CN111954679A - Hpv特异性结合分子 - Google Patents
Hpv特异性结合分子 Download PDFInfo
- Publication number
- CN111954679A CN111954679A CN201880076631.8A CN201880076631A CN111954679A CN 111954679 A CN111954679 A CN 111954679A CN 201880076631 A CN201880076631 A CN 201880076631A CN 111954679 A CN111954679 A CN 111954679A
- Authority
- CN
- China
- Prior art keywords
- seq
- cdr
- amino acid
- alpha
- beta
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 230000009870 specific binding Effects 0.000 title description 3
- 108091008874 T cell receptors Proteins 0.000 claims abstract description 819
- 230000027455 binding Effects 0.000 claims abstract description 406
- 239000000427 antigen Substances 0.000 claims abstract description 351
- 102000036639 antigens Human genes 0.000 claims abstract description 351
- 108091007433 antigens Proteins 0.000 claims abstract description 351
- 239000012634 fragment Substances 0.000 claims abstract description 324
- 241000701806 Human papillomavirus Species 0.000 claims abstract description 77
- 239000000203 mixture Substances 0.000 claims abstract description 73
- 238000000034 method Methods 0.000 claims abstract description 56
- 238000011282 treatment Methods 0.000 claims abstract description 10
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 1015
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 claims description 818
- 210000004027 cell Anatomy 0.000 claims description 290
- 229910052717 sulfur Inorganic materials 0.000 claims description 183
- 108010047041 Complementarity Determining Regions Proteins 0.000 claims description 174
- 229910052757 nitrogen Inorganic materials 0.000 claims description 165
- 102100029452 T cell receptor alpha chain constant Human genes 0.000 claims description 145
- 239000002773 nucleotide Substances 0.000 claims description 138
- 125000003729 nucleotide group Chemical group 0.000 claims description 138
- 229910052720 vanadium Inorganic materials 0.000 claims description 137
- 108090000623 proteins and genes Proteins 0.000 claims description 136
- 150000007523 nucleic acids Chemical class 0.000 claims description 128
- 229910052727 yttrium Inorganic materials 0.000 claims description 125
- 229910052731 fluorine Inorganic materials 0.000 claims description 113
- 229910052698 phosphorus Inorganic materials 0.000 claims description 95
- 102000040430 polynucleotide Human genes 0.000 claims description 81
- 108091033319 polynucleotide Proteins 0.000 claims description 81
- 239000002157 polynucleotide Substances 0.000 claims description 81
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 72
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 69
- 229910052740 iodine Inorganic materials 0.000 claims description 63
- 108700026244 Open Reading Frames Proteins 0.000 claims description 62
- 235000001014 amino acid Nutrition 0.000 claims description 62
- 102000039446 nucleic acids Human genes 0.000 claims description 56
- 108020004707 nucleic acids Proteins 0.000 claims description 56
- 150000001413 amino acids Chemical group 0.000 claims description 49
- 230000008685 targeting Effects 0.000 claims description 48
- 108020005004 Guide RNA Proteins 0.000 claims description 45
- 230000036961 partial effect Effects 0.000 claims description 44
- 230000014509 gene expression Effects 0.000 claims description 42
- 229910052722 tritium Inorganic materials 0.000 claims description 42
- 239000003795 chemical substances by application Substances 0.000 claims description 40
- 229910052739 hydrogen Inorganic materials 0.000 claims description 39
- 239000013598 vector Substances 0.000 claims description 39
- 230000002068 genetic effect Effects 0.000 claims description 35
- 108091033409 CRISPR Proteins 0.000 claims description 33
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 33
- 230000000295 complement effect Effects 0.000 claims description 32
- 229910052805 deuterium Inorganic materials 0.000 claims description 32
- 108700019146 Transgenes Proteins 0.000 claims description 30
- 230000001747 exhibiting effect Effects 0.000 claims description 30
- 230000034431 double-strand break repair via homologous recombination Effects 0.000 claims description 29
- 210000001266 CD8-positive T-lymphocyte Anatomy 0.000 claims description 28
- 210000001744 T-lymphocyte Anatomy 0.000 claims description 28
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 claims description 28
- 229910052700 potassium Inorganic materials 0.000 claims description 26
- 230000004048 modification Effects 0.000 claims description 25
- 238000012986 modification Methods 0.000 claims description 25
- 108700024394 Exon Proteins 0.000 claims description 24
- 101000634853 Homo sapiens T cell receptor alpha chain constant Proteins 0.000 claims description 22
- 235000018417 cysteine Nutrition 0.000 claims description 22
- 238000006467 substitution reaction Methods 0.000 claims description 22
- 238000010361 transduction Methods 0.000 claims description 21
- 230000026683 transduction Effects 0.000 claims description 21
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 19
- 241000702141 Corynephage beta Species 0.000 claims description 18
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 claims description 17
- 201000010099 disease Diseases 0.000 claims description 17
- 229920001184 polypeptide Polymers 0.000 claims description 17
- 241000687983 Cerobasis alpha Species 0.000 claims description 16
- 108010076504 Protein Sorting Signals Proteins 0.000 claims description 16
- 208000035475 disorder Diseases 0.000 claims description 16
- 235000018102 proteins Nutrition 0.000 claims description 16
- 102000004169 proteins and genes Human genes 0.000 claims description 16
- 101800001494 Protease 2A Proteins 0.000 claims description 14
- 101800001066 Protein 2A Proteins 0.000 claims description 14
- 241000193996 Streptococcus pyogenes Species 0.000 claims description 13
- 102100037272 T cell receptor beta constant 1 Human genes 0.000 claims description 13
- 101000662909 Homo sapiens T cell receptor beta constant 1 Proteins 0.000 claims description 12
- 101000662902 Homo sapiens T cell receptor beta constant 2 Proteins 0.000 claims description 12
- 230000010354 integration Effects 0.000 claims description 12
- 230000001105 regulatory effect Effects 0.000 claims description 12
- 238000011144 upstream manufacturing Methods 0.000 claims description 12
- 206010028980 Neoplasm Diseases 0.000 claims description 11
- 230000001965 increasing effect Effects 0.000 claims description 11
- 239000013603 viral vector Substances 0.000 claims description 11
- 108091026890 Coding region Proteins 0.000 claims description 10
- 101710163270 Nuclease Proteins 0.000 claims description 10
- 102000004389 Ribonucleoproteins Human genes 0.000 claims description 10
- 108010081734 Ribonucleoproteins Proteins 0.000 claims description 10
- 238000012217 deletion Methods 0.000 claims description 10
- 230000037430 deletion Effects 0.000 claims description 10
- 102100037298 T cell receptor beta constant 2 Human genes 0.000 claims description 9
- 108020005345 3' Untranslated Regions Proteins 0.000 claims description 8
- 108020004705 Codon Proteins 0.000 claims description 8
- 238000003780 insertion Methods 0.000 claims description 8
- 230000037431 insertion Effects 0.000 claims description 8
- 238000004519 manufacturing process Methods 0.000 claims description 8
- 230000001939 inductive effect Effects 0.000 claims description 7
- 201000011510 cancer Diseases 0.000 claims description 6
- 238000004520 electroporation Methods 0.000 claims description 6
- 230000035772 mutation Effects 0.000 claims description 5
- 230000002829 reductive effect Effects 0.000 claims description 5
- 239000013607 AAV vector Substances 0.000 claims description 4
- 108091035707 Consensus sequence Proteins 0.000 claims description 4
- 102000010292 Peptide Elongation Factor 1 Human genes 0.000 claims description 4
- 108010077524 Peptide Elongation Factor 1 Proteins 0.000 claims description 4
- 108010017070 Zinc Finger Nucleases Proteins 0.000 claims description 4
- 101710185494 Zinc finger protein Proteins 0.000 claims description 4
- 102100023597 Zinc finger protein 816 Human genes 0.000 claims description 4
- 239000003623 enhancer Substances 0.000 claims description 4
- 230000004927 fusion Effects 0.000 claims description 4
- 238000000338 in vitro Methods 0.000 claims description 4
- 230000008488 polyadenylation Effects 0.000 claims description 4
- 239000002253 acid Substances 0.000 claims description 3
- 239000001506 calcium phosphate Substances 0.000 claims description 3
- 229910000389 calcium phosphate Inorganic materials 0.000 claims description 3
- 235000011010 calcium phosphates Nutrition 0.000 claims description 3
- 238000007906 compression Methods 0.000 claims description 3
- 230000006835 compression Effects 0.000 claims description 3
- 239000003814 drug Substances 0.000 claims description 3
- 238000001125 extrusion Methods 0.000 claims description 3
- 239000002245 particle Substances 0.000 claims description 3
- 238000001890 transfection Methods 0.000 claims description 3
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 claims description 3
- 241001655883 Adeno-associated virus - 1 Species 0.000 claims description 2
- 241000702423 Adeno-associated virus - 2 Species 0.000 claims description 2
- 241000202702 Adeno-associated virus - 3 Species 0.000 claims description 2
- 241000580270 Adeno-associated virus - 4 Species 0.000 claims description 2
- 241001634120 Adeno-associated virus - 5 Species 0.000 claims description 2
- 241000972680 Adeno-associated virus - 6 Species 0.000 claims description 2
- 241001164823 Adeno-associated virus - 7 Species 0.000 claims description 2
- 241001164825 Adeno-associated virus - 8 Species 0.000 claims description 2
- 238000010356 CRISPR-Cas9 genome editing Methods 0.000 claims description 2
- 108020004414 DNA Proteins 0.000 claims description 2
- 102000052510 DNA-Binding Proteins Human genes 0.000 claims description 2
- 230000004568 DNA-binding Effects 0.000 claims description 2
- 101710096438 DNA-binding protein Proteins 0.000 claims description 2
- 102100032049 E3 ubiquitin-protein ligase LRSAM1 Human genes 0.000 claims description 2
- 241000713772 Human immunodeficiency virus 1 Species 0.000 claims description 2
- 101150053558 TRBC1 gene Proteins 0.000 claims description 2
- 101150117561 TRBC2 gene Proteins 0.000 claims description 2
- 108010073062 Transcription Activator-Like Effectors Proteins 0.000 claims description 2
- 239000002299 complementary DNA Substances 0.000 claims description 2
- 239000013604 expression vector Substances 0.000 claims description 2
- 108020001507 fusion proteins Proteins 0.000 claims description 2
- 102000037865 fusion proteins Human genes 0.000 claims description 2
- 239000000546 pharmaceutical excipient Substances 0.000 claims description 2
- 230000001177 retroviral effect Effects 0.000 claims description 2
- 102220278926 rs759871071 Human genes 0.000 claims 4
- 101100166144 Staphylococcus aureus cas9 gene Proteins 0.000 claims 2
- 108091081024 Start codon Proteins 0.000 claims 2
- 108020004999 messenger RNA Proteins 0.000 claims 2
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims 1
- 241001663880 Gammaretrovirus Species 0.000 claims 1
- 241000191967 Staphylococcus aureus Species 0.000 claims 1
- 230000009258 tissue cross reactivity Effects 0.000 abstract 1
- 229940024606 amino acid Drugs 0.000 description 38
- 101000716102 Homo sapiens T-cell surface glycoprotein CD4 Proteins 0.000 description 30
- 102100036011 T-cell surface glycoprotein CD4 Human genes 0.000 description 30
- 102100034922 T-cell surface glycoprotein CD8 alpha chain Human genes 0.000 description 28
- 108700018351 Major Histocompatibility Complex Proteins 0.000 description 20
- 230000020382 suppression by virus of host antigen processing and presentation of peptide antigen via MHC class I Effects 0.000 description 20
- 241000699666 Mus <mouse, genus> Species 0.000 description 19
- 238000000684 flow cytometry Methods 0.000 description 15
- 101000954493 Human papillomavirus type 16 Protein E6 Proteins 0.000 description 13
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 description 12
- 108050005493 CD3 protein, epsilon/gamma/delta subunit Proteins 0.000 description 12
- 238000003197 gene knockdown Methods 0.000 description 11
- 101100112922 Candida albicans CDR3 gene Proteins 0.000 description 10
- 229910052721 tungsten Inorganic materials 0.000 description 10
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 9
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 7
- 102100035360 Cerebellar degeneration-related antigen 1 Human genes 0.000 description 7
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 7
- 102000005962 receptors Human genes 0.000 description 7
- 108020003175 receptors Proteins 0.000 description 7
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 6
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Chemical compound CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 6
- 239000012636 effector Substances 0.000 description 6
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 description 6
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 description 5
- 241000194020 Streptococcus thermophilus Species 0.000 description 5
- 150000001945 cysteines Chemical class 0.000 description 5
- 230000001461 cytolytic effect Effects 0.000 description 5
- 238000006471 dimerization reaction Methods 0.000 description 5
- 230000002209 hydrophobic effect Effects 0.000 description 5
- 230000001404 mediated effect Effects 0.000 description 5
- 239000000047 product Substances 0.000 description 5
- 230000011664 signaling Effects 0.000 description 5
- 101710117290 Aldo-keto reductase family 1 member C4 Proteins 0.000 description 4
- 238000010453 CRISPR/Cas method Methods 0.000 description 4
- 108060003951 Immunoglobulin Proteins 0.000 description 4
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 4
- 125000000174 L-prolyl group Chemical group [H]N1C([H])([H])C([H])([H])C([H])([H])[C@@]1([H])C(*)=O 0.000 description 4
- 125000000510 L-tryptophano group Chemical group [H]C1=C([H])C([H])=C2N([H])C([H])=C(C([H])([H])[C@@]([H])(C(O[H])=O)N([H])[*])C2=C1[H] 0.000 description 4
- 125000003295 alanine group Chemical group N[C@@H](C)C(=O)* 0.000 description 4
- 102000018358 immunoglobulin Human genes 0.000 description 4
- 238000011534 incubation Methods 0.000 description 4
- 239000012528 membrane Substances 0.000 description 4
- 102220026974 rs111052004 Human genes 0.000 description 4
- 238000010186 staining Methods 0.000 description 4
- 101000737793 Homo sapiens Cerebellar degeneration-related antigen 1 Proteins 0.000 description 3
- 241000713666 Lentivirus Species 0.000 description 3
- 241000588650 Neisseria meningitidis Species 0.000 description 3
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 3
- 230000000890 antigenic effect Effects 0.000 description 3
- 210000005220 cytoplasmic tail Anatomy 0.000 description 3
- 238000010348 incorporation Methods 0.000 description 3
- 230000014828 interferon-gamma production Effects 0.000 description 3
- 230000002147 killing effect Effects 0.000 description 3
- 239000013642 negative control Substances 0.000 description 3
- 230000000717 retained effect Effects 0.000 description 3
- 230000028327 secretion Effects 0.000 description 3
- 102100035361 Cerebellar degeneration-related protein 2 Human genes 0.000 description 2
- 206010008342 Cervix carcinoma Diseases 0.000 description 2
- 239000004471 Glycine Substances 0.000 description 2
- 108010088652 Histocompatibility Antigens Class I Proteins 0.000 description 2
- 102000008949 Histocompatibility Antigens Class I Human genes 0.000 description 2
- 101000737796 Homo sapiens Cerebellar degeneration-related protein 2 Proteins 0.000 description 2
- 101000767631 Human papillomavirus type 16 Protein E7 Proteins 0.000 description 2
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 2
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 2
- 102000043129 MHC class I family Human genes 0.000 description 2
- 108091054437 MHC class I family Proteins 0.000 description 2
- 241000699670 Mus sp. Species 0.000 description 2
- 102000043276 Oncogene Human genes 0.000 description 2
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 2
- 241000194019 Streptococcus mutans Species 0.000 description 2
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 description 2
- 241000700605 Viruses Species 0.000 description 2
- 239000000370 acceptor Substances 0.000 description 2
- 102000006707 alpha-beta T-Cell Antigen Receptors Human genes 0.000 description 2
- 108010087408 alpha-beta T-Cell Antigen Receptors Proteins 0.000 description 2
- 125000000539 amino acid group Chemical group 0.000 description 2
- 210000000170 cell membrane Anatomy 0.000 description 2
- 201000010881 cervical cancer Diseases 0.000 description 2
- 108700010039 chimeric receptor Proteins 0.000 description 2
- 230000001086 cytosolic effect Effects 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 238000011156 evaluation Methods 0.000 description 2
- 230000003993 interaction Effects 0.000 description 2
- 230000019491 signal transduction Effects 0.000 description 2
- 206010061424 Anal cancer Diseases 0.000 description 1
- 208000007860 Anus Neoplasms Diseases 0.000 description 1
- 101100495352 Candida albicans CDR4 gene Proteins 0.000 description 1
- 102000011727 Caspases Human genes 0.000 description 1
- 108010076667 Caspases Proteins 0.000 description 1
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 1
- 102100029952 Double-strand-break repair protein rad21 homolog Human genes 0.000 description 1
- 101150071673 E6 gene Proteins 0.000 description 1
- 101150013359 E7 gene Proteins 0.000 description 1
- 101000584942 Homo sapiens Double-strand-break repair protein rad21 homolog Proteins 0.000 description 1
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 description 1
- 101000914484 Homo sapiens T-lymphocyte activation antigen CD80 Proteins 0.000 description 1
- 101150106931 IFNG gene Proteins 0.000 description 1
- 102000008070 Interferon-gamma Human genes 0.000 description 1
- 108010074328 Interferon-gamma Proteins 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 241000186805 Listeria innocua Species 0.000 description 1
- 208000032271 Malignant tumor of penis Diseases 0.000 description 1
- 101000686985 Mouse mammary tumor virus (strain C3H) Protein PR73 Proteins 0.000 description 1
- 241001529936 Murinae Species 0.000 description 1
- 101710153660 Nuclear receptor corepressor 2 Proteins 0.000 description 1
- 108700020796 Oncogene Proteins 0.000 description 1
- 206010031096 Oropharyngeal cancer Diseases 0.000 description 1
- 206010057444 Oropharyngeal neoplasm Diseases 0.000 description 1
- 208000002471 Penile Neoplasms Diseases 0.000 description 1
- 206010034299 Penile cancer Diseases 0.000 description 1
- 201000000582 Retinoblastoma Diseases 0.000 description 1
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 description 1
- 102100027222 T-lymphocyte activation antigen CD80 Human genes 0.000 description 1
- 206010047741 Vulval cancer Diseases 0.000 description 1
- 208000004354 Vulvar Neoplasms Diseases 0.000 description 1
- QTBSBXVTEAMEQO-UHFFFAOYSA-N acetic acid Substances CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 238000011467 adoptive cell therapy Methods 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- 238000004873 anchoring Methods 0.000 description 1
- 230000000259 anti-tumor effect Effects 0.000 description 1
- 201000011165 anus cancer Diseases 0.000 description 1
- 210000004899 c-terminal region Anatomy 0.000 description 1
- 230000036952 cancer formation Effects 0.000 description 1
- 210000000234 capsid Anatomy 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 230000010261 cell growth Effects 0.000 description 1
- 230000006037 cell lysis Effects 0.000 description 1
- 238000001516 cell proliferation assay Methods 0.000 description 1
- 230000010307 cell transformation Effects 0.000 description 1
- 230000000052 comparative effect Effects 0.000 description 1
- 230000016396 cytokine production Effects 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000018109 developmental process Effects 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 238000002825 functional assay Methods 0.000 description 1
- 125000000267 glycino group Chemical group [H]N([*])C([H])([H])C(=O)O[H] 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 239000000833 heterodimer Substances 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 230000002998 immunogenetic effect Effects 0.000 description 1
- 230000002779 inactivation Effects 0.000 description 1
- 229960003130 interferon gamma Drugs 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 239000003446 ligand Substances 0.000 description 1
- 238000010859 live-cell imaging Methods 0.000 description 1
- 230000002101 lytic effect Effects 0.000 description 1
- 238000010172 mouse model Methods 0.000 description 1
- 108091008819 oncoproteins Proteins 0.000 description 1
- -1 one Chemical class 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 201000006958 oropharynx cancer Diseases 0.000 description 1
- 210000004986 primary T-cell Anatomy 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 230000022983 regulation of cell cycle Effects 0.000 description 1
- 230000010076 replication Effects 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 238000002864 sequence alignment Methods 0.000 description 1
- 210000003491 skin Anatomy 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 231100000617 superantigen Toxicity 0.000 description 1
- 229940124597 therapeutic agent Drugs 0.000 description 1
- 238000002560 therapeutic procedure Methods 0.000 description 1
- 230000001875 tumorinhibitory effect Effects 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- 206010046885 vaginal cancer Diseases 0.000 description 1
- 208000013139 vaginal neoplasm Diseases 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- 201000005102 vulva cancer Diseases 0.000 description 1
Images
































































































Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/7051—T-cell receptor (TcR)-CD3 complex
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/08—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses
- C07K16/081—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses from DNA viruses
- C07K16/084—Papovaviridae, e.g. papillomavirus, polyomavirus, SV40, BK virus, JC virus
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2809—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against the T-cell receptor (TcR)-CD3 complex
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K39/46
- A61K2239/27—Indexing codes associated with cellular immunotherapy of group A61K39/46 characterized by targeting or presenting multiple antigens
- A61K2239/28—Expressing multiple CARs, TCRs or antigens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K35/00—Medicinal preparations containing materials or reaction products thereof with undetermined constitution
- A61K35/12—Materials from mammals; Compositions comprising non-specified tissues or cells; Compositions comprising non-embryonic stem cells; Genetically modified cells
- A61K35/14—Blood; Artificial blood
- A61K35/17—Lymphocytes; B-cells; T-cells; Natural killer cells; Interferon-activated or cytokine-activated lymphocytes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/461—Cellular immunotherapy characterised by the cell type used
- A61K39/4611—T-cells, e.g. tumor infiltrating lymphocytes [TIL], lymphokine-activated killer cells [LAK] or regulatory T cells [Treg]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/463—Cellular immunotherapy characterised by recombinant expression
- A61K39/4632—T-cell receptors [TCR]; antibody T-cell receptor constructs
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/464838—Viral antigens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
- A61P31/20—Antivirals for DNA viruses
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/90—Stable introduction of foreign DNA into chromosome
- C12N15/902—Stable introduction of foreign DNA into chromosome using homologous recombination
- C12N15/907—Stable introduction of foreign DNA into chromosome using homologous recombination in mammalian cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0636—T lymphocytes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
- C12N9/22—Ribonucleases RNAses, DNAses
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2833—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against MHC-molecules, e.g. HLA-molecules
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/32—Immunoglobulins specific features characterized by aspects of specificity or valency specific for a neo-epitope on a complex, e.g. antibody-antigen or ligand-receptor
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/03—Fusion polypeptide containing a localisation/targetting motif containing a transmembrane segment
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/20—Type of nucleic acid involving clustered regularly interspaced short palindromic repeats [CRISPRs]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2510/00—Genetically modified cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2800/00—Nucleic acids vectors
- C12N2800/80—Vectors containing sites for inducing double-stranded breaks, e.g. meganuclease restriction sites
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Immunology (AREA)
- Organic Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Medicinal Chemistry (AREA)
- Cell Biology (AREA)
- Zoology (AREA)
- Biomedical Technology (AREA)
- Microbiology (AREA)
- Molecular Biology (AREA)
- Biochemistry (AREA)
- Animal Behavior & Ethology (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Biotechnology (AREA)
- Wood Science & Technology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Pharmacology & Pharmacy (AREA)
- Epidemiology (AREA)
- Mycology (AREA)
- Biophysics (AREA)
- General Engineering & Computer Science (AREA)
- Virology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Hematology (AREA)
- Toxicology (AREA)
- Gastroenterology & Hepatology (AREA)
- Oncology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- General Chemical & Material Sciences (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Developmental Biology & Embryology (AREA)
- Communicable Diseases (AREA)
- Peptides Or Proteins (AREA)
Abstract
提供了结合分子,如TCR或其抗原结合片段和抗体及其抗原结合片段,如识别或结合人乳头瘤病毒(HPV)16,包括HPV16 E6和HPV16 E7的那些。还提供了含有此类结合分子的工程化细胞、含有所述结合分子或工程化细胞的组合物以及诸如给予所述结合分子、工程化细胞或组合物的治疗方法。
Description
相关申请的交叉引用
本申请要求2017年10月3日提交的标题为“HPV特异性结合分子(HPV-SPECIFICBINDING MOLECULES)”的美国临时专利申请62/567,750、2017年12月11日提交的标题为“HPV特异性结合分子(HPV-SPECIFIC BINDING MOLECULES)”的美国临时专利申请62/597,411和2018年4月5日提交的标题为“HPV特异性结合分子(HPV-SPECIFIC BINDINGMOLECULES)”的美国临时专利申请62/653,529的优先权,将其内容通过引用以其整体并入。
通过引用并入序列表
本申请是与电子格式的序列表一起提交的。序列表以2018年9月28日创建的名为735042014140SeqList.txt的文件提供,其大小为2,288,524字节。将电子格式的序列表中的信息通过引用以其整体并入。
技术领域
在一些方面,本公开文本涉及结合分子,如识别或结合在主要组织相容性复合物(MHC)分子的背景下的人乳头瘤病毒(HPV)16E6或E7的肽表位的那些。具体地,本公开文本涉及结合或识别HPV 16E6或E7的肽表位的T细胞受体(TCR)或抗体,包括其抗原结合片段。本公开文本进一步涉及包含此类结合分子例如TCR或抗体(和含有所述抗体的嵌合抗原受体)的工程化细胞及其在过继细胞疗法中的用途。
背景技术
人乳头瘤病毒(HPV)是人类受试者中常见的病毒,其在一些情况下可以通过皮肤接触传播并且是常见的性传播病毒。HPV的某些亚型(如HPV 16)可能引起某些癌症,如宫颈癌和其他癌症。在一些情况下,癌症可能与HPV癌蛋白E6和/或E7的表达相关。例如,HPV E6和/或E7可以通过靶向参与细胞生长控制的肿瘤抑制信号传导途径来促进癌症进展。某些靶向HPV 16表达细胞或癌症的治疗剂是可用的,但是需要针对HPV 16的改良剂。提供了满足此类需求的实施方案。
发明内容
本文提供了T细胞受体(TCR)或其抗原结合片段。在一些实施方案中,所述TCR包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链,其中:所述Vα区含有SEQ ID NO:691、709、726、741、759、775、787、799、815、830、845、857、869、881、895、908、925、937、951、963、975、987、999或1390中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列;和/或所述Vβ区含有SEQ IDNO:700、718、735、750、768、781、793、808、824、839、851、863、875、887、901、917、931、945、957、969、981、993、1008或1380中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列。
在一些实施方案中,所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1185)的互补决定区3(CDR-3),其中X2是A、G、V、Q、M或E;X3是S、G、N、A、Y、R或P;X4是E、S、A、G、F、N、D、V、P、L、I、M或R;X5是R、N、H、T、D、G、S、P、L、Q或F;X6是G、H、A、S、T或空;X7是T、S、G或空;X8是G或空;X9是G、N、S或空;X10是T、G、S、D、F、Y、A或N;X11是Y、F、Q、R或N;X12是K、Q或D;X13是Y、L、T、M、F或V;X14是I、T、S、R、Y或V;所述Vα区包含含有氨基酸序列X1X2X3X4X5X6X7X8X9X10KX12I(SEQ ID NO:1186)的互补决定区3(CDR-3),其中X1是A或V;X2是A、V或E;X3是S、N、T、R或P;X4是E、A、G、F、V、P、I、D或S;X5是R、H、T、AP、S、G或F;X6是G、H、L、T、S或A、空;X7是S、T或空;X8是G或空;X9是G、T或空;X10是F、Y或N;X12是Y、T或L;所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9YKYI(SEQ ID NO:1187)的互补决定区3(CDR-3),其中X2是A、V或E;X3是S、N或R;X4是E、G、V、P、I或D;X5是R、T、P、S、G或F;X6是G、T、S或空;X7是S或空;X8是G或空;X9是T或空;所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1188)的互补决定区3(CDR-3),其中X2是G、V、Q或M;X3是G、A、Y、S、N或R;X4是S、G、L、I、M或R;X5是N、D、G、S、L、Q或R;X6是A、S、G或空;X7是G或空;X8是G或空;X9是G、N、S或空;X10是S、D、Y、A、N或空;X11是Y、Q或R;X12是K或Q;X13是L或V;X14是S、T或V;所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13T(S EQ ID NO:1189)的互补决定区3(CDR-3),其中X2是G、V或Q;X3是G、Y、S或N;X4是S、L或M;X5是N、G、L或R;X6是A、S、G或空;X7是G或空;X8是G或空;X9是G、S或空;X10是S、Y、A、N或空;X11是Y、Q或R;X12是K或Q;X13是L或V;所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7YKLS(SEQ ID NO:1190)的互补决定区3(CDR-3),其中X2是G或V;X3是A或Y;X4是G、S或R;X5是D或S;X6是N或空;X7是D或空。
在一些实施方案中,所述Vβ区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1200)的互补决定区3(CDR-3),X2是S、V或I;X3是S、N或A;X4是R、V、S、L、P、G、I或A;X5是F、G、Y、L、V、R、T或S;X6是L、G、A、D、R、V或空;X7是G、D、R、S、T或空;X8是S或空;X9是S、H、G、V、T、D、L或空;X10是T、S、A、G、P、N或Y;X11是D、Y、E、G或N;X12是T、E、G或K;X13是Q、Y或L;X14是Y、F、T或I;所述Vβ区包含含有氨基酸序列ASSX4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1201)的互补决定区3(CDR-3),其中X4是R、V、S、L、G或A;X5是F、G、Y、L、V、T或S;X6是A、L、R、D、G或空;X7是G、D、T或空;X8是S或空;X9是S、H、G、T、D、L或空;X10是T、S、A、G、P、N或Y;X11是D、Y、E、G或N;X12是T、E或G;X13是Q、Y或L;X14是Y、F或T;所述Vβ区包含含有氨基酸序列ASSX4X5X6X7X8X9X10TQY(SEQ ID NO:1202)的互补决定区3(CDR-3),其中X4是R、L或G;X5是F、V、T或Y;X6是L或A、空;X7是G或空;X8是S、G或空;X9是T、G、P或S;X10是D或E。
本文提供了包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链的T细胞受体(TCR)或其抗原结合片段,其中:所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X1 3X14(SEQ ID NO:1185)的互补决定区3(CDR-3),其中X2是A、G、V、Q、M或E;X3是S、G、N、A、Y、R或P;X4是E、S、A、G、F、N、D、V、P、L、I、M或R;X5是R、N、H、T、D、G、S、P、L、Q或F;X6是G、H、A、S、T或空;X7是T、S、G或空;X8是G或空;X9是G、N、S或空;X10是T、G、S、D、F、Y、A或N;X11是Y、F、Q、R或N;X12是K、Q或D;X13是Y、L、T、M、F或V;X14是I、T、S、R、Y或V;所述Vα区包含含有氨基酸序列X1X2X3X4X5X6X7X8X9X10KX12I(SEQ ID NO:1186)的互补决定区3(CDR-3),其中X1是A或V;X2是A、V或E;X3是S、N、T、R或P;X4是E、A、G、F、V、P、I、D或S;X5是R、H、T、A P、S、G或F;X6是G、H、L、T、S或A、空;X7是S、T或空;X8是G或空;X9是G、T或空;X10是F、Y或N;X12是Y、T或L;所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9YKYI(SEQ ID NO:1187)的互补决定区3(CDR-3),其中X2是A、V或E;X3是S、N或R;X4是E、G、V、P、I或D;X5是R、T、P、S、G或F;X6是G、T、S或空;X7是S或空;X8是G或空;X9是T或空;所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ IDNO:1188)的互补决定区3(CDR-3),其中X2是G、V、Q或M;X3是G、A、Y、S、N或R;X4是S、G、L、I、M或R;X5是N、D、G、S、L、Q或R;X6是A、S、G或空;X7是G或空;X8是G或空;X9是G、N、S或空;X10是S、D、Y、A、N或空;X11是Y、Q或R;X12是K或Q;X13是L或V;X14是S、T或V;所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13T(SEQ ID NO:1189)的互补决定区3(CDR-3),其中X2是G、V或Q;X3是G、Y、S或N;X4是S、L或M;X5是N、G、L或R;X6是A、S、G或空;X7是G或空;X8是G或空;X9是G、S或空;X10是S、Y、A、N或空;X11是Y、Q或R;X12是K或Q;X13是L或V;所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7YKLS(SEQ ID NO:1190)的互补决定区3(CDR-3),其中X2是G或V;X3是A或Y;X4是G、S或R;X5是D或S;X6是N或空;X7是D或空。
本文提供了包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链的T细胞受体(TCR)或其抗原结合片段,其中:所述Vβ区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X1 3X14(SEQ ID NO:1200)的互补决定区3(CDR-3),X2是S、V或I;X3是S、N或A;X4是R、V、S、L、P、G、I或A;X5是F、G、Y、L、V、R、T或S;X6是L、G、A、D、R、V或空;X7是G、D、R、S、T或空;X8是S或空;X9是S、H、G、V、T、D、L或空;X10是T、S、A、G、P、N或Y;X11是D、Y、E、G或N;X12是T、E、G或K;X13是Q、Y或L;X14是Y、F、T或I;所述Vβ区包含含有氨基酸序列ASSX4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1201)的互补决定区3(CDR-3),其中X4是R、V、S、L、G或A;X5是F、G、Y、L、V、T或S;X6是A、L、R、D、G或空;X7是G、D、T或空;X8是S或空;X9是S、H、G、T、D、L或空;X10是T、S、A、G、P、N或Y;X11是D、Y、E、G或N;X12是T、E或G;X13是Q、Y或L;X14是Y、F或T;所述Vβ区包含含有氨基酸序列ASSX4X5X6X7X8X9X10TQY(SEQ ID NO:1202)的互补决定区3(CDR-3),其中X4是R、L或G;X5是F、V、T或Y;X6是L或A、空;X7是G或空;X8是S、G或空;X9是T、G、P或S;X10是D或E。
本文提供了包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链的T细胞受体(TCR)或其抗原结合片段,其中:所述Vα区含有SEQ ID NO:694、712、729、744、762、776、788、802、818、832、846、858、870、882、896、911、926、940、952、964、976、988、1002或与其展现出至少60%、65%、70%、75%、80%、85%、90%或95%序列同一性的序列中任一个所示的互补决定区3(CDR-3);所述Vβ区含有SEQ ID NO:703、721、736、753、769、782、794、809、825、840、852、864、876、888、902、919、932、946、958、970、982、994或1010或与其展现出至少60%、65%、70%、75%、80%、85%、90%或95%序列同一性的序列中任一个所示的互补决定区3(CDR-3)。
在一些实施方案中,所述Vα区含有:含有氨基酸序列X1X2X3X4X5X6(SEQ ID NO:1191)的互补决定区1(CDR-1),其中X1是N、S、D、T或V;X2是S、V、R、T或I;X3是M、F、G、S、N、A、L、V或P;X4是F、S、N、A或空;X5是D、S、Q、Y、N、V、T或P;并且X6是Y、S、R、N、G或T;和/或含有氨基酸序列X1X2X3X4X5X6X7X8(SEQ ID NO:1192)的互补决定区2(CDR-2),其中X1是I、V、L、G、N、T、Y或M;X2是S、V、Y、L、P、F、I或T;X3是S、Y、K、L、T或F;X4是I、G、N、A、S或空;X5是S、D或空;X6是K、G、N、S、D、T或E;X7是D、E、G、A、K、L或N;并且X8是K、V、D、P、N、T、L或M。
在一些实施方案中,所述Vβ区含有:含有氨基酸序列SX2X3X4X5(SEQ ID NO:1203)的互补决定区1(CDR-1),其中X2是G或N;X3是H或D;X4是T、L、N或V;并且X5是A、S、Y或T;和/或含有氨基酸序列X1X2X3X4X5X6(SEQ ID NO:1204)的互补决定区2(CDR-2),其中X1是F或Y;X2是Q、Y或N;X3是G、N、R或Y;X4是N、G、E或T;X5是S、E、A或G;并且X6是A、E、I或Q。
在一些实施方案中,所述TCR或其抗原结合片段结合至或识别在MHC分子的背景下的人乳头瘤病毒(HPV)16E7的肽表位,所述肽表位是或包含E7(11-19)YMLDLQPET(SEQ IDNO:236)。
在本文提供的TCR的一些实施方案中,所述Vα区包含含有SEQ ID NO:694、712、729、744、762、776、788、802、818、832、846、858、870、882、896、911、926、940、952、964、976、988或1002中任一个所示的氨基酸序列的互补决定区3(CDR-3)或者SEQ ID NO:691、709、726、741、759、775、787、799、815、830、845、857、869、881、895、908、925、937、951、963、975、987或999中任一个所示的氨基酸序列内所含的CDR3;和/或所述Vβ区包含含有SEQ ID NO:703、721、736、753、769、782、794、809、825、840、852、864、876、888、902、919、932、946、958、970、982、994、1010或1381中任一个所示的氨基酸序列的互补决定区3(CDR-3)或者SEQ IDNO:700、718、735、750、768、781、793、808、824、839、851、863、875、887、901、917、931、945、957、969、981、993、1008或1380中任一个所示的氨基酸序列内所含的CDR3。
在一些实施方案中,所述Vα区还包含:含有SEQ ID NO:692、710、727、742、760、171、800、816、570、909、938、151或1000中任一个所示的氨基酸序列的互补决定区1(CDR-1);和/或含有SEQ ID NO:693、711、728、743、761、172、801、817、831、571、910、939、152或1001中任一个所示的氨基酸序列的互补决定区2(CDR-2)。
在一些实施方案中,所述Vβ区含有:含有SEQ ID NO:701、719、154、751或139中任一个所示的氨基酸序列的互补决定区1(CDR-1);和/或含有SEQ ID NO:702、720、155、752、140或918中任一个所示的氨基酸序列的互补决定区2(CDR-2)。
在一些实施方案中,所述Vα区包含分别含有SEQ ID NO:692、693和694的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:701、702和703的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:710、711和712的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:719、720和721的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:727、728和729的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:154、155和736的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:742、743和744的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:751、752和753的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:760、761和762的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:719、720和769的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:171、172和776的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:154、155和782的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:742、743和788的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:139、140和794的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:800、801和802的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:751、752和809的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:816、817和818的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:154、155和825的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:816、831和832的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:154、155和840的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:171、172和846的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:154、155和852的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:816、831和858的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:154、155和864的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:727、728和870的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:154、155和876的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:570、571和882的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:719、720和888的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:816、817和896的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:701、702和902的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:909、910和911的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:701、702和919的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:727、728和926的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:154、155和932的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:938、939和940的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:154、155和946的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:727、728和952的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:154、155和958的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:151、152和964的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:719、720和970的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:727、728和976的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:154、155和982的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:710、711和988的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:719、729和994的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:1000、1001和1002的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:139、1009和1010的氨基酸序列的CDR-1、CDR-2和CDR-3。
在一些实施方案中,所述Vα区含有互补决定区1(CDR-1)、CDR-2和CDR-3,其分别含有SEQ ID NO:691、709、726、741、759、775、787、799、815、830、845、857、869、881、895、908、925、937、951、963、975、987、999或1390中任一个所示的Vα区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列;和/或所述Vβ区含有互补决定区1(CDR-1)、CDR-2和CDR-3,其分别含有SEQ ID NO:700、718、735、750、768、781、793、808、824、839、851、863、875、887、901、917、931、945、957、969、981、993、1008或1380中任一个所示的Vβ区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列。
在一些实施方案中,所述Vα和Vβ区分别包含SEQ ID NO:691和700的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:709和718的氨基酸序列;所述Vα和Vβ区分别包含SEQ IDNO:726和735的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:741和750的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:759和768的氨基酸序列;所述Vα和Vβ区分别包含SEQ IDNO:775和781的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:787和793的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:799和808的氨基酸序列;所述Vα和Vβ区分别包含SEQ IDNO:815和824的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:830和839的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:845和851的氨基酸序列;所述Vα和Vβ区分别包含SEQ IDNO:857和863的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:869和875的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:881和887的氨基酸序列;所述Vα和Vβ区分别包含SEQ IDNO:895和901的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:908和917的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:925和931的氨基酸序列;所述Vα和Vβ区分别包含SEQ IDNO:937和945的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:951和957的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:963和969的氨基酸序列;所述Vα和Vβ区分别包含SEQ IDNO:975和981的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:987和993的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:999和1008的氨基酸序列;或者所述Vα和Vβ区分别包含SEQID NO:1390和1380的氨基酸序列。
在一些实施方案中,所述α链还包含α恒定(Cα)区和/或所述β链还包含β恒定(Cβ)区。
在一些实施方案中,所述Cα和Cβ区是小鼠恒定区。在一些实施方案中,所述Cα区含有SEQ ID NO:262、833、1012、1014、1015、1017、1018、1362所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列;和/或所述Cβ区含有SEQ ID NO:263、1013或1016所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列。
在一些实施方案中,所述Cα和Cβ区是人恒定区。在一些实施方案中,所述Cα区含有SEQ ID NO:212、213、215、217、218、220或524中任一个所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列;和/或所述Cβ区含有SEQ ID NO:214、216、631或889中任一个所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列。
在一些实施方案中,a)所述α链包含:SEQ ID NO:687、705、722、737、755、771、783、795、811、826、841、853、865、877、891、904、921、933、947、959、971、983、995、1386中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQ ID NO:1049、1051、1055、1057、1059、1061、1063、1065、1067、1069、1071、1073、1075、1077、1079、1081、1083、1085、1087、1089、1091中任一个所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列;和/或所述β链包含:SEQ ID NO:696、714、731、746、764、777、789、804、820、835、847、859、871、883、897、913、927、941、953、965、977、989、1004或1376中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQID NO:1050、1052、1056、1058、1060、1062、1064、1066、1068、1070、1072、1074、1076、1078、1080、1082、1084、1086、1088、1090或1092所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列。
在一些实施方案中,所述α和β链分别包含SEQ ID NO:687和696的氨基酸序列;所述α和β链分别包含SEQ ID NO:705和714的氨基酸序列;所述α和β链分别包含SEQ ID NO:722和731的氨基酸序列;所述α和β链分别包含SEQ ID NO:737和746的氨基酸序列;所述α和β链分别包含SEQ ID NO:755和764的氨基酸序列;所述α和β链分别包含SEQ ID NO:771和777的氨基酸序列;所述α和β链分别包含SEQ ID NO:783和789的氨基酸序列;所述α和β链分别包含SEQ ID NO:795和804的氨基酸序列;所述α和β链分别包含SEQ ID NO:811和820的氨基酸序列;所述α和β链分别包含SEQ ID NO:826和835的氨基酸序列;所述α和β链分别包含SEQ ID NO:841和847的氨基酸序列;所述α和β链分别包含SEQ ID NO:853和859的氨基酸序列;所述α和β链分别包含SEQ ID NO:865和871的氨基酸序列;所述α和β链分别包含SEQ IDNO:877和883的氨基酸序列;所述α和β链分别包含SEQ ID NO:891和897的氨基酸序列;所述α和β链分别包含SEQ ID NO:904和913的氨基酸序列;所述α和β链分别包含SEQ ID NO:921和927的氨基酸序列;所述α和β链分别包含SEQ ID NO:933和941的氨基酸序列;所述α和β链分别包含SEQ ID NO:947和953的氨基酸序列;所述α和β链分别包含SEQ ID NO:959和965的氨基酸序列;所述α和β链分别包含SEQ ID NO:971和977的氨基酸序列;所述α和β链分别包含SEQ ID NO:983和989的氨基酸序列;所述α和β链分别包含SEQ ID NO:995和1004的氨基酸序列;或者所述α和β链分别包含SEQ ID NO:1386和1376的氨基酸序列。
在一些实施方案中,所述TCR或抗原结合片段在所述α链和/或β链中包含一种或多种修饰,使得当所述TCR或其抗原结合片段在细胞中表达时,所述TCRα链和β链与内源TCRα链和β链之间的错配频率降低,所述TCRα链和β链的表达增加,和/或所述TCRα链和β链的稳定性增加,各自与不含所述一种或多种修饰的TCR或其抗原结合片段在细胞中的表达相比。在一些实施方案中,所述一种或多种修饰是在所述Cα区和/或所述Cβ区中的一个或多个氨基酸的置换、缺失或插入。在一些实施方案中,所述一种或多种修饰包含一个或多个置换,以引入能够在所述α链与β链之间形成一个或多个非天然二硫桥的一个或多个半胱氨酸残基。
在一些实施方案中,所述TCR包含Cα区,所述Cα区在对应于按照如SEQ ID NO:212、213、217、218或524所示编号的位置48的位置处或在对应于按照如SEQ ID NO:215或220所示编号的位置49的位置处含有半胱氨酸;和/或Cβ区,所述Cβ区在对应于按照如SEQ ID NO:214或216所示编号的位置57的位置处或在对应于按照如SEQ ID NO:631或889所示编号的位置58的位置处含有半胱氨酸。在一些实施方案中,所述Cα区含有SEQ ID NO:196、198、200、201、203或525中任一个所示的氨基酸序列或与其具有至少90%序列同一性的含有能够与所述β链形成非天然二硫键的一个或多个半胱氨酸残基的氨基酸序列;和/或所述Cβ区含有SEQ ID NO:197、199、632或890中任一个所示的氨基酸序列或与其具有至少90%序列同一性的含有能够与所述α链形成非天然二硫键的一个或多个半胱氨酸残基的氨基酸序列。
在一些实施方案中,所述TCR或其抗原结合片段由已经密码子优化的核苷酸序列编码。在一些实施方案中,a)所述α链包含:SEQ ID NO:688、706、723、738、756、772、784、796、812、827、842、854、866、878、892、905、922、934、948、960、972、984、996或1387中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQ ID NO:1129、1131、1133、1135、1137、1139、1141、1143、1145、1147、1149、1151、1153、1155、1157、1159、1161、1163、1165、1167、1169、1171、1173或1385中任一个所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列;和/或所述β链包含:SEQ ID NO:697、715、732、747、765、778、790、805、821、836、848、860、872、884、898、914、928、942、954、966、978、990、1005或1377中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQ ID NO:1130、1132、1134、1136、1138、1140、1142、1144、1146、1148、1150、1152、1154、1156、1158、1160、1162、1164、1166、1168、1170、1172、1174或1375所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列。
在一些实施方案中,所述α和β链分别包含SEQ ID NO:688和697的氨基酸序列;所述α和β链分别包含SEQ ID NO:706和715的氨基酸序列;所述α和β链分别包含SEQ ID NO:723和732的氨基酸序列;所述α和β链分别包含SEQ ID NO:738和747的氨基酸序列;所述α和β链分别包含SEQ ID NO:756和765的氨基酸序列;所述α和β链分别包含SEQ ID NO:772和778的氨基酸序列;所述α和β链分别包含SEQ ID NO:784和790的氨基酸序列;所述α和β链分别包含SEQ ID NO:796和805的氨基酸序列;所述α和β链分别包含SEQ ID NO:812和821的氨基酸序列;所述α和β链分别包含SEQ ID NO:827和836的氨基酸序列;所述α和β链分别包含SEQ ID NO:842和848的氨基酸序列;所述α和β链分别包含SEQ ID NO:854和860的氨基酸序列;所述α和β链分别包含SEQ ID NO:866和872的氨基酸序列;所述α和β链分别包含SEQ IDNO:878和884的氨基酸序列;所述α和β链分别包含SEQ ID NO:892和898的氨基酸序列;所述α和β链分别包含SEQ ID NO:905和914的氨基酸序列;所述α和β链分别包含SEQ ID NO:922和928的氨基酸序列;所述α和β链分别包含SEQ ID NO:934和942的氨基酸序列;所述α和β链分别包含SEQ ID NO:948和954的氨基酸序列;所述α和β链分别包含SEQ ID NO:960和966的氨基酸序列;所述α和β链分别包含SEQ ID NO:972和978的氨基酸序列;所述α和β链分别包含SEQ ID NO:984和990的氨基酸序列;或者所述α和β链分别包含SEQ ID NO:996和1005的氨基酸序列;或者所述α和β链分别包含SEQ ID NO:1387和1377的氨基酸序列。
在一些实施方案中,所述α和/或β链还包含信号肽。
在一些实施方案中,所述α链包含含有SEQ ID NO:181、184、187、189、190、192、193、310、311中任一个所示的氨基酸序列的信号肽;和/或所述β链包含含有SEQ ID NO:182、185、186、188、191或194中任一个所示的氨基酸序列的信号肽。
在一些实施方案中,所提供的TCR或其抗原结合片段是分离的或纯化的或者是重组的。在一些实施方案中,所提供的TCR或其抗原结合片段是人的。在一些实施方案中,所提供的TCR或其抗原结合片段是单克隆的。在一些实施方案中,所提供的TCR或其抗原结合片段是单链。在一些实施方案中,所提供的TCR或其抗原结合片段包含两条链。
在所提供的TCR或其抗原结合片段的一些实施方案中,抗原特异性是至少部分地CD8非依赖性的。
在所提供的TCR或其抗原结合片段的一些实施方案中,所述MHC分子是HLA-A2分子。
本文还提供了编码本文所述的任何TCR或其抗原结合片段或者所述任何TCR或其抗原结合片段的α或β链的核酸分子。
在一些实施方案中,所述核酸分子含有编码α链的核苷酸序列和/或编码β链的核苷酸序列,其中:编码α链的所述核苷酸序列包含SEQ ID NO:1049、1051、1055、1057、1059、1061、1063、1065、1067、1069、1071、1073、1075、1077、1079、1081、1083、1085、1087、1089、1091中任一个所示的序列或与其具有至少90%序列同一性的核苷酸序列;编码β链的所述核苷酸序列包含SEQ ID NO:1050、1052、1056、1058、1060、1062、1064、1066、1068、1070、1072、1074、1076、1078、1080、1082、1084、1086、1088、1090或1092所示的序列或与其具有至少90%序列同一性的核苷酸序列。
在一些实施方案中,所述核苷酸序列是经密码子优化的。
在一些实施方案中,所述核酸分子含有编码α链的核苷酸序列和/或编码β链的核苷酸序列,其中:编码α链的所述核苷酸序列包含SEQ ID NO:1129、1131、1133、1135、1137、1139、1141、1143、1145、1147、1149、1151、1153、1155、1157、1159、1161、1163、1165、1167、1169、1171、1173或1385中任一个所示的序列或与其具有至少90%序列同一性的核苷酸序列;编码β链的所述核苷酸序列包含SEQ ID NO:1130、1132、1134、1136、1138、1140、1142、1144、1146、1148、1150、1152、1154、1156、1158、1160、1162、1164、1166、1168、1170、1172、1174或1375所示的序列或与其具有至少90%序列同一性的核苷酸序列。
在一些实施方案中,编码所述α链的核苷酸序列和编码所述β链的核苷酸序列由引起核糖体跳跃的肽序列隔开。在一些实施方案中,引起核糖体跳跃的所述肽是P2A或T2A肽和/或包含SEQ ID NO:204或211所示的氨基酸序列。
在一些实施方案中,所述核酸分子含有SEQ ID NO:448、449、450、451、452、453、454、455、456、457、458、459、460、461、462、463、464、465、466、467、468、469、470、471、472或1382中任一个所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列。
本文还提供了包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链的T细胞受体(TCR)或其抗原结合片段,其中:所述Vα区含有SEQ ID NO:477、492、504、510、522、536、554、569、587、599、611、623、637、649、661或676中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列;和/或所述Vβ区含有SEQ ID NO:483、498、516、530、545、560、578、593、605、617、629、643、655、667或685中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列。
在一些实施方案中,所述Vα区包含含有氨基酸序列AX2RX4AX6NNDMR的互补决定区3(CDR-3),其中X2是V或M;X4是P或D;并且X6是N或R(SEQ ID NO:1221)。在一些实施方案中,所述Vβ区包含含有氨基酸序列ASSX4WGX7SNQPX12H的互补决定区3(CDR-3),其中X4是L、F或P;X7是R或Q;并且X12是Q或L(SEQ ID NO:1216);或者所述Vβ区包含含有氨基酸序列ASSX4X5X6X7X8SGNTIY的互补决定区3(CDR-3),其中X4是L或R;X5是W或Q;X6是G或P;X7是R或S;并且X8是S或空(SEQ ID NO:1217)。
本文还提供了包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链的T细胞受体(TCR)或其抗原结合片段,其中所述Vα区包含含有氨基酸序列AX2RX4AX6NNDMR的互补决定区3(CDR-3),其中X2是V或M;X4是P或D;并且X6是N或R(SEQ ID NO:1221)。
本文还提供了包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链的T细胞受体(TCR)或其抗原结合片段,其中:所述Vβ区包含含有氨基酸序列ASSX4WGX7SNQPX12H的互补决定区3(CDR-3),其中X4是L、F或P;X7是R或Q;并且X12是Q或L(SEQ ID NO:1216);或者所述Vβ区包含含有氨基酸序列ASSX4X5X6X7X8SGNTIY的互补决定区3(CDR-3),其中X4是L或R;X5是W或Q;X6是G或P;X7是R或S;并且X8是S或空(SEQ ID NO:1217)。
本文还提供了包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链的T细胞受体(TCR)或其抗原结合片段,其中:所述Vα区含有SEQ ID NO:478、493、505、511、523、539、555、572、588、600、612、624、638、650、662或679或与其展现出至少60%、65%、70%、75%、80%、85%、90%或95%序列同一性的序列中任一个所示的互补决定区3(CDR-3);所述Vβ区含有SEQ ID NO:486、499、517、531、548、563、581、594、606、618、630、644、656、670或686或与其展现出至少60%、65%、70%、75%、80%、85%、90%或95%序列同一性的序列中任一个所示的互补决定区3(CDR-3)。
在本文提供的任何一些实施方案中,所述Vα区含有:含有氨基酸序列X1X2X3X4X5X6(SEQ ID NO:1191)的互补决定区1(CDR-1),其中X1是N、S、D、T或V;X2是S、V、R、T或I;X3是M、F、G、S、N、A、L、V或P;X4是F、S、N、A或空;X5是D、S、Q、Y、N、V、T或P;并且X6是Y、S、R、N、G或T;和/或含有氨基酸序列X1X2X3X4X5X6X7X8(SEQ ID NO:1192)的互补决定区2(CDR-2),其中X1是I、V、L、G、N、T、Y或M;X2是S、V、Y、L、P、F、I或T;X3是S、Y、K、L、T或F;X4是I、G、N、A、S或空;X5是S、D或空;X6是K、G、N、S、D、T或E;X7是D、E、G、A、K、L或N;并且X8是K、V、D、P、N、T、L或M。
在本文提供的任何一些实施方案中,所述Vβ区含有:含有氨基酸序列SX2X3X4X5(SEQ ID NO:1203)的互补决定区1(CDR-1),其中X2是G或N;X3是H或D;X4是T、L、N或V;并且X5是A、S、Y或T;和/或含有氨基酸序列X1X2X3X4X5X6(SEQ ID NO:1204)的互补决定区2(CDR-2),其中X1是F或Y;X2是Q、Y或N;X3是G、N、R或Y;X4是N、G、E或T;X5是S、E、A或G;并且X6是A、E、I或Q。
在一些实施方案中,所述TCR或其抗原结合片段结合至或识别在MHC分子的背景下的人乳头瘤病毒(HPV)16E6的肽表位,所述肽表位是或包含E6(29-38)TIHDIILECV(SEQ IDNO:233)。
在一些实施方案中,所述Vα区包含含有SEQ ID NO:478、493、505、511、523、539、555、572、588、600、612、624、638、650、662或679中任一个所示的氨基酸序列的互补决定区3(CDR-3)或者SEQ ID NO:477、492、504、510、522、536、554、569、587、599、611、623、637、649、661或676中任一个所示的氨基酸序列内所含的CDR3;和/或所述Vβ区包含含有SEQ ID NO:486、499、517、531、548、563、581、594、606、618、630、644、656、670或686中任一个所示的氨基酸序列的互补决定区3(CDR-3)或者SEQ ID NO:483、498、516、530、545、560、578、593、605、617、629、643、655、667或685中任一个所示的氨基酸序列内所含的CDR3。
在一些实施方案中,所述Vα区还含有:含有SEQ ID NO:136、161、165、537、570、142、171或677中任一个所示的氨基酸序列的互补决定区1(CDR-1);和/或含有SEQ ID NO:137、162、166、538、571、143、172或678中任一个所示的氨基酸序列的互补决定区2(CDR-2)。
在一些实施方案中,所述Vβ区含有:含有SEQ ID NO:484、148、546、561、579、168、668或154中任一个所示的氨基酸序列的互补决定区1(CDR-1);和/或含有SEQ ID NO:485、149、547、562、580、169、669或155中任一个所示的氨基酸序列的互补决定区2(CDR-2)。
在一些实施方案中,所述Vα区包含分别含有SEQ ID NO:136、137和478的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:484、485和486的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:161、162和493的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:148、149和499的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:165、166和505的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:148、149和499的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:161、162和511的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:148、149和517的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:136、137和523的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:148、149和531的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:537、538和539的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:546、547和548的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:136、137和555的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:561、562和563的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:570、571和572的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:579、580和581的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:136、137和600的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:148、149和594的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:136、137和600的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:148、149和606的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:136、137和612的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:148、149和618的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:136、137和624的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:168、169和630的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:142、143和638的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:561、562和644的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:171、172和650的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:148、149和656的氨基酸序列的CDR-1、CDR-2和CDR-3;所述Vα区包含分别含有SEQ ID NO:136、137和662的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:668、669和670的氨基酸序列的CDR-1、CDR-2和CDR-3;或者所述Vα区包含分别含有SEQ ID NO:677、678和679的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别含有SEQ ID NO:154、155和686的氨基酸序列的CDR-1、CDR-2和CDR-3。
在一些实施方案中,所述Vα区含有互补决定区1(CDR-1)、CDR-2和CDR-3,其分别含有SEQ ID NO:477、492、504、510、522、536、554、569、587、599、611、623、637、649、661或676中任一个所示的Vα区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列;和/或所述Vβ区含有互补决定区1(CDR-1)、CDR-2和CDR-3,其分别含有SEQ ID NO:483、498、516、530、545、560、578、593、605、617、629、643、655、667或685中任一个所示的Vβ区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列。
在一些实施方案中,所述Vα和Vβ区分别包含SEQ ID NO:477和483的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:492和498的氨基酸序列;所述Vα和Vβ区分别包含SEQ IDNO:504和498的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:510和516的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:522和530的氨基酸序列;所述Vα和Vβ区分别包含SEQ IDNO:536和545的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:554和560的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:569和578的氨基酸序列;所述Vα和Vβ区分别包含SEQ IDNO:587和593的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:599和605的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:611和617的氨基酸序列;所述Vα和Vβ区分别包含SEQ IDNO:623和629的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:637和643的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:649和655的氨基酸序列;所述Vα和Vβ区分别包含SEQ IDNO:661和667的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:676和685的氨基酸序列。
在一些实施方案中,所述α链还包含α恒定(Cα)区和/或所述β链还包含β恒定(Cβ)区。
在一些实施方案中,所述Cα和Cβ区是小鼠恒定区。
在一些实施方案中,所述Cα区含有SEQ ID NO:262、833、1012、1014、1015、1017、1018或1362所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列;和/或所述Cβ区含有SEQ ID NO:263、1013或1016所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列。
在一些实施方案中,所述Cα和Cβ区是人恒定区。在一些实施方案中,所述Cα区含有SEQ ID NO:212、213、215、217、218、220或524中任一个所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列;和/或所述Cβ区含有SEQ ID NO:214、216、631或889中任一个所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列。
在一些实施方案中,a)所述α链包含:SEQ ID NO:473、488、500、506、518、532、550、565、583、595、607、619、633、645、657或672中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQ ID NO:389、430、1019、1021、1023、1025、1027、1029、1031、1033、1035、1037、1039、1041、1043或1045中任一个所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列;和/或所述β链包含:SEQ ID NO:479、494、512、526、541、556、574、589、601、613、625、639、651、663或681中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQ ID NO:390、431、1020、1022、1024、1026、1028、1030、1032、1034、1036、1038、1040、1042、1044或1046所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列。
在一些实施方案中,所述α和β链分别包含SEQ ID NO:473和479的氨基酸序列;所述α和β链分别包含SEQ ID NO:488和494的氨基酸序列;所述α和β链分别包含SEQ ID NO:500和494的氨基酸序列;所述α和β链分别包含SEQ ID NO:506和512的氨基酸序列;所述α和β链分别包含SEQ ID NO:518和526的氨基酸序列;所述α和β链分别包含SEQ ID NO:532和541的氨基酸序列;所述α和β链分别包含SEQ ID NO:550和556的氨基酸序列;所述α和β链分别包含SEQ ID NO:565和574的氨基酸序列;所述α和β链分别包含SEQ ID NO:583和589的氨基酸序列;所述α和β链分别包含SEQ ID NO:595和601的氨基酸序列;所述α和β链分别包含SEQ ID NO:607和613的氨基酸序列;所述α和β链分别包含SEQ ID NO:619和625的氨基酸序列;所述α和β链分别包含SEQ ID NO:633和639的氨基酸序列;所述α和β链分别包含SEQ IDNO:645和651的氨基酸序列;所述α和β链分别包含SEQ ID NO:657和663的氨基酸序列;或者所述α和β链分别包含SEQ ID NO:672和681的氨基酸序列。
在一些实施方案中,所述TCR或抗原结合片段在所述α链和/或β链中包含一种或多种修饰,使得当所述TCR或其抗原结合片段在细胞中表达时,所述TCRα链和β链与内源TCRα链和β链之间的错配频率降低,所述TCRα链和β链的表达增加,和/或所述TCRα链和β链的稳定性增加,各自与不含所述一种或多种修饰的TCR或其抗原结合片段在细胞中的表达相比。在一些实施方案中,所述一种或多种修饰是在所述Cα区和/或所述Cβ区中的一个或多个氨基酸的置换、缺失或插入。在一些实施方案中,所述一种或多种修饰包含一个或多个置换,以引入能够在所述α链与β链之间形成一个或多个非天然二硫桥的一个或多个半胱氨酸残基。在一些实施方案中,含有Cα区,所述Cα区在对应于按照如SEQ ID NO:212、213、217、218或524所示编号的位置48的位置处或在对应于按照如SEQ ID NO:215或220所示编号的位置49的位置处含有半胱氨酸;和/或Cβ区,所述Cβ区在对应于按照如SEQ ID NO:214或216所示编号的位置57的位置处或在对应于按照如SEQ ID NO:631或889所示编号的位置58的位置处含有半胱氨酸。
在一些实施方案中,所述Cα区含有SEQ ID NO:196、198、200、201、203或525中任一个所示的氨基酸序列或与其具有至少90%序列同一性的含有能够与所述β链形成非天然二硫键的一个或多个半胱氨酸残基的氨基酸序列;和/或所述Cβ区含有SEQ ID NO:197、199、632或890中任一个所示的氨基酸序列或与其具有至少90%序列同一性的含有能够与所述α链形成非天然二硫键的一个或多个半胱氨酸残基的氨基酸序列。
在一些实施方案中,所述TCR或其抗原结合片段由已经密码子优化的核苷酸序列编码。
在一些实施方案中,a)所述α链包含:SEQ ID NO:474、489、501、507、519、533、551、566、584、596、608、620、634、646、658或673中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQ ID NO:1097、1099、1101、1103、1105、1107、1109、1111、1113、1115、1117、1119、1121、1123、1125或1127中任一个所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列;和/或所述β链包含:SEQ ID NO:480、495、513、527、542、557、575、590、602、614、626、640、652、664或682中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQ ID NO:1098、1100、1102、1104、1106、1108、1110、1112、1114、1116、1118、1120、1122、1124、1126或1128所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列。
在一些实施方案中,所述α和β链分别包含SEQ ID NO:474和482的氨基酸序列;所述α和β链分别包含SEQ ID NO:489和497的氨基酸序列;所述α和β链分别包含SEQ ID NO:501和497的氨基酸序列;所述α和β链分别包含SEQ ID NO:507和515的氨基酸序列;所述α和β链分别包含SEQ ID NO:519和529的氨基酸序列;所述α和β链分别包含SEQ ID NO:533和544的氨基酸序列;所述α和β链分别包含SEQ ID NO:551和559的氨基酸序列;所述α和β链分别包含SEQ ID NO:566和577的氨基酸序列;所述α和β链分别包含SEQ ID NO:584和592的氨基酸序列;所述α和β链分别包含SEQ ID NO:596和604的氨基酸序列;所述α和β链分别包含SEQ ID NO:608和616的氨基酸序列;所述α和β链分别包含SEQ ID NO:620和628的氨基酸序列;所述α和β链分别包含SEQ ID NO:634和642的氨基酸序列;所述α和β链分别包含SEQ IDNO:646和654的氨基酸序列;所述α和β链分别包含SEQ ID NO:658和666的氨基酸序列;或者所述α和β链分别包含SEQ ID NO:673和684的氨基酸序列。
在一些实施方案中,所述α和/或β链还包含信号肽。在一些实施方案中,所述α链包含含有SEQ ID NO:181、184、187、189、190、192、193、310、311中任一个所示的氨基酸序列的信号肽;和/或所述β链包含含有SEQ ID NO:182、185、186、188、191或194中任一个所示的氨基酸序列的信号肽。
在一些实施方案中,所提供的TCR或其抗原结合片段是分离的或纯化的或者是重组的。在一些实施方案中,所提供的TCR或其抗原结合片段是人的。在一些实施方案中,所提供的TCR或其抗原结合片段是单克隆的。在一些实施方案中,所提供的TCR或其抗原结合片段是单链。在一些实施方案中,所提供的TCR或其抗原结合片段包含两条链。
在所提供的TCR或其抗原结合片段的一些实施方案中,抗原特异性是至少部分地CD8非依赖性的。
在所提供的TCR或其抗原结合片段的一些实施方案中,所述MHC分子是HLA-A2分子。
本文还提供了编码本文所述的任何TCR或其抗原结合片段或者所述任何TCR或其抗原结合片段的α或β链的核酸分子。
在一些实施方案中,所提供的核酸分子含有编码α链的核苷酸序列和/或编码β链的核苷酸序列,其中:编码α链的所述核苷酸序列包含SEQ ID NO:389、430、1019、1021、1023、1025、1027、1029、1031、1033、1035、1037、1039、1041、1043或1045中任一个所示的序列或与其具有至少90%序列同一性的核苷酸序列;编码β链的所述核苷酸序列包含SEQ IDNO:390、431、1020、1022、1024、1026、1028、1030、1032、1034、1036、1038、1040、1042、1044或1046所示的序列或与其具有至少90%序列同一性的核苷酸序列。
在一些实施方案中,所述核苷酸序列是经密码子优化的。
在一些实施方案中,所提供的核酸分子含有编码α链的核苷酸序列和/或编码β链的核苷酸序列,其中:编码α链的所述核苷酸序列包含SEQ ID NO:1097、1099、1101、1103、1105、1107、1109、1111、1113、1115、1117、1119、1121、1123、1125或1127中任一个所示的序列或与其具有至少90%序列同一性的核苷酸序列;编码β链的所述核苷酸序列包含SEQ IDNO:1098、1100、1102、1104、1106、1108、1110、1112、1114、1116、1118、1120、1122、1124、1126或1128所示的序列或与其具有至少90%序列同一性的核苷酸序列。
在一些实施方案中,编码所述α链的核苷酸序列和编码所述β链的核苷酸序列由引起核糖体跳跃的肽序列隔开。在一些实施方案中,引起核糖体跳跃的所述肽是P2A或T2A肽和/或包含SEQ ID NO:204或211所示的氨基酸序列。
在一些实施方案中,所提供的核酸分子含有SEQ ID NO:432、433、434、435、436、437、438、439、440、441、442、443、444、445、446或447中任一个所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列。
在一些实施方案中,所述核酸是合成的。在一些实施方案中,所述核酸是cDNA。
本文还提供了多核苷酸,其含有(a)编码本文提供的任何一种TCR或其抗原结合部分的核酸序列,或含有编码本文提供的任何所提供的TCR或其抗原结合片段的核酸分子;以及(b)与所述核酸序列连接的一个或多个同源臂,其中所述一个或多个同源臂包含与T细胞受体α恒定区(TRAC)基因座的开放阅读框的一个或多个区域同源的序列。
本文还提供了一种多核苷酸,其含有(a)编码T细胞受体(TCR)的一部分的核酸序列,所述核酸序列编码(i)包含本文提供的任何一种TCR或其抗原结合片段的可变β(Vβ)和恒定β(Cβ)的T细胞受体β(TCRβ)链;和(ii)包含本文提供的任何一种TCR或其抗原结合片段的可变α(Vα)的T细胞受体α(TCRα)链的一部分,其中所述TCRα链的所述部分少于全长TCRα链;以及(b)与所述核酸序列连接的一个或多个同源臂,其中所述一个或多个同源臂包含与T细胞受体α恒定区(TRAC)基因座的开放阅读框的一个或多个区域同源的序列。
在本文提供的任何多核苷酸的一些实施方案中,所述TCRα链包含恒定α(Cα),其中当所述TCR或其抗原结合片段从引入了所述多核苷酸的细胞表达时,所述Cα的至少一部分由所述内源TRAC基因座的开放阅读框或其部分序列编码。在本文提供的任何多核苷酸的一些实施方案中,(a)的所述核酸序列以及所述一个或多个同源臂之一一起包含编码少于天然Cα的全长的Cα的核苷酸序列,其中当所述TCR或其抗原结合片段从引入了所述多核苷酸的细胞表达时,所述Cα的至少一部分由所述内源TRAC基因座的开放阅读框或其部分序列编码。在一些实施方案中,编码所述TCRβ链的核酸序列在编码所述TCRα链的所述部分的核酸序列的上游。
在本文提供的任何多核苷酸的一些实施方案中,(a)的所述核酸序列不包含内含子。在一些实施方案中,(a)的所述核酸序列是对T细胞、任选地人T细胞的内源基因组TRAC基因座的开放阅读框外源或异源的序列。在一些实施方案中,(a)的所述核酸序列与所述一个或多个同源臂中所含的TRAC基因座的开放阅读框的一个或多个外显子或其部分序列、任选地外显子1或其部分序列符合读框。在一些实施方案中,所述Cα的一部分由所述内源TRAC基因座的开放阅读框或其部分序列编码,并且所述Cα的另外的部分由(a)的所述核酸序列编码,其中Cα的所述另外的部分少于天然Cα的全长。在一些实施方案中,所述Cα的所述另外的部分由起始于SEQ ID NO:348所示的序列的残基3直至残基3155的核苷酸序列或其一个或多个外显子,或者由与起始于SEQ ID NO:348所示的序列的残基3直至残基3155的核苷酸序列或其一个或多个外显子展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列或者其部分序列编码。在一些实施方案中,所述Cα的所述另外的部分由SEQ ID NO:1364所示的序列或者与SEQ IDNO:1364展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列或者其部分序列编码。在一些实施方案中,与天然Cα区和/或天然Cβ区相比,由(a)的所述核酸序列编码的Cα和/或Cβ区的所述另外的部分包含一种或多种修饰,任选地一个或多个氨基酸的置换、缺失或插入,任选地所述一种或多种修饰引入能够在所述α链与β链之间形成一个或多个非天然二硫桥的一个或多个半胱氨酸残基。
在本文提供的任何多核苷酸的一些实施方案中,所述一个或多个同源臂包含5'同源臂和/或3'同源臂。在一些实施方案中,所述5'同源臂包含:a)包含与SEQ ID NO:1343所示的序列展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列的150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个连续核苷酸的序列;b)包含SEQ ID NO:1343所示的序列的150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个连续核苷酸的序列;或者c)SEQ ID NO:1343所示的序列。在一些实施方案中,所述3'同源臂包含:a)包含与SEQ ID NO:1344所示的序列展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列的150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个连续核苷酸的序列;b)包含SEQ ID NO:1344所示的序列的150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个连续核苷酸的序列;或者c)SEQ ID NO:1344所示的序列。
本文提供了一种多核苷酸,其含有(a)编码本文的任何一种TCR或抗原结合片段的核酸序列或本文提供的编码TCR或其抗原结合片段的任何一种核酸分子;以及(b)与所述核酸序列连接的一个或多个同源臂,其中所述一个或多个同源臂包含与T细胞受体β恒定区(TRBC)基因座的开放阅读框的一个或多个区域同源的序列。
本文提供了一种多核苷酸,其含有(a)编码T细胞受体(TCR)的一部分的核酸序列,所述核酸序列编码(i)包含本文提供的任何一种TCR或其抗原结合片段的可变α(Vα)和恒定α(Cα)的T细胞受体α(TCRα)链;和(ii)包含所述任何一种TCR或其抗原结合片段的可变β(Vβ)的T细胞受体β(TCRβ)链的一部分,其中所述TCRβ链的所述部分少于全长TCRβ链;以及(b)与所述核酸序列连接的一个或多个同源臂,其中所述一个或多个同源臂包含与T细胞受体β恒定区(TRBC)基因座的开放阅读框的一个或多个区域同源的序列。
在任何所提供的多核苷酸的一些实施方案中,所述TCRβ链包含恒定β(Cβ),其中当所述TCR或其抗原结合片段从引入了所述多核苷酸的细胞表达时,所述Cβ的至少一部分由所述内源TRBC基因座的开放阅读框或其部分序列编码。在一些实施方案中,(a)的所述核酸序列以及所述一个或多个同源臂之一一起包含编码少于天然Cβ的全长的Cβ的核苷酸序列,其中当所述TCR或其抗原结合片段从引入了所述多核苷酸的细胞表达时,所述Cβ的至少一部分由所述内源TRAC基因座的开放阅读框或其部分序列编码。在一些实施方案中,编码所述TCRα链的核酸序列在编码所述TCRβ链的所述部分的核酸序列的上游。
在任何所提供的多核苷酸的一些实施方案中,(a)的所述核酸序列不包含内含子。在一些实施方案中,(a)的所述核酸序列是对T细胞、任选地人T细胞的内源基因组TRBC基因座的开放阅读框外源或异源的序列。在一些实施方案中,(a)的所述核酸序列与所述一个或多个同源臂中所含的TRBC基因座的开放阅读框的一个或多个外显子或其部分序列、任选地外显子1或其部分序列符合读框。在一些实施方案中,所述Cβ的一部分由所述内源TRBC基因座的开放阅读框或其部分序列编码,并且所述Cβ的另外的部分由(a)的所述核酸序列编码,其中Cβ的所述另外的部分少于天然Cβ的全长。在一些实施方案中,所述Cβ的所述另外的部分由起始于SEQ ID NO:349所示的序列的残基3直至残基1445的核苷酸序列或其一个或多个外显子或者与起始于SEQ ID NO:349所示的序列的残基3直至残基1445的核苷酸序列或其一个或多个外显子展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列或者其部分序列;或者起始于SEQ ID NO:1047所示的序列的残基3直至残基1486的核苷酸序列或其一个或多个外显子或者与起始于SEQ ID NO:1047所示的序列的残基3直至残基1486的核苷酸序列或其一个或多个外显子展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列或者其部分序列编码。在一些实施方案中,与天然Cβ区和/或天然Cα区相比,由(a)的所述核酸序列编码的Cβ和/或Cα区的所述另外的部分包含一种或多种修饰,任选地一个或多个氨基酸的置换、缺失或插入,任选地所述一种或多种修饰引入能够在所述α链与β链之间形成一个或多个非天然二硫桥的一个或多个半胱氨酸残基。
在任何所提供的多核苷酸的一些实施方案中,所述一个或多个同源臂包含5'同源臂和/或3'同源臂。
在任何所提供的多核苷酸的一些实施方案中,(a)的所述核酸序列包含一个或多个多顺反子元件。在一些实施方案中,所述一个或多个多顺反子元件位于编码所述TCRα或其部分的核酸序列与编码所述TCRβ或其部分的核酸序列之间。在一些实施方案中,所述一个或多个多顺反子元件在编码所述TCR或所述TCR的一部分的核酸序列或编码所述TCR的核酸分子的上游。在一些实施方案中,所述一个或多个多顺反子元件是或包含核糖体跳跃序列,任选地其中所述核糖体跳跃序列是T2A、P2A、E2A或F2A元件。
在任何所提供的多核苷酸的一些实施方案中,(a)的所述核酸序列包含一个或多个异源或调节控制元件,所述元件可操作地连接以控制当从引入了所述多核苷酸的细胞表达时所述TCR的表达。在一些实施方案中,所述一个或多个异源调节或控制元件包含启动子、增强子、内含子、多腺苷酸化信号、Kozak共有序列、剪接受体序列和/或剪接供体序列。在一些实施方案中,所述异源调节或控制元件包含异源启动子,任选地人延伸因子1α(EF1α)启动子或MND启动子或其变体。
在一些实施方案中,所提供的多核苷酸是线性多核苷酸,任选地双链多核苷酸或单链多核苷酸。
本文还提供了含有本文所述的任何核酸分子或本文所述的任何多核苷酸的载体。在一些实施方案中,所述载体是表达载体。在一些实施方案中,所述载体是病毒载体。在一些实施方案中,所述病毒载体是逆转录病毒载体。在一些实施方案中,所述病毒载体是慢病毒载体。在一些实施方案中,所述慢病毒载体源自HIV-1。在任何所提供的载体的一些实施方案中,所述病毒载体是AAV载体。在一些实施方案中,所述AAV载体选自AAV1、AAV2、AAV3、AAV4、AAV5、AAV6、AAV7或AAV8载体。
本文还提供了工程化细胞。在一些实施方案中,所提供的工程化细胞含有本文提供的任何核酸分子、本文提供的任何多核苷酸或本文提供的任何载体。
本文还提供了工程化细胞。在一些实施方案中,所提供的工程化细胞含有本文所述的任何TCR或其抗原结合片段。
在一些实施方案中,所提供的工程化细胞含有T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏。在一些实施方案中,所述TRBC基因是T细胞受体β恒定区1(TRBC1)或T细胞受体β恒定区2(TRBC2)基因之一或两者。
本文还提供了工程化细胞,所述工程化细胞含有TCR或其抗原结合片段,任选地重组TCR或其抗原结合片段,其中:(1)所述细胞包含T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏和/或不表达内源TRAC或TRBC的基因产物,或不以可检测的水平表达内源TRAC或TRBC的基因产物,或表达少于野生型水平的20%、15%、10%、5%、4%、3%、2%或1%的内源TRAC或TRBC的基因产物;并且(2)所述TCR或其抗原结合片段或者所述重组TCR或其抗原结合片段包含本文提供的任何一种TCR或其抗原结合片段,任选地重组TCR或抗原结合片段。在一些实施方案中,所述工程化细胞包含T细胞受体α恒定区(TRAC)基因座的遗传破坏。
在任何所提供的工程化细胞的一些实施方案中,通过任选地经由同源定向修复(HDR)将编码任何一种TCR或其抗原结合片段的核酸序列整合在所述TRAC基因座处来进一步修饰所述内源TRAC基因座。在一些实施方案中,通过任选地经由同源定向修复(HDR)整合编码所述TCR或其抗原结合片段的一部分的转基因序列来进一步修饰所述内源TRAC基因座。
本文还提供了一种工程化细胞,所述工程化细胞包含编码本文提供的任何一种TCR或其抗原结合片段的经修饰的TRAC基因座。
本文还提供了一种包含经修饰的TRAC基因座的工程化细胞,其中通过整合编码所述TCR的一部分的转基因序列来修饰所述内源TRAC基因座,所述转基因序列编码(i)包含任何一种TCR或其抗原结合片段的可变β(Vβ)和恒定β(Cβ)的T细胞受体β(TCRβ)链;和(ii)包含所述任何一种TCR或其抗原结合片段的可变α(Vα)的T细胞受体α(TCRα)链的一部分,其中所述TCR的恒定α(Cα)的至少一部分由所述内源TRAC基因座的开放阅读框或其部分序列编码。
在所提供的工程化细胞的一些任何实施方案中,所述TCR或其抗原结合片段包含Cα,所述Cα的至少一部分由所述内源TRAC基因座的开放阅读框或其部分序列编码。在一些实施方案中,所述经修饰的TRAC基因座包含(i)编码所述TCR的一部分的转基因序列和(ii)所述内源TRAC基因座的开放阅读框或其部分序列的框内融合物。在一些实施方案中,所述转基因序列不包含编码3'UTR的序列或内含子。在一些实施方案中,所述开放阅读框或其部分序列包含所述内源TRAC基因座的3'UTR。
在所提供的工程化细胞的一些任何实施方案中,所述转基因序列整合在所述内源TRAC基因座的开放阅读框的外显子1的最5'核苷酸的下游且在外显子1的最3'核苷酸的上游。在一些实施方案中,Cα的所述至少一部分由所述内源TRAC基因座的开放阅读框的至少外显子2-4编码。在一些实施方案中,Cα的所述至少一部分由所述内源TRAC基因座的开放阅读框的外显子1的至少一部分和外显子2-4编码。
在任何所提供的工程化细胞的一些实施方案中,所述转基因序列编码T细胞受体β(TCRβ)链和/或TCRα可变区(Vα)。
在任何所提供的工程化细胞的一些实施方案中,所述工程化细胞还包含T细胞受体β恒定区(TRBC)基因座、任选地TRBC1或TRBC2基因座的遗传破坏。
在任何所提供的工程化细胞的一些实施方案中,所述工程化细胞包含T细胞受体β恒定区(TRBC)基因座的遗传破坏。在一些实施方案中,通过任选地经由HDR将编码所述TCR或其抗原结合片段的核酸序列整合在所述TRBC基因座处来进一步修饰所述内源TRBC基因座。在一些实施方案中,通过任选地经由同源定向修复(HDR)整合编码所述TCR或其抗原结合片段的一部分的转基因序列来进一步修饰所述内源TRBC基因座。
本文提供了一种工程化细胞,所述工程化细胞含有编码任何一种TCR或其抗原结合片段的经修饰的TRBC基因座。
本文提供了一种含有经修饰的TRBC基因座的工程化细胞,其中通过整合编码所述TCR的一部分的转基因序列来修饰所述内源TRBC基因座,所述转基因序列编码(i)包含任何一种TCR或其抗原结合片段的可变α(Vα)和恒定α(Cα)的T细胞受体α(TCRα)链;和(ii)包含所述任何一种TCR或其抗原结合片段的可变β(Vβ)的T细胞受体β(TCRβ)链的一部分,其中所述TCR的恒定β(Cβ)的至少一部分由所述内源TRBC基因座的开放阅读框或其部分序列编码。
在任何所提供的工程化细胞的一些实施方案中,所述TCR或其抗原结合片段包含Cβ,所述Cβ的至少一部分由所述内源TRBC基因座的开放阅读框或其部分序列编码。在一些实施方案中,所述经修饰的TRBC基因座包含(i)编码所述TCR的一部分的转基因序列和(ii)所述内源TRBC基因座的开放阅读框或其部分序列的框内融合物。在一些实施方案中,所述转基因序列不包含编码3'UTR的序列或内含子。在一些实施方案中,所述开放阅读框或其部分序列包含所述内源TRBC基因座的3'UTR。在一些实施方案中,所述转基因序列整合在所述内源TRBC基因座的开放阅读框的外显子1的最5'核苷酸的下游且在外显子1的最3'核苷酸的上游。在一些实施方案中,Cβ的所述至少一部分由所述内源TRBC基因座的开放阅读框的至少外显子2-4编码。在一些实施方案中,Cβ的所述至少一部分由所述内源TRBC基因座的开放阅读框的外显子1的至少一部分和外显子2-4编码。
在任何所提供的工程化细胞的一些实施方案中,所述转基因序列编码T细胞受体α(TCRα)链和/或TCRβ可变区(Vβ)。
在任何所提供的工程化细胞的一些实施方案中,所述TRBC基因座是T细胞受体β恒定区1(TRBC1)或T细胞受体β恒定区2(TRBC2)基因座之一或两者。在一些实施方案中,所述工程化细胞还包含T细胞受体α恒定区(TRAC)基因座的遗传破坏。
在任何所提供的工程化细胞的一些实施方案中,编码所述TCR或其抗原结合片段的转基因序列或核酸序列包含一个或多个多顺反子元件。在一些实施方案中,所述一个或多个多顺反子元件在编码所述TCR或其抗原结合片段的转基因序列或核酸序列的上游。在一些实施方案中,所述一个或多个多顺反子元件位于编码所述TCRα或其部分的核酸序列与编码所述TCRβ或其部分的核酸序列之间。在一些实施方案中,所述一个或多个多顺反子元件是或包含核糖体跳跃序列,任选地其中所述核糖体跳跃序列是T2A、P2A、E2A或F2A元件。
在任何所提供的工程化细胞的一些实施方案中,编码所述TCR或其抗原结合片段的转基因序列或核酸序列包含一个或多个异源或调节控制元件,所述元件可操作地连接以控制当从引入了所述工程化细胞的细胞表达时所述TCR的表达。在一些实施方案中,所述一个或多个异源调节或控制元件包含启动子、增强子、内含子、多腺苷酸化信号、Kozak共有序列、剪接受体序列和/或剪接供体序列。在一些实施方案中,所述异源调节或控制元件包含异源启动子,任选地人延伸因子1α(EF1α)启动子或MND启动子或其变体。
在任何所提供的工程化细胞的一些实施方案中,所述TCR或其抗原结合片段对所述细胞是异源的。在一些实施方案中,所述工程化细胞是细胞系。在一些实施方案中,所述工程化细胞是获自受试者的原代细胞。在一些实施方案中,所述受试者是哺乳动物受试者。在一些实施方案中,所述受试者是人。在一些实施方案中,所述工程化细胞是T细胞。在一些实施方案中,所述T细胞是CD8+。在一些实施方案中,所述T细胞是CD4+。
本文还提供了用于产生本文所述的任何工程化细胞的方法,所述方法包括在体外或离体地将本文所述的任何载体引入细胞中。在一些实施方案中,所述载体是病毒载体,并且所述引入是通过转导进行的。
本文还提供了一种用于产生细胞的方法,其包括在体外或离体地将编码本文提供的任何一种TCR或其抗原结合片段的核酸分子、本文提供的任何一种核酸分子、本文提供的任何一种多核苷酸或本文提供的任何一种载体引入细胞中。
在一些实施方案中,本文提供的方法包括将一种或多种药剂引入所述细胞中,其中所述一种或多种药剂中的每一种独立地能够诱导T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏。在一些实施方案中,能够诱导遗传破坏的所述一种或多种药剂包含特异性结合至或杂交至所述靶位点的DNA结合蛋白或DNA结合核酸。在一些实施方案中,能够诱导遗传破坏的所述一种或多种药剂包含(a)含有DNA靶向蛋白和核酸酶的融合蛋白或(b)RNA指导的核酸酶。在一些实施方案中,所述DNA靶向蛋白或RNA指导的核酸酶包含对所述TRAC和/或TRBC基因内的靶位点具特异性的锌指蛋白(ZFP)、TAL蛋白或成簇的规律间隔的短回文核酸(CRISPR)相关核酸酶(Cas)。在一些实施方案中,所述一种或多种药剂包含特异性结合至、识别或杂交至所述靶位点的锌指核酸酶(ZFN)、TAL效应子核酸酶(TALEN)或和CRISPR-Cas9组合。在一些实施方案中,所述一种或多种药剂中的每一种包含具有与所述至少一个靶位点互补的靶向结构域的指导RNA(gRNA)。
在一些实施方案中,将所述一种或多种药剂作为含有所述gRNA和Cas9蛋白的核糖核蛋白(RNP)复合物引入。在一些实施方案中,经由电穿孔、粒子枪、磷酸钙转染、细胞压缩或挤压来引入所述RNP。在一些实施方案中,经由电穿孔来引入所述RNP。
在一些实施方案中,将所述一种或多种药剂作为编码所述gRNA和/或Cas9蛋白的一种或多种多核苷酸引入。
在任何所提供的方法的一些实施方案中,所述一种或多种药剂和所述核酸分子、所述多核苷酸或所述载体同时或以任何顺序依序引入。在一些实施方案中,在引入所述一种或多种药剂之后引入所述核酸分子、所述多核苷酸或所述载体。在一些实施方案中,在引入所述药剂之后立即引入所述核酸分子、所述多核苷酸或所述载体,或者在引入所述药剂之后约30秒、1分钟、2分钟、3分钟、4分钟、5分钟、6分钟、6分钟、8分钟、9分钟、10分钟、15分钟、20分钟、30分钟、40分钟、50分钟、60分钟、90分钟、2小时、3小时或4小时内引入所述核酸分子、所述多核苷酸或所述载体。
本文还提供了组合物。在一些实施方案中,所述组合物含有本文所述的任何工程化细胞。在一些实施方案中,所述工程化细胞包含CD4+和/或CD8+T细胞。在一些实施方案中,所述工程化细胞包含CD4+和CD8+T细胞。
本文还提供了组合物。在一些实施方案中,所述组合物含有本文所述的任何工程化CD8+细胞和任何工程化CD4+细胞。
在一些实施方案中,所述TCR或其抗原结合片段至少部分地CD8非依赖性地结合至或识别在MHC分子的背景下的HPV 16的肽表位。在一些实施方案中,将所述CD8+细胞和CD4+细胞用相同的TCR或其抗原结合片段工程化和/或将所述CD8+细胞和CD4+细胞各自用结合至或识别在MHC分子的背景下的HPV 16的相同肽表位的TCR或其抗原结合片段工程化。
在一些实施方案中,本文提供的任何组合物还含有药学上可接受的赋形剂。
本文还提供了治疗方法。在一些实施方案中,所提供的治疗方法包括向患有与HPV相关的疾病或障碍的受试者给予本文所述的任何工程化细胞。
本文还提供了治疗方法。在一些实施方案中,所提供的治疗方法包括向患有与HPV相关的疾病或障碍的受试者给予本文所述的任何组合物。在一些实施方案中,所述疾病或障碍与HPV16相关。在一些实施方案中,所述疾病或障碍是癌症。在一些实施方案中,所述受试者是人。
本文还提供了用于治疗与HPV相关的疾病或障碍的组合物,如本文所述的任何组合物。
本文还提供了组合物(如本文提供的任何组合物)用于制造治疗与HPV相关的疾病或障碍的药物的用途。在一些实施方案中,所述疾病或障碍与HPV16相关。在一些实施方案中,所述疾病或障碍是癌症。在一些实施方案中,所述受试者是人。
附图说明
图1示出了基于各个评估时间点的半胱天冬酶阳性靶细胞的百分比,与SiHa细胞或Caski靶细胞一起孵育的表达示例性TCR的单克隆T细胞系的裂解活性。具体地,示出了表达经修饰形式的TCR 5和经修饰形式的TCR 12的T细胞系的结果。
图2A-2L示出了CD4+Jurkat衍生的细胞系(阴性对照CD4+)、表达各种E6(29-38)特异性TCR的CD4+Jurkat衍生的细胞系(CD4+TCR-E6(29))、还表达外源CD8的CD4+Jurkat衍生的细胞系(CD8)或还表达外源CD8和各种E6(29-38)特异性TCR的CD4+Jurkat衍生的细胞系(CD8+TCR-E6(29))的四聚体结合的流式细胞术结果。具体地,示出了参考TCR、经修饰形式的TCR5、经修饰形式的TCR 4、经修饰形式的TCR 3和经修饰形式的TCR 8的结果。
图3A-3D示出了CD4+Jurkat衍生的细胞系(阴性对照CD4+)、表达各种E7(11-19)特异性TCR的CD4+Jurkat衍生的细胞系(CD4+TCR-E7(11-19))、还表达外源CD8的CD4+Jurkat衍生的细胞系(CD8)或还表达外源CD8和各种E7(11-19)特异性TCR的CD4+Jurkat衍生的细胞系(CD8+TCR-E7(11-19))的四聚体结合的流式细胞术结果。具体地,示出了经修饰形式的TCR 7和经修饰形式的TCR 12的结果。
图4A-4B示出了CD4+Jurkat衍生的细胞系(阴性对照CD4+)、表达各种E7(86-93)特异性TCR的CD4+Jurkat衍生的细胞系(CD4+TCR-E7(86-93))、还表达外源CD8的CD4+Jurkat衍生的细胞系(CD8)或还表达外源CD8和各种E7(86-93)特异性TCR的CD4+Jurkat衍生的细胞系(CD8+TCR-E7(86-93))的四聚体结合的流式细胞术结果。具体地,示出了经修饰形式的TCR 11的结果。
图5A-5C示出了在CD8+细胞中,四聚体结合以及在Jurkat衍生的细胞系中的流式细胞术结果,所述细胞系还表达外源CD8和各种E6(29-38)特异性TCR。示出了TCR 9、TCR13、TCR14、能够与HLA-A2/E6(29-38)结合的参考TCR(参考TCR)和已经模拟转染的细胞(模拟)(图5A);TCR 17、TCR 21、TCR 22、参考TCR和模拟(图5B);以及TCR 18、TCR 23、TCR 24和TCR27(图5C)的结果。
图5D-5F示出了四聚体结合以及在Jurkat衍生的细胞系中的流式细胞术结果,所述细胞系还表达外源CD8和各种E6(29-38)特异性TCR。示出了TCR 15、TCR 16、TCR 17、TCR19、TCR 20和TCR 21(图5D);TCR 18、TCR23、TCR 24、TCR 27和TCR 28(图5E);以及TCR 25、TCR 26、TCR 29和TCR 30(图5F)的结果。
图6A-6G示出了四聚体结合以及在Jurkat衍生的细胞系中的流式细胞术结果,所述细胞系还表达外源CD8和各种E7(11-19)特异性TCR。示出了TCR 12和已经模拟转染的细胞(模拟)(图6A);TCR 31、TCR 32、TCR 33和TCR 34(图6B);TCR 12、TCR 49、TCR 50和TCR51(图6C);TCR 35、TCR 36、TCR 37、TCR 38、TCR 53和TCR 54(图6D);TCR 39、TCR 40、TCR41、TCR 42、TCR 43和TCR 44(图6E);以及TCR 45、TCR 46、TCR 47、TCR 48、TCR 54和TCR 55(图6F)的结果。图6G示出了工程化以表达重组TCR的细胞中四聚体结合的相应流式细胞术结果,观察到所述细胞显示出CD8依赖性四聚体结合(左,TCR49)或CD8非依赖性四聚体结合(右,TCR37)。
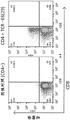
图7A和7B示出了原代T细胞中内源TCR基因的敲除效率,如通过使用流式细胞术评价CD3表达的评价所测量的。
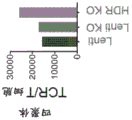
图8A示出了用以评估与对照细胞(内源TCR WT)相比用靶向内源TCR基因的RNP电穿孔的细胞(内源TCR KO)中敲除效率的流式细胞术结果。图8B示出了评估CD4和CD8细胞中TCR表达的替代标记的表达和E6四聚体结合的流式细胞术分析的结果。图8C示出了TCR 16和31以及与模拟转导对照相比的内源TCR(内源TCR WT)和内源TCR KO(内源TCR KO)细胞的IFNγ的产生。
图9A-9J示出了工程化以表达各种示例性重组TCR的细胞中TCR的表达,如通过与抗原特异性靶细胞一起孵育后的E7(11-19)四聚体结合、细胞溶解活性和干扰素-γ产生所评估的。图9A(TCR 49)、图9D(TCR 53)和图9G(TCR 37)示出了TCR的表达,如通过E7(11-19)四聚体结合所评估的。图9B(TCR 49)、图9E(TCR 53)、图9H(TCR 37)和图9J(TCR 37)示出了细胞溶解活性,如通过减少的NucRed光信号所监测的。图9C(TCR 49)、图9F(TCR 53)、图9I(TCR 37)和图9J(TCR 37)示出了与抗原特异性靶细胞一起孵育后TCR表达细胞的干扰素-γ产生。
图10A-10B示出了与保留内源TCR基因的细胞相比,具有内源TCR基因的敲除的细胞中示例性TCR的表达,如通过E7(11-19)四聚体结合所评估的。
图11A-11B示出了与保留内源TCR基因的细胞相比,具有内源TCR基因的敲除的细胞中示例性TCR的肽敏感性的评估,如通过与肽脉冲的T2细胞一起孵育后的干扰素γ产生所评估的。
图12A示出了靶细胞裂解,如使用活细胞成像通过每2小时的靶标损失所测量的。图12B-12C示出了与保留内源TCR基因的细胞相比,具有内源TCR基因的敲除的细胞中细胞溶解活性和示例性TCR的干扰素γ细胞因子产生的评估。
图13示出了与未接受任何处理的小鼠(圆形)相比,具有皮下UPCI:SCC152( CRL-3240TM)肿瘤的小鼠模型中肿瘤体积随时间的变化,所述小鼠模型被仅给予CD4+重组TCR表达细胞(倒三角形)、被仅给予CD8+重组TCR表达细胞(三角形)或被给予CD4+和CD8+重组TCR表达细胞的混合物(正方形)。
CRL-3240TM)肿瘤的小鼠模型中肿瘤体积随时间的变化,所述小鼠模型被仅给予CD4+重组TCR表达细胞(倒三角形)、被仅给予CD8+重组TCR表达细胞(三角形)或被给予CD4+和CD8+重组TCR表达细胞的混合物(正方形)。
图14A-14G是几种示例性gRNA的表示。
图14A描绘了作为双链体结构的部分地源自化脓链球菌(Streptococcuspyogenes/S.pyogenes)(或部分地在来自其的序列上建模)的模块化gRNA分子(按出现顺序分别为国际PCT公开号WO 2015161276的SEQ ID NO:42和43);
图14B描绘了作为双链体结构的部分地源自化脓链球菌的单分子(或嵌合)gRNA分子(国际PCT公开号WO 2015161276的SEQ ID NO:44);
图14C描绘了作为双链体结构的部分地源自化脓链球菌的单分子gRNA分子(国际PCT公开号WO 2015161276的SEQ ID NO:45);
图14D描绘了作为双链体结构的部分地源自化脓链球菌的单分子gRNA分子(国际PCT公开号WO 2015161276的SEQ ID NO:46);
图14E描绘了作为双链体结构的部分地源自化脓链球菌的单分子gRNA分子(国际PCT公开号WO 2015161276的SEQ ID NO:47);
图14F描绘了作为双链体结构的部分地源自嗜热链球菌(Streptococcusthermophilus/S.thermophilus)的模块化gRNA分子(按出现顺序分别为国际PCT公开号WO2015161276的SEQ ID NO:48和49);
图14G描绘了化脓链球菌和嗜热链球菌的模块化gRNA分子的比对(按出现顺序分别为国际PCT公开号WO 2015161276的SEQ ID NO:50-53)。
图15A-15G描绘了来自Chylinski等人(RNA Biol.2013;10(5):726-737)的Cas9序列的比对。N末端RuvC样结构域加框并用“y”指示。其他两个RuvC样结构域加框并用“b”指示。HNH样结构域加框并以“g”指示。Sm:变形链球菌(S.mutans)(SEQ ID NO:1331);Sp:化脓链球菌(SEQ ID NO:1332);St:嗜热链球菌(SEQ ID NO:1333);Li:无害李斯特菌(L.innocua)(SEQ ID NO:1334)。基序:这是基于四个序列的基序:在全部四个序列中保守的残基以单字母氨基酸缩写指示;“*”指示在四个序列中的任一个的相应位置发现的任何氨基酸;并且“-”指示任何氨基酸,例如20种天然存在的氨基酸中的任一种。
图16A-16C描绘了来自化脓链球菌和脑膜炎奈瑟氏菌(Neisseria meningitides/N.meningitidis)的Cas9序列的比对。N末端RuvC样结构域加框并用“Y”指示。其他两个RuvC样结构域加框并用“B”指示。HNH样结构域加框并用“G”指示。Sp:化脓链球菌;Nm:脑膜炎奈瑟氏菌。基序:这是基于两个序列的基序:在两个序列中保守的残基以单氨基酸名称指示;“*”指示在两个序列中的任一个的相应位置发现的任何氨基酸;“-”指示任何氨基酸,例如20种天然存在的氨基酸中的任一种;并且“-”指示任何氨基酸,例如20种天然存在的氨基酸中的任一种,或不存在。
图17A描绘了经历内源TCR编码基因的敲除的工程化以使用各种表达方法表达TCR49的T细胞的CD8和与示例性重组TCR(TCR 49)所识别的抗原复合的肽-MHC四聚体的表面表达,如通过流式细胞术所评估的:经历慢病毒转导以随机整合重组TCR编码序列的细胞(“TCR 49Lenti”);经历随机整合和TRAC的CRISPR/Cas9介导的敲除(KO)的细胞(“TCR49Lenti KO”);或经历在人EF1α启动子的控制下在重组TCR编码序列的TRAC基因座处通过HDR进行靶向整合的细胞(TCR 49HDR KO)。图17B和17C描绘了工程化以表达TCR 49的CD8+T细胞中肽-MHC四聚体的结合的细胞表面表达的平均荧光强度(MFI;图17B)和变异系数(细胞群内信号的标准差除以各自群体中信号的平均值;图17C)。
图18A-18C描绘了使用对重组TCR或肽-MHC四聚体具特异性的抗Vβ22抗体对TCR(TCR 49)的染色和受体密度。
图19描绘了在将如上所述的效应细胞与表达HPV 16E7的靶细胞以效应子与靶标(E:T)的比率为10:1、5:1和2.5:1一起孵育后,由2个供体产生的如上所述的各种重组TCR49表达CD8+T细胞的平均细胞溶解活性,由杀伤%的曲线下面积(AUC)表示,与模拟转导对照相比并相对于上述各组的Vβ22表达(重组TCR特异性染色)归一化。将用编码能够与HPV16E7结合但含有小鼠Cα和Cβ区的参考TCR的慢病毒转导的CD8+细胞作为对照(“LentiRef”)评估。
图20描绘了如上所述的各种重组TCR 49表达CD8+T细胞的平均IFNγ分泌(pg/mL)。
图21A和21B描绘了经历内源TCR编码基因的敲除的工程化以使用各种表达方法表达重组T细胞受体(TCR)的T细胞的CD8、CD3、Vβ22(重组TCR特异性染色)和与重组TCR所识别的抗原复合的肽-MHC四聚体的表面表达,如通过流式细胞术所评估的:经历TRAC和TRBC的CRISPR/Cas9介导的敲除(KO)的细胞(“TCRαβKO”)或保留内源TCR的表达的细胞(“TCRαβWT”);经历与EF1α或MND启动子连接的重组TCR编码序列在TRAC基因座处通过HDR进行靶向整合的细胞(“HDR EF1α”或“HDR MND”);经历慢病毒转导以随机整合重组TCR编码序列的细胞(“lenti人”)或经历慢病毒转导以随机整合含有小鼠恒定结构域的重组TCR编码序列的细胞(“lenti小鼠”)或经历模拟转导作为对照的细胞(“模拟转导”)。
图21C和21D描绘了工程化以使用如上所述的各种表达方法表达重组T细胞受体(TCR)的CD8+(图21C)或CD4+(图21D)T细胞中Vβ22的细胞表面表达和肽-MHC四聚体的结合的几何平均荧光强度(gMFI)。
图21E和21F示出了工程化以使用如上所述的各种表达方法表达重组T细胞受体(TCR)的CD8+T细胞中肽-MHC四聚体的表达(图21E)和Vβ22的结合(图21F)的变异系数(细胞群内信号的标准差除以各自群体中信号的平均值)。
图22A-22C描绘了经历内源TCR编码基因的敲除的工程化以使用各种表达方法表达重组T细胞受体(TCR)的T细胞的CD3和CD8的表面表达,如通过流式细胞术所评估的:经历TRAC、TRBC或TRAC和TRBC两者的CRISPR/Cas9介导的敲除(KO)的细胞;经历与EF1α启动子、MND启动子或使用P2A核糖体跳跃序列的内源TCRα启动子连接的重组TCR编码序列在TRAC基因座处通过HDR进行靶向整合的细胞(分别为“HDR EF1α”、“HDR MND”或“HDR P2A”)或经历模拟转导作为对照的细胞(“模拟转导”)(图22A);保留内源TCR的表达并经历慢病毒转导以随机整合与EF1α启动子(“lenti EF1α”)或MND启动子(“lenti MND”)连接的或与具有编码截短受体的序列作为替代标记的EF1α启动子(“lenti EF1α/t受体”)连接的重组TCR编码序列的细胞或经历模拟转导作为对照的细胞(“模拟”)(图22B)。图22C描绘了上述各组中CD8+细胞中CD3+CD8+细胞的百分比。
图23A-23C描绘了经历内源TCR编码基因的敲除的工程化以使用各种表达方法表达重组T细胞受体(TCR)的T细胞的肽-MHC四聚体的结合和CD8的表面表达,如通过流式细胞术所评估的:经历TRAC、TRBC或TRAC和TRBC两者的CRISPR/Cas9介导的敲除(KO)的细胞;经历与EF1α启动子、MND启动子或使用P2A核糖体跳跃序列的内源TCRα启动子连接的重组TCR编码序列在TRAC基因座处通过HDR进行靶向整合的细胞(分别为“HDR EF1α”、“HDR MND”或“HDR P2A”)或经历模拟转导作为对照的细胞(“模拟转导”)(图23A);保留内源TCR的表达并经历慢病毒转导以随机整合与EF1α启动子(“lenti EF1α”)或MND启动子(“lenti MND”)连接的或与具有编码截短受体的序列作为替代标记的EF1α启动子(“lenti EF1α/t受体”)连接的重组TCR编码序列的细胞或经历模拟转导作为对照的细胞(“模拟”)(图23B)。图23C描绘了在第7天和第13天,上述各组中CD8+细胞中四聚体+CD8+细胞的百分比。
图24A-24D描绘了经历内源TCR编码基因的敲除的工程化以使用各种表达方法表达重组T细胞受体(TCR)的T细胞的Vβ22(重组TCR特异性染色)和CD8的表面表达,如通过流式细胞术所评估的:经历TRAC、TRBC或TRAC和TRBC两者的CRISPR/Cas9介导的敲除(KO)的细胞;经历与EF1α启动子、MND启动子或使用P2A核糖体跳跃序列的内源TCRα启动子连接的重组TCR编码序列在TRAC基因座处通过HDR进行靶向整合的细胞(分别为“HDR EF1α”、“HDRMND”或“HDR P2A”)或经历模拟转导作为对照的细胞(“模拟转导”)(图24A);保留内源TCR的表达并经历慢病毒转导以随机整合与EF1α启动子(“lenti EF1α”)或MND启动子(“lentiMND”)连接的或与具有编码截短受体的序列作为替代标记的EF1α启动子(“lenti EF1α/受体”)连接的重组TCR编码序列的细胞或经历模拟转导作为对照的细胞(“模拟”)(图24B)。图24C和24D描绘了在第7天和第13天,上述各组中CD8+细胞中Vβ22+CD8+细胞的百分比(图24C)和CD4+细胞中Vβ22+CD4+细胞的百分比(图24D)。
图25描绘了通过将如上所述的效应细胞与表达HPV 16E7的靶细胞以效应子与靶标(E:T)的比率为10:1、5:1和2.5:1一起孵育,如上所述的各种重组TCR表达CD8+T细胞的细胞溶解活性,由杀伤%的曲线下面积(AUC)表示,与模拟转导对照相比并相对于各组的Vβ22表达归一化。将用编码能够与HPV 16E7结合但含有小鼠Cα和Cβ区的参考TCR的慢病毒转导的CD8+细胞作为对照(“lenti小鼠E7 ref”)评估。
图26描绘了通过将如上所述的效应细胞与表达HPV 16E7的靶细胞以效应子与靶标(E:T)的比率为10:1和2.5:1一起孵育,如上所述的各种重组TCR表达CD8+T细胞的IFNγ分泌(pg/mL)。将用编码能够与HPV 16E7结合但含有小鼠Cα和Cβ区的参考TCR的慢病毒转导的CD8+细胞作为对照(“lenti小鼠E7 ref”)评估。
图27描绘了热图,其示出了在各种功能测定中如上所述的各种重组TCR表达T细胞的相对活性:在E:T比率为10:1、5:1和2.5:1下的杀伤%的AUC(“AUC”),在第7天和第13天CD8+细胞中的四聚体结合(“四聚体CD8”),使用SCC152细胞或用抗原肽脉冲的T2靶细胞的增殖测定(“CTV计数”)以及IFNγ从CD8+细胞中的分泌(“CD8分泌的IFNg”)。
具体实施方式
I.T细胞受体和其他HPV特异性结合分子
本文提供了结合分子,如结合或识别在MHC分子的背景下的人乳头瘤病毒(HPV)16的肽表位(例如,HPV 16E6或E7的肽表位)那些。此类结合分子包括对结合或识别HPV 16E6或HPV 16E7的肽表位展现出抗原特异性的T细胞受体(TCR)及其抗原结合片段以及抗体及其抗原结合片段。在一些实施方案中,还提供了编码结合分子的核酸分子、含有结合分子的工程化细胞、组合物以及涉及给予此类结合分子、工程化细胞或组合物的治疗方法。
HPV是在大部分情况下的宫颈癌的致病生物,并且已经牵涉于肛门癌、阴道癌、外阴癌、阴茎癌和口咽癌以及其他癌症。通常,HPV基因组包含含有六个开放阅读框(E1、E2、E4、E5、E6和E7)的早期区域,所述开放阅读框编码参与细胞转化和复制的蛋白质;以及含有两个开放阅读框(L1和L2)的晚期区域,所述开放阅读框编码病毒衣壳的蛋白质。通常,E6和E7是可影响细胞周期调节并有助于癌症形成的致癌基因。例如,E6基因产物可以引起p53降解,并且E7基因产物以引起成视网膜母细胞瘤(Rb)失活。
在一些方面,所提供的HPV 16结合分子(包括TCR或其抗原结合片段或抗HPV 16抗体(例如,其抗体片段))以及蛋白质(如含有前述一种或多种的嵌合分子,如嵌合受体,例如TCR样CAR)和/或表达TCR或CAR的工程化细胞与源自HPV16 E6蛋白的肽表位结合。在一些方面,所提供的HPV 16结合分子(包括TCR或其抗原结合片段或抗HPV 16抗体(例如,抗体片段))以及含有所述结合分子的蛋白质(如嵌合受体,例如TCR样CAR)和/或表达TCR或CAR的工程化细胞与源自HPV16 E7蛋白的肽表位结合。
在一些方面,结合分子识别或结合在MHC分子(如MHC I类分子)的背景下的HPV16E6或E7表位。在一些方面,MHC I类分子是HLA-A2分子,包括其任何一种或多种亚型,例如HLA-A*0201、HLA-A*0202、HLA-A*0203、HLA-A*0206或HLA-A*0207。在一些情况下,不同群体之间亚型的频率可能不同。例如,在一些实施方案中,超过95%的HLA-A2阳性高加索人口是HLA-A*0201,而据报道在中国人口中所述频率是大约23%HLA-A*0201、45%HLA-A*0207、8%HLA-A*0206和23%HLA-A*0203。在一些实施方案中,MHC分子是HLA-A*0201。
在一些实施方案中,TCR或其抗原结合片段识别或结合至HPV16 E6或HPV 16E7的表位或区域,如含有SEQ ID NO:232-239中任一个所示的氨基酸序列且如表1所示的肽表位。

