KR100291494B1 - 노광데이타작성방법과노광데이타작성장치 - Google Patents
노광데이타작성방법과노광데이타작성장치 Download PDFInfo
- Publication number
- KR100291494B1 KR100291494B1 KR1019970078530A KR19970078530A KR100291494B1 KR 100291494 B1 KR100291494 B1 KR 100291494B1 KR 1019970078530 A KR1019970078530 A KR 1019970078530A KR 19970078530 A KR19970078530 A KR 19970078530A KR 100291494 B1 KR100291494 B1 KR 100291494B1
- Authority
- KR
- South Korea
- Prior art keywords
- exposure
- data
- pattern data
- integrated
- exposure pattern
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 70
- 239000004065 semiconductor Substances 0.000 title claims abstract description 39
- 230000003252 repetitive effect Effects 0.000 claims abstract description 60
- 239000011159 matrix material Substances 0.000 claims description 111
- 230000010354 integration Effects 0.000 claims description 80
- 238000010276 construction Methods 0.000 claims description 9
- 238000013075 data extraction Methods 0.000 claims description 6
- 239000011295 pitch Substances 0.000 description 85
- 238000012545 processing Methods 0.000 description 26
- 238000010586 diagram Methods 0.000 description 20
- 238000010894 electron beam technology Methods 0.000 description 17
- 238000013461 design Methods 0.000 description 11
- 240000006829 Ficus sundaica Species 0.000 description 7
- 239000000284 extract Substances 0.000 description 7
- 239000000543 intermediate Substances 0.000 description 6
- 238000003860 storage Methods 0.000 description 4
- 238000007596 consolidation process Methods 0.000 description 3
- 238000011161 development Methods 0.000 description 3
- 238000007796 conventional method Methods 0.000 description 2
- 238000000605 extraction Methods 0.000 description 2
- 230000007423 decrease Effects 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 230000001172 regenerating effect Effects 0.000 description 1
- 238000013341 scale-up Methods 0.000 description 1
- 238000004513 sizing Methods 0.000 description 1
Images










Classifications
-
- G—PHYSICS
- G03—PHOTOGRAPHY; CINEMATOGRAPHY; ANALOGOUS TECHNIQUES USING WAVES OTHER THAN OPTICAL WAVES; ELECTROGRAPHY; HOLOGRAPHY
- G03F—PHOTOMECHANICAL PRODUCTION OF TEXTURED OR PATTERNED SURFACES, e.g. FOR PRINTING, FOR PROCESSING OF SEMICONDUCTOR DEVICES; MATERIALS THEREFOR; ORIGINALS THEREFOR; APPARATUS SPECIALLY ADAPTED THEREFOR
- G03F7/00—Photomechanical, e.g. photolithographic, production of textured or patterned surfaces, e.g. printing surfaces; Materials therefor, e.g. comprising photoresists; Apparatus specially adapted therefor
- G03F7/70—Microphotolithographic exposure; Apparatus therefor
- G03F7/70483—Information management; Active and passive control; Testing; Wafer monitoring, e.g. pattern monitoring
- G03F7/70491—Information management, e.g. software; Active and passive control, e.g. details of controlling exposure processes or exposure tool monitoring processes
- G03F7/70508—Data handling in all parts of the microlithographic apparatus, e.g. handling pattern data for addressable masks or data transfer to or from different components within the exposure apparatus
-
- B—PERFORMING OPERATIONS; TRANSPORTING
- B82—NANOTECHNOLOGY
- B82Y—SPECIFIC USES OR APPLICATIONS OF NANOSTRUCTURES; MEASUREMENT OR ANALYSIS OF NANOSTRUCTURES; MANUFACTURE OR TREATMENT OF NANOSTRUCTURES
- B82Y10/00—Nanotechnology for information processing, storage or transmission, e.g. quantum computing or single electron logic
-
- B—PERFORMING OPERATIONS; TRANSPORTING
- B82—NANOTECHNOLOGY
- B82Y—SPECIFIC USES OR APPLICATIONS OF NANOSTRUCTURES; MEASUREMENT OR ANALYSIS OF NANOSTRUCTURES; MANUFACTURE OR TREATMENT OF NANOSTRUCTURES
- B82Y40/00—Manufacture or treatment of nanostructures
-
- G—PHYSICS
- G03—PHOTOGRAPHY; CINEMATOGRAPHY; ANALOGOUS TECHNIQUES USING WAVES OTHER THAN OPTICAL WAVES; ELECTROGRAPHY; HOLOGRAPHY
- G03F—PHOTOMECHANICAL PRODUCTION OF TEXTURED OR PATTERNED SURFACES, e.g. FOR PRINTING, FOR PROCESSING OF SEMICONDUCTOR DEVICES; MATERIALS THEREFOR; ORIGINALS THEREFOR; APPARATUS SPECIALLY ADAPTED THEREFOR
- G03F7/00—Photomechanical, e.g. photolithographic, production of textured or patterned surfaces, e.g. printing surfaces; Materials therefor, e.g. comprising photoresists; Apparatus specially adapted therefor
- G03F7/70—Microphotolithographic exposure; Apparatus therefor
- G03F7/70383—Direct write, i.e. pattern is written directly without the use of a mask by one or multiple beams
- G03F7/704—Scanned exposure beam, e.g. raster-, rotary- and vector scanning
-
- G—PHYSICS
- G03—PHOTOGRAPHY; CINEMATOGRAPHY; ANALOGOUS TECHNIQUES USING WAVES OTHER THAN OPTICAL WAVES; ELECTROGRAPHY; HOLOGRAPHY
- G03F—PHOTOMECHANICAL PRODUCTION OF TEXTURED OR PATTERNED SURFACES, e.g. FOR PRINTING, FOR PROCESSING OF SEMICONDUCTOR DEVICES; MATERIALS THEREFOR; ORIGINALS THEREFOR; APPARATUS SPECIALLY ADAPTED THEREFOR
- G03F7/00—Photomechanical, e.g. photolithographic, production of textured or patterned surfaces, e.g. printing surfaces; Materials therefor, e.g. comprising photoresists; Apparatus specially adapted therefor
- G03F7/70—Microphotolithographic exposure; Apparatus therefor
- G03F7/70483—Information management; Active and passive control; Testing; Wafer monitoring, e.g. pattern monitoring
- G03F7/70605—Workpiece metrology
- G03F7/706835—Metrology information management or control
-
- H—ELECTRICITY
- H01—ELECTRIC ELEMENTS
- H01J—ELECTRIC DISCHARGE TUBES OR DISCHARGE LAMPS
- H01J37/00—Discharge tubes with provision for introducing objects or material to be exposed to the discharge, e.g. for the purpose of examination or processing thereof
- H01J37/30—Electron-beam or ion-beam tubes for localised treatment of objects
- H01J37/302—Controlling tubes by external information, e.g. programme control
- H01J37/3023—Programme control
- H01J37/3026—Patterning strategy
-
- H—ELECTRICITY
- H01—ELECTRIC ELEMENTS
- H01J—ELECTRIC DISCHARGE TUBES OR DISCHARGE LAMPS
- H01J37/00—Discharge tubes with provision for introducing objects or material to be exposed to the discharge, e.g. for the purpose of examination or processing thereof
- H01J37/30—Electron-beam or ion-beam tubes for localised treatment of objects
- H01J37/317—Electron-beam or ion-beam tubes for localised treatment of objects for changing properties of the objects or for applying thin layers thereon, e.g. for ion implantation
- H01J37/3174—Particle-beam lithography, e.g. electron beam lithography
-
- H—ELECTRICITY
- H01—ELECTRIC ELEMENTS
- H01J—ELECTRIC DISCHARGE TUBES OR DISCHARGE LAMPS
- H01J2237/00—Discharge tubes exposing object to beam, e.g. for analysis treatment, etching, imaging
- H01J2237/30—Electron or ion beam tubes for processing objects
- H01J2237/317—Processing objects on a microscale
- H01J2237/3175—Lithography
- H01J2237/31761—Patterning strategy
- H01J2237/31764—Dividing into sub-patterns
-
- H—ELECTRICITY
- H01—ELECTRIC ELEMENTS
- H01J—ELECTRIC DISCHARGE TUBES OR DISCHARGE LAMPS
- H01J2237/00—Discharge tubes exposing object to beam, e.g. for analysis treatment, etching, imaging
- H01J2237/30—Electron or ion beam tubes for processing objects
- H01J2237/317—Processing objects on a microscale
- H01J2237/3175—Lithography
- H01J2237/31776—Shaped beam
Landscapes
- Chemical & Material Sciences (AREA)
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Nanotechnology (AREA)
- Analytical Chemistry (AREA)
- Crystallography & Structural Chemistry (AREA)
- Theoretical Computer Science (AREA)
- Mathematical Physics (AREA)
- Condensed Matter Physics & Semiconductors (AREA)
- Manufacturing & Machinery (AREA)
- Electron Beam Exposure (AREA)
- Exposure And Positioning Against Photoresist Photosensitive Materials (AREA)
Abstract
반복이 많은 노광 패턴 데이타의 데이타량을 적게 할 수 있는 노광 데이타 생성 방법을 제공한다.
단계 52에서, 반도체 집적 회로의 기데이타로부터 반복성이 있는 노광 패턴 데이타를 노광 패턴 데이타군으로서 추출한다. 단계 54에서, 기데이타를 변환한 가노광 데이타를 작성한다. 단계 55에서, 노광 패턴 데이타군을 구성하는 반복 노광 패턴 데이타를 소정의 통합 영역에 재배열하는 통합 정보 테이블을 작성한다. 그리고, 단계 57에서, 통합 정보 테이블에 기초하여 가노광 데이타를 재배열한 노광 데이타를 재작성한다.
Description
본 발명은 노광 데이타 작성 방법, 노광 데이타 작성 장치에 관한 것이다.
근래의 반도체 집적 회로(LSI)에 있어서, 대규모화 및 고집적화가 진행되어, 그 LSI를 작성하기 위해서 필요한 노광 데이타의 데이타량도 증대하고 있다. 노광 데이타의 증대는 노광 시간의 장시간화, 나아가서는 LSI의 제조 시간의 장시간화를초래하기 때문에, 노광 데이타의 데이타량 삭감이 요구되고 있다.
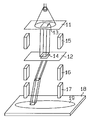
도 22는 가변 직사각형 전자빔(EB) 노광 장치의 개략 구성도이다. EB 노광 장치(10)는 제1, 제2 개구(aperture)(11,12)를 구비하고, 각 개구(11,12)에는 각각 소정 면적의 직사각형창(13,14)이 형성되어 있다. EB 노광 장치(11)는 개구 맞춤용 전자 편향기(제1 전자 편향기)(15)를 제어하여, 제1 개구(11)에 의해 성형된 빔과 제2 개구(12)의 직사각형창(14)과의 겹치는 상태를 변경시키고, 직사각형창(14)을 투과하는 빔의 단면 형상, 즉 노광 패턴을 제어한다. 그리고, 노광 장치(10)는 위치 맞춤용 전자 편향기(제2 전자 편향기)(16), 패턴용 전자 편향기(제3 전자 편향기)(17)를 제어하여 투과빔을 편향시키는 동시에, 스테이지(18)를 X, Y 축 방향으로 이동시켜, 상기 스테이지(18)상에 장착된 반도체 웨이퍼(19)에 원하는 패턴을 노광한다.
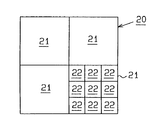
제1∼제3 전자 편향기(15∼17) 및 스테이지(18)의 제어는 반도체 웨이퍼(19)상에 묘화되는 반도체 칩의 설계 데이타(패턴 데이타)에 의해 작성된 노광 데이타에 기초하여 제어된다. 예컨대, 반도체 웨이퍼(19)에는 도 23에 도시되는 반도체 칩(20)이 매트릭스형으로 형성된다. 반도체 칩(20)은 복수의 필드(21)로 분할되고, 각 필드(21)는 다시 복수의 서브필드(22)로 분할된다.
그리고, 제1 전자 편향기(15)는 서브필드(22)로 그 때에 노광되는 패턴의 크기에 기초하여 제어되고, 직사각형창(14)을 투과하는 빔이 패턴의 크기에 대응한 단면 형상으로 제어된다. 그리고, 제2, 제3 전자 편향기(16,17) 및 스테이지(18)는 그때그때마다 묘화되는 패턴의 위치에 기초하여 제어된다. 예컨대, 스테이지(18)에의해 1개의 필드(21)가 선택되고, 제2 전자 편향기(16)에 의해 1개의 서브필드(22)가 선택된다. 그리고, 제3 전자 편향기(17)에 의해 선택된 서브필드(22)내의 패턴이 노광된다.
그런데, 반도체 칩(20)의 노광 패턴 데이타는 도시하지 않은 노광 데이타 작성 장치에 의해 작성되어, 상기 EB 노광 장치(10)에 공급된다. 종래의 노광 데이타 작성 장치는 반도체 칩(20)의 노광 패턴 데이타에 있어서, 중간의 반복이 많은 패턴 데이타를 매트릭스 인식에 의해 추출하여, 매트릭스 표현으로써 노광 데이타를 작성하고 있었다. 또, 노광 데이타 작성 장치는 노광 데이타를 기초가 되는 설계 데이타와 동일하게 계층화하고, 반복이 많은 노광 패턴 데이타를 노광 패턴 데이타군으로 하여, 그 데이타군을 반복 배치 정의함으로써, 노광 데이타의 데이타량을 감소시키고 있었다.
추출되는 노광 패턴 데이타군에는 반복이 많은 패턴 데이타, 예컨대 메모리셀의 공통 부분이 추출된다. 그 때문에, 메모리셀의 공통 부분을 추출한 노광 패턴 데이타군은 영역적으로 작아지므로, 배치수 및 노광 횟수가 많아지며, 노광 데이타도 그만큼 많아진다. 또한, 대부분의 노광 장치에 있어서는 각종 편향에 의해 전자빔을 소정의 배치 위치까지 이동시킨다. 예컨대, 도 22에 도시된 EB 노광 장치(10)에 있어서는 제1, 제2 개구(11,12)에 의해 성형된 전자빔은 제2, 제3 전자 편향기(16,17), 스테이지(18)의 각극 편향에 의해 반도체 웨이퍼(19)의 소정 배치 위치까지 이동된다.
따라서, 반복되는 노광 패턴 데이타의 배치 위치를 나타내는 배치 데이타가 많아지면, 제2, 제3 전자 편향기(16,17)에서는 원하는 배치 위치까지 빔을 이동시킬 수 없게 되며, 스테이지(18)를 제어함으로써 웨이퍼(19)의 위치를 제2, 제3 전자 편향기(16,17)에 의해 이동 가능한 위치까지 이동시키지 않으면 안된다. 스테이지(18)에 의한 이동은 제2, 제3 전자 편향기(16,17)에 의한 이동에 비하여 시간이 걸린다. 그 때문에, 빔의 이동 시간이 길어지고, 반도체 웨이퍼(19) 전체의 노광 시간이 증대한다.
또, 각종 편향에 있어서는 목적한 배치 위치에 맞출 때의 제어적인 문제(스테이지의 기계적 정밀도등)에 의해, 위치 맞춤 오차가 발생하는 경우가 있다. 그렇게 하면, 배치 횟수가 많을수록 위치 맞춤 오차가 발생하는 지점이 많아지며, 칩 전체의 노광 정밀도가 저하한다. 이 때문에, 큰 영역에서의 반복 단위를 구하는 것이 요구되지만, 큰 영역의 노광 패턴에는 반복성이 없는 패턴이 부착하기 때문에, 매트릭스 인식의 방해가 되는 동시에, 추출하는 대상이 되는 데이타량이 증가하므로 추출 처리 시간이 증가한다.
본 발명은 상기 문제점을 해결하기 위해서 이루어진 것으로, 그 목적은 반복이 많은 노광 패턴 데이타의 데이타량을 적게 할 수 있는 노광 데이타 생성 방법 및 노광 데이타 생성 장치를 제공하는 데 있다.
도 1은 일실시 형태의 노광 데이타 작성 장치의 개략 구성도.
도 2는 일실시 형태의 노광 데이타 작성 처리의 흐름도.
도 3은 일실시 형태의 통합 처리의 흐름도.
도 4는 일실시 형태의 통합 정보 테이블 작성 처리의 흐름도.
도 5는 일실시 형태의 통합 정보 테이블 작성 처리의 흐름도.
도 6은 반복 노광 영역과 통합 영역과의 관계를 나타내는 설명도.
도 7은 반복 패턴의 통합 방법을 나타내는 설명도.
도 8은 통합 정보 테이블의 개략 구성도.
도 9의 (a)와 (b)는 반복 노광 패턴 데이타의 전개를 나타내는 설명도.
도 10은 반복 패턴과 영역을 나타내는 설명도.
도 11은 반복 패턴의 통합 정보 테이블을 나타내는 설명도.
도 12는 생성되는 노광 패턴 데이타와 묘화 상태를 나타내는 설명도.
도 13은 반복 패턴과 영역을 나타내는 설명도.
도 14는 반복 패턴의 통합 정보 테이블을 나타내는 설명도.
