, 또는 중쇄- 또는 경쇄 CDR, 단일 쇄 Fv, 또는 이들의 단편 또는 변이체)를 암호화하는 뉴클레오타이드 서열을 포함할 수 있다(예를 들면, PCT Publication 제WO 86/05807호; PCT 공개 제WO 89/01036호; 및 U.S.P.N. 제5,122,464호 참조).
다양한 숙주-발현 벡터 시스템들이 상업적으로 이용가능하고, 다수는 본원의 교시에 적합한 것이며 본 발명의 조절물질을 발현시키는데에 사용될 수 있다. 이러한 시스템들에는 조절물질 암호 서열이 포함된 재조합 박테리오파지 DNA, 플라스미드 DNA 또는 코스미드 DNA 발현 벡터로 형질전환된 박테리아(예를 들면, 이. 콜라이(E. coli), 비. 서브틸리스(B. subtilis), 스트렙토마이세스(Streptomyces))와 같은 미생물; 조절물질 암호 서열이 포함된 재조합 이스트 발현 벡터로 형질감염된 이스트(예를 들면, 사카로마이세스(Saccharomyces), 피치아(Pichia)); 조절물질 암호 서열이 포함된 재조합 바이러스 발현 벡터(예를 들면, 바쿨로바이러스)로 감염된 곤충 세포 시스템; 조절물질 암호 서열이 포함된 재조합 바이러스 발현 벡터(예를 들면, 콜리플라워 모자이크 바이러스(cauliflower mosaic virus); 담배 모자이크 바이러스(tobacco mosaic virus))로 감염되거나 재조합 플라스미드 발현 벡터(예를 들면, Ti 플라스미드)로 형질감염된 식물 세포 시스템(예를 들면, 니코티아나(Nicotiana), 아라비돕시스(애기장대, Arabidopsis), 오리잡초, 옥수수, 밀, 감자 등); 또는 포유동물 세포의 유전체로부터 유도된 (예를 들면, 메탈로티오네인 프로모터) 또는 포유동물 바이러스로부터 유도된 (예를 들면, 아데노바이러스 후기 프로모터; 우두 바이러스 7.5K 프로모터) 프로모터가 포함된 재조합 발현 작제물을 품은 포유동물 세포 시스템(예를 들면, COS, CHO, BHK, 293, 3T3 세포 등)이 포함되지만, 이들에 한정되는 것은 아니다.
본원에 사용되는 바와 같이, 용어 "숙주 세포(host cell)"는 본 발명의 폴리펩타이드 및 항원-결합 분자를 생성하도록 조작처리될 수가 있는 임의의 종류의 세포 시스템을 포함한다. 한 실시형태에서, 숙주 세포는 변형된 글리코형(glycoform)을 가진 항원 결합 분자의 생성이 가능하도록 조작처리된다. 바람직한 실시형태에서, 항원 결합 분자, 또는 변이체 항원 결합 분자는 항체, 항체 단편, 또는 융합 단백질이다. 소정 실시형태들에서, 숙주 세포는 N-아세틸글루코사미닐트랜스퍼라제 III(GnTI11) 활성을 가진 하나 이상의 폴리펩타이드의 증가된 수준을 발현하도록 더욱 조작되었다. 적합한 숙주 세포에는 배양 세포, 예를 들면, CHO 세포, BHK 세포, NSO 세포, SP2/0 세포, YO 골수종 세포, P3X63 마우스 골수종 세포, PER 세포, PER.C6 세포 또는 하이브리도마 세포와 같은 포유동물 배양 세포, 이스트 세포, 곤충 세포, 및 식물 세포가 포함되지만, 단지 몇 가지만 언급한 것으로, 유전자이식 동물, 유전자이식 식물 또는 배양 식물 또는 동물 조직 내에 포함된 세포들도 있다.
재조합 단백질들의 장기간의 고-수율 생성을 위해서는 안정된 발현이 바람직하다. 따라서, 선택된 조절물질을 안정되게 발현하는 세포주를 표준의 당해 분야에서 인정되고 있는 기술들을 사용하여 조작처리할 수 있다. 바이러스 기원의 복제가 포함된 발현 벡터를 사용하기 보다는, 적합한 발현 통제 요소들(예를 들면, 프로모터, 인핸서, 서열, 전사 종결인자, 폴리아데닐화 자리 등)에 의해 통제되는 DNA, 및 선별 마커로 숙주 세포들을 형질전환시킬 수가 있다. 당해 분야에 잘 알려진 선별 시스템들의 임의의 것이라도 사용할 수 있는데, 소정 일정한 조건 하에 발현을 증대시키기에 효율적인 접근방법을 제공해 주는 글루타민 신테타제 유전자 발현 시스템(GS 시스템)이 포함된다. GS 시스템은 EP 특허 제0 216 846호, 제0 256 055호, 제0 323 997호 및 제0 338 841호 그리고 U.S.P.N.s 제5,591,639호와 제5,879,936호에 관련하여 전부 또는 일부 논의되어 있는데, 그 각각이 참조로 본원에 인용되어 있다. 또 다른 바람직한 발현 시스템으로, Life Technologies(카탈로그 번호 A13696-01)에 의해서 상업적으로 공급되는 FreedomTM CHO-S Kit도 조절물질 제조에 사용될 수 있는 안정된 세포주의 개발을 가능하게 한다.
이러한 숙주-발현 시스템들은 관심의 암호 서열들을 제조하고 이후 정제할 수 있는 운반체들을 나타낼 뿐 아니라, 적합한 뉴클레오타이드 암호 서열들로 형질전환 또는 형질감염시켰을 때, 본 발명의 분자를 제 자리에서(in situ) 발현할 수 있는 세포들을 나타낸다. 숙주 세포는 본 발명의 두 가지 발현 벡터, 예를 들면, 중쇄 유래 폴리펩타이드를 암호화하는 제1 벡터와 경쇄 유래 폴리펩타이드를 암호화하는 제2 벡터로 동시-형질감염될 수 있다.
따라서, 소정 실시형태들에서, 본 발명은 항체 또는 이들의 부분들의 발현을 가능하게 해 주는 재조합 숙주 세포를 제공한다. 이러한 재조합 숙주 세포들에서의 발현에 의해 생성된 항체는 본원에서 재조합 항체라고 부른다. 본 발명은 또한 이러한 숙주 세포의 자손 세포들, 그리고 이들에 의해 생성된 항체를 제공한다.
C. 화학적 합성
또한, 조절물질은 당해 분야에 알려진 기술들을 사용하여 화학적으로 합성될 수 있다(예를 들면, 문헌 참조; Creighton, 1983, Proteins: Structures and Molecular Principles, W.H. Freeman & Co., N.Y., and Hunkapiller, M., et al., 1984, Nature 310:105-111). 게다가, 원한다면, 비고전적인 아미노산 또는 화학적 아미노산 유사체들(이를 테면 공통 아미노산의 D-이성질체, 2,4-디아미노부티르산, a-아미노 이소부티르산, 4-아미노부티르산 등)을 폴리펩타이드 서열로 치환 또는 부가 형태로 도입할 수가 있다.
D. 유전자이식 시스템
다른 실시형태들에서 조절물질은 면역글로불린의 중쇄 및 경쇄 서열들과 같은 재조합 분자들의 유전자가 이식된 그리고 회수가능한 형태로 목적하는 화합물을 생성하는 포유동물 또는 식물의 제조를 통한 유전자이식으로 생산될 수 있다. 이것에는, 예를 들면, 염소, 소, 또는 다른 포유동물의 우유 상태의 단백질 조절물질(예를 들면, 항체)의 생산, 및 이로부터의 회수가 포함된다. 예를 들면, U.S.P.Ns. 제5,827,690호, 제5,756,687호, 제5,750,172호, 및 제5,741,957호를 참조한다. 소정 실시형태들에서, 사람 면역글로불린 유전자자리를 포함한 비사람 유전자이식 동물을 면역화시켜 항체를 생산한다.
다른 유전자이식 기술들은 문헌[참조; Hogan et al., Manipulating the Mouse Embryo: A Laboratory Manual 2nd ed., Cold Spring Harbor Press (1999); Jackson et al., Mouse Genetics and Transgenics: A Practical Approach, Oxford University Press (2000); and Pinkert, Transgenic Animal Technology: A Laboratory Handbook, Academic Press (1999)] 및 U.S. P.N. 제6,417,429호에 제시되어 있다. 소정 실시형태들에서, 비사람 동물은 마우스, 래트, 양, 돼지, 염소, 소 또는 말이며, 목적하는 산물은 혈액, 우유, 오줌, 침, 눈물, 점액 및 당해 분야에서 인정되고 있는 기술들을 사용하여 용이하게 얻을 수 있는 다른 체액으로 생산된다.
다른 적합한 생산 시스템에는 예를 들면, U.S.P.Ns. 제6,046,037호와 제5,959,177호에 기술된 것과 같은 식물에서 항체를 만들기 위한 방법이 포함되는데, 상기 기술들에 관련하여 본원에 인용되어 있다.
E. 단리/정제
일단 본 발명의 조절물질이 재조합 발현 또는 다른 임의의 개시된 기술들에 의해서 생산되었으면, 면역글로불린 또는 단백질의 정제를 위한 당해 분야에 알려진 임의의 방법에 의해서 정제될 수 있다. 이와 관련하여 조절물질은 "단리될(isolated)" 수 있는데, 이는 그것이 동정되어 그것의 본래 환경의 성분으로부터 분리 및/또는 회수된 것을 의미한다. 그것의 본래 환경의 오염물질 성분은 폴리펩타이드의 진단적 또는 치료적 사용을 방해할 수 있는 물질이며 효소, 호르몬, 및 다른 단백질성 또는 비단백질성 용질을 포함할 수 있다. 단리된 조절물질에는 폴리펩타이드의 본래 환경의 적어도 한 가지 성분이 존재하지 않을 것이기 때문에 재조합 세포들 속의 제자리의 조절물질이 포함된다.
만일 원하는 분자가 세포내에서 생성되면, 제1 단계로서, 미립자 부스러기가, 숙주 세포이든 용해된 단편이든, 예를 들면, 원심분리 또는 초미세여과에 의해서 제거될 수 있다. 조절물질이 매질로 분비되는 경우에는, 이러한 발현 시스템의 상층액을 일반적으로는 상업적으로 이용가능한 단백질 농축 필터, 예를 들면, Amicon 또는 Pellicon 초미세여과 장치(Millipore Corp.)를 사용하여 먼저 농축한다. 일단 불용성의 오염물질들이 제거되면 조절물질 제제를 예를 들면, 하이드록실아파타이트 크로마토그래피, 젤 전기영동, 투석, 및 친화력 크로마토그래피와 같은 표준 기술들을 사용하여 더 정제할 수 있으며, 친화력 크로마토그래피가 특히 중요하다. 이와 관련하여 단백질 A를 사용하여 사람 IgG1, IgG2 또는 IgG4의 중쇄에 기초하는 항체를 정제할 수가 있는 반면(문헌 참조; Lindmark, et al., J Immunol Meth 62:1 (1983)) 단백질 G는 모든 마우스 이소형과 사람 IgG3에 추천된다(문헌 참조; Guss, et al., EMBO J 5:1567 (1986)). 이온-교환 칼럼 상의 분획화, 에탄올 침전, 역상 HPLC, 실리카 상의 크로마토그래피, 헤파린 상의 크로마토그래피, (폴리아스파르트산 칼럼과 같은) 음이온 또는 양이온 교환 수지 상의 세파로오스 크로마토그래피, 크로마토포커싱, SDS-PAGE 및 암모늄 설페이트 침전과 같은 단백질 정제를 위한 다른 기술들도 또한 회수하고자 하는 항체에 따라 이용가능하다. 특히 바람직한 실시형태들에서 본 발명의 조절물질은, 적어도 부분적으로, 단백질 A 또는 단백질 G 친화력 크로마토그래피를 사용하여 정제될 것이다.
VI. SEZ6 조절물질 단편 및 유도체
소정 발생 및 제조 방법론들이 선택되던지, 본 발명의 조절물질은 표적 결정인자(예를 들면, 항원)와 반응, 결합, 조합, 복합, 연결, 부착, 접합, 상호작용 또는 그렇지 않으면 회합함으로써 원하는 결과를 제공할 것이다. 조절물질이 항체 또는 단편, 작제물 또는 이들의 유도체를 포함하는 경우, 상기 회합은 항체 상에서 발현된 하나 이상의 "결합 부위" 또는 "결합 성분"을 통해 이루어질 수 있으며, 여기서 결합 부위는 표적 분자 또는 관심 항원에의 선택적 결합을 책임지는 폴리펩타이드의 영역을 포함한다. 결합 도메인은 적어도 하나의 결합 부위를 포함한다(예를 들면, 온전한 IgG 항체는 2개의 결합 도메인과 2개의 결합 부위를 가질 것이다). 예시적인 결합 도메인에는 항체 가변 도메인, 리간드의 수용체-결합 도메인, 수용체의 리간드-결합 도메인 또는 효소 도메인이 포함된다.
A. 항체
위에 기술된 바와 같이, 용어 "항체"는 적어도 폴리클로날 항체, 멀티클론성 항체, 키메라 항체, CDR 절편이식된 항체, 사람화된 및 영장류화 항체, 사람 항체, 재조합으로 생산된 항체, 내부체, 다중특이성 항체, 이중특이성 항체, 1가 항체, 다가 항체, 항-유전자형 항체 뿐만 아니라 합성 항체를 포함하는 것으로 의도된다.
B. 단편
소정 형태의 조절물질(예를 들면, 키메라, 사람화 등)이 본 발명을 실시하기 위해 선택되는지와는 무관하게, 본원에 교시된 내용에 따라, 동일한 면역반응성 단편들이 사용될 수 있음을 알 것이다. "항체 단편"은 온전한 항체의 적어도 일부를 포함한다. 본원에서 사용된 바와 같이, 용어 항체 분자의 "단편"은 항체의 항원-결합 단편을 포함하며, 용어 "항원 결합 단편"은 선택된 항원 또는 이의 면역원 결정인자와 면역특이적으로 결합 또는 반응하거나, 단편이 특이적 항원 결합을 위해 유도된 온전한 항체와 경쟁하는 면역글로불린 또는 항체의 폴리펩타이드 단편을 가리킨다.
예시적인 단편에는 VL, VH, scFv, F(ab')2 단편, Fab 단편, Fd 단편, Fv 단편, 단일 도메인 항체 단편, 이중항체, 선형 항체, 단일-쇄 항체 분자 및 항체 단편으로부터 형성된 다중특이적 항체가 포함된다. 게다가, 활성 단편은 항원/기질 또는 수용체와 상호반응하고, (다소 낮은 효력을 갖고 있음에도 불구하고) 온전한 항체와 유사한 방식으로 이들을 변형시킬 수 있는 능력을 보유하는 항체의 일부를 포함한다.
다른 실시형태에서, 항체 단편은 Fc 부위를 포함하는 단편 및 FcRn 결합, 항체 반감기 조절, ADCC 기능 및 보체 결합과 같은, 온전한 항체내에 존재할 때 Fc 부위와 정상적으로 회합되는 생물학적 기능들 중 적어도 하나를 보유하는 단편이다. 한 실시형태에서, 항체 단편은, 온전한 항체와 실질적으로 유사한 생체내 반감기를 갖는 1가 항체이다. 예를 들면, 이러한 항체 단편은 단편에 생체내 안정성을 부여할 수 있는 Fc 서열에 연결된 항원 결합 아암(arm)을 포함할 수 있다.
당업자들에게 잘 알려져 있는 바와 같이, 단편들은 온전한 또는 완전한 항체 또는 항체 쇄의 화학적 또는 효소적 처리(예를 들면, 파파인 또는 펩신)를 통해, 또는 재조합 수단들에 의해 얻어질 수 있다. 예를 들면, 항체 단편에 대한 보다 상세한 설명을 위해, 문헌[Fundamental Immunology, W. E. Paul, ed., Raven Press, N.Y. (1999)]을 참조한다.
C. 유도체
본 발명은 면역반응성 조절물질 유도체, 및 하나 이상의 변형을 포함하는 항원 결합 분자를 추가로 포함한다.
1. 다가 항체
한 실시형태에서, 본 발명의 조절물질은 1가 또는 다가(예를 들면, 2가, 3가 등)일 수 있다. 본원에서 사용된 바와 같이, 용어 "결합가"는 항체와 회합되는 잠재적인 표적 결합 부위들을 의미한다. 각 표적 결합 부위는 1개의 표적 분자 또는 표적 분자 상의 특정 위치 또는 자리에 특이적으로 결합한다. 항체가 1가인 경우, 분자의 각 결합 부위는 단일 항원 위치 또는 에피토프에 특이적으로 결합할 것이다. 항체가 하나 이상의 표적 결합 부위(다가)를 포함하는 경우, 각 표적 결합 부위는 동일하거나 상이한 분자에 특이적으로 결합할 수 있다(예를 들면, 상이한 리간드 또는 상이한 항원, 또는 동일한 항원 상의 상이한 에피토프 또는 위치에 결합할 수 있음). 예를 들면 U.S.P.N. 제2009/0130105호를 참조한다. 각 경우에, 결합 부위들 중 적어도 하나는 SEZ6 이소형과 회합된 에피토프, 모티프 또는 도메인을 포함할 것이다.
한 실시형태에서, 조절물질은 문헌[참조; Millstein et al., 1983, Nature, 305:537-539]에 기재된 바와 같이, 2개의 쇄들이 다른 특이성을 갖는 이중특이성 항체이다. 다른 실시형태들은 삼중특이성 항체와 같은 추가의 특이성을 갖는 항체를 포함한다. 다른 보다 정교한 적합한 다중특이성 작제물 및 이들의 제조방법은 U.S.P.N. 제2009/0155255호 뿐만 아니라 제WO 94/04690호; Suresh et al., 1986, Methods in Enzymology, 121:210; 및 제WO 96/27011호에 개시되어 있다.
상기 언급되어 있는 바와 같이, 다가 항체는 원하는 표적 분자의 상이한 에피토프들에 면역특이적으로 결합할 수 있거나, 이질성 폴리펩타이드 또는 고체 지지체 물질과 같은 이질성 에피토프 뿐만 아니라 표적 분자 둘 다에 면역특이적으로 결합할 수 있다. 항-SEZ6 항체의 바람직한 실시형태들은 단지 2개의 항원(즉, 이중특이성 항체)과 결합하는 반면, 삼중특이성 항체와 같은 추가의 특이성을 갖는 항체도 본 발명에 의해 포함된다. 이중특이성 항체는 또한 교차-결합된 또는 "헤테로접합된(heteroconjugate)" 항체를 포함한다. 예를 들면, 헤테로접합체 속의 항체 중 하나는 아비딘에 결합될 수 있으며, 나머지 하나는 바이오틴에 결합될 수 있다. 이러한 항체는, 예를 들면, 원치않는 세포에 면역계 세포를 표적화시키기 위해(U.S.P.N. 제4,676,980호), 및 HIV 감염을 치료하기 위해(제WO 91/00360호, 제WO 92/200373호, 및 제EP 03089호) 제안되어 왔다. 헤테로접합체 항체는 편리한 교차-결합 방법을 사용하여 제조될 수 있다. 적당한 교차-결합제들은 당업계에 잘 알려져 있으며, 여러 개의 교차결합 기술들과 함께 U.S.P.N. 제4,676,980호에 개시되어 있다.
또 다른 실시형태에서, 원하는 결합 특이성을 갖는 항체 가변 도메인(항체-항원 결합 부위)은 당해 분야의 통상의 숙련가들에게 잘 알려진 방법을 사용하여, 힌지, CH2, 및/또는 CH3 영역들의 적어도 일부를 포함하는 면역글로불린 중쇄 불변 도메인과 같은 면역글로불린 불변 도메인 서열에 융합된다.
2. Fc 부위 변형
개시된 조절물질(예를 들면, Fc-SEZ6 또는 항-SEZ6 항체)의 가변 또는 결합 부위에 대한 다양한 변형, 치환, 부가 또는 결실에 더해, 당업계의 숙련가들은 본 발명의 선택된 실시형태들이 불변 영역(즉, Fc 부위)의 치환 또는 변형도 포함할 수 있음을 알 것이다. 더욱 구체적으로, 본 발명의 SEZ6 조절물질은 무엇보다도 하나 이상의 추가의 아미노산 잔기 치환, 돌연변이 및/또는 변형을 함유할 수 있으며, 이들은 변경된 약동학, 증가된 혈청 반감기, 증가된 결합 친화력, 감소된 면역원성, 증가된 생산성, Fc 수용체(FcR)에 대한 변경된 Fc 리간드 결합력, 개선된 또는 감소된 "ADCC"(항체-의존성 세포 매개 세포독성) 또는 "CDC"(보체-의존성 세포독성) 활성, 변경된 글리코실화 및/또는 디설파이드 결합 및 변형된 결합 특이성을 포함하지만 이에 제한되지 않는 바람직한 특성들을 갖는 화합물을 야기한다. 이와 관련하여, 상기 Fc 변이체들이 개시된 조절물질의 효과적인 항-종양 특성들을 개선시키기 는데 유리하게 사용될 수 있음을 알 것이다.
이러한 목적을 위해 본 발명의 특정 실시형태는 Fc 부위의 치환 또는 변형, 예를 들면, 하나 이상의 아미노산 잔기의 부가, 개선된 또는 바람직한 Fc 효과물질 기능들을 갖는 화합물을 생성하기 위한 치환, 돌연변이 및/또는 변형을 포함할 수 있다. 예를 들면, Fc 도메인과 Fc 수용체(예를 들면, FcγRI, FcγRIIA 및 B, FcγRIII 및 FcRn) 사이의 상호반응에 연관된 아미노산 잔기들에서의 변화는 세포독성을 증가시키고/증가시키거나 증가된 혈청 반감기와 같은 약동학들을 변경시킬 수 있다(예를 들면, 문헌[Ravetch and Kinet, Annu. Rev. Immunol 9:457-92 (1991); Capel et al., Immunomethods 4:25-34 (1994); and de Haas et al., J. Lab. Clin. Med. 126:330-41 (1995)] 참조, 이들 각각은 본원에 참조로 인용된다).
선택된 실시형태들에서, 증가된 생체내 반감기를 갖는 항체는 Fc 도메인과 FcRn 수용체 사이의 상호반응에 연관된 것으로 동정된 아미노산 잔기들을 변형(예를 들면, 치환, 결실, 또는 부가)시킴으로써 생성될 수 있다(예를 들면, 국제공보 제WO 97/34631호; 제WO 04/029207호; U.S.P.N. 제6,737,056호 및 U.S.P.N. 제2003/0190311호 참조). 상기 실시형태들과 관련하여, Fc 변이체들은 포유동물, 바람직하게 사람에서 5일 이상, 10일 이상, 15일 이상, 바람직하게 20일 이상, 25일 이상, 30일 이상, 35일 이상, 40일 이상, 45일 이상, 2개월 이상, 3개월 이상, 4개월 이상, 또는 5개월 이상의 반감기를 제공할 수 있다. 반감기가 증가됨으로써, 혈청 역가가 높아져서, 항체의 투여 빈도를 감소시키고/시키거나 투여되는 항체의 농도를 감소시킨다. 생체내 사람 FcRn에 대한 결합 및 사람 FcRn 고친화력 결합 폴리펩타이드의 혈청 반감기는, 예를 들면, 변이 Fc 부위를 갖는 폴리펩타이드가 투여되는 영장류에서, 또는 유전자이식 마우스 또는 사람 FcRn을 발현하는 형질감염 사람 세포주에서 분석될 수 있다. 제WO 2000/42072호에는 FcRn에 대한 결합을 개선 또는 감소시킨 항체 변이체들이 기술되어 있다. 예를 들면, 문헌[Shields et al. J. Biol. Chem. 9(2):6591-6604 (2001)]을 참조한다.
다른 실시형태에서, Fc 변형은 ADCC 또는 CDC 활성을 개선 또는 감소시킬 수 있다. 당업계에 알려져 있는 바와 같이, CDC는 보체의 존재하에서의 표적 세포의 융해(lysis)를 가리키며, ADCC는 특정 세포독성 세포(예를 들면, 자연살해세포, 호중구, 및 대식세포) 상에 존재하는 FcR에 결합되어 분비된 Ig가 세포독성 효과물질 세포들을 항원-포함 표적 세포에 특이적으로 결합할 수 있게 하여, 세포독소를 표적 세포를 살해할 수 있는 세포독성의 한 형태를 가리킨다. 본 발명의 맥락에서, 항체 변이체에는 "변경된" FcR 결합 친화력이 제공되며, 이는 천연형 서열 FcR을 포함하는 항체 또는 모 항체 또는 비변성 항체와 비교하여, 개선된 또는 감소된 결합력을 가진다. 감소된 결합력을 나타내는 이러한 변이체들은, 예를 들면, 당업계에 알려진 기술들에 의해 측정되는 바와 같이, 천연형 서열과 비교하여, FcR에 대하여 약한 또는 거의 인지할 수 없는 결합력, 예를 들면 0-20% 결합력을 가질 수 있다. 다른 실시형태에서, 변이체는 천연 면역글로불린 Fc 도메인과 비교하여, 개선된 결합력을 나타낼 것이다. 이러한 종류의 Fc 변이체들은 개시된 항체의 효과적인 항-종양 특성들을 개선시키는데 유리하게 사용될 수 있음을 알 것이다. 또 다른 실시형태에서, 이러한 변형들은 결합 친화력을 증가시키고, 면역원성을 감소시키며, 생산력을 증가시키고, 글리코실화 및/또는 디설파이드 결합(예를 들면, 접합 자리)을 변형시키고, 결합 특이성을 변형시키고, 포식세포를 증가시키고; 및/또는 세포 표면 수용체(예를 들면, B 세포 수용체; BCR)를 하향 조절시킨다.
3. 변형된 글리코 실화
또 다른 실시형태들은 하나 이상의 이상의 조작처리된 글리코형, 즉 단백질에(예를 들면, Fc 도메인에) 공유결합된 변형된 탄수화물 조성물 또는 변형된 글리코실화 패턴을 포함하는 SEZ6 조절물질을 포함한다. 예를 들면, 문헌[Shields, R. L. et al. (2002) J. Biol . Chem . 277:26733-26740]을 참고한다. 조작처리된 글리코형은 효과물질 기능을 개선 또는 감소시키는 것, 표적에 대한 조절물질의 친화력을 증가시키는 것 또는 조절물질의 생성을 촉진하는 것을 포함하지만 이에 제한되지 않는 여러 목적에 유용할 수 있다. 감소된 효과물질 기능을 목적으로 하는 특정 실시형태에서, 비글리코실화 형태를 발현하도록 분자가 조작처리될 수 있다. 하나 이상의 가변 영역 프레임워크 글리코실화 부위들을 제거하여 그 부위에서의 글리코실화를 제거할 수 있는 치환은 잘 알려져 있다(예를 들면, U.S.P.N. 제5,714,350호 및 제6,350,861호 참조). 역으로, 개선된 효과물질 기능 또는 개선된 결합력은 하나 이상의 추가의 글리코실화 부위를 조작처리함으로써 Fc 함유 분자에 부여될 수 있다.
다른 실시형태들은 감소된 양의 푸코실 잔기를 갖는 하이포푸코실화(hypofucosylated) 항체 또는 증가된 2등분 GlcNAc 구조를 갖는 항체와 같은, 변형된 글리코실화 조성물을 갖는 Fc 변이체를 포함한다. 이러한 변형된 글리코실화 패턴은 항체의 ADCC 능력을 증가시키는 것으로 입증되어 왔다. 조작처리된 글리코형은 당업계의 통상의 숙련가들에게 공지된 방법으로, 예를 들면, 조작처리된 또는 변이체 발현 변종을 사용하여, 하나 이상의 효소(예를 들면, N-아세틸글루코사미닐트랜스퍼라제 III(GnTI11))와 동시-발현함으로써, 여러 유기체의 Fc 부위 또는 여러 유기체로부터의 세포주를 포함하는 분자를 발현시킴으로써 또는 Fc 부위를 포함하는 분자가 발현된 후 탄수화물(들)을 변형시킴으로써 생성될 수 있다(예를 들면, 제WO 2012/117002호 참조).
4. 추가 처리
조절물질은 글리코실화, 아세틸화, 인산화, 아미드화, 공지된 보호/차단 기들에 의한 유도체화, 단백질분해 제거, 항체 분자에 대한 결합 또는 다른 세포성 리간드 등에 의해 제조 중에 또는 제조 후에 별도로 변형될 수 있다. 수많은 화학적 변형들 중 어느 것이나, 시아노겐 브로마이드, 트립신, 키모트립신, 파파인, V8 프로테아제, NaBH4에 의한 특수한 화학적 제거, 아세틸화, 포르밀화, 산화, 환원, 튜니카마이신의 존재하에서의 대사 합성을 포함하지만 이에 제한되지 않는 공지된 기술들에 의해 실시될 수 있다.
본 발명에 의해 포함되는 여러가지의 번역후 변형들은, 예를 들면, N-연결형 또는 O-연결형 탄수화물 쇄, N-말단 또는 C-말단 끝의 처리, 아미노산 주쇄에 대한 화학적 모이어티의 부착, N-연결형 또는 O-연결형 탄수화물 쇄의 화학적 변형, 및 무핵 숙주 세포 발현의 결과로서 N-말단 메티오닌 잔기의 부가 또는 결실을 포함한다. 게다가, 조절물질은 또한 조절물질의 검출 및 분리를 가능하게 하는 효소성, 형광성, 방사성 동위원소성 또는 친화성 표지와 같은 검출가능한 표지로 변형될 수도 있다.
VII. 조절물질 특성들
얻는 방법이 무엇이든, 또는 상기 형태들 중 조절물질이 소정 형태를 취했는지와 무관하게, 개시된 조절물질의 다양한 실시형태들은 특정한 특성들을 나타낼 수 있다. 선택된 실시형태들에서, 항체-생성 세포들(예를 들면, 하이브리도마 또는 이스트 콜로니)은 강한 성장, 높은 조절물질 생산력 및, 하기에 상술된 바와 같이, 바람직한 조절물질 특성들을 포함하는 유리한 특성들을 위해 선택, 클로닝 및 추가 선별될 수 있다. 다른 경우, 조절물질의 특성들은 동물의 접종을 위한 표적 항원의 면역반응성 단편 또는 특정 항원(예를 들면, 특정 SEZ6 이소형 또는 이의 단편)을 선택함으로써 부여받거나 또는 영향을 받을 수 있다. 또 다른 실시형태들에서, 선택된 조절물질은 친화력 또는 약동학과 같은 면역화학적 특성들을 개선 또는 개량하기 위해 상기한 바와 같이 조작처리될 수 있다.
A. 중화 조절물질
특정 실시형태에서, 조절물질은 "중화" 항체 또는 이들의 유도체 또는 단편을 포함할 것이다. 즉, 본 발명은 특정 도메인, 모티프 또는 에피토프에 결합하고 SEZ6의 생물학적 활성을 차단, 감소 또는 억제할 수 있는 항체 분자를 포함할 수 있다. 일반적으로, 용어 "중화 항체"는 표적 분자 또는 리간드에 결합하거나 상호반응하고, 수용체 또는 기질과 같은 결합 파트너에의 표적 분자의 결합 또는 회합을 막음으로써 분자들의 상호반응으로부터 야기되는 생물학적 반응을 방해하는 항체를 의미한다.
당해 분야에 공지된 경쟁적 결합 분석법이 항체 또는 면역기능 단편 또는 이의 유도체의 결합 및 특이성을 평가하기 위해 사용될 수 있음을 이해할 수 있을 것이다. 본 발명과 관련하여 항체 또는 단편은, 예를 들면, 손상된 신경성장 리간드 활성에 의해 또는 시험관내 경쟁적 결합 분석법에 의해 측정되는 바와 같이 과량의 항체가 SEZ6에 결합된 결합 파트너의 양을 적어도 약 20%, 30%, 40%, 50%, 60%, 70%, 80%, 85%, 90%, 95%, 97%, 99% 또는 그 이상까지 감소시킬 때, 결합 파트너 또는 기질(예를 들면, 신경성장 리간드)에 대한 SEZ6의 결합을 억제 또는 감소시키기 위해 유지될 것이다. SEZ6에 대한 항체의 경우에, 예를 들면, 중화 항체 또는 길항제는 바람직하게는 적어도 약 20%, 30%, 40%, 50%, 60%, 70%, 80%, 85%, 90%, 95%, 97%, 99% 또는 그 이상까지 리간드 활성을 변화시킬 것이다. 이 변화된 활성은 당업계에 공지된 기술들을 사용하여 직접 측정될 수 있거나 변화된 활성이 하류영역(예를 들면, 종양원성, 세포생존 또는 경로 활성화)에 미치는 영향에 의해 측정될 수 있음을 이해할 수 있을 것이다.
B. 내재화 조절물질
SEZ6 또는 이의 선택된 이소형이 수용성 형태로 존재할 수 있음을 나타내는 증거가 있지만, 적어도 일부 SEZ6은 아마도 세포 표면과 회합한 상태로 있어서 개시된 조절물질의 내재화를 가능하게 하는 것 같다. 따라서, 본 발명의 항-SEZ6 항체는 SEZ6을 발현하는 세포들에 의해, 적어도 어느 정도까지는, 내재화될 수 있다. 예를 들면, 종양-개시 세포의 표면 상에서 SEZ6에 결합하는 항-SEZ6 항체는 종양-개시 세포에 의해 내재화될 수 있다. 특히 바람직한 실시형태들에서 이러한 항-SEZ6 항체는 내재화시 세포를 살해하는 세포독성 모이어티와 같은 항암제와 회합 또는 접합될 수 있다. 특히 바람직한 실시형태들에서, 조절물질은 내재화 항체 약물 접합체를 포함할 것이다.
본원에서 사용된 바와 같이 "내재화하는" 조절물질은 회합된 항원 또는 수용체에 결합시 세포에 의해 (소정 적재물과 함께) 흡수되는 물질이다. 잘 평가되고 있는 바와 같이, 내재화 조절물질은, 바람직한 실시형태에서, 항체 접합체 뿐만 아니라 항체 단편 및 이들의 유도체를 포함하는 항체를 포함한다. 내재화는 시험관내 또는 생체내에서 일어날 수 있다. 치료적 용도를 위해, 이를 필요로 하는 대상체의 생체내에서 내재화가 바람직하게 일어날 것이다. 내재화된 항체 분자들의 수는 항원-발현 세포, 특히 항원-발현 암 줄기 세포를 죽이기에 충분하거나 적당할 수 있다. 소정 경우, 항체 또는 항체 접합체의 효능에 따라, 항체가 결합하는 표적 세포를 죽이기 위해 세포로 단일 항체분자가 흡수되는 것만으로도 충분하다. 예를 들면, 특정 독소는 대단히 강력해서, 항체에 접합된 독소의 적은 분자들의 내재화로도 종양세포를 죽이기에 충분하다. 포유동물 세포에 결합시 항체가 내재화하는지의 여부는 하기 실시예에 설명된 것을 포함한 다양한 분석법들에 의해 측정될 수 있다(예를 들면, 실시예 15, 17 및 18). 항체가 세포로 내재화하는지의 여부를 검출하는 방법은 또한 U.S.P.N. 제7,619,068호에 기재되어 있으며, 이는 본원에 전부 참조로 인용된다.
C. 고갈화 조절물질
다른 실시형태에서, 항체는 고갈화 항체 또는 이들의 유도체 또는 단편을 포함할 것이다. 용어 "고갈화" 항체는 세포 표면 상에서 또는 부근에서 항원과 결합 또는 회합하여 (예를 들면, CDC, ADCC 또는 세포독성제의 도입에 의해) 세포의 사망 또는 제거를 유도, 촉진 또는 유발하는 항체를 가리킨다. 소정 실시형태에서, 선택된 고갈화 항체는 세포독성제에 회합 또는 접합될 것이다.
바람직하게는, 고갈화 항체는 정해진 세포 개체군내 SEZ6 종양원성 세포의 적어도 20%, 30%, 40%, 50%, 60%, 70%, 80%, 85%, 90%, 95%, 97%, 또는 99%를 제거하거나 무력화하거나 없애거나 살해할 수 있을 것이다. 소정 실시형태에서, 세포 개체군은 증대된, 절개된, 정제된 또는 단리된 종양 영속화 세포를 포함할 수 있다. 다른 실시형태에서, 세포 개체군은 종양 영속화 세포를 포함하는 이질성 종양추출물 또는 전체 종양 샘플들을 포함할 수 있다. 당업계의 숙련가들은 하기 실시예(예를 들면, 실시예 14 및 15)에 기재된 표준 생화학 기술들이 본원의 교시에 따라 종양원성 세포 또는 종양영속화 세포의 고갈화를 모니터링하고 정량하는데 사용될 수 있음을 알 것이다.
D. 빈화 (binning) 및 에피토프 결합
개시된 항-SEZ6 항체 조절물질이 선택된 표적 또는 이들의 단편에 의해 제공된 별도의 에피토프 또는 면역원성 결정인자와 회합하거나 결합할 것을 추가로 알 것이다. 특정 실시형태에서, 에피토프 또는 면역원성 결정인자는 아미노산, 당 측쇄, 포스포릴기 또는 설포닐기와 같은 분자들의 화학적으로 활성인 표면 배치를 포함하며, 특정 실시형태에서, 특정 3차원 구조적 특성들 및/또는 특정 전하 특성들을 가질 수 있다. 따라서, 본원에서 사용된 바와 같이, 용어 "에피토프"는 면역글로불린 또는 T-세포 수용체에 특이적으로 결합하거나, 그렇지 않으면 분자와 상호작용할 수 있는 단백질 결정인자를 포함한다. 특정 실시형태에서, 항체는 단백질 및/또는 거대분자의 복합 혼합물에서 이의 표적 항원을 우선적으로 인지할 때 항원과 특이적으로 결합(또는 면역특이적으로 결합 또는 반응)하는 것이라고 한다. 바람직한 실시형태에서, 항체는 평형 해리상수(KD)가 10-6M 이하 또는 10-7M 이하일 때, 보다 바람직하게는 평형 해리상수가 10-8M 이하 및 보다 더 바람직하게 10-9M 이하일 때 항원과 특이적으로 결합한다고 한다.
보다 직접적으로, 용어 "에피토프"는 일반적인 생화학적 의미로 사용되며, 특정 항체 조절물질에 의해 인지되고 특이적으로 결합될 수 있는 표적 항원의 일부를 가리킨다. 항원이 SEZ6과 같은 폴리펩타이드일 때, 에피토프는 인접한 아미노산 및 단백질의 삼차 폴딩(folding)에 의해 병치된 비인접한 아미노산 둘 다로부터 일반적으로 형성될 수 있다("입체구조적 에피토프"). 이러한 입체구조적 에피토프에서, 상호반응의 지점은 서로로부터 선형으로 단리된 단백질 상에 아미노산 잔기를 가로질러 일어난다. (때로는 "선형" 또는 "연속성" 에피토프라고도 하는) 인접한 아미노산으로부터 형성된 에피토프들은 전형적으로 단백질 변성시에 보유되는 반면, 삼차 폴딩에 의해 형성된 에피토프들은 전형적으로 단백질 변성시에 손실된다. 어느 경우에나, 항체 에피토프는 전형적으로 특별한 공간적인 구조내에 적어도 3개, 및 보다 일반적으로 적어도 5개 또는 8개 내지 10개의 아미노산을 포함한다.
이와 관련하여, 소정 실시형태들에서, 에피토프가 SEZ6 단백질의 하나 이상의 부위, 도메인 또는 모티프(예를 들면, 성숙 이소형 1의 아미노산 1-906)와 회합하거나, 또는 소재함을 이해할 수 있을 것이다. 본원에 더욱 상술된 바와 같이, SEZ6 단백질의 세포외 영역은 N-말단 도메인과 함께 다섯 개의 스시 도메인과 두 개의 CUB 도메인을 포함하는 일련의 일반적으로 인지된 도메인을 포함한다. 본원 개시의 목적을 위해, 용어 "도메인"은 이의 일반적으로 허용된 의미에 따라 사용될 것이며, 고유한 2차 구조 내용물을 나타내는 단백질내 인식가능한 또는 정의할 수 있는 보존된 구조적 실체를 가리킬 것이다. 많은 경우, 공통의 기능을 갖는 상동 도메인들은 일반적으로 서열 유사성을 나타내며, 여러 이질적인 단백질(예를 들면, 스시 도메인은 보고에 따르면 다수의 서로 다른 단백질들에서 발견됨)에서 발견될 것이다. 유사하게, 당업계에 인지된 용어 "모티프"는 이의 일반적인 의미에 따라 사용될 것이며, 전형적으로 10 내지 20개의 인접한 아미노산 잔기들인 단백질의 짧은 보존된 영역을 가리킬 것이다. 전체적으로 논의된 바와 같이, 선택된 실시형태들은 SEZ6의 특정 영역, 도메인 또는 모티프내 에피토프와 회합 또는 결합하는 조절물질을 포함한다.
어느 경우에나 항원 상의 목적하는 에피토프가 결정되면, 본 발명에 기재된 기술들을 사용하여 에피토프를 포함하는 펩타이드로 면역화함으로써, 그 에피토프에 대한 항체를 생성시킬 수 있다. 대안으로, 발견 과정 중에, 항체의 생성 및 특성평가가 특정 도메인 또는 모티프내에 위치된 바람직한 에피토프들에 대한 정보를 설명할 수 있다. 이러한 정보로부터, 동일한 에피토프에 대한 결합을 위해 항체를 경쟁적으로 선별할 수 있다. 이를 달성하기 위한 접근법은 서로 경쟁적으로 결합하는 항체, 즉 항원에 결합하기 위해 경쟁하는 항체를 발견하기 위한 경쟁 연구를 수행하는 것이다. 교차-경쟁에 기초하여 항체를 빈화하기 위한 고성능 방법은 제WO 03/48731호에 기재되어 있다. 이스트 상의 항원 단편 발현 또는 조절물질 경쟁을 포함하는 에피토프 맵핑 또는 빈화 또는 도메인 수준의 다른 방법은 하기 실시예 9 및 10에 개시되어 있다.
본원에서 사용된 바와 같이, 용어 "빈화"는 그들의 항원 결합 특성 및 경쟁에 기초하여 항체를 그룹화 또는 분류하는데 사용된 방법을 가리킨다. 이 기술들이 본 발명의 조절물질을 정의하고 범주화하는데 유용하지만, 빈은 에피토프와 항상 직접 서로 연관되어 있지 않으며, 에피토프 결합의 이러한 초기 결정들은 본원에 기술된 바와 같은 그 밖의 기술-인지된 방법론에 의해 추가로 개선 및 동정될 수 있다. 그러나, 하기 실시예에 설명 및 도시된 바와 같이, 각 빈에 대한 항체 조절물질의 경험적 할당은 개시된 조절물질의 치료적 잠재력의 지표가 될 수 있는 정보를 제공한다.
보다 구체적으로는, 당업계에 공지되고 하기 실시예에 개시된 방법을 사용함으로써, 선택된 표준 항체(또는 그의 단편)가 2차 시험 항체와 결합하기 위해 동일한 에피토프에 결합하는지 또는 교차 경쟁하는지의 여부를 측정할 수 있다. 한 실시형태에서, 표준 항체 조절물질은 포화 조건하에 SEZ6 항원과 회합되며, SEZ6에 결합할 수 있는 2차 또는 시험 항체 조절물질의 능력은 표준 면역화학 기술들을 사용하여 측정된다. 시험 항체가 기준의 항-SEZ6 항체와 동시에 SEZ6에 실질적으로 결합할 수 있다면, 2차 또는 시험 항체는 1차 또는 표준 항체와 다른 에피토프에 결합한다. 그러나, 시험 항체가 SEZ6에 실질적으로 동시에 결합할 수 없다면, 시험 항체는 동일한 에피토프, 오버랩핑 에피토프, 또는 1차 항체에 의해 결합된 에피토프에 (적어도 입체구조적으로) 매우 가까운 에피토프에 결합한다. 즉, 시험 항체는 항원 결합을 위해 경쟁하며, 표준 항체와 동일한 빈에 있다.
용어 "경쟁하다" 또는 "경쟁 항체"는 개시된 조절물질의 맥락에서 사용될 때, 시험 하에 시험 항체 또는 면역기능 단편이 공통의 항원에 대한 표준 항체의 특이적 결합을 방해 또는 억제하는 분석법에 의해 측정되는 바와 같이 항체들 사이의 경쟁을 의미한다. 전형적으로, 이러한 분석법은 비표지된 시험 면역글로불린 및 표지된 기준 면역글로불린 중 하나를 함유하는 고체 표면 또는 세포들에 결합된 정제 항원(예를 들면, SEZ6 또는 이의 도메인 또는 단편)의 사용을 포함한다. 경쟁적 억제는 시험 면역글로불린의 존재하에서 고체 표면 또는 세포들에 결합된 표지의 양을 결정함으로써 측정된다. 일반적으로, 시험 면역글로불린은 과량으로 존재하고/하거나 먼저 결합된다. 경쟁 분석법(경쟁 항체)에 의해 동정된 항체는 표준 항체와 동일한 에피토프에 결합하는 항체 및 발생할 입체 장해를 위해 표준 항체에 의해 결합된 에피토프에 충분히 근접한 인접 에피토프에 결합하는 항체를 항체를 포함한다. 경쟁적 결합을 측정하기 위한 방법에 관한 추가의 상세한 설명들은 본원의 실시예에 제공되어 있다. 보통, 경쟁하는 항체가 과량으로 존재할 때, 공통의 항원에 대한 표준 항체의 특이적 결합을 적어도 30%, 40%, 45%, 50%, 55%, 60%, 65%, 70% 또는 75%까지 억제할 것이다. 소정 경우들에서, 결합은 적어도 80%, 85%, 90%, 95%, 또는 97%, 또는 그 이상까지 억제된다.
역으로, 표준 항체가 결합될 때, 이것은 이후에 첨가된 시험 항체(즉, SEZ6 조절물질)의 결합을 바람직하게는 적어도 30%, 40%, 45%, 50%, 55%, 60%, 65%, 70% 또는 75%까지 억제할 것이다. 소정 경우들에서, 시험 항체의 결합은 적어도 80%, 85%, 90%, 95%, 또는 97%, 또는 그 이상까지 억제된다.
본 발명과 관련하여, 그리고 하기 실시예들 9 및 10에 제시된 바와 같이, SEZ6의 세포외 도메인은 본원에서 "빈 A" 내지 "빈 F" 및 빈 U라고 부르는 경쟁적 결합에 의해 적어도 7개의 빈들을 정의하는 것으로 (표면 플라스몬 공명 또는 바이오-레이어 간섭분석법을 통해) 결정될 수 있었다.
이런 양상에서, 그리고 당업계에 알려지고 하기 실시예에 설명된 바와 같이, 목적하는 빈화 또는 경쟁적 결합 데이터는 고체상 직접 또는 간접 방사면역분석법(RIA), 고체상 직접 또는 간접 효소 면역분석법(EIA 또는 ELISA), 샌드위치 경쟁분석법, Biacore™ 2000 시스템(즉, 표면 플라스몬 공명-GE Healthcare), ForteBio®분석기(즉, 바이오-레이어 간섭분석법-ForteBio, Inc.) 또는 유동 세포측정법을 사용하여 얻어질 수 있다. 용어 "표면 플라스몬 공명"은, 본원에서 사용된 바와 같이, 바이오센서 매트릭스내 단백질 농도 변화를 검출함으로써, 실시간 특이적 상호반응을 분석할 수 있는 광학 현상을 가리킨다. 용어 "바이오-레이어 간섭분석법"은 바이오센서 팁 상의 고정 단백질 층 및 내부 기준 층의 두 층으로부터 반사된 백색 광의 간섭 패턴을 분석하는 광학 분석 기술을 가리킨다. 바이오센서 팁에 결합된 분자의 수의 변화는 실시간 측정될 수 있는 간섭 패턴의 이동을 야기한다. 특히 바람직한 실시형태들에서, 분석(표면 플라스몬 공명, 바이오-레이어 간섭분석법 또는 유동 세포측정법이든)은 하기 실시예에 입증된 바와 같이 Biacore 또는 ForteBio 장비 또는 유동 세포측정기(예를 들면, FACSAria II)를 사용하여 수행된다.
개시된 SEZ6 항체 조절물질이 회합하거나 결합하는 에피토프를 추가로 특성평가하기 위해, 도메인-수준 에피토프 맵핑을 문헌[참조; Cochran et al. (J Immunol Methods. 287 (1-2):147-158 (2004) 참조로 본원에 인용됨)]에 의해 기술된 프로토콜의 변형을 사용하여 수행하였다. 간단히, 특정 아미노산 서열들을 포함하는 SEZ6의 각 도메인들을 이스트 표면 상에서 발현시키고, 유동 세포측정법을 통해 각 SEZ6 항체에 의한 결합을 측정하였다. 결과는 하기 실시예 10에 논의되어 있으며, 도 14a 및 도 14b에 도시되어 있다.
다른 적합한 에피토프 맵핑 기술들은 알라닌 스캐닝 돌연변이, 펩타이드 블롯(문헌 참조; Reineke (2004) Methods Mol Biol 248:443-63)(전부 본원에 참조로 인용됨), 또는 펩타이드 절단 분석법을 포함한다. 또한, 에피토프 적출, 에피토프 추출 및 항원의 화학적 변형과 같은 방법이 사용될 수 있다(문헌 참조; Tomer (2000) Protein Science 9: 487-496)(전부 본원에 참조로 인용된다). 다른 실시형태에서, 항원 구조-기반 항체 프로파일링(ASAP)이라고도 알려져 있는 변형-보조 프로파일링(MAP)은, 화학적으로 또는 효소적으로 변형된 항원 표면들에 대한 각 항체의 결합 프로파일의 유사성에 따라 동일한 항원에 대한 다수의 모노클로날 항체(mAbs)을 범주화하는 방법을 제공한다(U.S.P.N. 제2004/0101920호, 전부 본원에 참조로 인용된다). 각 범주는 다른 범주에 의해 나타낸 에피토프와 뚜렷하게 상이하거나 또는 부분적으로 오버랩핑된 고유한 에피토프를 반영할 수 있다. 이 기술은 특성평가가 유전적으로 구별되는 항체에서 집중될 수 있도록 유전적으로 동일한 항체를 급속하게 필터링할 수 있다. MAP가 본 발명의 hSEZ6 항체 조절물질을 다른 에피토프들을 결합하는 항체의 그룹들로 분류하는데 사용될 수 있음을 알 것이다.
고정 항원의 구조를 변경시키는데 유용한 제제는 단백질분해 효소(예를 들면, 트립신, 엔도프로테이나제 Glu-C, 엔도프로테이나제 Asp-N, 키모트립신 등)와 같은 효소들을 포함한다. 고정 항원의 구조를 변경시키는데 유용한 제제들은 또한 화학작용제, 예를 들면 숙신이미딜 에스테르 및 이들의 유도체, 1차 아민-함유 화합물, 하이드라진 및 카보하이드라진, 유리 아미노산 등일 수 있다.
항원 단백질은 바이오센서 칩 표면 또는 폴리스티렌 비드 상에서 고정될 수 있다. 후자는, 예를 들면, 멀티플렉스 LUMINEX™ 검출 분석법(Luminex Corp.)과 같은 분석법으로 처리될 수 있다. 100개 이하의 다른 종류의 비드들에 의해 멀티플렉스 분석을 취급할 수 있는 LUMINEX의 용량 때문에, LUMINEX는 다양하게 변형된 거의 무제한의 항원 표면을 제공하여, 바이오센서 분석 동안 항체 에피토프 프로파일링에서 개선된 해결을 야기한다.
E. 조절물질 결합 특성들
에피토프 특이성 외에, 개시된 항체는, 예를 들면, 결합 친화력과 같은 물리적 특성을 사용하여 특성평가될 수 있다. 이와 관련하여, 본 발명은 하나 이상의 SEZ6 이소형, 또는 범-항체의 경우, 하나 이상의 SEZ6 패밀리 구성원에 대한 높은 결합 친화력을 갖는 항체를 사용하는 것을 추가로 포함한다.
본원에서 사용된 용어 "KD"는 특정 항체-항원 상호반응의 해리상수를 나타내는 것으로 의도된다. 본 발명의 항체는 해리상수 KD (koff/kon)가 10-7M 이하일 때 이의 표적 항원에 면역특이적으로 결합한다고 한다. 항체는 KD가 5x10-9M 이하일 때 항원과 높은 친화력으로, 및 KD가 5x10-10M 이하일 때 더 높은 친화력으로 특이적으로 결합한다. 본 발명의 한 실시형태에서, 항체는 10-9M 이하의 KD 및 약 1x10-4/sec의 해리-속도를 갖는다. 본 발명의 한 실시형태에서, 해리-속도는 1x10-5/sec 미만이다. 본 발명의 다른 실시형태에서, 항체는 약 10-7M 내지 10-10M의 KD로 SEZ6에 결합할 것이며, 또 다른 실시형태에서, 2x10-10M 이하의 KD로 결합할 것이다. 본 발명의 또 다른 선택된 실시형태들은 10-2M 미만, 5x10-2M 미만, 10-3M 미만, 5x10-3M 미만, 10-4M 미만, 5x10-4M 미만, 10-5M 미만, 5x10-5M 미만, 10-6M 미만, 5x10-6M 미만, 10-7M 미만, 5x10-7M 미만, 10-8M 미만, 5x10-8M 미만, 10-9M 미만, 5x10-9M 미만, 10-10M 미만, 5x10-10M 미만, 10-11M 미만, 5x10-11M 미만, 10-12M 미만, 5x10-12M 미만, 10-13M 미만, 5x10-13M 미만, 10-14M 미만, 5x10-14M 미만, 10-15M 미만 또는 5x10-15M 미만의 해리 상수 또는 KD (koff/kon)를 갖는 항체를 포함한다.
특정 실시형태에서, SEZ6에 면역특이적으로 결합하는 본 발명의 항체는 적어도 105M-1s-1, 적어도 2x105M-1s-1, 적어도 5x105M-1s-1, 적어도 106M-1s-1, 적어도 5x106M-1s-1, 적어도 107M-1s-1, 적어도 5x107M-1s-1, 또는 적어도 108M-1s-1의 해리 속도 상수 또는 k on (또는 k a ) 속도 (SEZ6 (Ab) + 항원 (Ag)k on←Ab-Ag)를 갖는다.
다른 실시형태에서, SEZ6에 면역특이적으로 결합하는 본 발명의 항체는 10-1s-1 미만, 5x10-1s-1 미만, 10-2s-1 미만, 5x10-2s-1 미만, 10-3s-1 미만, 5x10-3s-1 미만, 10-4s-1 미만, 5x10-4s-1 미만, 10-5s-1 미만, 5x10-5s-1 미만, 10-6s-1 미만, 5x10-6s-1 미만, 10-7s-1 미만, 5x10-7s-1 미만, 10-8s-1 미만, 5x10-8s-1 미만, 10-9s-1 미만, 5x10-9s-1 미만 또는 10-10s-1 미만의 해리 속도 상수 또는 k off (또는 k d ) 속도 (SEZ6 (Ab) + 항원 (Ag)k off←Ab-Ag)를 갖는다.
본 발명의 다른 선택된 실시형태에서, 항-SEZ6 항체는 적어도 102M-1, 적어도 5x102M-1, 적어도 103M-1, 적어도 5x103M-1, 적어도 104M-1, 적어도 5x104M-1, 적어도 105M-1, 적어도 5x105M-1, 적어도 106M-1, 적어도 5x106M-1, 적어도 107M-1, 적어도 5x107M-1, 적어도 108M-1, 적어도 5x108M-1, 적어도 109M-1, 적어도 5x109M-1, 적어도 1010M-1, 적어도 5x1010M-1, 적어도 1011M-1, 적어도 5x1011M-1, 적어도 1012M-1, 적어도 5x1012M-1, 적어도 1013M-1, 적어도 5x1013M-1, 적어도 1014M-1, 적어도 5x1014M-1, 적어도 1015M-1 또는 적어도 5x1015M-1의 친화력 상수 또는 Ka (kon/koff)를 가질 것이다.
상기 조절물질 특성들 외에, 본 발명의 항체는, 예를 들면, 열 안정성(즉, 용융 온도; Tm) 및 등전점을 포함하는 추가의 물리적 특성들을 사용하여 추가로 특성평가될 수 있다(예를 들면, 문헌 참조; Bjellqvist et al., 1993, Electrophoresis 14:1023; Vermeer et al., 2000, Biophys. J. 78:394-404; Vermeer et al., 2000, Biophys. J. 79: 2150-2154, 이들 각각은 참조로 인용됨).
VIII. 접합 조절물질
A. 개요
일단 본 발명의 조절물질이 본원의 교시에 따라 생성 및/또는 제조 및 선택되면, 이들은 약제학적 활성 또는 진단학적 모이어티, 치료학적 모이어티 또는 생체적합성 변형제들과 연결되거나, 융합되거나, 접합되거나(예를 들면, 공유결합적으로 또는 비공유결합적으로) 또는 그렇지 않으면 회합될 수 있다. 본 발명의 조절물질(예를 들면, 항체)은 치료학적 모이어티에 직접적으로 또는 간접적으로 접합될 수 있다. 항체를 치료학적 모이어티 또는 다른 모이어티에 연결시키는 링커(링커는 아래에 보다 상세하게 기재된다)를 사용하지 않고서 이러한 항체가 이러한 모이어티에 회합, 연결 또는 융합될 때에 항체는 치료학적 모이어티 또는 기타의 모이어티, 예를 들면, 리포터에 "직접적으로 접합"된다. 항체가 이러한 모이어티에 항체를 연결시키는 링커를 사용하여 이들 모이어티에 회합, 연결 또는 융합될 때에 항체는 치료학적 모이어티 또는 기타의 모이어티, 예를 들면, 리포터에 "간접적으로 접합"된다. 본원에서 사용된 용어 "접합체" 또는 "조절물질 접합체" 또는 "항체 접합체"는 광범위하게 사용될 것이며, 회합 방법과 무관하게 개시된 조절물질과 회합된 생물학적으로 활성인 또는 검출가능한 분자 또는 약물을 의미할 것이다. 이러한 양상에서, 상기 접합체는, 개시된 조절물질에 더해, 펩타이드, 폴리펩타이드, 단백질, 생체내에서 활성제로 대사작용되는 프로드럭, 폴리머, 핵산 분자, 소분자, 결합제, 모방제, 합성 약물, 무기 분자, 유기 분자 및 방사성 동위원소를 포함할 수 있다고 이해될 것이다. 게다가, 상기 나타낸 바와 같이, 선택된 접합체는 조절물질과 공유결합적으로 또는 비공유결합적으로 회합되거나 연결되고, 적어도 부분적으로 접합을 실시하는데 사용되는 방법에 따라 다양한 화학양론적 몰 비율을 나타낼 수 있다.
본 발명의 특히 바람직한 양상은 증식성 장애의 진단 및/또는 치료에 사용될 수 있는 항체 조절물질 접합체 또는 항체-약물 접합체를 포함할 것이다. 문맥에 달리 명시되어 있지 않는 한, 용어 "항체-약물 접합체" 또는 "ADC" 또는 화학식 M-[L-D]n은 치료학적 모이어티와 진단학적 모이어티 둘 다를 포함하는 접합체를 포함하는 것으로 이해될 것이다. 이러한 실시형태에서, 항체-약물 접합체 화합물은 조절물질 또는 세포 결합 단위(본원에서는 CBA, M, 또는 Ab로 약칭함)로서 SEZ6 조절물질(일반적으로 항-SEZ6 항체), 치료학적(예를 들면, 항암제) 또는 진단학적 모이어티(D), 및 임의로 약물 및 항원 결합 제제를 결합시키는 링커(L)를 포함할 것이다. 본 발명내용의 목적을 위해, "n"은 1 내지 20의 정수를 의미한다. 바람직한 실시예에서, 조절물질은 상기 기재된 바와 같이 중쇄 가변 부위 및 경쇄 가변 부위로부터 적어도 하나의 CDR을 포함하는 SEZ6 mAb이다.
당업계의 숙련가들은 결합제에 대한 치료학적 또는 진단학적 모이어티 및/또는 링커의 부착 또는 회합을 위해 많은 다른 반응들이 이용 가능하다는 것을 알 것이다. 선택된 실시형태에서, 이것은 결합제의 아미노산 잔기, 예를 들면 라이신의 아민 그룹, 글루탐산 및 아스파르트산의 유리 카복실산 그룹, 시스테인의 설프하이드릴 그룹 및 방향족 아미노산의 여러 잔기들을 포함하는 항체 분자의 반응에 의해 달성될 수 있다. 공유 부착의 가장 일반적으로 사용되는 비-특이적 방법 중 하나는 항체의 아미노(또는 카복시) 그룹에 카복시(또는 아미노) 그룹을 연결시키기 위한 카보디아미드 반응이다. 또한, 디알데히드 또는 이미도에스테르와 같은 이중기능(bifunctional) 작용제들은 항체 분자의 아미노 그룹에 화합물의 아미노 그룹을 연결하기 위해 사용되어 왔다. 또한, 결합제에 약물을 부착하기 위해, 쉬프(Schiff) 염기 반응이 이용가능하다. 이 방법은 결합제와 반응되는 알데히드를 형성시키는, 글리콜 또는 하이드록시 그룹을 함유하는 약물의 과요오드산염 산화반응을 포함한다. 부착은 결합제의 아미노 그룹에 의한 쉬프 염기의 형성을 통해 일어난다. 이소티오시아네이트 및 아즐락톤이 결합제에 약물을 공유결합하기 위한 커플링제로서 사용될 수도 있다.
다른 실시형태에서, 본 발명의 개시된 조절물질은 선택된 특징들을 부여하는 단백질, 폴리펩타이드 또는 펩타이드(예를 들면, 바이오독소, 바이오마커, 정제 태그 등)와 접합 또는 회합될 수 있다. 소정 바람직한 실시형태에서, 본 발명은 이종 단백질 또는 펩타이드에 재조합에 의해 융합되거나 화학적으로 접합된 (공유 및 비공유 접합 둘 다를 포함함) 조절물질 또는 이의 단편들을 포함하며, 여기서 상기 단백질 또는 펩타이드는 적어도 10, 적어도 20, 적어도 30, 적어도 40, 적어도 50, 적어도 60, 적어도 70, 적어도 80, 적어도 90 또는 적어도 100개의 아미노산을 포함한다. 작제물은 반드시 직접 연결될 필요는 없지만, 아미노산 링커 서열을 통해 발생할 수 있다. 예를 들면, 항체는 이중특이성 작제물을 제공하기 위해 특정 세포 표면 수용체에 대하여 특이적인 항체에 본 발명의 조절물질을 융합 또는 접합함으로써 시험관내 또는 생체내에서 SEZ6을 발현하는 특정 세포 타입에 이종 폴리펩타이드를 표적화하는데 사용될 수 있다. 게다가, 이종 폴리펩타이드에 융합 또는 접합된 조절물질은 시험관내 면역분석법에 사용될 수도 있으며, 당업계에 알려져 있는 바와 같은 정제 방법(예를 들면, his-태그들)과 특히 호환될 수 있다. 예를 들면, 국제공보 제WO 93/21232호; 유럽특허 제EP 439,095호; 문헌[Naramura et al., 1994, Immunol. Lett. 39:91-99]; 미국특허 제5,474,981호; 문헌[Gillies et al., 1992, PNAS 89:1428-1432; 및 Fell et al., 1991, J. Immunol. 146:2446-2452]을 참조한다.
B. 링커
상기한 펩타이드 링커들 또는 스페이서들 외에, 다수의 다른 변이체들 또는 링커들 종류가 개시된 조절물질을 약제학적 활성 또는 진단학적 모이어티 또는 생체적합성 변형제와 회합하는데 사용될 수 있음을 이해할 수 있을 것이다. 소정 실시형태에서, 링커의 절단이 세포내 환경에서 항체로부터 약물 단위를 방출시키도록 링커는 세포내 조건하에서 절단될 수 있다. 또 다른 실시형태에서, 링커 단위는 절단될 수 없으며, 약물은, 예를 들면, 항체 분해에 의해 방출된다.
ADC의 링커들은 바람직하게 세포외적으로 안정하며, ADC 분자들의 응집을 막고, 수성 매질 및 모노머 상태에서 ADC가 자유롭게 가용성이도록 유지해준다. 세포로 수송 또는 전달하기 전에, 항체-약물 접합체(ADC)는 바람직하게는 안정하며, 온전하게 남아 있으며, 즉 항체는 약물 물질에 결합된 상태로 있다. 링커들은 표적 세포 외부에서 안정하며, 세포내에서 일부 유효 비율로 절단될 수 있다. 효과적인 링커는 (i) 항체의 특이 결합 특성들을 유지하며; (ii) 접합체 또는 약물 모이어티를 세포내로 전달시키고; (iii) 접합체가 이의 표적 부위로 전달 또는 수송될 때까지 안정하고 온전하며, 즉 절단되지 않으며; (iv) PBD 약물 모이어티의 세포독성, 세포-살해 효과 또는 세포분열억제 효과를 유지할 것이다. ADC의 안정성은 질량분석법, HPLC 및 분리/분석 기술 LC/MS와 같은 표준 분석기술들에 의해 측정될 수 있다. 항체 및 약물 모이어티의 공유결합은 링커가 2개의 반응성 작용기, 즉 반응성 의미에서 2가를 갖는 것을 필요로 한다. 펩타이드, 핵산, 약물, 독소, 항체, 합텐 및 리포터 그룹과 같은 2개 이상의 작용성 또는 생물학적 활성 모니어티들을 결합시키는데 유용한 2가 링커 시약들은 공지되어 있으며, 방법은 그 결과 생기는 접합체들을 설명하고 있다(문헌 참조; Hermanson, G.T. (1996) Bioconjugate Techniques; Academic Press: New York, p 234-242).
이를 위하여, 본 발명의 소정 실시형태는 세포내 환경(예를 들면, 리소좀 또는 엔도솜 또는 포낭내)에 존재하는 절단제(cleaving agent)에 의해 절단가능한 링커를 사용하는 것을 포함한다. 링커는 리소좀 또는 엔도솜 프로테아제를 포함하지만 이에 한정되지 않는 세포내 펩티다제 또는 프로테아제 효소에 의해 절단되는, 예를 들면, 펩타이딜 링커일 수 있다. 소정 실시형태에서, 펩타이딜 링커는 적어도 2개의 아미노산 또는 적어도 3개의 아미노산 길이이다. 절단제는 카텝신 B 및 D 및 플라스민을 포함할 수 있으며, 이들 각각은 디펩타이드 약물 유도체들을 가수분해시켜 표적 세포들 안으로 활성 약물을 방출시키는 것으로 알려져 있다. 카텝신-B는 암조직에서 많이 발현되는 것으로 밝혀져 있으므로, 티올-의존성 프로테아제 카텝신-B에 의해 절단가능한 예시적인 펩타이딜 링커는 Phe-Leu를 포함하는 펩타이드이다. 상기 링커들의 다른 예가, 예를 들면, U.S.P.N. 제6,214,345호 및 U.S.P.N. 제2012/0078028호에 기재되어 있으며, 이들 각각은 전부 참조로 본원에 인용되어 있다. 특히 바람직한 실시형태에서, 세포내 프로테아제에 의해 절단가능한 펩타이딜 링커는 U.S.P.N. 제6,214,345호에 기재된 바와 같은 Val-Cit 링커, Ala-Val 링커 또는 Phe-Lys 링커이다. 치료제의 세포내 단백질분해 방출을 사용하는 것의 한가지 이점은 접합될 때 치료제가 일반적으로 약독화되고 접합체의 혈청 안정성이 전형적으로 높다는 점이다.
다른 실시형태에서, 절단가능한 링커는 pH-민감성이며, 즉 특정 pH 값에서 가수분해에 대하여 민감하다. 전형적으로, pH-민감성 링커는 산성 조건하에 가수분해할 수 있다. 예를 들면, 리소좀에서 가수분해할 수 있는 산-불안정한 링커(예를 들면, 하이드라존, 옥심, 세미카바존, 티오세미카바존, 시스-아코니트산 아미드, 오르토에스테르, 아세탈, 케탈 등)가 사용될 수 있다(예를 들면, U.S.P.N. 제5,122,368호; 제5,824,805호; 제5,622,929호 참조). 이러한 링커들은 혈액내 조건들과 같은 중성의 pH 조건하에서 비교적 안정하지만, 리소좀의 pH와 비슷한 pH 5.5 또는 5.0 이하에서는 불안정하다.
또 다른 실시형태에서, 링커는 환원 조건하에서 절단가능하다(예를 들면, 디설파이드 링커). 예를 들면, SATA(N-숙신이미딜-S-아세틸티오아세테이트), SPDP(N-숙신이미딜-3-(2-피리딜디티오)프로피오네이트), SPDB(N-숙신이미딜-3-(2-피리딜디티오)부티레이트) 및 SMPT(N-숙신이미딜-옥시카보닐-알파-메틸-알파-(2-피리딜-디티오)톨루엔)를 사용하여 형성될 수 있는 링커들을 포함하여, 다양한 디설파이드 링커들이 당업계에 공지되어 있다. 또 다른 특정 실시형태에서, 링커는 말로네이트 링커(문헌 참조; Johnson et al., 1995, Anticancer Res. 15:1387-93), 말레이미도벤조일 링커(문헌 참조; Lau et al., 1995, Bioorg-Med-Chem. 3(10):1299-1304), 또는 3'-N-아미드 유사체(문헌 참조; Lau et al., 1995, Bioorg-Med-Chem. 3(10):1305-12)이다. 또 다른 실시형태에서, 링커 단위는 절단될 수 없으며, 항체 분해에 의해 약물이 방출된다. (모든 목적들을 위해, 전부 참조로 본원에 인용되어 있는 미국 공보 제2005/0238649호 참조).
보다 특히, 바람직한 실시형태에서(전부 참조로 본원에 인용되어 있는 U.S.P.N. 제2011/0256157호에 개시되어 있음), 호환성 링커는 하기를 포함할 것이다:

여기서, 별표는 세포독성제에 대한 부착점을 나타내고, CBA는 세포 결합제/조절물질이며, L1은 링커이고, A는 세포 결합제에 L1을 연결하는 연결 그룹이며, L2는 공유결합이거나, -OC(=O)-와 함께 자기-희생 링커를 형성하고, L1 또는 L2는 절단가능한 링커이다.
L1은 바람직하게는 절단가능한 링커이며, 절단을 위한 링커의 활성화를 위한 촉발제(trigger)로서 언급될 수 있다.
L1 및 L2의 성질은, 존재하는 경우, 매우 다양할 수 있다. 상기 그룹들은 이들의 절단 특성들을 기준으로 선택되며, 이것은 접합체가 전달되는 부위에서의 조건에 의해 지시될 수 있다. pH의 변화(예를 들면, 산 또는 염기 불안정), 온도 또는 조사(예를 들면, 광불안정)에 의해 절단가능한 링커들도 또한 사용될 수 있지만, 효소의 작용에 의해 절단되는 상기 링커들이 바람직하다. 환원 또는 산화 조건하에 절단가능한 링커들이 또한 본 발명에서 사용될 수 있다.
L1은 아미노산의 인접한 서열을 포함할 수 있다. 아미노산 서열은 효소 절단을 위한 표적 기질일 수 있으며, 이에 의해, N10 위치로부터 R10을 방출시킨다.
한 실시형태에서, L1은 효소의 작용에 의해 절단가능하다. 한 실시형태에서, 효소는 에스테라제 또는 펩티다제이다.
한 실시형태에서, L2가 존재하며, -C(=O)O-와 함께 자기-희생 링커를 형성한다. 한 실시형태에서, L2는 효소활성을 위한 기질이며, 이에 의해 N10 위치로부터 R10을 방출시킨다.
한 실시형태에서, L1은 효소 작용에 의해 절단가능하며, L2가 존재하고, 효소가 L1과 L2 사이의 결합을 절단한다.
L1 및 L2는, 존재하는 경우, 하기로부터 선택된 결합에 의해 연결될 수 있다:
-C(=O)NH-, -C(=O)O-, -NHC(=O)-, -OC(=O)-, -OC(=O)O-, -NHC(=O)O-, -OC(=O)NH-, 및 -NHC(=O)NH-.
L2에 연결하는 L1의 아미노 그룹은 아미노산의 N-말단일 수 있거나, 아미노산 측쇄, 예를 들면, 라이신 아미노산 측쇄의 아미노 그룹으로부터 유도될 수 있다.
L2에 연결하는 L1의 카복실 그룹은 아미노산의 C-말단일 수 있거나, 아미노산 측쇄, 예를 들면, 글루탐산 아미노산 측쇄의 카복실 그룹으로부터 유도될 수 있다.
L2에 연결하는 L1의 하이드록실 그룹은 아미노산 측쇄, 예를 들면, 세린 아미노산 측쇄의 하이드록실 그룹으로부터 유도될 수 있다.
용어 "아미노산 측쇄"은 (i) 천연 발생 아미노산, 예를 들면, 알라닌, 아르기닌, 아스파라긴, 아스파르트산, 시스테인, 글루타민, 글루탐산, 글라이신, 히스티딘, 이소루신, 루신, 라이신, 메티오닌, 페닐알라닌, 프롤린, 세린, 트레오닌, 트립토판, 티로신 및 발린; (ii) 마이너 아미노산, 예를 들면, 오르니틴 및 시트룰린; (iii) 천연 발생 아미노산의 비천연 아미노산, 베타-아미노산, 합성 유사체 및 유도체들; 및 (iv) 이들의 모든 거울상이성질체, 부분입체이성질체, 이성질체 풍부한, 동위원소 표지된(예를 들면, 2H, 3H, 14C, 15N), 보호된 형태 및 라세믹 혼합물에서 발견되는 상기 그룹들을 포함한다.
한 실시형태에서, -C(=O)O- 및 L2는 함께 하기의 그룹을 형성한다:

여기서, 별표는 약물에 대한 부착점 또는 세포독성제 위치를 나타내고, 물결선은 링커 L1에 대한 부착점을 나타내며, Y는 -N(H)-, -O-, -C(=O)N(H)- 또는 -C(=O)O-이고, n은 0 내지 3이다. 페닐렌 환은 본원에 기재된 바와 같은 1개, 2개 또는 3개의 치환체로 임의로 치환된다. 한 실시형태에서, 페닐렌 그룹은 할로, NO2, R 또는 OR로 임의로 치환된다.
한 실시형태에서, Y는 NH이다.
한 실시형태에서, n은 0 또는 1이다. 바람직하게는, n은 0이다.
Y가 NH이고, n이 0인 경우, 자기-희생 링커는 p-아미노벤질카보닐 링커(PABC)로서 언급될 수 있다.
자기-희생 링커는 원격 부위가 활성화될 때, 보호된 화합물을 방출시킬 것이며, 하기에 나타낸 선을 따라 진행한다(n=0인 경우):

여기서, L*은 링커의 남은 부위의 활성화 형태이다. 상기 그룹들은 보호된 화합물로부터 활성화 부위를 분리하는 이점을 가진다. 위에 기재된 바와 같이, 페닐렌 그룹은 임의로 치환될 수 있다.
본원에 기재된 한 실시형태에서, 그룹 L*은 본원에 기재된 바와 같은 링커 L1이며, 이는 디펩타이드 그룹을 포함할 수 있다.
다른 실시형태에서, -C(=O)O- 및 L2는 함께 하기로부터 선택되는 그룹을 형성한다:

여기서, 별표, 물결선, Y 및 n은 상기 정의된 바와 같다. 각 페닐렌 환은 본원에 기재된 바와 같이, 1개, 2개 또는 3개의 치환체로 임의로 치환된다. 한 실시형태에서, Y 치환체를 갖는 페닐렌 환은 임의로 치환되며, Y 치환체를 갖지 않는 페닐렌 환은 치환되지 않는다. 한 실시형태에서, Y 치환체를 갖는 페닐렌 환은 치환되지 않으며, Y 치환체를 갖지 않는 페닐렌 환은 임의로 치환된다.
다른 실시형태에서, -C(=O)O- 및 L2는 함께 하기로부터 선택된 그룹을 형성한다:

여기서, 별표, 물결선, Y 및 n은 상기 정의된 바와 같고, E는 O, S 또는 NR이며, D는 N, CH 또는 CR이고, F는 N, CH 또는 CR이다.
한 실시형태에서, D는 N이다.
한 실시형태에서, D는 CH이다.
한 실시형태에서, E는 O 또는 S이다.
한 실시형태에서, F는 CH이다.
바람직한 실시형태에서, 링커는 카텝신 불안정성 링커이다.
한 실시형태에서, L1은 디펩타이드를 포함한다. 디펩타이드는 -NH-X1-X2-CO-로 나타내어질 수 있으며, 여기서, -NH- 및 -CO-는 아미노산 그룹 X1 및 X2의 N-말단 및 C-말단을 각각 나타낸다. 디펩타이드내 아미노산은 천연 아미노산의 조합일 수 있다. 링커가 카텝신 불안정성 링커인 경우, 디펩타이드는 카텝신-매개 절단을 위한 작용 부위일 수 있다.
추가로, 카복실 또는 아미노 측쇄 작용기, 예를 들면 Glu 및 Lys를 각각 갖는 상기 아미노산 그룹에 대하여, CO 및 NH가 그 측쇄 작용기를 나타낼 수 있다.
한 실시형태에서, 디펩타이드내 그룹 -X1-X2-, -NH-X1-X2-CO-는 하기로부터 선택된다:
-Phe-Lys-, -Val-Ala-, -Val-Lys-, -Ala-Lys-, -Val-Cit-, -Phe-Cit-, -Leu-Cit-, -Ile-Cit-, -Phe-Arg- 및 -Trp-Cit-, 여기에서 Cit는 시트룰린이다.
바람직하게는, 디펩타이드내 그룹 -X1-X2-, -NH-X1-X2-CO-는 하기로부터 선택된다:
-Phe-Lys-, -Val-Ala-, -Val-Lys-, -Ala-Lys-, 및 -Val-Cit-.
가장 바람직하게는, 디펩타이드내 그룹 -X1-X2-, -NH-X1-X2-CO-는 -Phe-Lys- 또는 -Val-Ala-이다.
다른 디펩타이드 조합들도 사용될 수 있으며, 문헌[참조; Dubowchik et al., Bioconjugate Chemistry, 2002, 13,855-869]에 기재된 것들을 포함하며, 이는 전부 참조로 본원에 인용되어 있다.
한 실시형태에서, 경우에 따라, 아미노산 측쇄가 유도체화된다. 예를 들면, 아미노산 측쇄의 아미노 그룹 또는 카복실 그룹이 유도체화될 수 있다.
한 실시형태에서, 라이신과 같은 측쇄 아미노산의 아미노 그룹 NH2는 NHR 및 NRR'로 이루어진 그룹으로부터 선택되는 유도체화된 형태이다.
한 실시형태에서, 아스파르트산과 같은 측쇄 아미노산의 카복시 그룹 COOH는 COOR, CONH2, CONHR 및 CONRR'로 이루어진 그룹으로부터 선택되는 유도체화된 형태이다.
한 실시형태에서, 아미노산 측쇄는 경우에 따라 화학적으로 보호된다. 측쇄 보호 그룹은 그룹 RL와 관련되어 이하에 논의된 바와 같은 그룹일 수 있다. 보호된 아미노산 서열은 효소에 의해 절단가능하다. 예를 들면, Boc 측쇄-보호된 Lys 잔기를 포함하는 디펩타이드 서열이 카텝신에 의해 절단가능하다고 인정된다.
아미노산의 측쇄를 위한 보호 그룹들은 당업계에 잘 알려져 있으며, Novabiochem 카탈로그에 설명되어 있다. 추가의 보호 그룹 전략들은 문헌[참조; Protective Groups in Organic Synthesis, Greene and Wuts]에 제시되어 있다.
가능한 측쇄 보호 그룹들이 반응성 측쇄 작용기를 갖는 상기 아미노산에 대하여 하기에 나타나 있다:
Arg: Z, Mtr, Tos;
Asn: Trt, Xan;
Asp: Bzl, t-Bu;
Cys: Acm, Bzl, Bzl-OMe, Bzl-Me, Trt;
Glu: Bzl, t-Bu;
Gln: Trt, Xan;
His: Boc, Dnp, Tos, Trt;
Lys: Boc, Z-Cl, Fmoc, Z, Alloc;
Ser: Bzl, TBDMS, TBDPS;
Thr: Bz;
Trp: Boc;
Tyr: Bzl, Z, Z-Br.
한 실시형태에서, 측쇄 보호는, 존재하는 경우, 캡핑 그룹으로서 또는 캡핑 그룹의 일부로서 제공되는 그룹에 대하여 직교로 선택된다. 따라서, 측쇄 보호 그룹의 제거가 캡핑 그룹, 또는 캡핑 그룹의 일부인 보호 그룹 작용기를 제거하지는 않는다.
본 발명의 다른 실시형태에서, 선택된 아미노산은 반응성 측쇄 작용기를 갖지 않는 것들이다. 예를 들면, 아미노산은 Ala, Gly, Ile, Leu, Met, Phe, Pro, 및 Val로부터 선택될 수 있다.
한 실시형태에서, 디펩타이드는 자기-희생 링커와 조합하여 사용된다. 자기-희생 링커는 -X2-에 연결될 수 있다.
자기-희생 링커가 존재하는 경우, -X2-는 자기-희생 링커에 직접 연결된다. 바람직하게는, 그룹 -X2-CO-는 Y에 연결되며, 여기서 Y는 NH이며, 이에 의해 rfnq -X2-CO-NH-를 형성한다.
-NH-X1-은 A에 직접 연결된다. A는 작용기 -CO-를 포함함으로써, -X1-과 아미드 결합을 형성할 수 있다.
한 실시형태에서, L1 및 L2는 -OC(=O)-와 함께, 그룹 NH-X1-X2-CO-PABC-를 포함한다. PABC 그룹은 세포독성제에 직접 연결된다. 바람직하게는, 자기-희생 링커 및 디펩타이드는 함께 그룹 -NH-Phe-Lys-CO-NH-PABC-를 형성하며, 이는 하기에 도시되어 있다:

여기서, 별표는 선택된 세포독성 모이어티에 대한 부착점을 나타내고, 물결선은 링커 L1의 나머지 부분에 대한 부착점 또는 A에 대한 부착점을 나타낸다. 바람직하게는, 물결선은 A에 대한 부착점을 나타낸다. Lys 아미노산의 측쇄는, 예를 들면, 상기 기재된 바와 같이, Boc, Fmoc 또는 Alloc로 보호될 수 있다.
대안으로, 자기-희생 링커 및 디펩타이드는 함께 그룹 -NH-Val-Ala-CO-NH-PABC-를 형성하며, 이는 하기에 도시되어 있다:

여기서, 별표 및 물결선은 상기 정의된 바와 같다.
대안으로, 자기-희생 링커 및 디펩타이드는 함께 그룹 -NH-Val-Cit-CO-NH-PABC-를 형성하며, 이는 하기에 도시되어 있다:

여기서, 별표 및 물결선은 상기 정의된 바와 같다.
본 발명의 소정 실시형태에서, 약물 모이어티가 비보호된 이민 결합을 함유한다면, 예를 들면 모이어티 B가 존재한다면, 링커는 유리 아미노(H2N-) 그룹을 함유하지 않는 것이 바람직할 수 있다. 따라서, 링커가 구조 -A-L1-L2-를 가진다면, 이는 유리 아미노 그룹을 함유하지 않는 것이 바람직하다. 이러한 바람직한 경우는 링커가, 예를 들면, L1로서 디펩타이드를 함유할 때에 특히 관련되며; 이러한 실시형태에서, 2개의 아미노산 중 하나는 라이신으로부터 선택되지 않는 것이 바람직하다.
이론에 구애받지 않으면서, 약물 모이어티내 비보호된 이민 결합과 링커내 유리 아미노 그룹의 조합은 약물-링커 모이어티의 다이머화를 일으킬 수 있으며, 이것이 상기 항체에 대한 약물-링커 모이어티의 접합을 방해할 수 있다. 강산(예를 들면, TFA)이 유리 아미노 그룹을 탈보호하는데 사용된 경우와 같이, 유리 아미노 그룹이 암모늄 이온(H3N+-)으로서 존재하는 경우에, 상기 그룹들의 교차결합 반응이 촉진될 수 있다.
한 실시형태에서, A는 공유결합이다. 따라서, L1 및 세포 결합제는 직접 연결된다. 예를 들면, L1이 인접한 아미노산 서열을 포함하는 경우, 서열의 N-말단은 세포 결합제에 직접 연결될 수 있다.
따라서, A가 공유결합인 경우, 세포 결합제와 L1 사이의 연결은 하기로부터 선택될 수 있다:
-C(=O)NH-, -C(=O)O-, -NHC(=O)-, -OC(=O)-, -OC(=O)O-, -NHC(=O)O-, -OC(=O)NH-, -NHC(=O)NH-, -C(=O)NHC(=O)-, -S-, -S-S-, -CH2C(=O)-, 및 =N-NH-.
SEZ6 조절물질에 연결되는 L1의 아미노 그룹은 아미노산의 N-말단일 수 있거나, 아미노산 측쇄, 예를 들면 라이신 아미노산 측쇄의 아미노 그룹으로부터 유도될 수 있다.
조절물질에 연결되는 L1의 카복실 그룹은 아미노산의 C-말단일 수 있거나, 아미노산 측쇄, 예를 들면 글루탐산 아미노산 측쇄의 카복실 그룹으로부터 유도될 수 있다.
세포 결합제에 연결되는 L1의 하이드록실 그룹은 아미노산 측쇄, 예를 들면 세린 아미노산 측쇄의 하이드록실 그룹으로부터 유도될 수 있다.
조절물질 제제에 연결되는 L1의 티올 그룹은 아미노산 측쇄, 예를 들면, 세린 아미노산 측쇄의 티올 그룹으로부터 유도될 수 있다.
L1의 아미노 그룹, 카복실 그룹, 하이드록실 그룹 및 티올 그룹과 관련된 상기 코멘트들은 세포 결합제에도 적용된다.
한 실시형태에서, L2는 -OC(=O)-와 함께 하기를 나타낸다:

여기서, 별표는 N10 위치에 대한 부착점을 나타내고, 물결선은 L1에 대한 부착점을 나타내며, n은 0 내지 3이고, Y는 공유결합 또는 작용기이며, E는, 예를 들면, 효소 작용 또는 빛에 의해 활성가능한 그룹으로서 자기-희생 단위를 생성한다. 페닐렌 환은 본원에 기재된 바와 같이, 1개, 2개 또는 3개의 치환체로 임의로 추가 치환된다. 한 실시형태에서, 페닐렌 그룹은 할로, NO2, R 또는 OR로 임의로 추가 치환된다. 바람직하게는, n은 0 또는 1이고, 가장 바람직하게는 0이다.
E는, 예를 들면, 빛 또는 효소의 작용에 의해 그룹이 활성화되기 쉽도록 선택된다. E는 -NO2 또는 글루코론산일 수 있다. 전자는 니트로리덕타제의 작용에 민감할 수 있으며, 후자는 β-글루코로니다제의 작용에 민감할 수 있다.
이러한 실시형태에서, 자기-희생 링커는 E가 활성화될 때 보호 화합물을 방출시킬 것이며, 하기 도시된 선을 따라 진행한다(n=0인 경우):

여기서, 별표는 N10 위치에 대한 부착점을 나타내고, E*는 E의 활성화 형태이며, Y는 상기 기재된 바와 같다. 이러한 그룹들은 보호된 화합물로부터 활성화 부위를 분리시키는 이점을 가진다. 상기 기재된 바와 같이, 페닐렌 그룹은 임의로 추가 치환될 수 있다.
그룹 Y는 L1에 대한 공유결합일 수 있다.
그룹 Y는 하기로부터 선택되는 작용기일 수 있다:
-C(=O)-, -NH-, -O-, -C(=O)NH-, -C(=O)O-, -NHC(=O)-, -OC(=O)-, -OC(=O)O-, -NHC(=O)O-, -OC(=O)NH-, -NHC(=O)NH-, -NHC(=O)NH, -C(=O)NHC(=O)-, 및 -S-.
L1이 디펩타이드인 경우, Y는 -NH- 또는 -C(=O)-이며, 이에 의해 L1 및 Y 사이의 아미드 결합을 형성하는 것이 바람직하다. 이러한 실시형태에서, 디펩타이드 서열은 효소 활성을 위한 기질일 필요가 없다.
다른 실시형태에서, A는 스페이서 그룹이다. 따라서, L1 및 세포 결합제는 간접적으로 연결된다.
L1 및 A는 하기로부터 선택되는 결합에 의해 연결될 수 있다:
-C(=O)NH-, -C(=O)O-, -NHC(=O)-, -OC(=O)-, -OC(=O)O-, -NHC(=O)O-, -OC(=O)NH-, 및 -NHC(=O)NH-.
바람직하게는, 링커는 조절물질 상의 친핵성 작용기와 반응하기 위한 친전자성 작용기를 함유한다. 항체 상의 친핵성 그룹은 (i) N-말단 아민 그룹, (ii) 측쇄 아민 그룹, 예를 들면 라이신, (iii) 측쇄 티올 그룹, 예를 들면 시스테인, 및 (iv) 당 하이드록실 또는 아미노 그룹을 포함하지만, 이에 제한되지 않으며, 이 경우 항체는 글리코실화된다. 아민, 티올, 및 하이드록실 그룹은 친핵성이며, (i) 말레이미드 그룹, (ii) 활성화 디설파이드, (iii) 활성 에스테르, 예를 들면 NHS(N-하이드록시숙신이미드) 에스테르, HOBt (N-하이드록시벤조트리아졸) 에스테르, 할로포르메이트 및 산 할로겐화물; (iv) 알킬 및 벤질 할로겐화물, 예를 들면 할로아세트아미드; 및 (v) 알데히드, 케톤, 카복실 및 하기 예시된 것들 중 일부를 포함하는 링커 모이어티 및 링커 제제들 상의 친전자성 그룹과 공유결합을 형성하기 위해 반응할 수 있다:

특정 항체는 환원성 쇄간 디설파이드, 즉 시스테인 브릿지를 가진다. 항체는 DTT(디티오트레이톨)와 같은 환원제로 처리함으로써 링커 제제와의 접합을 위해 반응성이 될 수 있다. 따라서, 각 시스테인 브릿지는 이론적으로 2개의 반응성 티올 친핵체를 형성할 것이다. 추가의 친핵성 기들은 라이신과 2-이미노티올란(트라우트 제제(Traut's reagent))과의 반응을 통해 항체에 도입될 수 있으며, 그 결과 아민을 티올로 전환시킬 수 있다. 반응성 티올 그룹은 1개, 2개, 3개, 4개 또는 그 이상의 시스테인 잔기들을 도입함으로써 (예를 들면, 하나 이상의 비-천연 시스테인 아미노산 잔기를 포함하는 돌연변이 항체를 제조함으로써), 항체(또는 이의 단편)로 도입될 수 있다. 미국특허 제7521541호는 반응성 시스테인 아미노산의 도입에 의해 항체를 조작처리하는 것을 교시하고 있다.
소정 실시형태에서, 링커는 항체 상에 존재하는 친전자성 그룹과 반응성인 반응성 친핵성 그룹을 가진다. 항체 상의 유용한 친전자성 그룹은 알데히드 및 케톤 카보닐 그룹을 포함하지만, 이에 제한되지 않는다. 링커의 친핵성 그룹의 헤테로원자는 항체 상의 친전자성 그룹과 반응할 수 있으며, 항체 단위에 대하여 공유결합을 형성할 수 있다. 링커 상의 유용한 친핵성 그룹은 하이드라지드, 옥심, 아미노, 하이드록실, 하이드라진, 티오세미카르바존, 하이드라진 카복실레이트 및 아릴하이드라지드를 포함하지만, 이에 제한되지 않는다. 항체 상의 친전자성 그룹은 링커에 대하여 부착을 위한 편리한 부위를 제공한다.
한 실시형태에서, 그룹 A는 다음과 같다:

여기서, 별표는 L1에 대한 부착점을 나타내고, 물결선은 세포 결합제에 대한 부착점을 나타내며, n은 0 내지 6이다. 한 실시형태에서, n은 5이다.
한 실시형태에서, 그룹 A는 다음과 같다:

여기서, 별표는 L1에 대한 부착점을 나타내고, 물결선은 세포 결합제에 대한 부착점을 나타내며, n은 0 내지 6이다. 한 실시형태에서, n은 5이다.
한 실시형태에서, 그룹 A는 다음과 같다:

여기서, 별표는 L1에 대한 부착점을 나타내고, 물결선은 세포 결합제에 대한 부착점을 나타내며, n은 0 또는 1이고, m은 0 내지 30이다. 바람직한 실시형태에서, n은 1이며, m은 0 내지 10, 1 내지 8, 바람직하게는 4 내지 8, 및 가장 바람직하게는 4 또는 8이다. 다른 실시형태에서, m은 10 내지 30, 바람직하게는 20 내지 30이다. 대안으로, m은 0 내지 50이다. 이러한 실시형태에서, m은 바람직하게는 10 내지 40이며, n은 1이다.
한 실시형태에서, 그룹 A는 다음과 같다:

여기서, 별표는 L1에 대한 부착점을 나타내고, 물결선은 세포 결합제에 대한 부착점을 나타내며, n은 0 또는 1이며, m은 0 내지 30이다. 바람직한 실시형태에서, n은 1이며, m은 0 내지 10, 1 내지 8, 바람직하게는 4 내지 8, 및 가장 바람직하게는 4 또는 8이다. 다른 실시형태에서, m은 10 내지 30, 바람직하게는 20 내지 30이다. 대안으로, m은 0 내지 50이다. 이러한 실시형태에서, m은 바람직하게는 10 내지 40이며, n은 1이다.
한 실시형태에서, 세포 결합제와 A 사이의 연결은 세포 결합제의 티올 잔기와 A의 말레이미드 그룹을 통해 이루어진다.
한 실시형태에서, 세포 결합제와 A 사이의 연결은 다음과 같다:

여기서, 별표는 A의 나머지 부분에 대한 부착점을 나타내고, 물결선은 세포 결합제의 나머지 부분에 대한 부착점을 나타낸다. 이러한 실시형태에서, S 원자는 전형적으로 조절물질로부터 유도된다.
상기 각 실시형태에서, 또 다른 작용기가 하기 도시된 말레이미드-유도된 그룹 대신에 사용될 수 있다:

여기서, 물결선은 상기와 같이 세포 결합제에 대한 부착점을 나타내고, 별표는 A 그룹의 나머지 부분에 대한 결합을 나타낸다.
한 실시형태에서, 말레이미드-유도된 그룹은 하기 그룹으로 대체된다:

여기서, 물결선은 세포 결합제에 대한 부착점을 나타내고, 별표는 A 그룹의 나머지 부분에 대한 결합을 나타낸다.
한 실시형태에서, 말레이미드-유도된 그룹은 임의로 세포 결합제와 함께, 하기로부터 선택되는 그룹으로 대체된다:
-C(=O)NH-, -C(=O)O-, -NHC(=O)-, -OC(=O)-, -OC(=O)O-, -NHC(=O)O-, -OC(=O)NH-, -NHC(=O)NH-, -NHC(=O)NH, -C(=O)NHC(=O)-, -S-, -S-S-, -CH2C(=O)-, -C(=O)CH2-, =N-NH- 및 -NH-N=.
한 실시형태에서, 말레이미드-유도된 그룹은 임의로 세포 결합제와 함께, 하기 그룹들로부터 선택되는 그룹으로 대체된다:

여기서, 물결선은 세포 결합제에 대한 부착점 또는 A 그룹의 나머지 부분에 대한 결합을 나타내고, 별표는 세포 결합제에 대한 부착점 또는 A 그룹의 나머지 부분에 대한 결합 중 다른 하나를 나타낸다.
선택된 조절물질에 L1을 연결하는데 적합한 다른 그룹들은 제WO 2005/082023호에 기재되어 있다.
다른 바람직한 실시형태에서, 본 발명의 조절물질은 약물 링커 단위들을 포함하는 생체적합성 폴리머들과 회합될 수 있다. 이와 관련하여 한 가지 이러한 종류의 적합한 폴리머는 Fleximer®폴리머(Mersana Therapeutics)를 포함한다. 이러한 폴리머들은 전해진 바에 따르면 생분해성이며, 잘 받아들어지고, 임상적으로 입증되어 있다. 게다가, 이러한 폴리머들은 약동학 조절, 약물 방출의 국소화 및 개선된 생체분포를 가능하게 하는 여러 제작용 링커 기술 및 화학과 호환된다.
선택된 조절물질은 또한 직접 접합된 방사성 동위원소일 수 있거나, 방사성금속 이온들을 접합하는데 유용한 거대고리 킬레이터들을 포함할 수 있다(본원에 기재된 바와 같음). 특정 실시형태에서, 거대고리 킬레이터는 링커 분자를 통해 항체에 부착될 수 있는 1,4,7,10-테트라아자사이클로도데칸-N,N',N'',N''-테트라아세트산(DOTA)이다. 상기 링커 분자들은 당업계에 통상적으로 알려져 있으며, 문헌[참조; Denardo et al., 1998, Clin Cancer Res. 4:2483; Peterson et al., 1999, Bioconjug. Chem. 10:553; and Zimmerman et al., 1999, Nucl. Med. Biol. 26:943]에 기재되어 있다.
보다 일반적으로, 조절물질에 치료학적 모이어티 또는 세포독성제를 접합하기 위한 기술들은 잘 알려져 있다. 위에 논의된 바와 같이, 모이어티는 알데히드/쉬프 결합, 설피드릴 결합, 산-불안정 결합, 시스-아코니틸 결합, 하이드라존 결합, 효소분해성 결합을 포함하지만, 이에 제한되지 않는 당업계에 인지된 방법에 의해 조절물질에 접합될 수 있다(일반적으로 문헌[Garnett, 2002, Adv Drug Deliv Rev 53:171] 참조). 또한, 예를 들면, 문헌[Amon et al., "Monoclonal Antibodies For Immunotargeting Of Drugs In Cancer Therapy", in Monoclonal Antibodies And Cancer Therapy, Reisfeld et al. (eds.), pp. 243-56 (Alan R. Liss, Inc. 1985); Hellstrom et al., "Antibodies For Drug Delivery", in Controlled Drug Delivery (2nd Ed.), Robinson et al. (eds.), pp. 623-53 (Marcel Dekker, Inc. 1987); Thorpe, "Antibody Carriers Of Cytotoxic Agents In Cancer Therapy: A Review", in Monoclonal Antibodies '84: Biological And Clinical Applications, Pinchera et al. (eds.), pp. 475-506 (1985); "Analysis, Results, And Future Prospective Of The Therapeutic Use Of Radiolabeled Antibody In Cancer Therapy", in Monoclonal Antibodies For Cancer Detection And Therapy, Baldwin et al. (eds.), pp. 303-16 (Academic Press 1985), and Thorpe et al., 1982, Immunol. Rev. 62:119]을 참조한다. 바람직한 실시형태에서, 치료학적 모이어티 또는 세포독성제에 접합된 SEZ6 조절물질은 세포 표면과 회합된 SEZ6 분자에 결합시 세포에 의해 내재화될 수 있어서, 치료 적재물을 전달할 수 있다.
C. 생체적합성 변형제
선택된 실시형태에서, 본 발명의 조절물질은 조절물질 특성들을 원하는대로 조절, 변경, 개선 또는 조정하는데 사용될 수 있는 생체적합성 변형제와 접합 또는 회합될 수 있다. 예를 들면, 생체내 반감기가 증가된 항체 또는 융합 작제물은 상업적으로 이용가능한 폴리에틸렌 글리콜(PEG) 또는 유사한 생체적합성 폴리머들과 같은 비교적 고분자량 폴리머 분자들을 부착시킴으로써 생성될 수 있다. 당업계의 숙련가들은 항체에 특정 특성들을 부여하기 위해 선택될 수 있는 분자 구성들 및 많은 다른 분자량으로 PEG가 얻어질 수 있음을 알 것이다(예를 들면, 반감기가 조절될 수 있음). PEG는 상기 항체 또는 항체 단편의 N-말단 또는 C-말단에 PEG를 부위-특이적 접합을 통해, 또는 라이신 잔기 상에 존재하는 엡실론-아미노 그룹들을 통해 다기능 링커와 함께 또는 없이 조절물질 또는 항체 단편들 또는 유도체들에 부착될 수 있다. 생물학적 활성이 최소한으로 손실된 선형 또는 분지형 폴리머 유도가 사용될 수 있다. 접합 정도는 항체 분자들에 대한 PEG 분자들의 최적 접합을 보장하도록 SDS-PAGE 및 질량 분석법에 의해 밀접하게 모니터링될 수 있다. 미반응 PEG는, 예를 들면, 크기 배제 또는 이온-교환 크로마토그래피에 의해 항체-PEG 접합체들로부터 분리될 수 있다. 유사한 방식으로, 개시된 조절물질은 생체내에서 보다 안정한 항체 또는 항체 단편을 제조하기 위해, 또는 생체내에서 더 긴 반감기를 가지기 위해 알부민에 접합될 수 있다. 이 기술들은 당업계에 잘 알려져 있으며, 예를 들면 국제공보 제WO 93/15199호, 제WO 93/15200호, 및 제WO 01/77137호; 그리고 유럽특허 제0 413,622호를 참조한다. 다른 생체적합성 접합체들이 통상의 숙련가들에게 분명하며, 본원의 교시에 따라 쉽게 확인될 수 있다.
D. 진단제 또는 검출제
다른 바람직한 실시형태에서, 본 발명의 조절물질, 또는 이의 단편들 또는 유도체들은, 예를 들면, 생물학적 분자(예를 들면, 펩타이드 또는 뉴클레오타이드), 소분자, 형광단 또는 방사성 동위원소일 수 있는 진단제 또는 검출제, 마커 또는 리포터에 접합된다. 표지된 조절물질은 개시된 조절물질(즉, 치료진단제)을 포함하는 특정 치료법의 효능을 측정하기 위해, 또는 향후의 치료과정을 측정하기 위해, 임상 실험 과정의 일부로서 또는 이상증식 질환의 발병 또는 진행을 모니터링하는데 유용할 수 있다. 이러한 마커들 또는 리포터들은 또한 선택된 조절물질을 정제하고, 조절물질 분석(예를 들면, 에피토프 결합 또는 항체 빈화), TIC를 분리 또는 단리하거나 임상전 과정들 또는 독성 연구들에서 유용할 수 있다.
상기 진단 분석 및/또는 검출은, 예를 들면, 서양고추냉이 퍼옥시다제, 알칼리성 포스파타제, 베타-갈락토시다제, 또는 아세틸콜린에스테라제를 포함하는 여러 효소를 포함하지만 이에 제한되지 않는 검출가능한 물질들; 스트렙타비딘/바이오틴 및 아비딘/바이오틴과 같지만 이에 제한되지 않는 보결원자단; 엄벨리페론, 플루오레세인, 플루오레세인 이소티오시아네이트, 로다민, 디클로로트리아지닐아민 플루오레세인, 댄실 클로라이드 또는 피코에리트린과 같지만 이에 제한되지 않는 형광물질; 루미놀과 같지만 이에 제한되지 않는 발광물질; 루시페라제, 루시페린, 및 에쿼린과 같지만 이에 제한되지 않는 생체발광물질; 요오드(131I, 125I, 123I, 121I,), 탄소(14C), 황(35S), 트리튬(3H), 인듐(115In, 113In, 112In, 111In,), 및 테크네튬(99Tc), 탈륨(201Ti), 갈륨(68Ga, 67Ga), 팔라듐(103Pd), 몰리브덴(99Mo), 크세논(133Xe), 불소(18F), 153Sm, 177Lu, 159Gd, 149Pm, 140La, 175Yb, 166Ho, 90Y, 47Sc, 186Re, 188Re, 142Pr, 105Rh, 97Ru, 68Ge, 57Co, 65Zn, 85Sr, 32P, 153Gd, 169Yb, 51Cr, 54Mn, 75Se, 113Sn, 및 117Tin과 같지만 이에 제한되지 않는 방사성 물질; 다양한 양전자 방출 단층촬영을 사용한 양전자 방출 금속, 비방사성 상자성 금속 이온 및 방사성표시되거나 특정 방사성 동위원소들에 접합된 분자들을 포함하는 검출가능한 물질들에 조절물질을 결합시킴으로써 수행될 수 있다. 이러한 실시형태에서, 적당한 검출방법은 당업계에 잘 알려져 있으며, 수많은 상업적 공급원들로부터 쉽게 이용가능하다.
위에 나타낸 바와 같이, 다른 실시형태에서, 조절물질 또는 이들의 단편은 면역조직화학, 바이오-레이어 간섭측정법, 표면 플라스몬 공명, 유동 세포분석법, 경쟁적 ELISA, FAC 등과 같은 정제법 또는 진단법 또는 분석 과정들을 촉진시키기 위해, 펩타이드 또는 형광단과 같은 마커 서열 또는 화합물에 융합 또는 접합될 수 있다. 바람직한 실시형태에서, 마커는 다른 것들 중에서 pQE 벡터에 의해 제공된 것과 같은 his-태그(Qiagen)를 포함하며, 이들 중 많은 것들이 상업적으로 이용가능하다. 정제에 유용한 다른 펩타이드 태그들은 혈구응집소 "HA" 태그를 포함하지만 이에 제한되지 않으며, 이것은 인플루엔자 혈구응집소 단백질(Wilson et al., 1984, Cell 37:767) 및 "플래그" 태그(U.S.P.N. 제4,703,004호)로부터 유도된 에피토프에 상응한다.
E. 치료학적 모이어티
상기 언급한 바와 같이, 조절물질 또는 이들의 단편 또는 이들의 유도체는 또한 세포독성제, 세포정지제, 항신생혈관제, 용적축소제, 화학요법제, 방사선 치료 및 방사선치료제, 표적 항암제, BRM, 치료용 항체, 암 백신, 사이토카인, 호르몬 치료법, 방사선 치료법 및 항-전이제 및 면역치료제를 포함하지만 이에 제한되지 않는 항증식제 또는 항암제와 같은 "치료학적 모이어티" 또는 "약물"에 접합, 연결, 또는 융합되거나, 그렇지 않으면 회합될 수 있다.
바람직한 예시적인 항암제는 사이토칼라신 B, 그라미시딘 D, 브롬화 에티듐, 에메틴, 미토마이신, 에토포시드, 테노포시드, 빈크리스틴, 빈블라스틴, 콜키신, 독소루비신, 다우노루비신, 디하이드록시 안트라신, 메이타시노이드들, 예를 들면 DM-1 및 DM-4(Immunogen, Inc.), 디온, 미톡산트론, 미스라마이신, 악티노마이신 D, 1-디하이드로테스토스테론, 글루코코르티코이드, 프로카인, 테트라카인, 리도카인, 프로프라놀롤, 퓨로마이신, 에피루비신, 및 사이클로포스파미드 및 이들의 유사체 또는 동족체를 포함한다. 추가의 호환성 세포독소은 돌라스타틴 및 아우리스타틴(모노메틸 아우리스타틴 E(MMAE) 및 모노메틸 아우리스타틴 F(MMAF) 포함)(Seattle Genetics, Inc.), 아마니틴, 예를 들면 알파-아마니틴, 베타-아마니틴, 감마-아마니틴 또는 엡실론-아마니틴(Heidelberg Pharma AG), DNA 작은틈(minor groove) 결합제, 예를 들면 듀오카르마이신 유도체들(Syntarga, B.V.) 및 변경된 피롤로벤조디아제핀 다이머(Spirogen, Ltd.), 스플라이싱 억제제, 예를 들면 메야마이신 유사체 또는 유도체(예를 들면, FR901464, U.S.P.N. 제7,825,267호에 개시됨), 관형 결합제, 예를 들면 에포틸론 유사체 및 파클리탁셀 및 DNA 손상제, 예를 들면 칼리케마이신 및 에스페라마이신을 포함한다. 더욱이, 특정 실시형태에서 본 발명의 SEZ6 조절물질은 세포독성 T-세포를 모집하고 이들이 종양 개시 세포를 표적으로 삼도록 하기 위해 항-CD3 결합 분자들과 회합될 수 있다(BiTE technology; 예를 들면, 문헌[Fuhrmann, S. et. al. Annual Meeting of AACR Abstract No. 5625 (2010)]을 참조하며, 이는 전부 참조로 본원에 인용되어 있다).
여전히 추가의 적합한 항암제는 대사길항제(예를 들면, 메토트렉세이트, 6-머캅토퓨린, 6-티오구아닌, 시타라빈, 5-플루오로우라실 디카르바진), 알킬화제(예를 들면, 메클로레타민, 티오에파, 클로람부실, 멜팔란, 카뮤스틴(BCNU) 및 로뮤스틴(CCNU), 부설판, 디브로모만니톨, 스트렙토조토신, 및 시스디클로로디아민 플레티늄(II)(DDP) 시스플라틴), 안트라사이클린(예를 들면, 다우노루비신(예전에는 다우노마이신) 및 독소루비신), 항생제(예를 들면, 닥티노마이신(예전에는 악티노마이신), 블레오마이신, 및 안트라마이신(AMC)), 및 유사분열 방지제(예를 들면, 빈크리스틴 및 빈블라스틴)를 포함하지만, 이에 제한되지 않는다. 치료학적 모이어티의 보다 광범위한 목록은 PCT 공보 제WO 03/075957호 및 U.S.P.N. 제2009/0155255호에서 발견될 수 있으며, 이들 각각은 전부 참조로 본원에 인용되어 있다.
위에 나타낸 바와 같이, 본 발명의 선택된 실시형태들은 세포독성제로서 피롤로벤조디아제핀(PBD)을 포함하는 항-SEZ6 항체 약물 접합체와 같은 접합된 SEZ6 조절물질에 관한 것이다. PBD는 작은 틈에 DNA를 공유결합시키고 핵산 합성을 억제함으로써, 항암 활성을 발휘하는 알킬화제들임을 이해할 수 있을 것이다. 이와 관련하여 PBD는 최소한의 골수 쇠약을 나타내면서 강력한 항암 특성들을 가지는 것으로 보여진다. 본 발명에 적합한 PBD는 여러 종류의 링커들 중 하나(예를 들면, 유리 설프하이드릴을 갖는 말레이미도 잔기를 포함하는 펩타이딜 링커)를 사용하여 SEZ6 조절물질에 연결될 수 있으며, 특정 실시형태에서, 다이머 형태로 있다(즉, PBD 다이머). 개시된 조절물질에 접합될 수 있는 적합한 PBD(및 임의의 링커)는, 예를 들면, U.S.P.N. 제6,362,331호, 제7,049,311호, 제7,189,710호, 제7,429,658호, 제7,407,951호, 제7,741,319호, 제7,557,099호, 제8,034,808호, 제8,163,736호, U.S.P.N. 제2011/0256157호 및 PCT 출원 제WO2011/130613호, 제WO2011/128650호 및 제WO2011/130616호에 기재되어 있으며, 이들 각각은 참조로 본원에 인용되어 있다. 따라서, 특히 바람직한 실시형태에서, 조절물질은 하나 이상의 PBD 다이머들과 접합 또는 회합된 항 SEZ6 항체(즉, SEZ6-PBD ADC)를 포함할 것이다.
특히 바람직한 실시형태에서, 개시된 조절물질에 접합될 수 있는 적합한 PBD는 U.S.P.N. 제2011/0256157호에 기재되어 있다. 본 명세서에서, PBD 다이머, 즉, 2개의 PBD 모이어티를 포함하는 것이 바람직할 수 있다. 따라서, 본 발명의 바람직한 접합체들은 하기 화학식 AB 또는 AC를 갖는 것이다:
[화학식 AB]

[화학식 AC]

상기 화학식에서:
점선은 C1과 C2 또는 C2와 C3 사이에 이중결합이 임의로 존재함을 보여주고;
R2는 H, OH, =O, =CH2, CN, R, OR, =CH-RD, =C(RD)2, O-SO2-R, CO2R 및 COR로부터 독립적으로 선택되고, 임의로 할로 또는 디할로로부터 추가로 선택되며;
여기서 RD는 R, CO2R, COR, CHO, CO2H, 및 할로로부터 독립적으로 선택되고;
R6 및 R9는 H, R, OH, OR, SH, SR, NH2, NHR, NRR', NO2, Me3Sn 및 할로로부터 독립적으로 선택되고;
R7은 H, R, OH, OR, SH, SR, NH2, NHR, NRR', NO2, Me3Sn 및 할로로부터 독립적으로 선택되고;
R10은 상기 기재된 바와 같은, 조절물질 또는 이들의 단편 또는 유도체에 연결된 링커이고;
Q는 O, S 및 NH로부터 독립적으로 선택되고;
R11은 H, 또는 R이거나, Q가 O인 경우 O, SO3M이고, 여기서 M은 금속 양이온이며;
R 및 R'은 임의로 치환된 C1-12 알킬, C3-20 헤테로사이클릴 및 C5-20 아릴기로부터 각각 독립적으로 선택되고, 임의로 그룹 NRR', R 및 R'과 관련하여, 이들이 부착되는 질소원자와 함께, 임의로 치환된 4-, 5-, 6- 또는 7-원 헤테로사이클릭 환을 형성하며;
여기서 R2", R6", R7", R9", X", Q" 및 R11"은 각각 R2, R6, R7, R9, X, Q 및 R11 에 따라 정의된 바와 같으며, RC는 캡핑 그룹이다.
이중결합
한 실시형태에서, C1과 C2 사이, 및 C2와 C3 사이에는 이중결합이 존재하지 않는다.
한 실시형태에서, 점선은 하기에 나타낸 바와 같이, C2와 C3 사이에 이중결합이 임의로 존재함을 나타낸다:

한 실시형태에서, 상기 R2가 C5-20 아릴 또는 C1-12 알킬일 때 C2와 C3 사이에 이중결합이 존재한다.
한 실시형태에서, 점선은 하기에 도시된 바와 같이, C1과 C2 사이에 이중결합이 임의로 존재함을 나타낸다:

한 실시형태에서, R2가 C5-20 아릴 또는 C1-12 알킬일 때 C1과 C2 사이에 이중결합이 존재한다.
R
2
한 실시형태에서, R2는 H, OH, =O, =CH2, CN, R, OR, =CH-RD, =C(RD)2, O-SO2-R, CO2R 및 COR로부터 독립적으로 선택되고, 임의로 할로 또는 디할로로부터 추가로 선택된다.
한 실시형태에서, R2는 H, OH, =O, =CH2, CN, R, OR, =CH-RD, =C(RD)2, O-SO2-R, CO2R 및 COR로부터 독립적으로 선택된다.
한 실시형태에서, R2는 H, =O, =CH2, R, =CH-RD, 및 =C(RD)2로부터 독립적으로 선택된다.
한 실시형태에서, R2는 독립적으로 H이다.
한 실시형태에서, R2는 독립적으로 =O이다.
한 실시형태에서, R2는 독립적으로 =CH2이다.
한 실시형태에서, R2는 독립적으로 =CH-RD이다. PBD 화합물 내에서, 그룹 =CH-RD는 아래 도시된 입체구조를 가질 수 있다:
[화학식 I]

[화학식 II]

한 실시형태에서, 입체구조는 입체구조 (I)이다.
한 실시형태에서, R2는 독립적으로 =C(RD)2이다.
한 실시형태에서, R2는 독립적으로 =CF2이다.
한 실시형태에서, R2는 독립적으로 R이다.
한 실시형태에서, R2는 독립적으로 임의로 치환된 C5 -20 아릴이다.
한 실시형태에서, R2는 독립적으로 임의로 치환된 C1-12 알킬이다.
한 실시형태에서, R2는 독립적으로 임의로 치환된 C5-20 아릴이다.
한 실시형태에서, R2는 독립적으로 임의로 치환된 C5-7 아릴이다.
한 실시형태에서, R2는 독립적으로 임의로 치환된 C8-10 아릴이다.
한 실시형태에서, R2는 독립적으로 임의로 치환된 페닐이다.
한 실시형태에서, R2는 독립적으로 임의로 치환된 나프틸이다.
한 실시형태에서, R2는 독립적으로 임의로 치환된 피리딜이다.
한 실시형태에서, R2는 독립적으로 임의로 치환된 퀴놀리닐 또는 이소퀴놀리닐이다.
한 실시형태에서, R2는 1개 내지 3개의 치환기를 가지며, 1개 및 2개가 보다 바람직하고, 단일치환된 그룹들이 가장 바람직하다. 치환체들은 소정 위치에나 있을 수 있다.
R2가 C5-7 아릴 그룹인 경우, 단일 치환체는 바람직하게는 화합물의 나머지에 대한 결합과 인접하지 않는 환 원자 상에 있으며, 즉 화합물의 나머지에 대한 결합에 대하여 β 또는 γ인 것이 바람직하다. 따라서, C5-7 아릴 그룹이 페닐인 경우, 치환체는 메타- 또는 파라-위치에 있는 것이 바람직하며, 파라-위치에 있는 것이 보다 바람직하다.
한 실시형태에서, R2는 하기로부터 선택된다:

여기서, 별표는 부착점을 나타낸다.
R2가 C8-10 아릴 그룹, 예를 들면 퀴놀리닐 또는 이소퀴놀리닐인 경우, 퀴놀린 또는 이소퀴놀린 환의 어느 위치에서나 다수의 치환체들을 가질 수 있다. 소정 실시형태에서, 이것은 1개, 2개 또는 3개의 치환체를 가지며, 이들은 근위 및 원위 환 또는 둘 다(1개 이상의 치환체인 경우)에 있을 수 있다.
한 실시형태에서, R2가 임의로 치환되는 경우, 치환체들은 하기 치환체 부분에 제공된 치환체들로부터 선택된다.
R이 임의로 치환되는 경우, 치환체들은 하기로부터 바람직하게 선택된다:
할로, 하이드록실, 에테르, 포르밀, 아실, 카복시, 에스테르, 아실옥시, 아미노, 아미도, 아실아미도, 아미노카보닐옥시, 우레이도, 니트로, 시아노 및 티오에테르.
한 실시형태에서, R 또는 R2가 임의로 치환되는 경우, 치환체들은 R, OR, SR, NRR', NO2, 할로, CO2R, COR, CONH2, CONHR, 및 CONRR'로 이루어진 그룹으로부터 선택된다.
R2가 C1-12 알킬인 경우, 임의의 치환체는 C3-20 헤테로사이클릴 및 C5-20 아릴 그룹을 추가로 포함할 수 있다.
R2가 C3-20 헤테로사이클릴인 경우, 임의의 치환체는 C1-12 알킬 및 C5-20 아릴 그룹을 추가로 포함할 수 있다.
R2가 C5-20 아릴 그룹인 경우, 임의의 치환체는 C3-20 헤테로사이클릴 및 C1-12 알킬 그룹을 추가로 포함할 수 있다.
용어 "알킬"은 하위분류 알케닐 및 알키닐 뿐만 아니라 사이클로알킬을 포함하는 것으로 이해된다. 따라서, R2가 임의로 치환된 C1-12 알킬인 경우, 알킬 그룹은 1개 이상의 탄소-탄소 이중 또는 삼중 결합들을 임의로 함유하여, 접합된 시스템의 일부를 형성할 수 있다고 이해된다. 한 실시형태에서, 임의로 치환된 C1-12 알킬 그룹은 1개 이상의 탄소-탄소 이중 또는 삼중 결합을 함유하며, 이 결합은 C1과 C2 사이, 또는 C2와 C3 사이에 존재하는 이중 결합과 접합된다. 한 실시형태에서, C1-12 알킬 그룹은 포화 C1-12 알킬, C2-12 알케닐, C2-12 알키닐 및 C3-12 사이클로알킬로부터 선택되는 그룹이다.
R2 상의 치환체가 할로라면, 이것은 바람직하게는 F 또는 Cl, 보다 바람직하게는 Cl이다.
R2 상의 치환체가 에테르라면, 이것은 소정 실시형태에서는 알콕시 그룹, 예를 들면 C1-7 알콕시 그룹(예를 들면, 메톡시, 에톡시)일 수 있거나, 소정 실시형태에서는 C5-7 아릴옥시 그룹(예를 들면, 페녹시, 피리딜옥시, 푸라닐옥시)일 수 있다.
R2 상의 치환체가 C1-7 알킬이라면, 이것은 바람직하게는 C1-4 알킬 그룹(예를 들면, 메틸, 에틸, 프로필, 부틸)일 수 있다.
R2 상의 치환체가 C3-7 헤테로사이클릴이라면, 이것은 소정 실시형태에서, C6 질소 함유 헤테로사이클릴 그룹, 예를 들면, 모르폴리노, 티오모르폴리노, 피페리디닐, 피페라지닐을 함유할 수 있다. 상기 그룹들은 질소원자를 통해 PBD 모이어티의 나머지에 결합될 수 있다. 상기 그룹들은 예를 들면, C1-4 알킬 그룹에 의해 추가로 치환될 수 있다.
R2 상의 치환체가 비스-옥시-C1-3 알킬렌이라면, 이것은 바람직하게는 비스-옥시-메틸렌 또는 비스-옥시-에틸렌이다.
R2에 대한 특히 바람직한 치환체들은 메톡시, 에톡시, 플루오로, 클로로, 시아노, 비스-옥시-메틸렌, 메틸-피페라지닐, 모르폴리노 및 메틸-티에닐을 포함한다.
특히 바람직한 치환된 R2 그룹은 4-메톡시-페닐, 3-메톡시페닐, 4-에톡시-페닐, 3-에톡시-페닐, 4-플루오로-페닐, 4-클로로-페닐, 3,4-비스옥시메틸렌-페닐, 4-메틸티에닐, 4-시아노페닐, 4-페녹시페닐, 퀴놀린-3-일 및 퀴놀린-6-일, 이소퀴놀린-3-일 및 이소퀴놀린-6-일, 2-티에닐, 2-푸라닐, 메톡시나프틸, 및 나프틸을 포함하지만, 이들에 제한되지 않는다.
한 실시형태에서, R2는 할로 또는 디할로이다. 한 실시형태에서, R2는 -F 또는 -F2이며, 여기서 치환체들은 하기 III 및 IV로 각각 도시된다:
[화학식 III]

[화학식 IV]

R
D
한 실시형태에서, RD는 R, CO2R, COR, CHO, CO2H, 및 할로로부터 독립적으로 선택된다.
한 실시형태에서, RD는 독립적으로 R이다.
한 실시형태에서, RD는 독립적으로 할로이다.
R
6
한 실시형태에서, R6은 H, R, OH, OR, SH, SR, NH2, NHR, NRR', NO2, Me3Sn- 및 할로로부터 독립적으로 선택된다.
한 실시형태에서, R6은 H, OH, OR, SH, NH2, NO2 및 할로로부터 독립적으로 선택된다.
한 실시형태에서, R6은 H 및 할로로부터 독립적으로 선택된다.
한 실시형태에서, R6은 독립적으로 H이다.
한 실시형태에서, R6 및 R7은 함께 그룹 -O-(CH2)p-O-를 형성하고, 여기서, p는 1 또는 2이다.
R
7
R7은 H, R, OH, OR, SH, SR, NH2, NHR, NRR', NO2, Me3Sn 및 할로로부터 독립적으로 선택된다.
한 실시형태에서, R7은 독립적으로 OR이다.
한 실시형태에서, R7은 독립적으로 OR7A이고, 여기서, R7A는 독립적으로 임의로 치환된 C1-6 알킬이다.
한 실시형태에서, R7A는 독립적으로 임의로 치환된 포화 C1-6 알킬이다.
한 실시형태에서, R7A는 독립적으로 임의로 치환된 C2-4 알케닐이다.
한 실시형태에서, R7A는 독립적으로 Me이다.
한 실시형태에서, R7A는 독립적으로 CH2Ph이다.
한 실시형태에서, R7A는 독립적으로 알릴이다.
한 실시형태에서, 화합물은 각 모노머의 R7 그룹들이 모노머들을 연결하는 구조식 X-R"-X를 갖는 다이머 브릿지를 함께 형성하는 다이머이다.
R
8
한 실시형태에서, 화합물은 각 모노머의 R8 그룹들이 모노머들을 연결하는 구조식 X-R"-X를 갖는 다이머 브릿지를 함께 형성하는 다이머이다.
한 실시형태에서, R8은 독립적으로 OR8A이고, 여기서, R8A는 독립적으로 임의로 치환된 C1-4 알킬이다.
한 실시형태에서, R8A는 독립적으로 임의로 치환된 포화 C1-6 알킬 또는 임의로 치환된 C2-4 알케닐이다.
한 실시형태에서, R8A는 독립적으로 Me이다.
한 실시형태에서, R8A는 독립적으로 CH2Ph이다.
한 실시형태에서, R8A는 독립적으로 알릴이다.
한 실시형태에서, R8 및 R7은 함께 그룹 -O-(CH2)p-O-를 형성하고, 여기서, p는 1 또는 2이다.
한 실시형태에서, R8 및 R9는 함께 그룹 -O-(CH2)p-O-를 형성하고, 여기서, p는 1 또는 2이다.
R
9
한 실시형태에서, R9는 H, R, OH, OR, SH, SR, NH2, NHR, NRR', NO2, Me3Sn- 및 할로로부터 독립적으로 선택된다.
한 실시형태에서, R9는 독립적으로 H이다.
한 실시형태에서, R9는 독립적으로 R 또는 OR이다.
R 및 R'
한 실시형태에서, R은 임의로 치환된 C1-12 알킬, C3-20 헤테로사이클릴 및 C5-20 아릴 그룹으로부터 독립적으로 선택된다. 상기 그룹들은 하기 치환체 부분에서 각각 정의된다.
한 실시형태에서, R은 독립적으로 임의로 치환된 C1-12 알킬이다.
한 실시형태에서, R은 독립적으로 임의로 치환된 C3-20 헤테로사이클릴이다.
한 실시형태에서, R은 독립적으로 임의로 치환된 C5-20 아릴이다.
한 실시형태에서, R은 독립적으로 임의로 치환된 C1-12 알킬이다.
R2에 관하여 위에 기재된 것들은 바람직한 알킬 그룹 및 아릴 그룹 및 임의의 치환체들의 정체 및 수에 관한 여러 실시형태들이다. R에 적용된 바와 같이, R2에 대하여 나타낸 선호는, 경우에 따라, 모든 다른 그룹들 R, 예를 들면 R6, R7, R8 또는 R9가 R인 경우에, 적용가능하다.
R에 대한 선호도 또한 R'에 적용된다.
본 발명의 소정 실시형태에서, 치환체 그룹 -NRR'을 갖는 화합물이 제공된다. 한 실시형태에서, R 및 R'은 이들이 부착된 질소원자와 함께 임의로 치환된 4-, 5-, 6- 또는 7-원 헤테로사이클릭 환을 형성한다. 환은 추가의 헤테로원자, 예를 들면 N, O 또는 S를 포함할 수 있다.
한 실시형태에서, 헤테로사이클릭 환은 그룹 R에 의해 자체 치환된다. 추가의 N 헤테로원자가 존재하는 경우, 치환체가 N 헤테로원자 상에 있을 수 있다.
R"
R"는 1개 이상의 헤테로원자, 예를 들면 O, S, N(H), NMe 및/또는 방향족 환, 예를 들면 벤젠 또는 피리딘(여기서, 환은 임의로 치환된다)에 의해 쇄가 중단될 수 있는 C3-12 알킬렌 그룹이다.
한 실시형태에서, R"은 1개 이상의 헤테로원자 및/또는 방향족 환, 예를 들면 벤젠 또는 피리딘에 의해 쇄가 중단될 수 있는 C3-12 알킬렌 그룹이다.
한 실시형태에서, 알킬렌 그룹은 O, S, 및 NMe로부터 선택되는 1개 이상의 헤테로원자 및/또는 방향족 환(여기서, 환은 임의로 치환된다)에 의해 임의로 중단된다.
한 실시형태에서, 방향족 환은 C5-20 아릴렌 그룹이며, 여기서 아릴렌은 방향족 화합물의 2개의 방향족 환 원자로부터 2개의 수소원자를 제거함으로써 얻어진 2가 잔기에 속하며, 여기서, 잔기는 5개 내지 20개의 환 원자를 갖는다.
한 실시형태에서, R"는 C3-12 알킬렌 그룹이며, 상기 쇄는 1개 이상의 헤테로원자, 예를 들면 O, S, N(H), NMe 및/또는 방향족 환, 예를 들면 벤젠 또는 피리딘에 의해 중단될 수 있으며, 상기 환은 NH2에 의해 임의로 치환된다.
한 실시형태에서, R"는 C3-12 알킬렌 그룹이다.
한 실시형태에서, R"는 C3, C5, C7, C9 및 C11 알킬렌 그룹으로부터 선택된다.
한 실시형태에서, R"는 C3, C5 및 C7 알킬렌 그룹으로부터 선택된다.
한 실시형태에서, R"는 C3 및 C5 알킬렌 그룹으로부터 선택된다.
한 실시형태에서, R"는 C3 알킬렌 그룹이다.
한 실시형태에서, R"는 C5 알킬렌 그룹이다.
상기 열거된 알킬렌 그룹은 1개 이상의 헤테로원자 및/또는 방향족 환, 예를 들면 벤젠 또는 피리딘에 의해 임의로 중단될 수 있으며, 상기 환은 임의로 치환된다.
상기 열거된 알킬렌 그룹은 1개 이상의 헤테로원자 및/또는 방향족 환, 예를 들면 벤젠 또는 피리딘에 의해 임의로 중단될 수 있다.
상기 열거된 알킬렌 그룹은 비치환된 선형 지방족 알킬렌 그룹일 수 있다.
X
한 실시형태에서, X는 O, S, 또는 N(H)로부터 선택된다.
바람직하게는 X는 O이다.
R
10
상기 기재된 것들과 같은 바람직하게 적합한 링커들은 SEZ6 조절물질(CBA/Ab/M)을, R10 위치(즉, N10)에서 공유결합(들)을 통해 PBD 약물 모이어티(D)에 부착한다. 링커는 1개 이상의 약물 모이어티(D)와 조절물질(바람직하게는 항체)을 연결하여 항체-약물 접합체(ADC)를 형성하는데 사용될 수 있는 이중기능성 또는 다중기능성 모이어티이다. 링커(L)는 세포 밖에서, 즉 세포외적으로 안정할 수 있거나, 또는 효소 활성, 가수분해 또는 다른 대사 조건들에 의해 절단될 수 있다. 항체-약물 접합체(ADC)는 약물 모이어티 및 항체에 결합하기 위한 반응성 작용기를 갖는 링커를 사용하여 편리하게 제조될 수 있다. 시스테인 티올, 또는 아민, 예를 들면 항체(Ab)의 N-말단 또는 아미노산 측쇄, 예를 들면 라이신은 링커 또는 스페이서 제제, PBD 약물 모이어티(D) 또는 약물-링커 제제(D-L)의 작용기와 결합을 형성할 수 있다.
PBD 모이어티의 N10 위치에 부착된 링커 상의 많은 작용기들은 세포 결합제와 반응하는데 유용할 수 있다. 예를 들면, 에스테르, 티오에스테르, 아미드, 티오아미드, 카바메이트, 티오카바메이트, 우레아, 티오우레아, 에테르, 티오에테르 또는 디설파이드 결합들은 링커-PBD 약물 중간물질과 세포 결합제의 반응으로부터 형성될 수 있다.
다른 실시형태에서, 링커는 응집, 용해도 또는 반응성을 조절하는 그룹들에 의해 치환될 수 있다. 예를 들면, 설포네이트 치환체는 ADC를 제조하기 위해 사용되는 합성 경로에 따라, 시약의 수 용해도를 높이고, 링커 시약과 항체 또는 약물 모이어티의 커플링 반응을 촉진시키거나, Ab-L과 D의 커플링 반응 또는 D-L과 Ab의 커플링 반응을 촉진시킬 수 있다.
한 바람직한 실시형태에서, R10은 하기의 그룹이다:

여기서, 별표는 N10 위치에 대한 부착점을 나타내고, CBA는 세포 결합제/조절물질이며, L1은 링커이고, A는 세포 결합제에 L1을 연결하는 연결 그룹이며, L2는 공유결합 또는 -OC(=O)-와 함께 자기-희생 링커를 형성하고, L1 또는 L2는 절단가능한 링커이다.
L1은 바람직하게는 절단가능한 링커이며, 절단을 위한 링커의 활성화를 위한 촉발제로서 언급될 수 있다.
상기 링커 부분에서 논의된 바와 같이, L1 및 L2의 성질은, 존재하는 경우, 매우 다양할 수 있다. 상기 그룹들은 이들의 절단 특성들을 기준으로 선택되며, 이것은 접합체가 전달되는 부위에서의 조건에 의해 지시될 수 있다. pH의 변화(예를 들면, 산 또는 염기 불안정), 온도 또는 조사(예를 들면, 광불안정)에 의해 절단가능한 링커들도 또한 사용될 수 있지만, 효소의 작용에 의해 절단되는 상기 링커들이 바람직하다. 환원 또는 산화 조건하에 절단가능한 링커들이 또한 본 발명에서 사용될 수 있다.
L1은 아미노산의 인접한 서열을 포함할 수 있다. 아미노산 서열은 효소 절단을 위한 표적 기질일 수 있으며, 이에 의해, N10 위치로부터 R10을 방출시킨다.
한 실시형태에서, L1은 효소의 작용에 의해 절단가능하다. 한 실시형태에서, 효소는 에스테라제 또는 펩티다제이다.
한 실시형태에서, L2가 존재하며, -C(=O)O-와 함께 자기-희생 링커를 형성한다. 한 실시형태에서, L2는 효소활성을 위한 기질이며, 이에 의해 N10 위치로부터 R10을 방출시킨다.
한 실시형태에서, L1이 효소 작용에 의해 절단가능하며, L2가 존재하는 경우, 효소는 L1과 L2 사이의 결합을 절단한다.
선택된 PBD에 선택된 링커를 부착시키는 것과 관련하여, 그룹 RC는 N10-C11 이민 결합, 카르비놀아민, 치환된 카르비놀아민(여기서, QR11은 OSO3M이다), 중아황산염 부가물, 티오카르비놀아민, 치환된 티오카르비놀아민, 또는 치환된 카르비날아민을 남기기 위해 특정 PBD 모이어티의 N10 위치로부터 제거가능하다.
한 실시형태에서, RC는 N10-C11 이민 결합, 카르비놀아민, 치환된 카르비놀아민, 또는 QR11이 OSO3M인 경우, 중아황산염 부가물을 남기기 위해 제거가능한 보호 그룹일 수 있다. 한 실시형태에서, RC는 N10-C11 이민 결합을 남기기 위해 제거가능한 보호 그룹이다.
그룹 RC는 그룹 R10을 제거하기 위해, 예를 들면 N10-C11 이민 결합, 카르비놀아민 등을 생성하기 위해 필요한 것과 같은 조건하에서 제거될 수 있는 것으로 의도된다. 캡핑 그룹은 N10 위치에서 의도된 작용기를 위한 보호 그룹로서 작용한다. 캡핑 그룹은 세포 결합제에 대해 반응성이지 않은 것으로 의도된다. 예를 들면, RC는 RL과 동일하지 않다.
캡핑 그룹을 갖는 화합물은 이민 모노머를 갖는 다이머의 합성에서 중간물질로서 사용될 수 있다. 대안으로, 캡핑 그룹을 갖는 화합물은 접합체로서 사용될 수 있으며, 여기서, 상기 캡핑 그룹은 표적 위치에서 제거되어 이민, 카르비놀아민, 치환된 카르비놀아민 등을 생성한다. 따라서, 이러한 실시형태에서, 캡핑 그룹은 제WO 00/12507호에 정의된 바와 같이, 치료용으로 제거가능한 질소 보호 그룹인 것으로 언급될 수 있다.
한 실시형태에서, 그룹 RC는 그룹 R10의 링커 RL을 절단하는 조건하에서 제거가능하다. 따라서, 한 실시형태에서, 캡핑 그룹은 효소의 작용에 의해 절단가능하다.
대안적인 실시형태에서, 캡핑 그룹은 조절물질에 링커 RL을 연결하기 전에 제거가능하다. 이러한 실시형태에서, 캡핑 그룹은 링커 RL을 절단하지 않는 조건하에서 제거가능하다.
화합물이 세포 결합제에 대한 연결을 형성하는 작용기 G1을 포함한다면, 캡핑 그룹은 G1의 첨가 또는 언마스킹(unmasking) 전에 제거가능하다.
캡핑 그룹은 다이머내 모노머 단위들 중 하나만 세포 결합제에 연결되도록 하기 위한 보호 그룹 전략의 일부로서 사용될 수 있다.
캡핑 그룹은 N10-C11 이민 결합을 위한 마스크로서 사용될 수 있다. 캡핑 그룹은 이민 작용기가 화합물에 필요한 시간에 제거될 수 있다. 캡핑 그룹은 또한, 상기 기재된 바와 같이, 카르비놀아민, 치환된 카르비놀아민 및 중아황산염 부가물을 위한 마스크이다.
한 실시형태에서, RC는 카바메이트 보호 그룹이다.
한 실시형태에서, 카바메이트 보호 그룹은 하기로부터 선택된다:
Alloc, Fmoc, Boc, Troc, Teoc, Psec, Cbz 및 PNZ.
임의로, 카바메이트 보호 그룹은 Moc로부터 추가로 선택된다.
한 실시형태에서, RC는 세포 결합제에 연결하기 위한 작용기가 결여된 링커 그룹 RL이다.
본 출원은 카바메이트인 상기 RC 그룹과 특히 관련되어 있다.
한 실시형태에서, RC는 하기 그룹이다:

여기서, 별표는 N10 위치에 대한 부착점을 나타내고, G2는 말단화 그룹이며, L3은 공유결합 또는 절단가능한 링커 L1이고, L2는 공유결합 또는 OC(=O)와 함께 자기-희생 링커를 형성한다.
L3 및 L2가 둘 다 공유결합인 경우, G2 및 OC(=O)는 함께 상기 정의된 바와 같은 카바메이트 보호 그룹을 형성한다.
L1은 R10과 관련하여 상기 정의된 바와 같다.
L2는 R10과 관련하여 상기 정의된 바와 같다.
다양한 말단화 그룹들이 잘 알려진 보호 그룹들을 기본으로 하는 것들을 포함하여 하기에 기재되어 있다.
한 실시형태에서, L3은 절단가능한 링커 L1이며, L2는, OC(=O)와 함께 자기-희생 링커를 형성한다. 이러한 실시형태에서, G2는 Ac(아세틸) 또는 Moc, 또는 하기로부터 선택된 카바메이트 보호 그룹이다: Alloc, Fmoc, Boc, Troc, Teoc, Psec, Cbz 및 PNZ. 임의로, 카바메이트 보호 그룹은 Moc로부터 추가로 선택된다.
다른 실시형태에서, G2는 아실 그룹 -C(=O)G3이며, 여기서, G3은 알킬(사이클로알킬, 알케닐 및 알키닐을 포함함), 헤테로알킬, 헤테로사이클릴 및 아릴(헤테로아릴 및 카보아릴을 포함함)로부터 선택된다. 상기 그룹들은 임의로 치환될 수 있다. 아실 그룹은 L3 또는 L2의 아미노 그룹과 함께, 경우에 따라, 아미드 결합을 형성할 수 있다. 아실 그룹은 L3 또는 L2의 하이드록시 그룹과 함께, 경우에 따라, 에스테르 결합을 형성할 수 있다.
한 실시형태에서, G3은 헤테로알킬이다. 헤테로알킬 그룹은 폴리에틸렌 글리콜을 포함할 수 있다. 헤테로알킬 그룹은 아실 그룹에 인접한 헤테로원자, 예를 들면 O 또는 N을 가질 수 있어서, 경우에 따라, 그룹 L3 또는 L2에 존재하는 헤테로원자와 함께 적당한 경우, 카바메이트 또는 카보네이트 그룹을 형성할 수 있다.
한 실시형태에서, G3은 NH2, NHR 및 NRR'로부터 선택된다. 바람직하게, G3은 NRR'이다.
한 실시형태에서, G2는 하기 그룹이다:
여기서, 별표는 L3에 대한 부착점을 나타내고, n은 0 내지 6이며, G4는 OH, OR, SH, SR, COOR, CONH2, CONHR, CONRR', NH2, NHR, NRR', NO2, 및 할로로부터 선택된다. 그룹 OH, SH, NH2 및 NHR은 보호된다. 한 실시형태에서, n은 1 내지 6이고, 바람직하게는 n은 5이다. 한 실시형태에서, G4는 OR, SR, COOR, CONH2, CONHR, CONRR', 및 NRR'이다. 한 실시형태에서, G4는 OR, SR, 및 NRR'이다. 바람직하게 G4는 OR 및 NRR'로부터 선택되며, 가장 바람직하게는 G4는 OR이다. 가장 바람직하게는 G4는 OMe이다.
한 실시형태에서, 그룹 G2는 하기이다:

여기서, 별표는 L3에 대한 부착점을 나타내고, n 및 G4는 상기 정의된 바와 같다.
한 실시형태에서, 그룹 G2는 하기이다:

여기서, 별표는 L3에 대한 부착점을 나타내고, n은 0 또는 1이며, m은 0 내지 50이고, G4는 OH, OR, SH, SR, COOR, CONH2, CONHR, CONRR', NH2, NHR, NRR', NO2, 및 할로로부터 선택된다. 바람직한 실시형태에서, n은 1이며, m은 0 내지 10, 1 내지 2, 바람직하게 4 내지 8, 및 가장 바람직하게 4 또는 8이다. 다른 실시형태에서, n은 1이며, m은 10 내지 50, 바람직하게 20 내지 40이다. 그룹 OH, SH, NH2 및 NHR은 보호된다. 한 실시형태에서, G4는 OR, SR, COOR, CONH2, CONHR, CONRR', 및 NRR'이다. 한 실시형태에서, G4는 OR, SR, 및 NRR'이다. 바람직하게, G4는 OR 및 NRR'로부터 선택되며, 가장 바람직하게는 G4는 OR이다. 바람직하게, G4는 OMe이다.
한 실시형태에서, 그룹 G2는 하기이다:

여기서, 별표는 L3에 대한 부착점을 나타내며, n, m 및 G4는 상기 정의된 바와 같다.
한 실시형태에서, 그룹 G2는 하기이다:

여기서, n은 1-20이고, m은 0-6이며, G4는 OH, OR, SH, SR, COOR, CONH2, CONHR, CONRR', NH2, NHR, NRR', NO2, 및 할로로부터 선택된다. 한 실시형태에서, n은 1-10이다. 다른 실시형태에서, n은 10 내지 50, 바람직하게 20 내지 40이다. 한 실시형태에서, n은 1이다. 한 실시형태에서, m은 1이다. 그룹 OH, SH, NH2 및 NHR은 보호된다. 한 실시형태에서, G4는 OR, SR, COOR, CONH2, CONHR, CONRR', 및 NRR'이다. 한 실시형태에서, G4는 OR, SR, 및 NRR'이다. 바람직하게 G4는 OR 및 NRR'로부터 선택되며, 가장 바람직하게는 G4는 OR이다. 바람직하게 G4는 OMe이다.
한 실시형태에서, 그룹 G2는 하기이다:

여기서, 별표는 L3에 대한 부착점을 나타내며, n, m 및 G4는 상기 정의된 바와 같다.
상기 실시형태들 각각에서, G4는 OH, SH, NH2 및 NHR일 수 있다. 상기 그룹들은 바람직하게 보호된다.
한 실시형태에서, OH는 Bzl, TBDMS, 또는 TBDPS로 보호된다.
한 실시형태에서, SH는 Acm, Bzl, Bzl-OMe, Bzl-Me, 또는 Trt로 보호된다.
한 실시형태에서, NH2 또는 NHR은 Boc, Moc, Z-Cl, Fmoc, Z, 또는 Alloc로 보호된다.
한 실시형태에서, 그룹 G2는 그룹 L3과 조합하여 존재하며, 이 그룹은 디펩타이드이다.
캡핑 그룹은 조절물질에 연결하기 위한 것은 아니다. 따라서, 다이머에 존재하는 다른 모노머는 링커를 통한 조절물질에 연결지점으로서 작용한다. 따라서, 캡핑 그룹은 존재하는 작용기가 조절물질과의 반응에 이용가능하지 않은 것이 바람직하다. 따라서, OH, SH, NH2, COOH와 같은 반응성 작용기들이 피하는 것이 바람직하다. 그러나, 상기 작용기는 상기 기재된 바와 같이, 보호된다면, 캡핑 그룹내에 존재할 수 있다.
따라서, 본원의 교시에 따라, 본 발명의 한 실시형태는 하기 화합물을 포함하는 접합체를 포함한다:

여기서, CBA는 세포 결합제/조절물질이며, n은 0 또는 1이다. L1은 위에 정의된 바와 같으며, RE 및 RE"는 H 또는 RD로부터 각각 독립적으로 선택된다.
다른 실시형태에서, 접합체는 하기 화합물을 포함한다:

여기서, CBA는 세포 결합제/조절물질이고, L1은 위에 정의된 바와 같으며, Ar1 및 Ar2는 각각 독립적으로 임의로 치환된 C5-20 아릴이고, n은 0 또는 1이다.
당업계의 통상의 숙련가들은 다른 대칭 및 비대칭 PBD 다이머들과 링커들이 본 발명에 적합하며 본원의 교시 및 선행 기술에 근거하여 과도한 실험없이 선택될 수 있음을 이해할 것이다.
본 발명의 또 다른 양상은 방사성 동위원소를 포함하는 ADC를 포함한다. 상기 실시형태에 적합할 수 있는 예시적인 방사성 동위원소는 요오드(131I, 125I, 123I, 121I,), 탄소(14C), 구리(62Cu, 64Cu, 67Cu), 황(35S), 트리튬(3H), 인듐(115In, 113In, 112In, 111In,), 비스무트(212Bi, 213Bi), 테크네튬(99Tc), 탈륨(201Ti), 갈륨(68Ga, 67Ga), 팔라듐(103Pd), 몰리브덴(99Mo), 크세논(133Xe), 불소(18F), 153Sm, 177Lu, 159Gd, 149Pm, 140La, 175Yb, 166Ho, 90Y, 47Sc, 186Re, 188Re, 142 Pr, 105Rh, 97Ru, 68Ge, 57Co, 65Zn, 85Sr, 32P, 153Gd, 169Yb, 51Cr, 54Mn, 75Se, 113Sn, 117Sn, 225Ac, 76Br, 및 211At를 포함하지만, 이에 제한되지 않는다. 다른 방사성핵종이 또한 진단제 및 치료제로서 이용가능하며, 특히 60 내지 4,000 keV의 에너지 범위의 것들이 그러하다. 치료조건 및 원하는 치료 프로파일에 따라, 당업계의 숙련가들은 개시된 조절물질과 함께 사용하기 위한 적당한 방사성 동위원소를 쉽게 선택할 수 있다.
본 발명의 SEZ6 조절물질은 또한 주어진 생체 반응을 변경시키는 치료학적 모이어티 또는 약물(예를 들면, 생체 반응 조절물질 또는 BRM)에 접합될 수 있다. 즉, 본 발명에 적합한 치료제 또는 모이어티는 전형적인 화학치료제에 제한되는 것으로 해석되어서는 안된다. 예를 들면, 특히 바람직한 실시형태에서, 약물 모이어티는 원하는 생물학적 활성을 갖는 단백질 또는 폴리펩타이드 또는 이들의 단편일 수 있다. 상기 단백질은 예를 들면 아브린, 라이신 A, 옹코네이스(또는 다른 세포독성 RNase), 슈도모나스 엑소톡신, 콜레라 독소, 또는 디프테리아 독소와 같은 독소; 종양인자, α-인터페론, β-인터페론, 신경성장인자, 혈소판유도 성장인자, 조직 플라스미노겐 활성인자, 세포사멸제, 예를 들면, TNF-α TNF-β AIM I(국제공보 제WO 97/33899호 참조), AIM II(국제공보 제WO 97/34911호 참조), Fas 리간드(Takahashi et al., 1994, J. Immunol., 6:1567), 및 VEGI(국제공보 제WO 99/23105호 참조), 트롬보 제제 또는 항-트롬보 제제 또는 항-세포사멸제, 예를 들면, 안지오스태틴 또는 엔도스태틴; 또는, 생체 반응 조절물질, 예를 들면, 림포카인(예를 들면, 인터루킨-1("IL-1"), 인터루킨-2("IL-2"), 인터루킨-6("IL-6"), 과립구 대식세포 콜로니 자극인자("GM-CSF"), 및 과립구 콜로니 자극인자("G-CSF")), 또는 성장인자(예를 들면, 성장호르몬("GH"))를 포함할 수 있다. 위에 제시된 바와 같이, 조절물질을 폴리펩타이드 모이어티에 융합 또는 접합하는 방법은 당업계에 알려져 있다. 이미 개시된 주된 참고문헌들에 더해, 예를 들면, U.S.P.Ns. 제5,336,603호; 제5,622,929호; 제5,359,046호; 제5,349,053호; 제5,447,851호, 및 제5,112,946호; EP 제307,434호; EP 제367,166호; PCT 공보 제WO 96/04388호 및 제WO 91/06570호; 문헌[참조; Ashkenazi et al., 1991, PNAS USA 88:10535; Zheng et al., 1995, J Immunol 154:5590; and Vil et al., 1992, PNAS USA 89:11337]을 참조하며, 이들 각각은 참조로 본원에 인용되어 있다. 게다가, 위에 제시된 바와 같이, 조절물질을 이러한 모이어티와 반드시 직접 회합시킬 필요는 없지만, 링커 서열을 통해 일어날 수는 있다. 위에서 이미 언급한 바와 같이, 상기 링커 분자들은 당업계에 통상적으로 알려져 있고, 문헌[참조; Denardo et al., 1998, Clin Cancer Res 4:2483; Peterson et al., 1999, Bioconjug Chem 10:553; Zimmerman et al., 1999, Nucl Med Biol 26:943; Garnett, 2002, Adv Drug Deliv Rev 53:171]에 기재되어 있으며, 이들 각각은 본원에 인용되어 있다.
IX. 진단 및 선별
A. 진단
다른 실시형태에서, 본 발명은 증식성 장애들을 검출, 진단 또는 모니터링하는 시험관내 또는 생체내 방법들 및 환자로부터 세포들을 선별하여 CSC를 포함하는 종양형성성 세포들을 동정하는 방법들을 제공한다. 상기 방법들은 환자로부터 수득된 샘플 또는 환자를 본 명세서에 기술된 조절물질과 접촉시키는 단계(즉, 생체내 또는 시험관내) 및 샘플 중의 결합된 또는 유리된 표적 분자들에 대한 조절물질의 존재 또는 부재, 또는 회합 수준을 검사하는 단계를 포함하는, 암을 치료하거나 또는 암의 진행을 모니터링하기 위해, 암을 갖는 개체를 동정하는 것을 포함한다. 특히 바람직한 실시형태에서, 조절물질은 본 명세서에 기술된 바와 같은 검출가능한 표지 또는 리포터 분자를 포함할 것이다.
일부 실시형태에서, 항체와 같은 조절물질을 샘플 중의 특정 세포들과 회합시키는 것은 샘플이 CSC를 함유하여, 암을 갖는 개체가 본 명세서에 기술된 조절물질에 의해 효과적으로 치료될 수 있음을 보여준다는 것을 암시한다. 상기 방법은 대조군에 대한 결합수준을 비교하는 단계를 추가로 포함할 수 있다. 역으로, 조절물질이 Fc-작제물일 경우, 결합 특성은 샘플과 접촉하여 원하는 정보를 제공할 때(직접 또는 간접으로, 생체내 또는 시험관내) 활용 및 모니터링될 수 있다.
예시적인 적합한 검정 방법에는 방사면역검정, 효소면역검정, 경쟁적-결합 검정, 형광 면역검정, 면역블롯 검정, 웨스턴블롯 검정, 유세포분석 검정, 및 ELISA 검정들이 포함된다. 적합한 생체내 치료진단 또는 진단법은 당업자들에게 공지되어 있는 바와 같이, 자기공명영상, 컴퓨터단층촬영법(예를 들면, CAT 스캔), 양전자 단층촬영법(예를 들면, PET 스캔) 방사선촬영법, 초음파 등과 같은 공지된 영상화 기술 또는 모니터링 기술을 포함할 수 있다.
다른 실시형태에서, 본 발명은 생체내 암 진행 및/또는 발병을 분석하는 방법을 제공한다. 다른 실시형태에서, 생체내 암 진행 및/또는 발병을 분석하는 것은 종양 진행의 정도를 측정하는 단계를 포함한다. 다른 실시형태에서, 분석은 종양을 동정하는 단계를 포함한다. 다른 실시형태에서, 종양 진행의 분석은 1차 종양 상에서 수행된다. 다른 실시형태에서, 분석은 당업자들에게 공지되어 있는 바와 같이, 암의 종류에 따라 시간에 걸쳐 수행된다. 다른 실시형태에서, 1차 종양의 전이 세포들로부터 유래된 2차 종양의 추가 분석은 생체내에서 분석된다. 다른 실시형태에서, 2차 종양의 크기 및 모양이 분석된다. 일부 실시형태에서, 추가의 생체외 분석이 수행된다.
다른 실시형태에서, 본 발명은 세포 전이를 측정하거나 순환하는 종양세포들의 수준을 검출 및 정량화하는 단계를 포함하는, 생체내 암 진행 및/또는 발병을 분석하는 방법을 제공한다. 또 다른 실시형태에서, 세포 전이의 분석은 1차 종양으로부터 불연속적인 부위에서 세포의 진행성 성장을 측정하는 단계를 포함한다. 다른 실시형태에서, 세포 전이 분석의 부위는 종양이 확산되는 경로를 포함한다. 일부 실시형태에서, 세포들은 혈관구조를 통해, 림프샘을 통해, 체강내에서 또는 이들의 조합으로 분산될 수 있다. 다른 실시형태에서, 세포 전이 분석은 세포 이동, 전파, 혈관외유출, 증식 또는 이들의 조합의 관점에서 수행된다.
따라서, 특히 바람직한 실시형태에서, 본 발명의 조절물질들은 환자 샘플(예를 들면, 혈장 또는 혈액) 중의 SEZ6 수준을 검출 및 정량화하는데 사용될 수 있고, 이는 또한 증식성 장애들을 포함하는 SEZ6 관련 장애들을 검출, 진단 또는 모니터링하는데 사용될 수 있다. 관련 실시형태에서, 본 발명의 조절물질들은 생체내 또는 시험관내에서 순환하는 종양 세포들을 검출, 모니터링 및/또는 정량화하는데 사용될 수 있다(예를 들면, WO 2012/0128801을 참조하며, 이는 본원에서 참조로 포함된다). 또 다른 바람직한 실시형태에서, 순환하는 종양세포들은 암 줄기세포들을 포함할 수 있다.
특정 예에서, 대상체 또는 또는 대상체의 샘플 중의 종양형성성 세포는 기준선을 확립하기 위해 치료요법 또는 용법 이전에 개시된 조절물질들을 사용하여 평가 또는 특성평가될 수 있다. 다른 실시예에서는, 샘플은 치료받은 대상체로부터 유래한다. 일부 실시예들에서, 대상체가 치료를 시작 또는 종료한 후 적어도 약 1, 2, 4, 6, 7, 8, 10, 12, 14, 15, 16, 18, 20, 30, 60, 90일, 6개월, 9개월, 12개월, 또는 12개월 후에 대상체로부터 샘플을 수집한다. 특정 예에서, 특정 투약 횟수 후(예를 들면, 치료제의 2, 5, 10, 20, 30회 또는 그 이상의 투약 후)에 발암 세포를 특성평가하거나 특성평가한다. 다른 실시예에서, 1회 이상의 치료요법 후 1주, 2주, 1개월, 2개월, 1년, 2년, 3년, 4년 또는 그 이상 후 종양형성성 세포를 특성평가 또는 평가한다.
다른 양상에서, 하기에 보다 상세히 논의되는 바와 같이, 본 발명은 과증식성 장애를 검출, 모니터링 또는 진단하고, 가능한 치료를 위해 상기 장애를 갖는 개체를 동정하거나 환자에서의 장애의 진행(또는 퇴행)을 모니터링하기 위한 키트를 제공하며, 상기 키트는 본 명세서에 기술된 조절물질, 및 샘플 상에 조절물질이 미치는 영향을 검출하기 위한 시약을 포함한다.
본 발명의 또 다른 양상은 면역조직화학(IHC)을 위한 표지된 SEZ6의 용도를 포함한다. 이 점에서, SEZ6 IHC는 다양한 증식성 장애들의 진단을 돕기 위한 그리고 SEZ6 조절물질 치료를 포함하는 치료들에 대한 잠재적인 반응을 모니터링하기 위한 진단 도구로서 사용될 수 있다. 적합한 진단 검정은 화학적으로 고정되고(포름알데히드, 글루테르알데히드, 사산화오스뮴, 이크롬화칼륨, 아세트산, 알코올, 아연 염들, 염화수은, 사산화크로뮴 및 피크르산을 포함하나, 이에 제한되지 않음), 포매되거나(글리콜 메타크릴레이트, 파라핀 및 수지를 포함하나 이에 제한되지 않음) 또는 동결 보존된 조직 상에서 수행될 수 있다. 하기에 보다 상세히 논의되는 바와 같이, 상기 검정들은 치료 결정을 안내하고, 투약 용법 및 시기를 결정하는데 사용될 수 있다.
바람직한 실시형태에서, 본 발명은 (a) 대상체로부터의 소세포 폐암 종양 샘플을 제공하는 단계; (b) 상기 종양 샘플을 리포터로 표지된 항-SEZ6 항체에 노출시키고, 여기서 상기 항-SEZ6 항체는 상기 종양 샘플과 회합하는 단계; 및 (c) 상기 종양 샘플과 회합된 리포터를 검출하는 단계를 포함하는, 백금 내성 소세포 폐암의 진단 방법에 관한 것이다. 바람직한 실시형태에서, 이러한 리포터는 시험관내 진단 방법(예를 들면, IHC, 제자리 하이브리드화(in situ hybridization) 또는 유세포분석)을 사용하여 검출할 수 있다. 일부 실시형태에서, 종양 샘플을 제공하는 단계는 종양 샘플을 항-SEZ6 항체에 노출시키는 단계 또는 종양 샘플과 회합된 리포터를 검출하는 단계와 별도로 수행할 수 있다.
다른 실시형태에서, 본 발명은 (a) 대상체로부터의 수질 갑상선 종양 샘플을 제공하는 단계; (b) 상기 종양 샘플을 리포터로 표지된 항-SEZ6 항체에 노출시키고, 여기서 상기 항-SEZ6 항체는 상기 종양 샘플과 회합하는 단계; 및 (c) 상기 종양 샘플과 회합된 리포터를 검출하는 단계를 포함하는, 수질 갑상선암의 진단 방법에 관한 것이다. 바람직한 실시형태에서, 이러한 리포터는 시험관내 진단 방법(예를 들면, IHC, 제자리 하이브리드화 또는 유세포분석법)을 사용하여 검출할 수 있다. 일부 실시형태에서, 종양 샘플을 제공하는 단계는 종양 샘플을 항-SEZ6 항체에 노출시키는 단계 또는 종양 샘플과 회합된 리포터를 검출하는 단계와 별도로 수행할 수 있다.
B. 선별
특정 실시형태에서, 조절물질은 항원(예를 들면, 이의 유전자형 또는 표현형 성분들)과 상호작용함으로써, 종양형성성 세포 또는 이의 자손의 기능 또는 활성을 변경시키는 화합물 또는 물질(예를 들면, 약물)을 선별 또는 동정하는데 사용될 수도 있다. 상기 화합물 및 물질들은 예를 들면 증식성 장애를 치료하기 위해 선별되는 약물 후보가 될 수 있다. 한 실시형태에서, 시스템 또는 방법은 SEZ6을 포함하는 종양형성성 세포들 및, 화합물 또는 물질(예를 들면, 약물)을 포함하며, 여기서 상기 세포들 및 화합물 또는 물질은 서로 접촉한다. 상기 실시형태에서, 대상 세포들은 개시된 조절물질을 사용하여 동정, 모니터링 및/또는 증대(enrich)될 수 있다.
또 다른 실시형태에서, 방법은 종양형성성 세포들 또는 이의 후손을 시험 물질 또는 화합물과 직접 또는 간접적으로 접촉시키는 단계 및 시험 물질 또는 화합물이 항원-관련 종양형성성 세포들의 활성 또는 기능을 조절하는지를 측정하는 단계를 포함한다. 직접 상호작용의 한 예는 물리적 상호작용인 반면, 간접 상호작용은 중간물질 분자에 조성물이 작용하는 것을 포함하고, 이는 또한 기준이 되는 실체(예를 들면, 세포 또는 세포 배양물)에 작용한다. 조절될 수 있는 활성들 또는 기능들의 예는 세포 형태학 또는 생존력의 변화, 마커 발현, 분화 또는 탈분화, 세포 호흡, 미토콘드리아 활성, 막 무결성(integrity), 성숙, 증식, 생존력, 아폽토시스(apoptosis) 또는 세포사를 포함한다.
물질들 및 화합물들을 선별 및 동정하는 방법들은 임의로 예정된 위치 또는 어드레스에서 위치된 또는 놓여진 세포들의 어레이들(예를 들면, 마이크로어레이들)을 포함하는, 고처리량 선별에 적합한 방법들을 포함한다. 예를 들면, 세포들은 배양접시, 튜브, 플라스크, 회전병 또는 플레이트(예를 들면, 8, 16, 32, 64, 96, 384 및 1536개의 다중-웰 플레이트 또는 접시와 같은 단일 다중-웰 플레이트 또는 접시) 상에 위치하거나 놓여질(미리 접종될) 수 있다. 고처리량 로봇식 또는 수동 처리 방법들은 단시간 내에 많은 유전자들의 화학적 상호작용을 조사하고, 발현 수준을 측정할 수 있다. (예를 들면, 형광단을 통한)분자 신호들을 사용하는 기술 및 매우 빠른 속도로 정보를 처리하는 자동화 분석들이 개발되었다(예를 들면, Pinhasov et al., Comb. Chem. High Throughput Screen. 7:133 (2004) 참조). 예를 들면, 마이크로어레이 기술은 한번에 수천개의 유전자들의 상호작용을 조사하는데 광범위하게 사용된 반면, 특정 유전자를 위한 정보를 제공한다(예를 들면, Mocellin and Rossi, Adv. Exp. Med. Biol. 593:19 (2007) 참조).
선별될 수 있는 라이브러리들은 예를 들면, 소분자 라이브러리, 파아지 디스플레이 라이브러리, 완전 사람 항체 효모 디스플레이 라이브러리(Adimab, LLC), siRNA 라이브러리, 및 아데노바이러스 형질감염 벡터들을 포함한다.
X. 약제 제조 및 치료학적 용도
A. 제형 및 투여경로
소정 임의적 접합체, 의도된 전달 방식, 치료 또는 모니터링되는 질환 및 수많은 다른 변수들과 함께 조절물질의 형태에 의존하여, 본 발명의 조성물은 당해 분야에 인정된 기술들을 사용하여 원하는 대로 제형화될 수 있다. 일부 실시형태에서, 본 발명의 치료 조성물은 순수하게 또는 최소량의 추가 성분들과 함께 투여될 수 있는 반면, 다른 것들은 당해 분야에 익히 공지된 부형제들 및 보조제들을 포함하는 적합한 약제학적으로 허용되는 담체들을 함유하도록 선택적으로 제형화될 수 있다[예를 들면, Gennaro, Remington: The Science and Practice of Pharmacy with Facts and Comparisons: Drugfacts Plus, 20th ed. (2003); Ansel et al., Pharmaceutical Dosage Forms and Drug Delivery Systems, 7th ed., Lippencott Williams and Wilkins (2004); Kibbe et al., Handbook of Pharmaceutical Excipients, 3rd ed., Pharmaceutical Press (2000) 참조]. 부형제, 보조제 및 희석제들을 포함하는 다양한 약제학적으로 허용되는 담체들은 많은 상업적 공급원으로부터 쉽게 입수가능하다. 게다가, pH 조정제 및 완충제, 등장성 조정제, 안정화제, 습윤제 등과 같은 약제학적으로 허용되는 보조 물질들의 종합도 또한 사용가능하다. 특정의 비-제한적인 예시적 담체들에는 식염수, 완충식염수, 덱스트로오스, 물, 글리세롤, 에탄올 및 이들의 조합들이 포함된다.
더욱 특히, 일부 실시형태에서, 본 발명의 치료학적 조성물이 순수하게 또는 최소량의 추가 성분들과 함께 투여될 수 있음을 이해할 수 있을 것이다. 역으로, 본 발명의 SEZ6 조절물질들은 당해 분야에 널리 공지되어 있고, 조절물질의 투여를 용이하게 하거나 작용부위로의 전달을 위해 약제학적으로 최적화된 제제(preparation)로의 활성 화합물의 가공을 돕는 비교적 불활성의 물질들인 부형제 및 보조제들을 포함하는 적당한 약제학적으로 허용되는 담체들을 함유하도록 임의로 제형화될 수 있다. 예를 들면, 부형제는 형태 또는 농도를 제공할 수 있거나, 조절물질의 약동학 또는 안정성을 개선시키기 위해 희석제로서 작용할 수 있다. 적당한 부형제들 또는 첨가제들은 안정화제, 습윤제 및 유화제, 삼투압 조절용 염, 캡슐화제, 완충제 및 피부침투 증진제들을 포함하나 이에 제한되지 않는다. 특정 바람직한 실시형태에서, 약제학적 조성물은 동결건조된 형태로 제공되며, 투여되기 전에 예를 들면 완충 식염수에서 재구성될 수 있다.
전신 투여를 위한 개시된 조절물질들은 장내, 비경구 또는 국소 투여를 위해 제형화될 수 있다. 게다가, 3종류의 모든 제형이 동시에 사용되어, 활성 성분을 전신 투여할 수 있다. 비경구 및 비-비경구 약물 전달을 위한 제형 뿐만 아니라 부형제들은 문헌[참조: Remington, The Science and Practice of Pharmacy 20th Ed. Mack Publishing (2000)]에 개시되어 있다. 비경구 투여를 위한 적당한 제형은 수용성 형태의 활성 화합물들의 수용액, 예를 들면 수용해성 염을 포함한다. 게다가, 유성 주사 현탁액에 적당한 활성 화합물의 현탁액이 투여될 수 있다. 적합한 친유성 용매 또는 비히클들은 지방 오일, 예를 들면 헥실치환된 폴리(락티드), 참기름, 또는 합성 지방산 에스테르, 예를 들면 에틸 올레에이트 또는 트리글리세라이드를 포함한다. 수성 주사 현탁액은 현탁액의 점도를 증가시키는 물질들을 함유할 수 있으며, 예를 들면, 나트륨 카르복시메틸 셀룰로오스, 소르비톨 및/또는 덱스트란을 포함한다. 임의로, 현탁액은 또한 안정화제를 함유할 수 있다. 리포좀들은 또한, 세포에 전달하기 위한 제제를 캡슐화하기 위해 사용될 수 있다.
장내 투여를 위한 적합한 제형은 경질 또는 연질 젤라틴 캡슐제, 환제, 제피정을 포함하는 정제, 엘릭시르, 현탁제, 시럽제 또는 이들의 흡입형 및 서방출 형태를 포함한다.
일반적으로, SEZ6 조절물질을 포함하는 본 발명의 화합물 및 조성물은 경구, 정맥내, 동맥내, 피하, 비경구, 비강내, 근육내, 두개내, 심장내, 심실내, 기관내, 구강, 직장내, 복강내, 진피, 국소, 경피 및 척수내를 포함하나 이에 제한되지 않는 다양한 경로들 또는 그렇지 않으면 이식 또는 흡입에 의해 이를 필요로 하는 대상체에게 생체내 투여될 수 있다. 대상 조성물들은 고체, 반-고체, 액체, 또는 기체 형태의 제제로 제형화될 수 있으며; 정제, 캡슐제, 산제, 과립제, 연고제, 용액제, 좌제, 관장제, 주사제, 흡입제 및 에어로졸을 포함하나 이에 제한되지 않는다. 적당한 제형 및 투여 경로는 의도된 적용 및 치료 용법에 따라 선택될 수 있다.
B. 용량
유사하게, 특정 투약 용법, 즉 용량, 타이밍 및 반복은 특정 개체 및 개체의 병력 뿐만 아니라 약동학과 같은 경험적인 고려사항들(예를 들면, 반감기, 청소율 등)에 따라 좌우될 것이다. 투여 빈도는 치료요법 과정 동안 측정 및 조정될 수 있으며, 증식성 또는 종양형성성 세포들의 수를 감소시키거나, 이러한 신생물성 세포들의 감소를 유지하거나, 신생물성 세포들의 증식을 감소시키거나, 전이 발생을 지연시키는 것에 기초한다. 다른 실시형태에서, 투여된 용량은 잠재적인 부작용 및/또는 독성을 관리하기 위해 조정되거나 감쇠될 수 있다. 대안적으로, 대상 치료학적 조성물의 지속적 연속 방출 제형들이 적합할 수 있다.
일반적으로, 본 발명의 조절물질은 다양한 여러 범위로 투여될 수 있다. 이들은 용량당 체중 1kg당 약 10㎍ 내지 약 100mg; 용량당 체중 1kg당 약 50㎍ 내지 약 5mg; 용량당 체중 1kg당 약 100㎍ 내지 약 10mg을 포함한다. 다른 범위들은 용량당 체중 1kg당 약 100㎍ 내지 약 20mg 및 용량당 체중 1kg당 약 0.5mg 내지 약 20mg을 포함한다. 특정 실시형태에서, 용량은 체중 1kg당 적어도 약 100㎍, 체중 1kg당 적어도 약 250㎍, 체중 1kg당 적어도 약 750㎍, 체중 1kg당 적어도 약 3mg, 체중 1kg당 적어도 약 5mg, 체중 1kg당 적어도 약 10mg이다.
선택된 실시형태에서, 조절물질들은 용량당 체중 1kg당 약 10, 20, 30, 40, 50, 60, 70, 80, 90 또는 100㎍으로 투여될 것이다. 다른 실시형태들은 용량당 체중 1kg당 200, 300, 400, 500, 600, 700, 800 또는 900㎍의 조절물질을 투여하는 것을 포함할 것이다. 다른 바람직한 실시형태에서, 개시된 조절물질은 1, 2, 3, 4, 5, 6, 7, 8, 9 또는 10mg/kg 투여될 것이다. 또 다른 실시형태에서, 조절물질은 용량당 체중 1kg당 12, 14, 16, 18 또는 20mg 투여될 수 있다. 또 다른 실시형태에서, 조절물질은 용량당 체중 1kg당 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 90 또는 100mg으로 투여될 것이다. 본 명세서의 교시에 따르면, 상기 용량들은 접합되지 않은 조절물질들과 세포독성제에 접합된 조절물질들 둘 다에 대하여 적용할 수 있음을 이해할 수 있을 것이다. 당업자라면 임상전 동물연구, 임상 관찰 및 표준 의료 및 생화학 기술 및 측정에 기초하여, 여러 접합된 및 비접합된 조절물질들에 대한 적당한 용량을 쉽게 결정할 수 있다.
접합된 조절물질과 관련하여, 특히 바람직한 실시형태는 용량당 체중 1kg당 약 50㎍ 내지 약 5mg의 용량을 포함할 것이다. 이것과 관련하여, 접합된 조절물질들은 용량당 체중 1kg당 50, 75 또는 100㎍ 또는 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9 또는 1mg으로 투여될 수 있다. 다른 바람직한 실시형태에서, 본 발명의 접합된 조절물질들은 용량당 체중 1kg당 1.25, 1.5, 1.75, 2, 2.25, 2.5, 2.75, 3, 3.25, 3.5, 3.75, 4, 4.25, 4.5, 4.75 또는 5mg으로 투여될 수 있다. 특히 바람직한 실시형태에서, 상기 접합된 조절물질 용량은 시간 기간에 걸쳐 정맥내 투여될 것이다. 게다가, 상기 용량은 정해진 치료 과정 동안 여러 번 투여될 수 있다.
다른 투약 용법들은 미국 특허 제7,744,877호에 개시된 바와 같이 체표면적(BSA) 계산에 근거를 둘 수 있다. 익히 공지되어 있는 바와 같이, BSA는 환자의 신장과 체중을 이용하여 계산하며, 그 또는 그녀의 체표면적으로서 대상체의 크기 측정치를 제공한다. 특정 실시형태에서, 조절물질들은 10mg/m2 내지 800mg/m2, 50mg/m2 내지 500mg/m2의 용량 및 100mg/m2, 150mg/m2, 200mg/m2, 250mg/m2, 300mg/m2, 350mg/m2, 400mg/m2 또는 450mg/m2의 용량으로 투여될 수 있다.
접합된 조절물질들(즉, ADC들)에 대한 적당한 용량을 결정하기 위해, 당해 분야에 인정된 기술들 및 경험적 기술들이 사용될 수 있음이 또한 잘 이해될 것이다.
소정 경우라도, SEZ6 조절물질들(접합된 것 및 접합되지 않은 것 둘 다)은 이를 필요로 하는 대상체들에게 필요에 따라 투여되는 것이 바람직하다. 투여 빈도를 결정하는 것은 치료받는 병태, 치료받는 대상체의 연령, 치료받는 병태의 중증도, 치료받는 대상체의 전반적 건강상태 등을 고려하여 담당 주치의와 같은 당업자에 의해 이루어질 수 있다. 일반적으로, 유효 용량의 SEZ6 조절물질은 1회 이상 대상에게 투여된다. 특히, 유효 용량의 조절물질은 대상에게, 1개월에 1회, 1개월에 1회 이상 또는 1개월에 1회 미만 투여된다. 특정 실시형태에서, 유효 용량의 SEZ6 조절물질은 적어도 1개월, 적어도 6개월, 적어도 1년, 적어도 2년 또는 수년의 기간을 포함하는 다수 횟수로 투여될 수 있다. 또 다른 실시형태에서, 개시된 조절물질들의 투여 사이에, 수일(2, 3, 4, 5, 6 또는 7), 수주(1, 2, 3, 4, 5, 6, 7 또는 8) 또는 수개월(1, 2, 3, 4, 5, 6, 7 또는 8) 또는 심지어 1년 또는 수년이 경과될 수 있다.
특정 바람직한 실시형태에서, 접합된 조절물질들을 포함하는 치료 과정은 수주 또는 수개월 동안 다중 용량의 선택된 약물 제품(즉, ADC)을 포함할 것이다. 보다 구체적으로, 본 발명의 접합된 조절물질들은 1일에 1회, 2일에 1회, 4일에 1회, 매주, 10일에 1회, 2주에 1회, 3주에 1회, 1개월에 1회, 6주에 1회, 2개월에 1회, 10주에 1회 또는 3개월에 1회 투여될 수 있다. 이와 관련하여, 환자 반응 및 임상 실습에 기초하여, 용량이 변경되거나, 간격이 조정될 수 있음을 이해할 수 있을 것이다.
용량 및 용법은 또한 1회 이상의 투여(들)가 제공된 개체들에서 개시된 치료학적 조성물에 대하여 경험적으로 결정될 수도 있다. 예를 들면, 개체들에게는 본 명세서에 기술된 바와 같이 제조된 치료학적 조성물의 점증적 용량이 제공될 수 있다. 선택된 실시형태에서, 용량은 경험적으로 측정된 또는 관찰된 부작용 또는 독성에 기초하여 각각 점진적으로 증가 또는 감소 또는 감쇠될 수 있다. 선택된 조성물의 효능을 평가하기 위해, 특정한 질환, 장애 또는 병태의 마커가 앞서 기술한 바와 같이 뒤따를 수 있다. 개체가 암을 갖는 실시형태에서, 이들은 촉진 또는 육안 관찰을 통한 종양 크기의 직접적인 측정, x-선 또는 다른 영상 기술들에 의한 종양 크기의 간접적인 측정; 종양 샘플의 직접적인 종양 생검 및 현미경 조사에 의해 평가된 개선; 간접적인 종양 마커(예를 들면, 전립선 암의 경우 PSA) 또는 본 명세서에 기술된 방법에 따라 동정된 항원, 통증 또는 마비 감소의 측정; 종양과 관련된 개선된 언어능력, 시력, 호흡 또는 다른 장애; 증가된 식욕; 또는 허용된 시험 또는 생존 연장에 의해 측정된 삶의 질 증가를 포함한다. 용량이 개체, 신생물성 병태(neoplastic condition)의 종류, 신생물성 병태의 병기(신생물성 병태가 개체의 다른 부위로의 전이가 시작되었는지의 여부) 및 사용된 과거 및 병행 치료에 따라 다양할 것임을 당업자라면 분명히 알 것이다.
C. 병용 치료요법
병용 치료요법은 원치않는 신생물성 세포 증식의 감소 또는 저해, 암 발생의 감소, 암 재발의 감소 또는 예방, 또는 암의 확산 또는 전이의 감소 또는 예방에 특히 유용할 수 있다. 상기 경우, 본 발명의 조절물질들은 달리 종양괴를 받치고, 영속화하는 CSC들을 제거함으로써, 용적축소 치료(care debulking) 또는 항암제의 현행 표준을 보다 효과적으로 사용할 수 있게 함으로써 감작제 또는 약제감작제로서 기능할 수 있다. 본 명세서에서 사용되는 "병용 치료요법"은 적어도 하나의 SEZ6 조절물질 및 적어도 하나의 치료학적 모이어티(therapeutic moiety)(예를 들면, 항암제)를 포함하는 병용물의 투여를 의미하며, 여기서 상기 병용물은 바람직하게는 상승 작용을 갖거나 암(예를 들면, 갑상선수질암 또는 SCLC)의 치료시에 (i) 단독으로 사용된 SEZ6 조절물질 또는 (ii) 단독으로 사용된 치료학적 모이어티 또는 (iii) SEZ6 조절물질의 부가 없이 다른 치료학적 모이어티와 병용된 치료학적 모이어티의 사용보다 측정가능한 치료학적 효과를 개선시킨다. 본 명세서에서 사용되는 "치료학적 상승 작용"이란 용어는 SEZ6 조절물질과 하나 이상의 치료학적 모이어티(들)의 병용물이 SEZ6 조절물질과 하나 이상의 치료학적 모이어티(들)의 병용물의 상가 효과보다 큰 치료학적 효과를 갖는 것을 의미한다.
본 발명의 "병용 치료요법"의 범주에서, 치료학적 모이어티는 세포독성제, 세포정지제, 항-혈관신생제, 용적축소제, 화학치료제, 방사선치료요법 및 방사선치료제, 표적 항암제(모노클로날 항체 및 소분자 실체들을 둘 다를 포함), BRM, 치료학적 항체, 암 백신, 사이토킨, 호르몬 치료요법, 방사선 치료요법 및 항-전이제 및, 특이적 및 비특이적 접근법 둘 다를 포함하는 면역치료제를 포함하나 이에 제한되지 않는 하나 이상의 항암제들을 포함할 수 있다.
개시된 병용물들의 원하는 결과는 대조군 또는 기준선 측정과 비교하여 정량화한다. 본 명세서에서 사용되는 바와 같이, "개선시키다", "증가하다" 또는 "감소하다"와 같은 상대적인 용어들은 본 명세서에 기술된 처리 개시 전에 동일한 개체에서의 측정 또는 본 명세서에 기술된 SEZ6 조절물질은 부재이나 표준 관리 치료(standard of care treatment)와 같은 다른 치료학적 모이어티(들) 존재 하의 대조 개체(또는 다수의 대조 개체들)에서의 측정과 같은 대조군에 상대적인 값들을 나타낸다. 대표적인 대조 개체는 (치료된 개체와 대조 개체에서 질환 병기가 비슷하다는 것을 보장하기 위해) 치료될 개체와 거의 동일한 연령인, 치료될 개체와 동일한 형태의 암에 시달리는 개체이다.
치료요법에 대한 반응으로서 변화 또는 개선은 일반적으로 통계학적으로 유의적이다. 본 명세서에서 사용되는 바와 같이, "유의성" 또는 "유의적인"이란 용어는 2개 이상의 실체 간에 비-임의 연관성이 있을 확률의 통계분석에 관한 것이다. 관계가 "유의적인"지 또는 "유의성"을 갖는지 여부를 결정하기 위해, "p-값"을 계산할 수 있다. 사용자 정의 절사점(cut-off point)을 하회하는 p-값들은 유의적인 것으로 간주된다. 0.1 이하, 0.05 미만, 0.01 미만, 0.005 미만 또는 0.001 미만의 p-값들은 유의적인 것으로 간주될 수 있다.
상승적 치료 효과는 단일 치료학적 모이어티 또는 SEZ6 조절물질에 의해 유발되는 치료 효과, 또는 SEZ6 조절물질 또는 소정의 조합의 단일 치료학적 모이어티(들)에 의해 유발되는 치료 효과들의 합보다 적어도 약 2배 큰, 적어도 약 5배 큰, 적어도 약 10배 큰, 적어도 약 20배 큰, 적어도 약 50배 큰 또는 적어도 약 100배 큰 효과일 수 있다. 상승적 치료 효과는 단일 치료학적 모이어티 또는 SEZ6 조절물질에 의해 유발되는 치료 효과, 또는 SEZ6 조절물질 또는 소정의 조합의 단일 치료학적 모이어티(들)에 의해 유발되는 치료 효과들의 합과 비교해 적어도 10%, 적어도 20%, 적어도 30%, 적어도 40%, 적어도 50%, 적어도 60%, 적어도 70%, 적어도 80%, 적어도 90%, 적어도 100% 또는 그 이상의 치료 효과 증가로서 관찰될 수도 있다.
병용 치료요법을 실시하는데 있어서, 조절물질 및 항암제는 동일하거나 상이한 투여경로들을 사용하여, 단일 조성물 또는 2개 이상의 별개의 조성물들로서 대상에게 동시에 투여될 수 있다. 대안적으로, 조절물질은, 예를 들면, 몇분 내지 몇주 범위의 간격에 의해 항암제 치료를 선행하거나 뒤따를 수 있다. 각 전달 사이의 시간 주기는 항암제 및 조절물질이 종양에 병용 효과를 발휘할 수 있도록 한다. 적어도 한 실시형태에서, 항암제와 조절물질 둘 다는 서로 약 5분 내지 약 2주 내에 투여된다. 또 다른 실시형태에서, 조절물질과 항암제 투여 사이에 수일(2, 3, 4, 5, 6 또는 7), 수주(1, 2, 3, 4, 5, 6, 7 또는 8) 또는 수개월(1, 2, 3, 4, 5, 6, 7 또는 8)이 경과할 수 있다.
병용 치료요법은 병태가 치료, 완화 또는 치유될 때까지 일정 시간 동안 적어도 1회, 2회 또는 3회 투여될 수 있다. 일부 실시형태에서, 병용 치료요법은 여러 번, 예를 들면 1일에 3회 내지 6개월에 1회 투여된다. 투여는 1일에 3회, 1일에 2회, 1일에 1회, 2일에 1회, 3일에 1회, 매주 1회, 2주에 1회, 매월 1회, 2개월에 1회, 3개월에 1회, 6개월에 1회와 같은 스케쥴로, 또는 미니펌프를 통해 연속 투여될 수 있다. 병용 치료요법은 이미 주지한 바와 같이, 임의의 경로를 통해, 투여될 수 있다. 병용 치료요법은 종양 부위로부터 먼 부위에 투여될 수 있다.
한 실시형태에서, 조절물질은 이를 필요로 하는 대상체에 짧은 치료 주기 동안 하나 이상의 항암제들과 병용 투여된다. 본 발명은 또한, 여러 차례의 부분적인 투여들로 세분화되는 불연속적 투여 또는 매일 투약을 고려한다. 조절물질 및 항암제는 격일 또는 격주로 서로 교환가능하게 투여될 수 있으며; 또는 항체 치료 순서가 주어진 후, 1회 이상의 항암제 치료요법 치료가 뒤따를 수 있다. 어떠한 상황에서도, 당업자들에게 공지되어 있는 바와 같이, 화학요법제의 적당한 용량은 일반적으로 임상 치료요법에서 이미 사용된 것에 근접할 것이며, 상기 화학요법제는 단독으로 또는 다른 화학요법제들과 병용 투여된다.
다른 바람직한 실시형태에서, 본 발명의 SEZ6 조절물질은 종양 재발 후 장애의 초기 발현할 기회를 감소 또는 제거하기 위한 유지 치료요법에 사용될 수 있다. 바람직하게, 장애는 치료될 것이며, 초기 종양괴가 제거, 감소 또는 그렇지 않으면 경감되어, 환자는 증상이 없거나 차도가 있을 것이다. 이때, 표준 진단과정들을 사용하여 질환의 증상이 적거나 없더라도, 대상체는 약제학적 유효량의 개시된 조절물질들을 1회 이상 투여받을 수 있다. 일부 실시형태에서, 조절물질은 일정 시간 동안 규칙적인 스케쥴, 예를 들면 매주, 2주에 1회, 매월, 6주에 1회, 2개월에 1회, 3개월에 1회, 6개월에 1회 또는 연간 투여될 것이다. 본 명세서의 교시를 고려하여, 당업자는 질환 재발의 잠재성을 감소시키기 위해 바람직한 용량 및 투약 용법들을 쉽게 결정할 수 있다. 게다가, 상기 치료는 환자 반응 및 임상 변수와 진단 변수들에 따라 수주 동안, 수개월 동안, 수년 동안 또는 무기한으로 진행될 수 있다.
또 다른 바람직한 실시형태에서, 본 발명의 조절물질은 용적축소 절차 후 종양 전이의 가능성을 방지 또는 감소시키기 위한 보조 치료요법으로서 또는 예방적으로 사용될 수 있다. 본 명세서에 사용된 바와 같이, "용적축소 절차"는 종양 또는 종양 증식을 제거, 감소, 치료 또는 경감시키는 임의의 절차, 기술 또는 방법을 의미하며, 광범위하게 정의된다. 용적축소 절차들의 예로는 수술, 방사선 치료(즉, 빔 조사), 화학치료요법, 면역치료요법 또는 절개술을 포함하나 이에 제한되지 않는다. 본 명세서의 관점에서 당업자에 의해 쉽게 측정되는 적당한 시간에, 개시된 조절물질들은 종양전이를 감소시키기 위해, 임상적, 진단적 또는 치료적 과정들에 의해 제시된 바와 같이 투여될 수 있다. 조절물질들은 표준 기술들을 사용하여 측정된 바와 같이 약제학적 용량으로 1회 이상 투여될 수 있다. 바람직하게, 투약 용법은 변형시킬 적당한 진단 또는 모니터링 기술들에 의해 수행될 것이다.
본 발명의 또 다른 실시형태는 증식성 장애를 발생할 위험에도 무증상인 대상체들에게 개시된 조절물질들을 투여하는 것을 포함한다. 즉, 본 발명의 조절물질들은 진정한 예방 차원에 사용될 수 있으며, 검사 또는 시험된 환자들 및 하나 이상의 주지된 위험 인자들(예를 들면, 유전체 징후들, 가족력, 생체내 또는 시험관내 시험 결과 등)을 갖지만, 신생물이 발생하지 않은 환자들에게도 제공될 수 있다. 상기 경우, 당업자들은 경험적 관찰 또는 허용된 임상실습을 통해 효과적인 투약 용법을 결정할 수 있다.
일부 실시형태에서, SEZ6 조절물질은 백금계 제제(예를 들면, 카보플라틴, 시스플라틴 및/또는 옥살라플라틴)와 같은 다양한 제1선 SCLC 치료와 병용하여 사용될 수 있다. 한 실시형태에서, 병용 치료요법은 SEZ6 조절물질과 백금계 제제(예를 들면, 카보플라틴, 시스플라틴 및/또는 옥살라플라틴) 및 임의로 하나 이상의 기타 치료학적 모이어티(들)의 사용을 포함한다. 다른 실시형태에서, SEZ6 조절물질은 사이클로포스파미드 및 임의로 독소루비신 및/또는 빈크리스틴과 병용하여 사용될 수 있다. 또 다른 실시형태에서, SEZ6 조절물질은 에토포시드와 병용하여 사용될 수 있다. 추가 실시형태에서, SEZ6 조절물질은 토포테칸 또는 파클리탁셀과 병용하여 사용될 수 있다.
다른 실시형태에서, SEZ6 조절물질은 카보잔티닙 또는 반데타닙과 같은 다양한 제1선 수질 갑상선 치료와 병용하여 사용될 수 있다. 한 실시형태에서, 병용 치료요법은 SEZ6 조절물질과 카보잔티닙 및 임의로 하나 이상의 기타 치료학적 모이어티(들)의 사용을 포함한다. 다른 실시형태에서, 병용 치료요법은 SEZ6 조절물질과 반데타닙 및 임의로 하나 이상의 기타 치료학적 모이어티(들)의 사용을 포함한다.
병용 치료요법은 돌연변이된 또는 비정상적으로 발현된 유전자 또는 단백질(예를 들면, RET)을 포함하는 수질 갑상선 종양에 효과적인 다른 치료학적 모이어티와 병용된 SEZ6 조절물질을 포함할 수 있다. .
본 발명은 또한 SEZ6 조절물질과 방사선치료요법의 병용을 제공한다. 다른 실시형태에서, SEZ6 조절물질은 하기하는 하나 이상의 항암제와 병용하여 사용될 수 있다.
D.
항암제
용어 "항암제" 또는 "항-증식제"는 암과 같은 세포증식성 장애를 치료하기 위해 사용될 수 있는 임의의 제제를 의미하며, 세포독성제, 세포정지제, 항-혈관신생제, 용적축소 치료제, 화학요법제, 방사선요법 및 방사선 치료요법 치료제, 표적 항암제, BRM들, 치료용 항체들, 암 백신들, 사이토킨, 호르몬 치료요법, 방사선 치료요법 및 항-전이 치료제 및 면역치료제를 포함하나 이에 제한되지 않는다. 상기 논의된 선택된 실시형태에서, 상기 항암제들은 접합체들을 포함할 수 있으며, 투여되기 전에 조절물질들과 회합될 수 있음을 알 것이다. 특정 실시형태에서, 개시된 항암제는 SEZ6 조절물질에 연결되어, 본 명세서에 개시된 바와 같이 ADC를 제공할 것이다.
본 명세서에 사용된 용어 "세포독성제"는 세포에 대하여 독성이고 세포들의 기능을 감소 또는 저해하며/하거나, 세포들의 파괴를 야기하는 물질을 의미한다. 일반적으로, 물질은 살아있는 유기체로부터 유래된 천연발생 분자이다. 세포독성제의 예로는 세균의 소분자 독소 또는 효소적 활성 독소(예를 들면, 디프테리아 독소, 슈도모나스 내독소 및 외독소, 스타필로코커스 장독소 A), 진균(예를 들면, α-사신, 레스트릭토신(restrictocin)), 식물(예를 들면, 아브린, 라이신, 모데신, 비스쿠민, 포크위드(pokeweed) 항바이러스 단백질, 사포린, 겔로닌, 모모리딘, 트리코산틴, 보리 독소, 알레우리테스 포르디(Aleurites fordii) 단백질들, 디안틴 단백질들, 파이토라카 메리카나(Phytolacca mericana) 단백질들(PAPI, PAPII, 및 PAP-S), 모모르디카 차란티아(Momordica charantia) 저해제, 커신(curcin), 크로틴(crotin), 사포나리아 오피시날리스(saponaria officinalis) 저해제, 겔로닌, 미테겔린, 레스트릭토신(restrictocin), 페노마이신, 네오마이신 및 트리코테센(tricothecenes)) 또는 동물들(예를 들면, 세포독성 RNase, 예를 들면, 세포외 췌장 RNase; DNase I, 이들의 단편 및/또는 변이체를 포함)이 포함되나, 이에 제한되지 않는다.
본 발명의 목적을 위해, "화학요법제"는 암 세포들의 성장, 증식 및/또는 생존을 비특이적으로 감소시키거나 저해하는 화학 화합물(예를 들면, 세포독성제 또는 세포정지제)을 포함한다. 상기 화학요법제는 세포 성장 또는 분열에 필요한 세포내 과정들에 적용되며, 따라서 일반적으로 급속하게 성장 및 분열하는 암 세포들에 대하여 특히 효과적이다. 예를 들면, 빈크리스틴은 미소관들을 탈중합시켜서 세포가 유사분열되는 것을 저해한다. 일반적으로, 화학요법제는 암 세포 또는 암성으로 되기 쉽거나 발암성 자손(예를 들면, TIC)를 생성하기 쉬운 세포를 저해하거나, 저해하기 위해 설계된 화학요법제를 포함할 수 있다. 상기 요법제들은 종종 투여되며, CHOP 또는 FOLFIRI와 같은 용법에서 병용시 가장 효과적이다. 다시, 선택된 실시형태에서, 상기 화학요법제들은 개시된 조절물질들에 접합될 수 있다.
본 발명의 조절물질들과 병용(하거나 접합되어) 사용될 수 있는 항암제들의 예로는 알킬화제, 알킬 설포네이트, 아지리딘, 에틸렌이민 및 메틸아멜라민(methylamelamine), 아세토게닌(acetogenin), 캡토테신(camptothecin), 브리오스테틴(bryostatin), 칼리스테틴(callystatin), CC-1065, 크립토타이신(cryptophycins), 돌라스테틴(dolastatin), 듀오카르마이신(duocarmycin), 엘류테로빈(eleutherobin), 판크라티스테틴(pancratistatin), 사르코딕타인(sarcodictyin), 스폰기스테틴(spongistatin), 질소 머스타드(nitrogen mustards), 항생제(antibiotics), 에네다인(enediyne) 항생제, 다이네미신(dynemicin), 비스포스포네이트(bisphosphonates), 에스페라미신(esperamicin), 크로모단백질 에네다인 항생제 발색단(chromoprotein enediyne antiobiotic chromophores), 아클라시노마이신(aclacinomysin), 악티노마이신(actinomycin), 아우트라마이신(authramycin), 아자세린(azaserine), 블레오마이신(bleomycins), 칵티노마이신(cactinomycin), 카라비신(carabicin), 카르미노마이신(carminomycin), 카르지노필린(carzinophilin), 크로모마이시니스(chromomycinis), 닥티노마이신(dactinomycin), 다우노루비신(daunorubicin), 데토루비신(detorubicin), 6-디아조-5-옥소-L-놀류신, ADRIAMYCIN® 독소루비신, 에피루비신, 에소루비신, 이다루비신, 마르셀로마이신, 미토마이신, 미코페놀산, 노갈라마이신, 올리보마이신, 페플로마이신, 폿피로마이신(potfiromycin), 퓨로마이신(puromycin), 큐엘라마이신(quelamycin), 로도루비신(rodorubicin), 스트렙토니그린(streptonigrin), 스트렙토조신(streptozocin), 튜버시딘(tubercidin), 유베니멕스(ubenimex), 지노스테틴(zinostatin), 조로비신(zorubicin); 항-대사물질, 에르로티니브(erlotinib), 베무라페니브(vemurafenib), 크리조티니브(crizotinib), 소라페니브(sorafenib), 이브루티니브(ibrutinib), 엔잘루타미드(enzalutamide), 엽산 유사체, 푸린 유사체, 안드로겐, 항-아드레날, 엽산 보충물, 예를 들면 프롤린산, 아세글라톤(aceglatone), 알도포스파미드 글라이코시드(aldophosphamide glycoside), 아미노레불린산(aminolevulinic acid), 에닐우라실(eniluracil), 암사크린(amsacrine), 베스트라부실(bestrabucil), 비산트렌(bisantrene), 에다트락세이트(edatraxate), 데포파민(defofamine), 데메콜신(demecolcine), 디아지큐온(diaziquone), 엘포니틴(elfornithine), 엘립티늄 아세테이트(elliptinium acetate), 에포틸론(epothilone), 에토글루시드(etoglucid), 갈륨 나이트레이트(gallium nitrate), 하이드록시우레아(hydroxyurea), 레티난(lentinan), 로니다이닌(lonidainine), 마이탄시노이드(maytansinoids), 미토구아존(mitoguazone), 미톡산트론(mitoxantrone), 모피단몰(mopidanmol), 나이트라에린(nitraerine), 펜토스타틴(pentostatin), 페나메트(phenamet), 피라루비신(pirarubicin), 로속산트론(losoxantrone), 포도필린산(podophyllinic acid), 2-에틸하이드라지드, 프로카르바진(procarbazine), PSK® 폴리사카라이드 접합체(JHS Natural Products, Eugene, OR), 라족세인(razoxane); 리족신(rhizoxin); 시조피란(sizofiran); 스피로게르마늄(spirogermanium); 테누아존산(tenuazonic acid); 트리아지큐온(triaziquone); 2,2',2"-트리클로로트리에틸아민; 트리코테센(특히 T-2 독소, 베라큐린 A, 로리딘 A 및 안귀딘); 우레탄; 빈데신(vindesine); 다카르바진(dacarbazine); 만노무스틴(mannomustine); 미토브로니톨(mitobronitol); 미톨락톨(mitolactol); 피포브로만(pipobroman); 가시토신(gacytosine); 아라비노시드("Ara-C"); 시클로포스파미드; 티오테파; 탁소이드, 클로란부실; GEMZAR® 겜시타빈(gemcitabine); 6-티오구아닌; 머캅토푸린; 메토트렉세이트; 백금 유사체, 빈블라스틴; 백금; 에토포시드(VP-16); 이포스파미드; 미톡산트론; 빈크리스틴; NAVELBINE®비노렐빈; 노반트론; 테니포시드; 에다트렉세이트; 다우노마이신; 아미노프테린(aminopterin); 크셀로다(xeloda); 이반드로네이트(ibandronate); 이리노테칸(irinotecan)(Camptosar, CPT-11), 토포이소머라제 저해제 RFS 2000; 다이플루오로메틸오르니틴; 레티노이드들; 카페시타빈(capecitabine); 콤브레타스타틴(combretastatin); 류코보린(leucovorin); 옥살리플라틴(oxaliplatin); 세포증식을 감소시키는 PKC-알파, Raf, H-Ras, EGFR 및 VEGF-A의 저해제 및 이들 중 어느 하나의 약제학적으로 허용되는 염들, 산 또는 유도체들이 포함되며, 여기에 제한되지 않는다. 또한, 이 정의에 종양 상에서의 호르몬 작용을 조절 또는 저해하는 항-호르몬제, 예를 들면 항-에스트로겐 및 선택적 에스트로겐 수용체 조절물질, 부신에서의 에스트로겐 생성을 조절하는 효소 아로마타제를 저해하는 아로마타제 저해제 및 항-안드로겐; 뿐만 아니라 트록사시타빈(troxacitabine)(1,3-디옥솔란 뉴클레오시드 사이토신 유사체); 안티센스 올리고뉴클레오타이드, 리보자임, 예를 들면 VEGF 발현 저해제 및 HER2 발현 저해제; 백신, PROLEUKIN®rIL-2; LURTOTECAN®토포아이소머라제 1 저해제; ABARELIX®rmRH; 비노렐빈(Vinorelbine) 및 에스페라미신(Esperamicins) 및 이들 중 어느 하나의 약제학적으로 허용되는 염, 산 또는 유도체들이 포함된다.
다른 실시형태에서, 본 발명의 조절물질들은 현재 임상실험중이거나 상업적으로 입수가능한 수많은 항체들(또는 면역요법제) 중 어느 하나와 병용하여 사용될 수 있다. 이 때문에, 개시된 조절물질들은 아바고보맵(abagovomab), 아데카투무맵(adecatumumab), 아푸투주맵(afutuzumab), 알렘투주맵(alemtuzumab), 알투모맵(altumomab), 아마툭시맵(amatuximab), 아나투모맵(anatumomab), 아르시투모맵(arcitumomab), 바비툭시맵(bavituximab), 벡투모맵(bectumomab), 베바시주맵(bevacizumab), 비바투주맵(bivatuzumab), 블리나투모맵(blinatumomab), 브렌툭시맵(brentuximab), 칸투주맵(cantuzumab), 카투맥소맵(catumaxomab), 세툭시맵(cetuximab), 시타투주맵(citatuzumab), 식수투무맵(cixutumumab), 클리바투주맵(clivatuzumab), 코나투무맵(conatumumab), 다라투무맵(daratumumab), 드로지투맵(drozitumab), 둘리고투맵(duligotumab), 두시기투맵(dusigitumab), 데투모맵(detumomab), 다세투주맵(dacetuzumab), 달로투주맵(dalotuzumab), 에크로멕시맵(ecromeximab), 엘로투주맵(elotuzumab), 엔시툭시맵(ensituximab), 에르투맥소맵(ertumaxomab), 에타라시주맵(etaracizumab), 팔레투주맵(farletuzumab), 피클라투주맵(ficlatuzumab), 피기투무맵(figitumumab), 플라보투맵(flanvotumab), 푸툭시맵(futuximab), 가니투맵(ganitumab), 겜투주맵(gemtuzumab), 기렌툭시맵(girentuximab), 글렘바투무맵(glembatumumab), 이브리투모맵(ibritumomab), 이고보맵(igovomab), 임가투주맵(imgatuzumab), 인다툭시맵(indatuximab), 이노투주맵(inotuzumab), 인테투무맵(intetumumab), 이플리무맵(ipilimumab), 이라투무맵(iratumumab), 라베투주맵(labetuzumab), 렉사투무맵(lexatumumab), 린투주맵(lintuzumab), 로보투주맵(lorvotuzumab), 루카투무맵(lucatumumab), 마파투무맵(mapatumumab), 마투주맵(matuzumab), 밀라투주맵(milatuzumab), 민레투모맵(minretumomab), 미투모맵(mitumomab), 목세투모맵(moxetumomab), 나르나투맵(narnatumab), 납투모맵(naptumomab), 네시투무맵(necitumumab), 니모투주맵(nimotuzumab), 노페투모맵(nofetumomab), 오카라투주맵(ocaratuzumab), 오파투무맵(ofatumumab), 올라라투맵(olaratumab), 오나투주맵(onartuzumab), 오포투주맵(oportuzumab), 오레고보맵(oregovomab), 패니투무맵(panitumumab), 파사투주맵(parsatuzumab), 파트리투맵(patritumab), 펨투모맵(pemtumomab), 퍼투주맵(pertuzumab), 핀투모맵(pintumomab), 프리투무맵(pritumumab), 라코투모맵(racotumomab), 라드레투맵(radretumab), 릴로투무맵(rilotumumab), 리툭시맵(rituximab), 로바투무맵(robatumumab), 사투모맵(satumomab), 시브로투주맵(sibrotuzumab), 실툭시맵(siltuximab), 심투주맵(simtuzumab), 솔리토맵(solitomab), 타카투주맵(tacatuzumab), 타플리투모맵(taplitumomab), 테나투모맵(tenatumomab), 테프로투무맵(teprotumumab), 티가투주맵(tigatuzumab), 토시투모맵(tositumomab), 트라스투주맵(trastuzumab), 투코투주맵(tucotuzumab), 우블리툭시맵(ublituximab), 벨투주맵(veltuzumab), 보르세투주맵(vorsetuzumab), 보투무맵(votumumab), 잘루투무맵(zalutumumab), CC49, 3F8 및 이들의 조합으로 이루어진 그룹으로부터 선택되는 항체와 병용하여 사용될 수 있다.
여전히 다른 특히 바람직한 실시형태들은 리툭시맵(rituximab), 트라스투주맵(trastuzumab), 겜투주맵 오조감신(gemtuzumab ozogamcin), 알렘투주맵(alemtuzumab), 이브리투모맵 티욱세탄(ibritumomab tiuxetan), 토시투모맵(tositumomab), 베바시주맵(bevacizumab), 세툭시맵(cetuximab), 파니투무맵(panitumumab), 오파투무맵(ofatumumab), 이필리무맵(ipilimumab) 및 브렌툭시맵 베도틴(brentuximab vedotin)을 포함하나 이에 제한되지 않는 암 치료요법용으로 승인된 항체들을 사용하는 것을 포함할 것이다. 당업자들은 본 명세서의 교시와 양립되는 추가의 항암제들을 쉽게 동정할 수 있을 것이다.
E.
방사선치료요법
본 발명은 조절물질들과 방사선치료요법(즉, 감마-조사, X-선, UV-조사, 마이크로파, 전자방출 등과 같이, 종양세포내에 국소적으로 DNA 손상을 유도하기 위한 기작)의 병용을 제공한다. 종양 세포에 방사성동위원소를 직접 전달하는 것을 사용하는 병용 치료요법도 또한 고려되며, 표적화 항암제 또는 다른 표적화 수단들과 관련되어 사용될 수 있다. 일반적으로, 방사선 치료요법은 약 1주 내지 약 2주 동안 주기적으로 투여된다. 방사선치료요법은 약 6주 내지 7주 동안 두경부암 대상체들에게 투여될 수 있다. 임의로, 방사선치료요법은 단일 선량으로 또는 다수의 순차적 선량으로 투여될 수 있다.
XI. 징후
본 발명의 조절물질은 임의의 SEZ6 관련 장애의 발생 또는 재발을 진단, 치료 또는 저해하는데 사용될 수 있음을 알 것이다. 따라서, 단독으로 투여되던지 또는 항암제 또는 방사선치료요법과 병용 투여되든지, 본 발명의 조절물질들은 양성 또는 악성 종양들(예를 들면, 부신, 간, 신장, 방광, 유방, 위장, 난소, 결장직장, 전립선, 췌장, 폐, 갑상선, 간, 자궁경부, 자궁내막, 식도 및 자궁 암종들; 육종들; 교아종들; 및 다양한 두경부 종양들); 백혈병 및 림프구 악성종양들; 다른 장애들, 예를 들면 뉴런, 신경교, 성상세포, 시상하부 및 다른 선, 대식세포, 상피, 기질 및 포배강 장애들; 및 염증성, 혈관신생, 면역학적 장애들 및 병원체에 의해 유발된 장애들을 포함하는 환자 또는 대상체들의 신생물성 병태들을 일반적으로 치료하기 위해 유용하다. 본 발명의 범주 내에 혈액 악성종양이 있더라도, 특히, 치료를 위한 중요한 표적은 고형 종양을 포함하는 신생물성 병태들이다. 치료되는 "대상체" 또는 "환자"는 본 명세서에 사용된 바와 같이, 특정 포유동물 종들을 포함하지만, 바람직하게는 사람일 것이다.
보다 특이적으로, 본 발명에 따라서 치료되는 신생물성 병태들은 부신 종양, AIDS-관련 암, 포상 연부 육종, 성상세포 종양, 방광암(편평세포 암종 및 이행세포 암종), 골암(법랑질종, 동맥류성 골낭종, 골연골종, 골육종), 뇌 및 척수암, 전이성 뇌종양, 유방암, 경동맥체 종양, 자궁경부암, 연골육종, 척삭종, 난염성 신장 세포 암종, 투명세포 암종, 결장암, 결장직장암, 피하 양성 섬유성 조직구종, 결합조직형성 소규모 원형세포종양, 상의세포종, 유잉 종양, 골외 점액성 연골육종, 골성 불완전 섬유생성증, 뼈의 섬유성골 이형성, 담낭암 및 담도암, 임신성 영양아층증, 생식세포 종양, 두경부암, 도세포 종양, 카포시 육종, 신장암(신아세포종, 유두상 신세포암), 백혈병, 지방종/양성 지방종성 종양, 지방육종/악성 지방종성 종양, 간암(간아세포종, 간세포 암종), 림프종, 폐암(소세포암종, 선암, 편평세포암, 대세포암 등), 수모세포종, 흑색종, 수막종, 복합 내분비선 신생물, 다발성 골수종, 골수 이형성 증후군, 신경아세포종, 신경내분비 종양, 난소암, 췌장암, 유두상 갑상선암, 부갑상선 종양, 소아과 암, 말초 신경초 종양, 크롬친화세포종, 뇌하수체 종양, 전립선암, 후부 포도막 흑색종(posterious unveal melanoma), 희귀 혈액학적 장애, 전이 신암, 간상소체 종양, 횡문근육종, 육종, 피부암, 연질-조직 육종, 편평세포암, 위암, 활막육종, 고환암, 흉선암, 흉선종, 전이 갑상선암, 및 자궁암(자궁경부의 암종, 자궁내막 암종 및 평활근종)으로 이루어진 그룹으로부터 선택될 수 있지만, 이들에 제한되지 않는다.
특정 바람직한 실시형태에서, 증식성 장애는 부신암, 간암, 신장암, 방광암, 유방암, 위암, 난소암, 자궁경부암, 자궁암, 식도암, 직장암, 전립선암, 췌장암, 폐암(소세포 및 비소세포 둘 다), 갑상선암, 암종, 육종, 교아종 및 여러 두경부 종양을 포함하나 이에 제한되지 않는 고형 종양을 포함할 것이다. 다른 바람직한 실시형태에서, 하기 실시예에 나타난 바와 같이, 개시된 조절물질들은 소세포 폐암(SCLC) 및 비-소세포 폐암(NSCLC)(예를 들면, 편평세포 비-소세포 폐암 또는 편평세포 소세포 폐암)을 치료하는데 특히 효과적이다.
한 실시형태에서, 소세포 또는 비소세포 폐암은 탁산(예를 들면, 도세탁셀, 파클리탁셀, 라로탁셀 또는 카바지탁셀) 및/또는 백금계 제제(예를 들면, 카보플라틴, 시스플라틴, 옥살리플라틴, 토포테칸 등)에 대해 불응성, 재발성 또는 내성이다. 백금계 제제와 관련하여, SCLC를 위한 주요 표준 관리 화학치료요법은 병용된 시스플라틴과 에토포시드이다. 치료 과정 후에, 많은 환자들은 백금계 제제에 대해 내성이 된다[참조: Stewart, 2004; PMID: 20047843]. 다른 여러 기작들 중에서, 막 조성의 변화, 저산소상태 증가, 구리 전달체 유전자 발현의 감소 및 다제 내성 유전자 발현의 증가를 포함하여 백금계 약물에 대한 다수의 내성 기작이 있다. 대부분의 SCLC 환자들이 우선 표준 관리 치료로 치료될 것이라는 점을 고려하면, 본 발명의 일부 실시형태에서, 본 명세서에 개시된 항체들은 반응하지 못했거나 재발된 환자들을 치료하는데 사용할 수 있다. 초기 백금 반응성은 높지만, 대다수의 암 환자들은 결국에는 시스플라틴-내성 질환이 재발될 것이다. 특히 바람직한 실시형태에서, 개시된 조절물질들은 소세포 폐암을 치료하기 위해 접합된 형태로 사용될 수 있다. 다른 바람직한 실시형태에서, 개시된 조절물질들은 이를 필요로 하는 대상체에서 백금 내성 소세포 폐암을 치료하기 위해 접합된 형태로 사용될 수 있다. 소세포 폐암과 관련하여, 특히 바람직한 실시형태는 접합된 조절물질들의 투여(ADC)를 포함할 것이다. 선택된 실시형태에서, 접합된 조절물질들은 제한된 병기 질환을 나타내는 환자들에게 투여될 것이다. 다른 실시형태에서, 개시된 조절물질들은 광범위한 병기의 질환을 나타내는 환자들에게 투여될 것이다. 다른 바람직한 실시형태에서, 개시된 접합된 조절물질들은 불응성 환자들(즉, 초기 치료요법 과정 동안 또는 완료 직후 재발한 환자들)에게 투여될 것이다. 또 다른 실시형태는 민감한 환자들(즉, 1차 치료요법 후 2 내지 3개월 이상 경과한 환자들)에게 개시된 조절물질들을 투여하는 단계를 포함한다. 각 경우에, 적합한 조절물질들은 선택된 투약 용법 및 임상 진단에 따라 접합된 또는 비접합된 상태가 될 수 있음을 이해할 수 있을 것이다.
상기 논의된 바와 같이, 개시된 조절물질들은 신경내분비 종양을 포함하는 신경내분비 특성들 또는 표현형들을 갖는 종양을 예방, 치료 또는 진단하기 위해 추가로 사용될 수 있다. 분산성 내분비계로부터 발생하는 진성의 또는 전형적인 신경내분비 종양들(NET)은 100,000명 당 2-5명이 발병할 정도로 비교적 희귀하지만, 매우 공격적이다. 내분비 종양은 신장, 비뇨생식관(방광, 전립선, 난소, 자궁경부 및 자궁내막), 위장관(결장, 위), 갑상선(갑상선 수질암), 및 폐(소세포 폐 암종 및 대세포 신경내분비 암종)에서 발생한다. 이러한 종양들은 카르시노이드 증후군으로 공지된 쇠약 증상들을 유발시킬 수 있는 세로토닌 및/또는 크로모그라닌 A를 포함하는 여러 호르몬들을 분비할 수 있다. 상기 종양들은 양성 면역조직화학 마커, 예를 들면 뉴런-특이적 에놀라제(NSE, 감마 에놀라제라고도 공지되어 있음, 유전자 기호 = ENO2), CD56(또는 NCAM1), 크로모그라닌 A(CHGA) 및 시냅토파이신(SYP)에 의해, 또는 ASCL1과 같은 높은 발현을 나타내는 것으로 공지된 유전자들에 의해 나타낼 수 있다. 불행히도, 전통적인 화학치료요법은 NET들을 치료하는데 특히 효과적이지 않으며, 간 전이가 흔한 결과이다.
본 발명의 일부 실시형태에서, 치료학적 모이어티에 직접 또는 간접적으로 접합되었고 SEZ6에 특이적으로 결합하는 항체를 포함하는 항체 약물 접합체들은 암(예를 들면, 수질 갑상선암)을 앓는 대상체를 치료하는데 사용할 수 있다. 바람직한 실시형태에서, 암(예를 들면, 수질 갑상선암)을 치료하는데 사용되는 항체 약물 접합체는 도 10a에 제시된 3개의 CDR을 포함하는 경쇄 가변 영역 및 도 10b에 제시된 3개의 CDR을 포함하는 중쇄 가변 영역을 포함하는 항-SEZ6 항체를 포함할 것이다. 다른 실시형태에서, 암(예를 들면, 수질 갑상선암)을 치료하는데 사용되는 항체 약물 접합체는 도 10a 및 10b에 제시된 경쇄 및 중쇄 가변 영역들을 포함하는 항-SEZ6 항체들과 경쟁할 수 있다. 또 다른 실시형태에서, 암(예를 들면, 수질 갑상선암)을 치료하는데 사용되는 항체 약물 접합체는 사람화된 항-SEZ6 항체, 예를 들면, 도 10a 및 10b에 제시된 hSC17.16, hSC17.17, hSC17.24, hSC17.28, hSC17.34, hSC17.46, hSC17.151, hSC17.155, hSC17.156, hSC17.161 및 hSC17.200 및 이러한 사람화된 항체들과 경쟁하는 임의의 항체들을 포함할 수 있다. 본 발명의 다른 실시형태에서, 치료학적 모이어티에 직접 또는 간접적으로 접합되었고 SEZ6에 특이적으로 결합하는 항체를 포함하는 항체 약물 접합체는 소세포 폐암(예를 들면, 백금 내성 소세포 폐암)을 앓는 대상체를 치료하는데 사용될 수 있다. 바람직한 실시형태에서, 소세포 폐암(예를 들면, 백금 내성 소세포 폐암)을 앓는 대상체를 치료하는데 사용되는 항체 약물 접합체는 사람화된 항-SEZ6 항체, 예를 들면, 도 10a 및 10b에 제시된 hSC17.16, hSC17.17, hSC17.24, hSC17.28, hSC17.34, hSC17.46, hSC17.151, hSC17.155, hSC17.156, hSC17.161 및 hSC17.200 및 이러한 사람화된 항체들과 경쟁하는 임의의 항체들을 포함할 수 있다. 바람직한 실시형태에서, 소세포 폐암을 앓는 대상체는 이미 백금계 제제로 치료될 수 있다.
개시된 조절물질들이 신경내분비 종양들을 치료하는데 유리하게 사용될 수 있지만, 이들은 전형적인 전형적인 신경내분비 종양을 유전자형으로 또는 표현형으로 모사하고 전형적인 신경내분비 종양과 공통된 특성들을 나타내는 가성 신경내분비 종양(pNET)들을 치료, 예방 또는 진단하는데 사용될 수도 있다. 가성 신경내분비 종양 또는 신경내분비 특성들을 갖는 종양들은 확산성 신경내분비계의 세포들, 또는 신경내분비 분화 캐스케이드가 종양형성 과정 동안 비정상적으로 재활성된 세포들로부터 발생되는 종양들이다. 상기 pNETs는 생물학적으로 활성인 아민, 신경전달물질들 및 펩타이드 호르몬의 서브세트를 생성할 수 있는 능력을 포함하는, 일반적으로 정의된 신경내분비 종양과 특정 표현형 또는 생화학적 특성들을 통상 공유한다. 조직학적으로, 상기 종양들(NETs 및 pNETs)은 단조로운 세포병리학의 최소한의 세포질 및 원형 내지 타원형의 점묘형 핵을 갖는 조밀하게 연결된 소세포들을 종종 나타내는 공통된 겉모습을 공유한다. 본 발명의 목적을 위해, 신경내분비 및 가성 신경내분비 종양을 정의하는데 사용될 수 있는, 일반적으로 발현된 조직학적 마커 또는 유전학적 마커는 크로모그라닌 A, CD56, 시냅토파이신, PGP9.5, ASCL1 및 뉴런-특이적 에놀라제(NSE)를 포함할 수 있으나 이에 제한되지 않는다.
따라서, 본 발명의 조절물질들은 가성 신경내분비 종양 및 전형적인 신경내분비 종양 둘 다를 치료하기 위해 유익하게 사용될 수 있다. 이와 관련하여, 본 명세서에 기술된 바와 같이 조절물질들이 신장, 비뇨생식관(방광, 전립선, 난소, 자궁경관, 및 자궁내막), 위장관(직장, 위), 갑상선(갑상선 수질암), 및 폐(소세포 폐암종 및 대세포 신경내분비 암종)에서 발생하는 신경내분비 종양들(NET 및 pNET 둘 다)을 치료하기 위해 사용될 수 있다. 게다가, 본 발명의 조절물질들은 NSE, CD56, 시냅토파이신, 크로모그라닌 A, ASCL1 및 PGP9.5(UCHL1)로 이루어진 그룹으로부터 선택되는 하나 이상의 마커들을 발현하는 종양들을 치료하기 위해 사용될 수 있다. 즉, 본 발명은 NSE+ 또는 CD56+ 또는 PGP9.5+ 또는 ASCL1+ 또는 SYP+ 또는 CHGA+ 또는 이들의 조합인 종양을 앓는 대상체를 치료하기 위해 사용될 수 있다.
혈액 악성종양들에 관련하여, 본 발명의 화합물들 및 방법들이 저급/NHL 여포성 림프종(FCC), 외투세포 림프종(MCL), 확산성 대세포성 림프종(DLCL), 소림프구(SL) NHL, 중급/여포 NHL, 중간 등급 확산된 NHL, 고급 면역아세포성 NHL, 고급 림프아세포성 NHL, 고급 소형 비-분해 세포 NHL, 거대 종양(bulky disease) NHL, 발덴스트롬 마크로글로불린혈증(Waldenstrom's Macroglobulinemia), 림프형질세포성 림프종(LPL), 외투세포 림프종(MCL), 여포성 림프종(FL), 확산성 대세포 림프종(DLCL), 버키트 림프종(Burkitt's lymphoma)(BL), AIDS-관련 림프종, 단핵구성 B세포 림프종, 혈관면역모세포 림프절병증, 소림프구성, 여포성, 확산성 대세포, 확산성 소형 분해세포, 대세포 면역모세포종 림프아세포종, 소형, 비-분해된, 버키트(Burkitt's) 및 비-버키트(non-Burkitt's), 여포성, 대부분 대세포; 여포성, 대부분 소형 분해세포; 및 여포성, 혼합된 소형 분해 및 대형 세포 림프종을 포함하는 다양한 B-세포 림프종을 치료하는데 특히 효과적일 수 있음을 알 것이다[참조: Gaidono et al., "Lymphomas", IN CANCER: PRINCIPLES & PRACTICE OF ONCOLOGY, Vol. 2: 2131-2145 (DeVita et al., eds., 5.sup.th ed. 1997]. 상기 림프종이 분류 체계의 변화로 인해 상이한 명칭들을 종종 가질 것이고, 상이한 명칭으로 분류된 림프종을 갖는 환자들도 본 발명의 병용 치료 용법으로부터 이익을 얻을 수 있음이 당업자에게는 분명해 질 것이다.
본 발명은 또한, 양성 또는 전암성 종양 소견을 나타내는 대상체의 보존적 또는 예방적 치료를 제공한다. SEZ6 관련 장애 이외에, 특정 종류의 종양 또는 증식성 장애가 본 발명을 사용하는 치료로부터 배제되어야 한다고 생각되지 않는다. 그러나, 종양세포의 종류는 2차 치료제들, 특히 화학요법제 및 표적화 항암제들과 병용하여 본 발명의 용도와 관련될 수 있다.
XII. 연구 시약
본 발명의 다른 바람직한 실시형태는 또한, 유세포분석법, 형광 활성화 세포분류(FACS), 자기 활성화 세포분류(MACS) 또는 레이저 매개 분할과 같은 방법들을 통해 종양 개시 세포들의 집단 또는 아집단을 동정하거나, 모니터링하거나, 단리하거나, 분할하거나 또는 증대시키는데 유용한 도구로서 개시된 조절물질들의 특성들을 이용한다. 당업자라면 조절물질들이 암 줄기 세포들을 포함하는 TIC를 특성평가하고 조작하기 위한 여러 적합한 기술들에 사용될 수 있음을 이해할 것이다(예를 들면, U.S.S.N. 제12/686,359호, 제12/669,136호 및 제12/757,649호를 참조하며, 이들은 각각 본원에 참조로 포함된다).
XIII. 제조 물품들
하나 이상의 용량의 SEZ6 조절물질을 포함하는, 하나 이상의 내용물들을 포함하는 약제학적 팩 및 키트도 또한 제공된다. 특정 실시형태에서, 하나 이상의 부가적 치료제들과 함께 또는 없이 예를 들면, 항-SEZ6 항체를 포함하는 예정된 양의 조성물을 함유하는 단위 용량이 제공된다. 다른 실시형태에 있어, 상기 단위 용량은 1회용 사전충전형 주사용 주사기에 공급된다. 또 다른 실시형태에서, 단위 용량에 함유된 조성물은 식염수, 수크로오스 등; 포스페이트와 같은 완충제 등을 포함할 수 있고/있거나; 안정적이고 유효한 pH 범위 내에서 제형화될 수 있다. 대안적으로, 특정 실시형태에서, 조성물은 멸균수와 같은 적당한 액체의 첨가시 재구성될 수 있는 동결건조 분말로서 제공될 수 있다. 특정 바람직한 실시형태에서, 조성물은 수크로오스 및 아르기닌을 포함하나 이에 제한되지 않는 단백질 응집을 저해하는 하나 이상의 물질들을 포함한다. 용기(들)와 관련된 또는 용기(들)상의 임의의 라벨은 담겨진 조성물이 선택된 질환 상태를 진단 또는 치료하기 위해 사용됨을 나타낸다.
본 발명은 또한 SEZ6 조절물질 및 임의로 하나 이상의 항암제들의 단일-투여 또는 다중-투여 단위를 생성하기 위한 키트를 제공한다. 상기 키트는 용기 및 라벨 또는 용기와 회합되거나 패키지 삽입을 포함한다. 적합한 용기들은 예를 들면 병, 바이알, 주사기 등을 포함한다. 용기들은 유리 또는 플라스틱과 같은 다양한 재료들로 제조될 수 있으며, 접합체 또는 비접합체 형태의 개시된 조절물질들의 약제학적 유효량을 함유할 수 있다. 다른 바람직한 실시형태에서, 용기(들)은 멸균 접촉포트(예를 들면, 용기는 피하 주사바늘에 의해 뚫을 수 있는 스토퍼를 갖는 바이알 또는 정맥내 용액 백일 수 있다)를 포함한다. 상기 키트들은 일반적으로 적당한 용기 내에 SEZ6 조절물질의 약제학적으로 허용되는 제형 및 임의로 동일하거나 상이한 용기에 하나 이상의 항암제들을 함유할 것이다. 상기 키트들은 진단 또는 병용 치료요법을 위해 다른 약제학적으로 허용되는 제형을 함유할 수도 있다. 예를 들면, 본 발명의 SEZ6 조절물질 이외에, 상기 키트들은 화학요법 또는 방사선요법 약물과 같은 항암제; 항-혈관신생제; 항-전이제; 표적화 항암제; 세포독성제; 및/또는 다른 항암제들과 같은 광범위한 항암제 중 어느 하나를 함유할 수 있다. 상기 키트들은 또한, SEZ6 조절물질을 항암제 또는 진단제와 접합하기에 적당한 시약들을 제공할 수 있다(예를 들면, 미국 특허 제7,422,739호 참조, 본원에 전부 참조로 포함됨).
보다 구체적으로, 키트들은 추가의 성분들과 함께 또는 없이 SEZ6 조절물질을 함유하는 단일 용기를 가지거나, 각각 원하는 제제를 위한 별개의 용기들을 가질 수 있다. 병용 치료제들이 접합을 위해 제공되는 경우, 단일 용액은 몰당량 조합으로 또는 한 성분과 과량의 다른 성분과 함께 미리 혼합될 수 있다. 대안적으로, SEZ6 조절물질 및 키트의 임의의 항암제는 환자에게 투여하기 전에 구별된 용기들 내에서 유지될 수 있다. 키트들은 또한, 주사용 정균수(BWFI), 포스페이트-완충 식염수(PBS), 링거액 및 덱스트로오스 용액과 같은 멸균의 약제학적으로 허용되는 완충제 또는 다른 희석제를 함유하기 위한 제2/제3 용기 수단을 포함할 수 있다.
키트의 성분들이 하나 이상의 액체 용액으로 제공될 경우, 액체 용액은 수용액인 것이 바람직하며, 멸균 수용액이 특히 바람직하다. 그러나, 키트의 성분들은 건조 분말(들)로서 제공될 수 있다. 시약들 또는 성분들이 건조 분말로 제공되는 경우, 분말은 적당한 용매를 첨가함으로써 재구성될 수 있다. 용매가 다른 용기내에 제공될 수도 있다.
앞서 간략히 기술된 같이, 키트들은 동물 또는 환자에게 항체 및 임의의 선택적 성분들을 투여하는 수단들, 예를 들면 하나 이상의 바늘 또는 주사기, 또는 점적기, 피펫 또는 다른 상기 유사 기구를 포함할 수도 있으며, 제형은 동물에게 주사 또는 도입되거나, 신체의 환부에 적용될 수 있다. 본 발명의 키트들은 또한 일반적으로 바이알 등을 포함하기 위한 수단들 및 원하는 바이알 및 다른 장치들이 위치 및 보유된 주입식 또는 사출성형식 플라스틱 용기들과 같이, 상업적으로 시판되는 좁은 공간의 다른 요소를 포함할 것이다. 특정 라벨 또는 패키지 삽입물은 SEZ6 조절물질 조성물이 암, 예를 들면 소세포 폐암을 치료하는데 사용됨을 보여준다.
다른 바람직한 실시형태에서, 본 발명의 조절물질들은 증식성 장애들을 진단 또는 치료하는데 유용한 진단 또는 치료 장치들과 함께 사용되거나 이들을 포함할 수 있다. 예를 들면, 바람직한 실시형태에서, 본 발명의 화합물 및 조성물은 증식성 장애의 병인 또는 발현에 관여된 세포들 또는 마커를 검출, 모니터링, 정량화 또는 프로파일링하는데 사용될 수 있는 특정 진단 장치 또는 장비와 조합될 수 있다. 선택된 실시형태를 위해, 마커 화합물은 NSE, CD56, 시냅토파이신, 크로모그라닌 A, 및 PGP9.5를 함유할 수 있다.
특히 바람직한 실시형태에서, 장치들이 생체내 또는 시험관내에서 순환하는 종양 세포들을 검출, 모니터링 및/또는 정량화하기 위해 사용될 수 있다(예를 들면, WO 2012/0128801을 참조하며, 이는 본원에 참조로 포함됨). 또 다른 바람직한 실시형태에서, 그리고 상기 논의된 바와 같이, 순환하는 종양세포들은 암 줄기세포를 포함할 수 있다.
XIV. 기타 사항들
본 명세서에서 달리 정의되지 않는 한, 본 발명과 관련되어 사용된 과학적, 기술적 용어들은 당업자들에게 일반적으로 이해되는 의미들을 가질 것이다. 그리고, 본 명세서에서 달리 요구되지 않는 한, 단수 용어는 복수를 포함할 것이며, 복수 용어는 단수를 포함할 것이다. 보다 구체적으로, 본 명세서 및 첨부된 청구범위에 사용된 바와 같이, 단수 형태 부정관사 정관사("a", "an" 및 "the")는 달리 명확하게 기술하지 않는 한 복수를 포함한다. 따라서, 예를 들면, "단백질"에 대한 언급은 복수의 단백질들을 포함하며; "세포"에 대한 언급은 세포들의 혼합물들을 포함한다. 게다가, 본 명세서 및 첨부된 청구범위에 제공된 범위들은 상한과 하한, 및 상한과 하한 사이의 모든 지점들을 포함한다. 그러므로, 2.0 내지 3.0의 범위는 2.0, 3.0, 및 2.0과 3.0 사이의 모든 지점들을 포함한다.
일반적으로, 본 명세서에 기술된 세포 및 조직 배양, 분자생물학, 면역학, 미생물학, 유전학 및 단백질 및 핵산 화학 및 하이브리드화와 관련되어 사용된 명명법들 및 기술들은 당해 분야에 익히 공지된 것들이며, 당해 분야에서 일반적으로 사용된 것들이다. 본 발명의 방법들 및 기술들은 당해 분야에 익히 공지된 종래의 방법들에 따라, 그리고 달리 지시되지 않는 한 본 명세서 전체에 인용 및 기술된 다양한 일반적인 및 더욱 구체적인 참조문헌들에 기술된 바와 같이 수행된다. 예를 들면, 문헌[참조: Abbas et al., Cellular and Molecular Immunology, 6th ed., W.B. Saunders Company (2010); Sambrook J. & Russell D. Molecular Cloning: A Laboratory Manual, 3rd ed., Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y. (2000); Ausubel et al., Short Protocols in Molecular Biology: A Compendium of Methods from Current Protocols in Molecular Biology, Wiley, John & Sons, Inc. (2002); Harlow and Lane Using Antibodies: A Laboratory Manual, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y. (1998); 그리고 Coligan et al., Short Protocols in Protein Science, Wiley, John & Sons, Inc. (2003)]을 참조한다. 효소 반응 및 정제 기술들은 당해 분야에서 통상적으로 수행되거나 본 명세서에 기술된 바와 같이 제조업자의 지시에 따라 수행된다. 본 명세서에 기술된 분석화학, 합성 유기화학, 및 의약 및 약제 화학과 관련되어 사용된 명명법 및 실험과정들 및 기술들은 익히 공지되어 있는 것들이며, 당해 분야에 일반적으로 사용된 것들이다. 게다가, 본 명세서에 사용된 섹션 제목들은 구성적인 목적일 뿐, 본 명세서의 주제를 제한하기 위한 것은 안된다.
XV. SEZ6 참조문헌들
본 명세서에 개시되거나 인용된 모든 참조문헌들 또는 기록들은, 제한 없이, 그 전체가 참조로 본원에 포함되어 있다. 더욱이, 본 명세서에서 사용된 어떠한 항목 제목들이라도 구성상의 목적들만을 위한 것이며 기술된 주제대상을 한정하는 것으로 해석되지 않아야 한다.