在一些实施方案中,结合分子(例如,TCR或其抗原结合片段或者抗体或其抗原结合片段)是分离的或纯化的或者是重组的。在一些方面,结合分子(例如,TCR或其抗原结合片段或者抗体或其抗原结合片段)是人的。在一些实施方案中,结合分子是单克隆的。在一些方面,结合分子是单链。在其他实施方案中,结合分子含有两条链。在一些实施方案中,结合分子(例如,TCR或其抗原结合片段或者抗体或其抗原结合片段)在细胞表面上表达。
在一些方面,所提供的结合分子具有一种或多种指定的功能特征,如结合特性,包括与特定表位的结合和/或如所述的特定结合亲和力。
A.T细胞受体(TCR)
在一些实施方案中,识别或结合HPV 16的表位或区域的结合分子是T细胞受体(TCR)或其抗原结合片段。
在一些实施方案中,“T细胞受体”或“TCR”是含有可变α和β链(也分别称为TCRα和TCRβ)或可变γ和δ链(也分别称为TCRγ和TCRδ)的分子或其抗原结合部分,并且所述分子或其抗原结合部分能够与结合至MHC分子的肽特异性结合。在一些实施方案中,TCR呈αβ形式。通常,以αβ和γδ形式存在的TCR在结构上总体上相似,但是表达它们的T细胞可以具有不同的解剖学位置或功能。TCR可以在细胞表面上发现或以可溶形式发现。通常,在T细胞(或T淋巴细胞)的表面上发现TCR,在此处它通常负责识别结合至主要组织相容性复合物(MHC)分子的抗原。
除非另有说明,否则术语“TCR”应当理解为涵盖完整的TCR以及其抗原结合部分或抗原结合片段。在一些实施方案中,TCR是完整或全长TCR,如含有α链和β链的TCR。在一些实施方案中,TCR是这样的抗原结合部分,其少于全长TCR但与在MHC分子中结合的特定肽结合,如与MHC-肽复合物结合。在一些情况下,TCR的抗原结合部分或片段可以仅含有全长或完整TCR的结构性结构域的一部分,但是仍能够结合与完整TCR结合的肽表位(如MHC-肽复合物)。在一些情况下,抗原结合部分含有TCR或其抗原结合片段的可变结构域(如TCR的可变α(Vα)链和可变β(Vβ)链),足以形成用于与特定MHC-肽复合物结合的结合位点。
在一些实施方案中,TCR的可变结构域含有互补决定区(CDR),其通常是肽、MHC和/或MHC-肽复合物的抗原识别以及结合能力和特异性的主要贡献者。在一些实施方案中,TCR的CDR或其组合形成给定TCR分子的全部或基本上全部的抗原结合位点。TCR链的可变区内的各个CDR通常由框架区(FR)隔开,与CDR相比,所述框架区通常在TCR分子之间展示较低可变性(参见例如,Jores等人,Proc.Nat'l Acad.Sci.U.S.A.87:9138,1990;Chothia等人,EMBO J.7:3745,1988;还参见Lefranc等人,Dev.Comp.Immunol.27:55,2003)。在一些实施方案中,CDR3是负责抗原结合或特异性的主要CDR,或者在给定TCR可变区上在三个CDR中对于抗原识别和/或对于与肽-MHC复合物的经加工肽部分的相互作用最重要。在一些情境下,α链的CDR1可以与某些抗原肽的N末端部分相互作用。在一些情境下,β链的CDR1可以与肽的C末端部分相互作用。在一些情境下,CDR2对与MHC-肽复合物的MHC部分的相互作用或识别具有最强的作用或者是主要的负责CDR。在一些实施方案中,β链的可变区可以含有其他高变区(CDR4或HVR4),其通常参与超抗原结合而非抗原识别(Kotb(1995)ClinicalMicrobiology Reviews,8:411-426)。
在一些实施方案中,TCR的α链和/或β链还可以含有恒定结构域、跨膜结构域和/或短胞质尾(参见例如,Janeway等人,Immunobiology:The Immune System in Health andDisease,第3版,Current Biology Publications,第4页:33,1997)。在一些方面,TCR的每条链(例如α或β)可以具有一个N末端免疫球蛋白可变结构域、一个免疫球蛋白恒定结构域、跨膜区和位于C末端的短胞质尾。在一些实施方案中,TCR例如经由胞质尾与参与介导信号转导的CD3复合物的不变蛋白质缔合。在一些情况下,所述结构允许TCR与其他分子(像CD3)及其亚基缔合。例如,含有恒定结构域与跨膜区的TCR可以将蛋白质锚定在细胞膜中并与CD3信号传导设备或复合物的不变亚基缔合。CD3信号传导亚基(例如CD3γ、CD3δ、CD3ε和CD3ζ链)的细胞内尾含有一个或多个基于免疫受体酪氨酸的激活基序或ITAM并且通常涉及TCR复合物的信号传导能力。
确定或鉴定TCR的各个结构域或区域在熟练技术人员的能力范围内。在一些情况下,结构域或区域的确切基因座可能取决于特定结构或同源性建模或用于描述特定结构域的其他特征而变化。应理解,提及氨基酸(包括提及用于描述TCR的结构域组织的作为SEQID NO所示的特定序列)是出于说明的目的,并不意在限制所提供实施方案的范围。在一些情况下,特定结构域(例如可变或恒定)可以是更长或更短的几个氨基酸(如一个、两个、三个或四个)。在一些方面,TCR的残基是已知的,或者可以根据国际免疫遗传学信息系统(International Immunogenetics Information System,IMGT)编号系统来鉴定(参见例如www.imgt.org;还参见,Lefranc等人(2003)Developmental and ComparativeImmunology,2&;55-77;和The T Cell Factsbook第2版,Lefranc and LeFranc AcademicPress 2001)。使用此系统,TCR Vα链和/或Vβ链内的CDR1序列对应于残基编号27-38之间存在的氨基酸(包含端值),TCR Vα链和/或Vβ链内的CDR2序列对应于残基编号56-65之间存在的氨基酸(包含端值),并且TCR Vα链和/或Vβ链内的CDR3序列对应于残基编号105-117之间存在的氨基酸(包含端值)。
在一些实施方案中,TCR的α链和β链各自还含有恒定结构域。在一些实施方案中,α链恒定结构域(Cα)和β链恒定结构域(Cβ)单独地是哺乳动物(如人或鼠)恒定结构域。在一些实施方案中,恒定结构域与细胞膜相邻。例如,在一些情况下,由两条链形成的TCR的细胞外部分含有两个膜近端恒定结构域和两个膜远端可变结构域,所述可变结构域各自含有CDR。
在一些实施方案中,Cα和Cβ结构域中的每一个是人的。在一些实施方案中,Cα由TRAC基因编码(IMGT命名法)或者是其变体。在一些实施方案中,Cα具有或包含SEQ ID NO:213或220所示的氨基酸序列或与SEQ ID NO:213或220展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列。在一些实施方案中,Cα具有或包含SEQ ID NO:212、215或217所示的氨基酸序列或与SEQ ID NO:212、215或217展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列。在一些实施方案中,Cα具有或包含SEQ ID NO:212、213、215、217、220或524中任一个所示的氨基酸序列。在一些实施方案中,Cβ由TRBC1或TRBC2基因编码(IMGT命名法)或者是其变体。在一些实施方案中,Cβ具有或包含SEQ ID NO:214、216、631或889所示的氨基酸序列或与SEQ ID NO:214、216、631或889展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列。在一些实施方案中,Cβ具有或包含SEQ ID NO:214、216、631或889所示的氨基酸序列。
在一些实施方案中,任何所提供的TCR或其抗原结合片段可以是人/小鼠嵌合TCR。在一些情况下,TCR或其抗原结合片段包含含有小鼠恒定区的α链和/或β链。在一些实施方案中,Cα是小鼠恒定区,其是或包含SEQ ID NO:262、317、833、1012、1014、1015、1017或1018所示的氨基酸序列或与SEQ ID NO:262、317、833、1012、1014、1015、1017或1018展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列。在一些实施方案中,Cα是或包含SEQ ID NO:262、317、833、1012、1014、1015、1017或1018所示的氨基酸序列。在一些实施方案中,Cβ是小鼠恒定区,其是或包含SEQ ID NO:263、109、1013或1016所示的氨基酸序列或与SEQ ID NO:263、109、1013或1016展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列。在一些实施方案中,Cβ是或包含SEQ ID NO:263、109、1013或1016所示的氨基酸序列。在一些实施方案中,Cα是或包含SEQID NO:262或1014所示的氨基酸序列或与SEQ ID NO:262或1014展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列,和/或Cβ是或包含SEQ ID NO:263所示的氨基酸序列或与SEQ ID NO:263展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列。在一些实施方案中,Cα和/或Cβ是或包含WO 2015/184228、WO 2015/009604和WO 2015/009606中描述的任何Cα和/或Cβ。
在一些实施方案中,本文的TCR或其抗原结合片段包含α链和/或β链的变体,例如包含小鼠恒定区的α和/或β链。在一些实施方案中,变体包含本文所述的任何TCR的在α或β链的恒定区具有一个、两个、三个或四个或更多个氨基酸取代的氨基酸序列。在一些实施方案中,变体包含本文所述的任何恒定区的在恒定区具有一个、两个、三个或四个或更多个氨基酸取代的氨基酸序列。在一些实施方案中,包含所述一个或多个经取代的氨基酸序列的TCR(或其功能性部分)有利地提供与包含未经取代的氨基酸序列的亲本TCR相比增加的HPV16靶标识别、增加的宿主细胞表达和增加的抗肿瘤活性中的一种或多种。
在一些实施方案中,TCRα和β链的小鼠恒定区的经取代的氨基酸序列(分别为SEQID NO:1015和1016)分别与未经取代的小鼠恒定区氨基酸序列SEQ ID NO:1014和263的全部或部分对应,其中SEQ ID NO:1015当与SEQ ID NO:1014相比时具有一个、两个、三个或四个氨基酸取代,并且SEQ ID NO:1016当与SEQ ID NO:263相比时具有一个氨基酸取代。在一些实施方案中,TCR的变体包含(a)SEQ ID NO:1015(α链的恒定区)的氨基酸序列,其中(i)位置48处的X是Thr或Cys;(ii)位置112处的X是Ser、Gly、Ala、Val、Leu、Ile、Pro、Phe、Met或Trp;(iii)位置114处的X是Met、Gly、Ala、Val、Leu、Ile、Pro、Phe、Met或Trp;并且(iv)位置115处的X是Gly、Ala、Val、Leu、Ile、Pro、Phe、Met或Trp;以及(b)SEQ ID NO:1016(β链的恒定区)的氨基酸序列,其中位置56处的X是Ser或Cys。在一些实施方案中,Cα是或包含SEQ IDNO:1015所示的氨基酸序列或与SEQ ID NO:1015展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列,和/或Cβ是或包含SEQ ID NO:1016所示的氨基酸序列或与SEQ ID NO:1016展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列。
在一些实施方案中,TCR可以是如通过一个或多个二硫键连接的两条链α和β的异二聚体。在一些实施方案中,TCR的恒定结构域可以含有短连接序列,其中半胱氨酸残基形成二硫键,从而连接TCR的两条链。在一些实施方案中,TCR可以在α和β链中的每一个中具有另外的半胱氨酸残基,使得TCR在恒定结构域中含有两个二硫键。在一些实施方案中,恒定和可变结构域中的每一个包含由半胱氨酸残基形成的二硫键。
在一些实施方案中,TCR可以含有引入的一个或多个二硫键。在一些实施方案中,不存在天然二硫键。在一些实施方案中,形成天然链间二硫键的一个或多个天然半胱氨酸(例如在α链和β链的恒定结构域中)被取代为另一种残基,如被取代为丝氨酸或丙氨酸。在一些实施方案中,可以通过将α和β链上的非半胱氨酸残基(如在α链和β链的恒定结构域中)突变为半胱氨酸来形成引入的二硫键。TCRα和β链中相对的半胱氨酸提供了这样的二硫键,其将经取代的TCR的TCRα和β链的恒定区彼此连接,并且不存在于包含未经取代的人恒定区或未经取代的小鼠恒定区的TCR中。在一些实施方案中,重组TCR中非天然半胱氨酸残基的存在(例如产生一个或多个非天然二硫键)可以有利于引入了它的细胞中所需重组TCR的产生而不是含有天然TCR链的错配的TCR对的表达。
TCR的示例性非天然二硫键描述于已公开的国际PCT号WO2006/000830和WO 2006/037960中。在一些实施方案中,可以在Cα链的残基Thr48和Cβ链的Ser57处、在Cα链的残基Thr45和Cβ链的Ser77处、在Cα链的残基Tyr10和Cβ链的Ser17处、在Cα链的残基Thr45和Cβ链的Asp59处和/或在Cα链的残基Ser15和Cβ链的Glu15处引入或取代半胱氨酸,参考SEQ IDNO:212、213、217或524中任一个所示的Cα或者SEQ ID NO:214或216所示的Cβ的编号。在一些实施方案中,TCR的变体是半胱氨酸取代的嵌合TCR,其中SEQ ID NO:1014的天然Thr48和SEQ ID NO:263的天然Ser57之一或两者被Cys取代。在一些实施方案中,Cα是或包含SEQ IDNO:1017所示的氨基酸序列或与SEQ ID NO:1017展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列,和/或Cβ是或包含SEQ ID NO:1016所示的氨基酸序列或与SEQ ID NO:1013展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列。
在一些实施方案中,任何所提供的半胱氨酸突变都可以在另一个序列中(例如,在上述小鼠Cα和Cβ序列中)的相应位置进行。关于蛋白质的位置,如陈述氨基酸位置“对应于”如序列表所示的公开序列中的氨基酸位置,术语“相应”是指基于结构序列比对或使用标准比对算法(如GAP算法)与公开序列比对后鉴定的氨基酸位置。例如,可以通过如本文所述的结构比对方法将参考序列与SEQ ID NO:212、213、215、217、220或524中任一个所示的Cα序列或者SEQ ID NO:214、216、631或889所示的Cβ序列进行比对来确定相应残基。通过比对序列,本领域技术人员可以例如使用保守和相同的氨基酸残基作为指导来鉴定相应残基。
在一些实施方案中,变体包括疏水性氨基酸对α和β链之一或两者的恒定区的跨膜(TM)结构域中的一个、两个或三个氨基酸的取代,以提供疏水性氨基酸取代的TCR。与在TM结构域中缺乏所述一个或多个疏水性氨基酸取代的TCR相比,TCR的TM结构域中的所述一个或多个疏水性氨基酸取代可以增加TCR的TM结构域的疏水性。在一些实施方案中,TCR的变体包含SEQ ID NO:1014的天然Ser 112、Met 114和Gly 115中的一个、两个或三个,其可以独立地被Gly、Ala、Val、Leu、Ile、Pro、Phe、Met或Trp,例如被Leu、Ile或Val取代。在一些实施方案中,Cα是或包含SEQ ID NO:1018所示的氨基酸序列或与SEQ ID NO:1018展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列,和/或Cβ是或包含SEQ ID NO:263所示的氨基酸序列或与SEQ ID NO:263展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列。
在一些实施方案中,变体包括在α和β链之一或两者的恒定区中的半胱氨酸取代以及疏水性氨基酸对α和β链之一或两者的恒定区的跨膜(TM)结构域中的一个、两个或三个氨基酸的所述一个或多个取代。在一些实施方案中,变体具有被Cys取代的SEQ ID NO:1014的天然Thr48;分别被Gly、Ala、Val、Leu、Ile、Pro、Phe、Met或Trp,例如被Leu、Ile或Val取代的SEQ ID NO:1014的天然Ser 112、Met 114和Gly 115中的一个、两个或三个;以及被Cys取代的SEQ ID NO:19的天然Ser56。在一些实施方案中,Cα是或包含SEQ ID NO:833所示的氨基酸序列或与SEQ ID NO:833展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列,和/或Cβ是或包含SEQ ID NO:1013所示的氨基酸序列或与SEQ ID NO:1013展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列。
下文描述了所提供的TCR的示例性序列(例如CDR、Vα/或Vβ和恒定区序列)。
在一些实施方案中,TCR是全长TCR。在一些实施方案中,TCR是抗原结合部分。在一些实施方案中,TCR是二聚体TCR(dTCR)。在一些实施方案中,TCR是单链TCR(sc-TCR)。TCR可以是细胞结合的或呈可溶形式。在一些实施方案中,TCR呈在细胞表面上表达的细胞结合形式。
在一些实施方案中,dTCR含有第一多肽(其中对应于所提供的TCRα链可变区序列的序列与对应于TCRα链恒定区细胞外序列的序列的N末端融合)和第二多肽(其中对应于所提供的TCRβ链可变区序列的序列与对应于TCRβ链恒定区细胞外序列的序列的N末端融合),所述第一和第二多肽通过二硫键连接。在一些实施方案中,所述键可以对应于天然二聚体αβTCR中存在的天然链间二硫键。在一些实施方案中,链间二硫键不存在于天然TCR中。例如,在一些实施方案中,可以将一个或多个半胱氨酸掺入dTCR多肽对的恒定区细胞外序列中。在一些情况下,可能需要天然和非天然二硫键两者。在一些实施方案中,TCR含有跨膜序列以锚定至膜。
在一些实施方案中,dTCR含有所提供的TCRα链,所述TCRα链含有可变α结构域、恒定α结构域和附着于恒定α结构域C末端的第一二聚化基序;以及所提供的TCRβ链,所述TCRβ链包含可变β结构域、恒定β结构域和附着于恒定β结构域C末端的第一二聚化基序,其中所述第一和第二二聚化基序易于相互作用以在第一二聚化基序的氨基酸与第二二聚化基序的氨基酸之间形成共价键,从而将TCRα链与TCRβ链连接在一起。
在一些实施方案中,TCR是scTCR,其是能够与MHC-肽复合物结合的含有α链和β链的单条氨基酸链。通常,可以使用本领域技术人员已知的方法来产生scTCR,参见例如国际公开PCT号WO 96/13593、WO 96/18105、WO 99/18129、WO 04/033685、WO 2006/037960、WO2011/044186;美国专利号7,569,664;以及Schlueter,C.J.等人J.Mol.Biol.256,859(1996)。
在一些实施方案中,scTCR含有第一区段(其由对应于所提供的TCRα链可变区的序列的氨基酸序列构成)、第二区段(其由与对应于TCRβ链恒定结构域细胞外序列的氨基酸序列的N末端融合的对应于所提供的TCRβ链可变区序列的氨基酸序列构成)和接头序列(其将第一区段的C末端连接至第二区段的N末端)。
在一些实施方案中,scTCR含有第一区段(其由对应于所提供的TCRβ链可变区的氨基酸序列构成)、第二区段(其由与对应于TCRα链恒定结构域细胞外序列的氨基酸序列的N末端融合的对应于所提供的TCRα链可变区序列的氨基酸序列构成)和接头序列(其将第一区段的C末端连接至第二区段的N末端)。
在一些实施方案中,scTCR含有第一区段(其由与α链细胞外恒定结构域序列的N末端融合的所提供的α链可变区序列构成)和第二区段(其由与序列β链细胞外恒定和跨膜序列的N末端融合的所提供的β链可变区序列构成)以及任选地接头序列(其将第一区段的C末端连接至第二区段的N末端)。
在一些实施方案中,scTCR含有第一区段(其由与β链细胞外恒定结构域序列的N末端融合的所提供的TCRβ链可变区序列构成)和第二区段(其由与序列α链细胞外恒定和跨膜序列的N末端融合的所提供的α链可变区序列构成)以及任选地接头序列(其将第一区段的C末端连接至第二区段的N末端)。
在一些实施方案中,为了使scTCR结合MHC-肽复合物,α和β链必须配对,使得其可变区序列被定向用于这种结合。促进scTCR中α和β配对的各种方法是本领域熟知的。在一些实施方案中,包括连接α和β链以形成单条多肽链的接头序列。在一些实施方案中,接头应当具有足够的长度以跨越α链的C末端与β链的N末端之间的距离,或反之亦然,同时还确保接头长度不那么长以至于其阻断或减少scTCR与靶肽-MHC复合物的结合。
在一些实施方案中,scTCR的连接第一和第二TCR区段的接头可以是能够在保留TCR结合特异性的同时形成单条多肽链的任何接头。在一些实施方案中,接头序列可以例如具有式-P-AA-P-,其中P是脯氨酸,并且AA表示氨基酸序列,其中氨基酸是甘氨酸和丝氨酸。在一些实施方案中,第一和第二区段配对,使得其可变区序列被定向用于这种结合。因此,在一些情况下,接头具有足够的长度以跨越第一区段的C末端与第二区段的N末端之间的距离,或反之亦然,但是不能太长而阻断或减少scTCR与靶配体的结合。在一些实施方案中,接头可以含有从或从约10至45个氨基酸,如10至30个氨基酸或26至41个氨基酸残基,例如29、30、31或32个氨基酸。在一些实施方案中,接头具有式-PGGG-(SGGGG)n-P-,其中n是5或6,并且P是脯氨酸,G是甘氨酸且S是丝氨酸(SEQ ID NO:266)。在一些实施方案中,接头具有序列GSADDAKKDAAKKDGKS(SEQ ID NO:267)。
在一些实施方案中,scTCR在单条氨基酸链的残基之间含有二硫键,其在一些情况下可以促进单链分子的α与β区之间的配对的稳定性(参见例如美国专利号7,569,664)。在一些实施方案中,scTCR含有共价二硫键,其将单链分子的α链的恒定结构域的免疫球蛋白区域的残基连接至单链分子的β链的恒定结构域的免疫球蛋白区域的残基。在一些实施方案中,二硫键对应于天然dTCR中存在的天然二硫键。在一些实施方案中,不存在天然TCR中的二硫键。在一些实施方案中,二硫键是引入的非天然二硫键,例如通过将一个或多个半胱氨酸掺入scTCR多肽的第一和第二链区的恒定区细胞外序列中。示例性半胱氨酸突变包括如上所述的任何突变。在一些情况下,可能存在天然和非天然二硫键两者。
在一些实施方案中,scTCR是非二硫键连接的截短的TCR,其中与其C末端融合的异源亮氨酸拉链促进链缔合(参见例如国际公开PCT号WO 99/60120)。在一些实施方案中,scTCR含有经由肽接头与TCRβ可变结构域共价连接的TCRα可变结构域(参见例如,国际公开PCT号WO 99/18129)。
在一些实施方案中,任何所提供的TCR(包括dTCR或scTCR)可以与信号传导结构域连接,从而在T细胞表面上产生活性TCR。在一些实施方案中,TCR在细胞表面上表达。在一些实施方案中,TCR确实含有对应于跨膜序列的序列。在一些实施方案中,跨膜结构域带正电荷。在一些实施方案中,跨膜结构域可以是Cα或Cβ跨膜结构域。在一些实施方案中,跨膜结构域可以来自非TCR来源,例如来自CD3z、CD28或B7.1的跨膜区。在一些实施方案中,TCR确实含有对应于胞质序列的序列。在一些实施方案中,TCR含有CD3z信号传导结构域。在一些实施方案中,TCR能够与CD3形成TCR复合物。
在一些实施方案中,TCR是可溶性TCR。在一些实施方案中,可溶性TCR具有如WO99/60120或WO 03/020763中所述的结构。在一些实施方案中,TCR不含有对应于跨膜序列的序列,例如以允许膜锚定到表达它的细胞中。在一些实施方案中,TCR不含有对应于胞质序列的序列。
1.示例性TCR
在一些实施方案中,结合或识别在MHC的背景下的HPV 16的肽表位(例如HPV 16E6的肽表位或HPV 16E7的肽表位)的所提供的TCR或其抗原结合片段包括单独地含有如所述的任何α和/或β链可变(Vα或Vβ)区序列或此类链的足够抗原结合部分的TCR或其抗原结合片段。在一些实施方案中,所提供的HPV 16TCR或其抗原结合片段(例如抗HPV 16E6或抗HPV16E7 TCR)包含含有如所述的CDR-1、CDR-2和/或CDR-3的Vα区序列或其足够抗原结合部分。在一些实施方案中,所提供的HPV 16TCR或其抗原结合片段(例如抗HPV 16E6或抗HPV 16E7TCR)包含含有如所述的CDR-1、CDR-2和/或CDR-3的Vβ区序列或足够抗原结合部分。在一些实施方案中,抗HPV 16TCR或其抗原结合片段(例如抗HPV 16E6或抗HPV 16E7 TCR)包含含有如所述的CDR-1、CDR-2和/或CDR-3的Vα区序列,并且包含含有如所述的CDR-1、CDR-2和/或CDR-3的Vβ区序列。所提供的TCR还包括具有与这样的序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR含有Vα区,其含有包含氨基酸序列X1X2X3X4X5X6X7X8X9X10X1 1X12X13X14X15X16X17X18(SEQ ID NO:1365)的互补决定区3(CDR-3),其中X1是A、I或V;X2是M、L、V、E或A;X3是R、L、N或S;X4是E、V、P、T、F、I、R或A;X5是G、I、L、A、P、R、D或H;X6是R、T、G、S、N或H;X7是G、R、A、N或空;X8是T、G或空;X9是空、A或G;X10是空或G;X11是空或G;X12是空或T;X13是F、Y、A、S或空;X14是G、Y或N;X15是F、G、T、N、Q或Y;X16是K、P、V、N或A;X17是T、L或F;并且X18是I、V、T、H或N。
在一些实施方案中,TCR含有Vα区,其含有包含氨基酸序列X1X2X3X4X5X6X7X8X9X10X1 1X12X13X14X15X16X17X18(SEQ ID NO:251)的互补决定区3(CDR-3),其中X1是A、I或V;X2是M、L、V、E或S;X3是R、L、N、Q、P或S;X4是E、V、P、T、F、I、R、G、S或A;X5是G、I、L、A、P、R、D、空或H;X6是R、T、G、S、N、空或A;X7是G、R、N或空;X8是T、G或空;X9是空或A;X10是空或G;X11是空或G;X12是空或T;X13是F、Y、S或空;X14是G、Y、空或N;X15是F、G、T、N、Q或Y;X16是K、P、V、N或A;X17是T、L或F;并且X18是I、V、T、H、F或N。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有包含SEQ IDNO:138、144、147、153、159、163、167、173、175、301、304、308、478、493、505、511、523、539、555、572、588、600、612、624、638、650、662、679、694、712、729、744、762、776、788、802、818、832、846、858、870、882、896、911、926、940、952、964、976、988或1002中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列的互补决定区3(CDR-3)。在一些方面,TCR或其抗原结合片段含有Vα区,所述Vα区含有SEQ ID NO:111、113、115、117、119、121、123、125、127、295、297、299、477、492、504、510、522、536、554、569、587、599、611、623、637、649、661、676、691、709、726、741、759、775、787、799、815、830、845、857、869、881、895、908、925、937、951、963、975、987或999中任一个所示的氨基酸序列或与这样的序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列内所含的CDR3。
在一些实施方案中,TCR含有Vβ区,其含有包含氨基酸序列X1X2X3X4X5X6X7X8X9X10X1 1X12X13X14X15(SEQ ID NO:1366)的互补决定区3(CDR-3),其中X1是A或S;X2是S、I或V;X3是S、T或V;X4是H、P、L、Y、T、D或Q;X5是L、G、W、F、S或R;X6是A、G、L、S或T;X7是G、E、A、T、R或空;X8是空或G;X9是空或G;X10是空、F、G、T、S或A;X11是T、N、H、A、S或F;X12是G、T、Q、D、Y或L;X13是E、P、T、G或W;X14是L、A、Q、Y或K;并且X15是F、H、Y或T。
在一些实施方案中,TCR含有Vβ区,其含有包含氨基酸序列X1X2X3X4X5X6X7X8X9X10X1 1X12X13X14X15(SEQ ID NO:261)的互补决定区3(CDR-3),其中X1是A或S;X2是S、I或V;X3是S、T或V;X4是H、P、L、Y、T、D或F;X5是L、G、W、F、S、T或R;X6是A、G、L、S或T;X7是G、E、A、T、R、Q或空;X8是空或G;X9是空或G;X10是空、F、G、T、S或R;X11是T、N、H、A、S、R或E;X12是G、T、Q、D、Y或R;X13是E、P、T或G;X14是L、A、Q或Y;并且X15是F、H、Y或T。
在一些情形中,TCR含有Vβ区,其含有包含SEQ ID NO:141、146、150、156、160、164、170、174、178、305、309、486、499、517、531、548、563、581、594、606、618、630、644、656、670、686、703、721、736、753、769、782、794、809、825、840、852、864、876、888、902、919、932、946、958、970、982、994、1010或1381中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列的互补决定区3(CDR-3)。在一些实施方案中,TCR含有Vβ区,其含有SEQ ID NO:112、114、116、118、120、122、124、126、128、296、298、300、483、498、516、530、545、560、578、593、605、617、629、643、655、667、685、700、718、735、750、768、781、793、808、824、839、851、863、875、887、901、917、931、945、957、969、981、993、1008或1380中任一个所示的氨基酸序列或与这样的序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列内所含的CDR3。
在一些方面,Vα区还含有包含氨基酸序列X1X2X3X4X5X6X7(SEQ ID NO:1367)的互补决定区1(CDR-1),其中X1是T、D、N或V;X2是I或S;X3是S、D、A、P或M;X4是G、Q、P或空;X5是T、S、I或F;X6是D、Y、Q、T或S;并且X7是Y、G、N或Q。在一些实施方案中,Vα区还含有包含氨基酸序列X1X2X3X4X5X6X7X8(SEQ ID NO:247)的互补决定区2(CDR-2),其中X1是G、Q、I、V或M;X2是L、S、Q、Y、F、T或G;X3是T、G、S或F;X4是Y、S、N、I或空;X5是空或D;X6是空、E、Q、S、M或K;X7是S、Q、R、G、D或N;并且X8是N、E、M、T或K。
在一些方面,Vα区还含有包含氨基酸序列X1X2X3X4X5X6X7(SEQ ID NO:243)的互补决定区1(CDR-1),其中X1是T、D、N、S或V;X2是I或S;X3是S、D、A、P、N或Y;X4是G、Q、P或空;X5是T、S、I或F;X6是D、Y、Q、T、P或S;并且X7是Y、G、N、A、S或Q。
在一些实施方案中,Vα区含有包含SEQ ID NO:136、142、151、157、161、165、171、302、306、537、570、677、692、710、727、742、760、800、816、909、938或1000中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列的互补决定区1(CDR-1)。在一些方面,Vα区含有SEQ ID NO:111、113、115、117、119、121、123、125、127、295、297、299、477、492、504、510、522、536、554、569、587、599、611、623、637、649、661、676、691、709、726、741、759、775、787、799、815、830、845、857、869、881、895、908、925、937、951、963、975、987或999中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列内所含的CDR-1。在一些实施方案中,Vα区含有包含SEQ ID NO:137、143、152、158、162、166、172、303、307、538、571、678、693、711、728、743、761、801、817、831、910、939或1001中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列的互补决定区2(CDR-2)。在一些实施方案中,Vα区含有SEQ ID NO:111、113、115、117、119、121、123、125、127、295、297、299、477、492、504、510、522、536、554、569、587、599、611、623、637、649、661、676、691、709、726、741、759、775、787、799、815、830、845、857、869、881、895、908、925、937、951、963、975、987或999中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列内所含的CDR-2。
在一些方面,Vβ区还含有包含氨基酸序列X1X2X3X4X5(SEQ ID NO:1369)的互补决定区1(CDR-1),其中X1是S、M或L;X2是G、E、D、N或Q;X3是H或V;X4是V、N、E、L或T;并且X5是S、R、N、Y、A或M。在一些实施方案中,Vβ区还含有包含氨基酸序列X1X2X3X4X5X6X7(SEQ ID NO:1368)的互补决定区2(CDR-2),其中X1是F、Y、S或A;X2是Q、Y、V或N;X3是N、D、G、F或Q;X4是空或G;X5是E、V、N、K或S;X6是A、K、G或E;并且X7是Q、M、T、I或A。
在一些方面,Vβ区还含有包含氨基酸序列X1X2X3X4X5(SEQ ID NO:254)的互补决定区1(CDR-1),其中X1是S或M;X2是G、E、D、N或Q;X3是H或V;X4是V、N、E、L或T;并且X5是S、R、N、Y或M。在一些实施方案中,Vβ区还含有包含氨基酸序列X1X2X3GX5X6X7(SEQ ID NO:257)的互补决定区2(CDR-2),其中X1是F、S或A;X2是Q、Y、V或N;X3是N、D、G或Q;X5是E、V、N或S;X6是A、K、G或E;并且X7是Q、M、T、I或A。
在一些情形中,Vβ区含有包含SEQ ID NO:139、145、148、154、168、176、484、546、561、579、668、701、719或751中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列的互补决定区1(CDR-1)。在一些方面,Vβ区含有SEQ ID NO:112、114、116、118、120、122、124、126、128、296、298、300、483、498、516、530、545、560、578、593、605、617、629、643、655、667、685、700、718、735、750、768、781、793、808、824、839、851、863、875、887、901、917、931、945、957、969、981、993、1008或1380中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列内所含的CDR-1。在一些实施方案中,Vβ区含有包含SEQ ID NO:140、149、155、169、177、485、547、562、580、669、702、720、752、918或1009中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列的互补决定区2(CDR-2)。在一些实施方案中,Vβ区含有SEQ ID NO:112、114、116、118、120、122、124、126、128、296、298、300、483、498、516、530、545、560、578、593、605、617、629、643、655、667、685、700、718、735、750、768、781、793、808、824、839、851、863、875、887、901、917、931、945、957、969、981、993、1008或1380中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列内所含的CDR-2。
在一些实施方案中,Vα区含有SEQ ID NO:111、113、115、117、119、121、123、125、127、295、297、299、477、492、504、510、522、536、554、569、587、599、611、623、637、649、661、676、691、709、726、741、759、775、787、799、815、830、845、857、869、881、895、908、925、937、951、963、975、987或999中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列。在一些情形中,Vβ区含有SEQ ID NO:112、114、116、118、120、122、124、126、128、296、298、300、483、498、516、530、545、560、578、593、605、617、629、643、655、667、685、700、718、735、750、768、781、793、808、824、839、851、863、875、887、901、917、931、945、957、969、981、993或1008中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列。在一些实施方案中,TCR含有包含任何此类Vα链序列和任何此类Vβ链序列的α链。
在一些实施方案中,TCR或其抗原结合片段的α链还含有α恒定(Cα)区或其部分。在一些方面,β链还含有β恒定(Cβ)区或其部分。因此,在一些实施方案中,TCR(例如,HPV 16E6或E7 TCR或其抗原结合片段)含有包含可变α(Vα)区和α恒定(Cα)区或其部分的α链和/或包含可变β(Vβ)区和β恒定区(Cβ)或其部分的β链。
在一些情况下,Cα和Cβ区是小鼠恒定区。在一些实施方案中,Cα区含有SEQ ID NO:262或317所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。在一些情况下,Cβ区含有SEQ ID NO:263或109所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。
在一些实施方案中,所述Cα和Cβ区是人恒定区。在一些此类实施方案中,Cα区包含SEQ ID NO:212、213、215、217、218、220或524中任一个所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。在一些方面,Cβ区含有SEQ ID NO:214、216、631或889所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。
在一些实施方案中,例如通过掺入一个或多个非天然半胱氨酸残基来修饰Cα和/或Cβ区。在一些实施方案中,恒定区是人恒定区的经修饰形式(例如,与SEQ ID NO:212、213、215、217、218、220或524中任一个所示的Cα区和/或SEQ ID NO:214、216、631或889所示的Cβ区相比是经修饰的)。在一些实施方案中,修饰是通过在Cα链的残基Thr48和/或Cβ链的Ser57处、在Cα链的残基Thr45和/或Cβ链的Ser77处、在Cα链的残基Tyr10和/或Cβ链的Ser17处、在Cα链的残基Thr45和Cβ链的Asp59处和/或在Cα链的残基Ser15和Cβ链的Glu15处引入半胱氨酸进行的,参考SEQ ID NO:212、213、217、218或524中任一个所示的Cα或者SEQ IDNO:214或216所示的Cβ的编号。可以通过将参考序列与SEQ ID NO:212、213、217、218、524、214或216中的任一个进行比对来鉴定相应残基。例如,Cα链中的Thr48与SEQ ID NO:215或220所示的序列中的Thr49对齐或与其相对应,并且Cβ链中的Ser57与SEQ ID NO:631或889所示的序列中的Ser58对齐或与其相对应。在一些此类实施方案中,Cα区在残基48处(或在相应残基,例如残基49处)含有非天然半胱氨酸,并且包含SEQ ID NO:196、198、200、201、203、525中任一个所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性且含有引入的一个或多个非天然半胱氨酸残基的序列。在一些方面,Cβ区在残基57处(或在相应残基,例如残基58处)含有非天然半胱氨酸,并且含有SEQ ID NO:197、199、632、890或1363所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性且含有一个或多个非天然半胱氨酸残基的序列。
在一些实施方案中,TCR或其抗原结合片段包含α链,所述α链包含SEQ ID NO:18、28、38、48、58、68、78、88、98、287或291所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列;和/或β链,所述β链包含SEQ ID NO:22、32、42、52、62、72、82、92、102、285、289、293、479、494、512、526、541、556、574、589、601、613、625、639、651、663、681、696、714、731、746、764、777、789、804、820、835、847、859、871、883、897、913、927、941、953、965、977、989、1004或1376所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。
在一些实施方案中,TCR或其抗原结合片段包含α链,所述α链包含SEQ ID NO:19、29、39、49、59、69、79、89、99、284、288、292、474、489、501、507、519、533、551、566、584、596、608、620、634、646、658、673、688、706、723、738、756、772、784、796、812、827、842、854、866、878、892、905、922、934、948、960、972、984、996或1387所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列;和/或β链,所述β链包含SEQ ID NO:23、33、43、53、63、73、83、93、103、286、290、294、480、495、513、527、542、557、575、590、602、614、626、640、652、664、682、697、715、732、747、765、778、790、805、821、836、848、860、872、884、898、914、928、942、954、966、978、990、1005或1377所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。
在一些实施方案中,TCR的α链和/或β链由包含信号肽的核苷酸序列(也称为前导序列)编码。这样的信号肽的非限制性例子是具有或包含SEQ ID NO:181-182、184-194、310、311、487、540、549、564、573、582、671、680、695、704、713、730、745、754、763、770、803、810、819、834、903、912、920、1003或1011中任一个所示的氨基酸序列的信号肽。在一些实施方案中,TCR或其抗原结合片段由核苷酸序列编码,所述核苷酸序列编码:a)α链,所述α链包含SEQ ID NO:318、319、322、323、326、327、330、331、334、335、338、339、130、131、134、135、195、205、222、242、253、256、313、314、475、476、490、491、502、503、508、509、520、521、534、535、552、553、567、568、585、586、597、598、609、610、621、622、635、636、647、648、659、660、674、675、689、690、707、708、724、725、739、740、757、758、773、774、785、786、797、798、813、814、828、829、843、844、855、856、867、868、879、880、893、894、906、907、923、924、935、936、949、950、961、962、973、974、985、986、997、998、1388、1389所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列;和/或b)β链,所述β链包含SEQ IDNO:320、321、324、325、328、329、332、333、336、337、110、129、132、133、179、180、206、221、246、250、260、312、315、316、481、482、496、497、514、515、616、528、529、543、544、558、559、576、577、591、592、603、604、615、627、628、641、642、653、654、665、666、683、684、698、699、716、717、733、734、748、749、766、767、779、780、791、792、806、807、822、823、837、838、849、850、861、862、873、874、885、886、899、900、915、916、929、930、943、944、955、956、967、968、979、980、991、992、1006、1007或1378-1379所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。在一些实施方案中,α链和β链可以经由接头(如本文其他地方所述的任何接头)连接。
在一些实施方案中,TCR或其抗原结合片段识别或结合至HPV16 E6的表位或区域,如含有SEQ ID NO:232-234中任一个所示的氨基酸序列的肽表位。在一些情况下,TCR或其抗原结合片段不识别或结合包含氨基酸序列TIHDIILECV(SEQ ID NO.233)的表位E6(29-38)。在一些情形中,识别或结合源自HPV16 E6的肽表位的TCR或其抗原结合片段是或包含SEQ ID NO:232或SEQ ID NO:234所示的序列。
在一些方面,TCR或抗原结合片段识别或结合至HPV16 E7蛋白的表位或区域,如含有SEQ ID NO:235-239中任一个所示的氨基酸序列的肽表位。在一些实施方案中,TCR或其抗原结合片段不识别或结合包含氨基酸序列YMLDLQPET(SEQ ID NO.236)的表位E7(11-19)。在一些情况下,源自HPV16 E7的肽是或含有SEQ ID NO:235所示的序列。
a.HPV 16E6(29-38)
在一些情况下,TCR识别或结合源自HPV16 E6的肽表位,其是或含有E6(29-38)TIHDIILECV(SEQ ID NO:233)。在一些实施方案中,TCR识别或结合在MHC(如MHC I类,例如HLA-A2)的背景下的HPV 16E6(29-38)。在一些实施方案中,HPV 16E6含有SEQ ID NO:264所示的序列。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有包含氨基酸序列X1X2X3X4X5X6X7X8X9X10X11X12X13X14X15X16X17X18(SEQ ID NO:1370)的互补决定区3(CDR-3),其中X1是A、I或V;X2是M、L、S或V;X3是R、L、Q或N;X4是E、V、T、P、G或F;X5是G、I、L、A、空或P;X6是R、T、G、空或S;X7是G、R或空;X8是T、G或空;X9是空或A;X10是空或G;X11是空或G;X12是空或T;X13是空或S;X14是G、Y、空或N;X15是F、G、N或T;X16是K、N或P;X17是T或L;并且X18是I、F、V或T。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有包含氨基酸序列X1X2X3X4X5X6X7X8X9X10X11X12X13X14X15X16X17X18(SEQ ID NO:248)的互补决定区3(CDR-3),其中X1是A、I或V;X2是M、L、S或V;X3是R、L、Q或N;X4是E、V、T、P、G或F;X5是G、I、L、A、空或P;X6是R、T、G、空或S;X7是G、R或空;X8是T、G或空;X9是空或A;X10是空或G;X11是空或G;X12是空或T;X13是空或S;X14是G、Y、空或N;X15是F、G、N或T;X16是K、N或P;X17是T或L;并且X18是I、V、F或T。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有包含氨基酸序列X1X2X3X4X5X6X7X8X9X10X11X12X13X14X15X16X17X18(SEQ ID NO:1205)的互补决定区3(CDR-3),其中X1是A、I或V;X2是M、L、A、V、S或E;X3是R、L、N、S、Q、K、G或W;X4是E、V、P、T、F、A、G、N、D或L;X5是G、I、D、L、A、P、H、N、R、T或空;X6是G、N、R、T、M、S、P或空;X7是G、V、D、L、Q、T、R、N或空;X8是T、D、S、L、G或空;X9是A、G、Q或空;X10是G或空;X11是G或空;X12是T或空;X13是S、A、T、G或空;X14是G、Y、T、N、A、W或空;X15是F、G、N、T、Y、D、S、R、Q或E;X16是K、P、A、N、D或Q;X17是L、M、I、V或T;并且X18是I、T、V、N、F、R或Q。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有包含氨基酸序列X1X2X3X4X5X6X7X8X9X10X11X12X13X14X15X16X17X18(SEQ IDNO:1220)的互补决定区3(CDR-3),其中X1是A、I或V;X2是M、L、A、V、S或E;X3是R、L、N、S、Q、K、G或W;X4是E、V、P、T、F、A、G、N、D或L;X5是G、I、D、L、A、P、N、R、T或空;X6是G、N、R、T、M、S、P或空;X7是G、V、D、L、Q、T、R或空;X8是T、D、S、L、G或空;X9是A、G、Q或空;X10是G或空;X11是G或空;X12是T或空;X13是S、A、T、G或空;X14是G、Y、T、N、A、W或空;X15是F、G、N、T、Y、D、S、R、Q或E;X16是K、P、A、D或Q;X17是L、M、I、V或T;并且X18是I、T、V、F、R或Q。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有包含氨基酸序列X1X2X3X4X5X6X7X8X9X10X11X12X13X14X15X16LT(SEQ ID NO:1206)的互补决定区3(CDR-3),其中X1是A、I或V;X2是L、M、V或E;X3是L、R、N、G或S;X4是V、T、F、N、E、P、G或L;X5是I、A、P、N、G或T;X6是R、G、S或T;X7是G、R、L、V或T;X8是T、G、L或空;X9是A、G、Q或空;X10是G或空;X11是G或空;X12是T或空;X13是S、T或G;X14是Y、A、G或N;X15是G、S、N、R或E;并且X16是K或Q。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有包含氨基酸序列AMRX4X5X6X7X8X9X10X11X12X13X14X15(SEQ ID NO:1207)的互补决定区3(CDR-3),其中X4是E、T、A、D或L;X5是G、A、N或R;X6是R、G、R、T、M或S;X7是G、V、D、L或空;X8是T、D或空;X9是G或空;X10是S、T、G或空;X11是G、Y、N、A或W;X12是F、G、N、D、S或Y;X13是K、D、Q;X14是T、L、M或I;并且X15是I、T、R或Q。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有包含氨基酸序列X1X2X3X4X5X6X7X8X9X10X11X12X13X14X15KX17X18(SEQ ID NO:1208)的互补决定区3(CDR-3),其中X1是I或V;X2是L或V;X3是L、N或R;X4是V、F或G;X5是I、P、G或T;X6是R、S、P或G;X7是G、R、Q、T或V;X8是T、G、S或L;X9是A、G、Q或空;X10是G或空;X11是G或空;X12是T或空;X13是G或S;X14是Y或N;X15是G、Q或E;X17是V或L;并且X18是I或T。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有包含氨基酸序列AX2RX4AX6NNDMR(SEQ ID NO:1221)的互补决定区3(CDR-3),其中X2是V或M;X4是P或D;X6是N或R。
在一些实施方案中,Vα区含有包含氨基酸序列X1X2X3X4X5X6X7(SEQ ID NO:1371)的互补决定区1(CDR-1),其中X1是T、D或N;X2是I或S;X3是S、D或A;X4是G、Q、P或空;X5是T、S或I;X6是D、Y或Q;并且X7是Y、G、N或Q。在一些实施方案中,Vα区含有包含氨基酸序列X1X2X3X4X5X6X7(SEQ ID NO:240)的互补决定区1(CDR-1),其中X1是T、D、S或N;X2是I或S;X3是S、D、N、Y或A;X4是G、Q、P或空;X5是T、S、F或I;X6是D、Y、P或Q;并且X7是Y、G、N、A、S或Q。在一些实施方案中,Vα区含有包含氨基酸序列X1X2X3X4X5X6X7(SEQ ID NO:1209)的互补决定区1(CDR-1),其中X1是T、N、D或S;X2是S、I或R;X3是D、S、M、A、Y、N或G;X4是Q、G、P或空;X5是S、T、F、I或N;X6是Y、D、Q、P、N或E;并且X7是G、Y、N、S或A。
在一些例子中,Vα区含有包含氨基酸序列X1X2X3X4X5X6X7X8(SEQ ID NO:1372)的互补决定区2(CDR-2),其中X1是G、Q、I或V;X2是L、S、Q或Y;X3是T、G或S;X4是Y、S或空;X5是空或D;X6是空、E、Q或S;X7是S、Q、R或G;并且X8是N或E。在一些例子中,Vα区含有包含氨基酸序列X1X2X3X4X5X6X7X8(SEQ ID NO:244)的互补决定区2(CDR-2),其中X1是G、Q、I、M、Y或V;X2是L、S、Q、T或Y;X3是T、G、L或S;X4是Y、S、N、A或空;X5是空、A或D;X6是空、E、Q、T或S;X7是S、Q、R、L或G;并且X8是N、V或E。在一些例子中,Vα区含有包含氨基酸序列X1X2X3X4X5X6X7X8(SEQ ID NO:1210)的互补决定区2(CDR-2),其中X1是Q、G、I、V、Y、M、R或N;X2是G、L、S、Q、Y、T、N或V;X3是S、T、L或K;X4是Y、I、S、A、N、F或空;X5是D、A或空;X6是E、K、Q、S、T、G、D或空;X7是Q、S、N、R、G、L或D;并且X8是N、K、E、V或L。
在一些方面,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列ASSX4X5X6X7X8X9X10X11X12X13(SEQ ID NO:1373)的互补决定区3(CDR-3),其中X4是H、P、L或Y;X5是L、G、W、F或S;X6是A、G或L;X7是G、E、A、T或空;X8是F、G、T或S;X9是T、N、H或A;X10是G、T、Q、D或Y;X11是E、P、T或G;X12是L、A、Q或Y;并且X13是F、H、Y或T。
在一些方面,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列ASX3X4X5X6X7X8X9X10X11X12X13(SEQ ID NO:258)的互补决定区3(CDR-3),其中X3是S或T;X4是H、P、L、F或Y;X5是L、G、W、F、T或S;X6是A、G或L;X7是G、E、A、T、Q或空;X8是F、G、T、R或S;X9是T、N、H、R、E或A;X10是G、T、Q、D、R或Y;X11是E、P、T或G;X12是L、A、Q或Y;并且X13是F、H、Y或T。
在一些方面,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列X1X2X3X4X5X6X7X8X9X10X11X12X13X14X15(SEQ ID NO:1211)的互补决定区3(CDR-3),其中X1是A、S或V;X2是S、A或V;X3是S、V、R或Q;X4是H、P、Q、L、Y、G、T、F、S、R或E;X5是L、G、R、W、F、S、V、T、Y、Q或空;X6是A、G、L、T、E、P或空;X7是G、T、A、R、Q、N、S或空;X8是G、S或空;X9是G或空;X10是F、G、A、S、T、R、Q、L或空;X11是T、N、F、A、R、S、G或空;X12是G、T、L D、Y、N、Q、S或E;X13是E、W、T、G、K、N或P;X14是L、A、K、Q、Y或I;并且X15是F、H、Y、T或I。
在一些方面,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列X1X2X3X4X5X6X7X8X9X10X11X12X13X14X15(SEQ ID NO:1222)的互补决定区3(CDR-3),其中X1是A、S或V;X2是S、A或V;X3是S、R或Q;X4是H、P、Q、L、Y、G、T、F、S、R或E;X5是L、G、R、W、F、S、V、T、Y、Q或空;X6是A、G、L、E、P或空;X7是G、T、A、R、Q、N、S或空;X8是G、S或空;X9是G或空;X10是F、G、A、S、T、R、Q、L或空;X11是T、N、F、A、R、S、G或空;X12是G、T、L D、Y、N、Q、S或E;X13是E、W、T、G、K、N或P;X14是L、A、K、Q、Y或I;并且X15是F、H、Y、T或I。
在一些方面,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列ASSX4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1212)的互补决定区3(CDR-3),其中X4是H、P、Q、L、Y、F、R或E;X5是L、G、R、W、F、S、V、T、Y或Q;X6是A、G、L、E P;X7是G、T、A、R、Q、S或空;X8是G、S或空;X9是F、G、A、S、T、R、L或空;X10是T、N、A、F、R、S或G;X11是G、T、L、D、Y、Q、S、E或N;X12是E、W、T、G、P、K;X13是L、A、K、Q、Y或I;并且X14是F、H、Y或T。
在一些方面,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列X1X2X3X4X5X6X7X8X9X10X11X12X13QY(SEQ ID NO:1213)的互补决定区3(CDR-3),其中X1是A或S;X2是S、V或A;X3是S或V;X4是L、Y、P或S;X5是W、F、V、L或Y;X6是G、T或A;X7是A、R、Q、S或空;X8是G或空;X9是G或空;X10是S、T、R或G;X11是T、A、R、S或N;X12是D、Y、T或G;并且X13是T或E。
在一些方面,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列X1X2SX4X5X6X7X8X9X10X11X12X13QY(SEQ ID NO:1223)的互补决定区3(CDR-3),其中X1是A或S;X2是S或A;X4是L、Y、P或S;X5是W、F、V、L或Y;X6是G或A;X7是A、R、Q、S或空;X8是G或空;X9是G或空;X10是S、T、R或G;X11是T、A、R、S或N;X12是D、Y、T或G;并且X13是T或E。
在一些方面,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列ASX3X4X5X6X7X8X9X10X11X12F(SEQ ID NO:1214)的互补决定区3(CDR-3),其中X3是S、Q或R;X4是H、P、T或E;X5是L、G、W或F;X6是A、G或空;X7是G、N、S、R或空;X8是F、G、Q、L、A或空;X9是T、N或A;X10是G、T、N或E;X11是E、N或K;并且X12是L、A或Q。
在一些方面,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列ASSX4X5X6X7X8NYX11YT(SEQ ID NO:1215)的互补决定区3(CDR-3),其中X4是L或R;X5是S或T;X6是G、T或A;X7是T或空;X8是G或空;并且X11是G或空。
在一些方面,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列ASSX4WGX7SNQPX12H(SEQ ID NO:1216)的互补决定区3(CDR-3),其中X4是L、F或P;X7是R或Q;并且X12是Q或L。
在一些方面,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列ASSX4X5X6X7X8SGNTIY(SEQ ID NO:1217)的互补决定区3(CDR-3),其中X4是L或R;X5是W或Q;X6是G或P;X7是R或S;并且X8是S或空。
在一些情形中,Vβ区含有包含氨基酸序列X1X2HX4X5(SEQ ID NO:252)的互补决定区1(CDR-1),其中X1是S或M;X2是G、E、D或N;X4是V、N或E;并且X5是S、R、N或Y。在一些情形中,Vβ区含有包含氨基酸序列X1X2X3X4X5X6(SEQ ID NO:1218)的互补决定区1(CDR-1),其中X1是S、M、D或L;X2是G、E、D、N、Q、S或F;X3是H、V、Y、N或Q;X4是A、S、F或空;X5是W V、N、E、T、P、Y、K、D或L;并且X6是S、R、A、N、Y、M或T。
在一些情况下,Vβ区含有包含氨基酸序列X1X2X3X4X5X6(SEQ ID NO:255)的互补决定区2(CDR-2),其中X1是F或S;X2是Q、Y或V;X3是N、D或G;X4是E或V;X5是A、K或G;并且X6是Q、M或T。在一些情况下,Vβ区含有包含氨基酸序列X1X2X3X4X5X6X7(SEQ ID NO:1219)的互补决定区2(CDR-2),其中X1是F、Y、S、A M;X2是N、Q、V、T、Y或A;X3是N、D、E、S、G、I、F、Q或L;X4是G、A、N或空;X5是E、K、V、E、S、T、G或N;X6是A、E、K、G、L、D、V或N;并且X7是Q、M、T、A、V、E、P、D或I。
在一些实施方案中,Vα区含有包含SEQ ID NO:138、144、147、163、167、173、304、308、478、493、505、511、523、539、555、572、588、600、612、624、638、650、662或679中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列的互补决定区3(CDR-3)。在一些例子中,Vα区含有SEQID NO:111、113、115、121、123 125、297、299、477、492、504、510、522、536、554、569、587、599、611、623、637、649、661或676中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列内所含的CDR3。在一些实施方案中,Vα区还含有包含SEQ ID NO:136、142、161、165 171、302、306、537、570或677中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列的互补决定区1(CDR-1)。在一些方面,Vα区含有SEQ ID NO:111、113、115、121、123 125、297、299、477、492、504、510、522、536、554、569、587、599、611、623、637、649、661或676中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列内所含的CDR-1。在一些实施方案中,Vα区还含有包含SEQ ID NO:137、143、162、166、172、303、307、538、571或678中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列的互补决定区2(CDR-2)。在一些情况下,Vα区含有SEQ ID NO:111、113、115、121、123 125、297、299、477、492、504、510、522、536、554、569、587、599、611、623、637、649、661或676中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列内所含的CDR-2。
在一些实施方案中,Vβ区含有包含SEQ ID NO:141、146、150、164、170 174、305、309、486、499、517、531、548、563、581、594、606、618、630、644、656、670或686中任一个所示的氨基酸序列的互补决定区3(CDR-3)、或者SEQ ID NO:112、114、116、122、124 126、298、300、483、498、516、530、545、560、578、593、605、617、629、643、655、667或685中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列内所含的CDR3。在一些实施方案中,Vβ区含有包含SEQ IDNO:139、145、148、168、484、546、561、579或668中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列的互补决定区1(CDR-1)。在一些情形中,Vβ区含有SEQ ID NO:112、114、116、122、124126、298、300、483、498、516、530、545、560、578、593、605、617、629、643、655、667或685中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列内所含的CDR-1。在一些实施方案中,Vβ区还含有包含SEQ ID NO:140、149、169、485、547、562、580或669中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列的互补决定区2(CDR-2)。在一些例子中,Vβ区含有SEQ ID NO:112、114、116、122、124 126、298、300、483、498、516、530、545、560、578、593、605、617、629、643、655、667或685中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列内所含的CDR-2。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有包含SEQ IDNO:136、142、161、165、171、302、306、537、570或677中任一个所示的氨基酸序列的互补决定区1(CDR-1),包含SEQ ID NO:137、143、162、166、172、303、307、538、571或678中任一个所示的氨基酸序列的互补决定区2(CDR-2),和/或包含SEQ ID NO:138、144、147、163、167 173、304、308、478、493、505、511、523、539、555、572、588、600、612、624、638、650、662或679中任一个所示的氨基酸序列的互补决定区3(CDR-3)。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。在一些方面,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含SEQ ID NO:139、145、148、168、484、546、561、579或668中任一个所示的氨基酸序列的互补决定区1(CDR-1),包含SEQID NO:140、149、169、485、547、562、580或669中任一个所示的氨基酸序列的互补决定区2(CDR-2),和/或包含SEQ ID NO:141、146、150、164、170 174、305、309、486、499、517、531、548、563、581、594、606、618、630、644、656、670或686中任一个所示的氨基酸序列的互补决定区3(CDR-3)。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:136、137和138的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:139、140和141的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,Vα区含有分别包含SEQ ID NO:142、143和144的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:145、140和146的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,Vα区含有分别包含SEQ ID NO:136、137和147的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:148、149和150的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,Vα区含有分别包含SEQ ID NO:161、162和163的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:148、149和164的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,Vα区含有分别包含SEQ ID NO:165、166和167的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:168、169和170的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,Vα区含有分别包含SEQ ID NO:171、172和173的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:148、149和174的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,Vα区含有分别包含SEQ ID NO:302、303和304的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:139、140和305的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,Vα区含有分别包含SEQ ID NO:306、307和308的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:148、149和309的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:136、137和478的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:484、485和486的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:161、162和493的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:148、149和499的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:165、166和505的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:148、149和499的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:161、162和511的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:148、149和517的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:136、137和523的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:148、149和531的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:537、538和539的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:546、547和548的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:136、137和555的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:561、562和563的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:570、571和572的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:579、580和581的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:136、137和588的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:148、149和594的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:136、137和600的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:148、149和606的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:136、137和612的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:148、149和618的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:136、137和624的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:168、169和630的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:142、143和638的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:561、562和644的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:171、172和650的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:148、149和656的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:136、137和662的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:668、669和670的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:677、678和679的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:154、155和686的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,Vα区含有互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:111、113、115、121、123 125、297、299、477、492、504、510、522、536、554、569、587、599、611、623、637、649、661或676中任一个所示的Vα区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列。在一些方面,Vβ区含有互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:112、114、116、122、124 126、298、300、483、498、516、530、545、560、578、593、605、617、629、643、655、667或685中任一个所示的Vβ区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列。所提供的TCR还包括含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或抗原结合片段包括Vα区,所述Vα区含有互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含表2所列的CDR-1、CDR-2和CDR-3氨基酸序列;以及Vβ区,所述Vβ区含有互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含表2所列的CDR-1、CDR-2和CDR-3氨基酸序列。所提供的TCR还包括含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。含有此类CDR的示例性TCR或其如本文其他地方所述的经修饰形式也列于表2中。


在一些情形中,TCR或其抗原结合片段含有分别含有SEQ ID NO:111和112的氨基酸序列的Vα和Vβ区。在一些实施方案中,Vα和Vβ区分别含有SEQ ID NO:113和114的氨基酸序列。在一些情况下,Vα和Vβ区分别含有SEQ ID NO:115和116的氨基酸序列。在一些实施方案中,Vα和Vβ区分别含有SEQ ID NO:121和122的氨基酸序列。在一些方面,Vα和Vβ区分别含有SEQ ID NO:123和124的氨基酸序列。在一些例子中,Vα和Vβ区分别含有SEQ ID NO:125和126的氨基酸序列。在一些例子中,Vα和Vβ区分别含有SEQ ID NO:297和298的氨基酸序列。在一些例子中,Vα和Vβ区分别含有SEQ ID NO:299和300的氨基酸序列。在一些实施方案中,Vα和Vβ区分别含有SEQ ID NO:477和483的氨基酸序列。在一些例子中,Vα和Vβ区分别含有SEQ ID NO:492和498的氨基酸序列。在一些情况下,Vα和Vβ区分别含有SEQ ID NO:504和498的氨基酸序列。在一些情形中,TCR或其抗原结合片段含有分别含有SEQ ID NO:510和516的氨基酸序列的Vα和Vβ区。在一些实施方案中,Vα和Vβ区分别含有SEQ ID NO:522和530的氨基酸序列。在一些例子中,Vα和Vβ区分别含有SEQ ID NO:536和545的氨基酸序列。在一些情况下,Vα和Vβ区分别含有SEQ ID NO:554和560的氨基酸序列。在一些情形中,TCR或其抗原结合片段含有分别含有SEQ ID NO:569和578的氨基酸序列的Vα和Vβ区。在一些实施方案中,Vα和Vβ区分别含有SEQ ID NO:587和593的氨基酸序列。在一些例子中,Vα和Vβ区分别含有SEQ ID NO:599和605的氨基酸序列。在一些实施方案中,Vα和Vβ区分别含有SEQ IDNO:611和617的氨基酸序列。在一些情况下,Vα和Vβ区分别含有SEQ ID NO:623和629的氨基酸序列。在一些情形中,Vα和Vβ区分别含有SEQ ID NO:637和643的氨基酸序列。在一些情况下,Vα和Vβ区分别含有SEQ ID NO:649和655的氨基酸序列。在一些例子中,Vα和Vβ区分别含有SEQ ID NO:661和667的氨基酸序列。在一些情况下,Vα和Vβ区分别含有SEQ ID NO:676和685的氨基酸序列。所提供的TCR还包括含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段的α链还含有Cα区或其部分和/或β链还含有Cβ区或其部分。在一些实施方案中,Cα区或其部分包含SEQ ID NO:212、213、215、218或524中任一个所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。在一些方面,Cβ区含有SEQ ID NO:214、216或631所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。在一些实施方案中,例如通过掺入一个或多个非天然半胱氨酸残基(如本文所述的任何非天然半胱氨酸残基)来修饰Cα和/或Cβ区。在一些实施方案中,Cα区或其部分在残基48处含有非天然半胱氨酸,并且包含SEQ IDNO:196、198、201、203或525中任一个所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性且含有引入的非天然半胱氨酸残基(例如Cys48)的序列。在一些方面,Cβ区在残基57处含有非天然半胱氨酸,并且含有SEQ ID NO:197、199或632所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。
在一些实施方案中,TCR或其抗原结合片段包含α链,所述α链包含SEQ ID NO:18、28、38、68、78、88、287、291、473、488、500、506、518、532、550、565、583、595、607、619、633、645、657或672所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列;和/或β链,所述β链包含SEQ ID NO:22、32、42、72、82、92、289、293、479、494、512、526、541、556、574、589、601、613、625、639、651、663或681所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。
在一些实施方案中,TCR或其抗原结合片段包含α链,所述α链包含SEQ ID NO:19、29、39、69、79、89、288、292、474、489、501、507、519、533、551、566、584、596、608、620、634、646、658或673所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列;和/或β链,所述β链包含SEQ ID NO:23、33、43、73、83、93、290、294、480、495、513、527、542、557、575、590、602、614、626、640、652、664或682所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。
在一些实施方案中,Vα和Vβ区含有对应于表3或表4所列的SEQ ID NO.的氨基酸序列。在一些方面,TCR含有恒定α和恒定β区序列,如对应于表3或表4所列的SEQ ID NO.的那些。在一些情况下,TCR含有包含可变链和恒定链的完整序列,如对应于表3或4所列的SEQID NO.的序列(“完整”)。在一些实施方案中,含有可变区和恒定区的完整序列还包括信号序列,因此包含对应于表3或4所列的SEQ ID NO.的序列(“完整+信号”)。所提供的TCR还包括含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。含有此类序列的示例性TCR或其如本文其他地方所述的经修饰形式也分别列于表3和4中。



b.HPV 16 E7(11-19)
在一些情况下,TCR识别或结合源自HPV 16E7的肽表位,其是或含有E7(11-19)YMLDLQPET(SEQ ID NO:236)。在一些实施方案中,TCR识别或结合在MHC(如MHC I类,例如HLA-A2)的背景下的HPV 16E7(11-19)。在一些实施方案中,HPV 16E7含有SEQ ID NO:265所示的序列。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有包含氨基酸序列X1X2X3X4X5X6X7X8X9X10X11(SEQ ID NO:249)的互补决定区3(CDR-3),其中X1是A或V;X2是E或V;X3是S或P;X4是I、S或R;X5是R、G或D;X6是G、A或N;X7是F、空或Y;X8是G或T;X9是T、Q或N;X10是V、K或N;X11是L或F;并且X12=H、I或V。在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有包含氨基酸序列X1X2SX4X5X6X7X8X9X10X11(SEQ ID NO:1374)的互补决定区3(CDR-3),其中X1是A或V;X2是E或V;X4是I或R;X5是R或D;X6是G或N;X7是F或Y;X8是N或Q;X9是V或N;X10是L或F;并且X11是H或V。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有包含氨基酸序列X1X2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1183)的互补决定区3(CDR-3),其中X1是V或A;X2是V、A、G、Q、M或E;X3是S、G、A、N、Y、R、T或P;X4是E、A、S、G、R、F、N、D、V、P、L、I或M;X5是R、N、H、T、D、G、S、A、P、L、Q或F;X6是G、H、N、A、S、L、T或空;X7是T、S、G或空;X8是G或空;X9是G、Y、N、S或空;X10是T、G、S、D、F、Y、A、N或空;X11是Y、F、Y、Q、N或R;X12是N、K、Q或D;X13是Y、L、T、F、M或V;并且X14是I、T、S、V、R或Y。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有包含氨基酸序列VVX3X4X5X6X7X8GX10X11X12X13(SEQ ID NO:1184)的互补决定区3(CDR-3),其中X3是S、N或T;X4是R或F;X5是D或A;X6是N或L;X7是T或空;X8是Y或G;X10是Q或F;X11是N或K;X12是F或T;并且X13是V或I。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有包含氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1185)的互补决定区3(CDR-3),其中X2是A、G、V、Q、M或E;X3是S、G、N、A、Y、R或P;X4是E、S、A、G、F、N、D、V、P、L、I、M或R;X5是R、N、H、T、D、G、S、P、L、Q或F;X6是G、H、A、S、T或空;X7是T、S、G或空;X8是G或空;X9是G、N、S或空;X10是T、G、S、D、F、Y、A或N;X11是Y、F、Q、R或N;X12是K、Q或D;X13是Y、L、T、M、F或V;并且X14是I、T、S、R、Y或V。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有包含氨基酸序列X1X2X3X4X5X6X7X8X9X10KX12I(SEQ ID NO:1186)的互补决定区3(CDR-3),其中X1是A或V;X2是A、V或E;X3是S、N、T、R或P;X4是E、A、G、F、V、P、I、D或S;X5是R、H、T、AP、S、G或F;X6是G、H、L、T、S、A或空;X7是S、T或空;X8是G或空;X9是G、T或空;X10是F、Y或N;并且X12是Y、T或L。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有包含氨基酸序列AX2X3X4X5X6X7X8X9YKYI(SEQ ID NO:1187)的互补决定区3(CDR-3),其中X2是A、V或E;X3是S、N或R;X4是E、G、V、P、I或D;X5是R、T、P、S、G或F;X6是G、T、S或空;X7是S或空;X8是G或空;并且X9是T或空。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有包含氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1188)的互补决定区3(CDR-3),其中X2是G、V、Q或M;X3是G、A、Y、S、N或R;X4是S、G、L、I、M或R;X5是N、D、G、S、L、Q或R;X6是A、S、G或空;X7是G或空;X8是G或空;X9是G、N、S或空;X10是S、D、Y、A、N或空;X11是Y、Q或R;X12是K或Q;X13是L或V;并且X14是S、T或V。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有包含氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13T(SEQ ID NO:1189)的互补决定区3(CDR-3),其中X2是G、V或Q;X3是G、Y、S或N;X4是S、L或M;X5是N、G、L或R;X6是A、S、G或空;X7是G或空;X8是G或空;X9是G、S或空;X10是S、Y、A、N或空;X11是Y、Q或R;X12是K或Q;并且X13是L或V。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有包含氨基酸序列AX2X3X4X5X6X7YKLS(SEQ ID NO:1190)的互补决定区3(CDR-3),其中X2是G或V;X3是A或Y;X4是G、S或R;X5是D或S;X6是N或空;并且X7是D或空。
在一些实施方案中,Vα区含有包含氨基酸序列X1SX3X4X5X6(SEQ ID NO:241)的互补决定区1(CDR-1),其中X1是D或V;X3是S或P;X4是S或F;X5是T或S;并且X6是Y或N。在一些实施方案中,Vα区含有包含氨基酸序列X1X2X3X4X5X6(SEQ ID NO:1191)的互补决定区1(CDR-1),其中X1是N、S、D、T或V;X2是S、V、R、T或I;X3是M、F、G、S、N、A、L、V或P;X4是F、S、N、A或空;X5是D、S、Q、Y、N、V、T或P;并且X6是Y、S、R、N、G或T。
在一些情况下,Vα区含有包含氨基酸序列X1X2X3X4X5X6X7(SEQ ID NO:245)的互补决定区2(CDR-2),其中X1是I或M;X2是F或T;X3是S或F;X4是N或S;X5是M或E;X6是D或N;并且X7是M或T。在一些实施方案中,Vα区含有包含氨基酸序列X1X2X3X4X5X6X7X8(SEQ ID NO:1192)的互补决定区2(CDR-2),其中X1是I、V、L、G、N、T、Y或M;X2是S、V、Y、L、P、F、I或T;X3是S、Y、K、L、T或F;X4是I、G、N、A、S或空;X5是S、D或空;X6是K、G、N、S、D、T或E;X7是D、E、G、A、K、L或N;并且X8是K、V、D、P、N、T、L或M。
在一些方面,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列AX2TX4RX6X7YX9X10X11(SEQ ID NO:259)的互补决定区3(CDR-3),其中X2是S或I;X4是T或D;X6是S或T;X7是S或N;X9是E或G;X10是Q或Y;并且X11是Y或T。
在一些实施方案中,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1193)的互补决定区3(CDR-3),其中X2是S、M、I、K或V;X3是S、T、N或A;X4是R、V P、S、T、G、L、A、I或D;X5是F、G、R、Y、S、L、V或T;X6是L、G、D、A、S、T、V、R或空;X7是G、D、R、S、T或空;X8是S或空;X9是S、H、G、R、V、T、D、L或空;X10是T、S、A、Y、N、G或P;X11是D、Y、N、E、K或G;X12是T、E、G或K;X13是Q、Y、A或L;并且X14是Y、F、T或I。
在一些实施方案中,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列AX2TX4X5X6X7X8X9X10X11X12(SEQ ID NO:1194)的互补决定区3(CDR-3),其中X2是S、M、I或K;X4是P、T、G、A、S或D;X5是R或S;X6是D、G、S、T或V;X7是R、S或空;X8是T、Y、G、N或S;X9是Y、N或K;X10是E或G;X11是Q、A或Y;并且X12是Y、F或T。
在一些实施方案中,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1195)的互补决定区3(CDR-3),其中X2是S、M、I或K;X3是S、T、A或N;X4是R、V、S、P、T、G、L或A;X5是F、G、R、Y、S、V或T;X6是L、G、D、A、S、T、V或空;X7是G、D、R、T或空;X8是S或空;X9是S、H、G、R、V、T、L或空;X10是T、S、Y、A、N、G或P;X11是D、Y、N、K、E或G;X12是T或E;X13是Q、A或L;并且X14是Y或F。
在一些实施方案中,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列AX2X3X4X5X6X7X8X9X10X11QY(SEQ ID NO:1196)的互补决定区3(CDR-3),其中X2是S、M、I或K;X3是S、T、A或N;X4是R、P、S、G、L、A或T;X5是F、R、Y、V或T;X6是L、D、A、S、T、V或空;X7是G、R或空;X8是S、G、V或空;X9是T、A、G、N、S或P;X10是D、Y或E;并且X11是T或E。
在一些实施方案中,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列AX2X3X4X5X6X7X8X91YEQY(SEQ ID NO:1197)的互补决定区3(CDR-3),其中X2是S、M、I或K;X3是S、T、A或N;X4是P、S、G、T或A;X5是R或Y;X6是D、A、S、T或V;X7是R或空;X8是G、V或空;并且X9是S、T、A或N。
在一些实施方案中,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列ASTX4X5X6X7X8X9X10X11EX13X14(SEQ ID NO:1198)的互补决定区3(CDR-3),其中X4是T、P或G;X5是R或S;X6是S、D、G或V;X7是D或空;X8是S或空;X9是S、R或空;X10是S、T、Y或G;X11是Y、N或K;X13是Q或A;并且X14是Y或F。
在一些实施方案中,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列AX2X3X4X5X6X7X8YGYT(SEQ ID NO:1199)的互补决定区3(CDR-3),其中X2是S或I;X3是S或T;X4是L、A或D;X5是L、T或R;X6是L、T或R;X7是G、D或空;并且X8是A或N。
在一些实施方案中,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1200)的互补决定区3(CDR-3),其中X2是S、V或I;X3是S、N或A;X4是R、V、S、L、P、G、I或A;X5是F、G、Y、L、V、R、T或S;X6是L、G、A、D、R、V或空;X7是G、D、R、S、T或空;X8是S或空;X9是S、H、G、V、T、D、L或空;X10是T、S、A、G、P、N或Y;X11是D、Y、E、G或N;X12是T、E、G或K;X13是Q、Y或L;并且X14是Y、F、T或I。
在一些实施方案中,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列ASSX4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1201)的互补决定区3(CDR-3),其中X4是R、V、S、L、G或A;X5是F、G、Y、L、V、T或S;X6是A、L、R、D、G或空;X7是G、D、T或空;X8是S或空;X9是S、H、G、T、D、L或空;X10是T、S、A、G、P、N或Y;X11是D、Y、E、G或N;X12是T、E、G或T;X13是Q、Y或L;并且X14是Y、F或T。
在一些实施方案中,TCR或其抗原结合片段含有Vβ区,所述Vβ区含有包含氨基酸序列ASSX4X5X6X7X8X9X10TQY(SEQ ID NO:1202)的互补决定区3(CDR-3),其中X4是R、L或G;X5是F、V、T或Y;X6是L、A或空;X7是G或空;X8是S、G或空;X9是T、G、P或S;并且X10是D或E。
在一些实施方案中,Vβ区含有包含氨基酸序列SX2X3X4X5(SEQ ID NO:1203)的互补决定区1(CDR-1),其中X2是G或N;X3是H或D;X4是T、L、N或V;并且X5是A、S、Y或T。
在一些实施方案中,Vβ区含有包含氨基酸序列X1X2X3X4X5X6(SEQ ID NO:1204)的互补决定区2(CDR-2),其中X1是F或Y;X2是Q、Y或N;X3是G、N、R或Y;X4是N、G、E或T;X5是S、E、A或G;并且X6是A、E、I或Q。
在一些方面,Vβ区含有包含SEQ ID NO:154、701、719或751所示的氨基酸序列的互补决定区1(CDR-1)。在一些实施方案中,Vβ区含有包含SEQ ID NO:155、702、720、752、918或1009所示的氨基酸序列的互补决定区2(CDR-2)。
在一些实施方案中,Vα区含有包含SEQ ID NO:153、159、301、694、712、729、744、762、776、788、802、818、832、846、858、870、882、896、911、926、940、952、964、976、988、1002或1391中任一个所示的氨基酸序列的互补决定区3(CDR-3)、或者SEQ ID NO:117、119、295、691、709、726、741、759、775、787、799、815、830、845、857、869、881、895、908、925、937、951、963、975、987、999或1390中任一个所示的氨基酸序列内所含的CDR3。在一些实施方案中,Vα区含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的CDR3序列。
在一些实施方案中,Vα区还含有包含SEQ ID NO:151、157、171、692、710、727、742、760、800、816、909、938或1000中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列的互补决定区1(CDR-1)。在一些方面,Vα区还含有包含SEQ ID NO:152、158、172、693、711、728、743、761、801、817、831、910、939或1001中任一个所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列的互补决定区2(CDR-2)。
在一些方面,Vβ区含有包含SEQ ID NO:156、160、703、721、736、753、769、782、794、809、825、840、852、864、876、888、902、919、932、946、958、970、982、994、1010或1381中任一个所示的氨基酸序列的互补决定区3(CDR-3)、或者SEQ ID NO:118、120、296、700、718、735、750、768、781、793、808、824、839、851、863、875、887、901、917、931、945、957、969、981、993、1008、1380中任一个所示的氨基酸序列内所含的CDR3。在一些实施方案中,Vβ区含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的CDR3序列。在一些实施方案中,Vβ区含有包含SEQ ID NO:154、701、719或751所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列的互补决定区1(CDR-1)。在一些情形中,Vβ区含有包含SEQ ID NO:155、702、720、752、918或1009所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列的互补决定区2(CDR-2)。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:151、152和153的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:154、155和156的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些方面,Vα区含有分别包含SEQ ID NO:157、158和159的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类方面,Vβ区含有分别包含SEQ ID NO:154、155和160的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,Vα区含有分别包含SEQ ID NO:151、152和301的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:154、155和156的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:692、693和694的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:701、702和703的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:710、711和712的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:719、720和721的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:727、728和729的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:154、155和736的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:742、743和744的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:751、752和753的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:760、761和762的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:719、720和769的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:171、172和776的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:154、155和782的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:742、743和788的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:139、140和794的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:800、801和802的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:751、752和809的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:816、817和818的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:154、155和825的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:816、831和832的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:154、155和840的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:171、172和846的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:154、155和852的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:816、831和858的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:154、155和864的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:727、728和870的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:154、155和876的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:570、571和882的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:719、720和888的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:816、817和896的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:701、702和902的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:909、910和911的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:701、918和919的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:727、728和926的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:154、155和932的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:938、939和940的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:154、155和946的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:727、728和952的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:154、155和958的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:151、152和964的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:719、720和970的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:727、728和976的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:154、155和982的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:710、711和988的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:719、720和994的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:1000、1001和1002的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:139、1009和1010的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段含有Vα区,所述Vα区含有分别包含SEQID NO:171、172和1391的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:154、155和1381的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些情形中,Vα区含有互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ IDNO:117、119、295、691、709、726、741、759、775、787、799、815、830、845、857、869、881、895、908、925、937、951、963、975、987、999或1390中任一个所示的Vα区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列。在一些情况下,Vβ区含有互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:118、120、296、700、718、735、750、768、781、793、808、824、839、851、863、875、887、901、917、931、945、957、969、981、993、1008或1380中任一个所示的Vβ区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列。所提供的TCR还包括含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或抗原结合片段包括Vα区,所述Vα区含有互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含表5所列的CDR-1、CDR-2和CDR-3氨基酸序列;以及Vβ区,所述Vβ区含有互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含表5所列的CDR-1、CDR-2和CDR-3氨基酸序列。所提供的TCR还包括含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。含有此类CDR的示例性TCR或其如本文其他地方所述的经修饰形式也列于表5中。


在一些实施方案中,TCR或其抗原结合片段含有分别含有SEQ ID NO:117和118或296的氨基酸序列的Vα和Vβ区。在一些方面,Vα和Vβ区分别含有SEQ ID NO:119和120的氨基酸序列。在一些方面,Vα和Vβ区分别含有SEQ ID NO:295和118或296的氨基酸序列。所提供的TCR还包括含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。在一些情况下,Vα和Vβ区分别含有SEQ ID NO:691和700的氨基酸序列。在一些情形中,Vα和Vβ区分别含有SEQ ID NO:709和718的氨基酸序列。在一些方面,Vα和Vβ区分别含有SEQ ID NO:726和735的氨基酸序列。在一些实施方案中,Vα和Vβ区分别含有SEQ ID NO:741和750的氨基酸序列。在一些情况下,Vα和Vβ区分别含有SEQ IDNO:759和768的氨基酸序列。在一些方面,Vα和Vβ区分别含有SEQ ID NO:775和781的氨基酸序列。在一些实施方案中,Vα和Vβ区分别含有SEQ ID NO:787和793的氨基酸序列。在一些例子中,Vα和Vβ区分别含有SEQ ID NO:799和808的氨基酸序列。在一些情况下,Vα和Vβ区分别含有SEQ ID NO:815和824的氨基酸序列。在一些情形中,Vα和Vβ区分别含有SEQ ID NO:830和839的氨基酸序列。在一些实施方案中,Vα和Vβ区分别含有SEQ ID NO:845和851的氨基酸序列。在一些方面,Vα和Vβ区分别含有SEQ ID NO:857和863的氨基酸序列。在一些情况下,Vα和Vβ区分别含有SEQ ID NO:869和875的氨基酸序列。在一些情形中,Vα和Vβ区分别含有SEQ ID NO:881和887的氨基酸序列。在一些实施方案中,Vα和Vβ区分别含有SEQ ID NO:895和901的氨基酸序列。在一些方面,Vα和Vβ区分别含有SEQ ID NO:908和917的氨基酸序列。在一些情况下,Vα和Vβ区分别含有SEQ ID NO:925和931的氨基酸序列。在一些情形中,Vα和Vβ区分别含有SEQ ID NO:937和945的氨基酸序列。在一些例子中,Vα和Vβ区分别含有SEQID NO:951和957的氨基酸序列。在一些情况下,Vα和Vβ区分别含有SEQ ID NO:963和969的氨基酸序列。在一些情形中,Vα和Vβ区分别含有SEQ ID NO:975和981的氨基酸序列。在一些情况下,Vα和Vβ区分别含有SEQ ID NO:987和993的氨基酸序列。在一些实施方案中,Vα和Vβ区分别含有SEQ ID NO:999和1008的氨基酸序列。在一些实施方案中,Vα和Vβ区分别含有SEQ ID NO:1390和1380的氨基酸序列。
在一些实施方案中,TCR或其抗原结合片段的α链还含有Cα区或其部分和/或β链还含有Cβ区或其部分。在一些实施方案中,Cα区或其部分包含SEQ ID NO:213、217、218或524中任一个所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。在一些方面,Cβ区含有SEQ ID NO:214、216、631或889所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。在一些实施方案中,例如通过掺入一个或多个非天然半胱氨酸残基(如本文所述的任何非天然半胱氨酸残基)来修饰Cα和/或Cβ区。在一些实施方案中,Cα区或其部分在残基48处含有非天然半胱氨酸,并且包含SEQ IDNO:196、200、201、203或525中任一个所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性且含有引入的非天然半胱氨酸残基(例如,Cys48)的序列。在一些方面,Cβ区在残基57处含有非天然半胱氨酸,并且含有SEQ ID NO:197、199、890或1363所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。
在一些实施方案中,TCR或其抗原结合片段包含α链,所述α链包含SEQ ID NO:48、58、283、687、705、722、737、755、771、783、795、811、826、841、853、865、877、891、904、921、933、947、959、971、983、995或1386所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列;和/或β链,所述β链包含SEQ ID NO:52、285、62、696、714、731、746、764、777、789、804、820、835、847、859、871、883、897、913、927、941、953、965、977、989、1004或1376所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。
在一些实施方案中,TCR或其抗原结合片段包含α链,所述α链包含SEQ ID NO:49、59、284、688、706、723、738、756、772、784、796、812、827、842、854、866、878、892、905、922、934、948、960、972、984、996或1387所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列;和/或β链,所述β链包含SEQ ID NO:53、63、286、697、715、732、747、765、778、790、805、821、836、848、860、872、884、898、914、928、942、954、966、978、990、1005或1377所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。
在一些实施方案中,Vα和Vβ区含有对应于表6或表7所列的SEQ ID NO.的氨基酸序列。在一些方面,TCR含有恒定α和恒定β区序列,如对应于表6或表7所列的SEQ ID NO.的那些。在一些情况下,TCR含有包含可变链和恒定链的完整序列,如对应于表6或表7所列的SEQID NO.的序列(“完整”)。在一些实施方案中,含有可变区和恒定区的完整序列还包括信号序列,因此包含对应于表6或表7所列的SEQ ID NO.的序列(“完整+信号”)。所提供的TCR还包括含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。含有此类序列的示例性TCR或其如本文其他地方所述的经修饰形式也分别列于表6和7中。




c.HPV 16E7(86-93)
在一些情况下,TCR识别或结合源自HPV16 E7的肽表位,其是或含有E7(86-93)TLGIVCPI(SEQ ID NO:235)。在一些实施方案中,TCR识别或结合在MHC(如MHC I类,例如HLA-A2)的背景下的HPV 16E7(86-93)。
在一些实施方案中,Vα区含有包含SEQ ID NO:175所示的氨基酸序列的互补决定区3(CDR-3)。在一些实施方案中,Vα区含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的CDR3序列。在一些方面,Vα区含有包含SEQID NO:142所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列的互补决定区1(CDR-1)。在一些方面,Vα包含含有SEQ ID NO:143所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列的互补决定区2(CDR-2)。
在一些实施方案中,Vβ区含有包含SEQ ID NO:178所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列的互补决定区3(CDR-3)。在一些情况下,Vβ区含有包含SEQ ID NO:176所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列的互补决定区1(CDR-1)。在一些方面,Vβ区含有包含SEQ ID NO:177所示的氨基酸序列或与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列的互补决定区2(CDR-2)。
在一些实施方案中,Vα区含有分别包含SEQ ID NO:142、143和175的氨基酸序列的CDR-1、CDR-2和CDR-3。在一些此类实施方案中,Vβ区含有分别包含SEQ ID NO:176、177和178的氨基酸序列的CDR-1、CDR-2和CDR-3。所提供的TCR还包括具有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些方面,Vα区含有互补决定区1(CDR-1),CDR-2和CDR-3,其分别包含SEQ IDNO:127所示的Vα区氨基酸序列所含的CDR-1、CDR-2和CDR-3氨基酸序列。在一些实施方案中,Vβ区含有CDR-1,CDR-2和CDR-3,其分别包含SEQ ID NO:128所示的Vβ区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列。所提供的TCR还包括含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或抗原结合片段包括Vα区,所述Vα区含有互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含表8所列的CDR-1、CDR-2和CDR-3氨基酸序列;以及Vβ区,所述Vβ区含有互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含表8所列的CDR-1、CDR-2和CDR-3氨基酸序列。所提供的TCR还包括含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。含有此类CDR的示例性TCR或其如本文其他地方所述的经修饰形式也列于表8中。

在一些实施方案中,TCR或其抗原结合片段含有分别包含SEQ ID NO:127和128的氨基酸序列的Vα和Vβ区。所提供的TCR还包括含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,TCR或其抗原结合片段的α链还含有Cα区或其部分和/或β链还含有Cβ区或其部分。在一些实施方案中,Cα区或其部分包含SEQ ID NO:212、213或217中任一个所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。在一些方面,Cβ区含有SEQ ID NO:214或216所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。在一些实施方案中,例如通过掺入一个或多个非天然半胱氨酸残基(如本文所述的任何非天然半胱氨酸残基)来修饰Cα和/或Cβ区。在一些实施方案中,Cα区或其部分在残基48处含有非天然半胱氨酸,并且包含SEQ ID NO:200所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性且含有引入的非天然半胱氨酸残基(例如Cys48)的序列。在一些方面,Cβ区在残基57处含有非天然半胱氨酸,并且含有SEQ ID NO:197或199所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。
在一些实施方案中,TCR或其抗原结合片段包含α链,所述α链包含SEQ ID NO:98所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列;和/或β链,所述β链包含SEQ ID NO:102所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。
在一些实施方案中,TCR或其抗原结合片段包含α链,所述α链包含SEQ ID NO:99所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列;和/或β链,所述β链包含SEQ ID NO:103所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列,如与这样的序列具有至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%同一性的序列。
在一些实施方案中,Vα和Vβ区含有对应于表9或表10所列的SEQ ID NO.的氨基酸序列。在一些方面,TCR含有恒定α和恒定β区序列,如对应于表9或表10所列的SEQ ID NO.的那些。在一些情况下,TCR含有包含可变链和恒定链的完整序列,如对应于表9或表10所列的SEQ ID NO.的序列(“完整”)。在一些实施方案中,含有可变区和恒定区的完整序列还包括信号序列,因此包含对应于表9或表10所列的SEQ ID NO.的序列(“完整+信号”)。所提供的TCR还包括含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。含有此类序列的示例性TCR或其如本文其他地方所述的经修饰形式也分别列于表9和10中。


