-
Die Erfindung betrifft Verfahren und Vorrichtungen für ein autostereoskopisches Display, auf welchem aus einem zugeführten Stereobild in einem beliebigen 3D-Format eine Vielzahl von Perspektiven, im allgemeinen mehr als 100, verkämmt auf einem Display angezeigt werden, welches aus einem optischen Element und einer bilderzeugenden Einheit besteht. Die Vielzahl von Perspektiven wird in der Weise erzeugt, dass immer nur diejenigen Pixel einer Perspektive erzeugt werden, welche auch angezeigt werden müssen. Die bilderzeugende Einheit des Displays besteht aus Pixeln/Subpixeln, welche entweder eine Farbe, z. B. Rot, Grün oder Blau, abstrahlen, oder aus Pixeln/Subpixeln, welche zur Verbesserung des Raumbildeindruckes des Betrachters auch Kanteninformation anzeigen.
-
Die Vorstellung, welche Eigenschaften ein perfekter 3D-Fernseher haben sollte, haben sich in den letzten Jahren stark konkretisiert. Dazu gehören z. B. die Anforderung, dass man keine 3D-Brille tragen muss, dass man aus allen Richtungen und Entfernungen 3D sehen kann, dass das 3D-Bild qualitativ genau so gut ist wie das 2D-Bild und dass man ihn auch für 2D-Inhalte mit gleicher Qualität verwenden kann. Diese Anforderungen sollen mit den hier vorgestellten Verfahren und Vorrichtungen vollständig erfüllt werden.
-
Das dieser Anmeldung zu Grunde liegende Display ist in der Lage ein 3D-Bild oder eine 3D-Bildfolge in jedem Format, wie z. B. einem Stereobild oder einer Stereobildfolge, zu empfangen. Andere Format, wie z. B. Stereobild inklusive einer Disparitätskarte, können ebenso empfangen und verarbeitet werden.
-
Ein solch empfangenes Stereobild wird zunächst rektifiziert, d. h. auf Stereo-Normalform, gebracht. Ist dies schon der Fall, so ergibt sich hier die identische Abbildung.
-
Sodann werden aus den beiden Bildern verschiedene Merkmale, wie z. B. Kanten oder markante Bildpunkte (SURF) identifiziert. Verschiedene Merkmale können hier extrahiert werden. Eine besondere Einschränkung ist nicht gegeben. Diese Merkmale werden sowohl für die Berechnung der Disparitätskarte, falls dies erforderlich ist, als auch für die Visualisierung in bestimmten zusätzlichen Subpixeln verwendet. Dies ist die erste der dieser Anmeldung zu Grunde liegenden neuen Eigenschaft.
-
Wurde die Disparitätskarte bereits mit empfangen, so wird der nächste Schritt übersprungen. Im anderen Fall wird die Disparitätskarte des Stereobildes berechnet. Sie enthält eine Zuordnung der linken und rechten Pixel, welche in beiden empfangenen Perspektiven vorhanden sind. Gleichzeitig werden die Links- und Rechtsverdeckungen identifiziert.
-
Mithilfe der Disparitätskarte des empfangenen Stereobildes und der Merkmale werden sodann beliebig viele Perspektiven synthetisiert. Dabei wird so vorgegangen, dass immer nur diejenigen Subpixel synthetisiert werden, welche auf dem Display auch tatsächlich angezeigt werden müssen. Dies gilt in gleicher Weise auch für die vorher beschriebenen Merkmale, welche in besonderen Subpixeln angezeigt werden. Das bedeutet, dass bei 100 anzuzeigenden Perspektiven aus jeder Perspektive nur 1% der Subpixel berechnet werden.
-
Die Information, welche Perspektive auf welchem Subpixel angezeigt werden soll, ist in der Perspektivenkarte P festgelegt. Diese wird bei der Produktion des Displays durch einen Kalibrierungsprozess zwischen Subpixeln und optischen System festgelegt und abgespeichert. Benachbarte Subpixel sind im Allgemeinen unterschiedlichen Perspektiven zugeordnet. Die Speicherung der verschiedenen Subpixel aus den unterschiedlichen Perspektiven im pseudoholographischen Bild B soll im folgenden zur Vereinfachung der Beschreibung als „Verkämmung” bezeichnet werden.
-
Das Display selbst ist charakterisiert durch ein Panel von Subpixeln und einem vorgeschalteten optischen Element. Die Subpixel können sowohl Farbsubpixel wie z. B. RGB oder CMY als auch Hell/Dunkel-Subpixel sein. In den Farbsubpixeln wird die Farbinformation der Subpixel der darzustellenden Perspektiven angezeigt. Die Hell/Dunkel-Subpixel enthalten z. B. als Grauwerte den 3D-Eindruck unterstützende Bildmerkmale. Dieses Konzept berücksichtigt die Tatsache, dass das menschliche Auge ca. 110 Mio. Hell/Dunkel-Rezeptoren und nur ca. 6.5 Mio. Farbrezeptoren besitzt. Ebenfalls bekannt ist die Tatsache, dass das menschliche Gehirn zu einem wesentlichen Teil Kanten an Objekten dazu verwendet, um im Gehirn das dreidimensionale Raumbild aufzubauen. Werden also über Hell/Dunkel-Subpixel Kanteninformationen angezeigt, so wird diese Bildinformation über die viel größere Anzahl der Hell/Dunkel-Rezeptoren aufgenommen. Die Arbeit des Gehirns wird dadurch erleichtert. Das hier vorgestellte Display ist daher an die Anatomie des Auges und die nachgeschaltete Informationsverarbeitung besser angepasst. Dies ist die zweite dieser Anmeldung zu Grunde liegende neue Eigenschaft.
-
Zur Verbesserung der Qualität des Bildes wird zusätzlich die Anzahl der angezeigten Subpixel wesentlich erhöht. Ein pseudoholographisches Display dieser Patentanmeldung besitzt mindestens 10 bis 20 mal so viele Subpixel wie im empfangenen Stereobild vorhanden sind. Diese größere Anzahl der Subpixel ermöglicht es, aus den vielen Perspektiven, die synthetisiert werden, eine größere Anzahl von Pixeln pro Perspektive darzustellen. High-Definition-Bilder und -Videos der heutigen Generation besitzen i. A. 1920×1080 Pixel mit 5760 Subpixel pro Zeile. Bei einer Verzehnfachung und unter Berücksichtigung derjenigen Subpixel, welche Merkmalsinformationen anzeigen, besitzt ein Display der hier vorgestellten Patentanmeldung also mindestens 76.800×1080 Subpixel. Dabei wird berücksichtigt, dass bei den autostereoskopischen Displays die Zuordnung der Perspektiven auf Subpixel-Ebene geschieht. Eine Zusammenfassung zu Pixeln ist dort nicht relevant. Die Anforderung, dass alle Subpixel eines Pixels zusammen ein Quadrat bilden, wird in der hier vorliegenden Patentanmeldung fallen gelassen. Vielmehr ist jeder Subpixel ein eigenständiges Element. Jeder dieser Subpixel besitzt eine Farbe des gewählten Farbsystems und besitzt in horizontaler und vertikaler Richtung die gleiche Ausdehnung. Dies ist die dritte dieser Anmeldung zu Grunde liegende neue Eigenschaft. Mit der heutigen Displaytechnologie der OLED- oder Nano-Technologie ist dies technisch problemlos realisierbar.
-
Da die bisher vorgestellten Verfahrensschritte der Rektifizierung, Disparitätsberechnung und Perspektivensynthese in Echtzeit durchgeführt werden müssen, ist eine angemessene Verarbeitungskapazität erforderlich. Diese wird dadurch sichergestellt, dass eine Vielzahl von Recheneinheiten Bestandteil des Displays sind. Jeder sogenannten Zeilenrecheneinheit ist eine eigene kleine Anzahl von Zeilen des Displays zugeordnet. Im Extremfall, der hier nicht ausgeschlossen und durchaus realistisch ist, wird jeder Zeilenrecheneinheit eine eigene Zeile des Displays zugeordnet.
-
Alle Verfahrensschritte sind so implementiert, dass sie zeilenweise unabhängig von einander und parallel durchgeführt werden können.
-
Besitzt das Display also beispielsweise 1080 Zeilen, was dem heutigen HD-Format entspricht, so besitzt die Recheneinheit 1080 Zeilenrecheneinheiten. Alle Recheneinheiten verfügen über lokalen Speicher zur Durchführung ihrer Operationen und können parallel auf einen globalen Speicher zugreifen. Eine Kontrolleinheit sorgt für die Synchronisation der einzelnen Verarbeitungsschritte. Diese Architektur ist die vierte dieser Anmeldung zu Grunde liegende neue Eigenschaft.
-
Die Herstellung dieses autostereoskopischen Displays wird so durchgeführt, dass das bildgebende Panel direkt auf der Rückseite des optischen Elements aufgebracht wird. Dabei erkennt ein optisches Sensorelement die exakte Lage der Linsen bzw. Barrieren. Diese Information wird sodann zur Steuerung des Aufbringungsprozesses der bildgebenden Subpixel verwendet. Dies ist die fünfte dieser Anmeldung zu Grunde liegende neue Eigenschaft.