XVI. 서열목록 요약
수많은 핵산 및 아미노산 서열을 포함하는 서열목록이 본 출원에 첨부된다. 하기 표 2는 포함된 서열의 요약을 제공한다.



XVII. 본 발명의 선택된 실시형태들
본원의 개시내용 외에도, 본 발명은 바로 하기에 구체적으로 기재된 선택된 실시형태들에 관한 것이기도 하다.
실시예
따라서, 상기 일반적으로 기술된 본 발명은 하기 실시예들을 참조하여 보다 쉽게 이해될 것이며, 이는 예시의 방법으로 제공되며 본 발명을 한정하기 위한 것은 아니다. 본 실시예들은 하기 실험예들이 수행된 모든 또는 유일한 실험들임을 나타내기 위한 것이 아니다. 달리 나타내지 않는 한, 부는 중량부이며, 분자량은 중량평균 분자량이며, 온도는 섭씨 온도이고, 압력은 대기압이거나 또는 대기압 부근이다.
실시예 1
신경내분비
특징을 갖는 종양의 동정 및 전체
전사체
서열분석을 사용한
마커
발현의 분석
분산성 내분비계로부터 발생하는 신경내분비 종양(NET)들은 100,000명 당 2-5명이 발병할 정도로 희귀하지만, 매우 공격적이다. 신경내분비 종양은 부신, 신장, 비뇨생식관(방광, 전립선, 난소, 자궁경관 및 자궁내막), 췌장, 위장관(위 및 직장), 갑상선(갑상선 수질암) 및 폐(소세포 폐암종, 대세포 신경내분비 암종 및 카르시노이드)에서 발생한다. 이러한 종양들은 카르시노이드 증후군으로 공지되어 있는 쇠약 증상을 유발할 수 있는 세로토닌 및/또는 크로모그라닌 A를 포함하는 여러 호르몬들을 분비할 수 있다. 이러한 종양들은 신경-특이적 에놀라제(NSE, 감마 에놀라제라고도 공지되어 있음, 유전자 기호=ENO2), CD56/NCAM1 및 시냅토파이신과 같은 양성 면역조직화학적 마커들에 의해 표시될 수 있다. 전통적인 화학요법들은 NET들을 치료하는데 성공적이지 못했으며, 전이성 확산으로 인한 사망률이 공통된 결과이다. 불행히도, 대부분의 경우, 조기 발견 및 종양 전이되기 전에만, 수술이 유일한 가능한 치료적 치료요법이다. 이와 관련해서, 신경내분비 특성들을 포함하는 종양들과 연관된 새로운 치료적 표적들을 동정하기 위한 작업이 착수되었다.
암 환자에 존재하는 종양들을 동정 및 특성평가하기 위해, 거대 비전통적 이종이식(NTX) 종양 은행(tumor bank)를 개발하고, 당해 분야에 공지된 기술들을 사용하여 유지시켰다. 본래 다양한 고형 종양 악성종양들에 시달리는 수많은 암 환자들로부터 수득된 이종 종양 세포들의 다수의 계대배양을 통해 면역약화된 마우스에 상당수의 별개의 종양 세포주들을 포함하는 NTX 종양 은행을 증식시켰다. (본 실시예 및 도면 중 일부에서, 시험 샘플의 계대배양 횟수는 샘플 지정에 p0-p#으로 표시되며, p0은 환자 종양으로부터 직접 수득된 비-계대배양 샘플의 표시이며 p#는 시험 전 마우스를 통해 종양이 계대배양된 횟수의 표시임을 주지한다.) 잘 정의된 계통(lineage)을 갖는 별개의 초기의 계대배양 NTX 종양 세포주들의 많은 수의 연속적인 이용가능성은 세포주들로부터의 정제된 세포들의 동정 및 특성평가를 용이하게 한다. 상기 작업에서, 최소로 계대배양된 NTX 세포주들의 사용은 생체내 실험을 간소화하며, 쉽게 확증가능한 결과들을 제공한다. 게다가, 초기 계대배양 NTX 종양들은 이리노테칸(즉, Camptosar®)과 같은 치료제 및 시스플라틴/에토포시드 용법에 반응하며, 이들은 종양 성장, 현행 치료요법에 대한 내성 및 종양 재발을 유도하는 기본적 기작에 대한 임상적으로 적절한 통찰을 제공한다.
NTX 종양 세포주가 확립됨에 따라, 이들의 표현형은 전체적 유전자 발현을 검사하기 위한 다양한 방식으로 특성평가되었다. 은행내 NTX주가 NET인지 동정하기 위해, 완전 전사체 서열분석 및/또는 마이크로어레이 분석에 의해 유전자 발현 프로파일들이 생성되었다. 특히, 이 데이터는 NET들에서 상승된 것으로 공지되어 있고, 신경내분비 분화의 조직화학적 마커들(예: ASCL1, NCAM1, CHGA) 뿐만 아니라 노치(NOTCH) 신호전달의 억압의 지표인 노치 경로 유전자들의 변화(예: 노치 수용체의 수준 감소, 및 리간드 및 이펙터 분자들로 변화)를 갖는 종양으로서 사용된 특정한 유전자들의 높은 수준들을 발현하는 종양들을 동정하기 위해 조사되었다.
보다 특히, 다양한 NTX 종양 세포주들을 확립할 때, 심각하게 면역약화된 마우스내 사람 종양에 대하여 통상적으로 실시되는 바와 같이, 종양을 800 내지 2,000 mm3에 도달한 후 절제하고, 당해 분야에 공지된 효소 분해 기술들을 사용하여 세포들을 해리시키고 현탁액으로 분산시켰다(예를 들면, 미국 특허 2007/0292414를 참조하며, 이는 본원에 참조로 포함됨). 그 후, 이들 NTX주로부터 해리된 세포 제제에서 뮤린 세포를 고갈시키고, 이어서 사람 종양 세포 아집단을 형광 활성화 세포 분류에 의해 추가 단리시키고 RLTplus RNA 용해 완충제(Qiagen) 중에 용해시켰다. 그 후, 이들 용해물을 사용할 때까지 -80℃에서 저장하였다. 해동되면, 총 RNA를 판매사의 지시에 따라 RNeasy 단리 키트(Qiagen)를 사용하여 추출하고, 제조업자의 프로토콜 및 권장 기기 설정을 사용하여 Nanodrop 분광광도계(Thermo Scientific) 및 Bioanalyzer 2100 (Agilent Technologies) 상에서 다시 정량화하였다. 수득된 총 RNA 제제는 유전자 서열분석 및 유전자 발현 분석에 적합하였다.
Applied Biosystems(ABI) SOLiD(Sequencing by Oligo Ligation/Detection) 4.5 또는 SOLiD 5500xl 차세대 서열분석 시스템(Life Technologies)을 사용한 완전 전사체 서열분석은 NTX주들로부터의 RNA 샘플들 상에서 수행하였다. 저 투입량 총 RNA를 위해 설계된 ABI의 변형된 완전 전사체(WT) 프로토콜 또는 Ovation RNA-Seq 시스템 V2TM(NuGEN Technologies Inc.)의 어느 것을 사용하여 총 RNA 샘플들로부터 cDNA가 생성되었다. 변형된 저투입량 WT 프로토콜은 총 RNA 1.0ng을 사용하여, 맵핑된 유전자 발현의 무거운 3' 편향으로 선도하는 3' 말단에서 mRNA를 증폭시키는 반면, NuGen의 시스템은 전사체 전체에 걸쳐 보다 일관된 증폭을 하며, 무작위 헥사머를 사용하여 mRNA와 비-폴리아데닐화 전사체 cDNA 둘 다의 증폭을 포함한다. cDNA 라이브러리를 단편화하고, 바코드 어댑터를 부가하여, 다른 샘플들로부터 단편 라이브러리들을 풀링(pooling)시켰다.
ABI의 SOLiD 4.5 및 SOLiD 5500xl 차세대 서열분석 플랫폼들은 여러 NTX주들 및 분류된 집단들로부터 전사체들의 병렬 서열분석을 가능하게 한다. 각 RNA 샘플로부터 cDNA 라이브러리를 작제하고, 단편화하고, 바코드 입력하였다. 각 단편 라이브러리의 바코드들은 여러 샘플들을 같은 농도에서 풀링시키며 함께 진행하여, 동일한 특이성을 보장한다. ABI의 SOLiDTM EZ BeadTM 로봇 시스템을 사용한 에멀젼 PCR을 통해 샘플들을 취해서, 샘플 일관성을 확보한다. 풀내에 존재하는 단일 비이드 상에서 각 클론 증폭된 단편에 대하여, 페어드-엔드 서열분석(Paired-end sequencing)은 5'에서 3' 방향으로 50개의 염기 리드(read) 및 3'에서 5' 방향으로 25개의 염기 리드를 생성시킨다. 5500xl 플랫폼의 경우, 상기 방법에서 풀링된 8개의 샘플들의 모든 세트에 대하여, 비이드들은 단일 칩 상의 6개의 단일 채널 레인들로 균일하게 침착된다. 이는, 8개의 샘플들 각각에 대하여, 평균 5천만 50개의 염기 리드 및 5천만 25개의 염기 리드를 생성시킬 것이며, 종양 세포내 mRNA 전사체의 매우 정확한 재현(representation)을 생성한다. SOLiD 플랫폼에 의해 생성된 데이터는, 공개된 사람 유전체의 NCBI 버전 hg19.2를 사용한 RefSeq 버전 47에 의해 주석이 달린 34,609개의 유전자에 대해 맵핑되었고 대부분의 샘플 중 RNA 수준의 검증가능한 측정치를 제공하였다.
SOLiD 플랫폼은 발현뿐만 아니라 SNP들, 공지된 및 공지되지 않은 교호되는 스플라이싱 사건들, 소형 비-암호화 RNA들 및 리드 범위(coverage)(사전에, 주석이 달리지 않은 유전체 위치로 유일하게 맵핑된 리드)에만 기초한 잠재적으로 새로운 엑손 발견들을 포획할 수 있다. 따라서, 발현된 mRNA 전사체들의 특이적 스플라이싱 변이형들을 위한 차이점 및/또는 선호도뿐만 아니라 차등적 전사체 발현의 발견을 위해, 독점 데이터 분석 및 가시화 소프트웨어와 쌍을 이룬 차세대 서열분석 플랫폼을 사용하게 된다. SOLiD 플랫폼으로부터의 서열분석 데이터는 표준 실습에서와 같이 기초적인 차등적 발현 분석을 가능하게 하는, 메트릭스 RPM(백만개당 리드) 및 RPKM(백만개당 킬로베이스 당 리드)을 사용하여, 전사체 발현값으로서 명목적으로 재현된다.
4개의 소세포 폐암(SCLC) 종양들(LU73, LU64, LU86 및 LU95), 1개의 난소 종양(OV26) 및 대세포 신경내분비 암종(LCNEC; LU37)을 완전 전사체 서열분석을 하면, NET들에서 통상적으로 발견되는 유전자 발현 패턴이 측정되었다(도 6a). 보다 구체적으로, 상기 종양들은 높은 발현의 수개의 NET 마커들(ASCL1, NCAM1, CHGA) 뿐만 아니라 감소된 수준의 노치 수용체들 및 이펙터 분자들(예를 들면, HES1, HEY1) 및 노치 억압의 상승된 마커들(예를 들면, DLL3 및 HES6)을 가졌다. 이와 대조적으로 4개의 정상적인 폐 샘플들, 3개의 폐 선암종 종양들(LU137, LU146 및 LU153), 및 3개의 편평세포 폐 암종(LU49, LU70 및 LU76)은 모두 다양한 노치 수용체 및 이펙터 분자들의 발현을 가지며, HES6 및 DLL3과 같은 노치 억압제의 높은 발현은 나타내지 않는다.
더욱이, 도 6b에 도시된 바와 같이, 정상 조직 샘플들을 신경내분비 특성들을 갖는 다양한 폐 NTX 집단들과 비교하는 완전 전사체 데이터의 분석은, SEZ6이, 시험된 정상 조직들에서의 매우 낮거나 또는 없는 전사 발현과 비교해 신경내분비 특성들을 갖는 4개의 폐암 집단들(LU73, LU64, LU86 및 LU95)에서는 mRNA 전사 수준에서 상향-조절되었음을 보여주었다. 이러한 결과들은 SEZ6이 특정 암들(신경내분비 특성들을 갖는 폐암을 포함)의 종양형성 및 유지에 중요한 역할을 할 수 있음을 제시한다. 이에 기초하여, SEZ6은 잠재적인 면역치료적 표적으로서 추가 분석을 위해 선택되었다.
실시예 2
신경내분비
특징을 갖는 선택된
NTX
종양에서 유전자 발현의
마이크로어레이
및 RT-PCR 분석
기존의 SOLiD 완전 전사체 데이터에 대한 것 외에, 상기 NTX 은행내 추가의 NET들을 동정하기 위한 노력으로, 마이크로어레이 분석을 사용하여 더 큰 세트의 NTX주들을 조사하였다. 구체적으로, 사람 유전체내 19,380개의 유전자들에 대하여 설계된 29,187개의 프로브들을 함유하는, OneArray ® 마이크로어레이 플랫폼(Phalanx Biotech Group)을 사용하여, 46개의 NTX주들의 전체 종양들 또는 2개의 정상 조직들로부터 유래된 총 RNA 샘플들 2 내지 6㎍을 분석하였다. 보다 구체적으로, RNA 샘플들은 결장직장(CR), 흑색종(SK), 신장(KD), 폐(LU), 난소(OV), 자궁내막(EM), 유방(BR), 간(LIV), 또는 췌장(PA) 암들을 포함하는 46명 환자 유래의 완전 NTX 종양들로부터 수득하였다(실시예 1에 기술된 바와 같음). 정상 결장직장(NormCR) 및 정상 췌장(NormPA) 조직은 대조군으로서 사용하였다. 보다 더 구체적으로, 폐종양은 소세포 폐암(SCLC), 편평세포암(SCC) 또는 대세포 신경내분비 암종(LCNEC)으로 추가로 하위분류되었다. 제조업자의 프로토콜들을 사용하여 RNA 샘플들을 3중으로 진행하고, 각 샘플 중의 대상 유전자에 대하여 수득된 측정된 강도 값을 표준화 및 변환하기 위한 표준 산업 관행들을 사용하여, 상기 수득된 데이터를 분석하였다. 상기 48개의 샘플들에 대한 표준 마이크로어레이 계통수를 생성하기 위해, hclust.2라 지칭되는 패키지의 R/BioConductor 세트에서 비편중 피어슨 스피어만 계층 군집화 알고리즘을 사용하였다. 당해 분야에 공지되어 있는 바와 같이, R/BioConductor는 학계, 재무 및 데이터 분석을 위한 약제산업에 널리 사용되는 오픈-소스 통계 프로그래밍 언어이다. 일반적으로, 종양들은 유전자 발현 패턴, 발현 세기 등에 기초하여 배열 및 군집화되었다.
도 7a에 도시된 바와 같이, 48개 샘플들에서 유래된 그리고 모두 19,380개 유전자들을 가로지르는 계통수(系統樹)는 이들의 종양타입 또는 기원조직에 기초하여 함께 NTX주들을 군집화하였다. 신경내분비 표현형과 일반적으로 관련된 여러 종양들은 (1)로 표시된 가지 상에서 함께 군집화하였다; 이들은 피부암, 수많은 폐암들 및 다른 NET들을 포함하였다. 흥미롭게도, (2)로 표시된 하위-가지는 신경내분비 특징들을 갖는 2개의 대세포 폐암들(LU50.LCNEC 및 LU37.LCNEC) 및 소세포 폐암(LU102.SCLC)이 난소(OV26) 및 신장(KD66) 종양(군집 C)에 의해 군집화되고, 이들 이후 종양들이 또한 신경내분비 표현형들을 가짐을 나타냄을 보여준다. 더욱이, 도 7a는 3개의 추가의 SCLC 종양들로 구성된 군집 D를 나타내는데 이의 우측에 추가의 SCLC 종양(LU100) 및 신경내분비 자궁내막 종양(EM6)을 함유하는 소형 군집(군집 E)이 있다. 학술문헌 및 병리학 실험에 기초하여, 군집 D 및 군집 E의 모든 종양들은 보통 어느 정도의 신경내분비 특징들을 가지는 것으로 이해된다. SCC로 구성된 군집 G가 도 7a의 계통수의 완전히 다른 가지 상에서 발견될 수 있다는 사실은 군집화가 종양에 대한 기원의 기관에 의해 배타적으로 유도되지 않음을 보여준다.
NET들과 연관된 유전자 마커들의 컬렉션을 보다 자세히 조사해 보면(도 7b), 이들이 군집 C 및 군집 D를 포함하는 종양에서 강하게 발현되는 반면, 군집 G에서는 종양에 최소로 발현되고(폐의 편평세포 암종), 이는 군집 C 및 군집 D가 신경내분비 표현형을 갖는 NET들 또는 종양들을 대표함을 제시한다는 사실을 보여준다. 보다 구체적으로, 군집 C NET들은 ASCL1, CALCA, CHGA, SST 및 NKX2-1을 높게 발현하는 반면, 군집 D NET들은 CHGA, ENO2, 및 NCAM1을 높게 발현하고, 이는 상기 종양들의 군집화에 부분적으로 반응하는 상기 신경내분비 표현형 유전자들의 발현이다. 흥미있는 특징은 다른 맥락에서 종양형성과 분명하게 관련되어 있지만, 신경내분비 종양들과 연관된 것으로 가끔 보고된 유전자인, 군집 D내 KIT가 강하게 발현된다는 점이다. 이는 상기 유전자들 중 어느 하나의 강한 발현이 결여된 군집 G에서 SCC 종양들과 대조적이다(도 7b).
군집 C내 종양들은 노치 신호전달에서 감소와 일치하는 표현형; 임의의 노치 수용체의 발현 결여, JAG1 및 HES1 발현의 상대적인 결여, 및 강한 수준의 ASCL1 발현을 나타낸다(도 7c). 흥미롭게도, 군집 D는 이종이량체 형성을 통해 HES1 활성을 길항시킴으로써, ASCL1 활성을 지지할 수 있는 전사 인자인 HES6의 고발현을 나타낸다.
상기 결과의 관점에서, 제조업자의 프로토콜들에 따른 Taqman 실시간 정량화적 RT-PCR(qRT-PCR)을 수행하기 위해 Applied Biosystems 7900HT Machine (Life Technologies)을 사용하여 다양한 NTX주들 및 정상 조직들로부터 HES6의 mRNA 발현을 조사하였다. 상기한 바와 같이 RNA를 단리하고, 유전자 발현 분석에 적당한 품질을 보장하기 위해 점검하였다. 정상 조직으로부터의 RNA는 구입하였다(Agilent Technologies and Life Technologies). cDNA 아카이브 키트(Life Technologies)를 사용하여 cDNA 합성을 위해 RNA 200ng을 사용하였다. HES6의 mRNA 수준을 측정하기 위한 HES6 Taqman에 포함된 Taqman 저밀도 어레이(TLDA; Life Technologies) 상에서 qRT-PCR 분석을 위해 cDNA를 사용하였다.
HES6 mRNA 수준은 내인성 대조군에 대해 표준화한 후 각 NTX주 또는 정상 조직 샘플(그래프 상의 단일 도트)에 대하여 나타낸다. 표준화된 값들은 독성 우려의 정상 조직들에서의 평균 발현과 관련하여 플롯팅한다(NormTox). 이 기술은 HES6 및 다른 관련 마커들의 측정을 통해 NTX 종양 은행으로부터 신경내분비 특징들을 갖는 다양한 종양들을 신속하게 동정 및 특성평가한다. 도 7d는 정상 조직들, 유방, 결장, 간 및 다른 선택된 종양들과 비교되는, 신경내분비 특징들을 갖는 샘플 종양들(예를 들면, LU-SCLC, LU-LCNEC)에서 HES6의 일반적인 과발현을 도시하고 있다. 중요하게는, 상기 마이크로어레이 및 qPCR 데이터는 적어도 일부의 자궁내막, 신장 및 난소 종양이 신경내분비 종양 특징들을 나타낼 수 있음을 보여준다(도 7a 및 도 7d).
앞서 기술된 바와 같이 생성된 마이크로어레이 데이터는 군집 C, 군집 D 및 군집 E에서 종양이 다양한 신경내분비 마커들을 나타냈음을 보여줄 뿐만 아니라, 상기 군집들내 종양들이 신경발생, 신경 연루 또는 신경 운명들로의 분화의 지표가 되는 마커들을 발현함을 보여주었다(도 7e). 특히 흥미롭게도, 군집 D내 종양은 상기 마커들(예, BEX1 및 BEX4, CD56, NRCAM, SEMA 수용체들, SOX 및 ZIC 인자들) 중 대부분의 더욱 강하고 더욱 일관된 상향조절을 종종 나타내며 더욱 많은 신경 표현형을 제시하는, 다른 군집들에 대하여 감소된 호르몬 상향조절을 종종 나타낸다. 놀랍게도, 동일한 군집 내의 종양은 높은 수준의 SEZ6 전사체를 또한 나타냈으며, 이는 SEZ6이 신경내분비 및 신경 특징을 갖는 종양과 연관됨을 시사한다(도 7f).
실시예 3
신경내분비 및 신경 특징들을 갖는 종양에서의 SEZ6 mRNA 발현
완전 전사체 서열분석(실시예 1) 및 마이크로어레이 및 qRT-PCR (실시예 2)을 포함하는 신경내분비 특성들을 나타내는 종양들을 동정하기 위해 다양한 기술들이 사용되었다. 비신경내분비 종양들 및 정상 조직들과 비교할 때 신경내분비 종양들에서 크게 발현되는 잠재적 치료 표적들을 발견하기 위해, 이렇게 생성된 데이터가 추가로 분석되었다. 실시예 1에 논의된 바와 같이, 정상 뇌에서 주로 발현되는 단일 통과 막관통 단백질인 SEZ6이 많은 신경내분비 종양들에서 높은 발현을 가짐을 발견하였다(도 6b).
실시예 2에서 생성된 마이크로어레이 데이터는 군집 C, 군집 D 및 군집 E에 위치된 종양들이 신경내분비 마커들(도 7b) 및 신경 마커들(도 7e)을 발현함을 보여주었다. 상기 동일한 군집들에서 종양들은 높은 수준의 SEZ6 전사를 나타냈으며, 이는 SEZ6이 신경내분비 및 신경 특성들을 갖는 종양과 관련되어 있음을 시사한다(도 7f). 이는 성인의 출생 후의 전뇌 발달 및 해마의 특정 부위에서의 지속된 발현에 있어서 SEZ6의 공지된 역할과 일치한다. SEZ6은 세포-세포 인식 및 신호전달에서 중요한 역할을 하는 것으로 생각된다. 종종, 발달상 경로들이 종양내에서 부적절하게 발현된다.
다양한 샘플 NTX 종양주들에서 SEZ6 mRNA 발현수준을 측정하기 위해 상기 실시예 2에 기술된 바와 같이 기본적으로 SEZ6 Taqman 검정을 사용하여 qRT-PCR을 수행하였다. 도 8a는 정상 조직에서의 평균 발현과 관련되고, 내인성 조절 유전자 ALAS1의 발현에 대해 표준화된 SEZ6 발현을 나타낸다. SEZ6 유전자 발현은 정상 조직에 비해 신경내분비 NTX 군집에서 10,000,000배 이상 높다. 도 8a에 도시된 SCLC NTX주들 중 5개는 1차 생검(p0)으로부터 직접 추출된 mRNA 샘플들이다. 상기 비통과 종양들에서 SEZ6의 발현은 SEZ6 발현이 마우스내에서 성장하는 사람 종양들로부터 수득되는 인공물이 아님을 증명한다. NSCLC의 세 서브타입들은 도 8a에 또한 도시되어 있다: LU25는 방추형 세포암종이며, LU50은 대세포 신경내분비 암종(LCNEC)이며, 및 LU85는 편평세포 암종(SCC)이다. 신장 및 난소 종양인 KDY66 및 OV26은 각각, SCLC 및 LCNEC 종양에 의해 마이크로어레이상에서 군집화되었으며(도 7a), 이는 이들이 또한 신경내분비 특성들을 가지고 있음을 보여준다.
SEZ6 발현 분석을 종양 시료들의 좀더 광범위한 어레이로 확장하기 위해, qRT-PCR을 Fluidigm BioMarkTM HD 시스템을 사용하여 수행하였다. 간략하게는, 실시예 1에서 기술된 바와 같이 제조된 1ng의 RNA를 cDNA 아카이브 키트(Life Technologies)를 사용하여 cDNA로 전환시켰다. cDNA는 SEZ6 특정의 Taqman 검정을 사용하여 예비증폭시켰으며 qRT-PCR을 수행하기 위해 사용되었다. 정상 조직들에서의 발현(NormTox 또는 Norm)을 하기 NTX주들에서의 발현과 대조하고, 괄호 안의 숫자는 시험된 고유 NTX주들의 수를 나타낸다: BR(13), CR(24), KDY(10), OV(35), PA(21), 폐 선암종(LU-아데노)(23), LU-CAR(1), LU-LCC(8), SCC(12), SCLC(30) 및 갑상선 수질암(THY)(1)(도 8b). SCLC, THY LU-CAR 및 LC-LCC NTX는 SEZ6의 가장 높은 발현을 나타냈지만, SEZ6의 일부 발현은 정상 조직 샘플들과 비교해 OV, PA, BR, CR 및 LU-아데노 NTX주들에서 보여졌다.
"NormTox"는 정상 조직의 하기 샘플들을 나타낸다: 1개의 부신, 4개의 결장, 4개의 신장, 4개의 간, 3개의 폐, 3개의 췌장, 3개의 심장, 3개의 식도, 1개의 골격근, 1개의 피부, 2개의 진피 섬유모세포, 2개의 각질세포, 3개의 소장, 1개의 비장, 2개의 위장 및 2개의 기도 샘플. "Norm"으로 표시되는 다른 세트의 정상 조직들은 하기의 정상 조직 샘플들을 나타낸다: 지방, B 세포, 방광, 뇌, 유방, 자궁경관, 멜라닌세포, 단핵구, NK 세포, 난소, 말초혈 단핵구, 태반, 전립선, 타액선, T 세포, 고환, 흉선 및 갑상선. 대부분의 정상 조직들은 SEZ6의 발현을 가지지 않는 반면, 췌장, 결장, 간 및 폐에서 낮은 발현이 관찰되며, 뇌에서 높은 발현이 관찰된다. 상기와 동일한 방법을 기본적으로 사용하여 상이한 SEZ6 특이적 Taqman 검정을 다양한 NTX 종양주들 상에서 실시하였다. 각각의 종양 타입에 대하여 시험된 종양 주들의 수는 분모로 표시한 반면, SEZ6을 발현한 종양들의 수는 분자로 표시한다: 2/6 CR, 2/4 GA, 1/1 GB(교아종), 1/1 KDY, 2/6 SK, 2/5 LU-아데노, 4/4 LCNEC, 2/7 LU-SCC, 9/9 SCLC 및 1/2 OV(데이터는 제시되지 않음).
종합하면, 이러한 데이터는 SEZ6이 신경내분비 및 신경 특성들을 나타내는 종양들에서 상향조절되어, 이것이 상기 종류의 종양들을 치료하기 위한 치료적 표적으로서 제공할 수 있음을 시사한다.
실시예 4
qRT-PCR을 사용한 다양한 종양 및 정상 조직 피검물들에서 SEZ6 mRNA의 발현
SEZ6 발현의 분석을 광범위한 어레이의 종양 피검물들로 확장하기 위해, Taqman qRT-PCR을 TissueScanTMqPCR(Origene Technologies) 384웰 어레이 상에서 실질적으로 이전 실시예들에 기술된 바와 같이 수행하였다. 이 어레이는 각각의 종양 타입 및 정상적인 인접 조직에 대하여, 다수의 환자에게서 수득된 샘플들과 18개의 다른 고형 종양 타입들에서 유전자 발현을 비교할 수 있게 한다.
이와 관련하여, 도 9a 및 도 9b는 18개의 다른 고형 종양 타입들을 갖는 환자들로부터, 전체 종양 피검물들(회색 점들) 또는 정상 인접 조직(NAT; 백색 점들)내 SEZ6의 상대적 및 절대적 유전자 발현 수준을 각각 나타낸다. 보다 구체적으로는, 도 9a는 다양한 완전 종양 피검물들 또는 매치된 정상 인접 조직에서 SEZ6의 절대 mRNA 발현 수준을 나타낸다. 도 9b는 β-액틴에 대하여 표준화되고, 분석된 각 종양 타입마다의 정상적인 인접 조직내 발현에 대하여 플로팅한, SEZ6의 발현 수준을 나타낸다. SEZ6이 검출되지 않은 피검물들은 50의 Ct 값으로 할당하였고, 이는 실험용 프로토콜에서 마지막 증폭 주기를 나타낸다. 각 점은 단일조직 피검물을 나타내며, 기하평균값은 흑색 선으로 나타내었다.
이러한 Origene 어레이를 사용하여, SEZ6의 과발현이 부신, 간, 폐, 난소 및 췌장 암의 서브세트에서 관찰되었으며, 이들 중 대다수가 신경내분비 종양, 또는 저분화된 신경내분비 표현형들을 갖는 종양들을 나타낼 수 있다. 이는 1/1 수질 갑상선암 및 1/3 갑상선 여포 변종성 유두상 암종, 8/8 신경내분비 췌장 종양, 4/4 췌장 섬세포 종양, 1/2 대세포 신경내분비 폐 암종 및 3/3 폐 유암종 종양에서의 높은 발현을 포함한다. 도 9a에서 절대 유전자 발현으로 도시된 바와 같이, 정상 고환 및 췌장은 높은 발현의 SEZ6을 갖는 유일한 정상 조직들이다. 이는 SEZ6이 신경내분비 및 신경 특성들을 갖는 종양들을 포함하나 이에 제한되지 않는 광범위한 종양들로 종양형성 및/또는 종양 진행에서 역할을 할 수 있음을 제시한다.
실시예 5
재조합 SEZ6 단백질들의 클로닝 및 발현
사람 SEZ6(hSEZ6)
SEZ6 동종형 1 단백질의 아미노산 서열(서열번호 3) 및 SEZ6 동종형 2 단백질의 아미노산 서열(서열번호 4)는 각각 도 1c 및 1d에 제시되어 있다. SEZ6 동종형들 각각의 세포외 도메인은 동일하다. 도 1c 및 1d에서, 19개의 아미노산을 포함하는 리더 서열은 굵게 밑줄이 쳐져 있다. 서열번호 3 및 서열번호 4 각각의 나머지 아미노산 잔기들은 성숙한 SEZ6 단백질을 포함한다. 사람 SEZ6에 관한 본 발명에 요구되는 모든 분자 및 세포 물질들을 생성 및 발달시키기 위해, 완전한 성숙 사람 SEZ6 단백질(도 3b, 서열번호 6)을 암호화하는 cDNA(도 3a; 서열번호 5)를 하기와 같이 생성시켰다. 상업용 사람 SEZ6 cDNA는 Open Biosystems로부터 구입했으며, 여기서 상기 cDNA 서열은 NCBI 수탁번호 BC146292에 상응한다. 서열 정렬은 내인성 사람 SEZ6 단백질을 암호화하는 RefSeq NP_849191(잔기들 414, 415 및 417 참조, 도 3c)의 것과 수개의 잔기들이 상이한 BC146292에 의해 암호화된 단백질을 나타냈다. BC146292 클론으로부터 2개의 분리된 cDNA 단편들을 증폭시키기 위해 PCR을 사용하였으며, 여기서 사용된 프라이머들은 내인성 사람 SEZ6 단백질을 암호화하는 mRNA 서열인 NM_178860에 의해 암호화되는 서열과 동일한 서열을 갖는 성숙 SEZ6 단백질을 암호화하는 cDNA를 생성하기 위해, 중복 PCR 과정 동안 잔기 414 내지 417번에서 cDNA로 원하는 변화들을 도입시켰다. 복구된 cDNA 클론, 일명 hSEZ6(도 3a)은 성숙한 사람 SEZ6 단백질 또는 이의 단편을 발현하는 작제물들의 모든 후속적 조작을 위해 사용되었다.
SEZ6 분자에 대한 면역반응성 또는 면역특이적 조절물질들을 생성하기 위해, 사람 IgG2 Fc 도메인(도 4a, 서열번호 8)에 사람 SEZ6 단백질의 ECD 부분이 융합된 키메릭 융합 유전자를 발생시켰다. 이는 하기와 같이 수행하였다: SEZ6의 ECD를 암호화하는 cDNA를 hSEZ6 cDNA 클론으로부터 PCR 증폭시키고(도 3a), 표준 분자기술들을 사용하여, IgK 신호 펩타이드 서열의 프레임 및 하류 그리고 사람 IgG2 Fc cDNA의 상류에서 상기 PCR 생성물을 CMV 유도된 발현 벡터 내로 서브클로닝시켰다. hSEZ6-Fc 융합 단백질을 암호화하는 cDNA 서열, 일명 hSEZ6-Fc ORF는 도 4a에 도시되어 있으며; hSEZ6-Fc ORF에 의해 암호화되는 상응하는 단백질 서열은 도 4b에 도시되어 있다(서열번호 9). 서열들의 밑줄친 영역들은 사람 IgG2 Fc에 해당한다. 진한 글씨의 밑줄친 영역들은 IgK 신호 펩타이드에 해당하며, 및 진한 글씨의 서열들은 SEZ6 ECD 측면의 클로닝 제한부위들에 의해 암호화되는 융합 단백질의 일부에 해당한다.
재조합 hSEZ6 ECD 단백질을 생성하기 위하여 유사한 PCR-기반 전략을 사용하였다. SEZ6의 ECD를 암호화하는 cDNA 단편을 hSEZ6 cDNA 클론으로부터 증폭시켰고, IgK 신호 펩타이드 서열의 프레임 및 하류에서 그리고 9-히스티딘 에피토프 태그를 암호화하는 서열의 프레임 상류(서열번호 201)에서, CMV 유도성 발현 벡터 내로 서브클로닝시켰다.
CMV-유도성 발현 벡터는 HEK-293T 및/또는 CHO-S 세포들 내에서 높은 수준의 일시적인 발현을 허용한다. 형질감염 시약으로서 폴리에틸렌이민 중합체를 사용하여, HEK-293T 세포들의 현탁액 또는 접착성 배양물, 또는 CHO-S 세포들의 현탁액을 hSEZ6 ECD-Fc 또는 hSEZ6-ECD-His 단백질들을 암호화하는 발현 작제물로 형질감염시켰다. 형질감염 3일 내지 5일 후, AKTA 익스플로러 및 MabSelect SuRe™ 단백질 A(GE Healthcare Life Sciences) 또는 Nickel-EDTA(Qiagen) 칼럼을 각각 사용하여, hSEZ6 ECD-Fc 또는 hSEZ6-ECD-His 단백질들을 청정화된 세포-상층액으로부터 정제하였다.
재조합 사람 SEZ6을 과발현하는 안정한 세포주를 하기와 같이 HEK-293T 세포들을 형질도입하는 렌티바이러스 벡터들을 사용하여 작제하였다: 성숙 사람 SEZ6 단백질을 암호화하는 cDNA 단편을 생성하기 위해 주형으로서 사람 SEZ6 클론을 사용하여, PCR 증폭을 수행하였다. 표준 분자클로닝 기술들을 사용하여, pCDH-EF1-MCS-T2A-GFP(System Biosciences)의 다중 클로닝 부위의 상류에서 미리 조작된 IgK 신호 펩타이드 및 DDK 에피토프 태그를 암호화하는 서열의 프레임 하류에서 상기 생성된 단편들을 서브클로닝시켰다. 수득된 이시스트론성 렌티바이러스 벡터를 사람 SEZ6-T2A 펩타이드-GFP 폴리펩타이드를 과발현하는 세포주들을 조작하기 위해 사용하였다. T2A 서열은 펩타이드 결합 축합의 리보솜 스키핑(ribosomal skipping)을 촉진시켜서, 2개의 독립적 단백질, 이러한 경우에는 SEZ6 및 GFP를 생성시킨다.
마우스 SEZ6(mSEZ6)
기본적으로 재조합 사람 SEZ6에 대하여 위에 설명한 바와 같이, 재조합 마우스 SEZ6을 과발현하는 안정한 세포주를 조작하였다. HEK-293T 세포들을 뮤린 SEZ6을 발현하는 렌티바이러스 벡터로 형질도입시켰다. 기본적으로 상기 벡터를 하기와 같이 조작하였다. NCBI 데이터베이스에서 RefSeq NM_021286(도 5b; 서열번호 11)으로 기재된 성숙한 마우스 SEZ6 단백질을 암호화하는 cDNA 단편(도 5a; 서열번호 10)은 상업용 마우스 SEZ6 cDNA(Origene; #MC203634)로부터 PCR 증폭에 의해 수득되고, 표준 분자클로닝 기술들을 사용하여, pCDH-EF1-MCS-IRES-RFP(System Biosciences)의 다중 클로닝 부위의 상류에서 사전조작된 DDK 에피토프 태그 서열 및 IgK 신호 펩타이드 서열의 하류를 서브클로닝하였다. 이로써, 이시스트론성 렌티바이러스 벡터가 생성되었으며, 이를 마우스 SEZ6 및 RFP를 과발현하는 HEK-293T 세포주를 제조하는데 사용하였다.
래트 SEZ6(rSEZ6)
래트 SEZ6 단백질들에 관해 본 발명에서 요구되는 모든 분자 및 세포 물질들을 생성 및 개발하기 위해, 완전한 성숙한 래트 SEZ6 단백질(도 5d, 서열번호 13)을 암호화하는 cDNA(도 5c, 서열번호 12)를 하기와 같이 수득하였다. 전체길이 성숙한 래트 단백질(즉, 전체길이 단백질에서 야생형 신호 펩타이드를 제외한)을 암호화하는 cDNA를 래트 뇌 마라톤-레디 cDNA(Clontech #639412)로부터 증폭하였다. 서열 정렬은 NCBI 데이터베이스에서, RefSeq NP_001099224로 기록된 내인성 래트 SEZ6 단백질과 상동성인 암호화된 단백질의 ECD를 나타냈다. 이 cDNA 클론, 일명 rSEZ6(도 5d)은 래트 SEZ6 단백질 단편들을 발현하는 작제물의 후속적 조작을 위해 사용하였다.
시노몰구스 SEZ6(cSEZ6)
시노몰구스 SEZ6 단백질들에 관한 본 발명에 요구되는 모든 분자 및 세포 물질들을 생성 및 전개하기 위해, 시노몰구스 SEZ6 단백질(도 5f, 서열번호 15)을 암호화하는 cDNA(도 5e, 서열번호 14)를 하기와 같이 수득하였다: 예측된 시노몰구스 SEZ6 ORF 서열을 하기 방법에서 생물정보학 분석에 의해 집합시켰다: 사람 SEZ6 유전자의 ORF를 NCBI 수탁번호 NM_178860으로부터 수득하고, BLAST 알고리즘을 사용하여, NCBI 데이터베이스내 전체 유전체 샷건 서열분석 콘티그와 대조하였다. 그 후, 추정의 시노몰구스 SEZ6 ORF를 어셈블링하기 위해, BLAST 결과들을 사용하였다. 시노몰구스 SEZ6의 예측된 야생형 신호 펩타이드를 암호화하는 서열을 상기 BLAST 유도된 서열로부터 제거하고, IgK 신호 펩타이드 서열을 암호화하는 서열로 치환하였다. 포유동물 세포에서의 생산을 위해 코돈 최적화 후, 상기 완전한 하이브리드 ORF 서열을 합성 유전자(GeneWiz)로서 지정하였다. 상기 최적화된 cDNA 클론, 일명 cSEZ6(도 5e)를 시노몰구스 SEZ6 단백질 단편들을 발현하는 작제물들의 후속적 조작을 위해 사용하였다.
사람 SEZ6L 및 SEZ6L2
사람 유전체에는, SEZ6-발작 관련 6 상동체-유사(SEZ6L) 및 발작 관련 6 상동체 유사-2(SEZ6L2)와 밀접하게 관련된 2개의 유전자들이 있다. 전체적인 동일성 비율(%)은 3개의 단백질들 사이에서 비교적 낮지만(약 42%), 단백질 쌍들 사이 또는 모든 3개의 단백질들 사이에 완벽한 동일성의 더 작은 신장부(stretch)들이 있다. 항-SEZ6 조절물질들과 사람 SEZ6L 및 SEZ6L2 단백질들과의 임의의 가능한 교차 반응성을 조사하기 위해, 사람 SEZ6L 단백질(NP_0066938) 및 사람 SEZ6L2 단백질(NP_001230261)의 ECD들을 암호화하는 오픈 리딩 프레임을 코돈 최적화하고 합성하였다(GeneWiz). 사람 SEZ6L 또는 SEZ6L2 단백질들의 ECD들을 암호화하는 상기 최적화된 cDNA 서열들은 도 5g 및 도 5i에 도시되어 있다.
교차-반응성 연구를 위한 물질
본 발명의 SEZ6 조절물질이 래트 및/또는 시노몰구스 SEZ6 상동체, 또는 밀접하게 관련된 사람 SEZ6L 및 SEZ6L2 단백질들과 교차-반응하는지의 여부를 연구하기 위하여 물질을 생성시켰다. 래트 또는 시노몰구스 SEZ6 단백질(각각, 도 5d 및 도 5f에 밑줄쳐 있음)의 ECD 부분이 9-히스티딘 에피토프 태그(서열번호 201)에 융합된 키메릭 융합 유전자를 설계하였다. PCR을 사용하여, 래트 또는 시노몰구스 SEZ6의 ECD를 암호화하는 cDNA 단편을 각각 rSEZ6 또는 cSEZ6로부터 증폭하고, IgK 신호 펩타이드 서열의 프레임 및 하류 및 9-히스티딘 에피토프 태그를 암호화하는 서열(서열번호 201)의 프레임 및 상류에서 CMV 유도된 발현 벡터 내로 서브클로닝시켰다. 유사하게, 사람 SEZ6L 또는 SEZ6L2 단백질들의 ECD 부분을 암호화하는 오픈 리딩 프레임이 IgK 신호 펩타이드 서열의 프레임 및 하류 그리고 9-히스티딘 에피토프 태그를 암호화하는 서열(서열번호 201)의 프레임 및 상류에서 CMV 유도된 발현 벡터 내로 서브클로닝된 키메릭 융합 유전자들이 설계되었다. 상기 융합 단백질들에 대하여 수득된 암호화된 단백질 서열들은 도 5h 및 도 5j에 각각 도시되어 있으며, 밑줄친 서열은 고려 중인 특정 단백질의 ECD를 나타낸다.
상기 생성된 래트 및 시노몰구스 SEZ6 ECD-His 벡터들은 하기와 같이 재조합 rSEZ6-ECD-His 단백질 및 cSEZ6-ECD-His 단백질을 각각 제조 및 정제하는데 사용하였다: 당해 분야에-공지된 기술들을 사용하여, HEK-293T 세포들의 현탁액 또는 접착성 배양물, 또는 CHO-S 세포들의 현탁액을 rSEZ6-ECD-His 또는 cSEZ6-ECD-His 단백질을 암호화하는 발현 벡터들로 형질감염시켰다. 폴리에틸렌이민 중합체를 형질감염 시약으로 사용하였다. 형질감염 3일 내지 5일 후, AKTA 익스플로러 및 Nickel-EDTA(Qiagen) 칼럼을 사용하여, rSEZ6-ECD-His 또는 cSEZ6-ECD-His 단백질을 맑아진 세포-상층액으로부터 정제하였다. 유사하게, 래트 및 시노몰구스 상동체들에 대하여 설명한 바와 같이, 재조합 사람 SEZ6L 및 사람 SEZ6L2 ECD-His 단백질들을 제조 및 정제하기 위해 사람 SEZ6L 및 SEZ6L2 ECD-His 벡터들을 사용하였다.
실시예 6
항-SEZ6 뮤린 조절물질들의 생성
뮤린 항체 형태의 SEZ6 조절물질들을 사람 SEZ6-Fc에 의한 접종을 통해 본 명세서의 내용에 따라 제조하였다. 이와 관련하여, 3종의 마우스 스트레인들을, 다양한 증식성 장애들을 예방 및/또는 치료하기 위해 SEZ6과 회합시키고/시키거나 SEZ6의 작용을 저해하는데 사용될 수 있는 고친화성 뮤린 모노클로날 항체 조절물질들을 생성시키는데 사용하였다. 구체적으로는, Balb/c, CD-1 및 FVB 마우스 스트레인들을 사람 재조합 SEZ6-Fc로 면역화하고, 하이브리도마들을 제조하는데 사용하였다.
SEZ6-Fc 항원은 실시예 5에 개시된 바에 따라 작제물 SEZ6-Fc를 과발현하는 CHO-S 세포의 상층액으로부터 정제하였다(도 4a 및 도 4b). 첫번째 면역화를 위해 10㎍의 SEZ6-Fc 면역원을 사용하고, 이후 3회의 면역화 및 5회의 면역화를 위해 각각 5㎍ 및 2.5㎍의 SEZ6-Fc 면역원을 사용하였다. 동일한 용적의 TITERMAX®골드(CytRx Corporation) 또는 백반(alum) 보조제로 유화시킨 면역원을 사용하여 모든 면역화를 수행하였다. 뮤린 항체들은 모든 주사에 대해 발바닥 경로를 통해 6마리의 암컷 마우스(2마리씩 각각: Balb/c, CD-1, FVB)를 면역화함으로써 생성되었다.
사람 SEZ6에 대하여 특이적인 마우스 IgG 항체들을 위한 마우스 혈청을 선별하기 위해 고체상 ELISA 검정을 사용하였다. 배경값 초과의 양성 시그널은 SEZ6에 대하여 특이적인 항체들의 지표가 되었다. 간략하게 말하면, 96개의 웰 플레이트(VWR International, Cat. #610744)를 ELISA 코팅 완충제 중의 0.5㎍/ml에서 재조합 SEZ6-His로 밤새 코팅하였다. 0.02%(v/v) Tween 20을 함유하는 PBS에 의해 세척한 후, 실온(RT)에서 1시간 동안 웰들을 웰당 200μL의 PBS 중의 3%(w/v) BSA로 차단하였다. 마우스 혈청을 역가측정하고(1:100, 1:200, 1:400 및 1:800), SEZ6 코팅된 플레이트에 웰당 50μL를 첨가하고, RT에서 1시간 동안 항온배양하였다. 플레이트를 세척하고, 그 후 PBS 중의 3% BSA-PBS 또는 2% FCS로 1:10,000 희석된 50μL/웰 HRP-표지된 염소 항-마우스 IgG와 함께 RT에서 1시간 동안 항온배양하였다. 다시, 플레이트를 세척하고, RT에서 40μL/웰의 TMB 기질 용액(Thermo Scientific 34028)을 15분 동안 첨가하였다. 전개 후, 기질 전개를 정지시키기 위해 동일 용적의 2N H2SO4를 첨가하고, OD 450에서 분광광도계에 의해 플레이트를 분석하였다.
혈청-양성 면역화 마우스를 희생시키고, 배출된 림프절(확대한다면, 슬와, 사타구니 및 내관골)을 해부하고, 항체 생산 세포를 위한 공급원으로서 사용하였다. B세포들의 단일 세포 현탁액(228.9x106 세포들)을 비분비성 P3x63Ag8.653 골수 세포들(ATCC #CRL-1580)과 전기세포융합에 의해 1:1의 비율로 융합하였다. 전기융합은 제조업자의 지시에 따라, BTX HybrimmuneTM시스템(BTX Harvard Apparatus)을 사용하여 수행하였다. 융합과정 후, 15% 태아 클론 I 혈청(Hyclone), 10% BM Condimed(Roche Applied Sciences), 4 mM L-글루타민, 100 IU 페니실린-스트렙토마이신 및 50 μM 2-머캅토에탄올을 함유하는 나트륨 피루베이트(Cellgro cat #15-017-CM)를 갖는 고 글루코오스 DMEM 배지, 아자세린(Sigma #A9666)이 보충된 하이브리도마 선택 배지에 세포들을 재현탁시키고, 플라스크당 90mL 선택 배지로 3개의 T225 플라스크에 플레이팅하였다. 그 후, 플라스크를 5% CO2 및 95% 공기를 함유하는 가습된 37℃ 항온배양기에 6-7일 동안 두었다.
6일 내지 7일간 성장시킨 후, T225에서 대량으로 성장한 세포들로 구성된 라이브러리를 Aria I 세포 분류기를 사용하여 Falcon 96 웰 U-바닥 플레이트 내에 웰당 1개의 세포로 플레이팅하였다. 그 후, 15% 태아 클론 I 혈청(Hyclone), 10% BM-Condimed(Roche Applied Sciences), 1 mM 나트륨 피루베이트, 4 mM L-글루타민, 100 IU 페니실린-스트렙타마이신, 50μM 2-머캅토에탄올 및 100μM 하이포크산틴을 함유하는 배양 배지 200μL에서 상기 선택된 하이브리도마를 성장시켰다. 임의의 남은 사용되지 않은 하이브리도마 라이브러리 세포들을 추후의 라이브러리 시험을 위해 동결시켰다. 10일 내지 11일간 배양한 후, 플레이팅된 세포들의 각 웰로부터 상층액을 ELISA 및 FACS 검정에 의해 SEZ6에 대하여 반응성인 항체들에 대하여 분석하였다.
ELISA에 의해 선별하기 위해, 96개의 웰 플레이트들을 PBS 1mL당 0.3㎍로 SEZ6-Fc에 의해 밤새 4℃에서 코팅하였다. 플레이트들을 세척하고, 37℃에서 1시간 동안 PBS/Tween 중의 3% BSA에 의해 차단하고, 바로 사용하거나, 4℃에서 유지하였다. 비희석 하이브리도마 상층액들을 플레이트 상에서 1시간 동안 RT에서 항온배양하였다. 플레이트를 세척하고, RT에서 1시간 동안 3% BSA-PBS로 1:10,000 희석된 HRP 표지된 염소 항-마우스 IgG에 의해 프로빙하였다. 그 후, 플레이트를 위에 설명한 바와 같이 기질 용액과 함께 항온배양하고, OD 450에서 판독하였다. 배경값 초과의 신호에 의해 측정되는 사람 SEZ6에 우선적으로 결합된 면역글로불린을 함유하는 웰들을 옮기고 확장시켰다.
뮤린 면역글로불린을 분비하는 선택된 성장 양성 하이브리도마 웰들도 또한, 상기 실시예에서 생성된 선택된 항원 또는 작제물들을 과발현하도록 조작된 293개의 세포들을 이용하는 유세포분석법 기반 검정을 사용하여, 사람 SEZ6 특이성 및 시노몰구스, 래트 및 뮤린 SEZ6 교차반응성에 대하여 선별하였다.
유세포분석법을 위해, 사람, 시노몰구스, 래트 또는 뮤린 SEZ6이 각각 형질도입된 50x104 h293 세포들을 25 내지 100μL 하이브리도마 상층액과 함께 30분 항온배양하였다. 세포들을 PBS, 2% FCS로 2회 세척한 후, PBS/2% FCS에서 1:200 희석된 DyLight 649에 접합된 2차에 특이적인 염소-항-마우스 IgG Fc 단편 50μL와 함께 항온배양하였다. 15분 항온배양 후, 세포들을 PBS, 2% FCS로 2회 세척하고, DAPI를 갖는 동일한 완충제에 재현탁하였으며 제조업자의 지시에 따라 FACSCanto II를 사용하여 유세포분석법에 의해 분석하였다. SEZ6+ GFP+ 세포들에 우선적으로 결합된 면역글로불린을 함유하는 웰들을 옮기고 확장시켰다. 수득된 hSEZ6 특이적 클론성 하이브리도마들을 CS-10 동결 배지(Biolife Solutions)에서 저온보존하고, 액체 질소에 저장하였다. 사람, 시노몰구스, 래트 또는 뮤린 SEZ6 세포들과 결합된 항체들은 교차-반응성인 것으로 주지되었다.(도 11a 참조).
ELISA 및 유세포분석법은 대부분의 또는 모든 상기 하이브리도마로부터 정제된 항체가 농도-의존적 방식으로 SEZ6과 결합함을 확인시켜 주었다. SEZ6 GFP 세포들이 결합된 면역글로불린을 함유하는 웰들을 옮기고 확장하였다. 수득된 클론성 하이브리도마들을 CS-10 동결배지(Biolife Solutions)에 저온보존하고, 액체 질소에 저장하였다.
1회 융합을 수행하고, 48개의 플레이트들에 접종하였다(약 40% 클로닝 효율에서 4608개의 웰들). 초기 스크린은 사람 SEZ6과 회합된 63개의 뮤린 항체들을 생성하였다. 두번째 스크린을 후속적으로 수행하고, 사람 SEZ6과 회합된 134개의 항체들을 생성하였다.
실시예 7
SEZ6 뮤린 조절물질들의 서열분석
상기 내용에 근거하여, 매우 높은 친화력을 갖는 고정화된 사람 SEZ6 또는 h293-hSEZ6 세포들과 결합하는 예시적인 별개의 수많은 모노클로날 항체들은 서열분석 및 추가의 분석을 위해 선택되었다. 도 10a 및 10b의 표 형식에 도시된 바와 같이, 실시예 6에서 생성된 선택된 모노클로날 항체들로부터 경쇄 가변 영역(도 10a) 및 중쇄 가변 영역(도 10b)의 서열 분석은 많은 것이 새로운 상보성 결정부위들을 가졌고, 종종 새로운 VDJ 배열들을 나타냈음을 확인하였다. 도 10a 및 10b에 개시된 상보성 결정 영역들은 상기 카뱃(Kabat) 등에 따라 정의되어 있음을 주목한다.
예시적인 조절물질을 서열분석하는데 있어서 제1 단계로서, 선택된 하이브리도마 세포들을 Trizol®시약(Trizol Plus RNA Purification System, Life Technologies)에서 용해시켜 RNA를 제조하였다. 이와 관련하여, 104 내지 105 개 세포들을 1mL 트리졸에 재현탁하고, 200μL의 클로로포름을 첨가한 후 격렬하게 진탕시켰다. 그 후, 샘플들을 4℃에서 10분 동안 원심분리하고, 수성상을 신선한 원심분리용(microfuge) 튜브로 옮기고, 여기에 동일 용적의 이소프로판올을 첨가하였다. 다시 튜브를 격렬하게 진탕시켰고, 4℃에서 10분 동안 원심분리하기 전에 RT에서 10분 동안 항온배양하였다. 수득된 RNA 펠릿들을 1 mL의 70% 에탄올로 1회 세척하고, 40μL의 DEPC-처리수에 재현탁하기 전에, RT에서 간단하게 건조시켰다. RNA 제제는 사용될 때까지 -80℃에서 저장하기 전에, 1% 아가로오스 젤로 3μL 분획화함으로써 그 품질을 측정하였다.
각 하이브리도마의 Ig 중쇄의 가변 영역은, 모든 마우스 Ig 동종형에 대하여 특이적인 3' 마우스 Cγ프라이머와 조합하여, 완전한 마우스 VH 레퍼토리를 표적화하기 위해 설계된, 32개의 마우스 특이적 리더 서열 프라이머들을 포함하는 5' 프라이머 믹스를 사용하여 증폭되었다. 동일한 PCR 프라이머들을 사용하여 양 말단으로부터 VH의 400bp PCR 단편을 서열분석하였다. 이와 유사하게 마우스 카파 불변 영역에 대하여 특이적인 단일의 역 프라이머와 조합된 Vκ 마우스 패밀리 각각을 증폭하도록 설계된 32개의 5' Vκ 리더 서열 프라이머들의 혼합물은 카파 경쇄를 증폭 및 서열분석하는데 사용되었다. 역전사효소 폴리머라제 쇄 반응(RT-PCR)을 사용하여 VH 및 VL 전사체를 100ng 총 RNA로부터 증폭시켰다.
총 8개의 RT-PCR 반응을 각 하이브리도마에 대하여 진행하였다: 4개는 Vκ경쇄에 대하여, 및 4개는 V 감마 중쇄(γ1)에 대하여. 원스텝 RT-PCR 키트를 증폭을 위해 사용하였다(Qiagen). 이 키트는 센시스크립트 및 옴니스크립트 역전사효소의 혼합물, HotStarTaq DNA 폴리머라제, dNTP 혼합물, 완충제 및 Q-용액, "어려운"(예를 들면, GC-풍부) 주형의 유효한 증폭을 가능하게 하는 새로운 첨가제를 제공한다. 3μL의 RNA, 0.5의 100 μM의 중쇄 또는 카파 경쇄 프라이머들(종종 IDT에 의해 합성됨), 5μL의 5xRT-PCR 완충제, 1μL dNTPs, 역전사효소 및 DNA 중합효소를 함유하는 1μL의 효소 혼합물, 및 0.4μL의 리보뉴클레아제 저해제 RNasin(1단위)을 포함하는 반응 혼합물을 제조하였다. 이 반응 혼합물은 역전사 및 PCR을 위해 필요한 모든 시약들을 함유한다. 열순환기 프로그램은 RT 스텝 50℃에서 30분간, 95℃에서 15분간, 30주기의 PCR(95℃에서 30초, 48℃에서 30초, 72℃에서 1분간)에서 설정하였다. 그 후, 72℃에서 10분 동안 최종 항온배양하였다.
직접적인 DNA 서열분석을 위한 PCR 생성물을 제조하기 위해, 제조업자의 프로토콜에 따라 QIAquickTMPCR 정제 키트(Qiagen)를 사용하여 이들을 정제하였다. 멸균수 50μL를 사용하여 스핀 칼럼으로부터 DNA를 용출하고, 양 가닥들로부터 이들을 직접 서열분석하였다. 추출된 PCR 생성물들을 특수한 V 부위 프라이머들을 사용하여 직접 서열분석하였다. 가장 높은 서열 상동성을 갖는 생식세포계열 V, D 및 J 유전자 구성원들을 동정하기 위해, IMGT를 사용하여 뉴클레오타이드 서열들을 분석하였다. 하기 제시된 바와 같이 사람화된 작제물의 제조를 돕기 위해, 상기 유도된 서열들을, V-BASE2(Retter et al., supra)를 사용하여 마우스 생식세포계열 데이터베이스에 대한 VH 및 VL 유전자들의 정렬에 의해 Ig V-영역 및 J-영역들의 공지된 생식세포계열 DNA 서열들과 추가 비교하였다.
보다 구체적으로, 도 10a는 항-SEZ6 항체들로부터의 74개의 독특한 새로운 뮤린 경쇄 가변 영역들(서열번호 20 내지 168, 짝수들)의 연속적 아미노산 서열들 및 대표적인 뮤린의 경쇄들로부터 유도된 11개의 사람화 경쇄 가변 영역들(서열번호 170 내지 192, 짝수들)을 도시하고 있다. 마찬가지로, 도 10b는 동일한 항-SEZ6 항체들로부터의 74개의 새로운 뮤린 중쇄 가변 영역들(서열번호 21 내지 169, 홀수들)의 연속적 아미노산 서열들 및 사람화 경쇄들을 제공하는 동일한 뮤린 항체들로부터의 11개의 사람화 중쇄 가변 영역들(서열번호 171 내지 193, 홀수들)을 도시하고 있다. 따라서, 도 10a 및 도 10b는 함께, 74개의 독특한 작동가능한 뮤린 항-SEZ6 항체들(즉, SC17.1, SC17.2, SC17.3, SC17.4, SC17.8, SC17.9, SC17.10, SC17.11, SC17.14, SC17.15, SC17.16(SC17.6의 복사체), SC17.17, SC17.18, SC17.19, SC17.22, SC17.24(SC17.2의 복사 서열), SC17.27, SC17.28, SC17.29, SC17.30, SC17.32, SC17.34, SC17.35, SC17.36, SC17.38, SC17.39, SC17.40, SC17.41, SC17.42, SC17.45, SC17.46, SC17.47, SC17.49, SC17.50, SC17.53, SC17.54, SC17.56, SC17.57, SC17.59, SC17.61, SC17.63, SC17.71, SC17.72, SC17.74, SC17.76, SC17.77, SC17.79, SC17.81, SC17.82, SC17.84, SC17.85, SC17.87, SC17.89, SC17.90, SC17.91, SC17.93, SC17.95, SC17.97, SC17.99, SC17.102, SC17.114, SC17.115, SC17.120, SC17121, SC17.122, SC17.140, SC17.151, SC17.156, SC17.161, SC17.166, SC17.187, SC17.191, SC17.193, SC17.199 및 SC17.200으로 명명됨) 및 11개의 사람화 항체들(즉, hSC17.16, hSC17.17, hSC17.24, hSC17.28, hSC17.34, hSC17.46, hSC17.151, hSC17.155, hSC17.156, hSC17.161 및 hSC17.200으로 명명됨)의 주석이 달린 서열을 제공한다. 이러한 동일한 명칭들은 대상 항체를 생성하는 클론을 의미할 수 있으며, 상기와 같이 특정 명칭의 사용은 주변 개시내용의 문맥에서 해석되어야 함을 주목한다.
추가로, hSC17.200vL1(서열번호 192)은 사람화 경쇄 작제물 hSC17.200(서열번호 190)의 변이체이며, hSC17.155vH1 - hSC17.155vH6(서열번호 193 내지 198)은 SC17.90(서열번호 127)로부터 유도된 중쇄 작제물 hSC17.155(서열번호 184)의 변이체이며, hSC161vH1(서열번호 199)은 중쇄 작제물 hSC17.161(서열번호 189)의 변이체이다. 하기에 보다 상세히 논의되는 바와 같이, 이러한 변이체들은 모 항체의 하나 이상의 생화학적 특성들을 최적화하기 위해 작제되고 시험되었다.
게다가, 도 10a 및 도 10b에 개시된, 74개의 예시된 뮤린 조절물질들 및 11개의 사람화 조절물질들 각각의 상응하는 핵산 서열들 및 변이체들은 본 출원의 서열목록(서열번호 220 내지 399)에 포함된다.
본 출원의 목적을 위해, 각 특정 항체의 서열 목록 번호들은 순차적이다. 따라서, mAb SC17.1은 경쇄 및 중쇄 가변 영역들 각각에 대하여 서열번호 20 및 21을 포함한다. 이와 관련하여, SC17.2는 서열번호 22 및 23을 포함하며, SC17.9는 서열번호 24 및 25 등을 포함한다. 더욱이, 도 10a 및 도 10b에서 각 항체 아미노산 서열에 대한 상응하는 핵산 서열들은 서열 목록에 제시되어 있다. 서열 목록에서, 포함된 핵산서열들은 200개 이상의 상응하는 아미노산 서열(경쇄 또는 중쇄)인 서열번호들을 포함한다. 따라서, mAb SC17.1의 경쇄 및 중쇄 가변 영역 아미노산 서열들을 암호화하는 핵산 서열들(즉, 서열번호 20 및 21)은 서열번호 220 및 221을 포함한다. 이와 관련하여, 사람화 작제물들 및 이들의 변이형들을 암호화하는 서열들을 포함하는, 경쇄 및 중쇄 가변 영역 아미노산 서열들을 모두 암호화하는 핵산 서열들은 유사하게 번호매김되어 있으며, 서열번호 220 내지 399를 포함한다.
실시예 8
키메릭 및 사람화 SEZ6 조절물질들의 생성
상기 언급된 바와 같이, 실시예 7로부터의 뮤린 항체들 중 11개를 상보성 결정 영역(CDR) 이식을 이용하여 사람화하였다. 중쇄 및 경쇄들을 위한 사람 프레임워크는 기능성 사람 생식세포계열 유전자에 관한 서열 및 구조 유사성에 기초하여 선택하였다. 이와 관련하여, 사람 후보물질에 대한 마우스 정준(定準) CDR 구조를 코티아(Chothia) 등(상기)에 기술된 동일한 정준 구조들과 대조함으로써 구조적 유사성을 평가하였다.
특히, 11개의 뮤린 항체들 SC17.16, SC17.17, SC17.24, SC17.28, SC17.34, SC17.46, SC17.151, SC17.155(SC17.90의 복사체), SC17.156, SC17.161 및 SC17.200을 컴퓨터-보조 CDR-이식 방법(Abysis Database, UCL Business Plc.) 및 표준 분자공학기술들을 사용하여 사람화하여, hSC17.16, hSC17.17, hSC17.24, hSC17.28, hSC17.34, hSC17.46, hSC17.151, hSC17.155, hSC17.156, hSC17.161 및 hSC17.200 조절물질들을 제공하였다. 가변 영역들의 사람 프레임워크 영역은 대상 마우스 프레임워크 서열 및 이의 정준 구조에 대한 이들의 최상의 서열 상동성에 기초하여 선택하였다. 사람화 분석의 목적을 위해, CDR 도메인들의 각각에 아미노산들을 할당하는 것은 카뱃(Kabat) 등 번호매김(상기 참조)에 따른다.
분자공학과정들은 당해 분야에 인정된 기술들을 사용하여 실시하였다. 이를 위해, 하이브리도마들로부터 전체 mRNA를 추출하고, 바로 상기 실시예 7에 개시된 바와 같이 증폭시켰다.
뉴클레오티드 서열 정보로부터, 대상 뮤린 항체들의 중쇄 및 경쇄들의 V, D 및 J 유전자 절편들과 관련된 데이터가 수득되었다. 서열 데이터에 기초하여, 항체들의 Ig VH 및 VK 경쇄의 리더 서열에 특이적인 새로운 프라이머 세트들을 재조합 모노클로날 항체의 클로닝을 위해 설계하였다. 이어서, V-(D)-J 서열들을 마우스 Ig 생식세포계열 서열들과 함께 정렬하였다. 11개의 사람화된 작제물 각각에 대한 수득된 유전자 배열들은 하기 표 3에 제시되어 있다.