도 15는 생성되는 노광 패턴 데이타와 묘화 상태를 나타내는 설명도.
도 16은 반복 패턴과 영역을 나타내는 설명도.
도 17은 반복 패턴의 통합 정보 테이블을 나타내는 설명도.
도 18은 생성되는 노광 패턴 데이타와 묘화 상태를 나타내는 설명도.
도 19는 반복 패턴과 영역을 나타내는 설명도.
도 20은 반복 패턴의 통합 정보 테이블을 나타내는 설명도.
도 21은 생성되는 노광 패턴 데이타와 묘화 상태를 나타내는 설명도.
도 22는 전자빔 노광 장치의 개략 구성도.
도 23은 반도체 칩의 개략 평면도.
〈도면의 주요 부분에 대한 부호의 설명〉
52: 반복 데이타 추출 수단
54: 가노광 데이타 작성 수단
55: 통합 수단
57: 노광 데이타 구축 수단
상기 목적을 달성하기 위해서, 청구 범위 제1항에 기재한 발명은 반도체 집적 회로를 노광 매체에 대하여 노광하기 위해서 이용되는 노광 데이타를 상기 반도체 집적 회로의 기데이타를 변환하여 작성하는 노광 데이타 작성 방법으로서, 상기 기데이타로부터 반복성이 있는 노광 패턴 데이타를 노광 패턴 데이타군으로서 추출하는 단계와, 상기 노광 패턴 데이타군을 구성하는 반복 노광 패턴 데이타를 소정의 통합 영역에서 재배열하는 통합 정보 테이블을 작성하는 단계와, 상기 통합 정보 테이블에 기초하여 상기 기데이타를 재배열한 노광 데이타를 작성하는 단계로 구성된다.
청구 범위 제2항에 기재한 발명은 반도체 집적 회로를 노광 매체에 대하여 노광하기 위해서 이용되는 노광 데이타를 상기 반도체 집적 회로의 기데이타를 변환하여 작성하는 노광 데이타 작성 방법으로서, 상기 기데이타로부터 반복성이 있는 노광 패턴 데이타를 노광 패턴 데이타군으로서 추출하는 단계와, 상기 기데이타를 변환한 가노광 데이타를 작성하는 단계와, 상기 노광 패턴 데이타군을 구성하는 반복 노광 패턴 데이타를 소정의 통합 영역에서 재배열하는 통합 정보 테이블을 작성하는 단계와, 상기 통합 정보 테이블에 기초하여 상기 가노광 데이타를 재배열한 노광 데이타를 재작성하는 단계로 구성된다.
청구 범위 제3항에 기재한 발명은 청구범위 제1항 또는 제2항에 기재한 노광 데이타 작성 방법에 있어서, 상기 통합 정보 테이블은 상기 통합 영역에 다시 통합된 복수의 반복 노광 패턴 데이타를 원래의 노광 패턴 데이타를 나타내는 어드레스와, 원래의 노광 패턴 데이타의 반복 개수 및 반복 피치로 이루어지는 매트릭스 표현으로써 격납한 통합 테이블과, 상기 노광 패턴 데이타군에 대하여 사용하는 상기 통합 영역을 상기 통합 영역을 나타내는 어드레스를 반복 배치하는 반복 개수와 반복 피치로 이루어지는 매트릭스 표현으로써 격납한 배치 테이블로 구성된다.
청구 범위 제4항에 기재한 발명은 청구범위 제3항에 기재한 노광 데이타 작성 방법에 있어서, 상기 통합 정보를 작성하는 단계는 상기 노광 패턴 데이타군을 매트릭스 인식하여, 상기 노광 패턴 데이타군을 구성하는 노광 패턴 데이타의 반복 개수와 반복 피치를 구하는 제1 단계와, 상기 노광 패턴 데이타의 반복 개수와 반복 피치에 기초하여, 상기 통합 영역에 격납하는 원래의 노광 패턴 데이타의 통합 정보 테이블을 구하는 제2 단계와, 상기 통합 정보 테이블에 기초하여, 상기 노광 패턴 데이타군의 배치 데이타를 재작성하는 제3 단계와, 상기 통합 정보 테이블에 기초하여, 상기 노광 패턴 데이타의 패턴 데이타를 재작성하는 제4 단계로 구성된다.
청구 범위 제5항에 기재한 발명은 청구범위 제4항에 기재한 노광 데이타 작성 방법에 있어서, 상기 제2 단계는 상기 통합 영역에 대하여 상기 반복 노광 패턴 데이타를 격납하는 최대 개수를 구하는 단계와, 상기 노광 패턴 데이타군의 모든 반복 노광 패턴 데이타를 격납하는데 필요한 통합 영역의 개수를 구하는 단계와, 상기 통합 영역에 대하여 반복 노광 패턴 데이타를 균등 배치할 수 있는지의 여부를 판단하여, 그 판단 결과에 기초하여 균등 배치할 수 있는 경우에 상기 통합 영역에 반복 패턴 데이타를 균등하게 배치하는 개수를 후보치로 설정하는 단계와, 상기 후보치에 기초하여, 상기 후보치가 설정되어 있지 않은 경우에는 상기 최대 개수를 통합 영역에 대한 상기 반복 패턴 데이타의 병합치로 설정하고, 상기 후보치가 설정되어 있는 경우에는 상기 후보치를 병합치로 설정하는 단계와, 상기 후보치와 병합치에 기초하여 상기 통합 정보 테이블을 작성하는 단계로 구성된다.
청구 범위 제6항에 기재한 발명은 청구범위 제4항 또는 제5항에 기재한 노광 데이타 작성 방법에 있어서, 상기 통합 정보를 작성하는 단계는 상기 통합 영역에 대한 x 방향과 y 방향의 후보치 및 병합치에 기초하여 상기 통합 테이블 및 배치 테이블을 작성하는 것으로, 상기 모든 통합 영역에 대하여 균등 배치할 수 있는 경우에는 1종류의 상기 통합 테이블과 배치 테이블을 작성하는 단계와, 상기 x 방향 또는 y 방향에 대하여 균등 배치할 수 있는 경우에는 각각 2종류의 통합 테이블과 배치 테이블을 작성하는 단계와, 상기 x 방향 및 y 방향에 대하여 균등 배치할 수 없는 경우에는 4종류의 통합 테이블과 배치 테이블을 작성하는 단계로 구성된다.
청구 범위 제7항에 기재한 발명은 청구범위 제4항에 기재한 노광 데이타 작성 방법에 있어서, 상기 제4 단계는 원래의 노광 패턴 데이타가 단독 표현인지, 복수의 기본 패턴 데이타를 반복하는 매트릭스 표현인지를 판단하는 단계와, 상기 판단 결과에 기초하여, 노광 패턴 데이타가 단독 표현인 경우에 노광 데이타의 재작성을 행하는 단계와, 상기 판단 결과에 기초하여, 원래의 노광 패턴 데이타가 매트릭스 표현인 경우에, 상기 원래의 노광 패턴 데이타를 전개하여 노광 데이타의 재작성을 행하는 단계로 구성된다.
청구 범위 제8항에 기재한 발명은 청구범위 제7항에 기재한 노광 데이타 작성 방법에 있어서, 상기 노광 패턴 데이타를 전개할 때에, 상기 원래의 노광 패턴 데이타의 반복 개수와, 상기 노광 패턴 데이타를 구성하는 기본 패턴 데이타의 매트릭스 개수를 비교하여, 적은 쪽을 전개하여 새로운 반복 노광 패턴 데이타를 작성하도록 한 것을 요지로 한다.
청구범위 제9항에 기재한 발명은 청구범위 제1항 내지 제2항 중 어느 한 항에 기재한 노광 데이타 작성 방법에 있어서, 상기 노광 데이타는 노광 장치에 구비되어 노광 매체를 이동시키는 스테이지와, 상기 노광 매체를 노광하는 빔을 상기 노광 매체의 소망 위치로 이동시키는 편향기를 제어하기 위해서 이용되는 것으로, 상기 통합 영역은 상기 노광 장치의 빔 이동시키는 편향기에 대응한 영역으로 설정된 것을 요지로 한다.
청구범위 제10항에 기재한 발명은 반도체 집적 회로를 노광 매체에 대하여 노광하기 위해서 이용되는 노광 데이타를 상기 반도체 집적 회로의 기데이타를 변환하여 작성하는 노광 데이타 작성 장치로서, 상기 기데이타로부터 반복성이 있는 노광 패턴 데이타를 노광 패턴 데이타군으로서 추출하는 반복 데이타 추출 수단과, 상기 노광 패턴 데이타군을 구성하는 반복 노광 패턴 데이타를 소정의 통합 영역에 서 재배열하는 통합 정보 테이블을 작성하는 통합 수단과, 상기 통합 정보 테이블에 기초하여 상기 기데이타를 재배열한 노광 데이타를 작성하는 노광 데이타 구축 수단을 구비한 것을 요지로 한다.
청구범위 제11항에 기재한 발명은 반도체 집적 회로를 노광 매체에 대하여 노광하기 위해서 이용되는 노광 데이타를 상기 반도체 집적 회로의 기데이타를 변환하여 상기 노광 데이타를 작성하는 노광 데이타 작성 장치로서, 상기 기데이타로부터 반복성이 있는 노광 패턴 데이타를 반복 노광 패턴 데이타로 하여, 상기 패턴 데이타에 의해 구성되는 노광 패턴 데이타군을 추출하는 반복 데이타 추출 수단과,상기 기데이타를 변환한 가노광 데이타를 작성하는 가노광 데이타 작성 수단과, 상기 노광 패턴 데이타군을 구성하는 반복 노광 패턴 데이타를 소정의 통합 영역에 서 재배열하는 통합 정보 테이블을 작성하는 통합 수단과, 상기 통합 정보 테이블에 기초하여 상기 가노광 데이타를 재배열한 노광 데이타를 재작성하는 노광 데이타 구축 수단을 구비한 것을 요지로 한다.
따라서, 청구범위 제1항에 기재한 발명에 따르면, 기데이타로부터 반복성이 있는 노광 패턴 데이타가 노광 패턴 데이타군으로서 추출되어, 노광 패턴 데이타군을 구성하는 반복 노광 패턴 데이타를 소정의 통합 영역에서 재배열하는 통합 정보 테이블이 작성된다. 그 통합 정보 테이블에 기초하여 기데이타가 다시 배열된 노광 데이타가 작성된다.
청구범위 제2항에 기재한 발명에 따르면, 기데이타로부터 반복성이 있는 노광 패턴 데이타를 반복 노광 패턴 데이타가 노광 패턴 데이타군으로서 추출된다. 또한, 기데이타를 변환한 가노광 데이타가 작성된다. 그리고, 노광 패턴 데이타군을 구성하는 반복 노광 패턴 데이타를 소정의 통합 영역에서 재배열하는 통합 정보 테이블이 작성되고, 그 통합 정보 테이블에 기초하여 가노광 데이타가 다시 배열된 노광 데이타가 재작성된다.
청구범위 제3항에 기재한 발명에 따르면, 통합 정보 테이블은 통합 테이블과 배치 테이블로 구성된다. 통합 테이블에는 통합 영역에 다시 통합된 복수의 반복 노광 패턴 데이타가 원래의 노광 패턴 데이타를 나타내는 어드레스와, 원래의 노광 패턴 데이타의 반복 개수 및 반복 피치로 이루어지는 매트릭스 표현으로써 격납된다. 배치 테이블에는 노광 패턴 데이타군에 대하여 사용하는 통합 영역이, 통합 영역을 나타내는 어드레스를 반복 배치하는 반복 개수와 반복 피치로 이루어지는 매트릭스 표현으로써 격납된다.
청구범위 제4항에 기재한 발명에 따르면, 통합 정보를 작성하는 단계는 제1∼제4 단계에 의해 구성된다. 제1 단계는 노광 패턴 데이타군이 매트릭스 인식되며, 노광 패턴 데이타군을 구성하는 노광 패턴 데이타의 반복 개수와 반복 피치가 요청된다. 제2 단계에서는 노광 패턴 데이타의 반복 개수와 반복 피치에 기초하여, 통합 영역에 격납하는 원래의 노광 패턴 데이타의 통합 정보 테이블이 요청된다. 제3 단계에서는 통합 정보 테이블에 기초하여, 노광 패턴 데이타군의 배치 데이타가 재작성된다. 제4 단계에서는 통합 정보 테이블에 기초하여, 노광 패턴 데이타의 패턴 데이타가 재작성된다.
청구범위 제5항에 기재한 발명에 따르면, 제2 단계에서, 통합 영역에 대하여 반복 노광 패턴 데이타를 격납하는 최대 개수와, 노광 패턴 데이타군의 모든 반복 노광 패턴 데이타를 격납하는데 필요한 통합 영역의 개수가 요청된다. 통합 영역 대하여 반복 노광 패턴 데이타를 균등 배치할 수 있는지의 여부가 판단되어, 그 판단 결과에 기초하여 균등 배치할 수 있는 경우에 통합 영역에 반복 패턴 데이타를 균등하게 배치하는 개수가 후보치로 설정되며, 후보치에 기초하여, 후보치가 설정되어 있지 않은 경우에는 상기 최대 개수를 통합 영역에 대한 반복 패턴 데이타의 병합치로 설정하고, 후보치가 설정되어 있는 경우에는 후보치가 병합치로 설정된다. 그리고, 후보치와 병합치에 기초하여 통합 정보 테이블이 작성된다.
청구범위 제6항에 기재한 발명에 따르면, 통합 정보를 작성하는 단계는 통합 영역에 대한 x 방향과 y 방향의 후보치 및 병합치에 기초하여 통합 테이블 및 배치 테이블을 작성하는 것으로, 모든 통합 영역에 대하여 균등 배치할 수 있는 경우에는 1종류의 통합 테이블과 배치 테이블이 작성된다. 또한, x 방향 또는 y 방향에 대하여 균등 배치할 수 있는 경우에는 각각 2종류의 통합 테이블과 배치 테이블이 작성된다. 또, x 방향 및 y 방향에 대하여 균등 배치할 수 없는 경우에는 4종류의 통합 테이블과 배치 테이블이 작성된다.
청구범위 제7항에 기재한 발명에 따르면, 제4 단계에서, 원래의 노광 패턴 데이타가 단독 표현인지, 복수의 기본 패턴 데이타를 반복하는 매트릭스 표현인지가 판단되며, 판단 결과에 기초하여 노광 패턴 데이타가 단독 표현인 경우에 노광 데이타의 재작성이 행해진다. 또한, 판단 결과에 기초하여, 원래의 노광 패턴 데이타가 매트릭스 표현인 경우에, 원래의 노광 패턴 데이타가 전개되어 노광 데이타의 재작성이 행해진다.
청구범위 제8항에 기재한 발명에 따르면, 노광 패턴 데이타가 전개될 때에, 원래의 노광 패턴 데이타의 반복 개수와, 노광 패턴 데이타를 구성하는 기본 패턴 데이타의 매트릭스 개수가 비교되며, 적은 쪽이 전개되어 새로운 반복 노광 패턴 데이타가 작성된다.
청구범위 제9항에 기재한 발명에 따르면, 노광 데이타는 노광 장치에 구비되어 노광 매체를 이동시키는 스테이지와, 노광 매체를 노광하는 빔을 노광 매체의 소망 위치로 이동시키는 편향기를 제어하기 위해서 이용되는 것이고, 통합 영역은노광 장치의 빔 이동시키는 편향기에 대응한 영역으로 설정된다.
청구범위 제10항에 기재한 발명에 따르면, 반복 데이타 추출 수단은 기데이타로부터 반복성이 있는 노광 패턴 데이타를 노광 패턴 데이타군으로서 추출한다. 통합 수단은 노광 패턴 데이타군을 구성하는 반복 노광 패턴 데이타를 소정의 통합 영역에서 재배열하는 통합 정보 테이블을 작성한다. 노광 데이타 구축 수단은 통합 정보 테이블에 기초하여 기데이타를 다시 배열한 노광 데이타를 작성한다.
청구범위 제11항에 기재한 발명에 따르면, 반복 데이타 추출 수단은 기데이타로부터 반복성이 있는 노광 패턴 데이타를 반복 노광 패턴 데이타로 하여, 패턴 데이타에 의해 구성되는 노광 패턴 데이타군을 추출한다. 가노광 데이타 작성 수단은 기데이타를 변환한 가노광 데이타를 작성한다. 통합 수단은 노광 패턴 데이타군을 구성하는 반복 노광 패턴 데이타를 소정의 통합 영역에서 재배열하는 통합 정보 테이블을 작성한다. 노광 데이타 구축 수단은 통합 정보 테이블에 기초하여 가노광 데이타를 다시 배열한 노광 데이타를 재작성한다.
이하, 본 발명을 구체화한 일실시 형태를 도 1∼도 21에 따라서 설명한다.
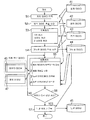
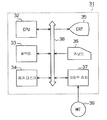
도 1은 본 발명을 적용한 노광 데이타 작성 장치의 시스템 구성을 나타내는 모식도이다. 노광 데이타 작성 장치(31)는 중앙 처리 장치(이하, CPU라 약칭)(32), 메모리(33), 자기 디스크(34), 표시기(35), 키보드(36), 테이프 장치(37)를 구비하고, 그것들은 버스(38)에 의해 서로 접속되어 있다.