-
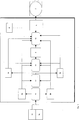
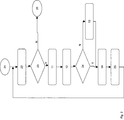
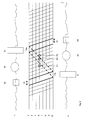
Ein Blockdiagramm des Gesamtsystems ist in 1 dargestellt. 2 zeigt das zugehörige Flussdiagramm und 3 beinhaltet das Hardware-Layout des Gesamtsystems. Die Details werden im Folgenden beschrieben.
-
Stand der Technik
-
Verfahren der Rektifizierung sind in der Literatur weitläufig bekannt und haben bereits ihren Einzug in die Standardliteratur der Stereobildverarbeitung gefunden [7]. Sie brauchen hier nicht detailliert erwähnt zu werden. Eine Hardware-Implementierung ist in [8] beschrieben.
-
Auch die Merkmalextraktion, wie z. B. SURF- oder Kanten-Operatoren, sind in jedem Buch der digitalen Bildverarbeitung dargestellt 31]
-
Verfahren der Disparitätsschätzung sind z. B. in [2], [4] und [6] beschrieben. Wichtig ist der Unterschied zwischen iterativen Verfahren und Verfahren, welche die lineare Programmierung als Basis verwenden. In letzterem Fall wird i. A. eine Monotonie der Zuordnung vorausgesetzt. Dies bedeutet: Rl(i, j1) ≤ Rl(i, j2) ==> Rr(i, D(j1)) ≤ Rr(i, D(j2)).
-
In einer beliebigen Szene, wie sie aus dramaturgischen Gründen aber möglicherweise erforderlich ist, kann diese Voraussetzung jedoch nicht immer erfüllt sein. Ein schmales Objekt im Vordergrund kann leicht zu einer „Inversion” der Zuordnung in der Disparitätskarte führen. Daher soll in der vorgelegten Offenlegung diese Voraussetzung fallen gelassen werden.
-
Das hier vorgestellte Verfahren soll jedoch nicht auf den Farb- oder Grauwerten der Pixel beruhen. Vielmehr wird jeder Pixel zur Sicherung der Zuordnung um die vorher berechneten Merkmalswerte erweitert. Eine Disparitätsschätzung, bei der jeder Pixel einen Merkmalsvektor darstellt, ist das Ergebnis.
-
Die pseudoholographische Bildsynthese ist schon im
PCT/EP2007/003546 beschrieben. Dieses Verfahren wird hier so verallgemeinert, dass das Monotoniegesetz nicht mehr erfüllt sein muss, um die darzustellenden Pixel einer Perspektive zu berechnen. Ein iteratives, zeilenorientiertes Verfahren, bei welchem immer nur diejenigen Pixel einer Perspektive berechnet werden, die auch tatsächlich auf dem Display angezeigt werden müssen, ist die Folge.
-
Hardware-Architekturen von autostereoskopischen Displays, bei denen neben den Farbwerten RGB oder CMY, auch Merkmale wie Kanten oder markante Punkte visualisiert werden, um die Erkennung der Räumlichkeit durch das menschliche Gehirn zu erleichtern, sind in der Literatur bisher nicht beschrieben.
-
Ebenso sind Architekturen von autostereoskopischen Displays, bei denen jede Zeile oder sogar jeder einzelne Subpixel über eine eigene Recheneinheit verfügt, in der Literatur bisher nicht beschrieben.
-
Bezugszeichenliste
-
Fig. 1: Blockdiagramm des Gesamtsystems
- 1a
- Empfanges linkes Teilbild Il,
- 1b
- Empfanges rechtes Teilbild Ir,
- 2a
- Rektifiziertes linkes Teilbild Rl,
- 2b
- Rektifiziertes rechtes Teilbild Rr,
- 3a
- Matrix Ml der pro Pixel berechneten Merkmale 1...K des linkes Teilbildes,
- 3b
- Matrix Mr der pro Pixel berechneten Merkmale 1...K des rechten Teilbildes,
- 4
- Disparitätskarte D,
- 5
- Pseudoholographisch verkämmtes Bild B mit M verkämmten Perspektiven,
- 6
- Perspektivenkarte P,
- 7
- Autostereoskopisches Display,
- 11
- Bilder rektifizieren und in 2a und 2b ablegen,
- 12
- Merkmale extrahieren und in 3a und 3b ablegen,
- 13
- Disparitätskarte berechnen, falls nicht zugeführt, und in 4 ablegen,
- 14
- Pseudoholographisches Bild B der verkämmten Perspektiven erzeugen und in 5 ablegen.
Fig. 2: Flussdiagramm des Gesamtsystems - 11
- Bilder rektifizieren,
- 12
- Merkmale extrahieren,
- 13
- Disparitätskarte erstellen,
- 14
- Pseudoholographische Perspektiven synthetisieren,
- 21
- Start,
- 22
- Bilder einlesen,
- 23
- Bilder eingelesen?,
- 24
- Disparitätskarte vorhanden?,
- 25
- Pseudoholographisches Bild auf Display ausgeben,
- 26
- Stop.
Fig. 3: Hardware-Layout des Gesamtsystems - 1
- Prozessor,
- 2
- Lokaler Speicher,
- 3
- Zeilenrecheneinheit 1,
- 4
- Zeilenrecheneinheit n,
- 5
- Kontrolleinheit,
- 6
- Globale Speichereinheit,
- 7
- Single-Chip-Implementierung,
- 8
- Steuerbus,
- 9
- Datenbus,
- 10
- Autostereoskopisches Display.
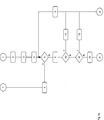
Fig. 4: Alte und neues Subpixel-Layout bei 36 unterschiedlichen Perspektiven - A
- Altes Subpixel-Layout,
- N
- Neues Subpixel-Layout,
- R
- Rot,
- G
- Grün,
- B
- Blau,
- W
- Weiß
- 1–36
- Nummer der anzuzeigenden Perspektive in diesem Subpixel.
Fig. 5: Disparitätskarte entsprechend dem Monotoniegesetz - 1
- Linke Szene,
- 2
- Zeile einer Disparitätskarte,
- 3
- Linkes Teilbild,
- 4
- Zwischenperspektive 1,
- 5
- Zwischenperspektive 2,
- 6
- Zwischenperspektive 3,
- 7
- Zwischenperspektive 4,
- 8
- Zwischenperspektive 5,
- 9
- Zwischenperspektive 6,
- 10
- Rechtes Teilbild,
- 11
- Rechte Szene,
- 12
- Rechtsverdeckung im linken Teilbild,
- 13
- Linksverdeckung im rechten Teilbild.
Fig. 6: Disparitätskarte mit „Cross-over” - 1
- Linke Szene,
- 2a
- Rechtsverdeckung des vorderen Objektes im linken Teilbild,
- 2b
- Hinteres Objekt,
- 2c
- Vorderes Objekt,
- 2d
- Linksverdeckung des vorderen Objektes im rechten Teilbild
- 3
- Linkes Teilbild,
- 4
- Zwischenperspektive 1,
- 5
- Zwischenperspektive 2,
- 6
- Zwischenperspektive 3,
- 7
- Zwischenperspektive 4,
- 8
- Zwischenperspektive 5,
- 9
- Zwischenperspektive 6,
- 10
- Rechtes Teilbild,
- 11
- Rechte Szene,
- 12
- Rechtsverdeckung im linken Teilbild,
- 13
- Linksverdeckung im rechten Teilbild,
- 14a
- Cross-over-Bildsegment C1 im linken Teilbild,
- 14b
- Cross-over-Bildsegment C1 im rechten Teilbild,
- P1
- jr/3 liegt links von jrmin_PositionNeu,
- P2
- jr/3 liegt zwischen jrmin_PositionNeu und jrmax_PositionNeu,
- P3
- jr/3 liegt rechts von jrmax_PositionNeu.
Fig. 7: Cross-over Vorverarbeitung - N
- Nein,
- Y
- Ja,
- 1
- Start,
- 2
- j = 1,
- 3
- j ≥ NrPixel?,
- 4
- Stop,
- 5
- j = j + 1,
- 6
- Wohin(i, j) ≥ 0?,
- 7
- Crossover(j) = 0,
- 8
- Wohin(i, j) < Wohin(i, j – 1)?,
- 9
- CrossAnf = j,
- 10
- Crossover(j) = 1,
- 11
- j = j + 1,
- 12
- Wohin(i, j) > Wohin(i, CrossAnf – 1)?.