표 3에 나타낸 사람화 항체들은 도 10a 및 도 10b에 제시된 주석이 달린 경쇄 및 중쇄 서열들(서열번호 170 내지 191)에 상응한다. 경쇄 및 중쇄 가변 영역들의 상응하는 핵산 서열들은 첨부된 서열목록에 제시되어 있다. 표 3은 결합 조절물질들의 바람직한 특성들을 유지하기 위해 매우 적은 프레임워크 변화들이 필요함을 추가로 보여준다. 이점에서, 프레임워크 변화 또는 복귀 돌연변이는 오직 3개의 중쇄 가변 영역들에서만 이루어졌으며, 경쇄 가변 영역들에 오직 2개의 프레임워크 변형만 포함되었다.
일부 사람화된 경쇄 및 중쇄 가변 영역들의 경우, 항원 결합을 유지하면서 안정성을 개선시키기 위해 아미노산 변이가 FR들 또는 CDR들에 도입되었음을 주지하라. SC17.155의 경우, hSC17.155vH1 내지 hSC17.155vH6으로 명명된 6개의 변이체가 생산되었다. 이러한 변이체들 각각에서, hSC17.155의 중쇄 가변 영역의 FR 또는 CDR들이 변화된 반면, 경쇄 가변 영역이 변화되지 않은 상태로 남겨졌다. hSC17.155vH1 및 hSC17.155vH2의 경우, hSC17.155의 중쇄 가변 영역의 FR1(서열번호 471 및 472)에 점 돌연변이가 도입되었다. hSC17.155vH3의 경우, hSC17.155 중쇄 가변 영역의 CDRH1(서열번호 473)에 점 돌연변이가 도입되었다. hSC17.155vH4 내지 hSC17.155vH6의 경우, hSC17.155 중쇄 가변 영역의 CDRH2(각각 서열번호 474, 475 및 476)에 점 돌연변이가 도입되었다. hSC17.161의 경우, 중쇄 가변 영역의 FR1(서열번호 477); FR2(서열번호 478) 및 FR3(서열번호 479) 내의 특정 아미노산들이 변화된 반면, 경쇄 가변 영역은 변형되지 않았다. 마지막으로, hSC200vL1의 경우, hSC17.200 경쇄 가변 영역의 CDRL1(서열번호 480)에 점 돌연변이가 도입되었고 중쇄 가변 영역은 변형되지 않았다. 각 경우, 변형된 CDR들 또는 FR들을 갖는 항체들의 결합 친화성은 상응하는 키메라 또는 뮤린 항체에 동등한 것으로 밝혀졌다. 9개의 예시된 사람화 변이체 쇄들(경쇄 및 중쇄)의 서열은 도 10a 및 도 10b의 끝부분(서열번호 192 내지 199)에 기재되어 있으며, 이들이 변경된 것을 표시하기 위한 표기법(예를 들면, hSC17.200vL1, hSC17.155vH1-6 및 hSC17.161vH1)으로 사람화된 모체 쇄를 지정하고 있다. 예시적인 사람화된 항체들 hSC17.200 및 hSC17.200vL1의 전체길이 아미노산 서열은 서열번호 400 내지 402로서 도 10c에 제시되어 있다. 사람화된 항체 변이체 hSC17.200vL1은 사람화된 항체 hSC17.200으로부터 유래하며 hSC17.200 항체와 공통의 HC를 공유한다. 따라서, hSC17.200의 전체길이 LC 및 HC는 각각 서열번호 400 및 401에 상응하며; hSC17.200vL1의 전체길이 LC 및 HC는 각각 서열번호 403 및 401에 상응한다. 상기 모든 선택된 항체들을 CDR 이식에 의해 사람화한 후, 수득된 경쇄 및 중쇄 가변 영역 아미노산 서열들을 분석하여 뮤린 공여체 및 사람 수용체의 경쇄 및 중쇄 가변 영역들에 관한 이들의 상동성을 측정하였다. 하기 표 4에 나타낸 결과들은 사람화 작제물들이 뮤린 공여체 서열들보다 사람 수용체 서열들에 관하여 보다 높은 상동성을 일관되게 나타냄을 보여준다. 보다 구체적으로, 사람화된 중쇄 및 경쇄 가변 영역들은 일반적으로 사람화된 가변 영역 서열들 및 공여체 하이브리도마 단백질 서열들의 상동성(74% 내지 89%)과 비교해 사람 생식세포계열 유전자들의 가장 근접한 매치에 대한 보다 높은 상동성 비율(84% 내지 95%)을 나타낸다.

시험시, 실시예 9에서 논의되는 바와 같이, 각각의 사람화 작제물들은 뮤린 모체 항체들에 의해 나타난 결합 특성과 대략 유사한 바람직한 결합 특성들을 나타냈다(데이터는 제시되지 않음).
사람화 또는 뮤린에 관계없이, 가변 영역들의 핵산 서열들이 일단 결정되면, 본 발명의 항체들은 당해 분야에 인정된 기술들을 사용하여 발현 및 단리시킬 수 있다. 이를 위해, 선택된 중쇄(사람화 또는 뮤린) 가변 영역의 합성 DNA 단편들을 사람 IgG1 발현 벡터 내로 클로닝시켰다. 유사하게, (다시 사람화된 또는 뮤린) 가변 영역 경쇄 DNA 단편을 사람 경쇄 발현 벡터 내로 클로닝시켰다. 그 후, 상기 선택된 항체를, 유도된 중쇄 및 경쇄 핵산 작제물을 CHO 세포들로 형질감염시킴으로써 발현시켰다.
더욱 특히, 한가지 적합한 항체 생산 방법은 (PCR을 사용하여 증폭된) 뮤린 또는 사람화 가변 영역 유전자들을 선택된 사람 면역글로불린 발현 벡터들로 방향성 클로닝하는 것을 포함하였다. Ig 유전자-특이적 PCR들에 사용된 모든 프라이머들은 제한 부위들을 포함하였으며, 이는 사람 IgG1 중쇄 및 경쇄 불변 영역들을 함유하는 발현 벡터로 직접 클로닝되도록 한다. 간단히 말하면, PCR 생성물들은 Qiaquick PCR 정제 키트(Qiagen)에 의해 정제된 후, (중쇄를 위한) AgeI 및 XhoI 및 (경쇄를 위한) XmaI 및 DraIII 각각에 의해 분해시켰다. 분해된 PCR 생성물을 발현 벡터에 연결시키기 전에 정제하였다. 200U T4-DNA 리가아제(New England Biolabs), 7.5μL의 분해 및 정제된 유전자-특이적 PCR 생성물 및 25ng 선형화된 벡터 DNA에 의해 10μL의 총 용적으로 연결 반응을 수행하였다. 42℃에서 열충격을 통해 경쟁적 이. 콜라이(E. coli) DH10B 세균(Life Technologies)을 3μL 연결 생성물에 의해 변환시키고, 암피실린 플레이트(100㎍/mL)에 플레이팅하였다. VH 부위의 AgeI-EcoRI 단편은 pEE6.4HuIgG1 발현 벡터의 동일한 부위에 삽입시킨 반면, 합성 XmaI-DraIII VK 삽입물은 각 pEE12.4Hu-카파 발현 벡터의 XmaI-DraIII 부위 내로 클로닝하였다.
선택된 항체를 생성하는 세포들은 293펙틴을 사용하여 HEK 293 세포들을 적당한 플라스미드에 의해 형질감염시킴으로써 생성되었다. 이에 관련하여, 플라스미드 DNA를 QIAprep 스핀 칼럼(Qiagen)에 의해 정제하였다. 10% 열 불활성화 FCS, 100㎍/mL 스트렙토마이신, 100 U/mL 페니실린 G(모두 Life Technologies 제조)가 보충된 둘베코 변형 이글 배지(Dulbecco's Modified Eagle's Medium)(DMEM)에서 표준 조건하에 사람 배아 신장(HEK) 293T(ATCC No CRL-11268) 세포들을 150mm 플레이트(Falcon, Becton Dickinson)에서 배양하였다.
일시적인 형질감염을 위해, 세포들을 80% 컨플루언시(confluency)로 성장시켰다. 1.5 mL Opti-MEM 중의 50μL HEK 293 형질감염 시약과 혼합된 1.5 mL Opti-MEM에 동일한 양의 IgH 및 대응하는 IgL 쇄 벡터 DNA(각각 12.5㎍)를 첨가하였다. 이 혼합물을 실온에서 30분 동안 항온배양하고, 배양 플레이트에 균일하게 분포시켰다. 상층액을 형질감염 3일 후 수거하고, 10% FBS가 보충된 새로운 DMEM 20mL로 대체하고, 형질감염 6일 후 다시 수거하였다. 800xg에서 10분 동안 원심분리하여, 배양물 상층액에서 세포파괴물을 제거하고, 4℃에서 저장하였다. 재조합 키메릭 및 사람화 항체들을 단백질 G 비이드들(GE Healthcare)로 정제하고, 적당한 조건하에 저장하였다.
실시예 9
SEZ6 조절물질들의 특성들
상기 제시된 바와 같이 생성된 선택된 SEZ6 조절물질들의 결합 및 면역화학적 특성들을 분석하기 위해, 다양한 방법들을 사용하였다. 구체적으로, 수많은 항체 조절물질들은 유세포분석법을 포함한 당해 분야에 공지된 방법들에 의해, SEZ6L 및 SEZ6L2 단백질들과 함께, 사람, 시노몰구스, 래트 및 마우스 SEZ6 항원에 관한 친화도, 빈화, 및 교차 반응성으로서 특성평가하였다. 선택된 조절물질들의 친화성 및 반응속도 상수 kon 및 koff는 제조업자의 지시에 따라 각각 ForteBio RED(ForteBio, Inc.) 상의 바이오-층 간섭분석법 또는 Biacore 2000을 사용한 표면 플라즈몬 공명을 사용하여 측정되었다.
특성평가 결과는 도 11a에 표 형태로 제시되어 있으며, 여기서 선택된 조절물질들이 일반적으로, 나노몰 범위의 비교적 높은 친화력을 나타내고, 대부분의 경우 하나 이상의 SEZ6 이종상동체(ortholog)들과 교차-반응성임을 알 수 있다. 도 11a는 대상 조절물질이 점유한 경험적으로 측정된 빈(bin)을 추가로 개시하고 있다. 종합해 보면, 이러한 데이터는 동물 모델에서 개시된 조절물질의 다양한 결합 특성뿐만 아니라 이들의 반응성에 기초한 약제 개발을 위한 이들의 잠재적 적합성을 입증하고 있다.
이와 관련하여, 선택된 SC17 항체 조절물질들이 사람 SEZ6과 면역특이적으로 회합할 수 있는지 확인하기 위해 그리고 동일한 조절물질들이 SEZ6L 및 SEZ6L2 이외에 시노몰구스, 래트 및/또는 뮤린 SEZ6과 교차반응하는지의 여부를 측정하기 위해, 제조업자의 지시에 따라 FACSCanto II를 사용하여 유세포분석법을 수행하였다. 보다 특히, 조절물질들은 각각 마우스 SEZ6 및 래트 SEZ6을 발현하는 Neuro2a(ATCC 카탈로그 번호 CCL131) 및 RIN-m5F(ATCC 카탈로그 번호 CRL-11605) 세포주들에 대하여, 유세포분석법에 의해 뮤린 SEZ6 및 래트 SEZ6에 대한 교차 반응성을 시험하였다. 시노몰구스 SEZ6에 대한 교차 반응성을 시험하기 위해, 시노몰구스 SEZ6의 세포외 도메인을 디스플레이하는 효모(Boder et al, 1997)를 유세포분석법 분석에 사용하였다.
간략하게는, 웰당 1x105개 세포들의, Neuro2a, RIN-5mF, 또는 시노몰구스 SEZ6 세포들을 디스플레이하는 효모를 5㎍/mL 항체를 갖는 50μL PBS(2% FCS) 완충제와 함께 30분 동안 항온배양하였다. 세포들을 동일한 완충제로 2회 세척하고, 그 후 PBS 완충제 중에 1:200 희석된 Fc 단편 특이적 2차 항체인 DyLight 649 표지된 염소-항-마우스 IgG 샘플당 50μL와 함께 항온배양하였다. 15분 동안 항온배양한 후, 세포들을 PBS 완충제로 2회 세척하고, Neuro2a 및 Rin-m5F의 유세포분석법 분석을 위해 DAPI를 갖는 동일 완충제 중에 또는 cSEZ6을 갖는 효모 세포의 유세포분석법분석을 위해 DAPI가 없는 완충제 중에 재현탁시켰다. Neuro2a 또는 RIN-m5F 세포주들, 또는 시노몰구스 SEZ6을 디스플레이하는 효모에 결합된 항체들은, 각각 뮤린 SEZ6, 래트 SEZ6, 또는 시노몰구스 SEZ6에 대하여 교차반응성인 것으로 고려되었다. 도 11a는 교차반응성 결과들을 도시한다. 6개의 항체들이 사람 및 마우스 SEZ6에 대하여 교차반응성이었고(SC17.6(SC17.16의 복사체), SC17.7, SC17.19, SC17.24, SC17.26 및 SC17.42); 6개의 항체들이 사람 및 래트 SEZ6에 대하여 교차반응성이었으며(SC17.6, SC17.17, SC17.19, SC17.26, SC17.28, SC17.34 및 SC17.42); 6개의 항체들이 사람 및 시노몰구스 SEZ6에 대하여 교차반응성이었다(SC17.17, SC17.24, SC17.26, SC17.34, SC17.36 및 SC17.45). SC17.6은 SC17.16의 복사체이며 동일한 결합특성을 나타냄을 주목한다.
래트 SEZ6에 대한 상기 교차 반응성을 확인하기 위해 그리고 선택된 이펙터들의 친화성 및 반응속도 상수 kon 및 koff를 측정하기 위해, ForteBio RED(ForteBio, Inc.) 상에서 바이오-층 간섭법 분석 또는 Biacore 2000(GE Healthcare) 상에서 표면 플라즈몬 공명을 실시하였다. 실시예 5에서 생성된 사람 재조합 SEZ6-His 및 래트 재조합 SEZ6-His 둘 다에 대한 친화성을 측정하였다. 도 11a에 도시된 바와 같이, 시험한 수많은 항체들이 래트 SEZ6과 교차반응하였다. 선택된 조절물질들은 래트 및 사람 SEZ6 둘 다에 대하여 나노몰 범위로 비교적 높은 친화성을 나타냈다.
패밀리 구성원 단백질들, SEZ6L 및 SEZ6L2에 대한 교차 반응성을 측정하기 위해, ELISA-기반 검정을 사용하였다. PBS 1mL 당 0.2㎍로 SEZ6, SEZ6L, 또는 SEZ6L2 단백질들에 의해 밤새 플레이트들을 코팅하였다. 0.05%(v/v) Tween 20을 함유하는 PBS(PBST)로 세척한 후, 웰들을 실온에서 1시간 동안 웰당 100μL의 양으로 PBS 중의 2%(w/v) BSA(PBSA)에 의해 차단하였다. 그 후, 실온에서 1시간 동안 100μL PBSA에 1㎍/mL로 항체를 첨가하였다. PBST에 의해 세척한 후, 실온에서 1시간 동안 PBSA에서 100μL/웰 HRP-표지된 염소 항-마우스 IgG를 1:2,000 희석하였다. 플레이트들을 세척하고, 웰당 100μL의 TMB 기질용액(Thermo Scientific 34028)을 실온에서 15분 동안 첨가하였다. 전개 후, 기질 전개를 정지시키기 위해 동일 용적의 2M H2SO4를 첨가하고, OD 450에서 분광광도계에 의해 분석하였다. 도 11a는 1개의 항체가 SEZ6L과 교차반응성이고(SC17.7), 5개의 항체가 SEZ6L2와 교차반응성임(SC17.6, SC17.7, SC17.19, SC17.26 및 SC17.28)을 보여준다. 위에 설명한 바와 같이, 상기 범-SEZ6 항체들은 본 명세서의 교시내용과 양립가능하며 개시된 방법들과 함께 사용될 수 있다.
CDR 이식 과정이 이들의 결합 특성들을 눈에 띄게 변경시켰는지의 여부를 측정하기 위해, 실시예 8로부터의 하기 사람화 작제물들, hSC17.16, hSC17.17, hSC17.24, hSC17.28, hSC17.34 및 hSC17.46의 결합 특성들을 분석하였다. 사람화 작제물들(CDR 이식됨)을, 사람화 작제물에 사용된 것과 실질적으로 균등한 사람 불변 영역 및 뮤린 모체(또는 공여체)의 중쇄 및 경쇄 가변 도메인들을 포함하는 "전통적인" 키메릭 항체들과 대조하였다. 사람화 과정을 일으키는 속도 상수의 임의의 미묘한 변화들을 동정하기 위해, Biacore 2000(GE Healthcare)을 사용하여, 상기 작제물 표면에 의해 표면 플라즈몬 공명을 실시하였다. 모든 경우, 사람화 항체들은 상응하는 뮤린 항체들과 동등하거나 또는 더 나은 결합 친화도를 가졌다(데이터는 제시되지 않음).
도 11a에 도시된 바와 같이 다양한 SEZ6 조절물질들에 대하여, 항체 결합을 측정하였다. 동일하거나 다른 빈에 결합된 경쟁 항체들을 동정하기 위해, 제조업자의 지시에 따라 ForteBio RED를 사용하였다. 간략하게는, 항-마우스 포획 칩 상에서 참고 항체(Ab1)를 포획하고, 칩을 차단하기 위해 고농도의 비결합 항체를 사용하고, 기준선을 수집하였다. 그 후, 단량체, 재조합 사람 SEZ6(실시예 5에 설명됨)을 특이적 항체(Ab1)에 의해 포획하고, 그 끝을 대조군으로서 동일한 항체(Ab1)를 갖는 웰에 또는 다른 시험 항체(Ab2)를 갖는 웰에 침지시켰다. 새로운 항체와의 추가 결합이 관찰되었다면, 그 후 Ab1 및 Ab2는 상이한 빈에 있는 것으로 측정되었다. 대조 Ab1과의 결합 수준들을 대조함으로써 측정된 바와 같이, 추가의 결합이 일어나지 않았다면, 그 후 Ab2는 동일한 빈에 있는 것으로 측정되었다. 당해 분야에 공지되어 있는 바와 같이, 이러한 방법은 96웰 플레이트에서 독특한 빈을 나타내는 전체 열의 항체들을 사용하여 독특한 항체들의 큰 라이브러리들을 선별하기 위해 확장될 수 있다. 본 경우, 상기 빈화(binning) 과정은 선별된 항체들이 SEZ6 단백질 상에서 적어도 7개의 다른 빈에 결합되었음을 보여주었다. 빈 A-F는 SEZ6 단백질에 결합하기 위해 서로 경쟁하는 각각의 상기 빈 내에 함유된 항체들(다른 정의된 빈으로부터의 항체와는 경쟁하지 않음) 및 독특한 빈이다. 빈 U는 빈 A 내지 F 내의 항체들과 경쟁하지 않지만, 서로 결합하기 위해 경쟁할 수 있는 항체들을 함유한다. 도 11b는 특정 에피토프에 결합하는 항체들과 SEZ6을 과발현하는 HEK-293T 세포를 치사시키는 이러한 항체 그룹들의 능력 간의 상관관계를 보여준다(하기 실시예 10에 보다 상세히 기재되어 있음).
실시예 10
SEZ6 조절물질들의 에피토프 맵핑
개시된 SEZ6 항체 조절물질들이 회합 또는 결합한 에피토프들을 특성평가하기 위해, 코크란(Cochran) 등[참조: J Immunol Methods. 287 (1-2):147-158 (2004), 이는 본원에 참조로 포함됨]에 기술된 프로토콜의 변형을 사용하여 도메인-수준 에피토프 맵핑을 수행하였다. SEZ6의 각 도메인들은 효모 표면상에서 발현되고, 각 SEZ6 항체에 의한 결합은 유세포분석법을 통해 측정하였다.
효모 디스플레이 플라스미드 작제물들은 하기 작제물들의 발현을 위해 생성되었다: SEZ6 세포외 도메인(아미노산 1-904); 스시(Sushi) 도메인 1(아미노산 336-395), CUB 도메인 1(아미노산 297-508), 스시 도메인 2(아미노산 511-572), CUB 도메인 2 (아미노산 574-685), 스시 도메인 3(아미노산 690-748), 스시 도메인 4(아미노산 750-813), 스시 도메인 5(아미노산 817-878), 및 스시 도메인 5 + C-말단(아미노산 817-904). 추가로, N 말단 도메인(아미노산 1-335)을 3개의 단편들, 즉 N1(아미노산 1-70), N2(아미노산 71-169) 및 N3(아미노산 169-335)으로 나누었으며, 이들 각각은 효모 디스플레이 플라스미드 내로 클로닝되었다. 아미노산 번호매김은 19개 아미노산 리더 펩타이드를 포함하지 않는다. 도메인 정보를 위해서는, 일반적으로 UniProtKB/Swiss-Prot 데이터베이스 엔트리 Q53EL9를 참조한다. 이러한 플라스미드들을 효모 내로 형질전환시켰고, 그 후 이를 코크란(Cochran) 등에 기술된 바와 같이 성장시키고 유도시켰다. 모든 아미노산 번호매김은 19개 아미노산 리더 서열이 없는 성숙한 SEZ6 단백질에 기초하고 있음을 주목한다.
특정 작제물에 대한 결합을 시험하기 위해, 원하는 작제물을 발현하는 200,000개의 유도된 효모 세포들을 PBS + 1mg/mL BSA(PBSA)로 2회 세척하고, 0.1㎍/mL로 닭 항 c-myc(Life Technologies)를 갖는 50μL의 PBSA에서 항온배양하고, 50nM 정제된 항체 또는 하이브리도마들로부터 비정제 상층액의 1:2 희석액을 7일간 항온배양하였다. 세포들을 빙상에서 90분 동안 항온배양하고, PBSA에서 2회 세척하였다. 그 후, 세포들을 적당한 2차 항체들과 50μL의 PBSA 중에서 항온배양하고; 뮤린 항체들에 대하여, Alexa 488 접합된 항-닭 및 Alexa 647 접합된 염소 항-마우스(둘 다 Life Technologies)를 각각 1㎍/mL로 첨가하고, 각 사람화 또는 키메릭 항체들에 대하여, Alexa 647 접합된 항-닭(Life Technologies) 및 R-피코에리트린 접합된 염소 항 사람(Jackson Immunoresearch)을 각각 1㎍/mL로 첨가하였다. 빙상에서 20분 동안 항온배양한 후, 세포들을 PBSA로 2회 세척하고, FACS Canto II 상에서 분석하였다.
모든 조절물질들은 효모 세포들 상에서 발현된 단일 도메인에 유일하게 결합된다. 일부 경우, 항체 클론들은 스시 도메인 5 + C-말단을 발현하는 효모에 특이적으로 결합하지만, 스시 도메인 5를 발현하는 효모에는 결합하지 않는다. 상기 항체 클론들은 C-말단 영역에만 결합하는 것으로 결론 내려졌다(아미노산 879-904).
에피토프들은 입체구조적(즉, 불연속적) 또는 선형으로 분류되었다. 항원을 변성시키기 위해, SEZ6 ECD 작제물을 디스플레이하는 효모를 80℃에서 30분 동안 열처리하고, 빙냉 PBSA로 2회 세척하고, 그 후 상기 설명한 바와 같이 동일한 염색 프로토콜 및 유세포분석법 분석에 적용하였다. 변성된 효모와 천연 효모 둘 다에 결합된 항체들은 선형 에피토프에 결합한 것으로 분류된 반면, 천연 효모에는 결합되었지만 변성 효모에는 결합되지 않은 항체들은 입체구조적인 것으로 분류되었다.
시험된 항체들의 도메인-수준 에피토프 맵핑 데이터의 요약은 하기 표 5에 나타나 있다. 선형 에피토프와 결합하는 항체들은 밑줄쳐 있으며, SEZ6 패밀리 구성원들 SEZ6L 및 SEZ6L2와 결합하는 항체들은 각각 별표 및/또는 단검표로 표시된다.

본 실시예 10에 설명한 도메인-맵핑된 SEZ6 항체 조절물질들을 사용하여 시험관내 세포 치사 검정을 수행할 때, 흥미있고 놀라운 경향이 관찰되었다. 실시예 14에 하기 기술된 바와 같이 기본적으로 수행된, 상기 시험관내 치사 검정은 HEK-293 세포들을 내재화하고 치사할 수 있는 특정 항체의 능력을 측정하였다. 도 11b는 시험된 항체들 대 이들이 결합하는 도메인들의 효능 도식도이다. N1, N3, 스시 도메인 1, 및 스시 도메인 4를 포함하는, 특정 도메인들에 결합하는 항체들은 개선된 시험관내 치사를 나타냈다. 세포들을 내재화하고 치사하는데 매우 효과적인 스시 도메인 4와 회합한 항체들은, IGHV1-34 및 IKV4-59 뮤린 생식세포계열 프레임워크 영역들과 강력한 상관관계를 나타낸다.
선택된 항체들 상에서, 이들이 결합된 특정 아미노산들을 측정하기 위해, 정교한 에피토프 맵핑을 추가로 수행하였다. 선형 에피토프에 결합된 항체들은 Ph.D.-12 파아지 디스플레이 펩타이드 라이브러리 키트(New England Biolabs E8110S)를 사용하여 맵핑하였다. 에피토프 맵핑을 위해 선택된 항체를 Nunc MaxiSorp 튜브(Nunc)상에서 pH 8의 0.1M 중탄산나트륨 용액 3mL내 50㎍/mL로 코팅하고, 밤새 항온배양하였다. 이 튜브를 중탄산나트륨 용액 중의 3% BSA 용액으로 차단하였다. 그 후, PBS + 0.1% Tween-20 내 1011 투입 파아지를 결합시켜, 0.1% Tween-20으로 10회 연속 세척에 의해 비결합 파아지를 세척하였다. 남은 파아지를 실온에서 조심스럽게 교반하여 10분 동안 1mL 0.2 M 글라이신에 의해 용출시키고, pH 9의 150μL 1M Tris-HCl로 중화하였다. 용출된 파아지를 증폭시키고, 세척 단계 동안 0.5% Tween-20을 사용하여, 1011 투입 파아지로 다시 패닝(panning)하여, 선택 엄중도를 증가시켰다. Qiaprep M13 스핀 키트(Qiagen)를 사용하여, 제2 라운드로부터 용출된 파아지의 24개의 플라크로부터의 DNA를 단리하고 서열분석하였다. ELISA 검정을 사용하여 클론성 파아지의 결합을 확인하고, 맵핑 항체 또는 대조 항체를 ELISA 플레이트 상에 코팅하고 차단하고, 각 클론 파아지에 노출시켰다. 서양고추냉이 퍼옥시다제 접합된 항-M13 항체(GE Healthcare) 및 1-스텝 터보 TMB ELISA 용액(Pierce)을 사용하여 파아지 결합을 검출하였다. 항원 ECD 펩타이드 서열에 대한 벡터 NTI(Life Technologies)를 사용하여, 특이적으로 결합하는 파아지로부터의 파아지 펩타이드 서열을 정렬하여, 결합 에피토프를 측정하였다.
불연속적 에피토프에 결합된 선택된 항체들은 카오(Chao) 등(2007)에 의해 설명된 기술을 사용하여 맵핑하였다. 클론당 1개의 아미노산 돌연변이의 표적 돌연변이유발 속도를 위해, 뉴클레오타이드 유사체 8-옥소-2'데옥시구아노신-5'-트리포스페이트 및 2'-데옥시-p-뉴클레오시드-5'트리포스페이트(둘 다 TriLink Bio 제조)를 사용하여 실수 유발 PCR(error prone PCR)에 의해 SEZ6 ECD 돌연변이체들의 라이브러리를 생성하였다. 이들은 효모 디스플레이 포맷으로 변형되었다. 도메인-수준 맵핑을 위해 상기 설명된 기술을 사용하여, 50nM에서 c-myc 및 항체 결합을 위해 라이브러리를 염색하였다. FACS Aria(BD)를 사용하여, 야생형 SEZ6 ECD와 비교되는 결합 손실을 나타내는 클론들을 분류하였다. 이들 클론들을 재성장시키고, 표적 항체에 대한 결합 손실에 대한 FACS 분류의 다른 라운드에 적용하였다. Zymoprep 효모 플라스미드 미니프렙(Miniprep) 키트(Zymo Research)를 사용하여, 각 ECD 클론들을 분류하고 서열분석하였다. 필요한 경우, Quikchange 부위 지향성 돌연변이유발 키트(Agilent)를 사용하여 단일-돌연변이 ECD 클론들로 돌연변이를 개편하였다.
결합 손실이 에피토프내 돌연변이에 의한 것인지 또는 미스폴딩(misfolding)을 야기시키는 돌연변이에 의한 것인지 결정하기 위하여 각 ECD 클론들을 이어서 선별하였다. 시스테인, 프롤린 및 정지 코돈들을 포함한 돌연변이들은 미스폴딩 돌연변이가 일어나기 쉬워서 자동으로 폐기되었다. 비경쟁적, 형태적으로 특이적인 항체에 결합시키기 위해, 남은 ECD 클론들을 선별하였다. 비경쟁적이고 형태적으로 특이적인 항체들에 대한 결합력을 손실한 ECD 클론들은 미스폴딩 돌연변이를 함유할 것으로 결론이 내려진 반면, 야생형 SEZ6 ECD와 동일한 결합력을 보유한 ECD 클론들은 적당하게 폴딩된 것으로 결론지었다. 후자 그룹에서 ECD 클론들의 변이는 에피토프 내에 있는 것으로 결론이 내려졌다. 에피토프 내에 있는 것으로 동정된 잔기들이: 1) 폴딩된 상동성 모델에서 서로 근접하게 위치되어 있고, 및 2) 용매 노출되고 묻히지 않은 측들을 가짐을 확인하기 위해, MODELLER를 사용하여, 단리된 도메인들의 상동성 모델들을 또한 작제하였는데, 그 이유는 묻힌 잔기들은 미스폴딩을 야기할 기회를 더 많이 가지며, 결합하는 에피토프의 부분이 되기 어렵기 때문이다. 항체와 이들의 에피토프의 요약은 표 6에 기재되어 있다. 에피토프의 구조에 가장 현저하게 기여하는 것으로 밝혀진 잔기들은 밑줄이 쳐져있다.