자기 디스크(34)에는 도 2∼도 5에 도시된 노광 데이타 작성 처리의 프로그램 데이타가 미리 기억되어 있다. 그 노광 데이타 작성 처리의 프로그램 데이타는기억 매체로서의 자기 테이프(MT)(39)에 기억되어, 공급된다. 자기 테이프(39)는 테이프 장치(37)에 세트되고, 프로그램 데이타는 그 테이프 장치(37)에 의해 자기 테이프(39)로부터 독출되어, 버스(38)를 통해 자기 디스크(34)로 전송되어 기억된다. 도 1중의 CPU(32)는 키보드(36)의 조작에 기초하여 기동되면, 도 2∼도 5에 나타내는 단계에 따라서 노광 데이타 작성 처리를 실행한다.
또한, 자기 디스크(34)에는 도 2에 도시되는 데이타 화일(41)이 기억되어 있다. 데이타 화일(41)에는 예컨대 도시하지 않은 CAD 장치에 의해 회로 설계 및 레이아웃 설계된 메모리 등의 반복이 많은 패턴을 포함하는 반도체 장치(LSI) 칩의 설계 데이타가 미리 격납되어 있다. 도 1에 도시되는 CPU(32)는 데이타 화일(41)로부터 설계 데이타인 기데이타를 입력하여, 그 기데이타에 기초하여 도 2에 도시되는 노광 데이타 작성 처리를 실행한다.
또한, 도 1중의 자기 디스크(34)에는 도 2에 도시되는 데이타 화일(42∼45)이 격납된다. 또한, 도 1중의 메모리(33)에는 도 2에 도시되는 데이타 화일(46,47)이 격납된다. 도 1중의 CPU(32)는 도 2에 도시되는 흐름도의 단계 51∼57에 따라서 노광 데이타 작성 처리를 실행하며, 그 처리에 있어서 작성한 각 데이타를 도 2에 도시되는 데이타 화일(42∼47)에 격납한다.
즉, 도 2의 단계 51는 처리 데이타 입력 처리(처리 데이타 입력 수단)로서, 도 1중의 CPU(32)는 데이타 화일(41)로부터 설계 데이타를 기데이타로서 입력한다.
다음에, 도 2의 단계 52는 반복 데이타 추출 처리(반복 데이타 추출 수단)로서, 도 1중의 CPU(32)는 입력한 기데이타로부터 반복성이 있는 노광 패턴 데이타를노광 패턴 데이타군으로서 인식 추출한다. 그리고, CPU(32)는 추출한 노광 패턴 데이타군을 배치 데이타로서 도 2중의 데이타 화일(42)에 격납한다. 배치 데이타의 격납을 종료하면, 도 1중의 CPU(32)는 도 2에 나타내는 단계 52에서 단계 53으로 이동한다.
다음에, 도 2의 단계 53에서, 도 1중의 CPU(32)는 모든 기데이타, 즉, 도 2중의 단계 52에서 추출한 패턴 데이타군과, 추출한 후의 패턴 데이타에 대하여, 소정의 도형 처리, 예컨대, OR 처리, 사이징(sizing) 처리, 쉬링크(shrink) 처리 등과 같이, LSI의 노광 데이타를 작성하는 데에 있어서 필요한 도형 처리를 실시한다. 그리고, 도 1에 도시되는 CPU(32)는 도형 처리 후의 레이아웃 데이타를 중간 데이타로서 자기 디스크(34)상의 데이타 화일(43)에 격납한다. 중간 데이타의 격납을 종료하면, 도 1중의 CPU(32)는 도 2에 나타내는 단계 53에서 단계 54로 이동한다.
다음에, 단계 54는 가노광 데이타 작성 처리(가노광 데이타 작성 수단)로서, 도 1중의 CPU(32)는 단계 53에서 도형 처리한 중간 데이타를 노광 데이타로 변환한다. 그리고, CPU(32)는 변환후의 노광 데이타를 가노광 데이타로서 도 2중의 데이타 화일(44)에 격납한다. 가노광 데이타의 격납을 종료하면, 도 1중의 CPU(32)는 도 2의 단계 54에서 단계 55로 이동한다.
단계 55는 통합 처리(통합 수단)로서, 도 1중의 CPU(32)는 단계 52에서 작성한 배치 데이타에 기초하여 추출한 노광 패턴 데이타군에 대하여 통합 처리를 실행한다. 통합 처리는 노광 패턴 데이타군에 포함되는 미소한 반복 노광 패턴 데이타와 노광 패턴 데이타군이 차지하는 면적보다도 작은 원하는 크기의 통합 영역내에 반복 패턴으로서 다시 통합하는 처리이다. 또, 통합 처리는 재배열한 반복 노광 패턴 데이타가 각 통합 영역에 있어서 같은 배치가 되도록 재통합한다.
도 2에 도시된 바와 같이, 통합 처리는 크게 4개의 단계로 구성된다. 제1 단계는 매트릭스 인식 처리(매트릭스 인식 수단)로서, 도 1중의 CPU(32)는 도 2중의 데이타 화일(42)에 격납된 배치 데이타, 즉, 도 2중의 단계 52에서 추출한 노광 패턴 데이타군에 대하여 매트릭스 인식을 행한다. 매트릭스 인식은 노광 패턴 데이타군을 구성하는 반복 노광 패턴 데이타(이하, 단순히 반복 패턴이라 함)가 원하는 통합 영역에 다시 통합할 수 있는지의 여부를 인식하는 처리이다.
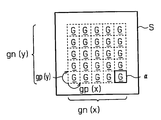
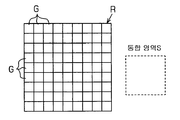
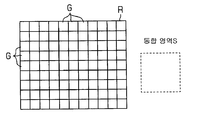
그 매트릭스 인식 처리에 있어서, CPU(32)는 우선, 노광 패턴 데이타군을 구성하는 반복 패턴이 차지하는 영역의 면적(이하, 단지 영역이라 함), 반복 피치, 반복 개수를 구한다. 예컨대, 도 6에 도시된 바와 같이, 도 1중의 CPU(32)는 반복 패턴 G의 영역 α, 반복 패턴 G의 반복 피치(이하, 매트릭스 피치라 함) gp(X 방향의 매트릭스 피치를 gp(x), Y 방향의 매트릭스 피치를 gp(y)로 한다), 반복 패턴 G의 반복 개수(이하, 매트릭스 개수라 함) gn(X 방향의 매트릭스 개수를 gn(x), Y 방향의 매트릭스 개수를 gn(y)로 한다)을 구한다.
또한, 도 6에 있어서는 1개의 통합 영역 S에 통합된 반복 패턴 G를 도시하고 있고, 실제로는 도 2중의 단계 52에서, 도 7에 도시된 바와 같이 통합 영역 S보다도 큰 면적의 노광 패턴 데이타군 R이 추출되며, 그 노광 패턴 데이타군 R을 구성하는 일부의 복수 반복 패턴 G가 통합 영역 S에 다시 통합된다.
다음에, CPU(32)는 구한 영역 α 등이, 매트릭스 인식의 인식 조건을 만족하는지의 여부를 판단한다. 그 매트릭스 인식의 인식 조건은 반복 패턴 G의 영역 α가 원하는 통합 영역 S 면적의 절반 이하이고, 매트릭스 피치 gp가 통합 영역 S보다도 작은 것이다. 이 인식 조건을 충족시키지 않을 경우는 복수의 영역 α를 통합 영역 S에 통합하는 것이 불가능해진다.
또한, 본 실시 형태에서는 원하는 통합 영역 S는 도 23에 도시되는 서브필드(22)의 크기로 설정되어 있다. 따라서, 통합 영역 S에 다시 통합된 복수의 반복 패턴 G는 도 22에 도시되는 EB 노광 장치(10)의 제3 전자 편향기(17)를 제어함으로써 노광된다.
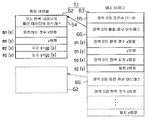
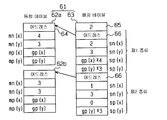
제2 단계는 통합 정보 테이블 작성 처리(통합 정보 테이블 작성 수단)로서, 도 1중의 CPU(32)는 제1 단계에서 인식 조건을 만족하는 영역 α의 반복 패턴 G의 통합 정보를 구한다. 그리고, CPU(32)는 구한 통합 정보를 통합 정보 테이블로서 도 2중의 데이타 화일(46,47)에 격납한다. 도 8에 도시된 바와 같이, 통합 정보 테이블(61)은 통합 테이블(62)과 배치 테이블(63)로 구성된다. 도 1중의 CPU(32)는 통합 테이블(62)을 데이타 화일(46)에, 배치 테이블(63)을 데이타 화일(47)에 격납한다.
통합 테이블(62)은 원래의 반복 패턴 데이타를 나타내는 어드레스(64), x 방향의 통합 개수 mn(x), y 방향의 통합 개수 mn(y), x 방향의 반복 피치 mp(x), 및, y 방향의 반복 피치 mp(y)로 구성된다. 어드레스(62)는 통합 영역 S에 통합하는 반복 패턴 G의 패턴 데이타의 어드레스가 격납된다. 통합 개수 mn(x), mn(y)는 각각통합 영역 S에 통합되는 반복 패턴 G의 x 방향과 y 방향과의 개수를 나타내고 있다. 피치 mp(x), mp(y)는 각각 반복 패턴 G의 x 방향과 y 방향과의 반복 피치를 나타내고 있다. 따라서, 통합 테이블(61)에는 통합 영역 S에 대하여, 반복 패턴 G를 x 방향과 y 방향에 어떻게 배치하여 통합하는지를 나타낸 정보가 격납된다.
배치 테이블(63)은 종류수 65, 통합 정보 어드레스(66), x 방향의 반복 개수sn(x), y 방향의 반복 개수 sn(y), x 방향의 반복 피치 sp(x), 및, y 방향의 반복 피치 sp(y)로 구성된다. 통합 정보 어드레스(66)에는 사용하는 통합 영역 S의 정보가 격납된 통합 테이블(62)의 선두 어드레스가 격납된다. 반복 개수 sn(x), sn(y)와 반복 피치 sp(x), sp(y)에는 통합 영역 S의 반복 개수와 반복 피치가 각각 격납된다.
종류수는 65에는 통합 영역 S의 종류의 수가 격납되고, 통합 영역 S의 종류는 그 통합 영역 S에 통합된 반복 패턴 G의 상태에 따라서 설정된다.
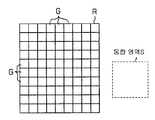
도 7에 도시된 바와 같이, 추출한 노광 패턴 데이타군 R의 각 반복 패턴 G를 통합 영역 S에 다시 통합하는 즉, 복수의 반복 패턴 G를 복수의 통합 영역 S로 분할하는 방법으로서, 도 7 좌측 밑에 도시하는 「단순 배치」와, 도 7 우측 밑에 도시하는 「균등 배치」가 있다. 「단순 배치」는 통합 영역 S에 통합되는(수용되는) 최대 개수의 반복 패턴 G를 소정의 방향(도 7에 있어서, x 방향에서는 좌단, y 방향에서는 하단)에서부터 순서대로 통합 영역 S로 분할하는 방법이다. 도 7에는 x 방향과 y 방향에 「단순 배치」된 경우가 도시되어 있다.
도 1중의 CPU(32)는 추출한 노광 패턴 데이타군 R의 각 반복 패턴 G를 x 방향과 y 방향에 각각 복수의 통합 영역 S에 대하여 「균등 배치」가능한지의 여부를 판단한다. x, y 방향의 각각에 대하여 「균등 배치」가능한 경우, CPU(32)는 반복 패턴 G를 복수의 통합 영역 S에 대하여 균등하게 배치하여 다시 통합한 노광 데이타를 작성한다. 한편, x, y 방향의 각각 대하여 「균등 배치」불가능한 경우, CPU(32)는 반복 패턴 G를 복수의 통합 영역 S에 대하여 「단순 배치」를 행한다. 그리고, CPU(32)는 반복 패턴 G를 복수의 통합 영역에 대하여 단순히 배치하여 다시 통합한 노광 데이타를 작성한다.
「단순 배치」하는 방법에서는 최대 개수의 반복 패턴 G가 다시 통합된 통합 영역 S(도 7에 있어서 통합 영역 S1)와, 나머지 반복 패턴 G가 다시 통합된 통합 영역 S(도 7에 있어서 통합 영역 S2∼S4)가 발생한다. 또한, 통합 영역 S2에는 x 방향의 나머지 반복 패턴 G가, 통합 영역 S3에는 y 방향의 나머지 반복 패턴 G가, 통합 영역 S4에는 xy 방향의 나머지 반복 패턴 G가 격납된다. 따라서, xy 방향에 「단순 배치」된 경우, 통합 영역 S내의 반복 패턴 G의 상태, 즉, 통합 영역 S의 종류는 4종류가 되고, 도 8중의 종류수 65에는 「4」가 격납된다.
한편, 「균등 배치」는 복수의 통합 영역 S에 대하여, 같은 수의 반복 패턴 G를 분할하는 방법이다. 도 7에는 x 방향과 y 방향에 「균등 배치」된 경우가 도시되어 있다. 이 경우, 모든 통합 영역 S내의 반복 패턴 G의 상태는 같아지므로, 통합 영역 S의 종류는 1종류가 되며, 도 8중의 종류수 65에는 「1」이 격납된다.
또한, 도 7에 있어서, x 방향(도 7의 좌우 방향)과 y 방향(도 7의 상하 방향)으로 다른 분할 방법이 채용되는 경우가 있다. 즉, x 방향으로 「단순 배치」되고, y 방향으로 「균등 배치」된다. 이 경우, x 방향의 통합 영역 S는 2종류, y 방향의 통합 영역 S는 1종류가 되며, 전체로서 통합 영역 S의 종류는 2종류가 되므로, 도 8중의 종류수 65에는 「2」가 격납된다. 동일하게, x 방향으로 「균등 배치」되고, y 방향으로 「단순 배치」된 경우, x 방향의 통합 영역 S는 1종류, y 방향의 통합 영역 S는 2종류가 되며, 전체로서 통합 영역 S의 종류는 2종류가 되므로, 도 8중의 종류수 65에는 「2」가 격납된다.
따라서, 통합 테이블(62)은 통합 영역의 종류수만큼 작성된다. 예컨대, 통합 영역 S가 2종류인 경우, 도 8의 실선으로 도시하는 통합 테이블(62)과 점선으로 도시하는 통합 테이블(62)의 합계 2개의 통합 테이블(62)이 작성된다. 그리고, 배치 테이블(63)에는 각 통합 테이블(62)에 대하여 상기 통합 정보 어드레스(65)에서 y 방향의 반복 피치 sp(y)까지의 정보가 격납된다.
즉, 배치 테이블(63)에는 복수의 반복 패턴 G를 다시 통합한 통합 영역 S가 몇 종류 있고, 어떤 종류의 통합 영역 S를 몇 개 어떻게 배치하는지를 나타낸 정보가 격납된다.
따라서, 노광 패턴 데이타군은 복수의 통합 영역의 패턴 데이타에 의해 표현되고, 각 통합 영역의 패턴 데이타는 같은 배치의 미소한 반복 노광 패턴 데이타에 의해 표현된다. 즉, 노광 패턴 데이타군은 미소한 반복 노광 패턴 데이타에 의한 통합 영역의 패턴 데이타의 반복에 의해서 표현된다. 종래의 방법에서는 노광 패턴 데이타군은 미소한 반복 노광 패턴 데이타의 매트릭스(반복)에 의해서 표현된다. 따라서, 본 실시 형태에 있어서의 노광 패턴 데이타군의 데이타량은 종래의 데이타량에 비하여 적어진다.
제3 단계는 노광 데이타(배치 데이타) 재작성 처리(노광 데이타(배치 데이타) 재작성 수단)로서, 도 1중의 CPU(32)는 도 2중의 데이타 화일(42)에 격납된 배치 데이타를 입력한다. 그리고, CPU(32)는 상기 제2 단계에서 작성한 도 8중의 통합 정보 테이블(61)에 기초하여, 원래의 배치 데이타를 통합한 후의 배치 데이타로 재작성하고, 그 재작성후의 배치 데이타를 중간 데이타로서 데이타 화일(44)에 격납한다.
제4 단계는 노광 데이타(패턴) 재작성 처리(노광 데이타(패턴) 재작성 수단)로서, 도 1중의 CPU(32)는 도 2중의 데이타 화일(44)에 격납된 가노광 데이타를 입력한다. 다음에, CPU(32)는 상기 제2 단계에서 작성한 도 8중의 통합 정보 테이블(61)에 기초하여, 원래의 반복 노광 패턴 데이타를 통합한 후의 반복 노광 패턴 데이타로 재작성한다. 그리고, CPU(32)는 그 재작성후의 반복 노광 패턴 데이타를 데이타 화일(44)에 격납하고, 도 2중의 단계 55에서의 통합 처리를 종료하며, 단계 56으로 이동한다.