Fig. 8a–Fig. 8c: Cross-over Nachverarbeitung - N
- Nein,
- Y
- Ja,
- A
- Anknüpfungspunkt A,
- B
- Anknüpfungspunkt B,
- C
- Anknüpfungspunkt C,
- D
- Anknüpfungspunkt D,
- 1
- Start,
- 2
- jl = –1,
- 3
- jl = jl + 1,
- 4
- jl ≥ NrPixel?,
- 5
- Crossover(jl) = 0?,
- 6
- jlmin = jl,
- 7
- Crossover(jl) = 0 oder jl ≥ NrPixel?,
- 8
- jl = jl + 1,
- 9
- jlmax = jlmin,
- 10
- jrmin = jlmin,
- 11
- Wohin(jlmin) < jlmin?,
- 12
- jrmin = Wohin(jlmin),
- 13
- jrmax = jlmax,
- 14
- Wohin(jlmax) > jrmax?,
- 15
- jrmax = Wohin(jlmax),
- 16
- j_scale = (jlmax – jlmin + 1)/(Wohin(jlmax) – Wohin(jlmin) + 1),
- 17
- jr = (jrmin – 1)*3,
- 18
- jr > jrmax*3?,
- 19
- P(i, jr) holen,
- 20
- P(i, j) = 0?,
- 21
- jr = jr + 1,
- 22
- P(i, j) = NS – 1?,
- 23
- jrmin_PositionNeu berechnen,
- 24
- jrmin_Position Neu > jr/3?,
- 25
- jrmax_PositionNeu berechnen,
- 26
- jrmax_PositionNeu < jr/3?,
- 27
- CrossoverPixel = jlmin + (jr/3 – jrmin_PositionNeu)*j_scale,
- 28
- Richtigen Subpixel von CrossoverPixel vom linken Teilbild holen,
- 29
- Stop.
Fig. 9a–Fig. 9b: Bildsynthese mit Crossover-Verarbeitung - N
- Nein,
- Y
- Ja,
- A
- Anknüpfungspunkt A,
- B
- Anknüpfungspunkt B,
- 1
- Start,
- 2
- Crossover Vorverarbeitung,
- 3
- jr = 0; jl = 0,
- 4
- jl = jl +1,
- 5
- jr/3 > NrPixel?,
- 6
- Crossover Nachverarbeitung,
- 7
- Stop,
- 8
- P(i, jr) holen,
- 9
- jr = jr +1,
- 10
- P(i, jr) = 0?,
- 11
- Subpixel vom linken Teilbild holen,
- 12
- P(i, jr) = N – 1?,
- 13
- Subpixel vom rechten Teilbild holen,
- 14
- oben = false; unten = false,
- 15
- oben = false oder unten = false?,
- 16
- Subpixel holen,
- 17
- jl_PositionNeu berechnen,
- 18
- jl_PositionNeu = jr/3?,
- 19
- j_oben = jl; j_unten = jl; oben = true; unten = true,
- 20
- jl_PositionNeu > jr/3?,
- 21
- j_oben = jl; oben = true,
- 22
- jl = jl – 1,
- 23
- Crossover(jl) = 1 oder D(i, jl) = –1?,
- 24
- j_unten = jl; unten = true,
- 25
- jl = jl + 1,
- 26
- Crossover(jl) = 1 oder D(i, jl) = –1?,
Fig. 10: Zeilenweiser Scan eines Lasersensors zur Erkennung der exakten Position der optischen Struktur - 1
- x-Position
- 2
- Gemessene Tiefe,
- 3
- Gemessenen Entfernungen zum Lasersensor,
- 4
- Erkannte Grenzen der einzelnen optischen Elemente zur Berechnung der Aufbringungsparameter.
-
Detaillierte Beschreibung Software
-
Im Folgenden werden alle Schritte im Einzelnen beschrieben. Im Rahmen dieser Patentschrift wird davon ausgegangen, dass durch ein Empfangsmodul z. B. über Antenne oder Internet eine Bildfolge von Stereobildern empfangen wird, dekodiert wird und in den Speicherbereichen Il und Ir zur Verfügung gestellt wird. Dieses Format wird hier exemplarisch angenommen. Der Empfang anderer 3D-Formate ist hier nicht genauer beschrieben und sei dem kundigen Lesen überlassen. Nach dem Empfang wird das Stereobild auf die Auflösung des angeschlossenen pseudoholographischen Displays vergrößert bzw. verkleinert. Ein Display der Auflösung 19.200×10.800 Pixel kann als hochauflösend hier angenommen werden. In diesem Fall wird z. B. ein Stereo-HD-Bild zehnfach horizontal und vertikal vergrößert.
-
In einem ersten Schritt wird die Rektifizierung durchgeführt. Diese Verfahren sind in der Literatur bereits ausgiebig beschrieben und sollen hier nicht wiederholt werden. In der vorliegenden Implementierung werden im linken Teilbild Il neun markante Punkte, welche gleichmäßig über das Bild verteilt sind, nach dem SURF-Verfahren gesucht. Die Koordinate eines jeden markanten Punktes wird als Mittelpunkt eines Suchblockes im rechten Teilbild Ir verwendet. In diesem Suchblock wird der ähnlichste Punkt im rechten Teilbild Ir gesucht. Mit Hilfe der Disparitäten der neun markanten Punkte wird eine lineare Transformationsmatrix definiert, mit welcher jedes der Teilbilder Il und Ir nach Rl und Rr rektifiziert wird:
Il → Rl und Ir → Rr.
-
Damit ist die Rektifizierung durchgeführt, sodass nun die Epipolaren parallel zu den Zeilen des Bildes laufen und alle späteren Operationen zeilenweise durchgeführt werden können.
-
Für eine qualitativ hochwertige dichte Disparitätskarte werden im zweiten Schritt die rektifizierten Teilbilder durch verschiedene Merkmale ergänzt.
-
Diese Merkmale werden in den folgenden Schritten einerseits zur Verbesserung der Sicherheit der berechneten Disparitätskarte verwendet und andererseits auf dem autostereoskopischen Display visualisiert, um die Erzeugung des Raumbildes im Gehirn zu erleichtern.
-
Die spätere Berechnung der Disparitätskarte ist dadurch gekennzeichnet, dass sie sehr schnell durchgeführt werden kann, weil die Disparitäten massiv parallel für jede Zeile getrennt berechnet werden. Dies hat jedoch den Nachteil, dass lokale Merkmale wie z. B. Formen, Texturen oder Kanten nicht berücksichtigt werden. Daher werden in der Merkmalextraktionsphase verschiedene Merkmale berechnet, welche lokale Eigenschaften beschreiben.
-
In der Literatur wird eine sehr große Zahl von Merkmalen und ihre Berechnung beschrieben. Nur exemplarisch und ohne Anspruch auf Vollständigkeit sollen hier zwei Verfahren und ihre massiv parallele Implementierung beschrieben werden:
- 1. SURF: Speed up Robust Features [1] und
- 2. Sobel-Edge-Detector [3].
-
SURF-Merkmalsextraktion:
-
Dieses Verfahren beruht darauf, dass für jeden Pixel die Determinante der Hesse-Matrix approximiert wird. Dabei wird wie folgt vorgegangen.
-
In einer Matrix Isum, welche jeweils für das linke und rechte rektifizierte Teilbild erstellt wird, werden für jeden Pixel die Teilsummen der Grauwerte des unteren Bildbereiches gespeichert:
wobei NZ die Anzahl der Zeilen und NS die Anzahl der Spalten ist.
-
In der Berechnung wird so vorgegangen, dass zunächst jeder Zeile i eine Zeilenrecheneinheit i zugeordnet wird, welche die Teilsumme rekursiv berechnet: Isumi(j) ≔ Isumi(j – 1) + Rr(i, j) für i ≔ 1, ... NZ und j ≔ 1, .. NS und in Isum abspeichert. Danach wird jeder Spalte j eine Recheneinheit j zugeordnet, welche die Spaltensumme rekursiv berechnet: Isum(i, j) ≔ Isum (i – 1, j) + Isumi(j) für i ≔ 1, ... NZ und j ≔ 1, .. NS.
-
Die so berechnete Matrix enthält nun für jedes Teilbild links und rechts die gewünschten Teilsummen. Nun wird jeder Zeile i wieder eine Recheneinheit i (= Zeilenrecheneinheit i) zugeordnet, welche zunächst die folgenden Zwischenwerte berechnet: Dxx(i, j) ≔ Isum(i – 4, j – 5) – Isum(i + 2, j – 5)
+ Isum(i + 2, j + 4) – Isum(i – 4, j + 4)
– 3·Isum(i + 2, j + 1) + 3·Isum(i + 2, j – 2)
+ 3·Isum(i – 4, j + 1) – 3·Isum(i – 4, j – 2), Dyy(i, j) ≔ Isum(i + 4, j + 2) – Isum(i + 4, j – 3)
– Isum(i – 5, j + 2) + Isum(i – 5, j – 3)
– 3·Isum(i + 1, j + 2) + 3·Isum(i + 1, j – 3)
+ 3·Isum(i – 2, j + 2) – 3·Isum(i – 2, j – 3), DRO(i, j) ≔ Isum(i + 3, j + 3) – Isumi(i + 3, j)
– Isum(i, j + 3) + Isum(i, j), DLO(i, j) ≔ Isum(i + 3, j – 1) – Isum(i + 3, j – 4)
– Isum(i, j – 1) + Isum(i, j – 4), DLU(i, j) ≔ Isum(i – 1, j – 1) – Isum(i – 1, j – 4)
– Isum(i – 4, j – 1) + Isum(I – 4, j – 4), DRU(i, j) ≔ Isum(i – 1, j + 3) – Isum(i – 1, j) – Isum(I – 4, j + 3) + Isum(I – 4, j).
