ES2705249T3 - Polipéptidos reguladores de glucosa y métodos para su producción y uso - Google Patents
Polipéptidos reguladores de glucosa y métodos para su producción y uso Download PDFInfo
- Publication number
- ES2705249T3 ES2705249T3 ES10786730T ES10786730T ES2705249T3 ES 2705249 T3 ES2705249 T3 ES 2705249T3 ES 10786730 T ES10786730 T ES 10786730T ES 10786730 T ES10786730 T ES 10786730T ES 2705249 T3 ES2705249 T3 ES 2705249T3
- Authority
- ES
- Spain
- Prior art keywords
- xten
- sequence
- fusion protein
- gpxten
- seq
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 108090000765 processed proteins & peptides Proteins 0.000 title claims abstract description 318
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 title claims abstract description 107
- 239000008103 glucose Substances 0.000 title claims abstract description 107
- 230000001105 regulatory effect Effects 0.000 title claims abstract description 70
- 102000004196 processed proteins & peptides Human genes 0.000 title claims description 198
- 229920001184 polypeptide Polymers 0.000 title claims description 155
- 238000000034 method Methods 0.000 title claims description 134
- 238000004519 manufacturing process Methods 0.000 title claims description 20
- 108020001507 fusion proteins Proteins 0.000 claims abstract description 385
- 102000037865 fusion proteins Human genes 0.000 claims abstract description 384
- 150000001413 amino acids Chemical group 0.000 claims abstract description 133
- 102000040430 polynucleotide Human genes 0.000 claims abstract description 127
- 108091033319 polynucleotide Proteins 0.000 claims abstract description 127
- 239000002157 polynucleotide Substances 0.000 claims abstract description 123
- 230000004071 biological effect Effects 0.000 claims abstract description 44
- 150000007523 nucleic acids Chemical class 0.000 claims abstract description 40
- 230000000295 complement effect Effects 0.000 claims abstract description 35
- 108010011459 Exenatide Proteins 0.000 claims abstract description 32
- 102000039446 nucleic acids Human genes 0.000 claims abstract description 32
- 108020004707 nucleic acids Proteins 0.000 claims abstract description 32
- 229960001519 exenatide Drugs 0.000 claims abstract description 31
- DTHNMHAUYICORS-KTKZVXAJSA-N Glucagon-like peptide 1 Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC=1N=CNC=1)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=CC=C1 DTHNMHAUYICORS-KTKZVXAJSA-N 0.000 claims abstract description 30
- JUFFVKRROAPVBI-PVOYSMBESA-N chembl1210015 Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)N[C@H]1[C@@H]([C@@H](O)[C@H](O[C@H]2[C@@H]([C@@H](O)[C@@H](O)[C@@H](CO[C@]3(O[C@@H](C[C@H](O)[C@H](O)CO)[C@H](NC(C)=O)[C@@H](O)C3)C(O)=O)O2)O)[C@@H](CO)O1)NC(C)=O)C(=O)NCC(=O)NCC(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CO)C(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)CNC(=O)[C@@H](N)CC=1NC=NC=1)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=CC=C1 JUFFVKRROAPVBI-PVOYSMBESA-N 0.000 claims abstract description 29
- 101710198884 GATA-type zinc finger protein 1 Proteins 0.000 claims abstract description 24
- 235000001014 amino acid Nutrition 0.000 claims description 130
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 100
- 210000004027 cell Anatomy 0.000 claims description 99
- 230000001225 therapeutic effect Effects 0.000 claims description 82
- 125000000539 amino acid group Chemical group 0.000 claims description 73
- 230000014509 gene expression Effects 0.000 claims description 70
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 claims description 68
- 208000035475 disorder Diseases 0.000 claims description 52
- 201000010099 disease Diseases 0.000 claims description 48
- 239000013598 vector Substances 0.000 claims description 42
- 239000004471 Glycine Substances 0.000 claims description 34
- 239000013604 expression vector Substances 0.000 claims description 34
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 claims description 28
- 238000004422 calculation algorithm Methods 0.000 claims description 28
- 239000003814 drug Substances 0.000 claims description 27
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 claims description 26
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 claims description 25
- 235000004279 alanine Nutrition 0.000 claims description 25
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 claims description 24
- 239000004473 Threonine Substances 0.000 claims description 24
- 229930195712 glutamate Natural products 0.000 claims description 24
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 claims description 22
- 208000008589 Obesity Diseases 0.000 claims description 20
- 235000020824 obesity Nutrition 0.000 claims description 20
- 208000001072 type 2 diabetes mellitus Diseases 0.000 claims description 16
- 210000001744 T-lymphocyte Anatomy 0.000 claims description 15
- 206010067584 Type 1 diabetes mellitus Diseases 0.000 claims description 14
- 201000001421 hyperglycemia Diseases 0.000 claims description 12
- 241000588724 Escherichia coli Species 0.000 claims description 10
- 208000013016 Hypoglycemia Diseases 0.000 claims description 10
- 208000011580 syndromic disease Diseases 0.000 claims description 10
- 230000001154 acute effect Effects 0.000 claims description 9
- 210000002700 urine Anatomy 0.000 claims description 8
- 206010007559 Cardiac failure congestive Diseases 0.000 claims description 7
- 208000032928 Dyslipidaemia Diseases 0.000 claims description 7
- 206010016654 Fibrosis Diseases 0.000 claims description 7
- 206010019280 Heart failures Diseases 0.000 claims description 7
- 208000017170 Lipid metabolism disease Diseases 0.000 claims description 7
- 206010029164 Nephrotic syndrome Diseases 0.000 claims description 7
- 206010037423 Pulmonary oedema Diseases 0.000 claims description 7
- 208000001647 Renal Insufficiency Diseases 0.000 claims description 7
- 230000007882 cirrhosis Effects 0.000 claims description 7
- 208000019425 cirrhosis of liver Diseases 0.000 claims description 7
- 230000030136 gastric emptying Effects 0.000 claims description 7
- 208000002551 irritable bowel syndrome Diseases 0.000 claims description 7
- 201000006370 kidney failure Diseases 0.000 claims description 7
- 208000010125 myocardial infarction Diseases 0.000 claims description 7
- 208000005333 pulmonary edema Diseases 0.000 claims description 7
- 210000000056 organ Anatomy 0.000 claims description 6
- 206010018404 Glucagonoma Diseases 0.000 claims description 5
- 230000001684 chronic effect Effects 0.000 claims description 5
- 210000003527 eukaryotic cell Anatomy 0.000 claims description 5
- 230000002218 hypoglycaemic effect Effects 0.000 claims description 5
- 230000004770 neurodegeneration Effects 0.000 claims description 5
- 210000001236 prokaryotic cell Anatomy 0.000 claims description 5
- 230000003248 secreting effect Effects 0.000 claims description 5
- 208000032781 Diabetic cardiomyopathy Diseases 0.000 claims description 4
- 206010012735 Diarrhoea Diseases 0.000 claims description 4
- 208000000059 Dyspnea Diseases 0.000 claims description 4
- 206010013975 Dyspnoeas Diseases 0.000 claims description 4
- 101000788682 Homo sapiens GATA-type zinc finger protein 1 Proteins 0.000 claims description 4
- 206010020772 Hypertension Diseases 0.000 claims description 4
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 claims description 4
- 208000001132 Osteoporosis Diseases 0.000 claims description 4
- ZLMJMSJWJFRBEC-UHFFFAOYSA-N Potassium Chemical compound [K] ZLMJMSJWJFRBEC-UHFFFAOYSA-N 0.000 claims description 4
- 208000006011 Stroke Diseases 0.000 claims description 4
- 206010003246 arthritis Diseases 0.000 claims description 4
- 230000017531 blood circulation Effects 0.000 claims description 4
- 230000001925 catabolic effect Effects 0.000 claims description 4
- 208000015114 central nervous system disease Diseases 0.000 claims description 4
- 208000028867 ischemia Diseases 0.000 claims description 4
- 208000017169 kidney disease Diseases 0.000 claims description 4
- 208000002089 myocardial stunning Diseases 0.000 claims description 4
- 208000015122 neurodegenerative disease Diseases 0.000 claims description 4
- 230000000422 nocturnal effect Effects 0.000 claims description 4
- 201000010065 polycystic ovary syndrome Diseases 0.000 claims description 4
- 230000002980 postoperative effect Effects 0.000 claims description 4
- 239000011591 potassium Substances 0.000 claims description 4
- 229910052700 potassium Inorganic materials 0.000 claims description 4
- 230000010410 reperfusion Effects 0.000 claims description 4
- 208000037803 restenosis Diseases 0.000 claims description 4
- 239000011734 sodium Substances 0.000 claims description 4
- 229910052708 sodium Inorganic materials 0.000 claims description 4
- 208000004476 Acute Coronary Syndrome Diseases 0.000 claims description 3
- 206010049694 Left Ventricular Dysfunction Diseases 0.000 claims description 3
- 210000000805 cytoplasm Anatomy 0.000 claims description 3
- 230000029142 excretion Effects 0.000 claims description 3
- 238000002360 preparation method Methods 0.000 claims description 3
- 210000002345 respiratory system Anatomy 0.000 claims description 3
- 208000037816 tissue injury Diseases 0.000 claims description 3
- 238000012258 culturing Methods 0.000 claims description 2
- 102400000322 Glucagon-like peptide 1 Human genes 0.000 claims 1
- 208000019622 heart disease Diseases 0.000 claims 1
- 102100025101 GATA-type zinc finger protein 1 Human genes 0.000 abstract 1
- 108090000623 proteins and genes Proteins 0.000 description 185
- 239000000203 mixture Substances 0.000 description 140
- 229940024606 amino acid Drugs 0.000 description 129
- 102000004169 proteins and genes Human genes 0.000 description 106
- 235000018102 proteins Nutrition 0.000 description 99
- 230000027455 binding Effects 0.000 description 87
- 230000000875 corresponding effect Effects 0.000 description 80
- 102000005962 receptors Human genes 0.000 description 79
- 108020003175 receptors Proteins 0.000 description 79
- 239000000306 component Substances 0.000 description 77
- 125000006850 spacer group Chemical group 0.000 description 60
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 59
- 230000000694 effects Effects 0.000 description 55
- 238000003776 cleavage reaction Methods 0.000 description 53
- 230000007017 scission Effects 0.000 description 53
- 230000002829 reductive effect Effects 0.000 description 51
- 230000003252 repetitive effect Effects 0.000 description 47
- 230000001965 increasing effect Effects 0.000 description 46
- 125000003275 alpha amino acid group Chemical group 0.000 description 38
- 230000001976 improved effect Effects 0.000 description 37
- 108020004414 DNA Proteins 0.000 description 34
- 238000003556 assay Methods 0.000 description 34
- 108020004705 Codon Proteins 0.000 description 32
- 229960002449 glycine Drugs 0.000 description 32
- 102000035195 Peptidases Human genes 0.000 description 31
- 108091005804 Peptidases Proteins 0.000 description 31
- 239000004365 Protease Substances 0.000 description 31
- 238000010367 cloning Methods 0.000 description 31
- 102000004877 Insulin Human genes 0.000 description 29
- 108090001061 Insulin Proteins 0.000 description 29
- 230000004927 fusion Effects 0.000 description 29
- 229940125396 insulin Drugs 0.000 description 29
- 210000004899 c-terminal region Anatomy 0.000 description 27
- MASNOZXLGMXCHN-ZLPAWPGGSA-N glucagon Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O)C(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC=1NC=NC=1)[C@@H](C)O)[C@@H](C)O)C1=CC=CC=C1 MASNOZXLGMXCHN-ZLPAWPGGSA-N 0.000 description 27
- 102000051325 Glucagon Human genes 0.000 description 26
- 108060003199 Glucagon Proteins 0.000 description 26
- 210000004369 blood Anatomy 0.000 description 26
- 239000008280 blood Substances 0.000 description 26
- 229960004666 glucagon Drugs 0.000 description 26
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 25
- 229960001153 serine Drugs 0.000 description 25
- 235000004400 serine Nutrition 0.000 description 25
- 102100040918 Pro-glucagon Human genes 0.000 description 24
- 229960003767 alanine Drugs 0.000 description 23
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 22
- 239000012634 fragment Substances 0.000 description 22
- 229940049906 glutamate Drugs 0.000 description 22
- 239000008194 pharmaceutical composition Substances 0.000 description 22
- 235000008521 threonine Nutrition 0.000 description 22
- 229960002898 threonine Drugs 0.000 description 22
- 238000011282 treatment Methods 0.000 description 22
- 230000000144 pharmacologic effect Effects 0.000 description 21
- 125000003729 nucleotide group Chemical group 0.000 description 20
- 230000006872 improvement Effects 0.000 description 19
- 239000000047 product Substances 0.000 description 19
- 239000002773 nucleotide Substances 0.000 description 18
- 230000004913 activation Effects 0.000 description 17
- 229940079593 drug Drugs 0.000 description 17
- 239000003446 ligand Substances 0.000 description 17
- 230000004962 physiological condition Effects 0.000 description 16
- 210000002966 serum Anatomy 0.000 description 16
- 238000005457 optimization Methods 0.000 description 15
- 239000000243 solution Substances 0.000 description 15
- 239000000126 substance Substances 0.000 description 15
- 241001465754 Metazoa Species 0.000 description 14
- 108091028043 Nucleic acid sequence Proteins 0.000 description 14
- 108010076504 Protein Sorting Signals Proteins 0.000 description 14
- 230000005847 immunogenicity Effects 0.000 description 14
- 230000000670 limiting effect Effects 0.000 description 14
- 206010022489 Insulin Resistance Diseases 0.000 description 13
- 230000008901 benefit Effects 0.000 description 13
- 230000036765 blood level Effects 0.000 description 13
- 239000003795 chemical substances by application Substances 0.000 description 13
- 206010012601 diabetes mellitus Diseases 0.000 description 13
- 230000008030 elimination Effects 0.000 description 13
- 238000003379 elimination reaction Methods 0.000 description 13
- 230000001404 mediated effect Effects 0.000 description 13
- 241000282414 Homo sapiens Species 0.000 description 12
- 239000000556 agonist Substances 0.000 description 12
- 230000009286 beneficial effect Effects 0.000 description 12
- 230000015572 biosynthetic process Effects 0.000 description 12
- 230000005714 functional activity Effects 0.000 description 12
- 239000005090 green fluorescent protein Substances 0.000 description 12
- 239000003550 marker Substances 0.000 description 12
- 239000012071 phase Substances 0.000 description 12
- 239000013612 plasmid Substances 0.000 description 12
- 229920000642 polymer Polymers 0.000 description 12
- 230000009467 reduction Effects 0.000 description 12
- 238000006467 substitution reaction Methods 0.000 description 12
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 12
- 108010041872 Islet Amyloid Polypeptide Proteins 0.000 description 11
- 102000036770 Islet Amyloid Polypeptide Human genes 0.000 description 11
- 241000124008 Mammalia Species 0.000 description 11
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 11
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 11
- 238000010276 construction Methods 0.000 description 11
- 230000001186 cumulative effect Effects 0.000 description 11
- 230000002209 hydrophobic effect Effects 0.000 description 11
- 238000001727 in vivo Methods 0.000 description 11
- 238000010348 incorporation Methods 0.000 description 11
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 10
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 10
- 210000003719 b-lymphocyte Anatomy 0.000 description 10
- 235000012631 food intake Nutrition 0.000 description 10
- 230000006870 function Effects 0.000 description 10
- 230000003914 insulin secretion Effects 0.000 description 10
- 238000000746 purification Methods 0.000 description 10
- 230000002441 reversible effect Effects 0.000 description 10
- 238000012360 testing method Methods 0.000 description 10
- 210000001519 tissue Anatomy 0.000 description 10
- 108091034117 Oligonucleotide Proteins 0.000 description 9
- -1 TEV Proteins 0.000 description 9
- 238000013461 design Methods 0.000 description 9
- 230000037406 food intake Effects 0.000 description 9
- 238000009472 formulation Methods 0.000 description 9
- 230000014101 glucose homeostasis Effects 0.000 description 9
- 229940088597 hormone Drugs 0.000 description 9
- 239000005556 hormone Substances 0.000 description 9
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 9
- 230000008569 process Effects 0.000 description 9
- 238000001542 size-exclusion chromatography Methods 0.000 description 9
- 238000003860 storage Methods 0.000 description 9
- 241000282567 Macaca fascicularis Species 0.000 description 8
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 8
- 230000021615 conjugation Effects 0.000 description 8
- 238000010790 dilution Methods 0.000 description 8
- 239000012895 dilution Substances 0.000 description 8
- 230000002163 immunogen Effects 0.000 description 8
- 238000000338 in vitro Methods 0.000 description 8
- 230000002035 prolonged effect Effects 0.000 description 8
- 241000894007 species Species 0.000 description 8
- 231100000419 toxicity Toxicity 0.000 description 8
- 230000001988 toxicity Effects 0.000 description 8
- 238000013518 transcription Methods 0.000 description 8
- 230000035897 transcription Effects 0.000 description 8
- 239000003981 vehicle Substances 0.000 description 8
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 7
- 108091026890 Coding region Proteins 0.000 description 7
- 241000282412 Homo Species 0.000 description 7
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 7
- 239000005557 antagonist Substances 0.000 description 7
- 230000015556 catabolic process Effects 0.000 description 7
- 238000006731 degradation reaction Methods 0.000 description 7
- 235000018977 lysine Nutrition 0.000 description 7
- 230000002503 metabolic effect Effects 0.000 description 7
- 229930182817 methionine Natural products 0.000 description 7
- 208000024891 symptom Diseases 0.000 description 7
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 6
- 241000282472 Canis lupus familiaris Species 0.000 description 6
- 108010035563 Chloramphenicol O-acetyltransferase Proteins 0.000 description 6
- 102000004127 Cytokines Human genes 0.000 description 6
- 108090000695 Cytokines Proteins 0.000 description 6
- 102000053602 DNA Human genes 0.000 description 6
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 6
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 6
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 6
- 239000004472 Lysine Substances 0.000 description 6
- 241000699670 Mus sp. Species 0.000 description 6
- 108700026244 Open Reading Frames Proteins 0.000 description 6
- 230000002411 adverse Effects 0.000 description 6
- 235000009582 asparagine Nutrition 0.000 description 6
- 229960001230 asparagine Drugs 0.000 description 6
- 239000003124 biologic agent Substances 0.000 description 6
- 230000037396 body weight Effects 0.000 description 6
- 230000008859 change Effects 0.000 description 6
- 230000015271 coagulation Effects 0.000 description 6
- 238000005345 coagulation Methods 0.000 description 6
- 235000018417 cysteine Nutrition 0.000 description 6
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 6
- 238000010494 dissociation reaction Methods 0.000 description 6
- 230000005593 dissociations Effects 0.000 description 6
- HTQBXNHDCUEHJF-URRANESESA-N exendin-4 Chemical compound C([C@@H](C(=O)N[C@@H](C(C)CC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(=O)NCC(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CO)C(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)CNC(=O)[C@@H](N)CC=1N=CNC=1)C(C)O)C(C)O)C(C)C)C1=CC=CC=C1 HTQBXNHDCUEHJF-URRANESESA-N 0.000 description 6
- 238000009396 hybridization Methods 0.000 description 6
- 229960003646 lysine Drugs 0.000 description 6
- 239000011159 matrix material Substances 0.000 description 6
- 108020004999 messenger RNA Proteins 0.000 description 6
- 208000030159 metabolic disease Diseases 0.000 description 6
- 239000000902 placebo Substances 0.000 description 6
- 229940068196 placebo Drugs 0.000 description 6
- 208000002815 pulmonary hypertension Diseases 0.000 description 6
- 230000010076 replication Effects 0.000 description 6
- 230000004044 response Effects 0.000 description 6
- 230000019491 signal transduction Effects 0.000 description 6
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 6
- 229940124597 therapeutic agent Drugs 0.000 description 6
- 239000004475 Arginine Substances 0.000 description 5
- 102100029727 Enteropeptidase Human genes 0.000 description 5
- 108010013369 Enteropeptidase Proteins 0.000 description 5
- YQYJSBFKSSDGFO-UHFFFAOYSA-N Epihygromycin Natural products OC1C(O)C(C(=O)C)OC1OC(C(=C1)O)=CC=C1C=C(C)C(=O)NC1C(O)C(O)C2OCOC2C1O YQYJSBFKSSDGFO-UHFFFAOYSA-N 0.000 description 5
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 5
- 108090000190 Thrombin Proteins 0.000 description 5
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 5
- 230000009471 action Effects 0.000 description 5
- 238000004220 aggregation Methods 0.000 description 5
- 239000007864 aqueous solution Substances 0.000 description 5
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 5
- 235000009697 arginine Nutrition 0.000 description 5
- 229960003121 arginine Drugs 0.000 description 5
- 230000004087 circulation Effects 0.000 description 5
- 239000002299 complementary DNA Substances 0.000 description 5
- 238000004590 computer program Methods 0.000 description 5
- 238000007796 conventional method Methods 0.000 description 5
- 208000029078 coronary artery disease Diseases 0.000 description 5
- 235000005911 diet Nutrition 0.000 description 5
- 230000037213 diet Effects 0.000 description 5
- 239000003937 drug carrier Substances 0.000 description 5
- 238000004128 high performance liquid chromatography Methods 0.000 description 5
- 238000003780 insertion Methods 0.000 description 5
- 230000037431 insertion Effects 0.000 description 5
- 239000000463 material Substances 0.000 description 5
- 230000003285 pharmacodynamic effect Effects 0.000 description 5
- 229920001223 polyethylene glycol Polymers 0.000 description 5
- 238000003752 polymerase chain reaction Methods 0.000 description 5
- NRKVKVQDUCJPIZ-MKAGXXMWSA-N pramlintide acetate Chemical compound C([C@@H](C(=O)NCC(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](CS)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CCCCN)[C@@H](C)O)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=CC=C1 NRKVKVQDUCJPIZ-MKAGXXMWSA-N 0.000 description 5
- 230000000069 prophylactic effect Effects 0.000 description 5
- 150000003839 salts Chemical class 0.000 description 5
- 239000000523 sample Substances 0.000 description 5
- 238000012163 sequencing technique Methods 0.000 description 5
- 239000003826 tablet Substances 0.000 description 5
- 229960004072 thrombin Drugs 0.000 description 5
- VOUAQYXWVJDEQY-QENPJCQMSA-N 33017-11-7 Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)NCC(=O)NCC(=O)N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](C)C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N1[C@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O)CCC1 VOUAQYXWVJDEQY-QENPJCQMSA-N 0.000 description 4
- 108010075254 C-Peptide Proteins 0.000 description 4
- 229940117937 Dihydrofolate reductase inhibitor Drugs 0.000 description 4
- 102000004190 Enzymes Human genes 0.000 description 4
- 108090000790 Enzymes Proteins 0.000 description 4
- ZHNUHDYFZUAESO-UHFFFAOYSA-N Formamide Chemical compound NC=O ZHNUHDYFZUAESO-UHFFFAOYSA-N 0.000 description 4
- 150000008575 L-amino acids Chemical class 0.000 description 4
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 4
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 4
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 4
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 4
- 239000002202 Polyethylene glycol Substances 0.000 description 4
- 241000700159 Rattus Species 0.000 description 4
- 230000002159 abnormal effect Effects 0.000 description 4
- 238000010521 absorption reaction Methods 0.000 description 4
- 238000004458 analytical method Methods 0.000 description 4
- 230000001580 bacterial effect Effects 0.000 description 4
- 108010005774 beta-Galactosidase Proteins 0.000 description 4
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 4
- 230000001413 cellular effect Effects 0.000 description 4
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 description 4
- 238000012875 competitive assay Methods 0.000 description 4
- 150000001875 compounds Chemical class 0.000 description 4
- 239000003166 dihydrofolate reductase inhibitor Substances 0.000 description 4
- 238000009826 distribution Methods 0.000 description 4
- 229940088598 enzyme Drugs 0.000 description 4
- 238000011156 evaluation Methods 0.000 description 4
- 108010015174 exendin 3 Proteins 0.000 description 4
- LMHMJYMCGJNXRS-IOPUOMRJSA-N exendin-3 Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(=O)NCC(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CO)C(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC=1N=CNC=1)[C@H](C)O)[C@H](C)O)C(C)C)C1=CC=CC=C1 LMHMJYMCGJNXRS-IOPUOMRJSA-N 0.000 description 4
- 239000000945 filler Substances 0.000 description 4
- 239000000499 gel Substances 0.000 description 4
- 102000034238 globular proteins Human genes 0.000 description 4
- 108091005896 globular proteins Proteins 0.000 description 4
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 4
- 235000004554 glutamine Nutrition 0.000 description 4
- 229960002743 glutamine Drugs 0.000 description 4
- 210000003000 inclusion body Anatomy 0.000 description 4
- 238000002347 injection Methods 0.000 description 4
- 239000007924 injection Substances 0.000 description 4
- 230000003993 interaction Effects 0.000 description 4
- 229910052757 nitrogen Inorganic materials 0.000 description 4
- 238000007410 oral glucose tolerance test Methods 0.000 description 4
- 230000007170 pathology Effects 0.000 description 4
- 230000037361 pathway Effects 0.000 description 4
- 239000000813 peptide hormone Substances 0.000 description 4
- 229960003611 pramlintide Drugs 0.000 description 4
- 108010029667 pramlintide Proteins 0.000 description 4
- 238000012545 processing Methods 0.000 description 4
- 238000000159 protein binding assay Methods 0.000 description 4
- 230000002797 proteolythic effect Effects 0.000 description 4
- 230000028327 secretion Effects 0.000 description 4
- 238000007920 subcutaneous administration Methods 0.000 description 4
- 238000003786 synthesis reaction Methods 0.000 description 4
- 231100000331 toxic Toxicity 0.000 description 4
- 230000002588 toxic effect Effects 0.000 description 4
- 238000013519 translation Methods 0.000 description 4
- 238000001262 western blot Methods 0.000 description 4
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 3
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 3
- 210000002237 B-cell of pancreatic islet Anatomy 0.000 description 3
- 102100026189 Beta-galactosidase Human genes 0.000 description 3
- 241000222120 Candida <Saccharomycetales> Species 0.000 description 3
- 102000014914 Carrier Proteins Human genes 0.000 description 3
- 108700010070 Codon Usage Proteins 0.000 description 3
- 102100024746 Dihydrofolate reductase Human genes 0.000 description 3
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 3
- 238000002965 ELISA Methods 0.000 description 3
- HTQBXNHDCUEHJF-XWLPCZSASA-N Exenatide Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(=O)NCC(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CO)C(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CO)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)CNC(=O)[C@@H](N)CC=1NC=NC=1)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=CC=C1 HTQBXNHDCUEHJF-XWLPCZSASA-N 0.000 description 3
- 108010079356 FIIa Proteins 0.000 description 3
- 101150117028 GP gene Proteins 0.000 description 3
- 208000018522 Gastrointestinal disease Diseases 0.000 description 3
- 102400000326 Glucagon-like peptide 2 Human genes 0.000 description 3
- 101800000221 Glucagon-like peptide 2 Proteins 0.000 description 3
- 229920002527 Glycogen Polymers 0.000 description 3
- 241000238631 Hexapoda Species 0.000 description 3
- 101500028775 Homo sapiens Glucagon Proteins 0.000 description 3
- 206010020919 Hypervolaemia Diseases 0.000 description 3
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 3
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 3
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 3
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 3
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 3
- 102000007330 LDL Lipoproteins Human genes 0.000 description 3
- 108010007622 LDL Lipoproteins Proteins 0.000 description 3
- 208000019693 Lung disease Diseases 0.000 description 3
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 3
- 206010036049 Polycystic ovaries Diseases 0.000 description 3
- 206010036105 Polyneuropathy Diseases 0.000 description 3
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 3
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 3
- 108091081024 Start codon Proteins 0.000 description 3
- 239000004480 active ingredient Substances 0.000 description 3
- 230000002776 aggregation Effects 0.000 description 3
- 108091007433 antigens Proteins 0.000 description 3
- 102000036639 antigens Human genes 0.000 description 3
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 3
- 108091008324 binding proteins Proteins 0.000 description 3
- 230000008827 biological function Effects 0.000 description 3
- 230000004663 cell proliferation Effects 0.000 description 3
- 230000005754 cellular signaling Effects 0.000 description 3
- 238000006243 chemical reaction Methods 0.000 description 3
- 230000002759 chromosomal effect Effects 0.000 description 3
- 238000001142 circular dichroism spectrum Methods 0.000 description 3
- 238000004132 cross linking Methods 0.000 description 3
- 230000002950 deficient Effects 0.000 description 3
- 238000012217 deletion Methods 0.000 description 3
- 230000037430 deletion Effects 0.000 description 3
- 238000001514 detection method Methods 0.000 description 3
- 238000010586 diagram Methods 0.000 description 3
- 238000002474 experimental method Methods 0.000 description 3
- TWSALRJGPBVBQU-PKQQPRCHSA-N glucagon-like peptide 2 Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O)[C@@H](C)CC)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@@H](NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@H](CO)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC=1NC=NC=1)[C@@H](C)O)[C@@H](C)CC)C1=CC=CC=C1 TWSALRJGPBVBQU-PKQQPRCHSA-N 0.000 description 3
- 150000002303 glucose derivatives Chemical class 0.000 description 3
- 125000000291 glutamic acid group Chemical group N[C@@H](CCC(O)=O)C(=O)* 0.000 description 3
- 229940096919 glycogen Drugs 0.000 description 3
- 239000008187 granular material Substances 0.000 description 3
- 230000036541 health Effects 0.000 description 3
- 239000003112 inhibitor Substances 0.000 description 3
- 238000007918 intramuscular administration Methods 0.000 description 3
- 238000004255 ion exchange chromatography Methods 0.000 description 3
- 210000004962 mammalian cell Anatomy 0.000 description 3
- 230000004060 metabolic process Effects 0.000 description 3
- 230000035772 mutation Effects 0.000 description 3
- 235000015097 nutrients Nutrition 0.000 description 3
- 210000000496 pancreas Anatomy 0.000 description 3
- 239000000816 peptidomimetic Substances 0.000 description 3
- 239000000546 pharmaceutical excipient Substances 0.000 description 3
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 3
- 230000007824 polyneuropathy Effects 0.000 description 3
- 239000000843 powder Substances 0.000 description 3
- 239000002243 precursor Substances 0.000 description 3
- 239000000651 prodrug Substances 0.000 description 3
- 229940002612 prodrug Drugs 0.000 description 3
- 235000004252 protein component Nutrition 0.000 description 3
- 108091008146 restriction endonucleases Proteins 0.000 description 3
- 239000007787 solid Substances 0.000 description 3
- 230000004936 stimulating effect Effects 0.000 description 3
- 230000002459 sustained effect Effects 0.000 description 3
- 238000013268 sustained release Methods 0.000 description 3
- 239000012730 sustained-release form Substances 0.000 description 3
- 238000012546 transfer Methods 0.000 description 3
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 3
- 230000002861 ventricular Effects 0.000 description 3
- 238000005406 washing Methods 0.000 description 3
- 241000894006 Bacteria Species 0.000 description 2
- 102100027995 Collagenase 3 Human genes 0.000 description 2
- 108050005238 Collagenase 3 Proteins 0.000 description 2
- 238000012286 ELISA Assay Methods 0.000 description 2
- 108010042407 Endonucleases Proteins 0.000 description 2
- 102000004533 Endonucleases Human genes 0.000 description 2
- 241000233866 Fungi Species 0.000 description 2
- 108010063919 Glucagon Receptors Proteins 0.000 description 2
- 102100040890 Glucagon receptor Human genes 0.000 description 2
- 101800000224 Glucagon-like peptide 1 Proteins 0.000 description 2
- 101800004266 Glucagon-like peptide 1(7-37) Proteins 0.000 description 2
- 208000002705 Glucose Intolerance Diseases 0.000 description 2
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 2
- 102000001398 Granzyme Human genes 0.000 description 2
- 108060005986 Granzyme Proteins 0.000 description 2
- 102000015779 HDL Lipoproteins Human genes 0.000 description 2
- 108010010234 HDL Lipoproteins Proteins 0.000 description 2
- 241000270431 Heloderma suspectum Species 0.000 description 2
- 229920002153 Hydroxypropyl cellulose Polymers 0.000 description 2
- 206010060378 Hyperinsulinaemia Diseases 0.000 description 2
- 102000018251 Hypoxanthine Phosphoribosyltransferase Human genes 0.000 description 2
- 108010091358 Hypoxanthine Phosphoribosyltransferase Proteins 0.000 description 2
- 102000001399 Kallikrein Human genes 0.000 description 2
- 108060005987 Kallikrein Proteins 0.000 description 2
- 244000285963 Kluyveromyces fragilis Species 0.000 description 2
- 241001138401 Kluyveromyces lactis Species 0.000 description 2
- ZQISRDCJNBUVMM-UHFFFAOYSA-N L-Histidinol Natural products OCC(N)CC1=CN=CN1 ZQISRDCJNBUVMM-UHFFFAOYSA-N 0.000 description 2
- ZQISRDCJNBUVMM-YFKPBYRVSA-N L-histidinol Chemical compound OC[C@@H](N)CC1=CNC=N1 ZQISRDCJNBUVMM-YFKPBYRVSA-N 0.000 description 2
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 2
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 2
- 102100027998 Macrophage metalloelastase Human genes 0.000 description 2
- 101710187853 Macrophage metalloelastase Proteins 0.000 description 2
- 102100029693 Matrix metalloproteinase-20 Human genes 0.000 description 2
- 108090000609 Matrix metalloproteinase-20 Proteins 0.000 description 2
- 241000699666 Mus <mouse, genus> Species 0.000 description 2
- 102100033174 Neutrophil elastase Human genes 0.000 description 2
- 108010079246 OMPA outer membrane proteins Proteins 0.000 description 2
- 241000235648 Pichia Species 0.000 description 2
- 241000288906 Primates Species 0.000 description 2
- 241000589516 Pseudomonas Species 0.000 description 2
- 108020004511 Recombinant DNA Proteins 0.000 description 2
- 241000191940 Staphylococcus Species 0.000 description 2
- 241000187747 Streptomyces Species 0.000 description 2
- 108010076818 TEV protease Proteins 0.000 description 2
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 2
- 239000000443 aerosol Substances 0.000 description 2
- 239000000427 antigen Substances 0.000 description 2
- 210000000612 antigen-presenting cell Anatomy 0.000 description 2
- 239000002246 antineoplastic agent Substances 0.000 description 2
- 238000013459 approach Methods 0.000 description 2
- 125000003118 aryl group Chemical group 0.000 description 2
- 229940009098 aspartate Drugs 0.000 description 2
- IVRMZWNICZWHMI-UHFFFAOYSA-N azide group Chemical group [N-]=[N+]=[N-] IVRMZWNICZWHMI-UHFFFAOYSA-N 0.000 description 2
- 210000000227 basophil cell of anterior lobe of hypophysis Anatomy 0.000 description 2
- 229920001400 block copolymer Polymers 0.000 description 2
- 230000000903 blocking effect Effects 0.000 description 2
- 239000000872 buffer Substances 0.000 description 2
- 230000003185 calcium uptake Effects 0.000 description 2
- 150000001720 carbohydrates Chemical class 0.000 description 2
- 235000014633 carbohydrates Nutrition 0.000 description 2
- 239000000969 carrier Substances 0.000 description 2
- 238000000423 cell based assay Methods 0.000 description 2
- 238000004113 cell culture Methods 0.000 description 2
- 238000005119 centrifugation Methods 0.000 description 2
- 239000003153 chemical reaction reagent Substances 0.000 description 2
- 235000012000 cholesterol Nutrition 0.000 description 2
- 230000007012 clinical effect Effects 0.000 description 2
- 239000008199 coating composition Substances 0.000 description 2
- 238000005056 compaction Methods 0.000 description 2
- 230000002860 competitive effect Effects 0.000 description 2
- 230000002596 correlated effect Effects 0.000 description 2
- 230000008878 coupling Effects 0.000 description 2
- 238000010168 coupling process Methods 0.000 description 2
- 238000005859 coupling reaction Methods 0.000 description 2
- 238000005520 cutting process Methods 0.000 description 2
- 229940127089 cytotoxic agent Drugs 0.000 description 2
- 230000007423 decrease Effects 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 230000029087 digestion Effects 0.000 description 2
- 238000006471 dimerization reaction Methods 0.000 description 2
- 229940042399 direct acting antivirals protease inhibitors Drugs 0.000 description 2
- 238000004520 electroporation Methods 0.000 description 2
- 239000000839 emulsion Substances 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 108010048367 enhanced green fluorescent protein Proteins 0.000 description 2
- 239000003623 enhancer Substances 0.000 description 2
- 230000002708 enhancing effect Effects 0.000 description 2
- 230000002255 enzymatic effect Effects 0.000 description 2
- 230000008029 eradication Effects 0.000 description 2
- 238000000684 flow cytometry Methods 0.000 description 2
- 230000002068 genetic effect Effects 0.000 description 2
- 235000013922 glutamic acid Nutrition 0.000 description 2
- 239000004220 glutamic acid Substances 0.000 description 2
- 125000000404 glutamine group Chemical group N[C@@H](CCC(N)=O)C(=O)* 0.000 description 2
- 102000005396 glutamine synthetase Human genes 0.000 description 2
- 108020002326 glutamine synthetase Proteins 0.000 description 2
- 125000001165 hydrophobic group Chemical group 0.000 description 2
- 239000001863 hydroxypropyl cellulose Substances 0.000 description 2
- 235000010977 hydroxypropyl cellulose Nutrition 0.000 description 2
- 230000003451 hyperinsulinaemic effect Effects 0.000 description 2
- 201000008980 hyperinsulinism Diseases 0.000 description 2
- 230000001900 immune effect Effects 0.000 description 2
- 230000028993 immune response Effects 0.000 description 2
- 210000000987 immune system Anatomy 0.000 description 2
- 230000016784 immunoglobulin production Effects 0.000 description 2
- 238000011532 immunohistochemical staining Methods 0.000 description 2
- 230000001939 inductive effect Effects 0.000 description 2
- 230000002401 inhibitory effect Effects 0.000 description 2
- 230000000977 initiatory effect Effects 0.000 description 2
- 239000000543 intermediate Substances 0.000 description 2
- 238000002955 isolation Methods 0.000 description 2
- 229960000310 isoleucine Drugs 0.000 description 2
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 2
- 210000003734 kidney Anatomy 0.000 description 2
- 238000002372 labelling Methods 0.000 description 2
- 238000011031 large-scale manufacturing process Methods 0.000 description 2
- 239000007788 liquid Substances 0.000 description 2
- 210000004185 liver Anatomy 0.000 description 2
- 210000004698 lymphocyte Anatomy 0.000 description 2
- 238000007726 management method Methods 0.000 description 2
- 231100000682 maximum tolerated dose Toxicity 0.000 description 2
- 235000012054 meals Nutrition 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 239000002609 medium Substances 0.000 description 2
- SXTAYKAGBXMACB-UHFFFAOYSA-N methionine sulfoximine Chemical compound CS(=N)(=O)CCC(N)C(O)=O SXTAYKAGBXMACB-UHFFFAOYSA-N 0.000 description 2
- 238000010369 molecular cloning Methods 0.000 description 2
- 210000004897 n-terminal region Anatomy 0.000 description 2
- 230000003472 neutralizing effect Effects 0.000 description 2
- 238000003199 nucleic acid amplification method Methods 0.000 description 2
- 239000003921 oil Substances 0.000 description 2
- 235000019198 oils Nutrition 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 230000003647 oxidation Effects 0.000 description 2
- 238000007254 oxidation reaction Methods 0.000 description 2
- 108090000155 pancreatic elastase II Proteins 0.000 description 2
- 239000002245 particle Substances 0.000 description 2
- 230000001575 pathological effect Effects 0.000 description 2
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 2
- 230000002093 peripheral effect Effects 0.000 description 2
- 239000000825 pharmaceutical preparation Substances 0.000 description 2
- 239000006187 pill Substances 0.000 description 2
- 230000036470 plasma concentration Effects 0.000 description 2
- 230000008488 polyadenylation Effects 0.000 description 2
- 239000002244 precipitate Substances 0.000 description 2
- 201000009104 prediabetes syndrome Diseases 0.000 description 2
- GCYXWQUSHADNBF-AAEALURTSA-N preproglucagon 78-108 Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC=1N=CNC=1)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=CC=C1 GCYXWQUSHADNBF-AAEALURTSA-N 0.000 description 2
- 230000002265 prevention Effects 0.000 description 2
- 238000001742 protein purification Methods 0.000 description 2
- 230000017854 proteolysis Effects 0.000 description 2
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical compound C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 description 2
- 238000003259 recombinant expression Methods 0.000 description 2
- 239000011347 resin Substances 0.000 description 2
- 229920005989 resin Polymers 0.000 description 2
- 230000036186 satiety Effects 0.000 description 2
- 235000019627 satiety Nutrition 0.000 description 2
- 125000003607 serino group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C(O[H])([H])[H] 0.000 description 2
- 238000003998 size exclusion chromatography high performance liquid chromatography Methods 0.000 description 2
- 150000003384 small molecules Chemical class 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- 229910001415 sodium ion Inorganic materials 0.000 description 2
- 239000002195 soluble material Substances 0.000 description 2
- 229910052717 sulfur Inorganic materials 0.000 description 2
- 239000006228 supernatant Substances 0.000 description 2
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 2
- 230000005030 transcription termination Effects 0.000 description 2
- 230000001131 transforming effect Effects 0.000 description 2
- 150000003626 triacylglycerols Chemical class 0.000 description 2
- 125000000430 tryptophan group Chemical group [H]N([H])C(C(=O)O*)C([H])([H])C1=C([H])N([H])C2=C([H])C([H])=C([H])C([H])=C12 0.000 description 2
- 208000035408 type 1 diabetes mellitus 1 Diseases 0.000 description 2
- 231100000402 unacceptable toxicity Toxicity 0.000 description 2
- 239000004474 valine Substances 0.000 description 2
- DIGQNXIGRZPYDK-WKSCXVIASA-N (2R)-6-amino-2-[[2-[[(2S)-2-[[2-[[(2R)-2-[[(2S)-2-[[(2R,3S)-2-[[2-[[(2S)-2-[[2-[[(2S)-2-[[(2S)-2-[[(2R)-2-[[(2S,3S)-2-[[(2R)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[2-[[(2S)-2-[[(2R)-2-[[2-[[2-[[2-[(2-amino-1-hydroxyethylidene)amino]-3-carboxy-1-hydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxypropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1,5-dihydroxy-5-iminopentylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxybutylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1,3-dihydroxypropylidene]amino]-1-hydroxyethylidene]amino]-1-hydroxy-3-sulfanylpropylidene]amino]-1-hydroxyethylidene]amino]hexanoic acid Chemical compound C[C@@H]([C@@H](C(=N[C@@H](CS)C(=N[C@@H](C)C(=N[C@@H](CO)C(=NCC(=N[C@@H](CCC(=N)O)C(=NC(CS)C(=N[C@H]([C@H](C)O)C(=N[C@H](CS)C(=N[C@H](CO)C(=NCC(=N[C@H](CS)C(=NCC(=N[C@H](CCCCN)C(=O)O)O)O)O)O)O)O)O)O)O)O)O)O)O)N=C([C@H](CS)N=C([C@H](CO)N=C([C@H](CO)N=C([C@H](C)N=C(CN=C([C@H](CO)N=C([C@H](CS)N=C(CN=C(C(CS)N=C(C(CC(=O)O)N=C(CN)O)O)O)O)O)O)O)O)O)O)O)O DIGQNXIGRZPYDK-WKSCXVIASA-N 0.000 description 1
- DSEKYWAQQVUQTP-XEWMWGOFSA-N (2r,4r,4as,6as,6as,6br,8ar,12ar,14as,14bs)-2-hydroxy-4,4a,6a,6b,8a,11,11,14a-octamethyl-2,4,5,6,6a,7,8,9,10,12,12a,13,14,14b-tetradecahydro-1h-picen-3-one Chemical compound C([C@H]1[C@]2(C)CC[C@@]34C)C(C)(C)CC[C@]1(C)CC[C@]2(C)[C@H]4CC[C@@]1(C)[C@H]3C[C@@H](O)C(=O)[C@@H]1C DSEKYWAQQVUQTP-XEWMWGOFSA-N 0.000 description 1
- OCUSNPIJIZCRSZ-ZTZWCFDHSA-N (2s)-2-amino-3-methylbutanoic acid;(2s)-2-amino-4-methylpentanoic acid;(2s,3s)-2-amino-3-methylpentanoic acid Chemical compound CC(C)[C@H](N)C(O)=O.CC[C@H](C)[C@H](N)C(O)=O.CC(C)C[C@H](N)C(O)=O OCUSNPIJIZCRSZ-ZTZWCFDHSA-N 0.000 description 1
- 102000008645 11-beta-Hydroxysteroid Dehydrogenase Type 1 Human genes 0.000 description 1
- 108010088011 11-beta-Hydroxysteroid Dehydrogenase Type 1 Proteins 0.000 description 1
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 description 1
- 108010091324 3C proteases Proteins 0.000 description 1
- SWLAMJPTOQZTAE-UHFFFAOYSA-N 4-[2-[(5-chloro-2-methoxybenzoyl)amino]ethyl]benzoic acid Chemical class COC1=CC=C(Cl)C=C1C(=O)NCCC1=CC=C(C(O)=O)C=C1 SWLAMJPTOQZTAE-UHFFFAOYSA-N 0.000 description 1
- 241000187844 Actinoplanes Species 0.000 description 1
- 101800002326 Adipokinetic hormone Proteins 0.000 description 1
- 108010088751 Albumins Proteins 0.000 description 1
- 102000009027 Albumins Human genes 0.000 description 1
- 108700028369 Alleles Proteins 0.000 description 1
- 229940077274 Alpha glucosidase inhibitor Drugs 0.000 description 1
- 102100022749 Aminopeptidase N Human genes 0.000 description 1
- 239000004382 Amylase Substances 0.000 description 1
- 102000013142 Amylases Human genes 0.000 description 1
- 108010065511 Amylases Proteins 0.000 description 1
- 108010039627 Aprotinin Proteins 0.000 description 1
- 241000205046 Archaeoglobus Species 0.000 description 1
- 241000205042 Archaeoglobus fulgidus Species 0.000 description 1
- 241000228212 Aspergillus Species 0.000 description 1
- 241000351920 Aspergillus nidulans Species 0.000 description 1
- 241000972773 Aulopiformes Species 0.000 description 1
- 208000023275 Autoimmune disease Diseases 0.000 description 1
- 244000063299 Bacillus subtilis Species 0.000 description 1
- 235000014469 Bacillus subtilis Nutrition 0.000 description 1
- 108010066768 Bacterial leucyl aminopeptidase Proteins 0.000 description 1
- 241000604933 Bdellovibrio Species 0.000 description 1
- 241000604931 Bdellovibrio bacteriovorus Species 0.000 description 1
- 229940123208 Biguanide Drugs 0.000 description 1
- 241000589968 Borrelia Species 0.000 description 1
- 241000589969 Borreliella burgdorferi Species 0.000 description 1
- OBMZMSLWNNWEJA-XNCRXQDQSA-N C1=CC=2C(C[C@@H]3NC(=O)[C@@H](NC(=O)[C@H](NC(=O)N(CC#CCN(CCCC[C@H](NC(=O)[C@@H](CC4=CC=CC=C4)NC3=O)C(=O)N)CC=C)NC(=O)[C@@H](N)C)CC3=CNC4=C3C=CC=C4)C)=CNC=2C=C1 Chemical compound C1=CC=2C(C[C@@H]3NC(=O)[C@@H](NC(=O)[C@H](NC(=O)N(CC#CCN(CCCC[C@H](NC(=O)[C@@H](CC4=CC=CC=C4)NC3=O)C(=O)N)CC=C)NC(=O)[C@@H](N)C)CC3=CNC4=C3C=CC=C4)C)=CNC=2C=C1 OBMZMSLWNNWEJA-XNCRXQDQSA-N 0.000 description 1
- 108010049990 CD13 Antigens Proteins 0.000 description 1
- 108010041397 CD4 Antigens Proteins 0.000 description 1
- 101100522123 Caenorhabditis elegans ptc-1 gene Proteins 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- 229940127291 Calcium channel antagonist Drugs 0.000 description 1
- UXVMQQNJUSDDNG-UHFFFAOYSA-L Calcium chloride Chemical compound [Cl-].[Cl-].[Ca+2] UXVMQQNJUSDDNG-UHFFFAOYSA-L 0.000 description 1
- 108010080937 Carboxypeptidases A Proteins 0.000 description 1
- 102000000496 Carboxypeptidases A Human genes 0.000 description 1
- 108090000994 Catalytic RNA Proteins 0.000 description 1
- 102000053642 Catalytic RNA Human genes 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- 241000192733 Chloroflexus Species 0.000 description 1
- 241000192731 Chloroflexus aurantiacus Species 0.000 description 1
- 108090000317 Chymotrypsin Proteins 0.000 description 1
- 101800004419 Cleaved form Proteins 0.000 description 1
- 102100022641 Coagulation factor IX Human genes 0.000 description 1
- 102000008186 Collagen Human genes 0.000 description 1
- 108010035532 Collagen Proteins 0.000 description 1
- 108020004635 Complementary DNA Proteins 0.000 description 1
- 244000180278 Copernicia prunifera Species 0.000 description 1
- 235000010919 Copernicia prunifera Nutrition 0.000 description 1
- 241000699802 Cricetulus griseus Species 0.000 description 1
- 101150074155 DHFR gene Proteins 0.000 description 1
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 1
- 108010067722 Dipeptidyl Peptidase 4 Proteins 0.000 description 1
- 102100025012 Dipeptidyl peptidase 4 Human genes 0.000 description 1
- 101150040523 EN gene Proteins 0.000 description 1
- 238000004435 EPR spectroscopy Methods 0.000 description 1
- 208000017701 Endocrine disease Diseases 0.000 description 1
- 241000194033 Enterococcus Species 0.000 description 1
- 241000194032 Enterococcus faecalis Species 0.000 description 1
- 241000194031 Enterococcus faecium Species 0.000 description 1
- 241000709661 Enterovirus Species 0.000 description 1
- 241000588722 Escherichia Species 0.000 description 1
- 239000001856 Ethyl cellulose Substances 0.000 description 1
- ZZSNKZQZMQGXPY-UHFFFAOYSA-N Ethyl cellulose Chemical compound CCOCC1OC(OC)C(OCC)C(OCC)C1OC1C(O)C(O)C(OC)C(CO)O1 ZZSNKZQZMQGXPY-UHFFFAOYSA-N 0.000 description 1
- 108700024394 Exon Proteins 0.000 description 1
- 108010076282 Factor IX Proteins 0.000 description 1
- 108010074860 Factor Xa Proteins 0.000 description 1
- 108010049003 Fibrinogen Proteins 0.000 description 1
- 102000008946 Fibrinogen Human genes 0.000 description 1
- 102400000921 Gastrin Human genes 0.000 description 1
- 108010052343 Gastrins Proteins 0.000 description 1
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 1
- 108010086246 Glucagon-Like Peptide-1 Receptor Proteins 0.000 description 1
- 108010088406 Glucagon-Like Peptides Proteins 0.000 description 1
- 102100032882 Glucagon-like peptide 1 receptor Human genes 0.000 description 1
- 102000005720 Glutathione transferase Human genes 0.000 description 1
- 108010070675 Glutathione transferase Proteins 0.000 description 1
- 102000006354 HLA-DR Antigens Human genes 0.000 description 1
- 108010058597 HLA-DR Antigens Proteins 0.000 description 1
- 241001149669 Hanseniaspora Species 0.000 description 1
- 241000270453 Heloderma horridum Species 0.000 description 1
- 101710154606 Hemagglutinin Proteins 0.000 description 1
- 229920000209 Hexadimethrine bromide Polymers 0.000 description 1
- 102000018713 Histocompatibility Antigens Class II Human genes 0.000 description 1
- 108010027412 Histocompatibility Antigens Class II Proteins 0.000 description 1
- 101001081479 Homo sapiens Islet amyloid polypeptide Proteins 0.000 description 1
- 101001126084 Homo sapiens Piwi-like protein 2 Proteins 0.000 description 1
- 101000740205 Homo sapiens Sal-like protein 1 Proteins 0.000 description 1
- 241000701044 Human gammaherpesvirus 4 Species 0.000 description 1
- UFHFLCQGNIYNRP-UHFFFAOYSA-N Hydrogen Chemical compound [H][H] UFHFLCQGNIYNRP-UHFFFAOYSA-N 0.000 description 1
- 208000035150 Hypercholesterolemia Diseases 0.000 description 1
- 101710177940 IgG receptor FcRn large subunit p51 Proteins 0.000 description 1
- 102100026120 IgG receptor FcRn large subunit p51 Human genes 0.000 description 1
- 108700002232 Immediate-Early Genes Proteins 0.000 description 1
- 108060003951 Immunoglobulin Proteins 0.000 description 1
- 102000018071 Immunoglobulin Fc Fragments Human genes 0.000 description 1
- 108010091135 Immunoglobulin Fc Fragments Proteins 0.000 description 1
- 208000031773 Insulin resistance syndrome Diseases 0.000 description 1
- 229940122355 Insulin sensitizer Drugs 0.000 description 1
- 102000006992 Interferon-alpha Human genes 0.000 description 1
- 108010047761 Interferon-alpha Proteins 0.000 description 1
- 108010029660 Intrinsically Disordered Proteins Proteins 0.000 description 1
- 108091092195 Intron Proteins 0.000 description 1
- 102100038297 Kallikrein-1 Human genes 0.000 description 1
- 101710176219 Kallikrein-1 Proteins 0.000 description 1
- 241000204082 Kitasatospora griseola Species 0.000 description 1
- 241000235649 Kluyveromyces Species 0.000 description 1
- 101100233178 Kluyveromyces marxianus INU1 gene Proteins 0.000 description 1
- 241000235058 Komagataella pastoris Species 0.000 description 1
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 1
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 1
- 241000481961 Lachancea thermotolerans Species 0.000 description 1
- 241000235651 Lachancea waltii Species 0.000 description 1
- 241000186660 Lactobacillus Species 0.000 description 1
- 241001468157 Lactobacillus johnsonii Species 0.000 description 1
- 240000006024 Lactobacillus plantarum Species 0.000 description 1
- 235000013965 Lactobacillus plantarum Nutrition 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- GDBQQVLCIARPGH-UHFFFAOYSA-N Leupeptin Natural products CC(C)CC(NC(C)=O)C(=O)NC(CC(C)C)C(=O)NC(C=O)CCCN=C(N)N GDBQQVLCIARPGH-UHFFFAOYSA-N 0.000 description 1
- 241000186781 Listeria Species 0.000 description 1
- 241000186805 Listeria innocua Species 0.000 description 1
- 241000186779 Listeria monocytogenes Species 0.000 description 1
- 108060001084 Luciferase Proteins 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- 208000016604 Lyme disease Diseases 0.000 description 1
- 102000043131 MHC class II family Human genes 0.000 description 1
- 108091054438 MHC class II family Proteins 0.000 description 1
- 101710141347 Major envelope glycoprotein Proteins 0.000 description 1
- 101710175625 Maltose/maltodextrin-binding periplasmic protein Proteins 0.000 description 1
- 241000255908 Manduca sexta Species 0.000 description 1
- 108010000684 Matrix Metalloproteinases Proteins 0.000 description 1
- 102000002274 Matrix Metalloproteinases Human genes 0.000 description 1
- 102100030219 Matrix metalloproteinase-17 Human genes 0.000 description 1
- 108090000585 Matrix metalloproteinase-17 Proteins 0.000 description 1
- 102000003792 Metallothionein Human genes 0.000 description 1
- 108090000157 Metallothionein Proteins 0.000 description 1
- 229920000168 Microcrystalline cellulose Polymers 0.000 description 1
- 102100025243 Myeloid cell surface antigen CD33 Human genes 0.000 description 1
- HSHXDCVZWHOWCS-UHFFFAOYSA-N N'-hexadecylthiophene-2-carbohydrazide Chemical compound CCCCCCCCCCCCCCCCNNC(=O)c1cccs1 HSHXDCVZWHOWCS-UHFFFAOYSA-N 0.000 description 1
- 125000000729 N-terminal amino-acid group Chemical group 0.000 description 1
- 229930193140 Neomycin Natural products 0.000 description 1
- 206010028980 Neoplasm Diseases 0.000 description 1
- 241000221960 Neurospora Species 0.000 description 1
- 241000221961 Neurospora crassa Species 0.000 description 1
- 238000000636 Northern blotting Methods 0.000 description 1
- 102000019040 Nuclear Antigens Human genes 0.000 description 1
- 108010051791 Nuclear Antigens Proteins 0.000 description 1
- 108020004711 Nucleic Acid Probes Proteins 0.000 description 1
- 241001072230 Oceanobacillus Species 0.000 description 1
- 241001072247 Oceanobacillus iheyensis Species 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 101710093908 Outer capsid protein VP4 Proteins 0.000 description 1
- 101710135467 Outer capsid protein sigma-1 Proteins 0.000 description 1
- 108010016731 PPAR gamma Proteins 0.000 description 1
- 235000019482 Palm oil Nutrition 0.000 description 1
- 241001057811 Paracoccus <mealybug> Species 0.000 description 1
- 241001117114 Paracoccus zeaxanthinifaciens Species 0.000 description 1
- 241000228143 Penicillium Species 0.000 description 1
- 102000057297 Pepsin A Human genes 0.000 description 1
- 108090000284 Pepsin A Proteins 0.000 description 1
- 101710176384 Peptide 1 Proteins 0.000 description 1
- 102000015731 Peptide Hormones Human genes 0.000 description 1
- 108010038988 Peptide Hormones Proteins 0.000 description 1
- 102000003728 Peroxisome Proliferator-Activated Receptors Human genes 0.000 description 1
- 108090000029 Peroxisome Proliferator-Activated Receptors Proteins 0.000 description 1
- 102100038825 Peroxisome proliferator-activated receptor gamma Human genes 0.000 description 1
- 102100029365 Piwi-like protein 2 Human genes 0.000 description 1
- 102000003827 Plasma Kallikrein Human genes 0.000 description 1
- 108090000113 Plasma Kallikrein Proteins 0.000 description 1
- 101710182846 Polyhedrin Proteins 0.000 description 1
- 108010076181 Proinsulin Proteins 0.000 description 1
- 101710176177 Protein A56 Proteins 0.000 description 1
- 108010094028 Prothrombin Proteins 0.000 description 1
- 102100027378 Prothrombin Human genes 0.000 description 1
- 241001453299 Pseudomonas mevalonii Species 0.000 description 1
- 108020005067 RNA Splice Sites Proteins 0.000 description 1
- 238000001069 Raman spectroscopy Methods 0.000 description 1
- 235000019484 Rapeseed oil Nutrition 0.000 description 1
- 101001081470 Rattus norvegicus Islet amyloid polypeptide Proteins 0.000 description 1
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 1
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 1
- 108700008625 Reporter Genes Proteins 0.000 description 1
- 241000223252 Rhodotorula Species 0.000 description 1
- 108091028664 Ribonucleotide Proteins 0.000 description 1
- 102100030852 Run domain Beclin-1-interacting and cysteine-rich domain-containing protein Human genes 0.000 description 1
- 241000235070 Saccharomyces Species 0.000 description 1
- 101000955420 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) Xanthine phosphoribosyltransferase 1 Proteins 0.000 description 1
- 102100037204 Sal-like protein 1 Human genes 0.000 description 1
- 241000293869 Salmonella enterica subsp. enterica serovar Typhimurium Species 0.000 description 1
- 241000235347 Schizosaccharomyces pombe Species 0.000 description 1
- 101000978266 Schizosaccharomyces pombe (strain 972 / ATCC 24843) Carboxypeptidase Y Proteins 0.000 description 1
- 241000311088 Schwanniomyces Species 0.000 description 1
- 241001123650 Schwanniomyces occidentalis Species 0.000 description 1
- 241000700584 Simplexvirus Species 0.000 description 1
- 102000000070 Sodium-Glucose Transport Proteins Human genes 0.000 description 1
- 108010080361 Sodium-Glucose Transport Proteins Proteins 0.000 description 1
- 102000005157 Somatostatin Human genes 0.000 description 1
- 108010056088 Somatostatin Proteins 0.000 description 1
- 238000002105 Southern blotting Methods 0.000 description 1
- 241000191967 Staphylococcus aureus Species 0.000 description 1
- 241000191963 Staphylococcus epidermidis Species 0.000 description 1
- 241000191984 Staphylococcus haemolyticus Species 0.000 description 1
- 241000194017 Streptococcus Species 0.000 description 1
- 241000193985 Streptococcus agalactiae Species 0.000 description 1
- 244000057717 Streptococcus lactis Species 0.000 description 1
- 235000014897 Streptococcus lactis Nutrition 0.000 description 1
- 241000194019 Streptococcus mutans Species 0.000 description 1
- 241000193998 Streptococcus pneumoniae Species 0.000 description 1
- 241000193996 Streptococcus pyogenes Species 0.000 description 1
- 229940100389 Sulfonylurea Drugs 0.000 description 1
- 206010071436 Systolic dysfunction Diseases 0.000 description 1
- 230000024932 T cell mediated immunity Effects 0.000 description 1
- 102100036011 T-cell surface glycoprotein CD4 Human genes 0.000 description 1
- 239000004098 Tetracycline Substances 0.000 description 1
- 241000204667 Thermoplasma Species 0.000 description 1
- 241000204673 Thermoplasma acidophilum Species 0.000 description 1
- 241000489996 Thermoplasma volcanium Species 0.000 description 1
- 229940123464 Thiazolidinedione Drugs 0.000 description 1
- 108010022394 Threonine synthase Proteins 0.000 description 1
- 102000006601 Thymidine Kinase Human genes 0.000 description 1
- 108020004440 Thymidine kinase Proteins 0.000 description 1
- 241001149964 Tolypocladium Species 0.000 description 1
- 108020004566 Transfer RNA Proteins 0.000 description 1
- 241000223259 Trichoderma Species 0.000 description 1
- 239000007983 Tris buffer Substances 0.000 description 1
- 102000004142 Trypsin Human genes 0.000 description 1
- 108090000631 Trypsin Proteins 0.000 description 1
- 230000028654 Type IV pili-dependent aggregation Effects 0.000 description 1
- 241000700618 Vaccinia virus Species 0.000 description 1
- 241000607598 Vibrio Species 0.000 description 1
- 241000607626 Vibrio cholerae Species 0.000 description 1
- 241000607272 Vibrio parahaemolyticus Species 0.000 description 1
- 241000607265 Vibrio vulnificus Species 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- 208000027418 Wounds and injury Diseases 0.000 description 1
- 241000235013 Yarrowia Species 0.000 description 1
- 108010084455 Zeocin Proteins 0.000 description 1
- GYMWQLRSSDFGEQ-ADRAWKNSSA-N [(3e,8r,9s,10r,13s,14s,17r)-13-ethyl-17-ethynyl-3-hydroxyimino-1,2,6,7,8,9,10,11,12,14,15,16-dodecahydrocyclopenta[a]phenanthren-17-yl] acetate;(8r,9s,13s,14s,17r)-17-ethynyl-13-methyl-7,8,9,11,12,14,15,16-octahydro-6h-cyclopenta[a]phenanthrene-3,17-diol Chemical compound OC1=CC=C2[C@H]3CC[C@](C)([C@](CC4)(O)C#C)[C@@H]4[C@@H]3CCC2=C1.O/N=C/1CC[C@@H]2[C@H]3CC[C@](CC)([C@](CC4)(OC(C)=O)C#C)[C@@H]4[C@@H]3CCC2=C\1 GYMWQLRSSDFGEQ-ADRAWKNSSA-N 0.000 description 1
- 230000005856 abnormality Effects 0.000 description 1
- 238000002835 absorbance Methods 0.000 description 1
- 230000021736 acetylation Effects 0.000 description 1
- 238000006640 acetylation reaction Methods 0.000 description 1
- 210000000577 adipose tissue Anatomy 0.000 description 1
- 238000009098 adjuvant therapy Methods 0.000 description 1
- 238000005377 adsorption chromatography Methods 0.000 description 1
- 238000001261 affinity purification Methods 0.000 description 1
- 125000003295 alanine group Chemical group N[C@@H](C)C(=O)* 0.000 description 1
- 125000003172 aldehyde group Chemical group 0.000 description 1
- 239000003888 alpha glucosidase inhibitor Substances 0.000 description 1
- 150000001408 amides Chemical class 0.000 description 1
- 150000001412 amines Chemical class 0.000 description 1
- 125000003277 amino group Chemical group 0.000 description 1
- BFNBIHQBYMNNAN-UHFFFAOYSA-N ammonium sulfate Chemical class N.N.OS(O)(=O)=O BFNBIHQBYMNNAN-UHFFFAOYSA-N 0.000 description 1
- 229960000723 ampicillin Drugs 0.000 description 1
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 1
- 235000019418 amylase Nutrition 0.000 description 1
- 238000001286 analytical centrifugation Methods 0.000 description 1
- 210000004102 animal cell Anatomy 0.000 description 1
- 230000000840 anti-viral effect Effects 0.000 description 1
- 230000030741 antigen processing and presentation Effects 0.000 description 1
- 230000000890 antigenic effect Effects 0.000 description 1
- 230000006907 apoptotic process Effects 0.000 description 1
- 235000019789 appetite Nutrition 0.000 description 1
- 230000036528 appetite Effects 0.000 description 1
- 229960004405 aprotinin Drugs 0.000 description 1
- 239000012062 aqueous buffer Substances 0.000 description 1
- 239000003125 aqueous solvent Substances 0.000 description 1
- 239000007900 aqueous suspension Substances 0.000 description 1
- 125000000637 arginyl group Chemical group N[C@@H](CCCNC(N)=N)C(=O)* 0.000 description 1
- 238000000149 argon plasma sintering Methods 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 235000013871 bee wax Nutrition 0.000 description 1
- 235000015278 beef Nutrition 0.000 description 1
- 239000012166 beeswax Substances 0.000 description 1
- 230000006399 behavior Effects 0.000 description 1
- WQZGKKKJIJFFOK-FPRJBGLDSA-N beta-D-galactose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@H]1O WQZGKKKJIJFFOK-FPRJBGLDSA-N 0.000 description 1
- 108010051210 beta-Fructofuranosidase Proteins 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 150000004283 biguanides Chemical class 0.000 description 1
- 230000000975 bioactive effect Effects 0.000 description 1
- 238000004166 bioassay Methods 0.000 description 1
- 230000031018 biological processes and functions Effects 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 230000008512 biological response Effects 0.000 description 1
- 238000013378 biophysical characterization Methods 0.000 description 1
- 239000012503 blood component Substances 0.000 description 1
- 210000004204 blood vessel Anatomy 0.000 description 1
- 210000001124 body fluid Anatomy 0.000 description 1
- 239000010839 body fluid Substances 0.000 description 1
- 238000006664 bond formation reaction Methods 0.000 description 1
- 229940084891 byetta Drugs 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- 239000000480 calcium channel blocker Substances 0.000 description 1
- 239000001110 calcium chloride Substances 0.000 description 1
- 229910001628 calcium chloride Inorganic materials 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 201000011510 cancer Diseases 0.000 description 1
- 238000005251 capillar electrophoresis Methods 0.000 description 1
- 239000002775 capsule Substances 0.000 description 1
- 150000001718 carbodiimides Chemical class 0.000 description 1
- 230000023852 carbohydrate metabolic process Effects 0.000 description 1
- 235000021256 carbohydrate metabolism Nutrition 0.000 description 1
- 239000004359 castor oil Substances 0.000 description 1
- 235000019438 castor oil Nutrition 0.000 description 1
- 239000012930 cell culture fluid Substances 0.000 description 1
- 230000030833 cell death Effects 0.000 description 1
- 230000006037 cell lysis Effects 0.000 description 1
- 230000012292 cell migration Effects 0.000 description 1
- 238000001516 cell proliferation assay Methods 0.000 description 1
- 230000036755 cellular response Effects 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 235000010980 cellulose Nutrition 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- AOXOCDRNSPFDPE-UKEONUMOSA-N chembl413654 Chemical compound C([C@H](C(=O)NCC(=O)N[C@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@H](CCSC)C(=O)N[C@H](CC(O)=O)C(=O)N[C@H](CC=1C=CC=CC=1)C(N)=O)NC(=O)[C@@H](C)NC(=O)[C@@H](CCC(O)=O)NC(=O)[C@@H](CCC(O)=O)NC(=O)[C@@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H]1N(CCC1)C(=O)CNC(=O)[C@@H](N)CCC(O)=O)C1=CC=C(O)C=C1 AOXOCDRNSPFDPE-UKEONUMOSA-N 0.000 description 1
- 229910052729 chemical element Inorganic materials 0.000 description 1
- 238000007385 chemical modification Methods 0.000 description 1
- 239000007795 chemical reaction product Substances 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 229960002376 chymotrypsin Drugs 0.000 description 1
- 238000002983 circular dichroism Methods 0.000 description 1
- 238000000978 circular dichroism spectroscopy Methods 0.000 description 1
- 238000012411 cloning technique Methods 0.000 description 1
- 229920001436 collagen Polymers 0.000 description 1
- 238000011109 contamination Methods 0.000 description 1
- 238000010924 continuous production Methods 0.000 description 1
- 239000002872 contrast media Substances 0.000 description 1
- 238000013270 controlled release Methods 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 239000000287 crude extract Substances 0.000 description 1
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- 230000006240 deamidation Effects 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 230000007812 deficiency Effects 0.000 description 1
- 239000003398 denaturant Substances 0.000 description 1
- 239000005547 deoxyribonucleotide Substances 0.000 description 1
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 1
- 230000001627 detrimental effect Effects 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 239000010432 diamond Substances 0.000 description 1
- 235000014113 dietary fatty acids Nutrition 0.000 description 1
- 238000000113 differential scanning calorimetry Methods 0.000 description 1
- 238000009792 diffusion process Methods 0.000 description 1
- 102000004419 dihydrofolate reductase Human genes 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- 239000000539 dimer Substances 0.000 description 1
- 230000008034 disappearance Effects 0.000 description 1
- 208000016097 disease of metabolism Diseases 0.000 description 1
- 230000006806 disease prevention Effects 0.000 description 1
- 208000037765 diseases and disorders Diseases 0.000 description 1
- 230000002124 endocrine Effects 0.000 description 1
- 210000003890 endocrine cell Anatomy 0.000 description 1
- 210000001163 endosome Anatomy 0.000 description 1
- 229940032049 enterococcus faecalis Drugs 0.000 description 1
- 238000006911 enzymatic reaction Methods 0.000 description 1
- 230000001667 episodic effect Effects 0.000 description 1
- 150000002148 esters Chemical class 0.000 description 1
- 229920001249 ethyl cellulose Polymers 0.000 description 1
- 235000019325 ethyl cellulose Nutrition 0.000 description 1
- 230000005284 excitation Effects 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 238000002270 exclusion chromatography Methods 0.000 description 1
- 108010069982 exendin receptor Proteins 0.000 description 1
- 238000013401 experimental design Methods 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 229960004222 factor ix Drugs 0.000 description 1
- 239000003925 fat Substances 0.000 description 1
- 235000019197 fats Nutrition 0.000 description 1
- 229930195729 fatty acid Natural products 0.000 description 1
- 239000000194 fatty acid Substances 0.000 description 1
- 150000004665 fatty acids Chemical class 0.000 description 1
- 150000002191 fatty alcohols Chemical class 0.000 description 1
- 229940012952 fibrinogen Drugs 0.000 description 1
- 239000012530 fluid Substances 0.000 description 1
- 230000004907 flux Effects 0.000 description 1
- 235000013305 food Nutrition 0.000 description 1
- 238000005194 fractionation Methods 0.000 description 1
- 238000004108 freeze drying Methods 0.000 description 1
- 238000002825 functional assay Methods 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 238000002523 gelfiltration Methods 0.000 description 1
- 238000012239 gene modification Methods 0.000 description 1
- 230000005017 genetic modification Effects 0.000 description 1
- 235000013617 genetically modified food Nutrition 0.000 description 1
- 208000004104 gestational diabetes Diseases 0.000 description 1
- 230000001434 glomerular Effects 0.000 description 1
- UKVFVQPAANCXIL-FJVFSOETSA-N glp-1 (1-37) amide Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC=1NC=NC=1)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=CC=C1 UKVFVQPAANCXIL-FJVFSOETSA-N 0.000 description 1
- 108010063245 glucagon-like peptide 1 (7-36)amide Proteins 0.000 description 1
- 230000004190 glucose uptake Effects 0.000 description 1
- 125000002791 glucosyl group Chemical group C1([C@H](O)[C@@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 1
- 230000002641 glycemic effect Effects 0.000 description 1
- ZEMPKEQAKRGZGQ-XOQCFJPHSA-N glycerol triricinoleate Natural products CCCCCC[C@@H](O)CC=CCCCCCCCC(=O)OC[C@@H](COC(=O)CCCCCCCC=CC[C@@H](O)CCCCCC)OC(=O)CCCCCCCC=CC[C@H](O)CCCCCC ZEMPKEQAKRGZGQ-XOQCFJPHSA-N 0.000 description 1
- 239000003572 glycogen synthase kinase 3 inhibitor Substances 0.000 description 1
- 230000013595 glycosylation Effects 0.000 description 1
- 238000006206 glycosylation reaction Methods 0.000 description 1
- 239000003102 growth factor Substances 0.000 description 1
- 101150118163 h gene Proteins 0.000 description 1
- 210000002443 helper t lymphocyte Anatomy 0.000 description 1
- 239000000185 hemagglutinin Substances 0.000 description 1
- 230000023597 hemostasis Effects 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 230000013632 homeostatic process Effects 0.000 description 1
- 230000003054 hormonal effect Effects 0.000 description 1
- 229920001477 hydrophilic polymer Polymers 0.000 description 1
- 238000004191 hydrophobic interaction chromatography Methods 0.000 description 1
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 1
- 229910052588 hydroxylapatite Inorganic materials 0.000 description 1
- 229920003088 hydroxypropyl methyl cellulose Polymers 0.000 description 1
- 239000001866 hydroxypropyl methyl cellulose Substances 0.000 description 1
- 235000010979 hydroxypropyl methyl cellulose Nutrition 0.000 description 1
- 102000018358 immunoglobulin Human genes 0.000 description 1
- 239000002955 immunomodulating agent Substances 0.000 description 1
- 229940121354 immunomodulator Drugs 0.000 description 1
- 238000007901 in situ hybridization Methods 0.000 description 1
- 238000000099 in vitro assay Methods 0.000 description 1
- 239000000859 incretin Substances 0.000 description 1
- MGXWVYUBJRZYPE-YUGYIWNOSA-N incretin Chemical class C([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)[C@@H](C)O)[C@@H](C)CC)C1=CC=C(O)C=C1 MGXWVYUBJRZYPE-YUGYIWNOSA-N 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 238000002664 inhalation therapy Methods 0.000 description 1
- 230000005764 inhibitory process Effects 0.000 description 1
- ZPNFWUPYTFPOJU-LPYSRVMUSA-N iniprol Chemical compound C([C@H]1C(=O)NCC(=O)NCC(=O)N[C@H]2CSSC[C@H]3C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@H](C(N[C@H](C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=4C=CC(O)=CC=4)C(=O)N[C@@H](CC=4C=CC=CC=4)C(=O)N[C@@H](CC=4C=CC(O)=CC=4)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CSSC[C@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC=4C=CC=CC=4)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC2=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CSSC[C@H](NC(=O)[C@H](CC=2C=CC=CC=2)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H]2N(CCC2)C(=O)[C@@H](N)CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N2[C@@H](CCC2)C(=O)N2[C@@H](CCC2)C(=O)N[C@@H](CC=2C=CC(O)=CC=2)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N2[C@@H](CCC2)C(=O)N3)C(=O)NCC(=O)NCC(=O)N[C@@H](C)C(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@H](C(=O)N1)C(C)C)[C@@H](C)O)[C@@H](C)CC)=O)[C@@H](C)CC)C1=CC=C(O)C=C1 ZPNFWUPYTFPOJU-LPYSRVMUSA-N 0.000 description 1
- 208000014674 injury Diseases 0.000 description 1
- 230000006362 insulin response pathway Effects 0.000 description 1
- 230000017730 intein-mediated protein splicing Effects 0.000 description 1
- 229950000038 interferon alfa Drugs 0.000 description 1
- 230000000968 intestinal effect Effects 0.000 description 1
- 238000010255 intramuscular injection Methods 0.000 description 1
- 239000007927 intramuscular injection Substances 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- 101150100175 inuE gene Proteins 0.000 description 1
- 239000001573 invertase Substances 0.000 description 1
- 235000011073 invertase Nutrition 0.000 description 1
- 230000001788 irregular Effects 0.000 description 1
- 210000004153 islets of langerhan Anatomy 0.000 description 1
- 238000005304 joining Methods 0.000 description 1
- 229940039696 lactobacillus Drugs 0.000 description 1
- 229940072205 lactobacillus plantarum Drugs 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- 210000002429 large intestine Anatomy 0.000 description 1
- 210000005240 left ventricle Anatomy 0.000 description 1
- 230000021633 leukocyte mediated immunity Effects 0.000 description 1
- GDBQQVLCIARPGH-ULQDDVLXSA-N leupeptin Chemical compound CC(C)C[C@H](NC(C)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C=O)CCCN=C(N)N GDBQQVLCIARPGH-ULQDDVLXSA-N 0.000 description 1
- 108010052968 leupeptin Proteins 0.000 description 1
- 238000012417 linear regression Methods 0.000 description 1
- 230000029226 lipidation Effects 0.000 description 1
- 238000001638 lipofection Methods 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 238000011068 loading method Methods 0.000 description 1
- 239000008176 lyophilized powder Substances 0.000 description 1
- 239000006166 lysate Substances 0.000 description 1
- 230000002934 lysing effect Effects 0.000 description 1
- 210000003712 lysosome Anatomy 0.000 description 1
- 230000001868 lysosomic effect Effects 0.000 description 1
- 229920002521 macromolecule Polymers 0.000 description 1
- 230000014759 maintenance of location Effects 0.000 description 1
- 238000004949 mass spectrometry Methods 0.000 description 1
- 229950004994 meglitinide Drugs 0.000 description 1
- 238000002844 melting Methods 0.000 description 1
- 230000008018 melting Effects 0.000 description 1
- 230000003340 mental effect Effects 0.000 description 1
- 239000002207 metabolite Substances 0.000 description 1
- 229960000485 methotrexate Drugs 0.000 description 1
- 230000000813 microbial effect Effects 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 239000008108 microcrystalline cellulose Substances 0.000 description 1
- 235000019813 microcrystalline cellulose Nutrition 0.000 description 1
- 229940016286 microcrystalline cellulose Drugs 0.000 description 1
- 238000000520 microinjection Methods 0.000 description 1
- 230000005012 migration Effects 0.000 description 1
- 238000013508 migration Methods 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 230000000116 mitigating effect Effects 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 102000035118 modified proteins Human genes 0.000 description 1
- 108091005573 modified proteins Proteins 0.000 description 1
- 238000001823 molecular biology technique Methods 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- AEMBWNDIEFEPTH-UHFFFAOYSA-N n-tert-butyl-n-ethylnitrous amide Chemical compound CCN(N=O)C(C)(C)C AEMBWNDIEFEPTH-UHFFFAOYSA-N 0.000 description 1
- 239000013642 negative control Substances 0.000 description 1
- 229960004927 neomycin Drugs 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 238000007899 nucleic acid hybridization Methods 0.000 description 1
- 239000002853 nucleic acid probe Substances 0.000 description 1
- 238000001668 nucleic acid synthesis Methods 0.000 description 1
- 238000012803 optimization experiment Methods 0.000 description 1
- 239000003960 organic solvent Substances 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 239000005022 packaging material Substances 0.000 description 1
- 239000002540 palm oil Substances 0.000 description 1
- 239000012188 paraffin wax Substances 0.000 description 1
- 235000019809 paraffin wax Nutrition 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 230000008506 pathogenesis Effects 0.000 description 1
- 230000006320 pegylation Effects 0.000 description 1
- 239000008188 pellet Substances 0.000 description 1
- XYJRXVWERLGGKC-UHFFFAOYSA-D pentacalcium;hydroxide;triphosphate Chemical compound [OH-].[Ca+2].[Ca+2].[Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O XYJRXVWERLGGKC-UHFFFAOYSA-D 0.000 description 1
- 229940111202 pepsin Drugs 0.000 description 1
- 108010091212 pepstatin Proteins 0.000 description 1
- 229950000964 pepstatin Drugs 0.000 description 1
- FAXGPCHRFPCXOO-LXTPJMTPSA-N pepstatin A Chemical compound OC(=O)C[C@H](O)[C@H](CC(C)C)NC(=O)[C@H](C)NC(=O)C[C@H](O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C(C)C)NC(=O)CC(C)C FAXGPCHRFPCXOO-LXTPJMTPSA-N 0.000 description 1
- 230000002688 persistence Effects 0.000 description 1
- 235000019271 petrolatum Nutrition 0.000 description 1
- 229940127557 pharmaceutical product Drugs 0.000 description 1
- CWCMIVBLVUHDHK-ZSNHEYEWSA-N phleomycin D1 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC[C@@H](N=1)C=1SC=C(N=1)C(=O)NCCCCNC(N)=N)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C CWCMIVBLVUHDHK-ZSNHEYEWSA-N 0.000 description 1
- 150000003904 phospholipids Chemical class 0.000 description 1
- 229910052698 phosphorus Inorganic materials 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 230000001766 physiological effect Effects 0.000 description 1
- 230000006461 physiological response Effects 0.000 description 1
- 239000013600 plasmid vector Substances 0.000 description 1
- 229920000232 polyglycine polymer Polymers 0.000 description 1
- 238000006116 polymerization reaction Methods 0.000 description 1
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 1
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 1
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 1
- 239000011148 porous material Substances 0.000 description 1
- 229940071643 prefilled syringe Drugs 0.000 description 1
- 238000004321 preservation Methods 0.000 description 1
- 230000003449 preventive effect Effects 0.000 description 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 1
- 230000004845 protein aggregation Effects 0.000 description 1
- 108020001580 protein domains Proteins 0.000 description 1
- 239000003801 protein tyrosine phosphatase 1B inhibitor Substances 0.000 description 1
- 210000001938 protoplast Anatomy 0.000 description 1
- 230000002685 pulmonary effect Effects 0.000 description 1
- 229950010131 puromycin Drugs 0.000 description 1
- 238000011867 re-evaluation Methods 0.000 description 1
- 238000001525 receptor binding assay Methods 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 238000005215 recombination Methods 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 238000004064 recycling Methods 0.000 description 1
- 238000009877 rendering Methods 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 238000012827 research and development Methods 0.000 description 1
- 230000000241 respiratory effect Effects 0.000 description 1
- 230000003979 response to food Effects 0.000 description 1
- 230000002207 retinal effect Effects 0.000 description 1
- 238000004007 reversed phase HPLC Methods 0.000 description 1
- 239000002336 ribonucleotide Substances 0.000 description 1
- 125000002652 ribonucleotide group Chemical group 0.000 description 1
- 108020004418 ribosomal RNA Proteins 0.000 description 1
- 210000003705 ribosome Anatomy 0.000 description 1
- 108091092562 ribozyme Proteins 0.000 description 1
- 210000003296 saliva Anatomy 0.000 description 1
- 235000019515 salmon Nutrition 0.000 description 1
- 238000007423 screening assay Methods 0.000 description 1
- 230000000580 secretagogue effect Effects 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 239000012176 shellac wax Substances 0.000 description 1
- 239000013605 shuttle vector Substances 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- 210000000813 small intestine Anatomy 0.000 description 1
- 229940126586 small molecule drug Drugs 0.000 description 1
- 238000005063 solubilization Methods 0.000 description 1
- 230000007928 solubilization Effects 0.000 description 1
- NHXLMOGPVYXJNR-ATOGVRKGSA-N somatostatin Chemical compound C([C@H]1C(=O)N[C@H](C(N[C@@H](CO)C(=O)N[C@@H](CSSC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CC=2C3=CC=CC=C3NC=2)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(=O)N1)[C@@H](C)O)NC(=O)CNC(=O)[C@H](C)N)C(O)=O)=O)[C@H](O)C)C1=CC=CC=C1 NHXLMOGPVYXJNR-ATOGVRKGSA-N 0.000 description 1
- 229960000553 somatostatin Drugs 0.000 description 1
- 238000000527 sonication Methods 0.000 description 1
- 235000012424 soybean oil Nutrition 0.000 description 1
- 239000003549 soybean oil Substances 0.000 description 1
- 230000003595 spectral effect Effects 0.000 description 1
- 238000004611 spectroscopical analysis Methods 0.000 description 1
- 239000003381 stabilizer Substances 0.000 description 1
- 229940037649 staphylococcus haemolyticus Drugs 0.000 description 1
- 210000002784 stomach Anatomy 0.000 description 1
- 229940031000 streptococcus pneumoniae Drugs 0.000 description 1
- 238000010254 subcutaneous injection Methods 0.000 description 1
- 239000007929 subcutaneous injection Substances 0.000 description 1
- 239000000829 suppository Substances 0.000 description 1
- 230000001629 suppression Effects 0.000 description 1
- 230000004083 survival effect Effects 0.000 description 1
- 239000000725 suspension Substances 0.000 description 1
- 238000010189 synthetic method Methods 0.000 description 1
- 239000006188 syrup Substances 0.000 description 1
- 235000020357 syrup Nutrition 0.000 description 1
- 230000009885 systemic effect Effects 0.000 description 1
- 239000003760 tallow Substances 0.000 description 1
- 230000008685 targeting Effects 0.000 description 1
- 238000010998 test method Methods 0.000 description 1
- 229960002180 tetracycline Drugs 0.000 description 1
- 229930101283 tetracycline Natural products 0.000 description 1
- 235000019364 tetracycline Nutrition 0.000 description 1
- 150000003522 tetracyclines Chemical class 0.000 description 1
- 238000011287 therapeutic dose Methods 0.000 description 1
- 238000002560 therapeutic procedure Methods 0.000 description 1
- 150000001467 thiazolidinediones Chemical class 0.000 description 1
- 125000003396 thiol group Chemical group [H]S* 0.000 description 1
- 230000000699 topical effect Effects 0.000 description 1
- 239000003053 toxin Substances 0.000 description 1
- 231100000765 toxin Toxicity 0.000 description 1
- 108700012359 toxins Proteins 0.000 description 1
- 238000012549 training Methods 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 238000001890 transfection Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000014621 translational initiation Effects 0.000 description 1
- 230000005945 translocation Effects 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 1
- 239000012588 trypsin Substances 0.000 description 1
- 229960001322 trypsin Drugs 0.000 description 1
- 238000010798 ubiquitination Methods 0.000 description 1
- 230000034512 ubiquitination Effects 0.000 description 1
- 241000701447 unidentified baculovirus Species 0.000 description 1
- 230000003827 upregulation Effects 0.000 description 1
- 229960005486 vaccine Drugs 0.000 description 1
- 235000015112 vegetable and seed oil Nutrition 0.000 description 1
- 239000008158 vegetable oil Substances 0.000 description 1
- 210000003501 vero cell Anatomy 0.000 description 1
- 229940118696 vibrio cholerae Drugs 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- 239000001993 wax Substances 0.000 description 1
- 230000036642 wellbeing Effects 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/575—Hormones
- C07K14/605—Glucagons
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
- A61P1/04—Drugs for disorders of the alimentary tract or the digestive system for ulcers, gastritis or reflux esophagitis, e.g. antacids, inhibitors of acid secretion, mucosal protectants
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
- A61P1/12—Antidiarrhoeals
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
- A61P1/16—Drugs for disorders of the alimentary tract or the digestive system for liver or gallbladder disorders, e.g. hepatoprotective agents, cholagogues, litholytics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P11/00—Drugs for disorders of the respiratory system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P13/00—Drugs for disorders of the urinary system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P13/00—Drugs for disorders of the urinary system
- A61P13/02—Drugs for disorders of the urinary system of urine or of the urinary tract, e.g. urine acidifiers
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P13/00—Drugs for disorders of the urinary system
- A61P13/12—Drugs for disorders of the urinary system of the kidneys
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P19/00—Drugs for skeletal disorders
- A61P19/02—Drugs for skeletal disorders for joint disorders, e.g. arthritis, arthrosis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P19/00—Drugs for skeletal disorders
- A61P19/08—Drugs for skeletal disorders for bone diseases, e.g. rachitism, Paget's disease
- A61P19/10—Drugs for skeletal disorders for bone diseases, e.g. rachitism, Paget's disease for osteoporosis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/28—Drugs for disorders of the nervous system for treating neurodegenerative disorders of the central nervous system, e.g. nootropic agents, cognition enhancers, drugs for treating Alzheimer's disease or other forms of dementia
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/04—Anorexiants; Antiobesity agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/06—Antihyperlipidemics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/08—Drugs for disorders of the metabolism for glucose homeostasis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/08—Drugs for disorders of the metabolism for glucose homeostasis
- A61P3/10—Drugs for disorders of the metabolism for glucose homeostasis for hyperglycaemia, e.g. antidiabetics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
- A61P9/04—Inotropic agents, i.e. stimulants of cardiac contraction; Drugs for heart failure
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
- A61P9/10—Drugs for disorders of the cardiovascular system for treating ischaemic or atherosclerotic diseases, e.g. antianginal drugs, coronary vasodilators, drugs for myocardial infarction, retinopathy, cerebrovascula insufficiency, renal arteriosclerosis
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
- A61P9/12—Antihypertensives
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/575—Hormones
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/575—Hormones
- C07K14/57563—Vasoactive intestinal peptide [VIP]; Related peptides
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/70—Vectors or expression systems specially adapted for E. coli
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P21/00—Preparation of peptides or proteins
- C12P21/02—Preparation of peptides or proteins having a known sequence of two or more amino acids, e.g. glutathione
-
- A—HUMAN NECESSITIES
- A23—FOODS OR FOODSTUFFS; TREATMENT THEREOF, NOT COVERED BY OTHER CLASSES
- A23V—INDEXING SCHEME RELATING TO FOODS, FOODSTUFFS OR NON-ALCOHOLIC BEVERAGES AND LACTIC OR PROPIONIC ACID BACTERIA USED IN FOODSTUFFS OR FOOD PREPARATION
- A23V2200/00—Function of food ingredients
- A23V2200/30—Foods, ingredients or supplements having a functional effect on health
- A23V2200/328—Foods, ingredients or supplements having a functional effect on health having effect on glycaemic control and diabetes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/31—Fusion polypeptide fusions, other than Fc, for prolonged plasma life, e.g. albumin
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/50—Fusion polypeptide containing protease site
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Medicinal Chemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Pharmacology & Pharmacy (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Animal Behavior & Ethology (AREA)
- Genetics & Genomics (AREA)
- Zoology (AREA)
- Biochemistry (AREA)
- Molecular Biology (AREA)
- Endocrinology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biophysics (AREA)
- Gastroenterology & Hepatology (AREA)
- Diabetes (AREA)
- Toxicology (AREA)
- Biomedical Technology (AREA)
- Cardiology (AREA)
- Wood Science & Technology (AREA)
- Physical Education & Sports Medicine (AREA)
- Urology & Nephrology (AREA)
- Obesity (AREA)
- Hematology (AREA)
- Heart & Thoracic Surgery (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- Vascular Medicine (AREA)
- Orthopedic Medicine & Surgery (AREA)
- Neurology (AREA)
- Neurosurgery (AREA)
- Rheumatology (AREA)
Abstract
Un acido nucleico aislado que comprende una secuencia de polinucleotido que codifica una proteina de fusion, que comprende un peptido regulador de la glucosa (GP), en donde la secuencia de polinucleotido (i) comprende una secuencia que hibrida en condiciones rigurosas con AE864 de la tabla 9 (SEQ ID NO: 243) o Ex4-AE864 de la tabla 36 (SEQ ID NO: 897) o el complemento de las mismas y tiene al menos un 70 % de identidad de secuencia o un 80 % o un 90 % o un 95 % o un 97 % o un 98 % o un 99 % hasta un 100 % de identidad de secuencia respecto de AE864 de la tabla 9 (SEQ ID NO: 243) o Ex4-AE864 de la tabla 36 (SEQ ID NO: 897) o el complemento de las mismas, y (ii) codifica una proteina de fusion que comprende (a) exendina-4 y que tiene una secuencia de aminoacidos que muestra al menos un 95 % de identidad de secuencia respecto de Ex4-AE864 de la tabla 36 (SEQ ID NO: 896) o (b) GLP-1 y que tiene una secuencia de aminoacidos que muestra al menos un 95 % de identidad de secuencia respecto de GLP1-AE864 de la tabla 36 (SEQ ID NO: 986) y que conserva al menos una parte de la actividad biologica del GP nativo.
Description
DESCRIPCIÓN
Polipéptidos reguladores de glucosa y métodos para su producción y uso
DECLARACIÓN CON RESPECTO A LA INVESTIGACIÓN CON FONDOS FEDERALES
La presente invención se realizó con soporte del gobierno con la subvención SBIR 2R44GM079873-02, otorgada por el National Institutes of Health. El Gobierno tiene ciertos derechos sobre la presente invención.
REFERENCIA CRUZADA A SOLICITUDES RELACIONADAS
La presente solicitud reivindica el beneficio de prioridad de las Solicitudes Provisionales de los Estados Unidos con n.° de serie 61/268.193, presentada el 8 de junio de 2009, 61/236.836, presentada el 25 de agosto de 2009, 61/280.955, presentada el 10 de noviembre de 2009 y la Solicitud de los Estados Unidos con n.° de serie 12/699.761 y la Solicitud PCT con n.° de serie PCT/US10/23106, ambas presentadas el 3 de febrero de 2010.
Antecedentes de la invención
Los péptidos reguladores de glucosa son componentes reguladores clave del metabolismo humano. Se han descrito diversos péptidos con efectos biológicos que dan como resultado o un aumento o una reducción en los niveles séricos de glucosa. Estos péptidos tienden a ser altamente homólogos entre sí, incluso cuando poseen funciones biológicas opuestas. Muchos péptidos reguladores de glucosa, incluyendo aquellos usados como agentes terapéuticos, normalmente son moléculas lábiles que muestran semividas cortas, en particular cuando se formulan en soluciones acuosas. Además, muchos péptidos reguladores de glucosa tienen una solubilidad limitada o se agregan durante la producción recombinante, lo que requiere complejos procedimientos de solubilización y replegado. Pueden unirse diversos polímeros químicos a dichos péptidos y proteínas para modificar sus propiedades. Son particularmente interesantes los polímeros hidrófilos que tienen conformaciones flexibles y se hidratan bien en soluciones acuosas. Un polímero frecuentemente usado es el polietilenglicol (PEG). Estos polímeros tienen tendencia a tener grandes radios hidrodinámicos en relación con su peso molecular (Kubetzko, S., et al. (2005) Mol Pharmacol, 68: 1439-54) y pueden dar como resultado propiedades farmacocinéticas potenciadas. Sin embargo, la conjugación química de los polímeros con proteínas requiere complejos procesos en múltiples etapas; normalmente, el componente de proteína ha de producirse y purificarse antes de la etapa de conjugación química y la etapa de conjugación puede dar como resultado la formación de mezclas de productos heterogéneos que han de separarse, lo que da lugar a una pérdida de producto significativa. Como alternativa, dichas mezclas pueden usarse como el producto farmacéutico final, pero son difíciles de estandarizar. Algunos ejemplos son los productos de interferón alfa PEGilado comercializados en la actualidad que se usan como mezclas (Wang, B. L., et al. (1998) J Submicrosc Cytol Pathol, 30: 503-9; Dhalluin, C., et al. (2005) Bioconjug Chem, 16: 504-17). Dichas mezclas son difíciles de fabricar de manera reproducible y se caracterizan por contener isómeros con una actividad terapéutica reducida o nula. Lee et al describen la síntesis, caracterización y estudios farmacocinéticos del péptido-1 similar a glucagón PEGilado (Bioconjugate Chem. 2005, 16, 377-382).
Se han usado albúmina y fragmentos de inmunoglobulina, tales como regiones Fc, para conjugar otras proteínas biológicamente activas, con resultados impredecibles respecto a los aumentos en la semivida o la inmunogenicidad. Lamentablemente, el dominio Fc no se pliega de manera eficaz durante la expresión recombinante y tiende a formar precipitados insolubles conocidos como cuerpos de inclusión. Estos cuerpos de inclusión han de solubilizarse y la proteína funcional ha de renaturalizarse. Este es un proceso laborioso, ineficaz y costoso que requiere etapas de fabricación adicional y normalmente complejos procedimientos de purificación.
Por tanto, sigue habiendo una necesidad significativa de composiciones y métodos que puedan mejorar las propiedades biológicas, farmacológicas, de seguridad y/o farmacéuticas de los péptidos reguladores de la glucosa.
Sumario
La presente divulgación se refiere a composiciones y métodos que pueden ser útiles para el tratamiento de cualquier enfermedad, trastorno o afección que se mejore, alivie o inhiba mediante la administración de un péptido regulador de la glucosa. En particular, la presente invención proporciona composiciones de proteínas de fusión, como se definen en las reivindicaciones, que comprenden uno o más polipéptidos recombinantes extendidos con una secuencia no repetitiva y/o una conformación no estructurada (XTEN) unidos a péptido regulador de glucosa (GP). En parte, la presente divulgación se refiere a composiciones farmacéuticas que comprenden las proteínas de fusión y los usos de las mismas para tratar enfermedades, trastornos o afecciones relacionadas con el péptido regulador de glucosa.
En un aspecto, la invención proporciona una proteína de fusión de acuerdo con la reivindicación 8. En una realización, el péptido regulador de glucosa de la proteína de fusión es péptido regulador de glucosa humano. En otra realización, la proteína de fusión aislada comprende al menos un segundo XTEN, en donde la proteína de fusión adopta una configuración de múltiples XTEN mostrada en la tabla 5 o una variante de la misma.
En otra realización, la secuencia de XTEN de las proteínas de fusión GPXTEN se caracteriza por que tiene más de un
90 % de formación de bucle aleatorio o aproximadamente un 95 % o aproximadamente un 96 % o aproximadamente un 97 % o aproximadamente un 98 % o aproximadamente un 99 % de conformación de bucle aleatorio, según se determina mediante el algoritmo GOR; y la secuencia de XTEN tiene menos de un 2 % de hélices alfa y un 2 % de hélices beta, según se determina mediante el algoritmo de Chou-Fasman.
En otra realización, la invención proporciona proteínas de fusión GPXTEN, en donde el XTEN se caracteriza por que la suma de restos de asparagina y glutamina es menor del 10 % de la secuencia de aminoácidos total del XTEN, la suma de restos de metionina y triptófano es menor del 2 % de la secuencia de aminoácidos total del XTEN, la secuencia de XTEN tiene menos de un 5 % de restos de aminoácido con una carga positiva, la secuencia de XTEN tiene más de un 90 % de formación de bucle aleatorio o aproximadamente un 95 % o aproximadamente un 96 % o aproximadamente un 97 % o aproximadamente un 98 % o aproximadamente un 99 % de conformación de bucle aleatorio, según se determina mediante el algoritmo GOR; y la secuencia de XTEN tiene menos de un 2 % de hélices alfa y un 2 % de hélices beta, según se determina mediante el algoritmo de Chou-Fasman.
En otra realización, la invención proporciona proteínas de fusión GPXTEN, en donde el XTEN se caracteriza por que al menos aproximadamente un 80 % o al menos aproximadamente un 90 % o al menos aproximadamente un 91 al menos aproximadamente un 92 % o al menos aproximadamente un 93 % o al menos aproximadamente un 94 al menos aproximadamente un 95 % o al menos aproximadamente un 96 % o al menos aproximadamente un 97 al menos aproximadamente un 98 % o al menos aproximadamente un 99 % de la secuencia de XTEN consiste en motivos de secuencia no solapantes, en donde cada uno de los motivos de secuencia tiene de aproximadamente 9 a aproximadamente 14 restos de aminoácido y en donde la secuencia de cualesquiera dos restos de aminoácidos contiguos no se produce más de dos veces en cada uno de los motivos de secuencia, consistiendo los motivos de secuencia en de dos a seis tipos de aminoácido seleccionados entre glicina (G), alanina (A), serina (S), treonina (T), glutamato (E) y prolina (P).
En algunas realizaciones, ningún tipo de aminoácido forma más de un 30 % de la secuencia de XTEN de la GPXTEN.
En otras realizaciones, el XTEN tiene una secuencia en la que no hay tres aminoácidos contiguos idénticos, salvo que el aminoácido sea serina, en cuyo caso no serán restos de serina más de tres aminoácidos contiguos. En otras realizaciones adicionales, al menos aproximadamente un 80 % o aproximadamente un 90 % o aproximadamente un
95 % o aproximadamente un 96 % o aproximadamente un 97 % o aproximadamente un 98 % o aproximadamente un
99 % o un 100 % de la secuencia de XTEN consiste en motivos de secuencia no solapantes, en donde cada uno de los motivos de secuencia tiene 12 restos de aminoácido. En una realización, la secuencia de XTEN consiste en motivos de secuencia no solapante, en donde los motivos de secuencia son de una o más secuencias de la tabla 2.
En algunas realizaciones, las proteínas de fusión GPXTEN muestran propiedades farmacocinéticas mejoradas en comparación con GP no unido a XTEN, en donde las propiedades mejoradas incluyen, pero sin limitación, una semivida terminal más prolongada, mayor área bajo la curva, aumento del tiempo en el que la concentración en sangre permanece dentro de la ventana terapéutica, aumento del tiempo entre dosis consecutivas y reducción de moles de dosis con el paso del tiempo. En algunas realizaciones, la semivida terminal de la proteína de fusión GPXTEN administrada a un sujeto aumenta en al menos aproximadamente dos veces o al menos aproximadamente tres veces o al menos aproximadamente cuatro veces o al menos aproximadamente cinco veces o al menos aproximadamente seis veces o al menos aproximadamente ocho veces o al menos aproximadamente diez veces o al menos aproximadamente 20 veces o al menos aproximadamente 40 veces o al menos aproximadamente 60 veces o al menos aproximadamente 100 veces en comparación con GP no unido a XTEN y administrado a un sujeto a una dosis comparable. En otras realizaciones, la propiedad farmacocinética mejorada se refleja por el hecho de que las concentraciones en sangre que permanecen dentro de la ventana terapéutica para la proteína de fusión GPXTEN durante un periodo dado son al menos aproximadamente dos veces o al menos aproximadamente tres veces o al menos aproximadamente cuatro veces o al menos aproximadamente cinco veces o al menos aproximadamente seis veces o al menos aproximadamente ocho veces o al menos aproximadamente diez veces mayores o al menos aproximadamente 20 veces o al menos aproximadamente 40 veces o al menos aproximadamente 60 veces o al menos aproximadamente 100 veces o incluso mayores en comparación con GP no unido a XTEN y administrado a un sujeto a una dosis comparable. El aumento de la semivida y el tiempo empleado dentro de la ventana terapéutica permite una dosificación menos frecuente y menores cantidades de la proteína de fusión (en equivalentes de moles) que se administran a un sujeto, en comparación con el GP correspondiente no unido a XTEN. En una realización, la pauta posológica terapéuticamente eficaz da como resultado una ganancia de tiempo de al menos dos veces o al menos tres veces o al menos cuatro veces o al menos cinco veces o al menos seis veces o al menos ocho veces o al menos
10 veces o al menos aproximadamente 20 veces o al menos aproximadamente 40 veces o al menos aproximadamente
60 veces o al menos aproximadamente 100 veces entre al menos dos picos de Cmáx y/o mínimos de Cmín consecutivos para los niveles en sangre de la proteína de fusión en comparación con el GP correspondiente no unido a la proteína de fusión y administrado usando una pauta posológica comparable a un sujeto.
En algunas realizaciones, el XTEN mejora la estabilidad térmica de una proteína biológicamente activa cuando se une a una proteína biológicamente activa, en donde la estabilidad térmica se determina midiendo la conservación de actividad biológica de la proteína biológicamente activa tras su exposición a una temperatura de aproximadamente
37 °C durante al menos aproximadamente 7 días, en comparación con el XTEN unido a la proteína biológicamente activa. En una realización de lo anterior, la conservación de la actividad biológica aumenta en al menos
aproximadamente un 50 %, al menos aproximadamente un 60 %, al menos aproximadamente un 70 %, al menos aproximadamente un 80 %, al menos aproximadamente un 90 %, al menos aproximadamente un 100 % o aproximadamente un 150 %, al menos aproximadamente un 200 %, al menos aproximadamente un 300 % o aproximadamente un 500 % mayor en comparación con el GP no unido al XTEN.
Como se define adicionalmente en las reivindicaciones, la proteína de fusión con al menos un primer XTEN comprende un GP, en donde el GP es el péptido regulador de glucosa humano. En algunas realizaciones, la proteína de fusión aislada comprende además un segundo XTEN, que puede ser idéntico o puede ser diferente al primer XTEN y en donde la proteína de fusión adopta una configuración de múltiples XTEN mostrada en la tabla 7. En una realización de lo anterior, el primer y el segundo XTEN pueden ser cada uno una secuencia seleccionada de la tabla 5 o puede mostrar al menos aproximadamente un 80 % o al menos aproximadamente un 90 % o al menos aproximadamente un 91 % o al menos aproximadamente un 92 % o al menos aproximadamente un 93 % o al menos aproximadamente un 94 % o al menos aproximadamente un 95 % o al menos aproximadamente un 96 % o al menos aproximadamente un 97 % o al menos aproximadamente un 98 % o al menos aproximadamente un 99 % o un 100 % de identidad de secuencia respecto de una secuencia seleccionada de la tabla 5. En otra realización, la proteína de fusión que comprende una segunda secuencia de XTEN adopta una configuración de múltiples XTEN mostrada en la tabla 7.
En una realización, la proteína de fusión aislada es menos inmunogénica en comparación con GP no unido al XTEN, en donde la inmunogenicidad se determina, por ejemplo, midiendo la producción de anticuerpos IgG que se unen de manera selectiva a la proteína biológicamente activa tras la administración de dosis comparables a un sujeto.
En algunas realizaciones, el péptido regulador de glucosa y el XTEN de la proteína de fusión se unen mediante un espaciador, en donde la secuencia espaciadora comprende entre aproximadamente 1 a aproximadamente 50 restos de aminoácidos que opcionalmente comprende una secuencia de escisión. En una realización, la secuencia de escisión es susceptible a la escisión por una proteasa. Los ejemplos no limitantes de dicha proteasa incluyen FXIa, FXIIa, calicreína, FVIIa, FIXa, FXa, trombina, elastasa-2, granzima B, MMP-12, MMP-13, m Mp -17 o MMP-20, TEV, enterocinasa, proteasa 3C de rinovirus y sortasa A.
En algunas realizaciones, la proteína de fusión aislada se configura para que tenga afinidad de unión reducida por un receptor diana del GP correspondiente, en comparación con el GP correspondiente no unido a la proteína de fusión.
En una realización, la proteína de fusión XTEN muestra una afinidad de unión por un receptor diana del GP en el intervalo de aproximadamente un 0,01 %-30 % o de aproximadamente un 0,1 % a aproximadamente un 20 % o de aproximadamente un 1 % a aproximadamente un 15 % o de aproximadamente un 2 % a aproximadamente un 10 % de la afinidad de unión del Gp correspondiente que carece del XTEN. En otra realización, la proteína de fusión GPXTEN muestra una afinidad de unión por un receptor diana del GP que se reduce en al menos aproximadamente 3 veces o al menos aproximadamente 5 veces o al menos aproximadamente 6-fold o al menos aproximadamente 7 veces o al menos aproximadamente 8 veces o al menos aproximadamente 9 veces o al menos aproximadamente 10 veces o al menos aproximadamente 12 veces o al menos aproximadamente 15 veces o al menos aproximadamente 17 veces o al menos aproximadamente 20 veces o al menos aproximadamente 30 veces o al menos aproximadamente 50 veces o al menos aproximadamente 100 veces menos afinidad de unión en comparación con GP no unido a XTEN.
En una realización relacionada, una proteína de unión con afinidad reducida puede tener una eliminación mediada por receptor reducida y un aumento correspondiente en la semivida de al menos aproximadamente 3 veces o al menos aproximadamente 5 veces o al menos aproximadamente 6 veces o al menos aproximadamente 7 veces o al menos aproximadamente 8 veces o al menos aproximadamente 9 veces o al menos aproximadamente 10 veces o al menos aproximadamente 12 veces o al menos aproximadamente 15 veces o al menos aproximadamente 17 veces o al menos aproximadamente 20 veces o al menos aproximadamente 30 veces o al menos aproximadamente 50 veces o al menos aproximadamente 100 veces mayor en comparación con el GP correspondiente que no está unido a la proteína de fusión.
En una realización, la invención proporciona una proteína de fusión GPXTEN aislada como se define por las reivindicaciones, que comprende una secuencia de aminoácidos que tiene al menos aproximadamente un 80 % o al menos aproximadamente un 90 % o al menos aproximadamente un 91 % o al menos aproximadamente un 92 % o al menos aproximadamente un 93 % o al menos aproximadamente un 94 % o al menos aproximadamente un 95 % o al menos aproximadamente un 96 % o al menos aproximadamente un 97 % o al menos aproximadamente un 98 % o al menos aproximadamente un 99 % o un 100 % de identidad de secuencia respecto de una secuencia seleccionada de la tabla 35, la tabla 36 y la tabla 37.
En algunas realizaciones, la invención proporciona proteínas de fusión GPXTEN, en donde la GPXTEN muestra una solubilidad aumentada de al menos tres veces o al menos aproximadamente cuatro veces o al menos aproximadamente cinco veces o al menos aproximadamente seis veces o al menos aproximadamente siete veces o al menos aproximadamente ocho veces o al menos aproximadamente nueve veces o la menos aproximadamente diez veces o al menos aproximadamente 15 veces o al menos 20 veces o al menos 40 veces o al menos 60 veces en condiciones fisiológicas, en comparación con el GP no unido a la proteína de fusión.
En algunas realizaciones, las proteínas de fusión GPXTEN muestran un peso molecular aparente aumentado, determinado mediante cromatografía por exclusión por tamaños, en comparación con el peso molecular real, en donde
el peso molecular aparente es de al menos aproximadamente 100 kD o al menos aproximadamente 150 kD o al menos aproximadamente 200 kD o al menos aproximadamente 300 kD o al menos aproximadamente 400 kD o al menos aproximadamente 500 kD o al menos aproximadamente 600 kD o al menos aproximadamente 700 kD, mientras que el peso molecular para cada componente de GP de la proteína de fusión es de menos de aproximadamente 25 kD. Por consiguiente, las proteínas de fusión GPXTEN pueden tener un peso molecular aparente que se aproximadamente 4 veces mayor o aproximadamente 5 veces mayor o aproximadamente 6 veces mayor o aproximadamente 7 veces mayor o aproximadamente 8 veces mayor que el peso molecular real de la proteína de fusión. En algunos casos, la proteína de fusión GPXTEN de las realizaciones anteriores muestra un factor de peso molecular aparente en condiciones fisiológicas que es mayor de aproximadamente 4 o aproximadamente 5 o aproximadamente 6 o aproximadamente 7 o aproximadamente 8.
También se divulgan en el presente documento composiciones de proteínas de fusión GPXTEN que comprenden, pero sin limitación, GP seleccionado de la tabla 1 (o fragmentos o variantes de secuencia del mismo), XTEN seleccionado de la tabla 5 (o variantes de secuencia del mismo) que se encuentran en una configuración seleccionada de la tabla 5. En general, la GPXTEN resultante conservará al menos parte de la actividad biológica del GP correspondiente no unido al XTEN. En otros casos, el componente GP o bien se vuelve biológicamente activo o tiene un aumento en su actividad tras su liberación del XTEN mediante la escisión de una secuencia de escisión opcional incorporada en las secuencias espaciadoras en la GPXTEN.
En una realización de la composición de GPXTEN, la invención proporciona una proteína de fusión de fórmula I:
(XTEN)x-GP-(XTEN)y I
en donde independientemente para cada aparición, GP es un péptido regulador de glucosa; x es 0 o 1 e y es 0 o 1, en donde x+y >1; y XTEN es un polipéptido recombinante extendido.
En algunas realizaciones, el XTEN se fusiona al péptido regulador de glucosa en un extremo N o C-terminal del péptido regulador de glucosa. También se divulga en el presente documento una proteína de fusión aislada que comprende un péptido regulador de glucosa humano y un primer y un segundo XTEN seleccionados entre AE912, AM923, AE144 y AE288.
En otra realización de la composición de GPXTEN, la invención reivindicada proporciona una proteína de fusión de fórmula II:
(XTEN)x-(GP)-(S)y-(XTEN)y II
en donde independientemente para cada aparición, GP es un péptido regulador de glucosa; S es una secuencia espaciadora que tiene entre 1 y aproximadamente 50 restos de aminoácido que puede incluir opcionalmente una secuencia de escisión; x es 0 o 1 e y es 0 o 1, en donde x+y >1; y XTEN es un polipéptido recombinante extendido. Las características adicionales de la invención son acordes con las reivindicaciones.
En otra realización, la invención reivindicada proporciona una proteína de fusión aislada, en donde la proteína de fusión es de fórmula III:
(GP)-(S)x-(XTEN)-(S)y-(GP)-(S)z-(XTEN)z III
en donde independientemente para cada aparición, GP es un péptido regulador de glucosa; S es una secuencia espaciadora que tiene entre 1 y aproximadamente 50 restos de aminoácido que puede incluir opcionalmente una secuencia de escisión; x es 0 o 1; y es 0 o 1; z es 0 o 1; y XTEN es un polipéptido recombinante extendido.
En otra realización, la invención reivindicada proporciona una proteína de fusión aislada, en donde la proteína de fusión es de fórmula IV:
(XTEN)x-(S)y-(GP)-(S)z-(XTEN)-(GP) IV
en donde independientemente para cada aparición, GP es un péptido regulador de glucosa; S es una secuencia espaciadora que tiene entre 1 y aproximadamente 50 restos de aminoácido que puede incluir opcionalmente una secuencia de escisión; x es 0 o 1; y es 0 o 1; z es 0 o 1; y XTEN es un polipéptido recombinante extendido.
En otra realización, la invención reivindicada proporciona un péptido regulador de glucosa de fusión aislado, en donde la proteína de fusión es de fórmula V:
(G P)x-(S)x-(GP)-(S)y-(XTEN) V
en donde independientemente para cada aparición, GP es un péptido regulador de glucosa; S es una secuencia espaciadora que tiene entre 1 y aproximadamente 50 restos de aminoácido que puede incluir opcionalmente una
secuencia de escisión; x es 0 o 1; y es 0 o 1; y XTEN es un polipéptido recombinante extendido.
En otra realización, la invención reivindicada proporciona una proteína de fusión aislada, en donde la proteína de fusión es de fórmula VI:
(XTEN)-(S)x-(GP)-(S)y-(GP) VI
en donde independientemente para cada aparición, GP es un péptido regulador de glucosa; S es una secuencia espaciadora que tiene entre 1 y aproximadamente 50 restos de aminoácido que puede incluir opcionalmente una secuencia de escisión; x es 0 o 1; y es 0 o 1; y XTEN es un polipéptido recombinante extendido.
En otra realización, la invención reivindicada proporciona una proteína de fusión aislada, en donde la proteína de fusión es de fórmula VII:
(XTEN)-(S)x-(GP)-(S)y-(GP)-(XTEN) VII
en donde independientemente para cada aparición, GP es un péptido regulador de glucosa; S es una secuencia espaciadora que tiene entre 1 y aproximadamente 50 restos de aminoácido que puede incluir opcionalmente una secuencia de escisión; x es 0 o 1; y es 0 o 1; y XTEN es un polipéptido recombinante extendido.
En otra realización, la invención reivindicada proporciona una proteína de fusión aislada, en donde la proteína de fusión es de fórmula VIII:
((S)m-(GP)x-(S)n-(XTEN)y-(S)o)t VIII
en donde t es un número entero mayor de 0 (1, 2, 3, etc.); independientemente, cada uno de m, n, o, x e y es un número entero (0, 1, 2, 3, etc.), GP es un péptido regulador de glucosa; S es un espaciador, que comprende opcionalmente un sitio de escisión; y XTEN es un polipéptido recombinante extendido, a condición de que: (1) x+y > 1, (2) cuando t = 1, x>0 e y>0, (3) cuando hay más de un GP, S o XTEN, cada uno de GP, XTEN o S son iguales o son diferentes de manera independiente; y (4) cuando t >1, cada uno de m, n, o, x o y dentro de cada subunidad son iguales o son diferentes de manera independiente.
La administración de una dosis terapéuticamente eficaz de una proteína de fusión de una realización de las fórmulas I-VIII a un sujeto que lo necesite puede dar como resultado una ganancia de tiempo de al menos dos veces o al menos tres veces o al menos cuatro veces o al menos cinco veces o más empleadas dentro de una ventana terapéutica para la proteína de fusión en comparación con el GP correspondiente no unido al XTEN y administrado con una dosis comparable a un sujeto. En otros casos, la administración de una dosis terapéuticamente eficaz de una proteína de fusión de una realización de las fórmulas I-VIII a un sujeto que lo necesite puede dar como resultado una ganancia de tiempo entre las dosis consecutivas necesarias para mantener una pauta posológica terapéuticamente eficaz de al menos 48 h o al menos 72 h o al menos aproximadamente 96 h o al menos aproximadamente 120 h o al menos aproximadamente 7 días o al menos aproximadamente 14 días o al menos aproximadamente 21 días entre dosis consecutivas en comparación con un GP no unido a XTEN y administrado con una dosis comparable.
Las proteínas de fusión pueden diseñarse para que tengan diferentes configuraciones, de N a C-terminal, de un GP, XTEN y secuencias espaciadoras opcionales,, incluyendo, pero sin limitación, XTEN-GP, GP-XTEN, XTEN-S-GP, GP-S-XTEN, XTEN-GP-XTEN, GP-GP-XTEN, XTEN-GP-GP, GP-S-GP-XTEN, XTEN-GP-S-GP y multímeros de los mismos o encontrarse en una configuración mostrada en la tabla 7. La elección de configuración puede, como se describe en el presente documento, conferir propiedades farmacocinéticas, fisicoquímicas o farmacológicas particulares.
En algunas realizaciones, la proteína de fusión aislada se caracteriza por que: (i) tiene una semivida más larga en comparación con el péptido regulador de glucosa correspondiente que carece del XTEN; (ii) cuando se administra una cantidad molar menor de la proteína de fusión a un sujeto en comparación con el péptido regulador de glucosa correspondiente que carece del XTEN administrado a un sujeto con una pauta posológica por lo demás equivalente, la proteína de fusión logra un área bajo la curva (ABC) comparable en relación con el péptido regulador de glucosa correspondiente que carece del XTEN; (iii) cuando se administra una cantidad molar menor de la proteína de fusión a un sujeto en comparación con el péptido regulador de glucosa correspondiente que carece del XTEN administrado a un sujeto con una pauta posológica por lo demás equivalente, la proteína de fusión logra un efecto terapéutico comparable al del péptido regulador de glucosa correspondiente que carece de XTEN; (iv) cuando se administra la proteína de fusión a un sujeto con menor frecuencia en comparación con el péptido regulador de glucosa correspondiente que carece del XTEN administrado a un sujeto usando una cantidad molar por lo demás equivalente, la proteína de fusión logra un área bajo la curva (ABC) comparable en relación con el péptido regulador de glucosa correspondiente que carece del XTEN; (v) cuando se administra la proteína de fusión a un sujeto con menor frecuencia en comparación con el péptido regulador de glucosa correspondiente que carece del XTEN administrado a un sujeto usando una cantidad molar por lo demás equivalente, la proteína de fusión logra un efecto terapéutico comparable al del péptido regulador de glucosa correspondiente que carece de XTEN; (vi) cuando se administra una cantidad molar
acumulativa menor de la proteína de fusión a un sujeto en comparación con el péptido regulador de glucosa correspondiente que carece del XTEN administrado a un sujeto en un periodo de dosificación por lo demás equivalente, la proteína de fusión logra un área bajo la curva (ABC) comparable en relación con el péptido regulador de glucosa correspondiente que carece del XTEN; o (vii) cuando se administra una cantidad molar acumulativa menor de la proteína de fusión a un sujeto en comparación con el péptido regulador de glucosa correspondiente que carece del XTEN administrado a un sujeto en un periodo de dosificación por lo demás equivalente, la proteína de fusión logra un efecto terapéutico comparable al del péptido regulador de glucosa correspondiente que carece de XTEN.
En una realización, las proteínas de fusión GPXTEN de las fórmulas I-VIII descritas anteriormente muestran una actividad biológica de al menos aproximadamente un 0,1 % o al menos aproximadamente un 1 % o al menos aproximadamente un 2 % o al menos aproximadamente un 3 % o al menos aproximadamente un 4 % o al menos aproximadamente un 5 % o al menos aproximadamente un 10 % o al menos aproximadamente un 20 % o al menos aproximadamente un 30 % o al menos un 40 % o al menos aproximadamente un 50 % o al menos aproximadamente un 60 % o al menos aproximadamente un 70 % o al menos aproximadamente un 80 % o al menos aproximadamente un 90 % o al menos aproximadamente un 95 % de la actividad biológica comparada con el GEP no unido a la proteína de fusión. En otra realización, las proteínas de fusión GPXTEN de las fórmulas I-VIII se unen a los mismos receptores que el GP parental correspondiente que no está unido covalentemente a la proteína de fusión.
La invención proporciona un método para producir una proteína de fusión de acuerdo con las reivindicaciones, que comprende un péptido regulador de glucosa fusionado a uno o más polipéptidos recombinantes extendidos (XTEN), que comprende: (a) proporcionar una célula hospedadora que comprende una molécula de polinucleótido recombinante que codifica la proteína de fusión, (b) cultivar la célula hospedadora en condiciones que permiten la expresión de la proteína de fusión; y (c) recuperar la proteína de fusión. En una realización del método, el péptido regulador de glucosa de la proteína de fusión tiene al menos un 90 % de identidad de secuencia respecto del péptido regulador de glucosa o una secuencia seleccionada de la tabla 1. En otra realización del método, los uno o más XTEN de la proteína de fusión expresada tienen al menos de aproximadamente un 90 % o aproximadamente un 91 % o aproximadamente un 92 % o aproximadamente un 93 % o aproximadamente un 94 % o aproximadamente un 95 % o aproximadamente un 96 % o aproximadamente un 97 % o aproximadamente un 98 % o aproximadamente un 99 % a aproximadamente un 100 % de identidad de secuencia respecto de una secuencia seleccionada de la tabla 5. En otra realización del método, el polinucleótido que codifica el XTEN se optimiza por codones para una expresión mejorada de dicha proteína de fusión en la célula hospedadora. En otra realización del método, la célula hospedadora es una célula procariota. En otra realización del método, la célula hospedadora es E. coli. En otra realización del método, la proteína de fusión aislada se recupera del citoplasma de la célula hospedadora en forma sustancialmente soluble.
La invención proporciona ácidos nucleicos aislados de acuerdo con las reivindicaciones 1-6. En una realización, la invención proporciona un ácido nucleico aislado que comprende una secuencia de polinucleótido que tiene al menos un 80 % de identidad de secuencia o de aproximadamente un 85 % o al menos aproximadamente un 90 % o aproximadamente un 91 % o aproximadamente un 92 % o aproximadamente un 93 % o aproximadamente un 94 % o aproximadamente un 95 % o aproximadamente un 96 % o aproximadamente un 97 % o aproximadamente un 98 % o aproximadamente un 99 % a aproximadamente un 100 % de identidad de secuencia respecto de AE864 de la tabla 9 (SEQ ID NO: 243) o Ex4-Ae 864 de la tabla 36 (SEQ ID NO: 897) o el complemento del mismo. La invención proporciona vectores de expresión que comprenden el ácido nucleico de cualquiera de las realizaciones descritas anteriormente en este epígrafe. En una realización, el vector de expresión de lo anterior comprende además una secuencia reguladora recombinante unida operativamente a la secuencia de polinucleótido. En otra realización, la secuencia de polinucleótido de los vectores de expresión de lo anterior se encuentra fusionada en fase a un polinucleótido que codifica una secuencia de señal de secreción, que puede ser una secuencia de señal procariota. En una realización, la secuencia de señal de secreción se selecciona entre las secuencias de señal OmpA, DsbA y PhoA.
La invención proporciona una célula hospedadora, que puede comprender un vector de expresión divulgado en el epígrafe anterior. En una realización, la célula hospedadora es una célula procariota. En otra realización, la célula hospedadora es E. coli. En otra realización, la célula hospedadora es una célula eucariota.
En una realización, la invención proporciona composiciones farmacéuticas que comprenden la proteína de fusión reivindicada y un vehículo farmacéuticamente aceptable. En otra realización, la invención proporciona kits, que comprenden material de embalaje y al menos un primer recipiente que comprende la composición farmacéutica de la realización anterior y una etiqueta que identifica la composición farmacéutica y las condiciones de almacenamiento y manipulación y una hoja de instrucciones para la reconstitución y/o administración de las composiciones farmacéuticas a un sujeto.
La invención proporciona la proteína de fusión reivindicada, para su uso en un método para tratar una afección relacionada con el péptido regulador de glucosa en un sujeto, que comprende administrar al sujeto una cantidad terapéuticamente eficaz de la proteína de fusión de cualquiera de las realizaciones anteriores. En una realización del método, la afección relacionada con el péptido regulador de glucosa se selecciona entre, pero sin limitación, diabetes juvenil, diabetes de tipo I, diabetes tipo II, obesidad, hipoglucemia aguda, hiperglucemia aguda, hipoglucemia nocturna, hiperglucemia crónica, glucagonomas, trastornos secretorios de las vías respiratorias, artritis, osteoporosis, enfermedad del sistema nervioso central, reestenosis, enfermedad neurodegenerativa, insuficiencia renal,
insuficiencia cardíaca congestiva, síndrome nefrótico, cirrosis, edema pulmonar, hipertensión y trastornos en donde se desea reducir la ingesta de alimento, ictus, síndrome del intestino irritable, infarto de miocardio (por ejemplo, reducción de la morbilidad y/o mortalidad asociada con el mismo), ictus, síndrome coronario agudo (por ejemplo, caracterizado por la ausencia de onda Q), infarto de miocardio, cambios catabólicos postquirúrgicos, hibernación miocárdica o cardiomiopatía diabética, insuficiencia de excreción de sodio en la orina, exceso de concentración de potasio en la orina, afecciones o trastornos asociados con la hipervolemia tóxica (por ejemplo, insuficiencia renal, insuficiencia cardíaca congestiva, síndrome nefrótico, cirrosis, edema pulmonar e hipertensión), síndrome del ovario poliquístico, disnea, nefropatía, disfunción sistólica del ventrículo izquierdo (por ejemplo, con una fracción de eyección ventricular izquierda anormal), trastornos gastrointestinales, tales como diarrea, síndrome postoperatorio de la evacuación gástrica rápida y síndrome del intestino irritable (es decir, mediante la inhibición de la movilidad antroduodenal), polineuropatía por enfermedad grave (CIPN), dislipidemia, lesión tisular en órganos provocada por la reperfusión del flujo sanguíneo después de una isquemia y síndrome de factor de riesgo de cardiopatía coronaria (CHDRF) y cualquier otra indicación para la que se utilice el péptido regulador de glucosa no modificado (por ejemplo, exendina-4, GLP-1 o glucagón) o cualquier otra indicación para la que pueda utilizarse GP (pero para la que los niveles endógenos de péptido regulador de glucosa en un sujeto no son necesariamente deficientes).
En algunas realizaciones, la composición puede administrarse por vía subcutánea, intramuscular o intravenosa. En una realización, la composición se administra en una cantidad terapéuticamente eficaz. En una realización, la cantidad terapéuticamente eficaz da como resultado una ganancia de tiempo empleado dentro de una ventana terapéutica para la proteína de fusión en comparación con el GP correspondiente de la proteína de fusión no unido a la proteína de fusión y administrado a una dosis comparable a un sujeto. La ganancia en el tiempo empleado dentro de la ventana terapéutica puede ser al menos tres veces mayor que el del GP correspondiente no unido a la proteína de fusión o como alternativa, al menos cuatro veces o cinco veces o seis veces o siete veces u ocho veces o nueve veces o al menos 10 veces o al menos 20 veces o al menos aproximadamente 30 veces o al menos aproximadamente 50 veces o al menos aproximadamente 100 veces mayor que la del GP correspondiente no unido a la proteína de fusión. En algunas realizaciones del método de tratamiento, (i) se administra una cantidad molar menor (por ejemplo, aproximadamente dos veces menor o aproximadamente tres veces menor o aproximadamente cuatro veces menor o aproximadamente cinco veces menor o aproximadamente seis veces menor o aproximadamente ocho veces menor o aproximadamente 100 veces menor o mayor) de la proteína de fusión en comparación con el péptido regulador de glucosa correspondiente que carece del x Te N en una pauta posológica por lo demás idéntica y la proteína de fusión logra un área bajo la curva comparable y/o un efecto terapéutico comparable que el péptido regulador de glucosa correspondiente que carece del XTEN; (ii) la proteína de fusión se administra con menor frecuencia (por ejemplo, cada dos días, aproximadamente cada siete días, aproximadamente cada 14 días, aproximadamente cada 21 días o aproximadamente cada mes) en comparación con el péptido regulador de glucosa correspondiente que carece del XTEN en una cantidad de dosis por lo demás idéntica y la proteína de fusión logra un área bajo la curva comparable y/o un efecto terapéutico comparable al del péptido regulador de glucosa correspondiente que carece del XTEN; o (ii) se administra una cantidad molar acumulativa menor (por ejemplo, aproximadamente un 5 % o aproximadamente un 10 % o aproximadamente un 20 % o aproximadamente un 40 % o aproximadamente un 50 % o aproximadamente un 60 % o aproximadamente un 70 % o aproximadamente un 80 % o aproximadamente un 90 % menor) de la proteína de fusión en comparación con el péptido regulador de glucosa correspondiente que carece del XTEN con una pauta posológica por lo demás idéntica logra un área bajo la curva comparable y/o un efecto terapéutico comparable al del péptido regulador de glucosa correspondiente que carece del XTEN. La cantidad molar acumulativa menor se mide durante un periodo de al menos aproximadamente una semana o aproximadamente 14 días o aproximadamente 21 días o aproximadamente un mes. En algunas realizaciones del método, el efecto terapéutico es un parámetro medido seleccionado entre concentraciones de HbA1c, concentraciones de insulina, péptido C estimulado, glucosa en plasma en ayunas (FPG), niveles séricos de citocinas, niveles de CRP, secreción de insulina e índice de sensibilidad a la insulina obtenido de una prueba de tolerancia a la glucosa oral (OGTT), peso corporal y consumo de alimento.
En otra realización, la invención proporciona la proteína de fusión reivindicada, para su uso en un método para tratar una enfermedad, trastorno o afección, que comprende administrar la composición farmacéutica descrita anteriormente a un sujeto usando múltiples dosis consecutivas de la composición farmacéutica administrada usando una pauta posológica terapéuticamente eficaz. En una realización de lo anterior, la pauta posológica terapéuticamente eficaz puede dar como resultado un aumento de tiempo de al menos tres veces o como alternativa, un tiempo al menos cuatro veces o cinco veces o seis veces o siete veces u ocho veces o nueve veces o al menos 10 veces o al menos 20 veces o al menos aproximadamente 30 veces o al menos aproximadamente 50 veces o al menos aproximadamente 100 veces mayor entre al menos dos picos consecutivos de Cmáx y/o mínimos Cmín para los niveles sanguíneos de la proteína de fusión en comparación con el GP correspondiente de la proteína de fusión no unido a la proteína de fusión y administrado con una pauta posológica comparable a un sujeto.
En otra realización de lo anterior, la administración de la proteína de fusión da como resultado una mejora en al menos un parámetro medido de una enfermedad relacionada con el péptido reglador de glucosa usando una dosificación menos frecuente o una dosis en moles total menor de la proteína de fusión de la composición farmacéutica en comparación con los componentes de proteína biológicamente activa correspondiente no unidos a la proteína de fusión y administrados a un sujeto usando una pauta posológica terapéuticamente eficaz.
La invención proporciona demás el uso de las composiciones que comprenden la proteína de fusión de cualquiera de
las realizaciones anteriores en la preparación de un medicamento para tratar una enfermedad, trastorno o afección en un sujeto que lo necesite. En una realización de lo anterior, la enfermedad, trastorno o afección se selecciona entre, pero sin limitación, diabetes juvenil, diabetes de tipo I, diabetes tipo II, obesidad, hipoglucemia aguda, hiperglucemia aguda, hipoglucemia nocturna, hiperglucemia crónica, glucagonomas, trastornos secretorios de las vías respiratorias, artritis, osteoporosis, enfermedad del sistema nervioso central, reestenosis, enfermedad neurodegenerativa, insuficiencia renal, insuficiencia cardíaca congestiva, síndrome nefrótico, cirrosis, edema pulmonar, hipertensión y trastornos en donde se desea reducir la ingesta de alimento, ictus, síndrome del intestino irritable, infarto de miocardio (por ejemplo, reducción de la morbilidad y/o mortalidad asociada con el mismo), ictus, síndrome coronario agudo (por ejemplo, caracterizado por la ausencia de onda Q), infarto de miocardio, cambios catabólicos postquirúrgicos, hibernación miocárdica o cardiomiopatía diabética, insuficiencia de excreción de sodio en la orina, exceso de concentración de potasio en la orina, afecciones o trastornos asociados con la hipervolemia tóxica (por ejemplo, insuficiencia renal, insuficiencia cardíaca congestiva, síndrome nefrótico, cirrosis, edema pulmonar e hipertensión), síndrome del ovario poliquístico, disnea, nefropatía, disfunción sistólica del ventrículo izquierdo (por ejemplo, con una fracción de eyección ventricular izquierda anormal), trastornos gastrointestinales, tales como diarrea, síndrome postoperatorio de la evacuación gástrica rápida y síndrome del intestino irritable (es decir, mediante la inhibición de la movilidad antro-duodenal), polineuropatía por enfermedad grave (CIPN), dislipidemia, lesión tisular en órganos provocada por la reperfusión del flujo sanguíneo después de una isquemia y síndrome de factor de riesgo de cardiopatía coronaria (CHDRF) y cualquier otra indicación para la que se utilice el péptido regulador de glucosa no modificado (por ejemplo, exendina-4, GLP-1 o glucagón) o cualquier otra indicación para la que pueda utilizarse GP (pero para la que los niveles endógenos de péptido regulador de glucosa en un sujeto no son necesariamente deficientes). Puede ponerse en práctica cualquiera de las realizaciones divulgadas sola o en combinación, dependiendo de la aplicación prevista.
Breve descripción de los dibujos
Las nuevas características de la invención se exponen con particularidad en las reivindicaciones adjuntas. Se obtendrá una mejor comprensión de las características y ventajas de la presente invención haciendo referencia a la siguiente descripción detallada que expone realizaciones ilustrativas, en la que se utilizan los principios de la invención y los dibujos adjuntos, en los que:
La FIG 1 muestra representaciones esquemáticas de proteínas de fusión GPXTEN a modo de ejemplo (FIGS. 1A-H), todas representadas en orientación de N a C-terminal. La FIG. 1A muestra dos configuraciones diferentes de proteínas de fusión GPXTEN (100), comprendiendo cada una un solo GP y un XTEN, teniendo la primera de ellas una molécula de XTEN (102) unida al extremo C-terminal de un GP (103) y teniendo la segunda una molécula de XTEN unida al extremo N-terminal de un GP (103). La FIG. 1B muestra dos configuraciones diferentes de proteínas de fusión GPXTEN (100), comprendiendo cada una un solo GP, una secuencia espaciadora y un XTEN, teniendo la primera una molécula de XTEN (102) unida al extremo C-terminal de una secuencia espaciadora (104) y la secuencia espaciadora unida al extremo C-terminal de un GP (103) y teniendo la segunda una molécula de XTEN unida al extremo N-terminal de una secuencia espaciadora (104) y la secuencia espaciadora unida al extremo N-terminal de un GP (103). La FIG. 1C muestra dos configuraciones diferentes de proteínas de fusión GPXTEN (101), comprendiendo cada una dos moléculas de un solo GP y una molécula de un XTEN, teniendo la primera un XTEN unido al extremo C-terminal de un primer GP y este GP está unido al extremo C-terminal de un segundo GP y teniendo la segunda la orientación opuesta, en la que el XTEN está unido al extremo N-terminal de un primer GP y este GP está unido al extremo N-terminal de un segundo GP. La FIG. 1D muestra dos configuraciones diferentes de proteínas de fusión GPXTEN (101), comprendiendo cada una dos moléculas de un solo GP, una secuencia espaciadora y una molécula de un XTEN, teniendo la primera un XTEN unido al extremo C-terminal de una secuencia espaciadora y la secuencia espaciadora unida al extremo C-terminal de un primer GP que está unido al extremo C-terminal de un segundo GP y encontrándose la segunda en la orientación opuesta, en la que el XTEN está unido al extremo N-terminal de una secuencia espaciadora y la secuencia espaciadora está unida al extremo N-terminal de un primer GP y este GP está unido al extremo N-terminal de un segundo GP. La FIG. 1E muestra dos configuraciones diferentes de proteínas de fusión GPXTEN (101), comprendiendo cada una dos moléculas de un solo GP, una secuencia espaciadora y una molécula de un XTEN, teniendo la primera un XTEN unido al extremo C-terminal de un primer GP y el primer GP unido al extremo C-terminal de una secuencia espaciadora que está unida al extremo C-terminal de una segunda molécula de GP y encontrándose la segunda en la configuración opuesta de XTEN unido al extremo N-terminal de un primer GP que está unido al extremo N-terminal de una secuencia espaciadora que a su vez está unida al extremo N-terminal de una segunda molécula de GP. La FIG.
1F muestra una configuración de una proteína de fusión GPXTEN (105), cada una comprendiendo una molécula de GP y dos moléculas de un XTEN unido al extremo N-terminal y al extremo C-terminal del GP. La FIG. 1G muestra una configuración (106) de un solo GP unido a dos XTEN, estando el segundo XTEN separado del GP mediante una secuencia espaciadora. La FIG. 1H muestra una configuración (106) de dos GP unidos a dos XTEN, con el segundo XTEN unido al extremo C-terminal del primer GP y al extremo N-terminal del segundo GP, que se encuentra en el extremo C-terminal de la GPXTEN.
La FIG. 2 es una ilustración esquemática de construcciones de polinucleótido a modo de ejemplo (FIGS. 2A-H) de genes de GPXTEN que codifican los polipéptidos de GPXTEN correspondientes de la FIG. 1; todos representados en orientación de 5' a 3'. En estos ejemplos ilustrativos, los genes codifican proteínas de fusión GPXTEN con un GP y XTEN (200); o un GP, una secuencia espaciadora y un XTEN (200); dos GP y un XTEN (201); o dos GP, una
secuencia espadadora y un XTEN (201); un GP y dos XTEN (205); o dos GP y dos XTEN (206). En estas representaciones, los polinucleótidos codifican los siguientes componentes: XTEN (202), GP (203) y aminoácidos espaciadores que pueden incluir una secuencia de escisión (204), con todas las secuencias unidas en fase. La FIG. 3 es una ilustración esquemática de dos GPXTEN monoméricas a modo de ejemplo y de la capacidad de las proteína de fusión monoméricas para unirse a un receptor diana en una superficie celular, con la consiguiente señalización celular. La FIG. 3A muestra una proteína de fusión GPXTEN (100) que consiste en un GP (103) y un XTEN (102) y una segunda proteína de fusión GPXTEN (105) que consiste en un GP unido a dos XTEN (105). La FIG. 3B muestra la interacción de la GPXTEN con el GP en el extremo C-terminal (100) y la GPXTEN con un XTEN en el extremo C-terminal (105) con receptores diana (108) para GP en una superficie celular (107). En este caso, la unión al receptor con alta afinidad se muestra cuando Gp tiene un extremo C-terminal libre, mientras que la GPXTEN con un XTEN C-terminal no se une estrechamente al receptor y se disocia, como se observa en la FIG.
3C. La FIG. 3D muestra que la GPXTEN (100) unida con alta afinidad de unión permanece unida al receptor (106) y se ha internalizado en un endosoma (110) dentro de la célula, lo que ilustra la eliminación mediada por receptor del GP unido y la activación de la señalización celular (109), representada en forma de citoplasma punteado. La FIG. 4 es un diagrama de flujo esquemático de etapas representativas en el ensamblaje, la producción y la evaluación de un XTEN.
La FIG. 5 es un diagrama de flujo esquemático de etapas representativas en el ensamblaje de una construcción de polinucleótido de GP-XTEN que codifica una proteína de fusión. Los oligonucleótidos individuales 501 se hibridan en motivos de secuencia 502, tal como un motivo de 12 aminoácidos ("12-mero"), que posteriormente se liga con un oligo que contiene sitios de restricción de BsbI y KpnI 503. Se hibridan motivos de secuencia adicionales procedentes de una biblioteca al 12-mero hasta que se alcanza la longitud deseada del gen de XTEN 504. El gen de XTEN se clona en un vector de relleno. El vector codifica una secuencia Flag 506 seguida de una secuencia de parada que está flanqueada por sitios de BsaI, BbsI y KpnI 507 y un gen de exendina-4 (Ex4) 508, que da como resultado el gen 500 que codifica una proteína de fusión GPXTEN.
La FIG. 6 es un diagrama de flujo esquemático de etapas representativas en el ensamblaje de un gen que codifica una proteína de fusión que comprende una proteína biológicamente activa (GP) y XTEN, su expresión y recuperación en forma de proteína de fusión y su evaluación como producto candidato de GPXTEN.
La FIG. 7 es una representación esquemática del diseño de vectores de expresión de Ex4XTEN con diferentes estrategias de procesamiento. La FIG. 7A muestra un vector de expresión a modo de ejemplo que codifica XTEN fusionado al extremo 3' de la secuencia que codifica la proteína Ex4 biológicamente activa. Obsérvese que no se necesitan secuencias líder adicionales en este vector. La FIG. 7B representa un vector de expresión que codifica XTEN fusionado al extremo 5' de la secuencia que codifica Ex4 con una secuencia líder de CBD y un sitio de proteasa TEV. La FIG. 7C representa un vector de expresión como en la FIG. 7B, donde se han reemplazado los sitios de procesamiento de c Bd y TEV por una secuencia líder N-terminal optimizada (NTS). La FIG. 7D representa un vector de expresión que codifica una secuencia NTS, un XTEN, una secuencia que codifica Ex4 y después, una segunda secuencia que codifica un XTEN.
La FIG. 8 es una representación esquemática de la construcción paso a paso de genes de GPXTEN que contienen secuencias codificantes de XTEN N-terminales unidas a una secuencia que codifica exendina-4 (Ex4) y el posterior enlace de secuencias que codifican 144 o 288 XTEN unidos al extremo C-terminal del XTEN, como se describe en el ejemplo 18.
La FIG. 9 muestra resultados de ensayos de expresión para las construcciones indicadas que comprenden secuencias de GFP y de XTEN. Los cultivos de expresión se ensayaron usando un lector de placas de fluorescencia (excitación a 395 nm, emisión a 510 nm) para determinar la cantidad de indicador de GFP presente. Los resultados, representados como gráficas de cajas y bigotes, indican que aunque la mediana de los niveles de expresión fue aproximadamente la mitad de los niveles de expresión en comparación con el "punto de referencia" del dominio auxiliar N-terminal de CBD, los mejores clones de las bibliotecas se encontraron mucho más próximos a los puntos de referencia, lo que indica que queda garantizada una optimización adicional alrededor de estas secuencias. Los resultados también muestran que las bibliotecas que comienzan con los aminoácidos MA tenían mejores niveles de expresión que aquellas que comienzan con ME (véase el ejemplo 14).
La FIG. 10 muestra tres bibliotecas aleatorizadas usadas para los codones tercero y cuarto en las secuencias N-terminales de los clones de LCW546, LCW547 y LCW552, como se describe en el ejemplo 15. Las bibliotecas se diseñaron con los restos tercero y cuarto modificados, de tal forma que se encontraban presentes en estas posiciones todas las combinaciones de codones de XTEN permisibles, tal como se muestra. A fin de incluir todos los codones de XTEN permisibles para cada biblioteca, se diseñaron nueve pares de oligonucleótidos que codificaban 12 aminoácidos con diversidades de codones de los restos tercero y cuarto, se hibridaron y se ligaron en el vector de relleno pCW0551 digerido con las enzimas de restricción NdeI/BsaI (Stuffer-XTEN_AM875-GFP) y se transformó en células E. coli BL21Gold(DE3) competentes para obtener colonias de las tres bibliotecas, LCW0569, LCW0570 y LCW0571.
La FIG. 11 muestra un histograma de un reevaluación de los 75 clones principales tras la etapa de optimización, como se describe en el ejemplo 15, para la señal de fluorescencia de GFP, en relación con la construcción de punto de referencia CBD_AM875. Los resultados indicaron que varios clones eran ahora superiores a los clones de referencia.
La FIG. 12 es un esquema de una estrategia combinatoria llevada a cabo para las preferencias de optimización de unión de codones para dos regiones los 48 aminoácidos del extremo N-terminal, como se describe en el ejemplo 16. La estrategia creó nuevos 48meros en el extremo N-terminal de la proteína XTEN para la evaluación de la optimización de la expresión que dio como resultado secuencias líder que pueden ser una solución para la
expresión de proteínas XTEN, donde el XTEN se encuentra en N-terminal respecto del GP.
La FIG. 13 muestra un gel de SDS-PAGE que confirma la expresión de clones preferidos obtenidos de los experimentos de optimización de codones N-terminales de XTEN, en comparación con clones de XTEN de referencia que comprenden secuencias líder CBD en el extremo N-terminal de las secuencias de la construcción. La FIG. 14 muestra un gel de SDS-PAGE de muestras procedentes de un estudio de estabilidad de la proteína de fusión de XTEN, AE864, fusionada al extremo N-terminal de GFP (véase el ejemplo 24). La GFP-XTEN se incubó en plasma de cinomolgo y lisado de riñón de rata durante hasta 7 días a 37°C. Además, también se evaluó GFP-XTEN administrado a monos cinomolgos. Se tomaron muestras a los 0, 1 y 7 días y se analizaron mediante SDS-PAGE, seguido de detección usando análisis de Western y detección con anticuerpos contra GFP.
La FIG. 15 muestra un gel de SDS-PAGE que confirma la expresión de glucagón fusionado a XTEN de diversas longitudes; es decir, Y288, Y144, Y72 y Y36, en comparación con los patrones de peso molecular.
La FIG. 16 muestra los resultados de un análisis por cromatografía de exclusión por tamaños de muestras de construcción de glucagón-XTEN, medidas frente a patrones de proteína de peso molecular conocido, con el resultado de la gráfica en forma de absorbancia frente a volumen de retención, como se describe en el ejemplo 22. Las construcciones de glucagón-XTEN son 1) glucagón-Y288; 2) glucagón-Y144; 3) glucagón-Y72; y 4) glucagón-Y36. Los resultados indican un aumento en el peso molecular aparente a medida que aumenta la longitud del resto de XTEN.
La FIG. 17 muestra los resultados farmacocinéticos de la GPXTEN, Ex4-AE864, administrada a monos cinomolgos por vía subcutánea e intravenosa (para detalles experimentales, véase el ejemplo 27).
La FIG. 18 ilustra los resultados de escalado alométrico para la respuesta en humanos predicha a Ex4-XTEN_AE864 basándose en los resultados medidos de cuatro especies animales; es decir, ratones, ratas, monos cinomolgos y perros, como se describe en el ejemplo 28. La FIG. 18A muestra la semivida terminal medida frente a la masa corporal, con una T1/2 predicha en seres humanos de 139 h. La FIG. 18B muestra la eliminación de fármaco medida frente a la masa corporal, con un valor de tasa de eliminación predicha de 30 ml/h en seres humanos. La FIG. 18C muestra el volumen de distribución medido frente a la masa corporal, con un valor predicho de 5970 ml en seres humanos.
La FIG. 19 muestra los resultados de estudios de la caracterización biofísica y la estabilidad de Gcg-XTEN (para detalles experimentales, véase el ejemplo 21). La FIG. 19A es un análisis SDS-PAGE del producto de proteína purificada (carril 2). Los marcadores de peso molecular se muestran en el carril 1 con los marcadores de tamaño relevantes marcados a la izquierda. Obsérvese que el peso molecular real de la molécula es de 16305 Dalton (confirmado mediante espectrometría de masas; no mostrado). Una lenta migración en la SDS-PAGE en relación con los patrones de proteína globular es típica de las proteínas de fusión de XTEN, debido a las diferencias en la composición primaria de aminoácidos. La FIG. 19B muestra resultados de un ensayo de flujo de Ca2+ del receptor de glucagón (GcgR) que compara la eficacia de Gcg-XTEN con la de glucagón no modificado. Se muestran los valores de CE50 calculados para cada ajuste de curva. La FIG. 19C muestra los resultados de un análisis HPLC C18 de fase reversa. La FIG. 19D muestra resultados de un análisis por cromatografía HPLC de exclusión por tamaños de la construcción Gcg-XTEN purificada en el momento de la producción. La FIG. 19E muestra los resultados de un análisis HPLC C18 de fase reversa. La FIG. 19F muestra los resultados de análisis HPLC de cromatografía de exclusión por tamaños de Gcg-XTEN tras 6 meses de almacenamiento a -80 °C, 2-8 °C o 25 °C, estando las tres curvas esencialmente superpuestas.
La FIG. 20 muestra los resultados de un estudio farmacodinámico en perros a los que se administró glucagón o Gcg-XTEN (para detalles experimentales, véase el ejemplo 29). Se inyectó glucagón (FIG. 20A) o Gcg-XTEN (FIG.
20B) a razón de 14 o 12 nmol/kg, respectivamente, en perros de raza Beagle sometidos a ayuno (n=4 por grupo) y se monitorizaron los niveles de glucosa en sangre en comparación con la inyección de placebo, como se muestra en la FIG. 20C. Se muestra la diferencia en el área bajo la curva de glucosa en sangre durante la primera hora tras la inyección de placebo, Gcg-XTEN o glucagón (Gcg) en relación con el punto de base antes de la inyección (n=4-8 animales por grupo). Se indica el nivel de dosis para cada grupo.
La FIG. 21 muestra los resultados de un estudio farmacodinámico en perros a los que se dosificó glucagón o Gcg-XTEN y se les expuso a insulina a fin de comprobar si Gcg-XTEN confiere resistencia controlada temporalmente a la hipoglucemia inducida por insulina en perros (para detalles experimentales, véase el ejemplo 30). Se alimentó a los perros de raza Beagle tres horas antes de comenzar el experimento y posteriormente se les sometió a ayuno. A tiempo = 0, los animales recibieron una dosis de 0,6 nmol/kg de Gcg-XTEN o de placebo (flechas abiertas). Los animales (n=4 por grupo) recibieron una exposición de 0,05 U/kg de insulina para inducir hipoglucemia a las 6 h (FIG. 21A), indicada por la flecha sólida o a las 12 h (FIG. 21B) tras la dosis inicial, indicada por la flecha sólida. La FIG. 21C representa una línea temporal hipotética para la administración a seres humanos a lo largo de un ciclo de comida-sueño-vigilia que se pretende que corresponda con la administración de la dosis y el diseño experimental del experimento.
La FIG. 22 muestra los resultados de un experimento farmacodinámico en el que se administró glucagón o Gcg-XTEN_Y288 (construcción 1) para probar la capacidad de los compuestos para inhibir un aumento en la glucosa en sangre tras finalizar el ayuno en monos cinomolgos (para detalles experimentales, véase el ejemplo 31). Las FIGS.22A-C muestran gráficas superpuestas de los perfiles de glucosa en sangre tras la administración de placebo o Gcg-XTEN288 para tres monos cinomolgos individuales. Las flechas sólidas marcan el momento cuando se devolvió la comida a los animales (t = 6 horas).
La FIG. 23 muestra los resultados en el peso corporal de un estudio farmacodinámico y metabólico usando una combinación de dos proteínas de fusión GPXTEN; es decir, glucagón unido a Y288 (Gcg-XTEN) y exendina-4 unida a AE864 (Ex4-XTEN) para evaluar la eficacia de la combinación en un modelo de obesidad inducida por la
dieta en ratones (para detalles experimentales, véase el ejemplo 26). La gráfica muestra el cambio en el peso corporal en ratones con obesidad inducida por la dieta a lo largo de 28 días de administración continua del fármaco. Los valores mostrados son la media /- DTM de 10 animales por grupo (20 animales en el grupo de placebo). La FIG. 24 muestra el cambio en los niveles de glucosa en ayunas de un estudio farmacodinámico y metabólico usando una sola y combinaciones de dos proteínas de fusión GPXTEN; es decir, glucagón unido a Y288 (Gcg-XTEN) y exendina-4 unida a AE864 (Ex4-XTEN) en un modelo de obesidad inducida por la dieta en ratones (para detalles experimentales, véase el ejemplo 26). Los grupos son los siguientes: Gr. 1 Vehículo de Tris; Gr. 2 Ex4-AE576, 10 mg/kg; Gr. 3 Ex4-AE576, 20 mg/kg; Gr. 4 Vehículo, DMSO al 50 %; Gr. 5 Exenatida, 30 |jg/kg/día; Gr.
6 Exenatida, 30 jl/kg/día Gcg-Y288 20 jg/kg; Gr. 7 Gcg-Y288, 20 jg/kg; Gr. 8 Gcg-Y288, 40 jg/kg; Gr. 9 Ex4-AE576 10 mg/kg Gcg-Y28820 jg/kg; Gr. 10 Gcg-Y28840 jg/kg Ex4-AE57620 mg/kg. La gráfica muestra el cambio en los niveles de glucosa en ayunas en ratones con obesidad inducida por la dieta a lo largo de 28 días de administración continua del fármaco. Los valores mostrados son la media /- DTM de 10 animales por grupo (20 animales en el grupo de placebo).
La FIG. 25 muestra los niveles de triglicéridos y colesterol en ratones con obesidad inducida por la dieta tras 28 días de administración continua de Gcg-XTEN y exendina-4, ya sea de manera individual o en combinación (para detalles experimentales, véase el ejemplo 26). Los valores mostrados son la media /- DTM de 10 animales por grupo.
La FIG. 26 muestra los resultados de un estudio farmacocinético en monos cinomolgos que prueba los efectos de la longitud del XTEN con diferentes composiciones de GFP unida a XTEN administradas por vía subcutánea o intravenosa, como se describe en el ejemplo 23. Las composiciones fueron GFP-L288, GFP-L576, GFP-AF576, GFP-Y576 y AD836-GFP. Los resultados se presentan en forma de concentración plasmática frente al tiempo (h) después de la dosis.
La FIG. 27 muestra el espectro de dicroísmo circular de UV cercano de Ex4-XTEN_AE864, llevado a cabo como se describe en el ejemplo 34.
La FIG. 28 muestra los resultados de los niveles sanguíneos frente al tiempo para las proteínas de fusión de glucagón-XTEN administradas a monos cinomolgos, como se describe en el ejemplo 32. Las GPXTEN administradas fueron glucagón-Y288, glucagón-Y144 y glucagón-Y72. Los resultados de la administración de glucagón-Y144 muestran una variación <3 veces en los niveles sanguíneos a lo largo de 0-6 h, descendiendo los niveles sanguíneos por debajo del umbral de 10x desde la Cmáx a las 10-12 horas.
La FIG.29 muestra los resultados de un ensayo celular in vitro para la actividad de GLP-1, que compara exendina-4 de dos fuentes comerciales (triángulos cerrados) con exendina-4 unida a Y288 (cuadrados cerrados), con células no tratadas (rombos cerrados) usadas como control negativo (para detalles experimentales, véase el ejemplo 35). La CE50 se indica por medio de la línea discontinua.
Descripción detallada
Antes de describir las realizaciones de la invención, ha de entenderse que dichas realizaciones se proporcionan únicamente a modo de ejemplo y que pueden emplearse en la práctica de la invención diversas alternativas a las realizaciones de la invención descrita en el presente documento, que han de interpretarse por referencia a las reivindicaciones. Los expertos en la materia inventarán numerosas variaciones, cambios y sustituciones sin separarse de la invención reivindicada.
Salvo que se definan de otro modo, todos los términos técnicos y científicos utilizados en el presente documento tienen el mismo significado que el que entiende comúnmente un experto familiarizado con la técnica a la cual pertenece la presente invención. Aunque pueden usarse métodos y materiales similares o equivalentes a los descritos en el presente documento a la hora de poner en práctica o probar la presente invención, a continuación se describen los métodos y materiales adecuados. En caso de conflicto, prevalecerá la memoria descriptiva de la patente, incluyendo las definiciones. Además, los materiales, métodos y ejemplos son solamente ilustrativos y no pretenden ser limitantes. Serán evidentes para los expertos en la materia numerosas variaciones, cambios y sustituciones sin desviarse de la invención.
DEFINICIONES
Tal como se usan en el presente documento, los siguientes términos y expresiones tienen los significados asignados, a menos que se especifique lo contrario.
Como se usa en la memoria descriptiva y las reivindicaciones, las formas en singular "un", "uno/a" y “el/la” incluyen las referencias en plural salvo que el contexto indique claramente otra cosa. Por ejemplo, la expresión "una célula" incluye una pluralidad de células, incluyendo mezclas de las mismas.
Los términos "polipéptido", "péptido" y "proteína" se usan de manera indistinta en el presente documento para hacer referencia a polímeros de aminoácidos de cualquier longitud. El polímero puede ser lineal o ramificado, puede comprender aminoácidos modificados y puede estar interrumpido por no aminoácidos. Los términos también abarcan un polímero de aminoácidos que se haya modificado, por ejemplo, mediante formación de enlaces disulfuro, glucosilación, lipidación, acetilación, fosforilación o cualquier otra manipulación, tal como conjugación con un componente de marcaje.
Como se usa en el presente documento, el término "aminoácido" se refiere a aminoácidos naturales y/o no naturales o sintéticos, incluyendo, pero sin limitación, glicina y los isómeros ópticos tanto D como L y análogos de aminoácidos y peptidomiméticos. Para nombrar los aminoácidos se usan los códigos de una o tres letras convencionales.
La expresión "L-aminoácido natural" significa las formas de isómero óptico L de glicina (G), prolina (P), alanina (A), valina (V), leucina (L), isoleucina (I), metionina (M), cisteína (C), fenilalanina (F), tirosina (Y), triptófano (W), histidina (H), lisina (K), arginina (R), glutamina (Q), asparagina (N), ácido glutámico (E), ácido aspártico (D), serina (S) y treonina (T).
La expresión "de origen no natural", en el sentido aplicado a secuencias y tal como se usa en el presente documento, significa secuencias de polipéptido o polinucleótido que no tienen un homólogo de, no son complementarias a o no tienen un alto grado de homología con una secuencia de tipo silvestre o de origen natural encontrada en un mamífero. Por ejemplo, un polipéptido de origen no natural puede compartir no más de un 99 %, 98 %, 95 %, 90 %, 80 %, 70 %, 60 %, 50 % o incluso menos identidad de secuencia de aminoácidos en comparación con una secuencia natural cuando se alinea de manera adecuada.
Los términos "hidrófilo" e "hidrófobo" se refieren al grado de afinidad que tiene una sustancia con el agua. Una sustancia hidrófila tiene una fuerte afinidad por el agua, tendiendo a disolverse en, mezclarse con o humedecerse por el agua, mientras que una sustancia hidrófoba carece de una afinidad sustancial por el agua, tendiendo a repeler y a no absorber agua y tendiendo a no disolverse o mezclarse o humectarse por el agua. Los aminoácidos pueden caracterizarse basándose en su carácter hidrófobo. Se han desarrollado varias escalas. Un ejemplo es una escala desarrollada por Levitt, M, et al., J Mol Biol (1976) 104:59, que se lista en Hopp, TP, et al., Proc Natl Acad Sci USA (1981) 78:3824. Son ejemplos de "aminoácidos hidrófilos" arginina, lisina, treonina, alanina, asparagina y glutamina. Son aminoácidos hidrófilos de particular interés aspartato, glutamato, serina y glicina. Son ejemplos de "aminoácidos hidrófilos" triptófano, tirosina, fenilalanina, metionina, leucina, isoleucina y valina.
Un "fragmento" es una forma truncada de una proteína nativa biológicamente activa que conserva al menos una parte de la actividad terapéutica y/o biológica. Una "variante" es una proteína con homología de secuencia respecto de la proteína biológicamente activa nativa que conserva al menos una parte de la actividad terapéutica y/o biológica de la proteína biológicamente activa. Por ejemplo, una proteína variante puede compartir al menos un 70 %, 75 %, 80 %, 85 %, 90 %, 95 %, 96 %, 97 %, 98 % o 99 % de la identidad de secuencia de aminoácidos respecto de la proteína biológicamente activa de referencia. Como se usa en el presente documento, la expresión "resto de proteína biológicamente activo" incluye proteínas modificadas de manera deliberada, como, por ejemplo, mediante mutagénesis de sitio dirigido, inserciones o accidentalmente mediante mutaciones.
Una "célula hospedadora" incluye una célula individual o un cultivo celular que puede ser o que haya sido receptor de los presentes vectores. Las células hospedadoras incluyen la descendencia de una sola célula hospedadora. La descendencia puede no ser necesariamente idéntica (en cuanto a su morfología o en su complemento genómico de ADN total) a la célula parental original debido a una mutación natural, accidental, o deliberada. Una célula hospedadora incluye células transfectadas in vivo con un vector de la presente invención.
"Aislado", cuando se usa para describir los diversos polipéptidos divulgados en el presente documento, significa un polipéptido que se ha identificado y separado y/o recuperado de un componente de su ambiente natural. Los componentes contaminantes de su ambiente natural son materiales que normalmente interferirían con los usos diagnósticos o terapéuticos para el polipéptido y pueden incluir enzimas, hormonas y otros solutos proteicos o no proteicos. Como saben los expertos en la materia, un polinucleótido, péptido, polipéptido, proteína, anticuerpo de origen no natural o fragmentos de los mismos, no requiere "aislamiento" para distinguirlo de su homólogo natural. Además, un polinucleótido, péptido, polipéptido, proteína, anticuerpo o fragmentos de los mismos "concentrado", "separado" o "diluido", se distingue de su homólogo de origen natural en que la concentración o el número de moléculas por volumen es generalmente mayor que el de su homólogo de origen natural. En general, un polipéptido producido por medios recombinantes y expresado en una célula hospedadora se considera "aislado".
Un polinucleótido o ácido nucleico que codifica un polipéptido u otro ácido nucleico que codifica un polipéptido "aislado" es una molécula de ácido nucleico que se identifica y separa de al menos una molécula de ácido nucleico contaminante con la que normalmente se asocia en la fuente natural del ácido nucleico que codifica un polipéptido. Una molécula de ácido nucleico que codifica un polipéptido aislada se encuentra en una forma o situación diferente a la que se encuentra en la naturaleza. Por lo tanto, las moléculas de ácido nucleico que codifican un polipéptido se distinguen de la molécula de ácido nucleico que codifica un polipéptido en la forma que existe en las células naturales. Sin embargo, una molécula de ácido nucleico que codifica un polipéptido aislada incluye moléculas de ácido nucleico que codifican un polipéptido contenidas en células que normalmente expresan el polipéptido donde, por ejemplo, la molécula de ácido nucleico se encuentra en una ubicación cromosómica o extracromosómica diferente a la de las células naturales.
Una proteína "quimérica" contiene al menos un polipéptido de fusión que comprende regiones en una posición diferente en la secuencia a la que se produce en la naturaleza. Las regiones pueden existir normalmente en proteínas separadas y se juntan en el polipéptido de fusión; o pueden existir normalmente en la misma proteína, pero se colocan en una disposición en el polipéptido de fusión. Puede crearse una proteína quimérica, por ejemplo, mediante síntesis
química o creando y traduciendo un polinucleótido en el que las regiones peptídicas están codificadas en la relación deseada.
"Conjugado", "unido", "fusionado" y "fusión" se usan de manera indistinta en el presente documento. Estos términos se refieren a la unión de dos o más elementos o componentes químicos, por cualquier medio, incluyendo conjugación química o medios recombinantes. Por ejemplo, un promotor o potenciador está operablemente unido a una secuencia de codificación si altera la transcripción de la secuencia. En general, "unido operativamente" significa que las secuencias de ADN que están unidas son contiguas y se encuentran en fase de lectura o en marco. Una "fusión en fase" se refiere a la unión de dos o más fases abiertas de lectura (ORF) para formar una ORF continua más larga, de un modo que mantenga la fase de lectura correcta de las ORF originales. Por tanto, la proteína de fusión recombinante resultante es una sola proteína que contiene dos o más segmentos que corresponden a polipéptidos codificados por las ORF originales (no encontrándose dichos segmentos normalmente unidos en la naturaleza).
En el contexto de los polipéptidos, una "secuencia lineal" o una "secuencia" es un orden de aminoácidos en un polipéptido en dirección del extremo amino al carboxilo, en la que los restos próximos entre sí son contiguos en la estructura primaria del polipéptido. Una "secuencia parcial" es una secuencia lineal de parte de un polipéptido que se sabe que comprende restos adicionales en una o ambas direcciones.
"Heterólogo" significa procedente de una entidad genotípicamente distinta al resto de la entidad con la que se está comparando. Por ejemplo, una secuencia rica en glicina extraída de su secuencia codificante natural y unida operativamente a una secuencia codificante distinta de la secuencia nativa es una secuencia rica en glicina heteróloga. El término "heterólogo", en el sentido que se aplica a un polinucleótido, un polipéptido, significa que el polinucleótido o el polipéptido procede de una entidad genotípicamente distinta a la del resto de la entidad con la que se está comparando.
Los términos "polinucleótidos", "aminoácidos", "nucleótidos" y "oligonucleótidos" se usan de manera indistinta. Se refieren a una forma polimérica de nucleótidos de cualquier longitud, ya sean desoxirribonucleótidos o ribonucleótidos o análogos de los mismos. Los polinucleótidos pueden tener cualquier estructura tridimensional y pueden realizar cualquier función, conocida o desconocida. Los siguientes son ejemplos no limitantes de polinucleótidos: regiones codificantes o no codificantes de un gen o fragmento de un gen, loci (locus) definidos mediante análisis de enlace, exones, intrones, ARN mensajero (ARNm), ARN de transferencia, ARN ribosómico, ribozimas, ADNc, polinucleótidos recombinantes, polinucleótidos ramificados, plásmidos, vectores, ADN aislado de cualquier secuencia, ARN aislado de cualquier secuencia, sondas de ácido nucleico y cebadores. Un polinucleótido puede comprender nucleótidos modificados, tales como nucleótidos y análogos de nucleótidos metilados. En caso de estar presentes, pueden impartirse modificaciones a la estructura de los nucleótidos antes o después del ensamblaje del polímero. La secuencia de nucleótidos puede estar interrumpida por componentes no nucleotídicos. Un polinucleótido puede modificarse adicionalmente después de la polimerización, tal como mediante conjugación con un componente de marcaje.
La expresión "complemento de un polinucleótido" indica una molécula de polinucleótido que tiene una secuencia de bases complementaria y orientación inversa, en comparación con una secuencia de referencia, de tal forma que puede hibridar con una secuencia de referencia con total fidelidad.
"Recombinante", en el sentido aplicado a un polinucleótido, significa que el polinucleótido es el producto de varias combinaciones de etapas de clonación in vitro, restricción y/o ligamiento y otros procedimientos que den como resultado una construcción que potencialmente pueda expresarse en una célula hospedadora.
Los términos "gen" o "fragmento génico" se usan de manera indistinta en el presente documento. Se refieren a un polinucleótido que contiene al menos una fase abierta de lectura que es capaz de codificar una proteína particular después de transcribirse y traducirse. Un gen o un fragmento génico puede ser ADN genómico o ADNc, en tanto que el polinucleótido contenga al menos una fase abierta de lectura, que puede abarcar la región codificante completa o un segmento de la misma. Un "gen de fusión" es un gen formado por al menos dos polinucleótidos heterólogos que se unen entre sí.
"Homología" u "homólogo" se refiere a similitud de secuencia o intercambiabilidad entre dos o más secuencias de polinucleótido o dos o más secuencias de polipéptido. Cuando se usa un programa, tal como BestFit para determinar la identidad, similitud u homología de secuencia entre dos secuencias de aminoácidos diferentes, puede usarse la configuración por defecto o puede seleccionarse una matriz de puntuación adecuada, tal como blosum45 o blosum80, para optimizar las puntuaciones de identidad, similitud u homología. Preferentemente, los polinucleótidos que son homólogos son aquellos que hibridan en condiciones rigurosas, como se definen en el presente documento y tienen al menos un 70 % o al menos un 80 % o al menos un 90 % o un 95 % o un 97 % o un 98 % o un 99 % de identidad de secuencia respecto de dichas secuencias.
"Ligamiento" se refiere al proceso de formar enlaces fosfodiéster entre dos fragmentos de ácido nucleico o genes, uniéndolos entre sí. Para ligar entre si los fragmentos de ADN o los genes, los extremos del ADN han de ser compatibles entre sí. En algunos casos, los extremos serán directamente compatibles tras la digestión con endonucleasas. Sin embargo, puede ser necesario convertir en primer lugar los extremos escalonados producidos
normalmente tras la digestión con endonucleasas en extremos romos para hacerlos compatibles para ligamiento.
Las expresiones "condiciones rigurosas" o "condiciones de hibridación rigurosas" incluyen referencia a condiciones en las que un polinucleótido hibridará con su secuencia diana, en un gado detectablemente mayor que a otras secuencias (por ejemplo, al menos 2 veces por encima del fondo). En general, la rigurosidad de la hibridación se expresa, en parte, haciendo referencia a la temperatura y la concentración salina en la que se lleva a cabo la etapa de lavado. Normalmente, las condiciones rigurosas serán aquellas en las que la concentración salina sea menor de aproximadamente 1,5 M de ion Na, normalmente, una concentración de ion Na (u otras sales) de aproximadamente 0,01 a 1,0 M a un pH de 7,0 a 8,3 y la temperatura es de al menos aproximadamente 30 °C para polinucleótidos cortos (por ejemplo, de 10 a 50 nucleótidos) y de al menos aproximadamente 60 °C para polinucleótidos largos (por ejemplo, de más de 50 nucleótidos), por ejemplo, las "condiciones rigurosas" pueden incluir hibridación en formamida al 50 %, NaCl 1 M, SDA al 1 % a 37 °C y tres lavados durante 15 min cada uno en 0,1 xSSC/SDS al 1 % a de 60 a 65 °C. Como alternativa, pueden usarse temperaturas de aproximadamente 65 °C, 60 °C, 55 °C o 42 °C. Puede variarse la concentración de SSC de aproximadamente 0,1 a 2xSSC, estando el SDS presente a aproximadamente el 0,1 %. Dichas temperaturas de lavado se seleccionan normalmente para que sean de aproximadamente 5 °C a 20 °C menores que el punto de fusión térmico para la secuencia específica en condiciones de fuerza iónica y pH definidas. La Tm es la temperatura (en condiciones de fuerza iónica y pH definidas) a la cual hibrida un 50 % de la secuencia diana con una sonda perfectamente coincidente. Puede encontrarse una ecuación bien conocida para calcular la Tm y las condiciones de hibridación de ácidos nucleicos en Sambrook, J. et al. (1989) Molecular Cloning: A Laboratory Manual, 2a ed., vol. 1-3, Cold Spring Harbor Press, Plainview N.Y.; véase específicamente el volumen 2 y el capítulo 9. Normalmente, se usan reactivos de bloqueo para bloquear la hibridación no especifica. Dichos reactivos de bloqueo incluyen, por ejemplo, ADN de esperma de salmón cortado y desnaturalizado a aproximadamente 100-200 |jg/ml. También puede usarse en circunstancias concretas un disolvente orgánico, tal como formamida, a una concentración de aproximadamente el 35-50 % v/v, tal como para hibridaciones de ARN:ADN. Resultarán evidentes para los expertos habituales en la materia variaciones útiles en estas condiciones de lavado.
Las expresiones "porcentaje de identidad" y "% de identidad", aplicadas a secuencias de polinucleótidos, se refieren al porcentaje de restos coincidentes entre al menos dos secuencias de polinucleótidos alineadas usando un algoritmo estándar. Dicho algoritmo puede insertar, de una manera estandarizada y reproducible, huecos en las secuencias que se estén comparando a fin de optimizar el alineamiento entre dos secuencias y de este modo lograr una comparación más significativa de las dos secuencias. El porcentaje de identidad puede medirse a lo largo de la longitud de una secuencia de polinucleótido definida, por ejemplo, definida por un número de SEQ ID concreto o puede medirse a lo largo de una longitud más corta, por ejemplo, a lo largo de una longitud de fragmento tomada de una secuencia de polinucleótido definida más larga, por ejemplo, un fragmento de al menos 45, al menos 60, al menos 90, al menos 120, al menos 150, al menos 210 o al menos 450 restos contiguos. Dichas longitudes son solo ilustrativas y se entiende que puede usarse cualquier longitud de fragmento soportada por las secuencias mostradas en el presente documento, en las tablas, figuras o el listado de secuencias, para describir una longitud sobre la cual pueda medirse el porcentaje de identidad.
"Porcentaje (%) de identidad de secuencia de aminoácidos" con respecto a las secuencias de polinucleótidos identificadas en el presente documento, se define como el porcentaje de restos de aminoácidos en una secuencia de búsqueda que son idénticos a los restos de aminoácidos de una segunda secuencia de polipéptido de referencia o una porción de la misma, después de alinear las secuencias e introducir huecos, en caso necesario, para lograr el porcentaje máximo de identidad de secuencia y sin tomar en consideración cualquier sustitución conservativa como parte de la identidad de secuencia. El alineamiento con el fin de determinar el porcentaje de identidad de secuencia de aminoácidos puede lograrse de varias maneras que se encuentran dentro de las capacidades de la técnica, por ejemplo, usando programas informáticos disponibles de manera pública, tales como los programas BLAST, BLAST-2, ALIGN o Megalign (DNASTAR). Los expertos en la materia pueden determinar los parámetros adecuados para medir la alineación, incluyendo cualquier algoritmo necesario para lograr un alineamiento máximo a lo largo de la longitud completa de las secuencias que se estén comparando. El porcentaje de identidad puede medirse a lo largo de la longitud de una secuencia de polipéptido definida, por ejemplo, definida por un número de SEQ ID concreto o puede medirse a lo largo de una longitud más corta, por ejemplo, a lo largo de una longitud de fragmento tomada de una secuencia de polipéptido definida más larga, por ejemplo, un fragmento de al menos 15, al menos 20, al menos 30, al menos 40, al menos 50, al menos 70 o al menos 150 restos contiguos. Dichas longitudes son solo ilustrativas y se entiende que puede usarse cualquier longitud de fragmento soportada por las secuencias mostradas en el presente documento, en las tablas, figuras o el listado de secuencias, para describir una longitud sobre la cual pueda medirse el porcentaje de identidad.
La expresión "no repetitividad", tal como se usa en el contexto de un polipéptido, se refiere a la falta o a un grado limitado de homología interna en una secuencia de péptido o polipéptido. La expresión "sustancialmente no repetitivo" puede significar, por ejemplo, que hay pocos o ningún caso de cuatro aminoácidos en la secuencia que sean tipos de aminoácidos idénticos o que el polipéptido tiene una puntuación de subsecuencia (descrita más adelante) de 10 o menos o que no hay un patrón en el orden, del extremo N al extremo C-terminal, de los motivos de secuencia que forman la secuencia de polinucleótido. El término "repetitividad", tal como se usa en el presente documento en el contexto de un polipéptido, se refiere al grado de homología interna en una secuencia de péptido o polipéptido. Por el contrario, una secuencia "repetitiva" puede contener múltiples copias idénticas de secuencias de aminoácidos cortas.
Por ejemplo, una secuencia de polipéptido de interés puede dividirse en secuencias de n-meros y puede contarse el número de secuencias idénticas. Las secuencias altamente repetitivas contienen una gran proporción de secuencias idénticas, mientras que las secuencias no repetitivas contienen pocas secuencias idénticas. En el contexto de un polipéptido, una secuencia puede contener múltiples copias de secuencias más cortas con longitudes o motivos definidos o variables, en la que los motivos por sí mismos son secuencias no repetitivas, haciendo que el polipéptido de longitud completa sea sustancialmente no repetitivo. La longitud de polipéptido en la que se mide la falta de repetitividad puede variar de 3 aminoácidos a aproximadamente 200 aminoácidos, y de aproximadamente 6 a aproximadamente 50 aminoácidos o de aproximadamente 9 a aproximadamente 14 aminoácidos.
La "repetitividad", usada en el contexto de secuencias de polinucleótido, se refiere al grado de homología interna en la secuencia, tal como, por ejemplo, la frecuencia de secuencias de nucleótidos idénticas de una longitud dad. La repetitividad puede medirse, por ejemplo, analizando la frecuencia de secuencias idénticas.
Un "vector" es una molécula de ácido nucleico, preferentemente autorreplicante en un hospedador adecuado, que transfiere una molécula de ácido nucleico insertada dentro de y/o entre células hospedadoras. El término incluye vectores cuya función principal es la inserción de ADN o ARN en una célula, la replicación de vectores cuya función principal es la replicación del ADN o ARN y vectores de expresión, cuya función es la transcripción y/o traducción del ADN o ARN. También se incluyen vectores que proporcionan más de una de las funciones anteriores. Un "vector de expresión" es un polinucleótido que, cuando se introduce en una célula hospedadora adecuada, puede transcribirse y traducirse en polipéptidos. Un "sistema de expresión" denota normalmente una célula hospedadora adecuada que comprende un vector de expresión cuya función puede ser proporcionar un producto de expresión deseado.
La "resistencia a la degradación en suero", en el sentido aplicado a un polipéptido, se refiere a la capacidad de los polipéptidos para resistir la degradación en la sangre o los componentes de la misma, lo que normalmente implica proteasas en el suero o el plasma. La resistencia a la degradación en suero puede medirse combinando la proteína con suero o plasma humano (o de ratón, rata o mono, según sea adecuado), normalmente a lo largo de un intervalo de días (por ejemplo, 0,25, 0,5, 1,2, 4, 8, 16 días), normalmente a aproximadamente 37 °C. Las muestras para estos puntos de tiempo pueden ejecutarse en un ensayo de transferencia de Western y la proteína se detecta con un anticuerpo. El anticuerpo puede ser para un marcador en la proteína. En caso de que la proteína muestre una sola banda en la transferencia de Western, donde el tamaño de la proteína es idéntico al de la proteína indicada, no se ha producido degradación. En este método a modo de ejemplo, el punto de tiempo en el que se ha degradado un 50 % de la proteína, según se valora mediante transferencias de Western o técnicas equivalentes, es la semivida de degradación en suero o "semivida en suero" de la proteína.
El término "ti /2 ", tal como se usa en el presente documento, significa la semivida terminal calculada como In(2)/Kei. Kei es la constante de eliminación terminal calculada mediante regresión lineal de la porción lineal terminal de la curva de log de concentración frente al tiempo. La semivida se refiere normalmente al tiempo necesario para que se metabolice o elimine mediante procesos biológicos normales la mitad de la cantidad de una sustancia administrada depositada en un organismo vivo. Los términos 'W , "semivida terminal", "semivida de eliminación" y "semivida en circulación" se usan de manera indistinta en el presente documento.
"Factor de peso molecular aparente" o "peso molecular aparente" son términos relacionados que se refieren a una medida del aumento o la reducción relativa en el peso molecular aparente mostrado por una secuencia de aminoácidos particular. El peso molecular aparente se determina usando cromatografía de exclusión por tamaños (SEC) y métodos similares, en comparación con patrones de proteína globular y se mide en unidades de "kD aparente". El factor de peso molecular aparente es la proporción entre el peso molecular aparente y el peso molecular real; prediciéndose este último sumando, basándose en la composición de aminoácidos, el peso molecular calculado de cada tipo de aminoácido en la composición.
El "radio hidrodinámico" o "radio de Stokes" es el radio eficaz (Rh en nm) de una molécula en una solución, medida suponiendo que es un cuerpo que se mueve por toda la solución y que encuentra resistencia por la viscosidad de la solución. En las realizaciones de la invención, las mediciones del radio hidrodinámico de las proteínas de fusión de XTEN se correlacionan con el "factor de peso molecular aparente", que es una medida más intuitiva. El "radio hidrodinámico" de una proteína afecta a su velocidad de difusión en solución acuosa, así como a su capacidad para migrar en geles de macromoléculas. El radio hidrodinámico de una proteína se determina mediante su peso molecular, así como mediante su estructura, incluyendo su forma y grado de compactación. Se conocen bien en la técnica métodos para determinar el radio hidrodinámico, tales como mediante el uso de cromatografía de exclusión por tamaños (SEC), como se describe en las patentes de los Estados Unidos n.° 6.406.632 y 7.294.513. La mayoría de proteínas tiene una estructura globular, que es la estructura tridimensional más compacta que puede tener una proteína, con el menor radio hidrodinámico. Algunas proteínas adoptan una conformación aleatoria y abierta, no estructurada o "lineal" y por consiguiente, tienen un radio hidrodinámico mucho mayor en comparación con proteínas globulares típicas con un peso molecular similar.
"Condiciones fisiológicas" se refiere a una serie de condiciones en un hospedador vivo así como a condiciones in vitro, incluyendo la temperatura, concentración salina, pH, que imitan a las condiciones de un sujeto vivo. Se ha determinado una serie de condiciones fisiológicamente relevantes para su uso en ensayos in vitro. En general, un tampón fisiológico
contiene una concentración fisiológica de sal y se ajusta a un pH neutro en el intervalo de aproximadamente 6,5 a aproximadamente 7,8 y preferentemente, de aproximadamente 7,0 a aproximadamente 7,5. Puede encontrarse una lista de diversos tapones fisiológicos en Sambrook et al. (1989). La temperatura fisiológicamente relevante varía de aproximadamente 25 °C a aproximadamente 38 °C y preferentemente, de aproximadamente 35 °C a aproximadamente 37 °C.
Un "grupo reactivo" es una estructura química que puede acoplarse a un segundo grupo reactivo. Son ejemplos de grupos reactivos los grupos amino, grupos carboxilo, grupos sulfhidrilo, grupos hidroxilo, grupos aldehído, grupos azida. Algunos grupos reactivos pueden activarse para facilitar el acoplamiento con un segundo grupo reactivo. Son ejemplos de la activación la reacción de un grupo carboxilo con carbodiimida, la conversión de un grupo carboxilo en un éster activado o la conversión de un grupo carboxilo en una función azida.
"Agente de liberación controlada", "agente de liberación lenta", "formulación en depósito" o "agente de liberación sostenida" se usan de manera indistinta para referirse a un agente capaz de prolongar la duración de la liberación de polipéptido de la invención en relación con la duración de la liberación cuando el polipéptido se administra en ausencia de agente. Las diferentes realizaciones de la presente invención pueden tener diferentes velocidades de liberación, dando como resultado diferentes cantidades terapéuticas.
Los términos "antígeno", "antígeno diana" o "inmunógeno" se usan de manera indistinta en el presente documento para referirse a la estructura o determinante de unión a la que se une un fragmento de anticuerpo o un agente terapéutico a base de fragmentos de anticuerpo o contra la que tiene especificidad.
El término "carga", tal como se usa en el presente documento, se refiere a una proteína o secuencia peptídica que tiene actividad biológica o terapéutica; el homólogo al farmacóforo de las moléculas pequeñas. Los ejemplos de cargas incluyen, pero sin limitación, citocinas, enzimas, hormonas y factores de crecimiento sanguíneos. Las cargas pueden comprender además restos fusionados genéticamente o conjugados químicamente, tales como agentes quimioterapéuticos, compuestos antivíricos, toxinas o agentes de contraste. Estos restos conjugados pueden unirse al resto del polipéptido mediante un enlazador que puede ser escindible o no escindible.
El término "antagonista", como se usa en el presente documento, incluye cualquier molécula que bloquee, inhiba o neutralice parcial o totalmente una actividad biológica de un polipéptido nativo divulgado en el presente documento. Los métodos para identificar antagonistas de un polipéptido pueden comprender poner en contacto un polipéptido nativo con un candidato a molécula antagonista y medir un cambio detectable en una o más actividades biológicas normalmente asociadas con el polipéptido nativo. En el contexto de la presente invención, los antagonistas pueden incluir proteínas, ácidos nucleicos, hidratos de carbono, anticuerpos o cualesquiera otras moléculas que reduzcan el efecto de una proteína biológicamente activa.
El término "agonista" se usa en su sentido más amplio e incluye cualquier molécula que imite una actividad biológica de un polipéptido nativo divulgado en el presente documento. Las moléculas agonistas adecuadas incluyen específicamente anticuerpos o fragmentos de anticuerpos agonistas, fragmentos o variantes de secuencia de aminoácidos de polipéptidos nativos, péptidos, moléculas orgánicas pequeñas, etc. Los métodos para identificar agonistas de un polipéptido nativo pueden comprender poner en contacto un polipéptido nativo con una molécula candidata a agonista y medir un cambio detectable en una o más actividades biológicas normalmente asociadas con el polipéptido nativo.
"Actividad", a efectos del presente documento, se refiere a una acción o efecto de un componente de una proteína de fusión que es coherente con la proteína biológicamente activa nativa correspondiente, en donde "actividad biológica" se refiere a una función o efecto biológico in vitro o in vivo, incluyendo, pero sin limitación, unión a receptores, actividad antagonista, actividad agonista o una respuesta celular o fisiológica.
Como se usa en el presente documento, "tratamiento" o "tratar", o "paliar" o "aliviar" se usan de manera indistinta en el presente documento. Estos términos se refieren a una estrategia para obtener resultados beneficiosos o deseados que incluyen, pero sin limitación, un beneficio terapéutico y/o un beneficio profiláctico. Por beneficio terapéutico se entiende la erradicación o mejora del trastorno subyacente que se esté tratando. Asimismo, se logra un beneficio terapéutico con la erradicación o la mejora de uno o más de los síntomas fisiológicos asociados con el trastorno subyacente, de tal forma que se observa una mejora en el sujeto, independientemente de que el sujeto pueda seguir estando afectado por el trastorno subyacente. Para un beneficio profiláctico, las composiciones pueden administrarse a un sujeto en riesgo de desarrollar una enfermedad particular o a un sujeto que comunica uno o más de los síntomas de una enfermedad, aun cuando pueda no haberse realizado un diagnóstico de esta enfermedad.
Un "efecto terapéutico", como se usa en el presente documento, se refiere a un efecto fisiológico, incluyendo, pero sin limitación, la cura, mitigación, mejora o prevención de enfermedades en seres humanos u otros animales o de otro modo, a mejorar el bienestar físico o mental de los seres humanos o animales, provocada por un polipéptido de fusión de la invención distinta de la capacidad para inducir la producción de un anticuerpo contra un epítopo antigénico poseído por la proteína biológicamente activa. La determinación de una cantidad terapéuticamente eficaz se encuentra dentro de las competencias de los expertos en la materia, especialmente a la luz de la divulgación detallada
proporcionada en el presente documento.
Las expresiones "cantidad terapéuticamente eficaz" y "dosis terapéuticamente eficaz", tal como se usan en el presente documento, se refieren a una cantidad de una proteína biológicamente activa, ya esté sola o como parte de una composición de proteína de fusión, que es capaz de tener cualquier efecto beneficioso detectable en cualquier síntoma, aspecto, parámetro medido o característica de una patología o afección cuando se administra en una o en dosis repetidas a un sujeto. No es absolutamente necesario que dicho efecto sea beneficioso.
La expresión "pauta posológica terapéuticamente eficaz", como se usa en el presente documento, se refiere a una pauta para dosis administradas de manera consecutiva de una proteína biológicamente activa, ya esté sola o como parte de una composición de proteína de fusión, en donde las dosis se administran en cantidades terapéuticamente eficaces para dar como resultado un efecto beneficioso sostenido sobre cualquier síntoma, aspecto, parámetro medido o característica de una patología o afección.
I) TÉCNICAS GENERALES
La práctica de la presente invención emplea, salvo que se indique de otro modo, técnicas convencionales de inmunología, bioquímica, química, biología molecular, microbiología, biología celular, genómica y ADN recombinante, que se encuentran entre las capacidades de la técnica. Véase Sambrook, J. et al., "Molecular Cloning: A Laboratory Manual," 3a edición, Cold Spring Harbor Laboratory Press, 2001; "Current protocols in molecular biology", F. M. Ausubel, et al. eds., 1987; la serie "Methods in Enzymology," Academic Press, San Diego, CA.; "PCR 2: a practical approach", M.J. MacPherson, B.D. Hames y G.R. Taylor eds., Oxford University Press, 1995; "Antibodies, a laboratory manual" Harlow, E. y Lane, D. eds., Cold Spring Harbor Laboratory, 1988; "Goodman & Gilman's The Pharmacological Basis of Therapeutics," 11a Edición, McGraw-Hill, 2005; y Freshney, R.I., "Culture of Animal Cells: A Manual of Basic Technique," 4 a edición, John Wiley & Sons, Somerset, n J, 2000.
II) PÉPTIDOS REGULADORES DE GLUCOSA
La invención reivindicada en el presente documento se refiere, en parte, a composiciones de proteínas de fusión que comprenden péptidos reguladores de la glucosa (GP). Dichas composiciones pueden ser útiles en el tratamiento o la prevención de ciertas enfermedades, trastornos o afecciones relacionados con la homeostasis de la glucosa, obesidad, resistencia a la insulina, dislipidemia, hipertensión y similares.
Las enfermedades o trastornos endocrinos y relacionados con la obesidad han alcanzado dimensiones epidémicas en la mayoría de países desarrollados y representan una carga sanitaria sustancial y creciente en la mayoría de países desarrollados, que incluye una gran variedad de afecciones que afectan a los órganos, tejidos y al sistema circulatorio del organismo. Son particularmente interesantes las enfermedades y los trastornos endocrinos y relacionados con la obesidad, entre los que destaca la diabetes; una de las principales causas de muerte en los Estados Unidos. La diabetes se divide en dos clases principales, de tipo I, también conocida como diabetes juvenil o diabetes mellitus insulinodependiente (IDDM) y de tipo II, también conocida como diabetes de inicio en la edad adulta o diabetes mellitus no insulinodependiente (NIDDM). La diabetes de tipo I es una forma de enfermedad autoinmunitaria que destruye total o parcialmente las células productoras de insulina del páncreas en dichos sujetos y requiere el uso de insulina endógena durante el resto de su vida. Incluso en los sujetos bien controlados, pueden producirse complicaciones episódicas, algunas de las cuales pueden ser mortales.
En los diabéticos de tipo II, el aumento de los niveles de glucosa en sangre después de las comidas no estimula de manera adecuada la producción de insulina por el páncreas. Además, los tejidos periféricos son generalmente resistentes a los efectos de la insulina y dichos sujetos tienen normalmente niveles plasmáticos de insulina por encima de lo normal (hiperinsulinemia) a medida que el organismo intenta superar su resistencia a la insulina. En los estados patológicos avanzados, también se deteriora la secreción de insulina.
También se han relacionado la resistencia a la insulina y la hiperinsulinemia con otros dos trastornos metabólicos que suponen un riesgo importante para la salud: la tolerancia alterada a la glucosa y la obesidad metabólica. La tolerancia alterada a la glucosa se caracteriza por niveles normales de glucosa antes de comer, con una tendencia hacia niveles elevados (hiperglucemia) después de una comida. Se considera que estos individuos se encuentran en mayor riesgo de diabetes y de enfermedad de las arterias coronarias. La obesidad también es un factor de riesgo para el grupo de afecciones denominadas síndrome de resistencia a la insulina o "síndrome X", tales como hipertensión, enfermedad de las arterias coronarias (arteriesclerosis) y lactoacidosis, así como estados patológicos relacionados. Se cree que la patogénesis de la obesidad es multifactorial, pero un problema subyacente es que en la población obesa, no hay equilibrio entre la disponibilidad de nutrientes y el gasto energético hasta el punto de que hay exceso de tejido adiposo. Otras enfermedades o trastornos relacionados incluyen, pero sin limitación, diabetes gestacional, diabetes juvenil, obesidad, exceso de apetito, saciedad insuficiente, trastorno metabólico, glucagonomas, procesos neurodegenerativos retinales y el "periodo de luna de miel" de la diabetes de tipo I.
La dislipidemia es de aparición frecuente entre la población diabética; normalmente se caracteriza por triglicéridos en plasma elevados, bajo colesterol de HDL (lipoproteína de alta densidad), niveles de normales a elevados de colesterol
de LDL (lipoproteína de baja densidad) y niveles amentados de pequeñas partículas densas de LDL en la sangre. La dislipidemia contribuye de manera importante al aumento de la incidencia de complicaciones coronarias y murete entre los sujetos diabéticos.
La mayoría de los procesos metabólicos en la homeostasis de la glucosa y la respuesta de insulina están regulados por múltiples péptidos y hormonas y muchos de estos péptidos y hormonas, así como los análogos de los mismos, han resultado ser útiles en el tratamiento de las enfermedades y trastornos metabólicos. Muchos de estos péptidos tienen tendencia a ser altamente homólogos entre sí, incluso cuando poseen funciones biológicas opuestas. Son ejemplos de péptidos que aumentan la glucosa la hormona peptídica, glucagón, mientras que los péptidos que reducen la glucosa incluyen exendina-4, péptido 1 similar a glucagón y amilina. Sin embargo, el uso de péptidos y/o hormonas terapéuticas, incluso cuando se aumentan mediante el uso de fármacos de molécula pequeña, ha alcanzado un éxito limitado en la gestión de dichas enfermedades, trastornos y afecciones. En particular, es importante la optimización de la dosis para fármacos y agentes biológicos usados en el tratamiento de enfermedades metabólicas, especialmente aquellos con una ventana terapéutica estrecha. En general, las hormonas y los péptidos implicados en la homeostasis de la glucosa tienen normalmente una estrecha ventana terapéutica. La estrecha ventana terapéutica, además del hecho de que dichas hormonas y péptidos tienen normalmente una semivida corta, por lo que se necesita una dosificación frecuente para lograr un beneficio clínico, dan como resultado dificultades en el control de dichos pacientes. Aunque las modificaciones químicas en una proteína terapéutica, tal como la pegilación, pueden modificar su velocidad de eliminación in vivo y la consiguiente semivida, requieren etapas de fabricación adicionales y dan como resultado un producto final heterogéneo. Además, se ha informado de efectos secundarios no aceptables provocados por la administración crónica. Como alternativa, la modificación genética mediante la fusión de un dominio Fc a la proteína o el péptido terapéutico aumenta el tamaño de la proteína terapéutica, reduciendo la velocidad de eliminación a través del riñón y favorece el reciclaje por los lisosomas a través del receptor FcRn. Lamentablemente, el dominio Fc no se pliega de manera eficaz durante la expresión recombinante y tiende a formar precipitados insolubles conocidos como cuerpos de inclusión. Estos cuerpos de inclusión han de solubilizarse y la proteína funcional ha de renaturalizarse; un proceso laborioso, ineficaz y caro.
Por tanto, un aspecto de la presente divulgación es la incorporación de péptidos implicados en la homeostasis de la glucosa, la resistencia a la insulina y la obesidad (de manera colectiva, "péptidos reguladores de la glucosa") en proteínas de fusión GPXTEN para crear composiciones que puedan usarse en el tratamiento de trastornos, enfermedades y afecciones relacionadas de la glucosa, la insulina y la obesidad (citadas en el presente documento como "enfermedades, trastornos o afecciones relacionadas con péptidos reguladores de la glucosa"). Los péptidos reguladores de la glucosa pueden incluir cualquier proteína con un interés o una función biológica, terapéutica o profiláctica que sea útil para prevenir, tratar, mediar o aliviar una enfermedad, trastorno o afección de la homeostasis de la glucosa o la resistencia a la insulina o la obesidad. Los péptidos reguladores de la glucosa adecuados que pueden unirse al XTEN para crear la GPXTEN incluyen todos los polipéptidos biológicamente activos que aumentan la secreción de insulina dependiente de la glucosa por las células beta pancreáticas o potencian la acción de la insulina o desempeñan un papel en la homeostasis de la glucosa. Los péptidos reguladores de la glucosa también pueden incluir todos los polipéptidos biológicamente activos que estimulan la transcripción del gen de proinsulina en las células beta pancreáticas. Además, los péptidos reguladores de la glucosa también pueden incluir todos los polipéptidos biológicamente activos que retrasan el tiempo de vaciado gástrico y reducen la ingesta de alimentos. Los péptidos reguladores de la glucosa también pueden incluir todos los polipéptidos biológicamente activos que inhiben la liberación de glucagón por las células alfa de los islotes de Langerhans. La tabla 1 proporciona una lista no limitante de secuencias de péptidos reguladores de la glucosa que están abarcados por las proteínas de fusión GPXTEN de la divulgación. Los péptidos reguladores de la glucosa de las composiciones de GPXTEN de la invención pueden ser un péptido que muestra al menos aproximadamente un 80 % de identidad de secuencia o como alternativa, un 81 %, 82 %, 83 %, 84 %, 85 %, 86 %, 87 %, 88 %, 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 % o 100 % de identidad de secuencia respecto de una proteína seleccionada de la tabla 1.
T l 1: P i r l r l i nim l