도 2에 나타내는 단계 56은 데이타 종료 판단 처리(데이타 종료 판단 수단)로서, 도 1중의 CPU(32)는 데이타 화일(42)에 격납된 배치 데이타, 즉, 단계 52에서 추출한 모든 패턴 데이타군에 대하여 단계 55의 통합 처리를 실행했는지의 여부를 판단한다. 그리고, 모든 패턴 데이타군에 대하여 통합 처리가 실행되고 있지 않은 경우, 도 1중의 CPU(32)는 단계 55로 되돌아가고, 다음 패턴 데이타군에 대하여 통합 처리를 실행한다.
즉, CPU(32)는 단계 55의 통합 처리를 반복 실행하며, 추출한 모든 패턴 데이타군에 대하여 통합 처리를 실행한다. 그리고, 추출한 모든 패턴 데이타군에 대한 통합 처리가 종료하면, 도 1중의 CPU(32)는 도 2에 나타내는 단계 56에서 단계 57로 이동한다.
단계 57은 노광 데이타 구축 처리(노광 데이타 구축 수단)로서, 도 1중의 CPU(32)는 단계 55에서 작성한 통합 테이블과 배치 테이블에 기초하여, 단계 54에서 작성한 가노광 데이타를 연결하여, 정식 노광 데이타로서 도 2에 도시된 데이타 화일(45)에 격납한다. 그리고, 정식 노광 데이타의 격납을 종료하면, 도 1중의 CPU(32)는 노광 데이타 작성 처리를 종료한다.
데이타 화일(45)에 격납된 정식 노광 데이타는 노광 매체로서의 웨이퍼(19)를 노광하는 경우에 이용된다. 즉, 도 22에 도시된 전자빔 노광 장치(10)에 있어서, 데이타 화일(45)에 격납된 노광 데이타에 기초하여, 제1∼제3 전자 편향기(15∼17) 및 스테이지(18)가 제어되며, 웨이퍼(19)의 소정 위치에 원하는 노광 패턴이 노광된다.
이 때, 도 23에 도시되는 반도체 칩(20)에 있어서, 반복 패턴 데이타 G는 통합 영역 S마다 노광된다. 즉, 그 시간의 통합 영역 S내에 다시 통합된 반복 패턴 데이타 G가 노광된다. 그리고, 통합 영역 S의 크기는 도 23에 도시된 반도체 칩(20)의 서브필드(22)의 크기로 설정되어 있다. 따라서, 통합 영역 S내에 다시 통합된 반복 패턴 G는 도 22에 있어서의 EB 노광 장치(10)의 제3 전자 편향기(17)의 제어에만 편광되는 전자빔에 의해서 노광되며, 제2 편향기(16) 및 스테이지(18)는제어되지 않는다.
그런데, 종래의 반복 노광 패턴 데이타 추출에 있어서도, 도 7에 나타내는 본 실시 형태의 반복 패턴 G로 이루어진 노광 패턴 데이타 R이 추출된다. 그리고, 노광 패턴 데이타군 R을 종래의 방법에 의해 변환한 노광 데이타를 이용한 경우, 각 반복 패턴 G는 예컨대, 최하열 좌단으로부터 상측을 향해 순서대로 노광된다.
이 경우, 반복 패턴 G는 도 8에 도시된 통합 영역 S에 다시 통합되어 있지 않기 때문에, EB 노광 장치(10)는 통합 영역 S를 넘어서, 즉, 도 23중의 서브필드(22)를 넘어서 반복 패턴 G를 노광한다. 즉, EB 노광 장치(10)는 노광 데이타에 기초하여 제2, 제3 전자 편향기(16,17)를 제어한다. 그렇게 하면, 서브 필드(22)내의 1열의 반복 패턴 G가 노광될 때마다, 제2 전자 편향기(16)가 제어된다. 즉, 도 23에 도시된 서브필드(22)내의 반복 노광 패턴 G를 노광하고 있는 동안에도 제2 전자 편향기(16)가 제어되므로, 제2 전자 편향기(16)가 제어되는 회수가 많아지며, 그만큼 빔 이동 시간이 길어진다.
한편, 본 실시 형태에서는 도 8에 도시된 통합 영역 S내의 복수의 반복 패턴 G를 노광하고 있는 동안, 제2 전자 편향기(16)는 제어되지 않으므로, 제2 전자 편향기(16)를 제어하는 회수가 종래에 비하여 감소한다. 따라서, 제2 전자 편향기(16)가 제어되지 않게 된만큼, 빔 이동 시간이 적어진다.
또, 통합 영역 S내의 반복 패턴 G가 제3 전자 편향기(17)에 의해 노광되는 동안, 제2 전자 편향기(16) 및 스테이지(18)는 제어되지 않으므로, 위치 맞춤 오차의 발생이 방지되며, 노광 정밀도가 향상된다.
다음에, 도 2중의 단계 55에서의 통합 처리와 도 3에 도시되는 흐름도의 단계 71∼81에 따라서 상세히 기술한다.
먼저, 도 3에 나타내는 단계 71은 도 2중의 단계 55에서의 제1 단계로서, 매트릭스 인식 처리(매트릭스 인식 수단)이다. 도 1중의 CPU(32)는 도 2중의 데이타 화일(42)에 격납된 배치 데이타, 즉, 도 2중의 단계 52에서 추출한 노광 패턴 데이타군에 대하여 매트릭스 인식을 행하고, 매트릭스 개수 gn(x), gn(y), 매트릭스 피치 gp(x), gp(y)를 구한다.
도 3에 나타내는 단계 72 내지 77은 도 2중의 단계 55에서의 제2 단계로서, 통합 정보 테이블 작성 처리(통합 정보 테이블 작성 수단)이다. 먼저, 도 1중의 CPU(32)는 도 7에 도시되는 노광 패턴 데이타군 R의 x 방향에 대하여 처리를 행한다.
단계 72에서, 도 1중의 CPU(32)는 도 2중의 단계 52에서 추출한 노광 패턴 데이타군 R(도 7 참조)의 반복 패턴 G가 통합 영역 S에 최대 몇 개 있는지를 구한다. 도 1중의 CPU(32)는 통합 영역 S의 x 방향의 길이를 반복 패턴 G의 영역 α의 x 방향의 길이로 제산하여, 나머지를 잘라 버린 결과를 통합 영역 S에 대하여 x 방향으로 수용가능한 최대 개수 a(x)로 한다.
다음에, 도 3에 나타내는 단계 73에서, 도 1중의 CPU(32)는 x 방향에 대하여 통합 영역 S의 필요한 개수를 구한다. CPU(32)는 도 7중의 노광 패턴 데이타군 R의 매트릭스 개수 gn(x)를 단계 72에서 구한 최대 개수 a로 제산하여, 완료된 결과를 통합 영역 S가 필요한 개수 b(x)로 한다.
다음에, 도 3에 나타내는 단계 74에서, 도 1중의 CPU(32)는 x 방향에 대하여 「균등 배치」가능한지의 여부를 판단한다. CPU(32)는 통합 영역 S에 대하여 분할하는 최소 개수 「2」에서 단계 73에서 구한 개수 b까지의 수로 x 방향의 매트릭스 개수 gn(x)를 제산한다. 또, CPU(32)는 그 제산 결과가 나누어 떨어지는 경우, 그 몫이 최대 개수 a(x) 이하인지의 여부를 판단한다. 그리고, CPU(32)는 나누어 떨어진 제산 결과의 몫이 최대 개수 a 이하인 경우, 「균등 배치」가능하다고 판단하여, 그 몫의 값을 통합 영역 S에 대한 분할 후보치 c(x)로 설정한다.
그리고, CPU(32)는 단계 73에서 구한 개수 b(x)까지 확인하면, 단계 74에서 단계 75로 이동한다. 개수 b까지밖에 확인하지 않은 것은 반복 패턴 G를 통합 영역 S의 필요 개수 b(x)보다도 많게 분배하면, 통합 영역 S의 배치 개수가 「단순 배치」인 경우보다도 많아지고, 오히려 노광 패턴 데이타의 데이타량을 많게 하기 위해, 유효하지 않기 때문이다. 또한, 제산 결과의 몫이 최대 개수 a(x)보다도 많은 경우에는 통합 영역 S내에 반복 패턴 G를 통합할 수 없기 때문에, 이 경우도 유효로 하지 않는다.
즉, CPU(32)는 통합 영역 S에 대한 반복 패턴 G의 배치수가 도 7에 도시된 바와 같이 좌측 아래부터 단순히 통합한 경우의 수 이하로서, 통합 영역 S에 총합하는 수가 그 통합 영역 S의 최대 개수 a(x) 이하이고, 또한, 모든 통합 영역 S에 있어서 균등한 경우이다. 이 이외의 경우, CPU(32)는 후보치 c(x)를 설정하지 않는다.
다음에, 도 3에 나타내는 단계 75에서, 도 1중의 CPU(32)는 반복 패턴 G를통합 영역 S에 통합하는 병합치 d(x)를 설정한다. 병합치 d(x)는 통합 영역 S에 대하여 x 방향으로 반복 패턴 G를 다시 통합할 때의 배치수이다.
CPU(32)는 도 3중의 단계 74에서 후보치 c(x)가 설정되어 있는 경우, 그 후보치 c(x)를 병합치 d(x)에 격납한다. 한편, 단계 74에서 후보치 c(x)가 설정되어 있지 않은 경우, 도 1중의 CPU(32)는 도 3중의 단계 72에서 구한 최대 개수 a(x)를 병합치 d(x)에 격납한다. 그리고, CPU(32)는 병합치 d(x)의 설정을 종료하면, 도 3중의 단계 75에서 단계 76으로 이동한다.
단계 76에서, 도 1중의 CPU(32)는 병합치의 설정을 x, y 방향 모두 종료했는지의 여부를 판단한다. 그리고, CPU(32)는 y 방향의 병합치 d(y)의 설정이 종료하지 않은 경우, 단계 72로 되돌아가서, y 방향에 대한 처리를 실행한다. 즉, 도 1중의 CPU(32)는 x 방향의 병합치 d(x)와 동일하게, 최대 개수 a(y), 필요 개수 b(y), 후보치 c(y)를 구하여, 병합치 d(y)를 설정한다. 그리고, y 방향에 대한 처리를 종료하면, 도 1중의 CPU(32)는 단계 76에서 단계 77로 이동한다.
도 3에 나타내는 단계 77은 통합 정보 테이블 작성 처리(통합 정보 테이블 작성 수단)로서, 도 1중의 CPU(32)는 도 3중의 단계 72에서 단계 76의 루프에 있어서 구한 x 방향의 후보치 c(x) 및 병합치 d(x)와 y 방향의 후보치 c(y) 및 병합치 d(y)에 기초하여, 통합 정보 테이블을 작성한다. 그 통합 정보 테이블의 작성에 있어서, 도 1중의 CPU(32)는 후보치 c(x), c(y) 및 병합치 d(x), d(y)에 의해 발생하는 통합 영역 S의 종류를 구한다.
이 때, X, Y 방향 각각에 b4로 후보치 c(x), c(y)가 설정되어 있는 경우와설정되어 있지 않은 경우가 있다. 후보치 c(x), c(y)가 각각 설정되어 있는 경우는 통합 영역 S에 대하여 반복 패턴 G가 균등하게 분배가능, 즉, 도 7에 나타내는 「균등 배치」의 경우이다. 한편, 후보치 c(x), c(y)가 각각 설정되어 있지 않은 경우, 통합 영역 S에 대하여 반복 패턴 G가 균등하게 분배불가능하며, 즉, 도 7에 나타내는 「단순 배치」의 경우이다.
따라서, 발생하는 통합 영역 S의 종류는 최대 4종류가 된다. 그리고, 도 1중의 CPU(32)는 각각의 조합에 따라서 통합 정보 테이블을 작성한다. 도 8에 도시된 바와 같이, 통합 정보 테이블(61)은 통합 테이블(62)과 배치 테이블(63)로 구성된다.
도 1중의 CPU(32)는 도 8중의 통합 테이블(62)에 대하여, 원래의 반복 노광 패턴 데이타를 어떻게 재통합할지의 정보를 매트릭스 표현으로 격납한다. 즉, CPU(32)는 다시 통합하는 원래의 반복 패턴 G의 어드레스를 어드레스(64)에 격납한다. 또, CPU(32)는 도 3중의 단계 72 내지 76에서 구한 후보치 c(x), c(y) 및 병합치 d(x), d(y)에 기초하여 도 8에 도시되는 통합 개수 mn(x), mn(y)를 구하여, 통합 테이블(62)에 격납한다. 또한, CPU(32)는 추출한 반복 패턴 G의 매트릭스 피치 gp(x), gp(y)를 각각 반복 피치 mp(x), mp(y)로서 통합 테이블(62)에 격납한다.
또한, CPU(32)는 도 8중의 배치 테이블(63)에 대하여, 다시 통합한 반복 노광 패턴 데이타를 어떤 위치에 배치하는 것인지의 정보를 매트릭스 표현으로 격납한다. 즉, CPU(32)는 다시 통합한 통합 영역 S의 종류를 종류수 65에 격납한다. 또, CPU(32)는 사용하는 종류의 통합 영역 S의 어드레스를 어드레스(66)에, 통합영역 S의 반복 개수 sn(x), sn(y), 통합 영역 S의 반복 피치 sp(x), sp(y)를 격납한다.
도 1중의 CPU(32)는 도 8에 도시되는 통합 테이블(62)을 도 1중의 데이타 테이블(46)에, 도 8에 도시되는 배치 테이블(63)을 도 1중의 데이타 화일(47)에 격납한다. 그리고, 양 데이타 화일(46,47)로의 격납이 종료하면, 도 1중의 CPU(32)는 도 3에 나타내는 단계 77에서 단계 78로 이동한다.
다음에, 도 3에 나타내는 단계 78은 도 2중의 단계 55에서의 제3 단계로서, 노광 데이타(배치 데이타) 재작성 처리(노광 데이타(배치 데이타) 재작성 수단)이다. 도 2중의 데이타 화일(42)에 격납된 배치 데이타를 입력한다. 그리고, 도 1중의 CPU(32)는 단계 77에서 작성한 도 8중의 통합 정보 테이블(61)에 기초하여, 원래의 배치 데이타를 통합한 후의 배치 데이타로 재작성하여, 그 재작성후의 배치 데이타를 중간 데이타로서 데이타 화일(44)에 격납한다.
다음에, 도 3에 나타내는 단계 79 내지 81은 도 2중의 단계 55에서의 제4 단계로서, 노광 데이타(패턴) 재작성 처리(노광 데이타(패턴) 재작성 수단)이다. 단계 79에서, 도 1중의 CPU(32)는 도 2중의 데이타 화일(44)에 격납된 가노광 데이타를 입력하여, 원래의 노광 패턴, 즉, 반복 패턴 G(도 7 참조)가 단독 표현인지의 여부를 판단한다. 그리고, 반복 패턴 G가 단독 표현인 경우, 도 1중의 CPU(32)는 도 3에 나타내는 단계 79에서 단계 80으로 이동한다.
단계 80에서, 도 1중의 CPU(32)는 단계 77에서 작성한 도 8중의 통합 정보 테이블(61)에 기초하여, 원래의 반복 노광 패턴 데이타를 통합한 후의 반복 노광패턴 데이타로 재작성한다. 그리고, CPU(32)는 그 재작성후의 반복 노광 패턴 데이타를 데이타 화일(44)에 격납한다.
한편, 도 3중의 단계 79에서 반복 패턴 G가 단독 표현이 아닌, 즉, 반복 패턴 G가 다시 복수의 기본 패턴 데이타를 x, y 방향으로 반복하는 매트릭스 표현인 경우, 도 1중의 CPU(32)는 단계 79에서 단계 81로 이동한다. 단계 81은 패턴 데이타 전개 처리(패턴 데이타 전개 수단)로서, 도 1중의 CPU(32)는 매트릭스 표현의 반복 패턴 G의 전개 처리를 행한다.
이 때, 도 1중의 CPU(32)는 입력한 반복 패턴 G를 구성하는 기본 패턴 데이타의 매트릭스 개수와, 도 3중의 단계 77에서 구해져 도 8중의 통합 테이블(62)에 격납된 반복 패턴 G의 통합 개수 mn(x), mn(y)를 비교한다. 그리고, CPU(32)는 비교 결과에 기초하여, 개수가 적은 쪽을 전개한 매트릭스 표현으로써 재작성한 새로운 노광 패턴 데이타를 데이타 화일(44)에 격납한다.
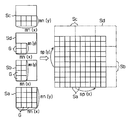
예컨대, 도 9의 (a)에 도시된 바와 같이, 통합 영역 S에는 9개의 반복 패턴 G가 다시 통합되어 있고, 각 반복 패턴 G는 각각 4개의 기본 패턴 데이타 G1의 매트릭스에 의해 표현되어 있다. 이 경우, 반복 패턴 G가 통합 개수 mn(x), mn(y)는 각각 「3」이고, 기본 패턴 데이타 G1의 매트릭스 개수는 x, y 방향으로 각각 「2」이다. 그리고, 도 9의 (a)에 실선으로 도시하는 노광 패턴 데이타 G1에 의해 구성되는 반복 패턴 G를 점선으로 도시된 바와 같이 x방향, y 방향으로 9회 반복 노광한다.