-
Danach ergibt sich Dxy(i, j) ≔ DLO(i, j) + DRU(i, j) × DRO(i, j) – DLU(i, j).
-
Die approximierte Determinante der Hessematrix wird sodann für jeden Pixel des rechten Teilbildes in der Merkmalsmatrix Mr(1) abgespeichert: Mr(i, j, 1) ≔ Dxx(i, j) × Dyy(i, j) – 0,81 × Dxy(i, j) × Dxy(i, j)
-
Die gleiche Vorgehensweise wird für jeden Pixel des linken Teilbildes R1 durchgeführt und in der Merkmalsmatrix Ml(1) abgespeichert. Insgesamt ergeben sich die Merkmalsmatrizen Mr(1) und Ml(1).
-
Da auf die rektifizierten Teilbilder Rr und Rl von allen Zeilenrecheneinheiten nur lesend zugegriffen wird und alle Zeilenrecheneinheiten i ihr Ergebnis in M(i, j, 1) abspeichern, gibt es keine Blockierungen und Wartezeiten. Weitere Details dieses Verfahrens sind z. B. in [1] beschrieben.
-
Sobel-Merkmalsextraktion:
-
Der Sobel-Operator ist nur einer aus einer großen Anzahl von Kanten-Operatoren. Er soll daher hier nur exemplarisch beschrieben werden.
-
Für die Disparitätskarte ist ein Kanten-Operator von besonderer Bedeutung, da er hilft, dass bei der Zuordnung den Kanten eine höhere Bedeutung zugeteilt wird als den glatten Flächen. Da eine Kante immer auch eine regionale Eigenschaft ist, ermöglicht diese Vorgehensweise innerhalb einer Zeile auch die Eigenschaften von lokalen Regionen mit berücksichtigen zu können.
-
Der Sobel-Prewitt-Operator arbeitet z. B. mit 3×3.Matrizen, welche die Kanten in verschiedene Richtungen detektieren. Grundsätzlich sind hier horizontale, vertikale, links und rechts diagonale Kanten zu unterscheiden. Zu ihrer Detektion werden die folgenden 3×3-Matrizen verwendet:
-
Eine Implementierung auf einem massiv parallelen System geht dabei so vor, dass jeder Zeile i eine Zeilenrecheneinheit i zugeordnet wird. Für alle Zeilen i und Spalten j wird das recheneinheiten-lokale Feld Kante(1) bis Kante(9) aus dem rechten rektifizierten Teilbild R
r wie folgt gefüllt:
| Kante(1) ≔ Rr(i – 1, j – 1), | Kante(2) ≔ Rr(i – 1, j), |
| Kante(3) ≔ Rr(i – 1, j + 1), | Kante(4) ≔ Rr(i, j – 1), |
| Kante(5) ≔ Rr(i, j), | Kante(6) ≔ Rr(i, j + 1), |
| Kante(7) ≔ Rr(i + 1, j – 1), | Kante(8) ≔ Rr(i + 1, j), |
| Kante(9) ≔ Rr(i + 1, j + 1) für i ≔ 1, ..., NZ und j ≔ 1, ..., NS |
-
Sodann berechnet jede Zeilenrecheneinheit i für jeden Index j: H1 ≔ 2·Kante(2) + 2·Kante(5) + 2·Kante(8)
– Kante(1) – Kante(4) – Kante(7)
– Kante(3) – Kante(6) – Kante(9), H2 ≔ 2·Kante(4) + 2·Kante(5) + 2·Kante(6)
– Kante(1) – Kante(2) – Kante(3)
– Kante(7) – Kante(8) – Kante(9), H3 ≔ 2·Kante(7) + 2·Kante(5) + 2·Kante(3)
– Kante(1) – Kante(2) – Kante(4)
– Kante(8) – Kante(9) – Kante(6), H4 ≔ 2·Kante(2) + 2·Kante(5) + 2·Kante(9)
– Kante(2) – Kante(3) – Kante(6)
– Kante(4) – Kante(7) – Kante(8).
-
Mr(i, j, 2) ergibt sich dann als Mr(i, j, 2) ≔ H1 + H2 + H3 + H4 für i = 1, ..., NZ und j = 1, ... NS. Dieses Verfahren wird in gleicher Weise für das linke rektifizierte Teilbild Rl durchgeführt. Insgesamt ergeben sich die Merkmalsmatrizen Mr(2) und Ml(2).
-
Besteht das empfangene Stereobild nur aus den Teilbildern Ir und Il und wurden keine weiteren Zusatzinformationen wie Disparitätskarte oder Tiefenkarte mit übertragen, so muss in einem Zwischenschritt die Disparitätskarte erstellt werden.
-
Hierfür stehen jetzt die rektifizierten Bilder Rr und Rl und die Merkmalsmatrizen Mr und Ml zur Verfügung. Ohne Beschränkung der Allgemeingültigkeit soll hier exemplarisch das Verfahren nach Falkenhagen [4] beschrieben werden.
-
In der von Falkenhagen beschrieben Vorgehensweise wird für jede Zeile i die Verbundwahrscheinlichkeit des Disparitätsvektors d ^
i maximiert:
-
Diese Vorgehensweise wird sodann in eine dynamische Optimierungsaufgabe umgeformt:
um den Punkt R
l(i, j). Die Details sind in [4] nachzulesen.
-
Hierin bezeichnet corrlr(Rl(i, j), d(Rl(i, j))) die Korrelation zwischen dem Punkt Rl(i, j) des linken Teilbildes und dem Punkt Rr(i, j – d(Rl(i, j))) des rechter Teilbildes, d. h. des um die Disparität d(Rl(i, j)) verschobenen Punktes des linken Teilbildes.
-
In der hier vorgelegten Offenlegung werden die folgenden Veränderungen vorgenommen:
- 1. Die einfachen Intensitätswerte Rr und Rl der Teilbilder werden für jeden Pixel durch den Merkmalsvektor Mr(i, j) ≔ (Mr(i, j, 1), ..., Mr(i, j, K)) und Ml(i, j) ≔ (Ml(i, j, 1), ..., Ml(i, j, K)) ersetzt. Dieser kann z. B. die Luminanzwerte und/oder die Farbwerte und/oder den Kanten-Operator Sobel und/oder den Struktur-Operator SURF enthalten. Weitere Merkmale können sinngemäß hinzugefügt werden.
-
Dafür geht der Kreuzkorrelationskoeffizient corr
lr(R
l(i, j), d(R
l(i, j))) unter Verwendung einer beliebigen Vektornorm über in:
unter Verwendung des Skalarproduktes θ zweier Vektoren M
l(p
b) und M
r(p
b – d
i(p
ij)) und des Betragsoperators ||·||. B
x bezeichnet die Blockgröße des Referenzblockes U um M
l(i, j) in horizontaler und B
y die Blockgröße in vertikaler Richtung. p
b bezeichnet die Punkte aus dem Referenzblock um M
l(i, j).
- 1. Die a-priori-Wahrscheinlichkeit kann nicht als Markov-Prozess 1. Ordnung dargestellt werden.
-
Die Pixel Rl(i, j) des linken als auch des rechten Teilbildes sind Projektionen von Raumpunkten, die zu gewissen Objekten der Szene gehören. Pixel Rl(i, j) eines gemeinsamen Objektes haben daher hinsichtlich ihres Projektionsverhaltens eine hohe Korrelation; zumindest solange man von starren Objekten ausgeht.
-
Die allgemeine empirische Wahrscheinlichkeit einer Disparitätsänderung pΔd ist daher entsprechend korreliert mit der Projektion benachbarter Raumpunkte eines gemeinsamen Objektes. Dies geht dabei auch über die Zeilen hinaus und kann nicht unabhängig voneinander berechnet werden.
-
Das hier vorgestellte und in [4] grundsätzlich beschriebene Verfahren wird in der Weise erweitert, dass zunächst für jeden Bildpunkt Rl(i, j) des Teilbildes Rl in einer Umgebung Uij, definiert durch Uij ≔ {pi*j* ≔ Rl(xi*, yi*) ∊ Rl, |xi* – xi| < s und |yi* – yi| < s} mit einer fest gewählten Reichweite s, alle Korrelationskoeffizienten Corrij ≔ {corr(pij, pi*j*)|pi*j* ∊ Uij} berechnet werden.
-
In Anlehnung an das vorher beschriebene Skalarprodukt wird corr(pij, pi*j*) wie folgt definiert: corr(pij, pi*j*) ≔ Ml(pij) θ Ml(pi*j*)/(||Ml(pij)||·||Ml(pi*j*)||).
-
Nachdem in einem ersten Schritt eine Disparitätskarte D berechnet wurde mit
D ≔ {dij|i = 1, ..., M; j = 1, ..., N} und d
ij die Disparität für Pixel R
l(i, j) des linken Teilbildes ist, wird im zweiten Schritt eine mit der geometrischen Korrelation gewichtete Glättung durchgeführt:
-
Alle geglätteten Disparitäten werden in der geglätteten Disparitätskarte D' zusammengefasst.