NR은 에피토프들이 불연속적임에 따라 서열번호가 배정되지 않음을 나타낸다.
SC17.34, SC17.36, SC17.200 및 SC17.46의 정교한 에피토프 맵핑의 목적을 위해, 점 돌연변이들은 단리된 도메인, 스시 도메인 1 상에서 작제하였으며, 이는 도메인-수준 에피토프 맵핑에 의한 결합의 도메인인 것으로 측정되었다. 일부 경우, 선별을 위한 후보 돌연변이들은 효모 디스플레이된 라이브러리와 무관하게 결정되었다. 예를 들면, SC17.46의 경우, 선별을 위한 후보 돌연변이들은 라이브러리-기반 스크린에서 동정되지 않았으며; 이들은 도메인 맵핑, 시노몰구스 SEZ6 ECD 및 래트 SEZ6 ECD에 대한 교차 반응성의 결여, 및 종의 1차 서열에서의 차이점들을 동정하기 위한 상이한 종들의 서열 정렬에 기반하여 동정하였다. SC17.102, SC17.121, SC17.140, SC17.156, SC17.166, SC17.191 및 17.200의 경우, 후보 잔기들은 알라닌 스캐닝 및 도메인 결합 분석의 병용을 사용하여 동정하였다. 모든 경우에, 후보 돌연변이들은 그 후보 돌연변이가 라이브러리 기반 접근법에 의해 동정된 다른 항체들과 동일하게 분석하였다.
본 발명은 SEZ6 단백질(예를 들면, 서열번호 3 또는 4의 SEZ6 단백질을 포함) 상의 에피토프에 결합하는 항-SEZ6 항체 및 항체 약물 접합체에 관한 것으로, 여기서 상기 에피토프는 (i) 잔기 Q12, P14, I16, E17, E18; (ii) 잔기 R762, L764, Q777, I779, D781, Q782; (iii) 잔기 L73, P74, F75, Q76, P77, D78, P79; (iv) 잔기 T352, S353, H375; (v) 잔기 T352, S353, H375, S359; (vi) 잔기 R342, K389; (vii) 잔기 R762, L764, Q777, I779, D781, Q782; 또는 (viii) 잔기 R807, K810으로 이루어진 그룹으로부터 선택되는 아미노산 잔기들을 포함한다. 한 실시형태에서, 본 발명은 SEZ6 단백질(예를 들면, 서열번호 3 또는 4의 SEZ6 단백질을 포함) 상의 에피토프에 결합하는 항-SEZ6 항체 및 항체 약물 접합체에 관한 것으로, 여기서 상기 에피토프는 (i) 잔기 Q12, P14, I16, E17, E18; (ii) 잔기 R762, L764, Q777, I779, D781, Q782; (iii) 잔기 L73, P74, F75, Q76, P77, D78, P79; (iv) 잔기 T352, S353, H375; (v) 잔기 T352, S353, H375, S359; (vi) 잔기 R342, K389; (vii) 잔기 R762, L764, Q777, I779, D781, Q782; 또는 (viii) 잔기 R807, K810으로 이루어진 그룹으로부터 선택되는 아미노산 잔기들을 포함한다. 다른 실시형태에서, 본 발명은 하기 항체들 중 어느 하나와 같은, SEZ6 단백질(예를 들면, 서열번호 3 또는 4의 SEZ6 단백질을 포함) 상의 동일한 에피토프에 결합하는 항-SEZ6 항체 및 항체 약물 접합체에 관한 것이다: SC17.4, SC17.17, SC17.24, SC17.34, SC17.36, SC17.46, SC17.102, SC17.121, SC17.140, SC17.156, SC17.166, SC17.191 및 SC17.200.
실시예 11
유세포분석법에 의한 SEZ6 표면 발현의 검출
실시예 5에 기술된 바와 같이 작제된, 조작된 HEK-293T 세포주들의 표면 상에서 사람 SEZ6 단백질의 존재를 검출하기 위해 생성된 항-SEZ6 항체들의 특이성을 평가하기 위하여 유세포분석법을 사용하였다. 염색 특이성을 확인하기 위하여 동종형-염색된 및 형광 마이너스 원(fluorescence minus one; FMO) 대조군을 사용하였다. 간략하게는, 사람 SEZ6 및 GFP(실시예 5 참조) 또는 수거된 NTX 종양 샘플들로 형질감염시킨 HEK-293T를 해리시키고 당해 분야에 인정된 효소분해기술들(참조예는 U.S.P.N. 2007/0292414로서 본원에 포함됨)을 사용하여 현탁액으로 분산시켰으며, 항-SEZ6 항체와 함께 30분 동안 항온배양하였다. 세포들을 PBS(2% FCS)로 2회 세척하고, PBS 완충제 중에 1:200으로 희석된 샘플 DyLight 649 표지된 염소-항-마우스 IgG, Fc 단편 특이적 2차 50μL와 함께 항온배양하였다. 15분 항온배양 후, 세포들을 PBS에 의해 2회 세척하고, DAPI에 의해 PBS에 재현탁시키고, 위에 논의한 바와 같이 유세포분석법에 의해 분석하였다.
SC17.33에 대하여 도 12a에 도시된 대표적인 데이터에 의해 입증되는 바와 같이, SEZ6 조절물질은 HEK-293T-HuSEZ6 세포들을 강력하게 인식하였다. 이들 데이터는 세포 표면상에서 발현된 사람 SEZ6을 특이적으로 인식하는 조절물질들이 생산되었음을 입증한다.
수개의 예시적인 SC17 항체들을 사용한 유세포분석법에 의해, 선택된 NTX 종양들의 표면상에서의 사람 SEZ6 단백질 발현을 평가하였다. SC17.6(SC17.16의 복사체) 항체를 사용하여 LU37, LU86 및 KDY66에서 SEZ6의 발현을 시험한 반면, SC17.10, SC17.42 및 SC17.28 항체들을 각각 사용하여 LU50, LU100 및 LU73에서 SEZ6의 발현을 시험하였다. 그 결과는 도 13a에 개시되어 있다. NTX 종양을 수거하고 해리시키고, 상업용으로 입수가능한 항-마우스 CD45, 항-마우스 H-2Kd, 항-사람 EpCAM 및 1개의 상기 마우스 항-사람 SEZ6 항체들에 의해 공동-염색하였다. 도 13a에 도시된 데이터는 상기 항-마우스 항체들에 대하여 양성으로 염색되지 않지만, 항-사람 EpCAM에 대하여 양성으로 염색된 세포들을 사용하여 생성되었다. 상기 HEK-293T-염색 실험과 유사하게, 동종형-염색된 및 형광 마이너스 원(FMO) 대조군을 염색 특이성을 확인하기 위해 사용하였다. 도 13a에 도시된 바와 같이, 항-SEZ6 염색은 폐 NTX 종양 LU37, LU50 및 LU86 및 신장 NTX 종양 KDY66에 대하여, 우측으로의 형광 프로파일 이동에 의해 및 평균형광세기(MFI) 값들의 변화에 의해 표시되는 바와 같이, 사람 NTX 종양 세포들 모두에서 FMO보다 높았다. 이들 데이터는 SEZ6 단백질이 다양한 NTX 종양들의 표면상에서 발현되고, 따라서 항-SEZ6 항체를 사용하여 조절을 위해 처리할 수 있음을 제시하고 있다.
실시예 12
다양한 종양들에서 SEZ6 단백질의 발현
다양한 종양들과 관련된 상승된 SEZ6 mRNA 전사체 수준을 고려하여, NTX 종양들에서 SEZ6 단백질의 발현이 상응하게 증가하는 것을 입증하기 위한 작업이 실시되었다. SEZ6 단백질 발현은 (i) MSD 디스커버리 플랫폼(Meso Scale Discovery, LLC)을 사용한 전기화학발광 SEZ6 샌드위치 ELISA 분석; 및 (ii) 면역조직화학 염색에 의해 검출되었다.
마우스로부터 NTX 종양들을 절제하고, 드라이 아이스/에탄올 상에서 급속 냉동하였다. 해동된 종양 피검물들에 단백질 추출 완충제(Biochain Institute, Inc.)를 첨가하고, TissueLyser 시스템(Qiagen)을 사용하여 종양들을 분쇄하였다. 원심분리(20,000g, 20분, 4℃)에 의해 용해물들을 청소하고, 각 용해물내 총 단백질 농도를 비신코닌산을 사용하여 정량화하였다. 단백질 용해물을 검정할 때까지 -80℃에서 저장하였다. 정상 조직 용해물들은 상업적 공급원으로부터 구입하였다.
용해물 샘플들로부터의 SEZ6 단백질 농도는 정제된 재조합 SEZ6 단백질을 사용하여 생성된 표준 단백질 농도 곡선으로부터 값들을 내삽하여 측정하였다(실시예 5). SEZ6 단백질 표준 곡선 및 단백질 정량화 분석은 하기와 같이 진행하였다:
MSD 표준 플레이트를 PBS 중의 2㎍/mL에서 30μL의 SC17.17 항체로 4℃에서 밤새 코팅하였다. 플레이트들을 PBST에서 세척하고, 150μL MSD 3% 차단제(Blocker) A 용액에서 1시간 동안 차단하였다. 플레이트를 PBST에서 다시 세척하였다. MSD 1% 차단제 A 중의 25μL의 10배 희석된 용해물 또는 10% 단백질 추출 완충제를 함유하는 MSD 1% Blocker A 중의 연속 희석된 재조합 SEZ6 표준물을 또한 웰에 첨가하고, 2시간 동안 항온배양하였다. 플레이트들을 PBST로 세척하였다. 이어서, SC17.36 항체를 MSD 설포-태그와 접합시키고, 25μL의 태그된 SC17.36을 MSD 1% 차단제 A에서 0.5㎍/mL로 상기 세척된 플레이트에 첨가하였다. 계면활성제를 갖는 MSD 리드 완충제(Read Buffer) T를 물로 1X까지 희석시키고, 150μL를 각 웰에 첨가하였다. 표준 곡선으로부터 내삽을 통해 NTX 샘플들 중의 SEZ6 농도를 유도하기 위해, 통합형 소프트웨어 분석프로그램을 사용하여 MSD Sector Imager 2400 상에서 플레이트들을 판독하였다. 그 후, 값들을 총 단백질 농도로 나눠서, 전체 용해물 단백질 밀리그램당 SEZ6의 나노그램을 산출하였다. 수득된 농도들은 도 12b에 제시되어 있으며, 여기서 각 스팟은 단일 NTX 종양주로부터 유도된 SEZ6 단백질 농도를 나타낸다. 각 스팟은 단일 NTX주로부터 유도되는 반면, 대부분의 경우 동일한 NTX주로부터의 다수의 생물학적 샘플들은 시험되었고, 값들을 평균내어 데이터 포인트를 제공하였다.
도 12b는 정상 조직 용해물과 비교할 때, 선택된 신장, 난소 및 LCNEC 종양샘플들이 중간정도의 SEZ6 단백질 발현을 나타낸 반면, 가장 높은 SEZ6 단백질 발현은 SCLC 종양들에서 보여짐을 도시하고 있다. 모든 정상 조직 용해물들은 정상 사람 뇌 및 눈 용해물을 제외하고는, SEZ6 단백질 발현에 대하여 음성이었다.
SEZ6이 특정 PDX 종양들의 표면 상에서 발현되는 것을 확인하기 위해 그리고 종양 구조 내에서 SEZ6 단백질의 위치를 결정하기 위해, 면역조직화학(IHC)을 PDX 종양들 상에서 수행하였다. 간접 검출방법을 사용하여 포르말린 고정 파라핀 포매된(FFPE) 조직 절편들 상에서 IHC를 수행하였으며, 상기 검출방법은 SEZ6에 대한 뮤린 모노클로날 1차 항체(SC17.140), 마우스 특이적 바이오틴 접합된 2차 항체들, 서양고추냉이 퍼옥시다제와 커플링된 아비딘/바이오틴 복합체, 및 DAB 검출(Nakene PK 1968; 16:557-60)을 포함하였다. 실시예 5에 기술된 바와 같이 제조된, 순수한(naive) HEK-293T 세포 펠릿들과 비교해 SEZ6을 과발현하는 HEK-293T 세포 펠릿들의 FFPE 절편 상에서의 특이적 염색을 나타냄으로써, SC17.140이 IHC에 적절한 것으로 검증 및 확인되었다. IHC에 의해 SEZ6을 발현하는 것으로 나타난 NTX 종양들 및 사람 SEZ6을 과발현하는 HEK-293T 세포들 상에서 5몰 과량의 정제된 재조합 SEZ6과의 경쟁 신호에 의해 특이성을 추가로 확인하였다(데이터는 제시되지 않음).
SEZ6 발현은 SCLC NTX 종양들에서 IHC로 측정하였으며, 여기서 시험된 14개의 SCLC NTX 종양 중 13개가 SEZ6을 발현하였다(도 16a). 추가의 IHC 분석을 SCLC 환자로부터 절제된 174개의 사람 종양의 중심제거된(cored) 절편을 사용하여 생성된 5개의 조직 마이크로어레이(TMA)(Vanderbilt University, Memorial Sloan Kettering Cancer Center and Biomax, Inc.)상에서 수행하였다. 도 16b는 상기 5개의 TMA에 포함된 174개의 1차 환자 SCLC 종양에서 IHC로 측정된 SEZ6 발현을 도시하며, 여기서 122/174개의 SCLC 샘플, 2/3 SCLC/선암종 샘플 및 1/1 SCLC/방추상 세포 샘플은 SEZ6을 발현하는 것으로 나타났다. 대조적으로, 시험된 정상 폐 조직 샘플은 SEZ6을 발현하지 않았다(도 16b). 도 16a 및 16b에 도시된 IHC 결과를, 세포 표면 염색의 강도를 정량화하고 각 강도 수준(염색되지 않은 경우 0 및 강한 염색의 경우 3)에서 염색된 종양 세포의 비율을 반영하는 최종 "H-스코어"를 제공하는 자동화 영상 분석 소프트웨어 패키지(Leica Biosystems)를 사용하여 분석하였다. H-스코어는 다음과 같이 계산하였다: (0에서 %) * 0 + (1+에서 %) * 1 + (2+에서 %) * 2 + (3+에서 %) * 3. 따라서, H-스코어는 0 내지 300 범위의 연속 변수를 생성한다.
IHC를 또한 수질 갑상선암 환자들로부터의 FFPE 절편에서도 수행하였다. 시험된 모든 환자 샘플들은 SEZ6를 발현하는 것으로 나타났다(도 16c). 상기 갑상선암 샘플들을 발현 없음의 경우 (-) 및 증가하는 염색 강도를 나타내는 (+, ++ 또는 +++)로 하여 수동으로 스코어를 매겼다. SEZ6을 발현하는 것으로 추정된 FFPE 절편에서의 종양 세포의 비율도 또한 도 16c에 도시되어 있다.
RNA 제자리 하이브리드화(ISH)를 사용하여, 앞서 기술된 IHC로 측정된 SEZ6 발현 결과를 검증하였다. RNAscope® 2.0 시약 키트(Advanced Cell Diagnostics; Wang et al, 2012, PMID: 22166544)를 사용하여 ISH를 수동으로 수행하였다. 사용된 RNAscope 프로브는 SEZ6의 ECD에 대해 특이적이었다. 각 샘플을 세포의 소포체 내에 위치하는 사이클로스포린-결합 단백질인 펩티딜프로필 이소머라제 B(PPIB)에 특이적인 RNAscope 프로브를 사용하여 RNA 무결성(integrity)에 대해 품질 관리하였다. 디아미노피멜레이트(DiAminoPimelate; dapB) RNA에 특이적인 프로브를 사용하여 배경 염색을 측정하였다. 간략하게 언급하면, 도 16b에서 사용된 SCLC 종양 마이크로어레이 중 3개로부터의 5㎛ FFPE 조직 절편을 SEZ6 RNA 올리고뉴클레오타이드 프로브와의 하이브리드화 전에 열 및 프로테아제로 전처리하였다. 이어서, 전치증폭기, 증폭기 및 HRP 표지된 올리고뉴클레오타이드를 순차적으로 하이브리드화시킨 다음, 발색 침전물을 3,3'-디아미노벤지딘으로 발색시켰다. 특이적 RNA 염색 신호는 갈색 반점모양의 도트로서 동정되었다. 샘플을 길스 헤마톡실린(Gill's Hematoxylin)으로 대조염색하였다. FFPE 절편을 광현미경 하에 분석하고, 염색을 0부터 4의 척도로 수동으로 스코어를 매겼고, 여기서 0 = 염색 없음 또는 10개 세포당 1개 미만의 도트; 1 = 세포당 1 내지 3개 도트; 2 = 세포당 4 내지 10개 도트; 3 = 세포당 10개 초과 도트 및 군집에서 발견되는 10% 미만 도트이다. 또한, 예를 들면, 샘플 중 5 내지 30%의 세포가 1의 스코어를 갖고 70% 초과의 세포가 0의 스코어를 갖는 경우, 0.5의 스코어가 부여되었다. 시험된 종양 샘플 중에서, 5/32(16%)는 SEZ6을 발현하지 않았고; 17/32(53%)는 1의 스코어를 가졌고; 8/32(25%)는 2의 스코어를 가졌고 2/32(6%)는 3의 스코어를 가졌다. 조직 마이크로어레이에서 1차 환자 SCLC 샘플 중 전체 84%는 SEZ6 RNA를 어느 정도 발현하였다. 이는 IHC로부터 수득된 결과와 대체로 일치한다.
실시예 4에 제시된 SEZ6 발현 및 실시예 11에 제시된 SEZ6의 세포표면 발현에 대한 mRNA 전사 데이터와 조합된 이러한 데이터는 SEZ6 결정인자들이 치료적 중재를 위한 매력적인 표적을 제공한다는 제안을 강력하게 강화한다.
실시예 13
종양 개시 세포 집단들의 증대
종양 세포들은 두 종류의 세포 아집단들로 광범위하게 분류될 수 있다: 비종양형성 세포들(NTG) 및 종양개시 세포(TIC)들. TIC는 면역약화된 마우스에 이식될 때 종양을 형성할 수 있는 능력을 갖는다. 암 줄기세포(CSC)들은 TIC들의 서브세트이며, 다중계통 분화를 위한 능력을 유지하면서 무한정으로 자가-복제할 수 있다. SEZ6 발현이 개선된 종양형성 완전 전사체 서열분석과 상관관계가 있는지 여부를 측정하기 위해 유세포분석법 및 종양형성 검정을 수행하였으며, 이들 모두 본 명세서에 설명되어 있다.
다양한 종양 샘플들에서 SEZ6 발현의 완전 전사체 분석은 실시예 1에 기술된 바와 같이 수행하였다. CSC들은 다양한 종양들에서 줄기세포들의 마커인 것으로 나타난 CD324의 발현에 기초하여 동정되었다(PCT 출원 2012/031280 참조). 도 6b의 결과는 SEZ6 mRNA 발현이 2개의 SCLC NTX 종양주들(LU86 및 LU95)로부터 단리된 NTG 세포들과 대조되는 CSC들에서 높아짐을 보여준다.
유세포분석법은 실시예 11에 기술된 바와 같이 기본적으로 NTX 폐 종양들로부터의 세포들 상에서 수행하였다. SEZ6이 상기 집단들 상에서 별도로 발현되는지를 측정하기 위해, 각각 LU86, LU117 및 LU64 세포들을 CSC 집단의 마커인 CD324(PCT 출원 2012/031280 참조), 및 항-SEZ6 항체, SC17.10, SC17.28 또는 SC17.42와 공동-염색하였다. 도 13b에 도시된 바와 같이, CD324 및 SEZ6 둘 다에 대하여 양성으로 염색하는 LU86, LU117 및 LU64 세포들(흑색 실선)은 SEZ6 단독에 대하여 양성으로 염색하는 세포들(흑색 점선)에 비해 우측으로 좀더 이동되며, 이는 SEZ6이 NTG 세포 집단에 비하여 CSC들 상에서 보다 높게 발현됨을 보여준다. 대량의 집단 동종형 대조군은 회색의 채워진 히스토그램으로 나타낸다(MOPC = IgG1).
세포 표면 SEZ6 발현이 종양을 생성시킬 수 있는 개선된 능력과 상호관련될 수 있는지의 여부를 측정하기 위하여, 종양형성 연구를 진행하였다. 당해 분야에 인정된 효소 분해 기술들을 사용하여 NTX 종양 샘플들을 해리하고, 현탁액으로 분산시켰다(참조예는 미국 특허 2007/0292414로서 본원에 포함됨). 상기 NTX주들로부터의 분해된 세포 제조물들은 뮤린 CD45, H2kD, 사람 CD324, 그리고 사람 SEZ6, 클론 SC17.42를 특이적으로 인지하는 형광결합된 항체들에 의해 염색하였다. FACSAriaTM 유세포분석기(BD Biosciences)를 사용하여, (뮤린 세포들의 세포 제조물을 고갈시키기 위해) 뮤린 CD45 또는 H2kD에 의한 염색의 부재에 기초하여 동정되는, 사람 세포들의 두 서브세트들을 단리하였다. 한 서브세트가 CD324 및 SEZ6 공동-발현에 기초하여 단리되는 반면, 다른 서브세트는 CD324+SEZ6- 표현형에 기초하여 단리되었다. 구별된 마커-증대된 아집단들은 마우스당 약 50개의 세포들의 용량으로 포유동물 지방 패드에 피하 주사에 의해 면역약화된 암컷 NOD/SCID 마우스에 이식하였다.
도 14a 및 도 14b는 환자들로부터 수득된 NSCLC 종양들로부터 유도된 대표적인 NTX 세포주들을 사용하여 진행된 상기 실험들의 결과를 나타낸다. 도 14a는 모체 종양 및 분류된 추정의 종양형성 세포들의 mCD45-H2kD- 부분집합의 분포를 나타내는 산포도(CD324 및 SEZ6을 사용하여 개폐됨)이다. 도 14b는 분류된 세포 아집단들을 면역약화된 마우스에 이식함으로써 일어나는 측정된 종양 용적을 그래프로 도시하고 있다. 괄호 안의 값들은 이식된 마우스당 발생된 종양들의 수를 나타낸다.
유의적으로, 도 14의 데이터는 종양형성이 높은 수준의 CD324와 조합하여 SEZ6을 발현하는 세포들의 아집단과 일관되게 관련됨을 보여준다. 역으로, 상기 동일한 데이터는 SEZ6을 발현하지 않거나 낮은 수준으로 발현하는 종양 세포들이 이들의 높거나 양성인 대응짝보다 훨씬 덜 종양형성적임을 입증하고 있다. 생성된 데이터에 기초하여, 놀랍게도, CD324+SEZ6+ 표현형을 발현하는 종양세포들의 아집단이 대다수의 종양형성 능력을 함유하고, SEZ6이 종양형성성 세포 조절에 효과적인 치료적 표적을 제공할 수 있음을 제시하고 있다는 것이 밝혀졌다.
실시예 14
SEZ6
조절물질들은
SEZ6
-발현
HEK
-293T 세포들로의
세포독성제
전달을 용이하게 한다
본 발명의 SEZ6 조절물질이 생세포들에 세포독성제를 전달하는 것을 매개할 수 있는지를 입증하기 위하여, 사포린 독소에 결합된 선택된 SEZ6 항체 조절물질들을 사용하여 시험관내 세포 치사 검정법을 수행하였다. 사포린은 세포질내 리보솜들을 불활성화시킴으로써 세포들을 치사한다. 따라서, 하기 검정을 사용한 세포사는 SEZ6 항체들이 세포독성제들을 표적 세포의 세포질에 내재화할 수 있으며 전달할 수 있음을 보여주는 것이다.
사포린에 공유결합된 항-마우스 IgG Fab 단편("Fab-사포린")(Advanced Targeting Systems, #IT-48)을 표지되지 않은 SEZ6 항체들과 배합하고, 사람 SEZ6을 발현하는 HEK-293T 세포들과 함께 항온배양하였다(실시예 5 참조). 수득된 사포린 접합체들이 세포들을 내재화하고 치사할 수 있는 능력은 세포 생존능력을 측정함으로써 72시간 후에 측정하였다.
구체적으로는, 10% 소태아 혈청이 보충된 DMEM내 웰당 500개의 세포들을, 항체 및 독소를 첨가하기 하루 전에 96개의 웰 조직 배양물 처리된 플레이트에 플레이팅하였다. 사람 SEZ6을 발현하는 HEK-293T 세포들을, 2nM Fab-사포린과 함께, 대조군(IgG1, IgG2a 또는 IgG2b) 또는 100, 50 또는 10pM의 농도의 정제된 뮤린 SEZ6 조절물질들로 처리하였다. 세포들을 3일간 배양하고, 그 후 제조업자의 지시에 따라, Cell Titer Glo®(Promega)를 사용하여 생존가능한 세포수들을 열거하였다. 사포린 Fab 단편을 갖는 세포들을 함유하는 배양물들을 사용하여 미처리 발광 단위(Raw Luminescence Units; RLU)를 100% 기준값으로 설정하고, 모든 다른 계수들은 그에 따라 계산하였다(표준화 RLU 또는 "세포 생존율(%)"이라고 함). 도 15a는 시험된 많은 SEZ6 조절물질들이 농도 의존성 방식으로 HEK-293T 세포들의 치사를 매개하였음을 보여준다. 동종형 대조군(IgG2a, IgG2b, 및 IgG1)은 도 15a의 첫번째 3개 열의 결과들에 의해 알 수 있는 바와 같이 세포에 영향을 미치지 않았다(ND = 측정되지 않음).
본 검정은, 내재화는 추가의 가교결합 또는 이량체화 필요없이 세포표면에 SEZ6-특이적 항체의 결합시에 일어날 수 있음을 입증하고 있다.
실시예 15
SEZ6 조절물질들은 시험관내에서 폐 종양 세포들의 세포독성을 매개한다
실시예 14의 결과를 확증하고 SEZ6 조절물질들이 (조작된 세포들과 대조적으로) 사람 종양세포들의 독소 내재화 및 세포 치사를 매개할 수 있는지를 측정하기 위해, 마우스 계통-고갈된(lineage-depleted) NTX 세포들을 플레이팅하고, 그 후 항-SEZ6 항체들 및 Fab-사포린에 노출시켰다.
NTX 종양들을 단일 세포 현탁액으로 해리시키고 당해 분야에 공지된 바와 같이 성장인자 보충된 무혈청 배지에서 PrimariaTM 플레이트(BD Biosciences)상에 플레이팅하였다. 세포들을 37℃/5%CO2/5%O2에서 1일 동안 배양한 후, 실시예 14에 기술된 바와 같이 대조군(IgG1, IgG2a 또는 IgG2b) 또는 뮤린 SEZ6 조절물질 및 Fab-사포린으로 처리하였다. 7일 후, Cell Titer Glo를 사용하여 남아있는 살아있는 세포의 수를 정량화하여, 조절물질-매개 사포린 세포독성을 평가하였다.
도 15b에 도시된 바와 같이, 종양 세포 수의 감소는 LU37, NSCLC 종양 및 LU80, SCLC 종양이 SC17.6(SC17.16의 복사체 서열) 및 SC17.33 SEZ6 조절물질들에 노출될 때 명백하였다. 유사하게, LU100, SCLC 종양이 50 및 500 pM의 4개의 SEZ6 조절물질들, SC17.6, SC17.19, SC17.33 및 SC17.34에 노출될 때, 종양세포가 감소되었다. 대조적으로, 동종형 대조 항체들은 처리 후 살아 있는 세포의 수에 영향을 미치지 않았다.
본 데이터는 본 명세서에 기술된 예시적인 항체들이 세포 표면상에서 SEZ6 항원과 결합할 수 있고 세포사를 야기하는 세포독성 적재물의 전달을 용이하게 할 뿐 아니라, 다수의 항-SEZ6 항체들이 다양한 NTX 종양 세포들의 치사를 매개할 수 있음을 입증하였다.
실시예 16
SEZ6 항체-약물 접합체의 제조
실시예 14 및 15에서의 사포린에 의한 시험관내 치사 검정에 기초하여, 본 발명의 다재성을 추가로 입증하기 위하여, 상기와 같이 M-[L-D] 구조를 갖는 항-SEZ6 항체 약물 접합체들을 제조하였다. 즉, 공유결합된 세포독성제를 사용하여 항-SEZ6 항체 약물 접합체(SEZ6-ADC)들을 제조하였다. 보다 구체적으로는, 본 명세서 또는 바로 아래의 참조문헌에 기술된 바와 같은 링커, 그리고 개시된 조절물질들에 공유결합으로 부착된 선택된 피롤로벤조디아제핀(PBD) 이량체들을 포함하는 SEZ6-ADC들이 제조되었다(참조예는 미국 특허들 2011/0256157과 2012/0078028 그리고 미국 특허 제6,214,345호로서, 이들 각각은 전부 본원에 참조로 인용된다).
참고문헌들의 관점에서 당해 분야에 인정된 기술들을 사용하여, PBD 약물-링커 조합을 합성하고, 정제하였다. 선택된 약물-링커 조합을 제조하기 위해, 다양한 PBD 이량체 및 링커들이 사용된 반면, 각 링커 단위는 유리 설피드릴을 갖는 말단 말레이미도 물질을 포함하였다. 이러한 링커들을 사용하여, 트리스(2-카르복시에틸)-포스핀(TCEP)에 의한 mAb의 부분 환원 후, 환원된 Cys 잔기들과 말레이미도-링커 적재물의 반응에 의해 접합체들을 제조하였다.
더욱 구체적으로, 선택된 SEZ6 항체 조절물질을 25 mM Tris HCl pH 7.5 및 5 mM EDTA 완충제에서 37℃에서 2시간 동안 mAb 1mol당 1.3mol TCEP로 환원시켰다. 반응을 15℃로 냉각시키고, DMSO내 링커 적재물을 mAb 1mol당 2.7 mol의 비율로 첨가한 후, 6%(v/v)의 최종 농도로 추가량의 DMSO를 첨가하였다. 이 반응을 1시간 동안 진행시켰다. 반응하지 않은 약물-링커는 과량의 N-아세틸 시스테인의 첨가에 의해 캡핑되었다. 그 후, 응집된 고분자량 항체, 공용매 및 소분자들을 제거하기 위해, AKTA 익스플로러 FPLC 시스템(G.E. Healthcare)을 사용한 이온교환 컬럼에 의해 SEZ6-ADC(또는 SC17-ADC)를 정제하였다. 그 후, 용출된 ADC를 접선유도여과(TFF)에 의해 제형 완충제로 완충제-교환하고, 그 후 농도를 조정하고, 세제를 첨가하였다. 최종 ADC를 단백질 농도(UV를 측정함으로써), 응집(SEC), 역상(RP) HPLC에 의한 항체에 대한 약물의 비율(DAR), 소수성 상호작용 크로마토그래피(HIC) HPLC에 의한 비접합 항체의 존재, RP HPLC에 의한 비-단백질성 물질들 및 SEZ6 발현 세포주를 사용한 시험관내 세포독성에 대하여 분석하였다.
상기 절차, 또는 실질적으로 유사한 방법을 사용하여, 다양한 SEZ6 조절물질들 및 PBD 이량체들을 포함하는 다수의 ADC들(즉, M-[L-D]n)을 다양한 생체내 및 시험관내 모델들에서 생성 및 시험하였다. 상기 실시예들 및 본 명세서의 목적을 위해, 상기 ADC들은 일반적으로 SEZ6-ADCs 또는 SC17-ADCs라고 부를 수 있다. 별도의 ADC들은 항체(예를 들면, SC17.17) 및 특이적 링커-세포독성제 명명 ADC1, ADC2 등에 따라 명명할 것이다. 따라서, 본 발명에 적합한 예시적인 조절물질들은 SC17.17-ADC1 또는 SC17.24-ADC2를 포함할 수 있으며, 여기서 ADC1 및 ADC2는 각 PBD 이량체 세포독성제(및 임의로 링커)를 나타낸다.
초기 기준으로서, hSC17.17-ADC1의 시험관내 세포독성은 SEZ6을 과발현하는 HEK293 세포들에 노출될 때 11nM의 IC50에서 측정하였다(데이터는 제시되지 않음).
실시예 17
접합된
SEZ6
조절물질들은
시험관내
폐 및 난소 종양 세포들에서 세포독성을 매개한다
상기 실시예 16에서 생성된 ADC들은 이들이 시험관내 1차 사람 종양세포들의 독소 내재화 및 세포 치사를 매재할 수 있는지의 여부를 측정하기 위해 시험되었다.
Fab-사포린을 첨가하지 않은 것 외에는, 실시예 15에 기술된 방법과 같은 방법을 사용하여, 마우스 계통-고갈된 NTX 종양 세포들을 항-SEZ6 ADC들 또는 마우스 동종형 대조군(msIgG1)에 노출시켰다. LU64, SCLC 종양 및 OV26, NET 난소 종양이 항-SEZ6 ADC(SC17.24-ADC2, SC17.28-ADC2 및 SC17.34-ADC2)들에 의해 처리될 때, 생존성 세포들의 비율 감소가 대조 msIgG1에 비해 증가했음이 관찰되었다(도 17a). msIgG1이 고농도에서 세포에 세포독성일 수 있는 반면, 시험된 3개의 모든 항-SEZ6 ADC들은 보다 강력해서, 이는 PBD 세포독소에 대한 일반적인 반응보다는 SEZ6에 대한 면역특이적 반응을 가리킨다.
실시예 18
접합된 SEZ6 조절물질들에 의한 생체내 종양성장의 억압
상기 실시예 16에서 생성된 ADC들은 면역결핍 마우스에서 사람 NTX 종양 성장을 축소시키고 억압할 수 있는 이들의 능력을 입증하기 위해 시험되었다.
환자-유래의 NTX 종양들은 당해 분야에 인정된 기술들을 사용하여 암컷 NOD/SCID 수용체 마우스의 양 옆구리에서 피하 성장시켰다. 종양 용적 및 마우스 체중을 1주일에 2회 모니터링하였다. 종양 용적이 150 내지 250mm3에 도달했을 때, 마우스를 치료군들로 무작위 할당하고, SC17-ADC1 또는 대조 MsIgG1-ADC1을 복강내 주사하였다. 마우스에 7일 기간 동안 1mg/kg를 3회 주사하였다(도 17b에서 수직선으로 표시함). 처리 후, 종양이 800 mm3를 초과하거나, 마우스가 병들 때까지, 종양 용적 및 마우스 체중을 모니터링하였다.
도 17b는 뮤린 항-SEZ6 ADC들이 마우스에서 SCLC 종양(예: LU86) 및 LCNEC 종양(예: LU50)의 생체내 성장을 억압할 수 있음을 보여준다. LU86의 경우, 시험된 5개의 ADC들(SC17.3-ADC1, SC17.24-ADC1, SC17.26-ADC1, SC17.28-ADC1 및 SC17.34-ADC1)은 일부 경우 처리 후 120일 이후에도 차도가 지속되었다. 특히, SC17.34-ADC1 처리는 상기 용량에서 연구 지속 기간 동안 종양 성장을 저해한 반면, SC17.24-ADC1은 50일 이상의 진행에 의해 종양 성장을 유의적으로 저해하였다. 유사하게, 5개의 예시적인 ADC들(SC17.3-ADC1, SC17.17-ADC1, SC17.24-ADC1, SC17.34-ADC1 및 SC17.46-ADC1)에 의해 LU50을 처리하면, SC17.46에 의해 35일만큼 오랫 동안 종양성장이 저해되었다. 더욱이, SC17-ADC1에 의해 처리된 마우스는 면역결핍, 종양-함유 NOD/SCID 마우스에서 통상적으로 보여지는 것 이상으로 건강에 부작용을 나타내지 않았다. 이러한 결과들은 상기 ADC들이 종양성장을 효과적으로 억압할 수 있고 특정의 SC17 조절물질 결합이 생체내 효능에 영향을 끼칠 수 있음을 보여준다.
보다 직접적으로는, 연장된 시간 동안 생체내 종양 성장을 극적으로 지연시키거나 억압할 수 있는 다양한 접합된 조절물질들의 능력은 증식성 장애의 치료를 위한 치료 표적으로서의 SEZ6의 용도를 추가로 입증한다.
실시예 19
사람화된 접합된 SEZ6 조절물질들은 종양 성장을 억압한다
뮤린 항-SEZ6 ADC 조절물질들에 의해 인상적인 결과들이 수득되었다는 점을 고려할 때, 생체내 및 시험관내 갑상선암 세포주 및 생체내 SCLC 종양을 치료하는데 있어서 예시적인 사람화 항-SEZ6 ADC 조절물질들의 효능을 입증하기 위해 추가의 실험들을 수행하였다.
갑상선암 세포주를 구입하고(ATCC, CRL-1803), 37℃에서 10% 소태아 혈청(FBS)이 보충된 F-12K 배지(ATCC; 카탈로그 번호 30-2004)에서 96웰 플레이트에 웰당 500개 세포로 플레이팅하였다. 실시예 16에 제시된 바와 같이 생산된 5nM의 hSC17.200-ADC1 또는 대조 IgG1-ADC1을 상기 세포들에 부가하였다. 8일 후, 생존가능 세포 수를 제조업자의 지시에 따라서 Cell Titer Glo®(Promega)를 사용하여 열거하였다. 미처리 발광 단위(Raw Luminescence Unit; RLU)를 사용하여 효능을 측정하고, 여기서 미처리된 세포의 RLU를 100% 기준값으로서 설정하고 모든 나머지 RLU 값들은 기준값과 비교하여 계산하였다(표준화된 RLU로서 언급됨). 도 18a의 결과는 항-SEZ6 항체 약물 접합체, hSC17.200-ADC1이 사람 IgG1-ADC1 대조군보다 유의적으로 갑상선암 세포의 성장을 억압하였음을 보여준다.
생체내에서 수질 갑상선 종양 용적을 감소시키는 사람화 항-SEZ6 ADC의 능력을 또한 시험하였다. 갑상선 세포주(ATCC, CRL-1803)를 37℃에서 10% FBS가 보충된 F-12K 배지에서 96웰 플레이트 내에서 웰당 500개 세포로 배양하였다. 세포를 수거하고 5마리의 NOD/SCID 마우스에 피하 이식하였다. 마우스 내의 종양이 평균 200mm3에 도달하면, 2mg/kg hSC17.200-ADC1의 단일 용량을 복강내 주사를 통해 투여하였다. 매주 종양 용적을 측정하여 효능을 모니터링하였고, 평균 종양 용적 및 표준오차 평균(SEM)을 시간(일)에 대해 플롯팅하였다. hSC17.200-ADC1 투여 후, 종양 용적의 현저한 감소가 관찰되었다(도 18b).
SCLC 종양 용적을 감소시키는 사람화된 항-SEZ6 ADC의 능력을 또한 시험하였다. 항-SEZ6 ADC들(hSC17.17, hSC17.24, hSC17.34 및 hSC17.46) 및 사람 IgG1 동종형 대조군 ADC(huIgG1)를 다양한 환자 유래의 NTX 종양을 보유한 면역결핍 마우스에게 투여하였다. 마우스에게는 7일의 기간에 걸쳐서 1mg/kg(도 18c 및 18d에서 수직선으로 표시함)로 3회 주사하였다. 처리 후, 종양 용적 및 마우스 체중을 종양이 800 mm3을 초과하거나 마우스가 병들 때까지 모니터링하였다. 상기 실험의 결과들은 도 18c 및 도 18d에 제시되어 있다. 4개의 SCLC 종양에 사람화 항-SEZ6 ADC들을 투여함으로써 종양괴의 완전하고 지속가능한 제거가 달성되었다. 도 18c는 hSC17.17-ADC1 및 hSC17.46-ADC1에 의한 LU80 종양의 감소; 및 hSC17.17-ADC1, hSC17.34-ADC1 및 hSC17.46-ADC1에 의한 LU64 종양의 제거를 보여준다. 도 18d는 hSC17.17-ADC1 및 hSC17.46-ADC1에 의한 LU117 종양의 감소; 및 hSC17.34-ADC1 및 hSC17.46-ADC1에 의한 LU111 종양의 감소를 보여준다.
이러한 결과들은 상이한 종양들의 성장을 효과적으로 지연시킬 수 있는 다양한 사람화 SEZ6 조절물질들의 놀라운 적용성을 입증한다.
실시예 20
약제내성(chemoresistant) PDX 세포주의 생성
이미 제1선 화학요법 치료를 받았던 종양에서 SEZ6의 발현을 시험하기 위해 약제내성 SCLC 주를 생성시켰다. 약제내성 세포주는 당해 분야에 인정된 기술들을 사용하여 PDX 종양 은행으로부터 수득된 종양 SCLC 환자 유래의 이종이식(PDX) 종양 세포주로부터 발달시켰다. 상기 PDX 종양 은행은 본래 다양한 고형 종양 악성에 시달리는 수많은 암 환자들로부터 수득된 이종 종양 세포들의 다수의 계대배양을 걸쳐서 면역약화된 마우스에서 증식된 상당수의 별개의 종양 세포주를 포함한다. 시험된 샘플의 계대배양 횟수는 p0-p#로 표시하고, 여기서 p0은 환자 종양으로부터 직접 수득된 계대배양되지 않은 샘플을 나타내고, p#는 시험 전에 종양이 마우스를 통해 계대배양된 횟수를 나타낸다. 초기 계대 PDX 종양은 이리노테칸(즉, Camptosar®) 및 시스플라틴/에토피시드 용법과 같은 치료제에 반응하여, 종양 성장, 현행 치료요법에 대한 내성 및 종양 재발을 유도하는 기본적인 기작에 대한 임상적으로 적절한 식견을 제공한다.
시스플라틴, 및 옥살리플라틴을 포함한 이의 유도체는 SCLC를 위한 표준 관리이다. 옥살리플라틴-내성 SCLC PDX주는 시스플라틴이 조직 배양 배지 중에서 안정하지 않을 수 있다는 염려로 인해 개발되었다[참조: Schuldes et al., 1997, PMID: 9128988]. 옥살리플라틴-내성 SCLC 주를 LU124p2, NOD.SCID 마우스를 통해 2회 피하 계대배양된 SCLC PDX 주로부터 사람 세포를 단리시켜 생성시켰다. LU124p2 종양을 800 내지 2,000mm3에 도달한 후 마우스로부터 절제하고, 당해 분야에 인정된 효소 분해 기술들[참조: 예를 들면, US2007/0292414]을 사용하여 단일 세포 현탁액으로 해리시키고, 뮤린 세포로부터 고갈시켰다. 그 후, 세포들을 세척하고 5% 산소 및 무혈청 배지에서 배양하고 1μM의 옥살리플라틴으로 즉시 처리하였다. 옥살리플라틴에 노출시킨지 7일 후, 세포들을 세척하고, 표준 무혈청 배지에서 배지를 주 2회 새로이 재생시키면서 2주 동안 회수하였다. 회수 기간 후, 세포들을 세척하고 7일 이상 동안 1μM의 옥살리플라틴을 함유한 새로운 플라스크에 재플레이팅한 다음, 최종 세척 및 2주 회수 기간을 수행하였다. 수득된 세포주는 LU124OXAHIp2로 명명하였다. 단일 세포 현탁액을 베르센(Versene)(Invitrogen)을 사용하여 생성시켰다. 세포들 중 일부는 LU124OXAHIp2 세포주를 증식시키기 위해 마우스에게 주사한 한편, 나머지 세포들은 옥살리플라틴에 대한 민감성을 시험하기 위해 생체내에서 배양하였다.
LU124OXAHIp2의 옥살리플라틴 민감성을 다음과 같이 시험하였다: LU124OXAHIp2 세포들을 96웰 플레이트에 플레이팅하고 당해 분야에서 표준인 무혈청 배지 중의 옥살리플라틴 역가측정으로 처리하였다. 배양물 중에서 7일 후, 세포들을 제조업자의 지시에 따라서 Cell Titer Glo®(Promega)를 사용하여 수거하였고, 용량 곡선을 수득하였다. LU124OXAHIp2는 모 세포주(LU124p2)(IC50 = 0.036 μM)와 비교해 보다 높은 용량의 옥살리플라틴에 보다 내성이었다(IC50 = 2 내지 2.5 mM)(도 19). 내성이 안정적인지 여부를 측정하기 위해, LU124OXAHIp2 세포들을 다시 면역약화된 마우스를 통해 계대배양하여 LU124OXAHIp3이라 지칭된 세포주를 생성시켰다. 내성은 LU124OXAHIp3에서 유지되었으며, 이는 심지어 선택압의 부재 하에, 즉 심지어 옥살리플라틴이 부재한 경우라도 세포주의 내성이 유지되었음을 보여준다.
실시예
21
마이크로어레이를
사용한 약제내성 종양 세포에서의
SEZ6
발현
마이크로어레이 발현 프로파일링을 사용하여, 약제민감성(chemo-sensitive) 모 주와 비교해 LU124OXAHIp3상에서 상향조절된 잠재적 세포 표면 표적을 동정하였다. 검정을 위한 준비로서, LU124p3 및 LU124OXAHIp3 PDX 주로부터 종양을 절제하고 단일 세포 현탁액으로 해리시키고 실시예 1에 기술된 바와 같이 뮤린 세포로부터 고갈시켰다. 상기 세포들을 제조업자의 지시에 따라 RLTplus RNA 용해 완충제에 용해시키고 -80℃에서 저장하고 mRNA 추출을 위해 해동하였다. 해동되면, 총 mRNA를 RNeasy 단리 키트(Qiagen)를 사용하여 추출하고, 제조업자의 프로토콜 및 권장된 기기 설정을 사용하여 Nanodrop 분광광도계(Thermo Scientific) 및/또는 Bioanalyzer 2100(Agilent Technologies)를 사용함으로써 정량화한다. 수득된 총 mRNA 제제를 유전자 서열분석 및 유전자 발현 분석에 적합한지를 평가한다.
1 내지 2㎍의 전체 종양 총 mRNA 샘플들을 27,958개 유전자 및 7,419개 lncRNA에 대해 설계된 50,599개 생물학적 프로브를 함유하는 Agilent SurePrint GE Human 8x60 v2 마이크로어레이 플랫폼을 사용하여 분석하였다. 각 샘플의 유전자 발현을 정량화하기 위해 표준 산업 관행을 사용하여 강도 값들을 표준화하고 변환시켰다. SEZ6 mRNA(Agilent 프로브 ID: A_23_P49849)는, 매치된 모 주 LU124p3 및 또한 이전의 뮤린 계대 LU124p1과 비교해 LU124OXAHIp3에서 하향조절되는 것으로 동정되었다(도 20).
실시예 22
약제내성 종양 세포주에서의
SEZ6
단백질 발현
실시예 1에서 기술한 바와 같이 생성된 옥살리플라틴-내성 세포주와 연관된 상승된 SEZ6 mRNA 전사체 수준을 고려하여, SEZ6 단백질 발현도 상기 세포주에서 상승되었는지 여부를 시험하기 위한 작업을 착수하였다. SEZ6 단백질 발현을 검출하고 정량화하기 위해, MSD 디스커버리 플랫폼(Meso Scale Discovery)을 사용하여 전기화학발광 SEZ6 샌드위치 ELISA 검정을 개발하였다.
LU124p3 세포 및 LU124OXAHIp3 세포를 드라이 아이스/에탄올 상에서 급속 냉동시켰다. 단백질 추출 완충제(Biochain Institute)를 해동된 세포를 부가하고, 용해물을 원심분리(20,000g, 20분, 4℃)에 의해 청정화하고, 각 용해물 중의 총 단백질 농도를 비신코닌산을 사용하여 정량화하였다. 단백질 용해물을 검정할 때까지 -80℃에서 저장하였다. 용해물 샘플들로부터의 SEZ6 단백질 농도를, 정제된 재조합 SEZ6 단백질을 사용하여 생성된 표준 단백질 농도 곡선으로부터 값들을 내삽하여 측정하였다.
MSD 표준 플레이트들을 4℃에서 포스페이트 완충 염수(PBS) 중의 1㎍/mL에서 30μL의 항-SEZ6 항체 SC17.17로 밤새 코팅하였다. 상기 플레이트들을 PBST로 세척하고 1시간 동안 진탕시키면서 150μL MSD 3% 차단제 A 용액 중에서 차단시켰다. 플레이트들을 다시 PBST로 세척하였다. 10% 단백질 추출 완충제를 함유하는 MSD 1% 차단제 A 중의 25μL의 10x 희석된 용해물(또는 연속적으로 희석된 재조합 SEZ6 표준)을 또한 상기 웰들에 부가하고 2시간 동안 진탕시키면서 항온배양하였다. 플레이트들을 다시 PBST로 세척하였다. 항-SEZ6 항체 SC17.36 항체를 설포-태그시키고 25μL의 태그된 SC17.36 항체를 실온에서 1시간 동안 진탕시키면서 MSD 1% 차단제 A 중의 0.5㎍/mL로 상기 세척된 플레이트들에 부가하였다. 플레이트들을 PBST로 세척하였다. 계면활성제를 갖는 MSD 리드 완충제 T를 물 속에 1X로 희석시키고 150μL를 각 웰에 부가하였다. 플레이트들을 표준 곡선으로부터의 내삽을 통해 PDX 샘플 중의 SEZ6 농도를 도출하는 통합형 소프트웨어 분석 프로그램을 사용하여 MSD Sector Imager 2400상에서 판독하였다. 그 후, 값들을 총 단백질 농도로 나누어 총 용해물 단백질 mg당 SEZ6 ng을 산출하였다. 수득된 농도는 도 21에 제시되어 있으며, 여기서 막대 그래프는 LU124p3 및 LU124OXAHIp3 세포주로부터 유도된 SEZ6 단백질 농도를 나타낸다. LU124 세포 용해물 중의 SEZ6 발현은 총 단백질 mg당 5.8ng이었던 반면, LU124 옥살리플라틴 내성 주에서의 SEZ6 발현은 총 단백질 mg당 14.6ng이었다. 도 21은 옥살리플라틴-내성 LU124OXAHIp3 세포주가 모 LU124p3 세포들과 비교해 높은 SEZ6 단백질 발현을 나타냈다는 것을 보여준다. 이러한 데이터는, 상기 실시예들에 제시된 SEZ6 발현에 대한 mRNA 전사 데이터와 함께, SEZ6 단백질 발현이 약제내성을 나타내는 종양에서 상향조절된다는 제안을 강화시킨다.
당해 분야의 숙련가라면 본 발명이 본 발명의 취지 또는 중심 속성들로부터 벗어나지 않으면서 다른 특정 형태들로 구체화할 수 있음도 이해할 수 있을 것이다. 본 발명의 상기 설명이 오로지 본 발명의 예시적인 실시형태들만을 개시한 점에서, 다른 변형 실시형태들도 본 발명의 범주 내에 있는 것으로 고려될 수 있음을 이해하여야 한다. 따라서, 본 발명은 본원에 상세히 기술된 특정 실시형태들로 한정되지 않는다. 오히려, 본 발명의 범주 및 내용을 나타내는 첨부된 청구범위들을 참고하여야 한다.
SEQUENCE LISTING
<110> STEMCENTRX,INC.
<120> NOVEL SEZ6 MODULATORS AND METHODS OF USE
<130> S69697 1130WO/sc1702.pct
<150> US 61/871,289
<151> 2013-08-28
<160> 480
<170> KopatentIn 3.0
<210> 1
<211> 4249
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<223> SEZ6 isoform 1 mRNA
<400> 1
gatccccggc gccgtcgcca ggcgctggcc gtggtgctga ttctgtcagg cgctggcggc 60
ggcagcggcg gtgacggctg cggccccgct ccctctaccc ggccggaccc ggctctgccc 120
ccgcgcccaa gccccaccaa gccccccgcc ctcccgccgc ggtcccagcc cagggcgcgg 180
ccgcaaccag caccatgcgc ccggtagccc tgctgctcct gccctcgctg ctggcgctcc 240
tggctcacgg actctcttta gaggccccaa ccgtggggaa aggacaagcc ccaggcatcg 300
aggagacaga tggcgagctg acagcagccc ccacacctga gcagccagaa cgaggcgtcc 360
actttgtcac aacagccccc accttgaagc tgctcaacca ccacccgctg cttgaggaat 420
tcctacaaga ggggctggaa aagggagatg aggagctgag gccagcactg cccttccagc 480
ctgacccacc tgcacccttc accccaagtc cccttccccg cctggccaac caggacagcc 540
gccctgtctt taccagcccc actccagcca tggctgcggt acccactcag ccccagtcca 600
aggagggacc ctggagtccg gagtcagagt cccctatgct tcgaatcaca gctcccctac 660
ctccagggcc cagcatggca gtgcccaccc taggcccagg ggagatagcc agcactacac 720
cccccagcag agcctggaca ccaacccaag agggtcctgg agacatggga aggccgtggg 780
ttgcagaggt tgtgtcccag ggcgcaggga tcgggatcca ggggaccatc acctcctcca 840
cagcttcagg agatgatgag gagaccacca ctaccaccac catcatcacc accaccatca 900
ccacagtcca gacaccaggc ccttgtagct ggaatttctc aggcccagag ggctctctgg 960
actcccctac agacctcagc tcccccactg atgttggcct ggactgcttc ttctacatct 1020
ctgtctaccc tggctatggc gtggaaatca aggtccagaa tatcagcctc cgggaagggg 1080
agacagtgac tgtggaaggc ctgggggggc ctgacccact gcccctggcc aaccagtctt 1140
tcctgctgcg gggccaagtc atccgcagcc ccacccacca agcggccctg aggttccaga 1200
gcctcccgcc accggctggc cctggcacct tccatttcca ttaccaagcc tatctcctga 1260
gctgccactt tccccgtcgt ccagcttatg gagatgtgac tgtcaccagc ctccacccag 1320
ggggtagtgc ccgcttccat tgtgccactg gctaccagct gaagggcgcc aggcatctca 1380
cctgtctcaa tgccacccag cccttctggg attcaaagga gcccgtctgc atcgctgctt 1440
gcggcggagt gatccgcaat gccaccaccg gccgcatcgt ctctccaggc ttcccgggca 1500
actacagcaa caacctcacc tgtcactggc tgcttgaggc tcctgagggc cagcggctac 1560
acctgcactt tgagaaggtt tccctggcag aggatgatga caggctcatc attcgcaatg 1620
gggacaacgt ggaggcccca ccagtgtatg attcctatga ggtggaatac ctgcccattg 1680
agggcctgct cagctctggc aaacacttct ttgttgagct cagtactgac agcagcgggg 1740
cagctgcagg catggccctg cgctatgagg ccttccagca gggccattgc tatgagccct 1800
ttgtcaaata cggtaacttc agcagcagca cacccaccta ccctgtgggt accactgtgg 1860
agttcagctg cgaccctggc tacaccctgg agcagggctc catcatcatc gagtgtgttg 1920
acccccacga cccccagtgg aatgagacag agccagcctg ccgagccgtg tgcagcgggg 1980
agatcacaga ctcggctggc gtggtactct ctcccaactg gccagagccc tacggtcgtg 2040
ggcaggattg tatctggggt gtgcatgtgg aagaggacaa gcgcatcatg ctggacatcc 2100
gagtgctgcg cataggccct ggtgatgtgc ttaccttcta tgatggggat gacctgacgg 2160
cccgggttct gggccagtac tcagggcccc gtagccactt caagctcttt acctccatgg 2220
ctgatgtcac cattcagttc cagtcggacc ccgggacctc agtgctgggc taccagcagg 2280
gcttcgtcat ccacttcttt gaggtgcccc gcaatgacac atgtccggag ctgcctgaga 2340
tccccaatgg ctggaagagc ccatcgcagc ctgagctagt gcacggcacc gtggtcactt 2400
accagtgcta ccctggctac caggtagtgg gatccagtgt cctcatgtgc cagtgggacc 2460
taacttggag tgaggacctg ccctcatgcc agagggtgac ttcctgccac gatcctggag 2520
atgtggagca cagccgacgc ctcatatcca gccccaagtt tcccgtgggg gccaccgtgc 2580
aatatatctg tgaccagggt tttgtgctga tgggcagctc catcctcacc tgccatgatc 2640
gccaggctgg cagccccaag tggagtgacc gggcccctaa atgtctcctg gaacagctca 2700
agccatgcca tggtctcagt gcccctgaga atggtgcccg aagtcctgag aagcagctac 2760
acccagcagg ggccaccatc cacttctcgt gtgcccctgg ctatgtgctg aagggccagg 2820
ccagcatcaa gtgtgtgcct gggcacccct cgcattggag tgacccccca cccatctgta 2880
gggctgcctc tctggatggg ttctacaaca gtcgcagcct ggatgttgcc aaggcacctg 2940
ctgcctccag caccctggat gctgcccaca ttgcagctgc catcttcttg ccactggtgg 3000
cgatggtgtt gttggtagga ggtgtatact tctacttctc caggctccag ggaaaaagct 3060
ccctgcagct gccccgcccc cgcccccgcc cctacaaccg cattaccata gagtcagcgt 3120
ttgacaatcc aacttacgag actggatctc tttcctttgc aggagacgag agaatatgaa 3180
gtctccatct aggtgggggc agtctaggga agtcaactca gacttgcacc acagtccagc 3240
agcaaggctc cttgcttcct gctgtccctc cacctcctgt atataccacc taggaggaga 3300
tgccaccaag ccctcaagaa gttgtgccct tccccgcctg cgatgcccac catggcctat 3360
tttcttggtg tcattgccca cttggggccc ttcattgggc ccatgtcagg gggcatctac 3420
ctgtgggaag aacatagctg gagcacaagc atcaacagcc agcatcctga gcctcctcat 3480
gccctggacc agcctggaac acactagcag agcaggagta cctttctcca catgaccacc 3540
atcccgccct ggcatggcaa cctgcagcag gattaacttg accatggtgg gaactgcacc 3600
agggtactcc tcacagcgca tcaccaatgg ccaaaactcc tctcaacggt gacctctggg 3660
tagtcctggc atgccaacat cagcctcttg ggaggtctct agttctctaa agttctggac 3720
agttctgcct cctgccctgt cccagtggag gcagtaattc taggagatcc taaggggttc 3780
agggggaccc tacccccacc tcaggttggg cttccctggg cactcatgct ccacaccaaa 3840
gcaggacacg ccattttcca ctgaccaccc tataccctga ggaaagggag actttcctcc 3900
gatgtttatt tagctgttgc aaacatcttc accctaatag tccctcctcc aattccagcc 3960
acttgtcagg ctctcctctt gaccactgtg ttatgggata aggggagggg gtgggcatat 4020
tctggagagg agcagaggtc caaggaccca ggaatttggc atggaacagg tggtaggaga 4080
gccccaggga gacgcccagg agctggctga aagccacttt gtacatgtaa tgtattatat 4140
ggggtctggg ctccagccag agaacaatct tttatttctg ttgtttcctt attaaaatgg 4200
tgtttttgga aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaa 4249
<210> 2
<211> 4234
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<223> SEZ6 isoform 2 mRNA
<400> 2
gatccccggc gccgtcgcca ggcgctggcc gtggtgctga ttctgtcagg cgctggcggc 60
ggcagcggcg gtgacggctg cggccccgct ccctctaccc ggccggaccc ggctctgccc 120
ccgcgcccaa gccccaccaa gccccccgcc ctcccgccgc ggtcccagcc cagggcgcgg 180
ccgcaaccag caccatgcgc ccggtagccc tgctgctcct gccctcgctg ctggcgctcc 240
tggctcacgg actctcttta gaggccccaa ccgtggggaa aggacaagcc ccaggcatcg 300
aggagacaga tggcgagctg acagcagccc ccacacctga gcagccagaa cgaggcgtcc 360
actttgtcac aacagccccc accttgaagc tgctcaacca ccacccgctg cttgaggaat 420
tcctacaaga ggggctggaa aagggagatg aggagctgag gccagcactg cccttccagc 480
ctgacccacc tgcacccttc accccaagtc cccttccccg cctggccaac caggacagcc 540
gccctgtctt taccagcccc actccagcca tggctgcggt acccactcag ccccagtcca 600
aggagggacc ctggagtccg gagtcagagt cccctatgct tcgaatcaca gctcccctac 660
ctccagggcc cagcatggca gtgcccaccc taggcccagg ggagatagcc agcactacac 720
cccccagcag agcctggaca ccaacccaag agggtcctgg agacatggga aggccgtggg 780
ttgcagaggt tgtgtcccag ggcgcaggga tcgggatcca ggggaccatc acctcctcca 840
cagcttcagg agatgatgag gagaccacca ctaccaccac catcatcacc accaccatca 900
ccacagtcca gacaccaggc ccttgtagct ggaatttctc aggcccagag ggctctctgg 960
actcccctac agacctcagc tcccccactg atgttggcct ggactgcttc ttctacatct 1020
ctgtctaccc tggctatggc gtggaaatca aggtccagaa tatcagcctc cgggaagggg 1080
agacagtgac tgtggaaggc ctgggggggc ctgacccact gcccctggcc aaccagtctt 1140
tcctgctgcg gggccaagtc atccgcagcc ccacccacca agcggccctg aggttccaga 1200
gcctcccgcc accggctggc cctggcacct tccatttcca ttaccaagcc tatctcctga 1260
gctgccactt tccccgtcgt ccagcttatg gagatgtgac tgtcaccagc ctccacccag 1320
ggggtagtgc ccgcttccat tgtgccactg gctaccagct gaagggcgcc aggcatctca 1380
cctgtctcaa tgccacccag cccttctggg attcaaagga gcccgtctgc atcgctgctt 1440
gcggcggagt gatccgcaat gccaccaccg gccgcatcgt ctctccaggc ttcccgggca 1500
actacagcaa caacctcacc tgtcactggc tgcttgaggc tcctgagggc cagcggctac 1560
acctgcactt tgagaaggtt tccctggcag aggatgatga caggctcatc attcgcaatg 1620
gggacaacgt ggaggcccca ccagtgtatg attcctatga ggtggaatac ctgcccattg 1680
agggcctgct cagctctggc aaacacttct ttgttgagct cagtactgac agcagcgggg 1740
cagctgcagg catggccctg cgctatgagg ccttccagca gggccattgc tatgagccct 1800
ttgtcaaata cggtaacttc agcagcagca cacccaccta ccctgtgggt accactgtgg 1860
agttcagctg cgaccctggc tacaccctgg agcagggctc catcatcatc gagtgtgttg 1920
acccccacga cccccagtgg aatgagacag agccagcctg ccgagccgtg tgcagcgggg 1980
agatcacaga ctcggctggc gtggtactct ctcccaactg gccagagccc tacggtcgtg 2040
ggcaggattg tatctggggt gtgcatgtgg aagaggacaa gcgcatcatg ctggacatcc 2100
gagtgctgcg cataggccct ggtgatgtgc ttaccttcta tgatggggat gacctgacgg 2160
cccgggttct gggccagtac tcagggcccc gtagccactt caagctcttt acctccatgg 2220
ctgatgtcac cattcagttc cagtcggacc ccgggacctc agtgctgggc taccagcagg 2280
gcttcgtcat ccacttcttt gaggtgcccc gcaatgacac atgtccggag ctgcctgaga 2340
tccccaatgg ctggaagagc ccatcgcagc ctgagctagt gcacggcacc gtggtcactt 2400
accagtgcta ccctggctac caggtagtgg gatccagtgt cctcatgtgc cagtgggacc 2460
taacttggag tgaggacctg ccctcatgcc agagggtgac ttcctgccac gatcctggag 2520
atgtggagca cagccgacgc ctcatatcca gccccaagtt tcccgtgggg gccaccgtgc 2580
aatatatctg tgaccagggt tttgtgctga tgggcagctc catcctcacc tgccatgatc 2640
gccaggctgg cagccccaag tggagtgacc gggcccctaa atgtctcctg gaacagctca 2700
agccatgcca tggtctcagt gcccctgaga atggtgcccg aagtcctgag aagcagctac 2760
acccagcagg ggccaccatc cacttctcgt gtgcccctgg ctatgtgctg aagggccagg 2820
ccagcatcaa gtgtgtgcct gggcacccct cgcattggag tgacccccca cccatctgta 2880
gggctgcctc tctggatggg ttctacaaca gtcgcagcct ggatgttgcc aaggcacctg 2940
ctgcctccag caccctggat gctgcccaca ttgcagctgc catcttcttg ccactggtgg 3000
cgatggtgtt gttggtagga ggtgtatact tctacttctc caggctccag ggaaaaagct 3060
ccctgcagct gccccgcccc cgcccccgcc cctacaaccg cattaccata gagtcagcgt 3120
ttgacaatcc aacttacgag actggagaga cgagagaata tgaagtctcc atctaggtgg 3180
gggcagtcta gggaagtcaa ctcagacttg caccacagtc cagcagcaag gctccttgct 3240
tcctgctgtc cctccacctc ctgtatatac cacctaggag gagatgccac caagccctca 3300
agaagttgtg cccttccccg cctgcgatgc ccaccatggc ctattttctt ggtgtcattg 3360
cccacttggg gcccttcatt gggcccatgt cagggggcat ctacctgtgg gaagaacata 3420
gctggagcac aagcatcaac agccagcatc ctgagcctcc tcatgccctg gaccagcctg 3480
gaacacacta gcagagcagg agtacctttc tccacatgac caccatcccg ccctggcatg 3540
gcaacctgca gcaggattaa cttgaccatg gtgggaactg caccagggta ctcctcacag 3600
cgccatcacc aatggccaaa actcctctca acggtgacct ctgggtagtc ctggcatgcc 3660
aacatcagcc tcttgggagg tctctagttc tctaaagttc tggacagttc tgcctcctgc 3720
cctgtcccag tggaggcagt aattctagga gatcctaagg ggttcagggg gaccctaccc 3780
ccacctcagg ttgggcttcc ctgggcactc atgctccaca ccaaagcagg acacgccatt 3840
ttccactgac caccctatac cctgaggaaa gggagacttt cctccgatgt ttatttagct 3900
gttgcaaaca tcttcaccct aatagtccct cctccaattc cagccacttg tcaggctctc 3960
ctcttgacca ctgtgttatg ggataagggg agggggtggg catattctgg agaggagcag 4020
aggtccaagg acccaggaat ttggcatgga acaggtggta ggagagcccc agggagacgc 4080
ccaggagctg gctgaaagcc actttgtaca tgtaatgtat tatatggggt ctgggctcca 4140
gccagagaac aatcttttat ttctgttgtt tccttattaa aatggtgttt ttggaaaaaa 4200
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaa 4234
<210> 3
<211> 994
<212> PRT
<213> Homo sapiens
<220>
<221> MISC_FEATURE
<223> SEZ6 isoform 1 precursor protein
<220>
<221> MISC_FEATURE
<222> (1)..(19)
<223> Leader sequence
<220>
<221> MISC_FEATURE
<222> (20)..(994)
<223> Mature protein
<400> 3
Met Arg Pro Val Ala Leu Leu Leu Leu Pro Ser Leu Leu Ala Leu Leu
1 5 10 15
Ala His Gly Leu Ser Leu Glu Ala Pro Thr Val Gly Lys Gly Gln Ala
20 25 30
Pro Gly Ile Glu Glu Thr Asp Gly Glu Leu Thr Ala Ala Pro Thr Pro
35 40 45
Glu Gln Pro Glu Arg Gly Val His Phe Val Thr Thr Ala Pro Thr Leu
50 55 60
Lys Leu Leu Asn His His Pro Leu Leu Glu Glu Phe Leu Gln Glu Gly
65 70 75 80
Leu Glu Lys Gly Asp Glu Glu Leu Arg Pro Ala Leu Pro Phe Gln Pro
85 90 95
Asp Pro Pro Ala Pro Phe Thr Pro Ser Pro Leu Pro Arg Leu Ala Asn
100 105 110
Gln Asp Ser Arg Pro Val Phe Thr Ser Pro Thr Pro Ala Met Ala Ala
115 120 125
Val Pro Thr Gln Pro Gln Ser Lys Glu Gly Pro Trp Ser Pro Glu Ser
130 135 140
Glu Ser Pro Met Leu Arg Ile Thr Ala Pro Leu Pro Pro Gly Pro Ser
145 150 155 160
Met Ala Val Pro Thr Leu Gly Pro Gly Glu Ile Ala Ser Thr Thr Pro
165 170 175
Pro Ser Arg Ala Trp Thr Pro Thr Gln Glu Gly Pro Gly Asp Met Gly
180 185 190
Arg Pro Trp Val Ala Glu Val Val Ser Gln Gly Ala Gly Ile Gly Ile
195 200 205
Gln Gly Thr Ile Thr Ser Ser Thr Ala Ser Gly Asp Asp Glu Glu Thr
210 215 220
Thr Thr Thr Thr Thr Ile Ile Thr Thr Thr Ile Thr Thr Val Gln Thr
225 230 235 240
Pro Gly Pro Cys Ser Trp Asn Phe Ser Gly Pro Glu Gly Ser Leu Asp
245 250 255
Ser Pro Thr Asp Leu Ser Ser Pro Thr Asp Val Gly Leu Asp Cys Phe
260 265 270
Phe Tyr Ile Ser Val Tyr Pro Gly Tyr Gly Val Glu Ile Lys Val Gln
275 280 285
Asn Ile Ser Leu Arg Glu Gly Glu Thr Val Thr Val Glu Gly Leu Gly
290 295 300
Gly Pro Asp Pro Leu Pro Leu Ala Asn Gln Ser Phe Leu Leu Arg Gly
305 310 315 320
Gln Val Ile Arg Ser Pro Thr His Gln Ala Ala Leu Arg Phe Gln Ser
325 330 335
Leu Pro Pro Pro Ala Gly Pro Gly Thr Phe His Phe His Tyr Gln Ala
340 345 350
Tyr Leu Leu Ser Cys His Phe Pro Arg Arg Pro Ala Tyr Gly Asp Val
355 360 365
Thr Val Thr Ser Leu His Pro Gly Gly Ser Ala Arg Phe His Cys Ala
370 375 380
Thr Gly Tyr Gln Leu Lys Gly Ala Arg His Leu Thr Cys Leu Asn Ala
385 390 395 400
Thr Gln Pro Phe Trp Asp Ser Lys Glu Pro Val Cys Ile Ala Ala Cys
405 410 415
Gly Gly Val Ile Arg Asn Ala Thr Thr Gly Arg Ile Val Ser Pro Gly
420 425 430
Phe Pro Gly Asn Tyr Ser Asn Asn Leu Thr Cys His Trp Leu Leu Glu
435 440 445
Ala Pro Glu Gly Gln Arg Leu His Leu His Phe Glu Lys Val Ser Leu
450 455 460
Ala Glu Asp Asp Asp Arg Leu Ile Ile Arg Asn Gly Asp Asn Val Glu
465 470 475 480
Ala Pro Pro Val Tyr Asp Ser Tyr Glu Val Glu Tyr Leu Pro Ile Glu
485 490 495
Gly Leu Leu Ser Ser Gly Lys His Phe Phe Val Glu Leu Ser Thr Asp
500 505 510
Ser Ser Gly Ala Ala Ala Gly Met Ala Leu Arg Tyr Glu Ala Phe Gln
515 520 525
Gln Gly His Cys Tyr Glu Pro Phe Val Lys Tyr Gly Asn Phe Ser Ser
530 535 540
Ser Thr Pro Thr Tyr Pro Val Gly Thr Thr Val Glu Phe Ser Cys Asp
545 550 555 560
Pro Gly Tyr Thr Leu Glu Gln Gly Ser Ile Ile Ile Glu Cys Val Asp
565 570 575
Pro His Asp Pro Gln Trp Asn Glu Thr Glu Pro Ala Cys Arg Ala Val
580 585 590
Cys Ser Gly Glu Ile Thr Asp Ser Ala Gly Val Val Leu Ser Pro Asn
595 600 605
Trp Pro Glu Pro Tyr Gly Arg Gly Gln Asp Cys Ile Trp Gly Val His
610 615 620
Val Glu Glu Asp Lys Arg Ile Met Leu Asp Ile Arg Val Leu Arg Ile
625 630 635 640
Gly Pro Gly Asp Val Leu Thr Phe Tyr Asp Gly Asp Asp Leu Thr Ala
645 650 655
Arg Val Leu Gly Gln Tyr Ser Gly Pro Arg Ser His Phe Lys Leu Phe
660 665 670
Thr Ser Met Ala Asp Val Thr Ile Gln Phe Gln Ser Asp Pro Gly Thr
675 680 685
Ser Val Leu Gly Tyr Gln Gln Gly Phe Val Ile His Phe Phe Glu Val
690 695 700
Pro Arg Asn Asp Thr Cys Pro Glu Leu Pro Glu Ile Pro Asn Gly Trp
705 710 715 720
Lys Ser Pro Ser Gln Pro Glu Leu Val His Gly Thr Val Val Thr Tyr
725 730 735
Gln Cys Tyr Pro Gly Tyr Gln Val Val Gly Ser Ser Val Leu Met Cys
740 745 750
Gln Trp Asp Leu Thr Trp Ser Glu Asp Leu Pro Ser Cys Gln Arg Val
755 760 765
Thr Ser Cys His Asp Pro Gly Asp Val Glu His Ser Arg Arg Leu Ile
770 775 780
Ser Ser Pro Lys Phe Pro Val Gly Ala Thr Val Gln Tyr Ile Cys Asp
785 790 795 800
Gln Gly Phe Val Leu Met Gly Ser Ser Ile Leu Thr Cys His Asp Arg
805 810 815
Gln Ala Gly Ser Pro Lys Trp Ser Asp Arg Ala Pro Lys Cys Leu Leu
820 825 830
Glu Gln Leu Lys Pro Cys His Gly Leu Ser Ala Pro Glu Asn Gly Ala
835 840 845
Arg Ser Pro Glu Lys Gln Leu His Pro Ala Gly Ala Thr Ile His Phe
850 855 860
Ser Cys Ala Pro Gly Tyr Val Leu Lys Gly Gln Ala Ser Ile Lys Cys
865 870 875 880
Val Pro Gly His Pro Ser His Trp Ser Asp Pro Pro Pro Ile Cys Arg
885 890 895
Ala Ala Ser Leu Asp Gly Phe Tyr Asn Ser Arg Ser Leu Asp Val Ala
900 905 910
Lys Ala Pro Ala Ala Ser Ser Thr Leu Asp Ala Ala His Ile Ala Ala
915 920 925
Ala Ile Phe Leu Pro Leu Val Ala Met Val Leu Leu Val Gly Gly Val
930 935 940
Tyr Phe Tyr Phe Ser Arg Leu Gln Gly Lys Ser Ser Leu Gln Leu Pro
945 950 955 960
Arg Pro Arg Pro Arg Pro Tyr Asn Arg Ile Thr Ile Glu Ser Ala Phe
965 970 975
Asp Asn Pro Thr Tyr Glu Thr Gly Ser Leu Ser Phe Ala Gly Asp Glu
980 985 990
Arg Ile
<210> 4
<211> 993
<212> PRT
<213> Homo sapiens
<220>
<221> MISC_FEATURE
<223> SEZ6 isoform 2 precursor protein
<220>
<221> MISC_FEATURE
<222> (1)..(19)
<223> Leader sequence
<220>
<221> MISC_FEATURE
<222> (20)..(993)
<223> Mature protein
<400> 4
Met Arg Pro Val Ala Leu Leu Leu Leu Pro Ser Leu Leu Ala Leu Leu
1 5 10 15
Ala His Gly Leu Ser Leu Glu Ala Pro Thr Val Gly Lys Gly Gln Ala
20 25 30
Pro Gly Ile Glu Glu Thr Asp Gly Glu Leu Thr Ala Ala Pro Thr Pro
35 40 45
Glu Gln Pro Glu Arg Gly Val His Phe Val Thr Thr Ala Pro Thr Leu
50 55 60
Lys Leu Leu Asn His His Pro Leu Leu Glu Glu Phe Leu Gln Glu Gly
65 70 75 80
Leu Glu Lys Gly Asp Glu Glu Leu Arg Pro Ala Leu Pro Phe Gln Pro
85 90 95
Asp Pro Pro Ala Pro Phe Thr Pro Ser Pro Leu Pro Arg Leu Ala Asn
100 105 110
Gln Asp Ser Arg Pro Val Phe Thr Ser Pro Thr Pro Ala Met Ala Ala
115 120 125
Val Pro Thr Gln Pro Gln Ser Lys Glu Gly Pro Trp Ser Pro Glu Ser
130 135 140
Glu Ser Pro Met Leu Arg Ile Thr Ala Pro Leu Pro Pro Gly Pro Ser
145 150 155 160
Met Ala Val Pro Thr Leu Gly Pro Gly Glu Ile Ala Ser Thr Thr Pro
165 170 175
Pro Ser Arg Ala Trp Thr Pro Thr Gln Glu Gly Pro Gly Asp Met Gly
180 185 190
Arg Pro Trp Val Ala Glu Val Val Ser Gln Gly Ala Gly Ile Gly Ile
195 200 205
Gln Gly Thr Ile Thr Ser Ser Thr Ala Ser Gly Asp Asp Glu Glu Thr
210 215 220
Thr Thr Thr Thr Thr Ile Ile Thr Thr Thr Ile Thr Thr Val Gln Thr
225 230 235 240
Pro Gly Pro Cys Ser Trp Asn Phe Ser Gly Pro Glu Gly Ser Leu Asp
245 250 255
Ser Pro Thr Asp Leu Ser Ser Pro Thr Asp Val Gly Leu Asp Cys Phe
260 265 270
Phe Tyr Ile Ser Val Tyr Pro Gly Tyr Gly Val Glu Ile Lys Val Gln
275 280 285
Asn Ile Ser Leu Arg Glu Gly Glu Thr Val Thr Val Glu Gly Leu Gly
290 295 300
Gly Pro Asp Pro Leu Pro Leu Ala Asn Gln Ser Phe Leu Leu Arg Gly
305 310 315 320
Gln Val Ile Arg Ser Pro Thr His Gln Ala Ala Leu Arg Phe Gln Ser
325 330 335
Leu Pro Pro Pro Ala Gly Pro Gly Thr Phe His Phe His Tyr Gln Ala
340 345 350
Tyr Leu Leu Ser Cys His Phe Pro Arg Arg Pro Ala Tyr Gly Asp Val
355 360 365
Thr Val Thr Ser Leu His Pro Gly Gly Ser Ala Arg Phe His Cys Ala
370 375 380
Thr Gly Tyr Gln Leu Lys Gly Ala Arg His Leu Thr Cys Leu Asn Ala
385 390 395 400
Thr Gln Pro Phe Trp Asp Ser Lys Glu Pro Val Cys Ile Ala Ala Cys
405 410 415
Gly Gly Val Ile Arg Asn Ala Thr Thr Gly Arg Ile Val Ser Pro Gly
420 425 430
Phe Pro Gly Asn Tyr Ser Asn Asn Leu Thr Cys His Trp Leu Leu Glu
435 440 445
Ala Pro Glu Gly Gln Arg Leu His Leu His Phe Glu Lys Val Ser Leu
450 455 460
Ala Glu Asp Asp Asp Arg Leu Ile Ile Arg Asn Gly Asp Asn Val Glu
465 470 475 480
Ala Pro Pro Val Tyr Asp Ser Tyr Glu Val Glu Tyr Leu Pro Ile Glu
485 490 495
Gly Leu Leu Ser Ser Gly Lys His Phe Phe Val Glu Leu Ser Thr Asp
500 505 510
Ser Ser Gly Ala Ala Ala Gly Met Ala Leu Arg Tyr Glu Ala Phe Gln
515 520 525
Gln Gly His Cys Tyr Glu Pro Phe Val Lys Tyr Gly Asn Phe Ser Ser
530 535 540
Ser Thr Pro Thr Tyr Pro Val Gly Thr Thr Val Glu Phe Ser Cys Asp
545 550 555 560
Pro Gly Tyr Thr Leu Glu Gln Gly Ser Ile Ile Ile Glu Cys Val Asp
565 570 575
Pro His Asp Pro Gln Trp Asn Glu Thr Glu Pro Ala Cys Arg Ala Val
580 585 590
Cys Ser Gly Glu Ile Thr Asp Ser Ala Gly Val Val Leu Ser Pro Asn
595 600 605
Trp Pro Glu Pro Tyr Gly Arg Gly Gln Asp Cys Ile Trp Gly Val His
610 615 620
Val Glu Glu Asp Lys Arg Ile Met Leu Asp Ile Arg Val Leu Arg Ile
625 630 635 640
Gly Pro Gly Asp Val Leu Thr Phe Tyr Asp Gly Asp Asp Leu Thr Ala
645 650 655
Arg Val Leu Gly Gln Tyr Ser Gly Pro Arg Ser His Phe Lys Leu Phe
660 665 670
Thr Ser Met Ala Asp Val Thr Ile Gln Phe Gln Ser Asp Pro Gly Thr
675 680 685
Ser Val Leu Gly Tyr Gln Gln Gly Phe Val Ile His Phe Phe Glu Val
690 695 700
Pro Arg Asn Asp Thr Cys Pro Glu Leu Pro Glu Ile Pro Asn Gly Trp
705 710 715 720
Lys Ser Pro Ser Gln Pro Glu Leu Val His Gly Thr Val Val Thr Tyr
725 730 735
Gln Cys Tyr Pro Gly Tyr Gln Val Val Gly Ser Ser Val Leu Met Cys
740 745 750
Gln Trp Asp Leu Thr Trp Ser Glu Asp Leu Pro Ser Cys Gln Arg Val
755 760 765
Thr Ser Cys His Asp Pro Gly Asp Val Glu His Ser Arg Arg Leu Ile
770 775 780
Ser Ser Pro Lys Phe Pro Val Gly Ala Thr Val Gln Tyr Ile Cys Asp
785 790 795 800
Gln Gly Phe Val Leu Met Gly Ser Ser Ile Leu Thr Cys His Asp Arg
805 810 815
Gln Ala Gly Ser Pro Lys Trp Ser Asp Arg Ala Pro Lys Cys Leu Leu
820 825 830
Glu Gln Leu Lys Pro Cys His Gly Leu Ser Ala Pro Glu Asn Gly Ala
835 840 845
Arg Ser Pro Glu Lys Gln Leu His Pro Ala Gly Ala Thr Ile His Phe
850 855 860
Ser Cys Ala Pro Gly Tyr Val Leu Lys Gly Gln Ala Ser Ile Lys Cys
865 870 875 880
Val Pro Gly His Pro Ser His Trp Ser Asp Pro Pro Pro Ile Cys Arg
885 890 895
Ala Ala Ser Leu Asp Gly Phe Tyr Asn Ser Arg Ser Leu Asp Val Ala
900 905 910
Lys Ala Pro Ala Ala Ser Ser Thr Leu Asp Ala Ala His Ile Ala Ala
915 920 925
Ala Ile Phe Leu Pro Leu Val Ala Met Val Leu Leu Val Gly Gly Val
930 935 940
Tyr Phe Tyr Phe Ser Arg Leu Gln Gly Lys Ser Ser Leu Gln Leu Pro
945 950 955 960
Arg Pro Arg Pro Arg Pro Tyr Asn Arg Ile Thr Ile Glu Ser Ala Phe
965 970 975
Asp Asn Pro Thr Tyr Glu Thr Gly Glu Thr Arg Glu Tyr Glu Val Ser
980 985 990
Ile
<210> 5
<211> 2925
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<223> cDNA sequence of hSCRx17 ORF
<400> 5
ctgagcctgg aggccccaac cgtggggaaa ggacaagccc caggcatcga ggagacagat 60
ggcgagctga cagcagcccc cacacctgag cagccagaac gaggcgtcca ctttgtcaca 120
acagccccca ccttgaagct gctcaaccac cacccgctgc ttgaggaatt cctacaagag 180
gggctggaaa agggagatga ggagttgagg ccagcactgc ccttccagcc tgacccacct 240
gcacccttca ccccaagtcc ccttccccgc ctggccaacc aggacagccg ccctgtcttt 300
accagcccca ctccagccat ggctgcggta cccactcagc cccagtccaa ggagggaccc 360
tggagtccgg agtcagagtc ccctatgctt cgaatcacag ctcccctacc tccagggccc 420
agcatggcag tgcccaccct aggcccaggg gagatagcca gcactacacc ccccagcaga 480
gcctggacac caacccaaga gggtcctgga gacatgggaa ggccgtgggt tgcagaggtt 540
gtgtcccagg gcgcggggat cgggatccag gggaccatca cctcctccac agcttcagga 600
gatgatgagg agaccaccac taccaccacc atcatcacca ccaccatcac cacagtccag 660
acaccaggcc cttgtagctg gaatttctca ggcccagagg gctctctgga ctcccctaca 720
gacctcagct cccccactga tgttggcctg gactgcttct tctacatctc tgtctaccct 780
ggctatggcg tggaaatcaa ggtccagaat atcagcctcc gggaagggga gacagtgact 840
gtggaaggcc tgggggggcc cgacccactg cccctggcca accagtcttt cctgctgcgg 900
ggccaagtca tccgcagccc cacccaccaa gcggccctga ggttccagag cctcccgcca 960
ccggctggcc ctggcacctt ccatttccat taccaagcct atctcctgag ctgccacttt 1020
ccccgtcgtc cagcttatgg agatgtgact gtcaccagcc tccacccagg gggtagtgcc 1080
cgcttccatt gtgccactgg ctaccagctg aagggcgcca ggcatctcac ctgtctcaat 1140
gccacccagc ccttctggga ttcaaaggag cccgtctgca tcgctgcttg cggcggagtg 1200
atccgcaatg ccaccaccgg ccgcatcgtc tctccaggct tcccgggcaa ctacagcaac 1260
aacctcacct gtcactggct gcttgaggct cctgagggcc agcggctaca cctgcacttt 1320
gagaaggttt ccctggcaga ggatgatgac aggctcatca ttcgcaatgg ggacaacgtg 1380
gaggccccac cagtgtatga ttcctatgag gtggaatacc tgcccattga gggcctgctc 1440
agctctggca aacacttctt tgttgagctc agtactgaca gcagcggggc agctgcaggc 1500
atggccctgc gctatgaggc cttccagcag ggccattgct atgagccctt tgtcaaatac 1560
ggtaacttca gcagcagcac acccacctac cctgtgggta ccactgtgga gttcagctgc 1620
gaccctggct acaccctgga gcagggctcc atcatcatcg agtgtgttga cccccacgac 1680
ccccagtgga atgagacaga gccagcctgc cgagccgtgt gcagcgggga gatcacagac 1740
tcggctggcg tggtactctc tcccaactgg ccagagccct acggtcgtgg gcaggattgt 1800
atctggggtg tgcatgtgga agaggacaag cgcatcatgc tggacatccg agtgctgcgc 1860
ataggccctg gtgatgtgct taccttctat gatggggatg acctgacggc ccgggttctg 1920
ggccagtact cagggccccg tagccacttc aagctcttta cctccatggc tgatgtcacc 1980
attcagttcc agtcggaccc cgggacctca gtgctgggct accagcaggg cttcgtcatc 2040
cacttctttg aggtgccccg caatgacaca tgtccggagc tgcctgagat ccccaatggc 2100
tggaagagcc catcgcagcc tgagctagtg cacggcaccg tggtcactta ccagtgctac 2160
cctggctacc aggtagtggg atccagtgtc ctcatgtgcc agtgggacct aacttggagt 2220
gaggacctgc cctcatgcca gagggtgact tcctgccacg atcctggaga tgtggagcac 2280
agccgacgcc tcatatccag ccccaagttt cccgtggggg ccaccgtgca atatatctgt 2340
gaccagggtt ttgtgctgat gggcagctcc atcctcacct gccatgatcg ccaggctggc 2400
agccccaagt ggagtgaccg ggcccctaaa tgtctcctgg aacagctcaa gccatgccat 2460
ggtctcagtg cccctgagaa tggtgcccga agtcctgaga agcagctaca cccagcaggg 2520
gccaccatcc acttctcgtg tgcccctggc tatgtgctga agggccaggc cagcatcaag 2580
tgtgtgcctg ggcacccctc gcattggagt gaccccccac ccatctgtag ggctgcctct 2640
ctggatgggt tctacaacag tcgcagcctg gatgttgcca aggcacctgc tgcctccagc 2700
accctggatg ctgcccacat tgcagctgcc atcttcttgc cactggtggc gatggtgttg 2760
ttggtaggag gtgtatactt ctacttctcc aggctccagg gaaaaagctc cctgcagctg 2820
ccccgccccc gcccccgccc ctacaaccgc attaccatag agtcagcgtt tgacaatcca 2880
acttacgaga ctggatctct ttcctttgca ggagacgaga gaata 2925
<210> 6
<211> 975
<212> PRT
<213> Homo sapiens
<220>
<221> MISC_FEATURE
<223> hSCRx17 protein
<400> 6
Leu Ser Leu Glu Ala Pro Thr Val Gly Lys Gly Gln Ala Pro Gly Ile
1 5 10 15
Glu Glu Thr Asp Gly Glu Leu Thr Ala Ala Pro Thr Pro Glu Gln Pro
20 25 30
Glu Arg Gly Val His Phe Val Thr Thr Ala Pro Thr Leu Lys Leu Leu
35 40 45
Asn His His Pro Leu Leu Glu Glu Phe Leu Gln Glu Gly Leu Glu Lys
50 55 60
Gly Asp Glu Glu Leu Arg Pro Ala Leu Pro Phe Gln Pro Asp Pro Pro
65 70 75 80
Ala Pro Phe Thr Pro Ser Pro Leu Pro Arg Leu Ala Asn Gln Asp Ser
85 90 95
Arg Pro Val Phe Thr Ser Pro Thr Pro Ala Met Ala Ala Val Pro Thr
100 105 110
Gln Pro Gln Ser Lys Glu Gly Pro Trp Ser Pro Glu Ser Glu Ser Pro
115 120 125
Met Leu Arg Ile Thr Ala Pro Leu Pro Pro Gly Pro Ser Met Ala Val
130 135 140
Pro Thr Leu Gly Pro Gly Glu Ile Ala Ser Thr Thr Pro Pro Ser Arg
145 150 155 160
Ala Trp Thr Pro Thr Gln Glu Gly Pro Gly Asp Met Gly Arg Pro Trp
165 170 175
Val Ala Glu Val Val Ser Gln Gly Ala Gly Ile Gly Ile Gln Gly Thr
180 185 190
Ile Thr Ser Ser Thr Ala Ser Gly Asp Asp Glu Glu Thr Thr Thr Thr
195 200 205
Thr Thr Ile Ile Thr Thr Thr Ile Thr Thr Val Gln Thr Pro Gly Pro
210 215 220
Cys Ser Trp Asn Phe Ser Gly Pro Glu Gly Ser Leu Asp Ser Pro Thr
225 230 235 240
Asp Leu Ser Ser Pro Thr Asp Val Gly Leu Asp Cys Phe Phe Tyr Ile
245 250 255
Ser Val Tyr Pro Gly Tyr Gly Val Glu Ile Lys Val Gln Asn Ile Ser
260 265 270
Leu Arg Glu Gly Glu Thr Val Thr Val Glu Gly Leu Gly Gly Pro Asp
275 280 285
Pro Leu Pro Leu Ala Asn Gln Ser Phe Leu Leu Arg Gly Gln Val Ile
290 295 300
Arg Ser Pro Thr His Gln Ala Ala Leu Arg Phe Gln Ser Leu Pro Pro
305 310 315 320
Pro Ala Gly Pro Gly Thr Phe His Phe His Tyr Gln Ala Tyr Leu Leu
325 330 335
Ser Cys His Phe Pro Arg Arg Pro Ala Tyr Gly Asp Val Thr Val Thr
340 345 350
Ser Leu His Pro Gly Gly Ser Ala Arg Phe His Cys Ala Thr Gly Tyr
355 360 365
Gln Leu Lys Gly Ala Arg His Leu Thr Cys Leu Asn Ala Thr Gln Pro
370 375 380
Phe Trp Asp Ser Lys Glu Pro Val Cys Ile Ala Ala Cys Gly Gly Val
385 390 395 400
Ile Arg Asn Ala Thr Thr Gly Arg Ile Val Ser Pro Gly Phe Pro Gly
405 410 415
Asn Tyr Ser Asn Asn Leu Thr Cys His Trp Leu Leu Glu Ala Pro Glu
420 425 430
Gly Gln Arg Leu His Leu His Phe Glu Lys Val Ser Leu Ala Glu Asp
435 440 445
Asp Asp Arg Leu Ile Ile Arg Asn Gly Asp Asn Val Glu Ala Pro Pro
450 455 460
Val Tyr Asp Ser Tyr Glu Val Glu Tyr Leu Pro Ile Glu Gly Leu Leu
465 470 475 480
Ser Ser Gly Lys His Phe Phe Val Glu Leu Ser Thr Asp Ser Ser Gly
485 490 495
Ala Ala Ala Gly Met Ala Leu Arg Tyr Glu Ala Phe Gln Gln Gly His
500 505 510
Cys Tyr Glu Pro Phe Val Lys Tyr Gly Asn Phe Ser Ser Ser Thr Pro
515 520 525
Thr Tyr Pro Val Gly Thr Thr Val Glu Phe Ser Cys Asp Pro Gly Tyr
530 535 540
Thr Leu Glu Gln Gly Ser Ile Ile Ile Glu Cys Val Asp Pro His Asp
545 550 555 560
Pro Gln Trp Asn Glu Thr Glu Pro Ala Cys Arg Ala Val Cys Ser Gly
565 570 575
Glu Ile Thr Asp Ser Ala Gly Val Val Leu Ser Pro Asn Trp Pro Glu
580 585 590
Pro Tyr Gly Arg Gly Gln Asp Cys Ile Trp Gly Val His Val Glu Glu
595 600 605
Asp Lys Arg Ile Met Leu Asp Ile Arg Val Leu Arg Ile Gly Pro Gly
610 615 620
Asp Val Leu Thr Phe Tyr Asp Gly Asp Asp Leu Thr Ala Arg Val Leu
625 630 635 640
Gly Gln Tyr Ser Gly Pro Arg Ser His Phe Lys Leu Phe Thr Ser Met
645 650 655
Ala Asp Val Thr Ile Gln Phe Gln Ser Asp Pro Gly Thr Ser Val Leu
660 665 670
Gly Tyr Gln Gln Gly Phe Val Ile His Phe Phe Glu Val Pro Arg Asn
675 680 685
Asp Thr Cys Pro Glu Leu Pro Glu Ile Pro Asn Gly Trp Lys Ser Pro
690 695 700
Ser Gln Pro Glu Leu Val His Gly Thr Val Val Thr Tyr Gln Cys Tyr
705 710 715 720
Pro Gly Tyr Gln Val Val Gly Ser Ser Val Leu Met Cys Gln Trp Asp
725 730 735
Leu Thr Trp Ser Glu Asp Leu Pro Ser Cys Gln Arg Val Thr Ser Cys
740 745 750
His Asp Pro Gly Asp Val Glu His Ser Arg Arg Leu Ile Ser Ser Pro
755 760 765
Lys Phe Pro Val Gly Ala Thr Val Gln Tyr Ile Cys Asp Gln Gly Phe
770 775 780
Val Leu Met Gly Ser Ser Ile Leu Thr Cys His Asp Arg Gln Ala Gly
785 790 795 800
Ser Pro Lys Trp Ser Asp Arg Ala Pro Lys Cys Leu Leu Glu Gln Leu
805 810 815
Lys Pro Cys His Gly Leu Ser Ala Pro Glu Asn Gly Ala Arg Ser Pro
820 825 830
Glu Lys Gln Leu His Pro Ala Gly Ala Thr Ile His Phe Ser Cys Ala
835 840 845
Pro Gly Tyr Val Leu Lys Gly Gln Ala Ser Ile Lys Cys Val Pro Gly
850 855 860
His Pro Ser His Trp Ser Asp Pro Pro Pro Ile Cys Arg Ala Ala Ser
865 870 875 880
Leu Asp Gly Phe Tyr Asn Ser Arg Ser Leu Asp Val Ala Lys Ala Pro
885 890 895
Ala Ala Ser Ser Thr Leu Asp Ala Ala His Ile Ala Ala Ala Ile Phe
900 905 910
Leu Pro Leu Val Ala Met Val Leu Leu Val Gly Gly Val Tyr Phe Tyr
915 920 925
Phe Ser Arg Leu Gln Gly Lys Ser Ser Leu Gln Leu Pro Arg Pro Arg
930 935 940
Pro Arg Pro Tyr Asn Arg Ile Thr Ile Glu Ser Ala Phe Asp Asn Pro
945 950 955 960
Thr Tyr Glu Thr Gly Ser Leu Ser Phe Ala Gly Asp Glu Arg Ile
965 970 975
<210> 7
<211> 994
<212> PRT
<213> Homo sapiens
<220>
<221> MISC_FEATURE
<223> hSEZ6 BC146292 protein
<400> 7
Met Arg Pro Val Ala Leu Leu Leu Leu Pro Ser Leu Leu Ala Leu Leu
1 5 10 15
Ala His Gly Leu Ser Leu Glu Ala Pro Thr Val Gly Lys Gly Gln Ala
20 25 30
Pro Gly Ile Glu Glu Thr Asp Gly Glu Leu Thr Ala Ala Pro Thr Pro
35 40 45
Glu Gln Pro Glu Arg Gly Val His Phe Val Thr Thr Ala Pro Thr Leu
50 55 60
Lys Leu Leu Asn His His Pro Leu Leu Glu Glu Phe Leu Gln Glu Gly
65 70 75 80
Leu Glu Lys Gly Asp Glu Glu Leu Arg Pro Ala Leu Pro Phe Gln Pro
85 90 95
Asp Pro Pro Ala Pro Phe Thr Pro Ser Pro Leu Pro Arg Leu Ala Asn
100 105 110
Gln Asp Ser Arg Pro Val Phe Thr Ser Pro Thr Pro Ala Met Ala Ala
115 120 125
Val Pro Thr Gln Pro Gln Ser Lys Glu Gly Pro Trp Ser Pro Glu Ser
130 135 140
Glu Ser Pro Met Leu Arg Ile Thr Ala Pro Leu Pro Pro Gly Pro Ser
145 150 155 160
Met Ala Val Pro Thr Leu Gly Pro Gly Glu Ile Ala Ser Thr Thr Pro
165 170 175
Pro Ser Arg Ala Trp Thr Pro Thr Gln Glu Gly Pro Gly Asp Met Gly
180 185 190
Arg Pro Trp Val Ala Glu Val Val Ser Gln Gly Ala Gly Ile Gly Ile
195 200 205
Gln Gly Thr Ile Thr Ser Ser Thr Ala Ser Gly Asp Asp Glu Glu Thr
210 215 220
Thr Thr Thr Thr Thr Ile Ile Thr Thr Thr Ile Thr Thr Val Gln Thr
225 230 235 240
Pro Gly Pro Cys Ser Trp Asn Phe Ser Gly Pro Glu Gly Ser Leu Asp
245 250 255
Ser Pro Thr Asp Leu Ser Ser Pro Thr Asp Val Gly Leu Asp Cys Phe
260 265 270
Phe Tyr Ile Ser Val Tyr Pro Gly Tyr Gly Val Glu Ile Lys Val Gln
275 280 285
Asn Ile Ser Leu Arg Glu Gly Glu Thr Val Thr Val Glu Gly Leu Gly
290 295 300
Gly Pro Asp Pro Leu Pro Leu Ala Asn Gln Ser Phe Leu Leu Arg Gly
305 310 315 320
Gln Val Ile Arg Ser Pro Thr His Gln Ala Ala Leu Arg Phe Gln Ser
325 330 335
Leu Pro Pro Pro Ala Gly Pro Gly Thr Phe His Phe His Tyr Gln Ala
340 345 350
Tyr Leu Leu Ser Cys His Phe Pro Arg Arg Pro Ala Tyr Gly Asp Val
355 360 365
Thr Val Thr Ser Leu His Pro Gly Gly Ser Ala Arg Phe His Cys Ala
370 375 380
Thr Gly Tyr Gln Leu Lys Gly Ala Arg His Leu Thr Cys Leu Asn Ala
385 390 395 400
Thr Gln Pro Phe Trp Asp Ser Lys Glu Pro Val Cys Ile Gly Glu Cys
405 410 415
Pro Gly Val Ile Arg Asn Ala Thr Thr Gly Arg Ile Val Ser Pro Gly
420 425 430
Phe Pro Gly Asn Tyr Ser Asn Asn Leu Thr Cys His Trp Leu Leu Glu
435 440 445
Ala Pro Glu Gly Gln Arg Leu His Leu His Phe Glu Lys Val Ser Leu
450 455 460
Ala Glu Asp Asp Asp Arg Leu Ile Ile Arg Asn Gly Asp Asn Val Glu
465 470 475 480
Ala Pro Pro Val Tyr Asp Ser Tyr Glu Val Glu Tyr Leu Pro Ile Glu
485 490 495
Gly Leu Leu Ser Ser Gly Lys His Phe Phe Val Glu Leu Ser Thr Asp
500 505 510
Ser Ser Gly Ala Ala Ala Gly Met Ala Leu Arg Tyr Glu Ala Phe Gln
515 520 525
Gln Gly His Cys Tyr Glu Pro Phe Val Lys Tyr Gly Asn Phe Ser Ser
530 535 540
Ser Thr Pro Thr Tyr Pro Val Gly Thr Thr Val Glu Phe Ser Cys Asp
545 550 555 560
Pro Gly Tyr Thr Leu Glu Gln Gly Ser Ile Ile Ile Glu Cys Val Asp
565 570 575
Pro His Asp Pro Gln Trp Asn Glu Thr Glu Pro Ala Cys Arg Ala Val
580 585 590
Cys Ser Gly Glu Ile Thr Asp Ser Ala Gly Val Val Leu Ser Pro Asn
595 600 605
Trp Pro Glu Pro Tyr Gly Arg Gly Gln Asp Cys Ile Trp Gly Val His
610 615 620
Val Glu Glu Asp Lys Arg Ile Met Leu Asp Ile Arg Val Leu Arg Ile
625 630 635 640
Gly Pro Gly Asp Val Leu Thr Phe Tyr Asp Gly Asp Asp Leu Thr Ala
645 650 655
Arg Val Leu Gly Gln Tyr Ser Gly Pro Arg Ser His Phe Lys Leu Phe
660 665 670
Thr Ser Met Ala Asp Val Thr Ile Gln Phe Gln Ser Asp Pro Gly Thr
675 680 685
Ser Val Leu Gly Tyr Gln Gln Gly Phe Val Ile His Phe Phe Glu Val
690 695 700
Pro Arg Asn Asp Thr Cys Pro Glu Leu Pro Glu Ile Pro Asn Gly Trp
705 710 715 720
Lys Ser Pro Ser Gln Pro Glu Leu Val His Gly Thr Val Val Thr Tyr
725 730 735
Gln Cys Tyr Pro Gly Tyr Gln Val Val Gly Ser Ser Val Leu Met Cys
740 745 750
Gln Trp Asp Leu Thr Trp Ser Glu Asp Leu Pro Ser Cys Gln Arg Val
755 760 765
Thr Ser Cys His Asp Pro Gly Asp Val Glu His Ser Arg Arg Leu Ile
770 775 780
Ser Ser Pro Lys Phe Pro Val Gly Ala Thr Val Gln Tyr Ile Cys Asp
785 790 795 800
Gln Gly Phe Val Leu Met Gly Ser Ser Ile Leu Thr Cys His Asp Arg
805 810 815
Gln Ala Gly Ser Pro Lys Trp Ser Asp Arg Ala Pro Lys Cys Leu Leu
820 825 830
Glu Gln Leu Lys Pro Cys His Gly Leu Ser Ala Pro Glu Asn Gly Ala
835 840 845
Arg Ser Pro Glu Lys Gln Leu His Pro Ala Gly Ala Thr Ile His Phe
850 855 860
Ser Cys Ala Pro Gly Tyr Val Leu Lys Gly Gln Ala Ser Ile Lys Cys
865 870 875 880
Val Pro Gly His Pro Ser His Trp Ser Asp Pro Pro Pro Ile Cys Arg
885 890 895
Ala Ala Ser Leu Asp Gly Phe Tyr Asn Ser Arg Ser Leu Asp Val Ala
900 905 910
Lys Ala Pro Ala Ala Ser Ser Thr Leu Asp Ala Ala His Ile Ala Ala
915 920 925
Ala Ile Phe Leu Pro Leu Val Ala Met Val Leu Leu Val Gly Gly Val
930 935 940
Tyr Phe Tyr Phe Ser Arg Leu Gln Gly Lys Ser Ser Leu Gln Leu Pro
945 950 955 960
Arg Pro Arg Pro Arg Pro Tyr Asn Arg Ile Thr Ile Glu Ser Ala Phe
965 970 975
Asp Asn Pro Thr Tyr Glu Thr Gly Ser Leu Ser Phe Ala Gly Asp Glu
980 985 990
Arg Ile
<210> 8
<211> 3483
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<223> hSCRx17-Fc ORF
<400> 8
atggagacag acacactcct gctatgggta ctgctgctct gggttcccgg gtccactggt 60
gacggcgcgc ctggatccct gagcctggag gccccaaccg tggggaaagg acaagcccca 120
ggcatcgagg agacagatgg cgagctgaca gcagccccca cacctgagca gccagaacga 180
ggcgtccact ttgtcacaac agcccccacc ttgaagctgc tcaaccacca cccgctgctt 240
gaggaattcc tacaagaggg gctggaaaag ggagatgagg agttgaggcc agcactgccc 300
ttccagcctg acccacctgc acccttcacc ccaagtcccc ttccccgcct ggccaaccag 360
gacagccgcc ctgtctttac cagccccact ccagccatgg ctgcggtacc cactcagccc 420
cagtccaagg agggaccctg gagtccggag tcagagtccc ctatgcttcg aatcacagct 480
cccctacctc cagggcccag catggcagtg cccaccctag gcccagggga gatagccagc 540
actacacccc ccagcagagc ctggacacca acccaagagg gtcctggaga catgggaagg 600
ccgtgggttg cagaggttgt gtcccagggc gcggggatcg ggatccaggg gaccatcacc 660
tcctccacag cttcaggaga tgatgaggag accaccacta ccaccaccat catcaccacc 720
accatcacca cagtccagac accaggccct tgtagctgga atttctcagg cccagagggc 780
tctctggact cccctacaga cctcagctcc cccactgatg ttggcctgga ctgcttcttc 840
tacatctctg tctaccctgg ctatggcgtg gaaatcaagg tccagaatat cagcctccgg 900
gaaggggaga cagtgactgt ggaaggcctg ggggggcccg acccactgcc cctggccaac 960
cagtctttcc tgctgcgggg ccaagtcatc cgcagcccca cccaccaagc ggccctgagg 1020
ttccagagcc tcccgccacc ggctggccct ggcaccttcc atttccatta ccaagcctat 1080
ctcctgagct gccactttcc ccgtcgtcca gcttatggag atgtgactgt caccagcctc 1140
cacccagggg gtagtgcccg cttccattgt gccactggct accagctgaa gggcgccagg 1200
catctcacct gtctcaatgc cacccagccc ttctgggatt caaaggagcc cgtctgcatc 1260
gctgcttgcg gcggagtgat ccgcaatgcc accaccggcc gcatcgtctc tccaggcttc 1320
ccgggcaact acagcaacaa cctcacctgt cactggctgc ttgaggctcc tgagggccag 1380
cggctacacc tgcactttga gaaggtttcc ctggcagagg atgatgacag gctcatcatt 1440
cgcaatgggg acaacgtgga ggccccacca gtgtatgatt cctatgaggt ggaatacctg 1500
cccattgagg gcctgctcag ctctggcaaa cacttctttg ttgagctcag tactgacagc 1560
agcggggcag ctgcaggcat ggccctgcgc tatgaggcct tccagcaggg ccattgctat 1620
gagccctttg tcaaatacgg taacttcagc agcagcacac ccacctaccc tgtgggtacc 1680
actgtggagt tcagctgcga ccctggctac accctggagc agggctccat catcatcgag 1740
tgtgttgacc cccacgaccc ccagtggaat gagacagagc cagcctgccg agccgtgtgc 1800
agcggggaga tcacagactc ggctggcgtg gtactctctc ccaactggcc agagccctac 1860
ggtcgtgggc aggattgtat ctggggtgtg catgtggaag aggacaagcg catcatgctg 1920
gacatccgag tgctgcgcat aggccctggt gatgtgctta ccttctatga tggggatgac 1980
ctgacggccc gggttctggg ccagtactca gggccccgta gccacttcaa gctctttacc 2040
tccatggctg atgtcaccat tcagttccag tcggaccccg ggacctcagt gctgggctac 2100
cagcagggct tcgtcatcca cttctttgag gtgccccgca atgacacatg tccggagctg 2160
cctgagatcc ccaatggctg gaagagccca tcgcagcctg agctagtgca cggcaccgtg 2220
gtcacttacc agtgctaccc tggctaccag gtagtgggat ccagtgtcct catgtgccag 2280
tgggacctaa cttggagtga ggacctgccc tcatgccaga gggtgacttc ctgccacgat 2340
cctggagatg tggagcacag ccgacgcctc atatccagcc ccaagtttcc cgtgggggcc 2400
accgtgcaat atatctgtga ccagggtttt gtgctgatgg gcagctccat cctcacctgc 2460
catgatcgcc aggctggcag ccccaagtgg agtgaccggg cccctaaatg tctcctggaa 2520
cagctcaagc catgccatgg tctcagtgcc cctgagaatg gtgcccgaag tcctgagaag 2580
cagctacacc cagcaggggc caccatccac ttctcgtgtg cccctggcta tgtgctgaag 2640
ggccaggcca gcatcaagtg tgtgcctggg cacccctcgc attggagtga ccccccaccc 2700
atctgtaggg ctgcctctct ggatgggttc tacaacagtc gcagcctgga tgttgccaag 2760
gcacctgctg cctccagcac cctggatgct gcccacctgg ccggccacag atctgtcgag 2820
tgcccaccgt gcccagcacc acctgtggca ggaccgtcag tcttcctctt ccccccaaaa 2880
cccaaggaca ccctcatgat ctcccggacc cctgaggtca cgtgcgtggt ggtggacgtg 2940
agccacgaag accccgaggt ccagttcaac tggtacgtgg acggcgtgga ggtgcataat 3000
gccaagacaa agccacggga ggagcagttc aacagcacgt tccgtgtggt cagcgtcctc 3060
accgttgtgc accaggactg gctgaacggc aaggagtaca agtgcaaggt ctccaacaaa 3120
ggcctcccag cccccatcga gaaaaccatc tccaaaacca aagggcagcc ccgagaacca 3180
caggtgtaca ccctgccccc atccagggag gagatgacca agaaccaggt cagcctgacc 3240
tgcctggtca aaggcttcta ccccagcgac atcgccgtgg agtgggagag caatgggcag 3300
ccggagaaca actacaagac cacgcctccc atgctggact ccgacggctc cttcttcctc 3360
tacagcaagc tcaccgtgga caagagcagg tggcagcagg ggaacgtctt ctcatgctcc 3420
gtgatgcatg aggctctgca caaccactac acgcagaaga gcctctccct gtctccgggt 3480
tga 3483
<210> 9
<211> 1160
<212> PRT
<213> Homo sapiens
<220>
<221> MISC_FEATURE
<223> hSCRx17-Fc protein
<400> 9
Met Glu Thr Asp Thr Leu Leu Leu Trp Val Leu Leu Leu Trp Val Pro
1 5 10 15
Gly Ser Thr Gly Asp Gly Ala Pro Gly Ser Leu Ser Leu Glu Ala Pro
20 25 30
Thr Val Gly Lys Gly Gln Ala Pro Gly Ile Glu Glu Thr Asp Gly Glu
35 40 45
Leu Thr Ala Ala Pro Thr Pro Glu Gln Pro Glu Arg Gly Val His Phe
50 55 60
Val Thr Thr Ala Pro Thr Leu Lys Leu Leu Asn His His Pro Leu Leu
65 70 75 80
Glu Glu Phe Leu Gln Glu Gly Leu Glu Lys Gly Asp Glu Glu Leu Arg
85 90 95
Pro Ala Leu Pro Phe Gln Pro Asp Pro Pro Ala Pro Phe Thr Pro Ser
100 105 110
Pro Leu Pro Arg Leu Ala Asn Gln Asp Ser Arg Pro Val Phe Thr Ser
115 120 125
Pro Thr Pro Ala Met Ala Ala Val Pro Thr Gln Pro Gln Ser Lys Glu
130 135 140
Gly Pro Trp Ser Pro Glu Ser Glu Ser Pro Met Leu Arg Ile Thr Ala
145 150 155 160
Pro Leu Pro Pro Gly Pro Ser Met Ala Val Pro Thr Leu Gly Pro Gly
165 170 175
Glu Ile Ala Ser Thr Thr Pro Pro Ser Arg Ala Trp Thr Pro Thr Gln
180 185 190
Glu Gly Pro Gly Asp Met Gly Arg Pro Trp Val Ala Glu Val Val Ser
195 200 205
Gln Gly Ala Gly Ile Gly Ile Gln Gly Thr Ile Thr Ser Ser Thr Ala
210 215 220
Ser Gly Asp Asp Glu Glu Thr Thr Thr Thr Thr Thr Ile Ile Thr Thr
225 230 235 240
Thr Ile Thr Thr Val Gln Thr Pro Gly Pro Cys Ser Trp Asn Phe Ser
245 250 255
Gly Pro Glu Gly Ser Leu Asp Ser Pro Thr Asp Leu Ser Ser Pro Thr
260 265 270
Asp Val Gly Leu Asp Cys Phe Phe Tyr Ile Ser Val Tyr Pro Gly Tyr
275 280 285
Gly Val Glu Ile Lys Val Gln Asn Ile Ser Leu Arg Glu Gly Glu Thr
290 295 300
Val Thr Val Glu Gly Leu Gly Gly Pro Asp Pro Leu Pro Leu Ala Asn
305 310 315 320
Gln Ser Phe Leu Leu Arg Gly Gln Val Ile Arg Ser Pro Thr His Gln
325 330 335
Ala Ala Leu Arg Phe Gln Ser Leu Pro Pro Pro Ala Gly Pro Gly Thr
340 345 350
Phe His Phe His Tyr Gln Ala Tyr Leu Leu Ser Cys His Phe Pro Arg
355 360 365
Arg Pro Ala Tyr Gly Asp Val Thr Val Thr Ser Leu His Pro Gly Gly
370 375 380
Ser Ala Arg Phe His Cys Ala Thr Gly Tyr Gln Leu Lys Gly Ala Arg
385 390 395 400
His Leu Thr Cys Leu Asn Ala Thr Gln Pro Phe Trp Asp Ser Lys Glu
405 410 415
Pro Val Cys Ile Ala Ala Cys Gly Gly Val Ile Arg Asn Ala Thr Thr
420 425 430
Gly Arg Ile Val Ser Pro Gly Phe Pro Gly Asn Tyr Ser Asn Asn Leu
435 440 445
Thr Cys His Trp Leu Leu Glu Ala Pro Glu Gly Gln Arg Leu His Leu
450 455 460
His Phe Glu Lys Val Ser Leu Ala Glu Asp Asp Asp Arg Leu Ile Ile
465 470 475 480
Arg Asn Gly Asp Asn Val Glu Ala Pro Pro Val Tyr Asp Ser Tyr Glu
485 490 495
Val Glu Tyr Leu Pro Ile Glu Gly Leu Leu Ser Ser Gly Lys His Phe
500 505 510
Phe Val Glu Leu Ser Thr Asp Ser Ser Gly Ala Ala Ala Gly Met Ala
515 520 525
Leu Arg Tyr Glu Ala Phe Gln Gln Gly His Cys Tyr Glu Pro Phe Val
530 535 540
Lys Tyr Gly Asn Phe Ser Ser Ser Thr Pro Thr Tyr Pro Val Gly Thr
545 550 555 560
Thr Val Glu Phe Ser Cys Asp Pro Gly Tyr Thr Leu Glu Gln Gly Ser
565 570 575
Ile Ile Ile Glu Cys Val Asp Pro His Asp Pro Gln Trp Asn Glu Thr
580 585 590
Glu Pro Ala Cys Arg Ala Val Cys Ser Gly Glu Ile Thr Asp Ser Ala
595 600 605
Gly Val Val Leu Ser Pro Asn Trp Pro Glu Pro Tyr Gly Arg Gly Gln
610 615 620
Asp Cys Ile Trp Gly Val His Val Glu Glu Asp Lys Arg Ile Met Leu
625 630 635 640
Asp Ile Arg Val Leu Arg Ile Gly Pro Gly Asp Val Leu Thr Phe Tyr
645 650 655
Asp Gly Asp Asp Leu Thr Ala Arg Val Leu Gly Gln Tyr Ser Gly Pro
660 665 670
Arg Ser His Phe Lys Leu Phe Thr Ser Met Ala Asp Val Thr Ile Gln
675 680 685
Phe Gln Ser Asp Pro Gly Thr Ser Val Leu Gly Tyr Gln Gln Gly Phe
690 695 700
Val Ile His Phe Phe Glu Val Pro Arg Asn Asp Thr Cys Pro Glu Leu
705 710 715 720
Pro Glu Ile Pro Asn Gly Trp Lys Ser Pro Ser Gln Pro Glu Leu Val
725 730 735
His Gly Thr Val Val Thr Tyr Gln Cys Tyr Pro Gly Tyr Gln Val Val
740 745 750
Gly Ser Ser Val Leu Met Cys Gln Trp Asp Leu Thr Trp Ser Glu Asp
755 760 765
Leu Pro Ser Cys Gln Arg Val Thr Ser Cys His Asp Pro Gly Asp Val
770 775 780
Glu His Ser Arg Arg Leu Ile Ser Ser Pro Lys Phe Pro Val Gly Ala
785 790 795 800
Thr Val Gln Tyr Ile Cys Asp Gln Gly Phe Val Leu Met Gly Ser Ser
805 810 815
Ile Leu Thr Cys His Asp Arg Gln Ala Gly Ser Pro Lys Trp Ser Asp
820 825 830
Arg Ala Pro Lys Cys Leu Leu Glu Gln Leu Lys Pro Cys His Gly Leu
835 840 845
Ser Ala Pro Glu Asn Gly Ala Arg Ser Pro Glu Lys Gln Leu His Pro
850 855 860
Ala Gly Ala Thr Ile His Phe Ser Cys Ala Pro Gly Tyr Val Leu Lys
865 870 875 880
Gly Gln Ala Ser Ile Lys Cys Val Pro Gly His Pro Ser His Trp Ser
885 890 895
Asp Pro Pro Pro Ile Cys Arg Ala Ala Ser Leu Asp Gly Phe Tyr Asn
900 905 910
Ser Arg Ser Leu Asp Val Ala Lys Ala Pro Ala Ala Ser Ser Thr Leu
915 920 925
Asp Ala Ala His Leu Ala Gly His Arg Ser Val Glu Cys Pro Pro Cys
930 935 940
Pro Ala Pro Pro Val Ala Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
945 950 955 960
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
965 970 975
Val Val Asp Val Ser His Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr
980 985 990
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
995 1000 1005
Gln Phe Asn Ser Thr Phe Arg Val Val Ser Val Leu Thr Val Val
1010 1015 1020
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser
1025 1030 1035
Asn Lys Gly Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Thr
1040 1045 1050
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
1055 1060 1065
Arg Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
1070 1075 1080
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
1085 1090 1095
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Met Leu Asp
1100 1105 1110
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
1115 1120 1125
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
1130 1135 1140
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
1145 1150 1155
Pro Gly
1160
<210> 10
<211> 2919
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> cDNA sequence encoding mature murine SEZ6
<400> 10
ctctcctcag aggctccgat cacgggggaa ggtcatgcca cgggcatcag ggagacggat 60
ggggagctga ccgcagcccc tacacctgag cagtcagacc gaggcgtcca cttcgtcacc 120
acagccccta ccctcaagct gctcaaccac cacccacttc tggaagaatt tcttcaagag 180
gggctagaaa gagaggaagc gccgcagcct gcactgccct tccagccgga ctcacctaca 240
cactttactc caagccccct cccccgcctc accaaccagg acaaccgccc cgtctttacc 300
agtccgactc cagccgtggc tgcagcaccc acccagcccc actccaggga gaaaccttgg 360
aacctagaat ccaaaccccc tgagctttct atcacatcgt cccttcctcc agggccgagt 420
atggcagtgc ccacactgct cccagaggac agacccagta ctacaccccc tagccaagca 480
tggactccaa ctcaggaggg tcctggagac atggacagac cttgggttcc agaggtcatg 540
tctaagacca cagggcttgg tgtcgaggga accattgcca cctccacagc ttcaggggat 600
gacgaagaga ccactaccac catcattacc actactgtca ccacagttca gccaccaggc 660
ccctgtagct ggaatttctc aggcccagag ggctctctgg attcccccac ggcccccagc 720
tcaccctctg atgttggcct ggactgtttc tactatatct ctgtctaccc tggatatgga 780
gtagagatca aggtggagaa catcagcctt caggaagggg agaccatcac cgtggagggc 840
ctggggggcc ccgatccact gcccttggct aaccagtcgt tcctgctgag gggccaggtc 900
atccgcagcc ccacccacca agcagccctg aggttccaga gcctcccgct acccgctggg 960
cctggcactt tccatttccg ctaccaagcc tatctcctga gctgccactt tccccgacgt 1020
ccagcgtatg gagatgtgac tgtcaccagt ctccacccag gaggcagcgc ccacttccat 1080
tgtgccactg gctaccagct caagggtgcc aggttcctca cctgtctcaa tgccacccag 1140
cccttttggg attcccaaga gcctgtttgc attgctgctt gtggtggagt gattcggaat 1200
gccaccactg gccgcattgt ctctcctggc ttcccgggga actacagcaa caacctcacc 1260
tgccactggt tgctagaggc tccagagagc cagcggctgc acctgcactt tgaaaaggtc 1320
tccctggcag aagacgacga caggctcatc atccgcaatg gaaataacgt ggaggccccg 1380
ccggtgtacg actcctatga ggtggaatac ctgcccattg agggcctgct cagctctggc 1440
agacacttct tcgtggagtt cagtactgac agcagtgggg cagctgcagg catggccctg 1500
cgctatgagg ccttccagca aggacattgc tatgagccct ttgtcaaata cggcaacttc 1560
agcagcagtg caccgtccta ccctgtgggt acaactgtgg agttcagctg tgaccctggc 1620
tacaccctgg agcagggctc catcatcatc gaatgcgtcg acctccacga cccccagtgg 1680
aatgagacag agccagcctg ccgagccgtg tgcagcgggg agatcacaga ctctgcaggc 1740
gtggtgctct ctccaaactg gccggagcct tatggccgag ggcaggactg catctggggt 1800
gtgcatgtgg aggaggacaa gcgcatcatg ctggacatcc gagtgctgcg cataggctct 1860
ggggatgtac tgaccttcta cgatggggat gacctcacag cccgggtcct gggccaatac 1920
tcagggcccc gtggccactt caagctcttt acctccatgg ccgatgtcac catccagttc 1980
cagtcagacc ctgggacctc ggcgctgggt taccagcaag gatttgtcat ccacttcttt 2040
gaggttcccc gcaacgacac atgtccagag ctacccgaga tccccaacgg ctggaagaac 2100
ccatcacagc ctgagctggt gcacggcacg gtggtcacct atcagtgcta ccctggttac 2160
caggtggtgg gatccagtat tctcatgtgc cagtgggacc taagctggag tgaggacctg 2220
ccttcatgcc agagagtgac atcttgccat gacccagggg atgtggagca cagccgacgc 2280
ctcatatcca gccccaagtt tcccgtggga gcaactgtgc aatatgtctg tgaccagggt 2340
tttgtgctga cggggagtgc cattctcacc tgccatgatc ggcaagcagg cagtcccaag 2400
tggagtgaca gggcccccaa gtgtctcttg gaacaattca agccgtgcca tggcctcagc 2460
gccccggaga atggtgcccg cagccctgag aagcggcttc acccagcagg ggccaccatc 2520
cacttctcct gtgcccctgg ttatgtgctg aagggccagg ccagcatcaa atgcgtgcct 2580
ggacacccct cgcattggag tgacccacca cccatctgta gggctgcctc tctggatggg 2640
ttctacaacg gccgtagcct ggatgttgcc aaggcacctg ccgcctccag tgccctggac 2700
gctgctcacc tggctgctgc catcttccta ccattggtgg ccatggtgtt gctggtggga 2760
ggagtgtacc tctatttttc cagattccag gggaaaagtc ccctgcaact tccccgaact 2820
catcctcgcc cctataaccg catcacggta gagtcagcat ttgacaatcc aacttatgag 2880
actggatctc tttcctttgc aggagacgag agaatatga 2919
<210> 11
<211> 972
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> mSCRx17 protein
<400> 11
Leu Ser Ser Glu Ala Pro Ile Thr Gly Glu Gly His Ala Thr Gly Ile
1 5 10 15
Arg Glu Thr Asp Gly Glu Leu Thr Ala Ala Pro Thr Pro Glu Gln Ser
20 25 30
Asp Arg Gly Val His Phe Val Thr Thr Ala Pro Thr Leu Lys Leu Leu
35 40 45
Asn His His Pro Leu Leu Glu Glu Phe Leu Gln Glu Gly Leu Glu Arg
50 55 60
Glu Glu Ala Pro Gln Pro Ala Leu Pro Phe Gln Pro Asp Ser Pro Thr
65 70 75 80
His Phe Thr Pro Ser Pro Leu Pro Arg Leu Thr Asn Gln Asp Asn Arg
85 90 95
Pro Val Phe Thr Ser Pro Thr Pro Ala Val Ala Ala Ala Pro Thr Gln
100 105 110
Pro His Ser Arg Glu Lys Pro Trp Asn Leu Glu Ser Lys Pro Pro Glu
115 120 125
Leu Ser Ile Thr Ser Ser Leu Pro Pro Gly Pro Ser Met Ala Val Pro
130 135 140
Thr Leu Leu Pro Glu Asp Arg Pro Ser Thr Thr Pro Pro Ser Gln Ala
145 150 155 160
Trp Thr Pro Thr Gln Glu Gly Pro Gly Asp Met Asp Arg Pro Trp Val
165 170 175
Pro Glu Val Met Ser Lys Thr Thr Gly Leu Gly Val Glu Gly Thr Ile
180 185 190
Ala Thr Ser Thr Ala Ser Gly Asp Asp Glu Glu Thr Thr Thr Thr Ile
195 200 205
Ile Thr Thr Thr Val Thr Thr Val Gln Pro Pro Gly Pro Cys Ser Trp
210 215 220
Asn Phe Ser Gly Pro Glu Gly Ser Leu Asp Ser Pro Thr Ala Pro Ser
225 230 235 240
Ser Pro Ser Asp Val Gly Leu Asp Cys Phe Tyr Tyr Ile Ser Val Tyr
245 250 255
Pro Gly Tyr Gly Val Glu Ile Lys Val Glu Asn Ile Ser Leu Gln Glu
260 265 270
Gly Glu Thr Ile Thr Val Glu Gly Leu Gly Gly Pro Asp Pro Leu Pro
275 280 285
Leu Ala Asn Gln Ser Phe Leu Leu Arg Gly Gln Val Ile Arg Ser Pro
290 295 300
Thr His Gln Ala Ala Leu Arg Phe Gln Ser Leu Pro Leu Pro Ala Gly
305 310 315 320
Pro Gly Thr Phe His Phe Arg Tyr Gln Ala Tyr Leu Leu Ser Cys His
325 330 335
Phe Pro Arg Arg Pro Ala Tyr Gly Asp Val Thr Val Thr Ser Leu His
340 345 350
Pro Gly Gly Ser Ala His Phe His Cys Ala Thr Gly Tyr Gln Leu Lys
355 360 365
Gly Ala Arg Phe Leu Thr Cys Leu Asn Ala Thr Gln Pro Phe Trp Asp
370 375 380
Ser Gln Glu Pro Val Cys Ile Ala Ala Cys Gly Gly Val Ile Arg Asn
385 390 395 400
Ala Thr Thr Gly Arg Ile Val Ser Pro Gly Phe Pro Gly Asn Tyr Ser
405 410 415
Asn Asn Leu Thr Cys His Trp Leu Leu Glu Ala Pro Glu Ser Gln Arg
420 425 430
Leu His Leu His Phe Glu Lys Val Ser Leu Ala Glu Asp Asp Asp Arg
435 440 445
Leu Ile Ile Arg Asn Gly Asn Asn Val Glu Ala Pro Pro Val Tyr Asp
450 455 460
Ser Tyr Glu Val Glu Tyr Leu Pro Ile Glu Gly Leu Leu Ser Ser Gly
465 470 475 480
Arg His Phe Phe Val Glu Phe Ser Thr Asp Ser Ser Gly Ala Ala Ala
485 490 495
Gly Met Ala Leu Arg Tyr Glu Ala Phe Gln Gln Gly His Cys Tyr Glu
500 505 510
Pro Phe Val Lys Tyr Gly Asn Phe Ser Ser Ser Ala Pro Ser Tyr Pro
515 520 525
Val Gly Thr Thr Val Glu Phe Ser Cys Asp Pro Gly Tyr Thr Leu Glu
530 535 540
Gln Gly Ser Ile Ile Ile Glu Cys Val Asp Leu His Asp Pro Gln Trp
545 550 555 560
Asn Glu Thr Glu Pro Ala Cys Arg Ala Val Cys Ser Gly Glu Ile Thr
565 570 575
Asp Ser Ala Gly Val Val Leu Ser Pro Asn Trp Pro Glu Pro Tyr Gly
580 585 590
Arg Gly Gln Asp Cys Ile Trp Gly Val His Val Glu Glu Asp Lys Arg
595 600 605
Ile Met Leu Asp Ile Arg Val Leu Arg Ile Gly Ser Gly Asp Val Leu
610 615 620
Thr Phe Tyr Asp Gly Asp Asp Leu Thr Ala Arg Val Leu Gly Gln Tyr
625 630 635 640
Ser Gly Pro Arg Gly His Phe Lys Leu Phe Thr Ser Met Ala Asp Val
645 650 655
Thr Ile Gln Phe Gln Ser Asp Pro Gly Thr Ser Ala Leu Gly Tyr Gln
660 665 670
Gln Gly Phe Val Ile His Phe Phe Glu Val Pro Arg Asn Asp Thr Cys
675 680 685
Pro Glu Leu Pro Glu Ile Pro Asn Gly Trp Lys Asn Pro Ser Gln Pro
690 695 700
Glu Leu Val His Gly Thr Val Val Thr Tyr Gln Cys Tyr Pro Gly Tyr
705 710 715 720
Gln Val Val Gly Ser Ser Ile Leu Met Cys Gln Trp Asp Leu Ser Trp
725 730 735
Ser Glu Asp Leu Pro Ser Cys Gln Arg Val Thr Ser Cys His Asp Pro
740 745 750
Gly Asp Val Glu His Ser Arg Arg Leu Ile Ser Ser Pro Lys Phe Pro
755 760 765
Val Gly Ala Thr Val Gln Tyr Val Cys Asp Gln Gly Phe Val Leu Thr
770 775 780
Gly Ser Ala Ile Leu Thr Cys His Asp Arg Gln Ala Gly Ser Pro Lys
785 790 795 800
Trp Ser Asp Arg Ala Pro Lys Cys Leu Leu Glu Gln Phe Lys Pro Cys
805 810 815
His Gly Leu Ser Ala Pro Glu Asn Gly Ala Arg Ser Pro Glu Lys Arg
820 825 830
Leu His Pro Ala Gly Ala Thr Ile His Phe Ser Cys Ala Pro Gly Tyr
835 840 845
Val Leu Lys Gly Gln Ala Ser Ile Lys Cys Val Pro Gly His Pro Ser
850 855 860
His Trp Ser Asp Pro Pro Pro Ile Cys Arg Ala Ala Ser Leu Asp Gly
865 870 875 880
Phe Tyr Asn Gly Arg Ser Leu Asp Val Ala Lys Ala Pro Ala Ala Ser
885 890 895
Ser Ala Leu Asp Ala Ala His Leu Ala Ala Ala Ile Phe Leu Pro Leu
900 905 910
Val Ala Met Val Leu Leu Val Gly Gly Val Tyr Leu Tyr Phe Ser Arg
915 920 925
Phe Gln Gly Lys Ser Pro Leu Gln Leu Pro Arg Thr His Pro Arg Pro
930 935 940
Tyr Asn Arg Ile Thr Val Glu Ser Ala Phe Asp Asn Pro Thr Tyr Glu
945 950 955 960
Thr Gly Ser Leu Ser Phe Ala Gly Asp Glu Arg Ile
965 970
<210> 12
<211> 2919
<212> DNA
<213> Rattus rattus
<220>
<221> misc_feature
<223> cDNA sequence of rSCRx17 ORF
<400> 12
ctctcctcag aggctccaat cacgggggaa ggtcaagcca cgggcatcag ggagatggat 60
ggggagctga ccgcagcccc tacacctgag cagtcagacc gaggcgtcca cttcgtcacc 120
acagccccta ccctcaagct actcaaccac cacccacttc tggaggaatt tcttcaagag 180
gggctagaag ggagagagga agctccgagg ccggcactgc ccttccagcc agactcacct 240
acacccttta ctccaagccc ccttccccgc ctcaccaacc aggacaaccg ccctgtcttt 300
accagtccga cgccagctgt agctgcggca cccacgcagc cccactccag aaagaaaccc 360
tggaacccag agtcagagcc cccggagctt tacatcacat ctcccctccc tccagggccg 420
agtatggcag tgcccacact gcacccagag gacagaccca gcactacacc ccccagccaa 480
gcatggactc caacccagga gggtcctgga gacatgggca gaccttgggt tccagagatc 540
atgtctaaga ccacagggct tggtatcgag gggaccattg ccacctccac agcttcaggg 600
gatgacgaag agaccaccac caccaccatc attaccaccg tcaccacaat tcagccacca 660
ggcccctgta gctggaattt ctcaggcccg gagggctctc tggattcccc tgcggtcccc 720
agcgtcccct ctgatgttgg cctggactgt ctctactaca tctctgtcta ccctggatat 780
ggagtcgaga tcaaggtgaa gaacatcagc cttcaggaag gagagaccat aaccgtggag 840
ggcctggggg ggcctgaccc actgcccttg gctaaccagt ctttcctgct gaggggccag 900
gtcatccgca gccccaccca ccaggcagcc gtgaggttcc aaagccttcc acttcccgct 960
ggacctggta ctttccattt ccactaccaa gcctatctcc tgagctgcca ctttcctcgg 1020
cgtccagctt atggagatgt gactgtcacc agcctccacc caggaggcag cgcccgcttc 1080
cactgtgcca ctggctacca gctaaagggt gccaggttcc tcacctgtct caatgccacc 1140
cagccctttt gggattccca agagcctgtc tgcattgctg cttgtggagg agtgattcgg 1200
aatgccacca ctggccgcat tgtctctcct ggctttcccg ggaactacag caacaacctc 1260
acctgccact ggctgctaga agcccccgag agccagcggc tgcacctgca ctttgaaaag 1320
gtctccctgg cagaagatga cgacaggctc atcatccgta acgggaataa cgtggaggcc 1380
ccgccagtgt atgactccta tgaggtggag tacctgccca ttgagggcct gctcagttct 1440
ggcagacact tcttcgtgga gttcagtact gacagcagcg gggcagccgc aggcatggca 1500
ctgcgctatg aggccttcca gcaaggacat tgctatgagc cctttgtcaa atacggtaac 1560
ttcagcagca gcgcaccgtc ctaccctgtg ggtacgactg tggagttcag ctgtgaccct 1620
ggctacaccc tggagcaggg ttccatcatc atcgaatgcg tcgacctccg tgacccccag 1680
tggaatgaga cagaaccagc ctgccgagcc gtgtgcagcg gggagatcac agactctgca 1740
ggcgtggtgc tctctccaaa ctggccggag ccttatggcc gagggcagga ctgcatctgg 1800
ggtgtgcatg tggaggagga caagcgcatc atgctggaca tccgagtgct gcgcataggc 1860
tctggggatg tactgacctt ctacgatggg gatgacctga cagcccgggt cctgggccaa 1920
tactcagggc cccgtggcca cttcaagctc tttacctcca tggctgatgt caccattcag 1980
ttccagtcag accctgggac gtcggcgctg ggttaccagc aaggatttgt catccacttc 2040
tttgaggtgc cccgcaatga cacatgtcca gagcttcccg agatccccaa cggctggaag 2100
aacccatcac agcctgagct ggtgcatggc acggtggtca cctatcagtg ctaccccggt 2160
taccaggtgg tgggatccag tattctcatg tgccagtggg acctgagctg gagtgaggac 2220
ctgccctcat gccagagagt gacatcctgc catgacccag gggatgtgga gcacagccga 2280
cgcctcatat ccagcctcaa gtttcctgtg ggagcaactg tgcagtatat ctgtgaccag 2340
ggttttgtgc tcacgggtag cgccatcctt acttgccatg atcgtcaagc gggcagtccc 2400
aagtggagtg acagggcccc caagtgtctc ttggaacagt tcaaaccatg tcatggcctc 2460
agtgcccctg agaatggtgc ccgcagccct gagaagaggc tccacccagc aggggccacc 2520
attcacttct cctgtgcccc tggttatgtg ctgaagggcc aggccagcat caaatgcgtg 2580
cctggacacc cctcacattg gagtgatcct ccacccatct gtagggctgc ttctctggat 2640
gggttctaca acggccgtag cctggatgtt gccaaggcac ctgccacctc cagtgccctg 2700
gatgctgccc acatggcagc tgccatcttt ctaccattgg tggccatggt gttgctggtg 2760
ggaggagtgt acctctattt ctccagactc cagggaaaaa gtcctctgca gcttcccgga 2820
actcatcctc gcccctataa ccgtatcacg gtagagtcag catttgacaa tccaacttat 2880
gagaccggat ctctttcctt tgcaggagac gagagaata 2919
<210> 13
<211> 973
<212> PRT
<213> Rattus rattus
<220>
<221> MISC_FEATURE
<223> rSCRx17 protein
<400> 13
Leu Ser Ser Glu Ala Pro Ile Thr Gly Glu Gly Gln Ala Thr Gly Ile
1 5 10 15
Arg Glu Met Asp Gly Glu Leu Thr Ala Ala Pro Thr Pro Glu Gln Ser
20 25 30
Asp Arg Gly Val His Phe Val Thr Thr Ala Pro Thr Leu Lys Leu Leu
35 40 45
Asn His His Pro Leu Leu Glu Glu Phe Leu Gln Glu Gly Leu Glu Gly
50 55 60
Arg Glu Glu Ala Pro Arg Pro Ala Leu Pro Phe Gln Pro Asp Ser Pro
65 70 75 80
Thr Pro Phe Thr Pro Ser Pro Leu Pro Arg Leu Thr Asn Gln Asp Asn
85 90 95
Arg Pro Val Phe Thr Ser Pro Thr Pro Ala Val Ala Ala Ala Pro Thr
100 105 110
Gln Pro His Ser Arg Lys Lys Pro Trp Asn Pro Glu Ser Glu Pro Pro
115 120 125
Glu Leu Tyr Ile Thr Ser Pro Leu Pro Pro Gly Pro Ser Met Ala Val
130 135 140
Pro Thr Leu His Pro Glu Asp Arg Pro Ser Thr Thr Pro Pro Ser Gln
145 150 155 160
Ala Trp Thr Pro Thr Gln Glu Gly Pro Gly Asp Met Gly Arg Pro Trp
165 170 175
Val Pro Glu Ile Met Ser Lys Thr Thr Gly Leu Gly Ile Glu Gly Thr
180 185 190
Ile Ala Thr Ser Thr Ala Ser Gly Asp Asp Glu Glu Thr Thr Thr Thr
195 200 205
Thr Ile Ile Thr Thr Val Thr Thr Ile Gln Pro Pro Gly Pro Cys Ser
210 215 220
Trp Asn Phe Ser Gly Pro Glu Gly Ser Leu Asp Ser Pro Ala Val Pro
225 230 235 240
Ser Val Pro Ser Asp Val Gly Leu Asp Cys Leu Tyr Tyr Ile Ser Val
245 250 255
Tyr Pro Gly Tyr Gly Val Glu Ile Lys Val Lys Asn Ile Ser Leu Gln
260 265 270
Glu Gly Glu Thr Ile Thr Val Glu Gly Leu Gly Gly Pro Asp Pro Leu
275 280 285
Pro Leu Ala Asn Gln Ser Phe Leu Leu Arg Gly Gln Val Ile Arg Ser
290 295 300
Pro Thr His Gln Ala Ala Val Arg Phe Gln Ser Leu Pro Leu Pro Ala
305 310 315 320
Gly Pro Gly Thr Phe His Phe His Tyr Gln Ala Tyr Leu Leu Ser Cys
325 330 335
His Phe Pro Arg Arg Pro Ala Tyr Gly Asp Val Thr Val Thr Ser Leu
340 345 350
His Pro Gly Gly Ser Ala Arg Phe His Cys Ala Thr Gly Tyr Gln Leu
355 360 365
Lys Gly Ala Arg Phe Leu Thr Cys Leu Asn Ala Thr Gln Pro Phe Trp
370 375 380
Asp Ser Gln Glu Pro Val Cys Ile Ala Ala Cys Gly Gly Val Ile Arg
385 390 395 400
Asn Ala Thr Thr Gly Arg Ile Val Ser Pro Gly Phe Pro Gly Asn Tyr
405 410 415
Ser Asn Asn Leu Thr Cys His Trp Leu Leu Glu Ala Pro Glu Ser Gln
420 425 430
Arg Leu His Leu His Phe Glu Lys Val Ser Leu Ala Glu Asp Asp Asp
435 440 445
Arg Leu Ile Ile Arg Asn Gly Asn Asn Val Glu Ala Pro Pro Val Tyr
450 455 460
Asp Ser Tyr Glu Val Glu Tyr Leu Pro Ile Glu Gly Leu Leu Ser Ser
465 470 475 480
Gly Arg His Phe Phe Val Glu Phe Ser Thr Asp Ser Ser Gly Ala Ala
485 490 495
Ala Gly Met Ala Leu Arg Tyr Glu Ala Phe Gln Gln Gly His Cys Tyr
500 505 510
Glu Pro Phe Val Lys Tyr Gly Asn Phe Ser Ser Ser Ala Pro Ser Tyr
515 520 525
Pro Val Gly Thr Thr Val Glu Phe Ser Cys Asp Pro Gly Tyr Thr Leu
530 535 540
Glu Gln Gly Ser Ile Ile Ile Glu Cys Val Asp Leu Arg Asp Pro Gln
545 550 555 560
Trp Asn Glu Thr Glu Pro Ala Cys Arg Ala Val Cys Ser Gly Glu Ile
565 570 575
Thr Asp Ser Ala Gly Val Val Leu Ser Pro Asn Trp Pro Glu Pro Tyr
580 585 590
Gly Arg Gly Gln Asp Cys Ile Trp Gly Val His Val Glu Glu Asp Lys
595 600 605
Arg Ile Met Leu Asp Ile Arg Val Leu Arg Ile Gly Ser Gly Asp Val
610 615 620
Leu Thr Phe Tyr Asp Gly Asp Asp Leu Thr Ala Arg Val Leu Gly Gln
625 630 635 640
Tyr Ser Gly Pro Arg Gly His Phe Lys Leu Phe Thr Ser Met Ala Asp
645 650 655
Val Thr Ile Gln Phe Gln Ser Asp Pro Gly Thr Ser Ala Leu Gly Tyr
660 665 670
Gln Gln Gly Phe Val Ile His Phe Phe Glu Val Pro Arg Asn Asp Thr
675 680 685
Cys Pro Glu Leu Pro Glu Ile Pro Asn Gly Trp Lys Asn Pro Ser Gln
690 695 700
Pro Glu Leu Val His Gly Thr Val Val Thr Tyr Gln Cys Tyr Pro Gly
705 710 715 720
Tyr Gln Val Val Gly Ser Ser Ile Leu Met Cys Gln Trp Asp Leu Ser
725 730 735
Trp Ser Glu Asp Leu Pro Ser Cys Gln Arg Val Thr Ser Cys His Asp
740 745 750
Pro Gly Asp Val Glu His Ser Arg Arg Leu Ile Ser Ser Leu Lys Phe
755 760 765
Pro Val Gly Ala Thr Val Gln Tyr Ile Cys Asp Gln Gly Phe Val Leu
770 775 780
Thr Gly Ser Ala Ile Leu Thr Cys His Asp Arg Gln Ala Gly Ser Pro
785 790 795 800
Lys Trp Ser Asp Arg Ala Pro Lys Cys Leu Leu Glu Gln Phe Lys Pro
805 810 815
Cys His Gly Leu Ser Ala Pro Glu Asn Gly Ala Arg Ser Pro Glu Lys
820 825 830
Arg Leu His Pro Ala Gly Ala Thr Ile His Phe Ser Cys Ala Pro Gly
835 840 845
Tyr Val Leu Lys Gly Gln Ala Ser Ile Lys Cys Val Pro Gly His Pro
850 855 860
Ser His Trp Ser Asp Pro Pro Pro Ile Cys Arg Ala Ala Ser Leu Asp
865 870 875 880
Gly Phe Tyr Asn Gly Arg Ser Leu Asp Val Ala Lys Ala Pro Ala Thr
885 890 895
Ser Ser Ala Leu Asp Ala Ala His Met Ala Ala Ala Ile Phe Leu Pro
900 905 910
Leu Val Ala Met Val Leu Leu Val Gly Gly Val Tyr Leu Tyr Phe Ser
915 920 925
Arg Leu Gln Gly Lys Ser Pro Leu Gln Leu Pro Gly Thr His Pro Arg
930 935 940
Pro Tyr Asn Arg Ile Thr Val Glu Ser Ala Phe Asp Asn Pro Thr Tyr
945 950 955 960
Glu Thr Gly Ser Leu Ser Phe Ala Gly Asp Glu Arg Ile
965 970
<210> 14
<211> 2997
<212> DNA
<213> Macaca fascicularis
<220>
<221> misc_feature
<223> cDNA sequence of cSCRx17 ORF
<400> 14
atggagacag acacactcct gctatgggta ctgctgctct gggttccagg ttccactggt 60
gacggcgcgc cactcagcag cgaagctccc acaatgggca agggacaggc ccccggaatt 120
gaagaaaccg atggcgaact caccgctgcc cctacccctg agcaacccga aaggggagtg 180
cactttgtga ccaccgctcc caccctgaag ctgctcaatc accaccccct cctggaggag 240