2.变体和修饰
在一些实施方案中,结合分子(例如,TCR或其抗原结合片段)被修饰或已经被修饰。在某些实施方案中,与本文所述的结合分子(例如,TCR)的序列相比,结合分子(例如,TCR或其抗原结合片段)包括一个或多个氨基酸变化,例如取代、缺失、插入和/或突变。示例性变体包括设计用于改善结合分子的结合亲和力和/或其他生物特性的那些。可以通过将适当的修饰引入编码结合分子的核苷酸序列中或者通过肽合成来制备结合分子的氨基酸序列变体。此类修饰包括例如结合分子的氨基酸序列内的残基的缺失和/或插入和/或取代。可以进行缺失、插入和取代的任何组合以得到最终的构建体,条件是最终的构建体具有所需特征,例如抗原结合。
在一些实施方案中,使用定向进化方法来产生具有改变的特性(如对在MHC分子的背景下的特定肽具有较高亲和力)的TCR。在一些实施方案中,通过展示方法实现定向进化,所述展示方法包括但不限于酵母展示(Holler等人(2003)Nat Immunol,4,55-62;Holler等人(2000)Proc Natl Acad Sci U SA,97,5387-92)、噬菌体展示(Li等人(2005)NatBiotechnol,23,349-54)或T细胞展示(Chervin等人(2008)J Immunol Methods,339,175-84)。在一些实施方案中,展示方法涉及工程化或修饰已知的亲本或参考TCR。例如,在一些情况下,参考TCR(如本文提供的任何参考TCR)可以用作模板以用于产生经诱变的TCR,其中CDR的一个或多个残基被突变,并且选择具有所需改变的特性(如对在MHC分子的背景下的肽表位具有较高亲和力)的突变体。
在某些实施方案中,例如与本文所述的结合分子(例如,TCR)序列相比和/或与天然库(例如,人库)的序列相比,结合分子(例如,TCR或其抗原结合片段)包括一个或多个氨基酸取代。替代诱变的目的位点包括CDR、FR和/或恒定区。可以将氨基酸取代引入目的结合分子中,并且筛选产物的所需活性,例如保留/改善的抗原亲和力或亲合力、降低的免疫原性、改善的半衰期、CD8非依赖性结合或活性、表面表达、促进TCR链配对和/或其他改善的特性或功能。
在一些实施方案中,亲本结合分子(例如,TCR)的CDR内的一个或多个残基被取代。在一些实施方案中,进行取代以将序列或序列中的位置恢复为种系序列,如在种系(例如,人种系)中发现的结合分子序列,例如以降低免疫原性的可能性,例如在给予人类受试者以后。
在某些实施方案中,取代、插入或缺失可以在一个或多个CDR内发生,只要此类改变基本上不降低结合分子(例如,TCR或其抗原结合片段)结合抗原的能力。例如,可以在CDR中进行基本上不降低结合亲和力的保守改变(例如,如本文提供的保守取代)。此类改变可以例如在CDR中的抗原接触残基之外。在本文提供的可变序列的某些实施方案中,每个CDR不变,或者含有不超过一个、两个或三个氨基酸取代。
氨基酸序列插入包括长度范围从一个残基到含有一百个或更多个残基的多肽的氨基末端和/或羧基末端融合,以及单个或多个氨基酸残基的序列内插入。
在一些方面,TCR或其抗原结合片段可以在α链和/或β链中含有一种或多种修饰,使得当TCR或其抗原结合片段在细胞中表达时,TCRα链和β链与内源TCRα链和β链之间的错配频率降低,TCRα链和β链的表达增加,和/或TCRα链和β链的稳定性增加。
在一些实施方案中,TCR含有一个或多个非天然半胱氨酸残基,以引入共价二硫键,其将α链的恒定结构域的免疫球蛋白区域的残基连接至β链的恒定结构域的免疫球蛋白区域的残基。在一些实施方案中,可以将一个或多个半胱氨酸掺入TCR多肽的第一和第二区段的恒定区细胞外序列中。本文描述了在TCR中用于引入非天然半胱氨酸残基的示例性非限制性修饰(还参见国际PCT号WO 2006/000830和WO 2006037960)。在一些情况下,可能需要天然和非天然二硫键两者。在一些实施方案中,修饰TCR或抗原结合片段,使得不存在天然TCR中的链间二硫键。
在一些实施方案中,可以修饰TCR恒定区的跨膜结构域以含有更多的疏水性残基(参见例如Haga-Friedman等人(2012)Journal of Immunology,188:5538-5546)。在一些实施方案中,TCRα链的跨膜区含有一个或多个对应于S116L、G119V或F120L的突变,参考SEQID NO:212、213、215、217、220或524中任一个所示的Cα的编号。
在一些实施方案中,表达TCR的细胞还包括标记(如细胞表面标记),其可以用于确认细胞被转导或工程化以表达TCR,如细胞表面受体的截短形式,如截短的EGFR(tEGFR)。示例性替代标记可以包括细胞表面多肽的截短形式,如是非功能性的并且不转导或不能转导信号或通常由细胞表面多肽的全长形式转导的信号、和/或不内化或不能内化的截短形式。示例性截短的细胞表面多肽包括生长因子或其他受体的截短形式,如截短的人表皮生长因子受体2(tHER2)、截短的表皮生长因子受体(tEGFR,SEQ ID NO:273或343所示的示例性tEGFR序列)或前列腺特异性膜抗原(PSMA)或其经修饰形式。tEGFR可以含有抗体西妥昔单抗( )或其他治疗性抗EGFR抗体或结合分子识别的表位,其可以用于鉴定或选择已经用tEGFR构建体和编码的外源蛋白质工程化的细胞,和/或用于消除或分离表达所编码的外源蛋白质的细胞。参见美国专利号8,802,374和Liu等人,Nature Biotech.2016年4月;34(4):430-434。在一些方面,标记(例如替代标记)包括全部或部分(例如,截短形式)的CD34、NGFR、CD19或截短的CD19(例如,截短的非人CD19)或表皮生长因子受体(例如,tEGFR)。在一些实施方案中,标记是或包含荧光蛋白,如绿色荧光蛋白(GFP)、增强型绿色荧光蛋白(EGFP)(如超折叠GFP(sfGFP))、红色荧光蛋白(RFP)(如tdTomato、mCherry、mStrawberry、AsRed2、DsRed或DsRed2)、青色荧光蛋白(CFP)、蓝绿色荧光蛋白(BFP)、增强型蓝色荧光蛋白(EBFP)和黄色荧光蛋白(YFP)及其变体,包括荧光蛋白的物种变体、单体变体和密码子优化的和/或增强的变体。在一些实施方案中,标记是或包含酶(如萤光素酶)、来自大肠杆菌(E.coli)的lacZ基因、碱性磷酸酶、分泌型胚胎碱性磷酸酶(SEAP)、氯霉素乙酰转移酶(CAT)。示例性发光报告基因包括萤光素酶(luc)、β-半乳糖苷酶、氯霉素乙酰转移酶(CAT)、β-葡糖醛酸糖苷酶(GUS)或其变体。
)或其他治疗性抗EGFR抗体或结合分子识别的表位,其可以用于鉴定或选择已经用tEGFR构建体和编码的外源蛋白质工程化的细胞,和/或用于消除或分离表达所编码的外源蛋白质的细胞。参见美国专利号8,802,374和Liu等人,Nature Biotech.2016年4月;34(4):430-434。在一些方面,标记(例如替代标记)包括全部或部分(例如,截短形式)的CD34、NGFR、CD19或截短的CD19(例如,截短的非人CD19)或表皮生长因子受体(例如,tEGFR)。在一些实施方案中,标记是或包含荧光蛋白,如绿色荧光蛋白(GFP)、增强型绿色荧光蛋白(EGFP)(如超折叠GFP(sfGFP))、红色荧光蛋白(RFP)(如tdTomato、mCherry、mStrawberry、AsRed2、DsRed或DsRed2)、青色荧光蛋白(CFP)、蓝绿色荧光蛋白(BFP)、增强型蓝色荧光蛋白(EBFP)和黄色荧光蛋白(YFP)及其变体,包括荧光蛋白的物种变体、单体变体和密码子优化的和/或增强的变体。在一些实施方案中,标记是或包含酶(如萤光素酶)、来自大肠杆菌(E.coli)的lacZ基因、碱性磷酸酶、分泌型胚胎碱性磷酸酶(SEAP)、氯霉素乙酰转移酶(CAT)。示例性发光报告基因包括萤光素酶(luc)、β-半乳糖苷酶、氯霉素乙酰转移酶(CAT)、β-葡糖醛酸糖苷酶(GUS)或其变体。
在一些实施方案中,标记是选择标记。在一些实施方案中,选择标记是或包含赋予对外源药剂或药物的抗性的多肽。在一些实施方案中,选择标记是抗生素抗性基因。在一些实施方案中,选择标记是向哺乳动物细胞赋予抗生素抗性的抗生素抗性基因。在一些实施方案中,选择标记是或包含嘌呤霉素抗性基因、潮霉素抗性基因、杀稻瘟菌素抗性基因、新霉素抗性基因、遗传霉素抗性基因或博莱霉素抗性基因或其经修饰形式。
在一些方面,标记包括全部或部分(例如,截短形式)的CD34、NGFR或表皮生长因子受体(例如,tEGFR)。在一些实施方案中,编码标记的核酸与编码接头序列(如可切割接头序列,例如T2A)的多核苷酸可操作地连接。参见WO 2014031687。在一些实施方案中,引入编码由T2A、P2A或其他核糖体开关隔开的TCR和EGFRt的构建体可以表达来自相同构建体的两种蛋白质,使得EGFRt可以用作检测表达这种构建体的细胞的标记。下文描述了可以使用的示例性的此类标记。
在一些实施方案中,TCR或其抗原结合片段由密码子优化或已经密码子优化的核苷酸序列编码。在本文其他地方描述了示例性的密码子优化的变体。
B.抗体
在一些实施方案中,结合分子是含有如上关于TCR所述的任何一个或多个CDR的抗体或其抗原结合片段。
在一些实施方案中,抗体或抗原结合片段含有可变重链和轻链,其含有如表2、表5或表8所列的α链中所含的CDR1、CDR2和/或CDR3以及β链中所含的CDR1、CDR2和/或CDR3。所提供的抗体或抗原结合片段还包括含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,抗体或抗原结合片段含有可变区,所述可变区含有互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:111、113、115、121、123 125、297、299、477、492、504、510、522、536、554、569、587、599、611、623、637、649、661或676中任一个所示的Vα区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列。在一些方面,抗体或抗原结合片段含有可变区,所述可变区含有互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQID NO:112、114、116、122、124 126、298、300、483、498、516、530、545、560、578、593、605、617、629、643、655、667或685中任一个所示的Vβ区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列。所提供的抗体或抗原结合片段还包括含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。
在一些实施方案中,所提供的抗体或抗体片段是人抗体。在一些实施方案中,所提供的抗体或抗体片段含有VH区,其含有与由种系核苷酸人重链V区段编码的氨基酸序列具有至少95%、96%、97%、98%、99%或100%序列同一性的部分、与由种系核苷酸人重链D区段编码的氨基酸序列具有至少95%、96%、97%、98%、99%或100%同一性的部分和/或与由种系核苷酸人重链J区段编码的氨基酸序列具有至少95%、96%、97%、98%、99%或100%同一性的部分;和/或含有VL区,其含有与由种系核苷酸人κ或λ链V区段编码的氨基酸序列具有至少95%、96%、97%、98%、99%或100%同一性的部分和/或与由种系核苷酸人κ或λ链J区段编码的氨基酸序列具有至少95%、96%、97%、98%、99%或100%同一性的部分。在一些实施方案中,VH区的所述部分对应于CDR-H1、CDR-H2和/或CDR-H3。在一些实施方案中,VH区的所述部分对应于框架区1(FR1)、FR2、FR2和/或FR4。在一些实施方案中,VL区的所述部分对应于CDR-L1、CDR-L2和/或CDR-L3。在一些实施方案中,VL区的所述部分对应于FR1、FR2、FR2和/或FR4。
在一些实施方案中,抗体或抗原结合片段包含含有人种系基因区段序列的框架区。例如,在一些实施方案中,抗体或抗原结合片段含有VH区,其中框架区(例如FR1、FR2、FR3和FR4)与由人种系抗体区段(如V和/或J区段)编码的框架区具有至少95%、96%、97%、98%、99%或100%序列同一性。在一些实施方案中,人抗体含有VL区,其中框架区(例如FR1、FR2、FR3和FR4)与由人种系抗体区段(如V和/或区段)编码的框架区具有至少95%、96%、97%、98%、99%或100%序列同一性。例如,在一些此类实施方案中,与由人种系抗体区段编码的框架区相比,VH和/或VL序列的框架序列相差不超过10个氨基酸,如不超过9、8、7、6、5、4、3、2或1个氨基酸。在一些实施方案中,抗体及其抗原结合片段(例如TCR样抗体)特异性识别在MHC分子(如MHC I类)的背景下的肽表位。在一些情况下,MHC I类分子是HLA-A2分子,例如HLA-A2*01。
在一些实施方案中,抗体或其抗原结合片段识别或结合至HPV16 E6的表位或区域,如含有SEQ ID NO:232-234中任一个所示的氨基酸序列的肽表位。在一些情形中,识别或结合源自HPV16 E6的肽表位的TCR或其抗原结合片段是或包含SEQ ID NO:233所示的序列。
在一些方面,TCR或抗原结合片段识别或结合至HPV16 E7蛋白的表位或区域,如含有SEQ ID NO:235-239中任一个所示的氨基酸序列的肽表位。在一些实施方案中,TCR或其抗原结合片段不识别或结合包含氨基酸序列YMLDLQPET(SEQ ID NO.236)的表位E7(11-19)。在一些情况下,源自HPV16 E7的肽是或含有SEQ ID NO:235所示的序列。
因此,在一些实施方案中,提供了抗HPV抗体,包括功能性抗体片段。在一些实施方案中,抗体VH和/或VL结构域或其抗原结合位点并且能够与HPV 16的肽表位特异性结合。在一些实施方案中,抗体包括可变重链和可变轻链,如scFv。抗体包括与HPV(例如,HPV 16E6或HPV 16E7)特异性结合的抗体。所提供的抗HPV抗体包括人抗体。抗体包括分离的抗体。还提供了含有此类抗体的分子,例如单链蛋白、融合蛋白和/或重组受体,如嵌合受体,包括抗原受体。
本文中的术语“抗体”在最广泛的意义上使用,并且包括多克隆和单克隆抗体,包括完整抗体和功能性(抗原结合)抗体片段,包括片段抗原结合(Fab)片段、F(ab')2片段、Fab'片段、Fv片段、重组IgG(rIgG)片段、能够特异性结合抗原的可变重链(VH)区、单链抗体片段(包括单链可变片段(scFv))以及单结构域抗体(例如,sdAb、sdFv、纳米抗体)片段。所述术语涵盖免疫球蛋白的基因工程化的和/或以其他方式修饰的形式,如胞内抗体、肽体、嵌合抗体、全人抗体、人源化抗体和异缀合抗体、多特异性(例如,双特异性)抗体、双抗体、三抗体和四抗体、串联二-scFv、串联三-scFv。除非另有说明,否则术语“抗体”应当理解为涵盖其功能性抗体片段。所述术语还涵盖完整或全长抗体,包括任何类别或亚类(包括IgG及其亚类、IgM、IgE、IgA和IgD)的抗体。
在一些实施方案中,抗体的重链和轻链可以是全长的或者可以是抗原结合部分(Fab、F(ab’)2、Fv或单链Fv片段(scFv))。在其他实施方案中,抗体重链恒定区选自例如IgG1、IgG2、IgG3、IgG4、IgM、IgA1、IgA2、IgD和IgE,特别是选自例如IgG1、IgG2、IgG3和IgG4,更特别是IgG1(例如,人IgG1)。在另一个实施方案中,抗体轻链恒定区选自例如κ或λ,特别是κ。
所提供的抗体包括抗体片段。“抗体片段”是指不同于完整抗体的分子,其包含完整抗体的结合完整抗体所结合的抗原的一部分。抗体片段的例子包括但不限于Fv、Fab、Fab'、Fab'-SH、F(ab')2;双抗体;线性抗体;可变重链(VH)区、单链抗体分子(如scFv)和单结构域VH单一抗体;和由抗体片段形成的多特异性抗体。在特定实施方案中,抗体是包含可变重链区和/或可变轻链区的单链抗体片段,如scFv。
当关于抗体(如抗体片段)使用时,术语“可变区”或“可变结构域”是指抗体重链或轻链的参与抗体与抗原的结合的结构域。天然抗体的重链和轻链的可变结构域(分别为VH和VL)通常具有相似的结构,每个结构域包含四个保守的框架区(FR)和三个CDR。(参见例如,Kindt等人KubyImmunology,第6版,W.H.Freeman and Co.,第91页(2007))。单个VH或VL结构域可以足以赋予抗原结合特异性。此外,可以使用来自结合抗原的抗体的VH或VL结构域分离结合所述特定抗原的抗体,以分别筛选互补的VL或VH结构域的文库。参见例如,Portolano等人,J.Immunol.150:880-887(1993);Clarkson等人,Nature 352:624-628(1991)。
单结构域抗体是包含抗体的全部或部分重链可变结构域或者全部或部分轻链可变结构域的抗体片段。在某些实施方案中,单结构域抗体是人单结构域抗体。
抗体片段可以通过各种技术制备,包括但不限于完整抗体的蛋白水解消化以及通过重组宿主细胞产生。在一些实施方案中,抗体是重组产生的片段,如包含天然不存在的排列的片段(如具有通过合成接头(例如,肽接头)连接的两个或更多个抗体区或链的那些),和/或可以不通过酶消化天然存在的完整抗体产生的片段。在一些方面,抗体片段是scFv。
所提供的抗HPV抗体包括人抗体。“人抗体”是具有与人或人细胞或者利用人抗体库或其他人抗体编码序列(包括人抗体文库)的非人来源产生的抗体的氨基酸序列对应的氨基酸序列的抗体。所述术语不包括包含非人抗原结合区的非人抗体的人源化形式,如全部或基本上全部CDR都是非人的那些。所述术语包括人抗体的抗原结合片段。
“人源化”抗体是这样的抗体,其中全部或基本上全部CDR氨基酸残基源自非人CDR并且全部或基本上全部FR氨基酸残基源自人FR。人源化抗体任选地可以包括源自人抗体的抗体恒定区的至少一部分。非人抗体的“人源化形式”是指所述非人抗体的变体,其已经经历人源化以通常降低对人的免疫原性,同时保留亲本非人抗体的特异性和亲和力。在一些实施方案中,人源化抗体中的一些FR残基被来自非人抗体(例如,衍生出CDR残基的抗体)的相应残基取代,例如以恢复或改善抗体特异性或亲和力。
人抗体可以通过将免疫原给予转基因动物来制备,所述转基因动物已经被修饰以响应于抗原激发产生完整人抗体或具有人可变区的完整抗体。此类动物通常含有人免疫球蛋白基因座的全部或一部分,其替代内源免疫球蛋白基因座,或者其存在于染色体外或随机整合至动物染色体中。在此类转基因动物中,通常已经使内源免疫球蛋白基因座失活。人抗体也可以源自含有源自人库的抗体编码序列的人抗体文库,包括噬菌体展示和无细胞文库。
所提供的抗体包括单克隆抗体,包括单克隆抗体片段。如本文所用的术语“单克隆抗体”是指从基本上同质抗体的群体(即,构成所述群体的单独抗体是相同的,但含有天然存在的突变或在单克隆抗体制剂的产生期间产生的可能变体除外,此类变体通常以少量存在)获得或在所述群体内的抗体。与通常包括针对不同表位的不同抗体的多克隆抗体制剂相反,单克隆抗体制剂的每种单克隆抗体针对抗原上的单个表位。所述术语不应解释为需要通过任何特定方法产生抗体。单克隆抗体可以通过多种技术制备,包括但不限于从杂交瘤产生、重组DNA方法、噬菌体展示和其他抗体展示方法。
如本文所用,提及抗体的“相应形式”意指当比较两种抗体的特性或活性时,使用相同形式的抗体来比较特性。例如,如果声明抗体与第一抗体的相应形式的活性相比具有更高的活性,则意味着特定形式(如所述抗体的scFv)与第一抗体的scFv形式相比具有更高的活性。
“效应子功能”是指可归因于抗体Fc区的那些生物活性,其随抗体同种型的变化而变化。抗体效应子功能的例子包括:C1q结合和补体依赖性细胞毒性(CDC);Fc受体结合;抗体依赖性细胞介导的细胞毒性(ADCC);吞噬作用;细胞表面受体(例如B细胞受体)的下调;和B细胞激活。
在一些实施方案中,抗体(例如,抗体片段)可以含有免疫球蛋白恒定区的至少一部分,如一个或多个恒定区结构域。在一些实施方案中,恒定区包括轻链恒定区和/或重链恒定区1(CH1)。在一些实施方案中,抗体包括CH2和/或CH3结构域,如Fc区。在一些实施方案中,Fc区是人IgG(如IgG1或IgG4)的Fc区。
本文中的术语“Fc区”用于定义免疫球蛋白重链的含有恒定区的至少一部分的C末端区。所述术语包括天然序列Fc区和变体Fc区。在一个实施方案中,人IgG重链Fc区从Cys226或从Pro230延伸至重链的羧基末端。然而,Fc区的C末端赖氨酸(Lys447)可以存在或可以不存在。除非本文另有说明,否则Fc区或恒定区中氨基酸残基的编号是根据EU编号系统,也称为EU索引,如Kabat等人,Sequences of Proteins of Immunological Interest,第5版Public Health Service,National Institutes of Health,Bethesda,MD,1991中所描述。
术语“全长抗体”、“完整抗体”和“全抗体”在本文中可互换地使用以指代具有与天然抗体结构基本上相似的结构或具有含有如本文所定义的Fc区的重链的抗体。
“分离的”抗体是已经与其天然环境的组分分开的抗体。在一些实施方案中,如通过例如电泳(例如,SDS-PAGE、等电点聚焦(IEF)、毛细管电泳)或色谱(例如,离子交换或反相HPLC)确定的,将抗体纯化至大于95%或99%的纯度。关于评估抗体纯度的方法的综述,参见例如,Flatman等人,J.Chromatogr.B 848:79-87(2007)。
1.变体和修饰
在某些实施方案中,与本文所述的抗体的序列相比,抗体或其抗原结合片段包括一个或多个氨基酸变化,例如取代、缺失、插入和/或突变。示例性变体包括设计用于改善抗体的结合亲和力和/或其他生物特性的那些。可以通过将适当的修饰引入编码抗体的核苷酸序列中或者通过肽合成来制备抗体的氨基酸序列变体。此类修饰包括例如抗体的氨基酸序列内的残基的缺失和/或插入和/或取代。可以进行缺失、插入和取代的任何组合以得到最终的构建体,条件是最终的构建体具有所需特征,例如抗原结合。
在某些实施方案中,例如与本文所述的抗体序列相比和/或与天然库(例如,人库)的序列相比,抗体包括一个或多个氨基酸取代。替代诱变的目的位点包括CDR和FR。可以将氨基酸取代引入目的抗体中,并且筛选产物的所需活性,例如保留/改善的抗原结合、降低的免疫原性、改善的半衰期和/或改善的效应子功能,如促进抗体依赖性细胞毒性(ADCC)或补体依赖性细胞毒性(CDC)的能力。
在一些实施方案中,亲本抗体(例如人源化或人抗体)的CDR内的一个或多个残基被取代。在一些实施方案中,进行取代以将序列或序列中的位置恢复为种系序列,如在种系(例如,人种系)中发现的抗体序列,例如以降低免疫原性的可能性,例如在给予人类受试者以后。
在一些实施方案中,在CDR“热点”残基中进行改变,所述CDR“热点”残基由在体细胞成熟过程期间以高频率发生突变的密码子编码(参见例如,Chowdhury,MethodsMol.Biol.207:179-196(2008)),和/或在接触抗原的残基中进行改变,测试所得变体VH或VL的结合亲和力。通过构建二级文库和从二级文库中重新选择而进行的亲和力成熟已经在例如Hoogenboom等人Methods in Molecular Biology 178:1-37(O’Brien等人编辑,HumanPress,Totowa,NJ,(2001))中进行了描述。在亲和力成熟的一些实施方案中,通过多种方法(例如,易错PCR、链改组或寡核苷酸定向诱变)中的任一种将多样性引入选择用于成熟的可变基因中。然后可以创建二级文库并进行筛选,以鉴定具有所需亲和力的任何抗体变体。引入多样性的另一种方法涉及CDR指导的方法,其中随机化几个CDR残基(例如,一次4-6个残基)。可以例如使用丙氨酸扫描诱变或建模来特异性鉴定参与抗原结合的CDR残基。特别是通常靶向CDR-H3和CDR-L3。
在某些实施方案中,取代、插入或缺失可以在一个或多个CDR内发生,只要此类改变基本上不降低抗体结合抗原的能力。例如,可以在CDR中进行基本上不降低结合亲和力的保守改变(例如,如本文提供的保守取代)。此类改变可以例如在CDR中的抗原接触残基之外。在上文提供的变体VH和VL序列的某些实施方案中,每个CDR不变,或者含有不超过一个、两个或三个氨基酸取代。
氨基酸序列插入包括长度范围从一个残基到含有一百个或更多个残基的多肽的氨基末端和/或羧基末端融合,以及单个或多个氨基酸残基的序列内插入。末端插入的例子包括具有N末端甲硫酰基残基的抗体。抗体分子的其他插入变体包括抗体的N末端或C末端与增加抗体的血清半衰期的酶或多肽的融合物。
在某些实施方案中,改变抗体或其抗原结合片段以增加或降低抗体被糖基化的程度,例如通过改变氨基酸序列来去除或插入一个或多个糖基化位点和/或通过例如使用某些细胞系来修饰附着于糖基化位点的一种或多种寡糖。
示例性修饰、变体和细胞系描述于例如专利公开号US 2003/0157108、US 2004/0093621、US 2003/0157108;WO 2000/61739;WO 2001/29246;US 2003/0115614;US 2002/0164328;US 2004/0093621;US 2004/0132140;US 2004/0110704;US 2004/0110282;US2004/0109865;WO 2003/085119;WO 2003/084570;WO 2005/035586;WO 2005/035778;WO2005/053742;WO 2002/031140;Okazaki等人J.Mol.Biol.336:1239-1249(2004);Yamane-Ohnuki等人Biotech.Bioeng.87:614(2004);Ripka等人Arch.Biochem.Biophys.249:533-545(1986);美国专利申请号US 2003/0157108A1,Presta,L;和WO 2004/056312A1;Yamane-Ohnuki等人Biotech.Bioeng.87:614(2004);Kanda,Y.等人,Biotechnol.Bioeng.,94(4):680-688(2006);和WO 2003/085107;WO 2003/011878(Jean-Mairet等人);美国专利号6,602,684(Umana等人);和US 2005/0123546(Umana等人);WO 1997/30087(Patel等人);WO1998/58964(Raju,S.);以及WO 1999/22764(Raju,S.)。
经修饰的抗体包括在Fc区具有一种或多种氨基酸修饰的那些,如具有在一个或多个氨基酸位置处包含氨基酸修饰(例如,取代)的人Fc区序列或恒定区的其他部分(例如,人IgG1、IgG2、IgG3或IgG4 Fc区)的那些。
可以进行此类修饰,例如以改善半衰期、改变与一种或多种类型的Fc受体的结合和/或改变效应子功能。
变体还包括半胱氨酸工程化的抗体,如“thioMAb”和其他半胱氨酸工程化的变体,其中抗体的一个或多个残基被半胱氨酸残基取代,以便在可及位点处产生反应性硫醇基,例如用于缀合药剂和接头剂,以产生免疫缀合物。半胱氨酸工程化的抗体描述于例如美国专利号7,855,275和7,521,541中。
在一些实施方案中,修饰抗体以含有另外的非蛋白质部分,包括水溶性聚合物。示例性聚合物包括但不限于聚乙二醇(PEG)、乙二醇/丙二醇共聚物、羧甲基纤维素、葡聚糖、聚乙烯醇、聚乙烯吡咯烷酮、聚1,3-二氧戊环、聚1,3,6-三氧杂环己烷、乙烯/马来酸酐共聚物、聚氨基酸(均聚物或无规共聚物)和葡聚糖或聚(n-乙烯吡咯烷酮)聚乙二醇、聚丙二醇均聚物、聚环氧丙烷/环氧乙烷共聚物、聚氧乙烯化多元醇(例如,甘油)、聚乙烯醇及其混合物。聚乙二醇丙醛由于在水中的稳定性而在制造中可能具有优势。聚合物可以具有任何分子量,并且可以是支链或非支链的。附着于抗体的聚合物的数量可以变化,并且如果附着超过一种聚合物,则它们可以是相同或不同的分子。通常,用于衍生化的聚合物的数量和/或类型可以基于以下考虑因素来确定,所述考虑因素包括但不限于待改善抗体的特定特性或功能、抗体衍生物是否将在定义的条件用于疗法中等。
2.TCR样CAR
在一些实施方案中,抗体或其抗原结合部分作为重组受体(如抗原受体)的一部分在细胞上表达。抗原受体包括功能性非TCR抗原受体,如嵌合抗原受体(CAR)。通常,含有针对在MHC分子的背景下的肽展现出TCR样特异性的抗体或抗原结合片段的CAR也可以称为TCR样CAR。
因此,所提供的结合分子(例如,HPV 16E6或E7结合分子)包括抗原受体,如包括所提供的抗体(例如,TCR样抗体)之一的那些。在一些实施方案中,抗原受体和其他嵌合受体与HPV16 E6或E7的区域或表位特异性结合,如含有所提供的抗HPV 16E6或E7抗体或抗体片段(例如TCR样抗体)的抗原受体。抗原受体包括功能性非TCR抗原受体,如嵌合抗原受体(CAR)。还提供了表达CAR的细胞及其在过继细胞疗法中的用途,如与HPV 16E6或E7表达相关的疾病和障碍的治疗。
因此,本文提供了含有非TCR分子的TCR样CAR,所述非TCR分子展现出T细胞受体特异性,如对当在MHC分子的背景下展示或呈递时的T细胞表位或肽表位。在一些实施方案中,TCR样CAR可以含有如本文所述的抗体或其抗原结合部分,例如TCR样抗体。在一些实施方案中,抗体或其抗体结合部分对在MHC分子的背景下的特定肽表位具有反应性,其中抗体或抗体片段可以将在MHC分子的背景下的特定肽与仅MHC分子、仅特定肽和在一些情况下在MHC分子的背景下的无关肽区分开。在一些实施方案中,抗体或其抗原结合部分可以展现出比T细胞受体更高的结合亲和力。
示例性抗原受体(包括CAR)以及用于将此类受体工程化和引入细胞中的方法包括例如国际专利申请公开号WO 2000/14257、WO 2013/126726、WO 2012/129514、WO 2014/031687、WO 2013/166321、WO 2013/071154、WO 2013/123061;美国专利申请公开号US2002/131960、US 2013/287748、US 2013/0149337;美国专利号6,451,995、7,446,190、8,252,592、8,339,645、8,398,282、7,446,179、6,410,319、7,070,995、7,265,209、7,354,762、7,446,191、8,324,353和8,479,118;以及欧洲专利申请号EP2537416中所述的那些;和/或Sadelain等人,Cancer Discov.2013年4月;3(4):388-398;Davila等人(2013)PLoSONE 8(4):e61338;Turtle等人,Curr.Opin.Immunol.,2012年10月;24(5):633-39;Wu等人,Cancer,2012年3月18(2):160-75所述的那些。在一些方面,抗原受体包括如美国专利号7,446,190中所述的CAR以及国际专利申请公开WO 2014/055668A1中描述的那些。示例性的CAR包括这样的CAR,如在任何前述出版物中所披露,例如像WO 2014/031687、US 8,339,645、US 7,446,179、US 2013/0149337、美国专利号7,446,190、美国专利号8,389,282,并且其中抗原结合部分(例如,scFv)被例如如本文提供的抗体替代。
在一些实施方案中,CAR通常包括在一些方面经由接头和/或一个或多个跨膜结构域与一种或多种胞内信号传导组分连接的细胞外抗原(或配体)结合结构域,包括作为对在MHC分子的背景下的肽具特异性的抗体或其抗原结合片段。在一些实施方案中,此类分子通常可以通过天然抗原受体(如TCR)模拟或接近信号,并且任选地通过这样的受体与共刺激受体组合模拟或接近信号。
在一些实施方案中,CAR通常在其细胞外部分中包括一种或多种抗原结合分子,如一个或多个抗原结合片段、结构域或部分,或者一个或多个抗体可变结构域,和/或抗体分子。在一些实施方案中,CAR包括抗体分子的一个或多个抗原结合部分,如源自单克隆抗体(mAb)的可变重链(VH)和可变轻链(VL)的单链抗体片段(scFv)。在一些实施方案中,CAR含有TCR样抗体,如特异性识别在MHC分子的背景下在细胞表面上呈递的肽表位的抗体或抗原结合片段(例如,scFv)。
在一些方面,抗原特异性结合或识别组分与一个或多个跨膜和细胞内信号传导结构域连接。在一些实施方案中,CAR包括与CAR的细胞外结构域融合的跨膜结构域。在一个实施方案中,使用天然与CAR中的一个结构域缔合的跨膜结构域。在一些情形中,通过氨基酸取代选择或修饰跨膜结构域,以避免此类结构域与相同或不同表面膜蛋白的跨膜结构域结合,以使与受体复合物的其他成员的相互作用最小化。
在一些实施方案中,跨膜结构域源自天然来源或源自合成来源。在来源是天然的情况下,结构域在一些方面源自任何膜结合蛋白或跨膜蛋白。跨膜区包括源自以下的那些(即包含以下的至少一个或多个跨膜区):T细胞受体的α、β或ζ链,CD28,CD3ε,CD45,CD4,CD5,CD8,CD9,CD16,CD22,CD33,CD37,CD64,CD80,CD86,CD134,CD137,CD154。可替代地,在一些实施方案中,跨膜结构域是合成的。在一些方面,合成跨膜结构域主要包含疏水性残基,如亮氨酸和缬氨酸。在一些方面,将在合成跨膜结构域的每个末端发现苯丙氨酸、色氨酸和缬氨酸的三联体。
在一些实施方案中,存在短的寡肽或多肽接头,例如长度在2与10个氨基酸之间的接头(如含有甘氨酸和丝氨酸的接头,例如甘氨酸-丝氨酸双联体),并且在CAR的跨膜结构域与胞质信号传导结构域之间形成连接。
在一些实施方案中,CAR(例如TCR样CAR,如其抗体部分)还包括间隔子,所述间隔子可以是或包括免疫球蛋白恒定区的至少一部分或其变体或经修饰形式,如铰链区(例如,IgG4铰链区)和/或CH1/CL和/或Fc区。在一些实施方案中,恒定区或部分是人IgG(如IgG4或IgG1)的。在一些方面,恒定区的所述部分用作抗原识别组分(例如,scFv)与跨膜结构域之间的间隔子区。与不存在间隔子的情况相比,间隔子的长度可以提供在抗原结合后增加的细胞反应性。在一些例子中,间隔子的长度为或为约12个氨基酸或者长度不超过12个氨基酸。示例性间隔子包括具有至少约10至229个氨基酸、约10至200个氨基酸、约10至175个氨基酸、约10至150个氨基酸、约10至125个氨基酸、约10至100个氨基酸、约10至75个氨基酸、约10至50个氨基酸,约10至40个氨基酸、约10至30个氨基酸、约10至20个氨基酸或约10至15个氨基酸(并且包括任何列出的范围的端点之间的任何整数)的那些。在一些实施方案中,间隔子区具有约12个或更少的氨基酸、约119个或更少的氨基酸或约229个或更少的氨基酸。示例性间隔子包括仅IgG4铰链、与CH2和CH3结构域连接的IgG4铰链或与CH3结构域连接的IgG4铰链。示例性间隔子包括但不限于Hudecek等人(2013)Clin.Cancer Res.,19:3153或国际专利申请公开号WO 2014/031687中描述的那些。
在一些实施方案中,恒定区或部分是人IgG(如IgG4或IgG1)的。在一些实施方案中,间隔子具有序列ESKYGPPCPPCP(示于SEQ ID NO:268中),并且由SEQ ID NO:269所示的序列编码。在一些实施方案中,间隔子具有SEQ ID NO:270所示的序列。在一些实施方案中,间隔子具有SEQ ID NO:271所示的序列。在一些实施方案中,恒定区或部分是IgD的。在一些实施方案中,间隔子具有SEQ ID NO:272所示的序列。在一些实施方案中,间隔子具有SEQID NO:268、270、271或272中任一个展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列。
抗原识别结构域通常与一种或多种细胞内信号传导组分(如通过抗原受体复合物(如TCR复合物)(在CAR的情况下)模拟激活和/或通过另一种细胞表面受体模拟信号的信号传导组分)连接。因此,在一些实施方案中,抗体或其抗原结合片段与一个或多个跨膜和细胞内信号传导结构域连接。在一些实施方案中,跨膜结构域与细胞外结构域融合。在一个实施方案中,使用天然与受体(例如,CAR)中的一个结构域缔合的跨膜结构域。在一些情形中,通过氨基酸取代选择或修饰跨膜结构域,以避免此类结构域与相同或不同表面膜蛋白的跨膜结构域结合,以使与受体复合物的其他成员的相互作用最小化。
在一些实施方案中,跨膜结构域源自天然来源或源自合成来源。在来源是天然的情况下,结构域在一些方面源自任何膜结合蛋白或跨膜蛋白。跨膜区包括源自以下的那些(即包含以下的至少一个或多个跨膜区):T细胞受体的α、β或ζ链,CD28,CD3ε,CD45,CD4,CD5,CD8,CD9,CD 16,CD22,CD33,CD37,CD64,CD80,CD86,CD134,CD137,CD154。可替代地,在一些实施方案中,跨膜结构域是合成的。在一些方面,合成跨膜结构域主要包含疏水性残基,如亮氨酸和缬氨酸。在一些方面,将在合成跨膜结构域的每个末端发现苯丙氨酸、色氨酸和缬氨酸的三联体。在一些实施方案中,连接是通过接头、间隔子和/或一个或多个跨膜结构域进行的。
细胞内信号传导结构域包括通过天然抗原受体模拟或接近信号、通过这样的受体与共刺激受体的组合模拟或接近信号、和/或仅通过共刺激受体模拟或接近信号的那些。在一些实施方案中,存在短的寡肽或多肽接头,例如长度在2与10个氨基酸之间的接头(如含有甘氨酸和丝氨酸的接头,例如甘氨酸-丝氨酸双联体),并且在CAR的跨膜结构域与胞质信号传导结构域之间形成连接。
CAR通常包括至少一种或多种细胞内信号传导组分。在一些实施方案中,CAR包括TCR复合物的细胞内组分,如介导T细胞激活和细胞毒性的TCRCD3+链,例如CD3ζ链。因此,在一些方面,抗原结合分子与一个或多个细胞信号传导模块连接。在一些实施方案中,细胞信号传导模块包括CD3跨膜结构域、CD3细胞内信号传导结构域和/或其他CD跨膜结构域。在一些实施方案中,CAR还包括一种或多种另外的分子(如Fc受体γ、CD8、CD4、CD25或CD16)的一部分。例如,在一些方面,CAR包括CD3-zeta(CD3-ζ)或Fc受体γ与CD8、CD4、CD25或CD16之间的嵌合分子。
在一些实施方案中,在连接CAR后,CAR的胞质结构域或细胞内信号传导结构域激活免疫细胞(例如,工程化以表达CAR的T细胞)的正常效应子功能或反应中的至少一种。例如,在一些情境下,CAR诱导T细胞的功能,如细胞溶解活性或T辅助活性,如细胞因子或其他因子的分泌。在一些实施方案中,使用抗原受体组分或共刺激分子的细胞内信号传导结构域的截短部分代替完整的免疫刺激链,例如如果所述截短部分转导效应子功能信号的话。在一些实施方案中,所述一个或多个细胞内信号传导结构域包括T细胞受体(TCR)的胞质序列,并且在一些方面还包括共受体(其在天然背景下与这种受体一齐作用以在抗原受体接合后启动信号转导)和/或此类分子的任何衍生物或变体的那些,和/或具有相同功能能力的任何合成序列。
在天然TCR的背景下,完全激活通常不仅需要通过TCR进行信号传导,还需要共刺激信号。因此,在一些实施方案中,为了促进完全激活,用于产生次级或共刺激信号的组分也被包括在CAR中。在其他实施方案中,CAR不包括用于产生共刺激信号的组分。在一些方面,另外的CAR在同一细胞中表达,并且提供用于产生次级或共刺激信号的组分。在一些方面,细胞包含第一CAR,其含有信号传导结构域以诱导初级信号;和第二CAR,其与第二抗原结合并且含有用于产生共刺激信号的组分。例如,第一CAR可以是激活CAR,并且第二CAR可以是共刺激CAR。在一些方面,两种CAR必须连接以便在细胞中诱导特定的效应子功能,这可以为被靶向的细胞类型提供特异性和选择性。
在一些方面,将T细胞激活描述为由两个类别的胞质信号传导序列来介导:通过TCR启动抗原依赖性初级激活的那些(初级胞质信号传导序列)以及以抗原非依赖性方式作用以提供次级或共刺激信号的那些(次级胞质信号传导序列)。在一些方面,CAR包括此类信号传导组分之一或两者。
在一些方面,CAR包括调节TCR复合物的初级激活的初级胞质信号传导序列。以刺激方式起作用的初级胞质信号传导序列可以含有信号传导基序(其称为基于免疫受体酪氨酸的激活基序或ITAM)。含有ITAM的初级胞质信号传导序列的例子包括源自TCR或CD3ζ、FcRγ、CD3γ、CD3δ或CD3ε的那些。在一些实施方案中,CAR中的一种或多种胞质信号传导分子含有源自CD3ζ的胞质信号传导结构域、其部分或序列。
在一些实施方案中,CAR包括共刺激受体(如CD28、4-1BB、OX40、DAP10和ICOS)的信号传导结构域和/或跨膜部分。在一些方面,同一CAR包括激活和共刺激组分两者;在其他方面,激活结构域由一种CAR提供,而共刺激组分由识别另一种抗原的另一种CAR提供。
在一些实施方案中,激活结构域被包括在一种CAR内,而共刺激组分由识别另一种抗原的另一种嵌合受体提供。在一些实施方案中,CAR包括在同一细胞上表达的激活或刺激受体和共刺激CAR(参见WO 2014/055668)。在一些方面,含有HPV 16E6或E7抗体的受体是刺激或激活CAR;在其他方面,它是共刺激受体。在一些实施方案中,细胞还包括抑制性CAR(iCAR,参见Fedorov等人,Sci.Transl.Medicine,5(215)(2013年12月)),如识别除了HPV16E6或HPV16 E7以外的肽表位的抑制性受体,借此通过抑制性CAR与其配体的结合来减小或抑制通过靶向HPV 16的CAR递送的激活信号,例如以减小脱靶效应。
在一些实施方案中,表达所提供的TCR或其他结合分子的细胞还表达另外的受体,如能够递送共刺激或存活促进信号的受体,如共刺激受体(参见WO 2014/055668),和/或阻断或改变抑制信号的结果的受体,所述抑制信号是例如通常经由免疫检查点或其他免疫抑制分子(如在肿瘤微环境中表达的免疫抑制分子)递送的抑制信号,例如以便促进此类工程化细胞的功效增加。参见例如,Tang等人,Am J Transl Res.2015;7(3):460-473。在一些实施方案中,细胞还可以包括一种或多种其他外源或重组或工程化的组分(如一种或多种外源因子和/或共刺激配体),其在细胞上或细胞中表达或由细胞分泌并且可以促进功能,例如在微环境中。示例性的此类配体和组分包括例如TNFR和/或Ig家族受体或配体,例如41BBL、CD40、CD40L、CD80、CD86、细胞因子、趋化因子和/或抗体或其他分子(如scFv)。参见例如,专利申请公开号WO 2008121420A1、WO 2014134165A1、US20140219975A1。在一些实施方案中,细胞包含一种或多种抑制性受体(iCAR,参见Fedorov等人,Sci.Transl.Medicine,5(215)(2013年12月)),如和与疾病或病症不相关或不在其中或其上表达的配体或抗原结合的抑制受体。
在某些实施方案中,细胞内信号传导结构域包含与CD3(例如,CD3-ζ)细胞内结构域连接的CD28跨膜和信号传导结构域。在一些实施方案中,细胞内信号传导结构域包含与CD3ζ细胞内结构域连接的嵌合CD28和CD137(4-1BB,TNFRSF9)共刺激结构域。
在一些实施方案中,CAR涵盖在胞质部分中的一个或多个(例如,两个或更多个)共刺激结构域和激活结构域(例如,初级激活结构域)。示例性CAR包括CD3-ζ、CD28和4-1BB的细胞内组分。
在一些实施方案中,表达CAR或其他抗原受体的细胞还包括标记(如细胞表面标记),其可以用于确认细胞被转导或工程化以表达受体,如细胞表面受体的截短形式,如截短的EGFR(tEGFR)。示例性替代标记可以包括细胞表面多肽的截短形式,如是非功能性的并且不转导或不能转导信号或通常由细胞表面多肽的全长形式转导的信号、和/或不内化或不能内化的截短形式。示例性截短的细胞表面多肽包括生长因子或其他受体的截短形式,如截短的人表皮生长因子受体2(tHER2)、截短的表皮生长因子受体(tEGFR,SEQ ID NO:273或343所示的示例性tEGFR序列)或前列腺特异性膜抗原(PSMA)或其经修饰形式。tEGFR可以含有抗体西妥昔单抗( )或其他治疗性抗EGFR抗体或结合分子识别的表位,其可以用于鉴定或选择已经用tEGFR构建体和编码的外源蛋白质工程化的细胞,和/或用于消除或分离表达所编码的外源蛋白质的细胞。参见美国专利号8,802,374和Liu等人,NatureBiotech.2016年4月;34(4):430-434。在一些方面,标记(例如替代标记)包括全部或部分(例如,截短形式)的CD34、NGFR、CD19或截短的CD19(例如,截短的非人CD19)或表皮生长因子受体(例如,tEGFR)。在一些实施方案中,标记是或包含荧光蛋白,如绿色荧光蛋白(GFP)、增强型绿色荧光蛋白(EGFP)(如超折叠GFP(sfGFP))、红色荧光蛋白(RFP)(如tdTomato、mCherry、mStrawberry、AsRed2、DsRed或DsRed2)、青色荧光蛋白(CFP)、蓝绿色荧光蛋白(BFP)、增强型蓝色荧光蛋白(EBFP)和黄色荧光蛋白(YFP)及其变体,包括荧光蛋白的物种变体、单体变体和密码子优化的和/或增强的变体。在一些实施方案中,标记是或包含酶(如萤光素酶)、来自大肠杆菌(E.coli)的lacZ基因、碱性磷酸酶、分泌型胚胎碱性磷酸酶(SEAP)、氯霉素乙酰转移酶(CAT)。示例性发光报告基因包括萤光素酶(luc)、β-半乳糖苷酶、氯霉素乙酰转移酶(CAT)、β-葡糖醛酸糖苷酶(GUS)或其变体。
)或其他治疗性抗EGFR抗体或结合分子识别的表位,其可以用于鉴定或选择已经用tEGFR构建体和编码的外源蛋白质工程化的细胞,和/或用于消除或分离表达所编码的外源蛋白质的细胞。参见美国专利号8,802,374和Liu等人,NatureBiotech.2016年4月;34(4):430-434。在一些方面,标记(例如替代标记)包括全部或部分(例如,截短形式)的CD34、NGFR、CD19或截短的CD19(例如,截短的非人CD19)或表皮生长因子受体(例如,tEGFR)。在一些实施方案中,标记是或包含荧光蛋白,如绿色荧光蛋白(GFP)、增强型绿色荧光蛋白(EGFP)(如超折叠GFP(sfGFP))、红色荧光蛋白(RFP)(如tdTomato、mCherry、mStrawberry、AsRed2、DsRed或DsRed2)、青色荧光蛋白(CFP)、蓝绿色荧光蛋白(BFP)、增强型蓝色荧光蛋白(EBFP)和黄色荧光蛋白(YFP)及其变体,包括荧光蛋白的物种变体、单体变体和密码子优化的和/或增强的变体。在一些实施方案中,标记是或包含酶(如萤光素酶)、来自大肠杆菌(E.coli)的lacZ基因、碱性磷酸酶、分泌型胚胎碱性磷酸酶(SEAP)、氯霉素乙酰转移酶(CAT)。示例性发光报告基因包括萤光素酶(luc)、β-半乳糖苷酶、氯霉素乙酰转移酶(CAT)、β-葡糖醛酸糖苷酶(GUS)或其变体。
在一些实施方案中,标记是选择标记。在一些实施方案中,选择标记是或包含赋予对外源药剂或药物的抗性的多肽。在一些实施方案中,选择标记是抗生素抗性基因。在一些实施方案中,选择标记是向哺乳动物细胞赋予抗生素抗性的抗生素抗性基因。在一些实施方案中,选择标记是或包含嘌呤霉素抗性基因、潮霉素抗性基因、杀稻瘟菌素抗性基因、新霉素抗性基因、遗传霉素抗性基因或博莱霉素抗性基因或其经修饰形式。
在一些方面,标记包括全部或部分(例如,截短形式)的CD34、NGFR或表皮生长因子受体(例如,tEGFR)。在一些实施方案中,编码标记的核酸与编码接头序列(如可切割接头序列,例如T2A)的多核苷酸可操作地连接。参见WO 2014031687。在一些实施方案中,引入编码由T2A核糖体开关隔开的CAR和EGFRt的构建体可以表达来自相同构建体的两种蛋白质,使得EGFRt可以用作检测表达这种构建体的细胞的标记。在一些实施方案中,标记和任选地接头序列可以是如已公开的专利申请号WO 2014031687中所披露的任一种。例如,标记可以是截短的EGFR(tEGFR),其任选地连接至接头序列,如T2A可切割接头序列。截短的EGFR(例如tEGFR)的示例性多肽包含SEQ ID NO:273或343所示的氨基酸序列或与SEQ ID NO:273或343展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列。示例性T2A接头序列包含SEQ ID NO:211或274所示的氨基酸序列或与SEQ ID NO:211或274展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列。
在一些实施方案中,标记是并未在T细胞上天然发现的或并未在T细胞表面上天然发现的分子(例如,细胞表面蛋白)或其部分。
在一些实施方案中,分子是非自身分子(例如,非自身蛋白),即不被宿主的免疫系统识别为“自身”的分子,所述细胞将被过继转移至所述宿主中。
在一些实施方案中,标记不起任何治疗作用和/或不产生除了用作基因工程化的标记(例如,用于选择成功工程化的细胞)以外的作用。在其他实施方案中,标记可以是治疗性分子或以其他方式发挥一些所需作用的分子,如在体内将遇到的细胞的配体,如共刺激或免疫检查点分子,以在过继转移和遇到配体时增强和/或减弱细胞的应答。
在一些情况下,CAR称为第一代、第二代和/或第三代CAR。在一些方面,第一代CAR是在抗原结合后仅提供CD3链诱导的信号的CAR;在一些方面,第二代CAR是提供这样的信号和共刺激信号的CAR,如包括来自共刺激受体(如CD28或CD137)的细胞内信号传导结构域的CAR;在一些方面,第三代CAR是在一些方面包括不同共刺激受体的多个共刺激结构域的CAR。
在一些实施方案中,嵌合抗原受体包括含有本文所述的TCR样抗体或片段的细胞外部分和细胞内信号传导结构域。在一些实施方案中,抗体或片段包括scFv,并且细胞内结构域含有ITAM。在一些方面,细胞内信号传导结构域包括CD3-zeta(CD3ζ)链的ζ链的信号传导结构域。在一些实施方案中,嵌合抗原受体包括将细胞外结构域与细胞内信号传导结构域连接的跨膜结构域。在一些方面,跨膜结构域含有CD28的跨膜部分。细胞外结构域和跨膜可以直接或间接连接。在一些实施方案中,细胞外结构域和跨膜通过间隔子(如本文所述的任何间隔子)连接。在一些实施方案中,嵌合抗原受体含有T细胞共刺激分子的细胞内结构域,如在跨膜结构域与细胞内信号传导结构域之间。在一些方面,T细胞共刺激分子是CD28或41BB。
例如,在一些实施方案中,CAR含有如本文提供的TCR样抗体(例如,抗体片段)、跨膜结构域(其是或含有CD28的跨膜部分或其功能变体)以及含有CD28的信号传导部分或其功能变体和CD3ζ的信号传导部分或其功能变体的细胞内信号传导结构域。在一些实施方案中,CAR含有如本文提供的TCR样抗体(例如,抗体片段)、跨膜结构域(其是或含有CD28的跨膜部分或其功能变体)以及含有4-1BB的信号传导部分或其功能变体和CD3ζ的信号传导部分或其功能变体的细胞内信号传导结构域。在一些此类实施方案中,CAR还包括含有Ig分子(如人Ig分子)的一部分(如Ig铰链,例如IgG4铰链)的间隔子,如仅铰链间隔子。
在一些实施方案中,受体(例如,TCR样CAR)的跨膜结构域是人CD28(例如,登录号P01747.1)的跨膜结构域或其变体,如包含SEQ ID NO:275所示的氨基酸序列或与SEQ IDNO:275展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列的跨膜结构域。在一些实施方案中,CAR的含有跨膜结构域的部分包含SEQ ID NO:276所示的氨基酸序列或与SEQ ID NO:276具有至少或至少约85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列。
在一些实施方案中,CAR(例如,TCR样CAR)的一种或多种细胞内信号传导组分含有人CD28的细胞内共刺激信号传导结构域或其功能变体或部分,如在天然CD28蛋白的位置186-187处具有LL至GG取代的结构域。例如,细胞内信号传导结构域可以包含SEQ ID NO:277或278所示的氨基酸序列或与SEQ ID NO:277或278展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列。在一些实施方案中,细胞内结构域包含4-1BB(例如,登录号Q07011.1)的细胞内共刺激信号传导结构域或其功能变体或部分,如SEQID NO:279所示的氨基酸序列或与SEQ IDNO:279展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列。
在一些实施方案中,CAR(例如,TCR样CAR)的细胞内信号传导结构域包含人CD3ζ刺激信号传导结构域或其功能变体,如人CD3ζ(登录号:P20963.2)的亚型3的112个AA的胞质结构域或如美国专利号7,446,190或美国专利号8,911,993中所述的CD3ζ信号传导结构域。例如,在一些实施方案中,细胞内信号传导结构域包含SEQ ID NO:280、281或282的氨基酸序列或与SEQ ID NO:280、281或282展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列。
在一些方面,间隔子仅含有IgG的铰链区,如仅IgG4或IgG1的铰链,如SEQ ID NO:268所示的仅铰链的间隔子。在其他实施方案中,间隔子是或含有任选地与CH2和/或CH3结构域连接的Ig铰链,例如IgG4衍生的铰链。在一些实施方案中,间隔子是与CH2和CH3结构域连接的Ig铰链,例如IgG4铰链,如SEQ ID NO:271所示。在一些实施方案中,间隔子是仅与CH3结构域连接的Ig铰链,例如IgG4铰链,如SEQ ID NO:270所示。在一些实施方案中,间隔子是或包含富甘氨酸-丝氨酸的序列或其他柔性接头,如已知的柔性接头。
例如,在一些实施方案中,TCR样CAR包括TCR样抗体或片段(如本文提供的任何抗体或片段,包括scFv)、间隔子(如任何含有Ig铰链的间隔子)、CD28跨膜结构域、CD28细胞内信号传导结构域和CD3ζ信号传导结构域。在一些实施方案中,TCR样CAR包括TCR样抗体或片段(如本文提供的任何抗体或片段,包括scFv)、间隔子(如任何含有Ig铰链的间隔子)、CD28跨膜结构域、CD28细胞内信号传导结构域和CD3ζ信号传导结构域。在一些实施方案中,此类TCR样CAR构建体还包括T2A核糖体跳跃元件和/或tEGFR序列,例如在CAR的下游。
在一些实施方案中,此类CAR构建体还包括T2A核糖体跳跃元件和/或tEGFR序列,例如在CAR的下游,如SEQ ID NO:211或274所示,和SEQ ID NO:273或343所示的tEGFR序列,或与SEQ ID NO:211、273、343或274展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列。
在一些实施方案中,CAR包括本文所述的HPV 16E6或E7抗体或片段(如任何HPV16E6或E7抗体,包括sdAb(例如仅含有VH区)和scFv)、间隔子(如任何含有Ig铰链的间隔子)、CD28跨膜结构域、CD28细胞内信号传导结构域和CD3ζ信号传导结构域。在一些实施方案中,CAR包括本文所述的HPV 16抗体或片段(如任何HPV 16E6或E7抗体,包括sdAb和scFv)、间隔子(如任何含有Ig铰链的间隔子)、CD28跨膜结构域、CD28细胞内信号传导结构域和CD3ζ信号传导结构域。在一些实施方案中,此类CAR构建体还包括T2A核糖体跳跃元件和/或tEGFR序列,例如在CAR的下游。
3.结合分子和工程化细胞的示例性特征
在一些方面,所提供的结合分子(例如TCR或TCR样CAR)具有一种或多种指定的功能特征,如结合特性,包括与特定表位的结合、脱靶结合或活性的缺乏和/或特定结合亲和力。在一些实施方案中,可以通过表达TCR,例如通过将编码TCR的一种或多种核酸引入T细胞(如原代T细胞或T细胞系)中来评估所提供的TCR的任何一种或多种特征。在一些实施方案中,T细胞系是Jurkat细胞或Jurkat衍生的细胞系。示例性的Jurkat衍生的细胞系是通过用辐照诱变处理Jurkat白血病细胞系并且用OKT3单克隆抗体进行阴性选择而产生的J.RT3-T3.5( TIB-153TM)细胞系(参见Weiss&Stobo,J.Ex.Med.160(5):1284-1299(1984))。
TIB-153TM)细胞系(参见Weiss&Stobo,J.Ex.Med.160(5):1284-1299(1984))。
在一些实施方案中,所提供的结合分子能够以至少一定亲和力与HPV16的肽表位(例如如上文所述的HPV 16E6或E7的表位)结合,如通过许多已知方法中的任一种所测量的。在一些实施方案中,肽表位是在MHC分子的背景下的肽或者配体。在一些实施方案中,亲和力由平衡解离常数(KD)或缔合常数(ka)表示。在一些实施方案中,亲和力由EC50表示。
在一些实施方案中,结合分子(例如,TCR)以等于或大于105M-1的亲和力或KA(即,以1/M为单位的特定结合相互作用的平衡缔合常数;等于此缔合反应(假设双分子相互作用)的缔合速率[kon或ka]与解离速率[koff或kd]的比率)与肽表位(例如,与MHC分子复合)结合(如特异性结合)。在一些实施方案中,TCR或其片段对肽表位以等于或小于10-5M的KD(即,以M为单位的特定结合相互作用的平衡解离常数;等于此缔合反应(假设双分子相互作用)的解离速率[koff或kd]与缔合速率[kon或ka]的比率)展现出结合亲和力。例如,平衡解离常数KD的范围从或从约10-5M至或至约10-12M,如从或从约10-6M至或至约10-10M、从或从约10-7M至或至约10-11M、从或从约10-6M至或至约10-8M或者从或从约10-7M至或至约10-8M。缔合速率(缔合速率常数;kon或ka;单位为1/Ms)和解离速率(解离速率常数;koff或kd;单位为1/s)可以使用本领域已知的任何测定方法(例如,表面等离子体共振(SPR))来确定。
在一些实施方案中,结合亲和力可以分类为高亲和力或分类为低亲和力。在一些情况下,展现出低至中等亲和力结合的结合分子(例如TCR)展现出高达107M-1、高达106M-1、高达105M-1的KA。在一些情况下,对特定表位展现出高亲和力结合的结合分子(例如TCR)以至少107M-1、至少108M-1、至少109M-1、至少1010M-1、至少1011M-1、至少1012M-1或至少1013M-1的KA与这种表位相互作用。在一些实施方案中,结合分子对HPV 16E6或E7的肽表位的结合亲和力(EC50)和/或解离常数是从或从约0.1nM至1μM、1nM至1μM、1nM至500nM、1nM至100nM、1nM至50nM、1nM至10nM、10nM至500nM、10nM至100nM、10nM至50nM、50nM至500nM、50nM至100nM或100nM至500nM。在某些实施方案中,结合分子对HPV 16E6或E7的肽表位的结合亲和力(EC50)和/或解离常数是或是约或者小于或小于约1μM、500nm、100nM、50nM、40nM、30nM、25nM、20nM、19nM、18nM、17nM、16nM、15nM、14nM、13nM、12nM、11nM、10nM、9nM、8nM、7nM、6nM、5nM、4nM、3nM、2nM或1nM。
已知多种用于评估结合亲和力和/或确定结合分子是否与特定配体(例如在MHC分子的背景下的肽)特异性结合的测定。例如通过使用本领域熟知的许多结合测定中的任一种确定结合分子(例如,TCR)对靶多肽的T细胞表位的结合亲和力在熟练技术人员的能力范围内。例如,在一些实施方案中,BIAcore机器可以用于确定两种蛋白质之间的复合物的结合常数。复合物的解离常数可以通过监测缓冲液在芯片上通过时折射率随时间的变化来确定。用于测量一种蛋白质与另一种蛋白质的结合的其他合适的测定包括例如免疫测定(如酶联免疫吸附测定(ELISA)和放射免疫测定(RIA))或通过荧光、紫外线吸收、圆二色性或核磁共振(NMR)监测蛋白质的光谱或光学特性的变化来确定结合。其他示例性测定包括但不限于Western印迹、ELISA、分析超离心、光谱学和表面等离子体共振( )分析(参见例如,Scatchard等人,Ann.N.Y.Acad.Sci.51:660,1949;Wilson,Science 295:2103,2002;Wolff等人,Cancer Res.53:2560,1993;和美国专利号5,283,173、5,468,614或等同物)、流式细胞术、测序和用于检测所表达的核酸的其他方法。在一个例子中,通过评估与各种浓度的四聚体的结合,例如通过使用经标记的四聚体的流式细胞术,来测量对TCR的表观亲和力。在一个例子中,使用在一定浓度范围内的经标记的四聚体的2倍稀释液测量TCR的表观KD,然后通过非线性回归确定结合曲线,表观KD被确定为产生半最大结合的配体浓度。
)分析(参见例如,Scatchard等人,Ann.N.Y.Acad.Sci.51:660,1949;Wilson,Science 295:2103,2002;Wolff等人,Cancer Res.53:2560,1993;和美国专利号5,283,173、5,468,614或等同物)、流式细胞术、测序和用于检测所表达的核酸的其他方法。在一个例子中,通过评估与各种浓度的四聚体的结合,例如通过使用经标记的四聚体的流式细胞术,来测量对TCR的表观亲和力。在一个例子中,使用在一定浓度范围内的经标记的四聚体的2倍稀释液测量TCR的表观KD,然后通过非线性回归确定结合曲线,表观KD被确定为产生半最大结合的配体浓度。
在一些实施方案中,与HPV 16E6或E7阴性细胞(如已知和/或本文所述的表达HPV16E6或E7和已知不表达HPV 16E6或E7的特定细胞)相比,结合分子对表达HPV 16E6或E7的细胞的抗原识别展示出结合偏好。在一些实施方案中,观察到结合偏好,其中与非HPV 16E6或E7表达细胞相比,测量到与表达HPV 16E6或E7的细胞显著更大程度的结合。在一些实施方案中,与非HPV 16E6或E7表达细胞相比与表达HPV 16E6或E7的细胞的检测到的结合程度的倍数变化(例如,如通过基于流式细胞术的测定中的平均荧光强度/或解离常数或EC50所测量的)是至少或至少约1.5、2、3、4、5、6或更多。
在一些实施方案中,结合分子(例如TCR)不展现出交叉反应性或脱靶结合,如不需要的脱靶结合,例如与健康或正常组织或细胞中存在的抗原的脱靶结合。在一些实施方案中,结合分子(例如TCR)仅识别(如特异性结合)一种肽表位或抗原复合物,如仅识别SEQ IDNO:232-239中任一个所示的特定HPV 16E6或E7表位或其抗原复合物。因此,在一些实施方案中,所提供的结合分子(例如TCR)具有降低的由于例如非靶肽表位的识别引起不想要的副作用的风险。
在一些实施方案中,结合分子(例如,TCR)不识别(如不特异性结合)SEQ ID NO:232-239中任一个所示的HPV 16E6或E7表位的序列相关肽表位,即不识别与SEQ ID NO:232-239中任一个所示的HPV 16E6或E7表位共有一些氨基酸的表位,如不识别当比对表位时与这种表位相差1、2、3、4、5或6个氨基酸残基的表位。在一些实施方案中,结合分子(例如,TCR)不识别SEQ ID NO:232-239中任一个所示的HPV 16E6或E7表位的序列无关表位,即不识别与SEQ ID NO:232-239中任一个所示的HPC 16E6或E7表位相比在序列上有实质性不同(如当比对表位时与这种表位相差超过6、7、8、9、10个或更多氨基酸残基)的表位。在一些实施方案中,结合分子(例如,TCR)不识别在不同MHC等位基因的背景下(如在除了HLA-A2以外的MHC等位基因的背景下)的SEQ ID NO:232-239中任一个所示的HPV 16E6或E7表位。
通常,结合分子(例如TCR)与肽表位(例如与MHC复合)的特异性结合是通过含有一个或多个互补决定区(CDR)的抗原结合位点的存在来控制的。通常,应理解,特异性结合并不意味着特定肽表位(例如与MHC复合)是MHC-肽分子可以结合的唯一物质,因为也可能发生与其他分子的非特异性结合相互作用。在一些实施方案中,结合分子与在MHC分子的背景下的肽的结合是以比与此类其他分子(例如在MHC分子的背景下的另一种肽或在MHC分子的背景下的无关(对照)肽)的结合更高的亲和力,如比与此类其他分子的结合亲和力高至少约2倍、至少约10倍、至少约20倍、至少约50倍或至少约100倍。
在一些实施方案中,可以使用本领域已知的许多筛选测定中的任一种来评估结合分子(例如,TCR)的安全性或脱靶结合活性。在一些实施方案中,可以在已知不表达靶肽表位的细胞的存在下测量对特定结合分子(例如,TCR)的免疫应答的产生,所述细胞是例如源自一种或多种正常组织、表达一种或多种不同MHC类型的同种异体细胞系或者其他组织或细胞来源的细胞。在一些实施方案中,细胞或组织包括正常细胞或组织。例如,在一些情况下,细胞或组织可以包括脑、肌肉、肝脏、结肠、肾脏、肺、卵巢、胎盘、心脏、胰腺、前列腺、上皮或皮肤、睾丸、肾上腺、肠、骨髓或脾脏。在一些实施方案中,可以在2维培养物中测试与细胞的结合。在一些实施方案中,可以在3维培养物中测试与细胞的结合。在一些实施方案中,作为对照,组织或细胞可以是已知表达靶表位的组织或细胞。可以直接或间接评估免疫应答,如通过评估免疫细胞(如T细胞的)激活(例如细胞毒性活性)、细胞因子(例如干扰素γ)的产生或信号传导级联的激活。
在一些实施方案中,可以通过使用特定靶表位对人基因组进行同源性扫描来鉴定潜在的脱靶,例如以鉴定潜在的序列相关表位。在一些情况下,可以分析蛋白质序列数据库以鉴定与靶肽表位具有相似性的肽。在一些实施方案中,为了便于鉴定潜在的目的序列相关表位,可以首先鉴定结合基序。在一些实施方案中,可以通过靶表位(例如,SEQ ID NO:232-239中任一个所示的HPV 16E6或E7表位)的肽扫描(如丙氨酸诱变扫描)来鉴定结合基序,以鉴定结合分子识别的结合基序,参见例如WO 2014/096803。在一些实施方案中,可以通过诱变靶肽来鉴定结合基序,使得产生一系列突变体,在其中每个氨基酸或其子集变为另一种氨基酸残基,测试其相对于原始靶表位的活性,并且鉴定出参与结合或为结合所需的那些残基。在一些实施方案中,可以制备一系列突变体,在其中靶表位的每个位置处的氨基酸残基被突变为全部替代氨基酸。在一些情况下,一旦鉴定出结合基序(即不耐受的并且参与结合或为结合所需的氨基酸残基),便可以在蛋白质数据库中搜索含有结合基序的蛋白质。
在一些实施方案中,合适的蛋白质数据库包括但不限于UniProtKB/Swiss-Prot(http://www.uniprot.org/)、蛋白质信息资源(Protein Information Resource,PIR)(http://pir.georgetown.edu/pirwww/index.shtml)和/或参考序列(ReferenceSequence,RefSeq)(www.ncbi.nlm.nih.gov/RefSeq)。可以使用许多工具中的任何一种来搜索肽基序,所述工具可以在生物信息学资源网站(如ExPASY(http://www.expasy.org/))上找到。例如,搜索工具ScanProsite在UniProtKB/Swiss-Prot蛋白质知识库中的全部蛋白质序列中鉴定用户定义的基序(De Castro等人Nucleic Acids Res.2006年7月1日;34(WebServer发布):W362-5)。在一些情况下,可以搜索人起源的肽或在人类中普遍存在的生物(如病毒或细菌病原体或共生细菌)的肽。
在一些实施方案中,如果鉴定出潜在的脱靶表位,则可以重新设计结合分子(例如,TCR),使得与所述一种或多种脱靶肽不再有任何交叉反应性,同时与靶肽表位保持结合,优选地以高亲和力。例如,可以使用WO 03/020763中描述的方法通过诱变来重新设计T细胞受体。
在一些实施方案中,结合分子(例如,包含结合分子(例如,TCR)的工程化细胞)引起针对HPV 16的免疫应答。在一些实施方案中,当使含有结合分子(例如,TCR)的细胞与靶细胞(如表达HPV 16(如HPV 16E6或HPV16E7)的细胞)接触时,可以激活细胞毒性T淋巴细胞(CTL)。例如,含有TCR的细胞可以诱导靶细胞裂解,所述靶细胞是例如表达HPV 16(例如,表达HPV 16E6或E7)的细胞。在一些方面,可以通过测量细胞因子释放来确定结合分子(如表达结合分子(例如,TCR或CAR)的细胞)引起免疫应答的能力。在一些实施方案中,响应于与表达结合分子(例如,TCR或CAR)的细胞共培养或暴露于表达结合分子(例如,TCR或CAR)的细胞,当细胞被已知表达HPV 16(如HPV 16E6或HPV 16E7)的适当靶细胞刺激时,释放多种细胞因子。此类细胞因子的非限制性例子包括IFN-γ、TNF-α和GM-CSF。已知表达HPV 16的示例性细胞包括但不限于CaSki细胞(ATCC编号CRL-1550,其含有约600个拷贝的整合的HPV16)或表达相关MHC分子和相应肽表位(例如,HPV 16E6或E7表位,如SEQ ID NO:232-239所示的那些中的任一种)的其他肿瘤细胞。
在一些实施方案中,可以确定CTL激活。存在多种用于测定CTL活性的技术。在一些实施方案中,CTL活性可以通过测定培养物中裂解放射标记的靶细胞(如特定的肽脉冲的靶标)的CTL的存在来评估。这些技术包括用诸如Na2、51CrO4或3H-胸苷等放射性核素标记靶细胞,并且测量放射性核素从靶细胞的释放或保留作为细胞死亡的指标。在一些实施方案中,已知当CTL被适当靶细胞(如表达相关MHC分子和相应肽表位的肿瘤细胞)刺激时释放多种细胞因子,并且此类表位特异性CTL的存在可以通过测量细胞因子释放来确定。此类细胞因子的非限制性例子包括IFN-γ、TNF-α和GM-CSF。这些细胞因子的测定是本领域熟知的,并且其选择留给熟练技术人员。用于测量靶细胞死亡和细胞因子释放两者作为CTL反应性的量度的方法给出于Coligan,J.E.等人(Current Protocols in Immunology,1999,JohnWiley&Sons,Inc.,New York)中。
在一些实施方案中,可以测量细胞因子产生作为免疫应答的指标。在一些情况下,此类经测量的细胞因子可以包括但不限于白介素-2(IL-2)、干扰素-γ(IFNγ)、白介素-4(IL-4)、TNF-α、白介素-6(IL-6)、白介素-10(IL-10)、白介素-12(IL-12)或TGF-β。测量细胞因子的测定是本领域熟知的,并且包括但不限于ELISA、细胞内细胞因子染色、流式微珠阵列、RT-PCR、ELISPOT、流式细胞术和生物测定,其中测试对相关细胞因子有反应的细胞在测试样品的存在下的反应性(例如增殖)。
在一些实施方案中,例如使用T细胞测定评估暴露于结合分子的细胞(例如含有结合分子(如TCR或CAR)的细胞)的免疫学读出。在一些实施方案中,含有结合分子的细胞可以激活CD8+T细胞应答。在一个实施方案中,可以通过使用以下测定监测CTL反应性来评估CD8+T细胞应答,所述测定包括但不限于经由51Cr释放的靶细胞裂解或检测干扰素γ释放,如通过酶联免疫吸附点测定(ELISA)、细胞内细胞因子染色或ELISPOT。在一些实施方案中,结合分子(例如,含有结合分子(如TCR或CAR)的细胞)可以激活CD4+T细胞应答。在一些方面,可以通过测量增殖的测定来评估CD4+T细胞应答,如通过将[3H]-胸苷掺入细胞DNA中和/或通过产生细胞因子,如通过ELISA、细胞内细胞因子染色或ELISPOT。在一些情况下,细胞因子可以包括例如白介素-2(IL-2)、干扰素-γ(IFN-γ)、白介素-4(IL-4)、TNF-α、白介素-6(IL-6)、白介素-10(IL-10)、白介素-12(IL-12)或TGFβ。在一些实施方案中,结合分子对肽表位(如MHC II类表位)的识别或结合可以引起或激活CD4+T细胞应答和/或CD8+T细胞应答。
在一些实施方案中,结合分子(例如,TCR或其抗原结合片段)的结合特异性和/或功能(例如,引起针对HPV 16的免疫应答的能力)是至少部分地CD8非依赖性的。在一些情况下,在CD8共受体的存在下促进在MHC分子的背景下的肽的TCR识别和随后的T细胞激活。例如,CD8共受体接合可以促进低至中等TCR亲和力相互作用和/或T细胞激活(参见例如,Kerry等人J.Immunology(2003)171(9):4493-4503和Robbins等人J Immunology(2008)180(9):6116-6131)。所提供的结合分子包括对HPV E6或E7肽表位展现出CD8非依赖性结合的分子,例如TCR。在一些实施方案中,与需要CD8共表达的存在的TCR或其抗原结合片段相比,此类结合分子(例如TCR)可能具有更高的功能亲合力或亲和力。在一些方面,所提供的CD8非依赖性结合分子(如TCR)可以在不表达CD8的细胞(例如T细胞)中表达或工程化,例如可以在CD4+细胞中表达或工程化。在一些实施方案中,所提供的工程化非CD8表达细胞(例如CD4+细胞)包括这样的细胞,其表达重组结合分子(例如,TCR或抗原结合片段),所述重组结合分子展现出在CD8+T细胞上表达的相同结合分子(例如,TCR或其抗原结合片段)的对在MHC分子的背景下的肽的结合特异性、亲和力和/或亲合力的至少或至少约20%、30%、40%、50%、60%、70%、80%、90%或更多。
II.核酸,载体和表达方法
还提供了编码任何所提供的结合分子的核酸,所述结合分子是例如TCR或其抗原结合片段或者抗体或其抗原结合片段或者含有此类抗体的CAR,如本文所述的那些。核酸可以包括包含天然和/或非天然存在的核苷酸和碱基的那些,例如包括具有骨架修饰的那些。术语“核酸分子”、“核酸”和“多核苷酸”可以可互换地使用,并且是指核苷酸的聚合物。核苷酸的此类聚合物可以含有天然和/或非天然核苷酸,并且包括但不限于DNA、RNA和PNA。“核酸序列”是指构成核酸分子或多核苷酸的核苷酸的线性序列。
在一些实施方案中,结合分子(例如TCR)或其抗原结合部分可以是重组产生的天然蛋白或其突变形式,其中一种或多种特性(如结合特征)已经发生改变。在一些方面,核酸是合成的。在一些情况下,核酸是或含有cDNA。在一些方面,可以修饰核酸分子以用于本文所述的构建体中,如用于密码子优化。在一些情况下,出于克隆到载体中的目的,可以将序列设计为含有末端限制性位点序列。
在一些实施方案中,编码结合分子(例如TCR)的核酸分子可以从多种来源获得,如通过一种或多种给定细胞内的或从所述一种或多种给定细胞中分离的编码核酸的聚合酶链式反应(PCR)扩增获得。在一些实施方案中,TCR是从生物来源获得,如来自细胞(如来自T细胞(例如细胞毒性T细胞))、T细胞杂交瘤或其他公众可获得的来源。在一些实施方案中,TCR可以源自多个动物物种之一,如人、小鼠、大鼠或其他哺乳动物,如通常来自人。在一些实施方案中,T细胞可以从体内分离的细胞获得,如来自正常(或健康)受试者或患病受试者,包括存在于外周血单核细胞(PBMC)或肿瘤浸润淋巴细胞(TIL)中的T细胞。在一些实施方案中,T细胞可以是经培养的T细胞杂交瘤或克隆。例如,在一些实施方案中,为了产生编码TCR的载体,可以将α和β链从表达目的TCR的T细胞克隆中分离的总cDNA进行PCR扩增,并且将其克隆到表达载体中。在一些实施方案中,α和β链可以合成产生。在一些实施方案中,将α和β链克隆到同一载体中。
在一些实施方案中,TCR或其抗原结合部分可以根据对TCR序列的知识合成产生。
在一些实施方案中,核酸分子含有编码α链的核酸序列和/或编码β链的核苷酸序列。
在一些实施方案中,编码α链的核酸序列包含以下之一:SEQ ID NO:20的残基61-816、SEQ ID NO:30的残基58-804、SEQ ID NO:40的残基61-825、SEQ ID NO:50的残基64-813、SEQ ID NO:60的残基64-816、SEQ ID NO:70的残基58-807、SEQ ID NO:80的残基61-825、SEQ ID NO:90的残基67-831、SEQ ID NO:100的残基58-801、SEQ ID NO:183的残基64-810、SEQ ID NO:202的残基58-801、SEQ ID NO:219的残基67-813、其简并序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列。在一些方面,编码β链的核苷酸序列包含以下之一:SEQ ID NO:17的残基58-936、SEQ IDNO:16的残基58-930、SEQ ID NO:24的残基58-939、SEQ ID NO:34或44的残基64-930、SEQID NO:55的残基58-933、SEQ ID NO:64的残基58-927、SEQ ID NO:74的残基64-936、SEQ IDNO:84的残基58-933、SEQ ID NO:94的残基63-930、SEQ ID NO:104的残基46-936、SEQ IDNO:108的残基58-933、其简并序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列。
在一些实施方案中,编码α链的核苷酸序列和/或编码β链的核苷酸序列是经密码子优化的。通常,密码子优化涉及使所选择的密码子的百分比与已公开的人类转移RNA的丰度平衡,使得没有一者过载或受限。在一些情况下,这可能是必要的,因为大多数氨基酸由超过一种密码子编码,并且密码子使用因生物而异。经转染的基因与宿主细胞之间的密码子使用差异可能会影响核酸构建体的蛋白质表达和免疫原性。通常,对于密码子优化,选择密码子以选择与人类使用频率平衡的那些密码子。通常,氨基酸密码子的冗余度使得不同的密码子编码一种氨基酸。在一些实施方案中,在选择用于置换的密码子时,可能需要所得突变是沉默突变,使得密码子改变不影响氨基酸序列。通常,密码子的最后一个核苷酸可以保持不变而不会影响氨基酸序列。
在一些情况下,编码α链的核酸序列含有以下之一:SEQ ID NO:10的残基67-825、SEQ ID NO:11的残基58-813、SEQ ID NO:12的残基64-822、SEQ ID NO:21的残基61-825、SEQ ID NO:31的残基58-813、SEQ ID NO:41的残基61-834、SEQ ID NO:51的残基63-822、SEQ ID NO:61的残基64-825、SEQ ID NO:71的残基58-816、SEQ ID NO:81的残基61-834、SEQ ID NO:91的残基67-840、SEQ ID NO:101的残基58-810、其简并序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列。在一些例子中,编码β链的核苷酸序列包含以下之一:SEQ ID NO:7的残基58-930、SEQ ID NO:8的残基58-936、SEQ ID NO:9的残基58-933、SEQ ID NO:25的残基58-939、SEQ ID NO:35、45或95的残基64-930、SEQ ID NO:54或85的残基58-933、SEQ ID NO:65的残基58-927、SEQ IDNO:75的残基64-936、SEQ ID NO:105的残基46-936、其简并序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列。
在一些实施方案中,编码TCR的α链和/或β链的核酸分子包含对应于表11所列的SEQ ID NO.的核酸序列。所提供的编码TCR的核酸分子还包括含有与此类序列至少或至少约90%、91%、92%、93%、94%、95%、96%、97%、98%或99%相同的序列的那些。由此类序列编码的示例性TCR或其经修饰形式也列于表11中。



还提供了含有此类核酸分子的载体或构建体。在一些实施方案中,载体或构建体含有与编码α链和/或β链的核苷酸可操作地连接的一种或多种启动子。在一些实施方案中,启动子与一种或超过一种核酸分子可操作地连接。
在一些实施方案中,载体或构建体可以含有驱动一种或多种核酸分子表达的单个启动子。在一些实施方案中,此类启动子可以是多顺反子的(双顺反子的或三顺反子的,参见例如,美国专利号6,060,273)。例如,在一些实施方案中,转录单元可以被工程化为含有IRES(内部核糖体进入位点)的双顺反子单元,其允许通过来自单个启动子的信息来共表达基因产物(例如编码TCR的α链和/或β链)。可替代地,在一些情况下,单个启动子可以引导RNA的表达,所述RNA在单个开放阅读框(ORF)中含有两个或三个基因(例如编码TCR的α链和/或β链),所述基因由编码自切割肽(例如,T2A)或蛋白酶识别位点(例如,弗林蛋白酶)的序列彼此隔开。因此,ORF编码单一多蛋白,其在翻译期间(在2A(例如,T2A)的情况下)或翻译之后被切割成单独蛋白质。在一些情况下,肽(如T2A)可以引起核糖体跳过(核糖体跳跃)2A元件C末端处的肽键的合成,从而导致2A序列末端与下游的下一个肽之间的分离(参见例如,de Felipe.Genetic Vaccines and Ther.2:13(2004)和deFelipe等人Traffic 5:616-626(2004))。2A切割肽(包括可以诱导核糖体跳跃的那些)的例子是如美国专利公开号2007/0116690中所述的明脉扁刺蛾β四体病毒(T2A,例如SEQ ID NO:211或274)、猪捷申病毒-1(P2A,例如SEQ ID NO:204或345)、马甲型鼻炎病毒(E2A,例如SEQ ID NO:346)和来自口蹄疫病毒的2A序列(F2A,例如SEQ ID NO:344)。
在一些情况下,编码α链的核苷酸序列和编码β链的核苷酸序列由编码内部核糖体进入位点(IRES)的核苷酸序列或引起核糖体跳跃的肽序列隔开。在一些情形中,编码α链的核苷酸序列和编码β链的核苷酸序列由引起核糖体跳跃的肽序列隔开。在一些此类情形中,引起核糖体跳跃的肽是P2A或T2A肽和/或含有SEQ ID NO:204、211、274或345所示的氨基酸序列。在一些方面,编码引起核糖体跳跃的肽的核苷酸序列含有SEQ ID NO:4、5、6、207、208、209、或210、347、1096、1179、1180或1181所示的序列。
在一些实施方案中,编码α链的核酸序列和编码β链的核苷酸序列以任何顺序存在,由编码内部核糖体进入位点(IRES)的核苷酸序列或引起核糖体跳跃的肽序列隔开。例如,在一些实施方案中,核酸分子以所述顺序包含编码β链的核酸序列、编码IRES的核酸序列或引起核糖体跳跃的肽序列(例如,如本文所述的P2A或T2A序列)以及编码α链的核酸序列。在其他实施方案中,核酸分子以所述顺序含有编码α链的核酸序列、编码IRES的核酸序列或引起核糖体跳跃的肽序列以及编码β链的核酸序列。
因此,在一些方面,核酸分子编码以所述顺序包含β链、IRES或引起核糖体跳跃的肽和α链的多肽。在其他方面,核酸分子编码以所述顺序包含α链、IRES或引起核糖体跳跃的肽和β链的多肽。
在一些实施方案中,核酸分子编码含有表12所列的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的序列的多肽。在一些实施方案中,核酸分子编码SEQ ID NO:1、2、3、27、37、47、57、67、77、87、97、107、223、224、225、226、227、228、229、230、231、340-342、350-388、391-429或1383-1384或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的序列中任一个所示的多肽。在一些实施方案中,核酸分子包含SEQ ID NO:13、14、15、26、36、46、56、66、76、86、96、106、432-472或1382中任一个所示的核酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的序列。
还提供了含有由任何所提供的核酸编码的序列的多肽。在一些方面,多肽包含对应于表12所示的SEQ ID NO.的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的序列。在一些实施方案中,多肽包含SEQ ID NO1、2、3、27、37、47、57、67、77、87、97、107、223、224、225、226、227、228、229、230、231、340-342、350-388、或391-429或1383-1384中任一个所示的序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的序列。示例性的此类TCR或其经修饰形式也列于表12中。



在一些实施方案中,核酸分子还可以编码标记(例如EGFRt或如所述的其他标记),所述标记通过接头(如可切割接头序列)或引起核糖体跳跃的肽序列(例如,T2A或P2A)与CAR分离或与TCR链分离。
在一些实施方案中,能以任何顺序排列构建体,使得编码标记序列在α和/或β序列的3',在α和/或β序列的5'和/或在α与β序列之间,其中在一些情况下,每种单独的组分由可切割接头序列或引起核糖体跳跃的肽(例如T2A或P2A)或IRES隔开。在一些实施方案中,核酸分子含有核酸序列,其以所述顺序编码标记(例如,EGFRt)、可切割接头或核糖体跳跃序列(例如T2A或P2A)、β链、可切割接头或核糖体跳跃序列(例如T2A或P2A)和α链。在一些实施方案中,核酸分子含有核酸序列,其以所述顺序编码标记(例如,EGFRt)、可切割接头或核糖体跳跃序列(例如,T2A或P2A)、α链、可切割接头或核糖体跳跃序列(例如,T2A或P2A)和β链。在一些实施方案中,核酸分子含有核酸序列,其以所述顺序编码β链、可切割接头或核糖体跳跃序列(例如,T2A或P2A)、α链、可切割接头或核糖体跳跃序列(例如,T2A或P2A)和标记(例如EGFRt)。在一些实施方案中,核酸分子含有核酸序列,其以所述顺序编码α链、可切割接头或核糖体跳跃序列(例如T2A或P2A)、β链、可切割接头或核糖体跳跃序列(例如,T2A或P2A)和标记(例如,EGFRt)。在一些实施方案中,核酸分子含有核酸序列,其以所述顺序编码α链、可切割接头或核糖体跳跃序列(例如,T2A或P2A)、标记(例如,EGFRt)、可切割接头或核糖体跳跃序列(例如,T2A或P2A)和β链。在一些实施方案中,核酸分子含有核酸序列,其以所述顺序编码β链、可切割接头或核糖体跳跃序列(例如,T2A或P2A)、标记(例如EGFRt)、可切割接头或核糖体跳跃序列(例如,T2A或P2A)和α链。
在一些实施方案中,引入编码由T2A核糖体开关隔开的CAR和EGFRt的构建体可以表达来自相同构建体的两种蛋白质,使得EGFRt可以用作检测表达这种构建体的细胞的标记。
核酸可以编码分别包含TCR或抗体的可变α(Vα)区或可变轻(VL)区的氨基酸序列。在一些情况下,核酸编码分别包含TCR或抗体的可变β(Vβ)区或可变重(VH)区的氨基酸序列。在进一步的实施方案中,提供了包含这种核酸的一种或多种载体(例如,表达载体)。
还提供了载体,如含有本文所述的任何核酸的那些。在一些实施方案中,将编码结合分子(例如,TCR)的一条或两条链的一种或多种核酸克隆到合适的一种或多种表达载体中。表达载体可以是任何合适的重组表达载体,并且可以用于转化或转染任何合适的宿主。合适的载体包括设计用于繁殖和扩增或用于表达或用于两者的那些,如质粒和病毒。在一些实施方案中,所述载体是表达载体。
在一些实施方案中,载体可以是以下系列的载体:pUC系列(Fermentas LifeSciences)、pBluescript系列(Stratagene,加利福尼亚州拉霍亚)、pET系列(Novagen,威斯康星州麦迪逊)、pGEX系列(Pharmacia Biotech,瑞典乌普萨拉)或pEX系列(Clontech,加利福尼亚州帕洛阿尔托)。在一些情况下,也可以使用噬菌体载体,如λG10、λGT11、λZapII(Stratagene)、λEMBL4和λNM1149。在一些实施方案中,可以使用植物表达载体,并且包括pBI01、pBI101.2、pBI101.3、pBI121和pBIN19(Clontech)。在一些实施方案中,动物表达载体包括pEUK-Cl、pMAM和pMAMneo(Clontech)。在一些情况下,载体是病毒载体。在一些此类方面,病毒载体是逆转录病毒载体,如慢病毒载体。在一些情形中,慢病毒载体源自HIV-1。
在一些实施方案中,重组表达载体可以使用标准的重组DNA技术来制备。在一些实施方案中,载体可以含有调节序列(如转录和翻译起始和终止密码子),其对待引入载体的宿主的类型(例如,细菌、真菌、植物或动物)具有特异性,酌情并考虑载体是基于DNA还是基于RNA。在一些实施方案中,载体可以含有与编码结合分子(如TCR、抗体或其抗原结合片段)的核苷酸序列可操作连接的非天然启动子。在一些实施方案中,启动子可以是非病毒启动子或病毒启动子,如巨细胞病毒(CMV)启动子、SV40启动子、RSV启动子和在鼠干细胞病毒的长末端重复序列中发现的启动子。也考虑了熟练技术人员已知的其他启动子。
还提供了制备结合分子(包括抗原结合片段)的方法。在一些实施方案中,提供了包含这种核酸的宿主细胞。为了重组产生结合分子,可以将编码结合分子(例如,如上所述的)的核酸分离,并且将其插入一种或多种载体中,以在宿主细胞中进一步克隆和/或表达。可以使用常规程序(例如,通过使用能够与编码TCR的α和β链或抗体的重链和轻链的基因特异性结合的寡核苷酸探针)容易地分离和测序这种核酸。在一些实施方案中,提供了制备结合分子的方法,其中所述方法包括在适合于表达结合分子的条件下培养如上所提供的包含编码结合分子的核酸的宿主细胞,以及任选地从宿主细胞(或宿主细胞培养基)回收结合分子。
在一个这样的实施方案中,宿主细胞包含载体(例如,已经用其转化),所述载体包含编码包含TCR或其抗原结合片段的Vβ区的氨基酸序列的核酸以及编码包含TCR或其抗原结合片段的Vα区的氨基酸序列的核酸。在另一个这样的实施方案中,宿主细胞包含载体(例如已经用其转化),所述载体包含编码包含抗体或其抗原结合片段的VH和抗体或其抗原结合片段的VL的氨基酸序列的核酸。在一些方面,宿主细胞包含第一载体和第二载体(例如,已经用其转化),所述第一载体包含编码包含TCR或其抗原结合片段的Vα区的氨基酸序列的核酸,并且所述第二载体包含编码包含TCR或其抗原结合片段的Vβ区的氨基酸序列的核酸。在其他方面,宿主细胞包含第一载体和第二载体(例如已经用其转化),所述第一载体包含编码包含抗体或其抗原结合片段的VL的氨基酸序列的核酸,并且所述第二载体包含编码包含抗体或其抗原结合片段的VH的氨基酸序列的核酸。
除原核生物外,真核微生物(如丝状真菌或酵母)也是结合分子编码载体的合适克隆或表达宿主,包括其糖基化途径已经被修饰以模仿或接近人细胞中的那些的真菌和酵母菌株。参见Gerngross,Nat.Biotech.22:1409-1414(2004)和Li等人,Nat.Biotech.24:210-215(2006)。
可以用于表达多肽的示例性真核细胞包括但不限于COS细胞,包括COS7细胞;293细胞,包括293-6E细胞;CHO细胞,包括CHO-S、DG44.Lec13 CHO细胞和FUT8 CHO细胞; 细胞;以及NSO细胞。在一些实施方案中,基于其对结合分子进行所需的翻译后修饰的能力来选择特定的真核宿主细胞。例如,在一些实施方案中,CHO细胞产生的多肽的唾液酸化水平高于在293细胞中产生的相同多肽。在一些实施方案中,结合分子在无细胞系统中产生。示例性的无细胞系统描述于例如Sitaraman等人,Methods Mol.Biol.498:229-44(2009);Spirin,Trends Biotechnol.22:538-45(2004);Endo等人,Biotechnol.Adv.21:695-713(2003)。
细胞;以及NSO细胞。在一些实施方案中,基于其对结合分子进行所需的翻译后修饰的能力来选择特定的真核宿主细胞。例如,在一些实施方案中,CHO细胞产生的多肽的唾液酸化水平高于在293细胞中产生的相同多肽。在一些实施方案中,结合分子在无细胞系统中产生。示例性的无细胞系统描述于例如Sitaraman等人,Methods Mol.Biol.498:229-44(2009);Spirin,Trends Biotechnol.22:538-45(2004);Endo等人,Biotechnol.Adv.21:695-713(2003)。
III.用于鉴定和产生T细胞受体的方法
在一些实施方案中,提供了用于鉴定和产生针对靶抗原的T细胞受体的方法。在一些方面,所述方法涉及使含有T细胞(如原代T细胞,包括源自正常供体或患有目的疾病或病症的患者的那些)的生物样品经历多轮抗原暴露和评估。在一些方面,所述轮次涉及使用人工或工程化抗原呈递细胞,如自体树突细胞或用所需肽抗原脉冲的其他APC,以促进在MHC(如I类或II类MHC)上的呈递。在一些方面,进行多轮抗原暴露,并且在一些方面,例如基于结合所需抗原(如肽-MHC四聚体)的能力,在一轮或多轮之后分选T细胞。在一些方面,通过流式细胞术进行分选。在一些方面,例如通过单细胞测序方法评估来自被认为与所需抗原结合的细胞(阳性级分)和被认为不与抗原结合的细胞的细胞。在一些方面,所述方法在单细胞水平上测序和鉴定每种样品中存在的TCR对。在一些方面,所述方法可以定量样品中存在的给定TCR对的拷贝数,并且这样可以评估给定样品中给定TCR对的丰度和/或其在另一种样品上的富集,如例如经过一轮或多轮,例如与阴性级分相比,在阳性(抗原结合)级分中的富集或丰度。在一些方面,进行此类测定以产生与人乳头瘤病毒16或18肽抗原特异性结合且在多轮抗原刺激后存在和/或随时间富集的抗原特异性T细胞受体(TCR),所述肽抗原例如是例如呈递在MHC-I分子上的源自E6或E7的肽,如E6(29-38)或E7(11-19)肽。在一些方面,产生克隆T细胞系,并且使用高通量配对TCR测序在单细胞的基础上确定各个群体中单独配对的TCRα和β链的序列及其丰度。
在一些方面,用HPV 16E6(29-38)肽(TIHDIILECV;SEQ ID NO:233)或E7(11-19)肽(YMLDLQPET;SEQ ID NO:236)产生肽脉冲的HLA:A02:01APC。将来自正常人供体的自体CD8+T细胞与肽脉冲的细胞一起孵育多轮,并且基于与负载肽的自体MHC四聚体的结合进行选择。
在一些方面,在肽脉冲的细胞的存在下(如三轮中维持1000ng/mL的特定肽浓度),使细胞经历多轮(如总共两轮或三轮或更多轮)刺激。在一轮或多轮刺激后,如在第一轮刺激后和/或在第二轮和第三轮刺激后,通过流式细胞术将细胞分选为分别对与含有适当四聚体的肽-MHC四聚体的结合呈阳性和阴性的群体。在一些方面,使在一轮或多轮中的每一轮或者一轮或多轮(如第二轮和第三轮)后四聚体阳性和阴性群体的细胞经历单细胞TCR测序,以评估不同群体中单独TCR的存在和频率以及TCR克隆经过多轮抗原刺激的持久性。
在一些方面,在一轮或多轮后,使来自阳性和阴性级分的细胞群(即,通过流式细胞术基于分别对与相关抗原(如肽-MHC,如负载的四聚体)的结合呈阳性和阴性染色进行分选,例如如通过流式细胞术所确定的)经历针对TCRα和β链对的高通量单细胞测序。在一些方面,总体上如已公开的PCT专利申请公开号WO 2012/048340、WO 2012/048341和WO 2016/044227中所述的进行高通量单细胞TCR测序。因此,在一些方面,测序方法采用单细胞液滴以及样品和分子条形码,以针对存在于单一起始组合物中的大量(例如,数百万个)单细胞中的每一个在单细胞水平上鉴定单独的TCRα和β链序列对,并且评估在所评估的各个群体中每个TCR对的丰度。在一些实施方案中,在单细胞水平上鉴定和定量TCR对的能力允许评估单独的阳性和阴性级分中的每一个中各个TCR对中的每一个的频率,并且评估TCR经过多轮抗原刺激的富集和持久性。
在一些方面,所述方法产生、鉴定、分离和/或选择在至少一个且在一些方面多个多轮刺激后富含抗原结合(例如,肽结合)级分的TCR对。在一些方面,TCR在1轮、2轮和/或和3轮且在一些方面至少多轮抗原暴露中存在和/或在1轮、2轮和/或和3轮且在一些方面至少多轮抗原暴露中以所需丰度存在和/或在1轮、2轮和/或和3轮且在一些方面至少多轮抗原暴露后优先富集。在一些方面,在多轮暴露于抗原后,TCR随时间在群体中富集。还提供了使用此类方法产生或鉴定的TCR,如具有这样的特性的TCR,所述特性是例如经过多轮抗原暴露存活和/或扩增的能力(如在肽脉冲的APC测定中)。
IV.工程化细胞
还提供了细胞,如已经被工程化以含有本文所述的结合分子的细胞。还提供了此类细胞的群体、含有此类细胞和/或富含此类细胞的组合物,如其中表达结合分子的细胞构成组合物中总细胞或者某种类型的细胞(如T细胞或CD8+或CD4+细胞)的至少15%、20%、25%、30%、35%、40%、50%、60%、70%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多百分比。在一些实施方案中,细胞是原代T细胞。组合物包括用于给予(如用于过继细胞疗法)的药物组合物和配制品。还提供了用于向受试者(例如,患者)给予细胞和组合物的治疗方法。
因此,还提供了表达结合分子的基因工程化细胞。细胞通常是真核细胞,如哺乳动物细胞,并且通常是人细胞。在一些实施方案中,细胞源自血液、骨髓、淋巴或淋巴器官,是免疫系统的细胞,如先天免疫或适应性免疫的细胞,例如骨髓或淋巴样细胞(包括淋巴细胞,通常是T细胞和/或NK细胞)。其他示例性细胞包括干细胞,如多潜能干细胞和多能干细胞,包括诱导多能干细胞(iPSC)。细胞通常是原代细胞,如直接从受试者分离和/或从受试者分离并冷冻的那些。在一些实施方案中,细胞包括T细胞或其他细胞类型的一个或多个子集,如整个T细胞群、CD4+细胞、CD8+细胞及其亚群,如由以下所定义的那些:功能、激活状态、成熟度、分化的可能性、扩增、再循环、定位和/或持久能力、抗原特异性、抗原受体类型、在特定器官或区室中的存在、标记或细胞因子分泌谱和/或分化程度。关于待治疗的受试者,细胞可以是同种异体的和/或自体的。所述方法包括现成的方法。在一些方面,如对于现成的技术,细胞是多能的和/或多潜能的,如干细胞,如诱导多能干细胞(iPSC)。在一些实施方案中,所述方法包括从受试者中分离细胞,如本文所述制备、加工、培养和/或工程化它们,并且在冷冻保存之前或之后将它们重新引入同一患者体内。
T细胞和/或CD4+和/或CD8+T细胞的亚型和亚群包括幼稚T(TN)细胞、效应T细胞(TEFF)、记忆T细胞及其亚型(如干细胞记忆T(TSCM)、中枢记忆T(TCM)、效应记忆T(TEM)或终末分化的效应记忆T细胞)、肿瘤浸润淋巴细胞(TIL)、未成熟T细胞、成熟T细胞、辅助T细胞、细胞毒性T细胞、粘膜相关恒定T(MAIT)细胞、天然存在和适应性调节T(Treg)细胞、辅助T细胞(如TH1细胞、TH2细胞、TH3细胞、TH17细胞、TH9细胞、TH22细胞、滤泡性辅助T细胞)、α/βT细胞以及δ/γT细胞。
在一些实施方案中,细胞是自然杀伤(NK)细胞。在一些实施方案中,细胞是单核细胞或粒细胞,例如骨髓细胞、巨噬细胞、嗜中性粒细胞、树突细胞、肥大细胞、嗜酸性粒细胞和/或嗜碱性粒细胞。
在一些实施方案中,细胞包括经由基因工程化引入的一种或多种核酸,从而表达此类核酸的重组或基因工程化产物。在一些实施方案中,核酸是异源的,即通常不存在于细胞或从细胞获得的样品中,如从另一种生物或细胞获得的核酸,例如,所述核酸通常不在被工程化的细胞和/或衍生出这种细胞的生物中发现。在一些实施方案中,核酸不是天然存在的,如在自然界中未发现的核酸,包括包含编码来自多种不同细胞类型的各种结构域的核酸的嵌合组合的核酸。
在一些实施方案中,所提供的细胞和/或含有此类细胞的组合物中的基因和/或基因产物(和/或其表达)被减少、缺失、消除、敲除或破坏。在一些方面,此类基因和/或基因产物包括编码TCRα恒定区(TRAC)和/或TCRβ恒定区(TRBC;在人中由TRBC1或TRBC2编码)(或其产物)的一个或多个基因,例如以减少或阻止内源TCR和/或其链在细胞(例如T细胞)中的表达。在一些实施方案中,在本文提供的任何工程化细胞中和/或在本文提供的用于产生工程化细胞的任何方法中基因和/或基因产物(如TRAC和/或TRBC)被减少、缺失、消除、敲除或破坏。在一些实施方案中,工程化细胞和/或通过所述方法产生的工程化细胞是已经被工程化以表达本文所述的结合分子的细胞、此类细胞的群体、含有此类细胞和/或富含此类细胞的组合物。在一些实施方案中,原代T细胞中的基因和/或基因产物(如TRAC和/或TRBC)被减少、缺失、消除、敲除或破坏,以减少、缺失、消除、敲除或破坏内源TCR在原代T细胞中的表达,所述原代T细胞例如被工程化以表达本文所述的任何结合分子,例如TCR。
在一些实施方案中,例如通过例如在下面的第V章中的本文所述的任何方法或过程进行编码TCR或其链、结构域和/或区域的内源基因的减少、缺失、消除、敲除或破坏。
A.用于基因工程化的细胞的制备
在一些实施方案中,工程化细胞的制备包括一个或多个培养和/或制备步骤。用于引入结合分子(例如,TCR或CAR)的细胞可以从样品(如生物样品,例如获自或源自受试者的生物样品)中分离。在一些实施方案中,分离出细胞的受试者是患有疾病或病症或需要细胞疗法或将给予细胞疗法的受试者。在一些实施方案中,受试者是需要特定治疗性干预(如所分离、加工和/或工程化的细胞所用于的过继细胞疗法)的人。
因此,在一些实施方案中,细胞是原代细胞,例如原代人细胞。样品包括直接取自受试者的组织、流体和其他样品,以及来自一个或多个加工步骤(如分离、离心、基因工程化(例如用病毒载体转导)、洗涤和/或孵育)的样品。生物样品可以是直接从生物来源获得的样品或经过加工的样品。生物样品包括但不限于体液(如血液、血浆、血清、脑脊液、滑液、尿液和汗液)、组织和器官样品,包括由其衍生的加工样品。
在一些方面,衍生出或分离出细胞的样品是血液或血液衍生的样品,或者是或源自单采术或白细胞单采术产物。示例性样品包括全血、外周血单核细胞(PBMC)、白细胞、骨髓、胸腺、组织活检、肿瘤、白血病、淋巴瘤、淋巴结、肠相关淋巴组织、粘膜相关淋巴组织、脾脏、其他淋巴组织、肝脏、肺、胃、肠、结肠、肾脏、胰腺、乳房、骨、前列腺、子宫颈、睾丸、卵巢、扁桃体或其他器官和/或由其衍生的细胞。在细胞疗法(例如,过继细胞疗法)的背景下,样品包括来自自体和同种异体来源的样品。
在一些实施方案中,细胞源自细胞系,例如T细胞系。在一些实施方案中,细胞获自异种来源,例如获自小鼠、大鼠、非人灵长类动物或猪。
在一些实施方案中,细胞的分离包括一个或多个制备步骤和/或非基于亲和力的细胞分离步骤。在一些例子中,将细胞在一种或多种试剂的存在下洗涤、离心和/或孵育,例如以去除不需要的组分、富集所需组分、裂解或去除对特定试剂敏感的细胞。在一些例子中,基于一种或多种特性(如密度、粘附特性、大小、对特定组分的敏感性和/或抗性)分离细胞。
在一些例子中,来自受试者的循环血液的细胞例如通过单采术或白细胞单采术获得。在一些方面,样品含有淋巴细胞,包括T细胞、单核细胞、粒细胞、B细胞、其他有核白细胞、红细胞和/或血小板,并且在一些方面含有除了红细胞和血小板以外的细胞。
在一些实施方案中,洗涤从受试者收集的血细胞,例如以去除血浆级分并将细胞置于适当的缓冲液或介质中以用于随后的加工步骤。在一些实施方案中,用磷酸盐缓冲盐水(PBS)洗涤细胞。在一些实施方案中,洗涤溶液缺乏钙和/或镁和/或许多或全部二价阳离子。在一些方面,洗涤步骤是通过半自动“流通”离心机(例如,Cobe 2991细胞加工器,Baxter)根据制造商的说明书完成的。在一些方面,洗涤步骤是通过切向流过滤(TFF)根据制造商的说明书完成的。在一些实施方案中,洗涤之后将细胞重悬于多种生物相容性缓冲液(例如像不含Ca++/Mg++的PBS)中。在某些实施方案中,去除血细胞样品的组分并将细胞直接重悬于培养基中。
在一些实施方案中,所述方法包括基于密度的细胞分离方法,如通过溶解红细胞并通过Percoll或Ficoll梯度进行离心来从外周血制备白细胞。
在一些实施方案中,分离方法包括基于细胞中一种或多种特定分子(如表面标记(例如,表面蛋白)、细胞内标记或核酸)的表达或存在来分离不同细胞类型。在一些实施方案中,可以使用任何已知的基于此类标记的分离方法。在一些实施方案中,分离是基于亲和力或基于免疫亲和力的分离。例如,在一些方面,分离包括基于一种或多种标记(通常是细胞表面标记)在细胞中的表达或表达水平来分离细胞和细胞群,例如通过与和此类标记特异性结合的抗体或结合配偶体一起孵育,之后通常进行洗涤步骤并将已结合所述抗体或结合配偶体的细胞与尚未结合至所述抗体或结合配偶体的那些细胞分离。
此类分离步骤可以基于阳性选择(其中保留已结合试剂的细胞以供进一步使用)和/或阴性选择(其中保留尚未结合至抗体或结合配偶体的细胞)。在一些例子中,保留两种级分以供进一步使用。在一些方面,在无法获得专门鉴定异质性群体中的细胞类型的抗体,使得最好基于除了所需群体以外的细胞表达的标记来进行分离的情况下,阴性选择可以特别有用。
分离不需要导致100%富集或去除特定细胞群体或表达特定标记的细胞。例如,针对特定类型的细胞(如表达标记的那些)的阳性选择或富集是指增加此类细胞的数量或百分比,但不需要导致不表达所述标记的细胞的完全不存在。同样,特定类型的细胞(如表达标记的那些)的阴性选择、去除或耗尽是指减少此类细胞的数量或百分比,但不需要导致全部此类细胞的完全去除。
在一些例子中,进行多轮分离步骤,其中使来自一个步骤的阳性或阴性选择的级分经历另一个分离步骤,如后续阳性或阴性选择。在一些例子中,单个分离步骤可以同时耗尽表达多种标记的细胞,如通过将细胞与多种抗体或结合配偶体(每种抗体或结合配偶体对被靶向用于阴性选择的标记具特异性)一起孵育。同样,通过将细胞与在各种细胞类型上表达的多种抗体或结合配偶体一起孵育,可以同时阳性选择多种细胞类型。
例如,在一些方面,通过阳性或阴性选择技术来分离T细胞的特定亚群,如对高水平的一种或多种表面标记呈阳性或表达所述高水平的一种或多种表面标记的细胞,例如CD28+、CD62L+、CCR7+、CD27+、CD127+、CD4+、CD8+、CD45RA+和/或CD45RO+T细胞。
例如,可以使用抗CD3/抗CD28缀合的磁珠(例如, M-450 CD3/CD28 T Cell Expander)阳性选择CD3+、CD28+T细胞。
M-450 CD3/CD28 T Cell Expander)阳性选择CD3+、CD28+T细胞。
在一些实施方案中,通过经由阳性选择富集特定细胞群,或经由阴性选择耗尽特定细胞群来进行分离。在一些实施方案中,阳性或阴性选择是通过将细胞与一种或多种抗体或其他结合剂一起孵育完成的,所述一种或多种抗体或其他结合剂与分别在阳性或阴性选择的细胞上表达(标记+)或以相对较高水平表达(标记高)的一种或多种表面标记特异性结合。
在一些实施方案中,通过阴性选择在非T细胞(如B细胞、单核细胞或其他白细胞)上表达的标记(如CD14),将T细胞与PBMC样品分离。在一些方面,CD4+或CD8+选择步骤用于分离CD4+辅助T细胞和CD8+细胞毒性T细胞。通过对在一种或多种幼稚、记忆和/或效应T细胞亚群上表达或以相对较高程度表达的标记的阳性或阴性选择,可以将此类CD4+和CD8+群体进一步分选为亚群。
在一些实施方案中,如通过基于与相应亚群相关的表面抗原进行阳性或阴性选择,将CD8+细胞针对幼稚、中枢记忆、效应记忆和/或中枢记忆干细胞进一步富集或耗尽。在一些实施方案中,针对中枢记忆T(TCM)细胞进行富集以增加功效,如以改善给予后的长期存活、扩增和/或移植,这在一些方面在此类亚群中特别稳健。参见Terakura等人(2012)Blood.1:72-82;Wang等人(2012)J Immunother.35(9):689-701。在一些实施方案中,组合富含TCM的CD8+T细胞与CD4+T细胞进一步增强功效。
在实施方案中,记忆T细胞存在于CD8+外周血淋巴细胞的CD62L+和CD62L-两个子集中。可以例如使用抗CD8和抗CD62L抗体将PBMC针对CD62L-CD8+和/或CD62L+CD8+级分进行富集或耗尽。
在一些实施方案中,中枢记忆T(TCM)细胞的富集是基于CD45RO、CD62L、CCR7、CD28、CD3和/或CD 127的阳性或高表面表达;在一些方面,它是基于对表达或高度表达CD45RA和/或颗粒酶B的细胞的阴性选择。在一些方面,通过表达CD4、CD14、CD45RA的细胞的耗尽和表达CD62L的细胞的阳性选择或富集来进行富含TCM细胞的CD8+群体的分离。在一方面,对中枢记忆T(TCM)细胞的富集是用基于CD4表达选择的阴性细胞级分开始进行的,使所述阴性细胞级分经历基于CD14和CD45RA的表达的阴性选择和基于CD62L的阳性选择。在一些方面,此类选择是同时进行的,并且在其他方面,是以任何顺序依序进行的。在一些方面,用于制备CD8+细胞群或亚群的相同的基于CD4表达的选择步骤也用于产生CD4+细胞群或亚群,使得来自基于CD4的分离的阳性和阴性两种级分被保留并用于所述方法的后续步骤中,任选地在一个或多个其他阳性或阴性选择步骤之后。
在特定例子中,使PBMC样品或其他白细胞样品经历CD4+细胞的选择,其中保留了阴性和阳性两种级分。然后使阴性级分经历基于CD14和CD45RA的表达的阴性选择和基于中枢记忆T细胞所特有的标记(如CD62L或CCR7)的阳性选择,其中阳性和阴性选择是以任何顺序进行的。
通过鉴定具有细胞表面抗原的细胞群,将CD4+T辅助细胞分选为幼稚、中枢记忆和效应细胞。CD4+淋巴细胞可以通过标准方法来获得。在一些实施方案中,幼稚CD4+T淋巴细胞是CD45RO-、CD45RA+、CD62L+、CD4+T细胞。在一些实施方案中,中枢记忆CD4+细胞呈CD62L+和CD45RO+。在一些实施方案中,效应CD4+细胞呈CD62L-和CD45RO-。
在一个例子中,为了通过阴性选择富集CD4+细胞,单克隆抗体混合剂通常包括针对CD14、CD20、CD11b、CD16、HLA-DR和CD8的抗体。在一些实施方案中,抗体或结合配偶体结合至固体支持物或基质(如磁珠或顺磁珠),以允许分离细胞以供阳性和/或阴性选择。例如,在一些实施方案中,使用免疫磁性(或亲和磁性)分开技术来分开或分离细胞和细胞群(综述于Methods in Molecular Medicine,第58卷:Metastasis Research Protocols,第2卷:Cell Behavior In Vitro and In Vivo,第17-25页S.A.Brooks和U.Schumacher编辑 Humana Press Inc.,新泽西州托托瓦)。
Humana Press Inc.,新泽西州托托瓦)。
在一些方面,将待分离的细胞的样品或组合物与小的可磁化或磁响应材料(如磁响应颗粒或微粒,如顺磁珠(例如像Dynabeads或MACS珠))一起孵育。磁响应材料(例如,颗粒)通常直接或间接地附着于结合配偶体(例如,抗体),所述结合配偶体与希望分离(例如,希望阴性地或阳性地选择)的一个细胞、多个细胞或细胞群上存在的分子(例如,表面标记)特异性结合。
在一些实施方案中,磁粒或磁珠包含结合至特异性结合成员(如抗体或其他结合配偶体)的磁响应材料。存在许多用于磁分离方法的熟知的磁响应材料。合适的磁粒包括在Molday的美国专利号4,452,773和欧洲专利说明书EP452342B中描述的那些,将所述文献通过引用特此并入。胶体大小的颗粒如在Owen的美国专利号4,795,698和Liberti等人的美国专利号5,200,084中描述的那些是其他例子。
孵育通常在这样的条件下进行,由此抗体或结合配偶体或者与附着于磁粒或磁珠的此类抗体或结合配偶体特异性结合的分子(如二抗或其他试剂)与细胞表面分子(如果存在于样品内的细胞上的话)特异性结合。
在一些方面,将样品置于磁场中,并且具有附着于其上的磁响应或可磁化颗粒的那些细胞将被吸引至磁体并与未标记的细胞分离。对于阳性选择,保留被吸引至磁体的细胞;对于阴性选择,保留未被吸引的细胞(未标记的细胞)。在一些方面,在同一选择步骤期间进行阳性与阴性选择的组合,其中保留阳性和阴性级分并进一步加工或使其经历进一步的分离步骤。
在某些实施方案中,磁响应颗粒被包被在一抗或其他结合配偶体、二抗、凝集素、酶或链霉亲和素中。在某些实施方案中,磁粒经由对一种或多种标记具特异性的一抗的包被而附着于细胞。在某些实施方案中,用一抗或结合配偶体标记细胞而不是珠,然后添加细胞类型特异性二抗或其他结合配偶体(例如,链霉亲和素)包被的磁粒。在某些实施方案中,链霉亲和素包被的磁粒是与生物素化的一抗或二抗结合使用的。
在一些实施方案中,磁响应颗粒保持附着于细胞,所述细胞随后被孵育、培养和/或工程化;在一些方面,颗粒保持附着于细胞以用于给予患者。在一些实施方案中,从细胞中去除可磁化或磁响应颗粒。用于从细胞中去除可磁化颗粒的方法是已知的,并且包括例如使用竞争性非标记抗体、可磁化颗粒或与可切割接头缀合的抗体等。在一些实施方案中,可磁化颗粒是可生物降解的。
在一些实施方案中,基于亲和力的选择是经由磁激活细胞分选(MACS)(MiltenyiBiotec,加利福尼亚州奥本)来进行的。磁激活细胞分选(MACS)系统能够高纯度选择具有附着于其上的磁化颗粒的细胞。在某些实施方案中,MACS以这样的模式操作,其中在施加外部磁场之后依序洗脱非靶种类和靶种类。也就是说,附着于磁化颗粒的细胞被保持在适当的位置,而未附着的种类被洗脱。然后,在完成这个第一洗脱步骤之后,以某种方式释放被捕获在磁场中并被阻止洗脱的种类,使得它们可以被洗脱和回收。在某些实施方案中,标记非靶细胞并将其从异质性细胞群中耗尽。
在某些实施方案中,使用这样的系统、装置或设备进行分离或分开,所述系统、装置或设备进行所述方法的分离、细胞制备、分开、加工、孵育、培养和/或配制步骤中的一个或多个。在一些方面,所述系统用于在封闭或无菌环境中进行这些步骤中的每一个,例如以最小化错误、用户操作和/或污染。在一个例子中,所述系统是如国际专利申请公开号WO2009/072003或US 2011/0003380 A1中描述的系统。
在一些实施方案中,所述系统或设备在集成或独立系统中和/或以自动或可编程方式进行分离、加工、工程化和配制步骤中的一个或多个(例如,全部)。在一些方面,所述系统或设备包括与所述系统或设备通信的计算机和/或计算机程序,其允许用户编程、控制、评估加工、分离、工程化和配制步骤的结果和/或调整加工、分离、工程化和配制步骤的各个方面。
在一些方面,分离和/或其他步骤是使用CliniMACS系统(Miltenyi Biotec)来进行的,例如用于在封闭且无菌的系统中以临床规模水平自动化分离细胞。部件可以包括集成微计算机、磁分离单元、蠕动泵和各种夹管阀。在一些方面,集成计算机控制仪器的全部部件并指示所述系统以标准化顺序执行重复程序。在一些方面,磁分离单元包括可移动的永磁体和用于选择柱的支架。蠕动泵控制整个管组的流速,并且与夹紧阀一起确保经过所述系统的缓冲液的受控流动和细胞的连续悬浮。
在一些方面,CliniMACS系统使用抗体偶联的可磁化颗粒,其在无菌、无热原的溶液中提供。在一些实施方案中,在用磁粒标记细胞之后,洗涤细胞以去除过量的颗粒。然后将细胞制备袋连接到管组,所述管组又连接到含有缓冲液的袋和细胞收集袋。管组由预装配的无菌管(包括预柱和分离柱)组成,并且仅供一次性使用。在启动分离程序之后,所述系统将细胞样品自动施加到分离柱上。标记的细胞保留在柱内,而未标记的细胞通过一系列洗涤步骤去除。在一些实施方案中,用于与本文所述的方法一起使用的细胞群未被标记并且不保留在柱中。在一些实施方案中,用于与本文所述的方法一起使用的细胞群被标记并保留在柱中。在一些实施方案中,用于与本文所述方法一起使用的细胞群在去除磁场之后从柱中洗脱,并收集在细胞收集袋内。
在某些实施方案中,使用CliniMACS Prodigy系统(Miltenyi Biotec)进行分离和/或其他步骤。在一些方面,CliniMACS Prodigy系统配备有细胞加工联合体,其允许通过离心自动化洗涤和分级细胞。CliniMACS Prodigy系统还可以包括机载相机和图像识别软件,其通过辨识源细胞产品的宏观层来确定最佳细胞分级终点。例如,可以将外周血自动分离成红细胞、白细胞和血浆层。CliniMACS Prodigy系统还可以包括集成细胞培育室,其实现细胞培养方案,例如像细胞分化和扩增、抗原负载和长期细胞培养。输入端口可以允许无菌移除和补充培养基,并且可以使用集成显微镜监测细胞。参见例如,Klebanoff等人(2012)J Immunother.35(9):651-660;Terakura等人(2012)Blood.1:72-82;和Wang等人(2012)J Immunother.35(9):689-701。
在一些实施方案中,经由流式细胞术收集并富集(或耗尽)本文所述的细胞群,其中针对多种细胞表面标记染色的细胞携载于流体流中。在一些实施方案中,经由制备规模(FACS)分选来收集并富集(或耗尽)本文所述的细胞群。在某些实施方案中,通过使用微机电系统(MEMS)芯片与基于FACS的检测系统组合来收集并富集(或耗尽)本文所述的细胞群(参见例如,WO 2010/033140;Cho等人(2010)Lab Chip 10,1567-1573;和Godin等人(2008)J Biophoton.1(5):355-376)。在两种情况下,可以用多种标记来标记细胞,从而允许以高纯度分离明确限定的T细胞子集。
在一些实施方案中,用一种或多种可检测标记来标记抗体或结合配偶体,以促进分离供阳性和/或阴性选择。例如,分离可以基于与荧光标记的抗体的结合。在一些例子中,基于对一种或多种细胞表面标记具特异性的抗体或其他结合配偶体的结合来分离细胞携载于流体流中,如通过荧光激活细胞分选(FACS)(包括制备规模(FACS))和/或微机电系统(MEMS)芯片,例如与流式细胞检测系统组合。此类方法允许基于多种标记同时进行阳性和阴性选择。
在一些实施方案中,制备方法包括在分离、孵育和/或工程化之前或之后冷冻(例如,冷冻保存)细胞的步骤。在一些实施方案中,冷冻和后续解冻步骤去除细胞群中的粒细胞,并且在一定程度上去除单核细胞。在一些实施方案中,例如在洗涤步骤后将细胞悬浮在冷冻溶液中以去除血浆和血小板。在一些方面,可以使用多种已知的冷冻溶液和参数中的任一种。一个例子涉及使用含有20%DMSO和8%人血清白蛋白(HSA)的PBS,或其他合适的细胞冷冻培养基。然后用培养基将其1:1稀释,使得DMSO和HSA的最终浓度分别为10%和4%。然后将细胞以1°/分钟的速率冷冻至-80°℃并储存在液氮储罐的气相中。
在一些实施方案中,所提供的方法包括培育、孵育、培养和/或基因工程化步骤。例如,在一些实施方案中,提供了用于孵育和/或工程化耗尽的细胞群和培养起始组合物的方法。
因此,在一些实施方案中,在培养起始组合物中孵育细胞群。孵育和/或工程化可以在培养容器中进行,所述培养容器是例如单元、室、孔、柱、管、管组、阀、小瓶、培养皿、袋或其他用于培养或培育细胞的容器。
在一些实施方案中,在基因工程化之前或与其结合地孵育和/或培养细胞。孵育步骤可以包括培养、培育、刺激、激活和/或繁殖。在一些实施方案中,在刺激条件或刺激剂的存在下孵育组合物或细胞。此类条件包括针对以下而设计的那些:诱导群体中的细胞的增殖、扩增、激活和/或存活,模拟抗原暴露,和/或引发细胞用于基因工程化(如用于引入抗原受体)。
所述条件可以包括以下中的一种或多种:特定培养基、温度、氧含量、二氧化碳含量、时间、药剂(例如,营养素、氨基酸、抗生素、离子和/或刺激因子(如细胞因子、趋化因子、抗原、结合配偶体、融合蛋白、重组可溶性受体和任何其他旨在激活细胞的药剂))。
在一些实施方案中,刺激条件或刺激剂包括能够激活TCR复合物的细胞内信号传导结构域的一种或多种药剂(例如,配体)。在一些方面,所述药剂在T细胞中开启或启动TCR/CD3细胞内信号传导级联。此类药剂可以包括抗体,如对TCR组分和/或共刺激受体具特异性的那些,例如抗CD3。在一些实施方案中,刺激条件包括能够刺激共刺激受体的一种或多种药剂(例如配体),例如抗CD28。在一些实施方案中,此类药剂和/或配体可以结合至固体支持物(如珠)和/或一种或多种细胞因子。任选地,扩增方法还可以包括向培养基中(例如,以至少约0.5ng/ml的浓度)添加抗CD3和/或抗CD28抗体的步骤。在一些实施方案中,刺激剂包括IL-2、IL-15和/或IL-7。在一些方面,IL-2浓度为至少约10单位/mL。
在一些方面,孵育是根据多种技术来进行的,所述技术是例如以下文献中描述的那些:授予Riddell等人的美国专利号6,040,177;Klebanoff等人(2012)J Immunother.35(9):651-660;Terakura等人(2012)Blood.1:72-82;和/或Wang等人(2012)JImmunother.35(9):689-701。
在一些实施方案中,通过以下方式扩增T细胞:向培养起始组合物中添加饲养细胞(如非分裂外周血单核细胞(PBMC))(例如,使得所得细胞群含有至少约5、10、20或40种或更多种PBMC饲养细胞,以使初始群体中的每种T淋巴细胞进行扩增);以及孵育培养物(例如持续足以扩增T细胞数的时间)。在一些方面,非分裂饲养细胞可以包含γ辐照的PBMC饲养细胞。在一些实施方案中,用约3000至3600拉德范围内的γ射线辐照PBMC以阻止细胞分裂。在一些方面,在添加T细胞群之前将饲养细胞添加至培养基中。
在一些实施方案中,刺激条件包括适合于人T淋巴细胞生长的温度,例如至少约25摄氏度,通常为至少约30摄氏度,并且通常为或为约37摄氏度。任选地,孵育还可以包括添加非分裂EBV转化的类淋巴母细胞(LCL)作为饲养细胞。可以用约6000至10,000拉德范围内的γ射线辐照LCL。在一些方面,LCL饲养细胞以任何合适的量(如LCL饲养细胞与初始T淋巴细胞的比率为至少约10:1)提供。
在实施方案中,通过用抗原刺激幼稚或抗原特异性T淋巴细胞获得抗原特异性T细胞,如抗原特异性CD4+和/或CD8+T细胞。例如,可以通过从感染的受试者中分离T细胞并用相同的抗原在体外刺激细胞,针对巨细胞病毒抗原产生抗原特异性T细胞系或克隆。
B.用于基因工程化的载体和方法
还提供了用于表达结合分子以及用于产生表达此类结合分子的基因工程化细胞的方法、核酸、组合物和试剂盒。基因工程化通常涉及将编码结合分子(例如TCR或CAR,例如TCR样CAR)的核酸例如通过逆转录病毒转导、转染或转化引入细胞中。
在一些实施方案中,通过以下方式完成基因转移:首先刺激细胞,如通过将其与诱导反应(如增殖、存活和/或激活)的刺激物进行组合,例如如通过细胞因子或激活标记的表达所测量的,然后转导激活的细胞,并且在培养中扩增至足以用于临床应用的数量。
在一些情境下,刺激因子(例如,淋巴因子或细胞因子)的过表达可能对受试者有毒。因此,在一些情境下,工程化细胞包括导致细胞在体内(如在过继免疫疗法中给予时)对阴性选择易感的基因区段。例如,在一些方面,将细胞工程化,使得它们可以作为给予它们的患者的体内状况的改变的结果而被消除。阴性选择性表型可以由赋予对所给予的药剂(例如,化合物)的敏感性的基因的插入而产生。阴性选择性基因包括单纯疱疹病毒I型胸苷激酶(HSV-I TK)基因(Wigler等人,Cell 2:223,I977),其赋予更昔洛韦敏感性;细胞次黄嘌呤磷酸核糖基转移酶(HPRT)基因;细胞腺嘌呤磷酸核糖基转移酶(APRT)基因;细菌胞嘧啶脱氨酶(Mullen等人,Proc.Natl.Acad.Sci.USA.89:33(1992))。
在一些方面,细胞被进一步工程化以促进细胞因子或其他因子的表达。用于引入基因工程化组分的各种方法是熟知的,并且可以与所提供的方法和组合物一起使用。示例性方法包括用于转移编码结合分子的核酸的那些,包括经由病毒(例如,逆转录病毒或慢病毒)转导、转座子和电穿孔。
在一些实施方案中,使用重组感染性病毒颗粒(例如像源自猿猴病毒40(SV40)、腺病毒、腺相关病毒(AAV)的载体)将重组核酸转移到细胞中。在一些实施方案中,使用重组慢病毒载体或逆转录病毒载体(如γ-逆转录病毒载体)将重组核酸转移到T细胞中(参见例如,Koste等人(2014)Gene Therapy 2014年4月3日.doi:10.1038/gt.2014.25;Carlens等人(2000)Exp Hematol 28(10):1137-46;Alonso-Camino等人(2013)Mol Ther Nucl Acids2,e93;Park等人,Trends Biotechnol.2011年11月29(11):550-557)。
在一些实施方案中,逆转录病毒载体具有长末端重复序列(LTR),例如源自莫洛尼鼠白血病病毒(MoMLV)、骨髓增生性肉瘤病毒(MPSV)、鼠胚胎干细胞病毒(MESV)、鼠干细胞病毒(MSCV)、脾病灶形成病毒(SFFV)的逆转录病毒载体。大多数逆转录病毒载体源自鼠逆转录病毒。在一些实施方案中,逆转录病毒包括源自任何禽类或哺乳动物细胞来源的那些。逆转录病毒通常是双嗜性的,这意味着它们能够感染包括人在内的若干种物种的宿主细胞。在一个实施方案中,待表达的基因替代逆转录病毒gag、pol和/或env序列。已经描述了许多说明性逆转录病毒系统(例如,美国专利号5,219,740;6,207,453;5,219,740;Miller和Rosman(1989)BioTechniques 7:980-990;Miller,A.D.(1990)Human Gene Therapy 1:5-14;Scarpa等人(1991)Virology180:849-852;Burns等人(1993)Proc.Natl.Acad.Sci.USA 90:8033-8037;以及Boris-Lawrie和Temin(1993)Cur.Opin.Genet.Develop.3:102-109)。
慢病毒转导的方法是已知的。示例性方法描述于例如Wang等人(2012)J.Immunother.35(9):689-701;Cooper等人(2003)Blood.101:1637-1644;Verhoeyen等人(2009)Methods Mol Biol.506:97-114;以及Cavalieri等人(2003)Blood.102(2):497-505。
在一些实施方案中,经由电穿孔将重组核酸转移到T细胞中(参见例如,Chicaybam等人(2013)PLoS ONE 8(3):e60298和Van Tedeloo等人(2000)Gene Therapy 7(16):1431-1437)。在一些实施方案中,经由转座将重组核酸转移到T细胞中(参见例如,Manuri等人(2010)Hum Gene Ther 21(4):427-437;Sharma等人(2013)Molec Ther Nucl Acids 2,e74;以及Huang等人(2009)Methods Mol Biol 506:115-126)。在免疫细胞中引入和表达遗传材料的其他方法包括磷酸钙转染(例如,如在Current Protocols in MolecularBiology,John Wiley&Sons,New York.N.Y.中所述)、原生质体融合、阳离子脂质体介导的转染;钨粒子促进的微粒轰击(Johnston,Nature,346:776-777(1990));和磷酸锶DNA共沉淀(Brash等人,Mol.Cell Biol.,7:2031-2034(1987))。
用于转移编码结合分子或重组产物的核酸的其他方法和载体是例如国际专利申请公开号WO 2014/055668和美国专利号7,446,190中描述的那些。
另外的核酸(例如,用于引入的基因)包括:用于改进治疗功效的那些,如通过促进所转移细胞的活力和/或功能;用于提供用于选择和/或评价细胞(如用于评估体内存活或定位)的遗传标记的基因;用于改进安全性的基因,例如通过使细胞在体内对阴性选择敏感,如以下文献中所述:Lupton S.D.等人,Mol.and Cell Biol.,11:6(1991);和Riddell等人,Human Gene Therapy3:319-338(1992);还参见Lupton等人的PCT/US91/08442和PCT/US94/05601的公开,所述文献描述了使用通过将显性阳性选择性标记与阴性选择性标记融合而衍生的双功能选择性融合基因。参见例如,Riddell等人,美国专利号6,040,177,第14-17栏。
因此,在一些实施方案中,提供了工程化细胞,如含有如本文所述的结合分子(如TCR或其抗原结合片段或者抗体或其抗原结合片段)、核酸或载体的那些。在一些方面,通过在体外或离体地用本文所述的载体转导细胞来产生细胞。在一些方面,细胞是T细胞,如CD8+或CD4+T细胞。在一些实施方案中,结合分子对细胞是异源的。
在一些情况下,工程化细胞含有识别或结合源自HPV16 E6的肽表位的异源TCR或其抗原结合片段。在一些情况下,TCR或其抗原结合片段不识别或结合包含氨基酸序列TIHDIILECV(SEQ ID NO.233)的表位E6(29-38)。在一些情形中,识别或结合源自HPV16 E6的肽表位的TCR或其抗原结合片段是或包含SEQ ID NO:232或SEQ ID NO:234所示的序列。
在一些实施方案中,工程化细胞含有识别或结合源自HPV16 E7的肽表位的异源TCR或其抗原结合片段。在一些实施方案中,TCR或其抗原结合片段不识别或结合包含氨基酸序列YMLDLQPET(SEQ ID NO.236)的表位E7(11-19)。在一些情形中,识别或结合源自HPV16 E7的肽表位的TCR或其抗原结合片段是或含有SEQ ID NO:235-239中任一个所示的序列。在一些情况下,源自HPV16 E7的肽是或含有SEQ ID NO:235所示的序列。
V.用于编辑编码T细胞受体(TCR)的内源基因以及通过靶向整合将细胞工程化以表达结合分子的方法
在一些方面,在工程化细胞(例如,工程化T细胞)中表达所提供的结合分子,例如重组T细胞受体(TCR)或其片段或链。在一些实施方案中,提供了例如用于过继细胞疗法的表达本文提供的任何所述结合分子(例如,重组TCR或其片段或链)的基因工程化T细胞,以及相关组合物、方法、用途以及用于进行所述方法的试剂盒和制品。在一些方面,例如通过基因编辑来修饰工程化细胞中的一种或多种内源基因和/或基因产物(和/或其表达)。在一些方面,基因编辑导致一种或多种内源基因产物(和/或其表达)的减少、缺失、消除、敲除或破坏和/或经由诸如同源定向修复(HDR)等方法进行的外源、异源或转基因序列(例如,编码结合分子(例如,重组TCR)的序列)的靶向整合。在一些实施方案中,免疫细胞被工程化以表达任何结合分子(例如,重组TCR),并且可以经由基因编辑方法(如HDR)将编码结合分子(例如,重组TCR)的序列靶向特定基因座。
在一些实施方案中,例如通过引入遗传破坏(如DNA断裂)来减少、缺失、消除、敲除或破坏所提供的细胞和/或含有此类细胞的组合物中的一种或多种内源基因和/或基因产物(和/或其表达)。在一些实施方案中,工程化以表达本文提供的任何结合分子(例如,重组TCR)的任何细胞中的基因和/或基因产物被减少、缺失、消除、敲除或破坏。在一些实施方案中,提供了已经被工程化以表达本文所述的结合分子(例如,重组TCR)的细胞、此类细胞的群体、含有此类细胞和/或富含此类细胞的组合物。
在一些实施方案中,所提供的细胞和/或含有此类细胞的组合物中的一种或多种内源基因和/或基因产物(和/或其表达)被减少、缺失、消除、敲除或破坏,包括编码TCRα恒定区(TRAC)和/或TCRβ恒定区(TRBC;在人中由TRBC1或TRBC2编码)(或其产物)的一个或多个基因,例如以减少或阻止内源TCR和/或其链在细胞(例如T细胞)中的表达。在一些实施方案中,在本文提供的任何工程化细胞中和/或在本文提供的用于产生工程化细胞的任何方法中基因和/或基因产物(如TRAC和/或TRBC)被减少、缺失、消除、敲除或破坏。在一些实施方案中,工程化细胞和/或通过所述方法产生的工程化细胞是已经被工程化以表达本文所述的结合分子的细胞、此类细胞的群体、含有此类细胞和/或富含此类细胞的组合物。在一些实施方案中,原代T细胞中的基因和/或基因产物(如TRAC和/或TRBC)被减少、缺失、消除、敲除或破坏,以减少、缺失、消除、敲除或破坏内源TCR在原代T细胞中的表达,所述原代T细胞例如被工程化以表达本文所述的任何T细胞受体。
在一些实施方案中,例如经由HDR进行基因编辑涉及:i)将一种或多种药剂引入免疫细胞中,所述药剂能够诱导编码T细胞受体α(TCRα)链的结构域或区域的基因和/或一个或多个编码T细胞受体β(TCRβ)链的结构域或区域的一个或多个基因内的一个或多个靶位点的遗传破坏;以及ii)将多核苷酸(例如,模板多核苷酸)引入免疫细胞中,所述多核苷酸包含编码结合分子(例如,重组TCR或其链,如任何所提供的重组TCR)的转基因,其中编码结合分子(例如,重组TCR或其链)的转基因经由同源定向修复(HDR)靶向在所述至少一个靶位点中的一个处或附近。
在一些方面,可以将多核苷酸(例如,模板多核苷酸)引入在内源TRAC和/或TRBC基因座处含有遗传破坏的细胞中,所述多核苷酸含有编码结合分子(例如,重组TCR或其链)的转基因序列(在本文也称为外源或异源核酸序列)和与遗传破坏区域同源的序列。在一些方面,在靶向遗传破坏(例如,DNA断裂)的存在下,核酸序列可以用作DNA修复模板,以基于靶位点周围的内源基因序列与模板多核苷酸中包含的5'和/或3'同源臂之间的同源性通过HDR在靶向遗传破坏的位点处或附近有效地拷贝和整合转基因序列,例如编码结合分子(例如,重组TCR或其链)的核酸序列。
在一些实施方案中,修饰基因工程化细胞以含有TRAC和/或TRBC基因座,所述基因座含有编码任何所提供的结合分子(例如,重组TCR或其片段)的核酸序列。在一些方面,例如通过基因编辑修饰基因工程化细胞中的TRAC和/或TRBC基因座以包括编码结合分子(例如,重组TCR或其链)的转基因序列,其被整合到通常编码TCRα或TCRβ恒定结构域的内源TRAC和/或TRBC基因座中。在一些实施方案中,基因编辑涉及在编码TCRα或TCRβ恒定结构域的一个或多个内源基因中诱导靶向遗传破坏,以及使用一种或多种含有编码结合分子(例如,重组TCR或其链)的转基因的模板多核苷酸进行同源依赖性修复(HDR),从而将转基因靶向整合在TRAC和/或TRBC基因座处。在一些实施方案中,转基因编码重组TCR的一部分,并且框内地整合到TCR开放阅读框和/或基因座中。在某些实施方案中,转基因编码重组TCR的一部分,并且框内地插入编码TCR恒定结构域的内源开放阅读框内。在一些实施方案中,转基因整合到基因座中修饰和/或产生编码完整重组TCR的经修饰的基因座。
A.内源TCR编码基因的遗传破坏
在一些实施方案中,靶向遗传破坏发生在编码内源T细胞受体(TCR)的一个或多个结构域、区域和/或链的内源基因处。在一些实施方案中,遗传破坏靶向在编码TCRα和/或TCRβ的内源基因座处。在一些实施方案中,遗传破坏靶向在编码TCRα恒定结构域(在人中为TRAC)和/或TCRβ恒定结构域(在人中为TRBC1或TRBC2)的基因处。
在一些实施方案中,被靶向用于减少、缺失、消除、敲除或破坏的基因和/或基因产物是编码TCR或其链、结构域和/或区域的内源基因。在一些实施方案中,用于破坏的靶位点在T细胞受体α恒定区(TRAC)基因中。在一些实施方案中,用于破坏的靶位点在T细胞受体β恒定区1(TRBC1)或T细胞受体β恒定区2(TRBC2)基因中。在一些实施方案中,所述一个或多个靶位点在TRAC基因以及TRBC1和TRBC2基因之一或两者中。
在一些实施方案中,内源TCR Cα由TRAC基因编码(IMGT命名法)。人T细胞受体α恒定链(TRAC)基因座的示例性核苷酸序列如SEQ ID NO:348所示(NCBI参考序列:NG_001332.3,TRAC)。在一些实施方案中,内源TCRCβ由TRBC1或TRBC2基因编码(IMGT命名法)。人T细胞受体β恒定链1(TRBC1)基因座的示例性核苷酸序列如SEQ ID NO:349所示(NCBI参考序列:NG_001333.2,TRBC1);并且人T细胞受体β恒定链2(TRBC2)基因座的示例性核苷酸序列如SEQ ID NO:1047所示(NCBI参考序列:NG_001333.2,TRBC2)。
在一些实施方案中,内源TCR Cα由TRAC基因编码(IMGT命名法)。人T细胞受体α链恒定结构域(TRAC)基因座的示例性序列如SEQ ID NO:348所示(NCBI参考序列:NG_001332.3,TRAC)。在某些实施方案中,遗传破坏靶向在TRAC基因座处、附近或之内。在特定实施方案中,遗传破坏靶向在TRAC基因座的开放阅读框处、附近或之内。在某些实施方案中,遗传破坏靶向在编码TCRα恒定结构域的开放阅读框处、附近或之内。在一些实施方案中,遗传破坏靶向在基因座处、附近或之内,所述基因座具有SEQ ID NO:348所示的核酸序列或与SEQ ID NO:348所示的核酸序列的全部或部分(例如,500、1,000、1,500、2,000、2,500、3,000、3,500或4,000个或者至少500、1,000、1,500、2,000、2,500、3,000、3,500或4,000个连续核苷酸)具有70%、75%、80%、85%、90%、95%、97%、98%、99%、99.5%或99.9%或者至少70%、75%、80%、85%、90%、95%、97%、98%、99%、99.5%或99.9%序列同一性的序列。
在人类中,TRAC的示例性基因组基因座包含含有4个外显子和3个内含子的开放阅读框。参考人类基因组版本GRCh38(UCSC Genome Browser on Human 2013年12月(GRCh38/hg38)Assembly),TRAC的示例性mRNA转录物可以跨越对应于正向链上的坐标第14号染色体:22,547,506-22,552,154的序列。表13列出了示例性人TRAC基因座的开放阅读框的外显子和内含子以及转录物的非翻译区的坐标。
表13.示例性人TRAC基因座的外显子和内含子的坐标(GRCh38,第14号染色体,正向链)。
| 起始(GrCh38) | 终止(GrCh38) | 长度 | |
| 5'UTR和外显子1 | 22,547,506 | 22,547,778 | 273 |
| 内含子1-2 | 22,547,779 | 22,549,637 | 1,859 |
| 外显子2 | 22,549,638 | 22,549,682 | 45 |
| 内含子2-3 | 22,549,683 | 22,550,556 | 874 |
| 外显子3 | 22,550,557 | 22,550,664 | 108 |
| 内含子3-4 | 22,550,665 | 22,551,604 | 940 |
| 外显子4和3'UTR | 22,551,605 | 22,552,154 | 550 |
在一些实施方案中,内源TCR Cβ由TRBC1或TRBC2基因编码(IMGT命名法)。人T细胞受体β链恒定结构域1(TRBC1)基因座的示例性序列如SEQ ID NO:349所示(NCBI参考序列:NG_001333.2,TRBC1);并且人T细胞受体β链恒定结构域2(TRBC2)基因座的示例性序列如SEQ ID NO:1047所示(NCBI参考序列:NG_001333.2,TRBC2)。在一些实施方案中,遗传破坏靶向在TRBC1基因座处、附近或之内。在特定实施方案中,遗传破坏靶向在TRBC1基因座的开放阅读框处、附近或之内。在某些实施方案中,遗传破坏靶向在编码TCRβ恒定结构域的开放阅读框处、附近或之内。在一些实施方案中,遗传破坏靶向在基因座处、附近或之内,所述基因座具有SEQ ID NO:349所示的核酸序列或与SEQ ID NO:349所示的核酸序列的全部或部分(例如,500、1,000、1,500、2,000、2,500、3,000、3,500或4,000个或者至少500、1,000、1,500、2,000、2,500、3,000、3,500或4,000个连续核苷酸)具有70%、75%、80%、85%、90%、95%、97%、98%、99%、99.5%或99.9%或者至少70%、75%、80%、85%、90%、95%、97%、98%、99%、99.5%或99.9%序列同一性的序列。
在人类中,TRBC1的示例性基因组基因座包含含有4个外显子和3个内含子的开放阅读框。参考人类基因组版本GRCh38(UCSC Genome Browser on Human 2013年12月(GRCh38/hg38)Assembly),TRBC1的示例性mRNA转录物可以跨越对应于正向链上的坐标第7号染色体:142,791,694-142,793,368的序列。表14列出了示例性人TRBC1基因座的开放阅读框的外显子和内含子以及转录物的非翻译区的坐标。
表14.示例性人TRBC1基因座的外显子和内含子的坐标(GRCh38,第7号染色体,正向链)。
| 起始(GrCh38) | 终止(GrCh38) | 长度 | |
| 5'UTR和外显子1 | 142,791,694 | 142,792,080 | 387 |
| 内含子1-2 | 142,792,081 | 142,792,521 | 441 |
| 外显子2 | 142,792,522 | 142,792,539 | 18 |
| 内含子2-3 | 142,792,540 | 142,792,691 | 152 |
| 外显子3 | 142,792,692 | 142,792,798 | 107 |
| 内含子3-4 | 142,792,799 | 142,793,120 | 322 |
| 外显子4和3'UTR | 142,793,121 | 142,793,368 | 248 |
在特定实施方案中,遗传破坏靶向在TRBC2基因座处、附近或之内。在特定实施方案中,遗传破坏靶向在TRBC2基因座的开放阅读框处、附近或之内。在某些实施方案中,遗传破坏靶向在编码TCRβ恒定结构域的开放阅读框处、附近或之内。在一些实施方案中,遗传破坏靶向在基因座处、附近或之内,所述基因座具有SEQ ID NO:1047所示的核酸序列或与SEQID NO:1047所示的核酸序列的全部或部分(例如,500、1,000、1,500、2,000、2,500、3,000、3,500或4,000个或者至少500、1,000、1,500、2,000、2,500、3,000、3,500或4,000个连续核苷酸)具有70%、75%、80%、85%、90%、95%、97%、98%、99%、99.5%或99.9%或者至少70%、75%、80%、85%、90%、95%、97%、98%、99%、99.5%或99.9%序列同一性的序列。
在人类中,TRBC2的示例性基因组基因座包含含有4个外显子和3个内含子的开放阅读框。参考人类基因组版本GRCh38(UCSC Genome Browser on Human 2013年12月(GRCh38/hg38)Assembly),TRBC2的示例性mRNA转录物可以跨越对应于正向链上的坐标第7号染色体:142,801,041-142,802,748的序列。表15列出了示例性人TRBC2基因座的开放阅读框的外显子和内含子以及转录物的非翻译区的坐标。
表15.示例性人TRBC2基因座的外显子和内含子的坐标(GRCh38,第7号染色体,正向链)。
| 起始(GrCh38) | 终止(GrCh38) | 长度 | |
| 5'UTR和外显子1 | 142,801,041 | 142,801,427 | 387 |
| 内含子1-2 | 142,801,428 | 142,801,943 | 516 |
| 外显子2 | 142,801,944 | 142,801,961 | 18 |
| 内含子2-3 | 142,801,962 | 142,802,104 | 143 |
| 外显子3 | 142,802,105 | 142,802,211 | 107 |
| 内含子3-4 | 142,802,212 | 142,802,502 | 291 |
| 外显子4和3'UTR | 142,802,503 | 142,802,748 | 246 |
在一些实施方案中,被靶向用于破坏或敲除的一个或多个基因在TRAC、TRBC1和/或TRBC2基因座中的一个或多个处或附近。在一些实施方案中,敲除TRAC基因。在一些实施方案中,敲除TRBC1基因。在一些实施方案中,敲除TRBC2基因。在一些实施方案中,敲除TRAC基因和TRBC1基因。在一些实施方案中,敲除TRAC基因和TRBC2基因。在一些实施方案中,敲除TRAC基因以及TRBC1和TRBC2基因两者,例如靶向在TRBC1与TRBC2之间保守的序列。
在一些实施方案中,减少或阻止内源TCR表达可以导致工程化TCR与内源TCR的链之间的错配风险或机会降低,从而产生新的TCR,其可能潜在地导致不希望的或非计划中的抗原识别的风险更高和/或副作用,和/或可能降低所需外源TCR的表达水平。在一些方面,与不减少或阻止TCR表达的细胞相比,减少或阻止内源TCR表达可以增加工程化TCR在细胞中的表达,如增加1.5倍、2倍、3倍、4倍、5倍或更多倍。例如,在一些情况下,由于与内源TCR和/或与具有错配链的TCR竞争参与允许复合物在细胞表面上表达的恒定CD3信号传导分子,可能发生工程化或重组TCR的次优表达。
在一些实施方案中,减少、缺失、消除、敲除或破坏涉及使用一种或多种药剂,所述药剂能够在基因组DNA中的靶位点处引入遗传破坏、切割、双链断裂(DSB)和/或切口,从而在通过各种细胞DNA修复机制修复之后导致减少、缺失、消除、敲除或破坏。
在一些实施方案中,能够引入切割的所述一种或多种药剂包含特异性结合至或杂交至基因组中(例如,在TRAC和/或TRBC基因中)的靶位点的DNA结合蛋白或DNA结合核酸。在一些方面,使用蛋白质或核酸实现编码TCR的内源基因的靶向切割(例如,DNA断裂),所述蛋白质或核酸与基因编辑核酸酶偶联或复合,如以嵌合或融合蛋白的形式。在一些实施方案中,能够引入切割的所述一种或多种药剂包含含有DNA靶向蛋白和核酸酶或RNA指导的核酸酶的融合蛋白。
在一些实施方案中,例如使用锌指核酸酶(ZFN)、TALEN或具有切割TCR基因的工程化单一指导RNA的CRISPR/Cas系统,通过基因编辑方法进行减少、缺失、消除、敲除或破坏。在一些实施方案中,使用针对编码特定TCR(例如,TCR-α和TCR-β)的靶核酸的抑制性核酸分子来减少内源TCR的表达。在一些实施方案中,抑制性核酸是或含有或编码小干扰RNA(siRNA)、微小RNA适应的shRNA、短发夹RNA(shRNA)、发夹siRNA、微小RNA(miRNA前体)或微小RNA(miRNA)。用于减少或阻止内源TCR表达的示例性方法是本领域已知的,参见例如美国专利号9,273,283;美国公开号US 2014/0301990;和PCT公开号WO 2015/161276。
在一些实施方案中,能够引入靶向切割的药剂包含各种组分,如包含DNA靶向蛋白和核酸酶或RNA指导的核酸酶的融合蛋白。在一些实施方案中,使用DNA靶向分子进行靶向切割,所述DNA靶向分子包括与核酸酶(如核酸内切酶)融合的DNA结合蛋白,如一种或多种锌指蛋白(ZFP)或转录激活因子样效应物(TALE)。在一些实施方案中,使用RNA指导的核酸酶(如成簇的规律间隔的短回文核酸(CRISPR)相关核酸酶(Cas)系统(包括Cas和/或Cfp1))进行靶向切割。在一些实施方案中,使用能够引入切割的药剂进行靶向切割,所述药剂是例如专门工程化和/或设计为靶向所述至少一个靶位点、基因序列或其部分的序列特异性或靶向核酸酶,包括DNA结合靶向核酸酶和基因编辑核酸酶,如锌指核酸酶(ZFN)和转录激活因子样效应物核酸酶(TALEN)以及RNA指导的核酸酶,如CRISPR相关核酸酶(Cas)系统。
1.工程化核酸酶
在一些实施方案中,所述一种或多种药剂特异性靶向所述至少一个靶位点,例如在TRAC和/或TRBC基因处或附近。在一些实施方案中,所述药剂包含特异性结合至、识别或杂交至所述一个或多个靶位点的ZFN、TALEN或CRISPR/Cas9组合。在一些实施方案中,CRISPR/Cas9系统包括工程化crRNA/tracr RNA(“单一指导RNA”),以指导特异性切割。在一些实施方案中,所述药剂包含基于Argonaute系统的核酸酶(例如,来自嗜热栖热菌(T.thermophilus),称为“TtAgo”(Swarts等人(2014)Nature 507(7491):258-261))。
锌指蛋白(ZFP)、转录激活因子样效应物(TALE)和CRISPR系统结合结构域可以被“工程化”以与预定的核苷酸序列结合,例如经由工程化(改变一个或多个氨基酸)天然存在的ZFP或TALE蛋白的识别螺旋区。工程化的DNA结合蛋白(ZFP或TALE)是非天然存在的蛋白质。设计的合理标准包括应用替代规则和计算机化算法,以处理存储现有ZFP和/或TALE设计和结合数据的信息的数据库中的信息。参见例如,美国专利号6,140,081;6,453,242;和6,534,261;还参见WO 98/53058;WO 98/53059;WO 98/53060;WO 02/016536和WO 03/016496以及美国公开号20110301073。示例性ZFN、TALE和TALEN描述于例如Lloyd等人,Frontiers in Immunology,4(221):1-7(2013)。
在一些实施方案中,在自然界中未发现工程化锌指蛋白、TALE蛋白或CRISPR/Cas系统,并且其产生主要来自经验过程,如噬菌体展示、相互作用陷阱或杂交选择。参见例如,美国专利号5,789,538;美国专利号5,925,523;美国专利号6,007,988;美国专利号6,013,453;美国专利号6,200,759;WO 95/19431;WO 96/06166;WO 98/53057;WO 98/54311;WO00/27878;WO 01/60970;WO 01/88197和WO 02/099084。
在一些实施方案中,可以通过工程化ZFN靶向TRAC和/或TRBC基因进行切割。靶向内源T细胞受体(TCR)基因的示例性ZFN包括例如US 2015/0164954、US 2011/0158957、US2015/0056705、US 8956828和Torikawa等人(2012)Blood 119:5697-5705中描述的那些,将其公开内容通过引用以其整体而并入。
在一些实施方案中,可以通过工程化TALEN靶向TRAC和/或TRBC基因进行切割。靶向内源T细胞受体(TCR)基因的示例性TALEN包括例如WO 2017/070429、WO 2015/136001、US20170016025和US 20150203817中描述的那些,将其公开内容通过引用以其整体而并入。
2.CRISPR相关方法
在一些实施方案中,可以使用成簇的规律间隔的短回文重复序列(CRISPR)和CRISPR相关(Cas)蛋白靶向TRAC和/或TRBC基因进行切割。参见Sander和Joung,(2014)Nature Biotechnology,32(4):347-355。在一些实施方案中,“CRISPR系统”统指转录物和涉及CRISPR相关(“Cas”)基因的表达或引导其活性的其他元件,包括编码Cas基因的序列、tracr(反式激活CRISPR)序列(例如tracrRNA或活性部分tracrRNA)、tracr配对序列(涵盖“同向重复序列”和在内源CRISPR系统的背景下的tracrRNA加工的部分同向重复序列)、指导序列(在内源CRISPR系统的背景下也称为“间隔子”)和/或来自CRISPR基因座的其他序列和转录物。
在一些方面,CRISPR/Cas核酸酶或CRISPR/Cas核酸酶系统包括序列特异性结合至DNA的非编码指导RNA(gRNA)和具有核酸酶功能性的Cas蛋白(例如,Cas9)。
在一些实施方案中,基因编辑导致所靶向基因座处的插入或缺失,或所靶向基因座的“敲除”以及所编码蛋白质的表达的消除。在一些实施方案中,通过使用CRISPR/Cas9系统进行非同源末端连接(NHEJ)实现基因编辑。在一些实施方案中,一种或多种指导RNA(gRNA)分子可以与一种或多种Cas9核酸酶、Cas9切口酶、酶促失活的Cas9或其变体一起使用。下文描述了所述一种或多种gRNA分子和所述一种或多种Cas9分子的示例性特征。
在一些实施方案中,CRISPR/Cas核酸酶系统包含以下中的至少一种:具有与TRAC基因的靶位点互补的靶向结构域的指导RNA(gRNA);具有与TRBC1和TRBC2基因之一或两者的靶位点互补的靶向结构域的gRNA;或至少一种编码所述gRNA的核酸。
在一些实施方案中,指导序列(例如,指导RNA)是至少包含序列部分(例如,靶向结构域)的任何多核苷酸序列,所述序列部分与靶位点序列(如人中的TRAC、TRBC1和/或TRBC2基因中的靶位点)具有足够的互补性以与靶位点处的靶序列杂交并引导CRISPR复合物与靶序列的序列特异性结合。在一些实施方案中,在形成CRISPR复合物的背景下,“靶位点”(也称为“靶位置(target position)”、“靶DNA序列”或“靶位置(target location)”)可以指代指导序列被设计为与其具有互补性的序列,其中靶序列与指导RNA的结构域(例如,靶向结构域)之间的杂交促进了CRISPR复合物的形成。如果存在足够的互补性以引起杂交并促进CRISPR复合物的形成,则不一定需要完全互补性。在一些实施方案中,指导序列被选择为降低指导序列内的二级结构的程度。可以通过任何合适的多核苷酸折叠算法来确定二级结构。
在一些方面,将与指导序列组合(并且任选地与其复合)的CRISPR酶(例如Cas9核酸酶)递送到细胞中。例如,CRISPR系统的一种或多种元件源自I型、II型或III型CRISPR系统。例如,CRISPR系统的一种或多种元件源自包含内源CRISPR系统的特定生物,如化脓链球菌、金黄色葡萄球菌(Staphylococcus aureus)或脑膜炎奈瑟氏菌。
在一些实施方案中,将对靶位点(例如人中的TRAC、TRBC1和/或TRBC2)具特异性的指导RNA(gRNA)与RNA指导的核酸酶(例如,Cas)一起用于在靶位点或靶位置处引入DNA断裂。用于设计gRNA和示例性靶向结构域的方法可以包括例如国际PCT公开号WO 2015/161276中描述的那些。可以将靶向结构域掺入用于将Cas9核酸酶靶向靶位点或靶位置的gRNA中。
用于靶序列的选择和验证以及脱靶分析的方法描述于例如Mali等人,2013SCIENCE 339(6121):823-826;Hsu等人NAT BIOTECHNOL,31(9):827-32;Fu等人,2014NAT BIOTECHNOL,doi:10.1038/nbt.2808.PubMed PMID:24463574;Heigwer等人,2014NAT METHODS 11(2):122-3.doi:10.1038/nmeth.2812.PubMed PMID:24481216;Bae等人,2014BIOINFORMATICS PubMedPMID:24463181;Xiao A等人,2014BIOINFORMATICSPubMed PMID:24389662。用于CRISPR基因组编辑的全基因组gRNA数据库是公众可获得的,其含有靶向人类基因组或小鼠基因组中基因的组成性外显子的示例性单一指导RNA(sgRNA)序列(参见例如,genescript.com/gRNA-database.html;还参见,Sanjana等人(2014)Nat.Methods,11:783-4)。在一些方面,gRNA序列是或包含与非靶位点或位置具有最小脱靶结合的序列。
a)指导RNA(gRNA)分子
在一些实施方案中,所述药剂包含靶向TRAC、TRBC1和/或TRBC2基因座的区域的gRNA。“gRNA分子”是指促进gRNA分子/Cas9分子复合物特异性靶向或归巢到靶核酸(如细胞基因组DNA上的基因座)的核酸。gRNA分子可以是单分子的(具有单一RNA分子),有时在本文称为“嵌合”gRNA;或者模块化的(包含超过一种、通常两种独立的RNA分子)。
在图14A-14G中提供了几种示例性gRNA结构,其上指示有结构域。尽管不希望受到理论的束缚,关于活性形式的gRNA的三维形式或链内或链间相互作用,高互补性的区域有时在图14A-14G中显示为双链体以及本文提供的其他描绘。
在一些情况下,gRNA是单分子或嵌合gRNA,其从5'至3'包含:与靶核酸(如来自TRAC、TRBC1和/或TRBC2基因的序列(编码序列分别如SEQ IDNO:348、349和1047所示))互补的靶向结构域;第一互补结构域;连接结构域;第二互补结构域(其与第一互补结构域互补);近端结构域;以及任选地尾结构域。
在其他情况下,gRNA是包含第一和第二链的模块化gRNA。在这些情况下,第一链从5'至3'优选地包括:靶向结构域(其与靶核酸(如来自TRAC、TRBC1和/或TRBC2基因的序列,编码序列分别如SEQ ID NO:348、349和1047所示)互补)和第一互补结构域。第二链从5'至3'通常包括:任选地5'延伸结构域;第二互补结构域;近端结构域;以及任选地尾结构域。
在一些情况下,gRNA是单分子或嵌合gRNA,其从5'至3'包含:靶向结构域,其靶向靶位点或位置,如在来自TRAC基因座的序列内(人TRAC基因座的示例性核苷酸序列如SEQID NO:348所示;NCBI参考序列:NG_001332.3,TRAC;示例性基因组序列描述于本文的表13中);第一互补结构域;连接结构域;第二互补结构域(其与第一互补结构域互补);近端结构域;以及任选地尾结构域。在一些情况下,gRNA是单分子或嵌合gRNA,其从5'至3'包含:靶向结构域,其靶向靶位点或位置,如在来自TRBC1或TRBC2基因座的序列内(人TRBC1基因座的示例性核苷酸序列如SEQ ID NO:349所示;NCBI参考序列:NG_001333.2,TRBC1;示例性基因组序列描述于本文的表14中;人TRBC2基因座的示例性核苷酸序列如SEQ ID NO:1047所示;NCBI参考序列:NG_001333.2,TRBC2;示例性基因组序列描述于本文的表15中);第一互补结构域;连接结构域;第二互补结构域(其与第一互补结构域互补);近端结构域;以及任选地尾结构域。
在其他情况下,gRNA是包含第一和第二链的模块化gRNA。在这些情况下,第一链从5'至3'优选地包括:靶向结构域(其靶向靶位点或位置,如在来自TRAC基因座(人TRAC基因座的示例性核苷酸序列如SEQ ID NO:348所示;NCBI参考序列:NG_001332.3,TRAC;示例性基因组序列描述于本文的表13中)或者TRBC1或TRBC2基因座(人TRBC1基因座的示例性核苷酸序列如SEQ ID NO:349所示;NCBI参考序列:NG_001333.2,TRBC11;示例性基因组序列描述于本文的表14中;人TRBC2基因座的示例性核苷酸序列如SEQ ID NO:1047所示;NCBI参考序列:NG_001333.2,TRBC2)的序列内);和第一互补结构域。第二链从5'至3'通常包括:任选地5'延伸结构域;第二互补结构域;近端结构域;以及任选地尾结构域。
在下文简要讨论这些结构域:
(1)靶向结构域
图14A-14G提供了靶向结构域放置的例子。
靶向结构域包含与靶核酸上的靶序列互补(例如至少80%、85%、90%、95%、98%或99%互补,例如完全互补)的核苷酸序列。靶核酸的包含靶序列的链在本文中称为靶核酸的“互补链”。可以在例如Fu Y等人,NatBiotechnol 2014(doi:10.1038/nbt.2808)和Sternberg SH等人,Nature 2014(doi:10.1038/nature13011)中找到有关靶向结构域选择的指南。
靶向结构域是RNA分子的一部分,因此将包含碱基尿嘧啶(U),而编码gRNA分子的任何DNA都将包含碱基胸腺嘧啶(T)。尽管不希望受到理论的束缚,在一个实施方案中,认为靶向结构域与靶序列的互补性有助于gRNA分子/Cas9分子复合物与靶核酸的相互作用的特异性。应理解,在靶向结构域和靶序列对中,靶向结构域中的尿嘧啶碱基将与靶序列中的腺嘌呤碱基配对。在一个实施方案中,靶结构域自身在5'至3'方向上包含任选的二级结构域以及核心结构域。在一个实施方案中,核心结构域与靶序列完全互补。在一个实施方案中,靶向结构域的长度为5至50个核苷酸。靶核酸的与靶向结构域互补的链在本文中称为互补链。结构域的一些或全部核苷酸可以具有修饰,例如以使其不易降解、改善生物相容性等。通过非限制性举例的方式,可以用硫代磷酸酯或其他一种或多种修饰来修饰靶结构域的骨架。在一些情况下,靶向结构域的核苷酸可以包含2'修饰(例如2-乙酰化,例如2'甲基化)或其他一种或多种修饰。
在各个实施方案中,靶向结构域的长度为16-26个核苷酸(即它的长度为16个核苷酸或长度为17个核苷酸,或长度为18、19、20、21、22、23、24、25或26个核苷酸)。
(2)示例性靶向结构域
在一些实施方案中,当T细胞靶敲除位置是TRAC编码区(例如,早期编码区),并且超过一种gRNA用于在靶核酸序列中定位断裂(例如,两个单链断裂或两个双链断裂或者单链和双链断裂的组合,例如以产生一个或多个indel)时,每种指导RNA独立地选自国际PCT公开号WO 2015161276的表25A-G或表29之一。
在另一个实施方案中,当T细胞靶敲除位置是TRAC编码区(例如,早期编码区),并且超过一种gRNA用于在靶核酸序列中定位断裂(例如,两个单链断裂或两个双链断裂或者单链和双链断裂的组合,例如以产生一个或多个indel)时,每种指导RNA独立地选自国际PCT公开号WO 2015161276的表25A-G或表29之一,使得以超过10%的效率产生断裂。
在一个实施方案中,当T细胞靶敲除位置是TRBC编码区(例如,早期编码区),并且超过一种gRNA用于在靶核酸序列中定位断裂(例如,两个单链断裂或两个双链断裂或者单链和双链断裂的组合,例如以产生一个或多个indel)时,每种指导RNA独立地选自国际PCT公开号WO 2015161276的表26A-G或表27之一。
在一个实施方案中,当T细胞靶敲除位置是TRBC编码区(例如,早期编码区),并且超过一种gRNA用于在靶核酸序列中定位断裂(例如,两个单链断裂或两个双链断裂或者单链和双链断裂的组合,例如以产生一个或多个indel)时,每种指导RNA独立地选自国际PCT公开号WO 2015161276的表26A-G或表27之一,使得以超过10%的效率产生断裂。
在一些实施方案中,示例性指导RNA靶向结构域序列包括国际PCT公开号WO2015161276中描述的那些中的任一个。在一些实施方案中,参考国际PCT公开号WO2015161276中所示的表格,将其内容通过引用以其整体并入本文,下文描述了示例性指导RNA序列。
国际PCT公开号WO 2015161276的表25A提供了靶向结构域,其用于使用根据第一层参数选择的化脓链球菌Cas9敲除TRAC基因。靶向结构域在起始密码子下游的编码序列的前500bp内结合并且具有良好的正交性。本文考虑了靶向结构域通过互补碱基配对与靶结构域杂交。表中的任何靶向结构域都可以与产生双链断裂(Cas9核酸酶)或单链断裂(Cas9切口酶)的化脓链球菌Cas9分子一起使用。在一个实施方案中,双重靶向用于通过使用具有两个与相对DNA链互补的靶向结构域的化脓链球菌Cas9切口酶在相对DNA链上产生两个切口,例如,包含任何负链靶向结构域的gRNA可以与包含正链靶向结构域的任何gRNA配对,条件是两种gRNA在DNA上这样定向,使得PAM朝外,并且gRNA的5'末端之间的距离为0-50bp。在一个实施方案中,两种gRNA用于靶向两种Cas9核酸酶或两种Cas9切口酶,例如,具有来自组A的靶向结构域的gRNA可以与具有来自组B的靶向结构域的gRNA配对,如国际PCT公开号WO2015161276的表25-1所示。
国际PCT公开号WO 2015161276的表25B提供了靶向结构域,其用于使用根据第二层参数选择的化脓链球菌Cas9敲除TRAC基因。靶向结构域在起始密码子下游的编码序列的前500bp内结合,并且不需要良好的正交性。本文考虑了靶向结构域通过互补碱基配对与靶结构域杂交。表中的任何靶向结构域都可以与产生双链断裂(Cas9核酸酶)或单链断裂(Cas9切口酶)的化脓链球菌Cas9分子一起使用。在一个实施方案中,双重靶向用于通过使用具有两个与相对DNA链互补的靶向结构域的化脓链球菌Cas9切口酶在相对DNA链上产生两个切口,例如,包含任何负链靶向结构域的gRNA可以与包含正链靶向结构域的任何gRNA配对,条件是两种gRNA在DNA上这样定向,使得PAM朝外,并且gRNA的5'末端之间的距离为0-50bp。
国际PCT公开号WO 2015161276的表25C提供了靶向结构域,其用于使用根据第一层参数选择的金黄色葡萄球菌Cas9敲除TRAC基因。靶向结构域是在编码序列的前500bp内选择的,具有高度的正交性,并且含有NNGRRTPAM。本文考虑了靶向结构域通过互补碱基配对与靶结构域杂交。表中的任何靶向结构域都可以与产生双链断裂(Cas9核酸酶)或单链断裂(Cas9切口酶)的金黄色葡萄球菌Cas9分子一起使用。在一个实施方案中,双重靶向用于通过使用具有两个与相对DNA链互补的靶向结构域的金黄色葡萄球菌Cas9切口酶在相对DNA链上产生两个切口,例如,包含任何负链靶向结构域的gRNA可以与包含正链靶向结构域的任何gRNA配对,条件是两种gRNA在DNA上这样定向,使得PAM朝外,并且gRNA的5'末端之间的距离为0-50bp。在一个实施方案中,两种gRNA用于靶向两种Cas9核酸酶或两种Cas9切口酶,例如,具有来自组A的靶向结构域的gRNA可以与具有来自组B的靶向结构域的gRNA配对,如国际PCT公开号WO 201516127的表25-2所示。
国际PCT公开号WO 2015161276的表25D提供了靶向结构域,其用于使用根据第二层参数选择的金黄色葡萄球菌Cas9敲除TRAC基因。靶向结构域是在编码序列的前500bp内选择的,不需要正交性水平,并且含有NNGRRTPAM。本文考虑了靶向结构域通过互补碱基配对与靶结构域杂交。表中的任何靶向结构域都可以与产生双链断裂(Cas9核酸酶)或单链断裂(Cas9切口酶)的金黄色葡萄球菌Cas9分子一起使用。在一个实施方案中,双重靶向用于通过使用具有两个与相对DNA链互补的靶向结构域的金黄色葡萄球菌Cas9切口酶在相对DNA链上产生两个切口,例如,包含任何负链靶向结构域的gRNA可以与包含正链靶向结构域的任何gRNA配对,条件是两种gRNA在DNA上这样定向,使得PAM朝外,并且gRNA的5'末端之间的距离为0-50bp。
国际PCT公开号WO 2015161276的表25E提供了靶向结构域,其用于使用根据第三层参数选择的金黄色葡萄球菌Cas9敲除TRAC基因。靶向结构域是在下游的编码序列的其余部分内选择的,并且含有NNGRRT PAM。本文考虑了靶向结构域通过互补碱基配对与靶结构域杂交。表中的任何靶向结构域都可以与产生双链断裂(Cas9核酸酶)或单链断裂(Cas9切口酶)的金黄色葡萄球菌Cas9分子一起使用。在一个实施方案中,双重靶向用于通过使用具有两个与相对DNA链互补的靶向结构域的金黄色葡萄球菌Cas9切口酶在相对DNA链上产生两个切口,例如,包含任何负链靶向结构域的gRNA可以与包含正链靶向结构域的任何gRNA配对,条件是两种gRNA在DNA上这样定向,使得PAM朝外,并且gRNA的5'末端之间的距离为0-50bp。
国际PCT公开号WO 2015161276的表25F提供了靶向结构域,其用于使用根据第一层参数选择的脑膜炎奈瑟氏菌(N.meningitides)Cas9敲除TRAC基因。靶向结构域在起始密码子下游的编码序列的前500bp内结合并且具有良好的正交性。本文考虑了靶向结构域通过互补碱基配对与靶结构域杂交。表中的任何靶向结构域都可以与产生双链断裂(Cas9核酸酶)或单链断裂(Cas9切口酶)的脑膜炎奈瑟氏菌Cas9分子一起使用。在一个实施方案中,双重靶向用于通过使用具有两个与相对DNA链互补的靶向结构域的脑膜炎奈瑟氏菌切口酶在相对DNA链上产生两个切口,例如,包含任何负链靶向结构域的gRNA可以与包含正链靶向结构域的任何gRNA配对,条件是两种gRNA在DNA上这样定向,使得PAM朝外,并且gRNA的5'末端之间的距离为0-50bp。
国际PCT公开号WO 2015161276的表25G提供了靶向结构域,其用于使用根据第二层参数选择的脑膜炎奈瑟氏菌Cas9敲除TRAC基因。靶向结构域在起始密码子下游的编码序列的前500bp内结合,并且不需要良好的正交性。本文考虑了靶向结构域通过互补碱基配对与靶结构域杂交。表中的任何靶向结构域都可以与产生双链断裂(Cas9核酸酶)或单链断裂(Cas9切口酶)的脑膜炎奈瑟氏菌Cas9分子一起使用。在一个实施方案中,双重靶向用于通过使用具有两个与相对DNA链互补的靶向结构域的脑膜炎奈瑟氏菌Cas9切口酶在相对DNA链上产生两个切口,例如,包含任何负链靶向结构域的gRNA可以与包含正链靶向结构域的任何gRNA配对,条件是两种gRNA在DNA上这样定向,使得PAM朝外,并且gRNA的5'末端之间的距离为0-50bp。
国际PCT公开号WO 2015161276的表26A提供了靶向结构域,其用于使用根据第一层参数选择的化脓链球菌Cas9敲除TRBC基因。靶向结构域在起始密码子下游的编码序列的前500bp内结合并且具有良好的正交性。本文考虑了靶向结构域通过互补碱基配对与靶结构域杂交。表中的任何靶向结构域都可以与产生双链断裂(Cas9核酸酶)或单链断裂(Cas9切口酶)的化脓链球菌Cas9分子一起使用。在一个实施方案中,双重靶向用于通过使用具有两个与相对DNA链互补的靶向结构域的化脓链球菌Cas9切口酶在相对DNA链上产生两个切口,例如,包含任何负链靶向结构域的gRNA可以与包含正链靶向结构域的任何gRNA配对,条件是两种gRNA在DNA上这样定向,使得PAM朝外,并且gRNA的5'末端之间的距离为0-50bp。在一个实施方案中,两种gRNA用于靶向两种Cas9核酸酶或两种Cas9切口酶,例如,具有来自组A的靶向结构域的gRNA可以与具有来自组B的靶向结构域的gRNA配对,如国际PCT公开号WO201516127的表26-1所示。
国际PCT公开号WO 2015161276的表26B提供了靶向结构域,其用于使用根据第二层参数选择的化脓链球菌Cas9敲除TRBC基因。靶向结构域在起始密码子下游的编码序列的前500bp内结合,并且不需要良好的正交性。本文考虑了靶向结构域通过互补碱基配对与靶结构域杂交。表中的任何靶向结构域都可以与产生双链断裂(Cas9核酸酶)或单链断裂(Cas9切口酶)的化脓链球菌Cas9分子一起使用。在一个实施方案中,双重靶向用于通过使用具有两个与相对DNA链互补的靶向结构域的化脓链球菌Cas9切口酶在相对DNA链上产生两个切口,例如,包含任何负链靶向结构域的gRNA可以与包含正链靶向结构域的任何gRNA配对,条件是两种gRNA在DNA上这样定向,使得PAM朝外,并且gRNA的5'末端之间的距离为0-50bp。
国际PCT公开号WO 2015161276的表26C提供了靶向结构域,其用于使用根据第一层参数选择的金黄色葡萄球菌Cas9敲除TRBC基因。靶向结构域是在编码序列的前500bp内选择的,具有高度的正交性,并且含有N GRRTPAM。本文考虑了靶向结构域通过互补碱基配对与靶结构域杂交。表中的任何靶向结构域都可以与产生双链断裂(Cas9核酸酶)或单链断裂(Cas9切口酶)的金黄色葡萄球菌Cas9分子一起使用。在一个实施方案中,双重靶向用于通过使用具有两个与相对DNA链互补的靶向结构域的金黄色葡萄球菌Cas9切口酶在相对DNA链上产生两个切口,例如,包含任何负链靶向结构域的gRNA可以与包含正链靶向结构域的任何gRNA配对,条件是两种gRNA在DNA上这样定向,使得PAM朝外,并且gRNA的5'末端之间的距离为0-50bp。在一个实施方案中,两种gRNA用于靶向两种Cas9核酸酶或两种Cas9切口酶,例如,具有来自组A的靶向结构域的gRNA可以与具有来自组B的靶向结构域的gRNA配对,如国际PCT公开号WO 201516127的表26-2所示。
国际PCT公开号WO 2015161276的表26D提供了靶向结构域,其用于使用根据第二层参数选择的金黄色葡萄球菌Cas9敲除TRBC基因。靶向结构域是在编码序列的前500bp内选择的,不需要正交性水平,并且含有NNGRRTPAM。本文考虑了靶向结构域通过互补碱基配对与靶结构域杂交。表中的任何靶向结构域都可以与产生双链断裂(Cas9核酸酶)或单链断裂(Cas9切口酶)的金黄色葡萄球菌Cas9分子一起使用。在一个实施方案中,双重靶向用于通过使用具有两个与相对DNA链互补的靶向结构域的金黄色葡萄球菌Cas9切口酶在相对DNA链上产生两个切口,例如,包含任何负链靶向结构域的gRNA可以与包含正链靶向结构域的任何gRNA配对,条件是两种gRNA在DNA上这样定向,使得PAM朝外,并且gRNA的5'末端之间的距离为0-50bp。
国际PCT公开号WO 2015161276的表26E提供了靶向结构域,其用于使用根据第三层参数选择的金黄色葡萄球菌Cas9敲除TRBC基因。靶向结构域是在下游的编码序列的其余部分内选择的,并且含有NNGRRT PAM。本文考虑了靶向结构域通过互补碱基配对与靶结构域杂交。表中的任何靶向结构域都可以与产生双链断裂(Cas9核酸酶)或单链断裂(Cas9切口酶)的金黄色葡萄球菌Cas9分子一起使用。在一个实施方案中,双重靶向用于通过使用具有两个与相对DNA链互补的靶向结构域的金黄色葡萄球菌Cas9切口酶在相对DNA链上产生两个切口,例如,包含任何负链靶向结构域的gRNA可以与包含正链靶向结构域的任何gRNA配对,条件是两种gRNA在DNA上这样定向,使得PAM朝外,并且gRNA的5'末端之间的距离为0-50bp。
国际PCT公开号WO 2015161276的表26F提供了靶向结构域,其用于使用根据第一层参数选择的脑膜炎奈瑟氏菌Cas9敲除TRBC基因。靶向结构域在起始密码子下游的编码序列的前500bp内结合并且具有良好的正交性。本文考虑了靶向结构域通过互补碱基配对与靶结构域杂交。表中的任何靶向结构域都可以与产生双链断裂(Cas9核酸酶)或单链断裂(Cas9切口酶)的脑膜炎奈瑟氏菌Cas9分子一起使用。在一个实施方案中,双重靶向用于通过使用具有两个与相对DNA链互补的靶向结构域的脑膜炎奈瑟氏菌切口酶在相对DNA链上产生两个切口,例如,包含任何负链靶向结构域的gRNA可以与包含正链靶向结构域的任何gRNA配对,条件是两种gRNA在DNA上这样定向,使得PAM朝外,并且gRNA的5'末端之间的距离为0-50bp。
国际PCT公开号WO 2015161276的表26G提供了靶向结构域,其用于使用根据第二层参数选择的脑膜炎奈瑟氏菌Cas9敲除TRBC基因。靶向结构域在起始密码子下游的编码序列的前500bp内结合,并且不需要良好的正交性。本文考虑了靶向结构域通过互补碱基配对与靶结构域杂交。表中的任何靶向结构域都可以与产生双链断裂(Cas9核酸酶)或单链断裂(Cas9切口酶)的脑膜炎奈瑟氏菌Cas9分子一起使用。在一个实施方案中,双重靶向用于通过使用具有两个与相对DNA链互补的靶向结构域的脑膜炎奈瑟氏菌Cas9切口酶在相对DNA链上产生两个切口,例如,包含任何负链靶向结构域的gRNA可以与包含正链靶向结构域的任何gRNA配对,条件是两种gRNA在DNA上这样定向,使得PAM朝外,并且gRNA的5'末端之间的距离为0-50bp。
在一些实施方案中,靶序列(靶结构域)在TRAC、TRBC1和/或TRBC2基因座处或附近,如SEQ ID NO:348、349和1047分别所示的TRAC、TRBC1和/或TRBC2编码序列的任何部分。在一些实施方案中,与靶向结构域互补的靶核酸位于目的基因(如TRAC、TRBC1和/或TRBC2)的早期编码区处。早期编码区的靶向可以用于敲除目的基因(即,消除其表达)。在一些实施方案中,目的基因的早期编码区包括紧接起始密码子(例如,ATG)之后或者在起始密码子的500bp内(例如,小于500bp、450bp、400bp、350bp、300bp、250bp、200bp、150bp、100bp、50bp、40bp、30bp、20bp或10bp)的序列。在特定例子中,靶核酸在起始密码子的200bp、150bp、100bp、50bp、40bp、30bp、20bp或10bp内。在一些例子中,gRNA的靶向结构域与靶核酸(如TRAC、TRBC1和/或TRBC2基因座中的靶核酸)上的靶序列互补,例如至少80%、85%、90%、95%、98%或99%互补,例如完全互补。
在一些实施方案中,遗传破坏(例如,DNA断裂)靶向在或非常靠近编码区(例如,早期编码区(例如,距起始密码子500bp内)或其余编码序列(例如,在起始密码子的前500bp的下游))的起点。在一些实施方案中,遗传破坏(例如,DNA断裂)靶向在目的基因(例如,TRAC、TRBC1和/或TRBC2)的早期编码区处,包括紧接转录起始位点之后、在编码序列的第一外显子内、或在转录起始位点的500bp内(例如,小于500、450、400、350、300、250、200、150、100或50bp)、或在起始密码子的500bp内(例如,小于500、450、400、350、300、250、200、150、100或50bp)的序列。
在一些实施方案中,靶位点在内源TRAC、TRBC1和/或TRBC2基因座的外显子内。在某些实施方案中,靶位点在内源TRAC、TRBC1和/或TRBC2基因座的内含子内。在一些方面,靶位点在TRAC、TRBC1和/或TRBC2基因座的调节或控制元件(例如,启动子、5'非翻译区(UTR)或3'UTR)内。在某些实施方案中,靶位点在内源TRAC、TRBC1和/或TRBC2基因座的开放阅读框内。在特定实施方案中,靶位点在TRAC、TRBC1和/或TRBC2基因座的开放阅读框内的外显子内。
在特定实施方案中,遗传破坏(例如,DNA断裂)靶向在目的基因或基因座(例如,TRAC、TRBC1和/或TRBC2)的开放阅读框处或之内。在一些实施方案中,遗传破坏靶向在目的基因或基因座的开放阅读框内的内含子处或之内。在一些实施方案中,遗传破坏靶向在目的基因或基因座的开放阅读框内的外显子内。
在特定实施方案中,遗传破坏(例如,DNA断裂)靶向在内含子处或之内。在某些实施方案中,遗传破坏(例如,DNA断裂)靶向在外显子处或之内。在一些实施方案中,遗传破坏(例如,DNA断裂)靶向在目的基因(例如,TRAC、TRBC1和/或TRBC2)的外显子处或之内。
在一些实施方案中,遗传破坏(例如,DNA断裂)靶向在TRAC基因、开放阅读框或基因座的外显子内。在某些实施方案中,遗传破坏在TRAC基因、开放阅读框或基因座的第一外显子、第二外显子、第三外显子或第四外显子内。在特定实施方案中,遗传破坏在TRAC基因、开放阅读框或基因座的第一外显子内。在一些实施方案中,遗传破坏在TRAC基因、开放阅读框或基因座中第一外显子的5'末端下游的500个碱基对(bp)内。在特定实施方案中,遗传破坏在外显子1的最5'核苷酸与外显子1的最3'核苷酸的上游之间。在某些实施方案中,遗传破坏在TRAC基因、开放阅读框架或基因座中第一外显子的5'末端下游的400bp、350bp、300bp、250bp、200bp、150bp、100bp或50bp内。在特定实施方案中,遗传破坏在TRAC基因、开放式阅读框或基因座中第一外显子的5'末端下游的1bp与400bp之间、50bp与300bp之间、100bp与200bp之间或100bp与150bp之间,每个都包含端值。在某些实施方案中,遗传破坏在TRAC基因、开放阅读框或基因座中第一外显子的5'末端下游的100bp与150bp之间,包含端值。
在特定实施方案中,遗传破坏(例如,DNA断裂)靶向在TRBC基因、开放阅读框或基因座(例如,TRBC1和/或TRBC2)的外显子内。在某些实施方案中,遗传破坏在TRBC1和/或TRBC2基因、开放阅读框或基因座的第一外显子、第二外显子、第三外显子或第四外显子内。在一些实施方案中,遗传破坏在TRBC1和/或TRBC2基因、开放阅读框或基因座的第一外显子内。在某些实施方案中,遗传破坏在TRBC1和/或TRBC2基因、开放阅读框或基因座的第一外显子、第二外显子、第三外显子或第四外显子内。在一些实施方案中,遗传破坏在外显子1的最5'核苷酸与外显子1的最3'核苷酸的上游之间。在特定实施方案中,遗传破坏在TRBC基因、开放阅读框或基因座的第一外显子内。在一些实施方案中,遗传破坏在TRBC1和/或TRBC2基因、开放阅读框架或基因座中第一外显子的5'末端下游的400bp、350bp、300bp、250bp、200bp、150bp、100bp或50bp内。在特定实施方案中,遗传破坏在TRBC1和/或TRBC2基因、开放式阅读框或基因座中第一外显子的5'末端下游的1bp与400bp之间、50bp与300bp之间、100bp与200bp之间或100bp与150bp之间,每个都包含端值。在某些实施方案中,遗传破坏在TRBC1和/或TRBC2基因、开放阅读框或基因座中第一外显子的5'末端下游的100bp与150bp之间,包含端值。
在一些实施方案中,用于敲除或敲低TRAC、TRBC1和/或TRBC2的靶向结构域是或包含选自SEQ ID NO:1048、1053、1229-1315中任一个的序列。
gRNA内所含的用于靶向人TRAC、TRBC1或TRBC2的遗传破坏的示例性靶向结构域包括例如WO 2015/161276、WO 2017/193107、WO 2017/093969、US 2016/272999和US 2015/056705中描述的那些或可以与前述的靶向序列结合的靶向结构域。gRNA内所含的用于靶向使用Cas9核酸酶(如化脓链球菌或金黄色葡萄球菌Cas9)进行的人TRAC基因座的遗传破坏的示例性靶向结构域可以包括下表16所列的那些中的任一种。
表16.示例性TRAC gRNA靶向结构域序列