-
Dieses Verfahren wird sowohl hierarchisch als auch zeitlich strukturiert, indem die Teilbilder Rl und Rr zusammen mit den Merkmalsmatrizen Ml und Mr in einer Informationspyramide verwendet werden. Auf der obersten Ebene wird eine Berechnung der Disparitätskarte iterativ solange durchgeführt bis die Zuordnungen von links nach rechts und umgekehrt konsistent sind.
-
Als Anfangswerte der Disparitätskarte werden dabei die Disparitäten des vorherigen Teilbildes Rl k-1 verwendet, sofern kein sogenannter „Hardcut” in der Bildsequenz zwischen dem aktuellen Stereobild k und dem vorherigen Stereobild k – 1 erkannt wird. Ist dies jedoch der Fall, wird die identische Disparitätskarte DE' ≔ {0|i = 1, ..., NZ; j = 1, ..., NS} als Startkarte verwendet. Ansonsten werden zunächst in einer Voranalyse diejenigen Bereiches des linken Teilbildes identifiziert, welche sich nicht verändert haben. Dazu wird z. B. das gesamte linke Teilbild in Blöcke der Größe 16×16 Pixel eingeteilt, wie dies auch bei der MPEG-Kodierung der Fall ist. Liegt die Differenz zwischen dem aktuellen Block und dem selben Block des vorherigen Bild unter einer Schwelle SMPEG, so wird der Block als konstant markiert und die vorherigen Disparitätswerte dieses Blockes können übernommen werden. Ist dies nicht der Fall, so müssen in diesem Block die Disparitäten neu berechnet werden.
-
Im Falle einer MPEG-Kompression kann man sich auf die dabei mit übertragenen Werte konstanter Bereiche beziehen und braucht diese Identifikation nicht noch einmal durchzuführen.
-
Durch diese Vorgehensweise wird eine gewisse Kontinuität in der Disparitätenkartenfolge erreicht und der sogenannte „Disparity Jitter” vermieden.
-
Ist auf der obersten Ebene eine konsistente Disparitätskarte erstellt worden, so wird diese auf die nächstniedrigere Ebene expandiert und als Startkarte für die dortige detailliertere Disparitätskarte verwendet. In dieser Weise wird weiter vorgegangen, bis der unterste und damit höchste Detaillierungsgrad erreicht ist.
-
Ist im vorherigen Schritt die Disparitätskarte berechnet worden oder wurde sie mit empfangen, so wird im nächsten Schritt die pseudoholographische Bildsynthese durchgeführt.
-
Hier wird das in
WO2007/121970 beschriebene Verfahren als Basis verwendet. Dies hat jedoch in der dort dokumentierten Form den Nachteil, dass keine sogenannten „Cross-Over”-Effekte behandelt werden können und wird daher hier verallgemeinert. Cross-Over-Effekte treten auf, wenn sich sehr dicht vor der Kamera ein relativ schmales Objekt O
1 befindet. In diesem Fall wird das Monotonie-Gesetz der Stereoskopie verletzt:
Rl(i, j1) ≤ Rl(i, j2) => Rr(i, j1 + D(i, j1)) ≤ Rr(i, j2 + D(i, j2)). -
Es kann dann der Fall sein, dass das linke Auge ein entfernteres Objekt O
2 links von O
1 sieht, während das rechte Auge das Objekt O
2 rechts von O
1 sieht. Dies soll im folgenden als Cross-Over-Effekt bezeichnet werden. in
6 ist ein solcher Fall mit seiner Auswirkung auf die Disparitätskarte dargestellt. In der hier vorgelegten Patentanmeldung wird für die Bildsynthese so vorgegangen, dass in einem ersten Teilschritt in jeder Zeile diejenigen Bildsegmente gesucht werden, bei denen ein Cross-Over-Effekt vorliegt. Dies wird als Cross-Over-Vorverarbeitung bezeichnet. Ihr Ziel ist es, ein Feld Crossover (j) zu erzeugen mit folgender Eigenschaft:
-
Zur Bestimmung der Werte dieses Feldes wird wie folgt vorgegangen:
Zunächst wird die i-te Zeile der Disparitätskarte D in ein Zuordnungsfeld überführt mit Wohin(j) ≔ j + D(i, j).
-
In diesem Feld sind Rechtsverdeckungen durch den Wert –1 gekennzeichnet. Ansonsten sind die Werte von Wohin immer größer gleich 0.
-
Im Feld Wohin sind Cross-Over-Effekte dadurch gekennzeichnet, dass Wohin(j) < Wohin(j – 1) ist. Dort beginnt ein Cross-Over-Bildsegment und der Index CrossAnf = j wird gespeichert. Das Ende dieses Bildsegmentes ist durch die Eigenschaft Wohin(j) > Wohin(CrossAnf – 1) gekennzeichnet.
-
Daher wird eine Laufvariable j zunächst auf 1 gesetzt und fortlaufend inkrementiert. Crossover(j) wird auf 0 gesetzt. Trift die Laufvariable auf ein Pixel CrossAnf, für welchen gilt Wohin(CrossAnf) < Wohin(CrossAnf – 1) gilt, so beginnt dort das Cross-Over-Bildsegment und Crossover(j) wird dort beginnend auf 1 gesetzt. Nun wird j weiter inkrementiert bis die Bedingung Wohin(j) > Wohin(CrossAnf – 1) erfüllt ist. Ab dort wird Crossover(j) wieder auf 0 gesetzt bis zum nächsten Cross-Over-Bildsegment oder dem Ende der Zeile i. Ein Flussdiagramm dieser Cross-Over-Vorverarbeitung ist in 7 dargestellt.
-
Im zweiten Teilschritt wird für jede Zeile eine Laufvariable jr über alle Subpixel des Displaybildes B laufen gelassen. Zur Erleichterung des Verständnisses wird in der hier vorliegenden Beschreibung angenommen, dass jeder Pixel aus 3 Subpixeln besteht. Daher wird beim Übergang vom Subpixel auf den zugehörigen Pixel immer durch 3 dividiert. Besteht ein Pixel aus mehr Subpixeln, z. B. 4 Subpixeln, so muss dementsprechend durch 4 dividiert werden. Mittels der oben festgelegten Laufvariablen jr wird zunächst die anzuzeigende Perspektive aus der Matrix P geholt. Diese Matrix P gibt für jeden Subpixel des Displays an, welche Perspektive dort angezeigt werden soll. Demgegenüber ist eine Laufvariable jl jeder Zeile des linken Teilbildes zugeordnet, welche zunächst auf 0 (dem linken Rand des Displaybildes B) gesetzt ist. Im Zusammenhang mit der Disparitätskarte D kann nun eine Variable jl_PositionNeu berechnet werden, welche angibt, auf welcher Pixelposition die P(i, jr)-te Perspektive des Pixels Rl(i, jl) des linken Teilbildes dargestellt würde. Ist diese Position größer als jr/3, so muss jl dekrementiert werden. Ist diese Position kleiner als jr/3, so muss jl inkrementiert werden. Dieses Verfahren wird so lange fortgesetzt bis eine Position j_unten gefunden ist, welche gerade unterhalb von jr/3 ist. In gleicher Weise wird jl so lange inkrementiert bzw. dekrementiert bis eine Position j_oben gefunden ist, welche gerade oberhalb von jr/3 ist.
-
In Abhängigkeit von der Differenz j_oben – j_unten und der Differenz Wohin(i, j_unten) – Wohin(i, j_oben) kann herausgefunden werden, ob zwischen j_unten und j_oben eine reguläre Disparität, eine Links-, eine Rechts-Verdeckung oder ein Cross-Over-Effekt vorliegt.
-
Hier sind die folgenden Fälle zu unterscheiden:
- 1. j-oben – j_unten ≤ 1 und Wohin(j_oben) – Wohin(j_unten) ≤ 1
Dies ist eine reguläre Disparität. Der Subpixel kann von Rl(i, j_oben) bzw. Rl(i, j_unten) geholt werden.
- 2. j-oben – j_unten > 1 und Wohin(j_oben) – Wohin(j_unten) ≤ 1
Dies ist eine Rechtsverdeckung. Der zugehörige Pixel muss aus Rl durch Interpolation zwischen Rl(i, j_unten) und Rl(i, j_oben) und Abbildung auf die Perspektive P(i, jr) errechnet werden. Daraus wird sodann der erforderliche Subpixel extrahiert.
- 3. j-oben – j_unten ≤ 1 und Wohin(j_oben) – Wohin(j_unten) > 1
Dies ist eine Linksverdeckung. Der zugehörige Pixel muss aus Rr durch Interpolation zwischen Rr(i, Wohin(j_unten)) und Rr(i, Wohin(j_oben)) und Abbildung auf die Perspektive P(i, jr) errechnet werden. Daraus wird sodann der erforderliche Subpixel extrahiert.