tttctgcagg aaggcctgga aaaaggcgac gaggaactca gacctgccct gcccttccaa 300
cccgaccctc ctaccccctt tacacctagc cctctcccta gactggccaa ccaagactcc 360
agacctgtgt tcaccagccc tacacctgct acagctgccg tccctaccca acctcaatcc 420
aaggagggac cttggagcct cgagagcgag cctcccgtgc tgagaatcac agctcctctc 480
cctcctggcc cttccatggc tgtccccaca ctcggacctg gcgaaaggcc cagcacaaca 540
cccccctcca gagcctggac ccctacacaa gaaggccctg gcgacatggg aaggccttgg 600
gtccctgaag tcgtgagcca aggcgccggc atcggaatcc agggaaccat cgccagctcc 660
acagccagcg gagacgatga ggaaacaacc accacaacca ccatcatcac caccacaatc 720
acaacagtcc agacccccgg cccttgcagc tggaattttt ccggccctga gggatccctg 780
gattccccca cagatctgtc ctcccctcct gacgtgggcc tcgactgttt cttctatatc 840
tccgtgtatc ctggctacgg cgtcgaaatc aaagtccaga acatctccct gagggagggc 900
gaaacagtca ccgtggaagg actgggcgga cccgctcctc tgcctctcgc caaccaatcc 960
ttcctcctca ggggccaagt gattagatcc cccacacatc aagctgctct caggttccaa 1020
agcctccctc cccccgctgg acccggaacc tttcacttcc actaccaagc ctatctcctc 1080
agctgccatt tcccccacag gcccgcttat ggagatgtca cagtcacctc cctgcatcct 1140
ggcggctccg ctagattcca ctgcgctacc ggataccaac tcaagggcgc caggcatctg 1200
acatgtctca atgctaccca gcccttctgg gacagcaagg agcccgtctg cattgccgct 1260
tgcggaggcg tcatcagaaa tgccaccacc ggcagaatcg tgagccccgg cttccctggc 1320
aactactcca acaacctgac atgccactgg ctgctggaag ctcctgaggg ccagagactg 1380
catctgcact tcgagaaggt cagcctggcc gaagatgacg acagactcat catcaggaac 1440
ggcgacaacg tggaggctcc ccccgtctat gattcctacg aggtcgagta cctccccatc 1500
gagggactgc tgtcctccgg caagcatttt ttcgtggagc tgtccacaga ttccagcgga 1560
gctgccgccg gaatggctct caggtacgag gctttccaac agggccactg ttacgagccc 1620
tttgtgaagt acggcaactt ctccagctcc gctcctacct accccgtcgg cacaaccgtc 1680
gaatttagct gcgaccctgg atacacactc gagcaaggct ccatcatcat cgagtgtgtc 1740
gacccccacg acccccaatg gaacgagaca gagcccgcct gtagggccgt gtgtagcgga 1800
gagattaccg actccgccgg agtggtgctc tcccctaatt ggcctgaacc ctacggcaga 1860
ggacaagatt gtatttgggg cgtccatgtc gaggaggaca agaggattat gctcgacgtg 1920
agggtgctga ggattggacc tggcgacgtg ctcacattct atgacggcga cgatctcacc 1980
gccagagtcc tgggacaata ctccggccct cacagccact tcaagctgtt caccagcatg 2040
gctgacgtga ccatccagtt ccagtccgat cctggaacat ccgtgctggg ataccagcag 2100
ggcttcgtca tccacttctt cgaggtcccc aggaacgaca cctgccccga actgcccgag 2160
attcccaacg gctggaaatc cccctcccaa cctgatctcg tgcacggcac cgtcgtcacc 2220
taccaatgct accctggata ccaagtcgtc ggcagcagcg tgctgatgtg ccaatgggac 2280
ctcacctgga gcgaggatct gccctcctgc cagagagtca cctcctgcca cgatcccggc 2340
gatgtggaac actccaggag gctgattagc tcccccaagt tccctgtcgg agccaccgtg 2400
caatacatct gcgaccaggg ctttgtgctg accggaacca gcatcctcac atgccacgac 2460
aggcaagctg gatcccccaa gtggtccgat agggccccca aatgcctcct ggaacagctg 2520
aagccttgtc atggcctcag cgctcctgaa aacggcgcta ggagccccga aaagaggctc 2580
caccctgccg gagccaccat ccacttttcc tgtgcccccg gatacgtgct gaagggccag 2640
gcctccatta agtgcgtgcc cggacatcct tcccactggt ccgacccccc tcccatctgt 2700
aaagccgcct ccctggacgg attctataac agcagaagcc tggacgtcgc taaggcccct 2760
gctgcttcct ccaccctgga tgctgctcac atcgctgctg ccatctttct gcccctcgtc 2820
gccatggtgc tgctggtggg aggcgtctac ttctacttct ccaggctgca gggaaagagc 2880
tccctgcaac tgcctaggac aagacccagg ccctacaata ggatcacagt cgagagcgcc 2940
ttcgacaacc ccacatacga gacaggatcc ctgagctttg ccggagacga gagaatt 2997
<210> 15
<211> 999
<212> PRT
<213> Macaca fascicularis
<220>
<221> MISC_FEATURE
<223> cSCRx17 protein
<400> 15
Met Glu Thr Asp Thr Leu Leu Leu Trp Val Leu Leu Leu Trp Val Pro
1 5 10 15
Gly Ser Thr Gly Asp Gly Ala Pro Leu Ser Ser Glu Ala Pro Thr Met
20 25 30
Gly Lys Gly Gln Ala Pro Gly Ile Glu Glu Thr Asp Gly Glu Leu Thr
35 40 45
Ala Ala Pro Thr Pro Glu Gln Pro Glu Arg Gly Val His Phe Val Thr
50 55 60
Thr Ala Pro Thr Leu Lys Leu Leu Asn His His Pro Leu Leu Glu Glu
65 70 75 80
Phe Leu Gln Glu Gly Leu Glu Lys Gly Asp Glu Glu Leu Arg Pro Ala
85 90 95
Leu Pro Phe Gln Pro Asp Pro Pro Thr Pro Phe Thr Pro Ser Pro Leu
100 105 110
Pro Arg Leu Ala Asn Gln Asp Ser Arg Pro Val Phe Thr Ser Pro Thr
115 120 125
Pro Ala Thr Ala Ala Val Pro Thr Gln Pro Gln Ser Lys Glu Gly Pro
130 135 140
Trp Ser Leu Glu Ser Glu Pro Pro Val Leu Arg Ile Thr Ala Pro Leu
145 150 155 160
Pro Pro Gly Pro Ser Met Ala Val Pro Thr Leu Gly Pro Gly Glu Arg
165 170 175
Pro Ser Thr Thr Pro Pro Ser Arg Ala Trp Thr Pro Thr Gln Glu Gly
180 185 190
Pro Gly Asp Met Gly Arg Pro Trp Val Pro Glu Val Val Ser Gln Gly
195 200 205
Ala Gly Ile Gly Ile Gln Gly Thr Ile Ala Ser Ser Thr Ala Ser Gly
210 215 220
Asp Asp Glu Glu Thr Thr Thr Thr Thr Thr Ile Ile Thr Thr Thr Ile
225 230 235 240
Thr Thr Val Gln Thr Pro Gly Pro Cys Ser Trp Asn Phe Ser Gly Pro
245 250 255
Glu Gly Ser Leu Asp Ser Pro Thr Asp Leu Ser Ser Pro Pro Asp Val
260 265 270
Gly Leu Asp Cys Phe Phe Tyr Ile Ser Val Tyr Pro Gly Tyr Gly Val
275 280 285
Glu Ile Lys Val Gln Asn Ile Ser Leu Arg Glu Gly Glu Thr Val Thr
290 295 300
Val Glu Gly Leu Gly Gly Pro Ala Pro Leu Pro Leu Ala Asn Gln Ser
305 310 315 320
Phe Leu Leu Arg Gly Gln Val Ile Arg Ser Pro Thr His Gln Ala Ala
325 330 335
Leu Arg Phe Gln Ser Leu Pro Pro Pro Ala Gly Pro Gly Thr Phe His
340 345 350
Phe His Tyr Gln Ala Tyr Leu Leu Ser Cys His Phe Pro His Arg Pro
355 360 365
Ala Tyr Gly Asp Val Thr Val Thr Ser Leu His Pro Gly Gly Ser Ala
370 375 380
Arg Phe His Cys Ala Thr Gly Tyr Gln Leu Lys Gly Ala Arg His Leu
385 390 395 400
Thr Cys Leu Asn Ala Thr Gln Pro Phe Trp Asp Ser Lys Glu Pro Val
405 410 415
Cys Ile Ala Ala Cys Gly Gly Val Ile Arg Asn Ala Thr Thr Gly Arg
420 425 430
Ile Val Ser Pro Gly Phe Pro Gly Asn Tyr Ser Asn Asn Leu Thr Cys
435 440 445
His Trp Leu Leu Glu Ala Pro Glu Gly Gln Arg Leu His Leu His Phe
450 455 460
Glu Lys Val Ser Leu Ala Glu Asp Asp Asp Arg Leu Ile Ile Arg Asn
465 470 475 480
Gly Asp Asn Val Glu Ala Pro Pro Val Tyr Asp Ser Tyr Glu Val Glu
485 490 495
Tyr Leu Pro Ile Glu Gly Leu Leu Ser Ser Gly Lys His Phe Phe Val
500 505 510
Glu Leu Ser Thr Asp Ser Ser Gly Ala Ala Ala Gly Met Ala Leu Arg
515 520 525
Tyr Glu Ala Phe Gln Gln Gly His Cys Tyr Glu Pro Phe Val Lys Tyr
530 535 540
Gly Asn Phe Ser Ser Ser Ala Pro Thr Tyr Pro Val Gly Thr Thr Val
545 550 555 560
Glu Phe Ser Cys Asp Pro Gly Tyr Thr Leu Glu Gln Gly Ser Ile Ile
565 570 575
Ile Glu Cys Val Asp Pro His Asp Pro Gln Trp Asn Glu Thr Glu Pro
580 585 590
Ala Cys Arg Ala Val Cys Ser Gly Glu Ile Thr Asp Ser Ala Gly Val
595 600 605
Val Leu Ser Pro Asn Trp Pro Glu Pro Tyr Gly Arg Gly Gln Asp Cys
610 615 620
Ile Trp Gly Val His Val Glu Glu Asp Lys Arg Ile Met Leu Asp Val
625 630 635 640
Arg Val Leu Arg Ile Gly Pro Gly Asp Val Leu Thr Phe Tyr Asp Gly
645 650 655
Asp Asp Leu Thr Ala Arg Val Leu Gly Gln Tyr Ser Gly Pro His Ser
660 665 670
His Phe Lys Leu Phe Thr Ser Met Ala Asp Val Thr Ile Gln Phe Gln
675 680 685
Ser Asp Pro Gly Thr Ser Val Leu Gly Tyr Gln Gln Gly Phe Val Ile
690 695 700
His Phe Phe Glu Val Pro Arg Asn Asp Thr Cys Pro Glu Leu Pro Glu
705 710 715 720
Ile Pro Asn Gly Trp Lys Ser Pro Ser Gln Pro Asp Leu Val His Gly
725 730 735
Thr Val Val Thr Tyr Gln Cys Tyr Pro Gly Tyr Gln Val Val Gly Ser
740 745 750
Ser Val Leu Met Cys Gln Trp Asp Leu Thr Trp Ser Glu Asp Leu Pro
755 760 765
Ser Cys Gln Arg Val Thr Ser Cys His Asp Pro Gly Asp Val Glu His
770 775 780
Ser Arg Arg Leu Ile Ser Ser Pro Lys Phe Pro Val Gly Ala Thr Val
785 790 795 800
Gln Tyr Ile Cys Asp Gln Gly Phe Val Leu Thr Gly Thr Ser Ile Leu
805 810 815
Thr Cys His Asp Arg Gln Ala Gly Ser Pro Lys Trp Ser Asp Arg Ala
820 825 830
Pro Lys Cys Leu Leu Glu Gln Leu Lys Pro Cys His Gly Leu Ser Ala
835 840 845
Pro Glu Asn Gly Ala Arg Ser Pro Glu Lys Arg Leu His Pro Ala Gly
850 855 860
Ala Thr Ile His Phe Ser Cys Ala Pro Gly Tyr Val Leu Lys Gly Gln
865 870 875 880
Ala Ser Ile Lys Cys Val Pro Gly His Pro Ser His Trp Ser Asp Pro
885 890 895
Pro Pro Ile Cys Lys Ala Ala Ser Leu Asp Gly Phe Tyr Asn Ser Arg
900 905 910
Ser Leu Asp Val Ala Lys Ala Pro Ala Ala Ser Ser Thr Leu Asp Ala
915 920 925
Ala His Ile Ala Ala Ala Ile Phe Leu Pro Leu Val Ala Met Val Leu
930 935 940
Leu Val Gly Gly Val Tyr Phe Tyr Phe Ser Arg Leu Gln Gly Lys Ser
945 950 955 960
Ser Leu Gln Leu Pro Arg Thr Arg Pro Arg Pro Tyr Asn Arg Ile Thr
965 970 975
Val Glu Ser Ala Phe Asp Asn Pro Thr Tyr Glu Thr Gly Ser Leu Ser
980 985 990
Phe Ala Gly Asp Glu Arg Ile
995
<210> 16
<211> 2781
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<223> cDNA sequence of human SEZ6L ECD
<400> 16
ctcgagaggg atgctctgcc tgagggagat gcttcccctc tcggacctta tctgctgccc 60
agcggagctc ctgagagggg atcccccgga aaggagcatc ccgaagaaag agtggtcaca 120
gctcccccta gctccagcca gagcgctgag gtgctgggag aactggtcct cgacggaaca 180
gccccttccg cccatcacga tattcctgcc ctcagccctc tcctccccga ggaagctagg 240
cctaaacacg ccctcccccc taaaaagaag ctgccttccc tcaagcaggt caattccgcc 300
aggaagcagc tcagacccaa ggccacctcc gctgctacag tccaaagagc tggatcccag 360
cctgccagcc agggactcga tctgctcagc agctccacag aaaaacctgg acctcctggc 420
gatcctgacc ctattgtggc cagcgaagaa gctagcgaag tccctctgtg gctggacagg 480
aaggagtccg ctgtccccac cacacccgct cctctccaga tcagcccctt cacctcccag 540
ccttatgtcg ctcatacact gcctcagagg cctgagcctg gcgaacctgg acctgacatg 600
gctcaggagg ctcctcagga ggacaccagc cctatggccc tgatggataa gggcgagaat 660
gaactgaccg gaagcgccag cgaggaaagc caggagacca ccaccagcac aatcatcacc 720
accaccgtca tcaccaccga acaggccccc gctctgtgtt ccgtgtcctt ttccaacccc 780
gagggctaca ttgacagcag cgattacccc ctgctccctc tcaacaactt cctcgagtgc 840
acctacaatg tgaccgtgta caccggctac ggagtcgaac tccaggtgaa gtccgtgaac 900
ctctccgatg gcgaactgct ctccattagg ggcgtcgatg gccctacact caccgtcctg 960
gctaaccaaa ccctgctcgt cgaaggccag gtgattaggt cccccaccaa caccatctcc 1020
gtctacttca ggacctttca agacgacgga ctgggaacct tccaactgca ttaccaggcc 1080
ttcatgctgt cctgtaattt ccccaggaga cccgactccg gagacgtcac cgtcatggat 1140
ctgcactccg gaggcgtggc ccactttcat tgtcacctcg gctacgagct ccagggcgcc 1200
aagatgctga catgcatcaa cgccagcaaa cctcactggt ccagccagga gcctatctgt 1260
agcgctcctt gcggcggagc cgtgcacaat gctacaattg gcagagtgct cagcccttcc 1320
taccctgaaa acaccaacgg ctcccagttc tgcatctgga caatcgaggc ccccgaaggc 1380
caaaagctgc acctgcactt tgagaggctc ctgctccacg acaaagacag gatgaccgtg 1440
cactccggcc agaccaataa gtccgccctc ctgtatgaca gcctgcagac agagtccgtc 1500
ccttttgaag gcctgctgtc cgagggcaat accatcagga ttgagttcac atccgaccaa 1560
gccagggctg ctagcacctt caacattagg tttgaggctt tcgaaaaggg acactgctac 1620
gagccctata ttcagaatgg caatttcaca acctccgacc ccacctacaa tatcggcaca 1680
attgtggagt ttacctgcga ccctggacac agcctggagc agggacctgc catcatcgaa 1740
tgcatcaacg tcagggaccc ctactggaac gacacagaac ctctgtgtag ggctatgtgc 1800
ggaggcgaac tgagcgctgt ggctggagtc gtgctctccc ctaactggcc cgaaccctat 1860
gtggagggcg aagattgcat ctggaagatc cacgtcggcg aggaaaaaag gatctttctg 1920
gacatccagt tcctgaatct ctccaacagc gacatcctga ccatctacga cggagatgag 1980
gtcatgcccc acattctggg ccagtatctc ggaaactccg gcccccaaaa gctctactcc 2040
tccacccccg acctcacaat ccaattccac agcgatcctg ctggcctcat ctttggaaag 2100
ggacaaggct ttatcatgaa ttacatcgag gtcagcagaa acgacagctg ctccgacctg 2160
cctgagatcc agaacggatg gaagaccacc tcccacaccg agctcgtcag gggagctagg 2220
atcacatacc agtgcgaccc cggatacgac atcgtcggct ccgataccct gacatgccag 2280
tgggatctga gctggagctc cgaccccccc ttttgtgaga agatcatgta ctgcaccgac 2340
cccggcgaag tcgatcatag caccaggctc atcagcgatc ctgtgctgct cgtcggcaca 2400
accatccaat acacctgtaa ccccggattc gtgctcgaag gatcctccct gctcacctgt 2460
tacagcaggg aaaccggcac ccccatttgg acatccaggc tgcctcactg cgtgtccgaa 2520
gagagcctgg cttgcgataa tcccggcctg cctgagaacg gataccagat tctgtacaaa 2580
aggctgtacc tccccggcga gtccctgacc ttcatgtgct acgaaggatt cgagctcatg 2640
ggcgaagtca ccatcaggtg catcctcggc cagccctccc actggaacgg acctctcccc 2700
gtctgtaagg tcaatcagga ttccttcgag cacgctctgg aagtcgctga ggctgccgcc 2760
gagacaagcc tggaaggcgg c 2781
<210> 17
<211> 964
<212> PRT
<213> Homo sapiens
<220>
<221> MISC_FEATURE
<223> Human SEZ6L ECD protein
<400> 17
Met Glu Thr Asp Thr Leu Leu Leu Trp Val Leu Leu Leu Trp Val Pro
1 5 10 15
Gly Ser Thr Gly Asp His Gly Ala Pro Leu Glu Arg Asp Ala Leu Pro
20 25 30
Glu Gly Asp Ala Ser Pro Leu Gly Pro Tyr Leu Leu Pro Ser Gly Ala
35 40 45
Pro Glu Arg Gly Ser Pro Gly Lys Glu His Pro Glu Glu Arg Val Val
50 55 60
Thr Ala Pro Pro Ser Ser Ser Gln Ser Ala Glu Val Leu Gly Glu Leu
65 70 75 80
Val Leu Asp Gly Thr Ala Pro Ser Ala His His Asp Ile Pro Ala Leu
85 90 95
Ser Pro Leu Leu Pro Glu Glu Ala Arg Pro Lys His Ala Leu Pro Pro
100 105 110
Lys Lys Lys Leu Pro Ser Leu Lys Gln Val Asn Ser Ala Arg Lys Gln
115 120 125
Leu Arg Pro Lys Ala Thr Ser Ala Ala Thr Val Gln Arg Ala Gly Ser
130 135 140
Gln Pro Ala Ser Gln Gly Leu Asp Leu Leu Ser Ser Ser Thr Glu Lys
145 150 155 160
Pro Gly Pro Pro Gly Asp Pro Asp Pro Ile Val Ala Ser Glu Glu Ala
165 170 175
Ser Glu Val Pro Leu Trp Leu Asp Arg Lys Glu Ser Ala Val Pro Thr
180 185 190
Thr Pro Ala Pro Leu Gln Ile Ser Pro Phe Thr Ser Gln Pro Tyr Val
195 200 205
Ala His Thr Leu Pro Gln Arg Pro Glu Pro Gly Glu Pro Gly Pro Asp
210 215 220
Met Ala Gln Glu Ala Pro Gln Glu Asp Thr Ser Pro Met Ala Leu Met
225 230 235 240
Asp Lys Gly Glu Asn Glu Leu Thr Gly Ser Ala Ser Glu Glu Ser Gln
245 250 255
Glu Thr Thr Thr Ser Thr Ile Ile Thr Thr Thr Val Ile Thr Thr Glu
260 265 270
Gln Ala Pro Ala Leu Cys Ser Val Ser Phe Ser Asn Pro Glu Gly Tyr
275 280 285
Ile Asp Ser Ser Asp Tyr Pro Leu Leu Pro Leu Asn Asn Phe Leu Glu
290 295 300
Cys Thr Tyr Asn Val Thr Val Tyr Thr Gly Tyr Gly Val Glu Leu Gln
305 310 315 320
Val Lys Ser Val Asn Leu Ser Asp Gly Glu Leu Leu Ser Ile Arg Gly
325 330 335
Val Asp Gly Pro Thr Leu Thr Val Leu Ala Asn Gln Thr Leu Leu Val
340 345 350
Glu Gly Gln Val Ile Arg Ser Pro Thr Asn Thr Ile Ser Val Tyr Phe
355 360 365
Arg Thr Phe Gln Asp Asp Gly Leu Gly Thr Phe Gln Leu His Tyr Gln
370 375 380
Ala Phe Met Leu Ser Cys Asn Phe Pro Arg Arg Pro Asp Ser Gly Asp
385 390 395 400
Val Thr Val Met Asp Leu His Ser Gly Gly Val Ala His Phe His Cys
405 410 415
His Leu Gly Tyr Glu Leu Gln Gly Ala Lys Met Leu Thr Cys Ile Asn
420 425 430
Ala Ser Lys Pro His Trp Ser Ser Gln Glu Pro Ile Cys Ser Ala Pro
435 440 445
Cys Gly Gly Ala Val His Asn Ala Thr Ile Gly Arg Val Leu Ser Pro
450 455 460
Ser Tyr Pro Glu Asn Thr Asn Gly Ser Gln Phe Cys Ile Trp Thr Ile
465 470 475 480
Glu Ala Pro Glu Gly Gln Lys Leu His Leu His Phe Glu Arg Leu Leu
485 490 495
Leu His Asp Lys Asp Arg Met Thr Val His Ser Gly Gln Thr Asn Lys
500 505 510
Ser Ala Leu Leu Tyr Asp Ser Leu Gln Thr Glu Ser Val Pro Phe Glu
515 520 525
Gly Leu Leu Ser Glu Gly Asn Thr Ile Arg Ile Glu Phe Thr Ser Asp
530 535 540
Gln Ala Arg Ala Ala Ser Thr Phe Asn Ile Arg Phe Glu Ala Phe Glu
545 550 555 560
Lys Gly His Cys Tyr Glu Pro Tyr Ile Gln Asn Gly Asn Phe Thr Thr
565 570 575
Ser Asp Pro Thr Tyr Asn Ile Gly Thr Ile Val Glu Phe Thr Cys Asp
580 585 590
Pro Gly His Ser Leu Glu Gln Gly Pro Ala Ile Ile Glu Cys Ile Asn
595 600 605
Val Arg Asp Pro Tyr Trp Asn Asp Thr Glu Pro Leu Cys Arg Ala Met
610 615 620
Cys Gly Gly Glu Leu Ser Ala Val Ala Gly Val Val Leu Ser Pro Asn
625 630 635 640
Trp Pro Glu Pro Tyr Val Glu Gly Glu Asp Cys Ile Trp Lys Ile His
645 650 655
Val Gly Glu Glu Lys Arg Ile Phe Leu Asp Ile Gln Phe Leu Asn Leu
660 665 670
Ser Asn Ser Asp Ile Leu Thr Ile Tyr Asp Gly Asp Glu Val Met Pro
675 680 685
His Ile Leu Gly Gln Tyr Leu Gly Asn Ser Gly Pro Gln Lys Leu Tyr
690 695 700
Ser Ser Thr Pro Asp Leu Thr Ile Gln Phe His Ser Asp Pro Ala Gly
705 710 715 720
Leu Ile Phe Gly Lys Gly Gln Gly Phe Ile Met Asn Tyr Ile Glu Val
725 730 735
Ser Arg Asn Asp Ser Cys Ser Asp Leu Pro Glu Ile Gln Asn Gly Trp
740 745 750
Lys Thr Thr Ser His Thr Glu Leu Val Arg Gly Ala Arg Ile Thr Tyr
755 760 765
Gln Cys Asp Pro Gly Tyr Asp Ile Val Gly Ser Asp Thr Leu Thr Cys
770 775 780
Gln Trp Asp Leu Ser Trp Ser Ser Asp Pro Pro Phe Cys Glu Lys Ile
785 790 795 800
Met Tyr Cys Thr Asp Pro Gly Glu Val Asp His Ser Thr Arg Leu Ile
805 810 815
Ser Asp Pro Val Leu Leu Val Gly Thr Thr Ile Gln Tyr Thr Cys Asn
820 825 830
Pro Gly Phe Val Leu Glu Gly Ser Ser Leu Leu Thr Cys Tyr Ser Arg
835 840 845
Glu Thr Gly Thr Pro Ile Trp Thr Ser Arg Leu Pro His Cys Val Ser
850 855 860
Glu Glu Ser Leu Ala Cys Asp Asn Pro Gly Leu Pro Glu Asn Gly Tyr
865 870 875 880
Gln Ile Leu Tyr Lys Arg Leu Tyr Leu Pro Gly Glu Ser Leu Thr Phe
885 890 895
Met Cys Tyr Glu Gly Phe Glu Leu Met Gly Glu Val Thr Ile Arg Cys
900 905 910
Ile Leu Gly Gln Pro Ser His Trp Asn Gly Pro Leu Pro Val Cys Lys
915 920 925
Val Asn Gln Asp Ser Phe Glu His Ala Leu Glu Val Ala Glu Ala Ala
930 935 940
Ala Glu Thr Ser Leu Glu Gly Gly Leu Ala Gly His His His His His
945 950 955 960
His His His His
<210> 18
<211> 2487
<212> DNA
<213> Homo sapiens
<220>
<221> misc_feature
<223> cDNA sequence of human SEZ6L2 ECD
<400> 18
ctgcctctca aagaggaaga gattctcccc gagcccggat ccgagacacc cacagtggct 60
tccgaagccc tcgctgaact gctgcacgga gccctcctga gaaggggacc tgaaatgggc 120
tatctccctg gctccgacag agatcccaca ctcgccacac ctcctgctgg acagaccctc 180
gctgtgcctt ccctgcccag agccacagaa cccggaacag gccctctcac aacagctgtg 240
acccctaacg gcgtcagagg agctggacct acagcccctg agctgctgac acctcctcct 300
ggcacaaccg ctcctcctcc tccttcccct gctagccctg gaccccctct cggacctgaa 360
ggaggcgagg aggagacaac caccaccatt attaccacca ccaccgtgac aaccacagtg 420
accagccctg tcctgtgcaa caacaacatc agcgaaggcg aaggctatgt ggaatcccct 480
gacctgggct cccctgtgtc cagaacactc ggcctcctgg attgcacata ctccattcac 540
gtgtaccccg gctacggaat cgagattcag gtgcagaccc tgaatctgtc ccaggaggag 600
gaactgctgg tgctggctgg cggaggaagc cctggcctcg ctcctagact cctcgctaac 660
tcctccatgc tcggcgaagg ccaggtcctc agatccccta ccaacaggct gctcctgcac 720
ttccagagcc ccagagtgcc tagaggaggc ggcttcagga ttcactacca ggcctatctc 780
ctgagctgtg gattccctcc cagacccgct catggcgatg tctccgtcac cgacctccac 840
cccggaggaa cagccacctt ccactgtgat tccggatacc agctgcaagg cgaggagacc 900
ctgatttgcc tcaatggcac caggcccagc tggaacggag agacacctag ctgcatggct 960
agctgcggcg gaaccatcca taatgccacc ctcggcagga tcgtcagccc tgaacctggc 1020
ggagctgtgg gacctaacct cacatgcaga tgggtgatcg aagctgctga aggcaggaga 1080
ctccacctcc acttcgagag ggtgtccctg gacgaggaca acgacaggct catggtcaga 1140
agcggcggaa gccctctcag ccctgtgatt tacgacagcg acatggacga tgtgcctgag 1200
aggggcctca tctccgatgc ccaaagcctg tacgtggaac tcctctccga gacccccgct 1260
aaccccctcc tcctgagcct cagattcgag gccttcgagg aggacagatg tttcgctcct 1320
tttctggccc atggcaacgt gaccacaacc gaccccgagt acagacccgg agctctggct 1380
accttcagct gtctgcctgg ctacgccctc gaacctcccg gacctcctaa tgccatcgaa 1440
tgtgtggatc ccaccgaacc ccattggaac gacaccgagc ccgcttgtaa ggctatgtgc 1500
ggcggagaac tcagcgaacc tgccggagtg gtcctctccc ctgattggcc ccagagctat 1560
tcccccggac aagactgtgt ctggggcgtg cacgtccagg aggaaaagag gatcctcctc 1620
caggtggaga ttctgaacgt cagagaggga gacatgctga ccctgttcga cggagacgga 1680
ccttccgcca gagtcctcgc tcagctgaga ggccctcagc ccagaaggag actgctcagc 1740
tccggccccg atctgacact ccagtttcag gccccccctg gcccccctaa tcctggcctg 1800
ggacagggct tcgtgctcca cttcaaggag gtccccagga atgatacatg ccccgaactg 1860
cctcctcccg agtggggatg gaggacagct tcccatggcg acctgatcag gggaaccgtg 1920
ctgacatatc agtgtgaacc cggctacgag ctgctgggaa gcgatatcct gacctgtcag 1980
tgggatctct cctggagcgc tgctccccct gcctgtcaga aaatcatgac ctgcgctgac 2040
cctggagaga tcgctaacgg ccacaggacc gcttccgacg ctggatttcc cgtgggctcc 2100
cacgtgcaat acaggtgcct ccccggatac tccctcgaag gcgctgccat gctgacatgc 2160
tacagcaggg acaccggcac acccaagtgg tccgacaggg tgcccaaatg tgctctgaag 2220
tacgagccct gtctcaatcc cggagtgccc gagaacggat accagaccct gtacaagcac 2280
cactatcagg ccggcgaatc cctgagattc ttctgctacg agggcttcga gctcatcggc 2340
gaggtgacaa ttacctgtgt gcccggccat ccttcccagt ggaccagcca gccccctctc 2400
tgtaaggtcg cctacgaaga gctgctcgac aataggaagc tggaggtcac ccagaccacc 2460
gacccttcca gacaactgga aggcggc 2487
<210> 19
<211> 865
<212> PRT
<213> Homo sapiens
<220>
<221> MISC_FEATURE
<223> Human SEZ6L2 ECD protein
<400> 19
Met Glu Thr Asp Thr Leu Leu Leu Trp Val Leu Leu Leu Trp Val Pro
1 5 10 15
Gly Ser Thr Gly Asp Gly Ala Pro Leu Pro Leu Lys Glu Glu Glu Ile
20 25 30
Leu Pro Glu Pro Gly Ser Glu Thr Pro Thr Val Ala Ser Glu Ala Leu
35 40 45
Ala Glu Leu Leu His Gly Ala Leu Leu Arg Arg Gly Pro Glu Met Gly
50 55 60
Tyr Leu Pro Gly Ser Asp Arg Asp Pro Thr Leu Ala Thr Pro Pro Ala
65 70 75 80
Gly Gln Thr Leu Ala Val Pro Ser Leu Pro Arg Ala Thr Glu Pro Gly
85 90 95
Thr Gly Pro Leu Thr Thr Ala Val Thr Pro Asn Gly Val Arg Gly Ala
100 105 110
Gly Pro Thr Ala Pro Glu Leu Leu Thr Pro Pro Pro Gly Thr Thr Ala
115 120 125
Pro Pro Pro Pro Ser Pro Ala Ser Pro Gly Pro Pro Leu Gly Pro Glu
130 135 140
Gly Gly Glu Glu Glu Thr Thr Thr Thr Ile Ile Thr Thr Thr Thr Val
145 150 155 160
Thr Thr Thr Val Thr Ser Pro Val Leu Cys Asn Asn Asn Ile Ser Glu
165 170 175
Gly Glu Gly Tyr Val Glu Ser Pro Asp Leu Gly Ser Pro Val Ser Arg
180 185 190
Thr Leu Gly Leu Leu Asp Cys Thr Tyr Ser Ile His Val Tyr Pro Gly
195 200 205
Tyr Gly Ile Glu Ile Gln Val Gln Thr Leu Asn Leu Ser Gln Glu Glu
210 215 220
Glu Leu Leu Val Leu Ala Gly Gly Gly Ser Pro Gly Leu Ala Pro Arg
225 230 235 240
Leu Leu Ala Asn Ser Ser Met Leu Gly Glu Gly Gln Val Leu Arg Ser
245 250 255
Pro Thr Asn Arg Leu Leu Leu His Phe Gln Ser Pro Arg Val Pro Arg
260 265 270
Gly Gly Gly Phe Arg Ile His Tyr Gln Ala Tyr Leu Leu Ser Cys Gly
275 280 285
Phe Pro Pro Arg Pro Ala His Gly Asp Val Ser Val Thr Asp Leu His
290 295 300
Pro Gly Gly Thr Ala Thr Phe His Cys Asp Ser Gly Tyr Gln Leu Gln
305 310 315 320
Gly Glu Glu Thr Leu Ile Cys Leu Asn Gly Thr Arg Pro Ser Trp Asn
325 330 335
Gly Glu Thr Pro Ser Cys Met Ala Ser Cys Gly Gly Thr Ile His Asn
340 345 350
Ala Thr Leu Gly Arg Ile Val Ser Pro Glu Pro Gly Gly Ala Val Gly
355 360 365
Pro Asn Leu Thr Cys Arg Trp Val Ile Glu Ala Ala Glu Gly Arg Arg
370 375 380
Leu His Leu His Phe Glu Arg Val Ser Leu Asp Glu Asp Asn Asp Arg
385 390 395 400
Leu Met Val Arg Ser Gly Gly Ser Pro Leu Ser Pro Val Ile Tyr Asp
405 410 415
Ser Asp Met Asp Asp Val Pro Glu Arg Gly Leu Ile Ser Asp Ala Gln
420 425 430
Ser Leu Tyr Val Glu Leu Leu Ser Glu Thr Pro Ala Asn Pro Leu Leu
435 440 445
Leu Ser Leu Arg Phe Glu Ala Phe Glu Glu Asp Arg Cys Phe Ala Pro
450 455 460
Phe Leu Ala His Gly Asn Val Thr Thr Thr Asp Pro Glu Tyr Arg Pro
465 470 475 480
Gly Ala Leu Ala Thr Phe Ser Cys Leu Pro Gly Tyr Ala Leu Glu Pro
485 490 495
Pro Gly Pro Pro Asn Ala Ile Glu Cys Val Asp Pro Thr Glu Pro His
500 505 510
Trp Asn Asp Thr Glu Pro Ala Cys Lys Ala Met Cys Gly Gly Glu Leu
515 520 525
Ser Glu Pro Ala Gly Val Val Leu Ser Pro Asp Trp Pro Gln Ser Tyr
530 535 540
Ser Pro Gly Gln Asp Cys Val Trp Gly Val His Val Gln Glu Glu Lys
545 550 555 560
Arg Ile Leu Leu Gln Val Glu Ile Leu Asn Val Arg Glu Gly Asp Met
565 570 575
Leu Thr Leu Phe Asp Gly Asp Gly Pro Ser Ala Arg Val Leu Ala Gln
580 585 590
Leu Arg Gly Pro Gln Pro Arg Arg Arg Leu Leu Ser Ser Gly Pro Asp
595 600 605
Leu Thr Leu Gln Phe Gln Ala Pro Pro Gly Pro Pro Asn Pro Gly Leu
610 615 620
Gly Gln Gly Phe Val Leu His Phe Lys Glu Val Pro Arg Asn Asp Thr
625 630 635 640
Cys Pro Glu Leu Pro Pro Pro Glu Trp Gly Trp Arg Thr Ala Ser His
645 650 655
Gly Asp Leu Ile Arg Gly Thr Val Leu Thr Tyr Gln Cys Glu Pro Gly
660 665 670
Tyr Glu Leu Leu Gly Ser Asp Ile Leu Thr Cys Gln Trp Asp Leu Ser
675 680 685
Trp Ser Ala Ala Pro Pro Ala Cys Gln Lys Ile Met Thr Cys Ala Asp
690 695 700
Pro Gly Glu Ile Ala Asn Gly His Arg Thr Ala Ser Asp Ala Gly Phe
705 710 715 720
Pro Val Gly Ser His Val Gln Tyr Arg Cys Leu Pro Gly Tyr Ser Leu
725 730 735
Glu Gly Ala Ala Met Leu Thr Cys Tyr Ser Arg Asp Thr Gly Thr Pro
740 745 750
Lys Trp Ser Asp Arg Val Pro Lys Cys Ala Leu Lys Tyr Glu Pro Cys
755 760 765
Leu Asn Pro Gly Val Pro Glu Asn Gly Tyr Gln Thr Leu Tyr Lys His
770 775 780
His Tyr Gln Ala Gly Glu Ser Leu Arg Phe Phe Cys Tyr Glu Gly Phe
785 790 795 800
Glu Leu Ile Gly Glu Val Thr Ile Thr Cys Val Pro Gly His Pro Ser
805 810 815
Gln Trp Thr Ser Gln Pro Pro Leu Cys Lys Val Ala Tyr Glu Glu Leu
820 825 830
Leu Asp Asn Arg Lys Leu Glu Val Thr Gln Thr Thr Asp Pro Ser Arg
835 840 845
Gln Leu Glu Gly Gly Leu Ala Gly His His His His His His His His
850 855 860
His
865
<210> 20
<211> 107
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.1 VL
<400> 20
Gln Ile Val Leu Thr Gln Ser Pro Ala Leu Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Ser Leu Thr Cys Ser Ala Asn Ser Thr Val Ser Phe Met
20 25 30
Tyr Trp Tyr Gln Gln Lys Pro Arg Ser Ser Pro Thr Pro Trp Ile Tyr
35 40 45
Leu Thr Ser Asn Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Asn Ser Pro Ile
85 90 95
Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys
100 105
<210> 21
<211> 117
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.1 VH
<400> 21
Asp Val Gln Leu Gln Asp Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Ser Leu Ser Val Thr Cys Thr Val Thr Gly Tyr Ser Ile Thr Trp Gly
20 25 30
Tyr Tyr Trp Asn Trp Ile Arg Gln Phe Pro Gly Asn Lys Leu Glu Trp
35 40 45
Met Gly Asn Ile His Asn Ser Gly Gly Thr Asn Tyr Asn Pro Ser Leu
50 55 60
Lys Ser Arg Ile Ser Ile Thr Arg Asp Thr Ser Lys Asn Gln Phe Phe
65 70 75 80
Leu Gln Leu Asn Ser Val Thr Thr Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Thr Thr Asn Trp Asp Tyr Phe Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Leu Thr Val Ser Ser
115
<210> 22
<211> 112
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.2 VL
<400> 22
Asp Ile Val Met Ser Gln Ser Pro Ser Ser Leu Ala Val Ser Val Gly
1 5 10 15
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Tyr Ser
20 25 30
Ser Asn Gln Lys Ser Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ser Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val Tyr Tyr Cys Lys Gln
85 90 95
Ser Tyr Asn Leu Arg Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 23
<211> 117
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.2 VH
<400> 23
Gln Val Gln Leu Gln Gln Ser Asp Ala Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Val Ser Gly Tyr Thr Phe Thr Asp His
20 25 30
Thr Ile His Trp Met Lys Gln Arg Pro Glu Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Tyr Pro Arg Asp Gly Ser Thr Lys Tyr Asn Glu Glu Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Asn Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Phe Cys
85 90 95
Ala Arg Ser Tyr Ser Asn Tyr Phe Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Leu Thr Val Ser Ser
115
<210> 24
<211> 111
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.9 VL
<400> 24
Asp Ile Val Met Ser Gln Ser Pro Ser Ser Leu Ala Val Ser Val Gly
1 5 10 15
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Tyr Ser
20 25 30
Ser Asn Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ser Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Val Lys Ala Glu Asp Leu Ala Val Tyr Phe Cys Gln Gln
85 90 95
Tyr Tyr Asn Tyr Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Lys
100 105 110
<210> 25
<211> 119
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.9 VH
<400> 25
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Ile Val Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
Trp Met Asn Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Ala Ile Asp Pro Ser Asp Ser Tyr Thr Ser Tyr Asn Pro Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val Asp Thr Ser Ser Ser Ser Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Phe Cys
85 90 95
Ala Arg Arg Gly Thr Pro Gly Lys Pro Leu Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ala
115
<210> 26
<211> 107
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.16 VL
<400> 26
Asp Ile Gln Met Thr Gln Ser Pro Ala Ser Leu Ser Val Ser Val Gly
1 5 10 15
Glu Thr Val Thr Ile Thr Cys Arg Ala Ser Ala Asn Ile Asn Ser Asn
20 25 30
Leu Val Trp Tyr Gln Gln Lys Gln Gly Lys Ser Pro Gln Leu Leu Val
35 40 45
Tyr Ala Ala Thr Asn Leu Ala Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Gln Tyr Ser Leu Lys Ile Asn Ser Leu Gln Ser
65 70 75 80
Glu Asp Phe Gly Asn Tyr Tyr Cys Gln His Phe Trp Gly Thr Pro Arg
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 27
<211> 116
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.16 VH
<400> 27
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Met Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
Asn Met Tyr Trp Val Lys Gln Asn Gln Gly Lys Ser Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn Pro Asn Asn Gly Gly Thr Ala Tyr Asn Gln Lys Phe
50 55 60
Arg Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Asp Lys Gly Phe Asp Tyr Trp Gly Gln Gly Thr Thr Leu
100 105 110
Thr Val Ser Ser
115
<210> 28
<211> 111
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.38 VL
<400> 28
Asp Ile Val Val Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Gln Arg Ala Thr Ile Ser Cys Arg Ala Ser Glu Ser Val Glu Tyr Tyr
20 25 30
Gly Thr Ser Leu Met Gln Trp Phe Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Lys Leu Leu Ile Tyr Ala Ala Ser Asn Val Glu Ser Gly Val Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Ser Leu Asn Ile His
65 70 75 80
Pro Val Glu Glu Asp Asp Ile Ala Met Tyr Phe Cys Gln Gln Asp Arg
85 90 95
Lys Val Pro Trp Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 29
<211> 120
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.38 VH
<400> 29
Gln Val Thr Leu Lys Glu Ser Gly Pro Gly Ile Leu Gln Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ser Phe Ser Gly Phe Ser Leu Asn Thr Ser
20 25 30
Gly Met Ser Val Gly Trp Val Arg Gln Pro Ser Gly Arg Gly Leu Glu
35 40 45
Trp Leu Ala Pro Ile Trp Trp Asn Gly Asp Lys Tyr Tyr Asn Pro Ala
50 55 60
Leu Lys Ser Arg Leu Thr Ile Ser Lys Asp Thr Ser Asn Asn Gln Val
65 70 75 80
Phe Leu Lys Ile Ala Ser Val Val Thr Ala Asp Thr Ala Thr Tyr Phe
85 90 95
Cys Ala Arg Ile Arg Gln Tyr Tyr Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Ser Val Thr Val Ser Ser
115 120
<210> 30
<211> 112
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.3 VL
<400> 30
Asp Ile Val Met Ser Gln Ser Pro Ser Ser Leu Ala Val Ser Val Gly
1 5 10 15
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Tyr Ser
20 25 30
Ser Asn Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ser Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Val Lys Ala Glu Asp Leu Ala Val Tyr Tyr Cys Gln Gln
85 90 95
Tyr Tyr Ser Tyr Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 31
<211> 118
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.3 VH
<400> 31
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Pro Ser Tyr
20 25 30
Trp Ile His Cys Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Val Ile Asn Pro Ser Asn Gly Arg Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Asn Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Val Arg Gly Gly Thr Gly Tyr Thr Met Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Ser Val Thr Val Ser Ser
115
<210> 32
<211> 107
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.4 VL
<400> 32
Asp Ile Lys Met Thr Gln Ser Pro Ser Ser Met Tyr Ala Ser Leu Gly
1 5 10 15
Glu Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Ser Tyr
20 25 30
Leu Thr Trp Phe Gln Gln Lys Pro Gly Lys Ser Pro Lys Thr Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Leu Ile Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Gln Asp Tyr Ser Leu Thr Ile Ser Ser Leu Asp Tyr
65 70 75 80
Glu Asp Met Gly Ile Tyr Tyr Cys Leu Gln Tyr Asp Asp Phe Pro Trp
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 33
<211> 116
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.4 VH
<400> 33
Gln Ile Gln Leu Val Gln Ser Gly Pro Glu Leu Lys Lys Pro Gly Glu
1 5 10 15
Thr Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
Ser Met His Trp Val Lys Gln Ala Pro Gly Lys Gly Leu Lys Trp Leu
35 40 45
Gly Trp Ile Asn Thr Glu Thr Gly Glu Pro Thr Tyr Ser Glu Asp Phe
50 55 60
Lys Gly Arg Phe Ala Phe Ser Leu Glu Thr Ser Ala Ser Thr Ala Tyr
65 70 75 80
Leu Gln Ile Asn Asn Leu Lys Asn Glu Asp Thr Ala Thr Tyr Phe Cys
85 90 95
Val Lys Asn Lys Gly Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ala
115
<210> 34
<211> 112
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.8 VL
<400> 34
Asp Val Val Met Thr Gln Thr Pro Leu Ser Leu Pro Val Ser Leu Gly
1 5 10 15
Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Val His Ser
20 25 30
Asn Gly Asp Thr Tyr Leu His Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Leu Tyr Phe Cys Ser Gln Ser
85 90 95
Thr Leu Ile Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Asp Ile Lys
100 105 110
<210> 35
<211> 114
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.8 VH
<400> 35
Gln Val His Leu Gln Gln Ser Gly Thr Glu Val Met Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Thr Gly Tyr Thr Phe Ser Ser Tyr
20 25 30
Trp Ile Glu Trp Ile Lys Gln Arg Pro Gly His Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile Leu Pro Gly Ser Gly Asn Thr Asn Asn Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Ile Thr Ala Asp Thr Ser Ser Asn Ile Ala Tyr
65 70 75 80
Ile Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Gly Gly Pro Ala Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val
100 105 110
Ser Ala
<210> 36
<211> 113
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.10 VL
<400> 36
Asp Ile Val Met Ser Gln Ser Pro Ser Ser Leu Ala Val Ser Val Gly
1 5 10 15
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Tyr Ser
20 25 30
Ser Asn Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ser Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Val Lys Thr Glu Asp Leu Ala Leu Tyr Tyr Cys Gln Gln
85 90 95
Tyr Tyr Trp Phe Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile
100 105 110
Lys
<210> 37
<211> 113
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.10 VH
<400> 37
Glu Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Thr Ala Ser Gly Phe Asn Ile Lys Asp Thr
20 25 30
Tyr Met His Trp Val Lys Gln Arg Pro Glu Gln Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Asp Pro Ala Asn Val Asn Thr Lys Tyr Asp Pro Lys Phe
50 55 60
Gln Gly Lys Ala Thr Ile Thr Ala Asp Thr Ser Ser Asn Thr Ala Tyr
65 70 75 80
Leu Gln Leu Ser Ser Leu Thr Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Arg Gly Asn Val Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
100 105 110
Ala
<210> 38
<211> 108
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.11 VL
<400> 38
Glu Asn Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Arg Ala Ser Ser Ser Val Ser Ser Ser
20 25 30
Tyr Leu His Trp Tyr Gln Gln Lys Ser Gly Ala Ser Pro Lys Leu Trp
35 40 45
Ile Tyr Ser Thr Ser Asn Leu Ala Ser Gly Val Pro Ala Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Val Glu
65 70 75 80
Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Asp Tyr Pro
85 90 95
Phe Thr Phe Gly Ser Gly Thr Lys Leu Val Ile Lys
100 105
<210> 39
<211> 122
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.11 VH
<400> 39
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Leu Val Met Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
Tyr Met His Trp Val Lys Gln Ser His Gly Gln Ser Leu Glu Trp Ile
35 40 45
Gly Glu Val Ile Pro Tyr Asn Asp Glu Thr Phe Tyr Asn Arg Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Ile Tyr Tyr Cys
85 90 95
Ala Arg Arg His Arg Tyr Asp Gly Phe Arg Tyr Ala Ile Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Ser Val Thr Val Ser Ser
115 120
<210> 40
<211> 112
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.14 VL
<400> 40
Asp Val Leu Met Thr Gln Thr Pro Leu Ser Leu Pro Val Ser Leu Gly
1 5 10 15
Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Ile Val His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu Glu Trp Phe Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Tyr Cys Phe Gln Gly
85 90 95
Ser His Val Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 41
<211> 118
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.14 VH
<400> 41
Glu Val Gln Leu Gln Gln Ser Gly Pro Val Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Ile Thr Asp Tyr
20 25 30
Asn Met Asn Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile
35 40 45
Gly Val Ile Asn Pro Tyr Asn Gly Asn Thr Arg Tyr Asn Gln Met Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Asn Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Trp Gly Thr Thr Val Val Gly Ala Asn Trp Gly Gln Gly Thr
100 105 110
Thr Leu Thr Val Ser Ser
115
<210> 42
<211> 106
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.15 VL
<400> 42
Gln Ile Val Leu Thr Gln Ser Pro Ala Leu Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Ser Ala Ser Ser Ser Val Asn Tyr Met
20 25 30
Tyr Trp Tyr Gln Gln Lys Pro Arg Ser Ser Pro Lys Pro Trp Ile Tyr
35 40 45
Leu Thr Ser Asn Leu Ala Ser Gly Val Pro Val Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Asn Asn Pro Pro Thr
85 90 95
Phe Gly Ser Gly Thr Lys Leu Glu Leu Lys
100 105
<210> 43
<211> 122
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.15 VH
<400> 43
Asp Val Lys Leu Val Glu Ser Gly Gly Gly Leu Val Lys Leu Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Thr Pro Glu Lys Arg Leu Glu Trp Val
35 40 45
Ala Thr Ile Thr Ser Gly Gly Gly Asn Thr Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Arg Arg Asp Tyr Tyr Gly Ser Ser Tyr Val Met Phe Ala Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ala
115 120
<210> 44
<211> 106
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.17 VL
<400> 44
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
His Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Leu Pro Ser Gly Val Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Thr Pro Pro Thr
85 90 95
Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys
100 105
<210> 45
<211> 120
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.17 VH
<400> 45
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Val Met Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
Asn Met His Trp Val Lys Gln Asn Gln Gly Lys Ser Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn Pro Asn Ile Gly Gly Thr Gly Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val His Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Thr Tyr Ser Tyr Tyr Ser Tyr Glu Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ala
115 120
<210> 46
<211> 107
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.18 VL
<400> 46
Asp Ile Gln Met Thr Gln Ser Ser Ser Tyr Leu Ser Val Ser Leu Gly
1 5 10 15
Gly Arg Val Thr Ile Thr Cys Lys Ala Ser Asp His Ile Asn Asn Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Asn Ala Pro Arg Leu Leu Ile
35 40 45
Ser Gly Ala Thr Ser Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Lys Asp Tyr Thr Leu Ser Ile Thr Ser Leu Gln Thr
65 70 75 80
Glu Asp Val Ala Thr Tyr Tyr Cys Gln Gln Tyr Trp Ser Ile Pro Leu
85 90 95
Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys
100 105
<210> 47
<211> 123
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.18 VH
<400> 47
Gln Val Thr Leu Lys Glu Ser Gly Pro Gly Ile Leu Gln Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ser Phe Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Thr Met Gly Val Gly Trp Ile Arg Gln Pro Ser Gly Lys Gly Leu Glu
35 40 45
Trp Leu Ala Asp Ile Trp Trp Asp Asp Ser Lys Tyr Tyr Asn Pro Ser
50 55 60
Leu Lys Ser Arg Leu Thr Ile Ser Lys Asp Thr Ser Ser Asn Gln Val
65 70 75 80
Phe Leu Lys Ile Thr Ser Val Asp Thr Ala Asp Thr Ala Thr Tyr Tyr
85 90 95
Cys Ala Arg Lys Gly Arg Thr Ala Arg Ala Thr Arg Gly Phe Ala Tyr
100 105 110
Trp Gly His Gly Thr Leu Val Thr Val Ser Ala
115 120
<210> 48
<211> 109
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.19 VL
<400> 48
Asp Ile Val Leu Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Gln Arg Ala Ala Ile Ser Cys Lys Pro Ser Gln Ser Val Asp Tyr Asp
20 25 30
Gly Asp Ser Tyr Met Asn Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Lys Leu Leu Ile Tyr Ala Ala Ser Asn Leu Glu Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Asn Ile His
65 70 75 80
Pro Val Glu Glu Glu Asp Ala Ala Thr Tyr Tyr Cys His Gln Ile Asn
85 90 95
Asp Asp Pro Trp Thr Phe Gly Gly Gly Thr Lys Leu Lys
100 105
<210> 49
<211> 121
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.19 VH
<400> 49
Asp Val Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Ser Leu Ser Val Thr Cys Thr Val Thr Gly Tyr Ser Ile Thr Ser Ser
20 25 30
Tyr Thr Trp Asn Trp Ile Arg Gln Phe Pro Gly Asn Lys Leu Glu Trp
35 40 45
Met Gly Tyr Ile His Tyr Ser Gly Ser Thr Asn Tyr Asn Pro Ser Leu
50 55 60
Arg Ser Arg Ile Ser Ile Thr Arg Asp Thr Ser Lys Asn Gln Phe Phe
65 70 75 80
Leu Gln Leu Asn Ser Val Thr Thr Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Arg Ser Arg Tyr Tyr Tyr Asp Ala Tyr Gly Phe Ala Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ala
115 120
<210> 50
<211> 112
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.22 VL
<400> 50
Asp Val Val Leu Thr Gln Thr Pro Leu Ser Leu Pro Val Ser Leu Gly
1 5 10 15
Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Ile Val His Ile
20 25 30
Asn Arg His Thr Tyr Leu Gly Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Leu Lys Leu Leu Ile Tyr Gly Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Met Gly Val Tyr Tyr Cys Phe Gln Gly
85 90 95
Thr His Val Pro Phe Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 51
<211> 121
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.22 VH
<400> 51
Gln Ile Gln Met Met Gln Ser Gly Pro Glu Leu Lys Lys Pro Gly Glu
1 5 10 15
Thr Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Asn Tyr
20 25 30
Gly Met Asn Trp Val Lys Gln Ala Pro Gly Lys Gly Leu Lys Trp Met
35 40 45
Gly Trp Ile Asn Thr Tyr Thr Gly Glu Pro Thr Tyr Ala Asp Asp Phe
50 55 60
Lys Gly Arg Phe Ala Phe Ser Leu Glu Thr Ser Ala Ser Thr Ala Tyr
65 70 75 80
Leu Gln Ile Asn Asn Leu Lys Asn Glu Asp Met Ala Thr Tyr Phe Cys
85 90 95
Thr Arg Gly Tyr Tyr Gly Ser Ser Tyr Asp Ala Leu Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Ser Val Thr Val Ser Ser
115 120
<210> 52
<211> 112
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.24 VL
<400> 52
Asp Ile Val Met Ser Gln Ser Pro Ser Ser Leu Ala Val Ser Val Gly
1 5 10 15
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Tyr Ser
20 25 30
Ser Asn Gln Lys Ser Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ser Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val Tyr Tyr Cys Lys Gln
85 90 95
Ser Tyr Asn Leu Arg Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 53
<211> 117
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.24 VH
<400> 53
Gln Val Gln Leu Gln Gln Ser Asp Ala Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Val Ser Gly Tyr Thr Phe Thr Asp His
20 25 30
Thr Ile His Trp Met Lys Gln Arg Pro Glu Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Tyr Pro Arg Asp Gly Ser Thr Lys Tyr Asn Glu Glu Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Asn Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Phe Cys
85 90 95
Ala Arg Ser Tyr Ser Asn Tyr Phe Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Leu Thr Val Ser Ser
115
<210> 54
<211> 112
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.27 VL
<400> 54
Asp Val Val Met Thr Gln Thr Pro Leu Thr Leu Ser Val Thr Ile Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Lys Ser Ser Gln Ser Leu Leu Glu Ser
20 25 30
Asp Gly Lys Thr Tyr Leu Asn Trp Leu Leu Gln Arg Pro Gly Gln Ser
35 40 45
Pro Lys Arg Leu Ile Tyr Leu Val Ser Lys Leu Asp Ser Gly Val Pro
50 55 60
Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Tyr Cys Trp Gln Gly
85 90 95
Ile Gln His Pro Arg Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 55
<211> 113
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.27 VH
<400> 55
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Val Arg Pro Gly Ala
1 5 10 15
Ser Val Thr Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
Glu Met His Trp Val Lys Gln Thr Pro Val His Gly Leu Glu Trp Ile
35 40 45
Gly Gly Ile Asp Pro Glu Thr Gly Gly Thr Ala Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Phe Cys
85 90 95
Thr Arg Trp Phe Ser Tyr Trp Gly Pro Gly Thr Leu Val Thr Val Ser
100 105 110
Ala
<210> 56
<211> 107
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.28 VL
<400> 56
Asp Ile Leu Leu Thr Gln Ser Pro Ala Ile Leu Ser Val Ser Pro Gly
1 5 10 15
Glu Gly Val Ser Phe Ser Cys Arg Ala Ser Gln Ser Ile Gly Thr Ser
20 25 30
Ile His Trp Tyr Gln Gln Arg Thr Asn Gly Ser Pro Arg Leu Leu Ile
35 40 45
Lys Tyr Ala Ser Glu Ser Ile Ser Gly Ile Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Arg Ile Asn Ser Leu Glu Ser
65 70 75 80
Glu Asp Ile Ala Asp Tyr Tyr Cys Gln Gln Ser Asn Ser Trp Pro Leu
85 90 95
Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys
100 105
<210> 57
<211> 117
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.28 VH
<400> 57
Gln Val His Leu Pro Gln Ser Arg Pro Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Gly Phe Thr Arg Ser
20 25 30
Tyr Ile His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Ser Ser Gly Ser Gly Gly Thr Thr Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Ala Ser Leu Thr Ala Asp Asn Pro Ser Ser Thr Ala Tyr
65 70 75 80
Met His Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Ile Tyr Phe Cys
85 90 95
Ala Arg Gly Gly Val Arg Tyr Phe Asp Val Trp Gly Ala Gly Thr Thr
100 105 110
Val Thr Val Ser Ser
115
<210> 58
<211> 107
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.29 VL
<400> 58
Asp Ile Val Met Thr Gln Ser His Lys Phe Met Ser Thr Ser Val Gly
1 5 10 15
Asp Arg Val Ser Ile Thr Cys Lys Ala Ser Gln Asp Val Gly Thr Asp
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ser Pro Lys Leu Leu Ile
35 40 45
Tyr Trp Ala Ser Thr Arg His Thr Gly Val Pro Asp Arg Phe Thr Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Asn Val Gln Ser
65 70 75 80
Glu Asp Leu Ala Asp Tyr Phe Cys Gln Gln Tyr Ser Ser Tyr Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 59
<211> 116
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.29 VH
<400> 59
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Met Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
Asn Met His Trp Val Lys Gln Asn Gln Gly Lys Ser Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn Pro His Asn Gly Gly Thr Gly Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ser Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Gly Gly Tyr Pro Ala Phe Asp Tyr Trp Gly Gln Gly Thr Thr Leu
100 105 110
Thr Val Ser Ser
115
<210> 60
<211> 108
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.30 VL
<400> 60
Glu Asn Val Leu Thr Gln Ser Pro Ala Ile Val Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Arg Ala Ser Ser Ser Val Ile Ser Ser
20 25 30
Tyr Leu His Trp Tyr Gln Gln Lys Ser Gly Ala Ser Pro Lys Leu Trp
35 40 45
Ile Tyr Ser Thr Ser Asn Leu Ala Ser Gly Val Pro Ala Arg Phe Ser
50 55 60
Gly Ser Ala Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Val Glu
65 70 75 80
Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Gly Tyr Pro
85 90 95
Leu Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys
100 105
<210> 61
<211> 124
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.30 VH
<400> 61
Glu Val Lys Leu Val Glu Ser Glu Gly Gly Leu Val Gln Pro Gly Ser
1 5 10 15
Ser Met Lys Leu Ser Cys Thr Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Tyr Met Ala Trp Val Arg Gln Val Pro Glu Lys Gly Leu Glu Trp Val
35 40 45
Ala Asn Ile Asn Tyr Asp Gly Ser Ser Thr Tyr Tyr Leu Asp Ser Leu
50 55 60
Lys Ser Arg Phe Ile Ile Ser Arg Asp Asn Ala Lys Asn Ile Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Lys Ser Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Arg Asp Asp Tyr Tyr Gly Ser Ser Pro Ser Tyr Trp Tyr Phe Asp
100 105 110
Val Trp Gly Ala Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 62
<211> 107
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.32 VL
<400> 62
Asp Ile Gln Met Thr Gln Ser Pro Ala Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Glu Thr Val Thr Met Thr Cys Arg Ala Ser Gly Asn Ile His Asn Tyr
20 25 30
Leu Val Trp Tyr Gln Gln Lys Gln Gly Lys Ser Pro Gln Leu Leu Val
35 40 45
Tyr Asn Ala Lys Thr Leu Ala Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Gln Tyr Ser Leu Lys Ile Asn Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Gly Ser Tyr Tyr Cys Gln His Phe Trp Ser Thr Pro Pro
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 63
<211> 119
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.32 VH
<400> 63
Glu Val Lys Leu Glu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Met Lys Leu Ser Cys Val Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Trp Met Ser Trp Val Arg Gln Ser Pro Glu Lys Gly Leu Glu Trp Val
35 40 45
Ala Glu Ile Arg Leu Lys Ser Asn Asn Tyr Ala Thr His Tyr Ala Glu
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Ser Ser
65 70 75 80
Val Phe Leu Gln Met Asn Asn Leu Arg Thr Glu Asp Thr Gly Ile Tyr
85 90 95
Tyr Cys Thr Arg His Tyr Tyr Tyr Ala Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 64
<211> 107
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.34 VL
<400> 64
Asp Ile Lys Met Thr Gln Ser Pro Ser Ser Met Tyr Ala Ser Leu Gly
1 5 10 15
Glu Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Ser Tyr
20 25 30
Leu Ser Trp Phe Gln Gln Lys Pro Gly Lys Ser Pro Lys Thr Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Leu Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Gln Asp Tyr Ser Leu Thr Ile Ser Ser Leu Glu Tyr
65 70 75 80
Glu Asp Met Gly Ile Tyr Tyr Cys Leu Gln Tyr Asp Glu Phe Pro Pro
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 65
<211> 118
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.34 VH
<400> 65
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ser
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
Asn Met Asp Trp Val Lys Gln Ser His Gly Lys Arg Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Tyr Pro Asp Asn Gly Gly Ala Gly Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ser Arg Ser Ile Thr Thr Ala Trp Phe Ala Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ala
115
<210> 66
<211> 108
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.35 VL
<400> 66
Glu Asn Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Leu Thr Cys Arg Ala Ser Ser Ser Met Ser Ser Ser
20 25 30
Tyr Leu His Trp Tyr Gln Gln Lys Ser Gly Ala Ser Pro Lys Leu Trp
35 40 45
Ile Tyr Ser Thr Ser Asn Leu Ala Ser Gly Val Pro Ala Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Val Glu
65 70 75 80
Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Ala Tyr Pro
85 90 95
Phe Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 67
<211> 121
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.35 VH
<400> 67
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Leu Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
Tyr Ile His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn Pro Tyr Asn Gly Glu Thr Phe Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Arg Gly Trp Tyr Leu Thr Gly Tyr Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Ser Val Thr Val Ser Ser
115 120
<210> 68
<211> 106
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.36 VL
<400> 68
Gln Ile Val Leu Thr Gln Ser Pro Ala Leu Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Tyr Trp Tyr Gln Gln Lys Pro Arg Ser Ser Pro Lys Pro Trp Ile Tyr
35 40 45
Leu Thr Ser Asn Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Asn Pro Pro Thr
85 90 95
Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 69
<211> 120
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.36 VH
<400> 69
Glu Val Gln Leu Gln Glu Ser Gly Pro Ser Leu Val Lys Pro Ser Gln
1 5 10 15
Ser Gln Ser Leu Thr Cys Ser Val Thr Gly Asp Ser Ile Thr Ser Asp
20 25 30
Tyr Trp Asn Trp Ile Arg Lys Phe Pro Gly Lys Lys Val Glu Tyr Met
35 40 45
Gly Tyr Ile Asn Tyr Ser Gly Ser Thr Tyr Tyr Asn Pro Ser Leu Lys
50 55 60
Ser Arg Ile Ser Ile Thr Arg Asp Thr Ser Lys Asn Gln Tyr Tyr Leu
65 70 75 80
Gln Leu Asn Ser Val Thr Ser Glu Asp Thr Ala Thr Tyr Tyr Cys Ala
85 90 95
Arg Thr Ser Tyr Tyr Asn Lys Phe Leu Pro Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ala
115 120
<210> 70
<211> 112
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.39 VL
<400> 70
Asp Val Leu Met Thr Gln Thr Pro Leu Ser Leu Pro Val Ser Leu Gly
1 5 10 15
Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Val His Arg
20 25 30
Asn Gly Asn Thr Tyr Phe His Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Phe Cys Ser Gln Ser
85 90 95
Thr Tyr Val Pro Trp Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 71
<211> 117
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.39 VH
<400> 71
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Arg Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Glu Lys Gly Leu Glu Trp Val
35 40 45
Ala Tyr Ile Ser Ser Asn Asp Gly Thr Ile Tyr Tyr Ala Asp Thr Val
50 55 60
Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Phe
65 70 75 80
Leu Gln Met Thr Ser Leu Arg Ser Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Arg Pro Ser Asn Trp Val Phe Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Leu Thr Val Ser Ser
115
<210> 72
<211> 112
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.40 VL
<400> 72
Asp Val Val Met Thr Gln Thr Pro Leu Ser Arg Pro Val Thr Leu Gly
1 5 10 15
Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Val His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu His Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Phe Cys Ser Gln Asn
85 90 95
Thr His Val Pro Phe Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 73
<211> 116
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.40 VH
<400> 73
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Ile Val Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
Trp Met Asn Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Thr Ile Asp Pro Ser Asp Ser Tyr Thr Arg Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val Asp Thr Ser Phe Ser Ser Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Phe Cys
85 90 95
Ala Ser Gly Gly Arg Gly Phe Gly Tyr Trp Gly Gln Gly Thr Pro Val
100 105 110
Thr Val Ser Val
115
<210> 74
<211> 106
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.41 VL
<400> 74
Gln Ile Val Leu Thr Gln Ser Pro Ala Leu Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Tyr Trp Tyr Gln Gln Lys Pro Arg Ser Ser Pro Lys Pro Trp Ile Tyr
35 40 45
Leu Thr Ser Asn Leu Ala Ser Gly Val Pro Thr Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Gly Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Asn Thr Asn Pro Pro Thr
85 90 95
Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys
100 105
<210> 75
<211> 121
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.41 VH
<400> 75
Asp Val Lys Leu Val Glu Ser Gly Gly Gly Leu Val Lys Leu Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met Ser Trp Val Arg Gln Thr Pro Glu Lys Arg Leu Glu Trp Val
35 40 45
Ala Thr Ile Ser Ser Gly Gly Gly Asn Thr Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Arg Arg Asp Tyr Tyr Gly Thr Ser Tyr Val Met Phe Ala Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser
115 120
<210> 76
<211> 106
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.42 VL
<400> 76
Glu Asn Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Ser Ala Ser Ser Ser Val Asn Tyr Met
20 25 30
Tyr Trp Tyr Gln Gln Lys Ser Ser Thr Ser Pro Lys Leu Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Leu Thr Ser Gly Val Pro Gly Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Asn Ser Tyr Ser Leu Thr Ile Ser Asn Met Glu Ala Glu
65 70 75 80
Asp Val Ala Thr Tyr Tyr Cys Phe Gln Gly Ser Gly Tyr Pro Leu Thr
85 90 95
Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 77
<211> 112
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.42 VH
<400> 77
Asp Val Lys Leu Val Glu Ser Gly Gly Gly Leu Val Arg Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Arg Tyr
20 25 30
Thr Met Ser Trp Val Arg Gln Thr Pro Glu Lys Arg Leu Glu Trp Ala
35 40 45
Ala Thr Ile Asn Ser Gly Gly Ser Asn Thr Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Phe
65 70 75 80
Leu Gln Met Ser Ser Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Thr Asn Gly Asn His Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
100 105 110
<210> 78
<211> 106
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.45 VL
<400> 78
Glu Asn Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Ser Ala Ser Ser Ser Val Asn Tyr Met
20 25 30
Tyr Trp Tyr Gln Gln Lys Ser Ser Thr Ser Pro Lys Leu Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Leu Thr Ser Gly Val Pro Gly Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Asn Ser Tyr Ser Leu Thr Ile Ser Asn Met Glu Ala Glu
65 70 75 80
Asp Val Ala Thr Tyr Tyr Cys Phe Gln Gly Ser Gly Tyr Pro Leu Thr
85 90 95
Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 79
<211> 114
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.45 VH
<400> 79
Gln Val Gln Leu Gln Gln Pro Gly Ser Val Leu Val Arg Pro Gly Asp
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Trp Met His Trp Val Lys Gln Ser Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile His Pro His Ser Gly Ser Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val Asp Thr Ser Ser Ser Thr Ala Tyr
65 70 75 80
Val Asp Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Val Gly Gly His Tyr Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val
100 105 110
Ser Ser
<210> 80
<211> 107
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.46 VL
<400> 80
Ser Phe Val Met Thr Gln Thr Pro Lys Phe Leu Leu Val Ser Ala Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ser Val Asn Asn Asp
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ser Pro Lys Leu Leu Ile
35 40 45
Tyr Tyr Ala Ser Asn Arg Tyr Thr Gly Val Pro Asp Arg Phe Thr Gly
50 55 60
Ser Gly Tyr Gly Thr Asp Phe Thr Phe Thr Ile Ser Thr Val Gln Ala
65 70 75 80
Glu Asp Leu Ala Val Tyr Phe Cys Gln Gln Asp Tyr Ser Ser Pro Arg
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 81
<211> 119
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.46 VH
<400> 81
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Met Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Trp Ile Asn Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Asn Ile Phe Pro Asp Thr Thr Thr Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Ser Lys Ala Thr Leu Thr Val Asp Thr Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Asp Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Tyr Tyr Asp Gly Thr Tyr Asp Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Ser Val Thr Val
115
<210> 82
<211> 106
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.47 VL
<400> 82
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Ser Met Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
His Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Ser Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Thr Pro Pro Thr
85 90 95
Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 83
<211> 119
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.47 VH
<400> 83
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Asp Tyr
20 25 30
Tyr Met Arg Trp Val Lys Gln Ser Pro Glu Lys Ser Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn Pro Ser Thr Gly Gly Thr Thr Tyr Asn Gln Asn Phe
50 55 60
Lys Ala Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Lys Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Tyr Phe Leu Tyr Tyr Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Thr Leu Thr Val Ser Ser
115
<210> 84
<211> 112
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.49 VL
<400> 84
Asp Val Val Met Thr Gln Thr Pro Leu Thr Leu Ser Val Thr Ile Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Lys Ser Ser Gln Ser Leu Leu Glu Ser
20 25 30
Asp Gly Lys Thr Tyr Leu Asn Trp Leu Leu Gln Arg Pro Gly Gln Ser
35 40 45
Pro Lys Arg Leu Ile Tyr Leu Val Ser Lys Leu Asp Ser Gly Val Pro
50 55 60
Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Tyr Cys Trp Gln Gly
85 90 95
Ile Gln His Pro Arg Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 85
<211> 113
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.49 VH
<400> 85
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Val Arg Pro Gly Ala
1 5 10 15
Ser Val Thr Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
Glu Met His Trp Val Lys Gln Thr Pro Val His Gly Leu Glu Trp Ile
35 40 45
Gly Gly Ile Asp Pro Glu Thr Gly Gly Thr Ala Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Phe Cys
85 90 95
Thr Arg Trp Phe Ser Tyr Trp Gly Pro Gly Thr Leu Val Thr Val Ser
100 105 110
Ala
<210> 86
<211> 111
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.50 VL
<400> 86
Asp Ile Val Leu Thr Gln Ser Pro Ala Ser Leu Ala Ala Ser Leu Gly
1 5 10 15
Gln Arg Ala Thr Ile Ser Cys Arg Ala Ser Gln Ser Val Ser Thr Ser
20 25 30
Ser Tyr Ser Tyr Met His Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Lys Leu Leu Ile Lys Tyr Ala Ser Asn Leu Glu Ser Gly Val Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Asn Ile His
65 70 75 80
Pro Val Glu Glu Glu Asp Thr Ala Thr Tyr Tyr Cys Gln His Ser Trp
85 90 95
Glu Ile Pro Trp Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 87
<211> 121
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.50 VH
<400> 87
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Glu Lys Gly Leu Glu Trp Val
35 40 45
Ala Tyr Ile Ser Ser Gly Ser Arg Thr Ile Tyr Tyr Ala Asp Thr Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Phe
65 70 75 80
Leu Gln Met Thr Ser Leu Arg Ser Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Arg Val Tyr Tyr Gly Ser Thr Tyr Gly Tyr Phe Asp Val Trp Gly
100 105 110
Thr Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 88
<211> 111
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.53 VL
<400> 88
Asp Ile Val Leu Thr Gln Ser Pro Ala Ser Leu Ala Ala Ser Leu Gly
1 5 10 15
Gln Arg Ala Thr Ile Ser Cys Arg Ala Ser Gln Ser Val Ser Thr Ser
20 25 30
Ser Tyr Ser Tyr Met His Trp Tyr Gln Gln Lys Pro Gly His Pro Pro
35 40 45
Lys Leu Leu Ile Arg Tyr Ala Ser Asn Leu Glu Ser Gly Val Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Asn Ile His
65 70 75 80
Pro Val Glu Glu Glu Asp Thr Ala Thr Tyr Tyr Cys Gln His Ser Trp
85 90 95
Glu Ile Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 89
<211> 119
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.53 VH
<400> 89
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
Asn Met His Trp Val Lys Gln Ser His Gly Lys Arg Leu Glu Trp Ile
35 40 45
Gly Tyr Ile His Pro Tyr Asn Gly Gly Ser Gly Tyr Asn Gln Lys Phe
50 55 60
Lys Arg Lys Ala Thr Leu Thr Val Asp Asn Ser Ser Asn Thr Thr Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Tyr Asp Tyr Asp Thr Trp Phe Gly Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Arg Ala
115
<210> 90
<211> 112
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.54 VL
<400> 90
Asp Val Val Leu Thr Gln Thr Pro Leu Thr Leu Ser Val Thr Ile Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Lys Ser Ser Gln Ser Leu Leu Tyr Ser
20 25 30
Asp Gly Lys Thr Tyr Leu Asn Trp Leu Leu Gln Arg Pro Gly Gln Ser
35 40 45
Pro Lys Arg Leu Ile Tyr Leu Val Ser Lys Leu Asp Ser Gly Val Pro
50 55 60
Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Leu Tyr Tyr Cys Trp Gln Gly
85 90 95
Thr His Phe Pro Trp Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 91
<211> 113
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.54 VH
<400> 91
Glu Val Lys Leu Glu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Met Lys Leu Ser Cys Val Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Trp Ile Asn Trp Val Arg Gln Ser Pro Glu Lys Gly Leu Glu Trp Val
35 40 45
Ala Glu Ile Arg Met Lys Ser Asn Asn Tyr Ala Thr His Tyr Ala Glu
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Ser Cys
65 70 75 80
Val Tyr Leu Gln Met Asn Asn Leu Arg Pro Glu Asp Thr Gly Ile Tyr
85 90 95
Tyr Cys Thr Arg Gly Gly Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val
100 105 110
Ser
<210> 92
<211> 113
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.56 VL
<400> 92
Asp Ile Val Met Ser Gln Ser Pro Ser Ser Leu Ala Val Ser Val Gly
1 5 10 15
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Tyr Ser
20 25 30
Ser Asn Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ser Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Val Lys Ala Glu Asp Leu Ala Val Tyr Phe Cys Gln Gln
85 90 95
Tyr Tyr Asn Tyr Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile
100 105 110
Lys
<210> 93
<211> 116
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.56 VH
<400> 93
Gln Ile Gln Leu Val Gln Ser Gly Pro Glu Leu Lys Lys Pro Gly Glu
1 5 10 15
Thr Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Gly Met Asn Trp Val Lys Gln Ala Pro Gly Lys Gly Leu Lys Trp Met
35 40 45
Ala Trp Ile Asn Thr Tyr Thr Gly Glu Pro Thr Tyr Ala Asp Asp Phe
50 55 60
Lys Gly Arg Phe Ala Phe Ser Leu Glu Thr Ser Ala Ser Thr Ala Ser
65 70 75 80
Leu Gln Ile Ile Asn Leu Lys Asn Glu Asp Thr Ala Thr Tyr Phe Cys
85 90 95
Ala Arg Ile Gly Asp Ser Ser Pro Ser Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Thr Leu Thr Val
115
<210> 94
<211> 108
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.57 VL
<400> 94
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Leu Gly
1 5 10 15
Glu Arg Val Thr Met Thr Cys Thr Ala Ser Ser Ser Val Ser Ser Ser
20 25 30
Tyr Leu His Trp Tyr Gln Gln Lys Pro Gly Ser Ser Pro Lys Leu Trp
35 40 45
Ile Tyr Ser Thr Ser Asn Leu Ala Ser Gly Val Pro Pro Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu
65 70 75 80
Ala Glu Asp Ala Ala Thr Tyr Tyr Cys His Gln Tyr His Arg Ser Pro
85 90 95
Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 95
<211> 121
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.57 VH
<400> 95
Gln Ile Gln Leu Val Gln Ser Gly Pro Glu Leu Lys Lys Pro Gly Glu
1 5 10 15
Thr Val Lys Ile Ser Cys Lys Ala Ser Asp Tyr Thr Phe Thr Asp Phe
20 25 30
Ser Ile His Trp Val Arg Gln Ser Pro Gly Lys Gly Leu Lys Trp Met
35 40 45
Gly Trp Ile Asn Thr Glu Thr Gly Glu Pro Thr Val Ala Glu Asp Phe
50 55 60
Lys Gly Arg Phe Ala Phe Ser Leu Glu Thr Ser Ala Ser Thr Ala Phe
65 70 75 80
Leu Gln Ile Tyr Asn Leu Lys Asn Glu Asp Ser Ala Thr Tyr Phe Cys
85 90 95
Ala Arg Gly Arg Tyr Tyr Gly His Asp Tyr Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Ser Val Thr Val Ser Ser
115 120
<210> 96
<211> 107
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.59 VL
<400> 96
Asp Ile Gln Met Thr Gln Ser Pro Ala Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Glu Thr Val Thr Ile Thr Cys Arg Ala Ser Gly Asn Leu His Asn Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Gln Gly Lys Ser Pro Gln Leu Leu Val
35 40 45
Tyr Asn Ala Lys Thr Leu Ala Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Gln Tyr Ser Leu Lys Ile Asn Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Gly Thr Tyr Phe Cys Gln His Phe Trp Ser Ile Pro Pro
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 97
<211> 119
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.59 VH
<400> 97
Glu Val Lys Leu Glu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Met Lys Leu Ser Cys Val Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Trp Met Asn Trp Val Arg Gln Ser Pro Glu Lys Gly Leu Glu Trp Val
35 40 45
Ala Glu Ile Arg Leu Lys Ser Asn Asn Tyr Ala Thr His Tyr Ala Glu
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Ser Ser
65 70 75 80
Val Tyr Leu Gln Met Asn Asn Leu Arg Ala Glu Asp Thr Gly Ile Tyr
85 90 95
Tyr Cys Thr Arg Leu Trp Asp Phe Ala Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 98
<211> 106
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.61 VL
<400> 98
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Ile Ser Cys Ser Ala Ser Ser Ser Val Ser Tyr Ile
20 25 30
Tyr Trp Tyr Gln Gln Lys Pro Gly Ser Ser Pro Lys Pro Trp Ile Tyr
35 40 45
Arg Thr Ser Asn Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Tyr His Ser Tyr Pro Trp Thr
85 90 95
Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 99
<211> 125
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.61 VH
<400> 99
Gln Val Thr Leu Lys Glu Ser Gly Pro Gly Ile Leu Gln Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ser Phe Ser Gly Phe Ser Leu Ser Thr Phe
20 25 30
Gly Met Gly Val Gly Trp Ile Arg Gln Pro Ser Gly Lys Gly Leu Glu
35 40 45
Trp Leu Ala Gln Ile Trp Trp Asp Asp Tyr Lys Tyr Tyr Asn Pro Ala
50 55 60
Leu Lys Ser Arg Leu Thr Ile Ser Lys Asp Thr Ser Lys Asn Gln Val
65 70 75 80
Phe Leu Lys Ile Ala Asn Val Asp Thr Ala Asp Thr Ala Thr Tyr Tyr
85 90 95
Cys Ala Arg Ile Gly Tyr Tyr Ser Gly Ser Ser Arg Cys Trp Tyr Phe
100 105 110
Asp Val Trp Gly Thr Gly Ser Thr Val Thr Val Ser Ser
115 120 125
<210> 100
<211> 107
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.63 VL
<400> 100
Ser Ile Val Met Thr Gln Thr Pro Lys Phe Leu Leu Val Ser Ala Gly
1 5 10 15
Asp Arg Val Ala Ile Thr Cys Lys Ala Ser Gln Ser Val Ser Asn Asp
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ser Pro Thr Leu Leu Ile
35 40 45
Ser Tyr Ala Ser Asn Arg Tyr Thr Gly Val Pro Asp Arg Phe Thr Gly
50 55 60
Ser Gly Tyr Gly Thr Asp Phe Thr Phe Thr Ile Ser Thr Val Gln Ala
65 70 75 80
Glu Asp Leu Ala Val Tyr Phe Cys Gln Gln Gly Tyr Ser Ser Pro Phe
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 101
<211> 116
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.63 VH
<400> 101
Gln Val Gln Leu Gln Gln Ser Asp Ala Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Ala Gly Tyr Thr Phe Thr Asp Leu
20 25 30
Thr Ile His Trp Val Lys Gln Arg Pro Glu Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Tyr Pro Gly Asp Ser Asn Thr Lys Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Asn Ser Leu Thr Ser Glu Asp Ser Val Val Tyr Phe Cys
85 90 95
Ala Arg Met Ile Thr Pro Tyr Tyr Phe Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Thr Leu Thr Val
115
<210> 102
<211> 107
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.71 VL
<400> 102
Asp Ile Gln Met Thr Gln Ser Pro Ala Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Glu Thr Val Thr Ile Ala Cys Arg Ala Ser Gly Asn Ile His Asn Tyr
20 25 30
Leu Thr Trp Tyr Gln Gln Arg Gln Gly Lys Ser Pro Gln Leu Leu Val
35 40 45
Tyr Asn Ala Lys Thr Leu Ala Val Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Gln Tyr Ser Leu Lys Ile Asn Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Gly Ser Tyr Tyr Cys Gln His Phe Trp Asn Thr Pro Pro
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 103
<211> 119
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.71 VH
<400> 103
Glu Val Lys Leu Glu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Met Lys Leu Ser Cys Val Ala Ser Gly Ile Ile Phe Ser Asn Tyr
20 25 30
Trp Met Asn Trp Val Arg Gln Ser Pro Glu Lys Gly Leu Glu Trp Val
35 40 45
Ala Glu Ile Arg Leu Lys Ser Asn Asn Tyr Ser Thr His Tyr Ala Glu
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Ser Ser
65 70 75 80
Val Tyr Leu Gln Met Asn Asn Leu Arg Ala Glu Asp Thr Gly Ile Tyr
85 90 95
Tyr Cys Thr Arg His Tyr Tyr Tyr Ala Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 104
<211> 107
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.72 VL
<400> 104
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Ser Ala Ser Gln Gly Ile Ser Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Asp Gly Thr Val Lys Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Lys Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Leu Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Tyr
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 105
<211> 119
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.72 VH
<400> 105
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Gly Met Ser Trp Val Arg Gln Thr Pro Glu Lys Arg Leu Glu Trp Val
35 40 45
Ala Ala Ile Asn Ser Asn Gly Gly Ser Thr Tyr Tyr Pro Asp Thr Val
50 55 60
Lys Gly Arg Leu Thr Ile Ser Arg Asp Asn Gly Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Arg Ser Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Val Arg Asp Asp Gly Tyr Tyr Val Phe Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ala
115
<210> 106
<211> 107
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.74 VL
<400> 106
Asp Ile Gln Met Thr Gln Ser Ser Ser Tyr Leu Ser Val Ser Leu Gly
1 5 10 15
Gly Arg Val Thr Ile Thr Cys Lys Ala Ser Asp His Ile Asn Asn Trp
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Asn Ala Pro Arg Leu Leu Ile
35 40 45
Ser Gly Ala Thr Ser Leu Glu Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Lys Asp Tyr Thr Leu Ser Ile Thr Ser Leu Gln Thr
65 70 75 80
Glu Asp Val Ala Thr Tyr Tyr Cys Gln Gln Tyr Trp Ser Thr Pro Pro
85 90 95
Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys
100 105
<210> 107
<211> 119
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.74 VH
<400> 107
Gln Val Gln Leu Lys Gln Ser Gly Pro Gly Leu Val Ala Pro Ser Gln
1 5 10 15
Ser Leu Ser Ile Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Ser Tyr
20 25 30
Gly Val Asp Trp Val Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Leu
35 40 45
Gly Val Ile Trp Gly Gly Gly Ser Thr Asn Tyr Asn Ser Ala Leu Lys
50 55 60
Ser Arg Leu Ser Ile Thr Lys Asp Asn Ser Lys Ser Gln Val Phe Leu
65 70 75 80
Lys Met Asn Ser Leu Gln Thr Asp Asp Thr Ala Met Tyr Tyr Cys Ala
85 90 95
Ser Gly Asp Tyr Asp Gly Ser Leu Trp Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ala
115
<210> 108
<211> 112
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.76 VL
<400> 108
Asp Ile Val Ile Thr Gln Asp Glu Leu Ser Asn Pro Val Thr Ser Gly
1 5 10 15
Glu Ser Val Ser Ile Ser Cys Arg Ser Ser Lys Ser Leu Leu Tyr Lys
20 25 30
Asp Gly Lys Thr Tyr Leu Asn Trp Phe Leu Gln Arg Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Met Ser Thr Arg Ala Ser Gly Val Ser
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Glu Ile
65 70 75 80
Ser Arg Val Lys Ala Glu Asp Val Gly Val Tyr Tyr Cys Gln Gln Leu
85 90 95
Val Glu Tyr Pro Arg Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 109
<211> 113
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.76 VH
<400> 109
Glu Val Gln Leu Val Glu Ser Gly Gly Asp Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Val Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Gly Met Ser Trp Val Arg Gln Thr Pro Asp Lys Arg Leu Glu Trp Val
35 40 45
Ala Thr Ile Ser Ser Gly Gly Thr Phe Thr Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Val Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ser Arg His Gly Trp Gly Trp Gly Gln Gly Thr Leu Val Thr Val Ser
100 105 110
Ala
<210> 110
<211> 107
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.77 VL
<400> 110
Asp Ile Gln Met Thr Gln Ser Pro Ala Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Glu Thr Val Thr Ile Thr Cys Arg Ala Ser Gly Asn Ile His Asn Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Gln Gly Lys Ser Pro Gln Leu Leu Val
35 40 45
Tyr Asn Ala Lys Ala Leu Ala Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Gln Tyr Ser Leu Lys Ile Asn Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Gly Ser Tyr Tyr Cys Gln His Phe Trp Ser Ile Pro Pro
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 111
<211> 119
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.77 VH
<400> 111
Glu Val Lys Leu Glu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Met Lys Leu Ser Cys Val Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Trp Met Asn Trp Val Arg Gln Ser Pro Glu Lys Gly Leu Glu Trp Val
35 40 45
Ala Glu Ile Arg Leu Lys Ser Asn Asn Tyr Ala Thr His Tyr Ala Glu
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Ser Ser
65 70 75 80
Val Tyr Leu Gln Met Asn Asn Leu Arg Val Glu Asp Thr Ala Ile Tyr
85 90 95
Tyr Cys Thr Arg His Tyr Asp Tyr Ala Met Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 112
<211> 107
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.79 VL
<400> 112
Asp Ile Gln Met Thr Gln Ser Pro Ala Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Glu Thr Val Thr Ile Thr Cys Arg Ala Ser Gly Asn Ile His Asn Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Gln Gly Lys Ser Pro Gln Leu Leu Val
35 40 45
Tyr Asn Ala Lys Thr Leu Ala Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Gln Tyr Ser Leu Arg Ile Asn Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Gly Ser Tyr Tyr Cys Gln His Phe Trp Ser Thr Pro Pro
85 90 95
Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105
<210> 113
<211> 119
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.79 VH
<400> 113
Glu Val Lys Leu Glu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Met Lys Leu Ser Cys Val Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Trp Met Asn Trp Val Arg Gln Ser Pro Glu Lys Gly Leu Glu Leu Val
35 40 45
Ala Glu Ile Arg Leu Ile Ser Asn Asn Tyr Ala Thr His Tyr Ala Glu
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Ser Ser
65 70 75 80
Val Tyr Leu Gln Met Asn Asn Leu Arg Ala Glu Asp Thr Gly Ile Tyr
85 90 95
Tyr Cys Thr Arg His Tyr Tyr Tyr Ala Leu Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Ser Val Thr Val Ser Ser
115
<210> 114
<211> 113
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.81 VL
<400> 114
Asp Ile Val Met Ser Gln Ser Pro Ser Ser Leu Thr Val Ser Val Gly
1 5 10 15
Glu Lys Val Thr Leu Ser Cys Lys Ser Ser Gln Ser Leu Leu Tyr Ser
20 25 30
Thr Asn Gln Lys Ile Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ser Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Ala
65 70 75 80
Ile Ser Asn Val Lys Ala Glu Asp Leu Ala Val Tyr Tyr Cys Gln Gln
85 90 95
Tyr Tyr Ser Tyr Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile
100 105 110
Lys
<210> 115
<211> 113
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.81 VH
<400> 115
Glu Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Thr Ala Ser Gly Phe Asn Ile Asn Asp Thr
20 25 30
Tyr Tyr His Trp Leu Lys Gln Arg Pro Glu Gln Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Asp Pro Ala Asn Val Asn Thr Lys Tyr Asp Pro Lys Phe
50 55 60
Gln Gly Lys Ala Thr Leu Thr Ala Asp Thr Ser Ser Asn Thr Ala Tyr
65 70 75 80
Leu Gln Leu Ser Ser Leu Thr Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Gly Arg Gly Asn Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
100 105 110
Ala
<210> 116
<211> 104
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.82 VL
<400> 116
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Leu Gly
1 5 10 15
Glu Glu Ile Thr Leu Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
His Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Leu Leu Ile Tyr
35 40 45
Ser Thr Ser Asn Leu Ala Ser Gly Val Pro Ser Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Phe Tyr Ser Leu Thr Ile Ser Ser Val Glu Ala Glu
65 70 75 80
Asp Ala Ala Asp Tyr Tyr Cys His Gln Trp Ser Ser Phe Thr Phe Gly
85 90 95
Ser Gly Thr Lys Leu Glu Ile Lys
100
<210> 117
<211> 120
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.82 VH
<400> 117
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Ser
20 25 30
Tyr Met Asn Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile
35 40 45
Gly Arg Val Asn Pro Asn Asn Gly Gly Ala Ser Tyr Asn His Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Leu Ser Thr Ala Tyr
65 70 75 80
Met Arg Leu Asn Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ser Arg Ser Gly Asp Leu Tyr Tyr Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Ser Val Thr Val Ser Ser
115 120
<210> 118
<211> 106
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.84 VL
<400> 118
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Ser Ala Ser Ser Ser Ile Ser Tyr Met
20 25 30
His Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Asn Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Thr Pro Pro Thr
85 90 95
Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 119
<211> 117
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.84 VH
<400> 119
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Met Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Ile Phe Thr Asp Tyr
20 25 30
Asn Met His Trp Val Lys Gln Asn Gln Gly Lys Ser Leu Glu Trp Ile
35 40 45
Gly Glu Val Asn Pro Asn Thr Gly Gly Ile Gly Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Asp Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Asn Tyr Cys Phe Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Leu Thr Val Ser Ser
115
<210> 120
<211> 111
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.85 VL
<400> 120
Asp Ile Val Met Thr Gln Ala Ala Phe Ser Asn Pro Val Thr Leu Gly
1 5 10 15
Thr Ser Ala Ser Ile Ser Cys Arg Ser Ser Lys Ser Leu Leu His Ser
20 25 30
Asn Gly Ile Thr Tyr Leu Tyr Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Gln Met Ser Asn Leu Ala Ser Gly Val Pro
50 55 60
Glu Arg Phe Ser Ser Ser Gly Ser Gly Ser Asp Phe Thr Leu Arg Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Ala Gln Asn
85 90 95
Leu Glu His Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 121
<211> 120
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.85 VH
<400> 121
Glu Val Gln Leu Val Glu Ser Gly Gly Asp Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asn Tyr
20 25 30
Gly Met Ser Trp Val Arg Gln Thr Pro Asp Lys Arg Leu Glu Trp Val
35 40 45
Ala Thr Ile Ser Thr Gly Gly Thr Tyr Thr Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Val Gly Gln Ser Tyr Ser Asp Tyr Val Ser Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Gln Val Thr Val Ser Ala
115 120
<210> 122
<211> 112
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.87 VL
<400> 122
Asp Val Val Met Thr Gln Thr Pro Leu Ser Leu Pro Val Ser Leu Gly
1 5 10 15
Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Val His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu His Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Lys Leu Leu Ile Ser Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Phe Cys Ser Gln Ser
85 90 95
Thr His Val Pro Pro Met Phe Gly Gly Gly Thr Arg Leu Glu Ile Lys
100 105 110
<210> 123
<211> 115
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.87 VH
<400> 123
Glu Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Leu Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Thr Ala Ser Gly Leu Asn Ile Lys Asp Tyr
20 25 30
Tyr Ile His Trp Val Tyr Gln Arg Pro Glu Gln Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Asp Pro Glu Ser Asp Asn Thr Leu Tyr Asp Pro Lys Phe
50 55 60
Gln Gly Lys Ala Ser Ile Thr Ala Asp Thr Ser Ser Asn Thr Ala Tyr
65 70 75 80
Leu Gln Leu Ser Ser Leu Thr Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Thr Asn Thr Pro Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Thr
115
<210> 124
<211> 112
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.89 VL
<400> 124
Asp Val Leu Met Thr Gln Thr Pro Leu Ser Leu Pro Val Ser Leu Gly
1 5 10 15
Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Ile Val His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu Glu Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Tyr Cys Phe Gln Gly
85 90 95
Ser His Val Pro Phe Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 125
<211> 120
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.89 VH
<400> 125
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Val Arg Pro Gly Thr
1 5 10 15
Ser Val Lys Val Ser Cys Lys Thr Ser Gly Tyr Ala Phe Thr Asn Tyr
20 25 30
Leu Ile Glu Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Val Ile Asn Pro Gly Ser Gly Gly Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Val Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Thr Ser Leu Thr Ser Asp Asp Ser Ala Val Tyr Phe Cys
85 90 95
Thr Arg Arg Asp Gly Tyr Phe Phe Pro Trp Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ala
115 120
<210> 126
<211> 113
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.90 VL
<400> 126
Asp Ile Val Met Ser Gln Ser Pro Ser Ser Leu Ala Val Ser Val Gly
1 5 10 15
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Tyr Ser
20 25 30
Ser Asn Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ser Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Lys Ser Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Val Lys Ala Glu Asp Leu Ala Val Tyr Tyr Cys His Gln
85 90 95
Tyr Tyr Ser Tyr Pro Leu Thr Phe Ala Ala Gly Thr Lys Leu Glu Leu
100 105 110
Lys
<210> 127
<211> 115
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.90 VH
<400> 127
Gln Val Gln Leu Gln Gln Pro Gly Ser Val Leu Val Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Trp Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile His Pro Asn Asn Gly Ser Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val Asp Thr Ser Ser Ser Thr Ala Tyr
