ES2791183T3 - Anticuerpos anti-GDF15 - Google Patents
Anticuerpos anti-GDF15 Download PDFInfo
- Publication number
- ES2791183T3 ES2791183T3 ES13827058T ES13827058T ES2791183T3 ES 2791183 T3 ES2791183 T3 ES 2791183T3 ES 13827058 T ES13827058 T ES 13827058T ES 13827058 T ES13827058 T ES 13827058T ES 2791183 T3 ES2791183 T3 ES 2791183T3
- Authority
- ES
- Spain
- Prior art keywords
- seq
- acid sequence
- immunoglobulin
- amino acid
- variable region
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/22—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against growth factors ; against growth regulators
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
- A61K39/39533—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals
- A61K39/3955—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals against proteinaceous materials, e.g. enzymes, hormones, lymphokines
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K45/00—Medicinal preparations containing active ingredients not provided for in groups A61K31/00 - A61K41/00
- A61K45/06—Mixtures of active ingredients without chemical characterisation, e.g. antiphlogistics and cardiaca
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/02—Nutrients, e.g. vitamins, minerals
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/30—Non-immunoglobulin-derived peptide or protein having an immunoglobulin constant or Fc region, or a fragment thereof, attached thereto
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/10—Cells modified by introduction of foreign genetic material
Abstract
Un anticuerpo aislado que se une al GDF15 humano, que comprende una región variable de una cadena pesada de una inmunoglobulina y una región variable de la cadena ligera de una inmunoglobulina que comprende una secuencia de aminoácidos seleccionada entre el grupo que consiste en: (a) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 248 (Hu01G06 IGHV1-18 F2) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 254 (Hu01 G06 IGKV1-39 F2); (b) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 250 (Hu01G06 IGHV1-69 F1) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 92 (Hu01G06 IGKV1-39 F1); (c) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 40 (01G06, Ch01G06 quimérica) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 76 (01G06, Ch01G06 quimérica); (d) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 54 (Hu01G06 IGHV1-18) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 90 (Hu01G06 IGKV1-39); (e) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 56 (Hu01G06 IGHV1-69) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 90 (Hu01 G06 IGKV1-39); (f) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 246 (Hu01G06 IGHV1-18 F1) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 92 (Hu01 G06 IGKV1-39 F1); (g) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 252 (Hu01G06 IGHV1-69 F2) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 92 (Hu01 G06 IGKV1-39 F1); y (h) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 252 (Hu01G06 IGHV1-69 F2) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 254 (Hu01G06 IGKV1-39 F2).
Description
DESCRIPCIÓN
Anticuerpos anti-GDF15
Campo de la invención
El campo de la invención es la biología molecular, la inmunología, la caquexia y los trastornos seudocaquécticos, y la oncología. Más particularmente, el campo son los anticuerpos terapéuticos.
Antecedentes
La pérdida involuntaria de peso puede clasificarse en tres etiologías primarias que incluyen la caquexia, la sarcopenia y la inanición. La caquexia es un síndrome metabólico debilitante asociado con numerosas enfermedades que incluyen el cáncer, el SIDA, la insuficiencia cardiaca crónica (conocida también como insuficiencia cardiaca congestiva), la enfermedad pulmonar obstructiva crónica (EPOC), la enfermedad renal crónica, la tuberculosis, el síndrome séptico y otras formas de inflamación sistémica. La caquexia varía en sus manifestaciones, pero generalmente implica una pérdida involuntaria de la masa del músculo esquelético y alguna forma de enfermedad subyacente (Evans et al. (2008) CLIN. NUTR. 27: 793-799). La caquexia es un trastorno de consunción que implica la pérdida involuntaria de peso y puede estar asociada con una inflamación sistémica y/o una respuesta inflamatoria aguda (Thomas (2007) CLIN. NUTRITION 26: 389-39). La pérdida de masa grasa, así como de masa magra, tal como la masa muscular, a menudo es una característica clínica destacada de la caquexia. En muchos, pero no en todos los casos, la caquexia progresa a través de unas fases que se han denominado precaquexia, caquexia y caquexia resistente (Fearon et al. (2011) LANCET ONC. 12: 489-495). Parece que hay dos procesos diferentes, pero en ocasiones solapantes, que dirigen el desarrollo y la progresión de la caquexia: (a) procesos metabólicos que actúan directamente sobre el músculo, reduciendo su masa y su función; y (b) una reducción en la ingesta de alimentos, que da lugar a una pérdida tanto de grasa como de músculo (Tsai et al. (2012) J. CACHEXIA SARCOPENIA MUSCLE 3: 239-243).
Aunque la caquexia es un síndrome complejo y no totalmente comprendido, es evidente que el GDF15 (también conocido como MIC-1, PLAB, PDF y NAG-1), un miembro de la superfamilia del TGF-p, es un importante mediador de la caquexia en diversas enfermedades (Tsai et al., supra). Al menos algunos tumores sobreexpresan y secretan el GDF15, y se han asociado unos niveles séricos elevados del GDF15 con diversos cánceres (Johnen et al. (2007) NAT. MED. 13: 1333-1340; Bauskin et al. (2006) CANCER RES. 66: 4983-4986). Se han reconocido los anticuerpos monoclonales contra el GDF15 como potenciales agentes terapéuticos anticaquécticos. Véase, por ejemplo, la Patente de los Estados Unidos n.° 8.192.735. El documento WO 2007/021293 divulga anticuerpos para modular el apetito y/o el peso corporal en un sujeto.
La pérdida de peso resultante de la caquexia está asociada con un mal pronóstico en diversas enfermedades (Evans et al., supra), y se considera que la caquexia y sus consecuencias son la causa directa de muertes en aproximadamente el 20 % de las muertes por cáncer (Tisdale (2002) NAT. REV. CANCER 2: 862-871). La caquexia es poco frecuentemente revertida mediante la intervención nutricional, y actualmente este síndrome raras veces se trata con terapia farmacológica (Evans et al., supra).
La sarcopenia es una afección clínica relacionada con la caquexia que se caracteriza por una pérdida de la masa muscular esquelética y de la fuerza muscular. La reducción en la masa muscular puede dar lugar a un deterioro importante, con pérdida de fuerza, un aumento en la probabilidad de caídas y una pérdida de autonomía. La función respiratoria también puede estar deteriorada, con una capacidad vital reducida. Durante el estrés metabólico, la proteína muscular es rápidamente movilizada con objeto de proporcionar aminoácidos al sistema inmunitario, el hígado y el intestino, particularmente glutamina. La sarcopenia es a menudo una enfermedad geriátrica; sin embargo, su desarrollo también puede estar asociado con la inactividad muscular y la malnutrición, y puede coincidir con la caquexia. La sarcopenia puede ser diagnosticada sobre la base de las observaciones funcionales, tales como un bajo peso muscular y una baja velocidad de marcha. Véase, por ejemplo, Muscaritoli et al. (2010) CLIN. NUTRITION 29: 154-159.
La inanición da normalmente como resultado una pérdida de la grasa corporal y de la masa magra debido a una inadecuada dieta y/o ingesta de nutrientes (Thomas (2007) supra). Los efectos de la inanición a menudo se revierten mejorando la dieta y la ingesta de nutrientes, por ejemplo, de proteínas.
Los anticuerpos naturales son proteínas multiméricas que contienen cuatro cadenas polipeptídicas (FIG. 1). Dos de las cadenas polipeptídicas se denominan cadenas pesadas (cadenas H), y dos de las cadenas polipeptídicas se denominan cadenas ligeras (cadenas L). Las cadenas pesada y ligera de las inmunoglobulinas están conectadas por un puente de disulfuro intercatenario. Las cadenas pesadas de las inmunoglobulinas están conectadas por puentes de disulfuro intercatenarios. Una cadena ligera consiste en una región variable (VLen la FIG. 1) y una región constante (Cl en la FIG. 1). La cadena pesada consiste en una región variable (Vh en la FIG. 1) y al menos tres regiones constantes (Ch1, Ch2 y Ch3 en la FIG. 1). Las regiones variables determinan la especificidad del anticuerpo. Cada región variable comprende tres regiones hipervariables conocidas también como regiones determinantes de la
complementariedad (CDR) flanqueadas por cuatro regiones estructurales relativamente conservadas (FR). Las tres CDR, denominadas CDR1, CDR2 y CDR3 , contribuyen a la especificidad de unión al anticuerpo. Los anticuerpos naturales se han usado como material de partida para los anticuerpos genomodificados, tales como los anticuerpos quiméricos y los anticuerpos humanizados.
Existe una significativa necesidad no satisfecha de agentes terapéuticos eficaces para el tratamiento de la caquexia y de la sarcopenia, incluyendo anticuerpos monoclonales dirigidos contra el GDF15. Dichos agentes terapéuticos tienen el potencial de jugar un papel importante en el tratamiento de diversos cánceres y de otras enfermedades potencialmente mortales.
Sumario
La invención se basa, en parte, en el descubrimiento de una familia de anticuerpos que se unen especialmente al GDF15 humano (hGDF15). Los anticuerpos contienen sitios de unión al hGDF15 basados en las CDR de los anticuerpos. Los anticuerpos pueden usarse como agentes terapéuticos. Cuando se usan como agentes terapéuticos, los anticuerpos son genomodificados, por ejemplo, humanizados, para reducir o eliminar una respuesta inmunitaria cuando se administran a un paciente humano.
La presente invención proporciona un anticuerpo aislado que se une al GDF15 humano, que comprende una región variable de una cadena pesada de una inmunoglobulina y una región variable de la cadena ligera de una inmunoglobulina que comprende una secuencia de aminoácidos seleccionada entre el grupo que consiste en:
(a) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 248 (Hu01G06 IGHV1-18 F2) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 254 (Hu01G06 IGKV1-39 F2); (b) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 250 (Hu01G06 IGHV1-69 F1) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 92 (Hu01G06 IGKV1-39 F1); (c) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 40 (01G06, Ch01G06 quimérica) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 76 (01G06, Ch01G06 quimérica); (d) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 54 (Hu01G06 IGHV1-18) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 90 (Hu01G06 IGKV1-39);
(e) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 56 (Hu01G06 IGHV1-69) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 90 (Hu01 G06 IGKV1-39);
(f) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 246 (Hu01G06 IGHV1-18 F1) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 92 (Hu01G06 IGKV1-39 F1); (g) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 252 (Hu01G06 IGHV1-69 F2) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 92 (Hu01G06 IGKV1-39 F1); y (h) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 252 (Hu01G06 IGHV1-69 F2) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 254 (Hu01G06 IGKV1-39 F2).
En algunas realizaciones, el anticuerpo aislado que se une al GDF15 humano comprende una cadena pesada de una inmunoglobulina y una cadena ligera de una inmunoglobulina seleccionadas entre el grupo que consiste en:
(a) una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 258 (Hu01G06 IGHV1-18 F2) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 264 (Hu01G06 IGKV1-39 F2);
(b) una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 260 (Hu01G06 IGHV1-69 F1) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 208 (Hu01G06 IGKV1-39 F1);
(c) una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 176 (Ch01G06 quimérica) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID nO: 204 (Ch01G06 quimérica);
(d) una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 178 (Hu01G06 IGHV1-18) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 206 (Hu01G06 IGKV1-39);
(e) una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 180 (Hu01G06 IGHV1-69) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 206 (Hu01G06 IGKV1-39);
(f) una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 256
(Hu01G06 IGHV1-18 F1) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 208 (Hu01G06 IGKV1-39 F1);
(g) una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 262 (Hu01G06 IGHV1-69 F2) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 208 (Hu01G06 IGKV1-39 F1); y
(h) una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 262 (Hu01G06 IGHV1-69 F2) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 264 (Hu01G06 IGKV1-39 F2).
La presente invención también proporciona un ácido nucleico aislado o ácidos nucleicos que comprenden una secuencia de nucleótidos que codifica una cadena pesada de una inmunoglobulina y una cadena ligera de una inmunoglobulina de la presente invención.
La presente invención también proporciona un vector o vectores de expresión que comprenden el ácido nucleico o nucleico de la presente invención.
La presente invención también proporciona una célula hospedadora que comprende dicho vector o vectores de expresión.
La presente invención también proporciona un método para producir un anticuerpo que se une al GDF15 humano, o un fragmento de unión al antígeno del anticuerpo, método que comprende:
(a) cultivar una célula hospedadora de la presente invención en unas condiciones tales que la célula hospedadora exprese un polipéptido o polipéptidos que comprenden la cadena pesada de la inmunoglobulina y la cadena ligera de la inmunoglobulina, produciendo así el anticuerpo o el fragmento de unión al antígeno del anticuerpo; y
(b) el anticuerpo o el fragmento de unión al antígeno del anticuerpo.
También se proporciona un anticuerpo de la presente invención, en donde el anticuerpo tiene una KD de 300 pM o menor, de 150 pM o menor o de 100 pM o menor, medida mediante resonancia de plasmón superficial o interferometría de biocapa.
También se proporciona un anticuerpo de la presente invención para su uso en el tratamiento de la caquexia y/o de la sarcopenia en un mamífero.
En algunas realizaciones, el anticuerpo de la presente invención puede usarse en el tratamiento de la caquexia y/o de la sarcopenia en un mamífero, en donde el uso comprende adicionalmente la administración de un segundo agente al mamífero en necesidad del mismo, en donde el segundo agente se selecciona entre el grupo que consiste en un inhibidor de la Activina-A, un inhibidor del ActRIIB, un inhibidor de la IL-6, un inhibidor de la IL-6R, un inhibidor del péptido de melanocortina, un inhibidor del receptor de la melanocortina, una grelina, un mimético de la grelina, un agonista del GHS-R1a, un SARM, un inhibidor del TNFa, un inhibidor de la IL-1 a, un inhibidor de la miostatina, un betabloqueante y un agente antineoplásico.
Los anticuerpos divulgados impiden o inhiben (es decir, neutralizan) la actividad del hGDF15. Cuando se administran a un mamífero, los anticuerpos pueden inhibir la pérdida de masa muscular, por ejemplo, la pérdida de masa muscular asociada con una enfermedad subyacente. La enfermedad subyacente puede seleccionarse entre el grupo que consiste en cáncer, insuficiencia cardiaca crónica, enfermedad renal crónica, EPOC, SIDA, esclerosis múltiple, artritis reumatoide, síndrome séptico y tuberculosis. La pérdida de masa muscular puede estar acompañada por una pérdida de masa grasa. Los anticuerpos divulgados también pueden usarse para inhibir la pérdida de peso involuntaria en un mamífero. Los anticuerpos divulgados también pueden usarse para inhibir la pérdida de masa de un órgano. Además, los anticuerpos pueden usarse para el tratamiento de la caquexia y/o de la sarcopenia en un mamífero.
Puede usarse una proteína de fusión rhGDF15-Fc de inmunoglobulina (Fc-rhGDF 15) según se describe en el presente documento para un método para el establecimiento de un nivel de estado estacionario del GDF15 humano recombinante maduro (rhGDF15) en plasma o suero en un mamífero, que comprende la administración de una proteína de fusión rhGDF15-Fc de inmunoglobulina (Fc-rhGDF15) al mamífero. La Fc-rhGDF15 puede ser un GDF15 humano recombinante maduro de la Fc de ratón (mFc-rhGDF15). El mamífero puede ser un roedor, por ejemplo, un ratón.
En el presente documento también se describe una Fc-rhGDF15 para su uso en el tratamiento de la obesidad en un mamífero, por ejemplo, un ser humano, que comprende administrar una cantidad terapéuticamente eficaz de una FcrhGDF15, por ejemplo, un GDF15 humano recombinante maduro de la Fc humana (hFc-rhGDF15), al mamífero en necesidad del mismo. También se divulgan composiciones farmacéuticas que comprenden una proteína de fusión Fc-rhGDF15 y un portador farmacéuticamente aceptable.
Estos y otros aspectos y ventajas de la invención serán evidentes a partir de la consideración de las siguientes figuras, la descripción detallada y las reivindicaciones. Como se usa en el presente documento, "incluyendo" significa sin limitación, y los ejemplos mencionados no son limitantes. Como se usa en el presente documento, "anticuerpo 01G06, 03G05, 04F08, 06C11, 08G01, 14F11 o 17B11" significa anticuerpo 01G06, 03G05, 04F08, 06C11, 08G01, 14F11 o 17B11, o variantes humanizadas de los mismos.
Descripción de los dibujos
La invención puede comprenderse más completamente con referencia a los siguientes dibujos.
La FIG. 1 (técnica anterior) es una representación esquemática de un anticuerpo natural típico.
La FIG. 2 es una gráfica que representa los resultados de un experimento para medir los niveles séricos de hGDF15 en ratones sin tratamiento previo o en ratones portadores de xenoinjertos de tumores humanos (Chago, RPMI7951, PC3, TOV21G, HT-1080, K-562, LS1034), según se determina mediante un ELISA.
La FIG. 3 es una representación gráfica que representa los resultados de un experimento para determinar la farmacocinética en plasma (PK) del rhGDF15 escindido administrado mediante una inyección subcutánea (1 mg/g) a ratones ICR-SCID sin tratamiento previo, según se determina mediante un ELISA.
La FIG. 4 es una gráfica que resume los resultados de un experimento para medir la actividad caquéctica de la proteína rhGDF15 escindida (■) y el control negativo (PBS (•)) para inducir una pérdida de peso corporal en ratones no inmunocompetentes, iCR-SCID. Las flechas indican unas dosis subcutáneas de 1 pg/g de rhGDF15. Las FIGS. 5A y 5B son gráficas que resumen los resultados de un experimento para medir la actividad caquéctica de la mFc-rhGDF15 (una Fc de ratón fusionada con el amino terminal de un GDF15 humano recombinante maduro; ■), rFc-rmGDF15 (una Fc de conejo fusionada con el amino terminal de un GDF15 de ratón recombinante maduro; A), y el control negativo (PBS; •) para inducir una pérdida de peso corporal en ratones Balb/C inmunocompetentes (FIG. 5A) y en ratones CB17-SCID no inmunocompetentes (FIG. 5B). Las flechas indican unas dosis subcutáneas de 1 pg/g de proteína recombinante.
Las FIGS. 6A-6E son gráficas que resumen los resultados de un experimento para demostrar la actividad caquéctica de la mFc-rhGDF15 (■) y el control negativo (PBS; •) para inducir una pérdida de peso corporal en ratones ICR-SCID no inmunocompetentes (FIG. 6A; las flechas indican unas dosis subcutáneas de 1 pg/g de mFc-rhGDF15); para inducir una pérdida de tejido adiposo o de masa grasa gonadal (FIG. 6B); para inducir una pérdida de masa muscular del músculo gastrocnemio (FIG. 6C; Masa del gastroc); y para aumentar la expresión del ARNm de los marcadores moleculares de la degradación muscular (mMuRF1 (FIG. 6D) y mAtrogina (FIG.
6E)).
La FIG. 7 es una gráfica que resume los resultados de un experimento para medir la actividad caquéctica de la mFc-rhGDF15 (■) y el control negativo (PBS; •) para inducir una pérdida de peso corporal en ratones Balb/C atímicos no inmunocompetentes. Las flechas indican unas dosis subcutáneas de 1,33 pg/g de mFc-rhGDF15. La FIG. 8 es una gráfica que resume los resultados de un experimento para medir los niveles séricos de la mFcrhGDF15 en ratones a los que se les ha administrado la proteína recombinante. La presencia de la mFcrhGDF15 se determinó mediante una inmunoelectrotransferencia. Se cuantificaron dos bandas positivas correspondientes a la mFc-rhGDF15 y al rhGDF15 (según el tamaño molecular apropiado) mediante Licor. Se calculó el porcentaje de rhGDF15 liberado con respecto a la mFc-rhGDF15.
La FIG. 9A es una gráfica que resume los resultados de un experimento para medir la actividad caquéctica de la mFc-rhGDF15 (0,1 pg/g (■), 0,01 pg/g (A)) y el control negativo (0,1 pg/g de mIgG (•)) para inducir una pérdida de peso corporal en ratones ICR-SCID no inmunocompetentes. Las flechas indican la dosis intraperitoneal de la proteína recombinante. La FIG. 9B es una gráfica que representa el nivel total del rhGDF15 en el plasma de ratones a los que se les ha administrado la mFc-rhGDF15 (0,1 pg/g (□), 0,01 pg/g (■)) cinco días después de la administración, según se determina mediante un ELISA.
La FIG. 10 es una alineación de la secuencia que muestra la secuencia de aminoácidos de la región variable de la cadena pesada de la inmunoglobulina completa de los anticuerpos 01G06, 03G05, 04F08, 06C11, 08G01, 14F11 y 17B11. Las secuencias de aminoácidos de cada anticuerpo están alineadas por parejas, y las CDR1, CDR2 y CDR3 , están identificadas en recuadros. Las secuencias fuera de los recuadros representan las secuencias estructurales (FR). El posicionamiento de la alineación (huecos) se basa en la numeración de Kabat, en lugar de en un algoritmo de alineación tal como Clustal. La numeración anterior de las secuencias representa la numeración de Kabat.
La FIG. 11 es una alineación de la secuencia que muestra las secuencias CDR1, CDR2 y CDR3 para cada una de las secuencias de la región variable de la cadena pesada de la inmunoglobulina de la FIG. 10.
La FIG. 12 es una alineación de la secuencia que muestra la secuencia de aminoácidos de la región variable de la cadena ligera de la inmunoglobulina completa de los anticuerpos 01G06, 03G05, 04F08, 06C11, 08G01, 14F11 y 17B11. Las secuencias de aminoácidos de cada anticuerpo están alineadas por parejas, y las CDR1, CDR2 y CDR3 , están identificadas en recuadros. Las secuencias fuera de los recuadros representan las secuencias estructurales (FR). El posicionamiento de la alineación (huecos) se basa en la numeración de Kabat, en lugar de en un algoritmo de alineación tal como Clustal. La numeración anterior de las secuencias representa la numeración de Kabat.
La FIG. 13 es una alineación de la secuencia que muestra las secuencias CDR1, CDR2 y CDR3 para cada una de las secuencias de la región variable de la cadena ligera de la inmunoglobulina de la FIG. 12.
La FIG. 14 es una gráfica que resume los resultados de un experimento para medir la actividad inhibidora caquéctica de los anticuerpos anti-GDF15 01G06 (■), 03G05 (*), 04F08 (T), 06C11 (O), 14F11 (O) y 17B11 (□), y un control de IgG murina (•; mIgG) administrados a 10 mg/kg en un modelo caquéctico de mFc-rhGDF15 en ratones ICR-SCID. La flecha indica la inyección intraperitoneal del anticuerpo.
La FIG. 15 es una gráfica que resume los resultados de un experimento para medir la actividad inhibidora caquéctica de los anticuerpos anti-GDF1501G06 (*), 03G05 (O), 04F08 (V), 06C11(n), 08G01 (■), 14F11 (♦) y 17B11 (* ) , y un control de IgG murina (•; mlgG), administrados a 10 mg/kg en un modelo de xenoinjerto tumoral de fibrosarcoma HT-1080 en ratones ICR-SCID. Las flechas indican la inyección intraperitoneal del anticuerpo cada tres días.
Las FIGS. 16A-16E son gráficas que resumen los resultados de un experimento para demostrar la actividad anti caquéctica del anticuerpo anti-GDF15 01G06 (■), administrado a 10 mg/kg, en ratones no inmunocompetentes (ICR-SCID) portadores de un modelo de xenoinjerto tumoral de fibrosarcoma HT-1080. El tratamiento con el anticuerpo 01G06 revertió la pérdida de peso corporal (FIG. 16A); indujo un aumento significativo en el consumo de alimentos durante hasta tres días después de la administración (FIG. 16B); indujo una ganancia de masa grasa gonadal (FIG. 16C); indujo una ganancia de masa muscular del músculo gastrocnemio (FIG. 16D); y disminuyó la expresión del ARNm de los marcadores moleculares de degradación del músculo (mMuRF1 y mAtrogina (FIG. 16E)) en comparación con el control negativo (IgG murina (•)). En la FIG. 16A, la flecha indica la inyección intraperitoneal del anticuerpo.
Las FIGS. 17A-17B son gráficas que resumen los resultados de un experimento para demostrar la actividad anti caquéctica del anticuerpo anti-GDF15 01G06 (■), administrado a 2 mg/kg, en ratones no inmunocompetentes (ICR-SCID) portadores de un modelo de xenoinjerto tumoral de fibrosarcoma HT-1080. El tratamiento con el anticuerpo 01G06 revertió la pérdida de peso corporal en comparación con la IgG murina (•) (FIG. 17A); e indujo una ganancia de masa en los órganos (hígado, corazón, bazo, riñón) e indujo una ganancia de masa tisular (gonadal y del gastrocnemio) (FIG. 17B) en comparación con el control negativo (IgG murina) y la situación inicial (día 1). Las flechas de la FIG. 17A indican la inyección intraperitoneal del anticuerpo.
La FIG. 18 es una gráfica que resume los resultados de un experimento para medir la actividad inhibidora caquéctica de los anticuerpos anti-GDF15 01G06 (■), 03G05 (A), 04F08 (X), 06C11(4), 08G01(O), 14F11(n) y 17B11 (A), y un control de IgG murina (•) administrados a 10 mg/kg en un modelo de xenoinjerto de tumor de leucemia K-562 en ratones no inmunocompetentes (CB17SCRFMF). Las flechas indican la inyección intraperitoneal del anticuerpo.
La FIG. 19 es una alineación de la secuencia que muestra la secuencia de aminoácidos de la región variable de la cadena pesada de la inmunoglobulina completa de la región variable quimérica 01G06 indicada como Ch01G06 quimérica; las regiones variables de la cadena pesada 01G06 humanizada indicadas como Hu01G06 IGHV1-18, Hu01 G06 IGHV1-69, Sh01G06 IGHV1-18 M69L, Sh01G06 IGHV1-18 M69L K64Q G44S, Sh01G06 IGHV1-18 M69L K64Q, Sh01G06 IGHV1-69 T30S I69L, Sh01G06 IGHV1-69 T30S K64Q I69L, Hu01G06 IGHV1-18 F1, Hu01 G06 IGHV1-18 F2, Hu01G06 IGHV1-69 F1 y Hu01G06 IGHV1-69 F2; 06C11 quimérica indicada como Ch06C11 quimérica; las regiones variables de la cadena pesada 06C11 humanizada indicadas como HE LM 06C11 IGHV2-70 y Hu06C11 IGHV2-5; quimérica indicada como Ch14F11 quimérica; y las regiones variables de la cadena pesada humanizada indicadas como Sh14F11 IGHV2-5 y Sh14F11 IGHV2-70. Las secuencias de aminoácidos de cada anticuerpo están alineadas por parejas, y las CDR1, CDR2 y CDR3 , están identificadas en recuadros. Las secuencias fuera de los recuadros representan las secuencias estructurales (FR). El posicionamiento de la alineación (huecos) se basa en la numeración de Kabat, en lugar de en un algoritmo de alineación tal como Clustal. La numeración anterior de las secuencias representa la numeración de Kabat.
La FIG. 20 es una alineación de la secuencia que muestra las secuencias CDR1, CDR2 y CDR3 para cada una de las secuencias de la región variable de la cadena pesada de la inmunoglobulina de la FIG. 19.
La FIG. 21 es una alineación de la secuencia que muestra la secuencia de aminoácidos de la región variable de la cadena ligera de la inmunoglobulina completa de la región variable quimérica 01G06 indicada como Ch01G06
quimérica; las regiones variables de la cadena ligera 01G06 humanizada indicadas como Hu01G06 IGKV1-39, Hu01 G06 IGKV1-39 S43A V48I, Hu01G06 IGKV1-39 V48I, Hu01G06 IGKV1-39 F1 y Hu01G06 IGKV1-39 F2; 06C11 quimérica indicada como Ch06C11 quimérica; la región variable de la cadena ligera 06C11 humanizada indicada como Sh06C11 IGKV1-16; quimérica indicada como Ch14F11 quimérica; y la región variable de la cadena ligera 14F11 humanizada indicada como Hu14F11 IGKV1-16. Las secuencias de aminoácidos de cada anticuerpo están alineadas por parejas, y las CDR1, CDR2 y CDR3 , están identificadas en recuadros. Las secuencias fuera de los recuadros representan las secuencias estructurales (FR). El posicionamiento de la alineación (huecos) se basa en la numeración de Kabat, en lugar de en un algoritmo de alineación tal como Clustal. La numeración anterior de las secuencias representa la numeración de Kabat.
La FIG. 22 es una alineación de la secuencia que muestra las secuencias CDR1, CDR2 y CDR3 para cada una de las secuencias de la región variable de la cadena ligera de la inmunoglobulina de la FIG. 21.
La FIG. 23 es una gráfica que resume los resultados de un experimento para medir la actividad inhibidora caquéctica de los anticuerpos anti-GDF15 01G06 (■), Hu01G06-46 (A) y Hu01G06-52 (*), y un control de IgG murina (•) administrada a 2 mg/kg en un modelo de xenoinjerto tumoral de fibrosarcoma HT-1080 en ratones ICR-SCID. La flecha indica la inyección intraperitoneal del anticuerpo.
La FIG. 24 es una gráfica que resume los resultados de un experimento para medir la actividad inhibidora caquéctica de los anticuerpos anti-GDF15 06C11 (♦), Hu06C11-27 () y Hu06C11-30 (A), y un control de IgG murina (•) administrada a 2 mg/kg en un modelo de xenoinjerto tumoral de fibrosarcoma HT-1080 en ratones ICR-SCID. La flecha indica la inyección intraperitoneal del anticuerpo.
La FIG. 25 es una gráfica que resume los resultados de un experimento para medir la actividad inhibidora caquéctica de los anticuerpos anti-GDF15 (A), Hu14F11-39 (□) y Hu14F11-47 (♦), y un control de IgG murina (•) administrada a 2 mg/kg en un modelo de xenoinjerto tumoral de fibrosarcoma HT-1080 en ratones ICR-SCID. La flecha indica la inyección intraperitoneal del anticuerpo.
La FIG. 26 es una gráfica que resume los resultados de un experimento para medir la actividad inhibidora caquéctica de los anticuerpos anti-GDF15 Hu01G06 -122 (▼), Hu01G06-127 (□), Hu01G06-135 (◊), Hu01G06-138 (■) y Hu01G06-146 (*), y un control de IgG humana (•) administrada a 2 mg/kg en un modelo de xenoinjerto tumoral de fibrosarcoma HT-1080 en ratones ICR-SCID. La flecha indica la inyección intraperitoneal del anticuerpo.
La FIG. 27 es una gráfica que resume los resultados de un experimento para medir la actividad inhibidora caquéctica de los anticuerpos anti-GDF15 Hu01G06 -122 (▼), Hu01G06-127 (□), Hu01G06-135 (◊), Hu01G06 -138 (■) y Hu01G06 -146 (*), y un control de IgG humana (•) administrada a 2 mg/kg en un modelo caquéctico de mFc-rhGDF15 en ratones ICR- SCID. La flecha indica la inyección intraperitoneal del anticuerpo.
La FIG. 28 es una gráfica que resume los resultados de un experimento para medir la actividad inhibidora de la respuesta a la dosis caquéctica de los anticuerpos anti-GDF15 Hu01G06-127 administrados a 20 mg/kg (□), 2 mg/kg (A) y 0,2 mg/kg (V); Hu01G06-135 a 20 mg/kg (■), 2 mg/kg (A) y 0,2 mg/kg (▼), y un control de IgG humana a 20 mg/kg (•) en un modelo de xenoinjerto tumoral de fibrosarcoma HT-1080 en ratones ICR-SCID. La flecha indica la inyección intravenosa del anticuerpo.
Las FIGS. 29A-29C son gráficas que resumen los resultados de un experimento para demostrar la actividad anti caquéctica de los anticuerpos anti-GDF15 Hu01G06-127 (■), administrados a 10 mg/kg, en ratones no inmunocompetentes (ICR-SCID) portadores de un modelo de xenoinjerto tumoral de fibrosarcoma HT-1080. El tratamiento con el anticuerpo Hu01G06-127 revertió la pérdida de peso corporal (FIG. 29A); indujo una ganancia de masa grasa gonadal (FIG. 29B); e indujo una ganancia de masa muscular del músculo gastrocnemio (FIG. 29 C) en comparación con el control negativo (hlgG (•); FIG. 29A) similar a los niveles encontrados en los ratones no portadores de tumores (TESTIGO A (); FIG. 29A). Las flechas de la FIG. 29A indican la inyección intraperitoneal del anticuerpo.
Descripción detallada
Los anticuerpos anti-GDF 15 divulgados en el presente documento se basan en los sitios de unión al antígeno de determinados anticuerpos monoclonales que se han seleccionado sobre la base de la unión y la neutralización del GDF15 humano (hGDF15). Los anticuerpos contienen secuencias de la CDR de la región variable de la inmunoglobulina que definen un sitio de unión para el hGDF15.
En virtud de la actividad neutralizante de estos anticuerpos, son útiles para el tratamiento de la caquexia y/o de la sarcopenia. Para su uso como agentes terapéuticos, los anticuerpos pueden ser genomanipulados para minimizar o eliminar una respuesta inmunitaria cuando se administran a un paciente humano. A continuación se analizan con más detalle diversas características y afectos de la invención.
Como se usa en el presente documento, "caquexia" significa un síndrome metabólico asociado con una enfermedad subyacente y que se caracteriza por la pérdida involuntaria de masa muscular. La caquexia está acompañada a menudo por una pérdida involuntaria de peso, pérdida de masa grasa, anorexia, inflamación, resistencia a la insulina, astenia, debilidad, pérdida significativa del apetito y/o aumento en la degradación de la proteína muscular. La caquexia es distinta de la inanición, la pérdida de masa muscular relacionada con la edad, la malabsorción y el hipertiroidismo. Algunas enfermedades subyacentes asociadas con la caquexia incluyen cáncer, insuficiencia cardiaca crónica, enfermedad renal crónica, EPOC, SIDA, esclerosis múltiple, artritis reumatoide, síndrome séptico y tuberculosis.
Como se usa en el presente documento, se entiende que la "sarcopenia" es una afección caracterizada fundamentalmente por la pérdida de masa muscular esquelética y de fuerza muscular. La sarcopenia está asociada frecuentemente con el envejecimiento. Véase, Ruegg y Glass (2011) ANNUAL REV. PHARMa Co L. TOXICOL. 51: 373-395. En una estrategia, la sarcopenia puede identificarse en un sujeto si el valor de la masa muscular esquelética de las extremidades de un sujeto dividida por la altura del sujeto en metros es mayor de dos desviaciones típicas por debajo de la media normal de young. (Thomas (2007) supra; véase también Baumgartner et al. (1999) MECH. AGEING DEV. 147: 755-763).
Como se usa en el presente documento, salvo que se indique de otro modo, "anticuerpo" significa un anticuerpo intacto (por ejemplo, un anticuerpo monoclonal intacto) o un fragmento de unión al antígeno de un anticuerpo, incluyendo un anticuerpo intacto o un fragmento de unión al antígeno que ha sido modificado o genomanipulado, o que es un anticuerpo humano. Algunos ejemplos de anticuerpos que han sido modificados o genomanipulados son anticuerpos quiméricos, anticuerpos humanizados y anticuerpos multiespecíficos (por ejemplo, anticuerpos biespecíficos). Algunos ejemplos de fragmentos de unión al antígeno incluyen Fab, Fab', F(ab')2 , Fv, anticuerpos monocatenarios (por ejemplo, scFv), minicuerpos y diacuerpos.
I. Anticuerpos que se unen al GDF15
Los anticuerpos divulgados en el presente documento comprenden: (a) una región variable de la cadena pesada de una inmunoglobulina que comprende la estructura CDRh1-CDRh2-CDRh3 y (b) una región variable de la cadena ligera de una inmunoglobulina que comprende la estructura CDRl1-CDRl2-Cd Rl3, en donde la región variable de la cadena pesada y la región variable de la cadena ligera definen conjuntamente un único sitio de unión para la unión de la proteína hGDF15.
Como se describe en el presente documento, el anticuerpo comprende: (a) una región variable de la cadena pesada de una inmunoglobulina que comprende la estructura CDRh1-CDRh2-CDRh3 y (b) una región variable de la cadena ligera de una inmunoglobulina, en donde la región variable de la cadena pesada y la región variable de la cadena ligera definen conjuntamente un único sitio de unión para la unión del hGDF15. Una CDRh1 comprende una secuencia de aminoácidos seleccionada entre el grupo que consiste en SEQ ID NO: 1 (01G06, 08G01, Ch01G06 quimérica, Hu01G06 IGHV1-18, Hu01G06 IGHV1-69, Sh01G06 IGHV1-18 M69L, Sh01G06 IGHV1-18 M69L K64Q G44S, Sh01G06 IGHV1-18 M69L K64Q, Sh01G06 IGHV1-69 T30S I69L, Sh01G06 IGHV1-69 T30S K64Q I69L, Hu01G06 IGHV1-18 F1, Hu01G06 IGHV1-18 F2, Hu01G06 IGHV1-69 F1, Hu01G06 IGHV1-69 F2), SEQ ID NO: 2 (03G05), SEQ ID NO: 3 (04F08), SEQ ID NO: 4 (06C11, Ch06C11 quimérica, HE LM 06C11 IGHV2-70, Hu06C11 IGHV2-5), SEQ ID NO: 5 (14F11, Ch14F11 quimérica, Sh14F11 IGHV2-5, Sh14F11 IGHV2-70), y SEQ ID NO: 6 (17B11); una CDRH2comprende una secuencia de aminoácidos seleccionada entre el grupo que consiste en SEQ ID NO: 7 (01G06, Ch01G06 quimérica, Hu01G06 IGHV1-18, Hu01G06 IGHV1-69, Sh01G06 IGHV1-18 M69L, Sh01G06 IGHV1-69 T30S I69L), SEQ ID NO: 8 (03G05), SEQ ID NO: 9 (04F08, 06C11, Ch06C11 quimérica, Hu06C11 IGHV2-5), SEQ ID NO: 10 (08G01), SEQ ID NO: 11 (14F11, Ch14F11 quimérica, Sh14F11 IGHV2-5, Sh14F11 IGHV2-70), SEQ ID NO: 12 (17B11), SEQ ID NO13 (Sh01G06 IGHV1-18 M69L K64Q G44S, Sh01G06 IGHV1-18 M69L K64Q, Sh01G06 IGHV1-69 T30S K64Q I69L), SEQ ID NO: 236 (Hu01G06 IGHV1-18 F1), SEQ ID NO: 237 (Hu01G06 IGHV1-18 F2), SEQ ID NO: 238 (Hu01G06 IGHV1-69 F1), SEQ ID NO: 239 (Hu01G06 IGHV1-69 F2) y SEQ ID NO: 14 (HE LM 06C11 IGHV2-70); y una CDRH3 comprende una secuencia de aminoácidos seleccionada entre el grupo que consiste en SEQ ID NO: 15 (01G06, 08G01, Ch01G06 quimérica, Hu01G06 IGHV1-18, Hu01G06 IGHV1-69, Sh01G06 IGHV1-18 M69L, Sh01G06 IGHV1-18 M69L K64Q G44S, Sh01G06 IGHV1-18 M69L K64Q, Sh01G06 IGHV1-69 T30S I69L, Sh01G06 IGHV1-69 T30S K64Q I69L, Hu01G06 IGHV1-18 F1, Hu01G06 IGHV1-18 F2, Hu01G06 IGHV1-69 F1, Hu01G06 IGHV1-69 F2), SEQ ID NO16 (03G05), SEQ ID NO: 17 (04F08), SEQ ID NO: 18 (06C11, Ch06C11 quimérica, HE LM 06C11 IGHV2-70, Hu06C11 IGHV2-5), SEQ ID NO: 19 (14F11, Ch14F11 quimérica, Sh14F11 IGHV2-5, Sh14F11 IGHV2-70), y SEQ ID NO: 20 (17B11). A lo largo de esta memoria descriptiva, una SEQ ID NO. en particular está seguida entre paréntesis por el anticuerpo que era el origen de esa secuencia. Por ejemplo, "SEQ ID NO: 2 (03G05)" significa que la SEQ ID NO: 2 procede del anticuerpo 03G05.
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende una CDRh1 que comprende la secuencia de aminoácidos de SEQ ID NO: 1 (01G06, Ch01G06 quimérica, Hu01G06 IGHV1-18, Hu01G06 IGHV1-69, Sh01G06 IGHV1-69 T30S I69L, Hu01G06 IGHV1-18 F1, Hu01G06 IGHV1-18 F2, Hu01G06 IGHV1-69 F1, Hu01G06 IGHV1-69 F2), una CDRh2 que comprende la secuencia de aminoácidos de SEQ ID NO: 7 (01G06, Ch01G06 quimérica, Hu01G06 IGHV1-18,
Hu01G06 IGHV1-69, Sh01G06 IGHV1-69 T30S I69L), y una CDRh3 que comprende la secuencia de aminoácidos de SEQ ID NO: 15 (01G06, Ch01G06 quimérica, Hu01G06 IGHV1-18, Hu01G06 IGHV1-69, Sh01G06 IGHV1-69 T30S I69L, Hu01G06 IGHV1-18 F1, Hu01G06 IGHV1-18 F2, Hu01G06 IGHV1-69 F1, Hu01G06 IGHV1-69 F2).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende una CDRh1 que comprende la secuencia de aminoácidos de SEQ ID NO: 2 (03G05), una CDRh2 que comprende la secuencia de aminoácidos de SEQ ID NO: 8 (03G05), y una CDRh3 que comprende la secuencia de aminoácidos de SEQ ID NO: 16 (03G05).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende una CDRh1 que comprende la secuencia de aminoácidos de SEQ ID NO: 3 (04F08), una CDRH2que comprende la secuencia de aminoácidos de SEQ ID NO: 9 (04F08) y una CDRh3 que comprende la secuencia de aminoácidos de SEQ ID NO: 17 (04F08).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende una CDRh1 que comprende la secuencia de aminoácidos de SEQ ID NO: 4 (06C11, Ch06C11 quimérica, Hu06C11 IGHV2-5), una CDRh2 que comprende la secuencia de aminoácidos de SEQ ID NO: 9 (06C11, Ch06C11 quimérica, Hu06C11 IGHV2-5), y una CDRh3 que comprende la secuencia de aminoácidos de SEQ ID NO: 18 (06C11, Ch06C11 quimérica, Hu06C11 IGHV2-5).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende una CDRh1 que comprende la secuencia de aminoácidos de SEQ ID NO: 1 (08G01), una CDRh2 que comprende la secuencia de aminoácidos de SEQ ID NO: 10 (08G01), y una CDRh3 que comprende la secuencia de aminoácidos de SEQ ID NO: 15 (08G01).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende una CDRh1 que comprende la secuencia de aminoácidos de SEQ ID NO: 5 (14F11, Ch14F11 quimérica, Sh14F11 IGHV2-5, Sh14F11 IGHV2-70), una CDRh2 que comprende la secuencia de aminoácidos de SEQ ID NO: 11 (14F11, Ch14F11 quimérica, Sh14F11 IGHV2-5, Sh14F11 IGHV2-70)y una CDRh3 que comprende la secuencia de aminoácidos de s Eq ID NO: 19 (14F11, Ch14F11 quimérica, Sh14F11 IGHV2-5, Sh14F11 IGHV2-70).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende una CDRh1 que comprende la secuencia de aminoácidos de SEQ ID NO: 6 (17B11), una CDRh2 que comprende la secuencia de aminoácidos de SEQ ID NO: 12 (17B11), y una CDRh3 que comprende la secuencia de aminoácidos de SEQ ID NO: 20 (17B11).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende una CDRh1 que comprende la secuencia de aminoácidos de SEQ ID NO: 1 (Sh01G06 IGHV1-18 M69L K64Q G44S, Sh01G06 IGHV1-18 M69L K64Q, Sh01G06 IGHV1-69 T30S K64Q I69L, Hu01G06 IGHV1-18 F1, Hu01G06 IGHV1-18 F2, Hu01G06 IGHV1-69 F1, Hu01G06 IGHV1-69 F2), una CDRh2 que comprende la secuencia de aminoácidos de SEQ ID NO: 13 (Sh01G06 IGHV1-18 M69L K64Q G44S, Sh01G06 IGHV1-18 M69L K64Q, Sh01G06 IGHV1-69 T30S K64Q I69L), y una CDRh3 que comprende la secuencia de aminoácidos de SEQ ID NO: 15 (Sh01G06 IGHV1-18 M69L K64Q G44S, Sh01G06 IGHV1-18 M69L K64Q, Sh01G06 IGHV1-69 T30S K64Q I69L, Hu01G06 IGHV1-18 F1, Hu01G06 IGHV1-18 F2, Hu01G06 IGHV1-69 F1, Hu01G06 IGHV1-69 F2).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende una CDRh1 que comprende la secuencia de aminoácidos de SEQ ID NO: 1 (Sh01G06 IGHV1-18 M69L K64Q G44S, Sh01G06 IGHV1-18 M69L K64Q, Sh01G06 IGHV1-69 T30S K64Q I69L, Hu01G06 IGHV1-18 F1, Hu01G06 IGHV1-18 F2, Hu01G06 IGHV1-69 F1, Hu01G06 IGHV1-69 F2), una CDRh2 que comprende la secuencia de aminoácidos de SEQ ID NO: 236 (Hu01G06 IGHV1-18 F1), y una CDRh3 que comprende la secuencia de aminoácidos de SEQ ID NO: 15 (Sh01G06 IGHV1-18 M69L K64Q G44S, Sh01G06 IGHV1-18 M69L K64Q, Sh01G06 IGHV1-69 T30S K64Q I69L, Hu01G06 IGHV1-18 F1, Hu01G06 IGHV1-18 F2, Hu01G06 IGHV1-69 F1, Hu01G06 IGHV1-69 F2).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende una CDRh1 que comprende la secuencia de aminoácidos de SEQ ID NO: 1 (Sh01G06 IGHV1-18 M69L K64Q G44S, Sh01G06 IGHV1-18 M69L K64Q, Sh01G06 IGHV1-69 T30S K64Q I69L, Hu01G06 IGHV1-18 F1, Hu01G06 IGHV1-18 F2, Hu01G06 IGHV1-69 F1, Hu01G06 IGHV1-69 F2), una CDRh2 que comprende la secuencia de aminoácidos de SEQ ID NO: 237 (Hu01G06 IGHV1-18 F2), y una CDRh3 que comprende la secuencia de aminoácidos de SEQ ID NO: 15 (Sh01G06 IGHV1-18 M69L K64Q G44S, Sh01G06 IGHV1-18 M69L K64Q, Sh01G06 IGHV1-69 T30S K64Q I69L, Hu01G06 IGHV1-18 F1, Hu01G06 IGHV1-18 F2, Hu01G06 IGHV1-69 F1, Hu01G06 IGHV1-69 F2).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de
una inmunoglobulina que comprende una CDRhi que comprende la secuencia de aminoácidos de SEQ ID NO: 1 (Sh01G06 IGHV1-18 M69L K64Q G44S, Sh01G06 IGHV1-18 M69L K64Q, Sh01G06 IGHV1-69 T30S K64Q I69L, Hu01G06 IGHV1-18 F1, Hu01G06 IGHV1-18 F2, Hu01G06 IGHV1-69 F1, Hu01G06 IGHV1-69 F2), una CDRh2 que comprende la secuencia de aminoácidos de SEQ ID NO: 238 (Hu01G06 IGHV1-69 F1), y una CDRh3 que comprende la secuencia de aminoácidos de SEQ ID NO: 15 (Sh01G06 IGHV1-18 M69L K64Q G44S, Sh01G06 IGHV1-18 M69L K64Q, Sh01G06 IGHV1-69 T30S K64Q I69L, Hu01G06 IGHV1-18 F1, Hu01G06 IGHV1-18 F2, Hu01G06 IGHV1-69 F1, Hu01G06 IGHV1-69 F2).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende una CDRh1 que comprende la secuencia de aminoácidos de SEQ ID NO: 1 (Sh01G06 IGHV1-18 M69L K64Q G44S, Sh01G06 IGHV1-18 M69L K64Q, Sh01G06 IGHV1-69 T30S K64Q I69L, Hu01G06 IGHV1-18 F1, Hu01G06 IGHV1-18 F2, Hu01G06 IGHV1-69 F1, Hu01G06 IGHV1-69 F2), una CDRh2 que comprende la secuencia de aminoácidos de SEQ ID NO: 239 (Hu01G06 IGHV1-69 F2), y una CDRh3 que comprende la secuencia de aminoácidos de SEQ ID NO: 15 (Sh01G06 IGHV1-18 M69L K64Q G44S, Sh01G06 IGHV1-18 M69L K64Q, Sh01G06 IGHV1-69 T30S K64Q I69L, Hu01G06 IGHV1-18 F1, Hu01G06 IGHV1-18 F2, Hu01G06 IGHV1-69 F1, Hu01G06 IGHV1-69 F2).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende una CDRh1 que comprende la secuencia de aminoácidos de SEQ ID NO: 4 (HE LM 06C11 IGHV2-70), una CDRh2 que comprende la secuencia de aminoácidos de SEQ ID NO: 14 (HE LM 06C11 IGHV2-70), y una CDRh3 que comprende la secuencia de aminoácidos de SEQ ID NO: 18 (HE LM 06C11 IGHV2-70).
Preferentemente, las secuencias CDRh1, CDRh2 y CDRh3 están interpuestas entre las secuencias FR de inmunoglobulinas completamente humanas o humanizadas.
Como se describe en el presente documento, el anticuerpo comprende (a) una región variable de la cadena ligera de una inmunoglobulina que comprende la estructura CDRl1-CDRl2-CDRl3, y (b) una región variable de la cadena pesada de una inmunoglobulina, en donde la región variable de la cadena ligera de la inmunoglobulina y la región variable de la cadena pesada definen conjuntamente un único sitio de unión para la unión del hGDF15. Una CDRl1 comprende una secuencia de aminoácidos seleccionada entre el grupo que consiste en SEQ ID NO: 21 (01G06, Ch01G06 quimérica, Hu01G06 IGKV1-39, Hu01G06 IGKV1-39 S43A V48I, Hu01G06 IGKV1-39 V48I, Hu01G06 IGKV1-39 F1, Hu01G06 IGKV1-39 F2), SEQ ID NO: 22 (03G05), SEQ ID NO: 23 (04F08, 06C11, Ch06C11 quimérica, Sh06C11 IGKV1-16, 14F11, Ch14F11 quimérica, Hu14F11 IGKV1-16), SEQ ID NO24 (08G01) y SEQ ID NO: 25 (17B11); una CDRl2 comprende una secuencia de aminoácidos seleccionada entre el grupo que consiste en SEQ ID NO: 26 (01G06, Ch01G06 quimérica, Hu01G06 IGKV1-39, Hu01G06 IGKV1-39 S43A V48I, Hu01G06 IGKV1-39 V48I, Hu01G06 IGKV1-39 F1, Hu01G06 IGKV1-39 F2), SEQ ID NO: 27 (03G05), SEQ ID NO: 28 (04F08, 06C11, Ch06C11 quimérica, Sh06C11 IGKV1-16), SEQ ID NO: 29 (08G01), SEQ ID NO: 30 (14F11, Ch14F11 quimérica, Hu14F11 IGKV1-16), y SEQ ID nO: 31 (17B11); y una c DRl3 comprende una secuencia de aminoácidos seleccionada entre el grupo que consiste en SEQ iD NO: 32 (01G06, Ch01G06 quimérica, Hu01G06 IGKV1-39, Hu01G06 IGKV1-39 S43A V48I, Hu01G06 IGKV1-39 V48I, 08G01, Hu01G06 IGKV1-39 F1), SEQ ID NO: 244 (Hu01G06 IGKV1-39 F2), SEQ ID NO: 33 (03G05), SEQ ID NO: 34 (04F08), SEQ ID NO: 35 (06C11, Ch06C11 quimérica, Sh06C11 IGKV1-16), SEQ ID NO: 36 (14F11, Ch14F11 quimérica, Hu14F11 IGKV1-16), y SEQ ID NO: 37 (17B11).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena ligera de una inmunoglobulina que comprende una CDRl1 que comprende la secuencia de aminoácidos de SEQ ID NO: 21 (01G06, Ch01G06 quimérica, Hu01G06 IGKV1-39, Hu01G06 IGKV1-39 S43A V48I, Hu01G06 IGKV1-39 V48I, Hu01G06 IGKV1-39 F1, Hu01G06 IGKV1-39 F2), una CDRl2 que comprende la secuencia de aminoácidos de SEQ ID NO: 26 (01G06, Ch01G06 quimérica, Hu01G06 IGKV1-39, Hu01G06 IGKV1-39 S43A V48I, Hu01G06 IGKV1-39 V48I, Hu01G06 IGKV1-39 F1, Hu01G06 IGKV1-39 F2), y una CDRl3 que comprende la secuencia de aminoácidos de SEQ ID NO: 32 (01G06, Ch01G06 quimérica, Hu01G06 IGKV1-39, Hu01G06 IGKV1-39 S43A V48I, Hu01G06 IGKV1-39 V48I, Hu01G06 IGKV1-39 F1).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena ligera de una inmunoglobulina que comprende una CDRl1 que comprende la secuencia de aminoácidos de SEQ ID NO: 21 (01G06, Ch01G06 quimérica, Hu01G06 IGKV1-39, Hu01G06 IGKV1-39 S43A V48I, Hu01G06 IGKV1-39 V48I, Hu01G06 IGKV1-39 F1, Hu01G06 IGKV1-39 F2), una CDRl2 que comprende la secuencia de aminoácidos de SEQ ID NO: 26 (01G06, Ch01G06 quimérica, Hu01G06 IGKV1-39, Hu01G06 IGKV1-39 S43A V48I, Hu01G06 IGKV1-39 V48I, Hu01G06 IGKV1-39 F1, Hu01G06 IGKV1-39 F2), y una CDRl3 que comprende la secuencia de aminoácidos de SEQ ID NO: 244 (Hu01G06 IGKV1-39 F2).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena ligera de una inmunoglobulina que comprende una CDRl1 que comprende la secuencia de aminoácidos de SEQ ID NO: 22 (03G05), una CDRl2 que comprende la secuencia de aminoácidos de SEQ ID NO: 27 (03G05), y una CDRl3 que comprende la secuencia de aminoácidos de SEQ ID NO: 33 (03G05).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena ligera de una inmunoglobulina que comprende una CDRl1 que comprende la secuencia de aminoácidos de SEQ ID NO: 23 (04F08), una CDRl2 que comprende la secuencia de aminoácidos de SEQ ID NO: 28 (04F08), y una CDRl3 que comprende la secuencia de aminoácidos de SEQ ID NO: 34 (04F08).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena ligera de una inmunoglobulina que comprende una CDRl1 que comprende la secuencia de aminoácidos de SEQ ID NO: 23 (06C11, Ch06C11 quimérica, Sh06C11 IGKV1-16), una CDRl2 que comprende la secuencia de aminoácidos de SEQ ID NO: 28 (06C11, Ch06C11 quimérica, Sh06C11 IGKV1-16), y una CDRl3 que comprende la secuencia de aminoácidos de SEQ ID NO: 35 (06C11, Ch06C11 quimérica, Sh06C11 IGKV1-16).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena ligera de una inmunoglobulina que comprende una CDRL1 que comprende la secuencia de aminoácidos de SEQ ID NO: 24 (08G01), una CDRl2 que comprende la secuencia de aminoácidos de SEQ ID NO: 29 (08G01), y una CDRl3 que comprende la secuencia de aminoácidos de SEQ ID NO: 32 (08G01).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena ligera de una inmunoglobulina que comprende una CDRl1 que comprende la secuencia de aminoácidos de SEQ ID NO: 23 (14F11, Ch14F11 quimérica, Hu14F11 IGKV1-16), una Cd Rl2 que comprende la secuencia de aminoácidos de SEQ ID NO: 30 (14F11, Ch14F11 quimérica, Hu14F11 IGKV1-16), y una CDRl3 que comprende la secuencia de aminoácidos de SEQ ID NO: 36 (14F11, Ch14F11 quimérica, Hu14F11 IGKV1-16).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena ligera de una inmunoglobulina que comprende una CDRL1 que comprende la secuencia de aminoácidos de SEQ ID NO: 25 (17B11), una CDRl2 que comprende la secuencia de aminoácidos de SEQ ID NO: 31 (17B11), y una CDRl3 que comprende la secuencia de aminoácidos de SEQ ID NO: 37 (17B11).
Preferentemente, la CDRl1, las secuencias CDRl2 y CDRl3 están interpuestas entre secuencias FR de inmunoglobulinas completamente humanas o humanizadas.
Como se describe en el presente documento, el anticuerpo comprende: (a) una región variable de la cadena pesada de una inmunoglobulina que comprende la estructura CDRh1-CDRh2-CDRh3 y (b) una región variable de la cadena ligera de una inmunoglobulina que comprende la estructura CDRl1-CDRl2-CDRl3, en donde la región variable de la cadena pesada y la región variable de la cadena ligera definen conjuntamente un único sitio de unión para la unión del hGDF15. La CDRh1 es una secuencia de aminoácidos seleccionada entre el grupo que consiste en SEQ ID NO: 1 (01G06, 08G01, Ch01G06 quimérica, Hu01G06 IGHV1-18, Hu01G06 IGHV1-69, Sh01G06 IGHV1-18 M69L, Sh01G06 IGHV1-18 M69L K64Q G44S, Sh01G06 IGHV1-18 M69L K64Q, Sh01G06 IGHV1-69 T30S I69L, Sh01G06 IGHV1-69 T30S K64Q I69L, Hu01G06 IGHV1-18 F1, Hu01G06 IGHV1-18 F2, Hu01G06 IGHV1-69 F1, Hu01G06 IGHV1-69 F2), SEQ ID NO: 2 (03G05), SEQ ID NO: 3 (04F08), SEQ ID NO: 4 (06C11, Ch06C11 quimérica, HE LM 06C11 IGHV2-70, Hu06C11 IGHV2-5), SEQ ID NO: 5 (14F11, Ch14F11 quimérica, Sh14F11 IGHV2-5, Sh14F11 IGHV2-70), y SeQ ID NO: 6 (17B11); la CDRh2 es una secuencia de aminoácidos seleccionada entre el grupo que consiste en SEQ ID NO: 7 (01G06, Ch01G06 quimérica, Hu01G06 IGHV1-18, Hu01G06 IGHV1-69, Sh01G06 IGHV1-18 M69L, Sh01G06 IGHV1-69 T30S I69L), SEQ ID NO: 8 (03G05), SEQ ID NO: 9 (04F08, 06C11, Ch06C11 quimérica, Hu06C11 IGHV2-5), SEQ ID NO: 10 (08G01), SEQ ID NO: 11 (14F11, Ch14F11 quimérica, Sh14F11 IGHV2-5, Sh14F11 IGHV2-70), SEQ ID NO: 12 (17B11), SEQ ID NO: 13 (Sh01G06 IGHV1-18 M69L K64Q G44S, Sh01G06 IGHV1-18 M69L K64Q, Sh01G06 IGHV1-69 T30S K64Q I69L), SEQ ID NO: 236 (Hu01G06 IGHV1-18 F1), SEQ ID NO: 237 (Hu01G06 IGHV1-18 F2), SEQ ID NO: 238 (Hu01G06 IGHV1-69 F1), SEQ ID NO: 239 (Hu01G06 IGHV1-69 F2) y SEQ ID NO: 14 (HE LM 06C11 IGHV2-70); y la CDRh3 es una secuencia de aminoácidos seleccionada entre el grupo que consiste en SEQ ID NO: 15 (01G06, 08G01, Ch01G06 quimérica, Hu01G06 IGHV1-18, Hu01G06 IGHV1-69, Sh01G06 IGHV1-18 M69L, Sh01G06 IGHV1-18 M69L K64Q G44S, Sh01G06 IGHV1-18 M69L K64Q, Sh01G06 IGHV1-69 T30S I69L, Sh01G06 IGHV1-69 T30S K64Q I69L, Hu01G06 IGHV1-18 F1, Hu01G06 IGHV1-18 F2, Hu01G06 IGHV1-69 F1, Hu01G06 IGHV1-69 F2), SEQ ID NO: 16 (03G05), SEQ ID NO: 17 (04F08), SEQ ID NO: 18 (06C11, Ch06C11 quimérica, HE LM 06C11 IGHV2-70, Hu06C11 IGHV2-5), SEQ ID NO: 19 (14F11, Ch14F11 quimérica, Sh14F11 IGHV2-5, Sh14F11 IGHV2-70), y SEQ ID NO: 20 (17B11). La CDRl1 es una secuencia de aminoácidos seleccionada entre el grupo que consiste en SEQ ID NO21 (01G06, Ch01G06 quimérica, Hu01G06 IGKV1-39, Hu01G06 IGKV1-39 S43A V48I, Hu01G06 IGKV1-39 V48I, Hu01G06 IGKV1-39 F1, Hu01G06 IGKV1-39 F2), SEQ ID NO: 22 (03G05), SEQ ID NO: 23 (04F08, 06C11, Ch06C11 quimérica, Sh06C11 IGKV1-16, 14F11, Ch14F11 quimérica, Hu14F11 IGKV1-16), SEQ ID NO24 (08G01) y SEQ ID NO: 25 (17B11); la CDRl2 es una secuencia de aminoácidos seleccionada entre el grupo que consiste en SEQ ID NO: 26 (01G06, Ch01G06 quimérica, Hu01G06 IGKV1-39, Hu01G06 IGKV1-39 S43A V48I, Hu01G06 IGKV1-39 V48I, Hu01G06 IGKV1-39 F1, Hu01G06 IGKV1-39 F2), SEQ ID NO: 27 (03G05), SEQ ID NO: 28 (04F08, 06C11, Ch06C11 quimérica, Sh06C11 IGKV1-16), SEQ ID NO: 29 (08G01), SEQ ID NO: 30 (14F11, Ch14F11 quimérica, Hu14F11 IGKV1-16), y SEQ ID NO: 31 (17B11); y la CDRl3 es una secuencia de aminoácidos seleccionada entre el grupo que consiste en SEQ ID NO32 (01G06, Ch01G06 quimérica, Hu01G06 IGKV1-39, Hu01G06 IGKV1-39 S43A V48I, Hu01G06 IGKV1-39 V48I, 08G01, Hu01G06 IGKV1-39 F1), SEQ ID NO: 244
(Hu01G06 IGKV1-39 F2), SEQ ID NO: 33 (03G05), SEQ ID NO: 34 (04F08), SEQ ID NO: 35 (06C11, Ch06C11 quimérica, Sh06C11 IGKV1-16), SEQ ID NO: 36 (14F11, Ch14F11 quimérica, Hu14F11 IGKV1-16), y SEQ ID NO: 37 (17B11).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende una CDRh1 que comprende una secuencia de aminoácidos seleccionada entre el grupo que consiste en SEQ ID NO: 1 y SEQ ID NO: 38 (Hu01G06 IGHV1-18 F1), una CDRh2 que comprende una secuencia de aminoácidos seleccionada entre el grupo que consiste en SEQ ID NO: 236 y SEQ ID NO: 240 (Hu01G06 IGHV1-18 F1), y una CDRh3 que comprende la secuencia de aminoácidos de SEQ iD NO: 15 (Hu01G06 IGHV1-18 F1); y una región variable de la cadena ligera de una inmunoglobulina que comprende una CDRL1 que comprende la secuencia de aminoácidos de SEQ ID NO: 21 (Hu01G06 IGKV1-39 F1), una CDRl2 que comprende la secuencia de aminoácidos de SEQ ID NO: 26 (Hu01G06 IGKV1-39 F1) y una CDRl3 que comprende la secuencia de aminoácidos de SEQ ID NO: 32 (Hu01G06 iGkV1-39 F1).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende una CDRH1 que comprende una secuencia de aminoácidos seleccionada entre el grupo que consiste en SEQ ID NO: 1 y SEQ ID NO: 38 (Hu01G06 IGHV1-18 F2), una CDRh2 que comprende una secuencia de aminoácidos seleccionada entre el grupo que consiste en SEQ ID NO: 237 y SEQ ID NO: 241 (Hu01G06 IGHV1-18 F2) y una CDRh3 que comprende la secuencia de aminoácidos de SEQ iD NO: 15 (Hu01G06 IGHV1-18 F2); y una región variable de la cadena ligera de una inmunoglobulina que comprende una CDRL1 que comprende la secuencia de aminoácidos de SEQ ID NO: 21 (Hu01G06 IGKV1-39 F2), una CDRl2 que comprende la secuencia de aminoácidos de SEQ ID NO: 26 (Hu01G06 IGKV1-39 F2) y una CDRl3 que comprende la secuencia de aminoácidos de SEQ ID NO: 244 (Hu01G06 IGKV1-39 F2).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende una CDRH1 que comprende una secuencia de aminoácidos seleccionada entre el grupo que consiste en SeQ ID NO: 1 y SEQ iD NO: 234 (Hu01G06 IGHV1-69 F1), una CDRh2 que comprende una secuencia de aminoácidos seleccionada entre el grupo que consiste en SEQ ID NO: 238 y SEQ ID NO: 241 (Hu01G06 IGHV1-69 F1) y una CDRh3 que comprende la secuencia de aminoácidos de SEQ ID NO: 15 (Hu01G06 IGHV1-69 F1); y una región variable de la cadena ligera de una inmunoglobulina que comprende una CDRL1 que comprende la secuencia de aminoácidos de SEQ ID NO: 21 (Hu01G06 IGKV1-39 F1), una CDRl2 que comprende la secuencia de aminoácidos de SEQ ID NO: 26 (Hu01G06 IGKV1-39 F1) y una CDRl3 que comprende la secuencia de aminoácidos de SEQ ID NO: 32 (Hu01G06 lGKV1-39 F1).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende una CDRH1 que comprende una secuencia de aminoácidos seleccionada entre el grupo que consiste en SeQ ID NO: 1 y SEQ iD NO: 234 (Hu01G06 IGHV1-69 F2), una CDRh2 que comprende una secuencia de aminoácidos seleccionada entre el grupo que consiste en SEQ ID NO: 239 y SEQ ID NO: 240 (Hu01G06 IGHV1-69 F2) y una CDRh3 que comprende la secuencia de aminoácidos de SEQ ID NO: 15 (Hu01G06 IGHV1-69 F2); y una región variable de la cadena ligera de una inmunoglobulina que comprende una CDRL1 que comprende la secuencia de aminoácidos de SEQ ID NO: 21 (Hu01G06 IGKV1-39 F1), una CDRl2 que comprende la secuencia de aminoácidos de SEQ ID NO: 26 (Hu01G06 IGKV1-39 F1) y una CDRl3 que comprende la secuencia de aminoácidos de SEQ ID NO: 32 (Hu01G06 lGKV1-39 F1).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende una CDRH1 que comprende una secuencia de aminoácidos seleccionada entre el grupo que consiste en SeQ ID NO: 1 y SEQ iD NO: 234 (Hu01G06 IGHV1-69 F2), una CDRh2 que comprende una secuencia de aminoácidos seleccionada entre el grupo que consiste en SEQ ID NO: 239 y SEQ ID NO: 240 (Hu01G06 IGHV1-69 F2) y una CDRh3 que comprende la secuencia de aminoácidos de SEQ ID NO: 15 (Hu01G06 IGHV1-69 F2); y una región variable de la cadena ligera de una inmunoglobulina que comprende una CDRL1 que comprende la secuencia de aminoácidos de SEQ ID NO: 21 (Hu01G06 IGKV1-39 F2), una CDRl2 que comprende la secuencia de aminoácidos de SEQ ID NO: 26 (Hu01G06 IGKV1-39 F2) y una CDRl3 que comprende la secuencia de aminoácidos de SEQ ID NO: 244 (Hu01G06 IGKV1-39 F2).
Los anticuerpos divulgados en el presente documento comprenden una región variable de la cadena pesada de una inmunoglobulina y una región variable de la cadena ligera de una inmunoglobulina. Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina seleccionada entre el grupo que consiste en SEQ ID NO: 40 (01G06, Ch01G06 quimérica), SEQ ID NO: 42 (03G05), SEQ ID NO: 44 (04F08), SEQ ID NO: 46 (06C11, Ch06C11 quimérica), SEQ ID NO: 48 (08G01), SEQ ID NO: 50 (14F11, Ch14F11 quimérica), SEQ ID NO: 52 (17B11), SEQ ID NO: 54 (Hu01G06 IGHV1-18), SEQ ID NO: 56 (Hu01G06 IGHV1-69), SEQ ID NO: 58 (Sh01G06 IGHV1-18 M69L), SEQ ID NO: 60 (Sh01G06 IGHV1-18 M69L K64Q G44S), SEQ ID NO: 62 (Sh01G06 IGHV1-18 M69L K64Q), SEQ ID NO: 64 (Sh01G06 IGHV1-69 T30S I69L), SEQ ID NO: 66 (Sh01G06 IGHV1-69 T30S K64Q I69L), SEQ ID NO: 246 (Hu01G06 IGHV1-18 F1), SEQ ID NO: 248 (Hu01G06 IGHV1-18 F2), SEQ ID NO: 250 (Hu01G06 IGHV1-69 F1), SEQ ID NO: 252 (Hu01G06 IGHV1-69 F2), SEQ ID NO: 68 (HE LM 06C11 IGHV2-70), SEQ ID NO: 70 (Hu06C11 IGHV2-5), SEQ ID NO: 72 (Sh14F11 IGHV2-5) y SEQ ID NO: 74 (Sh14F11 IGHV2-70); y una región variable de la cadena ligera de una inmunoglobulina.
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena ligera de una inmunoglobulina seleccionada entre el grupo que consiste en SEQ ID NO: 76 (01G06, Ch01G06 quimérica), SEQ ID NO: 78 (03G05), SEQ ID NO: 80 (04F08), SEQ ID NO: 82 (06C11, Ch06C11 quimérica), SEQ ID NO: 84 (08G01), SEQ ID NO: 86 (14F11, Ch14F11 quimérica), SEQ ID NO: 88 (17B11), SEQ ID NO: 90 (Hu01G06 IGKV1-39), SEQ ID NO: 92 (Hu01G06 IGKV1-39 S43A V48I o Hu01G06 IGKV1-39 F1), SEQ ID NO: 94 (Hu01G06 IGKV1-39 V48I), SEQ ID NO: 96 (Sh06C11 IGKV1-16), SEQ ID NO: 254 (Hu01G06 IGKV1-39 F2) y SEQ ID NO: 98 (Hu14F11 IGKV1-16), y una región variable de la cadena pesada de una inmunoglobulina.
Según se reivindica o se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina seleccionada entre el grupo que consiste en SEQ ID NO: 40 (01G06, Ch01G06 quimérica), SEQ ID NO: 42 (03G05), SEQ ID NO: 44 (04F08), SEQ ID NO: 46 (06C11, Ch06C11 quimérica), SEQ ID NO: 48 (08G01), SEQ ID NO: 50 (14F11, Ch14F11 quimérica), SEQ ID NO: 52 (17B11), SEQ ID NO: 54 (Hu01G06 IGHV1-18), SEQ ID NO: 56 (Hu01G06 IGHV1-69), SEQ ID NO: 58 (Sh01G06 IGHV1-18 M69L), SEQ ID NO: 60 (Sh01G06 IGHV1-18 M69L K64Q G44S), SEQ ID NO: 62 (Sh01G06 IGHV1-18 M69L K64Q), SEQ ID NO: 64 (Sh01G06 IGHV1-69 T30S I69L), SEQ ID NO: 66 (Sh01G06 IGHV1-69 T30S K64Q I69L), SEQ ID NO: 246 (Hu01G06 IGHV1-18 F1), SEQ ID NO: 248 (Hu01G06 IGHV1-18 F2), SEQ ID NO: 250 (Hu01G06 IGHV1-69 F1), SEQ ID NO: 252 (Hu01G06 IGHV1-69 F2), SEQ ID NO: 68 (HE LM 06C11 IGHV2-70), SEQ ID NO: 70 (Hu06C11 IGHV2-5), SEQ ID NO: 72 (Sh14F11 IGHV2-5) y SEQ ID NO: 74 (Sh14F11 IGHV2-70), y una región variable de la cadena ligera de una inmunoglobulina seleccionada entre el grupo que consiste en SEQ ID NO: 76 (01G06, Ch01G06 quimérica), SEQ ID NO: 78 (03G05), SEQ ID NO: 80 (04F08), SEQ ID NO: 82 (06C11, Ch06C11 quimérica), SEQ ID NO: 84 (08G01), SEQ ID NO: 86 (14F11, Ch14F11 quimérica), SEQ ID NO: 88 (17B11), SEQ ID NO: 90 (Hu01G06 IGKV1-39), SEQ ID NO: 92 (Hu01G06 IGKV1-39 S43A V48I o Hu01G06 IGKV1-39 F1), SEQ ID NO: 94 (Hu01G06 IGKV1-39 V48I), SEQ ID NO: 96 (Sh06C11 IGKV1-16), SEQ ID NO: 254 (Hu01G06 IGKV1-39 F2) y SEQ ID NO: 98 (Hu14F11 IGKV1-16).
En algunas realizaciones, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 40 (01G06, Ch01G06 quimérica) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 76 (01G06, Ch01G06 quimérica).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 42 (03G05) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 78 (03G05).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 44 (04F08) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 80 (04F08).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 46 (06C11) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 82 (06C11).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 48 (08G01) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 84 (08G01).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 50 (14F11) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 86 (14F11).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 52 (17B11) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 88 (17B11).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 54 (Hu01G06 IGHV1-18) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEq ID NO: 76 (Hu01G06 quimérica).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 56 (Hu01G06 IGHV1-69) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEq ID NO: 76 (Hu01G06 quimérica).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 58 (Sh01G06 IGHV1-18 M69L) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 76 (Ch01G06 quimérica).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 60 (Sh01G06 IGHV1-18 M69L K64Q G44S) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de la SEQ ID NO: 76 (Ch01G06 quimérica).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 62 (Sh01G06 IGHV1-18 M69L K64Q) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 76 (Ch01G06 quimérica).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 64 (Sh01G06 IGHV1-69 T30S I69L) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 76 (Ch01G06 quimérica).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 66 (Sh01G06 IGHV1-69 T30S K64Q I69L) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de la SEQ ID NO: 76 (Ch01G06 quimérica).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 40 (Ch01G06 quimérica) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEq ID NO: 90 (Hu01G06 IGKV1-39).
En algunas realizaciones, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 54 (Hu01G06 IGHV1-18) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 90 (Hu01G06 IGKV1-39).
En algunas realizaciones, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 56 (Hu01G06 IGHV1-69) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 90 (Hu01G06 IGKV1-39).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 58 (Sh01G06 IGHV1-18 M69L) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 90 (Hu01G06 IGKV1-39).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 60 (Sh01G06 IGHV1-18 M69L K64Q G44S) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 90 (Hu01G06 IGKV1-39).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 62 (Sh01G06 IGHV1-18 M69L K64Q) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 90 (Hu01G06 IGKV1-39).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 64 (Sh01G06 IGHV1-69 T30S I69L) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 90 (Hu01G06 IGKV1-39).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de
una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 66 (Sh01G06 IGHV1-69 T30S K64Q I69L) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 90 (Hu01G06 IGKV1-39).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 40 (Ch01G06 quimérica) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 92 (Hu01G06 IGKV1-39 S43A V48I).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 54 (Hu01G06 IGHV1-18), y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 92 (Hu01G06 IGKV1-39 S43A V48I).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 56 (Hu01G06 IGHV1-69), y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 92 (Hu01G06 IGKV1-39 S43A V48I).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 58 (Sh01G06 IGHV1-18 M69L) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 92 (Hu01G06 IGKV1-39 S43A V48I).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 60 (Sh01G06 IGHV1-18 M69L K64Q G44S) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 92 (Hu01G06 IGKV1-39 S43A V48I).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 62 (Sh01G06 IGHV1-18 M69L K64Q) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 92 (Hu01G06 IGKV1-39 S43A V48I).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 64 (Sh01G06 IGHV1-69 T30S I69L) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 92 (Hu01G06 IGKV1-39 S43A V48I).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 66 (Sh01G06 IGHV1-69 T30S K64Q I69L) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 92 (Hu01G06 IGKV1-39 S43A V48I).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 40 (Ch01G06 quimérica) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 94 (Hu01G06 IGKV1-39 V48I).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 54 (Hu01G06 IGHV1-18), y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 94 (Hu01G06 IGKV1-39 V48I).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 56 (Hu01G06 IGHV1-69), y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 94 (Hu01G06 IGKV1-39 V48I).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 58 (Sh01G06 IGHV1-18 M69L) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 94 (Hu01G06 IGKV1-39 V48I).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 60 (Sh01G06 IGHV1-18 M69L
K64Q G44S) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 94 (Hu01G06 IGKV1-39 V48I).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 62 (Sh01G06 IGHV1-18 M69L K64Q), y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 94 (Hu01G06 IGKV1-39 V48I).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 64 (Sh01G06 IGHV1-69 T30S I69L), y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 94 (Hu01G06 IGKV1-39 V48I).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 66 (Sh01G06 IGHV1-69 T30S K64Q I69L) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 94 (Hu01G06 IGKV1-39 V48I).
En algunas realizaciones, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 246 (Hu01G06 IGHV1-18 F1) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 92 (Hu01G06 IGKV1-39 F1).
En algunas realizaciones, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 248 (Hu01G06 IGHV1-18 F2) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 254 (Hu01G06 IGKV1-39 F2).
En algunas realizaciones, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 250 (Hu01G06 IGHV1-69 F1) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 92 (Hu01G06 IGKV1-39 F1).
En algunas realizaciones, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 252 (Hu01G06 IGHV1-69 F2) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 92 (Hu01G06 IGKV1-39 F1).
En algunas realizaciones, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 252 (Hu01G06 IGHV1-69 F2) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 254 (Hu01G06 IGKV1-39 F2).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 68 (HE LM 06C11 IGHV2-70) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 82 (Ch06C11 quimérica).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 70 (Hu06C11 IGHV2-5) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEq ID NO: 82 (Ch06C11 quimérica).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 46 (Ch06C11 quimérica) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEq ID NO: 96 (Sh06C11 IGKV1-16).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 68 (HE LM 06C11 IGHV2-70) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 96 (Sh06C11 IGKV1-16).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 70 (Hu06C11 IGHV2-5) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEq ID
NO: 96 (Sh06C11 IGKV1-16).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 72 (Sh14F11 IGHV2-5) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de s Eq ID NO: 86 (Ch14F11 quimérica).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 74 (Sh14F11 IGHV2-70) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 86 (Ch14F11 quimérica).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 50 (Ch14F11 quimérica) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 98 (Hu14F11 IGKV1-16).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 72 (Sh14F11 IGHV2-5) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 98 (Hu14F11 IGKV1-16).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 74 (Sh14F11 IGHV2-70) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 98 (Hu14F11 IGKV1-16).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 46 (Ch06C11 quimérica) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 80 (04F08).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 50 (Ch14F11 quimérica) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 80 (04F08).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 44 (04F08) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 82 (Ch06C11 quimérica).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 50 (Ch14F11 quimérica) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 82 (Ch06C11 quimérica).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 44 (04F08) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 86 (Ch14F11 quimérica).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 46 (Ch06C11 quimérica) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 86 (Ch14F11 quimérica).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 48 (08G01) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 76 (Ch01G06 quimérica).
Como se describe en el presente documento, el anticuerpo comprende una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 40 (Ch01G06 quimérica) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 84 (08G01).
En ciertas realizaciones, Los anticuerpos divulgados en el presente documento comprenden una cadena pesada de una inmunoglobulina y una cadena ligera de una inmunoglobulina. Como se describe en el presente documento, el anticuerpo comprende una cadena pesada de una inmunoglobulina seleccionada entre el grupo que consiste en SEQ ID NO: 100 (01G06), SEQ ID NO: 104 (03G05), SEQ ID NO: 108 (04F08), SEQ ID NO: 112 (06C11), SEQ ID NO: 116 (08G01), SEQ ID NO: 120 (14F11), SEQ ID NO: 124 (17B11), SEQ ID NO: 176 (Ch01G06 quimérica), SEQ ID NO: 178 (Hu01G06 IGHV1-18), SEQ ID NO: 180 (Hu01G06 IGHV1-69), SEQ ID NO: 182 (Sh01G06 IGHV1-18 M69L), SEQ ID NO: 184 (Sh01G06 IGHV1-18 M69L K64Q G44S), SEQ ID NO: 186 (Sh01G06 IGHV1-18 M69L K64Q), SEQ ID NO: 188 (Sh01G06 IGHV1-69 T30S I69L), SEQ ID NO: 190 (Sh01G06 IGHV1-69 T30S K64Q I69L), SEQ ID NO: 256 (Hu01G06 IGHV1-18 F1), SEQ ID NO: 258 (Hu01G06 IGHV1-18 F2), SEQ ID NO: 260 (Hu01G06 IGHV1-69 F1), SEQ ID NO: 262 (Hu01G06 IGHV1-69 F2), SEQ ID NO: 192 (Ch06C11 quimérica), SEQ ID NO: 194 (HE LM 06C11 IGHV2-70), SEQ ID NO: 196 (Hu06C11 IGHV2-5), SEQ ID NO: 198 (Ch14F11 quimérica), SEQ ID NO: 200 (Sh14F11 IGHV2-5) y SEQ ID NO: 202 (Sh14F11 IGHV2-70); y una cadena ligera de una inmunoglobulina. Como se describe en el presente documento, el anticuerpo comprende una cadena ligera de una inmunoglobulina seleccionada entre el grupo que consiste en SEQ ID NO: 102 (01G06), SEQ ID NO: 106 (03G05), SEQ ID NO: 110 (04F08), SEQ ID NO: 114 (06C11), SEQ ID NO: 118 (08G01), SEQ ID NO: 122 (14F11), SEQ ID NO: 126 (17B11), SEQ ID NO: 204 (Ch01G06 quimérica), SEQ ID NO: 206 (Hu01G06 IGKV1-39), SEQ ID NO: 208 (Hu01G06 IGKV1-39 S43A V48I o Hu01G06 IGKV1-39 F1), SEQ ID NO: 210 (Hu01G06 IGKV1-39 V48I), SEQ ID NO: 264 (Hu01G06 IGKV1-39 F2), SEQ ID NO: 212 (Ch06C11 quimérica), SEQ ID NO: 214 (Sh06C11 IGKV1-16), SEQ ID NO: 216 (Ch14F11 quimérica) y SEQ ID NO: 218 (Hu14F11 IGKV1-16) y una cadena pesada de una inmunoglobulina.
Según se reivindica o se describe en el presente documento, el anticuerpo comprende (i) una cadena pesada de una inmunoglobulina seleccionada entre el grupo que consiste en SEQ ID NO: 100 (01G06), SEQ ID NO: 104 (03G05), SEQ ID NO: 108 (04F08), SEQ ID NO: 112 (06C11), SEQ ID NO: 116 (08G01), SEQ ID NO: 120 (14F11), SEQ ID NO: 124 (17B11), SEQ ID NO: 176 (Ch01G06 quimérica), SEQ ID NO: 178 (Hu01G06 IGHV1-18), SEQ ID NO: 180 (Hu01G06 IGHV1-69), SEQ ID NO: 182 (Sh01G06 IGHV1-18 M69L), SEQ ID NO: 184 (Sh01G06 IGHV1-18 M69L K64Q G44S), SEQ ID NO: 186 (Sh01G06 IGHV1-18 M69L K64Q), SEQ ID NO: 188 (Sh01G06 IGHV1-69 T30S I69L), SEQ ID NO: 190 (Sh01G06 IGHV1-69 T30S K64Q I69L), SEQ ID NO: 256 (Hu01G06 IGHV1-18 F1), SEQ ID NO: 258 (Hu01G06 IGHV1-18 F2), SEQ ID NO: 260 (Hu01G06 IGHV1-69 F1), SEQ ID NO: 262 (Hu01G06 IGHV1-69 F2), SEQ ID NO: 192 (Ch06C11 quimérica), SEQ ID NO: 194 (HELM 06C11 IGHV2-70), SEQ ID NO: 196 (Hu06C11 IGHV2-5), SEQ ID NO: 198 (Ch14F11 quimérica), SEQ ID NO: 200 (Sh14F11 IGHV2-5) y SEQ ID NO: 202 (Sh14F11 IGHV2-70), y (ii) una cadena ligera de una inmunoglobulina seleccionada entre el grupo que consiste en SEQ ID NO: 102 (01G06), SEQ ID NO: 106 (03G05), SEQ ID NO: 110 (04F08), SEQ ID NO: 114 (06C11), SEQ ID NO: 118 (08G01), SEQ ID NO: 122 (14F11), SEQ ID NO: 126 (17B11), SEQ ID NO: 204 (Ch01G06 quimérica), SEQ ID NO: 206 (Hu01G06 IGKV1-39), SEQ ID NO: 208 (Hu01G06 IGKV1-39 S43A V48I o Hu01G06 IGKV1-39 F1), SEQ ID NO: 210 (Hu01G06 IGKV1-39 V48I), SEQ ID NO: 264 (Hu01G06 IGKV1-39 F2), SEQ ID NO: 212 (Ch06C11 quimérica), SEQ ID NO: 214 (Sh06C11 IGKV1-16), SEQ ID NO: 216 (Ch14F11 quimérica) y SEQ ID NO: 218 (Hu14F11 IGKV1-16).
En algunas realizaciones, el anticuerpo comprende una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 176 (Ch01G06 quimérica) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 204 (Ch01G06 quimérica).