gRNA内所含的用于靶向使用Cas9核酸酶(如化脓链球菌或金黄色葡萄球菌Cas9)进行的人TRBC1或TRBC2基因座的遗传破坏的示例性靶向结构域可以包括下表17所列的那些中的任一种。
表17.示例性TRBC1或TRBC2 gRNA靶向结构域序列


在一些实施方案中,用于靶向TRAC、TRBC1和/或TRBC2的gRNA可以是本文所述的或在其他地方(例如,在WO 2015/161276、WO 2017/193107、WO 2017/093969、US 2016/272999和US 2015/056705中)描述的任何gRNA或可以与前述的靶向序列结合的靶向结构域。在一些实施方案中,TRAC基因座中的由CRISPR/Cas9 gRNA靶向的序列是GAGAATCAAAATCGGTGAAT(SEQ ID NO:1348)或ATTCACCGATTTTGATTCTC(SEQ ID NO:1182)。在一些实施方案中,TRBC1和/或TRBC2基因座中的由CRISPR/Cas9gRNA靶向的序列是GGCCTCGGCGCTGACGATCT(SEQ IDNO:1349)或AGATCGTCAGCGCCGAGGCC(SEQ ID NO:1054)。在一些实施方案中,用于靶向TRAC基因座中的靶位点的gRNA靶向结构域序列是GAGAAUCAAAAUCGGUGAAU(SEQ ID NO:1048)。在一些实施方案中,用于靶向TRBC1和/或TRBC2基因座中的靶位点的gRNA靶向结构域序列是GGCCUCGGCGCUGACGAUCU(SEQ ID NO:1053)。
在一些实施方案中,用于靶向TRAC基因座的gRNA可以通过体外转录序列


 (如SEQ ID NO:1350所示;粗体且加下划线的部分与TRAC基因座中的靶位点互补)来获得,或者可以化学合成,其中gRNA具有序列
(如SEQ ID NO:1350所示;粗体且加下划线的部分与TRAC基因座中的靶位点互补)来获得,或者可以化学合成,其中gRNA具有序列


 (如SEQ ID NO:1351所示;参见Osborn等人,Mol Ther.24(3):570-581(2016))。其他示例性gRNA序列或gRNA中所含的靶向结构域和/或基因编辑和/或敲除靶向内源TCR基因(例如,TRAC和/或TRBC基因)的其他方法包括例如以下文献中描述的任一种:美国公开号US 2011/0158957、US 2014/0301990、US 2015/0098954、US 2016/0208243;US 2016/272999和US 2015/056705;国际PCT公开号WO 2014/191128、WO 2015/136001、WO 2015/161276、WO 2016/069283、WO 2016/016341、WO2017/193107和WO 2017/093969;以及Osborn等人(2016)Mol.Ther.24(3):570-581。任何已知方法可以用于产生编码TCR结构域或区域的内源基因的切割,其可以用于本文提供的实施方案中,例如用于在细胞系和/或原代T细胞中进行工程化。
(如SEQ ID NO:1351所示;参见Osborn等人,Mol Ther.24(3):570-581(2016))。其他示例性gRNA序列或gRNA中所含的靶向结构域和/或基因编辑和/或敲除靶向内源TCR基因(例如,TRAC和/或TRBC基因)的其他方法包括例如以下文献中描述的任一种:美国公开号US 2011/0158957、US 2014/0301990、US 2015/0098954、US 2016/0208243;US 2016/272999和US 2015/056705;国际PCT公开号WO 2014/191128、WO 2015/136001、WO 2015/161276、WO 2016/069283、WO 2016/016341、WO2017/193107和WO 2017/093969;以及Osborn等人(2016)Mol.Ther.24(3):570-581。任何已知方法可以用于产生编码TCR结构域或区域的内源基因的切割,其可以用于本文提供的实施方案中,例如用于在细胞系和/或原代T细胞中进行工程化。
在一些实施方案中,靶向结构域包括用于使用化脓链球菌Cas9、金黄色葡萄球菌Cas9或使用脑膜炎奈瑟氏菌Cas9敲除TRAC、TRBC1和/或TRBC2基因的那些。
在一些实施方案中,靶向结构域包括用于使用化脓链球菌Cas9敲除TRAC、TRBC1和/或TRBC2基因的那些。任何靶向结构域都可以与产生双链断裂(Cas9核酸酶)或单链断裂(Cas9切口酶)的化脓链球菌Cas9分子一起使用。
在一个实施方案中,双重靶向用于通过使用具有两个与相对DNA链互补的靶向结构域的化脓链球菌Cas9切口酶在相对DNA链上产生两个切口,例如,包含任何负链靶向结构域的gRNA可以与包含正链靶向结构域的任何gRNA配对。在一些实施方案中,两种gRNA在DNA上这样定向,使得PAM朝外,并且gRNA的5'末端之间的距离为0-50bp。在一个实施方案中,两种gRNA用于靶向两种Cas9核酸酶或两种Cas9切口酶,例如使用由两种不同gRNA分子指导的一对Cas9分子/gRNA分子复合物来切割在靶结构域的相对链上具有两个单链断裂的靶结构域。在一些实施方案中,两种Cas9切口酶可以包括具有HNH活性的分子,例如RuvC活性失活的Cas9分子,例如在D10处具有突变(例如,D10A突变)的Cas9分子;具有RuvC活性的分子,例如HNH活性失活的Cas9分子,例如在H840处具有突变(例如,H840A)的Cas9分子;或具有RuvC活性的分子,例如HNH活性失活的Cas9分子,例如在N863处具有突变(例如,N863A)的Cas9分子。在一些实施方案中,两种gRNA中的每一种与D10A Cas9切口酶复合。
(3)第一互补结构域
图14A-14G提供了第一互补结构域的例子。第一互补结构域与下述第二互补结构域互补,并且通常与第二互补结构域具有足够的互补性以在至少某些生理条件下形成双链体区。第一互补结构域的长度通常为5至30个核苷酸,并且长度可以为5至25个核苷酸,长度可以为7至25个核苷酸,长度可以为7至22个核苷酸,长度可以为7至18个核苷酸,或者长度可以为7至15个核苷酸。在各个实施方案中,第一互补结构域的长度为5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24或25个核苷酸。
通常,第一互补结构域与第二互补结构域靶标不具有确切的互补性。在一些实施方案中,第一互补结构域可以具有1、2、3、4或5个与第二互补结构域的相应核苷酸不互补的核苷酸。例如,第一互补结构域的1、2、3、4、5或6个(例如,3个)核苷酸的区段可以在双链体中不配对,并且可以形成非双链体或环出区域。在一些情形中,未配对的或环出的区域(例如,3个核苷酸的环出)存在于第二互补结构域上。此未配对区域任选地开始于距第二互补结构域的5'末端的1、2、3、4、5或6个核苷酸,例如4个核苷酸。
第一互补结构域可以包括3个子结构域,其在5'至3'方向上是:5'子结构域、中央子结构域和3'子结构域。在一个实施方案中,5'子结构域的长度为4-9个(例如,4、5、6、7、8或9个)核苷酸。在一个实施方案中,中央子结构域的长度为1、2或3个(例如,1个)核苷酸。在一个实施方案中,3'子结构域的长度为3至25个(例如,4-22、4-18或4至10个,或者3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24或25个)核苷酸。
在一些实施方案中,第一和第二互补结构域在双链体化时例如在gRNA序列中包含11个配对的核苷酸(一条配对的链加下划线,一条加粗):
在一些实施方案中,第一和第二互补结构域在双链体化时例如在gRNA序列中包含15个配对的核苷酸(一条配对的链加下划线,一条加粗):
在一些实施方案中,第一和第二互补结构域在双链体化时例如在gRNA序列中包含16个配对的核苷酸(一条配对的链加下划线,一条加粗):
在一些实施方案中,第一和第二互补结构域在双链体化时例如在gRNA序列中包含21个配对的核苷酸(一条配对的链加下划线,一条加粗):

在一些实施方案中,例如在gRNA序列中交换核苷酸以去除聚U束(交换核苷酸加下划线):NNNNNNNNNNNNNNNNNNNNGUAUUAGAGCUAGAAAUAGCAAGUUAAUAUAAGGCUAGUCCGUUAUCAACUUGAAAAAGUGGCACCGAGUCGGUGC(SEQ ID NO:1320);NNNNNNNNNNNNNNNNNNNNGUUUAAGAGCUAGAAAUAGCAAGUUUAAAUAAGGCUAGUCCGUUAUCAACUUGAAAAAGUGGCACCGAGUCGGUGC(SEQ ID NO:1321);和NNNNNNNNNNNNNNNNNNNNGUAUUAGAGCUAUGCUGUAUUGGAAACAAUACAGCAUAGCAAGUUAAUAUAAGGCUAGUCCGUUAUCAACUUGAAAAAGUGGCACCGAGUCGGUGC(SEQ ID NO:1322)。
第一互补结构域可以与天然存在的第一互补结构域具有同源性,或者源自天然存在的第一互补结构域。在一个实施方案中,它与本文公开的第一互补结构域(例如,化脓链球菌、金黄色葡萄球菌、脑膜炎奈瑟氏菌或嗜热链球菌第一互补结构域)具有至少50%同源性。
应当注意,第一互补结构域的一个或多个或甚至全部核苷酸可以具有沿着上文针对靶向结构域讨论的路线的修饰。
(4)连接结构域
图14A-14G提供了连接结构域的例子。
在单分子或嵌合gRNA中,连接结构域用于将单分子gRNA的第一互补结构域与第二互补结构域连接。连接结构域可以共价地或非共价地连接第一和第二互补结构域。在一个实施方案中,连接是共价的。在一个实施方案中,连接结构域共价地偶联第一和第二互补结构域,参见例如图14B-14E。在一个实施方案中,连接结构域是或包含插入在第一互补结构域与第二互补结构域之间的共价键。通常,连接结构域包含一个或多个(例如,2、3、4、5、6、7、8、9或10个)核苷酸,但是在各个实施方案中,接头的长度可以为20、30、40、50或甚至100个核苷酸。
在模块化gRNA分子中,两种分子凭借互补结构域的杂交而缔合,并且可以不存在连接结构域。参见例如,图14A。
各种各样的连接结构域适用于单分子gRNA分子。连接结构域可以由共价键组成,或者短至一个或几个核苷酸,例如长度为1、2、3、4或5个核苷酸。在一个实施方案中,连接结构域的长度为2、3、4、5、6、7、8、9、10、15、20或25个或更多个核苷酸。在一个实施方案中,连接结构域的长度为2至50、2至40、2至30、2至20、2至10或2至5个核苷酸。在一个实施方案中,连接结构域与天然存在的序列具有同源性,或者源自天然存在的序列,所述序列是例如第二互补性结构域的5'的tracrRNA的序列。在一个实施方案中,连接结构域与本文公开的连接结构域具有至少50%同源性。
如上文结合第一互补结构域所讨论的,连接结构域的一些或全部核苷酸可以包括修饰。
(5)5'延伸结构域
在一些情况下,模块化gRNA可以在第二互补域的5'包含另外的序列,在本文中称为5'延伸结构域,参见例如图14A。在一个实施方案中,5'延伸结构域的长度为2-10、2-9、2-8、2-7、2-6、2-5或2-4个核苷酸。在一个实施方案中,5'延伸结构域的长度为2、3、4、5、6、7、8、9或10个或更多个核苷酸。
(6)第二互补结构域
图14A-14G提供了第二互补结构域的例子。第二互补结构域与第一互补结构域互补,并且通常与第二互补结构域具有足够的互补性以在至少一些生理条件下形成双链体区。在一些情况下,例如,如图14A-14B所示,第二互补结构域可以包括与第一互补结构域缺乏互补性的序列,例如从双链体区环出的序列。
第二互补结构域的长度可以为5至27个核苷酸,并且在一些情况下可以比第一互补区长。例如,第二互补结构域的长度可以为7至27个核苷酸,长度可以为7至25个核苷酸,长度可以为7至20个核苷酸,或者长度可以为7至17个核苷酸。更通常地,互补结构域的长度可以为5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25或26个核苷酸。
在一个实施方案中,第二互补结构域包含3个子结构域,其在5'至3'方向上是:5'子结构域、中央子结构域和3'子结构域。在一个实施方案中,5'子结构域的长度为3至25个(例如,4至22、4至18或4至10个,或者3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24或25个)核苷酸。在一个实施方案中,中央子结构域的长度为1、2、3、4或5个(例如,3个)核苷酸。在一个实施方案中,3'子结构域的长度为4至9个(例如,4、5、6、7、8或9个)核苷酸。
在一个实施方案中,第一互补结构域的5'子结构域和3'子结构域分别与第二互补结构域的3'子结构域和5'子结构域互补,例如完全互补。
第二互补结构域可以与天然存在的第二互补结构域具有同源性,或者源自天然存在的第二互补结构域。在一个实施方案中,它与本文公开的第二互补结构域(例如,化脓链球菌、金黄色葡萄球菌、脑膜炎奈瑟氏菌或嗜热链球菌第一互补结构域)具有至少50%同源性。
第二互补结构域的一些或全部核苷酸可以具有修饰,例如在本文的第VIII章中发现的修饰。
(7)近端结构域
图14A-14G提供了近端结构域的例子。
在一个实施方案中,近端结构域的长度为5至20个核苷酸。在一个实施方案中,近端结构域可以与天然存在的近端结构域具有同源性,或者源自天然存在的近端结构域。在一个实施方案中,它与本文公开的近端结构域(例如,化脓链球菌、金黄色葡萄球菌、脑膜炎奈瑟氏菌或嗜热链球菌近端结构域)具有至少50%同源性。
近端结构域的一些或全部核苷酸可以具有沿上述路线的修饰。
(8)尾结构域
图14A-14G提供了尾结构域的例子。
通过检查图14A和图14B-14F中的尾结构域可以看出,广泛的尾结构域适用于gRNA分子。在各个实施方案中,尾结构域的长度为0(不存在)、1、2、3、4、5、6、7、8、9或10个核苷酸。在某些实施方案中,尾结构域核苷酸来自天然存在的尾结构域的5'末端的序列或者与其具有同源性,参见例如图14D或14E。尾结构域还任选地包括彼此互补并且在至少一些生理条件下形成双链体区的序列。
尾结构域可以与天然存在的近端尾结构域具有同源性,或者源自天然存在的近端尾结构域。通过非限制性举例的方式,根据本公开文本的各个实施方案的给定尾结构域可以与本文公开的天然存在的尾结构域(化脓链球菌、金黄色葡萄球菌、脑膜炎奈瑟氏菌或嗜热链球菌尾结构域)具有至少50%同源性。
在某些情况下,尾结构域在3'末端包括与体外或体内转录方法有关的核苷酸。当T7启动子用于gRNA的体外转录时,这些核苷酸可以是DNA模板3'末端之前存在的任何核苷酸。当U6启动子用于体内转录时,这些核苷酸可以是序列UUUUUU。当使用替代pol-III启动子时,这些核苷酸可以是各种数量或尿嘧啶碱基,或者可以包括替代碱基。
作为非限制性例子,在各个实施方案中,近端和尾结构域合在一起包含以下序列:
AAGGCUAGUCCGUUAUCAACUUGAAAAAGUGGCACCGAGUCGGUGCU(SEQ ID NO:1323)、AAGGCUAGUCCGUUAUCAACUUGAAAAAGUGGCACCGAGUCGGUGGUGC(SEQ ID NO:1324)、AAGGCUAGUCCGUUAUCAACUUGAAAAAGUGGCACCGAGUCGGUGCGGAUC(SEQ ID NO:1325)、AAGGCUAGUCCGUUAUCAACUUGAAAAAGUG(SEQ ID NO:1326)、AAGGCUAGUCCGUUAUCA(SEQ ID NO:1327)或AAGGCUAGUCCG(SEQ ID NO:1328)。
在一个实施方案中,例如如果U6启动子用于转录,则尾结构域包含3'序列UUUUUU。
在一个实施方案中,例如如果H1启动子用于转录,则尾结构域包含3'序列UUUU。
在一个实施方案中,尾结构域包含可变数量的3'U,这取决于例如所使用的pol-III启动子的终止信号。
在一个实施方案中,如果使用T7启动子,则尾结构域包含源自DNA模板的可变3'序列。
在一个实施方案中,例如如果使用体外转录产生RNA分子,则尾结构域包含源自DNA模板的可变3'序列。
在一个实施方案中,例如如果使用pol-II启动子来驱动转录,则尾结构域包含源自DNA模板的可变3'序列。
在一个实施方案中,gRNA具有以下结构:
5’[靶向结构域]-[第一互补结构域]-[连接结构域]-[第二互补结构域]-[近端结构域]-[尾结构域]-3’
其中,靶向结构域包含核心结构域和任选地二级结构域,并且长度为10至50个核苷酸;第一互补结构域的长度为5至25个核苷酸,并且在一个实施方案中,与本文公开的参考第一互补结构域具有至少50%、60%、70%、80%、85%、90%、95%、98或99%同源性;连接结构域的长度为1至5个核苷酸;近端结构域的长度为5至20个核苷酸,并且在一个实施方案中,与本文公开的参考近端结构域具有至少50%、60%、70%、80%、85%、90%、95%、98%或99%同源性;并且
尾结构域不存在或者核苷酸序列的长度为1至50个核苷酸,并且在一个实施方案中,与本文公开的参考尾结构域具有至少50%、60%、70%、80%、85%、90%、95%、98%或99%同源性。
(9)示例性嵌合gRNA
在一个实施方案中,单分子或嵌合gRNA优选地从5'至3'包含:靶向结构域,例如其包含15、16、17、18、19、20、21、22、23、24、25或26个核苷酸(其与靶核酸互补);第一互补结构域;连接结构域;第二互补结构域(其与第一互补结构域互补);近端结构域;以及尾结构域,其中,(a)近端和尾结构域当合在一起时包含至少15、18、20、25、30、31、35、40、45、49、50或53个核苷酸;(b)在第二互补结构域的最后一个核苷酸的3'有至少15、18、20、25、30、31、35、40、45、49、50或53个核苷酸;或者(c)在第二互补结构域的与第一互补结构域的其相应核苷酸互补的最后一个核苷酸的3'有至少16、19、21、26、31、32、36、41、46、50、51或54个核苷酸。
在一个实施方案中,来自(a)、(b)或(c)的序列与天然存在的gRNA的相应序列或与本文所述的gRNA具有至少60%、75%、80%、85%、90%、95%或99%同源性。在一个实施方案中,近端和尾结构域当合在一起时包含至少15、18、20、25、30、31、35、40、45、49、50或53个核苷酸。在一个实施方案中,在第二互补结构域的最后一个核苷酸的3'有至少15、18、20、25、30、31、35、40、45、49、50或53个核苷酸。在一个实施方案中,在第二互补结构域的与第一互补结构域的其相应核苷酸互补的最后一个核苷酸的3'有至少16、19、21、26、31、32、36、41、46、50、51或54个核苷酸。在一个实施方案中,靶向结构域包含,具有与靶结构域具有互补性的16、17、18、19、20、21、22、23、24、25或26个核苷酸(例如,16、17、18、19、20、21、22、23、24、25或26个连续核苷酸)或者由其组成,例如,靶结构域的长度为16、17、18、19、20、21、22、23、24、25或26个核苷酸。
在一个实施方案中,单分子或嵌合gRNA分子(包含靶向结构域、第一互补结构域、连接结构域、第二互补结构域、近端结构域和任选地尾结构域)包含以下序列,其中靶向结构域被描绘为20个N,但是可以是任何序列并且长度的范围是从16至26个核苷酸,并且其中gRNA序列后接6个U,其用作U6启动子的终止信号,但是可以不存在或数量更少:NNNNNNNNNNNNNNNNNNNNGUUUUAGAGCUAGAAAUAGCAAGUUAAAAUAAGGCUAGUCCGUUAUCAACUUGAAAAAGUGGCACCGAGUCGGUGCUUUUUU(SEQ ID NO:1329)。在一个实施方案中,单分子或嵌合gRNA分子是化脓链球菌gRNA分子。
在一些实施方案中,单分子或嵌合gRNA分子(包含靶向结构域、第一互补结构域、连接结构域、第二互补结构域、近端结构域和任选地尾结构域)包含以下序列,其中靶向结构域被描绘为20个N,但是可以是任何序列并且长度的范围是从16至26个核苷酸,并且其中gRNA序列后接6个U,其用作U6启动子的终止信号,但是可以不存在或数量更少:NNNNNNNNNNNNNNNNNNNNGUUUUAGUACUCUGGAAACAGAAUCUACUAAAACAAGGCAAAAUGCCGUGUUUAUCUCGUCAACUUGUUGGCGAGAUUUUUU(SEQ ID NO:1330)。在一个实施方案中,单分子或嵌合gRNA分子是金黄色葡萄球菌gRNA分子。
在一些实施方案中,示例性嵌合gRNA中的靶向结构域是或包含选自SEQ ID NO:1048、1053、1229-1315中任一个的序列。在一些实施方案中,示例性嵌合gRNA中的靶向结构域是或包含选自表16或17所列的那些中任一个的序列。
示例性嵌合gRNA的序列和结构也示于图14A-14B中。
(10)示例性模块化gRNA
在一个实施方案中,模块化gRNA包含第一和第二链。第一链优选地从5'至3'包含;靶向结构域,例如其包含15、16、17、18、19、20、21、22、23、24、25或26个核苷酸;第一互补结构域。第二链优选地从5'至3'包含;任选地5'延伸结构域;第二互补结构域;近端结构域;以及尾结构域,其中:(a)近端和尾结构域当合在一起时包含至少15、18、20、25、30、31、35、40、45、49、50或53个核苷酸;(b)在第二互补结构域的最后一个核苷酸的3'有至少15、18、20、25、30、31、35、40、45、49、50或53个核苷酸;或者(c)在第二互补结构域的与第一互补结构域的其相应核苷酸互补的最后一个核苷酸的3'有至少16、19、21、26、31、32、36、41、46、50、51或54个核苷酸。
在一个实施方案中,来自(a)、(b)或(c)的序列与天然存在的gRNA的相应序列或与本文所述的gRNA具有至少60%、75%、80%、85%、90%、95%或99%同源性。在一个实施方案中,近端和尾结构域当合在一起时包含至少15、18、20、25、30、31、35、40、45、49、50或53个核苷酸。在一个实施方案中,在第二互补结构域的最后一个核苷酸的3'有至少15、18、20、25、30、31、35、40、45、49、50或53个核苷酸。
在一个实施方案中,在第二互补结构域的与第一互补结构域的其相应核苷酸互补的最后一个核苷酸的3'有至少16、19、21、26、31、32、36、41、46、50、51或54个核苷酸。
在一个实施方案中,靶向结构域具有与靶结构域具有互补性的16、17、18、19、20、21、22、23、24、25或26个核苷酸(例如,16、17、18、19、20、21、22、23、24、25或26个连续核苷酸)或者由其组成,例如,靶结构域的长度为16、17、18、19、20、21、22、23、24、25或26个核苷酸。
在一些实施方案中,示例性模块化gRNA中的靶向结构域是或包含选自SEQ ID NO:1048、1053、1229-1315中任一个的序列。在一些实施方案中,示例性嵌合gRNA中的靶向结构域是或包含选自表16或17所列的那些中任一个的序列。
b)Cas9
多种物种的Cas9分子可以用于本文所述的方法和组合物中。尽管化脓链球菌、金黄色葡萄球菌、脑膜炎奈瑟氏菌和嗜热链球菌Cas9分子是本文的许多公开内容的主题,也可以使用源自或基于本文所列其他物种的Cas9蛋白的Cas9分子。换句话说,尽管本文的许多描述使用化脓链球菌、金黄色葡萄球菌、脑膜炎奈瑟氏菌和嗜热链球菌Cas9分子,来自其他物种的Cas9分子可以替代它们。此类物种包括:燕麦食酸菌(Acidovorax avenae)、胸膜肺炎放线杆菌(Actinobacillus pleuropneumoniae)、琥珀酸放线杆菌(Actinobacillussuccinogenes)、猪放线杆菌(Actinobacillus suis)、放线菌属物种(Actinomyces sp.)、Cycliphilusdenitrificans、寡食氨基酸单胞菌(Aminomonas paucivorans)、蜡样芽孢杆菌(Bacillus cereus)、史氏芽孢杆菌(Bacillus smithii)、苏云金芽孢杆菌(Bacillusthuringiensis)、拟杆菌属物种(Bacteroides sp.)、Blastopirellula marina、慢生根瘤菌属物种(Bradyrhizobium sp.)、侧孢短芽孢杆菌(Brevibacillus laterosporus)、结肠弯曲菌(Campylobacter coli)、空肠弯曲菌(Campylobacter jejuni)、红嘴鸥弯曲菌(Campylobacter lari)、Candidatus puniceispirillum、解纤维梭菌(Clostridiumcellulolyticum)、产气荚膜梭菌(Clostridium perfringens)、拥挤棒杆菌(Corynebacterium accolens)、白喉棒杆菌(Corynebacterium diphtheria)、马氏棒杆菌(Corynebacterium matruchotii)、Dinoroseobacter shibae、细长真杆菌(Eubacteriumdolichum)、γ-变形菌(Gammaproteobacterium)、重氮营养葡糖酸醋杆菌(Gluconacetobacter diazotrophicus)、副流感嗜血杆菌(Haemophilusparainfluenzae)、Haemophilus sputorum、加拿大螺杆菌(Helicobacter canadensis)、同性恋螺杆菌(Helicobacter cinaedi)、雪貂螺杆菌(Helicobacter mustelae)、营养泥杆菌(Ilyobacter polytropus)、金氏金氏菌(Kingella kingae)、卷曲乳杆菌(Lactobacilluscrispatus)、伊氏李斯特菌(Listeria ivanovii)、单核细胞增生李斯特菌(Listeriamonocytogenes)、李斯特氏菌(Listeriaceae bacterium)细菌、甲基孢囊菌属物种(Methylocystis sp.)、甲基弯菌(Methylosinus trichosporium)、羞怯动弯杆菌(Mobiluncus mulieris)、杆菌状奈瑟氏菌(Neisseria bacilliformis)、灰色奈瑟氏菌(Neisseria cinerea)、金黄奈瑟氏菌(Neisseria flavescens)、乳糖奈瑟氏菌(Neisserialactamica)、脑膜炎奈瑟氏菌(Neisseria meningitidis)、奈瑟氏菌属物种(Neisseriasp.)、瓦茨瓦尔西奈瑟氏菌(Neisseria wadsworthii)、亚硝化单胞菌属物种(Nitrosomonas sp.)、Parvibaculum lavamentivorans、多杀巴斯德菌(Pasteurellamultocida)、Phascolarctobacterium succinatutens、Ralstonia syzygii、沼泽红假单胞菌(Rhodopseudomonas palustris)、小红卵菌属物种(Rhodovulum sp.)、米氏西蒙斯菌(Simonsiella muelleri)、鞘氨醇单胞菌属物种(Sphingomonas sp.)、葡萄园芽孢乳杆菌(Sporolactobacillus vineae)、金黄色葡萄球菌、路邓葡萄球菌(Staphylococcuslugdunensis)、链球菌属物种(Streptococcus sp.)、Subdoligranulum sp.、运动替斯崔纳菌(Tistrella mobilis)、密螺旋体属物种(Treponema sp.)或Verminephrobactereiseniae。
如所述术语在本文所用,Cas9分子或Cas9多肽是指可以与gRNA分子相互作用并且与gRNA分子一齐归巢或定位到包含靶结构域和PAM序列的位点的分子或多肽。如那些术语在本文所用,Cas9分子和Cas9多肽是指天然存在的Cas9分子,并且是指与参考序列(例如,最相似的天然存在的Cas9分子或SEQ ID NO:1331-1336、1338、1340和1341所示的氨基酸序列)相差例如至少一个氨基酸残基的经工程化的、经改变的或经修饰的Cas9分子或Cas9多肽。
(1)Cas9结构域
已经确定了两种不同的天然存在的细菌Cas9分子(Jinek等人,Science,343(6176):1247997,2014)和具有指导RNA的化脓链球菌Cas9(例如,crRNA和tracrRNA的合成融合物)(Nishimasu等人,Cell,156:935-949,2014;和Anders等人,Nature,2014,doi:10.1038/nature13579)的晶体结构。
天然存在的Cas9分子包含两种叶:识别(REC)叶和核酸酶(NUC)叶;其各自还包含本文所述的结构域。在整个本公开文本中使用的结构域命名法和每个结构域所涵盖的氨基酸残基的编号如Nishimasu等人中所述。氨基酸残基的编号参考来自化脓链球菌的Cas9。
REC叶包含富含精氨酸的桥螺旋(BH)、REC1结构域和REC2结构域。REC叶与其他已知蛋白质没有结构相似性,表明它是Cas9特异性功能结构域。BH结构域是长的α-螺旋且富含精氨酸的区域,并且包含化脓链球菌Cas9的序列的氨基酸60-93。REC1结构域对于识别例如gRNA或tracrRNA的重复:抗重复双链体是重要的,因此通过识别靶序列对Cas9活性至关重要。REC1结构域在化脓链球菌Cas9的序列的氨基酸94至179和308至717处包含两个REC1基序。这两个REC1结构域虽然在线性一级结构中由REC2结构域隔开,但是在三级结构中组装形成REC1结构域。REC2结构域或其部分也可能在识别重复:抗重复双链体中起作用。REC2结构域包含化脓链球菌Cas9的序列的氨基酸180-307。
NUC叶包含RuvC结构域(在本文中也称为RuvC样结构域)、HNH结构域(在本文中也称为HNH样结构域)和PAM相互作用(PI)结构域。RuvC结构域与逆转录病毒整合酶超家族成员具有结构相似性,并且切割单链,例如靶核酸分子的非互补链。RuvC结构域由三个分别在化脓链球菌Cas9的序列的氨基酸1-59、718-769和909-1098处的分离的RuvC基序(RuvC I、RuvCII和RuvCIII,其在本领域通常称为RuvCI结构域或N末端RuvC结构域、RuvCII结构域和RuvCIII结构域)组装而成。与REC1结构域相似,三个RuvC基序在一级结构中由其他结构域线性隔开,然而在三级结构中,三个RuvC基序组装并形成RuvC结构域。HNH结构域与HNH核酸内切酶具有结构相似性,并且切割单链,例如靶核酸分子的互补链。HNH结构域位于RuvCII-III基序之间,并且包含化脓链球菌Cas9的序列的氨基酸775-908。PI结构域与靶核酸分子的PAM相互作用,并且包含化脓链球菌Cas9的序列的氨基酸1099-1368。
(a)RuvC样结构域和HNH样结构域
在一个实施方案中,Cas9分子或Cas9多肽包含HNH样结构域和RuvC样结构域。在一个实施方案中,切割活性取决于RuvC样结构域和HNH样结构域。Cas9分子或Cas9多肽(例如,eaCas9分子或eaCas9多肽)可以包含一种或多种以下结构域:RuvC样结构域和HNH样结构域。在一个实施方案中,Cas9分子或Cas9多肽是eaCas9分子或eaCas9多肽,并且eaCas9分子或eaCas9多肽包含RuvC样结构域(例如,下述RuvC样结构域)和/或HNH样结构域(例如,下述HNH样结构域)。
(b)RuvC样结构域
在一个实施方案中,RuvC样结构域切割单链,例如靶核酸分子的非互补链。Cas9分子或Cas9多肽可以包括超过一个RuvC样结构域(例如,一个、两个、三个或更多个RuvC样结构域)。在一个实施方案中,RuvC样结构域的长度为至少5、6、7、8个氨基酸,但是长度不超过20、19、18、17、16或15个氨基酸。在一个实施方案中,Cas9分子或Cas9多肽包含约10至20个氨基酸(例如,长度为约15个氨基酸)的N末端RuvC样结构域。
(c)N末端RuvC样结构域
一些天然存在的Cas9分子包含超过一个RuvC样结构域,其切割取决于N末端RuvC样结构域。因此,Cas9分子或Cas9多肽可以包含N末端RuvC样结构域。
(d)另外的RuvC样结构域
除N末端RuvC样结构域外,Cas9分子或Cas9多肽(例如,eaCas9分子或eaCas9多肽)还可以包含一个或多个另外的RuvC样结构域。在一个实施方案中,Cas9分子或Cas9多肽可以包含两个另外的RuvC样结构域。优选地,另外的RuvC样结构域的长度为至少5个氨基酸,例如长度小于15个氨基酸,例如长度为5至10个氨基酸,例如长度为8个氨基酸。
(e)HNH样结构域
在一个实施方案中,HNH样结构域切割单链互补结构域,例如双链核酸分子的互补链。在一个实施方案中,HNH样结构域的长度为至少15、20、25个氨基酸,但是长度不超过40、35或30个氨基酸,例如长度为20至35个氨基酸,例如长度为25至30个氨基酸。下文描述了示例性HNH样结构域。
在一个实施方案中,HNH样结构域具有切割能力。
在一个实施方案中,HNH样结构域无切割能力。
(2)Cas9活性
(a)核酸酶和解旋酶活性
在一个实施方案中,Cas9分子或Cas9多肽能够切割靶核酸分子。通常,野生型Cas9分子切割靶核酸分子的两条链。Cas9分子和Cas9多肽可以被工程化以改变核酸酶切割(或其他特性),例如以提供作为切口酶或缺乏切割靶核酸的能力的Cas9分子或Cas9肽。能够切割靶核酸分子的Cas9分子或Cas9多肽在本文中称为eaCas9分子或eaCas9多肽。
在一个实施方案中,eaCas9分子或eaCas9多肽包含一种或多种以下活性:
切口酶活性,即切割单链(例如,核酸分子的非互补链或互补链)的能力;
双链核酸酶活性,即切割双链核酸的两条链并产生双链断裂的能力,在一个实施方案中,这是存在两种切口酶活性;
核酸内切酶活性;
核酸外切酶活性;以及
解旋酶活性,即解旋双链核酸的螺旋结构的能力。
在一个实施方案中,酶促活性或eaCas9分子或eaCas9多肽切割两条链并导致双链断裂。在一个实施方案中,eaCas9分子仅切割一条链,例如和gRNA杂交的链或与和gRNA杂交的链互补的链。在一个实施方案中,eaCas9分子或eaCas9多肽包含与HNH样结构域相关的切割活性。在一个实施方案中,eaCas9分子或eaCas9多肽包含与N末端RuvC样结构域相关的切割活性。在一个实施方案中,eaCas9分子或eaCas9多肽包含与HNH样结构域相关的切割活性和与N末端RuvC样结构域相关的切割活性。在一个实施方案中,eaCas9分子或eaCas9多肽包含有活性的或有切割能力的HNH样结构域和无活性的或无切割能力的N末端RuvC样结构域。在一个实施方案中,eaCas9分子或eaCas9多肽包含无活性的或无切割能力的HNH样结构域和有活性的或有切割能力的N末端RuvC样结构域。
一些Cas9分子或Cas9多肽具有与gRNA分子相互作用的能力,并且与gRNA分子结合定位到核心靶结构域,但是不能切割靶核酸,或者不能以有效速率切割。没有或没有实质切割活性的Cas9分子在本文中称为eiCas9分子或eiCas9多肽。例如,eiCas9分子或eiCas9多肽可能缺乏切割活性或具有参考Cas9分子或eiCas9多肽的显著更低(例如,小于20%、10%、5%、1%或0.1%)的切割活性,如通过本文所述的测定所测量的。
(b)靶向和PAM
Cas9分子或Cas9多肽是可以与指导RNA(gRNA)分子相互作用并且与gRNA分子一齐定位到包含靶结构域和PAM序列的位点的多肽。
在一个实施方案中,eaCas9分子或eaCas9多肽与靶核酸相互作用并切割靶核酸的能力是PAM序列依赖性的。PAM序列是靶核酸中的序列。在一个实施方案中,靶核酸的切割发生在PAM序列的上游。来自不同细菌物种的eaCas9分子可以识别不同的序列基序(例如,PAM序列)。在一个实施方案中,化脓链球菌的eaCas9分子识别序列基序NGG、NAG、NGA,并且引导靶核酸序列在所述序列上游1至10个(例如,3至5个)碱基对处的切割。参见例如,Mali等人,SCIENCE 2013;339(6121):823-826。在一个实施方案中,嗜热链球菌的eaCas9分子识别序列基序NGGNG和/或NNAGAAW(W=A或T),并且引导靶核酸序列在这些序列上游1至10个(例如,3至5个)碱基对处的切割。参见例如,Horvath等人,SCIENCE 2010;327(5962):167-170;和Deveau等人,J Bacteriol 2008;190(4):1390-1400。在一个实施方案中,变形链球菌的eaCas9分子识别序列基序NGG和/或NAAR(R=A或G),并且引导核心靶核酸序列在此序列上游1至10个(例如,3至5个)碱基对处的切割。参见例如,Deveau等人,J Bacteriol 2008;190(4):1390-1400。在一个实施方案中,金黄色葡萄球菌的eaCas9分子识别序列基序NNGRR(R=A或G),并且引导靶核酸序列在所述序列上游1至10个(例如,3至5个)碱基对处的切割。在一个实施方案中,金黄色葡萄球菌的eaCas9分子识别序列基序NNGRRT(R=A或G),并且引导靶核酸序列在所述序列上游1至10个(例如,3至5个)碱基对处的切割。在一个实施方案中,金黄色葡萄球菌的eaCas9分子识别序列基序NNGRRV(R=A或G),并且引导靶核酸序列在所述序列上游1至10个(例如,3至5个)碱基对处的切割。在一个实施方案中,脑膜炎奈瑟氏菌的eaCas9分子识别序列基序NNNNGATT或NNNGCTT(R=A或G,V=A、G或C),并且引导靶核酸序列在所述序列上游1至10个(例如,3至5个)碱基对处的切割。参见例如,Hou等人,PNAS早期版本2013,1-6。可以例如使用在Jinek等人,SCIENCE 2012 337:816中描述的转化测定确定Cas9分子识别PAM序列的能力。在前述实施方案中,N可以是任何核苷酸残基,例如A、G、C或T中的任一个。
如本文所讨论的,Cas9分子可以被工程化以改变Cas9分子的PAM特异性。
示例性的天然存在的Cas9分子描述于Chylinski等人,RNA Biology 201310:5,727-737。此类Cas9分子包括簇1-78细菌家族的Cas9分子。
示例性的天然存在的Cas9分子包括簇1细菌家族的Cas9分子。例子包括以下的Cas9分子:化脓链球菌(例如,菌株SF370、MGAS10270、MGAS10750、MGAS2096、MGAS315、MGAS5005、MGAS6180、MGAS9429、NZ131和SSI-1)、嗜热链球菌(例如,菌株LMD-9)、伪豕链球菌(S.pseudoporcinus)(例如,菌株SPIN 20026)、变形链球菌(例如,菌株UA159、NN2025)、猕猴链球菌(S.macacae)(例如,菌株NCTC11558)、解没食子酸链球菌(S.gallolyticus)(例如,菌株UCN34、ATCC BAA-2069)、马肠链球菌(S.equines)(例如,菌株ATCC 9812、MGCS124)、停乳链球菌(S.dysdalactiae)(例如,菌株GGS 124)、牛链球菌(S.bovis)(例如,菌株ATCC 700338)、咽峡炎链球菌(S.anginosus)(例如,菌株F0211)、无乳链球菌(S.agalactiae)(例如,菌株NEM316、A909)、单核细胞增生李斯特菌(例如,菌株F6854)、无害李斯特菌(Listeria innocua/L.innocua,例如菌株Clip11262)、意大利肠球菌(Enterococcus italicus)(例如,菌株DSM 15952)或屎肠球菌(Enterococcus faecium)(例如,菌株1,231,408)。另一种示例性Cas9分子是脑膜炎奈瑟氏菌的Cas9分子(Hou等人,PNAS早期版本2013,1-6)。
在一个实施方案中,Cas9分子或Cas9多肽(例如,eaCas9分子或eaCas9多肽)包含这样的氨基酸序列:
所述氨基酸序列与本文所述的任何Cas9分子序列或天然存在的Cas9分子序列具有60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或99%同源性;当与其相比时相差不超过2%、5%、10%、15%、20%、30%或40%的氨基酸残基;
与其相差至少1、2、5、10或20个氨基酸,但是相差不超过100、80、70、60、50、40或30个氨基酸;或与其相同,所述天然存在的Cas9分子序列是例如来自本文所列物种或描述于Chylinski等人,RNA Biology 2013 10:5,727-737;Hou等人,PNAS早期版本2013,1-6;SEQID NO:1331-1334(变形链球菌(SEQ ID NO:1331);化脓链球菌(SEQ ID NO:1332);嗜热链球菌(SEQ ID NO:1333);无害李斯特菌(SEQ ID NO:1334))中的Cas9分子。在一个实施方案中,Cas9分子或Cas9多肽包含一种或多种以下活性:切口酶活性;双链切割活性(例如,核酸内切酶和/或核酸外切酶活性);解旋酶活性;或与gRNA分子一起归巢到靶核酸的能力。
在一个实施方案中,Cas9分子或Cas9多肽包含图15A-15G的共有序列的氨基酸序列,其中“*”指示变形链球菌(SEQ ID NO:1331);化脓链球菌(SEQ ID NO:1332);嗜热链球菌(SEQ ID NO:1333);无害李斯特菌(SEQ ID NO:1334)的Cas9分子的氨基酸序列的相应位置中发现的任何氨基酸,并且“-”指示任何氨基酸。在一个实施方案中,Cas9分子或Cas9多肽与图15A-15G中公开的共有序列的序列相差至少1个,但是不超过2、3、4、5、6、7、8、9或10个氨基酸残基。在一个实施方案中,Cas9分子或Cas9多肽包含图16A-16C的SEQ ID NO:1336的氨基酸序列,其中“*”指示化脓链球菌(SEQ ID NO:1336)或脑膜炎奈瑟氏菌(SEQ ID NO:1335)的Cas9分子的氨基酸序列的相应位置中发现的任何氨基酸,并且“-”指示任何氨基酸或不存在。在一个实施方案中,Cas9分子或Cas9多肽与图16A-16C中公开的SEQ ID NO:1335或1336的序列相差至少1个,但是不超过2、3、4、5、6、7、8、9或10个氨基酸残基。
许多Cas9分子的序列比较表明某些区域是保守的。这些区域鉴定如下:
区域1(残基1至180,或在区域1'的情况下,残基120至180);
区域2(残基360至480);
区域3(残基660至720);
区域4(残基817至900);以及
区域5(残基900至960)。
在一个实施方案中,Cas9分子或Cas9多肽包含区域1-5以及足够的另外的Cas9分子序列以提供生物活性分子,例如具有本文所述的至少一种活性的Cas9分子。在一个实施方案中,区域1-6中的每一个独立地与本文所述的Cas9分子或Cas9多肽(例如,来自图15A-15G或来自图16A-16C的序列)的相应残基具有50%、60%、70%或80%同源性。
在一个实施方案中,Cas9分子或Cas9多肽(例如,eaCas9分子或eaCas9多肽)包含称为区域1的氨基酸序列:其与化脓链球菌Cas9的氨基酸序列的氨基酸1-180(编号是根据图15A-15G中的基序序列;图15A-15G中四个Cas9序列中52%的残基是保守的)具有50%、60%、70%、80%、85%、90%、95%、96%、97%、98%或99%同源性;与化脓链球菌、嗜热链球菌、变形链球菌或无害李斯特菌Cas9的氨基酸序列的氨基酸1-180相差至少1、2、5、10或20个氨基酸,但是相差不超过90、80、70、60、50、40或30个氨基酸;或者与化脓链球菌、嗜热链球菌、变形链球菌或无害李斯特菌Cas9的氨基酸序列的1-180相同。
在一个实施方案中,Cas9分子或Cas9多肽(例如,eaCas9分子或eaCas9多肽)包含称为区域1'的氨基酸序列:其与化脓链球菌、嗜热链球菌、变形链球菌或无害李斯特菌Cas9的氨基酸序列的氨基酸120-180(图15A-15G中四个Cas9序列中55%的残基是保守的)具有55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或99%同源性;与化脓链球菌、嗜热链球菌、变形链球菌或无害李斯特菌Cas9的氨基酸序列的氨基酸120-180相差至少1、2或5个氨基酸,但是相差不超过35、30、25、20或10个氨基酸;或者与化脓链球菌、嗜热链球菌、变形链球菌或无害李斯特菌Cas9的氨基酸序列的120-180相同。
在一个实施方案中,Cas9分子或Cas9多肽(例如,eaCas9分子或eaCas9多肽)包含称为区域2的氨基酸序列:其与化脓链球菌、嗜热链球菌、变形链球菌或无害李斯特菌Cas9的氨基酸序列的氨基酸360-480(图11A-11G中四个Cas9序列中52%的残基是保守的)具有50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或99%同源性;与化脓链球菌、嗜热链球菌、变形链球菌或无害李斯特菌Cas9的氨基酸序列的氨基酸360-480相差至少1、2或5个氨基酸,但是相差不超过35、30、25、20或10个氨基酸;或者与化脓链球菌、嗜热链球菌、变形链球菌或无害李斯特菌Cas9的氨基酸序列的360-480相同。
在一个实施方案中,Cas9分子或Cas9多肽(例如,eaCas9分子或eaCas9多肽)包含称为区域3的氨基酸序列:其与化脓链球菌、嗜热链球菌、变形链球菌或无害李斯特菌Cas9的氨基酸序列的氨基酸660-720(图15A-15G中四个Cas9序列中56%的残基是保守的)具有55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或99%同源性;与化脓链球菌、嗜热链球菌、变形链球菌或无害李斯特菌Cas9的氨基酸序列的氨基酸660-720相差至少1、2或5个氨基酸,但是相差不超过35、30、25、20或10个氨基酸;或者与化脓链球菌、嗜热链球菌、变形链球菌或无害李斯特菌Cas9的氨基酸序列的660-720相同。
在一个实施方案中,Cas9分子或Cas9多肽(例如,eaCas9分子或eaCas9多肽)包含称为区域4的氨基酸序列:其与化脓链球菌、嗜热链球菌、变形链球菌或无害李斯特菌Cas9的氨基酸序列的氨基酸817-900(图11A-11G中四个Cas9序列中55%的残基是保守的)具有50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或99%同源性;与化脓链球菌、嗜热链球菌、变形链球菌或无害李斯特菌Cas9的氨基酸序列的氨基酸817-900相差至少1、2或5个氨基酸,但是相差不超过35、30、25、20或10个氨基酸;或者与化脓链球菌、嗜热链球菌、变形链球菌或无害李斯特菌Cas9的氨基酸序列的817-900相同。
在一个实施方案中,Cas9分子或Cas9多肽(例如,eaCas9分子或eaCas9多肽)包含称为区域5的氨基酸序列:其与化脓链球菌、嗜热链球菌、变形链球菌或无害李斯特菌Cas9的氨基酸序列的氨基酸900-960(图15A-15G中四个Cas9序列中60%的残基是保守的)具有50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或99%同源性;与化脓链球菌、嗜热链球菌、变形链球菌或无害李斯特菌Cas9的氨基酸序列的氨基酸900-960相差至少1、2或5个氨基酸,但是相差不超过35、30、25、20或10个氨基酸;或者与化脓链球菌、嗜热链球菌、变形链球菌或无害李斯特菌Cas9的氨基酸序列的900-960相同。
(3)经工程化的或经改变的Cas9分子和Cas9多肽
本文所述的Cas9分子和Cas9多肽(例如,天然存在的Cas9分子)可以具有许多特性中的任一种,包括:切口酶活性;核酸酶活性(例如,核酸内切酶和/或核酸外切酶活性);解旋酶活性;在功能上与gRNA分子缔合的能力;以及靶向(或定位到)核酸上的位点的能力(例如,PAM识别和特异性)。在一个实施方案中,Cas9分子或Cas9多肽可以包括这些特性的全部或子集。在典型的实施方案中,Cas9分子或Cas9多肽具有与gRNA分子相互作用的能力,并且与gRNA分子一齐定位到核酸中的位点。其他活性(例如,PAM特异性、切割活性或解旋酶活性)在Cas9分子和Cas9多肽中可能变化更广泛。
Cas9分子包括经工程化的Cas9分子和经工程化的Cas9多肽(如在此上下文中所用,“工程化”仅意味着Cas9分子或Cas9多肽与参考序列不同,并且不暗示过程或来源限制)。经工程化的Cas9分子或Cas9多肽可以包含改变的酶学特性,例如改变的核酸酶活性(与天然存在的或其他参考Cas9分子相比)或改变的解旋酶活性。如本文所讨论的,经工程化的Cas9分子或Cas9多肽可以具有切口酶活性(与双链核酸酶活性相反)。在一个实施方案中,经工程化的Cas9分子或Cas9多肽可以具有改变其大小的改变,例如减小其大小的氨基酸序列的缺失,例如对一种或多种或任何Cas9活性没有显著影响。在一个实施方案中,经工程化的Cas9分子或Cas9多肽可以包含影响PAM识别的改变。例如,可以改变经工程化的Cas9分子以识别除了内源野生型PI结构域识别的PAM序列以外的PAM序列。在一个实施方案中,Cas9分子或Cas9多肽可以在序列上不同于天然存在的Cas9分子,但是在一种或多种Cas9活性上没有显著改变。
具有所需特性的Cas9分子或Cas9多肽能以许多方式制备,例如通过改变亲本(例如,天然存在的)Cas9分子或Cas9多肽,以提供具有所需特性的经改变的Cas9分子或Cas9多肽。例如,可以引入相对于亲本Cas9分子(例如,天然存在的或经工程化的Cas9分子)的一个或多个突变或差异。此类突变和差异包含:取代(例如,保守取代或非必需氨基酸的取代);插入;或缺失。在一个实施方案中,Cas9分子或Cas9多肽相对于参考(例如,亲本Cas9分子)可以包含一个或多个突变或差异,例如至少1、2、3、4、5、10、15、20、30、40或50个突变,但是少于200、100或80个突变。
在一个实施方案中,一个或多个突变对Cas9活性(例如本文所述的Cas9活性)没有实质性影响。在一个实施方案中,一个或多个突变对Cas9活性(例如本文所述的Cas9活性)具有实质性影响。
(a)非切割和经修饰的切割Cas9分子和Cas9多肽
在一个实施方案中,Cas9分子或Cas9多肽包含不同于天然存在的Cas9分子(例如,不同于具有最接近同源性的天然存在的Cas9分子)的切割特性。例如,Cas9分子或Cas9多肽可以不同于天然存在的Cas9分子(例如,化脓链球菌的Cas9分子),如下:其调节(例如,减少或增加)双链核酸切割的能力(核酸内切酶和/或核酸外切酶活性),例如与天然存在的Cas9分子(例如,化脓链球菌的Cas9分子)相比;其调节(例如,减少或增加)核酸单链(例如,核酸分子的非互补链或核酸分子的互补链)切割的能力(切口酶活性),例如与天然存在的Cas9分子(例如,化脓链球菌的Cas9分子)相比;或者可以消除切割核酸分子(例如,双链或单链核酸分子)的能力。
(b)经修饰的切割eaCas9分子和eaCas9多肽
在一个实施方案中,eaCas9分子或eaCas9多肽包含一种或多种以下活性:与N末端RuvC样结构域相关的切割活性;与HNH样结构域相关的切割活性;与HNH样结构域相关的切割活性和与N末端RuvC样结构域相关的切割活性。
在一个实施方案中,eaCas9分子或eaCas9多肽包含有活性的或有切割能力的HNH样结构域和无活性的或无切割能力的N末端RuvC样结构域。示例性的无活性的或无切割能力的N末端RuvC样结构域可以在N末端RuvC样结构域中具有天冬氨酸的突变,例如,在图15A-15G中公开的共有序列的位置9处的天冬氨酸或在SEQ ID NO:1336的位置10处的天冬氨酸例如可以被丙氨酸取代。在一个实施方案中,eaCas9分子或eaCas9多肽在N末端RuvC样结构域中与野生型不同,并且不切割靶核酸,或以显著更低的效率切割,例如小于参考Cas9分子的切割活性的20%、10%、5%、1%或.1%,例如如通过本文所述的测定所测量的。参考Cas9分子可以是天然存在的未经修饰的Cas9分子,例如天然存在的Cas9分子,如化脓链球菌或嗜热链球菌的Cas9分子。在一个实施方案中,参考Cas9分子是具有最接近序列同一性或同源性的天然存在的Cas9分子。
在一个实施方案中,eaCas9分子或eaCas9多肽包含无活性的或无切割能力的HNH结构域和有活性的或有切割能力的N末端RuvC样结构域。示例性的无活性的或无切割能力的HNH样结构域可在以下一个或多个处具有突变:HNH样结构域中的组氨酸(例如,在图15A-15G的位置856处所示的组氨酸)例如可以被丙氨酸取代;并且HNH样结构域中的一个或多个天冬酰胺(例如,在图15A-15G的位置870处和/或在图15A-15G的位置879处所示的天冬酰胺)例如可以被丙氨酸取代。在一个实施方案中,eaCas9在HNH样结构域中与野生型不同,并且不切割靶核酸,或以显著更低的效率切割,例如小于参考Cas9分子的切割活性的20%、10%、5%、1%或0.1%,例如如通过本文所述的测定所测量的。参考Cas9分子可以是天然存在的未经修饰的Cas9分子,例如天然存在的Cas9分子,如化脓链球菌或嗜热链球菌的Cas9分子。在一个实施方案中,参考Cas9分子是具有最接近序列同一性或同源性的天然存在的Cas9分子。
在一个实施方案中,eaCas9分子或eaCas9多肽包含无活性的或无切割能力的HNH结构域和有活性的或有切割能力的N末端RuvC样结构域。示例性的无活性的或无切割能力的HNH样结构域可在以下一个或多个处具有突变:HNH样结构域中的组氨酸(例如,在图15A-15G的位置856处所示的组氨酸)例如可以被丙氨酸取代;并且HNH样结构域中的一个或多个天冬酰胺(例如,在图15A-15G的位置870处和/或在图15A-15G的位置879处所示的天冬酰胺)例如可以被丙氨酸取代。在一个实施方案中,eaCas9在HNH样结构域中与野生型不同,并且不切割靶核酸,或以显著更低的效率切割,例如小于参考Cas9分子的切割活性的20%、10%、5%、1%或0.1%,例如如通过本文所述的测定所测量的。参考Cas9分子可以是天然存在的未经修饰的Cas9分子,例如天然存在的Cas9分子,如化脓链球菌或嗜热链球菌的Cas9分子。在一个实施方案中,参考Cas9分子是具有最接近序列同一性或同源性的天然存在的Cas9分子。
(c)切割靶核酸的一条或两条链的能力的改变
在一个实施方案中,示例性Cas9活性包含PAM特异性、切割活性和解旋酶活性中的一种或多种。一个或多个突变可以存在于例如:一个或多个RuvC样结构域,例如N末端RuvC样结构域;HNH样结构域;RuvC样结构域和HNH样结构域之外的区域中。在一些实施方案中,一个或多个突变存在于RuvC样结构域(例如,N末端RuvC样结构域)中。在一些实施方案中,一个或多个突变存在于HNH样结构域中。在一些实施方案中,突变存在于RuvC样结构域(例如,N末端RuvC样结构域)和HNH样结构域两者中。
参考化脓链球菌序列,可以在RuvC结构域或HNH结构域中进行的示例性突变包括:D10A、E762A、H840A、N854A、N863A和/或D986A。
在一个实施方案中,Cas9分子或Cas9多肽是与参考Cas9分子相比在RuvC结构域中和/或在HNH结构域中包含一个或多个差异的eiCas9分子或eiCas9多肽,并且eiCas9分子或eiCas9多肽不切割核酸,或以比野生型显著更低的效率切割,例如当在例如如本文所述的切割测定中与野生型相比时,以少于参考Cas9分子的50%、25%、10%或1%切割,如通过本文所述的测定所测量的。
例如,可以通过评价突变是否是保守的或者通过第IV章中所述的方法来评价或预测特定序列(例如,取代)是否会影响一种或多种活性,如靶向活性、切割活性等。在一个实施方案中,如在Cas9分子的背景下所用,“非必需”氨基酸残基是可以从Cas9分子(例如,天然存在的Cas9分子,例如eaCas9分子)的野生型序列改变而不消除或更优选地基本上不改变Cas9活性(例如,切割活性)的残基,而改变“必需”氨基酸残基导致活性(例如,切割活性)的实质性损失。
在一个实施方案中,Cas9分子或Cas9多肽包含不同于天然存在的Cas9分子(例如,不同于具有最接近同源性的天然存在的Cas9分子)的切割特性。例如,Cas9分子或Cas9多肽可以不同于天然存在的Cas9分子(例如,金黄色葡萄球菌、化脓链球菌或空肠弯曲菌的Cas9分子),如下:其调节(例如,减少或增加)双链断裂切割的能力(核酸内切酶和/或核酸外切酶活性),例如与天然存在的Cas9分子(例如,金黄色葡萄球菌、化脓链球菌或空肠弯曲菌的Cas9分子)相比;其调节(例如,减少或增加)核酸单链(例如,核酸分子的非互补链或核酸分子的互补链)切割的能力(切口酶活性),例如与天然存在的Cas9分子(例如,金黄色葡萄球菌、化脓链球菌或空肠弯曲菌的Cas9分子)相比;或者可以消除切割核酸分子(例如,双链或单链核酸分子)的能力。
在一个实施方案中,经改变的Cas9分子或Cas9多肽是包含一种或多种以下活性的eaCas9分子或eaCas9多肽:与RuvC结构域相关的切割活性;与HNH结构域相关的切割活性;与HNH结构域相关的切割活性和与RuvC结构域相关的切割活性。
在一个实施方案中,经改变的Cas9分子或Cas9多肽是这样的eiCas9分子或eaCas9多肽,其不切割核酸分子(双链或单链核酸分子)或以显著更低的效率切割核酸分子,例如小于参考Cas9分子的切割活性的20%、10%、5%、1%或0.1%,例如如通过本文所述的测定所测量的。参考Cas9分子可以是天然存在的未经修饰的Cas9分子,例如天然存在的Cas9分子,如化脓链球菌、嗜热链球菌、金黄色葡萄球菌、空肠弯曲菌或脑膜炎奈瑟氏菌的Cas9分子。在一个实施方案中,参考Cas9分子是具有最接近序列同一性或同源性的天然存在的Cas9分子。在一个实施方案中,eiCas9分子或eiCas9多肽缺乏与RuvC结构域相关的实质切割活性和与HNH结构域相关的切割活性。
在一个实施方案中,经改变的Cas9分子或Cas9多肽是包含图15A-15G中公开的共有序列中所示的化脓链球菌的固定氨基酸残基的eaCas9分子或eaCas9多肽,并且具有在图15A-15G中公开的共有序列或SEQ ID NO:1336中由“-”表示的一个或多个残基(例如,2、3、5、10、15、20、30、50、70、80、90、100、200个氨基酸残基)处不同于化脓链球菌的氨基酸序列(例如,具有取代)的一个或多个氨基酸。
在一个实施方案中,经改变的Cas9分子或Cas9多肽包含这样的序列,其中:
对应于图15A-15G中公开的共有序列的固定序列的序列与图15A-15G中公开的共有序列相差不超过1%、2%、3%、4%、5%、10%、15%或20%的固定残基;
对应于图15A-15G中公开的共有序列中由“*”标识的残基的序列与天然存在的Cas9分子(例如,化脓链球菌Cas9分子)的相应序列相差不超过1%、2%、3%、4%、5%、10%、15%、20%、25%、30%、35%或40%的“*”残基;并且,
对应于图15A-15G中公开的共有序列中由“-”标识的残基的序列与天然存在的Cas9分子(例如,化脓链球菌Cas9分子)的相应序列相差不超过5%、10%、15%、20%、25%、30%、35%、40%、45%、55%或60%的“-”残基。
在一个实施方案中,经改变的Cas9分子或Cas9多肽是包含图15A-15G中公开的共有序列中所示的嗜热链球菌的固定氨基酸残基的eaCas9分子或eaCas9多肽,并且具有在图15A-15G中公开的共有序列中由“-”表示的一个或多个残基(例如,2、3、5、10、15、20、30、50、70、80、90、100、200个氨基酸残基)处不同于嗜热链球菌的氨基酸序列(例如,具有取代)的一个或多个氨基酸。
在一个实施方案中,经改变的Cas9分子或Cas9多肽包含这样的序列,其中:
对应于图15A-15G中公开的共有序列的固定序列的序列与图15A-15G中公开的共有序列相差不超过1%、2%、3%、4%、5%、10%、15%或20%的固定残基;
对应于图15A-15G中公开的共有序列中由“*”标识的残基的序列与天然存在的Cas9分子(例如,嗜热链球菌Cas9分子)的相应序列相差不超过1%、2%、3%、4%、5%、10%、15%、20%、25%、30%、35%或40%的“*”残基;并且,
对应于图15A-15G中公开的共有序列中由“-”标识的残基的序列与天然存在的Cas9分子(例如,嗜热链球菌Cas9分子)的相应序列相差不超过5%、10%、15%、20%、25%、30%、35%、40%、45%、55%或60%的“-”残基。
在一个实施方案中,经改变的Cas9分子或Cas9多肽是包含图15A-15G中公开的共有序列中所示的变形链球菌的固定氨基酸残基的eaCas9分子或eaCas9多肽,并且具有在图15A-15G中公开的共有序列中由“-”表示的一个或多个残基(例如,2、3、5、10、15、20、30、50、70、80、90、100、200个氨基酸残基)处不同于变形链球菌的氨基酸序列(例如,具有取代)的一个或多个氨基酸。
在一个实施方案中,经改变的Cas9分子或Cas9多肽包含这样的序列,其中:
对应于图15A-15G中公开的共有序列的固定序列的序列与图15A-15G中公开的共有序列相差不超过1%、2%、3%、4%、5%、10%、15%或20%的固定残基;
对应于图15A-15G中公开的共有序列中由“*”标识的残基的序列与天然存在的Cas9分子(例如,变形链球菌Cas9分子)的相应序列相差不超过1%、2%、3%、4%、5%、10%、15%、20%、25%、30%、35%或40%的“*”残基;并且,
对应于图15A-15G中公开的共有序列中由“-”标识的残基的序列与天然存在的Cas9分子(例如,变形链球菌Cas9分子)的相应序列相差不超过5%、10%、15%、20%、25%、30%、35%、40%、45%、55%或60%的“-”残基。
在一个实施方案中,经改变的Cas9分子或Cas9多肽是包含图15A-15G中公开的共有序列中所示的无害李斯特菌(L.innocula)的固定氨基酸残基的eaCas9分子或eaCas9多肽,并且具有在图15A-15G中公开的共有序列中由“-”表示的一个或多个残基(例如,2、3、5、10、15、20、30、50、70、80、90、100、200个氨基酸残基)处不同于无害李斯特菌的氨基酸序列(例如,具有取代)的一个或多个氨基酸。
在一个实施方案中,经改变的Cas9分子或Cas9多肽包含这样的序列,其中:
对应于图15A-15G中公开的共有序列的固定序列的序列与图15A-15G中公开的共有序列相差不超过1%、2%、3%、4%、5%、10%、15%或20%的固定残基;
对应于图15A-15G中公开的共有序列中由“*”标识的残基的序列与天然存在的Cas9分子(例如,无害李斯特菌Cas9分子)的相应序列相差不超过1%、2%、3%、4%、5%、10%、15%、20%、25%、30%、35%或40%的“*”残基;并且,
对应于图15A-15G中公开的共有序列中由“-”标识的残基的序列与天然存在的Cas9分子(例如,无害李斯特菌Cas9分子)的相应序列相差不超过5%、10%、15%、20%、25%、30%、35%、40%、45%、55%或60%的“-”残基。
在一个实施方案中,经改变的Cas9分子或Cas9多肽(例如,eaCas9分子)可以是例如两种或更多种不同的Cas9分子或Cas9多肽(例如,不同物种的两种或更多种天然存在的Cas9分子)的融合物。例如,一种物种的天然存在的Cas9分子的片段可以与第二物种的Cas9分子的片段融合。作为例子,可以将包含N末端RuvC样结构域的化脓链球菌的Cas9分子的片段与包含HNH样结构域的除了化脓链球菌以外的物种(例如,嗜热链球菌)的Cas9分子的片段融合。
(d)具有改变的PAM识别或没有PAM识别的Cas9分子
天然存在的Cas9分子可以识别特定的PAM序列,例如上文针对例如化脓链球菌、嗜热链球菌、变形链球菌、金黄色葡萄球菌和脑膜炎奈瑟氏菌所述的PAM识别序列。
在一个实施方案中,Cas9分子或Cas9多肽具有与天然存在的Cas9分子相同的PAM特异性。在其他实施方案中,Cas9分子或Cas9多肽具有与天然存在的Cas9分子不相关的PAM特异性或者与和其具有最接近序列同源性的天然存在的Cas9分子不相关的PAM特异性。例如,可以改变天然存在的Cas9分子,例如以改变PAM识别,例如以改变Cas9分子或Cas9多肽识别的PAM序列,以减少脱靶位点和/或改善特异性;或消除PAM识别要求。在一个实施方案中,可以改变Cas9分子,例如以增加PAM识别序列的长度和/或将Cas9特异性改善至高水平的同一性,例如以减少脱靶位点和增加特异性。在一个实施方案中,PAM识别序列的长度在长度上为至少4、5、6、7、8、9、10或15个氨基酸。
可以使用定向进化来产生识别不同PAM序列和/或具有降低的脱靶活性的Cas9分子或Cas9多肽。可以用于Cas9分子的定向进化的示例性方法和系统描述于例如Esvelt等人Nature 2011,472(7344):499-503。可以评价候选Cas9分子。
(4)编码Cas9分子的核酸
本文提供了编码Cas9分子或Cas9多肽(例如,eaCas9分子或eaCas9多肽)的核酸。
编码Cas9分子或Cas9多肽的示例性核酸描述于Cong等人,Science 2013,399(6121):819-823;Wang等人,Cell 2013,153(4):910-918;Mali等人,Science 2013,399(6121):823-826;Jinek等人,Science 2012,337(6096):816-821。编码Cas9分子或Cas9多肽的另一种示例性核酸在WO 2015161276的图8中以黑色显示。
在一个实施方案中,编码Cas9分子或Cas9多肽的核酸可以是合成核酸序列。例如,可以化学修饰合成核酸分子。在一个实施方案中,Cas9 mRNA具有一种或多种(例如,全部)以下特性:它被加帽,多腺苷酸化,被5-甲基胞苷和/或假尿苷取代。
另外或可替代地,可以对合成核酸序列进行密码子优化,例如,至少一个非常见密码子或较不常见密码子已经被常见密码子替代。例如,合成核酸可以引导经优化的信使mRNA的合成,例如针对在例如本文所述的哺乳动物表达系统中表达进行优化。
另外或可替代地,编码Cas9分子或Cas9多肽的核酸可以包含核定位序列(NLS)。核定位序列是本领域已知的。
SEQ ID NO:1337是编码化脓链球菌的Cas9分子的示例性的经密码子优化的核酸序列。SEQ ID NO:1338是化脓链球菌Cas9分子的相应氨基酸序列。SEQ ID NO:1339是编码脑膜炎奈瑟氏菌的Cas9分子的示例性的经密码子优化的核酸序列。SEQ ID NO:1340是脑膜炎奈瑟氏菌Cas9分子的相应氨基酸序列。SEQ ID NO:1341是编码金黄色葡萄球菌Cas9的Cas9分子的示例性的经密码子优化的核酸序列。SEQ ID NO:1342是金黄色葡萄球菌Cas9分子的氨基酸序列。
如果任何以上Cas9序列在C末端与肽或多肽融合,则应理解终止密码子将被去除。
(5)其他Cas分子和Cas多肽
各种类型的Cas分子或Cas多肽可以用于实施本文公开的发明。在一些实施方案中,使用II型Cas系统的Cas分子。在其他实施方案中,使用其他Cas系统的Cas分子。例如,可以使用I型或III型Cas分子。示例性Cas分子(和Cas系统)描述于例如Haft等人,PLoSComputational Biology 2005,1(6):e60和Makarova等人,Nature Review Microbiology2011,9:467-477,将两个参考文献的内容都通过引用以其整体并入本文。示例性Cas分子(和Cas系统)也示于表18中。
表18.Cas系统