- 4. j-oben – j_unten > 1 und Wohin(j_oben) – Wohin(j_unten) > 1
In diesem Fall hat man ein Cross-Over-Bildsegment erreicht. Hier sind zwei Unterfälle zu unterscheiden:
4a. Wohin(i, j) = –1 für j_unten < j < j_oben
Dieser Fall ist wie eine Rechtsverdeckung zu behandeln. Das Bildsegment muss von links nach rechts ausgeblendet werden. (Siehe Nr. 12 in 6)
4b. Wohin(i, j) ≥ 0 für j_unten < j < j_oben
Dieser Fall ist wie eine Linksverdeckung zu behandeln. Das Bildsegment muss von links nach rechts eingeblendet werden. (Siehe Nr. 13 in 6)
-
Diese Vorgehensweise wird fortgesetzt bis die Laufvariable jr am rechten Rand der i-ten Zeile des Displaybildes B der verkämmten Perspektiven angelangt ist.
-
Cross-Over-Bildsegmente werden in diesem Teilschritt ignoriert.
-
Im dritten Teilschritt wird die Cross-Over-Nachverarbeitung durchgeführt. In diesem Teilschritt brauchen nur die Zwischenperspektiven bearbeitet zu werden. Das linke und rechte zugeführte Teilbild sind als Perspektive 0 und M – 1 gesetzt und sind automatisch richtig bearbeitet worden. Für die Zwischenperspektiven wird wie folgt vorgegangen:
Beginnend von links wird mittels einer Variablen jl der Anfang eines Cross-over-Bildsegmentes gesucht. Dieses ist wegen Crossover(j) = 1 leicht zu finden. Der linke Rand sei mit Pixelposition jlmin bezeichnet. Der rechte Rand sei mit jlmax bezeichnet. In 6 ist dieser Bereich als Nr. 14a gekennzeichnet. Für jede dieser Variablen ist Wohin(jlmin) und Wohin(jlmax) gegeben. Man weiß damit wohin das Cross-Over-Bildsegment ins rechte Teilbild abgebildet wird. Dieser Bildbereich ist in 6 als Nr. 14b gekennzeichnet. Nun seien: jrmin ≔ min(jlmin, Wohin(jlmin)) und jrmax ≔ max(jlmax, Wohin(jlmax)) die Pixelindices, zwischen welchen das Cross-Over-Bildsegment vom linken Teilbild Rl zum rechten Teilbild Rr „wandern” muss.
-
Eine Laufvariable jr läuft nun vom linken Subpixel jrmin·3 bis zum rechten Subpixel jrmax*3. Für jeden dieser Subpixel kann wieder die anzuzeigende Perspektive P(i, jr) gewählt werden.
-
Ist Perspektive P(i, jr) = 0 oder P(i, jr) = M – 1, so muss dort ein Subpixel aus dem zugeführten linken bzw. rechten Teilbild angezeigt werden. Dieser Fall ist jedoch schon vorher korrekt bearbeitet worden und kann hier ignoriert werden Mittels der gesuchten Perspektive P(i, jr) kann eine Position jrmin_PositionNeu wie folgt berechnet werden: jrmin_PositionNeu ≔ j_unten + (Wohin(j_unten) – j_unten)·P(i, jr)/M – 1).
-
Ist jrmin_PositionNeu > jr/3, so liegt jr links vom zu überlagernden Cross-Over-Bereich in der Perspektive P(i, jr). In diesem Fall muss nichts geschehen. jr kann inkrementiert werden. Dieser Fall ist in 6 mit „P1” gekennzeichnet. In gleicher Weise kann jrmax_PositionNeu ≔ j_oben + (Wohin(j_oben) – j_oben)·P(i, jr)/M – 1).. berechnet werden. Ist hier jrmax_PositionNeu < jr/3, so liegt jr rechts vom zu überlagernden Cross-Over-Bereich in der Perspektive P(i, jr). In diesem Fall muss ebenfalls nichts geschehen. jr kann inkrementiert werden. Dieser Fall ist in 6 mit „P3” gekennzeichnet. Eine Überlagerung muss also nur durchgeführt werden, wenn jrmin_PositionNeu ≤ jr ≤ jrmax_PositionNeu gilt. In diesem Fall wird der Pixel CrossoverPixel mit CrossoverPixel ≔ (jlmin + (jr/3 – jrminPositionNeu)*j_scale aus dem Cross-OVer-Bildsegment Rl(i, CrossoverPixel) des linken Teilbildes genommen. j_scale bezeichnet eine Variable, welche den Cross-Over-Bildbereich zwischen Ri(i, jlmin) und Rl(i, jlmax) auf den Cross-Over-Bildbereich der Perspektive P(i, jr) abbildet, denn es ist nicht vorausgesetzt, dass jlmax – jlmin = Wohin(jlmax) – Wohin(jlmin) ist.
-
Von CrossoverPixel wird der entsprechende Subpixel ins Displaybild B der verkämmten Perspektiven übertragen. Dieser Fall ist in 6 mit „P2” gekennzeichnet.
-
Nun wird jl ≔ jlmax + 1 gesetzt und weiter inkrementiert bis zum nächsten Cross-Over-Bildsegment oder das Ende der Zeile mit jl ≥ NS – 1 erreicht ist. jr ≥ N – 1 am rechten Rand des Displaybildes angelangt ist.
-
Ein Flussdiagramm zu diesem Verfahrensteilschritt der Cross-Over-Nachverarbeitung ist in 8a bis 8c dargestellt.
-
Eine Szene ohne Cross-Over-Bildsegment ist in 5 exemplarisch dargestellt. Eine Szene mit einem solchen Cross-Over-Bildsegement ist in 6 exemplarisch dargestellt.
-
Mit den Teilschritten 1 bis 3 ist das gesamte Verfahren zur Bildsynthese in 9a und 9b als Flussdiagramm beschrieben.
-
Für die Beziehung zwischen jlmax – jlmin und Wohin(i, jlmax) – Wohin(i, jlmin) kann folgendes festgehalten werden:
-
- 1. jlmax – jlmin = Wohin(i, jlmax) – Wohin(i, jlmin)
In diesem Fall ist die Objektfläche des Cross-Over-Objektes parallel zur Stereobasis.
- 2. jlmax – jlmin > Wohin(i, jlmax) – Wohin(i, jlmin)
In diesem Fall ist die Objektfläche des Cross-Over-Objektes der linken Kamera mit dem linken Teilbild zugewandt. Hier sind Zwischenbereiche des Cross-Over-Bildbereiches wie Rechtsverdeckungen zu behandeln und müssen im Laufe des Überganges zum rechten Teilbild ausgeblendet werden. Die Vorgehensweise hierfür ist im Schritt für die reguläre Disparitätsverarbeitung beschrieben.
- 3. jlmax – jlmin < Wohin(i, jlmax) – Wohin(i, jlmin)
In diesem Fall ist die Objektfläche des Cross-Over-Objektes der rechten Kamera mit dem rechten Teilbild zugewandt. Hier sind Zwischenbereiche des Cross-Over-Bildbereiches wie Linksverdeckungen zu behandeln und müssen im Laufe des Überganges zum rechten Teilbild eingeblendet werden. Die Vorgehensweise hierfür ist im Schritt für die reguläre Disparitätsverarbeitung beschrieben.
-
Da alle Schritte sich immer nur auf die Zeile i beziehen eignet sich eine solche Vorgehensweise ganz besonders für eine massiv parallele Verarbeitung. Dies wird im Abschnitt über die Hardware-Struktur noch weiter erläutert werden.
-
Autostereoskopische Visualisierung von 2D-Bildern:
Mit der bisher dargelegten Beschreibung wird der Fall beschrieben, wie zu verfahren ist, wenn 3D-Bilder in einem dafür definierten Format empfangen werden. Im Falle des Empfanges von 2D-Bildern, wird im allgemeinen so verfahren, dass das Bild vollständig auf die Größe des Displays angepasst und sodann angezeigt wird. In der hier vorliegenden Offenlegung soll jedoch anders verfahren werden.
-
Wird das 2D-Bild vollständig auf dem Display angezeigt, so hat der Betrachter den Eindruck das Bild befindet sich auf der Oberfläche des Displays. Unter Ausnutzung des vorher beschriebenen pseudoholographischen Bildsyntheseverfahrens soll nun jedoch wie folgt vorgegangen werden:
In einem ersten Schritt wird das empfangene 2D-Bild als linkes Teilbild verwendet. Als rechtes Teilbild wird das gleiche 2D-Bild jedoch um einen Betrag m > 0 nach rechts verschoben verwendet. Gleichzeitig wird eine Disparitätsmatrix der folgenden Art erzeugt: D2D' ≔ {m| i = 1, ..., NZ; j = 1, ..., NS}
-
Dadurch haben alle Betrachter den Eindruck, das 2D-Bild (welches noch als solches empfunden wird) schwebt in einem gewissen Abstand vor dem Display.