"Amilina" significa la hormona peptídica humana citada como amilina, pramlintida y variantes de especie de la misma, como se describe en la Patente de los Estados Unidos n.° 5.234.906, que tiene al menos parte de la actividad biológica de la amilina natural. La amilina es una hormona peptídica de 37 aminoácidos que se secreta junto con la insulina por las células beta pancreáticas en respuesta a la ingesta de alimento (Koda et al., Lancet 339:1179-1180. 1992) y se ha comunicado que modula varias vías clave del metabolismo de los hidratos de carbono, incluyendo la incorporación de glucosa en glucógeno. Las proteínas de fusión que contienen amilina de la divulgación pueden ser particularmente útiles en la diabetes y la obesidad para regular el vaciado gástrico, suprimir la secreción de glucagón y la ingesta de comida, afectando de este modo a la velocidad de aparición de la glucosa en la circulación. Por tanto, las proteínas de fusión pueden complementar la acción de la insulina, que regula la velocidad de desaparición de la glucosa de la circulación y su captación por los tejidos periféricos. Se han clonado análogos de amilina, como se describe en las Patentes de los Estados Unidos n.° 5.686.411 y 7.271.238. Pueden crearse miméticos de amilina que conservan la actividad biológica. Por ejemplo, la pramlintida tiene la secuencia KCNTATCATNRLANFLVHSSNNFGPILPPTNVGSNTY, en donde se sustituyen aminoácidos en la secuencia de amilina humana por aminoácidos de la secuencia de amilina de rata. En una realización, la divulgación contempla proteínas de fusión que comprenden miméticos de amilina con la secuencia
KCNTAT CATXi RLANFLVHSSNNFGX2 ILX2X2T NVGSNTY
en donde X i es independientemente N o Q y X2 es independientemente S, P o G. En una realización, el mimético de amilina incorporado en una GPXTEN tiene la secuencia KCNTATCATNRLANFLVHSSNNFGGILGGTNVGSNTY. En otra realización, en donde el mimético de amilina se usa en el extremo C-terminal de la GPXTEN, el mimético tiene la secuencia
KCNTAT CATNRLANFLVHSSNNF GGILGGTNVGSNTY (NH2)
"Exendina-3" significa un péptido regulador de la glucosa aislado de Heloderma horridum y variantes de secuencia del mismo que tienen al menos una parte de la actividad biológica de la exendina-3 nativa. La amida de exendina-3 es un antagonista específico del receptor de exendina que media un aumento en el AMPc pancreático y la liberación de insulina y amilasa. Las proteínas de fusión que contienen exendina-3 de la divulgación pueden ser particularmente útiles en el tratamiento de la diabetes y de los trastornos de resistencia a la insulina. La secuencia y sus métodos de ensayo se describen en la Patente de los Estados Unidos 5.424.286.
"Exendina-4" significa un péptido regulador de la glucosa hallado en la saliva del monstruo de Gila, Heloderma suspectum, así como variantes de especie y secuencia de la misma, e incluye la secuencia nativa de 39 aminoácidos His-Gly-Glu-Gly-Thr-Phe-Thr-Ser-Asp-Leu-Ser-Lys-Gln-Met-Glu-Glu-Glu-Ala-Val-Arg-Leu-Phe-Ile-Glu-Trp-Leu-Lys-Asn-Gly-Gly-Pro-Ser-Ser-Gly-Ala-Pro-Pro-Pro-Ser y secuencias homólogas y peptidomiméticos y variantes de la misma; secuencias naturales, tales como de primates y no naturales que tienen al menos una parte de la actividad biológica de la exendina-4 nativa. La exendina-4 es una hormona polipeptídica de incretina que reduce la glucosa en sangre, promueve la secreción de insulina, frena el vaciado gástrico y mejora la saciedad, proporcionando una mejora notable en la hiperglucemia postprandial. Las exendinas tienen cierto grado de similitud de secuencia respecto de miembros de la familia de péptidos similares a glucagón, encontrándose la máxima similitud con GLP-1 (Goke, et al, J. Biol. Chem., 268:19650-55 (1993)). Varias secuencias homólogas puede ser funcionalmente equivalente a la exendina-4 nativa y a GLP-1. La conservación de secuencias de GLP-1 de diferentes especies se presenta en Regulatory Peptides 2001 98 p. 1-12. La tabla 2 muestra las secuencias de una gran variedad de especies, mientras que la tabla 3 muestra una lista de análogos sintéticos de GLP-1; todos los cuales se contemplan para su uso como péptidos reguladores de la glucosa en las GPXTEN descritas en el presente documento. La exendina-4 se une a receptores de GLP-1 en las células pTC1 secretoras de insulina y también estimula la liberación de somatostatina e inhibe la liberación de gastrina en estómagos aislados (Goke, et al., J. Biol. Chem. 268:19650-55, 1993). Como mimético de GLP-1, la exendina-4 muestra una amplia gama similar de actividades biológicas, aunque tiene una semivida más larga que GLP-1, con una semivida terminal media de 2,4 h. La exenatida es una versión sintética de exendina-4, comercializada por Byetta. Sin embargo, debido a su corta semivida, la exenatida se administra en la actualidad dos veces al día, lo que limita su utilidad. Las proteínas de fusión que contienen exendina-4 de la invención pueden ser particularmente útiles en el tratamiento de la diabetes y de los trastornos de resistencia a la insulina.
"Glucagón" significa el péptido regulador de la glucosa, glucagón humano o variantes de especie y de secuencia del mismo, incluyendo la secuencia nativa de 29 aminoácidos y secuencias homólogos; naturales, tales como de primates y variantes de secuencia no naturales que tienen al menos parte de la actividad biológica del glucagón nativo. El término "glucagón", tal como se usa en el presente documento, también incluye peptidomiméticos del glucagón. El glucagón nativo se produce por el páncreas, se libera cuando los niveles de glucosa en sangre bajan demasiado, haciendo que el hígado convierta el glucógeno almacenado en glucosa y la libera al torrente sanguíneo. Aunque la
acción del glucagón es opuesta a la de la insulina, que envía señales a las células del organismo para captar la glucosa de la sangre, el glucagón también estimula la liberación de insulina, de tal forma que la glucosa nuevamente disponible en el torrente sanguíneo puede captarse y usarse por los tejidos dependientes de insulina. Las proteínas de fusión de la invención que contienen glucagón pueden ser particularmente útiles para aumentar los niveles de glucosa en sangre en individuos con depósitos de glucógeno hepático existentes y mantener la homeostasis de la glucosa en la diabetes. El glucagón se ha clonado, como se describe en la Patente de los Estados Unidos n.° 4.826.763.
"GLP-1" significa péptido-1 similar a glucagón humano y variantes de secuencia del mismo que tengan al menos una parte de la actividad biológica del GLP-1 nativo. El término "GLP-1" incluye GLP-1(1-37) humano, GLP-1(7-37) y GLP-1 (7-36)amida. GLP-1 estimula la secreción de insulina, pero solo durante periodos de hiperglucemia. La seguridad del GLP-1 en comparación con la insulina mejora debido a esta propiedad y por la observación de que la cantidad de insulina secretada es proporcional a la magnitud de la hiperglucemia. La semivida biológica de GLP-1(7-37)OH es de tan solo 3 a 5 minutos (Patente de los Estados Unidos n.° 5.118.666). Las proteínas de fusión que contienen GLP-1 de la invención pueden ser particularmente útiles en el tratamiento de la diabetes y de los trastornos de resistencia a la insulina para la regulación de la glucosa. Se ha clonado GLP-1 y se han preparado derivados, como se describe en la Patente de los Estados Unidos n.° 5.118.666. Los ejemplos no limitantes de secuencias de GLP-1 de una gran variedad de especies se muestran en la tabla 2, mientras que la tabla 3 muestra las secuencias de una serie de análogos sintéticos de GLP-1; todos los cuales se contemplan para su uso como péptidos reguladores de la glucosa en las composiciones de GPXTEN descritas en el presente documento.
T l 2: H m l LP-1 n r l