Como se describe en el presente documento, el anticuerpo comprende una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 192 (Ch06C11 quimérica) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 212 (Ch06C11 quimérica).
Como se describe en el presente documento, el anticuerpo comprende una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 198 (Ch14F11 quimérica) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 216 (Ch14F11 quimérica).
En algunas realizaciones, el anticuerpo comprende una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 178 (Hu01G06 IGHV1-18) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 206 (Hu01G06 IGKV1-39).
En algunas realizaciones, el anticuerpo comprende una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 180 (Hu01G06 IGHV1-69) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 206 (Hu01G06 IGKV1-39).
Como se describe en el presente documento, el anticuerpo comprende una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ iD NO: 184 (Sh01G06 IGHV1-18 M69L K64Q G44S) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 210 (Hu01G06 IGKV1-39 V48I).
Como se describe en el presente documento, el anticuerpo comprende una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ iD NO: 188 (Sh01G06 IGHV1-69 T30S I69L) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 210 (Hu01G06 IGKV1-39 V48I).
Como se describe en el presente documento, el anticuerpo comprende una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ iD NO: 184 (Sh01G06 IGHV1-18 M69L K64Q G44S) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 208 (Hu01G06 IGKV1-39 S43A V48I).
Como se describe en el presente documento, el anticuerpo comprende una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ iD NO: 188 (Sh01G06 IGHV1-69 T30S I69L) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 208 (Hu01G06 IGKV1-39 S43A V48I).
En algunas realizaciones, el anticuerpo comprende una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 256 (Hu01G06 IGHV1-18 F1) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 208 (Hu01G06 IGKV1-39 F1).
En algunas realizaciones, el anticuerpo comprende una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 258 (Hu01G06 IGHV1-18 F2) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 264 (Hu01G06 IGKV1-39 F2).
En algunas realizaciones, el anticuerpo comprende una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 260 (Hu01G06 IGHV1-69 F1) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 208 (Hu01G06 IGKV1-39 F1).
En algunas realizaciones, el anticuerpo comprende una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 262 (Hu01G06 IGHV1-69 F2) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 208 (Hu01G06 IGKV1-39 F1).
En algunas realizaciones, el anticuerpo comprende una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 262 (Hu01G06 IGHV1-69 F2) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 264 (Hu01G06 IGKV1-39 F2).
Como se describe en el presente documento, el anticuerpo comprende una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 194 (HE LM 06C11 IGHV2-70) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 214 (Sh06C11 IGKV1-16). Como se describe en el presente documento, el anticuerpo comprende una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 196 (Hu06C11 IGHV2-5) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de s Eq ID NO: 214 (Sh06C11 IGKV1-16).
Como se describe en el presente documento, el anticuerpo comprende una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ iD NO: 200 (Sh14F11 IGHV2-5) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 218 (Hu14F11 IGKV1-16) Como se describe en el presente documento, el anticuerpo comprende una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 202 (Sh14F11 IGHV2-70) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 218 (Hu14F11 IGKV1-16).
Como se describe en el presente documento, un anticuerpo aislado que se une a1HGDF15 comprende una región variable de la cadena pesada de una inmunoglobulina que comprende una secuencia de aminoácidos que es idéntica en al menos un 70 %, un 75 %, un 80 %, un 85 %, un 90 %, un 95 %, 98 % o un 99 % a la región variable completa o a la secuencia FR de SEQ ID NO: 40 (01G06, Ch01G06 quimérica), SEQ ID NO: 42 (03G05), SEQ ID NO: 44 (04F08), SEQ ID NO: 46 (06C11, Ch06C11 quimérica), SEQ ID NO: 48 (08G01), SEQ ID NO: 50 (14F11, Ch14F11 quimérica), SEQ ID NO: 52 (17B11), SEQ ID NO: 54 (Hu01G06 IGHV1-18), SEQ ID NO: 56 (Hu01G06 IGHV1-69), SEQ ID NO: 58 (Sh01G06 IGHV1-18 M69L), SEQ ID NO: 60 (Sh01G06 IGHV1-18 M69L K64Q G44S), SEQ ID NO: 62 (Sh01G06 IGHV1-18 M69L K64Q), SEQ ID NO: 64 (Sh01G06 IGHV1-69 T30S I69L), SEQ ID NO: 66 (Sh01G06 IGHV1-69 T30S K64Q I69L), SEQ ID NO: 246 (Hu01G06 IGHV1-18 F1), SEQ ID NO: 248 (Hu01G06 IGHV1-18 F2), SEQ ID NO: 250 (Hu01G06 IGHV1-69 F1), SEQ ID NO: 252 (Hu01G06 IGHV1-69 F2), SEQ ID NO: 68 (HE LM 06C11 IGHV2-70), SEQ ID NO: 70 (Hu06C11 IGHV2-5), SEQ ID NO: 72 (Sh14F11 IGHV2-5) y SEQ ID NO: 74 (Sh14F11 IGHV2-70).
Como se describe en el presente documento, un anticuerpo aislado que se une a1HGDF15 comprende una región variable de la cadena ligera de una inmunoglobulina que comprende una secuencia de aminoácidos que es idéntica
en al menos un 70 %, un 75 %, un 80 %, un 85 %, un 90 %, un 95 %, un 98 % o un 99 % a la región variable completa o a la secuencia FR de SEQ ID NO: 76 (01G06, Ch01G06 quimérica), SEQ ID NO: 78 (03G05), SEQ ID NO: 80 (04F08), SEQ ID NO: 82 (06C11, Ch06C11 quimérica), SEQ ID NO: 84 (08G01), SEQ ID NO: 86 (14F11, Ch14F11 quimérica), SEQ ID NO: 88 (17B11), SEQ ID NO: 90 (Hu01G06 IGKV1-39), SEQ ID NO: 92 (Hu01G06 IGKV1-39 S43AV48I o Hu01G06 IGKV1-39 F1), SEQ ID NO: 94 (Hu01G06 IGKV1-39 V48I), SEQ ID NO: 254 (Hu01G06 IGKV1-39 F2), SEQ ID NO: 96 (Sh06C11 IGKV1-16) y SEQ ID NO: 98 (Hu14F11 IGKV1-16).
La identidad de la secuencia puede determinarse de diversas formas que están en la pericia de la persona experta en la materia, por ejemplo, usando programas informáticos disponibles públicamente, tales como los programas informáticos BLAST, BlAsT-2, ALIg N o Megalign (DNASTAR). Los análisis BLAST (Basic Local Alignment Search Tool) que usan el algoritmo empleado por los programas blastp, blastn, blastx, tblastn y tblastx (Karlin et al., (1990) PROC. NATL. ACAD. SCI. EE.UU. 87: 2264-2268; Altschul, (1993) J. MOL. EVOL. 36: 290-300; Altschul et al., (1997) NUCLEIC ACIDS RES. 25: 3389-3402), son idóneos para la búsqueda de similitudes entre las secuencias. Para un análisis de los aspectos básicos en la búsqueda de bases de datos de secuencias, véase Altschul et al., (1994) NATURE GENETICS 6: 119-129. Los expertos en la materia pueden determinar los parámetros apropiados para medir la alineación, incluyendo cualquier algoritmo necesario para lograr una alineación máxima a lo largo de la longitud completa de las secuencias que se estén comparando. Los parámetros de búsqueda para histogramas, descripciones, alineaciones, expectativa (es decir, el umbral de significación estadística para la notificación de coincidencias frente a las secuencias de las bases de datos), límite, matriz y filtro están en los parámetros por defecto. La matriz de puntuación por defecto usada por blastp, blastx, tblastn y tblastx es la matriz BLOSUM62 (Henikoff et al., (1992) PROC. NATL. ACAD. SCI. EE.UU. 89: 10915-10919). Pueden ajustarse cuatro parámetros de blastn como sigue: Q = 10 (penalización por creación de hueco); R = 10 (penalización por extensión de hueco); wink = 1 (genera aciertos de palabra en cada posición wink.sup.th a lo largo de la consulta); y gapw = 16 (establece el ancho de ventana dentro del cual se generan las alineaciones con huecos). Los ajustes de parámetros equivalentes de Blastp pueden ser Q = 9; R = 2; wink = 1; y gapw = 32. Las búsquedas también pueden realizarse usando el parámetro de opción avanzada del BLAST del NCBI (National Center for Biotechnology Information) (por ejemplo: -G, Coste para abrir un hueco [número entero]: por defecto = 5 para nucleótidos / 11 para proteínas; -E, Coste para extender un hueco [número entero]: por defecto = 2 para nucleótidos / 1 para proteínas; -q, Penalización por falta de coincidencia de nucleótidos [número entero]: por defecto = -3; -r, recompensa por coincidencia de nucleótidos [número entero]: por defecto = 1; -e, valor esperado [real]: por defecto = 10; -W, tamaño de palabra [número entero]: por defecto = 11 para nucleótidos / 28 para megablast / 3 para proteínas; -y, condición de parada (X) para las extensiones de blast en bits: por defecto = 20 para blastn / 7 para otros; -X, valor de la condición de parada X para la alineación con huecos (en bits): por defecto = 15 para todos los programas, no aplicable a blastn; y -Z, valor final de la condición de parada X para la alineación con huecos (en bits): 50 para blastn, 25 para otros). También puede usarse ClustalW para la alineación de proteínas por parejas (los parámetros por defecto pueden incluir, por ejemplo, matriz Blosum62 y penalización por apertura de hueco = 10 y penalización por extensión de hueco = 0,1). Una comparación Bestfit entre las secuencias, disponible en la versión del paquete GCG 10.0, usa los parámetros del ADN GAP = 50 (penalización por creación de hueco) y LEN = 3 (penalización por extensión de hueco). Los parámetros equivalentes en las comparaciones entre proteínas son GAP = 8 y LEN = 2.
Como se describe en el presente documento, en el presente documento se contempla que las secuencias de la región variable de la cadena pesada y/o las secuencias de la región variable de la cadena ligera de la inmunoglobulina que se unen conjuntamente al GDF15 humano puedan contener alteraciones de aminoácidos (por ejemplo, al menos 1, 2, 3, 4, 5 o 10 sustituciones, deleciones o adiciones de aminoácidos) en las regiones estructurales de las regiones variables de la cadena pesada y/o ligera.
Como se describe en el presente documento, el anticuerpo se une al hGDF15 con una Kd de aproximadamente 300 pM, 250 pM, 200 pM, 190 pM, 180 pM, 170 pM, 160 pM, 150 pM, 140 pM, 130 pM, 120 pM, 110 pM, 100 pM, 90 pM, 80 pM, 70 pM, 60 pM, 50 pM, 40 pM, 30 pM, 20 pM o 10 pM o menor. A menos que se especifique de otro modo, los valores de Kd se determinan mediante métodos de resonancia de plasmón superficial o de interferometría de biocapa en las condiciones descritas en los Ejemplos 8, 14 y 15.
Como se describe en el presente documento, un anticuerpo monoclonal se une al mismo epítopo del hGDF15 (por ejemplo, el hGDF15 maduro o el rhGDF15 escindido) al que se unen uno o más de los anticuerpos divulgados en el presente documento (por ejemplo, los anticuerpos 01G06, 03G05, 04F08, 06C11,08G01, 14F11 o 17B11). Como se describe en el presente documento, un anticuerpo monoclonal compite por la unión al hGDF15 con uno o más de los anticuerpos divulgados en el presente documento (por ejemplo, el anticuerpo 01G06, 03G05, 04F08, 06C11,08G01, 14F11 o 17B11).
Los ensayos de competición para determinar si un anticuerpo se une al mismo epítopo que, o compite por la unión con, un anticuerpo anti-GDF 15 divulgado en el presente documento son conocidos en la técnica. Algunos ejemplos de ensayos de competición incluyen inmunoensayos (por ejemplo, ensayos ELISA, ensayos RIA), análisis por resonancia de plasmón superficial (por ejemplo, usando un instrumento BIAcore™), interferometría de biocapa y citometría de flujo.
Normalmente, un ensayo de competición implica el uso de un antígeno (por ejemplo, una proteína hGDF15 o un
fragmento de la misma) unido a una superficie sólida o expresado en la superficie de una célula, un anticuerpo analítico de unión anti-GDF15 y un anticuerpo de referencia (por ejemplo, el anticuerpo 01G06, 03G05, 04F08, 06C11,08G01, 14F11 o 17B11). El anticuerpo de referencia está marcado y el anticuerpo analítico no está marcado. La inhibición competitiva se mide determinando la cantidad de anticuerpo de referencia marcado unido a la superficie sólida o a las células en presencia del anticuerpo analítico. Habitualmente, el anticuerpo analítico está presente en exceso (por ejemplo, 1x, 5x, 10x, 20x o 100x). Los anticuerpos identificados mediante el ensayo de competición (es decir, los anticuerpos competidores) incluyen anticuerpos que se unen al mismo epítopo, o a epítopos similares (por ejemplo, solapantes), que el anticuerpo de referencia, y los anticuerpos que se unen a un epítopo adyacente suficientemente próximo al epítopo unido por el anticuerpo de referencia para que se produzca un impedimento estérico.
En un ejemplo de ensayo de competición, Se biotinila un anticuerpo de referencia anti-GDF15 (por ejemplo, un anticuerpo 01G06, 03G05, 04F08, 06C11, 08G01, 14F11 o 17B11) usando reactivos disponibles comercialmente. El anticuerpo de referencia biotinilado se mezcla con diluciones sucesivas del anticuerpo analítico o del anticuerpo de referencia sin marcar (control de autocompetición), dando como resultado una mezcla de diversas proporciones molares (por ejemplo, 1x, 5x, 10x, 20x o 100x) del anticuerpo analítico (o del anticuerpo de referencia sin marcar) con respecto al anticuerpo de referencia marcado. La mezcla de anticuerpos se añade a una placa de ELISA recubierta con polipéptido hGDF15. Después, la placa se lava y se añade peroxidasa de rábano picante (HRP)-estrepavidina a la placa como reactivo de detección. La cantidad de anticuerpo de referencia marcado unido al antígeno objetivo se detecta tras la adición de un sustrato cromógeno (por ejemplo, TMB (3,3',5,5'-tetrametilbencidina) o ABTS (2,2"-azin-di-(3-etilbenztiazolin-6-sulfonato)), que se conocen en la técnica. Las lecturas de la densidad óptica (unidades de DO) se miden usando un espectrómetro SpectraMax® M2 (Molecular Devices). Las unidades de DO correspondientes a un porcentaje de inhibición de cero se determinan a partir de los pocillos sin anticuerpo competidor. Las unidades de DO correspondientes a un 100 % de inhibición, es decir, el fondo del ensayo, se determinan a partir de los pocillos sin anticuerpo de referencia marcado ni anticuerpo analítico. El porcentaje de inhibición del anticuerpo de referencia marcado frente al GDF15 por parte del anticuerpo analítico (o el anticuerpo de referencia no marcado) en cada concentración se calcula como sigue: % de inhibición = (1-(unidades de DO - 100 % de inhibición)/(0 % de inhibición - 100 % de inhibición))*100. Las personas expertas en la materia apreciarán que el ensayo de competición puede realizarse usando diversos sistemas de detección conocidos en la técnica.
Un ensayo de competición puede realizarse en ambas direcciones para asegurar que la presencia del marcador no interfiere ni inhibe la unión de otro modo. Por ejemplo, en la primera dirección, el anticuerpo de referencia está marcado y el anticuerpo analítico no está marcado, y en la segunda dirección, el anticuerpo analítico está marcado y el anticuerpo de referencia no está marcado.
El anticuerpo analítico compite con el anticuerpo de referencia por la unión específica al antígeno o si un exceso de un anticuerpo (por ejemplo, 1 x, 5x, 10x, 20x o 100x) inhibe la unión del otro anticuerpo, por ejemplo, en al menos un 50 %, un 75 %, un 90 %, un 95 % o un 99 %, según se mide en un ensayo de unión competitiva.
Dos anticuerpos se unen al mismo epítopo si esencialmente todas las mutaciones de aminoácidos del antígeno que reduce o eliminan la unión de un anticuerpo, reducen o eliminan la unión del otro. Dos anticuerpos se unen a epítopos solapantes si únicamente un subconjunto de las mutaciones de aminoácidos que reducen o eliminan la unión del anticuerpo, reducen o eliminan la unión del otro.
II. Producción de anticuerpos
Los métodos para producir los anticuerpos, tales como los divulgados en el presente documento, son conocidos en la técnica. Por ejemplo, las moléculas de ADN que codifican las regiones variables de la cadena ligera y/o las regiones variables de la cadena pesada pueden ser sintetizadas químicamente usando la información de la secuencia proporcionada en el presente documento. Las moléculas de ADN sintético pueden ser ligadas a otras secuencias de nucleótidos apropiadas, incluyendo, por ejemplo, las secuencias codificantes de la región constante y las secuencias de control de la expresión, para producir construcciones de expresión génica convencionales que codifican los anticuerpos deseados. La producción de construcciones génicas definidas está en la pericia rutinaria de la técnica. Como alternativa, las secuencias proporcionadas en el presente documento pueden ser clonadas fuera de hibridomas mediante técnicas de hibridación convencionales o técnicas de reacción en cadena de la polimerasa (PCR), usando sondas sintéticas de ácidos nucleicos cuyas secuencias se basan en la información de la secuencia proporcionada en el presente documento, o información de la secuencia de la técnica anterior relativa a los genes que codifican las cadenas pesada y ligera de los anticuerpos murinos en células de hibridoma.
Los ácidos nucleicos que codifican los anticuerpos deseados pueden ser incorporados (ligados) en vectores de expresión, que pueden ser introducidos en células hospedadoras a través de técnicas convencionales de transfección o de transformación. Algunos ejemplos de células hospedadoras son células de E. coli, células de ovario de hámster chino (CHO), células de riñón embrionario humano 293 (HEK 293), células HeLa, células de riñón de cría de hámster (BHK), células de riñón de mono (COS), células de carcinoma hepatocelular humano (por ejemplo, Hep G2) y células de mieloma que no producen de otro modo la proteína IgG. Las células hospedadoras
transformadas pueden cultivarse en unas condiciones que permitan que las células hospedadoras expresen los genes que codifican las regiones variables de la cadena ligera y/o pesada de la inmunoglobulina.
Las condiciones específicas de expresión y de purificación variarán dependiendo del sistema de expresión empleado. Por ejemplo, si un gen se va a expresar en E. coli, en primer lugar se clona en un vector de expresión posicionando el gen genomanipulado secuencia abajo de un promotor bacteriano adecuado, por ejemplo, Trp o Tac, y una secuencia de señal procariota. La proteína secretada expresada se acumula en cuerpos refringentes o de inclusión, y puede ser recogida después de la disrupción de las células con una prensa francesa o la aplicación de ultrasonidos. Después, los cuerpos refringentes se solubilizan y las proteínas se repliegan y se escinden mediante métodos conocidos en la técnica.
Si el gen genomanipulado va a ser expresado en células hospedadoras eucariotas, por ejemplo, células CHO, en primer lugar se inserta en un vector de expresión que contiene un promotor eucariota adecuado, una señal de secreción, una secuencia de poli A y un codón de terminación. Opcionalmente, el vector o la construcción génica pueden contener potenciadores e intrones. Este vector de expresión contiene opcionalmente secuencias que codifican toda o parte de una región constante, permitiendo que la totalidad, o una parte de, una cadena pesada o ligera sea expresada. La construcción génica puede ser introducida en células hospedadoras eucariotas usando técnicas convencionales. La célula hospedadora expresa fragmentos VL o VH, heterodímeros VL-VH, polipéptidos de cadena única Vh-Vl o Vl-Vh, cadenas pesadas o ligeras completas de inmunoglobulinas, o porciones de las mismas, cada una de las cuales puede estar unida a una fracción que tiene otra función (por ejemplo, citotoxicidad). En algunas realizaciones, una célula hospedadora es transfectada con un único vector que expresa un polipéptido que expresa la totalidad, o parte de, una cadena pesada (por ejemplo, una región variable de la cadena pesada) o una cadena ligera (por ejemplo, una región variable de la cadena ligera). En algunas realizaciones, una célula hospedadora es transfectada con un único vector que codifica (a) un polipéptido que comprende una región variable de la cadena pesada y un polipéptido que comprende una región variable de la cadena ligera, o (b) una cadena pesada completa de una inmunoglobulina y una cadena ligera completa de una inmunoglobulina. En algunas realizaciones, una célula hospedadora es cotransfectada con más de un vector de expresión (por ejemplo, un vector de expresión que expresa un polipéptido que comprende la totalidad, o parte de, una cadena pesada o una región variable de la cadena pesada, y otro vector de expresión que expresa un polipéptido que comprende la totalidad, o parte de, una cadena ligera o una región variable de la cadena ligera).
Un polipéptido que comprende una región variable de la cadena pesada o una región variable de la cadena ligera de una inmunoglobulina puede ser producido cultivando una célula hospedadora transfectada con un vector de expresión que codifica dicha región variable, en unas condiciones que permitan la expresión del polipéptido. Después de la expresión, el polipéptido puede ser recogido y purificado o aislado usando técnicas conocidas en la técnica, por ejemplo, etiquetas de afinidad tales como la glutatión-S-transferasa (GST) o etiquetas de histidina. Un anticuerpo monoclonal que se une al hGDF15, o un fragmento de unión al antígeno del anticuerpo, puede ser producido cultivando una célula hospedadora transfectada con: (a) un vector de expresión que codifica una cadena pesada completa o parcial de una inmunoglobulina, y un vector de expresión aparte que codifica una cadena ligera completa o parcial de una inmunoglobulina; o (b) un único vector de expresión que codifica ambas cadenas (por ejemplo, la cadena pesada y ligera completa o parcial), en unas condiciones que permitan la expresión de ambas cadenas. El anticuerpo intacto (o el fragmento de unión al antígeno) puede ser recogido y purificado o aislado usando técnicas conocidas en la técnica, por ejemplo, Proteína A, Proteína G, etiquetas de afinidad tales como la glutatión-S-transferasa (GST) o etiquetas de histidina. Está en la pericia habitual de la técnica expresar la cadena pesada y la cadena ligera a partir de un único vector de expresión o a partir de dos vectores de expresión individuales.
III. Modificaciones de los anticuerpos
Los métodos para reducir o eliminar la antigenicidad de los anticuerpos y de los fragmentos de anticuerpos son conocidos en la técnica. Cuando se van a administrar los anticuerpos a un ser humano, los anticuerpos están preferentemente "humanizados" para reducir o eliminar la antigenicidad en seres humanos. Preferentemente, cada anticuerpo humanizado tiene la misma o sustancialmente la misma afinidad por el antígeno que el anticuerpo de ratón no humanizado a partir del cual deriva.
En una estrategia de humanización, se crean proteínas quiméricas en las que se sustituyen las regiones constantes de una inmunoglobulina de ratón por las regiones constantes de una inmunoglobulina humana. Véase, por ejemplo, Morrison et al.,1984, PROC. NAT. ACAD. SCI. 81: 6851-6855, Neuberger et al., 1984, NATURE 312: 604-608; las patentes de EE.UU. n° 6.893.625 (Robinson); 5.500.362 (Robinson); y 4.816.567 (Cabilly).
En una estrategia conocida como injerto de CDR, se injertan las CDR de las regiones variables de la cadena ligera y pesada en las regiones estructurales de otra especie. Por ejemplo, pueden injertarse CDR murinas en FR humanas. En algunas realizaciones, las CDR de las regiones variables de la cadena ligera y pesada de un anticuerpo anti-GDF 15 el se injertan en FR humanas o en FR consenso humanas. Para crear FR consenso humanas, se alinean FR de varias secuencias de aminoácidos de cadena pesada o de cadena ligera humana para identificar una secuencia de
aminoácidos consenso. El injerto de CDR se describe en las Patentes de los Estados Unidos n.° 7.022.500 (Queen); 6.982.321 (Winter); 6.180.370 (Queen); 6.054.297 (Carter); 5.693.762 (Queen); 5.859.205 (Adair); 5.693.761 (Queen); 5.565.332 (Hoogenboom); 5.585.089 (Queen); 5.530.101 (Queen); Jones et al. (1986) NATURE 321: 522 525; Riechmann et al. (1988) NATURE 332: 323-327; Verhoeyen et al. (1988) SCIENCE 239: 1534-1536; y Winter (1998) FEBS LETT 430: 92-94.
En una estrategia denominada "SUPERHUMANIZATION™", se eligen secuencias de CDR humanas a partir de genes de la estirpe germinal humana, sobre la base de la similitud estructural de las CDR humanas con aquellas del anticuerpo de ratón que se va a humanizar. Véase, por ejemplo, la Patente de los Estados Unidos n.° 6.881.557 (Foote); y Tan et al., 2002, J. IMMUNOL. 169: 1119-1125.
Otros métodos para reducir la inmunogenicidad incluyen "remodelación", "hiperquimerización", y "rebarnizado/rechapado". Véase, por ejemplo, Vaswami et al., 1998, ANNALS OF ALLERGY, ASTHMA, & IMMUNOL. 81: 105; Roguska et al., 1996, PROT. ENGINEER 9: 895-904; y la Patente de los Estados Unidos n.° 6.072.035 (Hardman). En la estrategia de rebarnizado/rechapado, los residuos de aminoácidos accesibles de la superficie del anticuerpo murino son sustituidos por residuos de aminoácidos que se encuentran más frecuentemente en las mismas posiciones en un anticuerpo humano. Este tipo de rebarnizado del anticuerpo se describe, por ejemplo, en la Patente de los Estados Unidos n° 5.639.641 (Pedersen).
Otra estrategia para convertir un anticuerpo de ratón en una forma adecuada para su uso médico en seres humanos se conoce como la tecnología ACTIVMAB™ (Vaccinex, Inc., Rochester, NY), que implica un vector basado en un virus de la variolovacuna para expresar los anticuerpos en células de mamífero. Se dice que se producen unos elevados niveles de diversidad combinatoria de las cadenas pesada y ligera de la IgG. Véanse, por ejemplo, las Patentes de los Estados Unidos n.° 6.706.477 (Zauderer); 6.800.442 (Zauderer); y 6.872.518 (Zauderer).
Otra estrategia para convertir un anticuerpo de ratón en una forma adecuada para su uso en seres humanos es la tecnología comercializada por KaloBios Pharmaceuticals, Inc. (Palo Alto, CA). Esta tecnología implica el uso de una colección patentada de "aceptores" humanos para producir una colección "orientada al epítopo" para la selección de anticuerpos.
Otra estrategia para modificar un anticuerpo de ratón en una forma adecuada para su uso médico en seres humanos es la tecnología HUMAN ENGINEERING™, que es comercializada por Xo Ma (US) LLC. Véanse, por ejemplo, la Publicación PCT n° WO 93/11794 y las Patentes de EE.UU. n° 5.766.886 (Studnicka); 5.770.196 (Studnicka); 5.821.123 (Studnicka); y 5.869.619 (Studnicka).
Puede usarse cualquier estrategia adecuada, incluyendo cualquiera de las estrategias anteriores, para reducir o eliminar la inmunogenicidad humana de un anticuerpo.
Además, es posible crear anticuerpos completamente humanos en ratones. Los AcMc completamente humanos que carecen de cualquier secuencia no humana pueden ser preparados a partir de ratones transgénicos con inmunoglobulinas humanas mediante las técnicas referenciadas en, por ejemplo, Lonberg et al., NATURE 368: 856 859, 1994; Fishwild et al., NATURE BIOTECHNOLOGY 14: 845-851, 1996; y Mendez et al., NATURE GENETICS 15: 146-156, 1997. Los AcMc completamente humanos también pueden ser preparados y optimizados a partir de colecciones de expresión en fagos mediante las técnicas referenciadas en, por ejemplo, Knappik et al., J. MOL. BIOL. 296: 57-86, 2000; y Krebs et al., J. Immunol. Meth. 254: 67-842001).
IV. Usos terapéuticos
Los anticuerpos divulgados en el presente documento pueden usarse para tratar diversos trastornos, por ejemplo, caquexia y/o sarcopenia. Los anticuerpos divulgados en el presente documento (por ejemplo, 01G06, 03G05, 04F08, 06C11,08G01, 14F11 o 17B11) pueden usarse para inhibir la pérdida de masa muscular, por ejemplo, la pérdida de masa muscular asociada con una enfermedad subyacente. Algunas enfermedades subyacentes asociadas con la caquexia incluyen, pero no se limitan a, cáncer, insuficiencia cardiaca crónica, enfermedad renal crónica, EPOC, SIDA, esclerosis múltiple, artritis reumatoide, síndrome séptico y tuberculosis. Los anticuerpos divulgados inhiben la pérdida de masa muscular en al menos un 40 %, un 50 %, un 60 %, un 70 %, un 80 %, un 90 %, un 95 %, un 98 %, un 99 % o un 100 %.
Una pérdida de masa muscular puede estar acompañada por una pérdida de masa grasa. Los anticuerpos divulgados en el presente documento (por ejemplo, 01G06, 03G05, 04F08, 06C11, 08G01, 14F11 o 17B11) pueden inhibir la pérdida de masa grasa en al menos un 40 %, un 50 %, un 60 %, un 70 %, un 80 %, un 90 %, un 95 %, un 98 %, un 99 % o un 100 %.
Los anticuerpos divulgados en el presente documento (por ejemplo, 01G06, 03G05, 04F08, 06C11, 08G01, 14F11 o 17B11) pueden usarse para tratar una o más características que acompañan a la caquexia y/o a la sarcopenia, por ejemplo, la pérdida involuntaria de peso corporal. Los anticuerpos revierten la pérdida involuntaria de peso corporal en al menos un 2 %, un 5 %, un 10 %, un 15 %, un 20 %, un 25 %, un 30 % o un 35 %.
Los anticuerpos divulgados en el presente documento (por ejemplo, 01G06, 03G05, 04F08, 06C11,08G01, 14F11 o 17B11) pueden usarse para inhibir la pérdida de masa de un órgano, por ejemplo, la pérdida de masa de un órgano asociada con una enfermedad subyacente. Algunas enfermedades subyacentes asociadas con la caquexia incluyen, pero no se limitan a, cáncer, insuficiencia cardiaca crónica, enfermedad renal crónica, EPOC, SIDA, esclerosis múltiple, artritis reumatoide, síndrome séptico y tuberculosis. Los anticuerpos divulgados inhiben la pérdida de masa de un órgano en al menos un 40 %, un 50 %, un 60 %, un 70 %, un 80 %, un 90 %, un 95 %, un 98 %, un 99 % o un 100 %. La pérdida de masa de un órgano se observa en corazón, hígado, riñón y/o bazo. La pérdida de masa órgano puede estar acompañada por una pérdida de masa muscular, una pérdida de masa grasa y/o una pérdida involuntaria de peso.
El anticuerpo 01G06, 03G05, 04F08, 06C11, 08G01, 14F11 o 17B11 puede usarse en terapia. Por ejemplo, el anticuerpo 01G06, 03G05, 04F08, 06C11, 08G01, 14F11 o 17B11 puede usarse en terapia para tratar la caquexia y/o la sarcopenia. El uso del anticuerpo 01G06, 03G05, 04F08, 06C11, 08G01, 14F11 o 17B11 para tratar la caquexia y/o la sarcopenia en un mamífero comprende la administración al mamífero de una cantidad terapéuticamente eficaz del anticuerpo.
La sarcopenia, los trastornos de consunción muscular y las pérdidas significativas de peso muscular pueden producirse en ausencia de caquexia, de una disminución del apetito o de una pérdida de peso corporal. En ciertas realizaciones, por lo tanto, y uno o más de los anticuerpos anti-GDF de la invención (por ejemplo, el anticuerpo 01G06, 03G05, 04F08, 06C11, 08G01, 14F11 o 17B11) puede usarse para tratar a un sujeto que padece, o al que se le ha diagnosticado, sarcopenia, un trastorno de consunción muscular y/o una pérdida significativa de peso muscular, tanto si el sujeto tiene, o se le ha diagnosticado, como si no, caquexia o una disminución del apetito. Dicho método comprende la administración de una cantidad terapéuticamente eficaz de uno o más anticuerpos de la invención al sujeto en necesidad de los mismos.
Las proteínas de fusión Fc-rhGDF15 divulgadas en el presente documento pueden usarse para tratar la obesidad. Las proteínas de fusión hFc-rhGDF15 divulgadas en el presente documento pueden usarse para inhibir la ganancia de peso o para reducir el peso corporal en al menos un 5 %, un 10 %, un 15 %, un 20 %, un 25 %, un 30 %, un 35 %, un 40 %, un 45 % o un 50 %. El uso de una proteína de fusión hFc-hGDF15 para tratar la obesidad en un mamífero comprende la administración al mamífero de una cantidad terapéuticamente eficaz de la proteína de fusión.
Como se usa en el presente documento, "tratar", y "tratamiento" significan el tratamiento de una enfermedad en un mamífero, por ejemplo, en un ser humano. Esto incluye: (a) la inhibición de la enfermedad, es decir, detener su desarrollo; y (b) el alivio de la enfermedad, es decir, provocar la regresión de la patología.
En general, una cantidad terapéuticamente eficaz de un componente activo (por ejemplo, un anticuerpo o una proteína de fusión), está en el intervalo de entre 0,1 mg/kg y 100 mg/kg, por ejemplo, entre 1 mg/kg y 100 mg/kg, por ejemplo, entre 1 mg/kg y 10 mg/kg, por ejemplo, entre 2,0 mg/kg y 10 mg/kg. La cantidad administrada dependerá de variables tales como el tipo y la magnitud de la enfermedad o la indicación que se va a tratar, el estado de salud general del paciente, la potencia in vivo del anticuerpo o de la proteína de fusión, la formulación farmacéutica, la semivida sérica del anticuerpo o de la proteína de fusión, y de la vía de administración. La dosis inicial puede aumentarse más allá del nivel superior con objeto de conseguir rápidamente el nivel sanguíneo o tisular deseado. Como alternativa, la dosis inicial puede ser menor que la óptima, y la dosis puede aumentarse progresivamente durante el transcurso del tratamiento. La dosis en seres humanos puede optimizarse, por ejemplo, en un estudio de aumento de la dosis convencional de Fase I diseñado para que varíe entre 0,5 mg/kg y 20 mg/kg. La frecuencia de la administración puede variar dependiendo de factores tales como la vía de administración, la cantidad de dosis, la semivida sérica del anticuerpo o de la proteína de fusión, y de la enfermedad que se está tratando. Algunos ejemplos de frecuencias de administración son una vez al día, una vez por semana y una vez cada dos semanas. En algunas realizaciones, la administración es una vez cada dos semanas. Una vía de administración preferida es la parenteral, por ejemplo, infusión intravenosa. La formulación de fármacos basados en un anticuerpo monoclonal y de fármacos basados en una proteína de fusión está en la pericia habitual de la técnica. En algunas realizaciones, el anticuerpo o la proteína de fusión se liofiliza, y después se reconstituye en solución salina tamponada, en el momento de la administración. La cantidad eficaz de un segundo agente activo, por ejemplo, un agente antineoplásico o los otros agentes analizados a continuación, también seguirá los principios analizados más arriba y se elegirá de forma que desencadene el beneficio terapéutico requerido en el paciente.
Para su uso terapéutico, un anticuerpo se combina preferentemente con un portador farmacéuticamente aceptable. Como se usa en el presente documento, "portador farmacéuticamente aceptable" significa tampones, portadores y excipientes adecuados para su uso en contacto con los tejidos de seres humanos y de animales sin una excesiva toxicidad, irritación, respuesta alérgica u otro problema o complicación, acordes con una relación beneficio/riesgo razonable. El (los) portador(es) debe(n) ser "aceptable(s)" en el sentido de ser compatible(s) con los demás ingredientes de las formulaciones y no perjudicial(es) para el receptor. Algunos portadores farmacéuticamente aceptables incluyen tampones, disolventes, medios de dispersión, recubrimientos, agentes isotónicos y retardantes de la absorción, y similares, que son compatibles con la administración farmacéutica. El uso de dichos medios y
agentes para sustancias farmacéuticamente activas es conocido en la técnica.
Las composiciones farmacéuticas que contienen los anticuerpos o las proteínas de fusión, tales como los divulgados en el presente documento, pueden ser presentados en una forma de dosificación unitaria y pueden ser preparados mediante cualquier método adecuado. Una composición farmacéutica debe estar formulada para que sea compatible con su vía de administración prevista. Algunos ejemplos de vías de administración son intravenosa (IV), intradérmica, por inhalación, transdérmica, tópica, transmucosa y rectal. La vía de administración preferida para los anticuerpos monoclonales es la infusión IV. Las formulaciones útil es pueden prepararse mediante métodos conocidos en el arte farmacéutico. Por ejemplo, véase Remington's Pharmaceutical Sciences, 18a ed. (Mack Publishing Company, 1990). Los componentes de la formulación adecuados para la administración parenteral incluyen un diluyente estéril tal como agua para inyección, solución salina, aceites no volátiles, polietilenglicoles, glicerina, propilenglicol u otros disolventes sintéticos; agentes antibacterianos tales como alcohol bencílico o metil parabeno; antioxidantes, tales como ácido ascórbico o bisulfito sódico; agentes quelantes tales como EDTA; tampones, tales como acetatos, citratos o fosfatos; y agentes para el ajuste de la tonicidad tales como cloruro de sodio o dextrosa.
Para la administración intravenosa, algunos vehículos adecuados incluyen suero salino fisiológico, agua bacteriostática, Cremophor ELTM (BASF, Parsippany, NJ) o suero salino tamponado con fosfato (PBS). El portador de ser estable a las condiciones de fabricación y conservación, y debe ser preservado frente a los microorganismos. El portador puede ser un disolvente o un medio de dispersión que contiene, por ejemplo, agua, etanol, poliol (por ejemplo, glicerol, propilenglicol y polietilenglicol líquido), y mezclas adecuadas de los mismos.
Las formulaciones farmacéuticas son preferentemente estériles. La esterilización puede conseguirse, por ejemplo, mediante filtración a través de membranas de filtración estériles. Cuando la composición está liofilizada, puede realizarse una esterilización por filtro antes o después de la liofilización y la reconstitución.
Además de la ruta del GDF15 (es decir, MIC-1/PLAB/PDF/NAG-1), otras citocinas implicadas en la caquexia incluyen la Activina A y la IL-6. Se ha asociado el aumento en los niveles de la activina con la caquexia asociada al cáncer y los tumores gonadales. Véase, por ejemplo, Marino et al. (2013) CYTOKINE & GROWTH FACTOR REV.
24: 477-484. La Activina A es un miembro de la familia del TGF-beta, y es un ligando del receptor de la activina de tipo 2, el ActRIIB. Véase, por ejemplo, Zhou et al. (2010) CELL 142: 531-543. No se ha demostrado que los niveles de la IL-6 en circulación estén relacionados con la pérdida de peso en los pacientes oncológicos, ni tampoco con la reducción en la supervivencia. Véase, por ejemplo, Fearon et al. (2012) CeLl METABOLISM 16: 153-166.
Por consiguiente, en determinadas realizaciones de la presente invención, pueden administrarse uno o más inhibidores de la Activina-A o del receptor de la Activina-A, el ActRIIB, de la IL-6 o del receptor de la IL-6 (el IL-6R) en combinación con (por ejemplo, administrados en el mismo momento que, administrados antes o administrados después), un anticuerpo de la presente invención que inhibe la actividad del DF15. Algunos ejemplos de inhibidores de la Activina-A o del ActRIIB incluyen, por ejemplo, un anticuerpo anti-Activina-A o un fragmento de unión al antígeno del mismo, un anticuerpo anti-ActRIIB o un fragmento de unión al antígeno del mismo, un inhibidor de molécula pequeña de la Activina-A, un inhibidor de molécula pequeña del ActRIIB, y un receptor 'señuelo' del ActRIIB, tal como un receptor ActRIIB soluble y una fusión del receptor ActRIIB soluble con una molécula Fc (ActRIIB-Fc). Véase, por ejemplo, Zhou et al. (2010), supra. Algunos inhibidores adecuados de la IL-6 o del IL-6R incluyen un anticuerpo anti-IL-6 o un fragmento de unión al antígeno del mismo, un anticuerpo anti-IL-6R o un fragmento de unión al antígeno del mismo, un inhibidor de molécula pequeña de la IL-6, un inhibidor de molécula pequeña del IL-6R, y un receptor 'señuelo' del IL-6R, tal como un receptor IL-6 soluble y una fusión del receptor IL-6 soluble con una molécula Fc (IL6R-Fc). Véase, por ejemplo, Enomoto et al. (2004) BIo Ch EM. AND BIOPHYS. RES. COMM. 323: 1096-1102; Argiles et al. (2011) EUR. J. PHARMACOL. 668: S81-S86; Tuca et al. (2013) ONCOLOGY/HEMATOLOGY 88: 625-636. Algunos inhibidores adecuados de la IL-6 o del IL-6R pueden incluir, por ejemplo, tocilizumab (Actemra®, Hoffmann-LaRoche), un anticuerpo monoclonal anti-IL-6R humanizado aprobado para el tratamiento del artritis reumatoide, y Sarilumab/REGN88 (Regeneron), un anticuerpo anti-IL6R humanizado en desarrollo clínico para el tratamiento del artritis reumatoide; y Selumetinib/ AZD6244 (AstraZeneca), un inhibidor alostérico de la MEK, que se ha demostrado que inhibe la producción de la IL-6. Prado et al. (2012) BRITISH J. CANCER 106: 1583-1586.
El TNFa y la IL-1 son citocinas que se sabe que están implicadas en la mediación de la respuesta proinflamatoria, que también están implicadas en el agotamiento muscular, la anorexia y la caquexia. Un aumento en los niveles del TNFa en circulación parece inhibir la miogénesis. El TNFa, conocido también como "caquectina", estimula la secreción de la interleucina-1 y está implicado en la inducción de la caquexia. La IL-1 es un potente desencadenante de la respuesta inflamatoria en fase aguda, y se ha demostrado que la infusión de IL-1 puede dar lugar a una notable pérdida de peso y pérdida del apetito. Se ha demostrado que la IL-1 contribuye al inicio de la caquexia cancerosa en ratones portadores de un adenocarcinoma murino de colon-26 (Strassmann et al. (1993) J. IMMUNOL. 150: 2341). Véase también, Matis y Billiau (1997) NUTRITION 13: 763-770; Fong et al. (1989) AM. J. PHYSIOL. -REGULATORY, INTEGRATIVE AND COMPARATIVE PHYSIOL., 256: R659-R665. Por lo tanto, los inhibidores del TNFa y los inhibidores de la IL-1 que se usan en el tratamiento de la artritis reumatoide también pueden ser útiles en el tratamiento de la caquexia.
Por consiguiente, en determinadas realizaciones de la presente invención, pueden administrarse uno o más inhibidores del TNFa o de la IL-1 en combinación con (por ejemplo, administrados al mismo tiempo que, administrados antes o administrados después), un anticuerpo de la presente invención que inhibe la actividad del GDF15. Algunos inhibidores adecuados del TNFa o de la IL-1 incluyen un anticuerpo anti-TNFa o un fragmento de unión al antígeno del mismo, un anticuerpo anti-IL-1 o un fragmento de unión al antígeno del mismo, un inhibidor de molécula pequeña del TNFa o de la IL-1, y un receptor 'señuelo' del TNFa o de la IL-1, tal como un receptor del TNFa o de la IL-1 soluble y una fusión de la forma soluble del TNFa o de la IL-1 con una molécula Fc. Algunos inhibidores adecuados del TNFa incluyen, por ejemplo, etanercept (Enbrel®, Pfizer/Amgen), infliximab (Remicade®, Janssen Biotech), adalimumab (Humira®, Abbvie), golimumab (Simponi®, Johnson and Johnson/Merck) y certolizumab pegol (Cimzia®, UCB). Algunos inhibidores adecuados de la IL-1 incluyen, por ejemplo, Xilonix®, un anticuerpo que se dirige a la IL-1 a (XBiotech), anikinra (Kinaret®, Amgen), canakinumab (Ilaris®, Novartis) y rilonacept (Arcalyst®, Regeneron). En ciertas realizaciones, el inhibidor del TNFa o el inhibidor de la IL-1, que normalmente se administran sistémicamente para el tratamiento de la artritis reumatoide, pueden ser administrados localmente, y directamente en el sitio del tumor.
La miostatina, conocida también como GDF8, es un miembro de la familia de péptidos del TGF-p que es un regulador negativo de la masa muscular, según demuestra el aumento en la masa muscular en los mamíferos deficientes en miostatina. La miostatina es un ligando del receptor de la activina de tipo 2, el ActRIIB. Por consiguiente, en determinadas realizaciones de la presente invención, pueden administrarse uno o más inhibidores de la miostatina o de su receptor en combinación con (por ejemplo, administrados al mismo tiempo que, administrados antes o administrados después), un anticuerpo de la invención que inhibe la actividad del GDF15. Algunos inhibidores adecuados de la miostatina o del ActRIIB incluyen un anticuerpo anti-miostatina o un fragmento de unión al antígeno del mismo, un anticuerpo anti-ActRIIB o un fragmento de unión al antígeno del mismo, un inhibidor de molécula pequeña de la miostatina, un inhibidor de molécula pequeña del ActRIIB, y un receptor 'señuelo' del GDF-8, tal como un ActRIIB soluble y una fusión de la forma soluble del ActRIIB con una molécula Fc. Véase, por ejemplo, Lokireddy et al. (2012) BIOCHEM. J. 446 (1): 23-26. Algunos inhibidores de la miostatina que pueden ser adecuados para la presente invención incluyen REGN1033 (Regeneron); véase Bauerlein et al. (2013) J. CACHEXIA SARCOPENIA m Us CLE: Abstracts of the 7th Cachexia Conference, Kobe/Osaka, Japón, 9-11 de diciembre de 2013, Resumen 4-06; LY2495655 (Lilly), un anticuerpo anti-miostatina humanizado en desarrollo clínico por Eli Lilly; véase también "A PHASE 2 STUDY OF LY2495655 IN PARTICIPANTS WITH PANCREATIC CANCER", disponible en internet en clinicaltrials.gov/ct2/NCT01505530; identificador NML: NCT01505530; ACE-031 (Acceleron Pharma); y stamulumab (Pfizer).
Algunos agentes tales como la grelina o miméticos de la grelina, u otros secretagogos de la hormona del crecimiento (GHS) que son capaces de activar el receptor de la GHS (GHS-R1 a), conocido también como receptor de la grelina, pueden ser útiles para aumentar la ingesta de alimentos y el peso corporal en seres humanos. Véase Guillory et al. (2013) en VITAMINS AND HORMONES vol. 92, cap. 3; y Steinman y DeBoer (2013) VITAMINS AND HORMONES vol. 92, Cap. 8. Algunos miméticos de la de grelina adecuados incluyen anamorelin (Helsinn, Lugano, CH); Véase Temel et al. (2013) J. CACHEXIA SARCOPENIA MUSCLE: Abstracts of the 7th Cachexia Conference, Kobe/Osaka, Japón, 9-11 de diciembre de 2013, Resumen 5-01. Otras moléculas GHS adecuadas pueden ser identificadas, por ejemplo, usando el ensayo de competición de la grelina del receptor secretagogo de la hormona del crecimiento descrito en las Publicaciones PCT n° WO2011/117254 y WO2012/113103.
Los agonistas del receptor de andrógenos, incluyendo moléculas pequeñas y otros moduladores selectivos del receptor de andrógenos (SARM) pueden ser útiles en el tratamiento de la caquexia y/o de la sarcopenia. Véase, por ejemplo, Mohler et al. (2009) J. MED. CHEM. 52: 3597-3617; Nagata et al. (2011) BIOORGANIC AND MED. CHEM. LEtTe Rs 21: 1744-1747; y Chen et al. (2005) MOL. INTErV. 5: 173-188. De manera ideal, los SARM deben actuar como agonistas totales, como la testosterona, en tejidos objetivo anabólicos, tales como el músculo y el hueso, pero deben mostrar únicamente unas actividades antagonistas del receptor de andrógenos parciales o puras en el tejido prostático. Véase, por ejemplo, Bovee et al. (2010) J. STEROID BiOCHEM. & MOL. BiOL. 118: 85-92. Los SARM adecuados pueden ser identificados, por ejemplo, mediante el uso de los métodos y los ensayos descritos en Zhang et al. (2006) BIOORG. MED. CHEM. LETT. 16: 5763-5766; y en Zhang et al. (2007) BIOORG. MED. CHEM. LETT.
17: 439-443. Algunos SARM adecuados incluyen, por ejemplo, GTx-024 (enobosarm, Ostarine®, GTx, Inc.), un SARM en desarrollo clínico en fase II de GTx, Inc. Véase también, Dalton et al. (2011) J. CACHEXlA SARCOPENIA MUSCLE 2: 153-161. Otros SARM adecuados incluyen 2-(2,2,2)-trifluoroetil-bencimidazoles (Ng et al. (2007) BIOORG. MED. CHEM. LETT. 17: 1784-1787) y JNJ-26146900 (Allan et al. (2007) J. STEROID BIOCHEM. & MOL. BIOL. 103: 76-83).
Los bloqueantes del receptor p-adrenérgico, o betabloqueantes, se han estudiado por su efecto sobre el peso corporal en sujetos caquécticos, y se han asociado con una reversión parcial de la caquexia en pacientes con insuficiencia cardiaca congestiva. Véase, por ejemplo, Hryniewicz et al. (2003) J. CARDIAC FAILURE 9: 464-468. El betabloqueante MT-102 (PsiOxus Therapeutics, Ltd.) se ha evaluado en un ensayo clínico en fase 2 para sujetos con caquexia cancerosa. Véase Coats et al. (2011) J. CACHEXIA SARCOPENIA MUSCLE 2: 201 -207.
Los ratones con el receptor de la melanocortina inactivado, con un defecto genético en la señalización de la
melanocortina, muestran un fenotipo opuesto al de la caquexia: un aumento del apetito, un aumento en la masa magra corporal y una disminución en el metabolismo. Por lo tanto, el antagonismo de la melanocortina ha surgido como un potencial tratamiento para la caquexia asociada con una enfermedad crónica (DeBoer y Marks (2006) TRENDS IN ENDOCRINOLOGY AND MEtAbOLISM 17: 199-204). Por consiguiente, en determinadas realizaciones de la presente invención, pueden administrarse uno o más inhibidores de un péptido de melanocortina o de un receptor de la melanocortina en combinación (por ejemplo, administrados al mismo tiempo que, administrados antes o administrados después) con un anticuerpo de la invención que inhibe la actividad del GDF15. Algunos inhibidores adecuados de las melanocortinas o de los receptores de la melanocortina incluyen un anticuerpo anti-péptido de melanocortina o un fragmento de unión al antígeno del mismo, un anticuerpo anti-receptor de la melanocortina o un fragmento de unión al antígeno del mismo, un inhibidor de molécula pequeña de un péptido de melanocortina, un inhibidor de molécula pequeña de un receptor de la melanocortina, y un receptor 'señuelo' de un receptor de la melanocortina, tal como un receptor de la melanocortina soluble y una fusión de un receptor soluble de la melanocortina con una molécula Fc. Algunos inhibidores adecuados del receptor de la melacortina incluyen, por ejemplo, el péptido antagonista del receptor de la melanocortina relacionado con agouri (AgRP(83-132)), que se ha demostrado que previene los síntomas relacionados con la caquexia en un modelo de ratón de caquexia relacionada con cáncer (Joppa et al. (2007) PEPTIDES 28: 636-642).
Algunos agentes antineoplásicos, especialmente aquellos que pueden causar caquexia y elevar los niveles del GDF15, tales como el cisplatino, pueden usarse en los métodos de la presente invención en combinación con (por ejemplo, administrados al mismo tiempo que, administrados antes o administrados después) un anticuerpo anti-GDF15 de la invención. Muchos pacientes oncológicos están debilitados por los duros tratamientos de radio- y/o quimioterapia, que puede limitar la capacidad del paciente para tolerar dichas terapias, y por lo tanto restringir el régimen de dosificación. Ciertos agentes neoplásicos, tales como fluorouracilo, adriamicina, metotrexato y cisplatino, pueden contribuir a la caquexia, por ejemplo, induciendo complicaciones gastrointestinales graves. Véase, por ejemplo, Inui (2002) CANc Er J. FOr CLINiCiANS 52: 72-91. Mediante los métodos de la presente invención, en los que se administra a un agente antineoplásico en combinación con un anticuerpo anti-GDF15 de la invención, es posible reducir la incidencia y/o la gravedad de la caquexia, y finalmente aumentar la dosis máxima tolerada adición dicho agente antineoplásico. Por consiguiente, la eficacia del tratamiento con agentes antineoplásicos que pueden causar caquexia puede mejorarse reduciendo la incidencia de la caquexia como un efecto adverso limitante de la dosis, y permitiendo la administración a unas dosis mayores de un agente antineoplásico dado.
Por lo tanto, la presente invención incluye composiciones farmacéuticas que comprenden un anticuerpo anti-GDF15 de la presente invención en combinación con un agente seleccionado entre el grupo que consiste en: un inhibidor de la Activina-A, un inhibidor del ActRIIB, un inhibidor de la IL-6 o un inhibidor del IL-6R, una grelina, un mimético de la grelina o un agonista del GHS-R1a, un SARM, un inhibidor del TNFa, un inhibidor de la IL-1 a, un inhibidor de la miostatina, un betabloqueante, un inhibidor del péptido de melanocortina, un inhibidor del receptor de la melanocortina y un agente antineoplásico,. La presente invención también incluye un uso médico de tratamiento, prevención o minimización de la caquexia y/o de la sarcopenia en un mamífero que comprende la administración al mamífero en necesidad de las mismas de una composición o composiciones farmacéuticas que comprenden una cantidad eficaz de un anticuerpo anti-GDF15 de la invención en combinación con una cantidad eficaz de un inhibidor de la Activina-A, un inhibidor del ActRIIB, un inhibidor de la IL-6 o un inhibidor del IL-6R, una grelina, un mimético de la grelina o un agonista del GHS-R1a, un SARM, un inhibidor del TNFa, un inhibidor de la IL-1 a, un inhibidor de la miostatina, un betabloqueante, un inhibidor del péptido de melanocortina o un inhibidor del receptor de la melanocortina,.
Un uso médico de inhibir la pérdida de masa muscular asociada con una enfermedad subyacente que comprende la administración a un mamífero en necesidad de las mismas de una composición o composiciones farmacéuticas que comprenden una cantidad eficaz de un anticuerpo anti-GDF15 de la invención en combinación con una cantidad eficaz de un inhibidor de la Activina-A, un inhibidor del ActRIIB, un inhibidor de la IL-6 o un inhibidor del IL-6R, una grelina, un mimético de la grelina o un agonista del GHS-R1 a, un SARM, un inhibidor del TNFa, un inhibidor de la IL-1a, un inhibidor de la miostatina, un betabloqueante, en el presente documento se describe un inhibidor del péptido de melanocortina o un inhibidor del receptor de la melanocortina para prevenir o reducir la pérdida de masa muscular. La enfermedad subyacente puede seleccionarse entre el grupo que consiste en cáncer, insuficiencia cardiaca crónica, enfermedad renal crónica, EPOC, SIDA, esclerosis múltiple, artritis reumatoide, síndrome séptico y tuberculosis. Adicionalmente, la pérdida de masa muscular está acompañada por una pérdida de masa grasa.
Un uso médico de inhibir o reducir la pérdida involuntaria de peso en un mamífero que comprende la administración a un mamífero en necesidad de las mismas de una composición farmacéutica o de composiciones farmacéuticas que comprenden una cantidad eficaz de un anticuerpo anti-GDF15 de la invención en combinación con una cantidad eficaz de un inhibidor de la Activina-A, un inhibidor del ActRIIB, un inhibidor de la IL-6 o un inhibidor del IL-6R, una grelina, un mimético de la grelina o un agonista del GHS-R1 a, un SARM, un inhibidor del TNFa, un inhibidor de la IL-1a, un inhibidor de la miostatina, un betabloqueante, en el presente documento también se describe un inhibidor del péptido de melanocortina o un inhibidor del receptor de la melanocortina.
Ciertos agentes antineoplásicos, tales como el cisplatino, tienen uno o más efectos adversos indeseables que implican causar o aumentar uno o más síndromes tales como caquexia, sarcopenia, consunción muscular,
consunción ósea o pérdida involuntaria de peso corporal. Por consiguiente, la presente invención se refiere al uso médico para el tratamiento del cáncer, a la vez que previene, minimiza o reduce la aparición, la frecuencia o la gravedad de la caquexia, la sarcopenia o la consunción muscular, la consunción ósea o la pérdida involuntaria de peso corporal en un mamífero, que comprende la administración a un mamífero en necesidad de la misma de una composición farmacéutica que comprende una cantidad eficaz de un anticuerpo anti-GDF15 de la presente invención en combinación con uno o más agentes antineoplásicos. La invención se refiere al uso médico para el tratamiento del cáncer, a la vez que previene, minimiza o reduce la aparición, la frecuencia o la gravedad de la caquexia, la sarcopenia o la consunción muscular, la consunción ósea o la pérdida involuntaria de peso corporal en un mamífero, que comprende la administración a un mamífero en necesidad de la misma de una composición farmacéutica que comprende una cantidad eficaz de un anticuerpo anti-GDF15 de la invención en combinación con uno o más agentes antineoplásicos que se sabe que causan o aumentan la aparición, la frecuencia o la gravedad de la caquexia, la sarcopenia o la consunción muscular, la consunción ósea o la pérdida involuntaria de peso corporal en un mamífero.
Ejemplos
Los siguientes Ejemplos son meramente ilustrativos y no pretenden limitar el ámbito o el contenido de la invención en modo alguno.
Ejemplo 1: Niveles séricos del GDF15 humano en modelos de xenoinjerto tumoral de ratón
En este ejemplo, se midió la cantidad de hGDF15 en el suero de ratones portadores de diversos tumores xenoinjertados. Se recogió el suero de tres ratones para cada uno de los siguientes modelos de xenoinjerto tumoral: Chago, RPMI7951, PC3, TOV21G, HT-1080, K-562 y LS1034. También se recogió el suero de tres ratones sin tratamiento previo como control. Los niveles séricos del GDF15 humano se determinaron mediante un ELISA (R&D Systems, n° de cat. DY957E). Los ratones portadores de tumores humanos xenoinjertados que inducen caquexia tenían unos niveles séricos del hGDF15 por encima de 2 ng/ml, mientras que los ratones portadores de tumores humanos xenoinjertados que no inducen caquexia tenían unos niveles séricos del hGDF15 por debajo de 1 ng/ml (FIG. 2). Los ratones sin tratamiento previo no tenían hGDF15 detectable (control). Estos resultados indican que un nivel sérico de aproximadamente 2 ng/ml de GDF15 es un umbral para la inducción de caquexia en este modelo de ratón. También se observaron unos niveles similares de hGDF15 en plasma cuando se determinaron mediante un ELISA.
Ejemplo 2: Modelo de caquexia en ratón no portador de tumor
Un modelo existente de caquexia en ratón no portador de tumores se basa en la inyección de rhGDF15 maduro en un ratón (Johnen et al. (1997) NAT. MED. 13: 1333-1340). El rhGDF15 maduro se corresponde con los aminoácidos 197 hasta 308 de la proteína hGDF15. El rhGDF15 maduro puede producirse en la levadura Pichia pastoris según se describe en Fairlie et al. (2000) GENE 254: 67-76). El rhGDF15 escindido se corresponde con los aminoácidos 197 hasta 308 de la proteína hGDF15 liberada desde una proteína de fusión Fc-rhGDF15. En las FIGS. 3-4 descritas a continuación, el rhGDF15 escindido se produjo mediante una digestión enzimática de la proteína de fusión mFcrhGDF15 con Factor Xa, y la posterior purificación, antes de su inyección en ratones.
Para investigar la semivida del rhGDF15 escindido, se recogió plasma de un grupo de tres ratones después de una única dosis del rhGDF15 escindido (1 pg/g) en diferentes puntos temporales (2, 5, 8, 11 y 23 horas). Los niveles plasmáticos del GDF15 humano se determinaron mediante un ELISA (R&D Systems, n° de cat. DY957E). Como se muestra en la Figura 3, el rhGDF15 escindido fue rápidamente eliminado del plasma después de la inyección. Once horas después de la inyección, la cantidad del rhGDF15 escindido en el plasma era inferior a 10 ng/ml, y, en 23 horas, el rhGDF15 escindido estaba casi completamente eliminado del plasma.
Se investigó adicionalmente la rápida eliminación del rhGDF15 escindido en ratones no portadores de tumor. Se dividieron aleatoriamente ratones ICR-SCID hembra de ocho semanas de edad en dos grupos de diez ratones cada uno. A los ratones se les administró subcutáneamente en el costado cada ocho horas durante tres días (un total de nueve dosis) uno de los siguientes tratamientos: PBS (control) o rhGDF15 escindido a 1 pg/g. El peso corporal se midió diariamente. Se realizaron análisis estadísticos usando un ANOVA bifactorial.
Como se muestra en la FIG.4, el rhGDF15 escindido indujo una pérdida de peso corporal. Después de nueve dosis lo largo de un periodo de tres días, el porcentaje de peso corporal cayó hasta un 88 % el día 4 (p < 0,001), pero aproximadamente 24 horas después de la última dosis, los ratones comenzaron a ganar peso. El día 6, el último día del experimento, el porcentaje de peso corporal aumentó hasta un 94,8 por ciento (p < 0,001). Estos resultados indican que la pérdida de peso inducida por el rhGDF15 escindido no se sostiene durante largos periodos de tiempo. La actividad observada con el rhGDF15 escindido descrito en el presente documento era similar a la observada con el rhGDF15 maduro en el modelo de ratón existente (Johnen et al., supra).
El modelo de ratón no portador de tumor existente para la caquexia se basa en la inyección de grandes cantidades de rhGDF15 maduro administrado en múltiples dosis al día para inducir la pérdida muscular y la pérdida de peso corporal (Johnen et al., supra). Resulta que si se usa el rhGDF15 maduro o el rhGDF15 escindido, los ratones la
mantienen la pérdida de peso muscular ni la pérdida de peso corporal durante largos periodos de tiempo o sin un administración continua. Esto limita la utilidad de dichos modelos. Además, las repetidas administraciones requieren la frecuente manipulación de estos ratones, lo que introduce un estrés que puede comprometer la fiabilidad de las mediciones de la pérdida de peso corporal. Por ejemplo, como se muestra en la FIG. 4, los ratones tratados con múltiples dosis de PBS mostraron una caída en el peso corporal debido al estrés de las repetidas administraciones y manipulaciones.
Ejemplo 3: Proteínas de fusión GDF15
En vista de las grandes cantidades de rhGDF 15 maduro (o de rhGDF15 escindido) y la intensidad del esfuerzo requerido para inducir modelos de ratón de caquexia no portador de tumor (así como las limitaciones resultantes de estos modelos), investigamos formas alternativas del rhGDF 15 para inducir un fenotipo caquéctico en ratones. Este Ejemplo describe la construcción en la producción de dos proteínas de fusión que consisten en GDF15 y un fragmento Fc de inmunoglobulina, denominadas mFc-rhGDF15 (Fc de la IgG1 de ratón fusionada con el amino terminal del GDF15 maduro humano) y rFc-rmGDF15 (Fc de la IgG1 de conejo fusionada con el amino terminal del GDF15 maduro de ratón). Las proteínas de fusión GDF15 se diseñaron usando métodos conocidos en la técnica. Las secuencias de ADN de la mFc-rhGDF15 se construyeron a partir de fragmentos usando una PCR de extensión con solapamiento para incluir (en el siguiente orden): un sitio de restricción HindIII en 5', una secuencia consenso Kozak, una secuencia de señal amino terminal, una Fc de la IgG1 de ratón, un sitio de escisión del Factor Xa, un conector polipeptídico (GGGGS) (SEQ ID NO: 139), un hGDF15 maduro, un codón de terminación y un sitio de restricción 3' EcoRI. Las secuencias de aminoácidos de la rFc-rmGDF15 se convirtieron en secuencias de ADN con codones optimizados y se sintetizaron para incluir (en el siguiente orden): un sitio de restricción HindIII en 5', una secuencia consenso Kozak, una secuencia de señal amino terminal, la Fc de la IgG1 de conejo, un conector polipeptídico (GGGG) (SEQ ID NO: 265), un GDF15 maduro de ratón, un codón de terminación y un sitio de restricción 3' EcoRI.
Las proteínas de fusión GDF15 se subclonaron en el vector de expresión de mamífero pEE14.4 (Lonza, Basilea, Suiza) a través de los sitios HindIII y EcoRI usando una clonación por PCR In-Fusion™ (Clontech, Mountain View, CA). Las proteínas de fusión GDF15 se expresaron de forma estable en células CHOK1SV usando el GS System™ (Lonza Biologics) con objeto de producir grandes cantidades de proteína purificada. Cada vector de expresión fue linealizado y transfectado en células CHOK1SV. Los clones estables fueron seleccionados en presencia de metionina sulfoximina. Las proteínas secretadas producidas por las líneas celulares CHOK1SV transfectadas de forma estable se purificaron mediante Proteína A y una cromatografía de exclusión por tamaños.
La secuencia de ácidos nucleicos y la secuencia proteica codificada que define la proteína de fusión Fc de la IgG1 de ratón-GDF15 maduro humano (mFc-rhGDF15) se muestran a continuación. La mFc-rhGDF15 contiene la Fc de la IgG1 de ratón desde los aminoácidos 1-222, el sitio de escisión del Factor Xa desde los aminoácidos 223-228, una secuencia conectora artificial desde los aminoácidos 229-233 y el hGDF15 maduro desde los aminoácidos 234-345.
Secuencia de ácidos nucleicos que codifica la proteína de fusión Fc de la IgG1 de ratón - GDF15 maduro humano (mFc-rhGDF15) (SEQ ID NO: 219)
1 gggtgtaaac cctgcatctg cacggtgccg gaggtgtcct ccgtctttat cttccctccc 61 aaacccaagg atgtgctgac aatcactttg actccaaaag tcacatgcgt agtcgtggac 121 atctcgaaag acgacccgga agtgcagttc tcgtggtttg ttgatgatgt agaagtgcat 181 accgctcaaa cccagccgag ggaagaacag tttaacagca cgtttaggag tgtgtcggaa 241 ctgcccatta tgcaccagga ttggcttaat gggaaggagt tcaaatgtcg cgtgaatagt 301 gcggcgttcc cagcccctat tgaaaagact atttccaaaa cgaagggtcg gcccaaagct 361 ccccaagtat acacaatccc tccgccgaaa gaacaaatgg caaaagacaa agtgagtttg 421 acgtgcatga tcacggactt tttcccggag gatatcaccg tcgaatggca atggaatggg 481 caacctgccg aaaactacaa gaatacacaa cccattatgg ataccgatgg atcgtatttc 541 gtctactcaa agttgaacgt acagaagtca aattgggagg cagggaatac gttcacttgc 601 agtgttttgc acgaaggcct ccataaccac catacggaaa agtcactgtc gcactccccg 661 ggaaaaatcg agggcagaat ggatggtgga ggagggtcgg cgcgcaacgg ggaccactgt 721 ccgctcgggc ccgggcgttg ctgccgtctg cacacggtcc gcgcgtcgct ggaagacctg 781 ggctgggccg attgggtgct gtcgccacgg gaggtgcaag tgaccatgtg catcggcgcg 841 tgcccgagcc agttccgggc ggcaaacatg cacgcgcaga tcaagacgag cctgcaccgc 901 ctgaagcccg acacggtgcc agcgccctgc tgcgtgcccg ccagctacaa tcccatggtg 961 ctcattcaaa agaccgacac cggggtgtcg ctccagacct atgatgactt gttagccaaa 1021 gactgccact gcata
Secuencia de proteínas que define la proteína de fusión Fc de la IgG1 de ratón - GDF15 maduro humano (mFcrhGDF15) (SEQ ID NO: 220)
i gckpcictvp evssvfifpp kpkdvltitl tpkvtcvvvd iskddpevqf swfvddvevh
61 taqtqpreeq fnstfrsvse lpimhqdwln gkefkcrvns aafpapiekt isktkgrpka
121 pqvytipppk eqmakdkvsl tcmitdffpe ditvewqwng qpaenykntq pimdtdgsyf
181 vysklnvqks nweagntfte svlheglhnh htekslshsp gkiegrmdgg ggsarngdhc
241 plgpgrccr1 htvrasledl gwadwvlspr evqvtmciga cpsqfraanm haqiktslhr
301 lkpdtvpapc cvpasynpmv liqktdtgvs lqtyddllak dehei
La secuencia de ácidos nucleicos y la secuencia de proteínas codificada que define la proteína de fusión Fc de la IgG1 de conejo-GDF15 maduro de ratón (rFc-rmGDF15) se muestran a continuación. La rFc-rmGDF15 contiene la Fc de la IgG 1 de conejo desde los aminoácidos 1 -223, una secuencia conectora artificial desde los aminoácidos 224 227 y el GDF15 maduro de ratón desde los aminoácidos 228-342.
Secuencia de ácidos nucleicos que codifica la proteína de fusión Fc de la IgG1 de conejo - GDF15 maduro de ratón (rFc-rmGDF15) (SEQ ID NO: 221)
1 tcgaaaccca cttgccctcc tccggagctg ttgggcggac cctccgtgtt tatctttccc 61 ccgaagccga aagataccct tatgatctca cggacgccgg aggtcacttg cgtagtagtg
121 gatgtgtcgg aggatgaccc cgaagtccag ttcacctggt atatcaataa cgagcaagtg
181 aggacagcga ggcccccact tagggagcag cagttcaact ccacaattcg ggtcgtcagc
241 actttgccca tcgctcatga ggactggctc cgcggaaaag agttcaagtg taaggtgcat
301 aacaaggcat tgccagcgcc tattgaaaag acaatctcga aggcgcgagg gcagccgctc
361 gagcccaaag tgtatacgat gggacccccg agggaagaat tgtcgtcgcg ctcagtaagc
421 cttacgtgca tgattaacgg tttctaccct agcgacatca gcgtagagtg ggaaaagaat
481 ggaaaggcgg aggataacta caagacgact cccgcggtgc tggattcgga tgggtcgtac
541 tttctgtata gcaaattgtc agtcccgacc tcagaatggc agaggggtga cgtgttcacg
601 tgctccgtga tgeaegaage acttcacaat cactacaccc agaaatcaat ctcgcggtcc
661 ccaggcaaag gtggaggagg gtcggctcac gcccaccctc gcgattcgtg tccgctgggg
721 cctggtagat gctgtcatct cgagacagtc caggccacgc tggaggacct cgggtggtca
781 gactgggtcc tgtccccacg acaactgcag ctttcgatgt gcgtggggga atgtccgcac
841 ttgtacagat cggcgaatac ccacgctcag attaaggcac gactccatgg tttgcagcca
901 gataaagtcc ccgcaccttg ctgtgtcccc agctcatata ctcctgtcgt actcatgcat
961 cggacagaca gcggcgtgtc gcttcaaacg tatgacgacc tcgtagcgag aggatgtcat 1021 tgcgcc
Secuencia de proteínas que define la proteína de fusión Fc de la IgG1 de conejo - GDF15 maduro de ratón (rFcrmGDF15) (SEQ ID NO: 222)
1 skptcpppellggpsvfifp pkpkdtlmis rtpevtcvvv dvseddpevq ftwyinneqv 61 rtarpplreq qfnstirvvs tlpiahedwl rgkefkckvh nkalpapiek tiskargqpl
121 epkvytmgpp reelssrsvs ltcmingfyp sdisvewekn gkaednyktt pavldsdgsy
181 flysklsvptsewqrgdvft csvmhealhn hytqksisrs pgkggggsah ahprdscplg
241 pgrcchletv qatledlgws dwvlsprqlq lsmcvgecph lyrsanthaq ikarlhglqp
301 dkvpapccvp ssytpvvlmh rtdsgvslqt yddlvargch ca
Las siguientes secuencias representan ejemplos de secuencias de proteínas para las proteínas de fusión Fc de la IgG1 humana-GDF15 maduro humano (hFc-rhGDF15). La hFc-rhGDF15 Xa consiste en la Fc de la IgG1 humana desde los aminoácidos 1-227, el sitio de escisión del Factor Xa desde los aminoácidos 228-233, una secuencia conectora artificial desde los aminoácidos 234-238 y el hGDF15 maduro desde los aminoácidos 239-350. La hFcrhGDF15 consiste en la Fc de la IgG 1 humana desde los aminoácidos 1-227, una secuencia conectora artificial desde los aminoácidos 228-232 y el hGDF15 maduro desde los aminoácidos 233-344.
Secuencia de proteínas que define la proteína de fusión Fc de la IgG1 humana - GDF15 maduro humano con un sitio de escisión Xa (hFc-hGDF15 Xa) (SEQ ID NO: 223)
1 dkthtcppcp apellggpsv flfppkpkdt lmisrtpevt cvvvdvshed pevkfnwyvd 61 gvevhnaktk preeqynsty rvvsvltvlh qdwlngkeyk ckvsnkalpa piektiskak 121 gqprepqvyt lppsreemtk nqvsltclvk gfypsdiave wesngqpenn ykttppvlds 181 dgsfflyskl tvdksrwqqg nvfscsvmhe alhnhytqks lslspgkieg rmdggggsar 241 ngdhcplgpg rccrlhtvra sledlgwadw vlsprevqvt mcigacpsqf raanmhaqik 301 tslhrlkpdt vpapccvpas ynpmvliqkt dtgvslqtyd dllakdchci
Secuencia de proteínas que define la proteína de fusión Fc de la IgG1 humana - GDF15 maduro humano con thFchGDF15) (SEQ ID NO: 224)
1 dkthtcppcp apellggpsv flfppkpkdt lmisrtpevt cvvvdvshed pevkfnwyvd 61 gvevhnaktk preeqynsty rvvsvltvlh qdwlngkeyk ckvsnkalpa piektiskak
121 gqprepqvyt lppsreemtk nqvsltclvk gfypsdiave wesngqpenn ykttppvlds
181 dgsfflyskl tvdksrwqqg nvfscsvmhe alhnhytqks lslspgkggg gsarngdhcp
241 lgpgrccrlh tvrasledlg wadwvlspre vqvtmcigac psqfraanmh aqiktslhrl
301 kpdtvpapccvpasynpmvl iqktdtgvsl qtyddllakd chci
Ejemplo 4: Modelo de caquexia inducida por Fc-rhGDF15
Este Ejemplo describe la generación de un modelo de caquexia inducida por Fc-GDF15 en ratones. Se dividieron aleatoriamente ratones inmunocompetentes (Balb/C) y no inmunocompetentes (CB17-Scid) en tres grupos de diez ratones cada uno. Cada grupo recibió uno de los siguientes tratamientos: PBS (control), mFc-rhGDF15 (como se describe en el Ejemplo 3), o rFc-rmGDF15 (como se describe en el Ejemplo 3) a 1 mg/g. A ratones hembra de ocho semanas de edad se les administró subcutáneamente en el costado durante tres días (Balb/C) o una vez (CB17-Scid). El peso corporal se midió diariamente.
Como se muestra en las FIG. 5A y FIG. 5B, la administración de la mFc-rhGDF15 o de la rFc-rmGDF15 indujo una pérdida de peso corporal en los ratones inmunocompetentes (FIG. 5A) y en los no inmunocompetentes (FIG. 5B). Estos resultados indican que se consiguió un nivel de estado estacionario del rhGDF15 activo, porque, independientemente de la dosis (una frente a tres dosis), tanto la mFc-rhGDF15 como la rFc-rmGDF15 indujeron una pérdida de peso sostenida en el periodo de tiempo medido (7 días).
Las proteínas de fusión, mFc-rhGDF15 y rFc-rmGDF15, se analizaron adicionalmente en razas de ratones inmunocompetentes (C57BL6, Swiss Webster) y no inmunocompetentes (ICR-SCID). En cada raza de ratón analizada, la administración de mFc-rhGDF15 o de rFc-rmGDF15 inducía una caquexia, medida por la pérdida de peso corporal. Se obtenían unos resultados similares independientemente de si la mFc-rhGDF15 se administraba por vía subcutánea o intraperitoneal.
También se investigó si la mFc-rhGDF15 inducía una pérdida de peso independientemente de la edad de los ratones tratados con la proteína de fusión. Se dividieron ratones hembra Swiss Webster (inmunocompetentes) de diferentes edades (7, 13 y 25 semanas de edad) en dos grupos de diez, y se trataron con tres dosis al día de mFc-rhGDF15 o de PBS (0,8 pg/g, ratones de 7 semanas de edad; 0,6 pg/g, ratones de 13 semanas de edad; o 0,4 pg/g, ratones de 25 semanas de edad). La pérdida de peso inducida por la mFc-rhGDF15 se observó en las tres poblaciones de edad de ratones. En cada población de edad, los ratones perdían aproximadamente un 10 % de su peso corporal de después del tratamiento con mFc-rhGDF15 medido diez días después del tratamiento.
En otro experimento, se investigó la inducción de caquexia de la mFc-rhGDF15 midiendo la pérdida de peso corporal, la pérdida de masa muscular, la pérdida de masa grasa y los niveles de expresión de dos marcadores moleculares indicativos de degradación muscular (es decir, mMuRF1 y mAtrogina). La MuRF1 y la Atrogina son ligasas de E3-ubquitina que están reguladas por aumento en múltiples modelos de atrofia muscular y de caquexia (Glass, D. (2010) CURR. OPIN. CLIN. NUTR. MET. CARE 13: 225-229).
Se dividieron aleatoriamente ratones ICR-SCID hembra de ocho semanas de edad en diez grupos de diez ratones cada uno. A cinco grupos (de diez de ratones cada uno) se les administró subcutáneamente en el costado PBS (control) y a cinco grupos (de diez de ratones cada uno) les administró subcutáneamente en el costado mFcrhGDF15 a 1,6 pg/g el día uno. El peso corporal se midió diariamente durante hasta 17 días. Se sacrificó un grupo de control y un grupo de tratamiento en diferentes puntos temporales (0, 1, 3, 7 y 16 días después de la administración). Se extrajo quirúrgicamente la grasa gonadal y los músculos gastrocnemios de cada grupo de ratones en el momento de sacrificio indicado, y se pesaron. Los tejidos se congelaron instantáneamente en nitrógeno líquido y se aisló el ARN a partir de las muestras de los músculos gastrocnemios. Se midieron los niveles de ARNm de mMuRF1 y de mAtrogina mediante una qRT-PCR en las muestras correspondientes a los grupos recogidas después de 1, 7 y 16 días después de la administración. Se realizaron análisis estadísticos usando un ANOVA bifactorial.
Como se muestra en la FIG. 6A, la mFc-rhGDF15 indujo una pérdida de peso corporal en los ratones ICR-SCID. El porcentaje de peso corporal era del 79,4 por ciento cuando se midió después de 16 días después de una dosis de mFc-rhGDF15 (p < 0,001). La mFc-rhGDF15 también indujo una pérdida de grasa (tejido adiposo), como se observó por la pérdida de grasa gonadal (FIG. 6B; p < 0,01 el día 7 y p < 0,001 el día 16) y pérdida de músculo, como se observó por la pérdida del músculo gastrocnemio (FIG. 6C; p < 0,05 los días 1 y 3, y p < 0,0001 los días 7 y 16). La
administración de la mFc-rhGDF15 también elevó la expresión génica de dos enzimas asociadas con la degradación muscular y la caquexia, la mMuRF1 (FIG. 6D; 6 < 0,001 los días 1, 7 y 16) y la mAtrogina (FIG. 6E; p < 0,001 los días 1 y 7, y p < 0,01 el día 16).
Estos resultados indicaban que la mFc-rhGDF15 induce caquexia en ratones.
Ejemplo 5: La mFc-rhGDF15 induce caquexia con una semivida sérica más larga del GDF15
En este Ejemplo, se midieron los niveles séricos de la hGDF15 después de la administración de la mFc-rhGDF15, para determinar la semivida de la rhGDF15 en este modelo. Se dividieron aleatoriamente ratones Balb/C atímicos hembra de ocho semanas de edad en dos grupos de doce ratones cada uno. A los ratones se les administró subcutáneamente en el costado cada doce horas durante tres días (un total de seis dosis) uno de los siguientes tratamientos: PBS (control) o mFc-rhGDF15 a 1,33 pg/g. El peso corporal se midió diariamente. Como se muestra en la Figura 7, la mFc-rhGDF15 indujo una pérdida de peso corporal sostenida durante al menos una semana después de la inyección inicial.
En este experimento, se midieron los niveles séricos de hGDF150,2, 5 y 8 días después de la última dosis de mFcrhGDF15. Los ratones se sacrificaron en el momento indicado y se recogieron los sueros. Los niveles séricos del GDF15 humano se determinaron mediante un ELISA (R&D Systems, n° de cat. DY957E). La Tabla 1 proporciona los niveles séricos (pg/ml) para cada ratón del estudio.
Tabla 1