c)Cpf1
在一些实施方案中,指导RNA或gRNA促进RNA指导的核酸酶(如Cas9或Cpf1)与靶序列(如细胞中的基因组或游离序列)的特异性关联靶向。通常,gRNA可以是单分子的(包含单一RNA分子,并且可替代地称为嵌合的),或者模块化的(包含超过一种、通常两种独立的RNA分子(如crRNA和tracrRNA),其通常相关例如通过双链体化彼此缔合)。gRNA及其组成部分在整个文献中都有描述,例如在Briner等人(Molecular Cell 56(2),333-339,10月23日,2014(Briner),将其通过引用并入)中以及在Cotta-Ramusino中。
无论是单分子的还是模块化的,指导RNA通常都包括与靶标完全或部分互补的靶向结构域,并且长度通常为10-30个核苷酸,并且在某些实施方案中,长度为16-24个核苷酸(例如,长度为16、17、18、19、20、21、22、23或24个核苷酸)。在一些方面,在Cas9 gRNA的情况下,靶向结构域在gRNA的5'末端处或附近,并且在Cpf1 gRNA的情况下,靶向结构域在gRNA的3'末端处或附近。尽管前述描述集中在用于与Cas9一起使用的gRNA上,应当理解,已经(或将来可能)发现或发明其他RNA指导的核酸酶,所述酶利用与在这一点上所述的那些在一些方面有所不同的gRNA。例如,Cpf1(“来自普氏菌属和弗朗西斯菌属的CRISPR 1(CRISPRfrom Prevotella and Franciscella1)”)是最近发现的RNA指导的核酸酶,其不需要tracrRNA起作用。(Zetsche等人,2015,Cell 163,759-771 2015年10月22日(Zetsche I),通过引用并入本文)。用于Cpf1基因组编辑系统的gRNA通常包括靶向结构域和互补结构域(可替代地称为“手柄(handle)”)。还应当注意,在用于与Cpf1一起使用的gRNA中,靶向结构域通常存在于3'末端处或附近,而不是如上结合Cas9gRNA所述的5'末端(手柄在Cpf1 gRNA的5'末端处或附近)。
尽管在来自不同原核物种的gRNA之间或在Cpf1与Cas9 gRNA之间可能存在结构差异,gRNA起作用的原理通常是一致的。由于起作用的这种一致性,在广义上,gRNA可以通过其靶向结构域序列来定义,并且熟练技术人员将理解,可以将给定的靶向结构域序列掺入任何合适的gRNA中,所述任何合适的gRNA包括单分子或嵌合gRNA或者包括一种或多种化学修饰和/或序列修饰(取代、另外的核苷酸、截短等)的gRNA。因此,在一些方面,在本公开文本中,可以仅依据其靶向结构域序列来描述gRNA。
更通常地,本公开文本的一些方面涉及可以使用多种RNA指导的核酸酶实施的系统、方法和组合物。除非另有说明,否则应当将术语gRNA理解为涵盖可以与任何RNA指导的核酸酶一起使用的任何合适的gRNA,而不仅仅是与Cas9或Cpf1的特定种类相容的那些gRNA。通过说明的方式,在某些实施方案中,术语gRNA可以包括用于与存在于2类CRISPR系统(如II型或V型或CRISPR系统)中的任何RNA指导的核酸酶或者源自或适应于此的RNA指导的核酸酶一起使用的gRNA。
此章中讨论的某些示例性修饰可以被包括在gRNA序列内的任何位置处,包括但不限于在5'末端处或附近(例如,在5'末端的1-10、1-5或1-2个核苷酸内)和/或在3'末端处或附近(例如,在3'末端的1-10、1-5或1-2个核苷酸内)。在一些情况下,修饰位于功能性基序(如Cas9 gRNA的重复-抗重复双链体、Cas9或Cpf1 gRNA的茎环结构和/或gRNA的靶向结构域)内。
RNA指导的核酸酶包括但不限于天然存在的2类CRISPR核酸酶(如Cas9和Cpf1)以及源自或获自其中的其他核酸酶。从功能上讲,RNA指导的核酸酶被定义为那些核酸酶,它们:(a)与gRNA相互作用(例如与其形成复合物);并且(b)gRNA一起与DNA的靶区域缔合,并且任选地对其进行切割或修饰,所述靶区域包括(i)与gRNA的靶向结构域互补的序列和任选地(ii)将在下文更详细地描述的称为“原型间隔子邻近基序”或“PAM”的另外的序列。如以下例子将说明的那样,在广义上,RNA指导的核酸酶可以通过其PAM特异性和切割活性来定义,即使具有相同PAM特异性或切割活性的单独的RNA指导的核酸酶之间可能存在差异。熟练技术人员将理解,本公开文本的一些方面涉及可以使用具有某种PAM特异性和/或切割活性的任何合适的RNA指导的核酸酶实施的系统、方法和组合物。因此,除非另有说明,否则术语RNA指导的核酸酶应当理解为通用术语,并且不限于RNA指导的核酸酶的任何特定类型(例如Cas9与Cpf1)、种类(例如化脓链球菌与金黄色葡萄球菌)或变异(例如全长的与截短的或分离的;天然存在的PAM特异性与工程化的PAM特异性等)。
除识别PAM和原型间隔子的特定顺序取向外,在一些实施方案中,RNA指导的核酸酶还可以识别特定的PAM序列。例如,金黄色葡萄球菌Cas9通常识别NNGRRT或NNGRRV的PAM序列,其中N残基紧靠gRNA靶向结构域识别的区域的3'。化脓链球菌Cas9通常识别NGG PAM序列。并且新凶手弗朗西斯菌(F.novicida)Cpf1通常识别TTN PAM序列。
Yamano等人(Cell.2016年5月5日;165(4):949-962(Yamano),通过引用并入本文)已经解决了与crRNA和包括TTTN PAM序列的双链(ds)DNA靶标复合的氨基酸球菌属物种(Acidaminococcus sp.)Cpf1的晶体结构。像Cas9一样,Cpf1也有两种叶:REC(识别)叶和NUC(核酸酶)叶。REC叶包括REC1和REC2结构域,其与任何已知的蛋白质结构都缺乏相似性。同时,NUC叶包括三个RuvC结构域(RuvC-I、RuvC-II和RuvC-III)和BH结构域。然而,与Cas9相反,Cpf1 REC叶缺乏HNH结构域,并且包括与已知蛋白质结构也缺乏相似性的其他结构域:结构独特的PI结构域、三个Wedge(WED)结构域(WED-I、WED-II和WED-III)和核酸酶(Nuc)结构域。
尽管Cas9和Cpf1在结构和功能上具有相似性,应当理解,某些Cpf1活性是由与任何Cas9结构域都不相似的结构性结构域介导的。例如,靶DNA互补链的切割似乎是由Nuc结构域介导的,所述Nuc结构域与Cas9的HNH结构域在顺序和空间上有所不同。此外,Cpf1gRNA的非靶向部分(手柄)采用假结结构,而不是由Cas9 gRNA中的重复:抗重复双链体形成的茎环结构。
本文提供了编码RNA指导的核酸酶(例如,Cas9、Cpf1或其功能片段)的核酸。先前已经描述了编码RNA指导的核酸酶的示例性核酸(参见例如,Cong 2013;Wang 2013;Mali2013;Jinek 2012)。
3.基因组编辑方法和递送方法
a)基因组编辑方法
通常,应理解,根据本文所述方法的任何基因的改变都可以通过任何机制介导,并且任何方法都不限于特定机制。可以与基因改变相关的示例性机制包括但不限于非同源末端连接(例如,经典的或替代的)、微同源介导的末端连接(MMEJ)、同源定向修复(例如,内源供体模板介导的)、合成依赖性链退火(SDSA)、单链退火、单链侵入、单链断裂修复(SSBR)、错配修复(MMR)、碱基切除修复(BER)、链间交联(ICL)跨损伤合成(TLS)或无错复制后修复(PRR)。本文描述了用于靶向敲除TRAC、TRBC1和/或TRBC2中的一个或全部的一个或两个等位基因的示例性方法。
(1)用于基因靶向的NHEJ方法
如本文所述,核酸酶诱导的非同源末端连接(NHEJ)可以用于靶向基因特异性敲除。核酸酶诱导的NHEJ也可以用于去除(例如,缺失)目的基因中的序列插入。
尽管不希望受到理论的束缚,认为在一个实施方案中,与本文所述方法相关的基因组改变依赖于核酸酶诱导的NHEJ和NHEJ修复途径的易错性质。NHEJ通过将两个末端连接在一起来修复DNA中的双链断裂;然而,通常,只有完美连接两个相容末端(在它们恰好由双链断裂形成时)才能恢复原始序列。双链断裂的DNA末端经常是酶加工的对象,从而导致在重新连接末端之前在一条或两条链处添加或去除核苷酸。这导致在DNA序列中在NHEJ修复位点处存在插入和/或缺失(indel)突变。这些突变的三分之二通常改变阅读框,因此产生非功能性蛋白质。此外,维持阅读框但插入或缺失大量序列的突变可能破坏蛋白质的功能性。这是基因座依赖性的,因为关键功能结构域中的突变可能比蛋白质非关键区域中的突变耐受性低。NHEJ产生的indel突变本质上是不可预测的;然而,在给定的断裂位点处,某些indel序列受到青睐,并且在群体中有过高的代表,这可能是由于微同源性的小区域所致。缺失的长度可以广泛地变化;最常见地在1-50bp的范围内,但是它们可以容易地达到大于100-200bp。插入往往较短,并且通常包括紧邻断裂位点周围的序列的短重复。然而,有可能获得大的插入,并且在这些情况下,所插入的序列通常被追踪到基因组的其他区域或细胞中存在的质粒DNA。
因为NHEJ是诱变过程,它也可以用于缺失小序列基序,只要不需要产生特定的最终序列。如果双链断裂靶向在短靶序列附近,则由NHEJ修复引起的缺失突变通常跨越,因此去除不需要的核苷酸。对于较大的DNA区段的缺失,在序列的每一侧上引入两个双链断裂可以在末端之间导致NHEJ,并且去除整个间插序列。在一些实施方案中,一对gRNA可以用于引入两个双链断裂,从而导致缺失两个断裂之间的间插序列。
这两种方法均可以用于缺失特定的DNA序列;然而,NHEJ的易错性质仍可能在修复位点处产生indel突变。
双链切割eaCas9分子和单链或切口酶eaCas9分子均可以用于本文所述的方法和组合物中,以产生NHEJ介导的indel。靶向目的基因(例如,基因的编码区,例如早期编码区)的NHEJ介导的indel可以用于敲除目的基因(即,消除其表达)。例如,目的基因的早期编码区包括紧接转录起始位点之后、在编码序列的第一外显子内或在转录起始位点的500bp内(例如,小于500、450、400、350、300、250、200、150、100或50bp)的序列。
在一个实施方案中,将NHEJ介导的indel引入一个或多个T细胞表达的基因(如TRAC、TRBC1和/或TRBC2)中。提供了靶向所述基因的单独的gRNA或gRNA对以及Cas9双链核酸酶或单链切口酶。
(2)双链或单链断裂相对于靶位置的放置
在gRNA和Cas9核酸酶产生双链断裂以用于诱导NHEJ介导的indel的目的的实施方案中,gRNA(例如,单分子(或嵌合)或模块化gRNA分子)被配置将双链断裂定位地非常靠近靶位置的核苷酸。在一个实施方案中,切割位点在距离靶位置0-30bp之间(例如,距离靶位置小于30、25、20、15、10、9、8、7、6、5、4、3、2或1bp)。
在与Cas9切口酶复合的两种gRNA诱导两个单链断裂以用于诱导NHEJ介导的indel的目的的实施方案中,两种gRNA(例如,独立地为单分子(或嵌合)或模块化gRNA)被配置为定位两个单链链断裂以提供NHEJ修复靶位置的核苷酸。在一个实施方案中,gRNA被配置为将切割定位在不同链上的相同位置处或彼此的几个核苷酸内,从而本质上模拟双链断裂。在一个实施方案中,较近的切口在距离靶位置0-30bp之间(例如,距离靶位置小于30、25、20、15、10、9、8、7、6、5、4、3、2或1bp),并且两个切口在彼此25-55bp内(例如,在25至50、25至45、25至40、25至35、25至30、50至55、45至55、40至55、35至55、30至55、30至50、35至50、40至50、45至50、35至45或40至45bp之间)且彼此相距不超过100bp(例如,不超过90、80、70、60、50、40、30、20或10bp)。在一个实施方案中,gRNA被配置为将单链断裂放置在靶位置的核苷酸的任一侧上。
双链切割eaCas9分子和单链或切口酶eaCas9分子均可以用于本文所述的方法和组合物中,以在靶位置的两侧产生断裂。可以在靶位置的两侧上产生双链或成对的单链断裂,以去除两个切割之间的核酸序列(例如,缺失两个断裂之间的区域)。在一个实施方案中,两种gRNA(例如,独立地为单分子(或嵌合)或模块化gRNA)被配置为将双链断裂定位在靶位置的两侧上。在一个替代实施方案中,三种gRNA(例如,独立地为单分子(或嵌合)或模块化gRNA)被配置为将双链断裂(即,一种gRNA与cas9核酸酶复合)和两个单链断裂或成对的单链断裂(即,两种gRNA与Cas9切口酶复合)定位在靶位置的任一侧上。在另一个实施方案中,四种gRNA(例如,独立地为单分子(或嵌合)或模块化gRNA)被配置为在靶位置的任一侧上产生两对单链断裂(即,两对两种gRNA与Cas9切口酶复合)。所述一个或多个双链断裂或一对中两个单链切口中的较近者将理想地在靶位置的0-500bp内(例如,距离靶位置不超过450、400、350、300、250、200、150、100、50或25bp)。当使用切口酶时,一对中的两个切口在彼此的25-55bp内(例如,在25至50、25至45、25至40、25至35、25至30、50至55、45至55、40至55、35至55、30至55、30至50、35至50、40至50、45至50、35至45或40至45bp之间)且彼此相距不超过100bp(例如,不超过90、80、70、60、50、40、30、20或10bp)。
(3)靶向敲低
与通过在DNA水平上突变基因永久地消除或减少表达的CRISPR/Cas介导的基因敲除不同,CRISPR/Cas敲低允许通过使用人工转录因子暂时减少基因表达。突变Cas9蛋白的两个DNA切割域中的关键残基(例如,D10A和H840A突变)导致产生催化失活的Cas9(eiCas9,其也称为死Cas9或dCas9)。催化失活的Cas9与gRNA复合并且定位到由所述gRNA的靶向结构域指定的DNA序列,然而,它不切割靶DNA。dCas9与效应子结构域(例如,转录阻遏结构域)的融合使得能够将效应子募集到由gRNA指定的任何DNA位点。尽管已经显示eiCas9自身在募集到编码序列中的早期区域时可以阻断转录,可以通过将转录阻遏结构域(例如KRAB、SID或ERD)与Cas9融合并将其募集到基因的启动子区来实现更稳健的阻遏。可能的是,靶向启动子的DNA酶I超敏区可能产生更有效的基因阻遏或激活,因为这些区域更可能是Cas9蛋白可及的,并且也更可能包含内源转录因子的位点。尤其是对于基因阻遏,本文考虑了阻断内源转录因子的结合位点将有助于下调基因表达。在另一个实施方案中,可以将eiCas9与染色质修饰蛋白融合。改变染色质状态可以导致靶基因表达降低。
在一个实施方案中,可以将gRNA分子靶向已知的转录应答元件(例如,启动子、增强子等)、已知的上游激活序列(UAS)和/或怀疑能够控制靶DNA的表达的具有未知或已知功能的序列。
在一个实施方案中,CRISPR/Cas介导的基因敲低可以用于减少一个或多个T细胞表达的基因的表达。在本文所述的eiCas9或eiCas9融合蛋白用于敲低两个T细胞表达的基因(例如,TRAC、TRBC1和/或TRBC2基因中的任何两个或更多个)的实施方案中,提供了靶向两个或全部基因的单独的gRNA或gRNA对以及eiCas9或eiCas9融合蛋白。
(4)单链退火
单链退火(SSA)是另一种DNA修复过程,其修复靶核酸中存在的两个重复序列之间的双链断裂。SSA途径利用的重复序列的长度通常大于30个核苷酸。在断裂末端进行切除以揭示靶核酸的两条链上的重复序列。在切除之后,用RPA蛋白包被含有重复序列的单链突出端,以防止重复序列不适当地退火,例如自身退火。RAD52与突出端上的每个重复序列结合并对齐序列,以使得互补重复序列能够退火。在退火之后,切割突出端的单链瓣(flap)。新DNA合成填充任何缺口,并且连接恢复DNA双链体。作为加工的结果,缺失两个重复之间的DNA序列。缺失的长度可以取决于许多因素,包括所利用的两个重复的位置以及切除的途径或进行性(processivity)。
与HDR途径相反,SSA不需要模板核酸来改变或校正靶核酸序列。相反,利用互补重复序列。
(5)其他DNA修复途径
(a)SSBR(单链断裂修复)
基因组中的单链断裂(SSB)通过SSBR途径修复,这是与上文讨论的DSB修复机制不同的机制。SSBR途径具有四个主要阶段:SSB检测、DNA末端加工、DNA缺口填充和DNA连接。更详细的解释给出于Caldecott,Nature Reviews Genetics 9,619-631(2008年8月),并且这里给出了概述。
在第一阶段,当形成SSB时,PARP1和/或PARP2识别断裂并募集修复机器。PARP1在DNA断裂处的结合和活性是短暂的,并且似乎通过促进损伤处SSBr蛋白复合物的局灶积累或稳定性来加速SSBr。可以说,这些SSBr蛋白中最重要的是XRCC1,它起分子支架的作用,所述分子支架与SSBr过程的多种酶促组分(包括负责清洁DNA 3'和5'末端的蛋白质)相互作用,对其进行稳定并对其进行刺激。例如,XRCC1与促进末端加工的几种蛋白质(DNA聚合酶β、PNK和三种核酸酶APE1、APTX和APLF)相互作用。APE1具有核酸内切酶活性。APLF展现出核酸内切酶和3'至5'核酸外切酶活性。APTX具有核酸内切酶和3'至5'核酸外切酶活性。
此末端加工是SSBR的重要阶段,因为大多数(如果不是全部)SSB的3'末端和/或5'末端“受损”。末端加工通常涉及将受损的3'末端恢复为羟基化状态和/或将受损的5'末端恢复为磷酸部分,使得末端变得有连接能力。可以加工受损的3'末端的酶包括PNKP、APE1和TDP1。可以加工受损的5'末端的酶包括PNKP、DNA聚合酶β和APTX。LIG3(DNA连接酶III)也可以参与末端加工。一旦末端得到了清洁,便会发生缺口填充。
在DNA缺口填充阶段,通常存在的蛋白质是PARP1、DNA聚合酶β、XRCC1、FEN1(瓣状核酸内切酶1)、DNA聚合酶δ/ε、PCNA和LIG1。缺口填充有两种方式,即短补丁修复和长补丁修复。短补丁修复涉及缺失的单个核苷酸的插入。在一些SSB处,“缺口填充”可能继续置换两个或更多个核苷酸(已经报道了置换多达12个碱基)。FEN1是去除置换的5'残基的核酸内切酶。多种DNA聚合酶(包括Polβ)参与SSB的修复,其中DNA聚合酶的选择受SSB的来源和类型的影响。
在第四阶段,DNA连接酶(如LIG1(连接酶I)或LIG3(连接酶III))催化末端的连接。短补丁修复使用连接酶III,并且长补丁修复使用连接酶I。
有时,SSBR是复制偶联的。此途径可以涉及CtIP、MRN、ERCC1和FEN1中的一种或多种。可以促进SSBR的另外的因子包括:aPARP、PARP1、PARP2、PARG、XRCC1、DNA聚合酶b、DNA聚合酶d、DNA聚合酶e、PCNA、LIG1、PNK、PNKP、APE1、APTX、APLF、TDP1、LIG3、FEN1、CtIP、MRN和ERCC1。
(b)MMR(错配修复)
细胞含有三种切除修复途径:MMR、BER和NER。切除修复途径具有的共同特征在于它们通常识别DNA一条链上的损伤,然后核酸外切/核酸内切酶去除损伤并留下1-30个核苷酸的缺口,其随后被DNA聚合酶填充并最终被连接酶密封起来。更完整的画面给出于Li,Cell Research(2008)18:85-98,并且这里提供了概述。
错配修复(MMR)对错配的DNA碱基进行操作。
MSH2/6或MSH2/3复合物均具有ATP酶活性,这在错配识别和修复启动中起重要作用。MSH2/6优先识别碱基-碱基错配并鉴定1或2个核苷酸的错配,而MSH2/3优先识别较大的ID错配。
hMLH1与hPMS2异二聚体形成hMutLα,其具有ATP酶活性并且对于MMR的多个步骤是重要的。它具有PCNA/复制因子C(RFC)依赖性核酸内切酶活性,这在涉及EXO1的3'切口指导的MMR中起重要作用。(EXO1是HR和MMR两者的参与者。)它调控错配引起的切除的终止。连接酶I是此途径的相关连接酶。可以促进MMR的另外的因子包括:EXO1、MSH2、MSH3、MSH6、MLH1、PMS2、MLH3、DNA Pol d、RPA、HMGB1、RFC和DNA连接酶I。
(c)碱基切除修复(BER)
碱基切除修复(BER)途径在整个细胞周期中都是活跃的;它主要负责从基因组中去除小的非螺旋扭曲的碱基损伤。相反,相关的核苷酸切除修复途径(在下一章中讨论)修复庞大的螺旋扭曲损伤。更详细的解释给出于Caldecott,Nature Reviews Genetics 9,619-631(2008年8月),并且这里给出了概述。
一旦DNA碱基受损,便启动碱基切除修复(BER),并且所述过程可以简化为五个主要步骤:(a)去除受损的DNA碱基;(b)切下随后的碱基位点;(c)清理DNA末端;(d)将正确的核苷酸插入修复缺口中;以及(e)连接DNA骨架中的其余切口。这些最后步骤类似于SSBR。
在第一步,受损特异性DNA糖基化酶通过切割将碱基与糖磷酸骨架连接的N-糖苷键来切除受损的碱基。然后,AP核酸内切酶-1(APE1)或具有相关裂解酶活性的双功能DNA糖基化酶切开磷酸二酯骨架,以产生DNA单链断裂(SSB)。BER的第三步涉及清理DNA末端。BER中的第四步由Polβ进行,它将新的互补核苷酸添加到修复缺口中,并且在最终步骤,XRCC1/连接酶III将DNA骨架中的其余切口密封起来。这样就完成了短补丁BER途径,其中大部分(约80%)受损的DNA碱基得到了修复。然而,如果步骤3中的5'末端对末端加工活性具有抗性,则在通过Polβ插入一个核苷酸后,然后将聚合酶转换为复制性DNA聚合酶Polδ/ε,其然后再将约2-8核苷酸添加到DNA修复缺口中。这产生了5'瓣结构,其被瓣状核酸内切酶-1(FEN-1)联合进行性因子增殖细胞核抗原(PCNA)识别并切除。然后,DNA连接酶I将DNA骨架中的其余切口密封起来,并且完成了长补丁BER。可以促进BER途径的另外的因子包括:DNA糖基化酶、APE1、Polb、Pold、Pole、XRCC1、连接酶III、FEN-1、PCNA、RECQL4、WRN、MYH、PNKP和APTX。
(d)核苷酸切除修复(NER)
核苷酸切除修复(NER)是重要的切除机制,其从DNA中去除庞大的螺旋扭曲的损伤。有关NER的另外的细节给出于Marteijn等人,Nature Reviews Molecular CellBiology 15,465-481(2014),并且这里给出了概述。NER的广泛途径涵盖两个较小的途径:全基因组NER(GG-NER)和转录偶联修复NER(TC-NER)。GG-NER和TC-NER使用不同的因子来识别DNA受损。然而,它们使用相同的机器进行损伤切除、修复和连接。
一旦识别出受损,细胞便去除含有损伤的短单链DNA区段。核酸内切酶XPF/ERCC1和XPG(由ERCC5编码)通过切割损伤任一侧上的受损链来去除损伤,从而产生22-30个核苷酸的单链缺口。接下来,细胞进行DNA缺口填充合成和连接。参与此过程的是:PCNA、RFC、DNAPolδ、DNA Polε或DNA Polκ和DNA连接酶I或XRCC1/连接酶III。复制细胞往往使用DNA polε和DNA连接酶I,而非复制细胞往往使用DNA Polδ、DNA Polκ和XRCC1/连接酶III复合物进行连接步骤。
NER可能涉及以下因子:XPA-G、POLH、XPF、ERCC1、XPA-G和LIG1。转录偶联NER(TC-NER)可能涉及以下因子:CSA、CSB、XPB、XPD、XPG、ERCC1和TTDA。可以促进NER修复途径的另外的因子包括XPA-G、POLH、XPF、ERCC1、XPA-G、LIG1、CSA、CSB、XPA、XPB、XPC、XPD、XPF、XPG、TTDA、UVSSA、USP7、CETN2、RAD23B、UV-DDB、CAK亚复合物、RPA和PCNA。
(e)链内交联(ICL)
称为ICL修复途径的专用途径修复链间交联。在复制或转录期间可能发生链间交联或不同DNA链中碱基之间的共价交联。ICL修复涉及多个修复过程(特别是溶核活性、跨损伤合成(TLS)和HDR)的协调。募集核酸酶以切除交联碱基任一侧上的ICL,同时协调TLS和HDR以修复切割链。ICL修复可能涉及以下因子:核酸内切酶(例如,XPF和RAD51C)、核酸内切酶(如RAD51)、跨损伤聚合酶(例如,DNA聚合酶ζ和Rev1)以及范科尼贫血(FA)蛋白(例如,FancJ)。
(f)其他途径
在哺乳动物中存在几种其他DNA修复途径。
跨损伤合成(TLS)是用于修复有缺陷的复制事件之后留下的单链断裂的途径,并且涉及跨损伤聚合酶,例如DNA polζ和Rev1。
无错复制后修复(PRR)是用于修复有缺陷的复制事件之后留下的单链断裂的另一种途径。
(6)基因组编辑方法中gRNA的例子
如本文所述的任何gRNA分子都可以与产生双链断裂或单链断裂的任何Cas9分子一起使用,以改变靶核酸(例如,靶位置或靶遗传特征)的序列。在一些例子中,靶核酸在TRAC、TRBC1和/或TRBC2基因座(如所述的任何基因座)处或附近。在一些实施方案中,将核糖核酸分子(如gRNA分子)和蛋白质(如Cas9蛋白或其变体)引入本文提供的任何工程化细胞中。下文描述了在这些方法中有用的gRNA分子。
在一个实施方案中,gRNA(例如,嵌合gRNA)被配置成使得它包含一种或多种以下特性:
a)例如,当靶向进行双链断裂的Cas9分子时,它可以将双链断裂定位(i)在靶位置的50、100、150、200、250、300、350、400、450或500个核苷酸内,或者(ii)足够接近以使靶位置在末端切除区域内;
b)它具有至少16个核苷酸的靶向结构域,例如(i)16、(ii)17、(iii)18、(iv)19、(v)20、(vi)21、(vii)22、(viii)23、(ix)24、(x)25或(xi)26个核苷酸的靶向结构域;以及
c)
(i)近端和尾结构域当合在一起时包含至少15、18、20、25、30、31、35、40、45、49、50或53个核苷酸,例如至少15、18、20、25、30、31、35、40、45、49、50或53个来自天然存在的化脓链球菌、嗜热链球菌、金黄色葡萄球菌或脑膜炎奈瑟氏菌尾和近端结构域或与其相差不超过1、2、3、4、5、6、7、8、9或10个核苷酸的序列的核苷酸;
(ii)在第二互补结构域的最后一个核苷酸的3'有至少15、18、20、25、30、31、35、40、45、49、50或53个核苷酸,例如至少15、18、20、25、30、31、35、40、45、49、50或53个来自天然存在的化脓链球菌、嗜热链球菌、金黄色葡萄球菌或脑膜炎奈瑟氏菌gRNA的相应序列或与其相差不超过1、2、3、4、5、6、7、8、9或10个核苷酸的序列的核苷酸;
(iii)在第二互补结构域的与第一互补结构域的其相应核苷酸互补的最后一个核苷酸的3'有至少16、19、21、26、31、32、36、41、46、50、51或54个核苷酸,例如至少16、19、21、26、31、32、36、41、46、50、51或54个来自天然存在的化脓链球菌、嗜热链球菌、金黄色葡萄球菌或脑膜炎奈瑟氏菌gRNA的相应序列或与其相差不超过1、2、3、4、5、6、7、8、9或10个核苷酸的序列的核苷酸;
(iv)尾结构域的长度为至少10、15、20、25、30、35或40个核苷酸,例如,它包含至少10、15、20、25、30、35或40个来自天然存在的化脓链球菌、嗜热链球菌、金黄色葡萄球菌或脑膜炎奈瑟氏菌尾结构域或与其相差不超过1、2、3、4、5、6、7、8、9或10个核苷酸的序列的核苷酸;或者
(v)尾结构域包含天然存在的尾结构域(例如,天然存在的化脓链球菌、嗜热链球菌、金黄色葡萄球菌或脑膜炎奈瑟氏菌尾结构域)的15、20、25、30、35、40个核苷酸或全部相应部分。
在一个实施方案中,gRNA被配置成使得它包含特性:a和b(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a和b(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a和b(iii)。在一个实施方案中,gRNA被配置成使得它包含特性:a和b(iv)。在一个实施方案中,gRNA被配置成使得它包含特性:a和b(v)。在一个实施方案中,gRNA被配置成使得它包含特性:a和b(vi)。在一个实施方案中,gRNA被配置成使得它包含特性:a和b(vii)。在一个实施方案中,gRNA被配置成使得它包含特性:a和b(viii)。在一个实施方案中,gRNA被配置成使得它包含特性:a和b(ix)。在一个实施方案中,gRNA被配置成使得它包含特性:a和b(x)。在一个实施方案中,gRNA被配置成使得它包含特性:a和b(xi)。在一个实施方案中,gRNA被配置成使得它包含特性:a和c。在一个实施方案中,gRNA被配置成使得它包含特性:a、b和c。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(i)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(i)和c(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(ii)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(ii)和c(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(iii)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(iii)和c(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(iv)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(iv)和c(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(v)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(v)和c(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(vi)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(vi)和c(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(vii)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(vii)和c(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(viii)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(viii)和c(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(ix)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(ix)和c(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(x)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(x)和c(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(xi)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(xi)和c(ii)。
在一个实施方案中,gRNA(例如,嵌合gRNA)被配置成使得它包含一种或多种以下特性:
a)例如,当靶向进行单链断裂的Cas9分子时,gRNA之一或两者可以将双链断裂定位(i)在靶位置的50、100、150、200、250、300、350、400、450或500个核苷酸内,或者(ii)足够接近以使靶位置在末端切除区域内;
b)一者或两者具有至少16个核苷酸的靶向结构域,例如(i)16、(ii)17、(iii)18、(iv)19、(v)20、(vi)21、(vii)22、(viii)23、(ix)24、(x)25或(xi)26个核苷酸的靶向结构域;以及
c)
(i)近端和尾结构域当合在一起时包含至少15、18、20、25、30、31、35、40、45、49、50或53个核苷酸,例如至少15、18、20、25、30、31、35、40、45、49、50或53个来自天然存在的化脓链球菌、嗜热链球菌、金黄色葡萄球菌或脑膜炎奈瑟氏菌尾和近端结构域或与其相差不超过1、2、3、4、5、6、7、8、9或10个核苷酸的序列的核苷酸;
(ii)在第二互补结构域的最后一个核苷酸的3'有至少15、18、20、25、30、31、35、40、45、49、50或53个核苷酸,例如至少15、18、20、25、30、31、35、40、45、49、50或53个来自天然存在的化脓链球菌、嗜热链球菌、金黄色葡萄球菌或脑膜炎奈瑟氏菌gRNA的相应序列或与其相差不超过1、2、3、4、5、6、7、8、9或10个核苷酸的序列的核苷酸;
(iii)在第二互补结构域的与第一互补结构域的其相应核苷酸互补的最后一个核苷酸的3'有至少16、19、21、26、31、32、36、41、46、50、51或54个核苷酸,例如至少16、19、21、26、31、32、36、41、46、50、51或54个来自天然存在的化脓链球菌、嗜热链球菌、金黄色葡萄球菌或脑膜炎奈瑟氏菌gRNA的相应序列或与其相差不超过1、2、3、4、5、6、7、8、9或10个核苷酸的序列的核苷酸;
(iv)尾结构域的长度为至少10、15、20、25、30、35或40个核苷酸,例如,它包含至少10、15、20、25、30、35或40个来自天然存在的化脓链球菌、嗜热链球菌、金黄色葡萄球菌或脑膜炎奈瑟氏菌尾结构域或与其相差不超过1、2、3、4、5、6、7、8、9或10个核苷酸的序列的核苷酸;或者
(v)尾结构域包含天然存在的尾结构域(例如,天然存在的化脓链球菌、嗜热链球菌、金黄色葡萄球菌或脑膜炎奈瑟氏菌尾结构域)的15、20、25、30、35、40个核苷酸或全部相应部分。
在一个实施方案中,gRNA被配置成使得它包含特性:a和b(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a和b(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a和b(iii)。在一个实施方案中,gRNA被配置成使得它包含特性:a和b(iv)。在一个实施方案中,gRNA被配置成使得它包含特性:a和b(v)。在一个实施方案中,gRNA被配置成使得它包含特性:a和b(vi)。在一个实施方案中,gRNA被配置成使得它包含特性:a和b(vii)。在一个实施方案中,gRNA被配置成使得它包含特性:a和b(viii)。在一个实施方案中,gRNA被配置成使得它包含特性:a和b(ix)。在一个实施方案中,gRNA被配置成使得它包含特性:a和b(x)。在一个实施方案中,gRNA被配置成使得它包含特性:a和b(xi)。在一个实施方案中,gRNA被配置成使得它包含特性:a和c。在一个实施方案中,gRNA被配置成使得它包含特性:a、b和c。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(i)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(i)和c(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(ii)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(ii)和c(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(iii)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(iii)和c(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(iv)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(iv)和c(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(v)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(v)和c(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(vi)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(vi)和c(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(vii)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(vii)和c(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(viii)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(viii)和c(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(ix)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(ix)和c(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(x)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(x)和c(ii)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(xi)和c(i)。在一个实施方案中,gRNA被配置成使得它包含特性:a(i)、b(xi)和c(ii)。
在一个实施方案中,将gRNA与具有HNH活性的Cas9切口酶分子(例如RuvC活性失活的Cas9分子,例如在D10处具有突变(例如,D10A突变)的Cas9分子)一起使用。
在一个实施方案中,将gRNA与具有RuvC活性的Cas9切口酶分子(例如HNH活性失活的Cas9分子,例如在H840处具有突变(例如,H840A)的Cas9分子)一起使用。
在一个实施方案中,包含第一和第二gRNA的一对gRNA(例如,一对嵌合gRNA)被配置成使得它们包含一种或多种以下特性:
a)例如,当靶向进行单链断裂的Cas9分子时,gRNA之一或两者可以将双链断裂定位(i)在靶位置的50、100、150、200、250、300、350、400、450或500个核苷酸内,或者(ii)足够接近以使靶位置在末端切除区域内;
b)一者或两者具有至少16个核苷酸的靶向结构域,例如(i)16、(ii)17、(iii)18、(iv)19、(v)20、(vi)21、(vii)22、(viii)23、(ix)24、(x)25或(xi)26个核苷酸的靶向结构域;
c)对于一者或两者:
(i)近端和尾结构域当合在一起时包含至少15、18、20、25、30、31、35、40、45、49、50或53个核苷酸,例如至少15、18、20、25、30、31、35、40、45、49、50或53个来自天然存在的化脓链球菌、嗜热链球菌、金黄色葡萄球菌或脑膜炎奈瑟氏菌尾和近端结构域或与其相差不超过1、2、3、4、5、6、7、8、9或10个核苷酸的序列的核苷酸;
(ii)在第二互补结构域的最后一个核苷酸的3'有至少15、18、20、25、30、31、35、40、45、49、50或53个核苷酸,例如至少15、18、20、25、30、31、35、40、45、49、50或53个来自天然存在的化脓链球菌、嗜热链球菌、金黄色葡萄球菌或脑膜炎奈瑟氏菌gRNA的相应序列或与其相差不超过1、2、3、4、5、6、7、8、9或10个核苷酸的序列的核苷酸;
(iii)在第二互补结构域的与第一互补结构域的其相应核苷酸互补的最后一个核苷酸的3'有至少16、19、21、26、31、32、36、41、46、50、51或54个核苷酸,例如至少16、19、21、26、31、32、36、41、46、50、51或54个来自天然存在的化脓链球菌、嗜热链球菌、金黄色葡萄球菌或脑膜炎奈瑟氏菌gRNA的相应序列或与其相差不超过1、2、3、4、5、6、7、8、9或10个核苷酸的序列的核苷酸;
(iv)尾结构域的长度为至少10、15、20、25、30、35或40个核苷酸,例如,它包含至少10、15、20、25、30、35或40个来自天然存在的化脓链球菌、嗜热链球菌、金黄色葡萄球菌或脑膜炎奈瑟氏菌尾结构域或与其相差不超过1、2、3、4、5、6、7、8、9或10个核苷酸的序列的核苷酸;或者
(v)尾结构域包含天然存在的尾结构域(例如,天然存在的化脓链球菌、嗜热链球菌、金黄色葡萄球菌或脑膜炎奈瑟氏菌尾结构域)的15、20、25、30、35、40个核苷酸或全部相应部分;
d)gRNA被配置成使得当与靶核酸杂交时,它们由0-50、0-100、0-200、至少10、至少20、至少30或至少50个核苷酸隔开;
e)第一gRNA和第二gRNA进行的断裂在不同的链上;以及
f)PAM朝外。
在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a和b(i)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a和b(ii)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a和b(iii)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a和b(iv)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a和b(v)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a和b(vi)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a和b(vii)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a和b(viii)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a和b(ix)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a和b(x)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a和b(xi)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a和c。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a、b和c。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(i)和c(i)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(i)和c(ii)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(i)、c和d。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(i)、c和e。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(i)、c、d和e。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(ii)和c(i)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(ii)和c(ii)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(ii)、c和d。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(ii)、c和e。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(ii)、c、d和e。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(iii)和c(i)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(iii)和c(ii)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(iii)、c和d。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(iii)、c和e。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(iii)、c、d和e。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(iv)和c(i)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(iv)和c(ii)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(iv)、c和d。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(iv)、c和e。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(iv)、c、d和e。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(v)和c(i)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(v)和c(ii)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(v)、c和d。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(v)、c和e。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(v)、c、d和e。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(vi)和c(i)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(vi)和c(ii)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(vi)、c和d。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(vi)、c和e。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(vi)、c、d和e。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(vii)和c(i)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(vii)和c(ii)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(vii)、c和d。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(vii)、c和e。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(vii)、c、d和e。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(viii)和c(i)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(viii)和c(ii)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(viii)、c和d。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(viii)、c和e。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(viii)、c、d和e。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(ix)和c(i)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(ix)和c(ii)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(ix)、c和d。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(ix)、c和e。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(ix)、c、d和e。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(x)和c(i)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(x)和c(ii)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(x)、c和d。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(x)、c和e。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(x)、c、d和e。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(xi)和c(i)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(xi)和c(ii)。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(xi)、c和d。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(xi)、c和e。在一个实施方案中,gRNA之一或两者被配置成使得它包含特性:a(i)、b(xi)、c、d和e。
在一个实施方案中,将gRNA与具有HNH活性的Cas9切口酶分子(例如RuvC活性失活的Cas9分子,例如在D10处具有突变(例如,D10A突变)的Cas9分子)一起使用。
在一个实施方案中,将gRNA与具有RuvC活性的Cas9切口酶分子(例如HNH活性失活的Cas9分子,例如在H840处具有突变(例如,H840A)的Cas9分子)一起使用。在一个实施方案中,将gRNA与具有RuvC活性的Cas9切口酶分子(例如HNH活性失活的Cas9分子,例如在N863处具有突变(例如,N863A)的Cas9分子)一起使用。
(7)用于基因编辑的药剂的功能分析
可以通过本领域已知的方法或如本文所述的评价任何Cas9分子、gRNA分子、Cas9分子/gRNA分子复合物。例如,用于评价Cas9分子的核酸内切酶活性的示例性方法描述于例如Jinek等人,Science 2012,337(6096):816-821。
(a)结合和切割测定:测试Cas9分子的核酸内切酶活性
可以在质粒切割测定中评价Cas9分子/gRNA分子复合物结合至并切割靶核酸的能力。在此测定中,通过加热至95℃并缓慢冷却至室温,将合成的或体外转录的gRNA分子在反应前预退火。将天然的或限制性消化线性化的质粒DNA(300ng(约8nM))与经纯化的Cas9蛋白分子(50-500nM)和gRNA(50-500nM,1:1)在含或不含10mM MgCl2的Cas9质粒切割缓冲液(20mMHEPES pH 7.5,150mM KCl,0.5mM DTT,0.1mM EDTA)中在37℃下一起孵育60min。将反应用5X DNA上样缓冲液(30%甘油,1.2%SDS,250mMEDTA)终止,通过0.8%或1%琼脂糖凝胶电泳解析,并且通过溴化乙锭可视化。所得切割产物指示了Cas9分子是切割两条DNA链还是仅切割两条链之一。例如,线性DNA产物指示了两条DNA链的切割。带切口的开放圆形产物表明仅切割了两条链之一。
可替代地,可以在寡核苷酸DNA切割测定中评价Cas9分子/gRNA分子复合物结合至并切割靶核酸的能力。在此测定中,将DNA寡核苷酸(10pmol)通过在50μL反应中与5个单位的T4多核苷酸激酶和1X T4多核苷酸激酶反应缓冲液中的约3-6pmol(约20-40mCi)[γ-32P]-ATP在37℃下一起孵育30min来进行放射性标记。在热灭活(65℃持续20min)之后,将反应物通过柱纯化,以去除未掺入的标记。通过如下方式产生双链体底物(100nM):将经标记的寡核苷酸与等摩尔量的未经标记的互补寡核苷酸在95℃下退火3min,然后缓慢冷却至室温。对于切割测定,通过如下方式使gRNA分子退火:加热至95℃持续30s,然后缓慢冷却至室温。将Cas9(终浓度为500nM)与退火的gRNA分子(500nM)在切割测定缓冲液(20mM HEPESpH 7.5,100mMKCl,5mM MgCl2,1mM DTT,5%甘油)中预孵育,总体积为9μl。通过添加1μl靶DNA(10nM)使反应开始,并且在37℃下孵育1h。将反应通过添加20μl上样染料(5mM EDTA,0.025%SDS,5%甘油,在甲酰胺中)淬灭,并且加热至95℃持续5min。将切割产物在含有7M尿素的12%变性聚丙烯酰胺凝胶上解析,并且通过磷光成像可视化。所得切割产物表明切割了互补链、非互补链还是两者。
这些测定之一或两者可以用于评价所提供的任何gRNA分子或Cas9分子的适合性。
(b)结合测定:测试Cas9分子与靶DNA的结合
用于评价Cas9分子与靶DNA的结合的示例性方法描述于例如Jinek等人,SCIENCE2012;337(6096):816-821。
例如,在电泳迁移率变动测定中,通过如下方式形成靶DNA双链体:将每条链(10nmol)在去离子水中混合,加热至95℃持续3min并且缓慢冷却至室温。将全部DNA在含有1X TBE的8%天然凝胶上纯化。将DNA条带通过UV遮蔽可视化,切下并通过将凝胶碎片浸泡在DEPC处理的H2O中进行洗脱。将经洗脱的DNA进行乙醇沉淀,并且溶解在DEPC处理的H2O中。使用T4多核苷酸激酶将DNA样品用[γ-32P]-ATP在37℃下5'末端标记30min。将多核苷酸激酶在65°℃下热变性20min,并且使用柱去除未掺入的放射性标记。在总体积为10μl的含有20mM HEPES pH 7.5、100mM KCl、5mM MgCl2、1mMDTT和10%甘油的缓冲液中进行结合测定。将Cas9蛋白分子用等摩尔量的预退火gRNA分子编程,并且从100pM滴定至1μM。添加放射性标记的DNA至终浓度为20pM。将样品在37℃下孵育1h,并且在4℃下在含有1X TBE和5mMMgCl2的8%天然聚丙烯酰胺凝胶上解析。将凝胶干燥,并且将DNA通过磷光成像可视化。
(c)用于测量Cas9/gRNA复合物的热稳定性的技术
可以通过差示扫描荧光测定法(DSF)和其他技术来检测Cas9-gRNA核糖核蛋白(RNP)复合物的热稳定性。蛋白质的热稳定性可以在有利的条件(如添加结合性RNA分子,例如gRNA)下增加。因此,关于Cas9/gRNA复合物的热稳定性的信息对于确定复合物是否稳定是有用的。
(d)差示扫描荧光测定法(DSF)
可以经由DSF测量Cas9-gRNA核糖核蛋白(RNP)复合物的热稳定性。如下所述,RNP复合物包括核糖核苷酸序列(如RNA或gRNA)和蛋白质(如Cas9蛋白或其变体)。此技术测量蛋白质的热稳定性,其可以在有利的条件(如添加结合性RNA分子,例如gRNA)下增加。
所述测定能以许多方式应用。示例性方案包括但不限于确定用于RNP形成的所需溶液条件的方案(测定1,参见下文)、测试gRNA:Cas9蛋白的所需化学计量比的方案(测定2,参见下文)、筛选Cas9分子(例如,野生型或突变型Cas9分子)的有效gRNA分子的方案(测定3,参见下文)以及在靶DNA的存在下检查RNP形成的方案(测定4)。在一些实施方案中,使用两种不同的方案进行测定,一种用于测试gRNA:Cas9蛋白的最佳化学计量比,并且另一种用于确定RNP形成的最佳溶液条件。
为了确定形成RNP复合物的最佳溶液,将Cas9在水+10x SYPRO (LifeTechnologies目录号S-6650)中的2uM溶液分配到384孔板中。然后添加等摩尔量的在具有不同pH和盐的溶液中稀释的gRNA。在室温下孵育10'并短暂离心以去除任何气泡之后,使用具有Bio-Rad CFX Manager软件的Bio-Rad CFX384TM实时系统C1000 TouchTM热循环仪运行从20℃至90℃的梯度,其中温度每10秒升高1°。
(LifeTechnologies目录号S-6650)中的2uM溶液分配到384孔板中。然后添加等摩尔量的在具有不同pH和盐的溶液中稀释的gRNA。在室温下孵育10'并短暂离心以去除任何气泡之后,使用具有Bio-Rad CFX Manager软件的Bio-Rad CFX384TM实时系统C1000 TouchTM热循环仪运行从20℃至90℃的梯度,其中温度每10秒升高1°。
第二测定由将各种浓度的gRNA与2uM Cas9在来自上述方法1的最佳缓冲液中混合并且在384孔板中于室温下孵育10'组成。添加等体积的最佳缓冲液+10x SYPRO (Life Technologies目录号S-6650),并且将板用
(Life Technologies目录号S-6650),并且将板用 B粘合剂(MSB-1001)密封起来。短暂离心以去除任何气泡后,使用具有Bio-Rad CFX Manager软件的Bio-Rad CFX384TM实时系统C1000TouchTM热循环仪运行从20℃至90℃的梯度,其中温度每10秒升高1°。
B粘合剂(MSB-1001)密封起来。短暂离心以去除任何气泡后,使用具有Bio-Rad CFX Manager软件的Bio-Rad CFX384TM实时系统C1000TouchTM热循环仪运行从20℃至90℃的梯度,其中温度每10秒升高1°。
在第三测定中,纯化目的Cas9分子(例如Cas9蛋白,例如Cas9变体蛋白)。合成变体gRNA分子文库,并且将其重悬至20μM的浓度。在5x SYPRO (Life Technologies目录号S-6650)的存在下,将Cas9分子与gRNA分子(各自的终浓度为1μM)在预定的缓冲液中一起孵育。在室温下孵育10分钟并在2000rpm下离心2分钟以去除任何气泡之后,使用具有Bio-Rad CFXManager软件的Bio-Rad CFX384TM实时系统C1000 TouchTM热循环仪运行从20℃至90℃的梯度,其中温度每10秒升高1°。
(Life Technologies目录号S-6650)的存在下,将Cas9分子与gRNA分子(各自的终浓度为1μM)在预定的缓冲液中一起孵育。在室温下孵育10分钟并在2000rpm下离心2分钟以去除任何气泡之后,使用具有Bio-Rad CFXManager软件的Bio-Rad CFX384TM实时系统C1000 TouchTM热循环仪运行从20℃至90℃的梯度,其中温度每10秒升高1°。
在第四测定中,对以下样品进行DSF实验:仅Cas9蛋白、Cas9蛋白与gRNA、Cas9蛋白与gRNA和靶DNA以及Cas9蛋白与靶DNA。混合组分的顺序为:反应溶液、Cas9蛋白、gRNA、DNA和SYPRO Orange。反应溶液含有10mM HEPES pH 7.5、100mM NaCl,不存在或存在MgCl2。在2000rpm下离心2分钟以去除任何气泡后,使用具有Bio-Rad CFX Manager软件的Bio-RadCFX384TM实时系统C1000 TouchTM热循环仪运行从20℃至90℃的梯度,其中温度每10秒升高1°。
b)用于基因编辑的药剂的递送
在一些实施方案中,使用许多已知的用于引入或传递至细胞中的方法或媒介物中的任一种,例如使用慢病毒递送载体,或者使用任何已知的用于递送Cas9分子和gRNA的方法或媒介物,通过将能够引入切割的一种或多种药剂(例如,Cas9和/或gRNA组分)递送或引入细胞中来进行编码TCR的内源基因(如TRAC和TRBC1或TRBC2)的减少、缺失、消除、敲除或破坏。示例性方法描述于例如Wang等人(2012)J.Immunother.35(9):689-701;Cooper等人(2003)Blood.101:1637-1644;Verhoeyen等人(2009)Methods Mol Biol.506:97-114;和Cavalieri等人(2003)Blood.102(2):497-505;WO 2015/161276;US 2015/0056705;US2016/0272999;US 2017/0211075;或US 2017/0016027。在一些实施方案中,例如通过本文所述的或已知的用于将核酸引入细胞中的任何方法,将编码能够引入切割(例如,DNA断裂)的一种或多种药剂的一种或多种组分的核酸序列引入细胞中。在一些实施方案中,可以将编码能够引入切割的一种或多种药剂(如CRISPR指导RNA和/或Cas9酶)的组分的载体递送到细胞中。
Cas9分子和gRNA分子(例如,Cas9分子/gRNA分子复合物)可以用于操纵细胞,例如在各种各样的细胞中编辑靶核酸。
在一个实施方案中,通过编辑一个或多个靶基因(例如,在其中诱导突变)来操纵细胞,例如如本文所述。在一些实施方案中,调节一个或多个靶基因(例如,TRAC、TRBC1和/或TRBC2基因)的表达。在另一个实施方案中,通过编辑一个或多个靶基因(例如,在其中诱导突变)和/或调节一个或多个靶基因(例如,TRAC、TRBC1和/或TRBC2基因)的表达来离体操纵细胞,并且将其给予受试者。用于离体操纵的靶细胞的来源可以包括例如受试者的血液、受试者的脐带血或受试者的骨髓。用于离体操纵的靶细胞的来源还可以包括例如异源供体血液、脐带血或骨髓。
可以将本文所述的Cas9和gRNA分子递送到靶细胞中。在一个实施方案中,靶细胞是T细胞(例如,CD8+T细胞(例如,CD8+幼稚T细胞、中枢记忆T细胞或效应记忆T细胞)、CD4+T细胞、自然杀伤T细胞(NKT细胞)、调节性T细胞(Treg)、干细胞记忆T细胞)、淋巴祖细胞、造血干细胞、自然杀伤细胞(NK细胞)或树突细胞。在一个实施方案中,靶细胞是诱导多能干(iPS)细胞或源自iPS细胞(例如,产生自受试者的iPS细胞)的细胞,被操纵以改变一个或多个靶基因(例如,TRAC、TRBC1和/或TRBC2基因)(例如,在其中诱导突变)或者操纵其表达,并且分化成例如T细胞(例如,CD8+T细胞(例如,CD8+幼稚T细胞、中枢记忆T细胞或效应记忆T细胞、CD4+T细胞、干细胞记忆T细胞)、淋巴祖细胞或造血干细胞。
在一个实施方案中,已经改变靶细胞以含有特定T细胞受体(TCR)基因(例如,TRAC和TRBC基因)。在另一个实施方案中,TCR对肿瘤相关抗原具有结合特异性,所述肿瘤相关抗原是例如癌胚抗原(CEA)、GP100、被T细胞识别的黑色素瘤抗原1(MART1)、黑色素瘤抗原A3(MAGEA3)、NYESO1或p53。
在一个实施方案中,已经改变靶细胞以含有特异性嵌合抗原受体(CAR)。在一个实施方案中,CAR对肿瘤相关抗原具有结合特异性,所述肿瘤相关抗原是例如CD19、CD20、碳酸酐酶IX(CAIX)、CD171、CEA、ERBB2、GD2、α-叶酸受体、路易斯Y抗原、前列腺特异性膜抗原(PSMA)或肿瘤相关糖蛋白72(TAG72)。
在另一个实施方案中,已经改变靶细胞以例如通过TCR或CAR结合一种或多种以下肿瘤抗原。肿瘤抗原可以包括但不限于AD034、AKT1、BRAP、CAGE、CDX2、CLP、CT-7、CT8/HOM-TES-85、cTAGE-1、衰老关键蛋白(Fibulin)-1、HAGE、HCA587/MAGE-C2、hCAP-G、HCE661、HER2/neu、HLA-Cw、HOM-HD-21/半乳凝素9、HOM-MEEL-40/SSX2、HOM-RCC-3.1.3/CAXII、HOXA7、HOXB6、Hu、HUB1、KM-HN-3、KM-KN-1、KOC1、KOC2、KOC3、KOC3、LAGE-1、MAGE-1、MAGE-4a、MPP11、MSLN、NNP-1、NY-BR-1、NY-BR-62、NY-BR-85、NY-CO-37、NY-CO-38、NY-ESO-1、NY-ESO-5、NY-LU-12、NY-REN-10、NY-REN-19/LKB/STK11、NY-REN-21、NY-REN-26/BCR、NY-REN-3/NY-CO-38、NY-REN-33/SNC6、NY-REN-43、NY-REN-65、NY-REN-9、NY-SAR-35、OGFr、PLU-1、Rab38、RBPJκ、RHAMM、SCP1、SCP-1、SSX3、SSX4、SSX5、TOP2A、TOP2B或酪氨酸酶。
(1)组分向靶细胞的离体递送方法
可以使用多种递送方法和配制品以各种形式将组分(例如,Cas9分子和gRNA分子)引入靶细胞中,参见例如表19和20。当Cas9或gRNA组分被编码为DNA用于递送时,DNA通常可以但不一定包括控制区,例如包含启动子,以实现表达。Cas9分子序列的有用启动子包括例如CMV、EF-1a、EFS、MSCV、PGK或CAG启动子。gRNA的有用启动子包括例如H1、EF-1a、tRNA或U6启动子。可以选择具有相似或不相似强度的启动子来调整组分的表达。编码Cas9分子的序列可以包含核定位信号(NLS),例如SV40 NLS。在一个实施方案中,Cas9分子或gRNA分子的启动子可以独立地是可诱导的、组织特异性的或细胞特异性的。在一些实施方案中,能够诱导遗传破坏的药剂是引入的RNP复合物。RNP复合物包括核糖核苷酸序列(如RNA或gRNA分子)和蛋白质(如Cas9蛋白或其变体)。在一些实施方案中,将Cas9蛋白作为核糖核蛋白(RNP)复合物递送,所述复合物包含本文提供的Cas9蛋白和本文提供的gRNA分子,例如TRAC、TRBC1和/或TRBC2的gRNA。在一些实施方案中,经由物理递送(例如,电穿孔、粒子枪、磷酸钙转染、细胞压缩或挤压)、脂质体或纳米颗粒将包括靶向TRAC、TRBC1和/或TRBC2的一种或多种gRNA分子(如所述的任何gRNA分子)和Cas9酶或其变体的RNP直接引入细胞中。在特定实施方案中,RNP包括靶向TRAC、TRBC1和/或TRBC2的一种或多种gRNA分子,并且经由电穿孔来引入Cas9酶或其变体。
表19提供了可以将组分递送到靶细胞中的形式的例子。
表19.示例性递送方法

表20概述了用于如本文所述的Cas系统的组分(例如,Cas9分子组分和gRNA分子组分)的各种递送方法。
表20.示例性递送方法的比较


(a)Cas9分子和/或gRNA分子的基于DNA的递送
可以通过本领域已知的方法或如本文所述的将编码Cas9分子(例如,eaCas9分子)和/或gRNA分子的DNA递送到细胞中。例如,可以例如通过载体(例如,病毒或非病毒载体)、基于非载体的方法(例如,使用裸DNA或DNA复合物)或其组合递送Cas9编码和/或gRNA编码DNA。
在一些实施方案中,通过载体(例如,病毒载体/病毒或质粒)递送Cas9和/或gRNA编码DNA。
载体可以包含编码Cas9分子和/或gRNA分子的序列。载体还可以包含与例如Cas9分子序列融合的编码信号肽的序列(例如,用于核定位、核仁定位、线粒体定位)。例如,载体可以包含与编码Cas9分子的序列融合的核定位序列(例如,来自SV40)。
一种或多种调节/控制元件(例如,启动子、增强子、内含子、多腺苷酸化信号、Kozak共有序列、内部核糖体进入位点(IRES)、2A序列和剪接受体或供体)可以被包括在载体中。在一个实施方案中,启动子被RNA聚合酶II识别(例如,CMV启动子)。在另一个实施方案中,启动子被RNA聚合酶III识别(例如,U6启动子)。在另一个实施方案中,启动子是调节型启动子(例如,诱导型启动子)。在另一个实施方案中,启动子是组成型启动子。在另一个实施方案中,启动子是组织特异性启动子。在另一个实施方案中,启动子是病毒启动子。在另一个实施方案中,启动子是非病毒启动子。
在一个实施方案中,载体或递送媒介物是病毒载体(例如,用于产生重组病毒)。在一个实施方案中,病毒是DNA病毒(例如,dsDNA或ssDNA病毒)。在一个实施方案中,病毒是RNA病毒(例如,ssRNA病毒)。示例性病毒载体/病毒包括例如逆转录病毒、慢病毒、腺病毒、腺相关病毒(AAV)、痘苗病毒、痘病毒和单纯疱疹病毒。
在一个实施方案中,病毒感染分裂细胞。在另一个实施方案中,病毒感染非分裂细胞。在另一个实施方案中,病毒感染分裂和非分裂两种细胞。在另一个实施方案中,病毒可以整合到宿主基因组中。在另一个实施方案中,病毒被工程化以具有降低的免疫性,例如在人体内。在另一个实施方案中,病毒有复制能力。在另一个实施方案中,病毒是复制缺陷型的,例如另外几轮病毒体复制和/或包装所需的基因的一个或多个编码区被其他基因替代或缺失。在另一个实施方案中,病毒引起Cas9分子和/或gRNA分子的短暂表达。在另一个实施方案中,病毒引起Cas9分子和/或gRNA分子的长期(例如,至少1周、2周、1个月、2个月、3个月、6个月、9个月、1年、2年)或永久表达。病毒的包装容量可以例如从至少约4kb变化到至少约30kb,例如至少约5kb、10kb、15kb、20kb、25kb、30kb、35kb、40kb、45kb或50kb。
在一个实施方案中,通过重组逆转录病毒递送Cas9和/或gRNA编码DNA。在另一个实施方案中,逆转录病毒(例如,莫洛尼鼠白血病病毒)包含例如允许整合到宿主基因组中的逆转录酶。在一个实施方案中,逆转录病毒有复制能力。在另一个实施方案中,逆转录病毒是复制缺陷型的,例如另外几轮病毒体复制和包装所必需的基因的一个或多个编码区被其他基因替代或缺失。
在一个实施方案中,通过重组慢病毒递送Cas9和/或gRNA编码DNA。例如,慢病毒是复制缺陷型的,例如不包含病毒复制所需的一个或多个基因。
在一个实施方案中,通过重组腺病毒递送Cas9和/或gRNA编码DNA。在另一个实施方案中,腺病毒被工程化以在人体内具有降低的免疫性。
在一个实施方案中,通过重组AAV递送Cas9和/或gRNA编码DNA。在一个实施方案中,AAV可以将其基因组掺入宿主细胞(例如,如本文所述的靶细胞)的基因组中。在另一个实施方案中,AAV是自我互补的腺相关病毒(scAAV),例如包装一起退火的两条链以形成双链DNA的scAAV。可以在所公开的方法中使用的AAV血清型包括AAV1、AAV2、经修饰的AAV2(例如,在Y444F、Y500F、Y730F和/或S662V处的修饰)、AAV3、经修饰的AAV3(例如,在Y705F、Y731F和/或T492V处的修饰)、AAV4、AAV5、AAV6、经修饰的AAV6(例如,在S663V和/或T492V处的修饰)、AAV8、AAV 8.2、AAV9、AAV rh l0,并且假型化的AAV(如AAV2/8、AAV2/5和AAV2/6)也可以在所公开的方法中使用。
在一个实施方案中,通过杂合病毒(例如,本文所述的一种或多种病毒的杂合体)递送Cas9和/或gRNA编码DNA。
包装细胞用于形成能够感染靶细胞的病毒颗粒。这样的细胞包括可以包装腺病毒的293细胞和可以包装逆转录病毒的ψ2细胞或PA317细胞。用于基因疗法中的病毒载体通常由将核酸载体包装到病毒颗粒中的生产细胞系产生。载体通常含有包装和随后整合到宿主或靶细胞中(如果适用)所需的最小病毒序列,并且其他病毒序列被编码待表达的蛋白质(例如Cas9)的表达盒替代。例如,用于基因疗法中的AAV载体通常仅具有来自AAV基因组的反向末端重复(ITR)序列,所述序列为在宿主或靶细胞中进行包装和基因表达所需。失去的病毒功能由包装细胞系反式提供。此后,将病毒DNA包装在细胞系中,所述细胞系含有编码其他AAV基因(即,rep和cap)但缺乏ITR序列的辅助质粒。细胞系还被作为辅助者的腺病毒感染。辅助病毒促进AAV载体的复制和来自辅助质粒的AAV基因的表达。由于缺乏ITR序列,辅助质粒并未被大量包装。腺病毒的污染可以通过例如热处理来减少,腺病毒对所述热处理比AAV更敏感。
在一个实施方案中,病毒载体具有细胞类型识别的能力。例如,病毒载体可以用不同的/替代的病毒包膜糖蛋白假型化;用细胞类型特异性受体工程化(例如,病毒包膜糖蛋白的遗传修饰以掺入靶向配体,如肽配体、单链抗体、生长因子);和/或工程化以具有分子桥,所述分子桥具有双重特异性,其一端识别病毒糖蛋白,并且另一端识别靶细胞表面的部分(例如,配体-受体、单克隆抗体、亲和素-生物素和化学缀合)。
在一个实施方案中,病毒载体实现细胞类型特异性表达。例如,可以构建组织特异性启动子以限制仅在特定靶细胞中表达转基因(Cas 9和gRNA)。载体的特异性也可以通过转基因表达的微小RNA依赖性控制来介导。在一个实施方案中,病毒载体具有增加的病毒载体与靶细胞膜融合的效率。例如,可以掺入融合蛋白(如有融合能力的血凝素(HA)),以增加病毒摄取到细胞中。在一个实施方案中,病毒载体具有核定位的能力。例如,可以改变需要核膜分解(在细胞分裂期间)并因此不感染非分裂细胞的病毒,以在病毒的基质蛋白中掺入核定位肽,从而使得能够转导非增殖细胞。
在一个实施方案中,通过基于非载体的方法(例如,使用裸DNA或DNA复合物)递送Cas9和/或gRNA编码DNA。例如,可以例如通过有机改性的二氧化硅或硅酸盐(Ormosil)、电穿孔、短暂细胞压缩或挤压(例如,如Lee等人[2012]Nano Lett 12:6322-27所述)、基因枪、声孔、磁转染、脂质介导的转染、树枝状大分子、无机纳米颗粒、磷酸钙或其组合递送DNA。
在一个实施方案中,经由电穿孔进行的递送包括将细胞与Cas9和/或gRNA编码DNA在盒、室或比色皿中混合,并且施加具有限定的持续时间和振幅的一个或多个电脉冲。在一个实施方案中,经由电穿孔进行的递送是使用这样的系统进行的,在其中将细胞与Cas9和/或gRNA编码DNA在连接至装置(例如,泵)的容器中混合,所述装置将混合物进料到盒、室或比色皿中,其中施加具有限定的持续时间和振幅的一个或多个电脉冲,这之后将细胞递送到第二容器中。
在一个实施方案中,通过载体和基于非载体的方法的组合递送Cas9和/或gRNA编码DNA。例如,病毒体包含与灭活病毒(例如,HIV或流感病毒)组合的脂质体,其可以导致比仅病毒或脂质体方法更有效的基因转移。
在一个实施方案中,递送媒介物是非病毒载体。在一个实施方案中,非病毒载体是无机纳米颗粒。示例性无机纳米颗粒包括例如磁性纳米颗粒(例如,Fe3MnO2)和二氧化硅。纳米颗粒的外表面可以与带正电荷的聚合物(例如,聚乙烯亚胺、聚赖氨酸、聚丝氨酸)缀合,其允许有效载荷的附着(例如,缀合或截留)。在一个实施方案中,非病毒载体是有机纳米颗粒。示例性有机纳米颗粒包括例如SNALP脂质体,其含有阳离子脂质和被聚乙二醇(PEG)包被的中性辅助脂质;以及被脂质包被的鱼精蛋白-核酸复合物。
用于基因转移的示例性脂质示于下表21中。
表21.用于基因转移的脂质