65 70 75 80
Val Asp Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Trp Thr Leu Phe Thr Tyr Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ala
115
<210> 128
<211> 112
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.91 VL
<400> 128
Asp Val Val Met Thr Gln Thr Pro Leu Ser Leu Pro Val Ser Leu Gly
1 5 10 15
Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Val His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu Leu Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Ala Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Phe Cys Ser Gln Ser
85 90 95
Thr His Val Pro Trp Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 129
<211> 117
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.91 VH
<400> 129
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Arg Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Tyr
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Glu Lys Gly Leu Glu Trp Val
35 40 45
Ala Tyr Ile Ser Arg Gly Ser Ser Thr Ile His Tyr Ala Asp Thr Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Phe
65 70 75 80
Leu Gln Met Thr Ser Leu Arg Ser Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Arg Pro Phe Asn Trp Tyr Phe Asp Val Trp Gly Ala Gly Thr Thr
100 105 110
Val Thr Val Ser Ser
115
<210> 130
<211> 113
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.93 VL
<400> 130
Asp Ile Val Met Ser Gln Ser Pro Ser Ser Leu Ala Val Ser Val Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Lys Ser Ser Gln Ser Leu Leu Tyr Ser
20 25 30
Ser Asn Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ser Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Ile Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Val Lys Ala Glu Asp Leu Ala Ile Tyr Tyr Cys Gln Gln
85 90 95
Tyr Tyr Arg Tyr Pro Leu Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu
100 105 110
Lys
<210> 131
<211> 121
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.93 VH
<400> 131
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Met Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Trp Val His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Val Ile Asn Pro Arg Asn Gly Arg Asn Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Thr Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Pro Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Asp Tyr Asp Gly Gly Asp Tyr Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Ser Val Thr Val Ser Ser
115 120
<210> 132
<211> 107
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.95 VL
<400> 132
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Ser Ala Ser Gln Gly Ile Asn Asn Tyr
20 25 30
Leu Asn Trp Tyr Gln Gln Lys Pro Asp Gly Thr Val Thr Leu Leu Ile
35 40 45
Tyr Tyr Thr Ser Ser Leu His Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Ser Leu Thr Ile Ser Asn Leu Glu Pro
65 70 75 80
Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Gln Tyr Ser Lys Leu Pro Trp
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 133
<211> 121
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.95 VH
<400> 133
Glu Val Glu Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Thr Ser Gly Asn Thr Tyr Thr Glu Tyr
20 25 30
Thr Met Gln Trp Val Lys Leu Ser His Gly Lys Ser Leu Glu Trp Ile
35 40 45
Gly Gly Ile Asn Pro Asn Asn Gly Ile Thr Ser Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Lys Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ala Gly Leu Gly Asn Tyr Val Trp Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Ala Ser Val Thr Val Ser Ser
115 120
<210> 134
<211> 112
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.97 VL
<400> 134
Asp Val Val Met Thr Gln Thr Pro Leu Ser Leu Pro Val Ser Leu Gly
1 5 10 15
Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Val His Asn
20 25 30
Asn Gly Asn Thr Tyr Leu His Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Asn Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Ile Val Glu Ala Glu Asp Leu Gly Leu Tyr Phe Cys Ser Gln Ser
85 90 95
Thr His Val Pro Arg Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 135
<211> 119
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.97 VH
<400> 135
Gln Val Gln Leu Pro Gln Ser Gly Ala Glu Leu Ala Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Phe Thr Phe Thr Ser Tyr
20 25 30
Trp Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Asn Pro Ser Thr Asp Tyr Thr Glu Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Gly Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Ser Tyr Gly Ser Ser Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Ser Thr Leu Thr Val Ser Ser
115
<210> 136
<211> 113
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.99 VL
<400> 136
Asp Ile Val Met Ser Gln Ser Pro Ser Ser Leu Ala Val Ser Val Gly
1 5 10 15
Glu Lys Val Thr Met Asn Cys Glu Ser Ser Gln Ser Leu Leu Tyr Ser
20 25 30
Ser Asn Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ser Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Asp Ser Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Val Arg Ala Glu Asp Pro Ala Val Tyr Tyr Cys Gln Gln
85 90 95
Tyr Tyr Ser Tyr Pro Leu Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu
100 105 110
Arg
<210> 137
<211> 116
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.99 VH
<400> 137
Glu Val Lys Leu Glu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Met Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Ala
20 25 30
Trp Met Asp Trp Val Arg Gln Ser Pro Glu Lys Gly Leu Glu Trp Val
35 40 45
Ala Glu Ile Arg Ser Lys Ala Asn Asn His Ala Thr Tyr Tyr Ala Glu
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Ser Ser
65 70 75 80
Ala Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Gly Ile Tyr
85 90 95
Tyr Cys Val Ser Thr Gly Thr Ser Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ala
115
<210> 138
<211> 106
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.102 VL
<400> 138
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
His Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Leu Ala Ser Gly Val Pro Pro Arg Phe Ser Gly Arg
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln His Trp Ser Ser Asn Pro Pro Thr
85 90 95
Phe Gly Ala Gly Thr Lys Leu Glu Met Lys
100 105
<210> 139
<211> 116
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.102 VH
<400> 139
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Met Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Ala Ser Gly Asp Thr Phe Thr Asp Tyr
20 25 30
Asn Ile His Trp Val Lys Gln Asn Gln Gly Lys Ser Leu Glu Trp Ile
35 40 45
Gly Glu Val Asn Pro Asn Ile Gly Gly Ile Gly Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Met Gly Arg Trp Tyr Phe Asp Val Trp Gly Ala Gly Thr Thr Val
100 105 110
Thr Val Ser Ser
115
<210> 140
<211> 112
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.114 VL
<400> 140
Asp Val Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Ser Leu Gly
1 5 10 15
Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Val His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu His Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Ser Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Phe Cys Ser Gln Ser
85 90 95
Thr His Val Pro Phe Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 141
<211> 115
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.114 VH
<400> 141
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Met Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
Tyr Met His Trp Val Lys Gln Ser His Gly Lys Ser Leu Glu Trp Ile
35 40 45
Gly Arg Val Asn Thr Asn Asn Gly Gly Thr Ser Tyr Asp Gln Lys Phe
50 55 60
Glu Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Asn Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Val Ile Pro Ala Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ala
115
<210> 142
<211> 112
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.115 VL
<400> 142
Asp Ile Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Ser Leu Gly
1 5 10 15
Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Val His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu His Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Lys Leu Leu Ile Tyr Arg Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Phe Cys Ser Gln Ser
85 90 95
Thr His Leu Pro Arg Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 143
<211> 114
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.115 VH
<400> 143
Gln Val Gln Leu Gln Gln Ser Gly Ser Val Leu Val Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Trp Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Glu Ile His Pro Asn Ser Gly Asn Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val Asp Thr Ser Ser Ser Thr Ala Tyr
65 70 75 80
Val Asp Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Gly Gly Asn Tyr Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val
100 105 110
Ser Ser
<210> 144
<211> 111
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.120 VL
<400> 144
Asp Ile Val Leu Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Gln Arg Ala Thr Ile Ser Cys Arg Ala Ser Glu Ser Val Asp Ser Tyr
20 25 30
Gly Asn Ser Phe Met His Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Lys Val Leu Ile Tyr Arg Ala Ser Asn Leu Glu Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Arg Thr Asp Phe Thr Leu Thr Ile Asn
65 70 75 80
Pro Val Glu Asp Glu Asp Val Ala Thr Tyr Tyr Cys Gln Gln Ser Asn
85 90 95
Glu Asp Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 145
<211> 117
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.120 VH
<400> 145
Glu Val Gln Leu Glu Gln Ser Gly Thr Val Leu Ala Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Trp Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Ala Phe Tyr Pro Gly Asn Ser Gly Thr Tyr Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Lys Leu Thr Ala Val Thr Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Thr Asn Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ser Arg Ser Gly Ser Gly Arg Phe Ala Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ala
115
<210> 146
<211> 106
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.121 VL
<400> 146
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
His Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Thr Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Asn Thr Pro Pro Thr
85 90 95
Phe Gly Ser Val Thr Lys Leu Glu Ile Lys
100 105
<210> 147
<211> 116
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.121 VH
<400> 147
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Met Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp His
20 25 30
Asn Ile His Trp Val Lys Gln His Gln Gly Lys Ser Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn Pro Asn Thr Gly Gly Thr Gly Tyr Asn Gln Lys Phe
50 55 60
Gln Gly Lys Ala Thr Met Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Val Arg Gly Leu Tyr Phe Phe Asp Tyr Trp Gly Gln Gly Thr Thr Leu
100 105 110
Thr Val Ser Ser
115
<210> 148
<211> 112
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.122 VL
<400> 148
Asp Ile Val Ile Thr Gln Asp Asp Leu Ser Asn Pro Val Thr Ser Gly
1 5 10 15
Glu Ser Val Ser Ile Ser Cys Arg Ser Ser Lys Ser Leu Leu Tyr Lys
20 25 30
Asp Gly Lys Thr Tyr Leu Asn Trp Phe Leu Gln Arg Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Met Ser Thr Arg Ala Ser Gly Val Ser
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Glu Ile
65 70 75 80
Ser Arg Val Lys Ala Glu Asp Val Gly Val Tyr Tyr Cys Gln Gln Leu
85 90 95
Val Glu Tyr Pro Arg Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 149
<211> 113
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.122 VH
<400> 149
Glu Val His Leu Val Glu Ser Gly Gly Asp Leu Val Lys Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Gly Met Ser Trp Val Arg Gln Thr Pro Asp Lys Arg Leu Glu Trp Val
35 40 45
Ala Thr Ile Ser Ser Gly Gly Thr Tyr Thr Tyr Tyr Pro Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Ser Ser Leu Lys Ser Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ser Arg His Gly Trp Gly Trp Gly Gln Gly Thr Leu Val Thr Val Ser
100 105 110
Ala
<210> 150
<211> 106
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.140 VL
<400> 150
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
His Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Thr Pro Pro Thr
85 90 95
Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 151
<211> 120
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.140 VH
<400> 151
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Met Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
Asn Met His Trp Val Lys Gln Asn Gln Gly Lys Ser Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn Pro Asn Thr Gly Gly Thr Gly Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Phe Ser Ser Thr Ala Phe
65 70 75 80
Ile Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Ile Tyr Tyr Cys
85 90 95
Thr Arg Gly Gly Tyr Asp His Tyr Trp Tyr Phe Asp Val Trp Gly Ala
100 105 110
Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 152
<211> 111
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.151 VL
<400> 152
Asp Ile Val Leu Thr Gln Phe Pro Ala Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Gln Arg Ala Thr Ile Pro Cys Arg Ala Ser Glu Ser Val Asp Ser Tyr
20 25 30
Gly Asn Ser Phe Met His Trp Phe Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Lys Leu Leu Ile Tyr Arg Ala Ser Asn Leu Glu Ser Glu Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Asn
65 70 75 80
Pro Val Glu Ala Asp Asp Val Ala Thr Tyr Tyr Cys Gln Gln Ser His
85 90 95
Glu Asp Pro Tyr Thr Phe Gly Gly Gly Thr Lys Met Glu Ile Lys
100 105 110
<210> 153
<211> 117
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.151 VH
<400> 153
Glu Val Gln Leu Gln Gln Ser Gly Thr Val Leu Ala Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Trp Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Ala Ile Tyr Pro Gly Lys Asn Asp Thr Thr Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Ala Lys Leu Thr Ala Val Thr Ser Ala Ser Thr Leu Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Thr Asn Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Ser Gly Lys Gly Tyr Phe Ala Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ala
115
<210> 154
<211> 112
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.156 VL
<400> 154
Asp Val Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Ser Leu Gly
1 5 10 15
Asp Gln Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Ile Val His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu Glu Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Lys Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Leu Gly Val Tyr Tyr Cys Phe Gln Gly
85 90 95
Ser His Val Pro Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 155
<211> 118
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.156 VH
<400> 155
Gln Val Thr Leu Lys Glu Ser Gly Pro Gly Ile Leu Gln Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ser Phe Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Gly Met Gly Val Ser Trp Ile Arg Lys Thr Ser Gly Lys Gly Leu Glu
35 40 45
Trp Leu Ala His Ile Phe Trp Asp Asp Asp Lys Trp Tyr Asn Pro Ser
50 55 60
Leu Lys Ser Arg Leu Thr Ile Ser Lys Ala Thr Ser Ser Asn Gln Val
65 70 75 80
Phe Leu Ile Leu Thr Ser Val Asp Thr Ala Asp Thr Ala Thr Tyr Tyr
85 90 95
Cys Ala Thr Phe Tyr Gly Leu Tyr Phe Ala Tyr Trp Gly Gln Gly Thr
100 105 110
Thr Leu Thr Val Ser Ser
115
<210> 156
<211> 113
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.161 VL
<400> 156
Asp Ile Val Met Ser Gln Ser Pro Ser Ser Leu Ala Val Ser Val Gly
1 5 10 15
Glu Lys Val Thr Met Asn Cys Glu Ser Ser Gln Ser Leu Leu Tyr Asn
20 25 30
Ser Asn Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ser Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Asp Ser Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Val Arg Ala Asp Asp Pro Ala Val Tyr Tyr Cys Gln Gln
85 90 95
Tyr Phe Asn Tyr Pro Leu Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu
100 105 110
Lys
<210> 157
<211> 116
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.161 VH
<400> 157
Glu Val Lys Leu Glu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Met Lys Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Ala
20 25 30
Trp Met Asp Trp Val Arg Gln Ser Pro Glu Lys Gly Leu Glu Trp Val
35 40 45
Ala Glu Ile Arg Ser Lys Pro Asn Asn His Ala Thr Tyr Tyr Ala Glu
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Ser Ser
65 70 75 80
Ala Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Gly Ile Tyr
85 90 95
Tyr Cys Val Ser Thr Gly Thr Ser Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ala
115
<210> 158
<211> 106
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.166 VL
<400> 158
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Ser Ala Ser Ser Ser Ile Ser Tyr Met
20 25 30
His Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Asn Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Thr Pro Pro Thr
85 90 95
Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 159
<211> 117
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.166 VH
<400> 159
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Met Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Ile Phe Thr Asp Tyr
20 25 30
Asn Met His Trp Val Lys Gln Asn Gln Gly Lys Ser Leu Glu Trp Ile
35 40 45
Gly Glu Val Asn Pro Asn Thr Gly Gly Ile Gly Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Asp Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Gly Asn Tyr Cys Phe Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Leu Thr Val Ser Ser
115
<210> 160
<211> 107
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.187 VL
<400> 160
Asp Ile Lys Met Thr Gln Ser Pro Ser Ser Met Tyr Ala Ser Leu Gly
1 5 10 15
Glu Arg Val Thr Leu Thr Cys Lys Ala Ser Gln Asp Ile Asn Ser Tyr
20 25 30
Leu Ser Trp Phe Gln Gln Lys Pro Gly Lys Ser Pro Glu Thr Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Leu Ile Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Gln Asp Tyr Ser Leu Thr Ile Ser Ser Leu Glu Tyr
65 70 75 80
Glu Asp Met Gly Ile Tyr Tyr Cys Leu Gln Tyr Asp Glu Phe Pro Pro
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 161
<211> 118
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.187 VH
<400> 161
Glu Val His Leu Gln Gln Ser Gly Pro Glu Leu Val Asn Pro Gly Ser
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Ala Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
Asn Met Asp Trp Val Lys Gln Ser His Gly Lys Arg Leu Glu Trp Ile
35 40 45
Gly Asn Ile Tyr Pro Asn Asn Gly Gly Ala Gly Tyr Asn Gln Asn Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Ile Thr Ala Ala Trp Phe Ala Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ala
115
<210> 162
<211> 106
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.191 VL
<400> 162
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
His Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Leu Ala Ser Gly Val Pro Ala Arg Phe Thr Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Ser Pro Pro Thr
85 90 95
Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys
100 105
<210> 163
<211> 120
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.191 VH
<400> 163
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Met Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
Asn Met His Trp Val Lys Gln Asn Gln Gly Lys Ser Leu Glu Trp Ile
35 40 45
Gly Glu Ile Asn Pro Asn Thr Gly Gly Thr Gly Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ile Pro Ser Leu Arg Arg Tyr Tyr Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Thr Leu Thr Val Ser Ser
115 120
<210> 164
<211> 111
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.193 VL
<400> 164
Asp Leu Val Leu Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Gln Arg Ala Thr Ile Ser Cys Arg Ala Ser Glu Ser Val Ser Thr Ser
20 25 30
Gly Tyr Ser Tyr Met His Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Lys Leu Leu Ile Tyr Leu Ala Ser Asn Leu Glu Ser Gly Val Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Asn Ile His
65 70 75 80
Pro Val Glu Glu Glu Asp Ala Thr Thr Tyr Tyr Cys Gln His Ser Arg
85 90 95
Glu Leu Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 165
<211> 122
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.193 VH
<400> 165
Gln Val Thr Leu Lys Glu Ser Gly Pro Gly Ile Leu Gln Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ser Phe Ser Gly Phe Ser Leu Ile Thr Tyr
20 25 30
Gly Ile Gly Val Gly Trp Ile Arg Gln Pro Ser Gly Lys Gly Leu Glu
35 40 45
Trp Leu Ala His Ile Trp Trp Asn Asp Asn Lys Tyr Tyr Asn Thr Ala
50 55 60
Leu Lys Ser Arg Leu Thr Ile Ser Lys Asp Thr Ser Asn Asn Gln Val
65 70 75 80
Phe Leu Lys Ile Ala Asn Val Asp Thr Ala Asp Thr Ala Thr Tyr Tyr
85 90 95
Cys Ala Arg Met Val Tyr Tyr Asp Tyr Asp Gly Gly Phe Ala Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ala
115 120
<210> 166
<211> 111
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.199 VL
<400> 166
Asp Ile Val Leu Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Gln Arg Ala Thr Ile Ser Cys Arg Ala Ser Glu Ser Val Asp Ser Tyr
20 25 30
Gly Asn Ser Phe Met His Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Lys Pro Leu Ile Tyr Arg Ala Ser Asn Leu Glu Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Arg Thr Asp Phe Thr Leu Thr Ile Asn
65 70 75 80
Pro Val Glu Ala Asp Asp Val Ala Thr Tyr Tyr Cys Gln Gln Ser Asn
85 90 95
Glu Asp Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 167
<211> 116
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.199 VH
<400> 167
Glu Val Gln Leu Gln Gln Ser Gly Thr Val Leu Ala Arg Pro Gly Ala
1 5 10 15
Ser Val Arg Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Trp Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Ala Ile Tyr Pro Gly Asn Ser Asp Thr Ser Tyr Asn His Lys Phe
50 55 60
Lys Gly Lys Ala Lys Leu Thr Ala Val Thr Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Thr Asn Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Ser Gly Thr Gly Trp Phe Ala Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser
115
<210> 168
<211> 111
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17.200 VL
<400> 168
Asp Ile Val Leu Thr Gln Ser Pro Ala Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Gln Arg Ala Thr Ile Phe Cys Arg Ala Ser Gln Ser Val Asp Tyr Asn
20 25 30
Gly Ile Ser Tyr Met His Trp Phe Gln Gln Lys Pro Gly Gln Pro Pro
35 40 45
Lys Leu Leu Ile Tyr Ala Ala Ser Asn Val Gln Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Asn Ile His
65 70 75 80
Pro Val Glu Glu Glu Asp Ala Ala Thr Phe Tyr Cys Gln Gln Ser Ile
85 90 95
Glu Asp Pro Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 169
<211> 115
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> Murine SC17. VH
<220>
<221> MISC_FEATURE
<223> Murine SC17.200 VH
<400> 169
Gln Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ala Phe Ser Ser Ser
20 25 30
Trp Ile Asn Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Arg Ile Tyr Pro Gly Glu Gly Asp Thr Asn Tyr Ser Gly Asn Phe
50 55 60
Glu Gly Lys Ala Thr Leu Thr Ala Asp Lys Ser Ser Thr Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Val Asp Ser Ala Val Tyr Phe Cys
85 90 95
Thr Arg Gly Leu Val Met Asp Tyr Trp Gly Gln Gly Thr Ala Leu Thr
100 105 110
Val Ser Ser
115
<210> 170
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.16 VL
<400> 170
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Ala Asn Ile Asn Ser Asn
20 25 30
Leu Val Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Ala Ala Thr Asn Leu Ala Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Gln His Phe Trp Gly Thr Pro Arg
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 171
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.16 VH
<400> 171
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
Asn Met Tyr Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Glu Ile Asn Pro Asn Asn Gly Gly Thr Ala Tyr Asn Gln Lys Phe
50 55 60
Arg Gly Lys Val Thr Met Thr Arg Asp Thr Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Asp Lys Gly Phe Asp Tyr Trp Gly Gln Gly Thr Thr Val
100 105 110
Thr Val Ser Ser
115
<210> 172
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.17 VL
<400> 172
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr
35 40 45
Asp Thr Ser Lys Leu Pro Ser Gly Ile Pro Ala Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro Glu
65 70 75 80
Asp Phe Ala Val Tyr Tyr Cys Gln Gln Trp Ser Ser Thr Pro Pro Thr
85 90 95
Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 173
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.17 VH
<400> 173
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
Asn Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Glu Ile Asn Pro Asn Ile Gly Gly Thr Gly Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Arg Val Thr Met Thr Arg Asp Thr Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Thr Tyr Ser Tyr Tyr Ser Tyr Glu Phe Ala Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 174
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.24 VL
<400> 174
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Leu Leu Tyr Ser
20 25 30
Ser Asn Gln Lys Ser Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Lys Gln
85 90 95
Ser Tyr Asn Leu Arg Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
<210> 175
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.24 VH
<400> 175
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Thr Val Lys Ile Ser Cys Lys Val Ser Gly Tyr Thr Phe Thr Asp His
20 25 30
Thr Ile His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Tyr Pro Arg Asp Gly Ser Thr Lys Tyr Asn Glu Glu Phe
50 55 60
Lys Gly Arg Val Thr Ile Thr Ala Asp Thr Ser Thr Asp Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Tyr Ser Asn Tyr Phe Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser
115
<210> 176
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.28 VL
<400> 176
Glu Ile Val Leu Thr Gln Ser Pro Asp Phe Gln Ser Val Thr Pro Lys
1 5 10 15
Glu Lys Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Gly Thr Ser
20 25 30
Ile His Trp Tyr Gln Gln Lys Pro Asp Gln Ser Pro Lys Leu Leu Ile
35 40 45
Lys Tyr Ala Ser Glu Ser Ile Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Asn Ser Leu Glu Ala
65 70 75 80
Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Ser Asn Ser Trp Pro Leu
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 177
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.28 VH
<400> 177
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Arg Ser
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Tyr Ile Ser Ser Gly Ser Gly Gly Thr Thr Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Arg Val Thr Ser Thr Arg Asp Thr Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Gly Val Arg Tyr Phe Asp Val Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser
115
<210> 178
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.34 VL
<400> 178
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile Asn Ser Tyr
20 25 30
Leu Ser Trp Phe Gln Gln Lys Pro Gly Lys Ala Pro Lys Ser Leu Ile
35 40 45
Tyr Arg Ala Asn Arg Leu Val Asp Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Glu Phe Pro Pro
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 179
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.34 VH
<400> 179
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr
20 25 30
Asn Met Asp Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Tyr Pro Asp Asn Gly Gly Ala Gly Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Arg Val Thr Ile Thr Val Asp Thr Ser Ala Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ser Arg Ser Ile Thr Thr Ala Trp Phe Ala Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 180
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.46 VL
<400> 180
Ala Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Ser Val Asn Asn Asp
20 25 30
Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Tyr Tyr Ala Ser Asn Arg Tyr Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Phe Cys Gln Gln Asp Tyr Ser Ser Pro Arg
85 90 95
Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 181
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.46 VH
<400> 181
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Trp Ile Asn Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Asn Ile Phe Pro Asp Thr Thr Thr Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Val Thr Leu Thr Arg Asp Thr Ser Ile Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Arg Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Tyr Tyr Asp Gly Thr Tyr Asp Ala Met Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 182
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.151 VL
<400> 182
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Glu Ser Val Asp Ser Tyr
20 25 30
Gly Asn Ser Phe Met His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro
35 40 45
Arg Leu Leu Ile Tyr Arg Ala Ser Asn Leu Glu Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Ser Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Ser His
85 90 95
Glu Asp Pro Tyr Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 183
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.151 VH
<400> 183
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Ala Ile Tyr Pro Gly Lys Ser Asp Thr Thr Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Gly Lys Gly Tyr Phe Ala Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 184
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.155 VL
<400> 184
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Lys Ser Ser Gln Ser Leu Leu Tyr Ser
20 25 30
Ser Asn Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Lys Ser Gly Val
50 55 60
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys His Gln
85 90 95
Tyr Tyr Ser Tyr Pro Leu Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile
100 105 110
Lys
<210> 185
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.155 VH
<400> 185
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Asn Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Glu Ile His Pro Asn Asn Gly Ser Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Trp Thr Leu Phe Thr Tyr Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val
<210> 186
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.156 VL
<400> 186
Asp Ile Val Met Thr Gln Thr Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Ile Val His Ser
20 25 30
Asn Gly Asn Thr Tyr Leu Glu Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Lys Val Ser Asn Arg Phe Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Phe Gln Gly
85 90 95
Ser His Val Pro Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105 110
<210> 187
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.156 VH
<400> 187
Gln Val Thr Leu Lys Glu Ser Gly Pro Val Leu Val Lys Pro Thr Glu
1 5 10 15
Thr Leu Thr Leu Thr Cys Thr Val Ser Gly Phe Ser Leu Ser Thr Ser
20 25 30
Gly Met Gly Val Ser Trp Ile Arg Gln Pro Pro Gly Lys Ala Leu Glu
35 40 45
Trp Leu Ala His Ile Phe Trp Asp Asp Asp Lys Trp Tyr Asn Pro Ser
50 55 60
Leu Lys Ser Arg Leu Thr Ile Ser Lys Asp Thr Ser Lys Ser Gln Val
65 70 75 80
Val Leu Thr Met Thr Asn Met Asp Pro Val Asp Thr Ala Thr Tyr Tyr
85 90 95
Cys Ala Thr Phe Tyr Gly Leu Tyr Phe Ala Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 188
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.161 VL
<400> 188
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Asn Cys Glu Ser Ser Gln Ser Leu Leu Tyr Asn
20 25 30
Ser Asn Gln Lys Asn Tyr Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln
85 90 95
Tyr Phe Asn Tyr Pro Leu Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile
100 105 110
Lys
<210> 189
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.161 VH
<400> 189
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Phe Thr Phe Ser Asp Ala
20 25 30
Trp Met Asp Trp Val Arg Gln Ala Pro Gly Gln Arg Leu Glu Trp Met
35 40 45
Gly Glu Ile Arg Ser Lys Pro Asn Asn His Ala Thr Tyr Tyr Ala Glu
50 55 60
Ser Val Lys Gly Arg Val Thr Ile Thr Arg Asp Thr Ser Ala Ser Thr
65 70 75 80
Ala Tyr Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Ala Arg Thr Gly Thr Ser Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 190
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.200 VL
<400> 190
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Asp Tyr Asn
20 25 30
Gly Ile Ser Tyr Met His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro
35 40 45
Arg Leu Leu Ile Tyr Ala Ala Ser Asn Val Gln Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Ser Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Ser Ile
85 90 95
Glu Asp Pro Pro Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
<210> 191
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.200 VH
<400> 191
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Lys Ile Ser Cys Lys Gly Ser Gly Tyr Ser Phe Thr Ser Ser
20 25 30
Trp Ile Asn Trp Val Arg Gln Met Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Tyr Pro Gly Glu Gly Asp Thr Asn Tyr Ser Gly Asn Phe
50 55 60
Glu Gly Gln Val Thr Ile Ser Ala Asp Lys Ser Ile Ser Thr Ala Tyr
65 70 75 80
Leu Gln Trp Ser Ser Leu Lys Ala Ser Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Thr Arg Gly Leu Val Met Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 192
<211> 111
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.200 VL
<400> 192
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Asp Tyr Asp
20 25 30
Gly Ile Ser Tyr Met His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro
35 40 45
Arg Leu Leu Ile Tyr Ala Ala Ser Asn Val Gln Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Ser Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Ser Ile
85 90 95
Glu Asp Pro Pro Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys
100 105 110
<210> 193
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.155 VH1
<400> 193
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Asp Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Glu Ile His Pro Asn Asn Gly Ser Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Trp Thr Leu Phe Thr Tyr Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val
<210> 194
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.155 VH2
<400> 194
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Glu Ile His Pro Asn Asn Gly Ser Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Trp Thr Leu Phe Thr Tyr Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val
<210> 195
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.155 VH3
<400> 195
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Asn Tyr Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Glu Ile His Pro Asn Asn Gly Ser Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Trp Thr Leu Phe Thr Tyr Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val
<210> 196
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.155 VH4
<400> 196
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Asn Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Glu Ile His Pro Asn Asp Gly Ser Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Trp Thr Leu Phe Thr Tyr Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val
<210> 197
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.155 VH5
<400> 197
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Asn Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Glu Ile His Pro Asn Gly Gly Ser Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Trp Thr Leu Phe Thr Tyr Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val
<210> 198
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.155 VH6
<400> 198
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Asn Ser Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Glu Ile His Pro Asn Ser Gly Ser Thr Asn Tyr Asn Glu Lys Phe
50 55 60
Lys Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Trp Thr Leu Phe Thr Tyr Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val
<210> 199
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.161 VH1
<400> 199
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Asp Ala
20 25 30
Trp Met Asp Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Gly Glu Ile Arg Ser Lys Pro Asn Asn His Ala Thr Tyr Tyr Ala Glu
50 55 60
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Ser
65 70 75 80
Leu Tyr Leu Gln Met Asn Ser Leu Lys Thr Glu Asp Thr Ala Val Tyr
85 90 95
Tyr Cys Ala Arg Thr Gly Thr Ser Tyr Trp Gly Gln Gly Thr Leu Val
100 105 110
Thr Val Ser Ser
115
<210> 200
<211> 4
<212> PRT
<213> Homo sapiens
<220>
<221> MISC_FEATURE
<223> C-terminal cytoplasmic domain motif
<400> 200
Asn Pro Thr Tyr
1
<210> 201
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> His tag
<400> 201
His His His His His His His His His
1 5
<210> 202
<400> 202
000
<210> 203
<400> 203
000
<210> 204
<400> 204
000
<210> 205
<400> 205
000
<210> 206
<400> 206
000
<210> 206
<400> 206
000
<210> 207
<400> 207
000
<210> 208
<400> 208
000
<210> 209
<400> 209
000
<210> 210
<400> 210
000
<210> 211
<400> 211
000
<210> 212
<400> 212
000
<210> 213
<400> 213
000
<210> 214
<400> 214
000
<210> 215
<400> 215
000
<210> 216
<400> 216
000
<210> 217
<400> 217
000
<210> 218
<400> 218
000
<210> 219
<400> 219
000
<210> 220
<211> 321
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.1 VL
<400> 220
caaattgttc tcacccagtc tccagcactc atgtctgcat ctccagggga aaaggtctcc 60
ctgacctgca gtgccaactc aactgtaagt ttcatgtact ggtaccagca gaagccaaga 120
tcctccccca caccctggat ttatctcaca tccaacctgg cttctggagt ccctgctcgc 180
ttcagtggca gtgggtctgg gacctcttac tctcttacaa tcagcagcat ggaggctgaa 240
gatgctgcca cttattactg ccagcagtgg agtagtaact cacccatcac gttcggtgct 300
gggaccaagc tggagctgaa a 321
<210> 221
<211> 351
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.1 VH
<400> 221
gatgtgcagc ttcaggactc aggacctggc ctggtgaaac cttctcagtc tctgtccgtc 60
acctgcactg tcactggcta ctccatcacc tggggttatt actggaactg gatccggcag 120
tttccaggaa acaaactgga gtggatgggt aacatacaca acagtggtgg cactaactac 180
aacccatctc tcaagagtcg aatctctatc actcgagaca catccaagaa ccagttcttc 240
ctgcagttga attctgtgac tactgaggac acagccacat attactgtgc aaccacaaac 300
tgggactact ttgactactg gggccaaggc accactctca cagtctcctc a 351
<210> 222
<211> 336
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.2 VL
<400> 222
gacattgtga tgtcacagtc tccatcctcc ctggctgtgt cagttggaga gaaggtcact 60
atgagctgca agtccagtca gagcctttta tatagtagca atcaaaagag ctacttggcc 120
tggtaccagc agaaaccagg gcagtctcct aaactgttaa tctactgggc atccactagg 180
gaatctgggg tccctgaccg cttcacaggc agtggatcag ggacagattt cactctcacc 240
atcagcagtg tgcaggctga agacctggcc gtttattact gcaagcaatc ttataatctt 300
cggacgttcg gtggaggcac caagctggaa atcaaa 336
<210> 223
<211> 351
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.2 VH
<400> 223
caggttcagc tgcagcagtc tgacgctgag ttggtgaaac ctggagcttc agtgaagata 60
tcctgcaagg tttctggcta caccttcact gaccatacta ttcactggat gaagcagagg 120
cctgaacagg gcctggaatg gattggatat atttatccta gagatggtag tactaagtac 180
aatgaggagt tcaagggcaa ggccacattg actgcagaca aatcctccag cacagcctac 240
atgcagctca acagcctgac atctgaggac tctgcagtct atttctgtgc aagatcatat 300
agtaactact ttgactactg gggccaaggc accactctca cagtctcctc a 351
<210> 224
<211> 333
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.9 VL
<400> 224
gacattgtga tgtcacagtc tccatcctcc ctagctgtgt cagttggaga gaaggttact 60
atgagctgca agtccagtca gagcctttta tatagtagca atcaaaagaa ctacttggcc 120
tggtaccagc agaaaccagg gcagtctcct aaactgctga tttactgggc atccactagg 180
gaatctgggg tccctgatcg cttcacaggc agtggatctg ggacagattt cactctcacc 240
atcagcagtg tgaaggctga agacctggca gtttatttct gtcagcaata ttataactat 300
ccgtacacgt tcggaggggg gaccaagctg aaa 333
<210> 225
<211> 357
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.9 VH
<400> 225
caggtccaac tgcagcaacc tggggctgaa attgtgaggc ctggggcttc agtgaagctg 60
tcctgcaagg cttctggcta cacctttacc gactattgga tgaactgggt aaaacagagg 120
cctggacaag gccttgagtg gatcggagca attgatcctt ctgatagtta tactagctac 180
aatccaaaat tcaagggcaa ggccacattg actgtagaca cctcctccag ctcagcctac 240
atgcagctca gcagcctgac atctgaggac tctgcggtct atttctgtgc aagaagagga 300
acccctggta aaccccttgt ttactggggc caagggactc tggtcactgt ctctgca 357
<210> 226
<211> 321
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.16 VL
<400> 226
gacatccaga tgactcagtc tccagcctcc ctatctgtat ctgtgggaga aactgtcacc 60
atcacatgtc gagcaagtgc gaatattaac agtaatttag tatggtatca gcagaaacag 120
ggaaaatctc ctcagctcct ggtctatgct gcaacaaact tagcggatgg tgtgccatca 180
cggttcagtg gcagtggatc aggcacacag tattccctca agatcaacag cctgcagtct 240
gaagattttg ggaattacta ctgtcaacat ttttggggta ctcctcggac gttcggtgga 300
ggcaccaagc tggaaatcaa a 321
<210> 227
<211> 348
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.16 VH
<400> 227
gaggtccagc tgcaacagtc tggacctgag ctaatgaagc ctggggcttc agtgaagatg 60
tcctgcaagg cttctggata cacattcact gactacaaca tgtactgggt gaagcagaac 120
caaggaaaga gcctagagtg gataggagaa attaatccta acaatggtgg tactgcctac 180
aaccagaagt tcagaggcaa ggccacgttg actgtagaca agtcctccag cacagcctac 240
atggagctcc gcagcctgac atctgaggac tctgcagtct attactgtgc aagatatgat 300
aaggggtttg actactgggg ccaaggcacc actctcacag tctcctca 348
<210> 228
<211> 333
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.38 VL
<400> 228
gacattgtgg tcacccaatc tccagcttct ttggctgtgt ctctggggca gagagccacc 60
atctcctgca gagccagtga aagtgttgaa tattatggca caagtttaat gcagtggttc 120
caacagaaac caggacagcc acccaaactc ctcatctatg ctgcatccaa cgtagaatct 180
ggggtccctg ccaggtttag tggcagtggg tctgggacag acttcagcct caacatccat 240
cctgtggagg aggatgatat tgcaatgtat ttctgtcagc aagataggaa ggttccttgg 300
acgttcggtg gaggcaccaa gctggaaatc aaa 333
<210> 229
<211> 360
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.38 VH
<400> 229
caggttactc tgaaagagtc tggccctggg atattgcagc cctcccagac cctcagtcta 60
acttgttctt tctctgggtt ttcactgaac acatctggta tgagtgtagg ctgggttcgt 120
cagccttcag ggaggggtct ggaatggctg gcccccattt ggtggaatgg tgataagtac 180
tataacccag ccctgaaaag ccggctcaca atctccaagg atacctccaa caaccaggtt 240
ttcctcaaga tcgccagtgt ggtcactgca gatactgcca catacttctg tgctcgaata 300
cggcaatatt actatgctat ggactactgg ggtcaaggaa cctcagtcac cgtctcctca 360
<210> 230
<211> 336
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.3 VL
<400> 230
gacattgtga tgtcacagtc tccatcctcc ctagctgtgt cagttggaga gaaggttact 60
atgagctgca agtccagtca gagcctttta tatagtagca atcaaaagaa ctacttggcc 120
tggtaccagc agaaaccagg gcagtctcct aaactgctga tttactgggc atccactagg 180
gaatctgggg tccctgatcg cttcacaggc agtggatctg ggacagattt cactctcacc 240
atcagcagtg tgaaggctga agacctggca gtttattact gtcagcaata ttatagctat 300
ccgacgttcg gtggaggcac caagctggaa atcaaa 336
<210> 231
<211> 354
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.3 VH
<400> 231
caggtccaac tgcagcagcc tggggctgag cttgtgaagc ctggggcttc agtgaagctg 60
tcctgcaagg cttctggcta caccttcccc agctactgga tacactgtgt gaagcagagg 120
cctggacaag gccttgagtg gattggagtg attaatccta gcaacggtcg tactaactac 180
aatgagaagt tcaagaacaa ggccacactg actgtagaca aatcctccag cacagcctac 240
atgcaactca gcagcctgac atctgaggac tctgcggtct attactgtgt cagggggggg 300
acgggctata ctatggacta ctggggtcaa ggaacctcag tcaccgtctc ctca 354
<210> 232
<211> 321
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.4 VL
<400> 232
gacatcaaga tgacccagtc tccatcttcc atgtatgcct ctctaggaga gagagtcact 60
atcacttgca aggcgagtca ggacattaat agctatttaa cctggttcca gcagaaacca 120
gggaaatctc ctaagaccct gatctatcgt gcaaacagat tgatagatgg ggtcccatca 180
aggttcagtg gcagtggatc tgggcaagat tattctctca ccatcagcag cctggattat 240
gaagatatgg gaatttatta ttgtctacag tatgatgact ttccgtggac gttcggtgga 300
ggcaccaagc tggaaatcaa a 321
<210> 233
<211> 348
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.4 VH
<400> 233
cagatccagt tggtgcagtc tggacctgag ctgaagaagc ctggagagac agtcaagatc 60
tcctgcaagg cttctggtta taccttcaca gactattcaa tgcactgggt gaagcaggct 120
ccaggaaagg gtttaaagtg gctgggctgg ataaacactg agactggcga gccaacatat 180
tcagaagact tcaagggacg gtttgccttc tctttggaaa cctctgccag cactgcctat 240
ttgcagatca acaacctcaa aaatgaagac acggctactt atttctgtgt taaaaataag 300
ggctggtttg cttattgggg ccaagggact ctggtcactg tctctgca 348
<210> 234
<211> 336
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.8 VL
<400> 234
gatgttgtga tgacccaaac tccactctcc ctgcctgtca gtcttggaga tcaagcctcc 60
atctcttgca gatctagtca gagccttgta cacagtaatg gagacaccta tttacattgg 120
tacctgcaga agccaggcca gtctccaaaa ctcctgatct acaaagtttc caaccgattt 180
tctggggtcc cagacaggtt cagtggcagt ggatcaggga cagatttcac actcaagatc 240
agcagagtgg aggctgagga tctgggactt tatttctgct ctcaaagtac acttattccg 300
tacacgttcg gaggggggac caagctggac ataaaa 336
<210> 235
<211> 342
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.8 VH
<400> 235
caggttcacc tgcagcagtc tggaactgaa gtgatgaagc ctggggcctc agtgaagata 60
tcctgcaagg ctactggcta cacattcagt agctactgga tagagtggat aaagcagagg 120
cctggacatg gccttgagtg gattggagag attttgcctg gaagtggtaa tactaacaac 180
aatgagaagt tcaagggcaa ggccacaatc actgcagata catcctccaa tatagcctac 240
atacaattaa gcagcctgac atctgaggac tctgccgtct attactgtgc gggaggcccg 300
gcggcttact ggggccaagg gactctggtc actgtctctg ca 342
<210> 236
<211> 339
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.10 VL
<400> 236
gacattgtga tgtcacagtc tccatcctcc ctagctgtgt cagttggaga gaaggttact 60
atgagctgca agtccagtca gagcctttta tatagtagca atcaaaagaa ctacttggcc 120
tggtaccagc agaaaccagg gcagtctcct aaactgctga tttactgggc atccactagg 180
gaatctgggg tccctgatcg cttcacaggc agtggatctg ggacagattt cactctcacc 240
atcagcagtg tgaagactga agacctggca ctttattact gtcagcaata ttattggttt 300
ccgtacacgt tcggaggggg gaccaagctg gaaataaaa 339
<210> 237
<211> 339
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.10 VH
<400> 237
gaggttcagc tgcagcagtc tggggcagaa cttgtgaagc caggggcctc agtcaagttg 60
tcctgcacag cttctggctt caacattaaa gacacctata tgcactgggt gaagcagagg 120
cctgaacagg gcctggagtg gattggaagg attgatcctg cgaatgttaa tactaaatat 180
gacccgaagt tccagggcaa ggccactata acagcagaca catcctccaa cacagcctac 240
ctgcagctca gcagcctgac atctgaggac actgccgtct attactgtgt tagggggaat 300
gtttactggg gccaagggac tctggtcact gtctctgca 339
<210> 238
<211> 324
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.11 VL
<400> 238
gaaaatgtgc tcacccagtc tccagcaatc atgtctgcat ctccagggga aaaggtcacc 60
atgacctgca gggccagctc aagtgtaagt tccagttact tgcactggta ccagcagaag 120
tcaggtgcct cccccaaact ctggatttat agcacatcca acttggcttc tggagtccct 180
gctcgcttca gtggcagtgg gtctgggacc tcttactctc tcacaatcag cagtgtggag 240
gctgaagatg ctgccactta ttactgccag cagtacagtg attacccatt cacgttcggc 300
tcggggacaa agttggtaat aaaa 324
<210> 239
<211> 366
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.11 VH
<400> 239
gaggtccagc tgcagcagtc tggacctgag ctggtgaaac ctggggcttt agtgatgatg 60
tcctgcaagg cttctggata cacattcact gactactaca tgcactgggt gaagcagagc 120
catggacaga gccttgagtg gattggagag gttattcctt acaatgatga aactttctac 180
aaccggaagt tcaaggacaa ggccacattg actgtagaca aatcctctag tacagcctac 240
atggagctcc ggagcctgac atctgaggac tctgcaatct attattgtgc aagaagacat 300
aggtacgacg ggtttcgtta tgctatagac tactggggtc aaggaacctc agtcaccgtc 360
tcctca 366
<210> 240
<211> 336
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.14 VL
<400> 240
gatgttttga tgacccaaac tccactctcc ctgcctgtca gtcttggaga tcaagcctcc 60
atctcttgca gatctagtca gagcattgtc catagtaatg gaaacaccta tttagagtgg 120
ttcctgcaga aaccaggcca gtctccaaag ctcctgatct acaaagtttc caaccgattt 180
tctggggtcc cagacaggtt cagtggcagt ggatcaggga cagatttcac actcaagatc 240
agcagagtgg aggctgagga tctgggagtt tattactgct ttcaaggttc acatgttccg 300
tacacgttcg gaggggggac caagctggaa ataaaa 336
<210> 241
<211> 354
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.14 VH
<400> 241
gaggtccagc tgcaacagtc tggacctgtg ctggtgaagc ctggggcttc agtgaagatg 60
tcctgtaagg cttctggata cacaatcact gactacaata tgaactgggt gaagcagagc 120
catggaaaga gccttgagtg gattggagtt attaatcctt acaacggtaa tactagatat 180
aaccagatgt tcaagggcaa ggccacattg actgttgaca agtcctccag cacagcctac 240
atggagctca acagcctgac atctgaggac tctgcagtct attactgtac aagatggggt 300
actacggtgg taggtgcgaa ctggggccaa ggcaccactc tcacagtctc ctca 354
<210> 242
<211> 318
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.15 VL
<400> 242
caaattgttc tcacccagtc tccagcactc atgtctgcat ctccagggga gaaggtcacc 60
atgacctgca gtgccagctc aagtgtaaat tacatgtact ggtaccagca gaagccaaga 120
tcctccccca aaccctggat ttatctcaca tccaacctgg cttctggagt ccctgttcgc 180
ttcagtggca gtgggtctgg gacctcttac tctctcacaa tcagcagcat ggaggctgaa 240
gatgctgcca cttactactg ccagcagtgg agtaataacc cacccacgtt cggttctggg 300
accaagctgg agctgaaa 318
<210> 243
<211> 366
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.15 VH
<400> 243
gacgtgaagc tcgtggagtc tgggggaggc ttagtgaagc ttggagggtc cctgaaactc 60
tcctgtgcag cctctggatt cactttcagt agctatgcca tgtcttgggt tcgccagact 120
ccggagaaga ggctggagtg ggtcgcaacc attactagtg gtggtggtaa cacctactat 180
ccagacagtg tgaagggtcg attcaccatc tccagagaca atgccaagaa caccctgtac 240
ctgcaaatga gcagtttgaa gtctgaggac acggccatgt attactgtgc aagaagggat 300
tactacggta gtagttacgt tatgtttgct tattggggcc aagggactct ggtcactgtc 360
tctgca 366
<210> 244
<211> 318
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.17 VL
<400> 244
caaattgttc tcacccagtc tccagcaatc atgtctgcat ctccagggga gaaggtcacc 60
atgacctgca gtgccagctc aagtgtaagt tacatgcact ggtaccagca gaagtcaggc 120
acctccccca aaagatggat ttatgacaca tccaaactgc cttctggagt ccctgctcgc 180
ttcagtggca gtgggtctgg gacctcttac tctctcacaa tcagcagcat ggaggctgaa 240
gatgctgcca cttattactg ccagcagtgg agtagtaccc cacccacgtt cggtgctggg 300
accaagctgg agctgaaa 318
<210> 245
<211> 360
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.17 VH
<400> 245
gaggtccagc tgcaacagtc tggacctgag gtaatgaagc ctggggcttc agtgaagatg 60
tcctgcaagg cttctggata cacattcact gactacaaca tgcactgggt gaagcagaac 120
caaggaaaga gcctagagtg gataggagaa attaatccta acattggtgg tactggctac 180
aaccagaagt tcaaaggcaa ggccacattg actgtacaca agtcctccag cacagcctac 240
atggagctcc gcagcctgac atctgaggac tctgcagtct attactgtgc aagaacctat 300
agttactata gttacgagtt tgcttactgg ggccaaggga ctctggtcac tgtctctgca 360
<210> 246
<211> 321
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.18 VL
<400> 246
gacatccaga tgacacaatc ttcatcctac ttgtctgtat ctctaggagg cagagtcacc 60
attacttgca aggcaagtga ccacattaat aattggttag cctggtatca gcagaaacca 120
ggaaatgctc ctaggctctt aatatctggt gcaaccagtt tggaaactgg ggttccttca 180
agattcagtg gcagtggatc tggaaaggat tacactctca gcattaccag tcttcagact 240
gaagatgttg ctacttatta ctgtcaacag tattggagta ttccgctcac gttcggtgcg 300
gggaccaagc tggagctgaa a 321
<210> 247
<211> 369
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.18 VH
<400> 247
caggttactc tgaaagagtc tggccctggg atattgcagc cctcccagac cctcagtctg 60
acttgttctt tctctgggtt ttcactgagc acttctacta tgggtgtagg ctggattcgt 120
cagccttcag gaaagggtct agagtggctg gcagacattt ggtgggatga cagtaagtac 180
tataatccat ccctgaagag ccggctcaca atctccaagg atacctccag caaccaggta 240
ttcctcaaga tcaccagtgt ggacactgca gatactgcca cttactactg tgcgcgaaag 300
ggaaggacag ctcgggctac gagagggttt gcttactggg gccacgggac tctggtcact 360
gtctctgca 369
<210> 248
<211> 327
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.19 VL
<400> 248
gacattgtgc tgacccaatc tccagcttct ttggctgtgt ctctagggca gagggccgcc 60
atctcttgca agcccagcca aagtgttgat tatgatggtg atagttatat gaactggtac 120
caacagaaac caggccagcc acccaaactc ctcatttatg ctgcatccaa tctagaatct 180
gggatcccag ccaggtttag tggcagtggg tctgggacag acttcaccct caacatccat 240
cctgtggagg aggaggatgc tgcaacctat tactgtcacc aaattaatga cgatccgtgg 300
acgttcggtg gaggcaccaa gctgaaa 327
<210> 249
<211> 363
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.19 VH
<400> 249
gatgtgcagc ttcaggagtc aggacctggc ctggtgaaac cttctcagtc tctgtctgtc 60
acctgcactg tcactggcta ctccatcacc agtagttata cctggaactg gatccggcag 120
tttccaggaa acaaactgga gtggatgggc tacatacatt acagtggtag cactaactac 180
aacccatctc tcagaagtcg aatctctatt actcgagaca cgtccaagaa ccagttcttc 240
ctgcagttga attctgtgac tactgaggac acagccacat attactgtgc aagatcccgt 300
tattactacg atgcttacgg gtttgcttac tggggccaag ggactctggt cactgtctct 360
gca 363
<210> 250
<211> 336
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.22 VL
<400> 250
gatgttgtgt tgacccaaac tccactctcc ctgcctgtca gtcttggaga tcaagcctcc 60
atctcttgca gatctagtca gagcattgta cacattaata gacacaccta cttaggatgg 120
tacctgcaga aaccaggcca gtcgctaaag ctcctgatat atggggtttc caaccgattt 180
tctggggtcc cagacaggtt cagtggcagt ggatcaggga cagatttcac actcaagatc 240
agcagagtgg aggctgagga tatgggagtt tattactgct ttcaaggtac acatgttcca 300
ttcacgttcg gctcggggac aaagttggaa ataaaa 336
<210> 251
<211> 363
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.22 VH
<400> 251
cagatccaga tgatgcagtc tggacctgag ctgaagaagc ctggagagac agtcaagatc 60
tcctgcaagg cttctgggta ttccttcaca aactatggaa tgaactgggt gaagcaggct 120
ccaggaaagg gtttaaagtg gatgggctgg ataaacacct acactggaga gccaacatat 180
gctgatgact tcaagggacg gtttgccttc tctttggaaa cctctgccag cactgcctat 240
ttgcagatca acaacctcaa aaatgaggac atggctacat atttctgtac aagaggttac 300
tacggtagta gctacgatgc tttggactac tggggtcaag gaacctcagt caccgtctcc 360
tca 363
<210> 252
<211> 336
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.24 VL
<400> 252
gacattgtga tgtcacagtc tccatcctcc ctggctgtgt cagttggaga gaaggtcact 60
atgagctgca agtccagtca gagcctttta tatagtagca atcaaaagag ctacttggcc 120
tggtaccagc agaaaccagg gcagtctcct aaactgttaa tctactgggc atccactagg 180
gaatctgggg tccctgaccg cttcacaggc agtggatcag ggacagattt cactctcacc 240
atcagcagtg tgcaggctga agacctggcc gtttattact gcaagcaatc ttataatctt 300
cggacgttcg gtggaggcac caagctggaa atcaaa 336
<210> 253
<211> 351
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.24 VH
<400> 253
caggttcagc tgcagcagtc tgacgctgag ttggtgaaac ctggagcttc agtgaagata 60
tcctgcaagg tttctggcta caccttcact gaccatacta ttcactggat gaagcagagg 120
cctgaacagg gcctggaatg gattggatat atttatccta gagatggtag tactaagtac 180
aatgaggagt tcaagggcaa ggccacattg actgcagaca aatcctccag cacagcctac 240
atgcagctca acagcctgac atctgaggac tctgcagtct atttctgtgc aagatcatat 300
agtaactact ttgactactg gggccaaggc accactctca cagtctcctc a 351
<210> 254
<211> 336
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.27 VL
<400> 254
gatgttgtga tgacccagac tccactcact ttgtcggtta ccattggaca accagcctcc 60
atctcttgca agtcaagtca gagcctctta gaaagtgatg gaaagacata tttgaattgg 120
ttgttacaga ggccaggcca gtctccaaag cgcctaatct atctggtgtc taaactggac 180
tctggagtcc ctgacaggtt cacgggcagt ggatcaggga cagatttcac actgaaaatc 240
agcagagtgg aggctgagga tttgggagtt tattattgct ggcaaggtat acaacatcct 300
cggacgttcg gtggaggcac caagctggaa atcaaa 336
<210> 255
<211> 339
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.27 VH
<400> 255
caggttcaac tgcagcagtc tggggctgag ctggtgaggc ctggggcttc agtgacgctg 60
tcctgcaagg cttcgggcta cacatttact gactatgaaa tgcactgggt gaagcagaca 120
cctgtgcatg gcctggaatg gattggaggt attgatcctg aaactggtgg tactgcctac 180
aatcagaagt tcaagggcaa ggccacactg actgcagaca aatcctccag cacagcctac 240
atggagctcc gcagcctgac atctgaggac tctgccgtct acttctgtac aagatggttt 300
tcttactggg gcccagggac tctggtcact gtctctgca 339
<210> 256
<211> 321
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.28 VL
<400> 256
gacatcttgc tgactcagtc tccagccatc ctgtctgtga gtccaggaga aggagtcagt 60
ttctcctgca gggccagtca gagcattggc acaagcatac actggtatca gcaaagaaca 120
aatggttctc caagacttct cataaagtat gcttctgagt ctatctctgg gatcccttct 180
aggtttagtg gcagtgggtc agggacagat tttactcttc gcatcaacag tctggagtct 240
gaagatattg cagattatta ctgtcaacaa agtaatagct ggccactcac gttcggtgct 300
gggaccaagc tggagctgaa a 321
<210> 257
<211> 351
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.28 VH
<400> 257
caggtccacc tgccgcagtc tagacctgaa ctggtgaagc ctggagcttc agtgaagata 60
tcctgcaagg cttctggcta cggcttcaca cgcagctata tacactgggt gaagcagagg 120
cctggacagg gcctagagtg gattggatat atttcttctg gaagtggtgg tactacctac 180
aatcagaagt ttaagggcaa ggcctcactg actgcagaca atccctccag cactgcctac 240
atgcatctca gtagcctgac atctgaggac tctgcgatct atttctgtgc aagagggggg 300
gtacggtact tcgatgtctg gggcgcaggg accacggtca ccgtctcctc a 351
<210> 258
<211> 321
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.29 VL
<400> 258
gacattgtga tgacccagtc tcacaaattc atgtccacat cagtaggaga cagggtcagc 60
atcacctgca aggccagtca ggatgtgggt actgatgtag cctggtatca acagaaacca 120
gggcaatctc ctaaactact gatttactgg gcatccaccc ggcacactgg agtccctgat 180
cgcttcacag gcagtggatc tgggacagat ttcactctca ccattagcaa tgtgcagtct 240
gaagacttgg cagattattt ctgtcagcaa tatagcagct atccgtacac gttcggaggg 300
gggacaaagc tggaaataaa a 321
<210> 259
<211> 348
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.29 VH
<400> 259
gaggtccagc tgcaacagtc tggacctgag ctaatgaagc ctggggcttc agtgaagatg 60
tcctgcaagg cttctggata cacattcact gactacaaca tgcactgggt gaagcagaac 120
caaggaaaga gcctagagtg gattggagaa attaatcctc acaatggtgg tactggctac 180
aaccagaagt tcaaaggcaa ggccacattg actgtagaca agtcctccag cacatcctac 240
atggagctcc gcagcctgac atctgaggac tctgcagtct attactgtgc aggcggttac 300
ccggcctttg actactgggg ccaaggcacc actctcacag tctcctca 348
<210> 260
<211> 324
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.30 VL
<400> 260
gaaaatgtgc tcacccagtc tccagcaatc gtgtctgcat ctccagggga aaaggtcacc 60
atgacctgca gggccagctc aagtgtaatt tccagttact tgcactggta ccagcagaag 120
tcaggtgcct cccccaaact ctggatttat agcacatcca acttggcttc tggagtccct 180
gctcgcttca gtggcagtgc gtctgggacc tcttactctc tcacaatcag cagtgtggag 240
gctgaagatg ctgccactta ttactgccag cagtacagtg gttacccgct cacgttcggt 300
gctgggacca agctggagct gaaa 324
<210> 261
<211> 372
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.30 VH
<400> 261
gaagtgaagc tggtggagtc tgagggaggc ttagtgcagc ctggaagttc catgaaactc 60
tcctgcacag cctctggatt cactttcagt gactattaca tggcttgggt ccgccaggtt 120
ccagaaaagg gtctagaatg ggttgcaaac attaattatg atggtagtag cacttactat 180
ctggactcct tgaagagccg tttcatcatc tcgagagaca atgcaaagaa cattctatac 240
ctgcaaatga gcagtctgaa gtctgaggac acagccacgt attactgtgc aagagatgat 300
tattacggta gtagcccaag ctactggtac ttcgatgtct ggggcgcagg gaccacggtc 360
accgtctcct ca 372
<210> 262
<211> 321
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.32 VL
<400> 262
gacatccaga tgactcagtc tccagcctcc ctatctgcat ctgtgggaga aactgtcacc 60
atgacatgtc gagcaagtgg gaatattcac aattatttag tatggtatca gcagaaacag 120
ggaaaatctc ctcagctcct ggtctataat gcaaaaacct tagcagatgg tgtgccatca 180
aggttcagtg gcagtggatc aggaacacaa tattctctca agatcaacag cctgcagcct 240
gaagattttg ggagttatta ctgtcaacat ttttggagta ctcctccgac gttcggtgga 300
ggcaccaagc tggaaatcaa a 321
<210> 263
<211> 357
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.32 VH
<400> 263
gaagtgaaac ttgaggagtc tggaggaggc ttggtgcaac ctggaggatc catgaaactc 60
tcctgtgttg cctctggatt cactttcagt aactactgga tgagctgggt ccgccagtct 120
ccagagaagg ggcttgagtg ggttgctgaa attagattga aatctaataa ttatgcaaca 180
cattatgcgg agtctgtgaa agggaggttc accatctcaa gagacgattc caaaagtagt 240
gtcttcctgc aaatgaacaa cttaagaact gaagacactg gcatttatta ctgtaccagg 300
cactattact atgctatgga ctactggggt caaggaacct cagtcaccgt ctcctca 357
<210> 264
<211> 321
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.34 VL
<400> 264
gacatcaaga tgacccagtc tccatcttcc atgtatgcat ctctaggaga gagagtcact 60
atcacctgca aggcgagtca ggacattaat agctatttaa gctggttcca gcagaaacca 120
gggaaatctc ctaagaccct gatctatcgt gcaaacagat tggtagatgg ggtcccatca 180
aggttcagtg gcagtggatc tgggcaagat tattctctca ccatcagtag cctggagtat 240
gaagatatgg gaatttatta ttgtctacag tatgatgagt ttcctccgac gttcggtgga 300
ggcaccaagc tggaaatcaa a 321
<210> 265
<211> 354
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.34 VH
<400> 265
gaggtccagc tacaacagtc tggacctgag ctggtgaagc ctgggtcttc agtgaagata 60
tcctgcaagg cttctggata cacattcact gactacaaca tggactgggt gaagcagagc 120
catggaaaga gacttgagtg gattggatat atttatcctg acaatggtgg tgctggctac 180
aaccagaagt tcaagggcaa ggccacattg actgtagaca agtcctccag cacagcctac 240
atggagctcc gcagcctgac atctgaggac tctgcagtct attactgttc aagatccatt 300
actacggctt ggtttgctta ctggggccaa gggactctgg tcactgtctc tgca 354
<210> 266
<211> 324
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.35 VL
<400> 266
gaaaatgtgc tcacccagtc tccagcaatc atgtctgcat ctccagggga aaaggtcacc 60
ctgacctgca gggccagctc aagtatgagt tccagttact tgcactggta ccagcagaag 120
tcaggtgcct cccccaaact ctggatttat agcacatcca acttggcttc tggagtccct 180
gctcgcttca gtggcagtgg gtctgggacc tcttactctc tcacaatcag cagtgtggag 240
gctgaagatg ctgccactta ttactgccag cagtacagtg cttacccatt cacgttcggc 300
tcggggacaa agttggaaat aaaa 324
<210> 267
<211> 363
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.35 VH
<400> 267
gaggtccagc tgcagcagtc tggacctgag ctagtgaaac ctggggcttt agtgaagatg 60
tcctgcaagg cttctggata cacattcact gactactaca tacactgggt gaagcagagc 120
catggaaaga gccttgagtg gattggagaa attaatcctt acaatggtga gactttctac 180
aaccagaagt tcaagggcaa ggccacattg actgtagaca aatcctctag tacagcctac 240
atggaactcc ggagcctgac atctgaggac tctgcagtct attattgtgc aagaagggga 300
tggtatctaa caggctatgc tatggactac tggggtcaag gaacctcagt caccgtctcc 360
tca 363
<210> 268
<211> 318
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.36 VL
<400> 268
caaattgttc tcacccagtc tccagcactc atgtctgcat ctccagggga gaaggtcacc 60
atgacctgca gtgccagctc aagtgtaagt tacatgtact ggtaccagca gaagccaaga 120
tcctccccca aaccctggat ttatctcaca tccaacctgg cttctggagt ccctgctcgc 180
ttcagtggca gtgggtctgg gacctcttac tctctcacaa tcagcagcat ggaggctgaa 240
gatgctgcca cttattactg ccagcagtgg agtagtaacc cacccacgtt cggagggggg 300
accaagctgg aaataaaa 318
<210> 269
<211> 360
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.36 VH
<400> 269
gaggtgcagc ttcaggagtc aggacctagc ctcgtgaaac cttctcagtc tcagtccctc 60
acctgttctg tcactggcga ctccatcacc agtgattact ggaactggat ccggaaattc 120
ccagggaaga aagttgagta catggggtac ataaactaca gtggtagcac ttactacaat 180
ccatctctca aaagtcgaat ctccatcact cgagacacat ccaagaacca gtactacctg 240
cagttgaact ctgtgacttc tgaggacaca gccacatatt actgtgcacg tacctcgtac 300
tataataagt ttctaccatt tgcttactgg ggccaaggga ctctggtcac tgtctctgca 360
<210> 270
<211> 336
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.39 VL
<400> 270
gatgttttaa tgacccaaac tccactctcc ctgcctgtca gtcttggaga tcaagcctcc 60
atctcttgca gatctagtca gagtcttgta cacagaaatg gaaacaccta ttttcattgg 120
tacctgcaga agccaggcca gtctccaaag ctcctgatct acaaagtttc caaccgattt 180
tctggggtcc cagacaggtt cagtggcagt ggatcaggga cagatttcac actcaagatc 240
agcagagtgg aggctgagga tctgggagtt tatttctgct ctcaaagtac atatgttccg 300
tggacgttcg gtggaggcac caagctggaa atcaaa 336
<210> 271
<211> 351
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.39 VH
<400> 271
gaggtgcagc tggtggagtc tgggggaggc ttagtgcagc ctggagggtc ccggaaactc 60
tcctgtgcag cctctggatt cactttcagt agctatggaa tgcactgggt ccgtcaggct 120
ccagagaagg ggctggagtg ggtcgcatat attagtagta acgatggtac catctactat 180
gcagacacag tgaggggccg attcaccatc tccagagaca atgccaagaa caccctgttc 240
ttgcaaatga ccagtctaag gtctgaggac acggccatgt attactgtgc aagaccttct 300
aactgggtct ttgactactg gggccaaggc accactctca cagtctcctc a 351
<210> 272
<211> 336
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.40 VL
<400> 272
gatgttgtga tgacccaaac tccactctcc cggcctgtca ctcttggaga tcaagcctcc 60
atctcttgca gatctagtca gagccttgta cacagtaatg gaaacaccta tttacattgg 120
tacctgcaga agccaggcca gtctccaaag ctcctgatct acaaagtttc caaccgattt 180
tctggggtcc ctgacaggtt cagtggcagt ggatcaggga cagatttcac actcaagatc 240
agcagagtgg aggctgagga tctgggagtt tatttctgct ctcaaaatac acatgttcca 300
ttcacgttcg gctcggggac aaagttggaa ataaaa 336
<210> 273
<211> 348
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.40 VH
<400> 273
caggtccaac tgcagcagcc tggggctgaa attgtgaggc ctggggcttc agtgaagctg 60
tcctgcaagg cttctggcta cacctttacc gactattgga tgaactgggt gaagcagagg 120
cctggacaag gccttgagtg gatcggaaca attgatcctt ctgatagtta tactcgttac 180
aatcaaaagt tcaagggcaa ggccacattg actgtagaca catccttcag ctcagcctac 240
atgcagctca gcagcctgac atctgaggac tctgcggtct atttctgtgc aagtggggga 300
cgggggtttg gttactgggg ccaagggact ccggtcactg tctctgta 348
<210> 274
<211> 318
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.41 VL
<400> 274
caaattgttc tcacccagtc tccagcactc atgtctgcat ctccagggga gaaggtcacc 60
atgacctgca gtgccagctc aagtgtaagt tacatgtact ggtaccagca gaagccaaga 120
tcctccccca aaccctggat ttatctcaca tccaacctgg cttctggagt ccctactcgc 180
ttcagtggca gtgggtctgg gacctcttac tctctcacaa tcagcagcat gggggctgaa 240
gatgctgcca cttattactg ccagcagtgg aatactaacc cacccacgtt cggtgctggg 300
accaagctgg agctgaaa 318
<210> 275
<211> 363
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.41 VH
<400> 275
gacgtgaagc tcgtggagtc tgggggaggc ttagtgaagc ttggagggtc cctgaaactc 60
tcctgtgcag cctctggatt cactttcagt agctatgcca tgtcttgggt tcgccagact 120
ccggagaaga ggctggagtg ggtcgcaacc attagtagtg gtggtggtaa cacctactat 180
ccagacagtg tgaagggtcg attcaccatc tccagagaca atgccaagaa caccctgtac 240
ctgcaaatga gcagtttgaa gtctgaggac acggccatgt attactgtgc aagaagggat 300
tactacggta ctagctacgt tatgtttgct tactggggcc aagggactct ggtcactgtc 360
tct 363
<210> 276
<211> 318
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.42 VL
<400> 276
gaaaatgttc tcacccagtc tccagcaatc atgtctgcat ctccagggga aaaggtcacc 60
atgacctgta gtgccagctc aagtgtaaat tacatgtact ggtaccagca gaagtcaagc 120
acctccccca aactctggat ttatgacaca tccaaactga cttctggagt cccaggtcgc 180
ttcagtggca gtgggtctgg aaactcttac tctctcacga tcagcaacat ggaggctgaa 240
gatgttgcca cttattactg ttttcagggg agtgggtacc cactcacgtt cggctcgggg 300
acaaaattgg aaataaaa 318
<210> 277
<211> 336
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.42 VH
<400> 277
gacgtgaagc tggtggagtc ggggggaggc ttagtgaggc ctggagggtc cctgaaactc 60
tcctgtgcag cctctggatt cactttcagt agatatacca tgtcttgggt tcgccagaca 120
ccggagaaga ggctggagtg ggccgcaacc attaatagtg gtggtagtaa cacctactat 180
ccagacagtg tgaagggccg attcaccatc tccagagaca atgccaagaa caccctgttc 240
ctgcaaatga gcagtctgaa gtctgaggac acagccatgt attactgtac aaatggtaac 300
cactggggcc aaggcaccac tctcacagtc tcctca 336
<210> 278
<211> 318
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.45 VL
<400> 278
gaaaatgttc tcacccagtc tccagcaatc atgtctgcat ctccagggga aaaggtcacc 60
atgacctgta gtgccagctc aagtgtaaat tacatgtact ggtaccagca gaagtcaagc 120
acctccccca aactctggat ttatgacaca tccaaactga cttctggagt cccaggtcgc 180
ttcagtggca gtgggtctgg aaactcttac tctctcacga tcagcaacat ggaggctgaa 240
gatgttgcca cttattactg ttttcagggg agtgggtacc cactcacgtt cggctcgggg 300
acaaaattgg aaataaaa 318
<210> 279
<211> 342
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.45 VH
<400> 279
caggtgcaac tgcagcagcc tgggtctgtg ctggtgaggc ctggagattc agtgaagctg 60
tcgtgcaagg cttctggcta cacattcacc agctactgga tgcactgggt gaagcagagc 120
cctggacaag gccttgagtg gattggagag attcatcctc atagtggtag tactaactac 180
aatgagaagt tcaagggcaa ggccacactg actgtagaca catcctccag cacagcctac 240
gtggatctca gcagcctgac atctgaggac tctgcggtct attactgtgt aggtggtcac 300
tacgactact ggggccaagg caccactctc acagtctcct ca 342
<210> 280
<211> 321
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.46 VL
<400> 280
agttttgtga tgacccaaac tcccaaattc ctgcttgtat cagcaggaga cagggttacc 60
ataacctgca aggccagtca gagtgtgaat aatgatgtag cttggtacca acagaagcca 120
gggcagtctc ctaaactgct gatatactat gcatccaatc gctacactgg agtccctgat 180
cgcttcactg gcagtggata tgggacggat ttcactttca ccatcagcac tgtgcaggct 240
gaagacctgg cagtttattt ctgtcagcag gattatagct ctcctcggac gttcggtgga 300
ggcaccaagc tggaaatcaa a 321
<210> 281
<211> 357
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.46 VH
<400> 281
caggtccaac tgcagcagcc tggtgctgag cttgtgaagc ctggggcctc aatgaagctg 60
tcctgcaagg cttctggcta cactttcacc agctactgga taaactgggt gaagcagagg 120
cctggacaag gccttgagtg gattggaaat atttttcctg atactactac tactaactac 180
aatgagaagt tcaagagcaa ggccacactg actgtagaca catcctccag cacagcctat 240
atgcagctca gcagcctgac atctgacgac tctgcggtct attattgtgc aagggagtac 300
tacgatggta cctacgatgc tatggattac tggggtcaag gaacctcagt caccgtc 357
<210> 282
<211> 318
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.47 VL
<400> 282
caaattgttc tcacccagtc tccagcaatc atgtctgcat ctccagggga gaaggtctcc 60
atgacctgca gtgccagctc aagtgtaagt tacatgcact ggtaccagca gaagtcaggc 120
acctccccca aaagatggat ttatgacaca tccaaactgg cttctggagt ccctgctcgc 180
ttcagtggca gtgggtctgg gtcctcttac tctctcacaa tcagcagcat ggaggctgaa 240
gatgctgcca cttattactg ccagcagtgg agtagcaccc cccccacgtt cggagggggg 300
accaagctgg aaataaaa 318
<210> 283
<211> 357
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.47 VH
<400> 283
gaggtccagc tgcagcagtc tggacctgag ctggtgaagc ctggggcttc agtgaagata 60
tcctgcaagg cttctggtta ctcattcact gactactaca tgcgctgggt gaagcaaagt 120
cctgaaaaga gccttgagtg gattggagag attaatccta gcactggtgg tactacctac 180
aaccagaact tcaaggccaa ggccacattg actgtagaca aatcctccag cacagcctac 240
atgcagctca agagcctgac atctgaggac tctgcagtct attactgtgc aagagggggt 300
tacttcttgt actactttga ctactggggc caaggcacca ctctcacagt ctcctca 357
<210> 284
<211> 336
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.49 VL
<400> 284
gatgttgtga tgacccagac tccactcact ttgtcggtta ccattggaca accagcctcc 60
atctcttgca agtcaagtca gagcctctta gaaagtgatg gaaagacata tttgaattgg 120
ttgttacaga ggccaggcca gtctccaaag cgcctaatct atctggtgtc taaactggac 180
tctggagtcc ctgacaggtt cacgggcagt ggatcaggga cagatttcac actgaaaatc 240
agcagagtgg aggctgagga tttgggagtt tattattgct ggcaaggtat acaacatcct 300
cggacgttcg gtggaggcac caagctggaa atcaaa 336
<210> 285
<211> 339
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.49 VH
<400> 285
caggttcaac tgcagcagtc tggggctgag ctggtgaggc ctggggcttc agtgacgctg 60
tcctgcaagg cttcgggcta cacatttact gactatgaaa tgcactgggt gaagcagaca 120
cctgtgcatg gcctggaatg gattggaggt attgatcctg aaactggtgg tactgcctac 180
aatcagaagt tcaagggcaa ggccacactg actgcagaca aatcctccag cacagcctac 240
atggagctcc gcagcctgac atctgaggac tctgccgtct acttctgtac aagatggttt 300
tcttactggg gcccagggac tctggtcact gtctctgca 339
<210> 286
<211> 333
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.50 VL
<400> 286
gacattgtgc tgacacagtc tcctgcttcc ttagctgcat ctctggggca gagggccacc 60
atctcatgca gggccagcca aagtgtcagt acatctagct atagttatat gcactggtac 120
caacagaaac caggacagcc acccaaactc ctcatcaagt atgcatccaa cctagaatct 180
ggggtccctg ccaggttcag tggcagtggg tctgggacag acttcaccct caacatccat 240
cctgtggagg aggaggatac tgcaacatat tactgtcagc acagttggga gattccgtgg 300
acgttcggtg gaggcaccaa gctggaaatc aaa 333
<210> 287
<211> 363
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.50 VH
<400> 287
gaggtgcagc tggtggagtc tgggggaggc ttagtgaagc ctggagggtc cctgaaactc 60
tcctgtgcag cctctggatt cactttcagt gactatggaa tgcactgggt tcgtcaggct 120
ccagagaagg ggctggagtg ggttgcatac attagtagtg gcagtagaac catctactat 180
gcagacacag tgaagggccg attcaccatc tccagagaca atgccaagaa caccctgttc 240
ctgcaaatga ccagtctgag gtctgaggac acggccatgt attactgtgc aagggtttac 300
tacggaagta cctacgggta tttcgatgtc tggggcacag ggaccacggt caccgtctcc 360
tca 363
<210> 288
<211> 333
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.53 VL
<400> 288
gacattgtgc tgacacagtc tcctgcttcc ttagctgcat ctctggggca gagggccacc 60
atctcatgca gggccagtca aagtgtcagt acatctagct atagttatat gcactggtac 120
caacagaagc caggacatcc acccaaactc ctcatcaggt atgcatccaa cctagagtct 180
ggggtccctg ccaggttcag tggcagtggg tctgggacag acttcaccct caacatccat 240
cctgtggagg aggaggatac tgcaacatat tactgtcagc acagttggga gattccgtac 300
acgttcggag gggggaccaa gctggaaata aaa 333
<210> 289
<211> 357
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.53 VH
<400> 289
gaggtccagc ttcagcagtc aggacctgag ctggtgaaac ctggggcctc agtgaagata 60
tcctgcaagg cttctggata cacattcact gactacaaca tgcactgggt gaagcagagc 120
catggaaagc gccttgagtg gattggatat attcatcctt acaatggtgg tagtggctac 180
aaccagaagt tcaagaggaa ggccacattg actgtagaca attcctccaa cacaacctac 240
atggagctcc gcagcctgac atctgaggac tctgcagtct attactgtgc aagatcttat 300
gattacgaca cctggtttgg ttactggggc caagggactc tggtcactgt ccgtgca 357
<210> 290
<211> 336
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.54 VL
<400> 290
gatgttgtgc tgacccagac tccactcact ttgtcggtta ccattggaca accagcctcc 60
atctcttgca agtcaagtca gagcctctta tatagtgatg gaaagacata tttgaattgg 120
ttgttacaga ggccaggcca gtctccaaag cgcctaatct atctggtgtc taaactggac 180
tctggagtcc ctgacaggtt cactggcagt ggatcaggga cagatttcac actgaaaatc 240
agcagagtgg aggctgagga tttgggactt tattattgct ggcaaggtac acattttccg 300
tggacgttcg gtggaggcac caagctggaa atcaaa 336
<210> 291
<211> 339
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.54 VH
<400> 291
gaagtgaaac ttgaggagtc tggaggaggc ttggtgcaac ctggaggatc catgaaactc 60
tcctgtgttg cctctggatt cactttcagt aactactgga taaactgggt ccgccagtct 120
ccagagaagg ggcttgagtg ggttgctgaa atcagaatga aatctaataa ttatgcaaca 180
cattatgcgg agtctgtgaa agggaggttc accatctcaa gagatgattc caaaagttgt 240
gtctacctgc aaatgaacaa cttaagacct gaagacactg gcatttatta ctgtaccagg 300
gggggctact ggggccaagg caccactctc accgtctcc 339
<210> 292
<211> 339
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.56 VL
<400> 292
gacattgtga tgtcacagtc tccatcctcc ctagctgtgt cagttggaga gaaggttact 60
atgagctgca agtccagtca gagcctttta tatagtagca atcaaaagaa ctacttggcc 120
tggtaccagc agaaaccagg gcagtctcct aaactgctga tttactgggc atccactagg 180
gaatctgggg tccctgatcg cttcacaggc agtggatctg ggacagattt cactctcacc 240
atcagcagtg tgaaggctga agacctggca gtttatttct gtcagcaata ttataactat 300
ccgtacacgt tcggaggggg gaccaagctg gaaataaaa 339
<210> 293
<211> 348
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.56 VH
<400> 293
cagatccagt tggtgcagtc tggacctgaa ctgaagaagc ctggagagac agtcaagatc 60
tcctgcaagg cttctgggta taccttcaca aactatggaa tgaactgggt gaagcaggct 120
ccaggaaagg gtttaaagtg gatggcctgg ataaacacct acactggaga gccaacatat 180
gctgatgact tcaagggacg gtttgccttc tctttggaaa cctctgccag cactgcctct 240
ttgcagatca tcaacctcaa aaatgaggac acggctacat atttctgtgc aaggatcggc 300
gatagtagtc cctctgacta ctggggccag ggcaccactc tcacagtc 348
<210> 294
<211> 324
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.57 VL
<400> 294
caaattgttc tcacccagtc tccagcaatc atgtctgcat ctctagggga acgggtcacc 60
atgacctgca ctgccagctc aagtgtaagt tccagttact tgcactggta ccagcagaag 120
ccaggatcct cccccaaact ctggatttat agcacatcca acctggcttc tggagtccca 180
cctcgcttca gtggcagtgg gtctgggacc tcttactctc tcacaatcag cagcatggag 240
gctgaagatg ctgccactta ttactgccac cagtatcatc gttccccacc gacgttcggt 300
ggaggcacca agctggaaat caaa 324
<210> 295
<211> 363
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.57 VH
<400> 295
cagatccagt tggtgcagtc tggacctgaa ctgaagaagc ctggagagac agtcaagatc 60
tcctgcaagg cttctgatta taccttcaca gacttttcaa tacactgggt gaggcagtct 120
ccaggaaagg gtttaaagtg gatgggctgg ataaacactg agactggtga gccaacagtt 180
gcagaagact tcaagggacg gtttgccttc tctttggaga cctctgccag cactgccttt 240
ttgcagatct acaacctcaa aaatgaggac tcggcaacat atttctgtgc tagggggcgt 300
tactacggcc atgactatgc tatggactac tggggtcaag gaacctcagt caccgtctcc 360
tca 363
<210> 296
<211> 321
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.59 VL
<400> 296
gacatccaga tgactcagtc tccagcctcc ctatctgcat ctgtgggaga aactgtcacc 60
atcacatgtc gagcaagtgg gaatcttcac aattatttag catggtatca gcagaaacag 120
ggaaaatctc ctcagctcct ggtctataat gcaaaaacct tagcagatgg tgtgccatca 180
aggttcagtg gcagtggatc aggaacacaa tattctctca agatcaacag cctgcagcct 240
gaagattttg ggacttattt ctgtcaacat ttttggagta ttcctcccac gttcgggggg 300
gggaccaagc tggaaataaa a 321
<210> 297
<211> 357
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.59 VH
<400> 297
gaagtgaagc ttgaggagtc tggaggaggc ttggtgcaac ctgggggatc catgaaactc 60
tcctgtgttg cctctggatt cactttcagt aactattgga tgaactgggt ccgccagtct 120
ccagagaagg ggcttgagtg ggttgctgaa attagattga aatctaataa ttatgcaaca 180
cattatgcgg agtctgtgaa agggaggttc accatctcaa gagatgattc caaaagtagt 240
gtctacctgc aaatgaacaa cttaagagct gaagacactg gcatttatta ctgtaccaga 300
ctctgggact ttgctatgga ctactggggt caaggaacct cagtcaccgt ctcctca 357
<210> 298
<211> 318
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.61 VL
<400> 298
caaattgttc tcacccagtc tccagcaatc atgtctgcat ctccagggga gaaggtcacc 60
atatcctgca gtgccagctc aagtgtaagt tacatatact ggtaccagca gaagccagga 120
tcctccccca aaccctggat ttatcgcaca tccaacctgg cttctggagt ccctgctcgc 180
ttcagtggca gtgggtctgg gacctcttac tctctcacaa tcagcagcat ggaggctgaa 240
gatgctgcca cttattactg ccagcagtat catagttacc cgtggacgtt cggtggaggc 300
accaagctgg aaatcaaa 318
<210> 299
<211> 375
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.61 VH
<400> 299
caggttactc tgaaagagtc tggccctggg atattgcagc cctcccagac cctcagtctg 60
acttgttctt tctctgggtt ttcactgagc acttttggta tgggtgtagg ctggattcgt 120
cagccttcag ggaagggtct ggagtggctg gcacagattt ggtgggatga ttataagtac 180
tataacccag ccctgaagag tcggctcaca atctccaagg atacctccaa aaaccaggta 240
ttcctcaaga tcgccaatgt ggacactgca gatactgcca catactactg tgctcgaatc 300
ggatattact ccggtagtag ccgttgctgg tacttcgatg tctggggcac agggagcacg 360
gtcaccgtct cctca 375
<210> 300
<211> 321
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.63 VL
<400> 300
agtattgtga tgacccagac tcccaaattc ctgcttgtat cagcaggaga cagggttgcc 60
ataacctgca aggccagtca gagtgtgagt aatgatgtag cttggtacca acagaagcca 120
gggcagtctc ctacactgct gatatcctat gcatccaatc gctacactgg agtccctgat 180
cgcttcactg gcagtggata tgggacggat ttcactttca ccatcagcac tgtgcaggct 240
gaagacctgg cagtttattt ctgtcagcag ggttatagct ctccgttcac gttcggaggg 300
gggaccaagc tggaaataaa a 321
<210> 301
<211> 348
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.63 VH
<400> 301
caggttcagc tgcaacagtc tgacgctgag ttggtgaaac ctggggcttc agtgaagata 60
tcctgcaagg ctgctggcta caccttcact gaccttacta ttcactgggt gaaacagagg 120
cctgaacagg gcctggagtg gattggatat atttatcctg gagatagtaa tactaagtac 180
aatgagaagt tcaagggcaa ggccacattg actgcagata aatcctccag cactgcctat 240
atgcagctca acagcctgac atctgaggat tctgtagtgt atttctgtgc aagaatgatt 300
actccttact actttgacta ctggggccaa ggcaccactc tcacagtc 348
<210> 302
<211> 321
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.71 VL
<400> 302
gacatccaga tgactcagtc tccagcctcc ctatctgcct ctgtgggaga aactgtcacc 60
atcgcatgtc gagcaagtgg gaatattcac aattatttaa catggtatca gcagagacag 120
ggaaaatctc ctcagctcct ggtctataat gcaaaaacct tagcagttgg tgtgccatca 180
aggttcagtg gcagtggctc aggaacacaa tattctctca agatcaacag cctgcagcct 240
gaagattttg ggagttatta ctgtcaacat ttttggaata ctcctccgac gttcggtgga 300
ggcaccaagc tggaaatcaa a 321
<210> 303
<211> 357
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.71 VH
<400> 303
gaagtgaagc ttgaggagtc tggaggaggc ttggtgcaac ctggaggatc catgaaactc 60
tcctgtgttg cctctggaat cattttcagt aactactgga tgaattgggt ccgccagtct 120
ccagagaagg ggcttgagtg ggttgctgaa attagattga aatctaataa ttattcaaca 180
cattatgcgg agtctgtgaa agggaggttc accatctcaa gagatgattc caaaagtagt 240
gtctacctgc aaatgaacaa cttaagagct gaagacactg gcatttatta ctgtaccagg 300
cactattact atgctatgga ctactggggt caaggaacct cagtcaccgt ctcctca 357
<210> 304
<211> 321
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.72 VL
<400> 304
gatatccaga tgacacagac tacatcctcc ctgtctgcct ctctgggaga cagagtcacc 60
atcagttgca gtgcaagtca gggcattagc aattatttaa actggtatca gcagaaacca 120
gatggaactg ttaaactcct gatctattac acatcaagtt tacactcagg agtcccatca 180
aagttcagtg gcagtgggtc tgggacagat tattctctca ccatcagcaa cctggaacct 240
gaagatatcg ccacttacta ttgtcagcag tatagtaagc ttccgtacac gttcggaggg 300
gggaccaagc tggaaataaa a 321
<210> 305
<211> 357
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.72 VH
<400> 305
gaggtgcagc tggtggagtc tgggggaggc ttagtgaagc ctggagggtc cctgaaactc 60
tcctgtgcag cctctggatt cactttcagt agctatggca tgtcttgggt tcgccagact 120
ccggagaaga ggctggagtg ggtcgcagcc attaatagta atggtggtag cacctactat 180
ccagacactg tgaagggccg actcaccatc tccagagaca atggcaagaa caccctgtac 240
ctgcaaatga gcagtctgag gtctgaggac acagccttgt attactgtgt aagggatgat 300
ggttactacg ttttctttgc ttactggggc caagggactc tggtcactgt ctctgca 357
<210> 306
<211> 321
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.74 VL
<400> 306
gacatccaga tgacacaatc ttcatcctac ttgtctgtat ctctaggagg cagagtcacc 60
attacttgca aggcaagtga ccacattaat aattggttag cctggtatca gcagaaacca 120
ggaaatgctc ctaggctctt aatatctggt gcaaccagtt tggaaactgg ggttccttca 180
agattcagtg gcagtggatc tggaaaggat tacactctca gcattaccag tcttcagact 240
gaagatgttg ctacttatta ctgtcaacag tattggagta ctcctcccac gttcggtgct 300
gggaccaagc tggagctgaa a 321
<210> 307
<211> 357
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.74 VH
<400> 307
caggtgcagc tgaagcagtc aggacctggc ctagtggcgc cctcacagag cctgtccatc 60
acatgcactg tctctgggtt ctcattaacc agctatggtg tagactgggt tcgccagtct 120
ccaggaaagg gtctggagtg gctgggagtg atatggggtg gtggaagcac aaattataat 180
tcagctctca aatccagact gagcatcacc aaggacaact ccaagagcca agttttctta 240
aaaatgaaca gtctgcaaac tgatgacaca gccatgtact actgtgccag tggagactac 300
gatggtagcc tctggtttgc ttactggggc caagggactc tggtcactgt ctctgca 357
<210> 308
<211> 336
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.76 VL
<400> 308
gatattgtga taacccagga tgaactctcc aatcctgtca cttctggaga atcagtttcc 60
atctcctgca ggtctagtaa gagtctccta tataaggatg ggaagacata cttgaattgg 120
tttctgcaga gaccaggaca atctcctcag ctcctgatct atttgatgtc cacccgtgca 180
tcaggagtct cagaccggtt tagtggcagt gggtcaggaa cagatttcac cctggaaatc 240
agtagagtga aggctgagga tgtgggtgtg tattactgtc aacaacttgt agagtatcct 300
cggacgttcg gtggaggcac caagctggaa atcaaa 336
<210> 309
<211> 339
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.76 VH
<400> 309
gaggtgcagc tggtggagtc tgggggagac ttagtgaagc ctggagggtc cctgaaactc 60
tcctgtgtag cctctggatt cactttcagt agctatggca tgtcttgggt tcgccagact 120
ccagacaaga ggctggagtg ggtcgcaacc attagtagtg gtggtacttt cacctactat 180
ccagacagtg tgaaggggcg attcaccgtc tccagagaca atgccaagaa caccctgtac 240
ctgcaaatga gcagtctgaa gtctgaggac acagccatgt attactgttc aagacatggg 300
tggggctggg gccaagggac tctggtcact gtctctgca 339
<210> 310
<211> 321
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.77 VL
<400> 310
gacatccaga tgactcagtc tccagcctcc ctatctgcat ctgtgggaga aactgtcacc 60
atcacatgtc gagcaagtgg gaatattcac aattatttag catggtatca gcagaaacag 120
ggaaaatctc ctcagctcct ggtctataat gcaaaagcct tagcagatgg tgtgccatca 180
aggttcagtg gcagtggatc aggaacacaa tattctctca agatcaacag cctgcagcct 240
gaagattttg ggagttatta ctgtcaacat ttttggagta ttcctccgac gttcggtgga 300
ggcaccaagc tggaaatcaa a 321
<210> 311
<211> 357
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.77 VH
<400> 311
gaagtgaagc ttgaggagtc tggaggaggc ttggtgcaac ctggaggatc catgaaactc 60
tcctgtgttg cctctggatt cactttcagt aactactgga tgaactgggt ccgccagtct 120
ccagagaagg ggcttgagtg ggttgctgaa attagattga aatctaataa ttatgcaaca 180
cattatgcgg agtctgtgaa agggaggttc accatctcaa gagatgattc caaaagtagt 240
gtctacctgc aaatgaacaa cttaagagtt gaagacactg ccatttatta ctgtaccagg 300
cactatgact atgctatgga ctactggggt caaggaacct cagtcaccgt ctcctca 357
<210> 312
<211> 321
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.79 VL
<400> 312
gacatccaga tgactcagtc tccagcctcc ctatctgcat ctgtgggaga aactgtcacc 60
atcacatgtc gagcaagtgg gaatattcac aattatttag catggtatca gcagaaacag 120
ggaaaatctc ctcagctcct ggtctataat gcaaaaacct tagcagatgg tgtgccatca 180
aggttcagtg gcagtggatc aggaacacaa tattctctca ggatcaacag cctgcagcct 240
gaagattttg ggagttatta ctgtcaacat ttttggagta ctcctccgac gttcggtgga 300
ggcaccaagg tggaaatcaa a 321
<210> 313
<211> 357
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.79 VH
<400> 313
gaagtgaagc ttgaggagtc tggaggaggc ttggtacaac ctggaggatc catgaaactc 60
tcctgtgttg cctctggatt cactttcagt gactactgga tgaactgggt ccgccagtct 120
ccagagaagg ggcttgagtt ggttgctgaa attagattga tatctaataa ttatgcaaca 180
cattatgcgg agtctgtgaa agggaggttc accatctcaa gagatgattc caaaagtagt 240
gtctacctgc aaatgaacaa cttaagagct gaagacactg gcatttatta ctgtaccagg 300
cactattact atgctttgga ctactggggt caaggaacct cagtcaccgt ctcctca 357
<210> 314
<211> 339
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.81 VL
<400> 314