따라서, 도 1중의 CPU(32)는 적은 쪽, 즉, 기본 패턴 데이타 G1의 매트릭스개수를 전개하여, 3×3의 매트릭스 표현된 기본 패턴 데이타 G1에 의해 구성되는 2×2, 즉, 4개의 새로운 반복 패턴 G2로 전개한다. 그리고, 도 9의 (a)와 동일하게 도 9의 (b)에 있어서도 실선으로 도시하는 노광 패턴 데이타 G1에 의해 구성되는 반복 패턴 G2를 점선으로 도시된 바와 같이 x방향, y 방향으로 4회 반복 노광한다. 따라서, 통합 영역 S의 반복수는 9개에서 4개로 감소한다.
그런데, 노광 데이타는 반복 노광되는 반복 노광 패턴 데이타가 그 반복수만큼 열거하여 기술된다. 따라서, 노광 데이타는 통합 영역 S를 구성하는 9개의 반복 패턴 G를 4개의 반복 패턴 G2로 변경함으로써, 그만큼 데이타량이 적어진다.
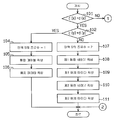
다음에, 단계 77에 있어서의 통합 정보 테이블 작성 처리(통합 정보 테이블 작성 수단)을 도 4 및 도 5에 도시된 흐름도에 따라서 상세히 기술한다.
먼저, 도 4중의 단계 101, 102와 도 5중의 단계 103에서, 도 1중의 CPU(32)는 통합 영역 S에 대한 분할 방법에 따라서 분기한다. 즉, CPU(32)는 x 방향과 y 방향으로 각각 설정되는 「균등 배치」 또는「단순 배치」에 기초하여, 분기한다.
구체적으로는 도 1중의 CPU(32)는 먼저 도 4중의 단계 101에서, 도 3중의 단계 74에서 구한 후보치 c(x)와 병합치 d(x)를 비교한다. 그리고, CPU(32)는 후보치 c(x)와 병합치 d(x)가 일치하는 경우에는 단계 102로, 일치하지 않는 경우에는 도 5중의 단계 103으로 분기한다.
다음에, 단계 102, 103에, 도 1중의 CPU(32)는 도 3중의 단계 74에서 구한 후보치 c(y)와 병합치 d(y)를 각각 비교한다. 그리고, CPU(32)는 도 4의 단계 102에서, 후보치 c(y)와 병합치 d(y)가 일치하는 경우에는 단계 104로, 일치하지 않는경우에는 단계 107로 분기한다. 또한, CPU(32)는 도 5의 단계 103에서 후보치 c(y)와 병합치 d(y)가 일치하는 경우에는 단계 112로, 일치하지 않는 경우에는 단계 117로 분기한다.
즉, 도 1중의 CPU(32)는 후보치 c(x), c(y)와 병합치 d(x), d(y)가 일치하는 즉, x 방향 및 y 방향으로 「균등 배치」되는 경우에 도 4중의 단계 104로 분기한다. 그리고, CPU(32)는 먼저 단계 104에서, 도 8중의 배치 테이블(63)의 종류수 66에 작성하는 통합 영역 S의 종류수 「1」을 격납한다.
다음에, 도 1중의 CPU(32)는 도 4중의 단계 105에 있어서 통합 테이블(62)(도 8 참조)을 작성한다. 즉, CPU(32)는 통합 테이블(62)의 통합 개수 mn(x)에 병합치 d(x)와 통합 개수 mn(y)에 병합치 d(y)를 격납한다. 또한, CPU(32)는 반복 피치 mp(x), mp(y)에 각각 도 3중의 단계 71에서 구한 반복 패턴 G의 매트릭스 피치 gp(x), gp(y)를 격납한다.
또, 도 1중의 CPU(32)는 도 4중의 단계 106에 있어서 배치 테이블(63)(도 8 참조)을 작성한다. 즉, CPU(32)는 매트릭스 인식(도 3, 단계 71)에 있어서 구한 매트릭스 개수 gn(x), gn(y)를 각각 병합치 d(x), d(y)로써 제산한 결과를 배치 테이블(63)의 반복 개수 sn(x), sn(y)에 격납한다. 또한, CPU(32)는 구한 매트릭스 피치 gp(x), gp(y)와 병합치 d(x), d(y)를 각각 승산한 결과를 반복 피치 sp(x), sp(y)에 격납한다.
또한, 도 1중의 CPU(32)는 후보치c(x)와 병합치 d(x)가 일치하여 후보치 c(y)와 병합치 d(y)가 일치하지 않는 즉, x 방향으로는 「균등 배치」되고 y 방향으로는 「단순 배치」되는 경우에 도 4중의 단계 107로 분기한다. 그리고, CPU(32)는 먼저 단계 107에 있어서, 도 8중의 배치 테이블(63)의 종류수 66에 작성하는 통합 영역 S의 종류수 「2」를 격납한다.
다음에, 도 1중의 CPU(32)는 도 4중의 단계 108에 있어서 1종류째의 통합 테이블(62)(도 8 참조)을 작성한다. 즉, CPU(32)는 통합 테이블(62)의 통합 개수 mn(x)에 병합치 d(x)를 격납한다. 또한, CPU(32)는 통합 개수 mn(y)에 병합치 d(y), 즉, y 방향의 최대 개수 a(y)를 격납한다. 또, CPU(32)는 반복 피치 mp(x), mp(y)에 각각 도 3중의 단계 71에 있어서 구한 반복 패턴 G의 매트릭스 피치 gp(x), gp(y)를 격납한다.
또, 도 1중의 CPU(32)는 도 4중의 단계 109에 있어서 1종류째의 배치 테이블(63)(도 8 참조)을 작성한다. 즉, CPU(32)는 매트릭스 인식(도 3, 단계 71)에 있어서 구한 매트릭스 개수 gn(x), gn(y)를 각각 병합치 d(x), d(y)(= 최대 개수 a(y))로 제산한 결과를 배치 테이블(63)의 반복 개수 sn(x), sn(y)에 격납한다. 또한, CPU(32)는 구한 매트릭스 피치 gp(x), gp(y)와 병합치 d(x), d(y)(= 최대 개수 a(y))를 각각 승산한 결과를 반복 피치 sp(x), sp(y)에 격납한다.
다음에, 도 1중의 CPU(32)는 도 4중의 단계 110에 있어서 2종류째의 통합 테이블(62)(도 8 참조)을 작성한다. 즉, CPU(32)는 통합 테이블(62)의 통합 개수 mn(x)에 병합치 d(x)를 격납한다. 또한, CPU(32)는 통합 개수 mn(y)에 매트릭스 개수 gn(y)를 최대 개수 a(y)로써 제산한 나머지를 격납한다. 또, CPU(32)는 반복 피치 mp(x), mp(y)에 각각 도 3중의 단계 71에서 구한 반복 패턴 G의 매트릭스 피치gp(x), gp(y)를 격납한다.
또, 도 1중의 CPU(32)는 도 4중의 단계 111에 있어서 2종류째의 배치 테이블(63)(도 8 참조)을 작성한다. 즉, CPU(32)는 x 방향에 대하여 매트릭스 인식(도 3, 단계 71)에 있어서 구한 매트릭스 개수 gn(x)를 병합치 d(x)로써 제산한 결과를 반복 개수 sn(x)에 격납한다. 한편, y 방향에 대해서는 2종류째의 통합 영역 S에는 단순 배치된 나머지 반복 패턴 G가 격납되기 때문에, 통합 영역 S의 y 방향으로의 반복은 없다. 그 때문에, CPU(32)는 y 방향의 반복 개수 sn(y)에 「1」을 격납한다.
또한, CPU(32)는 x 방향에 대하여 구한 매트릭스 피치 gp(x)와 병합치 d(x)를 승산한 결과를 반복 피치 sp(x)에 격납한다. 한편, y 방향에 대하여 통합 영역 S의 반복이 없기 때문에, CPU(32)는 매트릭스 피치 sp(y)에 「0」을 격납한다.
또한, 도 1중의 CPU(32)는 후보치 c(x)와 병합치 d(x)가 일치하지 않고 후보치 c(y)와 병합치 d(y)가 일치하는 즉, x 방향으로는 「단순 배치」되고 y 방향으로는 「균등 배치」되는 경우에 도 5중의 단계 112로 분기한다. 그리고, CPU(32)는 먼저 단계 112에 있어서, 도 8중의 배치 테이블(63)의 종류수 66에 작성하는 통합 영역 S의 종류수 「2」를 격납한다.
다음에, 도 1중의 CPU(32)는 도 5중의 단계 113에 있어서 1종류째의 통합 테이블(62)(도 8 참조)을 작성한다. 즉, CPU(32)는 통합 테이블(62)의 통합 개수 mn(x)에 병합치 d(x), 즉, x 방향의 최대 개수 a(x)를 격납한다. 또한, CPU(32)는 통합 개수 mn(y)에 병합치 d(y)를 격납한다. 또, CPU(32)는 반복 피치 mp(x),mp(y)에 각각 도 3중의 단계 71에서 구한 반복 패턴 G의 매트릭스 피치 gp(x), gp(y)를 격납한다.
또, 도 1중의 CPU(32)는 도 5중의 단계 114에 있어서 1종류째의 배치 테이블(63)을 작성한다. 즉, CPU(32)는 매트릭스 인식(도 3, 단계 71)에 있어서 구한 매트릭스 개수 gn(x), gn(y)를 각각 병합치 d(x)(= 최대 개수 a(x)), d(y)로 제산한 결과를 배치 테이블(63)의 반복 개수 sn(x), sn(y)에 격납한다. 또한, CPU(32)는 구한 매트릭스 피치 gp(x), gp(y)와 병합치 d(x)(= 최대 개수 a(x)), d(y)를 각각 승산한 결과를 반복 피치 sp(x), sp(y)에 격납한다.
다음에, 도 1중의 CPU(32)는 도 5중의 단계 115에 있어서 2종류째의 통합 테이블(62)(도 8 참조)을 작성한다. 즉, CPU(32)는 통합 테이블(62)의 통합 개수 mn(x)에 매트릭스 개수 gn(x)를 병합치 d(x)로서 제산한 나머지를 격납한다. 또한, CPU(32)는 통합 개수 mn(y)에 병합치 d(y)를 격납한다. 또, CPU(32)는 반복 피치 mp(x), mp(y)에 각각 도 3중의 단계 71에서 구한 반복 패턴 G의 매트릭스 피치 gp(x), gp(y)를 격납한다.
또, 도 1중의 CPU(32)는 도 5중의 단계 116에 있어서 2종류째의 배치 테이블(63)(도 8 참조)을 작성한다. 즉, x 방향에 대하여 2종류째의 통합 영역 S에는 단순 배치된 나머지 반복 패턴 G가 격납되므로, 통합 영역 S의 x 방향으로의 반복은 없다. 그 때문에, CPU(32)는 x 방향의 매트릭스 개수 sn(x)에 「1」을 격납한다. 한편, CPU(32)는 y 방향에 대하여 매트릭스 인식(도 3, 단계 71)에 있어서 구한 매트릭스 개수 gn(y)를 병합치 d(y)로써 제산한 결과를 배치 테이블(63)의 반복개수sn(y)에 격납한다.
또한, x 방향에 대하여 통합 영역 S의 반복이 없기 때문에, CPU(32)는 매트릭스 피치 sp(x)에 「0」을 격납한다. 한편, CPU(32)는 y 방향에 대하여 구한 매트릭스 피치 gp(y)와 병합치 d(y)를 승산한 결과를 반복 피치 sp(y)에 격납한다.
또한, 도 1중의 CPU(32)는 후포치 c(x), c(y)와 병합치 d(x), d(y)가 모두 일치하지 않는 즉, x 방향 및 y 방향으로 「단순 배치」되는 경우에 도 5중의 단계 117로 분기한다. 그리고, CPU(32)는 먼저 단계 117에 있어서, 도 8중의 배치 테이블(63)의 종류수 66에 작성하는 통합 영역 S의 종류수 「4」를 격납한다.
다음에, 도 1중의 CPU(32)는 도 5중의 단계 118에 있어서 1종류째의 통합 테이블(62)(도 8 참조)을 작성한다. 즉, CPU(32)는 통합 테이블(62)의 통합 개수 mn(x)에 병합치 d(x)(= 최대 개수 a(x))와 통합 개수 mn(y)에 병합치 d(y)(= 최대 개수 a(y))를 격납한다. 또한, CPU(32)는 반복 피치 mp(x), mp(y)에 각각 도 3중의 단계 71에서 구한 반복 패턴 G의 매트릭스 피치 gp(x), gp(y)를 격납한다.
또, 도 1중의 CPU(32)는 도 5중의 단계 119에 있어서 1종류째의 배치 테이블(63)(도 8 참조)을 작성한다. 즉, CPU(32)는 매트릭스 인식(도 3, 단계 71)에 있어서 구한 매트릭스 개수 gn(x), gn(y)를 각각 병합치 d(x)(= 최대 개수 a(x)), d(y)(= 최대 개수 a(y))로써 제산한 결과를 배치 테이블(63)의 반복 개수 sn(x), sn(y)에 격납한다. 또한, CPU(32)는 구한 매트릭스 피치 gp(x), gp(y)와 병합치 d(x)(= 최대 개수 a(x)), d(y)(= 최대 개수 a(y))를 각각 승산한 결과를 반복 피치 sp(x), sp(y)에 격납한다.
다음에, 도 1중의 CPU(32)는 도 5중의 단계 120에 있어서 2종류째의 통합 테이블(62)(도 8 참조)을 작성한다. 즉, CPU(32)는 통합 테이블(62)의 통합 개수 mn(x)에 매트릭스 개수 gn(x)를 병합치 d(x)로써 제산한 나머지를 격납한다. 또한, CPU(32)는 통합 개수 mn(y)에 병합치 d(y)(= 최대 개수 a(y))를 격납한다. 또한, CPU(32)는 반복 피치 mp(x), mp(y)에 각각 도 3중의 단계 71에서 구한 반복 패턴 G의 매트릭스 피치 gp(x), gp(y)를 격납한다.
또, 도 1중의 CPU(32)는 도 5중의 단계 121에 있어서 2종류째의 배치 테이블(63)(도 8 참조)을 작성한다. 즉, x 방향에 대하여 2종류째의 통합 영역 S에는 단순 배치된 나머지 반복 패턴 G가 격납되므로, 통합 영역 S의 x 방향으로의 반복은 없다. 그 때문에, CPU(32)는 x 방향의 매트릭스 개수 sn(x)에 「1」을 격납한다. 한편, CPU(32)는 y 방향에 대하여 매트릭스 인식(도 3, 단계 71)에 있어서 구한 매트릭스 개수 gn(y)를 병합치 d(y)로써 제산한 결과를 배치 테이블(63)의 반복 개수 sn(y)에 격납한다.
또한, x 방향에 대하여 통합 영역 S의 반복이 없기 때문에, CPU(32)는 매트릭스 피치 sp(x)에 「0」을 격납한다. 한편, CPU(32)는 y 방향에 대하여 구한 매트릭스 피치 gp(y)와 병합치 d(y)를 승산한 결과를 반복 피치 sp(y)에 격납한다.
다음에, 도 1중의 CPU(32)는 도 5중의 단계 122에 있어서 3종류째의 통합 테이블(62)(도 8 참조)을 작성한다. 즉, CPU(32)는 통합 테이블(62)의 통합 개수 mn(x)에 병합치 d(x)(= 최대 개수 a(x))를 격납한다. 또한, CPU(32)는 통합 개수 mn(y)에 매트릭스 개수 gn(y)를 최대 개수 a(y)로써 제산한 나머지를 격납한다.또, CPU(32)는 반복 피치 mp(x), m p(y)에 각각 도 3중의 단계 71에서 구한 반복 패턴 G의 매트릭스 피치 gp(x), gp(y)를 격납한다.
또, 도 1중의 CPU(32)는 도 5중의 단계 123에 있어서 3종류째의 배치 테이블(63)(도 8 참조)을 작성한다. 즉, CPU(32)는 x 방향에 대하여 매트릭스 인식(도 3, 단계 71)에 있어서 구한 매트릭스 개수 gn(x)를 병합치 d(x)로써 제산한 결과를 반복 개수 sn(x)에 격납한다. 한편, y 방향에 대해서는 3종류째의 통합 영역 S에는 단순 배치된 나머지 반복 패턴 G가 격납되므로, 통합 영역 S의 y 방향으로의 반복은 없다. 그 때문에, CPU(32)는 y 방향의 반복 개수 sn(y)에 「1」을 격납한다.
또한, CPU(32)는 x 방향에 대하여 구한 매트릭스 피치 gp(x)와 병합치 d(x)를 승산한 결과를 반복 피치 sp(x)에 격납한다. 한편, y 방향에 대하여 통합 영역 S의 반복이 없기 때문에, CPU(32)는 매트릭스 피치 sp(y)에 「0」을 격납한다.
다음에, 도 1중의 CPU(32)는 도 5중의 단계 124에 있어서 4종류째의 통합 테이블(62)(도 8 참조)을 작성한다. 즉, CPU(32)는 통합 테이블(62)의 통합 개수 mn(x), mn(y)에 대하여, 매트릭스 개수 gn(x), gn(y)를 각각 최대 개수 a(x), a(y)로써 제산한 나머지를 격납한다. 또한, CPU(32)는 반복 피치 mp(x), mp(y)에 각각 도 3중의 단계 71에서 구한 반복 패턴 G의 매트릭스 피치 gp(x), gp(y)를 격납한다.