Los resultados de la Tabla 1 revelan que hay presentes unos fuertes niveles séricos sostenidos de hGDF15 al menos ocho días después de la última dosis de mFc-rhGDF15.
También se analizaron las muestras séricas del día 0,2 y del día 5 después de la última dosis mediante una inmunoelectrotransferencia (gel reductor; membrana con anticuerpo contra el hGDF15 (R&D Systems, n° de cat. AF957)) y se cuantificó mediante Licor para determinar la estabilidad de la mFc-rhGDF15 en el suero. Inesperadamente, se observaron dos bandas. La banda superior era de aproximadamente 40 kDa y parecía ser la mFc-rhGDF15. La banda inferior era de aproximadamente 15 kDa y parecía ser el rhGDF15 maduro escindido. Esto indicaba que el rhGDF15 maduro era liberado de la mFc-rhGDF15 en el suero. La cuantificación de las dos bandas demostró que aproximadamente el 90 % del rhGDF15 presente en el suero estaba en forma de mFc-rhGDF15, estando aproximadamente un 10 % del rhGDF15 total del suero presente como la forma madura escindida (FIG. 8). La cuantificación mostró una ligera disminución en la mFc-rhGDF15 en las muestras séricas recogidas cinco días después de la última dosis, pero, sorprendentemente, en el suero permanecía un nivel constante del rhGDF15 maduro. La proporción entre el rhGDF15 maduro y la mFc-rhGDF15 aumentó ligeramente con el tiempo, como resultado de una disminución en mFc-rhGDF15 en el suero. Se observaron unos resultados similares cuando se inyectó la rFc-rmGDF15 en ratones.
Los resultados presentados en las FIGS. 7-8 y en la Tabla 1 eran inesperados. La expectativa era que muy poco, si lo hubiera, rhGDF15 maduro sería escindido (liberado) de la mFc-rhGDF15 el día 0,2, y que cualquier rhGDF15 escindido sería rápidamente eliminado del suero, como se había observado previamente. Por ejemplo, en la FIG. 4, se requirió una serie de nueve dosis a 1 pg/g por dosis (para un total de 9 pg/g) de rhGDF15 escindido para inducir una pérdida de peso corporal significativa en los ratones. Estos ratones ganaron peso, casi inmediatamente cuando se cesó la administración. Por el contrario, una única dosis de mFc-rhGDF15 a 0,1 mg/g era suficiente para inducir una pérdida de peso corporal significativa durante al menos ocho días (FIG. 9A; a diez ratones ICR-SCID se les
administraron intraperitonealmente 0,1 pg/g el día 1). Los datos de la Tabla 1 revelaron que los niveles séricos del rhGDF15 eran estables durante al menos ocho días, cuando se administraba el rhGDF15 en forma de una proteína de fusión mFc-rhGDF15.
Para determinar la fuente de actividad que da como resultado una pérdida de peso corporal sostenida, cualquier investigamos si la actividad observada del rhGDF15 era atribuible a la proteína de fusión mFc-rhGDF15, a la forma madura liberada del rhGDF 15, o a ambos. Como se muestra en la FIG. 9A, una dosis baja de la mFc-rhGDF15 (0,1 pg/g) dio como resultado una pérdida de peso corporal que continuó durante al menos ocho días. Una dosis menor de la mFc-rhGDF15 (0,01 pg/g) también indujo una pérdida de peso corporal, pero el efecto no se sostuvo más de 3 días después de la administración.
En este experimento, se recogió el plasma de tres ratones, a cada uno de los cuales se les habían administrado 0,1 pg/g o 0,01 pg/g, 5 días después de la administración. El rhGDF15 total se midió mediante un ELISA como se describe más arriba. Los niveles plasmáticos totales de rhGDF15 en los ratones a los que se les administraron 0,1 pg/g estaban por encima de 70 ng/ml, lo que es coherente con la observación de que estos ratones tenían una pérdida de peso significativa (FIG. 9B). Los niveles plasmáticos totales de rhGDF15 en ratones a los que se les administraron 0,01 pg/g eran de aproximadamente de 3,3 ng/ml, pero se observó que estos ratones estaban ganando peso (FIG. 9A y FIG. 9B). Como se describe en la FIG. 2, el umbral del hGDF15 para la inducción de caquexia en ratones portadores de tumores es de aproximadamente 2 ng/ml. Por lo tanto, si ambas formas del rhGDF15 eran activas (es decir, la mFc-rhGDF15 y el rhGDF15 maduro liberado), entonces estos ratones deberían estar perdiendo peso, no ganando peso (es decir, 3,3 ng/ml de rhGDF 15 total está por encima del umbral de aproximadamente 2 ng/ml de hGDF15).
Para determinar qué forma era la forma activa (es decir, la mFc-rhGDF15 o el rhGDF15 maduro liberado), consideramos los datos de la FIG. 8 que demostraban que aproximadamente un 90 % del rhGDF15 sérico total estaba en forma de la mFc-rhGDF15 y el 10 % restante era la forma madura liberada. Sobre la base de esta extrapolación, aproximadamente 3,0 ng/ml del rhGDF 15 plasmático estaba en la forma mFc-rhGDF15 (es decir, el 90 % de 3,3 ng/ml). Una vez más, si la mFc-rhGDF15 era activa, estos ratones deberían estar perdiendo peso, no ganando peso, porque 3,3 ng/ml de la mFc-rhGDF15 está por encima del umbral de aproximadamente 2 ng/ml de hGDF15. Los ratones a los que se les administraron 0,1 pg/g de mFc-rhGDF15 sirvieron como control interno, debido a que estos ratones tenían una pérdida de peso corporal sostenida indicativa de que al menos una de las dos formas debía ser activa. Un cálculo del 10 % de 70 ng/ml de rhGDF 15 total en estos ratones es de 7 ng/ml de rhGDF15 maduro liberado. Esta cantidad es coherente con la inducción de la pérdida de peso corporal observada y con el umbral observado en la FIG. 2. Por lo tanto, los datos indican que la mFc-rhGDF15 no es una forma activa de la proteína, y únicamente el rhGDF 15 maduro es activo. Estos resultados fueron inesperados, debido a que: (a) no había ninguna razón para predecir que la proteína de fusión Fc (mFc-rhGDF15) sería inactiva; y (b) no había ninguna razón para predecir que la proteína de fusión Fc liberaría el rhGDF15 maduro a la velocidad observada.
Estos resultados indican que la mFc-rhGDF15 sostiene un fenotipo caquéctico al liberar lentamente el rhGDF15 maduro en el suero. Estos resultados indican además que puede conseguirse un nivel de estado estacionario del rhGDF 15 maduro en el plasma o en el suero en un ratón no portador de tumor mediante la administración de la mFc-rhGDF15 al ratón. Por lo tanto, la administración de la mFc-rhGDF15 a ratones no portadores de tumor es particularmente útil como modelo de ratón de la caquexia con una robusta y sostenida pérdida de masa muscular, pérdida de masa grasa y pérdida de peso corporal (véanse las FIGS. 6A-C).
Ejemplo 6: Anticuerpos anti-GDF15
Este Ejemplo describe la producción de anticuerpos monoclonales anti-GDF15. Las inmunizaciones, las fusiones y los cribados primarios se realizaron usando métodos convencionales siguiendo el protocolo de sitios múltiples de inmunización repetitiva (RIMMS). Se inmunizaron cinco ratones AJ y cinco ratones Balb/c con GDF15 humano recombinante marcado con 6XHis (SEQ ID NO: 266) (His-rhGDF15) (R&D Systems, Inc., Mineápolis, MN). Se eligieron dos ratones Balb/c con unos sueros que muestran la actividad anti-GDF15 más alta mediante un ensayo de inmunoadsorción enzimática (ELISA) para la fusión posterior. Se recolectaron los bazos y los nódulos linfáticos de los ratones apropiados. Se recolectaron los linfocitos B y se fusionaron con una línea de mieloma. Los productos de la fusión se diluyeron sucesivamente en cuarenta placas de 96 pocillos hasta casi clonalidad. Se eligieron dos ratones AJ con unos sueros que muestran la actividad anti-GDF15 más alta mediante un ELISA para la fusión posterior. Se recolectaron los bazos y los nódulos linfáticos de los ratones apropiados. Se recolectaron los linfocitos B y se fusionaron con una línea de mieloma. Los productos de la fusión se diluyeron sucesivamente en cuarenta placas de 96 pocillos hasta casi clonalidad.
Se cribaron aproximadamente 3.840 sobrenadantes de las fusiones celulares mediante un ELISA para analizar la unión al rhGDF15. Adicionalmente, se caracterizaron in vitro un total de 172 sobrenadantes que contienen los anticuerpos contra el GDF15. Se seleccionó un conjunto de hibridomas, se subclonó y se expandió. Los anticuerpos se expresaron y posteriormente se purificaron mediante una cromatografía de afinidad en una resina de Proteína G, en las condiciones habituales.
Ejemplo 7: Análisis de la secuencia del anticuerpo
Se determinó el isotipo de la cadena ligera y el isotipo de la cadena pesada de cada anticuerpo monoclonal del Ejemplo 6 usando el IsoStrip™ Mouse Monoclonal Antibody Isotyping Kit según las instrucciones del vendedor del kit (Roche Applied Science, Indianápolis, IN). Se averiguó que todo los anticuerpos tenían una cadena ligera kappa y una cadena pesada IgG1 o IgG2b.
Las regiones variables de la cadena pesada y ligera de los anticuerpos monoclonales de ratón se secuenciaron usando una 5' RACE (amplificación rápida de los extremos del ADNc). El ARN total se extrajo de cada línea celular de hibridoma monoclonal usando el kit RNeasy® Miniprep según las instrucciones del vendedor del kit (Qiagen, Valencia, CA). Se generó una primera hebra completa de ADNc que contiene los extremos 5' usando el SMARTer™ RACE cDNA Amplification Kit (Clontech, Mountain View, CA) según las instrucciones del vendedor del kit para la 5' RACE.
Las regiones variables de la cadena ligera (kappa) y pesada (IgG1 o IgG2b) se amplificaron mediante una PCR usando el KOD Hot Start Polymerase (EMD Chemicals, Gibbstown, NJ) según las instrucciones del vendedor del kit. Para la amplificación de los extremos 5' del ADNc junto con el SMARTer™ RACE cDNA Amplification Kit, se usó el cebador Universal Primer Mix A (Clontech), una mezcla de: 5' CT AAT ACGACTCACT AT AGGGCAAGCAGTGGT ATCAACGCAGAGT 3' (SEQ ID NO: 233) y 5' CTAATACGACTCACTATAGGGC 3' (SEQ ID NO: 225), como cebador en 5'. Las regiones variables de la cadena pesada se amplificaron usando los anteriores cebadores en 5' y un cebador en 3' específico para la región constante IgG1, 5' TATGCAAGGCTTACAACCACA 3' (SEQ ID NO: 226), o un cebador en 3' específico para la región constante IgG2b, 5' AGGACAGGGGTTGATTGTTGA 3' (SEQ iD NO: 227). Las regiones variables de la cadena kappa se amplificaron en primer lugar con los anteriores cebadores en 5' y un cebador en 3' específico para la región constante de la kappa, 5' CTCATTCCTGTTGAAGCTCTTGACAAT 3' (SEQ ID NO: 228). Las cadenas ligeras se sometieron a una segunda ronda anidada de PCR usando el cebador Nested Universal Primer A (Clontech) 5', 5' AAGCAGTGGTATCAACGCAGAGT 3' (SEQ ID NO: 229) y un cebador anidado en 3' específico para la región constante de la kappa, 5' CGACTGAGGCACCTCCAGATGTT 3' (SEQ ID NO: 230). Los productos individuales de la PCR se purificaron usando el kit Qiaquick® PCR Purification o se aislaron mediante una electroforesis en gel de agarosa y se purificaron usando el kit Qiaquick® Gel Purification según las instrucciones del vendedor del kit (Qiagen). Los productos de la PCR se clonaron posteriormente en el que plásmido pCR®4Blunt usando el Zero Blunt® TOPO® PCR Cloning según las instrucciones del vendedor del kit (Invitrogen) y se transformaron en bacterias DH5-a (Invitrogen) a través de las técnicas habituales de biología molecular. El ADN de plásmido aislado a partir de los clones bacterianos transformados se secuenciaron usando los cebadores M13 directo (5' GTAAAACGACGGCCAGT 3') (SEQ ID NO: 231) y M13 inverso (5' CAGGAAACAGCTATGACC 3') (SEQ ID NO: 232) de Beckman Genomics (Danvers, MA), usando los métodos de secuenciación habituales de ADN didesoxi para identificar la secuencia de las secuencias de la región variable. Las secuencias se analizaron usando el programa informático Vector NTI (Invitrogen) y el servidor de internet IMGT/V-Quest (imgt.cines.fr) para identificar y confirmar las secuencias de la región variable.
Las secuencias de ácidos nucleicos que codifican y las secuencias de proteínas que definen las regiones variables de los anticuerpos monoclonales murinos se muestran a continuación (las secuencias del péptido de señal amino terminal no se muestran). Las secuencias de las CDR (definición de Kabat) están indicadas en negrita y subrayadas en las secuencias de aminoácidos.
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada del anticuerpo 01G06 (SEQ ID NO: 39)
1 gaggtcctgc tgcaacagtc tggacctgag ctggtgaagc ctggggcttc agtgaagata
61 ccctgcaagg cttctggata cacattcact gactacaaca tggactgggt gaagcagagc
121 catggaaaga gccttgagtg gattggacaa attaatccta acaatggtgg tattttcttc
181 aaccagaagt tcaagggcaa ggccacattg actgtagaca agtcctccaa tacagccttc
241 atggaggtcc gcagcctgac atctgaggac actgcagtct attactgtgc aagagaggca
301 attactacgg taggcgctat ggactactgg ggtcaaggaa cctcagtcac cgtctcctca
Secuencia de proteínas que define región variable de la cadena pesada del anticuerpo 01G06 (SEQ ID NO: 40)
1 evllqqsgpe lvkpgasvki pckasgytft dynmdwvkqs hgkslewigg inpnnggiff
61 nqkfkgkatl tvdkssntaf mevrsltsed tavyycarea ittvgamdyw gqgtsvtvss
Secuencia de ácidos nucleicos que codifica la región variable de la cadena kappa del anticuerpo 01G06 (SEQ ID NO: 75)
1 gacatccaga tgactcagtc tccagcctcc ctatctgcat ctgtgggaga aactgtcacc 61 atcacatgtc gaacaagtga gaatcttcac aattatttag catggtatca gcagaaacag 121 ggaaaatctc ctcagctcct ggtctatgat gcaaaaacct tagcagatgg tgtgccatca 181 aggttcagtg gcagtggatc aggaacacaa tattctctca agatcaacag cctgcagcct 241 gaagattttg ggagttatta ctgtcaacat ttttggagta gtccttacac gttcggaggg 301 gggaccaagc tggaaataaaa
Secuencia de proteínas que define la región variable de la cadena kappa del anticuerpo 01G06 (SEQ ID NO: 76)
1 diqmtqspas lsasvgetvt itcrtsenlh nylawyqqkq gkspqllvyd aktladgvps 61 rfsgsgsgtq yslkinslqp edfqsyycqh fwsspytfqq gtkleik
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada del anticuerpo 03G05 (SEQ ID NO: 41)
1 caggtccaac tgcagcagcc tggggctgaa ctggtgaagc ctggggcttc agtgaagctg 61 tcctgcaagg cttctggcta caccttcacc agctactgga ttcactgggt gaaccagagg 121 cctggacaag gccttgagtg gattggagac attaatccta gcaacggccg tagtaagtat 181 aatgagaagt tcaagaacaa ggccacaatg actgcagaca aatcctccaa cacagcctac 241 atgcaactca gcagcctgac atctgaggac tctgcggtct attactgtgc aagagaggtt 301 ctggatggtg ctatggacta ctggggtcaa ggaacctcag tcaccgtctc ctca
Secuencia de proteínas que define región variable de la cadena pesada del anticuerpo 03G05 (SEQ ID NO: 42)
1 qvqlqqpgae lvkpgasvkl sckasgytft sywihwvnqr pgqglewigd inpsngrsky 61 nekfknkatm tadkssntay mqlssltsed savyycarev ldqamdywqq gtsvtvss
Secuencia de ácidos nucleicos que codifica la región variable de la cadena kappa del anticuerpo 03G05 (SEQ ID NO: 77)
1 gacattgtgt tgacccaatctccagcttct ttggctgtgt ctctagggca gagggccacc
61 atctcctgca gagccagcgaaagtgttgat aattatggca ttagttttat gaactggttc
121 caacagaaac caggacagccacccaaactc ctcatctatg ctgcatccaa ccaaggctcc
181 ggggtccctg ccaggtttagtggcagtggg tctgggacag acttcagcct caacatccat
241 cctatggagg aggatgatactgcaatgtat ttctgtcagc aaagtaagga ggttccgtgg
301 acgttcggtg gaggctccaagctggaaatc aaa
Secuencia de proteínas que define la región variable de la cadena kappa del anticuerpo 03G05 (SEQ ID NO: 78)
1 divltqspas lavslgqrat iscrasesvd nygisfmnwf qqkpgqppkl liyaasnqgs
61 gvparfsgsg sgtdfslnih pmeeddtamy fcqqskevpw tfgggsklei k
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada del anticuerpo 04F08 (SEQ ID NO: 43)
1 caggttactctgaaagagtc tggccctggg atattgcagc cctcccagac cctcagtctg 61 acttgttctttctctgggtt ttcactgagc acttatggta tgggtgtgac ctggattcgt 121 cagccttcaggaaagggtct ggagtggctg gcacacattt actgggatga tgacaagcgc 181 tataacccatccctgaagag ccggctcaca atctccaagg atacctccaa caaccaggta 241 ttcctcaagatcaccagtgt ggacactgca gatactgcca catactactg tgctcaaacg 301 gggtatagtaacttgtttgc ttactggggc caagggactc tggtcactgt ctctgca
S e cu e n c ia de p ro te ín a s que de fin e reg ión v a r ia b le de la ca d e n a pe sa d a de l a n ticu e rp o 04 F 08 (S E Q ID NO : 44)
1 qvtlkesgpg ilqpsqtlsl tcsfsgfsls tyqmqvtwir qpsqkglewl ahiywdddkr
61 ynpslksrlt iskdtsnnqv flkitsvdta dtatyycaqt gysnlfaywq qgtlvtvsa
Secuencia de ácidos nucleicos que codifica la región variable de la cadena kappa del anticuerpo 04F08 (SEQ ID NO: 79)
1 gacattgtga tgacccagtc tcaaaaattc atgtccacat cagtaggaga cagggtcagc 61 gtcacctgca aggccagtca gaatgtgggt actaatgtag cctggtatca acagaaatta 121 ggacaatctc ctaaaacact gatttactcg gcatcctacc ggtacagtgg agtccctgat 181 cgcttcacag gcagtggatc tgggacagat ttcactctca ccatcagcaa tgtgcagtct 241 gaagacttgg cagagtattt ctgtcagcaa tataacagct atccgtacac gttcggaggg 301 gggaccaagc tggaaataaa a
Secuencia de proteínas que define la región variable de la cadena kappa del anticuerpo 04F08 (SEQ ID NO: 80)
1 divmtqsqkf mstsvgdrvs vtckasqnvg tnvawyqqkl gqspktliys asyrysgvpd
61 rftgsgsgtd ftltisnvqs edlaeyfcqg ynsypytfgg gtkleik
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada del anticuerpo 06C11 (SEQ ID NO: 45)
1 caggttactc tgaaagagtc tggccctggg atattgcagc cctcccagac cctcagtctg 61 acttgttctt tctctgggtt ttcactgaac acttatggta tgggtgtgag ctggattcgt
121 cagccttcag gaaagggtct ggagtggctg gcacacattt actgggatga tgacaagcgc
181 tataacccat ccctgaagag ccggctcaca atctccaagg atgcctccaa caaccgggtc 241 ttcctcaaga tcaccagtgt ggacactgca gatactgcca catactactg tgctcaaaga
301 ggttatgatg attactgggg ttactggggc caagggactc tggtcactat ctctgca
Secuencia de proteínas que define región variable de la cadena pesada del anticuerpo 06C11 (SEQ ID NO: 46)
1 qvtlkesgpg ilqpsqtlsl tcsfsgfsln tygmgvswir qpsgkglewl ahiywdddkr 61 ynpslksrlt iskdasnnrv flkitsvdta dtatyycaqr gyddywgywq qgtlvtisa
Secuencia de ácidos nucleicos que codifica la región variable de la cadena kappa del anticuerpo 06C11 (SEQ ID NO: 81)
1 gacattgtga tgacccagtc tcaaaaattc atgtccacat cagtaggaga cagggtcagc 61 gtcacctgca aggccagtca gaatgtgggt actaatgtag cctggtttca acagaaacca 121 ggtcaatctc ctaaagcact gatttactcg gcatcttaccggtacagtggagtccctgat 181 cgcttcacag gcagtggatc  tgggacagat ttcattctcaccatcagcaatgtgcagtct 241 gaagacctgg cagagtattt
tgggacagat ttcattctcaccatcagcaatgtgcagtct 241 gaagacctgg cagagtattt  ctgtcagcaa tataacaactatcctctcacgttcggtgct 301 gggaccaagc tggagctgaa a
ctgtcagcaa tataacaactatcctctcacgttcggtgct 301 gggaccaagc tggagctgaa a
Secuencia de proteínas que define la región variable de la cadena kappa del anticuerpo 06C11 (SEQ ID NO: 82)
1 divmtqsqkf mstsvgdrvs vtckasqnvg tnvawfqqkp gqspkaliys asyrysgvpd
61 rftgsgsgtd filtisnvqs edlaeyfcqg ynnypltfga gtkleik
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada del anticuerpo 08G01 (SEQ ID NO: 47)
1 gaggtcctgc tgcaacagtc tggacctgag gtggtgaagc ctggggcttc agtgaagata
61 ccctgcaagg cttctggata cacattcact gactacaaca tggactgggt gaagcagagc
121 catggaaaga gccttgagtg gattggagag attaatccta acaatggtgg tactttctac
181 aaccagaagt tcaagggcaa ggccacattg actgtagaca agtcctccag cacagcctac
241 atggagctcc gcagcctgac atctgaggac actgcagtct attactgtgc aagagaggca
301 attactacgg taggcgctat ggactactgg ggtcaaggaa cctcagtcac cgtctcctca
S e cu e n c ia d e p ro te ín a s q u e d e fin e reg ión v a r ia b le de la ca d e n a p e sa d a de l an ticu e rp o 08G01 (S E Q ID NO : 48)
1 evllqqsgpe vvkpgasvki pckasgytft dynmdwvkqs hgkslewige inpnnqqtfy
61 nqkfkgkatl tvdkssstay melrsltsed tavyycarea ittvgamdyw gqgtsvtvss
Secuencia de ácidos nucleicos que codifica la región variable de la cadena kappa del anticuerpo 08G01 (SEQ ID NO: 83)
1 gacatccaga tgactcagtc tccagcctcc ctatctgcat ctgtgggaga aactgtcacc 61 atcacatgtc gagcaagtgg gaatattcac aattatttag catggtatca gcagaaacag 121 ggaaaatctc ctcagctcct ggtctataat gcaaaaacct tagcagatgg tgtgccatca 181 aggttcagtg gcagtggatc aggaacacaa tattctctca agatcaacag cctgcagcct 241 gaagattttg ggagttatta ctgtcaacat ttttggagtt ctccttacac gttcggaggg 301 gggaccaagc tggaaataaa a
Secuencia de proteínas que define la región variable de la cadena kappa del anticuerpo 08G01 (SEQ ID NO: 84)
1 diqmtqspas lsasvgetvt itcrasqnih nylawyqqkq gkspqllvyn aktladgvps 61 rfsgsgsgtq yslkinslqp edfgsyycqh fwsspytfgg gtkleik
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada del anticuerpo 14F11 (SEQ ID NO: 49)
l caggttactc tgaaagagtc tggccctgga atattgcagc cctcccagac cctcagtctg 61 acttgttctt tctctgggtt ttcactgagc acttatggta tgggtgtagg ctggattcgt 121 cagccttcag gaaagggtct agagtggctg gcagacattt ggtgggatga cgataagtac 181 tataacccat ccctgaagag ccggctcaca atctccaagg atacctccag caatgaggta 241 ttcctcaaga tcgccattgt ggacactgca gatactgcca cttactactg tgctcgaaga 301 ggtcactact ctgctatgga ctactggggt caaggaacct cagtcaccgt ctcctca
Secuencia de proteínas que define región variable de la cadena pesada del anticuerpo 14F11 (SEQ ID NO: 50)
1 qvtlkesgpg ilqpsqtlsl tcsfsgfsls tygmgvgwir qpsgkglewl adiwvrdddky
61 ynpslksrlt iskdtssnev flkiaivdta dtatyycarr ghysamdywg qgtsvtvss
Secuencia de ácidos nucleicos que codifica la región variable de la cadena kappa del anticuerpo 14F11 (SEQ ID NO: 85)
1 gacattgtaa tgacccagtc tcaaaaattc atgtccacat cagtaggaga cagggtcagc 61 gtcacctgca aggccagtca gaatgtgggt actaatgtag cctggtatca acagaaacca 121 gggcaatctc ctaaagcact gatttactcg ccatcctacc ggtacagtgg agtccctgat
181 cgcttcacag gcagtggatc tgggacagat ttcactctca ccatcagcaa tgtgcagtct
241 gaagacttgg cagaatattt ctgtcagcaa tataacagct atcctcacac gttcggaggg
301 gggaccaagc tggaaatgaa a
Secuencia de proteínas que define la región variable de la cadena kappa del anticuerpo 14F11 (SEQ ID NO: 86)
1 divmtqsqkf mstsvgdrvs vtckasqnvg tnvawyqqkp gqspkaliys psyrysgvpd
61 rftgsgsgtd ftltisnvqs edlaeyfcqq ynsyphtfqq gtklemk
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada del anticuerpo 17B11 (SEQ ID NO: 51)
i caggttactc tgaaagagtc tggccctggg atattgeage cctcccagac cctcagtctg
61 acttgttctt tctctgggtt ttcactgagc acttctggta tgggtgtgag ttggattcgt
121 cagccttcag gaaagggtct ggagtggctg gcacacaatg actgggatga tgacaagcgc
181 tataagtcat ccctgaagag ccggctcaca atatccaagg atacctccag aaaccaggta
241 ttcctcaaga tcaccagtgt ggacactgca gatactgcca catactactg tgetegaaga
301 gttgggggat tagagggcta ttttgattac tggggccaag gcaccactct cacagtctcc
361 tea
Secuencia de proteínas que define región variable de la cadena pesada del anticuerpo 17B11 (SEQ ID NO: 52)
1 qvtlkesgpg ilqpsqtlsl tcsfsgfsls tsqmqvswir qpsgkglewl ahndwdddkr 61 yksslksrlt iskdtsrnqv flkitsvdta dtatyycarr vgglegyfdy wgqgttltvs
121 s
Secuencia de ácidos nucleicos que codifica la región variable de la cadena kappa del anticuerpo 17B11 (SEQ ID NO: 87)
1 gacattgtgc tgacacagtc tcctgcttcc ttagctgtat ctctggggca gagggccacc
61 atctcatgca gggccagcca aagtgtcagt acatctaggt ttagttatat gcactggttc
121 caacagaaac caggacaggc acccaaactc ctcatcaagt atgcatccaa cctagaatct
181 ggggtccctg ccaggttcag tggcagtggg tctgggacag acttcaccct caacatccat
241 cctgtggagg gggaggatac tgcaacatat tactgtcagc acagttggga gattccgtac
301 acgttcggag gggggaccaa gctggaaata aaa
Secuencia de proteínas que define la región variable de la cadena kappa del anticuerpo 17B11 (SEQ ID NO: 88)
1 divltqspas lavslgqrat iscrasgsvs tsrfsymhwf qqkpgqapkl likyasnles
61 gvparfsgsg sgtdftlnih pvegedtaty ycqhsweipy tfgggtklei k
Las secuencias de aminoácidos que definen las regiones variables de la cadena pesada de una inmunoglobulina para los anticuerpos producidos en el Ejemplo 6 están alineadas en la FIG. 10. Las secuencias del péptido de señal amino terminal (para la expresión/secreción) no se muestran. La CDR1, la CDR2 y la CDR3 (definición de Kabat) están identificadas por recuadros. La FIG. 11 muestra una alineación de las secuencias individuales de la CDR1, de la CDR2 y de la CDR3 para cada anticuerpo.
Las secuencias de aminoácidos que definen las regiones variables de la cadena ligera de una inmunoglobulina de los anticuerpos del Ejemplo 6 están alineadas en la FIG. 12. Las secuencias del péptido de señal amino terminal (para la expresión/secreción) no se muestran. La CDR1, la CDR2 y la CDR3 están identificadas por recuadros. La FlG. 13 muestra una alineación de las secuencias individuales de la CDR1 , de la CDR2 y de la CDR3 para cada anticuerpo.
La Tabla 2 muestra la SEQ ID NO. de cada secuencia analizada en este Ejemplo.
Tabla 2