gacattgtga tgtcacagtc tccatcctcc ctaactgtgt cagttggaga gaaggttact 60
ttgagctgca agtccagtca gagcctttta tatagtacca atcaaaagat ctacttggcc 120
tggtaccagc agaaaccagg gcagtctcct aaactgctga tttactgggc atccactagg 180
gaatctgggg tccctgatcg cttcacaggc agtggatctg ggacagattt cactctcgcc 240
atcagcaatg tgaaggctga agacctggca gtttattact gtcagcaata ttatagctat 300
ccgtacacgt tcggaggggg gaccaagctg gaaataaaa 339
<210> 315
<211> 339
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.81 VH
<400> 315
gaggttcagc tgcagcagtc tggggcagag cttgtgaagc caggggcctc agtcaagttg 60
tcctgcacag cttctggctt caacattaat gacacctatt accattggtt gaagcagagg 120
cctgaacagg gcctggagtg gattggaagg attgatcctg cgaatgttaa tactaaatat 180
gacccgaagt tccagggcaa ggccacttta acagcagaca catcctccaa cacagcctac 240
ctgcagctca gcagcctgac atctgaggac actgccgtct attactgtgg tagggggaat 300
gcttactggg gccaagggac tctggtcact gtctctgca 339
<210> 316
<211> 312
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.82 VL
<400> 316
caaattgttc tcacccagtc tccagcaatc atgtctgcat ctctagggga ggagatcacc 60
ctaacctgca gtgccagttc gagtgtaagt tacatgcact ggtaccagca gaagtcaggc 120
acttctccca aactcttgat ttatagcaca tccaacctgg cttctggagt cccttctcgc 180
ttcagtggca gtgggtctgg gaccttttat tctctcacaa tcagcagtgt ggaggctgaa 240
gatgctgccg attattactg ccatcagtgg agtagtttca cgttcggctc ggggacaaag 300
ttggaaataa aa 312
<210> 317
<211> 360
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.82 VH
<400> 317
gaggtccagc tgcaacagtc tggacctgag ctggtgaagc ctggggcttc agtgaagatg 60
tcctgtaagg cttctggata cacattcact gactcctaca tgaactgggt gaagcagagt 120
catggaaaga gccttgagtg gattggacgt gttaatccta acaatggtgg tgctagctac 180
aaccacaagt tcaagggcaa ggccacattg acagtagaca aatccctcag cacagcctac 240
atgcgcctca acagcctgac atctgaggac tctgcggtct attactgttc aagatctgga 300
gacctttatt actatgctat ggactactgg ggtcaaggaa cctcagtcac cgtctcctca 360
<210> 318
<211> 318
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.84 VL
<400> 318
caaattgttc tcacccagtc tccagcaatc atgtctgcat ctccagggga gaaggtcacc 60
atgacctgca gtgccagctc aagtataagt tacatgcact ggtaccagca gaagtcaggc 120
acctccccca aaagatggat ttatgacaca tccaaactgg cttctggagt ccctgctcgc 180
ttcagtggca gtgggtctgg gacctcttac tctctcacaa tcagcaacat ggaggctgaa 240
gatgctgcca cttattactg ccagcagtgg agtagtaccc cacccacgtt cggagggggg 300
accaagctgg aaataaaa 318
<210> 319
<211> 351
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.84 VH
<400> 319
gaggtccagt tgcaacagtc tggacctgag ctaatgaagc ctggggcttc agtgaagatg 60
tcctgcaagg cttctggata tatatttact gactacaaca tgcactgggt gaagcagaac 120
caaggaaaga gcctagagtg gataggagaa gttaatccta acactggtgg tattggctac 180
aatcagaaat tcaaaggcaa ggccacattg actgtagaca agtcctccag cacagcctac 240
atggacctcc gcagcctgac atctgaggac tctgcagtct attactgtgc aagagatggc 300
aattattgct ttgactactg gggccaaggc accactctca cagtctcctc a 351
<210> 320
<211> 333
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.85 VL
<400> 320
gatattgtga tgacgcaggc tgcattctcc aatccagtca ctcttggaac atcagcttcc 60
atctcctgca ggtctagtaa gagtctccta catagtaatg gcatcactta tttgtattgg 120
tatctgcaga agccaggcca gtctcctcag ctcctgattt atcagatgtc caaccttgcc 180
tcaggagtcc cagagaggtt cagtagcagt gggtcaggat ctgatttcac actgagaatc 240
agcagagtgg aggctgagga tgtgggtgtt tattactgtg ctcaaaatct agaacatccg 300
acgttcggtg gaggcaccaa gctggaaatc aaa 333
<210> 321
<211> 360
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.85 VH
<400> 321
gaggtgcagc tggtggagtc tgggggagac ttagtgaagc ctggagggtc cctgaaactc 60
tcctgtgcag cctctggatt cactttcagt aactatggca tgtcttgggt tcgccagact 120
ccagacaaga ggctggagtg ggtcgcaacc attagtactg gtggtactta cacctactat 180
ccagacagtg tgaaggggcg attcaccatc tccagagaca atgccaagaa caccctgtac 240
ctgcaaatga gcagtctgaa gtctgaggac acagccatgt attactgtgt aggacagtcc 300
tatagtgact acgtctcgtt tgcttattgg ggccaaggga ctcaggtcac tgtctctgca 360
<210> 322
<211> 336
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.87 VL
<400> 322
gatgttgtga tgacccaaac tccactctcc ctgcctgtca gtcttggaga tcaagcctcc 60
atctcttgca gatctagtca gagccttgta cacagtaatg gaaacaccta tttacattgg 120
tacctgcaga agccaggcca gtctccaaag ctcctgatct ccaaagtttc caaccgattt 180
tctggggtcc cagacaggtt cagtggcagt ggatcaggga cagatttcac tctcaagatc 240
agcagagtgg aggctgaaga tctgggagtt tatttctgct ctcaaagtac acatgttcct 300
cccatgttcg gaggggggac caggctggaa ataaaa 336
<210> 323
<211> 345
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.87 VH
<400> 323
gaggttcagc tgcagcagtc tggggctgag cttctgaagc caggggcctc agtcaagttg 60
tcctgcacag cttctggcct caacattaaa gactactata tacactgggt gtaccagagg 120
cctgaacagg gcctggagtg gattggaagg attgatcctg agagtgataa tactttatat 180
gacccgaagt tccagggcaa ggccagtata acagcagaca catcctccaa cacagcctac 240
ctgcagctca gcagcctgac atctgaggac actgccgtct attactgtac tactaatacc 300
ccttttgctt actggggcca agggactctg gtcactgtct ctaca 345
<210> 324
<211> 336
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.89 VL
<400> 324
gatgttttga tgacccaaac tccactctcc ctgcctgtca gtcttggaga tcaagcctcc 60
atctcttgca gatctagtca gagcattgta catagtaatg gaaacaccta tttagaatgg 120
tacctgcaga aaccaggcca gtctccaaag ctcctgatct acaaagtttc caaccgattt 180
tctggggtcc cagacaggtt cagtggcagt ggatcaggga cagatttcac actcaagatc 240
agtagagtgg aggctgagga tctgggagtt tattattgct ttcaaggttc acatgttcca 300
ttcacgttcg gctcggggac aaagttggaa ataaaa 336
<210> 325
<211> 360
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.89 VH
<400> 325
caggtccagt tgcaacagtc tggagctgaa ctggtaaggc ctgggacttc agtgaaggtg 60
tcctgcaaga cttctggata cgccttcact aattacttga tagagtgggt aaagcagagg 120
cctggacagg gccttgagtg gattggggtg attaatcctg gaagtggtgg tactaactac 180
aatgagaagt tcaaggtcaa ggcaacactg actgcagaca aatcctccag cactgcctac 240
atgcagctca ccagcctgac atctgatgac tctgcggtct atttctgtac aagaagggat 300
ggttacttct ttccctggtt tgcttactgg ggccaaggga ctctggtcac tgtctctgca 360
<210> 326
<211> 339
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.90 VL
<400> 326
gacattgtga tgtcacagtc tccatcctcc ctagctgtgt cagttggaga gaaggttact 60
atgagctgca agtccagtca gagcctttta tatagtagca atcaaaagaa ctacttggcc 120
tggtaccagc agaaaccagg gcagtctcct aaactgctga tttactgggc atccactagg 180
aaatctgggg tccctgatcg cttcacaggc agtggatctg ggacagattt cactctcacc 240
atcagcagtg tgaaggctga agacctggca gtttattact gtcatcaata ttatagctat 300
ccgctcacgt tcgctgctgg gaccaagctg gagctgaaa 339
<210> 327
<211> 345
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.90 VH
<400> 327
caggtgcaac tgcagcagcc tgggtctgtg ctggtgaggc ctggagcttc agtgaagctg 60
tcctgcaagg cttctggcta cacattcacc agctactgga tgcactgggt gaagcagagg 120
cctggacaag gccttgagtg gattggagag attcatccta ataatggtag tactaactac 180
aatgagaagt tcaagggcaa ggccacactg actgtagaca catcctccag cacagcctac 240
gtggatctca gcagcctgac atctgaggac tctgcggtct attactgtgc aagatggact 300
ttgtttactt actggggcca agggactctg gtcactgtct ctgca 345
<210> 328
<211> 336
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.91 VL
<400> 328
gatgttgtga tgacccaaac tccactctcc ctgcctgtca gtcttggaga tcaagcctcc 60
atctcttgca gatctagtca gagccttgta cacagtaatg gaaacaccta tttactttgg 120
tacctgcaga agccaggcca gtctccaaag ctcctgatct acaaagtttc caaccgattt 180
tctggggtcc cagacaggtt cagtggcagt ggatcaggga cagatttcgc actcaagatc 240
agcagagtgg aggctgagga tctgggagtt tatttctgct ctcaaagtac acatgttccg 300
tggacgttcg gtggaggcac caagctggaa atcaaa 336
<210> 329
<211> 351
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.91 VH
<400> 329
gaggtgcagc tggtggagtc tgggggaggc ttagtgaagc ctggagggtc ccggaaactc 60
tcctgtgcag cctctggatt cactttcagt gactatggaa tgcactgggt ccgtcaggct 120
ccagagaagg ggctggagtg ggttgcatac attagtcgtg gcagtagtac catccactat 180
gcagacacag tgaagggccg attcaccatc tccagagaca atgccaagaa caccctgttc 240
ctgcaaatga ccagtctaag gtctgaggac acagccatgt attactgtgc aaggcctttc 300
aactggtact tcgatgtctg gggcgcaggg acaacggtca ccgtctcctc a 351
<210> 330
<211> 339
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.93 VL
<400> 330
gacattgtga tgtcacagtc tccatcctcc ctagctgtgt cagttggaga gaaggttact 60
atgacctgca agtccagtca gagcctttta tatagtagca atcaaaagaa ctacttggcc 120
tggtaccagc agaaaccagg gcagtctcct aaactactaa tttactgggc atccactagg 180
gaatctgggg tccctgatcg cttcataggc agtggctctg ggacagattt cactctcacc 240
atcagcagtg tgaaggctga agacctggca atttattact gtcagcaata ttatcgctat 300
ccgctcacgt tcggtgctgg gaccaaactg gagctgaaa 339
<210> 331
<211> 363
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.93 VH
<400> 331
caggtccaac tgcagcagcc tggggctgag cttgtgaagc ctggggcttc agtgatgctg 60
tcctgcaagg cttctggcta caccttcacc agctactggg tacactgggt gaagcagagg 120
cctggacaag gccttgagtg gattggagtg attaatccta gaaacggtcg taacaattac 180
aatgagaagt tcaagaccaa ggccacactg actgtagaca aatcatccag cacagcctac 240
atgcaactca gcagcccgac atctgaggac tctgcggtct attactgtgc acgagaggat 300
tacgacgggg gggactatgc tatggactac tggggtcaag gaacctcagt caccgtctcc 360
tca 363
<210> 332
<211> 321
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.95 VL
<400> 332
gatatccaga tgacacagac tacatcctcc ctgtcggcct ctctgggaga cagggtcacc 60
atcagttgca gtgcaagtca gggcattaac aattatttaa actggtatca gcagaaacca 120
gatggaactg ttacactcct gatctattac acatcaagtt tacactcagg agtcccatcc 180
aggttcagtg gcagtgggtc tgggacagat tattctctca ccatcagcaa cctggaacct 240
gaagatattg ccacttacta ttgtcagcag tatagtaagc ttccgtggac gttcggtgga 300
ggcaccaagc tggaaatcaa a 321
<210> 333
<211> 363
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.95 VH
<400> 333
gaggtcgagc tgcaacagtc tggacctgag ctggtgaagc cgggggcttc agtgaagata 60
tcctgcaaga cttccggaaa cacatacact gaatacacca tgcagtgggt gaagctgagc 120
catggaaaga gccttgagtg gattggaggt attaatccta acaatggtat tactagttac 180
aaccagaagt tcaagggcaa ggccacattg actgtagaca agtcctccag cacagcctac 240
atggagctcc gcagcctgaa atctgaggat tctgcagtct attactgtgc aagagcggga 300
cttggtaact acgtttgggc tatggactac tggggtcaag gagcctcagt caccgtctcc 360
tca 363
<210> 334
<211> 336
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.97 VL
<400> 334
gatgttgtga tgacccaaac tccactctcc ctgcctgtca gtcttggaga tcaagcctcc 60
atctcttgca gatctagtca gagccttgta cacaataatg gaaacaccta tttacattgg 120
tacctgcaga agccaggcca gtctccaaac ctcctgatct acaaagtttc caaccgattt 180
tctggggtcc cagacaggtt cagtggcagt ggatcaggga cagatttcac actcaagatc 240
agcatagtgg aggctgagga tctgggactt tatttctgct ctcaaagtac acatgttcct 300
cggacgttcg gtggaggcac caagctggaa atcaaa 336
<210> 335
<211> 357
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.97 VH
<400> 335
caggtccagc ttccgcagtc tggggctgaa ctggcaaaac ctggggcctc agtgaaaatc 60
tcctgcaagg cttctggctt cacctttact tcctactgga tgcactgggt aaaacagagg 120
cctggacagg gtctggaatg gattggatac attaatccta gcactgatta tactgagtac 180
aatcagaagt tcaaggacaa ggccacattg actgcagaca aatcctccag cacagcctac 240
atgcaactgg gcagcctgac atctgaggac tctgcagtct attactgtgc aagatcttcc 300
tacggtagta gcccctttga ttattggggc caaggctcca ctctcacagt ctcctca 357
<210> 336
<211> 339
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.99 VL
<400> 336
gacattgtga tgtcacagtc tccatcctcc ctagctgtgt ctgttggaga gaaggttact 60
atgaactgcg agtccagtca gagcctttta tatagtagca atcaaaagaa ctacttggcc 120
tggtaccagc agaaaccagg gcagtctcct aaactgctga tttactgggc atccactagg 180
gattctgggg tccctgatcg cttcacaggc agtggatctg ggacagattt cactctcacc 240
atcagcagtg tgagggctga agacccggca gtttattact gtcagcaata ttatagctat 300
ccgctcacgt tcggtgctgg gaccaagctg gagctgaga 339
<210> 337
<211> 348
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.99 VH
<400> 337
gaagtgaagc ttgaggagtc tggaggaggc ttggtgcaac ctggaggatc catgaaactc 60
tcttgcgctg cctctggatt cacttttagt gacgcctgga tggactgggt ccgccagtct 120
ccagagaagg ggcttgagtg ggttgctgaa ataagaagca aagctaataa tcatgcaaca 180
tactatgctg agtctgtgaa agggaggttc accatctcaa gagatgattc caaaagtagt 240
gcctacctgc aaatgaacag cttaagagct gaagacactg gcatttatta ttgtgtttca 300
acagggactt cttactgggg ccaagggact ctggtcactg tctctgca 348
<210> 338
<211> 318
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.102 VL
<400> 338
caaattgttc tcacccagtc tccagcaatc atgtctgcat ctccagggga gaaggtcacc 60
atgacctgca gtgccagctc aagtgtaagt tacatgcact ggtaccagca gaagtcaggc 120
acctccccca aaagatggat ttatgacaca tccaaactgg cttctggagt ccctcctcgc 180
ttcagtggcc gtgggtctgg gacctcttac tctctcacaa tcagcagcat ggaggctgaa 240
gatgctgcca cttattactg ccagcattgg agtagtaacc cacccacgtt cggtgctggg 300
accaagctgg agatgaaa 318
<210> 339
<211> 348
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.102 VH
<400> 339
gaggtccagc tgcaacagtc tggacctgag ctaatgaagc ctggggcttc agtgaagatg 60
tcctgcaagg cttctggaga cacattcact gactacaaca tacactgggt gaagcagaac 120
caaggaaaga gcctagagtg gataggagaa gttaatccta acattggtgg tattggctat 180
aaccagaagt tcaaaggcaa ggccacattg actgtagaca agtcctccag cacagcctac 240
atggagctcc gcagcctgac atctgaggac tctgcagtct attactgtgc aatggggagg 300
tggtacttcg atgtctgggg cgcagggacc acggtcaccg tctcctca 348
<210> 340
<211> 336
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.114 VL
<400> 340
gatgttgtga tgacccagtc tccactctcc ctgcctgtca gtcttggaga tcaagcctcc 60
atctcttgca gatctagtca gagccttgta cacagtaatg gaaacaccta tttacattgg 120
tacctgcaga agccaggcca gtctccaaag ctcctgatct acaaagtttc cagccgattt 180
tctggggtcc cagacaggtt cagtggcagt ggatcaggga cagatttcac actcaagatc 240
agcagagtgg aggctgagga tctgggagtt tatttctgct ctcaaagtac acatgttcca 300
ttcacgttcg gctcggggac aaagttggaa ataaaa 336
<210> 341
<211> 345
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.114 VH
<400> 341
gaggtccagc tgcagcagtc tggacctgag atggtgaagc ctggggcttc agtgaagata 60
tcctgcaagg cttctggata cacattcact gactactaca tgcactgggt gaaacagagc 120
catggaaaga gccttgagtg gattggacgt gttaatacta acaatggtgg aactagctac 180
gaccagaagt tcgagggcaa ggccacattg actgttgaca aatcttccag cacagcctac 240
atggagctca acagcctgac atctgaggac tctgcggtct attactgtgt aatccctgcc 300
tggtttgctt actggggcca agggactctg gtcactgtct ctgca 345
<210> 342
<211> 336
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.115 VL
<400> 342
gatattgtga tgacccagtc tccactctcc ctgcctgtca gtcttggaga tcaagcctcc 60
atctcttgca gatctagtca gagccttgta cacagtaatg gaaacaccta tttacattgg 120
tacctgcaga agccaggcca gtctccaaag ctcctgatct acagagtttc caaccgattt 180
tctggggtcc cagacaggtt cagtggcagt ggatcaggga cagatttcac actcacgatc 240
agcagagtgg aggctgagga tctgggagtt tatttctgct ctcaaagtac acatcttcct 300
cggacgttcg gtggaggcac caagctggag atcaaa 336
<210> 343
<211> 342
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.115 VH
<400> 343
caggtgcaac tgcagcagtc tgggtctgtg ctggtgaggc ctggagcttc agtgaagctg 60
tcctgcaagg cttctggcta cacattcacc agctactgga tgcactgggt gaagcagagg 120
cctggacaag gccttgagtg gattggagag attcatccta atagtgggaa tactaattac 180
aatgagaagt tcaagggcaa ggccacactg actgtagaca catcctccag cacagcctac 240
gtggatctca gcagcctgac atctgaggac tctgcggtct attattgtgc aggtggtaac 300
tacgactact ggggccaagg caccactctc acagtctcct ca 342
<210> 344
<211> 333
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.120 VL
<400> 344
gacattgtgc tgacccaatc tccagcttct ttggctgtat ctctagggca gagggccacc 60
atatcctgca gagccagtga aagtgttgat agttatggca atagttttat gcactggtac 120
cagcagaaac caggacagcc acccaaagtc ctcatctatc gtgcatccaa cctagaatct 180
gggatccctg ccaggttcag tggcagtggg tctaggacag acttcaccct caccattaat 240
cctgtggagg atgaagatgt tgcaacctat tactgtcagc aaagtaatga ggatccgtac 300
acgttcgggg gggggaccaa gctggaaata aaa 333
<210> 345
<211> 351
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.120 VH
<400> 345
gaggttcagc tcgagcagtc tgggactgtg ctggcaaggc ctggggcttc agtgaagatg 60
tcctgcaagg cttctggcta cacctttacc agctactgga tgcactgggt gaaacagagg 120
cctggacagg gtctggaatg gattggcgct ttttatcctg gaaacagtgg tacttattac 180
aaccaaaaat tcaaggacaa ggccaaactg actgcagtca catctgccag cactgcctac 240
atggagctca gcagcctgac aaatgaggac tctgcggtct attactgttc aagatcaggg 300
tcaggaaggt ttgcttactg gggccaaggg actctggtca ctgtctctgc a 351
<210> 346
<211> 318
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.121 VL
<400> 346
caaattgttc tcacccagtc tccagcaatc atgtctgcat ctccagggga gaaggtcacc 60
atgacctgca gtgccagctc aagtgtgagt tacatgcact ggtaccagca gaagtcaggc 120
acctccccca aaagatggat ttatgacaca tccaaactgg cttctggagt ccctgctcgc 180
ttcagtggca gtgggtctgg gacctcttac tctctcacaa tcagcagcat ggagactgaa 240
gatgctgcca cttattactg ccagcagtgg agtaataccc cacccacgtt cggctcggtg 300
acaaagttgg aaataaaa 318
<210> 347
<211> 348
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.121 VH
<400> 347
gaggtccagc tgcaacagtc tggacctgag ctaatgaagc ctggggcttc agtgaagatg 60
tcctgcaagg cttctggata cacattcact gaccacaaca tacactgggt gaaacagcac 120
caaggaaaga gcctagagtg gataggagaa attaatccta acactggtgg tactggctac 180
aaccagaagt tccaaggcaa ggccacaatg actgtagaca agtcctccag cacagcctac 240
atggaactcc gcagcctgac atctgaggac tctgcagtct attactgtgt tagaggactg 300
tacttctttg actactgggg ccaaggcacc actctcacag tctcctca 348
<210> 348
<211> 336
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.122 VL
<400> 348
gatattgtga taacccagga tgatctctcc aatcctgtca cttctggaga atcagtttcc 60
atctcctgca ggtctagtaa gagtctccta tataaggatg ggaagacata cttgaattgg 120
tttctgcaga gaccaggaca atctcctcag ctcctgatct atttgatgtc cacccgtgca 180
tcaggagtct cagaccggtt tagtggcagt gggtcaggaa cagatttcac cctggaaatc 240
agtagagtga aggctgagga tgtgggtgtg tattactgtc aacaacttgt agagtatcct 300
cggacgttcg gtggaggcac caagctggaa atcaaa 336
<210> 349
<211> 339
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.122 VH
<400> 349
gaggtgcacc tggtggagtc tgggggagac ttagtgaagc ctggagggtc cctgaaactc 60
tcctgtgcag cctctggatt cactttcagt agctatggca tgtcttgggt tcgccagact 120
ccagacaaga ggctggagtg ggtcgcaacc attagtagtg gtggtactta cacctactat 180
ccagacagtg tgaaggggcg attcaccatc tccagagaca atgccaagaa caccctgtat 240
ctgcaaatga gcagtctgaa gtctgaggac acagccatgt attactgttc aagacatggg 300
tggggctggg gccaagggac tctggtcact gtctctgca 339
<210> 350
<211> 318
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.140 VL
<400> 350
caaattgttc tcacccagtc tccagcaatc atgtctgcat ctccagggga gaaggtcacc 60
atgacctgca gtgccagctc aagtgttagt tacatgcact ggtaccagca gaagtcaggc 120
acctccccca aaagatggat ttatgacaca tccaaactgg cttctggagt ccctgctcgc 180
ttcagtggca gtgggtctgg gacctcttac tctctcacaa tcagcagcat ggaggctgaa 240
gatgctgcca cttattactg ccagcagtgg agtagtaccc cacccacgtt cggctcgggg 300
acaaagttgg aaataaaa 318
<210> 351
<211> 360
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.140 VH
<400> 351
gaggtccagc tgcaacagtc tggacctgag ctaatgaagc ctggggcttc agtgaagatg 60
tcctgcaagg cttctggata cacattcact gactacaaca tgcactgggt gaagcagaac 120
caaggaaaga gcctagagtg gataggagaa attaatccca acactggtgg tactggctac 180
aaccagaagt tcaaaggcaa ggccacattg actgtagaca agttttccag cacagccttc 240
attgagctcc gcagcctgac atctgaggac tctgcaatct attactgtac aagagggggt 300
tacgaccact attggtactt cgatgtctgg ggcgcaggga ccacggtcac cgtctcctca 360
<210> 352
<211> 333
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.151 VL
<400> 352
gacattgtgc tgacccaatt tccagcttct ttggctgtgt ctctagggca gagggccacc 60
ataccctgca gagccagtga aagtgttgat agttatggca atagttttat gcactggttc 120
cagcagaaac caggacagcc acccaaactc ctcatctatc gtgcatccaa cctagaatct 180
gagatccctg ccaggttcag tggcagtggg tctgggacag acttcaccct caccattaat 240
cctgtggagg ctgatgatgt tgcaacctat tactgtcagc aaagtcatga ggatccgtac 300
acgttcggag gggggaccaa gatggaaata aaa 333
<210> 353
<211> 351
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.151 VH
<400> 353
gaggttcagc tgcagcagtc tgggactgtg ctggcaaggc ctggggcttc agtgaagatg 60
tcctgcaagg cttctggcta tacctttacc agctactgga tgcactgggt aaaacagagg 120
cctggacagg gtctggaatg gattggcgct atttatcctg gaaagaatga tactacctac 180
aaccagaagt tcaagggcaa ggccaaactg actgcagtca catctgccag cactttatac 240
atggagctca gcagcctgac aaatgaggac tctgcggtct attactgtac aagatctgga 300
aagggttact ttgcttactg gggccaaggg actctggtca ctgtctctgc a 351
<210> 354
<211> 336
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.156 VL
<400> 354
gatgttgtga tgacccagtc tccactctcc ctgcctgtca gtcttggaga tcaagcctcc 60
atctcttgca gatctagtca gagcattgta catagtaatg gaaacaccta tttagaatgg 120
tacctgcaga aaccaggcca gtctccaaag ctcctgatct acaaagtttc caaccgattt 180
tctggggtcc cagacaggtt cagtggcagt ggatcaggga cagatttcac actcaagatc 240
agcagagtgg aggctgagga tctgggagtt tattactgct ttcaaggttc acatgttcct 300
ccgacgttcg gtggaggcac caaactggaa atcaaa 336
<210> 355
<211> 354
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.156 VH
<400> 355
caggttactc tgaaagagtc tggccctggg atattgcagc cctcccagac cctcagtctg 60
acttgttctt tctctgggtt ttcactgagc acttctggta tgggtgtgag ctggattcgt 120
aagacttcag gaaagggtct ggaatggctg gcacacattt tctgggatga tgacaagtgg 180
tataatccat ccctgaagag ccggctcaca atctccaagg ctacctccag caaccaggta 240
ttcctcatac tcaccagtgt ggatactgcc gatactgcca catactactg tgctaccttc 300
tatggtctct actttgccta ctggggccaa ggcaccactc tcacagtctc ctca 354
<210> 356
<211> 339
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.161 VL
<400> 356
gacattgtga tgtcacagtc tccatcctcc ctagctgtgt ctgttggaga gaaggttact 60
atgaactgcg agtccagtca gagcctttta tataatagca atcaaaagaa ctacttggcc 120
tggtaccagc agaaaccagg gcagtctcct aaactgctga tttactgggc atccactagg 180
gattctgggg tccctgatcg cttcacaggc agtggatctg ggacagattt cactctcacc 240
atcagcagtg tgagggctga tgacccggca gtttattact gtcagcaata ttttaactat 300
ccgctcacgt tcggtgctgg gaccaagctg gagctgaaa 339
<210> 357
<211> 348
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.161 VH
<400> 357
gaagtgaagc ttgaggagtc tggaggaggc ttggtgcaac ctggaggatc catgaaactc 60
tcttgcgctg cctctggatt cacttttagt gacgcctgga tggactgggt ccgccagtct 120
ccagagaagg ggcttgagtg ggttgctgaa ataagaagca aacctaataa tcatgcaaca 180
tactatgctg agtctgtgaa agggaggttc accatctcaa gagatgattc caaaagtagt 240
gcctacctgc aaatgaacag cttaagagct gaagacactg gcatttatta ctgtgtttca 300
acagggactt cttactgggg ccaagggact ctggtcactg tctctgca 348
<210> 358
<211> 318
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.166 VL
<400> 358
caaattgttc tcacccagtc tccagcaatc atgtctgcat ctccagggga gaaggtcacc 60
atgacctgca gtgccagctc aagtataagt tacatgcact ggtaccagca gaagtcaggc 120
acctccccca aaagatggat ttatgacaca tccaaactgg cttctggagt ccctgctcgc 180
ttcagtggca gtgggtctgg gacctcttac tctctcacaa tcagcaacat ggaggctgaa 240
gatgctgcca cttattactg ccagcagtgg agtagtaccc cacccacgtt cggagggggg 300
accaagctgg aaataaaa 318
<210> 359
<211> 351
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.166 VH
<400> 359
gaggtccagt tgcaacagtc tggacctgag ctaatgaagc ctggggcttc agtgaagatg 60
tcctgcaagg cttctggata tatatttact gactacaaca tgcactgggt gaagcagaac 120
caaggaaaga gcctagagtg gataggagaa gttaatccta acactggtgg tattggctac 180
aatcagaaat tcaaaggcaa ggccacattg actgtagaca agtcctccag cacagcctac 240
atggacctcc gcagcctgac atctgaggac tctgcagtct attactgtgc aagagatggc 300
aattattgct ttgactactg gggccaaggc accactctca cagtctcctc a 351
<210> 360
<211> 321
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.187 VL
<400> 360
gacatcaaga tgacccagtc tccatcttcc atgtatgcat ctctaggaga gagagtcact 60
ctcacttgca aggcgagtca ggacattaat agctatttaa gctggttcca gcagaaacca 120
gggaaatctc ctgagaccct gatctatcgt gcaaacagat tgatagatgg ggtcccatca 180
aggttcagtg gcagtggatc tgggcaagat tattctctca ccatcagcag cctggagtat 240
gaagatatgg ggatttatta ttgtctacag tatgatgagt ttcctccgac gttcggtgga 300
ggcaccaagc tggaaatcaa a 321
<210> 361
<211> 354
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.187 VH
<400> 361
gaggtccacc tacaacagtc tggacctgaa ctggtgaacc ctgggtcttc agtgaagata 60
tcctgcaagg ctgctggata cacattcact gactacaaca tggactgggt gaagcagagc 120
catggaaaga gacttgagtg gattggaaat atttatccta acaatggtgg tgctggatac 180
aaccagaact tcaaggacaa ggccacattg actgtagaca agtcctccag cacagcctac 240
atggagctcc gcagcctgac atctgaggac tctgcagtct attactgtgc aagatccatt 300
actgcggctt ggtttgctta ctggggccaa gggactctgg tcactgtctc tgca 354
<210> 362
<211> 318
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.191 VL
<400> 362
caaattgttc tcacccagtc tccagcaatc atgtctgcat ctccagggga gaaggtcacc 60
atgacctgca gtgccagctc aagtgtaagt tacatgcact ggtaccagca gaagtcaggc 120
acctccccca aaagatggat ttatgacaca tccaaactgg cttctggagt ccctgctcgc 180
ttcactggca gtgggtctgg gacctcttac tctctcacaa tcagcagcat ggaggctgaa 240
gatgctgcca cttattactg ccagcagtgg agtagtagcc cacccacgtt cggtgctggg 300
accaagctgg aactgaaa 318
<210> 363
<211> 360
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.191 VH
<400> 363
gaggtccagc tgcaacagtc tggacctgag ctaatgaagc ctggggcttc agtgaagatg 60
tcctgcaagg cttctggata cacattcact gactacaaca tgcactgggt gaagcagaac 120
caaggaaaga gcctagagtg gataggagaa attaatccta acactggtgg tactggctac 180
aaccagaagt tcaaagacaa ggccacattg actgtagaca agtcctccag cacagcctac 240
atggagctcc gcagcctgac atctgaggac tctgcagtct attactgtgc aagaattccc 300
tccctgagac gatactactt tgactactgg ggccaaggca ccactctcac agtctcctca 360
<210> 364
<211> 333
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.193 VL
<400> 364
gaccttgtgc tgacacagtc tcctgcttcc ttagctgtat ctctggggca gagggccacc 60
atctcatgca gggccagcga aagtgtcagt acatctggct atagttatat gcactggtac 120
caacagaaac caggacagcc acccaaactc ctcatctatc ttgcatccaa cctcgaatct 180
ggggtccctg ccaggttcag tggcagtggg tctgggacag acttcaccct caacatccat 240
cctgtggagg aggaggatgc tacaacctat tactgtcagc acagtaggga gcttccgtac 300
acgttcggag gggggaccaa gctggaaata aaa 333
<210> 365
<211> 366
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.193 VH
<400> 365
caggttactc tgaaagagtc tggccctggg atattgcagc cctcccagac cctcagtctg 60
acttgttctt tctctgggtt ttcactgatc acttatggta taggagtagg ctggattcgt 120
cagccttcag ggaagggtct ggagtggctg gcacacattt ggtggaatga taataagtac 180
tataacacag ccctgaagag ccggctcaca atctccaagg atacctccaa caaccaggta 240
ttcctcaaga tcgccaatgt ggacactgca gatactgcca catactactg tgctcgaatg 300
gtctactatg attacgacgg ggggtttgct tactggggcc aagggactct ggtcactgtc 360
tctgca 366
<210> 366
<211> 333
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.199 VL
<400> 366
gacattgtgc tgacccaatc tccagcttct ttggctgtgt ctctagggca gagggccacc 60
atatcctgca gagccagtga aagtgttgat agttatggca atagttttat gcactggtac 120
cagcagaaac caggacagcc acccaaaccc ctcatttatc gtgcatccaa cctagaatct 180
gggatccctg ccagattcag tggcagtggg tctaggacag acttcaccct caccattaat 240
cctgtggagg ctgatgatgt tgcaacctat tactgtcagc aaagtaatga ggatccgtac 300
acgttcggag gggggaccaa gctggaaata aaa 333
<210> 367
<211> 348
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.199 VH
<400> 367
gaggtgcagc tgcagcagtc tgggactgtg ctggcaaggc ctggggcttc agtaaggatg 60
tcctgcaagg cttctggcta cacctttacc agctactgga tgcactgggt aaaacaaagg 120
cctggacagg gtctggaatg gattggcgct atttatcctg gaaatagtga tactagctac 180
aaccataagt tcaagggcaa ggccaaactg actgcagtca catctgccag cactgcctac 240
atggagctca gcagcctgac aaatgaggac tctgcggtct attactgtac aagatctggg 300
acgggctggt ttgcttactg gggccaaggg actctggtca ctgtctct 348
<210> 368
<211> 333
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.200 VL
<400> 368
gacattgtgc tgacccaatc tccagcttct ttggctgtgt ctctaggaca gagagccact 60
atcttctgca gagccagcca gagtgtcgat tataatggaa ttagttatat gcactggttc 120
caacaaaaac caggacagcc acccaaactc ctcatctatg ctgcatccaa cgttcaatct 180
gggatccctg ccaggttcag tggcagtggg tctgggacag acttcaccct caacatccat 240
cctgtggagg aggaagatgc tgcaaccttt tactgtcagc aaagtattga ggatcctccg 300
acgttcggtg gaggcaccaa gctggaaatc aaa 333
<210> 369
<211> 345
<212> DNA
<213> Mus musculus
<220>
<221> misc_feature
<223> Murine SC17.200 VH
<400> 369
caggtccagc tgcagcagtc tggacctgag ctggtgaaac ctggggcctc agtgaagatt 60
tcctgcaaag cttctggcta cgcattcagt agttcttgga ttaactgggt gaagcagagg 120
cctggacagg gtcttgagtg gattggacgg atttatcctg gagaaggtga tactaactac 180
agtgggaatt tcgagggcaa ggccacactg actgcagaca aatcctccac cacagcctac 240
atgcagctca gcagtctgac ctctgtggac tctgcggtct atttctgtac aagaggacta 300
gtcatggact actggggcca aggcaccgct ctcacagtct cctca 345
<210> 370
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.16 VL
<400> 370
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgcc gggcaagtgc gaacattaac agcaatttag tttggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctatgct gcaaccaatt tggcagatgg ggtcccatca 180
aggttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg caacttacta ctgtcaacat ttttggggta ctcctcggac gttcggtgga 300
ggcaccaagc tggaaatcaa a 321
<210> 371
<211> 348
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.16 VH
<400> 371
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggata caccttcacc gactacaata tgtactgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggagag atcaacccta acaatggtgg cacagcctat 180
aatcagaagt ttaggggcaa ggtcaccatg accagggaca cgtccatcag cacagcctac 240
atggagctga gcaggctgag atctgacgac acggccgtgt attactgtgc gagatatgat 300
aaggggtttg actactgggg ccaaggcacc actgtcacag tctcctca 348
<210> 372
<211> 318
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.17 VL
<400> 372
gaaattgtgt tgacacagtc tccagccacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gtgccagtag cagtgttagc tacatgcatt ggtaccaaca gaaacctggc 120
caggctccca ggctcctcat ctatgataca tccaaattgc ccagtggcat cccagccagg 180
ttcagtggca gtgggtctgg gacagacttc actctcacca tcagcagcct agagcctgaa 240
gattttgcag tttattactg tcagcagtgg agtagtaccc cacccacgtt cggtcagggg 300
accaagctgg agattaaa 318
<210> 373
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.17 VH
<400> 373
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggata caccttcacc gactacaata tgcactgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggagag atcaacccta acattggtgg cacaggctat 180
aaccagaagt ttaagggcag ggtcaccatg accagggaca cgtccatcag cacagcctac 240
atggagctga gcaggctgag atctgacgac acggccgtgt attactgtgc gagaacctat 300
agttactata gttacgagtt tgcttactgg ggccaaggga ctctggtcac tgtctcttca 360
<210> 374
<211> 336
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.24 VL
<400> 374
gacatcgtga tgacccagtc tccagactcc ctggctgtgt ctctgggcga gagggccacc 60
atcaactgca agtccagcca gagtcttctc tacagctcca accagaagag ctacttagct 120
tggtaccagc agaaaccagg acagcctcct aagctgctca tttactgggc atctacccgg 180
gaatccgggg tccctgaccg attcagtggc agcgggtctg ggacagattt cactctcacc 240
atcagcagcc tgcaggctga agatgtggca gtttattact gtaagcaatc ttataatctt 300
cggacgttcg gtggaggcac caaggtggaa atcaaa 336
<210> 375
<211> 351
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.24 VH
<400> 375
gaagtgcagc tggtgcagtc tggggctgag gtgaagaagc ctggggccac cgtgaagata 60
tcctgcaagg tgtctggata caccttcaca gaccacacta tacactgggt gcgacaggcc 120
cctggaaagg ggcttgagtg gattggatac atctaccctc gtgatggtag cacaaaatac 180
aacgaggagt tcaaaggcag agtcaccatc accgccgaca cgtccacgga cacagcctac 240
atggagctga gcagcctgag atctgaggac acggccgtgt attactgtgc gagatcatat 300
agtaactact ttgactactg gggccaaggc accactgtca cagtctcctc a 351
<210> 376
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.28 VL
<400> 376
gaaattgtgc tgactcagtc tccagacttt cagtctgtga ctccaaagga gaaagtcacc 60
atcacctgcc gggccagtca gagcattggt actagcatac actggtacca gcagaaacca 120
gatcagtctc caaagctcct catcaagtat gcttccgagt ccatctcagg ggtcccctcg 180
aggttcagtg gcagtggatc tgggacagat ttcaccctca ccatcaatag cctggaagct 240
gaagatgctg caacgtatta ctgtcagcaa agtaatagct ggccactcac gttcggtcaa 300
gggaccaagc tggagataaa a 321
<210> 377
<211> 351
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.28 VH
<400> 377
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggata caccttcacc agaagctata tccactgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggatac atcagcagtg gcagtggtgg cacaacctat 180
aaccagaagt ttaagggcag ggtcaccagt accagggaca cgtccatcag cacagcctac 240
atggagctga gcaggctgag atctgacgac acggccgtgt attactgtgc gagagggggg 300
gtacggtact tcgatgtctg gggccaaggg accacggtca ccgtctcctc a 351
<210> 378
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.34 VL
<400> 378
gacatccaga tgacccagtc tccatcctca ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgta aggcgagtca ggacattaat agttatttat cctggtttca gcagaaacca 120
gggaaagccc ctaagtccct gatctataga gcaaacagat tggtagatgg ggtcccatca 180
aggttcagcg gcagtggatc tgggacagat tacactctca ccatcagcag cctgcagcct 240
gaagattttg caacttatta ctgcctacag tatgatgagt ttcctccgac gttcggtcag 300
ggcaccaagc tggaaatcaa a 321
<210> 379
<211> 354
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.34 VL
<400> 379
caggtccagc ttgtgcagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtt 60
tcctgcaagg cttctggata caccttcact gactataata tggattgggt gcgccaggcc 120
cccggacaaa ggcttgagtg gattggatac atctaccctg acaatggtgg cgcaggatat 180
aatcagaagt tcaagggcag agtcaccatt accgtggaca catccgcgag cacagcctac 240
atggagctga gcagcctgag atctgaagac acggctgtgt attactgttc aagatccatt 300
actacggctt ggtttgctta ctggggccaa gggactctgg tcactgtctc ttca 354
<210> 380
<211> 321
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.46 VL
<400> 380
gccatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgca aggcaagtca gagcgttaat aatgatgtag cctggtatca gcagaaacca 120
gggaaagccc ctaagctcct gatctattat gcatccaatc gatatactgg ggtcccatca 180
aggttcagcg gcagtggatc tggcacagat ttcactctca ccatcagcag cctgcagcct 240
gaagattttg caacttattt ctgtcagcag gattatagct ctcctcggac gttcggtcag 300
gggaccaagc tggaaataaa g 321
<210> 381
<211> 363
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.46 VH
<400> 381
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggata caccttcacc agctactgga tcaactgggt gcgacaggcc 120
cctggacaag ggcttgagtg gattggaaac atcttccctg acactactac cacaaactat 180
aacgagaagt ttaagggcag ggtcaccctg accagggaca cgtccatcag cacagcctac 240
atggagctga gcaggctgag atctgacgac acggccgtgt attactgtgc gagagagtac 300
tacgatggta cctacgatgc tatggattac tggggtcaag gaaccctagt caccgtctcc 360
tca 363
<210> 382
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.151 VL
<400> 382
gagatcgtgc tgacccagag ccctgctaca ctgtccctgt cccctggaga gagggccaca 60
ctctcctgca gggcttccga gtccgtggat tcctacggca actccttcat gcactggtac 120
cagcagaaac ccggccaggc ccctaggctg ctgatctaca gggcctccaa cctggagtcc 180
ggcatccctg ctaggttctc cggatccggc tccggcaccg actttaccct gaccatctcc 240
tccctggagc ccgaggactt cgccgtgtac tactgccagc agtcccacga ggacccctac 300
accttcggcc agggcaccaa gctggagatc aag 333
<210> 383
<211> 351
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.151 VH
<400> 383
caggtccagc tggtgcagag cggcgctgag gtgaagaagc ctggcgccag cgtgaaggtg 60
tcctgcaaag ccagcggcta caccttcacc tcctactgga tgcattgggt gaggcaggct 120
cctggccaag gactggagtg gatgggcgcc atctaccccg gcaagtccga caccacctac 180
aaccagaagt tcaagggcag ggtgaccatg acacgggaca cctccacctc caccgtgtac 240
atggagctgt cctccctgag gtccgaggac accgccgtgt actactgcgc caggtccggc 300
aagggctatt tcgcctactg gggccagggc acactggtga ccgtgtcctc c 351
<210> 384
<211> 339
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.155 VL
<400> 384
gacatcgtga tgacccagtc tccagactcc ctggctgtgt ctctgggcga gagggccacc 60
atcaactgca agtccagcca gagtttatta tacagctcca accaaaagaa ctacttagct 120
tggtaccagc agaaaccagg acagcctcct aagctgctca tttactgggc atctacccgg 180
aaatccgggg tccctgaccg attcagtggc agcgggtctg ggacagattt cactctcacc 240
atcagcagcc tgcaggctga agatgtggca gtttattact gtcatcaata ttatagctat 300
ccgctcacgt tcggtcaagg caccaagctg gaaatcaaa 339
<210> 385
<211> 339
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.155 VH
<400> 385
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtt 60
tcctgcaagg catctggata caccttcaac agctactgga tgcactgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggagaa atccacccta ataatggtag cacaaactac 180
aacgagaagt tcaagggcag agtcaccatg accagggaca cgtccacgag cacagtctac 240
atggagctga gcagcctgag atctgaggac acggccgtgt attactgtgc gagatggact 300
ttgtttactt actggggcca agggactctg gtcactgtc 339
<210> 386
<211> 336
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.156 VL
<400> 386
gacatcgtga tgacccagac ccctctgtcc ctgcctgtga cccctggaga acccgccagc 60
atctcctgca ggtcctccca gtccatcgtg cactccaacg gcaacaccta cctggagtgg 120
tacctgcaga agcccggaca gtccccccag ctgctgatct acaaggtgtc caataggttt 180
tccggagtgc ccgacaggtt ctccggatcc ggatccggca ccgacttcac cctgaagatc 240
tccagggtgg aggccgagga cgtgggagtg tactactgct tccagggcag ccacgtgccc 300
cctacattcg gaggcggcac caagctggag atcaag 336
<210> 387
<211> 354
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.156 VH
<400> 387
caggtcaccc tgaaggagtc cggccccgtg ctggtgaaac ccaccgagac cctcaccctg 60
acctgcaccg tctccggctt ctccctgtcc acctccggca tgggagtgtc ctggatcagg 120
cagccccctg gaaaggctct ggagtggctg gcccacatct tctgggacga cgacaagtgg 180
tacaacccct ccctgaagtc caggctgacc atctccaagg acacctccaa gtcccaggtg 240
gtgctgacca tgaccaacat ggaccccgtg gacaccgcca cctactactg cgctaccttc 300
tacggcctgt acttcgccta ctggggccag ggaaccctgg tgaccgtgtc ctcc 354
<210> 388
<211> 339
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.161 VL
<400> 388
gacatcgtga tgacccagtc ccccgattcc ctggctgtga gcctgggaga gagggccacc 60
atcaactgcg agtcctccca gtccctgctg tacaactcca accagaagaa ctacctggcc 120
tggtaccagc agaagcccgg acagcccccc aagctgctga tctactgggc ttccacaagg 180
gagtccggag tgcccgatcg gttcagcgga tccggatccg gcaccgactt caccctcacc 240
atcagctccc tgcaagccga ggacgtggcc gtgtactact gccagcagta cttcaactac 300
cctctgacct tcggccaggg caccaagctg gagatcaag 339
<210> 389
<211> 348
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.161 VH
<400> 389
caggtgcagc tggtccagtc cggagctgag gtgaagaagc ccggcgcctc cgtgaaggtg 60
tcctgcaagg ccagcggctt caccttctcc gatgcctgga tggactgggt gaggcaggct 120
cctggccaaa ggctggagtg gatgggcgag atcaggtcca agcccaacaa ccacgccacc 180
tactacgccg agagcgtgaa gggcagggtg accatcacaa gggatacatc cgcctccacc 240
gcctacatgg agctgtcctc cctgaggtcc gaggacaccg ccgtgtacta ctgtgccagg 300
accggaacct cctactgggg ccagggcaca ctggtgaccg tgtcctcc 348
<210> 390
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.200 VL
<400> 390
gaaattgtgt tgacacagtc tccagccacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttgac tataatggaa ttagctacat gcactggtac 120
caacagaaac ctggccaggc tcccaggctc ctcatctatg ctgcatccaa cgtgcagagt 180
ggcatcccag ccaggttcag tggcagtggg tctgggacag acttcactct caccatcagc 240
agcctagagc ctgaagattt tgcagtttat tactgtcagc agagtattga ggatcctccg 300
acgttcggtg gaggcaccaa ggtggaaatc aaa 333
<210> 391
<211> 345
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.200 VH
<400> 391
gaggtgcagc tggtgcagtc tggagcagag gtgaaaaagc ccggggagtc tctgaagatc 60
tcctgtaagg gttctggata cagctttacc agctcctgga tcaactgggt gcgccagatg 120
cccgggaaag gcctggagtg gatggggaga atctatcctg gtgagggtga taccaactac 180
agcgggaact tcgaaggcca ggtcaccatc tcagccgaca agtccatcag caccgcctac 240
ctgcagtgga gcagcctgaa ggcctcggac accgccatgt attactgtac aagaggacta 300
gtcatggact actggggcca aggcaccctt gtcacagtct cgagc 345
<210> 392
<211> 333
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.200 VL1
<400> 392
gaaattgtgt tgacacagtc tccagccacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttgac tatgatggaa ttagctacat gcactggtac 120
caacagaaac ctggccaggc tcccaggctc ctcatctatg ctgcatccaa cgtgcagagt 180
ggcatcccag ccaggttcag tggcagtggg tctgggacag acttcactct caccatcagc 240
agcctagagc ctgaagattt tgcagtttat tactgtcagc agagtattga ggatcctccg 300
acgttcggtg gaggcaccaa ggtggaaatc aaa 333
<210> 393
<211> 339
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.155 VH1
<400> 393
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtt 60
tcctgcaagg catctggata caccttcgac agctactgga tgcactgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggagaa atccacccta ataatggtag cacaaactac 180
aacgagaagt tcaagggcag agtcaccatg accagggaca cgtccacgag cacagtctac 240
atggagctga gcagcctgag atctgaggac acggccgtgt attactgtgc gagatggact 300
ttgtttactt actggggcca agggactctg gtcactgtc 339
<210> 394
<211> 339
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.155 VH2
<400> 394
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtt 60
tcctgcaagg catctggata caccttcacc agctactgga tgcactgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggagaa atccacccta ataatggtag cacaaactac 180
aacgagaagt tcaagggcag agtcaccatg accagggaca cgtccacgag cacagtctac 240
atggagctga gcagcctgag atctgaggac acggccgtgt attactgtgc gagatggact 300
ttgtttactt actggggcca agggactctg gtcactgtc 339
<210> 395
<211> 339
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.155 VH3
<400> 395
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtt 60
tcctgcaagg catctggata caccttcaac tactactgga tgcactgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggagaa atccacccta ataatggtag cacaaactac 180
aacgagaagt tcaagggcag agtcaccatg accagggaca cgtccacgag cacagtctac 240
atggagctga gcagcctgag atctgaggac acggccgtgt attactgtgc gagatggact 300
ttgtttactt actggggcca agggactctg gtcactgtc 339
<210> 396
<211> 339
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.155 VH4
<400> 396
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtt 60
tcctgcaagg catctggata caccttcaac agctactgga tgcactgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggagaa atccacccta atgatggtag cacaaactac 180
aacgagaagt tcaagggcag agtcaccatg accagggaca cgtccacgag cacagtctac 240
atggagctga gcagcctgag atctgaggac acggccgtgt attactgtgc gagatggact 300
ttgtttactt actggggcca agggactctg gtcactgtc 339
<210> 397
<211> 339
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.155 VH5
<400> 397
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtt 60
tcctgcaagg catctggata caccttcaac agctactgga tgcactgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggagaa atccacccta atggtggtag cacaaactac 180
aacgagaagt tcaagggcag agtcaccatg accagggaca cgtccacgag cacagtctac 240
atggagctga gcagcctgag atctgaggac acggccgtgt attactgtgc gagatggact 300
ttgtttactt actggggcca agggactctg gtcactgtc 339
<210> 398
<211> 339
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.155 VH6
<400> 398
caggtgcagc tggtgcagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtt 60
tcctgcaagg catctggata caccttcaac agctactgga tgcactgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggagaa atccacccta atagtggtag cacaaactac 180
aacgagaagt tcaagggcag agtcaccatg accagggaca cgtccacgag cacagtctac 240
atggagctga gcagcctgag atctgaggac acggccgtgt attactgtgc gagatggact 300
ttgtttactt actggggcca agggactctg gtcactgtc 339
<210> 399
<211> 348
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized hSC17.161 VH1
<400> 399
gaggtgcagc tggtggaatc cggaggcggc ctggtgcaac ctggaggatc cctcaggctg 60
tcctgtgccg cttccggatt caccttctcc gatgcctgga tggactgggt gaggcaggcc 120
cctggcaaag gactggaatg ggtgggcgag atcaggtcca aacccaacaa ccacgccacc 180
tactacgccg agtccgtgaa gggcaggttc accatctcca gggacgactc caagaactcc 240
ctgtacctgc agatgaactc cctgaagacc gaggacaccg ccgtgtacta ctgcgctagg 300
accggcacct cctattgggg acagggcacc ctggtgaccg tgtcctcc 348
<210> 400
<211> 218
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.200 light chain
<400> 400
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Asp Tyr Asn
20 25 30
Gly Ile Ser Tyr Met His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro
35 40 45
Arg Leu Leu Ile Tyr Ala Ala Ser Asn Val Gln Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Ser Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Ser Ile
85 90 95
Glu Asp Pro Pro Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105 110
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
115 120 125
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
130 135 140
Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
145 150 155 160
Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr
165 170 175
Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys
180 185 190
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro
195 200 205
Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 401
<211> 444
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.200 heavy chain
<400> 401
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Lys Ile Ser Cys Lys Gly Ser Gly Tyr Ser Phe Thr Ser Ser
20 25 30
Trp Ile Asn Trp Val Arg Gln Met Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Tyr Pro Gly Glu Gly Asp Thr Asn Tyr Ser Gly Asn Phe
50 55 60
Glu Gly Gln Val Thr Ile Ser Ala Asp Lys Ser Ile Ser Thr Ala Tyr
65 70 75 80
Leu Gln Trp Ser Ser Leu Lys Ala Ser Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Thr Arg Gly Leu Val Met Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro
115 120 125
Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val
130 135 140
Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala
145 150 155 160
Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly
165 170 175
Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly
180 185 190
Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys
195 200 205
Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys
210 215 220
Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu
290 295 300
Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
340 345 350
Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
435 440
<210> 402
<211> 218
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized hSC17.200vL1 light chain
<400> 402
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Asp Tyr Asp
20 25 30
Gly Ile Ser Tyr Met His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro
35 40 45
Arg Leu Leu Ile Tyr Ala Ala Ser Asn Val Gln Ser Gly Ile Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Ser Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Ser Ile
85 90 95
Glu Asp Pro Pro Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105 110
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
115 120 125
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
130 135 140
Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
145 150 155 160
Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr
165 170 175
Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys
180 185 190
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro
195 200 205
Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 403
<211> 107
<212> PRT
<213> Homo sapiens
<220>
<221> MISC_FEATURE
<223> Kappa light chain constant region
<400> 403
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
1 5 10 15
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
20 25 30
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
35 40 45
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
50 55 60
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
65 70 75 80
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
85 90 95
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
100 105
<210> 404
<211> 329
<212> PRT
<213> Homo sapiens
<220>
<221> MISC_FEATURE
<223> IgG1 heavy chain constant region
<400> 404
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
225 230 235 240
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly
325
<210> 405
<211> 11
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.16 CDRL1
<400> 405
Arg Ala Ser Ala Asn Ile Asn Ser Asn Leu Val
1 5 10
<210> 406
<211> 7
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.16 CDRL2
<400> 406
Ala Ala Thr Asn Leu Ala Asp
1 5
<210> 407
<211> 9
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.16 CDRL3
<400> 407
Gln His Phe Trp Gly Thr Pro Arg Thr
1 5
<210> 408
<211> 5
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.16 CDRH1
<400> 408
Asp Tyr Asn Met Tyr
1 5
<210> 409
<211> 17
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.16 CDRH2
<400> 409
Glu Ile Asn Pro Asn Asn Gly Gly Thr Ala Tyr Asn Gln Lys Phe Arg
1 5 10 15
Gly
<210> 410
<211> 7
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.16 CDRH3
<400> 410
Tyr Asp Lys Gly Phe Asp Tyr
1 5
<210> 411
<211> 10
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.17 CDRL1
<400> 411
Ser Ala Ser Ser Ser Val Ser Tyr Met His
1 5 10
<210> 412
<211> 7
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.17 CDRL2
<400> 412
Asp Thr Ser Lys Leu Pro Ser
1 5
<210> 413
<211> 9
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.17 CDRL3
<400> 413
Gln Gln Trp Ser Ser Thr Pro Pro Thr
1 5
<210> 414
<211> 5
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.17 CDRH1
<400> 414
Asp Tyr Asn Met His
1 5
<210> 415
<211> 17
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.17 CDRH2
<400> 415
Glu Ile Asn Pro Asn Ile Gly Gly Thr Gly Tyr Asn Gln Lys Phe Lys
1 5 10 15
Gly
<210> 416
<211> 11
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.17 CDRH3
<400> 416
Thr Tyr Ser Tyr Tyr Ser Tyr Glu Phe Ala Tyr
1 5 10
<210> 417
<211> 17
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.24 CDRL1
<400> 417
Lys Ser Ser Gln Ser Leu Leu Tyr Ser Ser Asn Gln Lys Ser Tyr Leu
1 5 10 15
Ala
<210> 418
<211> 7
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.24 CDRL2
<400> 418
Trp Ala Ser Thr Arg Glu Ser
1 5
<210> 419
<211> 8
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.24 CDRL3
<400> 419
Lys Gln Ser Tyr Asn Leu Arg Thr
1 5
<210> 420
<211> 5
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.24 CDRH1
<400> 420
Asp His Thr Ile His
1 5
<210> 421
<211> 17
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.24 CDRH2
<400> 421
Tyr Ile Tyr Pro Arg Asp Gly Ser Thr Lys Tyr Asn Glu Glu Phe Lys
1 5 10 15
Gly
<210> 422
<211> 8
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.24 CDRH3
<400> 422
Ser Tyr Ser Asn Tyr Phe Asp Tyr
1 5
<210> 423
<211> 11
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.28 CDRL1
<400> 423
Arg Ala Ser Gln Ser Ile Gly Thr Ser Ile His
1 5 10
<210> 424
<211> 7
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.28 CDRL2
<400> 424
Tyr Ala Ser Glu Ser Ile Ser
1 5
<210> 425
<211> 9
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.28 CDRL3
<400> 425
Gln Gln Ser Asn Ser Trp Pro Leu Thr
1 5
<210> 426
<211> 5
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.28 CDRH1
<400> 426
Arg Ser Tyr Ile His
1 5
<210> 427
<211> 17
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.28 CDRH2
<400> 427
Tyr Ile Ser Ser Gly Ser Gly Gly Thr Thr Tyr Asn Gln Lys Phe Lys
1 5 10 15
Gly
<210> 428
<211> 8
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.28 CDRH3
<400> 428
Gly Gly Val Arg Tyr Phe Asp Val
1 5
<210> 429
<211> 11
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.34 CDRL1
<400> 429
Lys Ala Ser Gln Asp Ile Asn Ser Tyr Leu Ser
1 5 10
<210> 430
<211> 7
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.34 CDRL2
<400> 430
Arg Ala Asn Arg Leu Val Asp
1 5
<210> 431
<211> 9
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.34 CDRL1
<220>
<221> MISC_FEATURE
<223> hSC17.34 CDRL3
<400> 431
Leu Gln Tyr Asp Glu Phe Pro Pro Thr
1 5
<210> 432
<211> 5
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.34 CDRH1
<400> 432
Asp Tyr Asn Met Asp
1 5
<210> 433
<211> 17
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.34 CDRH1
<400> 433
Tyr Ile Tyr Pro Asp Asn Gly Gly Ala Gly Tyr Asn Gln Lys Phe Lys
1 5 10 15
Gly
<210> 434
<211> 9
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.34 CDRH3
<400> 434
Ser Ile Thr Thr Ala Trp Phe Ala Tyr
1 5
<210> 435
<211> 11
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.46 CDRL1
<400> 435
Lys Ala Ser Gln Ser Val Asn Asn Asp Val Ala
1 5 10
<210> 436
<211> 7
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.46 CDRL2
<400> 436
Tyr Ala Ser Asn Arg Tyr Thr
1 5
<210> 437
<211> 9
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.46 CDRL3
<400> 437
Gln Gln Asp Tyr Ser Ser Pro Arg Thr
1 5
<210> 438
<211> 5
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.46 CDRH1
<400> 438
Ser Tyr Trp Ile Asn
1 5
<210> 439
<211> 17
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.46 CDRH2
<400> 439
Asn Ile Phe Pro Asp Thr Thr Thr Thr Asn Tyr Asn Glu Lys Phe Lys
1 5 10 15
Gly
<210> 440
<211> 12
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.46 CDRH1
<400> 440
Glu Tyr Tyr Asp Gly Thr Tyr Asp Ala Met Asp Tyr
1 5 10
<210> 441
<211> 15
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.151 CDRL1
<400> 441
Arg Ala Ser Glu Ser Val Asp Ser Tyr Gly Asn Ser Phe Met His
1 5 10 15
<210> 442
<211> 7
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.151 CDRL2
<400> 442
Arg Ala Ser Asn Leu Glu Ser
1 5
<210> 443
<211> 9
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.151 CDRL3
<400> 443
Gln Gln Ser His Glu Asp Pro Tyr Thr
1 5
<210> 444
<211> 5
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.151 CDRH1
<400> 444
Ser Tyr Trp Met His
1 5
<210> 445
<211> 17
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.151 CDRH2
<400> 445
Ala Ile Tyr Pro Gly Lys Ser Asp Thr Thr Tyr Asn Gln Lys Phe Lys
1 5 10 15
Gly
<210> 446
<211> 8
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.151 CDRH3
<400> 446
Ser Gly Lys Gly Tyr Phe Ala Tyr
1 5
<210> 447
<211> 17
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.155 and hSC17.155vH1-6 CDRL1
<400> 447
Lys Ser Ser Gln Ser Leu Leu Tyr Ser Ser Asn Gln Lys Asn Tyr Leu
1 5 10 15
Ala
<210> 448
<211> 7
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.155 and hSC17.155vH1-6 CDRL2
<400> 448
Trp Ala Ser Thr Arg Lys Ser
1 5
<210> 449
<211> 9
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.155 and hSC17.155vH1-6 CDRL3
<400> 449
His Gln Tyr Tyr Ser Tyr Pro Leu Thr
1 5
<210> 450
<211> 5
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.155 and hSC17.155vH1, vH2 and vH4-6 CDRH1
<400> 450
Ser Tyr Trp Met His
1 5
<210> 451
<211> 17
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.155 and hSC17.155vH1-3 CDRH2
<400> 451
Glu Ile His Pro Asn Asn Gly Ser Thr Asn Tyr Asn Glu Lys Phe Lys
1 5 10 15
Gly
<210> 452
<211> 6
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.155 and hSC17.155vH1-6 CDRH3
<400> 452
Trp Thr Leu Phe Thr Tyr
1 5
<210> 453
<211> 16
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.156 CDRL1
<400> 453
Arg Ser Ser Gln Ser Ile Val His Ser Asn Gly Asn Thr Tyr Leu Glu
1 5 10 15
<210> 454
<211> 7
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.156 CDRL2
<400> 454
Lys Val Ser Asn Arg Phe Ser
1 5
<210> 455
<211> 9
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.156 CDRL3
<400> 455
Phe Gln Gly Ser His Val Pro Pro Thr
1 5
<210> 456
<211> 7
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.156 CDRH1
<400> 456
Thr Ser Gly Met Gly Val Ser
1 5
<210> 457
<211> 16
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.156 CDRH2
<400> 457
His Ile Phe Trp Asp Asp Asp Lys Trp Tyr Asn Pro Ser Leu Lys Ser
1 5 10 15
<210> 458
<211> 8
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.156 CDRH3
<400> 458
Phe Tyr Gly Leu Tyr Phe Ala Tyr
1 5
<210> 459
<211> 17
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.161 and hSC17.161v1 CDRL1
<400> 459
Glu Ser Ser Gln Ser Leu Leu Tyr Asn Ser Asn Gln Lys Asn Tyr Leu
1 5 10 15
Ala
<210> 460
<211> 7
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.161 and hSC17.161vL1 CDRL2
<400> 460
Trp Ala Ser Thr Arg Glu Ser
1 5
<210> 461
<211> 9
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.161 and hSC17.161vL1 CDRL3
<400> 461
Gln Gln Tyr Phe Asn Tyr Pro Leu Thr
1 5
<210> 462
<211> 5
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.161 and hSC17.161vL1 CDRH1
<400> 462
Asp Ala Trp Met Asp
1 5
<210> 463
<211> 19
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.161 and hSC17.161vL1 CDRH2
<400> 463
Glu Ile Arg Ser Lys Pro Asn Asn His Ala Thr Tyr Tyr Ala Glu Ser
1 5 10 15
Val Lys Gly
<210> 464
<211> 5
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.161 and and hSC17.161vL1 CDRH3
<400> 464
Thr Gly Thr Ser Tyr
1 5
<210> 465
<211> 15
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.200 CDRL1
<400> 465
Arg Ala Ser Gln Ser Val Asp Tyr Asn Gly Ile Ser Tyr Met His
1 5 10 15
<210> 466
<211> 7
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.200 and hSC17.200vL1 CDRL2
<400> 466
Ala Ala Ser Asn Val Gln Ser
1 5
<210> 467
<211> 9
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.200 and hSC17.200vL1 CDRL3
<400> 467
Gln Gln Ser Ile Glu Asp Pro Pro Thr
1 5
<210> 468
<211> 5
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.200 and hSC17.200vL1 CDRH1
<400> 468
Ser Ser Trp Ile Asn
1 5
<210> 469
<211> 17
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.200 and hSC17.200vL1 CDRH2
<400> 469
Arg Ile Tyr Pro Gly Glu Gly Asp Thr Asn Tyr Ser Gly Asn Phe Glu
1 5 10 15
Gly
<210> 470
<211> 6
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.200 and hSC17.200vL1 CDRH3
<400> 470
Gly Leu Val Met Asp Tyr
1 5
<210> 471
<211> 30
<212> PRT
<213> Homo sapiens
<220>
<221> MISC_FEATURE
<223> hSC17.155vH1 FR1
<400> 471
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Asp
20 25 30
<210> 472
<211> 30
<212> PRT
<213> Homo sapiens
<220>
<221> MISC_FEATURE
<223> hSC17.155vH2 FR1
<400> 472
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr
20 25 30
<210> 473
<211> 5
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.155vH3 CDRH1
<400> 473
Tyr Tyr Trp Met His
1 5
<210> 474
<211> 17
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.155vH4 CDRH2
<400> 474
Glu Ile His Pro Asn Asp Gly Ser Thr Asn Tyr Asn Glu Lys Phe Lys
1 5 10 15
Gly
<210> 475
<211> 17
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.155vH5 CDRH2
<400> 475
Glu Ile His Pro Asn Gly Gly Ser Thr Asn Tyr Asn Glu Lys Phe Lys
1 5 10 15
Gly
<210> 476
<211> 17
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.155vH6 CDRH2
<400> 476
Glu Ile His Pro Asn Ser Gly Ser Thr Asn Tyr Asn Glu Lys Phe Lys
1 5 10 15
Gly
<210> 477
<211> 30
<212> PRT
<213> Homo sapiens
<220>
<221> MISC_FEATURE
<223> hSC17.161vH1 FR1
<400> 477
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser
20 25 30
<210> 478
<211> 14
<212> PRT
<213> Homo sapiens
<220>
<221> MISC_FEATURE
<223> hSC17.161vH1 FR2
<400> 478
Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Gly
1 5 10
<210> 479
<211> 32
<212> PRT
<213> Homo sapiens
<220>
<221> MISC_FEATURE
<223> hSC17.161vH1 FR3
<400> 479
Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Ser Leu Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Lys Thr Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg
20 25 30
<210> 480
<211> 15
<212> PRT
<213> Mus musculus
<220>
<221> MISC_FEATURE
<223> hSC17.200vL1 CDRL1
<400> 480
Arg Ala Ser Gln Ser Val Asp Tyr Asp Gly Ile Ser Tyr Met His
1 5 10 15
Claims (19)
- SEZ6 단백질 상의 에피토프에 특이적으로 결합하는 단리된 항체로서, 상기 에피토프는 (i) 잔기 R762, L764, Q777, I779, D781 및 Q782; (ii) 잔기 R342 및 K389 및 (iii) 잔기 T352, S353 및 H375로 이루어진 그룹으로부터 선택되는 아미노산 잔기를 포함하는, SEZ6 단백질 상의 에피토프에 특이적으로 결합하는 단리된 항체.
- 치료학적 모이어티(therapeutic moiety)에 직접적으로 또는 간접적으로 접합된 항체를 포함하는 항체 약물 접합체로서, 상기 항체는 SEZ6 단백질 상의 에피토프에 특이적으로 결합하고, 상기 에피토프는 (i) 잔기 R762, L764, Q777, I779, D781 및 Q782; (ii) 잔기 R342 및 K389 및 (iii) 잔기 T352, S353 및 H375로 이루어진 그룹으로부터 선택되는 아미노산 잔기를 포함하는, 치료학적 모이어티에 직접적으로 또는 간접적으로 접합된 항체를 포함하는 항체 약물 접합체.
- 제2항에 있어서, 상기 치료학적 모이어티가 아우리스타틴, 아마니틴 및 피롤로벤조디아제핀으로 이루어진 그룹으로부터 선택되는, 항체 약물 접합체.
- 치료학적 모이어티에 직접적으로 또는 간접적으로 접합된 항체를 포함하는 치료학적 유효량의 항체 약물 접합체를 투여함을 포함하는 암에 걸린 대상체를 치료하는 방법으로서, 상기 항체는 SEZ6 단백질 상의 에피토프에 특이적으로 결합하고, 상기 에피토프는 (i) 잔기 R762, L764, Q777, I779, D781 및 Q782; (ii) 잔기 R342 및 K389 및 (iii) 잔기 T352, S353 및 H375로 이루어진 그룹으로부터 선택되는 아미노산 잔기를 포함하는, 암에 걸린 대상체를 치료하는 방법.
- 제4항에 있어서, 상기 치료학적 모이어티가 아우리스타틴, 아마니틴 및 피롤로벤조디아제핀으로 이루어진 그룹으로부터 선택되는, 방법.
- 제4항에 있어서, 상기 대상체가 이전에 백금계 제제로 치료받은, 방법.
- 치료학적 모이어티에 직접적으로 또는 간접적으로 접합된 항체를 포함하는 치료학적 유효량의 항체 약물 접합체를 투여함을 포함하는 백금 내성 소세포 폐암에 걸린 대상체를 치료하는 방법으로서, 상기 항체는 SEZ6 단백질 상의 에피토프에 특이적으로 결합하고, 상기 에피토프는 (i) 잔기 R762, L764, Q777, I779, D781 및 Q782; (ii) 잔기 R342 및 K389 및 (iii) 잔기 T352, S353 및 H375로 이루어진 그룹으로부터 선택되는 아미노산 잔기를 포함하는, 백금 내성 소세포 폐암에 걸린 대상체를 치료하는 방법.
- 제7항에 있어서, 상기 치료학적 모이어티가 아우리스타틴, 아마니틴 및 피롤로벤조디아제핀으로 이루어진 그룹으로부터 선택되는, 방법.
- 치료학적 모이어티에 직접적으로 또는 간접적으로 접합된 항체를 포함하는 치료학적 유효량의 항체 약물 접합체를 투여함을 포함하는 갑상선 수질암에 걸린 환자를 치료하는 방법으로서, 상기 항체는 SEZ6 단백질 상의 에피토프에 특이적으로 결합하는, 갑상선 수질암에 걸린 환자를 치료하는 방법.
- 제9항에 있어서, 상기 에피토프가 (i) 잔기 R762, L764, Q777, I779, D781 및 Q782; (ii) 잔기 R342 및 K389 및 (iii) 잔기 T352, S353 및 H375로 이루어진 그룹으로부터 선택되는 아미노산 잔기를 포함하는, 방법.
- 제9항에 있어서, 상기 치료학적 모이어티가 아우리스타틴, 아마니틴 및 피롤로벤조디아제핀으로 이루어진 그룹으로부터 선택되는, 방법.
- a. 대상체로부터 백금 내성 소세포 폐암 종양 샘플을 제공하는 단계;
b. 상기 종양 샘플을 리포터로 표지된 항-SEZ6 항체에 노출시키는 단계(여기서, 상기 항-SEZ6 항체는 상기 종양 샘플과 회합한다); 및
c. 상기 종양 샘플과 회합된 리포터를 검출하는 단계
를 포함하는, 백금 내성 소세포 폐암을 진단하는 방법. - 제12항에 있어서, 상기 리포터가 시험관내에서 검출되는, 방법.
- 제12항에 있어서, 상기 리포터가 면역조직화학을 사용하여 검출되는, 방법.
- 제12항 내지 제14항 중 어느 한 항에 있어서, 상기 항-SEZ6 항체가 SEZ6 단백질 상의 에피토프에 결합하고, 여기서, 상기 에피토프가 아미노산 잔기 R762, L764, Q777, I779, D781 및 Q782를 포함하는, 방법.
- a. 대상체로부터 갑상선 수질암 종양 샘플을 제공하는 단계;
b. 상기 종양 샘플을 리포터로 표지된 항-SEZ6 항체에 노출시키는 단계(여기서, 상기 항-SEZ6 항체는 상기 종양 샘플과 회합한다); 및
c. 상기 종양 샘플과 회합된 리포터를 검출하는 단계
를 포함하는, 갑상선 수질암을 진단하는 방법. - 제16항에 있어서, 상기 리포터가 시험관내에서 검출되는, 방법.
- 제16항에 있어서, 상기 리포터가 면역조직화학을 사용하여 검출되는, 방법.
- 제16항 내지 제18항 중 어느 한 항에 있어서, 상기 항-SEZ6 항체가 SEZ6 단백질 상의 에피토프에 결합하고, 여기서, 상기 에피토프가 아미노산 잔기 R762, L764, Q777, I779, D781 및 Q782를 포함하는, 방법.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201361871289P | 2013-08-28 | 2013-08-28 | |
| US61/871,289 | 2013-08-28 | ||
| PCT/US2014/053014 WO2015031541A1 (en) | 2013-08-28 | 2014-08-27 | Novel sez6 modulators and methods of use |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20160046914A true KR20160046914A (ko) | 2016-04-29 |
Family
ID=52587309
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020167008239A KR20160046914A (ko) | 2013-08-28 | 2014-08-27 | 신규한 sez6 조절물질 및 사용방법 |
Country Status (13)
| Country | Link |
|---|---|
| US (2) | US9993566B2 (ko) |
| EP (2) | EP3038634A4 (ko) |
| JP (1) | JP2016538318A (ko) |
| KR (1) | KR20160046914A (ko) |
| CN (1) | CN105792836A (ko) |
| AU (1) | AU2014312310A1 (ko) |
| BR (1) | BR112016004245A2 (ko) |
| CA (1) | CA2922529A1 (ko) |
| HK (1) | HK1248596A1 (ko) |
| MX (1) | MX2016002574A (ko) |
| RU (1) | RU2016111139A (ko) |
| SG (1) | SG11201601416VA (ko) |
| WO (1) | WO2015031541A1 (ko) |
Families Citing this family (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3539985A1 (en) * | 2012-02-24 | 2019-09-18 | AbbVie Stemcentrx LLC | Anti sez6 antibodies and methods of use |
| MX2016002547A (es) * | 2013-08-28 | 2016-06-17 | Stemcentrx Inc | Metodos de conjugacion de anticuerpos especificos de sitio y composiciones. |
| BR112016018891A2 (pt) | 2014-02-21 | 2017-10-10 | Abbvie Stemcentrx Llc | anticorpos anti-dll3 e conjugados de fármacos para uso em melanoma |
| WO2016207103A1 (de) * | 2015-06-23 | 2016-12-29 | Bayer Pharma Aktiengesellschaft | Antikörper-wirkstoff-konjugate (adcs) von ksp-inhibitoren mit anti-b7h3-antikörpern |
| JP6632118B2 (ja) * | 2015-09-04 | 2020-01-15 | 学校法人 岩手医科大学 | 腫瘍の再発を抑制する医薬 |
| BR112018067379A2 (pt) | 2016-03-02 | 2019-01-15 | Eisai R&D Man Co Ltd | conjugado anticorpo-droga, composição, método para tratamento de um paciente que tem ou corre o risco de ter um câncer, para produzir o conjugado anticorpo-droga ou a composição, para determinar se um paciente será responsivo a um tratamento com o conjugado anticorpo-droga ou a composição, e, uso de um conjugado anticorpo-droga ou de uma composição. |
| SG11201901548SA (en) * | 2016-08-26 | 2019-03-28 | Beigene Ltd | Anti-tim-3 antibodies and use thereof |
| KR102187291B1 (ko) | 2016-11-21 | 2020-12-07 | 나노스트링 테크놀로지스, 인크. | 화학적 조성물 및 이것을 사용하는 방법 |
| EP3559043A4 (en) | 2016-12-23 | 2020-08-05 | Bluefin Biomedicine, Inc. | ANTI-SEZ6L2 ANTIBODIES AND ANTIBODY ACTIVE CONJUGATES |
| US11813339B2 (en) | 2017-02-08 | 2023-11-14 | Igl Pharma, Inc. | Method of use for therapeutic bone agents |
| CN111010867B (zh) * | 2017-05-30 | 2023-05-12 | 俄克拉何马大学董事会 | 抗双皮层蛋白样激酶1抗体及其使用方法 |
| CA3122010A1 (en) | 2017-12-04 | 2019-06-13 | Coare Holdings, Inc. | Anti-dclk1 antibodies and chimeric antigen receptors, and compositions and methods of use thereof |
| CN108038352B (zh) * | 2017-12-15 | 2021-09-14 | 西安电子科技大学 | 结合差异化分析和关联规则挖掘全基因组关键基因的方法 |
| US11549139B2 (en) | 2018-05-14 | 2023-01-10 | Nanostring Technologies, Inc. | Chemical compositions and methods of using same |
| AU2019278870A1 (en) * | 2018-05-30 | 2020-10-29 | Abbvie Stemcentrx Llc | Anti-SEZ6 antibody drug conjugates and methods of use |
| EP4188432A4 (en) | 2020-07-31 | 2024-08-21 | Scherer Technologies Llc R P | ANTIBODY SPECIFIC TO MUCIN-1 AND METHODS OF USE THEREOF |
| CN113721030B (zh) * | 2021-08-30 | 2024-02-13 | 河南中医药大学 | 用于桥本甲状腺炎不同证候特征性自身抗体检测的生物标志物及其应用 |
Family Cites Families (136)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| FR2413974A1 (fr) | 1978-01-06 | 1979-08-03 | David Bernard | Sechoir pour feuilles imprimees par serigraphie |
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| US4703004A (en) | 1984-01-24 | 1987-10-27 | Immunex Corporation | Synthesis of protein with an identification peptide |
| CA1319120C (en) | 1985-04-01 | 1993-06-15 | John Henry Kenten | Transformed myeloma cell-line and a process for the expression of a gene coding for a eukaryotic polypeptide employing same |
| US4676980A (en) | 1985-09-23 | 1987-06-30 | The United States Of America As Represented By The Secretary Of The Department Of Health And Human Services | Target specific cross-linked heteroantibodies |
| GB8601597D0 (en) | 1986-01-23 | 1986-02-26 | Wilson R H | Nucleotide sequences |
| US6548640B1 (en) | 1986-03-27 | 2003-04-15 | Btg International Limited | Altered antibodies |
| EP0307434B2 (en) | 1987-03-18 | 1998-07-29 | Scotgen Biopharmaceuticals, Inc. | Altered antibodies |
| US5750172A (en) | 1987-06-23 | 1998-05-12 | Pharming B.V. | Transgenic non human mammal milk |
| GB8717430D0 (en) | 1987-07-23 | 1987-08-26 | Celltech Ltd | Recombinant dna product |
| US5336603A (en) | 1987-10-02 | 1994-08-09 | Genentech, Inc. | CD4 adheson variants |
| IL89220A (en) | 1988-02-11 | 1994-02-27 | Bristol Myers Squibb Co | Immunoconjugates of anthracycline, their production and pharmaceutical preparations containing them |
| US5879936A (en) | 1988-04-18 | 1999-03-09 | Aluguisse Holding A.G. | Recombinant DNA methods, vectors and host cells |
| GB8809129D0 (en) | 1988-04-18 | 1988-05-18 | Celltech Ltd | Recombinant dna methods vectors and host cells |
| US5223409A (en) | 1988-09-02 | 1993-06-29 | Protein Engineering Corp. | Directed evolution of novel binding proteins |
| GB8823869D0 (en) | 1988-10-12 | 1988-11-16 | Medical Res Council | Production of antibodies |
| KR900005995A (ko) | 1988-10-31 | 1990-05-07 | 우메모또 요시마사 | 변형 인터류킨-2 및 그의 제조방법 |
| US5530101A (en) | 1988-12-28 | 1996-06-25 | Protein Design Labs, Inc. | Humanized immunoglobulins |
| WO1991000360A1 (en) | 1989-06-29 | 1991-01-10 | Medarex, Inc. | Bispecific reagents for aids therapy |
| US5112946A (en) | 1989-07-06 | 1992-05-12 | Repligen Corporation | Modified pf4 compositions and methods of use |
| FR2650598B1 (fr) | 1989-08-03 | 1994-06-03 | Rhone Poulenc Sante | Derives de l'albumine a fonction therapeutique |
| WO1991006570A1 (en) | 1989-10-25 | 1991-05-16 | The University Of Melbourne | HYBRID Fc RECEPTOR MOLECULES |
| US5959177A (en) | 1989-10-27 | 1999-09-28 | The Scripps Research Institute | Transgenic plants expressing assembled secretory antibodies |
| US5633076A (en) | 1989-12-01 | 1997-05-27 | Pharming Bv | Method of producing a transgenic bovine or transgenic bovine embryo |
| US6075181A (en) | 1990-01-12 | 2000-06-13 | Abgenix, Inc. | Human antibodies derived from immunized xenomice |
| US6150584A (en) | 1990-01-12 | 2000-11-21 | Abgenix, Inc. | Human antibodies derived from immunized xenomice |
| US5314995A (en) | 1990-01-22 | 1994-05-24 | Oncogen | Therapeutic interleukin-2-antibody based fusion proteins |
| US5427908A (en) | 1990-05-01 | 1995-06-27 | Affymax Technologies N.V. | Recombinant library screening methods |
| US5349053A (en) | 1990-06-01 | 1994-09-20 | Protein Design Labs, Inc. | Chimeric ligand/immunoglobulin molecules and their uses |
| JPH06500011A (ja) | 1990-06-29 | 1994-01-06 | ラージ スケール バイオロジー コーポレイション | 形質転換された微生物によるメラニンの製造 |
| GB9015198D0 (en) | 1990-07-10 | 1990-08-29 | Brien Caroline J O | Binding substance |
| JPH06508511A (ja) | 1990-07-10 | 1994-09-29 | ケンブリッジ アンティボディー テクノロジー リミティド | 特異的な結合ペアーの構成員の製造方法 |
| US5625126A (en) | 1990-08-29 | 1997-04-29 | Genpharm International, Inc. | Transgenic non-human animals for producing heterologous antibodies |
| US5633425A (en) | 1990-08-29 | 1997-05-27 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US5545806A (en) | 1990-08-29 | 1996-08-13 | Genpharm International, Inc. | Ransgenic non-human animals for producing heterologous antibodies |
| DK0546073T3 (da) | 1990-08-29 | 1998-02-02 | Genpharm Int | Frembringelse og anvendelse af transgene, ikke-humane dyr, der er i stand til at danne heterologe antistoffer |
| US5661016A (en) | 1990-08-29 | 1997-08-26 | Genpharm International Inc. | Transgenic non-human animals capable of producing heterologous antibodies of various isotypes |
| ATE164395T1 (de) | 1990-12-03 | 1998-04-15 | Genentech Inc | Verfahren zur anreicherung von proteinvarianten mit geänderten bindungseigenschaften |
| AU643109B2 (en) | 1990-12-14 | 1993-11-04 | Cell Genesys, Inc. | Chimeric chains for receptor-associated signal transduction pathways |
| AU1545692A (en) | 1991-03-01 | 1992-10-06 | Protein Engineering Corporation | Process for the development of binding mini-proteins |
| DE69233367T2 (de) | 1991-04-10 | 2005-05-25 | The Scripps Research Institute, La Jolla | Bibliotheken heterodimerer rezeptoren mittels phagemiden |
| DE4122599C2 (de) | 1991-07-08 | 1993-11-11 | Deutsches Krebsforsch | Phagemid zum Screenen von Antikörpern |
| US5622929A (en) | 1992-01-23 | 1997-04-22 | Bristol-Myers Squibb Company | Thioether conjugates |
| US5667988A (en) | 1992-01-27 | 1997-09-16 | The Scripps Research Institute | Methods for producing antibody libraries using universal or randomized immunoglobulin light chains |
| FR2686901A1 (fr) | 1992-01-31 | 1993-08-06 | Rhone Poulenc Rorer Sa | Nouveaux polypeptides antithrombotiques, leur preparation et compositions pharmaceutiques les contenant. |
| FR2686899B1 (fr) | 1992-01-31 | 1995-09-01 | Rhone Poulenc Rorer Sa | Nouveaux polypeptides biologiquement actifs, leur preparation et compositions pharmaceutiques les contenant. |
| US5447851B1 (en) | 1992-04-02 | 1999-07-06 | Univ Texas System Board Of | Dna encoding a chimeric polypeptide comprising the extracellular domain of tnf receptor fused to igg vectors and host cells |
| ZA932522B (en) | 1992-04-10 | 1993-12-20 | Res Dev Foundation | Immunotoxins directed against c-erbB-2(HER/neu) related surface antigens |
| AU668423B2 (en) | 1992-08-17 | 1996-05-02 | Genentech Inc. | Bispecific immunoadhesins |
| WO1994004670A1 (en) | 1992-08-26 | 1994-03-03 | President And Fellows Of Harvard College | Use of the cytokine ip-10 as an anti-tumor agent |
| PT752248E (pt) | 1992-11-13 | 2001-01-31 | Idec Pharma Corp | Aplicacao terapeutica de anticorpos quimericos e marcados radioactivamente contra antigenios de diferenciacao restrita de linfocitos b humanos para o tratamento do linfoma de celulas b |
| US7744877B2 (en) | 1992-11-13 | 2010-06-29 | Biogen Idec Inc. | Expression and use of anti-CD20 Antibodies |
| AU693436B2 (en) | 1993-03-09 | 1998-07-02 | Genzyme Corporation | Isolation of components of interest from milk |
| US6214345B1 (en) | 1993-05-14 | 2001-04-10 | Bristol-Myers Squibb Co. | Lysosomal enzyme-cleavable antitumor drug conjugates |
| US5827690A (en) | 1993-12-20 | 1998-10-27 | Genzyme Transgenics Corporatiion | Transgenic production of antibodies in milk |
| WO1996004388A1 (en) | 1994-07-29 | 1996-02-15 | Smithkline Beecham Plc | Novel compounds |
| US6046037A (en) | 1994-12-30 | 2000-04-04 | Hiatt; Andrew C. | Method for producing immunoglobulins containing protection proteins in plants and their use |
| US5731168A (en) | 1995-03-01 | 1998-03-24 | Genentech, Inc. | Method for making heteromultimeric polypeptides |
| WO1997008320A1 (en) | 1995-08-18 | 1997-03-06 | Morphosys Gesellschaft Für Proteinoptimierung Mbh | Protein/(poly)peptide libraries |
| DK0871490T3 (da) | 1995-12-22 | 2003-07-07 | Bristol Myers Squibb Co | Forgrenede hydrazonlinkere |
| AU5711196A (en) | 1996-03-14 | 1997-10-01 | Human Genome Sciences, Inc. | Apoptosis inducing molecule i |
| AU728657B2 (en) | 1996-03-18 | 2001-01-18 | Board Of Regents, The University Of Texas System | Immunoglobulin-like domains with increased half-lives |
| WO1997034911A1 (en) | 1996-03-22 | 1997-09-25 | Human Genome Sciences, Inc. | Apoptosis inducing molecule ii |
| DE69833755T2 (de) | 1997-05-21 | 2006-12-28 | Biovation Ltd. | Verfahren zur herstellung von nicht-immunogenen proteinen |
| WO1999023105A1 (en) | 1997-11-03 | 1999-05-14 | Human Genome Sciences, Inc. | Vegi, an inhibitor of angiogenesis and tumor growth |
| JP4460155B2 (ja) | 1997-12-05 | 2010-05-12 | ザ・スクリプス・リサーチ・インステイチユート | マウス抗体のヒト化 |
| EP1193270B1 (en) | 1998-08-27 | 2003-05-14 | Spirogen Limited | Pyrrolobenzodiazepines |
| GB9818731D0 (en) | 1998-08-27 | 1998-10-21 | Univ Portsmouth | Compounds |
| EP1051432B1 (en) | 1998-12-08 | 2007-01-24 | Biovation Limited | Method for reducing immunogenicity of proteins |
| NZ539776A (en) | 1999-01-15 | 2006-12-22 | Genentech Inc | Polypeptide variants with altered effector function |
| US6737056B1 (en) | 1999-01-15 | 2004-05-18 | Genentech, Inc. | Polypeptide variants with altered effector function |
| US20040067490A1 (en) | 2001-09-07 | 2004-04-08 | Mei Zhong | Therapeutic polypeptides, nucleic acids encoding same, and methods of use |
| EP2213743A1 (en) | 2000-04-12 | 2010-08-04 | Human Genome Sciences, Inc. | Albumin fusion proteins |
| WO2001083552A2 (en) | 2000-04-28 | 2001-11-08 | Eli Lilly And Company | Human sez6 nucleic acids and polypeptides |
| US7138496B2 (en) | 2002-02-08 | 2006-11-21 | Genetastix Corporation | Human monoclonal antibodies against human CXCR4 |
| US7608704B2 (en) | 2000-11-08 | 2009-10-27 | Incyte Corporation | Secreted proteins |
| CA2431600C (en) | 2000-12-12 | 2012-04-17 | Medimmune, Inc. | Molecules with extended half-lives, compositions and uses thereof |
| US6362331B1 (en) | 2001-03-30 | 2002-03-26 | Council Of Scientific And Industrial Research | Process for the preparation of antitumor agents |
| US20030211991A1 (en) * | 2001-04-17 | 2003-11-13 | Su Eric Wen | Human sez6 nucleic acids and polypeptides |
| CN1343774A (zh) | 2001-05-28 | 2002-04-10 | 复旦大学 | 一种癫痫相关蛋白编码序列,其编码的多肽、制法及用途 |
| EP1461423B1 (en) | 2001-12-03 | 2008-05-14 | Amgen Fremont Inc. | Antibody categorization based on binding characteristics |
| US20040001835A1 (en) | 2002-03-04 | 2004-01-01 | Medimmune, Inc. | Prevention or treatment of cancer using integrin alphavbeta3 antagonists in combination with other agents |
| EP2364996B1 (en) | 2002-09-27 | 2016-11-09 | Xencor Inc. | Optimized FC variants and methods for their generation |
| US20040101920A1 (en) | 2002-11-01 | 2004-05-27 | Czeslaw Radziejewski | Modification assisted profiling (MAP) methodology |
| GB0226593D0 (en) | 2002-11-14 | 2002-12-24 | Consultants Ltd | Compounds |
| WO2004072266A2 (en) | 2003-02-13 | 2004-08-26 | Kalobios Inc. | Antibody affinity engineering by serial epitope-guided complementarity replacement |
| ATE516047T1 (de) | 2003-05-09 | 2011-07-15 | Diadexus Inc | Ovr110-antikörperzusammensetzungen und anwendungsverfahren |
| GB0321295D0 (en) | 2003-09-11 | 2003-10-15 | Spirogen Ltd | Synthesis of protected pyrrolobenzodiazepines |
| PT1725249E (pt) | 2003-11-06 | 2014-04-10 | Seattle Genetics Inc | Compostos de monometilvalina capazes de conjugação a ligandos |
| EP1718667B1 (en) | 2004-02-23 | 2013-01-09 | Genentech, Inc. | Heterocyclic self-immolative linkers and conjugates |
| DK2270010T3 (da) | 2004-03-01 | 2012-05-14 | Spirogen Ltd | 11-hydroxy-5h-pyrrolo[2,1-c][1,4]benzodiazepin-5-on-derivater som vigtige mellemprodukter i fremstillingen af c2-substituerede pyrrolobenzodiazepiner |
| GB0404577D0 (en) | 2004-03-01 | 2004-04-07 | Spirogen Ltd | Pyrrolobenzodiazepines |
| US7189710B2 (en) | 2004-03-30 | 2007-03-13 | Council Of Scientific And Industrial Research | C2-fluoro pyrrolo [2,1−c][1,4]benzodiazepine dimers |
| FR2869231B1 (fr) | 2004-04-27 | 2008-03-14 | Sod Conseils Rech Applic | Composition therapeutique contenant au moins un derive de la pyrrolobenzodiazepine et la fludarabine |
| US7709611B2 (en) | 2004-08-04 | 2010-05-04 | Amgen Inc. | Antibodies to Dkk-1 |
| DK1791565T3 (en) | 2004-09-23 | 2016-08-01 | Genentech Inc | Cysteingensplejsede antibodies and conjugates |
| EP2298895A1 (en) * | 2005-07-27 | 2011-03-23 | Oncotherapy Science, Inc. | Method of diagnosing small cell lung cancer |
| US20070123448A1 (en) | 2005-11-23 | 2007-05-31 | The Hospital For Sick Children | Novel chemical entities affecting neuroblastoma tumor-initiating cells |
| CN101336300A (zh) | 2005-12-16 | 2008-12-31 | 健泰科生物技术公司 | 神经胶质瘤的诊断、预后和治疗方法 |
| ES2374964T3 (es) | 2006-01-25 | 2012-02-23 | Sanofi | Agentes citotóxicos que comprenden nuevos derivados de tomaimicina. |
| PL2446904T3 (pl) | 2006-05-30 | 2015-10-30 | Genentech Inc | Przeciwciała anty-CD22, ich immunokoniugaty oraz ich zastosowania |
| AU2007258744A1 (en) | 2006-06-06 | 2007-12-21 | University Of Tennessee Research Foundation | Compositions enriched in neoplastic stem cells and methods comprising same |
| PL3207941T6 (pl) | 2006-09-07 | 2020-11-16 | Scott & White Memorial Hospital | Sposoby i kompozycje oparte na koniugacie ludzkiej interleukiny (IL)-3 z toksyną błoniczą |
| US7825267B2 (en) | 2006-09-08 | 2010-11-02 | University Of Pittsburgh-Of The Commonwealth System Of Higher Education | Synthesis of FR901464 and analogs with antitumor activity |
| JP2010516259A (ja) | 2007-01-22 | 2010-05-20 | レイベン バイオテクノロジーズ | ヒトがん幹細胞 |
| EP2190481B1 (en) | 2007-07-17 | 2014-12-24 | The General Hospital Corporation | Methods to identify and enrich for populations of ovarian cancer stem cells and somatic ovarian stem cells and uses thereof |
| EP2022848A1 (en) | 2007-08-10 | 2009-02-11 | Hubrecht Institut | A method for identifying, expanding, and removing adult stem cells and cancer stem cells |
| CA2697922A1 (en) | 2007-08-28 | 2009-03-12 | Biogen Idec Ma Inc. | Compositions that bind multiple epitopes of igf-1r |
| WO2009043051A2 (en) | 2007-09-27 | 2009-04-02 | Biogen Idec Ma Inc. | Cd23 binding molecules and methods of use thereof |
| AU2009205995B2 (en) * | 2008-01-18 | 2014-04-03 | Medimmune, Llc | Cysteine engineered antibodies for site-specific conjugation |
| US8384551B2 (en) | 2008-05-28 | 2013-02-26 | MedHab, LLC | Sensor device and method for monitoring physical stresses placed on a user |
| WO2010037134A2 (en) | 2008-09-29 | 2010-04-01 | Stemlifeline, Inc. | Multi-stage stem cell carcinogenesis |
| WO2010081171A2 (en) | 2009-01-12 | 2010-07-15 | Cyntellect, Inc. | Laser mediated sectioning and transfer of cell colonies |
| US20110020221A1 (en) | 2009-04-09 | 2011-01-27 | The Johns Hopkins University | Cancer stem cell expression patterns and compounds to target cancer stem cells |
| HRP20211444T1 (hr) | 2010-01-29 | 2021-12-24 | Chugai Seiyaku Kabushiki Kaisha | Anti-dll3 antitijelo |
| GB201006340D0 (en) | 2010-04-15 | 2010-06-02 | Spirogen Ltd | Synthesis method and intermediates |
| WO2011130616A1 (en) | 2010-04-15 | 2011-10-20 | Spirogen Limited | Pyrrolobenzodiazepines used to treat proliferative diseases |
| KR101772354B1 (ko) | 2010-04-15 | 2017-08-28 | 시애틀 지네틱스, 인크. | 표적화된 피롤로벤조디아제핀 접합체 |
| SI2528625T1 (sl) * | 2010-04-15 | 2013-11-29 | Spirogen Sarl | Pirolobenzodiazepini in njihovi konjugati |
| EP2579897A1 (en) | 2010-06-08 | 2013-04-17 | Genentech, Inc. | Cysteine engineered antibodies and conjugates |
| US20120100560A1 (en) | 2010-07-23 | 2012-04-26 | The Johns Hopkins University | Device for capture, enumeration, and profiling of circulating tumor cells |
| SG189212A1 (en) | 2010-09-03 | 2013-05-31 | Stem Centrx Inc | Identification and enrichment of cell subpopulations |
| US20130061342A1 (en) | 2011-09-02 | 2013-03-07 | Stem Centrx, Inc. | Identification and Enrichment of Cell Subpopulations |
| US20130061340A1 (en) | 2011-09-02 | 2013-03-07 | Stem Centrx, Inc. | Identification and Enrichment of Cell Subpopulations |
| US9778264B2 (en) | 2010-09-03 | 2017-10-03 | Abbvie Stemcentrx Llc | Identification and enrichment of cell subpopulations |
| WO2013119964A2 (en) | 2012-02-08 | 2013-08-15 | Stem Centrx, Inc. | Identification and enrichment of cell subpopulations |
| US9696320B2 (en) | 2010-09-17 | 2017-07-04 | National Institute Of Advanced Industrial Science And Technology | Lung cancer differential marker |
| KR20130130709A (ko) | 2010-09-29 | 2013-12-02 | 어젠시스 인코포레이티드 | 191p4d12 단백질에 결합하는 항체 약물 컨쥬게이트(adc) |
| KR20140010067A (ko) | 2011-02-15 | 2014-01-23 | 이뮤노젠 아이엔씨 | 컨쥬게이트의 제조방법 |
| CA2827722C (en) | 2011-03-02 | 2020-05-12 | Roche Glycart Ag | Anti-cea antibodies |
| US20130058947A1 (en) | 2011-09-02 | 2013-03-07 | Stem Centrx, Inc | Novel Modulators and Methods of Use |
| CA2850103C (en) | 2011-10-14 | 2019-09-10 | Spirogen Sarl | Pyrrolobenzodiazepines |
| EP3539985A1 (en) | 2012-02-24 | 2019-09-18 | AbbVie Stemcentrx LLC | Anti sez6 antibodies and methods of use |
| WO2015031693A1 (en) | 2013-08-28 | 2015-03-05 | Stem Centrx, Inc. | Engineered anti-dll3 conjugates and methods of use |
| MX2016002547A (es) | 2013-08-28 | 2016-06-17 | Stemcentrx Inc | Metodos de conjugacion de anticuerpos especificos de sitio y composiciones. |
| EP3209334A2 (en) | 2014-10-20 | 2017-08-30 | Igenica Biotherapeutics, Inc. | Novel antibody-drug conjugates and related compounds, compositions, and methods of use |
-
2014
- 2014-08-27 KR KR1020167008239A patent/KR20160046914A/ko not_active Application Discontinuation
- 2014-08-27 RU RU2016111139A patent/RU2016111139A/ru not_active Application Discontinuation
- 2014-08-27 WO PCT/US2014/053014 patent/WO2015031541A1/en active Application Filing
- 2014-08-27 SG SG11201601416VA patent/SG11201601416VA/en unknown
- 2014-08-27 EP EP14839298.8A patent/EP3038634A4/en not_active Withdrawn
- 2014-08-27 AU AU2014312310A patent/AU2014312310A1/en not_active Abandoned
- 2014-08-27 JP JP2016537831A patent/JP2016538318A/ja active Pending
- 2014-08-27 BR BR112016004245A patent/BR112016004245A2/pt not_active Application Discontinuation
- 2014-08-27 US US14/915,563 patent/US9993566B2/en active Active
- 2014-08-27 EP EP17203670.9A patent/EP3338793A1/en not_active Withdrawn
- 2014-08-27 MX MX2016002574A patent/MX2016002574A/es unknown
- 2014-08-27 CN CN201480056096.1A patent/CN105792836A/zh active Pending
- 2014-08-27 CA CA2922529A patent/CA2922529A1/en not_active Abandoned
-
2018
- 2018-06-11 US US16/005,249 patent/US20190022241A1/en not_active Abandoned
- 2018-07-03 HK HK18108493.5A patent/HK1248596A1/zh unknown
Also Published As
| Publication number | Publication date |
|---|---|
| US9993566B2 (en) | 2018-06-12 |
| JP2016538318A (ja) | 2016-12-08 |
| RU2016111139A (ru) | 2017-10-03 |
| MX2016002574A (es) | 2016-06-14 |
| AU2014312310A1 (en) | 2016-04-07 |
| EP3338793A1 (en) | 2018-06-27 |
| US20160287720A1 (en) | 2016-10-06 |
| EP3038634A4 (en) | 2017-10-11 |
| EP3038634A1 (en) | 2016-07-06 |
| HK1248596A1 (zh) | 2018-10-19 |
| SG11201601416VA (en) | 2016-03-30 |
| US20190022241A1 (en) | 2019-01-24 |
| CN105792836A (zh) | 2016-07-20 |
| RU2016111139A3 (ko) | 2018-03-20 |
| WO2015031541A1 (en) | 2015-03-05 |
| CA2922529A1 (en) | 2015-03-05 |
| BR112016004245A2 (pt) | 2017-10-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102099073B1 (ko) | 항 sez6 항체들 및 사용 방법 | |
| US9855343B2 (en) | Anti-DLL3 antibody drug conjugates | |
| KR20160046914A (ko) | 신규한 sez6 조절물질 및 사용방법 | |
| KR20160044042A (ko) | 부위-특이적 항체 접합 방법 및 조성물 | |
| KR20170010764A (ko) | 신규한 항-rnf43 항체 및 사용 방법 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| N231 | Notification of change of applicant | ||
| WITN | Application deemed withdrawn, e.g. because no request for examination was filed or no examination fee was paid |