用于基因转移的示例性聚合物示于下表22中。表22.用于基因转移的聚合物


在一个实施方案中,媒介物具有靶向修饰以增加纳米颗粒和脂质体(例如,细胞特异性抗原、单克隆抗体、单链抗体、适体、聚合物、糖和细胞穿透肽)的靶细胞更新。在一个实施方案中,媒介物使用促融合和破坏内体的肽/聚合物。在一个实施方案中,媒介物经历酸触发的构象变化(例如,以加速货物的内体逃逸)。在一个实施方案中,使用刺激可切割的聚合物,例如用于在细胞区室中释放。例如,可以使用在还原性细胞环境中切割的基于二硫化物的阳离子聚合物。
在一个实施方案中,递送媒介物是生物非病毒递送媒介物。在一个实施方案中,媒介物是减毒细菌(例如,天然或人工工程化为侵入性但减毒以预防发病机理和表达转基因(例如,单核细胞增生李斯特菌、某些沙门氏菌属(Salmonella strains)菌株、长双歧杆菌(Bifidobacterium longum)和经修饰的大肠杆菌(Escherichia coli))、具有营养和组织特异性向性以靶向特定细胞的细菌、具有经修饰的表面蛋白以改变靶细胞特异性的细菌)。在一个实施方案中,媒介物是基因修饰的噬菌体(例如,具有大包装容量、较低免疫原性、含有哺乳动物质粒维持序列并掺入了靶向配体的工程化噬菌体)。在一个实施方案中,媒介物是哺乳动物病毒样颗粒。例如,可以产生经修饰的病毒颗粒(例如,通过纯化“空”颗粒,然后将病毒与所需货物离体组装)。媒介物也可以被工程化以掺入靶向配体以改变靶组织特异性。在一个实施方案中,媒介物是生物脂质体。例如,生物脂质体是源自人细胞的基于磷脂的颗粒(例如,红细胞血影,其是源自受试者的分解成球形结构的红细胞(例如,组织靶向可以通过附着各种组织或细胞特异性配体实现))或分泌性外来体—内吞起源的受试者衍生的膜结合纳米囊泡(30-100nm)(例如,可以从各种细胞类型产生,因此可以被细胞摄取而不需要靶向配体)。
在一个实施方案中,递送除了Cas系统的组分(例如,本文所述的Cas9分子组分和/或gRNA分子组分)以外的一种或多种核酸分子(例如,DNA分子)。在一个实施方案中,与Cas系统的一种或多种组分同时递送核酸分子。在一个实施方案中,在递送Cas系统的一种或多种组分之前或之后(例如,少于约30分钟、1小时、2小时、3小时、6小时、9小时、12小时、1天、2天、3天、1周、2周或4周)递送核酸分子。在一个实施方案中,通过与Cas系统的一种或多种组分(例如,Cas9分子组分和/或gRNA分子组分)不同的方式递送核酸分子。可以通过本文所述的任何递送方法来递送核酸分子。例如,可以通过病毒载体(例如,逆转录病毒或慢病毒)递送核酸分子,并且可以通过电穿孔递送Cas9分子组分和/或gRNA分子组分。在一个实施方案中,核酸分子编码TRAC基因、TRBC基因或CAR基因。
(b)编码Cas9分子的RNA的递送
可以通过本领域已知的方法或如本文所述的将编码Cas9分子(例如,eaCas9分子、eiCas9分子或eiCas9融合蛋白)和/或gRNA分子的RNA递送到细胞(例如,本文所述的靶细胞)中。例如,可以例如通过显微注射、电穿孔、短暂细胞压缩或挤压(例如,如Lee等人[2012]Nano Lett 12:6322-27所述)、脂质介导的转染、肽介导的递送或其组合递送Cas9编码和/或gRNA编码RNA。
在一个实施方案中,经由电穿孔进行的递送包括将细胞与编码Cas9分子(例如,eaCas9分子、eiCas9分子或eiCas9融合蛋白)和/或gRNA分子的RNA在盒、室或比色皿中混合,并且施加具有限定的持续时间和振幅的一个或多个电脉冲。在一个实施方案中,经由电穿孔进行的递送是使用这样的系统进行的,在其中将细胞与编码Cas9分子(例如,eaCas9分子、eiCas9分子或eiCas9融合蛋白)和/或gRNA分子的RNA在连接至装置(例如,泵)的容器中混合,所述装置将混合物进料到盒、室或比色皿中,其中施加具有限定的持续时间和振幅的一个或多个电脉冲,这之后将细胞递送到第二容器中。
(c)Cas9蛋白和核糖核蛋白(RNP)的递送
在一些实施方案中,将能够引入切割的所述一种或多种药剂(例如,Cas9/gRNA)作为核糖核蛋白(RNP)复合物引入细胞中。RNP复合物包括核糖核苷酸序列(如RNA或gRNA分子)和蛋白质(如Cas9蛋白或其变体)。例如,例如使用电穿孔或其他物理递送方法,将Cas9蛋白作为RNP复合物递送,所述复合物包含Cas9蛋白和靶向靶序列的gRNA分子。在一些实施方案中,将RNP精油电穿孔或其他物理方式(例如,粒子枪、磷酸钙转染、细胞压缩或挤压)递送到细胞中。在一些实施方案中,RNP可以穿过细胞的质膜而无需另外的递送剂(例如,小分子剂、脂质等)。
在一些实施方案中,将能够诱导遗传破坏的所述一种或多种药剂(例如,CRISPR/Cas9)作为RNP递送提供了这样的优点,即靶向破坏例如在引入了RNP的细胞中短暂发生,而不将药剂传播到细胞后代。例如,通过RNP进行的递送使被遗传到其后代最小化,从而减小后代中脱靶遗传破坏的可能性。
在一些实施方案中,将超过一种药剂或其组分递送到细胞中。例如,在一些实施方案中,将能够诱导基因组中的两个或更多个位置(例如,TRAC、TRBC1和/或TRBC2基因座)的遗传破坏的一种或多种药剂递送到细胞中。在一些实施方案中,使用一种方法递送一种或多种药剂及其组分。例如,在一些实施方案中,将用于诱导TRAC、TRBC1和/或TRBC2基因座的遗传破坏的一种或多种药剂作为对用于遗传破坏的组分编码的多核苷酸递送。在一些实施方案中,一种多核苷酸可以编码靶向TRAC、TRBC1和/或TRBC2基因座的药剂。在一些实施方案中,两种或更多种不同的多核苷酸可以编码靶向TRAC、TRBC1和/或TRBC2基因座的药剂。在一些实施方案中,能够诱导遗传破坏的药剂可以作为核糖核蛋白(RNP)复合物递送,并且两种或更多种不同的RNP复合物可以作为混合物一起递送或分开递送。
可以通过本领域已知的方法或如本文所述的将Cas9分子(例如,eaCas9分子、eiCas9分子或eiCas9融合蛋白)递送到细胞中。例如,可以例如通过显微注射、电穿孔、短暂细胞压缩或挤压(例如,如Lee等人[2012]Nano Lett12:6322-27所述)、脂质介导的转染、肽介导的递送或其组合递送Cas9蛋白分子。递送可以伴随编码gRNA的DNA或伴随gRNA。在一些实施方案中,将Cas9蛋白作为核糖核蛋白(RNP)复合物递送,所述复合物包含本文提供的Cas9蛋白和本文提供的gRNA分子,例如TRAC、TRBC1和/或TRBC2的gRNA。在一些实施方案中,RNP复合物包括核糖核苷酸序列(如RNA或gRNA分子)和蛋白质(如Cas9蛋白或其变体)。在一些实施方案中,经由物理递送(例如,电穿孔、粒子枪、磷酸钙转染、细胞压缩或挤压)、脂质体或纳米颗粒将包括靶向TRAC、TRBC1和/或TRBC2的一种或多种gRNA分子(如所述的任何gRNA分子)和Cas9酶或其变体直接引入细胞中。在特定实施方案中,RNP包括靶向TRAC、TRBC1和/或TRBC2的一种或多种gRNA分子(如所述的任何gRNA分子),并且经由电穿孔来引入Cas9酶或其变体。
在一个实施方案中,经由电穿孔进行的递送包括将细胞与Cas9分子(例如,eaCas9分子、eiCas9分子或eiCas9融合蛋白)、与或不与gRNA分子在盒、室或比色皿中混合,并且施加具有限定的持续时间和振幅的一个或多个电脉冲。在一个实施方案中,经由电穿孔进行的递送是使用这样的系统进行的,在其中将细胞与Cas9分子(例如,eaCas9分子、eiCas9分子或eiCas9融合蛋白)、与或不与gRNA分子在连接至装置(例如,泵)的容器中混合,所述装置将混合物进料到盒、室或比色皿中,其中施加具有限定的持续时间和振幅的一个或多个电脉冲,这之后将细胞递送到第二容器中。
B.通过同源定向修复(HDR)进行靶向整合
在本文提供的一些实施方案中,同源定向修复(HDR)可用于模板多核苷酸的特定部分在基因组中的特定位置(例如TRAC、TRBC1和/或TRBC2基因座)处的靶向整合,所述模板多核苷酸的特定部分包含转基因,例如编码任何所提供的重组受体例如重组T细胞受体(TCR)的核酸序列。在一些实施方案中,将包含编码重组T细胞受体(TCR)或其抗原结合片段或链的核酸序列(例如转基因)的模板多核苷酸引入在T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因内的靶位点具有遗传破坏的细胞例如免疫细胞中。在一些实施方案中,将编码重组TCR或其抗原结合片段或链的核酸序列或转基因通过同源定向修复(HDR)靶向整合在靶位点处或附近。在特定实施方案中,在靶位点处或附近的整合在TRAC和/或TRBC基因的编码序列的一部分内,如例如在靶位点下游或3'的编码序列的一部分内。
在一些实施方案中,靶位点在T细胞受体α恒定区(TRAC)基因中。在一些实施方案中,一个或多个靶位点在T细胞受体β恒定区1(TRBC1)或T细胞受体β恒定区2(TRBC2)基因中。在一些实施方案中,一个或多个靶位点在TRAC基因以及TRBC1和TRBC2基因之一或两者中。在一些实施方案中,将含有编码重组受体如任何所提供的TCR或其部分的核酸序列和/或转基因的模板多核苷酸引入在TRAC、TRBC1、和/或TRBC2基因内的一个或多个靶位点具有遗传破坏的免疫细胞中,经由HDR靶向在至少一个靶位点中的一个处或附近。
在一些实施方案中,重组受体编码核酸通过HDR进行的靶向遗传破坏和靶向整合发生在内源基因的一个或多个靶位点(也称为“靶位置”、“靶DNA序列”或“靶定位”)处,所述内源基因编码内源T细胞受体(TCR)的一个或多个结构域、区域和/或链。在某些实施方案中,本文提供的实施方案涉及通过基因编辑技术在一个或多个内源TCR基因座(例如编码TCRα和/或TCRβ恒定结构域的内源基因)处进行一个或多个靶向遗传破坏(例如DNA断裂),结合通过同源定向修复(HDR)将编码重组受体(例如重组TCR或CAR)的核酸靶向敲入。在一些实施方案中,DNA断裂是因基因编辑步骤发生的,例如,由用于引入靶向遗传破坏的靶向核酸酶产生的DNA断裂,例如本文所述的任一种。用于对内源TCR基因座进行基因编辑的示例性方法是已知的,并且包括但不限于本文或其他地方例如美国公开号US 2011/0158957、US 2014/0301990、US 2015/0098954、US 2016/0208243、US 2016/272999和US 2015/056705;国际PCT公开号WO 2014/191128、WO 2015/136001、WO 2015/161276、WO 2016/069283、WO 2016/016341、WO 2017/193107和WO 2017/093969;和Osborn等人(2016)Mol.Ther.24(3):570-581描述的那些方法。
可以通过HDR用外源提供的模板多核苷酸(也称为供体多核苷酸或模板序列)在靶位点处发生核酸序列的改变。例如,模板多核苷酸提供了靶序列的改变,例如插入模板多核苷酸内包含的转基因。在一些实施方案中,质粒或载体可以用作同源重组的模板。在一些实施方案中,线性DNA片段可以用作同源重组的模板。在一些实施方案中,单链模板多核苷酸可以用作通过靶序列与模板多核苷酸之间的同源定向修复的替代方法(例如,单链退火)来改变靶序列的模板。模板多核苷酸造成的靶序列改变取决于核酸酶例如靶向核酸酶如CRISPR/Cas9的切割。核酸酶的切割可包括双链断裂或两个单链断裂。
在一些实施方案中,用于HDR的方法涉及将一种或多种药剂引入免疫细胞例如T细胞中,其中所述一种或多种药剂中的每一种独立地能够诱导T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏。在一些实施方案中,所述一种或多种药剂可包括锌指核酸酶(ZFN)、TAL效应子核酸酶(TALEN)或和CRISPR-Cas9组合,所述CRISPR-Cas9组合特异性结合、识别或杂交至TRAC或TRBC基因座中的靶位点,例如使用上文V.A部分所述的方法。在一些实施方案中,使用CRISPR-Cas9组合引入一种或多种药剂,其中所述一种或多种药剂中的每一种包含具有与所述至少一个靶位点互补的靶向结构域的指导RNA(gRNA)。靶向TRAC或TRBC基因座的任何gRNA靶向结构域序列(包括上述的任何)均可用于进行遗传破坏。在一些实施方案中,用于靶向TRAC基因座的TRAC基因座是GAGAAUCAAAAUCGGUGAAU(SEQ ID NO:1048)。在一些实施方案中,用于靶向TRBC基因座的gRNA靶向结构域序列是GGCCUCGGCGCUGACGAUCU(SEQ ID NO:1053)。
在一些实施方案中,HDR涉及将能够诱导T细胞受体α恒定区(TRAC)基因的遗传破坏的一种或多种gRNA靶向序列引入免疫细胞例如T细胞中。
在一些实施方案中,遗传破坏是通过将gRNA靶向结构域序列与Cas9一起引入细胞中例如使用上述方法来进行的。可以将Cas9作为核酸或编码的蛋白质引入。在一些实施方案中,遗传破坏是通过例如经由电穿孔将包含gRNA和Cas9蛋白的核糖核蛋白(RNP)复合物引入细胞中例如使用上述方法来进行的。
在一些实施方案中,HDR方法还包括将多核苷酸例如模板多核苷酸引入细胞中,所述模板多核苷酸包含(a)编码任何所提供的TCR或其抗原结合部分的核酸序列,和(b)与所述核酸序列连接的一个或多个同源臂,其中所述一个或多个同源臂包含与T细胞受体α恒定区(TRAC)基因座的开放阅读框的一个或多个区域同源的序列。在一些实施方案中,所述一个或多个同源臂促进遗传信息从模板多核苷酸向靶基因座(例如TRAC位点的靶位点)的转移。
在一些实施方案中,“重组”是指两个多核苷酸之间交换遗传信息的过程。在一些实施方案中,“同源重组(HR)”是指这种交换的特化形式,其发生在例如通过同源定向修复机制修复细胞中的双链断裂期间。这个过程需要核苷酸序列同源性,使用模板多核苷酸对靶DNA(即,经历双链断裂的DNA,例如内源基因中的靶位点)进行模板修复,并且因为其导致遗传信息从模板多核苷酸转移至靶标,被不同地称为“非交换型基因转化”或“短束基因转化”。在一些实施方案中,这种转移可涉及在破坏的靶标(例如由于遗传破坏所致)与模板多核苷酸之间形成的异源双链DNA的错配校正,和/或“合成依赖性链退火”(其中模板多核苷酸用于重新合成将成为靶标一部分的遗传信息),和/或相关过程。这种特化的HR通常导致靶分子序列的改变,使得模板多核苷酸的部分或全部序列掺入靶多核苷酸中。
在一些实施方案中,模板多核苷酸,例如含有转基因的多核苷酸,经由不依赖于同源性的机制整合到细胞的基因组中。所述方法包括在细胞基因组中产生双链断裂(DSB),并使用核酸酶切割模板多核苷酸分子,使得模板多核苷酸整合在DSB的位点处。在一些实施方案中,模板多核苷酸通过非同源性依赖性方法(例如,NHEJ)整合。在体内切割后,模板多核苷酸可以按靶向方式整合到DSB位置处的细胞基因组中。模板多核苷酸可包含用于产生DSB的一种或多种核酸酶的一个或多个相同靶位点。因此,模板多核苷酸可以被用于切割需要整合的内源基因的一种或多种相同核酸酶切割。在一些实施方案中,模板多核苷酸包括与用于诱导DSB的核酸酶不同的核酸酶靶位点。如本文所述,可以通过任何机制,例如ZFN、TALEN、CRISPR/Cas9系统或TtAgo核酸酶来产生靶位点或靶位置的遗传破坏。
在本文提供的一些实施方案中,同源定向修复(HDR)可用于模板多核苷酸的特定部分在基因组中的特定位置(例如TRAC、TRBC1和/或TRBC2基因座)处的靶向整合,所述模板多核苷酸的特定部分包含转基因,例如编码任何所提供的重组受体例如重组TCR的核酸序列。在一些实施方案中,遗传破坏(例如,DNA断裂)和多核苷酸例如含有一个或多个同源臂的模板多核苷酸(例如,与遗传破坏周围的序列同源的核酸序列)的存在用于诱导或引导HDR,其中同源序列作为DNA修复的模板。
在一些实施方案中,与内源DNA中一个或多个靶位点处或附近的序列具有同源性的模板多核苷酸可用于改变靶DNA的结构,例如转基因的靶向插入。在一些实施方案中,模板多核苷酸包含位于转基因(例如编码重组受体的核酸序列)侧翼的同源序列(例如同源臂),用于靶向插入。在一些实施方案中,同源序列将转基因靶向在TRAC、TRBC1和/或TRBC2基因座中的一个或多个处。在一些实施方案中,模板多核苷酸在同源臂之间包括另外的序列(编码或非编码序列),如调节序列(如启动子和/或增强子),剪接供体和/或受体位点,内部核糖体进入位点(IRES),编码核糖体跳跃元件(例如2A肽)的序列,标记和/或SA位点,和/或一种或多种另外的转基因。
在某些实施方案中,模板多核苷酸包括或包含转基因,转基因的一部分,和/或核酸编码包含一个或多个可变结构域和一个或多个恒定结构域的重组受体(如重组TCR)或其链。在某些实施方案中,重组TCR或其链包含一个或多个恒定结构域,其与内源TCR恒定结构域的全部或部分和/或片段例如以或以约100%同一性完全共享。在一些实施方案中,转基因编码恒定结构域的全部或部分,例如恒定结构域的一部分或片段,其与内源TCR恒定结构域完全或部分相同。在一些实施方案中,转基因包含以下序列的核苷酸,所述序列与SEQ IDNO:348、349或1047中所示的全部或部分核酸序列具有为或至少70%、75%、80%、85%、90%、95%、97%、98%、99%、99.5%、或99.9%的序列同一性。
在一些实施方案中,转基因包含编码TCRα和/或TCRβ链的序列或者所述序列的已经过密码子优化的部分。在一些实施方案中,转基因编码TCRα和/或TCRβ链的一部分,其与天然或内源TCRα和/或TCRβ链的相应部分具有小于100%的氨基酸序列同一性。在一些实施方案中,编码的TCRα和/或TCRβ链包含与相应的天然或内源TCRα和/或TCRβ链具有、具有约、或具有至少70%、75%、80%、85%、90%、95%、98%、99%或大于99%的同一性但小于100%的同一性的氨基酸序列。在特定实施方案中,转基因编码与相应的天然或内源TCRα和/或TCRβ恒定结构域具有小于100%氨基酸序列同一性的TCRα和/或TCRβ恒定结构域或其部分。在一些实施方案中,TCRα和/或TCRβ恒定结构域包含与相应的天然或内源TCRα和/或TCRβ链具有、具有约、或具有至少70%、75%、80%、85%、90%、95%、98%、99%或大于99%的同一性但小于100%的同一性的氨基酸序列。在特定实施方案中,转基因编码TCRα和/或TCRβ链和/或TCRα和/或TCRβ链恒定结构域,其含有一种或多种修饰以引入一个或多个二硫键。在一些实施方案中,转基因编码TCRα和/或TCRβ链和/或TCRα和/或TCRβ,其具有一种或多种修饰以去除或防止例如在转基因编码的TCRα与内源TCRβ链之间或在转基因编码的TCRβ与内源TCRα链之间的天然二硫键。在一些实施方案中,形成和/或能够形成天然链间二硫键的一个或多个天然半胱氨酸被另一残基例如丝氨酸或丙氨酸取代。在一些实施方案中,修饰TCRα和/或TCRβ链和/或TCRα和/或TCRβ链恒定结构域以将一个或多个非半胱氨酸残基替换为半胱氨酸。在一些实施方案中,一个或多个非天然半胱氨酸残基能够例如在由转基因编码的重组TCRα与TCRβ链之间形成非天然二硫键。在一些实施方案中,参考SEQ ID NO:1352所示的TCRα恒定结构域的编号,将半胱氨酸引入残基Thr48、Thr45、Tyr10、Thr45和Ser15中的一个或多个处。在某些实施方案中,可参考SEQ ID NO:1353所示的TCRβ链的编号,将半胱氨酸引入TCRβ链的残基Ser57、Ser77、Ser17、Asp59或Glu15处。TCR的示例性非天然二硫键描述于公开的国际PCT号WO 2006/000830、WO 2006/037960和Kuball等人(2007)Blood,109:2331-2338。
在某些实施方案中,转基因包含一种或多种修饰,以引入能够在TCRα链与TCRβ链之间形成一个或多个非天然二硫桥的一个或多个半胱氨酸残基。在一些实施方案中,转基因编码包含TCRα恒定结构域的TCRα链或其部分或片段,所述TCRα恒定结构域在对应于SEQID NO:1355所示编号的位置48的位置处包含半胱氨酸。在一些实施方案中,TCRα恒定结构域具有SEQ ID NO:1352或1355中任一个所示的氨基酸序列,或与其具有、具有约、或具有至少70%、75%、80%、85%、90%、95%、97%、98%、99%序列同一性的包含能够与TCRβ链形成非天然二硫键的一个或多个半胱氨酸残基的氨基酸序列。在一些实施方案中,转基因编码包含TCRβ恒定结构域的TCRβ链或其部分,所述TCRβ恒定结构域在对应于SEQ ID NO:1353所示编号的位置57的位置处包含半胱氨酸。在一些实施方案中,TCRβ恒定结构域具有SEQID NO:1353、1354或1356中任一个所示的氨基酸序列,或与其具有、具有约、或具有至少70%、75%、80%、85%、90%、95%、97%、98%、99%序列同一性的包含能够与TCRα链形成非天然二硫键的一个或多个半胱氨酸残基的氨基酸序列。
模板多核苷酸可以是单链和/或双链的DNA,并且可以按线性或环状形式引入细胞中。还参见美国专利公开号20100047805和20110207221。模板多核苷酸也可以按DNA形式引入,可以按环形或线性形式引入细胞中。如果以线性形式引入,则可以通过已知的方法保护模板多核苷酸的末端(例如,防止核酸外切降解)。例如,将一个或多个双脱氧核苷酸残基添加至线性分子的3'末端和/或将自身互补的寡核苷酸连接至一个或两个末端。参见,例如,Chang等人(1987)Proc.Natl.Acad.Sci.USA 84:4959-4963;Nehls等人(1996)Science272:886-889。保护外源多核苷酸免于降解的另外的方法包括但不限于一个或多个末端氨基的添加以及修饰的核苷酸间连接(例如硫代磷酸酯、氨基磷酸酯、和O-甲基核糖或脱氧核糖残基)的使用。如果以双链形式引入,则模板多核苷酸可包含一个或多个核酸酶靶位点,例如在有待整合到细胞基因组中的转基因的侧翼的核酸酶靶位点。参见例如美国专利公开号20130326645。
在一些实施方案中,模板多核苷酸包含转基因,例如重组受体编码核酸序列,所述转基因的侧翼为在5'和3'末端的同源序列(也称为“同源臂”),以允许DNA修复机制,例如同源重组机制,以使用模板多核苷酸作为模板用于修复,从而将转基因有效地插入基因组中整合的靶位点中。同源臂应至少延伸到可能发生末端切除的区域,例如,以便允许切除的单链突出端在模板多核苷酸内找到互补区域。在一些实施方案中,同源臂不延伸到重复的元件,例如ALU重复或LINE重复中。基于围绕遗传破坏的内源基因序列与多核苷酸(例如模板多核苷酸)中包含的5'和/或3'同源臂之间的同源性,细胞DNA修复机制可以使用模板多核苷酸修复DNA断裂并重新合成基因在遗传破坏位点的信息,从而有效地将在模板多核苷酸中的转基因序列插入或整合在遗传破坏位点或附近。
在一些实施方案中,模板多核苷酸包含以下组分:[5'同源臂]-[转基因]-[3'同源臂]。同源臂提供用于重组到染色体中,从而将转基因插入在切割位点(例如一个或多个靶位点)处或附近的DNA中。在一些实施方案中,同源臂位于最远端的一个或多个靶位点的侧翼。
在一些方面,模板多核苷酸内的转基因(例如外源核酸序列)可用于指导靶位点和/或同源臂的位置。在一些方面,遗传破坏的靶位点可用作设计HDR所用的模板多核苷酸和/或同源性臂的指导。在一些实施方案中,遗传破坏可以靶向在转基因序列(例如,编码重组TCR或其部分)的靶向整合的期望位点附近。在一些方面,靶位点在TRAC、TRBC1和/或TRBC2基因座的开放阅读框的外显子内。在一些方面,靶位点在TRAC、TRBC1和/或TRBC2基因座的开放阅读框的内含子内。
示例性同源臂长度包括至少或至少约或为或为约50、100、200、250、300、400、500、600、700、750、800、900、1000、2000、3000、4000或5000个核苷酸。示例性同源臂长度包括少于或少于约或为或为约50、100、200、250、300、400、500、600、700、750、800、900、1000、2000、3000、4000或5000个核苷酸。在一些实施方案中,同源臂长是50-100、100-250、250-500、500-750、750-1000、1000-2000、2000-3000、3000-4000、或4000-5000个核苷酸。在某些实施方案中,模板多核苷酸包含与例如在TRAC、TRBC1和/或TRBC2基因、基因座或开放阅读框内的靶位点的5’、靶位点的3’或靶位点的5’和3’二者具有同源性的至少或少于或约200、300、400、500、600、700、800、900或1000个碱基对。在特定实施方案中,模板多核苷酸包含核苷酸序列,例如同源臂,所述核苷酸序列与例如在TRAC基因、基因座或开放阅读框内的靶位点的5'、靶位点的3'或靶位点的5'和3'二者具有同源性。在一些实施方案中,分别在SEQ ID NO:1343和1344中示出了用于在TRAC基因座处靶向整合的示例性5’和3’同源臂。
在一些实施方案中,模板多核苷酸可以是线性单链DNA。在一些实施方案中,模板多核苷酸是(i)可以与靶DNA的带切口链退火的线性单链DNA,(ii)可以与靶DNA的完整链退火的线性单链DNA,(iii)可以与靶DNA的转录链退火的线性单链DNA,(iv)可以与靶DNA的非转录链退火的线性单链DNA,或多于一个的前述项。
在一些实施方案中,模板多核苷酸包含用于靶向内源TRAC基因座(SEQ ID NO:348所示的人TRAC基因座的示例性核苷酸序列;NCBI参考序列:NG_001332.3,TRAC,或本文表13中所述)的同源臂。在一些实施方案中,将TRAC基因座的遗传破坏引入基因的早期编码区,包括紧接转录起始位点之后的序列、在编码序列的第一外显子内、或在转录起始位点的500bp之内(例如,小于500、450、400、350、300、250、200、150、100或50bp)、或在起始密码子的500bp之内(例如,小于500、450、400、350、300、250、200、150、100或50bp)。在一些实施方案中,使用任何靶向核酸酶和/或gRNA引入遗传破坏。在一些实施方案中,模板多核苷酸包含与由靶向核酸酶和/或gRNA引入的遗传破坏的任一侧上同源的约500至1000个例如600至900个或700至800个碱基对。在一些实施方案中,模板多核苷酸包含:约500、600、700、800、900或1000个碱基对的5'同源臂序列,其与在遗传破坏(例如,在TRAC基因座处)5'的序列的500、600、700、800、900或1000个碱基对同源;转基因;和约500、600、700、800、900或1000个碱基对的3'同源臂序列,其与遗传破坏(例如,在TRAC基因座处)3'的序列的500、600、700、800、900或1000个碱基对同源。在一些实施方案中,在SEQ ID NO:1343和1344中示出了用于在TRAC基因座处靶向整合的示例性5’和3’同源臂。
在一些实施方案中,模板多核苷酸包含用于靶向内源TRBC1或TRBC2基因座(SEQID NO:349所示的人TRBC1基因座的示例性核苷酸序列;NCBI参考序列:NG_001333.2,TRBC1,如本文表14所示;SEQ ID NO:1047所示的人TRBC2基因座的示例性核苷酸序列;NCBI参考序列:NG_001333.2,TRBC2,如本文表15所述)的同源臂。在一些实施方案中,将TRBC1或TRBC2基因座的遗传破坏引入基因的早期编码区,包括紧接转录起始位点之后的序列、在编码序列的第一外显子内、或在转录起始位点的500bp之内(例如,小于500、450、400、350、300、250、200、150、100或50bp)、或在起始密码子的500bp之内(例如,小于500、450、400、350、300、250、200、150、100或50bp)。在一些实施方案中,使用本文所述的任何靶向核酸酶和/或gRNA引入遗传破坏。在一些实施方案中,模板多核苷酸包含与由靶向核酸酶和/或gRNA引入的遗传破坏的任一侧上同源的约500至1000个例如600至900个或700至800个碱基对。在一些实施方案中,模板多核苷酸包含:约500、600、700、800、900或1000个碱基对的5'同源臂序列,其与在遗传破坏(例如,在TRBC1或TRBC2基因座处)5'的序列的500、600、700、800、900或1000个碱基对同源;转基因;和约500、600、700、800、900或1000个碱基对的3'同源臂序列,其与遗传破坏(例如,在TRBC1或TRBC2基因座处)3'的序列的500、600、700、800、900或1000个碱基对同源。
在一些情况下,模板多核苷酸包含启动子,例如外源和/或不存在于靶基因座处或附近的启动子。在一些实施方案中,启动子仅在特定细胞类型(例如,T细胞或B细胞或NK细胞特异性启动子)中驱动表达。在其中功能性多肽编码序列无启动子的一些实施方案中,则通过由目的区域中的内源启动子或其他控制元件驱动的转录来确保整合的转基因的表达。
可以插入转基因(包括编码重组受体或其抗原结合部分或其链的转基因和/或更多另外的转基因),以使得其表达由在整合位点处的内源启动子驱动,所述内源启动子即驱动插入所述转基因之处的内源TCR基因(例如TRAC、TRBC1和/或TRBC2)的表达的启动子。例如,在一些实施方案中,可以将转基因中的编码序列在没有启动子但是与内源靶基因的编码序列在框内的情况下插入,从而使得整合的转基因的表达受整合位点处的内源启动子的转录控制。在一些实施方案中,编码重组TCR或其抗原结合片段或链的转基因和/或一个或多个第二转基因独立地可操作地连接至在靶位点处的基因的内源启动子。在一些实施方案中,将核糖体跳跃元件/自切割元件(例如2A元件)放置于转基因编码序列的上游,使得将核糖体跳跃元件/自切割元件放置为与内源基因在框内。在一些实施方案中,编码重组TCR或其抗原结合片段或其部分的转基因与在靶位点处的基因(例如TRAC、TRBC1和/或TRBC2)的内源启动子可操作地连接。
在一些实施方案中,转基因可包含启动子和/或增强子,例如组成型启动子或诱导型或组织特异性启动子。在一些实施方案中,启动子是或包括组成型启动子。示例性组成型启动子包括例如猿病毒40早期启动子(SV40)、巨细胞病毒立即早期启动子(CMV)、人泛素C启动子(UBC)、人延伸因子1α启动子(EF1α)、小鼠磷酸甘油酸激酶1启动子(PGK)、和与CMV早期增强子偶联的鸡β-肌动蛋白启动子(CAGG)。在一些实施方案中,组成型启动子是合成的或修饰的启动子。在一些实施方案中,启动子是或包含MND启动子(含有具有骨髓增生性肉瘤病毒增强子的经修饰的MoMuLV LTR的U3区的一种合成启动子)(SEQ ID NO:1361或1347所示的序列)(参见Challita等人(1995)J.Virol.69(2):748-755)。在一些实施方案中,启动子是组织特异性启动子。在另一个实施方案中,启动子是病毒启动子。在另一个实施方案中,启动子是非病毒启动子。在一些情况下,启动子选自人延伸因子1α(EF1α)启动子(SEQID NO:1359或1360所示的序列)或其修饰形式(具有HTLV1增强子的EF1α启动子;SEQ IDNO:1345所示的序列)、或MND启动子(SEQID NO:1361或1347所示的序列。在一些实施方案中,转基因不包括调节元件,例如启动子。
可以将转基因插入内源基因中,从而使得表达全部、部分内源基因或不表达任何内源基因。在一些实施方案中,转基因(例如,具有或不具有肽编码序列)整合到任何内源基因座中。在一些实施方案中,转基因被整合到TRAC,TRBC1和/或TRBC2基因座中。
另外,可以包括剪接受体序列。示例性的已知剪接受体位点序列包括例如CTGACCTCTTCTCTTCCTCCCACAG(SEQ ID NO:1357)(来自人HBB基因)和TTTCTCTCCACAG(SEQID NO:1358)(来自人免疫球蛋白-γ基因)。
在示例性实施方案中,模板多核苷酸包括用于靶向TRAC基因座的同源臂、调节序列(例如启动子)、和编码重组受体(例如TCR)的核酸序列。在示例性实施方案中,采用了另外的模板多核苷酸,其包括用于靶向TRBC1和/或TRBC2基因座的同源臂、调节序列(例如启动子)、和编码另一因子的核酸序列。
在一些实施方案中,示例性模板多核苷酸包含:编码重组T细胞受体的转基因,所述转基因在人延伸因子1α(EF1α)启动子与HTLV1增强子(SEQID NO:1345所示的序列)或MND启动子(SEQ ID NO:1361或1347所示的序列)的可操作控制下,或连接至编码P2A核糖体跳跃元件的核酸序列(SEQ ID NO:204所示的序列),以驱动重组TCR从内源靶基因座(例如TRAC)的表达;约600bp的5'同源臂序列(例如,SEQ ID NO:1343所示),约600bp的3'同源臂序列(例如,SEQ ID NO:1344所示),这些同源臂序列与人TCRα恒定区(TRAC)基因的外显子1中的靶整合位点周围的序列同源。在一些实施方案中,模板多核苷酸还包含其他核酸序列,例如编码标记(例如表面标记或选择标记)的核酸序列。在一些实施方案中,模板多核苷酸还包含病毒载体序列,例如腺相关病毒(AAV)载体序列。
在一些实施方案中,转基因还编码一种或多种标记。在一些实施方案中,所述一种或多种标记是转导标记、替代标记和/或选择标记,包括但不限于本文所述的任何替代和/或选择标记。
在一些实施方案中,多核苷酸,例如模板多核苷酸,包含编码重组受体或其链(例如重组TCR或其链)的一段和/或一部分的核酸序列,并靶向在编码内源受体的基因座(例如编码TCR链或结构域的内源基因)内的一个或多个靶位点。在某些实施方案中,所述核酸序列靶向用于在内源基因座内的框内整合。在特定实施方案中,框内整合产生重组受体的编码序列,所述编码序列包含编码重组受体的部分和/或片段的核酸序列,所述核酸序列与基因座的部分和/或片段(编码受体的其余部分和/或片段)在框内,例如以整合外源和内源核酸序列,以得到编码完整、全部和/或全长重组受体的编码序列。在某些实施方案中,整合在遗传上破坏了由靶位点处的基因编码的内源受体的表达。在特定实施方案中,编码重组受体部分的转基因经由HDR靶向基因座内。
在一些实施方案中,转基因编码重组TCR的一部分,并且框内地整合到编码TCR的链或结构域的内源开放阅读框和/或基因座中。在某些实施方案中,转基因编码重组TCR的一部分,并且框内地插入编码TCR恒定结构域的内源开放阅读框内。在一些实施方案中,转基因整合到基因座中修饰和/或产生编码完整重组TCR的经修饰的基因座。在特定实施方案中,编码的重组TCR的一部分由转基因中存在的核酸序列编码,而重组TCR的其余部分由编码TCRα或TCRβ恒定结构域的内源基因的开放阅读框(例如,本文表13-15中所述)中存在的核酸序列编码。在特定实施方案中,经修饰的基因座的转录产生编码重组TCR的mRNA。在特定实施方案中,mRNA的一部分是从存在于转基因中的核酸序列转录,并且mRNA的其余或另一部分是从存在于内源基因的开放阅读框中的核酸序列转录。在一些实施方案中,转基因被整合在靶位点处,所述靶位点紧邻编码重组TCR的其余部分的开放阅读框的区域或部分的上游,并与所述区域或部分在框内。
在特定实施方案中,修饰的TRAC或TRBC基因座包括编码重组TCR的核酸序列。在一些方面,基因工程化细胞中的经修饰的TRAC或TRBC基因座包含转基因序列(本文也称为外源或异源核酸序列),所述转基因序列编码整合到内源TRAC或TRBC基因座(通常编码TCRα或TCRβ恒定结构域)中的重组TCR的一部分。在一些实施方案中,所述方法涉及使用含有编码一部分重组TCR的转基因的模板多核苷酸来诱导靶向遗传破坏和同源依赖性修复(HDR),从而将转基因靶向整合到TRAC或TRBC基因座处。
在一些实施方案中,编码重组TCR的一部分的转基因序列包含编码TCRβ链和一部分TCRα链的核苷酸序列。在一些实施方案中,由转基因序列编码的所述TCRα链的部分包含小于全长的TCRα链。在特定实施方案中,所述TCRα链的部分包含TCRα可变结构域和一部分TCRα恒定结构域,所述一部分TCRα恒定结构域小于全长TCRα恒定结构域(例如全长天然TCRα恒定结构域);或不包含编码TCRα恒定结构域的序列。在一些方面,在将转基因序列整合到内源TRAC基因座中后,所得的经修饰的TRAC基因座编码重组TCR受体,所述重组TCR受体由转基因(通过HDR靶向)与内源TRAC基因座的开放阅读框或其部分序列的融合物编码。在一些实施方案中,编码的重组TCR包含TCRα链,例如能够与TCRβ链结合的功能性TCRα链。
在特定实施方案中,编码重组TCR的一部分的转基因序列包含编码TCRα链和一部分TCRβ链的核苷酸序列。在一些实施方案中,由转基因序列编码的所述TCRβ链的部分是或包含小于全长的TCRβ链。在特定实施方案中,所述TCRβ链的部分包含TCRβ可变结构域和一部分TCRβ恒定结构域,所述一部分TCRβ恒定结构域小于全长TCRβ恒定结构域(例如全长天然TCRβ恒定结构域);或不包含编码TCRβ恒定结构域的序列。在一些方面,在将转基因序列整合到内源TRBC基因座(例如TRBC1和/或TRBC2基因座)中后,所得的经修饰的TRBC基因座编码重组TCR受体,所述重组TCR受体由转基因(通过HDR靶向)与内源TRBC基因座的开放阅读框或其部分序列的融合物编码。在一些实施方案中,编码的重组TCR包含TCRβ链,例如能够与TCRα链结合的功能性TCRβ链。
在特定实施方案中,重组受体是包含一个或多个可变结构域和一个或多个恒定结构域的重组TCR或其链。在特定实施方案中,转基因编码重组TCR的不包含TCR恒定结构域的部分和/或片段,并且转基因与编码内源TCR恒定结构域的序列(例如基因组DNA序列)在框内整合。在某些实施方案中,整合产生编码完整、全部和/或全长重组TCR或其链的编码序列。在一些实施方案中,编码序列包含编码TCR或其链的部分或片段的转基因序列和编码内源TCR恒定结构域的内源序列。
在一些实施方案中,重组TCR的部分包含全长TCRβ链(包含TCRβ可变结构域和TCRβ恒定结构域)、TCRα可变结构域、和一部分TCRα恒定结构域。在某些实施方案中,将转基因插入或整合到在靶位点处的TRAC基因座例如TRAC开放阅读框中,导致转基因框内插入对TCRα恒定结构域的内源其余部分编码的开放阅读框的区域或部分。在某些实施方案中,插入产生了编码完整重组TCR的经修饰的TRAC基因座。在一些实施方案中,经修饰的TRAC基因座编码重组TCR,所述重组TCR的一部分,例如包括全长TCRβ链(包含TCRβ可变结构域和TCRβ恒定结构域)、TCRα可变结构域和一部分TCRα恒定结构域的一部分由转基因的核酸序列编码;而其余或另一部分(例如TCRα恒定结构域的其余或另一部分)由内源和/或天然TRAC序列编码。在某些实施方案中,内源和/或天然TRAC序列编码重组TCR的其余部分。在一些实施方案中,模板多核苷酸还包含其他核酸序列,例如编码标记(例如表面标记或选择标记)的核酸序列。在一些实施方案中,模板多核苷酸还包含病毒载体序列,例如腺相关病毒(AAV)载体序列。
在一些实施方案中,将多核苷酸例如编码重组T细胞受体的多核苷酸例如模板多核苷酸以核苷酸形式(例如作为多核苷酸或载体)引入细胞中。在一些实施方案中,除了能够诱导靶向遗传破坏的一种或多种药剂(例如核酸酶和/或gRNA)之外,还将模板多核苷酸引入细胞中以进行工程化。在一些实施方案中,可以在将能够诱导靶向遗传破坏的一种或多种药剂引入细胞之前、同时或之后递送一种或多种模板多核苷酸。在一些实施方案中,将一种或多种模板多核苷酸与药剂同时递送。在一些实施方案中,将模板多核苷酸在药剂之前递送,例如在模板多核苷酸之前数秒至数小时至数天,包括但不限于在药剂之前1至60分钟(或其间的任何时间),在药剂之前1至24小时(或其间的任何时间),或在药剂之前多于24小时。在一些实施方案中,将模板多核苷酸在药剂之后递送,模板多核苷酸之后数秒至数小时至数天,包括在药剂递送之后立即,例如在药剂递送之后1分钟至4小时之间,例如约10分钟、20分钟、30分钟、40分钟、50分钟、60分钟、90分钟、2小时、3小时或4小时,和/或优选在药剂递送的4小时内。在一些实施方案中,将模板多核苷酸在药剂递送之后多于4小时递送。
在一些实施方案中,可以使用与能够诱导靶向遗传破坏的一种或多种药剂(例如核酸酶和/或gRNA)相同的递送系统来递送模板多核苷酸。在一些实施方案中,可以使用与能够诱导靶向遗传破坏的一种或多种药剂(例如核酸酶和/或gRNA)不同的递送系统来递送模板多核苷酸。在一些实施方案中,将模板多核苷酸与一种或多种药剂同时递送。在其他实施方案中,将模板多核苷酸在递送一种或多种药剂之前或之后的不同时间递送。在某些实施方案中,已知用于将多核苷酸引入细胞中的任何合适方法可用于递送药剂和/或模板DNA,包括本文所述的那些。
在特定实施方案中,将多核苷酸例如模板多核苷酸以核苷酸形式例如作为非病毒载体或在非病毒载体内引入细胞中。在一些实施方案中,非病毒载体是或包括多核苷酸,例如DNA或RNA多核苷酸,其适合于通过任何合适的和/或已知的非病毒方法进行转导和/或转染以用于基因递送,所述非病毒方法例如不限于显微注射、电穿孔、瞬时细胞压缩或挤压(例如,如Lee等人(2012)Nano Lett 12:6322-27所述)、脂质介导的转染、肽介导的递送(例如细胞穿透肽)、或其组合。
在一些实施方案中,模板多核苷酸序列可以被包含在载体分子中,所述载体分子包含与基因组DNA中的目的区域不同源的序列。在一些实施方案中,病毒是DNA病毒(例如,dsDNA或ssDNA病毒)。在一些实施方案中,病毒是RNA病毒(例如,ssRNA病毒)。示例性病毒载体/病毒包括例如逆转录病毒、慢病毒、腺病毒、腺相关病毒(AAV)、痘苗病毒、痘病毒和单纯疱疹病毒、或本文其他地方所述的任何病毒。
在一些实施方案中,使用重组感染性病毒颗粒(例如像源自猿猴病毒40(SV40)、腺病毒、腺相关病毒(AAV)的载体)将模板多核苷酸转移到细胞中。在一些实施方案中,使用重组慢病毒载体或逆转录病毒载体如γ-逆转录病毒载体(参见例如,Koste等人(2014)GeneTherapy 2014Apr 3.doi:10.1038/gt.2014.25;Carlens等人(2000)Exp Hematol 28(10):1137-46;Alonso-Camino等人(2013)Mol Ther Nucl Acids 2,e93;Park等人,TrendsBiotechnol.2011年11月29日(11):550-557)或HIV-1衍生的慢病毒载体将模板多核苷酸转移到T细胞中。
在一些实施方案中,逆转录病毒载体具有长末端重复序列(LTR),例如源自莫洛尼鼠白血病病毒(MoMLV)、骨髓增生性肉瘤病毒(MPSV)、鼠胚胎干细胞病毒(MESV)、鼠干细胞病毒(MSCV)、或脾病灶形成病毒(SFFV)的逆转录病毒载体。大多数逆转录病毒载体源自鼠逆转录病毒。在一些实施方案中,逆转录病毒包括源自任何禽类或哺乳动物细胞来源的那些。逆转录病毒通常是双嗜性的,这意味着它们能够感染包括人在内的若干种物种的宿主细胞。在一个实施方案中,待表达的基因替代逆转录病毒gag、pol和/或env序列。已经描述了许多说明性逆转录病毒系统(例如,美国专利号5,219,740;6,207,453;5,219,740;Miller和Rosman(1989)BioTechniques 7:980-990;Miller,A.D.(1990)Human GeneTherapy 1:5-14;Scarpa等人(1991)Virology180:849-852;Burns等人(1993)Proc.Natl.Acad.Sci.USA 90:8033-8037;以及Boris-Lawrie和Temin(1993)Cur.Opin.Genet.Develop.3:102-109)。
在其他方面,通过病毒和/或非病毒基因转移方法递送模板多核苷酸。在一些实施方案中,将模板多核苷酸经由腺相关病毒(AAV)递送至细胞。可以使用任何AAV载体,包括但不限于AAV1、AAV2、AAV3、AAV4、AAV5、AAV6、AAV7、AAV8及其组合。在一些情况下,与衣壳血清型相比,AAV包括异源血清型的LTR(例如,具有AAV5、AAV6或AAV8衣壳的AAV2 ITR)。可以使用与用于递送核酸酶的相同基因转移系统(包括在相同载体上)来递送模板多核苷酸,或者可以使用针对核酸酶的不同递送系统来递送模板多核苷酸。在一些实施方案中,使用病毒载体(例如,AAV)递送模板多核苷酸,并且以mRNA形式递送一种或多种核酸酶。还可以在递送病毒载体(例如,携带一种或多种核酸酶和/或模板多核苷酸)之前、同时和/或之后,用抑制病毒载体与如本文所述的细胞表面受体结合的一种或多种分子来处理细胞。
在一些实施方案中,将一种或多种药剂和模板多核苷酸以相同的形式或方法递送。例如,在一些实施方案中,一种或多种药剂和模板多核苷酸均被包含在载体例如病毒载体中。在一些实施方案中,模板多核苷酸与Cas9和gRNA被编码在相同的载体主链(例如AAV基因组、质粒DNA)上。在一些方面,一种或多种药剂和模板多核苷酸处于不同的形式,例如,对于Cas9-gRNA药剂为核糖核酸-蛋白质复合物(RNP),而对于模板多核苷酸为线性DNA,但是它们被使用相同的方法递送。在一些实施方案中,模板多核苷酸和核酸酶可以在相同载体例如AAV载体(例如,AAV6)上。在一些实施方案中,使用AAV载体递送模板多核苷酸,并且以不同的形式(例如以编码核酸酶和/或gRNA的mRNA)递送能够诱导靶向遗传破坏的一种或多种药剂(例如核酸酶和/或gRNA)。在一些实施方案中,将模板多核苷酸和核酸酶使用相同类型的方法例如病毒载体但是在分开的载体上递送。在一些实施方案中,将模板多核苷酸在与能够诱导遗传破坏的药剂(例如核酸酶和/或gRNA)不同的递送系统中递送。在一些实施方案中,模板多核苷酸在体内被从载体骨架中切除,例如,所述模板多核苷酸的侧翼为gRNA识别序列。在一些实施方案中,模板多核苷酸在与Cas9和gRNA分开的多核苷酸分子上。在一些实施方案中,将Cas9和gRNA以核糖核蛋白(RNP)复合物的形式引入,并且将模板多核苷酸作为例如在载体或线性核酸分子(例如线性DNA)中的多核苷酸分子引入。用于递送的核酸类型和载体包括本文所述的那些中的任一种。
VI.组合物、方法和用途
还提供了包括结合分子(例如TCR)和工程化细胞的组合物(包括药物组合物和配制品),以及分子和组合物例如在治疗表达HPV16 E6或E7的疾病、病症和障碍中和/或在检测、诊断和预后方法中的使用方法和用途。
A.药物组合物和配制品
提供了包含结合分子(例如TCR或其抗原结合片段)或者抗体或其抗原结合片段、和/或表达结合分子的工程化细胞的药物配制品。药物组合物和配制品通常包括一种或多种任选的药学上可接受的载体或赋形剂。在一些实施方案中,组合物包括至少一种另外的治疗剂。
术语“药物配制品”是指这样的制剂,其所采取的形式允许其中所含活性成分的生物活性有效,并且其不含对待给予配制品的受试者具有不可接受的毒性的任何另外的组分。
“药学上可接受的载体”是指药物配制品中除了活性成分之外对受试者无毒的成分。药学上可接受的载体包括但不限于缓冲液、赋形剂、稳定剂或防腐剂。
在一些方面,载体的选择部分取决于特定细胞或结合分子和/或给予方法。因此,存在多种合适的配制品。例如,药物组合物可以含有防腐剂。合适的防腐剂可以包括例如对羟基苯甲酸甲酯、对羟基苯甲酸丙酯、苯甲酸钠和苯扎氯铵。在一些方面,使用两种或更多种防腐剂的混合物。防腐剂或其混合物通常以按总组合物的重量计约0.0001%至约2%的量存在。载体描述于例如Remington’s Pharmaceutical Sciences第16版,Osol,A.编辑(1980)。药学上可接受的载体在所用剂量和浓度下通常对接受者无毒,并且包括但不限于:缓冲液,如磷酸盐、柠檬酸盐和其他有机酸;抗氧化剂,包括抗坏血酸和甲硫氨酸;防腐剂(如十八烷基二甲基苄基氯化铵;六甲氯铵;苯扎氯铵;苄索氯铵;苯酚、丁醇或苄醇;烷基对羟基苯甲酸酯,如对羟基苯甲酸甲酯或对羟基苯甲酸丙酯;儿茶酚;间苯二酚;环己醇;3-戊醇;和间甲酚);低分子量(少于约10个残基)多肽;蛋白质,如血清白蛋白、明胶或免疫球蛋白;亲水性聚合物,如聚乙烯吡咯烷酮;氨基酸,如甘氨酸、谷氨酰胺、天冬酰胺、组氨酸、精氨酸或赖氨酸;单糖、二糖和其他碳水化合物,包括葡萄糖、甘露糖或糊精;螯合剂,如EDTA;糖类,如蔗糖、甘露醇、海藻糖或山梨醇;成盐抗衡离子,如钠;金属络合物(例如锌-蛋白质络合物);和/或非离子表面活性剂,如聚乙二醇(PEG)。
在一些方面,组合物中包括缓冲剂。合适的缓冲剂包括例如柠檬酸、柠檬酸钠、磷酸、磷酸钾和各种其他酸和盐。在一些方面,使用两种或更多种缓冲剂的混合物。所述缓冲剂或其混合物通常以按总组合物的重量计约0.001%至约4%的量存在。用于制备可给予的药物组合物的方法是已知的。示例性方法更详细地描述于例如Remington:The Scienceand Practice of Pharmacy,Lippincott Williams&Wilkins;第21版(2005年5月1日)中。
结合分子的配制品可包括冻干配制品和水溶液。所述配制品或组合物还可以含有可用于用所述结合分子或细胞治疗的特定适应症、疾病或病症的多于一种的活性成分,优选地具有与所述结合分子或细胞互补的活性的那些,其中各活性不会相互产生不利影响。此类活性成分以有效用于既定目的的量以合适的方式组合存在。因此,在一些实施方案中,所述药物组合物进一步包括其他药物活性剂或药物,如化学治疗剂,例如天冬酰胺酶、白消安、卡铂、顺铂、道诺霉素、多柔比星、氟尿嘧啶、吉西他滨、羟基脲、甲氨蝶呤、紫杉醇、利妥昔单抗、长春碱、长春新碱等。在一些实施方案中,所述细胞或结合分子是以盐(例如,药学上可接受的盐)的形式给予。合适的药学上可接受的酸加成盐包括源自以下的那些:无机酸,如盐酸、氢溴酸、磷酸、偏磷酸、硝酸和硫酸;以及有机酸,如酒石酸、乙酸、柠檬酸、苹果酸、乳酸、富马酸、苯甲酸、乙醇酸、葡萄糖酸、琥珀酸和芳基磺酸(例如对甲苯磺酸)。
可以将活性成分包埋在微胶囊、胶体药物递送系统(例如,脂质体、白蛋白微球、微乳液、纳米颗粒和纳米胶囊)或粗乳液中。在某些实施方案中,将药物组合物配制为包合物(如环糊精包合物)或配制成脂质体。脂质体可以用于将所述宿主细胞(例如,T细胞或NK细胞)靶向特定组织。许多方法可用于制备脂质体,如在例如Szoka等人,Ann.Rev.Biophys.Bioeng.,9:467(1980)以及美国专利4,235,871、4,501,728、4,837,028和5,019,369中所述的那些。
在一些方面,所述药物组合物可以利用定时释放、延迟释放和持续释放递送系统,使得所述组合物的递送发生在待治疗部位的致敏之前并且有足够的时间引起致敏。许多类型的释放递送系统是可用的并且是已知的。此类系统可以避免重复给予所述组合物,从而增加对受试者和医师的便利性。
在一些实施方案中,所述药物组合物含有有效治疗或预防所述疾病或病症的量(如治疗有效量或预防有效量)的结合分子和/或细胞。在一些实施方案中,通过定期评估所治疗的受试者来监测治疗或预防功效。对于数天或更长时间的重复给予,根据病症,重复治疗直至出现疾病症状的所需抑制为止。然而,其他剂量方案可能是有用的并且可以被确定。所需剂量可以通过单次推注给予组合物、通过多次推注给予组合物、或通过连续输注给予组合物来递送。
在某些实施方案中,在含有结合分子的基因工程化细胞的情境下,以约100万至约1000亿个细胞,像例如100万至约500亿个细胞(例如,约500万个细胞、约2500万个细胞、约5亿个细胞、约10亿个细胞、约50亿个细胞、约200亿个细胞、约300亿个细胞、约400亿个细胞或由任两个前述值限定的范围),如约1000万至约1000亿个细胞(例如,约2000万个细胞、约3000万个细胞、约4000万个细胞、约6000万个细胞、约7000万个细胞、约8000万个细胞、约9000万个细胞、约100亿个细胞、约250亿个细胞、约500亿个细胞、约750亿个细胞、约900亿个细胞或由任两个前述值限定的范围),并且在一些情况下约1亿个细胞至约500亿个细胞(例如,约1.2亿个细胞、约2.5亿个细胞、约3.5亿个细胞、约4.5亿个细胞、约6.5亿个细胞、约8亿个细胞、约9亿个细胞、约30亿个细胞、约300亿个细胞、约450亿个细胞)或在这些范围之间的任何值,和/或这样的数量的细胞/公斤受试者体重给予受试者。
可以使用标准给予技术、配制品和/或装置给予所述细胞或结合分子。提供了用于储存和给予组合物的配制品和装置,如注射器和小瓶。所述细胞的给予可以是自体的或异源的。例如,免疫应答细胞或祖细胞可以获自一名受试者,并且给予至同一受试者或不同的相容受试者。外周血衍生的免疫应答细胞或其后代(例如,体内、离体或体外衍生的)可以经由局部注射(包括导管给予)、全身注射、局部注射、静脉内注射或肠胃外给予来给予。在给予治疗组合物(例如,含有遗传修饰的免疫应答细胞的药物组合物)时,通常将其配制成单位剂量可注射形式(溶液、悬浮液、乳液)。
配制品包括用于口服、静脉内、腹膜内、皮下、经肺、透皮、肌内、鼻内、经颊、舌下或栓剂给予的那些。在一些实施方案中,肠胃外给予所述细胞群。如本文所用,术语“肠胃外”包括静脉内、肌内、皮下、直肠、阴道、颅内、胸腔内和腹膜内给予。在一些实施方案中,使用通过静脉内、腹膜内或皮下注射的外周全身递送将所述细胞群给予受试者。
在一些实施方案中,组合物被提供为无菌液体制剂(例如,等渗水溶液、悬浮液、乳液、分散体或粘性组合物),其在一些方面可以被缓冲至选择的pH。液体制剂通常比凝胶、其他粘性组合物和固体组合物更容易制备。另外地,液体组合物稍微更方便给予,特别是通过注射。在另一方面,粘性组合物可以配制在适当的粘度范围内,以提供与特定组织的更长的接触时间。液体或粘性组合物可以包含载体,所述载体可以是溶剂或分散介质,所述溶剂或分散介质含有例如水、盐水、磷酸盐缓冲盐水、多元醇(例如,甘油、丙二醇、液体聚乙二醇)及其合适的混合物。
无菌可注射溶液可以通过将所述结合分子掺入溶剂中来制备,例如与合适的载体、稀释剂或赋形剂(如无菌水、生理盐水、葡萄糖、右旋糖等)混合。组合物也可以是冻干的。组合物可以含有辅助物质,如润湿剂、分散剂或乳化剂(例如,甲基纤维素)、pH缓冲剂、胶凝或粘度增强添加剂、防腐剂、调味剂、颜料等,这取决于所需的给予途径和制剂。在一些方面,可以参考标准文本来制备合适的制剂。
可以添加增强组合物的稳定性和无菌性的各种添加剂,包括抗微生物防腐剂、抗氧化剂、螯合剂和缓冲液。可以通过各种抗细菌剂和抗真菌剂(例如对羟基苯甲酸酯、氯丁醇、苯酚、山梨酸等)来确保对微生物作用的防止。可以通过使用吸收延迟剂(例如单硬脂酸铝和明胶)来实现可注射药物形式的延长吸收。
可以制备持续释放制剂。持续释放制剂的合适例子包括含有抗体的固体疏水聚合物的半透性基质,所述基质呈成型制品(例如薄膜或微胶囊)的形式。
用于体内给予的配制品通常是无菌的。可以例如通过经无菌滤膜过滤容易地实现无菌性。
B.治疗和预防方法及用途
还提供了给予和使用结合分子和/或表达结合分子的工程化细胞的方法和用途,例如治疗和预防用途,所述结合分子包括TCR及其抗原结合片段以及抗体或其抗原结合片段。此类方法和用途包括治疗方法和用途,例如,涉及将分子、细胞或包含所述分子、细胞的组合物给予患有表达HPV(例如HPV16)或与HPV相关和/或其中细胞或组织表达例如特异性表达HPV16(例如HPV16 E6或E7)的疾病、病症或障碍的受试者。在一些实施方案中,以实现治疗疾病或障碍的有效量给予所述分子、细胞和/或组合物。用途包括结合分子和细胞在此类方法和治疗中以及在制备药物以实施此类治疗方法中的用途。在一些实施方案中,通过向患有、已经患有或怀疑患有所述疾病或病症的受试者给予所述结合分子或细胞或者包含所述结合分子或细胞的组合物来进行所述方法。在一些实施方案中,所述方法从而治疗受试者的疾病或病症或障碍。
如本文所用,“治疗”(“treatment”)(及其语法变体如“治疗”(“treat”或“treating”))是指疾病或病症或障碍、或者与之相关的症状、不良效果或结果或表型的完全或部分改善或减轻。所希望的治疗效果包括但不限于预防疾病的发生或复发、症状的缓和、疾病的任何直接或间接病理后果的减少、预防转移、降低疾病进展的速度、改善或缓和疾病状态,以及缓解或改进预后。所述术语并不暗示完全治愈疾病或完全消除任何症状或对所有症状或结果的一种或多种效果。
如本文所用,“延迟疾病的发展”意指推迟、阻碍、减缓、延缓、稳定、抑制和/或延期疾病(如癌症)的发展。此延迟可以具有不同的时间长度,这取决于病史和/或所治疗的个体。对于本领域技术人员清楚的是,足够或显著的延迟实际上可以涵盖预防,使个体不会患上疾病。例如,可能延迟晚期癌症,诸如转移的发展。
如本文所用,“预防”包括提供关于受试者的疾病的发生或复发的预防,所述受试者可能易患所述疾病但尚未被诊断患有所述疾病。在一些实施方案中,所提供的分子和组合物用于延迟疾病的发展或减慢疾病的进展。
如本文所用,“抑制”功能或活性是当与除了目的条件或参数以外的原本相同的条件相比时,或者与另一种条件相比时,降低功能或活性。例如,与不存在结合分子或组合物或细胞的情况下的肿瘤生长速率相比,抑制肿瘤生长的结合分子或组合物或细胞降低肿瘤的生长速率。
在给予的情境下,药剂(例如,药物配制品、结合分子、或细胞或组合物)的“有效量”是指在必要的剂量/量下和必要的时间段内有效实现所需结果(如治疗或预防结果)的量。
药剂(例如,药物配制品、结合分子或细胞)的“治疗有效量”是指在所需剂量下和所需时间段中有效实现所需治疗结果(如针对疾病、病症或障碍的治疗)和/或治疗的药代动力学或药效学作用的量。治疗有效量可以根据诸如以下的因素而变化:疾病状态、受试者的年龄、性别和体重、和所给予的细胞群。在一些实施方案中,所提供的方法涉及以有效量(例如,治疗有效量)给予结合分子、细胞和/或组合物。
“预防有效量”是指在必要的剂量下和必要的时间段内有效实现所需预防结果的量。通常但不是必须的,因为预防剂量是在疾病之前或疾病较早期在受试者中使用的,所以预防有效量将小于治疗有效量。
如本文所用,“受试者”是哺乳动物,如人或其他动物,并且通常是人。
待治疗的疾病包括癌症,通常为HPV相关癌症,以及任何HPV相关例如HPV 16相关疾病或病症,或其中表达HPV癌蛋白例如E6或E7(例如HPV 16癌蛋白,例如HPV 16E6或E7)的疾病或病症。在某些疾病和病症中,病毒蛋白例如癌蛋白如HPV 16E6或E7在恶性细胞和癌症中表达或由其表达,和/或其肽表位在此类恶性癌症或组织中例如通过MHC呈递的方式表达。在一些实施方案中,所述疾病或病症是表达HPV16的癌症。在一些实施方案中,癌症是由HPV例如HPV-16引起或以其他方式与HPV例如HPV-16相关的癌、黑色素瘤或其他癌前状态或癌性状态。在一些实施方案中,癌可以是鳞状细胞癌或腺癌。在一些实施方案中,所述疾病或病症的特征在于与致癌性HPV感染相关的上皮细胞异常,例如凹空细胞增生;角化过度;癌前病症(包括上皮内瘤变或上皮内病变);高度发育不良;以及浸润性或恶性癌症。可以治疗的HPV 16相关疾病或病症包括但不限于宫颈癌、子宫癌、肛门癌、结直肠癌、阴道癌、外阴癌、阴茎癌、口咽癌、扁桃体癌、咽癌(pharynx cancer)、喉癌(larynx cancer)、口腔癌、皮肤癌、食道癌、头颈癌(例如鳞状细胞癌(SCC)头颈癌)、或小细胞肺癌。在一些实施方案中,所述疾病或病症是宫颈癌。
在一些实施方案中,所述方法可以包括多个步骤或特征以鉴定患有、怀疑患有HPV16相关疾病或障碍或者处于发展HPV 16相关疾病或障碍的风险中的受试者(参见例如美国专利号6,355,424和8,968,995),和/或待治疗的受试者可以是被鉴定为患有这种HPV相关疾病或病症或癌症或者如此处于患有或发展这种HPV相关疾病或病症或癌症的风险中的受试者。因此,在一些方面,提供了用于鉴定患有与HPV 16E6或E7表达相关的疾病或障碍的受试者并选择他们以治疗和/或用提供的HPV 16结合分子治疗此类受试者(例如,选择性地治疗此类受试者)的方法,所述治疗在一些方面包括用工程化为表达此类结合分子的细胞进行,在一些方面包括HPV 16E6或E7 TCR或其抗原结合片段或者抗HPV 16E6或E7抗体(例如抗体片段)、和含有它们的蛋白质(如嵌合受体,例如TCR样CAR)中的任一个、和/或表达TCR或CAR的工程化细胞。
例如,可以针对与HPV 16E6或E7表达相关的疾病或障碍,例如表达HPV16E6或E7的癌症的存在,对受试者进行筛选。在一些实施方案中,所述方法包括针对HPV 16E6或E7相关疾病例如肿瘤的存在进行筛选或对其进行检测。因此,在一些方面,可以从怀疑患有与HPV16E6或E7表达相关的疾病或障碍的患者获得样品,并测定HPV 16E6或E7的表达水平。在一些方面,可以选择HPV 16E6或E7相关疾病或障碍测试呈阳性的受试者通过本发明方法进行治疗,并且可以向所述受试者给予治疗有效量的本文所述的结合分子、表达这种结合分子的CAR、包含所述结合分子的细胞、或其药物组合物(如本文所述)。在一些实施方案中,所述方法可用于例如在通过所述方法治疗之前、期间或之后随时间监测表达HPV 16E6或E7的组织(例如肿瘤)的大小或密度。在一些方面,已经根据这样的方法,例如在治疗开始之前或治疗期间,选择或测试了通过本文提供的方法治疗的HPV表达阳性受试者。
在一些实施方案中,给予所提供的HPV 16结合分子(包括HPV 16E6或E7 TCR或其抗原结合片段或者抗HPV 16E6或E7抗体(例如抗体片段))和含有所述结合分子的蛋白质(如嵌合受体,例如TCR样CAR)中的任一个)和/或表达TCR或CAR的工程化细胞可以与另一种用于治疗HPV疾病的治疗剂组合。例如,另外的治疗剂治疗可以包括用另一种抗癌剂治疗以治疗宫颈癌。由于药剂和所提供的HPV 16结合分子的组合用(协同作用),可以降低这种共同给予的药剂的合适剂量。
在一些实施方案中,例如在用另一种HPV 16特异性结合分子和/或表达靶向HPV16的结合分子的细胞和/或其他疗法(包括化学疗法、放射和/或造血干细胞移植(HSCT)例如同种异体HSCT)治疗之后,受试者患有持续性或复发性疾病。在一些实施方案中,尽管受试者已经对另一种靶向HPV 16的疗法产生抗性,但所述给予有效治疗了所述受试者。在一些实施方案中,所述受试者尚未复发,但是被确定为处于复发风险中,例如处于高复发风险中,并且因此预防性地给予化合物或组合物,例如以降低复发的可能性或预防复发。
在一些实施方案中,治疗不诱导受试者对疗法的免疫应答,和/或不诱导这种应答至阻止有效治疗疾病或病症的程度。在一些方面,免疫原性和/或移植物抗宿主应答的程度小于用不同但可比较的治疗观察到的程度。例如,在使用表达TCR或CAR(包含所提供的结合分子)的细胞的过继细胞疗法的情况下,与包含不同结合分子的TCR或CAR相比,在一些实施方案中免疫原性的程度降低。
在一些实施方案中,所述方法包括过继细胞疗法,借此将表达所提供的结合分子的基因工程化细胞给予受试者。这种给予能以靶向HPV 16的方式促进细胞激活(例如,T细胞激活),使得疾病或障碍的细胞被靶向破坏。
因此,所提供的方法和用途包括用于过继细胞疗法的方法和用途。在一些实施方案中,所述方法包括将细胞或含有所述细胞的组合物给予受试者、组织或细胞,如患有疾病、病症或障碍,具有疾病、病症或障碍的风险,或怀疑患有疾病、病症或障碍的受试者、组织或细胞。在一些实施方案中,将所述细胞、群体和组合物给予至患有待治疗的特定疾病或病症的受试者,例如经由过继细胞疗法,如过继T细胞疗法。在一些实施方案中,将所述细胞或组合物给予受试者,如患有或有风险患上所述疾病或病症的受试者。在一些方面,所述方法由此例如通过减轻表达HPV 16E6或E7的癌症中的肿瘤负荷来治疗例如改善疾病或病症的一种或多种症状。
用于过继细胞疗法的细胞的给予方法是已知的,并且可以与所提供的方法和组合物一起使用。例如,过继T细胞治疗方法描述于例如Gruenberg等人的美国专利申请公开号2003/0170238;Rosenberg的美国专利号4,690,915;Rosenberg(2011)Nat Rev ClinOncol.8(10):577-85)。参见例如Themeli等人(2013)Nat Biotechnol.31(10):928-933;Tsukahara等人(2013)Biochem Biophys Res Commun 438(1):84-9;Davila等人(2013)PLoS ONE 8(4):e61338。
在一些实施方案中,细胞疗法(例如过继细胞疗法,例如过继T细胞疗法)通过自体转移进行,其中从要接受细胞疗法的受试者或从源自这个受试者的样品分离和/或以其他方式制备细胞。因此,在一些方面,所述细胞源自需要治疗的受试者(例如,患者),并且在分离和加工后将所述细胞给予同一受试者。
在一些实施方案中,细胞疗法(例如过继细胞疗法,例如过继T细胞疗法)是通过同种异体转移进行,其中从除了要接受或最终接受所述细胞疗法的受试者以外的受试者(例如,第一受试者)分离和/或以其他方式制备细胞。在此类实施方案中,然后将所述细胞给予相同物种的不同受试者,例如第二受试者。在一些实施方案中,所述第一和第二受试者在遗传上是相同的。在一些实施方案中,第一和第二受试者在遗传上是相似的。在一些实施方案中,第二受试者与第一受试者表达相同的HLA类别或超类型。
在一些实施方案中,被给予所述细胞、细胞群或组合物的受试者是灵长类动物,如人。在一些实施方案中,所述灵长类动物是猴或猿。受试者可以是雄性或雌性,并且可以处于任何合适的年龄,包括婴儿、幼年、青春期、成年和老年受试者。在一些实施方案中,受试者是非灵长类哺乳动物,如啮齿动物。在一些例子中,所述患者或受试者是用于疾病、过继细胞疗法和/或用于评估毒性结果(如细胞因子释放综合征(CRS))的经验证的动物模型。
所提供的结合分子(例如TCR及其抗原结合片段以及抗体及其抗原结合片段)以及表达其的细胞可以通过任何合适的方式给予,例如通过注射,例如静脉内或皮下注射、眼内注射、眼周注射、视网膜下注射、玻璃体内注射、经中隔注射、巩膜下注射、脉络膜内注射、前房内注射、结膜下(subconjectval)注射、结膜下(subconjuntival)注射、眼球筋膜囊下(sub-Tenon)注射、眼球后注射、眼球周注射或后近巩膜(posterior juxtascleral)递送。在一些实施方案中,它们通过肠胃外、肺内和鼻内给予以及(如果需要用于局部治疗的话)病灶内给予。肠胃外输注包括肌内、静脉内、动脉内、腹膜内、颅内、胸腔内、或皮下给予。给药和给予可以部分取决于给予是短暂的还是长期的。各种给药时间表包括但不限于在不同时间点的单次或多次给予、推注给予和脉冲输注。
为了预防或治疗疾病,所述结合分子或细胞的适当剂量可以取决于待治疗的疾病类型、结合分子的类型、疾病的严重程度和病程、给予所述结合分子用于预防还是治疗目的、先前疗法、患者的临床病史和对所述结合分子的反应以及主治医师的判断。在一些实施方案中,将所述组合物和分子和细胞合适地一次或在一系列治疗中给予患者。
在某些实施方案中,在含有所述结合分子的基因工程化细胞的情境下,以约100万至约1000亿个细胞和/或每公斤体重所述细胞量的范围给予受试者,像例如100万至约500亿个细胞(例如,约500万个细胞、约2500万个细胞、约5亿个细胞、约10亿个细胞、约50亿个细胞、约200亿个细胞、约300亿个细胞、约400亿个细胞或由任两个前述值限定的范围),如约1000万至约1000亿个细胞(例如,约2000万个细胞、约3000万个细胞、约4000万个细胞、约6000万个细胞、约7000万个细胞、约8000万个细胞、约9000万个细胞、约100亿个细胞、约250亿个细胞、约500亿个细胞、约750亿个细胞、约900亿个细胞或由任两个前述值限定的范围),并且在一些情况下约1亿个细胞至约500亿个细胞(例如,约1.2亿个细胞、约2.5亿个细胞、约3.5亿个细胞、约4.5亿个细胞、约6.5亿个细胞、约8亿个细胞、约9亿个细胞、约30亿个细胞、约300亿个细胞、约450亿个细胞)或在这些范围和/或每公斤体重的这些范围之间的任何值。同样,剂量可以根据疾病或障碍和/或患者和/或其他治疗特有的属性而变化。
在一些实施方案中,将所述结合分子或细胞作为组合治疗的一部分给予,如与另一种治疗性干预如另一种TCR、抗体或工程化细胞或受体或药剂(如细胞毒性剂或治疗剂)同时给予或以任何顺序依序给予。
在一些实施方案中将所述细胞或抗体与一种或多种另外的治疗剂或结合另一种治疗性干预同时或以任何顺序依序共给予。在一些情境下,将所述细胞与另一种疗法共给予,其时间足够接近,使得细胞群增强一种或多种另外的治疗剂的作用,或反之亦然。在一些实施方案中,将细胞或抗体在所述一种或多种另外的治疗剂之前给予。在一些实施方案中,将所述细胞或抗体在一种或多种另外的治疗剂之后给予。
一旦将所述细胞给予哺乳动物(例如,人),在一些方面中,便通过许多已知方法中的任何一种来测量工程化细胞群和/或结合分子的生物活性。要评估的参数包括工程化或天然T细胞或其他免疫细胞与抗原的特异性结合,在体内例如通过成像进行评估,或离体例如通过ELISA或流式细胞术进行评估。在某些实施方案中,工程化细胞破坏靶细胞的能力可以使用本领域已知的任何合适的方法来测量,所述方法例如描述于例如以下文献中的细胞毒性测定:Kochenderfer等人,J.Immunotherapy,32(7):689-702(2009),和Herman等人J.Immunological Methods,285(1):25-40(2004)。在某些实施方案中,还可以通过测定某些细胞因子(如CD107a、IFNγ、IL-2和TNF)的表达和/或分泌来测量所述细胞的生物活性。在一些方面,生物学活性是通过评估临床结果(如肿瘤负荷或负担的减少)来测量。
在某些实施方案中,将工程化细胞以任何数量的方式进行修饰,使得其治疗或预防功效增加。例如,在一些实施方案中,由工程化细胞表达的工程化TCR或表达抗体的CAR直接或间接地通过接头缀合至靶向部分。将化合物(例如,TCR或CAR)与靶向部分缀合的实践在本领域是已知的。参见例如,Wadwa等人,J.Drug Targeting 3:1 1 1(1995)和美国专利5,087,616。
C.诊断和检测方法
还提供了涉及在检测HPV 16(例如HPV 16E6或HPV 16E7)中,例如在与表达HPV 16的疾病或病症相关的诊断和/或预后方法中,使用所提供的结合分子(例如TCR或其抗原结合片段以及抗体及其抗原结合片段)的方法。在一些实施方案中的方法包括将生物样品与结合分子一起孵育和/或将结合分子给予受试者。在某些实施方案中,生物样品包括细胞或组织,例如肿瘤或癌组织。在针对HPV 16(例如HPV 16E6或E7)的区域或肽表位的某些结合分子中,并检测在结合分子与肽表位之间是否形成复合物。这种方法可以是体外或体内方法。在一个实施方案中,例如在HPV 16(例如HPV 16E6或E7)是用于选择患者的生物标记的情况下,使用抗HPV 16结合分子以选择适合于用抗HPV 16结合分子或包含此类分子的工程化细胞进行治疗的受试者。
在一些实施方案中,使样品(例如细胞、组织样品、裂解物、组合物、或源自其的其他样品)与结合分子接触,并确定或检测在结合分子与样品(例如,样品中HPV16的区域或表位)之间的结合或复合物形成。当与相同组织类型的参考细胞相比,证明或检测到测试样品中的结合时,这可指示相关疾病或病症的存在。在一些实施方案中,样品来自人组织。
可以使用本领域已知的用于检测特异性结合分子-抗原结合的各种方法。示例性免疫测定包括荧光偏振免疫测定(FPIA)、荧光免疫测定(FIA)、酶免疫测定(EIA)、比浊法抑制免疫测定(NIA)、酶联免疫吸附测定(ELISA)和放射免疫测定(RIA)。可以将指示剂部分或标记基团附接到主题结合分子上并可以进行选择以满足所述方法的通常由测定设备的可用性和相容的免疫测定程序决定的各种应用的需要。示例性标记包括放射性核素(例如125I、131I、35S、3H或32P)、酶(例如,碱性磷酸酶、辣根过氧化物酶、萤光素酶或p-乳糖苷酶)、荧光部分或蛋白质(例如,荧光素、罗丹明、藻红蛋白、GFP或BFP)或发光部分(例如,由加利福尼亚州帕洛阿尔托(Palo Alto,Calif.)的Quantum Dot Corporation提供的QdotTM纳米颗粒)。用于进行上述各种免疫测定的一般技术是本领域普通技术人员已知的。
出于诊断目的,可以用可检测部分标记所述结合分子,所述可检测部分包括但不限于放射性同位素、荧光标记和本领域已知的各种酶-底物标记。将标记与结合分子例如TCR或抗体缀合的方法是本领域已知的。在一些实施方案中,不需要对结合分子进行标记,并且可以使用与结合分子结合的经标记的抗体来检测所述结合分子的存在。
在一些实施方案中,提供的结合分子可以用于任何已知的测定方法,例如竞争性结合测定、直接和间接夹心测定以及免疫沉淀测定。所述结合分子也可用于诸如体内成像等的体内诊断测定。通常,将结合分子用放射性核素(例如111In、99Tc、14C、131I、125I或3H)标记,以使得在向受试者给予后,可以在体内定位目的细胞或组织。结合分子还可以例如使用已知技术在病理学中用作染色试剂。
VII.制品
还提供了包含所提供的结合分子例如TCR、抗体和CAR和/或工程化细胞和/或组合物的制品。所述制品可以包括容器和在所述容器上或与所述容器相关的标签或包装说明书。合适的容器包括例如瓶子、小瓶、注射器、IV溶液袋等。所述容器可以由诸如玻璃或塑料的多种材料形成。在一些实施方案中,容器容纳组合物自身或组合物与有效治疗、预防和/或诊断病症的另一种组合物的组合。在一些实施方案中,容器具有无菌接入端口。示例性容器包括静脉内溶液袋、小瓶,包括具有可被注射用针刺穿的塞子的那些。标签或包装说明书可以指示将组合物用于治疗表达HPV 16E6或E7的疾病或病症或者HPV 16E6或E7相关的疾病或病症。所述制品可以包括(a)其中含有组合物的第一容器,其中所述组合物包括抗体或工程化抗原受体;和(b)其中含有组合物的第二容器,其中所述组合物包括另外的药剂,例如细胞毒性剂或否则为治疗剂。所述制品还可以包括包装说明书,其指示组合物可以用于治疗特定病症。可替代地或另外地,制品还可以包括另一个或相同容器,所述容器包含药学上可接受的缓冲液。它还可以包括其他材料,如其他缓冲液、稀释剂、过滤器、针和/或注射器。
VIII.定义
除非另有定义,否则本文使用的所有技术术语、符号和其他技术和科学术语或用辞旨在具有与所要求保护的主题所属领域的普通技术人员通常理解的含义相同的含义。在一些情况下,为了清楚和/或为了便于参考而在本文中定义具有通常理解的含义的术语,并且本文中包含的此类定义不一定应当被解释为表示与本领域通常理解的实质性差异。
术语“多肽”和“蛋白质”可互换使用,是指氨基酸残基的聚合物,并且不限于最小长度。多肽(包括所提供的抗体和抗体链以及其他肽(例如接头))可以包括含有天然和/或非天然氨基酸残基的氨基酸残基。所述术语还包括多肽的表达后修饰,例如糖基化、唾液酸化、乙酰化、磷酸化等。在一些方面,多肽可含有关于原生或天然序列的修饰,只要蛋白质保持所需活性即可。这些修饰可能是故意的(如通过定点诱变),或者可能是偶然的(如通过产生所述蛋白质的宿主的突变或由于PCR扩增引起的错误)。
“分离的”核酸是指已经与其天然环境的组分分开的核酸分子。分离的核酸包括细胞中含有的核酸分子,所述细胞通常含有所述核酸分子,但所述核酸分子存在于染色体外或存在于不同于其天然染色体位置的染色体位置。
“编码TCR或抗体的分离的核酸”是指编码抗体重链和轻链(或其片段)的TCRα或β链(或其片段)的一种或多种核酸分子,包括在单个载体或单独载体中这样的一种或多种核酸分子、以及在宿主细胞中的一个或多个位置存在的这样的一种或多种核酸分子。
术语“宿主细胞”、“宿主细胞系”和“宿主细胞培养物”可互换使用,并且是指已引入外源核酸的细胞,包括此类细胞的后代。宿主细胞包括“转化体”和“转化细胞”,其包括原代转化细胞和源自其的后代,不考虑传代次数。后代在核酸含量上可能与亲代细胞不完全相同,但可能含有突变。本文包括如在初始转化细胞中所筛选或选择的具有相同功能或生物学活性的突变型后代。
如本文所用,在关于氨基酸序列(参考多肽序列)使用时,“氨基酸序列同一性百分比(%)”和“同一性百分比”定义为,在比对序列并在必要时引入空位以实现最大序列同一性百分比并且不将任何保守取代视作序列同一性的一部分之后,候选序列(例如,主题抗体或片段)中与参考多肽序列中的氨基酸残基相同的氨基酸残基的百分比。用于确定氨基酸序列同一性百分比的比对可以按本领域熟知的多种方式来实现,例如使用公众可获得的计算机软件,如BLAST、BLAST-2、ALIGN或Megalign(DNASTAR)软件。本领域技术人员可以确定用于比对序列的合适参数,包括在所比较的序列的全长上实现最大比对所需的任何算法。
氨基酸取代可以包括用另一种氨基酸替代多肽中的一个氨基酸。可以将氨基酸取代引入目的结合分子(例如TCR或抗体)、和针对所希望的活性(例如保留/改进的抗原结合、降低的免疫原性或改进的细胞溶解活性)筛选的产物中。
通常可以根据以下常见的侧链特性将氨基酸进行分组:
(1)疏水性的:正亮氨酸、Met、Ala、Val、Leu、Ile;
(2)中性亲水性的:Cys、Ser、Thr、Asn、Gln;
(3)酸性的:Asp、Glu;
(4)碱性的:His、Lys、Arg;
(5)影响链取向的残基:Gly、Pro;
(6)芳香族的:Trp、Tyr、Phe。
在一些实施方案中,保守取代可能涉及将这些类别之一的成员交换为同一类别的另一个成员。在一些实施方案中,非保守氨基酸取代可能涉及将这些类别之一的成员交换为另一个类别。
如本文所用,术语“载体”是指能够传播其所连接的另一核酸分子的核酸分子。所述术语包括作为自我复制核酸结构的载体以及掺入已引入其的宿主细胞的基因组中的载体。某些载体能够指导它们可操作地连接的核酸的表达。此类载体在本文中称为“表达载体”。
术语“包装说明书”用于指代通常包括在治疗产品的商业包装中的说明书,其含有关于使用此类治疗产品的适应症、用法、剂量、给予、组合疗法、禁忌症和/或警告的信息。
除非上下文另有明确规定,否则如本文所用,单数形式“一种/一个”(“a”)、“一种/一个”(“an”)和“所述”(“the”)包括复数指示物。例如,“一种/一个”(“a”)或“一种/一个”(“an”)意指“至少一种/至少一个”或“一种或多种/一个或多个”。应理解,本文所述的方面和变化包括“由方面和变化组成”和/或“本质上由方面和变化组成”。
在整个本公开文本中,所要求保护的主题的各个方面以范围形式呈现。应当理解,范围形式的描述仅仅是为了方便和简洁,并且不应当被解释为对所要求保护的主题的范围的硬性限制。因此,应当将范围的描述视为已明确公开所有可能的子范围以及该范围内的单独数值。例如,在提供值的范围的情况下,应理解,该范围的上限与下限之间的每个中间值以及该所陈述范围中的任何其他所陈述值或中间值涵盖在所要求保护的主题内。这些较小范围的上限和下限可以独立地被包括在所述较小范围内,并且也涵盖在所要求保护的主题内,受制于在所陈述范围内任何明确排除的限值。在所陈述范围包括所述限值中的一个或两个的情况下,排除那些所包括限值中的任何一个或两个的范围也被包括在所要求保护的主题内。无论范围的广度如何,这都适用。
如本文所用的术语“约”是指本技术领域的技术人员容易知道的相应值的常用误差范围。本文对“约”某一值或参数的提及包括(并描述)涉及所述值或参数本身的实施方案。例如,提及“约X”的描述包括“X”的描述。
如本文所用的,组合物是指两种或更多种产物、物质或化合物(包括细胞)的任何混合物。它可以是溶液、悬浮液、液体、粉末、糊剂、水性的、非水性的或其任何组合。
如本文所用,细胞或细胞群针对特定标记呈“阳性”的陈述是指,特定标记(通常是表面标记)在细胞上或细胞中的可检测存在。当提及表面标记时,所述术语是指如通过流式细胞术检测到的,表面表达的存在,例如通过用与所述标记特异性地结合的抗体进行染色并检测所述抗体,其中所述染色通过流式细胞术以如下水平是可检测的,所述水平基本上高于在其他方面相同的条件下用同种型匹配对照进行相同程序检测到的染色,和/或所述水平与已知对所述标记呈阳性的细胞的水平基本上相似,和/或所述水平基本上高于已知对所述标记呈阴性的细胞的水平。
如本文所用,细胞或细胞群对特定标记呈“阴性”的陈述是指,特定标记(通常是表面标记)在细胞上或细胞中不存在基本上可检测的存在。当提及表面标记时,所述术语是指如通过流式细胞术检测到的,表面表达的不存在,例如通过用与所述标记特异性地结合的抗体进行染色并检测所述抗体,其中所述染色通过流式细胞术以如下水平没有检测到,所述水平基本上高于在其他方面相同的条件下用同种型匹配对照进行相同程序检测到的染色,和/或所述水平基本上低于已知对所述标记呈阳性的细胞的水平,和/或所述水平与已知对所述标记呈阴性的细胞的水平相比是基本上相似的。
本申请中提及的所有出版物(包括专利文献、科学文章和数据库)出于所有目的通过引用以其整体并入,在程度上如同每个单独的出版物通过引用单独并入。如果本文所述的定义与通过引用并入本文的专利、申请、公开的申请和其他出版物中所述的定义相反或在其他方面不一致,则本文所述的定义优先于通过引用并入本文的定义。
本文使用的章节标题仅用于组织目的,而不应解释为限制所描述的主题。
IX.示例性实施方案
所提供的实施方案包括:
1.一种T细胞受体(TCR)或其抗原结合片段,所述T细胞受体(TCR)或其抗原结合片段包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链,其中:
所述Vα区包含SEQ ID NO:691、709、726、741、759、775、787、799、815、830、845、857、869、881、895、908、925、937、951、963、975、987、999或1390中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列;和/或
所述Vβ区包含SEQ ID NO:700、718、735、750、768、781、793、808、824、839、851、863、875、887、901、917、931、945、957、969、981、993 1008或1380中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列。
2.根据实施方案1所述的TCR或其抗原结合片段,其中:
所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1185)的互补决定区3(CDR-3),其中X2是A、G、V、Q、M或E;X3是S、G、N、A、Y、R或P;X4是E、S、A、G、F、N、D、V、P、L、I、M或R;X5是R、N、H、T、D、G、S、P、L、Q或F;X6是G、H、A、S、T或空;X7是T、S、G或空;X8是G或空;X9是G、N、S或空;X10是T、G、S、D、F、Y、A或N;X11是Y、F、Q、R或N;X12是K、Q或D;X13是Y、L、T、M、F或V;X14是I、T、S、R、Y或V;
所述Vα区包含含有氨基酸序列X1X2X3X4X5X6X7X8X9X10KX12I(SEQ ID NO:1186)的互补决定区3(CDR-3),其中X1是A或V;X2是A、V或E;X3是S、N、T、R或P;X4是E、A、G、F、V、P、I、D或S;X5是R、H、T、A P、S、G或F;X6是G、H、L、T、S或A、空;X7是S、T或空;X8是G或空;X9是G、T或空;X10是F、Y或N;X12是Y、T或L;
所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9YKYI(SEQ ID NO:1187)的互补决定区3(CDR-3),其中X2是A、V或E;X3是S、N或R;X4是E、G、V、P、I或D;X5是R、T、P、S、G或F;X6是G、T、S或空;X7是S或空;X8是G或空;X9是T或空;
所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1188)的互补决定区3(CDR-3),其中X2是G、V、Q或M;X3是G、A、Y、S、N或R;X4是S、G、L、I、M或R;X5是N、D、G、S、L、Q或R;X6是A、S、G或空;X7是G或空;X8是G或空;X9是G、N、S或空;X10是S、D、Y、A、N或空;X11是Y、Q或R;X12是K或Q;X13是L或V;X14是S、T或V;
所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13T(SEQ ID NO:1189)的互补决定区3(CDR-3),其中X2是G、V或Q;X3是G、Y、S或N;X4是S、L或M;X5是N、G、L或R;X6是A、S、G或空;X7是G或空;X8是G或空;X9是G、S或空;X10是S、Y、A、N或空;X11是Y、Q或R;X12是K或Q;X13是L或V;
所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7YKLS(SEQ ID NO:1190)的互补决定区3(CDR-3),其中X2是G或V;X3是A或Y;X4是G、S或R;X5是D或S;X6是N或空;X7是D或空。
3.根据实施方案1或实施方案2所述的TCR或其抗原结合片段,其中:
所述Vβ区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1200)的互补决定区3(CDR-3),X2是S、V或I;X3是S、N或A;X4是R、V、S、L、P、G、I或A;X5是F、G、Y、L、V、R、T或S;X6是L、G、A、D、R、V或空;X7是G、D、R、S、T或空;X8是S或空;X9是S、H、G、V、T、D、L或空;X10是T、S、A、G、P、N或Y;X11是D、Y、E、G或N;X12是T、E、G或K;X13是Q、Y或L;X14是Y、F、T或I;
所述Vβ区包含含有氨基酸序列ASSX4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1201)的互补决定区3(CDR-3),其中X4是R、V、S、L、G或A;X5是F、G、Y、L、V、T或S;X6是A、L、R、D、G或空;X7是G、D、T或空;X8是S或空;X9是S、H、G、T、D、L或空;X10是T、S、A、G、P、N或Y;X11是D、Y、E、G或N;X12是T、E或G;X13是Q、Y或L;X14是Y、F或T;
所述Vβ区包含含有氨基酸序列ASSX4X5X6X7X8X9X10TQY(SEQ ID NO:1202)的互补决定区3(CDR-3),其中X4是R、L或G;X5是F、V、T或Y;X6是L或A、空;X7是G或空;X8是S、G或空;X9是T、G、P或S;X10是D或E。
4.一种T细胞受体(TCR)或其抗原结合片段,所述T细胞受体(TCR)或其抗原结合片段包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链,其中:
所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1185)的互补决定区3(CDR-3),其中X2是A、G、V、Q、M或E;X3是S、G、N、A、Y、R或P;X4是E、S、A、G、F、N、D、V、P、L、I、M或R;X5是R、N、H、T、D、G、S、P、L、Q或F;X6是G、H、A、S、T或空;X7是T、S、G或空;X8是G或空;X9是G、N、S或空;X10是T、G、S、D、F、Y、A或N;X11是Y、F、Q、R或N;X12是K、Q或D;X13是Y、L、T、M、F或V;X14是I、T、S、R、Y或V;
所述Vα区包含含有氨基酸序列X1X2X3X4X5X6X7X8X9X10KX12I(SEQ ID NO:1186)的互补决定区3(CDR-3),其中X1是A或V;X2是A、V或E;X3是S、N、T、R或P;X4是E、A、G、F、V、P、I、D或S;X5是R、H、T、A P、S、G或F;X6是G、H、L、T、S或A、空;X7是S、T或空;X8是G或空;X9是G、T或空;X10是F、Y或N;X12是Y、T或L;
所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9YKYI(SEQ ID NO:1187)的互补决定区3(CDR-3),其中X2是A、V或E;X3是S、N或R;X4是E、G、V、P、I或D;X5是R、T、P、S、G或F;X6是G、T、S或空;X7是S或空;X8是G或空;X9是T或空;
所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1188)的互补决定区3(CDR-3),其中X2是G、V、Q或M;X3是G、A、Y、S、N或R;X4是S、G、L、I、M或R;X5是N、D、G、S、L、Q或R;X6是A、S、G或空;X7是G或空;X8是G或空;X9是G、N、S或空;X10是S、D、Y、A、N或空;X11是Y、Q或R;X12是K或Q;X13是L或V;X14是S、T或V;
所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13T(SEQ ID NO:1189)的互补决定区3(CDR-3),其中X2是G、V或Q;X3是G、Y、S或N;X4是S、L或M;X5是N、G、L或R;X6是A、S、G或空;X7是G或空;X8是G或空;X9是G、S或空;X10是S、Y、A、N或空;X11是Y、Q或R;X12是K或Q;X13是L或V;
所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7YKLS(SEQ ID NO:1190)的互补决定区3(CDR-3),其中X2是G或V;X3是A或Y;X4是G、S或R;X5是D或S;X6是N或空;X7是D或空。
5.一种T细胞受体(TCR)或其抗原结合片段,所述T细胞受体(TCR)或其抗原结合片段包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链,其中:
所述Vβ区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1200)的互补决定区3(CDR-3),X2是S、V或I;X3是S、N或A;X4是R、V、S、L、P、G、I或A;X5是F、G、Y、L、V、R、T或S;X6是L、G、A、D、R、V或空;X7是G、D、R、S、T或空;X8是S或空;X9是S、H、G、V、T、D、L或空;X10是T、S、A、G、P、N或Y;X11是D、Y、E、G或N;X12是T、E、G或K;X13是Q、Y或L;X14是Y、F、T或I;
所述Vβ区包含含有氨基酸序列ASSX4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1201)的互补决定区3(CDR-3),其中X4是R、V、S、L、G或A;X5是F、G、Y、L、V、T或S;X6是A、L、R、D、G或空;X7是G、D、T或空;X8是S或空;X9是S、H、G、T、D、L或空;X10是T、S、A、G、P、N或Y;X11是D、Y、E、G或N;X12是T、E或G;X13是Q、Y或L;X14是Y、F或T;
所述Vβ区包含含有氨基酸序列ASSX4X5X6X7X8X9X10TQY(SEQ ID NO:1202)的互补决定区3(CDR-3),其中X4是R、L或G;X5是F、V、T或Y;X6是L或A、空;X7是G或空;X8是S、G或空;X9是T、G、P或S;X10是D或E。
6.一种T细胞受体(TCR)或其抗原结合片段,所述T细胞受体(TCR)或其抗原结合片段包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链,其中:
所述Vα区包含SEQ ID NO:694、712、729、744、762、776、788、802、818、832、846、858、870、882、896、911、926、940、952、964、976、988、1002或与其展现出至少60%、65%、70%、75%、80%、85%、90%或95%序列同一性的序列中任一个所示的互补决定区3(CDR-3);
所述Vβ区包含SEQ ID NO:703、721、736、753、769、782、794、809、825、840、852、864、876、888、902、919、932、946、958、970、982、994或1010或与其展现出至少60%、65%、70%、75%、80%、85%、90%或95%序列同一性的序列中任一个所示的互补决定区3(CDR-3)。
7.根据实施方案1-6中任一项所述的TCR或其抗原结合片段,其中所述Vα区包含:
包含氨基酸序列X1X2X3X4X5X6(SEQ ID NO:1191)的互补决定区1(CDR-1),其中X1是N、S、D、T或V;X2是S、V、R、T或I;X3是M、F、G、S、N、A、L、V或P;X4是F、S、N、A或空;X5是D、S、Q、Y、N、V、T或P;并且X6是Y、S、R、N、G或T;和/或
包含氨基酸序列X1X2X3X4X5X6X7X8(SEQ ID NO:1192)的互补决定区2(CDR-2),其中X1是I、V、L、G、N、T、Y或M;X2是S、V、Y、L、P、F、I或T;X3是S、Y、K、L、T或F;X4是I、G、N、A、S或空;X5是S、D或空;X6是K、G、N、S、D、T或E;X7是D、E、G、A、K、L或N;并且X8是K、V、D、P、N、T、L或M。
8.根据实施方案1-7中任一项所述的TCR或其抗原结合片段,其中所述Vβ区包含:
包含氨基酸序列SX2X3X4X5(SEQ ID NO:1203)的互补决定区1(CDR-1),其中X2是G或N;X3是H或D;X4是T、L、N或V;并且X5是A、S、Y或T;和/或
包含氨基酸序列X1X2X3X4X5X6(SEQ ID NO:1204)的互补决定区2(CDR-2),其中X1是F或Y;X2是Q、Y或N;X3是G、N、R或Y;X4是N、G、E或T;X5是S、E、A或G;并且X6是A、E、I或Q。
9.根据实施方案1-8中任一项所述的TCR或其抗原结合片段,其中所述TCR或其抗原结合片段结合至或识别在MHC分子的背景下的人乳头瘤病毒(HPV)16E7的肽表位,所述肽表位是或包含E7(11-19)YMLDLQPET(SEQ ID NO:236)。
10.根据实施方案1-9中任一项所述的TCR或抗原结合片段,其中:
所述Vα区包含含有SEQ ID NO:694、712、729、744、762、776、788、802、818、832、846、858、870、882、896、911、926、940、952、964、976、988或1002中任一个所示的氨基酸序列的互补决定区3(CDR-3)、或者SEQ ID NO:691、709、726、741、759、775、787、799、815、830、845、857、869、881、895、908、925、937、951、963、975、987或999中任一个所示的氨基酸序列内所含的CDR3;和/或
所述Vβ区包含含有SEQ ID NO:703、721、736、753、769、782、794、809、825、840、852、864、876、888、902、919、932、946、958、970、982、994、1010或1381中任一个所示的氨基酸序列的互补决定区3(CDR-3)、或者SEQ ID NO:700、718、735、750、768、781、793、808、824、839、851、863、875、887、901、917、931、945、957、969、981、993或1008或1380中任一个所示的氨基酸序列内所含的CDR3。
11.根据实施方案1-10中任一项所述的TCR或其抗原结合片段,其中所述Vα区还包含:
包含SEQ ID NO:171、692、710、727、742、760、171、800、816、570、909、938、151、1000中任一个所示的氨基酸序列的互补决定区1(CDR-1);和/或
包含SEQ ID NO:172、693、711、728、743、761、172、801、817、831、571、910、939、152或1001中任一个所示的氨基酸序列的互补决定区2(CDR-2)。
12.根据实施方案1-11中任一项所述的TCR或其抗原结合片段,其中所述Vβ区包含:
包含SEQ ID NO:701、719、154、751或139中任一个所示的氨基酸序列的互补决定区1(CDR-1);和/或
包含SEQ ID NO:702、720、155、752、140或918中任一个所示的氨基酸序列的互补决定区2(CDR-2)。
13.根据实施方案1-12中任一项所述的TCR或其抗原结合片段,其中:
所述Vα区包含分别包含SEQ ID NO:692、693和694的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:701、702和703的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:710、711和712的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:719、720和721的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:727、728和729的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和736的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:742、743和744的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:751、752和753的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:760、761和762的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:719、720和769的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:171、172和776的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和782的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:742、743和788的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:139、140和794的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:800、801和802的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:751、752和809的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:816、817和818的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和825的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:816、831和832的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和840的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:171、172和846的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和852的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:816、833和858的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和864的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:727、728和870的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和876的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:570、571和882的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:719、720和888的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:816、817和896的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:701、702和902的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:909、910和911的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:701、702和919的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:727、728和926的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和932的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:938、939和940的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和946的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:727、728和952的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和958的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:151、152和964的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:719、720和970的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:727、728和976的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和982的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:710、711和988的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:719、729和994的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:1000、1001和1002的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:139、1009和1010的氨基酸序列的CDR-1、CDR-2和CDR-3;或者
所述Vα区包含分别包含SEQ ID NO:171、172和1391的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和1381的氨基酸序列的CDR-1、CDR-2和CDR-3。
14.根据实施方案1-13中任一项所述的TCR或其抗原结合片段,其中:
所述Vα区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:691、709、726、741、759、775、787、799、815、830、845、857、869、881、895、908、925、937、951、963、975、987、999或1390中任一个所示的Vα区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列;和/或
所述Vβ区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:700、718、735、750、768、781、793、808、824、839、851、863、875、887、901、917、931、945、957、969、981、993、1008或1380中任一个所示的Vβ区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列。
15.根据实施方案1-14中任一项所述的TCR或其抗原结合片段,其中:
所述Vα和Vβ区分别包含SEQ ID NO:691和700的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:709和718的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:726和735的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:741和750的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:759和768的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:775和781的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:787和793的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:799和808的氨基酸序列;所述Vα和Vβ区分别包含SEQID NO:815和824的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:830和839的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:845和851的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:857和863的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:869和875的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:881和887的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:895和901的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:908和917的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:925和931的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:937和945的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:951和957的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:963和969的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:975和981的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:987和993的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:999和1008的氨基酸序列;或者所述Vα和Vβ区分别包含SEQ ID NO:1390和1380的氨基酸序列。
16.根据实施方案1-15中任一项所述的TCR或其抗原结合片段,其中所述α链还包含α恒定(Cα)区和/或所述β链还包含β恒定(Cβ)区。
17.根据实施方案16所述的TCR或其抗原结合片段,其中所述Cα和Cβ区是小鼠恒定区。
18.根据实施方案16或实施方案17所述的TCR或其抗原结合片段,其中:
所述Cα区包含SEQ ID NO:262、833、1012、1014、1015、1017、1018所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列;和/或
所述Cβ区包含SEQ ID NO:263、1013或1016所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列。
19.根据实施方案16所述的TCR或其抗原结合片段,其中所述Cα和Cβ区是人恒定区。
20.根据实施方案16或实施方案19所述的TCR或其抗原结合片段,其中:
所述Cα区包含SEQ ID NO:212、213、215、217、218、220或524中任一个所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列;和/或
所述Cβ区包含SEQ ID NO:214、216、631或889中任一个所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列。
21.根据实施方案1-20中任一项所述的TCR或其抗原结合片段,其中:
a)所述α链包含:
SEQ ID NO:687、705、722、737、755、771、783、795、811、826、841、853、865、877、891、904、921、933、947、959、971、983、995、1386中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQ ID NO:1049、1051、1055、1057、1059、1061、1063、1065、1067、1069、1071、1073、1075、1077、1079、1081、1083、1085、1087、1089、1091中任一个所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列;和/或
b)所述β链包含:
SEQ ID NO:696、714、731、746、764、777、789、804、820、835、847、859、871、883、897、913、927、941、953、965、977、989、1004或1376中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQ ID NO:1050、1052、1056、1058、1060、1062、1064、1066、1068、1070、1072、1074、1076、1078、1080、1082、1084、1086、1088、1090或1092所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列。
22.根据实施方案1-20中任一项所述的TCR或其抗原结合片段,其中:
所述α和β链分别包含SEQ ID NO:687和696的氨基酸序列;所述α和β链分别包含SEQ ID NO:705和714的氨基酸序列;所述α和β链分别包含SEQ IDNO:722和731的氨基酸序列;所述α和β链分别包含SEQ ID NO:737和746的氨基酸序列;所述α和β链分别包含SEQ IDNO:755和764的氨基酸序列;所述α和β链分别包含SEQ ID NO:771和777的氨基酸序列;所述α和β链分别包含SEQ ID NO:783和789的氨基酸序列;所述α和β链分别包含SEQ ID NO:795和804的氨基酸序列;所述α和β链分别包含SEQ ID NO:811和820的氨基酸序列;所述α和β链分别包含SEQ ID NO:826和835的氨基酸序列;所述α和β链分别包含SEQ ID NO:841和847的氨基酸序列;所述α和β链分别包含SEQ ID NO:853和859的氨基酸序列;所述α和β链分别包含SEQ ID NO:865和871的氨基酸序列;所述α和β链分别包含SEQ ID NO:877和883的氨基酸序列;所述α和β链分别包含SEQ ID NO:891和897的氨基酸序列;所述α和β链分别包含SEQID NO:904和913的氨基酸序列;所述α和β链分别包含SEQ ID NO:921和927的氨基酸序列;所述α和β链分别包含SEQ ID NO:933和941的氨基酸序列;所述α和β链分别包含SEQ ID NO:947和953的氨基酸序列;所述α和β链分别包含SEQ ID NO:959和965的氨基酸序列;所述α和β链分别包含SEQ ID NO:971和977的氨基酸序列;所述α和β链分别包含SEQ ID NO:983和989的氨基酸序列;所述α和β链分别包含SEQ ID NO:995和1004的氨基酸序列;或者所述α和β链分别包含SEQ ID NO:1386和1376的氨基酸序列。
23.根据实施方案1-19中任一项所述的TCR或其抗原结合片段,其中所述TCR或抗原结合片段在所述α链和/或β链中包含一种或多种修饰,使得当所述TCR或其抗原结合片段在细胞中表达时,所述TCRα链和β链与内源TCRα链和β链之间的错配频率降低,所述TCRα链和β链的表达增加,和/或所述TCRα链和β链的稳定性增加,各自与不含所述一种或多种修饰的TCR或其抗原结合片段在细胞中的表达相比。
24.根据实施方案23所述的TCR或其抗原结合片段,其中所述一种或多种修饰是在所述Cα区和/或所述Cβ区中的一个或多个氨基酸的置换、缺失或插入。
25.根据实施方案23或实施方案24所述的TCR或其抗原结合片段,其中所述一种或多种修饰包含一个或多个置换,以引入能够在所述α链与β链之间形成一个或多个非天然二硫桥的一个或多个半胱氨酸残基。
26.根据实施方案1-16、19和23-25中任一项所述的TCR或其抗原结合片段,所述TCR或其抗原结合片段包含Cα区,所述Cα区在对应于按照如SEQ ID NO:212、213、217、218或524所示编号的位置48的位置处或在对应于按照如SEQ ID NO:215或220所示编号的位置49的位置处包含半胱氨酸;和/或Cβ区,所述Cβ区在对应于按照如SEQ ID NO:214或216所示编号的位置57的位置处或在对应于按照如SEQ ID NO:631或889所示编号的位置58的位置处包含半胱氨酸。
27.根据实施方案16、19和23-26中任一项所述的TCR或其抗原结合片段,其中:
所述Cα区包含SEQ ID NO:196、198、200、201、203或525中任一个所示的氨基酸序列或与其具有至少90%序列同一性的包含能够与所述β链形成非天然二硫键的一个或多个半胱氨酸残基的氨基酸序列;和/或
所述Cβ区包含SEQ ID NO:197、199、632或890中任一个所示的氨基酸序列或与其具有至少90%序列同一性的含有能够与所述α链形成非天然二硫键的一个或多个半胱氨酸残基的氨基酸序列。
28.根据实施方案1-27中任一项所述的TCR或其抗原结合片段,其中所述TCR或其抗原结合片段由已经密码子优化的核苷酸序列编码。
29.根据实施方案1-19和23-28中任一项所述的TCR或其抗原结合片段,其中:
a)所述α链包含:
SEQ ID NO:688、706、723、738、756、772、784、796、812、827、842、854、866、878、892、905、922、934、948、960、972、984、996或1387中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQ ID NO:1129、1131、1133、1135、1137、1139、1141、1143、1145、1147、1149、1151、1153、1155、1157、1159、1161、1163、1165、1167、1169、1171、1173或1385中任一个所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列;和/或
b)所述β链包含:
SEQ ID NO:697、715、732、747、765、778、790、805、821、836、848、860、872、884、898、914、928、942、954、966、978、990、1005或1377中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQ ID NO:1130、1132、1134、1136、1138、1140、1142、1144、1146、1148、1150、1152、1154、1156、1158、1160、1162、1164、1166、1168、1170、1172、1174或1375所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列。
30.根据实施方案1-19和23-29中任一项所述的TCR或其抗原结合片段,其中:所述α和β链分别包含SEQ ID NO:688和697的氨基酸序列;所述α和β链分别包含SEQ ID NO:706和715的氨基酸序列;所述α和β链分别包含SEQ ID NO:723和732的氨基酸序列;所述α和β链分别包含SEQ ID NO:738和747的氨基酸序列;所述α和β链分别包含SEQ ID NO:756和765的氨基酸序列;所述α和β链分别包含SEQ ID NO:772和778的氨基酸序列;所述α和β链分别包含SEQ ID NO:784和790的氨基酸序列;所述α和β链分别包含SEQ ID NO:796和805的氨基酸序列;所述α和β链分别包含SEQ ID NO:812和821的氨基酸序列;所述α和β链分别包含SEQID NO:827和836的氨基酸序列;所述α和β链分别包含SEQ ID NO:842和848的氨基酸序列;所述α和β链分别包含SEQ ID NO:854和860的氨基酸序列;所述α和β链分别包含SEQ ID NO:866和872的氨基酸序列;所述α和β链分别包含SEQ ID NO:878和884的氨基酸序列;所述α和β链分别包含SEQ ID NO:892和898的氨基酸序列;所述α和β链分别包含SEQ ID NO:905和914的氨基酸序列;所述α和β链分别包含SEQ ID NO:922和928的氨基酸序列;所述α和β链分别包含SEQ ID NO:934和942的氨基酸序列;所述α和β链分别包含SEQ ID NO:948和954的氨基酸序列;所述α和β链分别包含SEQ ID NO:960和966的氨基酸序列;所述α和β链分别包含SEQ ID NO:972和978的氨基酸序列;所述α和β链分别包含SEQ ID NO:984和990的氨基酸序列;所述α和β链分别包含SEQ ID NO:996和1005的氨基酸序列;或者所述α和β链分别包含SEQ ID NO:1387和1377的氨基酸序列。
31.根据实施方案1-30中任一项所述的TCR或其抗原结合片段,其中所述α和/或β链还包含信号肽。
32.根据实施方案31所述的TCR或其抗原结合片段,其中:
所述α链包含含有SEQ ID NO:181、184、187、189、190、192、193、310、311中任一个所示的氨基酸序列的信号肽;和/或
所述β链包含含有SEQ ID NO:182、185、186、188、191或194中任一个所示的氨基酸序列的信号肽。
33.根据实施方案1-32中任一项所述的TCR或其抗原结合片段,所述TCR或其抗原结合片段是分离的或纯化的或者是重组的。
34.根据实施方案1-33中任一项所述的TCR或其抗原结合片段,所述TCR或其抗原结合片段是人的。
35.根据实施方案1-34中任一项所述的TCR或其抗原结合片段,所述TCR或其抗原结合片段是单克隆的。
36.根据实施方案1-35中任一项所述的TCR或其抗原结合片段,其中所述TCR或其抗原结合片段是单链。
37.根据实施方案1-35中任一项所述的TCR或其抗原结合片段,其中所述TCR或其抗原结合片段包含两条链。
38.根据实施方案1-37中任一项所述的TCR或其抗原结合片段,其中抗原特异性是至少部分地CD8非依赖性的。
39.根据实施方案9-38中任一项所述的TCR或抗原结合片段,其中所述MHC分子是HLA-A2分子。
40.一种核酸分子,所述核酸分子编码根据实施方案1-39中任一项所述的TCR或其抗原结合片段或者所述TCR或其抗原结合片段的α或β链。
41.根据实施方案40所述的核酸分子,其包含编码α链的核苷酸序列和/或编码β链的核苷酸序列,其中:
编码α链的所述核苷酸序列包含SEQ ID NO:1049、1051、1055、1057、1059、1061、1063、1065、1067、1069、1071、1073、1075、1077、1079、1081、1083、1085、1087、1089、1091中任一个所示的序列或与其具有至少90%序列同一性的核苷酸序列;
编码β链的所述核苷酸序列包含SEQ ID NO:1050、1052、1056、1058、1060、1062、1064、1066、1068、1070、1072、1074、1076、1078、1080、1082、1084、1086、1088、1090或1092所示的序列或与其具有至少90%序列同一性的核苷酸序列。
42.根据实施方案40所述的核酸分子,其中所述核苷酸序列是经密码子优化的。
43.根据实施方案40或实施方案42所述的核酸分子,其包含编码α链的核苷酸序列和/或编码β链的核苷酸序列,其中:
编码α链的所述核苷酸序列包含SEQ ID NO:1129、1131、1133、1135、1137、1139、1141、1143、1145、1147、1149、1151、1153、1155、1157、1159、1161、1163、1165、1167、1169、1171、1173或1385中任一个所示的序列或与其具有至少90%序列同一性的核苷酸序列;
编码β链的所述核苷酸序列包含SEQ ID NO:1130、1132、1134、1136、1138、1140、1142、1144、1146、1148、1150、1152、1154、1156、1158、1160、1162、1164、1166、1168、1170、1172、1174或1375所示的序列或与其具有至少90%序列同一性的核苷酸序列。
44.根据实施方案40-43中任一项所述的核酸分子,其中编码所述α链的核苷酸序列和编码所述β链的核苷酸序列由引起核糖体跳跃的肽序列隔开。
45.根据实施方案44所述的核酸分子,其中引起核糖体跳跃的所述肽是P2A或T2A肽和/或包含SEQ ID NO:204或211所示的氨基酸序列。
46.根据实施方案40-45中任一项所述的核酸分子,所述核酸分子包含SEQ ID NO:448、449、450、451、452、453、454、455、456、457、458、459、460、461、462、463、464、465、466、467、468、469、470、471、472或1382中任一个所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列。
47.一种T细胞受体(TCR)或其抗原结合片段,所述T细胞受体(TCR)或其抗原结合片段包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链,其中:
所述Vα区包含SEQ ID NO:477、492、504、510、522、536、554、569、587、599、611、623、637、649、661或676中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列;和/或
所述Vβ区包含SEQ ID NO:483、498、516、530、545、560、578、593、605、617、629、643、655、667或685中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列。
48.根据实施方案47所述的TCR或其抗原结合片段,其中所述Vα区包含含有氨基酸序列AX2RX4AX6NNDMR的互补决定区3(CDR-3),其中X2是V或M;X4是P或D;并且X6是N或R(SEQID NO:1221)。
49.根据实施方案47或实施方案48所述的TCR或其抗原结合片段,其中:
所述Vβ区包含含有氨基酸序列ASSX4WGX7SNQPX12H的互补决定区3(CDR-3),其中X4是L、F或P;X7是R或Q;并且X12是Q或L(SEQ ID NO:1216);或者
所述Vβ区包含含有氨基酸序列ASSX4X5X6X7X8SGNTIY的互补决定区3(CDR-3),其中X4是L或R;X5是W或Q;X6是G或P;X7是R或S;并且X8是S或空(SEQ ID NO:1217)。
50.一种T细胞受体(TCR)或其抗原结合片段,所述T细胞受体(TCR)或其抗原结合片段包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链,其中所述Vα区包含含有氨基酸序列AX2RX4AX6NNDMR的互补决定区3(CDR-3),其中X2是V或M;X4是P或D;并且X6是N或R(SEQID NO:1221)。
51.一种T细胞受体(TCR)或其抗原结合片段,所述T细胞受体(TCR)或其抗原结合片段包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链,其中:
所述Vβ区包含含有氨基酸序列ASSX4WGX7SNQPX12H的互补决定区3(CDR-3),其中X4是L、F或P;X7是R或Q;并且X12是Q或L(SEQ ID NO:1216);或者
所述Vβ区包含含有氨基酸序列ASSX4X5X6X7X8SGNTIY的互补决定区3(CDR-3),其中X4是L或R;X5是W或Q;X6是G或P;X7是R或S;并且X8是S或空(SEQ ID NO:1217)。
52.一种T细胞受体(TCR)或其抗原结合片段,所述T细胞受体(TCR)或其抗原结合片段包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链,其中:
所述Vα区包含SEQ ID NO:478、493、505、511、523、539、555、572、588、600、612、624、638、650、662或679或与其展现出至少60%、65%、70%、75%、80%、85%、90%或95%序列同一性的序列中任一个所示的互补决定区3(CDR-3);
所述Vβ区包含SEQ ID NO:486、499、517、531、548、563、581、594、606、618、630、644、656、670或686或与其展现出至少60%、65%、70%、75%、80%、85%、90%或95%序列同一性的序列中任一个所示的互补决定区3(CDR-3)。
53.根据实施方案47-52中任一项所述的TCR或其抗原结合片段,其中所述Vα区包含:
包含氨基酸序列X1X2X3X4X5X6(SEQ ID NO:1191)的互补决定区1(CDR-1),其中X1是N、S、D、T或V;X2是S、V、R、T或I;X3是M、F、G、S、N、A、L、V或P;X4是F、S、N、A或空;X5是D、S、Q、Y、N、V、T或P;并且X6是Y、S、R、N、G或T;和/或
包含氨基酸序列X1X2X3X4X5X6X7X8(SEQ ID NO:1192)的互补决定区2(CDR-2),其中X1是I、V、L、G、N、T、Y或M;X2是S、V、Y、L、P、F、I或T;X3是S、Y、K、L、T或F;X4是I、G、N、A、S或空;X5是S、D或空;X6是K、G、N、S、D、T或E;X7是D、E、G、A、K、L或N;并且X8是K、V、D、P、N、T、L或M。
54.根据实施方案47-53中任一项所述的TCR或其抗原结合片段,其中所述Vβ区包含:
包含氨基酸序列SX2X3X4X5(SEQ ID NO:1203)的互补决定区1(CDR-1),其中X2是G或N;X3是H或D;X4是T、L、N或V;并且X5是A、S、Y或T;和/或
包含氨基酸序列X1X2X3X4X5X6(SEQ ID NO:1204)的互补决定区2(CDR-2),其中X1是F或Y;X2是Q、Y或N;X3是G、N、R或Y;X4是N、G、E或T;X5是S、E、A或G;并且X6是A、E、I或Q。
55.根据实施方案47-54中任一项所述的TCR或其抗原结合片段,其中所述TCR或其抗原结合片段结合至或识别在MHC分子的背景下的人乳头瘤病毒(HPV)16E6的肽表位,所述肽表位是或包含E6(29-38)TIHDIILECV(SEQ ID NO:233)。
56.根据实施方案47-55中任一项所述的TCR或抗原结合片段,其中:
所述Vα区包含含有SEQ ID NO:478、493、505、511、523、539、555、572、588、600、612、624、638、650、662或679中任一个所示的氨基酸序列的互补决定区3(CDR-3)、或者SEQID NO:477、492、504、510、522、536、554、569、587、599、611、623、637、649、661或676中任一个所示的氨基酸序列内所含的CDR3;和/或
所述Vβ区包含含有SEQ ID NO:486、499、517、531、548、563、581、594、606、618、630、644、656、670或686中任一个所示的氨基酸序列的互补决定区3(CDR-3)、或者SEQ IDNO:483、498、516、530、545、560、578、593、605、617、629、643、655、667或685中任一个所示的氨基酸序列内所含的CDR3。
57.根据实施方案47-56中任一项所述的TCR或其抗原结合片段,其中所述Vα区还包含:
包含SEQ ID NO:136、161、165、537、570、142、171或677中任一个所示的氨基酸序列的互补决定区1(CDR-1);和/或
包含SEQ ID NO:137、162、166、538、571、143、172或678中任一个所示的氨基酸序列的互补决定区2(CDR-2)。
58.根据实施方案47-56中任一项所述的TCR或其抗原结合片段,其中所述Vβ区包含:
包含SEQ ID NO:484、148、546、561、579、168、668或154中任一个所示的氨基酸序列的互补决定区1(CDR-1);和/或
包含SEQ ID NO:485、149、547、562、580、169、669或155中任一个所示的氨基酸序列的互补决定区2(CDR-2)。
59.根据实施方案47-58中任一项所述的TCR或其抗原结合片段,其中:
所述Vα区包含分别包含SEQ ID NO:136、137和478的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:484、485和486的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:161、162和493的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和499的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:165、166和505的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和499的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:161、162和511的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和517的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:136、137和523的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和531的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:537、538和539的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:546、547和548的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:136、137和555的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:561、562和563的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:570、571和572的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:579、580和581的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:136、137和600的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和594的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:136、137和600的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和606的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:136、137和612的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和618的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:136、137和624的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:168、169和630的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:142、143和638的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:561、562和644的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:171、172和650的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和656的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:136、137和662的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:668、669和670的氨基酸序列的CDR-1、CDR-2和CDR-3;或者
所述Vα区包含分别包含SEQ ID NO:677、678和679的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和686的氨基酸序列的CDR-1、CDR-2和CDR-3。
60.根据实施方案47-59中任一项所述的TCR或其抗原结合片段,其中:
所述Vα区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:477、492、504、510、522、536、554、569、587、599、611、623、637、649、661或676中任一个所示的Vα区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列;和/或
所述Vβ区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:483、498、516、530、545、560、578、593、605、617、629、643、655、667或685中任一个所示的Vβ区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列。
61.根据实施方案47-60中任一项所述的TCR或其抗原结合片段,其中:所述Vα和Vβ区分别包含SEQ ID NO:477和483的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:492和498的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:504和498的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:510和516的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:522和530的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:536和545的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:554和560的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:569和578的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:587和593的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:599和605的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:611和617的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:623和629的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:637和643的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:649和655的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:661和667的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:676和685的氨基酸序列。
62.根据实施方案47-61中任一项所述的TCR或其抗原结合片段,其中所述α链还包含α恒定(Cα)区和/或所述β链还包含β恒定(Cβ)区。
63.根据实施方案62所述的TCR或其抗原结合片段,其中所述Cα和Cβ区是小鼠恒定区。
64.根据实施方案62或实施方案63所述的TCR或其抗原结合片段,其中:
所述Cα区包含SEQ ID NO:262、833、1012、1014、1015、1017、1018所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列;和/或
所述Cβ区包含SEQ ID NO:263、1013或1016所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列。
65.根据实施方案62所述的TCR或其抗原结合片段,其中所述Cα和Cβ区是人恒定区。
66.根据实施方案62或实施方案65所述的TCR或其抗原结合片段,其中:
所述Cα区包含SEQ ID NO:212、213、215、217、218、220或524中任一个所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列;和/或
所述Cβ区包含SEQ ID NO:214、216、631或889中任一个所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列。
67.根据实施方案47-66中任一项所述的TCR或其抗原结合片段,其中:
a)所述α链包含:
SEQ ID NO:473、488、500、506、518、532、550、565、583、595、607、619、633、645、657或672中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQ ID NO:389、430、1019、1021、1023、1025、1027、1029、1031、1033、1035、1037、1039、1041、1043或1045中任一个所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列;和/或
b)所述β链包含:
SEQ ID NO:479、494、512、526、541、556、574、589、601、613、625、639、651、663或681中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQID NO:390、431、1020、1022、1024、1026、1028、1030、1032、1034、1036、1038、1040、1042、1044或1046所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列。
68.根据实施方案47-67中任一项所述的TCR或其抗原结合片段,其中:所述α和β链分别包含SEQ ID NO:473和479的氨基酸序列;所述α和β链分别包含SEQ ID NO:488和494的氨基酸序列;所述α和β链分别包含SEQ ID NO:500和494的氨基酸序列;所述α和β链分别包含SEQ ID NO:506和512的氨基酸序列;所述α和β链分别包含SEQ ID NO:518和526的氨基酸序列;所述α和β链分别包含SEQ ID NO:532和541的氨基酸序列;所述α和β链分别包含SEQIDNO:550和556的氨基酸序列;所述α和β链分别包含SEQ ID NO:565和574的氨基酸序列;所述α和β链分别包含SEQ ID NO:583和589的氨基酸序列;所述α和β链分别包含SEQ ID NO:595和601的氨基酸序列;所述α和β链分别包含SEQ ID NO:607和613的氨基酸序列;所述α和β链分别包含SEQ ID NO:619和625的氨基酸序列;所述α和β链分别包含SEQ ID NO:633和639的氨基酸序列;所述α和β链分别包含SEQ ID NO:645和651的氨基酸序列;所述α和β链分别包含SEQ ID NO:657和663的氨基酸序列;或者所述α和β链分别包含SEQ ID NO:672和681的氨基酸序列。
69.根据实施方案47-68中任一项所述的TCR或其抗原结合片段,其中所述TCR或抗原结合片段在所述α链和/或β链中包含一种或多种修饰,使得当所述TCR或其抗原结合片段在细胞中表达时,所述TCRα链和β链与内源TCRα链和β链之间的错配频率降低,所述TCRα链和β链的表达增加,和/或所述TCRα链和β链的稳定性增加,各自与不含所述一种或多种修饰的TCR或其抗原结合片段在细胞中的表达相比。
70.根据实施方案69所述的TCR或其抗原结合片段,其中所述一种或多种修饰是在所述Cα区和/或所述Cβ区中的一个或多个氨基酸的置换、缺失或插入。
71.根据实施方案69或实施方案70所述的TCR或其抗原结合片段,其中所述一种或多种修饰包含一个或多个置换,以引入能够在所述α链与β链之间形成一个或多个非天然二硫桥的一个或多个半胱氨酸残基。
72.根据实施方案47-62、65和69-71中任一项所述的TCR或其抗原结合片段,所述TCR或其抗原结合片段包含Cα区,所述Cα区在对应于按照如SEQID NO:212、213、217、218或524所示编号的位置48的位置处或在对应于按照如SEQ ID NO:215或220所示编号的位置49的位置处包含半胱氨酸;和/或Cβ区,所述Cβ区在对应于按照如SEQ ID NO:214或216所示编号的位置57的位置处或在对应于按照如SEQ ID NO:631或889所示编号的位置58的位置处包含半胱氨酸。
73.根据实施方案62、65和69-72中任一项所述的TCR或其抗原结合片段,其中:
所述Cα区包含SEQ ID NO:196、198、200、201、203或525中任一个所示的氨基酸序列或与其具有至少90%序列同一性的包含能够与所述β链形成非天然二硫键的一个或多个半胱氨酸残基的氨基酸序列;和/或
所述Cβ区包含SEQ ID NO:197、199、632或890中任一个所示的氨基酸序列或与其具有至少90%序列同一性的含有能够与所述α链形成非天然二硫键的一个或多个半胱氨酸残基的氨基酸序列。
74.根据实施方案47-73中任一项所述的TCR或其抗原结合片段,其中所述TCR或其抗原结合片段由已经密码子优化的核苷酸序列编码。
75.根据实施方案47-62、65和69-74中任一项所述的TCR或其抗原结合片段,其中:
a)所述α链包含:
SEQ ID NO:474、489、501、507、519、533、551、566、584、596、608、620、634、646、658或673中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQ ID NO:1097、1099、1101、1103、1105、1107、1109、1111、1113、1115、1117、1119、1121、1123、1125或1127中任一个所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列;和/或
b)所述β链包含:
SEQ ID NO:480、495、513、527、542、557、575、590、602、614、626、640、652、664或682中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQID NO:1098、1100、1102、1104、1106、1108、1110、1112、1114、1116、1118、1120、1122、1124、1126或1128所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列。
76.根据实施方案47-62、65和69-75中任一项所述的TCR或其抗原结合片段,其中所述α和β链分别包含SEQ ID NO:474和482的氨基酸序列;所述α和β链分别包含SEQ ID NO:489和497的氨基酸序列;所述α和β链分别包含SEQ ID NO:501和497的氨基酸序列;所述α和β链分别包含SEQ ID NO:507和515的氨基酸序列;所述α和β链分别包含SEQ ID NO:519和529的氨基酸序列;所述α和β链分别包含SEQ ID NO:533和544的氨基酸序列;所述α和β链分别包含SEQ ID NO:551和559的氨基酸序列;所述α和β链分别包含SEQ IDNO:566和577的氨基酸序列;所述α和β链分别包含SEQ ID NO:584和592的氨基酸序列;所述α和β链分别包含SEQ ID NO:596和604的氨基酸序列;所述α和β链分别包含SEQ ID NO:608和616的氨基酸序列;所述α和β链分别包含SEQ ID NO:620和628的氨基酸序列;所述α和β链分别包含SEQ IDNO:634和642的氨基酸序列;所述α和β链分别包含SEQ ID NO:646和654的氨基酸序列;所述α和β链分别包含SEQ ID NO:658和666的氨基酸序列;或者所述α和β链分别包含SEQ ID NO:673和684的氨基酸序列。
77.根据实施方案47-76中任一项所述的TCR或其抗原结合片段,其中所述α和/或β链还包含信号肽。
78.根据实施方案77所述的TCR或其抗原结合片段,其中:
所述α链包含含有SEQ ID NO:181、184、187、189、190、192、193、310、311中任一个所示的氨基酸序列的信号肽;和/或
所述β链包含含有SEQ ID NO:182、185、186、188、191或194中任一个所示的氨基酸序列的信号肽。
79.根据实施方案47-78中任一项所述的TCR或其抗原结合片段,所述TCR或其抗原结合片段是分离的或纯化的或者是重组的。
80.根据实施方案47-79中任一项所述的TCR或其抗原结合片段,所述TCR或其抗原结合片段是人的。
81.根据实施方案47-80中任一项所述的TCR或其抗原结合片段,所述TCR或其抗原结合片段是单克隆的。
82.根据实施方案47-81中任一项所述的TCR或其抗原结合片段,其中所述TCR或其抗原结合片段是单链。
83.根据实施方案47-81中任一项所述的TCR或其抗原结合片段,其中所述TCR或其抗原结合片段包含两条链。
84.根据实施方案47-83中任一项所述的TCR或其抗原结合片段,其中抗原特异性是至少部分地CD8非依赖性的。
85.根据实施方案47-84中任一项所述的TCR或抗原结合片段,其中所述MHC分子是HLA-A2分子。
86.一种核酸分子,所述核酸分子编码根据实施方案47-85中任一项所述的TCR或其抗原结合片段或者所述TCR或其抗原结合片段的α或β链。
87.根据实施方案86所述的核酸分子,其包含编码α链的核苷酸序列和/或编码β链的核苷酸序列,其中:
编码α链的所述核苷酸序列包含SEQ ID NO:389、430、1019、1021、1023、1025、1027、1029、1031、1033、1035、1037、1039、1041、1043或1045中任一个所示的序列或与其具有至少90%序列同一性的核苷酸序列;
编码β链的所述核苷酸序列包含SEQ ID NO:390、431、1020、1022、1024、1026、1028、1030、1032、1034、1036、1038、1040、1042、1044或1046所示的序列或与其具有至少90%序列同一性的核苷酸序列。
88.根据实施方案86所述的核酸分子,其中所述核苷酸序列是经密码子优化的。
89.根据实施方案86或实施方案88所述的核酸分子,其包含编码α链的核苷酸序列和/或编码β链的核苷酸序列,其中:
编码α链的所述核苷酸序列包含SEQ ID NO:1097、1099、1101、1103、1105、1107、1109、1111、1113、1115、1117、1119、1121、1123、1125或1127中任一个所示的序列或与其具有至少90%序列同一性的核苷酸序列;
编码β链的所述核苷酸序列包含SEQ ID NO:1098、1100、1102、1104、1106、1108、1110、1112、1114、1116、1118、1120、1122、1124、1126或1128所示的序列或与其具有至少90%序列同一性的核苷酸序列。
90.根据实施方案86-89中任一项所述的核酸分子,其中编码所述α链的核苷酸序列和编码所述β链的核苷酸序列由引起核糖体跳跃的肽序列隔开。
91.根据实施方案90所述的核酸分子,其中引起核糖体跳跃的所述肽是P2A或T2A肽和/或包含SEQ ID NO:204或211所示的氨基酸序列。
92.根据实施方案86-91中任一项所述的核酸分子,所述核酸分子包含SEQ ID NO:432、433、434、435、436、437、438、439、440、441、442、443、444、445、446或447中任一个所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列。
93.根据实施方案40-46和86-92中任一项所述的核酸分子,其中所述核酸分子是合成的。
94.根据实施方案40-46和86-93中任一项所述的核酸分子,其中所述核酸分子是cDNA。
95.一种多核苷酸,其包含:
(a)编码根据实施方案1-39和47-85中任一项所述的TCR或其抗原结合部分的核酸序列或者根据实施方案40-46和86-94中任一项所述的核酸分子,以及
(b)与所述核酸序列连接的一个或多个同源臂,其中所述一个或多个同源臂包含与T细胞受体α恒定区(TRAC)基因座的开放阅读框的一个或多个区域同源的序列。
96.一种多核苷酸,其包含:
(a)编码T细胞受体(TCR)的一部分的核酸序列,所述核酸序列编码(i)包含根据实施方案1-14、21-23、28-39、47-61、67-69和74-85中任一项所述的TCR或其抗原结合片段的可变β(Vβ)和恒定β(Cβ)的T细胞受体β(TCRβ)链;和(ii)包含根据实施方案1-14、21-23、28-39、47-61、67-69和74-85中任一项所述的TCR或其抗原结合片段的可变α(Vα)的T细胞受体α(TCRα)链的一部分,其中所述TCRα链的所述部分少于全长TCRα链,以及
(b)与所述核酸序列连接的一个或多个同源臂,其中所述一个或多个同源臂包含与T细胞受体α恒定区(TRAC)基因座的开放阅读框的一个或多个区域同源的序列。
97.根据实施方案96所述的多核苷酸,其中所述TCRα链包含恒定α(Cα),其中当所述TCR或其抗原结合片段从引入了所述多核苷酸的细胞表达时,所述Cα的至少一部分由所述内源TRAC基因座的开放阅读框或其部分序列编码。
98.根据实施方案96或实施方案97所述的多核苷酸,其中(a)的所述核酸序列以及所述一个或多个同源臂之一一起包含编码少于天然Cα的全长的Cα的核苷酸序列,其中当所述TCR或其抗原结合片段从引入了所述多核苷酸的细胞表达时,所述Cα的至少一部分由所述内源TRAC基因座的开放阅读框或其部分序列编码。
99.根据实施方案96-98中任一项所述的多核苷酸,其中编码所述TCRβ链的核酸序列在编码所述TCRα链的所述部分的核酸序列的上游。
100.根据实施方案96-99中任一项所述的多核苷酸,其中(a)的所述核酸序列不包含内含子。
101.根据实施方案96-100中任一项所述的多核苷酸,其中(a)的所述核酸序列是对T细胞、任选地人T细胞的内源基因组TRAC基因座的开放阅读框外源或异源的序列。
102.根据实施方案96-101中任一项所述的多核苷酸,其中(a)的所述核酸序列与所述一个或多个同源臂中所含的TRAC基因座的开放阅读框的一个或多个外显子或其部分序列、任选地外显子1或其部分序列符合读框。
103.根据实施方案97-102中任一项所述的多核苷酸,其中所述Cα的一部分由所述内源TRAC基因座的开放阅读框或其部分序列编码,并且所述Cα的另外的部分由(a)的所述核酸序列编码,其中Cα的所述另外的部分少于天然Cα的全长。
104.根据实施方案103所述的多核苷酸,其中所述Cα的所述另外的部分由起始于SEQ ID NO:348所示的序列的残基3直至残基3155的核苷酸序列或其一个或多个外显子或者与起始于SEQ ID NO:348所示的序列的残基3直至残基3155的核苷酸序列或其一个或多个外显子展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列或者其部分序列编码。
105.根据实施方案103或实施方案104所述的多核苷酸,其中所述Cα的所述另外的部分由SEQ ID NO:1364所示的序列或者与SEQ ID NO:1364展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列或者其部分序列编码。
106.根据实施方案103-105中任一项所述的多核苷酸,其中与天然Cα区和/或天然Cβ区相比,由(a)的所述核酸序列编码的Cα和/或Cβ区的所述另外的部分包含一种或多种修饰,任选地一个或多个氨基酸的置换、缺失或插入,任选地所述一种或多种修饰引入能够在所述α链与β链之间形成一个或多个非天然二硫桥的一个或多个半胱氨酸残基。
107.根据实施方案95-106中任一项所述的多核苷酸,其中所述一个或多个同源臂包含5'同源臂和/或3'同源臂。
108.根据实施方案95-107中任一项所述的多核苷酸,其中所述5'同源臂包含:
a)包含与SEQ ID NO:1343所示的序列展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列的150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个连续核苷酸的序列;
b)包含SEQ ID NO:1343所示的序列的150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个连续核苷酸的序列;或者
c)SEQ ID NO:1343所示的序列。
109.根据实施方案95-108中任一项所述的多核苷酸,其中所述3'同源臂包含:
a)包含与SEQ ID NO:1344所示的序列展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列的150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个连续核苷酸的序列;
b)包含SEQ ID NO:1344所示的序列的150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个连续核苷酸的序列;或者
c)SEQ ID NO:1344所示的序列。
110.一种多核苷酸,其包含:
(a)编码根据实施方案1-39和47-86中任一项所述的TCR或其抗原结合部分的核酸序列或者根据实施方案40-46和86-92中任一项所述的核酸分子,以及
(b)与所述核酸序列连接的一个或多个同源臂,其中所述一个或多个同源臂包含与T细胞受体β恒定区(TRBC)基因座的开放阅读框的一个或多个区域同源的序列。
111.一种多核苷酸,其包含:
(a)编码T细胞受体(TCR)的一部分的核酸序列,所述核酸序列编码(i)包含根据实施方案1-14、21-23、28-39、47-61、67-69和74-85中任一项所述的TCR或其抗原结合片段的可变α(Vα)和恒定α(Cα)的T细胞受体α(TCRα)链;和(ii)包含根据实施方案1-14、21-23、28-39、47-61、67-69和74-85中任一项所述的TCR或其抗原结合片段的可变β(Vβ)的T细胞受体β(TCRβ)链的一部分,其中所述TCRβ链的所述部分少于全长TCRβ链,以及
(b)与所述核酸序列连接的一个或多个同源臂,其中所述一个或多个同源臂包含与T细胞受体β恒定区(TRBC)基因座的开放阅读框的一个或多个区域同源的序列。
112.根据实施方案111所述的多核苷酸,其中所述TCRβ链包含恒定β(Cβ),其中当所述TCR或其抗原结合片段从引入了所述多核苷酸的细胞表达时,所述Cβ的至少一部分由所述内源TRBC基因座的开放阅读框或其部分序列编码。
113.根据实施方案111或实施方案112所述的多核苷酸,其中(a)的所述核酸序列以及所述一个或多个同源臂之一一起包含编码少于天然Cβ的全长的Cβ的核苷酸序列,其中当所述TCR或其抗原结合片段从引入了所述多核苷酸的细胞表达时,所述Cβ的至少一部分由所述内源TRAC基因座的开放阅读框或其部分序列编码。
114.根据实施方案111-113中任一项所述的多核苷酸,其中编码所述TCRα链的核酸序列在编码所述TCRβ链的所述部分的核酸序列的上游。
115.根据实施方案111-114中任一项所述的多核苷酸,其中(a)的所述核酸序列不包含内含子。
116.根据实施方案111-115中任一项所述的多核苷酸,其中(a)的所述核酸序列是对T细胞、任选地人T细胞的内源基因组TRBC基因座的开放阅读框外源或异源的序列。
117.根据实施方案111-116中任一项所述的多核苷酸,其中(a)的所述核酸序列与所述一个或多个同源臂中所含的TRBC基因座的开放阅读框的一个或多个外显子或其部分序列、任选地外显子1或其部分序列符合读框。
118.根据实施方案111-117中任一项所述的多核苷酸,其中所述Cβ的一部分由所述内源TRBC基因座的开放阅读框或其部分序列编码,并且所述Cβ的另外的部分由(a)的所述核酸序列编码,其中Cβ的所述另外的部分少于天然Cβ的全长。
119.根据实施方案118所述的多核苷酸,其中所述Cβ的所述另外的部分由以下编码:
起始于SEQ ID NO:349所示的序列的残基3直至残基1445的核苷酸序列或其一个或多个外显子或者与起始于SEQ ID NO:349所示的序列的残基3直至残基1445的核苷酸序列或其一个或多个外显子展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列或者其部分序列;或者
起始于SEQ ID NO:1047所示的序列的残基3直至残基1486的核苷酸序列或其一个或多个外显子或者与起始于SEQ ID NO:1047所示的序列的残基3直至残基1486的核苷酸序列或其一个或多个外显子展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列或者其部分序列。
120.根据实施方案118或实施方案119所述的多核苷酸,其中与天然Cβ区和/或天然Cα区相比,由(a)的所述核酸序列编码的Cβ和/或Cα区的所述另外的部分包含一种或多种修饰,任选地一个或多个氨基酸的置换、缺失或插入,任选地所述一种或多种修饰引入能够在所述α链与β链之间形成一个或多个非天然二硫桥的一个或多个半胱氨酸残基。
121.根据实施方案110-120中任一项所述的多核苷酸,其中所述一个或多个同源臂包含5'同源臂和/或3'同源臂。
122.根据实施方案95-121中任一项所述的多核苷酸,其中(a)的所述核酸序列包含一个或多个多顺反子元件。
123.根据实施方案122所述的多核苷酸,其中所述一个或多个多顺反子元件位于编码所述TCRα或其部分的核酸序列与编码所述TCRβ或其部分的核酸序列之间。
124.根据实施方案122或实施方案123所述的多核苷酸,其中所述一个或多个多顺反子元件在编码所述TCR或所述TCR的一部分的核酸序列或编码所述TCR的核酸分子的上游。
125.根据实施方案122-124中任一项所述的多核苷酸,其中所述一个或多个多顺反子元件是或包含核糖体跳跃序列,任选地其中所述核糖体跳跃序列是T2A、P2A、E2A或F2A元件。
126.根据实施方案95-125中任一项所述的多核苷酸,其中(a)的所述核酸序列包含一个或多个异源或调节控制元件,所述元件可操作地连接以控制当从引入了所述多核苷酸的细胞表达时所述TCR的表达。
127.根据实施方案126所述的多核苷酸,其中所述一个或多个异源调节或控制元件包含启动子、增强子、内含子、多腺苷酸化信号、Kozak共有序列、剪接受体序列和/或剪接供体序列。
128.根据实施方案126或实施方案127所述的多核苷酸,其中所述异源调节或控制元件包含异源启动子,任选地人延伸因子1α(EF1α)启动子或MND启动子或其变体。
129.根据实施方案95-128中任一项所述的多核苷酸,其是线性多核苷酸,任选地双链多核苷酸或单链多核苷酸。
130.一种载体,其包含根据实施方案40-46和86-94中任一项所述的核酸分子或根据实施方案95-129中任一项所述的多核苷酸。
131.根据实施方案130所述的载体,其中所述载体是表达载体。
132.根据实施方案130或实施方案131所述的载体,其中所述载体是病毒载体。
133.根据实施方案132所述的载体,其中所述病毒载体是逆转录病毒载体。
134.根据实施方案132或实施方案133所述的载体,其中所述病毒载体是慢病毒载体。
135.根据实施方案134所述的载体,其中所述慢病毒载体源自HIV-1。
137.根据实施方案132所述的载体,其中所述病毒载体是AAV载体。
138根据实施方案137所述的载体,其中所述AAV载体选自AAV1、AAV2、AAV3、AAV4、AAV5、AAV6、AAV7或AAV8载体。
139.一种工程化细胞,其包含根据实施方案40-46和86-94中任一项所述的核酸分子、根据实施方案95-129中任一项所述的多核苷酸或根据实施方案130-138中任一项所述的载体。
140.一种工程化细胞,所述工程化细胞包含根据实施方案1-39和47-85中任一项所述的TCR或其抗原结合片段,任选地根据实施方案1-39和47-85中任一项所述的重组TCR或抗原结合片段。
141.根据实施方案139或实施方案140所述的工程化细胞,其包含内源T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏。
142.根据实施方案141所述的工程化细胞,其中所述TRBC基因是T细胞受体β恒定区1(TRBC1)或T细胞受体β恒定区2(TRBC2)基因之一或两者。
143.根据实施方案141或实施方案142所述的工程化细胞,其中所述工程化细胞不含有连续的TRAC和/或TRBC基因;不含有TRAC和/或TRBC基因;不含有功能性TRAC和/或TRBC基因;和/或不表达内源TRAC或TRBC的基因产物,不以可检测的水平表达内源TRAC或TRBC的基因产物,或表达少于野生型水平的20%、15%、10%、5%、4%、3%、2%或1%的内源TRAC或TRBC的基因产物。
144.一种工程化细胞,所述工程化细胞包含TCR或其抗原结合片段,任选地重组TCR或其抗原结合片段,其中:
(1)所述细胞包含T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏和/或不表达内源TRAC或TRBC的基因产物,或不以可检测的水平表达内源TRAC或TRBC的基因产物,或表达少于野生型水平的20%、15%、10%、5%、4%、3%、2%或1%的内源TRAC或TRBC的基因产物;并且
(2)所述TCR或其抗原结合片段或者所述重组TCR或其抗原结合片段包含根据实施方案1-39和47-85中任一项所述的TCR或其抗原结合片段,任选地根据实施方案1-39和47-85中任一项所述的重组TCR或抗原结合片段。
145.一种工程化细胞,所述工程化细胞包含TCR或其抗原结合片段,任选地重组TCR或其抗原结合片段,其中:
(1)所述细胞包含T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏和/或不表达内源TRAC或TRBC的基因产物,或不以可检测的水平表达内源TRAC或TRBC的基因产物,或表达少于野生型水平的20%、15%、10%、5%、4%、3%、2%或1%的内源TRAC或TRBC的基因产物;并且
(2)所述TCR或其抗原结合片段或者所述重组TCR或其抗原结合片段包含:
(a)包含SEQ ID NO:117、119或295中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列的可变α(Vα)区和包含SEQ ID NO:118、120或296中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列的可变β(Vβ)区;和/或
(b)包含含有SEQ ID NO:153、159或301中任一个所示的氨基酸序列的互补决定区3(CDR-3)或SEQ ID NO:117、119或295中任一个所示的氨基酸序列内所含的CDR3的Vα区和包含含有SEQ ID NO:156或160中任一个所示的氨基酸序列的互补决定区3(CDR-3)或SEQID NO:118、120或296中任一个所示的氨基酸序列内所含的CDR3的Vβ区。
146.根据实施方案145所述的工程化细胞,其中:
所述Vα区还包含含有SEQ ID NO:151或157中任一个所示的氨基酸序列的互补决定区1(CDR-1);和/或含有SEQ ID NO:152或158中任一个所示的氨基酸序列的互补决定区2(CDR-2);和/或
所述Vβ区还包含含有SEQ ID NO:154所示的氨基酸序列的互补决定区1(CDR-1);和/或含有SEQ ID NO:155所示的氨基酸序列的互补决定区2(CDR-2)。
147.根据实施方案145或实施方案146所述的工程化细胞,其中所述Vα区和Vβ区包含:
分别包含SEQ ID NO:151、152和153的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和156的氨基酸序列的CDR-1、CDR-2和CDR-3;
分别包含SEQ ID NO:157、158和159的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和160的氨基酸序列的CDR-1、CDR-2和CDR-3;或者
分别包含SEQ ID NO:151、152和301的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和156的氨基酸序列的CDR-1、CDR-2和CDR-3。
148.根据实施方案145-147中任一项所述的工程化细胞,其中:
所述Vα区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:117、119或295中任一个所示的Vα区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列;和/或
所述Vβ区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:118、120或296中任一个所示的Vβ区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列。
149.根据实施方案145-148中任一项所述的工程化细胞:
所述Vα和Vβ区分别包含SEQ ID NO:117和118或296的氨基酸序列;
所述Vα和Vβ区分别包含SEQ ID NO:119和120的氨基酸序列;或者
所述Vα和Vβ区分别包含SEQ ID NO:295和118或296的氨基酸序列。
150.根据实施方案145-149中任一项所述的工程化细胞,其中所述TCR或其抗原结合片段结合至或识别在MHC分子的背景下的人乳头瘤病毒(HPV)16E7的肽表位,所述肽表位是或包含E7(11-19)YMLDLQPET(SEQ ID NO:236)。
151.一种工程化细胞,所述工程化细胞包含TCR或其抗原结合片段,任选地重组TCR或其抗原结合片段,其中:
(1)所述细胞包含T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏和/或不表达内源TRAC或TRBC的基因产物,或不以可检测的水平表达内源TRAC或TRBC的基因产物,或表达少于野生型水平的20%、15%、10%、5%、4%、3%、2%或1%的内源TRAC或TRBC的基因产物;并且
(2)所述TCR或其抗原结合片段或者所述重组TCR或其抗原结合片段包含:
(a)包含SEQ ID NO:111、113、115、121、123、125、297或299中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列的可变α(Vα)区Vα区;和/或包含SEQ ID NO:112、114、116、122、124、126、298或300中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列的Vβ区;和/或
(b)包含含有SEQ ID NO:138、144、147、163、167、173、304或308中任一个所示的氨基酸序列的互补决定区3(CDR-3)或SEQ ID NO:111、113、115、121、123、125、297或299中任一个所示的氨基酸序列内所含的CDR3的Vα区和包含含有SEQ ID NO:141、146、150、164、170、174、305或309中任一个所示的氨基酸序列的互补决定区3(CDR-3)或SEQ ID NO:112、114、116、122、124、126、298或300中任一个所示的氨基酸序列内所含的CDR3的Vβ区。
152.根据实施方案151所述的工程化细胞,其中:
所述Vα区还包含含有SEQ ID NO:136、142、161、165、171、302或306中任一个所示的氨基酸序列的互补决定区1(CDR-1)或SEQ ID NO:111、113、115、121、123、125、297或299中任一个所示的氨基酸序列内所含的CDR-1;和/或含有SEQ ID NO:137、143、162、166、172、303或307中任一个所示的氨基酸序列的互补决定区2(CDR-2)或SEQ ID NO:111、113、115、121、123、125、297或299中任一个所示的氨基酸序列内所含的CDR-2;和/或
所述Vβ区还包含含有SEQ ID NO:139、145、148、168中任一个所示的氨基酸序列的互补决定区1(CDR-1)或SEQ ID NO:112、114、116、122、124、126、298或300中任一个所示的氨基酸序列内所含的CDR-1;和/或含有SEQ ID NO:140、149或169中任一个所示的氨基酸序列的互补决定区2(CDR-2)或SEQ ID NO:112、114、116、122、124、126、298或300中任一个所示的氨基酸序列内所含的CDR-2。
153.根据实施方案151或实施方案152所述的工程化细胞,其中:
所述Vα区包含分别包含SEQ ID NO:136、137和138的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:139、140和141的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:142、143和144的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:145、140和146的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:136、137和147的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和150的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:161、162和163的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和164的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:165、166和167的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:168、169和170的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:171、172和173的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和174的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:302、303和304的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:139、140和305的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:306、307和308的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和309的氨基酸序列的CDR-1、CDR-2和CDR-3。
154.根据实施方案151-153中任一项所述的工程化细胞,其中:
所述Vα区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:111、113、115、121、123、125、297或299中任一个所示的Vα区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列;和/或
所述Vβ区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:112、114、116、122、124、126、298或300中任一个所示的Vβ区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列。
155.根据实施方案151-154中任一项所述的工程化细胞:所述Vα和Vβ区分别包含SEQ ID NO:111和112的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:113和114的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:115和116的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:121和122的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:123和124的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:125和126的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:297和298的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:299和300的氨基酸序列。
156.根据实施方案151-155中任一项所述的工程化细胞,其中所述TCR或其抗原结合片段结合至或识别在MHC分子的背景下的人乳头瘤病毒(HPV)16E6的肽表位,所述肽表位是或包含E6(29-38)TIHDIILECV(SEQ ID NO:233)。
157.根据实施方案145-156中任一项所述的工程化细胞,其中所述α链还包含α恒定(Cα)区和/或所述β链还包含β恒定(Cβ)区。
158.根据实施方案143-157中任一项所述的工程化细胞,其中所述基因产物是由所述TRAC或TRBC基因编码的mRNA或蛋白质。
159.根据实施方案141-158中任一项所述的工程化细胞,其中所述遗传破坏包含在所述TRAC或TRBC基因的区域中的突变或缺失,所述区域在所述基因的编码区、任选地早期编码区内,在所述基因的外显子1内,在所述基因的起始密码子的500、400、300、200、100或50个碱基对内的编码区中,在与具有选自SEQ ID NO:1053和1259-1315中任一个的序列的指导RNA(gRNA)靶向结构域的靶向位点互补的靶位点序列内,和/或与具有选自SEQ IDNO:1053和1259-1315的序列的靶向结构域特异性杂交,和/或在与具有选自SEQ ID NO:1048和1229-1258中任一个的序列的gRNA靶向结构域的靶向位点互补的靶位点序列内,和/或与具有选自SEQ ID NO:1048和1229-1258的序列的靶向结构域特异性杂交。
160.根据实施方案141-159中任一项所述的工程化细胞,其中所述遗传破坏是通过一种或多种药剂实现的,所述一种或多种药剂包含(a)具有与TRAC基因和/或TRBC基因的靶结构域互补的靶向结构域的至少一种gRNA或(b)编码所述至少一种gRNA的至少一种核酸。
161.根据实施方案141-160中任一项所述的工程化细胞,其中所述一种或多种药剂包含Cas9分子和具有与TRAC基因和/或TRBC基因的靶结构域互补的靶向结构域的所述至少一种gRNA的至少一种复合物。
162.根据实施方案160或实施方案161中任一项所述的工程化细胞,其中所述至少一种gRNA包含与TRAC基因的靶结构域互补的靶向结构域,所述靶向结构域包含选自UCUCUCAGCUGGUACACGGC(SEQ ID NO:1229)、UGGAUUUAGAGUCUCUCAGC(SEQ ID NO:1230)、ACACGGCAGGGUCAGGGUUC(SEQ ID NO:1231)、GAGAAUCAAAAUCGGUGAAU(SEQ ID NO:1048)、GCUGGUACACGGCAGGGUCA(SEQ ID NO:1232)、CUCAGCUGGUACACGGC(SEQ ID NO:1233)、UGGUACACGGCAGGGUC(SEQ ID NO:1234)、GCUAGACAUGAGGUCUA(SEQ ID NO:1235)、GUCAGAUUUGUUGCUCC(SEQ ID NO:1236)、UCAGCUGGUACACGGCA(SEQ ID NO:1237)、GCAGACAGACUUGUCAC(SEQ ID NO:1238)、GGUACACGGCAGGGUCA(SEQ ID NO:1239)、CUUCAAGAGCAACAGUGCUG(SEQ ID NO:1240)、AGAGCAACAGUGCUGUGGCC(SEQ ID NO:1241)、AAAGUCAGAUUUGUUGCUCC(SEQ ID NO:1242)、ACAAAACUGUGCUAGACAUG(SEQ ID NO:1243)、AAACUGUGCUAGACAUG(SEQ ID NO:1244)、UGUGCUAGACAUGAGGUCUA(SEQ ID NO:1245)、GGCUGGGGAAGAAGGUGUCUUC(SEQ ID NO:1246)、GCUGGGGAAGAAGGUGUCUUC(SEQ ID NO:1247)、GGGGAAGAAGGUGUCUUC(SEQ ID NO:1248)、GUUUUGUCUGUGAUAUACACAU(SEQ ID NO:1249)、GGCAGACAGACUUGUCACUGGAUU(SEQ ID NO:1250)、GCAGACAGACUUGUCACUGGAUU(SEQ ID NO:1251)、GACAGACUUGUCACUGGAUU(SEQ ID NO:1252)、GUGAAUAGGCAGACAGACUUGUCA(SEQ IDNO:1253)、GAAUAGGCAGACAGACUUGUCA(SEQ ID NO:1254)、GAGUCUCUCAGCUGGUACACGG(SEQ IDNO:1255)、GUCUCUCAGCUGGUACACGG(SEQ ID NO:1256)、GGUACACGGCAGGGUCAGGGUU(SEQ IDNO:1257)和GUACACGGCAGGGUCAGGGUU(SEQ ID NO:1258)的序列。
163.根据实施方案160-162中任一项所述的工程化细胞,其中所述gRNA包含与TRBC基因的、任选地在TRBC1和TRBC2基因之一或两者中的靶结构域互补的靶向结构域,所述靶向结构域包含选自CACCCAGAUCGUCAGCGCCG(SEQ ID NO:1259)、CAAACACAGCGACCUCGGGU(SEQ ID NO:1260)、UGACGAGUGGACCCAGGAUA(SEQ ID NO:1261)、GGCUCUCGGAGAAUGACGAG(SEQ ID NO:1262)、GGCCUCGGCGCUGACGAUCU(SEQ ID NO:1053)、GAAAAACGUGUUCCCACCCG(SEQ ID NO:1263)、AUGACGAGUGGACCCAGGAU(SEQ ID NO:1264)、AGUCCAGUUCUACGGGCUCU(SEQ ID NO:1265)、CGCUGUCAAGUCCAGUUCUA(SEQ ID NO:1266)、AUCGUCAGCGCCGAGGCCUG(SEQ ID NO:1267)、UCAAACACAGCGACCUCGGG(SEQ ID NO:1268)、CGUAGAACUGGACUUGACAG(SEQ ID NO:1269)、AGGCCUCGGCGCUGACGAUC(SEQ ID NO:1270)、UGACAGCGGAAGUGGUUGCG(SEQID NO:1271)、UUGACAGCGGAAGUGGUUGC(SEQ ID NO:1272)、UCUCCGAGAGCCCGUAGAAC(SEQID NO:1273)、CGGGUGGGAACACGUUUUUC(SEQ ID NO:1274)、GACAGGUUUGGCCCUAUCCU(SEQ IDNO:1275)、GAUCGUCAGCGCCGAGGCCU(SEQ ID NO:1276)、GGCUCAAACACAGCGACCUC(SEQ ID NO:1277)、UGAGGGUCUCGGCCACCUUC(SEQ ID NO:1278)、AGGCUUCUACCCCGACCACG(SEQ ID NO:1279)、CCGACCACGUGGAGCUGAGC(SEQ ID NO:1280)、UGACAGGUUUGGCCCUAUCC(SEQ ID NO:1281)、CUUGACAGCGGAAGUGGUUG(SEQ ID NO:1282)、AGAUCGUCAGCGCCGAGGCC(SEQ ID NO:1283)、GCGCUGACGAUCUGGGUGAC(SEQ ID NO:1284)、UGAGGGCGGGCUGCUCCUUG(SEQ ID NO:1285)、GUUGCGGGGGUUCUGCCAGA(SEQ ID NO:1286)、AGCUCAGCUCCACGUGGUCG(SEQ ID NO:1287)、GCGGCUGCUCAGGCAGUAUC(SEQ ID NO:1288)、GCGGGGGUUCUGCCAGAAGG(SEQ ID NO:1289)、UGGCUCAAACACAGCGACCU(SEQ ID NO:1290)、ACUGGACUUGACAGCGGAAG(SEQ ID NO:1291)、GACAGCGGAAGUGGUUGCGG(SEQ ID NO:1292)、GCUGUCAAGUCCAGUUCUAC(SEQ ID NO:1293)、GUAUCUGGAGUCAUUGAGGG(SEQ ID NO:1294)、CUCGGCGCUGACGAUCU(SEQ ID NO:1295)、CCUCGGCGCUGACGAUC(SEQ ID NO:1296)、CCGAGAGCCCGUAGAAC(SEQ ID NO:1297)、CCAGAUCGUCAGCGCCG(SEQ ID NO:1298)、GAAUGACGAGUGGACCC(SEQ ID NO:1299)、GGGUGACAGGUUUGGCCCUAUC(SEQ ID NO:1300)、GGUGACAGGUUUGGCCCUAUC(SEQ ID NO:1301)、GUGACAGGUUUGGCCCUAUC(SEQ ID NO:1302)、GACAGGUUUGGCCCUAUC(SEQ ID NO:1303)、GAUACUGCCUGAGCAGCCGCCU(SEQ ID NO:1304)、GACCACGUGGAGCUGAGCUGGUGG(SEQ ID NO:1305)、GUGGAGCUGAGCUGGUGG(SEQ ID NO:1306)、GGGCGGGCUGCUCCUUGAGGGGCU(SEQ ID NO:1307)、GGCGGGCUGCUCCUUGAGGGGCU(SEQ ID NO:1308)、GCGGGCUGCUCCUUGAGGGGCU(SEQ IDNO:1309)、GGGCUGCUCCUUGAGGGGCU(SEQ ID NO:1310)、GGCUGCUCCUUGAGGGGCU(SEQ ID NO:1311)、GCUGCUCCUUGAGGGGCU(SEQ ID NO:1312)、GGUGAAUGGGAAGGAGGUGCACAG(SEQ ID NO:1313)、GUGAAUGGGAAGGAGGUGCACAG(SEQ ID NO:1314)和GAAUGGGAAGGAGGUGCACAG(SEQ IDNO:1315)的序列。
164.根据实施方案141-163中任一项所述的工程化细胞,其中:
所述工程化细胞包含T细胞受体α恒定区(TRAC)基因和T细胞受体β恒定区(TRBC)基因的遗传破坏;和/或
所述一种或多种药剂包含含有具有与TRAC基因的靶结构域互补的靶向结构域的至少一种gRNA的药剂和含有具有与TRBC基因、任选地TRBC1基因和TRBC2基因之一或两者的靶结构域互补的靶结构域的至少一种gRNA的药剂。
165.根据实施方案159-164中任一项所述的工程化细胞,其中所述靶向结构域包含与TRAC基因的靶结构域互补的序列,并且所述靶向结构域包含序列GAGAAUCAAAAUCGGUGAAU(SEQ ID NO:1048)。
166.根据实施方案159-165中任一项所述的工程化细胞,其中所述靶向结构域包含与TRBC基因的靶结构域互补的序列,并且所述靶向结构域包含序列GGCCUCGGCGCUGACGAUCU(SEQ ID NO:1053)。
167.根据实施方案159-166中任一项所述的工程化细胞,其中所述gRNA还包含第一互补结构域、与所述第一互补结构域互补的第二互补结构域、近端结构域和任选地尾结构域。
168.根据实施方案167所述的工程化细胞,其中所述第一互补结构域和第二互补结构域通过连接结构域连接。
169.根据实施方案167或实施方案168所述的工程化细胞,其中所述指导RNA包含3'聚A尾和5'抗反向帽类似物(ARCA)帽。
170.根据实施方案161-169中任一项所述的工程化细胞,其中所述Cas9分子是酶促活性Cas9。
171.根据实施方案161-170中任一项所述的工程化细胞,其中所述Cas9分子是金黄色葡萄球菌(S.aureus)Cas9分子。
172.根据实施方案161-171中任一项所述的工程化细胞,其中所述Cas9分子是化脓链球菌(S.pyogenes)Cas9。
173.根据实施方案141-172中任一项所述的工程化细胞,其中所述工程化细胞包含T细胞受体α恒定区(TRAC)基因座的遗传破坏。
174.根据实施方案141-173中任一项所述的工程化细胞,其中通过任选地经由HDR将编码所述TCR或其抗原结合片段的核酸序列整合在所述TRAC基因座处来进一步修饰所述内源TRAC基因座。
175.根据实施方案141-173中任一项所述的工程化细胞,其中通过任选地经由同源定向修复(HDR)整合编码所述TCR或其抗原结合片段的一部分的转基因序列来进一步修饰所述内源TRAC基因座。
176.一种工程化细胞,所述工程化细胞包含编码根据实施方案1-39和47-85中任一项所述的TCR或其抗原结合片段的经修饰的TRAC基因座。
177.一种工程化细胞,所述工程化细胞包含经修饰的TRAC基因座,其中通过整合编码所述TCR的一部分的转基因序列来修饰所述内源TRAC基因座,所述转基因序列编码(i)包含根据实施方案1-14、21-23、28-39、47-61、67-69和74-85中任一项所述的TCR或其抗原结合片段的可变β(Vβ)和恒定β(Cβ)的T细胞受体β(TCRβ)链;和(ii)包含根据实施方案1-14、21-23、28-39、47-61、67-69和74-85中任一项所述的TCR或其抗原结合片段的可变α(Vα)的T细胞受体α(TCRα)链的一部分,其中所述TCR的恒定α(Cα)的至少一部分由所述内源TRAC基因座的开放阅读框或其部分序列编码。
178.根据实施方案174-176中任一项所述的工程化细胞,其中所述TCR或其抗原结合片段包含Cα,所述Cα的至少一部分由所述内源TRAC基因座的开放阅读框或其部分序列编码。
179.根据实施方案174-178中任一项所述的工程化细胞,其中所述经修饰的TRAC基因座包含(i)编码所述TCR的一部分的转基因序列和(ii)所述内源TRAC基因座的开放阅读框或其部分序列的框内融合物。
180.根据实施方案175、177和179中任一项所述的工程化细胞,其中所述转基因序列不包含编码3'UTR的序列或内含子。
181.根据实施方案177-180中任一项所述的工程化细胞,其中所述开放阅读框或其部分序列包含所述内源TRAC基因座的3'UTR。
182.根据实施方案176、177和179-181中任一项所述的工程化细胞,其中所述转基因序列整合在所述内源TRAC基因座的开放阅读框的外显子1的最5'核苷酸的下游且在外显子1的最3'核苷酸的上游。
183.根据实施方案177-182中任一项所述的工程化细胞,其中Cα的所述至少一部分由所述内源TRAC基因座的开放阅读框的至少外显子2-4编码。
184.根据实施方案177-183中任一项所述的工程化细胞,其中Cα的所述至少一部分由所述内源TRAC基因座的开放阅读框的外显子1的至少一部分和外显子2-4编码。
185.根据实施方案175、177和179-184中任一项所述的工程化细胞,其中所述转基因序列编码T细胞受体β(TCRβ)链和/或TCRα可变区(Vα)。
186.根据实施方案173-185中任一项所述的工程化细胞,其还包含T细胞受体β恒定区(TRBC)基因座、任选地TRBC1或TRBC2基因座的遗传破坏。
187.根据实施方案141-173中任一项所述的工程化细胞,其中所述工程化细胞包含T细胞受体β恒定区(TRBC)基因座的遗传破坏。
188.根据实施方案141-173中任一项所述的工程化细胞,其中通过任选地经由HDR将编码所述TCR或其抗原结合片段的核酸序列整合在所述TRBC基因座处来进一步修饰所述内源TRBC基因座。
189.根据实施方案141-173中任一项所述的工程化细胞,其中通过任选地经由同源定向修复(HDR)整合编码所述TCR或其抗原结合片段的一部分的转基因序列来进一步修饰所述内源TRBC基因座。
190.一种工程化细胞,所述工程化细胞包含编码根据实施方案1-39和47-85中任一项所述的TCR或其抗原结合片段的经修饰的TRBC基因座。
191.一种工程化细胞,所述工程化细胞包含经修饰的TRBC基因座,其中通过整合编码所述TCR的一部分的转基因序列来修饰所述内源TRBC基因座,所述转基因序列编码(i)包含根据实施方案1-14、21-23、28-39、47-61、67-69和74-85中任一项所述的TCR或其抗原结合片段的可变α(Vα)和恒定α(Cα)的T细胞受体α(TCRα)链;和(ii)包含根据实施方案1-14、21-23、28-39、47-61、67-69和74-85中任一项所述的TCR或其抗原结合片段的可变β(Vβ)的T细胞受体β(TCRβ)链的一部分,其中所述TCR的恒定β(Cβ)的至少一部分由所述内源TRBC基因座的开放阅读框或其部分序列编码。
192.根据实施方案188-190中任一项所述的工程化细胞,其中所述TCR或其抗原结合片段包含Cβ,所述Cβ的至少一部分由所述内源TRBC基因座的开放阅读框或其部分序列编码。
193.根据实施方案188-192中任一项所述的工程化细胞,其中所述经修饰的TRBC基因座包含(i)编码所述TCR的一部分的转基因序列和(ii)所述内源TRBC基因座的开放阅读框或其部分序列的框内融合物。
194.根据实施方案189、191和193中任一项所述的工程化细胞,其中所述转基因序列不包含编码3'UTR的序列或内含子。
195.根据实施方案192-194中任一项所述的工程化细胞,其中所述开放阅读框或其部分序列包含所述内源TRBC基因座的3'UTR。
196.根据实施方案189、191和193-195中任一项所述的工程化细胞,其中所述转基因序列整合在所述内源TRBC基因座的开放阅读框的外显子1的最5'核苷酸的下游且在外显子1的最3'核苷酸的上游。
197.根据实施方案191-196中任一项所述的工程化细胞,其中Cβ的所述至少一部分由所述内源TRBC基因座的开放阅读框的至少外显子2-4编码。
198.根据实施方案191-197中任一项所述的工程化细胞,其中Cβ的所述至少一部分由所述内源TRBC基因座的开放阅读框的外显子1的至少一部分和外显子2-4编码。
199.根据实施方案189、191和193-198中任一项所述的工程化细胞,其中所述转基因序列编码T细胞受体α(TCRα)链和/或TCRβ可变区(Vβ)。
200.根据实施方案187-199中任一项所述的工程化细胞,其中TRBC基因座是T细胞受体β恒定区1(TRBC1)或T细胞受体β恒定区2(TRBC2)基因座之一或两者。
201.根据实施方案188-200中任一项所述的工程化细胞,其还包含T细胞受体α恒定区(TRAC)基因座的遗传破坏。
202.根据实施方案174-186和188-201中任一项所述的工程化细胞,其中编码所述TCR或其抗原结合片段的转基因序列或核酸序列包含一个或多个多顺反子元件。
203.根据实施方案202所述的工程化细胞,其中所述一个或多个多顺反子元件在编码所述TCR或其抗原结合片段的转基因序列或核酸序列的上游。
204.根据实施方案174-186和188-203中任一项所述的工程化细胞,其中所述一个或多个多顺反子元件位于编码所述TCRα或其部分的核酸序列与编码所述TCRβ或其部分的核酸序列之间。
205.根据实施方案174-186和188-204中任一项所述的工程化细胞,其中所述一个或多个多顺反子元件是或包含核糖体跳跃序列,任选地其中所述核糖体跳跃序列是T2A、P2A、E2A或F2A元件。
206.根据实施方案174-186和188-205中任一项所述的工程化细胞,其中编码所述TCR或其抗原结合片段的转基因序列或核酸序列包含一个或多个异源或调节控制元件,所述元件可操作地连接以控制当从引入了所述工程化细胞的细胞表达时所述TCR的表达。
207.根据实施方案206所述的工程化细胞,其中所述一个或多个异源调节或控制元件包含启动子、增强子、内含子、多腺苷酸化信号、Kozak共有序列、剪接受体序列和/或剪接供体序列。
208.根据实施方案206或实施方案207所述的工程化细胞,其中所述异源调节或控制元件包含异源启动子,任选地人延伸因子1α(EF1α)启动子或MND启动子或其变体。
209.根据实施方案139-208中任一项所述的工程化细胞,其中所述TCR或其抗原结合片段或者所述TCR或其抗原结合片段的一部分对所述细胞是异源的。
210.根据实施方案139-209中任一项所述的工程化细胞,其中所述工程化细胞是细胞系。
211.根据实施方案139-210中任一项所述的工程化细胞,其中所述工程化细胞是获自受试者的原代细胞。
212.根据实施方案211所述的工程化细胞,其中所述受试者是哺乳动物受试者。
213.根据实施方案211或实施方案212所述的工程化细胞,其中所述受试者是人。
214.根据实施方案139-214中任一项所述的工程化细胞,其中所述工程化细胞是T细胞。
215.根据实施方案214所述的工程化细胞,其中所述T细胞是CD8+。
216.根据实施方案214所述的工程化细胞,其中所述T细胞是CD4+。
217.一种用于产生根据实施方案139-216中任一项所述的细胞的方法,其包括在体外或离体地将根据实施方案130-138中任一项所述的载体引入细胞中。
218.一种用于产生细胞的方法,其包括在体外或离体地将编码根据实施方案1-39和47-85中任一项所述的TCR或其抗原结合片段的核酸分子、根据实施方案40-46和86-94中任一项所述的核酸分子、根据实施方案95-129中任一项所述的多核苷酸或根据实施方案130-138中任一项所述的载体引入细胞中。
219.根据实施方案217或实施方案218所述的方法,其中所述载体是病毒载体,并且所述引入是通过转导进行的。
220.根据实施方案217-219中任一项所述的方法,其还包括将一种或多种药剂引入所述细胞中,其中所述一种或多种药剂中的每一种独立地能够诱导T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏。
221.一种用于产生工程化细胞的方法,其包括:
(i)将编码根据实施方案1-39和47-85中任一项所述的TCR或其抗原结合片段的核酸分子、根据实施方案40-46和86-94中任一项所述的核酸分子、根据实施方案95-129中任一项所述的多核苷酸或根据实施方案130-138中任一项所述的载体引入细胞中;以及
(ii)将一种或多种药剂引入所述细胞中,其中所述一种或多种药剂中的每一种独立地能够诱导T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏。
222.根据实施方案221所述的方法,其中所述TRBC基因是T细胞受体β恒定区1(TRBC1)或T细胞受体β恒定区2(TRBC2)基因之一或两者。
223.根据实施方案222中任一项所述的方法,其中能够诱导遗传破坏的所述一种或多种药剂包含特异性结合至或杂交至所述靶位点的DNA结合蛋白或DNA结合核酸。
224.根据实施方案223所述的方法,其中能够诱导遗传破坏的所述一种或多种药剂包含(a)包含DNA靶向蛋白和核酸酶的融合蛋白或(b)RNA指导的核酸酶。
225.根据实施方案224所述的方法,其中所述DNA靶向蛋白或RNA指导的核酸酶包含对所述TRAC和/或TRBC基因内的靶位点具特异性的锌指蛋白(ZFP)、TAL蛋白或成簇的规律间隔的短回文核酸(CRISPR)相关核酸酶(Cas)。
226.根据实施方案225所述的方法,其中所述一种或多种药剂包含特异性结合至、识别或杂交至所述靶位点的锌指核酸酶(ZFN)、TAL效应子核酸酶(TALEN)或和CRISPR-Cas9组合。
227.根据实施方案225或实施方案226所述的方法,其中所述一种或多种药剂中的每一种包含具有与所述至少一个靶位点互补的靶向结构域的指导RNA(gRNA)。
228.根据实施方案217-227所述的方法,其中所述TRBC基因是T细胞受体β恒定区1(TRBC1)或T细胞受体β恒定区2(TRBC2)基因之一或两者。
229.根据实施方案221-228中任一项所述的方法,其中所述遗传破坏是通过一种或多种药剂实现的,所述一种或多种药剂包含(a)具有与TRAC基因和/或TRBC基因的靶结构域互补的靶向结构域的至少一种gRNA或(b)编码所述至少一种gRNA的至少一种核酸。
230.根据实施方案229所述的方法,其中将所述一种或多种药剂作为包含所述gRNA和Cas9蛋白的核糖核蛋白(RNP)复合物引入。
231.根据实施方案230所述的方法,其中经由电穿孔、粒子枪、磷酸钙转染、细胞压缩或挤压来引入所述RNP。
232.根据实施方案230或实施方案231所述的方法,其中经由电穿孔来引入所述RNP。
233.根据实施方案227-232中任一项所述的方法,其中将所述一种或多种药剂作为编码所述gRNA和/或Cas9蛋白的一种或多种多核苷酸引入。
234.根据实施方案220-233中任一项所述的方法,其中所述一种或多种药剂包含Cas9分子和具有与TRAC基因和/或TRBC基因的靶结构域互补的靶向结构域的所述至少一种gRNA的至少一种复合物。
235.根据实施方案220-234中任一项所述的方法,其中所述一种或多种药剂包含Cas9分子和具有靶向结构域的gRNA的至少一种复合物,所述靶向结构域是以下之一或两者:(1)与TRAC基因的靶结构域互补,所述靶向结构域包含选自SEQ ID NO:1048和1229-1258中任一个的序列;和(2)与TRBC基因、任选地TRBC1和TRBC2基因之一或两者的靶结构域互补,所述靶向结构域包含选自SEQ ID NO:1053和1259-1315中任一个的序列。
236.根据实施方案229-235中任一项所述的方法,其中所述靶向结构域包含与TRAC基因的靶结构域互补的序列,并且所述靶向结构域包含序列GAGAAUCAAAAUCGGUGAAU(SEQ ID NO:1048)。
237.根据实施方案229-236中任一项所述的方法,其中所述靶向结构域包含与TRBC基因的靶结构域互补的序列,并且所述靶向结构域包含序列GGCCUCGGCGCUGACGAUCU(SEQ ID NO:1053)。
238.根据实施方案229-237中任一项所述的方法,其中所述指导RNA还包含第一互补结构域、与所述第一互补结构域互补的第二互补结构域、近端结构域和任选地尾结构域。
239.根据实施方案238所述的方法,其中所述第一互补结构域和第二互补结构域通过连接结构域连接。
240.根据实施方案239中任一项所述的方法,其中所述指导RNA包含3'聚A尾和5'抗反向帽类似物(ARCA)帽。
241.根据实施方案226-240中任一项所述的方法,其中所述Cas9分子是酶促活性Cas9。
242.根据实施方案226-241中任一项所述的方法,其中所述Cas9分子是金黄色葡萄球菌Cas9分子。
243.根据实施方案226-241中任一项所述的方法,其中所述Cas9分子是化脓链球菌Cas9。
244.根据实施方案220-243中任一项所述的方法,其中多个工程化细胞中至少或大于35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、90%或95%的所述细胞在所述TRAC基因和/或TRBC基因内包含遗传破坏。
245.根据实施方案220-244中任一项所述的方法,其中多个工程化细胞中至少或大于90%、95%、96%、97%或98%的所述细胞在所述TRAC基因和/或TRBC基因内包含遗传破坏。
246.根据实施方案217-245中任一项所述的方法,其中多个工程化细胞中至少或大于5%、10%、15%、20%、25%、30%、40%、50%或更多的所述细胞表达所述引入的TCR或其抗原结合片段,和/或展现出与HPV蛋白、任选地HPV E6或HPV E7的抗原结合。
247.根据实施方案217-245中任一项所述的方法,其中多个工程化细胞中至少或大于5%、10%、15%、20%、25%、30%、40%、50%或更多的所述细胞表达所述引入的TCR或其抗原结合片段,和/或展现出与HPV蛋白、任选地HPV E6或HPV E7的抗原结合。
248.根据实施方案217-247中任一项所述的方法,其中多个工程化细胞中至少或大于5%、10%、15%、20%、25%、30%、40%、50%或更多的所述细胞表达所述引入的TCR或其抗原结合片段,和/或展现出与HPV蛋白、任选地HPV E6或HPV E7的抗原结合。
249.根据实施方案220-248中任一项所述的方法,其中所述一种或多种药剂和所述核酸分子、所述多核苷酸或所述载体同时或以任何顺序依序引入。
250.根据实施方案220-249中任一项所述的方法,其中在引入所述一种或多种药剂之后引入所述核酸分子、所述多核苷酸或所述载体。
251.根据实施方案250所述的方法,其中在引入所述药剂之后立即引入所述核酸分子、所述多核苷酸或所述载体,或者在引入所述药剂之后约30秒、1分钟、2分钟、3分钟、4分钟、5分钟、6分钟、6分钟、8分钟、9分钟、10分钟、15分钟、20分钟、30分钟、40分钟、50分钟、60分钟、90分钟、2小时、3小时或4小时内引入所述核酸分子、所述多核苷酸或所述载体。
252.一种组合物,其包含根据实施方案139-216中任一项所述的工程化细胞。
253.一种组合物,其包含使用根据实施方案217-251中任一项所述的方法产生的工程化细胞。
254.根据实施方案252或实施方案253所述的组合物,其中:
所述组合物中至少70%、75%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的所述工程化细胞在内源T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因中包含遗传破坏或包含内源T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏;和/或
所述组合物中至少80%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的所述工程化细胞不表达或不表达可检测水平的内源TRAC或TRBC基因的基因产物。
255.一种组合物,其包含多个工程化细胞,每个工程化细胞包含TCR或其抗原结合片段,其中:
(1)所述组合物中至少70%、75%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的所述工程化细胞在内源T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因中包含遗传破坏或包含内源T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏,和/或其中所述组合物中至少80%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的所述工程化细胞不表达或不表达可检测水平的内源TRAC或TRBC基因的基因产物;并且
(2)所述TCR或其抗原结合片段包含:
(a)包含SEQ ID NO:117、119或295中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列的可变α(Vα)区和包含SEQ ID NO:118、120或296中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列的可变β(Vβ)区;和/或
(b)包含含有SEQ ID NO:153、159或301中任一个所示的氨基酸序列的互补决定区3(CDR-3)或SEQ ID NO:117、119或295中任一个所示的氨基酸序列内所含的CDR3的Vα区和包含含有SEQ ID NO:156或160中任一个所示的氨基酸序列的互补决定区3(CDR-3)或SEQID NO:118、120或296中任一个所示的氨基酸序列内所含的CDR3的Vβ区。
256.根据实施方案255所述的组合物,其中:
所述Vα区还包含含有SEQ ID NO:151或157中任一个所示的氨基酸序列的互补决定区1(CDR-1);和/或含有SEQ ID NO:152或158中任一个所示的氨基酸序列的互补决定区2(CDR-2);和/或
所述Vβ区还包含含有SEQ ID NO:154所示的氨基酸序列的互补决定区1(CDR-1);和/或含有SEQ ID NO:155所示的氨基酸序列的互补决定区2(CDR-2)。
257.根据实施方案255或实施方案256所述的组合物,其中所述Vα区和Vβ区包含:
分别包含SEQ ID NO:151、152和153的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和156的氨基酸序列的CDR-1、CDR-2和CDR-3;
分别包含SEQ ID NO:157、158和159的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和160的氨基酸序列的CDR-1、CDR-2和CDR-3;或者
分别包含SEQ ID NO:151、152和301的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和156的氨基酸序列的CDR-1、CDR-2和CDR-3。
258.根据实施方案255-257中任一项所述的组合物,其中:
所述Vα区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:117、119或295中任一个所示的Vα区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列;和/或
所述Vβ区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:118、120或296中任一个所示的Vβ区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列。
259.根据实施方案255-258中任一项所述的组合物:
所述Vα和Vβ区分别包含SEQ ID NO:117和118或296的氨基酸序列;
所述Vα和Vβ区分别包含SEQ ID NO:119和120的氨基酸序列;或者
所述Vα和Vβ区分别包含SEQ ID NO:295和118或296的氨基酸序列。
260.根据实施方案255-259中任一项所述的组合物,其中所述TCR或其抗原结合片段结合至或识别在MHC分子的背景下的人乳头瘤病毒(HPV)16E7的肽表位,所述肽表位是或包含E7(11-19)YMLDLQPET(SEQ ID NO:236)。
261.一种组合物,其包含多个工程化细胞,每个工程化细胞包含TCR或其抗原结合片段,其中:
(1)所述组合物中至少70%、75%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的所述工程化细胞在内源T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因中包含遗传破坏或包含内源T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏,和/或其中所述组合物中至少80%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的所述工程化细胞不表达或不表达可检测水平的内源TRAC或TRBC基因的基因产物;并且
(2)所述TCR或其抗原结合片段或者所述重组TCR或其抗原结合片段包含:
(a)包含SEQ ID NO:111、113、115、121、123、125、297或299中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列的可变α(Vα)区Vα区;和/或包含SEQ ID NO:112、114、116、122、124、126、298或300中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列的Vβ区;和/或
(b)包含含有SEQ ID NO:138、144、147、163、167、173、304或308中任一个所示的氨基酸序列的互补决定区3(CDR-3)或SEQ ID NO:111、113、115、121、123、125、297或299中任一个所示的氨基酸序列内所含的CDR3的Vα区和包含含有SEQ ID NO:141、146、150、164、170、174、305或309中任一个所示的氨基酸序列的互补决定区3(CDR-3)或SEQ ID NO:112、114、116、122、124、126、298或300中任一个所示的氨基酸序列内所含的CDR3的Vβ区。
262.根据实施方案261所述的组合物,其中:
所述Vα区还包含含有SEQ ID NO:136、142、161、165、171、302或306中任一个所示的氨基酸序列的互补决定区1(CDR-1)或SEQ ID NO:111、113、115、121、123、125、297或299中任一个所示的氨基酸序列内所含的CDR-1;和/或含有SEQ ID NO:137、143、162、166、172、303或307中任一个所示的氨基酸序列的互补决定区2(CDR-2)或SEQ ID NO:111、113、115、121、123、125、297或299中任一个所示的氨基酸序列内所含的CDR-2;和/或
所述Vβ区还包含含有SEQ ID NO:139、145、148、168中任一个所示的氨基酸序列的互补决定区1(CDR-1)或SEQ ID NO:112、114、116、122、124、126、298或300中任一个所示的氨基酸序列内所含的CDR-1;和/或含有SEQ ID NO:140、149或169中任一个所示的氨基酸序列的互补决定区2(CDR-2)或SEQ ID NO:112、114、116、122、124、126、298或300中任一个所示的氨基酸序列内所含的CDR-2。
263.根据实施方案261或实施方案262所述的组合物,其中:
所述Vα区包含分别包含SEQ ID NO:136、137和138的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:139、140和141的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:142、143和144的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:145、140和146的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:136、137和147的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和150的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:161、162和163的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和164的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:165、166和167的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:168、169和170的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:171、172和173的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和174的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:302、303和304的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:139、140和305的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:306、307和308的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和309的氨基酸序列的CDR-1、CDR-2和CDR-3。
264.根据实施方案261-263中任一项所述的组合物,其中:
所述Vα区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:111、113、115、121、123、125、297或299中任一个所示的Vα区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列;和/或
所述Vβ区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:112、114、116、122、124、126、298或300中任一个所示的Vβ区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列。
265.根据实施方案261-264中任一项所述的组合物:所述Vα和Vβ区分别包含SEQID NO:111和112的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:113和114的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:115和116的氨基酸序列;所述Vα和Vβ区分别包含SEQID NO:121和122的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:123和124的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:125和126的氨基酸序列;所述Vα和Vβ区分别包含SEQID NO:297和298的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:299和300的氨基酸序列。
266.根据实施方案261-265中任一项所述的组合物,其中所述TCR或其抗原结合片段结合至或识别在MHC分子的背景下的人乳头瘤病毒(HPV)16E6的肽表位,所述肽表位是或包含E6(29-38)TIHDIILECV(SEQ ID NO:233)。
267.根据实施方案255-266中任一项所述的组合物,其中所述α链还包含α恒定(Cα)区和/或所述β链还包含β恒定(Cβ)区。
268.根据实施方案252-267中任一项所述的组合物,其中所述组合物中至少或大于90%、95%、96%、97%或98%的所述细胞含有内源TRAC基因和/或TRBC基因的遗传破坏和/或不表达或不表达可检测水平的内源TRAC或TRBC基因的基因产物。
269.根据实施方案252-268中任一项所述的组合物,其中所述组合物中至少或大于70%、75%、80%、85%、90%、95%、96%、97%或98%的所述细胞(i)表达所述工程化或重组TCR或其抗原结合片段并且(ii)含有内源TRAC基因和/或TRBC基因的遗传破坏和/或不表达或不表达可检测水平的内源TRAC或TRBC基因的基因产物。
270.根据实施方案254-259中任一项所述的组合物,其中所述TRBC基因是T细胞受体β恒定区1(TRBC1)或T细胞受体β恒定区2(TRBC2)基因之一或两者。
271.根据实施方案254-260中任一项所述的组合物,其中所述基因产物是由所述TRAC或TRBC基因编码的mRNA或蛋白质。
272.根据实施方案252-271中任一项所述的组合物,其中所述工程化细胞包含CD4+和/或CD8+T细胞。
273.根据实施方案252-272中任一项所述的组合物,其中所述工程化细胞包含CD4+和CD8+T细胞。
274.一种组合物,其包含根据实施方案215所述的工程化CD8+细胞和根据实施方案216所述的工程化CD4+细胞。
275.根据实施方案252-274中任一项所述的组合物,其中所述TCR或其抗原结合片段至少部分地CD8非依赖性地结合至或识别在MHC分子的背景下的HPV 16的肽表位。
276.根据实施方案272-275中任一项所述的组合物,其中将所述CD8+细胞和CD4+细胞用相同的TCR或其抗原结合片段工程化和/或将所述CD8+细胞和CD4+细胞各自用结合至或识别在MHC分子的背景下的HPV 16的相同肽表位的TCR或其抗原结合片段工程化。
277.根据实施方案254-276中任一项所述的组合物,其中:
所述遗传破坏包含在所述TRAC或TRBC基因的区域中的突变或缺失,所述区域在所述基因的编码区、任选地早期编码区内,在所述基因的外显子1内,在所述基因的起始密码子的500、400、300、200、100或50个碱基对内的编码区中,在与具有选自SEQ ID NO:1053和1259-1315中任一个的序列的gRNA靶向结构域的靶向位点互补的靶位点序列内,和/或与具有选自SEQ ID NO:1053和1259-1315的序列的靶向结构域特异性杂交,和/或在与具有选自SEQ ID NO:1048和1229-1258中任一个的序列的gRNA靶向结构域的靶向位点互补的靶位点序列内,和/或与具有选自SEQ ID NO:1048和1229-1258的序列的靶向结构域特异性杂交。
278.根据实施方案274-277所述的组合物,其中至少一个所述工程化细胞是根据实施方案1-141中任一项所述的细胞。
279.根据实施方案252-278中任一项所述的组合物,其中所述遗传破坏是通过一种或多种药剂实现的,所述一种或多种药剂包含(a)具有与TRAC基因和/或TRBC基因的靶结构域互补的靶向结构域的至少一种gRNA或(b)编码所述至少一种gRNA的至少一种核酸。
280.根据实施方案279所述的组合物,其中将所述一种或多种药剂作为包含所述gRNA和Cas9蛋白的核糖核蛋白(RNP)复合物引入。
281.根据实施方案280所述的组合物,其中经由电穿孔、粒子枪、磷酸钙转染、细胞压缩或挤压来引入所述RNP。
282.根据实施方案280或实施方案281所述的组合物,其中经由电穿孔来引入所述RNP。
283.根据实施方案279-282中任一项所述的组合物,其中将所述一种或多种药剂作为编码所述gRNA和/或Cas9蛋白的一种或多种多核苷酸引入。
284.根据实施方案279-283中任一项所述的组合物,其中所述一种或多种药剂包含Cas9分子和具有与TRAC基因和/或TRBC基因的靶结构域互补的靶向结构域的所述至少一种gRNA的至少一种复合物。
285.根据实施方案279-284中任一项所述的组合物,其中所述一种或多种药剂包含Cas9分子和具有靶向结构域的gRNA的至少一种复合物,所述靶向结构域是以下之一或两者:(1)与TRAC基因的靶结构域互补,所述靶向结构域包含选自SEQ ID NO:1048和1229-1258中任一个的序列;和(2)与TRBC基因、任选地TRBC1和TRBC2基因之一或两者的靶结构域互补,所述靶向结构域包含选自SEQ ID NO:1053和1259-1315中任一个的序列。
286.根据实施方案279-285中任一项所述的组合物,其中所述靶向结构域包含与TRAC基因的靶结构域互补的序列,并且所述靶向结构域包含序列GAGAAUCAAAAUCGGUGAAU(SEQ ID NO:1048)。
287.根据实施方案279-286中任一项所述的组合物,其中所述靶向结构域包含与TRBC基因的靶结构域互补的序列,并且所述靶向结构域包含序列GGCCUCGGCGCUGACGAUCU(SEQ ID NO:1053)。
288.根据实施方案279-287中任一项所述的组合物,其中所述指导RNA还包含第一互补结构域、与所述第一互补结构域互补的第二互补结构域、近端结构域和任选地尾结构域。
289.根据实施方案288所述的组合物,其中所述第一互补结构域和第二互补结构域通过连接结构域连接。
290.根据实施方案289中任一项所述的组合物,其中所述指导RNA包含3'聚A尾和5'抗反向帽类似物(ARCA)帽。
291.根据实施方案279-290中任一项所述的组合物,其中所述Cas9分子是酶促活性Cas9。
292.根据实施方案279-291中任一项所述的组合物,其中所述Cas9分子是金黄色葡萄球菌Cas9分子。
293.根据实施方案279-291中任一项所述的组合物,其中所述Cas9分子是化脓链球菌Cas9。
294.根据实施方案252-293中任一项所述的组合物,其还包含药学上可接受的赋形剂。
295.一种治疗方法,其包括将根据实施方案139-216中任一项所述的工程化细胞给予患有与HPV相关的疾病或障碍的受试者。
296.一种治疗方法,其包括将根据实施方案252-294中任一项所述的组合物给予患有与HPV相关的疾病或障碍的受试者。
297.根据实施方案295或实施方案296所述的方法,其中所述疾病或障碍与HPV16相关。
298.根据实施方案295-297中任一项所述的方法,其中所述疾病或障碍是癌症。
299.根据实施方案295-298中任一项所述的方法,其中所述受试者是人。
300.根据实施方案252-294中任一项所述的组合物,用于治疗与HPV相关的疾病或障碍。
301.根据实施方案252-2954中任一项所述的组合物用于制造治疗与HPV相关的疾病或障碍的药物的用途。
302.根据实施方案300所述的组合物或根据实施方案301所述的用途,其中所述疾病或障碍与HPV16相关。
303.根据实施方案300-302中任一项所述的组合物或用途,其中所述疾病或障碍是癌症。
304.根据实施方案300-303中任一项所述的组合物或用途,其中所述受试者是人。
X.实施例
仅出于说明性目的包括以下实施例,并不意图限制本发明的范围。
实施例1:从正常供体中筛选和选择HPV-16E6和E7表位特异性T细胞受体
进行使用自体树突细胞和T细胞的示例性自体筛选过程(总体上如Ho等人,J.Immunol.Methods,310:1-2,40-52所述,具有所指出的修饰),以产生与MHC-1分子上呈递的人乳头瘤病毒16(HPV16)E6和E7蛋白的肽表位特异性结合的抗原特异性T细胞。产生克隆的T细胞系,并克隆通过此方法克隆的其TCR序列。
A.人HPV特异性T细胞和TCR的产生和克隆
简而言之,通过以下方式从获自正常人HLA-A02:01供体的外周血单核细胞(PBMC)样品的粘附部分产生树突细胞:在GM-CSF和IL-4的存在下培养两天,然后在第3天在促炎性细胞因子的存在下开始孵育,以产生成熟的树突细胞。在第4天,收获所得的成熟树突细胞,洗涤并用HPV-16E6或E7衍生的肽脉冲,所述肽例如表23中所示的一些,包括肽表位E6(29-38)、E7(11-19)和E7(86-93)。