Las secuencias de GLP nativas pueden describirse por varios motivos de secuencia, que se presentan a continuación. Las letras entre corchetes representan aminoácidos aceptables en cada posición de secuencia: [HVY] [AGISTV] [DEHQ] [AG] [ILMPSTV] [FLY] [DESIST] [ADEKNST] [ADENSTV] [LMVY] [ANRSTY] [EHIKNQRST] [AHILMQVY] [LMRT] [ADEGKQS] [ADEGKNQSY] [AEIKLMQR] [AKQRSVY] [AILMQSTV] [GKQR] [DEKLQR] [FHLVWY] [ILV] [ADEGPIKNQRST] [ADEGNRSTW] [GILVW] [AIKLMQSV] [ADGIKNQRST] [GKRSY]. Además, los análogos sintéticos de GLP-1 y la pramlintida pueden ser útiles como compañeros de fusión con XTEN para crear GPXTEN con una actividad biológica útil en el tratamiento de trastornos relacionados con la glucosa. Los ejemplos no limitantes de secuencias de GLP-1 y pramlintida pueden encontrarse en la tabla 3. Además, pueden encontrarse secuencias adicionales homólogas a GLP-1, pramlintida, así como secuencias homólogas a exendina-4, amilina o glucagón mediante técnicas de búsqueda de homología convencionales.
T l : An l in i LP-1 r mlin i