또, 도 1중의 CPU(32)는 도 5중의 단계 125에 있어서 4종류째의 배치 테이블(63)(도 8 참조)을 작성한다. 즉, x 방향에 대하여, 4종류째의 통합 영역 S에는 단순 배치된 나머지 반복 패턴 G가 격납되므로, 통합 영역 S의 x 방향으로의 반복은 없다. 또한, y 방향에 대하여 4종류째의 통합 영역 S에는 단순 배치된 나머지 반복 패턴 G가 격납되므로, 통합 영역 S의 y 방향으로의 반복은 없다. 그 때문에, CPU(32)는 x, y 방향의 반복 개수 sn(x), sn(y)에 「1」을 격납한다.
또한, x 방향에 대하여 통합 영역 S의 반복이 없다. 또한, y 방향에 대하여 통합 영역 S의 반복이 없다. 따라서, CPU(32)는 매트릭스 피치 sp(x), sp(y)에 「0」을 격납한다.
다음에, 상기한 바와 같이 구성된 노광 데이타 작성 장치(31)의 작용을 도 10∼21에 따라서 설명한다.
먼저, 도 10∼12에 따라서, X, Y 방향 모두 균등 배치할 수 있는 경우에 관해서 설명한다.
도 1중의 CPU(32)는 도 2중의 데이타 화일(41)에 격납된 설계 데이타로부터 도 10에 도시된 노광 패턴 데이타군 R을 추출한다. 노광 패턴 데이타군 R은 81개의 반복 패턴 G가 x 방향과 y 방향의 매트릭스에 배열되어 있다.
도 1중의 CPU는 반복 패턴 G를 입력하고, 도 3중의 단계 71에 있어서 반복 패턴 G의 매트릭스 인식을 행하며, 매트릭스 개수 gn(x)=9, gn(y)=9와, 매트릭스 피치 gp(x), gp(y)를 구한다.
다음에, CPU(32)는 도 3중의 단계 72에 있어서 도 10에 도시된 통합 영역 S에 수용가능한 최대 개수 a(x)=4와 도 3중의 단계 73에 있어서 통합 영역 S의 필요 개수 b(x)=3을 구한다.
CPU(32)는 도 3중의 단계 74에 있어서 판정 조건에 적합하기 때문에 균등 배치가능하다고 판단하여, 후보치 c(x)=3을 설정한다. 이것에 의해, CPU(32)는 도 3중의 단계 75에 있어서 후보치 c(x)가 설정되어 있기 때문에, 병합치 d(x)=후보치 c(x)=3을 설정한다.
CPU(32)는 도 3중의 단계 76에 있어서 y 방향에 대하여 처리를 종료하고 있지 않기 때문에, 도 3중의 단계 72 내지 75에 있어서 y 방향의 매트릭스 개수 gn(y)에 관해서 동일한 처리를 행하고, 최대 개수 a(y)=4, 필요 개수 b(y)=3을 구한다. 또, CPU(32)는 단계 74에 있어서 판정 조건에 적합하기 때문에 균등 배치가능하다고 판단하여 후보치 c(y)=3을 설정하며, 단계 75에 있어서 병합치 d(y)=후보치 c(y)=3을 설정한다.
다음에, 도 3중의 단계 77에 있어서, 도 1중의 CPU(32)는 통합 정보를 작성한다. 이 때, 도 3중의 단계 74에 있어서 후보치 c(x), c(y) 모두 설정되어 있기 때문에, 도 1중의 CPU(32)는 도 4중의 단계 101, 102의 판정에 의해 단계 104로 분기한다.
도 4중의 단계 104에 있어서, 도 1중의 CPU(32)는 X, Y 방향 모두 균등 배치할 수 있기 때문에 통합 영역 S의 종류는 1종류가 되고, 도 8중의 통합 테이블(62)의 종류수 65에 「1」을 격납한다.
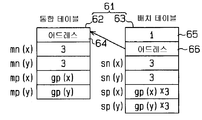
다음에, 도 4중의 단계 105에 있어서, 도 1중의 CPU(32)는 통합 테이블(62)을 작성한다. 통합 영역 S에 다시 통합하는 반복 패턴 G의 병합치 d(x)=3, d(y)=3이기 때문에, CPU(32)는 통합 테이블(62)의 통합 개수 mn(x)=d(x)=3, mn(y)=d(y)=3을 설정한다.
또, 도 4중의 단계 106에 있어서, 도 1중의 CPU(32)는 배치 테이블(63)을 작성한다. 이 때, 반복 패턴 G의 반복 개수 gn(x)=9, gn(y)=9, 병합치 d(x)=3, d(y)=3이기 때문에, 통합 영역 S의 x 방향의 반복 개수 sn(x)=gn(x)÷d(x)=9÷3=3, y 방향의 반복 개수 sn(y)=gn(y)÷d(y)=9÷3=3이 된다. 또한, 통합 영역 S의 x 방향의 반복 피치 sp(x)=gp(x)×d(x)=gp(x)×3, y 방향의 반복 피치 sp(y)=gp(y)×d(y)=gp(y)×3이 된다.
그 결과, 도 11에 도시된 바와 같이, 각 값이 격납된 1종류의 통합 테이블(62)과 배치 테이블(63)에 의해 도 10중의 노광 패턴 데이타군 R의 통합 정보 테이블(61)이 구성된다.
도 3중의 단계 78에 있어서, 도 1중의 CPU(32)는 작성한 통합 정보 테이블에 기초하여, 단계 71로써 입력한 81개의 반복 패턴 G의 배치 데이타를 9개의 통합 영역 S의 배치 데이타로 대체한다. 또, CPU(32)는 도 3중의 단계 79∼81에 있어서 원래의 반복 노광 패턴 데이타를 통합 정보 테이블(61)에 기초하여 전개하여, 새로운 반복 노광 패턴 데이타로서 출력한다.
따라서, 도 10에 도시된 노광 패턴 데이타군 R의 배치수는 81개에서 9개로 감소한다. 그리고, 도 12에 도시된 바와 같이, 반복 개수 mn(x)×mn(y)=3×3개의 반복 패턴 G에 의해 구성되는 1종류의 통합 영역 S와 반복 피치 sp(x), sp(y)로써 노광함으로써, 노광 패턴 데이타군 R이 노광된다.
다음에, 도 13∼15에 따라서, X 방향으로만 균등 배치할 수 있는 경우에 관해서 설명한다.
도 1중의 CPU(32)는 도 2중의 데이타 화일(41)에 격납된 설계 데이타로부터 도 13에 도시된 노광 패턴 데이타군 R을 추출한다. 노광 패턴 데이타군 R은 90개의 반복 패턴 G가 x 방향과 y 방향의 매트릭스에 배열되어 있다.
도 1중의 CPU는 반복 패턴 G를 입력하고, 도 3중의 단계 71에 있어서 반복 패턴 G의 매트릭스 인식을 행하여, 매트릭스 개수 gn(x)=9, gn(y)=10과, 매트릭스 피치 gp(x), gp(y)를 구한다.
다음에, CPU(32)는 도 3중의 단계 72에 있어서 도 13에 도시된 통합 영역 S에 수용가능한 최대 개수 a(x)=4와 도 3중의 단계 73에 있어서 통합 영역 S의 필요 개수 b(x)=3를 구한다.
CPU(32)는 도 3중의 단계 74에 있어서 판정 조건에 적합하기 때문에 균등 배치가능하다고 판단하여, 후보치 c(x)=3을 설정한다. 그 때문에, CPU(32)는 도 3중의 단계 75에 있어서 후보치 c(x)가 설정되어 있으므로, 병합치 d(x)=후보치 c(x)=3을 설정한다.
CPU(32)는 도 3중의 단계 76에 있어서 y 방향에 대하여 처리를 종료하고 있지 않기 때문에, 도 3중의 단계 72 내지 75에 있어서 y 방향의 매트릭스 개수 gn(y)에 대해서 동일한 처리를 행하여, 최대 개수 a(y)=4, 필요 개수 b(y)=3을 구한다. 또, CPU(32)는 단계 74에 있어서 판정 조건에 적합하지 않기 때문에 균등 배치 불가능하다고 판단하여 후보치 c(y)를 설정하지 않는다. 그 때문에, CPU(32)는 단계 75에 있어서 병합치 d(y)=최대 개수 a(y)=4를 설정한다
다음에, 도 3중의 단계 77에 있어서, 도 1중의 CPU(32)는 통합 정보를 작성한다. 이 때, 도 3중의 단계 74에 있어서 후보치 c(x)는 설정되어 있지만 후보치 c(y)는 설정되어 있지 않으므로, 도 1중의 CPU(32)는 도 4중의 단계 101, 102의 판정에 의해 단계 107로 분기한다. 그리고, 도 4중의 단계 1071에 있어서, 도 1중의 CPU(32)는 도 8중의 통합 테이블(62)의 종류수 65에 통합 영역 S의 종류수 「2」를 격납한다.
다음에, 도 4중의 단계 108에 있어서, 도 1중의 CPU(32)는 1종류째의 통합 테이블(62a)(도 14 참조)을 작성한다. 통합 영역 S에 다시 통합하는 반복 패턴 G의 병합치 d(x)=3, d(y)=4이기 때문에, CPU(32)는 통합 테이블(62a)의 통합 개수 mn(x)=d(x)=3, mn(y)=d(y)=4를 설정한다.
또, 도 4중의 단계 109에 있어서, 도 1중의 CPU(32)는 1종류째의 배치 테이블(63)을 작성한다. 이 때, 반복 패턴 G의 반복 개수 gn(x)=9, gn(y)=10, 병합치 d(x)=3, d(y)=4이기 때문에 통합 영역 S의 x 방향의 반복 개수 sn(x)=gn(x)÷d(x)=9÷3=3, y 방향의 반복 개수 sn(y)=gn(y)÷d(y)=10÷4=2(몫)가 된다. 또한, 통합 영역 S의 x 방향의 반복 피치 sp(x)=gp(x)×d(x)=gp(x)×3, y 방향의 반복 피치 sp(y)=gp(y)×d(y)=gp(y)×4가 된다.
다음에, 도 4중의 단계 110에 있어서, 도 1중의 CPU(32)는 2종류째의 통합 테이블(62b)(도 14 참조)을 작성한다. 통합 영역 S에 다시 통합하는 반복 패턴 G의 병합치 d(x)=3, d(y)=a(y)=4이기 때문에, CPU(32)는 통합 테이블(62b)의 x 방향의 통합 개수 mn(x)=d(x)=3을 설정한다. 또, CPU(32)는 y 방향의 통합 개수 mn(y)=2(반복 개수 gn(y)÷최대 개수 a(y)=10÷4의 나머지)를 설정한다.
또, 도 4중의 단계 111에 있어서, 도 1중의 CPU(32)는 2종류째의 배치 테이블(63)을 작성한다. 이 때, 반복 패턴 G의 반복 개수 gn(x)=9, 병합치 d(x)=3이기 때문에, 통합 영역 S의 x 방향의 반복 개수 sn(x)=gn(x)÷d(x)=9÷3=3이 된다. 한편, 2종류째의 통합 영역 S에는 나머지 반복 패턴 G가 격납되는 y 방향의 반복 배치가 없기 때문에, 반복 개수 sn(y)=1이 된다.
또한, 통합 영역 S의 x 방향의 반복 피치 sp(x)=gp(x)×d(x)=gp(x)×3가 된다. 한편, 2종류째의 통합 영역 S에는 나머지 반복 패턴 G가 격납되고 y 방향의 반복 배치는 없기 때문에, 반복 피치 sp(y)=0이 된다.
그 결과, 도 14에 도시된 바와 같이, 각 값이 격납된 2종류의 통합 테이블(62a,62b)과, 배치 테이블(63)에 의해 도 13중의 노광 패턴 데이타군 R의 통합 정보 테이블(61)이 구성된다. 따라서, 도 15에 도시된 바와 같이, 반복 개수 mn(x)×mn(y)=3×4의 매트릭스의 반복 패턴 G로 이루어지는 1종류째의 통합 영역 Sa와, 반복 개수 mn(x)×mn(y)=3×2의 매트릭스의 반복 패턴 G로 이루어지는 2종류째의 통합 영역 Sb가 구성된다. 그리고, 노광 패턴 데이타군 R은 6개의 1종류째의 통합 영역 Sa와 3개의 2종류째의 통합 영역 Sb에 의해 노광된다.
도 3중의 단계 78에 있어서, 도 1중의 CPU(32)는 작성한 통합 정보 테이블에 기초하여, 단계 71로써 입력한 90개의 반복 패턴 G의 배치 데이타를 9개의 통합 영역 S(6개의 통합 영역 Sa와 3개의 통합 영역 Sb)의 배치 데이타로 대체한다. 또, CPU(32)는 도 3중의 단계 79 내지 81에 있어서 원래의 반복 노광 패턴 데이타를 통합 정보 테이블(61)에 기초하여 전개하며, 새로운 반복 노광 패턴 데이타로서 출력한다. 이 결과, 반복 패턴 데이타의 배치수는 90개에서 9개로 감소한다.
다음에, 도 16∼18에 따라서, Y 방향으로만 균등 배치할 수 있는 경우에 관해서 설명한다.
도 1중의 CPU(32)는 도 2중의 데이타 화일(41)에 격납된 설계 데이타로부터 도 16에 도시하는 노광 패턴 데이타군 R을 추출한다. 노광 패턴 데이타군 R은 99개의 반복 패턴 G가 x 방향과 y 방향의 매트릭스에 배열되어 있다.
도 1중의 CPU는 반복 패턴 G를 입력하고, 도 3중의 단계 71에 있어서 반복 패턴 G의 매트릭스 인식을 행하여, 매트릭스 개수 gn(x)=11, gn(y)=9와, 매트릭스 피치 gp(x), gp(y)를 구한다.
다음에, CPU(32)는 도 3중의 단계 72에 있어서 도 16에 도시되는 통합 영역 S에 수용가능한 최대 개수 a(x)=4와 도 3중의 단계 73에 있어서 통합 영역 S의 필요 개수 b(x)=3을 구한다.
CPU(32)는 도 3중의 단계 74에 있어서 판정 조건에 적합하지 않기 때문에 균등 배치 불가능하다고 판단하여, 후보치 c(x)를 설정하지 않는다. 그 때문에, CPU(32)는 도 3중의 단계 75에 있어서 후보치 c(x)가 설정되어 있지 않기 때문에, 병합치 d(x)=최대 개수 a(x)=4를 설정한다.
CPU(32)는 도 3중의 단계 76에 있어서 y 방향에 대하여 처리를 종료하지 않고 있기 때문에, 도 3중의 단계 72∼75에 있어서 y 방향의 매트릭스 개수 gn(y)에 대해서 동일한 처리를 행하여, 최대 개수 a(y)=4, 필요 개수 b(y)=3을 구한다. 또,CPU(32)는 단계 74에 있어서 판정 조건에 적합하기 때문에 균등 배치 가능하다고 판단하여 후보치 c(y)=3을 설정한다. 그 때문에, CPU(32)는 단계 75에 있어서 후보치 c(y)가 설정되어 있으므로, 병합치 d(y)=후보치 c(y)=3을 설정한다.
다음에, 도 3중의 단계 77에 있어서, 도 1중의 CPU(32)는 통합 정보를 작성한다. 이 때, 도 3중의 단계 74에 있어서 후보치 c(x)는 설정되어 있지 않지만 후보치 c(y)는 설정되어 있기 때문에, 도 1중의 CPU(32)는 도 4중의 단계 101 및 도 5중의 단계 103의 판정에 의해 단계 112로 분기한다. 그리고, 도 5중의 단계 112에 있어서, 도 1중의 CPU(32)는 도 8중의 통합 테이블(62)의 종류수 65에 통합 영역 S의 종류수 「2」를 격납한다.
다음에, 도 5중의 단계 113에 있어서, 도 1중의 CPU(32)는 1종류째의 통합 테이블(62a)(도 17 참조)을 작성한다. 통합 영역 S에 다시 통합하는 반복 패턴 G의 병합치 d(x)=a(x)=4, d(y)=3이기 때문에, CPU(32)는 통합 테이블(62a)의 통합 개수 mn(x)=d(x)=4, mn(y)=d(y)=3을 설정한다.
또, 도 5중의 단계 114에 있어서, 도 1중의 CPU(32)는 1종류째의 배치 테이블(63)을 작성한다. 이 때, 반복 패턴 G의 반복 개수 gn(x)=11, gn(y)=9, 병합치 d(x)=4, d(y)=3이기 때문에, 통합 영역 S의 x 방향의 반복 개수 sn(x)=gn(x)÷d(x)=11÷4=3(몫), y 방향의 반복 개수 sn(y)=gn(y)÷d(y)=9÷3=3이 된다. 또한, 통합 영역 S의 x 방향의 반복 피치 sp(x)=gp(x)×d(x)=gp(x)4, y 방향의 반복 피치 sp(y)=gp(y)×d(y)=gp(y)×3이 된다.