在第5天,将来自正常人供体的自体CD8+T细胞与肽脉冲的树突细胞一起孵育。
在第8天,测量培养物中的IFNγ作为含有抗原特异性T细胞的培养物的指示物。选择来自反应性共培养物的细胞,并用肽脉冲的树突细胞再刺激两次或三次,以富集特定的T细胞。重复刺激后,通过流式细胞术鉴定对负载肽的自体MHC四聚体染色呈阳性的细胞群。本质上Ho等人2006所述,通过细胞分选和/或有限稀释克隆产生克隆系。
将克隆与肽脉冲的T2细胞(缺乏与抗原转运相关的转运蛋白(TAP)但表达MHC-1并且因此能够将负载的肽呈递到细胞上的细胞)一起培养,用相关的肽例如E6(29-38)、E7(11-19)或E7(86-93)进行脉冲。与通过与负载有非HPV衍生的(阴性对照)肽的细胞共培养得到的培养物中IFNγ水平相比,测量出培养物中IFNγ的水平作为T细胞对肽-MHC的特异性和功能活性的指标。使用基于流式细胞术的染色评估克隆细胞系以肽特异性方式与标记的肽-MHC(HLA-A02:01)四聚体(HLA-A2/E6(29-38)、HLA-A2/E7(11-19)或HLA-A2/E7(86-93))结合的能力;含有无关肽的四聚体作为阴性对照)。
表24列出了与由经由此过程产生的克隆T细胞系表达的TCRα和β链相对应的序列标识符。
使用肽脉冲的T2细胞和/或表达抗原的癌细胞系的细胞评估了克隆系以抗原特异性方式裂解靶细胞的能力。
在示例性测定中,将表达TCR的单克隆细胞系与CaSki靶细胞(ATCC号CRL-1550,含有大约600个拷贝的整合HPV16)以各种效应子:靶标(E:T)比率孵育。通过测量靶细胞中的半胱天冬酶并评估在开始与T细胞孵育后历经50小时的各个时间点对半胱天冬酶呈阳性的此类细胞的百分比来评估裂解活性。阴性对照包括将T细胞与SiHa细胞(ATCC号HTB-35,对内源靶抗原本质上呈阴性,具有不超过大约一个或两个拷贝的整合HPV16基因组)孵育,以及未与T细胞克隆一起孵育的Caski细胞。两个示例性克隆T细胞系的结果示于图1中。如所示,观察到单克隆T细胞系对呈递在HLA-A02:01背景下的主题HPV16衍生肽的细胞展现出裂解活性。产生了许多CD8+克隆,并通过此过程证实展现出抗原特异性结合和功能性。
使用突变型MHC I类四聚体(在其CD8结合位点处包含D227K突变,使其无法与T细胞上的CD8共受体接合)评估了克隆系的T细胞独立于CD8共受体而与肽表位特异性结合的能力。参见Kerry等人J Immunol(2003)171:4493-4503;Kerry等人Immunology(2005)114:44-52。表24列出了由通过此方法产生的示例性克隆细胞系表达的示例性TCR。在本研究中观察到这些细胞系中的每一种均以抗原特异性方式结合所指示的肽-MHC复合物,如与对照相比通过四聚体染色所指示。另外,观察到所指示的克隆系特异性结合在突变型(非CD8相互作用性)四聚体的背景下的相关肽的能力,指示由这些克隆系表达的TCR独立于CD8特异性结合同源抗原的能力。
B.克隆由克隆细胞系表达的TCR
从T细胞系扩增具有编码来自如上所述产生的克隆系的TCR的多肽链的序列的多核苷酸,并使用cDNA末端的5'快速扩增(RACE)进行测序。表24分别提供了通过此过程产生的多个TCR的α和β链核苷酸和氨基酸序列的序列标识符(SEQ ID NO)。表24还列出了如下SEQ ID NO,其对应于包含每个对应TCR的β和α链序列的示例性全长编码氨基酸序列,所述β和α链序列由核糖体跳跃P2A序列(SEQ ID NO:204所示的P2A接头,其可以由SEQ ID NO:4、5、6、207-210中任一个所示的核苷酸序列编码)隔开(称为“β-P2A-α”)。如下所述,将编码许多TCR中每一个的这种全长序列的核苷酸序列插入载体中,以便转移到宿主细胞,例如原代人细胞,例如T细胞,如下所述。在核苷酸序列的翻译和分隔TCR链的P2A序列的自切割之后,TCR的重组α和β链外源地表达于宿主细胞,例如原代T细胞,例如原代人T细胞中。表24还列出了每个克隆的TCR的特定Vα和Vβ使用。


C.密码子优化、修饰和慢病毒表达
通过密码子优化和/或通过一个或多个突变来修饰编码如上所述产生的TCR的核苷酸序列,以促进在TCR恒定结构域之间的界面中形成非天然二硫键,以增加TCR的配对和稳定性。通过在TCR链的Cα区中在残基48处将Thr修饰为Cys,和在Cβ区中在残基57处将Ser修饰为Cys来促进非天然二硫键(参见Kuball等人(2007)Blood,109:2331-2338)。表25中示出了每个TCR的修饰形式的所得经修饰核苷酸序列和相应编码氨基酸序列的相应SEQ IDNO。
对于如上所述的经修饰的单独TCR,生成如下构建体,其包含编码对应的克隆TCRβ链和α链的经修饰核苷酸序列,所述β链和α链由编码P2A多肽的序列隔开;并将所述构建体插入慢病毒载体,以用于用标准方法转导T细胞系和原代人T细胞,以表达编码的TCR链。


实施例2:Jurkat细胞中示例性TCR的表达和抗原结合
评估如上所述产生的示例性E6特异性和E7特异性T细胞受体(TCR)在具有或不具有CD8相互作用的情况下在T细胞上的表面表达以及抗原特异性结合。具体地,具有或不具有外源表达的CD8的情况下(在图2A-2L、图3A-3D和图4A-4B中分别称为CD8+和CD4+),将源自在表面不表达内源TCR的Jurkat人T细胞系的细胞(CD4+Jurkat衍生的细胞)工程化以表达TCR的修饰形式。对于在此过程中评估的每个TCR,用如上所述产生的编码TCR的特定修饰形式的慢病毒载体颗粒转导Jurkat衍生的细胞。未用TCR转导的细胞(含有或不含外源CD8的细胞)用作对照。在用编码每个TCR的序列转导后第6天,在用与对应E6或E7肽复合的经标记的四聚体(HLA-A2/E6(29-38)、HLA-A2/E7(11-19)或HLA-A2/E7(86-93)四聚体)染色之后,通过流式细胞术评估TCR表达和功能活性。在本研究中还评估了能够结合HLA-A2/E6(29-38)的参考TCR(在国际PCT公开号和WO 2015/009606中描述)。参考TCR包含小鼠恒定区。
示例性结果示于图2A-2L(负载E6(29-38)的四聚体结合)、图3A-3D(负载E7(11-19)的四聚体结合)和图4A-4B(负载E7(86-93)的四聚体结合)中。示于图2A-2L、3A-3D和4A-4B中的流式细胞术图的所指示象限中的细胞百分比还在下文总结于表26A(图2A-2F)、表26B(图2G-2L)、表26C(图3A-3D)和表26D(图4A-4B)中。





如所示,克隆了通过这些方法产生的TCR,并观察到这些TCR在T细胞表面表达,并与在MHC四聚体背景下的HPV肽结合,在一些情况下所述结合独立于CD8共受体。
实施例3:用HPV-16E6和E7表位特异性T细胞受体转导的细胞的功能评估
用如上所述产生的编码对于在HLA:A2:01背景下的E6(29-38)有特异性的TCR的修饰形式的链的慢病毒载体颗粒转导原代CD8+人T细胞,所述修饰形式包括TCR:TCR 5、TCR4、TCR 3、TCR 8、TCR 9、TCR 10和TCR7的示例性修饰形式。评估此类转导的T细胞的功能活性,包括响应于表达肽:MHC的细胞产生细胞因子和展现裂解活性的能力。在这些研究中,示例性E7(11-19)特异性TCR用作阴性对照。
A.细胞因子的产生
为了评估响应于抗原的细胞因子产生,将细胞与T2细胞以10:1的E:T比率孵育4小时,所述T2细胞已用10μM的E6(29-38)肽脉冲过夜,或作为对照用10μM的E7(11-19)肽脉冲过夜。还评估了用佛波醇肉豆蔻酸乙酸酯(PMA)和布雷非德菌素A(BFA)或仅用BFA刺激的经转导T细胞的培养物中的细胞因子活性,作为阳性对照。通过流式细胞术测量培养细胞中的细胞内IFNγ。通过流式细胞术确定CD8和细胞内IFNγ阳性(%CD8+/IC IFNγ+)细胞的百分比。
结果示于表27。这些结果证实了表达通过这些方法产生的E6(29-38)特异性TCR的原代人T细胞响应于靶细胞以抗原特异性方式产生细胞因子的能力。


B.裂解活性
通过将CaSki细胞(在存在或不存在IFNγ的情况下)以10:1的E:T比率孵育来评估转导的原代人T细胞对表达HPV16的细胞的裂解活性。将其中SiHa细胞以相同的E:T比率用作靶细胞的样品用作阴性对照。还评估了针对用肽E6(29-38)脉冲的T2细胞的裂解活性。共培养后4小时,通过测量靶细胞中的活性半胱天冬酶来评估T细胞以抗原特异性方式引起裂解活性的能力。
实施例4:从正常供体中筛选和选择HPV-16E6和E7表位特异性T细胞受体
进行了使用自体树突细胞和T细胞的筛选过程,以生成抗原特异性T细胞受体(TCR),所述抗原特异性T细胞受体特异性结合至在MHC-I分子上呈递的人乳头瘤病毒16(HPV16)E6(29-38)或E7(11-19)肽,并且在多轮抗原刺激后存在和/或随时间富集。产生克隆T细胞系,并且使用高通量配对TCR测序在单细胞的基础上确定各个群体中单独配对的TCRα和β链的序列及其丰度。
A.人HPV特异性T细胞和TCR的产生和克隆
简而言之,基本上如实施例1中所述,由人供体的PBMC产生了肽脉冲的抗原呈递细胞。具体地,用HPV 16E6(29-38)肽(TIHDIILECV;SEQ ID NO:233)或E7(11-19)肽(YMLDLQPET;SEQ ID NO:236)产生肽脉冲的HLA:A02:01APC。将来自正常人供体的自体CD8+T细胞与肽脉冲的细胞一起孵育多轮,并且基于与负载肽的自体MHC四聚体的结合进行选择。通常,在肽脉冲的细胞的存在下,细胞总共经历三轮刺激(在三轮中肽浓度维持在1000ng/mL)。在第二轮和第三轮刺激后,通过流式细胞术将细胞分选为分别对与含有适当四聚体的肽-MHC四聚体的结合呈阳性和阴性的群体。使在第二轮和第三轮中的每一轮后四聚体阳性和阴性群体的细胞经历单细胞TCR测序,以评估不同群体中单独TCR的存在和频率以及TCR克隆经过多轮抗原刺激的持久性。
B.TCR序列的确定和TCR的评估
在第2轮和第3轮刺激后,使来自阳性和阴性级分的细胞群(即,通过流式细胞术基于分别对与负载E6(29-38)肽或负载E7(11-19)的MHC四聚体的结合呈阳性和阴性染色进行分选,如通过流式细胞术所确定的)经历针对TCRα和β链对的高通量单细胞测序。总体上如已公开的PCT专利申请公开号WO 2012/048340、WO 2012/048341和WO 2016/044227中所述的进行高通量单细胞TCR测序。测序方法采用单细胞液滴以及样品和分子条形码,以针对存在于单一起始组合物中的大量(例如,数百万个)单细胞中的每一个在单细胞水平上鉴定单独的TCRα和β链序列对,并且评估在所评估的各个群体中每个TCR对的丰度。在单细胞水平上鉴定和定量TCR对的能力允许评估单独的阳性和阴性级分中的每一个中各个TCR对中的每一个的频率,并且评估TCR经过多轮抗原刺激的富集和持久性。基于以下选择在此测定中鉴定的TCR对:在第2轮和第3轮后它们在肽结合级分中的存在,在这些轮次的每一轮中阳性级分相对于阴性级分较高的丰度,以及在多轮暴露于抗原后随时间的富集。
表28和29分别列出了根据此方法分离的示例性E6(29-38)和E7(11-19)特异性TCR,以及每个TCR的α和β链核苷酸和氨基酸序列的序列标识符(SEQ ID NO:)。表28和29还列出了对应于示例性全长编码氨基酸序列的序列标识符(SEQ ID NO),所述氨基酸序列包含每个对应TCR的β和α链序列,所述β和α链序列由编码核糖体跳跃P2A序列(SEQ ID NO:204所示的P2A接头)的序列隔开(称为“β-P2A-α”)。如下所述,将编码许多TCR中每一个的这种全长序列的核苷酸序列插入载体中,以便转移到宿主细胞,例如原代人细胞,例如T细胞,如下所述。在核苷酸序列的翻译和分隔TCR链的P2A序列的自切割之后,TCR的重组α和β链外源地表达于宿主细胞中。



C.密码子优化和修饰
通过密码子优化和/或通过一个或多个突变来修饰编码如上所述产生的TCR的核苷酸序列,以促进在TCR恒定结构域之间的界面中形成非天然二硫键,以增加TCR的配对和稳定性。通过在TCR链的Cα区中在残基48处将Thr修饰为Cys,和在Cβ区中在残基57处将Ser修饰为Cys来促进非天然二硫键(参见Kuball等人(2007)Blood,109:2331-2338)。表30(E6(29-38)特异性TCR)和表31(E7(11-19)特异性TCR)中示出了每个TCR的修饰形式的所得经修饰核苷酸序列和相应编码氨基酸序列的相应SEQ ID NO。
对于如上所述的经修饰的单独TCR,生成如下构建体,其包含编码对应的克隆TCRβ链和α链的经修饰核苷酸序列,所述β链和α链由编码P2A多肽的序列隔开;并将所述构建体插入载体例如慢病毒载体中,以用于使用标准方法在T细胞系和原代人T细胞中表达TCR链。



实施例5:示例性E6和E7特异性TCR的表达和抗原结合
如上文实施例4中所述鉴定的经密码子优化和半胱氨酸修饰的示例性E6和E7特异性T细胞受体(TCR)在T细胞中表达,并基本上如以上实施例2中所述,评估在具有或不具有CD8相互作用的情况下所述受体的表面表达和抗原特异性结合。具体而言,将未在表面表达内源TCR的CD4+Jurkat衍生的细胞(已经或尚未通过引入外源CD8进行修饰(修饰导致CD4+/CD8+细胞))以1:1的混合物混合,以用于用编码TCR的质粒DNA转染,以评估TCR的CD8非依赖性结合活性。对于转染,将CD4+和CD4+/CD8+细胞混合物用TCR编码质粒瞬时转染,并且在转染后48小时,通过流式细胞术评估细胞的(1)对在MHC分子(HLA:A02:01)的背景下的靶肽的结合,通过用E6(29-38)肽-或E7(11-19)肽-MHC四聚体试剂染色得出,和/或(2)对靶标的CD8+非依赖性结合,通过对四聚体标记的靶标和抗CD8抗体共染色得出。在本研究中还评估了已经模拟转染的细胞(模拟)和表达能够结合HLA-A2/E6(29-38)的参考TCR的细胞。
示例性结果示于图5A-5F(负载E6(29-38)的四聚体结合)和图6A-6F(负载E7(11-19)的四聚体结合)。在图5A-5H和6A-6H所示的流式细胞术图中在指示的象限中的细胞百分比还总结于以下表32(示出来自TCR转染的组合物的CD8+细胞的E6(29)四聚体和CD8+染色结果的流式细胞术图;图5A-5C)、表33(示出E6(29)特异性TCR转染的细胞组合物的流式细胞术图;图5D-5F)、以及表34(示出E7(11)特异性TCR的结果的流式细胞术图;图6A-6F)。具体地,图5A-5C描绘了CD8+群体中四聚体和CD8染色的流式细胞术图;图5D-5F和6A-6F描绘了反映CD8+和CD8-群体的染色的图。





如所示,示例性评估的TCR在T细胞表面上表达并识别在MHC四聚体的背景下的HPV肽。在一些情况下,结合不依赖于CD8共受体,如图5D-5F(表33中列出的百分比)和图6A-6F(表34中列出的百分比)中CD8-群体中的四聚体+细胞所指示。
另外的研究的结果示于图6G中,所述另外的研究评估了表达经密码子优化和半胱氨酸修饰的示例性重组E7特异性TCR(TCR37和TCR49)的细胞的CD8非依赖性四聚体结合。如所示,观察到表达示例性重组TCR TCR49的细胞展现出CD8依赖性四聚体结合(左图),并且观察到表达示例性重组TCRTCR37的细胞展现出一些CD8非依赖性四聚体结合。结果与如下发现一致:某些MHC I类限制性重组TCR可以在CD4+细胞中起作用,显示出CD8非依赖性四聚体结合。
实施例6:示例性重组T细胞受体(TCR)在原代T细胞中的表达和评估
评估了示例性重组E7特异性TCR在原代人T细胞中的表达和功能。
用编码以下的慢病毒制剂转导原代人CD4+和CD8+T细胞:对HPV 16E6(29-38)有特异性的TCR 16;以及各自对HPV 16E7(11-19)有特异性的TCR49、TCR 53和TCR 37(如上在以上实施例4中所述,并且经密码子优化和半胱氨酸修饰)。通过基于免疫亲和力的选择,从获自健康供体的人外周血单核细胞(PBMC)分离约5x 106个原代人CD4+和CD8+T细胞。在慢病毒转导之前,在37℃下,将细胞通过与抗CD3/抗CD28试剂一起在含有人血清和细胞因子的培养基中培养来刺激24小时。将经刺激的细胞用编码TCR 16、TCR 49、TCR 53或TCR 37的慢病毒制剂或模拟转导对照(在用于慢病毒转导的相同条件下处理但不添加慢病毒的细胞)转导。慢病毒构建体还包含编码EGFRt(作为转导和表达的替代标记)的序列,其与重组TCR编码序列由编码T2A核糖体跳跃序列的序列隔开。转导后,将细胞在包含人血清和细胞因子的培养基中培养。转导后第13天,针对用抗CD3抗体、抗CD8抗体和HPV 16E6(29-38)-或HPV16 E7(11-19)-肽-MHC四聚体复合物的染色通过流式细胞术评估细胞。在将重组TCR表达细胞与呈HPV+的抗原特异性靶细胞系鳞状细胞癌细胞系UPCI:SCC152( CRL-3240TM)以7.5:1或3.25:1的E:T比率(对于TCR 16表达细胞)和以2.5:1的E:T比率(对于TCR49、TCR 53或TCR 37表达细胞)孵育后,评估干扰素-γ(IFNγ)的产生。
CRL-3240TM)以7.5:1或3.25:1的E:T比率(对于TCR 16表达细胞)和以2.5:1的E:T比率(对于TCR49、TCR 53或TCR 37表达细胞)孵育后,评估干扰素-γ(IFNγ)的产生。
结果显示对于每种TCR有特异性的对应肽-MHC四聚体复合物的结合。在两种测试的E:T比率下,TCR 16表达细胞产生的IFNγ的水平都高于背景值。表达TCR 49、TCR 53或TCR 37的CD8+细胞产生的IFNγ的水平高于背景值,并且表达TCR 53和TCR 37的CD4+细胞产生的IFNγ水平高于背景值,这与这些TCR在原代T细胞中的CD8非依赖性功能一致。结果与重组TCR在原代T细胞中的表达、细胞表面表达和抗原特异性功能一致。
实施例7:用内源TCR基因敲除评估原代T细胞
分离并工程化人原代CD4+和CD8+T细胞以引入遗传破坏,以通过CRISPR/Cas9介导的基因编辑敲除(KO)编码T细胞受体α(TCRα)和β(TCRβ)链或两者的内源基因座。通过基于免疫亲和力的选择从获自健康供体的人外周血单核细胞(PBMC)分离来自两名健康人供体的原代CD4+和CD8+T细胞。将分离的CD4+和CD8+细胞通过与抗CD3/抗CD28试剂一起以1:1的珠:细胞比率在包含人血清、IL-2、IL-7和IL-15的培养基中培养来在37℃刺激72小时。
为了在TCR基因座处引入遗传破坏,去除了抗CD3/抗CD28试剂,并将细胞用包含化脓链球菌Cas9和靶向TCRα恒定区基因(TRAC)的指导RNA(gRNA)的2μM核糖核蛋白(RNP)复合物、或者用包含化脓链球菌Cas9和靶向TCRβ恒定区基因(TRBC)的gRNA的2μM RNP复合物电穿孔。为了靶向TRAC和TRBC二者,将RNP复合物的混合物用于电穿孔。具体地,用具有靶向结构域序列GAGAAUCAAAAUCGGUGAAU(SEQ ID NO:1048;TRAC的靶位点序列示于SEQ ID NO:1182中)的gRNA靶向TRAC基因座以进行遗传破坏,所述靶向结构域序列靶向在内源TCRα恒定区(TRAC)基因的外显子1内的遗传破坏。用靶向结构域序列GGCCUCGGCGCUGACGAUCU(SEQID NO:1053;TRBC的靶位点序列示于SEQ ID NO:1054中)靶向TRBC基因座以对TCRβ恒定区1和2的外显子1所共有的共有靶位点序列进行遗传破坏。作为对照,在与电穿孔所使用的相同条件下处理细胞,但不添加RNP(模拟)。
转染后5天,通过使用流式细胞术评价CD3表达来测量敲除效率,并确定CD3-群体的百分比。如图7A和7B所示,用靶向内源TCR基因的RNP对细胞电穿孔以破坏编码T细胞受体α(TCRα)恒定和β(TCRβ)恒定链或二者的内源基因座产生了不表达CD3的细胞,这指示这些细胞的内源TCR表达被敲除。在本研究中,如通过CD3表达所确定的,当单独地靶向TRAC或TRBC时大约80%的细胞被敲除了内源TCR,而当靶向TRAC和TRBC二者时更多数量的细胞被敲除了内源TCR。
实施例8:示例性重组T细胞受体(TCR)在具有内源TCR基因敲除的原代T细胞中的
表达
使用CRISPR/Cas9介导的基因编辑敲除原代人T细胞的内源T细胞受体编码基因,并将所述原代人T细胞用编码示例性重组E6或E7特异性TCR的慢病毒载体颗粒转导。
A.内源TCR基因的敲除和重组TCR在原代T细胞中的表达
通过基于免疫亲和力的选择,从获自健康供体的人外周血单核细胞(PBMC)分离约5x 106个原代人CD4+和CD8+T细胞。在慢病毒转导之前,在37℃下,将细胞通过与抗CD3/抗CD28试剂一起在含有人血清、白介素-2(IL-2)、IL-7和IL-15的培养基中培养来刺激24小时。将经刺激的细胞用编码以下的慢病毒制剂转导:对HPV 16E6(29-38)有特异性的TCR 16(经密码子优化和半胱氨酸修饰);对HPV 16E7(11-19)有特异性的TCR 31(经密码子优化和半胱氨酸修饰),如以上实施例4所述;或模拟转导对照(在慢病毒转导所使用的相同条件下处理细胞,但不添加慢病毒。慢病毒构建体还包含编码截短受体(作为转导和表达的替代标记)的序列,其与重组TCR编码序列由编码T2A核糖体跳跃序列的序列隔开。转导后,将细胞在包含人血清和IL-2、IL-7和IL-15的培养基中培养36-48小时。
为了敲除内源TCR基因,将细胞用包含被设计为靶向TCRα恒定区基因的外显子1内的靶位点的指导RNA(gRNA)(针对TRAC的gRNA靶向结构域序列示于SEQ ID NO:1048中;TRAC的靶位点序列示于SEQ ID NO:1182中)的核糖核蛋白(RNP)复合物与包含被设计为靶向TCRβ恒定区1和2二者的外显子1所共有的共有靶位点序列的gRNA(针对TRBC的gRNA靶向结构域序列示于SEQ ID NO:1053中;TRBC的靶位点序列示于SEQ ID NO:1054中)的RNP复合物的混合物以及化脓链球菌Cas9蛋白进行电穿孔,以用于CRISPR/Cas9介导的对TRAC和TRBC基因座的基因编辑(内源TCR KO)。
作为对照,在与电穿孔所使用的相同条件下处理细胞,但不添加RNP(内源TCRWT)。随后将细胞在包含细胞因子的培养基中培养。用RNP电穿孔后三天,通过用针对替代标记的抗体进行选择来富集转导的细胞,并再培养8天。
转导后第13天(电穿孔后第11天),针对用抗CD3抗体、抗CD8抗体、以及与由重组TCR识别的抗原(HPV16 E6或E7肽)复合的经标记MHC四聚体的染色通过流式细胞术评估细胞。在将重组TCR表达细胞与呈HPV+的抗原特异性靶细胞系鳞状细胞癌细胞系UPCI:SCC152( CRL-3240TM)以7.5:1、3.25:1或0:1的E:T比率孵育48小时后,监测细胞因子的产生。通过ELISA确定干扰素-γ(IFNγ)、IL-2和肿瘤坏死因子α(TNFα)的分泌。
CRL-3240TM)以7.5:1、3.25:1或0:1的E:T比率孵育48小时后,监测细胞因子的产生。通过ELISA确定干扰素-γ(IFNγ)、IL-2和肿瘤坏死因子α(TNFα)的分泌。
B.结果
通过确定CD3-群体的百分比评估内源TCR的敲除效率。如图8A所示,用靶向内源TCR基因的RNP电穿孔的超过98%的细胞(内源TCR KO)不表达CD3,指示所述细胞的内源TCR表达被敲除。相比之下,超过98%的对照细胞(内源TCR WT)表达CD3。结果表明,几乎所有细胞群体的内源TCR编码基因都被敲除。
比较了在具有或不具有内源TCR基因敲除的细胞中重组TCR的表达。如图8B所示,与经转导以表达TCR16的对照细胞(内源TCR WT)相比,在经转导以表达TCR 16的细胞中,表达TCR(如通过替代标记所评估)并结合肽-MHC四聚体的细胞的百分比在内源TCR敲除细胞(内源TCR KO)中有所增加。结果与以下发现是一致的:敲除原代T细胞中的内源TCR导致重组TCR的表达提高。
在与抗原特异性靶细胞系孵育后,与表达相同TCR的对照细胞(内源TCR WT)和模拟转导对照相比,表达重组TCR并且被敲除内源TCR基因的细胞(内源TCR KO)产生更多的IFNγ(图8C)。对于IL-2和TNFα产生观察到相似的结果。
实施例9:示例性重组T细胞受体(TCR)在具有或不具有内源TCR基因敲除的原代T
细胞中的表达和功能的评估
在具有或不具有内源TCR基因敲除的原代人T细胞中或其中重组E7特异性TCR被表达为具有小鼠恒定区的嵌合TCR的原代人T细胞中,评估了示例性重组E7特异性TCR的表达和功能。
使用基本上如实施例6中所述的方法,用编码各自对HPV 16E7(11-19)有特异性的TCR 49、TCR 53和TCR 37(经密码子优化和半胱氨酸修饰,如上文以上实施例4中所述)以及替代标记的慢病毒制剂转导原代人CD4+和CD8+T细胞。作为一种替代方法,用编码每种TCR的慢病毒制剂转导原代人CD4+和CD8+T细胞,其中重组TCR的Cα和Cβ被来自小鼠TCR的恒定区(小鼠恒定区;小鼠Cα序列示于SEQ ID NO:1012中;小鼠Cβ序列示于SEQ ID NO:1013中)替代。作为对照,在与慢病毒转导所使用的相同条件下处理细胞,但不添加慢病毒(模拟转导)。
基本上如实施例8所述,将用TCR 49、TCR 53或TCR 37(包含人恒定区)转导的细胞用靶向TRAC和TRBC的CRISPR/Cas9 RNP电穿孔以敲除内源TCR基因(内源TCR KO),或者在电穿孔所使用的相同条件下处理但不添加RNP(内源TCR WT)。其他转导的细胞条件也在用于电穿孔的相同条件下处理,但不添加RNP。总体上如以上实施例8A中所述来富集和培养细胞。
转导后第13天(电穿孔后第11天),针对用抗CD3抗体、抗CD8抗体和HPV16 E7(11-19)肽-MHC四聚体复合物的染色通过流式细胞术评估细胞。在重组TCR表达细胞与抗原特异性UPCI:SCC152靶细胞以2.5:1的E:T比率孵育后,评估干扰素-γ的产生。通过以下方式评估细胞溶解活性:将表达每种重组TCR的CD4+或CD8+细胞与抗原特异性UPCI:SCC152靶细胞(稳定表达NucLight Red)孵育,并使用自动显微镜评估随时间的整合荧光强度。
结果
如图9A(TCR 49)、图9D(TCR 53)和图9G(TCR 37)所示,如通过E7(11-19)四聚体结合所评估,与保留了内源TCR基因的细胞(内源TCR WT)相比,TCR的表达在敲除内源TCR基因的细胞(内源TCR KO)中更高。通过以包含小鼠恒定区的嵌合TCR的形式引入TCR,还实现了重组TCR在原代人T细胞中表达的增加。在一些情况下,观察到的CD8非依赖性四聚体结合在其中TCR表达为敲除内源TCR或表达为包含小鼠恒定区的嵌合TCR的细胞中也有所增加。
在与抗原特异性靶细胞孵育后,观察到TCR表达细胞的细胞溶解活性,如通过降低的NucRed光信号所监测,如图9B(TCR 49)、9E(TCR 53)、9H(TCR 37)和9J(TCR 37)中所示。对于每种TCR,细胞溶解活性的程度总体上与在各种评估的TCR表达细胞中观察到的TCR表达水平一致。在一些情况下,观察到CD4+细胞溶解活性与TCR的CD8非依赖性活性一致。
如图9C(TCR 49)、9F(TCR 53)、9I(TCR 37)和9J(TCR 37)所示,与抗原特异性靶细胞孵育后,由TCR表达细胞产生的干扰素-γ在敲除内源TCR基因的细胞中或者在TCR表达为具有小鼠恒定区的嵌合TCR的细胞中也有所增加。在一些情况下,在表达TCR的CD4+细胞中观察到干扰素-γ的表达增加,与TCR的CD8非依赖性活性一致。
实施例10:通过CRISPR/Cas9介导的对TRAC基因座的基因编辑来评价内源TCR消除
的原代T细胞中示例性重组T细胞受体(TCR)的表达、肽敏感性和功能
用编码对HPV 16E7(11-19)有特异性的各种示例性TCR(经密码子优化和半胱氨酸修饰,如实施例4中所述)的慢病毒制剂转导原代人CD4+和CD8+T细胞。作为对照,在与慢病毒转导所使用的相同条件下处理细胞,但不添加慢病毒(模拟)。将用TCR转导的细胞用靶向TRAC的CRISPR/Cas9 RNP(包含SEQ ID NO:1048所示的针对TRAC的gRNA靶向结构域序列)电穿孔,以敲除内源TCR基因(内源TCR KO),或在与电穿孔所使用的相同条件下处理但不添加RNP(内源TCR+)。其他转导的细胞条件也在用于电穿孔的相同条件下处理,但不添加RNP。基本上如实施例8所述来富集和培养细胞。
转导后6天(电穿孔后4天),针对用与由TCR识别的HPV16 E7肽复合的经标记MHC四聚体的染色,通过流式细胞术评估细胞。如图10A所示,与在保留内源TCR基因的细胞(内源TCR+/LV)中相比,在敲除内源TCR基因的CD8+T细胞(内源TCR KO/LV)中观察到示例性TCR36的表达提高。如通过E7(11-19)四聚体结合所评估,与在保留内源TCR基因的原代T细胞(内源TCR+)中相比,在内源TCR KO CD8+或CD4+原代T细胞中其他示例性测试TCR也以更高的水平表达(图10B)。
通过将E7(11-19)肽滴定到T2细胞上并评估TCR表达细胞的细胞因子产生,来评估在经转导以表达示例性TCR的内源TCR+或内源TCR KO CD8+原代T细胞中的肽敏感性。将重组TCR表达细胞与以各种浓度的抗原肽脉冲的T2靶细胞孵育后大约24小时,测量了上清液中的干扰素γ。如图11A所示,用示例性TCR 36工程化的原代人CD8+_T细胞中内源TCR的敲除改进了重组TCR的肽敏感性,这与TCR在细胞中表达的增加一致。在与肽(10ng/mL肽)脉冲的T2细胞孵育后基于干扰素γ产生,与内源TCR+原代人CD8+T细胞相比,当在TCR KO原代人CD8+T细胞中表达时,其他示例性TCR也展现出改进的肽敏感性(图11B)。
为了评估重组TCR的功能,通过将重组TCR表达效应细胞与表达HPV 16E7的靶细胞以5:1的效应子与靶标(E:T)孵育来评估细胞溶解活性。使用活细胞成像通过每2小时的靶标损失测量靶细胞裂解。如图12A所示,在表达示例性TCR 36的CD8+T细胞中,与在内源TCR+CD8+原代T细胞中相比,在内源TCR KO CD8+原代T细胞中观察到靶细胞裂解增加。与在保留内源TCR基因(内源TCR+)的CD8+原代T细胞中相比,在内源TCR KO CD8+原代T细胞中表达时,其他示例性TCR也展现出更大的细胞溶解活性(图12B)。在将重组TCR表达CD8+效应细胞与表达HPV 16E7的靶细胞以5:1的E:T比率孵育48小时后监测到的在内源TCR基因敲除的重组TCR表达细胞(内源TCR KO)中干扰素γ细胞因子的产生与在保留内源TCR基因的细胞(内源TCR+)中的干扰素γ细胞因子的产生相比更高(图12C)。
结果与以下观察结果一致:在许多测试的示例性重组TCR中,内源TCR的敲除导致示例性重组TCR的表达、肽敏感性和功能增加。
实施例11:重组TCR表达CD4+细胞介导的抗肿瘤反应
在小鼠模型中评估了表达重组TCR的CD4+和CD8+细胞的抗肿瘤反应。
A.抗肿瘤反应
通过皮下注射鳞状细胞癌细胞系UPCI:SCC152( CRL-3240TM)细胞来产生具有肿瘤细胞的小鼠模型。在注射肿瘤细胞后39天给予用载体转导的原代CD4+细胞、CD8+细胞或CD4+和CD8+细胞的混合物,所述载体编码能够结合HPV E7(11-19)的参考TCR(描述于国际PCT公开号WO 2015/184228;参考TCR包含小鼠恒定区)。在注射肿瘤后经长达63天的时间评估平均肿瘤体积。
CRL-3240TM)细胞来产生具有肿瘤细胞的小鼠模型。在注射肿瘤细胞后39天给予用载体转导的原代CD4+细胞、CD8+细胞或CD4+和CD8+细胞的混合物,所述载体编码能够结合HPV E7(11-19)的参考TCR(描述于国际PCT公开号WO 2015/184228;参考TCR包含小鼠恒定区)。在注射肿瘤后经长达63天的时间评估平均肿瘤体积。
如图13所示,与未接受任何处理的小鼠(圆形)相比,在被仅给予CD4+重组参考TCR表达细胞(倒三角形)、仅给予CD8+重组参考TCR表达细胞(三角形)、或CD4+和CD8+重组参考TCR表达细胞的混合物(正方形)的小鼠中小鼠的肿瘤体积减小了。这些结果与以下观察结果一致:仅给予CD4+重组TCR表达细胞促成抗肿瘤反应,但给予CD4+和CD8+重组TCR表达细胞的组合的效果更大。
实施例12:通过靶向敲入或随机整合编码TCR的序列表达重组T细胞受体(TCR)的
工程化T细胞的产生和评估
经由同源依赖性修复(HDR)在遗传破坏位点处通过CRISPR/Cas9介导的基因编辑和靶向整合,或通过经由慢病毒转导的随机整合,将编码示例性重组T细胞受体(TCR)的多核苷酸引入在编码T细胞受体α(TCRα)链的内源基因座处具有遗传破坏的T细胞中。
A.重组TCR转基因构建体
产生了示例性模板多核苷酸,以用于通过HDR靶向整合转基因,所述转基因包含编码两个示例性重组TCR之一的核酸序列。示例性模板多核苷酸的一般结构如下:[5'同源臂]-[转基因序列]-[3'同源臂]。同源臂包括与人TCRα恒定区(TRAC)基因的外显子1中的靶整合位点周围的序列同源的大约600bp核酸序列(5’同源臂序列示于SEQ ID NO:1343中;3’同源臂序列示于SEQ ID NO:1344中)。
转基因包括编码示例性重组TCR的α和β链的核酸序列,所述重组TCR识别人乳头瘤病毒(HPV)16癌蛋白E7的表位(TCR 49),其中编码TCRα和TCRβ链的序列由2A核糖体跳跃元件隔开。如实施例4中所述,还通过密码子优化和一个或多个突变来修饰编码TCR 49的核苷酸序列,以促进在TCR恒定结构域之间的界面中形成非天然二硫键,以增加TCR的配对和稳定性。通过在TCR链的TCRα链恒定区(Cα)区中在残基48处将Thr修饰为Cys,和在TCRβ链恒定区(Cβ)区中在残基57处将Ser修饰为Cys来促进非天然二硫键(参见Kuball等人(2007)Blood,109:2331-2338)。
转基因还包括:a)人延伸因子1α(EF1α)启动子,以驱动重组TCR编码序列(SEQ IDNO:1345所示的序列)的表达;或b)在重组TCR编码序列上游的编码P2A核糖体跳跃元件的序列(SEQ ID NO:1346所示的序列),以在HDR介导的框内靶向整合到人TCRα恒定区(TRAC)基因后驱动从内源TCRα基因座表达重组TCR。
为了通过HDR进行靶向整合,产生了包含上述模板多核苷酸的腺相关病毒(AAV)载体构建体。通过将包括模板多核苷酸、血清型辅助质粒和腺病毒辅助质粒的AAV载体三重转染到293T细胞系中来产生AAV储备液。收集转染的细胞,裂解,并收集AAV储备液用于细胞转导。
作为对照,对于随机整合,将编码上述示例性重组TCR转基因构建体的核酸序列、或编码能够与HPV 16E7结合但含有小鼠Cα和Cβ区的参考TCR的序列(在国际PCT公开号WO2015/184228中描述)在EF1α启动子的控制下掺入示例性HIV-1衍生的慢病毒载体中。通过用所得载体、辅助质粒(包含gagpol质粒和rev质粒)和假型化质粒瞬时转染HEK-293T细胞,经标准程序产生假型化慢病毒载体颗粒,并将所述假型化慢病毒载体颗粒用于转导细胞。
B.工程化T细胞的产生
通过基于免疫亲和力的选择从获自健康供体的人外周血单核细胞(PBMC)分离来自人供体的原代人CD4+和CD8+T细胞。将分离的CD4+和CD8+细胞通过与抗CD3/抗CD28试剂一起以1:1的珠:细胞比率在包含人血清、IL-2、IL-7和IL-15的培养基中培养来在37℃刺激72小时。为了通过CRISPR/Cas9介导的基因编辑在内源TRAC基因座处引入遗传破坏,去除了抗CD3/抗CD28试剂,并将细胞用包含化脓链球菌Cas9和指导RNA(gRNA)的2μM核糖核蛋白(RNP)复合物电穿孔,所述指导RNA具有靶向结构域序列GAGAAUCAAAAUCGGUGAAU(SEQ IDNO:1048),其靶向内源TCRα恒定区(TRAC)基因的外显子1内的遗传破坏。电穿孔后,将细胞与包含AAV制剂的培养基混合以用于转导(HDR KO),所述AAV制剂包含在EF1α启动子的控制下编码示例性重组TCR的HDR模板多核苷酸。作为对照,将细胞在与电穿孔所使用的相同条件下处理但不添加RNP(模拟KO),用编码重组TCR(Lenti)或能够与HPV 16E7结合但包含小鼠Cα和Cβ区的参考TCR(Lenti Ref)的慢病毒载体转导,或用编码重组TCR的慢病毒载体转导并且还用靶向TRAC基因座处的遗传破坏的RNP复合物电穿孔(Lenti KO)。转导后,将细胞在包含人血清和IL-2、IL-7和IL-15的培养基中培养大约7天。
C.TCR的表达
在电穿孔后的第7天,针对用抗CD3抗体、抗CD4抗体、抗CD8抗体、特异性针对重组TCR的抗Vβ22抗体、以及与HPV16 E7肽复合的肽-MHC四聚体的染色通过流式细胞术评估细胞。
表达TCR 49的CD8+细胞的结果示于图17A-17C中。如所示,在TRAC基因座处通过HDR介导的靶向整合表达TCR 49的细胞在CD8+细胞中展现出最高比例的由四聚体结合的细胞(图17A)和最高的四聚体染色平均荧光强度(图17B)。在由四聚体结合的CD8+细胞中,与通过慢病毒转导的随机整合相比,经历了HDR介导的整合的细胞中,由四聚体结合的程度通常更均匀,如通过较低的变异系数(细胞群体中的信号的标准差除以各自群体中信号的平均值;参见图17C)所示。
在使用与上述基本相同的方法进行的另一项实验中,使用对重组TCR或肽-MHC四聚体有特异性的抗Vβ22抗体对TCR染色证实了TCR49在敲除了内源TCR的CD8+原代人T细胞中的较高表达,所述敲除是通过用编码重组TCR的慢病毒载体转导并用靶向在TRAC基因座处的遗传破坏的RNP复合物进行电穿孔(Lenti KO)或通过将重组TCR定点插入TRAC基因座(HDR KO)进行(图18A)。如使用Bangs Lab方法测量的,密度评估包括:使用用于标记细胞的相同荧光团来标记用于流式细胞术的单色荧光参考标准物,并生成校准曲线以将荧光通道值与标准化荧光强度单位相关联。相对于校准曲线确定受体密度。基于四聚体(图18B)或Vβ22+(图18C)的密度评估证实了在T细胞上TCR密度增加,在所述T细胞中通过HDR定点靶向插入重组TCR而引入了重组TCR(HDR KO)。
D.细胞溶解活性和细胞因子的产生
在体外与表达HPV 16E7的靶细胞孵育后,评估如上所述工程化为通过HDR或通过随机整合来表达重组TCR 49的细胞的细胞溶解活性和细胞因子的产生。
通过将重组TCR表达效应细胞与表达HPV 16E7的靶细胞(经NucLight Red(NLR)标记)以10:1、5:1和2.5:1的效应子与靶标(E:T)比率进行培养来评估细胞溶解活性。通过共培养后每2小时至44小时测量标记的靶细胞的损失来评估T细胞以抗原特异性方式裂解靶细胞的能力。从每组中2个供体的杀伤%的曲线下面积(AUC)的平均值确定细胞溶解活性,针对Vβ表达归一化,并与模拟转导对照进行比较。在将重组TCR表达效应细胞与靶细胞孵育后测量细胞因子的产生。通过ELISA确定上清液中干扰素-γ(IFNγ)和白介素-2(IL-2)的分泌,归一化为Vβ表达,并对于每组2个供体取平均值。
基于两个独立的人供体的结果,TCR 49的结果示于图19-20中。与通过具有(TCR49Lenti)或不具有TRAC基因座敲除(TCR 49Lenti KO)的随机整合相比,在通过HDR介导的在TRAC基因座处的靶向整合(EF1α-TCR 49HDR KO)引入了由EF1α启动子驱动的重组TCR 49的细胞中杀伤和IFNγ分泌的程度更高。
E.结论
总体上,结果与以下观察结果一致:在一些情况下,与通过随机整合引入TCR相比,通过HDR靶向整合编码示例性重组TCR的核酸序列导致人TCR在人T细胞中的重组TCR表达更高,从而导致表达重组TCR的细胞的功能活性更高。
实施例13:通过在敲除了内源TCRα和TCRβ链的T细胞中靶向敲入或随机整合编码
TCR的序列产生重组T细胞受体(TCR)和评估所述重组T细胞受体的表达
在工程化为通过CRISPR/Cas9介导的基因编辑在遗传上破坏了编码T细胞受体α(TCRα)或β(TCRβ)链或二者的内源基因座的细胞中,编码示例性重组TCR之一的多核苷酸经由同源依赖性修复(HDR)靶向整合到遗传破坏位点之一或经由慢病毒转导通过随机整合被引入。
为了通过HDR进行靶向整合,基本上如实施例10中所述产生包含编码示例性重组TCR 49的模板多核苷酸构建体的AAV制剂,但具有以下差异:产生了另外的AAV构建体,其包含MND启动子(SEQ ID NO:1347所示的序列)和骨髓增生性肉瘤病毒增强子以控制重组TCR编码序列的表达,所述MND启动子是合成启动子,含有经修饰的MoMuLV LTR的U3区。
为了进行随机整合,总体上如实施例-10中所述产生包含编码示例性重组TCR 49的核酸序列(如实施例4中所述经密码子优化和半胱氨酸修饰;Lenti人)的慢病毒制剂。对于这些研究,慢病毒转导构建体还包含编码以下的多核苷酸:截短受体,其与重组TCR转基因由编码T2A核糖体跳跃序列的序列隔开,以从同一构建体中表达重组TCR和截短受体二者;所述截短受体用作转导的替代标记。作为对照,产生了编码嵌合TCR的多核苷酸,其中重组TCR的Cα和Cβ被来自小鼠TCR的恒定区(小鼠Cα序列示于SEQ ID NO:1012中;小鼠Cβ序列示于SEQ ID NO:1013中;Lenti小鼠)替代,或使细胞经历模拟转导(模拟转导)。
将原代人CD4+和CD8+T细胞分离,并且工程化以通过CRISPR/Cas9介导的基因编辑引入在内源TRAC和TRBC基因座处的遗传破坏,并用包含用于HDR的模板多核苷酸的AAV制剂或者用于随机整合的慢病毒制剂转导,总体上如以上实施例10B中所述,不同之处是还对细胞在内源TRBC基因座处进行了破坏(TRAC/TRBC KO,可互换地称为TCRαβKO)。将细胞用包含实施例10B中所述的TRAC靶向指导RNA(gRNA)(包含SEQ ID NO:1048所示的靶向结构域序列)的核糖核蛋白(RNP)复合物和包含gRNA(所述gRNA靶向TCRβ恒定区1和2二者的外显子1所共有的共有靶位点序列)(靶向结构域序列GGCCUCGGCGCUGACGAUCU(SEQ ID NO:1053))的RNP进行电穿孔。电穿孔后,将细胞与包含AAV制剂的培养基混合,以用于通过HDR转导在EF1α启动子(TCRαβKO/HDR EF1α)或MND启动子(TCRαβKO/HDR MND)控制下的示例性TCR 49。
作为对照,将分离的原代CD4+和CD8+T细胞用编码示例性重组TCR 49(TCRαβWT/Lenti人)或含有小鼠恒定区的嵌合受体(TCRαβWT/Lenti小鼠)的慢病毒制剂转导,并在电穿孔所使用的相同条件下进行处理但不添加RNP(模拟KO;也称为TCRαβWT或电穿孔对照),或者用编码示例性重组TCR 49的慢病毒制剂转导并经历用RNP复合物电穿孔以敲除TRAC和TRBC基因座(TCRαβKO/Lenti人)。
随后将细胞培养四(4)天,然后针对用抗CD3抗体、识别重组TCR 49的抗Vβ22抗体、以及与由重组TCR识别的抗原(HPV16 E7肽)复合的肽-MHC四聚体的染色通过流式细胞术评估细胞。还对细胞进行了针对CD8或CD4的共染色。
结果示于图21A-21F中。如图21A和21B所示,CRISPR/Cas9介导的对TRAC和TRBC的敲除(KO)(图中标记为“TCRαβKO”的图)导致CD8+细胞中TCR表达的几乎完全破坏,如通过经历KO和模拟转导的细胞中CD3染色的不存在所观察到的(标记为TCRαβKO/模拟转导的图)。在内源TCR被KO的细胞中在慢病毒转导(TCRαβKO/lenti人)后,与保留内源TCR表达的细胞(TCRαβWT/lenti人)相比,重组TCR的表达(如CD8+细胞中通过Vβ22抗体染色的细胞或对四聚体染色呈阳性的细胞所指示)稍有提高。在保留内源TCR的细胞中,与完全人重组TCR的慢病毒转导相比(比较TCRαβWT/lenti人和TCRαβWT/lenti小鼠),通过慢病毒转导包含小鼠恒定结构域的重组TCR提高了重组TCR表达。
HDR介导的重组TCR的靶向敲入和内源TCR的KO导致表达重组TCR的细胞比例比慢病毒转导后观察到的细胞比例高得多(在图21A和21B中与TCRαβKO/lenti人相比,前两个左图称为“HDR”)。与慢病毒转导相比,如通过CD8+细胞中的Vβ22或四聚体染色(图21C)或CD4+细胞中的Vβ22染色(图21D)评估的在经历HDR的细胞中重组TCR表达的几何平均荧光(gMFI)也明显较高。无论重组TCR是在EF1α启动子还是在MND启动子的控制下,通过HDR的重组TCR表达的程度均相似。
在对重组TCR表达呈阳性的细胞中,与随机整合慢病毒转导相比,在经历HDR介导的靶向整合的细胞中表达程度通常更均匀或更紧密(参见图21A和21B)。如图21E和图21F所示,与随机整合相比,在经历HDR介导的整合的CD8+细胞中,观察到重组TCR表达的变异系数较低(细胞群体中的信号的标准差除以各个群体中信号的平均值),如分别通过肽-MHC四聚体结合和Vβ22表达所确定的。结果与以下发现一致:与其他方法相比,将重组TCR靶向敲入内源TCRα基因座与将内源TCRαβ链敲除相结合,可在工程化为表达重组TCR的细胞群体中导致更高且更均匀的表达水平。
实施例14:在敲除了内源TCRα或TCRβ链或二者的T细胞中对HDR介导的敲入编码重
组T细胞受体(TCR)的序列的评估
为了进一步评估通过HDR的重组TCR表达,将进入TRAC基因座的编码示例性重组TCR的核酸序列靶向整合在包含TRAC和TRBC基因座的双重敲除、仅TRAC基因座敲除或仅TRBC基因座敲除的细胞中。
A.重组TCR转基因构建体和工程化细胞的产生
这些研究是使用编码示例性TCR 49(如实施例4所述经密码子优化和半胱氨酸修饰)的AAV(用于HDR)和慢病毒构建体(用于随机整合)基本上如实施例10和11中所述进行的,但具有以下差异:产生了包含以下多核苷酸的慢病毒构建体,所述多核苷酸编码在EF1α或MND启动子的可操作控制下的重组TCR。为了比较,还产生了包含以下多核苷酸的慢病毒构建体,所述多核苷酸编码在EF1α启动子的可操作控制下的重组TCR 49、以及截短受体,所述截短受体与重组TCR转基因由编码T2A核糖体跳跃序列的序列隔开。
为了通过HDR进行靶向整合,对原代人CD4+和CD8+T细胞进行刺激、培养、并经历用以下电穿孔:包含仅TRAC靶向gRNA的核糖核蛋白(RNP)复合物、包含仅TRBC靶向gRNA的RNP复合物、或者包含TRAC靶向gRNA的RNP和包含TRBC靶向gRNA的RNP二者的混合物,总体上如实施例10和11所述。在电穿孔后,将细胞用包含编码重组TCR的多核苷酸的AAV制剂转导,以靶向内源TRAC基因座,总体上如上所述。
对于随机整合,将原代人CD4+和CD8+T细胞解冻、刺激和培养,基本上如实施例10和11中所述,然后用编码重组TCR的慢病毒制剂转导。在本研究中,将慢病毒制剂转导到保留了内源TCR的原代T细胞中。作为对照,在与慢病毒转导所使用的相同条件下处理细胞,但不添加慢病毒(模拟转导)。
B.TCR的表达
随后将细胞再培养4-10天,并在用抗CD3抗体、对重组TCR 49有特异性的抗Vβ22抗体、以及与由TCR识别的抗原(HPV16 E7肽)复合的肽-MHC四聚体染色后,通过流式细胞术评估细胞。还对细胞进行了针对CD8或CD4的共染色。
CD3染色的结果示于图22A-22C中,四聚体染色示于图23A-23C中,以及Vβ22染色示于图24A-24D中。
如图22A和22C所示,用和靶向TRAC的gRNA复合的RNP与和靶向TRBC的gRNA复合的RNP的混合物进行电穿孔导致内源TCR的高效敲除,如通过CD3表面表达的不存在所证实(参见图22A中标记为KO/模拟转导的图;还参见示出CD8+细胞中CD3+CD8+细胞的百分比的图22C中标记为KO模拟的组)。具有靶向TRAC和TRBC二者的RNP的KO的程度要大于用与靶向仅TRAC或仅TRBC的gRNA复合的RNP电穿孔的细胞中的KO程度,这与以下观察结果一致:TCR链α和β的恒定结构域二者的双重靶向提高了破坏内源TCR表达的效率。在没有进行内源TCR破坏的用慢病毒载体转导的细胞中,CD3表达在所有测试条件下均相似(图22B和22C)。如图22A和22C所示,在通过HDR引入了重组TCR的细胞中,CD3表达也相似,这与在引入了重组TCR的细胞中的TCR/CD3表面表达一致。
如图23A和23C所示,结合肽-MHC四聚体的CD8+细胞的比例指示,与仅敲除了TRAC的细胞相比,在敲除了TRAC和TRBC二者的细胞中进行HDR的情况下重组TCR表达较高(比较图23A中的顶行和中间行;比较图23C中的TRAC&TRBC与仅TRAC)。如图23C所示,在第7天和第13天观察到相似的结果。无论采用在外源性EF1α或MND启动子的控制下还是在内源TCR启动子的控制下的构建体(包含P2A的构建体)进行HDR以便整合,在细胞中均观察到了重组TCR的相似表达。如图23B和图23C所示,在慢病毒介导的转导后,较少的细胞表达重组TCR(如通过四聚体染色评估的),无论慢病毒构建体中是否存在截短受体。
如图24A-24C所示,与以上结果相似,当用特异性识别重组TCR的Vβ链的抗体直接对重组TCR染色时,观察到重组TCR在CD8+T细胞上的表达。用也能检测在CD4+T细胞(CD8阴性群体)上的重组TCR的抗Vβ染色还显示在CD4+细胞中观察到了重组TCR的表达(图24A和图24D)。
对于以上所示的评估重组TCR表达的所有方法(抗CD3、四聚体和抗Vβ22),上述结果还显示,重组HDR经由HDR靶向整合至TRAC对于核酸酶诱导的在TRAC基因座处的DNA断裂具有特异性,这是因为用TRBC靶向RNP电穿孔的细胞不表达重组TCR(参见图中的“仅TRBC”情况)。
C.细胞溶解活性和细胞因子的产生
在体外与表达HPV 16E7的靶细胞孵育后,评估如上所述工程化为通过HDR或通过随机整合来表达重组TCR 49的CD8+细胞的细胞溶解活性和细胞因子的产生。除上述细胞外,还评估了用编码能够与HPV 16E7结合但包含小鼠Cα和Cβ区的参考TCR的慢病毒转导的原代人CD8+细胞。
通过将重组TCR表达效应细胞与表达HPV 16E7的靶细胞以10:1、5:1和2.5:1的效应子与靶标(E:T)比率孵育来评估细胞溶解活性。共培养后4小时,评估T细胞以抗原特异性方式裂解靶细胞的能力。从杀伤%的曲线下面积(AUC)确定细胞溶解活性,针对Vβ表达归一化,并与模拟转导对照进行比较。结果示于图25中。与通过随机整合相比,在通过HDR介导的靶向整合引入了重组TCR的细胞中的杀伤程度更高,这与以下发现一致:重组TCR在细胞中的更高表达导致更高的功能活性。
在将重组TCR表达CD8+效应细胞与表达HPV 16E7的靶细胞以10:1和2.5:1的E:T比率孵育48小时后,还监测了细胞因子的产生。通过ELISA确定上清液中的IFNγ分泌,并在每组将其归一化为Vβ22表达。结果示于图26中。与上文的细胞溶解活性的结果相似,与随机整合相比,经历HDR介导的整合的细胞中观察到更多的IFNγ产生。在细胞溶解活性测定和IFNγ分泌评估中,通过HDR介导的整合表达重组TCR的细胞的功能活性与经由慢病毒转导表达包含小鼠恒定结构域的参考TCR的细胞的活性相似。
在与SCC152靶细胞或用抗原肽脉冲的T2靶细胞孵育后,评估了重组TCR表达细胞的增殖。用CellTraceTM紫(ThermoFisher)染料标记细胞。如通过流式细胞术评估的,通过CellTraceTM紫染料稀释物指示活T细胞的分裂。
各种功能测定的结果描绘于图27中。如描绘了各种功能活性(在10:1、5:1和2.5:1的E:T比率下杀伤%的AUC(称为“AUC”),第7天和第13天在CD8+细胞中的四聚体结合(称为“四聚体CD8”),使用SCC152细胞或用抗原肽脉冲的T2靶细胞的增殖测定(称为“CTV计数”),以及IFNγ从CD8+细胞的分泌(称为“CD8分泌的IFNg”))中重组TCR表达细胞群体的相对活性的热图所示,总体上观察到其中重组TCR靶向敲入内源TCRα链恒定结构域基因座处和敲除了内源TCRαβ基因或TCRα基因的细胞的功能活性比其中随机整合了编码重组TCR的多核苷酸的细胞的功能活性更高。
总体上,结果与以下观察结果一致:与通过随机整合引入TCR相比,通过HDR的靶向整合导致在人T细胞中人TCR的重组TCR表达更高,从而导致表达重组TCR的细胞的功能活性更高。
本发明在范围上并不旨在限于具体公开的实施方案,所提供的实施方案例如是为了说明本发明的各个方面。根据本文的描述和传授,对所述组合物和方法的各种修改将变得清楚。可以在不背离本公开文本的真实范围和精神的情况下实践此类变化,并且此类变化旨在落入本公开文本的范围内。
序列表























































