continuación

continuación

Las secuencias de las CDR de la cadena pesada del anticuerpo monoclonal de ratón (definiciones de Kabat, Chothia e IMGT) se muestran en la Tabla 3.
Tabla 3

continuación

Las secuencias de las CDR de la cadena ligera kappa del anticuerpo monoclonal de ratón (definiciones de Kabat, Chothia e IMGT) se muestran en la Tabla 4.
Tabla 4

Para crear las secuencias completas de la cadena pesada o kappa del anticuerpo, cada secuencia variable anterior se combina con su respectiva región constante. Por ejemplo, una cadena pesada completa comprende una secuencia variable pesada seguida por la secuencia constante de la cadena pesada de la IgG1 o de la IgG2b murina, y una cadena kappa completa comprende una secuencia variable kappa seguida por la secuencia constante de la cadena ligera kappa murina.
S e cu e n c ia de ác ido s nu c le icos qu e c o d ific a la reg ión co n s ta n te de la ca d e n a p e sa d a de la IgG1 m u rin a (S E Q ID NO: 165)
1 gccaaaacga cacccccatc tgtctatcca ctggcccctg gatctgctgc ccaaactaac 61 tccatggtga ccctgggatg cctggtcaag ggctatttcc ctgagccagt gacagtgacc 121 tggaactctg gatccctgtc cagcggtgtg cacaccttcc cagctgtcct gcagtctgac 181 ctctacactc tgagcagctc agtgactgtc ccctccagca cctggcccag cgagaccgtc
241 acctgcaacg ttgcccaccc ggccagcagc accaaggtgg acaagaaaat tgtgcccagg
301 gattgtggtt gtaagccttg catatgtaca gtcccagaag tatcatctgt cttcatcttc
361 cccccaaagc ccaaggatgt gctcaccatt actctgactc ctaaggtcac gtgtgttgtg
421 gtagacatca gcaaggatga tcccgaggtc cagttcagct ggtttgtaga tgatgtggag
481 gtgcacacag ctcagacgca accccgggag gagcagttca acagcacttt ccgctcagtc
541 agtgaacttc ccatcatgca ccaggactgg ctcaatggca aggagttcaa atgcagggtc
601 aacagtgcag ctttccctgc ccccatcgag aaaaccatct ccaaaaccaa aggcagaccg
661 aaggctccac aggtgtacac cattccacct cccaaggagc agatggccaa ggataaagtc
721 agtctgacct gcatgataac agacttcttc cctgaagaca ttactgtgga gtggcagtgg
781 aatgggcagc cagcggagaa ctacaagaac actcagccca tcatggacac agatggctct
841 tacttcgtct acagcaagct caatgtgcag aagagcaact gggaggcagg aaatactttc
901 acctgctctg tgttacatga gggcctgcac aaccaccata ctgagaagag cctctcccac
961 tctcctggta aa
Secuencia de proteínas que define la región constante de la cadena pesada de la IgG1 murina (SEQ ID NO: 166)
1 akttppsvyplapgsaaqtn smvtlgclvk gyfpepvtvt wnsgslssgv htfpavlqsd 61 lytlsssvtvpsstwpsetv tcnvahpass tkvdkkivpr dcgckpcict vpevssvfif
121 ppkpkdvlti tltpkvtcvv vdiskddpevqfswfvddve vhtaqtqpreeqfnstfrsv 181 selpimhqdwlngkefkcrv nsaafpapie ktisktkgrp kapqvytipp pkeqmakdkv
241 sltcmitdffpeditvewqw ngqpaenykn tqpimdtdgs yfvysklnvq ksnweagntf
301 tcsvlheglh nhhtekslsh spgk
Secuencia de ácidos nucleicos que codifica la región constante de la cadena pesada de la IgG2b murina (SEQ ID NO: 167)
1 gccaaaacaa cacccccatc agtctatcca ctggcccctg ggtgtggaga tacaactggt
61 tcctccgtga ctctgggatg cctggtcaag ggctacttcc ctgagtcagt gactgtgact
121 tggaactctg gatccctgtc cagcagtgtg cacaccttcc cagctctcct gcagtctgga
181 ctctacacta tgagcagctc agtgactgtc ccctccagca cctggccaag tcagaccgtc
241 acctgcagcg ttgctcaccc agccagcagc accacggtgg acaaaaaact tgagcccagc
301 gggcccattt caacaatcaa cccctgtcct ccatgcaagg agtgtcacaa atgcccagct
361 cctaacctcg agggtggacc atccgtcttc atcttccctc caaatatcaa ggatgtactc
421 atgatctccc tgacacccaa ggtcacgtgt gtggtggtgg atgtgagcga ggatgaccca
- A1 ' Q •J 1 -L yuCy TCCu.'j 3. tcagctggtt agagaacaac gaggaagaac acacagcaca gacacaaacc
541 catagagagg attacaacag tactatccgg gtggtcagca ccctccccat ccagcaccag
601 gactggatga gtggcaagga gttcaaatgc aaggtcaaca acaaagacct cccatcaccc
661 atcgagagaa ccatctcaaa aattaaaggg ctagtcagag ctccacaagt atacatcttg
721 ccgccaccag cagagcagtt gtccaggaaa gatgtcagtc tcacttgcct ggtcgtgggc
781 ttcaaccctg gagacatcag tgtggagtgg accagcaatg ggcatacaga ggagaactac
841 aaggacaccg caccagtcct agactctgac ggttcttact tcatatatag caagctcaat
901 atgaaaacaa gcaagtggga gaaaacagat tccttctcat gcaacgtgag acacgagggt
961 ctgaaaaatt actacctgaa gaagaccatc tcccggtctc cgggtaaa
Secuencia de proteínas que define la región constante de la cadena pesada de la IgG2b murina (SEQ ID NO: 168)
1 akttppsvyp lapgcgdttg ssvtlgclvk gyfpesvtvt wnsgslsssv htfpallqsg
61 lytmsssvtv psstwpsqtv tcsvahpass ttvdkkleps gpistinpcp pckechkcpa
121 pnleggpsvf ifppnikdvl misltpkvtc vvvdvseddp dvqiswfvnn vevhtaqtqt
181 hredynstir vvstlpiqhq dwmsgkefkc kvnnkdlpsp iertiskikg lvrapqvyil
241 pppaeqlsrk dvsltclvvg fnpgdisvew tsnghteeny kdtapvldsd gsyfiyskln
301 mktskwektd sfscnvrheg lknyylkkti srspgk
Secuencia de ácidos nucleicos que codifica la región constante de la cadena ligera kappa murina (SEQ ID NO: 169)
1 cgggctgatg ctgcaccaac tgtatccatc ttcccaccat ccagtgagca gttaacatct
61 ggaggtgcct cagtcgtgtg cttcttgaac aacttctacc ccaaagacat caatgtcaag
121 tggaagattg atggcagtga acgacaaaat ggcgtcctga acagttggac tgatcaggac
181 agcaaagaca gcacctacag catgagcagc accctcacgt tgaccaagga cgagtatgaa
241 cgacataaca gctatacctg tgaggccact cacaagacat caacttcacc cattgtcaag
301 agcttcaaca ggaatgagtg t
Secuencia de proteínas que define la región constante de la cadena ligera kappa murina (SEQ ID NO: 170)
1 radaaptvsi fppsseqlts ggasvvcfln nfypkdinvk wkidgserqn gvlnswtdqd 61 skdstysmss tltltkdeye rhnsytceat hktstspivk sfnrnec
Las siguientes secuencias representan la secuencia completa real o contemplada de la cadena pesada y ligera (es decir, que contienen las secuencias de ambas regiones variable y constante) para cada anticuerpo descrito en este Ejemplo. Las secuencias de señal para la apropiada secreción de los anticuerpos (por ejemplo, las secuencias de señal en el extremo 5' de las secuencias de ADN o en el extremo amino terminal de las secuencias de la proteína) no se muestran en las secuencias completas de la cadena pesada y ligera divulgadas en el presente documento y no están incluidas en la proteína final secretada. Tampoco se muestran los codones de terminación para la terminación de la traducción requeridos en el extremo 3' de las secuencias de ADN. En la pericia habitual de la técnica está la selección de una secuencia de señal y/o de un codón de terminación para la expresión de las secuencias completas divulgadas de la cadena pesada y de la cadena ligera de la inmunoglobulina. También se contempla que las secuencias de la región variable puedan estar ligadas a otras secuencias de la región constante para producir las cadenas pesada y ligera activas completas de la inmunoglobulina.
Secuencia de ácidos nucleicos que codifica la secuencia completa de la cadena pesada (región variable de la cadena pesada y región constante de la IgG1) de 01G06 (SEQ ID NO: 99)
i gaggtcctgc tgcaacagtc tggacctgag ctggtgaagc ctggggcttc agtgaagata 61 ccctgcaagg cttctggata cacattcact gactacaaca tggactgggt gaagcagagc 121 catggaaaga gccttgagtg gattggacaa attaatccta acaatggtgg tattttcttc 181 aaccagaagt tcaagggcaa ggccacattg actgtagaca agtcctccaa tacagccttc 241 atggaggtcc gcagcctgac atctgaggac actgcagtct attactgtgc aagagaggca 301 attactacgg taggcgctat ggactactgg ggtcaaggaa cctcagtcac cgtctcctca 361 gccaaaacga cacccccatc tgtctatcca ctggcccctg gatctgctgc ccaaactaac 421 tccatggtga ccctgggatg cctggtcaag ggctatttcc ctgagccagt gacagtgacc 481 tggaactctg gatccctgtc cagcggtgtg cacaccttcc cagctgtcct gcagtctgac 541 ctctacactc tgagcagctc agtgactgtc ccctccagca cctggcccag cgagaccgtc 601 acctgcaacg ttgcccaccc ggccagcagc accaaggtgg acaagaaaat tgtgcccagg
661 gattgtggtt gtaagccttg catatgtaca gtcccagaag tatcatctgt cttcatcttc
721 cccccaaagc ccaaggatgt gctcaccatt actctgactc ctaaggtcac gtgtgttgtg
781 gtagacatca gcaaggatga tcccgaggtc cagttcagct ggtttgtaga tgatgtggag
841 gtgcacacag ctcagacgca accccgggag gagcagttca acagcacttt ccgctcagtc
901 agtgaacttc ccatcatgca ccaggactgg ctcaatggca aggagttcaa atgcagggtc
961 aacagtgcag ctttccctgc ccccatcgag aaaaccatct ccaaaaccaa aggcagaccg 1021 aaggctccac aggtgtacac cattccacct cccaaggagc agatggccaa ggataaagtc 1081 agtctgacct gcatgataac agacttcttc cctgaagaca ttactgtgga gtggcagtgg 1141 aatgggcagc cagcggagaa ctacaagaac actcagccca tcatggacac agatggctct 1201 tacttcgtct acagcaagct caatgtgcag aagagcaact gggaggcagg aaatactttc 1261 acctgctctg tgttacatga gggcctgcac aaccaccata ctgagaagag cctctcccac 1321 tctcctggta aa
Secuencia de proteínas que define la secuencia completa de la cadena pesada (región variable de la cadena pesada y región constante de la IgG1) de 01G06 (SEQ ID NO: 100)
1 evllqqsgpe lvkpgasvki pckasgytft dynmdwvkqs hgkslewigq inpnnggiff 61 nqkfkgkatl tvdkssntaf mevrsltsed tavyycarea ittvgamdyw gqgtsvtvss 121 akttppsvyp lapgsaaqtn smvtlgclvk gyfpepvtvt wnsgslssgv htfpavlqsd 181 lytlsssvtv psstwpsetv tcnvahpass tkvdkkivpr dcgckpcict vpevssvfif 241 ppkpkdvlti tltpkvtcvv vdiskddpev qfswfvddve vhtaqtqpre eqfnstfrsv 301 selpimhqdw lngkefkcrv nsaafpapie ktisktkgrp kapqvytipp pkeqmakdkv 361 sltcmitdff peditvewqw ngqpaenykn tqpimdtdgs yfvysklnvq ksnweagntf 421 tcsvlheglh nhhtekslsh spgk
Secuencia de ácidos nucleicos que codifica la secuencia completa de la cadena ligera (región variable y región constante de la cadena kappa) de 01G06 (SEQ ID NO: 101)
1 gacatccaga tgactcagtc tccagcctcc ctatctgcat ctgtgggaga aactgtcacc 61 atcacatgtc gaacaagtga gaatcttcac aattatttag catggtatca gcagaaacag
121 ggaaaatctc ctcagctcct ggtctatgat gcaaaaacct tagcagatgg tgtgccatca
181 aggttcagtg gcagtggatc aggaacacaa tattctctca agatcaacag cctgcagcct
241 gaagattttg ggagttatta ctgtcaacat ttttggagta gtccttacac gttcggaggg
301 gggaccaagc tggaaataaa acgggctgat gctgcaccaa ctgtatccat cttcccacca
361 tccagtgagc agttaacatc tggaggtgcc tcagtcgtgt gcttcttgaa caacttctac
421 cccaaagaca tcaatgtcaa gtggaagatt gatggcagtg aacgacaaaa tggcgtcctg
481 aacagttgga ctgatcagga cagcaaagac agcacctaca gcatgagcag caccctcacg
541 ttgaccaagg acgagtatga acgacataac agctatacct gtgaggccac tcacaagaca
601 tcaacttcac ccattgtcaa gagcttcaac aggaatgagt gt
Secuencia de proteínas que define la secuencia completa de la cadena ligera (región variable y región constante de la cadena kappa) de 01G06 (SEQ ID NO: 102)
l diqmtqspas lsasvgetvt itcrtsenlh nylawyqqkq gkspqllvyd aktladgvps 61 rfsgsgsgtq yslkinslqp edfgsyycqh fwsspytfgg gtkleikrad aaptvsifpp
121 sseqltsgga svvcflnnfy pkdinvkwki dgserqngvl nswtdqdskd stysmsstlt
181 ltkdeyerhn sytceathkt stspivksfn rnec
S e cu e n c ia de á c id o s nu c le icos qu e c o d ific a la s e cu e n c ia c o m p le ta d e la c a d e n a p e sa d a (reg ión v a r ia b le de la c a d e n a p e sa d a y reg ión c o n s ta n te de la Ig G 1 ) de 03 G 05 (S E Q ID NO : 103)
1 caggtccaac tgcagcagcc tggggctgaa ctggtgaagc ctggggcttc agtgaagctg
61 tcctgcaagg cttctggcta caccttcacc agctactgga ttcactgggt gaaccagagg
121 cctggacaag gccttgagtg gattggagac attaatccta gcaacggccg tagtaagtat
181 aatgagaagt tcaagaacaa ggccacaatg actgcagaca aatcctccaa cacagcctac
241 atgcaactca gcagcctgac atctgaggac tctgcggtct attactgtgc aagagaggtt
301 ctggatggtg ctatggacta ctggggtcaa ggaacctcag tcaccgtctc ctcagccaaa
"3 £ 1 ;=* n r r ;=* n ;=* n n n n r ' ;=* ■ n +■ rr ■ n +■ ;=* ■ n n +■ rr rr n n n n +■ r r r r ;=* ■ n +■ rr n r t n n r ' a a a n +■ ;=* ;=* n +■ n n ;=* ■ rr
421 gtgaccctgg gatgcctggt caagggctat ttccctgagc cagtgacagt gacctggaac
481 tctggatccc tgtccagcgg tgtgcacacc ttcccagctg tcctgcagtc tgacctctac
541 actctgagca gctcagtgac tgtcccctcc agcacctggc ccagcgagac cgtcacctgc
601 aacgttgccc acccggccag cagcaccaag gtggacaaga aaattgtgcc cagggattgt
661 ggttgtaagc cttgcatatg tacagtccca gaagtatcat ctgtcttcat cttcccccca
721 aagcccaagg atgtgctcac cattactctg actcctaagg tcacgtgtgt tgtggtagac
781 atcagcaagg atgatcccga ggtccagttc agctggtttg tagatgatgt ggaggtgcac
841 acagctcaga cgcaaccccg ggaggagcag ttcaacagca ctttccgctc agtcagtgaa
901 cttcccatca tgcaccagga ctggctcaat ggcaaggagt tcaaatgcag ggtcaacagt
961 gcagctttcc ctgcccccat cgagaaaacc atctccaaaa ccaaaggcag accgaaggct
1021 ccacaggtgt acaccattcc acctcccaag gagcagatgg ccaaggataa agtcagtctg
1081 acctgcatga taacagactt cttccctgaa gacattactg tggagtggca gtggaatggg
1141 cagccagcgg agaactacaa gaacactcag cccatcatgg acacagatgg ctcttacttc
1201 gtctacagca agctcaatgt gcagaagagc aactgggagg caggaaatac tttcacctgc
1261 tctgtgttac atgagggcct gcacaaccac catactgaga agagcctctc ccactctcct
1321 ggtaaa
Secuencia de proteínas que define la secuencia completa de la cadena pesada (región variable de la cadena pesada y región constante de la IgG1) de 03G05 (SEQ ID NO: 104)
1 qvqlqqpgae lvkpgasvkl sckasgytft sywihwvnqr pgqglewigd inpsngrsky
61 nekfknkatm tadkssntay mqlssltsed savyycarev ldgamdywgq gtsvtvssak
121 ttppsvypla pgsaaqtnsm vtlgclvkgy fpepvtvtwn sgslssgvht fpavlqsdly
181 tlsssvtvps stwpsetvtc nvahpasstk vdkkivprdc gckpcictvp evssvfifpp
241 kpkdvltitltpkvtcvvvd iskddpevqf swfvddvevh taqtqpreeq fnstfrsvse
301 lpimhqdwln gkefkcrvns aafpapiekt isktkgrpka pqvytipppk eqmakdkvsl
361 tcmitdffpe ditvewqwng qpaenykntq pimdtdgsyf vysklnvqks nweagntftc
421 svlheglhnh htekslshsp gk
Secuencia de ácidos nucleicos que codifica la secuencia completa de la cadena ligera (región variable y región constante de la cadena kappa) de 03G05 (SEQ ID NO: 105)
1 gacattgtgt tgacccaatc tccagcttct ttggctgtgt ctctagggca gagggccacc 61 atctcctgca gagccagcga aagtgttgat aattatggca ttagttttat gaactggttc 121 caacagaaac caggacagcc acccaaactc ctcatctatg ctgcatccaa ccaaggctcc 181 ggggtccctg ccaggtttag tggcagtggg tctgggacag acttcagcct caacatccat 241 cctatggagg aggatgatac tgcaatgtat ttctgtcagc aaagtaagga ggttccgtgg 301 acgttcggtg gaggctccaa gctggaaatc aaacgggctg atgctgcacc aactgtatcc 361 atcttcccac catccagtga gcagttaaca tctggaggtg cctcagtcgt gtgcttcttg 421 aacaacttct accccaaaga catcaatgtc aagtggaaga ttgatggcag tgaacgacaa 481 aatggcgtcc tgaacagttg gactgatcag gacagcaaag acagcaccta cagcatgagc 541 agcaccctca cgttgaccaa ggacgagtat gaacgacata acagctatac ctgtgaggcc 601 actcacaaga catcaacttc acccattgtc aagagcttca acaggaatga gtgt
Secuencia de proteínas que define la secuencia completa de la cadena ligera (región variable y región constante de la cadena kappa) de 03G05 (SEQ ID NO: 106)
i divltqspas lavslgqrat iscrasesvd nygisfmnwf qqkpgqppkl liyaasnqgs
61 gvparfsgsg sgtdfslnih pmeeddtamy fcqqskevpw tfgggsklei kradaaptvs 121 ifppsseqlt sggasvvcfl nnfypkdinv kwkidgserq ngvlnswtdq dskdstysms 181 stltltkdey erhnsytcea thktstspiv ksfnrnec
Secuencia de ácidos nucleicos que codifica la secuencia completa de la cadena pesada (región variable de la cadena pesada y región constante de la IgG1) de 04F08 (SEQ ID NO: 107)
l caggttactc tgaaagagtc tggccctggg atattgcagc cctcccagac cctcagtctg 61 acttgttctt tctctgggtt ttcactgagc acttatggta tgggtgtgac ctggattcgt 121 cagccttcag gaaagggtct ggagtggctg gcacacattt actgggatga tgacaagcgc 181 tataacccat ccctgaagag ccggctcaca atctccaagg atacctccaa caaccaggta 241 ttcctcaaga tcaccagtgt ggacactgca gatactgcca catactactg tgctcaaacg 301 gggtatagta acttgtttgc ttactggggc caagggactc tggtcactgt ctctgcagcc 361 aaaacgacac ccccatctgt ctatccactg gcccctggat ctgctgccca aactaactcc 421 atggtgaccc tgggatgcct ggtcaagggc tatttccctg agccagtgac agtgacctgg 481 aactctggat ccctgtccag cggtgtgcac accttcccag ctgtcctgca gtctgacctc 541 tacactctga gcagctcagt gactgtcccc tccagcacct ggcccagcga gaccgtcacc 601 tgcaacgttg cccacccggc cagcagcacc aaggtggaca agaaaattgt gcccagggat 661 tgtggttgta agccttgcat atgtacagtc ccagaagtat catctgtctt catcttcccc 721 ccaaagccca aggatgtgct caccattact ctgactccta aggtcacgtg tgttgtggta 781 gacatcagca aggatgatcc cgaggtccag ttcagctggt ttgtagatga tgtggaggtg 841 cacacagctc agacgcaacc ccgggaggag cagttcaaca gcactttccg ctcagtcagt 901 gaacttccca tcatgcacca ggactggctc aatggcaagg agttcaaatg cagggtcaac 961 agtgcagctt tccctgcccc catcgagaaa accatctcca aaaccaaagg cagaccgaag 1021 gctccacagg tgtacaccat tccacctccc aaggagcaga tggccaagga taaagtcagt 1081 ctgacctgca tgataacaga cttcttccct gaagacatta ctgtggagtg gcagtggaat 1141 gggcagccag cggagaacta caagaacact cagcccatca tggacacaga tggctcttac 1201 ttcgtctaca gcaagctcaa tgtgcagaag agcaactggg aggcaggaaa tactttcacc 1261 tgctctgtgt tacatgaggg cctgcacaac caccatactg agaagagcct ctcccactct 1321 cctggtaaa
Secuencia de proteínas que define la secuencia completa de la cadena pesada (región variable de la cadena pesada y región constante de la IgG1) de 04F08 (SEQ ID NO: 108)
1 qvtlkesgpg ilqpsqtlsl tcsfsgfsis tygmgvtwir qpsgkglewl ahiywdddkr 61 ynpslksrlt iskdtsnnqv flkitsvdta dtatyycaqt gysnlfaywg qgtlvtvsaa 121 kttppsvypl apgsaaqtns mvtlgclvkg yfpepvtvtw nsgslssgvh tfpavlqsdl 181 ytlsssvtvp sstwpsetvt cnvahpas st kvdkkivprd cgckpcictv pevssvfifp 241 pkpkdvltit ltpkvtcvvv diskddpevq fswfvddvev htaqtqpree qfnstfrsvs 301 elpimhqdwl ngkefkcrvn saafpapiek tisktkgrpk apqvytippp keqmakdkvs 361 ltcmitdffp editvewqwn gqpaenyknt qpimdtdgsy fvysklnvqk snweagntft 421 csvlheglhn hhtekslshs pgk
Secuencia de ácidos nucleicos que codifica la secuencia completa de la cadena ligera (región variable y región constante de la cadena kappa) de 04F08 (SEQ ID NO: 109)
1 gacattgtga tgacccagtc tcaaaaattc atgtccacat cagtaggaga cagggtcagc 61 gtcacctgca aggccagtca gaatgtgggt actaatgtag cctggtatca acagaaatta 121 ggacaatctc ctaaaacact gatttactcg gcatcctacc ggtacagtgg agtccctgat 181 cgcttcacag gcagtggatc tgggacagat ttcactctca ccatcagcaa tgtgcagtct 241 gaagacttgg cagagtattt ctgtcagcaa tataacagct atccgtacac gttcggaggg 301 gggaccaagc tggaaataaa acgggctgat gctgcaccaa ctgtatccat cttcccacca 361 tccagtgagc agttaacatc tggaggtgcc tcagtcgtgt gcttcttgaa caacttctac
421 cccaaagaca tcaatgtcaa gtggaagatt gatggcagtg aacgacaaaa tggcgtcctg
481 aacagttgga ctgatcagga cagcaaagac agcacctaca gcatgagcag caccctcacg
541 ttgaccaagg acgagtatga acgacataac agctatacct gtgaggccac tcacaagaca
601 tcaacttcac ccattgtcaa gagcttcaac aggaatgagt gt
S e cu e n c ia de p ro te ín a s qu e d e fin e la s e cu e n c ia co m p le ta de la ca d e n a lige ra (reg ión v a r ia b le y reg ión co n s ta n te de la ca d e n a kappa ) d e 04F08 (S E Q ID NO : 110)
1 divmtqsqkfmstsvgdrvs vtckasqnvg tnvawyqqkl gqspktliys asyrysgvpd 61 rftgsgsgtdftltisnvqs edlaeyfcqq ynsypytfgg gtkleikrad aaptvsifpp 121 sseqltsggasvvcflnnfy pkdinvkwki dgserqngvl nswtdqdskd stysmsstlt 181 ltkdeyerhnsytceathkt stspivksfn rnec
Secuencia de ácidos nucleicos que codifica la secuencia completa de la cadena pesada ('región variable de la cadena pesada y región constante de la IgG1) de 06C11 (SEQ ID NO: 111)
1 caggttactc tgaaagagtc tggccctggg atattgcagc cctcccagaccctcagtctg 61 acttgttctt tctctgggtt ttcactgaac acttatggta tgggtgtgagctggattcgt 121 cagccttcag gaaagggtct ggagtggctg gcacacatttactgggatga tgacaagcgc 181 tataacccat ccctgaagag ccggctcaca atctccaaggatgcctccaa caaccgggtc 241 ttcctcaaga tcaccagtgt ggacactgca gatactgccacatactactg tgctcaaaga 301 ggttatgatg attactgggg ttactggggc caagggactctggtcactat ctctgcagcc 361 aaaacgacac ccccatctgt ctatccactg gcccctggatctgctgccca aactaactcc 421 atggtgaccc tgggatgcct ggtcaagggc tatttccctgagccagtgac agtgacctgg 481 aactctggat ccctgtccag cggtgtgcac accttcccagctgtcctgca gtctgacctc 541 tacactctga gcagctcagt gactgtcccc tccagcacctggcccagcga gaccgtcacc 601 tgcaacgttg cccacccggc cagcagcacc aaggtggacaagaaaattgt gcccagggat 661 tgtggttgta agccttgcat atgtacagtc ccagaagtatcatctgtctt catcttcccc 721 ccaaagccca aggatgtgct caccattact ctgactcctaaggtcacgtg tgttgtggta 781 gacatcagca aggatgatcc cgaggtccag ttcagctggtttgtagatga tgtggaggtg 841 cacacagctc agacgcaacc ccgggaggag cagttcaacagcactttccg ctcagtcagt 901 gaacttccca tcatgcacca ggactggctc aatggcaaggagttcaaatg cagggtcaac 961 agtgcagctt tccctgcccc catcgagaaa accatctccaaaaccaaagg cagaccgaag 1021 gctccacagg tgtacaccat tccacctccc aaggagcaga tggccaagga taaagtcagt 1081 ctgacctgca tgataacaga cttcttccct gaagacatta ctgtggagtg gcagtggaat 1141 gggcagccag cggagaacta caagaacact cagcccatca tggacacaga tggctcttac 1201 ttcgtctaca gcaagctcaa tgtgcagaag agcaactggg aggcaggaaa tactttcacc 1261 tgctctgtgt tacatgaggg cctgcacaac caccatactg agaagagcct ctcccactct 1321 cctggtaaa
Secuencia de proteínas que define la secuencia completa de la cadena pesada (región variable de la cadena pesada y región constante de la IgG1) de 06C11 (SEQ ID NO: 112)
1 qvtlkesgpg ilqpsqtlsl tcsfsgfsin tygmgvswir qpsgkglewl ahiywdddkr 61 ynpslksrlt iskdasnnrv flkitsvdta dtatyycaqr gyddywgywg qgtlvtisaa 121 kttppsvypl apgsaaqtns mvtlgclvkg yfpepvtvtw nsgslssgvh tfpavlqsdl 181 ytlsssvtvp sstwpsetvt cnvahpasst kvdkkivprd cgckpcictv pevssvfifp 241 pkpkdvltit ltpkvtcvvv diskddpevq fswfvddvev htaqtqpree qfnstfrsvs 301 elpimhqdwl ngkefkcrvn saafpapiek tisktkgrpk apqvytippp keqmakdkvs 361 ltcmitdffp editvewqwn gqpaenyknt qpimdtdgsy fvysklnvqk snweagntft 421 csvlheglhn hhtekslshs pgk
S e cu e n c ia de ác ido s nu c le icos que co d ifica la s e cu e n c ia c o m p le ta de la c a d e n a lige ra (reg ión v a r ia b le y reg ión co n s ta n te de la c a d e n a kappa ) de 06 C 11 (S E Q ID NO : 113)
i gacattgtga tgacccagtc tcaaaaattc atgtccacat cagtaggaga cagggtcagc
61 gtcacctgca aggccagtca gaatgtgggt actaatgtag cctggtttca acagaaacca
121 ggtcaatctc ctaaagcact gatttactcg gcatcttacc ggtacagtgg agtccctgat
181 cgcttcacag gcagtggatc tgggacagat ttcattctca ccatcagcaa tgtgcagtct
241 gaagacctgg cagagtattt ctgtcagcaa tataacaact atcctctcac gttcggtgct
301 gggaccaagc tggagctgaa acgggctgat gctgcaccaa ctgtatccat cttcccacca
361 tccagtgagc agttaacatc tggaggtgcc tcagtcgtgt gcttcttgaa caacttctac
421 cccaaagaca tcaatgtcaa gtggaagatt gatggcagtg aacgacaaaa tggcgtcctg
481 aacagttgga ctgatcagga cagcaaagac agcacctaca gcatgagcag caccctcacg
541 ttgaccaagg acgagtatga acgacataac agctatacct gtgaggccac tcacaagaca
601 tcaacttcac ccattgtcaa gagcttcaac aggaatgagt gt
Secuencia de proteínas que define la secuencia completa de la cadena ligera (región variable y región constante de la cadena kappa) de 06C11 (SEQ ID NO: 114)
1 divmtqsqkfmstsvgdrvs vtckasqnvg tnvawfqqkp gqspkaliys asyrysgvpd 61 rftgsgsgtd filtisnvqs edlaeyfcqq ynnypltfga gtklelkrad aaptvsifpp 121 sseqltsggasvvcflnnfy pkdinvkwki dgserqngvl nswtdqdskd stysmsstlt 181 ltkdeyerhnsytceathkt stspivksfn rnec
Secuencia de ácidos nucleicos que codifica la secuencia completa de la cadena pesada tregión variable de la cadena pesada y región constante de la IgG2b! de 08G01 (SEQ ID NO: 115)
1 gaggtcctgc tgcaacagtc tggacctgag gtggtgaagc ctggggcttc agtgaagata 61 ccctgcaagg cttctggata cacattcact gactacaaca tggactgggt gaagcagagc 121 catggaaaga gccttgagtg gattggagag attaatccta acaatggtgg tactttctac 181 aaccagaagt tcaagggcaa ggccacattg actgtagaca agtcctccag cacagcctac 241 atggagctcc gcagcctgac atctgaggac actgcagtct attactgtgc aagagaggca 301 attactacgg taggcgctat ggactactgg ggtcaaggaa cctcagtcac cgtctcctca 361 gccaaaacaa cacccccatc agtctatcca ctggcccctg ggtgtggaga tacaactggt 421 tcctccgtga ctctgggatg cctggtcaag ggctacttcc ctgagtcagt gactgtgact 481 tggaactctg gatccctgtc cagcagtgtg cacaccttcc cagctctcct gcagtctgga 541 ctctacacta tgagcagctc agtgactgtc ccctccagca cctggccaag tcagaccgtc 601 acctgcagcg ttgctcaccc agccagcagc accacggtgg acaaaaaact tgagcccagc 661 r r r r r r n c * c s ' l ' t f cadcaatcaa cccctcftcct r r ' S ' l ' r r r ' s a r f r r a c Id f l '- r '3 f ' t ' r ' a r ' s a s f r f r r T ' s r f r ' f 721 cctaacctcg agggtggacc atccgtcttc atcttccctc caaatatcaa ggatgtactc 781 atgatctccc tgacacccaa ggtcacgtgt gtggtggtgg atgtgagcga ggatgaccca 841 gacgtccaga tcagctggtt tgtgaacaac gtggaagtac acacagctca gacacaaacc 901 catagagagg attacaacag tactatccgg gtggtcagca ccctccccat ccagcaccag 961 gactggatga gtggcaagga gttcaaatgc aaggtcaaca acaaagacct cccatcaccc 1021 atcgagagaa ccatctcaaa aattaaaggg ctagtcagag ctccacaagt atacatcttg 1081 ccgccaccag cagagcagtt gtccaggaaa gatgtcagtc tcacttgcct ggtcgtgggc 1141 ttcaaccctg gagacatcag tgtggagtgg accagcaatg ggcatacaga ggagaactac 1201 aaggacaccg caccagtcct agactctgac ggttcttact tcatatatag caagctcaat 1261 atgaaaacaa gcaagtggga gaaaacagat tccttctcat gcaacgtgag acacgagggt 1321 ctgaaaaatt actacctgaa gaagaccatc tcccggtctc cgggtaaa
Secuencia de proteínas que define la secuencia completa de la cadena pesada (región variable de la cadena pesada y región constante de la IgG2b) de 08G01 (SEQ ID NO: 116)
1 evllqqsgpevvkpgasvki pckasgytft dynmdwvkqs hgkslewige inpnnggtfy
61 nqkfkgkatltvdkssstay melrsltsed tavyycarea ittvgamdyw gqgtsvtvss
121 akttppsvyplapgcgdttg ssvtlgclvk gyfpesvtvt wnsgslsssv htfpallqsg
181 lytmsssvtvpsstwpsqtv tcsvahpass ttvdkkleps gpistinpcp pckechkcpa
241 pnleggpsvfifppnikdvl misltpkvtc vvvdvseddp dvqiswfvnn vevhtaqtqt
301 hredynstirvvstlpiqhq dwmsgkefkc kvnnkdlpsp iertiskikg lvrapqvyil
361 pppaeqlsrkdvsltclvvg fnpgdisvew tsnghteeny kdtapvldsd gsyfiyskln
421 mktskwektdsfscnvrheg lknyylkkti srspgk
Secuencia de ácidos nucleicos que codifica la secuencia completa de la cadena ligera (región variable y región constante de la cadena kappa) de 08G01 (SEQ ID NO: 117)
1 gacatccaga tgactcagtc tccagcctcc ctatctgcat ctgtgggaga aactgtcacc 61 atcacatgtc gagcaagtgg gaatattcac aattatttag catggtatca gcagaaacag 121 ggaaaatctc ctcagctcct ggtctataat gcaaaaacct tagcagatgg tgtgccatca 181 aggttcagtg gcagtggatc aggaacacaa tattctctca agatcaacag cctgcagcct 241 gaagattttg ggagttatta ctgtcaacat ttttggagtt ctccttacac gttcggaggg 301 gggaccaagc tggaaataaa acgggctgat gctgcaccaa ctgtatccat cttcccacca 361 tccagtgagc agttaacatc tggaggtgcc tcagtcgtgt gcttcttgaa caacttctac 421 cccaaagaca tcaatgtcaa gtggaagatt gatggcagtg aacgacaaaa tggcgtcctg 481 aacagttgga ctgatcagga cagcaaagac agcacctaca gcatgagcag caccctcacg 541 ttgaccaagg acgagtatga acgacataac agctatacct gtgaggccac tcacaagaca 601 tcaacttcac ccattgtcaa gagcttcaac aggaatgagt gt
Secuencia de proteínas que define la secuencia completa de la cadena ligera (región variable y región constante de la cadena kappa) de 08G01 (SEQ ID NO: 118)
1 diqmtqspas lsasvgetvt itcrasgnih nylawyqqkq gkspqllvyn aktladgvps 61 rfsgsgsgtq yslkinslqp edfgsyycqh fwsspytfgg gtkleikrad aaptvsifpp 121 sseqltsgga svvcflnnfy pkdinvkwki dgserqngvl nswtdqdskd stysmsstlt 181 ltkdeyerhn sytceathkt stspivksfn rnec
Secuencia de ácidos nucleicos que codifica la secuencia completa de la cadena pesada (región variable de la cadena pesada y región constante de la IgG1) de 14F11 (SEQ ID NO: 119)
1 caggttactc tgaaagagtc tggccctgga atattgcagc cctcccagac cctcagtctg 61 acttgttctt tctctgggtt ttcactgagc acttatggta tgggtgtagg ctggattcgt 121 cagccttcag gaaagggtct agagtggctg gcagacattt ggtgggatga cgataagtac 181 tataacccat ccctgaagag ccggctcaca atctccaagg atacctccag caatgaggta 241 ttcctcaaga tcgccattgt ggacactgca gatactgcca cttactactg tgctcgaaga 301 ggtcactact ctgctatgga ctactggggt caaggaacct cagtcaccgt ctcctcagcc 361 aaaacgacac ccccatctgt ctatccactg gcccctggat ctgctgccca aactaactcc 421 atggtgaccc tgggatgcct ggtcaagggc tatttccctg agccagtgac agtgacctgg 481 aactctggat ccctgtccag cggtgtgcac accttcccag ctgtcctgca gtctgacctc 541 tacactctga gcagctcagt gactgtcccc tccagcacct ggcccagcga gaccgtcacc 601 tgcaacgttg cccacccggc cagcagcacc aaggtggaca agaaaattgt gcccagggat 661 tgtggttgta agccttgcat atgtacagtc ccagaagtat catctgtctt catcttcccc 721 ccaaagccca aggatgtgct caccattact ctgactccta aggtcacgtg tgttgtggta 781 gacatcagca aggatgatcc cgaggtccag ttcagctggt ttgtagatga tgtggaggtg 841 cacacagctc agacgcaacc ccgggaggag cagttcaaca gcactttccg ctcagtcagt 901 gaacttccca tcatgcacca ggactggctc aatggcaagg agttcaaatg cagggtcaac 961 agtgcagctt tccctgcccc catcgagaaa accatctcca aaaccaaagg cagaccgaag 1021 gctccacagg tgtacaccat tccacctccc aaggagcaga tggccaagga taaagtcagt 1081 ctgacctgca tgataacaga cttcttccct gaagacatta ctgtggagtg gcagtggaat
1141 gggcagccagcggagaacta caagaacact cagcccatca tggacacaga tggctcttac 1201 ttcgtctacagcaagctcaa tgtgcagaag agcaactggg aggcaggaaa tactttcacc 1261 tgctctgtgttacatgaggg cctgcacaac caccatactg agaagagcct ctcccactct 1321 cctggtaaa
Secuencia de proteínas que define la secuencia completa de la cadena pesada (región variable de la cadena pesada y región constante de la IgG1) de 14F11 (SEQ ID NO: 120)
1 qvtlkesgpg ilqpsqtlsl tcsfsgfsis tygmgvgwir qpsgkglewl adiwwdddky
61 ynpslksrlt iskdtssnev flkiaivdta dtatyycarr ghysamdywg qgtsvtvssa
121 kttppsvypl apgsaaqtns mvtlgclvkg yfpepvtvtw nsgslssgvh tfpavlqsdl
181 ytlsssvtvp sstwpsetvt cnvahpasst kvdkkivprd cgckpcictv pevssvfifp
241 pkpkdvltit ltpkvtcvvv diskddpevq fswfvddvev htaqtqpree qfnstfrsvs
301 elpimhqdwl ngkefkcrvn saafpapiek tisktkgrpk apqvytippp keqmakdkvs
361 ltcmitdffp editvewqwn gqpaenyknt qpimdtdgsy fvysklnvqk snweagntft
421 csvlheglhn hhtekslshs pgk
Secuencia de ácidos nucleicos que codifica la secuencia completa de la cadena ligera (región variable y región
constante de la cadena kappa) de 14F11 (SEQ ID NO: 121)
1 gacattgtaa tgacccagtc tcaaaaattc atgtccacat cagtaggaga cagggtcagc
61 gtcacctgca aggccagtca gaatgtgggt actaatgtag cctggtatca acagaaacca
121 gggcaatctc ctaaagcact gatttactcg ccatcctacc ggtacagtgg agtccctgat
181 cgcttcacag gcagtggatc tgggacagat ttcactctca ccatcagcaa tgtgcagtct
241 gaagacttgg cagaatattt ctgtcagcaa tataacagct atcctcacac gttcggaggg
301 gggaccaagc tggaaatgaa acgggctgat gctgcaccaa ctgtatccat cttcccacca
361 tccagtgagc agttaacatc tggaggtgcc tcagtcgtgt gcttcttgaa caacttctac
421 cccaaagaca tcaatgtcaa gtggaagatt gatggcagtg aacgacaaaa tggcgtcctg
481 aacagttgga ctgatcagga cagcaaagac agcacctaca gcatgagcag caccctcacg
541 ttgaccaagg acgagtatga acgacataac agctatacct gtgaggccac tcacaagaca
601 tcaacttcac ccattgtcaa gagcttcaac aggaatgagt gt
Secuencia de proteínas que define la secuencia completa de la cadena ligera (región variable y región constante de la cadena kappa) de 14F11 (SEQ ID NO: 122)
1 divmtqsqkf mstsvgdrvs vtckasqnvg tnvawyqqkp gqspkaliys psyrysgvpd 61 rftgsgsgtd ftltisnvqs edlaeyfcqq ynsyphtfgg gtklemkrad aaptvsifpp 121 sseqltsggasvvcflnnfy pkdinvkwki dgserqngvl nswtdqdskd stysmsstlt 181 ltkdeyerhnsytceathkt stspivksfn rnec
Secuencia de ácidos nucleicos que codifica la secuencia completa de la cadena pesada (región variable de la cadena pesada y región constante de la IgG1) de 17B11 (SEQ ID NO: 123)
1 caggttactc tgaaagagtctggccctggg atattgcagc cctcccagac cctcagtctg 61 acttgttctt tctctgggttttcactgagc acttctggta tgggtgtgag ttggattcgt 121 cagccttcag gaaagggtctggagtggctg gcacacaatg actgggatga tgacaagcgc 181 tataagtcat ccctgaagagccggctcaca atatccaagg atacctccag aaaccaggta 241 ttcctcaaga tcaccagtgtggacactgca gatactgcca catactactg tgctcgaaga 301 gttgggggat tagagggctattttgattac tggggccaag gcaccactct cacagtctcc 361 tcagccaaaa cgacacccccatctgtctat ccactggccc ctggatctgc tgcccaaact 421 aactccatgg tgaccctgggatgcctggtc aagggctatt tccctgagcc agtgacagtg 481 acctggaact ctggatccctgtccagcggt gtgcacacct tcccagctgt cctgcagtct
541 gacctctaca ctctgagcag ctcagtgact gtcccctcca gcacctggcc cagcgagacc 601 gtcacctgca acgttgccca cccggccagc agcaccaagg tggacaagaa aattgtgccc 661 agggattgtg gttgtaagcc ttgcatatgt acagtcccag aagtatcatc tgtcttcatc 721 ttccccccaa agcccaagga tgtgctcacc attactctga ctcctaaggt cacgtgtgtt 781 gtggtagaca tcagcaagga tgatcccgag gtccagttca gctggtttgt agatgatgtg 841 gaggtgcaca cagctcagac gcaaccccgg gaggagcagt tcaacagcac tttccgctca 901 gtcagtgaac ttcccatcat gcaccaggac tggctcaatg gcaaggagtt caaatgcagg 961 gtcaacagtg cagctttccc tgcccccatc gagaaaacca tctccaaaac caaaggcaga 1021 ccgaaggctc cacaggtgta caccattcca cctcccaagg agcagatggc caaggataaa 1081 gtcagtctga cctgcatgat aacagacttc ttccctgaag acattactgt ggagtggcag 1141 tggaatgggc agccagcgga gaactacaag aacactcagc ccatcatgga cacagatggc 1201 tcttacttcg tctacagcaa gctcaatgtg cagaagagca actgggaggc aggaaatact 1261 ttcacctgct ctgtgttaca tgagggcctg cacaaccacc atactgagaa gagcctctcc 1321 cactctcctg gtaaa
Secuencia de proteínas que define la secuencia completa de la cadena pesada (región variable de la cadena pesada y región constante de la IgG1) de 17B11 (SEQ ID NO: 124)
1 qvtlkesgpg ilqpsqtlsl tcsfsgfsis tsgmgvswir qpsgkglewl ahndwdddkr 61 yksslksrlt iskdtsrnqv flkitsvdta dtatyycarr vgglegyfdy wgqgttltvs 121 sakttppsvy plapgsaaqt nsmvtlgclv kgyfpepvtv twnsgslssg vhtfpavlqs 181 dlytlsssvt vpsstwpset vtcnvahpas stkvdkkivp rdcgckpcic tvpevssvfi 241 fppkpkdvlt itltpkvtcv vvdiskddpe vqfswfvddv evhtaqtqpr eeqfnstfrs 301 vselpimhqd wlngkefkcr vnsaafpapi ektisktkgr pkapqvytip ppkeqmakdk 361 vsltcmitdf fpeditvewq wngqpaenyk ntqpimdtdg syfvysklnv qksnweagnt 421 ftcsvlhegl hnhhteksls hspgk
S e cu e n c ia d e ác idos n u c le icos qu e c o d ific a la se cu e n c ia c o m p le ta d e la c a d e n a lige ra (reg ión va r ia b le y reg ión c o n s ta n te de la c a d e n a kappa ) de 17 B 11 (S E Q ID NO : 125)
1 gacattgtgc tgacacagtc tcctgcttcc ttagctgtat ctctggggca gagggccacc 61 atctcatgca gggccagcca aagtgtcagt acatctaggt ttagttatat gcactggttc
121 caacagaaac caggacaggc acccaaactc ctcatcaagt atgcatccaa cctagaatct
181 ggggtccctg ccaggttcag tggcagtggg tctgggacag acttcaccct caacatccat
241 cctgtggagg gggaggatac tgcaacatat tactgtcagc acagttggga gattccgtac
301 acgttcggag gggggaccaa gctggaaata aaacgggctg atgctgcacc aactgtatcc
361 atcttcccac catccagtga gcagttaaca tctggaggtg cctcagtcgt gtgcttcttg
421 aacaacttct accccaaaga catcaatgtc aagtggaaga ttgatggcag tgaacgacaa
481 aatggcgtcc tgaacagttg gactgatcag gacagcaaag acagcaccta cagcatgagc
541 agcaccctca cgttgaccaa ggacgagtat gaacgacata acagctatac ctgtgaggcc
601 actcacaaga catcaacttc acccattgtc aagagcttca acaggaatga gtgt
Secuencia de proteínas que define la secuencia completa de la cadena ligera (región variable y región constante de la cadena kappa) de 17B11 (SEP ID NO: 126)
1 divltqspas lavslgqrat iscrasqsvs tsrfsymhwf qqkpgqapkl likyasnles
61 gvparfsgsg sgtdftlnih pvegedtaty ycqhsweipy tfgggtklei kradaaptvs
121 ifppsseqlt sggasvvcfl nnfypkdinv kwkidgserq ngvlnswtdq dskdstysms
181 stltltkdey erhnsytcea thktstspiv ksfnrnec
La Tabla 5 muestra la correspondencia entre las secuencias completas de los anticuerpos analizados en este Ejemplo con los presentados en la Lista de secuencias.
Tabla 5