다음에, 도 4중의 단계 115에 있어서, 도 1중의 CPU(32)는 2종류째의 통합테이블(62b)(도 17 참조)을 작성한다. 통합 영역 S에 다시 통합하는 반복 패턴 G의 병합치 d(x)=4, d(y)=3이기 때문에, CPU(32)는 통합 테이블(62b)의 x 방향의 통합 개수 mn(x)=3(반복 개수 gn(x)÷병합치 d(x)=11÷4의 나머지)를 설정한다. 또, CPU(32)는 y 방향의 통합 개수 mn(y)=d(y)=3을 설정한다.
또, 도 5중의 단계 116에 있어서, 도 1중의 CPU(32)는 2종류째의 배치 테이블(63)을 작성한다. 이 때, 2종류째의 통합 영역 S에는 나머지 반복 패턴 G가 격납되는 x 방향의 반복 배치가 없으므로, 반복 개수 sn(x)=1이 된다. 한편, 반복 패턴 G의 반복 개수 gn(y)=9, 병합치 d(y)=3이기 때문에, 통합 영역 S의 y 방향의 반복 개수 sn(y)=gn(y)÷d(y)=9÷3=3이 된다.
또한, 2종류째의 통합 영역 S에는 나머지 반복 패턴 G가 격납되어 x 방향의 반복 배치는 없으므로, 반복 피치 sp(x)=0이 된다. 한편, 통합 영역 S의 y 방향의 반복 피치 sp(y)=gp(y)×d(y)=gp(y)×3이 된다.
그 결과, 도 17에 도시된 바와 같이, 각 값이 격납된 2종류의 통합 테이블(62a,62b)과, 배치 테이블(63)에 의해 도 16중의 노광 패턴 데이타군 R의 통합 정보 테이블(61)이 구성된다. 따라서, 도 18에 도시된 바와 같이, 반복 개수 mn(x)×mn(y)=4×3의 매트릭스의 반복 패턴 G로 이루어지는 1종류째의 통합 영역 Sa와, 반복 개수 mn(x)×mn(y)=3×3의 매트릭스의 반복 패턴 G로 이루어지는 2종류째의 통합 영역 Sb가 구성된다. 그리고, 노광 패턴 데이타군 R은 6개의 1종류째의 통합 영역 Sa와 3개의 2종류째의 통합 영역 Sb에 의해 노광된다.
도 3중의 단계 78에 있어서, 도 1중의 CPU(32)는 작성한 통합 정보 테이블에기초하여, 단계 71로써 입력한 99개의 반복 패턴 G의 배치 데이타를 9개의 통합 영역 S(6개의 통합 영역 Sa와 3개의 통합 영역 Sb)의 배치 데이타로 대체한다. 또, CPU(32)는 도 3중의 단계 79∼81에 있어서 원래의 반복 노광 패턴 데이타를 통합 정보 테이블(61)에 기초하여 전개하며, 새로운 반복 노광 패턴 데이타로서 출력한다. 이 결과, 반복 패턴 데이타의 배치수는 99개에서 9개로 감소한다.
또 다음에, 도 19∼도 21에 따라서, X, Y 방향 모두 균등 배치할 수 없는 경우에 대해서 설명한다.
도 1중의 CPU(32)는 도 2중의 데이타 화일(41)에 격납된 설계 데이타로부터 도 19에 도시하는 노광 패턴 데이타군 R을 추출한다. 노광 패턴 데이타군 R은 100개의 반복 패턴 G가 x 방향과 y 방향의 매트릭스에 배열되어 있다.
도 1중의 CPU는 반복 패턴 G를 입력하고, 도 3중의 단계 71에 있어서 반복 패턴 G의 매트릭스 인식을 행하여, 매트릭스 개수 gn(x)=10, gn(y)=10과, 매트릭스 피치 gp(x), gp(y)를 구한다.
다음에, CPU(32)는 도 3중의 단계 72에 있어서 도 19에 도시되는 통합 영역 S에 수용가능한 최대 개수 a(x)=4와 도 3중의 단계 73에 있어서 통합 영역 S의 필요 개수 b(x)=3을 구한다.
CPU(32)는 도 3중의 단계 74에 있어서 판정 조건에 적합하지 않기 때문에 균등 배치 불가능하다고 판단하여, 후보치 c(x)를 설정하지 않는다. 그 때문에, CPU(32)는 도 3중의 단계 75에 있어서 후보치 c(x)가 설정되어 있지 않기 때문에, 병합치 d(x)=최대 개수 a(x)=4를 설정한다.
CPU(32)는 도 3중의 단계 76에 있어서 y 방향에 대하여 처리를 종료하고 있지 않기 때문에, 도 3중의 단계 72∼75에 있어서 y 방향의 매트릭스 개수 gn(y)에 대해서 동일한 처리를 행하여, 최대 개수 a(y)=4, 필요 개수 b(y)=3을 구한다. 또, CPU(32)는 단계 74에 있어서 판정 조건에 적합하지 않기 때문에 균등 배치 불가능하다고 판단하여 후보치 c(y)를 설정하지 않는다. 그 때문에, CPU(32)는 단계 75에 있어서 후보치 c(y)가 설정되어 있지 않기 때문에, 병합치 d(y)=최대치 a(y)=4를 설정한다.
다음에, 도 3중의 단계 77에 있어서, 도 1중의 CPU(32)는 통합 정보를 작성한다. 이 때, 도 3중의 단계 74에 있어서 후보치 c(x), c(y)는 모두 설정되어 있지 않으므로, 도 1중의 CPU(32)는 도 4중의 단계 101 및 도 5중의 단계 103의 판정에 의해 단계 117로 분기한다. 그리고, 도 5중의 단계 117에 있어서, 도 1중의 CPU(32)는 도 8중의 통합 테이블(62)의 종류수 65에 통합 영역 S의 종류수 「4」를 격납한다.
다음에, 도 5중의 단계 118에 있어서, 도 1중의 CPU(32)는 1종류째의 통합 테이블(62a)(도 20 참조)을 작성한다. 통합 영역 S에 다시 통합하는 반복 패턴 G의 병합치 d(x)=4, d(y)=4이기 때문에, CPU(32)는 통합 테이블(62a)의 통합 개수 mn(x)=d(x)=4, mn(y)=d(y)=4를 설정한다.
또, 도 5중의 단계 119에 있어서, 도 1중의 CPU(32)는 1종류째의 배치 테이블(63)(도 20 참조)을 작성한다. 이 때, 반복 패턴 G의 반복 개수 gn(x)=10, gn(y)=10, 병합치 d(x)=4, d(y)=4이기 때문에, 통합 영역 S의 x 방향의 반복 개수sn(kk)=gn(x)÷d(x)=10÷4=2(몫), y 방향의 반복 개수 sn(y)=gn(y)÷d(y)=10÷4=2(몫)이 된다. 또한, 통합 영역 S의 x 방향의 반복 피치 sp(x)=gp(x)×d(x)=gp(x)×4, y 방향의 반복 피치 sp(y)=gp(y)×d(y)=gp(y)×4가 된다.
다음에, 도 5중의 단계 120에 있어서, 도 1중의 CPU(32)는 2종류째의 통합 테이블(62b)(도 20 참조)을 작성한다. 통합 영역 S에 다시 통합하는 반복 패턴 G의 병합치 d(x)=4, d(y)=4이기 때문에, CPU(32)는 통합 테이블(62b)의 x 방향의 통합 개수 mn(x)=2(반복 개수 gn(x)÷병합치 d(x)=10÷4의 나머지)를 설정한다. 또, CPU(32)는 y 방향의 통합 개수 mn(y)=병합치 d(y)=4를 설정한다.
또, 도 5중의 단계 121에 있어서, 도 1중의 CPU(32)는 2종류째의 배치 테이블(63)(도 20 참조)을 작성한다. 이 때, 2종류째의 통합 영역 S에는 나머지 반복 패턴 G가 격납되어 x 방향의 반복 배치가 없기 때문에, 반복 개수 sn(x)=1이 된다. 한편, 반복 패턴 G의 반복 개수 gn(y)=10, 병합치 d(y)=4이기 때문에, 통합 영역 S의 y 방향의 반복 개수 sn(y)=2(반복 개수 gn(y)÷병합치 d(y)=10÷4의 나머지)가 된다.
또한, 2종류째의 통합 영역 S에는 나머지 반복 패턴 G가 격납되어 x 방향의 반복배치는 없기 때문에, 반복 피치 sp(x)=0이 된다. 한편, 통합 영역 S의 y 방향의 반복 피치 sp(y)=gp(y)×d(y)=gp(y)×4가 된다.
다음에, 도 5중의 단계 122에 있어서, 도 1중의 CPU(32)는 3종류째의 통합 테이블(62c)(도 20 참조)을 작성한다. 통합 영역 S에 다시 통합하는 반복 패턴 G의병합치 d(x)=a(x)=4, d(y)=a(y)=4이기 때문에, CPU(32)는 통합 테이블(62c)의 통합 개수 mn(x)=d(x)=4, mn(y)=2(반복 개수 gn(y)÷병합치 d(y)=10÷4의 나머지)를 설정한다.
또, 도 5중의 단계 123에 있어서, 도 1중의 CPU(32)는 3종류째의 배치 테이블(63)(도 20 참조)을 작성한다. 이 때, 반복 패턴 G의 반복 개수 gn(x)=10, 병합치 d(x)=4이기 때문에, 통합 영역 S의 x 방향의 반복 개수 sn(x)=gn(x)÷d(x)=10÷4=2(몫)이 된다. 한편, 3종류째의 통합 영역 S에는 y 방향의 나머지 반복 패턴 G가 격납되어 y 방향의 반복 배치가 없기 때문에, 반복 개수 sn(y)=1이 된다.
또한, 통합 영역 S의 x 방향의 반복 피치 sp(x)=gp(x)×d(x)=gp(x)×4가 된다. 한편, 3종류째의 통합 영역 S에는 y 방향의 나머지 반복 패턴 G가 격납되어 y 방향의 반복 배치는 없기 때문에, 반복 피치 sp(y)=0이 된다.
또 다음에, 도 5중의 단계 124에 있어서, 도 1중의 CPU(32)는 4종류째의 통합 테이블(62d)(도 20 참조)을 작성한다. 통합 영역 S에 다시 통합하는 반복 패턴 G의 병합치 d(x)=a(x)=4, d(y)=a(y)=4이기 때문에, CPU(32)는 통합 테이블(62d)의 통합 개수 mn(x)=2(반복 개수 gn(x)÷병합치 d(x)=10÷4의 나머지)와 통합 개수 mn(y)=2(반복 개수 gn(y)÷병합치 d(y)=10÷4의 나머지)를 설정한다.
다음에, 도 5중의 단계 125에 있어서, 도 1중의 CPU(32)는 4종류째의 배치 테이블(63)(도 20 참조)을 작성한다. 이 때, 3종류째의 통합 영역 S에는 x 방향 및 y 방향의 나머지 반복 패턴 G가 격납되어 x, y 방향 모두 반복 배치가 없기 때문에, 반복 개수 sn(x)=1, sn(y)=1이 된다. 또한, 3종류째의 통합 영역 S에는 x 방향 및 y 방향의 나머지 반복 패턴 G가 격납되어 x, y 방향 모두 반복 배치는 없기 때문에, 반복 피치 sp(x)=0, sp(y)=0이 된다.
그 결과, 도 20에 도시된 바와 같이, 각 값이 격납된 4종류의 통합 테이블(62a∼62d)과, 배치 테이블(63)에 의해 도 19중의 노광 패턴 데이타군 R의 통합 정보 테이블(61)이 구성된다. 따라서, 도 21에 도시된 바와 같이, 반복 개수 mn(x)×mn(y)=4×4의 매트릭스의 반복 패턴 G로 이루어지는 1종류째의 통합 영역 Sa와, 반복 개수 mn(x)×mn(y)=2×4의 매트릭스의 반복 패턴 G로 이루어지는 2종류째의 통합 영역 Sb와, 반복 개수 mn(x)×mn(y)=4×2의 매트릭스의 반복 패턴 G로 이루어지는 3종류째의 통합 영역 Sc와, 반복 개수 mn(x)×mn(y)=2×2의 매트릭스의 반복 패턴 G로 이루어지는 4종류째의 통합 영역 Sd가 구성된다. 그리고, 노광 패턴 데이타군 R은 4개의 1종류째의 통합 영역 Sa, 2개의 2종류째의 통합 영역 Sb, 2개의 3종류째의 통합 영역 Sc, 및, 1개의 4종류째의 통합 영역 Sd에 의해 노광된다.
그리고, 도 3중의 단계 78에 있어서, 도 1중의 CPU(32)는 작성한 통합 정보 테이블에 기초하여, 단계 71로써 입력한 100개의 반복 패턴 G의 배치 데이타를 9개의 통합 영역 S(4개의 통합 영역 Sa, 2개의 통합 영역 Sb, 2개의 통합 영역 Sc, 및, 1개의 통합 영역 Sd)의 배치 데이타로 대체한다. 또, CPU(32)는 도 3중의 단계 79∼81에 있어서 원래의 반복 노광 패턴 데이타를 통합 정보 테이블(61)에 기초하여 전개하며, 새로운 반복 노광 패턴 데이타로서 출력한다. 이 결과, 반복 패턴 데이타의 배치수는 100개에서 9개로 감소한다.
이상 기술한 바와 같이, 본 실시의 형태에 의하면, 이하의 효과를 발휘한다.
○ 반도체 집적 회로의 기데이타로부터 반복성이 있는 노광 패턴 데이타를 노광 패턴 데이타군으로서 추출하는 동시에, 기데이타를 변환한 가노광 데이타를 작성한다. 노광 패턴 데이타군을 구성하는 반복 노광 패턴 데이타를 소정의 통합 영역에 재배열하는 통합 정보 테이블을 작성한다. 그리고, 작성한 통합 정보 테이블에 기초하여, 가노광 패턴 데이타를 재배열한 정식 노광 데이타를 작성하도록 하였다. 그 결과, 반복 노광 패턴 데이타를 소정의 통합 영역에 재배열한 만큼, 노광 데이타의 데이타량을 적게 할 수 있다.
○ 데이타 화일(45)에 격납된 정식 노광 데이타는 노광 매체로서의 웨이퍼(19)를 노광하는 경우에 이용되고, 반복 패턴 데이타 G는 통합 영역 S마다 노광된다. 즉, 그 때의 통합 영역 S내에 재배열된 반복 패턴 데이타 G가 노광된다. 그리고, 통합 영역 S의 크기는 도 23에 도시되는 반도체 칩(20)의 서브필드(22)의 크기로 설정되어 있다. 따라서, 통합 영역 S내에 다시 통합된 반복 패턴 G는 도 22에 있어서의 EB 노광 장치(10)의 제3 전자 편향기(17)의 제어에만 편광되는 전자빔에 의해서 노광되며, 제2 편향기(16) 및 스테이지(18)는 제어되지 않는다. 그 결과, 제2 전자 편향기(16)를 제어하는 회수가 종래에 비하여 감소하고, 제2 전자 편향기(16)가 제어되지 않게 된만큼, 빔 이동 시간이 적어진다. 또, 통합 영역 S내의 반복 패턴 G가 제3 전자 편향기(17)에 의해 노광되는 동안, 제2 전자 편향기(16) 및 스테이지(18)는 제어되지 않으므로, 위치 맞춤 오차의 발생이 방지되며, 노광 정밀도가 향상된다.
또한, 본 발명은 상기 실시 형태 이외에, 이하의 양태로 실시하여도 좋다.
상기 실시 형태에서는 통합 영역 S의 크기를 도 23에 도시되는 반도체 칩(20)의 서브필드(22)의 크기로 설정하였지만, 적당히 변경하여 실시하여도 좋다. 예컨대, 통합 영역 S의 크기를 서브필드(22)를 다시 복수로 분할한 1개의 크기, 복수의 서브필드(22)를 통합한 크기, 필드(21)의 크기 등으로 설정하여 실시하여도 좋다.
상기 실시 형태에서는 도 3중의 단계 72∼76의 루프에 있어서 먼저 x 방향에 대한 병합치 d(x)등을 구하고, 다음에 y 방향에 대한 병합치 d(y) 등을 구하는 용으로 하였지만, 단계 72∼75에 있어서 x 방향과 y 방향의 각 값을 각각 구하고, 단계 76을 생략하여 실시하여도 좋다.
상기 실시 형태에 있어서, 블록 패턴 데이타(51)를 격납하는 데이타 화일(45)과, 블록 배치 데이타(61)를 격납하는 데이타 화일(46)을 메모리(33)상에 설치하였지만, 데이타 화일(45,46)을 각각 자기 디스크(34)상에 설치하여 실시하여도 좋다.
상기 실시 형태에서는 노광 매체로서 반도체 웨이퍼(19)에 LSI의 설계 패턴을 노광하는 경우에 대해서 설명하였지만, 노광 매체로서는 웨이퍼 이외의 것이라도 좋고, 예컨대, LCD나 PDP 등의 패널에 패턴을 노광하는 경우에 이용하여도 좋다.
상기 실시 형태의 프로그램을 기억한 기억 매체는 컴퓨터 소프트웨어를 기록할 수 있는 것 이라면 어떠한 것 이라도 좋다. 구체적으로는 반도체 메모리, 플로피 디스크(FD), 하드 디스크(HD), 광디스크(CD-ROM), 광자기 디스크(MO, MD), 상변화 디스크(PD), 자기 테이프 등을 포함하는 것이다.
이상 상세히 기술한 바와 같이, 청구범위 제1항 내지 제9항에 기재한 발명에의하면, 반복이 많은 노광 패턴 데이타의 데이타량을 적게 하는 것이 가능한 노광 데이타 생성 방법을 제공할 수 있다.
또한, 청구범위 제10항 또는 제11항에 기재한 발명에 의하면, 반복이 많은 노광 패턴 데이타의 데이타량을 적게 하는 것이 가능한 노광 데이타 생성 장치를 제공할 수 있다.
Claims (11)
- 반도체 집적 회로를 노광 매체에 대하여 노광하기 위해서 이용되는 노광 데이타를 상기 반도체 집적 회로의 기데이타를 변환하여 작성하는 노광 데이타 작성 방법에 있어서,상기 기데이타로부터 반복성이 있는 노광 패턴 데이타를 노광 패턴 데이타군으로서 추출하는 단계와,상기 노광 패턴 데이타군을 구성하는 반복 노광 패턴 데이타를 소정의 통합 영역에서 재배열하여 통합 정보 테이블을 작성하는 단계와,상기 통합 정보 테이블에 기초하여 상기 기데이타를 재배열하여 노광 데이타를 작성하는 단계를 포함하는 것을 특징으로 하는 노광 데이타 작성 방법.
- 반도체 집적 회로를 노광 매체에 대하여 노광하기 위해서 이용되는 노광 데이타를 상기 반도체 집적 회로의 기데이타를 변환하여 작성하는 노광 데이타 작성 방법에 있어서,상기 기데이타로부터 반복성이 있는 노광 패턴 데이타를 노광 패턴 데이타군으로서 추출하는 단계와,상기 기데이타를 변환한 가노광 데이타를 작성하는 단계와,상기 노광 패턴 데이타군을 구성하는 반복 노광 패턴 데이타를 소정의 통합 영역에서 재배열하여 통합 정보 테이블을 작성하는 단계와,상기 통합 정보 테이블에 기초하여 상기 가노광 데이타를 재배열하여 노광 데이타를 재작성하는 단계를 포함하는 것을 특징으로 하는 노광 데이타 작성 방법.
- 제1항 또는 제2항에 있어서, 상기 통합 정보 테이블은,상기 통합 영역에서 재배열한 반복 노광 패턴 데이타를 원래의 노광 패턴 데이타를 나타내는 어드레스와, 원래의 노광 패턴 데이타의 반복 개수 및 반복 피치로 이루어진 매트릭스 표현으로 격납한 통합 테이블과,상기 노광 패턴 데이타군에 대하여 사용하는 상기 통합 영역을 상기 통합 영역을 나타내는 어드레스를 반복하여 배치하는 반복 개수와 반복 피치로 이루어지는 매트릭스 표현으로써 격납한 배치 테이블로 구성된 것을 특징으로 하는 노광 데이타 작성 방법.
- 제3항에 있어서, 상기 통합 정보를 작성하는 단계는,상기 노광 패턴 데이타군을 매트릭스 인식하여, 상기 노광 패턴 데이타군을 구성하는 노광 패턴 데이타의 반복 개수와 반복 피치를 구하는 제1 단계와,상기 노광 패턴 데이타의 반복 개수와 반복 피치에 기초하여, 상기 통합 영역에 격납하는 원래의 노광 패턴 데이타의 통합 정보 테이블을 구하는 제2 단계와,상기 통합 정보 테이블에 기초하여, 상기 노광 패턴 데이타군의 배치 데이타를 재작성하는 제3 단계와,상기 통합 정보 테이블에 기초하여, 상기 노광 패턴 데이타의 패턴 데이타를재작성하는 제4 단계를 포함하는 것을 특징으로 하는 노광 데이타 작성 방법.
- 제4항에 있어서, 상기 제2 단계는,상기 통합 영역에 대하여 상기 반복 노광 패턴 데이타를 격납하는 최대 개수를 구하는 단계와,상기 노광 패턴 데이타군의 모든 반복 노광 패턴 데이타를 격납하는데 필요한 통합 영역의 개수를 구하는 단계와,상기 통합 영역에 대하여 반복 노광 패턴 데이타를 균등 배치할 수 있는지의 여부를 판단하여, 그 판단 결과에 기초하여 균등 배치할 수 있는 경우에 상기 통합 영역에 반복 패턴 데이타를 균등하게 배치하는 개수를 후보치로 설정하는 단계와,상기 후보치에 기초하여, 상기 후보치가 설정되어 있지 않은 경우에는 상기 최대 개수를 통합 영역에 대한 상기 반복 패턴 데이타의 병합치로 설정하고, 상기 후보치가 설정되어 있는 경우에는 상기 후보치를 병합치로 설정하는 단계와,상기 후보치와 병합치에 기초하여 상기 통합 정보 테이블을 작성하는 단계를 포함하는 것을 특징으로 하는 노광 데이타 작성 방법.
- 제4항 또는 제5항에 있어서, 상기 통합 정보를 작성하는 단계는,상기 통합 영역에 대한 x 방향과 y 방향의 후보치 및 병합치에 기초하여 상기 통합 테이블 및 배치 테이블을 작성하는 것으로,상기 모든 통합 영역에 대하여 균등 배치할 수 있는 경우에는 1종류의 상기통합 테이블과 배치 테이블을 작성하는 단계와,상기 x 방향 또는 y 방향에 대하여 균등 배치할 수 있는 경우에는 각각 2종류의 통합 테이블과 배치 테이블을 작성하는 단계와,상기 x 방향 및 y 방향에 대하여 균등 배치할 수 없는 경우에는 4종류의 통합 테이블과 배치 테이블을 작성하는 단계를 포함하는 것을 특징으로 하는 노광 데이타 작성 방법.
- 제4항에 있어서, 상기 제4 단계는,원래의 노광 패턴 데이타가 단독 표현인지, 복수의 기본 패턴 데이타를 반복하는 매트릭스 표현인지를 판단하는 단계와,상기 판단 결과에 기초하여, 노광 패턴 데이타가 단독 표현인 경우에 노광 데이타의 재작성을 행하는 단계와,상기 판단 결과에 기초하여, 원래의 노광 패턴 데이타가 매트릭스 표현인 경우에, 상기 원래의 노광 패턴 데이타를 전개하여 노광 데이타의 재작성을 행하는 단계를 포함하는 것을 특징으로 하는 노광 데이타 작성 방법.
- 제7항에 있어서, 상기 노광 패턴 데이타를 전개할 때에는 상기 원래의 노광 패턴 데이타의 반복 개수와, 상기 노광 패턴 데이타를 구성하는 기본 패턴 데이타의 매트릭스 개수를 비교하여, 적은 쪽을 전개하여 새로운 반복 노광 패턴 데이타를 작성하도록 한 것을 특징으로 하는 노광 데이타 작성 방법.
- 제1항 내지 제2항 중 어느 한 항에 있어서, 상기 노광 데이타는 노광 장치에 구비되어 노광 매체를 이동시키는 스테이지와, 상기 노광 매체를 노광하는 빔을 상기 노광 매체의 소망 위치로 이동시키는 편향기를 제어하기 위해서 이용되는 것이며, 상기 통합 영역은 상기 노광 장치의 빔 이동시키는 편향기에 대응한 영역으로 설정된 것을 특징으로 하는 노광 데이타 작성 방법.
- 반도체 집적 회로를 노광 매체에 대하여 노광하기 위해서 이용되는 노광 데이타를 상기 반도체 집적 회로의 기데이타를 변환하여 작성하는 노광 데이타 작성 장치에 있어서,상기 기데이타로부터 반복성이 있는 노광 패턴 데이타를 노광 패턴 데이타군으로서 추출하는 반복 데이타 추출 수단과,상기 노광 패턴 데이타군을 구성하는 반복 노광 패턴 데이타를 소정의 통합 영역에서 재배열하여 통합 정보 테이블을 작성하는 통합 수단과,상기 통합 정보 테이블에 기초하여 상기 기데이타를 재배열하여 노광 데이타를 작성하는 노광 데이타 구축 수단을 포함하는 것을 특징으로 하는 노광 데이타 작성 장치.
- 반도체 집적 회로를 노광 매체에 대하여 노광하기 위해서 이용되는 노광 데이타를 상기 반도체 집적 회로의 기데이타를 변환하여 작성하는 노광 데이타 작성장치에 있어서,상기 기데이타로부터 반복성이 있는 노광 패턴 데이타를 반복 노광 패턴 데이타로 하여, 상기 패턴 데이타에 의해 구성되는 노광 패턴 데이타군을 추출하는 반복 데이타 추출 수단과,상기 기데이타를 변환한 가노광 데이타를 작성하는 가노광 데이타 작성 수단과,상기 노광 패턴 데이타군을 구성하는 반복 노광 패턴 데이타를 소정의 통합 영역에서 재배열하여 통합 정보 테이블을 작성하는 통합 수단과,상기 통합 정보 테이블에 기초하여 상기 가노광 데이타를 재배열하여 노광 데이타를 재작성하는 노광 데이타 구축 수단을 포함하는 것을 특징으로 하는 노광 데이타 작성 장치.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP97-053396 | 1997-03-07 | ||
| JP05339697A JP3999301B2 (ja) | 1997-03-07 | 1997-03-07 | 露光データ作成方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR19980079561A KR19980079561A (ko) | 1998-11-25 |
| KR100291494B1 true KR100291494B1 (ko) | 2001-07-12 |
Family
ID=12941675
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1019970078530A KR100291494B1 (ko) | 1997-03-07 | 1997-12-30 | 노광데이타작성방법과노광데이타작성장치 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US5995878A (ko) |
| JP (1) | JP3999301B2 (ko) |
| KR (1) | KR100291494B1 (ko) |
Families Citing this family (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6278124B1 (en) * | 1998-03-05 | 2001-08-21 | Dupont Photomasks, Inc | Electron beam blanking method and system for electron beam lithographic processing |
| US6272398B1 (en) * | 1998-09-21 | 2001-08-07 | Siebolt Hettinga | Processor-based process control system with intuitive programming capabilities |
| KR100336525B1 (ko) * | 2000-08-07 | 2002-05-11 | 윤종용 | 반도체 장치의 제조를 위한 노광 방법 |
| US6812474B2 (en) * | 2001-07-13 | 2004-11-02 | Applied Materials, Inc. | Pattern generation method and apparatus using cached cells of hierarchical data |
| JP2003100603A (ja) * | 2001-09-25 | 2003-04-04 | Canon Inc | 露光装置及びその制御方法並びにデバイスの製造方法 |
| JP4989158B2 (ja) * | 2005-09-07 | 2012-08-01 | 株式会社ニューフレアテクノロジー | 荷電粒子線描画データの作成方法及び荷電粒子線描画データの変換方法 |
| KR100660045B1 (ko) * | 2005-10-13 | 2006-12-22 | 엘지전자 주식회사 | 마스크리스 노광기용 패턴정보 생성방법 및 노광방법 |
| JP4778776B2 (ja) * | 2005-11-01 | 2011-09-21 | 株式会社ニューフレアテクノロジー | 荷電粒子線描画データの作成方法 |
| JP4778777B2 (ja) * | 2005-11-01 | 2011-09-21 | 株式会社ニューフレアテクノロジー | 荷電粒子線描画データの作成方法 |
| JP5068515B2 (ja) * | 2006-11-22 | 2012-11-07 | 株式会社ニューフレアテクノロジー | 描画データの作成方法、描画データの変換方法及び荷電粒子線描画方法 |
| CN101252101B (zh) * | 2008-01-17 | 2010-08-11 | 中电华清微电子工程中心有限公司 | 采用曝光场拼接技术制作超大功率智能器件的方法 |
| US7941780B2 (en) * | 2008-04-18 | 2011-05-10 | International Business Machines Corporation | Intersect area based ground rule for semiconductor design |
| JP5357530B2 (ja) * | 2008-12-16 | 2013-12-04 | 株式会社ニューフレアテクノロジー | 描画用データの処理方法、描画方法、及び描画装置 |
| JP5498105B2 (ja) * | 2009-09-15 | 2014-05-21 | 株式会社ニューフレアテクノロジー | 荷電粒子ビーム描画方法及び荷電粒子ビーム描画装置 |
| JP5563385B2 (ja) | 2010-06-23 | 2014-07-30 | ラピスセミコンダクタ株式会社 | レイアウトパタン生成装置及びレイアウトパタン生成方法 |
| US9141730B2 (en) * | 2011-09-12 | 2015-09-22 | Applied Materials Israel, Ltd. | Method of generating a recipe for a manufacturing tool and system thereof |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH05182899A (ja) * | 1991-12-27 | 1993-07-23 | Fujitsu Ltd | ブロック露光用パターン抽出方法 |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5046012A (en) * | 1988-06-17 | 1991-09-03 | Fujitsu Limited | Pattern data processing method |
| US5253182A (en) * | 1990-02-20 | 1993-10-12 | Hitachi, Ltd. | Method of and apparatus for converting design pattern data to exposure data |
| JP3043031B2 (ja) * | 1990-06-01 | 2000-05-22 | 富士通株式会社 | 露光データ作成方法,パターン露光装置及びパターン露光方法 |
| US5590048A (en) * | 1992-06-05 | 1996-12-31 | Fujitsu Limited | Block exposure pattern data extracting system and method for charged particle beam exposure |
| EP0608657A1 (en) * | 1993-01-29 | 1994-08-03 | International Business Machines Corporation | Apparatus and method for preparing shape data for proximity correction |
| US5847959A (en) * | 1997-01-28 | 1998-12-08 | Etec Systems, Inc. | Method and apparatus for run-time correction of proximity effects in pattern generation |
-
1997
- 1997-03-07 JP JP05339697A patent/JP3999301B2/ja not_active Expired - Lifetime
- 1997-11-04 US US08/963,587 patent/US5995878A/en not_active Expired - Fee Related
- 1997-12-30 KR KR1019970078530A patent/KR100291494B1/ko not_active IP Right Cessation
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH05182899A (ja) * | 1991-12-27 | 1993-07-23 | Fujitsu Ltd | ブロック露光用パターン抽出方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| KR19980079561A (ko) | 1998-11-25 |
| US5995878A (en) | 1999-11-30 |
| JP3999301B2 (ja) | 2007-10-31 |
| JPH10256113A (ja) | 1998-09-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR100291494B1 (ko) | 노광데이타작성방법과노광데이타작성장치 | |
| US4377849A (en) | Macro assembler process for automated circuit design | |
| JP4999013B2 (ja) | 集積化されたopc検証ツール | |
| EP0404482A2 (en) | Simulation of selected logic circuit designs | |
| US20030088839A1 (en) | Method of designing integrated circuit and apparatus for designing integrated circuit | |
| WO1995008811A1 (en) | Data reduction in a system for analyzing geometric databases | |
| KR100311594B1 (ko) | 노광데이터작성방법,노광데이터작성장치및기록매체 | |
| KR970008535B1 (ko) | 배치요소 배치설계 시스템 | |
| CN117034822B (zh) | 基于三步式仿真的验证方法、电子设备和介质 | |
| US7269819B2 (en) | Method and apparatus for generating exposure data | |
| US5968692A (en) | Integrated circuit pattern lithography method capable of reducing the number of shots in partial batch exposure | |
| JP3923919B2 (ja) | 露光データ生成方法及び露光データ生成プログラム | |
| US6189129B1 (en) | Figure operation of layout for high speed processing | |
| US5838335A (en) | Graphic data processing method and device | |
| JP2001274060A (ja) | キャラクタ抽出方法およびコンピュータ読取り可能な記録媒体 | |
| JP3166847B2 (ja) | プリント基板設計における配線収容性評価プログラムを記録した記録媒体および装置 | |
| JPH05182899A (ja) | ブロック露光用パターン抽出方法 | |
| KR100546956B1 (ko) | 노광 데이터 작성 방법 | |
| JP2000066365A (ja) | フォトマスクパターン設計支援装置、フォトマスクパターン設計支援方法、および、フォトマスクパターン設計支援プログラムを記録した記録媒体 | |
| CN116306459A (zh) | 量子芯片版图的引脚布置方法、系统、介质及设备 | |
| JP3696302B2 (ja) | テストベクトル生成方法及び生成装置 | |
| JP4745278B2 (ja) | 回路パターンの設計方法及び回路パターンの設計システム | |
| JP2992081B2 (ja) | パターン作成装置 | |
| Sugihara | Optimal character-size exploration for increasing throughput of MCC lithographic systems | |
| JPH09325467A (ja) | 光強度シミュレーション装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| E902 | Notification of reason for refusal | ||
| E701 | Decision to grant or registration of patent right | ||
| GRNT | Written decision to grant | ||
| FPAY | Annual fee payment |
Payment date: 20080310 Year of fee payment: 8 |
|
| LAPS | Lapse due to unpaid annual fee |