-
Wird das 2D-Bild um einen gewissen Betrag m < 0 nach links verschoben, so haben die Betrachter den Eindruck, das Bild wird ins Display nach innen verschoben. Dieser Fall ist theoretisch möglich, optisch aber nicht besonders beeindruckend.
-
Lässt man den Betrachter den Betrag m interaktiv wählen, z. B. mittels einer Fernbedienung, so kann der Betrachter sich den „Pop-out”- oder „Pop-in”-Effekt jederzeit selbst einstellen. Die Verarbeitungszeit dafür ist in jedem Fall minimal.
-
Die Qualität des 2D-Eindruckes leidet unter dieser Vorgehensweise nicht, da die Auflösung des Displays größer ist als die Auflösung des 2D-Bildes.
-
Detaillierte Beschreibung Hardware
-
Display
-
Zur Anpassung an die anatomischen Gegebenheiten des menschlichen Auges werden zwei Eigenschaften berücksichtigt. Dies sind:
- 1. die Auflösung des Auges und
- 2. die Anzahl und Eigenschaften der Rezeptoren im Auge.
-
Die Auflösung des menschlichen Auges liegt i. A. zwischen 0,5' und 1.5'. Daher haben heutige Displays meistens einen Dot-Pitch von 0,2 bis 0,3 mm. Das heißt, ab einem Abstand von ca. 1 m sind die Pixel des Displays nicht mehr zu erkennen. Bei dem hier vorgestellten erfindungsgemäßen Display liegt die Linsenbreite des verwendeten Linsenrasters im Bereich von 0,2 mm. Das heißt ca. 125 LPI (Linsen pro Inch). Dadurch ist die Linsenstruktur ab einem Betrachtungsabstand von ca. 1 m nicht mehr zu erkennen. Die Anzahl der Subpixel, die hinter einer Linse liegen, liegt in der Größenordnung von 10 Subpixeln pro Linse. Das heißt, dass der Dot-Pitch eines pseudoholographischen Displays in der Größenordnung von ca. 0,06 mm liegt. Während man bei konventionellen Displays z. B. 1920×1080 Pixel (HD-TV) darstellt, besteht ein hier vorgestelltes pseudoholographisches Display aus mindestens 19.200×1080 Pixeln.
-
Das Linsenraster kann z. B. aus Lentikularlinsen oder auch aus Hexagonallinsen bestehen, die in diesem Falle einen Durchmesser von 0,2 mm besitzen.
-
Berücksichtigt man, dass im menschlichen Auge ca. 6,5 Mio. Farbrezeptoren vorhanden sind und ca. 100 Mio. Hell/Dunkel-Rezeptoren, so ist ersichtlich, dass ca. 15 mal so viele Hell/Dunkel-Rezeptoren vorhanden sind wie Farbrezeptoren. Diese anatomische Gegebenheit hatte ihren Niederschlag in den früher häufiger verwendeten Kompressionsparametern 4:2:2 gefunden. Bei der 4:2:2-Kompression werden doppelt so viele Schwarz/Weiß-Daten wir Farbdaten übertragen, weil man berücksichtigte, dass das menschliche Auge die Farbinformation sehr viel grober auflöst. Andererseits verwendet das menschliche Gehirn für die Erzeugung des inneren Raumbildes zu einem sehr großen Teil die Kanteninformation. Kanten geben mit den dort vorhandenen Rechts- und Linksverdeckungen Auskunft über die Vorne/Hinten-Beziehung von Objekten.
-
In einer ersten Ausführung werden daher die bekannten Subpixel RGB oder YMC durch Hell/Dunkel-Subpixel ergänzt, welche die in der Merkmalextraktionsphase durch die Kanten-Operatoren erzeugte Kanteninformation anzeigen.
-
Homogene Flächen enthalten keine Kanten. Die Hell/Dunkel-Subpixel stellen dort im Bild keine Information dar.
-
Kanten werden in den Hell/Dunkel-Subpixeln gemäß der Intensität der erkannten Kante heller dargestellt. Dadurch werden die im Bild vorhandenen Kanten hervorgehoben und durch die 100 Mio. Hell/Dunkel-Rezeptoren leichter erkannt.
-
Das Gehirn hat es so leichter das innere Raumbild zu erzeugen. Muster auf homogenen Flächen werden im menschlichen Gehirn aufgrund des Lerneffektes als solche erkannt und beeinflussen den Raumbildeindruck nicht.
-
Die geometrische Anordnung der Hell/Dunkel-Subpixel kann erfindungsgemäß variiert werden. In 4a und 4b sind verschiedene Aufteilungen dargestellt. Neben den Hell/Dunkel-Subpixeln zur Verbesserung der Kanten-Erkennung können noch weitere Merkmale zur Raumbilderzeugung hinzugefügt werden. Hier sei exemplarisch, aber nicht ausschließlich, der SURF-Operator genannt.
-
Zusätzlich wird die Aufteilung der Pixel in Farb-Subpixel (i. A. RGB-Subpixel) aufgehoben. Berücksichtigt man, dass die Zuordnung der Perspektiven für ein autostereoskopisches Display immer auf der Ebene der Subpixel mit Farb- und Hell/Dunkel-Subpixeln stattfindet, so wird in dem hier beschriebenen Display auf die Gruppierung von Subpixeln zu Pixeln verzichtet. Jeder Farb- oder Hell/Dunkel-Subpixel ist für sich ein eigenständiges Lichtelement, dem eine bestimmte Perspektive zugeordnet ist, und besitzt in horizontaler und vertikaler Richtung die gleiche Ausdehnung. Dies ist in 4a und 4b jeweils bei „N” bereits berücksichtigt. Eine Rückwärts-Kompatibilität ist weiterhin gegeben, sodass auch alle 2D-Bilder und -Videos problemlos dargestellt werden können. Zur Erleichterung des Verständnisses werden die bilderzeugenden Lichtelement weiterhin als „Subpixel” bezeichnet, obwohl sie eigentlich als „farbige Pixel” bezeichnet werden müssten.
-
Die Herstellung eines solchen Displays ist auf Basis der OLED-Technologie kein Problem.
-
In einer weiteren Ausführung, in welcher nur von den RGB- oder YMC-Subpixeln ausgegangen wird (wie sie in den bisherigen Displays gegeben sind) werden die Merkmale des verwendeten Kanten-Operators zur Hervorhebung der Kanten in den RGB-Subpixeln verwendet. Ein Pixel, z. B. bestehend aus den RGB-Subpixeln, wird wie folgt an die Anatomie des Auges angepasst: Rneu(i, j) ≔ R(i, j) + M(i, j, 1)·s, Gneu(i, j) ≔ G(i, j) + M(i, j, 1)·s, Bneu(i, j) ≔ B(i, j) + M(i, j, 1)·s, wobei R(i, j), G(i, j) und B(i, j) die jeweiligen Farben rot, grün und blau definieren. M(i, j, 1) ist der Wert des Kanten-Operators für den Pixel (i, j). s ist ein frei einzustellender Skalierungsparameter. Wenn er über eine Fernbedienung gesteuert wird, so kann sich jeder Betrachter die Kantenhervorhebung für sein Empfinden individuell einstellen.
-
Durch dieses Verfahren werden die Farbwerte des Stereobildes in den Kanten leicht aufgehellt (aber nicht farbverfälscht) und für die Hell/Dunkel-Rezeptoren leichter erkennbar.
-
Auch hier können mehrere Merkmale wie folgt integriert werden: Rneu(i, j) ≔ R(i, j) + s·ΣMl(i, j)·sl, Gneu(i, j) ≔ G(i, j) + s·ΣMl(i, j)·sl, Bneu(i, j) ≔ B(i, j) + s·ΣMl(i, j)·sl, mit den Merkmalsvektoren M(i, j) ≔ (M(i, j, 1), ..., M(i, j, K)) und dem Wichtungsvektor S ≔ (s1, ..., sK) für jeden Pixel (i, j). Eine solche optische Aufwertung kann natürlich auch multiplikativ erfolgen.
-
Verarbeitungseinheit
-
In den vorherigen Kapiteln sind die Verfahrensschritte im Detail beschrieben worden. Wie vorher beschrieben empfängt das erfindungsgemäße hochauflösende pseudoholographische Display zunächst ein Stereobild in einem der bekannten Formate mit einer Auflösung von beispielsweise 1920×1080 je Bild. Es wird sodann auf die Auflösung des Displays skaliert, die hier zur Vereinfachung der Beschreibung mit 19.200×1080 angenommen sei.
-
Dieses empfangene Stereobild wird analysiert und eine sehr große Anzahl von Zwischenperspektiven, z. B. 1.000 Perspektiven, daraus synthetisiert, welche nachfolgend auf einem Display z. B. mit Lentikularlinsen angezeigt werden.
-
Für die Analyse dieser Stereobilder wird die Durchführung in Echtzeit, d. h. i. A. in höchstens 20 ms gefordert. Dies erfordert eine sehr hohe Verarbeitungskapazität, welche nicht mehr in einer einzigen Verarbeitungseinheit erbracht werden kann.