continuación

Ejemplo 8: Afinidades de unión
Las afinidades de unión y las cinéticas de la unión de los anticuerpos al GDF15 humano recombinante marcado con 6X His (SEQ ID NO: 266) (His-rhGDF15 (R&D Systems, Inc.)), al GDF15 humano recombinante sin marcar (rhGDF15 (Peprotech, Rocky Hill, NJ) y al GDF15 humano recombinante producido bien como una Fc de ratón fusionada al GDF15 humano (mFc-rhGDF15) o bien como una versión en la que la Fc se eliminó enzimáticamente (rhGDF15 escindido) se midieron mediante una resonancia de plasmón superficial, usando un instrumento Biacore® T100 (GE Healthcare, Piscataway, NJ).
Las IgG de conejo anti-ratón (GE Healthcare) se inmovilizaron en chips sensores CM4 de dextrano carboximetilado (GE Healthcare) mediante un acoplamiento de amina, según un protocolo convencional. Los análisis se realizaron a 37 °C usando PBS que contiene tensioactivo P20 al 0,05% como tampón de ejecución. Los anticuerpos se capturaron en celdas de flujo individuales a un caudal de 10 pl/minuto. El tiempo de inyección se modificó para cada anticuerpo, para producir una Rmáx de entre 30 y 60 UR. Se inyectaron 250 pg/ml de Fc de ratón (Jackson ImmunoResearch, West Grove, PA) a 30 pl/minuto durante 120 segundos para bloquear la unión no específica de los anticuerpos de captura a la porción Fc de ratón de la proteína recombinante GDF15 cuando fue necesario. Se inyectaron secuencialmente tampón, mFc-rhGDF15, rhGDF15 escindido, His-rhGDF15 o rhGDF15 diluidos en tampón de ejecución sobre una superficie de referencia (sin anticuerpo capturado) y la superficie activa (el anticuerpo que se va a analizar) durante 240 segundos a 60 pl/minuto. La fase de disociación se monitorizó durante hasta 1.500 segundos. Después, la superficie se regeneró con dos inyecciones de 60 segundos de glicina-HCl 10 mM, a pH 1,7, a un caudal de 30 pl/minuto. El intervalo de concentración del GDF15 analizado era de entre 30 nM y 0,625 nM.
Los parámetros cinéticos se determinaron usando la función cinética del programa informático BIAevaluation (GE Healthcare) con una resta de referencia doble. Se determinaron los parámetros cinéticos de cada anticuerpo, ka (constante de velocidad de asociación), kd (constante de velocidad de disociación) y Kd (constante de velocidad de disociación en equilibrio). Los valores cinéticos de los anticuerpos monoclonales en mFc-rhGDF15, rhGDF15 escindido, His-rhGDF15 o rhGDF15 se resumen en las Tablas 6, 7, 8 y 9, respectivamente.
Tabla 6

Los datos de la Tabla 6 muestran que los anticuerpos se unen a la mFc-rhGDF15 con una Kd de aproximadamente 250 pM o menos, 200 pM o menos, 150 pM o menos, 100 pM o menos, 75 pM o menos o 50 pM o menos.
Los valores cinéticos de los anticuerpos monoclonales en rhGDF15 escindido se resumen en la Tabla 7.
Tabla 7

Los datos de la Tabla 7 muestran que los anticuerpos 01G06, 06C11 y 14F11 se unen al rhGDF15 escindido con una Kd de aproximadamente 200 pM o menos, 150 pM o menos o 100 pM o menos.
Los valores cinéticos de los anticuerpos monoclonales en His-rhGDF15 se resumen en la Tabla 8.
Tabla 8

Los datos de la Tabla 8 muestran que los anticuerpos 01G06, 06C11 y 14F11 se unen a1His-rhGDF15 con una Kd de aproximadamente 150 pM o menos, 100 pM o menos, 75 pM o menos o 50 pM o menos.
Los valores cinéticos de los anticuerpos monoclonales en rhGDF15 se resumen en la Tabla 9.
Tabla 9

Los datos de la Tabla 9 muestran que los anticuerpos 01G06, 06C11 y 14F11 se unen al rhGDF15 con una Kd de aproximadamente 250 pM o menos, 200 pM o menos, 150 pM o menos, 100 pM o menos, 75 pM o menos o 50 pM o menos.
Ejemplo 9: Reversión de la caquexia en un modelo inducido por mFc-rhGDF15
Este Ejemplo muestra la reversión de la caquexia (indicada por la pérdida de peso corporal) por el anticuerpo 01G06, 03G05, 04F08, 06C11, 14F11 o 17B11 en un modelo inducido por mFc-rhGDF15. Se administró subcutáneamente mFc-rhGDF15 (2 pg/g) en el costado de ratones ICR-SCID hembra de 8 semanas de edad. El peso corporal se midió diariamente. Cuando el peso corporal alcanzó el 93 %, los ratones se dividieron aleatoriamente en siete grupos de diez ratones cada uno. Cada grupo recibió uno de los siguientes tratamientos: IgG murina de control, 01G06, 03G05, 04F08, 06C11, 14F11 o 17B11 a 10 mg/kg. El tratamiento se administró una vez mediante una inyección intraperitoneal. El tratamiento con el anticuerpo 01G06, 03G05, 04F08, 06C11, 14F11 o 17B11 dio como resultado un aumento en el peso corporal con respecto al peso inicial o aproximadamente del 100 % (p < 0,001) (FIG. 14 y Tabla 10).
Tabla 10

Los datos de la FIG. 14 y de la Tabla 10 indican que los anticuerpos anti-GDF15 divulgados pueden revertir la caquexia en un modelo de ratón inducida por mFc-rhGDF15 (es decir, un modelo de ratón no portador de tumor). Ejemplo 10: Reversión de la caquexia en un modelo de xenoinjerto tumoral HT-1080
Este Ejemplo muestra la reversión de la caquexia (indicada por la pérdida de peso corporal) por el anticuerpo 01G06, 03G05, 04F08, 06C11, 08G01, 14F11 o 17B11 en un modelo de xenoinjerto de fibrosarcoma HT-1080. Se cultivaron células HT-1080 en un cultivo a 37 0C en una atmósfera que contiene un 5 % de CO2 , usando medio esencial mínimo de Eagle (ATCC, n° de catálogo 30-2003) que contiene FBS al 10 %. Las células se inocularon subcutáneamente en el costado de ratones ICR SCID hembra de 8 semanas de edad con 5 x 106células por ratón en matrigel al 50 %. El peso corporal se midió diariamente. Cuando el peso corporal alcanzó el 93 %, los ratones se
dividieron aleatoriamente en ocho grupos de diez ratones cada uno. Cada grupo recibió uno de los siguientes tratamientos: IgG murina de control, 01G06, 03G05, 04F08, 06C11, 08G01, 14F11 o 17B11 a 10 mg/kg. El tratamiento se administró cada tres días mediante una inyección intraperitoneal. El tratamiento con el anticuerpo 01G06, 03G05, 04F08, 06C11, 08G01, 14F11 o 17B11 dio como resultado un aumento en el peso corporal con respecto al peso inicial o aproximadamente del 100 % (p < 0,001) (FIG. 15 y Tabla 11).
Tabla 11

Los datos de la FIG. 15 y de la Tabla 11 indican que los anticuerpos anti-GDF15 divulgados pueden revertir la caquexia en un modelo de xenoinjerto de fibrosarcoma HT-1080.
Se realizaron estudios adicionales con el anticuerpo 01G06 para demostrar la reversión de la caquexia en este modelo de ratón. Se cultivaron células HT-1080 y se inocularon subcutáneamente en el costado de ratones ICR-SCID hembra de 8 semanas de edad como se describe más arriba. Cuando el peso corporal alcanzó el 93 %, los ratones se dividieron aleatoriamente en dos grupos de diez ratones cada uno. Cada grupo recibió uno de los siguientes tratamientos: IgG murina de control o 01G06 a 10 mg/kg. El tratamiento se administró una vez mediante una inyección intraperitoneal. Como se muestra en la FIG. 16A, el tratamiento con el anticuerpo 01G06 dio como resultado un aumento en el peso corporal con respecto al peso inicial o el 100 % (p < 0,001) (FIG. 16A).
El consumo de alimentos se determinó pensando la comida suministrada proporcionada diariamente a los ratones (FIG. 16B). Se observó un aumento significativo en el consumo de alimentos en el grupo tratado con 01G06 durante los primeros tres días después del tratamiento. Después de ese tiempo, no se observó ningún cambio significativo en comparación con el grupo de control (mIgG).
El consumo de agua se determinó pesando el suministro de agua proporcionado diariamente a los ratones. No se observó ningún cambio significativo en el consumo de agua entre los grupos.
En este experimento, se sacrificó un grupo de diez ratones en el momento de la administración (situación inicial o 93 % de peso corporal, sin tratamiento) y al final del estudio (siete días después de la administración, con mIgG o con 01G06). La grasa gonadal y el los músculos gastrocnemios se extrajeron quirúrgicamente y se pesaron como se describe más arriba en el Ejemplo 4, y los tejidos se congelaron instantáneamente en nitrógeno líquido. Se aisló el ARN de las muestras de músculo gastrocnemio para determinar los niveles de ARNm de mMuRF1 y de mAtrogina mediante una RT-PCR, como se describe en el Ejemplo 4.
Como se muestra en la FIG. 16C, se observó una reducción significativa en la masa grasa gonadal siete días después de la administración de mIgG, pero no en el grupo tratado con el anticuerpo 01G06. Además, los ratones tratados con mIgG mostraron una pérdida significativa del músculo gastrocnemio en comparación con el grupo de la situación inicial, mientras que el grupo de ratones tratados con el anticuerpo 01G06, no (FIG. 16D). Además, los niveles de los marcadores de degradación muscular, mMuRF1 y mAtrogina, eran significativamente mayores en el grupo con mIgG en comparación con el grupo con 01G06 (FIG. 16E).
Estos resultados indican que los anticuerpos anti-GDF 15 divulgados pueden revertir la caquexia medida por la pérdida de masa muscular, la pérdida de grasa y la pérdida involuntaria de peso en un modelo de xenoinjerto tumoral HT-1080.
Ejemplo 11: Reversión de la caquexia en un modelo de xenoinjerto tumoral HT-1080
Este Ejemplo muestra la reversión de la caquexia (indicada por la pérdida de peso corporal) por el anticuerpo 01G06 en un modelo de xenoinjerto de fibrosarcoma HT-1080. Se cultivaron células HT-1080 en un cultivo a 37 0C en una atmósfera que contiene un 5 % de CO2 , usando medio esencial mínimo de Eagle (ATCC, n° de catálogo 30-2003) que contiene FBS al 10 %. Las células se inocularon subcutáneamente en el costado de ratones ICR SCID hembra de 8 semanas de edad con 5 x 106células por ratón en matrigel al 50 %. El peso corporal se midió diariamente. Cuando el peso corporal alcanzó el 80 %, los ratones se dividieron aleatoriamente en dos grupos de cinco ratones cada uno. Cada grupo recibió uno de los siguientes tratamientos: IgG murina de control, 01G06 administrado a
2 mg/kg el día 1 y el día 7. El tratamiento se administró mediante una inyección intraperitoneal. El tratamiento con el anticuerpo 01G06 dio como resultado un aumento en el peso corporal con respecto al peso inicial o aproximadamente el 100 % (p < 0,001) (FIG. 17A y Tabla 12).
Tabla 12

Los datos de las FIGS. 17A-B y la Tabla 12 indican que los anticuerpos anti-GDF15 divulgados pueden revertir la caquexia en un modelo de xenoinjerto de fibrosarcoma HT-1080.
En este experimento, se sacrificó un grupo de cinco ratones en el momento de la administración (situación inicial u 80 % de peso corporal pérdida, sin tratamiento) y al final del estudio (siete días después de la administración, con mIgG o con 01G06). El hígado, el corazón, el bazo, el riñón, la grasa gonadal y los músculos gastrocnemios se extrajeron quirúrgicamente y se pesaron. Como se muestra en la FIG. 17B, se observó una pérdida significativa en la masa del hígado, el corazón, el bazo, el riñón, la grasa gonadal y el músculo gastrocnemio siete días después de la administración de la mIgG, pero no en el grupo tratado con el anticuerpo 01G06. Además, los ratones tratados con el anticuerpo 01G06 mostraron una ganancia significativa de músculo, hígado y gonadal en comparación con el grupo de la situación inicial (FIG. 17B).
Estos resultados indican que los anticuerpos anti-GDF 15 divulgados pueden revertir la caquexia medida por la pérdida de masa del órgano clave, la pérdida de masa muscular, la pérdida de grasa y la pérdida involuntaria de peso en un modelo de xenoinjerto tumoral HT-1080.
Ejemplo 12: Reversión de la caquexia en un modelo de xenoinjerto tumoral K-562
Este Ejemplo muestra la reversión de la caquexia (indicada por la pérdida de peso corporal) por el anticuerpo 01G06, 03G05, 04F08, 06C11, 08G01, 14F11 o 17B11 en un modelo de xenoinjerto de leucemia K-562. Se cultivaron células K-562 en un cultivo a 37 °C en una atmósfera que contiene un 5 % de CO2 , usando medio de Dulbecco modificado por Iscove (n° de catálogo de la ATCC 30-2005) que contiene FBS al 10 %. Las células se inocularon subcutáneamente en el costado de ratones CB17SCRFMF hembra de 8 semanas de edad con 2,5 x 106células por ratón en matrigel al 50 %. El peso corporal se midió diariamente. Cuando el peso corporal alcanzó el 93 %, los ratones se distribuyeron aleatoriamente en ocho grupos de diez ratones cada uno. Cada grupo recibió uno de los siguientes tratamientos: IgG murina de control, 01G06, 03G05, 04F08, 06C11, 08G01, 14F11 o 17B11 a 10 mg/kg. El tratamiento se administró cada tres días mediante una inyección intraperitoneal. El tratamiento con el anticuerpo 01G06, 03G05, 04F08, 06C11, 08G01, 14F11 o 17B11 dio como resultado un aumento en el peso corporal con respecto al peso inicial o aproximadamente del 100 % (p < 0,001) (FIG. 18 y Tabla 13).
Tabla 13

Los datos de la FIG. 18 y de la Tabla 13 indican que los anticuerpos anti-GDF15 divulgados pueden revertir la caquexia en un modelo de xenoinjerto tumoral K-562.
Ejemplo 13: Modelos de xenoinjerto tumoral adicionales
El anticuerpo 01G06 se analizó en modelos adicionales de xenoinjerto tumoral que incluyen el modelo de xenoinjerto de ovario TOV-21G y el modelo de xenoinjerto de colon LS1034. En cada modelo, el anticuerpo 01G06 revertió la pérdida de peso corporal en comparación con un control de PBS (p < 0,001 para el modelo TOV-21G y p < 0,01 para el modelo LS1034).
Ejemplo 14: Humanización de los anticuerpos anti-GDF15
Este Ejemplo describe la humanización y la quimerización de tres anticuerpos murinos, denominados 01G06, 06C11 y 14F11, y la caracterización de los anticuerpos humanizados resultantes. Se diseñaron los anticuerpos anti-GDF15 humanizados los anticuerpos, madurados por afinidad mediante una mutagénesis dirigida de la CDR y optimizados usando métodos conocidos en la técnica. Las secuencias de aminoácidos se convirtieron en secuencias de ADN con codones optimizados y se sintetizaron para incluir (en el siguiente orden): un sitio de restricción HindIII en 5', una secuencia consenso Kozak, una secuencia de señal amino terminal, una región variable humanizada, una región constante humana de IgG1 o kappa, un codón de terminación y un sitio de restricción 3' EcoRI.
También se construyeron cadenas quiméricas (región variable murina y región constante humana) 01G06, 06C11, y 14F11 pesada (IgG1 humana) y ligera (kappa humana). Para generar los anticuerpos quiméricos, se fusionaron las regiones variables murinas con la región constante humana y se sintetizaron las secuencias de ADN con los codones optimizados, incluyendo (en el siguiente orden): un sitio de restricción HindIII en 5', una secuencia consenso Kozak, una secuencia de señal amino terminal, una región variable de ratón, una región constante humana de IgG1 o kappa, un codón de terminación y un sitio de restricción EcoRI en 3'.
Las cadenas pesadas humanizada y quimérica se subclonaron en pEE6.4 (Lonza, Basilea, Suiza) a través de los sitios HindIII y EcoRI usando una clonación por PCR In-Fusion™ (Clontech, Mountain View, CA). Las cadenas ligeras kappa humanizada y quimérica se subclonaron en pEE14.4 (Lonza) a través de los sitios HindIII y EcoRI usando una clonación por PCR In-Fusion™.
Las cadenas del anticuerpo humanizado o las cadenas del anticuerpo quimérico se transfectaron temporalmente en células 293T para producir anticuerpo. El anticuerpo bien se purificó, o bien se usó en sobrenadantes de medios de cultivo celular para el posterior análisis in vitro. La unión de los anticuerpos quiméricos y humanizados al GDF15 humano se midió como se describe a continuación. Los resultados se resumen en las Tablas 24-27.
Cada una de las posibles combinaciones de las regiones variables quiméricas o humanizadas 01G06 de la cadena pesada de la inmunoglobulina y la cadena ligera de una inmunoglobulina se establece a continuación en la Tabla 14.
Tabla 14

continuación

continuación

Cada una de las posibles combinaciones de las regiones variables quiméricas o humanizadas 06C11 de la cadena pesada de la inmunoglobulina y la cadena ligera de una inmunoglobulina se establece a continuación en la Tabla 15.
Tabla 15

Cada una de las posibles combinaciones de las regiones variables quiméricas o humanizadas 14F11 de la cadena pesada de la inmunoglobulina y la cadena ligera de una inmunoglobulina se establece a continuación en la Tabla 16.
Tabla 16

Cada una de las posibles combinaciones de las regiones variables quiméricas 04F08, 06C11 y 14F11 de la cadena pesada de una inmunoglobulina y la cadena ligera de una inmunoglobulina se establece a continuación en la Tabla 17.
Tabla 17

Cada una de las posibles combinaciones de las regiones variables quiméricas 01G06 y 08G01 de la cadena pesada de una inmunoglobulina y la cadena ligera de una inmunoglobulina se establece a continuación en la Tabla 18.
Tabla 18

Las secuencias de ácidos nucleicos y las secuencias de la proteína codificada que definen las regiones variables de los anticuerpos quiméricos y humanizados 01G06, 06C11 y 14F11 se resumen a continuación (las secuencias del péptido de señal amino terminal no se muestran). Las secuencias de las CDR (definición de Kabat) se muestran en negrita y están subrayadas en las secuencias de aminoácidos.
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada quimérica Ch01 G06 (SEQ ID NO: 127)
1 gaagtgttgt tgcagcagtc agggccggag ttggtaaaac cgggagcgtc ggtgaaaatc
61 ccgtgcaaag cgtcggggta tacgtttacg gactataaca tggattgggt gaaacagtcg
121 catgggaaat cgcttgaatg gattggtcag atcaatccga ataatggagg aatcttcttt
181 aatcagaagt ttaaaggaaa agcgacgctt acagtcgata agtcgtcgaa cacggcgttc
241 atggaagtac ggtcgcttac gtcggaagat acggcggtct attactgtgc gagggaggcg
301 attacgacgg tgggagcgat ggactattgg ggacaaggga cgtcggtcac ggtatcgtcg
Secuencia de proteínas que define la región variable de la cadena pesada quimérica Ch01G06 (SEQ ID NO: 40)
1 evllqqsgpe lvkpgasvki pckasgytft dynmdwvkqs hgkslewigg inpnnggiff
61 nqkfkgkatl tvdkssntaf mevrsltsed tavyycarea ittvgamdyw gqgtsvtvss
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada Hu01G06 IGHV1-18 (SEQ ID NO: 53)
1 caagtgcaac ttgtgcagtcgggtgcggaa gtcaaaaagc cgggagcgtc ggtgaaagta
61 tcgtgtaaag cgtcgggatatacgtttacg gactataaca tggactgggt acgacaggca 121 ccggggaaat cgttggaatggatcggacag attaatccga acaatggggg aattttcttt 181 aatcagaaat tcaaaggacgggcgacgttg acggtcgata catcgacgaa tacggcgtat 241 atggaattga ggtcgcttcgctcggacgat acggcggtct attactgcgc cagggaggcg 301 atcacgacgg taggggcgatggattattgg ggacagggga cgcttgtgac ggtatcgtcg
Secuencia de proteínas que define la región variable de la cadena pesada Hu01 G06 IGHV1-18 (SEQ ID NO: 54)
1 qvqlvqsgae vkkpgasvkv sckasgytft dynmdwvrqa pgkslewigg inpnnggiff
61 nqkfkgratl tvdtstntay melrslrsdd tavyycarea ittvgamdyw gqgtlvtvss
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada Hu01G06 IGHV1-69 (SEQ ID NO: 55)
1 caagtccagcttgtccagtc gggagcggaa gtgaagaaac cggggtcgtc ggtcaaagta 61 tcgtgtaaagcgtcgggata tacgtttacg gactataaca tggattgggt acgacaggct 121 ccgggaaaatcattggaatg gattggacag attaatccga ataatggggg tatcttcttt 181 aatcaaaagtttaaagggag ggcgacgttg acggtggaca aatcgacaaa tacggcgtat 241 atggaattgtcgtcgcttcg gtcggaggac acggcggtgt attactgcgc gagggaggcg 301 atcacgacggtcggggcgat ggattattgg ggacagggaa cgcttgtgac ggtatcgtcg
Secuencia de proteínas que define la región variable de la cadena pesada Hu01 G06 IGHV1 -69 (SEQ ID NO: 56)
1 qvqlvqsgae vkkpgssvkv sckasgytft dynmdwvrqa pgkslewigg inpnnggiff 61 nqkfkgratl tvdkstntay melsslrsed tavyycarea ittvgamdyw gqgtlvtvss
S e cu e n c ia de ác id o s nu c le icos qu e c o d ifica la reg ión v a ria b le de la ca d e n a p e sa d a S h01 G 06 IG H V 1-18 M 69 L (S E Q ID NO : 57)
1 caggtccagcttgtgcaatc gggagcggaa gtgaagaaac cgggagcgtc ggtaaaagtc
61 tcgtgcaaagcgtcggggta tacgtttacg gactataaca tggactgggt gcgccaagcg 121 cctggacagggtcttgaatg gatggggcag attaatccga ataatggagg gatcttcttt
181 aatcagaaattcaaaggaag ggtaacgctg acgacagaca cgtcaacatc gacggcctat
241 atggaattgcggtcgttgcg atcagatgat acggcggtct actattgtgc gagggaggcg
301 attacgacggtgggagcgat ggattattgg ggacagggga cgttggtaac ggtatcgtcg
Secuencia de proteínas que define la región variable de la cadena pesada Sh01G06 IGHV1-18 M69L (SEQ ID NO: 58)
1 qvqlvqsgae vkkpgasvkv sckasgytft dynmdwvrqa pgqglewmgg inpnnggiff 61 nqkfkgrvtl ttdtststay melrslrsdd tavyycarea ittvgamdyw gqgtlvtvss
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada Sh01G06 IGHV1-18 M69L K64Q G44S (SEQ ID NO: 59)
1 caggtccagc ttgtgcaatc gggagcggaa gtgaagaaac cgggagcgtc ggtaaaagtc 61 tcgtgcaaag cgtcggggta tacgtttacg gactataaca tggactgggt gcgccaagcg 121 cctggacaga gccttgaatg gatggggcag attaatccga ataatggagg gatcttcttt 181 aatcagaaat tccagggaag ggtaacgctg acgacagaca cgtcaacatc gacggcctat 241 atggaattgc ggtcgttgcg atcagatgat acggcggtct actattgtgc gagggaggcg 301 attacgacgg tgggagcgat ggattattgg ggacagggga cgttggtaac ggtatcgtcg
Secuencia de proteínas que define la región variable de la cadena pesada Sh01G06 IGHV1-18 M69L K64Q G44S (SEQ ID NO: 60)
1 qvqlvqsgae vkkpgasvkv sckasgytft dynmdwvrqa pgqslewmgg inpnnggiff
61 nqkfqgrvtl ttdtststay melrslrsdd tavyycarea ittvgamdyw gqgtlvtvss
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada Sh01G06 IGHV1-18 M69L K64Q (SEQ ID NO: 61)
1 caggtccagc ttgtgcaatc gggagcggaa gtgaagaaac cgggagcgtc ggtaaaagtc 61 tcgtgcaaag cgtcggggta tacgtttacg gactataaca tggactgggt gcgccaagcg
121 cctggacagg gtcttgaatg gatggggcag attaatccga ataatggagg gatcttcttt
181 aatcagaaat tccagggaag ggtaacgctg acgacagaca cgtcaacatc gacggcctat
241 atggaattgc ggtcgttgcg atcagatgat acggcggtct actattgtgc gagggaggcg
301 attacgacgg tgggagcgat ggattattgg ggacagggga cgttggtaac ggtatcgtcg
Secuencia de proteínas que define la región variable de la cadena pesada Sh01 G06 IGHV1 -18 M69L K64Q (SEQ ID NO: 62)
1 qvqlvqsgae vkkpgasvkv sckasgytft dynmdwvrqa pgqglewmgg inpnnggiff
61 nqkfqgrvtl ttdtststay melrslrsdd tavyycarea ittvgamdyw gqgtlvtvss
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada Sh01G06 IGHV1-69 T30S I69L (SEQ ID NO: 63)
1 caagtacagc ttgtacagtc gggagcggaa gtcaagaaac cgggatcgtc ggtcaaagtg 61 tcgtgtaaag cgtcgggata tacgtttagc gactataaca tggattgggt gcgacaagcg
121 cctgggcagg gacttgaatg gatgggtcag atcaatccga ataatggggg aatctttttc
181 aatcagaagt ttaaagggag ggtaacgctg acggcggata aaagcacgtc aacggcgtat
241 atggagttgt cgtcgttgcg gtcggaggac acggcggtct attactgcgc gagggaagcg
301 attacgacgg tgggagcgat ggattattgg gggcagggaa cgcttgtaac ggtgtcatcg
Secuencia de proteínas que define la región variable de la cadena pesada Sh01G06 IGHV1-69 T30S I69L (SEQ ID NO: 64)
1 qvqlvqsgae vkkpgssvkv sckasgytfs dynmdwvrqa pgqglewmgq inpnnggiff 61 nqkfkgrvtl tadkststay melsslrsed tavyycarea ittvgamdyw gqgtlvtvss
S e cu e n c ia de ác ido s nu c le icos q u e co d ifica la reg ión v a r ia b le de la ca d e n a p e sa d a S h01G 06 IG H V 1-69 T 30 S K 64Q I69L (S E Q ID NO : 65)
1 caagtacagc ttgtacagtc gggagcggaa gtcaagaaac cgggatcgtc ggtcaaagtg 61 tcgtgtaaag cgtcgggata tacgtttagc gactataaca tggattgggt gcgacaagcg 121 cctgggcagg gacttgaatg gatgggtcag atcaatccga ataatggggg aatctttttc 181 aatcagaagt ttcaggggag ggtaacgctg acggcggata aaagcacgtc aacggcgtat 241 atggagttgt cgtcgttgcg gtcggaggac acggcggtct attactgcgc gagggaagcg 301 attacgacgg tgggagcgat ggattattgg gggcagggaa cgcttgtaac ggtgtcatcg
Secuencia de proteínas que define la región variable de la cadena pesada Sh01G06 IGHV1-69 T30S K64Q I69L (SEQ ID NO: 66)
1 gvqlvqsgae vkkpgssvkv sckasgytfs dynmdwvrqa pgqglewmgg inpnnqqiff 61 nqkfqgrvtl tadkststay melsslrsed tavyycarea ittvqamdyw gqgtlvtvss
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada Hu01G06 IGHV1-18 F1 (SEQ ID NO: 245)
1 caggtccagc ttgtgcaatc gggagcggaa gtgaagaaac cgggagcgtc ggtaaaagtc 61 tcgtgcaaag cgtcggggta tacgtttacg gactataaca tggactgggt gcgccaagcg 121 cctggacaga gccttgaatg gatggggcag attaatccgt acaatcacct gatcttcttt 181 aatcagaaat tccagggaag ggtaacgctg acgacagaca cgtcaacatc gacggcctat 241 atggaattgc ggtcgttgcg atcagatgat acggcggtct actattgtgc gagggaggcg 301 attacgacgg tgggagcgat ggattattgg ggacagggga cgttggtaac ggtatcgtcg
Secuencia de proteínas que define la región variable de la cadena pesada Hu01 G06 IGHV1 -18 F1 (SEQ ID NO: 246)
1 qvqlvqsgae vkkpgasvkv sckasgytft dynmdwvrqa pgqslewmgg inpynhliff 61 nqkfqgrvtl ttdtststay melrslrsdd tavyycarea ittvqamdyw gqgtlvtvss
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada Hu01G06 IGHV1-18 F2 (SEQ ID NO: 247)
1 caggtccagc ttgtgcaatc gggagcggaa gtgaagaaac cgggagcgtc ggtaaaagtc 61 tcgtgcaaag cgtcggggta tacgtttacg gactataaca tggactgggt gcgccaagcg 121 cctggacaga gccttgaatg gatggggcag attaatccga ataatggact gatcttcttt 181 aatcagaaat tccagggaag ggtaacgctg acgacagaca cgtcaacatc gacggcctat 241 atggaattgc ggtcgttgcg atcagatgat acggcggtct actattgtgc gagggaggcg 301 attacgacgg tgggagcgat ggattattgg ggacagggga cgttggtaac ggtatcgtcg
Secuencia de proteínas que define la región variable de la cadena pesada Hu01 G06 IGHV1 -18 F2 (SEQ ID NO: 248)
1 qvqlvqsgae vkkpgasvkv sckasgytft dynmdwvrqa pgqslewmgg inpnngliff
61 nqkfqgrvtl ttdtststay melrslrsdd tavyycarea ittvgamdyw gqgtlvtvss
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada Hu01G06 IGHV1-69 FI (SEQ ID NO: 249)
1 caagtacagc ttgtacagtc gggagcggaa gtcaagaaac cgggatcgtc ggtcaaagtg 61 tcgtgtaaag cgtcgggata tacgtttagc gactataaca tggattgggt gcgacaagcg 121 cctgggcagg gacttgaatg gatgggtcag atcaatccga ataatgggct gatctttttc 181 aatcagaagt ttaaagggag ggtaacgctg acggcggata aaagcacgtc aacggcgtat 241 atggagttgt cgtcgttgcg gtcggaggac acggcggtct attactgcgc gagggaagcg 301 attacgacgg tgggagcgat ggattattgg gggcagggaa cgcttgtaac ggtgtcatcg
S e cu e n c ia de p ro te ín a s q u e d e fin e la reg ión v a r ia b le d e la ca d e n a p e sa d a Hu01 G 06 IGHV1 -69 FI (S E Q ID NO : 250 )
1 qvqlvqsgae vkkpgssvkv sckasgytfs dynmdwvrqa pgqglewmgg inpnngliff
61 nqkfkgrvtl tadkststay melsslrsed tavyycarea ittvgamdyw gqgtlvtvss
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada Hu01G06 IGHV1-69 F2 (SEQ ID NO: 251)
1 caagtacagc ttgtacagtc gggagcggaa gtcaagaaac cgggatcgtc ggtcaaagtg 61 tcgtgtaaag cgtcgggata tacgtttagc gactataaca tggattgggt gcgacaagcg
121 cctgggcagggacttgaatg gatgggtcag atcaatccgt acaatcacct gatctttttc
181 aatcagaagt ttaaagggag ggtaacgctg acggcggata aaagcacgtc aacggcgtat
241 atggagttgt cgtcgttgcg gtcggaggac acggcggtct attactgcgc gagggaagcg
301 attacgacgg tgggagcgat ggattattgg gggcagggaa cgcttgtaac ggtgtcatcg
Secuencia de proteínas que define la región variable de la cadena pesada Hu01 G06 IGHV1 -69 F2 (SEQ ID NO: 252)
1 qvqlvqsgaevkkpgssvkv sckasgytfs dynmdwvrqa pgqglewmgg inpynhliff 61 nqkfkgrvtltadkststay melsslrsed tavyycarea ittvgamdyw gqgtlvtvss
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada quimérica Ch06C11 (SEQ ID NO: 129)
1 caggtgacac tcaaagaatc aggacccgga atccttcagc ccagccagac cttgtcgctg 61 acttgttcgt tctccggttt cagcctgaat acttatggga tgggtgtgtc atggatcagg 121 caaccgtccg ggaaaggatt ggagtggctc gcgcacatct actgggacga tgacaaacgc 181 tacaatcctt cgctgaagag ccgattgacg atttccaagg atgcctcgaa caaccgggta 241 tttcttaaga tcacgtcggt cgatacggca gacacggcga cctattactg cgcccaaaga 301 gggtacgatg actattgggg atattggggc caggggacac tcgtcacaat ttcagct
Secuencia de proteínas que define la región variable de la cadena pesada quimérica Ch06C11 (SEQ ID NO: 46)
1 qvtlkesgpg ilqpsqtlsl tcsfsgfsln tygmgvswir qpsgkglewl ahiywdddkr
61 ynpslksrlt iskdasnnrv flkitsvdta dtatyycaqr gyddywgywg qgtlvtisa
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada HE LM 06C11 IGHV2-70 (SEQ ID NO: 67)
1 caggtgactt tgaaagaatc cggtcccgca ttggtaaagc caacccagac acttacgctc 61 acatgtacat tttccggatt cagcttgaac acttacggga tgggagtgtc gtggattcgg 121 caacctccgg ggaaggctct ggagtggctg gcgcacatct actgggatga tgacaaaagg 181 tataacccct cacttaaaac gagactgacg atctcgaagg acacaagcaa gaatcaggtc 241 gtcctcacga ttacgaatgt agacccggtg gatactgccg tctattactg cgcgcaacgc 301 gggtatgatg actactgggg atattggggt cagggcaccc tcgtgaccat ctcgtca
Secuencia de proteínas que define la región variable de la cadena pesada HE LM 06C11 IGHV2-70 (SEQ ID NO: 68)
1 qvtlkesgpa lvkptqtltl tctfsgfsln tygmgvswir qppgkalewl ahiywdddkr 61 ynpslktrlt iskdtsknqv vltitnvdpv dtavyycaqr gyddywgywg qgtlvtiss
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada Hu06C11 IGHV2-5 (SEQ ID NO: 69)
1 caagtaacgc tcaaggagtc cggacccacc ttggtgaagc cgacgcagac cttgactctt 61 acgtgcactt tctcggggtt ttcactgaat acgtacggga tgggtgtctc atggatcagg 121 caacctccgg ggaaaggatt ggaatggctg gcgcacatct actgggatga cgataagaga 181 tataacccaa gcctcaagtc gcggctcacc attacaaaag atacatcgaa aaatcaggtc 241 gtacttacta tcacgaacat ggaccccgtg gacacagcaa catattactg tgcccagcgc 301 ggctatgacg attattgggg ttactgggga cagggaacac tggtcacggt gtccagc
S e cu e n c ia de p ro te ín a s q u e d e fin e la reg ión v a r ia b le d e la ca d e n a p e sa d a H u 06 C 11 IG H V 2-5 (S E Q ID NO : 70)
1 qvtlkesgpt lvkptqtltl tctfsgfsln tyqmqvswir qppgkglewl ahiywdddkr 61 ynpslksrlt itkdtsknqv vltitnmdpv dtatyycaqr gyddywgywg qgtlvtvss
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada quimérica Ch14F11 (SEQ ID NO: 131)
1 caggtcacgc tgaaagagtc aggtcccgga atccttcaac cttcgcagac attgtcactc 61 acatgttcct tctccgggtt ctcgctctcg acttatggca tgggtgtagg atggattcgg
121 cagcccagcg ggaaggggct tgagtggttg gcggatatct ggtgggacga cgacaaatac
181 tacaatccga gcctgaagtc ccgcctcacc atttcgaaag atacgtcatc aaacgaagtc
241 tttttgaaga tcgccatcgt ggacacggcg gatacagcga cgtattactg cgccagaagg
301 ggacactaca gcgcaatgga ttattgggga caggggacct cggtgactgt gtcgtcc
Secuencia de proteínas que define la región variable de la cadena pesada quimérica Ch14F11 (SEQ ID NO: 50)
1 qvtlkesgpg ilqpsqtlsl tcsfsgfsls tygmgvgwir qpsgkglewl adiwwdddky
61 ynpslksrlt iskdtssnev flkiaivdta dtatyycarr ghysamdywg qgtsvtvss
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada Sh14F11 IGHV2-5 (SEQ ID NO: 71)
1 cagatcactt tgaaagaaag cggaccgacc ttggtcaagc ccacacaaac cctcacgctc 61 acgtgtacat tttcggggtt ctcgctttca acttacggga tgggagtagg gtggattcgc 121 cagccgcctg gtaaagcgtt ggagtggctt gcagacatct ggtgggacga cgataagtac 181 tataatccct cgctcaagtc cagactgacc atcacgaaag atacgagcaa gaaccaggtc 241 gtgctgacaa tgactaacat ggacccagtg gatacggcta catattactg cgccaggcgg 301 ggtcactact cagcgatgga ttattggggc cagggaacac tggtaacggt gtcgtcc
Secuencia de proteínas que define la región variable de la cadena pesada Sh14F11 IGHV2-5 (SEQ ID NO: 72)
1 qitlkesgpt lvkptqtltl tctfsgfsls tygmgvgwir qppgkalewl adiwwdddky
61 ynpslksrlt itkdtsknqv vltmtnmdpv dtatyycarr ghysamdywg qgtlvtvss
Secuencia de ácidos nucleicos que codifica la región variable de la cadena pesada Sh14F11 IGHV2-70 (SEQ ID NO: 73)
1 caagtgactctcaaggagtc cggacccgcc ctggtcaaac caacgcagac actgacgctc 61 acatgcaccttcagcggatt ttcgttgtca acgtacggca tgggtgtggg gtggattcgc 121 cagcctccggggaaagccct tgaatggttg gcggacatct ggtgggatga tgacaagtac 181 tataatccctcacttaagtc acggttgacg atctcgaaag acaccagcaa gaaccaggta 241 gtgctgacaatgactaacat ggacccggtc gatacagcgg tctactattg tgctagaagg 301 ggacactactccgcaatgga ttattggggt caggggacgc tcgtaaccgt gtcgtcg
Secuencia de proteínas que define la región variable de la cadena pesada Sh14F11 IGHV2-70 (SEQ ID NO: 74)
1 qvtlkesgpa lvkptqtltl tctfsgfsls tygmgvgwir qppgkalewl adiwwdddky
61 ynpslksrlt iskdtsknqv vltmtnmdpv dtavyycarr ghysamdywg qgtlvtvss
Secuencia de ácidos nucleicos que codifica la región variable de la cadena kappa quimérica Ch01G06 (SEQ ID NO: 133)
l gacatccaaa tgacccagtc acccgcgagc ctttcggcgt cggtcggaga aacggtcacg
61 atcacgtgcc ggacatcaga gaatctccat aactacctcg cgtggtatca acagaagcag
121 gggaagtcgc cccagttgct tgtatacgat gcgaaaacgt tggcggatgg ggtgccgtcc
181 agattctcgg gatcgggctc ggggacgcag tactcgctca agatcaattc gctgcagccg
241 gaggactttg ggtcgtacta ttgtcagcat ttttggtcat caccgtatac atttggaggt
301 ggaacgaaac ttgagattaa g
S e cu e n c ia de p ro te ínas que de fin e la reg ión v a r ia b le d e la c a d e n a kap pa q u im é ric a Ch01 G 06 (S E Q ID N O : 76)
1 diqmtqspas lsasvgetvt itcrtsenlh nylawyqqkq gkspqllvyd aktladgvps

Secuencia de ácidos nucleicos que codifica la región variable de la cadena kappa Hu01G06 IGKV1-39 (SEQ ID NO: 89)
1 gacatccaaa tgacccagtc gccgtcgtcg ctttcagcgt cggtagggga tcgggtcaca 61 attacgtgcc gaacgtcaga gaatttgcat aactacctcg cgtggtatca gcagaagccc 121 gggaagtcac cgaaactcct tgtctacgat gcgaaaacgc tggcggatgg agtgccgtcg
181 agattctcgg gaagcggatc cggtacggac tatacgctta cgatctcatc gctccagccc
241 gaggactttg cgacgtacta ttgtcagcat ttttggtcgt cgccctacac atttgggcag
301 gggaccaagt tggaaatcaa g
Secuencia de proteínas que define la región variable de la cadena kappa Hu01G06 IGKV1 -39 (SEQ ID NO: 90)
1 diqmtqspss lsasvgdrvt itcrtsenlh nylawyqqkp gkspkllvyd aktladgvps 61 rfsgsgsgtd ytltisslqp edfatyycqh fwsspytfgq gtkleik
Secuencia de ácidos nucleicos que codifica la región variable de la cadena kappa Hu01G06 IGKV1-39 S43A V48I (denominada también en el presente documento región variable de la cadena kappa Hu01G06 IGKV1-39 FI; SEQ ID NO: 91)
1 gacatccaaa tgacccagtcgccgtcgtcg ctttcagcgt cggtagggga tcgggtcaca 61 attacgtgcc gaacgtcagagaatttgcat aactacctcg cgtggtatca gcagaagccc 121 gggaaggccc cgaaactccttatctacgat gcgaaaacgc tggcggatgg agtgccgtcg 181 agattctcgg gaagcggatccggtacggac tatacgctta cgatctcatc gctccagccc 241 gaggactttg cgacgtactattgtcagcat ttttggtcgt cgccctacac atttgggcag 301 gggaccaagt tggaaatcaag
Secuencia de proteínas que define la región variable de la cadena kappa Hu01G06 IGKV1-39 S43A V48I (denominada también en el presente documento región variable de la cadena kappa Hu01G06 IGKV1-39 FI; SEQ ID NO: 92)
1 diqmtqspss lsasvgdrvt itcrtsenlh nylawyqqkp gkapklliyd aktladgvps 61 rfsgsgsgtd ytltisslqp edfatyycqh fwsspytfgq gtkleik
Secuencia de ácidos nucleicos que codifica la región variable de la cadena kappa Hu01G06 IGKV1-39 V48I (SEQ ID NO: 93)
1 gacatccaaa tgacccagtc gccgtcgtcg ctttcagcgt cggtagggga tcgggtcaca 61 attacgtgcc gaacgtcaga gaatttgcat aactacctcg cgtggtatca gcagaagccc 121 gggaagtcac cgaaactcct tatctacgat gcgaaaacgc tggcggatgg agtgccgtcg 181 agattctcgg gaagcggatc cggtacggac tatacgctta cgatctcatc gctccagccc 241 gaggactttg cgacgtacta ttgtcagcat ttttggtcgt cgccctacac atttgggcag 301 gggaccaagt tggaaatcaa g
Secuencia de proteínas que define la región variable de la cadena kappa Hu01G06 IGKV1-39 V48I (SEQ ID NO: 94)
1 diqmtqspss lsasvgdrvt itcrtsenlh nylawyqqkp gkspklliyd aktladgvps
61 rfsgsgsgtd ytltisslqp edfatyycqh fwsspytfgq gtkleik
S e cu e n c ia de ác ido s n u c le icos qu e co d ifica la reg ión v a r ia b le d e la ca d e n a ka p p a H u 01 G 06 IG K V 1-39 F1 (d e n o m in a d a ta m b ié n en el p re se n te d o cu m e n to reg ión va r ia b le de la ca d e n a kap pa H u01G 06 IG K V 1-39 S 43 A V 48 I; S E Q ID N O : 91)
1 gacatccaaa tgacccagtc gccgtcgtcg ctttcagcgt cggtagggga tcgggtcaca 61 attacgtgcc gaacgtcaga gaatttgcat aactacctcg cgtggtatca gcagaagccc 121 gggaaggccc cgaaactcct tatctacgat gcgaaaacgc tggcggatgg agtgccgtcg 181 agattctcgg gaagcggatc cggtacggac tatacgctta cgatctcatc gctccagccc 241 gaggactttg cgacgtacta ttgtcagcat ttttggtcgt cgccctacac atttgggcag 301 gggaccaagt tggaaatcaa g
Secuencia de proteínas que define la región variable de la cadena kappa Hu01G06 IGKV1-39 F1 (denominada también en el presente documento región variable de la cadena kappa Hu01G06 IGKV1-39 S43A V48I; SEQ ID NO: 92)
1 diqmtqspss lsasvgdrvt itcrtsenlh nylawyqqkp gkapklliyd aktladgvps
61 rfsgsgsgtd ytltisslqp edfatyycqh fwsspytfqq gtkleik
Secuencia de ácidos nucleicos que codifica la región variable de la cadena kappa Hu01G06 IGKV1-39 F2 (SEQ ID NO: 253)
1 gacatccaaatgacccagtc gccgtcgtcg ctttcagcgt cggtagggga tcgggtcaca
61 attacgtgccgaacgtcaga gaatttgcat aactacctcg cgtggtatca gcagaagccc
121 gggaagtcaccgaaactccttatctacgat gcgaaaacgc tggcggatgg agtgccgtcg
181 agattctcgggaagcggatc cggtacggac tatacgctta cgatctcatc gctccagccc
241 gaggactttg cgacgtactattgtcagcat ttttggtcgg acccctacac atttgggcag
301 gggaccaagttggaaatcaag
Secuencia de proteínas que define la región variable de la cadena kappa Hu01G06 IGKV1-39 F2 (SEQ ID NO: 254)
1 diqmtqspss lsasvgdrvt itcrtsenlh nylawyqqkp gkspklliyd aktladgvps 61 rfsgsgsgtd ytltisslqp edfatyycqh fwsdpytfgq gtkleik
Secuencia de ácidos nucleicos que codifica la región variable de la cadena kappa quimérica Ch06C11 (SEQ ID NO: 135)
1 gatatcgtcatgacccagtc ccagaagttc atgtcaactt cagtgggaga cagagtgtcc
61 gtcacatgtaaagcctcgca aaatgtggga accaacgtag cgtggttcca gcagaaacct
121 ggccaatcaccgaaggcact gatctactcg gccagctata ggtactcggg agtaccagat
181 cggtttacggggtcggggag cgggacggac tttatcctca ctatttccaa tgtccagtcg
241 gaggaccttgcggaatactt ctgccagcag tataacaact atcccctcac gtttggtgct
301 ggtacaaaattggagttgaa g
Secuencia de proteínas que define la región variable de la cadena kappa quimérica Ch06C11 (SEQ ID NO: 82)
1 divmtqsqkf mstsvgdrvs vtckasqnvq tnvawfqqkp gqspkaliys asyrysgvpd
61 rftgsgsgtd filtisnvqs edlaeyfcqq ynnypltfga gtkleik
Secuencia de ácidos nucleicos que codifica la región variable de la cadena kappa Sh06C11 IGKV1 -16 (SEQ ID NO: 95)
1 gacatccaaa tgacccaatc gccctcctcc ctctccgcat cagtagggga ccgcgtcaca 61 attacttgca aagcgtcgca gaacgtcgga acgaatgtgg cgtggtttca gcagaagccc 121 ggaaaagctc cgaagagctt gatctactcg gcctcatata ggtattcggg tgtgccgagc 181 cggtttagcg ggtcggggtc aggtactgat ttcacgctca caatttcatc gttgcagcca 241 gaagatttcg ccacatatta ctgtcagcag tacaacaatt accctctgac gttcggccag 301 ggaaccaaac ttgagatcaa g
S e cu e n c ia de p ro te ín a s qu e d e fine la reg ión va r ia b le d e la c a d e n a kap pa S h 06 C 11 IG K V 1 -16 (S E Q ID NO : 96)
1 diqmtqspss lsasvgdrvt itckasqnvg tnvawfqqkp gkapksliys asyrysgvps
61 rfsgsgsgtd ftltisslqp edfatyycqq ynnypltfgq gtkleik
Secuencia de ácidos nucleicos que codifica la región variable de la cadena kappa quimérica Ch14F11 (SEQ ID NO: 137)
1 gacatcgtga tgacacagtc acagaaattc atgtccacat ccgtcggtga tagagtatcc
61 gtcacgtgta aggcctcgca aaacgtagga actaatgtgg cgtggtatca acagaagcca
121 ggacagtcac ccaaagcact catctacagc ccctcatatc ggtacagcgg ggtgccggac
181 aggttcacgg gatcggggag cgggaccgat tttacactga ccatttcgaa tgtccagtcg
241 gaggaccttg cggaatactt ctgccagcag tataactcgt accctcacac gtttggaggt
301 ggcactaagt tggagatgaa a
Secuencia de proteínas que define la región variable de la cadena kappa quimérica Ch14F11 (SEQ ID NO: 86)
1 divmtqsqkf mstsvgdrvs vtckasqnvg tnvawyqqkp gqspkaliys psyrysgvpd
61 rftgsgsgtd ftltisnvqs edlaeyfcqq ynsyphtfgg gtklemk
Secuencia de ácidos nucleicos que codifica la región variable de la cadena kappa Hu14F11 IGKV1-16 (SEQ ID NO: 97)
1 gatatccaga tgacacagtc accctcgtcg ctctcagctt ccgtaggcga cagggtcact
61 attacgtgta aagcatcaca gaacgtcgga acgaatgtgg cgtggtttca gcagaagccc
121 gggaagagcc ccaaagcgcttatctactcc ccgtcgtatc ggtattccgg tgtgccaagc
181 agattttcgg ggtcaggttc gggaactgac tttaccctga ccatctcgtc cctccaaccg
241 gaagatttcg ccacgtactt ctgccagcag tacaacagct atcctcacac attcggacaa
301 gggacaaagt tggagattaa a
Secuencia de proteínas que define la región variable de la cadena kappa Hu14F11 IGKV1-16 (SEQ ID NO: 98)
1 diqmtqspss lsasvgdrvt itckasqnvg tnvawfqqkp gkspkaliys psyrysgvps 61 rfsgsgsgtd ftltisslqp edfatyfcqq ynsyphtfqq gtkleik
Las secuencias de aminoácidos que definen las regiones variables de la cadena pesada de una inmunoglobulina para los anticuerpos producidos en el Ejemplo 13 están alineadas en la FIG. 19. Las secuencias del péptido de señal amino terminal (para la apropiada expresión/secreción) no se muestran. La CDR1, la CDR2 y la CDR3 (definición de Kabat) están identificadas por recuadros. La FIG. 20 muestra una alineación de las secuencias individuales de la CDR1, de la CDR2 y de la CDR3 para cada una de las secuencias de la región variable mostradas en la FIG. 19.
Las secuencias de aminoácidos que definen las regiones variables de la cadena ligera de una inmunoglobulina para los anticuerpos del Ejemplo 13 están alineadas en la FIG. 21. Las secuencias del péptido de señal amino terminal (para la apropiada expresión/secreción) no se muestran. La CDR1, la CDR2 y la CDR3 están identificadas por recuadros. La FIG. 22 muestra una alineación de las secuencias individuales de la CDR1, de la CDR2 y de la CDR3 para cada una de las secuencias de la región variable mostradas en la FIG.21.
La Tabla 19 es una gráfica de concordancia que muestra la SEQ ID NO. de cada secuencia analizada en este Ejemplo.
Tabla 19

continuación

continuación

continuación

Las secuencias de las CDR de la cadena pesada del anticuerpo monoclonal humanizado (definiciones de Kabat, Chothia e IMGT) se muestran en la Tabla 20.
Tabla 20

continuación

continuación

Las secuencias de las CDR de la cadena ligera kappa del anticuerpo monoclonal humanizado (definiciones de Kabat, Chothia e IMGT) se muestran en la Tabla 21.
Tabla 21

continuación

Para crear las secuencias completas de la cadena pesada o kappa quiméricas y humanizadas del anticuerpo, cada secuencia variable anterior se combina con su respectiva región constante humana. Por ejemplo, una cadena pesada completa comprende una secuencia variable pesada seguida por una secuencia constante de la cadena pesada de la IgG1 humana. Una cadena kappa completa comprende una secuencia variable kappa seguida por una secuencia constante de la cadena ligera kappa humana.
Secuencia de ácidos nucleicos que codifica la región constante de la cadena pesada de la IgG1 humana (SEQ ID NO: 171)
i gcctcaacaa aaggaccaag tgtgttccca ctcgccccta gcagcaagag tacatccggg
61 ggcactgcag cactcggctg cctcgtcaag gattattttc cagagccagt aaccgtgagc 121 tggaacagtg gagcactcac ttctggtgtc catacttttc ctgctgtcct gcaaagctct 181 ggcctgtact cactcagctc cgtcgtgacc gtgccatctt catctctggg cactcagacc 241 tacatctgta atgtaaacca caagcctagc aatactaagg tcgataagcg ggtggaaccc 301 aagagctgcg acaagactca cacttgtccc ccatgccctg cccctgaact tctgggcggt 361 cccagcgtct ttttgttccc accaaagcct aaagatactc tgatgataag tagaacaccc 421 gaggtgacat gtgttgttgt agacgtttcc cacgaggacc cagaggttaa gttcaactgg 481 tacgttgatg gagtcgaagt acataatgct aagaccaagc ctagagagga gcagtataat 541 agtacatacc gtgtagtcag tgttctcaca gtgctgcacc aagactggct caacggcaaa 601 gaatacaaat gcaaagtgtc caacaaagca ctcccagccc ctatcgagaa gactattagt 661 aaggcaaagg ggcagcctcg tgaaccacag gtgtacactc tgccacccag tagagaggaa 721 atgacaaaga accaagtctc attgacctgc ctggtgaaag gcttctaccc cagcgacatc 781 gccgttgagt gggagagtaa cggtcagcct gagaacaatt acaagacaac ccccccagtg 841 ctggatagtg acgggtcttt ctttctgtac agtaagctga ctgtggacaa gtcccgctgg 901 cagcagggta acgtcttcag ctgttccgtg atgcacgagg cattgcacaa ccactacacc 961 cagaagtcac tgagcctgag cccagggaag
Secuencia de proteínas que define la región constante de la cadena pesada de la IgG1 humana (SEQ ID NO: 172)
1 astkgpsvfplapsskstsg gtaalgclvk dyfpepvtvs wnsgaltsgv htfpavlqss
61 glyslssvvtvpssslgtqt yicnvnhkps ntkvdkrvep kscdkthtcp pcpapellgg
121 psvflfppkpkdtlmisrtp evtcvvvdvs hedpevkfnw yvdgvevhna ktkpreeqyn
181 styrvvsvltvlhqdwlngk eykckvsnka lpapiektis kakgqprepq vytlppsree
241 mtknqvsltclvkgfypsdi avewesngqp ennykttppv ldsdgsffly skltvdksrw
301 qqgnvfscsvmhealhnhyt qkslslspgk
Secuencia de ácidos nucleicos que codifica la región constante de la cadena ligera kappa humana (SEQ ID NO: 173)
1 cgcacagttg ctgcccccag cgtgttcatt ttcccaccta gcgatgagca gctgaaaagc 61 ggtactgcct ctgtcgtatg cttgctcaac aacttttacc cacgtgaggc taaggtgcag
121 tggaaagtgg ataatgcact tcaatctgga aacagtcaag agtccgtgac agaacaggac
181 agcaaagact caacttattc actctcttcc accctgactc tgtccaaggc agactatgaa
241 aaacacaagg tatacgcctg cgaggttaca caccagggtt tgtctagtcc tgtcaccaag
301 tccttcaata qqqqcqaatq t
Secuencia de proteínas que define la región constante de la cadena ligera kappa humana (SEQ ID NO: 174)
1 rtvaapsvfi fppsdeqlks gtasvvclln nfypreakvq wkvdnalqsg nsqesvteqd
61 skdstyslss tltlskadye khkvyacevt hqglsspvtk sfnrgec
Las siguientes secuencias representan la secuencia completa real o contemplada de la cadena pesada y ligera (es decir, que contienen las secuencias de ambas regiones variable y constante) para cada anticuerpo descrito en este Ejemplo. Las secuencias de señal para la apropiada secreción de los anticuerpos (por ejemplo, las secuencias de señal en el extremo 5' de las secuencias de ADN o en el extremo amino terminal de las secuencias de la proteína) no se muestran en las secuencias completas de la cadena pesada y ligera divulgadas en el presente documento y no están incluidas en la proteína final secretada. Tampoco se muestran los codones de terminación para la terminación de la traducción requeridos en el extremo 3' de las secuencias de ADN. En la pericia habitual de la técnica está la selección de una secuencia de señal y/o de un codón de terminación para la expresión de las secuencias completas divulgadas de la cadena pesada y de la cadena ligera de la inmunoglobulina. También se contempla que las secuencias de la región variable puedan estar ligadas a otras secuencias de la región constante para producir las cadenas pesada y ligera activas completas de la inmunoglobulina.
S e cu e n c ia de ác ido s n u c le icos que c o d ific a la ca d e n a p e sa d a q u im é ric a C h 01 G 06 co m p le ta (reg ión va r ia b le de la c a d e n a pe sa d a de ra tón y reg ión co n s ta n te de la IgG 1 hu m ana) (S E Q ID N O : 175)
i gaagtgttgt tgcagcagtc agggccggag ttggtaaaac cgggagcgtc ggtgaaaatc 61 ccgtgcaaag cgtcggggta tacgtttacg gactataaca tggattgggt gaaacagtcg 121 catgggaaat cgcttgaatg gattggtcag atcaatccga ataatggagg aatcttcttt 181 aatcagaagt ttaaaggaaa agcgacgctt acagtcgata agtcgtcgaa cacggcgttc 241 atggaagtac ggtcgcttac gtcggaagat acggcggtct attactgtgc gagggaggcg 301 attacgacgg tgggagcgat ggactattgg ggacaaggga cgtcggtcac ggtatcgtcg 361 gcctcaacaa aaggaccaag tgtgttccca ctcgccccta gcagcaagag tacatccggg 421 ggcactgcag cactcggctg cctcgtcaag gattattttc cagagccagt aaccgtgagc 481 tggaacagtg gagcactcac ttctggtgtc catacttttc ctgctgtcct gcaaagctct 541 ggcctgtact cactcagctc cgtcgtgacc gtgccatctt catctctggg cactcagacc 601 tacatctgta atgtaaacca caagcctagc aatactaagg tcgataagcg ggtggaaccc 661 aagagctgcg acaagactca cacttgtccc ccatgccctg cccctgaact tctgggcggt 721 cccagcgtct ttttgttccc accaaagcct aaagatactc tgatgataag tagaacaccc 781 gaggtgacat gtgttgttgt agacgtttcc cacgaggacc cagaggttaa gttcaactgg 841 tacgttgatg gagtcgaagt acataatgct aagaccaagc ctagagagga gcagtataat 901 agtacatacc gtgtagtcag tgttctcaca gtgctgcacc aagactggct caacggcaaa 961 gaatacaaat gcaaagtgtc caacaaagca ctcccagccc ctatcgagaa gactattagt 1021 aaggcaaagg ggcagcctcg tgaaccacag gtgtacactc tgccacccag tagagaggaa 1081 atgacaaaga accaagtctc attgacctgc ctggtgaaag gcttctaccc cagcgacatc 1141 gccgttgagt gggagagtaa cggtcagcct gagaacaatt acaagacaac ccccccagtg 1201 ctggatagtg acgggtcttt ctttctgtac agtaagctga ctgtggacaa gtcccgctgg 1261 cagcagggta acgtcttcag ctgttccgtg atgcacgagg cattgcacaa ccactacacc 1321 cagaagtcac tgagcctgag cccagggaag
Secuencia de proteínas que define la cadena pesada quimérica Ch01G06 completa (región variable de la cadena pesada de ratón y región constante de la IgG1 humana) (SEQ ID NO: 176)
l evllqqsgpe lvkpgasvki pckasgytft dynmdwvkqs hgkslewigq inpnnggiff 61 nqkfkgkatl tvdkssntaf mevrsltsed tavyycarea ittvgamdyw gqgtsvtvss
121 astkgpsvfp lapsskstsg gtaalgclvk dyfpepvtvs wnsgaltsgv htfpavlqss
181 glyslssvvt vpssslgtqt yicnvnhkps ntkvdkrvep kscdkthtcp pcpapellgg
241 psvflfppkp kdtlmisrtp evtcvvvdvs hedpevkfnw yvdgvevhna ktkpreeqyn
301 styrvvsvlt vlhqdwlngk eykckvsnka lpapiektis kakgqprepq vytlppsree
361 mtknqvsltc lvkgfypsdi avewesngqp ennykttppv ldsdgsffly skltvdksrw
421 qqgnvfscsv mhealhnhyt qkslslspgk
Secuencia de ácidos nucleicos que codifica la cadena pesada Hu01G06 IGHV1-18 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 177)
1 caagtgcaac ttgtgcagtc gggtgcggaa gtcaaaaagc cgggagcgtc ggtgaaagta 61 tcgtgtaaag cgtcgggata tacgtttacg gactataaca tggactgggt acgacaggca 121 ccggggaaat cgttggaatg gatcggacag attaatccga acaatggggg aattttcttt 181 aatcagaaat tcaaaggacg ggcgacgttg acggtcgata catcgacgaa tacggcgtat 241 atggaattga ggtcgcttcg ctcggacgat acggcggtct attactgcgc cagggaggcg 301 atcacgacgg taggggcgat ggattattgg ggacagggga cgcttgtgac ggtatcgtcg 361 gcctcaacaa aaggaccaag tgtgttccca ctcgccccta gcagcaagag tacatccggg 421 ggcactgcag cactcggctg cctcgtcaag gattattttc cagagccagt aaccgtgagc 481 tggaacagtg gagcactcac ttctggtgtc catacttttc ctgctgtcct gcaaagctct 541 ggcctgtact cactcagctc cgtcgtgacc gtgccatctt catctctggg cactcagacc 601 tacatctgta atgtaaacca caagcctagc aatactaagg tcgataagcg ggtggaaccc 661 aagagctgcg acaagactca cacttgtccc ccatgccctg cccctgaact tctgggcggt 721 cccagcgtct ttttgttccc accaaagcct aaagatactc tgatgataag tagaacaccc 781 gaggtgacat gtgttgttgt agacgtttcc cacgaggacc cagaggttaa gttcaactgg 841 tacgttgatg gagtcgaagt acataatgct aagaccaagc ctagagagga gcagtataat 901 agtacatacc gtgtagtcag tgttctcaca gtgctgcacc aagactggct caacggcaaa 961 gaatacaaat gcaaagtgtc caacaaagca ctcccagccc ctatcgagaa gactattagt 1021 aaggcaaagg ggcagcctcg tgaaccacag gtgtacactc tgccacccag tagagaggaa 1081 atgacaaaga accaagtctc attgacctgc ctggtgaaag gcttctaccc cagcgacatc 1141 gccgttgagt gggagagtaa cggtcagcct gagaacaatt acaagacaac ccccccagtg 1201 ctggatagtg acgggtcttt ctttctgtac agtaagctga ctgtggacaa gtcccgctgg 1261 cagcagggta acgtcttcag ctgttccgtg atgcacgagg cattgcacaa ccactacacc 1321 cagaagtcac tgagcctgag cccagggaag
Secuencia de proteínas que define la cadena pesada Hu01G06 IGHV1-18 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 178)
1 qvqlvqsgae vkkpgasvkv sckasgytft dynmdwvrqa pgkslewigq inpnnggiff 61 nqkfkgratl tvdtstntay melrslrsdd tavyycarea ittvgamdyw gqgtlvtvss 121 astkgpsvfp lapsskstsg gtaalgclvk dyfpepvtvs wnsgaltsgv htfpavlqss 181 glyslssvvt vpssslgtqt yicnvnhkps ntkvdkrvep kscdkthtcp pcpapellgg 241 psvflfppkp kdtlmisrtp evtcvvvdvs hedpevkfnw yvdgvevhna ktkpreeqyn 301 styrvvsvlt vlhqdwlngk eykckvsnka lpapiektis kakgqprepq vytlppsree 361 mtknqvsltc lvkgfypsdi avewesngqp ennykttppv ldsdgsffly skltvdksrw 421 qqgnvfscsv mhealhnhyt qkslslspgk
Secuencia de ácidos nucleicos que codifica la cadena pesada Hu01G06 IGHV1-69 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 179)
1 caagtccagc ttgtccagtc gggagcggaa gtgaagaaac cggggtcgtc ggtcaaagta 61 tcgtgtaaag cgtcgggata tacgtttacg gactataaca tggattgggt acgacaggct 121 ccgggaaaat cattggaatg gattggacag attaatccga ataatggggg tatcttcttt 181 aatcaaaagt ttaaagggag ggcgacgttg acggtggaca aatcgacaaa tacggcgtat 241 atggaattgt cgtcgcttcg gtcggaggac acggcggtgt attactgcgc gagggaggcg 301 atcacgacgg tcggggcgat ggattattgg ggacagggaa cgcttgtgac ggtatcgtcg 361 gcctcaacaa aaggaccaag tgtgttccca ctcgccccta gcagcaagag tacatccggg 421 ggcactgcag cactcggctg cctcgtcaag gattattttc cagagccagt aaccgtgagc 481 tggaacagtg gagcactcac ttctggtgtc catacttttc ctgctgtcct gcaaagctct 541 ggcctgtact cactcagctc cgtcgtgacc gtgccatctt catctctggg cactcagacc 601 tacatctgta atgtaaacca caagcctagc aatactaagg tcgataagcg ggtggaaccc 661 aagagctgcg acaagactca cacttgtccc ccatgccctg cccctgaact tctgggcggt 721 cccagcgtct ttttgttccc accaaagcct aaagatactc tgatgataag tagaacaccc 781 gaggtgacat gtgttgttgt agacgtttcc cacgaggacc cagaggttaa gttcaactgg 841 tacgttgatg gagtcgaagt acataatgct aagaccaagc ctagagagga gcagtataat 901 agtacatacc gtgtagtcag tgttctcaca gtgctgcacc aagactggct caacggcaaa 961 gaatacaaat gcaaagtgtc caacaaagca ctcccagccc ctatcgagaa gactattagt 1021 aaggcaaagg ggcagcctcg tgaaccacag gtgtacactc tgccacccag tagagaggaa 1081 atgacaaaga accaagtctc attgacctgc ctggtgaaag gcttctaccc cagcgacatc 1141 gccgttgagt gggagagtaa cggtcagcct gagaacaatt acaagacaac ccccccagtg 1201 ctggatagtg acgggtcttt ctttctgtac agtaagctga ctgtggacaa gtcccgctgg 1261 cagcagggta acgtcttcag ctgttccgtg atgcacgagg cattgcacaa ccactacacc 1321 cagaagtcac tgagcctgag cccagggaag
S e cu e n c ia de p ro te ín a s qu e d e fine la ca d e n a pe sa d a H u 01 G 06 IG H V 1-69 c o m p le ta (reg ión v a r ia b le de la ca d e n a p e sa d a h u m a n iza d a y reg ión c o n s ta n te de la IgG1 hu m an a ) (S E Q ID NO : 180)
1 qvqlvqsgae vkkpgssvkv sckasgytftdynmdwvrqa pgkslewigq inpnnggiff 61 nqkfkgratl tvdkstntay melsslrsed tavyycarea ittvgamdyw gqgtlvtvss
121 astkgpsvfp lapsskstsggtaalgclvk dyfpepvtvs wnsgaltsgv htfpavlqss
181 glyslssvvt vpssslgtqt yicnvnhkpsntkvdkrvep kscdkthtcppcpapellgg 241 psvflfppkp kdtlmisrtpevtcvvvdvs hedpevkfnw yvdgvevhna ktkpreeqyn
301 styrvvsvlt vlhqdwlngk eykckvsnkalpapiektis kakgqprepqvytlppsree 361 mtknqvsltc lvkgfypsdiavewesngqp ennykttppv ldsdgsffly skltvdksrw
421 qqgnvfscsv mhealhnhyt qkslslspgk
Secuencia de ácidos nucleicos que codifica la cadena pesada Sh01G06 IGHV1-18 M69L completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 181)
1 caggtccagcttgtgcaatc gggagcggaa gtgaagaaac cgggagcgtc ggtaaaagtc
61 tcgtgcaaagcgtcggggta tacgtttacg gactataaca tggactgggt gcgccaagcg
121 cctggacagggtcttgaatg gatggggcag attaatccga ataatggagg gatcttcttt
181 aatcagaaattcaaaggaag ggtaacgctg acgacagaca cgtcaacatc gacggcctat
241 atggaattgcggtcgttgcg atcagatgat acggcggtct actattgtgc gagggaggcg
301 attacgacggtgggagcgat ggattattgg ggacagggga cgttggtaac ggtatcgtcg
361 gcctcaacaa aaggaccaag tgtgttccca ctcgccccta gcagcaagag tacatccggg
421 ggcactgcag cactcggctg cctcgtcaag gattattttc cagagccagt aaccgtgagc
481 tggaacagtg gagcactcac ttctggtgtc catacttttc ctgctgtcct gcaaagctct
541 ggcctgtact cactcagctc cgtcgtgacc gtgccatctt catctctggg cactcagacc
601 tacatctgta atgtaaacca caagcctagc aatactaagg tcgataagcg ggtggaaccc
661 aagagctgcg acaagactca cacttgtccc ccatgccctg cccctgaact tctgggcggt
721 cccagcgtct ttttgttccc accaaagcct aaagatactc tgatgataag tagaacaccc
781 gaggtgacat gtgttgttgt agacgtttcc cacgaggacc cagaggttaa gttcaactgg
841 tacgttgatg gagtcgaagt acataatgct aagaccaagc ctagagagga gcagtataat
901 agtacatacc gtgtagtcag tgttctcaca gtgctgcacc aagactggct caacggcaaa
961 gaatacaaat gcaaagtgtc caacaaagca ctcccagccc ctatcgagaa gactattagt 1021 aaggcaaagg ggcagcctcg tgaaccacag gtgtacactc tgccacccag tagagaggaa 1081 atgacaaaga accaagtctc attgacctgc ctggtgaaag gcttctaccc cagcgacatc 1141 gccgttgagt gggagagtaa cggtcagcct gagaacaatt acaagacaac ccccccagtg 1201 ctggatagtg acgggtcttt ctttctgtac agtaagctga ctgtggacaa gtcccgctgg 1261 cagcagggta acgtcttcag ctgttccgtg atgcacgagg cattgcacaa ccactacacc 1321 cagaagtcac tgagcctgag cccagggaag
Secuencia de proteínas que define la cadena pesada Sh01G06 IGHV1-18 M69L completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 182)
1 qvqlvqsgae vkkpgasvkv sckasgytft dynmdwvrqa pgqglewmgq inpnnggiff
61 nqkfkgrvtl ttdtststay melrslrsdd tavyycarea ittvgamdyw gqgtlvtvss
121 astkgpsvfp lapsskstsg gtaalgclvk dyfpepvtvs wnsgaltsgv htfpavlqss
181 glyslssvvt vpssslgtqt yicnvnhkps ntkvdkrvep kscdkthtcp pcpapellgg
241 psvflfppkp kdtlmisrtp evtcvvvdvs hedpevkfnw yvdgvevhna ktkpreeqyn
301 styrvvsvlt vlhqdwlngk eykckvsnka lpapiektis kakgqprepq vytlppsree
361 mtknqvsltc lvkgfypsdi avewesngqp ennykttppv ldsdgsffly skltvdksrw
421 qqgnvfscsv mhealhnhyt qkslslspgk
S e cu e n c ia de ác ido s nu c le icos qu e c o d ific a la ca d e n a p e sa d a S h 01 G 06 IG H V 1-18 M 69L K 64Q G 44S co m p le ta (reg ión v a r ia b le de la c a d e n a pe sa d a h u m a n iza d a y reg ión co n s ta n te de la IgG1 h u m an a ) (S E Q ID N O : 183)
1 caggtccagc ttgtgcaatc gggagcggaa gtgaagaaac cgggagcgtc ggtaaaagtc 61 tcgtgcaaag cgtcggggta tacgtttacg gactataaca tggactgggt gcgccaagcg 121 cctggacaga gccttgaatg gatggggcag attaatccga ataatggagg gatcttcttt 181 aatcagaaat tccagggaag ggtaacgctg acgacagaca cgtcaacatc gacggcctat 241 atggaattgc ggtcgttgcg atcagatgat acggcggtct actattgtgc gagggaggcg 301 attacgacgg tgggagcgat ggattattgg ggacagggga cgttggtaac ggtatcgtcg 361 gcctcaacaa aaggaccaag tgtgttccca ctcgccccta gcagcaagag tacatccggg 421 ggcactgcag cactcggctg cctcgtcaag gattattttc cagagccagt aaccgtgagc 481 tggaacagtg gagcactcac ttctggtgtc catacttttc ctgctgtcct gcaaagctct 541 ggcctgtact cactcagctc cgtcgtgacc gtgccatctt catctctggg cactcagacc 601 tacatctgta atgtaaacca caagcctagc aatactaagg tcgataagcg ggtggaaccc 661 aagagctgcg acaagactca cacttgtccc ccatgccctg cccctgaact tctgggcggt 721 cccagcgtct ttttgttccc accaaagcct aaagatactc tgatgataag tagaacaccc 781 gaggtgacat gtgttgttgt agacgtttcc cacgaggacc cagaggttaa gttcaactgg 841 tacgttgatg gagtcgaagt acataatgct aagaccaagc ctagagagga gcagtataat 901 agtacatacc gtgtagtcag tgttctcaca gtgctgcacc aagactggct caacggcaaa 961 gaatacaaat gcaaagtgtc caacaaagca ctcccagccc ctatcgagaa gactattagt 1021 aaggcaaagg ggcagcctcg tgaaccacag gtgtacactc tgccacccag tagagaggaa
1081 atgacaaaga accaagtctc attgacctgc ctggtgaaag gcttctaccc cagcgacatc 1141 gccgttgagt gggagagtaa cggtcagcct gagaacaatt acaagacaac ccccccagtg 1201 ctggatagtg acgggtcttt ctttctgtac agtaagctga ctgtggacaa gtcccgctgg 1261 cagcagggta acgtcttcag ctgttccgtg atgcacgagg cattgcacaa ccactacacc 1321 cagaagtcac tgagcctgag cccagggaag
Secuencia de proteínas que define la cadena pesada Sh01G06 IGHV1-18 M69L K64Q G44S completa (región variable de la cadena pesada humanizada y región constante de la IaG1 humana) (SEQ ID NO: 184)
1 qvqlvqsgae vkkpgasvkv sckasgytft dynmdwvrqa pgqslewmgq inpnnggiff
61 nqkfqgrvtl ttdtststay melrslrsdd tavyycarea ittvgamdyw gqgtlvtvss
121 astkgpsvfp lapsskstsg gtaalgclvk dyfpepvtvs wnsgaltsgv htfpavlqss
181 glyslssvvt vpssslgtqt yicnvnhkps ntkvdkrvep kscdkthtcp pcpapellgg
241 psvflfppkp kdtlmisrtp evtcvvvdvs hedpevkfnw yvdgvevhna ktkpreeqyn
301 styrvvsvlt vlhqdwlngk eykckvsnka lpapiektis kakgqprepq vytlppsree
361 mtknqvsltc lvkgfypsdi avewesngqp ennykttppv ldsdgsffly skltvdksrw
421 qqgnvfscsv mhealhnhyt qkslslspgk
Secuencia de ácidos nucleicos que codifica la cadena pesada Sh01G06 IGHV1-18 M69L K64Q completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 185)
1 caggtccagc ttgtgcaatc gggagcggaa gtgaagaaac cgggagcgtc ggtaaaagtc 61 tcgtgcaaag cgtcggggta tacgtttacg gactataaca tggactgggt gcgccaagcg 121 cctggacagg gtcttgaatg gatggggcag attaatccga ataatggagg gatcttcttt 181 aatcagaaat tccagggaag ggtaacgctg acgacagaca cgtcaacatc gacggcctat 241 atggaattgc ggtcgttgcg atcagatgat acggcggtct actattgtgc gagggaggcg 301 attacgacgg tgggagcgat ggattattgg ggacagggga cgttggtaac ggtatcgtcg 361 gcctcaacaa aaggaccaag tgtgttccca ctcgccccta gcagcaagag tacatccggg 421 ggcactgcag cactcggctg cctcgtcaag gattattttc cagagccagt aaccgtgagc 481 tggaacagtg gagcactcac ttctggtgtc catacttttc ctgctgtcct gcaaagctct 541 ggcctgtact cactcagctc cgtcgtgacc gtgccatctt catctctggg cactcagacc 601 tacatctgta atgtaaacca caagcctagc aatactaagg tcgataagcg ggtggaaccc 661 aagagctgcg acaagactca cacttgtccc ccatgccctg cccctgaact tctgggcggt 721 cccagcgtct ttttgttccc accaaagcct aaagatactc tgatgataag tagaacaccc 781 gaggtgacat gtgttgttgt agacgtttcc cacgaggacc cagaggttaa gttcaactgg 841 tacgttgatg gagtcgaagt acataatgct aagaccaagc ctagagagga gcagtataat 901 agtacatacc gtgtagtcag tgttctcaca gtgctgcacc aagactggct caacggcaaa 961 gaatacaaat gcaaagtgtc caacaaagca ctcccagccc ctatcgagaa gactattagt 1021 aaggcaaagg ggcagcctcg tgaaccacag gtgtacactc tgccacccag tagagaggaa 1081 atgacaaaga accaagtctc attgacctgc ctggtgaaag gcttctaccc cagcgacatc 1141 gccgttgagt gggagagtaa cggtcagcct gagaacaatt acaagacaac ccccccagtg 1201 ctggatagtg acgggtcttt ctttctgtac agtaagctga ctgtggacaa gtcccgctgg 1261 cagcagggta acgtcttcag ctgttccgtg atgcacgagg cattgcacaa ccactacacc 1321 cagaagtcac tgagcctgag cccagggaag
S e cu e n c ia de p ro te ín a s que d e fine la c a d e n a pe sa d a S h 01G 06 IG H V 1-18 M 69L K 64Q c o m p le ta (reg ión va r ia b le de la ca d e n a pe sa d a h u m a n iza d a y reg ión co n s ta n te de la IgG1 h u m an a ) (S E Q ID N O : 186)
1 qvqlvqsgae vkkpgasvkv sckasgytft dynmdwvrqa pgqglewmgq inpnnggiff
61 nqkfqgrvtl ttdtststay melrslrsdd tavyycarea ittvgamdyw gqgtlvtvss 121 astkgpsvfp lapsskstsg gtaalgclvk dyfpepvtvs wnsgaltsgv htfpavlqss 181 glyslssvvt vpssslgtqt yicnvnhkps ntkvdkrvep kscdkthtcp pcpapellgg 241 psvflfppkp kdtlmisrtp evtcvvvdvs hedpevkfnw yvdgvevhna ktkpreeqyn 301 styrvvsvlt vlhqdwlngk eykckvsnka lpapiektis kakgqprepq vytlppsree 361 mtknqvsltc lvkgfypsdi avewesngqp ennykttppv ldsdgsffly skltvdksrw 421 qqgnvfscsv mhealhnhyt qkslslspgk
Secuencia de ácidos nucleicos que codifica la cadena pesada Sh01G06 IGHV1-69 T30S I69L completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 187)
1 caagtacagc ttgtacagtc gggagcggaa gtcaagaaac cgggatcgtc ggtcaaagtg 61 tcgtgtaaag cgtcgggata tacgtttagc gactataaca tggattgggt gcgacaagcg 121 cctgggcagg gacttgaatg gatgggtcag atcaatccga ataatggggg aatctttttc 181 aatcagaagt ttaaagggag ggtaacgctg acggcggata aaagcacgtc aacggcgtat 241 atggagttgt cgtcgttgcg gtcggaggac acggcggtct attactgcgc gagggaagcg 301 attacgacgg tgggagcgat ggattattgg gggcagggaa cgcttgtaac ggtgtcatcg 361 gcctcaacaa aaggaccaag tgtgttccca ctcgccccta gcagcaagag tacatccggg 421 ggcactgcag cactcggctg cctcgtcaag gattattttc cagagccagt aaccgtgagc 481 tggaacagtg gagcactcac ttctggtgtc catacttttc ctgctgtcct gcaaagctct 541 ggcctgtact cactcagctc cgtcgtgacc gtgccatctt catctctggg cactcagacc 601 tacatctgta atgtaaacca caagcctagc aatactaagg tcgataagcg ggtggaaccc 661 aagagctgcg acaagactca cacttgtccc ccatgccctg cccctgaact tctgggcggt 721 cccagcgtct ttttgttccc accaaagcct aaagatactc tgatgataag tagaacaccc 781 gaggtgacat gtgttgttgt agacgtttcc cacgaggacc cagaggttaa gttcaactgg 841 tacgttgatg gagtcgaagt acataatgct aagaccaagc ctagagagga gcagtataat 901 agtacatacc gtgtagtcag tgttctcaca gtgctgcacc aagactggct caacggcaaa 961 gaatacaaat gcaaagtgtc caacaaagca ctcccagccc ctatcgagaa gactattagt 1021 aaggcaaagg ggcagcctcg tgaaccacag gtgtacactc tgccacccag tagagaggaa 1081 atgacaaaga accaagtctc attgacctgc ctggtgaaag gcttctaccc cagcgacatc 1141 gccgttgagt gggagagtaa cggtcagcct gagaacaatt acaagacaac ccccccagtg 1201 ctggatagtg acgggtcttt ctttctgtac agtaagctga ctgtggacaa gtcccgctgg 1261 cagcagggta acgtcttcag ctgttccgtg atgcacgagg cattgcacaa ccactacacc 1321 cagaagtcac tgagcctgag cccagggaag
Secuencia de proteínas que define la cadena pesada Sh01G06 IGHV1-69 T30S I69L completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 188)
1 qvqlvqsgae vkkpgssvkv sckasgytfs dynmdwvrqa pgqglewmgq inpnnggiff
61 nqkfkgrvtl tadkststay melsslrsed tavyycarea ittvgamdyw gqgtlvtvss
121 astkgpsvfp lapsskstsg gtaalgclvk dyfpepvtvs wnsgaltsgv htfpavlqss
181 glyslssvvt vpssslgtqt yicnvnhkps ntkvdkrvep kscdkthtcp pcpapellgg
241 psvflfppkp kdtlmisrtp evtcvvvdvs hedpevkfnw yvdgvevhna ktkpreeqyn
301 styrvvsvlt vlhqdwlngk eykckvsnka lpapiektis kakgqprepq vytlppsree
361 mtknqvsltc lvkgfypsdi avewesngqp ennykttppv ldsdgsffly skltvdksrw
421 qqgnvfscsv mhealhnhytqkslslspgk
S e cu e n c ia de ác ido s nu c le icos qu e c o d ific a la c a d e n a p e sa d a S h 01 G 06 IG H V 1-69 T 30 S K 64 Q I69L co m p le ta (reg ión v a r ia b le de la c a d e n a pe sa d a h u m a n iza d a y reg ión co n s ta n te de la IgG1 h u m an a ) (S E Q ID N O : 189)
i caagtacagc ttgtacagtc gggagcggaa gtcaagaaac cgggatcgtc ggtcaaagtg 61 tcgtgtaaag cgtcgggata tacgtttagc gactataaca tggattgggt gcgacaagcg 121 cctgggcagg gacttgaatg gatgggtcag atcaatccga ataatggggg aatctttttc 181 aatcagaagt ttcaggggag ggtaacgctg acggcggata aaagcacgtc aacggcgtat 241 atggagttgt cgtcgttgcg gtcggaggac acggcggtct attactgcgc gagggaagcg 301 attacgacgg tgggagcgat ggattattgg gggcagggaa cgcttgtaac ggtgtcatcg 361 gcctcaacaa aaggaccaag tgtgttccca ctcgccccta gcagcaagag tacatccggg 421 ggcactgcag cactcggctg cctcgtcaag gattattttc cagagccagt aaccgtgagc 481 tggaacagtg gagcactcac ttctggtgtc catacttttc ctgctgtcct gcaaagctct 541 ggcctgtact cactcagctc cgtcgtgacc gtgccatctt catctctggg cactcagacc 601 tacatctgta atgtaaacca caagcctagc aatactaagg tcgataagcg ggtggaaccc 661 aagagctgcg acaagactca cacttgtccc ccatgccctg cccctgaact tctgggcggt 721 cccagcgtct ttttgttccc accaaagcct aaagatactc tgatgataag tagaacaccc 781 gaggtgacat gtgttgttgt agacgtttcc cacgaggacc cagaggttaa gttcaactgg 841 tacgttgatg gagtcgaagt acataatgct aagaccaagc ctagagagga gcagtataat 901 agtacatacc gtgtagtcag tgttctcaca gtgctgcacc aagactggct caacggcaaa 961 gaatacaaat gcaaagtgtc caacaaagca ctcccagccc ctatcgagaa gactattagt 1021 aaggcaaagg ggcagcctcg tgaaccacag gtgtacactc tgccacccag tagagaggaa 1081 atgacaaaga accaagtctc attgacctgc ctggtgaaag gcttctaccc cagcgacatc 1141 gccgttgagt gggagagtaa cggtcagcct gagaacaatt acaagacaac ccccccagtg 1201 ctggatagtg acgggtcttt ctttctgtac agtaagctga ctgtggacaa gtcccgctgg 1261 cagcagggta acgtcttcag ctgttccgtg atgcacgagg cattgcacaa ccactacacc 1321 cagaagtcac tgagcctgag cccagggaag
Secuencia de proteínas que define la cadena pesada Sh01G06 IGHV1-69 T30S K64Q I69L completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 190)
1 qvqlvqsgae vkkpgssvkv sckasgytfs dynmdwvrqa pgqglewmgq inpnnggiff
61 nqkfqgrvtl tadkststay melsslrsed tavyycarea ittvgamdyw gqgtlvtvss
121 astkgpsvfp lapsskstsg gtaalgclvk dyfpepvtvs wnsgaltsgv htfpavlqss
181 glyslssvvt vpssslgtqt yicnvnhkps ntkvdkrvep kscdkthtcp pcpapellgg
241 psvflfppkp kdtlmisrtp evtcvvvdvs hedpevkfnw yvdgvevhna ktkpreeqyn
301 styrvvsvlt vlhqdwlngk eykckvsnka lpapiektis kakgqprepq vytlppsree
361 mtknqvsltc lvkgfypsdi avewesngqp ennykttppv ldsdgsffly skltvdksrw
421 qqgnvfscsv mhealhnhyt qkslslspgk
Secuencia de ácidos nucleicos que codifica la cadena pesada Hu01G06 IGHV1-18 FI completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 255)
1 caggtccagc ttgtgcaatc gggagcggaagtgaagaaac cgggagcgtc ggtaaaagtc 61 tcgtgcaaag cgtcggggta tacgtttacg gactataaca tggactgggt gcgccaagcg 121 cctggacaga gccttgaatg gatggggcagattaatccgt acaatcacctgatcttcttt 181 aatcagaaat tccagggaag  ggtaacgctg acgacagacacgtcaacatcgacggcctat 241 atggaattgc ggtcgttgcg
ggtaacgctg acgacagacacgtcaacatcgacggcctat 241 atggaattgc ggtcgttgcg  atcagatgatacggcggtctactattgtgcgagggaggcg 301 attacgacgg tgggagcgat
atcagatgatacggcggtctactattgtgcgagggaggcg 301 attacgacgg tgggagcgat  ggattattgg ggacaggggacgttggtaacggtatcgtcg 361 gcctcaacaa aaggaccaag
ggattattgg ggacaggggacgttggtaacggtatcgtcg 361 gcctcaacaa aaggaccaag  tgtgttccca ctcgcccctagcagcaagagtacatccggg 421 ggcactgcag cactcggctg
tgtgttccca ctcgcccctagcagcaagagtacatccggg 421 ggcactgcag cactcggctg  cctcgtcaaggattattttccagagccagtaaccgtgagc 481 tggaacagtg gagcactcac
cctcgtcaaggattattttccagagccagtaaccgtgagc 481 tggaacagtg gagcactcac  ttctggtgtccatacttttcctgctgtcctgcaaagctct 541 ggcctgtact cactcagctc
ttctggtgtccatacttttcctgctgtcctgcaaagctct 541 ggcctgtact cactcagctc  cgtcgtgaccgtgccatctt catctctgggcactcagacc 601 tacatctgta atgtaaaccacaagcctagc aatactaagg tcgataagcg ggtggaaccc 661 aagagctgcg acaagactcacacttgtccc ccatgccctg cccctgaact tctgggcggt 721 cccagcgtct ttttgttccc accaaagcctaaagatactctgatgataag tagaacaccc
cgtcgtgaccgtgccatctt catctctgggcactcagacc 601 tacatctgta atgtaaaccacaagcctagc aatactaagg tcgataagcg ggtggaaccc 661 aagagctgcg acaagactcacacttgtccc ccatgccctg cccctgaact tctgggcggt 721 cccagcgtct ttttgttccc accaaagcctaaagatactctgatgataag tagaacaccc
781 gaggtgacatgtgttgttgt agacgtttcc cacgaggacc cagaggttaa gttcaactgg 841 tacgttgatggagtcgaagt acataatgct aagaccaagc ctagagagga gcagtataat 901 agtacataccgtgtagtcag tgttctcaca gtgctgcacc aagactggct caacggcaaa 961 gaatacaaatgcaaagtgtc caacaaagca ctcccagccc ctatcgagaa gactattagt 1021 aaggcaaaggggcagcctcg tgaaccacag gtgtacactc tgccacccag tagagaggaa 1081 atgacaaagaaccaagtctc attgacctgc ctggtgaaag gcttctaccc cagcgacatc 1141 gccgttgagtgggagagtaa cggtcagcct gagaacaatt acaagacaac ccccccagtg 1201 ctggatagtgacgggtcttt ctttctgtac agtaagctga ctgtggacaa gtcccgctgg 1261 cagcagggtaacgtcttcag ctgttccgtg atgcacgagg cattgcacaa ccactacacc 1321 cagaagtcactgagcctgag cccagggaag
S e cu e n c ia de p ro te ínas q u e d e fin e la ca d e n a p e sa d a H u 01 G 06 IG H V 1-18 FI c o m p le ta (reg ión v a r ia b le de la ca d e n a p e sa d a h u m a n iza d a y reg ión co n s ta n te de la IgG1 hu m an a ) (S E Q ID NO : 256)
1 qvq lvqsgae vkkpgasvkv s c k a s g y t f t dynmdwvrqa pgqslewmgq in p y n h l i f f
61 n q k fq g r v t l t t d t s t s t a y m e lrs lrs d d ta vyyca re a ittvgam dyw g q g t lv tv s s
1 2 1 a s tk g p s v fp la p s s k s ts g g ta a lg c lv k d y fp e p v tv s w n sg a ltsg v h t fp a v lq s s 181 g ly s ls s v v t v p s s s lg tq t  y icnvnhkps n tkvd k rve p k s c d k th tc p p c p a p e llg g 241 p s v f lfp p k p k d t lm is r tp e v tcvvvd vs hedpevkfnw yvdgvevhna k tkp reeqyn 301 s t y r v v s v l t v lhqdw lng k
y icnvnhkps n tkvd k rve p k s c d k th tc p p c p a p e llg g 241 p s v f lfp p k p k d t lm is r tp e v tcvvvd vs hedpevkfnw yvdgvevhna k tkp reeqyn 301 s t y r v v s v l t v lhqdw lng k  eykckvsnka lp a p ie k t is kakgqprepq v y t lp p s re e 361 m tk n q v s ltc lv k g fy p s d i avewesngqp e n n y k ttp p v ld s d g s f f ly s k ltv d k s rw 421 qqgnv fscsv m healhnhyt q k s ls ls p g k
eykckvsnka lp a p ie k t is kakgqprepq v y t lp p s re e 361 m tk n q v s ltc lv k g fy p s d i avewesngqp e n n y k ttp p v ld s d g s f f ly s k ltv d k s rw 421 qqgnv fscsv m healhnhyt q k s ls ls p g k
Secuencia de ácidos nucleicos que codifica la cadena pesada Hu01G06 IGHV1-18 F2 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 257)
1 caggtccagc t tg tg c a a tc gggagcggaa gtgaagaaac cgggagcgtc gg taaaag tc 61 tcg tg ca a a g cg tcgggg ta ta c g t t ta c g g a c ta ta a ca tg g a c tg g g t gcgccaagcg 121 cctggacaga g c c ttg a a tg gatggggcag a tta a tc c g a a ta a tg g a c t g a t c t t c t t t 181 aa tcaga aa t tccagggaag g g ta a cg c tg acgacagaca c g tc a a c a tc g a cg g cc ta t 241 a tg g a a ttg c g g tc g ttg c g a tc a g a tg a t a cg g cg g tc t a c ta t tg tg c gagggaggcg 301 a tta cg a cg g tgggagcga t g g a t ta t tg g ggacagggga c g ttg g ta a c g g ta tc g tc g 361 gcctcaacaa aaggaccaag tg tg t tc c c a c tc g c c c c ta gcagcaagag ta ca tccg g g 421 ggcactgcag c a c tc g g c tg c c tc g tc a a g g a t t a t t t t c cagagccagt aaccgtgagc 481 tggaaca g tg gagcactcac t t c t g g t g t c c a t a c t t t t c c tg c tg tc c t g ca a a g c tc t 541 g g c c tg ta c t c a c tc a g c tc c g tc g tg a c c g tg c c a tc t t c a tc tc tg g g cactcagacc 601 ta c a tc tg ta a tg taaa cca caagcctagc a a tac taa gg tcg a ta a g cg ggtggaaccc 661 aagagctgcg acaagactca c a c t tg tc c c c c a tg c c c tg c c c c tg a a c t tc tg g g c g g t 721 c c c a g c g tc t t t t t g t t c c c accaaagcct aa a g a ta c tc tg a tg a ta a g tagaacaccc 781 gagg tg aca t g t g t t g t t g t a g a c g tt tc c cacgaggacc cagagg ttaa g ttc a a c tg g 841 ta c g t tg a tg gag tcgaag t a c a ta a tg c t aagaccaagc ctagagagga g c a g ta ta a t 901 a g ta ca ta cc g tg ta g tc a g tg t tc tc a c a g tg c tg c a c c aagac tg gc t caacggcaaa 961 gaa taca aa t gcaaag tg tc caacaaagca c tccca g ccc c ta tcgaga a g a c ta t ta g t 1021 aaggcaaagg ggcagcctcg tgaaccacag g tg ta c a c tc tgccacccag tagagaggaa 1081 atgacaaaga a cca a g tc tc a ttg a c c tg c c tgg tgaa ag g c t tc ta c c c cagcgacatc 1141 g c c g ttg a g t gggagagtaa c g g tc a g c c t g agaa caa tt acaagacaac ccccccag tg 1201 c tg g a ta g tg a c g g g tc t t t c t t t c t g t a c ag taag c tga c tg tggaca a g tc c c g c tg g 1261 cagcagggta a c g tc ttc a g c tg t tc c g tg atgcacgagg ca ttg ca ca a ccac tacacc 1321 cagaagtcac tgagcc tga g cccagggaag
Secuencia de proteínas que define la cadena pesada Hu01 G06 IGHV1-18 F2 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 258)
1 qvq lvqsgae vkkpgasvkv s c k a s g y t f t dynmdwvrqa pgqslewmgq in p n n g l i f f 61 n q k fq g r v t l t t d t s t s t a y m e lrs lrs d d ta vyyca re a ittvgam dyw g q g t lv tv s s
1 2 1 a s tk g p s v fp la p s s k s ts g g ta a lg c lv k d y fp e p v tv s w n sg a ltsg v h t fp a v lq s s
181 g ly s ls s v v t v p s s s lg tq t y icnvnhkps n tkv d k rv e p k s c d k th tc p p c p a p e llg g
241 p s v f lfp p k p k d t lm is r tp e v tcvvvd vs hedpevkfnw yvdgvevhna k tkp reeqyn
301 s t y r v v s v l t v lh q d w ln g k eykckvsnka lp a p ie k t is kakgqprepq v y t lp p s re e
361 m tk n q v s ltc lv k g fy p s d i avewesngqp e n n y k ttp p v ld s d g s f f ly s k ltv d k s rw
421 qqgnv fscsv m healhnhyt q k s ls ls p g k
S e cu e n c ia de ác ido s nu c le icos que c o d ifica la ca d e n a p e sa d a H u 01 G 06 IG H V 1-69 FI co m p le ta (reg ión v a r ia b le de la ca d e n a p e sa d a h u m a n iza d a y reg ión co n s ta n te de la IgG1 hu m an a ) (S E Q ID NO : 259)
i caagtacagc ttgtacagtc gggagcggaa gtcaagaaac cgggatcgtc ggtcaaagtg 61 tcgtgtaaag cgtcgggata tacgtttagc gactataaca tggattgggt gcgacaagcg 121 cctgggcagg gacttgaatg gatgggtcag atcaatccga ataatgggct gatctttttc 181 aatcagaagt ttaaagggag ggtaacgctg acggcggata aaagcacgtc aacggcgtat 241 atggagttgt cgtcgttgcg gtcggaggac acggcggtct attactgcgc gagggaagcg 301 attacgacgg tgggagcgat ggattattgg gggcagggaa cgcttgtaac ggtgtcatcg 361 gcctcaacaa aaggaccaag tgtgttccca ctcgccccta gcagcaagag tacatccggg 421 ggcactgcag cactcggctg cctcgtcaag gattattttc cagagccagt aaccgtgagc 481 tggaacagtg gagcactcac ttctggtgtc catacttttc ctgctgtcct gcaaagctct 541 ggcctgtact cactcagctc cgtcgtgacc gtgccatctt catctctggg cactcagacc 601 tacatctgta atgtaaacca caagcctagc aatactaagg tcgataagcg ggtggaaccc 661 aagagctgcg acaagactca cacttgtccc ccatgccctg cccctgaact tctgggcggt 721 cccagcgtct ttttgttccc accaaagcct aaagatactc tgatgataag tagaacaccc 781 gaggtgacat gtgttgttgt agacgtttcc cacgaggacc cagaggttaa gttcaactgg 841 tacgttgatg gagtcgaagt acataatgct aagaccaagc ctagagagga gcagtataat 901 agtacatacc gtgtagtcag tgttctcaca gtgctgcacc aagactggct caacggcaaa 961 gaatacaaat gcaaagtgtc caacaaagca ctcccagccc ctatcgagaa gactattagt 1021 aaggcaaagg ggcagcctcg tgaaccacag gtgtacactc tgccacccag tagagaggaa 1081 atgacaaaga accaagtctc attgacctgc ctggtgaaag gcttctaccc cagcgacatc 1141 gccgttgagt gggagagtaa cggtcagcct gagaacaatt acaagacaac ccccccagtg 1201 ctggatagtg acgggtcttt ctttctgtac agtaagctga ctgtggacaa gtcccgctgg 1261 cagcagggta acgtcttcag ctgttccgtg atgcacgagg cattgcacaa ccactacacc 1321 cagaagtcac tgagcctgag cccagggaag
Secuencia de proteínas que define la cadena pesada Hu01G06 IGHV1-69 FI completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 260)
1 gvqlvgsgae vkkpgssvkv sckasgytfs dynmdwvrqa pgqglewmgq inpnngliff 61 nqkfkgrvtl tadkststay melsslrsed tavyycarea ittvgamdyw gqgtlvtvss 121 astkgpsvfp lapsskstsg gtaalgclvk dyfpepvtvs wnsgaltsgv htfpavlqss 181 glyslssvvt vpssslgtqt yicnvnhkps ntkvdkrvep kscdkthtcp pcpapellgg 241 psvflfppkp kdtlmisrtp evtcvvvdvs hedpevkfnw yvdgvevhna ktkpreeqyn 301 styrvvsvlt vlhqdwlngk eykckvsnka lpapiektis kakgqprepq vytlppsree
361 mtknqvsltc lvkgfypsdi avewesngqp ennykttppv ldsdgsffly skltvdksrw
421 qqgnvfscsv mhealhnhyt qkslslspgk
Secuencia de ácidos nucleicos que codifica la cadena pesada Hu01G06 IGHV1-69 F2 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 261)
i caagtacagc ttgtacagtc gggagcggaa gtcaagaaac cgggatcgtc ggtcaaagtg 61 tcgtgtaaag cgtcgggata tacgtttagc gactataaca tggattgggt gcgacaagcg 121 cctgggcagg gacttgaatg gatgggtcag atcaatccgt acaatcacct gatctttttc 181 aatcagaagt ttaaagggag ggtaacgctg acggcggata aaagcacgtc aacggcgtat 241 atggagttgt cgtcgttgcg gtcggaggac acggcggtct attactgcgc gagggaagcg 301 attacgacgg tgggagcgat ggattattgg gggcagggaa cgcttgtaac ggtgtcatcg 361 gcctcaacaa aaggaccaag tgtgttccca ctcgccccta gcagcaagag tacatccggg 421 ggcactgcag cactcggctg cctcgtcaag gattattttc cagagccagt aaccgtgagc 481 tggaacagtg gagcactcac ttctggtgtc catacttttc ctgctgtcct gcaaagctct 541 ggcctgtact cactcagctc cgtcgtgacc gtgccatctt catctctggg cactcagacc 601 tacatctgta atgtaaacca caagcctagc aatactaagg tcgataagcg ggtggaaccc 661 aagagctgcg acaagactca cacttgtccc ccatgccctg cccctgaact tctgggcggt 721 cccagcgtct ttttgttccc accaaagcct aaagatactc tgatgataag tagaacaccc 781 gaggtgacat gtgttgttgt agacgtttcc cacgaggacc cagaggttaa gttcaactgg 841 tacgttgatg gagtcgaagt acataatgct aagaccaagc ctagagagga gcagtataat 901 agtacatacc gtgtagtcag tgttctcaca gtgctgcacc aagactggct caacggcaaa 961 gaatacaaat gcaaagtgtc caacaaagca ctcccagccc ctatcgagaa gactattagt 1021 aaggcaaagg ggcagcctcg tgaaccacag gtgtacactc tgccacccag tagagaggaa 1081 atgacaaaga accaagtctc attgacctgc ctggtgaaag gcttctaccc cagcgacatc 1141 gccgttgagt gggagagtaa cggtcagcct gagaacaatt acaagacaac ccccccagtg 1201 ctggatagtg acgggtcttt ctttctgtac agtaagctga ctgtggacaa gtcccgctgg 1261 cagcagggta acgtcttcag ctgttccgtg atgcacgagg cattgcacaa ccactacacc 1321 cagaagtcac tgagcctgag cccagggaag
Secuencia de proteínas que define la cadena pesada Hu01G06 IGHV1-69 F2 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 262)
1 qvqlvqsgae vkkpgssvkv sckasgytfs dynmdwvrqa pgqglewmgq inpynhliff
61 nqkfkgrvtl tadkststay melsslrsed tavyycarea ittvgamdyw gqgtlvtvss
121 astkgpsvfp lapsskstsg gtaalgclvk dyfpepvtvs wnsgaltsgv htfpavlqss
181 glyslssvvt vpssslgtqt yicnvnhkps ntkvdkrvep kscdkthtcp pcpapellgg 241 psvflfppkp kdtlmisrtp evtcvvvdvs hedpevkfnw yvdgvevhna ktkpreeqyn
301 styrvvsvlt vlhqdwlngk eykckvsnka lpapiektis kakgqprepq vytlppsree
361 mtknqvsltc lvkgfypsdi avewesngqp ennykttppv ldsdgsffly skltvdksrw 421 qqgnvfscsv mhealhnhyt qkslslspgk
Secuencia de ácidos nucleicos que codifica la cadena pesada quimérica Ch06C11 completa (región variable de la cadena pesada de ratón y región constante de la IgG1 humana) (SEQ ID NO: 191)
1 caggtgacac tcaaagaatc aggacccgga atccttcagc ccagccagac cttgtcgctg 61 acttgttcgt tctccggttt cagcctgaat acttatggga tgggtgtgtc atggatcagg 121 caaccgtccg ggaaaggatt ggagtggctc gcgcacatct actgggacga tgacaaacgc 181 tacaatcctt cgctgaagag ccgattgacg atttccaagg atgcctcgaa caaccgggta 241 tttcttaaga tcacgtcggt cgatacggca gacacggcga cctattactg cgcccaaaga 301 gggtacgatg actattgggg atattggggc caggggacac tcgtcacaat ttcagctgcc
361 tcaacaaaaggaccaagtgt gttcccactc gcccctagca gcaagagtac atccgggggc 421 actgcagcactcggctgcct cgtcaaggat tattttccag agccagtaac cgtgagctgg 481 aacagtggagcactcacttc tggtgtccat acttttcctg ctgtcctgca aagctctggc 541 ctgtactcactcagctccgt cgtgaccgtg ccatcttcat ctctgggcac tcagacctac 601 atctgtaatgtaaaccacaa gcctagcaat actaaggtcg ataagcgggt ggaacccaag 661 agctgcgacaagactcacac ttgtccccca tgccctgccc ctgaacttct gggcggtccc 721 agcgtctttttgttcccacc aaagcctaaa gatactctga tgataagtag aacacccgag 781 gtgacatgtgttgttgtaga cgtttcccac gaggacccag aggttaagtt caactggtac 841 gttgatggagtcgaagtaca taatgctaag accaagccta gagaggagca gtataatagt 901 acataccgtgtagtcagtgt tctcacagtg ctgcaccaag actggctcaa cggcaaagaa 961 tacaaatgcaaagtgtccaa caaagcactc ccagccccta tcgagaagac tattagtaag 1021 gcaaaggggcagcctcgtga accacaggtg tacactctgc cacccagtag agaggaaatg 1081 acaaagaaccaagtctcatt gacctgcctg gtgaaaggct tctaccccag cgacatcgcc 1141 gttgagtgggagagtaacgg tcagcctgag aacaattaca agacaacccc cccagtgctg 1201 gatagtgacgggtctttctt tctgtacagt aagctgactg tggacaagtc ccgctggcag 1261 cagggtaacgtcttcagctg ttccgtgatg cacgaggcat tgcacaacca ctacacccag 1321 aagtcactgagcctgagccc agggaag
S e cu e n c ia de p ro te ín a s qu e d e fine la c a d e n a pe sa d a q u im é rica C h06C 11 c o m p le ta (reg ión va r ia b le de la cad en a p e sa d a de ratón y reg ión co n s ta n te d e la IgG1 hu m an a ) (S E Q ID NO : 192)
1 qvtlkesgpg ilqpsqtlsl tcsfsgfsin tygmgvswir qpsgkglewl ahiywdddkr 61 ynpslksrlt iskdasnnrv flkitsvdta dtatyycaqr gyddywgywg qgtlvtisaa 121 stkgpsvfpl apsskstsgg taalgclvkd yfpepvtvsw nsgaltsgvh tfpavlqssg 181 lyslssvvtv pssslgtqty icnvnhkpsn tkvdkrvepk scdkthtcpp cpapellggp 241 svflfppkpk dtlmisrtpe vtcvvvdvsh edpevkfnwy vdgvevhnak tkpreeqyns 301 tyrvvsvltv lhqdwlngke ykckvsnkal papiektisk akgqprepqv ytlppsreem 361 tknqvsltcl vkgfypsdia vewesngqpe nnykttppvl dsdgsfflys kltvdksrwq 421 qgnvfscsvm healhnhytq kslslspgk
Secuencia de ácidos nucleicos que codifica la cadena pesada HE LM 06C11 IGHV2-70 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 193)
1 caggtgactt tgaaagaatc cggtcccgca ttggtaaagc caacccagac acttacgctc 61 acatgtacat tttccggatt cagcttgaac acttacggga tgggagtgtc gtggattcgg 121 caacctccgg ggaaggctct ggagtggctg gcgcacatct actgggatga tgacaaaagg 181 tataacccct cacttaaaac gagactgacg atctcgaagg acacaagcaa gaatcaggtc 241 gtcctcacga ttacgaatgt agacccggtg gatactgccg tctattactg cgcgcaacgc 301 gggtatgatg actactgggg atattggggt cagggcaccc tcgtgaccat ctcgtcagcc 361 tcaacaaaag gaccaagtgt gttcccactc gcccctagca gcaagagtac atccgggggc 421 actgcagcac tcggctgcct cgtcaaggat tattttccag agccagtaac cgtgagctgg 481 aacagtggag cactcacttc tggtgtccat acttttcctg ctgtcctgca aagctctggc 541 ctgtactcac tcagctccgt cgtgaccgtg ccatcttcat ctctgggcac tcagacctac 601 atctgtaatg taaaccacaa gcctagcaat actaaggtcg ataagcgggt ggaacccaag 661 agctgcgaca agactcacac ttgtccccca tgccctgccc ctgaacttct gggcggtccc 721 agcgtctttt tgttcccacc aaagcctaaa gatactctga tgataagtag aacacccgag 781 gtgacatgtg ttgttgtaga cgtttcccac gaggacccag aggttaagtt caactggtac 841 gttgatggag tcgaagtaca taatgctaag accaagccta gagaggagca gtataatagt 901 acataccgtg tagtcagtgt tctcacagtg ctgcaccaag actggctcaa cggcaaagaa 961 tacaaatgca aagtgtccaa caaagcactc ccagccccta tcgagaagac tattagtaag 1021 gcaaaggggc agcctcgtga accacaggtg tacactctgc cacccagtag agaggaaatg 1081 acaaagaacc aagtctcatt gacctgcctg gtgaaaggct tctaccccag cgacatcgcc 1141 gttgagtggg agagtaacgg tcagcctgag aacaattaca agacaacccc cccagtgctg 1201 gatagtgacg ggtctttctt  tctgtacagtaagctgactg tggacaagtcccgctggcag
tctgtacagtaagctgactg tggacaagtcccgctggcag
1261 cagggtaacg tcttcagctg ttccgtgatgcacgaggcat tgcacaaccactacacccag 1321 aagtcactga gcctgagccc agggaag
Secuencia de proteínas que define la cadena pesada HE LM 06C11 IGHV2-70 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 194)
1 qvtlkesgpa lvkptqtltl tctfsgfsin tygmgvswir qppgkalewl ahiywdddkr
61 ynpslktrlt iskdtsknqv vltitnvdpv dtavyycaqr gyddywgywg qgtlvtissa
121 stkgpsvfpl apsskstsgg taalgclvkd yfpepvtvsw nsgaltsgvh tfpavlqssg
181 lyslssvvtv pssslgtqty icnvnhkpsn tkvdkrvepk scdkthtcpp cpapellggp
241 svflfppkpk dtlmisrtpe vtcvvvdvsh edpevkfnwy vdgvevhnak tkpreeqyns
301 tyrvvsvltv lhqdwlngke ykckvsnkal papiektisk akgqprepqv ytlppsreem
361 tknqvsltcl vkgfypsdia vewesngqpe nnykttppvl dsdgsfflys kltvdksrwq
421 qqnvfscsvm healhnhytq kslslspqk
S e cu e n c ia de ác ido s nu c le icos que co d ifica la c a d e n a pe sa d a H u 06 C 11 IG H V 2-5 c o m p le ta (reg ión v a r ia b le de la c a d e n a p e sa d a h u m a n iza d a y reg ión c o n s ta n te de la IgG1 hu m an a) (S E Q ID NO : 195)
1 caagtaacgctcaaggagtc cggacccacc ttggtgaagc cgacgcagac cttgactctt 61 acgtgcactttctcggggtt ttcactgaat acgtacggga tgggtgtctc atggatcagg 121 caacctccggggaaaggatt ggaatggctg gcgcacatct actgggatga cgataagaga 181 tataacccaagcctcaagtc gcggctcacc attacaaaag atacatcgaa aaatcaggtc 241 gtacttactatcacgaacat ggaccccgtg gacacagcaa catattactg tgcccagcgc 301 ggctatgacgattattgggg ttactgggga cagggaacac tggtcacggt gtccagcgcc 361 tcaacaaaaggaccaagtgt gttcccactc gcccctagca gcaagagtac atccgggggc 421 actgcagcactcggctgcct cgtcaaggat tattttccag agccagtaac cgtgagctgg 481 aacagtggagcactcacttc tggtgtccat acttttcctg ctgtcctgca aagctctggc 541 ctgtactcactcagctccgt cgtgaccgtg ccatcttcat ctctgggcac tcagacctac 601 atctgtaatgtaaaccacaa gcctagcaat actaaggtcg ataagcgggt ggaacccaag 661 agctgcgacaagactcacac ttgtccccca tgccctgccc ctgaacttct gggcggtccc 721 agcgtctttttgttcccacc aaagcctaaa gatactctga tgataagtag aacacccgag 781 gtgacatgtgttgttgtaga cgtttcccac gaggacccag aggttaagtt caactggtac 841 gttgatggagtcgaagtaca taatgctaag accaagccta gagaggagca gtataatagt 901 acataccgtgtagtcagtgt tctcacagtg ctgcaccaag actggctcaa cggcaaagaa 961 tacaaatgcaaagtgtccaa caaagcactc ccagccccta tcgagaagac tattagtaag 1021 gcaaaggggcagcctcgtga accacaggtg tacactctgc cacccagtag agaggaaatg 1081 acaaagaaccaagtctcatt gacctgcctg gtgaaaggct tctaccccag cgacatcgcc 1141 gttgagtgggagagtaacgg tcagcctgag aacaattaca agacaacccc cccagtgctg 1201 gatagtgacgggtctttctt tctgtacagt aagctgactg tggacaagtc ccgctggcag 1261 cagggtaacgtcttcagctg ttccgtgatg cacgaggcat tgcacaacca ctacacccag 1321 aagtcactgagcctgagccc agggaag
Secuencia de proteínas que define la cadena pesada Hu06C11 IGHV2-5 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 196)
1 qvtlkesgptlvkptqtltl tctfsgfsln tygmgvswir qppgkglewl ahiywdddkr 61 ynpslksrltitkdtsknqv vltitnmdpv dtatyycaqr gyddywgywg qgtlvtvssa 121 stkgpsvfplapsskstsgg taalgclvkd yfpepvtvsw nsgaltsgvh tfpavlqssg 181 lyslssvvtvpssslgtqty icnvnhkpsn tkvdkrvepk scdkthtcpp cpapellggp
241 svflfppkpk dtlmisrtpe vtcvvvdvsh edpevkfnwy vdgvevhnak tkpreeqyns
301 tyrvvsvltv lhqdwlngke ykckvsnkal papiektisk akgqprepqv ytlppsreem
361 tknqvsltcl vkgfypsdia vewesngqpe nnykttppvl dsdgsfflys kltvdksrwq
421 qgnvfscsvm healhnhytq kslslspgk
Secuencia de ácidos nucleicos que codifica la cadena pesada quimérica Ch14F11 completa (región variable de la cadena pesada de ratón y región constante de la IgG1 humana) (SEQ ID NO: 197)
1 caggtcacgctgaaagagtc aggtcccgga atccttcaac cttcgcagac attgtcactc 61 acatgttccttctccgggtt ctcgctctcg acttatggca tgggtgtagg atggattcgg 121 cagcccagcgggaaggggct tgagtggttg gcggatatct ggtgggacga cgacaaatac 181 tacaatccgagcctgaagtc ccgcctcacc atttcgaaag atacgtcatc aaacgaagtc 241 tttttgaagatcgccatcgt ggacacggcg gatacagcga cgtattactg cgccagaagg 301 ggacactacagcgcaatgga ttattgggga caggggacct cggtgactgt gtcgtccgcc 361 tcaacaaaaggaccaagtgt gttcccactc gcccctagca gcaagagtac atccgggggc 421 actgcagcactcggctgcct cgtcaaggat tattttccag agccagtaac cgtgagctgg 481 aacagtggagcactcacttc tggtgtccat acttttcctg ctgtcctgca aagctctggc 541 ctgtactcactcagctccgt cgtgaccgtg ccatcttcat ctctgggcac tcagacctac 601 atctgtaatgtaaaccacaa gcctagcaat actaaggtcg ataagcgggt ggaacccaag 661 agctgcgacaagactcacac ttgtccccca tgccctgccc ctgaacttct gggcggtccc 721 agcgtctttttgttcccacc aaagcctaaa gatactctga tgataagtag aacacccgag 781 gtgacatgtgttgttgtaga cgtttcccac gaggacccag aggttaagtt caactggtac 841 gttgatggagtcgaagtaca taatgctaag accaagccta gagaggagca gtataatagt 901 acataccgtgtagtcagtgt tctcacagtg ctgcaccaag actggctcaa cggcaaagaa 961 tacaaatgcaaagtgtccaa caaagcactc ccagccccta tcgagaagac tattagtaag 1021 gcaaaggggcagcctcgtga accacaggtg tacactctgc cacccagtag agaggaaatg 1081 acaaagaaccaagtctcatt gacctgcctg gtgaaaggct tctaccccag cgacatcgcc 1141 gttgagtgggagagtaacgg tcagcctgag aacaattaca agacaacccc cccagtgctg 1201 gatagtgacgggtctttctt tctgtacagt aagctgactg tggacaagtc ccgctggcag 1261 cagggtaacgtcttcagctg ttccgtgatg cacgaggcat tgcacaacca ctacacccag 1321 aagtcactgagcctgagccc agggaag
Secuencia de proteínas que define la cadena pesada quimérica Ch14F11 completa (región variable de la cadena pesada de ratón y región constante de la IaG1 humana) (SEQ ID NO: 198)
1 qvtlkesgpg ilqpsqtlsl tcsfsgfsls tygmgvgwir qpsgkglewl adiwwdddky 61 ynpslksrlt iskdtssnev flkiaivdta dtatyycarr ghysamdywg qgtsvtvssa 121 stkgpsvfpl apsskstsgg taalgclvkd yfpepvtvsw nsgaltsgvh tfpavlqssg 181 lyslssvvtv pssslgtqty icnvnhkpsn tkvdkrvepk scdkthtcpp cpapellggp 241 svflfppkpk dtlmisrtpe vtcvvvdvsh edpevkfnwy vdgvevhnak tkpreeqyns 301 tyrvvsvltv lhqdwlngke ykckvsnkal papiektisk akgqprepqv ytlppsreem 361 tknqvsltcl vkgfypsdia vewesngqpe nnykttppvl dsdgsfflys kltvdksrwq 421 qgnvfscsvm healhnhytq kslslspgk
Secuencia de ácidos nucleicos que codifica la cadena pesada Sh14F11 IGHV2-5 completa (región variable de la cadena pesada humanizada y región constante de la IaG1 humana) (SEQ ID NO: 199)
1 cagatcactt tgaaagaaag cggaccgacc ttggtcaagc ccacacaaac cctcacgctc
61 acgtgtacat tttcggggtt ctcgctttca acttacggga tgggagtagg gtggattcgc
121 cagccgcctg gtaaagcgtt ggagtggctt gcagacatct ggtgggacga cgataagtac
181 tataatccct cgctcaagtc cagactgacc atcacgaaag atacgagcaa gaaccaggtc
241 gtgctgacaa tgactaacat ggacccagtg gatacggcta catattactg cgccaggcgg
301 ggtcactactcagcgatgga ttattggggc cagggaacac tggtaacggt gtcgtccgcc 361 tcaacaaaaggaccaagtgt gttcccactc gcccctagca gcaagagtac atccgggggc 421 actgcagcactcggctgcct cgtcaaggat tattttccag agccagtaac cgtgagctgg 481 aacagtggagcactcacttc tggtgtccat acttttcctg ctgtcctgca aagctctggc 541 ctgtactcactcagctccgt cgtgaccgtg ccatcttcat ctctgggcac tcagacctac 601 atctgtaatgtaaaccacaa gcctagcaat actaaggtcg ataagcgggt ggaacccaag 661 agctgcgacaagactcacac ttgtccccca tgccctgccc ctgaacttct gggcggtccc 721 agcgtctttttgttcccacc aaagcctaaa gatactctga tgataagtag aacacccgag 781 gtgacatgtgttgttgtaga cgtttcccac gaggacccag aggttaagtt caactggtac 841 gttgatggagtcgaagtaca taatgctaag accaagccta gagaggagca gtataatagt 901 acataccgtgtagtcagtgt tctcacagtg ctgcaccaag actggctcaa cggcaaagaa 961 tacaaatgcaaagtgtccaa caaagcactc ccagccccta tcgagaagac tattagtaag 1021 gcaaaggggcagcctcgtga accacaggtg tacactctgc cacccagtag agaggaaatg 1081 acaaagaaccaagtctcatt gacctgcctg gtgaaaggct tctaccccag cgacatcgcc 1141 gttgagtgggagagtaacgg tcagcctgag aacaattaca agacaacccc cccagtgctg 1201 gatagtgacgggtctttctt tctgtacagt aagctgactg tggacaagtc ccgctggcag 1261 cagggtaacgtcttcagctg ttccgtgatg cacgaggcat tgcacaacca ctacacccag 1321 aagtcactgagcctgagccc agggaag
Secuencia de proteínas que define la cadena pesada Sh14F11 IGHV2-5 completa (región variable de la cadena pesada humanizada y región constante de la IaG1 humana) (SEQ ID NO: 200)
1 qitlkesgpt lvkptqtltl tctfsgfsls tygmgvgwir qppgkalewl adiwwdddky
61 ynpslksrlt itkdtsknqv vltmtnmdpv dtatyycarr ghysamdywg qgtlvtvssa
121 stkgpsvfpl apsskstsgg taalgclvkd yfpepvtvsw nsgaltsgvh tfpavlqssg
181 lyslssvvtv pssslgtqty icnvnhkpsn tkvdkrvepk scdkthtcpp cpapellggp
241 svflfppkpk dtlmisrtpe vtcvvvdvsh edpevkfnwy vdgvevhnak tkpreeqyns
301 tyrvvsvltv lhqdwlngke ykckvsnkal papiektisk akgqprepqv ytlppsreem
361 tknqvsltcl vkgfypsdia vewesngqpe nnykttppvl dsdgsfflys kltvdksrwq
421 qgnvfscsvm healhnhytq kslslspgk
Secuencia de ácidos nucleicos que codifica la cadena pesada Sh 14F11 IGHV2-70 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 201)
1 caagtgactc tcaaggagtc cggacccgcc ctggtcaaac caacgcagac actgacgctc 61 acatgcacct tcagcggatt ttcgttgtca acgtacggca tgggtgtggg gtggattcgc 121 cagcctccgg ggaaagccct tgaatggttg gcggacatct ggtgggatga tgacaagtac 181 tataatccct cacttaagtc acggttgacg atctcgaaag acaccagcaa gaaccaggta 241 gtgctgacaa tgactaacat ggacccggtc gatacagcgg tctactattg tgctagaagg 301 ggacactact ccgcaatgga ttattggggt caggggacgc tcgtaaccgt gtcgtcggcc 361 tcaacaaaag gaccaagtgt gttcccactc gcccctagca gcaagagtac atccgggggc 421 actgcagcac tcggctgcct cgtcaaggat tattttccag agccagtaac cgtgagctgg 481 aacagtggag cactcacttc tggtgtccat acttttcctg ctgtcctgca aagctctggc 541 ctgtactcac tcagctccgt cgtgaccgtg ccatcttcat ctctgggcac tcagacctac 601 atctgtaatg taaaccacaa gcctagcaat actaaggtcg ataagcgggt ggaacccaag 661 agctgcgaca agactcacac ttgtccccca tgccctgccc ctgaacttct gggcggtccc 721 agcgtctttt tgttcccacc aaagcctaaa gatactctga tgataagtag aacacccgag 781 gtgacatgtg ttgttgtaga cgtttcccac gaggacccag aggttaagtt caactggtac 841 gttgatggag tcgaagtaca taatgctaag accaagccta gagaggagca gtataatagt 901 acataccgtg tagtcagtgt tctcacagtg ctgcaccaag actggctcaa cggcaaagaa 961 tacaaatgca aagtgtccaa caaagcactc ccagccccta tcgagaagac tattagtaag 1021 gcaaaggggc agcctcgtga accacaggtg tacactctgc cacccagtag agaggaaatg
1081 acaaagaacc aagtctcatt gacctgcctg gtgaaaggct tctaccccag cgacatcgcc 1141 gttgagtggg agagtaacgg tcagcctgag aacaattaca agacaacccc cccagtgctg 1201 gatagtgacg ggtctttctt tctgtacagt aagctgactg tggacaagtc ccgctggcag 1261 cagggtaacg tcttcagctg ttccgtgatg cacgaggcat tgcacaacca ctacacccag 1321 aagtcactga gcctgagccc agggaag
S e cu e n c ia de p ro te ín a s q u e d e fin e la c a d e n a pe sa d a S h14F11 IG H V 2-70 co m p le ta (reg ión v a r ia b le de la ca d e n a p e sa d a h u m a n iza d a y reg ión c o n s ta n te de la IgG1 hu m an a ) (S E Q ID NO : 202)
i qvtlkesgpa lvkptqtltl tctfsgfsis tygmgvgwir qppgkalewl adiwwdddky
61 ynpslksrlt iskdtsknqv vltmtnmdpv dtavyycarr ghysamdywg qgtlvtvssa
121 stkgpsvfpl apsskstsgg taalgclvkd yfpepvtvsw nsgaltsgvh tfpavlqssg
181 lyslssvvtv pssslgtqty icnvnhkpsn tkvdkrvepk scdkthtcpp cpapellggp
241 svflfppkpk dtlmisrtpe vtcvvvdvsh edpevkfnwy vdgvevhnak tkpreeqyns
301 tyrvvsvltv lhqdwlngke ykckvsnkal papiektisk akgqprepqv ytlppsreem
361 tknqvsltcl vkgfypsdia vewesngqpe nnykttppvl dsdgsfflys kltvdksrwq
421 qgnvfscsvm healhnhytq kslslspgk
Secuencia de ácidos nucleicos que codifica la cadena ligera quimérica Ch01G06 completa (región variable de la cadena kappa de ratón y región constante de la kappa humana) (SEQ ID NO: 203)
1 gacatccaaa tgacccagtc acccgcgagc ctttcggcgt cggtcggaga aacggtcacg 61 atcacgtgcc ggacatcaga gaatctccat aactacctcg cgtggtatca acagaagcag 121 gggaagtcgc cccagttgct tgtatacgat gcgaaaacgt tggcggatgg ggtgccgtcc 181 agattctcgg gatcgggctc ggggacgcag tactcgctca agatcaattc gctgcagccg 241 gaggactttg ggtcgtacta ttgtcagcat ttttggtcat caccgtatac atttggaggt 301 ggaacgaaac ttgagattaa gcgcacagtt gctgccccca gcgtgttcat tttcccacct 361 agcgatgagc agctgaaaag cggtactgcc tctgtcgtat gcttgctcaa caacttttac 421 ccacgtgagg ctaaggtgca gtggaaagtg gataatgcac ttcaatctgg aaacagtcaa 481 gagtccgtga cagaacagga cagcaaagac tcaacttatt cactctcttc caccctgact 541 ctgtccaagg cagactatga aaaacacaag gtatacgcct gcgaggttac acaccagggt 601 ttgtctagtc ctgtcaccaa gtccttcaat aggggcgaat gt
Secuencia de proteínas que define la cadena ligera quimérica Ch01G06 completa (región variable de la cadena kappa de ratón y región constante de la kappa humana) (SEQ ID NO: 204)
1 diqmtqspas lsasvgetvt itcrtsenlh nylawyqqkq gkspqllvyd aktladgvps 61 rfsgsgsgtq yslkinslqp edfgsyycqh fwsspytfgg gtkleikrtv aapsvfifpp 121 sdeqlksgta svvcllnnfy preakvqwkv dnalqsgnsq esvteqdskd styslsstlt 181 lskadyekhk vyacevthqg lsspvtksfn rgec
Secuencia de ácidos nucleicos que codifica la cadena ligera Hu01G06 IGKV1-39 completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 205)
1 gacatccaaa tgacccagtc gccgtcgtcg ctttcagcgt cggtagggga tcgggtcaca 61 attacgtgcc gaacgtcaga gaatttgcat aactacctcg cgtggtatca gcagaagccc 121 gggaagtcac cgaaactcct tgtctacgat gcgaaaacgc tggcggatgg agtgccgtcg 181 agattctcgg gaagcggatc cggtacggac tatacgctta cgatctcatc gctccagccc 241 gaggactttg cgacgtacta ttgtcagcat ttttggtcgt cgccctacac atttgggcag 301 gggaccaagt tggaaatcaa gcgcacagtt gctgccccca gcgtgttcat tttcccacct
361 agcgatgagc agctgaaaag cggtactgcc tctgtcgtat gcttgctcaa caacttttac 421 ccacgtgagg ctaaggtgca gtggaaagtg gataatgcac ttcaatctgg aaacagtcaa 481 gagtccgtga cagaacagga cagcaaagac tcaacttatt cactctcttc caccctgact 541 ctgtccaagg cagactatga aaaacacaag gtatacgcct gcgaggttac acaccagggt 601 ttgtctagtc ctgtcaccaa gtccttcaat aggggcgaat gt
Secuencia de proteínas que define la cadena ligera Hu01G06 IGKV1-39 completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 206)
1 diqmtqspss lsasvgdrvt itcrtsenlh nylawyqqkp gkspkllvydaktladgvps 61 rfsgsgsgtd ytltisslqp edfatyycqh fwsspytfgq gtkleikrtvaapsvfifpp 121 sdeqlksgta svvcllnnfy preakvqwkv dnalqsgnsq esvteqdskdstyslsstlt 181 lskadyekhk vyacevthqg lsspvtksfn rgec
S e cu e n c ia de ác ido s nu c le icos qu e c o d ific a la c a d e n a lige ra H u 01 G 06 IG K V 1 -39 S 43 A V 48 I c o m p le ta (reg ión v a ria b le de la c a d e n a k a p p a h u m a n iza d a y reg ión co n s ta n te de la kap pa hu m an a ) (d e n o m in a d a ta m b ié n en el p re se n te d o cu m e n to ca d e n a lige ra H u 01 G 06 IG F V 1-39 FI c o m p le ta ; S E Q ID NO : 207)
1 gacatccaaatgacccagtc gccgtcgtcg ctttcagcgt cggtagggga tcgggtcaca 61 attacgtgccgaacgtcaga gaatttgcat aactacctcg cgtggtatca gcagaagccc 121 gggaaggccc cgaaactcct tatctacgat gcgaaaacgc tggcggatgg agtgccgtcg 181 agattctcgggaagcggatc cggtacggac tatacgctta cgatctcatc gctccagccc 241 gaggactttg cgacgtacta ttgtcagcat ttttggtcgt cgccctacac atttgggcag 301 gggaccaagt tggaaatcaa gcgcacagtt gctgccccca gcgtgttcat tttcccacct 361 agcgatgagcagctgaaaag cggtactgcc tctgtcgtat gcttgctcaa caacttttac 421 ccacgtgagg ctaaggtgca gtggaaagtg gataatgcac ttcaatctgg aaacagtcaa 481 gagtccgtga cagaacagga cagcaaagac tcaacttatt cactctcttc caccctgact 541 ctgtccaagg cagactatga aaaacacaag gtatacgcct gcgaggttac acaccagggt 601 ttgtctagtc ctgtcaccaa gtccttcaat aggggcgaat gt
Secuencia de proteínas que define la cadena ligera Hu01G06 IGKV1-39 S43A V48I completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (denominada también en el presente documento cadena ligera Hu01G06 IGFV1-39 FI completa; SEQ ID NO: 208)
1 diqmtqspss lsasvgdrvt itcrtsenlh nylawyqqkp gkapklliyd aktladgvps 61 rfsgsgsgtd ytltisslqp edfatyycqh fwsspytfgq gtkleikrtv aapsvfifpp 121 sdeqlksgta svvcllnnfy preakvqwkv dnalqsgnsq esvteqdskd styslsstlt 181 lskadyekhk vyacevthqg lsspvtksfn rgec
Secuencia de ácidos nucleicos que codifica la cadena ligera Hu01G06 IGKV1-39 V48I completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 209)
1 gacatccaaa tgacccagtc gccgtcgtcg ctttcagcgt cggtaggggatcgggtcaca 61 attacgtgcc gaacgtcaga gaatttgcat aactacctcg cgtggtatcagcagaagccc
121 gggaagtcac cgaaactcct tatctacgat gcgaaaacgctggcggatgg agtgccgtcg
181 agattctcgg gaagcggatc cggtacggac tatacgcttacgatctcatc gctccagccc
241 gaggactttg cgacgtacta ttgtcagcat ttttggtcgtcgccctacac atttgggcag
301 gggaccaagt tggaaatcaa gcgcacagtt gctgccccca gcgtgttcat tttcccacct 361 agcgatgagc agctgaaaag cggtactgcc tctgtcgtat gcttgctcaa caacttttac 421 ccacgtgagg ctaaggtgca gtggaaagtg gataatgcac ttcaatctgg aaacagtcaa 481 gagtccgtga cagaacagga cagcaaagac tcaacttatt cactctcttc caccctgact 541 ctgtccaagg cagactatga aaaacacaag gtatacgcct gcgaggttac acaccagggt 601 ttgtctagtc ctgtcaccaa gtccttcaat aggggcgaat gt
Secuencia de proteínas que define la cadena ligera Hu01 G06 IGKV1-39 V48I completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 210)
1 diqmtqspss lsasvgdrvt itcrtsenlh nylawyqqkp gkspklliydaktladgvps 61 rfsgsgsgtd ytltisslqp edfatyycqh fwsspytfgq gtkleikrtvaapsvfifpp 121 sdeqlksgta svvcllnnfy preakvqwkv dnalqsgnsqesvteqdskd styslsstlt
181 lskadyekhk vyacevthqg lsspvtksfn rgec
Secuencia de ácidos nucleicos que codifica la cadena ligera Hu01G06 IGKV1-39 F1 completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (denominada también en el presente documento cadena ligera Hu01G06 IGKV1-39 S43A V48I completa; SEQ ID NO: 207)
1 gacatccaaa tgacccagtc gccgtcgtcg ctttcagcgt cggtagggga tcgggtcaca 61 attacgtgcc gaacgtcaga gaatttgcat aactacctcg cgtggtatca gcagaagccc 121 gggaaggccc cgaaactcct tatctacgat gcgaaaacgc tggcggatgg agtgccgtcg 181 agattctcgg gaagcggatc cggtacggac tatacgctta cgatctcatc gctccagccc 241 gaggactttg cgacgtacta ttgtcagcat ttttggtcgt cgccctacac atttgggcag 301 gggaccaagt tggaaatcaa gcgcacagtt gctgccccca gcgtgttcat tttcccacct 361 agcgatgagc agctgaaaag cggtactgcc tctgtcgtat gcttgctcaa caacttttac 421 ccacgtgagg ctaaggtgca gtggaaagtg gataatgcac ttcaatctgg aaacagtcaa 481 gagtccgtga cagaacagga cagcaaagac tcaacttatt cactctcttc caccctgact 541 ctgtccaagg cagactatga aaaacacaag gtatacgcct gcgaggttac acaccagggt 601 ttgtctagtc ctgtcaccaa gtccttcaat aggggcgaat gt
Secuencia de proteínas que define la cadena ligera Hu01G06 IGKV1-39 F1 completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (denominada también en el presente documento cadena ligera Hu01G06 IGKV1-39 S43A V48I completa; SEQ ID NO: 208)
1 diqmtqspsslsasvgdrvt itcrtsenlh nylawyqqkp gkapklliyd aktladgvps 61 rfsgsgsgtdytltisslqp edfatyycqh fwsspytfgq gtkleikrtv aapsvfifpp 121 sdeqlksgtasvvcllnnfy preakvqwkv dnalqsgnsq esvteqdskd styslsstlt 181 lskadyekhkvyacevthqg lsspvtksfn rgec
Secuencia de ácidos nucleicos que codifica la cadena ligera Hu01G06 IGKV1-39 F2 completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 263)
1 gacatccaaa tgacccagtc gccgtcgtcg ctttcagcgt cggtagggga tcgggtcaca 61 attacgtgcc gaacgtcaga gaatttgcat aactacctcg cgtggtatca gcagaagccc 121 gggaagtcac cgaaactcct tatctacgat gcgaaaacgc tggcggatgg agtgccgtcg 181 agattctcgg gaagcggatc cggtacggac tatacgctta cgatctcatc gctccagccc
241 gaggactttg cgacgtacta ttgtcagcat ttttggtcgg acccctacac atttgggcag
301 gggaccaagt tggaaatcaa gcgcacagtt gctgccccca gcgtgttcat tttcccacct
361 agcgatgagc agctgaaaag cggtactgcc tctgtcgtat gcttgctcaa caacttttac
421 ccacgtgagg ctaaggtgca gtggaaagtg gataatgcac ttcaatctgg aaacagtcaa
481 gagtccgtga cagaacagga cagcaaagac tcaacttatt cactctcttc caccctgact
541 ctgtccaagg cagactatga aaaacacaag gtatacgcct gcgaggttac acaccagggt
601 ttgtctagtc ctgtcaccaa gtccttcaat aggggcgaat gt
Secuencia de proteínas que define la cadena ligera Hu01G06 IGKV1-39 F2 completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 264)
1 diqmtqspss lsasvgdrvt itcrtsenlh nylawyqqkp gkspklliyd aktladgvps 61 rfsgsgsgtd ytltisslqp edfatyycqh fwsdpytfgq gtkleikrtv aapsvfifpp 121 sdeqlksgta svvcllnnfy preakvqwkv dnalqsgnsq esvteqdskd styslsstlt 181 lskadyekhk vyacevthqg lsspvtksfn rgec
Secuencia de ácidos nucleicos que codifica la cadena ligera quimérica Ch06C11 completa (región variable de la cadena kappa de ratón y región constante de la kappa humana) (SEQ ID NO: 211)
1 gatatcgtca tgacccagtc ccagaagttc atgtcaactt cagtgggaga cagagtgtcc 61 gtcacatgta aagcctcgca aaatgtggga accaacgtag cgtggttcca gcagaaacct 121 ggccaatcac cgaaggcact gatctactcg gccagctata ggtactcggg agtaccagat 181 cggtttacgg ggtcggggag cgggacggac tttatcctca ctatttccaa tgtccagtcg 241 gaggaccttg cggaatactt ctgccagcag tataacaact atcccctcac gtttggtgct 301 ggtacaaaat tggagttgaa gcgcacagtt gctgccccca gcgtgttcat tttcccacct 361 agcgatgagc agctgaaaag cggtactgcc tctgtcgtat gcttgctcaa caacttttac 421 ccacgtgagg ctaaggtgca gtggaaagtg gataatgcac ttcaatctgg aaacagtcaa 481 gagtccgtga cagaacagga cagcaaagac tcaacttatt cactctcttc caccctgact 541 ctgtccaagg cagactatga aaaacacaag gtatacgcct gcgaggttac acaccagggt 601 ttgtctagtc ctgtcaccaa gtccttcaat aggggcgaat gt
Secuencia de proteínas que define la cadena ligera quimérica Ch06C11 completa (región variable de la cadena kappa de ratón y región constante de la kappa humana) (SEQ ID NO: 212)
1 divmtqsqkf mstsvgdrvs vtckasqnvgtnvawfqqkp gqspkaliys asyrysgvpd
61 rftgsgsgtd filtisnvqs edlaeyfcqqynnypltfga gtkleikrtv aapsvfifpp
121 sdeqlksgta svvcllnnfy preakvqwkvdnalqsgnsq esvteqdskd styslsstlt
181 lskadyekhk vyacevthqg lsspvtksfnrgec
S e cu e n c ia de ác ido s nu c le icos qu e co d ifica la c a d e n a lige ra S h06C 11 IG K V 1 -16 co m p le ta (reg ión v a r ia b le de la c a d e n a k a p p a h u m a n iza d a y reg ión co n s ta n te de la k a p p a hu m an a) (S E Q ID NO : 213)
1 gacatccaaatgacccaatc gccctcctcc ctctccgcat cagtagggga ccgcgtcaca 61 attacttgcaaagcgtcgca gaacgtcgga acgaatgtgg cgtggtttca gcagaagccc 121 ggaaaagctccgaagagctt gatctactcg gcctcatata ggtattcggg tgtgccgagc 181 cggtttagcgggtcggggtc aggtactgat ttcacgctca caatttcatc gttgcagcca 241 gaagatttcgccacatatta ctgtcagcag tacaacaatt accctctgac gttcggccag 301 ggaaccaaacttgagatcaa gcgcacagtt gctgccccca gcgtgttcat tttcccacct 361 agcgatgagcagctgaaaag cggtactgcc tctgtcgtat gcttgctcaa caacttttac 421 ccacgtgaggctaaggtgca gtggaaagtg gataatgcac ttcaatctgg aaacagtcaa
481 gagtccgtga cagaacagga cagcaaagac tcaacttatt cactctcttccaccctgact 541 ctgtccaagg cagactatga aaaacacaag gtatacgcct gcgaggttacacaccagggt 601 ttgtctagtc ctgtcaccaa gtccttcaat aggggcgaatgt
Secuencia de proteínas que define la cadena ligera Sh06C11 IGKV1-16 completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 214)
1 diqmtqspss lsasvgdrvt itckasqnvg tnvawfqqkp gkapksliys asyrysgvps 61 rfsgsgsgtd ftltisslqp edfatyycqq ynnypltfgq gtkleikrtv aapsvfifpp 121 sdeqlksgta svvcllnnfy preakvqwkv dnalqsgnsq esvteqdskd styslsstlt 181 lskadyekhk vyacevthqg lsspvtksfn rgec
Secuencia de ácidos nucleicos que codifica la cadena ligera quimérica Ch14F11 completa (región variable de la cadena kappa de ratón y región constante de la kappa humana) (SEQ ID NO: 215)
1 gacatcgtga tgacacagtc acagaaattc atgtccacat ccgtcggtga tagagtatcc 61 gtcacgtgta aggcctcgca aaacgtagga actaatgtgg cgtggtatca acagaagcca 121 ggacagtcac ccaaagcact catctacagc ccctcatatc ggtacagcgg ggtgccggac 181 aggttcacgg gatcggggag cgggaccgat tttacactga ccatttcgaa tgtccagtcg 241 gaggaccttg cggaatactt ctgccagcag tataactcgt accctcacac gtttggaggt 301 ggcactaagt tggagatgaa acgcacagtt gctgccccca gcgtgttcat tttcccacct 361 agcgatgagc agctgaaaag cggtactgcc tctgtcgtat gcttgctcaa caacttttac 421 ccacgtgagg ctaaggtgca gtggaaagtg gataatgcac ttcaatctgg aaacagtcaa 481 gagtccgtga cagaacagga cagcaaagac tcaacttatt cactctcttc caccctgact 541 ctgtccaagg cagactatga aaaacacaag gtatacgcct gcgaggttac acaccagggt 601 ttgtctagtc ctgtcaccaa gtccttcaat aggggcgaat gt
Secuencia de proteínas que define la cadena ligera quimérica Ch14F11 completa (región variable de la cadena kappa de ratón y región constante de la kappa humana) (SEQ ID NO: 216)
1 divmtqsqkf mstsvgdrvsvtckasqnvg tnvawyqqkp gqspkaliys psyrysgvpd 61 rftgsgsgtd ftltisnvqs edlaeyfcqq ynsyphtfgg gtklemkrtv aapsvfifpp 121 sdeqlksgta svvcllnnfy preakvqwkv dnalqsgnsq esvteqdskd styslsstlt 181 lskadyekhk vyacevthqg lsspvtksfn rgec
Secuencia de ácidos nucleicos que codifica la cadena ligera Hu14F11 IGKV1-16 completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 217)
1 gatatccaga tgacacagtc accctcgtcg ctctcagctt ccgtaggcga cagggtcact 61 attacgtgta aagcatcaca gaacgtcgga acgaatgtgg cgtggtttca gcagaagccc 121 gggaagagcc ccaaagcgct tatctactcc ccgtcgtatc ggtattccgg tgtgccaagc 181 agattttcgg ggtcaggttc gggaactgac tttaccctga ccatctcgtc cctccaaccg 241 gaagatttcg ccacgtactt ctgccagcag tacaacagct atcctcacac attcggacaa 301 gggacaaagt tggagattaa acgcacagtt gctgccccca gcgtgttcat tttcccacct 361 agcgatgagc agctgaaaag cggtactgcc tctgtcgtat gcttgctcaa caacttttac 421 ccacgtgagg ctaaggtgca gtggaaagtg gataatgcac ttcaatctgg aaacagtcaa 481 gagtccgtga cagaacagga cagcaaagac tcaacttatt cactctcttc caccctgact 541 ctgtccaagg cagactatga aaaacacaag gtatacgcct gcgaggttac acaccagggt 601 ttgtctagtc ctgtcaccaa gtccttcaat aggggcgaat gt
Secuencia de proteínas que define la cadena ligera Hu14F11 IGKV1-16 completa (región variable de la cadena
kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 218)
1 diqmtqspss lsasvgdrvt itckasqnvg tnvawfqqkp gkspkaliys psyrysgvps
61 rfsgsgsgtd ftltisslqp edfatyfcqq ynsyphtfgq gtkleikrtv aapsvfifpp
121 sdeqlksgta svvcllnnfy preakvqwkv dnalqsgnsq esvteqdskd styslsstlt
181 lskadyekhk vyacevthqg lsspvtksfn rgec
La Tabla 22 es una gráfica de concordancia que muestra la SEQ ID NO. de cada secuencia analizada en este Ejemplo.
Tabla 22

continuación

La siguiente Tabla 23 muestra anticuerpos que contienen cadenas pesadas y ligeras de inmunoglobulinas quiméricas, y ejemplos de combinaciones de cadenas pesadas y ligeras completas de inmunoglobulinas quiméricas o humanizadas.
Tabla 23

continuación

continuación

Las construcciones de anticuerpos que contienen las cadenas pesada y ligera quiméricas completas se indican a continuación:
01G06 (Hu01G06-1) quimérica = cadena pesada quimérica Ch01G06 completa (región variable de la cadena pesada de ratón y región constante de la IgG1 humana) (SEQ ID NO: 176) más la cadena ligera quimérica Ch01G06 completa (región variable de la cadena kappa de ratón y región constante de la kappa humana) (SEQ ID NO: 204)
06C11 (Hu06C11-1) quimérica = cadena pesada quimérica Ch06C11 completa (región variable de la cadena pesada de ratón y región constante de la IgG1 humana) (SEQ ID NO: 192) más la cadena ligera quimérica Ch06C11 completa (región variable de la cadena kappa de ratón y región constante de la kappa humana) (SEQ ID NO: 212)
14F11 (Hu14F11-1) quimérica = cadena pesada quimérica Ch14F11 completa (región variable de la cadena pesada de ratón y región constante de la IgG1 humana) (SEQ ID NO: 198) más la cadena ligera quimérica Ch14F11 completa (región variable de la cadena kappa de ratón y región constante de la kappa humana) (SEQ ID NO: 216)
Quince de las posibles construcciones de anticuerpos que contienen las cadenas pesada y ligera de la inmunoglobulina completa que contienen las regiones variables humanizadas se indican a continuación:
Hu01G06-46 = cadena pesada Hu01G06 IGHV1-18 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 178) más la cadena ligera Hu01G06 IGKV1-39 completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 206) Hu01G06-52 = cadena pesada Hu01G06 IGHV1-69 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 1 8 0 ) más la cadena ligera Hu01G06 IGKV1-39 completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 206) Hu01G06-107 = cadena pesada Sh01 G06 IGHV1-18 M69L K64Q G44S completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 184) más la cadena ligera Hu01G06
IGKV1-39 V48I completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID nO: 210)
Hu01G06-108 = cadena pesada Sh01G06 IGHV1-69 T30S I69L completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 188) más la cadena ligera Hu01G06 IGKV1-39 V48I completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 210)
Hu01G06-112 = cadena pesada Sh01 G06 IGHV1-18 M69L K64Q G44S completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 184) más la cadena ligera Hu01G06 IGKV1-39 S43A V48I completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 208)
Hu01G06-113 = cadena pesada Sh01G06 IGHV1-69 T30S I69L completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 188) más la cadena ligera Hu01G06 IGKV1-39 S43A V48I completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 208)
Hu01G06-122 = cadena pesada Hu01G06 IGHV1-18 F1 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 256) más la cadena ligera Hu01G06 IGKV1-39 F1 completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 208)
Hu01G06-127 = cadena pesada Hu01G06 IGHV1-18 F2 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 258) más la cadena ligera Hu01G06 IGKV1-39 F2 completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 264)
Hu01G06-135 = cadena pesada Hu01G06 IGHV1-69 F1 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 260) más la cadena ligera Hu01G06 IGKV1-39 F1 completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 208)
Hu01G06-138 = cadena pesada Hu01G06 IGHV1-69 F2 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 262) más la cadena ligera Hu01G06 IGKV1-39 F1 completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 208)
Hu01G06-146 = cadena pesada Hu01G06 IGHV1-69 F2 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 262) más la cadena ligera Hu01G06 IGKV1-39 F2 completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 264)
Hu06C11-27 = cadena pesada HE LM 06C11 IGHV2-70 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 194) más la cadena ligera Sh06C11 IGKV1-16 completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 214)
Hu06C11-30 = cadena pesada Hu06C11 IGHV2-5 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 196) más la cadena ligera Sh06C11 IGKV1-16 completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 214) Hu14F11-39 = cadena pesada Sh14F11 IGHV2-5 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 200) más la cadena ligera Hu14F11 IGKV1-16 completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 218) Hu14F11-47 = cadena pesada Sh14F11-IGHV2-70 completa (región variable de la cadena pesada humanizada y región constante de la IgG1 humana) (SEQ ID NO: 202) más la cadena ligera Hu14F11 IGKV1-16 completa (región variable de la cadena kappa humanizada y región constante de la kappa humana) (SEQ ID NO: 218) Ejemplo 15: Afinidades de unión de los anticuerpos monoclonales anti-GDF15 humanizados y quiméricos Las afinidades de unión y las cinéticas de la unión de los anticuerpos mFc-rhGDF15 humanizados y quiméricos se midieron mediante resonancia de plasmón superficial, usando un instrumento BIAcore® T100 (GE Healthcare, Piscataway, NJ).
Se inmovilizaron anti-IgG humanas de cabra (fragmento Fc específico, Jackson ImmunoResearch, West Grove, PA) en chips sensores CM4 de dextrano carboximetilado mediante un acoplamiento de amina, según un protocolo convencional. Los análisis se realizaron a 37 °C usando PBS que contiene tensioactivo P20 al 0,05% como tampón de ejecución. Los anticuerpos se capturaron en celdas de flujo individuales a un caudal de 10 pl/minuto. El tiempo de inyección se modificó para cada anticuerpo, para producir una Rmáx de entre 30 y 60 UR. Se inyectaron secuencialmente tampón o mFc-rhGDF15 diluidos en tampón de ejecución sobre una superficie de referencia (sin anticuerpo capturado) y la superficie activa (el anticuerpo que se va a analizar) durante 240 segundos a 60 pl/minuto. La fase de disociación se monitorizó durante hasta 1.200 segundos. Después, la superficie se regeneró con dos inyecciones de 60 segundos de glicina-HCl 10 mM, a pH 2,25, a un caudal de 30 pl/minuto. El intervalo de concentración del GDF15 analizado era de entre 20 nM y 0,625 nM.
Los parámetros cinéticos se determinaron usando la función cinética del programa informático BIAevaluation (GE Healthcare) con una resta de referencia doble. Se determinaron los parámetros cinéticos de cada anticuerpo, ka (constante de velocidad de asociación), kd (constante de velocidad de disociación) y Kd (constante de velocidad de disociación en equilibrio). Los valores cinéticos de los anticuerpos monoclonales purificados en mFc-rhGDF15 se resumen en la Tabla 24.
Tabla 24

Los resultados de la Tabla 24 muestran que los anticuerpos quiméricos y cada uno de los humanizados tienen unas velocidades de asociación rápidas (ka), unas velocidades de disociación lentas (kd y unas afinidades muy altas (Kd). En particular, los anticuerpos tienen unas afinidades que varían desde aproximadamente 65 pM hasta aproximadamente 200 pM.
Los valores cinéticos del 01G06 quimérico (Hu01G06-1), dos anticuerpos monoclonales inicialmente humanizados 01G06 (Hu01G06-46 y -52) y las variantes de anticuerpos monoclonales humanizados 01G06 con la secuencia optimizada Hu01G06-100 hasta -114 (en el sobrenadante) en mFc-rhGDF15, se resumen en la Tabla 25.
Tabla 25

Los resultados de la Tabla 25 muestran que los anticuerpos con la secuencia optimizada Hu01G06-100 hasta-114 tienen unas afinidades de unión que varían desde aproximadamente 89 pM hasta aproximadamente 160 pM.
Se midieron las afinidades de unión y las cinéticas de unión de las variantes pesadas del anticuerpo monoclonal de la mFc-rhGDF15 con la 14F11 quimérica (Hu 14F11-1), la ligera quimérica 14F11 con la pesada quimérica 06C11 (Hu14F11-23) y la ligera quimérica 06C11 con la pesada quimérica 14F11 (Hu14F11-24) (en el sobrenadante) usando interferometría de biocapa (BLI) en un instrumento Octet™ QK (ForteBio, Inc., Menlo Park, CA). El análisis con Octet se realizó a 30 °C usando Kinetics Buffer 1X (ForteBio, Inc.) como tampón de ensayo. Se usaron biosensores (AHC) de captura anti-Fc de la IgG humana (ForteBio, Inc.) para capturar los anticuerpos humanos en los sensores. Los sensores se saturaron con tampón de ensayo durante a 300 segundos antes del ensayo. Los anticuerpos se cargaron en los sensores sumergiendo los sensores en la solución del sobrenadante del anticuerpo durante 220 segundos, lo que normalmente da como resultado unos niveles de captura de 1,5-2 nm. La situación inicial se estableció sumergiendo los sensores en tampón de ensayo 1x durante 200 segundos. A continuación, la asociación se monitorizó durante 220 segundos en la proteína mFc-rhGDF15 400 nM, y la disociación se siguió durante 600 segundos solo con tampón.
Los parámetros cinéticos de Hu 14F11-1, Hu14F11-23 y Hu14F11-24 se determinaron usando la función cinética del programa informático ForteBio Analysis Versión 7.0. Se determinaron los parámetros cinéticos del anticuerpo, ka, kd y KD.
Los valores cinéticos de las variantes pesadas del anticuerpo monoclonal Hu14F11-1, Hu14F11-23 y Hu14F11-24 (en el sobrenadante) en mFc-rhGDF15 se resumen en la Tabla 26.
Tabla 26

Los resultados de la Tabla 26 muestran que Hu14F11-23 y Hu14F11-24, (es decir, los anticuerpos que consisten en una cadena 06C11 quimérica (pesada o ligera) mezclada con una cadena 14F11 quimérica (pesada o ligera)), conservan la unión al GDF15. En particular, los anticuerpos tienen unas altas afinidades que varían desde aproximadamente 180 pM hasta aproximadamente 310 pM.
Ejemplo 16: Afinidades de unión de los anticuerpos monoclonales anti-GDF15 humanizados madurados por afinidad
Las afinidades de unión y las cinéticas de la unión de los anticuerpos quiméricos y humanizados a la mFc-rhGDF15, el rhGDF15 escindido, el GDF15 de ratón recombinante maduro de la Fc de conejo (rFc-rmGDF15) y el GDF15 de mono cinomolgo recombinante maduro de la Fc de ratón (mFc-rcGDF15) mediante resonancia de plasmón superficial, usando un instrumento BIAcore® T100 (GE Healthcare, Piscataway, NJ).
Se inmovilizaron anti-IgG humanas de cabra (fragmento Fc específico, Jackson ImmunoResearch, West Grove, PA) en chips sensores CM4 de dextrano carboximetilado mediante un acoplamiento de amina, según un protocolo convencional. Los análisis se realizaron a 37 0C usando PBS que contiene tensioactivo P20 al 0,05% como tampón de ejecución. Los anticuerpos se capturaron en celdas de flujo individuales a un caudal de 10 pl/minuto. El tiempo de inyección se modificó para cada anticuerpo, para producir una Rmáx de entre 30 y 60 UR. Se inyectaron secuencialmente tampón, la mFc-rhGDF15, rhGDF15 escindido, la rFc-rmGDF15 o rhGDF15 diluidos en tampón de ejecución sobre una superficie de referencia (sin anticuerpo capturado) y la superficie activa (el anticuerpo que se va a analizar) durante 240 segundos a 60 pl/minuto. La fase de disociación se monitorizó durante hasta 1.500 segundos. Después, la superficie se regeneró con dos inyecciones de 60 segundos de glicina-HCl 10 mM, a pH 2,25, a un caudal de 30 pl/minuto. El intervalo de concentración de GDF15 analizado para cada proteína GDF15 era de entre 5 nM y 0,3125 nM (diluciones dobles).
Los parámetros cinéticos se determinaron usando la función cinética del programa informático BIAevaluation (GE Healthcare) con una resta de referencia doble. Se determinaron los parámetros cinéticos de cada anticuerpo, ka (constante de velocidad de asociación), kd (constante de velocidad de disociación) y KD (constante de velocidad de disociación en equilibrio). Los valores cinéticos de los anticuerpos monoclonales purificados en mFc-rhGDF15, GDF15 maduro humano, rFc-rmGDF15 y mFc-rcGDF15 se resumen en la Tabla 27.
Tabla 27
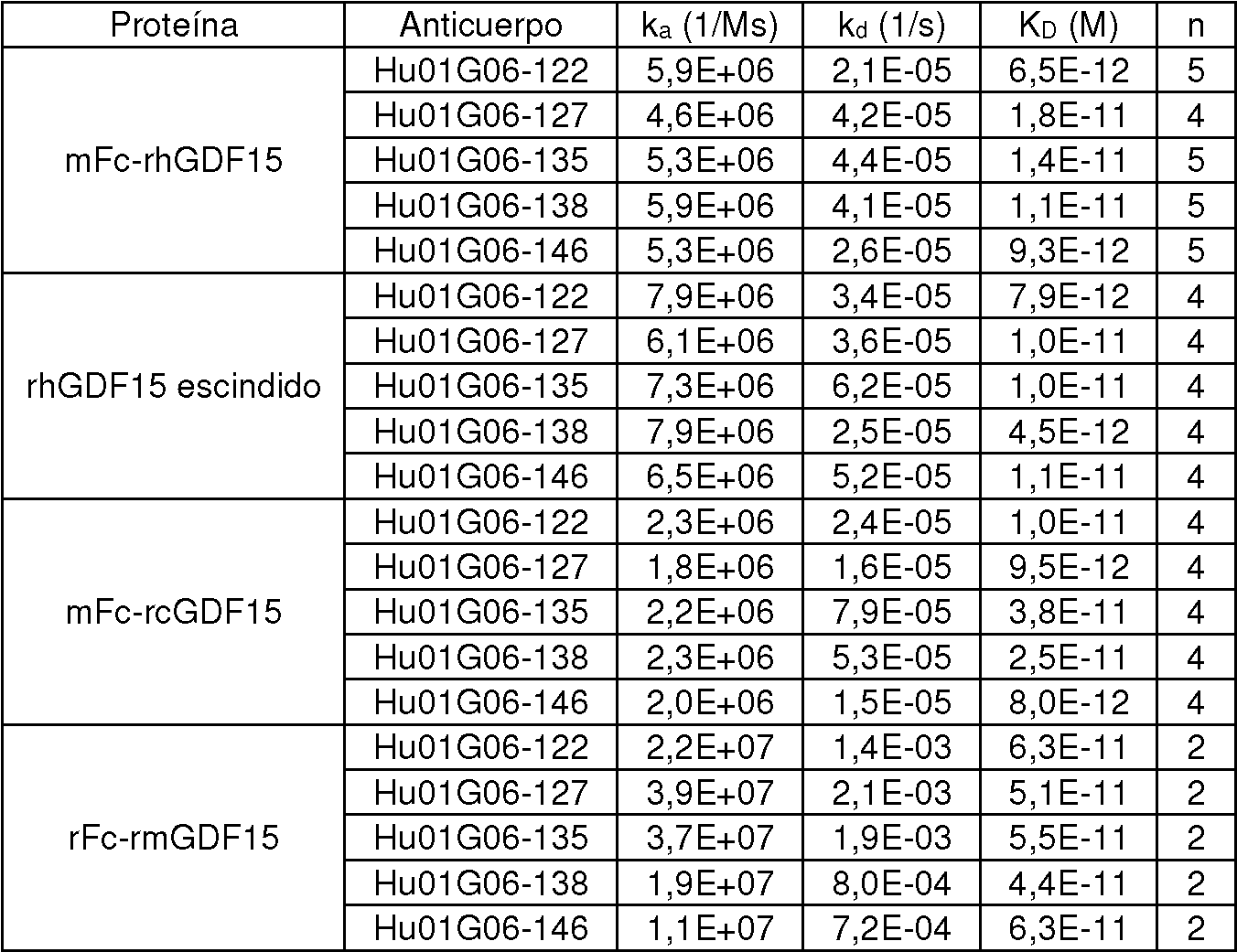
Los resultados de la Tabla 27 muestran que los anticuerpos quiméricos y cada uno de los humanizados tienen unas velocidades de asociación rápidas (ka), unas velocidades de disociación lentas (kd y unas afinidades muy altas (Kd). En particular, los anticuerpos tienen unas afinidades que varían desde menos de 5 pM (por ejemplo, de aproximadamente 4,5 pM) hasta aproximadamente 65 pM.
Ejemplo 17: Reversión de la caquexia en un modelo de xenoinjerto de fibroscarcoma HT-1080
Este Ejemplo muestra la reversión de la caquexia (indicada por la pérdida de peso corporal) por los anticuerpos humanizados 01G0606C1114F11 en un modelo de xenoinjerto de fibrosarcoma HT-1080. Se cultivaron células HT-1080 un cultivo a 37 0C y se inocularon subcutáneamente en el costado de ratones ICR-SCID hembra de 8 semanas de edad como se describe más arriba en el Ejemplo 10. El peso corporal se midió diariamente. Cuando el peso corporal alcanzó el 93 %, los ratones se dividieron aleatoriamente en grupos de diez ratones cada uno. Cada grupo recibió uno de los siguientes tratamientos: IgG murina de control, 01G06, 06C11, 14F11, y sus respectivas versiones humanizadas a 2 mg/kg. El tratamiento se administró una vez al día mediante una inyección intraperitoneal. El tratamiento con anticuerpo con 01G06, Hu01G06-46 y Hu01G06-52 dio como resultado un aumento en el peso corporal hasta el peso inicial o un 100 % (p < 0,001) (FIG. 23). El análisis estadístico se realizó usando un ANOVA. Los resultados de la reversión del peso corporal en el día en el modelo HT-1080 se muestran en la FIG. 23 y en la Tabla 28, respectivamente.
Tabla 28

Los datos de la FIG. 23 y de la Tabla 28 indicaban que los anticuerpos 01G06, Hu01G06-46 y Hu01G06-52 pueden revertir la caquexia en un modelo de xenoinjerto tumoral de fibrosarcoma HT-1080.
El tratamiento con anticuerpo con 06C11, Hu06C11-27 y Hu06C11-30 dio como resultado un aumento en el peso corporal con respecto al peso inicial o aproximadamente un 100 % (p < 0,001) (FIG. 24). El análisis estadístico se realizó usando un ANOVA. Los resultados de la reversión del peso corporal en el modelo HT-1080 se muestran en la FIG. 24 y en la Tabla 29.
Tabla 29

Los datos de la FIG. 24 y de la Tabla 29 indican que los anticuerpos 06C11, Hu06C11-27 y Hu06C11-30 pueden revertir la caquexia en un modelo de xenoinjerto de fibrosarcoma hT-1080.
El tratamiento con anticuerpo con 14F11, Hu14F11-39 y Hu14F11-47 dio como resultado un aumento en el peso corporal con respecto al peso inicial o aproximadamente un 100 % (p < 0,001) (FIG. 25). El análisis estadístico se realizó usando un ANOVA. Los resultados de la reversión del peso corporal en el modelo HT-1080 se muestran en la FIG. 25 y en la Tabla 30.
Tabla 30

Los datos de la FIG. 25 y de la Tabla 30 indicaban que los anticuerpos 14F11, Hu14F11-39 y Hu14F11-47 pueden revertir la caquexia en un modelo de xenoinjerto de fibrosarcoma HT-1080.
El tratamiento con un anticuerpo con los anticuerpos 01G06 humanizados (es decir, los anticuerpos Hu01G06-122, Hu01G06-127, Hu01G06-135, Hu01G06-138 y Hu01G06-146) dio como resultado un aumento en el peso corporal con respecto al peso inicial o aproximadamente un 100 % (p < 0,001) (FIG. 26). El análisis estadístico se realizó usando un ANOVa . Como control se usó el tratamiento con IgG humana (hIgG). Los resultados de la reversión de los pesos corporales en el modelo HT-1080 se muestran en la FIG. 26 y en la Tabla 31.
Tabla 31

Los datos de la FIG. 26 y de la Tabla 31 indicaban que los anticuerpos anti-GDF15 humanizados Hu01G06-122, Hu01G06-127, Hu01G06-135, Hu01G06-138 y Hu01G06-146 pueden revertir la caquexia en un modelo de xenoinjerto tumoral de fibrosarcoma HT-1080.
Ejemplo 18: Reversión de la caquexia en un modelo inducido por mFc-rhGDF15
Este Ejemplo muestra la reversión de la caquexia (indicada por la pérdida de peso corporal) por los anticuerpos 01G06 humanizados (es decir, el anticuerpo Hu01G06-122, Hu01G06-127, Hu01G06-135, Hu01G06-138 o Hu01G06-146) en un modelo de caquexia inducida por mFc-rhGDF15. Se administró subcutáneamente mFcrhGDF15 (1 pg/g) en el costado de ratones ICR-SCID hembra de 8 semanas de edad. El peso corporal se midió diariamente. Cuando el peso corporal alcanzó el 93 %, los ratones se dividieron aleatoriamente en seis grupos de diez ratones cada uno. Cada grupo recibió uno de los siguientes tratamientos: IgG humana de control (hIgG), Hu01G06-122, Hu01G06-127, Hu01G06-135, Hu01G06-138 o Hu01G06-146 a 2 mg/kg. El tratamiento se administró una vez mediante una inyección intraperitoneal. El tratamiento con el anticuerpo Hu01G06-122, Hu01G06-127, Hu01G06-135, Hu01G06-138 o Hu01G06-146 dio como resultado un aumento en el peso corporal con respecto al peso inicial o aproximadamente un 100 % (p < 0,001) (FIG. 27 y Tabla 32).
Tabla 32

Los datos de la FIG. 27 y de la Tabla 32 indican que los anticuerpos anti-GDF15 divulgados pueden revertir la caquexia en un modelo de ratón inducida por mFc-rhGDF15 (es decir, un modelo de ratón no portador de tumor). Estos resultados indican que los anticuerpos anti-GDF 15 humanizados pueden revertir la caquexia en un modelo de caquexia inducida por mFc-rhGDF15.
Ejemplo 19: Reversión dependiente de la dosis de la caquexia en un modelo de xenoinjerto de fibrosarcoma HT-1080
Este Ejemplo muestra la reversión de la caquexia dependiente de la dosis (indicada por la pérdida de peso corporal) por los anticuerpos humanizados Hu01G06-127 y Hu01G06-135 en un modelo de xenoinjerto de fibrosarcoma HT-1080. Se cultivaron células HT-1080 un cultivo a 37 0C y se inocularon subcutáneamente en el costado de ratones ICR-SCID hembra de 8 semanas de edad como se describe más arriba en el Ejemplo 10. El peso corporal se midió diariamente. Cuando el peso corporal alcanzó el 93 %, los ratones se dividieron aleatoriamente en grupos de diez ratones cada uno. Cada grupo recibió uno de los siguientes tratamientos: IgG humana de control (hIgG; 20 mg/kg), Hu01G06-127 (20 mg/kg, 2 mg/kg o 0,2 mg/kg) y Hu01G06-135 (20 mg/kg, 2 mg/kg o 0,2 mg/kg). El tratamiento se administró una vez al día mediante una inyección intravenosa. El tratamiento con anticuerpo con Hu01G06-127 y Hu01G06-135 a 20 mg/kg dio como resultado un aumento en el peso corporal por encima del peso inicial o del 108 % (p < 0,001) (FIG. 28). El tratamiento con anticuerpo con Hu01G06-127 y Hu01G06-135 a 2 mg/kg dio como resultado una reducción limitada en el peso corporal en comparación con el control (hIgG) desde el peso inicial o del 88-85 % (p < 0,001) (FIG. 28). El análisis estadístico se realizó usando un ANOVA. Los resultados de los cambios en el peso corporal al final del estudio en el modelo HT-1080 se muestran en la FIG. 28 y en la Tabla 33.
Tabla 33

Los datos de la FIG. 28 y de la Tabla 33 indicaban que los anticuerpos Hu01G06-127 y Hu01G06-135 pueden revertir la caquexia en un modelo de xenoinjerto de fibrosarcoma HT-1080 de una forma dependiente de la dosis. Ejemplo 20: Reversión de la pérdida de músculo y de grasa en un modelo de xenoinjerto tumora1HT-1080 Este Ejemplo muestra la reversión de la caquexia (indicada por la pérdida de peso corporal, la pérdida de masa muscular y la pérdida de masa grasa) por el anticuerpo 01G06 en un modelo de xenoinjerto de fibrosarcoma HT-1080. Se cultivaron células HT-1080 en un cultivo a 37 0C en una atmósfera que contiene un 5 % de CO2 , usando medio esencial mínimo de Eagle (ATCC, n° de catálogo 30-2003) que contiene FBS al 10 %. Las células se inocularon subcutáneamente en el costado de ratones ICR SCID hembra de 8 semanas de edad con 5 x 106células por ratón en matrigel al 50 %. Se seleccionó un grupo de diez ratones hembra ICR-SCID de 8 semanas de edad con el mismo peso corporal para la inoculación subcutánea en el costado de matrigel, como un grupo de control tumor (TESTIGO). El peso corporal se midió diariamente. Cuando el peso corporal alcanzó el 91 % en los ratones portadores de un tumor, los ratones se dividieron aleatoriamente en dos grupos de diez ratones cada uno. Cada grupo recibió uno de los siguientes tratamientos: IgG humana de control (hIgG) o Hu01G06-127 a 10 mg/kg el día 1, el día 3 y el día 6. El tratamiento se administró mediante una inyección intraperitoneal. El tratamiento con el anticuerpo Hu01G06-127 dio como resultado un aumento del peso corporal hasta el 105 % del peso inicial en comparación con los ratones de control no portadores de tumor (TESTIGO; p < 0,001) (FIG. 29A y Tabla 34).
Claims (9)
1. Un anticuerpo aislado que se une al GDF15 humano, que comprende una región variable de una cadena pesada de una inmunoglobulina y una región variable de la cadena ligera de una inmunoglobulina que comprende una secuencia de aminoácidos seleccionada entre el grupo que consiste en:
(a) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 248 (Hu01G06 IGHV1-18 F2) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 254 (Hu01 G06 IGKV1-39 F2); (b) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 250 (Hu01G06 IGHV1-69 F1) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 92 (Hu01G06 IGKV1-39 F1); (c) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 40 (01G06, Ch01G06 quimérica) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 76 (01G06, Ch01G06 quimérica); (d) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 54 (Hu01G06 IGHV1-18) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 90 (Hu01G06 IGKV1-39);
(e) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 56 (Hu01G06 IGHV1-69) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 90 (Hu01 G06 IGKV1-39);
(f) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 246 (Hu01G06 IGHV1-18 F1) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 92 (Hu01 G06 IGKV1-39 F1); (g) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 252 (Hu01G06 IGHV1-69 F2) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 92 (Hu01 G06 IGKV1-39 F1); y (h) una región variable de la cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 252 (Hu01G06 IGHV1-69 F2) y una región variable de la cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 254 (Hu01G06 IGKV1-39 F2).
2. El anticuerpo aislado de la reivindicación 1 que comprende una cadena pesada de una inmunoglobulina y una cadena ligera de una inmunoglobulina seleccionada entre el grupo que consiste en:
(a) una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 258 (Hu01G06 IGHV1-18 F2) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 264 (Hu01G06 IGKV1-39 F2);
(b) una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 260 (Hu01G06 IGHV1-69 F1) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 208 (Hu01G06 IGKV1-39 F1);
(c) una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 176 (Ch01G06 quimérica) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID nO: 204 (Ch01G06 quimérica);
(d) una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 178 (Hu01G06 IGHV1-18) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 206 (Hu01G06 IGKV1-39);
(e) una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 180 (Hu01G06 IGHV1-69) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 206 (Hu01G06 IGKV1-39);
(f) una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 256 (Hu01G06 IGHV1-18 F1) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 208 (Hu01G06 IGKV1-39 F1);
(g) una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 262 (Hu01G06 IGHV1-69 F2) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 208 (Hu01G06 IGKV1-39 F1); y
(h) una cadena pesada de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 262 (Hu01G06 IGHV1-69 F2) y una cadena ligera de una inmunoglobulina que comprende la secuencia de aminoácidos de SEQ ID NO: 264 (Hu01G06 IGKV1-39 F2).
3. Un ácido nucleico aislado o ácidos nucleicos que comprenden una secuencia de nucleótidos que codifica una cadena pesada de una inmunoglobulina de la reivindicación 1 o 2 y una secuencia de nucleótidos que codifica una cadena ligera de una inmunoglobulina de la reivindicación 1 o 2.
4. Un vector o vectores de expresión que comprenden el ácido nucleico o los ácidos nucleicos de la reivindicación 3.
5. Una célula hospedadora que comprende el vector o los vectores de expresión de la reivindicación 4.
6. Un método para producir un anticuerpo que se une al GDF15 humano según la reivindicación 1 o 2 o un fragmento de unión al antígeno del anticuerpo, método que comprende:
(a) cultivar la célula hospedadora de la reivindicación 5 en unas condiciones tales que la célula hospedadora exprese un polipéptido o polipéptidos que comprenden la cadena pesada de la inmunoglobulina y la cadena ligera de la inmunoglobulina, produciendo así el anticuerpo o el fragmento de unión al antígeno del anticuerpo; y (b) el anticuerpo o el fragmento de unión al antígeno del anticuerpo.
7. El anticuerpo de la reivindicación 1 o 2, en donde el anticuerpo tiene una KD de 300 pM o menor, de 150 pM o menor o de 100 pM o menor, medida mediante resonancia de plasmón superficial o interferometría de biocapa.
8. Un anticuerpo de una cualquiera de las reivindicaciones 1, 2 o 7 para su uso en el tratamiento de la caquexia y/o de la sarcopenia en un mamífero.
9. El anticuerpo para el uso según la reivindicación 8, en donde el uso comprende adicionalmente la administración de un segundo agente al mamífero en necesidad del mismo, en donde el segundo agente se selecciona entre el grupo que consiste en un inhibidor de la Activina-A, un inhibidor del ActRIIB, un inhibidor de la IL-6, un inhibidor de la IL-6R, un inhibidor del péptido de melanocortina, un inhibidor del receptor de la melanocortina, una grelina, un mimético de la grelina, un agonista del GHS-R1a, un SARM, un inhibidor del TNFa, un inhibidor de la IL-1 a, un inhibidor de la miostatina, un betabloqueante y un agente antineoplásico.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201261745508P | 2012-12-21 | 2012-12-21 | |
| US201361827325P | 2013-05-24 | 2013-05-24 | |
| PCT/US2013/077139 WO2014100689A1 (en) | 2012-12-21 | 2013-12-20 | Anti-gdf15 antibodies |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2791183T3 true ES2791183T3 (es) | 2020-11-03 |
Family
ID=50069279
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES13827058T Active ES2791183T3 (es) | 2012-12-21 | 2013-12-20 | Anticuerpos anti-GDF15 |
Country Status (14)
| Country | Link |
|---|---|
| US (4) | US9175076B2 (es) |
| EP (2) | EP2934584B1 (es) |
| JP (3) | JP6758832B2 (es) |
| KR (1) | KR102208861B1 (es) |
| CN (1) | CN105073133B (es) |
| AR (1) | AR094271A1 (es) |
| AU (1) | AU2013364133B2 (es) |
| CA (1) | CA2896076C (es) |
| DK (1) | DK2934584T3 (es) |
| EA (1) | EA038645B1 (es) |
| ES (1) | ES2791183T3 (es) |
| HK (1) | HK1215670A1 (es) |
| MX (1) | MX370720B (es) |
| WO (1) | WO2014100689A1 (es) |
Families Citing this family (69)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| ES2568436T3 (es) | 2006-03-31 | 2016-04-29 | Chugai Seiyaku Kabushiki Kaisha | Procedimiento para controlar la farmacocinética en sangre de anticuerpos |
| EP3689912A1 (en) | 2007-09-26 | 2020-08-05 | Chugai Seiyaku Kabushiki Kaisha | Method of modifying isoelectric point of antibody via amino acid substitution in cdr |
| EP4238993A3 (en) | 2008-04-11 | 2023-11-29 | Chugai Seiyaku Kabushiki Kaisha | Antigen-binding molecule capable of binding to two or more antigen molecules repeatedly |
| SG190727A1 (en) | 2010-11-30 | 2013-07-31 | Chugai Pharmaceutical Co Ltd | Antigen-binding molecule capable of binding to plurality of antigen molecules repeatedly |
| WO2012138919A2 (en) | 2011-04-08 | 2012-10-11 | Amgen Inc. | Method of treating or ameliorating metabolic disorders using growth differentiation factor 15 (gdf-15) |
| EP3683228A3 (en) | 2012-01-26 | 2020-07-29 | Amgen Inc. | Growth differentiation factor 15 (gdf-15) polypeptides |
| US9550819B2 (en) | 2012-03-27 | 2017-01-24 | Ngm Biopharmaceuticals, Inc. | Compositions and methods of use for treating metabolic disorders |
| JP6774164B2 (ja) | 2012-08-24 | 2020-10-21 | 中外製薬株式会社 | マウスFcγRII特異的Fc抗体 |
| TWI697501B (zh) | 2012-08-24 | 2020-07-01 | 日商中外製藥股份有限公司 | FcγRIIb特異性Fc區域變異體 |
| US20150239968A1 (en) | 2012-09-26 | 2015-08-27 | Julius-Maximilians-Universität Würzburg | Monoclonal antibodies to growth and differentiation factor 15 (gdf-15) |
| DK2934584T3 (da) | 2012-12-21 | 2020-05-18 | Aveo Pharmaceuticals Inc | Anti-gdf15-antistoffer |
| US9161966B2 (en) | 2013-01-30 | 2015-10-20 | Ngm Biopharmaceuticals, Inc. | GDF15 mutein polypeptides |
| CA2899170C (en) | 2013-01-30 | 2022-08-02 | Ngm Biopharmaceuticals, Inc. | Compositions and methods of use in treating metabolic disorders |
| WO2014163101A1 (ja) | 2013-04-02 | 2014-10-09 | 中外製薬株式会社 | Fc領域改変体 |
| LT3027642T (lt) | 2013-07-31 | 2020-10-12 | Amgen Inc. | Augimo ir diferenciacijos faktoriaus 15(gdf-15) konstruktai |
| BR112016009460B1 (pt) * | 2013-10-31 | 2020-09-29 | Regeneron Pharmaceuticals, Inc. | Método para detectar a presença de anticorpos neutralizantes |
| EP3685848B1 (en) | 2013-11-21 | 2021-09-15 | The Brigham and Women's Hospital, Inc. | Compositions and methods for treating pulmonary hypertension |
| WO2015143123A2 (en) | 2014-03-19 | 2015-09-24 | Mackay Memorial Hospital Of Taiwan Presbyterian Church And Mackay Memorial Social Work Foundation | Antibodies against immunogenic glycopeptides, composition comprising the same and use thereof |
| GB2524553C (en) * | 2014-03-26 | 2017-07-19 | Julius-Maximilians-Universitãt Würzburg | Monoclonal antibodies to growth and differentiation factor 15 (GDF-15), and uses thereof for treating cancer cachexia |
| GB2524552B (en) * | 2014-03-26 | 2017-07-12 | Julius-Maximilians-Universitãt Wurzburg | Monoclonal antibodies to growth and differentiation factor 15 (GDF-15), and use thereof for treating cancer |
| HUE047398T2 (hu) * | 2014-03-26 | 2020-04-28 | Univ Wuerzburg J Maximilians | Növekedési és differenciálódási faktor 15 (GDF-15) elleni monoklonális antitestek és azok alkalmazásai rákos sorvadás és rák kezelésére |
| US20170137505A1 (en) * | 2014-06-20 | 2017-05-18 | Aveo Pharmaceuticals, Inc. | Treatment of congestive heart failure and other cardiac dysfunction using a gdf15 modulator |
| BR112016029820A2 (pt) * | 2014-06-20 | 2017-10-24 | Aveo Pharmaceuticals Inc | tratamento de doença renal crônica e outras disfunções renais usando um modulador de gdf15 |
| US10588980B2 (en) | 2014-06-23 | 2020-03-17 | Novartis Ag | Fatty acids and their use in conjugation to biomolecules |
| WO2016018931A1 (en) | 2014-07-30 | 2016-02-04 | Ngm Biopharmaceuticals, Inc. | Compositions and methods of use for treating metabolic disorders |
| CN106794233B (zh) * | 2014-08-01 | 2021-11-12 | 布里格姆及妇女医院股份有限公司 | 与肺动脉高压的治疗有关的组合物和方法 |
| US20170306008A1 (en) * | 2014-09-25 | 2017-10-26 | Aveo Pharmaceuticals, Inc. | Methods of reversing cachexia and prolonging survival comprising administering a gdf15 modulator and an anti-cancer agent |
| US20170290885A1 (en) * | 2014-09-30 | 2017-10-12 | Universiteit Gent | A method of treating joint disease |
| EP3922259A1 (en) | 2014-10-30 | 2021-12-15 | Acceleron Pharma Inc. | Methods and compositions using gdf15 polypeptides for increasing red blood cells |
| AU2015339130C1 (en) | 2014-10-31 | 2021-03-18 | Ngm Biopharmaceuticals, Inc. | Compositions and methods of use for treating metabolic disorders |
| TWI808330B (zh) | 2014-12-19 | 2023-07-11 | 日商中外製藥股份有限公司 | 抗肌抑素之抗體、含變異Fc區域之多胜肽及使用方法 |
| TW202248212A (zh) | 2015-02-05 | 2022-12-16 | 日商中外製藥股份有限公司 | 包含離子濃度依賴之抗原結合域的抗體、Fc區變體、IL-8結合抗體與其用途 |
| EP3286223B8 (en) * | 2015-04-23 | 2024-04-03 | HaemaLogiX Ltd | Kappa myeloma antigen chimeric antigen receptors and uses thereof |
| CN106349388B (zh) * | 2015-07-17 | 2021-04-02 | 上海佳文英莉生物技术有限公司 | 一种促细胞程序性坏死抗体及其应用 |
| GB201512733D0 (en) * | 2015-07-20 | 2015-08-26 | Genagon Therapeutics Ab | Therapeutic agents for treating conditions associated with elevated GDF15 |
| KR20180054868A (ko) | 2015-10-02 | 2018-05-24 | 율리우스-막시밀리안스 우니버지태트 뷔르츠부르크 | 인간 증식 및 분화 인자 15 (gdf-15)의 저해제와 면역 체크포인트 차단제를 이용한 병용 요법 |
| EP4321866A3 (en) | 2015-10-02 | 2024-03-20 | Julius-Maximilians-Universität Würzburg | Gdf-15 as a diagnostic marker to predict the clinical outcome of a treatment with immune checkpoint blockers |
| WO2017074774A1 (en) * | 2015-10-28 | 2017-05-04 | Yale University | Humanized anti-dkk2 antibody and uses thereof |
| EP3394098A4 (en) | 2015-12-25 | 2019-11-13 | Chugai Seiyaku Kabushiki Kaisha | ANTI-MYOSTATIN ANTIBODIES AND METHODS OF USE |
| EP3411066A1 (en) * | 2016-02-01 | 2018-12-12 | Eli Lilly and Company | Parathyroid hormone anti-rankl antibody fusion compounds |
| EP3423094A4 (en) * | 2016-02-29 | 2019-11-06 | Eli Lilly and Company | GFRAL RECEPTOR THERAPIES |
| AU2017228489A1 (en) * | 2016-03-04 | 2018-09-06 | Ngm Biopharmaceuticals, Inc. | Compositions and methods for modulating body weight |
| PE20190126A1 (es) * | 2016-03-31 | 2019-01-17 | Ngm Biopharmaceuticals Inc | Proteinas de union y metodos de uso de las mismas |
| CN109071647B (zh) * | 2016-04-27 | 2022-11-22 | 诺华股份有限公司 | 抗生长分化因子15的抗体及其用途 |
| US10336812B2 (en) * | 2016-05-10 | 2019-07-02 | Janssen Biotech, Inc. | GDF15 fusion proteins and uses thereof |
| NL2017267B1 (en) * | 2016-07-29 | 2018-02-01 | Aduro Biotech Holdings Europe B V | Anti-pd-1 antibodies |
| EP3494991A4 (en) | 2016-08-05 | 2020-07-29 | Chugai Seiyaku Kabushiki Kaisha | COMPOSITION FOR PREVENTING OR TREATING DISEASES RELATING TO IL-8 |
| EA201990296A1 (ru) * | 2016-08-05 | 2019-08-30 | Аллакос, Инк. | Антитела против siglec-7 для лечения рака |
| JP7134960B2 (ja) * | 2016-12-06 | 2022-09-12 | セントビンセンツ ホスピタル シドニー リミテッド | 肥満及び摂食障害の治療 |
| GB201700567D0 (en) | 2017-01-12 | 2017-03-01 | Genagon Therapeutics Ab | Therapeutic agents |
| WO2019018402A2 (en) * | 2017-07-17 | 2019-01-24 | Janssen Biotech, Inc. | ANTIGEN-BINDING REGIONS DIRECTED AGAINST FIBRONECTIN TYPE III DOMAINS AND METHODS OF USING THE SAME |
| WO2019140273A1 (en) * | 2018-01-11 | 2019-07-18 | Allakos, Inc. | Anti-siglec-7 antibodies having reduced effector function |
| TWI724392B (zh) * | 2018-04-06 | 2021-04-11 | 美商美國禮來大藥廠 | 生長分化因子15促效劑化合物及其使用方法 |
| PE20201350A1 (es) | 2018-04-09 | 2020-11-30 | Amgen Inc | Proteinas de fusion del factor de diferenciacion de crecimiento 15 |
| US20210340263A1 (en) * | 2018-08-09 | 2021-11-04 | The Wistar Institute | Anti-Follicule Stimulating Hormone Receptor Antibodies |
| BR112021003173A2 (pt) * | 2018-08-20 | 2021-05-11 | Pfizer Inc. | anticorpos anti-gdf15, composições e métodos de uso |
| KR102238927B1 (ko) * | 2018-08-30 | 2021-04-12 | 서울대학교산학협력단 | 세포 내에서 nag-1 단백질의 이동을 조절하는 펩티드 및 이의 용도 |
| US20220048995A1 (en) * | 2018-09-10 | 2022-02-17 | INSERM (Institut National de la Santé et de la Recherche Médicale) | Use of an inhibitor of ntsr1 activation or expression for preventing weight loss, muscle loss, and protein blood level decrease in subjects in need thereof |
| WO2021111636A1 (ja) * | 2019-12-06 | 2021-06-10 | 大塚製薬株式会社 | 抗gdf15抗体 |
| CN114560938B (zh) * | 2020-03-30 | 2023-05-23 | 中国人民解放军第四军医大学 | 抗gdf15中和性单克隆抗体及其应用 |
| EP4163300A1 (en) * | 2020-06-04 | 2023-04-12 | Daegu Gyeongbuk Institute Of Science and Technology | Gfral-antagonistic antibody and use thereof |
| CN116997357A (zh) | 2021-03-08 | 2023-11-03 | 免疫医疗有限责任公司 | 针对gdf-15的抗体 |
| EP4314071A1 (en) | 2021-03-31 | 2024-02-07 | Cambridge Enterprise Limited | Therapeutic inhibitors of gdf15 signalling |
| IL310535A (en) | 2021-08-10 | 2024-03-01 | Byomass Inc | Anti-GDF15 antibodies, compositions and uses thereof |
| WO2023079430A1 (en) | 2021-11-02 | 2023-05-11 | Pfizer Inc. | Methods of treating mitochondrial myopathies using anti-gdf15 antibodies |
| WO2023122213A1 (en) | 2021-12-22 | 2023-06-29 | Byomass Inc. | Targeting gdf15-gfral pathway cross-reference to related applications |
| WO2023141815A1 (zh) * | 2022-01-26 | 2023-08-03 | 康源博创生物科技(北京)有限公司 | 抗生长分化因子15的抗体分子及其应用 |
| WO2023217068A1 (zh) * | 2022-05-09 | 2023-11-16 | 舒泰神(北京)生物制药股份有限公司 | 特异性识别gdf15的抗体及其应用 |
| CN116444667B (zh) * | 2023-06-13 | 2023-09-01 | 上海驯鹿生物技术有限公司 | 一种靶向gdf15的全人源抗体及其应用 |
Family Cites Families (49)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| US6548640B1 (en) | 1986-03-27 | 2003-04-15 | Btg International Limited | Altered antibodies |
| US6893625B1 (en) | 1986-10-27 | 2005-05-17 | Royalty Pharma Finance Trust | Chimeric antibody with specificity to human B cell surface antigen |
| IL85035A0 (en) | 1987-01-08 | 1988-06-30 | Int Genetic Eng | Polynucleotide molecule,a chimeric antibody with specificity for human b cell surface antigen,a process for the preparation and methods utilizing the same |
| US5530101A (en) | 1988-12-28 | 1996-06-25 | Protein Design Labs, Inc. | Humanized immunoglobulins |
| US5859205A (en) | 1989-12-21 | 1999-01-12 | Celltech Limited | Humanised antibodies |
| WO1994004679A1 (en) | 1991-06-14 | 1994-03-03 | Genentech, Inc. | Method for making humanized antibodies |
| US5565332A (en) | 1991-09-23 | 1996-10-15 | Medical Research Council | Production of chimeric antibodies - a combinatorial approach |
| US5869619A (en) | 1991-12-13 | 1999-02-09 | Xoma Corporation | Modified antibody variable domains |
| ES2202310T3 (es) | 1991-12-13 | 2004-04-01 | Xoma Corporation | Metodos y materiales para la preparacion de dominios variables de anticuerpos modificados y sus usos terapeuticos. |
| US6180602B1 (en) | 1992-08-04 | 2001-01-30 | Sagami Chemical Research Center | Human novel cDNA, TGF-beta superfamily protein encoded thereby and the use of immunosuppressive agent |
| WO1994003599A1 (en) | 1992-08-04 | 1994-02-17 | Sagami Chemical Research Center | HUMAN cDNA AND PROTEIN WHICH SAID cDNA CODES FOR |
| US5639641A (en) | 1992-09-09 | 1997-06-17 | Immunogen Inc. | Resurfacing of rodent antibodies |
| US6066718A (en) | 1992-09-25 | 2000-05-23 | Novartis Corporation | Reshaped monoclonal antibodies against an immunoglobulin isotype |
| WO1996018730A1 (en) | 1994-12-15 | 1996-06-20 | Human Genome Sciences, Inc. | Prostatic growth factor |
| US5994102A (en) | 1994-12-15 | 1999-11-30 | Human Genome Sciences, Inc. | Polynucleotides encoding prostatic growth factor and process for producing prostatic growth factor polypeptides |
| US6521227B1 (en) | 1999-11-18 | 2003-02-18 | Peter L. Hudson | Polynucleotides encoding prostatic growth factor and process for producing prostatic growth factor polypeptides |
| WO1997000958A1 (en) | 1995-06-22 | 1997-01-09 | St. Vincent's Hospital Sydney Limited | NOVEL TGF-β LIKE CYTOKINE |
| WO1999006445A1 (en) | 1997-07-31 | 1999-02-11 | The Johns Hopkins University School Of Medicine | Growth differentiation factor-15 |
| US6872518B2 (en) | 1997-09-22 | 2005-03-29 | University Of Rochester | Methods for selecting polynucleotides encoding T cell epitopes |
| EP1117805A2 (en) | 1998-10-07 | 2001-07-25 | STRYKER CORPORATION (a Michigan corporation) | Modified tgf-beta superfamily proteins |
| US6465181B2 (en) | 1999-03-25 | 2002-10-15 | Abbott Laboratories | Reagents and methods useful for detecting diseases of the prostate |
| JP2002543841A (ja) | 1999-05-17 | 2002-12-24 | バイオファーム ゲゼルシャフト ツア バイオテクノロジシェン エントヴィックルング ウント ツム フェルトリーブ フォン ファルマカ エムベーハー | TGF−βスーパーファミリーの新規のメンバーであるGDF―15の神経保護特性 |
| DE60142372D1 (de) | 2000-04-20 | 2010-07-22 | St Vincents Hosp Sydney | Diagnostischer Assay mit makrophagenhemmendem Zytokin-1 (MIC-1) |
| US7141661B2 (en) | 2000-09-08 | 2006-11-28 | The United States Of America As Represented By The Department Of Health And Human Services | Non-steroidal anti-inflammatory drug activated gene with anti-tumorigenic properties |
| WO2004006955A1 (en) | 2001-07-12 | 2004-01-22 | Jefferson Foote | Super humanized antibodies |
| US7919084B2 (en) | 2002-06-17 | 2011-04-05 | St. Vincent's Hospital Sydney Limited | Methods of diagnosis, prognosis and treatment of cardiovascular disease |
| US7157235B2 (en) | 2002-06-17 | 2007-01-02 | St. Vincent's Hospital Sydney Limited | Methods of diagnosis, prognosis and treatment of cardiovascular disease |
| EP1578367A4 (en) | 2002-11-01 | 2012-05-02 | Genentech Inc | COMPOSITIONS AND METHODS FOR THE TREATMENT OF IMMUNE DISEASES |
| AU2003295424A1 (en) | 2002-11-08 | 2004-06-03 | Barnes-Jewish Hospital | Methods and compositions for prostate epithelial cell differentiation |
| US20060188889A1 (en) | 2003-11-04 | 2006-08-24 | Christopher Burgess | Use of differentially expressed nucleic acid sequences as biomarkers for cancer |
| CA2542325A1 (en) | 2003-10-10 | 2005-04-21 | That Corporation | Low-power integrated-circuit signal processor with wide dynamic range |
| WO2005092383A1 (ja) | 2004-03-26 | 2005-10-06 | Takeda Pharmaceutical Company Limited | 呼吸器疾患の予防・治療剤 |
| JP5448338B2 (ja) | 2004-04-13 | 2014-03-19 | セントビンセンツ ホスピタル シドニー リミテッド | 食欲を調節する方法 |
| CA2534871C (en) | 2006-02-15 | 2015-08-04 | The Ohio State University Research Foundation | Three-gene test to differentiate malignant from benign thyroid nodules |
| US20070237713A1 (en) | 2006-04-04 | 2007-10-11 | Fan Rong A | PCan065 Antibody Compositions and Methods of Use |
| EP1884777A1 (en) | 2006-08-04 | 2008-02-06 | Medizinische Hochschule Hannover | Means and methods for assessing the risk of cardiac interventions based on GDF-15 |
| JP5309026B2 (ja) | 2006-08-04 | 2013-10-09 | メディツィニッシュ ホホシュール ハノーバー | Gdf−15に基づく心臓インターベンションの危険性を評価するための手段および方法 |
| US20100278843A1 (en) * | 2007-08-16 | 2010-11-04 | St. Vincent's Hospital Sydney Limited | Agents and methods for modulating macrophage inhibitory cytokine (mic-1) activity |
| CN101896192A (zh) | 2007-10-09 | 2010-11-24 | 圣文森特医院悉尼有限公司 | 一种通过去除或灭活巨噬细胞抑制因子-1而治疗恶病质的方法 |
| EP2103943A1 (en) | 2008-03-20 | 2009-09-23 | F. Hoffman-la Roche AG | GDF-15 for assessing a cardiovascular risk with respect to the administration of antiinflammatory drugs |
| WO2009141357A1 (en) | 2008-05-20 | 2009-11-26 | Roche Diagnostics Gmbh | Gdf-15 as biomarker in type 1 diabetes |
| GB0902793D0 (en) * | 2009-02-20 | 2009-04-08 | Univ Gent | GDF15 as molecular tool to monitor and enhance phenotypic stability of articular chondrocytes |
| US9212221B2 (en) * | 2010-03-03 | 2015-12-15 | Detroit R & D, Inc. | Form-specific antibodies for NAG-1 (MIC-1, GDF-15), H6D and other TGF-β subfamily and heart disease and cancer diagnoses |
| GB201004739D0 (en) | 2010-03-22 | 2010-05-05 | Prosidion Ltd | Receptor modulators |
| WO2012113103A1 (en) | 2011-02-25 | 2012-08-30 | Helsinn Healthcare S.A. | Asymmetric ureas and medical uses thereof |
| DK2934584T3 (da) | 2012-12-21 | 2020-05-18 | Aveo Pharmaceuticals Inc | Anti-gdf15-antistoffer |
| US20170137505A1 (en) | 2014-06-20 | 2017-05-18 | Aveo Pharmaceuticals, Inc. | Treatment of congestive heart failure and other cardiac dysfunction using a gdf15 modulator |
| BR112016029820A2 (pt) | 2014-06-20 | 2017-10-24 | Aveo Pharmaceuticals Inc | tratamento de doença renal crônica e outras disfunções renais usando um modulador de gdf15 |
-
2013
- 2013-12-20 DK DK13827058.2T patent/DK2934584T3/da active
- 2013-12-20 AR ARP130105017A patent/AR094271A1/es active IP Right Grant
- 2013-12-20 JP JP2015549810A patent/JP6758832B2/ja active Active
- 2013-12-20 WO PCT/US2013/077139 patent/WO2014100689A1/en active Application Filing
- 2013-12-20 US US14/137,415 patent/US9175076B2/en active Active
- 2013-12-20 MX MX2015007751A patent/MX370720B/es active IP Right Grant
- 2013-12-20 ES ES13827058T patent/ES2791183T3/es active Active
- 2013-12-20 AU AU2013364133A patent/AU2013364133B2/en active Active
- 2013-12-20 EA EA201591198A patent/EA038645B1/ru unknown
- 2013-12-20 EP EP13827058.2A patent/EP2934584B1/en active Active
- 2013-12-20 CA CA2896076A patent/CA2896076C/en active Active
- 2013-12-20 KR KR1020157019881A patent/KR102208861B1/ko active IP Right Grant
- 2013-12-20 CN CN201380073317.1A patent/CN105073133B/zh active Active
- 2013-12-20 EP EP20156883.9A patent/EP3689370A1/en active Pending
-
2015
- 2015-09-24 US US14/863,870 patent/US9725505B2/en active Active
-
2016
- 2016-03-30 HK HK16103611.5A patent/HK1215670A1/zh unknown
-
2017
- 2017-07-20 US US15/655,263 patent/US10597444B2/en active Active
-
2019
- 2019-01-21 JP JP2019007928A patent/JP2019056018A/ja not_active Withdrawn
-
2020
- 2020-03-19 US US16/824,034 patent/US11725047B2/en active Active
-
2021
- 2021-01-25 JP JP2021009528A patent/JP2021061864A/ja not_active Withdrawn
Also Published As
| Publication number | Publication date |
|---|---|
| KR102208861B1 (ko) | 2021-01-27 |
| AU2013364133A1 (en) | 2015-07-16 |
| CN105073133B (zh) | 2021-04-20 |
| JP2019056018A (ja) | 2019-04-11 |
| US11725047B2 (en) | 2023-08-15 |
| CN105073133A (zh) | 2015-11-18 |
| US9175076B2 (en) | 2015-11-03 |
| US20180142013A1 (en) | 2018-05-24 |
| JP2016508984A (ja) | 2016-03-24 |
| AU2013364133B2 (en) | 2018-10-11 |
| MX2015007751A (es) | 2015-11-30 |
| EA201591198A1 (ru) | 2015-11-30 |
| DK2934584T3 (da) | 2020-05-18 |
| EA038645B1 (ru) | 2021-09-28 |
| EP2934584B1 (en) | 2020-02-19 |
| AR094271A1 (es) | 2015-07-22 |
| JP6758832B2 (ja) | 2020-09-30 |
| WO2014100689A1 (en) | 2014-06-26 |
| EP3689370A1 (en) | 2020-08-05 |
| KR20150100837A (ko) | 2015-09-02 |
| EP2934584A1 (en) | 2015-10-28 |
| MX370720B (es) | 2019-12-20 |
| CA2896076C (en) | 2022-12-06 |
| US9725505B2 (en) | 2017-08-08 |
| US20160083465A1 (en) | 2016-03-24 |
| US20210101968A1 (en) | 2021-04-08 |
| US20140193427A1 (en) | 2014-07-10 |
| HK1215670A1 (zh) | 2016-09-09 |
| US10597444B2 (en) | 2020-03-24 |
| JP2021061864A (ja) | 2021-04-22 |
| CA2896076A1 (en) | 2014-06-26 |
| BR112015014768A2 (pt) | 2017-10-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11725047B2 (en) | Anti-GDF-15 antibodies | |
| US8481688B2 (en) | Anti-FGFR2 antibodies | |
| AU2011245636B2 (en) | Anti-ErbB3 antibodies | |
| US8829164B2 (en) | Anti-ron antibodies | |
| AU2011245636A1 (en) | Anti-ErbB3 antibodies | |
| WO2011156617A2 (en) | Anti-egfr antibodies | |
| WO2012003472A1 (en) | Anti-notch1 antibodies | |
| WO2014100435A1 (en) | Anti-notch3 antibodies | |
| BR112015014768B1 (pt) | Anticorpos anti-gdf15, seu método de produção, seu uso, e composição farmacêutica compreendendo os mesmos |