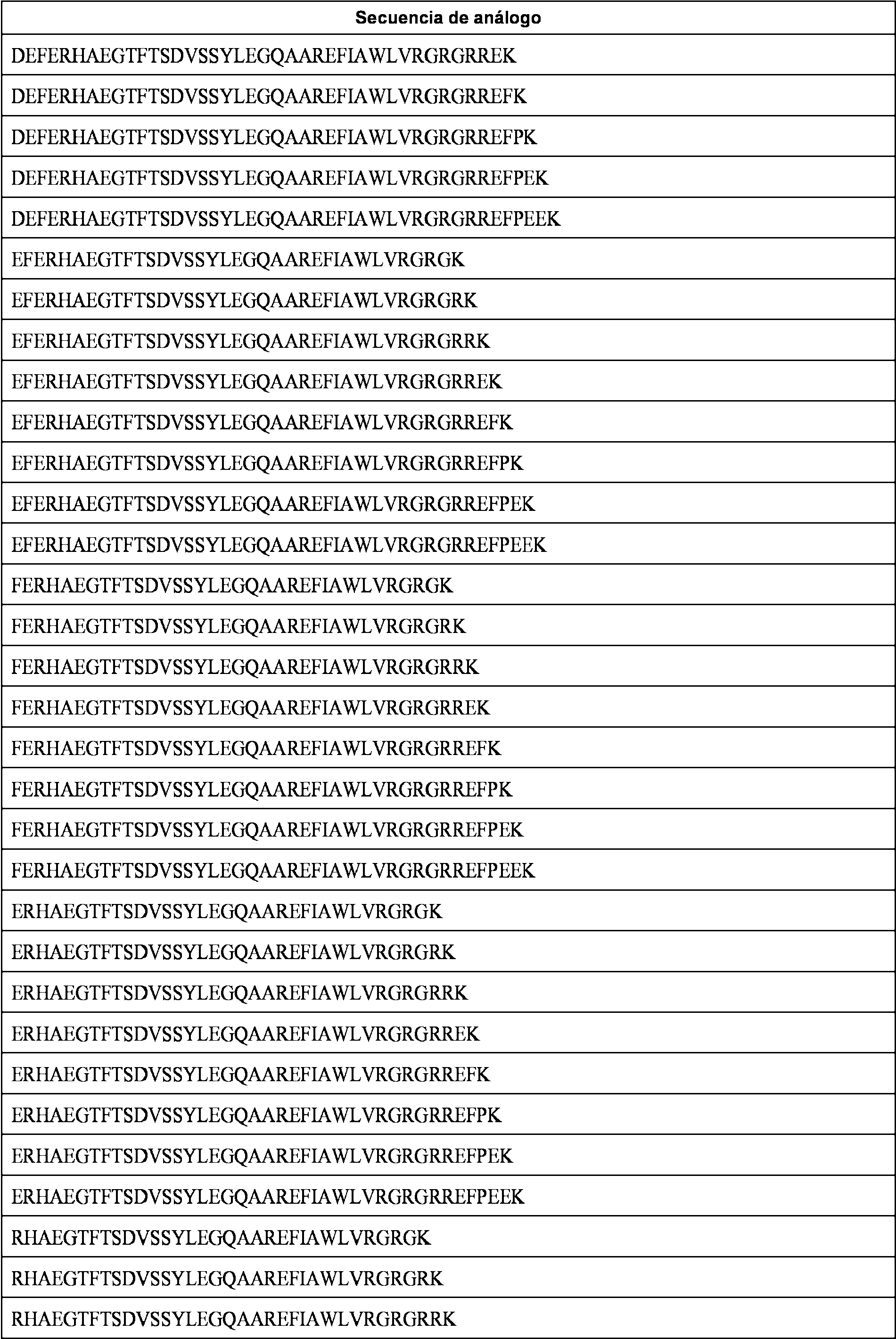

"GLP-2" significa péptido-2 similar a glucagón humano y variantes de secuencia del mismo que tengan al menos una parte de la actividad biológica del GLP-2 nativo. Más concretamente, GLP-2 es un péptido de 33 aminoácidos, secretado junto con GLP-1 por las células endocrinas intestinales en el intestino delgado y grueso.
NI) COMPOSICIONES DE PROTEINA DE FUSION DE PEPTIDO REGULADOR DE LA GLUCOSA
La presente invención se refiere, en parte, a composiciones de proteínas de fusión que comprenden péptidos reguladores de la glucosa (GP). En un aspecto, la invención proporciona proteínas de fusión monoméricas aisladas de acuerdo con las reivindicaciones, comprendiendo el GP la secuencia de longitud completa o variantes de secuencia
de GP unidas covalentemente a polipéptidos recombinantes extendidos ("XTEN"). Tal como se describe en más detalle más adelante, las proteínas de fusión pueden incluir opcionalmente secuencias espadadoras que comprenden además secuencias de escisión para liberar el GP de la proteína de fusión cuando actúa sobre ella una proteasa, liberando el GP de las secuencias de XTEN.
En algunos casos, la invención proporciona una proteína de fusión aislada que comprende al menos un primer péptido regulador de la glucosa biológicamente activo unido covalentemente a uno o más polipéptidos recombinantes extendidos ("XTEN"), dando como resultado una composición de proteína de fusión de péptido regulador de la glucosa-XTEN (en lo sucesivo, "GPXTEN"). En otros casos, el péptido regulador de la glucosa unido a uno o más XTEN es inactivo o tiene una actividad reducida que puede incluir opcionalmente secuencias espaciadoras que pueden comprender adicionalmente secuencias de escisión para liberar el GP de la proteína de fusión cuando actúa sobre ella una proteasa en una forma más activa.
El término "GPXTEN", como se usa en el presente documento, pretende abarcar polipéptidos de fusión que comprenden una o más regiones de carga, comprendiendo cada una un GP biológicamente activo que media una o más actividades biológicas o terapéuticas asociadas con un péptido regulador de la glucosa y al menos una región diferente que comprende al menos un primer polipéptido de XTEN que sirve como portador.
El GP de las presentes composiciones, en particular de las descritas en la tabla 1, junto con sus secuencias de ácido nucleico y aminoácidos correspondientes, se conocen bien en la técnica y hay disponibles descripciones y secuencias en bases de datos públicas, tales como Chemical Abstracts Services Databases (por ejemplo, el registro CAS), GenBank, The Universal Protein Resource (UniProt) y bases de datos proporcionadas por suscripción, tales como GenSeq (por ejemplo, Derwent). Las secuencias de polinucleótido pueden ser una secuencia de polinucleótido de tipo silvestre que codifica un GP dado (por ejemplo, ya sea de longitud completa o maduro), o en algunos casos, la secuencia puede ser una variante de la secuencia de polinucleótido de tipo silvestre (por ejemplo, un polinucleótido que codifica la proteína biológicamente activa de tipo silvestre, en donde la secuencia de ADN del polinucleótido se ha optimizado, por ejemplo, para su expresión en una especie particular; o un polinucleótido que codifica una variante de la proteína de tipo silvestre, tal como un mutante de sitio dirigido o una variante alélica. Se encuentra dentro de las capacidades del experto en la materia usar una secuencia de ADNc de tipo silvestre o consenso o una variante con codones optimizados de un GP para crear construcciones de GPXTEN contempladas por la invención usando métodos conocidos en la técnica y/o junto con la orientación y los métodos proporcionados en el presente documento y descritos con más detalle en los ejemplos.
El GP para su inclusión en la GPXTEN de la divulgación incluye cualquier péptido regulador de glucosa o una variante de secuencia con interés o función biológica, terapéutica, profiláctica o diagnóstica o que sea útil para mediar o prevenir o aliviar una enfermedad, trastorno o afección asociada con una deficiencia de péptido regulador de la glucosa o un defecto en la sensibilidad a uno o más GP por parte del sujeto. Son particularmente interesantes las composiciones de proteína de fusión GPXTEN para las que se prevé un aumento en un parámetro farmacocinético, aumento de la solubilidad, aumento de la estabilidad o alguna otra propiedad farmacéutica mejorada en comparación con el GP nativo o para el que el aumento de la semivida terminal podría mejorar la eficacia, la seguridad o dar como resultado una frecuencia de dosis reducida y/o mejorar el cumplimiento terapéutico. Por tanto, las composiciones de proteína de fusión GPXTEN se preparan con varios objetivos en mente, incluyendo la mejora de la eficacia terapéutica del GP bioactivo, por ejemplo, aumentando la exposición in vivo o el tiempo que la GPXTEN permanece dentro de la ventana terapéutica cuando se administra a un sujeto, en comparación con un GP no unido a XTEN.
En una realización, el GP incorporado en las presentes composiciones puede ser un polipéptido recombinante con una secuencia correspondiente a una proteína hallada en la naturaleza. En otra realización, el GP puede ser una variante de secuencia, fragmentos, homólogos y miméticos de una secuencia natural que conservan al menos una parte de la actividad biológica del GP nativo. En algunos casos, el GP para su incorporación en la GPXTEN de la divulgación puede ser una secuencia que muestra al menos aproximadamente un 80 % de identidad de secuencia o como alternativa, un 81 %, 82 %, 83 %, 84 %, 85 %, 86 %, 87 %, 88 %, 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 % o al menos aproximadamente un 99 % o 100 % de identidad de secuencia respecto de una secuencia de proteína seleccionada de las secuencias de la tabla 1, la tabla 2 y la tabla 3. En una realización, la proteína de fusión GPXTEN puede comprender una sola molécula de GP unida a un XTEN (como se describe en más detalle más adelante). En otra realización, la GPXTEN puede comprender un primer GP y una segunda molécula del mismo GP, dando como resultado una proteína de fusión que comprende los dos GP unidos a uno o más XTEN (por ejemplo, dos moléculas de GLP-1). En otra realización, la proteína de fusión GPXTEN puede comprender una sola molécula de GP unida a un primer y un segundo XTEN, con una configuración de N a C-terminal de XTEN-GP-XTEN, en la que el GP puede ser una secuencia que muestra al menos aproximadamente un 80 % de identidad de secuencia o como alternativa, un 81 %, 82 %, 83 %, 84 %, 85 %, 86 %, 87 %, 88 %, 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 % o al menos aproximadamente un 99 % o 100 % de identidad de secuencia respecto de una secuencia seleccionada de las secuencias de la tabla 1, la tabla 2 y la tabla 3 y el primer y/o el segundo XTEN pueden ser secuencias que muestran la menos aproximadamente un 80 % de identidad de secuencia o como alternativa, un 81 %, 82 %, 83 %, 84 %, 85 %, 86 %, 87 %, 88 %, 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 % o al menos aproximadamente un 99 % o 100 % de identidad de secuencia respecto de una secuencia seleccionada de las secuencias de la tabla 5.
En general, el componente de compañero de fusión de GP de la GPXTEN mostrará una especificidad de unión por una diana dada u otra característica biológica deseada cuando se usa in vivo o cuando se utiliza en un ensayo in vitro. Por ejemplo, la GPXTEN puede ser un agonista, que tiene la capacidad de unirse a un receptor celular para un péptido regulador de la glucosa. En una realización, la unión de la GPXTEN a su receptor puede ocasionar al menos parte de la activación de la vía de transducción de señales intercelulares en comparación con el péptido regulador de la glucosa nativo correspondiente no unido al XTEN. En una realización, la GPXTEN unida a un receptor celular para un péptido regulador de la glucosa puede mostrar al menos aproximadamente un 1 % o aproximadamente un 5 % o aproximadamente un 10 % o aproximadamente un 15 % o aproximadamente un 20 % o aproximadamente un 25 % o aproximadamente un 30 % o aproximadamente un 40 % o aproximadamente un 50 % o aproximadamente un 60 % o aproximadamente un 70 % o aproximadamente un 80 % o aproximadamente un 90 % o al menos aproximadamente un 95 % de la activación de la vía de transducción de señales intercelulares en comparación con el péptido regulador de la glucosa nativo no unido al XTEN.
La presente GPXTEN de la presente invención puede mostrar una mejora de uno o más parámetros farmacocinéticos, que pueden mejorarse opcionalmente para un efecto biológico mediante la liberación del GP de la proteína de fusión mediante la escisión de una secuencia espaciadora. La GPXTEN con parámetros farmacocinéticos mejorados podría permitir una dosificación menos frecuente o un efecto farmacológico potenciado, tal como, pero sin limitación, mantener la GPXTEN biológicamente activa dentro de la ventana terapéutica entre la dosis o concentración sanguínea mínima eficaz (Cmín) y la dosis o concentración sanguínea máxima tolerada (Cmáx). En dichos casos, la unión del GP a una proteína de fusión que comprende una secuencia de XTEN seleccionada puede dar como resultado una mejora en estas propiedades, haciendo que sean más útiles como agentes terapéuticos o preventivos en comparación con GP no unido a XTEN.
IV) POLIPÉPTIDOS RECOMBINANTES EXTENDIDOS
En un aspecto, la invención proporciona composiciones de polipéptido de XTEN que son útiles como compañero de proteína de fusión a los que se une el GP, dando como resultado una proteína de fusión GPXTEN. Los XTEN son normalmente polipéptidos de longitud extendida con secuencias de origen no natural, sustancialmente no repetitivas que están compuestas principalmente por aminoácidos hidrófilos pequeños, teniendo la secuencia un grado bajo o nulo de estructura secundaria o terciaria en condiciones fisiológicas.
Los XTEN pueden tener utilidad como compañeros de proteína de fusión ya que pueden servir como "vehículo", confiriendo ciertas propiedades farmacocinéticas, fisicoquímicas y farmacéuticas deseables cuando se unen a una proteína GP para crear una proteína de fusión. Dichas propiedades deseables incluyen, pero sin limitación, parámetros farmacocinéticos y características de solubilidad mejoradas de las composiciones, entre las otras propiedades que se describen más adelante. Dichas composiciones de proteína de fusión son útiles para tratar ciertas enfermedades, trastornos o afecciones relacionadas con péptidos reguladores de la glucosa, como se describe en el presente documento. Como se usa en el presente documento, "XTEN" excluye específicamente anticuerpos o fragmentos de anticuerpo, tal como anticuerpos monocatenarios o fragmentos Fc de una cadena ligera o una cadena pesada.
En algunas realizaciones, los XTEN son polipéptidos largos que tienen de más de aproximadamente 100 a aproximadamente 3000 restos de aminoácido, preferentemente, de más de 400 a aproximadamente 3000 restos cuando se usan como vehículo o de manera acumulativa, cuando se usa más de una unidad de XTEN en una sola proteína de fusión. En otros casos, cuando se usa como enlazador entre componentes de la proteína de fusión o cuando no se necesita un aumento en la semivida de la proteína d efusión pero se desea un aumento en la solubilidad u otra propiedad fisicoquímica para el componente compañero de fusión de GP, puede incorporarse una secuencia de XTEN menor de 100 aminoácidos, tal como de aproximadamente 96 o aproximadamente 84 o aproximadamente 72 o aproximadamente 60 o aproximadamente 48 o aproximadamente 36 restos de aminoácido en una composición de proteína de fusión con el GP para efectuar la propiedad.
Los criterios de selección para el XTEN que se va a unir a las proteínas biológicamente activas usadas para crear las composiciones de proteínas de fusión de la invención se refieren generalmente a atributos de propiedades físicas/químicas y a la estructura conformacional del XTEN que puede, a su vez, usarse para conferir propiedades farmacéuticas y farmacocinéticas mejoradas a las composiciones de proteína de fusión. El XTEN de la presente invención puede mostrar una o más de las siguientes propiedades ventajosas: flexibilidad conformacional, solubilidad acuosa mejorada, alto grado de resistencia a proteasas, baja inmunogenicidad, baja unión a receptores de mamífero y aumento de radios hidrodinámicos (o de Stokes); propiedades que pueden hacerlos particularmente útiles como compañeros de proteínas de fusión. Los ejemplos no limitantes de las propiedades de las proteínas de fusión que comprenden GP que pueden mejorarse mediante XTEN incluyen aumentos en la solubilidad general y/o la estabilidad metabólica, susceptibilidad reducida a la proteólisis, inmunogenicidad reducida, velocidad de absorción reducida cuando se administra por vía subcutánea o intramuscular y propiedades farmacocinéticas mejoradas, tales como semivida terminal más larga y aumento del área bajo la curva (ABC), absorción más lenta tras su inyección subcutánea o intramuscular en comparación con GP no unido al XTEN y administrado por una vía similar, de tal forma que la Cmáx es menor, que puede, a su vez, dar como resultado reducciones en los efectos adversos del GP que, junto con el aumento de la semivida y/o la ABC, pueden dar como resultado un aumento del periodo del tiempo durante el cual una proteína de fusión de una composición de GPXTEN administrada a un sujeto mantiene su actividad terapéutica.
Se conoce en la técnica una serie de métodos y ensayos para determinar las propiedades fisicoquímicas de proteínas, tales como las composiciones que comprenden el Xt En de la invención; propiedades tales como la solubilidad, estructura secundaria o terciaria, solubilidad, agregación de proteínas, propiedades de fusión, contaminación y contenido de agua. Dichos métodos incluyen centrifugación analítica, EPR, HPLC de intercambio de iones, HPLC de exclusión por tamaños, HPLC en fase inversa, dispersión de luz, electroforesis capilar, dicroísmo circular, calorimetría diferencial de barrido, fluorescencia, HPLC de intercambio de iones, HPLC de exclusión por tamaños, 1R, RMN, espectroscopía de Raman, refractometría y espectroscopía UV/visible. Se divulgan métodos adicionales en Amau et al., Prot Expr and Purif (2006) 48, 1-13. La aplicación de estos métodos a la invención se encontrará dentro de las capacidades de un experto en la materia.
Normalmente, los XTEN se diseñan para que se comporten como secuencias peptídicas desnaturalizadas en condiciones fisiológicas, a pesar de la longitud prolongada del polímero. Desnaturalizado describe el estado de un péptido en solución que se caracteriza por una gran libertad conformacional del armazón peptídico. La mayoría de péptidos y proteínas adoptan una conformación desnaturalizada en presencia de altas concentraciones de desnaturalizantes o a temperatura elevada. Los péptidos en conformación desnaturalizada tienen, por ejemplo, espectros de dicroísmo circular (CD) característicos y se caracterizan por una ausencia de interacciones de largo alcance, según se determina mediante RMN. "Conformación desnaturalizada" y "conformación no estructurada" se usan de manera sinónima en el presente documento. En algunos casos, la invención proporciona secuencias de XTEN que, en condiciones fisiológicas, pueden asemejarse a secuencias desnaturalizadas desprovistas en gran medida de estructura secundaria. En otros casos, las secuencias de XTEN pueden estar sustancialmente desprovistas de estructura secundaria en condiciones fisiológicas. "En gran medida desprovistas", como se usa en este contexto, significa que menos del 50 % de los restos de aminoácidos de la secuencia de XTEN contribuye a la estructura secundaria, según se mide o determina por los medios descritos en el presente documento. "Sustancialmente desprovistas", como se usa en este contexto, significa que al menos aproximadamente un 60 % o aproximadamente un 70 % o aproximadamente un 80 % o aproximadamente un 90 % o aproximadamente un 95 % o al menos aproximadamente un 99 % de los restos de aminoácido de XTEN de la secuencia del XTEN no contribuye a la estructura secundaria, como se mide o determina mediante los medios descritos en el presente documento.
Se ha establecido en la técnica una serie de métodos para discernir la presencia o ausencia de estructuras secundarias y terciarias en un polipéptido dado. En particular, la estructura secundaria puede medirse por medios espectrofotométricos, por ejemplo, por espectroscopía de dicroísmo circular en la región espectral del "UV lejano" (190-250 nm). Los elementos de estructura secundaria, tales como alfa-hélices o beta-láminas, dan lugar cada uno a una forma y magnitud característica de los espectros de CD. También puede predecirse la estructura secundaria para una secuencia de polipéptido mediante ciertos programas o algoritmos informáticos, tales como el conocido algoritmo de Chou-Fasman (Chou, P. Y., et al. (1974) Biochemistry, 13: 222-45) y el algoritmo de Garnier-Osguthorpe-Robson ("GOR") (Gamier J, Gibrat JF, Robson B. (1996), GOR method for predicting protein secondary structure from amino acid sequence. Methods Enzymol 266:540-553), tal como se describe en la Publicación de Solicitud de Patente de los Estados Unidos n.° 20030228309A1. Para una secuencia dada, los algoritmos pueden predecir si existe cierto grado o ausencia de estructura secundaria, expresada como el total y/o el porcentaje de los restos de la secuencia que forman, por ejemplo, alfa-hélices o beta-láminas o el porcentaje de restos de la secuencia que se predice que dan como resultado una formación de bucle aleatorio (que carece de estructura secundaria).
En algunos casos, las secuencias de XTEN usadas en las composiciones de proteína de fusión de la invención pueden tener un porcentaje de alfa-hélice que varía del 0 % a menos de aproximadamente el 5 %, según se determina mediante el algoritmo de Chou-Fasman. En otros casos, las secuencias de XTEN de las composiciones de proteína de fusión pueden tener un porcentaje de beta-lámina que varía del 0 % a menos de aproximadamente el 5 %, según se determina mediante el algoritmo de Chou-Fasman. En algunos casos, las secuencias de XTEN de las composiciones de proteína de fusión pueden tener un porcentaje de alfa-hélice que varía del 0 % a menos de aproximadamente el 5 % y un porcentaje de beta-lámina que varía del 0 % a menos de aproximadamente el 5 %, según se determina mediante el algoritmo de Chou-Fasman. En las realizaciones preferidas, las secuencias de XTEN de las composiciones de proteína de fusión tendrán un porcentaje de alfa-hélice menor de aproximadamente el 2 % y un porcentaje de beta-lámina menor de aproximadamente el 2 %. En otros casos, las secuencias de XTEN de las composiciones de proteína de fusión pueden tener un alto grado de porcentaje de bucle aleatorio, según se determina mediante el algoritmo GOR. En algunas realizaciones, una secuencia de XTEN puede tener al menos aproximadamente un 80 % o al menos aproximadamente un 90 % o al menos aproximadamente un 91 % o al menos aproximadamente un 92 % o al menos aproximadamente un 93 % o al menos aproximadamente un 94 % o al menos aproximadamente un 95 % o al menos aproximadamente un 96 % o al menos aproximadamente un 97 % o al menos aproximadamente un 98 % y lo más preferentemente al menos aproximadamente un 99 % de bucle aleatorio, según se determina mediante el algoritmo GOR.
1. Secuencias no repetitivas
Las secuencias de XTEN de las presentes composiciones pueden ser sustancialmente no repetitivas. En general, las secuencias de aminoácidos repetitivas tienen una tendencia a agregarse o formar estructuras de un orden mayor, tal como se ejemplifica por las secuencias repetitivas naturales, tales como colágenos y cremalleras de leucina o de contactos que dan como resultado estructuras cristalinas o pseudocristalinas. Por el contrario, la baja tendencia de las
secuencias no repetitivas a la agregación permite el diseño de XTEN de secuencia larga con una frecuencia relativamente baja de aminoácidos cargados que de lo contrario tendría tendencia a la agregación en caso de que las secuencias fuesen repetitivas. Normalmente, las proteínas de fusión GPXTEN comprenden secuencias de XTEN de más de aproximadamente 100 a aproximadamente 3000 restos de aminoácido, preferentemente más de aproximadamente 400 a aproximadamente 3000 restos acumulativos, en donde las secuencias son sustancialmente no repetitivas. En una realización, las secuencias de XTEN pueden tener de más de aproximadamente 100 a aproximadamente 3000 restos de aminoácidos, en las que ningún grupo de tres aminoácidos contiguos en la secuencia es de tipos de aminoácido idénticos, a menos que el aminoácido sea serina, en cuyo caso no serán restos de serina más de tres aminoácidos contiguos. En la realización anterior, la secuencia de XTEN sería sustancialmente no repetitiva.
El grado de repetitividad de un polipéptido o un gen puede medirse mediante programas o algoritmos informáticos o por otros medios conocidos en la técnica. La repetitividad en una secuencia de polipéptido puede evaluarse, por ejemplo, determinando el número de veces que las secuencias más cortas de una longitud dada se producen en el polipéptido. Por ejemplo, un polipéptido de 200 restos de aminoácido tiene 192 secuencias de 9 aminoácidos solapantes (o "marcos" de 9-meros) y 198 marcos de 3-meros, pero el número de secuencias de 9-meros o 3-meros únicas dependerá de la cantidad de repetitividad dentro de la secuencia. Puede generarse una puntuación (en lo sucesivo, "puntuación de subsecuencia") que refleja el grado de repetitividad de las subsecuencias en la secuencia de polipéptido general. En el contexto de la presente invención, "puntuación de subsecuencia" significa la suma de apariciones de cada marco de 3-mreo único a lo largo de una secuencia de 200 aminoácidos consecutivos del polipéptido, dividida entre el número absoluto de subsecuencias de 3-meros dentro de la secuencia de 200 aminoácidos. En el ejemplo 40 se proporcionan ejemplos de dichas puntuaciones de subsecuencia obtenidas de los primeros 200 aminoácidos de polipéptidos repetitivos y no repetitivos. La presente invención proporciona GPXTEN, cada una comprendiendo uno o más XTEN, en las que el XTEN tiene una puntuación de subsecuencia menor de 10, más preferentemente, menor de 9, más preferentemente, menor de 8, más preferentemente, menor de 7, más preferentemente menor de 6 y lo más preferentemente menor de 5 cuando se calcula a partir de un segmento de 200 restos de aminoácidos contiguos. En las realizaciones descritas anteriormente en este párrafo, un XTEN con una puntuación de subsecuencia menor de aproximadamente 10 (es decir, 9, 8, 7, etc.) será "sustancialmente no repetitivo".
Las características no repetitivas del XTEN pueden conferir a las proteínas de fusión con GP un mayor grado de solubilidad y menor tendencia a agregarse, en comparación con polipéptidos que tienen secuencias repetitivas. Estas propiedades pueden facilitar la formulación de composiciones farmacéuticas que comprenden XTEN que contienen concentraciones de fármaco extremadamente elevadas, en algunos casos, superando los 100 mg/ml.
Además, las secuencias de polipéptido de XTEN de las realizaciones se diseñan para que tengan un bajo grado de repetitividad interna para reducir o eliminar sustancialmente la inmunogenicidad cuando se administran a un mamífero. Las secuencias de polipéptido compuestas por motivos cortos repetidos limitados en gran medida a tres aminoácidos, tales como glicina, serina y glutamato, pueden dar como resultado títulos de anticuerpo relativamente elevados cuando se administran a un mamífero, a pesar de la ausencia de epítopos predichos para linfocitos T en estas secuencias. Esto puede estar causado por la naturaleza repetitiva de los polipéptidos, ya que se ha demostrado que los inmunógenos con epítopos repetidos, incluyendo agregados de proteínas, inmunógenos reticulados y carbohidratos repetitivos son altamente inmunogénicos y, por ejemplo, pueden dar como resultado la reticulación de receptores de linfocitos B, provocando la activación de linfocitos B. (Johansson, J., et al. (2007) Vaccine, 25:1676-82; Yankai, Z., et al. (2006) Biochem Biophys Res Commun, 345:1365-71; Hsu, C. T., et al. (2000) Cancer Res, 60:3701-5); Bachmann MF, et al. Eur J Immunol. (1995) 25(12):3445-3451).
2. Motivos de secuencia a modo de ejemplo
La presente invención abarca XTEN que pueden comprender múltiples unidades de secuencias o motivos más cortos, en los que las secuencias de aminoácidos de los motivos son no repetitivas. En el diseño de las secuencias de XTEN, se descubrió que el criterio de no repetitividad puede cumplirse a pesar del uso de una estrategia de "bloques de construcción" usando una biblioteca de motivos de secuencia que se multimerizan para crear las secuencias de XTEN. Por tanto, aunque una secuencia de XTEN puede consistir en múltiples unidades de tan pocos como cuatro tipos diferentes de motivos de secuencia, debido a que los motivos en sí consisten generalmente en secuencias de aminoácidos no repetitivas, la secuencia general de XTEN se hace sustancialmente no repetitiva.
En una realización, el XTEN puede tener una secuencia no repetitiva de más de aproximadamente 100 a aproximadamente 3000 restos de aminoácido o de más de 400 a aproximadamente 3000 restos, en donde al menos aproximadamente un 80 % o al menos aproximadamente un 85 % o al menos aproximadamente un 90 % o al menos aproximadamente un 95 % o al menos aproximadamente un 97 % o aproximadamente un 100 % de la secuencia de XTEN consiste en motivos de secuencia no solapantes, en donde cada uno de los motivos tiene de aproximadamente 9 a 36 restos de aminoácido. En otras realizaciones, al menos aproximadamente un 80 % o al menos aproximadamente un 85 % o al menos aproximadamente un 90 % o al menos aproximadamente un 95 % o al menos aproximadamente un 97 % o aproximadamente un 100 % de la secuencia de XTEN consiste en motivos de secuencia no solapantes, en donde cada uno de los motivos tiene de 9 a 14 restos de aminoácido. En otras realizaciones
adicionales, al menos aproximadamente un 80 % o al menos aproximadamente un 85 % o al menos aproximadamente un 90 % o al menos aproximadamente un 95 % o al menos aproximadamente un 97 % o aproximadamente un 100 % del componente de secuencia de XTEN consiste en motivos de secuencia no solapantes, en donde cada uno de los motivos tiene 12 restos de aminoácido. En estas realizaciones, se prefiere que los motivos de secuencia estén compuestos principalmente por aminoácidos hidrófilos pequeños, de tal forma que la secuencia general tenga una característica no estructurada y flexible. Son ejemplos de aminoácidos que pueden incluirse en el XTEN, por ejemplo, arginina, lisina, treonina, alanina, asparagina, glutamina, aspartato, glutamato, serina y glicina. Como resultado de las variables de ensayo, tales como optimización de codones, polinucleótidos de ensamblaje que codifican motivos de secuencia, expresión de proteína, distribución de cargas y solubilidad de la proteína expresada y de la estructura secundaria y terciaria, se descubrió que las composiciones de XTEN con características mejoradas incluyen principalmente restos de glicina (G), alanina (A), serina (S), treonina (T), glutamato (E) y prolina (P), en donde las secuencias se diseñan par que sean sustancialmente no repetitivas. En una realización preferida, Las secuencias de XTEN tienen predominantemente de cuatro a seis tipos de aminoácidos seleccionados entre glicina (G), alanina (A), serina (S), treonina (T), glutamato (E) o prolina (P) que se disponen en una secuencia sustancialmente no repetitiva que tiene una longitud mayor de aproximadamente 100 a aproximadamente 3000 restos de aminoácido o mayor de aproximadamente 400 a aproximadamente 3000 restos. En algunas realizaciones, el XTEN puede tener secuencias no repetitivas de más de aproximadamente 100 a aproximadamente 3000 restos de aminoácido o de más de 400 a aproximadamente 3000 restos, en donde al menos aproximadamente un 80 % de la secuencia consiste en motivos de secuencia no solapantes, en donde cada uno de los motivos tiene de 9 a 36 restos de aminoácido, en donde cada uno de los motivos consiste en 4 a 6 tipos de aminoácido seleccionados entre glicina (G), alanina (A), serina (S), treonina (T), glutamato (E) y prolina (P) y en donde el contenido de un tipo cualquiera de aminoácido en el XTEN de longitud completa no supera un 30 %. En otras realizaciones, al menos aproximadamente un 90 % de la secuencia de XTEN consiste en motivos de secuencia no solapantes, en donde cada uno de los motivos tiene de 9 a 36 restos de aminoácido, en donde los motivos consisten en 4 a 6 tipos de aminoácido seleccionados entre glicina (G), alanina (A), serina (S), treonina (T), glutamato (E) y prolina (P) y en donde el contenido de un tipo cualquiera de aminoácido en el XTEN de longitud completa no supera un 30 %. En otras realizaciones, al menos aproximadamente un 90 % de la secuencia de XTEN consiste en motivos de secuencia no solapantes, en donde cada uno de los motivos tiene 12 restos de aminoácido que consisten en 4 a 6 tipos de aminoácido seleccionados entre glicina (G), alanina (A), serina (S), treonina (T), glutamato (E) y prolina (P) y en donde el contenido de un tipo cualquiera de aminoácido en el XTEN de longitud completa no supera un 30 %. En otras realizaciones más, al menos aproximadamente un 90 % o aproximadamente un 91 % o aproximadamente un 92 % o aproximadamente un 93 % o aproximadamente un 94 % o aproximadamente un 95 % o aproximadamente un 96 % o aproximadamente un 97 % o aproximadamente un 98 % o aproximadamente un 99 %, hasta aproximadamente un 100 % de la secuencia de Xt En consiste en motivos de secuencia no solapantes, en donde cada uno de los motivos tiene 12 restos de aminoácido que consisten en glicina (G), alanina (A), serina (S), treonina (T), glutamato (E) y prolina (P) y en donde el contenido de un tipo cualquiera de aminoácido en el XTEN de longitud completa no supera un 30 %.
En otras realizaciones adicionales, los XTEN comprenden secuencias no repetitivas de más de aproximadamente 100 a aproximadamente 3000 restos de aminoácido o de más de 400 a aproximadamente 3000 restos de aminoácido, en donde al menos aproximadamente un 80 % o al menos aproximadamente un 90 % o aproximadamente un 91 % o aproximadamente un 92 % o aproximadamente un 93 % o aproximadamente un 94 % o aproximadamente un 95 % o aproximadamente un 96 % o aproximadamente un 97 % o aproximadamente un 98 % o aproximadamente un 99 % de la secuencia consiste en motivos de secuencia no solapantes de 9 a 14 restos de aminoácido, en donde los motivos consisten en 4 a 6 tipos de aminoácido seleccionados entre glicina (G), alanina (A), serina (S), treonina (T), glutamato (E) y prolina (P) y en donde la secuencia de cualesquiera dos restos de aminoácido contiguos en uno cualquiera de los motivos no se repite más de dos veces en el motivo de secuencia. En otras realizaciones, al menos aproximadamente un 90 % o aproximadamente un 91 % o aproximadamente un 92 % o aproximadamente un 93 % o aproximadamente un 94 % o aproximadamente un 95 % o aproximadamente un 96 % o aproximadamente un 97 % o aproximadamente un 98 % o aproximadamente un 99 % de una secuencia de XTEN consiste en motivos de secuencia no solapantes de 12 restos de aminoácido, en donde los motivos consisten en 4 a 6 tipos de aminoácido seleccionados entre glicina (G), alanina (A), serina (S), treonina (T), glutamato (E) y prolina (P) y en donde la secuencia de cualesquiera dos restos de aminoácido contiguos en uno cualquiera de los motivos de secuencia no se repite más de dos veces en el motivo de secuencia. En otras realizaciones, al menos aproximadamente un 90 % o aproximadamente un 91 % o aproximadamente un 92 % o aproximadamente un 93 % o aproximadamente un 94 % o aproximadamente un 95 % o aproximadamente un 96 % o aproximadamente un 97 % o aproximadamente un 98 % o aproximadamente un 99 % de una secuencia de XTEN consiste en motivos de secuencia no solapantes de 12 restos de aminoácido, en donde los motivos consisten en glicina (G), alanina (A), serina (S), treonina (T), glutamato (E) y prolina (P) y en donde la secuencia de cualesquiera dos restos de aminoácido contiguos en uno cualquiera de los motivos de secuencia no se repite más de dos veces en el motivo de secuencia. En otras realizaciones más, los XTEN consisten en 12 motivos de secuencia de aminoácidos en donde los aminoácidos se seleccionan entre glicina (G), alanina (A), serina (S), treonina (T), glutamato (E) y prolina (P) y en donde la secuencia de cualesquiera dos restos de aminoácido contiguos en uno cualquiera de los motivos de secuencia no se repite más de dos veces en el motivo de secuencia y en donde el contenido de un tipo cualquiera de aminoácido en el XTEN de longitud completa no supera un 30 %. En las realizaciones anteriores descritas anteriormente en este párrafo, las secuencias de XTEN serán sustancialmente no repetitivas.
En algunos casos, la invención proporciona composiciones que comprenden secuencias de XTEN no repetitivas de más de aproximadamente 100 a aproximadamente 3000 restos de aminoácido o de manera acumulativa, de más de aproximadamente 400 a aproximadamente 3000 restos, en donde al menos aproximadamente un 80 % o al menos aproximadamente un 90 % o aproximadamente un 91 % o aproximadamente un 92 % o aproximadamente un 93 % o aproximadamente un 94 % o aproximadamente un 95 % o aproximadamente un 96 % o aproximadamente un 97 % o aproximadamente un 98 % o aproximadamente un 99 % hasta aproximadamente un 100 % de la secuencia consiste en múltiples unidades de dos o más motivos de secuencia no solapantes seleccionados entre las secuencias de aminoácidos de la tabla 4. En algunos casos, el XTEN comprende motivos de secuencia no solapantes en el que aproximadamente un 80 % o al menos aproximadamente un 90 % o aproximadamente un 91 % o aproximadamente un 92 % o aproximadamente un 93 % o aproximadamente un 94 % o aproximadamente un 95 % o aproximadamente un 96 % o aproximadamente un 97 % o aproximadamente un 98 % o de aproximadamente un 99 % a aproximadamente un 100 % de la secuencia consiste en dos o más secuencias no solapantes seleccionadas entre una sola familia de motivos de la tabla 4, dando como resultado una "familia" de secuencias en la que la secuencia general sigue siendo sustancialmente no repetitiva. Por consiguiente, en estas realizaciones, una secuencia de XTEN puede comprender múltiples unidades de motivos de secuencia no solapantes de la familia de motivos AD o la familia de motivos AE o la familia de motivos AF o la familia de motivos AG o la familia de motivos AM o la familia de motivos AQ o la familia BC o la familia de secuencias BD de la tabla 4. En otros casos, el XTEN comprende secuencias de motivo de dos o más de las familias de motivos de la tabla 4.
T l 4: M iv n i XTEN 12 min i f mili m iv


En otros casos, la composición de GPXTEN puede comprender una o más secuencias de XTEN no repetitivas de más de aproximadamente 100 a aproximadamente 3000 restos de aminoácido o de manera acumulativa, de más de 400 a aproximadamente 3000 restos, en donde al menos aproximadamente un 80 % o al menos aproximadamente un 90 % o aproximadamente un 91 % o aproximadamente un 92 % o aproximadamente un 93 % o aproximadamente un 94 % o aproximadamente un 95 % o aproximadamente un 96 % o aproximadamente un 97 % o aproximadamente un 98 % o aproximadamente un 99 % hasta aproximadamente un 100 % de la secuencia consiste en 36 motivos de secuencia de aminoácidos no solapantes seleccionados entre una o más de las secuencias de polipéptido de las tablas 10-13.
En aquellas realizaciones en donde el componente de XTEN de la proteína de fusión GPXTEN tiene menos de un 100 % de sus aminoácidos que consisten en cuatro a seis aminoácidos seleccionados entre glicina (G), alanina (A), serina (S), treonina (T), glutamato (E) y prolina (P) o menos de un 100 % de la secuencia que consiste en los motivos de secuencia de la tabla 4 o menos de un 100 % de identidad de secuencia con un XTEN de la tabla 5, los otros restos de aminoácido pueden seleccionarse entre cualquiera de los otros 14 L-aminoácidos naturales, pero preferentemente, se seleccionan entre aminoácidos hidrófilos, de tal forma que la secuencia de XTEN contiene al menos aproximadamente un 90 % o al menos aproximadamente un 91 % o al menos aproximadamente un 92 % o al menos aproximadamente un 93 % o al menos aproximadamente un 94 % o al menos aproximadamente un 95 % o al menos aproximadamente un 96 % o al menos aproximadamente un 97 % o al menos aproximadamente un 98 % o al menos aproximadamente un 99 % de aminoácidos hidrófilos. Los aminoácidos del XTEN que no son glicina (G), alanina (A), serina (S), treonina (T), glutamato (E) y prolina (P) se encuentran dispersos por toda la secuencia de XTEN, se ubican dentro o entre los motivos de secuencia o se concentran en una o más series cortas de la secuencia de XTEN. En dichos casos donde el componente de XTEN de la GPXTEN comprende aminoácidos distintos de glicina (G), alanina (A), serina (S), treonina (T), glutamato (E) y prolina (P), se prefiere que los aminoácidos no sean restos hidrófobos y no deben conferir sustancialmente estructura secundaria al componente de XTEN. Los restos hidrófobos que se ven menos favorecidos a la hora de construir el XTEN incluyen triptófano, fenilalanina, tirosina, leucina, isoleucina, valina y metionina. Además, se pueden diseñar las secuencias de XTEN para que contengan pocos (por ejemplo, menos de un 5 %) o ninguno de los siguientes aminoácidos: cisteína (para evitar la formación de disulfuro y la oxidación), metionina (para evitar la oxidación), asparagina y glutamina (para evitar la desamidación). Por tanto, en una realización preferida de lo anterior, el componente de XTEN de la proteína de fusión GPXTEN que comprende otros aminoácidos además de glicina (G), alanina (A), serina (S), treonina (T), glutamato (E) y prolina (P) podría tener una secuencia con menos de un 5 % de los restos que contribuyan a las hélices alfa y las láminas beta, según se mide mediante el algoritmo de Chou-Fasman y podría tener al menos un 90 % o al menos aproximadamente un 95 % o más de formación en bucle aleatorio, medida mediante el algoritmo GOR.
3. Longitud de la secuencia
En otro aspecto de la presente invención, la invención abarca composiciones de GPXTEN que comprenden vehículos de polipéptidos de XTE con secuencias de longitud prolongada. La presente invención aprovecha el descubrimiento de que el aumento de la longitud de polipéptidos no repetitivos no estructurados mejora la naturaleza no estructurada de los XTEN y por consiguiente, mejora las propiedades biológicas y farmacocinéticas de las proteínas de fusión que comprenden el vehículo de XTEN. Tal como se describe con más detalle en los ejemplos, los aumentos proporcionales en la longitud del XTEN, incluso si se crea mediante un orden fijo de repetición de motivos de secuencia de una sola familia (por ejemplo, los cuatro motivos AE de la tabla 4), pueden dar como resultado una secuencia con un mayor porcentaje de formación de bucle aleatorio, según se determina mediante el algoritmo GOR, en comparación con longitudes de XTEN más cortas. En general, el aumento de la longitud del compañero de fusión de polipéptido no estructurado puede, como se describe en los ejemplos, dar como resultado una proteína de fusión con un aumento desproporcionado en la semivida terminal en comparación con proteínas de fusión con compañeros de polipéptido no estructurado con longitudes de secuencia más cortas.
Los ejemplos no limitantes de XTEN contemplados para su inclusión en la GPXTEN de la invención se presentan en la tabla 5. En una realización, la invención proporciona composiciones de GPXTEN en donde la longitud de secuencia
de las proteínas de fusión es mayor de aproximadamente 100 a aproximadamente 3000 restos de aminoácidos y en algunos casos, mayor de aproximadamente 400 a aproximadamente 3000 restos de aminoácidos, en donde el XTEN confiere propiedades farmacocinéticas mejoradas al GPXTEN en comparación con el GP no unido al XTEN. En algunos casos, las secuencias de XTEN de las composiciones de GPXTEN de la presente invención pueden tener aproximadamente 100 o aproximadamente 144 o aproximadamente 288 o aproximadamente 401 o aproximadamente 500 o aproximadamente 600 o aproximadamente 700 o aproximadamente 800 o aproximadamente 900 o aproximadamente 1000 o aproximadamente 1500 o aproximadamente 2000 o aproximadamente 2500 o hasta aproximadamente 3000 restos de aminoácido de longitud. En otros casos, las secuencias de XTEN pueden tener de aproximadamente 100 a 150, de aproximadamente 150 a 250, de aproximadamente 250 a 400, de 401 a aproximadamente 500, de aproximadamente 500 a 900, de aproximadamente 900 a 1500, de aproximadamente 1500 a 2000 o de aproximadamente 2000 a aproximadamente 3000 restos de aminoácido de longitud. En una realización, la GPXTEN puede comprender una secuencia de XTEN en donde la secuencia muestra al menos aproximadamente un 80 % de identidad de secuencia o como alternativa, un 81 %, 82 %, 83 %, 84 %, 85 %, 86 %, 87 %, 88 %, 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 % o 100 % de identidad de secuencia respecto de un XTEN seleccionado de la tabla 5. En algunos casos, la secuencia de XTEN se diseña para su expresión optimizada como el componente N-terminal de la GPXTEN mediante la inclusión de nucleótidos codificantes para una secuencia líder N-terminal (NTS) en la parte de XTEN del gen que codifica la proteína de fusión. En una realización de lo anterior, la secuencia de Xt En N-terminal de la GPXTEN expresada tiene al menos un 90 % de identidad de secuencia respecto de la secuencia de AE48 o AM48, AE624, o AE912 o AM923. En otra realización de lo anterior, el XTEN tiene los restos N-terminales descritos en los ejemplos 14-17.
En otros casos, la proteína de fusión GPXTEN puede comprender una primera y una segunda secuencia de XTEN, en donde el total acumulativo de los restos en las secuencias de XTEN es mayor de aproximadamente 400 a aproximadamente 3000 restos de aminoácido. En realizaciones de lo anterior, la proteína de fusión GPXTEN puede comprender una primera y una segunda secuencia de XTEN, en donde cada una de las secuencias muestra al menos aproximadamente un 80 % de identidad de secuencia o como alternativa, un 81 %, 82 %, 83 %, 84 %, 85 %, 86 %, 87 %, 88 %, 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 % o 100 % de identidad de secuencia respecto de al menos un primer o adicionalmente un segundo XTEN seleccionado de la tabla 5.
Tal como se describe en más detalle más adelante, la divulgación proporciona métodos en los que la GPXTEN se diseña seleccionando la longitud del XTEN para que confiera una semivida diana a una proteína de fusión administrada a un sujeto. En general, las longitudes de XTEN mayores de aproximadamente 400 restos acumulativos incorporadas en las composiciones de GPXTEN dan como resultado una mayor semivida, en comparación con longitudes acumulativas más cortas; por ejemplo, más cortas que aproximadamente 280 restos. Sin embargo, en otra realización, pueden diseñarse proteínas de fusión GPXTEN para que comprendan XTEN con una longitud de secuencia más larga que se selecciona para conferir además menores tasas de absorción sistémica tras su administración subcutánea o intramuscular a un sujeto. En dichos casos, se reduce la Cmáx en comparación con una dosis comparable de un GP no unido al XTEN, contribuyendo de este modo a su capacidad para mantener la GPXTEN dentro de la ventana terapéutica para la composición. Por tanto, el XTEN confiere la propiedad de un depósito a la GPXTEN administrada, además de las demás propiedades fisicoquímicas descritas en el presente documento.
T l : P li i XTEN


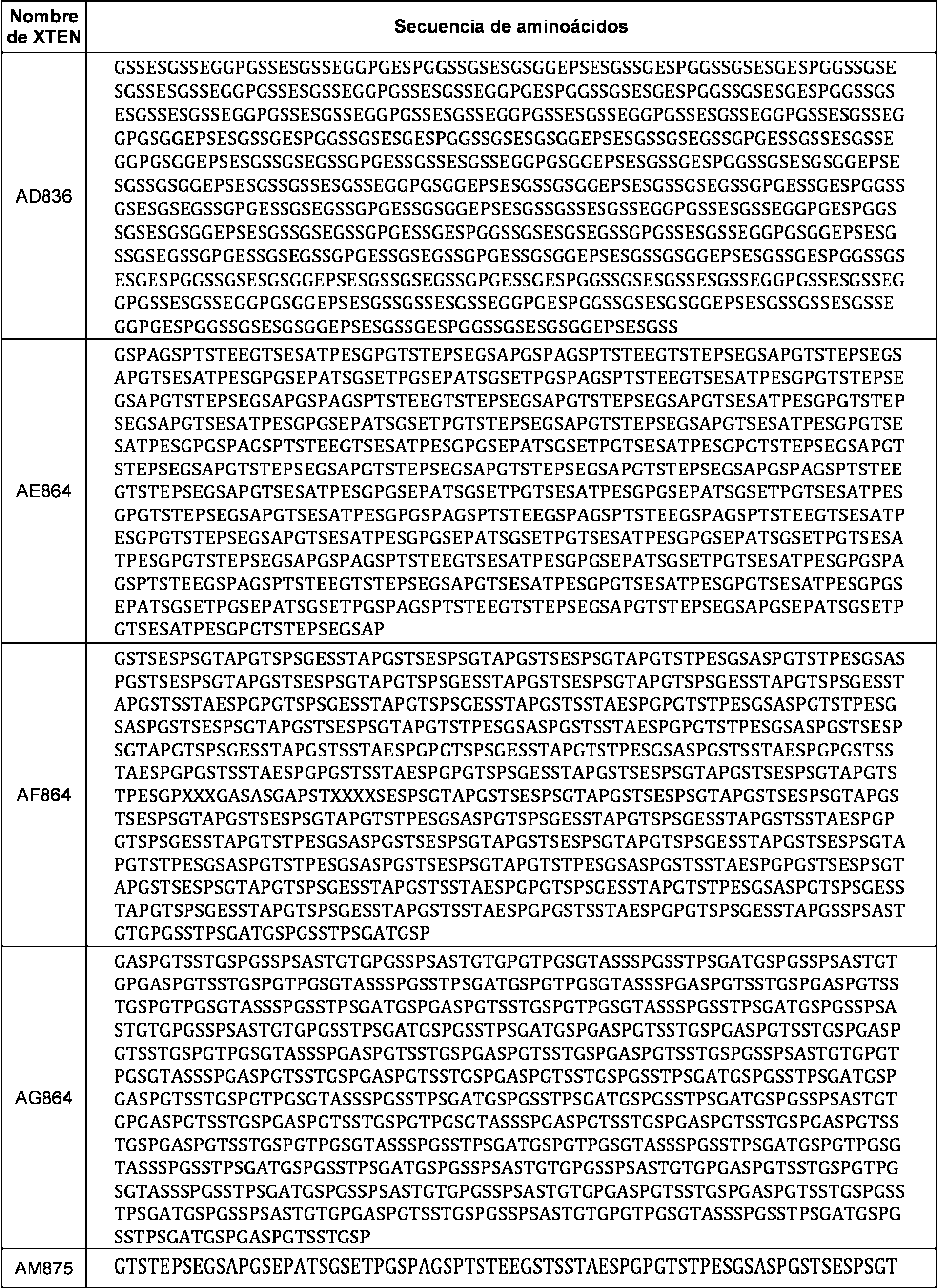


4. Segmentos de XTEN
En una realización, la divulgación proporciona una proteína de fusión GPXTEN en donde la longitud acumulativa del componente de XTEN es mayor de aproximadamente 100 a aproximadamente 3000 restos de aminoácido que contiene al menos un segmento de secuencia de polipéptido seleccionado de las tablas 5, 10, 11, 12 y 13 y en donde al menos aproximadamente un 90 % o al menos aproximadamente un 91 % o al menos aproximadamente un 92 % o al menos aproximadamente un 93 % o al menos aproximadamente un 94 % o al menos aproximadamente un 95 % o al menos aproximadamente un 96 % o al menos aproximadamente un 97 % o al menos aproximadamente un 98 % o más del resto de la secuencia de XTEN consiste en aminoácidos hidrófilos y menos de aproximadamente un 2 % del resto del XTEN contiene aminoácidos grandes, hidrófobos, aromáticos o de cisteína. En la realización anterior, el XTEN puede contener múltiples segmentos, en donde los segmentos son idénticos o diferentes. En otra realización, la divulgación proporciona una proteína de fusión GPXTEN aislada en donde la longitud acumulativa del componente de XTEN es mayor de aproximadamente 100 a aproximadamente 3000 restos de aminoácido y comprende al menos un segmento de secuencia de al menos aproximadamente 100 a aproximadamente 923 o de al menos aproximadamente 100 a aproximadamente 875 o de al menos aproximadamente 100 a aproximadamente 576 o de al menos aproximadamente 100 a aproximadamente 288 o de al menos aproximadamente 100 a aproximadamente 144 restos de aminoácido, en donde los segmentos de secuencia consisten en al menos tres tipos de aminoácidos diferentes y la suma de restos de glicina (G), alanina (A), serina (S), treonina (T), glutamato (E) y prolina (P) en los segmentos de secuencia constituye al menos aproximadamente un 90 % o al menos aproximadamente un 91 % o al menos aproximadamente un 92 % o al menos aproximadamente un 93 % o al menos aproximadamente un 94 % o al menos aproximadamente un 95 % o al menos aproximadamente un 96 % o al menos aproximadamente un 97 % o al menos aproximadamente un 98 % o al menos aproximadamente un 99 % de la secuencia de aminoácidos total del segmento de secuencia y al menos aproximadamente un 90 % o al menos aproximadamente un 91 % o al menos aproximadamente un 92 % o al menos aproximadamente un 93 % o al menos aproximadamente un 94 % o al menos aproximadamente un 95 % o al menos aproximadamente un 96 % o al menos aproximadamente un 97 % o al menos aproximadamente un 98 % del resto de las secuencias de XTEN consiste en aminoácidos hidrófilos y menos de aproximadamente un 2 % del resto de las secuencias de XTEN consiste en aminoácidos hidrófobos, aromáticos o de
cisteína. En otra realización, la divulgación proporciona una proteína de fusión GPXTEN aislada en donde la longitud acumulativa del componente de XTEN es mayor de aproximadamente 100 a aproximadamente 3000 restos de aminoácido y comprende al menos un segmento de secuencia de al menos aproximadamente 200 a aproximadamente
923 o de al menos aproximadamente 200 a aproximadamente 875 o de al menos aproximadamente 200 a aproximadamente 576 o de al menos aproximadamente 200 a aproximadamente 288 restos de aminoácido en donde la suma de restos de glicina (G), alanina (A), serina (S), treonina (T), glutamato (E) y prolina (P) en los segmentos de secuencia constituye al menos aproximadamente un 90 % o al menos aproximadamente un 91 % o al menos aproximadamente un 92 % o al menos aproximadamente un 93 % o al menos aproximadamente un 94 % o al aproximadamente un 95 % o al menos aproximadamente un 96 % o al menos aproximadamente un 97 % o al aproximadamente un 98 % o al menos aproximadamente un 99 % de la secuencia de aminoácidos total del segmento de secuencia y en donde la puntuación de subsecuencia del segmento es menor de 12, más preferentemente, menor de 10, más preferentemente, menor de 9, más preferentemente, menor de 8, más preferentemente, menor de 7, más preferentemente menor de 6 y lo más preferentemente, menor de 5 y al menos aproximadamente un 90 % o al menos aproximadamente un 91 % o al menos aproximadamente un 92 % o al menos aproximadamente un 93 % o al aproximadamente un 94 % o al menos aproximadamente un 95 % o al menos aproximadamente un 96 % o al aproximadamente un 97 % o al menos aproximadamente un 98 % del resto de las secuencias de XTEN consiste en aminoácidos hidrófilos y menos de aproximadamente un 2 % del resto de las secuencias de XTEN consiste en aminoácidos hidrófobos, aromáticos o de cisteína.
5. Secuencias potenciadoras de la expresión de XTEN N-terminal
En algunas realizaciones, la divulgación proporciona una secuencia de XTEN de longitud corta como parte N-terminal de la proteína de fusión GPXTEN. La expresión de la proteína de fusión se mejora en una célula hospedadora transformada con un vector de expresión adecuado que comprende una secuencia de polinucleótido líder N-terminal optimizada (que codifica el XTEN N-terminal) incorporada en el polinucleótido que codifica la proteína de fusión de unión. Se ha descubierto, como se describe en los ejemplos 14-17, que una célula hospedadora transformada con dicho vector de expresión que comprende una secuencia líder N-terminal (NTS) optimizada en el gen de la proteína de fusión de unión da como resultado una expresión mejorada en gran medida de la proteína de fusión en comparación con la expresión de una proteína de fusión correspondiente a partir de un polinucleótido que no comprende la NTS y puede obviar la necesidad de incorporar una secuencia líder distinta de XTEN usada para mejorar la expresión. En una realización, la divulgación proporciona proteínas de fusión GPXTEN que comprenden una NTS en donde se mejora la expresión de la proteína de fusión de unión a partir del gen codificante en una célula hospedadora aproximadamente un 50 % o aproximadamente un 75 % o aproximadamente un 100 % o aproximadamente un 150 % o aproximadamente un 200 % o aproximadamente un 400 % en comparación con la expresión de una proteína de fusión GPXTEN que no comprende la secuencia XTEN N-terminal (donde el gen codificante carece de la NTS).
En una realización, el polipéptido de XTEN N-terminal de la GPXTEN comprende una secuencia que muestra al menos aproximadamente un 80 % o al menos aproximadamente un 90 % o al menos aproximadamente un aproximadamente un 92 % o al  menos aproximadamente un 93 % o al menos aproximadamente un aproximadamente un 95 % o al menos aproximadamente un 96 % o al menos aproximadamente un aproximadamente un 98 % o al menos un 99 % o muestra un 100 % de identidad de secuencia respecto de la secuencia de aminoácidos de AE48 o AM48, cuyas respectivas secuencias son las siguientes:
menos aproximadamente un 93 % o al menos aproximadamente un aproximadamente un 95 % o al menos aproximadamente un 96 % o al menos aproximadamente un aproximadamente un 98 % o al menos un 99 % o muestra un 100 % de identidad de secuencia respecto de la secuencia de aminoácidos de AE48 o AM48, cuyas respectivas secuencias son las siguientes:
AE48: MAEPAGSPTSTEEGTPGSGTASSSPGSSTPSGATGSPGASPGTSSTGS
AM48: MAEPAGSPTSTEEGASPGTSSTGSPGSSTPSGATGSPGSSTPSGATGS
En otra realización, el XTEN N-terminal corto puede unirse a un XTEN de mayor longitud para formar la región N-terminal de la proteína de fusión GPXTEN, en donde la secuencia de polinucleótido que codifica el XTEN N-terminal corto confiere la propiedad de expresión mejorada en la célula hospedadora y en donde la larga longitud del XTEN expresado contribuye a las propiedades mejoradas del vehículo de XTEN en la proteína de fusión, como se ha descrito anteriormente. En lo anterior, el XTEN corto puede unirse a cualquiera de los XTEN divulgados en el presente documento (por ejemplo, un XTEN de la tabla 5) y el XTEN resultante, a su vez, está unido al extremo N-terminal del
GP divulgado en el presente documento (por ejemplo, un GP de las tablas 1-3) como componente de la proteína de fusión. Como alternativa, los polinucleótidos que codifican el XTEN corto (o su complemento) están unidos a polinucleótidos que codifican cualquiera de los XTEN (o sus complementos) divulgados en el presente documento y el gen resultante que codifica el XTEN N-terminal, a su vez, está unido al extremo 5' de polinucleótidos que codifican cualquiera de los GP (o al extremo 3' de su complemento) divulgado en el presente documento. En algunas realizaciones, el polipéptido XTEN N-terminal con longitud larga muestra al menos aproximadamente un 80 % o al menos aproximadamente un 90 % o al menos aproximadamente un 91 % o al menos aproximadamente un 92 % o al menos aproximadamente un 93 % o al menos aproximadamente un 94 % o al menos aproximadamente un 95 % o al menos aproximadamente un 96 % o al menos aproximadamente un 97 % o al menos aproximadamente un 98 % o al menos un 99 % o muestra un 100 % de identidad de secuencia respecto de una secuencia de aminoácido seleccionada entre el grupo que consiste en las secuencias AE624, AE912 y AM923.
En cualquiera de las realizaciones de XTEN N-terminal anteriores descritas, el XTEN N-terminal puede tener de aproximadamente uno a aproximadamente seis restos de aminoácido adicionales, seleccionados preferentemente
entre GESTPA, para acomodar los sitos de restricción de endonucleasas de restricción que podrían emplearse para unir los nucleótidos que codifican el XTEN N-terminal al gen que codifica el resto de direccionamiento de la proteína de fusión. Los métodos para la generación de las secuencias N-terminales y su incorporación en las proteínas de fusión de la invención se describen con más detalle en los ejemplos.
6. Carga neta
En otras realizaciones, los polipéptidos de XTEN tienen una característica no estructurada conferida por la incorporación de restos de aminoácido con una carga neta y/o reduciendo la proporción de aminoácidos hidrófobos en la secuencia de XTEN. La carga neta general y la densidad de carga neta se controlan modificando el contenido de aminoácidos cargados en las secuencias de XTEN. En algunas realizaciones, la densidad de carga neta del XTEN de las composiciones puede ser superior a 0,1 o inferior a -0,1 cargas/resto. En otras realizaciones, la carga neta de un XTEN puede ser de aproximadamente un 0 %, aproximadamente un 1 %, aproximadamente un 2 %, aproximadamente un 3 %, aproximadamente un 4 %, aproximadamente un 5 %, aproximadamente un 6 %,
aproximadamente un 7 %, aproximadamente un 8 %, aproximadamente un 9 %, aproximadamente un 10 %, aproximadamente un 11 %, aproximadamente un 12 %, aproximadamente un 13 %, aproximadamente un 14 %, aproximadamente un 15 %, aproximadamente un 16 %, aproximadamente un 17 %, aproximadamente un 18 %, aproximadamente un 19 % o aproximadamente un 20 % o más.
Ya que la mayoría de los tejidos y superficies en un ser humano o un animal tienen una carga neta negativa, en algunas realizaciones, las secuencias de XTEN se diseñan para que tengan una carga neta negativa para minimizar las interacciones no específicas entre las composiciones que contienen el XTEN y las diversas superficies, tales como los vasos sanguíneos, los tejidos sanos o diversos receptores. Sin quedar ligados a una teoría particular, el XTEN puede adoptar conformaciones abiertas debido a la repulsión electrostática entre aminoácidos individuales del polipéptido de XTEN que individualmente portan una carga neta negativa y que están distribuidos a lo largo de la secuencia del polipéptido de XTEN. Dicha distribución de carga neta negativa en las longitudes de secuencia extendidas de XTEN puede dar lugar a una conformación no estructurada que, a su vez, puede dar como resultado un aumento eficaz en el radio hidrodinámico. En las realizaciones preferidas, la carga neta negativa se confiere mediante la incorporación de restos de ácido glutámico. Por consiguiente, en una realización, la invención proporciona XTEN en los que las secuencias de XTEN contienen aproximadamente un 8, 10, 15, 20, 25 o incluso aproximadamente un 30 % de ácido glutámico. En general, los restos de ácido glutámico se espaciarán de manera uniforme por toda la secuencia de XTEN. En algunos casos, el XTEN puede contener aproximadamente 10-80 o aproximadamente 15-60 o aproximadamente 20-50 restos de ácido glutámico por cada 20kD de XTEN que puede dar como resultado un XTEN con restos cargados que podrían tener pKa muy similares, lo que puede aumentar la homogeneidad de carga del producto y ajustar su punto isoeléctrico, mejorando las propiedades fisicoquímicas de la proteína de fusión GPXTEN para, ejemplo, simplificar los procedimientos de purificación.
El XTEN de las composiciones de la presente invención tiene generalmente un contenido bajo o nulo de aminoácidos cargados positivamente. En algunas realizaciones, los XTEN pueden tener menos de aproximadamente un 10 % de restos de aminoácido con una carga positiva o menos de aproximadamente un 7 % o menos de aproximadamente un 5 % o menos de aproximadamente un 2 % o menos de aproximadamente un 1 % de restos de aminoácido con una carga positiva. Sin embargo, la invención contempla construcciones donde se incorpora un número limitado de aminoácidos con una carga positiva, tal como lisina, en el XTEN para permitir la conjugación entre la amina épsilon de la lisina y un grupo reactivo en un péptido, un puente enlazador o un grupo reactivo en un fármaco o molécula pequeña que se vaya a conjugar al armazón del XTEN. En una realización de lo anterior, el XTEN tiene entre de aproximadamente 1 a aproximadamente 100 restos de lisina o de aproximadamente 1 a aproximadamente 70 restos de lisina o de aproximadamente 1 a aproximadamente 50 restos de lisina o de aproximadamente 1 a aproximadamente 30 restos de lisina o de aproximadamente 1 a aproximadamente 20 restos de lisina o de aproximadamente 1 a aproximadamente 10 restos de lisina o de aproximadamente 1 a aproximadamente 5 restos de lisina o como alternativa, un solo resto de lisina. Usando el XTEN que contiene lisina anterior, se construyen proteínas de fusión que comprenden XTEN, un péptido regulador de la glucosa, más un agente quimioterapéutico útil en el tratamiento de enfermedades o trastornos de la glucosa, en donde el número máximo de moléculas del agente incorporado en el componente de XTEN se determina por el número de lisinas u otros aminoácidos con cadenas laterales reactivas (por ejemplo, cisteína) incorporados en el XTEN.
En algunas realizaciones, la secuencia de XTEN comprende restos cargados separados por otros restos, tales como serina o glicina, que da lugar a un mejor comportamiento de expresión o purificación. Basándose en la carga neta, algunos XTEN tienen un punto isoeléctrico (pI) de 1,0, 1,5, 2,0, 2,5, 3,0, 3,5, 4,0, 4,5, 5,0, 5,5, 6,0 o incluso 6,5. En las realizaciones preferidas, el XTEN tendrá un punto isoeléctrico entre 1,5 y 4,5. En estas realizaciones, el XTEN incorporado en las composiciones de proteína de fusión GPXTEN de la presente invención porta una carga neta negativa en condiciones fisiológicas que contribuye a la conformación no estructurada y a la unión reducida del componente de XTEN a las proteínas y tejidos de mamíferos.
Ya que los aminoácidos hidrófobos confieren estructura a un polipéptido, la invención proporciona que el contenido de aminoácidos hidrófobos en el XTEN será normalmente menor de un 5 % o menor de un 2 % o menor de un 1 % de contenido de aminoácidos hidrófobos. En una realización, el contenido de aminoácidos de metionina y triptófano en el
componente de XTEN de una proteína de fusión GPXTEN es normalmente menor de un 5 % o menor de un 2 % y lo más preferentemente, menor de un 1 %. En otra realización, el XTEN tendrá una secuencia que tiene menos de un 10 % de restos de aminoácido con una carga positiva o menos de aproximadamente un 7 % o menos de aproximadamente un 5 % o menos de aproximadamente un 2 % de restos de aminoácido con una carga positiva, siendo la suma de restos de metionina y triptófano menor de un 2 % y la suma de restos de asparagina y glutamina será menor de un 10 % de la secuencia total de XTEN.
7. Baja inmunogenicidad
En otro aspecto, la divulgación proporciona composiciones en las que las secuencias de XTEN tienen un bajo grado de inmunogenicidad o son sustancialmente no inmunogénicas. Varios factores pueden contribuir a la baja inmunogenicidad del XTEN, por ejemplo, la secuencia no repetitiva, la conformación no estructurada, el alto grado de solubilidad, el bajo grado o la ausencia de auto agregación, el bajo grado o la ausencia de sitios proteolíticos dentro de la secuencia y el bajo grado o la ausencia de epítopos en la secuencia de XTEN.
Los epítopos conformacionales se forman mediante regiones de la superficie de la proteína que están compuestas por múltiples secuencias de aminoácidos discontinuas del antígeno proteico. El plegamiento preciso de la proteína hace que estas secuencias se encuentren en configuraciones espaciales bien definidas y estables, también conocidas como epítopos, que pueden reconocerse como "extrañas" por el sistema inmunitario humoral del hospedador, dando como resultado la producción de anticuerpos contra la proteína o la activación de una respuesta inmunitaria mediada por células. En este último caso, la respuesta inmunitaria frente a una proteína en un individuo está fuertemente influenciada por el reconocimiento de epítopos para linfocitos T, que es una función de la especificidad de unión a péptidos del alotipo de HLA-DR de ese individuo. El acoplamiento de un complejo de péptido de la clase II del MHC mediante un receptor de linfocitos T afín sobre la superficie del linfocito T, junto con la unión cruzada de otros correceptores concretos, tales como la molécula CD4, pueden inducir un estado activado en el linfocito T. La activación da lugar a la liberación de citocinas que activan adicionalmente otros linfocitos, tales como los linfocitos B para que produzcan anticuerpos o que activan a los linfocitos T citotóxicos como una respuesta inmunitaria celular completa.
La capacidad de un péptido para unirse a una molécula de la clase II del MHC específica para su presentación sobre la superficie de una a Pc (célula presentadora de antígenos) depende de una serie de factores; principalmente, su secuencia primaria. En una realización, se logra un menor grado de inmunogenicidad diseñando secuencias de XTEN que resisten al procesamiento de antígenos en células presentadoras de antígenos y/o eligiendo secuencias que no se unen bien a receptores del MHC. La invención proporciona proteínas de fusión GPXTEN con polipéptidos de XTEN sustancialmente no repetitivos diseñados para reducir la unión a receptores de MHC II, así como evitar la formación de epítopos para receptores de linfocitos T o la unión a anticuerpos, dando como resultado un bajo grado de inmunogenicidad. La supresión de la inmunogenicidad es, en parte, el resultado directo de la flexibilidad conformacional de las secuencias de XTEN; es decir, la ausencia de estructura secundaria debida a la selección y el orden de los restos de aminoácido. Por ejemplo, son particularmente interesantes las secuencias que tienen una baja tendencia a adoptar conformaciones plegadas de manera compacta en solución acuosa o en condiciones fisiológicas que podrían dar como resultado epítopos conformacionales. La administración de proteínas de fusión que comprenden XTEN, usando prácticas y dosificaciones terapéuticas convencionales, en general no darían como resultado la formación de anticuerpos neutralizantes para la secuencia de XTEN y asimismo, reducirían la inmunogenicidad del compañero de fusión de GP en las composiciones de GPXTEN.
En una realización, las secuencias de XTEN utilizadas en las presentes proteínas de fusión pueden estar sustancialmente libres de epítopos reconocidos por los linfocitos T humanos. La eliminación de dichos epítopos a fin de generar proteínas menos inmunogénicas se ha divulgado previamente; véanse, por ejemplo, los documentos WO 98/52976, W o 02/079232 y WO 00/3317. Se han descrito ensayos para epítopos de linfocitos T (Stickler, M., et al. (2003) J Immunol Methods, 281:95-108). Son particularmente interesantes las secuencias peptídicas que pueden oligomerizarse sin generar epítopos para linfocitos T o secuencias no humanas. Esto se logra probando repeticiones directas de estas secuencias respecto de la presencia de epítopos de linfocitos T y respecto de la aparición de 6 a 15-meros y, en particular, secuencias de 9-meros que no son humanas y después, alterando el diseño de la secuencia de XTEN para eliminar o alterar la secuencia de epítopo. En algunas realizaciones, las secuencias de XTEN son sustancialmente no inmunogénicas mediante la restricción del número de epítopos del XTEN que se predice que se unen a receptores del MHC. Con una reducción en el número de epítopos capaces de unirse a receptores del MHC, se produce una reducción concomitante en el potencial de activación de linfocitos T así como en la función de linfocitos T colaboradores, una reducción de la activación o regulación positiva de linfocitos B un una producción de anticuerpos reducida. El bajo grado predicho de epítopos para linfocitos T puede determinarse mediante algoritmos de predicción de epítopos, tales como, por ejemplo, TEPITOPE (Sturniolo, T., et al. (1999) Nat Biotechnol, 17: 555-61), tal como se muestra en el ejemplo 45. La puntuación de TEPITOPE de un marco peptídico cado dentro de una proteína es el log de la Kd (constante de disociación, afinidad, velocidad de disociación) de la unión de ese marco peptídico a varios de los alelos del MHC humano más comunes, tal como se divulga en Sturniolo, T. et al. (1999) Nature Biotechnology 17:555). La puntuación varía a lo largo de al menos 20 log, de aproximadamente 10 a aproximadamente -10 (correspondientes a restricciones de unión de 10e10 Kd a 10e-10 Kd) y puede reducirse evitando aminoácidos hidrófobos que sirvan como restos de anclaje durante la presentación de péptidos en el MHC, tales como M, I, L, V, F. En algunas realizaciones, un componente de XTEN incorporado en un GPXTEN no tiene un epítopo de linfocitos T predicho con
una puntuación de TEPITOPE de aproximadamente -5 o mayor o -6 o mayor o -7 o mayor o -8 o mayor o una puntuación de TEPITOPE de -9 o mayor. Como se usa en el presente documento, una puntuación de "-9 o mayor" abarcará puntuaciones de TEPITOPE de 10 a -9, inclusive, pero no abarcara una puntuación de -10, ya que -10 es menor que -9.
En otra realización, las secuencias de XTEN de la invención, incluyendo aquellas incorporadas en las presentes proteínas de fusión GPXTEN, se hacen sustancialmente no inmunogénicas mediante la restricción de sitios proteolíticos conocidos de la secuencia del XTEN, reduciendo el procesamiento del XTEN en péptidos pequeños que puedan unirse a receptores del MHC II. En otra realización, la secuencia del XTEN se hace sustancialmente no inmunogénica mediante el uso de una secuencia que está sustancialmente desprovista de estructura secundaria, confiriéndole resistencia a muchas proteasas debido a la alta entropía de la estructura. Por consiguiente, la puntuación de TEPITOPE reducida y la eliminación de sitios proteolíticos conocidos del XTEN hacen que las composiciones de XTEN, incluyendo el Xt En de las composiciones de proteína de fusión GPXTEN, sean sustancialmente incapaces de unirse a receptores de mamífero, incluyendo aquellos del sistema inmunitario. En una realización, un XTEN de una proteína de fusión GPXTEN puede tener una unión Kd >100 nM a un receptor de mamífero o una Kd mayor de 500 nM, o una Kd mayor de 1 |jM frente a un receptor de polipéptido de mamífero de la superficie celular o en circulación.
Además, la secuencia no repetitiva y la correspondiente falta de epítopos de XTEN limitan la capacidad de los linfocitos B para unirse o para activarse por XTEN. Una secuencia repetitiva se reconoce y puede formar contactos multivalentes con incluso unos cuantos linfocitos B y, a consecuencia de la reticulación de múltiples receptores para linfocitos T independientes, puede estimular la proliferación de linfocitos B y la producción de anticuerpos. Por el contrario, aunque un XTEN puede efectuar contactos con muchos linfocitos B diferentes a lo largo de su secuencia extendida, cada linfocito B individual puede efectuar únicamente uno o un pequeño número de contactos con un XTEN individual debido a la ausencia de repetitividad de la secuencia. Sin quedar ligados a cualquier teoría, los XTEN tienen normalmente una tendencia mucho menor a estimular la proliferación de linfocitos B y por lo tanto, una respuesta inmunitaria. En una realización, la GPXTEN puede tener inmunogenicidad reducida en comparación con el GP correspondiente que no está fusionado. En una realización, la administración de hasta tres dosis parenterales de una GPXTEN a un mamífero da como resultado IgG anti-GPXTEN detectable en una dilución de suero de 1:100 pero no a una dilución de 1:1000. En otra realización, la administración de hasta tres dosis parenterales de una GPXTEN a un mamífero puede dar como resultado IgG anti-GP detectable en una dilución de suero de 1:100 pero no a una dilución de 1:1000. En otra realización, la administración de hasta tres dosis parenterales de una GPXTEN a un mamífero da como resultado IgG anti-GP detectable en una dilución de suero de 1:100 pero no a una dilución de 1:1000. En otra realización, la administración de hasta tres dosis parenterales de una GPXTEN a un mamífero da como resultado IgG anti-XTEN detectable en una dilución de suero de 1:100 pero no a una dilución de 1:1000. En las realizaciones anteriores, el mamífero puede ser un ratón, una rata, un conejo o un mono cinomolgo.
Una característica adicional de los XTEN con secuencias no repetitivas con un alto grado de repetitividad es que los XTEN no repetitivos forman contactos más débiles con los anticuerpos. Los anticuerpos son moléculas multivalentes. Por ejemplo, las IgG tienen dos sitios de unión idénticos y las IgM contienen 10 sitios de unión idénticos. Por lo tanto, los anticuerpos contra secuencias repetitivas pueden formar contactos multivalentes con dichas secuencias repetitivas con alta avidez, que pueden afectar a la potencia y/o eliminación de dichas secuencias repetitivas. Por el contrario, los anticuerpos contra XTEN no repetitivos pueden proporcionar interacciones monovalentes, que dan como resultado una menor probabilidad de eliminación, de tal forma que las composiciones de GPXTEN pueden permanecer en la circulación durante un periodo de tiempo aumentado.
8. Radio hidrodinámico aumentado
En otro aspecto, la presente invención proporciona XTEN en los que los polipéptidos de XTEN tienen un elevado radio hidrodinámico que confiere un correspondiente peso molecular aparente aumentado a la proteína de fusión GPXTEN que incorpora el XTEN. Tal como se detalla en el ejemplo 22, la unión de XTEN a secuencias de GP puede dar como resultado composiciones de GPXTEN que tienen radios hidrodinámicos aumentados, un peso molecular aparente aumentado y un factor de peso molecular aparente aumentado en comparación con un GP no unido a un Xt En . Por ejemplo, en aplicaciones terapéuticas en las que se desea una semivida prolongada, las composiciones en las que se incorpora un XTEN con un elevado radio hidrodinámico en una proteína de fusión que comprende uno o más Gp se puede agrandar de manera eficaz el radio hidrodinámico de la composición más allá del tamaño del poro glomerular de aproximadamente 3-5 nm (correspondiente a un peso molecular aparente de aproximadamente 70 kDa) (Caliceti.
2003. Pharmacokinetic and biodistribution properties of poly(ethylene glycol)-protein conjugates. Adv Drug Deliv Rev 55:1261-1277) dando como resultado una reducción en la eliminación renal de las proteínas en circulación. El radio hidrodinámico de una proteína se determina mediante su peso molecular, así como mediante su estructura, incluyendo su forma o grado de compactación. Sin quedar ligados a una teoría particular, el XTEN puede adoptar conformaciones abiertas debido a la repulsión electrostática entre cargas individuales del péptido o a la flexibilidad inherente conferida por los aminoácidos concretos en la secuencia que carecen de potencial para conferir estructura secundaria. La conformación abierta, extendida y no estructurada del polipéptido de XTEN puede tener un radio hidrodinámico proporcional mayor en comparación con polipéptidos con una longitud de secuencia y/o un peso molecular comparable que tienen estructura secundaria y/o terciaria, tales como las proteínas globulares típicas. Se conocen bien en la técnica métodos para determinar el radio hidrodinámico, tales como mediante el uso de cromatografía de exclusión
por tamaños (SEC), como se describe en las patentes de los Estados Unidos n.° 6.406.632 y 7.294.513. Tal como demuestran los resultados del ejemplo 22, la adición de longitudes crecientes de XTEN da como resultado aumentos proporcionales en los parámetros de radio hidrodinámico, el peso molecular aparente y el factor de peso molecular aparente, permitiendo el diseño de las GPXTEN a medida de las características deseadas de corte de pesos moleculares aparentes o de radios hidrodinámicos. Por consiguiente, en determinadas realizaciones, la proteína de fusión GPXTEN puede configurarse con un XTEN, de tal forma que la proteína de fusión puede tener un radio hidrodinámico de al menos aproximadamente 5 nm o al menos aproximadamente 8 nm o al menos aproximadamente 10 nm o 12 nm o al menos aproximadamente 15 nm. En las realizaciones anteriores, el gran radio hidrodinámico proporcionado por el XTEN en una proteína de fusión GPXTEN puede dar lugar a una eliminación renal reducida de la proteína de fusión resultante, lo que ocasiona un aumento correspondiente en la semivida terminal, un aumento en el tiempo medio de permanencia y/o una reducción en la velocidad de eliminación renal.
En otra realización, puede incorporarse de manera selectiva un XTEN de una longitud y secuencia seleccionada en un GPXTEN para crear una proteína de fusión que tiene, en condiciones fisiológicas, un peso molecular aparente de al menos aproximadamente 150 kDa o al menos aproximadamente 300 kDa o al menos aproximadamente 400 kDa o al menos aproximadamente 500 kDa o al menos aproximadamente 600 kDa o al menos aproximadamente 700 kDa o al menos aproximadamente 800 kDa o al menos aproximadamente 900 kDa o al menos aproximadamente 1000 kDa o al menos aproximadamente 1200 kDa o al menos aproximadamente 1500 kDa o al menos aproximadamente 1800 kDa o al menos aproximadamente 2000 kDa o al menos aproximadamente 2300 kDa o más. En otra realización, un XTEN de una longitud y secuencia seleccionada puede unirse de manera selectiva a un GP para dar como resultado una proteína de fusión GPXTEN que tiene, en condiciones fisiológicas, un factor de peso molecular aparente de al menos tres, como alternativa, de al menos cuatro, como alternativa, de al menos cinco, como alternativa, de al menos seis, como alternativa, de al menos ocho, como alternativa, de al menos 10, como alternativa, de al menos 15 o un factor de peso molecular aparente de al menos 20 o mayor. En otra realización, la proteína de fusión GPXTEN tiene, en condiciones fisiológicas, un factor de peso molecular aparente que es de aproximadamente 4 a aproximadamente 20 o es de aproximadamente 6 a aproximadamente 15 o es de aproximadamente 8 a aproximadamente 12 o es de aproximadamente 9 a aproximadamente 10 en relación con el peso molecular real de la proteína de fusión.
V) CONFIGURACIONES Y PROPIEDADES ESTRUCTURALES DE GPXTEN
Los GP de las presentes composiciones no se limitan a polipéptidos nativos de longitud completa, sino que también incluyen versiones recombinantes, así como variantes biológica y/o farmacológicamente activas o fragmentos de las mismas. Por ejemplo, se apreciará que pueden efectuarse diversas eliminaciones, inserciones y sustituciones de aminoácidos en el GP para crear variantes sin apartarse de la invención respecto de la actividad biológica o las propiedades farmacológicas del GP. Algunos ejemplos de sustituciones conservativas para aminoácidos en las secuencias de polipéptido se muestran en la tabla 6. Sin embargo, en las realizaciones de la GPXTEN en las que la identidad de secuencia del GP es menor del 100 % en comparación con una secuencia específica divulgada en el presente documento, la invención contempla la sustitución de un resto de aminoácido dado por cualquiera de los otros 19 L-aminoácidos naturales en el GP dado, que puede ser en cualquier posición dentro de la secuencia del GP, incluyendo restos de aminoácidos adyacentes. Si una cualquiera de las sustituciones diese como resultado un cambio no deseable en la actividad biológica, puede emplearse uno de los aminoácidos alternativos y se evaluaría la construcción mediante los métodos descritos en el presente documento o usando cualquiera de las técnicas y guías para mutaciones conservativas y no conservativas expuestas, por ejemplo, en la Patente de los Estados Unidos n.° 5.364.934 o usando métodos conocidos generalmente en la técnica. Además, las variantes pueden incluir, por ejemplo, polipéptidos en donde se añaden o eliminan uno o más restos de aminoácido en el extremo N o C-terminal de la secuencia de aminoácidos de longitud completa de un GP que conserva una parte o la totalidad de la actividad biológica del péptido nativo.
T l : i i n min i n rv iv il r iv

_________________________________________

a. Configuraciones de proteínas de fusión GPXTEN
La invención proporciona composiciones de proteína de fusión GPXTEN con los componentes de GP y XTEN unidos en configuraciones de N a C-terminal específicas. En algunas realizaciones, se unen uno o más GP a uno o más XTEN, ya sea en el extremo N-terminal o en el extremo C-terminal, con o sin un espaciador, para formar un copolímero de bloques y la disposición secuencial de los GP y los XTEN en la proteína de fusión GPXTEN es igual que la configuración conocida en la química de copolímeros de bloques. Cuando hay más de un GP, XTEN o espaciador, cada uno del GP, el XTEN o el espaciador tienen secuencias iguales o diferentes y los GP y/o XTEN se unen de manera continua o alterna (regular o irregular). Por tanto, en todas las fórmulas proporcionadas en el presente documento, cuando hay más de un GP, XTEN o espaciador, cada uno del GP, XTEN y espaciador son iguales o diferentes. En algunas realizaciones, el GPXTEN es una proteína de fusión monomérica con un GP unido a un polipéptido de XTEN. En otros casos, el GPXTEN es una proteína de fusión monomérica con un GP unido a dos o más polipéptidos de XTEN. En otras realizaciones adicionales, el GPXTEN es una proteína de fusión monomérica con dos o más GP unido a un polipéptido de XTEN. En otras realizaciones adicionales, el GPXTEN es una proteína de fusión monomérica con dos o más GP unidos a dos o más polipéptidos de XTEN. La tabla 7 proporciona ejemplos no limitantes de configuraciones que están abarcadas por las proteínas de fusión GPXTEN de la divulgación; serán evidentes numerosas variaciones diferentes para los expertos habituales en la materia, incluyendo la incorporación del espaciador y las secuencias de escisión divulgadas en el presente documento o conocidas en la técnica.
T l 7: nfi r i n PXTEN

La divulgación contempla composiciones de proteínas de fusión GPXTEN que comprenden, pero sin limitación, GP seleccionados de las secuencias de las tablas 1-3 (o fragmentos o variantes de secuencia de los mismos), XTEN seleccionados de la tabla 5 (o variantes de secuencia de los mismos) que se encuentran en una configuración mostrada en la tabla 7. En general, la GPXTEN resultante conservará al menos parte de la actividad biológica del GP correspondiente no unido al XTEN. En otras realizaciones, el componente GP o bien se vuelve biológicamente activo o tiene un aumento en su actividad tras su liberación del XTEN mediante la escisión de una secuencia de escisión opcional incorporada en las secuencias espaciadoras en la GPXTEN, descrita con más detalle más adelante.
En una realización de la composición de GPXTEN, la divulgación proporciona una proteína de fusión de fórmula I:
(XTEN)x-GP-(XTEN)y I
en donde independientemente para cada aparición, GP es un péptido regulador de glucosa; x es 0 o 1 e y es 0 o 1,
en donde x+y >1; y XTEN es un polipéptido recombinante extendido.
En otra realización de la composición de GPXTEN, la divulgación proporciona una proteína de fusión de fórmula II: (XTEN)x-(GP)-(S)y-(XTEN)y II
en donde independientemente para cada aparición, GP es un péptido regulador de glucosa; S es una secuencia espaciadora que tiene entre 1 y aproximadamente 50 restos de aminoácido que puede incluir opcionalmente una secuencia de escisión; x es 0 o 1 e y es 0 o 1, en donde x+y >1; y XTEN es un polipéptido recombinante extendido. En otra realización, la divulgación proporciona una proteína de fusión aislada, en donde la proteína de fusión es de fórmula III:
(GP)-(S)x-(XTEN)-(S)y-(GP)-(S)z-(XTEN)z III
en donde independientemente para cada aparición, GP es un péptido regulador de glucosa; S es una secuencia espaciadora que tiene entre 1 y aproximadamente 50 restos de aminoácido que puede incluir opcionalmente una secuencia de escisión; x es 0 o 1; y es 0 o 1; z es 0 o 1; y XTEN es un polipéptido recombinante extendido.
En otra realización, la divulgación proporciona una proteína de fusión aislada, en donde la proteína de fusión es de fórmula IV:
(XTEN)x-(S)y-(GP)-(S)z-(XTEN)-(GP) IV
en donde independientemente para cada aparición, GP es un péptido regulador de glucosa; S es una secuencia espaciadora que tiene entre 1 y aproximadamente 50 restos de aminoácido que puede incluir opcionalmente una secuencia de escisión; x es 0 o 1; y es 0 o 1; z es 0 o 1; y XTEN es un polipéptido recombinante extendido.
En otra realización, la divulgación proporciona una proteína de fusión aislada, en donde la proteína de fusión es de fórmula VIII:
((S)m-(GP)x-(S)n-(XTEN)y-(S)o)t VIII
en donde t es un número entero mayor de 0 (1,2, 3, 4, etc.); independientemente, cada uno de m, n, o, x e y es un número entero (0, 1, 2, 3, 4, etc.), GP es un péptido regulador de glucosa; S es un espaciador, que comprende opcionalmente un sitio de escisión; y XTEN es un polipéptido recombinante extendido, a condición de que: (1) x+y > 1, (2) cuando t = 1, x>0 e y>0, (3) cuando hay más de un GP, S o XTEN, cada uno de GP, XTEN o S son iguales o diferentes de manera independiente; y (4) cuando t >1, cada uno de m, n, o, x o y dentro de cada subunidad son iguales o son diferentes de manera independiente.
En algunos casos, la administración de una dosis terapéuticamente eficaz de una proteína de fusión de una realización de las fórmulas I-VIII a un sujeto que lo necesite puede dar como resultado una ganancia de tiempo de al menos dos veces o al menos tres veces o al menos cuatro veces o al menos cinco veces o más empleadas dentro de una ventana terapéutica para la proteína de fusión en comparación con el GP correspondiente no unido al XTEN y administrado con una dosis comparable a un sujeto. En otros casos, la administración de una dosis terapéuticamente eficaz de una proteína de fusión de una realización de las fórmulas I-VIII a un sujeto que lo necesite puede dar como resultado una ganancia de tiempo entre las dosis consecutivas necesarias para mantener una pauta posológica terapéuticamente eficaz de al menos 48 h o al menos 72 h o al menos aproximadamente 96 h o al menos aproximadamente 120 h o al menos aproximadamente 7 días o al menos aproximadamente 14 días o al menos aproximadamente 21 días entre dosis consecutivas en comparación con un GP no unido a XTEN y administrado con una dosis comparable.
Cualquier grupo de secuencia espaciadora es opcional en las proteínas de fusión abarcadas por la invención. Puede proporcionarse el espaciador para mejorar la expresión de la proteína de fusión a partir de una célula hospedadora o para reducir la impedancia estérica, de tal forma que el componente de GP puede adoptar su estructura terciaria deseada y/o interactuar de manera adecuada con su receptor diana. Para espaciadores y métodos para identificar espaciadores deseables, véase, por ejemplo, George, et al. (2003) Protein Engineering 15:871-879. En una realización, el espaciador comprende una o más secuencias peptídicas que tienen entre 1-50 restos de aminoácido de longitud o aproximadamente 1-25 restos o aproximadamente 1-10 restos de longitud. Las secuencias espaciadoras, excluyendo los sitios de escisión, pueden comprender cualquiera de los 20 L-aminoácidos naturales y preferentemente, comprenderán aminoácidos hidrófilos que no están impedidos estéricamente que pueden incluir, pero sin limitación, glicina (G), alanina (A), serina (S), treonina (T), glutamato (E) y prolina (P). En algunos casos, el espaciador puede ser poliglicinas o polialaninas o es predominantemente una mezcla de combinaciones de restos de glicina y alanina. El polipéptido espaciador exclusivo de una secuencia de escisión está en gran medida o sustancialmente desprovisto de estructura secundaria; por ejemplo, menos de aproximadamente un 10 % o menos de aproximadamente un 5 % según se determina mediante los algoritmos de Chou-Fasman y/o GOR. En una realización, una o ambas secuencias espaciadoras en una composición de proteína de fusión GPXTEN pueden contener una secuencia de escisión, que pueden ser idénticas o diferentes, en donde una proteasa puede actuar sobre la secuencia para liberar el GP de la proteína de fusión.
En algunos casos, la incorporación de la secuencia de escisión en la GPXTEN se diseña para permitir la liberación de un GP que se vuelve activo o más activo tras su liberación del XTEN. Las secuencias de escisión están ubicadas lo suficientemente próximas a las secuencias de GP, generalmente a menos de 18 o a menos de 12 o a menos de 6 o a menos de 2 aminoácidos del extremo de la secuencia de GP, de tal forma que cualquier otro resto unido al GP después de la escisión no interfiera de manera apreciable con la actividad (por ejemplo, tal como la unión a un receptor) del GP, y aun así proporcionar un acceso suficiente a la proteasa para que sea capaz de efectuar la escisión de la secuencia de escisión. En algunas realizaciones, el sito de escisión es una secuencia que puede escindirse mediante una proteasa endógena del sujeto mamífero, de tal forma que la GPXTEN puede escindirse tras su administración a un sujeto. En dichos casos, la GPXTEN puede servir como profármaco o como un depósito en circulación para el GP. Los ejemplos de sitios de escisión contemplados por la invención incluyen, pero sin limitación, una secuencia de polipéptido escindible mediante una proteasa endógena de mamífero seleccionada entre FXIa, FXIIa, calicreína, FVIIa, FIXa, FXa, FIIa (trombina), elastasa-2, granzima B, MMP-12, MMP-13, MMP-17 o MMP-20 o mediante proteasas no de mamífero, tales como TEV, enterocinasa, la proteasa PreScission™ (proteasa 3C de rinovirus) y sortasa A. Se conocen en la técnica secuencias que se sabe que se escinden por las anteriores y otras proteasas. En la tabla 8 se presentan secuencias de escisión y sitios de corte ilustrativos dentro de las secuencias, así como variantes de secuencia. Por ejemplo, la trombina (factor de coagulación II activado) actúa sobre la secuencia LTPRSLLV [Rawlings N.D., et al. (2008) Nucleic Acids Res., 36: D320], que podría cortarse tras la arginina en la posición 4 en la secuencia. El FIIa activo se produce mediante la escisión de FII por FXa en presencia de fosfolípidos y calcio y se encuentra aguas abajo del factor IX en la vía de coagulación. Una vez activado, su papel natural en la coagulación es escindir el fibrinógeno, que después, a su vez, comienza la formación de coágulos. La actividad del FIIa está estrechamente controlada y se produce únicamente cuando se necesita la coagulación para una hemostasia adecuada. Sin embargo, debido a que la coagulación es un proceso continuo en los mamíferos, al incorporar la secuencia LTPRSLLV en la GPXTEN entre el GP y el XTEN, se retiraría el dominio XTEN del GP anexo de manera concurrente con la activación de las vías de coagulación extrínsecas o intrínsecas cuando se necesita desde un punto de vista fisiológico la coagulación, liberando de este modo el GP con el paso del tiempo. De manera similar, la incorporación de otras secuencias en la GPXTEN sobre las que actúan proteasas endógenas podría posibilitar la liberación sostenida del GP que podría, en determinados casos, proporcionar un mayor grado de actividad para el GO a partir de la forma de "profármaco" de la GPXTEN.
En algunos casos, solo los dos o tres aminoácidos que flanquean a ambos lados del sitio de corte (de cuatro a seis aminoácidos en total) pueden incorporarse en la secuencia de escisión. En otros casos, la secuencia de escisión conocida puede tener una o más eliminaciones o inserciones o una o dos o tres sustituciones de aminoácidos para uno cualquiera o dos o tres aminoácidos en la secuencia conocida, en donde las eliminaciones, inserciones o sustituciones dan como resultado una susceptibilidad reducida o mejorada pero no una ausencia de susceptibilidad a la proteasa, dando como resultado la posibilidad de diseñar a medida la velocidad de liberación del GP del XTEN. Las sustituciones ilustrativas se muestran en la tabla 8.
T l : n i i i n r r


En una realización, un GP incorporado en una proteína de fusión GPXTEN puede tener una secuencia que muestra al menos aproximadamente un 80 % de identidad de secuencia respecto de una secuencia de las tablas 1-3, como alternativa, al menos aproximadamente un 81 % o aproximadamente un 82 % o aproximadamente un 83 % o aproximadamente un 84 % o aproximadamente un 85 % o aproximadamente un 86 % o aproximadamente un 87 % o aproximadamente un 88 % o aproximadamente un 89 % o aproximadamente un 90 % o aproximadamente un 91 % o aproximadamente un 92 % o aproximadamente un 93 % o aproximadamente un 94 % o aproximadamente un 95 % o aproximadamente un 96 % o aproximadamente un 97 % o aproximadamente un 98 % o aproximadamente un 99 % o aproximadamente un 100 % de identidad de secuencia en comparación con una secuencia de las tablas 1-3. Puede evaluarse la actividad del GP de la realización anterior usando ensayos o parámetros medidos o determinados, como se describe en el presente documento aquellas secuencias que conservan al menos aproximadamente un 40 % o aproximadamente un 50 % o aproximadamente un 55 % o aproximadamente un 60 % o aproximadamente un 70 % o aproximadamente un 80 % o aproximadamente un 90 % o aproximadamente un 95 % o más de actividad en comparación con la secuencia de GP nativa correspondiente se consideraría adecuada para su inclusión en las presentes GPXTEN. Puede unirse el GP que se observa que conserva un nivel adecuado de actividad a uno o más polipéptidos de XTEN descritos anteriormente en el presente documento. En una realización, puede unirse un GP que se observa que conserva un nivel adecuado de actividad a uno o más polipéptidos de XTEN que tienen al menos aproximadamente un 80 % de identidad de secuencia respecto de una secuencia de la tabla 5, como alternativa, al menos aproximadamente un 81 %, 82 %, 83 %, 84 %, 85 %, 86 %, 87 %, 88 %, 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 % o aproximadamente un 100 % de identidad de secuencia en comparación con una secuencia de la tabla 5, dando como resultado una proteína de fusión quimérica.
En la tabla 36 se presentan ejemplos no limitantes de secuencias de proteínas de fusión GPXTEN que contienen un solo GP unido a un solo XTEN y en la tabla 37 se presentan secuencias de proteínas de fusión GPXTEN que contienen un solo GP unido a dos XTEN. En una realización, una composición de GPXTEN podría comprender una proteína de fusión que tiene al menos aproximadamente un 80 % de identidad de secuencia respecto de una GPXTEN de las tablas 36-37, como alternativa, al menos aproximadamente un 81 %, 82 %, 83 %, 84 %, 85 %, 86 %, 87 %, 88 %, 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 % o aproximadamente un 100 % de identidad de secuencia en comparación con una GPXTEN de las tablas 36-37. Sin embargo, la divulgación también contempla la sustitución de otros GP con secuencias que muestran al menos aproximadamente un 90 % de identidad de secuencia respecto de una secuencia seleccionada de las tablas 1-3 unida a uno o dos XTEN, que puede ser igual o diferente, mostrando al menos aproximadamente un 90 % de identidad de secuencia respecto de una secuencia seleccionada de la tabla 5. En las proteínas de fusión anteriores descritas anteriormente en este párrafo, la proteína de fusión GPXTEN puede comprender además una secuencia de escisión de la tabla 8; ubicándose la secuencia de escisión entre el GP y el XTEN o entre GP adyacentes (en caso de que se incluya más de un GP en la GPXTEN). En algunos casos, la GPXTEN que comprende las secuencias de escisión también tendrá uno o más aminoácidos de secuencia espaciadora entre el GP y la secuencia de escisión o el XTEN y la secuencia de escisión para facilitar el acceso de la proteasa; los aminoácidos espaciadores que comprenden cualquier aminoácido natural, incluyendo glicina y alanina como aminoácidos preferidos. Los ejemplos no limitantes de GPXTEN que comprenden GP, XTEN, secuencias de escisión y aminoácidos espaciadores se presentan en la tabla 38. Sin embargo, la divulgación también contempla la sustitución de cualquiera de las secuencias de GP de las tablas 1-3 para una secuencia de GP de las tablas 36-38, la sustitución de cualquier secuencia de XTEN de la tabla 5 para una secuencia de XTEN de las tablas 36-38 y la sustitución de cualquier secuencia de escisión de la tabla 8 para una secuencia de escisión de la tabla 38.
b. Propiedades farmacocinéticas de la GPXTEN
La invención proporciona proteínas de fusión GPXTEN con una farmacocinética mejorada en comparación con el GP no unido al x Te N que, cuando se usa a la dosis determinada para la composición mediante los métodos descritos en el presente documento, pueden lograr una concentración circulante que da como resultado un efecto farmacológico, manteniéndose dentro del intervalo seguro para el componente biológicamente activo de la composición durante un periodo de tiempo prolongado en comparación con una dosis comparable del GP no unido al XTEN. En dichos casos, la GPXTEN se mantiene dentro de la ventana terapéutica para la composición de proteína de fusión durante el periodo
de tiempo prolongado. Como se usa en el presente documento, una "dosis comparable" significa una dosis con un equivalente de moles/kg para el farmacóforo GP activo que se administra a un sujeto de un modo comparable. Se entenderá en la técnica que una "dosis comparable" de proteína de fusión GPXTEN podría representar un mayor peso de agente pero podría tener esencialmente los mismos equivalentes en moles de GP en la dosis de la proteína de fusión y/o podría tener aproximadamente la misma concentración molar en relación con el GP.
Las propiedades farmacocinéticas de un GP que pueden mejorarse uniendo un XTEN dado al GP incluyen la semivida terminal, área bajo la curva (ABC), volumen de distribución de Cmáx y biodisponibilidad, proporcionando una utilidad mejorada en el tratamiento de trastornos, enfermedades y afecciones relacionadas con el péptido regulador de la glucosa. El GP de las composiciones de GPXTEN que muestran propiedades PK mejoradas puede ser una secuencia que muestra al menos aproximadamente un 80 % de identidad de secuencia o como alternativa, un 81 %, 82 %, 83 %, 84 %, 85 %, 86 %, 87 %, 88 %, 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 % o 100 % de identidad de secuencia respecto de una proteína seleccionada de las tablas 1-3, unido a uno o más XTEN que muestran al menos aproximadamente un 80 % de identidad de secuencia o como alternativa, un 81 %, 82 %, 83 %, 84 %, 85 %, 86 %, 87 %, 88 %, 89 %, 90 %, 91 %, 92 %, 93 %, 94 %, 95 %, 96 %, 97 %, 98 %, 99 % o 100 % de identidad de secuencia respecto de una secuencia de proteína seleccionada de la tabla 5 y puede estar en una configuración seleccionada entre las configuraciones de la tabla 7.
Tal como se describe con más detalle en los ejemplos relativos a las características farmacocinéticas de las proteínas de fusión que comprenden XTEN, se ha descubierto sorprendentemente que el aumento de la longitud de la secuencia de XTEN podría conferir un aumento desproporcionado en la semivida terminal de una proteína de fusión que comprende el XTEN. Por consiguiente, la divulgación proporciona proteínas de fusión GPXTEN que comprenden XTEN, en donde el XTEN puede seleccionarse para proporcionar una semivida diana para la composición de GPXTEN administrada a un sujeto. En algunas realizaciones, la divulgación proporciona proteínas de fusión monoméricas que comprenden XTEN, en donde el XTEN se selecciona para conferir un aumento en la semivida terminal para la GPXTEN administrada a un sujeto, en comparación con el GP correspondiente no unido a la proteína de fusión y administrado a una dosis comparable, de al menos dos veces mayor o al menos aproximadamente tres veces o al menos aproximadamente cuatro veces o al menos aproximadamente cinco veces o al menos aproximadamente seis veces o al menos aproximadamente siete veces o al menos aproximadamente ocho veces o al menos aproximadamente nueve veces o al menos aproximadamente diez veces o al menos aproximadamente 15 veces o al menos 20 veces o un aumento al menos 40 veces o al menos 80 veces o al menos 100 veces o mayor en la semivida terminal en comparación con el GP no unido a la proteína de fusión. Se ha informado que la exendina-4 administrada de manera exógena tiene una semivida terminal en seres humanos de 2,4 h y el glucagón tiene una semivida de menos de 20 minutos, mientras que diversas composiciones de GPXTEN divulgadas en el presente documento que se han administrado experimentalmente a diversas especies animales, como se describe en los ejemplos, han dado como resultado valores de semivida terminal de varias horas. De manera similar, las proteínas de fusión GPXTEN pueden tener un aumento en la ABC de al menos aproximadamente un 50 % o al menos aproximadamente un 60 % o al menos aproximadamente un 70 % o al menos aproximadamente un 80 % o al menos aproximadamente un 90 % o al menos aproximadamente un 100 % o al menos aproximadamente un 150 % o al menos aproximadamente un 200 % o al menos aproximadamente un 300 % o al menos aproximadamente un 500 % o al menos aproximadamente un 1000 % o al menos aproximadamente un 2000 % en comparación con el GP correspondiente no unido a la proteína de fusión y administrado a un sujeto a una dosis comparable. Los parámetros farmacocinéticos de una GPXTEN pueden determinarse mediante métodos convencionales que implican dosificación, extracción de muestras de sangre en intervalos de tiempo y la evaluación de la proteína usando ELISA, HPLC, radioensayo u otros métodos conocidos en la técnica o como se describen en el presente documento, seguido de cálculos convencionales de los datos para extraer la semivida y otros parámetros PK.
La invención proporciona además GPXTEN que comprenden una primera y una segunda molécula de GP, separadas opcionalmente por una secuencia espaciadora que puede comprender además una secuencia de escisión o separada por una segunda secuencia de XTEN. En una realización, el Gp tiene menos actividad cuando se une a la proteína de fusión en comparación con un GP correspondiente no unido a la proteína de fusión. En tal caso, como se ilustra en la FIG. 38, la GPXTEN puede diseñarse de tal forma que tras su administración a un sujeto, el componente de GP se libera gradualmente mediante la escisión de las secuencias de escisión, tras lo cual recupera la actividad o la capacidad de unirse a su receptor o ligando diana. Por consiguiente, la GPXTEN de lo anterior sirve como profármaco o como depósito circulante, dando como resultado una semivida terminal más larga en comparación con GP no unido a la proteína de fusión.
c. Farmacología y propiedades farmacéuticas de la GPXTEN
La presente invención proporciona composiciones de GPXTEN que comprenden GP unido covalentemente a XTEN que pueden tener propiedades mejoradas en comparación con GP no unido a XTEN, así como métodos para mejorar la actividad terapéutica y/o biológica o el efecto de los dos componentes de GP respectivos de las composiciones. Además, la invención proporciona composiciones de GPXTEN con propiedades mejoradas en comparación con las proteínas de fusión conocidas en la técnica que comprenden compañeros de polipéptidos de inmunoglobulina, polipéptidos de menor longitud y/o compañeros polipeptídicos con secuencias repetitivas. Además, las proteínas de fusión GPXTEN proporcionan ventajas significativas frente a los conjugados químicos, tales como construcciones
pegiladas, de manera destacable, el hecho de que pueden producirse proteínas de fusión de GPXTEN en sistemas de expresión bacterianos, que pueden reducir el tiempo y el coste en las etapas tanto de investigación y desarrollo como de fabricación de un producto, así como proporcionar un producto más homogéneo y definido con menos toxicidad tanto para el producto como para los metabolitos de la GPXTEN en comparación con los conjugados pegilados.
Como agentes terapéuticos, la GPXTEN puede poseer una serie de ventajas frente a agentes terapéuticos que no comprenden XTEN que incluyen una o más de las siguientes propiedades mejoradas no limitantes a modo de ejemplo; aumento de la solubilidad, estabilidad térmica aumentada, inmunogenicidad reducida, peso molecular aparente aumentado, eliminación renal reducida, proteólisis reducida, metabolismo reducido, eficacia terapéutica mejorada, una dosis terapéutica eficaz menor, biodisponibilidad aumentada, aumento del tiempo entre dosis capaces de mantener niveles sanguíneos dentro de la ventana terapéutica para el GP, una velocidad de absorción "diseñada", estabilidad durante la liofilización mejorada, estabilidad en suero/plasma mejorada, semivida terminal aumentada, solubilidad aumentada en el torrente sanguíneo, unión reducida a anticuerpos neutralizantes, reducción de la eliminación mediada por receptores, efectos secundarios reducidos, conservación de la afinidad de unión a receptor/ligando o la activación de receptor/ligando, estabilidad a la degradación, estabilidad frente a la congelación-descongelación, estabilidad a las proteasas, estabilidad a la ubiquitinación, facilidad de administración, compatibilidad con otros excipientes o vehículos farmacéuticos, persistencia en el sujeto, estabilidad durante el almacenamiento aumentada (por ejemplo, vida útil aumentada), toxicidad reducida en un organismo o en el ambiente y similares. El efecto neto de las propiedades mejoradas es que la GPXTEN puede dar como resultado un efecto terapéutico y/o biológico mejorado o un mejor cumplimiento terapéutico cuando se administra a un sujeto con una enfermedad o trastorno relacionada con un péptido regulador de la glucosa.
En otros casos donde es deseable una mejora de las propiedades farmacéuticas o fisicoquímicas del GP, (tales como el grado de solubilidad o estabilidad acuosa), pueden seleccionarse la longitud y/o la composición de familias de motivos de secuencia de las secuencias primera y segunda de XTEN de las proteínas de fusión primera y segunda para conferir un grado de solubilidad y/o estabilidad diferente a las proteínas de fusión respectivas, de tal forma que se mejoran las propiedades farmacéuticas de la composición de GPXTEN. Las proteínas de fusión GPXTEN pueden construirse y ensayarse, usando métodos descritos en el presente documento, para confirmar las propiedades fisicoquímicas y puede ajustarse el XTEN, según sea necesario, para dar como resultado las propiedades deseadas. En una realización, la secuencia de XTEN de la GPXTEN se selecciona de tal forma que la proteína de fusión tiene una solubilidad acuosa que es al menos aproximadamente un 25 % mayor en comparación con un GP no unido a la proteína de fusión o al menos aproximadamente un 30 % o al menos aproximadamente un 40 % o al menos aproximadamente un 50 % o al menos aproximadamente un 75 % o al menos aproximadamente un 100 % o al menos aproximadamente un 200 % o al menos aproximadamente un 300 % o al menos aproximadamente un 400 % o al menos aproximadamente un 500 % o al menos aproximadamente un 1000 % mayor que el GP correspondiente no unido a la proteína de fusión. En las realizaciones descritas anteriormente en este párrafo, el XTEN de las proteínas de fusión puede tener al menos aproximadamente un 80 % de identidad de secuencia o de aproximadamente un 90 % o aproximadamente un 91 % o aproximadamente un 92 % o aproximadamente un 93 % o aproximadamente un 94 % o aproximadamente un 95 % o aproximadamente un 96 % o aproximadamente un 97 % o aproximadamente un 98 % o aproximadamente un 99 %, a aproximadamente 100 % de identidad de secuencia respecto de un XTEN seleccionado de la tabla 5.
En una realización, la invención proporciona composiciones de GPXTEN que pueden mantener el componente de GP dentro de una ventana terapéutica durante un periodo de tiempo mayor en comparación con dosis comparables del GP correspondiente no unido a XTEN. Se entenderá en la técnica que una "dosis comparable" de proteína de fusión GPXTEN podría representar un mayor peso de agente pero podría tener aproximadamente los mismos equivalentes en moles de GP en la dosis de la proteína de fusión y/o podría tener aproximadamente la misma concentración molar en relación con el GP.
La divulgación también proporciona métodos para seleccionar el XTEN adecuado para conjugación para proporcionar las propiedades farmacocinéticas deseadas que, cuando se empareja con la selección de la dosis, posibilita una eficacia aumentada de la composición administrada manteniendo las concentraciones circulantes del GP dentro de la ventana terapéutica durante un periodo de tiempo mejorado. Como se usa en el presente documento, "ventana terapéutica" significa una cantidad de fármaco o agente biológico en forma de un intervalo de concentración sanguínea o plasmática, que proporciona eficacia o un efecto farmacológico deseado a lo largo del tiempo para la enfermedad o afección sin una toxicidad no aceptable; el intervalo de las concentraciones sanguíneas circulantes entre la cantidad mínima para lograr cualquier efecto terapéutico positivo y la cantidad máxima que da como resultado una respuesta que es la respuesta inmediatamente antes de toxicidad para el sujeto (a una dosis o concentración mayor). Además, la ventana terapéutica generalmente abarca un aspecto de tiempo; la concentración máxima y mínima que da como resultado un efecto farmacológico deseado a lo largo del tiempo que no da como resultado una toxicidad o eventos adversos no aceptables. También podría decirse que una composición dosificada que se mantiene dentro de la ventana terapéutica para el sujeto se encuentra dentro del "intervalo de seguridad".
Las características de las composiciones de GPXTEN de la invención, incluyendo las características funcionales o la actividad biológica o farmacológica y los parámetros resultantes, pueden determinarse mediante cualquier ensayo de
exploración adecuado conocido en la técnica para medir la característica deseada. La divulgación proporciona métodos para ensayar las proteínas de fusión GPXTEN con diferentes composiciones o configuraciones para proporcionar la GPXTEN con el grado deseado de actividad biológica y/o terapéutica, así como un perfil de seguridad. Pueden usarse ensayos biológicos in vivo y ex vivo específico para evaluar la actividad de cada GPXTEN configurada y/o componente de Gp que se vaya a incorporar en la GPXTEN, incluyendo, pero sin limitación, los ensayos de los ejemplos, los ensayos de la tabla 35, así como los siguientes ensayos u otros ensayos similares conocidos en la técnica para evaluar las propiedades y efectos del GP. Pueden llevarse a cabo ensayos que permiten determinar las características de unión de la GPXTEN para receptores de GP o un ligando, incluyendo la constante de unión (Kd), valores de CE50, así como su semivida de disociación del complejo de ligando-receptor (T1/2). La afinidad de unión puede medirse, por ejemplo, mediante un ensayo de unión de tipo competitivo que detecta cambios en la capacidad para unirse específicamente a un receptor (véanse, por ejemplo, los ejemplos). Además, pueden usarse técnicas, tales como citometría de flujo o resonancia de plasmón superficial para detectar los eventos de unión. Los ensayos pueden comprender moléculas de receptor solubles o pueden determinar la unión a receptores expresados en células. Dichos ensayos pueden incluir ensayos basados en células, incluyendo ensayos para flujo de calcio, transducción de señales y proliferación celular. Otros ensayos posibles pueden determinar la unión a receptores de polipéptidos expresados, en donde el ensayo puede comprender moléculas de receptor solubles o puede determinar la unión a receptores expresados en células. La afinidad de unión de una GPXTEN para los receptores diana del GP correspondiente puede ensayarse usando unión o ensayos de unión competitivos, tales como ensayos Biacore con receptores o proteínas de unión unidas a microplacas o ensayos ELISA, como se describe en la Patente de los Estados Unidos 5.534.617, ensayos descritos en los ejemplos del presente documento, ensayos con radiorreceptores u otros ensayos conocidos en la técnica. Además, las variantes de secuencia de GP (ensayadas como componentes individuales o como proteínas de fusión GPXTEN) pueden compararse con el GP nativo usando un ensayo de unión ELISA competitivo para determinar si tienen la misma especificidad y afinidad de unión que el GP nativo o alguna fracción del mismo, de tal forma que son adecuados para su inclusión en GPXTEN. Los ensayos funcionales pueden incluir concentraciones y/o generación de insulina con células diana como resultado de la exposición a GPXt En y/o los efectos estimulantes resultantes de las células beta, la captación y/u homeostasia de la glucosa, concentraciones de HbA1c, concentraciones de insulina, péptido C estimulado, glucosa en plasma en ayunas (FPG), niveles séricos de citocinas, niveles de CRP, secreción de insulina e índice de sensibilidad a la insulina obtenido de una prueba de tolerancia a la glucosa oral (OGTT), así como el peso corporal, el consumo de alimentos y otros marcadores de diabetes aceptados conocidos en la técnica, que serían parámetros adecuados para evaluar la actividad del GP para su inclusión en la proteína de fusión GPXTEN o la GpXt EN resultante.
La optimización de la dosis es importante para todos los fármacos, especialmente para aquellos con una ventana terapéutica estrecha. Por ejemplo, puede no ser siempre eficaz una sola dosis estandarizada de GP para todos los pacientes que presentan diversos síntomas o parámetros clínicos anormales. La toma en consideración de estos factores se encuentra dentro de las competencias del médico experto a fin de determinar la cantidad terapéutica o farmacológicamente eficaz de la GPXt En , frente a aquella cantidad que daría como resultado una toxicidad no aceptable y la colocaría fuera del intervalo de seguridad o con una potencia insuficiente, de tal forma que no se logra una mejora clínica.
En muchos casos, se ha determinado la ventana terapéutica para GP en sujetos de diferentes edades o grados de enfermedad y se encuentra disponible en la bibliografía publicada o se indican en el prospecto para productos aprobados que contienen el GP. En otros casos, puede determinarse la ventana terapéutica. Los métodos para determinar la ventana terapéutica para una composición dada se conocen por los expertos en la materia (véase, por ejemplo, Goodman & Gilman's The Pharmacological Basis of Therapeutics, 11a edición, McGraw-Hill (2005)). Por ejemplo, usando estudios de escalada de la dosis en sujetos con la enfermedad o el trastorno diana para determinar la eficacia o un efecto farmacológico deseado, la aparición de eventos adversos y la determinación de niveles sanguíneos en circulación, puede determinarse la ventana terapéutica para un fármaco o agente biológico dado o para combinaciones de agentes biológicos o fármacos para un sujeto dado o una población de sujetos. Los estudios de escalada de la dosis pueden evaluar la actividad de una GPXTEN mediante estudios metabólicos en un sujeto o grupo de sujetos que monitorizan parámetros fisiológicos o bioquímicos, tal como se conoce en la técnica o como se describe en el presente documento para uno o más parámetros asociados con la enfermedad o trastorno metabólico o parámetros clínicos asociados con un resultado beneficioso para la indicación particular, junto con observaciones y/o parámetros medidos para determinar la dosis sin efecto, eventos adversos, dosis máxima tolerada y similares, junto con medidas de parámetros farmacocinéticos que establecen los niveles circulantes en sangre determinados o derivados. Después, pueden correlacionarse los resultados con la dosis administrada y las concentraciones sanguíneas del agente terapéutico que son coincidentes con los parámetros o niveles de efecto anteriores determinados. Mediante estos métodos, puede correlacionarse un intervalo de dosis y concentraciones en sangre con la dosis mínima eficaz, así como con la dosis y concentración máxima a la cual se produce un efecto deseado y por encima de la cual se produce toxicidad, estableciendo de este modo la ventana terapéutica para el agente terapéutico administrado. Las concentraciones sanguíneas de la proteína de fusión (o medidas para el componente de GP) por encima del máximo se considerarían fuera de la ventana terapéutica o el intervalo de seguridad. Por tanto, mediante los métodos anteriores, podría establecerse un nivel en sangre de Cmín, por debajo del cual la proteína de fusión GPXTEN podría no tener el efecto farmacológico deseado y podría establecerse un nivel en sangre de Cmáx que podría representar la concentración circulante máxima antes de alcanzar una concentración que podría provocar efectos secundarios no aceptables, toxicidad o eventos adversos, situándose fuera del intervalo de seguridad para la
GPXTEN. Habiéndose establecido dichas concentraciones, puede refinarse adicionalmente la frecuencia de administración y la dosis midiendo la Cmáx y la Cmín para proporcionar la dosis adecuada y la frecuencia de dosificación para mantener las proteínas de fusión dentro de la ventana terapéutica. Un experto en la materia puede confirmar, por los medios divulgados en el presente documento o mediante otros métodos conocidos en la técnica, que la GPXTEN administrada permanece en la ventana terapéutica durante el intervalo deseado o si se necesita el ajuste de la dosis o de la longitud o la secuencia del XTEN. Además, la determinación de la dosis adecuada de la frecuencia de la dosis para mantener el GPXTEN dentro de la ventana terapéutica establece la pauta posológica terapéuticamente eficaz; la pauta para la administración de múltiples dosis consecutivas usando una dosis terapéuticamente eficaz de la proteína de fusión a un sujeto que lo necesita que da como resultado picos de Cmáx y/o mínimos de Cmín que permanecen dentro de la ventana terapéutica y que dan como resultado una mejora en al menos un parámetro medido relevante para la afección enfermedad, trastorno o afección. En algunos casos, la GPXTEN administrada a una dosis adecuada a un sujeto puede dar como resultado concentraciones en sangre de la proteína de fusión GPXTEN que permanecen dentro de la ventana terapéutica durante un periodo al menos aproximadamente dos veces más largo en comparación con el GP correspondiente no unido a XTEN y administrado a una dosis comparable; como alternativa, al menos aproximadamente tres veces mayor; como alternativa, al menos aproximadamente cuatro veces mayor; como alternativa, al menos aproximadamente cinco veces mayor; como alternativa, al menos aproximadamente seis veces mayor; como alternativa, al menos aproximadamente siete veces mayor; como alternativa, al menos aproximadamente ocho veces mayor; como alternativa al menos aproximadamente nueve veces mayor o al menos aproximadamente diez veces mayor o superior en comparación con el GP correspondiente no unido a XTEN y administrado a una dosis comparable. Como se usa en el presente documento, una "dosis adecuada" significa una dosis de un fármaco o agente biológico que, cuando se administra a un sujeto, dará como resultado un efecto terapéutico o farmacológico deseable y una concentración en sangre dentro de la ventana terapéutica.
En una realización, la GPXTEN administrada con una pauta posológica terapéuticamente eficaz da como resultado un aumento de tiempo de al menos aproximadamente tres veces o mayor; como alternativa, al menos aproximadamente cuatro veces mayor; como alternativa, al menos aproximadamente cinco veces mayor; como alternativa, al menos aproximadamente seis veces mayor; como alternativa, al menos aproximadamente siete veces mayor; como alternativa, al menos aproximadamente ocho veces mayor; como alternativa, al menos aproximadamente nueve veces mayor o al menos aproximadamente diez veces mayor entre al menos dos picos de Cmáx y/o mínimos de Cmín consecutivos para los niveles en sangre de la proteína de fusión en comparación con la proteína biológicamente activa correspondiente de la proteína de fusión no unida a la proteína de fusión y administrada con una pauta posológica comparable a un sujeto. En otra realización, la GPXTEN administrada con una pauta posológica terapéuticamente eficaz da como resultado una mejora comparable en uno o dos o tres o más parámetros medidos usando una dosificación menos frecuente o con una dosis total menor en moles de la proteína de fusión de la composición farmacéutica en comparación con los componentes de proteína biológicamente activa correspondientes no unidos a la proteína de fusión y administrados a un sujeto usando una pauta posológica terapéuticamente eficaz para el GP. Los parámetros medidos pueden incluir cualquiera de los parámetros clínicos bioquímicos o fisiológicos divulgados en el presente documento u otros conocidos en la técnica para evaluar a sujetos con trastornos relacionados con la glucosa o la insulina.
La actividad de las composiciones de GPXTEN de la invención, incluyendo las características funcionales o la actividad biológica o farmacológica y los parámetros resultantes, pueden determinarse mediante cualquier ensayo de exploración adecuado conocido en la técnica para medir la característica deseada. Pueden evaluarse la actividad y la estructura de los polipéptidos de XTEN que comprenden componentes de GP midiendo los parámetros descritos en el presente documento, mediante el uso de uno o más ensayos seleccionados de la tabla 35, los ensayos de los ejemplos o mediante métodos conocidos en la técnica para determinar el grado de solubilidad, la estructura y la conservación de la actividad biológica. Pueden llevarse a cabo ensayos que permiten determinar las características de unión de la GPXTEN para receptores de GP o un ligando, incluyendo la constante de unión (Kd), valores de CE50, así como su semivida de disociación del complejo de ligando-receptor (T1/2). La afinidad de unión puede medirse, por ejemplo, mediante un ensayo de unión de tipo competitivo que detecta cambios en la capacidad para unirse específicamente a un receptor o ligando (véanse, por ejemplo, los ejemplos). Además, pueden usarse técnicas, tales como citometría de flujo o resonancia de plasmón superficial para detectar los eventos de unión. Los ensayos pueden comprender moléculas de receptor solubles o pueden determinar la unión a receptores expresados en células. Dichos ensayos pueden incluir ensayos basados en células, incluyendo ensayos de proliferación, muerte celular, apoptosis y migración celular. Otros ensayos posibles pueden determinar la unión a receptores de polipéptidos expresados, en donde el ensayo puede comprender moléculas de receptor solubles o puede determinar la unión a receptores expresados en células. La afinidad de unión de una GPXTEN para los receptores o ligandos diana del GP correspondiente puede ensayarse usando ensayos de unión o de unión competitiva, tales como ensayos Biacore con receptores o proteínas de unión unidas a microplacas o ensayos ELISA, como se describe en la Patente de los Estados Unidos 5.534.617, ensayos descritos en los ejemplos del presente documento, ensayos con radiorreceptores u otros ensayos conocidos en la técnica. Además, las variantes de secuencia de GP (ensayadas como componentes individuales o como proteínas de fusión GPXTEN) pueden compararse con el GP nativo usando un ensayo de unión ELISA competitivo para determinar si tienen la misma especificidad y afinidad de unión que el GP nativo o alguna fracción del mismo, de tal forma que son adecuados para su inclusión en GPXTEN.
La invención proporciona GPXTEN aisladas en las que la afinidad de unión por receptores o ligandos diana de GP por
la GPXTEN puede ser al menos aproximadamente un 10 % o al menos aproximadamente un 20 % o al menos aproximadamente un 30 % o al menos aproximadamente un 40 % o al menos aproximadamente un 50 % o al menos aproximadamente un 60 % o al menos aproximadamente un 70 % o al menos aproximadamente un 80 % o al menos aproximadamente un 90 % o al menos aproximadamente un 95 % o al menos aproximadamente un 99 % o al menos aproximadamente un 100 % o más de la afinidad de un GP nativo no unido a XTEN por el receptor o ligando diana.
En algunos casos, la afinidad de unión Kd entre la presente GPXTEN y un receptor o ligando nativo de la GPXTEN es de al menos aproximadamente 10-4 M, como alternativa, de al menos aproximadamente 10-5 M, como de alternativa, de al menos aproximadamente 10-6 M o al menos aproximadamente 10-7 M o al menos aproximadamente 10-8 M o al menos aproximadamente 10-9 M de la afinidad entre la GPXTEN y un receptor o ligando nativo.
En otros casos, la divulgación proporciona proteínas de fusión GPXTEN aisladas diseñadas específicamente para que tengan afinidad de unión reducida al receptor de GP. En una realización, dichas proteínas de fusión comprenden un XTEN fusionado al extremo C-terminal del componente de GP. En algunos casos, la GPXTEN puede configurarse para que tenga afinidad de unión reducida, en donde la afinidad de unión se evalúa mediante un ensayo de unión a receptor celular in vitro, en donde la unión se reduce en al menos aproximadamente un 10 % o aproximadamente un 20 % o aproximadamente un 40 % o aproximadamente un 60 % o aproximadamente un 80 % o aproximadamente un 90 % en comparación con el GP nativo. En otros casos, la GPXTEN puede configurarse para que tenga una afinidad de unión reducida, en donde la afinidad de unión se evalúa mediante transducción de señales, en donde la proteína de fusión GPXTEN produce menos de aproximadamente un 80 % o menos de aproximadamente un 60 % o menos de aproximadamente un 40 % o menos de aproximadamente un 20 % o menos de un 10 % o menos de aproximadamente un 5 % de la activación de las vías de señalización de la célula con GPXTEN unida en comparación con las provocadas por el ligando de GP nativo. En los casos anteriores, la afinidad de unión se "reduce sustancialmente". Los ejemplos no limitantes de construcciones específicas de dichas GPXTEN con afinidad de unión reducida incluyen proteínas de fusión con al menos aproximadamente un 80 % de identidad de secuencia o al menos aproximadamente un 85 % de identidad de secuencia o al menos aproximadamente un 90 % de identidad de secuencia o al menos aproximadamente un 95 % de identidad de secuencia o al menos aproximadamente un 97 % de identidad de secuencia o al menos aproximadamente un 99 % de identidad de secuencia respecto de proteínas de fusión de GP seleccionadas entre AE912-GP-AE144, AE912-GP-AF144, AE912-GP-AE288, AM923-GP-AE144, AM923-GP-AF144, AM923-GP-AE288.
En algunos casos, las proteínas de fusión GPXTEN de la invención conservan al menos aproximadamente un 10 % o aproximadamente un 20 %, 30 %, 40 %, 50 %, 60 %, 70 %, 80 %, 90 %, 95 %, 98 % o 99 % de la actividad biológica del GP correspondiente no unido a la proteína de fusión respecto de una actividad biológica in vitro o un efecto farmacológico in vivo conocido o asociado con el uso del GP nativo en el tratamiento y la prevención de afecciones y trastornos metabólicos. Los ejemplos no limitantes de actividades o efectos farmacológicos que pueden ensayarse para evaluar la actividad conservada de las proteínas de fusión GPXTEN incluyen ensayos para flujo de calcio y/o transducción de señales en respuesta a la unión a receptores, concentraciones y/o generación de insulina con células diana como resultado de la exposición a GPXTEN y/o los efectos estimulantes resultantes de las células beta, la captación y/u homeostasia de la glucosa, concentraciones de HbA1c, concentraciones de insulina, péptido C estimulado, glucosa en plasma en ayunas (FPG), niveles séricos de citocinas, niveles de CRP, secreción de insulina e índice de sensibilidad a la insulina obtenido de una prueba de tolerancia a la glucosa oral (OGTT), así como el peso corporal, el consumo de alimentos y otros marcadores de diabetes aceptados conocidos en la técnica, que serían parámetros adecuados para evaluar la actividad del GP para su inclusión en la proteína de fusión GPXTEN o la GPXTEN resultante.
En algunos casos de la realización anterior, puede manifestarse la actividad del componente de GP por la proteína de fusión GPXTEN intacta, mientras que en otros casos, la actividad del componente de GP podría manifestarse principalmente tras la escisión y liberación del GP de la proteína de fusión mediante la acción de una proteasa que actúa en una secuencia de escisión incorporada en la proteína de fusión GPXTEN. En lo anterior, la GPXTEN puede diseñarse para reducir la afinidad de unión del componente de GP por el receptor o el ligando cuando se une al XTEN pero tiene afinidad aumentada cuando se libera del XTEN mediante la escisión de las secuencias de escisión incorporadas en la secuencia de GPXTEN, como se ha descrito anteriormente con más detalle.
En otros casos, la GPXTEN puede diseñarse para reducir la afinidad de unión del componente de GP al receptor de GP para aumentar la semivida terminal de la GPXTEN administrada a un sujeto, reduciendo la eliminación mediada por receptor; por ejemplo, añadiendo un XTEN al extremo C-terminal del componente de GP de la proteína de fusión.
En otros casos, las GPXTEN se diseñan para reducir la afinidad de unión del componente de GP al receptor de GP para reducir la toxicidad o los efectos secundarios causados por la composición administrada.
Por consiguiente, la invención proporciona un método para aumentar la semivida terminal de una GPXTEN produciendo una construcción de proteína de fusión monocatenaria con una configuración específica de N a C-terminal de los componentes que comprende al menos un primer GP y un primer y un segundo XTEN, en donde la proteína de fusión en una primera configuración de N a C-terminal de los componentes de GP y XTEN tiene eliminación mediada por receptor (RMC) reducida y un aumento correspondiente en la semivida terminal, en comparación con una GPXTEN en una segunda configuración de N a C-terminal. En una realización de lo anterior, la GPXTEN se configura, de N a C-terminal, en forma de XTEN-GP-XTEN, que tiene una unión a receptor reducida en comparación con una GPXTEN
configurada, de N a C-terminal, como XTEN-GP. En otra realización de lo anterior, la GPXTEN tiene la configuración
GP-XTEN. En las realizaciones anteriores, las dos moléculas de XTEN pueden ser idénticas o pueden tener una composición o longitud de cadena diferente. Los ejemplos no limitantes de la realización anterior con dos XTEN unidos a un solo GP incluyen las construcciones AE912-GP-AE144, AE912-GP-AE288, AE864-GP-AE144, AM923-GP-AE144 y AM923-GP-AE288. La divulgación contempla otras construcciones similares en las que los componentes respectivos de los ejemplos anteriores se sustituyen por un GP de las tablas 1-3 y un XTEN de la tabla 5 y pueden producirse, por ejemplo, en una configuración de la tabla 7, de tal forma que la construcción tiene eliminación mediada por receptor reducida en comparación con una configuración alternativa de los respectivos componentes. En algunos casos, el método anterior para aumentar la semivida terminal proporciona una GPXTEN configurada que puede dar como resultado un aumento en la semivida terminal de al menos aproximadamente un 50 % o aproximadamente un
75 % o aproximadamente un 100 % o aproximadamente un 150 % o aproximadamente un 200 % o aproximadamente un 300 % o aproximadamente un 400 % o más en comparación con la semivida de una GPXTEN en una segunda configuración donde no se reduce la unión al receptor. La invención se aprovecha del hecho de que pueden producirse ciertos ligandos con afinidad de unión reducida a un receptor, ya sea como resultado de una tasa de asociación reducida o una tasa de disociación aumentada, mediante la obstrucción del extremo N o C-terminal y el uso de ese extremo como unión a otro polipéptido de la composición, ya sea otra molécula de un GP, un XTEN o una secuencia espaciadora da como resultado la afinidad de unión reducida. La elección de la configuración particular de la proteína de fusión GPXTEN puede reducir el grado de afinidad de unión al receptor, de tal forma que puede lograrse una velocidad reducida de eliminación mediada por receptor. En general, la activación del receptor se acopla a RMC, de tal forma que la unión de un polipéptido a su receptor sin activación no ocasiona RMC, mientras que la activación del receptor provoca RMC. Sin embargo, en algunos casos, en particular en los que el ligando tiene una velocidad de disociación aumentada, el ligando puede ser capaz, sin embargo, de unirse lo suficiente para iniciar la señalización celular sin desencadenar la eliminación mediada por receptor, siendo el resultado neto que la GPXTEN siga estando biodisponible. En dichos casos, la GPXTEN configurada tiene una semivida aumentada en comparación con aquellas configuraciones que ocasionen un mayor grao de RMC.
En los casos donde se desea una reducción en la afinidad de unión a un péptido regulador de la glucosa a fin de reducir la eliminación mediada por receptor pero reteniendo al menos una parte de la actividad biológica, será evidente que, sin embargo, ha de mantenerse una afinidad de unión suficiente para obtener la activación del receptor deseada, por ejemplo, iniciando la transducción de señales. Por tanto, en una realización, la invención proporciona una GPXTEN configurada de tal modo que la afinidad de unión de la GPXTEN por un receptor diana se encuentra en el intervalo de aproximadamente un 0,01 %-40 % o aproximadamente un 0,1 %-30 % o aproximadamente un 1%-20 % de la afinidad de unión en comparación con una GPXTEN correspondiente en una configuración en donde no se reduce la afinidad de unión. Por lo tanto, se reduce la afinidad de unión de la GPXTEN configurada preferentemente en al menos aproximadamente un 60 % o al menos aproximadamente un 70 % o al menos aproximadamente un 80 % o al menos aproximadamente un 90 % o al menos aproximadamente un 95 % o al menos aproximadamente un 99 % o al menos aproximadamente un 99,99 % en comparación con la afinidad de unión de una GPXTEN correspondiente en una configuración en donde la afinidad de unión del componente de GP por el receptor diana no se reduce en comparación con el GP no unido a la proteína de fusión, determinada en condiciones comparables. Expresado de otro modo, el componente de GP de la GPXTEN configurada puede tener una afinidad de unión que es tan pequeña como aproximadamente un 0,01 % o al menos aproximadamente un 0,1 % o al menos aproximadamente un 1 % o al menos aproximadamente un 2 % o al menos aproximadamente un 3 % o al menos aproximadamente un 4 % o al menos aproximadamente un 5 % o al menos aproximadamente un 10 % o al menos aproximadamente un 20 % o al menos aproximadamente un 30 % o al menos un 40 % de la del componente de GP correspondiente de una GPXTEN en una configuración en donde no se reduce la afinidad de unión del componente de GP. En las realizaciones anteriores descritas anteriormente en este párrafo, la afinidad de unión de la GPXTEN configurada por el receptor diana podrá "reducirse sustancialmente" en comparación con un GP nativo correspondiente o una GPXTEN con una configuración en la que no se reduce la afinidad del componente de GP correspondiente. Por consiguiente, la presente invención proporciona composiciones y métodos para producir composiciones con RMC reducida mediante la configuración de la GPXTEN, cuyos ejemplos se proporcionaron anteriormente, a fin de ser capaces de unirse y activar un número suficiente de receptores para obtener una respuesta biológica in vivo deseada, evitando una activación de más receptores de los necesarios para obtener dicha respuesta. En las realizaciones anteriores descritas anteriormente en este párrafo, la semivida aumentada puede permitir mayores dosis y una frecuencia de dosificación reducida en comparación con GP no unido a XTEN o en comparación con configuraciones de GPXTEN en donde el componente de Gp conserva una actividad biológica o farmacológica suficiente para dar como resultado una composición que mantiene una eficacia clínica a pesar de la frecuencia de dosis reducida.
VI) USOS DE LAS COMPOSICIONES DE LA PRESENTE INVENCIÓN
En otro aspecto, la invención proporciona un método para lograr un efecto beneficioso en una enfermedad, trastorno o afección mediado por GP. La presente invención aborda las desventajas y/o las limitaciones de GP que tienen una semivida terminal relativamente corta y/o una ventana terapéutica estrecha entre la dosis mínima eficaz y la dosis máxima tolerada.
La mayoría de procesos implicados en la homeostasia de la glucosa están regulados por múltiples péptidos y hormonas y dichos péptidos y hormonas, así como los análogos de los mismos, han resultado ser útiles en el
tratamiento de enfermedades, trastornos y afecciones relacionadas con péptidos reguladores de la glucosa. Sin embargo, el uso de péptidos reguladores de la glucosa disponibles comercialmente, ha logrado un éxito no óptimo en el control de sujetos afectados por dichas enfermedades, trastornos y afecciones. En particular, la optimización de la dosis y la frecuencia de dosificación son importantes para agentes biológicos peptídicos y hormonales usados en el tratamiento de enfermedades y trastornos relacionados con péptidos reguladores de la glucosa. El hecho de que diversos péptidos reguladores de la glucosa tienen una corta semivida, hace necesaria una dosificación frecuente a fin de lograr un beneficio clínico, que da como resultado dificultades en la gestión de dichos pacientes.
En una realización, la divulgación proporciona un método para lograr un efecto beneficioso en un sujeto con una enfermedad, trastorno o afección relacionada con un péptido regulador de la glucosa, que comprende la etapa de administrar al sujeto una cantidad terapéutica o profilácticamente eficaz de una GPXTEN, en donde dicha administración da como resultado una mejora de uno o más parámetros o criterios de valoración bioquímicos o fisiológicos asociados con una enfermedad, trastorno o afección relacionada con un péptido regulador de la glucosa. La cantidad eficaz puede producir un efecto beneficioso para ayudar a tratar (por ejemplo, curar o reducir la gravedad) o prevenir (por ejemplo, reducir la probabilidad de aparición o la gravedad) de una enfermedad, trastorno o afección relacionada con un péptido regulador de la glucosa. En algunos casos, el método para lograr un efecto beneficioso puede incluir administrar una cantidad terapéuticamente eficaz de una composición de proteína de fusión GPXTEN para tratar a un sujeto con una enfermedad, trastorno o afección relacionada con un péptido regulador de la glucosa, incluyendo, pero sin limitación, diabetes juvenil, diabetes de tipo I, diabetes tipo II, obesidad, hipoglucemia aguda, hiperglucemia aguda, hipoglucemia nocturna, hiperglucemia crónica, glucagonomas, trastornos secretorios de las vías respiratorias, artritis, osteoporosis, enfermedad del sistema nervioso central, reestenosis, enfermedad neurodegenerativa, insuficiencia renal, insuficiencia cardíaca congestiva, síndrome nefrótico, cirrosis, edema pulmonar, hipertensión y trastornos en donde se desea reducir la ingesta de alimento, ictus, síndrome del intestino irritable, infarto de miocardio (por ejemplo, reducción de la morbilidad y/o mortalidad asociada con el mismo), ictus, síndrome coronario agudo (por ejemplo, caracterizado por la ausencia de onda Q), infarto de miocardio, cambios catabólicos postquirúrgicos, hibernación miocárdica o cardiomiopatía diabética, insuficiencia de excreción de sodio en la orina, exceso de concentración de potasio en la orina, afecciones o trastornos asociados con la hipervolemia tóxica (por ejemplo, insuficiencia renal, insuficiencia cardíaca congestiva, síndrome nefrótico, cirrosis, edema pulmonar e hipertensión), síndrome del ovario poliquístico, disnea, nefropatía, disfunción sistólica del ventrículo izquierdo (por ejemplo, con una fracción de eyección ventricular izquierda anormal), trastornos gastrointestinales, tales como diarrea, síndrome postoperatorio de la evacuación gástrica rápida y síndrome del intestino irritable (es decir, mediante la inhibición de la movilidad antro-duodenal), polineuropatía por enfermedad grave (CIPN), dislipidemia, lesión tisular en órganos provocada por la reperfusión del flujo sanguíneo después de una isquemia y síndrome de factor de riesgo de cardiopatía coronaria (CHDRF) y cualquier otra indicación para la que se utilice el péptido regulador de glucosa no modificado (por ejemplo, exendina-4, GLP-1 o glucagón) o cualquier otra indicación para la que pueda utilizarse GP (pero para la que los niveles endógenos de péptido regulador de glucosa en un sujeto no son necesariamente deficientes).
En otra realización, la divulgación proporciona un método para estimular la secreción de insulina en sujetos con una enfermedad, trastorno o afección relacionada con un péptido regulador de la glucosa. El método comprende la etapa de administrar una cantidad terapéuticamente eficaz de GPXTEN a un sujeto que da como resultado niveles sanguíneos aumentados y/o una duración aumentada con niveles sanguíneos aumentados de insulina en comparación con un sujeto que recibe un GP no unido a un XTEN y administrado a una dosis comparable. En algunos casos, el aumento en la secreción de insulina y/o en el área bajo la curva es de al menos aproximadamente un 20 % o al menos aproximadamente un 30 % o al menos aproximadamente un 40 % o al menos aproximadamente un 50 % o al menos aproximadamente un 75 % o al menos aproximadamente un 100 % o al menos aproximadamente un 200 % o al menos aproximadamente un 300 % en comparación con un sujeto que recibe un GP no unido a un XTEN y administrado a una dosis comparable.
Como resultado de los parámetros PK mejorados de GPXTEN, como se describe en el presente documento, el GP puede administrarse usando intervalos entre dosis menores en comparación con el GP correspondiente no unido a XTEN para prevenir, tratar, aliviar, revertir o mejorar síntomas o anomalías clínicas de la enfermedad, trastorno o afección relacionada con el péptido regulador de la glucosa o prolongar la supervivencia del sujeto que se esté tratando.
Los métodos de la divulgación pueden incluir la administración de dosis consecutivas de una cantidad terapéuticamente eficaz de la GPXTEN durante un periodo de tiempo suficiente para lograr y/o mantener el parámetro o efecto clínico deseado y dichas dosis consecutivas de una cantidad terapéuticamente eficaz establece la pauta posológica terapéuticamente eficaz para el GPXTEN; es decir, la pauta para dosis administradas de manera consecutiva de la composición de proteína de fusión, en donde las dosis se administran en cantidades terapéuticamente eficaces que dan como resultado un efecto beneficioso sostenido en cualquier signo clínico o síntoma, aspecto, parámetro medido o característica de una patología o afección metabólica, incluyendo, pero sin limitación, los descritos en el presente documento.
En una realización, el método comprende administrar una cantidad terapéuticamente eficaz de una composición farmacéutica que comprende una proteína de fusión GPXTEN que comprende un GP unido a una secuencia de XTEN
y al menos un vehículo farmacéuticamente aceptable a un sujeto que lo necesite que da como resultado una mayor mejora en al menos un parámetro, condición fisiológica o resultado clínico mediado por los componentes de GP (cuyos ejemplos no limitantes se han descrito anteriormente) en comparación con el efecto mediado por la administración de una composición farmacéutica que comprende un GP no unido a XTEN y administrado a una dosis comparable. En una realización, la composición farmacéutica se administra en una dosis terapéuticamente eficaz. En otra realización, la composición farmacéutica se administra usando múltiples dosis consecutivas usando una pauta posológica terapéuticamente eficaz (como se define en el presente documento) durante toda la duración del periodo de dosificación.
Una cantidad terapéuticamente eficaz de la GPXTEN puede variar dependiendo de factores, tales como la patología, la edad, el sexo y el peso del individuo y la capacidad del anticuerpo o la porción de anticuerpo para desencadenar una respuesta deseada en el individuo. Una cantidad terapéuticamente eficaz también es una en la que los efectos tóxicos o perjudiciales de la GPXTEN se ven superados por los efectos terapéuticamente beneficiosos. Una cantidad profilácticamente eficaz se refiere a una cantidad de GPXTEN necesaria durante el periodo de tiempo necesario para lograr el resultado profiláctico deseado.
Para los métodos de la invención, se prefieren composiciones de GPXTEN de mayor duración, para mejorar la comodidad del paciente, para aumentar el intervalo entre dosis y para reducir la cantidad de fármaco necesaria para lograr un efecto sostenido. En una realización, un método de tratamiento comprende la administración de una dosis terapéuticamente eficaz de una GPXTEN a un sujeto que lo necesite que dé como resultado un aumento del tiempo empleado dentro de una ventana terapéutica establecida para la proteína de fusión de la composición en comparación con los componentes de GP correspondientes no unidos a la proteína de fusión y administrados a una dosis comparable a un sujeto. En algunos casos, la ganancia en el tiempo empleado dentro de la ventana terapéutica es de al menos aproximadamente tres veces o al menos aproximadamente cuatro veces o al menos aproximadamente cinco veces o al menos aproximadamente seis veces o al menos aproximadamente ocho veces o al menos aproximadamente 10 veces o al menos aproximadamente 20 veces o al menos aproximadamente 40 veces en comparación con el componente de GP correspondiente no unido a la proteína de fusión y administrado a una dosis comparable a un sujeto. Los métodos proporcionan además que la administración de múltiples dosis consecutivas de una GPXTEN administrada usando una pauta posológica terapéuticamente eficaz a un sujeto que lo necesite puede dar como resultado una ganancia en el tiempo entre picos de Cmáx y/o mínimos de Cmín consecutivos para los niveles sanguíneos de la proteína de fusión, en comparación con el GP correspondiente no unido a la proteína de fusión y administrado usando una pauta posológica establecida para ese GP. En la realización anterior, la ganancia en el tiempo empleado entre picos de Cmáx y/o mínimos de Cmín consecutivos puede ser de al menos aproximadamente tres veces o al menos aproximadamente cuatro veces o al menos aproximadamente cinco veces o al menos aproximadamente seis veces o al menos aproximadamente ocho veces o al menos aproximadamente 10 veces o al menos aproximadamente 20 veces o al menos aproximadamente 40 veces en comparación con el componente de GP correspondiente no unido a la proteína de fusión y administrado usando una pauta posológica establecida para ese GP. En las realizaciones descritas anteriormente en este párrafo, la administración de la proteína de fusión puede dar como resultado una mejora en al menos uno de los parámetros (divulgados en el presente documento como útiles para evaluar las presentes enfermedades, afecciones o trastornos) usando una menor dosis unitaria en moles de la proteína de fusión en comparación con el componente de GP correspondiente no unido a la proteína de fusión y administrado a una dosis unitaria o una pauta posológica comparable a un sujeto.
El método de tratamiento comprende la administración de una GPXTEN usando una pauta posológica terapéuticamente eficaz para efectuar mejoras en uno o más parámetros asociados con enfermedades, trastornos o afecciones de péptidos reguladores de la glucosa. En algunos casos, la administración de la GPXTEN a un sujeto puede dar como resultado una mejora en uno o más de los parámetros bioquímicos, fisiológicos o clínicos que es de mayor magnitud que la del componente de GP correspondiente no unido al XTEN, determinados usando el mismo ensayo o basándose en un parámetro clínico medido. En otros casos, la administración de la GPXTEN a un sujeto puede dar como resultado una actividad en uno o más de los parámetros bioquímicos, fisiológicos o clínicos que tiene una mayor duración que la actividad de uno de los componentes de GP individuales no unidos a XTEN, determinados usando el mismo ensayo o basándose en un parámetro clínico medido. En una realización de lo anterior, la administración de la GPXTEN a un sujeto puede dar como resultado una mejora en las concentraciones máximas y el área bajo la curva de los niveles de GP en sangre de al menos aproximadamente un 10 % o aproximadamente un 20 % o aproximadamente un 30 % o aproximadamente un 40 % o aproximadamente un 50 % o más en el sujeto en comparación con una dosis comparable de GP no unido a XTEN administrado a un sujeto. En otra realización de lo anterior, la administración de la GPXTEN a un sujeto puede dar como resultado una mejora en uno o más parámetros seleccionados entre, pero sin limitación, concentraciones de HbA1c, concentraciones de insulina, péptido C estimulado, glucosa en plasma en ayunas (FPG), niveles séricos de citocinas, niveles de CRP, secreción de insulina e índice de sensibilidad a la insulina obtenido de una prueba de tolerancia a la glucosa oral (OGTT), peso corporal y consumo de alimento.
La invención contempla además que la GPXTEN usada de acuerdo con los métodos proporcionados en el presente documento puede administrarse junto con otros métodos de tratamiento y composiciones farmacéuticas útiles para tratar enfermedades, trastornos y afecciones relacionadas con un péptido regulador de la glucosa o afecciones cuya terapia adyuvante es con un péptido regulador de la glucosa; por ejemplo, resistencia a la insulina o mal control
glucémico. Dichas composiciones pueden incluir, por ejemplo, inhibidores de DPP-IV, insulina, análogos de insulina, agonistas de PPAR-gamma, agonistas de PPAR de acción dual, agonistas o análogos de GLP-1, inhibidores de PTP1B, inhibidores de SGLT, secretagogos de insulina, agonistas de RXR, inhibidores de glucógeno sintasa cinasa-3, sensibilizadores a la insulina, inmunomoduladores, antagonistas del receptor beta-adrenérgico-3, agonistas de pan-PPAR, inhibidores de 11beta-HSD1, biguanidas, inhibidores de alfa-glucosidasa, meglitinidas, tiazolidinedionas, sulfonilureas y otros medicamentos para la diabetes conocidos en la técnica o fármacos contra la hipertensión, bloqueadores de canales de calcio y productos relacionados. En algunos casos, la administración de una GPXTEN puede permitir el uso de dosis menores de la composición farmacéutica coadministrada para lograr un efecto clínico o parámetro medido comparable para la enfermedad, trastorno o afección en el sujeto.
En otro aspecto, la divulgación proporciona un método para diseñar las composiciones de GPXTEN con propiedades farmacológicas o farmacéuticas deseadas. Las proteínas de fusión GPXTEN se diseñan y preparan con diversos objetivos en mente (en comparación con los componentes de GP no unidos a la proteína de fusión), incluyendo mejorar la eficacia terapéutica para el tratamiento de enfermedades, trastornos o afecciones relacionadas con el péptido regulador de la glucosa, mejorar las características farmacocinéticas de las proteínas de fusión en comparación con el GP, reducir la dosis o la frecuencia de dosificación necesaria para lograr un efecto farmacológico, mejorar las propiedades farmacéuticas y mejorar la capacidad de los componentes de GP para permanecer dentro de la ventana terapéutica durante un periodo de tiempo prolongado.
En general, las etapas en el diseño y la producción de las proteínas de fusión y de las composiciones de la invención, tal como se ilustran en las FIG. 4-6, incluyen: (1) la selección de GP (por ejemplo, proteínas nativas, análogos o derivados con actividad) para tratar la enfermedad particular, trastorno o afección; (2) seleccionar el XTEN que conferirá las características PK y fisicoquímicas deseadas en el GPXTEN resultante (por ejemplo, la administración de la composición de a un sujeto da como resultado que la proteína de fusión se mantenga dentro de la ventana terapéutica durante un periodo mayor en comparación con GP no unido al XTEN); (3) establecer una configuración deseada del extremo N al C-terminal de la GPXTEN para lograr la eficacia o los parámetros PK deseados; (4) establecer el diseño del vector de expresión que codifica la GPXTEN configurada; (5) transformar un hospedador adecuado con el vector de expresión; y (6) expresar y recuperar la proteína de fusión resultante. Para las GPXTEN para las que se desea un aumento en la semivida (mayor de 24 h) o un periodo de tiempo aumentado dentro de una ventana terapéutica, el XTEN seleccionado para su incorporación tendrá generalmente al menos aproximadamente 500 o aproximadamente 576 o aproximadamente 864 o aproximadamente 875 o aproximadamente 912 o aproximadamente 923 restos de aminoácido donde un solo XTEN se va a incorporar en la GPXTEN. En otra realización, la GPXTEN puede comprender un primer XTEN de las longitudes anteriores y un segundo XTEN de aproximadamente 144 o aproximadamente 288 o aproximadamente 576 o aproximadamente 864 o aproximadamente 875 o aproximadamente 912 o aproximadamente 923 restos de aminoácido.
En otros casos, donde no se necesita un aumento de la semivida, pero se desea un aumento en una propiedad farmacéutica (por ejemplo, solubilidad), puede diseñarse una GPXTEN para incluir XTEN de longitudes más cortas. En algunas realizaciones de lo anterior, la GPXTEN puede comprender un GP unido a un XTEN que tiene al menos aproximadamente 24 o aproximadamente 36 o aproximadamente 48 o aproximadamente 60 o aproximadamente 72 o aproximadamente 84 o aproximadamente 96 restos de aminoácido, en el que la solubilidad de la proteína de fusión en condiciones fisiológicas es al menos tres veces mayor que el GP correspondiente no unido a XTEN o como alternativa, al menos cuatro veces o cinco veces o seis veces o siete veces u ocho veces o nueve veces o al menos 10 veces o al menos 20 veces o al menos 30 veces o al menos 50 veces o al menos 60 veces o más que el GP no unido al XTEN. En una realización de lo anterior, el GP es glucagón.
En otro aspecto, la invención proporciona métodos para producir composiciones de GPXTEN para mejorar la facilidad de fabricación, dar como resultado una estabilidad aumentada, aumento de solubilidad en agua y/o facilidad de formulación, en comparación con el GP nativo. En una realización, la invención incluye un método para aumentar la solubilidad en agua de un GP que comprende la etapa de unir el GP a uno o más XTEN, de tal forma que puede lograrse una mayor concentración en forma soluble de la GPXTEN resultante, en condiciones fisiológicas, en comparación con el GP en un estado no fusionado. Los factores que contribuyen a la propiedad del XTEN de conferir solubilidad en agua aumentada de los GP cuando se incorporan en una proteína de fusión incluyen la elevada solubilidad del compañero de fusión de XTEN y el bajo grado de auto agregación entre moléculas de XTEN en solución. En algunas realizaciones, el método da como resultado una proteína de fusión GPXTEN, en donde la solubilidad en agua es al menos aproximadamente un 20 % o al menos aproximadamente un 30 % mayor o al menos aproximadamente un 50 % mayor o al menos aproximadamente un 75 % mayor o al menos aproximadamente un 90 % mayor o al menos aproximadamente un 100 % mayor o al menos aproximadamente un 150 % mayor o al menos aproximadamente un 200 % mayor o al menos aproximadamente un 400 % mayor o al menos aproximadamente un 600 % mayor o al menos aproximadamente un 800 % mayor o al menos aproximadamente un 1000 % mayor o al menos aproximadamente un 2000 % mayor o al menos aproximadamente un 4000 % mayor o al menos aproximadamente un 6000 % mayor en condiciones fisiológicas, en comparación con el GP no fusionado.
En otra realización, la invención incluye un método para mejorar la vida útil de un GP que comprende la etapa de unir el GP con uno o más XTEN seleccionados de tal forma que la vida útil de la GPXTEN resultante se prolonga en comparación con el GP en un estado no fusionado. Como se usa en el presente documento, la vida útil se refiere al periodo de tiempo durante el cual permanece estable la actividad funcional de un GP o una GPXTEN que se encuentra
en solución o en otra formulación de almacenamiento sin una pérdida indebida de actividad. Como se usa en el presente documento, "actividad funcional" se refiere a un efecto farmacológico o a una actividad biológica, tal como la capacidad para unirse a un receptor o ligando o una actividad enzimática o mostrar una o más actividades funcionales conocidas asociadas con un GP, como se conoce en la técnica. Un GP que se degrada o agrega tiene normalmente una actividad funcional reducida o una biodisponibilidad reducida en comparación con uno que permanece en solución. Los factores que contribuyen a la capacidad del método para prologar la vida útil de los Gp cuando se incorporan a una proteína de fusión incluyen el aumento de la solubilidad en agua, la auto agregación reducida en solución y el aumento de la estabilidad térmica del compañero de fusión de XTEN. En particular, la baja tendencia a la agregación del XTEN facilita los métodos para formular preparaciones farmacéuticas que contienen concentraciones de fármaco mayores de GP y la estabilidad térmica del Xt En contribuye a la propiedad de las proteínas de fusión GPXTEN de permanecer solubles y funcionalmente activas durante periodos prolongados. En una realización, el método da como resultado proteínas de fusión GPXTEN con una vida útil "prolongada" o "extendida" que muestran una mayor actividad en relación con un patrón que se ha sometido a las mismas condiciones de almacenamiento y manipulado. El patrón puede ser GP de longitud completa no fusionado. En una realización, el método incluye la etapa de formular el GPXTEN aislado con uno o más excipientes farmacéuticamente aceptables que mejoran la capacidad del XTEN para conservar su conformación no estructurada y para que la GPXTEN permanezca soluble en la formulación durante un tiempo que es mayor que el del GP no fusionado correspondiente. En una realización, el método comprende unir un GP a uno o más XTEN para crear una proteína de fusión GPXTEN y da como resultado una solución que conserva más de aproximadamente un 100 % de la actividad funcional o más de aproximadamente un 105 %, 110 %, 120 %, 130 %, 150 % o 200 % de la actividad funcional de un patrón, cuando se compara en un punto de tiempo dado y cuando se somete a las mismas condiciones de almacenamiento y manipulación que el patrón, potenciando de este modo su vida útil.
La vida útil también puede evaluarse en términos de la actividad funcional restante tras el almacenamiento, normalizada a la actividad funcional cuando comenzó el almacenamiento. Las proteínas de fusión GPXTEN de la invención con una vida útil prolongada o extendida mostrada por una actividad funcional prolongada o extendida pueden conservar aproximadamente un 50 % o más de actividad funcional o aproximadamente un 60 %, 70 %, 80 % o 90 % más de la actividad funcional del GP equivalente no unido al XTEN cuando se le somete a las mismas condiciones durante el mismo periodo de tiempo. Por ejemplo, una proteína de fusión GPXTEN de la invención que comprende exendina-4 fusionada a una o más secuencias de XTEN puede conservar aproximadamente un 80 % o más de su actividad original en solución durante periodos de hasta 2 semanas o 4 semanas o 6 semanas o más en diversas condiciones de temperatura. En algunas realizaciones, la GPXTEN conserva al menos aproximadamente un 50 % o aproximadamente un 60 % o al menos aproximadamente un 70 % o al menos aproximadamente un 80 % y lo más preferentemente al menos aproximadamente un 90 % o más de su actividad original en solución cuando se calienta a 80 °C durante 10 min. En otras realizaciones, la GPXTEN conserva al menos aproximadamente un 50 %, preferentemente al menos aproximadamente un 60 % o al menos aproximadamente un 70 % o al menos aproximadamente un 80 % o como alternativa, al menos aproximadamente un 90 % o más de su actividad original en solución cuando se calienta o mantiene a 37 °C durante aproximadamente 7 días. En otra realización, la proteína de fusión GPXTEN conserva al menos aproximadamente un 80 % o más de su actividad funcional tras su exposición a una temperatura de aproximadamente 30 °C a aproximadamente 70 °C durante un periodo de tiempo de aproximadamente una hora a aproximadamente 8 horas. En las realizaciones anteriores descritas anteriormente en este párrafo, la actividad conservada de la GPXTEN podría ser al menos aproximadamente dos veces o al menos aproximadamente tres veces o al menos aproximadamente cuatro veces o al menos aproximadamente cinco veces o al menos aproximadamente seis veces mayor en un punto de tiempo dado que la del GP correspondiente no unido a la proteína de fusión.
VII) LAS SECUENCIAS DE ÁCIDO NUCLEICO DE LA INVENCIÓN
La presente invención proporciona ácidos polinucleicos que codifican proteínas de fusión quiméricas de GPXTEN y secuencias complementarias a las moléculas de ácidos polinucleicos que codifican proteínas de fusión quiméricas de GPXTEN, incluyendo variantes homólogas de las mismas, como se definen en las reivindicaciones 1-6. En otro aspecto, la invención abarca métodos para producir ácidos polinucleicos que codifican proteínas de fusión quiméricas de GPXTEN y secuencias complementarias a las moléculas de ácidos polinucleicos que codifican la proteína de fusión quimérica de GPXTEN, incluyendo variantes homólogas de las mismas. En general y como se ilustra en las FIG. 4-6, los métodos para producir una secuencia de polinucleótido que codifica una proteína de fusión GPXTEN y expresar el producto génico resultante incluyen ensamblar nucleótidos que codifican GP y XTEN, ligar los componentes en fase, incorporar el gen codificante en un vector de expresión adecuado y que pueda reconocerse por una célula hospedadora, transformar la célula hospedadora adecuada con el vector de expresión y cultivar la célula hospedadora en condiciones que provocan o permiten que la proteína de fusión se exprese en la célula hospedadora transformada, produciendo de este modo el polipéptido de GPXTEN biológicamente activo, que puede recuperarse en forma de una proteína de fusión aislada mediante métodos de purificación de proteínas convencionales conocidos en la técnica. Pueden usarse técnicas recombinantes convencionales en biología molecular para producir los polinucleótidos y vectores de expresión de la presente invención y pueden aplicarse en los métodos para crear los polinucleótidos, genes y vectores de expresión que codifican las GPXTEN divulgadas en el presente documento.
De acuerdo con la invención, las secuencias de ácido nucleico que codifican GPXTEN (o su complemento) pueden
usarse para generar moléculas de ADN recombinante que dirigen la expresión de las proteínas de fusión GPXTEN en células hospedadoras adecuadas. Se prevén como adecuadas varias estrategias de clonación para llevar a cabo la presente invención, muchas de las cuales pueden usarse para generar una construcción que comprende un gen que codifica una proteína de fusión de la composición de GPXTEN de la presente invención o su complemento. En algunos casos, podría usarse la estrategia de clonación para crear un gen que codifica una GPXTEN monomérica que comprende al menos un primer GP y al menos un primer polipéptido de XTEN o su complemento. En una realización de lo anterior, el gen podría comprender una secuencia que codifica un GP o una variante de secuencia. En otros casos, puede usarse la estrategia de clonación para crear un gen que codifica un GPXTEN monomérico que comprende nucleótidos que codifican al menos una primera molécula de GP o su complemento y una primera y al menos una segunda de XTEN o su complemento que puede usarse para transformar una célula hospedadora para la expresión de la proteína de fusión de la composición de GPXTEN. En las realizaciones anteriores descritas anteriormente en este párrafo, los genes pueden comprender además nucleótidos que codifican secuencias espaciadoras que también pueden codificar secuencias de escisión.
En el diseño de las secuencias de XTEN deseadas, se descubrió que la naturaleza no repetitiva del XTEN de las composiciones de la invención puede lograrse a pesar del uso de una estrategia molecular de "bloque de construcción" para la creación de las secuencias que codifican el XTEN. Esto se logró mediante el uso de una biblioteca de polinucleótidos que codifican motivos de secuencia peptídica, descritos anteriormente, que después se ligan y/o multimerizan para crear los genes que codifican las secuencias de XTEN (véanse las FIG. 4 y 5 y los ejemplos). Por tanto, aunque os XTEN de la proteína de fusión expresada pueden consistir en múltiples unidades o en tan pocos como cuatro motivos de secuencia diferente, debido a que los motivos en sí consisten en secuencias de aminoácidos no repetitivas, la secuencia general de XTEN se hace no repetitiva. Por consiguiente, en una realización, los polinucleótidos que codifican el XTEN comprenden múltiples polinucleótidos que codifican secuencias o motivos no repetitivos, unidos operablemente en fase y en los que las secuencias de aminoácidos de XTEN expresadas resultantes no son repetitivas.
En un enfoque, se prepara en primer lugar una construcción que contiene la secuencia de ADN correspondiente a la proteína de fusión GPXTEN. el ADN que codifica el GP de las composiciones puede obtenerse de una biblioteca de ADNc preparada usando métodos convencionales de tejidos o células aisladas que se cree que poseen ARNm de GP y que lo expresan a un nivel detectable. Las bibliotecas pueden explorarse con sondas que contienen, por ejemplo, de aproximadamente 20 a 100 bases diseñadas para identificar el gen de GP de interés mediante hibridación usando técnicas de biología molecular convencionales. Los mejores candidatos para sondas son aquellos que representan secuencias que son altamente homólogas para el péptido regulador de la glucosa dado y han de tener una longitud suficiente y ser lo suficientemente específicas como para minimizar los falsos positivos, pero pueden estar degeneradas en una o más posiciones. En caso necesario, puede obtenerse la secuencia codificante usando procedimientos de extensión de cebadores convencionales, tal como se describe en Sambrook, et al., citado anteriormente, para detectar precursores e intermedios de procesado del ARNm que pueden no haberse retrotranscrito en ADNc. Después, puede usarse la metodología de reacción en cadena de la polimerasa (PCR) para amplificar la secuencia codificante de ADN o ARN diana para obtener material suficiente para la preparación de las construcciones de GPXTEN que contienen los genes de GP. Después, pueden llevarse a cabo ensayos para confirmar que los genes hibridantes de longitud completa son los genes de GP deseados. Mediante estos métodos convencionales, puede obtenerse cómodamente ADN a partir de una biblioteca de ADNc preparada a partir de dichas fuentes. Los genes que codifican el GP también pueden obtenerse de una biblioteca genómica o crearse mediante procedimientos de síntesis convencionales conocidos en la técnica (por ejemplo, síntesis de ácidos nucleicos automatizada usando, por ejemplo, uno de los métodos descritos en Engels et al. (Agnew. Chem. Int. Ed. Engl., 28:716-734 1989)), usando secuencias de ADN obtenidas de bases de datos disponibles al público, patentes o referencias bibliográficas. Dichos procedimientos se conocen bien en la técnica y están bien descritos en la bibliografía científica y de patentes. Por ejemplo, pueden obtenerse secuencias de los Números de Registro del Chemical Abstracts Services (CAS) (publicados por la American Chemical Society) y/o los números de referencia de GenBank (por ejemplo, ID del locus, NP_XXXXX y XP_XXXXX), identificadores de modelo de proteína disponibles a través de la página web del National Center for Biotechnology Information (NCBI), disponibles en internet en ncbi.nlm.nih.gov que corresponden a entradas en el registro CAS o en la base de datos GenBank que contienen una secuencia de aminoácidos de la proteína de interés o de un fragmento o variante de la proteína. Para dichos identificadores de secuencia proporcionados en el presente documento, se citan las páginas de resumen asociadas con cada uno de estos números de referencia de CAS y de GenBank y GenSeq, así como las publicaciones de revistas especializadas citadas (por ejemplo, número de ID de PubMed (PMID)), en particular, respecto de las secuencias de aminoácidos descritas en los mismos. En una realización, el gen que codifica el GP codifica una proteína de una cualquiera de las tablas 1-3 o un fragmento o variante de la misma.
Un gen o polinucleótido que codifica la porción de GP de la presente proteína GPXTEN, en el caso de una proteína de fusión expresada que comprenderá un solo GP puede clonarse después en una construcción, que puede ser un plásmido u otro vector bajo el control de secuencias de transcripción y traducción adecuadas para la expresión de proteínas a alto nivel en un sistema biológico. En una etapa posterior, se fusiona génicamente un segundo gen o polinucleótido que codifica el XTEN a los nucleótidos que codifican el extremo N y/o C-terminal del gen de GP clonándolo en la construcción adyacente y en fase con los genes que codifican el GP. Esta segunda etapa puede producirse mediante una etapa de ligamiento o multimerización. En las realizaciones anteriores descritas
anteriormente en este párrafo, cabe destacar que las construcciones génicas que se crean pueden, como alternativa, ser el complemento de los genes respectivos que codifican las proteínas de fusión respectivas.
El gen que codifica el XTEN puede producirse en una o más etapas, ya sea de manera completamente sintética o mediante síntesis combinada con procesos enzimáticos, tales como clonación mediada por enzimas de restricción, PCR y extensión solapante, incluyendo métodos descritos con más detalle en los ejemplos. Los métodos divulgados en el presente documento pueden usarse, por ejemplo, para ligar secuencias cortas de polinucleótidos que codifican XTEN en genes de XTEN más largos con una longitud y secuencia deseadas. En una realización, el método liga dos o más oligonucleótidos con codones optimizados que codifican secuencias de motivo o segmento de XTEN de aproximadamente 9 a 14 aminoácidos o de aproximadamente 12 a 20 aminoácidos o de aproximadamente 18 a 36 aminoácidos o de aproximadamente 48 a aproximadamente 144 aminoácidos o de aproximadamente 144 a aproximadamente 288 o más largas o cualquier combinación de los intervalos anteriores de longitudes de motivo o segmento.
Como alternativa, puede usarse el método divulgado para multimerizar secuencias que codifican XTEN en secuencias más largas de una longitud deseada; por ejemplo, puede dimerizarse un gen que codifica 36 aminoácidos de XTEN en un gen que codifica 72 aminoácidos, después 144, después 288, etc. Incluso con multimerización, pueden construirse polipéptidos de XTEN de tal forma que el gen que codifica el XTEN tenga una baja o virtualmente nula repetitividad mediante el diseño de los codones seleccionados para los motivos de la unidad más corta usada, que pueden reducir la recombinación y aumentar la estabilidad del gen codificante en el hospedador transformado. Los genes que codifican el XTEN con secuencias no repetitivas pueden ensamblarse a partir de oligonucleótidos usando técnicas convencionales de síntesis génica. El diseño del gen puede llevarse a cabo usando algoritmos que optimizan el uso de codones y la composición de aminoácidos. En un método de la invención, se crea y posteriormente ensambla una biblioteca de construcciones de polinucleótido codificantes de XTEN relativamente cortos, como se ilustra en las FIG. 4 y 5. Esta puede ser una biblioteca de codones pura, de tal forma que cada miembro de la biblioteca tiene la misma secuencia de aminoácidos aunque sean posibles diferente secuencias codificantes. Dichas bibliotecas pueden ensamblarse a partir de oligonucleótidos parcialmente aleatorizados y usarse para generar bibliotecas grandes de segmentos de XTEN que comprenden los motivos de secuencia. El esquema de aleatorización puede optimizarse para controlar las elecciones de aminoácidos para cada posición, así como el uso de codones. En los ejemplos se divulgan métodos a modo de ejemplo para lograr lo anterior.
a. Bibliotecas de polinucleótidos
En otro aspecto, la divulgación proporciona bibliotecas de polinucleótidos que codifican secuencias de XTEN que pueden usarse para ensamblar genes que codifican XTEN de una longitud y secuencia deseada.
En determinadas realizaciones, las construcciones de bibliotecas que codifican XTEN comprenden polinucleótidos que codifican segmentos polipeptídicos de una longitud fija. Como etapa inicial, puede ensamblarse una biblioteca de oligonucleótidos que codifican motivos de 9-14 restos de aminoácidos. En una realización preferida, se ensamblan bibliotecas de oligonucleótidos que codifican motivos de 12 aminoácidos.
Los segmentos de secuencia que codifica XTEN pueden dimerizarse o multimerizarse en secuencias codificantes más largas. La dimerización o multimerización pueden realizarse mediante ligamiento, extensión de solape, ensamblaje PCR o técnicas de clonación similares conocidas en la técnica. Este proceso puede repetirse múltiples veces hasta que las secuencias codificantes de XTEN resultantes han alcanzado la organización de secuencia y la longitud deseada, proporcionando los genes codificantes de XTEN. Como se apreciará, una biblioteca de polinucleótidos que codifica, por ejemplo, motivos de 12 aminoácidos puede dimerizarse y/o ligarse en una biblioteca de polinucleótidos que codifica 36 aminoácidos. Las bibliotecas que codifican motivos de diferentes longitudes; por ejemplo, motivos de 9-14 aminoácidos que dan lugar a bibliotecas que codifican 27 a 42 aminoácidos se contemplan por la divulgación. A su vez, la biblioteca de polinucleótidos que codifican de 27 a 42 aminoácidos y preferentemente, de 36 aminoácidos (como se describen en los ejemplos) pueden dimerizarse en serie en una biblioteca que contiene longitudes sucesivamente más largas de polinucleótidos que codifican secuencias de XTEN de una longitud deseada para su incorporación en el gen que codifica la proteína de fusión GPXTEN, como se divulga en el presente documento. En algunas realizaciones, pueden ensamblarse bibliotecas de polinucleótidos que codifican aminoácidos que están limitados a familias de secuencia de XTEN específicas; por ejemplo, las secuencias AD, AE, AF, AG, AM o AQ de la tabla 1. En otras realizaciones, las bibliotecas pueden comprender secuencias que codifican dos o más de las secuencias de familias de motivos de la tabla 1. Los nombres y las secuencias de las secuencias de polinucleótido representativas no limitantes de las bibliotecas que codifican 36meros se presentan en las tablas 10-13 y los métodos usados para crearlas se describen con más detalle en los ejemplos. En otros casos, pueden construirse bibliotecas que codifican XTEN a partir de segmentos de codones de polinucleótidos unidos en una secuencia aleatoria que codifica aminoácidos, en donde al menos aproximadamente un 80 % o al menos aproximadamente un 90 % o al menos aproximadamente un 91 % o al menos aproximadamente un 92 % o al menos aproximadamente un 93 % o al menos aproximadamente un 94 % o al menos aproximadamente un 95 % o al menos aproximadamente un 97 % o al menos aproximadamente un 98 % o al menos aproximadamente un 99 % de los codones se seleccionan entre el grupo que consiste en codones para los aminoácidos glicina (G), alanina (A), serina (S), treonina (T), glutamato (E) y prolina (P). Las bibliotecas pueden usarse, a su vez, para la dimerización o ligamiento seriado para lograr bibliotecas
de secuencia de polinucleótido que codifican secuencias de XTEN, por ejemplo, de 48, 72, 144, 288, 576, 864, 912, 923, 1318 aminoácidos o de hasta una longitud total de aproximadamente 3000 aminoácidos, así como longitudes intermedias, en las que el XTEN codificado puede tener una o más de las propiedades divulgadas en el presente documento, cuando se expresa como un componente de una proteína de fusión GPXTEN. En algunos casos, las secuencias de biblioteca de polinucleótidos también pueden incluir bases adicionales usadas como "islas de secuenciación", descrita con más detalle más adelante.
La FIG. 5 es un diagrama de flujo esquemático de etapas representativas no limitantes en el ensamblaje de una construcción de polinucleótido de XTEN y una construcción de polinucleótido de GPXTEN en las realizaciones de la invención. Los oligonucleótidos individuales 501 pueden hibridarse en motivos de secuencia 502, tal como un motivo de 12 aminoácidos ("12-mero"), que posteriormente se liga con un oligo que contiene sitios de restricción de BsbI y KpnI 503. Se hibridan motivos de secuencia adicionales procedentes de una biblioteca al 12-mero hasta que se alcanza la longitud deseada del gen de XTEN 504. El gen de XTEN se clona en un vector de relleno. El vector puede codificar opcionalmente una secuencia Flag 506 seguida de una secuencia de relleno que está flanqueada por sitios para BsaI, BbsI y KpnI 507 y, en este caso, un solo gen de GP (que codifica Ex4 en este ejemplo) 508, dando como resultado una GPXTEN que comprende un solo GP 500. En la tabla 9 se proporciona una lista no exhaustiva de los nombres de XTEN para polinucleótidos que codifican XTEN y secuencias precursoras.
T = := n = =n i ADN= X T E N =n l i = n i =2r r r










Se puede clonar la biblioteca de genes que codifican XTEN en uno o más vectores de expresión conocidos en la técnica. Para facilitar la identificación de miembros de la biblioteca con buena expresión, se puede construir la biblioteca en forma de una fusión con una proteína indicadora. Los ejemplos no limitantes de genes indicadores adecuados son proteína fluorescente verde, luciferasa, fosfatasa alcalina y beta-galactosidasa. Mediante exploración, se pueden identificar secuencias de XTEN cortas que pueden expresarse a altas concentraciones en el organismo hospedador de elección. Posteriormente, se puede generar una biblioteca de dímeros de XTEN y repetir la exploración respecto de un alto nivel de expresión. Posteriormente, se pueden explorar las construcciones resultantes respecto de una serie de propiedades, tales como nivel de expresión, estabilidad de proteasas o unión a antisuero.
Un aspecto de la divulgación es proporcionar secuencias de polinucleótido que codifican los componentes de la proteína de fusión, en donde la creación de la secuencia ha sufrido optimización de codones. Es particularmente interesante la optimización de codones con el objetivo de mejorar la expresión de las composiciones polipeptídicas y para mejorar la estabilidad genética del gen codificante en los hospedadores de producción. Por ejemplo, la optimización de codones tiene una importancia particular para las secuencias de XTEN que son ricas en glicina o que tienen secuencias de aminoácidos muy repetitivas. La optimización de codones puede llevarse a cabo usando programas informáticos (Gustafsson, C., et al. (2004) Trends Biotechnol, 22: 346-53), algunos de los cuales minimizan la pausa ribosómica (Coda Genomics Inc.). En una realización, se puede llevar a cabo la optimización de codones construyendo bibliotecas de codones donde todos los miembros de la biblioteca codifican la misma secuencia de aminoácidos pero varía el uso de codones. Dichas bibliotecas pueden explorarse respecto de miembros de alta expresión y genéticamente estables que son particularmente adecuados para la producción a gran escala de productos que contienen XTEN. Cuando se diseñan secuencias de XTEN, se puede tomar en consideración una serie de propiedades. Se puede minimizar la repetitividad en las secuencias de ADN codificantes. Además, se puede evitar o minimizar el uso de codones que se usan escasamente por el hospedador de producción (por ejemplo, los codones para arginina AGG y AGA y un codón de leucina en E. coli). En el caso de E. coli, dos codones para glicina, GGA y GGG, rara vez se usan en proteínas altamente expresadas. Por lo tanto, puede ser muy deseable la optimización de codones del gen que codifica las secuencias de XTEN. Las secuencias de ADN que tienen un alto grado de glicina tienden a tener un alto contenido de GC que puede dar lugar a inestabilidad o a bajos niveles de expresión. Por tanto, cuando sea posible, es preferible seleccionar codones de tal forma que el contenido de GC de la secuencia que codifica XTEN es adecuado para el organismo de producción que se usará para producir el XTEN.
Opcionalmente, el gen que codifica XTEN de longitud completa puede comprender una o más islas de secuenciación. En este contexto, las islas de secuenciación son secuencias de serie corta que son distintas de las secuencias de construcción de la biblioteca de XTEN y que incluyen un sitio de restricción no presente o que no se espera que esté presente en el gen que codifica XTEN de longitud completa. En una realización, una isla de secuenciación es la secuencia
5’-AGGTGCAAGCGCAAGCGGCGCGCCAAGCACGGGAGGT-3’. En otra realización, una isla de secuenciación es la secuencia
5 ’-AGGTCCAGAACCAACGGGGCCGGCCCCAAGCGGAGGT-3’.
Como alternativa, pueden construirse bibliotecas de codones, donde todos los miembros de la biblioteca codifican la misma secuencia de aminoácidos, pero donde varía el uso de codones para los aminoácidos respectivos. Dichas
bibliotecas pueden explorarse respecto de miembros de alta expresión y genéticamente estables que son particularmente adecuados para la producción a gran escala de productos que contienen XTEN.
Opcionalmente, se pueden secuenciar clones en la biblioteca para eliminar aislados que contienen secuencias no deseadas. La biblioteca inicial de secuencias de XTEN cortas puede permitir cierto grado de variación en la secuencia de aminoácidos. Por ejemplo, se pueden aleatorizar algunos codones, de tal forma que pueda aparecer un número de aminoácidos hidrófilos que aparecen en una posición particular. Durante el proceso de multimerización iterativa se pueden explorar los miembros de la biblioteca resultantes respecto de otras características, tales como solubilidad o resistencia a proteasas, además de una exploración respecto de su expresión de alto nivel.
Una vez que se selecciona el gen que codifica el XTEN con la longitud y las propiedades deseadas, el método posibilita que se puedan fusionar genéticamente a los nucleótidos que codifican el extremo N y/o C-terminal de los genes de GP clonándolos en la construcción adyacente y en fase con el gen que codifica el GP u, opcionalmente, adyacente a una secuencia espaciadora. La invención proporciona diversas permutaciones de lo anterior, dependiendo del GPXTEN que se vaya a codificar. Por ejemplo, en un gen que codifica una proteína de fusión GPXTEN que comprende un GP y dos XTEN, tal como el representado por la fórmula VI, como se ha representado anteriormente, el gen podría tener polinucleótidos que codifican GP, que codifican dos XTEN, que pueden ser idénticos o diferentes en composición o longitud de secuencia. En una realización no limitante de lo anterior, los polinucleótidos de GP podrían codificar exendina-4 y los polinucleótidos que codifican el XTEN N-terminal podría codificar AE912 y los polinucleótidos que codifican el XTEN C-terminal podría codificar AE144. La etapa de clonar los genes de GP en la construcción de XTEN puede producirse mediante una etapa de ligamiento o multimerización. Como se muestra en la FIG. 2, las construcciones que codifican proteínas de fusión GPXTEN pueden diseñarse en diferentes configuraciones de los componentes XTEN 202, GP 203, y secuencias espaciadoras 204. En una realización, como se ilustra en la figura 2A, la construcción comprende secuencias de polinucleótidos complementarias a aquellas que codifican un polipéptido monomérico de componentes en el siguiente orden (5' a 3'): GP 203 y XTEN 202 o el orden inverso. En otra realización, como se ilustra en la FIG. 2B, la construcción comprende secuencias de polinucleótido complementarias a aquellas que codifican un polipéptido monomérico de los componentes en el siguiente orden (5' a 3'): GP 203, secuencia espaciadora 204, y XTEN 202 o el orden inverso. En otra realización, tal como se ilustra en la figura 2C, la construcción 201 codifica una GPXTEN monomérica que comprende secuencias de polinucleótidos complementarias a aquellas que codifican componentes en el siguiente orden (5' a 3'): dos moléculas de GP 203 y XTEN 202 o el orden inverso. En otra realización, tal como se ilustra en la figura 2D, la construcción comprende secuencias de polinucleótido complementarias a aquellas que codifican un polipéptido monomérico de los componentes en el siguiente orden (5' a 3'): dos moléculas de GP 203, secuencia espaciadora 204, y XTEN 202 o el orden inverso. En otra realización, tal como se ilustra en la figura 2E, la construcción comprende secuencias de polinucleótido complementarias a aquellas que codifican un polipéptido monomérico de los componentes en el siguiente orden (5' a 3'): GP 203, secuencia espaciadora 204, una segunda molécula de GP 203, y XTEN 202 o el orden inverso. En otra realización, tal como se ilustra en la figura 2F, la construcción comprende secuencias de polinucleótido complementarias a aquellas que codifican un polipéptido monomérico de los componentes en el siguiente orden (5' a 3'): GP 203, XTEN 202, GP 203, y un segundo x Te N 202 o la secuencia inversa. Los polinucleótidos espaciadores pueden comprender opcionalmente secuencias que codifican secuencias de escisión. Como será evidente para los expertos en la materia, son posibles otras permutaciones de lo anterior.
La divulgación también abarca polinucleótidos que comprenden variantes de polinucleótido que codifican XTEN que tienen un alto porcentaje de identidad de secuencia respecto de (a) una secuencia de polinucleótido de la tabla 9 o (b) secuencias que son complementarias a los polinucleótidos de (a). Un polinucleótido con un alto porcentaje de identidad de secuencia es uno que tiene al menos aproximadamente un 80 % de identidad de secuencia de ácido nucleico, como alternativa, al menos aproximadamente un 81 %, como alternativa, al menos aproximadamente un 82 %, como alternativa, al menos aproximadamente un 83 %, como alternativa, al menos aproximadamente un 84 %, como alternativa, al menos aproximadamente un 85 %, como alternativa, al menos aproximadamente un 86 %, como alternativa, al menos aproximadamente un 87 %, como alternativa, al menos aproximadamente un 88 %, como alternativa, al menos aproximadamente un 89 %, como alternativa, al menos aproximadamente un 90 %, como alternativa, al menos aproximadamente un 91 %, como alternativa, al menos aproximadamente un 92 %, como alternativa, al menos aproximadamente un 93 %, como alternativa, al menos aproximadamente un 94 %, como alternativa, al menos aproximadamente un 95 %, como alternativa, al menos aproximadamente un 96 %, como alternativa, al menos aproximadamente un 97 %, como alternativa, al menos aproximadamente un 98 % y como alternativa, al menos aproximadamente un 99 % de identidad de secuencia de ácido nucleico respecto de (a) o (b) de lo anterior o que puede hibridar con el polinucleótido diana o su complemento en condiciones rigurosas.
La homología, la similitud de secuencia o la identidad de secuencia de las secuencias de nucleótidos o aminoácidos también pueden determinarse de manera convencional usando software o programas informáticos conocidos, tales como los programas de comparación por pares BestFit o Gap (GCG Wisconsin Package, Genetics Computer Group, 575 Science Drive, Madison, Wis. 53711). BestFit usa el algoritmo de homología local de Smith y Waterman (Advances in Applied Mathematics. 1981. 2: 482-489), para encontrar el mejor segmento de identidad o similitud entre dos secuencias. Gap lleva a cabo alineamientos globales: todos los de una secuencia con todos los de otra secuencia similar usando el método de Needleman y Wunsch, (Journal of Molecular Biology. 1970. 48:443-453). Cuando se usa un programa de alineamiento de secuencias, tal como BestFit, para determinar el grado de homología, similitud o
identidad de secuencia, pueden usarse los ajustes por defecto o puede seleccionarse una matriz de puntuación adecuada para optimizar las puntuaciones de identidad, similitud u homología.
Las secuencias de ácido nucleico que son "complementarias" son aquellas que son capaces de efectuar un emparejamiento de bases de acuerdo con las reglas de complementariedad convencionales de Watson-Crick. Como se usa en el presente documento, la expresión "secuencias complementarias" significa secuencias de ácido nucleico que son sustancialmente complementarias, como puede evaluarse mediante la misma comparación de nucleótidos expuesta anteriormente o definidas como capaces de hibridar con los polinucleótidos que codifican las secuencias de GPXTEN en condiciones rigurosas, tales como las descritas en el presente documento.
Después, los polinucleótidos resultantes que codifican las proteínas de fusión quiméricas de GPXTEN pueden clonarse individualmente en un vector de expresión. La secuencia de ácido nucleico puede insertarse en el vector mediante una serie de procedimientos. En general, se inserta ADN en sitios de endonucleasas de restricción adecuados usando técnicas conocidas en la materia. Los componentes del vector incluyen generalmente, pero sin limitación, uno o más de una secuencia de señal, un origen de replicación, uno o más genes marcadores, un elemento potenciador, un promotor y una secuencia de terminación de la transcripción. La construcción de vectores adecuados que contienen uno o más de estos componentes emplea técnicas de ligamiento convencionales que son conocidas por los expertos en la materia. Dichas técnicas se conocen bien en la técnica y están bien descritas en la bibliografía científica y de patentes.
Se encuentran públicamente disponibles diversos vectores. El vector puede, por ejemplo, estar en forma de un plásmido, cósmido, partícula vírica o fago. La invención posibilita el uso de vectores plasmídicos que contienen secuencias de replicación y de control que son compatibles con y se reconocen por la célula hospedadora y están unidos operablemente al gen de GPXt En para la expresión controlada de proteínas de fusión GPXTEN. El vector porta normalmente un sitio de replicación, así como secuencias que codifican proteínas que son capaces de proporcionar selección fenotípica en células transformadas. Por ejemplo, puede transformarse E. coli usando pBR322, un plásmido derivado de una especie de E. coli (Mandel et al., J Mol. Biol., 53: 154 (1970)). El plásmido pBR322 contiene genes para resistencia a ampicilina y tetraciclina y por lo tanto, proporciona un medio de selección fácil. Se conocen bien dichas secuencias de vector para una serie de bacterias, levaduras y virus. Los vectores de expresión útiles que pueden usarse incluyen, por ejemplo, segmentos de secuencias de ADN cromosómico, no cromosómico y sintético. "Vector de expresión" se refiere a una construcción de ADN que contiene una secuencia de ADN que está unida operativamente a una secuencia de control capaz de efectuar la expresión del ADN que codifica la proteína de fusión en un hospedador adecuado. Dichas secuencias de control incluyen un promotor para efectuar la transcripción, una secuencia operadora opcional para controlar dicha transcripción, una secuencia que codifica sitios de unión a ribosomas de ARNm adecuados y secuencias que controlan la terminación de la transcripción y la traducción. Otros vectores adecuados incluyen, pero sin limitación, derivados de SV40 y pcDNA y plásmidos bacterianos conocidos, tales como col EI, pCRI, pBR322, pMal-C2, pET, pGEX como se describe por Smith, et al., Gene 57:31-40 (1988), pMB9 y derivados de los mismos, plásmidos, tales como RP4, ADN de fago, tales como los numerosos derivados del fago I, tales como NM989, así como otros ADN de fago, tales como M13 y ADN de fago monocatenario filamentoso; plásmidos de levadura, tales como el plásmido de 2 micrómetros o derivados del plásmido 2m, así como vectores lanzadera de levadura centroméricos e integrativos; vectores útiles en células eucariotas, tales como vectores útiles en células de insecto o mamífero; vectores derivados de combinaciones de plásmidos y ADN de fago, tales como plásmidos que se han modificado para emplear ADN de fago o las secuencias de control de la expresión; y similares. El requisito es que los vectores sean replicables y viables en la célula hospedadora de elección. Pueden usarse, según se desee, vectores con bajo o alto número de copias.
Los promotores adecuados para su uso en vectores de expresión con hospedadores procariotas incluyen los sistemas promotores de p-lactamasa y lactosa [Chang et al., Nature, 275:615 (1978); Goeddel et al., Nature, 281:544 (1979)], fosfatasa alcalina, un sistema de promotor de triptófano (trp) [Goeddel, Nucleic Acids Res., 8:4057 (1980); documento EP 36.776] y promotores híbridos, tales como el promotor tac [deBoer et al., Proc. Natl. Acad. Sci. USA, 80:21-25 (1983)], todos los cuales pueden unirse operablemente al ADN que codifica polipéptidos de GPXTEN. Los promotores para su uso en sistemas bacterianos también pueden contener una secuencia de Shine-Dalgamo (S.D.), unidos operablemente al ADN que codifica los polipéptidos de GPXTEN.
La invención contempla el uso de otros sistemas de expresión que incluyen, por ejemplo, puede usarse un sistema de expresión en baculovirus tanto con vectores de transferencia sin fusión, tales como, pero sin limitación, pVL941 (sitio de clonación de BamHI, disponible de Summers, et al., Virology 84:390-402 (1978)), pVL1393 (sitios de clonación de BamHI, Smal, Xbal, EcoRI, IVotl, Xmalll, BglII y Pstl; Invitrogen), pVL1392 (sitios de clonación de BglII, Pstl, Notl, Xmalll, EcoRI, Xball, Smal y BamHI; Summers, et al., Virology 84:390-402 (1978) e Invitrogen) y pBlueBacIII (sitios de clonación de BamHI, BgIII, Pstl, NcoI y Hindi II, con selección de recombinantes azul/blanco, Invitrogen) y vectores de transferencia de fusión, tales como, pero sin limitación, pAc700 (sitios de clonación de BamHI y Kpnl, en el que el sitio de reconocimiento de BamHI comienza con el codón de inicio; Summers, et al., Virology 84:390-402 (1978)), pAc701 y pAc70-2 (igual a pAc700, con diferentes fases de lectura), pAc360 [sitio de clonación de BamHI 36 pares de bases cadena debajo de un codón de inicio de polihedrina; Invitrogen (1995)) y pBlueBacHisA, B, C (tres fases de lectura diferentes con sitios de clonación de BamHI, BgI II, Pstl, Nco 1 y Hind III, un péptido N-terminal para la purificación ProBound y exploración de placas recombinante azul/blanco; Invitrogen (220).
Los vectores de expresión de mamífero pueden comprender un origen de replicación, un promotor y potenciador adecuado y también cualquier sitio de unión a ribosomas necesario, sitio de poliadenilación, sitios donantes y aceptores de corte y empalme, secuencias de terminación de la transcripción y secuencias 5' flanqueantes no transcritas. Pueden usarse secuencias de ADN procedentes del corte y empalme de SV40 y sitios de poliadenilación para proporcionar los elementos genéticos no transcritos necesarios. Los vectores de expresión de mamífero contemplados para su uso en la invención incluyen vectores con promotores inducibles, tales como los promotores de dihidrofolato reductasa, cualquier vector de expresión con un casete de expresión de DHFR o un vector de co amplificación de DHFR/metotrexato, tal como pED (sitios de clonación PstI, Sail, Sbal, Smal y EcoRI, expresando el vector tanto el gen clonado como DHFR; Randal J. Kaufman, 1991, Randal J. Kaufman, Current Protocols in Molecular Biology, 16,12 (1991)). Como alternativa, un vector de co-amplificación de glutamina sintetasa/metionina sulfoximina, tal como pEE14 (sitios de clonación de Hindlll, Xball, Smal, Sbal, EcoRI y Sell en los que el vector expresa glutamina sintetasa y el gen clonado; Celltech). Puede usarse un vector que dirige la expresión episómica bajo el control del virus de Epstein Barr. (EBV) o el antígeno nuclear (EBNA), tal como pREP4 (sitios de clonación de BamHI, SfH, Xhol, Notl, Nhel, HindIII, Nhel, PvuII y Kpnl, promotor r SV-LTR constitutivo, marcador de selección de higromicina; Invitrogen), pCEP4 (sitios de clonación de BamHI, SfH, Xhol, NotI, Nhel, Hindlll, Nhel, PvuII y Kpnl, promotor de gen temprano inmediato de hCMV constitutivo, marcador de selección de higromicina; Invitrogen), pMEP4 (sitios de clonación de Kpnl, Pvul, Nhel, Hindlll, Notl, Xhol, Sfil, BamHI, promotor inducible del gen de metalotioneína H, marcador de selección de higromicina, Invitrogen), pREP8 (sitios de clonación de BamHI, Xhol, NotI, Hindlll, Nhel y Kpnl, promotor de RSV-LTR, marcador de selección de histidinol; Invitrogen), pREP9 (sitios de clonación de Kpnl, Nhel, Hind 111, Notl, Xho 1, Sfi 1, BamH I, promotor de RSV-LTR, marcador de selección de G418; Invitrogen) y pEBVHis (promotor de RSV-LTR, marcador de selección de higromicina, péptido N-terminal purificable mediante resina ProBond y escindido por enterocinasa; Invitrogen).
Los vectores de expresión de mamífero de selección para su uso en la invención incluyen, pero sin limitación, pRc/CMV (sitios de clonación de HindHI, BstXI, NotI, Sbal y Apal, selección de G418, Invitrogen), pRc/RSV (sitios de clonación de Hind II, Spel BstXI, NotI, Xbal, selección de G418, Invitrogen) y similares. Los vectores de expresión de mamífero de virus Vaccinia (véase, por ejemplo, Randall J. Kaufman, Current Protocols in Molecular Biology 16.12 (Frederick M. Ausubel, et al., eds. Wiley 1991) que pueden usarse en la presente invención incluyen, pero sin limitación, pSC11 (sitio de clonación de Smal, selección de TK- y beta-gal), pMJ601 (sitios de clonación de Sal 1, Sma 1, A flI, Narl, BspMlI, BamHI, Apal, Nhel, SacII Kpnl y Hindlll; selección de TK- y -gal), pTKgptFIS (sitios de clonación de EcoRI, Pstl, SaIII, Accl, HindII, Sbal, BamHI y Hpa, selección de TK o XPRT) y similares.
Los sistemas de expresión en levaduras que también pueden usarse en la presente invención incluyen, pero sin limitación, el vector sin fusión pYES2 (sitios de clonación de XJbal, Sphl, Shol, NotI, GstXI, EcoRI, BstXI, BamHI, Sad, Kpnl y Hindlll, Invitrogen), el vector de fusión pYESHisA, B, C (sitios de clonación de Xball, Sphl, Shol, NotI, BstXI, EcoRI, BamHI, Sad, Kpnl y Hindi II, péptido N-terminal purificado con resina ProBond y escindido con enterocinasa; Invitrogen), vectores pRS y similares.
Además, el vector de expresión que contiene el polinucleótido que codifica la proteína de fusión quimérica GPXTEN puede incluir marcadores de selección de fármacos. Dichos marcadores ayudan en la clonación y en la selección o identificación de vectores que contienen moléculas de ADN quiméricas. Por ejemplo, los genes que confieren resistencia a la neomicina, puromicina, higromicina, inhibidor de dihidrofolato reductasa (DHFR), guanina fosforribosil transferasa (GPT), zeocina es histidinol son marcadores de selección útiles. Como alternativa, pueden emplearse enzimas, tales como timidina cinasa (tk) del virus del herpes simple o cloranfenicol acetiltransferasa (CAT). También pueden emplearse marcadores inmunológicos. Puede emplearse cualquier marcador de selección conocido en tanto que pueda expresarse simultáneamente con el ácido nucleico que codifica un producto génico. Los expertos en la materia conocen bien ejemplos adicionales de marcadores de selección e incluyen indicadores, tales como proteína verde fluorescente mejorada (EGFP), beta-galactosidasa (p-gal) o cloranfenicol acetiltransferasa (CAT).
En una realización, el polinucleótido que codifica una composición de proteína de fusión GPXTEN puede fusionarse en C-terminal a una secuencia de señal N-terminal adecuada para el sistema hospedador de expresión. Las secuencias de señal normalmente se eliminan proteolíticamente de la proteína durante el proceso de traslocación y secreción, generando un extremo N-terminal definido. Se ha descrito para la mayoría de sistemas de expresión una gran variedad de secuencias de señal, incluyendo sistemas bacterianos, de levadura, de insecto y de mamífero. A continuación se expone una lista no limitante de ejemplos preferidos para cada sistema de expresión. Las secuencias de señal preferidas son OmpA, PhoA y DsbA para expresión en E. coli. Los péptidos de señal preferidos para expresión en levaduras son ppL-alfa, DEX4, péptido de señal de invertasa, péptido de señal de fosfatasa alcalina, CPY o INU1. Para expresión en células de insecto, las secuencias de señal preferidas son el precursor de la hormona adipocinética de Manduca sexta, CP1, CP2, CP3, CP4, TPA, PAP o gp67. Para la expresión en mamíferos, las secuencias de señal preferidas son IL2L, SV40, IgG kappa e IgG lambda.
En otra realización, puede fusionarse una secuencia líder, que potencialmente comprende un dominio de proteína independiente bien expresado, al extremo N-terminal de la secuencia de GPXTEN, separada por un sitio de escisión de proteasa. Aunque puede usarse cualquier secuencia líder que no inhiba la escisión en el sitio proteolítico designado, las secuencias en las realizaciones preferidas comprenderán secuencias estables, bien expresadas, de tal forma que la expresión y el plegamiento de la composición general no se ve afectado significativamente de manera adversa y
preferentemente, se mejoran la eficacia de la expresión, solubilidad y/o plegamiento. Se ha descrito una gran variedad de secuencias líder adecuadas en la bibliografía. Una lista no limitante de secuencias adecuadas incluye proteína de unión a maltosa, dominio de unión a celulosa, glutatión S-transferasa, marcador de 6xHis, marcador FLAG, marcador de hemaglutinina y proteína fluorescente verde. La secuencia líder también puede mejorarse adicionalmente mediante optimización de codones, especialmente en la posición del segundo codón a continuación del codón de inicio de ATG, mediante métodos bien descritos en la bibliografía y anteriormente en el presente documento.
Se conocen diversos métodos enzimáticos in vitro para escindir proteínas en sitios específicos. Dichos métodos incluyen el uso de enterocinasa (DDDK), Factor Xa (IDGR), trombina (LVPRGS), PreScission™ (LEVLFQGP), proteasa TEV (EQLYFQG), proteasa 3C (ETLFQGP), Sortasa A (LPETG), Granzima B (D/X, N/X, M/N o S/X), inteínas, SUMO, DAPasa (TAGZyme™), aminopeptidasa de Aeromonas, aminopeptidasa M y carboxipeptidasas A y B. Se divulgan métodos adicionales en Arnau, et al., Protein Expression and Purification 48: 1-13 (2006).
En otros casos, la divulgación proporciona construcciones de polinucleótido y métodos para producir construcciones (por ejemplo, como se describe en los ejemplos) que comprenden una secuencia de polinucleótido optimizada que codifica de al menos aproximadamente 20 a aproximadamente 60 aminoácidos con características de XTEN que pueden incluirse en el extremo N-terminal de la secuencia que codifica XTEN para promover el inicio de la traducción para posibilitar la expresión de fusiones de XTEN en el extremo N-terminal de proteínas sin la presencia de un dominio auxiliar. En una ventaja de lo anterior, la secuencia no requiere de una escisión posterior de un dominio auxiliar, reduciendo de este modo el número de etapas para producir composiciones que contienen XTEN. Como se describe con más detalle en los ejemplos, la secuencia N-terminal optimizada tiene atributos de una proteína no estructurada, pero pueden incluir bases de nucleótidos que codifican aminoácidos seleccionados por su capacidad para promover el inicio de la traducción y una expresión mejorada. En una realización de lo anterior, el polinucleótido optimizado codifica una secuencia de XTEN con al menos aproximadamente un 90 % de identidad de secuencia respecto de AE912. En otra realización de lo anterior, el polinucleótido optimizado codifica una secuencia de XTEN con al menos aproximadamente un 90 % de identidad de secuencia respecto de AM923. En otra realización de lo anterior, el polinucleótido optimizado codifica una secuencia de XTEN con al menos aproximadamente un 90 % de identidad de secuencia respecto de AE624. En otra realización de lo anterior, el polinucleótido optimizado codifica una secuencia de XTEN con al menos aproximadamente un 90 % de identidad de secuencia respecto de AE48. En otra realización de lo anterior, el polinucleótido optimizado codifica una secuencia de XTEN con al menos aproximadamente un 90 % de identidad de secuencia respecto de AM48. En una realización, el polinucleótido optimizado NTS comprende una secuencia que muestra al menos aproximadamente un 80 %, al menos aproximadamente un 85 %, al menos aproximadamente un 90 %, al menos aproximadamente un 91 %, al menos aproximadamente un 92 %, al menos aproximadamente un 93 %, al menos aproximadamente un 94 %, al menos aproximadamente un 95 %, al menos aproximadamente un 96 %, al menos aproximadamente un 97 %, al menos aproximadamente un 98 % o al menos aproximadamente un 99 %, de identidad de secuencia respecto de una secuencia o su complemento seleccionada entre
AE 48: 5'-ATGGCTGAACCTGCTGGCTCTCCAACCTCCACTGAGGAAGGTACCCCGGGTAGCGGTACTGCTTCTTCCTCT CCAGGTAGCTCTACCCCTTCTGGTGCAACCGGCTCTCCAGGTGCTTCTCCGGGCACC AGCTCTACCGGTTCTCCA-3'
y
AM 48: 5'-ATGGCTGAACCTGCTGGCTCTCCAACCTCCACTGAGGAAGGTGCATCCCCGGGCACCAGCTCTACCGGTTC TCCAGGTAGCTCTACCCCGTCTGGTGCTACCGGCTCTCCAGGTAGCTCTACCCCGTCT GGTGCTACTGGCTCTCCA-3'
En otra realización, el sitio de proteasa de la construcción de secuencia líder se selecciona de tal forma que se reconoce por una proteasa in vivo. En esta realización, la proteína se purifica del sistema de expresión, a la vez que conserva el líder evitando el contacto con una proteasa adecuada. Después, se inyecta la construcción de longitud completa en un paciente. Tras la inyección, la construcción entra en contacto con la proteasa específica para el sitio de escisión y se escinde por la proteasa. En caso de que la secuencia no escindida sea sustancialmente menos activa que la forma escindida, este método tiene el efecto beneficioso de permitir mayores dosis iniciales a la vez que se evita la toxicidad, ya que la forma activa se genera lentamente in vivo. Algunos ejemplos no limitantes de proteasas in vivo que son útiles para esta aplicación incluyen calicreína tisular, calicreína plasmática, tripsina, pepsina, quimiotripsina, trombina y metaloproteinasas de matriz o las proteasas de la tabla 8.
De esta manera, se genera dentro de la construcción una molécula de ADN quimérica que codifica una proteína de fusión de GPXTEN monomérica. Opcionalmente, esta molécula de ADN quimérico puede transferirse o clonarse en otra construcción que es un vector de expresión más adecuado. En este punto, puede transformarse una célula hospedadora capaz de expresar la molécula de ADN quimérica con la molécula de ADN quimérica. Los vectores que contienen los segmentos de ADN de interés pueden transferirse a la célula hospedadora mediante métodos bien conocidos, dependiendo del tipo de hospedador celular. Por ejemplo, normalmente se usa transfección con cloruro de calcio para células procariotas, mientras que para otros hospedadores celulares puede usarse tratamiento con fosfato de calcio, lipofección o electroporación. Otros métodos usados para transformar células de mamífero incluyen el uso
de polibreno, fusión de protoplastos, liposomas, electroporación y microinyección. Véase, en general, Sambrook, et al., anteriormente citado.
La transformación puede producirse con o sin la utilización de un vehículo, tal como un vector de expresión. Después, la célula hospedadora transformada se cultiva en condiciones adecuadas para la expresión de la molécula de ADN quimérica que codifica GPXTEN.
La presente divulgación también proporciona una célula hospedadora para expresar las composiciones de proteína de fusión monomérica divulgadas en el presente documento. Los ejemplos de células hospedadoras eucariotas adecuadas incluyen, pero sin limitación, células de mamífero, tales como células VERO, células HeLa, tales como ATCC n.° CCL2, líneas celulares CHO, células COS, células WI38, células BHK, células HepG2, células 3T3, células A549, células PC12, células K562, células 293, células Sf9 y células Cvl. Los ejemplos de células eucariotas no de mamífero incluyen microbios eucariotas, tales como hongos filamentosos o levaduras, que son hospedadores de clonación o expresión adecuados para vectores codificantes. Saccharomyces cerevisiae es un microorganismo eucariota inferior comúnmente usado. Otras incluyen Schizosaccharomyces pombe (Beach y Nurse, Nature, 290: 140 [1981]; documento EP 139.383 publicado el 2 de mayo de 1985); hospedadores de Kluyveromyces (Patente de los Estados Unidos n.° 4.943.529; Fleer et al., Bio/Technology, 9:968-975 (1991)) tales como, por ejemplo, K. lactis (MW98-8C, CBS683, CBS4574; Louvencourt et al., J. Bacteriol., 737 [1983]), K. fragilis (ATCC 12.424), K. bulgaricus (ATCC 16.045), K. wickeramii (ATCC 24.178), K. waltii (ATCC 56.500), K. drosophilarum (ATCC 36.906; Van den Berg et al., Bio/Technology, 8:135 (1990)), K. thermotolerans, y K. marxianus; yarrowia (documento EP 402.226); Pichia pastoris (documento EP 183.070; Sreekrishna et al., J. Basic Microbiol., 28:265-278 [1988]); Candida; Trichoderma reesia (documento EP 244.234); Neurospora crassa (Case et al., Proc. Natl. Acad. Sci. USA, 76:5259-5263 [1979]); Schwanniomyces tales como Schwanniomyces occidentalis (documento EP 394.538 publicado el 31 de octubre de 1990); y hongos filamentosos, tales como, por ejemplo, Neurospora, Penicillium, Tolypocladium (documento WO 91/00357, publicado el 10 de enero de 1991) y hospedadores de Aspergillus, tales como A. nidulans (Ballance et al., Biochem. Biophys. Res. Commun., 112:284-289 [1983]; Tilbum et al., Gene, 26:205-221 [1983]; Yelton et al., Proc. Natl. Acad. Sci. USA, 81: 1470-1474 [1984]) y A niger (Kelly y Hynes, EMBO J., 4:475-479 [1985]). Las levaduras metilotrópicas son adecuadas en el presente documento e incluyen, pero sin limitación, levaduras capaces de crecer en metanol seleccionadas entre los géneros que consisten en Hansenula, Candida, Kloeckera, Pichia, Saccharomyces, Torulopsis, y Rhodotorula. Puede encontrarse una lista de especies concretas que son ilustrativas de esta clase de levadura en C. Anthony, The Biochemistry of Methylotrophs, 269 (1982).
Otras células adecuadas que pueden usarse en la presente invención incluyen, pero sin limitación, cepas de células hospedadoras procariotas, tales como Escherichia coli, (por ejemplo, la cepa DH5-a), Bacillus subtilis, Salmonella typhimurium, o cepas de los géneros de Pseudomonas, Streptomyces y Staphylococcus. Los ejemplos no limitantes de procariotas adecuados incluyen aquellos de los géneros: Actinoplanes; Archaeoglobus; Bdellovibrio; Borrelia; Chloroflexus; Enterococcus; Escherichia; Lactobacillus; Listeria; Oceanobacillus; Paracoccus; Pseudomonas; Staphylococcus; Streptococcus; Streptomyces; Thermoplasma; y Vibrio. Los ejemplos no limitantes de cepas específicas incluyen: Archaeoglobus fulgidus; Bdellovibrio bacteriovorus; Borrelia burgdorferi; Chloroflexus aurantiacus; Enterococcus faecalis; Enterococcus faecium; Lactobacillus johnsonii; Lactobacillus plantarum; Lactococcus lactis; Listeria innocua; Listeria monocytogenes; Oceanobacillus iheyensis; Paracoccus zeaxanthinifaciens; Pseudomonas mevalonii; Staphylococcus aureus; Staphylococcus epidermidis; Staphylococcus haemolyticus; Streptococcus agalactiae; Streptomyces griseolosporeus; Streptococcus mutans; Streptococcus pneumoniae, Streptococcus pyogenes; Thermoplasma acidophilum; Thermoplasma volcanium; Vibrio cholerae; Vibrio parahaemolyticus; y Vibrio vulnificus.
Pueden cultivarse células hospedadoras que contienen los polinucleótidos de interés en medio nutriente convencional (por ejemplo, mezcla nutriente de Ham) modificados según convenga para activar promotores, seleccionar transformantes o amplificar genes. Las condiciones de cultivo, tales como la temperatura, el pH y similares, son aquellas usadas previamente con la célula hospedadora seleccionada para la expresión y serán evidentes para un experto habitual en la materia. Las células normalmente se recogen por centrifugación, se rompen por medios físicos o químicos y el extracto en bruto resultante se conserva para su purificación adicional. Para composiciones secretadas por las células hospedadoras, se separa el sobrenadante de la centrifugación y se conserva para su purificación posterior. Las células microbianas empleadas en la expresión de proteínas pueden romperse mediante cualquier método conveniente, incluyendo ciclos de congelación/descongelación, sonicación, rotura mecánica o el uso de agentes de lisado de células, que son bien conocidos por los expertos en la materia. Las realizaciones que implican lisis celular pueden implicar le uso de un tampón que contiene inhibidores de proteasas que limitan la degradación tras la expresión de la molécula de ADN quimérico. Los inhibidores de proteasas adecuados incluyen, pero sin limitación, leupeptina, pepstatina o aprotinina. Después, puede precipitarse el sobrenadante con concentraciones progresivamente crecientes de sulfato de amonio saturado.
La expresión génica puede medirse directamente en una muestra, por ejemplo, mediante transferencia de Southern convencional, transferencia de Northern para cuantificar la transcripción de ARNm [Thomas, Proc. Natl. Acad. Sci. USA, 77:5201-5205 (1980)], transferencia de puntos (análisis de ADN) o hibridación in situ, usando una sonda marcada de manera adecuada, basándose en las secuencias proporcionadas en el presente documento. Como alternativa, pueden emplearse anticuerpos que puedan reconocer dúplex específicos, incluyendo dúplex de ADN, dúplex de ARN
y dúplex híbridos de ADN-ARN o dúplex de ADN-proteína. A su vez, pueden marcarse los anticuerpos y los ensayos pueden llevarse a cabo en los casos donde el dúplex esté unido a una superficie, de tal forma que tras la formación del dúplex sobre la superficie, puede detectarse la presencia de anticuerpo unido al dúplex.
La expresión génica, como alternativa, puede medirse mediante métodos inmunológicos o fluorescentes, tales como tinción inmunohistoquímica de células o secciones de tejido y ensayos de cultivo celular o fluidos corporales o la detección de marcadores de selección, para cuantificar directamente la expresión de producto génico. Los anticuerpos útiles para la tinción inmunohistoquímica y/o ensayo de muestras de fluidos pueden ser monoclonales o policlonales y pueden prepararse en cualquier mamífero. De manera conveniente, pueden prepararse los anticuerpos contra una secuencia nativa de polipéptido de GP o contra un péptido sintético basándose en las secuencias de ADN proporcionadas en el presente documento o contra una secuencia exógena fusionada a GP y que codifica un epítopo de anticuerpo específico. Los expertos en la materia conocen bien ejemplos de marcadores de selección e incluyen indicadores, tales como proteína verde fluorescente mejorada (EGFP), beta-galactosidasa (p-gal) o cloranfenicol acetiltransferasa (CAT).
Los productos polipeptídicos de GPXTEN expresados pueden purificarse mediante métodos conocidos en la técnica o mediante métodos divulgados en el presente documento. Pueden usarse procedimientos, tales como filtración en gel, purificación por afinidad, fraccionamiento salino, cromatografía de intercambio iónico, cromatografía de exclusión por tamaños, cromatografía de adsorción en hidroxiapatita, cromatografía de interacción hidrófoba y electroforesis en gel; cada uno diseñado a medida para recuperar y purificar la proteína de fusión producida por las células hospedadoras respectivas. Algunas GPXTEN expresadas pueden necesitar volver a plegarse durante el aislamiento y la purificación. Se describen métodos de purificación en Robert K. Scopes, Protein Purification: Principles and Practice, Charles R. Castor (ed.), Springer-Verlag 1994 y Sambrook, et al., anteriormente citado. También se describen separaciones de purificación en múltiples etapas en Baron, et al., Crit. Rev. Biotechnol. 10:179-90 (1990) y Below, et al., J. Chromatogr. A. 679:67-83 (1994).
VIII) COMPOSICIONES FARMACÉUTICAS
La presente invención proporciona composiciones farmacéuticas que comprenden la GPXTEN reivindicada. En una realización, la composición farmacéutica comprende la proteína de fusión GPXTEN y al menos un vehículo farmacéuticamente aceptable. Los polipéptidos de GPXTEN de la presente invención pueden formularse de acuerdo con métodos conocidos para preparar composiciones farmacéuticamente útiles, mediante los cuales el polipéptido se combina en una mezcla con un vehículo portador farmacéuticamente aceptable, tal como soluciones o tampones acuosos, suspensiones y emulsiones farmacéuticamente aceptables. Los ejemplos de disolventes no acuosos incluyen propiletilenglicol, polietilenglicol y aceites vegetales. Las formulaciones terapéuticas se preparan para su almacenamiento mezclando el principio activo que tiene el grado de pureza deseado con vehículos, excipientes o estabilizantes fisiológicamente aceptables, tal como se describe en Remington's Pharmaceutical Sciences 16a edición, Osol, A. Ed. (1980), en forma de formulaciones liofilizadas o de soluciones acuosas.
Las composiciones farmacéuticas se pueden administrar por vía oral, intranasal, parenteral o por terapia inhalatoria y pueden adoptar la forma de comprimidos, pastillas, gránulos, cápsulas, píldoras, ampollas, supositorios o forma de aerosol. También pueden estar en forma de suspensiones, soluciones y emulsiones del principio activo en diluyentes acuosos o no acuosos, jarabes, granulados o polvos. Además, las composiciones farmacéuticas también pueden contener otros compuestos farmacéuticamente activos o una pluralidad de compuestos de la invención.
Más concretamente, las presentes composiciones farmacéuticas pueden administrarse para terapia por cualquier vía adecuada, oral, rectal, nasal, tópica (incluyendo transdérmica, aerosol, bucal y sublingual), vaginal, parenteral (incluyendo subcutánea, subcutánea mediante bomba de infusión, intramuscular, intravenosa e intradérmica), intravítrea y pulmonar. También se apreciará que la vía preferida variará dependiendo del estado y la edad del receptor y de la enfermedad que se esté tratando.
En una realización, la composición farmacéutica se administra por vía subcutánea. En esta realización, la composición puede suministrarse en forma de un polvo liofilizado para su reconstitución antes de la administración. La composición también puede suministrarse en una forma líquida, que puede administrarse directamente a un paciente. En una realización, la composición se suministra en forma de un líquido en una jeringuilla precargada, de tal forma que un paciente puede auto administrarse fácilmente la composición.
Las formulaciones de liberación prolongada útiles en la presente invención pueden ser formulaciones orales que comprenden una matriz y una composición de recubrimiento. Los materiales de matriz adecuados pueden incluir ceras (por ejemplo, carnaúba, cera de abeja, cera de parafina, ceresina, cera de goma laca, ácidos grasos y alcoholes grasos), aceites, aceites o grasas endurecidas (por ejemplo, aceite de colza endurecido, aceite de ricino, sebo de vacuno, aceite de palma y aceite de soja) y polímeros (por ejemplo, hidroxipropil celulosa, polivinilpirrolidona, hidroxipropilmetilcelulosa y polietilenglicol). Otros materiales de matriz para comprimidos adecuados son celulosa microcristalina, celulosa en polvo, hidroxipropil celulosa, etilcelulosa, con otros vehículos y cargas. Los comprimidos también pueden contener granulados, polvos recubiertos o pellets. Los comprimidos también pueden ser multicapa. Se prefieren especialmente los polvos multicapa cuando los principios activos tienen perfiles farmacocinéticos
marcadamente diferentes. Opcionalmente, el comprimido terminado puede estar recubierto o sin recubrir.
La composición de recubrimiento puede comprender un polímero de matriz insoluble y/o un material hidrosoluble. Los materiales hidrosolubles pueden ser polímeros, tales como polietilenglicol, hidroxipropil celulosa, hidroxipropilmetilcelulosa, polivinilpirrolidona, alcohol polivinílico o materiales monoméricos, tales como azúcares (por ejemplo, lactosa, sacarosa, fructosa, manitol y similares), sales (por ejemplo, cloruro de sodio, cloruro de potasio y similares), ácidos orgánicos (por ejemplo, ácido fumárico, ácido succínico, ácido láctico y ácido tartárico) y mezclas de los mismos. Opcionalmente, puede incorporarse un polímero entérico en la composición de recubrimiento. Los polímeros entéricos adecuados incluyen hidroxipropilmetilcelulosa, acetato succinato, hidroxipropilmetilcelulosa, ftalato, ftalato acetato de polivinilo, ftalato acetato de celulosa, trimetilato acetato de celulosa, goma laca, zeína y polimetacrilatos que contienen grupos carboxilo. La composición de recubrimiento puede plastificarse añadiendo plastificantes adecuados, tales como, por ejemplo, ftalato de dietilo, ésteres de citrato, polietilenglicol, glicerol, glicéridos acetilados, ésteres de citrato acetilados, dibutilsebacato y aceite de ricino. La composición de recubrimiento también puede incluir una carga, que puede ser un material insoluble, tal como dióxido de silicio, dióxido de titanio, talco, caolín, alúmina, almidón, celulosa en polvo, MCC o polacrilina potásica. La composición de recubrimiento puede aplicarse en forma de una solución o látex en disolventes orgánicos o disolventes acuosos o mezclas de los mismos. Pueden usarse disolventes tales como agua, alcohol inferior, hidrocarburos inferiores clorados, cetonas o mezclas de los mismos.
Las composiciones de la invención pueden formularse usando diversos excipientes. Los excipientes adecuados incluyen celulosa microcristalina (por ejemplo, Avicel PH102, Avicel PH101), polimetacrilato, poli (acrilato de etilo, metacrilato de metilo, cloruro de trimetilamonioetil metacrilato) (tal como Eudragit RS-30D), hidroxipropilmetilcelulosa (Methocel K100M, Premium CR Methocel K100M, Methocel E5, Opadry®), estearato de magnesio, talco, citrato de trietilo, dispersión acuosa de etilcelulosa (Surelease®) y sulfato de protamina. El agente de liberación lenta también puede comprender un portador, que puede comprender, por ejemplo, disolventes, medios de dispersión, recubrimientos, agentes antibacterianos y antifúngicos, agentes isotónicos y agentes retardantes de la absorción. También pueden usarse sales farmacéuticamente aceptables en estos agentes de liberación lenta, por ejemplo, sales minerales, tales como clorhidratos, bromhidratos, fosfatos o sulfatos, así como sales de ácidos orgánicos, tales como acetatos, propionatos, malonatos o benzoatos. La composición también puede contener líquidos, tales como agua, solución salina, glicerol y etanol, así como sustancias, tales como agentes humectantes, agentes emulsionantes o agentes tamponadores del pH. Como portador, también pueden usarse liposomas.
En otra realización, las composiciones de la presente invención se encapsulan en liposomas, que han demostrado ser útiles para suministrar agentes activos beneficiosos de manera controlada durante periodos de tiempo prolongados. Los liposomas son membranas de bicapa cerradas que contienen un volumen acuoso atrapado. Los liposomas también pueden ser vesículas unilamelares que poseen una sola bicapa de membrana o vesículas multilamelares con múltiples bicapas de membrana, cada una separada de la siguiente por una capa acuosa. La estructura de la bicapa de membrana resultante es tal que las colas hidrófobas (no polares) del lípido se orientan hacia el centro de la bicapa, mientras que las cabezas hidrófilas (polares) se orientan hacia la fase acuosa. En una realización, el liposoma puede recubrirse con un polímero flexible soluble en agua que evita la captación por los órganos del sistema de fagocitos mononucleares, principalmente el hígado y el bazo. Los polímeros hidrófilos adecuados para rodear los liposomas incluyen, sin limitación, PEG, polivinilpirrolidona, metiléter de polivinilo, polimetiloxazolina, polietiloxazolina, polihidroxipropiloxazolina, polihidroxipropilmetacrilamida, polimetacrilamida, polidimetilacrilamida, polihidroxipropilmetacrilato, polihidroxietilacrilato, hidroximetilcelulosa, hidroxietilcelulosa, polietilenglicol, poliaspartamida y secuencias peptídicas hidrófilas, tal como se describen en las Patentes de los Estados Unidos n.° 6.316.024; 6.126.966; 6.056.973; 6.043.094.
Los liposomas pueden estar formados por cualquier lípido o combinación de lípidos conocida en la técnica. Por ejemplo, los lípidos formadores de vesículas pueden ser lípidos sintéticos de origen natural, incluyendo fosfolípidos, tales como fosfatidilcolina, fosfatidiletanolamina, ácido fosfatídico, fosfatidilserina, fosfatidilglicerol, fosfatidilinositol y esfingomielina, tal como se divulga en las Patentes de los Estados Unidos n.° 6.056.973 y 5.874.104. Los lípidos formadores de vesículas también pueden ser glucolípidos, cerebrósidos o lípidos catiónicos, tales como 1,2-dioleiloxi-3-(trimetilamino) propano (DOTAP); bromuro de N-[1-(2,3-ditetradeciloxi)propil]-N,N-dimetil-N-hidroxietilamonio (DMRIE); bromuro de N-[1[(2,3-dioleiloxi)propil]-N,N-dimetil-N-hidroxi etilamonio (DORIE); cloruro de N-[1-(2,3-dioleiloxi)propil]-N,N,N-trimetilamonio (DOTMA); 3 [N-(N',N'-dimetilaminoetano)carbamoil] colesterol (DC-Chol); o dimetildioctadecilamonio (DDAB), también como se divulga en la Patente de los Estados Unidos n.° 6.056.973. También puede haber presencia de colesterol en el intervalo adecuado para conferir estabilidad a la vesícula, tal como se divulga en las Patentes de los Estados Unidos n.° 5.916.588 y 5.874.104.
Se describen tecnologías liposómicas adicionales en las Patentes de los Estados Unidos n.° 6.759.057; 6.406.713; 6.352.716; 6.316.024; 6.294.191; 6.126.966; 6.056.973; 6.043.094; 5.965.156; 5.916.588; 5.874.104; 5.215.680; y 4.684.479. Estas describen liposomas y microburbujas recubiertas de lípidos y métodos para su preparación. Por tanto, un experto en la materia, tomando en consideración tanto la divulgación de la presente invención y la divulgación de estas otras patentes podría producir un liposoma para la liberación prolongada de los polipéptidos de la presente invención.
Para formulaciones líquidas, una propiedad deseada es que la formulación se suministre en una forma que pueda pasar a través de una aguja del calibre 25, 28, 30, 31 o 32 para administración intravenosa, intramuscular, intraarticular o subcutánea.
La administración mediante formulaciones transdérmicas puede llevarse a cabo usando métodos también conocidos en la técnica, incluyendo aquellos descritos de manera general en, por ejemplo, las Patentes de los Estados Unidos n.° 5.186.938 y 6.183.770, 4.861.800, 6.743.211, 6.945.952, 4.284.444 y el documento WO 89/09051. Una realización particularmente útil con polipéptidos que tienen problemas de absorción es un parche transdérmico. Pueden prepararse parches para controlar la liberación de principios activos permeables a la piel durante un periodo de 12 horas, 24 horas, 3 días y 7 días. En un ejemplo, se pone en un fluido no volátil un exceso diario 2 veces de un polipéptido de la presente invención. Las composiciones de la invención se proporcionan en forma de un líquido viscoso no volátil. Puede medirse la penetración a través de la piel de formulaciones específicas mediante métodos convencionales en la técnica (por ejemplo, Franz et al., J. Invest. Derm. 64:194-195 (1975)). Son ejemplos de parches adecuados los parches cutáneos de transferencia pasiva, parches cutáneos iontoforéticos o parches con microagujas, tales como Nicoderm.
En otras realizaciones, la composición puede suministrarse por vía intranasal, bucal o sublingual al cerebro para permitir la transferencia de los agentes activos a través de los conductos olfatorios al SNC y reducir la administración sistémica. Se incluyen dispositivos comúnmente usados para esta vía de administración en la Patente de los Estados Unidos n.° 6.715.485. Las composiciones administradas por esta vía pueden aumentar la dosificación al SNC o una carga corporal total reducida que reduce los riesgos de toxicidad sistémica asociados con ciertos fármacos. La preparación de una composición farmacéutica para el suministro en un dispositivo implantable por vía subdérmica puede llevarse a cabo usando métodos conocidos en la técnica, tales como los descritos en, por ejemplo, las Patentes de los Estados Unidos n.° 3.992.518; 5.660.848; y 5.756.115.
Pueden usarse bombas osmóticas como agentes de liberación lenta en forma de comprimidos, píldoras, cápsulas o dispositivos implantables. Se conocen bien en la técnica las bombas osmóticas y se encuentran fácilmente disponibles para un experto habitual en la materia de compañías expertas en proporcionar bombas osmóticas para el suministro de fármacos de liberación prolongada. Los ejemplos son DUROS™ de ALZA; OROS™ de ALZA; el sistema Osmodex™ de Osmotica Pharmaceutical; el sistema EnSoTrol™ de Shire Laboratories; y Alzet™. Las patentes que describen la tecnología de las bombas osmóticas son las Patentes de los Estados Unidos n.° 6.890.918; 6.838.093; 6.814.979; 6.713.086; 6.534.090; 6.514.532; 6.361.796; 6.352.721; 6.294.201; 6.284.276; 6.110.498; 5.573.776; 4.200.098; y 4.088.864. Un experto en la materia, tomando en consideración tanto la divulgación de la presente invención y la divulgación de estas otras patentes podría producir una bomba osmótica para la liberación prolongada de los polipéptidos de la presente invención.
También pueden usarse bombas de jeringa como agentes de liberación lenta. Dichos dispositivos se describen en las Patentes de los Estados Unidos n.° 4.976.696; 4.933.185; 5.017.378; 6.309.370; 6.254.573; 4.435.173; 4.398.908; 6.572.585; 5.298.022; 5.176.502; 5.492.534; 5.318.540; y 4.988.337. Un experto en la materia, tomando en consideración tanto la divulgación de la presente invención y la divulgación de estas otras patentes podría producir una bomba de jeringa para la liberación prolongada de las composiciones de la presente invención.
IX) KITS FARMACÉUTICOS
En otro aspecto, la invención proporciona un kit para facilitar el uso de los polipéptidos GPXTEN reivindicados. El kit comprende la composición farmacéutica proporcionada en el presente documento, una etiqueta que identifica la composición farmacéutica e instrucciones de almacenamiento, reconstitución y/o administración de las composiciones farmacéuticas a un sujeto. En algunas realizaciones, el kit comprende, preferentemente: (a) una cantidad de una composición de proteína de fusión GPXTEN suficiente para tratar una enfermedad, afección o trastorno tras su administración a un sujeto que lo necesite; y (b) una cantidad de un vehículo farmacéuticamente aceptable; juntas en una formulación lista para su inyección o reconstitución con agua estéril, tampón o dextrosa;
junto con una etiqueta que identifica el fármaco de GPXTEN y las condiciones de almacenamiento y manipulación y una hoja con las indicaciones aprobadas para el fármaco, instrucciones para la reconstitución y/o administración del fármaco de GPXTEN para su uso en la prevención y/o tratamiento de una indicación aprobada, la dosis adecuada e información de seguridad e información que identifica el lote y la caducidad del fármaco. En otra realización de lo anterior, el kit puede comprender un segundo recipiente que puede portar un diluyente adecuado para la composición de GPXTEN, que proporcionará al usuario la concentración adecuada de GPXTEN que se va a suministrar al sujeto.
Ejemplos
Ejemplo 1: Construcción de segmentos de motivo XTENAD36
El siguiente ejemplo describe la construcción de una colección de genes con codones optimizados que codifican secuencias de motivo de 36 aminoácidos. Como primera etapa, se construyó un vector de relleno pCW0359 basándose en un vector pET y que incluye un promotor de T7. pCW0359 codifica un dominio de unión a celulosa (CBD) y el sitio de reconocimiento de proteasa TEV seguido de una secuencia de relleno que está flanqueada por
sitios para Bsal, BbsI y Kpnl. Los sitios para Bsal y Bsbl se insertaron de tal forma que generan salientes compatibles tras la digestión. La secuencia de relleno va seguida de una versión truncada del gen de GFP y un marcador His. La secuencia de relleno contiene codones de paradas y por lo tanto, las células de E. coli que portan el plásmido de relleno pCW0359 forman colonias no fluorescentes. El vector de relleno pCW0359 se digirió con BsaI y KpnI para eliminar el segmento de relleno y el fragmento de vector resultante se aisló mediante purificación en gel de agarosa. Las secuencias se denominaron XTEN AD36, que reflejan la familia de motivos AD. Sus segmentos tienen la secuencia de aminoácidos [X]3, donde X es un péptido 12mero con las secuencias: GESPGGSSGSES, GSEGSSGPGESS, GSSESGSSEGGP o GSGGEPSESGSS. El inserto se obtuvo hibridando las siguientes parejas de pares de oligonucleótidos sintéticos fosforilados:
AD1 for: AGGTGAATCTCCDGGTGGYTCYAGCGGTTCYGARTC
AD1 rev: ACCTGAYTCRGAACCGCTRGARCCACCHGGAGATTC
AD2for: AGGTAGCGAAGGTTCTTCYGGTCCDGGYGARTCYTC
AD2rev: ACCTGARGAYTCRCCHGGACCRGAAGAACCTTCGCT
AD3for: AGGTTCYTCYGAAAGCGGTTCTTCYGARGGYGGTCC
AD3rev: ACCTGGACCRCCYTCRGAAGAACCGCTTTCRGARGA
AD4for: AGGTTCYGGTGGYGAACCDTCYGARTCTGGTAGCTC
También se hibridó el oligonucleótido fosforilado 3KpnIstopperFor: AGGTTCGTCTTCACTCGAGGGTAC y el oligonucleótido no fosforilado pr_3KpnIstopperRev: CCTCGAGTGAAGACGA. Se ligaron los pares de oligonucleótidos hibridados, que dieron como resultado una mezcla de productos con diversas longitudes que representan el diverso número de repeticiones de 12mero ligadas a un segmento de BbsI/KpnI. Los productos correspondientes a la longitud de 36 aminoácidos se aislaron de la mezcla mediante electroforesis en gel de agarosa preparativa en el vector de relleno pCW0359 digerido con BsaI/KpnI. La mayoría de los clones en la biblioteca resultante denominados LCW0401 mostraron fluorescencia verde tras la inducción, que muestra que la secuencia de XTENAD36 tenía ligado en fase el gen de GFP y que la mayoría de las secuencias de XTENAD36 tenían buenos niveles de expresión.
Se exploraron 96 aislados de la biblioteca LCW0401 respecto de un alto nivel de fluorescencia estampándolos sobre una placa de agar que contenía IPTG. Se evaluaron los mismos aislados mediante PCR y se identificaron 48 aislados que contenían segmentos con 36 aminoácidos, así como una fuerte fluorescencia. Estos aislados se secuenciaron y se identificaron 39 clones que contenían los segmentos de XTEN AD36 correctos. Los nombres de archivo de las construcciones de nucleótidos y aminoácidos para estos segmentos se listan en la tabla 10.




Ejemplo 2: Construcción de segmentos XTENAE36
Se construyó una biblioteca de codones que codifican secuencias de XTEN de 36 aminoácidos de longitud. La secuencia de XTEN se denominó XTEN AE36. Sus segmentos tienen la secuencia de aminoácidos [X]3 donde X es un péptido 12mero con la secuencia: GSPAGSPTSTEE, GSEPATSGSE TP, GTSESA TPESGP o GTSTEPSEGSAP. El inserto se obtuvo hibridando las siguientes parejas de pares de oligonucleótidos sintéticos fosforilados:
AE1for: AGGTAGCCCDGCWGGYTCTCCDACYTCYACYGARGA
AE1 rev: ACCTTCYTCRGTRGARGTHGGAGARCCWGCHGGGCT
AE2for: AG GT AGCGAACC KG CWACYT CYGGYT CT G ARACYCC
AE2rev: ACCTGGRGTYTCAGARCCRGARGTWGCMGGTTCGCT
AE3for: AGGTACYTCTGAAAGCGCWACYCCKGARTCYGGYCC
AE3rev: ACCTGGRCCRGAYTCMGGRGTWGCGCTTTCAGARGT
AE4for: AGGTACYTCTACYGAACCKTCYGARGGYAGCGCWCC
AE4rev: ACCTGGWGCGCTRCCYTCRGAMGGTTCRGTAGARGT
También se hibridó el oligonucleótido fosforilado 3KpnIstopperFor: AGGTTCGTCTTCACTCGAGGGTAC y el oligonucleótido no fosforilado pr_3KpnIstopperRev: CCTCGAGTGAAGACGA. Se ligaron los pares de oligonucleótidos hibridados, que dieron como resultado una mezcla de productos con diversas longitudes que representan el diverso número de repeticiones de 12mero ligadas a un segmento de BbsI/KpnI. Los productos correspondientes a la longitud de 36 aminoácidos se aislaron de la mezcla mediante electroforesis en gel de agarosa preparativa en el vector de relleno pCW0359 digerido con BsaI/KpnI. La mayoría de los clones en la biblioteca resultantes denominados LCW0402 mostraron fluorescencia verde tras la inducción, lo que muestra que la secuencia de XTEN AE36 se había ligado en fase con el gen de GFP y la mayoría de las secuencias de XTEN AE36 muestran buena expresión.
Se exploraron 96 aislados de la biblioteca LCW0402 respecto de un alto nivel de fluorescencia estampándolos sobre una placa de agar que contenía IPTG. Se evaluaron los mismos aislados mediante PCR y se identificaron 48 aislados que contenían segmentos con 36 aminoácidos, así como una fuerte fluorescencia. Estos aislados se secuenciaron y se identificaron 37 clones que contenían los segmentos de XTEN AE36 correctos. Los nombres de archivo de las construcciones de nucleótidos y aminoácidos para estos segmentos se listan en la tabla 11.




Ejemplo 3: Construcción de segmentos XTEN_AF36
Se construyó una biblioteca de codones que codifican secuencias de 36 aminoácidos de longitud. Las secuencias se denominaron XTEN AF36. Sus segmentos tienen la secuencia de aminoácidos [X]3 donde X es un péptido 12mero con la secuencia: GSTSESPSGTAP, GTSTPESGSASP, GTSPSGESSTAP o GsTs STAESPGP. El inserto se obtuvo hibridando las siguientes parejas de pares de oligonucleótidos sintéticos fosforilados:
AF1for: AGGTTCTACYAGCGAATCYCCKTCTGGYACYGCWCC
AF1 rev: ACCTGGWGCRGTRCCAGAMGGRGATTCGCTRGTAGA
AF2for: AGGTACYTCTACYCCKGAAAGCGGYTCYGCWTCTCC
AF2rev: ACCTGGAGAWGCRGARCCGCTTTCMGGRGTAGARGT
AF3for: AGGTACYTCYCCKAGCGGYGAATCTTCTACYGCWCC
AF3rev: ACCTGGWGCRGTAGAAGATTCRCCGCTMGGRGARGT
AF4for: AGGTTCYACYAGCTCTACYGCWGAATCTCCKGGYCC
AF4rev: ACCTGGRCCMGGAGATTCWGCRGTAGAGCTRGTRGA
También se hibridó el oligonucleótido fosforilado 3KpnIstopperFor: AGGTTCGTCTTCACTCGAGGGTAC y el oligonucleótido no fosforilado pr_3KpnIstopperRev: CCTCGAGTGAAGACGA. Se ligaron los pares de oligonucleótidos hibridados, que dio como resultado una mezcla de productos con diversas longitudes que representan el variante número de repeticiones de 12mero ligadas a un segmento de BbsI/KpnI. Los productos correspondientes a la longitud de 36 aminoácidos se aislaron de la mezcla mediante electroforesis en gel de agarosa preparativa y se ligaron en el vector de relleno pCW0359 digerido con BsaI/KpnI. La mayoría de los clones en la biblioteca resultantes denominados LCW0403 mostraron fluorescencia verde tras la inducción, lo que muestra que la secuencia de XTEN _AE36 se había ligado en fase con el gen de GFP y la mayoría de las secuencias de XTEN_AF36 muestran buena expresión.
Se exploraron 96 aislados de la biblioteca LCW0403 respecto de un alto nivel de fluorescencia estampándolos sobre una placa de agar que contenía IPTG. Se evaluaron los mismos aislados mediante PCR y se identificaron 48 aislados que contenían segmentos con 36 aminoácidos, así como una fuerte fluorescencia. Estos aislados se secuenciaron y se identificaron 44 clones que contenían los segmentos de XTEN_AF36 correctos. Los nombres de archivo de las construcciones de nucleótidos y aminoácidos para estos segmentos se listan en la tabla 12.




Ejemplo 4: Construcción de segmentos XTENAG36
Se construyó una biblioteca de codones que codifican secuencias de 36 aminoácidos de longitud. Las secuencias se denominaron XTEN AG36. Sus segmentos tienen la secuencia de aminoácidos [X]3 donde X es un péptido 12mero con la secuencia: GTPGSGTASSSP, GSSTPSGATGSP, GSSPSASTGTGP o GASPGTSSTGSP. El inserto se obtuvo hibridando las siguientes parejas de pares de oligonucleótidos sintéticos fosforilados:
AG1for: AGGTACYCCKGGYAGCGGTACYGCWTCTTCYTCTCC
AG1rev: ACCTGGAGARGAAGAWGCRGTACCGCTRCCMGGRGT
AG2for: AGGTAGCTCTACYCCKTCTGGTGCWACYGGYTCYCC
AG2rev: ACCTGGRGARCCRGTWGCACCAGAMGGRGTAGAGCT
AG3for: AGGTTCTAGCCCKTCTGCWTCYACYGGTACYGGYCC
AG3rev: ACCTGGRCCRGTACCRGTRGAWGCAGAMGGGCTAGA
AG4for: AG GTG CWT CYCCKG GYACYAG CTCTACYG GTTCTCC
AG4rev: ACCTGGAGAACCRGTAGAGCTRGTRCCMGGRGAWGC
También se hibridó el oligonucleótido fosforilado 3KpnIstopperFor: AGGTTCGTCTTCACTCGAGGGTAC y el oligonucleótido no fosforilado pr_3KpnIstopperRev: CCTCGAGTGAAGACGA. Se ligaron los pares de oligonucleótidos hibridados, que dieron como resultado una mezcla de productos con diversas longitudes que representan el diverso número de repeticiones de 12mero ligadas a un segmento de BbsI/KpnI. Los productos correspondientes a la longitud de 36 aminoácidos se aislaron de la mezcla mediante electroforesis en gel de agarosa preparativa en el vector de relleno pCW0359 digerido con BsaI/KpnI. La mayoría de los clones en la biblioteca resultantes denominados LCW0404 mostraron fluorescencia verde tras la inducción, lo que muestra que la secuencia de XTEN_AE36 se había ligado en fase con el gen de GFP y la mayoría de las secuencias de XTENAG36 muestran buena expresión.
Se exploraron 96 aislados de la biblioteca LCW0404 respecto de un alto nivel de fluorescencia estampándolos sobre una placa de agar que contenía IPTG. Se evaluaron los mismos aislados mediante PCR y se identificaron 48 aislados que contenían segmentos con 36 aminoácidos, así como una fuerte fluorescencia. Estos aislados se secuenciaron y se identificaron 44 clones que contenían los segmentos de XTEN_AG36 correctos. Los nombres de archivo de las construcciones de nucleótidos y aminoácidos para estos segmentos se listan en la tabla 13.
Tabla 13: Secuencias de ADN y aminoácidos para motivos 36-meros




Ejemplo 5: Construcción de XTENAE864
Se construyó XTEN AE864 a partir de la dimerización seriada de XTEN AE36 en AE72, 144, 288, 576 y 864. Se construyó una colección se segmentos XTEN AE72 a partir de 37 segmentos diferentes de XTEN_AE36. Se mezclaron cultivos de E. co lique portaban los 37 diferentes segmentos de 36 aminoácidos y se aislaron los plásmidos. El acervo de plásmidos se digirió con BsaI/NcoI para generar el fragmento pequeño como inserto. El acervo de plásmidos de muestra se digirió con BbsI/NcoI para generar el fragmento grande como vector. Los fragmentos de inserto y vector se ligaron, dando como resultado una duplicación de la longitud y la mezcla de ligamiento se transformó en células BL21Gold(DE3) para obtener colonias de XTEN AE72.
Esta biblioteca de segmentos XTEN AE72 se denominó LCW0406. Todos los clones de LCW0406 se combinaron y dimerizaron de nuevo usando el mismo proceso como se ha descrito anteriormente, para proporcionar la biblioteca LCW0410 de XTEN AE144. Todos los clones de LCW0410 se combinaron y dimerizaron de nuevo usando el mismo proceso como se ha descrito anteriormente, para proporcionar la biblioteca LCW0414 de XTEN AE288. Se recogieron aleatoriamente dos aislados de la biblioteca, LCW0414.001 y LCW0414.002 y se secuenciaron para verificar las identidades. Todos los clones de LCW0414 se combinaron y dimerizaron de nuevo usando el mismo proceso como se ha descrito anteriormente, para proporcionar la biblioteca LCW0418 de XTEN AE576. Se exploraron 96 aislados de la biblioteca LCW0418 respecto de un elevado nivel de fluorescencia de GFP. Se secuenciaron 8 aislados con los tamaños de los insertos adecuados mediante la PCR y fuerte fluorescencia y se seleccionaron 2 aislados (LCW0418.018 y LCW0418.052) para su uso futuro basándose en los datos de secuenciación y expresión.
El clon específico pCW0432 de XTEN AE864 se construyó combinando LCW0418.018 de XTEN AE576 y LCW0414.002 de XTEN AE288 usando el mismo proceso de dimerización descrito anteriormente.
Ejemplo 6: Construcción de XTENAM144
Se construyó una colección de segmentos XTEN_AM144 partiendo de 37 segmentos distintos de XTEN_AE36, 44 segmentos de XTEN_AF36 y 44 segmentos de XTEN AG36.
Se mezclaron cultivos de E. coli que portaban los 125 diferentes segmentos de 36 aminoácidos y se aislaron los plásmidos. El acervo de plásmidos se digirió con BsaI/NcoI para generar el fragmento pequeño como inserto. El acervo de plásmidos de muestra se digirió con BbsI/NcoI para generar el fragmento grande como vector. Los fragmentos de inserto y vector se ligaron, dando como resultado una duplicación de la longitud y la mezcla de ligamiento se transformó en células BL21Gold(DE3) para obtener colonias de XTEN AM72.
Esta biblioteca de segmentos XTEN AM72 se denominó LCW0461. Todos los clones de LCW0461 se combinaron y dimerizaron de nuevo usando el mismo proceso como se ha descrito anteriormente, para proporcionar la biblioteca LCW0462. Se exploraron 1512 aislados de la biblioteca LCW0462 respecto de su expresión de proteína. Las colonias individuales se transfirieron a placas de 96 pocillos y se cultivaron durante una noche como cultivos de partida. Estos cultivos de inicio se diluyeron en medio para autoinducción fresco y se cultivaron durante 20-30 h. La expresión se midió usando un lector de placas de fluorescencia con excitación a 395 nm y emisión a 510 nm. 192 aislados mostraron un alto nivel de expresión y se remitieron para secuenciación del ADN. La mayoría de los clones en la biblioteca LCW0462 mostró buena expresión y propiedades fisicoquímicas similares, lo que sugiere que la mayoría de combinaciones de segmentos XTEN_AM36 proporciona secuencias de XTEN útiles. Se seleccionaron 30 aislados de LCW0462 como colección preferida de segmentos XTEN AM144 para la construcción de proteínas multifuncionales que contienen múltiples segmentos de XTEN. Los nombres de archivo de las construcciones de nucleótidos y aminoácidos para estos segmentos se listan en la tabla 14.
Tabla 14: Secuencias de ADN y de aminoácidos para segmentos AM144





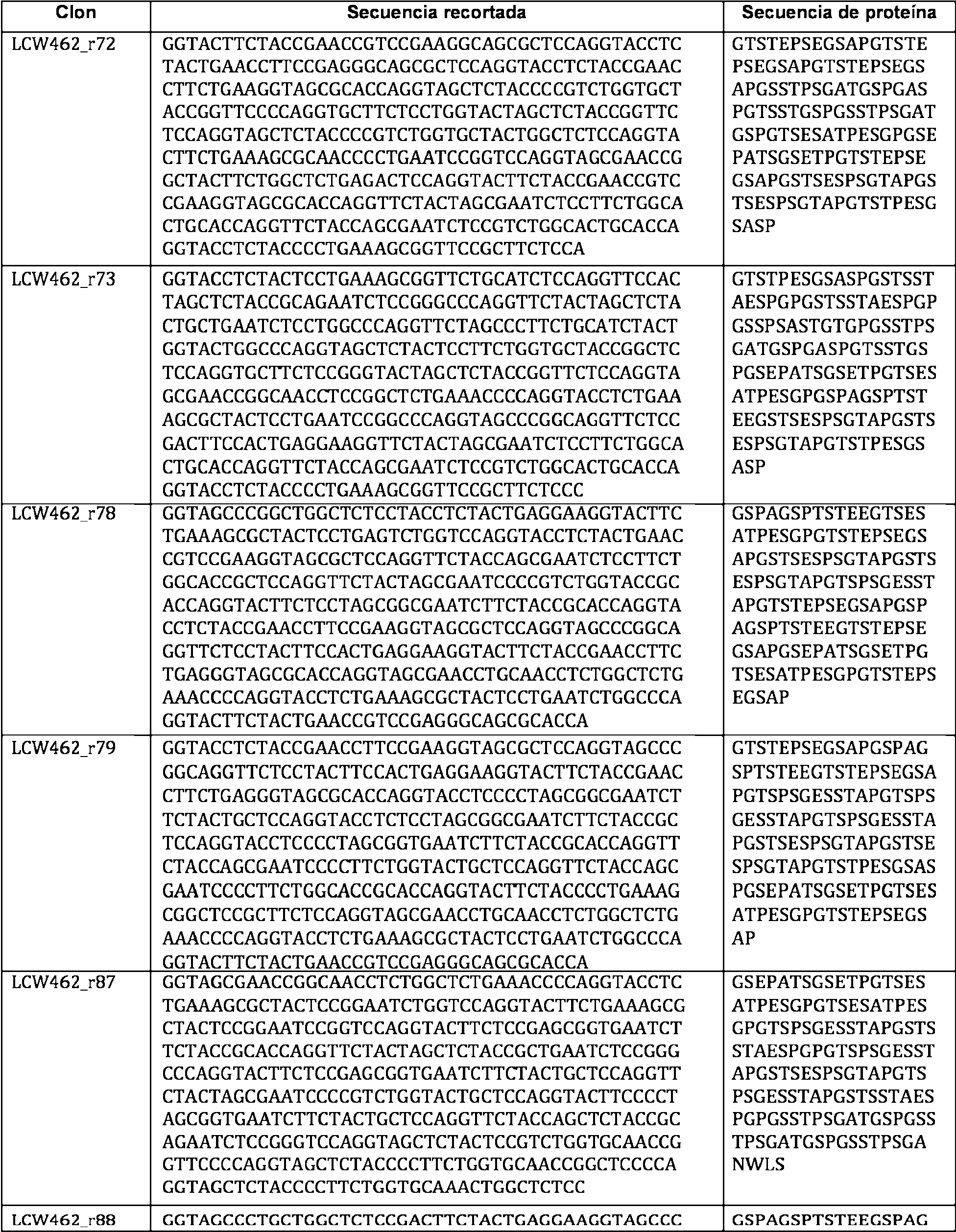

Ejemplo 7: Construcción de XTENAM288
Se dimerizó la biblioteca LCW0462 completa como se describe en el ejemplo 6, dando como resultado una biblioteca de clones de XTEN AM288 denominada LCW0463. Se seleccionaron 1512 aislados de la biblioteca LCW0463 usando el protocolo descrito en el ejemplo 6. Se secuenciaron 176 clones de alta expresión y se seleccionaron 40 segmentos preferidos de XTEN AM288 para la construcción de proteínas multifuncionales que contienen múltiples segmentos de XTEN con 288 restos de aminoácido.
Ejemplo 8: Construcción de XTENAM432
Se generó una biblioteca de segmentos XTEN AM432 recombinando segmentos de la biblioteca LCW0462 de segmentos XTEN AM144 y segmentos de la biblioteca LCW0463 de segmentos XTEN AM288. Esta nueva biblioteca de segmentos XTEN AM432 se denominó LCW0464. Se aislaron plásmidos de cultivos de E. coli que portan LCW0462 y LCW0463, respectivamente. Se seleccionaron 1512 aislados de la biblioteca LCW0464 usando el protocolo descrito en el ejemplo 6. Se secuenciaron 176 clones de alta expresión y se seleccionaron 39 segmentos preferidos de XTEN AM432 para la construcción de XTEN más largos y para la construcción de proteínas multifuncionales que contienen múltiples segmentos de XTEN con 432 restos de aminoácido.
En paralelo, se construyó la biblioteca LMS0100 de segmentos XTEN AM432 usando los segmentos preferidos de XTEN AM144 y XTEN AM288. La exploración de esta biblioteca proporcionó 4 aislados que se seleccionaron para su construcción adicional
Ejemplo 9: Construcción de XTEN AM875
El vector de relleno pCW0359 se digirió con BsaI y KpnI para eliminar el segmento de relleno y el fragmento de vector resultante se aisló mediante purificación en gel de agarosa.
Se hibridó el oligonucleótido fosforilado BsaI-AscI-KpnIforP:
AGGTGCAAGCGCAAGCGGCGCGCCAAGCACGGGAGGTTCGTCTTCACTCGAGGGTAC y el oligonucleótido no fosforilado BsaI-AscI-KpnIrev:
CCTCGAGTGAAGACGAACCTCCCGTGCTTGGCGCGCCGCTTGCGCTTGC para introducir la isla de secuenciación A (SI-A) que codifica los aminoácidos GASASGAPSTG y tiene la secuencia de reconocimiento para la enzima de restricción AscI, GGCGCGCC en su interior. Los pares de oligonucleótido hibridados se ligaron con el vector de relleno pCW0359 digerido con BsaI y KpnI preparado anteriormente para proporcionar pCW0466 que contenía SI-A. Después, se generó una biblioteca de segmentos XTEN AM443 recombinando 43 segmentos XTEN AM432 preferidos del ejemplo 8 y segmentos de SI-A de pCW0466 en el extremo C-terminal usando el mismo proceso de dimerización descrito en el ejemplo 5. Esta nueva biblioteca de segmentos XTEN AM443 se denominó LCW0479.
Se generó una biblioteca de segmentos XTEN AM875 recombinando segmentos de la biblioteca LCW0479 de segmentos XTEN AM443 y 43 segmentos XTEN AM432 preferidos del ejemplo 8 usando el mismo proceso de dimerización descrito en el ejemplo 5. Esta nueva biblioteca de segmentos XTEN AM875 se denominó LCW0481.
Ejemplo 10: Construcción de XTENAM1318
Se hibridó el oligonucleótido fosforilado Bsal-Fsel-KpnIforP:
AGGTCCAGAACCAACGGGGCCGGCCCCAAGCGGAGGTTCGTCTTCACTCGAGGGTAC y el oligonucleótido no fosforilado BsaI-FseI-KpnIrev:
CCTCGAGTGAAGACGAACCTCCGCTTGGGGCCGGCCCCGTTGGTTCTGG para introducir la isla de secuenciación B (SI-B) que codifica los aminoácidos GPEPTGPAPSG y tiene la secuencia de nucleótidos de reconocimiento para la enzima de restricción FseI, GGCCGGCC en su interior. Los pares de oligonucleótido hibridados se ligaron con el vector de relleno pCW0359 digerido con BsaI y KpnI como se usa en el ejemplo 9 para proporcionar pCW0467 que contenía SI-B. Después, se generó una biblioteca de segmentos XTEN AM443 recombinando 43 segmentos XTEN AM432 preferidos del ejemplo 8 y segmentos de SI-B de pCW0467 en el extremo C-terminal usando el mismo proceso de dimerización descrito en el ejemplo 5. Esta nueva biblioteca de segmentos XTEN AM443 se denominó LCW0480.
Se generó una biblioteca de segmentos XTEN AM1318 recombinando segmentos de la biblioteca LCW0480 de segmentos XTEN AM443 y segmentos de la biblioteca LCW0481 de segmentos XTEN AM875 usando el mismo proceso de dimerización que en el ejemplo 5. Esta nueva biblioteca de segmentos XTEN AM1318 se denominó LCW0487.
Ejemplo 11: Construcción de XTENAD864
Usando las diversas rondas de dimerización consecutivas, se ensambló una colección de secuencias XTEN AD864 partiendo de segmentos XTEN_AD36 listados en el ejemplo 1. Estas secuencias se ensamblaron como se describe en el ejemplo 5. Se evaluaron varios aislados de XTEN AD864 y se observó que mostraban buena expresión y una excelente solubilidad en condiciones fisiológicas. Se secuenció una construcción intermedia de XTEN AD576. Este clon se evaluó en un experimento PK en monos cinomolgos y se midió una semivida de aproximadamente 20 h.
Ejemplo 12: Construcción de XTEN AF864
Usando las diversas rondas de dimerización consecutivas, se ensambló una colección de secuencias XTEN AF864 partiendo de segmentos XTEN AF36 listados en el ejemplo 3. Estas secuencias se ensamblaron como se describe en el ejemplo 5. Se evaluaron varios aislados de Xt En AF864 y se observó que mostraban buena expresión y una excelente solubilidad en condiciones fisiológicas. Se secuenció una construcción intermedia de XTEN AF540. Este clon se evaluó en un experimento PK en monos cinomolgos y se midió una semivida de aproximadamente 20 h. Un clon de longitud completa de XTEN AF864 tuvo una excelente solubilidad y mostró una semivida que superaba las 60 h en monos cinomolgos. Se ensambló un segundo conjunto de secuencias XTEN_AF que incluyen una isla de secuenciación, tal como se describe en el ejemplo 9.
Ejemplo 13: Construcción de XTENAG864
Usando las diversas rondas de dimerización consecutivas, se ensambló una colección de secuencias XTEN AG864 partiendo de segmentos XTEN AD36 listados en el ejemplo 1. Estas secuencias se ensamblaron como se describe en el ejemplo 5. Se evaluaron varios aislados de XTEN AG864 y se observó que mostraban buena expresión y una excelente solubilidad en condiciones fisiológicas. Un clon de longitud completa de XTEN AG864 tuvo una excelente solubilidad y mostró una semivida que superaba las 60 h en monos cinomolgos.
Ejemplo 14: Construcción de extensiones N-terminales de construcciones de XTEN y exploración de bibliotecas de adición de 12meros
Este ejemplo detalla una etapa en la optimización del extremo N-terminal de la proteína XTEN para promover el inicio de la traducción para permitir la expresión de fusiones de XTEN en el extremo N-terminal de proteínas de fusión sin la presencia de un dominio auxiliar. Históricamente, la expresión de proteínas con XTEN en el extremo N-terminal ha sido escasa, proporcionando valores que podrían ser básicamente indetectables en el ensayo de fluorescencia de GFP (<25 % de la expresión con el dominio auxiliar CBD N-terminal). Para crear diversidad a nivel de codones, se seleccionaron y prepararon siete aminoácidos con diversos codones. Se diseñaron siete pares de oligonucleótidos que codificaban 12 aminoácidos con diversidad de codones, se hibridaron y se ligaron en el vector de relleno pCW0551 digerido con las enzimas de restricción NdeI/BsaI (Stuffer-XTEN_AM875-GFP) y se transformó en células E. coli BL21Gold(DE3) competentes para obtener colonias de las siete bibliotecas. Los clones resultantes tienen 12meros de XTEN N-terminales fusionados en fase a XTEN AM875-GFP para permitir el uso de fluorescencia de GFP para explorar la expresión. Se recogieron colonias individuales de las siete bibliotecas creadas y se cultivaron durante una noche hasta la saturación en 500 |jl de medio de caldo Super en una placa de 96 pocillos profundos. El número de colonias recogidas varió de aproximadamente la mitad a una tercera parte de la diversidad teórica de la biblioteca (véase la tabla 15).
Tabla 15: Diversidad teórica y número de muestras para las bibliotecas de adición de 12meros. Se subrayan los restos de aminoácidos con codones aleatorizados.

Los cultivos saturados durante una noche se usaron para inocular cultivos de 500 pl frescos en medio de autoinducción en el que se cultivaron durante una noche a 26 °C. Después, se evaluaron estos cultivos de expresión usando un lector de placas de fluorescencia (excitación a 395 nm, emisión a 510 nm) para determinar la cantidad de indicador de GFP presente (véase la FIG. 9 para los resultados de los ensayos de expresión). Los resultados, representados como gráficas de cajas y bigotes, indican que aunque la mediana de los niveles de expresión fue aproximadamente la mitad de los niveles de expresión en comparación con el "punto de referencia" del dominio auxiliar N-terminal de CBD, los mejores clones de las bibliotecas se encontraron mucho más próximos a los puntos de referencia, lo que indica que queda garantizada una optimización adicional alrededor de estas secuencias. Esto contrasta con las versiones previas de XTEN que tenían <25 % de los niveles de expresión del punto de referencia N-terminal de CBD. Los resultados también muestran que las bibliotecas que comienzan con los aminoácidos MA tenían mejores niveles de expresión que aquellas que comienzan con ME. Esto se evidenció cuando se observaron los mejores clones, que eran más próximos a los puntos de referencia, ya que la mayoría comienzan con MA. De los 176 dentro del 33 % del punto de referencia de CBD-AM875, el 87 % comienza con Ma , mientras que solo un 75 % de las secuencias en las bibliotecas comienzan con MA, una clara sobrerrepresentación de los clones que comienzan con MA con el máximo nivel de expresión. Se secuenciaron 96 de los mejores clones para confirmar la identidad y se seleccionaron doce secuencias (véase la tabla 16), 4 de LCW546, 4 de LCW547 y 4 de LCW552 para su optimización adicional.
T l 1 : n i n l i ADN 12m r v nz


Ejemplo 15: Construcción de extensiones N-terminales de construcción de XTEN y exploración de bibliotecas que optimizan los codones 3 y 4
Este ejemplo detalla una etapa en la optimización del extremo N-terminal de la proteína XTEN para promover el inicio de la traducción para permitir la expresión de fusiones de XTEN en el extremo N-terminal de proteínas sin la presencia de un dominio auxiliar. Habiéndose establecido las preferencias para los dos primeros codones (véase el ejemplo anterior), se aleatorizaron los codones tercero y cuarto para determinar las preferencias. Se diseñaron tres bibliotecas, basadas en los mejores clones de LCW546, LCW547 y LCW552 con los restos tercero y cuarto modificados, de tal forma que se encontraban presentes en estas posiciones todas las combinaciones de codones de XTEN permisibles (véase la FIG. 10). A fin de incluir todos los codones de XTEN permisibles para cada biblioteca, se diseñaron nueve pares de oligonucleótidos que codificaban 12 aminoácidos con diversidades de codones de los restos tercero y cuarto, se hibridaron y se ligaron en el vector de relleno pCW0551 digerido con las enzimas de restricción NdeI/BsaI (Stuffer-XTEN_AM875-GFP) y se transformó en células E. coli BL21Gold(DE3) competentes para obtener colonias de las tres bibliotecas LCW0569-571. Con 24 codones de XTEN, la diversidad teórica de cada biblioteca es de 576 clones únicos. Se recogió un total de 504 colonias individuales de las tres bibliotecas creadas y se cultivaron durante una noche hasta la saturación en 500 |jl de medio de caldo Super en una placa de 96 pocillos profundos. Esto proporcionó suficiente cobertura para comprender el rendimiento relativo y las preferencias de secuencia de las bibliotecas. Los cultivos saturados durante una noche se usaron para inocular nuevos cultivos de 500 j l en medio de autoinducción en el que se cultivaron durante una noche a 26 °C. Después, se evaluaron estos cultivos de expresión usando un lector de placas de fluorescencia (excitación a 395 nm, emisión a 510 nm) para determinar la cantidad de indicador de GFP presente. Se secuenciaron los 75 mejores clones y se volvieron a ensayar para la expresión indicadora de GFP frente a las muestras de referencia (véase la FIG. 11). 52 clones proporcionaron datos de secuenciación utilizables y se usaron para el análisis posterior. Los resultados se clasificaron por biblioteca e indican que LCW546 es la mejor biblioteca. Los resultados se presentan en la Tabla 17. Sorprendentemente, se descubrió que las lecturas de fluorescencia basales para los mejores clones eran de ~900 UA, mientras que el punto de referencia N-terminal de CBD tenía solo ~600 Ua . Esto indica que esta biblioteca suponía una mejora de aproximadamente el 33 % frente a los mejores clones de la biblioteca anterior, que tenían una expresión aproximadamente igual al punto de referencia N-terminal de CBD (ejemplo 14).
Tabte uarto

Se observaron tendencias adicionales en los datos, mostrando preferencias por codones particulares en la posición tercera y cuarta. En la biblioteca LCW569, se asociaron el codón GAA de glutamato en la tercera posición y el codón ACT de treonina con una mayor expresión, como se observa en la tabla 18.
T l 1 : n r r r r f ri n L W

Además, el reensayo de los 75 mejores clones indicó que varios eran superiores a los clones de referencia.
Ejemplo 16: Construcción de extensiones N-terminales de construcciones de XTEN y exploración de bibliotecas combinatorias de 12meros y 36meros
Este ejemplo detalla una etapa en la optimización del extremo N-terminal de la proteína XTEN para promover el inicio de la traducción para permitir la expresión de fusiones de XTEN en el extremo N-terminal de proteínas sin la presencia de un dominio auxiliar. Habiéndose establecido las preferencias para los dos primeros codones (véase el ejemplo anterior), se examinó el extremo N-terminal en un contexto más amplio combinando las 12 secuencias de 12mero seleccionadas (véase el ejemplo anterior) en el mismo extremo N-terminal, seguido de 125 segmentos de 36meros
construidos previamente (véase el ejemplo anterior) de un modo combinatorio. Esto creó nuevos 48meros en el extremo N-terminal de la proteína XTEn y permitió la evaluación del impacto de las interacciones de mayor rango en el extremo N-terminal en la expresión de las secuencias más largas (FIG. 12). De manera similar a los procedimientos de dimerización usados para ensamblar 36meros (véase el ejemplo más adelante), se digirieron los plásmidos que contenían los 125 segmentos de 36meros con las enzimas de restricción BbsI/NcoI y el fragmento adecuado se purificó en gel. También se digirió el plásmido del clon AC94 (CBD-XTENAM875-GFP) con BsaI/NcoI y los fragmentos adecuados se purificaron en gel. Estos fragmentos se ligaron y se transformaron en células E. coli BL21Gold(DE3) competentes para obtener colonias de la biblioteca LCW0579, que también sirvieron como el vector para clonar adicionalmente los 12 12meros seleccionados en el mismo extremo N-terminal. Los plásmidos de LCW0579 se digirieron con NdeI/EcoRI/BsaI y los fragmentos adecuados se purificaron en gel. se diseñaron 12 pares de oligonucleótidos que codifican las 12 secuencias de 12meros, se hibridaron y se ligaron con el vector LCW0579 digerido con NdcI/EcoRI/BsaI y se transformaron en células E. coli BL21 Gold(DE3) competentes para obtener colonias de la biblioteca LCW0580. Con una diversidad teórica de 1500 clones únicos, Se recogió un total de 1512 colonias individuales de la biblioteca creada y se cultivaron durante una noche hasta la saturación en 500 pl de medio de caldo Super en una placa de 96 pocillos profundos. Esto proporcionó suficiente cobertura para comprender el rendimiento relativo y las preferencias de secuencia de las bibliotecas. Los cultivos saturados durante una noche se usaron para inocular nuevos cultivos de 500 pl en medio de autoinducción en el que se cultivaron durante una noche a 26 °C. Después, se evaluaron estos cultivos de expresión usando un lector de placas de fluorescencia (excitación a 395 nm, emisión a 510 nm) para determinar la cantidad de indicador de GFP presente. Se secuenciaron los 90 mejores clones y se volvieron a ensayar para la expresión indicadora de GFP. 83 clones proporcionaron datos de secuenciación utilizables y se usaron para el análisis posterior. Los datos de secuenciación se usaron para determinar los mejores 12meros que estaban presentes en cada clon y se evaluó el impacto de cada 12mero en la expresión. Los clones LCW54606 y LCW54609 destacaron como los mejores extremos N-terminales (véase la tabla 19).
T l 1 : R n imi n r l iv l n mi nz n n L W 4 L W4

La secuenciación y el reensayo también revelaron varios casos de replicados independientes de la misma secuencia en los datos, produciendo resultados similares, aumentando por tanto la confianza en el ensayo. Además, 10 clones con 6 secuencias únicas fueron superiores al clon de referencia. Se presentan en la tabla 20. Se observó que estas eran las únicas apariciones de estas secuencias y en ningún caso se produjo una sola de estas secuencias y no lograron batir al clon de referencia. Estas seis secuencias se seleccionaron para su purificación adicional.
T l 2 : l n m in ri 12m r m r ri r l l n r f r n i


Ejemplo 17: Construcción de extensiones N-terminales de construcciones de XTEN y exploración de bibliotecas combinatorias de 12meros y 36meros para XTEN-AM875 y XTEN-AE864
Este ejemplo detalla una etapa en la optimización del extremo N-terminal de la proteína XTEN para promover el inicio de la traducción para permitir la expresión de fusiones de XTEN en el extremo N-terminal de proteínas sin la presencia de un dominio auxiliar. Habiéndose determinado las preferencias para los primeros cuatro codones (véanse los ejemplos anteriores y para el mejor emparejamiento de 12meros y 36meros N-terminales (véase el ejemplo anterior)), se llevó a cabo una estrategia combinatoria para examinar la unión de estas preferencias. Esto creó nuevos 48meros en el extremo N-terminal de la proteína XTEN y permitió comprobar la confluencia de las conclusiones anteriores. Además, se evaluó la capacidad de estas secuencias líder para ser una solución universal para todas las proteínas XTEN colocando los nuevos 48meros delante tanto de XTEN-AE864 como de XTEN-AM875. En lugar de usar los 125 clones de segmentos de 36meros, los plásmidos de los 6 clones seleccionados de segmentos de 36meros con mejor expresión de GFP en la biblioteca combinatoria se digirieron con NdeI/EcoRI/BsaI y los fragmentos adecuados se
purificaron en gel. Los plásmidos de los clones AC94 (CBD-XTEN AM875-GFP) y AC104 (CBD-XTEN AE864-GFP) se digirieron con NdeI/EcoRI/BsaI y se purificaron en gel los fragmentos adecuados. Estos fragmentos se ligaron y se transformaron en células E. coli BL21Gold(DE3) competentes para obtener colonias de las bibliotecas LCW0585 (-XTENAM875-GFP) y LCW0586 (-XTENAE864-GFP), que también podrían servir como los vectores para clonar adicionalmente 8 12meros seleccionados en el mismo extremo N-terminal. Los plásmidos de LCW0585 y LCW0586 se digirieron con NdeI/EcoRI/BsaI y los fragmentos adecuados se purificaron en gel. Se diseñaron 8 pares de oligonucleótidos que codificaban las 8 secuencias de 12meros seleccionadas con mejor expresión de GFP en la exploración previa (generación 2), se hibridaron y se ligaron con los vectores LCW0585 y LCW0586 digeridos con NdeI/EcoRI/BsaI y se transformaron en células E. coli BL21Gold(DE3) competentes para obtener colonias de las bibliotecas finales, LCW0587 (XTEN AM923-GFP) y LCW0588 (XTEN AE912-GFP). Con una diversidad teórica de 48 clones únicos, Se recogió un total de 252 colonias individuales de las bibliotecas creadas y se cultivaron durante una noche hasta la saturación en 500 pl de medio de caldo Super en una placa de 96 pocillos profundos. Esto proporcionó suficiente cobertura para comprender el rendimiento relativo y las preferencias de secuencia de las bibliotecas. Los cultivos saturados durante una noche se usaron para inocular nuevos cultivos de 500 pl en medio de autoinducción en el que se cultivaron durante una noche a 26 °C. Después, se evaluaron estos cultivos de expresión usando un lector de placas de fluorescencia (excitación a 395 nm, emisión a 510 nm) para determinar la cantidad de indicador de GFP presente. Se secuenciaron los 36 mejores clones y se volvieron a ensayar para la expresión indicadora de GFP.
36 clones proporcionaron datos de secuenciación utilizables y se usaron estos 36 para el análisis posterior. Los datos de secuenciación determinaron que el 12mero, el tercer codón, el cuarto codón y el 36mero estaban presentes en el clon y revelaron que muchos de los clones eran replicados independientes de la misma secuencia. Además, los resultados del reensayo de estos clones tienen valores semejantes, lo que indica que el proceso de exploración era robusto. Se observaron preferencias para ciertas combinaciones en el extremo N-terminal y de manera consistente proporcionaron mayores valores de fluorescencia aproximadamente un 50 % mayores que los controles de referencia (véanse las tablas 21 y 22). Estos datos respaldan la conclusión de que la inclusión de las secuencias que codifican el XTEN N-terminal optimizado en los genes de proteína de fusión confirió una mejora notable en la expresión de las proteínas de fusión.
T l 21: m in i n N- rmin l r f ri r XTEN-AM 7

T l 22: m in i n N- rmin l r f ri r XTEN-AE 4

De forma destacable, la combinación preferida del N-terminal para el XTEN-AM875 y la combinación preferida para el XTEN-AE864 no son iguales (tablas 2 l y 22), lo que indica que las interacciones más complejas más allá de las 150 bases del sitio de inicio tienen influencia en los niveles de expresión. Las secuencias para las secuencias de nucleótidos preferidas se listan en la tabla 23 y los clones preferidos se analizaron mediante SDS-PAGE para confirmar la expresión de manera independiente (véase la FIG. 13). Las secuencias completas de XTEN AM923 y XTEN AE912 se seleccionaron para su análisis adicional.
Tabla 23: Secuencias de nucleótidos de ADN preferidas para los primeros 48 restos de aminoácido de XTEN-


Ejemplo 18: Métodos para producir y evaluar GPXTEN; XTEN-Ex4 a modo de ejemplo
En la FIG. 6 se presenta un esquema general para producir y evaluar composiciones de GPXTEN y forma la base para la descripción general de este ejemplo. Usando los métodos divulgados y aquellos conocidos por un experto habitual en la materia, junto con la orientación proporcionada en los ejemplos ilustrativos, un experto en la materia puede crear y evaluar una serie de proteínas de fusión GPXTEN que comprenden, XTEN, GP y variantes de GP conocidas en la técnica. Por lo tanto, el ejemplo ha de interpretarse únicamente como ilustrativo y de ningún modo como limitante de los métodos; serán evidentes numerosas variaciones para un experto habitual en la materia. En este ejemplo, se crea una GPXTEN de exendina-4 ("Ex4") unida a un XTEN de la familia de motivos AE.
El esquema general para producir polinucleótidos que codifican XTEN se presenta en las FIG. 4 y 5. La FIG. 5 es un diagrama de flujo esquemático de etapas representativas en el montaje de una construcción de polinucleótido de XTEN en una de las realizaciones de la invención. Los oligonucleótidos individuales 501 se hibridan en motivos de secuencia 502, tal como un motivo de 12 aminoácidos ("12-mero"), que posteriormente se liga con un oligo que contiene sitios de restricción de BsbI y KpnI 503. Las bibliotecas de motivos pueden limitarse a familias de secuencia de XTEN específicas; por ejemplo, las secuencias AD, AE, AF, AG, AM o AQ de la tabla 1. En este caso, se usarán los motivos de la familia AE (SEQ ID NO: 186-189) como biblioteca de motivos, que se hibridan al 12-mero para crear una longitud de "bloque de construcción"; por ejemplo, un segmento que codifica 36 aminoácidos. El gen que codifica la secuencia de XTEN puede ensamblarse mediante ligamiento y multimerización de los "bloques de construcción" hasta que se logra la longitud deseada del gen de XTEN 504. Como se ilustra en la FIG. 5, la longitud del XTEN en este caso es de 48 restos de aminoácido, pero pueden lograrse longitudes más largas mediante este proceso. Por ejemplo, la multimerización puede realizarse mediante ligamiento, extensión de solape, ensamblaje PCR o técnicas de clonación similares conocidas en la técnica. El gen de XTEN puede clonarse en un vector de relleno. En el ejemplo que se ilustra en la FIG. 5, el vector puede codificar una secuencia Flag 506 seguida de una secuencia de relleno que está flanqueada por sitios para BsaI, BbsI y KpnI 507 y un gen de GP (por ejemplo, exendina-4) 508, dando como resultado el gen que codifica la GPXTEN 500, que, en este caso, codifica la proteína de fusión en la configuración, de N a C-terminal, x Te N-Ex4.
Las secuencias de ADN que codifican Ex4 (u otro GP candidato) pueden obtenerse de manera conveniente mediante procedimientos convencionales conocidos en la técnica a partir de una biblioteca de ADN preparada a partir de una fuente celular adecuada, a partir de una biblioteca genómica o pueden crearse sintéticamente (por ejemplo, síntesis de ácidos nucleicos automatizada) usando secuencias de ADN obtenidas de bases de datos disponibles al público, patentes o referencias bibliográficas. Después, puede clonarse un gen o polinucleótido que codifica la porción de Ex4 de la proteína en una construcción, como las descritas en el presente documento, que puede ser un plásmido u otro vector bajo el control de secuencias de transcripción y traducción adecuadas para la expresión de proteínas a alto nivel en un sistema biológico. Puede fusionarse genéticamente un segundo gen o polinucleótido que codifica la porción de XTEN (en el caso de la FIG. 5, ilustrado como un AE con 48 restos de aminoácido) a los nucleótidos que codifican el extremo N-terminal (o su complemento) del gen de Ex4 clonándolo en la construcción adyacente y en fase con el gen que codifica la Ex4, mediante una etapa de ligamiento o multimerización. Pueden ligarse nucleótidos adicionales que codifican XTEN de mayor longitud al gen de XTEN-Ex4 para lograr la longitud deseada del componente de XTEN. Además, pueden ligarse polinucleótidos que codifican XTEN adyacentes y en fase a los nucleótidos que codifican el extremo C-terminal (o su complemento) de la secuencia de Ex4, dando como resultado un gen que codifica GPXTEN con XTEN unido a los extremos N y C-terminales del péptido regulador de la glucosa, exendina-4, que incluye la secuencia N-terminal optimizada (NTS), como se ilustra en la FIG. 8. De esta manera, puede generarse dentro de la construcción una molécula de ADN quimérico que codifica (o es complementaria a) la proteína de fusión de GPXTEN, XTEN-Ex4. La construcción puede diseñarse en diferentes configuraciones para codificar las diversas permutaciones de los compañeros de fusión en forma de polipéptido monomérico. Por ejemplo, puede crearse el gen para que codifique la proteína de fusión en el orden (de N a C-terminal): Ex4-XTEN; XTEN-Ex4; Ex4-XTEN-Ex4; XTEN-Ex4-XTEN; así como multímeros de los anteriores. Opcionalmente, esta molécula de ADN quimérico puede transferirse o clonarse en otra construcción que es un vector de expresión más adecuado. En este punto, podría transformarse una célula hospedadora capaz de expresar la molécula de ADN quimérica con la molécula de ADN quimérica. Los vectores que contienen los segmentos de ADN de interés pueden transferirse a una célula hospedadora adecuada mediante métodos bien conocidos, dependiendo del tipo de hospedador celular, como se ha descrito anteriormente.
Las células hospedadoras que contienen el vector de expresión de XTEN-Ex4 pueden cultivarse en medio nutriente convencional modificado según sea adecuado para activar el promotor. Las condiciones de cultivo, tales como la temperatura, el pH y similares, son aquellas usadas previamente con la célula hospedadora seleccionada para la expresión y serán evidentes para un experto habitual en la materia. Tras la expresión de la proteína de fusión, pueden
recogerse las células por centrifugación, romperse por medios físicos o químicos y conservarse el extracto en bruto resultante para la purificación de la proteína de fusión, como se describe más adelante. Para las composiciones de GPXTEN secretadas por las células hospedadoras, puede separarse el sobrenadante de la centrifugación y conservarse para su purificación posterior.
La expresión génica se mediría directamente en una muestra, por ejemplo, mediante transferencia de Southern convencional, transferencia de Northern para cuantificar la transcripción de ARNm [Thomas, Proc. Natl. Acad. Sci. USA, 77:5201 -5205 (1980)], transferencia de puntos (análisis de ADN) o hibridación in situ, usando una sonda marcada de manera adecuada, basándose en las secuencias proporcionadas en el presente documento. Como alternativa, puede medirse la expresión génica mediante métodos inmunológicos o fluorescentes, tales como tinción inmunohistoquímica de células para cuantificar la expresión del producto génico. Los anticuerpos útiles para la tinción inmunohistoquímica y/o ensayo de muestras de fluidos pueden ser monoclonales o policlonales y pueden prepararse en cualquier mamífero. De manera conveniente, pueden prepararse los anticuerpos contra la secuencia de polipéptido de Ex4 usando un péptido sintético basándose en las secuencias proporcionadas en el presente documento o contra una secuencia exógena fusionada a Ex4 y que codifica un epítopo de anticuerpo específico. Los expertos en la materia conocen bien ejemplos de marcadores de selección e incluyen indicadores, tales como proteína verde fluorescente mejorada (EGFP), beta-galactosidasa (p-gal) o cloranfenicol acetiltransferasa (CAT).
El producto polipeptídico de XTEN-Ex4 puede purificarse mediante métodos conocidos en la técnica. Los procedimientos tales como filtración en gel, purificación por afinidad, fraccionamiento salino, cromatografía de intercambio iónico, cromatografía de exclusión por tamaños, cromatografía de adsorción en hidroxiapatita, cromatografía de interacción hidrófoba y electroforesis en gel son técnicas que pueden usarse en la purificación. Se describen métodos específicos de purificación en Robert K. Scopes, Protein Purification: Principles and Practice, Charles R. Castor, ed., Springer-Verlag 1994 y Sambrook, et al., anteriormente citado. También se describen separaciones de purificación en múltiples etapas en Baron, et al., Crit. Rev. Biotechnol. 10:179-90 (1990) y Below, et al., J. Chromatogr. A. 679:67-83 (1994).
Como se ilustra en la FIG. 6, después pueden caracterizarse las proteínas de fusión de XTEN-Ex4 aisladas respecto de sus propiedades químicas y su actividad. La proteína de fusión aislada puede caracterizarse, por ejemplo, respecto de su secuencia, pureza, peso molecular aparente, solubilidad y estabilidad usando métodos convencionales conocidos en la técnica. Después, puede evaluarse la actividad de la proteína de fusión que cumpla estándares esperados, que puede medirse in vitro o in vivo, usando uno o más ensayos divulgados en el presente documento; por ejemplo, los ensayos de los ejemplos o de la tabla 35.
Además, la proteína de fusión XTEN-Ex4 puede administrarse a una o más especies animales para determinar parámetros farmacocinéticos convencionales, como se describe en el ejemplo 25.
Mediante el proceso iterativo de producción, expresión y recuperación de las construcciones de XTEN-Ex4, seguido de su caracterización usando métodos divulgados en el presente documento u otros conocidos en la técnica, un experto en la materia puede producir y evaluar las composiciones de GPXTEN que comprenden Ex4 y un XTEN para confirmar las propiedades esperadas, tales como solubilidad mejorada, estabilidad mejorada, farmacocinética mejorada e inmunogenicidad reducida, que dan lugar a una actividad terapéutica general mejorada en comparación con el Ex4 correspondiente no fusionado. Para las proteínas de fusión que no poseen las propiedades deseadas, puede construirse, expresarse, aislarse y evaluarse una secuencia diferente mediante estos métodos para obtener una composición con dichas propiedades.
Ejemplo 19: Construcción de genes y vectores de exendina-4_XTEN
Se ensambló un dominio de unión a celulosa (CBD) con una secuencia codificante de exendina-4 y se fusionó genéticamente a una secuencia codificante para el extremo N-terminal de XTEN. El CBD va inmediatamente seguido de un sitio de escisión de proteasa del virus del grabado del tabaco (TEV) (ENLYFQ) para el procesado del extremo N-terminal nativo de exendina-4. Se ensambló el fragmento de CBD-exendina-4 amplificando el gen de CBD usando un oligonucleótido 3' que fusiona la secuencia de exendina-4 precedida por el sitio de escisión de TEV, dando como resultado una fusión en fase de la exendina-4 al extremo C-terminal del gen de CBD. Después, se amplificó CBD-exendina-4 de longitud completa mediante reacción en cadena de la polimerasa (PCR), que introdujo sitios de restricción de Ndel y Bbsl que son compatibles con los sitios de Ndel y Bsal que flanquean el relleno en el vector de destino de XTEN (FIG. 7A). El plásmido prXTEN es un derivado de pET30 de Novagen en el que se ha insertado una secuencia Stuffer-XTEN bajo el control del promotor T7, donde Stuffer puede ser una secuencia que codifica proteína fluorescente verde (GFP) o CBD, dependiendo del plásmido específico usado. El XTEN puede tener cualquier longitud, de 36 a 864 aminoácidos o más, dependiendo nuevamente del plásmido específico usado. Se generaron construcciones reemplazando la secuencia de relleno en prXTEN con el fragmento que codifica CBD-exendina-4 (FIG.
7B). El prXTEN presenta un promotor T7 cadena arriba de la secuencia de relleno y una secuencia XTEN fusionada en fase cadena debajo de la secuencia de relleno. La secuencia XTEN empleada en este ejemplo específico codifica AE864 con 864 aminoácidos. El fragmento de relleno se retiró mediante digestión de restricción usando las endonucleasas Ndel y Bsal. Los fragmentos CBD-exendina-4 digeridos con enzimas de restricción se ligaron en el vector pXTEN escindido usando ADN ligasa T4 y se electroporó en BL21 (DE3) Gold (Stratagene). Los transformantes
se exploraron mediante DNA Miniprep y se confirmó la construcción deseada mediante secuenciación de ADN. El vector final proporciona el gen CBD_exendina-4_XTEN bajo el control de un promotor T7.
Ejemplo 20: Construcción de genes y vectores de glucagón-XTEN
Se ensambló un dominio de unión a celulosa (CBD) con una secuencia codificante de glucagón y se fusionó genéticamente a una secuencia codificante para el XTEN. El CBD va inmediatamente seguido de un sitio de escisión de proteasa del virus del grabado del tabaco (TEV) (ENLYFQ) para el procesado del extremo N-terminal nativo de glucagón. Se ensambló el fragmento de CBD-glucagón amplificando el gen de CBD usando un oligonucleótido 3' que fusiona la secuencia de glucagón precedida por el sitio de escisión de TEV, dando como resultado una fusión en fase del glucagón al extremo C-terminal del gen de CBD. Después, se amplificó CBD-glucagón de longitud completa mediante reacción en cadena de la polimerasa (PCR), que introdujo sitios de restricción de NdeI y BbsI que son compatibles con los sitios de NdeI y BsaI que flanquean el relleno en el vector de destino de XTEN (pXTEN; Figura 9A). El plásmido pXTEN es un derivado de pET30 de Novagen en el que se ha insertado una secuencia Stuffer-XTEN bajo el control del promotor T7, donde Stuffer puede ser una secuencia que codifica proteína fluorescente verde (GFP) o CBD, dependiendo del plásmido específico usado. El XTEN puede tener cualquier longitud, de 36 a 875 aminoácidos o más, dependiendo nuevamente del plásmido específico usado. Se generaron construcciones reemplazando la secuencia de relleno en prXTEN con el fragmento que codifica CBD-glucagón. El pXTEN presenta un promotor T7 cadena arriba de la secuencia de relleno y una secuencia XTEN fusionada en fase cadena debajo de la secuencia de relleno. Las secuencias de XTEN empleadas en este ejemplo específico pertenecen a la familia Y de XTEN y codifica longitudes que incluyen 36, 72, 144, 288 y 576 aminoácidos. El fragmento de relleno se retiró mediante digestión de restricción usando las endonucleasas NdeI y BsaI. Los fragmentos CBD-glucagón digeridos con enzimas de restricción se ligaron en el vector prXTEN escindido usando ADN ligasa T4 y se electroporó en BL21(DE3) Gold (Stratagene). Los transformantes se exploraron mediante DNA Miniprep y se confirmó la construcción deseada mediante secuenciación de ADN. El vector final proporciona el gen CBD_glucagón_XTEN bajo el control de un promotor T7. Las secuencias de ADN resultantes pueden codificar glucagón unido a longitudes de XTEN de 36, 72, 144, 288 y 576 aminoácidos, respectivamente.
Ejemplo 21: Purificación y caracterización de Gcg-XTEN
La GPXTEN de glucagón unido a XTEN se produjo de manera recombinante en E. coli y se purificó hasta la homogeneidad usando etapas de tres columnas. La construcción final comprendía el gen que codifica el dominio de unión a celulosa de la región de cohesión de la proteína de anclaje al celulosoma (CBD) de C. thermocellum (n.° de referencia ABN54273) un sitio de reconocimiento para la proteasa del virus del grabado del tabaco (TEV) (ENLYFQ), la secuencia de glucagón y la secuencia de XTEN adecuada bajo el control de un promotor T7. En resumen, la expresión de proteína se indujo mediante la adición de IPTG 1 mM a un cultivo en fase logarítmica de E. coli BL21-Gold (DE3) que portan el plásmido de expresión. Se añadió la proteasa TEV a lisado celular tratado con calor que contenía Gcg-XTEN para retirar la secuencia de CBD y generar el extremo N-terminal nativo del glucagón. Después, la proteína escindida se purificó sobre columnas DE52, MacroCap Q y Butil Sepharose FF. El material final se formuló en Tris 20 mM a pH 7,5, NaCl 135 mM y se esterilizó por filtración usando un filtro de 0,22 micrómetros. Se determinó que la expresión era de aproximadamente 7 mg de proteína por gramo de peso celular húmedo (~100 mg/l a una DO final de ~4) y el rendimiento de purificación general fue de aproximadamente el 60 %.
Se llevó a cabo la cromatografía de exclusión por tamaños (SEC) usando una columna HPLC TSK-Gel, G3000 SWXL, de 7,8x300 mm (Tosoh Bioscience) conectada a un sistema HpLC equipado con un automuestreador y detector de UV/VIS (Shimadzu). El sistema se equilibró en suero salino tamponado con fosfato (PBS) a un caudal de 0,7 ml/min a temperatura ambiente. Para calibrar la columna, se usó un patrón de filtración en gel (BioRad, n.° de cat. 151-1901). Para el análisis de la muestra, se inyectaron 20 |jl de Gcg-XTEN a 1 mg/ml y se monitorizó la absorbancia durante 20 min usando DO214nm.
Se llevó a cabo una cromatografía C18 en fase reversa (RPC18) usando una columna Phenomenex Gemini 5 jm C18 - 110A, de 4,6x100 mm (Phenomenex) conectada a un sistema HPLC equipada con un automuestreador y detector UV/VIS (Shimadzu). El tampón A era TfA al 0,1 % en agua y el tampón B fue TFA al 0,1 % en acetonitrilo al 100 %. El sistema se hizo funcionar con un caudal combinado de 1 ml/min. La columna se equilibró con tampón B al 5 % a 35 °C. La separación por cromatografía de Gcg-XTEN se logró mediante un gradiente lineal de B del 5 % al 95 % durante 15 minutos. Para el análisis de la muestra, se inyectaron 10 j l de Gcg-XTEN a 1 mg/ml y se monitorizó la absorbancia usando DO214nm. Los análisis de la muestra se llevaron a cabo por el servicio GPCRProfiler® de Millipore usando una línea celular transfectada con GcgR (n.° de cat. HTS112C). El flujo de calcio se monitorizó en tiempo real mediante análisis FLIPR tras la adición de diluciones seriadas de Gcg-XTEN o glucagón sintético. Los resultados de los ensayos de caracterización y estabilidad se muestran en la FIG. 19. Los datos demuestran que Gcg-XTEN es una entidad química homogénea y bien definida. Además, la solubilidad y estabilidad de la proteína final mejoran significativamente frente al glucagón no modificado (datos no mostrados).
Ejemplo 22: Cromatografía de exclusión por tamaños analítica de proteínas de fusión de XTEN con diversas cargas
Se llevaron a cabo análisis de cromatografía de exclusión por tamaños de proteínas de fusión que contenían diversas proteínas terapéuticas y proteínas recombinantes no estructuradas de longitud creciente. Un ensayo ilustrativo usó una columna TSKGel-G40oO SWXL (7,8 mm x 30cm) en la que se separaron 40 |jg de proteína de fusión de glucagón purificada a una concentración de 1 mg/ml con un caudal de 0,6 ml/min en fosfato 20 mM, pH 6,8, NaCl 114 mM. Se monitorizaron los perfiles cromatográficos usando la DO a 214 nm y la DO a 280 nm. La calibración de la columna para todos los ensayos se llevó a cabo usando un patrón de calibración de exclusión por tamaños de BioRad; los marcadores incluyen tiroglobulina (670 kDa), gamma-globulina bovina (158 kDa), ovoalbúmina de pollo (44 kDa), mioglobulina equina (17 kDa) y vitamina B12 (1,35 kDa). Los perfiles cromatográficos representativos de glucagón-Y288, glucagón-Y144, glucagón-Y72, glucagón-Y36 se muestran superpuestos en la FIG. 16. Los datos demuestran que el peso molecular aparente de cada compuesto es proporcional a la longitud de la secuencia de XTEN unida. Sin embargo, los datos también demuestran que el peso molecular aparente de cada construcción es significativamente mayor al esperado para una proteína globular (tal como se muestra por comparación con las proteínas patrón ejecutadas en el mismo ensayo y por comparación con patrones de peso molecular mostrados en el gel de SDS de la FIG. 15). Basándose en análisis SEC para todas las construcciones evaluadas, incluyendo las composiciones de GPXTEN, los pesos moleculares aparentes, el factor de peso molecular aparente (expresado como la proporción de peso molecular aparente al peso molecular calculado) y el radio hidrodinámico (Rh en nm) se muestran en la tabla 24. Los resultados indican que la incorporación de diferentes XTEN de 576 aminoácidos o más confiere un peso molecular aparente a la proteína de fusión de aproximadamente 339 kDa a 760 y que un XTEN de 864 aminoácidos o más confiere un peso molecular aparente mayor de aproximadamente 800 kDa. Los resultados de aumentos proporcionales en el peso molecular aparente respecto del peso real fueron coherentes para proteínas de fusión creadas con XTEN de varias familias de motivos diferentes; es decir, AD, AE, AF, AG y AM, con aumentos de la menos cuatro veces y proporciones tan altas como de aproximadamente 17 veces. Además, la incorporación de compañeros de fusión de XTEN con 576 aminoácidos o más en las proteínas de fusión con las diversas cargas (y 288 restos en el caso de glucagón fusionado a Y288) dio como resultado un radio hidrodinámico de 7 nm o mayor; muy superior al tamaño de poro glomerular de aproximadamente 3-5 nm. Por consiguiente, se llegó a la conclusión de que las proteínas de fusión que comprendan crecimiento y XTEN pueden tener una eliminación renal reducida, que contribuye a la semivida terminal aumentada y a la mejora del efecto terapéutico o biológico en relación con una proteína de carga biológica correspondiente no fusionada.
T l 24: An li i E iv r li i
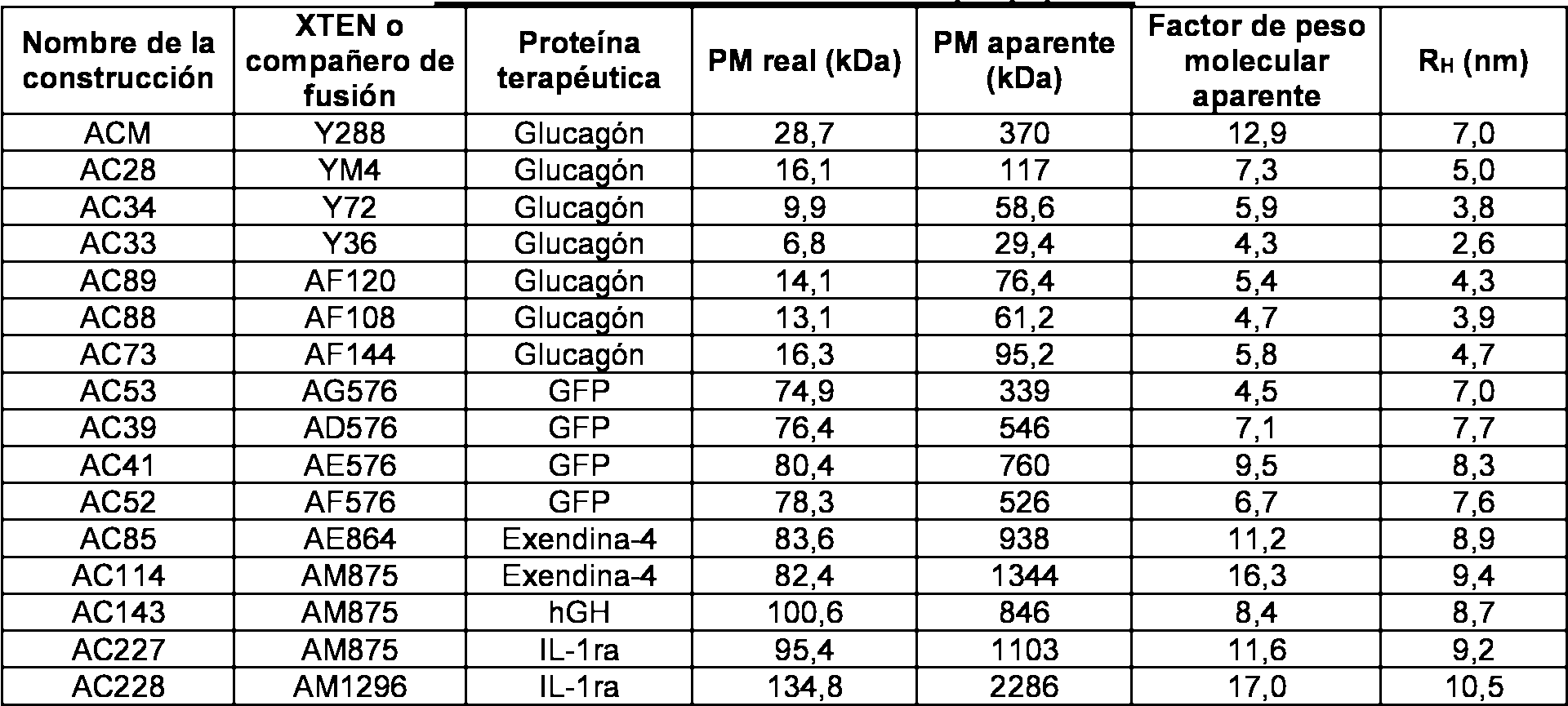
Ejemplo 23: Farmacocinética de polipéptidos extendidos fusionados a GFP en monos cinomolgos
Se evaluó la farmacocinética de GFP-L288, GFP-L576, GFP-XTEN AF576, GFP-XTEN Y576 y XTEN_AD836-GFP en monos cinomolgos para determinar el efecto de la composición y la longitud de los polipéptidos no estructurados en parámetros PK. Las muestras de sangre se analizaron en diversos instantes después de la inyección y se midió la concentración de GFP en plasma mediante ELISA usando un anticuerpo policlonal contra GFP para la captura y una preparación biotinilada del mismo anticuerpo policlonal para la detección. Los resultados se resumen en la FlG. 26. Estos muestran un aumento sorprendente en la semivida a medida que aumenta la longitud de la secuencia de XTEN. Por ejemplo, se determinó una semivida de 10 h para GFP-XTEN_L288 (con 288 restos de aminoácido en el XTEN). La duplicación de la longitud del compañero de fusión de polipéptido no estructurado hasta 576 aminoácidos aumentó la semivida hasta 20-22 h para múltiples construcciones de proteína de fusión; es decir, GFP-XTEN_L576, GFP-XTEN AF576, GFP-XTEN_Y576. Otro aumento de la longitud del compañero de fusión de polipéptido no estructurado hasta
836 restos dio como resultado una semivida de 72-75 h para XTEN AD836-GFP. Por tanto, el aumento de la longitud del polímero en 288 restos desde 288 hasta 576 restos aumentó la semivida in vivo en aproximadamente 10 h. Sin embargo, el aumento de la longitud del polipéptido en 260 restos, desde 576 restos hasta 836 restos aumentó la semivida en más de 50 h. Estos resultados demuestran que hay un umbral sorprendente de longitud del polipéptido no estructurado que da como resultado un aumento más que proporcional en la semivida in vivo. Por tanto, cabe esperar que las proteínas de fusión que comprenden polipéptidos extendidos no estructurados tengan la propiedad de una farmacocinética mejorada en comparación con polipéptidos de longitudes más cortas.
Ejemplo 24: Estabilidad sérica de XTEN
Se incubó una proteína de fusión que contenía XTEN AE864 al extremo N-terminal de GFP en plasma de mono y lisado de riñón de rata durante hasta 7 días a 37 °C. Las muestras se recogieron a tiempo 0, el día 1 y el día 7 y se analizaron mediante SDS PAGE seguido de detección usando análisis de Western y detección con anticuerpos contra GFP, tal como se muestra en la FIG. 14. La secuencia de XTEN AE864 muestra signos despreciables de degradación transcurridos 7 días en plasma. Sin embargo, XTEN AE864 se degradó rápidamente en lisado de riñón de rata transcurridos 3 días. Se probó la estabilidad in vivo de la proteína de fusión en muestras de plasma, en donde se inmunoprecipitó y analizó GFP-AE864 mediante SDS PAGE como se ha descrito anteriormente. Las muestras que se retiraron hasta 7 días después de la inyección mostraron pocos signos de degradación. Los resultados demuestran la resistencia de GPXTEN a la degradación a causa de las proteasas séricas; un factor en la mejora de las propiedades farmacocinéticas de las proteínas de fusión GPXTEN.
Ejemplo 25: Análisis PK de proteínas de fusión que comprenden exendina-4 y XTEN
Se evaluó la proteína de fusión GPXTEN, Ex4_AE864 en monos cinomolgos para determinar parámetros farmacocinéticos in vivo de las proteínas de fusión tras una sola dosis subcutánea.
Métodos: La proteína de fusión GPXTEN se formuló en Tris 20 mM, pH 7,5, NaCl 135 mM a dos concentraciones diferentes; 8 mg/ml y 40 mg/ml. Se administró a cada uno de tres grupos de cuatro monos (2 machos y 2 hembras, 2 6 kg) 1 mg/kg (Grupo 1, 0,125 ml/kg), 1 mg/kg (Grupo 2, 0,025 ml/kg) o 5 mg/kg (Grupo 3, 0,125 ml/kg) mediante inyección en bolo entre las capas cutáneas y subyacentes de tejido en la región escapular en la espalda de cada animal. Se extrajeron muestras de sangre seriadas (1 ml ± 0,5 ml) a lo largo de catorce días de la vena o arteria femoral de animales previamente aclimatados mediante una jeringuilla sin anestesia utilizando una inmovilización en silla. En caso necesario, la inmovilización en silla se utilizó durante un máximo de 30 minutos. Se sometió a ayuno a todos los animales durante una noche antes de la dosis y durante las 4 primeras horas de recogida de muestras de sangre (se volvió a alimentar en los 30 minutos después de la recogida de la última muestra de sangre en el intervalo de recogida de 4 horas, donde sea aplicable). Cada muestra de sangre se recogió en un separador de plasma con heparina y se mantuvo sobre hielo (2 °C a 8 °C) durante aproximadamente 5 minutos antes de la centrifugación. Se centrifugaron las muestras de sangre (8.000 x g durante 5 min) y el plasma se transfirió a un tubo de polipropileno. Las muestras de plasma se congelaron inmediatamente y se almacenaron a aproximadamente -70 °C hasta su ensayo. El análisis se llevó a cabo usando un formato ELISA en sándwich.
Resultados: Se calcularon en los monos los parámetros farmacocinéticos y los resultados se muestran en forma de tabla en la tabla 25. Los parámetros farmacocinéticos se analizaron usando un grupo de animales no expuestos previamente y usando un análisis en dos etapas convencional. Los resultados muestran una diferencia en la absorción de la proteína de fusión, basándose en el volumen de dosis administrado en el grupo 1 frente al grupo 2, evidenciado por los valores de Tmáx, Cmáx, ABC y volumen de distribución (Vz). Sin embargo, los valores de semivida calculados son comparables entre los tres grupos y superaron en gran medida la semivida terminal indicada de exenatida a las 2,4 h.
Tabla 25: Parámetros farmacocinéticos calculados a partir de la media de grupo para la GPXTEN
mini r .

Conclusiones: La unión de exendina-4 a XTEN para crear una fusión de GPXTEN da como resultado una mejora significativa de los parámetros farmacocinéticos para las tres formulaciones, como se demuestra en el modelo de primate, con un aumento de la semivida de al menos 30 veces.
Ejemplo 26: Uso de GPXTEN en el modelo de ratón con obesidad inducida por la dieta
Se evaluaron los efectos de la terapia combinada de péptidos reguladores de la glucosa unidos a XTEN en un modelo de ratón con obesidad inducida por la dieta para confirmar la utilidad de combinaciones fijas de proteínas de fusión monoméricas como única composición de GPXTEN.
Métodos: Se comprobaron los efectos de la terapia combinada de glucagón unido a Y-288-XTEN ("Gcg-XTEN") y exenatida unida a AE576-XTEN ("Ex4-XTEN") o exenatida sola en ratones C57BL/6J macho con obesidad inducida por la dieta (DIO), con una edad de 10 semanas. Los ratones criados con un 60 % de dieta alta en grasas se asignaron aleatoriamente a los grupos de tratamiento (n=10 por grupo) de Ex4-XTEN864 (10 mg/kg IP Q2D), Ex4-XTEN864 (20 mg/kg IP Q4D), Ex4-XTEN864 (10 mg/kg IP Q2D) más Gcg-XTEN288 (20 |jg/kg IP BID) y Ex4-XTEN864 (20 mg/kg IP Q4D) más Gcg-XTEN288 (40 jg/kg IP Q1D). Se probó en paralelo un grupo de placebo (n=10) tratado con Tris 20 mM a pH 7,5, NaCl 135 mM IP Q1D. Se administraron dosis continuas a los grupos durante 28 días. El peso corporal se controló a intervalos reguladores durante el estudio y la glucosa en sangre en ayunas se midió antes y después del periodo de tratamiento. Se dosificó a los grupos de manera continua durante un periodo de tratamiento de 28 días. El peso corporal se monitorizó de manera continua durante el estudio y se midió la glucosa en sangre en ayunas antes y después del periodo de tratamiento y se determinaron los niveles de lípido tras el periodo de tratamiento.
Resultados: Los resultados se muestran en las FIG. 23-25. Los datos indican que la dosificación continua durante un mes proporcionó una reducción significativa en la ganancia de peso en los animales tratados con Gcg-XTEN solo y Ex4-XTEN solo, en relación con el placebo durante el curso del estudio. Además, los animales a los que se dosificó Ex4-XTEN o Gcg-XTEN y Ex4-Xt En de manera concurrente mostró una mayor pérdida de peso estadísticamente significativa en comparación con Gcg-XTEN administrado solo y en comparación con placebo. Los efectos tóxicos de la administración de glucagón están bien documentados. Recientemente, se ha informado que la dosis máxima sin efecto para el glucagón en ratas y perros Beagle es de 1 mg/kg/día se consideró un nivel sin efecto tóxico evidente en ambas especies (Eistrup C, Glucagon produced by recombinant DNA technology: repeated dose toxicity studies, intravenous administration to CD rats and beagle dogs for four weeks. Pharmacol Toxicol. agosto de 1993;73(2):103-108).
Los datos también muestran que la dosificación continua durante un mes proporcionó una reducción significativa en la glucosa en sangre en ayunas para los animales tratados con Ex4-XTEN solo en relación con placebo, pero no para animales tratados solo con Gcg-XTEN. Sin embargo, los animales a los que se dosificó de manera concurrente Gcg-XTEN y exenatida mostraron una mayor reducción estadísticamente significativa en los niveles de glucosa en sangre en ayunas en comparación con cualquiera de los péptidos reguladores de la glucosa administrado en solitario. Cabe destacar que, las dosis de la composición de Gcg-XTEN que dieron como resultado los efectos beneficiosos en la combinación con Ex4-XTEN fueron de 20 y 40 jg/kg (peso de la composición de proteína de fusión completa); al menos 25 veces menor que la dosis sin efecto comunicada para solo glucagón en una especie de roedor. Además, los ratones que recibieron el GP tuvieron reducciones en los niveles de triglicéridos y de colesterol, en comparación con placebo.
Conclusiones: Los datos respaldan la conclusión de que la terapia combinada con dos proteínas de fusión de dos péptidos reguladores de la glucosa, tales como exendina-4 y glucagón, cada uno unido a un XTEN, puede dar como resultado un efecto beneficioso sinérgico frente al observado con un solo péptido regulador de la glucosa, de tal forma que puede diseñarse la administración de una composición combinada para reducir la frecuencia de la dosis o la dosis en comparación con la administración de un solo agente biológico a fin de reducir el riesgo de toxicidad o efectos secundarios no aceptables.
Ejemplo 27: Análisis PK de la GPXTEN, Ex4-XTEN en monos cinomolgos
Se determinó la farmacocinética de la GPXTEN, Ex4-AE864, en monos cinomolgos (tres por grupo), administrándose la GPXTEN mediante inyecciones subcutáneas o intravenosas de GPXTEN a 0,5 mg/kg durante un periodo de 1 minuto. Se recogieron muestras de plasma en diversos puntos de tiempo hasta 14 días después de la inyección y se analizaron mediante ELISA para determinar la concentración e inmunogenicidad de ambos artículos de ensayo. No se observaron anticuerpos contra los artículos de ensayo para Ex4-AE864 en cualquier animal tras la administración. Se llevó a cabo un ELISA en sándwich mediante una inmovilización de >12 h de 100 ng de anticuerpo de captura (antiexenatida de conejo, Peninsula Laboratories, San Carlos, CA) a cada pocillo en una placa de microtitulación de poliestireno (Costar 3690, Corning Inc, Corning, N.Y.), seguido del bloqueo con seroalbúmina bovina (BSA) al 3 %. Después de 3 lavados con PBS, se titularon en serie las muestras de plasma por toda la placa en PBS que contenía BSA al 1 % y Tween 20 al 0,5 %. Tras una incubación de 2 horas y de lavar, se sondaron las muestras mediante la adición de IgG biotinilada (anti-exenatida de conejo, biotinilada en el laboratorio, Peninsula Laboratories, San Carlos, CA) a cada pocillo. Tras la incubación y el lavado, se revelaron las placas mediante incubación con estreptavidina conjugada a peroxidasa de rábano picante (Thermo Fisher Scientific, Rockford, IL) seguido del sustrato de tetrametilbenzidina (Neogen Corporation, Lexington, KY), después se inactivó con H2SO40,2 N y se leyó a 450 nm. Se calcularon parámetros farmacocinéticos no compartimentales usando el programa WinNonLin, Versión 2.1 (Pharsight Corporation, Mt. View, CA).
Los resultados se representan en la FIG. 17. La semivida terminal de esta formulación de la construcción fue de 60 horas, con una biodisponibilidad del 80 % a partir de una inyección subcutánea. Esto es comparable con la semivida comunicada de 2,4 h para Byetta®, una versión comercial de exendina-4. De manera importante, tras la inyección subcutánea se observó una fase de absorción lenta, que parece ser característica de las proteínas de fusión de XTEN. La fase de absorción dio como resultado una Cmáx entre 24-48 horas tras la inyección y un perfil de concentración sérica esencialmente plano durante ~100 horas antes de alcanzar una fase de eliminación lineal.
Conclusiones: Puede concluirse a partir de los resultados que la adición de un XTEN a un péptido regulador de la glucosa, tal como exendina-4, puede aumentar en gran medida la semivida terminal, en comparación con el péptido no unido a XTEN y mejorar otros parámetros farmacocinéticos, también.
Ejemplo 28: Análisis PK de la GPXTEN Ex4-XTEN en múltiples especies y semivida predicha en seres humanos
Para determinar el perfil farmacocinético predicho en seres humanos de una proteína terapéutica fusionada a XTEN, se llevaron a cabo estudios usando exendina-4 fusionada al XTEN AE864 como un solo polipéptido de fusión. Se administró la construcción Ex4-XTEN a cuatro especies animales diferentes a 0,5-1,0 mg/kg, por vía subcutánea e intravenosa. Se recogieron muestras de suero a intervalos después de la administración, determinándose las concentraciones en suero usando métodos estándar. Se determinó la semivida para cada especie y se presenta como tabla en la tabla 26. Los resultados se usaron para predecir la semivida en seres humanos usando una escalada alométrica de la semivida terminal, el volumen de distribución y las velocidades de eliminación basándose en la masa corporal media. La FIG. 18A muestra una representación de la semivida terminal medida frente a la masa corporal en las especies animales, con una T1/2 predicha en un ser humano de 75 kg de 140 h, en comparación con la semivida comunicada de exenatida de 2,4 h (Bond, A. Proc (Bayl Univ Med Cent) 19(3): 281-284. (2006)). La FIG. 18B muestra la eliminación de fármaco medida frente a la masa corporal, con un valor de tasa de eliminación predicho de 30 ml/h en un ser humano de 75 kg. La FIG. 18C muestra el volumen de distribución medido frente a la masa corporal, con un valor predicho de 5970 ml en un ser humano de 75 kg.
Conclusiones: Puede concluirse a partir de los resultados que la adición de un XTEN a un péptido regulador de la glucosa, tal como exendina-4, puede aumentar en gran medida la semivida terminal, en comparación con el péptido no unido al XTEN y que una formulación de GPXTEN con una semivida comparable podría permitir una dosificación considerablemente menos frecuente que la empleada en la actualidad con productos comerciales de péptidos reguladores de la glucosa, siendo posible la dosificación a intervalos semanales, cada dos semanas o incluso mensuales.
T l 2 : mivi Ex4-XTEN

Ejemplo 29: Farmacocinética de Gcg-XTEN en perros
Se inyectó a perros de raza Beagle (cuatro por grupo) las dosis indicadas de glucagón sintético (American Peptide, Sunnyvale, CA), Gcg-XTEN o placebo. Se sometió a los animales a ayuno durante 12 horas antes de la dosis y 6 horas después de la dosis. Se hicieron pruebas de glucosa en sangre en los momentos indicados antes y después de la dosis usando un glucómetro manual (Walgreens TRUEresult™). Se corrigió el sesgo sistemático de los datos en bruto entre sangre de ser humano y de cánido por comparación con las muestras de referencia a lo largo del intervalo lineal completo (40-250 mg/dl) medido en paralelo en un laboratorio diagnóstico (Antech Diagnostics).
Los perfiles de glucosa en sangre después de la inyección se muestran en la FIG. 20. Los datos muestran que Gcg-XTEN eleva la glucosa en sangre durante un periodo de tiempo prolongado en relación con glucagón no modificado. Los niveles de glucosa en sangre tras la administración de Gcg-XTEN vuelven a los niveles basales a las 10-12 horas tras la administración, de manera coherente con el perfil PK determinado previamente en monos cinomolgos (datos no mostrados).
Conclusiones: La adición de XTEN al péptido regulador de la glucosa, glucagón, mejora notablemente las propiedades farmacocinéticas, incluyendo la semivida terminal, en comparación con la proteína nativa. Además, el diseño de la GPXTEN que contiene glucagón de una longitud seleccionada da como resultado una semivida que permite volver a los niveles basales en un intervalo que lo hace útil para el control de la hipoglucemia nocturna.
Ejemplo 30: Gcg-XTEN confiere una resistencia controlada en el tiempo a la hipoglucemia inducida por insulina en perros
Se sometió a perros de raza Beagle (cuatro por grupo, ocho en total) a un modelo de exposición a hipoglucemia en dos fases, separadas por un periodo de descanso terapéutico de cuatro días. En cada fase, se alimentó a los animales tres horas antes de la inyección, y después se les sometió a ayuno durante el resto del estudio. En cada fase, se inyectó por vía subcutánea a los grupos 0,6 nmol/kg de Gcg-XTEN o placebo en tiempo cero. En la primera fase, la exposición a hipoglucemia se inició 6 horas después de inyectar el artículo de ensayo mediante la administración de 0,05 U/kg de insulina (Novolin-R, Novo Nordisk Pharmaceuticals, Inc.). La exposición hipoglucémica en la fase 2 se inició de un modo idéntico, salvo que fue 12 horas después de inyectar el artículo de ensayo. Los niveles de glucosa en sangre se evaluaron en los instantes indicados usando un glucómetro manual, como en el caso anterior. Se tomaron muestras de sangre antes de la dosis y una hora después de la exposición a la insulina en todos los animales. Se evaluó la química clínica de las muestras para confirmar la precisión de las lecturas del glucómetro manual. Además, la química clínica confirmó niveles de insulina significativamente elevados después de la exposición a hipoglucemia en todos los grupos. Aunque es ligeramente menor (~30 %, datos no mostrados) en los grupos de Gcg-XTEN en relación con los grupos de placebo, las diferencias entre grupos no eran estadísticamente significativas.
Los resultados de las determinaciones secuenciales de glucosa se muestran en la FIG. 21. Los datos muestran que los animales que recibieron Gcg-XTEN eran resistentes a la hipoglucemia inducida con insulina 6 horas después de la dosis (FIG. 21A), pero no a las 12 horas después de la dosis (FIG. 21B). Basándose en una línea temporal hipotética en seres humanos, suponiendo una dosificación de Gcg-XTEN a las 21:00, 6 h después de la dosis corresponde a las 03:00 (durante el sueño) donde se desea la protección frente a la hipoglucemia y 12 h después de la dosis corresponde a las 09:00 donde el efecto farmacodinámico debe haberse agotado para posibilitar una comida matutina.
Conclusiones: La adición del XTEN al péptido regulador de la glucosa, glucagón y el diseño particular de la proteína de fusión GPXTEN en cuanto a la longitud del XTEN da como resultado un efecto farmacodinámico que 1) protege frente a la hipoglucemia inducida por insulina; y 2) tiene una duración que coincide con la hipoglucemia nocturna y después desaparece en el momento que sería coherente con una comida matutina. Este perfil farmacodinámico es adecuado para aplicaciones clínicas en la hipoglucemia en pacientes diabéticos.
Ejemplo 31: Gcg-XTEN288 inhibe el aumento en la glucosa en sangre al finalizar el ayuno en monos cinomolgos
Se evaluó el efecto de Gcg-XTEN_Y288 de larga duración en la supresión del apetito en monos cinomolgos normales. Se sometió a los animales a ayuno durante 12 horas antes de la dosis y 6 horas después de la dosis. A tiempo 0, los animales recibieron una dosis aleatorizada de 7 nmol/kg de Gcg-XTEN_Y288 (Construcción 1) o placebo. La glucosa en sangre se midió mediante un glucómetro manual en los momentos indicados durante el estudio. En una segunda fase, se trató a los animales con el artículo de ensayo alternativo de acuerdo con el mismo protocolo. La FIG. 22 muestra gráficas superpuestas de perfiles de glucosa en sangre tras la administración de placebo o Gcg-XTEN_Y288 para cada animal individual. Las flechas sólidas marcan el momento cuando se devolvió la comida a los animales (t = 6 horas).
En cada animal, cuando se le administró placebo, se observa un aumento de la glucosa en sangre inmediatamente después de permitirse el alimento después del periodo de ayuno de 18 h. Esto es coherente con los animales que comen cuando se les permite comer a voluntad. En comparación, cuando se administró a los mismos animales Gcg-XTEN288 seis horas antes de volver a comer, no se observó un aumento en la glucosa. Esta observación sugiere que el apetito de estos animales después del periodo de ayuno se suprimió mediante la administración de Gcg-XTEN288.
Ejemplo 32: Análisis PK de las composiciones de glucagón-XTEN en monos cinomolgos
Se evaluaron composiciones de GPXTEN de glucagón unido a XTEN de diversas longitudes para determinar los parámetros farmacocinéticos en monos cinomolgos. Se evaluaron los efectos de tres construcciones diferentes de diversas longitudes de XTEN fusionado a glucagón en los parámetros farmacocinéticos. Las construcciones glucagón-Y288, glucagón-Y144 y glucagon-Y72 se administraron a monos cinomolgos a una dosis de 0,2 mg/kg por vía subcutánea. Se recogieron muestras de suero en diversos puntos de tiempo después de la administración y se analizaron las concentraciones séricas de la construcción usando un formato de ELISA en sándwich. Se recubrieron los pocillos de una placa de ELISA con anticuerpo policlonal de conejo anti-XTEN_Y. Después, se incubaron muestras de suero en los pocillos a diversas diluciones para permitir la captura del compuesto mediante los anticuerpos recubiertos. Las células se lavaron exhaustivamente y la proteína unida se detectó usando una preparación biotinilada del anticuerpo policlonal anti-XTEN_Y y estreptavidina-HRP. Se calcularon las concentraciones séricas de proteína en cada punto de tiempo comparando la respuesta colorimétrica en cada dilución en suero con una curva patrón. Los parámetros farmacocinéticos se calcularon usando el paquete de software WinNonLin. La FIG. 28 muestra los resultados de los niveles en sangre frente al tiempo para las proteínas de fusión de glucagón-XTEN 1) glucagón-Y288; 2) glucagónY-144; y 3) glucagón-Y72. Los resultados de la administración de glucagón-Y144 muestran una variación <3 veces en los niveles sanguíneos a lo largo de 0-6 h, descendiendo los niveles sanguíneos por debajo del umbral de 10x desde la Cmáx a las 10-12 horas, indicando un perfil PK favorable para mantener a la GPXTEN dentro de una
ventana terapéutica para afecciones como la hipoglucemia nocturna.
Conclusiones: Los resultados indican que los glucagones con mayores longitudes de XTEN fueron detectables en sangre durante periodos de tiempo prolongados en comparación con construcciones de menor longitud.
Ejemplo 33: Aumento de la solubilidad y estabilidad de GP mediante su unión a XTEN
Para evaluar la capacidad de XTEN para mejorar las propiedades fisicoquímicas de solubilidad y estabilidad, se prepararon proteínas de fusión de glucagón más XTEN de secuencia más corta y se evaluaron. Los artículos de prueba se prepararon en suero salino tamponado con Tris a pH neutro y la caracterización de la solución de Gcg-XTEN se efectuó mediante cromatografía de exclusión por tamaños HPLC en fase inversa para confirmar que la proteína era homogénea y no se agregaba en solución. Los datos se presentan en la tabla 27. Con fines comparativos, se midió el límite de solubilidad del glucagón no modificado en el mismo tampón a 60 |jM (0,2 mg/ml) y el resultado demuestra que para todas las longitudes de XTEN añadidas, se logró un aumento sustancial de la solubilidad. De manera importante, en la mayoría de los casos, las proteínas de fusión de glucagón-XTEN se prepararon para lograr concentraciones diana y no se evaluaron para determinar los límites de solubilidad máxima para una construcción dada. Sin embargo, en el caso del glucagón unido a AF-144 XTEN, se determinó el límite de solubilidad, con el resultado de que se logró un aumento de 60 veces en la solubilidad, en comparación con glucagón no unido a XTEN. Además, se evaluó glucagón-AF144 GPXTEN respecto de su estabilidad y se observó que era estable en formulación líquida durante al menos 6 meses en condiciones refrigeradas y durante aproximadamente un mes a 37 °C (datos no mostrados).
Conclusiones: Los datos apoyan la conclusión de que la unión de polipéptidos de XTEN de corta longitud a una proteína biológicamente activa, tal como glucagón, pueden mejorar notablemente las propiedades de solubilidad de la proteína por la proteína de fusión resultante, así como conferir estabilidad a las concentraciones de proteína mayores.
T l 27: l ili n r i n l n-XTEN

Ejemplo 34: Caracterización de la estructura secundaria de GPXTEN
Se evaluó el grado de estructura secundaria de la GPXTEN, Ex4-AE864, mediante espectroscopía de dicroísmo circular. Se llevó a cabo la espectroscopía de CD en un espectropolarímetro Jasco J-715 (Jasco Corporation, Tokio, Japón) equipado con un controlador de la temperatura Jasco Peltier (TPC-348WI). Se ajustó la concentración de proteína a 0,2 mg/ml en fosfato de sodio 20 mM, pH 7,0 y NaCl 50 mM. Los experimentos se llevaron a cabo usando celdas de cuarzo HELLMA con una longitud de paso de 0,1 cm. Los espectros de CD se recogieron a 5°, 25°, 45° y 65 °C y se procesaron usando J-700 versión 1.08.01 (Compilación 1) del software de Jasco para Windows. Las muestras se equilibraron a cada temperatura durante 5 min antes de llevar a cabo las mediciones de CD. Todos los espectros se recogieron por duplicado de 300 nm a 185 nm usando un ancho de banda de 1 nm y una constante de tiempo de 2 s, a una velocidad de barrido de 100 nm/min. El espectro de CD mostrado en la FIG. 27 no muestra evidencias de estructura secundaria estable y es coherente con un polipéptido no estructurado.
Ejemplo 35: Actividad biológica de las construcciones de GPXTEN de glucagón y Ex4
Se ensayó la actividad biológica de glucagón purificado y exendina-3, cada uno unido a Y288 en forma de una proteína de fusión GPXTEN usando un ensayo celular in vitro. En resumen, se usó una línea celular de receptor de glucagón optimizada para calcio estable ChemiScreen para los ensayos de movilización en tiempo real para el glucagón y las construcciones de glucagón-XTEN, mientras que para exendina-4 y las construcciones de Ex4 se usó una línea celular optimizada para receptor de exendina-4 que expresa el receptor de GLP-1. En este sistema, las células expresan los receptores nativos y la activación de este receptor da como resultado un flujo de calcio dentro de la célula que puede detectarse usando un aparato FLIPR. Como se muestra en la FIG. 29, el glucagón nativo da como resultado un aumento en la señal de un modo dependiente de la dosis. Se observó que la CE50 para glucagón nativo en este sistema era de 4,1 nM. La titulación de la construcción de glucagón-Y288 produjo una curva de respuesta comparable, con una CE50 de 72 nM. Como se muestra en la FIG. 29, la exendina-4 nativa de dos fuentes comerciales diferentes (Anaspec y Tocris) da como resultado un aumento en la señal de un modo dependiente de la dosis, con CE50 (indicadas con una línea discontinua) de 75 pM y 110 pM, respectivamente. La titulación de la construcción de
exendina-4-Y576 proporcionó una curva de respuesta a la dosis comparable, con una CE50 de 98 pM, que indica que la fusión de la proteína accesoria conserva la actividad biológica completa.
Conclusiones: Los resultados indican que la fusión de los péptidos reguladores de la glucosa, exendina-4 y glucagón a un XTEN da como resultado composiciones que conservan actividad biológica.
Ejemplo 36: XTEN C-terminal que puede liberarse mediante Elastasa-2
Puede crearse una proteína de fusión GPXTEN que consiste en una proteína XTEN fusionada al extremo C-terminal de un GP, tal como exendina-4 (Ex4) con una secuencia de escisión de sitio de liberación de XTEN colocada entre medias de los componentes GP y XTEN. En la tabla 38 se proporcionan secuencias ilustrativas. En este caso, el sitio de liberación contiene una secuencia de aminoácidos que se reconoce y escinde por la proteasa elastasa-2 (EC 3.4.21.37, Uniprot P08246). Específicamente, la secuencia LGPVJ.SGVP [Rawlings N.D., et al. (2008) Nucleic Acids Res., 36: D320], podría cortarse tras la posición 4 en la secuencia. La elastasa se expresa de manera constitutiva por los neutrófilos y está presente en todo momento en la circulación. Su actividad está estrechamente controlada por serpinas y por lo tanto, es mínimamente activa la mayoría del tiempo. Por lo tanto, a medida que circula Ex4-XTEN de larga duración, podría escindirse una fracción de esta, creando un cúmulo de exendina-4 de vida más corta que puede usarse en la homeostasis de la glucosa. En una característica deseable de la composición de la invención, esto crea un depósito de profármaco circulante que libera constantemente una cantidad de exendina-4 libre completamente activa.
Ejemplo 37: XTEN C-terminal que puede liberarse mediante MMP-12
Puede crearse una proteína de fusión amilina-XTEN que consiste en una proteína XTEN fusionada al extremo C-terminal de amilina con una secuencia de escisión de sitio de liberación de XTEN colocada entre medias de los componentes amilina y XTEN. En la tabla 38 se proporcionan secuencias ilustrativas. En este caso, el sitio de liberación de GPXTEN contiene una secuencia de aminoácidos que se reconoce y escinde por la proteasa MMP-12 (EC 3.4.24.65, Uniprot P39900). Específicamente, la secuencia GPAGJ.LGGA [Rawlings N.D., et al. (2008) Nucleic Acids Res., 36: D320] podría cortarse tras la posición 4 en la secuencia. MMP-12 se expresa de manera constitutiva en la sangre completa. Por lo tanto, a medida que circula amilina-XTEN de larga duración, podría escindirse una fracción de esta, creando un cúmulo de amilina de vida más corta que puede usarse en la homeostasis de la glucosa. En una característica deseable de la composición de la invención, esto crea un depósito de profármaco circulante que libera constantemente una cantidad de amilina libre completamente activa.
Ejemplo 38: Diseños de ensayos clínicos en humanos para evaluar GPXTEN
Pueden diseñarse ensayos clínicos de tal forma que puede verificarse en seres humanos la eficacia y las ventajas de las composiciones de GPXTEN en relación con los agentes biológicos individuales. Por ejemplo, las construcciones de fusión que comprenden tanto glucagón como exenatida, como se ha descrito en los ejemplos anteriores, se usan en ensayos clínicos para caracterizar la eficacia de las composiciones. Los ensayos se llevan a cabo en una o más enfermedades, trastornos o afecciones metabólicas que se mejoran, alivian o inhiben mediante la administración de glucagón y exenatida. Dichos estudios en pacientes adultos comprenden tres fases. En primer lugar, se lleva a cabo un estudio de seguridad y farmacocinético de fase I en pacientes adultos para determinar la dosis máxima tolerada y la farmacocinética y farmacodinámica en seres humanos (ya sean sujetos normales o pacientes con una enfermedad o afección metabólica), así como para definir toxicidades y acontecimientos adversos potenciales para su seguimiento en estudios futuros. Se lleva a cabo un estudio en el que se administran dosis individuales crecientes de composiciones de proteínas de fusión de XTEN unido a glucagón y exenatida y se miden los parámetros bioquímicos, PK y clínicos. Esto permite determinar la dosis máxima tolerada y establece las concentraciones umbral y máxima de la dosis y de fármaco circulante que constituyen la ventana terapéutica para los respectivos componentes. Posteriormente, pueden llevarse a cabo ensayos clínicos en pacientes con la enfermedad, trastorno o afección.
Ensayo clínico en diabetes
Se lleva a cabo un estudio de dosificación de fase II en pacientes diabéticos, donde se mide la farmacodinámica de la glucosa en suero y otros parámetros fisiológicos, PK, de seguridad y clínicos (como los listados anteriormente) adecuados para la diabetes, la resistencia a la insulina y afecciones relacionadas con la obesidad en función de la dosis de las proteínas de fusión que comprenden XTEN unido a glucagón y exenatida, proporcionando información de intervalo de dosis en las dosis adecuadas para un ensayo de fase III, además de recoger datos de seguridad relacionados con los eventos adversos. Los parámetros PK están correlacionados con los datos fisiológicos, clínicos y de seguridad para establecer la ventana terapéutica para cada componente de la composición de GPXTEN, permitiendo al médico establecer la proporción adecuada de las proteínas de fusión de dos componentes, comprendiendo cada una un péptido regulador de la glucosa o para determinar la dosis individual para una GPXTEN monomérica que comprende dos péptidos reguladores de la glucosa. Finalmente, se lleva a cabo un estudio de eficacia de fase II en donde se administrará a pacientes diabéticos la composición de GPXTEN, un control positivo o un placebo a diario, bisemanalmente o semanalmente (u otra pauta posológica considerada adecuada en vista de las propiedades farmacocinéticas y farmacodinámicas de la composición de GPXTEN) durante un periodo de tiempo prolongado. Las
mediciones de resultado primario de eficacia podrían incluir concentraciones de HbA1c, mientras que las mediciones de resultado secundario incluyen la necesidad de insulina durante el estudio, las concentraciones de péptido C estimulado y de insulina, glucosa en plasma en ayunas (FPG), niveles séricos de citocinas, niveles de CRP y secreción de insulina y el índice de sensibilidad a la insulina obtenido de una OGTT con mediciones de insulina y glucosa, así como el peso corporal, el consumo de alimento y otros marcadores de diabéticos aceptados que se estudian en relación con el grupo de placebo o de control positivo. Los resultados de eficacia se determinan usando métodos estadísticos convencionales. Los marcadores de toxicidad y de eventos adversos también se siguen durante este estudio para verificar que el compuesto es seguro cuando se usa del modo descrito.
Ejemplo 39: Análisis de secuencias respecto de su estructura secundaria mediante algoritmos de predicción
Las secuencias de aminoácidos se evalúan respecto de su estructura secundaria mediante ciertos programas o algoritmos informáticos, tales como el conocido algoritmo de Chou-Fasman (Chou, P. Y., et al. (1974) Biochemistry, 13: 222-45) y el método de Garnier-Osguthorpe-Robson o "GOR" (Garnier J, Gibrat JF, Robson B. (1996). GOR method for predicting protein secondary structure from amino acid sequence. Methods Enzymol 266:540-553). Para una secuencia dada, los algoritmos pueden predecir si existe cierto grado o ausencia de estructura secundaria, expresada como el total y/o el porcentaje de los restos de la secuencia que forman, por ejemplo, alfa-hélices o betaláminas o el porcentaje de restos de la secuencia que se predice que dan como resultado una formación de bucle aleatorio.
Se han evaluado varias secuencias representativas de "familias" de XTEN usando dos herramientas algorítmicas para los métodos de Chou-Fasman y GOR para evaluar el grado de estructura secundaria en estas secuencias. La herramienta de Chou-Fasman fue proporcionada por William R. Pearson y la University of Virginia, en el sitio web de "Biosupport", URL ubicada en www.fasta.bioch.virginia.edu/fasta_www2/fasta_www.cgi?rm=misc1, según existía el 19 de junio de 2009. La herramienta GOR fue proporcionada por Pole Informatique Lyonnais en el sitio web de Network Protein Sequence Analysis, URL ubicada en www.npsa-pbil.ibcp.fr/cgi-bin/secpred_gor4.pl según existía el 19 de junio de 2008.
Como primera etapa en los análisis, se analizó una sola secuencia de XTEN mediante los dos algoritmos. La composición AE864 es un XTEN con 864 restos de aminoácidos creada a partir de múltiples copias de cuatro motivos de secuencia de 12 aminoácidos que consiste en los aminoácidos G, S, T, E, P y A. Los motivos de secuencia se caracterizan por el hecho de que hay una repetitividad limitada dentro de los motivos y dentro de la secuencia general, en tanto que la secuencia de dos aminoácidos consecutivos no se repite más de dos veces en un motivo cualquiera de 12 aminoácidos y en que no hay tres aminoácidos contiguos de XTEN de longitud completa idénticos. Se analizaron porciones sucesivamente más grandes de la secuencia AF 864 desde el extremo N-terminal mediante los algoritmos de Chou-Fasman y GOR (este último requiere una longitud mínima de 17 aminoácidos). Las secuencias se analizaron introduciendo las secuencias en formato FASTA en las herramientas de predicción y ejecutando el análisis. Los resultados de los análisis se presentan en la tabla 28.
Los resultados indican que, mediante los cálculos de Chou-Fasman, los cuatro motivos de la familia AE (tabla 4) no tienen alfa-hélices o beta-láminas. De manera similar, se observó que la secuencia de hasta 288 restos no tenía alfahélices o beta-láminas. Se predice que la secuencia de 432 restos tiene una pequeña cantidad de estructura secundaria, contribuyendo solo 2 aminoácidos a una alfa-hélice para un porcentaje total del 0,5 %. El polipéptido AF864 de longitud completa tiene los mismos dos aminoácidos que contribuyen a una alfa-hélice, para un porcentaje general del 0,2 %. Los cálculos de formación de bucle aleatorio revelaron que a medida que aumentaba la longitud, se aumentó el porcentaje de bucle aleatorio. Los primeros 24 aminoácidos de la secuencia tienen un 91 % de formación de bucle aleatorio, que aumenta a medida que aumentaba la longitud hasta el valor del 99,77 % para la secuencia de longitud completa.
También se analizaron numerosas secuencias de XTEN de 500 aminoácidos o más de las otras familias de motivos y revelaron que la mayoría tenía más de un 95 % de formación de bucle aleatorio. Las excepciones fueron las secuencias con una o más apariciones de tres restos de serina contiguos, que dieron como resultado la formación predicha de beta-lámina. Sin embargo, incluso estas secuencias seguían teniendo aproximadamente un 99 % de formación en bucle aleatorio.
Por el contrario, se evaluó una secuencia de polipéptido de 84 restos limitados a los aminoácidos A, S y P mediante el algoritmo de Chou-Fasman, con un alto grado predicho de alfa-hélices. La secuencia, que tenía múltiples secuencias de "AA" y "AAA" repetidas, tenía un porcentaje general predicho de estructura de alfa-hélice del 69 %. El algoritmo GOR predijo una formación de bucle aleatorio del 78,57 %; mucho menor que cualquier secuencia consistente en motivos de secuencia de 12 aminoácidos que consiste en los aminoácidos G, S, T, E, P, analizadas en el presente ejemplo.
Conclusiones: El análisis apoya la conclusión de que: 1) los XTEN creados a partir de múltiples motivos de secuencia de G, S, T, E, P y A que tienen una repetitividad limitada y se predice que los aminoácidos contiguos tienen cantidades muy bajas de alfa-hélices y beta-láminas; 2) el aumento de la longitud del XTEN no aumenta de manera apreciable la probabilidad de formación de alfa-hélices o beta-láminas; y 3) el aumento progresivo de la longitud de la secuencia de
XTEN mediante la adición de 12-meros no repetitivos que consisten en los aminoácidos G, S, T, E, P y A da como resultado la formación de un porcentaje aumentado de bucle aleatorio. Por el contrario, se predice que los polipéptidos creados de aminoácidos limitados a A, S y P que tienen un mayor grado de repetitividad interna tendrán un alto porcentaje de alfa-hélices, según se determina mediante el algoritmo de Chou-Fasman, así como formación de bucle aleatorio. Basándose en las numerosas secuencias evaluadas mediante estos métodos, se llega a la conclusión de que los XTEN creados a partir de motivos de secuencia de G, S, T, E, P y A que tienen una repetitividad limitada (definida como no más de dos aminoácidos idénticos contiguos en un motivo cualquiera) mayor de aproximadamente 400 restos de aminoácido de longitud tiene probabilidades de tener una estructura secundaria muy limitada. Con la excepción de motivos que contienen tres serinas contiguas, se cree que puede usarse cualquier orden o combinación de motivos de secuencia de la tabla 4 para crear un polipéptido de XTEN con una longitud mayor de aproximadamente 400 restos de aminoácidos que darán como resultado una secuencia de XTEN que está sustancialmente desprovista de estructura secundaria. Se espera que dichas secuencias tengan las características descritas en las realizaciones de GPXTEN divulgadas en el presente documento.
T l 2 : l l r i i n H -FA MAN R r r n ri










Ejemplo 40: Análisis de la repetitividad de secuencias de polipéptido
Puede evaluarse la repetitividad de secuencias de aminoácidos de polipéptidos cuantificando el número de veces que aparece una subsecuencia más corta dentro del polipéptido general. Por ejemplo, un polipéptido de 200 restos de aminoácido tiene 192 subsecuencias solapantes de 9 aminoácidos (o "marcos" de 9-meros), pero el número de subsecuencias de 9-mero únicas dependerá de la cantidad de repetitividad dentro de la secuencia. En el presente análisis, se evaluó la repetitividad de diferentes secuencias sumando la aparición de todas las subsecuencias únicas de 3-meros para cada marco de 3 aminoácidos a lo largo de los primeros 200 aminoácidos de la porción de polímero, dividida entre el número absoluto de subsecuencias de 3-meros únicas dentro de la secuencia de 200 aminoácidos. La puntuación de subsecuencia es un reflejo del grado de repetitividad dentro del polipéptido.
Los resultados, mostrados en la tabla 29, indican que los polipéptidos no estructurados que consisten en 2 o 3 tipos de aminoácidos tienen altas puntuaciones de subsecuencia, mientras que aquellos que consisten en motivos de 12 aminoácidos de los seis aminoácidos G, S, T, E, P y A con un bajo grado de repetitividad interna, tienen puntuaciones de subsecuencia menores de 10 y en algunos casos, menores de 5. Por ejemplo, la secuencia L288 tiene dos tipos de aminoácido y tiene secuencias cortas altamente repetitivas, que dan como resultado una puntuación de subsecuencia de 50,0. El polipéptido J288 tiene tres tipos de aminoácido pero también tiene secuencias cortas repetitivas, que dan como resultado una puntuación de subsecuencia de 33,3. Y576 también tiene tres tipos de aminoácido, pero no está formado por repeticiones internas, lo que se refleja en la puntuación de subsecuencia de 15,7 a lo largo de los 200 primeros aminoácidos. W576 consiste en cuatro tipos de aminoácido, pero tiene un mayor grado de repetitividad interna, por ejemplo, "GGSG", que dan como resultado una puntuación de subsecuencia de 23,4. AD576 consiste en cuatro tipos de motivos de 12 aminoácidos, consistiendo cada uno en cuatro tipos de aminoácidos. Debido al bajo grado de repetitividad interna de los motivos individuales, la puntuación de subsecuencia general a lo largo de los 200 primeros aminoácidos es de 13,6. Por el contrario, los XTEN que consisten en cuatro motivos contienen seis tipos de aminoácidos, cada uno con un bajo grado de repetitividad interna, tienen puntuaciones de subsecuencia más bajas; es decir, AE864 (6,1), AF864 (7,5) y AM875 (4,5).
Conclusiones: Los resultados indican que la combinación de 12 motivos de subsecuencia de aminoácidos, consistiendo cada uno en cuatro a seis tipos de aminoácidos que son esencialmente no repetitivos, en un polipéptido de XTEN más largo da como resultado una secuencia general que es no repetitiva. Esto sucede a pesar del hecho de que cada motivo de subsecuencia puede usarse múltiples veces a lo largo de la secuencia. Por el contrario, los polímeros creados a partir de números menos de tipos de aminoácidos dieron como resultado puntuaciones de subsecuencia más elevadas, aunque puede diseñarse la secuencia real para reducir el grado de repetitividad, para dar como resultado puntuaciones de subsecuencia menores.
T l 2 : l l n i n n i n i li i





Ejemplo 41: Cálculo de puntuaciones TEPITOPE
Pueden calcularse puntuaciones de TEPITOPE de secuencias de péptido de 9meros añadiendo potenciales de bolsillo, tal como se describe por Sturniolo [Sturniolo, T., etal. (1999) Nat Biotechnol, 17: 555]. En el presente ejemplo, se calcularon puntuaciones de Tepitope separadas para alelos de HLA individuales. La tabla 30 muestra, a modo de ejemplo, los potenciales de bolsillo para h La *0101B, que se produce con alta frecuencia en la población caucásica. Para calcular la puntuación de TEPITOPE de un péptido con la secuencia P1-P2-P3-P4-P5-P6-P7-P8-P9, se sumaron los potenciales de bolsillo individuales correspondientes en la tabla 30. La puntuación de HLA*0101B de un péptido 9mero con la secuencia FDKLPRTSG podría ser la suma de 0, -1,3, 0, 0,9, 0, -1,8, 0,09, 0, 0.
Para evaluar las puntuaciones de TEPITOPE para péptidos largos, se puede repetir el proceso para todas las subsecuencias de 9mero de las secuencias. Este proceso puede repetirse para las proteínas codificadas por otros alelos de HLA. Las tablas 31-34 proporcionan potenciales de bolsillo para los productos de proteína de los alelos de HLA que se producen con alta frecuencia en la población caucásica.
Las puntuaciones de TEPITOPE calculadas mediante este método varían de aproximadamente -10 hasta 10. Sin embargo, los péptidos 9meros que carecen de un aminoácido hidrófobo (FKLMVWY) en la posición P1 tienen puntuaciones de TEPITOPE calculadas en el intervalo de -1009 a -989. Este valor es biológicamente significativo y refleja el hecho de que un aminoácido hidrófobo sirve como resto de anclaje para la unión a HLA y los péptidos que carecen de un resto hidrófobo en P1 se consideran como moléculas que no se unen al HLA. Debido a que la mayoría de secuencias de XTEN carece de restos hidrófobos, todas las combinaciones de subsecuencias de 9meros tendrán puntuaciones de TEPITOPE en el intervalo de -1009 a -989. Este método confirma que los polipéptidos de XTEN pueden tener pocos o ningún epítopo para linfocitos T predichos.
*


T l 1: P n i l l il r l l l HLA* 1 B.

T l 2: P n i l l ill r l l l ^ HLA* 41B.


T l : P n i l l ill r l l l HLA* 71B.

T l 4: P n i l ill r l l l HLA*1 1B.

T l : A ivi i l i m m l . En il r iv in i i n r f ri r l P


Tabla 36: GPXTEN a modo de ejemplo que comprenden péptidos reguladores de la glucosa y una sola n i XTEN

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

* El nombre de la secuencia refleja la configuración del extremo N al extremo C-terminal de los componentes de factor de crecimiento y XTEN
Tabla 37: GPXTEN a modo de ejemplo que comprenden péptidos reguladores de la glucosa y dos n i XTEN

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

Tabla 38: GPXTEN a modo de ejemplo que comprenden péptidos reguladores de la glucosa, XTEN y n i i i n

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

(continuación)

Claims (15)
1. Un ácido nucleico aislado que comprende una secuencia de polinucleótido que codifica una proteína de fusión, que comprende un péptido regulador de la glucosa (GP),
en donde la secuencia de polinucleótido (i) comprende una secuencia que hibrida en condiciones rigurosas con AE864 de la tabla 9 (SEQ ID NO: 243) o Ex4-AE864 de la tabla 36 (SEQ ID n O: 897) o el complemento de las mismas y tiene al menos un 70 % de identidad de secuencia o un 80 % o un 90 % o un 95 % o un 97 % o un 98 % o un 99 % hasta un 100 % de identidad de secuencia respecto de AE864 de la tabla 9 (SEQ ID NO: 243) o Ex4-AE864 de la tabla 36 (SEQ ID NO: 897) o el complemento de las mismas,
y (ii) codifica una proteína de fusión que comprende (a) exendina-4 y que tiene una secuencia de aminoácidos que muestra al menos un 95 % de identidad de secuencia respecto de Ex4-AE864 de la tabla 36 (SEQ ID NO: 896) o (b) GLP-1 y que tiene una secuencia de aminoácidos que muestra al menos un 95 % de identidad de secuencia respecto de GLP1-AE864 de la tabla 36 (SEQ ID NO: 986) y que conserva al menos una parte de la actividad biológica del GP nativo.
2. El ácido nucleico aislado de la reivindicación 1, en donde el péptido regulador de la glucosa (GP) es al menos aproximadamente un 90 % o aproximadamente un 95 % idéntico a una secuencia de aminoácidos seleccionada de entre exendina-4 de la tabla 1 (SEQ ID NO: 4) o hGLP-1 de la tabla 1 (SEQ ID NO: 6) o GLP-1 humano de la tabla 1 (SEQ ID NO: 8).
3. El ácido nucleico aislado de la reivindicación 1 o la reivindicación 2, en donde dicha proteína de fusión, cuando se administra a un sujeto que lo necesite, logra un efecto terapéutico comparable al del GP correspondiente que carece del XTEN usando una cantidad molar por lo demás equivalente, incluso cuando la proteína de fusión se administra con menos frecuencia a un sujeto, en comparación con el GP correspondiente que carece del XTEN.
4. El ácido nucleico aislado de una cualquiera de las reivindicaciones 1-3, en donde la proteína de fusión comprende una secuencia de polipéptido de GLP1-AE864 de la tabla 36 (SEQ ID NO: 986).
5. El ácido nucleico aislado de la reivindicación 4, en donde la proteína de fusión comprende la secuencia de polipéptido de Ex4-AE864 de la tabla 36 (SEQ ID NO: 896).
6. El ácido nucleico aislado de la reivindicación 1, en donde la secuencia de polinucleótido comprende Ex4-AE864 de la tabla 36 (SEQ ID NO: 897).
7. Un vector de expresión que comprende la secuencia de polinucleótido de una cualquiera de las reivindicaciones 1 6.
8. Una proteína de fusión que comprende un GP que es al menos aproximadamente un 90 % o aproximadamente un 95 % idéntica a una secuencia de aminoácidos seleccionada entre exendina-4 de la tabla 1 (SEQ ID NO: 4) o hGLP-1 de la tabla 1 (SEQ ID NO: 6) o GLP-1 humano de la tabla 1 (SEQ ID NO: 8),
en donde dicho GP está unido a un péptido recombinante extendido (XTEN) de al menos aproximadamente 200 restos de aminoácido para su uso en un método para tratar una afección relacionada con un péptido regulador de la glucosa en un sujeto, comprendiendo el método
(i) expresar la proteína de fusión a partir de un polinucleótido que comprende una secuencia que hibrida en condiciones rigurosas con AE864 de la tabla 9 (SEq ID NO: 243) o el complemento de la misma y que tiene al menos un 70 % de identidad de secuencia o un 80 % o un 90 % o un 95 % o un 97 % o un 98 % o un 99 % hasta un 100 % de identidad de secuencia respecto de AE864 de la tabla 9 (SEQ ID NO: 243).
(ii) administrar al sujeto una cantidad terapéuticamente eficaz de la proteína de fusión, en donde el XTEN se caracteriza por que:
(a) la secuencia de XTEN comprende al menos aproximadamente 200 aminoácidos contiguos que muestra al menos un 90 % o aproximadamente un 95 % de identidad de secuencia respecto de la secuencia de aminoácidos AE864 de la tabla 5 (SEQ ID NO: 199);
(b) la secuencia de XTEN carece de un epítopo de linfocitos T predicho cuando se analiza mediante el algoritmo TEPITOPE, en donde la predicción por el algoritmo TEPITOPE para epítopos dentro de la secuencia de XTEN se basa en una puntuación de -9 o mayor;
(c) tiene una puntuación de subsecuencia menor de 10; y
(d) la suma de los restos de glicina (G), alanina (A), serina (S), treonina (T), glutamato (E) y prolina (P) constituye más de aproximadamente un 90 % de los restos de aminoácido totales del XTEN.
9. Uso de una proteína de fusión que comprende un GP que es al menos aproximadamente un 90 % o aproximadamente un 95 % idéntica a una secuencia de aminoácidos seleccionada entre exendina-4 de la tabla 1 (SEQ ID NO: 4) o hGLP-1 de la tabla 1 (SEQ ID NO: 6) o GLP-1 humano de la tabla 1 (SEQ ID NO: 8),
en donde dicho GP está unido a un péptido recombinante extendido (XTEN) de al menos aproximadamente 200 restos de aminoácido, en la preparación de un medicamento para tratar en un sujeto una afección relacionada con un péptido
regulador de la glucosa,
comprendiendo el uso
(i) expresar la proteína de fusión a partir de un polinucleótido que comprende una secuencia que híbrida en condiciones rigurosas con AE864 de la tabla 9 (SEQ ID NO: 243) o el complemento de la misma y tiene al menos un 70 % de identidad de secuencia o un 80 % o un 90 % o un 95 % o un 97 % o un 98 % o un 99 % hasta un 100 % de identidad de secuencia respecto de AE864 de la tabla 9 (SEQ ID NO: 243).
(ii) administrar al sujeto una cantidad terapéuticamente eficaz de la proteína de fusión, en donde el XTEN se caracteriza por que:
(a) la secuencia de XTEN comprende al menos aproximadamente 200 aminoácidos contiguos que muestra al menos un 90 % o aproximadamente un 95 % de identidad de secuencia respecto de la secuencia de aminoácidos AE864 de la tabla 5 (SEQ ID NO: 199);
(b) la secuencia de XTEN carece de un epítopo de linfocitos T predicho cuando se analiza mediante el algoritmo TEPITOPE, en donde la predicción por el algoritmo TEPITOPE para epítopos dentro de la secuencia de XTEN se basa en una puntuación de -9 o mayor;
(c) tiene una puntuación de subsecuencia menor de 10; y
(d) la suma de los restos de glicina (G), alanina (A), serina (S), treonina (T), glutamato (E) y prolina (P) constituye más de aproximadamente un 90 % de los restos de aminoácido totales del XTEN.
10. La proteína de fusión para su uso o el uso de acuerdo con la reivindicación 8 o la reivindicación 9, en donde el GP es exendina-4 de la tabla 1 (SEQ ID NO: 4).
11. Una proteína de fusión para su uso o el uso de acuerdo con las reivindicaciones 9 o 10, en donde:
i) dicha administración da como resultado una semivida terminal más larga cuando se administran a un sujeto en comparación con el péptido regulador de la glucosa correspondiente que carece del XTEN cuando se administran a un sujeto en una dosis molar comparable; y/o
ii) dicha proteína de fusión logra un efecto terapéutico comparable a un GP correspondiente que carece del XTEN usando una cantidad molar por lo demás equivalente, incluso cuando la proteína de fusión se administra con menos frecuencia a un sujeto, en comparación con el GP correspondiente que carece del XTEN.
12. Una proteína de fusión para su uso o el uso de acuerdo con una cualquiera de las reivindicaciones 8-11, en donde:
i) la proteína de fusión está codificada por un ácido nucleico que comprende una secuencia de polinucleótido que comprende una secuencia que hibrida en condiciones rigurosas con AE864 de la tabla 9 (SEQ ID NO: 243) o el complemento de la misma y que tiene al menos un 70 % de identidad de secuencia o un 80 % o un 90 % o un 95 % o un 97 % o un 98 % o un 99 % hasta un 100 % de identidad de secuencia respecto de la secuencia de polinucleótido de Ex4-AE864 de la tabla 36 (SEQ ID NO: 897); y/o
ii) la cantidad terapéuticamente eficaz da como resultado una ganancia en el tiempo empleado dentro de una ventana terapéutica establecida para la proteína de fusión de al menos tres veces en comparación con el GP correspondiente que carece del XTEN, cuando la proteína de fusión administrada y el GP correspondiente que carece del XTEN son de una dosis comparable; y/o
iii) la afección relacionada con el péptido regulador de la glucosa se selecciona entre diabetes juvenil, diabetes de tipo I, diabetes tipo II, obesidad, hipoglucemia aguda, hiperglucemia aguda, hipoglucemia nocturna, hiperglucemia crónica, glucagonomas, trastornos secretorios de las vías respiratorias, artritis, osteoporosis, enfermedad del sistema nervioso central, reestenosis, enfermedad neurodegenerativa, insuficiencia renal, insuficiencia cardíaca congestiva, síndrome nefrótico, cirrosis, edema pulmonar, hipertensión, ictus, síndrome del intestino irritable, infarto de miocardio, síndrome coronario agudo, cambios catabólicos postquirúrgicos, hibernación miocárdica, cardiomiopatía diabética, insuficiencia de excreción de sodio en la orina, exceso de concentración de potasio en la orina, síndrome del ovario poliquístico, disnea, nefropatía, disfunción sistólica del ventrículo izquierdo, diarrea, síndrome postoperatorio de la evacuación gástrica rápida, polineuropatía por enfermedad grave (CIPN), dislipidemia, lesión de tejido de órgano causada por la reperfusión del flujo sanguíneo tras una isquemia y síndrome de factor de riesgo de enfermedad cardiaca (CHDRF).
13. Un método para producir una proteína de fusión codificada por el ácido nucleico de una cualquiera de las reivindicaciones 1-6, que comprende:
(a) proporcionar una célula hospedadora que comprende el ácido nucleico de las reivindicaciones 1 o 2;
(b) cultivar la célula hospedadora en condiciones que permiten la expresión de la proteína de fusión; y
(c) recuperar la proteína de fusión.
14. El método de la reivindicación 13, en donde
i) la célula hospedadora es una célula procariota o eucariota; y
ii) la proteína de fusión aislada se recupera del citoplasma de la célula hospedadora en forma sustancialmente
soluble.
15. Una célula hospedadora aislada que comprende el ácido nucleico de una cualquiera de las reivindicaciones 1-6 o el vector de la reivindicación 7, en donde la célula hospedadora es una célula procariota o eucariota, en donde la célula hospedadora procariota es opcionalmente E. coli.
Applications Claiming Priority (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US26819309P | 2009-06-08 | 2009-06-08 | |
| US23683609P | 2009-08-25 | 2009-08-25 | |
| US28095509P | 2009-11-10 | 2009-11-10 | |
| US12/699,761 US8673860B2 (en) | 2009-02-03 | 2010-02-03 | Extended recombinant polypeptides and compositions comprising same |
| PCT/US2010/023106 WO2010091122A1 (en) | 2009-02-03 | 2010-02-03 | Extended recombinant polypeptides and compositions comprising same |
| PCT/US2010/037855 WO2010144508A1 (en) | 2009-06-08 | 2010-06-08 | Glucose-regulating polypeptides and methods of making and using same |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2705249T3 true ES2705249T3 (es) | 2019-03-22 |
Family
ID=43309202
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES10786730T Active ES2705249T3 (es) | 2009-06-08 | 2010-06-08 | Polipéptidos reguladores de glucosa y métodos para su producción y uso |
Country Status (12)
| Country | Link |
|---|---|
| US (3) | US8957021B2 (es) |
| EP (1) | EP2440228B8 (es) |
| JP (1) | JP5839597B2 (es) |
| CN (1) | CN102481331B (es) |
| AU (1) | AU2010258898B8 (es) |
| CA (1) | CA2764108A1 (es) |
| DK (1) | DK2440228T3 (es) |
| ES (1) | ES2705249T3 (es) |
| NZ (1) | NZ596778A (es) |
| PT (1) | PT2440228T (es) |
| WO (1) | WO2010144508A1 (es) |
| ZA (1) | ZA201200122B (es) |
Families Citing this family (82)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7855279B2 (en) | 2005-09-27 | 2010-12-21 | Amunix Operating, Inc. | Unstructured recombinant polymers and uses thereof |
| US9821031B2 (en) | 2007-01-08 | 2017-11-21 | The Trustees Of The University Of Pennsylvania | Methods and compositions for treating hypoglycemic disorders |
| NZ593833A (en) | 2009-02-03 | 2013-10-25 | Amunix Operating Inc | Extended recombinant polypeptides and compositions comprising same |
| US8703717B2 (en) | 2009-02-03 | 2014-04-22 | Amunix Operating Inc. | Growth hormone polypeptides and methods of making and using same |
| DK2440228T3 (en) | 2009-06-08 | 2018-12-17 | Amunix Operating Inc | Glucose regulating polypeptides and methods for their preparation and use |
| US9849188B2 (en) | 2009-06-08 | 2017-12-26 | Amunix Operating Inc. | Growth hormone polypeptides and methods of making and using same |
| AU2010290077C1 (en) | 2009-08-24 | 2015-12-03 | Bioverativ Therapeutics Inc. | Coagulation factor IX compositions and methods of making and using same |
| US8557961B2 (en) | 2010-04-02 | 2013-10-15 | Amunix Operating Inc. | Alpha 1-antitrypsin compositions and methods of making and using same |
| EP2552967A4 (en) * | 2010-04-02 | 2014-10-08 | Amunix Operating Inc | BINDING FUSION PROTEINS, BINDING FUSION PROTEIN MEDICINAL CONJUGATES, XTEN MEDICAMENT CONJUGATES, AND METHOD FOR THEIR PREPARATION AND USE |
| US20130017997A1 (en) * | 2010-08-19 | 2013-01-17 | Amunix Operating Inc. | Factor VIII Compositions and Methods of Making and Using Same |
| AU2012267484B2 (en) | 2011-06-10 | 2017-03-23 | Bioverativ Therapeutics Inc. | Pro-coagulant compounds and methods of use thereof |
| HK1198359A1 (en) * | 2011-08-12 | 2015-04-10 | Ascendis Pharma A/S | Carrier-linked treprostinil prodrugs |
| EP2741782B1 (en) * | 2011-08-12 | 2020-05-06 | Ascendis Pharma A/S | Protein carrier-linked prodrugs |
| US9006176B2 (en) | 2011-10-18 | 2015-04-14 | AmideBio LLC | Chemically and thermodynamically stable insulin analogues and improved methods for their production |
| CN111499760A (zh) | 2012-01-12 | 2020-08-07 | 比奥贝拉蒂治疗公司 | 嵌合因子viii多肽及其用途 |
| EP2817025A2 (en) * | 2012-02-08 | 2014-12-31 | Seneb Biosciences, Inc. | Treatment of hypoglycemia |
| CN111574632A (zh) | 2012-02-15 | 2020-08-25 | 比奥贝拉蒂治疗公司 | 因子viii组合物及其制备和使用方法 |
| JP6383666B2 (ja) | 2012-02-15 | 2018-08-29 | バイオベラティブ セラピューティクス インコーポレイテッド | 組換え第viii因子タンパク質 |
| EA037979B1 (ru) | 2012-02-27 | 2021-06-18 | Амуникс Оперейтинг Инк. | Композиции конъюгата xten и способы их получения |
| WO2013162078A1 (ja) | 2012-04-27 | 2013-10-31 | 学校法人日本大学 | 上皮及び内皮損傷の治療剤 |
| WO2013185113A1 (en) | 2012-06-08 | 2013-12-12 | Biogen Idec Ma Inc. | Procoagulant compounds |
| EP2863940A4 (en) | 2012-06-08 | 2016-08-10 | Biogen Ma Inc | CHIMERIC COAGULATION FACTORS |
| US10138291B2 (en) | 2012-07-11 | 2018-11-27 | Bioverativ Therapeutics Inc. | Factor VIII complex with XTEN and von Willebrand Factor protein, and uses thereof |
| RS64664B1 (sr) | 2013-02-15 | 2023-11-30 | Bioverativ Therapeutics Inc | Gen optimizovanog faktora viii |
| TWI683666B (zh) | 2013-03-15 | 2020-02-01 | 美商百歐維拉提夫治療公司 | 因子ix多肽調配物 |
| WO2014172488A2 (en) | 2013-04-17 | 2014-10-23 | AmideBio LLC | Chemically and thermodynamically stable insulin analogues and improved methods for their production |
| HK1223302A1 (zh) | 2013-06-28 | 2017-07-28 | Bioverativ Therapeutics Inc. | 具有xten的凝血酶可裂解連接子和其用途 |
| EP3043813B1 (en) | 2013-08-08 | 2021-01-13 | Bioverativ Therapeutics Inc. | Purification of chimeric fviii molecules |
| WO2015023891A2 (en) | 2013-08-14 | 2015-02-19 | Biogen Idec Ma Inc. | Factor viii-xten fusions and uses thereof |
| WO2015023894A1 (en) | 2013-08-14 | 2015-02-19 | Biogen Idec Ma Inc. | Recombinant factor viii proteins |
| EP3065769A4 (en) | 2013-11-08 | 2017-05-31 | Biogen MA Inc. | Procoagulant fusion compound |
| SI4176894T1 (sl) | 2014-01-10 | 2024-07-31 | Bioverativ Therapeutics Inc. | Himerni proteini faktorja VIII in njihova uporaba |
| US11311519B2 (en) | 2014-05-01 | 2022-04-26 | Eiger Biopharmaceuticals, Inc. | Treatment of hepatitis delta virus infection |
| EP3137494B1 (en) * | 2014-05-02 | 2021-08-04 | The Research Foundation for The State University of New York | Islet amyloid polypeptides with improved solubility |
| US11008561B2 (en) | 2014-06-30 | 2021-05-18 | Bioverativ Therapeutics Inc. | Optimized factor IX gene |
| DE102014112212A1 (de) * | 2014-08-26 | 2016-03-03 | Akesion Gmbh | Rekombinante Fusionsproteine zur Vorbeugung oder Behandlung von Adhäsionen bei Geweben oder Organen |
| MX2017003897A (es) | 2014-09-26 | 2017-06-28 | Bayer Pharma AG | Derivados estabilizados de adrenomedulina y uso de los mismos. |
| NZ730563A (en) | 2014-10-14 | 2019-05-31 | Halozyme Inc | Compositions of adenosine deaminase-2 (ada2), variants thereof and methods of using same |
| MA40835A (fr) | 2014-10-23 | 2017-08-29 | Biogen Ma Inc | Anticorps anti-gpiib/iiia et leurs utilisations |
| MA40861A (fr) | 2014-10-31 | 2017-09-05 | Biogen Ma Inc | Anticorps anti-glycoprotéines iib/iiia |
| WO2016191395A1 (en) | 2015-05-22 | 2016-12-01 | The Bot Of The Leland Stanford Junior University | Treatment of post-bariatric hypoglycemia with exendin(9-39) |
| CN108472337B (zh) | 2015-08-03 | 2022-11-25 | 比奥贝拉蒂治疗公司 | 因子ix融合蛋白以及其制备和使用方法 |
| IL307276B1 (en) | 2015-08-28 | 2025-04-01 | Amunix Operating Inc | Chimeric polypeptide composition and methods for its preparation and use |
| CN105524147B (zh) * | 2015-10-15 | 2020-06-09 | 中国药科大学 | 重组聚多肽及其应用 |
| EP3967707A1 (en) * | 2015-11-16 | 2022-03-16 | Ubiprotein, Corp. | A method for extending half-life of a protein |
| JP7026044B2 (ja) | 2015-12-23 | 2022-02-25 | ザ・ジョンズ・ホプキンス・ユニバーシティー | 神経性状態および神経変性状態の治療としての長時間作用型GLP-1rアゴニスト |
| CN106938050B (zh) | 2015-12-29 | 2021-08-24 | 派格生物医药(苏州)股份有限公司 | 包含glp-1受体激动剂和胰高血糖素受体激动剂的组合物及其用途 |
| SI3411478T1 (sl) | 2016-02-01 | 2022-10-28 | Bioverativ Therapeutics Inc. | Optimirani geni dejavnika VIII |
| WO2017152014A1 (en) * | 2016-03-04 | 2017-09-08 | Eiger Biopharmaceuticals, Inc. | Treatment of hyperinsulinemic hypoglycemia with exendin-4 derivatives |
| US20190248852A1 (en) * | 2016-05-24 | 2019-08-15 | Novo Nordisk A/S | MIC-1 Compounds and Use Thereof |
| US10738338B2 (en) | 2016-10-18 | 2020-08-11 | The Research Foundation for the State University | Method and composition for biocatalytic protein-oligonucleotide conjugation and protein-oligonucleotide conjugate |
| PT3541366T (pt) | 2016-11-21 | 2025-03-14 | Univ Leland Stanford Junior | Formulações tamponadas de exendina (9‑39) |
| JP2020500874A (ja) | 2016-12-02 | 2020-01-16 | バイオベラティブ セラピューティクス インコーポレイテッド | キメラ凝固因子を使用して血友病性関節症を処置する方法 |
| CN110520149A (zh) | 2016-12-02 | 2019-11-29 | 比奥维拉迪维治疗股份有限公司 | 诱导对凝血因子的免疫耐受性的方法 |
| CR20190389A (es) | 2017-01-31 | 2019-11-26 | Bioverativ Therapeutics Inc | Proteínas de fusión del factor ix y procedimientos de preparación y utilización de las mismas |
| US11028137B2 (en) * | 2017-02-01 | 2021-06-08 | The Research Foundation For The State University Of New York | Mutant islet amyloid polypeptides with improved solubility and methods for using the same |
| US10540366B2 (en) | 2017-03-09 | 2020-01-21 | Bank Of America Corporation | Transforming data structures and data objects for migrating data between databases having different schemas |
| SG11202000764RA (en) | 2017-08-09 | 2020-02-27 | Bioverativ Therapeutics Inc | Nucleic acid molecules and uses thereof |
| EP3728326A4 (en) | 2017-12-21 | 2021-12-15 | Amunix Pharmaceuticals, Inc. | RELEASE SEGMENTS AND LIAISON COMPOSITIONS INCLUDING THEM |
| BR112020015228A2 (pt) | 2018-02-01 | 2020-12-29 | Bioverativ Therapeutics Inc. | Uso de vetores lentivirais que expressam fator viii |
| JP7464530B2 (ja) | 2018-03-28 | 2024-04-09 | ブリストル-マイヤーズ スクイブ カンパニー | インターロイキン-2/インターロイキン-2受容体アルファ融合タンパク質および使用方法 |
| EP3784265A4 (en) * | 2018-04-25 | 2022-06-22 | Janssen Pharmaceutica NV | MODULATORS OF THE THIOETHER CYCLIC PEPTIDE AMYLIN RECEPTOR |
| JP2021523878A (ja) | 2018-05-18 | 2021-09-09 | バイオベラティブ セラピューティクス インコーポレイテッド | 血友病aを処置する方法 |
| WO2020010117A2 (en) | 2018-07-03 | 2020-01-09 | Bristol-Myers Squibb Company | Fgf21 formulations |
| CN119955796A (zh) | 2018-08-09 | 2025-05-09 | 比奥维拉迪维治疗股份有限公司 | 核酸分子及其用于非病毒基因疗法的用途 |
| US20220089704A1 (en) | 2018-10-29 | 2022-03-24 | Biogen Ma Inc. | Humanized and stabilized fc5 variants for enhancement of blood brain barrier transport |
| MX2021006648A (es) | 2018-12-06 | 2021-07-07 | Bioverativ Therapeutics Inc | Uso de vectores lentivirales que expresan el factor ix. |
| WO2020254197A1 (en) | 2019-06-18 | 2020-12-24 | Bayer Aktiengesellschaft | Adrenomedullin-analogues for long-term stabilization and their use |
| CN115279896A (zh) | 2019-09-30 | 2022-11-01 | 比奥维拉迪维治疗股份有限公司 | 慢病毒载体配制品 |
| BR112022009217A2 (pt) | 2019-11-13 | 2022-08-02 | Amunix Pharmaceuticals Inc | Polipeptídeos xten com código de barras e composições destes, e métodos para produzir e usar os mesmos |
| BR112022026127A2 (pt) | 2020-06-24 | 2023-01-17 | Bioverativ Therapeutics Inc | Métodos para remoção de fator viii livre de preparações de vetores lentivirais modificados para expressar referida proteína |
| BR112022026420A2 (pt) | 2020-06-25 | 2023-04-18 | Amunix Pharmaceuticals Inc | Composições biespecíficas direcionadas por her-2 e métodos para preparar e usar as mesmas |
| JP2023545684A (ja) | 2020-09-30 | 2023-10-31 | ベイジン キューエル バイオファーマシューティカル カンパニー,リミテッド | ポリペプチドコンジュゲートおよび使用の方法 |
| WO2023028440A2 (en) | 2021-08-23 | 2023-03-02 | Bioverativ Therapeutics Inc. | Baculovirus expression system |
| JP2024532262A (ja) | 2021-08-23 | 2024-09-05 | バイオベラティブ セラピューティクス インコーポレイテッド | 最適化第viii因子遺伝子 |
| TW202346327A (zh) | 2021-09-30 | 2023-12-01 | 美商百歐維拉提夫治療公司 | 編碼具有降低免疫原性的因子viii多肽之核酸 |
| WO2024102733A2 (en) * | 2022-11-07 | 2024-05-16 | Ubiquitx | Sequence-based framework to design peptide-guided degraders |
| US20240327538A1 (en) | 2023-02-10 | 2024-10-03 | Amunix Pharmaceuticals, Inc. | Compositions targeting prostate-specific membrane antigen and methods for making and using the same |
| US20240400696A1 (en) | 2023-04-17 | 2024-12-05 | Amunix Pharmaceuticals, Inc. | Compositions targeting epidermal growth factor receptor and methods for making and using the same |
| WO2024245946A1 (en) * | 2023-05-26 | 2024-12-05 | Gubra A/S | Secretin-derived glp1r selective agonists |
| WO2025122957A1 (en) | 2023-12-08 | 2025-06-12 | Amunix Pharmaceuticals, Inc. | Protease activatable cytokines and methods for making and using the same |
| CN118955627B (zh) * | 2024-10-17 | 2025-02-07 | 山东华涛食品有限公司 | 一种混合型抑制α-葡萄糖苷酶活性的甘薯肽组合物 |
Family Cites Families (121)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3992518A (en) | 1974-10-24 | 1976-11-16 | G. D. Searle & Co. | Method for making a microsealed delivery device |
| GB1478759A (en) | 1974-11-18 | 1977-07-06 | Alza Corp | Process for forming outlet passageways in pills using a laser |
| US4284444A (en) | 1977-08-01 | 1981-08-18 | Herculite Protective Fabrics Corporation | Activated polymer materials and process for making same |
| US4200098A (en) | 1978-10-23 | 1980-04-29 | Alza Corporation | Osmotic system with distribution zone for dispensing beneficial agent |
| ZA811368B (en) | 1980-03-24 | 1982-04-28 | Genentech Inc | Bacterial polypedtide expression employing tryptophan promoter-operator |
| US4398908A (en) | 1980-11-28 | 1983-08-16 | Siposs George G | Insulin delivery system |
| US4435173A (en) | 1982-03-05 | 1984-03-06 | Delta Medical Industries | Variable rate syringe pump for insulin delivery |
| US4943529A (en) | 1982-05-19 | 1990-07-24 | Gist-Brocades Nv | Kluyveromyces as a host strain |
| AU3145184A (en) | 1983-08-16 | 1985-02-21 | Zymogenetics Inc. | High expression of foreign genes in schizosaccharomyces pombe |
| US5231112A (en) | 1984-04-12 | 1993-07-27 | The Liposome Company, Inc. | Compositions containing tris salt of cholesterol hemisuccinate and antifungal |
| US5916588A (en) | 1984-04-12 | 1999-06-29 | The Liposome Company, Inc. | Peptide-containing liposomes, immunogenic liposomes and methods of preparation and use |
| EP0190262B1 (en) | 1984-07-24 | 1990-12-27 | Key Pharmaceuticals, Inc. | Adhesive transdermal dosage layer |
| US4879231A (en) | 1984-10-30 | 1989-11-07 | Phillips Petroleum Company | Transformation of yeasts of the genus pichia |
| DK27885A (da) | 1985-01-22 | 1986-07-23 | Novo Industri As | Fremstilling af peptider |
| US4684479A (en) | 1985-08-14 | 1987-08-04 | Arrigo Joseph S D | Surfactant mixtures, stable gas-in-liquid emulsions, and methods for the production of such emulsions from said mixtures |
| GB8610600D0 (en) | 1986-04-30 | 1986-06-04 | Novo Industri As | Transformation of trichoderma |
| US5118666A (en) | 1986-05-05 | 1992-06-02 | The General Hospital Corporation | Insulinotropic hormone |
| US6759057B1 (en) | 1986-06-12 | 2004-07-06 | The Liposome Company, Inc. | Methods and compositions using liposome-encapsulated non-steroidal anti-inflammatory drugs |
| IE60901B1 (en) | 1986-08-21 | 1994-08-24 | Vestar Inc | Improved treatment of systemic fungal infections with phospholipid particles encapsulating polyene antifungal antibiotics |
| US4933185A (en) | 1986-09-24 | 1990-06-12 | Massachusetts Institute Of Technology | System for controlled release of biologically active compounds |
| US6406713B1 (en) | 1987-03-05 | 2002-06-18 | The Liposome Company, Inc. | Methods of preparing low-toxicity drug-lipid complexes |
| US4976696A (en) | 1987-08-10 | 1990-12-11 | Becton, Dickinson And Company | Syringe pump and the like for delivering medication |
| US4861800A (en) | 1987-08-18 | 1989-08-29 | Buyske Donald A | Method for administering the drug deprenyl so as to minimize the danger of side effects |
| AU598958B2 (en) | 1987-11-12 | 1990-07-05 | Vestar, Inc. | Improved amphotericin b liposome preparation |
| US5270176A (en) * | 1987-11-20 | 1993-12-14 | Hoechst Aktiengesellschaft | Method for the selective cleavage of fusion proteins with lysostaphin |
| GB8807504D0 (en) | 1988-03-29 | 1988-05-05 | Sandoz Ltd | Improvements in/relating to organic compounds |
| JP2717808B2 (ja) | 1988-08-10 | 1998-02-25 | テルモ株式会社 | シリンジポンプ |
| US5534617A (en) | 1988-10-28 | 1996-07-09 | Genentech, Inc. | Human growth hormone variants having greater affinity for human growth hormone receptor at site 1 |
| EP0394538B1 (en) | 1989-04-28 | 1996-10-16 | Rhein Biotech Gesellschaft Für Neue Biotechnologische Prozesse Und Produkte Mbh | A yeast cell of the genus schwanniomyces |
| US5017378A (en) | 1989-05-01 | 1991-05-21 | The University Of Virginia Alumni Patents Foundation | Intraorgan injection of biologically active compounds contained in slow-release microcapsules or microspheres |
| US5599907A (en) * | 1989-05-10 | 1997-02-04 | Somatogen, Inc. | Production and use of multimeric hemoglobins |
| US5298022A (en) | 1989-05-29 | 1994-03-29 | Amplifon Spa | Wearable artificial pancreas |
| EP0402226A1 (en) | 1989-06-06 | 1990-12-12 | Institut National De La Recherche Agronomique | Transformation vectors for yeast yarrowia |
| FR2649120B1 (fr) | 1989-06-30 | 1994-01-28 | Cayla | Nouvelle souche et ses mutants de champignons filamenteux, procede de production de proteines recombinantes a l'aide de ladite souche et souches et proteines obtenues selon ce procede |
| US5318540A (en) | 1990-04-02 | 1994-06-07 | Pharmetrix Corporation | Controlled release infusion device |
| US5492534A (en) | 1990-04-02 | 1996-02-20 | Pharmetrix Corporation | Controlled release portable pump |
| US5176502A (en) | 1990-04-25 | 1993-01-05 | Becton, Dickinson And Company | Syringe pump and the like for delivering medication |
| US5215680A (en) | 1990-07-10 | 1993-06-01 | Cavitation-Control Technology, Inc. | Method for the production of medical-grade lipid-coated microbubbles, paramagnetic labeling of such microbubbles and therapeutic uses of microbubbles |
| US5234906A (en) | 1991-01-10 | 1993-08-10 | Amylin Pharmaceuticals, Inc. | Hyperglycemic compositions |
| US5206161A (en) | 1991-02-01 | 1993-04-27 | Genentech, Inc. | Human plasma carboxypeptidase B |
| HU222249B1 (hu) | 1991-03-08 | 2003-05-28 | Amylin Pharmaceuticals Inc. | Eljárás amilin agonista peptidszármazékok és ezeket tartalmazó gyógyszerkészítmények előállítására |
| US5573776A (en) | 1992-12-02 | 1996-11-12 | Alza Corporation | Oral osmotic device with hydrogel driving member |
| US5554730A (en) * | 1993-03-09 | 1996-09-10 | Middlesex Sciences, Inc. | Method and kit for making a polysaccharide-protein conjugate |
| US5424286A (en) | 1993-05-24 | 1995-06-13 | Eng; John | Exendin-3 and exendin-4 polypeptides, and pharmaceutical compositions comprising same |
| US5660848A (en) | 1994-11-02 | 1997-08-26 | The Population Council, Center For Biomedical Research | Subdermally implantable device |
| US7846455B2 (en) * | 1996-07-15 | 2010-12-07 | The United States Of America As Represented By The Department Of Health And Human Services | Attenuated chimeric respiratory syncytial virus |
| US6441025B2 (en) | 1996-03-12 | 2002-08-27 | Pg-Txl Company, L.P. | Water soluble paclitaxel derivatives |
| SI0932399T1 (sl) | 1996-03-12 | 2006-10-31 | Pg Txl Co Lp | Vodotopna paklitakselna predzdravila |
| CA2263455C (en) | 1996-08-23 | 2002-10-29 | Sequus Pharmaceuticals, Inc. | Liposomes containing a cisplatin compound |
| AU4907897A (en) | 1996-10-11 | 1998-05-11 | Sequus Pharmaceuticals, Inc. | Therapeutic liposome composition and method |
| US6056973A (en) | 1996-10-11 | 2000-05-02 | Sequus Pharmaceuticals, Inc. | Therapeutic liposome composition and method of preparation |
| NZ514133A (en) | 1996-10-15 | 2001-09-28 | Liposome Co Inc | N-acyl phosphatidylethanolamine-mediated liposomal drug delivery |
| ES2255103T3 (es) | 1996-10-25 | 2006-06-16 | Shire Laboratories Inc. | Sistema osmotico de administracion de dosis en forma soluble. |
| US6361796B1 (en) | 1996-10-25 | 2002-03-26 | Shire Laboratories, Inc. | Soluble form osmotic dose delivery system |
| US6294170B1 (en) * | 1997-08-08 | 2001-09-25 | Amgen Inc. | Composition and method for treating inflammatory diseases |
| AT405516B (de) * | 1997-02-27 | 1999-09-27 | Immuno Ag | Faktor x-analoge mit modifizierter proteasespaltstelle |
| ATE319745T1 (de) | 1997-05-21 | 2006-03-15 | Biovation Ltd | Verfahren zur herstellung von nicht-immunogenen proteinen |
| DE19747261A1 (de) | 1997-10-25 | 1999-04-29 | Bayer Ag | Osmotisches Arzneimittelfreisetzungssystem |
| US6309370B1 (en) | 1998-02-05 | 2001-10-30 | Biosense, Inc. | Intracardiac drug delivery |
| US6406632B1 (en) | 1998-04-03 | 2002-06-18 | Symyx Technologies, Inc. | Rapid characterization of polymers |
| US7090976B2 (en) * | 1999-11-10 | 2006-08-15 | Rigel Pharmaceuticals, Inc. | Methods and compositions comprising Renilla GFP |
| GB9815157D0 (en) | 1998-07-13 | 1998-09-09 | Metron Designs Ltd | High resolution pulse width setting from relatively low frequency clocks |
| US20030190740A1 (en) * | 1998-10-13 | 2003-10-09 | The University Of Georgia Research Foundation, Inc | Stabilized bioactive peptides and methods of identification, synthesis, and use |
| US6713086B2 (en) | 1998-12-18 | 2004-03-30 | Abbott Laboratories | Controlled release formulation of divalproex sodium |
| EP1555038B1 (en) | 1999-03-03 | 2011-06-29 | Optinose AS | Nasal delivery device |
| US6183770B1 (en) | 1999-04-15 | 2001-02-06 | Acutek International | Carrier patch for the delivery of agents to the skin |
| US7666400B2 (en) * | 2005-04-06 | 2010-02-23 | Ibc Pharmaceuticals, Inc. | PEGylation by the dock and lock (DNL) technique |
| US6743211B1 (en) | 1999-11-23 | 2004-06-01 | Georgia Tech Research Corporation | Devices and methods for enhanced microneedle penetration of biological barriers |
| US20030109428A1 (en) * | 1999-12-01 | 2003-06-12 | John Bertin | Novel molecules of the card-related protein family and uses thereof |
| US20050287153A1 (en) * | 2002-06-28 | 2005-12-29 | Genentech, Inc. | Serum albumin binding peptides for tumor targeting |
| US6352721B1 (en) | 2000-01-14 | 2002-03-05 | Osmotica Corp. | Combined diffusion/osmotic pumping drug delivery system |
| EP2295456A1 (en) * | 2000-04-12 | 2011-03-16 | Human Genome Sciences, Inc. | Albumin fusion proteins |
| US20030228309A1 (en) | 2000-11-08 | 2003-12-11 | Theodora Salcedo | Antibodies that immunospecifically bind to TRAIL receptors |
| US20030049689A1 (en) * | 2000-12-14 | 2003-03-13 | Cynthia Edwards | Multifunctional polypeptides |
| IN190699B (es) | 2001-02-02 | 2003-08-16 | Sun Pharmaceutical Ind Ltd | |
| US20020169125A1 (en) * | 2001-03-21 | 2002-11-14 | Cell Therapeutics, Inc. | Recombinant production of polyanionic polymers and uses thereof |
| WO2002079415A2 (en) | 2001-03-30 | 2002-10-10 | Lexigen Pharmaceuticals Corp. | Reducing the immunogenicity of fusion proteins |
| US6890918B2 (en) | 2001-04-30 | 2005-05-10 | Shire Laboratories, Inc. | Pharmaceutical compositions including ACE/NEP inhibitors and bioavailability enhancers |
| US6838093B2 (en) | 2001-06-01 | 2005-01-04 | Shire Laboratories, Inc. | System for osmotic delivery of pharmaceutically active agents |
| KR100407467B1 (ko) | 2001-07-12 | 2003-11-28 | 최수봉 | 리모컨 방식의 인슐린 자동주사기 |
| AU2002322394A1 (en) * | 2001-07-30 | 2003-02-17 | Eli Lilly And Company | Method for treating diabetes and obesity |
| US7125843B2 (en) * | 2001-10-19 | 2006-10-24 | Neose Technologies, Inc. | Glycoconjugates including more than one peptide |
| US20080167238A1 (en) * | 2001-12-21 | 2008-07-10 | Human Genome Sciences, Inc. | Albumin Fusion Proteins |
| US6945952B2 (en) | 2002-06-25 | 2005-09-20 | Theraject, Inc. | Solid solution perforator for drug delivery and other applications |
| US7294513B2 (en) | 2002-07-24 | 2007-11-13 | Wyatt Technology Corporation | Method and apparatus for characterizing solutions of small particles |
| US20070161087A1 (en) * | 2003-05-29 | 2007-07-12 | Wolfgang Glaesner | Glp-1 fusion proteins |
| US7498024B2 (en) * | 2003-06-03 | 2009-03-03 | Cell Genesys, Inc. | Compositions and methods for enhanced expression of immunoglobulins from a single vector using a peptide cleavage site |
| US20050152979A1 (en) | 2003-09-05 | 2005-07-14 | Cell Therapeutics, Inc. | Hydrophobic drug compositions containing reconstitution enhancer |
| WO2005027978A2 (en) * | 2003-09-19 | 2005-03-31 | Novo Nordisk A/S | Albumin-binding derivatives of therapeutic peptides |
| US20050123997A1 (en) * | 2003-10-30 | 2005-06-09 | Lollar John S. | Modified fVIII having reduced immunogenicity through mutagenesis of A2 and C2 epitopes |
| US20050143303A1 (en) | 2003-12-26 | 2005-06-30 | Nastech Pharmaceutical Company Inc. | Intranasal administration of glucose-regulating peptides |
| MXPA06008126A (es) * | 2004-01-14 | 2008-02-14 | Univ Ohio | Metodos para la produccion de peptidos/proteinas en plantas y peptidos/proteinas producidos de este modo. |
| BRPI0507026A (pt) * | 2004-02-09 | 2007-04-17 | Human Genome Sciences Inc | proteìnas de fusão de albumina |
| US8076288B2 (en) * | 2004-02-11 | 2011-12-13 | Amylin Pharmaceuticals, Inc. | Hybrid polypeptides having glucose lowering activity |
| EP3489257A1 (en) | 2004-07-23 | 2019-05-29 | Acceleron Pharma Inc. | Actrii receptor polypeptides, methods and compositions |
| EA011879B1 (ru) * | 2004-09-24 | 2009-06-30 | Эмджин Инк. | МОЛЕКУЛЫ С МОДИФИЦИРОВАННЫМ Fc ФРАГМЕНТОМ |
| RU2007132188A (ru) | 2005-01-25 | 2009-03-10 | Селл Терапьютикс, Инк. (Us) | Конъюгаты биологически активных белков, имеющие модифицированное время полужизни in vivo |
| US8263545B2 (en) * | 2005-02-11 | 2012-09-11 | Amylin Pharmaceuticals, Inc. | GIP analog and hybrid polypeptides with selectable properties |
| US7846445B2 (en) * | 2005-09-27 | 2010-12-07 | Amunix Operating, Inc. | Methods for production of unstructured recombinant polymers and uses thereof |
| US7855279B2 (en) * | 2005-09-27 | 2010-12-21 | Amunix Operating, Inc. | Unstructured recombinant polymers and uses thereof |
| EP1929073A4 (en) * | 2005-09-27 | 2010-03-10 | Amunix Inc | PROTEIN MEDICAMENT AND ITS USE |
| US8334257B2 (en) | 2005-12-20 | 2012-12-18 | Duke University | Methods and compositions for delivering active agents with enhanced pharmacological properties |
| EP1816201A1 (en) | 2006-02-06 | 2007-08-08 | CSL Behring GmbH | Modified coagulation factor VIIa with extended half-life |
| EP2863222A1 (en) | 2006-03-06 | 2015-04-22 | Amunix Operating Inc. | Unstructured recombinant polymers and uses thereof |
| US7683158B2 (en) * | 2006-03-31 | 2010-03-23 | Baxter International Inc. | Pegylated factor VIII |
| EP1867660A1 (en) * | 2006-06-14 | 2007-12-19 | CSL Behring GmbH | Proteolytically cleavable fusion protein comprising a blood coagulation factor |
| US7939632B2 (en) * | 2006-06-14 | 2011-05-10 | Csl Behring Gmbh | Proteolytically cleavable fusion proteins with high molar specific activity |
| CN101511868B (zh) * | 2006-07-24 | 2013-03-06 | 比奥雷克西斯制药公司 | 毒蜥外泌肽融合蛋白 |
| WO2008049711A1 (en) | 2006-10-27 | 2008-05-02 | Novo Nordisk A/S | Peptide extended insulins |
| US8754194B2 (en) | 2006-12-22 | 2014-06-17 | Csl Behring Gmbh | Modified coagulation factors with prolonged in vivo half-life |
| US8133865B2 (en) * | 2006-12-27 | 2012-03-13 | Nektar Therapeutics | von Willebrand factor- and factor VIII-polymer conjugates having a releasable linkage |
| ES2422007T3 (es) | 2007-06-21 | 2013-09-06 | Univ Muenchen Tech | Proteínas activas biológicas que tienen estabilidad aumentada in vivo y/o in vitro |
| CN103298935A (zh) * | 2007-08-15 | 2013-09-11 | 阿穆尼克斯公司 | 用于改善生物活性多肽性能的组合物和方法 |
| EP2307038A4 (en) | 2008-06-27 | 2013-03-27 | Univ Duke | ELASTIC PEPTIDES COMPREHENSIVE THERAPEUTIC AGENTS |
| NZ593833A (en) | 2009-02-03 | 2013-10-25 | Amunix Operating Inc | Extended recombinant polypeptides and compositions comprising same |
| PE20121539A1 (es) | 2009-06-08 | 2012-12-06 | Amunix Operating Inc | Polipeptidos de la hormona de crecimiento y metodos de preparacion |
| DK2440228T3 (en) | 2009-06-08 | 2018-12-17 | Amunix Operating Inc | Glucose regulating polypeptides and methods for their preparation and use |
| AU2010290077C1 (en) * | 2009-08-24 | 2015-12-03 | Bioverativ Therapeutics Inc. | Coagulation factor IX compositions and methods of making and using same |
| WO2011084808A2 (en) * | 2009-12-21 | 2011-07-14 | Amunix Operating Inc. | Bifunctional polypeptide compositions and methods for treatment of metabolic and cardiovascular diseases |
| US8557961B2 (en) * | 2010-04-02 | 2013-10-15 | Amunix Operating Inc. | Alpha 1-antitrypsin compositions and methods of making and using same |
| EP2552967A4 (en) * | 2010-04-02 | 2014-10-08 | Amunix Operating Inc | BINDING FUSION PROTEINS, BINDING FUSION PROTEIN MEDICINAL CONJUGATES, XTEN MEDICAMENT CONJUGATES, AND METHOD FOR THEIR PREPARATION AND USE |
-
2010
- 2010-06-08 DK DK10786730.1T patent/DK2440228T3/en active
- 2010-06-08 EP EP10786730.1A patent/EP2440228B8/en active Active
- 2010-06-08 PT PT10786730T patent/PT2440228T/pt unknown
- 2010-06-08 NZ NZ596778A patent/NZ596778A/xx unknown
- 2010-06-08 AU AU2010258898A patent/AU2010258898B8/en active Active
- 2010-06-08 JP JP2012515082A patent/JP5839597B2/ja active Active
- 2010-06-08 WO PCT/US2010/037855 patent/WO2010144508A1/en active Application Filing
- 2010-06-08 US US12/796,650 patent/US8957021B2/en active Active
- 2010-06-08 CA CA2764108A patent/CA2764108A1/en not_active Abandoned
- 2010-06-08 CN CN201080035271.0A patent/CN102481331B/zh active Active
- 2010-06-08 ES ES10786730T patent/ES2705249T3/es active Active
-
2012
- 2012-01-06 ZA ZA2012/00122A patent/ZA201200122B/en unknown
-
2014
- 2014-12-05 US US14/562,406 patent/US9540430B2/en active Active
-
2016
- 2016-11-30 US US15/365,792 patent/US10000543B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| US9540430B2 (en) | 2017-01-10 |
| NZ596778A (en) | 2013-11-29 |
| AU2010258898B2 (en) | 2015-01-29 |
| JP5839597B2 (ja) | 2016-01-06 |
| EP2440228A1 (en) | 2012-04-18 |
| CN102481331A (zh) | 2012-05-30 |
| US8957021B2 (en) | 2015-02-17 |
| EP2440228B1 (en) | 2018-09-26 |
| US20100323956A1 (en) | 2010-12-23 |
| JP2012529297A (ja) | 2012-11-22 |
| AU2010258898B8 (en) | 2015-02-05 |
| EP2440228B8 (en) | 2023-02-22 |
| WO2010144508A1 (en) | 2010-12-16 |
| US20150274800A1 (en) | 2015-10-01 |
| CA2764108A1 (en) | 2010-12-16 |
| EP2440228A4 (en) | 2013-06-26 |
| AU2010258898A1 (en) | 2011-12-22 |
| CN102481331B (zh) | 2017-09-22 |
| US20170158748A1 (en) | 2017-06-08 |
| PT2440228T (pt) | 2018-12-24 |
| DK2440228T3 (en) | 2018-12-17 |
| ZA201200122B (en) | 2013-03-27 |
| US10000543B2 (en) | 2018-06-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| ES2705249T3 (es) | Polipéptidos reguladores de glucosa y métodos para su producción y uso | |
| ES2643641T3 (es) | Polipéptidos de hormona del crecimiento y métodos de producción y uso de los mismos | |
| US20240067695A1 (en) | Glucagon-like peptide-2 compositions and methods of making and using same | |
| KR101544245B1 (ko) | 연장된 재조합 폴리펩티드 및 이를 포함하는 조성물 | |
| WO2011028344A2 (en) | Interleukin-1 receptor antagonist compositions and methods of making and using same | |
| US20170095567A1 (en) | Growth hormone polypeptides and methods of making and using same | |
| AU2015200260A1 (en) | Glucose-regulating polypeptides and methods of making and using same | |
| AU2017200870B2 (en) | Extended recombinant polypeptides and compositions comprising same | |
| HK1168775A (en) | Glucose-regulating polypeptides and methods of making and using same | |
| HK1168775B (en) | Glucose-regulating polypeptides and methods of making and using same | |
| HK1168776A (en) | Growth hormone polypeptides and methods of making and using same | |
| HK1168776B (en) | Growth hormone polypeptides and methods of making and using same |