-
In einer ersten Ausführungsform wird daher jeder Zeile des Displays eine eigene Verarbeitungseinheit mit dem erforderlichen lokalen Speicher zugeordnet. Diese wird im folgenden als „Zeilenrecheneinheit” bezeichnet.
-
Neben diesen lokalen Zeilenrecheneinheiten werden alle Einheiten von einer Steuer- und Kontrolleinheit synchronisiert.
-
Daten wie z. B. die Ausgangsbilder, die rektifizierten Bilder, die Merkmalsvektoren oder das verkämmte Ausgabebild werden in einem globalen Speicher gehalten, auf welchen alle Zeilenrecheneinheiten parallel zugreifen können. Da alle Einheiten auf diese Daten nur lesend zugreifen oder schreibend nur auf die ihnen zugeordnete Zeile des Bildes und Displays bestehen keine Synchronisations- oder Blockierungsprobleme. Für ein Display mit einer Auflösung von 19.200×1080 sind also mindestens 1080 Zeilenrecheneinheiten erforderlich. Eine Implementierung als Chip oder Single-Board-Einheit sind für die heutige Chip-Technologie kein Problem, da bereits Grafikkarten mit einer gleichen Anzahl von Recheneinheiten, Shader genannt, existieren.
-
In einer weiteren Ausführungsform werden jeder Zeile des Displays mehrere Verarbeitungseinheiten zugeordnet. Im Extremfall, der hier nicht ausgeschlossen ist, besitzt jeder Pixel eine eigene Verarbeitungseinheit.
-
In der Phase der Bildanalyse zur Erzeugung der Disparitätskarte wird in diesem Falle ein aus der Literatur bekanntes iteratives Verfahren implementiert. In der Synthesephase wird die anfängliche Iterationsvariable il nicht mehr sequentiell für jeden Pixel inkrementiert, sondern es wird für jeden Pixel ir einer Zeile mit einem Startwert il ≔ ir begonnen. Das sodann gestartete Suchverfahren läuft wie beschrieben weiter.
-
Die Struktur der pixelweise zugeordneten Zeilenrecheneinheiten ist in 3 dargestellt.
-
Der globale Speicher wird in den Speicher für Bilddaten, Merkmalsdaten, für Disparitätskarte und für pseudoholographisches Ausgabebild unterteilt. Im Falle eines empfangenen Stereo-HD-Bildes mit zweimal 1920×1080 Pixeln und einem angeschlossenen Display mit der Auflösung 19.200×1080 muss mit folgender Speicherkapazität kalkuliert werden:
Bilddaten: 33 MB,
Merkmalsdaten: 0 MB,
Disparitätskarte: 80 MB,
Ausgabebild: 80 MB.
-
Dies ergibt einen erforderlichen Speicherbedarf von ca. 233 MB. Insgesamt besitzt das erfindungsgemäße hochauflösende pseudoholographische Display daher inklusive verschiedener Zwischenvariable eine Speicherkapazität von 256 MB. Auf diesem Display lassen sich bereits 10 Perspektiven hochauflösend ohne Pixelverlust darstellen.
-
Displays dieser Struktur sind automatisch auch für eine 2D-Darstellung von Bilder und Videos geeignet und brauchen nicht mechanisch oder elektronisch umgeschaltet zu werden. Der 2D-Eindruck ergibt sich dadurch, dass die Bildanalyse ausgelassen wird und bei der Bildsynthese nur auf das eine empfangene Bild wie im vorherigen Kapitel beschrieben zugegriffen wird.
-
Herstellungsprozess
-
Bei der Herstellung wird anders als bei konventionellen 2D-Displays vorgegangen. Während in der Vergangenheit autostereoskopische Displays immer so hergestellt wurden, dass vor ein 2D-Display ein optisches Element gesetzt wurde, ist dies hier nicht der Fall. In den bisher angewandten Herstellungsprozessen wird die bilderzeugende Einheit auf einem Substrat aufgebracht und der Rand so geschnitten, dass sich die gewünschte Displaygröße ergibt.
-
Bei autostereoskopischen Displays ist die Positionierung von bilderzeugender Einheit zum optischen Element von zentraler Bedeutung. Hier kommt es auf Lageparameter in der Größenordnung von 0.001 mm an. Ist z. B. die Lage der bilderzeugenden Einheit zum optischen Element nicht vollkommen parallel, so kann es zu Moire-Effekten bei der Betrachtung kommen.
-
Es soll daher in dieser Patentanmeldung wie folgt vorgegangen:
- 1. Zuerst wird das optische Element als Linsenstruktur oder als Barrierenstruktur auf einem geeigneten Träger erzeugt.
- 2. Sodann wird eine erste elektrische Leitungsstruktur auf der Rückseite des Trägers aufgebracht. Dabei erkennt eine optische Sensoreinheit die exakte Lage des optischen Elementes und steuert durch diese Lageparameter den Aufbringungsprozess der bildgebenden Struktur.
- 3. Danach werden die Farbpixel RGB, RGBW oder andere Layouts auf der Leitungsstruktur aufgebracht. Dieser Schritt wird in gleicher Weise durch die vorher erkannten Lageparameter gesteuert.
- 4. In einem letzten Schritt wird die erforderliche ergänzende elektrische Leitungsstruktur auf der nun vorhandenen Subpixelstruktur aufgebracht. Auch dieser Schritt wird durch die vorher erkannten Lageparameter gesteuert.
-
Der Träger für das Display-Panel ist das optische Element selbst. Dadurch wird eine größere Genauigkeit bei der Zuordnung von Subpixel und optischem Element erreicht und gleichzeitig wird die Anzahl der Herstellungsschritte reduziert, wodurch auch die Herstellungszeit verringert wird. Ebenso ist eine Kalibrierung zwischen bilderzeugender Einheit und optischem Element nicht mehr erforderlich.
-
In einer ersten Ausführungsform besteht die optische Sensoreinheit aus einer Lichtquelle, welche die Vorderseite des optischen Elements beleuchtet. Auf der Rückseite des optischen Elements nimmt eine Kamera bzw. ein Scanner das Bild des durchleuchteten optischen Elementes auf. Dabei werden die Linsengrenzen (Rillen bzw. Barrieren) als schwarze Linien sichtbar. Durch einfache Bildverarbeitungsoperationen wird daraus die exakte Position der Linsengrenzen bzw. Barrieren erfasst und die Steuerparameter für den Aufbringungsprozess der Subpixel berechnet.
-
In einer zweiten Ausführungsform wird statt der Lichtquelle und Kamera ein Lasersensor verwendet, welcher von der Vorderseite den Abstand zur Oberfläche des optischen Elementes misst. Die Rillen bzw. Barrieren werden dabei durch einen größeren Abstand zum Lasersensor detektiert. Auch hier können wieder die Lageparameter der Linsen- bzw. Barrierestruktur berechnet und für den Aufbringungsprozess verwendet werden. Ein Diagramm eines solchen zeilenweisen Scans des Lasersensors ist in 10 dargestellt.
-
Referenzen
-
- 1. H. Bay, T. Tuytelaars and L. V. Gool, "SURF: Speeded Up Robust Features", Computer Vision and Image Understanding, 110(3), 2008, pp. 346–359.
- 2. M. Bleyer and M. Gelautz, "Temporally Consistent Disparity Maps from uncalibrated Stereo Videos", Proceedings of the 6th International Symposium an Image and Signal Processing and Analysis (ISPA 2009), Special Session an Stereo Analysis and 3D Video/TV, pp. 383–387.
- 3. W. K. Pratt, "Digital Image Processing", A Wiley-Interscience Publication, 1991, ISBN 0-471-85766-1, pp. 553 ff.
- 4. L. Falkenhagen, "Blockbasierte Disparitätsschätzung unter Berücksichtigung statistischer Abhängigkeiten der Disparitäten", 2001, Fortschritt-Berichte VDI Reihe 10, Nr. 657 ISBN 3-18-365710-4.
- 5. B. Girod, G. Greiner, H. Niemann, „Principles of 3D Image Analysis and Synthesis", Kluwer Academic Publishers, 2002, ISBN 0-7923-4850-4
- 6. O. Faugeras and Q-T Luong, "The Geometry of Multiple Images", MIT Press, London, 2001, ISBN 0-262-06220-8
- 7. O. Faugeras, "Three-dimensional Computer Vision", MIT Press, London, 2001, ISBN 0-262-06158-9
- 8. P. Courtney, N. Thacker & C. Brown, "A hardware architecture for image rectification and ground plane obstacle detection", Proc. Int. Conf. On Pattern Recognition 1992, pp. 23–26.
-
ZITATE ENTHALTEN IN DER BESCHREIBUNG
-
Diese Liste der vom Anmelder aufgeführten Dokumente wurde automatisiert erzeugt und ist ausschließlich zur besseren Information des Lesers aufgenommen. Die Liste ist nicht Bestandteil der deutschen Patent- bzw. Gebrauchsmusteranmeldung. Das DPMA übernimmt keinerlei Haftung für etwaige Fehler oder Auslassungen.
-
Zitierte Patentliteratur
-
- EP 2007/003546 [0021]
- WO 2007/121970 [0064]