Claims (304)
1.一种T细胞受体(TCR)或其抗原结合片段,所述T细胞受体(TCR)或其抗原结合片段包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链,其中:
所述Vα区包含SEQ ID NO:691、709、726、741、759、775、787、799、815、830、845、857、869、881、895、908、925、937、951、963、975、987、999或1390中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列;和/或
所述Vβ区包含SEQ ID NO:700、718、735、750、768、781、793、808、824、839、851、863、875、887、901、917、931、945、957、969、981、993、1008或1380中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列。
2.根据权利要求1所述的TCR或其抗原结合片段,其中:
所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1185)的互补决定区3(CDR-3),其中X2是A、G、V、Q、M或E;X3是S、G、N、A、Y、R或P;X4是E、S、A、G、F、N、D、V、P、L、I、M或R;X5是R、N、H、T、D、G、S、P、L、Q或F;X6是G、H、A、S、T或空;X7是T、S、G或空;X8是G或空;X9是G、N、S或空;X10是T、G、S、D、F、Y、A或N;X11是Y、F、Q、R或N;X12是K、Q或D;X13是Y、L、T、M、F或V;X14是I、T、S、R、Y或V;所述Vα区包含含有氨基酸序列X1X2X3X4X5X6X7X8X9X10KX12I(SEQ IDNO:1186)的互补决定区3(CDR-3),其中X1是A或V;X2是A、V或E;X3是S、N、T、R或P;X4是E、A、G、F、V、P、I、D或S;X5是R、H、T、AP、S、G或F;X6是G、H、L、T、S或A、空;X7是S、T或空;X8是G或空;X9是G、T或空;X10是F、Y或N;X12是Y、T或L;
所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9YKYI(SEQ ID NO:1187)的互补决定区3(CDR-3),其中X2是A、V或E;X3是S、N或R;X4是E、G、V、P、I或D;X5是R、T、P、S、G或F;X6是G、T、S或空;X7是S或空;X8是G或空;X9是T或空;
所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1188)的互补决定区3(CDR-3),其中X2是G、V、Q或M;X3是G、A、Y、S、N或R;X4是S、G、L、I、M或R;X5是N、D、G、S、L、Q或R;X6是A、S、G或空;X7是G或空;X8是G或空;X9是G、N、S或空;X10是S、D、Y、A、N或空;X11是Y、Q或R;X12是K或Q;X13是L或V;X14是S、T或V;
所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13T(SEQ ID NO:1189)的互补决定区3(CDR-3),其中X2是G、V或Q;X3是G、Y、S或N;X4是S、L或M;X5是N、G、L或R;X6是A、S、G或空;X7是G或空;X8是G或空;X9是G、S或空;X10是S、Y、A、N或空;X11是Y、Q或R;X12是K或Q;X13是L或V;
所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7YKLS(SEQ ID NO:1190)的互补决定区3(CDR-3),其中X2是G或V;X3是A或Y;X4是G、S或R;X5是D或S;X6是N或空;X7是D或空。
3.根据权利要求1或权利要求2所述的TCR或其抗原结合片段,其中:
所述Vβ区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1200)的互补决定区3(CDR-3),X2是S、V或I;X3是S、N或A;X4是R、V、S、L、P、G、I或A;X5是F、G、Y、L、V、R、T或S;X6是L、G、A、D、R、V或空;X7是G、D、R、S、T或空;X8是S或空;X9是S、H、G、V、T、D、L或空;X10是T、S、A、G、P、N或Y;X11是D、Y、E、G或N;X12是T、E、G或K;X13是Q、Y或L;X14是Y、F、T或I;
所述Vβ区包含含有氨基酸序列ASSX4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1201)的互补决定区3(CDR-3),其中X4是R、V、S、L、G或A;X5是F、G、Y、L、V、T或S;X6是A、L、R、D、G或空;X7是G、D、T或空;X8是S或空;X9是S、H、G、T、D、L或空;X10是T、S、A、G、P、N或Y;X11是D、Y、E、G或N;X12是T、E或G;X13是Q、Y或L;X14是Y、F或T;
所述Vβ区包含含有氨基酸序列ASSX4X5X6X7X8X9X10TQY(SEQ ID NO:1202)的互补决定区3(CDR-3),其中X4是R、L或G;X5是F、V、T或Y;X6是L或A、空;X7是G或空;X8是S、G或空;X9是T、G、P或S;X10是D或E。
4.一种T细胞受体(TCR)或其抗原结合片段,所述T细胞受体(TCR)或其抗原结合片段包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链,其中:
所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1185)的互补决定区3(CDR-3),其中X2是A、G、V、Q、M或E;X3是S、G、N、A、Y、R或P;X4是E、S、A、G、F、N、D、V、P、L、I、M或R;X5是R、N、H、T、D、G、S、P、L、Q或F;X6是G、H、A、S、T或空;X7是T、S、G或空;X8是G或空;X9是G、N、S或空;X10是T、G、S、D、F、Y、A或N;X11是Y、F、Q、R或N;X12是K、Q或D;X13是Y、L、T、M、F或V;X14是I、T、S、R、Y或V;
所述Vα区包含含有氨基酸序列X1X2X3X4X5X6X7X8X9X10KX12I(SEQ ID NO:1186)的互补决定区3(CDR-3),其中X1是A或V;X2是A、V或E;X3是S、N、T、R或P;X4是E、A、G、F、V、P、I、D或S;X5是R、H、T、A P、S、G或F;X6是G、H、L、T、S或A、空;X7是S、T或空;X8是G或空;X9是G、T或空;X10是F、Y或N;X12是Y、T或L;
所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9YKYI(SEQ ID NO:1187)的互补决定区3(CDR-3),其中X2是A、V或E;X3是S、N或R;X4是E、G、V、P、I或D;X5是R、T、P、S、G或F;X6是G、T、S或空;X7是S或空;X8是G或空;X9是T或空;
所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1188)的互补决定区3(CDR-3),其中X2是G、V、Q或M;X3是G、A、Y、S、N或R;X4是S、G、L、I、M或R;X5是N、D、G、S、L、Q或R;X6是A、S、G或空;X7是G或空;X8是G或空;X9是G、N、S或空;X10是S、D、Y、A、N或空;X11是Y、Q或R;X12是K或Q;X13是L或V;X14是S、T或V;
所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13T(SEQ ID NO:1189)的互补决定区3(CDR-3),其中X2是G、V或Q;X3是G、Y、S或N;X4是S、L或M;X5是N、G、L或R;X6是A、S、G或空;X7是G或空;X8是G或空;X9是G、S或空;X10是S、Y、A、N或空;X11是Y、Q或R;X12是K或Q;X13是L或V;
所述Vα区包含含有氨基酸序列AX2X3X4X5X6X7YKLS(SEQ ID NO:1190)的互补决定区3(CDR-3),其中X2是G或V;X3是A或Y;X4是G、S或R;X5是D或S;X6是N或空;X7是D或空。
5.一种T细胞受体(TCR)或其抗原结合片段,所述T细胞受体(TCR)或其抗原结合片段包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链,其中:
所述Vβ区包含含有氨基酸序列AX2X3X4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1200)的互补决定区3(CDR-3),X2是S、V或I;X3是S、N或A;X4是R、V、S、L、P、G、I或A;X5是F、G、Y、L、V、R、T或S;X6是L、G、A、D、R、V或空;X7是G、D、R、S、T或空;X8是S或空;X9是S、H、G、V、T、D、L或空;X10是T、S、A、G、P、N或Y;X11是D、Y、E、G或N;X12是T、E、G或K;X13是Q、Y或L;X14是Y、F、T或I;
所述Vβ区包含含有氨基酸序列ASSX4X5X6X7X8X9X10X11X12X13X14(SEQ ID NO:1201)的互补决定区3(CDR-3),其中X4是R、V、S、L、G或A;X5是F、G、Y、L、V、T或S;X6是A、L、R、D、G或空;X7是G、D、T或空;X8是S或空;X9是S、H、G、T、D、L或空;X10是T、S、A、G、P、N或Y;X11是D、Y、E、G或N;X12是T、E或G;X13是Q、Y或L;X14是Y、F或T;
所述Vβ区包含含有氨基酸序列ASSX4X5X6X7X8X9X10TQY(SEQ ID NO:1202)的互补决定区3(CDR-3),其中X4是R、L或G;X5是F、V、T或Y;X6是L或A、空;X7是G或空;X8是S、G或空;X9是T、G、P或S;X10是D或E。
6.一种T细胞受体(TCR)或其抗原结合片段,所述T细胞受体(TCR)或其抗原结合片段包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链,其中:
所述Vα区包含SEQ ID NO:694、712、729、744、762、776、788、802、818、832、846、858、870、882、896、911、926、940、952、964、976、988、1002或与其展现出至少60%、65%、70%、75%、80%、85%、90%或95%序列同一性的序列中任一个所示的互补决定区3(CDR-3);
所述Vβ区包含SEQ ID NO:703、721、736、753、769、782、794、809、825、840、852、864、876、888、902、919、932、946、958、970、982、994或1010或与其展现出至少60%、65%、70%、75%、80%、85%、90%或95%序列同一性的序列中任一个所示的互补决定区3(CDR-3)。
7.根据权利要求1-6中任一项所述的TCR或其抗原结合片段,其中所述Vα区包含:
包含氨基酸序列X1X2X3X4X5X6(SEQ ID NO:1191)的互补决定区1(CDR-1),其中X1是N、S、D、T或V;X2是S、V、R、T或I;X3是M、F、G、S、N、A、L、V或P;X4是F、S、N、A或空;X5是D、S、Q、Y、N、V、T或P;并且X6是Y、S、R、N、G或T;和/或
包含氨基酸序列X1X2X3X4X5X6X7X8(SEQ ID NO:1192)的互补决定区2(CDR-2),其中X1是I、V、L、G、N、T、Y或M;X2是S、V、Y、L、P、F、I或T;X3是S、Y、K、L、T或F;X4是I、G、N、A、S或空;X5是S、D或空;X6是K、G、N、S、D、T或E;X7是D、E、G、A、K、L或N;并且X8是K、V、D、P、N、T、L或M。
8.根据权利要求1-7中任一项所述的TCR或其抗原结合片段,其中所述Vβ区包含:
包含氨基酸序列SX2X3X4X5(SEQ ID NO:1203)的互补决定区1(CDR-1),其中X2是G或N;X3是H或D;X4是T、L、N或V;并且X5是A、S、Y或T;和/或
包含氨基酸序列X1X2X3X4X5X6(SEQ ID NO:1204)的互补决定区2(CDR-2),其中X1是F或Y;X2是Q、Y或N;X3是G、N、R或Y;X4是N、G、E或T;X5是S、E、A或G;并且X6是A、E、I或Q。
9.根据权利要求1-8中任一项所述的TCR或其抗原结合片段,其中所述TCR或其抗原结合片段结合至或识别在MHC分子的背景下的人乳头瘤病毒(HPV)16 E7的肽表位,所述肽表位是或包含E7(11-19)YMLDLQPET(SEQ ID NO:236)。
10.根据权利要求1-9中任一项所述的TCR或抗原结合片段,其中:
所述Vα区包含含有SEQ ID NO:694、712、729、744、762、776、788、802、818、832、846、858、870、882、896、911、926、940、952、964、976、988或1002中任一个所示的氨基酸序列的互补决定区3(CDR-3)、或者SEQ ID NO:691、709、726、741、759、775、787、799、815、830、845、857、869、881、895、908、925、937、951、963、975、987或999中任一个所示的氨基酸序列内所含的CDR3;和/或
所述Vβ区包含含有SEQ ID NO:703、721、736、753、769、782、794、809、825、840、852、864、876、888、902、919、932、946、958、970、982、994、1010或1381中任一个所示的氨基酸序列的互补决定区3(CDR-3)、或者SEQ ID NO:700、718、735、750、768、781、793、808、824、839、851、863、875、887、901、917、931、945、957、969、981、993、1008或1380中任一个所示的氨基酸序列内所含的CDR3。
11.根据权利要求1-10中任一项所述的TCR或其抗原结合片段,其中所述Vα区还包含:
包含SEQ ID NO:171、692、710、727、742、760、171、800、816、570、909、938、151或1000中任一个所示的氨基酸序列的互补决定区1(CDR-1);和/或
包含SEQ ID NO:172、693、711、728、743、761、172、801、817、831、571、910、939、152或1001中任一个所示的氨基酸序列的互补决定区2(CDR-2)。
12.根据权利要求1-11中任一项所述的TCR或其抗原结合片段,其中所述Vβ区包含:
包含SEQ ID NO:701、719、154、751或139中任一个所示的氨基酸序列的互补决定区1(CDR-1);和/或
包含SEQ ID NO:702、720、155、752、140或918中任一个所示的氨基酸序列的互补决定区2(CDR-2)。
13.根据权利要求1-12中任一项所述的TCR或其抗原结合片段,其中:
所述Vα区包含分别包含SEQ ID NO:692、693和694的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:701、702和703的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:710、711和712的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:719、720和721的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:727、728和729的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和736的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:742、743和744的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:751、752和753的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:760、761和762的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:719、720和769的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:171、172和776的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和782的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:742、743和788的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:139、140和794的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:800、801和802的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:751、752和809的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:816、817和818的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和825的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:816、831和832的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和840的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:171、172和846的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和852的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:816、831和858的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和864的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:727、728和870的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和876的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:570、571和882的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:719、720和888的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:816、817和896的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:701、702和902的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:909、910和911的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:701、702和919的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:727、728和926的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和932的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:938、939和940的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和946的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:727、728和952的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和958的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:151、152和964的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:719、720和970的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:727、728和976的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和982的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:710、711和988的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:719、729和994的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:1000、1001和1002的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:139、1009和1010的氨基酸序列的CDR-1、CDR-2和CDR-3;或者
所述Vα区包含分别包含SEQ ID NO:171、172和1391的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和1381的氨基酸序列的CDR-1、CDR-2和CDR-3。
14.根据权利要求1-13中任一项所述的TCR或其抗原结合片段,其中:
所述Vα区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:691、709、726、741、759、775、787、799、815、830、845、857、869、881、895、908、925、937、951、963、975、987、999或1390中任一个所示的Vα区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列;和/或
所述Vβ区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:700、718、735、750、768、781、793、808、824、839、851、863、875、887、901、917、931、945、957、969、981、993、1008或1380中任一个所示的Vβ区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列。
15.根据权利要求1-14中任一项所述的TCR或其抗原结合片段,其中:
所述Vα和Vβ区分别包含SEQ ID NO:691和700的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:709和718的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:726和735的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:741和750的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:759和768的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:775和781的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:787和793的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:799和808的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:815和824的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:830和839的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:845和851的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:857和863的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:869和875的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:881和887的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:895和901的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:908和917的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:925和931的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:937和945的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:951和957的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:963和969的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:975和981的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:987和993的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:999和1008的氨基酸序列;或者所述Vα和Vβ区分别包含SEQ ID NO:1390和1380的氨基酸序列。
16.根据权利要求1-15中任一项所述的TCR或其抗原结合片段,其中所述α链还包含α恒定(Cα)区和/或所述β链还包含β恒定(Cβ)区。
17.根据权利要求16所述的TCR或其抗原结合片段,其中所述Cα和Cβ区是小鼠恒定区。
18.根据权利要求16或权利要求17所述的TCR或其抗原结合片段,其中:
所述Cα区包含SEQ ID NO:262、833、1012、1014、1015、1017、1018所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列;和/或
所述Cβ区包含SEQ ID NO:263、1013或1016所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列。
19.根据权利要求16所述的TCR或其抗原结合片段,其中所述Cα和Cβ区是人恒定区。
20.根据权利要求16或权利要求19所述的TCR或其抗原结合片段,其中:
所述Cα区包含SEQ ID NO:212、213、215、217、218、220或524中任一个所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列;和/或
所述Cβ区包含SEQ ID NO:214、216、631或889中任一个所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列。
21.根据权利要求1-20中任一项所述的TCR或其抗原结合片段,其中:
a)所述α链包含:
SEQ ID NO:687、705、722、737、755、771、783、795、811、826、841、853、865、877、891、904、921、933、947、959、971、983、995、1386中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQ ID NO:1049、1051、1055、1057、1059、1061、1063、1065、1067、1069、1071、1073、1075、1077、1079、1081、1083、1085、1087、1089、1091中任一个所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列;和/或
b)所述β链包含:
SEQ ID NO:696、714、731、746、764、777、789、804、820、835、847、859、871、883、897、913、927、941、953、965、977、989、1004或1376中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQ ID NO:1050、1052、1056、1058、1060、1062、1064、1066、1068、1070、1072、1074、1076、1078、1080、1082、1084、1086、1088、1090或1092所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列。
22.根据权利要求1-20中任一项所述的TCR或其抗原结合片段,其中:
所述α和β链分别包含SEQ ID NO:687和696的氨基酸序列;所述α和β链分别包含SEQ IDNO:705和714的氨基酸序列;所述α和β链分别包含SEQ ID NO:722和731的氨基酸序列;所述α和β链分别包含SEQ ID NO:737和746的氨基酸序列;所述α和β链分别包含SEQ ID NO:755和764的氨基酸序列;所述α和β链分别包含SEQ ID NO:771和777的氨基酸序列;所述α和β链分别包含SEQ ID NO:783和789的氨基酸序列;所述α和β链分别包含SEQ ID NO:795和804的氨基酸序列;所述α和β链分别包含SEQ ID NO:811和820的氨基酸序列;所述α和β链分别包含SEQ ID NO:826和835的氨基酸序列;所述α和β链分别包含SEQ ID NO:841和847的氨基酸序列;所述α和β链分别包含SEQ ID NO:853和859的氨基酸序列;所述α和β链分别包含SEQID NO:865和871的氨基酸序列;所述α和β链分别包含SEQ ID NO:877和883的氨基酸序列;所述α和β链分别包含SEQ ID NO:891和897的氨基酸序列;所述α和β链分别包含SEQ ID NO:904和913的氨基酸序列;所述α和β链分别包含SEQ ID NO:921和927的氨基酸序列;所述α和β链分别包含SEQ ID NO:933和941的氨基酸序列;所述α和β链分别包含SEQ ID NO:947和953的氨基酸序列;所述α和β链分别包含SEQ ID NO:959和965的氨基酸序列;所述α和β链分别包含SEQ ID NO:971和977的氨基酸序列;所述α和β链分别包含SEQ ID NO:983和989的氨基酸序列;所述α和β链分别包含SEQ ID NO:995和1004的氨基酸序列;所述α和β链分别包含SEQ ID NO:1386和1376的氨基酸序列。
23.根据权利要求1-19中任一项所述的TCR或其抗原结合片段,其中所述TCR或抗原结合片段在所述α链和/或β链中包含一种或多种修饰,使得当所述TCR或其抗原结合片段在细胞中表达时,所述TCRα链和β链与内源TCRα链和β链之间的错配频率降低,所述TCRα链和β链的表达增加,和/或所述TCRα链和β链的稳定性增加,各自与不含所述一种或多种修饰的TCR或其抗原结合片段在细胞中的表达相比。
24.根据权利要求23所述的TCR或其抗原结合片段,其中所述一种或多种修饰是在所述Cα区和/或所述Cβ区中的一个或多个氨基酸的置换、缺失或插入。
25.根据权利要求23或权利要求24所述的TCR或其抗原结合片段,其中所述一种或多种修饰包含一个或多个置换,以引入能够在所述α链与β链之间形成一个或多个非天然二硫桥的一个或多个半胱氨酸残基。
26.根据权利要求1-16、19和23-25中任一项所述的TCR或其抗原结合片段,所述TCR或其抗原结合片段包含Cα区,所述Cα区在对应于按照如SEQ ID NO:212、213、217、218或524所示编号的位置48的位置处或在对应于按照如SEQ ID NO:215或220所示编号的位置49的位置处包含半胱氨酸;和/或Cβ区,所述Cβ区在对应于按照如SEQ ID NO:214或216所示编号的位置57的位置处或在对应于按照如SEQ ID NO:631或889所示编号的位置58的位置处包含半胱氨酸。
27.根据权利要求16、19和23-26中任一项所述的TCR或其抗原结合片段,其中:
所述Cα区包含SEQ ID NO:196、198、200、201、203或525中任一个所示的氨基酸序列或与其具有至少90%序列同一性的包含能够与所述β链形成非天然二硫键的一个或多个半胱氨酸残基的氨基酸序列;和/或
所述Cβ区包含SEQ ID NO:197、199、632或890中任一个所示的氨基酸序列或与其具有至少90%序列同一性的含有能够与所述α链形成非天然二硫键的一个或多个半胱氨酸残基的氨基酸序列。
28.根据权利要求1-27中任一项所述的TCR或其抗原结合片段,其中所述TCR或其抗原结合片段由已经密码子优化的核苷酸序列编码。
29.根据权利要求1-19和23-28中任一项所述的TCR或其抗原结合片段,其中:
a)所述α链包含:
SEQ ID NO:688、706、723、738、756、772、784、796、812、827、842、854、866、878、892、905、922、934、948、960、972、984、996或1387中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQ ID NO:1129、1131、1133、1135、1137、1139、1141、1143、1145、1147、1149、1151、1153、1155、1157、1159、1161、1163、1165、1167、1169、1171、1173或1385中任一个所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列;和/或
b)所述β链包含:
SEQ ID NO:697、715、732、747、765、778、790、805、821、836、848、860、872、884、898、914、928、942、954、966、978、990、1005或1377中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQ ID NO:1130、1132、1134、1136、1138、1140、1142、1144、1146、1148、1150、1152、1154、1156、1158、1160、1162、1164、1166、1168、1170、1172、1174或1375所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列。
30.根据权利要求1-19和23-29中任一项所述的TCR或其抗原结合片段,其中:所述α和β链分别包含SEQ ID NO:688和697的氨基酸序列;所述α和β链分别包含SEQ ID NO:706和715的氨基酸序列;所述α和β链分别包含SEQ ID NO:723和732的氨基酸序列;所述α和β链分别包含SEQ ID NO:738和747的氨基酸序列;所述α和β链分别包含SEQ ID NO:756和765的氨基酸序列;所述α和β链分别包含SEQ ID NO:772和778的氨基酸序列;所述α和β链分别包含SEQID NO:784和790的氨基酸序列;所述α和β链分别包含SEQ ID NO:796和805的氨基酸序列;所述α和β链分别包含SEQ ID NO:812和821的氨基酸序列;所述α和β链分别包含SEQ ID NO:827和836的氨基酸序列;所述α和β链分别包含SEQ ID NO:842和848的氨基酸序列;所述α和β链分别包含SEQ ID NO:854和860的氨基酸序列;所述α和β链分别包含SEQ ID NO:866和872的氨基酸序列;所述α和β链分别包含SEQ ID NO:878和884的氨基酸序列;所述α和β链分别包含SEQ ID NO:892和898的氨基酸序列;所述α和β链分别包含SEQ ID NO:905和914的氨基酸序列;所述α和β链分别包含SEQ ID NO:922和928的氨基酸序列;所述α和β链分别包含SEQ ID NO:934和942的氨基酸序列;所述α和β链分别包含SEQ ID NO:948和954的氨基酸序列;所述α和β链分别包含SEQ ID NO:960和966的氨基酸序列;所述α和β链分别包含SEQ IDNO:972和978的氨基酸序列;所述α和β链分别包含SEQ ID NO:984和990的氨基酸序列;或者所述α和β链分别包含SEQ ID NO:996和1005的氨基酸序列;或者所述α和β链分别包含SEQID NO:1387和1377的氨基酸序列。
31.根据权利要求1-30中任一项所述的TCR或其抗原结合片段,其中所述α和/或β链还包含信号肽。
32.根据权利要求31所述的TCR或其抗原结合片段,其中:
所述α链包含含有SEQ ID NO:181、184、187、189、190、192、193、310、311中任一个所示的氨基酸序列的信号肽;和/或
所述β链包含含有SEQ ID NO:182、185、186、188、191或194中任一个所示的氨基酸序列的信号肽。
33.根据权利要求1-32中任一项所述的TCR或其抗原结合片段,所述TCR或其抗原结合片段是分离的或纯化的或者是重组的。
34.根据权利要求1-33中任一项所述的TCR或其抗原结合片段,所述TCR或其抗原结合片段是人的。
35.根据权利要求1-34中任一项所述的TCR或其抗原结合片段,所述TCR或其抗原结合片段是单克隆的。
36.根据权利要求1-35中任一项所述的TCR或其抗原结合片段,其中所述TCR或其抗原结合片段是单链。
37.根据权利要求1-35中任一项所述的TCR或其抗原结合片段,其中所述TCR或其抗原结合片段包含两条链。
38.根据权利要求1-37中任一项所述的TCR或其抗原结合片段,其中抗原特异性是至少部分地CD8非依赖性的。
39.根据权利要求9-38中任一项所述的TCR或抗原结合片段,其中所述MHC分子是HLA-A2分子。
40.一种核酸分子,所述核酸分子编码根据权利要求1-39中任一项所述的TCR或其抗原结合片段或者所述TCR或其抗原结合片段的α或β链。
41.根据权利要求40所述的核酸分子,其包含编码α链的核苷酸序列和/或编码β链的核苷酸序列,其中:
编码α链的所述核苷酸序列包含SEQ ID NO:1049、1051、1055、1057、1059、1061、1063、1065、1067、1069、1071、1073、1075、1077、1079、1081、1083、1085、1087、1089、1091中任一个所示的序列或与其具有至少90%序列同一性的核苷酸序列;
编码β链的所述核苷酸序列包含SEQ ID NO:1050、1052、1056、1058、1060、1062、1064、1066、1068、1070、1072、1074、1076、1078、1080、1082、1084、1086、1088、1090或1092所示的序列或与其具有至少90%序列同一性的核苷酸序列。
42.根据权利要求40所述的核酸分子,其中所述核苷酸序列是经密码子优化的。
43.根据权利要求40或权利要求42所述的核酸分子,其包含编码α链的核苷酸序列和/或编码β链的核苷酸序列,其中:
编码α链的所述核苷酸序列包含SEQ ID NO:1129、1131、1133、1135、1137、1139、1141、1143、1145、1147、1149、1151、1153、1155、1157、1159、1161、1163、1165、1167、1169、1171、1173或1385中任一个所示的序列或与其具有至少90%序列同一性的核苷酸序列;
编码β链的所述核苷酸序列包含SEQ ID NO:1130、1132、1134、1136、1138、1140、1142、1144、1146、1148、1150、1152、1154、1156、1158、1160、1162、1164、1166、1168、1170、1172、1174或1375所示的序列或与其具有至少90%序列同一性的核苷酸序列。
44.根据权利要求40-43中任一项所述的核酸分子,其中编码所述α链的核苷酸序列和编码所述β链的核苷酸序列由引起核糖体跳跃的肽序列隔开。
45.根据权利要求44所述的核酸分子,其中引起核糖体跳跃的所述肽是P2A或T2A肽和/或包含SEQ ID NO:204或211所示的氨基酸序列。
46.根据权利要求40-45中任一项所述的核酸分子,所述核酸分子包含SEQ ID NO:448、449、450、451、452、453、454、455、456、457、458、459、460、461、462、463、464、465、466、467、468、469、470、471、472或1382中任一个所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列。
47.一种T细胞受体(TCR)或其抗原结合片段,所述T细胞受体(TCR)或其抗原结合片段包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链,其中:
所述Vα区包含SEQ ID NO:477、492、504、510、522、536、554、569、587、599、611、623、637、649、661或676中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列;和/或
所述Vβ区包含SEQ ID NO:483、498、516、530、545、560、578、593、605、617、629、643、655、667或685中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列。
48.根据权利要求47所述的TCR或其抗原结合片段,其中所述Vα区包含含有氨基酸序列AX2RX4AX6NNDMR的互补决定区3(CDR-3),其中X2是V或M;X4是P或D;并且X6是N或R。
49.根据权利要求47或权利要求48所述的TCR或其抗原结合片段,其中:
所述Vβ区包含含有氨基酸序列ASSX4WGX7SNQPX12H的互补决定区3(CDR-3),其中X4是L、F或P;X7是R或Q;并且X12是Q或L;或者
所述Vβ区包含含有氨基酸序列ASSX4X5X6X7X8SGNTIY的互补决定区3(CDR-3),其中X4是L或R;X5是W或Q;X6是G或P;X7是R或S;并且X8是S或空。
50.一种T细胞受体(TCR)或其抗原结合片段,所述T细胞受体(TCR)或其抗原结合片段包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链,其中所述Vα区包含含有氨基酸序列AX2RX4AX6NNDMR的互补决定区3(CDR-3),其中X2是V或M;X4是P或D;并且X6是N或R。
51.一种T细胞受体(TCR)或其抗原结合片段,所述T细胞受体(TCR)或其抗原结合片段包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链,其中:
所述Vβ区包含含有氨基酸序列ASSX4WGX7SNQPX12H的互补决定区3(CDR-3),其中X4是L、F或P;X7是R或Q;并且X12是Q或L;或者
所述Vβ区包含含有氨基酸序列ASSX4X5X6X7X8SGNTIY的互补决定区3(CDR-3),其中X4是L或R;X5是W或Q;X6是G或P;X7是R或S;并且X8是S或空。
52.一种T细胞受体(TCR)或其抗原结合片段,所述T细胞受体(TCR)或其抗原结合片段包含含有可变α(Vα)区的α链和含有可变β(Vβ)区的β链,其中:
所述Vα区包含SEQ ID NO:478、493、505、511、523、539、555、572、588、600、612、624、638、650、662或679或与其展现出至少60%、65%、70%、75%、80%、85%、90%或95%序列同一性的序列中任一个所示的互补决定区3(CDR-3);
所述Vβ区包含SEQ ID NO:486、499、517、531、548、563、581、594、606、618、630、644、656、670或686或与其展现出至少60%、65%、70%、75%、80%、85%、90%或95%序列同一性的序列中任一个所示的互补决定区3(CDR-3)。
53.根据权利要求47-52中任一项所述的TCR或其抗原结合片段,其中所述Vα区包含:
包含氨基酸序列X1X2X3X4X5X6(SEQ ID NO:1191)的互补决定区1(CDR-1),其中X1是N、S、D、T或V;X2是S、V、R、T或I;X3是M、F、G、S、N、A、L、V或P;X4是F、S、N、A或空;X5是D、S、Q、Y、N、V、T或P;并且X6是Y、S、R、N、G或T;和/或
包含氨基酸序列X1X2X3X4X5X6X7X8(SEQ ID NO:1192)的互补决定区2(CDR-2),其中X1是I、V、L、G、N、T、Y或M;X2是S、V、Y、L、P、F、I或T;X3是S、Y、K、L、T或F;X4是I、G、N、A、S或空;X5是S、D或空;X6是K、G、N、S、D、T或E;X7是D、E、G、A、K、L或N;并且X8是K、V、D、P、N、T、L或M。
54.根据权利要求47-53中任一项所述的TCR或其抗原结合片段,其中所述Vβ区包含:
包含氨基酸序列SX2X3X4X5(SEQ ID NO:1203)的互补决定区1(CDR-1),其中X2是G或N;X3是H或D;X4是T、L、N或V;并且X5是A、S、Y或T;和/或
包含氨基酸序列X1X2X3X4X5X6(SEQ ID NO:1204)的互补决定区2(CDR-2),其中X1是F或Y;X2是Q、Y或N;X3是G、N、R或Y;X4是N、G、E或T;X5是S、E、A或G;并且X6是A、E、I或Q。
55.根据权利要求47-54中任一项所述的TCR或其抗原结合片段,其中所述TCR或其抗原结合片段结合至或识别在MHC分子的背景下的人乳头瘤病毒(HPV)16 E6的肽表位,所述肽表位是或包含E6(29-38)TIHDIILECV(SEQ ID NO:233)。
56.根据权利要求47-55中任一项所述的TCR或抗原结合片段,其中:
所述Vα区包含含有SEQ ID NO:478、493、505、511、523、539、555、572、588、600、612、624、638、650、662或679中任一个所示的氨基酸序列的互补决定区3(CDR-3)、或者SEQ IDNO:477、492、504、510、522、536、554、569、587、599、611、623、637、649、661或676中任一个所示的氨基酸序列内所含的CDR3;和/或
所述Vβ区包含含有SEQ ID NO:486、499、517、531、548、563、581、594、606、618、630、644、656、670或686中任一个所示的氨基酸序列的互补决定区3(CDR-3)、或者SEQ ID NO:483、498、516、530、545、560、578、593、605、617、629、643、655、667或685中任一个所示的氨基酸序列内所含的CDR3。
57.根据权利要求47-56中任一项所述的TCR或其抗原结合片段,其中所述Vα区还包含:
包含SEQ ID NO:136、161、165、537、570、142、171或677中任一个所示的氨基酸序列的互补决定区1(CDR-1);和/或
包含SEQ ID NO:137、162、166、538、571、143、172或678中任一个所示的氨基酸序列的互补决定区2(CDR-2)。
58.根据权利要求47-56中任一项所述的TCR或其抗原结合片段,其中所述Vβ区包含:
包含SEQ ID NO:484、148、546、561、579、168、668或154中任一个所示的氨基酸序列的互补决定区1(CDR-1);和/或
包含SEQ ID NO:485、149、547、562、580、169、669或155中任一个所示的氨基酸序列的互补决定区2(CDR-2)。
59.根据权利要求47-58中任一项所述的TCR或其抗原结合片段,其中:
所述Vα区包含分别包含SEQ ID NO:136、137和478的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:484、485和486的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:161、162和493的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和499的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:165、166和505的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和499的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:161、162和511的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和517的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:136、137和523的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和531的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:537、538和539的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:546、547和548的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:136、137和555的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:561、562和563的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:570、571和572的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:579、580和581的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:136、137和600的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和594的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:136、137和600的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和606的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:136、137和612的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和618的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:136、137和624的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:168、169和630的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:142、143和638的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:561、562和644的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:171、172和650的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和656的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:136、137和662的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:668、669和670的氨基酸序列的CDR-1、CDR-2和CDR-3;或者
所述Vα区包含分别包含SEQ ID NO:677、678和679的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和686的氨基酸序列的CDR-1、CDR-2和CDR-3。
60.根据权利要求47-59中任一项所述的TCR或其抗原结合片段,其中:
所述Vα区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:477、492、504、510、522、536、554、569、587、599、611、623、637、649、661或676中任一个所示的Vα区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列;和/或
所述Vβ区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:483、498、516、530、545、560、578、593、605、617、629、643、655、667或685中任一个所示的Vβ区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列。
61.根据权利要求47-60中任一项所述的TCR或其抗原结合片段,其中:所述Vα和Vβ区分别包含SEQ ID NO:477和483的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:492和498的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:504和498的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:510和516的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:522和530的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:536和545的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:554和560的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:569和578的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:587和593的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:599和605的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:611和617的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:623和629的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:637和643的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:649和655的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:661和667的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:676和685的氨基酸序列。
62.根据权利要求47-61中任一项所述的TCR或其抗原结合片段,其中所述α链还包含α恒定(Cα)区和/或所述β链还包含β恒定(Cβ)区。
63.根据权利要求62所述的TCR或其抗原结合片段,其中所述Cα和Cβ区是小鼠恒定区。
64.根据权利要求62或权利要求63所述的TCR或其抗原结合片段,其中:
所述Cα区包含SEQ ID NO:262、833、1012、1014、1015、1017、1018所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列;和/或
所述Cβ区包含SEQ ID NO:263、1013或1016所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列。
65.根据权利要求62所述的TCR或其抗原结合片段,其中所述Cα和Cβ区是人恒定区。
66.根据权利要求62或权利要求65所述的TCR或其抗原结合片段,其中:
所述Cα区包含SEQ ID NO:212、213、215、217、218、220或524中任一个所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列;和/或
所述Cβ区包含SEQ ID NO:214、216、631或889中任一个所示的氨基酸序列或与其具有至少90%序列同一性的氨基酸序列。
67.根据权利要求47-66中任一项所述的TCR或其抗原结合片段,其中:
a)所述α链包含:
SEQ ID NO:473、488、500、506、518、532、550、565、583、595、607、619、633、645、657或672中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQID NO:389、430、1019、1021、1023、1025、1027、1029、1031、1033、1035、1037、1039、1041、1043或1045中任一个所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列;和/或
b)所述β链包含:
SEQ ID NO:479、494、512、526、541、556、574、589、601、613、625、639、651、663或681中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQ IDNO:390、431、1020、1022、1024、1026、1028、1030、1032、1034、1036、1038、1040、1042、1044或1046所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列。
68.根据权利要求47-67中任一项所述的TCR或其抗原结合片段,其中:所述α和β链分别包含SEQ ID NO:473和479的氨基酸序列;所述α和β链分别包含SEQ ID NO:488和494的氨基酸序列;所述α和β链分别包含SEQ ID NO:500和494的氨基酸序列;所述α和β链分别包含SEQID NO:506和512的氨基酸序列;所述α和β链分别包含SEQ ID NO:518和526的氨基酸序列;所述α和β链分别包含SEQ ID NO:532和541的氨基酸序列;所述α和β链分别包含SEQ ID NO:550和556的氨基酸序列;所述α和β链分别包含SEQ ID NO:565和574的氨基酸序列;所述α和β链分别包含SEQ ID NO:583和589的氨基酸序列;所述α和β链分别包含SEQ ID NO:595和601的氨基酸序列;所述α和β链分别包含SEQ ID NO:607和613的氨基酸序列;所述α和β链分别包含SEQ ID NO:619和625的氨基酸序列;所述α和β链分别包含SEQ ID NO:633和639的氨基酸序列;所述α和β链分别包含SEQ ID NO:645和651的氨基酸序列;所述α和β链分别包含SEQ ID NO:657和663的氨基酸序列;或者所述α和β链分别包含SEQ ID NO:672和681的氨基酸序列。
69.根据权利要求47-68中任一项所述的TCR或其抗原结合片段,其中所述TCR或抗原结合片段在所述α链和/或β链中包含一种或多种修饰,使得当所述TCR或其抗原结合片段在细胞中表达时,所述TCRα链和β链与内源TCRα链和β链之间的错配频率降低,所述TCRα链和β链的表达增加,和/或所述TCRα链和β链的稳定性增加,各自与不含所述一种或多种修饰的TCR或其抗原结合片段在细胞中的表达相比。
70.根据权利要求69所述的TCR或其抗原结合片段,其中所述一种或多种修饰是在所述Cα区和/或所述Cβ区中的一个或多个氨基酸的置换、缺失或插入。
71.根据权利要求69或权利要求70所述的TCR或其抗原结合片段,其中所述一种或多种修饰包含一个或多个置换,以引入能够在所述α链与β链之间形成一个或多个非天然二硫桥的一个或多个半胱氨酸残基。
72.根据权利要求47-62、65和69-71中任一项所述的TCR或其抗原结合片段,所述TCR或其抗原结合片段包含Cα区,所述Cα区在对应于按照如SEQ ID NO:212、213、217、218或524所示编号的位置48的位置处或在对应于按照如SEQ ID NO:215或220所示编号的位置49的位置处包含半胱氨酸;和/或Cβ区,所述Cβ区在对应于按照如SEQ ID NO:214或216所示编号的位置57的位置处或在对应于按照如SEQ ID NO:631或889所示编号的位置58的位置处包含半胱氨酸。
73.根据权利要求62、65和69-72中任一项所述的TCR或其抗原结合片段,其中:
所述Cα区包含SEQ ID NO:196、198、200、201、203或525中任一个所示的氨基酸序列或与其具有至少90%序列同一性的包含能够与所述β链形成非天然二硫键的一个或多个半胱氨酸残基的氨基酸序列;和/或
所述Cβ区包含SEQ ID NO:197、199、632或890中任一个所示的氨基酸序列或与其具有至少90%序列同一性的含有能够与所述α链形成非天然二硫键的一个或多个半胱氨酸残基的氨基酸序列。
74.根据权利要求47-73中任一项所述的TCR或其抗原结合片段,其中所述TCR或其抗原结合片段由已经密码子优化的核苷酸序列编码。
75.根据权利要求47-62、65和69-74中任一项所述的TCR或其抗原结合片段,其中:
a)所述α链包含:
SEQ ID NO:474、489、501、507、519、533、551、566、584、596、608、620、634、646、658或673中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQID NO:1097、1099、1101、1103、1105、1107、1109、1111、1113、1115、1117、1119、1121、1123、1125或1127中任一个所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列;和/或
b)所述β链包含:
SEQ ID NO:480、495、513、527、542、557、575、590、602、614、626、640、652、664或682中任一个所示的氨基酸序列、与其具有至少90%序列同一性的氨基酸序列;或者由SEQ IDNO:1098、1100、1102、1104、1106、1108、1110、1112、1114、1116、1118、1120、1122、1124、1126或1128所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列编码的氨基酸序列。
76.根据权利要求47-62、65和69-75中任一项所述的TCR或其抗原结合片段,其中所述α和β链分别包含SEQ ID NO:474和482的氨基酸序列;所述α和β链分别包含SEQ ID NO:489和497的氨基酸序列;所述α和β链分别包含SEQ ID NO:501和497的氨基酸序列;所述α和β链分别包含SEQ ID NO:507和515的氨基酸序列;所述α和β链分别包含SEQ ID NO:519和529的氨基酸序列;所述α和β链分别包含SEQ ID NO:533和544的氨基酸序列;所述α和β链分别包含SEQ ID NO:551和559的氨基酸序列;所述α和β链分别包含SEQ ID NO:566和577的氨基酸序列;所述α和β链分别包含SEQ ID NO:584和592的氨基酸序列;所述α和β链分别包含SEQ IDNO:596和604的氨基酸序列;所述α和β链分别包含SEQ ID NO:608和616的氨基酸序列;所述α和β链分别包含SEQ ID NO:620和628的氨基酸序列;所述α和β链分别包含SEQ ID NO:634和642的氨基酸序列;所述α和β链分别包含SEQ ID NO:646和654的氨基酸序列;所述α和β链分别包含SEQ ID NO:658和666的氨基酸序列;或者所述α和β链分别包含SEQ ID NO:673和684的氨基酸序列。
77.根据权利要求47-76中任一项所述的TCR或其抗原结合片段,其中所述α和/或β链还包含信号肽。
78.根据权利要求77所述的TCR或其抗原结合片段,其中:
所述α链包含含有SEQ ID NO:181、184、187、189、190、192、193、310、311中任一个所示的氨基酸序列的信号肽;和/或
所述β链包含含有SEQ ID NO:182、185、186、188、191或194中任一个所示的氨基酸序列的信号肽。
79.根据权利要求47-78中任一项所述的TCR或其抗原结合片段,所述TCR或其抗原结合片段是分离的或纯化的或者是重组的。
80.根据权利要求47-79中任一项所述的TCR或其抗原结合片段,所述TCR或其抗原结合片段是人的。
81.根据权利要求47-80中任一项所述的TCR或其抗原结合片段,所述TCR或其抗原结合片段是单克隆的。
82.根据权利要求47-81中任一项所述的TCR或其抗原结合片段,其中所述TCR或其抗原结合片段是单链。
83.根据权利要求47-81中任一项所述的TCR或其抗原结合片段,其中所述TCR或其抗原结合片段包含两条链。
84.根据权利要求47-83中任一项所述的TCR或其抗原结合片段,其中抗原特异性是至少部分地CD8非依赖性的。
85.根据权利要求47-84中任一项所述的TCR或抗原结合片段,其中所述MHC分子是HLA-A2分子。
86.一种核酸分子,所述核酸分子编码根据权利要求47-85中任一项所述的TCR或其抗原结合片段或者所述TCR或其抗原结合片段的α或β链。
87.根据权利要求86所述的核酸分子,其包含编码α链的核苷酸序列和/或编码β链的核苷酸序列,其中:
编码α链的所述核苷酸序列包含SEQ ID NO:389、430、1019、1021、1023、1025、1027、1029、1031、1033、1035、1037、1039、1041、1043或1045中任一个所示的序列或与其具有至少90%序列同一性的核苷酸序列;
编码β链的所述核苷酸序列包含SEQ ID NO:390、431、1020、1022、1024、1026、1028、1030、1032、1034、1036、1038、1040、1042、1044或1046所示的序列或与其具有至少90%序列同一性的核苷酸序列。
88.根据权利要求86所述的核酸分子,其中所述核苷酸序列是经密码子优化的。
89.根据权利要求86或权利要求88所述的核酸分子,其包含编码α链的核苷酸序列和/或编码β链的核苷酸序列,其中:
编码α链的所述核苷酸序列包含SEQ ID NO:1097、1099、1101、1103、1105、1107、1109、1111、1113、1115、1117、1119、1121、1123、1125或1127中任一个所示的序列或与其具有至少90%序列同一性的核苷酸序列;
编码β链的所述核苷酸序列包含SEQ ID NO:1098、1100、1102、1104、1106、1108、1110、1112、1114、1116、1118、1120、1122、1124、1126或1128所示的序列或与其具有至少90%序列同一性的核苷酸序列。
90.根据权利要求86-89中任一项所述的核酸分子,其中编码所述α链的核苷酸序列和编码所述β链的核苷酸序列由引起核糖体跳跃的肽序列隔开。
91.根据权利要求90所述的核酸分子,其中引起核糖体跳跃的所述肽是P2A或T2A肽和/或包含SEQ ID NO:204或211所示的氨基酸序列。
92.根据权利要求86-91中任一项所述的核酸分子,所述核酸分子包含SEQ ID NO:432、433、434、435、436、437、438、439、440、441、442、443、444、445、446或447中任一个所示的核苷酸序列或与其具有至少90%序列同一性的核苷酸序列。
93.根据权利要求40-46和86-92中任一项所述的核酸分子,其中所述核酸分子是合成的。
94.根据权利要求40-46和86-93中任一项所述的核酸分子,其中所述核酸分子是cDNA。
95.一种多核苷酸,其包含:
(a)编码根据权利要求1-39和47-85中任一项所述的TCR或其抗原结合部分的核酸序列或者根据权利要求40-46和86-94中任一项所述的核酸分子,以及
(b)与所述核酸序列连接的一个或多个同源臂,其中所述一个或多个同源臂包含与T细胞受体α恒定区(TRAC)基因座的开放阅读框的一个或多个区域同源的序列。
96.一种多核苷酸,其包含:
(a)编码T细胞受体(TCR)的一部分的核酸序列,所述核酸序列编码(i)包含根据权利要求1-14、21-23、28-39、47-61、67-69和74-85中任一项所述的TCR或其抗原结合片段的可变β(Vβ)和恒定β(Cβ)的T细胞受体β(TCRβ)链;和(ii)包含根据权利要求1-14、21-23、28-39、47-61、67-69和74-85中任一项所述的TCR或其抗原结合片段的可变α(Vα)的T细胞受体α(TCRα)链的一部分,其中所述TCRα链的所述部分少于全长TCRα链,以及
(b)与所述核酸序列连接的一个或多个同源臂,其中所述一个或多个同源臂包含与T细胞受体α恒定区(TRAC)基因座的开放阅读框的一个或多个区域同源的序列。
97.根据权利要求96所述的多核苷酸,其中所述TCRα链包含恒定α(Cα),其中当所述TCR或其抗原结合片段从引入了所述多核苷酸的细胞表达时,所述Cα的至少一部分由所述内源TRAC基因座的开放阅读框或其部分序列编码。
98.根据权利要求96或权利要求97所述的多核苷酸,其中(a)的所述核酸序列以及所述一个或多个同源臂之一一起包含编码少于天然Cα的全长的Cα的核苷酸序列,其中当所述TCR或其抗原结合片段从引入了所述多核苷酸的细胞表达时,所述Cα的至少一部分由所述内源TRAC基因座的开放阅读框或其部分序列编码。
99.根据权利要求96-98中任一项所述的多核苷酸,其中编码所述TCRβ链的核酸序列在编码所述TCRα链的所述部分的核酸序列的上游。
100.根据权利要求96-99中任一项所述的多核苷酸,其中(a)的所述核酸序列不包含内含子。
101.根据权利要求96-100中任一项所述的多核苷酸,其中(a)的所述核酸序列是对T细胞、任选地人T细胞的内源基因组TRAC基因座的开放阅读框外源或异源的序列。
102.根据权利要求96-101中任一项所述的多核苷酸,其中(a)的所述核酸序列与所述一个或多个同源臂中所含的TRAC基因座的开放阅读框的一个或多个外显子或其部分序列、任选地外显子1或其部分序列符合读框。
103.根据权利要求97-102中任一项所述的多核苷酸,其中所述Cα的一部分由所述内源TRAC基因座的开放阅读框或其部分序列编码,并且所述Cα的另外的部分由(a)的所述核酸序列编码,其中Cα的所述另外的部分少于天然Cα的全长。
104.根据权利要求103所述的多核苷酸,其中所述Cα的所述另外的部分由起始于SEQID NO:348所示的序列的残基3直至残基3155的核苷酸序列或其一个或多个外显子或者与起始于SEQ ID NO:348所示的序列的残基3直至残基3155的核苷酸序列或其一个或多个外显子展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列或者其部分序列编码。
105.根据权利要求103或权利要求104所述的多核苷酸,其中所述Cα的所述另外的部分由SEQ ID NO:1364所示的序列或者与SEQ ID NO:1364展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列或者其部分序列编码。
106.根据权利要求103-105中任一项所述的多核苷酸,其中与天然Cα区和/或天然Cβ区相比,由(a)的所述核酸序列编码的Cα和/或Cβ区的所述另外的部分包含一种或多种修饰,任选地一个或多个氨基酸的置换、缺失或插入,任选地所述一种或多种修饰引入能够在所述α链与β链之间形成一个或多个非天然二硫桥的一个或多个半胱氨酸残基。
107.根据权利要求95-106中任一项所述的多核苷酸,其中所述一个或多个同源臂包含5'同源臂和/或3'同源臂。
108.根据权利要求95-107中任一项所述的多核苷酸,其中所述5'同源臂包含:
a)包含与SEQ ID NO:1343所示的序列展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列的150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个连续核苷酸的序列;
b)包含SEQ ID NO:1343所示的序列的150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个连续核苷酸的序列;或者
c)SEQ ID NO:1343所示的序列。
109.根据权利要求95-108中任一项所述的多核苷酸,其中所述3'同源臂包含:
a)包含与SEQ ID NO:1344所示的序列展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列的150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个连续核苷酸的序列;
b)包含SEQ ID NO:1344所示的序列的150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个或者至少150、200、250、300、350、400、450、500、550或600个连续核苷酸的序列;或者
c)SEQ ID NO:1344所示的序列。
110.一种多核苷酸,其包含:
(a)编码根据权利要求1-39和47-86中任一项所述的TCR或其抗原结合部分的核酸序列或者根据权利要求40-46和86-92中任一项所述的核酸分子,以及
(b)与所述核酸序列连接的一个或多个同源臂,其中所述一个或多个同源臂包含与T细胞受体β恒定区(TRBC)基因座的开放阅读框的一个或多个区域同源的序列。
111.一种多核苷酸,其包含:
(a)编码T细胞受体(TCR)的一部分的核酸序列,所述核酸序列编码(i)包含根据权利要求1-14、21-23、28-39、47-61、67-69和74-85中任一项所述的TCR或其抗原结合片段的可变α(Vα)和恒定α(Cα)的T细胞受体α(TCRα)链;和(ii)包含根据权利要求1-14、21-23、28-39、47-61、67-69和74-85中任一项所述的TCR或其抗原结合片段的可变β(Vβ)的T细胞受体β(TCRβ)链的一部分,其中所述TCRβ链的所述部分少于全长TCRβ链,以及
(b)与所述核酸序列连接的一个或多个同源臂,其中所述一个或多个同源臂包含与T细胞受体β恒定区(TRBC)基因座的开放阅读框的一个或多个区域同源的序列。
112.根据权利要求111所述的多核苷酸,其中所述TCRβ链包含恒定β(Cβ),其中当所述TCR或其抗原结合片段从引入了所述多核苷酸的细胞表达时,所述Cβ的至少一部分由所述内源TRBC基因座的开放阅读框或其部分序列编码。
113.根据权利要求111或权利要求112所述的多核苷酸,其中(a)的所述核酸序列以及所述一个或多个同源臂之一一起包含编码少于天然Cβ的全长的Cβ的核苷酸序列,其中当所述TCR或其抗原结合片段从引入了所述多核苷酸的细胞表达时,所述Cβ的至少一部分由所述内源TRAC基因座的开放阅读框或其部分序列编码。
114.根据权利要求111-113中任一项所述的多核苷酸,其中编码所述TCRα链的核酸序列在编码所述TCRβ链的所述部分的核酸序列的上游。
115.根据权利要求111-114中任一项所述的多核苷酸,其中(a)的所述核酸序列不包含内含子。
116.根据权利要求111-115中任一项所述的多核苷酸,其中(a)的所述核酸序列是对T细胞、任选地人T细胞的内源基因组TRBC基因座的开放阅读框外源或异源的序列。
117.根据权利要求111-116中任一项所述的多核苷酸,其中(a)的所述核酸序列与所述一个或多个同源臂中所含的TRBC基因座的开放阅读框的一个或多个外显子或其部分序列、任选地外显子1或其部分序列符合读框。
118.根据权利要求111-117中任一项所述的多核苷酸,其中所述Cβ的一部分由所述内源TRBC基因座的开放阅读框或其部分序列编码,并且所述Cβ的另外的部分由(a)的所述核酸序列编码,其中Cβ的所述另外的部分少于天然Cβ的全长。
119.根据权利要求118所述的多核苷酸,其中所述Cβ的所述另外的部分由以下编码:
起始于SEQ ID NO:349所示的序列的残基3直至残基1445的核苷酸序列或其一个或多个外显子或者与起始于SEQ ID NO:349所示的序列的残基3直至残基1445的核苷酸序列或其一个或多个外显子展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列或者其部分序列;或者
起始于SEQ ID NO:1047所示的序列的残基3直至残基1486的核苷酸序列或其一个或多个外显子或者与起始于SEQ ID NO:1047所示的序列的残基3直至残基1486的核苷酸序列或其一个或多个外显子展现出至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的序列或者其部分序列。
120.根据权利要求118或权利要求119所述的多核苷酸,其中与天然Cβ区和/或天然Cα区相比,由(a)的所述核酸序列编码的Cβ和/或Cα区的所述另外的部分包含一种或多种修饰,任选地一个或多个氨基酸的置换、缺失或插入,任选地所述一种或多种修饰引入能够在所述α链与β链之间形成一个或多个非天然二硫桥的一个或多个半胱氨酸残基。
121.根据权利要求110-120中任一项所述的多核苷酸,其中所述一个或多个同源臂包含5'同源臂和/或3'同源臂。
122.根据权利要求95-121中任一项所述的多核苷酸,其中(a)的所述核酸序列包含一个或多个多顺反子元件。
123.根据权利要求122所述的多核苷酸,其中所述一个或多个多顺反子元件位于编码所述TCRα或其部分的核酸序列与编码所述TCRβ或其部分的核酸序列之间。
124.根据权利要求122或权利要求123所述的多核苷酸,其中所述一个或多个多顺反子元件在编码所述TCR或所述TCR的一部分的核酸序列或编码所述TCR的核酸分子的上游。
125.根据权利要求122-124中任一项所述的多核苷酸,其中所述一个或多个多顺反子元件是或包含核糖体跳跃序列,任选地其中所述核糖体跳跃序列是T2A、P2A、E2A或F2A元件。
126.根据权利要求95-125中任一项所述的多核苷酸,其中(a)的所述核酸序列包含一个或多个异源或调节控制元件,所述元件可操作地连接以控制当从引入了所述多核苷酸的细胞表达时所述TCR的表达。
127.根据权利要求126所述的多核苷酸,其中所述一个或多个异源调节或控制元件包含启动子、增强子、内含子、多腺苷酸化信号、Kozak共有序列、剪接受体序列和/或剪接供体序列。
128.根据权利要求126或权利要求127所述的多核苷酸,其中所述异源调节或控制元件包含异源启动子,任选地人延伸因子1α(EF1α)启动子或MND启动子或其变体。
129.根据权利要求95-128中任一项所述的多核苷酸,其是线性多核苷酸,任选地双链多核苷酸或单链多核苷酸。
130.一种载体,其包含根据权利要求40-46和86-94中任一项所述的核酸分子或根据权利要求95-129中任一项所述的多核苷酸。
131.根据权利要求130所述的载体,其中所述载体是表达载体。
132.根据权利要求130或权利要求131所述的载体,其中所述载体是病毒载体。
133.根据权利要求132所述的载体,其中所述病毒载体是逆转录病毒载体。
134.根据权利要求132或权利要求133所述的载体,其中所述病毒载体是慢病毒载体。
135.根据权利要求134所述的载体,其中所述慢病毒载体源自HIV-1。
136.根据权利要求132或权利要求133所述的载体,其中所述病毒载体是γ逆转录病毒载体。
137.根据权利要求132所述的载体,其中所述病毒载体是AAV载体。
138.根据权利要求137所述的载体,其中所述AAV载体选自AAV1、AAV2、AAV3、AAV4、AAV5、AAV6、AAV7或AAV8载体。
139.一种工程化细胞,其包含根据权利要求40-46和86-94中任一项所述的核酸分子、根据权利要求95-129中任一项所述的多核苷酸或根据权利要求130-138中任一项所述的载体。
140.一种工程化细胞,所述工程化细胞包含根据权利要求1-39和47-85中任一项所述的TCR或其抗原结合片段,任选地根据权利要求1-39和47-85中任一项所述的重组TCR或抗原结合片段。
141.根据权利要求139或权利要求140所述的工程化细胞,其包含内源T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏。
142.根据权利要求141所述的工程化细胞,其中所述TRBC基因是T细胞受体β恒定区1(TRBC1)或T细胞受体β恒定区2(TRBC2)基因之一或两者。
143.根据权利要求141或权利要求142所述的工程化细胞,其中所述工程化细胞不含有连续的TRAC和/或TRBC基因;不含有TRAC和/或TRBC基因;不含有功能性TRAC和/或TRBC基因;和/或不表达内源TRAC或TRBC的基因产物,不以可检测的水平表达内源TRAC或TRBC的基因产物,或表达少于野生型水平的20%、15%、10%、5%、4%、3%、2%或1%的内源TRAC或TRBC的基因产物。
144.一种工程化细胞,所述工程化细胞包含TCR或其抗原结合片段,任选地重组TCR或其抗原结合片段,其中:
(1)所述细胞包含T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏和/或不表达内源TRAC或TRBC的基因产物,或不以可检测的水平表达内源TRAC或TRBC的基因产物,或表达少于野生型水平的20%、15%、10%、5%、4%、3%、2%或1%的内源TRAC或TRBC的基因产物;并且
(2)所述TCR或其抗原结合片段或者所述重组TCR或其抗原结合片段包含根据权利要求1-39和47-85中任一项所述的TCR或其抗原结合片段,任选地根据权利要求1-39和47-85中任一项所述的重组TCR或抗原结合片段。
145.一种工程化细胞,所述工程化细胞包含TCR或其抗原结合片段,任选地重组TCR或其抗原结合片段,其中:
(1)所述细胞包含T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏和/或不表达内源TRAC或TRBC的基因产物,或不以可检测的水平表达内源TRAC或TRBC的基因产物,或表达少于野生型水平的20%、15%、10%、5%、4%、3%、2%或1%的内源TRAC或TRBC的基因产物;并且
(2)所述TCR或其抗原结合片段或者所述重组TCR或其抗原结合片段包含:
(a)包含SEQ ID NO:117、119或295中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列的可变α(Vα)区和包含SEQ ID NO:118、120或296中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列的可变β(Vβ)区;和/或
(b)包含含有SEQ ID NO:153、159或301中任一个所示的氨基酸序列的互补决定区3(CDR-3)或SEQ ID NO:117、119或295中任一个所示的氨基酸序列内所含的CDR3的Vα区和包含含有SEQ ID NO:156或160中任一个所示的氨基酸序列的互补决定区3(CDR-3)或SEQ IDNO:118、120或296中任一个所示的氨基酸序列内所含的CDR3的Vβ区。
146.根据权利要求145所述的工程化细胞,其中:
所述Vα区还包含含有SEQ ID NO:151或157中任一个所示的氨基酸序列的互补决定区1(CDR-1);和/或含有SEQ ID NO:152或158中任一个所示的氨基酸序列的互补决定区2(CDR-2);和/或
所述Vβ区还包含含有SEQ ID NO:154所示的氨基酸序列的互补决定区1(CDR-1);和/或含有SEQ ID NO:155所示的氨基酸序列的互补决定区2(CDR-2)。
147.根据权利要求145或权利要求146所述的工程化细胞,其中所述Vα区和Vβ区包含:
分别包含SEQ ID NO:151、152和153的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和156的氨基酸序列的CDR-1、CDR-2和CDR-3;
分别包含SEQ ID NO:157、158和159的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和160的氨基酸序列的CDR-1、CDR-2和CDR-3;或者
分别包含SEQ ID NO:151、152和301的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和156的氨基酸序列的CDR-1、CDR-2和CDR-3。
148.根据权利要求145-147中任一项所述的工程化细胞,其中:
所述Vα区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:117、119或295中任一个所示的Vα区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列;和/或
所述Vβ区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:118、120或296中任一个所示的Vβ区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列。
149.根据权利要求145-148中任一项所述的工程化细胞:
所述Vα和Vβ区分别包含SEQ ID NO:117和118或296的氨基酸序列;
所述Vα和Vβ区分别包含SEQ ID NO:119和120的氨基酸序列;或者
所述Vα和Vβ区分别包含SEQ ID NO:295和118或296的氨基酸序列。
150.根据权利要求145-149中任一项所述的工程化细胞,其中所述TCR或其抗原结合片段结合至或识别在MHC分子的背景下的人乳头瘤病毒(HPV)16 E7的肽表位,所述肽表位是或包含E7(11-19)YMLDLQPET(SEQ ID NO:236)。
151.一种工程化细胞,所述工程化细胞包含TCR或其抗原结合片段,任选地重组TCR或其抗原结合片段,其中:
(1)所述细胞包含T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏和/或不表达内源TRAC或TRBC的基因产物,或不以可检测的水平表达内源TRAC或TRBC的基因产物,或表达少于野生型水平的20%、15%、10%、5%、4%、3%、2%或1%的内源TRAC或TRBC的基因产物;并且
(2)所述TCR或其抗原结合片段或者所述重组TCR或其抗原结合片段包含:
(a)包含SEQ ID NO:111、113、115、121、123、125、297或299中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列的可变α(Vα)区Vα区;和/或包含SEQ ID NO:112、114、116、122、124、126、298或300中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列的Vβ区;和/或
(b)包含含有SEQ ID NO:138、144、147、163、167、173、304或308中任一个所示的氨基酸序列的互补决定区3(CDR-3)或SEQ ID NO:111、113、115、121、123、125、297或299中任一个所示的氨基酸序列内所含的CDR3的Vα区和包含含有SEQ ID NO:141、146、150、164、170、174、305或309中任一个所示的氨基酸序列的互补决定区3(CDR-3)或SEQ ID NO:112、114、116、122、124、126、298或300中任一个所示的氨基酸序列内所含的CDR3的Vβ区。
152.根据权利要求151所述的工程化细胞,其中:
所述Vα区还包含含有SEQ ID NO:136、142、161、165、171、302或306中任一个所示的氨基酸序列的互补决定区1(CDR-1)或SEQ ID NO:111、113、115、121、123、125、297或299中任一个所示的氨基酸序列内所含的CDR-1;和/或含有SEQ ID NO:137、143、162、166、172、303或307中任一个所示的氨基酸序列的互补决定区2(CDR-2)或SEQ ID NO:111、113、115、121、123、125、297或299中任一个所示的氨基酸序列内所含的CDR-2;和/或
所述Vβ区还包含含有SEQ ID NO:139、145、148、168中任一个所示的氨基酸序列的互补决定区1(CDR-1)或SEQ ID NO:112、114、116、122、124、126、298或300中任一个所示的氨基酸序列内所含的CDR-1;和/或含有SEQ ID NO:140、149或169中任一个所示的氨基酸序列的互补决定区2(CDR-2)或SEQ ID NO:112、114、116、122、124、126、298或300中任一个所示的氨基酸序列内所含的CDR-2。
153.根据权利要求151或权利要求152所述的工程化细胞,其中:
所述Vα区包含分别包含SEQ ID NO:136、137和138的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:139、140和141的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:142、143和144的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:145、140和146的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:136、137和147的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和150的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:161、162和163的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和164的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:165、166和167的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:168、169和170的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:171、172和173的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和174的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:302、303和304的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:139、140和305的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:306、307和308的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和309的氨基酸序列的CDR-1、CDR-2和CDR-3。
154.根据权利要求151-153中任一项所述的工程化细胞,其中:
所述Vα区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:111、113、115、121、123、125、297或299中任一个所示的Vα区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列;和/或
所述Vβ区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:112、114、116、122、124、126、298或300中任一个所示的Vβ区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列。
155.根据权利要求151-154中任一项所述的工程化细胞:所述Vα和Vβ区分别包含SEQID NO:111和112的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:113和114的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:115和116的氨基酸序列;所述Vα和Vβ区分别包含SEQID NO:121和122的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:123和124的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:125和126的氨基酸序列;所述Vα和Vβ区分别包含SEQID NO:297和298的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:299和300的氨基酸序列。
156.根据权利要求151-155中任一项所述的工程化细胞,其中所述TCR或其抗原结合片段结合至或识别在MHC分子的背景下的人乳头瘤病毒(HPV)16 E6的肽表位,所述肽表位是或包含E6(29-38)TIHDIILECV(SEQ ID NO:233)。
157.根据权利要求145-156中任一项所述的工程化细胞,其中所述α链还包含α恒定(Cα)区和/或所述β链还包含β恒定(Cβ)区。
158.根据权利要求143-157中任一项所述的工程化细胞,其中所述基因产物是由所述TRAC或TRBC基因编码的mRNA或蛋白质。
159.根据权利要求141-158中任一项所述的工程化细胞,其中所述遗传破坏包含在所述TRAC或TRBC基因的区域中的突变或缺失,所述区域在所述基因的编码区、任选地早期编码区内,在所述基因的外显子1内,在所述基因的起始密码子的500、400、300、200、100或50个碱基对内的编码区中,在与具有选自SEQ ID NO:1053和1259-1315中任一个的序列的指导RNA(gRNA)靶向结构域的靶向位点互补的靶位点序列内,和/或与具有选自SEQ ID NO:1053和1259-1315的序列的靶向结构域特异性杂交,和/或在与具有选自SEQ ID NO:1048和1229-1258中任一个的序列的gRNA靶向结构域的靶向位点互补的靶位点序列内,和/或与具有选自SEQ ID NO:1048和1229-1258的序列的靶向结构域特异性杂交。
160.根据权利要求141-159中任一项所述的工程化细胞,其中所述遗传破坏是通过一种或多种药剂实现的,所述一种或多种药剂包含(a)具有与TRAC基因和/或TRBC基因的靶结构域互补的靶向结构域的至少一种gRNA或(b)编码所述至少一种gRNA的至少一种核酸。
161.根据权利要求141-160中任一项所述的工程化细胞,其中所述一种或多种药剂包含Cas9分子和具有与TRAC基因和/或TRBC基因的靶结构域互补的靶向结构域的所述至少一种gRNA的至少一种复合物。
162.根据权利要求160或权利要求161中任一项所述的工程化细胞,其中所述至少一种gRNA包含与TRAC基因的靶结构域互补的靶向结构域,所述靶向结构域包含选自UCUCUCAGCUGGUACACGGC(SEQ ID NO:1229)、UGGAUUUAGAGUCUCUCAGC(SEQ ID NO:1230)、ACACGGCAGGGUCAGGGUUC(SEQ ID NO:1231)、GAGAAUCAAAAUCGGUGAAU(SEQ ID NO:1048)、GCUGGUACACGGCAGGGUCA(SEQ ID NO:1232)、CUCAGCUGGUACACGGC(SEQ ID NO:1233)、UGGUACACGGCAGGGUC(SEQ ID NO:1234)、GCUAGACAUGAGGUCUA(SEQ ID NO:1235)、GUCAGAUUUGUUGCUCC(SEQ ID NO:1236)、UCAGCUGGUACACGGCA(SEQ ID NO:1237)、GCAGACAGACUUGUCAC(SEQ ID NO:1238)、GGUACACGGCAGGGUCA(SEQ ID NO:1239)、CUUCAAGAGCAACAGUGCUG(SEQ ID NO:1240)、AGAGCAACAGUGCUGUGGCC(SEQ ID NO:1241)、AAAGUCAGAUUUGUUGCUCC(SEQ ID NO:1242)、ACAAAACUGUGCUAGACAUG(SEQ ID NO:1243)、AAACUGUGCUAGACAUG(SEQ ID NO:1244)、UGUGCUAGACAUGAGGUCUA(SEQ ID NO:1245)、GGCUGGGGAAGAAGGUGUCUUC(SEQ ID NO:1246)、GCUGGGGAAGAAGGUGUCUUC(SEQ ID NO:1247)、GGGGAAGAAGGUGUCUUC(SEQ ID NO:1248)、GUUUUGUCUGUGAUAUACACAU(SEQ ID NO:1249)、GGCAGACAGACUUGUCACUGGAUU(SEQ ID NO:1250)、GCAGACAGACUUGUCACUGGAUU(SEQ ID NO:1251)、GACAGACUUGUCACUGGAUU(SEQ ID NO:1252)、GUGAAUAGGCAGACAGACUUGUCA(SEQ IDNO:1253)、GAAUAGGCAGACAGACUUGUCA(SEQ ID NO:1254)、GAGUCUCUCAGCUGGUACACGG(SEQ IDNO:1255)、GUCUCUCAGCUGGUACACGG(SEQ ID NO:1256)、GGUACACGGCAGGGUCAGGGUU(SEQ IDNO:1257)和GUACACGGCAGGGUCAGGGUU(SEQ ID NO:1258)的序列。
163.根据权利要求160-162中任一项所述的工程化细胞,其中所述gRNA包含与TRBC基因的、任选地在TRBC1和TRBC2基因之一或两者中的靶结构域互补的靶向结构域,所述靶向结构域包含选自CACCCAGAUCGUCAGCGCCG(SEQ ID NO:1259)、CAAACACAGCGACCUCGGGU(SEQID NO:1260)、UGACGAGUGGACCCAGGAUA(SEQ ID NO:1261)、GGCUCUCGGAGAAUGACGAG(SEQ IDNO:1262)、GGCCUCGGCGCUGACGAUCU(SEQ ID NO:1053)、GAAAAACGUGUUCCCACCCG(SEQ ID NO:1263)、AUGACGAGUGGACCCAGGAU(SEQ ID NO:1264)、AGUCCAGUUCUACGGGCUCU(SEQ ID NO:1265)、CGCUGUCAAGUCCAGUUCUA(SEQ ID NO:1266)、AUCGUCAGCGCCGAGGCCUG(SEQ ID NO:1267)、UCAAACACAGCGACCUCGGG(SEQ ID NO:1268)、CGUAGAACUGGACUUGACAG(SEQ ID NO:1269)、AGGCCUCGGCGCUGACGAUC(SEQ ID NO:1270)、UGACAGCGGAAGUGGUUGCG(SEQ ID NO:1271)、UUGACAGCGGAAGUGGUUGC(SEQ ID NO:1272)、UCUCCGAGAGCCCGUAGAAC(SEQ ID NO:1273)、CGGGUGGGAACACGUUUUUC(SEQ ID NO:1274)、GACAGGUUUGGCCCUAUCCU(SEQ ID NO:1275)、GAUCGUCAGCGCCGAGGCCU(SEQ ID NO:1276)、GGCUCAAACACAGCGACCUC(SEQ ID NO:1277)、UGAGGGUCUCGGCCACCUUC(SEQ ID NO:1278)、AGGCUUCUACCCCGACCACG(SEQ ID NO:1279)、CCGACCACGUGGAGCUGAGC(SEQ ID NO:1280)、UGACAGGUUUGGCCCUAUCC(SEQ ID NO:1281)、CUUGACAGCGGAAGUGGUUG(SEQ ID NO:1282)、AGAUCGUCAGCGCCGAGGCC(SEQ ID NO:1283)、GCGCUGACGAUCUGGGUGAC(SEQ ID NO:1284)、UGAGGGCGGGCUGCUCCUUG(SEQ ID NO:1285)、GUUGCGGGGGUUCUGCCAGA(SEQ ID NO:1286)、AGCUCAGCUCCACGUGGUCG(SEQ ID NO:1287)、GCGGCUGCUCAGGCAGUAUC(SEQ ID NO:1288)、GCGGGGGUUCUGCCAGAAGG(SEQ ID NO:1289)、UGGCUCAAACACAGCGACCU(SEQ ID NO:1290)、ACUGGACUUGACAGCGGAAG(SEQ ID NO:1291)、GACAGCGGAAGUGGUUGCGG(SEQ ID NO:1292)、GCUGUCAAGUCCAGUUCUAC(SEQ ID NO:1293)、GUAUCUGGAGUCAUUGAGGG(SEQ ID NO:1294)、CUCGGCGCUGACGAUCU(SEQ ID NO:1295)、CCUCGGCGCUGACGAUC(SEQ ID NO:1296)、CCGAGAGCCCGUAGAAC(SEQ ID NO:1297)、CCAGAUCGUCAGCGCCG(SEQ ID NO:1298)、GAAUGACGAGUGGACCC(SEQ ID NO:1299)、GGGUGACAGGUUUGGCCCUAUC(SEQ ID NO:1300)、GGUGACAGGUUUGGCCCUAUC(SEQ ID NO:1301)、GUGACAGGUUUGGCCCUAUC(SEQ ID NO:1302)、GACAGGUUUGGCCCUAUC(SEQ ID NO:1303)、GAUACUGCCUGAGCAGCCGCCU(SEQ ID NO:1304)、GACCACGUGGAGCUGAGCUGGUGG(SEQ ID NO:1305)、GUGGAGCUGAGCUGGUGG(SEQ ID NO:1306)、GGGCGGGCUGCUCCUUGAGGGGCU(SEQ ID NO:1307)、GGCGGGCUGCUCCUUGAGGGGCU(SEQ ID NO:1308)、GCGGGCUGCUCCUUGAGGGGCU(SEQ IDNO:1309)、GGGCUGCUCCUUGAGGGGCU(SEQ ID NO:1310)、GGCUGCUCCUUGAGGGGCU(SEQ ID NO:1311)、GCUGCUCCUUGAGGGGCU(SEQ ID NO:1312)、GGUGAAUGGGAAGGAGGUGCACAG(SEQ ID NO:1313)、GUGAAUGGGAAGGAGGUGCACAG(SEQ ID NO:1314)和GAAUGGGAAGGAGGUGCACAG(SEQ IDNO:1315)的序列。
164.根据权利要求141-163中任一项所述的工程化细胞,其中:
所述工程化细胞包含T细胞受体α恒定区(TRAC)基因和T细胞受体β恒定区(TRBC)基因的遗传破坏;和/或
所述一种或多种药剂包含含有具有与TRAC基因的靶结构域互补的靶向结构域的至少一种gRNA的药剂和含有具有与TRBC基因、任选地TRBC1基因和TRBC2基因之一或两者的靶结构域互补的靶结构域的至少一种gRNA的药剂。
165.根据权利要求159-164中任一项所述的工程化细胞,其中所述靶向结构域包含与TRAC基因的靶结构域互补的序列,并且所述靶向结构域包含序列GAGAAUCAAAAUCGGUGAAU(SEQ ID NO:1048)。
166.根据权利要求159-165中任一项所述的工程化细胞,其中所述靶向结构域包含与TRBC基因的靶结构域互补的序列,并且所述靶向结构域包含序列GGCCUCGGCGCUGACGAUCU(SEQ ID NO:1053)。
167.根据权利要求159-166中任一项所述的工程化细胞,其中所述gRNA还包含第一互补结构域、与所述第一互补结构域互补的第二互补结构域、近端结构域和任选地尾结构域。
168.根据权利要求167所述的工程化细胞,其中所述第一互补结构域和第二互补结构域通过连接结构域连接。
169.根据权利要求167或权利要求168所述的工程化细胞,其中所述指导RNA包含3'聚A尾和5'抗反向帽类似物(ARCA)帽。
170.根据权利要求161-169中任一项所述的工程化细胞,其中所述Cas9分子是酶促活性Cas9。
171.根据权利要求161-170中任一项所述的工程化细胞,其中所述Cas9分子是金黄色葡萄球菌(S.aureus)Cas9分子。
172.根据权利要求161-171中任一项所述的工程化细胞,其中所述Cas9分子是化脓链球菌(S.pyogenes)Cas9。
173.根据权利要求141-172中任一项所述的工程化细胞,其中所述工程化细胞包含T细胞受体α恒定区(TRAC)基因座的遗传破坏。
174.根据权利要求141-173中任一项所述的工程化细胞,其中通过任选地经由HDR将编码所述TCR或其抗原结合片段的核酸序列整合在所述TRAC基因座处来进一步修饰所述内源TRAC基因座。
175.根据权利要求141-173中任一项所述的工程化细胞,其中通过任选地经由同源定向修复(HDR)整合编码所述TCR或其抗原结合片段的一部分的转基因序列来进一步修饰所述内源TRAC基因座。
176.一种工程化细胞,所述工程化细胞包含编码根据权利要求1-39和47-85中任一项所述的TCR或其抗原结合片段的经修饰的TRAC基因座。
177.一种工程化细胞,所述工程化细胞包含经修饰的TRAC基因座,其中通过整合编码所述TCR的一部分的转基因序列来修饰所述内源TRAC基因座,所述转基因序列编码(i)包含根据权利要求1-14、21-23、28-39、47-61、67-69和74-85中任一项所述的TCR或其抗原结合片段的可变β(Vβ)和恒定β(Cβ)的T细胞受体β(TCRβ)链;和(ii)包含根据权利要求1-14、21-23、28-39、47-61、67-69和74-85中任一项所述的TCR或其抗原结合片段的可变α(Vα)的T细胞受体α(TCRα)链的一部分,其中所述TCR的恒定α(Cα)的至少一部分由所述内源TRAC基因座的开放阅读框或其部分序列编码。
178.根据权利要求174-176中任一项所述的工程化细胞,其中所述TCR或其抗原结合片段包含Cα,所述Cα的至少一部分由所述内源TRAC基因座的开放阅读框或其部分序列编码。
179.根据权利要求174-178中任一项所述的工程化细胞,其中所述经修饰的TRAC基因座包含(i)编码所述TCR的一部分的转基因序列和(ii)所述内源TRAC基因座的开放阅读框或其部分序列的框内融合物。
180.根据权利要求175、177和179中任一项所述的工程化细胞,其中所述转基因序列不包含编码3'UTR的序列或内含子。
181.根据权利要求177-180中任一项所述的工程化细胞,其中所述开放阅读框或其部分序列包含所述内源TRAC基因座的3'UTR。
182.根据权利要求176、177和179-181中任一项所述的工程化细胞,其中所述转基因序列整合在所述内源TRAC基因座的开放阅读框的外显子1的最5'核苷酸的下游且在外显子1的最3'核苷酸的上游。
183.根据权利要求177-182中任一项所述的工程化细胞,其中Cα的所述至少一部分由所述内源TRAC基因座的开放阅读框的至少外显子2-4编码。
184.根据权利要求177-183中任一项所述的工程化细胞,其中Cα的所述至少一部分由所述内源TRAC基因座的开放阅读框的外显子1的至少一部分和外显子2-4编码。
185.根据权利要求175、177和179-184中任一项所述的工程化细胞,其中所述转基因序列编码T细胞受体β(TCRβ)链和/或TCRα可变区(Vα)。
186.根据权利要求173-185中任一项所述的工程化细胞,其还包含T细胞受体β恒定区(TRBC)基因座、任选地TRBC1或TRBC2基因座的遗传破坏。
187.根据权利要求141-173中任一项所述的工程化细胞,其中所述工程化细胞包含T细胞受体β恒定区(TRBC)基因座的遗传破坏。
188.根据权利要求141-173中任一项所述的工程化细胞,其中通过任选地经由HDR将编码所述TCR或其抗原结合片段的核酸序列整合在所述TRBC基因座处来进一步修饰所述内源TRBC基因座。
189.根据权利要求141-173中任一项所述的工程化细胞,其中通过任选地经由同源定向修复(HDR)整合编码所述TCR或其抗原结合片段的一部分的转基因序列来进一步修饰所述内源TRBC基因座。
190.一种工程化细胞,所述工程化细胞包含编码根据权利要求1-39和47-85中任一项所述的TCR或其抗原结合片段的经修饰的TRBC基因座。
191.一种工程化细胞,所述工程化细胞包含经修饰的TRBC基因座,其中通过整合编码所述TCR的一部分的转基因序列来修饰所述内源TRBC基因座,所述转基因序列编码(i)包含根据权利要求1-14、21-23、28-39、47-61、67-69和74-85中任一项所述的TCR或其抗原结合片段的可变α(Vα)和恒定α(Cα)的T细胞受体α(TCRα)链;和(ii)包含根据权利要求1-14、21-23、28-39、47-61、67-69和74-85中任一项所述的TCR或其抗原结合片段的可变β(Vβ)的T细胞受体β(TCRβ)链的一部分,其中所述TCR的恒定β(Cβ)的至少一部分由所述内源TRBC基因座的开放阅读框或其部分序列编码。
192.根据权利要求188-190中任一项所述的工程化细胞,其中所述TCR或其抗原结合片段包含Cβ,所述Cβ的至少一部分由所述内源TRBC基因座的开放阅读框或其部分序列编码。
193.根据权利要求188-192中任一项所述的工程化细胞,其中所述经修饰的TRBC基因座包含(i)编码所述TCR的一部分的转基因序列和(ii)所述内源TRBC基因座的开放阅读框或其部分序列的框内融合物。
194.根据权利要求189、191和193中任一项所述的工程化细胞,其中所述转基因序列不包含编码3'UTR的序列或内含子。
195.根据权利要求192-194中任一项所述的工程化细胞,其中所述开放阅读框或其部分序列包含所述内源TRBC基因座的3'UTR。
196.根据权利要求189、191和193-195中任一项所述的工程化细胞,其中所述转基因序列整合在所述内源TRBC基因座的开放阅读框的外显子1的最5'核苷酸的下游且在外显子1的最3'核苷酸的上游。
197.根据权利要求191-196中任一项所述的工程化细胞,其中Cβ的所述至少一部分由所述内源TRBC基因座的开放阅读框的至少外显子2-4编码。
198.根据权利要求191-197中任一项所述的工程化细胞,其中Cβ的所述至少一部分由所述内源TRBC基因座的开放阅读框的外显子1的至少一部分和外显子2-4编码。
199.根据权利要求189、191和193-198中任一项所述的工程化细胞,其中所述转基因序列编码T细胞受体α(TCRα)链和/或TCRβ可变区(Vβ)。
200.根据权利要求187-199中任一项所述的工程化细胞,其中TRBC基因座是T细胞受体β恒定区1(TRBC1)或T细胞受体β恒定区2(TRBC2)基因座之一或两者。
201.根据权利要求188-200中任一项所述的工程化细胞,其还包含T细胞受体α恒定区(TRAC)基因座的遗传破坏。
202.根据权利要求174-186和188-201中任一项所述的工程化细胞,其中编码所述TCR或其抗原结合片段的转基因序列或核酸序列包含一个或多个多顺反子元件。
203.根据权利要求202所述的工程化细胞,其中所述一个或多个多顺反子元件在编码所述TCR或其抗原结合片段的转基因序列或核酸序列的上游。
204.根据权利要求174-186和188-203中任一项所述的工程化细胞,其中所述一个或多个多顺反子元件位于编码所述TCRα或其部分的核酸序列与编码所述TCRβ或其部分的核酸序列之间。
205.根据权利要求174-186和188-204中任一项所述的工程化细胞,其中所述一个或多个多顺反子元件是或包含核糖体跳跃序列,任选地其中所述核糖体跳跃序列是T2A、P2A、E2A或F2A元件。
206.根据权利要求174-186和188-205中任一项所述的工程化细胞,其中编码所述TCR或其抗原结合片段的转基因序列或核酸序列包含一个或多个异源或调节控制元件,所述元件可操作地连接以控制当从引入了所述工程化细胞的细胞表达时所述TCR的表达。
207.根据权利要求206所述的工程化细胞,其中所述一个或多个异源调节或控制元件包含启动子、增强子、内含子、多腺苷酸化信号、Kozak共有序列、剪接受体序列和/或剪接供体序列。
208.根据权利要求206或权利要求207所述的工程化细胞,其中所述异源调节或控制元件包含异源启动子,任选地人延伸因子1α(EF1α)启动子或MND启动子或其变体。
209.根据权利要求139-208中任一项所述的工程化细胞,其中所述TCR或其抗原结合片段或者所述TCR或其抗原结合片段的一部分对所述细胞是异源的。
210.根据权利要求139-209中任一项所述的工程化细胞,其中所述工程化细胞是细胞系。
211.根据权利要求139-210中任一项所述的工程化细胞,其中所述工程化细胞是获自受试者的原代细胞。
212.根据权利要求211所述的工程化细胞,其中所述受试者是哺乳动物受试者。
213.根据权利要求211或权利要求212所述的工程化细胞,其中所述受试者是人。
214.根据权利要求139-213中任一项所述的工程化细胞,其中所述工程化细胞是T细胞。
215.根据权利要求214所述的工程化细胞,其中所述T细胞是CD8+。
216.根据权利要求214所述的工程化细胞,其中所述T细胞是CD4+。
217.一种用于产生根据权利要求139-216中任一项所述的细胞的方法,其包括在体外或离体地将根据权利要求130-138中任一项所述的载体引入细胞中。
218.一种用于产生细胞的方法,其包括在体外或离体地将编码根据权利要求1-39和47-85中任一项所述的TCR或其抗原结合片段的核酸分子、根据权利要求40-46和86-94中任一项所述的核酸分子、根据权利要求95-129中任一项所述的多核苷酸或根据权利要求130-138中任一项所述的载体引入细胞中。
219.根据权利要求217或权利要求218所述的方法,其中所述载体是病毒载体,并且所述引入是通过转导进行的。
220.根据权利要求217-219中任一项所述的方法,其还包括将一种或多种药剂引入所述细胞中,其中所述一种或多种药剂中的每一种独立地能够诱导T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏。
221.一种用于产生工程化细胞的方法,其包括:
(i)将编码根据权利要求1-39和47-85中任一项所述的TCR或其抗原结合片段的核酸分子、根据权利要求40-46和86-94中任一项所述的核酸分子、根据权利要求95-129中任一项所述的多核苷酸或根据权利要求130-138中任一项所述的载体引入细胞中;以及
(ii)将一种或多种药剂引入所述细胞中,其中所述一种或多种药剂中的每一种独立地能够诱导T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏。
222.根据权利要求221所述的方法,其中所述TRBC基因是T细胞受体β恒定区1(TRBC1)或T细胞受体β恒定区2(TRBC2)基因之一或两者。
223.根据权利要求221-222中任一项所述的方法,其中能够诱导遗传破坏的所述一种或多种药剂包含特异性结合至或杂交至所述靶位点的DNA结合蛋白或DNA结合核酸。
224.根据权利要求223所述的方法,其中能够诱导遗传破坏的所述一种或多种药剂包含(a)包含DNA靶向蛋白和核酸酶的融合蛋白或(b)RNA指导的核酸酶。
225.根据权利要求224所述的方法,其中所述DNA靶向蛋白或RNA指导的核酸酶包含对所述TRAC和/或TRBC基因内的靶位点具特异性的锌指蛋白(ZFP)、TAL蛋白或成簇的规律间隔的短回文核酸(CRISPR)相关核酸酶(Cas)。
226.根据权利要求225所述的方法,其中所述一种或多种药剂包含特异性结合至、识别或杂交至所述靶位点的锌指核酸酶(ZFN)、TAL效应子核酸酶(TALEN)或和CRISPR-Cas9组合。
227.根据权利要求225或权利要求226所述的方法,其中所述一种或多种药剂中的每一种包含具有与所述至少一个靶位点互补的靶向结构域的指导RNA(gRNA)。
228.根据权利要求217-227所述的方法,其中所述TRBC基因是T细胞受体β恒定区1(TRBC1)或T细胞受体β恒定区2(TRBC2)基因之一或两者。
229.根据权利要求221-228中任一项所述的方法,其中所述遗传破坏是通过一种或多种药剂实现的,所述一种或多种药剂包含(a)具有与TRAC基因和/或TRBC基因的靶结构域互补的靶向结构域的至少一种gRNA或(b)编码所述至少一种gRNA的至少一种核酸。
230.根据权利要求229所述的方法,其中将所述一种或多种药剂作为包含所述gRNA和Cas9蛋白的核糖核蛋白(RNP)复合物引入。
231.根据权利要求230所述的方法,其中经由电穿孔、粒子枪、磷酸钙转染、细胞压缩或挤压来引入所述RNP。
232.根据权利要求230或权利要求231所述的方法,其中经由电穿孔来引入所述RNP。
233.根据权利要求227-232中任一项所述的方法,其中将所述一种或多种药剂作为编码所述gRNA和/或Cas9蛋白的一种或多种多核苷酸引入。
234.根据权利要求220-233中任一项所述的方法,其中所述一种或多种药剂包含Cas9分子和具有与TRAC基因和/或TRBC基因的靶结构域互补的靶向结构域的所述至少一种gRNA的至少一种复合物。
235.根据权利要求220-234中任一项所述的方法,其中所述一种或多种药剂包含Cas9分子和具有靶向结构域的gRNA的至少一种复合物,所述靶向结构域是以下之一或两者:(1)与TRAC基因的靶结构域互补,所述靶向结构域包含选自SEQ ID NO:1048和1229-1258中任一个的序列;和(2)与TRBC基因、任选地TRBC1和TRBC2基因之一或两者的靶结构域互补,所述靶向结构域包含选自SEQ ID NO:1053和1259-1315中任一个的序列。
236.根据权利要求229-235中任一项所述的方法,其中所述靶向结构域包含与TRAC基因的靶结构域互补的序列,并且所述靶向结构域包含序列GAGAAUCAAAAUCGGUGAAU(SEQ IDNO:1048)。
237.根据权利要求229-236中任一项所述的方法,其中所述靶向结构域包含与TRBC基因的靶结构域互补的序列,并且所述靶向结构域包含序列GGCCUCGGCGCUGACGAUCU(SEQ IDNO:1053)。
238.根据权利要求229-237中任一项所述的方法,其中所述指导RNA还包含第一互补结构域、与所述第一互补结构域互补的第二互补结构域、近端结构域和任选地尾结构域。
239.根据权利要求238所述的方法,其中所述第一互补结构域和第二互补结构域通过连接结构域连接。
240.根据权利要求239中任一项所述的方法,其中所述指导RNA包含3'聚A尾和5'抗反向帽类似物(ARCA)帽。
241.根据权利要求226-240中任一项所述的方法,其中所述Cas9分子是酶促活性Cas9。
242.根据权利要求226-241中任一项所述的方法,其中所述Cas9分子是金黄色葡萄球菌Cas9分子。
243.根据权利要求226-241中任一项所述的方法,其中所述Cas9分子是化脓链球菌Cas9。
244.根据权利要求220-243中任一项所述的方法,其中多个工程化细胞中至少或大于35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、90%或95%的所述细胞在所述TRAC基因和/或TRBC基因内包含遗传破坏。
245.根据权利要求220-244中任一项所述的方法,其中多个工程化细胞中至少或大于90%、95%、96%、97%或98%的所述细胞在所述TRAC基因和/或TRBC基因内包含遗传破坏。
246.根据权利要求217-245中任一项所述的方法,其中多个工程化细胞中至少或大于5%、10%、15%、20%、25%、30%、40%、50%或更多的所述细胞表达所述引入的TCR或其抗原结合片段,和/或展现出与HPV蛋白、任选地HPV E6或HPV E7的抗原结合。
247.根据权利要求217-245中任一项所述的方法,其中多个工程化细胞中至少或大于5%、10%、15%、20%、25%、30%、40%、50%或更多的所述细胞表达所述引入的TCR或其抗原结合片段,和/或展现出与HPV蛋白、任选地HPV E6或HPV E7的抗原结合。
248.根据权利要求217-247中任一项所述的方法,其中多个工程化细胞中至少或大于5%、10%、15%、20%、25%、30%、40%、50%或更多的所述细胞表达所述引入的TCR或其抗原结合片段,和/或展现出与HPV蛋白、任选地HPV E6或HPV E7的抗原结合。
249.根据权利要求220-248中任一项所述的方法,其中所述一种或多种药剂和所述核酸分子、所述多核苷酸或所述载体同时或以任何顺序依序引入。
250.根据权利要求220-251中任一项所述的方法,其中在引入所述一种或多种药剂之后引入所述核酸分子、所述多核苷酸或所述载体。
251.根据权利要求250所述的方法,其中在引入所述药剂之后立即引入所述核酸分子、所述多核苷酸或所述载体,或者在引入所述药剂之后约30秒、1分钟、2分钟、3分钟、4分钟、5分钟、6分钟、6分钟、8分钟、9分钟、10分钟、15分钟、20分钟、30分钟、40分钟、50分钟、60分钟、90分钟、2小时、3小时或4小时内引入所述核酸分子、所述多核苷酸或所述载体。
252.一种组合物,其包含根据权利要求139-216中任一项所述的工程化细胞。
253.一种组合物,其包含使用根据权利要求217-251中任一项所述的方法产生的工程化细胞。
254.根据权利要求252或权利要求253所述的组合物,其中:
所述组合物中至少70%、75%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的所述工程化细胞在内源T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因中包含遗传破坏或包含内源T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏;和/或
所述组合物中至少80%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的所述工程化细胞不表达或不表达可检测水平的内源TRAC或TRBC基因的基因产物。
255.一种组合物,其包含多个工程化细胞,每个工程化细胞包含TCR或其抗原结合片段,其中:
(1)所述组合物中至少70%、75%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的所述工程化细胞在内源T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因中包含遗传破坏或包含内源T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏,和/或其中所述组合物中至少80%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的所述工程化细胞不表达或不表达可检测水平的内源TRAC或TRBC基因的基因产物;并且
(2)所述TCR或其抗原结合片段包含:
(a)包含SEQ ID NO:117、119或295中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列的可变α(Vα)区和包含SEQ ID NO:118、120或296中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列的可变β(Vβ)区;和/或
(b)包含含有SEQ ID NO:153、159或301中任一个所示的氨基酸序列的互补决定区3(CDR-3)或SEQ ID NO:117、119或295中任一个所示的氨基酸序列内所含的CDR3的Vα区和包含含有SEQ ID NO:156或160中任一个所示的氨基酸序列的互补决定区3(CDR-3)或SEQ IDNO:118、120或296中任一个所示的氨基酸序列内所含的CDR3的Vβ区。
256.根据权利要求255所述的组合物,其中:
所述Vα区还包含含有SEQ ID NO:151或157中任一个所示的氨基酸序列的互补决定区1(CDR-1);和/或含有SEQ ID NO:152或158中任一个所示的氨基酸序列的互补决定区2(CDR-2);和/或
所述Vβ区还包含含有SEQ ID NO:154所示的氨基酸序列的互补决定区1(CDR-1);和/或含有SEQ ID NO:155所示的氨基酸序列的互补决定区2(CDR-2)。
257.根据权利要求255或权利要求256所述的组合物,其中所述Vα区和Vβ区包含:
分别包含SEQ ID NO:151、152和153的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和156的氨基酸序列的CDR-1、CDR-2和CDR-3;
分别包含SEQ ID NO:157、158和159的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和160的氨基酸序列的CDR-1、CDR-2和CDR-3;或者
分别包含SEQ ID NO:151、152和301的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:154、155和156的氨基酸序列的CDR-1、CDR-2和CDR-3。
258.根据权利要求255-257中任一项所述的组合物,其中:
所述Vα区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:117、119或295中任一个所示的Vα区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列;和/或
所述Vβ区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:118、120或296中任一个所示的Vβ区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列。
259.根据权利要求255-258中任一项所述的组合物:
所述Vα和Vβ区分别包含SEQ ID NO:117和118或296的氨基酸序列;
所述Vα和Vβ区分别包含SEQ ID NO:119和120的氨基酸序列;或者
所述Vα和Vβ区分别包含SEQ ID NO:295和118或296的氨基酸序列。
260.根据权利要求255-259中任一项所述的组合物,其中所述TCR或其抗原结合片段结合至或识别在MHC分子的背景下的人乳头瘤病毒(HPV)16 E7的肽表位,所述肽表位是或包含E7(11-19)YMLDLQPET(SEQ ID NO:236)。
261.一种组合物,其包含多个工程化细胞,每个工程化细胞包含TCR或其抗原结合片段,其中:
(1)所述组合物中至少70%、75%、80%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的所述工程化细胞在内源T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因中包含遗传破坏或包含内源T细胞受体α恒定区(TRAC)基因和/或T细胞受体β恒定区(TRBC)基因的遗传破坏,和/或其中所述组合物中至少80%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的所述工程化细胞不表达或不表达可检测水平的内源TRAC或TRBC基因的基因产物;并且
(2)所述TCR或其抗原结合片段或者所述重组TCR或其抗原结合片段包含:
(a)包含SEQ ID NO:111、113、115、121、123、125、297或299中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列的可变α(Vα)区Vα区;和/或包含SEQ ID NO:112、114、116、122、124、126、298或300中任一个所示的氨基酸序列或与其具有至少90%、91%、92%、93%、94%、95%、96%、97%、98%或99%序列同一性的氨基酸序列的Vβ区;和/或
(b)包含含有SEQ ID NO:138、144、147、163、167、173、304或308中任一个所示的氨基酸序列的互补决定区3(CDR-3)或SEQ ID NO:111、113、115、121、123、125、297或299中任一个所示的氨基酸序列内所含的CDR3的Vα区和包含含有SEQ ID NO:141、146、150、164、170、174、305或309中任一个所示的氨基酸序列的互补决定区3(CDR-3)或SEQ ID NO:112、114、116、122、124、126、298或300中任一个所示的氨基酸序列内所含的CDR3的Vβ区。
262.根据权利要求261所述的组合物,其中:
所述Vα区还包含含有SEQ ID NO:136、142、161、165、171、302或306中任一个所示的氨基酸序列的互补决定区1(CDR-1)或SEQ ID NO:111、113、115、121、123、125、297或299中任一个所示的氨基酸序列内所含的CDR-1;和/或含有SEQ ID NO:137、143、162、166、172、303或307中任一个所示的氨基酸序列的互补决定区2(CDR-2)或SEQ ID NO:111、113、115、121、123、125、297或299中任一个所示的氨基酸序列内所含的CDR-2;和/或
所述Vβ区还包含含有SEQ ID NO:139、145、148、168中任一个所示的氨基酸序列的互补决定区1(CDR-1)或SEQ ID NO:112、114、116、122、124、126、298或300中任一个所示的氨基酸序列内所含的CDR-1;和/或含有SEQ ID NO:140、149或169中任一个所示的氨基酸序列的互补决定区2(CDR-2)或SEQ ID NO:112、114、116、122、124、126、298或300中任一个所示的氨基酸序列内所含的CDR-2。
263.根据权利要求261或权利要求262所述的组合物,其中:
所述Vα区包含分别包含SEQ ID NO:136、137和138的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:139、140和141的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:142、143和144的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:145、140和146的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:136、137和147的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和150的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:161、162和163的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和164的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:165、166和167的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:168、169和170的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:171、172和173的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和174的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:302、303和304的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:139、140和305的氨基酸序列的CDR-1、CDR-2和CDR-3;
所述Vα区包含分别包含SEQ ID NO:306、307和308的氨基酸序列的CDR-1、CDR-2和CDR-3,并且所述Vβ区包含分别包含SEQ ID NO:148、149和309的氨基酸序列的CDR-1、CDR-2和CDR-3。
264.根据权利要求261-263中任一项所述的组合物,其中:
所述Vα区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:111、113、115、121、123、125、297或299中任一个所示的Vα区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列;和/或
所述Vβ区包含互补决定区1(CDR-1)、CDR-2和CDR-3,其分别包含SEQ ID NO:112、114、116、122、124、126、298或300中任一个所示的Vβ区氨基酸序列内所含的CDR-1、CDR-2和CDR-3氨基酸序列。
265.根据权利要求261-264中任一项所述的组合物:所述Vα和Vβ区分别包含SEQ IDNO:111和112的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:113和114的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:115和116的氨基酸序列;所述Vα和Vβ区分别包含SEQ IDNO:121和122的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:123和124的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:125和126的氨基酸序列;所述Vα和Vβ区分别包含SEQ IDNO:297和298的氨基酸序列;所述Vα和Vβ区分别包含SEQ ID NO:299和300的氨基酸序列。
266.根据权利要求261-265中任一项所述的组合物,其中所述TCR或其抗原结合片段结合至或识别在MHC分子的背景下的人乳头瘤病毒(HPV)16 E6的肽表位,所述肽表位是或包含E6(29-38)TIHDIILECV(SEQ ID NO:233)。
267.根据权利要求255-266中任一项所述的组合物,其中所述α链还包含α恒定(Cα)区和/或所述β链还包含β恒定(Cβ)区。
268.根据权利要求252-267中任一项所述的组合物,其中所述组合物中至少或大于90%、95%、96%、97%或98%的所述细胞含有内源TRAC基因和/或TRBC基因的遗传破坏和/或不表达或不表达可检测水平的内源TRAC或TRBC基因的基因产物。
269.根据权利要求252-268中任一项所述的组合物,其中所述组合物中至少或大于70%、75%、80%、85%、90%、95%、96%、97%或98%的所述细胞(i)表达所述工程化或重组TCR或其抗原结合片段并且(ii)含有内源TRAC基因和/或TRBC基因的遗传破坏和/或不表达或不表达可检测水平的内源TRAC或TRBC基因的基因产物。
270.根据权利要求254-259中任一项所述的组合物,其中所述TRBC基因是T细胞受体β恒定区1(TRBC1)或T细胞受体β恒定区2(TRBC2)基因之一或两者。
271.根据权利要求254-260中任一项所述的组合物,其中所述基因产物是由所述TRAC或TRBC基因编码的mRNA或蛋白质。
272.根据权利要求252-271中任一项所述的组合物,其中所述工程化细胞包含CD4+和/或CD8+T细胞。
273.根据权利要求252-272中任一项所述的组合物,其中所述工程化细胞包含CD4+和CD8+T细胞。
274.一种组合物,其包含根据权利要求215所述的工程化CD8+细胞和根据权利要求216所述的工程化CD4+细胞。
275.根据权利要求252-274中任一项所述的组合物,其中所述TCR或其抗原结合片段至少部分地CD8非依赖性地结合至或识别在MHC分子的背景下的HPV 16的肽表位。
276.根据权利要求272-275中任一项所述的组合物,其中将所述CD8+细胞和CD4+细胞用相同的TCR或其抗原结合片段工程化和/或将所述CD8+细胞和CD4+细胞各自用结合至或识别在MHC分子的背景下的HPV 16的相同肽表位的TCR或其抗原结合片段工程化。
277.根据权利要求254-276中任一项所述的组合物,其中:
所述遗传破坏包含在所述TRAC或TRBC基因的区域中的突变或缺失,所述区域在所述基因的编码区、任选地早期编码区内,在所述基因的外显子1内,在所述基因的起始密码子的500、400、300、200、100或50个碱基对内的编码区中,在与具有选自SEQ ID NO:1053和1259-1315中任一个的序列的gRNA靶向结构域的靶向位点互补的靶位点序列内,和/或与具有选自SEQ ID NO:1053和1259-1315的序列的靶向结构域特异性杂交,和/或在与具有选自SEQID NO:1048和1229-1258中任一个的序列的gRNA靶向结构域的靶向位点互补的靶位点序列内,和/或与具有选自SEQ ID NO:1048和1229-1258的序列的靶向结构域特异性杂交。
278.根据权利要求274-277所述的组合物,其中至少一个所述工程化细胞是根据权利要求139-216中任一项所述的细胞。
279.根据权利要求252-278中任一项所述的组合物,其中所述遗传破坏是通过一种或多种药剂实现的,所述一种或多种药剂包含(a)具有与TRAC基因和/或TRBC基因的靶结构域互补的靶向结构域的至少一种gRNA或(b)编码所述至少一种gRNA的至少一种核酸。
280.根据权利要求279所述的组合物,其中将所述一种或多种药剂作为包含所述gRNA和Cas9蛋白的核糖核蛋白(RNP)复合物引入。
281.根据权利要求280所述的组合物,其中经由电穿孔、粒子枪、磷酸钙转染、细胞压缩或挤压来引入所述RNP。
282.根据权利要求280或权利要求281所述的组合物,其中经由电穿孔来引入所述RNP。
283.根据权利要求279-282中任一项所述的组合物,其中将所述一种或多种药剂作为编码所述gRNA和/或Cas9蛋白的一种或多种多核苷酸引入。
284.根据权利要求279-283中任一项所述的组合物,其中所述一种或多种药剂包含Cas9分子和具有与TRAC基因和/或TRBC基因的靶结构域互补的靶向结构域的所述至少一种gRNA的至少一种复合物。
285.根据权利要求279-284中任一项所述的组合物,其中所述一种或多种药剂包含Cas9分子和具有靶向结构域的gRNA的至少一种复合物,所述靶向结构域是以下之一或两者:(1)与TRAC基因的靶结构域互补,所述靶向结构域包含选自SEQ ID NO:1048和1229-1258中任一个的序列;和(2)与TRBC基因、任选地TRBC1和TRBC2基因之一或两者的靶结构域互补,所述靶向结构域包含选自SEQ ID NO:1053和1259-1315中任一个的序列。
286.根据权利要求279-285中任一项所述的组合物,其中所述靶向结构域包含与TRAC基因的靶结构域互补的序列,并且所述靶向结构域包含序列GAGAAUCAAAAUCGGUGAAU(SEQID NO:1048)。
287.根据权利要求279-286中任一项所述的组合物,其中所述靶向结构域包含与TRBC基因的靶结构域互补的序列,并且所述靶向结构域包含序列GGCCUCGGCGCUGACGAUCU(SEQID NO:1053)。
288.根据权利要求279-287中任一项所述的组合物,其中所述指导RNA还包含第一互补结构域、与所述第一互补结构域互补的第二互补结构域、近端结构域和任选地尾结构域。
289.根据权利要求288所述的组合物,其中所述第一互补结构域和第二互补结构域通过连接结构域连接。
290.根据权利要求289中任一项所述的组合物,其中所述指导RNA包含3'聚A尾和5'抗反向帽类似物(ARCA)帽。
291.根据权利要求279-290中任一项所述的组合物,其中所述Cas9分子是酶促活性Cas9。
292.根据权利要求279-291中任一项所述的组合物,其中所述Cas9分子是金黄色葡萄球菌Cas9分子。
293.根据权利要求279-291中任一项所述的组合物,其中所述Cas9分子是化脓链球菌Cas9。
294.根据权利要求252-293中任一项所述的组合物,其还包含药学上可接受的赋形剂。
295.一种治疗方法,其包括将根据权利要求139-216中任一项所述的工程化细胞给予患有与HPV相关的疾病或障碍的受试者。
296.一种治疗方法,其包括将根据权利要求252-294中任一项所述的组合物给予患有与HPV相关的疾病或障碍的受试者。
297.根据权利要求295或权利要求296所述的方法,其中所述疾病或障碍与HPV16相关。
298.根据权利要求295-297中任一项所述的方法,其中所述疾病或障碍是癌症。
299.根据权利要求295-298中任一项所述的方法,其中所述受试者是人。
300.根据权利要求252-294中任一项所述的组合物,用于治疗与HPV相关的疾病或障碍。
301.根据权利要求252-294中任一项所述的组合物用于制造治疗与HPV相关的疾病或障碍的药物的用途。
302.根据权利要求300所述的组合物或根据权利要求301所述的用途,其中所述疾病或障碍与HPV16相关。
303.根据权利要求300-302中任一项所述的组合物或用途,其中所述疾病或障碍是癌症。
304.根据权利要求300-303中任一项所述的组合物或用途,其中所述受试者是人。
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201762567750P | 2017-10-03 | 2017-10-03 | |
| US62/567,750 | 2017-10-03 | ||
| US201762597411P | 2017-12-11 | 2017-12-11 | |
| US62/597,411 | 2017-12-11 | ||
| US201862653529P | 2018-04-05 | 2018-04-05 | |
| US62/653,529 | 2018-04-05 | ||
| PCT/US2018/053650 WO2019070541A1 (en) | 2017-10-03 | 2018-09-28 | HPV-SPECIFIC BINDING MOLECULES |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN111954679A true CN111954679A (zh) | 2020-11-17 |
Family
ID=63963486
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201880076631.8A Pending CN111954679A (zh) | 2017-10-03 | 2018-09-28 | Hpv特异性结合分子 |
Country Status (13)
| Country | Link |
|---|---|
| US (1) | US11952408B2 (zh) |
| EP (2) | EP3692063A1 (zh) |
| JP (2) | JP2020537515A (zh) |
| KR (1) | KR20200104284A (zh) |
| CN (1) | CN111954679A (zh) |
| AU (1) | AU2018345539A1 (zh) |
| BR (1) | BR112020006643A2 (zh) |
| CA (1) | CA3080546A1 (zh) |
| IL (1) | IL273631A (zh) |
| MA (1) | MA50613A (zh) |
| MX (1) | MX2020003536A (zh) |
| SG (1) | SG11202002728VA (zh) |
| WO (1) | WO2019070541A1 (zh) |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113321726A (zh) * | 2020-02-28 | 2021-08-31 | 香雪生命科学技术(广东)有限公司 | 一种识别hpv的t细胞受体 |
| CN113789304A (zh) * | 2021-10-14 | 2021-12-14 | 深圳大学总医院 | 高亲和力tcr及其应用 |
| WO2022111475A1 (zh) * | 2020-11-26 | 2022-06-02 | 香雪生命科学技术(广东)有限公司 | 一种识别hpv抗原的tcr |
| WO2023005859A1 (zh) * | 2021-07-27 | 2023-02-02 | 香雪生命科学技术(广东)有限公司 | 针对抗原ssx2的高亲和力t细胞受体 |
| WO2023036169A1 (en) * | 2021-09-07 | 2023-03-16 | Corregene Biotechnology Co., Ltd. | Antigen binding proteins and uses thereof |
| WO2023040946A1 (zh) * | 2021-09-17 | 2023-03-23 | 香雪生命科学技术(广东)有限公司 | 一种识别ssx2的高亲和力tcr |
| WO2023050063A1 (zh) * | 2021-09-28 | 2023-04-06 | 溧阳瑅赛生物医药有限公司 | 一种识别hla-a*02:01/e629-38的tcr及其应用 |
| CN116589557A (zh) * | 2023-03-15 | 2023-08-15 | 北京大学人民医院 | 一种肿瘤新生抗原特异性tcr及其应用 |
| WO2023179768A1 (zh) * | 2022-03-24 | 2023-09-28 | 香雪生命科学技术(广东)有限公司 | 一种识别mage-a4抗原的高亲和力tcr及其序列和应用 |
Families Citing this family (31)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10704021B2 (en) | 2012-03-15 | 2020-07-07 | Flodesign Sonics, Inc. | Acoustic perfusion devices |
| US9725710B2 (en) | 2014-01-08 | 2017-08-08 | Flodesign Sonics, Inc. | Acoustophoresis device with dual acoustophoretic chamber |
| US11377651B2 (en) | 2016-10-19 | 2022-07-05 | Flodesign Sonics, Inc. | Cell therapy processes utilizing acoustophoresis |
| US11708572B2 (en) | 2015-04-29 | 2023-07-25 | Flodesign Sonics, Inc. | Acoustic cell separation techniques and processes |
| MX2019003768A (es) | 2016-10-03 | 2019-06-24 | Juno Therapeutics Inc | Moleculas de enlace especificas de hpv. |
| AU2017379900A1 (en) | 2016-12-22 | 2019-06-13 | Cue Biopharma, Inc. | T-cell modulatory multimeric polypeptides and methods of use thereof |
| EP3565829A4 (en) | 2017-01-09 | 2021-01-27 | Cue Biopharma, Inc. | MULTIMER POLYPEPTIDES T-LYMPHOCYTE MODULATORS AND THEIR METHODS OF USE |
| EP3596118B1 (en) | 2017-03-15 | 2024-08-21 | Cue Biopharma, Inc. | Combination of multimeric fusion polypeptides and immune checkpoint inhibitor for treating hpv-associated cancer |
| WO2019118921A1 (en) | 2017-12-14 | 2019-06-20 | Flodesign Sonics, Inc. | Acoustic transducer drive and controller |
| BR112020020245A2 (pt) * | 2018-04-05 | 2021-04-06 | Editas Medicine, Inc. | Métodos de produzir células expressando um receptor recombinante e composições relacionadas |
| KR20210019993A (ko) | 2018-04-05 | 2021-02-23 | 주노 쎄러퓨티크스 인코퍼레이티드 | Τ 세포 수용체 및 이를 발현하는 조작된 세포 |
| KR20220029584A (ko) * | 2019-05-27 | 2022-03-08 | 이매틱스 유에스 인코포레이티드 | 바이러스 벡터 및 입양 세포 요법에서 그 사용 |
| CN113072635B (zh) * | 2020-01-06 | 2023-08-25 | 香雪生命科学技术(广东)有限公司 | 一种识别hpv抗原的t细胞受体及其编码序列 |
| US20230348558A1 (en) * | 2020-03-23 | 2023-11-02 | The Council Of The Queensland Institute Of Medical Research | Compositions and methods for targeting hpv-infected cells |
| EP4126924A4 (en) * | 2020-03-27 | 2024-04-24 | 2seventy bio, Inc. | T CELL RECEPTORS |
| CN115776991A (zh) * | 2020-05-07 | 2023-03-10 | 华夏英泰(北京)生物技术有限公司 | 改进的t细胞受体-共刺激分子嵌合物 |
| IL296209A (en) | 2020-05-12 | 2022-11-01 | Cue Biopharma Inc | Multimeric t-cell modulatory polypeptides and methods of using them |
| CN113801217A (zh) * | 2020-06-17 | 2021-12-17 | 香雪生命科学技术(广东)有限公司 | 一种识别hpv抗原的高亲和力t细胞受体 |
| JP2023541366A (ja) | 2020-09-09 | 2023-10-02 | キュー バイオファーマ, インコーポレイテッド | 1型真性糖尿病(t1d)を治療するためのmhcクラスii t細胞調節多量体ポリペプチド及びその使用方法 |
| WO2022060904A1 (en) | 2020-09-16 | 2022-03-24 | Obsidian Therapeutics, Inc. | Compositions and methods for expression of t-cell receptors with small molecule-regulated cd40l in t cells |
| WO2022093694A1 (en) * | 2020-10-26 | 2022-05-05 | A2 Biotherapeutics, Inc. | Polypeptides targeting hpv peptide-mhc complexes and methods of use thereof |
| US20240009240A1 (en) * | 2020-11-05 | 2024-01-11 | Board Of Regents, The University Of Texas System | Engineered t cell receptors targeting egfr antigens and methods of use |
| EP4240833A1 (en) * | 2020-11-06 | 2023-09-13 | BioVentures, LLC | T cells and bifunctional protein against human papillomavirus |
| JP2024509853A (ja) | 2021-03-03 | 2024-03-05 | ジュノー セラピューティクス インコーポレイテッド | T細胞療法およびdgk阻害剤の組合せ |
| AU2022270361A1 (en) | 2021-05-05 | 2023-11-16 | Immatics Biotechnologies Gmbh | Antigen binding proteins specifically binding prame |
| CN113912701B (zh) * | 2021-10-14 | 2024-07-19 | 深圳大学总医院 | Tcr及其在诊断/治疗中的应用 |
| WO2023081900A1 (en) | 2021-11-08 | 2023-05-11 | Juno Therapeutics, Inc. | Engineered t cells expressing a recombinant t cell receptor (tcr) and related systems and methods |
| US20230272049A1 (en) * | 2021-11-10 | 2023-08-31 | Tscan Therapeutics, Inc. | Binding proteins recognizing hpv16 e7 antigen and uses thereof |
| WO2023196884A1 (en) * | 2022-04-06 | 2023-10-12 | Juno Therapeutics, Inc. | Detection assay for human papillomavirus (hpv) type 16 (hpv-16) |
| WO2023212551A1 (en) * | 2022-04-28 | 2023-11-02 | Cue Biopharma, Inc. | Modified cytotoxic t cells and methods of use thereof |
| WO2024054944A1 (en) | 2022-09-08 | 2024-03-14 | Juno Therapeutics, Inc. | Combination of a t cell therapy and continuous or intermittent dgk inhibitor dosing |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2015184228A1 (en) * | 2014-05-29 | 2015-12-03 | The United States Of America, As Represented By The Secretary, Department Of Health And Human Services | Anti-human papillomavirus 16 e7 t cell receptors |
| CN105452288A (zh) * | 2013-07-15 | 2016-03-30 | 美国卫生和人力服务部 | 抗人乳头瘤病毒16 e6 t细胞受体 |
| WO2016069282A1 (en) * | 2014-10-31 | 2016-05-06 | The Trustees Of The University Of Pennsylvania | Altering gene expression in modified t cells and uses thereof |
| WO2016146618A1 (en) * | 2015-03-16 | 2016-09-22 | Max-Delbrück-Centrum für Molekulare Medizin | Method of detecting new immunogenic t cell epitopes and isolating new antigen-specific t cell receptors by means of an mhc cell library |
| WO2018067618A1 (en) * | 2016-10-03 | 2018-04-12 | Juno Therapeutics, Inc. | Hpv-specific binding molecules |
Family Cites Families (177)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4235871A (en) | 1978-02-24 | 1980-11-25 | Papahadjopoulos Demetrios P | Method of encapsulating biologically active materials in lipid vesicles |
| US4452773A (en) | 1982-04-05 | 1984-06-05 | Canadian Patents And Development Limited | Magnetic iron-dextran microspheres |
| US4501728A (en) | 1983-01-06 | 1985-02-26 | Technology Unlimited, Inc. | Masking of liposomes from RES recognition |
| US5019369A (en) | 1984-10-22 | 1991-05-28 | Vestar, Inc. | Method of targeting tumors in humans |
| US4690915A (en) | 1985-08-08 | 1987-09-01 | The United States Of America As Represented By The Department Of Health And Human Services | Adoptive immunotherapy as a treatment modality in humans |
| US4795698A (en) | 1985-10-04 | 1989-01-03 | Immunicon Corporation | Magnetic-polymer particles |
| US4777239A (en) | 1986-07-10 | 1988-10-11 | The Board Of Trustees Of The Leland Stanford Junior University | Diagnostic peptides of human papilloma virus |
| IN165717B (zh) | 1986-08-07 | 1989-12-23 | Battelle Memorial Institute | |
| US4837028A (en) | 1986-12-24 | 1989-06-06 | Liposome Technology, Inc. | Liposomes with enhanced circulation time |
| US5219740A (en) | 1987-02-13 | 1993-06-15 | Fred Hutchinson Cancer Research Center | Retroviral gene transfer into diploid fibroblasts for gene therapy |
| WO1990007380A2 (en) | 1988-12-28 | 1990-07-12 | Stefan Miltenyi | Methods and materials for high gradient magnetic separation of biological materials |
| US5283173A (en) | 1990-01-24 | 1994-02-01 | The Research Foundation Of State University Of New York | System to detect protein-protein interactions |
| US5200084A (en) | 1990-09-26 | 1993-04-06 | Immunicon Corporation | Apparatus and methods for magnetic separation |
| EP0557459B1 (en) | 1990-11-13 | 1997-10-22 | Immunex Corporation | Bifunctional selectable fusion genes |
| DE4228458A1 (de) | 1992-08-27 | 1994-06-01 | Beiersdorf Ag | Multicistronische Expressionseinheiten und deren Verwendung |
| EP0804590A1 (en) | 1993-05-21 | 1997-11-05 | Targeted Genetics Corporation | Bifunctional selectable fusion genes based on the cytosine deaminase (cd) gene |
| US6140466A (en) | 1994-01-18 | 2000-10-31 | The Scripps Research Institute | Zinc finger protein derivatives and methods therefor |
| DE69534629D1 (de) | 1994-01-18 | 2005-12-29 | Scripps Research Inst | Derivate von zinkfingerproteinen und methoden |
| GB9824544D0 (en) | 1998-11-09 | 1999-01-06 | Medical Res Council | Screening system |
| USRE39229E1 (en) | 1994-08-20 | 2006-08-08 | Gendaq Limited | Binding proteins for recognition of DNA |
| US5827642A (en) | 1994-08-31 | 1998-10-27 | Fred Hutchinson Cancer Research Center | Rapid expansion method ("REM") for in vitro propagation of T lymphocytes |
| WO1996013593A2 (en) | 1994-10-26 | 1996-05-09 | Procept, Inc. | Soluble single chain t cell receptors |
| WO1996018105A1 (en) | 1994-12-06 | 1996-06-13 | The President And Fellows Of Harvard College | Single chain t-cell receptor |
| US5789538A (en) | 1995-02-03 | 1998-08-04 | Massachusetts Institute Of Technology | Zinc finger proteins with high affinity new DNA binding specificities |
| GB9603256D0 (en) | 1996-02-16 | 1996-04-17 | Wellcome Found | Antibodies |
| DE19608753C1 (de) | 1996-03-06 | 1997-06-26 | Medigene Gmbh | Transduktionssystem und seine Verwendung |
| US6451995B1 (en) | 1996-03-20 | 2002-09-17 | Sloan-Kettering Institute For Cancer Research | Single chain FV polynucleotide or peptide constructs of anti-ganglioside GD2 antibodies, cells expressing same and related methods |
| US5925523A (en) | 1996-08-23 | 1999-07-20 | President & Fellows Of Harvard College | Intraction trap assay, reagents and uses thereof |
| GB9710809D0 (en) | 1997-05-23 | 1997-07-23 | Medical Res Council | Nucleic acid binding proteins |
| GB9710807D0 (en) | 1997-05-23 | 1997-07-23 | Medical Res Council | Nucleic acid binding proteins |
| AU757627B2 (en) | 1997-06-24 | 2003-02-27 | Genentech Inc. | Methods and compositions for galactosylated glycoproteins |
| ATE533784T1 (de) | 1997-10-02 | 2011-12-15 | Altor Bioscience Corp | Lösliche, einzelkettige proteine des t- zellrezeptors |
| US6183746B1 (en) | 1997-10-09 | 2001-02-06 | Zycos Inc. | Immunogenic peptides from the HPV E7 protein |
| ATE419009T1 (de) | 1997-10-31 | 2009-01-15 | Genentech Inc | Methoden und zusammensetzungen bestehend aus glykoprotein-glykoformen |
| EP1038029A2 (en) | 1997-12-12 | 2000-09-27 | Digene Corporation | Universal collection medium |
| DK2180007T4 (da) | 1998-04-20 | 2017-11-27 | Roche Glycart Ag | Glycosyleringsteknik for antistoffer til forbedring af antistofafhængig cellecytotoxicitet |
| CA2328144A1 (en) | 1998-05-19 | 1999-11-25 | Avidex Limited | Multivalent t cell receptor complexes |
| EP1109921A4 (en) | 1998-09-04 | 2002-08-28 | Sloan Kettering Inst Cancer | FOR PROSTATE-SPECIFIC MEMBRANE-ANTI-SPECIFIC FUSION RECEPTORS AND THEIR USE |
| US6140081A (en) | 1998-10-16 | 2000-10-31 | The Scripps Research Institute | Zinc finger binding domains for GNN |
| AU2472400A (en) | 1998-10-20 | 2000-05-08 | City Of Hope | CD20-specific redirected T cells and their use in cellular immunotherapy of CD20+ malignancies |
| US6453242B1 (en) | 1999-01-12 | 2002-09-17 | Sangamo Biosciences, Inc. | Selection of sites for targeting by zinc finger proteins and methods of designing zinc finger proteins to bind to preselected sites |
| US6534261B1 (en) | 1999-01-12 | 2003-03-18 | Sangamo Biosciences, Inc. | Regulation of endogenous gene expression in cells using zinc finger proteins |
| EP2275541B1 (en) | 1999-04-09 | 2016-03-23 | Kyowa Hakko Kirin Co., Ltd. | Method for controlling the activity of immunologically functional molecule |
| EP1178785B1 (en) | 1999-05-06 | 2008-12-24 | Wake Forest University | Compositions and methods for identifying antigens which elicit an immune response |
| US7504256B1 (en) | 1999-10-19 | 2009-03-17 | Kyowa Hakko Kogyo Co., Ltd. | Process for producing polypeptide |
| US20020061512A1 (en) | 2000-02-18 | 2002-05-23 | Kim Jin-Soo | Zinc finger domains and methods of identifying same |
| WO2001088197A2 (en) | 2000-05-16 | 2001-11-22 | Massachusetts Institute Of Technology | Methods and compositions for interaction trap assays |
| US20020131960A1 (en) | 2000-06-02 | 2002-09-19 | Michel Sadelain | Artificial antigen presenting cells and methods of use thereof |
| JP2002060786A (ja) | 2000-08-23 | 2002-02-26 | Kao Corp | 硬質表面用殺菌防汚剤 |
| US7064191B2 (en) | 2000-10-06 | 2006-06-20 | Kyowa Hakko Kogyo Co., Ltd. | Process for purifying antibody |
| EA013224B1 (ru) | 2000-10-06 | 2010-04-30 | Киова Хакко Кирин Ко., Лтд. | Клетки, продуцирующие композиции антител |
| US6946292B2 (en) | 2000-10-06 | 2005-09-20 | Kyowa Hakko Kogyo Co., Ltd. | Cells producing antibody compositions with increased antibody dependent cytotoxic activity |
| AU2001297703B2 (en) | 2000-11-07 | 2006-10-19 | City Of Hope | CD19-specific redirected immune cells |
| EP1425039A4 (en) | 2001-03-23 | 2005-02-02 | Us Gov Health & Human Serv | PEPTIDES THAT GIVE AN IMMUNE REACTION WITH THE HUMAN PAPILLOMA VIRUS |
| GB0108491D0 (en) | 2001-04-04 | 2001-05-23 | Gendaq Ltd | Engineering zinc fingers |
| US7070995B2 (en) | 2001-04-11 | 2006-07-04 | City Of Hope | CE7-specific redirected immune cells |
| US20090257994A1 (en) | 2001-04-30 | 2009-10-15 | City Of Hope | Chimeric immunoreceptor useful in treating human cancers |
| NZ592087A (en) | 2001-08-03 | 2012-11-30 | Roche Glycart Ag | Antibody glycosylation variants having increased antibody-dependent cellular cytotoxicity |
| JP2005500061A (ja) | 2001-08-20 | 2005-01-06 | ザ スクリップス リサーチ インスティテュート | Cnnについての亜鉛フィンガー結合ドメイン |
| CA2457652C (en) | 2001-08-31 | 2012-08-07 | Avidex Limited | Soluble t cell receptor |
| AU2002337935B2 (en) | 2001-10-25 | 2008-05-01 | Genentech, Inc. | Glycoprotein compositions |
| US7939059B2 (en) | 2001-12-10 | 2011-05-10 | California Institute Of Technology | Method for the generation of antigen-specific lymphocytes |
| US20040093621A1 (en) | 2001-12-25 | 2004-05-13 | Kyowa Hakko Kogyo Co., Ltd | Antibody composition which specifically binds to CD20 |
| US20030170238A1 (en) | 2002-03-07 | 2003-09-11 | Gruenberg Micheal L. | Re-activated T-cells for adoptive immunotherapy |
| EP1498490A4 (en) | 2002-04-09 | 2006-11-29 | Kyowa Hakko Kogyo Kk | PROCESS FOR PREPARING ANTIBODY COMPOSITION |
| EP1498491A4 (en) | 2002-04-09 | 2006-12-13 | Kyowa Hakko Kogyo Kk | METHOD FOR INCREASING THE ACTIVITY OF AN ANTIBODY COMPOSITION FOR BINDING TO THE FC GAMMA RECEPTOR IIIA |
| JP4832719B2 (ja) | 2002-04-09 | 2011-12-07 | 協和発酵キリン株式会社 | FcγRIIIa多型患者に適応する抗体組成物含有医薬 |
| WO2003085107A1 (fr) | 2002-04-09 | 2003-10-16 | Kyowa Hakko Kogyo Co., Ltd. | Cellules à génome modifié |
| AU2003236017B2 (en) | 2002-04-09 | 2009-03-26 | Kyowa Kirin Co., Ltd. | Drug containing antibody composition |
| ES2362419T3 (es) | 2002-04-09 | 2011-07-05 | Kyowa Hakko Kirin Co., Ltd. | Células con depresión o deleción de la actividad de la proteína que participa en el transporte de gdp-fucosa. |
| US7446190B2 (en) | 2002-05-28 | 2008-11-04 | Sloan-Kettering Institute For Cancer Research | Nucleic acids encoding chimeric T cell receptors |
| JP4436319B2 (ja) | 2002-10-09 | 2010-03-24 | メディジーン リミテッド | 単鎖組換えt細胞レセプター |
| PT1572744E (pt) | 2002-12-16 | 2010-09-07 | Genentech Inc | Variantes de imunoglobulina e utilizações destas |
| US20050129671A1 (en) | 2003-03-11 | 2005-06-16 | City Of Hope | Mammalian antigen-presenting T cells and bi-specific T cells |
| EP1688439A4 (en) | 2003-10-08 | 2007-12-19 | Kyowa Hakko Kogyo Kk | HYBRID PROTEIN COMPOSITION |
| EP1705251A4 (en) | 2003-10-09 | 2009-10-28 | Kyowa Hakko Kirin Co Ltd | PROCESS FOR PRODUCING ANTIBODY COMPOSITION BY RNA INHIBITION OF FUNCTION OF $ G (A) 1,6-FUCOSYLTRANSFERASE |
| US7435596B2 (en) | 2004-11-04 | 2008-10-14 | St. Jude Children's Research Hospital, Inc. | Modified cell line and method for expansion of NK cell |
| SG10202008722QA (en) | 2003-11-05 | 2020-10-29 | Roche Glycart Ag | Cd20 antibodies with increased fc receptor binding affinity and effector function |
| WO2005053742A1 (ja) | 2003-12-04 | 2005-06-16 | Kyowa Hakko Kogyo Co., Ltd. | 抗体組成物を含有する医薬 |
| WO2005063286A1 (en) | 2003-12-23 | 2005-07-14 | Arbor Vita Corporation | Antibodies for oncogenic strains of hpv and methods of their use |
| WO2006000830A2 (en) | 2004-06-29 | 2006-01-05 | Avidex Ltd | Cells expressing a modified t cell receptor |
| CA2580141C (en) | 2004-09-23 | 2013-12-10 | Genentech, Inc. | Cysteine engineered antibodies and conjugates |
| CA2582963A1 (en) | 2004-10-01 | 2006-04-13 | Avidex Ltd | T-cell receptors containing a non-native disulfide interchain bond linked to therapeutic agents |
| JP2008044848A (ja) | 2004-11-30 | 2008-02-28 | Univ Kurume | Hla−a24拘束性腫瘍抗原ペプチド |
| US8252893B2 (en) | 2005-01-31 | 2012-08-28 | Board Of Trustees Of The University Of Arkansas | CD8 T cell epitopes in HPV 16 E6 and E7 proteins and uses thereof |
| US8968995B2 (en) | 2008-11-12 | 2015-03-03 | Oncohealth Corp. | Detection, screening, and diagnosis of HPV-associated cancers |
| US8278056B2 (en) | 2008-06-13 | 2012-10-02 | Oncohealth Corp. | Detection of early stages and late stages HPV infection |
| CA2682527C (en) | 2007-03-30 | 2017-07-11 | Memorial Sloan-Kettering Cancer Center | Constitutive expression of costimulatory ligands on adoptively transferred t lymphocytes |
| ES2411059T3 (es) | 2007-05-31 | 2013-07-04 | Academisch Ziekenhuis Leiden H.O.D.N. Lumc | Epítopos de HPV objetivos de células T que infiltran malignidades cervicales para su uso en vacunas |
| US20090117140A1 (en) | 2007-09-26 | 2009-05-07 | Mayumi Nakagawa | Human papilloma virus dominant CD4 T cell epitopes and uses thereof |
| EP3338895B1 (en) | 2007-12-07 | 2022-08-10 | Miltenyi Biotec B.V. & Co. KG | Sample processing systems and methods |
| US8479118B2 (en) | 2007-12-10 | 2013-07-02 | Microsoft Corporation | Switching search providers within a browser search box |
| KR20090103571A (ko) | 2008-03-28 | 2009-10-01 | 바이오코아 주식회사 | 면역성 펩타이드 및 그 펩타이드를 포함하는 hpv 관련질환 예방 또는 치료용 조성물 |
| US20120164718A1 (en) | 2008-05-06 | 2012-06-28 | Innovative Micro Technology | Removable/disposable apparatus for MEMS particle sorting device |
| JP5173594B2 (ja) | 2008-05-27 | 2013-04-03 | キヤノン株式会社 | 管理装置、画像形成装置及びそれらの処理方法 |
| KR20090125628A (ko) | 2008-06-02 | 2009-12-07 | 바이오코아 주식회사 | 면역성 펩타이드 및 그 펩타이드를 포함하는 hpv 관련질환 예방 또는 치료용 조성물 |
| KR20090125629A (ko) | 2008-06-02 | 2009-12-07 | 바이오코아 주식회사 | 면역성 펩타이드 및 그 펩타이드를 포함하는 hpv 관련질환 예방 또는 치료용 조성물 |
| KR20160015400A (ko) | 2008-08-22 | 2016-02-12 | 상가모 바이오사이언스 인코포레이티드 | 표적화된 단일가닥 분할 및 표적화된 통합을 위한 방법 및 조성물 |
| US20120141502A1 (en) | 2009-04-20 | 2012-06-07 | Eric Dixon | Antibodies specific to e6 proteins of hpv and use thereof |
| WO2011044186A1 (en) | 2009-10-06 | 2011-04-14 | The Board Of Trustees Of The University Of Illinois | Human single-chain t cell receptors |
| US9273283B2 (en) | 2009-10-29 | 2016-03-01 | The Trustees Of Dartmouth College | Method of producing T cell receptor-deficient T cells expressing a chimeric receptor |
| SI2496698T1 (sl) | 2009-11-03 | 2019-07-31 | City Of Hope | Skrajšan epiderimalni receptor faktorja rasti (EGFRt) za selekcijo transduciranih T celic |
| US8956828B2 (en) | 2009-11-10 | 2015-02-17 | Sangamo Biosciences, Inc. | Targeted disruption of T cell receptor genes using engineered zinc finger protein nucleases |
| JP2013518602A (ja) | 2010-02-09 | 2013-05-23 | サンガモ バイオサイエンシーズ, インコーポレイテッド | 部分的に一本鎖のドナー分子による標的化ゲノム改変 |
| ES2712892T3 (es) | 2010-02-16 | 2019-05-16 | Oesterreichische Akademie Der Wss | Anticuerpos anti-E7 del HPV |
| US9228007B1 (en) | 2010-03-11 | 2016-01-05 | The Regents Of The University Of California | Recombinant human progenitor cells, engineered human thymocytes, and engineered human T cells |
| EP3156062A1 (en) | 2010-05-17 | 2017-04-19 | Sangamo BioSciences, Inc. | Novel dna-binding proteins and uses thereof |
| KR101415554B1 (ko) | 2010-09-13 | 2014-07-04 | 바이오코아 주식회사 | 면역성 펩타이드 및 그 펩타이드를 포함하는 hpv 관련 질환 예방 또는 치료용 조성물 |
| GB2497912B (en) | 2010-10-08 | 2014-06-04 | Harvard College | High-throughput single cell barcoding |
| EP2625295B1 (en) | 2010-10-08 | 2019-03-13 | President and Fellows of Harvard College | High-throughput immune sequencing |
| SG190997A1 (en) | 2010-12-09 | 2013-07-31 | Univ Pennsylvania | Use of chimeric antigen receptor-modified t cells to treat cancer |
| CN106074601A (zh) | 2011-03-23 | 2016-11-09 | 弗雷德哈钦森癌症研究中心 | 用于细胞免疫治疗的方法和组合物 |
| US8398282B2 (en) | 2011-05-12 | 2013-03-19 | Delphi Technologies, Inc. | Vehicle front lighting assembly and systems having a variable tint electrowetting element |
| CN107266584B (zh) | 2011-07-29 | 2022-05-13 | 宾夕法尼亚大学董事会 | 转换共刺激受体 |
| EP2567972A1 (en) | 2011-09-12 | 2013-03-13 | Adriacell S.p.A. | Antibodies against E7 protein of Human Papilloma Virus (HPV) |
| PL3424947T3 (pl) | 2011-10-28 | 2021-06-14 | Regeneron Pharmaceuticals, Inc. | Myszy z genetycznie zmodyfikowanym receptorem komórek t |
| US10208086B2 (en) | 2011-11-11 | 2019-02-19 | Fred Hutchinson Cancer Research Center | Cyclin A1-targeted T-cell immunotherapy for cancer |
| US10391126B2 (en) | 2011-11-18 | 2019-08-27 | Board Of Regents, The University Of Texas System | CAR+ T cells genetically modified to eliminate expression of T-cell receptor and/or HLA |
| JP6850528B2 (ja) | 2012-02-13 | 2021-03-31 | シアトル チルドレンズ ホスピタル ドゥーイング ビジネス アズ シアトル チルドレンズ リサーチ インスティテュート | 二重特異性キメラ抗原受容体およびその治療的使用 |
| WO2013126726A1 (en) | 2012-02-22 | 2013-08-29 | The Trustees Of The University Of Pennsylvania | Double transgenic t cells comprising a car and a tcr and their methods of use |
| US9751928B2 (en) | 2012-05-03 | 2017-09-05 | Fred Hutchinson Cancer Research Center | Enhanced affinity T cell receptors and methods for making the same |
| CN104471067B (zh) | 2012-05-07 | 2020-08-14 | 桑格摩生物治疗股份有限公司 | 用于核酸酶介导的转基因靶向整合的方法和组合物 |
| CN104394877B (zh) | 2012-05-08 | 2017-11-28 | 约翰·霍普金斯大学 | 用于输注短暂植入的同种异体淋巴细胞的选定群体来治疗癌症的方法和组合物 |
| EP2855666B1 (en) | 2012-05-25 | 2019-12-04 | Cellectis | Use of pre t alpha or functional variant thereof for expanding tcr alpha deficient t cells |
| RU2700765C2 (ru) | 2012-08-20 | 2019-09-19 | Фред Хатчинсон Кансэр Рисёч Сентер | Способ и композиции для клеточной иммунотерапии |
| WO2014055668A1 (en) | 2012-10-02 | 2014-04-10 | Memorial Sloan-Kettering Cancer Center | Compositions and methods for immunotherapy |
| WO2014097442A1 (ja) | 2012-12-20 | 2014-06-26 | 三菱電機株式会社 | 車載装置及びプログラム |
| GB201223172D0 (en) | 2012-12-21 | 2013-02-06 | Immunocore Ltd | Method |
| RS60759B1 (sr) | 2013-02-26 | 2020-10-30 | Memorial Sloan Kettering Cancer Center | Sastavi i postupci za imunoterapiju |
| WO2014153470A2 (en) | 2013-03-21 | 2014-09-25 | Sangamo Biosciences, Inc. | Targeted disruption of t cell receptor genes using engineered zinc finger protein nucleases |
| CN116083487A (zh) | 2013-05-15 | 2023-05-09 | 桑格摩生物治疗股份有限公司 | 用于治疗遗传病状的方法和组合物 |
| EP3004337B1 (en) | 2013-05-29 | 2017-08-02 | Cellectis | Methods for engineering t cells for immunotherapy by using rna-guided cas nuclease system |
| ES2773548T3 (es) | 2013-07-15 | 2020-07-13 | Us Health | Métodos de preparación de células T anti-antígeno de virus del papiloma humano |
| CN103342738B (zh) | 2013-07-24 | 2015-02-18 | 广州恒上医药技术有限公司 | 人乳头瘤病毒e6蛋白可诱发同源蛋白间交叉反应性抗体的精细表位肽 |
| JP5921042B2 (ja) | 2013-07-30 | 2016-05-24 | シャープ株式会社 | 光拡散部材の製造方法 |
| EP3030900A2 (en) | 2013-08-08 | 2016-06-15 | Institut Pasteur | Correlation of disease activity with clonal expansions of human papillomavirus 16-specific cd8+ t-cells in patients with severe erosive oral lichen planus |
| US9108442B2 (en) | 2013-08-20 | 2015-08-18 | Ricoh Company, Ltd. | Image forming apparatus |
| US20150098954A1 (en) | 2013-10-08 | 2015-04-09 | Elwha Llc | Compositions and Methods Related to CRISPR Targeting |
| BR112016009898A2 (pt) | 2013-10-31 | 2017-12-05 | Hutchinson Fred Cancer Res | células-tronco/progenitoras hematopoiéticas e efetoras não-t modificadas e usos das mesmas |
| WO2015136001A1 (en) | 2014-03-11 | 2015-09-17 | Cellectis | Method for generating t-cells compatible for allogenic transplantation |
| CA2943569C (en) | 2014-03-27 | 2021-02-23 | British Columbia Cancer Agency Branch | T-cell epitope identification |
| CA2945335A1 (en) | 2014-04-18 | 2015-10-22 | Editas Medicine, Inc. | Crispr-cas-related methods, compositions and components for cancer immunotherapy |
| JP6933898B2 (ja) | 2014-04-24 | 2021-09-08 | ボード オブ リージェンツ, ザ ユニバーシティ オブ テキサス システムBoard Of Regents, The University Of Texas System | 養子細胞治療製品を製造するための誘導多能性幹細胞の適用 |
| WO2016007175A1 (en) | 2014-07-11 | 2016-01-14 | Intel Corporation | Bendable and stretchable electronic devices and methods |
| MY181834A (en) | 2014-07-21 | 2021-01-08 | Novartis Ag | Treatment of cancer using humanized anti-bcma chimeric antigen receptor |
| JP2017522884A (ja) | 2014-07-29 | 2017-08-17 | ファイザー・インク | がん免疫療法のためのEGFRvIII特異的キメラ抗原受容体 |
| EP3177314B1 (en) | 2014-08-04 | 2020-10-07 | Fred Hutchinson Cancer Research Center | T cell immunotherapy specific for wt-1 |
| US10590483B2 (en) | 2014-09-15 | 2020-03-17 | Abvitro Llc | High-throughput nucleotide library sequencing |
| GB201417803D0 (en) | 2014-10-08 | 2014-11-19 | Adaptimmune Ltd | T cell receptors |
| CA2988397A1 (en) | 2015-05-08 | 2016-11-17 | Eureka Therapeutics, Inc. | Constructs targeting hpv16-e7 peptide/mhc complexes and uses thereof |
| US9790490B2 (en) | 2015-06-18 | 2017-10-17 | The Broad Institute Inc. | CRISPR enzymes and systems |
| EP3322297A4 (en) | 2015-07-13 | 2019-04-17 | Sangamo Therapeutics, Inc. | RELEASE METHOD AND COMPOSITIONS FOR NUCLEASE-DERIVED GENOMINE ENGINEERING |
| US11047011B2 (en) | 2015-09-29 | 2021-06-29 | iRepertoire, Inc. | Immunorepertoire normality assessment method and its use |
| IL287319B2 (en) | 2015-10-05 | 2023-02-01 | Prec Biosciences Inc | Genetically modified cells containing a modified human t cell receptor alpha constant region gene |
| EP3156067A1 (en) | 2015-10-16 | 2017-04-19 | Max-Delbrück-Centrum Für Molekulare Medizin | High avidity hpv t-cell receptors |
| WO2017070429A1 (en) | 2015-10-22 | 2017-04-27 | Regents Of The University Of Minnesota | Methods involving editing polynucleotides that encode t cell receptor |
| JP6777841B2 (ja) | 2015-10-23 | 2020-10-28 | 国立大学法人金沢大学 | 細胞傷害性t細胞の作製方法 |
| SG10202109655VA (en) | 2015-12-04 | 2021-10-28 | Novartis Ag | Compositions and methods for immunooncology |
| EP3389677B1 (en) | 2015-12-18 | 2024-06-26 | Sangamo Therapeutics, Inc. | Targeted disruption of the t cell receptor |
| GB201604494D0 (en) | 2016-03-16 | 2016-04-27 | Immatics Biotechnologies Gmbh | Transfected T-Cells and T-Cell receptors for use in immunotherapy against cancers |
| GB201604953D0 (en) | 2016-03-23 | 2016-05-04 | Immunocore Ltd | T cell receptors |
| ES2914648T3 (es) | 2016-04-08 | 2022-06-15 | Immunocore Ltd | Receptores de células T |
| CA3022611A1 (en) | 2016-05-06 | 2017-11-09 | Juno Therapeutics, Inc. | Genetically engineered cells and methods of making the same |
| MA45491A (fr) | 2016-06-27 | 2019-05-01 | Juno Therapeutics Inc | Épitopes à restriction cmh-e, molécules de liaison et procédés et utilisations associés |
| US20200182884A1 (en) | 2016-06-27 | 2020-06-11 | Juno Therapeutics, Inc. | Method of identifying peptide epitopes, molecules that bind such epitopes and related uses |
| US20200000937A1 (en) | 2016-08-03 | 2020-01-02 | Washington University | Gene editing of car-t cells for the treatment of t cell malignancies with chimeric antigen receptors |
| US9642906B2 (en) | 2016-09-16 | 2017-05-09 | Baylor College Of Medicine | Generation of HPV-specific T-cells |
| WO2018073393A2 (en) | 2016-10-19 | 2018-04-26 | Cellectis | Tal-effector nuclease (talen) -modified allogenic cells suitable for therapy |
| JP7314115B2 (ja) | 2017-03-31 | 2023-07-25 | セレクティス ソシエテ アノニム | ユニバーサル抗cd22キメラ抗原受容体操作免疫細胞 |
| AU2018266698A1 (en) | 2017-05-08 | 2019-11-28 | Precision Biosciences, Inc. | Nucleic acid molecules encoding an engineered antigen receptor and an inhibitory nucleic acid molecule and methods of use thereof |
| IL270415B2 (en) | 2017-05-12 | 2024-08-01 | Crispr Therapeutics Ag | Materials and methods for cell engineering and their uses in immuno-oncology |
| JP7401312B2 (ja) | 2017-06-28 | 2023-12-19 | リジェネロン・ファーマシューティカルズ・インコーポレイテッド | 抗ヒトパピローマウイルス(hpv)抗原結合性タンパク質およびその使用方法 |
| JP2020529834A (ja) | 2017-06-30 | 2020-10-15 | プレシジョン バイオサイエンシズ,インク. | T細胞受容体アルファ遺伝子の改変されたイントロンを含む遺伝子改変t細胞 |
| MX2020004185A (es) * | 2017-09-27 | 2021-01-08 | Univ Southern California | Nuevas plataformas para coestimulacion, nuevos diseños car y otras mejoras para terapia celular adoptiva. |
| KR20210019993A (ko) | 2018-04-05 | 2021-02-23 | 주노 쎄러퓨티크스 인코퍼레이티드 | Τ 세포 수용체 및 이를 발현하는 조작된 세포 |
| BR112020020245A2 (pt) | 2018-04-05 | 2021-04-06 | Editas Medicine, Inc. | Métodos de produzir células expressando um receptor recombinante e composições relacionadas |
| CA3095084A1 (en) | 2018-04-05 | 2019-10-10 | Juno Therapeutics, Inc. | T cells expressing a recombinant receptor, related polynucleotides and methods |
-
2018
- 2018-09-28 JP JP2020519033A patent/JP2020537515A/ja active Pending
- 2018-09-28 US US16/652,379 patent/US11952408B2/en active Active
- 2018-09-28 SG SG11202002728VA patent/SG11202002728VA/en unknown
- 2018-09-28 CN CN201880076631.8A patent/CN111954679A/zh active Pending
- 2018-09-28 WO PCT/US2018/053650 patent/WO2019070541A1/en active Application Filing
- 2018-09-28 MX MX2020003536A patent/MX2020003536A/es unknown
- 2018-09-28 EP EP18792692.8A patent/EP3692063A1/en active Pending
- 2018-09-28 CA CA3080546A patent/CA3080546A1/en active Pending
- 2018-09-28 EP EP22213635.0A patent/EP4215543A3/en not_active Withdrawn
- 2018-09-28 KR KR1020207012701A patent/KR20200104284A/ko not_active Application Discontinuation
- 2018-09-28 AU AU2018345539A patent/AU2018345539A1/en active Pending
- 2018-09-28 BR BR112020006643-5A patent/BR112020006643A2/pt unknown
- 2018-09-28 MA MA050613A patent/MA50613A/fr unknown
-
2020
- 2020-03-26 IL IL273631A patent/IL273631A/en unknown
-
2023
- 2023-05-01 JP JP2023075371A patent/JP2023099142A/ja active Pending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105452288A (zh) * | 2013-07-15 | 2016-03-30 | 美国卫生和人力服务部 | 抗人乳头瘤病毒16 e6 t细胞受体 |
| WO2015184228A1 (en) * | 2014-05-29 | 2015-12-03 | The United States Of America, As Represented By The Secretary, Department Of Health And Human Services | Anti-human papillomavirus 16 e7 t cell receptors |
| CN106661098A (zh) * | 2014-05-29 | 2017-05-10 | 美国卫生和人力服务部 | 抗人乳头瘤病毒16 e7的t细胞受体 |
| WO2016069282A1 (en) * | 2014-10-31 | 2016-05-06 | The Trustees Of The University Of Pennsylvania | Altering gene expression in modified t cells and uses thereof |
| WO2016146618A1 (en) * | 2015-03-16 | 2016-09-22 | Max-Delbrück-Centrum für Molekulare Medizin | Method of detecting new immunogenic t cell epitopes and isolating new antigen-specific t cell receptors by means of an mhc cell library |
| WO2018067618A1 (en) * | 2016-10-03 | 2018-04-12 | Juno Therapeutics, Inc. | Hpv-specific binding molecules |
Non-Patent Citations (2)
| Title |
|---|
| LINDSEY M. DRAPER等: "Targeting of HPV-16+ Epithelial Cancer Cells by TCR Gene Engineered T Cells Directed against E6", CANCER THERAPY: PRECLINICAL, vol. 21, no. 19, 1 October 2015 (2015-10-01), pages 4431 - 4439, XP055437983, DOI: 10.1158/1078-0432.CCR-14-3341 * |
| MARK JOSBORN等: "Evaluation ofTCR Gene Editing Achieved by TALENs, CRISPR/Cas9, and megaTAL Nucleases", MOLECULAR THERAPY, vol. 24, no. 3, 5 January 2016 (2016-01-05), pages 570 - 581, XP055278002, DOI: 10.1038/mt.2015.197 * |
Cited By (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113321726A (zh) * | 2020-02-28 | 2021-08-31 | 香雪生命科学技术(广东)有限公司 | 一种识别hpv的t细胞受体 |
| CN113321726B (zh) * | 2020-02-28 | 2024-05-28 | 香雪生命科学技术(广东)有限公司 | 一种识别hpv的t细胞受体 |
| WO2022111475A1 (zh) * | 2020-11-26 | 2022-06-02 | 香雪生命科学技术(广东)有限公司 | 一种识别hpv抗原的tcr |
| WO2023005859A1 (zh) * | 2021-07-27 | 2023-02-02 | 香雪生命科学技术(广东)有限公司 | 针对抗原ssx2的高亲和力t细胞受体 |
| WO2023036169A1 (en) * | 2021-09-07 | 2023-03-16 | Corregene Biotechnology Co., Ltd. | Antigen binding proteins and uses thereof |
| WO2023040946A1 (zh) * | 2021-09-17 | 2023-03-23 | 香雪生命科学技术(广东)有限公司 | 一种识别ssx2的高亲和力tcr |
| WO2023050063A1 (zh) * | 2021-09-28 | 2023-04-06 | 溧阳瑅赛生物医药有限公司 | 一种识别hla-a*02:01/e629-38的tcr及其应用 |
| CN113789304A (zh) * | 2021-10-14 | 2021-12-14 | 深圳大学总医院 | 高亲和力tcr及其应用 |
| CN113789304B (zh) * | 2021-10-14 | 2023-03-31 | 深圳大学总医院 | 高亲和力tcr及其应用 |
| WO2023179768A1 (zh) * | 2022-03-24 | 2023-09-28 | 香雪生命科学技术(广东)有限公司 | 一种识别mage-a4抗原的高亲和力tcr及其序列和应用 |
| CN116589557A (zh) * | 2023-03-15 | 2023-08-15 | 北京大学人民医院 | 一种肿瘤新生抗原特异性tcr及其应用 |
| CN116589557B (zh) * | 2023-03-15 | 2024-04-02 | 北京大学人民医院 | 一种肿瘤新生抗原特异性tcr及其应用 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2020537515A (ja) | 2020-12-24 |
| AU2018345539A1 (en) | 2020-04-16 |
| CA3080546A1 (en) | 2019-04-11 |
| MX2020003536A (es) | 2020-09-14 |
| EP4215543A3 (en) | 2023-10-11 |
| RU2020115148A (ru) | 2021-11-09 |
| SG11202002728VA (en) | 2020-04-29 |
| MA50613A (fr) | 2020-08-12 |
| JP2023099142A (ja) | 2023-07-11 |
| EP4215543A2 (en) | 2023-07-26 |
| US20210284709A1 (en) | 2021-09-16 |
| IL273631A (en) | 2020-05-31 |
| EP3692063A1 (en) | 2020-08-12 |
| US11952408B2 (en) | 2024-04-09 |
| KR20200104284A (ko) | 2020-09-03 |
| WO2019070541A1 (en) | 2019-04-11 |
| BR112020006643A2 (pt) | 2020-09-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11952408B2 (en) | HPV-specific binding molecules | |
| US20220184131A1 (en) | Cells expressing a recombinant receptor from a modified tgfbr2 locus, related polynucleotides and methods | |
| US20210017249A1 (en) | Methods of producing cells expressing a recombinant receptor and related compositions | |
| CN112585277A (zh) | 表达重组受体的t细胞、相关多核苷酸和方法 | |
| CN116234558A (zh) | 条件性地表达重组受体的工程化t细胞、相关多核苷酸和方法 | |
| CN114007640A (zh) | 从修饰的cd247基因座表达嵌合受体的细胞、相关多核苷酸和方法 | |
| US20230398148A1 (en) | Cells expressing a chimeric receptor from a modified invariant cd3 immunoglobulin superfamily chain locus and related polynucleotides and methods | |
| RU2804664C2 (ru) | Hpv-специфические связывающие молекулы | |
| WO2023081900A1 (en) | Engineered t cells expressing a recombinant t cell receptor (tcr) and related systems and methods | |
| JP2024537991A (ja) | 共発現されるshRNAと論理ゲートシステムとを有する免疫細胞 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |