KR20210070305A - Arc 기반 캡시드 및 이의 용도 - Google Patents
Arc 기반 캡시드 및 이의 용도 Download PDFInfo
- Publication number
- KR20210070305A KR20210070305A KR1020217011429A KR20217011429A KR20210070305A KR 20210070305 A KR20210070305 A KR 20210070305A KR 1020217011429 A KR1020217011429 A KR 1020217011429A KR 20217011429 A KR20217011429 A KR 20217011429A KR 20210070305 A KR20210070305 A KR 20210070305A
- Authority
- KR
- South Korea
- Prior art keywords
- glu
- leu
- seq
- amino acid
- acid sequence
- Prior art date
Links
- 210000000234 capsid Anatomy 0.000 title claims description 297
- 108090000765 processed proteins & peptides Proteins 0.000 claims abstract description 436
- 102000004196 processed proteins & peptides Human genes 0.000 claims abstract description 386
- 229920001184 polypeptide Polymers 0.000 claims abstract description 383
- 238000000034 method Methods 0.000 claims abstract description 44
- 210000004027 cell Anatomy 0.000 claims description 180
- 150000007523 nucleic acids Chemical group 0.000 claims description 157
- 102000039446 nucleic acids Human genes 0.000 claims description 156
- 108020004707 nucleic acids Proteins 0.000 claims description 156
- 108090000623 proteins and genes Proteins 0.000 claims description 154
- 241000282414 Homo sapiens Species 0.000 claims description 77
- 239000013598 vector Substances 0.000 claims description 44
- 239000003814 drug Substances 0.000 claims description 30
- 229940124597 therapeutic agent Drugs 0.000 claims description 21
- 241000251539 Vertebrata <Metazoa> Species 0.000 claims description 15
- 108010079872 activity regulated cytoskeletal-associated protein Proteins 0.000 claims description 11
- 210000004962 mammalian cell Anatomy 0.000 claims description 7
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 6
- 210000003527 eukaryotic cell Anatomy 0.000 claims description 6
- 210000005260 human cell Anatomy 0.000 claims description 4
- 125000003275 alpha amino acid group Chemical group 0.000 claims 110
- 150000001413 amino acids Chemical group 0.000 description 530
- 125000003729 nucleotide group Chemical group 0.000 description 168
- 239000002773 nucleotide Substances 0.000 description 159
- 102000004169 proteins and genes Human genes 0.000 description 141
- 235000018102 proteins Nutrition 0.000 description 133
- 230000027455 binding Effects 0.000 description 89
- 235000001014 amino acid Nutrition 0.000 description 65
- -1 PNMA6 Proteins 0.000 description 58
- 241000894007 species Species 0.000 description 50
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 42
- 125000005647 linker group Chemical group 0.000 description 40
- 239000012634 fragment Substances 0.000 description 38
- 108020004414 DNA Proteins 0.000 description 28
- 230000004048 modification Effects 0.000 description 27
- 238000012986 modification Methods 0.000 description 27
- 239000011159 matrix material Substances 0.000 description 24
- 150000003384 small molecules Chemical class 0.000 description 23
- 241000880493 Leptailurus serval Species 0.000 description 21
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 21
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 20
- 239000000427 antigen Substances 0.000 description 20
- 108091007433 antigens Proteins 0.000 description 20
- 102000036639 antigens Human genes 0.000 description 20
- 108010013835 arginine glutamate Proteins 0.000 description 19
- 241000238631 Hexapoda Species 0.000 description 18
- 102100034349 Integrase Human genes 0.000 description 18
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 18
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 18
- 230000014509 gene expression Effects 0.000 description 18
- 239000002502 liposome Substances 0.000 description 17
- 108010003533 Viral Envelope Proteins Proteins 0.000 description 16
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 15
- 230000015572 biosynthetic process Effects 0.000 description 15
- RAXXELZNTBOGNW-UHFFFAOYSA-N imidazole Natural products C1=CNC=N1 RAXXELZNTBOGNW-UHFFFAOYSA-N 0.000 description 15
- 241000196324 Embryophyta Species 0.000 description 14
- 241000233866 Fungi Species 0.000 description 14
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 14
- 230000004570 RNA-binding Effects 0.000 description 14
- 230000028993 immune response Effects 0.000 description 14
- 210000004779 membrane envelope Anatomy 0.000 description 14
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 14
- 241000124008 Mammalia Species 0.000 description 13
- 206010028980 Neoplasm Diseases 0.000 description 13
- 108010015792 glycyllysine Proteins 0.000 description 13
- 108010034529 leucyl-lysine Proteins 0.000 description 13
- 241000251468 Actinopterygii Species 0.000 description 12
- BUAKRRKDHSSIKK-IHRRRGAJSA-N Glu-Glu-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 BUAKRRKDHSSIKK-IHRRRGAJSA-N 0.000 description 12
- 241000283984 Rodentia Species 0.000 description 12
- 108010051307 glycyl-glycyl-proline Proteins 0.000 description 12
- 210000000130 stem cell Anatomy 0.000 description 12
- NKBQZKVMKJJDLX-SRVKXCTJSA-N Arg-Glu-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O NKBQZKVMKJJDLX-SRVKXCTJSA-N 0.000 description 11
- OTZMRMHZCMZOJZ-SRVKXCTJSA-N Arg-Leu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O OTZMRMHZCMZOJZ-SRVKXCTJSA-N 0.000 description 11
- 241000270322 Lepidosauria Species 0.000 description 11
- 108010031719 prolyl-serine Proteins 0.000 description 11
- VCSABYLVNWQYQE-UHFFFAOYSA-N Ala-Lys-Lys Natural products NCCCCC(NC(=O)C(N)C)C(=O)NC(CCCCN)C(O)=O VCSABYLVNWQYQE-UHFFFAOYSA-N 0.000 description 10
- NABSCJGZKWSNHX-RCWTZXSCSA-N Arg-Arg-Thr Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H]([C@H](O)C)C(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N NABSCJGZKWSNHX-RCWTZXSCSA-N 0.000 description 10
- QNJNPKSWAHPYGI-JYJNAYRXSA-N Glu-Phe-Leu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=CC=C1 QNJNPKSWAHPYGI-JYJNAYRXSA-N 0.000 description 10
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 10
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 10
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 10
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 10
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 10
- 230000009437 off-target effect Effects 0.000 description 10
- IVPNEDNYYYFAGI-GARJFASQSA-N Asp-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N IVPNEDNYYYFAGI-GARJFASQSA-N 0.000 description 9
- GQZDDFRXSDGUNG-YVNDNENWSA-N Gln-Ile-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O GQZDDFRXSDGUNG-YVNDNENWSA-N 0.000 description 9
- UBRQJXFDVZNYJP-AVGNSLFASA-N Gln-Tyr-Ser Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O UBRQJXFDVZNYJP-AVGNSLFASA-N 0.000 description 9
- RYAOJUMWLWUGNW-QMMMGPOBSA-N Gly-Val-Gly Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O RYAOJUMWLWUGNW-QMMMGPOBSA-N 0.000 description 9
- IDNNYVGVSZMQTK-IHRRRGAJSA-N His-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N IDNNYVGVSZMQTK-IHRRRGAJSA-N 0.000 description 9
- 230000005867 T cell response Effects 0.000 description 9
- NZYNRRGJJVSSTJ-GUBZILKMSA-N Val-Ser-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NZYNRRGJJVSSTJ-GUBZILKMSA-N 0.000 description 9
- 108010068265 aspartyltyrosine Proteins 0.000 description 9
- 230000001580 bacterial effect Effects 0.000 description 9
- 108010078144 glutaminyl-glycine Proteins 0.000 description 9
- 108010054155 lysyllysine Proteins 0.000 description 9
- 238000004519 manufacturing process Methods 0.000 description 9
- 239000000203 mixture Substances 0.000 description 9
- 239000000816 peptidomimetic Substances 0.000 description 9
- 229920000642 polymer Polymers 0.000 description 9
- 102000005962 receptors Human genes 0.000 description 9
- 108020003175 receptors Proteins 0.000 description 9
- 239000011780 sodium chloride Substances 0.000 description 9
- 241000206602 Eukaryota Species 0.000 description 8
- JJGBXTYGTKWGAT-YUMQZZPRSA-N Gly-Pro-Glu Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O JJGBXTYGTKWGAT-YUMQZZPRSA-N 0.000 description 8
- 101000733752 Homo sapiens Retroviral-like aspartic protease 1 Proteins 0.000 description 8
- RIVKTKFVWXRNSJ-GRLWGSQLSA-N Ile-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N RIVKTKFVWXRNSJ-GRLWGSQLSA-N 0.000 description 8
- GQUDMNDPQTXZRV-DCAQKATOSA-N Lys-Arg-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O GQUDMNDPQTXZRV-DCAQKATOSA-N 0.000 description 8
- 241000235648 Pichia Species 0.000 description 8
- 102100033717 Retroviral-like aspartic protease 1 Human genes 0.000 description 8
- 108010005233 alanylglutamic acid Proteins 0.000 description 8
- 125000000217 alkyl group Chemical group 0.000 description 8
- 108020004999 messenger RNA Proteins 0.000 description 8
- 239000000693 micelle Substances 0.000 description 8
- 235000000346 sugar Nutrition 0.000 description 8
- 230000001225 therapeutic effect Effects 0.000 description 8
- 210000004881 tumor cell Anatomy 0.000 description 8
- 108010020532 tyrosyl-proline Proteins 0.000 description 8
- 102000004190 Enzymes Human genes 0.000 description 7
- 108090000790 Enzymes Proteins 0.000 description 7
- BBFCMGBMYIAGRS-AUTRQRHGSA-N Gln-Val-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O BBFCMGBMYIAGRS-AUTRQRHGSA-N 0.000 description 7
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 7
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 7
- 239000000872 buffer Substances 0.000 description 7
- 201000011510 cancer Diseases 0.000 description 7
- 238000003776 cleavage reaction Methods 0.000 description 7
- 229940088598 enzyme Drugs 0.000 description 7
- 239000013604 expression vector Substances 0.000 description 7
- 108010025306 histidylleucine Proteins 0.000 description 7
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 7
- 230000007017 scission Effects 0.000 description 7
- CXZFXHGJJPVUJE-CIUDSAMLSA-N Ala-Cys-Leu Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)O)N CXZFXHGJJPVUJE-CIUDSAMLSA-N 0.000 description 6
- IXIWEFWRKIUMQX-DCAQKATOSA-N Asp-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CC(O)=O IXIWEFWRKIUMQX-DCAQKATOSA-N 0.000 description 6
- 208000010839 B-cell chronic lymphocytic leukemia Diseases 0.000 description 6
- 101710130956 Copia protein Proteins 0.000 description 6
- 108010069514 Cyclic Peptides Proteins 0.000 description 6
- 102000001189 Cyclic Peptides Human genes 0.000 description 6
- 241000588724 Escherichia coli Species 0.000 description 6
- DRDSQGHKTLSNEA-GLLZPBPUSA-N Gln-Glu-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DRDSQGHKTLSNEA-GLLZPBPUSA-N 0.000 description 6
- SYDJILXOZNEEDK-XIRDDKMYSA-N Glu-Arg-Trp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O SYDJILXOZNEEDK-XIRDDKMYSA-N 0.000 description 6
- PVBBEKPHARMPHX-DCAQKATOSA-N Glu-Gln-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CCC(O)=O PVBBEKPHARMPHX-DCAQKATOSA-N 0.000 description 6
- BUZMZDDKFCSKOT-CIUDSAMLSA-N Glu-Glu-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O BUZMZDDKFCSKOT-CIUDSAMLSA-N 0.000 description 6
- ZIMTWPHIKZEHSE-UWVGGRQHSA-N His-Arg-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O ZIMTWPHIKZEHSE-UWVGGRQHSA-N 0.000 description 6
- 101001094811 Homo sapiens Paraneoplastic antigen-like protein 6A Proteins 0.000 description 6
- 101000699771 Homo sapiens Retrotransposon Gag-like protein 8A Proteins 0.000 description 6
- 101000699769 Homo sapiens Retrotransposon Gag-like protein 8B Proteins 0.000 description 6
- HFBCHNRFRYLZNV-GUBZILKMSA-N Leu-Glu-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HFBCHNRFRYLZNV-GUBZILKMSA-N 0.000 description 6
- NDORZBUHCOJQDO-GVXVVHGQSA-N Lys-Gln-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O NDORZBUHCOJQDO-GVXVVHGQSA-N 0.000 description 6
- ULUQBUKAPDUKOC-GVXVVHGQSA-N Lys-Glu-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O ULUQBUKAPDUKOC-GVXVVHGQSA-N 0.000 description 6
- GQFDWEDHOQRNLC-QWRGUYRKSA-N Lys-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN GQFDWEDHOQRNLC-QWRGUYRKSA-N 0.000 description 6
- OPJRECCCQSDDCZ-TUSQITKMSA-N Lys-Trp-Trp Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(O)=O OPJRECCCQSDDCZ-TUSQITKMSA-N 0.000 description 6
- ACYHZNZHIZWLQF-BQBZGAKWSA-N Met-Asn-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O ACYHZNZHIZWLQF-BQBZGAKWSA-N 0.000 description 6
- 102100035454 Paraneoplastic antigen-like protein 6A Human genes 0.000 description 6
- FYQSMXKJYTZYRP-DCAQKATOSA-N Pro-Ala-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 FYQSMXKJYTZYRP-DCAQKATOSA-N 0.000 description 6
- 102100029148 Retrotransposon Gag-like protein 8A Human genes 0.000 description 6
- 102100029149 Retrotransposon Gag-like protein 8B Human genes 0.000 description 6
- JIPVNVNKXJLFJF-BJDJZHNGSA-N Ser-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N JIPVNVNKXJLFJF-BJDJZHNGSA-N 0.000 description 6
- GLQFKOVWXPPFTP-VEVYYDQMSA-N Thr-Arg-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O GLQFKOVWXPPFTP-VEVYYDQMSA-N 0.000 description 6
- HOVLHEKTGVIKAP-WDCWCFNPSA-N Thr-Leu-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O HOVLHEKTGVIKAP-WDCWCFNPSA-N 0.000 description 6
- VTVVYQOXJCZVEB-WDCWCFNPSA-N Thr-Leu-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O VTVVYQOXJCZVEB-WDCWCFNPSA-N 0.000 description 6
- SYOMXKPPFZRELL-ONGXEEELSA-N Val-Gly-Lys Chemical compound CC(C)[C@@H](C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)O)N SYOMXKPPFZRELL-ONGXEEELSA-N 0.000 description 6
- GVJUTBOZZBTBIG-AVGNSLFASA-N Val-Lys-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N GVJUTBOZZBTBIG-AVGNSLFASA-N 0.000 description 6
- QTPQHINADBYBNA-DCAQKATOSA-N Val-Ser-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN QTPQHINADBYBNA-DCAQKATOSA-N 0.000 description 6
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 6
- 125000003277 amino group Chemical group 0.000 description 6
- 108010047857 aspartylglycine Proteins 0.000 description 6
- 210000003719 b-lymphocyte Anatomy 0.000 description 6
- 229910052799 carbon Inorganic materials 0.000 description 6
- 210000004671 cell-free system Anatomy 0.000 description 6
- 239000003795 chemical substances by application Substances 0.000 description 6
- 238000012217 deletion Methods 0.000 description 6
- 230000037430 deletion Effects 0.000 description 6
- 108010089804 glycyl-threonine Proteins 0.000 description 6
- 108010077515 glycylproline Proteins 0.000 description 6
- 230000003834 intracellular effect Effects 0.000 description 6
- 150000002632 lipids Chemical class 0.000 description 6
- 108010009298 lysylglutamic acid Proteins 0.000 description 6
- 108010012581 phenylalanylglutamate Proteins 0.000 description 6
- 108010070643 prolylglutamic acid Proteins 0.000 description 6
- 125000000548 ribosyl group Chemical group C1([C@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 6
- 239000000243 solution Substances 0.000 description 6
- 239000002691 unilamellar liposome Substances 0.000 description 6
- UHMQKOBNPRAZGB-CIUDSAMLSA-N Ala-Glu-Met Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCSC)C(=O)O)N UHMQKOBNPRAZGB-CIUDSAMLSA-N 0.000 description 5
- RZZMZYZXNJRPOJ-BJDJZHNGSA-N Ala-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](C)N RZZMZYZXNJRPOJ-BJDJZHNGSA-N 0.000 description 5
- LBYMZCVBOKYZNS-CIUDSAMLSA-N Ala-Leu-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O LBYMZCVBOKYZNS-CIUDSAMLSA-N 0.000 description 5
- NZGRHTKZFSVPAN-BIIVOSGPSA-N Ala-Ser-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N NZGRHTKZFSVPAN-BIIVOSGPSA-N 0.000 description 5
- DJAIOAKQIOGULM-DCAQKATOSA-N Arg-Glu-Met Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O DJAIOAKQIOGULM-DCAQKATOSA-N 0.000 description 5
- SKTGPBFTMNLIHQ-KKUMJFAQSA-N Arg-Glu-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SKTGPBFTMNLIHQ-KKUMJFAQSA-N 0.000 description 5
- DRDWXKWUSIKKOB-PJODQICGSA-N Arg-Trp-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C)C(O)=O DRDWXKWUSIKKOB-PJODQICGSA-N 0.000 description 5
- JBQORRNSZGTLCV-WDSOQIARSA-N Arg-Trp-Lys Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](CCCCN)C(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N)=CNC2=C1 JBQORRNSZGTLCV-WDSOQIARSA-N 0.000 description 5
- SXNJBDYEBOUYOJ-DCAQKATOSA-N Asn-His-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CC(=O)N)N SXNJBDYEBOUYOJ-DCAQKATOSA-N 0.000 description 5
- BXUHCIXDSWRSBS-CIUDSAMLSA-N Asn-Leu-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O BXUHCIXDSWRSBS-CIUDSAMLSA-N 0.000 description 5
- ZKAOJVJQGVUIIU-GUBZILKMSA-N Asp-Pro-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O ZKAOJVJQGVUIIU-GUBZILKMSA-N 0.000 description 5
- XYPJXLLXNSAWHZ-SRVKXCTJSA-N Asp-Ser-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XYPJXLLXNSAWHZ-SRVKXCTJSA-N 0.000 description 5
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 5
- 102000053602 DNA Human genes 0.000 description 5
- PGPJSRSLQNXBDT-YUMQZZPRSA-N Gln-Arg-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O PGPJSRSLQNXBDT-YUMQZZPRSA-N 0.000 description 5
- YRWWJCDWLVXTHN-LAEOZQHASA-N Gln-Ile-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCC(=O)N)N YRWWJCDWLVXTHN-LAEOZQHASA-N 0.000 description 5
- PSERKXGRRADTKA-MNXVOIDGSA-N Gln-Leu-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O PSERKXGRRADTKA-MNXVOIDGSA-N 0.000 description 5
- GLWXKFRTOHKGIT-ACZMJKKPSA-N Glu-Asn-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O GLWXKFRTOHKGIT-ACZMJKKPSA-N 0.000 description 5
- CKOFNWCLWRYUHK-XHNCKOQMSA-N Glu-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N)C(=O)O CKOFNWCLWRYUHK-XHNCKOQMSA-N 0.000 description 5
- SYWCGQOIIARSIX-SRVKXCTJSA-N Glu-Pro-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O SYWCGQOIIARSIX-SRVKXCTJSA-N 0.000 description 5
- MFYLRRCYBBJYPI-JYJNAYRXSA-N Glu-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O MFYLRRCYBBJYPI-JYJNAYRXSA-N 0.000 description 5
- FVGOGEGGQLNZGH-DZKIICNBSA-N Glu-Val-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 FVGOGEGGQLNZGH-DZKIICNBSA-N 0.000 description 5
- LXXANCRPFBSSKS-IUCAKERBSA-N Gly-Gln-Leu Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LXXANCRPFBSSKS-IUCAKERBSA-N 0.000 description 5
- YYPFZVIXAVDHIK-IUCAKERBSA-N Gly-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)CN YYPFZVIXAVDHIK-IUCAKERBSA-N 0.000 description 5
- QITBQGJOXQYMOA-ZETCQYMHSA-N Gly-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)CN QITBQGJOXQYMOA-ZETCQYMHSA-N 0.000 description 5
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 5
- LIXWIUAORXJNBH-QWRGUYRKSA-N Gly-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)CN LIXWIUAORXJNBH-QWRGUYRKSA-N 0.000 description 5
- CVFOYJJOZYYEPE-KBPBESRZSA-N Gly-Lys-Tyr Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CVFOYJJOZYYEPE-KBPBESRZSA-N 0.000 description 5
- DUAWRXXTOQOECJ-JSGCOSHPSA-N Gly-Tyr-Val Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O DUAWRXXTOQOECJ-JSGCOSHPSA-N 0.000 description 5
- 206010066476 Haematological malignancy Diseases 0.000 description 5
- 208000002250 Hematologic Neoplasms Diseases 0.000 description 5
- FBOMZVOKCZMDIG-XQQFMLRXSA-N His-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N FBOMZVOKCZMDIG-XQQFMLRXSA-N 0.000 description 5
- 101000969594 Homo sapiens Modulator of apoptosis 1 Proteins 0.000 description 5
- 101001123683 Homo sapiens Paraneoplastic antigen-like protein 5 Proteins 0.000 description 5
- 101001130132 Homo sapiens Protein LDOC1 Proteins 0.000 description 5
- 101001094537 Homo sapiens Retrotransposon Gag-like protein 3 Proteins 0.000 description 5
- 101000699774 Homo sapiens Retrotransposon Gag-like protein 6 Proteins 0.000 description 5
- 101001073409 Homo sapiens Retrotransposon-derived protein PEG10 Proteins 0.000 description 5
- 101000818754 Homo sapiens Zinc finger protein 18 Proteins 0.000 description 5
- YPWHUFAAMNHMGS-QSFUFRPTSA-N Ile-Ala-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N YPWHUFAAMNHMGS-QSFUFRPTSA-N 0.000 description 5
- OMDWJWGZGMCQND-CFMVVWHZSA-N Ile-Tyr-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N OMDWJWGZGMCQND-CFMVVWHZSA-N 0.000 description 5
- LJHGALIOHLRRQN-DCAQKATOSA-N Leu-Ala-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N LJHGALIOHLRRQN-DCAQKATOSA-N 0.000 description 5
- PJYSOYLLTJKZHC-GUBZILKMSA-N Leu-Asp-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCC(N)=O PJYSOYLLTJKZHC-GUBZILKMSA-N 0.000 description 5
- RSFGIMMPWAXNML-MNXVOIDGSA-N Leu-Gln-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O RSFGIMMPWAXNML-MNXVOIDGSA-N 0.000 description 5
- RVVBWTWPNFDYBE-SRVKXCTJSA-N Leu-Glu-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RVVBWTWPNFDYBE-SRVKXCTJSA-N 0.000 description 5
- JLWZLIQRYCTYBD-IHRRRGAJSA-N Leu-Lys-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JLWZLIQRYCTYBD-IHRRRGAJSA-N 0.000 description 5
- YRRCOJOXAJNSAX-IHRRRGAJSA-N Leu-Pro-Lys Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)O)N YRRCOJOXAJNSAX-IHRRRGAJSA-N 0.000 description 5
- WALVCOOOKULCQM-ULQDDVLXSA-N Lys-Arg-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O WALVCOOOKULCQM-ULQDDVLXSA-N 0.000 description 5
- SVJRVFPSHPGWFF-DCAQKATOSA-N Lys-Cys-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SVJRVFPSHPGWFF-DCAQKATOSA-N 0.000 description 5
- VSRXPEHZMHSFKU-IUCAKERBSA-N Lys-Gln-Gly Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O VSRXPEHZMHSFKU-IUCAKERBSA-N 0.000 description 5
- OBZHNHBAAVEWKI-DCAQKATOSA-N Lys-Pro-Asn Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O OBZHNHBAAVEWKI-DCAQKATOSA-N 0.000 description 5
- 102000018697 Membrane Proteins Human genes 0.000 description 5
- 108010052285 Membrane Proteins Proteins 0.000 description 5
- ZDJICAUBMUKVEJ-CIUDSAMLSA-N Met-Ser-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(N)=O ZDJICAUBMUKVEJ-CIUDSAMLSA-N 0.000 description 5
- HOTNHEUETJELDL-BPNCWPANSA-N Met-Tyr-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCSC)N HOTNHEUETJELDL-BPNCWPANSA-N 0.000 description 5
- 108091034117 Oligonucleotide Proteins 0.000 description 5
- 241000283283 Orcinus orca Species 0.000 description 5
- 102100028912 Paraneoplastic antigen-like protein 5 Human genes 0.000 description 5
- HQPWNHXERZCIHP-PMVMPFDFSA-N Phe-Leu-Trp Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CC=CC=C1 HQPWNHXERZCIHP-PMVMPFDFSA-N 0.000 description 5
- PEFJUUYFEGBXFA-BZSNNMDCSA-N Phe-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=CC=C1 PEFJUUYFEGBXFA-BZSNNMDCSA-N 0.000 description 5
- RMODQFBNDDENCP-IHRRRGAJSA-N Pro-Lys-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O RMODQFBNDDENCP-IHRRRGAJSA-N 0.000 description 5
- 102100035122 Retrotransposon Gag-like protein 3 Human genes 0.000 description 5
- 102100029147 Retrotransposon Gag-like protein 6 Human genes 0.000 description 5
- YRBGKVIWMNEVCZ-WDSKDSINSA-N Ser-Glu-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O YRBGKVIWMNEVCZ-WDSKDSINSA-N 0.000 description 5
- WNDUPCKKKGSKIQ-CIUDSAMLSA-N Ser-Pro-Gln Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O WNDUPCKKKGSKIQ-CIUDSAMLSA-N 0.000 description 5
- LGIMRDKGABDMBN-DCAQKATOSA-N Ser-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N LGIMRDKGABDMBN-DCAQKATOSA-N 0.000 description 5
- RWAYYYOZMHMEGD-XIRDDKMYSA-N Trp-Leu-Ser Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O)=CNC2=C1 RWAYYYOZMHMEGD-XIRDDKMYSA-N 0.000 description 5
- MPKPIWFFDWVJGC-IRIUXVKKSA-N Tyr-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O MPKPIWFFDWVJGC-IRIUXVKKSA-N 0.000 description 5
- DJIJBQYBDKGDIS-JYJNAYRXSA-N Tyr-Val-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)Cc1ccc(O)cc1)C(C)C)C(O)=O DJIJBQYBDKGDIS-JYJNAYRXSA-N 0.000 description 5
- XWYUBUYQMOUFRQ-IFFSRLJSSA-N Val-Glu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N)O XWYUBUYQMOUFRQ-IFFSRLJSSA-N 0.000 description 5
- FTKXYXACXYOHND-XUXIUFHCSA-N Val-Ile-Leu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O FTKXYXACXYOHND-XUXIUFHCSA-N 0.000 description 5
- XXWBHOWRARMUOC-NHCYSSNCSA-N Val-Lys-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)N)C(=O)O)N XXWBHOWRARMUOC-NHCYSSNCSA-N 0.000 description 5
- GBIUHAYJGWVNLN-UHFFFAOYSA-N Val-Ser-Pro Natural products CC(C)C(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O GBIUHAYJGWVNLN-UHFFFAOYSA-N 0.000 description 5
- QTXGUIMEHKCPBH-FHWLQOOXSA-N Val-Trp-Lys Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 QTXGUIMEHKCPBH-FHWLQOOXSA-N 0.000 description 5
- AEFJNECXZCODJM-UWVGGRQHSA-N Val-Val-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](C(C)C)C(=O)NCC([O-])=O AEFJNECXZCODJM-UWVGGRQHSA-N 0.000 description 5
- 241000700605 Viruses Species 0.000 description 5
- 239000000443 aerosol Substances 0.000 description 5
- 108010047495 alanylglycine Proteins 0.000 description 5
- 210000004102 animal cell Anatomy 0.000 description 5
- 230000003110 anti-inflammatory effect Effects 0.000 description 5
- 238000013459 approach Methods 0.000 description 5
- 108010038633 aspartylglutamate Proteins 0.000 description 5
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 5
- 230000004700 cellular uptake Effects 0.000 description 5
- 239000002299 complementary DNA Substances 0.000 description 5
- 108010042598 glutamyl-aspartyl-glycine Proteins 0.000 description 5
- 108010037850 glycylvaline Proteins 0.000 description 5
- 238000000338 in vitro Methods 0.000 description 5
- 239000002679 microRNA Substances 0.000 description 5
- 230000003278 mimic effect Effects 0.000 description 5
- 125000004573 morpholin-4-yl group Chemical group N1(CCOCC1)* 0.000 description 5
- 210000000663 muscle cell Anatomy 0.000 description 5
- 210000002569 neuron Anatomy 0.000 description 5
- IJGRMHOSHXDMSA-UHFFFAOYSA-N nitrogen Substances N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 5
- 229910052760 oxygen Inorganic materials 0.000 description 5
- 239000001301 oxygen Substances 0.000 description 5
- 108010090894 prolylleucine Proteins 0.000 description 5
- 239000001488 sodium phosphate Substances 0.000 description 5
- 229910000162 sodium phosphate Inorganic materials 0.000 description 5
- 238000011200 topical administration Methods 0.000 description 5
- RYFMWSXOAZQYPI-UHFFFAOYSA-K trisodium phosphate Chemical compound [Na+].[Na+].[Na+].[O-]P([O-])([O-])=O RYFMWSXOAZQYPI-UHFFFAOYSA-K 0.000 description 5
- TZCPCKNHXULUIY-RGULYWFUSA-N 1,2-distearoyl-sn-glycero-3-phosphoserine Chemical compound CCCCCCCCCCCCCCCCCC(=O)OC[C@H](COP(O)(=O)OC[C@H](N)C(O)=O)OC(=O)CCCCCCCCCCCCCCCCC TZCPCKNHXULUIY-RGULYWFUSA-N 0.000 description 4
- NXSFUECZFORGOG-CIUDSAMLSA-N Ala-Asn-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O NXSFUECZFORGOG-CIUDSAMLSA-N 0.000 description 4
- LXAARTARZJJCMB-CIQUZCHMSA-N Ala-Ile-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LXAARTARZJJCMB-CIQUZCHMSA-N 0.000 description 4
- FCXAUASCMJOFEY-NDKCEZKHSA-N Ala-Leu-Thr-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(O)=O FCXAUASCMJOFEY-NDKCEZKHSA-N 0.000 description 4
- VCSABYLVNWQYQE-SRVKXCTJSA-N Ala-Lys-Lys Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CCCCN)C(O)=O VCSABYLVNWQYQE-SRVKXCTJSA-N 0.000 description 4
- CHFFHQUVXHEGBY-GARJFASQSA-N Ala-Lys-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(=O)O)N CHFFHQUVXHEGBY-GARJFASQSA-N 0.000 description 4
- ZXKNLCPUNZPFGY-LEWSCRJBSA-N Ala-Tyr-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N2CCC[C@@H]2C(=O)O)N ZXKNLCPUNZPFGY-LEWSCRJBSA-N 0.000 description 4
- QIWYWCYNUMJBTC-CIUDSAMLSA-N Arg-Cys-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O QIWYWCYNUMJBTC-CIUDSAMLSA-N 0.000 description 4
- CVKOQHYVDVYJSI-QTKMDUPCSA-N Arg-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCCN=C(N)N)N)O CVKOQHYVDVYJSI-QTKMDUPCSA-N 0.000 description 4
- ZJBUILVYSXQNSW-YTWAJWBKSA-N Arg-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O ZJBUILVYSXQNSW-YTWAJWBKSA-N 0.000 description 4
- GJFYPBDMUGGLFR-NKWVEPMBSA-N Asn-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CC(=O)N)N)C(=O)O GJFYPBDMUGGLFR-NKWVEPMBSA-N 0.000 description 4
- YQPSDMUGFKJZHR-QRTARXTBSA-N Asn-Trp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC(=O)N)N YQPSDMUGFKJZHR-QRTARXTBSA-N 0.000 description 4
- JNCRAQVYJZGIOW-QSFUFRPTSA-N Asn-Val-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JNCRAQVYJZGIOW-QSFUFRPTSA-N 0.000 description 4
- WSWYMRLTJVKRCE-ZLUOBGJFSA-N Asp-Ala-Asp Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O WSWYMRLTJVKRCE-ZLUOBGJFSA-N 0.000 description 4
- XPGVTUBABLRGHY-BIIVOSGPSA-N Asp-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N XPGVTUBABLRGHY-BIIVOSGPSA-N 0.000 description 4
- NYLBGYLHBDFRHL-VEVYYDQMSA-N Asp-Arg-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NYLBGYLHBDFRHL-VEVYYDQMSA-N 0.000 description 4
- ATYWBXGNXZYZGI-ACZMJKKPSA-N Asp-Asn-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O ATYWBXGNXZYZGI-ACZMJKKPSA-N 0.000 description 4
- RDRMWJBLOSRRAW-BYULHYEWSA-N Asp-Asn-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O RDRMWJBLOSRRAW-BYULHYEWSA-N 0.000 description 4
- OEUQMKNNOWJREN-AVGNSLFASA-N Asp-Gln-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)O)N OEUQMKNNOWJREN-AVGNSLFASA-N 0.000 description 4
- HAFCJCDJGIOYPW-WDSKDSINSA-N Asp-Gly-Gln Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O HAFCJCDJGIOYPW-WDSKDSINSA-N 0.000 description 4
- ICZWAZVKLACMKR-CIUDSAMLSA-N Asp-His-Ser Chemical compound OC(=O)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CC1=CN=CN1 ICZWAZVKLACMKR-CIUDSAMLSA-N 0.000 description 4
- 241000271566 Aves Species 0.000 description 4
- 241000894006 Bacteria Species 0.000 description 4
- 241000222122 Candida albicans Species 0.000 description 4
- 201000007336 Cryptococcosis Diseases 0.000 description 4
- 241000221204 Cryptococcus neoformans Species 0.000 description 4
- SZQCDCKIGWQAQN-FXQIFTODSA-N Cys-Arg-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O SZQCDCKIGWQAQN-FXQIFTODSA-N 0.000 description 4
- 102000003951 Erythropoietin Human genes 0.000 description 4
- 108090000394 Erythropoietin Proteins 0.000 description 4
- UWZLBXOBVKRUFE-HGNGGELXSA-N Gln-Ala-His Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)N)N UWZLBXOBVKRUFE-HGNGGELXSA-N 0.000 description 4
- LZRMPXRYLLTAJX-GUBZILKMSA-N Gln-Arg-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O LZRMPXRYLLTAJX-GUBZILKMSA-N 0.000 description 4
- WLODHVXYKYHLJD-ACZMJKKPSA-N Gln-Asp-Ser Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N WLODHVXYKYHLJD-ACZMJKKPSA-N 0.000 description 4
- MWERYIXRDZDXOA-QEWYBTABSA-N Gln-Ile-Phe Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MWERYIXRDZDXOA-QEWYBTABSA-N 0.000 description 4
- UWKPRVKWEKEMSY-DCAQKATOSA-N Gln-Lys-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O UWKPRVKWEKEMSY-DCAQKATOSA-N 0.000 description 4
- HMIXCETWRYDVMO-GUBZILKMSA-N Gln-Pro-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O HMIXCETWRYDVMO-GUBZILKMSA-N 0.000 description 4
- MFORDNZDKAVNSR-SRVKXCTJSA-N Gln-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O MFORDNZDKAVNSR-SRVKXCTJSA-N 0.000 description 4
- RLZBLVSJDFHDBL-KBIXCLLPSA-N Glu-Ala-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O RLZBLVSJDFHDBL-KBIXCLLPSA-N 0.000 description 4
- KUTPGXNAAOQSPD-LPEHRKFASA-N Glu-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)O)N)C(=O)O KUTPGXNAAOQSPD-LPEHRKFASA-N 0.000 description 4
- HPJLZFTUUJKWAJ-JHEQGTHGSA-N Glu-Gly-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HPJLZFTUUJKWAJ-JHEQGTHGSA-N 0.000 description 4
- ZPASCJBSSCRWMC-GVXVVHGQSA-N Glu-His-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCC(=O)O)N ZPASCJBSSCRWMC-GVXVVHGQSA-N 0.000 description 4
- KDIBIWPCJYUPOI-HSCHXYMDSA-N Glu-Lys-Trp-Ala Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(O)=O)=CNC2=C1 KDIBIWPCJYUPOI-HSCHXYMDSA-N 0.000 description 4
- CBEUFCJRFNZMCU-SRVKXCTJSA-N Glu-Met-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O CBEUFCJRFNZMCU-SRVKXCTJSA-N 0.000 description 4
- ZIYGTCDTJJCDDP-JYJNAYRXSA-N Glu-Phe-Lys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZIYGTCDTJJCDDP-JYJNAYRXSA-N 0.000 description 4
- GUOWMVFLAJNPDY-CIUDSAMLSA-N Glu-Ser-Met Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(O)=O GUOWMVFLAJNPDY-CIUDSAMLSA-N 0.000 description 4
- RGJKYNUINKGPJN-RWRJDSDZSA-N Glu-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(=O)O)N RGJKYNUINKGPJN-RWRJDSDZSA-N 0.000 description 4
- FMVLWTYYODVFRG-BQBZGAKWSA-N Gly-Asn-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)CN FMVLWTYYODVFRG-BQBZGAKWSA-N 0.000 description 4
- LCNXZQROPKFGQK-WHFBIAKZSA-N Gly-Asp-Ser Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O LCNXZQROPKFGQK-WHFBIAKZSA-N 0.000 description 4
- BEQGFMIBZFNROK-JGVFFNPUSA-N Gly-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)CN)C(=O)O BEQGFMIBZFNROK-JGVFFNPUSA-N 0.000 description 4
- DENRBIYENOKSEX-PEXQALLHSA-N Gly-Ile-His Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 DENRBIYENOKSEX-PEXQALLHSA-N 0.000 description 4
- FHQRLHFYVZAQHU-IUCAKERBSA-N Gly-Lys-Gln Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O FHQRLHFYVZAQHU-IUCAKERBSA-N 0.000 description 4
- MHXKHKWHPNETGG-QWRGUYRKSA-N Gly-Lys-Leu Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O MHXKHKWHPNETGG-QWRGUYRKSA-N 0.000 description 4
- CQMFNTVQVLQRLT-JHEQGTHGSA-N Gly-Thr-Gln Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O CQMFNTVQVLQRLT-JHEQGTHGSA-N 0.000 description 4
- ZPVJJPAIUZLSNE-DCAQKATOSA-N His-Arg-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O ZPVJJPAIUZLSNE-DCAQKATOSA-N 0.000 description 4
- 101001123685 Homo sapiens Paraneoplastic antigen Ma3 Proteins 0.000 description 4
- 101000835745 Homo sapiens Teratocarcinoma-derived growth factor 1 Proteins 0.000 description 4
- DMHGKBGOUAJRHU-RVMXOQNASA-N Ile-Arg-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N DMHGKBGOUAJRHU-RVMXOQNASA-N 0.000 description 4
- DMHGKBGOUAJRHU-UHFFFAOYSA-N Ile-Arg-Pro Natural products CCC(C)C(N)C(=O)NC(CCCN=C(N)N)C(=O)N1CCCC1C(O)=O DMHGKBGOUAJRHU-UHFFFAOYSA-N 0.000 description 4
- YBJWJQQBWRARLT-KBIXCLLPSA-N Ile-Gln-Ser Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O YBJWJQQBWRARLT-KBIXCLLPSA-N 0.000 description 4
- 241000235058 Komagataella pastoris Species 0.000 description 4
- LZDNBBYBDGBADK-UHFFFAOYSA-N L-valyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C(C)C)C(O)=O)=CNC2=C1 LZDNBBYBDGBADK-UHFFFAOYSA-N 0.000 description 4
- 208000031671 Large B-Cell Diffuse Lymphoma Diseases 0.000 description 4
- GRZSCTXVCDUIPO-SRVKXCTJSA-N Leu-Arg-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O GRZSCTXVCDUIPO-SRVKXCTJSA-N 0.000 description 4
- KVMULWOHPPMHHE-DCAQKATOSA-N Leu-Glu-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KVMULWOHPPMHHE-DCAQKATOSA-N 0.000 description 4
- IWTBYNQNAPECCS-AVGNSLFASA-N Leu-Glu-His Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 IWTBYNQNAPECCS-AVGNSLFASA-N 0.000 description 4
- WQWSMEOYXJTFRU-GUBZILKMSA-N Leu-Glu-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O WQWSMEOYXJTFRU-GUBZILKMSA-N 0.000 description 4
- UCBPDSYUVAAHCD-UWVGGRQHSA-N Leu-Pro-Gly Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UCBPDSYUVAAHCD-UWVGGRQHSA-N 0.000 description 4
- IDGZVZJLYFTXSL-DCAQKATOSA-N Leu-Ser-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IDGZVZJLYFTXSL-DCAQKATOSA-N 0.000 description 4
- JIHDFWWRYHSAQB-GUBZILKMSA-N Leu-Ser-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O JIHDFWWRYHSAQB-GUBZILKMSA-N 0.000 description 4
- ADJWHHZETYAAAX-SRVKXCTJSA-N Leu-Ser-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N ADJWHHZETYAAAX-SRVKXCTJSA-N 0.000 description 4
- SQUFDMCWMFOEBA-KKUMJFAQSA-N Leu-Ser-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 SQUFDMCWMFOEBA-KKUMJFAQSA-N 0.000 description 4
- IDGRADDMTTWOQC-WDSOQIARSA-N Leu-Trp-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IDGRADDMTTWOQC-WDSOQIARSA-N 0.000 description 4
- VHTIZYYHIUHMCA-JYJNAYRXSA-N Leu-Tyr-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O VHTIZYYHIUHMCA-JYJNAYRXSA-N 0.000 description 4
- VQHUBNVKFFLWRP-ULQDDVLXSA-N Leu-Tyr-Val Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=C(O)C=C1 VQHUBNVKFFLWRP-ULQDDVLXSA-N 0.000 description 4
- 208000031422 Lymphocytic Chronic B-Cell Leukemia Diseases 0.000 description 4
- VHFFQUSNFFIZBT-CIUDSAMLSA-N Lys-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCCCN)N VHFFQUSNFFIZBT-CIUDSAMLSA-N 0.000 description 4
- GCMWRRQAKQXDED-IUCAKERBSA-N Lys-Glu-Gly Chemical compound [NH3+]CCCC[C@H]([NH3+])C(=O)N[C@@H](CCC([O-])=O)C(=O)NCC([O-])=O GCMWRRQAKQXDED-IUCAKERBSA-N 0.000 description 4
- DUTMKEAPLLUGNO-JYJNAYRXSA-N Lys-Glu-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O DUTMKEAPLLUGNO-JYJNAYRXSA-N 0.000 description 4
- JOSAKOKSPXROGQ-BJDJZHNGSA-N Lys-Ser-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JOSAKOKSPXROGQ-BJDJZHNGSA-N 0.000 description 4
- MEQLGHAMAUPOSJ-DCAQKATOSA-N Lys-Ser-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O MEQLGHAMAUPOSJ-DCAQKATOSA-N 0.000 description 4
- RPWTZTBIFGENIA-VOAKCMCISA-N Lys-Thr-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O RPWTZTBIFGENIA-VOAKCMCISA-N 0.000 description 4
- OOSPRDCGTLQLBP-NHCYSSNCSA-N Met-Glu-Val Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OOSPRDCGTLQLBP-NHCYSSNCSA-N 0.000 description 4
- XMQZLGBUJMMODC-AVGNSLFASA-N Met-His-Val Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(O)=O XMQZLGBUJMMODC-AVGNSLFASA-N 0.000 description 4
- 108700011259 MicroRNAs Proteins 0.000 description 4
- 102100021440 Modulator of apoptosis 1 Human genes 0.000 description 4
- 108010066427 N-valyltryptophan Proteins 0.000 description 4
- 241000289371 Ornithorhynchus anatinus Species 0.000 description 4
- 102100028922 Paraneoplastic antigen Ma3 Human genes 0.000 description 4
- 108091093037 Peptide nucleic acid Proteins 0.000 description 4
- AGYXCMYVTBYGCT-ULQDDVLXSA-N Phe-Arg-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O AGYXCMYVTBYGCT-ULQDDVLXSA-N 0.000 description 4
- BNBBNGZZKQUWCD-IUCAKERBSA-N Pro-Arg-Gly Chemical compound NC(N)=NCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H]1CCCN1 BNBBNGZZKQUWCD-IUCAKERBSA-N 0.000 description 4
- MCWHYUWXVNRXFV-RWMBFGLXSA-N Pro-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 MCWHYUWXVNRXFV-RWMBFGLXSA-N 0.000 description 4
- KDBHVPXBQADZKY-GUBZILKMSA-N Pro-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 KDBHVPXBQADZKY-GUBZILKMSA-N 0.000 description 4
- OWQXAJQZLWHPBH-FXQIFTODSA-N Pro-Ser-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O OWQXAJQZLWHPBH-FXQIFTODSA-N 0.000 description 4
- SNGZLPOXVRTNMB-LPEHRKFASA-N Pro-Ser-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N2CCC[C@@H]2C(=O)O SNGZLPOXVRTNMB-LPEHRKFASA-N 0.000 description 4
- FUOGXAQMNJMBFG-WPRPVWTQSA-N Pro-Val-Gly Chemical compound OC(=O)CNC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 FUOGXAQMNJMBFG-WPRPVWTQSA-N 0.000 description 4
- 102100031705 Protein LDOC1 Human genes 0.000 description 4
- 102100035844 Retrotransposon-derived protein PEG10 Human genes 0.000 description 4
- 241000235347 Schizosaccharomyces pombe Species 0.000 description 4
- RNMRYWZYFHHOEV-CIUDSAMLSA-N Ser-Gln-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RNMRYWZYFHHOEV-CIUDSAMLSA-N 0.000 description 4
- UOLGINIHBRIECN-FXQIFTODSA-N Ser-Glu-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UOLGINIHBRIECN-FXQIFTODSA-N 0.000 description 4
- VQBCMLMPEWPUTB-ACZMJKKPSA-N Ser-Glu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VQBCMLMPEWPUTB-ACZMJKKPSA-N 0.000 description 4
- CICQXRWZNVXFCU-SRVKXCTJSA-N Ser-His-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O CICQXRWZNVXFCU-SRVKXCTJSA-N 0.000 description 4
- MOINZPRHJGTCHZ-MMWGEVLESA-N Ser-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N MOINZPRHJGTCHZ-MMWGEVLESA-N 0.000 description 4
- FZEUTKVQGMVGHW-AVGNSLFASA-N Ser-Phe-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O FZEUTKVQGMVGHW-AVGNSLFASA-N 0.000 description 4
- XGQKSRGHEZNWIS-IHRRRGAJSA-N Ser-Pro-Tyr Chemical compound N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1ccc(O)cc1)C(O)=O XGQKSRGHEZNWIS-IHRRRGAJSA-N 0.000 description 4
- CKDXFSPMIDSMGV-GUBZILKMSA-N Ser-Pro-Val Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O CKDXFSPMIDSMGV-GUBZILKMSA-N 0.000 description 4
- 108020004459 Small interfering RNA Proteins 0.000 description 4
- 210000001744 T-lymphocyte Anatomy 0.000 description 4
- 102100026404 Teratocarcinoma-derived growth factor 1 Human genes 0.000 description 4
- SWIKDOUVROTZCW-GCJQMDKQSA-N Thr-Asn-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](C)C(=O)O)N)O SWIKDOUVROTZCW-GCJQMDKQSA-N 0.000 description 4
- IJVNLNRVDUTWDD-MEYUZBJRSA-N Thr-Leu-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O IJVNLNRVDUTWDD-MEYUZBJRSA-N 0.000 description 4
- HYNAKPYFEYJMAS-XIRDDKMYSA-N Trp-Arg-Glu Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O HYNAKPYFEYJMAS-XIRDDKMYSA-N 0.000 description 4
- UUIYFDAWNBSWPG-IHPCNDPISA-N Trp-Lys-Lys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)O)N UUIYFDAWNBSWPG-IHPCNDPISA-N 0.000 description 4
- IYHRKILQAQWODS-VJBMBRPKSA-N Trp-Trp-Glu Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CNC4=CC=CC=C43)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N IYHRKILQAQWODS-VJBMBRPKSA-N 0.000 description 4
- LNGFWVPNKLWATF-ZVZYQTTQSA-N Trp-Val-Glu Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LNGFWVPNKLWATF-ZVZYQTTQSA-N 0.000 description 4
- UOXPLPBMEPLZBW-WDSOQIARSA-N Trp-Val-Lys Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 UOXPLPBMEPLZBW-WDSOQIARSA-N 0.000 description 4
- BABINGWMZBWXIX-BPUTZDHNSA-N Trp-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N BABINGWMZBWXIX-BPUTZDHNSA-N 0.000 description 4
- GHUNBABNQPIETG-MELADBBJSA-N Tyr-Cys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CS)NC(=O)[C@H](CC2=CC=C(C=C2)O)N)C(=O)O GHUNBABNQPIETG-MELADBBJSA-N 0.000 description 4
- JHDZONWZTCKTJR-KJEVXHAQSA-N Tyr-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 JHDZONWZTCKTJR-KJEVXHAQSA-N 0.000 description 4
- BXJQKVDPRMLGKN-PMVMPFDFSA-N Tyr-Trp-Leu Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(O)=O)C1=CC=C(O)C=C1 BXJQKVDPRMLGKN-PMVMPFDFSA-N 0.000 description 4
- UEOOXDLMQZBPFR-ZKWXMUAHSA-N Val-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N UEOOXDLMQZBPFR-ZKWXMUAHSA-N 0.000 description 4
- AZSHAZJLOZQYAY-FXQIFTODSA-N Val-Ala-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O AZSHAZJLOZQYAY-FXQIFTODSA-N 0.000 description 4
- ISERLACIZUGCDX-ZKWXMUAHSA-N Val-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C(C)C)N ISERLACIZUGCDX-ZKWXMUAHSA-N 0.000 description 4
- OVLIFGQSBSNGHY-KKHAAJSZSA-N Val-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C(C)C)N)O OVLIFGQSBSNGHY-KKHAAJSZSA-N 0.000 description 4
- PIFJAFRUVWZRKR-QMMMGPOBSA-N Val-Gly-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)NCC(=O)NCC([O-])=O PIFJAFRUVWZRKR-QMMMGPOBSA-N 0.000 description 4
- AIWLHFZYOUUJGB-UFYCRDLUSA-N Val-Phe-Tyr Chemical compound C([C@H](NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 AIWLHFZYOUUJGB-UFYCRDLUSA-N 0.000 description 4
- 102100021377 Zinc finger protein 18 Human genes 0.000 description 4
- 108010029539 arginyl-prolyl-proline Proteins 0.000 description 4
- 108010062796 arginyllysine Proteins 0.000 description 4
- 210000004899 c-terminal region Anatomy 0.000 description 4
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 4
- DTPCFIHYWYONMD-UHFFFAOYSA-N decaethylene glycol Chemical compound OCCOCCOCCOCCOCCOCCOCCOCCOCCOCCO DTPCFIHYWYONMD-UHFFFAOYSA-N 0.000 description 4
- 206010012818 diffuse large B-cell lymphoma Diseases 0.000 description 4
- 229940105423 erythropoietin Drugs 0.000 description 4
- 230000004927 fusion Effects 0.000 description 4
- 230000009368 gene silencing by RNA Effects 0.000 description 4
- 108010080575 glutamyl-aspartyl-alanine Proteins 0.000 description 4
- 108010049041 glutamylalanine Proteins 0.000 description 4
- 108010010147 glycylglutamine Proteins 0.000 description 4
- 108010050848 glycylleucine Proteins 0.000 description 4
- 125000000623 heterocyclic group Chemical group 0.000 description 4
- 108010040030 histidinoalanine Proteins 0.000 description 4
- 108010036413 histidylglycine Proteins 0.000 description 4
- 108010085325 histidylproline Proteins 0.000 description 4
- 108010018006 histidylserine Proteins 0.000 description 4
- 230000002209 hydrophobic effect Effects 0.000 description 4
- 238000003384 imaging method Methods 0.000 description 4
- 238000001727 in vivo Methods 0.000 description 4
- 239000003112 inhibitor Substances 0.000 description 4
- 108010053037 kyotorphin Proteins 0.000 description 4
- 108010057821 leucylproline Proteins 0.000 description 4
- 230000036210 malignancy Effects 0.000 description 4
- YACKEPLHDIMKIO-UHFFFAOYSA-N methylphosphonic acid Chemical class CP(O)(O)=O YACKEPLHDIMKIO-UHFFFAOYSA-N 0.000 description 4
- 239000000178 monomer Substances 0.000 description 4
- 229950010203 nimotuzumab Drugs 0.000 description 4
- 229910052757 nitrogen Inorganic materials 0.000 description 4
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 4
- 150000003904 phospholipids Chemical class 0.000 description 4
- OXCMYAYHXIHQOA-UHFFFAOYSA-N potassium;[2-butyl-5-chloro-3-[[4-[2-(1,2,4-triaza-3-azanidacyclopenta-1,4-dien-5-yl)phenyl]phenyl]methyl]imidazol-4-yl]methanol Chemical compound [K+].CCCCC1=NC(Cl)=C(CO)N1CC1=CC=C(C=2C(=CC=CC=2)C2=N[N-]N=N2)C=C1 OXCMYAYHXIHQOA-UHFFFAOYSA-N 0.000 description 4
- 108010093296 prolyl-prolyl-alanine Proteins 0.000 description 4
- 230000002829 reductive effect Effects 0.000 description 4
- 229920002477 rna polymer Polymers 0.000 description 4
- 238000012360 testing method Methods 0.000 description 4
- 238000004627 transmission electron microscopy Methods 0.000 description 4
- YLTKNGYYPIWKHZ-ACZMJKKPSA-N Ala-Ala-Glu Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O YLTKNGYYPIWKHZ-ACZMJKKPSA-N 0.000 description 3
- WDIYWDJLXOCGRW-ACZMJKKPSA-N Ala-Asp-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WDIYWDJLXOCGRW-ACZMJKKPSA-N 0.000 description 3
- BEMGNWZECGIJOI-WDSKDSINSA-N Ala-Gly-Glu Chemical compound [H]N[C@@H](C)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O BEMGNWZECGIJOI-WDSKDSINSA-N 0.000 description 3
- MEFILNJXAVSUTO-JXUBOQSCSA-N Ala-Leu-Thr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MEFILNJXAVSUTO-JXUBOQSCSA-N 0.000 description 3
- 241001520221 Alligator sinensis Species 0.000 description 3
- 241000235349 Ascomycota Species 0.000 description 3
- QLRRUWXMMVXORS-UHFFFAOYSA-N Augustine Natural products C12=CC=3OCOC=3C=C2CN2C3CC(OC)C4OC4C31CC2 QLRRUWXMMVXORS-UHFFFAOYSA-N 0.000 description 3
- 241000221198 Basidiomycota Species 0.000 description 3
- 102100024220 CD180 antigen Human genes 0.000 description 3
- 241000282472 Canis lupus familiaris Species 0.000 description 3
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 description 3
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 3
- 241000255601 Drosophila melanogaster Species 0.000 description 3
- 102100031511 Fc receptor-like protein 2 Human genes 0.000 description 3
- 241000192125 Firmicutes Species 0.000 description 3
- 241000223218 Fusarium Species 0.000 description 3
- JTWZNMUVQWWGOX-SOUVJXGZSA-N Gln-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CCC(=O)N)N)C(=O)O JTWZNMUVQWWGOX-SOUVJXGZSA-N 0.000 description 3
- WZZSKAJIHTUUSG-ACZMJKKPSA-N Glu-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O WZZSKAJIHTUUSG-ACZMJKKPSA-N 0.000 description 3
- CGYDXNKRIMJMLV-GUBZILKMSA-N Glu-Arg-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O CGYDXNKRIMJMLV-GUBZILKMSA-N 0.000 description 3
- CYHBMLHCQXXCCT-AVGNSLFASA-N Glu-Asp-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CYHBMLHCQXXCCT-AVGNSLFASA-N 0.000 description 3
- RMWAOBGCZZSJHE-UMNHJUIQSA-N Glu-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N RMWAOBGCZZSJHE-UMNHJUIQSA-N 0.000 description 3
- QXUPRMQJDWJDFR-NRPADANISA-N Glu-Val-Ser Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O QXUPRMQJDWJDFR-NRPADANISA-N 0.000 description 3
- JUBDONGMHASUCN-IUCAKERBSA-N Gly-Glu-His Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O JUBDONGMHASUCN-IUCAKERBSA-N 0.000 description 3
- JZNWSCPGTDBMEW-UHFFFAOYSA-N Glycerophosphorylethanolamin Natural products NCCOP(O)(=O)OCC(O)CO JZNWSCPGTDBMEW-UHFFFAOYSA-N 0.000 description 3
- 101000980829 Homo sapiens CD180 antigen Proteins 0.000 description 3
- 101000844504 Homo sapiens Transient receptor potential cation channel subfamily M member 4 Proteins 0.000 description 3
- 108090000144 Human Proteins Proteins 0.000 description 3
- 102000003839 Human Proteins Human genes 0.000 description 3
- LKACSKJPTFSBHR-MNXVOIDGSA-N Ile-Gln-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N LKACSKJPTFSBHR-MNXVOIDGSA-N 0.000 description 3
- IBMVEYRWAWIOTN-UHFFFAOYSA-N L-Leucyl-L-Arginyl-L-Proline Natural products CC(C)CC(N)C(=O)NC(CCCN=C(N)N)C(=O)N1CCCC1C(O)=O IBMVEYRWAWIOTN-UHFFFAOYSA-N 0.000 description 3
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 3
- CQQGCWPXDHTTNF-GUBZILKMSA-N Leu-Ala-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O CQQGCWPXDHTTNF-GUBZILKMSA-N 0.000 description 3
- FJUKMPUELVROGK-IHRRRGAJSA-N Leu-Arg-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N FJUKMPUELVROGK-IHRRRGAJSA-N 0.000 description 3
- IBMVEYRWAWIOTN-RWMBFGLXSA-N Leu-Arg-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(O)=O IBMVEYRWAWIOTN-RWMBFGLXSA-N 0.000 description 3
- KGCLIYGPQXUNLO-IUCAKERBSA-N Leu-Gly-Glu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O KGCLIYGPQXUNLO-IUCAKERBSA-N 0.000 description 3
- IEWBEPKLKUXQBU-VOAKCMCISA-N Leu-Leu-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IEWBEPKLKUXQBU-VOAKCMCISA-N 0.000 description 3
- LVTJJOJKDCVZGP-QWRGUYRKSA-N Leu-Lys-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O LVTJJOJKDCVZGP-QWRGUYRKSA-N 0.000 description 3
- 239000005089 Luciferase Substances 0.000 description 3
- 241000282567 Macaca fascicularis Species 0.000 description 3
- 108700026244 Open Reading Frames Proteins 0.000 description 3
- 229910019142 PO4 Inorganic materials 0.000 description 3
- 241000711504 Paramyxoviridae Species 0.000 description 3
- 108091005804 Peptidases Proteins 0.000 description 3
- 241000283222 Physeter catodon Species 0.000 description 3
- 241001478881 Pogona vitticeps Species 0.000 description 3
- FRKBNXCFJBPJOL-GUBZILKMSA-N Pro-Glu-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O FRKBNXCFJBPJOL-GUBZILKMSA-N 0.000 description 3
- LEIKGVHQTKHOLM-IUCAKERBSA-N Pro-Pro-Gly Chemical compound OC(=O)CNC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 LEIKGVHQTKHOLM-IUCAKERBSA-N 0.000 description 3
- 102100036735 Prostate stem cell antigen Human genes 0.000 description 3
- 101710120463 Prostate stem cell antigen Proteins 0.000 description 3
- 239000004365 Protease Substances 0.000 description 3
- 108091030071 RNAI Proteins 0.000 description 3
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 3
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 3
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical group [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 3
- 230000029662 T-helper 1 type immune response Effects 0.000 description 3
- 238000010459 TALEN Methods 0.000 description 3
- NIEWSKWFURSECR-FOHZUACHSA-N Thr-Gly-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O NIEWSKWFURSECR-FOHZUACHSA-N 0.000 description 3
- XGJLNBNZNMVJRS-NRPADANISA-N Val-Glu-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O XGJLNBNZNMVJRS-NRPADANISA-N 0.000 description 3
- OQWNEUXPKHIEJO-NRPADANISA-N Val-Glu-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N OQWNEUXPKHIEJO-NRPADANISA-N 0.000 description 3
- YLRAFVVWZRSZQC-DZKIICNBSA-N Val-Phe-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N YLRAFVVWZRSZQC-DZKIICNBSA-N 0.000 description 3
- VIKZGAUAKQZDOF-NRPADANISA-N Val-Ser-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O VIKZGAUAKQZDOF-NRPADANISA-N 0.000 description 3
- 108010067390 Viral Proteins Proteins 0.000 description 3
- 241000235015 Yarrowia lipolytica Species 0.000 description 3
- 108010017070 Zinc Finger Nucleases Proteins 0.000 description 3
- 230000029936 alkylation Effects 0.000 description 3
- 238000005804 alkylation reaction Methods 0.000 description 3
- 239000005557 antagonist Substances 0.000 description 3
- 239000000611 antibody drug conjugate Substances 0.000 description 3
- 230000005875 antibody response Effects 0.000 description 3
- 229940049595 antibody-drug conjugate Drugs 0.000 description 3
- 239000003146 anticoagulant agent Substances 0.000 description 3
- 108010093581 aspartyl-proline Proteins 0.000 description 3
- 210000000601 blood cell Anatomy 0.000 description 3
- 229940095731 candida albicans Drugs 0.000 description 3
- 230000015556 catabolic process Effects 0.000 description 3
- 230000036755 cellular response Effects 0.000 description 3
- 150000001875 compounds Chemical class 0.000 description 3
- 238000006731 degradation reaction Methods 0.000 description 3
- 238000013461 design Methods 0.000 description 3
- CEJLBZWIKQJOAT-UHFFFAOYSA-N dichloroisocyanuric acid Chemical compound ClN1C(=O)NC(=O)N(Cl)C1=O CEJLBZWIKQJOAT-UHFFFAOYSA-N 0.000 description 3
- 150000002148 esters Chemical class 0.000 description 3
- 230000006870 function Effects 0.000 description 3
- 230000002538 fungal effect Effects 0.000 description 3
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 3
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 3
- 125000005842 heteroatom Chemical group 0.000 description 3
- 238000011534 incubation Methods 0.000 description 3
- 230000010354 integration Effects 0.000 description 3
- 102000006495 integrins Human genes 0.000 description 3
- 108010044426 integrins Proteins 0.000 description 3
- 210000004185 liver Anatomy 0.000 description 3
- 108010064235 lysylglycine Proteins 0.000 description 3
- 239000012528 membrane Substances 0.000 description 3
- 229930182817 methionine Natural products 0.000 description 3
- 229950003063 mitumomab Drugs 0.000 description 3
- 238000002156 mixing Methods 0.000 description 3
- 230000035772 mutation Effects 0.000 description 3
- 125000001624 naphthyl group Chemical group 0.000 description 3
- 230000007935 neutral effect Effects 0.000 description 3
- 150000003833 nucleoside derivatives Chemical group 0.000 description 3
- 230000037361 pathway Effects 0.000 description 3
- 239000010452 phosphate Substances 0.000 description 3
- 150000008104 phosphatidylethanolamines Chemical class 0.000 description 3
- 230000000770 proinflammatory effect Effects 0.000 description 3
- 210000001236 prokaryotic cell Anatomy 0.000 description 3
- 108010077112 prolyl-proline Proteins 0.000 description 3
- 108010087846 prolyl-prolyl-glycine Proteins 0.000 description 3
- 108010053725 prolylvaline Proteins 0.000 description 3
- 229940021993 prophylactic vaccine Drugs 0.000 description 3
- 108010026333 seryl-proline Proteins 0.000 description 3
- 210000004927 skin cell Anatomy 0.000 description 3
- 238000006467 substitution reaction Methods 0.000 description 3
- 239000011593 sulfur Chemical group 0.000 description 3
- 229910052717 sulfur Inorganic materials 0.000 description 3
- 229940021747 therapeutic vaccine Drugs 0.000 description 3
- 238000013519 translation Methods 0.000 description 3
- 230000032258 transport Effects 0.000 description 3
- 230000029069 type 2 immune response Effects 0.000 description 3
- 108010073969 valyllysine Proteins 0.000 description 3
- 239000003981 vehicle Substances 0.000 description 3
- MFRNYXJJRJQHNW-DEMKXPNLSA-N (2s)-2-[[(2r,3r)-3-methoxy-3-[(2s)-1-[(3r,4s,5s)-3-methoxy-5-methyl-4-[methyl-[(2s)-3-methyl-2-[[(2s)-3-methyl-2-(methylamino)butanoyl]amino]butanoyl]amino]heptanoyl]pyrrolidin-2-yl]-2-methylpropanoyl]amino]-3-phenylpropanoic acid Chemical compound CN[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(=O)N(C)[C@@H]([C@@H](C)CC)[C@H](OC)CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MFRNYXJJRJQHNW-DEMKXPNLSA-N 0.000 description 2
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 2
- CITHEXJVPOWHKC-UUWRZZSWSA-N 1,2-di-O-myristoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCCCCCCC CITHEXJVPOWHKC-UUWRZZSWSA-N 0.000 description 2
- KILNVBDSWZSGLL-KXQOOQHDSA-N 1,2-dihexadecanoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCCCCCCCCC KILNVBDSWZSGLL-KXQOOQHDSA-N 0.000 description 2
- SLKDGVPOSSLUAI-PGUFJCEWSA-N 1,2-dihexadecanoyl-sn-glycero-3-phosphoethanolamine zwitterion Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP(O)(=O)OCCN)OC(=O)CCCCCCCCCCCCCCC SLKDGVPOSSLUAI-PGUFJCEWSA-N 0.000 description 2
- PORPENFLTBBHSG-MGBGTMOVSA-N 1,2-dihexadecanoyl-sn-glycerol-3-phosphate Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP(O)(O)=O)OC(=O)CCCCCCCCCCCCCCC PORPENFLTBBHSG-MGBGTMOVSA-N 0.000 description 2
- YFWHNAWEOZTIPI-DIPNUNPCSA-N 1,2-dioctadecanoyl-sn-glycerol-3-phosphate Chemical compound CCCCCCCCCCCCCCCCCC(=O)OC[C@H](COP(O)(O)=O)OC(=O)CCCCCCCCCCCCCCCCC YFWHNAWEOZTIPI-DIPNUNPCSA-N 0.000 description 2
- NRJAVPSFFCBXDT-HUESYALOSA-N 1,2-distearoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCCCCCCCCCCC NRJAVPSFFCBXDT-HUESYALOSA-N 0.000 description 2
- LVNGJLRDBYCPGB-UHFFFAOYSA-N 1,2-distearoylphosphatidylethanolamine Chemical compound CCCCCCCCCCCCCCCCCC(=O)OCC(COP([O-])(=O)OCC[NH3+])OC(=O)CCCCCCCCCCCCCCCCC LVNGJLRDBYCPGB-UHFFFAOYSA-N 0.000 description 2
- OZSITQMWYBNPMW-GDLZYMKVSA-N 1,2-ditetradecanoyl-sn-glycerol-3-phosphate Chemical compound CCCCCCCCCCCCCC(=O)OC[C@H](COP(O)(O)=O)OC(=O)CCCCCCCCCCCCC OZSITQMWYBNPMW-GDLZYMKVSA-N 0.000 description 2
- BIABMEZBCHDPBV-MPQUPPDSSA-N 1,2-palmitoyl-sn-glycero-3-phospho-(1'-sn-glycerol) Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP(O)(=O)OC[C@@H](O)CO)OC(=O)CCCCCCCCCCCCCCC BIABMEZBCHDPBV-MPQUPPDSSA-N 0.000 description 2
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 2
- NEZDNQCXEZDCBI-UHFFFAOYSA-N 2-azaniumylethyl 2,3-di(tetradecanoyloxy)propyl phosphate Chemical compound CCCCCCCCCCCCCC(=O)OCC(COP(O)(=O)OCCN)OC(=O)CCCCCCCCCCCCC NEZDNQCXEZDCBI-UHFFFAOYSA-N 0.000 description 2
- HKOAFLAGUQUJQG-UHFFFAOYSA-N 2-pyrimidin-2-ylpyrimidine Chemical group N1=CC=CN=C1C1=NC=CC=N1 HKOAFLAGUQUJQG-UHFFFAOYSA-N 0.000 description 2
- UHPMCKVQTMMPCG-UHFFFAOYSA-N 5,8-dihydroxy-2-methoxy-6-methyl-7-(2-oxopropyl)naphthalene-1,4-dione Chemical compound CC1=C(CC(C)=O)C(O)=C2C(=O)C(OC)=CC(=O)C2=C1O UHPMCKVQTMMPCG-UHFFFAOYSA-N 0.000 description 2
- 239000000275 Adrenocorticotropic Hormone Substances 0.000 description 2
- 241000275062 Agrilus planipennis Species 0.000 description 2
- IETUUAHKCHOQHP-KZVJFYERSA-N Ala-Thr-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@H](C)N)[C@@H](C)O)C(O)=O IETUUAHKCHOQHP-KZVJFYERSA-N 0.000 description 2
- 241000270730 Alligator mississippiensis Species 0.000 description 2
- 102100032187 Androgen receptor Human genes 0.000 description 2
- VKKYFICVTYKFIO-CIUDSAMLSA-N Arg-Ala-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N VKKYFICVTYKFIO-CIUDSAMLSA-N 0.000 description 2
- VENMDXUVHSKEIN-GUBZILKMSA-N Arg-Ser-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O VENMDXUVHSKEIN-GUBZILKMSA-N 0.000 description 2
- RSMIHCFQDCVVBR-CIUDSAMLSA-N Asp-Gln-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CCCNC(N)=N RSMIHCFQDCVVBR-CIUDSAMLSA-N 0.000 description 2
- GHODABZPVZMWCE-FXQIFTODSA-N Asp-Glu-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O GHODABZPVZMWCE-FXQIFTODSA-N 0.000 description 2
- KPNUCOPMVSGRCR-DCAQKATOSA-N Asp-His-Arg Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O KPNUCOPMVSGRCR-DCAQKATOSA-N 0.000 description 2
- 241000228212 Aspergillus Species 0.000 description 2
- 241001513093 Aspergillus awamori Species 0.000 description 2
- 241001225321 Aspergillus fumigatus Species 0.000 description 2
- 241000351920 Aspergillus nidulans Species 0.000 description 2
- 241000228245 Aspergillus niger Species 0.000 description 2
- 240000006439 Aspergillus oryzae Species 0.000 description 2
- 235000002247 Aspergillus oryzae Nutrition 0.000 description 2
- 241000511228 Austrofundulus limnaeus Species 0.000 description 2
- 102100024222 B-lymphocyte antigen CD19 Human genes 0.000 description 2
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 description 2
- 206010005003 Bladder cancer Diseases 0.000 description 2
- 241000283690 Bos taurus Species 0.000 description 2
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 2
- 208000003174 Brain Neoplasms Diseases 0.000 description 2
- 206010006187 Breast cancer Diseases 0.000 description 2
- 208000026310 Breast neoplasm Diseases 0.000 description 2
- 244000027711 Brettanomyces bruxellensis Species 0.000 description 2
- 235000000287 Brettanomyces bruxellensis Nutrition 0.000 description 2
- 208000011691 Burkitt lymphomas Diseases 0.000 description 2
- 102100021943 C-C motif chemokine 2 Human genes 0.000 description 2
- 108010021064 CTLA-4 Antigen Proteins 0.000 description 2
- 229940045513 CTLA4 antagonist Drugs 0.000 description 2
- 241001491932 Camponotus atriceps Species 0.000 description 2
- 241000222120 Candida <Saccharomycetales> Species 0.000 description 2
- 241000222173 Candida parapsilosis Species 0.000 description 2
- 241000222178 Candida tropicalis Species 0.000 description 2
- 102100025475 Carcinoembryonic antigen-related cell adhesion molecule 5 Human genes 0.000 description 2
- 102100025473 Carcinoembryonic antigen-related cell adhesion molecule 6 Human genes 0.000 description 2
- 241001478369 Carlito syrichta Species 0.000 description 2
- 241000499489 Castor canadensis Species 0.000 description 2
- 102000053642 Catalytic RNA Human genes 0.000 description 2
- 108090000994 Catalytic RNA Proteins 0.000 description 2
- 241000700199 Cavia porcellus Species 0.000 description 2
- 241001481771 Chinchilla lanigera Species 0.000 description 2
- 241001185363 Chlamydiae Species 0.000 description 2
- 241000270627 Chrysemys picta bellii Species 0.000 description 2
- 206010009944 Colon cancer Diseases 0.000 description 2
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 2
- 102100030886 Complement receptor type 1 Human genes 0.000 description 2
- 102400000739 Corticotropin Human genes 0.000 description 2
- 101800000414 Corticotropin Proteins 0.000 description 2
- 241000699800 Cricetinae Species 0.000 description 2
- 241000699802 Cricetulus griseus Species 0.000 description 2
- 241000270313 Crocodylus porosus Species 0.000 description 2
- 241001522864 Cryptococcus gattii VGI Species 0.000 description 2
- 102000013701 Cyclin-Dependent Kinase 4 Human genes 0.000 description 2
- 108010025464 Cyclin-Dependent Kinase 4 Proteins 0.000 description 2
- 102000013698 Cyclin-Dependent Kinase 6 Human genes 0.000 description 2
- 108010025468 Cyclin-Dependent Kinase 6 Proteins 0.000 description 2
- HMFHBZSHGGEWLO-SOOFDHNKSA-N D-ribofuranose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-SOOFDHNKSA-N 0.000 description 2
- 230000004568 DNA-binding Effects 0.000 description 2
- 108091027757 Deoxyribozyme Proteins 0.000 description 2
- RTZKZFJDLAIYFH-UHFFFAOYSA-N Diethyl ether Chemical compound CCOCC RTZKZFJDLAIYFH-UHFFFAOYSA-N 0.000 description 2
- KLFKZIQAIPDJCW-HTIIIDOHSA-N Dipalmitoylphosphatidylserine Chemical compound CCCCCCCCCCCCCCCC(=O)OCC(COP(O)(=O)OC[C@H](N)C(O)=O)OC(=O)CCCCCCCCCCCCCCC KLFKZIQAIPDJCW-HTIIIDOHSA-N 0.000 description 2
- 241000699804 Dipodomys ordii Species 0.000 description 2
- 241000255581 Drosophila <fruit fly, genus> Species 0.000 description 2
- 102000001301 EGF receptor Human genes 0.000 description 2
- 108060006698 EGF receptor Proteins 0.000 description 2
- 102100038132 Endogenous retrovirus group K member 6 Pro protein Human genes 0.000 description 2
- 108010066687 Epithelial Cell Adhesion Molecule Proteins 0.000 description 2
- 102000018651 Epithelial Cell Adhesion Molecule Human genes 0.000 description 2
- 241000195621 Euglena longa Species 0.000 description 2
- 102100031517 Fc receptor-like protein 1 Human genes 0.000 description 2
- 241000282326 Felis catus Species 0.000 description 2
- 102100023593 Fibroblast growth factor receptor 1 Human genes 0.000 description 2
- 101710182386 Fibroblast growth factor receptor 1 Proteins 0.000 description 2
- 102100023600 Fibroblast growth factor receptor 2 Human genes 0.000 description 2
- 101710182389 Fibroblast growth factor receptor 2 Proteins 0.000 description 2
- 102100027842 Fibroblast growth factor receptor 3 Human genes 0.000 description 2
- 101710182396 Fibroblast growth factor receptor 3 Proteins 0.000 description 2
- 102100027844 Fibroblast growth factor receptor 4 Human genes 0.000 description 2
- 101710182387 Fibroblast growth factor receptor 4 Proteins 0.000 description 2
- 102000012673 Follicle Stimulating Hormone Human genes 0.000 description 2
- 108010079345 Follicle Stimulating Hormone Proteins 0.000 description 2
- 241000223195 Fusarium graminearum Species 0.000 description 2
- 241000233732 Fusarium verticillioides Species 0.000 description 2
- 102000003688 G-Protein-Coupled Receptors Human genes 0.000 description 2
- 108090000045 G-Protein-Coupled Receptors Proteins 0.000 description 2
- 101710177291 Gag polyprotein Proteins 0.000 description 2
- 102100021260 Galactosylgalactosylxylosylprotein 3-beta-glucuronosyltransferase 1 Human genes 0.000 description 2
- 241000205692 Galeopterus variegatus Species 0.000 description 2
- 241000360057 Gavialis gangeticus Species 0.000 description 2
- WQWMZOIPXWSZNE-WDSKDSINSA-N Gln-Asp-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O WQWMZOIPXWSZNE-WDSKDSINSA-N 0.000 description 2
- MCAVASRGVBVPMX-FXQIFTODSA-N Gln-Glu-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O MCAVASRGVBVPMX-FXQIFTODSA-N 0.000 description 2
- HLRLXVPRJJITSK-IFFSRLJSSA-N Gln-Thr-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HLRLXVPRJJITSK-IFFSRLJSSA-N 0.000 description 2
- QGWXAMDECCKGRU-XVKPBYJWSA-N Gln-Val-Gly Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCC(N)=O)C(=O)NCC(O)=O QGWXAMDECCKGRU-XVKPBYJWSA-N 0.000 description 2
- LKDIBBOKUAASNP-FXQIFTODSA-N Glu-Ala-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LKDIBBOKUAASNP-FXQIFTODSA-N 0.000 description 2
- AUTNXSQEVVHSJK-YVNDNENWSA-N Glu-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O AUTNXSQEVVHSJK-YVNDNENWSA-N 0.000 description 2
- IVGJYOOGJLFKQE-AVGNSLFASA-N Glu-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N IVGJYOOGJLFKQE-AVGNSLFASA-N 0.000 description 2
- GMVCSRBOSIUTFC-FXQIFTODSA-N Glu-Ser-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O GMVCSRBOSIUTFC-FXQIFTODSA-N 0.000 description 2
- NSTUFLGQJCOCDL-UWVGGRQHSA-N Gly-Leu-Arg Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N NSTUFLGQJCOCDL-UWVGGRQHSA-N 0.000 description 2
- VLIJYPMATZSOLL-YUMQZZPRSA-N Gly-Lys-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)CN VLIJYPMATZSOLL-YUMQZZPRSA-N 0.000 description 2
- GGLIDLCEPDHEJO-BQBZGAKWSA-N Gly-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)CN GGLIDLCEPDHEJO-BQBZGAKWSA-N 0.000 description 2
- NSVOVKWEKGEOQB-LURJTMIESA-N Gly-Pro-Gly Chemical compound NCC(=O)N1CCC[C@H]1C(=O)NCC(O)=O NSVOVKWEKGEOQB-LURJTMIESA-N 0.000 description 2
- BMWFDYIYBAFROD-WPRPVWTQSA-N Gly-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN BMWFDYIYBAFROD-WPRPVWTQSA-N 0.000 description 2
- DBUNZBWUWCIELX-JHEQGTHGSA-N Gly-Thr-Glu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O DBUNZBWUWCIELX-JHEQGTHGSA-N 0.000 description 2
- ZWZWYGMENQVNFU-UHFFFAOYSA-N Glycerophosphorylserin Natural products OC(=O)C(N)COP(O)(=O)OCC(O)CO ZWZWYGMENQVNFU-UHFFFAOYSA-N 0.000 description 2
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 2
- 102000003886 Glycoproteins Human genes 0.000 description 2
- 108090000288 Glycoproteins Proteins 0.000 description 2
- 241000282575 Gorilla Species 0.000 description 2
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 2
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 description 2
- 241000272484 Haliaeetus albicilla Species 0.000 description 2
- 244000286779 Hansenula anomala Species 0.000 description 2
- 235000014683 Hansenula anomala Nutrition 0.000 description 2
- 102100031573 Hematopoietic progenitor cell antigen CD34 Human genes 0.000 description 2
- 241000700586 Herpesviridae Species 0.000 description 2
- KZTLOHBDLMIFSH-XVYDVKMFSA-N His-Ala-Asp Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O KZTLOHBDLMIFSH-XVYDVKMFSA-N 0.000 description 2
- YAALVYQFVJNXIV-KKUMJFAQSA-N His-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CN=CN1 YAALVYQFVJNXIV-KKUMJFAQSA-N 0.000 description 2
- SKOKHBGDXGTDDP-MELADBBJSA-N His-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N SKOKHBGDXGTDDP-MELADBBJSA-N 0.000 description 2
- 101000980825 Homo sapiens B-lymphocyte antigen CD19 Proteins 0.000 description 2
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 description 2
- 101000914326 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 6 Proteins 0.000 description 2
- 101000727061 Homo sapiens Complement receptor type 1 Proteins 0.000 description 2
- 101000846911 Homo sapiens Fc receptor-like protein 2 Proteins 0.000 description 2
- 101000894906 Homo sapiens Galactosylgalactosylxylosylprotein 3-beta-glucuronosyltransferase 1 Proteins 0.000 description 2
- 101000777663 Homo sapiens Hematopoietic progenitor cell antigen CD34 Proteins 0.000 description 2
- 101000599951 Homo sapiens Insulin-like growth factor I Proteins 0.000 description 2
- 101000960936 Homo sapiens Interleukin-5 receptor subunit alpha Proteins 0.000 description 2
- 101000623901 Homo sapiens Mucin-16 Proteins 0.000 description 2
- 101000934338 Homo sapiens Myeloid cell surface antigen CD33 Proteins 0.000 description 2
- 101000738771 Homo sapiens Receptor-type tyrosine-protein phosphatase C Proteins 0.000 description 2
- 101000633784 Homo sapiens SLAM family member 7 Proteins 0.000 description 2
- HTDRTKMNJRRYOJ-SIUGBPQLSA-N Ile-Gln-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HTDRTKMNJRRYOJ-SIUGBPQLSA-N 0.000 description 2
- SAVXZJYTTQQQDD-QEWYBTABSA-N Ile-Phe-Glu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N SAVXZJYTTQQQDD-QEWYBTABSA-N 0.000 description 2
- 108060003951 Immunoglobulin Proteins 0.000 description 2
- 108010065920 Insulin Lispro Proteins 0.000 description 2
- 102100037852 Insulin-like growth factor I Human genes 0.000 description 2
- 108010050904 Interferons Proteins 0.000 description 2
- 102000014150 Interferons Human genes 0.000 description 2
- 102100039881 Interleukin-5 receptor subunit alpha Human genes 0.000 description 2
- 102000015696 Interleukins Human genes 0.000 description 2
- 108010063738 Interleukins Proteins 0.000 description 2
- 108010000837 Janus Kinase 1 Proteins 0.000 description 2
- 108010019421 Janus Kinase 3 Proteins 0.000 description 2
- 208000008839 Kidney Neoplasms Diseases 0.000 description 2
- 241001138401 Kluyveromyces lactis Species 0.000 description 2
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 2
- 102100033467 L-selectin Human genes 0.000 description 2
- 102100038204 Large neutral amino acids transporter small subunit 1 Human genes 0.000 description 2
- 241000251465 Latimeria chalumnae Species 0.000 description 2
- WGNOPSQMIQERPK-UHFFFAOYSA-N Leu-Asn-Pro Natural products CC(C)CC(N)C(=O)NC(CC(=O)N)C(=O)N1CCCC1C(=O)O WGNOPSQMIQERPK-UHFFFAOYSA-N 0.000 description 2
- HQUXQAMSWFIRET-AVGNSLFASA-N Leu-Glu-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN HQUXQAMSWFIRET-AVGNSLFASA-N 0.000 description 2
- 108090001030 Lipoproteins Proteins 0.000 description 2
- 102000004895 Lipoproteins Human genes 0.000 description 2
- 108060001084 Luciferase Proteins 0.000 description 2
- 206010058467 Lung neoplasm malignant Diseases 0.000 description 2
- 206010025323 Lymphomas Diseases 0.000 description 2
- LLSUNJYOSCOOEB-GUBZILKMSA-N Lys-Glu-Asp Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O LLSUNJYOSCOOEB-GUBZILKMSA-N 0.000 description 2
- SKRGVGLIRUGANF-AVGNSLFASA-N Lys-Leu-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SKRGVGLIRUGANF-AVGNSLFASA-N 0.000 description 2
- 208000025205 Mantle-Cell Lymphoma Diseases 0.000 description 2
- 241000283940 Marmota Species 0.000 description 2
- HGAJNEWOUHDUMZ-SRVKXCTJSA-N Met-Leu-Glu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O HGAJNEWOUHDUMZ-SRVKXCTJSA-N 0.000 description 2
- NHXXGBXJTLRGJI-GUBZILKMSA-N Met-Pro-Ser Chemical compound [H]N[C@@H](CCSC)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O NHXXGBXJTLRGJI-GUBZILKMSA-N 0.000 description 2
- 241001465754 Metazoa Species 0.000 description 2
- CERQOIWHTDAKMF-UHFFFAOYSA-N Methacrylic acid Chemical compound CC(=C)C(O)=O CERQOIWHTDAKMF-UHFFFAOYSA-N 0.000 description 2
- 102100023123 Mucin-16 Human genes 0.000 description 2
- 241001529936 Murinae Species 0.000 description 2
- 241000699670 Mus sp. Species 0.000 description 2
- 102100025243 Myeloid cell surface antigen CD33 Human genes 0.000 description 2
- SLEHROROQDYRAW-KQYNXXCUSA-N N(2)-methylguanosine Chemical compound C1=NC=2C(=O)NC(NC)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O SLEHROROQDYRAW-KQYNXXCUSA-N 0.000 description 2
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 2
- 241000649138 Nannospalax galili Species 0.000 description 2
- 241000566225 Neotoma lepida Species 0.000 description 2
- 101710163270 Nuclease Proteins 0.000 description 2
- 241000700124 Octodon degus Species 0.000 description 2
- 241000282960 Odocoileus virginianus texanus Species 0.000 description 2
- 241000320412 Ogataea angusta Species 0.000 description 2
- 241000272108 Ophiophagus hannah Species 0.000 description 2
- 241001416563 Otolemur garnettii Species 0.000 description 2
- 241000200171 Oxyrrhis marina Species 0.000 description 2
- FVJZSBGHRPJMMA-IOLBBIBUSA-N PG(18:0/18:0) Chemical compound CCCCCCCCCCCCCCCCCC(=O)OC[C@H](COP(O)(=O)OC[C@@H](O)CO)OC(=O)CCCCCCCCCCCCCCCCC FVJZSBGHRPJMMA-IOLBBIBUSA-N 0.000 description 2
- 108091007960 PI3Ks Proteins 0.000 description 2
- 241000776450 PVC group Species 0.000 description 2
- 206010061902 Pancreatic neoplasm Diseases 0.000 description 2
- 241000282516 Papio anubis Species 0.000 description 2
- 241001505424 Pelecanus crispus Species 0.000 description 2
- 241000736919 Pelodiscus sinensis Species 0.000 description 2
- 208000027190 Peripheral T-cell lymphomas Diseases 0.000 description 2
- 108090000430 Phosphatidylinositol 3-kinases Proteins 0.000 description 2
- 102000003993 Phosphatidylinositol 3-kinases Human genes 0.000 description 2
- 206010035226 Plasma cell myeloma Diseases 0.000 description 2
- 241000700625 Poxviridae Species 0.000 description 2
- 241000288906 Primates Species 0.000 description 2
- KIZQGKLMXKGDIV-BQBZGAKWSA-N Pro-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 KIZQGKLMXKGDIV-BQBZGAKWSA-N 0.000 description 2
- XQLBWXHVZVBNJM-FXQIFTODSA-N Pro-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 XQLBWXHVZVBNJM-FXQIFTODSA-N 0.000 description 2
- WVOXLKUUVCCCSU-ZPFDUUQYSA-N Pro-Glu-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WVOXLKUUVCCCSU-ZPFDUUQYSA-N 0.000 description 2
- LGSANCBHSMDFDY-GARJFASQSA-N Pro-Glu-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)O)C(=O)N2CCC[C@@H]2C(=O)O LGSANCBHSMDFDY-GARJFASQSA-N 0.000 description 2
- VYWNORHENYEQDW-YUMQZZPRSA-N Pro-Gly-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 VYWNORHENYEQDW-YUMQZZPRSA-N 0.000 description 2
- MKGIILKDUGDRRO-FXQIFTODSA-N Pro-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 MKGIILKDUGDRRO-FXQIFTODSA-N 0.000 description 2
- DMNANGOFEUVBRV-GJZGRUSLSA-N Pro-Trp-Gly Chemical compound N([C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)NCC(=O)O)C(=O)[C@@H]1CCCN1 DMNANGOFEUVBRV-GJZGRUSLSA-N 0.000 description 2
- IALSFJSONJZBKB-HRCADAONSA-N Pro-Tyr-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N3CCC[C@@H]3C(=O)O IALSFJSONJZBKB-HRCADAONSA-N 0.000 description 2
- FIODMZKLZFLYQP-GUBZILKMSA-N Pro-Val-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FIODMZKLZFLYQP-GUBZILKMSA-N 0.000 description 2
- 102100033237 Pro-epidermal growth factor Human genes 0.000 description 2
- 102100040678 Programmed cell death protein 1 Human genes 0.000 description 2
- 241000212139 Propithecus coquereli Species 0.000 description 2
- 206010060862 Prostate cancer Diseases 0.000 description 2
- 108010072866 Prostate-Specific Antigen Proteins 0.000 description 2
- 102100038358 Prostate-specific antigen Human genes 0.000 description 2
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 2
- 102000004022 Protein-Tyrosine Kinases Human genes 0.000 description 2
- 108090000412 Protein-Tyrosine Kinases Proteins 0.000 description 2
- 241001487808 Protobothrops mucrosquamatus Species 0.000 description 2
- 241000289053 Pteropus alecto Species 0.000 description 2
- 241000700159 Rattus Species 0.000 description 2
- 102100037422 Receptor-type tyrosine-protein phosphatase C Human genes 0.000 description 2
- 108020004511 Recombinant DNA Proteins 0.000 description 2
- 206010038389 Renal cancer Diseases 0.000 description 2
- 241000711931 Rhabdoviridae Species 0.000 description 2
- 241000881856 Rhinopithecus roxellana Species 0.000 description 2
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 description 2
- 102100029198 SLAM family member 7 Human genes 0.000 description 2
- 108091006232 SLC7A5 Proteins 0.000 description 2
- 241000235070 Saccharomyces Species 0.000 description 2
- 235000018370 Saccharomyces delbrueckii Nutrition 0.000 description 2
- 241001326564 Saccharomycotina Species 0.000 description 2
- OJPHFSOMBZKQKQ-GUBZILKMSA-N Ser-Gln-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CO OJPHFSOMBZKQKQ-GUBZILKMSA-N 0.000 description 2
- YMAWDPHQVABADW-CIUDSAMLSA-N Ser-Gln-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O YMAWDPHQVABADW-CIUDSAMLSA-N 0.000 description 2
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 2
- VXYQOFXBIXKPCX-BQBZGAKWSA-N Ser-Met-Gly Chemical compound CSCC[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CO)N VXYQOFXBIXKPCX-BQBZGAKWSA-N 0.000 description 2
- VLMIUSLQONKLDV-HEIBUPTGSA-N Ser-Thr-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VLMIUSLQONKLDV-HEIBUPTGSA-N 0.000 description 2
- PZHJLTWGMYERRJ-SRVKXCTJSA-N Ser-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N)O PZHJLTWGMYERRJ-SRVKXCTJSA-N 0.000 description 2
- JZRYFUGREMECBH-XPUUQOCRSA-N Ser-Val-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O JZRYFUGREMECBH-XPUUQOCRSA-N 0.000 description 2
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 2
- 108020004682 Single-Stranded DNA Proteins 0.000 description 2
- 208000000453 Skin Neoplasms Diseases 0.000 description 2
- 208000005718 Stomach Neoplasms Diseases 0.000 description 2
- 102100021947 Survival motor neuron protein Human genes 0.000 description 2
- 241000390529 Synergistetes Species 0.000 description 2
- 208000031672 T-Cell Peripheral Lymphoma Diseases 0.000 description 2
- 241001634922 Tausonia pullulans Species 0.000 description 2
- 241000857255 Temnothorax curvispinosus Species 0.000 description 2
- 241001143138 Thermodesulfobacteria <phylum> Species 0.000 description 2
- 241001143310 Thermotogae <phylum> Species 0.000 description 2
- BNGDYRRHRGOPHX-IFFSRLJSSA-N Thr-Glu-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O BNGDYRRHRGOPHX-IFFSRLJSSA-N 0.000 description 2
- VRUFCJZQDACGLH-UVOCVTCTSA-N Thr-Leu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VRUFCJZQDACGLH-UVOCVTCTSA-N 0.000 description 2
- PRTHQBSMXILLPC-XGEHTFHBSA-N Thr-Ser-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PRTHQBSMXILLPC-XGEHTFHBSA-N 0.000 description 2
- NDZYTIMDOZMECO-SHGPDSBTSA-N Thr-Thr-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O NDZYTIMDOZMECO-SHGPDSBTSA-N 0.000 description 2
- UQCNIMDPYICBTR-KYNKHSRBSA-N Thr-Thr-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O UQCNIMDPYICBTR-KYNKHSRBSA-N 0.000 description 2
- BZTSQFWJNJYZSX-JRQIVUDYSA-N Thr-Tyr-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O BZTSQFWJNJYZSX-JRQIVUDYSA-N 0.000 description 2
- 208000024770 Thyroid neoplasm Diseases 0.000 description 2
- 102000003978 Tissue Plasminogen Activator Human genes 0.000 description 2
- 108090000373 Tissue Plasminogen Activator Proteins 0.000 description 2
- 244000288561 Torulaspora delbrueckii Species 0.000 description 2
- 235000014681 Torulaspora delbrueckii Nutrition 0.000 description 2
- 102100026144 Transferrin receptor protein 1 Human genes 0.000 description 2
- 102100031228 Transient receptor potential cation channel subfamily M member 4 Human genes 0.000 description 2
- 241000499912 Trichoderma reesei Species 0.000 description 2
- 241000224527 Trichomonas vaginalis Species 0.000 description 2
- 241000223230 Trichosporon Species 0.000 description 2
- MVHHTXAUJCIOMZ-WDSOQIARSA-N Trp-Arg-Lys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O)N MVHHTXAUJCIOMZ-WDSOQIARSA-N 0.000 description 2
- VPRHDRKAPYZMHL-SZMVWBNQSA-N Trp-Leu-Glu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O)=CNC2=C1 VPRHDRKAPYZMHL-SZMVWBNQSA-N 0.000 description 2
- 102100022153 Tumor necrosis factor receptor superfamily member 4 Human genes 0.000 description 2
- 102100036856 Tumor necrosis factor receptor superfamily member 9 Human genes 0.000 description 2
- PRONOHBTMLNXCZ-BZSNNMDCSA-N Tyr-Leu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 PRONOHBTMLNXCZ-BZSNNMDCSA-N 0.000 description 2
- 102100033438 Tyrosine-protein kinase JAK1 Human genes 0.000 description 2
- 102100025387 Tyrosine-protein kinase JAK3 Human genes 0.000 description 2
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 2
- 108091008605 VEGF receptors Proteins 0.000 description 2
- YODDULVCGFQRFZ-ZKWXMUAHSA-N Val-Asp-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O YODDULVCGFQRFZ-ZKWXMUAHSA-N 0.000 description 2
- DOFAQXCYFQKSHT-SRVKXCTJSA-N Val-Pro-Pro Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DOFAQXCYFQKSHT-SRVKXCTJSA-N 0.000 description 2
- 108010053096 Vascular Endothelial Growth Factor Receptor-1 Proteins 0.000 description 2
- 108010053099 Vascular Endothelial Growth Factor Receptor-2 Proteins 0.000 description 2
- 108010053100 Vascular Endothelial Growth Factor Receptor-3 Proteins 0.000 description 2
- 102000009484 Vascular Endothelial Growth Factor Receptors Human genes 0.000 description 2
- 102100033178 Vascular endothelial growth factor receptor 1 Human genes 0.000 description 2
- 102100033177 Vascular endothelial growth factor receptor 2 Human genes 0.000 description 2
- 102100033179 Vascular endothelial growth factor receptor 3 Human genes 0.000 description 2
- 241000269368 Xenopus laevis Species 0.000 description 2
- 241000269457 Xenopus tropicalis Species 0.000 description 2
- 241000235013 Yarrowia Species 0.000 description 2
- 241000235017 Zygosaccharomyces Species 0.000 description 2
- 241000235029 Zygosaccharomyces bailii Species 0.000 description 2
- ATBOMIWRCZXYSZ-XZBBILGWSA-N [1-[2,3-dihydroxypropoxy(hydroxy)phosphoryl]oxy-3-hexadecanoyloxypropan-2-yl] (9e,12e)-octadeca-9,12-dienoate Chemical compound CCCCCCCCCCCCCCCC(=O)OCC(COP(O)(=O)OCC(O)CO)OC(=O)CCCCCCC\C=C\C\C=C\CCCCC ATBOMIWRCZXYSZ-XZBBILGWSA-N 0.000 description 2
- IEDXPSOJFSVCKU-HOKPPMCLSA-N [4-[[(2S)-5-(carbamoylamino)-2-[[(2S)-2-[6-(2,5-dioxopyrrolidin-1-yl)hexanoylamino]-3-methylbutanoyl]amino]pentanoyl]amino]phenyl]methyl N-[(2S)-1-[[(2S)-1-[[(3R,4S,5S)-1-[(2S)-2-[(1R,2R)-3-[[(1S,2R)-1-hydroxy-1-phenylpropan-2-yl]amino]-1-methoxy-2-methyl-3-oxopropyl]pyrrolidin-1-yl]-3-methoxy-5-methyl-1-oxoheptan-4-yl]-methylamino]-3-methyl-1-oxobutan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]-N-methylcarbamate Chemical compound CC[C@H](C)[C@@H]([C@@H](CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C)[C@@H](O)c1ccccc1)OC)N(C)C(=O)[C@@H](NC(=O)[C@H](C(C)C)N(C)C(=O)OCc1ccc(NC(=O)[C@H](CCCNC(N)=O)NC(=O)[C@@H](NC(=O)CCCCCN2C(=O)CCC2=O)C(C)C)cc1)C(C)C IEDXPSOJFSVCKU-HOKPPMCLSA-N 0.000 description 2
- 229950009084 adecatumumab Drugs 0.000 description 2
- 239000000556 agonist Substances 0.000 description 2
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 description 2
- 235000008206 alpha-amino acids Nutrition 0.000 description 2
- AWUCVROLDVIAJX-UHFFFAOYSA-N alpha-glycerophosphate Natural products OCC(O)COP(O)(O)=O AWUCVROLDVIAJX-UHFFFAOYSA-N 0.000 description 2
- 150000001408 amides Chemical class 0.000 description 2
- 125000004103 aminoalkyl group Chemical group 0.000 description 2
- 108010080146 androgen receptors Proteins 0.000 description 2
- 229940127219 anticoagulant drug Drugs 0.000 description 2
- 239000000074 antisense oligonucleotide Substances 0.000 description 2
- 238000012230 antisense oligonucleotides Methods 0.000 description 2
- 108010010430 asparagine-proline-alanine Proteins 0.000 description 2
- 229940091771 aspergillus fumigatus Drugs 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- 229960003008 blinatumomab Drugs 0.000 description 2
- 229940098773 bovine serum albumin Drugs 0.000 description 2
- 229940055022 candida parapsilosis Drugs 0.000 description 2
- 230000003197 catalytic effect Effects 0.000 description 2
- 230000032823 cell division Effects 0.000 description 2
- 210000000170 cell membrane Anatomy 0.000 description 2
- 210000003169 central nervous system Anatomy 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 description 2
- 210000001608 connective tissue cell Anatomy 0.000 description 2
- IDLFZVILOHSSID-OVLDLUHVSA-N corticotropin Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](C(C)C)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)NC(=O)[C@@H](N)CO)C1=CC=C(O)C=C1 IDLFZVILOHSSID-OVLDLUHVSA-N 0.000 description 2
- 229960000258 corticotropin Drugs 0.000 description 2
- 238000000502 dialysis Methods 0.000 description 2
- 229960003724 dimyristoylphosphatidylcholine Drugs 0.000 description 2
- 229940079593 drug Drugs 0.000 description 2
- 241001493065 dsRNA viruses Species 0.000 description 2
- 230000009977 dual effect Effects 0.000 description 2
- 210000003981 ectoderm Anatomy 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 210000002919 epithelial cell Anatomy 0.000 description 2
- GATNOFPXSDHULC-UHFFFAOYSA-N ethylphosphonic acid Chemical compound CCP(O)(O)=O GATNOFPXSDHULC-UHFFFAOYSA-N 0.000 description 2
- 238000001704 evaporation Methods 0.000 description 2
- 230000008020 evaporation Effects 0.000 description 2
- 229940028334 follicle stimulating hormone Drugs 0.000 description 2
- 201000003444 follicular lymphoma Diseases 0.000 description 2
- 206010017758 gastric cancer Diseases 0.000 description 2
- 238000010362 genome editing Methods 0.000 description 2
- 125000003630 glycyl group Chemical group [H]N([H])C([H])([H])C(*)=O 0.000 description 2
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 2
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 2
- 125000005843 halogen group Chemical group 0.000 description 2
- 210000003958 hematopoietic stem cell Anatomy 0.000 description 2
- 229940088597 hormone Drugs 0.000 description 2
- 239000005556 hormone Substances 0.000 description 2
- 229920001480 hydrophilic copolymer Polymers 0.000 description 2
- 229920001477 hydrophilic polymer Polymers 0.000 description 2
- 210000002865 immune cell Anatomy 0.000 description 2
- 102000018358 immunoglobulin Human genes 0.000 description 2
- 230000001771 impaired effect Effects 0.000 description 2
- 230000002401 inhibitory effect Effects 0.000 description 2
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 2
- 201000010982 kidney cancer Diseases 0.000 description 2
- 229950000518 labetuzumab Drugs 0.000 description 2
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 2
- 229950002884 lexatumumab Drugs 0.000 description 2
- 230000000670 limiting effect Effects 0.000 description 2
- 229950002950 lintuzumab Drugs 0.000 description 2
- 201000007270 liver cancer Diseases 0.000 description 2
- 208000014018 liver neoplasm Diseases 0.000 description 2
- 238000011068 loading method Methods 0.000 description 2
- 201000005202 lung cancer Diseases 0.000 description 2
- 208000020816 lung neoplasm Diseases 0.000 description 2
- 239000006166 lysate Substances 0.000 description 2
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 description 2
- 229950001869 mapatumumab Drugs 0.000 description 2
- 208000020968 mature T-cell and NK-cell non-Hodgkin lymphoma Diseases 0.000 description 2
- 229950008001 matuzumab Drugs 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 239000002609 medium Substances 0.000 description 2
- 210000002901 mesenchymal stem cell Anatomy 0.000 description 2
- 108010005942 methionylglycine Proteins 0.000 description 2
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 2
- 229950003734 milatuzumab Drugs 0.000 description 2
- 230000009149 molecular binding Effects 0.000 description 2
- 108010093470 monomethyl auristatin E Proteins 0.000 description 2
- 108010059074 monomethylauristatin F Proteins 0.000 description 2
- 229960000513 necitumumab Drugs 0.000 description 2
- 230000007996 neuronal plasticity Effects 0.000 description 2
- 229960003301 nivolumab Drugs 0.000 description 2
- 238000001668 nucleic acid synthesis Methods 0.000 description 2
- 239000002777 nucleoside Substances 0.000 description 2
- 229960002450 ofatumumab Drugs 0.000 description 2
- 230000000174 oncolytic effect Effects 0.000 description 2
- 201000002528 pancreatic cancer Diseases 0.000 description 2
- 208000008443 pancreatic carcinoma Diseases 0.000 description 2
- 229960001972 panitumumab Drugs 0.000 description 2
- 108010083444 peginesatide Proteins 0.000 description 2
- 229960004772 peginesatide Drugs 0.000 description 2
- 229960002621 pembrolizumab Drugs 0.000 description 2
- 210000001428 peripheral nervous system Anatomy 0.000 description 2
- 229960002087 pertuzumab Drugs 0.000 description 2
- 125000001997 phenyl group Chemical group [H]C1=C([H])C([H])=C(*)C([H])=C1[H] 0.000 description 2
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 2
- 238000002360 preparation method Methods 0.000 description 2
- 239000000047 product Substances 0.000 description 2
- 108010029020 prolylglycine Proteins 0.000 description 2
- 210000002307 prostate Anatomy 0.000 description 2
- 238000000746 purification Methods 0.000 description 2
- YUOCYTRGANSSRY-UHFFFAOYSA-N pyrrolo[2,3-i][1,2]benzodiazepine Chemical compound C1=CN=NC2=C3C=CN=C3C=CC2=C1 YUOCYTRGANSSRY-UHFFFAOYSA-N 0.000 description 2
- 229960002633 ramucirumab Drugs 0.000 description 2
- 239000011347 resin Substances 0.000 description 2
- 229920005989 resin Polymers 0.000 description 2
- 230000002441 reversible effect Effects 0.000 description 2
- 108091092562 ribozyme Proteins 0.000 description 2
- 229960004641 rituximab Drugs 0.000 description 2
- 230000035945 sensitivity Effects 0.000 description 2
- 108010071207 serylmethionine Proteins 0.000 description 2
- 201000000849 skin cancer Diseases 0.000 description 2
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 2
- 210000001082 somatic cell Anatomy 0.000 description 2
- 210000000278 spinal cord Anatomy 0.000 description 2
- 230000010473 stable expression Effects 0.000 description 2
- 201000011549 stomach cancer Diseases 0.000 description 2
- 150000008163 sugars Chemical class 0.000 description 2
- 150000003457 sulfones Chemical class 0.000 description 2
- 238000007910 systemic administration Methods 0.000 description 2
- 230000008685 targeting Effects 0.000 description 2
- 238000002560 therapeutic procedure Methods 0.000 description 2
- 150000003568 thioethers Chemical group 0.000 description 2
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 2
- 201000002510 thyroid cancer Diseases 0.000 description 2
- 229960000187 tissue plasminogen activator Drugs 0.000 description 2
- 230000010474 transient expression Effects 0.000 description 2
- 108010080629 tryptophan-leucine Proteins 0.000 description 2
- 108010015666 tryptophyl-leucyl-glutamic acid Proteins 0.000 description 2
- 201000005112 urinary bladder cancer Diseases 0.000 description 2
- 108010015385 valyl-prolyl-proline Proteins 0.000 description 2
- 229940124676 vascular endothelial growth factor receptor Drugs 0.000 description 2
- 230000003612 virological effect Effects 0.000 description 2
- 210000005253 yeast cell Anatomy 0.000 description 2
- LNAZSHAWQACDHT-XIYTZBAFSA-N (2r,3r,4s,5r,6s)-4,5-dimethoxy-2-(methoxymethyl)-3-[(2s,3r,4s,5r,6r)-3,4,5-trimethoxy-6-(methoxymethyl)oxan-2-yl]oxy-6-[(2r,3r,4s,5r,6r)-4,5,6-trimethoxy-2-(methoxymethyl)oxan-3-yl]oxyoxane Chemical compound CO[C@@H]1[C@@H](OC)[C@H](OC)[C@@H](COC)O[C@H]1O[C@H]1[C@H](OC)[C@@H](OC)[C@H](O[C@H]2[C@@H]([C@@H](OC)[C@H](OC)O[C@@H]2COC)OC)O[C@@H]1COC LNAZSHAWQACDHT-XIYTZBAFSA-N 0.000 description 1
- BRPMXFSTKXXNHF-IUCAKERBSA-N (2s)-1-[2-[[(2s)-pyrrolidine-2-carbonyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound OC(=O)[C@@H]1CCCN1C(=O)CNC(=O)[C@H]1NCCC1 BRPMXFSTKXXNHF-IUCAKERBSA-N 0.000 description 1
- AOUOVFRSCMDPFA-QSDJMHMYSA-N (2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-amino-3-carboxypropanoyl]amino]-4-carboxybutanoyl]amino]-3-methylbutanoyl]amino]butanedioic acid Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(O)=O AOUOVFRSCMDPFA-QSDJMHMYSA-N 0.000 description 1
- KQRHTCDQWJLLME-XUXIUFHCSA-N (2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-aminopropanoyl]amino]-4-methylpentanoyl]amino]propanoyl]amino]-4-methylpentanoic acid Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C)N KQRHTCDQWJLLME-XUXIUFHCSA-N 0.000 description 1
- WKJDWDLHIOUPPL-JSOSNVBQSA-N (2s)-2-amino-3-({[(2r)-2,3-bis(tetradecanoyloxy)propoxy](hydroxy)phosphoryl}oxy)propanoic acid Chemical compound CCCCCCCCCCCCCC(=O)OC[C@H](COP(O)(=O)OC[C@H](N)C(O)=O)OC(=O)CCCCCCCCCCCCC WKJDWDLHIOUPPL-JSOSNVBQSA-N 0.000 description 1
- PUDHBTGHUJUUFI-SCTWWAJVSA-N (4r,7s,10s,13r,16s,19r)-10-(4-aminobutyl)-n-[(2s,3r)-1-amino-3-hydroxy-1-oxobutan-2-yl]-19-[[(2r)-2-amino-3-naphthalen-2-ylpropanoyl]amino]-16-[(4-hydroxyphenyl)methyl]-13-(1h-indol-3-ylmethyl)-6,9,12,15,18-pentaoxo-7-propan-2-yl-1,2-dithia-5,8,11,14,17-p Chemical compound C([C@H]1C(=O)N[C@H](CC=2C3=CC=CC=C3NC=2)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(N[C@@H](CSSC[C@@H](C(=O)N1)NC(=O)[C@H](N)CC=1C=C2C=CC=CC2=CC=1)C(=O)N[C@@H]([C@@H](C)O)C(N)=O)=O)C(C)C)C1=CC=C(O)C=C1 PUDHBTGHUJUUFI-SCTWWAJVSA-N 0.000 description 1
- UUDAMDVQRQNNHZ-UHFFFAOYSA-N (S)-AMPA Chemical compound CC=1ONC(=O)C=1CC(N)C(O)=O UUDAMDVQRQNNHZ-UHFFFAOYSA-N 0.000 description 1
- LKUDPHPHKOZXCD-UHFFFAOYSA-N 1,3,5-trimethoxybenzene Chemical compound COC1=CC(OC)=CC(OC)=C1 LKUDPHPHKOZXCD-UHFFFAOYSA-N 0.000 description 1
- UTQUILVPBZEHTK-ZOQUXTDFSA-N 1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-3-methylpyrimidine-2,4-dione Chemical compound O=C1N(C)C(=O)C=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 UTQUILVPBZEHTK-ZOQUXTDFSA-N 0.000 description 1
- NEOJKYRRLHDYII-TURQNECASA-N 1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-5-(2-oxopropyl)pyrimidine-2,4-dione Chemical compound O=C1NC(=O)C(CC(=O)C)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 NEOJKYRRLHDYII-TURQNECASA-N 0.000 description 1
- WZIZREBAUZZJOS-TURQNECASA-N 1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-5-[2-(methylamino)ethyl]pyrimidine-2,4-dione Chemical compound O=C1NC(=O)C(CCNC)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 WZIZREBAUZZJOS-TURQNECASA-N 0.000 description 1
- QLOCVMVCRJOTTM-TURQNECASA-N 1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-5-prop-1-ynylpyrimidine-2,4-dione Chemical compound O=C1NC(=O)C(C#CC)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 QLOCVMVCRJOTTM-TURQNECASA-N 0.000 description 1
- SGKGZYGMLGVQHP-ZOQUXTDFSA-N 1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-6-methylpyrimidine-2,4-dione Chemical compound CC1=CC(=O)NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 SGKGZYGMLGVQHP-ZOQUXTDFSA-N 0.000 description 1
- GFYLSDSUCHVORB-IOSLPCCCSA-N 1-methyladenosine Chemical compound C1=NC=2C(=N)N(C)C=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O GFYLSDSUCHVORB-IOSLPCCCSA-N 0.000 description 1
- WJNGQIYEQLPJMN-IOSLPCCCSA-N 1-methylinosine Chemical compound C1=NC=2C(=O)N(C)C=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O WJNGQIYEQLPJMN-IOSLPCCCSA-N 0.000 description 1
- IIZPXYDJLKNOIY-JXPKJXOSSA-N 1-palmitoyl-2-arachidonoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCC\C=C/C\C=C/C\C=C/C\C=C/CCCCC IIZPXYDJLKNOIY-JXPKJXOSSA-N 0.000 description 1
- GZCWLCBFPRFLKL-UHFFFAOYSA-N 1-prop-2-ynoxypropan-2-ol Chemical compound CC(O)COCC#C GZCWLCBFPRFLKL-UHFFFAOYSA-N 0.000 description 1
- YMHOBZXQZVXHBM-UHFFFAOYSA-N 2,5-dimethoxy-4-bromophenethylamine Chemical compound COC1=CC(CCN)=C(OC)C=C1Br YMHOBZXQZVXHBM-UHFFFAOYSA-N 0.000 description 1
- PIINGYXNCHTJTF-UHFFFAOYSA-N 2-(2-azaniumylethylamino)acetate Chemical compound NCCNCC(O)=O PIINGYXNCHTJTF-UHFFFAOYSA-N 0.000 description 1
- IQZWKGWOBPJWMX-UHFFFAOYSA-N 2-Methyladenosine Natural products C12=NC(C)=NC(N)=C2N=CN1C1OC(CO)C(O)C1O IQZWKGWOBPJWMX-UHFFFAOYSA-N 0.000 description 1
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 1
- HTOVHZGIBCAAJU-UHFFFAOYSA-N 2-amino-2-propyl-1h-purin-6-one Chemical compound CCCC1(N)NC(=O)C2=NC=NC2=N1 HTOVHZGIBCAAJU-UHFFFAOYSA-N 0.000 description 1
- CDAWCLOXVUBKRW-UHFFFAOYSA-N 2-aminophenol Chemical group NC1=CC=CC=C1O CDAWCLOXVUBKRW-UHFFFAOYSA-N 0.000 description 1
- FEUFEGJTJIHPOF-UHFFFAOYSA-N 2-butyl acrylic acid Chemical compound CCCCC(=C)C(O)=O FEUFEGJTJIHPOF-UHFFFAOYSA-N 0.000 description 1
- WROUWQQRXUBECT-UHFFFAOYSA-N 2-ethylacrylic acid Chemical compound CCC(=C)C(O)=O WROUWQQRXUBECT-UHFFFAOYSA-N 0.000 description 1
- 125000006176 2-ethylbutyl group Chemical group [H]C([H])([H])C([H])([H])C([H])(C([H])([H])*)C([H])([H])C([H])([H])[H] 0.000 description 1
- IQZWKGWOBPJWMX-IOSLPCCCSA-N 2-methyladenosine Chemical compound C12=NC(C)=NC(N)=C2N=CN1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O IQZWKGWOBPJWMX-IOSLPCCCSA-N 0.000 description 1
- HEBDGRTWECSNNT-UHFFFAOYSA-N 2-methylidenepentanoic acid Chemical compound CCCC(=C)C(O)=O HEBDGRTWECSNNT-UHFFFAOYSA-N 0.000 description 1
- USCCECGPGBGFOM-UHFFFAOYSA-N 2-propyl-7h-purin-6-amine Chemical compound CCCC1=NC(N)=C2NC=NC2=N1 USCCECGPGBGFOM-UHFFFAOYSA-N 0.000 description 1
- RHFUOMFWUGWKKO-XVFCMESISA-N 2-thiocytidine Chemical compound S=C1N=C(N)C=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 RHFUOMFWUGWKKO-XVFCMESISA-N 0.000 description 1
- GJTBSTBJLVYKAU-XVFCMESISA-N 2-thiouridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=S)NC(=O)C=C1 GJTBSTBJLVYKAU-XVFCMESISA-N 0.000 description 1
- RDPUKVRQKWBSPK-UHFFFAOYSA-N 3-Methylcytidine Natural products O=C1N(C)C(=N)C=CN1C1C(O)C(O)C(CO)O1 RDPUKVRQKWBSPK-UHFFFAOYSA-N 0.000 description 1
- UTQUILVPBZEHTK-UHFFFAOYSA-N 3-Methyluridine Natural products O=C1N(C)C(=O)C=CN1C1C(O)C(O)C(CO)O1 UTQUILVPBZEHTK-UHFFFAOYSA-N 0.000 description 1
- QZPSOSOOLFHYRR-UHFFFAOYSA-N 3-hydroxypropyl prop-2-enoate Chemical compound OCCCOC(=O)C=C QZPSOSOOLFHYRR-UHFFFAOYSA-N 0.000 description 1
- RDPUKVRQKWBSPK-ZOQUXTDFSA-N 3-methylcytidine Chemical compound O=C1N(C)C(=N)C=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 RDPUKVRQKWBSPK-ZOQUXTDFSA-N 0.000 description 1
- LOJNBPNACKZWAI-UHFFFAOYSA-N 3-nitro-1h-pyrrole Chemical compound [O-][N+](=O)C=1C=CNC=1 LOJNBPNACKZWAI-UHFFFAOYSA-N 0.000 description 1
- NAROVGXVMKGQLH-UHFFFAOYSA-N 4-(1h-imidazol-2-yl)morpholine Chemical compound C1COCCN1C1=NC=CN1 NAROVGXVMKGQLH-UHFFFAOYSA-N 0.000 description 1
- ZLOIGESWDJYCTF-UHFFFAOYSA-N 4-Thiouridine Natural products OC1C(O)C(CO)OC1N1C(=O)NC(=S)C=C1 ZLOIGESWDJYCTF-UHFFFAOYSA-N 0.000 description 1
- BCZUPRDAAVVBSO-MJXNYTJMSA-N 4-acetylcytidine Chemical compound C1=CC(C(=O)C)(N)NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 BCZUPRDAAVVBSO-MJXNYTJMSA-N 0.000 description 1
- XXSIICQLPUAUDF-TURQNECASA-N 4-amino-1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-5-prop-1-ynylpyrimidin-2-one Chemical compound O=C1N=C(N)C(C#CC)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 XXSIICQLPUAUDF-TURQNECASA-N 0.000 description 1
- 229960000549 4-dimethylaminophenol Drugs 0.000 description 1
- VHYFNPMBLIVWCW-UHFFFAOYSA-N 4-dimethylaminopyridine Substances CN(C)C1=CC=NC=C1 VHYFNPMBLIVWCW-UHFFFAOYSA-N 0.000 description 1
- GCNTZFIIOFTKIY-UHFFFAOYSA-N 4-hydroxypyridine Chemical compound OC1=CC=NC=C1 GCNTZFIIOFTKIY-UHFFFAOYSA-N 0.000 description 1
- ZLOIGESWDJYCTF-XVFCMESISA-N 4-thiouridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=S)C=C1 ZLOIGESWDJYCTF-XVFCMESISA-N 0.000 description 1
- ZAYHVCMSTBRABG-UHFFFAOYSA-N 5-Methylcytidine Natural products O=C1N=C(N)C(C)=CN1C1C(O)C(O)C(CO)O1 ZAYHVCMSTBRABG-UHFFFAOYSA-N 0.000 description 1
- ZXIATBNUWJBBGT-JXOAFFINSA-N 5-methoxyuridine Chemical compound O=C1NC(=O)C(OC)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 ZXIATBNUWJBBGT-JXOAFFINSA-N 0.000 description 1
- SNNBPMAXGYBMHM-JXOAFFINSA-N 5-methyl-2-thiouridine Chemical compound S=C1NC(=O)C(C)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 SNNBPMAXGYBMHM-JXOAFFINSA-N 0.000 description 1
- ZAYHVCMSTBRABG-JXOAFFINSA-N 5-methylcytidine Chemical compound O=C1N=C(N)C(C)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 ZAYHVCMSTBRABG-JXOAFFINSA-N 0.000 description 1
- OZFPSOBLQZPIAV-UHFFFAOYSA-N 5-nitro-1h-indole Chemical compound [O-][N+](=O)C1=CC=C2NC=CC2=C1 OZFPSOBLQZPIAV-UHFFFAOYSA-N 0.000 description 1
- CKOMXBHMKXXTNW-UHFFFAOYSA-N 6-methyladenine Chemical compound CNC1=NC=NC2=C1N=CN2 CKOMXBHMKXXTNW-UHFFFAOYSA-N 0.000 description 1
- MSSXOMSJDRHRMC-UHFFFAOYSA-N 9H-purine-2,6-diamine Chemical compound NC1=NC(N)=C2NC=NC2=N1 MSSXOMSJDRHRMC-UHFFFAOYSA-N 0.000 description 1
- HDZZVAMISRMYHH-UHFFFAOYSA-N 9beta-Ribofuranosyl-7-deazaadenin Natural products C1=CC=2C(N)=NC=NC=2N1C1OC(CO)C(O)C1O HDZZVAMISRMYHH-UHFFFAOYSA-N 0.000 description 1
- 102100031585 ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Human genes 0.000 description 1
- 102100033350 ATP-dependent translocase ABCB1 Human genes 0.000 description 1
- 241001600456 Acanthochromis polyacanthus Species 0.000 description 1
- 108010051457 Acid Phosphatase Proteins 0.000 description 1
- 102000013563 Acid Phosphatase Human genes 0.000 description 1
- 241000580482 Acidobacteria Species 0.000 description 1
- 241001156739 Actinobacteria <phylum> Species 0.000 description 1
- 208000024893 Acute lymphoblastic leukemia Diseases 0.000 description 1
- 208000031261 Acute myeloid leukaemia Diseases 0.000 description 1
- 241000222382 Agaricomycotina Species 0.000 description 1
- 241000282452 Ailuropoda melanoleuca Species 0.000 description 1
- RLMISHABBKUNFO-WHFBIAKZSA-N Ala-Ala-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O RLMISHABBKUNFO-WHFBIAKZSA-N 0.000 description 1
- WRDANSJTFOHBPI-FXQIFTODSA-N Ala-Arg-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N WRDANSJTFOHBPI-FXQIFTODSA-N 0.000 description 1
- GFBLJMHGHAXGNY-ZLUOBGJFSA-N Ala-Asn-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O GFBLJMHGHAXGNY-ZLUOBGJFSA-N 0.000 description 1
- PBAMJJXWDQXOJA-FXQIFTODSA-N Ala-Asp-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N PBAMJJXWDQXOJA-FXQIFTODSA-N 0.000 description 1
- FUSPCLTUKXQREV-ACZMJKKPSA-N Ala-Glu-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O FUSPCLTUKXQREV-ACZMJKKPSA-N 0.000 description 1
- NJPMYXWVWQWCSR-ACZMJKKPSA-N Ala-Glu-Asn Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O NJPMYXWVWQWCSR-ACZMJKKPSA-N 0.000 description 1
- WMYJZJRILUVVRG-WDSKDSINSA-N Ala-Gly-Gln Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O WMYJZJRILUVVRG-WDSKDSINSA-N 0.000 description 1
- KMGOBAQSCKTBGD-DLOVCJGASA-N Ala-His-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CC1=CN=CN1 KMGOBAQSCKTBGD-DLOVCJGASA-N 0.000 description 1
- FOHXUHGZZKETFI-JBDRJPRFSA-N Ala-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](C)N FOHXUHGZZKETFI-JBDRJPRFSA-N 0.000 description 1
- KYDYGANDJHFBCW-DRZSPHRISA-N Ala-Phe-Gln Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N KYDYGANDJHFBCW-DRZSPHRISA-N 0.000 description 1
- OLVCTPPSXNRGKV-GUBZILKMSA-N Ala-Pro-Pro Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 OLVCTPPSXNRGKV-GUBZILKMSA-N 0.000 description 1
- RMAWDDRDTRSZIR-ZLUOBGJFSA-N Ala-Ser-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O RMAWDDRDTRSZIR-ZLUOBGJFSA-N 0.000 description 1
- AUFACLFHBAGZEN-ZLUOBGJFSA-N Ala-Ser-Cys Chemical compound N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O AUFACLFHBAGZEN-ZLUOBGJFSA-N 0.000 description 1
- MSWSRLGNLKHDEI-ACZMJKKPSA-N Ala-Ser-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O MSWSRLGNLKHDEI-ACZMJKKPSA-N 0.000 description 1
- PEEYDECOOVQKRZ-DLOVCJGASA-N Ala-Ser-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PEEYDECOOVQKRZ-DLOVCJGASA-N 0.000 description 1
- IOFVWPYSRSCWHI-JXUBOQSCSA-N Ala-Thr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C)N IOFVWPYSRSCWHI-JXUBOQSCSA-N 0.000 description 1
- QOIGKCBMXUCDQU-KDXUFGMBSA-N Ala-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C)N)O QOIGKCBMXUCDQU-KDXUFGMBSA-N 0.000 description 1
- KUFVXLQLDHJVOG-SHGPDSBTSA-N Ala-Thr-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](C)N)O KUFVXLQLDHJVOG-SHGPDSBTSA-N 0.000 description 1
- BOKLLPVAQDSLHC-FXQIFTODSA-N Ala-Val-Cys Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(=O)O)N BOKLLPVAQDSLHC-FXQIFTODSA-N 0.000 description 1
- ZCUFMRIQCPNOHZ-NRPADANISA-N Ala-Val-Gln Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N ZCUFMRIQCPNOHZ-NRPADANISA-N 0.000 description 1
- 102100024321 Alkaline phosphatase, placental type Human genes 0.000 description 1
- 241001136792 Alle Species 0.000 description 1
- 241000270728 Alligator Species 0.000 description 1
- 102100035248 Alpha-(1,3)-fucosyltransferase 4 Human genes 0.000 description 1
- 102100026277 Alpha-galactosidase A Human genes 0.000 description 1
- 102100022749 Aminopeptidase N Human genes 0.000 description 1
- 108010064760 Anidulafungin Proteins 0.000 description 1
- 241001135932 Anolis carolinensis Species 0.000 description 1
- 241000482146 Anser cygnoides domesticus Species 0.000 description 1
- 241000272814 Anser sp. Species 0.000 description 1
- 108020004519 Antisense Oligoribonucleotides Proteins 0.000 description 1
- 241001502973 Aotus nancymaae Species 0.000 description 1
- 102100040202 Apolipoprotein B-100 Human genes 0.000 description 1
- 108091023037 Aptamer Proteins 0.000 description 1
- 241000969729 Apteryx rowi Species 0.000 description 1
- 241001142141 Aquificae <phylum> Species 0.000 description 1
- OOBVTWHLKYJFJH-FXQIFTODSA-N Arg-Ala-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O OOBVTWHLKYJFJH-FXQIFTODSA-N 0.000 description 1
- GXCSUJQOECMKPV-CIUDSAMLSA-N Arg-Ala-Gln Chemical compound C[C@H](NC(=O)[C@@H](N)CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O GXCSUJQOECMKPV-CIUDSAMLSA-N 0.000 description 1
- IASNWHAGGYTEKX-IUCAKERBSA-N Arg-Arg-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(O)=O IASNWHAGGYTEKX-IUCAKERBSA-N 0.000 description 1
- ITVINTQUZMQWJR-QXEWZRGKSA-N Arg-Asn-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O ITVINTQUZMQWJR-QXEWZRGKSA-N 0.000 description 1
- OTCJMMRQBVDQRK-DCAQKATOSA-N Arg-Asp-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O OTCJMMRQBVDQRK-DCAQKATOSA-N 0.000 description 1
- TTXYKSADPSNOIF-IHRRRGAJSA-N Arg-Asp-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O TTXYKSADPSNOIF-IHRRRGAJSA-N 0.000 description 1
- YHQGEARSFILVHL-HJGDQZAQSA-N Arg-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N)O YHQGEARSFILVHL-HJGDQZAQSA-N 0.000 description 1
- YNSGXDWWPCGGQS-YUMQZZPRSA-N Arg-Gly-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O YNSGXDWWPCGGQS-YUMQZZPRSA-N 0.000 description 1
- DGFXIWKPTDKBLF-AVGNSLFASA-N Arg-His-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCCN=C(N)N)N DGFXIWKPTDKBLF-AVGNSLFASA-N 0.000 description 1
- YQGZIRIYGHNSQO-ZPFDUUQYSA-N Arg-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N YQGZIRIYGHNSQO-ZPFDUUQYSA-N 0.000 description 1
- GMFAGHNRXPSSJS-SRVKXCTJSA-N Arg-Leu-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GMFAGHNRXPSSJS-SRVKXCTJSA-N 0.000 description 1
- NMRHDSAOIURTNT-RWMBFGLXSA-N Arg-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N NMRHDSAOIURTNT-RWMBFGLXSA-N 0.000 description 1
- FSNVAJOPUDVQAR-AVGNSLFASA-N Arg-Lys-Arg Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FSNVAJOPUDVQAR-AVGNSLFASA-N 0.000 description 1
- ZDSVOHFDQKSTAY-UHFFFAOYSA-N Arg-Lys-Met-Phe Chemical compound NC(N)=NCCCC(N)C(=O)NC(CCCCN)C(=O)NC(CCSC)C(=O)NC(C(O)=O)CC1=CC=CC=C1 ZDSVOHFDQKSTAY-UHFFFAOYSA-N 0.000 description 1
- NPAVRDPEFVKELR-DCAQKATOSA-N Arg-Lys-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O NPAVRDPEFVKELR-DCAQKATOSA-N 0.000 description 1
- UGZUVYDKAYNCII-ULQDDVLXSA-N Arg-Phe-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O UGZUVYDKAYNCII-ULQDDVLXSA-N 0.000 description 1
- YCYXHLZRUSJITQ-SRVKXCTJSA-N Arg-Pro-Pro Chemical compound NC(=N)NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 YCYXHLZRUSJITQ-SRVKXCTJSA-N 0.000 description 1
- ICRHGPYYXMWHIE-LPEHRKFASA-N Arg-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O ICRHGPYYXMWHIE-LPEHRKFASA-N 0.000 description 1
- FRBAHXABMQXSJQ-FXQIFTODSA-N Arg-Ser-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O FRBAHXABMQXSJQ-FXQIFTODSA-N 0.000 description 1
- KSHJMDSNSKDJPU-QTKMDUPCSA-N Arg-Thr-His Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 KSHJMDSNSKDJPU-QTKMDUPCSA-N 0.000 description 1
- ZCSHHTFOZULVLN-SZMVWBNQSA-N Arg-Trp-Val Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N)=CNC2=C1 ZCSHHTFOZULVLN-SZMVWBNQSA-N 0.000 description 1
- 241000238421 Arthropoda Species 0.000 description 1
- 102100031491 Arylsulfatase B Human genes 0.000 description 1
- DAPLJWATMAXPPZ-CIUDSAMLSA-N Asn-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(N)=O DAPLJWATMAXPPZ-CIUDSAMLSA-N 0.000 description 1
- APHUDFFMXFYRKP-CIUDSAMLSA-N Asn-Asn-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N APHUDFFMXFYRKP-CIUDSAMLSA-N 0.000 description 1
- BHQQRVARKXWXPP-ACZMJKKPSA-N Asn-Asp-Glu Chemical compound C(CC(=O)O)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)N)N BHQQRVARKXWXPP-ACZMJKKPSA-N 0.000 description 1
- VJTWLBMESLDOMK-WDSKDSINSA-N Asn-Gln-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O VJTWLBMESLDOMK-WDSKDSINSA-N 0.000 description 1
- WPOLSNAQGVHROR-GUBZILKMSA-N Asn-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)N)N WPOLSNAQGVHROR-GUBZILKMSA-N 0.000 description 1
- UBKOVSLDWIHYSY-ACZMJKKPSA-N Asn-Glu-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O UBKOVSLDWIHYSY-ACZMJKKPSA-N 0.000 description 1
- HYQYLOSCICEYTR-YUMQZZPRSA-N Asn-Gly-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O HYQYLOSCICEYTR-YUMQZZPRSA-N 0.000 description 1
- PTSDPWIHOYMRGR-UGYAYLCHSA-N Asn-Ile-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O PTSDPWIHOYMRGR-UGYAYLCHSA-N 0.000 description 1
- HFPXZWPUVFVNLL-GUBZILKMSA-N Asn-Leu-Gln Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O HFPXZWPUVFVNLL-GUBZILKMSA-N 0.000 description 1
- HDHZCEDPLTVHFZ-GUBZILKMSA-N Asn-Leu-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O HDHZCEDPLTVHFZ-GUBZILKMSA-N 0.000 description 1
- RZNAMKZJPBQWDJ-SRVKXCTJSA-N Asn-Lys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)N)N RZNAMKZJPBQWDJ-SRVKXCTJSA-N 0.000 description 1
- GMUOCGCDOYYWPD-FXQIFTODSA-N Asn-Pro-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O GMUOCGCDOYYWPD-FXQIFTODSA-N 0.000 description 1
- IIQIOFVDFOLCHP-UHFFFAOYSA-N Asn-Pro-Ser-Ser Chemical compound NC(=O)CC(N)C(=O)N1CCCC1C(=O)NC(CO)C(=O)NC(CO)C(O)=O IIQIOFVDFOLCHP-UHFFFAOYSA-N 0.000 description 1
- UGXYFDQFLVCDFC-CIUDSAMLSA-N Asn-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O UGXYFDQFLVCDFC-CIUDSAMLSA-N 0.000 description 1
- SKQTXVZTCGSRJS-SRVKXCTJSA-N Asn-Tyr-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O SKQTXVZTCGSRJS-SRVKXCTJSA-N 0.000 description 1
- GHWWTICYPDKPTE-NGZCFLSTSA-N Asn-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N GHWWTICYPDKPTE-NGZCFLSTSA-N 0.000 description 1
- QXNGSPZMGFEZNO-QRTARXTBSA-N Asn-Val-Trp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O QXNGSPZMGFEZNO-QRTARXTBSA-N 0.000 description 1
- XEDQMTWEYFBOIK-ACZMJKKPSA-N Asp-Ala-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O XEDQMTWEYFBOIK-ACZMJKKPSA-N 0.000 description 1
- SOYOSFXLXYZNRG-CIUDSAMLSA-N Asp-Arg-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O SOYOSFXLXYZNRG-CIUDSAMLSA-N 0.000 description 1
- HOQGTAIGQSDCHR-SRVKXCTJSA-N Asp-Asn-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HOQGTAIGQSDCHR-SRVKXCTJSA-N 0.000 description 1
- KNMRXHIAVXHCLW-ZLUOBGJFSA-N Asp-Asn-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N)C(=O)O KNMRXHIAVXHCLW-ZLUOBGJFSA-N 0.000 description 1
- PXLNPFOJZQMXAT-BYULHYEWSA-N Asp-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC(O)=O PXLNPFOJZQMXAT-BYULHYEWSA-N 0.000 description 1
- DXQOQMCLWWADMU-ACZMJKKPSA-N Asp-Gln-Ser Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O DXQOQMCLWWADMU-ACZMJKKPSA-N 0.000 description 1
- ZEDBMCPXPIYJLW-XHNCKOQMSA-N Asp-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC(=O)O)N)C(=O)O ZEDBMCPXPIYJLW-XHNCKOQMSA-N 0.000 description 1
- YRBGRUOSJROZEI-NHCYSSNCSA-N Asp-His-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(O)=O YRBGRUOSJROZEI-NHCYSSNCSA-N 0.000 description 1
- QNFRBNZGVVKBNJ-PEFMBERDSA-N Asp-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N QNFRBNZGVVKBNJ-PEFMBERDSA-N 0.000 description 1
- HOBNTSHITVVNBN-ZPFDUUQYSA-N Asp-Ile-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC(=O)O)N HOBNTSHITVVNBN-ZPFDUUQYSA-N 0.000 description 1
- MYOHQBFRJQFIDZ-KKUMJFAQSA-N Asp-Leu-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MYOHQBFRJQFIDZ-KKUMJFAQSA-N 0.000 description 1
- UZFHNLYQWMGUHU-DCAQKATOSA-N Asp-Lys-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UZFHNLYQWMGUHU-DCAQKATOSA-N 0.000 description 1
- KPSHWSWFPUDEGF-FXQIFTODSA-N Asp-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC(O)=O KPSHWSWFPUDEGF-FXQIFTODSA-N 0.000 description 1
- QTIZKMMLNUMHHU-DCAQKATOSA-N Asp-Pro-His Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O QTIZKMMLNUMHHU-DCAQKATOSA-N 0.000 description 1
- ZVGRHIRJLWBWGJ-ACZMJKKPSA-N Asp-Ser-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZVGRHIRJLWBWGJ-ACZMJKKPSA-N 0.000 description 1
- HRVQDZOWMLFAOD-BIIVOSGPSA-N Asp-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N)C(=O)O HRVQDZOWMLFAOD-BIIVOSGPSA-N 0.000 description 1
- QOCFFCUFZGDHTP-NUMRIWBASA-N Asp-Thr-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QOCFFCUFZGDHTP-NUMRIWBASA-N 0.000 description 1
- RCGVPVZHKAXDPA-NYVOZVTQSA-N Asp-Trp-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CNC4=CC=CC=C43)C(=O)O)NC(=O)[C@H](CC(=O)O)N RCGVPVZHKAXDPA-NYVOZVTQSA-N 0.000 description 1
- PLNJUJGNLDSFOP-UWJYBYFXSA-N Asp-Tyr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O PLNJUJGNLDSFOP-UWJYBYFXSA-N 0.000 description 1
- QPDUWAUSSWGJSB-NGZCFLSTSA-N Asp-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N QPDUWAUSSWGJSB-NGZCFLSTSA-N 0.000 description 1
- 241000228197 Aspergillus flavus Species 0.000 description 1
- 102100038080 B-cell receptor CD22 Human genes 0.000 description 1
- 208000032791 BCR-ABL1 positive chronic myelogenous leukemia Diseases 0.000 description 1
- 241000304886 Bacilli Species 0.000 description 1
- 241000605059 Bacteroidetes Species 0.000 description 1
- 241001218100 Balaenoptera acutorostrata scammoni Species 0.000 description 1
- 241000984553 Banana streak virus Species 0.000 description 1
- DWRXFEITVBNRMK-UHFFFAOYSA-N Beta-D-1-Arabinofuranosylthymine Natural products O=C1NC(=O)C(C)=CN1C1C(O)C(O)C(CO)O1 DWRXFEITVBNRMK-UHFFFAOYSA-N 0.000 description 1
- 241000255789 Bombyx mori Species 0.000 description 1
- 102000007350 Bone Morphogenetic Proteins Human genes 0.000 description 1
- 108010007726 Bone Morphogenetic Proteins Proteins 0.000 description 1
- ZOXJGFHDIHLPTG-UHFFFAOYSA-N Boron Chemical compound [B] ZOXJGFHDIHLPTG-UHFFFAOYSA-N 0.000 description 1
- 241001416153 Bos grunniens Species 0.000 description 1
- 241001247317 Bos mutus Species 0.000 description 1
- 108010085074 Brevican Proteins 0.000 description 1
- 102100032312 Brevican core protein Human genes 0.000 description 1
- 241000030939 Bubalus bubalis Species 0.000 description 1
- 102100031658 C-X-C chemokine receptor type 5 Human genes 0.000 description 1
- 102000007269 CA-125 Antigen Human genes 0.000 description 1
- 108010008629 CA-125 Antigen Proteins 0.000 description 1
- 102100024217 CAMPATH-1 antigen Human genes 0.000 description 1
- 102100027207 CD27 antigen Human genes 0.000 description 1
- 102100038078 CD276 antigen Human genes 0.000 description 1
- 101710185679 CD276 antigen Proteins 0.000 description 1
- 102000049320 CD36 Human genes 0.000 description 1
- 108010045374 CD36 Antigens Proteins 0.000 description 1
- 101150013553 CD40 gene Proteins 0.000 description 1
- 102100032912 CD44 antigen Human genes 0.000 description 1
- 102100036008 CD48 antigen Human genes 0.000 description 1
- 108010065524 CD52 Antigen Proteins 0.000 description 1
- 102100022002 CD59 glycoprotein Human genes 0.000 description 1
- 102100025222 CD63 antigen Human genes 0.000 description 1
- IHOSMSZITNLZDU-UHFFFAOYSA-N COOP(O)=O Chemical compound COOP(O)=O IHOSMSZITNLZDU-UHFFFAOYSA-N 0.000 description 1
- QOSATKMQPHFEIW-UHFFFAOYSA-N COP(O)=S Chemical group COP(O)=S QOSATKMQPHFEIW-UHFFFAOYSA-N 0.000 description 1
- 108050007957 Cadherin Proteins 0.000 description 1
- 102000000905 Cadherin Human genes 0.000 description 1
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 1
- 102400000113 Calcitonin Human genes 0.000 description 1
- 108060001064 Calcitonin Proteins 0.000 description 1
- 241000288950 Callithrix jacchus Species 0.000 description 1
- 241001482571 Callorhinus ursinus Species 0.000 description 1
- 102000007590 Calpain Human genes 0.000 description 1
- 108010032088 Calpain Proteins 0.000 description 1
- 241000282828 Camelus bactrianus Species 0.000 description 1
- 241000282836 Camelus dromedarius Species 0.000 description 1
- 101100464170 Candida albicans (strain SC5314 / ATCC MYA-2876) PIR1 gene Proteins 0.000 description 1
- 241000222157 Candida viswanathii Species 0.000 description 1
- 241000282465 Canis Species 0.000 description 1
- 241000824799 Canis lupus dingo Species 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- 241000283705 Capra hircus Species 0.000 description 1
- 241000252229 Carassius auratus Species 0.000 description 1
- KXDHJXZQYSOELW-UHFFFAOYSA-M Carbamate Chemical compound NC([O-])=O KXDHJXZQYSOELW-UHFFFAOYSA-M 0.000 description 1
- BVKZGUZCCUSVTD-UHFFFAOYSA-L Carbonate Chemical compound [O-]C([O-])=O BVKZGUZCCUSVTD-UHFFFAOYSA-L 0.000 description 1
- 108010033547 Carbonic Anhydrase I Proteins 0.000 description 1
- 102100025518 Carbonic anhydrase 1 Human genes 0.000 description 1
- 229940122072 Carbonic anhydrase inhibitor Drugs 0.000 description 1
- 102000003846 Carbonic anhydrases Human genes 0.000 description 1
- 108090000209 Carbonic anhydrases Proteins 0.000 description 1
- 108010022366 Carcinoembryonic Antigen Proteins 0.000 description 1
- 102100024533 Carcinoembryonic antigen-related cell adhesion molecule 1 Human genes 0.000 description 1
- 102100025466 Carcinoembryonic antigen-related cell adhesion molecule 3 Human genes 0.000 description 1
- 102100025470 Carcinoembryonic antigen-related cell adhesion molecule 8 Human genes 0.000 description 1
- 102000014914 Carrier Proteins Human genes 0.000 description 1
- 108010076667 Caspases Proteins 0.000 description 1
- 102000011727 Caspases Human genes 0.000 description 1
- 102000004225 Cathepsin B Human genes 0.000 description 1
- 108090000712 Cathepsin B Proteins 0.000 description 1
- 241000700198 Cavia Species 0.000 description 1
- 235000009024 Ceanothus sanguineus Nutrition 0.000 description 1
- 241000643972 Cebus capucinus imitator Species 0.000 description 1
- 102000016289 Cell Adhesion Molecules Human genes 0.000 description 1
- 108010067225 Cell Adhesion Molecules Proteins 0.000 description 1
- 229920000623 Cellulose acetate phthalate Polymers 0.000 description 1
- 241000255580 Ceratitis <genus> Species 0.000 description 1
- 241001263020 Ceratotherium simum simum Species 0.000 description 1
- 241000202714 Cervus elaphus hippelaphus Species 0.000 description 1
- CXRFDZFCGOPDTD-UHFFFAOYSA-M Cetrimide Chemical compound [Br-].CCCCCCCCCCCCCC[N+](C)(C)C CXRFDZFCGOPDTD-UHFFFAOYSA-M 0.000 description 1
- 241000270605 Chelonia Species 0.000 description 1
- 241000270607 Chelonia mydas Species 0.000 description 1
- 102000009410 Chemokine receptor Human genes 0.000 description 1
- 108050000299 Chemokine receptor Proteins 0.000 description 1
- 241000700114 Chinchillidae Species 0.000 description 1
- 241000195597 Chlamydomonas reinhardtii Species 0.000 description 1
- 241000867607 Chlorocebus sabaeus Species 0.000 description 1
- 241001142109 Chloroflexi Species 0.000 description 1
- 108010062540 Chorionic Gonadotropin Proteins 0.000 description 1
- 102000011022 Chorionic Gonadotropin Human genes 0.000 description 1
- 241001143290 Chrysiogenetes <phylum> Species 0.000 description 1
- 241001100448 Chrysochloris asiatica Species 0.000 description 1
- 241001508813 Clavispora lusitaniae Species 0.000 description 1
- 241000193155 Clostridium botulinum Species 0.000 description 1
- 108020004705 Codon Proteins 0.000 description 1
- 102100025680 Complement decay-accelerating factor Human genes 0.000 description 1
- 102100032768 Complement receptor type 2 Human genes 0.000 description 1
- 241001282194 Condylura cristata Species 0.000 description 1
- RYGMFSIKBFXOCR-UHFFFAOYSA-N Copper Chemical compound [Cu] RYGMFSIKBFXOCR-UHFFFAOYSA-N 0.000 description 1
- 241000711573 Coronaviridae Species 0.000 description 1
- 241001275954 Cortinarius caperatus Species 0.000 description 1
- 241001655249 Corvus brachyrhynchos Species 0.000 description 1
- 241001053156 Corvus cornix Species 0.000 description 1
- 108010051219 Cre recombinase Proteins 0.000 description 1
- 241000195493 Cryptophyta Species 0.000 description 1
- 241000192700 Cyanobacteria Species 0.000 description 1
- 241000235646 Cyberlindnera jadinii Species 0.000 description 1
- BMHBJCVEXUBGFI-BIIVOSGPSA-N Cys-Cys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CS)NC(=O)[C@H](CS)N)C(=O)O BMHBJCVEXUBGFI-BIIVOSGPSA-N 0.000 description 1
- MBILEVLLOHJZMG-FXQIFTODSA-N Cys-Gln-Glu Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CS)N MBILEVLLOHJZMG-FXQIFTODSA-N 0.000 description 1
- KEBJBKIASQVRJS-WDSKDSINSA-N Cys-Gln-Gly Chemical compound C(CC(=O)N)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CS)N KEBJBKIASQVRJS-WDSKDSINSA-N 0.000 description 1
- VBPGTULCFGKGTF-ACZMJKKPSA-N Cys-Glu-Asp Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O VBPGTULCFGKGTF-ACZMJKKPSA-N 0.000 description 1
- SRIRHERUAMYIOQ-CIUDSAMLSA-N Cys-Leu-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SRIRHERUAMYIOQ-CIUDSAMLSA-N 0.000 description 1
- MKMKILWCRQLDFJ-DCAQKATOSA-N Cys-Lys-Arg Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MKMKILWCRQLDFJ-DCAQKATOSA-N 0.000 description 1
- CIVXDCMSSFGWAL-YUMQZZPRSA-N Cys-Lys-Gly Chemical compound C(CCN)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CS)N CIVXDCMSSFGWAL-YUMQZZPRSA-N 0.000 description 1
- XCDDSPYIMNXECQ-NAKRPEOUSA-N Cys-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CS XCDDSPYIMNXECQ-NAKRPEOUSA-N 0.000 description 1
- IZJLAQMWJHCHTN-BPUTZDHNSA-N Cys-Trp-Arg Chemical compound N[C@@H](CS)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(=O)N[C@@H](CCCNC(=N)N)C(=O)O IZJLAQMWJHCHTN-BPUTZDHNSA-N 0.000 description 1
- 108010079245 Cystic Fibrosis Transmembrane Conductance Regulator Proteins 0.000 description 1
- 102000004127 Cytokines Human genes 0.000 description 1
- 108090000695 Cytokines Proteins 0.000 description 1
- IGXWBGJHJZYPQS-SSDOTTSWSA-N D-Luciferin Chemical compound OC(=O)[C@H]1CSC(C=2SC3=CC=C(O)C=C3N=2)=N1 IGXWBGJHJZYPQS-SSDOTTSWSA-N 0.000 description 1
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical compound OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 description 1
- SNPLKNRPJHDVJA-ZETCQYMHSA-N D-panthenol Chemical compound OCC(C)(C)[C@@H](O)C(=O)NCCCO SNPLKNRPJHDVJA-ZETCQYMHSA-N 0.000 description 1
- 125000000824 D-ribofuranosyl group Chemical group [H]OC([H])([H])[C@@]1([H])OC([H])(*)[C@]([H])(O[H])[C@]1([H])O[H] 0.000 description 1
- 241000450599 DNA viruses Species 0.000 description 1
- 102000052510 DNA-Binding Proteins Human genes 0.000 description 1
- 108700020911 DNA-Binding Proteins Proteins 0.000 description 1
- 241001143296 Deferribacteres <phylum> Species 0.000 description 1
- CYCGRDQQIOGCKX-UHFFFAOYSA-N Dehydro-luciferin Natural products OC(=O)C1=CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 CYCGRDQQIOGCKX-UHFFFAOYSA-N 0.000 description 1
- 241000192095 Deinococcus-Thermus Species 0.000 description 1
- 241000283323 Delphinapterus leucas Species 0.000 description 1
- 108010053770 Deoxyribonucleases Proteins 0.000 description 1
- 102000016911 Deoxyribonucleases Human genes 0.000 description 1
- 241000288900 Desmodus rotundus Species 0.000 description 1
- 241000970811 Dictyoglomi Species 0.000 description 1
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 1
- 102100020743 Dipeptidase 1 Human genes 0.000 description 1
- 102100025012 Dipeptidyl peptidase 4 Human genes 0.000 description 1
- HJEINPVZRDJRBY-UHFFFAOYSA-N Disul Chemical compound OS(=O)(=O)OCCOC1=CC=C(Cl)C=C1Cl HJEINPVZRDJRBY-UHFFFAOYSA-N 0.000 description 1
- 102100030072 Doublesex- and mab-3-related transcription factor 3 Human genes 0.000 description 1
- 241000271571 Dromaius novaehollandiae Species 0.000 description 1
- 241000142891 Drosophila bipectinata Species 0.000 description 1
- 241000255477 Drosophila serrata Species 0.000 description 1
- 241000255345 Drosophila simulans Species 0.000 description 1
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 1
- 108010069091 Dystrophin Proteins 0.000 description 1
- 102000001039 Dystrophin Human genes 0.000 description 1
- 102100023471 E-selectin Human genes 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 101150029707 ERBB2 gene Proteins 0.000 description 1
- 241000288717 Echinops telfairi Species 0.000 description 1
- 102100029722 Ectonucleoside triphosphate diphosphohydrolase 1 Human genes 0.000 description 1
- 241001137323 Elephantulus edwardii Species 0.000 description 1
- 241000848685 Enhydra lutris kenyoni Species 0.000 description 1
- 241000224432 Entamoeba histolytica Species 0.000 description 1
- 101800003838 Epidermal growth factor Proteins 0.000 description 1
- 241001147414 Eptesicus fuscus Species 0.000 description 1
- 241000283086 Equidae Species 0.000 description 1
- 241000283074 Equus asinus Species 0.000 description 1
- 241000289669 Erinaceus europaeus Species 0.000 description 1
- 108090000371 Esterases Proteins 0.000 description 1
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 1
- 240000005708 Eugenia stipitata Species 0.000 description 1
- 235000006149 Eugenia stipitata Nutrition 0.000 description 1
- 101710190709 Eukaryotic translation initiation factor 4 gamma 2 Proteins 0.000 description 1
- 102000010834 Extracellular Matrix Proteins Human genes 0.000 description 1
- 108010037362 Extracellular Matrix Proteins Proteins 0.000 description 1
- 229940126611 FBTA05 Drugs 0.000 description 1
- 108010054218 Factor VIII Proteins 0.000 description 1
- 102000001690 Factor VIII Human genes 0.000 description 1
- 101710120224 Fc receptor-like protein 1 Proteins 0.000 description 1
- 108091006020 Fc-tagged proteins Proteins 0.000 description 1
- 101150051800 Fcrl1 gene Proteins 0.000 description 1
- 241000711950 Filoviridae Species 0.000 description 1
- BJGNCJDXODQBOB-UHFFFAOYSA-N Fivefly Luciferin Natural products OC(=O)C1CSC(C=2SC3=CC(O)=CC=C3N=2)=N1 BJGNCJDXODQBOB-UHFFFAOYSA-N 0.000 description 1
- 241000710781 Flaviviridae Species 0.000 description 1
- 241000746879 Fukomys damarensis Species 0.000 description 1
- 108010058643 Fungal Proteins Proteins 0.000 description 1
- 108090001126 Furin Proteins 0.000 description 1
- 102100035233 Furin Human genes 0.000 description 1
- 241000221778 Fusarium fujikuroi Species 0.000 description 1
- 241000223221 Fusarium oxysporum Species 0.000 description 1
- 241001453172 Fusobacteria Species 0.000 description 1
- 108091006027 G proteins Proteins 0.000 description 1
- 108010043685 GPI-Linked Proteins Proteins 0.000 description 1
- 102000002702 GPI-Linked Proteins Human genes 0.000 description 1
- 102000013446 GTP Phosphohydrolases Human genes 0.000 description 1
- 102000030782 GTP binding Human genes 0.000 description 1
- 108091000058 GTP-Binding Proteins 0.000 description 1
- 102100030708 GTPase KRas Human genes 0.000 description 1
- 108091006109 GTPases Proteins 0.000 description 1
- 241000287828 Gallus gallus Species 0.000 description 1
- 241000126130 Ganymedes Species 0.000 description 1
- 241000270288 Gekko Species 0.000 description 1
- 241001265526 Gemmatimonadetes <phylum> Species 0.000 description 1
- 241000699694 Gerbillinae Species 0.000 description 1
- RZSLYUUFFVHFRQ-FXQIFTODSA-N Gln-Ala-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O RZSLYUUFFVHFRQ-FXQIFTODSA-N 0.000 description 1
- SSWAFVQFQWOJIJ-XIRDDKMYSA-N Gln-Arg-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)N)N SSWAFVQFQWOJIJ-XIRDDKMYSA-N 0.000 description 1
- LLVXTGUTDYMJLY-GUBZILKMSA-N Gln-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)N)N LLVXTGUTDYMJLY-GUBZILKMSA-N 0.000 description 1
- CKNUKHBRCSMKMO-XHNCKOQMSA-N Gln-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O CKNUKHBRCSMKMO-XHNCKOQMSA-N 0.000 description 1
- ULXXDWZMMSQBDC-ACZMJKKPSA-N Gln-Asp-Asp Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N ULXXDWZMMSQBDC-ACZMJKKPSA-N 0.000 description 1
- CRRFJBGUGNNOCS-PEFMBERDSA-N Gln-Asp-Ile Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CRRFJBGUGNNOCS-PEFMBERDSA-N 0.000 description 1
- QFJPFPCSXOXMKI-BPUTZDHNSA-N Gln-Gln-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N QFJPFPCSXOXMKI-BPUTZDHNSA-N 0.000 description 1
- SNLOOPZHAQDMJG-CIUDSAMLSA-N Gln-Glu-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SNLOOPZHAQDMJG-CIUDSAMLSA-N 0.000 description 1
- PNENQZWRFMUZOM-DCAQKATOSA-N Gln-Glu-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O PNENQZWRFMUZOM-DCAQKATOSA-N 0.000 description 1
- VOLVNCMGXWDDQY-LPEHRKFASA-N Gln-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)N)N)C(=O)O VOLVNCMGXWDDQY-LPEHRKFASA-N 0.000 description 1
- NSNUZSPSADIMJQ-WDSKDSINSA-N Gln-Gly-Asp Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O NSNUZSPSADIMJQ-WDSKDSINSA-N 0.000 description 1
- MFJAPSYJQJCQDN-BQBZGAKWSA-N Gln-Gly-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O MFJAPSYJQJCQDN-BQBZGAKWSA-N 0.000 description 1
- SMLDOQHTOAAFJQ-WDSKDSINSA-N Gln-Gly-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SMLDOQHTOAAFJQ-WDSKDSINSA-N 0.000 description 1
- IWUFOVSLWADEJC-AVGNSLFASA-N Gln-His-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O IWUFOVSLWADEJC-AVGNSLFASA-N 0.000 description 1
- OOLCSQQPSLIETN-JYJNAYRXSA-N Gln-His-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CCC(=O)N)N)O OOLCSQQPSLIETN-JYJNAYRXSA-N 0.000 description 1
- TWIAMTNJOMRDAK-GUBZILKMSA-N Gln-Lys-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O TWIAMTNJOMRDAK-GUBZILKMSA-N 0.000 description 1
- ZEEPYMXTJWIMSN-GUBZILKMSA-N Gln-Lys-Ser Chemical compound NCCCC[C@@H](C(=O)N[C@@H](CO)C(O)=O)NC(=O)[C@@H](N)CCC(N)=O ZEEPYMXTJWIMSN-GUBZILKMSA-N 0.000 description 1
- XZUUUKNKNWVPHQ-JYJNAYRXSA-N Gln-Phe-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(O)=O XZUUUKNKNWVPHQ-JYJNAYRXSA-N 0.000 description 1
- OZEQPCDLCDRCGY-SOUVJXGZSA-N Gln-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCC(=O)N)N)C(=O)O OZEQPCDLCDRCGY-SOUVJXGZSA-N 0.000 description 1
- XUMFMAVDHQDATI-DCAQKATOSA-N Gln-Pro-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O XUMFMAVDHQDATI-DCAQKATOSA-N 0.000 description 1
- VNTGPISAOMAXRK-CIUDSAMLSA-N Gln-Pro-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O VNTGPISAOMAXRK-CIUDSAMLSA-N 0.000 description 1
- KVQOVQVGVKDZNW-GUBZILKMSA-N Gln-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N KVQOVQVGVKDZNW-GUBZILKMSA-N 0.000 description 1
- LPIKVBWNNVFHCQ-GUBZILKMSA-N Gln-Ser-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LPIKVBWNNVFHCQ-GUBZILKMSA-N 0.000 description 1
- VOUSELYGTNGEPB-NUMRIWBASA-N Gln-Thr-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O VOUSELYGTNGEPB-NUMRIWBASA-N 0.000 description 1
- XMWNHGKDDIFXQJ-NWLDYVSISA-N Gln-Thr-Trp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O XMWNHGKDDIFXQJ-NWLDYVSISA-N 0.000 description 1
- YMCPEHDGTRUOHO-SXNHZJKMSA-N Gln-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCC(=O)N)N YMCPEHDGTRUOHO-SXNHZJKMSA-N 0.000 description 1
- CMBXOSFZCFGDLE-IHRRRGAJSA-N Gln-Tyr-Gln Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O CMBXOSFZCFGDLE-IHRRRGAJSA-N 0.000 description 1
- WIMVKDYAKRAUCG-IHRRRGAJSA-N Gln-Tyr-Glu Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O WIMVKDYAKRAUCG-IHRRRGAJSA-N 0.000 description 1
- ZMXZGYLINVNTKH-DZKIICNBSA-N Gln-Val-Phe Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ZMXZGYLINVNTKH-DZKIICNBSA-N 0.000 description 1
- CSMHMEATMDCQNY-DZKIICNBSA-N Gln-Val-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O CSMHMEATMDCQNY-DZKIICNBSA-N 0.000 description 1
- HUWSBFYAGXCXKC-CIUDSAMLSA-N Glu-Ala-Met Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCSC)C(O)=O HUWSBFYAGXCXKC-CIUDSAMLSA-N 0.000 description 1
- NCWOMXABNYEPLY-NRPADANISA-N Glu-Ala-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O NCWOMXABNYEPLY-NRPADANISA-N 0.000 description 1
- MLCPTRRNICEKIS-FXQIFTODSA-N Glu-Asn-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MLCPTRRNICEKIS-FXQIFTODSA-N 0.000 description 1
- AFODTOLGSZQDSL-PEFMBERDSA-N Glu-Asn-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)O)N AFODTOLGSZQDSL-PEFMBERDSA-N 0.000 description 1
- JPHYJQHPILOKHC-ACZMJKKPSA-N Glu-Asp-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O JPHYJQHPILOKHC-ACZMJKKPSA-N 0.000 description 1
- XXCDTYBVGMPIOA-FXQIFTODSA-N Glu-Asp-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XXCDTYBVGMPIOA-FXQIFTODSA-N 0.000 description 1
- DSPQRJXOIXHOHK-WDSKDSINSA-N Glu-Asp-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O DSPQRJXOIXHOHK-WDSKDSINSA-N 0.000 description 1
- RTOOAKXIJADOLL-GUBZILKMSA-N Glu-Asp-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N RTOOAKXIJADOLL-GUBZILKMSA-N 0.000 description 1
- PBFGQTGPSKWHJA-QEJZJMRPSA-N Glu-Asp-Trp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O PBFGQTGPSKWHJA-QEJZJMRPSA-N 0.000 description 1
- OXEMJGCAJFFREE-FXQIFTODSA-N Glu-Gln-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O OXEMJGCAJFFREE-FXQIFTODSA-N 0.000 description 1
- GYCPQVFKCPPRQB-GUBZILKMSA-N Glu-Gln-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)O)N GYCPQVFKCPPRQB-GUBZILKMSA-N 0.000 description 1
- MUSGDMDGNGXULI-DCAQKATOSA-N Glu-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O MUSGDMDGNGXULI-DCAQKATOSA-N 0.000 description 1
- AIGROOHQXCACHL-WDSKDSINSA-N Glu-Gly-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O AIGROOHQXCACHL-WDSKDSINSA-N 0.000 description 1
- UHVIQGKBMXEVGN-WDSKDSINSA-N Glu-Gly-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O UHVIQGKBMXEVGN-WDSKDSINSA-N 0.000 description 1
- CXRWMMRLEMVSEH-PEFMBERDSA-N Glu-Ile-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O CXRWMMRLEMVSEH-PEFMBERDSA-N 0.000 description 1
- KRRFFAHEAOCBCQ-SIUGBPQLSA-N Glu-Ile-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KRRFFAHEAOCBCQ-SIUGBPQLSA-N 0.000 description 1
- PJBVXVBTTFZPHJ-GUBZILKMSA-N Glu-Leu-Asp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)O)N PJBVXVBTTFZPHJ-GUBZILKMSA-N 0.000 description 1
- BCYGDJXHAGZNPQ-DCAQKATOSA-N Glu-Lys-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O BCYGDJXHAGZNPQ-DCAQKATOSA-N 0.000 description 1
- HRBYTAIBKPNZKQ-AVGNSLFASA-N Glu-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(O)=O HRBYTAIBKPNZKQ-AVGNSLFASA-N 0.000 description 1
- NPMSEUWUMOSEFM-CIUDSAMLSA-N Glu-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N NPMSEUWUMOSEFM-CIUDSAMLSA-N 0.000 description 1
- UMHRCVCZUPBBQW-GARJFASQSA-N Glu-Met-Pro Chemical compound CSCC[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N UMHRCVCZUPBBQW-GARJFASQSA-N 0.000 description 1
- YBTCBQBIJKGSJP-BQBZGAKWSA-N Glu-Pro Chemical compound OC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(O)=O YBTCBQBIJKGSJP-BQBZGAKWSA-N 0.000 description 1
- SWDNPSMMEWRNOH-HJGDQZAQSA-N Glu-Pro-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O SWDNPSMMEWRNOH-HJGDQZAQSA-N 0.000 description 1
- SYAYROHMAIHWFB-KBIXCLLPSA-N Glu-Ser-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O SYAYROHMAIHWFB-KBIXCLLPSA-N 0.000 description 1
- JWNZHMSRZXXGTM-XKBZYTNZSA-N Glu-Ser-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JWNZHMSRZXXGTM-XKBZYTNZSA-N 0.000 description 1
- DDXZHOHEABQXSE-NKIYYHGXSA-N Glu-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O DDXZHOHEABQXSE-NKIYYHGXSA-N 0.000 description 1
- QLNKFGTZOBVMCS-JBACZVJFSA-N Glu-Tyr-Trp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O QLNKFGTZOBVMCS-JBACZVJFSA-N 0.000 description 1
- MLILEEIVMRUYBX-NHCYSSNCSA-N Glu-Val-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O MLILEEIVMRUYBX-NHCYSSNCSA-N 0.000 description 1
- YQPFCZVKMUVZIN-AUTRQRHGSA-N Glu-Val-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O YQPFCZVKMUVZIN-AUTRQRHGSA-N 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- 108010017544 Glucosylceramidase Proteins 0.000 description 1
- 102000004547 Glucosylceramidase Human genes 0.000 description 1
- 102000018899 Glutamate Receptors Human genes 0.000 description 1
- 108010027915 Glutamate Receptors Proteins 0.000 description 1
- 102100041003 Glutamate carboxypeptidase 2 Human genes 0.000 description 1
- RQZGFWKQLPJOEQ-YUMQZZPRSA-N Gly-Arg-Gln Chemical compound C(C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)CN)CN=C(N)N RQZGFWKQLPJOEQ-YUMQZZPRSA-N 0.000 description 1
- QSTLUOIOYLYLLF-WDSKDSINSA-N Gly-Asp-Glu Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O QSTLUOIOYLYLLF-WDSKDSINSA-N 0.000 description 1
- LLXVQPKEQQCISF-YUMQZZPRSA-N Gly-Asp-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)CN LLXVQPKEQQCISF-YUMQZZPRSA-N 0.000 description 1
- TZOVVRJYUDETQG-RCOVLWMOSA-N Gly-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CN TZOVVRJYUDETQG-RCOVLWMOSA-N 0.000 description 1
- DTRUBYPMMVPQPD-YUMQZZPRSA-N Gly-Gln-Arg Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O DTRUBYPMMVPQPD-YUMQZZPRSA-N 0.000 description 1
- XLFHCWHXKSFVIB-BQBZGAKWSA-N Gly-Gln-Gln Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O XLFHCWHXKSFVIB-BQBZGAKWSA-N 0.000 description 1
- QPDUVFSVVAOUHE-XVKPBYJWSA-N Gly-Gln-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)CN)C(O)=O QPDUVFSVVAOUHE-XVKPBYJWSA-N 0.000 description 1
- MBOAPAXLTUSMQI-JHEQGTHGSA-N Gly-Glu-Thr Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MBOAPAXLTUSMQI-JHEQGTHGSA-N 0.000 description 1
- CCQOOWAONKGYKQ-BYPYZUCNSA-N Gly-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)CN CCQOOWAONKGYKQ-BYPYZUCNSA-N 0.000 description 1
- BUEFQXUHTUZXHR-LURJTMIESA-N Gly-Gly-Pro zwitterion Chemical compound NCC(=O)NCC(=O)N1CCC[C@H]1C(O)=O BUEFQXUHTUZXHR-LURJTMIESA-N 0.000 description 1
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 1
- YFGONBOFGGWKKY-VHSXEESVSA-N Gly-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)CN)C(=O)O YFGONBOFGGWKKY-VHSXEESVSA-N 0.000 description 1
- TWTPDFFBLQEBOE-IUCAKERBSA-N Gly-Leu-Gln Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O TWTPDFFBLQEBOE-IUCAKERBSA-N 0.000 description 1
- HJARVELKOSZUEW-YUMQZZPRSA-N Gly-Pro-Gln Chemical compound [H]NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O HJARVELKOSZUEW-YUMQZZPRSA-N 0.000 description 1
- IMRNSEPSPFQNHF-STQMWFEESA-N Gly-Ser-Trp Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=CC=CC=C12)C(=O)O IMRNSEPSPFQNHF-STQMWFEESA-N 0.000 description 1
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 1
- GNNJKUYDWFIBTK-QWRGUYRKSA-N Gly-Tyr-Asp Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O GNNJKUYDWFIBTK-QWRGUYRKSA-N 0.000 description 1
- DNAZKGFYFRGZIH-QWRGUYRKSA-N Gly-Tyr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 DNAZKGFYFRGZIH-QWRGUYRKSA-N 0.000 description 1
- 102100031181 Glyceraldehyde-3-phosphate dehydrogenase Human genes 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 102000009465 Growth Factor Receptors Human genes 0.000 description 1
- 108010009202 Growth Factor Receptors Proteins 0.000 description 1
- 241000543540 Guillardia theta Species 0.000 description 1
- RVKIPWVMZANZLI-UHFFFAOYSA-N H-Lys-Trp-OH Natural products C1=CC=C2C(CC(NC(=O)C(N)CCCCN)C(O)=O)=CNC2=C1 RVKIPWVMZANZLI-UHFFFAOYSA-N 0.000 description 1
- 239000007995 HEPES buffer Substances 0.000 description 1
- 102100028972 HLA class I histocompatibility antigen, A alpha chain Human genes 0.000 description 1
- 102100028976 HLA class I histocompatibility antigen, B alpha chain Human genes 0.000 description 1
- 102100028971 HLA class I histocompatibility antigen, C alpha chain Human genes 0.000 description 1
- 102100031546 HLA class II histocompatibility antigen, DO beta chain Human genes 0.000 description 1
- 108010075704 HLA-A Antigens Proteins 0.000 description 1
- 108010058607 HLA-B Antigens Proteins 0.000 description 1
- 108010052199 HLA-C Antigens Proteins 0.000 description 1
- 241000700130 Heterocephalus Species 0.000 description 1
- 241000700131 Heterocephalus glaber Species 0.000 description 1
- 102100026122 High affinity immunoglobulin gamma Fc receptor I Human genes 0.000 description 1
- 241001113389 Hipposideros armiger Species 0.000 description 1
- HTZKFIYQMHJWSQ-INTQDDNPSA-N His-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CN=CN2)N HTZKFIYQMHJWSQ-INTQDDNPSA-N 0.000 description 1
- ZZLWLWSUIBSMNP-CIUDSAMLSA-N His-Asp-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZZLWLWSUIBSMNP-CIUDSAMLSA-N 0.000 description 1
- NWGXCPUKPVISSJ-AVGNSLFASA-N His-Gln-Lys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N NWGXCPUKPVISSJ-AVGNSLFASA-N 0.000 description 1
- VBOFRJNDIOPNDO-YUMQZZPRSA-N His-Gly-Asn Chemical compound C1=C(NC=N1)C[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)N)C(=O)O)N VBOFRJNDIOPNDO-YUMQZZPRSA-N 0.000 description 1
- PMWSGVRIMIFXQH-KKUMJFAQSA-N His-His-Leu Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1NC=NC=1)C1=CN=CN1 PMWSGVRIMIFXQH-KKUMJFAQSA-N 0.000 description 1
- JBSLJUPMTYLLFH-MELADBBJSA-N His-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC3=CN=CN3)N)C(=O)O JBSLJUPMTYLLFH-MELADBBJSA-N 0.000 description 1
- LDFWDDVELNOGII-MXAVVETBSA-N His-Lys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC1=CN=CN1)N LDFWDDVELNOGII-MXAVVETBSA-N 0.000 description 1
- WYKXJGWSJUULSL-AVGNSLFASA-N His-Val-Arg Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)Cc1cnc[nH]1)C(=O)N[C@@H](CCCNC(=N)N)C(=O)O WYKXJGWSJUULSL-AVGNSLFASA-N 0.000 description 1
- 108010027412 Histocompatibility Antigens Class II Proteins 0.000 description 1
- 102000018713 Histocompatibility Antigens Class II Human genes 0.000 description 1
- 241001272567 Hominoidea Species 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101000797917 Homo sapiens 1,5-anhydro-D-fructose reductase Proteins 0.000 description 1
- 101000777636 Homo sapiens ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Proteins 0.000 description 1
- 101001022185 Homo sapiens Alpha-(1,3)-fucosyltransferase 4 Proteins 0.000 description 1
- 101000757160 Homo sapiens Aminopeptidase N Proteins 0.000 description 1
- 101000889953 Homo sapiens Apolipoprotein B-100 Proteins 0.000 description 1
- 101000884305 Homo sapiens B-cell receptor CD22 Proteins 0.000 description 1
- 101000922405 Homo sapiens C-X-C chemokine receptor type 5 Proteins 0.000 description 1
- 101000914511 Homo sapiens CD27 antigen Proteins 0.000 description 1
- 101000868273 Homo sapiens CD44 antigen Proteins 0.000 description 1
- 101000716130 Homo sapiens CD48 antigen Proteins 0.000 description 1
- 101000897400 Homo sapiens CD59 glycoprotein Proteins 0.000 description 1
- 101000934368 Homo sapiens CD63 antigen Proteins 0.000 description 1
- 101000981093 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 1 Proteins 0.000 description 1
- 101000914337 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 3 Proteins 0.000 description 1
- 101000914324 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 5 Proteins 0.000 description 1
- 101000914320 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 8 Proteins 0.000 description 1
- 101000856022 Homo sapiens Complement decay-accelerating factor Proteins 0.000 description 1
- 101000941929 Homo sapiens Complement receptor type 2 Proteins 0.000 description 1
- 101100499854 Homo sapiens DPEP1 gene Proteins 0.000 description 1
- 101000908391 Homo sapiens Dipeptidyl peptidase 4 Proteins 0.000 description 1
- 101000864825 Homo sapiens Doublesex- and mab-3-related transcription factor 3 Proteins 0.000 description 1
- 101000622123 Homo sapiens E-selectin Proteins 0.000 description 1
- 101001012447 Homo sapiens Ectonucleoside triphosphate diphosphohydrolase 1 Proteins 0.000 description 1
- 101100119857 Homo sapiens FCRL2 gene Proteins 0.000 description 1
- 101000584612 Homo sapiens GTPase KRas Proteins 0.000 description 1
- 101000892862 Homo sapiens Glutamate carboxypeptidase 2 Proteins 0.000 description 1
- 101000866281 Homo sapiens HLA class II histocompatibility antigen, DO beta chain Proteins 0.000 description 1
- 101000913074 Homo sapiens High affinity immunoglobulin gamma Fc receptor I Proteins 0.000 description 1
- 101000976075 Homo sapiens Insulin Proteins 0.000 description 1
- 101001078158 Homo sapiens Integrin alpha-1 Proteins 0.000 description 1
- 101001078133 Homo sapiens Integrin alpha-2 Proteins 0.000 description 1
- 101000994378 Homo sapiens Integrin alpha-3 Proteins 0.000 description 1
- 101000994375 Homo sapiens Integrin alpha-4 Proteins 0.000 description 1
- 101000994369 Homo sapiens Integrin alpha-5 Proteins 0.000 description 1
- 101000994365 Homo sapiens Integrin alpha-6 Proteins 0.000 description 1
- 101001035237 Homo sapiens Integrin alpha-D Proteins 0.000 description 1
- 101001078143 Homo sapiens Integrin alpha-IIb Proteins 0.000 description 1
- 101001046686 Homo sapiens Integrin alpha-M Proteins 0.000 description 1
- 101001046677 Homo sapiens Integrin alpha-V Proteins 0.000 description 1
- 101000935043 Homo sapiens Integrin beta-1 Proteins 0.000 description 1
- 101000935040 Homo sapiens Integrin beta-2 Proteins 0.000 description 1
- 101001015004 Homo sapiens Integrin beta-3 Proteins 0.000 description 1
- 101000599852 Homo sapiens Intercellular adhesion molecule 1 Proteins 0.000 description 1
- 101000599862 Homo sapiens Intercellular adhesion molecule 3 Proteins 0.000 description 1
- 101001057504 Homo sapiens Interferon-stimulated gene 20 kDa protein Proteins 0.000 description 1
- 101001055144 Homo sapiens Interleukin-2 receptor subunit alpha Proteins 0.000 description 1
- 101001018097 Homo sapiens L-selectin Proteins 0.000 description 1
- 101000777628 Homo sapiens Leukocyte antigen CD37 Proteins 0.000 description 1
- 101000868279 Homo sapiens Leukocyte surface antigen CD47 Proteins 0.000 description 1
- 101000980823 Homo sapiens Leukocyte surface antigen CD53 Proteins 0.000 description 1
- 101000608935 Homo sapiens Leukosialin Proteins 0.000 description 1
- 101000878605 Homo sapiens Low affinity immunoglobulin epsilon Fc receptor Proteins 0.000 description 1
- 101000917826 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor II-a Proteins 0.000 description 1
- 101000917824 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor II-b Proteins 0.000 description 1
- 101000917858 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 description 1
- 101000917839 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-B Proteins 0.000 description 1
- 101001063392 Homo sapiens Lymphocyte function-associated antigen 3 Proteins 0.000 description 1
- 101001008874 Homo sapiens Mast/stem cell growth factor receptor Kit Proteins 0.000 description 1
- 101000578784 Homo sapiens Melanoma antigen recognized by T-cells 1 Proteins 0.000 description 1
- 101000961414 Homo sapiens Membrane cofactor protein Proteins 0.000 description 1
- 101000576802 Homo sapiens Mesothelin Proteins 0.000 description 1
- 101000628547 Homo sapiens Metalloreductase STEAP1 Proteins 0.000 description 1
- 101000628535 Homo sapiens Metalloreductase STEAP2 Proteins 0.000 description 1
- 101000946889 Homo sapiens Monocyte differentiation antigen CD14 Proteins 0.000 description 1
- 101000581981 Homo sapiens Neural cell adhesion molecule 1 Proteins 0.000 description 1
- 101001024605 Homo sapiens Next to BRCA1 gene 1 protein Proteins 0.000 description 1
- 101000622137 Homo sapiens P-selectin Proteins 0.000 description 1
- 101100408693 Homo sapiens PNMA3 gene Proteins 0.000 description 1
- 101100408695 Homo sapiens PNMA5 gene Proteins 0.000 description 1
- 101001098868 Homo sapiens Proprotein convertase subtilisin/kexin type 9 Proteins 0.000 description 1
- 101000881131 Homo sapiens RNA/RNP complex-1-interacting phosphatase Proteins 0.000 description 1
- 101100201921 Homo sapiens RTL3 gene Proteins 0.000 description 1
- 101100094533 Homo sapiens RTL6 gene Proteins 0.000 description 1
- 101001094545 Homo sapiens Retrotransposon-like protein 1 Proteins 0.000 description 1
- 101001059454 Homo sapiens Serine/threonine-protein kinase MARK2 Proteins 0.000 description 1
- 101001120990 Homo sapiens Short-wave-sensitive opsin 1 Proteins 0.000 description 1
- 101000884271 Homo sapiens Signal transducer CD24 Proteins 0.000 description 1
- 101000831940 Homo sapiens Stathmin Proteins 0.000 description 1
- 101000617738 Homo sapiens Survival motor neuron protein Proteins 0.000 description 1
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 description 1
- 101000800116 Homo sapiens Thy-1 membrane glycoprotein Proteins 0.000 description 1
- 101000835093 Homo sapiens Transferrin receptor protein 1 Proteins 0.000 description 1
- 101000611023 Homo sapiens Tumor necrosis factor receptor superfamily member 6 Proteins 0.000 description 1
- 101000851376 Homo sapiens Tumor necrosis factor receptor superfamily member 8 Proteins 0.000 description 1
- 102000002265 Human Growth Hormone Human genes 0.000 description 1
- 108010000521 Human Growth Hormone Proteins 0.000 description 1
- 239000000854 Human Growth Hormone Substances 0.000 description 1
- 241000700588 Human alphaherpesvirus 1 Species 0.000 description 1
- 241000701024 Human betaherpesvirus 5 Species 0.000 description 1
- 241000243251 Hydra Species 0.000 description 1
- 241000167869 Ictidomys tridecemlineatus Species 0.000 description 1
- 102000004627 Iduronidase Human genes 0.000 description 1
- 108010003381 Iduronidase Proteins 0.000 description 1
- JRHFQUPIZOYKQP-KBIXCLLPSA-N Ile-Ala-Glu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O JRHFQUPIZOYKQP-KBIXCLLPSA-N 0.000 description 1
- BSWLQVGEVFYGIM-ZPFDUUQYSA-N Ile-Gln-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N BSWLQVGEVFYGIM-ZPFDUUQYSA-N 0.000 description 1
- KMBPQYKVZBMRMH-PEFMBERDSA-N Ile-Gln-Asn Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O KMBPQYKVZBMRMH-PEFMBERDSA-N 0.000 description 1
- OVPYIUNCVSOVNF-ZPFDUUQYSA-N Ile-Gln-Pro Natural products CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O OVPYIUNCVSOVNF-ZPFDUUQYSA-N 0.000 description 1
- YGDWPQCLFJNMOL-MNXVOIDGSA-N Ile-Leu-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N YGDWPQCLFJNMOL-MNXVOIDGSA-N 0.000 description 1
- TVYWVSJGSHQWMT-AJNGGQMLSA-N Ile-Leu-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N TVYWVSJGSHQWMT-AJNGGQMLSA-N 0.000 description 1
- UIEZQYNXCYHMQS-BJDJZHNGSA-N Ile-Lys-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)O)N UIEZQYNXCYHMQS-BJDJZHNGSA-N 0.000 description 1
- YSGBJIQXTIVBHZ-AJNGGQMLSA-N Ile-Lys-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O YSGBJIQXTIVBHZ-AJNGGQMLSA-N 0.000 description 1
- JZNVOBUNTWNZPW-GHCJXIJMSA-N Ile-Ser-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)O)C(=O)O)N JZNVOBUNTWNZPW-GHCJXIJMSA-N 0.000 description 1
- PELCGFMHLZXWBQ-BJDJZHNGSA-N Ile-Ser-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)O)N PELCGFMHLZXWBQ-BJDJZHNGSA-N 0.000 description 1
- NURNJECQNNCRBK-FLBSBUHZSA-N Ile-Thr-Thr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NURNJECQNNCRBK-FLBSBUHZSA-N 0.000 description 1
- KXUKTDGKLAOCQK-LSJOCFKGSA-N Ile-Val-Gly Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O KXUKTDGKLAOCQK-LSJOCFKGSA-N 0.000 description 1
- 108090001061 Insulin Proteins 0.000 description 1
- 102000004877 Insulin Human genes 0.000 description 1
- 102100039688 Insulin-like growth factor 1 receptor Human genes 0.000 description 1
- 108010061833 Integrases Proteins 0.000 description 1
- 102000012330 Integrases Human genes 0.000 description 1
- 102100025323 Integrin alpha-1 Human genes 0.000 description 1
- 102100025305 Integrin alpha-2 Human genes 0.000 description 1
- 102100032819 Integrin alpha-3 Human genes 0.000 description 1
- 102100032818 Integrin alpha-4 Human genes 0.000 description 1
- 102100032817 Integrin alpha-5 Human genes 0.000 description 1
- 102100032816 Integrin alpha-6 Human genes 0.000 description 1
- 102100039904 Integrin alpha-D Human genes 0.000 description 1
- 102100022341 Integrin alpha-E Human genes 0.000 description 1
- 102100025306 Integrin alpha-IIb Human genes 0.000 description 1
- 102100022338 Integrin alpha-M Human genes 0.000 description 1
- 102100022337 Integrin alpha-V Human genes 0.000 description 1
- 102100022297 Integrin alpha-X Human genes 0.000 description 1
- 102100025304 Integrin beta-1 Human genes 0.000 description 1
- 102100025390 Integrin beta-2 Human genes 0.000 description 1
- 102100032999 Integrin beta-3 Human genes 0.000 description 1
- 102100033000 Integrin beta-4 Human genes 0.000 description 1
- 102100037877 Intercellular adhesion molecule 1 Human genes 0.000 description 1
- 102100037871 Intercellular adhesion molecule 3 Human genes 0.000 description 1
- 108010054267 Interferon Receptors Proteins 0.000 description 1
- 102000001617 Interferon Receptors Human genes 0.000 description 1
- 108010005716 Interferon beta-1a Proteins 0.000 description 1
- 102100027268 Interferon-stimulated gene 20 kDa protein Human genes 0.000 description 1
- 108010038453 Interleukin-2 Receptors Proteins 0.000 description 1
- 102000010789 Interleukin-2 Receptors Human genes 0.000 description 1
- 102000004310 Ion Channels Human genes 0.000 description 1
- 108090000862 Ion Channels Proteins 0.000 description 1
- 102000004195 Isomerases Human genes 0.000 description 1
- 108090000769 Isomerases Proteins 0.000 description 1
- 241000499509 Jaculus jaculus Species 0.000 description 1
- 241000235649 Kluyveromyces Species 0.000 description 1
- 108010092694 L-Selectin Proteins 0.000 description 1
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 1
- 239000002138 L01XE21 - Regorafenib Substances 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- 241000258916 Leptinotarsa decemlineata Species 0.000 description 1
- 241000283131 Leptonychotes weddellii Species 0.000 description 1
- 240000003553 Leptospermum scoparium Species 0.000 description 1
- WGNOPSQMIQERPK-GARJFASQSA-N Leu-Asn-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N WGNOPSQMIQERPK-GARJFASQSA-N 0.000 description 1
- XVSJMWYYLHPDKY-DCAQKATOSA-N Leu-Asp-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCSC)C(O)=O XVSJMWYYLHPDKY-DCAQKATOSA-N 0.000 description 1
- FQZPTCNSNPWHLJ-AVGNSLFASA-N Leu-Gln-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O FQZPTCNSNPWHLJ-AVGNSLFASA-N 0.000 description 1
- NEEOBPIXKWSBRF-IUCAKERBSA-N Leu-Glu-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O NEEOBPIXKWSBRF-IUCAKERBSA-N 0.000 description 1
- CFZZDVMBRYFFNU-QWRGUYRKSA-N Leu-His-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)NCC(O)=O CFZZDVMBRYFFNU-QWRGUYRKSA-N 0.000 description 1
- KVOFSTUWVSQMDK-KKUMJFAQSA-N Leu-His-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(C)C)CC1=CN=CN1 KVOFSTUWVSQMDK-KKUMJFAQSA-N 0.000 description 1
- OYQUOLRTJHWVSQ-SRVKXCTJSA-N Leu-His-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O OYQUOLRTJHWVSQ-SRVKXCTJSA-N 0.000 description 1
- AUBMZAMQCOYSIC-MNXVOIDGSA-N Leu-Ile-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O AUBMZAMQCOYSIC-MNXVOIDGSA-N 0.000 description 1
- QNBVTHNJGCOVFA-AVGNSLFASA-N Leu-Leu-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O QNBVTHNJGCOVFA-AVGNSLFASA-N 0.000 description 1
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 1
- ZGUMORRUBUCXEH-AVGNSLFASA-N Leu-Lys-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZGUMORRUBUCXEH-AVGNSLFASA-N 0.000 description 1
- WXDRGWBQZIMJDE-ULQDDVLXSA-N Leu-Phe-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(O)=O WXDRGWBQZIMJDE-ULQDDVLXSA-N 0.000 description 1
- XWEVVRRSIOBJOO-SRVKXCTJSA-N Leu-Pro-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O XWEVVRRSIOBJOO-SRVKXCTJSA-N 0.000 description 1
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 1
- AKVBOOKXVAMKSS-GUBZILKMSA-N Leu-Ser-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O AKVBOOKXVAMKSS-GUBZILKMSA-N 0.000 description 1
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 1
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 1
- ICYRCNICGBJLGM-HJGDQZAQSA-N Leu-Thr-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(O)=O ICYRCNICGBJLGM-HJGDQZAQSA-N 0.000 description 1
- ARNIBBOXIAWUOP-MGHWNKPDSA-N Leu-Tyr-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ARNIBBOXIAWUOP-MGHWNKPDSA-N 0.000 description 1
- FBNPMTNBFFAMMH-AVGNSLFASA-N Leu-Val-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N FBNPMTNBFFAMMH-AVGNSLFASA-N 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 102100031586 Leukocyte antigen CD37 Human genes 0.000 description 1
- 102100032913 Leukocyte surface antigen CD47 Human genes 0.000 description 1
- 102100024221 Leukocyte surface antigen CD53 Human genes 0.000 description 1
- 102100039564 Leukosialin Human genes 0.000 description 1
- 108010000817 Leuprolide Proteins 0.000 description 1
- 102000004086 Ligand-Gated Ion Channels Human genes 0.000 description 1
- 108090000543 Ligand-Gated Ion Channels Proteins 0.000 description 1
- 102000003960 Ligases Human genes 0.000 description 1
- 108090000364 Ligases Proteins 0.000 description 1
- 229940123917 Lipid kinase inhibitor Drugs 0.000 description 1
- 108010028921 Lipopeptides Proteins 0.000 description 1
- 241000249820 Lipotes vexillifer Species 0.000 description 1
- YSDQQAXHVYUZIW-QCIJIYAXSA-N Liraglutide Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCNC(=O)CC[C@H](NC(=O)CCCCCCCCCCCCCCC)C(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC=1NC=NC=1)[C@@H](C)O)[C@@H](C)O)C(C)C)C1=CC=C(O)C=C1 YSDQQAXHVYUZIW-QCIJIYAXSA-N 0.000 description 1
- 108010019598 Liraglutide Proteins 0.000 description 1
- 102100038007 Low affinity immunoglobulin epsilon Fc receptor Human genes 0.000 description 1
- 102100029204 Low affinity immunoglobulin gamma Fc region receptor II-a Human genes 0.000 description 1
- 102100029185 Low affinity immunoglobulin gamma Fc region receptor III-B Human genes 0.000 description 1
- 241000283093 Loxodonta africana Species 0.000 description 1
- DDWFXDSYGUXRAY-UHFFFAOYSA-N Luciferin Natural products CCc1c(C)c(CC2NC(=O)C(=C2C=C)C)[nH]c1Cc3[nH]c4C(=C5/NC(CC(=O)O)C(C)C5CC(=O)O)CC(=O)c4c3C DDWFXDSYGUXRAY-UHFFFAOYSA-N 0.000 description 1
- 235000015459 Lycium barbarum Nutrition 0.000 description 1
- 102100030984 Lymphocyte function-associated antigen 3 Human genes 0.000 description 1
- MPGHETGWWWUHPY-CIUDSAMLSA-N Lys-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN MPGHETGWWWUHPY-CIUDSAMLSA-N 0.000 description 1
- XFBBBRDEQIPGNR-KATARQTJSA-N Lys-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCCCN)N)O XFBBBRDEQIPGNR-KATARQTJSA-N 0.000 description 1
- GGNOBVSOZPHLCE-GUBZILKMSA-N Lys-Gln-Asp Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O GGNOBVSOZPHLCE-GUBZILKMSA-N 0.000 description 1
- GRADYHMSAUIKPS-DCAQKATOSA-N Lys-Glu-Gln Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O GRADYHMSAUIKPS-DCAQKATOSA-N 0.000 description 1
- PBIPLDMFHAICIP-DCAQKATOSA-N Lys-Glu-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PBIPLDMFHAICIP-DCAQKATOSA-N 0.000 description 1
- KNKJPYAZQUFLQK-IHRRRGAJSA-N Lys-His-Arg Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CCCCN)N KNKJPYAZQUFLQK-IHRRRGAJSA-N 0.000 description 1
- GTAXSKOXPIISBW-AVGNSLFASA-N Lys-His-Gln Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N GTAXSKOXPIISBW-AVGNSLFASA-N 0.000 description 1
- SPCHLZUWJTYZFC-IHRRRGAJSA-N Lys-His-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(O)=O SPCHLZUWJTYZFC-IHRRRGAJSA-N 0.000 description 1
- JYXBNQOKPRQNQS-YTFOTSKYSA-N Lys-Ile-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JYXBNQOKPRQNQS-YTFOTSKYSA-N 0.000 description 1
- RBEATVHTWHTHTJ-KKUMJFAQSA-N Lys-Leu-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O RBEATVHTWHTHTJ-KKUMJFAQSA-N 0.000 description 1
- UQRZFMQQXXJTTF-AVGNSLFASA-N Lys-Lys-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O UQRZFMQQXXJTTF-AVGNSLFASA-N 0.000 description 1
- GAHJXEMYXKLZRQ-AJNGGQMLSA-N Lys-Lys-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O GAHJXEMYXKLZRQ-AJNGGQMLSA-N 0.000 description 1
- YDDDRTIPNTWGIG-SRVKXCTJSA-N Lys-Lys-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O YDDDRTIPNTWGIG-SRVKXCTJSA-N 0.000 description 1
- BEGQVWUZFXLNHZ-IHPCNDPISA-N Lys-Lys-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCCN)C(O)=O)=CNC2=C1 BEGQVWUZFXLNHZ-IHPCNDPISA-N 0.000 description 1
- IOQWIOPSKJOEKI-SRVKXCTJSA-N Lys-Ser-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IOQWIOPSKJOEKI-SRVKXCTJSA-N 0.000 description 1
- WZVSHTFTCYOFPL-GARJFASQSA-N Lys-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCCCN)N)C(=O)O WZVSHTFTCYOFPL-GARJFASQSA-N 0.000 description 1
- DIBZLYZXTSVGLN-CIUDSAMLSA-N Lys-Ser-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O DIBZLYZXTSVGLN-CIUDSAMLSA-N 0.000 description 1
- MIFFFXHMAHFACR-KATARQTJSA-N Lys-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CCCCN MIFFFXHMAHFACR-KATARQTJSA-N 0.000 description 1
- HONVOXINDBETTI-KKUMJFAQSA-N Lys-Tyr-Cys Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CS)C(O)=O)CC1=CC=C(O)C=C1 HONVOXINDBETTI-KKUMJFAQSA-N 0.000 description 1
- 241000282560 Macaca mulatta Species 0.000 description 1
- 241000282561 Macaca nemestrina Species 0.000 description 1
- 101710125418 Major capsid protein Proteins 0.000 description 1
- 101710091439 Major capsid protein 1 Proteins 0.000 description 1
- 241000283956 Manis Species 0.000 description 1
- 241000283958 Manis javanica Species 0.000 description 1
- 102100027754 Mast/stem cell growth factor receptor Kit Human genes 0.000 description 1
- 229930126263 Maytansine Natural products 0.000 description 1
- 102100028389 Melanoma antigen recognized by T-cells 1 Human genes 0.000 description 1
- 241000288147 Meleagris gallopavo Species 0.000 description 1
- 108010047230 Member 1 Subfamily B ATP Binding Cassette Transporter Proteins 0.000 description 1
- 102000013013 Member 2 Subfamily G ATP Binding Cassette Transporter Human genes 0.000 description 1
- 108010090306 Member 2 Subfamily G ATP Binding Cassette Transporter Proteins 0.000 description 1
- 102100039373 Membrane cofactor protein Human genes 0.000 description 1
- 241000699684 Meriones unguiculatus Species 0.000 description 1
- 241000699673 Mesocricetus auratus Species 0.000 description 1
- 102000003735 Mesothelin Human genes 0.000 description 1
- 108090000015 Mesothelin Proteins 0.000 description 1
- 102100025096 Mesothelin Human genes 0.000 description 1
- LMKSBGIUPVRHEH-FXQIFTODSA-N Met-Ala-Asn Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(N)=O LMKSBGIUPVRHEH-FXQIFTODSA-N 0.000 description 1
- PHWSCIFNNLLUFJ-NHCYSSNCSA-N Met-Gln-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCSC)N PHWSCIFNNLLUFJ-NHCYSSNCSA-N 0.000 description 1
- 108010006035 Metalloproteases Proteins 0.000 description 1
- 102000005741 Metalloproteases Human genes 0.000 description 1
- 102100026712 Metalloreductase STEAP1 Human genes 0.000 description 1
- 102100026711 Metalloreductase STEAP2 Human genes 0.000 description 1
- UEZVMMHDMIWARA-UHFFFAOYSA-N Metaphosphoric acid Chemical compound OP(=O)=O UEZVMMHDMIWARA-UHFFFAOYSA-N 0.000 description 1
- WXJXBKBJAKPJRN-UHFFFAOYSA-N Methanephosphonothioic acid Chemical compound CP(O)(O)=S WXJXBKBJAKPJRN-UHFFFAOYSA-N 0.000 description 1
- 241000235048 Meyerozyma guilliermondii Species 0.000 description 1
- 241000352027 Microbotryomycetes Species 0.000 description 1
- 241001416539 Microcebus murinus Species 0.000 description 1
- 241001327088 Microtus ochrogaster Species 0.000 description 1
- 241001139947 Mida Species 0.000 description 1
- 244000171805 Mimulus langsdorfii Species 0.000 description 1
- 241001123318 Miniopterus natalensis Species 0.000 description 1
- 241000237852 Mollusca Species 0.000 description 1
- 102100035877 Monocyte differentiation antigen CD14 Human genes 0.000 description 1
- 241000736257 Monodelphis domestica Species 0.000 description 1
- 108010063954 Mucins Proteins 0.000 description 1
- 102000015728 Mucins Human genes 0.000 description 1
- 208000034578 Multiple myelomas Diseases 0.000 description 1
- 241000699666 Mus <mouse, genus> Species 0.000 description 1
- 241000699660 Mus musculus Species 0.000 description 1
- 101000623899 Mus musculus Mucin-13 Proteins 0.000 description 1
- 101100042271 Mus musculus Sema3b gene Proteins 0.000 description 1
- 241000282341 Mustela putorius furo Species 0.000 description 1
- 241000700562 Myxoma virus Species 0.000 description 1
- RSPURTUNRHNVGF-IOSLPCCCSA-N N(2),N(2)-dimethylguanosine Chemical compound C1=NC=2C(=O)NC(N(C)C)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O RSPURTUNRHNVGF-IOSLPCCCSA-N 0.000 description 1
- VQAYFKKCNSOZKM-IOSLPCCCSA-N N(6)-methyladenosine Chemical compound C1=NC=2C(NC)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O VQAYFKKCNSOZKM-IOSLPCCCSA-N 0.000 description 1
- 108010027520 N-Acetylgalactosamine-4-Sulfatase Proteins 0.000 description 1
- PESQCPHRXOFIPX-UHFFFAOYSA-N N-L-methionyl-L-tyrosine Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-UHFFFAOYSA-N 0.000 description 1
- AUEJLPRZGVVDNU-UHFFFAOYSA-N N-L-tyrosyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CC1=CC=C(O)C=C1 AUEJLPRZGVVDNU-UHFFFAOYSA-N 0.000 description 1
- 108010087066 N2-tryptophyllysine Proteins 0.000 description 1
- VQAYFKKCNSOZKM-UHFFFAOYSA-N NSC 29409 Natural products C1=NC=2C(NC)=NC=NC=2N1C1OC(CO)C(O)C1O VQAYFKKCNSOZKM-UHFFFAOYSA-N 0.000 description 1
- 241000224437 Naegleria gruberi Species 0.000 description 1
- BQVUABVGYYSDCJ-UHFFFAOYSA-N Nalpha-L-Leucyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)CC(C)C)C(O)=O)=CNC2=C1 BQVUABVGYYSDCJ-UHFFFAOYSA-N 0.000 description 1
- 241000515114 Nanorana Species 0.000 description 1
- 241000573494 Nanorana parkeri Species 0.000 description 1
- MRWXACSTFXYYMV-UHFFFAOYSA-N Nebularine Natural products OC1C(O)C(CO)OC1N1C2=NC=NC=C2N=C1 MRWXACSTFXYYMV-UHFFFAOYSA-N 0.000 description 1
- 102100035486 Nectin-4 Human genes 0.000 description 1
- 101710043865 Nectin-4 Proteins 0.000 description 1
- 241001147403 Neomonachus schauinslandi Species 0.000 description 1
- 241001166264 Neophocaena asiaeorientalis asiaeorientalis Species 0.000 description 1
- 102000003729 Neprilysin Human genes 0.000 description 1
- 108090000028 Neprilysin Proteins 0.000 description 1
- 108010025020 Nerve Growth Factor Proteins 0.000 description 1
- 102000007072 Nerve Growth Factors Human genes 0.000 description 1
- 102100027347 Neural cell adhesion molecule 1 Human genes 0.000 description 1
- 229940123424 Neuraminidase inhibitor Drugs 0.000 description 1
- 241001556089 Nilaparvata lugens Species 0.000 description 1
- 241000121237 Nitrospirae Species 0.000 description 1
- 241001667355 Nomascus Species 0.000 description 1
- 241000882862 Nomascus leucogenys Species 0.000 description 1
- 108010051791 Nuclear Antigens Proteins 0.000 description 1
- 102000019040 Nuclear Antigens Human genes 0.000 description 1
- 102000007399 Nuclear hormone receptor Human genes 0.000 description 1
- 108020005497 Nuclear hormone receptor Proteins 0.000 description 1
- 108091028043 Nucleic acid sequence Proteins 0.000 description 1
- 108091007494 Nucleic acid- binding domains Proteins 0.000 description 1
- 241000283965 Ochotona princeps Species 0.000 description 1
- 241000283214 Odobenus rosmarus divergens Species 0.000 description 1
- 241000282943 Odocoileus Species 0.000 description 1
- 108700020796 Oncogene Proteins 0.000 description 1
- 102000043276 Oncogene Human genes 0.000 description 1
- 241000277334 Oncorhynchus Species 0.000 description 1
- 241000277338 Oncorhynchus kisutch Species 0.000 description 1
- 241000277275 Oncorhynchus mykiss Species 0.000 description 1
- 241000712464 Orthomyxoviridae Species 0.000 description 1
- 241000370375 Orycteropus afer afer Species 0.000 description 1
- 206010033128 Ovarian cancer Diseases 0.000 description 1
- 206010061535 Ovarian neoplasm Diseases 0.000 description 1
- 241000283901 Ovis aries musimon Species 0.000 description 1
- 101800000989 Oxytocin Proteins 0.000 description 1
- 102400000050 Oxytocin Human genes 0.000 description 1
- XNOPRXBHLZRZKH-UHFFFAOYSA-N Oxytocin Natural products N1C(=O)C(N)CSSCC(C(=O)N2C(CCC2)C(=O)NC(CC(C)C)C(=O)NCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(CCC(N)=O)NC(=O)C(C(C)CC)NC(=O)C1CC1=CC=C(O)C=C1 XNOPRXBHLZRZKH-UHFFFAOYSA-N 0.000 description 1
- 102100023472 P-selectin Human genes 0.000 description 1
- 102100037601 P2X purinoceptor 4 Human genes 0.000 description 1
- 108091008606 PDGF receptors Proteins 0.000 description 1
- 241000282576 Pan paniscus Species 0.000 description 1
- 241000282322 Panthera Species 0.000 description 1
- 241000282373 Panthera pardus Species 0.000 description 1
- 241000609816 Pantholops hodgsonii Species 0.000 description 1
- 241000287124 Parus major Species 0.000 description 1
- 241001360334 Paulinella micropora Species 0.000 description 1
- 241000479842 Pella Species 0.000 description 1
- 102000035195 Peptidases Human genes 0.000 description 1
- 102000002508 Peptide Elongation Factors Human genes 0.000 description 1
- 108010068204 Peptide Elongation Factors Proteins 0.000 description 1
- 108010044843 Peptide Initiation Factors Proteins 0.000 description 1
- 102000005877 Peptide Initiation Factors Human genes 0.000 description 1
- 108010043958 Peptoids Proteins 0.000 description 1
- 241000150350 Peribunyaviridae Species 0.000 description 1
- 241001520299 Phascolarctos cinereus Species 0.000 description 1
- BBDSZDHUCPSYAC-QEJZJMRPSA-N Phe-Ala-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O BBDSZDHUCPSYAC-QEJZJMRPSA-N 0.000 description 1
- LDSOBEJVGGVWGD-DLOVCJGASA-N Phe-Asp-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 LDSOBEJVGGVWGD-DLOVCJGASA-N 0.000 description 1
- MPFGIYLYWUCSJG-AVGNSLFASA-N Phe-Glu-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 MPFGIYLYWUCSJG-AVGNSLFASA-N 0.000 description 1
- HBGFEEQFVBWYJQ-KBPBESRZSA-N Phe-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 HBGFEEQFVBWYJQ-KBPBESRZSA-N 0.000 description 1
- KXUZHWXENMYOHC-QEJZJMRPSA-N Phe-Leu-Ala Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O KXUZHWXENMYOHC-QEJZJMRPSA-N 0.000 description 1
- RSPUIENXSJYZQO-JYJNAYRXSA-N Phe-Leu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 RSPUIENXSJYZQO-JYJNAYRXSA-N 0.000 description 1
- YCCUXNNKXDGMAM-KKUMJFAQSA-N Phe-Leu-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YCCUXNNKXDGMAM-KKUMJFAQSA-N 0.000 description 1
- CMHTUJQZQXFNTQ-OEAJRASXSA-N Phe-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC1=CC=CC=C1)N)O CMHTUJQZQXFNTQ-OEAJRASXSA-N 0.000 description 1
- OXKJSGGTHFMGDT-UFYCRDLUSA-N Phe-Phe-Arg Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)C1=CC=CC=C1 OXKJSGGTHFMGDT-UFYCRDLUSA-N 0.000 description 1
- BELBBZDIHDAJOR-UHFFFAOYSA-N Phenolsulfonephthalein Chemical compound C1=CC(O)=CC=C1C1(C=2C=CC(O)=CC=2)C2=CC=CC=C2S(=O)(=O)O1 BELBBZDIHDAJOR-UHFFFAOYSA-N 0.000 description 1
- 108700019535 Phosphoprotein Phosphatases Proteins 0.000 description 1
- 102000045595 Phosphoprotein Phosphatases Human genes 0.000 description 1
- 102000004160 Phosphoric Monoester Hydrolases Human genes 0.000 description 1
- 108090000608 Phosphoric Monoester Hydrolases Proteins 0.000 description 1
- 108091000080 Phosphotransferase Proteins 0.000 description 1
- 241000235645 Pichia kudriavzevii Species 0.000 description 1
- 208000007452 Plasmacytoma Diseases 0.000 description 1
- 102100024616 Platelet endothelial cell adhesion molecule Human genes 0.000 description 1
- 102000011653 Platelet-Derived Growth Factor Receptors Human genes 0.000 description 1
- 241001289568 Pogonomyrmex barbatus Species 0.000 description 1
- 239000004952 Polyamide Substances 0.000 description 1
- 239000002202 Polyethylene glycol Substances 0.000 description 1
- 241000282405 Pongo abelii Species 0.000 description 1
- 102100025067 Potassium voltage-gated channel subfamily H member 4 Human genes 0.000 description 1
- 101710163352 Potassium voltage-gated channel subfamily H member 4 Proteins 0.000 description 1
- DZZCICYRSZASNF-FXQIFTODSA-N Pro-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 DZZCICYRSZASNF-FXQIFTODSA-N 0.000 description 1
- CGBYDGAJHSOGFQ-LPEHRKFASA-N Pro-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 CGBYDGAJHSOGFQ-LPEHRKFASA-N 0.000 description 1
- IHCXPSYCHXFXKT-DCAQKATOSA-N Pro-Arg-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O IHCXPSYCHXFXKT-DCAQKATOSA-N 0.000 description 1
- INXAPZFIOVGHSV-CIUDSAMLSA-N Pro-Asn-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H]1CCCN1 INXAPZFIOVGHSV-CIUDSAMLSA-N 0.000 description 1
- SWXSLPHTJVAWDF-VEVYYDQMSA-N Pro-Asn-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SWXSLPHTJVAWDF-VEVYYDQMSA-N 0.000 description 1
- AHXPYZRZRMQOAU-QXEWZRGKSA-N Pro-Asn-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H]1CCCN1)C(O)=O AHXPYZRZRMQOAU-QXEWZRGKSA-N 0.000 description 1
- XUSDDSLCRPUKLP-QXEWZRGKSA-N Pro-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H]1CCCN1 XUSDDSLCRPUKLP-QXEWZRGKSA-N 0.000 description 1
- HJSCRFZVGXAGNG-SRVKXCTJSA-N Pro-Gln-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H]1CCCN1 HJSCRFZVGXAGNG-SRVKXCTJSA-N 0.000 description 1
- YSUZKYSRAFNLRB-ULQDDVLXSA-N Pro-Gln-Trp Chemical compound N([C@@H](CCC(=O)N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C(=O)[C@@H]1CCCN1 YSUZKYSRAFNLRB-ULQDDVLXSA-N 0.000 description 1
- LXVLKXPFIDDHJG-CIUDSAMLSA-N Pro-Glu-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O LXVLKXPFIDDHJG-CIUDSAMLSA-N 0.000 description 1
- UEHYFUCOGHWASA-HJGDQZAQSA-N Pro-Glu-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1 UEHYFUCOGHWASA-HJGDQZAQSA-N 0.000 description 1
- HAEGAELAYWSUNC-WPRPVWTQSA-N Pro-Gly-Val Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O HAEGAELAYWSUNC-WPRPVWTQSA-N 0.000 description 1
- GURGCNUWVSDYTP-SRVKXCTJSA-N Pro-Leu-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GURGCNUWVSDYTP-SRVKXCTJSA-N 0.000 description 1
- WIPAMEKBSHNFQE-IUCAKERBSA-N Pro-Met-Gly Chemical compound CSCC[C@@H](C(=O)NCC(=O)O)NC(=O)[C@@H]1CCCN1 WIPAMEKBSHNFQE-IUCAKERBSA-N 0.000 description 1
- POQFNPILEQEODH-FXQIFTODSA-N Pro-Ser-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O POQFNPILEQEODH-FXQIFTODSA-N 0.000 description 1
- NBDHWLZEMKSVHH-UVBJJODRSA-N Pro-Trp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@@H]3CCCN3 NBDHWLZEMKSVHH-UVBJJODRSA-N 0.000 description 1
- HOJUNFDJDAPVBI-BZSNNMDCSA-N Pro-Trp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@@H]3CCCN3 HOJUNFDJDAPVBI-BZSNNMDCSA-N 0.000 description 1
- DLZBBDSPTJBOOD-BPNCWPANSA-N Pro-Tyr-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O DLZBBDSPTJBOOD-BPNCWPANSA-N 0.000 description 1
- IMNVAOPEMFDAQD-NHCYSSNCSA-N Pro-Val-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IMNVAOPEMFDAQD-NHCYSSNCSA-N 0.000 description 1
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 1
- 102100024216 Programmed cell death 1 ligand 1 Human genes 0.000 description 1
- 102100038955 Proprotein convertase subtilisin/kexin type 9 Human genes 0.000 description 1
- 108010029485 Protein Isoforms Proteins 0.000 description 1
- 102000001708 Protein Isoforms Human genes 0.000 description 1
- 108010001267 Protein Subunits Proteins 0.000 description 1
- 102000002067 Protein Subunits Human genes 0.000 description 1
- 241000192142 Proteobacteria Species 0.000 description 1
- 108010014608 Proto-Oncogene Proteins c-kit Proteins 0.000 description 1
- 102000016971 Proto-Oncogene Proteins c-kit Human genes 0.000 description 1
- 229930185560 Pseudouridine Natural products 0.000 description 1
- PTJWIQPHWPFNBW-UHFFFAOYSA-N Pseudouridine C Natural products OC1C(O)C(CO)OC1C1=CNC(=O)NC1=O PTJWIQPHWPFNBW-UHFFFAOYSA-N 0.000 description 1
- 241001157811 Pucciniomycotina Species 0.000 description 1
- 108010080192 Purinergic Receptors Proteins 0.000 description 1
- 241000190117 Pyrenophora tritici-repentis Species 0.000 description 1
- 241001521293 Python Species 0.000 description 1
- 241000760756 Python bivittatus Species 0.000 description 1
- 238000002123 RNA extraction Methods 0.000 description 1
- 238000012228 RNA interference-mediated gene silencing Methods 0.000 description 1
- 102000044126 RNA-Binding Proteins Human genes 0.000 description 1
- 108700020471 RNA-Binding Proteins Proteins 0.000 description 1
- 102100037566 RNA/RNP complex-1-interacting phosphatase Human genes 0.000 description 1
- 238000011529 RT qPCR Methods 0.000 description 1
- 241000700157 Rattus norvegicus Species 0.000 description 1
- 241000712907 Retroviridae Species 0.000 description 1
- 241000031819 Rhinolophus sinicus Species 0.000 description 1
- 241000813090 Rhizoctonia solani Species 0.000 description 1
- 241001663183 Rhizophagus irregularis Species 0.000 description 1
- 241000235527 Rhizopus Species 0.000 description 1
- 241000303962 Rhizopus delemar Species 0.000 description 1
- 241000593344 Rhizopus microsporus Species 0.000 description 1
- 241000223252 Rhodotorula Species 0.000 description 1
- 241000223254 Rhodotorula mucilaginosa Species 0.000 description 1
- 108010083644 Ribonucleases Proteins 0.000 description 1
- 102000006382 Ribonucleases Human genes 0.000 description 1
- 102000002278 Ribosomal Proteins Human genes 0.000 description 1
- 108010000605 Ribosomal Proteins Proteins 0.000 description 1
- 241000289054 Rousettus aegyptiacus Species 0.000 description 1
- ULXKXLZEOGLCRJ-BYPYZUCNSA-N S-ethyl-L-cysteine zwitterion Chemical compound CCSC[C@H](N)C(O)=O ULXKXLZEOGLCRJ-BYPYZUCNSA-N 0.000 description 1
- 102000014400 SH2 domains Human genes 0.000 description 1
- 108050003452 SH2 domains Proteins 0.000 description 1
- 108091006576 SLC34A2 Proteins 0.000 description 1
- 101100231811 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) HSP150 gene Proteins 0.000 description 1
- 241001531444 Saimiri boliviensis boliviensis Species 0.000 description 1
- 241000289607 Sarcophilus harrisii Species 0.000 description 1
- 101100464174 Schizosaccharomyces pombe (strain 972 / ATCC 24843) pir2 gene Proteins 0.000 description 1
- 241001326539 Schizosaccharomycetes Species 0.000 description 1
- 229940124639 Selective inhibitor Drugs 0.000 description 1
- 241000918527 Seminavis robusta Species 0.000 description 1
- ZUGXSSFMTXKHJS-ZLUOBGJFSA-N Ser-Ala-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O ZUGXSSFMTXKHJS-ZLUOBGJFSA-N 0.000 description 1
- HRNQLKCLPVKZNE-CIUDSAMLSA-N Ser-Ala-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O HRNQLKCLPVKZNE-CIUDSAMLSA-N 0.000 description 1
- BRKHVZNDAOMAHX-BIIVOSGPSA-N Ser-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N BRKHVZNDAOMAHX-BIIVOSGPSA-N 0.000 description 1
- JJKSSJVYOVRJMZ-FXQIFTODSA-N Ser-Arg-Cys Chemical compound C(C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N)CN=C(N)N JJKSSJVYOVRJMZ-FXQIFTODSA-N 0.000 description 1
- QWZIOCFPXMAXET-CIUDSAMLSA-N Ser-Arg-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O QWZIOCFPXMAXET-CIUDSAMLSA-N 0.000 description 1
- DKKGAAJTDKHWOD-BIIVOSGPSA-N Ser-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CO)N)C(=O)O DKKGAAJTDKHWOD-BIIVOSGPSA-N 0.000 description 1
- GHPQVUYZQQGEDA-BIIVOSGPSA-N Ser-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N)C(=O)O GHPQVUYZQQGEDA-BIIVOSGPSA-N 0.000 description 1
- WTPKKLMBNBCCNL-ACZMJKKPSA-N Ser-Cys-Glu Chemical compound C(CC(=O)O)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CO)N WTPKKLMBNBCCNL-ACZMJKKPSA-N 0.000 description 1
- DSSOYPJWSWFOLK-CIUDSAMLSA-N Ser-Cys-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O DSSOYPJWSWFOLK-CIUDSAMLSA-N 0.000 description 1
- YPUSXTWURJANKF-KBIXCLLPSA-N Ser-Gln-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O YPUSXTWURJANKF-KBIXCLLPSA-N 0.000 description 1
- SNVIOQXAHVORQM-WDSKDSINSA-N Ser-Gly-Gln Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O SNVIOQXAHVORQM-WDSKDSINSA-N 0.000 description 1
- WSTIOCFMWXNOCX-YUMQZZPRSA-N Ser-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CO)N WSTIOCFMWXNOCX-YUMQZZPRSA-N 0.000 description 1
- YIUWWXVTYLANCJ-NAKRPEOUSA-N Ser-Ile-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O YIUWWXVTYLANCJ-NAKRPEOUSA-N 0.000 description 1
- NLOAIFSWUUFQFR-CIUDSAMLSA-N Ser-Leu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O NLOAIFSWUUFQFR-CIUDSAMLSA-N 0.000 description 1
- XNCUYZKGQOCOQH-YUMQZZPRSA-N Ser-Leu-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O XNCUYZKGQOCOQH-YUMQZZPRSA-N 0.000 description 1
- IUXGJEIKJBYKOO-SRVKXCTJSA-N Ser-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CO)N IUXGJEIKJBYKOO-SRVKXCTJSA-N 0.000 description 1
- BYCVMHKULKRVPV-GUBZILKMSA-N Ser-Lys-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O BYCVMHKULKRVPV-GUBZILKMSA-N 0.000 description 1
- BSXKBOUZDAZXHE-CIUDSAMLSA-N Ser-Pro-Glu Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O BSXKBOUZDAZXHE-CIUDSAMLSA-N 0.000 description 1
- RHAPJNVNWDBFQI-BQBZGAKWSA-N Ser-Pro-Gly Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O RHAPJNVNWDBFQI-BQBZGAKWSA-N 0.000 description 1
- PPCZVWHJWJFTFN-ZLUOBGJFSA-N Ser-Ser-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O PPCZVWHJWJFTFN-ZLUOBGJFSA-N 0.000 description 1
- PYTKULIABVRXSC-BWBBJGPYSA-N Ser-Ser-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PYTKULIABVRXSC-BWBBJGPYSA-N 0.000 description 1
- RXUOAOOZIWABBW-XGEHTFHBSA-N Ser-Thr-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N RXUOAOOZIWABBW-XGEHTFHBSA-N 0.000 description 1
- PURRNJBBXDDWLX-ZDLURKLDSA-N Ser-Thr-Gly Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CO)N)O PURRNJBBXDDWLX-ZDLURKLDSA-N 0.000 description 1
- GSCVDSBEYVGMJQ-SRVKXCTJSA-N Ser-Tyr-Asp Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CO)N)O GSCVDSBEYVGMJQ-SRVKXCTJSA-N 0.000 description 1
- FHXGMDRKJHKLKW-QWRGUYRKSA-N Ser-Tyr-Gly Chemical compound OC[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=C(O)C=C1 FHXGMDRKJHKLKW-QWRGUYRKSA-N 0.000 description 1
- MFQMZDPAZRZAPV-NAKRPEOUSA-N Ser-Val-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CO)N MFQMZDPAZRZAPV-NAKRPEOUSA-N 0.000 description 1
- 102000012479 Serine Proteases Human genes 0.000 description 1
- 108010022999 Serine Proteases Proteins 0.000 description 1
- 102100028904 Serine/threonine-protein kinase MARK2 Human genes 0.000 description 1
- 108010034546 Serratia marcescens nuclease Proteins 0.000 description 1
- 102100038081 Signal transducer CD24 Human genes 0.000 description 1
- 108020004688 Small Nuclear RNA Proteins 0.000 description 1
- 102000039471 Small Nuclear RNA Human genes 0.000 description 1
- 108091027967 Small hairpin RNA Proteins 0.000 description 1
- 102100038437 Sodium-dependent phosphate transport protein 2B Human genes 0.000 description 1
- 241000736128 Solenopsis invicta Species 0.000 description 1
- 241000143991 Sorex araneus Species 0.000 description 1
- 244000300264 Spinacia oleracea Species 0.000 description 1
- 235000009337 Spinacia oleracea Nutrition 0.000 description 1
- 241001180364 Spirochaetes Species 0.000 description 1
- 241001222723 Sterna Species 0.000 description 1
- 229930182558 Sterol Natural products 0.000 description 1
- 101710172711 Structural protein Proteins 0.000 description 1
- 241000282887 Suidae Species 0.000 description 1
- 241000282898 Sus scrofa Species 0.000 description 1
- 241001453296 Synechococcus elongatus Species 0.000 description 1
- 208000031673 T-Cell Cutaneous Lymphoma Diseases 0.000 description 1
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 description 1
- 230000030429 T-helper 17 type immune response Effects 0.000 description 1
- 102000003618 TRPM4 Human genes 0.000 description 1
- 241000758531 Taphrinomycotina Species 0.000 description 1
- 229940123237 Taxane Drugs 0.000 description 1
- 241000131694 Tenericutes Species 0.000 description 1
- 101710098080 Teratocarcinoma-derived growth factor Proteins 0.000 description 1
- GUGOEEXESWIERI-UHFFFAOYSA-N Terfenadine Chemical compound C1=CC(C(C)(C)C)=CC=C1C(O)CCCN1CCC(C(O)(C=2C=CC=CC=2)C=2C=CC=CC=2)CC1 GUGOEEXESWIERI-UHFFFAOYSA-N 0.000 description 1
- 241000730270 Terrapene mexicana triunguis Species 0.000 description 1
- ZUXQFMVPAYGPFJ-JXUBOQSCSA-N Thr-Ala-Lys Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCCN ZUXQFMVPAYGPFJ-JXUBOQSCSA-N 0.000 description 1
- LXWZOMSOUAMOIA-JIOCBJNQSA-N Thr-Asn-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N)O LXWZOMSOUAMOIA-JIOCBJNQSA-N 0.000 description 1
- YBXMGKCLOPDEKA-NUMRIWBASA-N Thr-Asp-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O YBXMGKCLOPDEKA-NUMRIWBASA-N 0.000 description 1
- GARULAKWZGFIKC-RWRJDSDZSA-N Thr-Gln-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O GARULAKWZGFIKC-RWRJDSDZSA-N 0.000 description 1
- LIXBDERDAGNVAV-XKBZYTNZSA-N Thr-Gln-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O LIXBDERDAGNVAV-XKBZYTNZSA-N 0.000 description 1
- UDQBCBUXAQIZAK-GLLZPBPUSA-N Thr-Glu-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UDQBCBUXAQIZAK-GLLZPBPUSA-N 0.000 description 1
- AQAMPXBRJJWPNI-JHEQGTHGSA-N Thr-Gly-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O AQAMPXBRJJWPNI-JHEQGTHGSA-N 0.000 description 1
- NQVDGKYAUHTCME-QTKMDUPCSA-N Thr-His-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N)O NQVDGKYAUHTCME-QTKMDUPCSA-N 0.000 description 1
- AYCQVUUPIJHJTA-IXOXFDKPSA-N Thr-His-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O AYCQVUUPIJHJTA-IXOXFDKPSA-N 0.000 description 1
- YUOCMLNTUZAGNF-KLHWPWHYSA-N Thr-His-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N2CCC[C@@H]2C(=O)O)N)O YUOCMLNTUZAGNF-KLHWPWHYSA-N 0.000 description 1
- XOWKUMFHEZLKLT-CIQUZCHMSA-N Thr-Ile-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O XOWKUMFHEZLKLT-CIQUZCHMSA-N 0.000 description 1
- ODXKUIGEPAGKKV-KATARQTJSA-N Thr-Leu-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)O)N)O ODXKUIGEPAGKKV-KATARQTJSA-N 0.000 description 1
- WTMPKZWHRCMMMT-KZVJFYERSA-N Thr-Pro-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WTMPKZWHRCMMMT-KZVJFYERSA-N 0.000 description 1
- MROIJTGJGIDEEJ-RCWTZXSCSA-N Thr-Pro-Pro Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 MROIJTGJGIDEEJ-RCWTZXSCSA-N 0.000 description 1
- STUAPCLEDMKXKL-LKXGYXEUSA-N Thr-Ser-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O STUAPCLEDMKXKL-LKXGYXEUSA-N 0.000 description 1
- IVDFVBVIVLJJHR-LKXGYXEUSA-N Thr-Ser-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O IVDFVBVIVLJJHR-LKXGYXEUSA-N 0.000 description 1
- XHWCDRUPDNSDAZ-XKBZYTNZSA-N Thr-Ser-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O XHWCDRUPDNSDAZ-XKBZYTNZSA-N 0.000 description 1
- SGAOHNPSEPVAFP-ZDLURKLDSA-N Thr-Ser-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SGAOHNPSEPVAFP-ZDLURKLDSA-N 0.000 description 1
- AHERARIZBPOMNU-KATARQTJSA-N Thr-Ser-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O AHERARIZBPOMNU-KATARQTJSA-N 0.000 description 1
- IEZVHOULSUULHD-XGEHTFHBSA-N Thr-Ser-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O IEZVHOULSUULHD-XGEHTFHBSA-N 0.000 description 1
- PELIQFPESHBTMA-WLTAIBSBSA-N Thr-Tyr-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CC1=CC=C(O)C=C1 PELIQFPESHBTMA-WLTAIBSBSA-N 0.000 description 1
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 1
- 108090000190 Thrombin Proteins 0.000 description 1
- 108010000499 Thromboplastin Proteins 0.000 description 1
- 102100033523 Thy-1 membrane glycoprotein Human genes 0.000 description 1
- 108010034949 Thyroglobulin Proteins 0.000 description 1
- 102000009843 Thyroglobulin Human genes 0.000 description 1
- 102100030859 Tissue factor Human genes 0.000 description 1
- 239000004012 Tofacitinib Substances 0.000 description 1
- 241000710924 Togaviridae Species 0.000 description 1
- 108091023040 Transcription factor Proteins 0.000 description 1
- 102000040945 Transcription factor Human genes 0.000 description 1
- 108020004566 Transfer RNA Proteins 0.000 description 1
- 108010033576 Transferrin Receptors Proteins 0.000 description 1
- 102100026145 Transitional endoplasmic reticulum ATPase Human genes 0.000 description 1
- 101710132062 Transitional endoplasmic reticulum ATPase Proteins 0.000 description 1
- 241000254113 Tribolium castaneum Species 0.000 description 1
- 241000593405 Trichechus manatus latirostris Species 0.000 description 1
- 241000223259 Trichoderma Species 0.000 description 1
- 241000223260 Trichoderma harzianum Species 0.000 description 1
- 241000223229 Trichophyton rubrum Species 0.000 description 1
- OETOOJXFNSEYHQ-WFBYXXMGSA-N Trp-Ala-Asp Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O)=CNC2=C1 OETOOJXFNSEYHQ-WFBYXXMGSA-N 0.000 description 1
- PXYJUECTGMGIDT-WDSOQIARSA-N Trp-Arg-Leu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(C)C)C(O)=O)=CNC2=C1 PXYJUECTGMGIDT-WDSOQIARSA-N 0.000 description 1
- QNTBGBCOEYNAPV-CWRNSKLLSA-N Trp-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N)C(=O)O QNTBGBCOEYNAPV-CWRNSKLLSA-N 0.000 description 1
- HXNVJPQADLRHGR-JBACZVJFSA-N Trp-Glu-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)N HXNVJPQADLRHGR-JBACZVJFSA-N 0.000 description 1
- 102000004243 Tubulin Human genes 0.000 description 1
- 108090000704 Tubulin Proteins 0.000 description 1
- 102100029690 Tumor necrosis factor receptor superfamily member 13C Human genes 0.000 description 1
- 101710178300 Tumor necrosis factor receptor superfamily member 13C Proteins 0.000 description 1
- 101710165473 Tumor necrosis factor receptor superfamily member 4 Proteins 0.000 description 1
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 description 1
- 102100040403 Tumor necrosis factor receptor superfamily member 6 Human genes 0.000 description 1
- 102100036857 Tumor necrosis factor receptor superfamily member 8 Human genes 0.000 description 1
- 241001033908 Tupaia chinensis Species 0.000 description 1
- 241000283293 Tursiops Species 0.000 description 1
- WZQZUVWEPMGIMM-JYJNAYRXSA-N Tyr-Gln-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N)O WZQZUVWEPMGIMM-JYJNAYRXSA-N 0.000 description 1
- PDKILSUYSUGCAO-JBACZVJFSA-N Tyr-Gln-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC3=CC=C(C=C3)O)N PDKILSUYSUGCAO-JBACZVJFSA-N 0.000 description 1
- KSCVLGXNQXKUAR-JYJNAYRXSA-N Tyr-Leu-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O KSCVLGXNQXKUAR-JYJNAYRXSA-N 0.000 description 1
- KZOZXAYPVKKDIO-UFYCRDLUSA-N Tyr-Met-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 KZOZXAYPVKKDIO-UFYCRDLUSA-N 0.000 description 1
- QFXVAFIHVWXXBJ-AVGNSLFASA-N Tyr-Ser-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O QFXVAFIHVWXXBJ-AVGNSLFASA-N 0.000 description 1
- SQUMHUZLJDUROQ-YDHLFZDLSA-N Tyr-Val-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O SQUMHUZLJDUROQ-YDHLFZDLSA-N 0.000 description 1
- COQLPRJCUIATTQ-UHFFFAOYSA-N Uranyl acetate Chemical compound O.O.O=[U]=O.CC(O)=O.CC(O)=O COQLPRJCUIATTQ-UHFFFAOYSA-N 0.000 description 1
- 108010075653 Utrophin Proteins 0.000 description 1
- 102000011856 Utrophin Human genes 0.000 description 1
- 241000700618 Vaccinia virus Species 0.000 description 1
- DDRBQONWVBDQOY-GUBZILKMSA-N Val-Ala-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O DDRBQONWVBDQOY-GUBZILKMSA-N 0.000 description 1
- YFOCMOVJBQDBCE-NRPADANISA-N Val-Ala-Glu Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N YFOCMOVJBQDBCE-NRPADANISA-N 0.000 description 1
- UUYCNAXCCDNULB-QXEWZRGKSA-N Val-Arg-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(N)=O)C(O)=O UUYCNAXCCDNULB-QXEWZRGKSA-N 0.000 description 1
- PAPWZOJOLKZEFR-AVGNSLFASA-N Val-Arg-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O)N PAPWZOJOLKZEFR-AVGNSLFASA-N 0.000 description 1
- VLOYGOZDPGYWFO-LAEOZQHASA-N Val-Asp-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O VLOYGOZDPGYWFO-LAEOZQHASA-N 0.000 description 1
- TZVUSFMQWPWHON-NHCYSSNCSA-N Val-Asp-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C(C)C)N TZVUSFMQWPWHON-NHCYSSNCSA-N 0.000 description 1
- BRPKEERLGYNCNC-NHCYSSNCSA-N Val-Glu-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N BRPKEERLGYNCNC-NHCYSSNCSA-N 0.000 description 1
- GBESYURLQOYWLU-LAEOZQHASA-N Val-Glu-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N GBESYURLQOYWLU-LAEOZQHASA-N 0.000 description 1
- MHAHQDBEIDPFQS-NHCYSSNCSA-N Val-Glu-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)C(C)C MHAHQDBEIDPFQS-NHCYSSNCSA-N 0.000 description 1
- PMXBARDFIAPBGK-DZKIICNBSA-N Val-Glu-Tyr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 PMXBARDFIAPBGK-DZKIICNBSA-N 0.000 description 1
- CELJCNRXKZPTCX-XPUUQOCRSA-N Val-Gly-Ala Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O CELJCNRXKZPTCX-XPUUQOCRSA-N 0.000 description 1
- XXROXFHCMVXETG-UWVGGRQHSA-N Val-Gly-Val Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXROXFHCMVXETG-UWVGGRQHSA-N 0.000 description 1
- WNZSAUMKZQXHNC-UKJIMTQDSA-N Val-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N WNZSAUMKZQXHNC-UKJIMTQDSA-N 0.000 description 1
- JZWZACGUZVCQPS-RNJOBUHISA-N Val-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N JZWZACGUZVCQPS-RNJOBUHISA-N 0.000 description 1
- ZRSZTKTVPNSUNA-IHRRRGAJSA-N Val-Lys-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)C(C)C)C(O)=O ZRSZTKTVPNSUNA-IHRRRGAJSA-N 0.000 description 1
- OJOMXGVLFKYDKP-QXEWZRGKSA-N Val-Met-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(=O)O)C(=O)O)N OJOMXGVLFKYDKP-QXEWZRGKSA-N 0.000 description 1
- BCBFMJYTNKDALA-UFYCRDLUSA-N Val-Phe-Phe Chemical compound N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O BCBFMJYTNKDALA-UFYCRDLUSA-N 0.000 description 1
- SSYBNWFXCFNRFN-GUBZILKMSA-N Val-Pro-Ser Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O SSYBNWFXCFNRFN-GUBZILKMSA-N 0.000 description 1
- PQSNETRGCRUOGP-KKHAAJSZSA-N Val-Thr-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(N)=O PQSNETRGCRUOGP-KKHAAJSZSA-N 0.000 description 1
- DLRZGNXCXUGIDG-KKHAAJSZSA-N Val-Thr-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O DLRZGNXCXUGIDG-KKHAAJSZSA-N 0.000 description 1
- YQYFYUSYEDNLSD-YEPSODPASA-N Val-Thr-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O YQYFYUSYEDNLSD-YEPSODPASA-N 0.000 description 1
- JAIZPWVHPQRYOU-ZJDVBMNYSA-N Val-Thr-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O JAIZPWVHPQRYOU-ZJDVBMNYSA-N 0.000 description 1
- HVRRJRMULCPNRO-BZSNNMDCSA-N Val-Trp-Arg Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 HVRRJRMULCPNRO-BZSNNMDCSA-N 0.000 description 1
- SSKKGOWRPNIVDW-AVGNSLFASA-N Val-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N SSKKGOWRPNIVDW-AVGNSLFASA-N 0.000 description 1
- GXBMIBRIOWHPDT-UHFFFAOYSA-N Vasopressin Natural products N1C(=O)C(CC=2C=C(O)C=CC=2)NC(=O)C(N)CSSCC(C(=O)N2C(CCC2)C(=O)NC(CCCN=C(N)N)C(=O)NCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(CCC(N)=O)NC(=O)C1CC1=CC=CC=C1 GXBMIBRIOWHPDT-UHFFFAOYSA-N 0.000 description 1
- 108010004977 Vasopressins Proteins 0.000 description 1
- 102000002852 Vasopressins Human genes 0.000 description 1
- 241000545067 Venus Species 0.000 description 1
- 241001123668 Verticillium dahliae Species 0.000 description 1
- 241001416177 Vicugna pacos Species 0.000 description 1
- 241000282485 Vulpes vulpes Species 0.000 description 1
- 241000269370 Xenopus <genus> Species 0.000 description 1
- 108091007916 Zinc finger transcription factors Proteins 0.000 description 1
- 102000038627 Zinc finger transcription factors Human genes 0.000 description 1
- 241000235033 Zygosaccharomyces rouxii Species 0.000 description 1
- 241001360088 Zymoseptoria tritici Species 0.000 description 1
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 1
- 241000222124 [Candida] boidinii Species 0.000 description 1
- 241000222126 [Candida] glabrata Species 0.000 description 1
- 241000192286 [Candida] stellata Species 0.000 description 1
- 229950005008 abituzumab Drugs 0.000 description 1
- 229940081735 acetylcellulose Drugs 0.000 description 1
- 239000002253 acid Substances 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 125000005396 acrylic acid ester group Chemical group 0.000 description 1
- 239000012190 activator Substances 0.000 description 1
- 102000035181 adaptor proteins Human genes 0.000 description 1
- 108091005764 adaptor proteins Proteins 0.000 description 1
- 229950008459 alacizumab pegol Drugs 0.000 description 1
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 1
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 1
- 108010054982 alanyl-leucyl-alanyl-leucine Proteins 0.000 description 1
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 1
- 108010044940 alanylglutamine Proteins 0.000 description 1
- 108010011559 alanylphenylalanine Proteins 0.000 description 1
- 125000003172 aldehyde group Chemical group 0.000 description 1
- 125000005600 alkyl phosphonate group Chemical group 0.000 description 1
- WQZGKKKJIJFFOK-PHYPRBDBSA-N alpha-D-galactose Chemical compound OC[C@H]1O[C@H](O)[C@H](O)[C@@H](O)[C@H]1O WQZGKKKJIJFFOK-PHYPRBDBSA-N 0.000 description 1
- 102000013529 alpha-Fetoproteins Human genes 0.000 description 1
- 108010026331 alpha-Fetoproteins Proteins 0.000 description 1
- 108010030291 alpha-Galactosidase Proteins 0.000 description 1
- 150000001370 alpha-amino acid derivatives Chemical class 0.000 description 1
- 150000001371 alpha-amino acids Chemical class 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 229950001537 amatuximab Drugs 0.000 description 1
- 150000001412 amines Chemical group 0.000 description 1
- 125000000539 amino acid group Chemical group 0.000 description 1
- 230000000202 analgesic effect Effects 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 229950006061 anatumomab mafenatox Drugs 0.000 description 1
- JHVAMHSQVVQIOT-MFAJLEFUSA-N anidulafungin Chemical compound C1=CC(OCCCCC)=CC=C1C1=CC=C(C=2C=CC(=CC=2)C(=O)N[C@@H]2C(N[C@H](C(=O)N3C[C@H](O)C[C@H]3C(=O)N[C@H](C(=O)N[C@H](C(=O)N3C[C@H](C)[C@H](O)[C@H]3C(=O)N[C@H](O)[C@H](O)C2)[C@@H](C)O)[C@H](O)[C@@H](O)C=2C=CC(O)=CC=2)[C@@H](C)O)=O)C=C1 JHVAMHSQVVQIOT-MFAJLEFUSA-N 0.000 description 1
- 229960003348 anidulafungin Drugs 0.000 description 1
- 238000005571 anion exchange chromatography Methods 0.000 description 1
- 230000003288 anthiarrhythmic effect Effects 0.000 description 1
- 230000000844 anti-bacterial effect Effects 0.000 description 1
- 230000001773 anti-convulsant effect Effects 0.000 description 1
- 230000001430 anti-depressive effect Effects 0.000 description 1
- 230000001142 anti-diarrhea Effects 0.000 description 1
- 230000003474 anti-emetic effect Effects 0.000 description 1
- 230000000843 anti-fungal effect Effects 0.000 description 1
- 230000001387 anti-histamine Effects 0.000 description 1
- 230000003276 anti-hypertensive effect Effects 0.000 description 1
- 230000000845 anti-microbial effect Effects 0.000 description 1
- 230000000118 anti-neoplastic effect Effects 0.000 description 1
- 230000000561 anti-psychotic effect Effects 0.000 description 1
- 230000001754 anti-pyretic effect Effects 0.000 description 1
- 230000000840 anti-viral effect Effects 0.000 description 1
- 239000003416 antiarrhythmic agent Substances 0.000 description 1
- 239000001961 anticonvulsive agent Substances 0.000 description 1
- 239000000935 antidepressant agent Substances 0.000 description 1
- 229940005513 antidepressants Drugs 0.000 description 1
- 239000002111 antiemetic agent Substances 0.000 description 1
- 229960003965 antiepileptics Drugs 0.000 description 1
- 229940121375 antifungal agent Drugs 0.000 description 1
- 239000000739 antihistaminic agent Substances 0.000 description 1
- 239000004599 antimicrobial Substances 0.000 description 1
- 229940034982 antineoplastic agent Drugs 0.000 description 1
- 239000002221 antipyretic Substances 0.000 description 1
- 239000002825 antisense oligoribonucleotide Substances 0.000 description 1
- 239000003434 antitussive agent Substances 0.000 description 1
- 229940124584 antitussives Drugs 0.000 description 1
- 239000002249 anxiolytic agent Substances 0.000 description 1
- 230000000949 anxiolytic effect Effects 0.000 description 1
- 229950003145 apolizumab Drugs 0.000 description 1
- PYMYPHUHKUWMLA-WDCZJNDASA-N arabinose Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)C=O PYMYPHUHKUWMLA-WDCZJNDASA-N 0.000 description 1
- PYMYPHUHKUWMLA-UHFFFAOYSA-N arabinose Natural products OCC(O)C(O)C(O)C=O PYMYPHUHKUWMLA-UHFFFAOYSA-N 0.000 description 1
- 101150016797 arc gene Proteins 0.000 description 1
- 108010094001 arginyl-tryptophyl-arginine Proteins 0.000 description 1
- 108010060035 arginylproline Proteins 0.000 description 1
- KBZOIRJILGZLEJ-LGYYRGKSSA-N argipressin Chemical compound C([C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CSSC[C@@H](C(N[C@@H](CC=2C=CC(O)=CC=2)C(=O)N1)=O)N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(N)=O)C1=CC=CC=C1 KBZOIRJILGZLEJ-LGYYRGKSSA-N 0.000 description 1
- 235000019568 aromas Nutrition 0.000 description 1
- 229960004191 artemisinin Drugs 0.000 description 1
- BLUAFEHZUWYNDE-NNWCWBAJSA-N artemisinin Chemical compound C([C@](OO1)(C)O2)C[C@H]3[C@H](C)CC[C@@H]4[C@@]31[C@@H]2OC(=O)[C@@H]4C BLUAFEHZUWYNDE-NNWCWBAJSA-N 0.000 description 1
- 229930101531 artemisinin Natural products 0.000 description 1
- 108010077245 asparaginyl-proline Proteins 0.000 description 1
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 1
- 108010092854 aspartyllysine Proteins 0.000 description 1
- 238000003556 assay Methods 0.000 description 1
- 210000001130 astrocyte Anatomy 0.000 description 1
- 229960003852 atezolizumab Drugs 0.000 description 1
- 108010044540 auristatin Proteins 0.000 description 1
- 229940120638 avastin Drugs 0.000 description 1
- 125000000751 azo group Chemical group [*]N=N[*] 0.000 description 1
- 229940125717 barbiturate Drugs 0.000 description 1
- HNYOPLTXPVRDBG-UHFFFAOYSA-N barbituric acid Chemical compound O=C1CC(=O)NC(=O)N1 HNYOPLTXPVRDBG-UHFFFAOYSA-N 0.000 description 1
- 229960004669 basiliximab Drugs 0.000 description 1
- 229960003270 belimumab Drugs 0.000 description 1
- 229940022836 benlysta Drugs 0.000 description 1
- 239000002876 beta blocker Substances 0.000 description 1
- 229940097320 beta blocking agent Drugs 0.000 description 1
- SRBFZHDQGSBBOR-UHFFFAOYSA-N beta-D-Pyranose-Lyxose Natural products OC1COC(O)C(O)C1O SRBFZHDQGSBBOR-UHFFFAOYSA-N 0.000 description 1
- WGDUUQDYDIIBKT-UHFFFAOYSA-N beta-Pseudouridine Natural products OC1OC(CN2C=CC(=O)NC2=O)C(O)C1O WGDUUQDYDIIBKT-UHFFFAOYSA-N 0.000 description 1
- 150000001576 beta-amino acids Chemical class 0.000 description 1
- 229960000397 bevacizumab Drugs 0.000 description 1
- 125000002619 bicyclic group Chemical group 0.000 description 1
- 108091008324 binding proteins Proteins 0.000 description 1
- 230000003115 biocidal effect Effects 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 229960000074 biopharmaceutical Drugs 0.000 description 1
- 229940101815 blincyto Drugs 0.000 description 1
- 229960000182 blood factors Drugs 0.000 description 1
- 210000002449 bone cell Anatomy 0.000 description 1
- 229940112869 bone morphogenetic protein Drugs 0.000 description 1
- 229910052796 boron Inorganic materials 0.000 description 1
- 229940124630 bronchodilator Drugs 0.000 description 1
- BBBFJLBPOGFECG-VJVYQDLKSA-N calcitonin Chemical compound N([C@H](C(=O)N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1NC=NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N1[C@@H](CCC1)C(N)=O)C(C)C)C(=O)[C@@H]1CSSC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1 BBBFJLBPOGFECG-VJVYQDLKSA-N 0.000 description 1
- 229960004015 calcitonin Drugs 0.000 description 1
- HXCHCVDVKSCDHU-LULTVBGHSA-N calicheamicin Chemical compound C1[C@H](OC)[C@@H](NCC)CO[C@H]1O[C@H]1[C@H](O[C@@H]2C\3=C(NC(=O)OC)C(=O)C[C@](C/3=C/CSSSC)(O)C#C\C=C/C#C2)O[C@H](C)[C@@H](NO[C@@H]2O[C@H](C)[C@@H](SC(=O)C=3C(=C(OC)C(O[C@H]4[C@@H]([C@H](OC)[C@@H](O)[C@H](C)O4)O)=C(I)C=3C)OC)[C@@H](O)C2)[C@@H]1O HXCHCVDVKSCDHU-LULTVBGHSA-N 0.000 description 1
- 229930195731 calicheamicin Natural products 0.000 description 1
- 229940112129 campath Drugs 0.000 description 1
- 208000032343 candida glabrata infection Diseases 0.000 description 1
- 125000004432 carbon atom Chemical group C* 0.000 description 1
- 239000003489 carbonate dehydratase inhibitor Substances 0.000 description 1
- 125000002091 cationic group Chemical group 0.000 description 1
- 101150102092 ccdB gene Proteins 0.000 description 1
- 230000034303 cell budding Effects 0.000 description 1
- 239000002771 cell marker Substances 0.000 description 1
- 230000004663 cell proliferation Effects 0.000 description 1
- 239000002458 cell surface marker Substances 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 229920002301 cellulose acetate Polymers 0.000 description 1
- 229940081734 cellulose acetate phthalate Drugs 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 210000002230 centromere Anatomy 0.000 description 1
- 229960005395 cetuximab Drugs 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- TZRFSLHOCZEXCC-HIVFKXHNSA-N chembl2219536 Chemical compound N1([C@H]2C[C@@H]([C@H](O2)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C(NC(=O)C(C)=C2)=O)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C(N=C(N)C(C)=C2)=O)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C(NC(=O)C(C)=C2)=O)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C3=NC=NC(N)=C3N=C2)COP(O)(=O)S[C@H]2[C@H]([C@@H](O[C@@H]2COP(O)(=O)S[C@H]2[C@H]([C@@H](O[C@@H]2COP(O)(=O)S[C@H]2[C@H]([C@@H](O[C@@H]2COP(O)(=O)S[C@H]2[C@H]([C@@H](O[C@@H]2COP(O)(=O)S[C@H]2[C@H]([C@@H](O[C@@H]2CO)N2C3=C(C(NC(N)=N3)=O)N=C2)OCCOC)N2C(N=C(N)C(C)=C2)=O)OCCOC)N2C(N=C(N)C(C)=C2)=O)OCCOC)N2C(NC(=O)C(C)=C2)=O)OCCOC)N2C(N=C(N)C(C)=C2)=O)OCCOC)SP(O)(=O)OC[C@H]2O[C@H](C[C@@H]2SP(O)(=O)OC[C@H]2O[C@H](C[C@@H]2SP(O)(=O)OC[C@H]2O[C@H](C[C@@H]2SP(O)(=O)OC[C@@H]2[C@H]([C@H]([C@@H](O2)N2C3=C(C(NC(N)=N3)=O)N=C2)OCCOC)SP(O)(=O)OC[C@H]2[C@@H]([C@@H]([C@H](O2)N2C(N=C(N)C(C)=C2)=O)OCCOC)SP(O)(=O)OC[C@H]2[C@@H]([C@@H]([C@H](O2)N2C3=NC=NC(N)=C3N=C2)OCCOC)SP(O)(=O)OC[C@H]2[C@@H]([C@@H]([C@H](O2)N2C(N=C(N)C(C)=C2)=O)OCCOC)SP(O)(=O)OC[C@H]2[C@H](O)[C@@H]([C@H](O2)N2C(N=C(N)C(C)=C2)=O)OCCOC)N2C(N=C(N)C(C)=C2)=O)N2C(NC(=O)C(C)=C2)=O)N2C(NC(=O)C(C)=C2)=O)C=C(C)C(N)=NC1=O TZRFSLHOCZEXCC-HIVFKXHNSA-N 0.000 description 1
- 239000003153 chemical reaction reagent Substances 0.000 description 1
- 235000012000 cholesterol Nutrition 0.000 description 1
- MYSWGUAQZAJSOK-UHFFFAOYSA-N ciprofloxacin Chemical compound C12=CC(N3CCNCC3)=C(F)C=C2C(=O)C(C(=O)O)=CN1C1CC1 MYSWGUAQZAJSOK-UHFFFAOYSA-N 0.000 description 1
- 229950006647 cixutumumab Drugs 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 239000013599 cloning vector Substances 0.000 description 1
- 239000011248 coating agent Substances 0.000 description 1
- 238000000576 coating method Methods 0.000 description 1
- 230000002860 competitive effect Effects 0.000 description 1
- 229950007276 conatumumab Drugs 0.000 description 1
- LLLIKHLUUMWXPN-UHFFFAOYSA-N conatumumab Chemical compound C1=C(Cl)C(S(=O)(=O)N)=CC(C(O)=O)=C1NCC1=CC=CO1.C1C(CC(C2)C3)CC3C12C1=NC(N(C(N(CCC)C2=O)=O)CCC)=C2N1 LLLIKHLUUMWXPN-UHFFFAOYSA-N 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 229920001577 copolymer Polymers 0.000 description 1
- 229910052802 copper Inorganic materials 0.000 description 1
- 239000010949 copper Substances 0.000 description 1
- 239000011258 core-shell material Substances 0.000 description 1
- 239000003246 corticosteroid Substances 0.000 description 1
- 201000007241 cutaneous T cell lymphoma Diseases 0.000 description 1
- XLJMAIOERFSOGZ-UHFFFAOYSA-M cyanate group Chemical group [O-]C#N XLJMAIOERFSOGZ-UHFFFAOYSA-M 0.000 description 1
- 125000004093 cyano group Chemical group *C#N 0.000 description 1
- 125000004122 cyclic group Chemical group 0.000 description 1
- 108010060199 cysteinylproline Proteins 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical class NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 1
- 230000001086 cytosolic effect Effects 0.000 description 1
- 231100000433 cytotoxic Toxicity 0.000 description 1
- 230000001472 cytotoxic effect Effects 0.000 description 1
- 229950007409 dacetuzumab Drugs 0.000 description 1
- 229960002488 dalbavancin Drugs 0.000 description 1
- 108700009376 dalbavancin Proteins 0.000 description 1
- 229960002204 daratumumab Drugs 0.000 description 1
- 229940094732 darzalex Drugs 0.000 description 1
- 239000000850 decongestant Substances 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 229940124447 delivery agent Drugs 0.000 description 1
- 210000004443 dendritic cell Anatomy 0.000 description 1
- 229950008962 detumomab Drugs 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 239000000032 diagnostic agent Substances 0.000 description 1
- 229940039227 diagnostic agent Drugs 0.000 description 1
- ANCLJVISBRWUTR-UHFFFAOYSA-N diaminophosphinic acid Chemical group NP(N)(O)=O ANCLJVISBRWUTR-UHFFFAOYSA-N 0.000 description 1
- 230000004069 differentiation Effects 0.000 description 1
- 210000002249 digestive system Anatomy 0.000 description 1
- ZPTBLXKRQACLCR-XVFCMESISA-N dihydrouridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)CC1 ZPTBLXKRQACLCR-XVFCMESISA-N 0.000 description 1
- PGUYAANYCROBRT-UHFFFAOYSA-N dihydroxy-selanyl-selanylidene-lambda5-phosphane Chemical compound OP(O)([SeH])=[Se] PGUYAANYCROBRT-UHFFFAOYSA-N 0.000 description 1
- 229960005160 dimyristoylphosphatidylglycerol Drugs 0.000 description 1
- NAGJZTKCGNOGPW-UHFFFAOYSA-K dioxido-sulfanylidene-sulfido-$l^{5}-phosphane Chemical compound [O-]P([O-])([S-])=S NAGJZTKCGNOGPW-UHFFFAOYSA-K 0.000 description 1
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 1
- 201000010099 disease Diseases 0.000 description 1
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 1
- KPUWHANPEXNPJT-UHFFFAOYSA-N disiloxane Chemical class [SiH3]O[SiH3] KPUWHANPEXNPJT-UHFFFAOYSA-N 0.000 description 1
- 150000002019 disulfides Chemical class 0.000 description 1
- BPHQZTVXXXJVHI-AJQTZOPKSA-N ditetradecanoyl phosphatidylglycerol Chemical compound CCCCCCCCCCCCCC(=O)OC[C@H](COP(O)(=O)OC[C@@H](O)CO)OC(=O)CCCCCCCCCCCCC BPHQZTVXXXJVHI-AJQTZOPKSA-N 0.000 description 1
- 239000002934 diuretic Substances 0.000 description 1
- 230000001882 diuretic effect Effects 0.000 description 1
- 210000005064 dopaminergic neuron Anatomy 0.000 description 1
- 108010067396 dornase alfa Proteins 0.000 description 1
- 238000012377 drug delivery Methods 0.000 description 1
- 229960005501 duocarmycin Drugs 0.000 description 1
- VQNATVDKACXKTF-XELLLNAOSA-N duocarmycin Chemical compound COC1=C(OC)C(OC)=C2NC(C(=O)N3C4=CC(=O)C5=C([C@@]64C[C@@H]6C3)C=C(N5)C(=O)OC)=CC2=C1 VQNATVDKACXKTF-XELLLNAOSA-N 0.000 description 1
- 229930184221 duocarmycin Natural products 0.000 description 1
- 229950009791 durvalumab Drugs 0.000 description 1
- 229950011453 dusigitumab Drugs 0.000 description 1
- 102000009061 dystrobrevin Human genes 0.000 description 1
- 108010074202 dystrobrevin Proteins 0.000 description 1
- 229960001776 edrecolomab Drugs 0.000 description 1
- 229940096118 ella Drugs 0.000 description 1
- 229960004137 elotuzumab Drugs 0.000 description 1
- 238000010828 elution Methods 0.000 description 1
- 229950004255 emibetuzumab Drugs 0.000 description 1
- 229940038483 empliciti Drugs 0.000 description 1
- 230000002121 endocytic effect Effects 0.000 description 1
- 230000012202 endocytosis Effects 0.000 description 1
- 210000001900 endoderm Anatomy 0.000 description 1
- 210000004039 endoderm cell Anatomy 0.000 description 1
- 210000002889 endothelial cell Anatomy 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 229940007078 entamoeba histolytica Drugs 0.000 description 1
- 244000309457 enveloped RNA virus Species 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 238000002641 enzyme replacement therapy Methods 0.000 description 1
- 229940116977 epidermal growth factor Drugs 0.000 description 1
- 229950009760 epratuzumab Drugs 0.000 description 1
- 229940082789 erbitux Drugs 0.000 description 1
- 229950008579 ertumaxomab Drugs 0.000 description 1
- 229950009569 etaracizumab Drugs 0.000 description 1
- 125000001495 ethyl group Chemical group [H]C([H])([H])C([H])([H])* 0.000 description 1
- 230000006203 ethylation Effects 0.000 description 1
- 238000006200 ethylation reaction Methods 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 230000028023 exocytosis Effects 0.000 description 1
- 239000003172 expectorant agent Substances 0.000 description 1
- 230000003419 expectorant effect Effects 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 238000001125 extrusion Methods 0.000 description 1
- 229960000301 factor viii Drugs 0.000 description 1
- 239000003527 fibrinolytic agent Substances 0.000 description 1
- 229950002846 ficlatuzumab Drugs 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 238000000799 fluorescence microscopy Methods 0.000 description 1
- XCWFZHPEARLXJI-UHFFFAOYSA-N fomivirsen Chemical compound C1C(N2C3=C(C(NC(N)=N3)=O)N=C2)OC(CO)C1OP(O)(=S)OCC1OC(N(C)C(=O)\N=C(\N)C=C)CC1OP(O)(=S)OCC1OC(N2C3=C(C(NC(N)=N3)=O)N=C2)CC1OP(O)(=S)OCC1OC(N2C(NC(=O)C(C)=C2)=O)CC1OP(O)(=S)OCC1OC(N2C(NC(=O)C(C)=C2)=O)CC1OP(O)(=S)OCC1OC(N2C(NC(=O)C(C)=C2)=O)CC1OP(O)(=S)OCC1OC(N2C3=C(C(NC(N)=N3)=O)N=C2)CC1OP(O)(=S)OCC1OC(N2C(N=C(N)C=C2)=O)CC1OP(O)(=S)OCC(C(C1)OP(S)(=O)OCC2C(CC(O2)N2C(N=C(N)C=C2)=O)OP(O)(=S)OCC2C(CC(O2)N2C(NC(=O)C(C)=C2)=O)OP(O)(=S)OCC2C(CC(O2)N2C(NC(=O)C(C)=C2)=O)OP(O)(=S)OCC2C(CC(O2)N2C(N=C(N)C=C2)=O)OP(O)(=S)OCC2C(CC(O2)N2C(NC(=O)C(C)=C2)=O)OP(O)(=S)OCC2C(CC(O2)N2C(NC(=O)C(C)=C2)=O)OP(O)(=S)OCC2C(CC(O2)N2C(N=C(N)C=C2)=O)OP(O)(=S)OCC2C(CC(O2)N2C(NC(=O)C(C)=C2)=O)OP(O)(=S)OCC2C(CC(O2)N2C(NC(=O)C(C)=C2)=O)OP(O)(=S)OCC2C(CC(O2)N2C3=C(C(NC(N)=N3)=O)N=C2)OP(O)(=S)OCC2C(CC(O2)N2C(N=C(N)C=C2)=O)OP(O)(=S)OCC2C(CC(O2)N2C3=C(C(NC(N)=N3)=O)N=C2)O)OC1N1C=C(C)C(=O)NC1=O XCWFZHPEARLXJI-UHFFFAOYSA-N 0.000 description 1
- 229960001447 fomivirsen Drugs 0.000 description 1
- 108020001507 fusion proteins Proteins 0.000 description 1
- 102000037865 fusion proteins Human genes 0.000 description 1
- 210000001222 gaba-ergic neuron Anatomy 0.000 description 1
- 229960003082 galactose Drugs 0.000 description 1
- 210000000232 gallbladder Anatomy 0.000 description 1
- 229950004896 ganitumab Drugs 0.000 description 1
- 239000007789 gas Substances 0.000 description 1
- 238000001415 gene therapy Methods 0.000 description 1
- 229950002026 girentuximab Drugs 0.000 description 1
- 239000011521 glass Substances 0.000 description 1
- 210000001362 glutamatergic neuron Anatomy 0.000 description 1
- 235000013922 glutamic acid Nutrition 0.000 description 1
- 239000004220 glutamic acid Substances 0.000 description 1
- 108010013768 glutamyl-aspartyl-proline Proteins 0.000 description 1
- 108020004445 glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 1
- 150000002334 glycols Chemical class 0.000 description 1
- 108010000434 glycyl-alanyl-leucine Proteins 0.000 description 1
- 108010027668 glycyl-alanyl-valine Proteins 0.000 description 1
- 108010072405 glycyl-aspartyl-glycine Proteins 0.000 description 1
- 108010026364 glycyl-glycyl-leucine Proteins 0.000 description 1
- 108010020688 glycylhistidine Proteins 0.000 description 1
- 239000003163 gonadal steroid hormone Substances 0.000 description 1
- 210000003714 granulocyte Anatomy 0.000 description 1
- 239000003102 growth factor Substances 0.000 description 1
- 102000009543 guanyl-nucleotide exchange factor activity proteins Human genes 0.000 description 1
- 108040001860 guanyl-nucleotide exchange factor activity proteins Proteins 0.000 description 1
- 229910052736 halogen Inorganic materials 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 229940022353 herceptin Drugs 0.000 description 1
- 125000004051 hexyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 108010092114 histidylphenylalanine Proteins 0.000 description 1
- 102000053970 human LDOC1 Human genes 0.000 description 1
- 102000048563 human MOAP1 Human genes 0.000 description 1
- 102000057548 human PEG10 Human genes 0.000 description 1
- 102000044516 human RTL10 Human genes 0.000 description 1
- 102000050087 human ZNF18 Human genes 0.000 description 1
- 229940084986 human chorionic gonadotropin Drugs 0.000 description 1
- 125000000717 hydrazino group Chemical group [H]N([*])N([H])[H] 0.000 description 1
- 125000001183 hydrocarbyl group Chemical group 0.000 description 1
- 229920013821 hydroxy alkyl cellulose Polymers 0.000 description 1
- 229940031704 hydroxypropyl methylcellulose phthalate Drugs 0.000 description 1
- 229920003132 hydroxypropyl methylcellulose phthalate Polymers 0.000 description 1
- 239000003326 hypnotic agent Substances 0.000 description 1
- 230000000147 hypnotic effect Effects 0.000 description 1
- 230000002218 hypoglycaemic effect Effects 0.000 description 1
- IFSDAJWBUCMOAH-HNNXBMFYSA-N idelalisib Chemical compound C1([C@@H](NC=2C=3N=CNC=3N=CN=2)CC)=NC2=CC=CC(F)=C2C(=O)N1C1=CC=CC=C1 IFSDAJWBUCMOAH-HNNXBMFYSA-N 0.000 description 1
- 229960003445 idelalisib Drugs 0.000 description 1
- 229950005646 imgatuzumab Drugs 0.000 description 1
- 230000002163 immunogen Effects 0.000 description 1
- 229960003444 immunosuppressant agent Drugs 0.000 description 1
- 230000001861 immunosuppressant effect Effects 0.000 description 1
- 239000003018 immunosuppressive agent Substances 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 238000002347 injection Methods 0.000 description 1
- 239000007924 injection Substances 0.000 description 1
- 229940125396 insulin Drugs 0.000 description 1
- PBGKTOXHQIOBKM-FHFVDXKLSA-N insulin (human) Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@H]1CSSC[C@H]2C(=O)N[C@H](C(=O)N[C@@H](CO)C(=O)N[C@H](C(=O)N[C@H](C(N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=3C=CC(O)=CC=3)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=3C=CC(O)=CC=3)C(=O)N[C@@H](CSSC[C@H](NC(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=3C=CC(O)=CC=3)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=3NC=NC=3)NC(=O)[C@H](CO)NC(=O)CNC1=O)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O)=O)CSSC[C@@H](C(N2)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](NC(=O)CN)[C@@H](C)CC)[C@@H](C)CC)[C@@H](C)O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC=1C=CC=CC=1)C(C)C)C1=CN=CN1 PBGKTOXHQIOBKM-FHFVDXKLSA-N 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 229940079322 interferon Drugs 0.000 description 1
- 229960004461 interferon beta-1a Drugs 0.000 description 1
- 229940047124 interferons Drugs 0.000 description 1
- 102000002467 interleukin receptors Human genes 0.000 description 1
- 108010093036 interleukin receptors Proteins 0.000 description 1
- 229940047122 interleukins Drugs 0.000 description 1
- 210000001153 interneuron Anatomy 0.000 description 1
- 210000000936 intestine Anatomy 0.000 description 1
- 229950001014 intetumumab Drugs 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 238000010212 intracellular staining Methods 0.000 description 1
- 102000008371 intracellularly ATP-gated chloride channel activity proteins Human genes 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 238000007913 intrathecal administration Methods 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- 229960005386 ipilimumab Drugs 0.000 description 1
- 229950010939 iratumumab Drugs 0.000 description 1
- 229950007752 isatuximab Drugs 0.000 description 1
- 125000000959 isobutyl group Chemical group [H]C([H])([H])C([H])(C([H])([H])[H])C([H])([H])* 0.000 description 1
- 239000012948 isocyanate Substances 0.000 description 1
- 150000002513 isocyanates Chemical class 0.000 description 1
- 125000004491 isohexyl group Chemical group C(CCC(C)C)* 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- QRXWMOHMRWLFEY-UHFFFAOYSA-N isoniazide Chemical compound NNC(=O)C1=CC=NC=C1 QRXWMOHMRWLFEY-UHFFFAOYSA-N 0.000 description 1
- 125000001972 isopentyl group Chemical group [H]C([H])([H])C([H])(C([H])([H])[H])C([H])([H])C([H])([H])* 0.000 description 1
- BPHPUYQFMNQIOC-NXRLNHOXSA-N isopropyl beta-D-thiogalactopyranoside Chemical compound CC(C)S[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O BPHPUYQFMNQIOC-NXRLNHOXSA-N 0.000 description 1
- 125000001449 isopropyl group Chemical group [H]C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- 125000000468 ketone group Chemical group 0.000 description 1
- 150000002576 ketones Chemical class 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- 229940043355 kinase inhibitor Drugs 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- 108010021336 lanreotide Proteins 0.000 description 1
- 229960002437 lanreotide Drugs 0.000 description 1
- 239000008141 laxative Substances 0.000 description 1
- 230000002475 laxative effect Effects 0.000 description 1
- 239000000787 lecithin Substances 0.000 description 1
- 229940067606 lecithin Drugs 0.000 description 1
- 235000010445 lecithin Nutrition 0.000 description 1
- WOSKHXYHFSIKNG-UHFFFAOYSA-N lenvatinib Chemical compound C=12C=C(C(N)=O)C(OC)=CC2=NC=CC=1OC(C=C1Cl)=CC=C1NC(=O)NC1CC1 WOSKHXYHFSIKNG-UHFFFAOYSA-N 0.000 description 1
- 229960003784 lenvatinib Drugs 0.000 description 1
- 208000032839 leukemia Diseases 0.000 description 1
- GFIJNRVAKGFPGQ-LIJARHBVSA-N leuprolide Chemical compound CCNC(=O)[C@@H]1CCCN1C(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](CC(C)C)NC(=O)[C@@H](NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H]1NC(=O)CC1)CC1=CC=C(O)C=C1 GFIJNRVAKGFPGQ-LIJARHBVSA-N 0.000 description 1
- 229960004338 leuprorelin Drugs 0.000 description 1
- 239000003446 ligand Substances 0.000 description 1
- 229950001237 lilotomab Drugs 0.000 description 1
- KXGCNMMJRFDFNR-WDRJZQOASA-N linaclotide Chemical compound C([C@H](NC(=O)[C@@H]1CSSC[C@H]2C(=O)N[C@H]3CSSC[C@H](N)C(=O)N[C@H](C(N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=4C=CC(O)=CC=4)C(=O)N2)=O)CSSC[C@H](NC(=O)[C@H](C)NC(=O)[C@@H]2CCCN2C(=O)[C@H](CC(N)=O)NC3=O)C(=O)N[C@H](C(NCC(=O)N1)=O)[C@H](O)C)C(O)=O)C1=CC=C(O)C=C1 KXGCNMMJRFDFNR-WDRJZQOASA-N 0.000 description 1
- 108010024409 linaclotide Proteins 0.000 description 1
- 229960000812 linaclotide Drugs 0.000 description 1
- 229960002701 liraglutide Drugs 0.000 description 1
- 230000007787 long-term memory Effects 0.000 description 1
- 210000003750 lower gastrointestinal tract Anatomy 0.000 description 1
- 229950000128 lumiliximab Drugs 0.000 description 1
- 230000002132 lysosomal effect Effects 0.000 description 1
- 108010003700 lysyl aspartic acid Proteins 0.000 description 1
- 108010044348 lysyl-glutamyl-aspartic acid Proteins 0.000 description 1
- 210000002540 macrophage Anatomy 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- WKPWGQKGSOKKOO-RSFHAFMBSA-N maytansine Chemical compound CO[C@@H]([C@@]1(O)C[C@](OC(=O)N1)([C@H]([C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(C)=O)CC(=O)N1C)C)[H])\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 WKPWGQKGSOKKOO-RSFHAFMBSA-N 0.000 description 1
- 229960005558 mertansine Drugs 0.000 description 1
- ANZJBCHSOXCCRQ-FKUXLPTCSA-N mertansine Chemical compound CO[C@@H]([C@@]1(O)C[C@H](OC(=O)N1)[C@@H](C)[C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(=O)CCS)CC(=O)N1C)\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 ANZJBCHSOXCCRQ-FKUXLPTCSA-N 0.000 description 1
- 210000001704 mesoblast Anatomy 0.000 description 1
- 210000003716 mesoderm Anatomy 0.000 description 1
- 230000037353 metabolic pathway Effects 0.000 description 1
- 125000005397 methacrylic acid ester group Chemical group 0.000 description 1
- 108010056582 methionylglutamic acid Proteins 0.000 description 1
- 229920000609 methyl cellulose Polymers 0.000 description 1
- CAAULPUQFIIOTL-UHFFFAOYSA-N methyl dihydrogen phosphate Chemical compound COP(O)(O)=O CAAULPUQFIIOTL-UHFFFAOYSA-N 0.000 description 1
- 230000011987 methylation Effects 0.000 description 1
- 238000007069 methylation reaction Methods 0.000 description 1
- 239000001923 methylcellulose Substances 0.000 description 1
- 235000010981 methylcellulose Nutrition 0.000 description 1
- 108091070501 miRNA Proteins 0.000 description 1
- 238000012737 microarray-based gene expression Methods 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 239000011859 microparticle Substances 0.000 description 1
- 108091060283 mipomersen Proteins 0.000 description 1
- 229960004778 mipomersen Drugs 0.000 description 1
- 229950005674 modotuximab Drugs 0.000 description 1
- 210000002161 motor neuron Anatomy 0.000 description 1
- 238000010172 mouse model Methods 0.000 description 1
- 238000012243 multiplex automated genomic engineering Methods 0.000 description 1
- 201000005962 mycosis fungoides Diseases 0.000 description 1
- 201000000050 myeloid neoplasm Diseases 0.000 description 1
- 230000004070 myogenic differentiation Effects 0.000 description 1
- 239000003158 myorelaxant agent Substances 0.000 description 1
- HKUFIYBZNQSHQS-UHFFFAOYSA-N n-octadecyloctadecan-1-amine Chemical compound CCCCCCCCCCCCCCCCCCNCCCCCCCCCCCCCCCCCC HKUFIYBZNQSHQS-UHFFFAOYSA-N 0.000 description 1
- 210000004897 n-terminal region Anatomy 0.000 description 1
- 229950008353 narnatumab Drugs 0.000 description 1
- MRWXACSTFXYYMV-FDDDBJFASA-N nebularine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C2=NC=NC=C2N=C1 MRWXACSTFXYYMV-FDDDBJFASA-N 0.000 description 1
- 230000017074 necrotic cell death Effects 0.000 description 1
- 125000001971 neopentyl group Chemical group [H]C([*])([H])C(C([H])([H])[H])(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- 230000001537 neural effect Effects 0.000 description 1
- 210000004412 neuroendocrine cell Anatomy 0.000 description 1
- 210000004498 neuroglial cell Anatomy 0.000 description 1
- 239000003900 neurotrophic factor Substances 0.000 description 1
- XZXHXSATPCNXJR-ZIADKAODSA-N nintedanib Chemical compound O=C1NC2=CC(C(=O)OC)=CC=C2\C1=C(C=1C=CC=CC=1)\NC(C=C1)=CC=C1N(C)C(=O)CN1CCN(C)CC1 XZXHXSATPCNXJR-ZIADKAODSA-N 0.000 description 1
- 229960004378 nintedanib Drugs 0.000 description 1
- 125000002560 nitrile group Chemical group 0.000 description 1
- 125000000449 nitro group Chemical group [O-][N+](*)=O 0.000 description 1
- QJGQUHMNIGDVPM-UHFFFAOYSA-N nitrogen group Chemical group [N] QJGQUHMNIGDVPM-UHFFFAOYSA-N 0.000 description 1
- 125000000018 nitroso group Chemical group N(=O)* 0.000 description 1
- 108091027963 non-coding RNA Proteins 0.000 description 1
- 102000042567 non-coding RNA Human genes 0.000 description 1
- 229960003347 obinutuzumab Drugs 0.000 description 1
- FSAJWMJJORKPKS-UHFFFAOYSA-N octadecyl prop-2-enoate Chemical compound CCCCCCCCCCCCCCCCCCOC(=O)C=C FSAJWMJJORKPKS-UHFFFAOYSA-N 0.000 description 1
- 210000004248 oligodendroglia Anatomy 0.000 description 1
- 229950000846 onartuzumab Drugs 0.000 description 1
- 244000309459 oncolytic virus Species 0.000 description 1
- 229950002104 ontuxizumab Drugs 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 125000001181 organosilyl group Chemical group [SiH3]* 0.000 description 1
- 229950000121 otlertuzumab Drugs 0.000 description 1
- 150000002923 oximes Chemical class 0.000 description 1
- XNOPRXBHLZRZKH-DSZYJQQASA-N oxytocin Chemical compound C([C@H]1C(=O)N[C@H](C(N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CSSC[C@H](N)C(=O)N1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(N)=O)=O)[C@@H](C)CC)C1=CC=C(O)C=C1 XNOPRXBHLZRZKH-DSZYJQQASA-N 0.000 description 1
- 229960001723 oxytocin Drugs 0.000 description 1
- 229960004390 palbociclib Drugs 0.000 description 1
- AHJRHEGDXFFMBM-UHFFFAOYSA-N palbociclib Chemical compound N1=C2N(C3CCCC3)C(=O)C(C(=O)C)=C(C)C2=CN=C1NC(N=C1)=CC=C1N1CCNCC1 AHJRHEGDXFFMBM-UHFFFAOYSA-N 0.000 description 1
- 210000000496 pancreas Anatomy 0.000 description 1
- 238000007911 parenteral administration Methods 0.000 description 1
- 229950004260 parsatuzumab Drugs 0.000 description 1
- 239000004031 partial agonist Substances 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 229950010966 patritumab Drugs 0.000 description 1
- 239000008188 pellet Substances 0.000 description 1
- LQRJAEQXMSMEDP-XCHBZYMASA-N peptide a Chemical compound N([C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](C)C(=O)NCCCC[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)C(\NC(=O)[C@@H](CCCCN)NC(=O)CNC(C)=O)=C/C=1C=CC=CC=1)C(N)=O)C(=O)C(\NC(=O)[C@@H](CCCCN)NC(=O)CNC(C)=O)=C\C1=CC=CC=C1 LQRJAEQXMSMEDP-XCHBZYMASA-N 0.000 description 1
- 210000001539 phagocyte Anatomy 0.000 description 1
- 229960003531 phenolsulfonphthalein Drugs 0.000 description 1
- WTJKGGKOPKCXLL-RRHRGVEJSA-N phosphatidylcholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCCCCCCC=CCCCCCCCC WTJKGGKOPKCXLL-RRHRGVEJSA-N 0.000 description 1
- ACVYVLVWPXVTIT-UHFFFAOYSA-M phosphinate Chemical compound [O-][PH2]=O ACVYVLVWPXVTIT-UHFFFAOYSA-M 0.000 description 1
- 102000020233 phosphotransferase Human genes 0.000 description 1
- 230000004962 physiological condition Effects 0.000 description 1
- 229950010773 pidilizumab Drugs 0.000 description 1
- 230000001817 pituitary effect Effects 0.000 description 1
- 108010031345 placental alkaline phosphatase Proteins 0.000 description 1
- 239000013600 plasmid vector Substances 0.000 description 1
- 229920003023 plastic Polymers 0.000 description 1
- 239000004033 plastic Substances 0.000 description 1
- 229920003213 poly(N-isopropyl acrylamide) Polymers 0.000 description 1
- 229920000747 poly(lactic acid) Polymers 0.000 description 1
- 229920002647 polyamide Polymers 0.000 description 1
- 229920001223 polyethylene glycol Polymers 0.000 description 1
- 229940100467 polyvinyl acetate phthalate Drugs 0.000 description 1
- 229920002451 polyvinyl alcohol Polymers 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 208000025638 primary cutaneous T-cell non-Hodgkin lymphoma Diseases 0.000 description 1
- 210000001176 projection neuron Anatomy 0.000 description 1
- 108010014614 prolyl-glycyl-proline Proteins 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 125000001436 propyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 230000006207 propylation Effects 0.000 description 1
- 230000006916 protein interaction Effects 0.000 description 1
- 239000003909 protein kinase inhibitor Substances 0.000 description 1
- 238000001742 protein purification Methods 0.000 description 1
- PTJWIQPHWPFNBW-GBNDHIKLSA-N pseudouridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1C1=CNC(=O)NC1=O PTJWIQPHWPFNBW-GBNDHIKLSA-N 0.000 description 1
- 150000003212 purines Chemical class 0.000 description 1
- UBQKCCHYAOITMY-UHFFFAOYSA-N pyridin-2-ol Chemical compound OC1=CC=CC=N1 UBQKCCHYAOITMY-UHFFFAOYSA-N 0.000 description 1
- 150000003230 pyrimidines Chemical class 0.000 description 1
- JFINOWIINSTUNY-UHFFFAOYSA-N pyrrolidin-3-ylmethanesulfonamide Chemical compound NS(=O)(=O)CC1CCNC1 JFINOWIINSTUNY-UHFFFAOYSA-N 0.000 description 1
- 125000002112 pyrrolidino group Chemical group [*]N1C([H])([H])C([H])([H])C([H])([H])C1([H])[H] 0.000 description 1
- 229960000424 rasburicase Drugs 0.000 description 1
- 108010084837 rasburicase Proteins 0.000 description 1
- 108091008598 receptor tyrosine kinases Proteins 0.000 description 1
- 102000027426 receptor tyrosine kinases Human genes 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 238000005215 recombination Methods 0.000 description 1
- 239000004627 regenerated cellulose Substances 0.000 description 1
- 229960004836 regorafenib Drugs 0.000 description 1
- FNHKPVJBJVTLMP-UHFFFAOYSA-N regorafenib Chemical compound C1=NC(C(=O)NC)=CC(OC=2C=C(F)C(NC(=O)NC=3C=C(C(Cl)=CC=3)C(F)(F)F)=CC=2)=C1 FNHKPVJBJVTLMP-UHFFFAOYSA-N 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 210000002345 respiratory system Anatomy 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 230000001177 retroviral effect Effects 0.000 description 1
- 210000003705 ribosome Anatomy 0.000 description 1
- DWRXFEITVBNRMK-JXOAFFINSA-N ribothymidine Chemical compound O=C1NC(=O)C(C)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 DWRXFEITVBNRMK-JXOAFFINSA-N 0.000 description 1
- OHRURASPPZQGQM-GCCNXGTGSA-N romidepsin Chemical compound O1C(=O)[C@H](C(C)C)NC(=O)C(=C/C)/NC(=O)[C@H]2CSSCC\C=C\[C@@H]1CC(=O)N[C@H](C(C)C)C(=O)N2 OHRURASPPZQGQM-GCCNXGTGSA-N 0.000 description 1
- 108010091666 romidepsin Proteins 0.000 description 1
- 229960003452 romidepsin Drugs 0.000 description 1
- OHRURASPPZQGQM-UHFFFAOYSA-N romidepsin Natural products O1C(=O)C(C(C)C)NC(=O)C(=CC)NC(=O)C2CSSCCC=CC1CC(=O)NC(C(C)C)C(=O)N2 OHRURASPPZQGQM-UHFFFAOYSA-N 0.000 description 1
- RHFUOMFWUGWKKO-UHFFFAOYSA-N s2C Natural products S=C1N=C(N)C=CN1C1C(O)C(O)C(CO)O1 RHFUOMFWUGWKKO-UHFFFAOYSA-N 0.000 description 1
- 229960002181 saccharomyces boulardii Drugs 0.000 description 1
- 201000000306 sarcoidosis Diseases 0.000 description 1
- 229920006395 saturated elastomer Polymers 0.000 description 1
- 229930195734 saturated hydrocarbon Natural products 0.000 description 1
- 210000004116 schwann cell Anatomy 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 125000002914 sec-butyl group Chemical group [H]C([H])([H])C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- JRPHGDYSKGJTKZ-UHFFFAOYSA-K selenophosphate Chemical compound [O-]P([O-])([O-])=[Se] JRPHGDYSKGJTKZ-UHFFFAOYSA-K 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 230000000862 serotonergic effect Effects 0.000 description 1
- 108010048818 seryl-histidine Proteins 0.000 description 1
- 239000002911 sialidase inhibitor Substances 0.000 description 1
- 229960003323 siltuximab Drugs 0.000 description 1
- 229940115586 simulect Drugs 0.000 description 1
- 230000008591 skin barrier function Effects 0.000 description 1
- 239000004055 small Interfering RNA Substances 0.000 description 1
- 238000000527 sonication Methods 0.000 description 1
- 238000001179 sorption measurement Methods 0.000 description 1
- 125000006850 spacer group Chemical group 0.000 description 1
- 230000009870 specific binding Effects 0.000 description 1
- 238000012421 spiking Methods 0.000 description 1
- 238000010186 staining Methods 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 150000003432 sterols Chemical class 0.000 description 1
- 235000003702 sterols Nutrition 0.000 description 1
- 230000000638 stimulation Effects 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 125000000446 sulfanediyl group Chemical group *S* 0.000 description 1
- 229940124530 sulfonamide Drugs 0.000 description 1
- 150000003456 sulfonamides Chemical class 0.000 description 1
- 150000003462 sulfoxides Chemical class 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 230000004083 survival effect Effects 0.000 description 1
- 229940053017 sylvant Drugs 0.000 description 1
- 230000000946 synaptic effect Effects 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 229950010265 tabalumab Drugs 0.000 description 1
- DKPFODGZWDEEBT-QFIAKTPHSA-N taxane Chemical class C([C@]1(C)CCC[C@@H](C)[C@H]1C1)C[C@H]2[C@H](C)CC[C@@H]1C2(C)C DKPFODGZWDEEBT-QFIAKTPHSA-N 0.000 description 1
- ONUMZHGUFYIKPM-MXNFEBESSA-N telavancin Chemical compound O1[C@@H](C)[C@@H](O)[C@](NCCNCCCCCCCCCC)(C)C[C@@H]1O[C@H]1[C@H](OC=2C3=CC=4[C@H](C(N[C@H]5C(=O)N[C@H](C(N[C@@H](C6=CC(O)=C(CNCP(O)(O)=O)C(O)=C6C=6C(O)=CC=C5C=6)C(O)=O)=O)[C@H](O)C5=CC=C(C(=C5)Cl)O3)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](NC(=O)[C@@H](CC(C)C)NC)[C@H](O)C3=CC=C(C(=C3)Cl)OC=2C=4)O[C@H](CO)[C@@H](O)[C@@H]1O ONUMZHGUFYIKPM-MXNFEBESSA-N 0.000 description 1
- 229960005240 telavancin Drugs 0.000 description 1
- 108010089019 telavancin Proteins 0.000 description 1
- 229950001289 tenatumomab Drugs 0.000 description 1
- 229950010259 teprotumumab Drugs 0.000 description 1
- 125000000999 tert-butyl group Chemical group [H]C([H])([H])C(*)(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- 150000007970 thio esters Chemical group 0.000 description 1
- 150000003573 thiols Chemical group 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical group [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 description 1
- 108010061238 threonyl-glycine Proteins 0.000 description 1
- 229960004072 thrombin Drugs 0.000 description 1
- 229960000103 thrombolytic agent Drugs 0.000 description 1
- 230000002537 thrombolytic effect Effects 0.000 description 1
- 229940113082 thymine Drugs 0.000 description 1
- 229960002175 thyroglobulin Drugs 0.000 description 1
- 210000001685 thyroid gland Anatomy 0.000 description 1
- 229950004742 tigatuzumab Drugs 0.000 description 1
- 210000001519 tissue Anatomy 0.000 description 1
- 239000003104 tissue culture media Substances 0.000 description 1
- 229960001350 tofacitinib Drugs 0.000 description 1
- UJLAWZDWDVHWOW-YPMHNXCESA-N tofacitinib Chemical compound C[C@@H]1CCN(C(=O)CC#N)C[C@@H]1N(C)C1=NC=NC2=C1C=CN2 UJLAWZDWDVHWOW-YPMHNXCESA-N 0.000 description 1
- 229960005267 tositumomab Drugs 0.000 description 1
- 239000003204 tranquilizing agent Substances 0.000 description 1
- 230000002936 tranquilizing effect Effects 0.000 description 1
- 239000012581 transferrin Substances 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
- 230000014621 translational initiation Effects 0.000 description 1
- 230000005945 translocation Effects 0.000 description 1
- 229960000575 trastuzumab Drugs 0.000 description 1
- 229950007217 tremelimumab Drugs 0.000 description 1
- 125000005591 trimellitate group Chemical group 0.000 description 1
- 108010038745 tryptophylglycine Proteins 0.000 description 1
- 108010045269 tryptophyltryptophan Proteins 0.000 description 1
- HDZZVAMISRMYHH-KCGFPETGSA-N tubercidin Chemical compound C1=CC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O HDZZVAMISRMYHH-KCGFPETGSA-N 0.000 description 1
- 108010051110 tyrosyl-lysine Proteins 0.000 description 1
- 108010078580 tyrosylleucine Proteins 0.000 description 1
- 229950004593 ublituximab Drugs 0.000 description 1
- OOLLAFOLCSJHRE-ZHAKMVSLSA-N ulipristal acetate Chemical compound C1=CC(N(C)C)=CC=C1[C@@H]1C2=C3CCC(=O)C=C3CC[C@H]2[C@H](CC[C@]2(OC(C)=O)C(C)=O)[C@]2(C)C1 OOLLAFOLCSJHRE-ZHAKMVSLSA-N 0.000 description 1
- 238000000108 ultra-filtration Methods 0.000 description 1
- 229950005972 urelumab Drugs 0.000 description 1
- RVCNQQGZJWVLIP-VPCXQMTMSA-N uridin-5-yloxyacetic acid Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C(OCC(O)=O)=C1 RVCNQQGZJWVLIP-VPCXQMTMSA-N 0.000 description 1
- VBEQCZHXXJYVRD-GACYYNSASA-N uroanthelone Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)C(C)C)[C@@H](C)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CCSC)NC(=O)[C@H](CS)NC(=O)[C@@H](NC(=O)CNC(=O)CNC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CS)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CS)NC(=O)CNC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O)C(C)C)[C@@H](C)CC)C1=CC=C(O)C=C1 VBEQCZHXXJYVRD-GACYYNSASA-N 0.000 description 1
- 229960003726 vasopressin Drugs 0.000 description 1
- 230000007502 viral entry Effects 0.000 description 1
- 230000029812 viral genome replication Effects 0.000 description 1
- 239000013603 viral vector Substances 0.000 description 1
- 229950001212 volociximab Drugs 0.000 description 1
- 229920003176 water-insoluble polymer Polymers 0.000 description 1
- 229940055760 yervoy Drugs 0.000 description 1
- 229950008250 zalutumumab Drugs 0.000 description 1
- 229960001028 zanamivir Drugs 0.000 description 1
- ARAIBEBZBOPLMB-UFGQHTETSA-N zanamivir Chemical compound CC(=O)N[C@@H]1[C@@H](N=C(N)N)C=C(C(O)=O)O[C@H]1[C@H](O)[C@H](O)CO ARAIBEBZBOPLMB-UFGQHTETSA-N 0.000 description 1
- KGPGQDLTDHGEGT-JCIKCJKQSA-N zeven Chemical compound C=1C([C@@H]2C(=O)N[C@H](C(N[C@H](C3=CC(O)=C4)C(=O)NCCCN(C)C)=O)[C@H](O)C5=CC=C(C(=C5)Cl)OC=5C=C6C=C(C=5O[C@H]5[C@@H]([C@@H](O)[C@H](O)[C@H](O5)C(O)=O)NC(=O)CCCCCCCCC(C)C)OC5=CC=C(C=C5)C[C@@H]5C(=O)N[C@H](C(N[C@H]6C(=O)N2)=O)C=2C(Cl)=C(O)C=C(C=2)OC=2C(O)=CC=C(C=2)[C@H](C(N5)=O)NC)=CC=C(O)C=1C3=C4O[C@H]1O[C@H](CO)[C@@H](O)[C@H](O)[C@@H]1O KGPGQDLTDHGEGT-JCIKCJKQSA-N 0.000 description 1
- 229950007157 zolbetuximab Drugs 0.000 description 1
Images






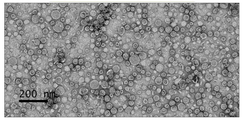




Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/005—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from viruses
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/46—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
- A61K48/0008—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'non-active' part of the composition delivered, e.g. wherein such 'non-active' part is not delivered simultaneously with the 'active' part of the composition
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K9/00—Medicinal preparations characterised by special physical form
- A61K9/48—Preparations in capsules, e.g. of gelatin, of chocolate
- A61K9/50—Microcapsules having a gas, liquid or semi-solid filling; Solid microparticles or pellets surrounded by a distinct coating layer, e.g. coated microspheres, coated drug crystals
- A61K9/51—Nanocapsules; Nanoparticles
- A61K9/5107—Excipients; Inactive ingredients
- A61K9/513—Organic macromolecular compounds; Dendrimers
- A61K9/5169—Proteins, e.g. albumin, gelatin
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K9/00—Medicinal preparations characterised by special physical form
- A61K9/48—Preparations in capsules, e.g. of gelatin, of chocolate
- A61K9/50—Microcapsules having a gas, liquid or semi-solid filling; Solid microparticles or pellets surrounded by a distinct coating layer, e.g. coated microspheres, coated drug crystals
- A61K9/51—Nanocapsules; Nanoparticles
- A61K9/5107—Excipients; Inactive ingredients
- A61K9/5176—Compounds of unknown constitution, e.g. material from plants or animals
- A61K9/5184—Virus capsids or envelopes enclosing drugs
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/86—Viral vectors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/90—Stable introduction of foreign DNA into chromosome
- C12N15/902—Stable introduction of foreign DNA into chromosome using homologous recombination
- C12N15/907—Stable introduction of foreign DNA into chromosome using homologous recombination in mammalian cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
- C12N9/22—Ribonucleases RNAses, DNAses
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/555—Medicinal preparations containing antigens or antibodies characterised by a specific combination antigen/adjuvant
- A61K2039/55511—Organic adjuvants
- A61K2039/55555—Liposomes; Vesicles, e.g. nanoparticles; Spheres, e.g. nanospheres; Polymers
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/20—Type of nucleic acid involving clustered regularly interspaced short palindromic repeats [CRISPRs]
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Organic Chemistry (AREA)
- Molecular Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Health & Medical Sciences (AREA)
- Zoology (AREA)
- Biomedical Technology (AREA)
- Biotechnology (AREA)
- Biochemistry (AREA)
- Medicinal Chemistry (AREA)
- Biophysics (AREA)
- Wood Science & Technology (AREA)
- General Engineering & Computer Science (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Physics & Mathematics (AREA)
- Microbiology (AREA)
- Gastroenterology & Hepatology (AREA)
- Plant Pathology (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Epidemiology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Toxicology (AREA)
- Virology (AREA)
- Immunology (AREA)
- Optics & Photonics (AREA)
- Nanotechnology (AREA)
- Mycology (AREA)
- Cell Biology (AREA)
- Botany (AREA)
- Peptides Or Proteins (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
- Medicinal Preparation (AREA)
Abstract
특정 실시양태에서, 재조합 Arc 및 내인성 Gag 폴리펩티드, 및 재조합 Arc 및 내인성 Gag 폴리펩티드를 사용하는 방법이 본원에 개시된다.
Description
상호 참조
본 출원은 2018년 9월 18일에 출원된 미국 가특허 출원 번호 62/733,015의 이익을 주장하며, 이는 그 전체가 본원에 참조로 포함된다.
개시내용의 요약
특정 실시양태에서, 재조합 및 조작된 Arc 폴리펩티드 및 재조합 및 조작된 내인성 Gag(endo-Gag) 폴리펩티드가 본원에 개시된다. 일부 실시양태에서, 또한 로딩된 또는 비어있는 Arc 기반 캡시드 및 endo-Gag 기반 캡시드, 및 캡시드를 제조하는 방법이 포함된다. 또한, Arc 기반 캡시드 및 endo-Gag 기반 캡시드를 관심 부위에 전달하는 방법이 포함된다.
특정 실시양태에서, 재조합 Arc 폴리펩티드 또는 재조합 내인성 Gag 폴리펩티드 및 치료제를 포함하는 캡시드가 본원에 개시된다. 일부 실시양태에서, 치료제는 핵산이다. 일부 실시양태에서, 핵산은 RNA이다. 일부 실시양태에서, 재조합 Arc 폴리펩티드는 서열번호 1인 아미노산 서열 또는 서열번호 1과 적어도 90% 동일한 아미노산 서열을 포함하는 인간 Arc 폴리펩티드이다. 일부 실시양태에서, 재조합 Arc 폴리펩티드는 a) 서열번호 2인 아미노산 서열 또는 서열번호 2와 적어도 90% 동일한 아미노산 서열; b) 서열번호 3인 아미노산 서열 또는 서열번호 3과 적어도 90% 동일한 아미노산 서열; c) 서열번호 4인 아미노산 서열 또는 서열번호 4와 적어도 90% 동일한 아미노산 서열; d) 서열번호 5인 아미노산 서열 또는 서열번호 5와 적어도 90% 동일한 아미노산 서열; e) 서열번호 6인 아미노산 서열 또는 서열번호 6과 적어도 90% 동일한 아미노산 서열; f) 서열번호 7인 아미노산 서열 또는 서열번호 7과 적어도 90% 동일한 아미노산 서열; g) 서열번호 8인 아미노산 서열 또는 서열번호 8과 적어도 90% 동일한 아미노산 서열; h) 서열번호 9인 아미노산 서열 또는 서열번호 9와 적어도 90% 동일한 아미노산 서열; i) 서열번호 10인 아미노산 서열 또는 서열번호 10과 적어도 90% 동일한 아미노산 서열; 또는 j) 서열번호 11인 아미노산 서열 또는 서열번호 11과 적어도 90% 동일한 아미노산 서열; 또는 k) 서열번호 12인 아미노산 서열 또는 서열번호 12와 적어도 90% 동일한 아미노산 서열; 또는 l) 서열번호 13인 아미노산 서열 또는 서열번호 13과 적어도 90% 동일한 아미노산 서열; 또는 m) 서열번호 14인 아미노산 서열 또는 서열번호 14와 적어도 90% 동일한 아미노산 서열; 또는 n) 서열번호 15인 아미노산 서열 또는 서열번호 15와 적어도 90% 동일한 아미노산 서열을 포함하는 Arc 폴리펩티드이다. 일부 실시양태에서, 재조합 내인성 Gag 폴리펩티드는 인간 내인성 Gag 폴리펩티드이다. 일부 실시양태에서, 재조합 내인성 Gag 폴리펩티드는 a) 서열번호 16인 아미노산 서열 또는 서열번호 16과 적어도 90% 동일한 아미노산 서열; b) 서열번호 17인 아미노산 서열 또는 서열번호 17과 적어도 90% 동일한 아미노산 서열; c) 서열번호 18인 아미노산 서열 또는 서열번호 18과 적어도 90% 동일한 아미노산 서열; d) 서열번호 19인 아미노산 서열 또는 서열번호 19와 적어도 90% 동일한 아미노산 서열; e) 서열번호 20인 아미노산 서열 또는 서열번호 20과 적어도 90% 동일한 아미노산 서열; f) 서열번호 21인 아미노산 서열 또는 서열번호 21과 적어도 90% 동일한 아미노산 서열; 또는 g) 서열번호 22인 아미노산 서열 또는 서열번호 22와 적어도 90% 동일한 아미노산 서열; 또는 h) 서열번호 23인 아미노산 서열 또는 서열번호 23과 적어도 90% 동일한 아미노산 서열; 또는 i) 서열번호 24인 아미노산 서열 또는 서열번호 24와 적어도 90% 동일한 아미노산 서열; 또는 j) 서열번호 25인 아미노산 서열 또는 서열번호 25와 적어도 90% 동일한 아미노산 서열; 또는 k) 서열번호 26인 아미노산 서열 또는 서열번호 26과 적어도 90% 동일한 아미노산 서열; 또는 l) 서열번호 27인 아미노산 서열 또는 서열번호 27과 적어도 90% 동일한 아미노산 서열 또는 m) 서열번호 28인 아미노산 서열 또는 서열번호 28과 적어도 90% 동일한 아미노산 서열을 포함하는 내인성 Gag 폴리펩티드이다.
특정 실시양태에서, 재조합 Arc 폴리펩티드 또는 재조합 내인성 Gag 폴리펩티드를 포함하고, 여기서 재조합 Arc 폴리펩티드는 래트 Arc 폴리펩티드 또는 인간 Arc 폴리펩티드가 아닌, 캡시드가 본원에 개시된다. 일부 실시양태에서, 캡시드는 카고(cargo)를 추가로 포함한다. 일부 실시양태에서, 카고는 핵산이다. 일부 실시양태에서, 카고는 RNA이다. 일부 실시양태에서, 카고는 치료제이다. 일부 실시양태에서, 재조합 Arc 폴리펩티드는 a) 서열번호 2인 아미노산 서열 또는 서열번호 2와 적어도 90% 동일한 아미노산 서열; b) 서열번호 3인 아미노산 서열 또는 서열번호 3과 적어도 90% 동일한 아미노산 서열; c) 서열번호 4인 아미노산 서열 또는 서열번호 4와 적어도 90% 동일한 아미노산 서열; d) 서열번호 5인 아미노산 서열 또는 서열번호 5와 적어도 90% 동일한 아미노산 서열; e) 서열번호 6인 아미노산 서열 또는 서열번호 6과 적어도 90% 동일한 아미노산 서열; f) 서열번호 7인 아미노산 서열 또는 서열번호 7과 적어도 90% 동일한 아미노산 서열; g) 서열번호 8인 아미노산 서열 또는 서열번호 8과 적어도 90% 동일한 아미노산 서열; h) 서열번호 9인 아미노산 서열 또는 서열번호 9와 적어도 90% 동일한 아미노산 서열; i) 서열번호 10인 아미노산 서열 또는 서열번호 10과 적어도 90% 동일한 아미노산 서열; 또는 j) 서열번호 11인 아미노산 서열 또는 서열번호 11과 적어도 90% 동일한 아미노산 서열; 또는 k) 서열번호 12인 아미노산 서열 또는 서열번호 12와 적어도 90% 동일한 아미노산 서열; 또는 l) 서열번호 13인 아미노산 서열 또는 서열번호 13과 적어도 90% 동일한 아미노산 서열; 또는 m) 서열번호 14인 아미노산 서열 또는 서열번호 14와 적어도 90% 동일한 아미노산 서열; 또는 n) 서열번호 15인 아미노산 서열 또는 서열번호 15와 적어도 90% 동일한 아미노산 서열을 포함하는 Arc 폴리펩티드이다. 일부 실시양태에서, 재조합 내인성 Gag 폴리펩티드는 a) 서열번호 16인 아미노산 서열 또는 서열번호 16과 적어도 90% 동일한 아미노산 서열; b) 서열번호 17인 아미노산 서열 또는 서열번호 17과 적어도 90% 동일한 아미노산 서열; c) 서열번호 18인 아미노산 서열 또는 서열번호 18과 적어도 90% 동일한 아미노산 서열; d) 서열번호 19인 아미노산 서열 또는 서열번호 19와 적어도 90% 동일한 아미노산 서열; e) 서열번호 20인 아미노산 서열 또는 서열번호 20과 적어도 90% 동일한 아미노산 서열; f) 서열번호 21인 아미노산 서열 또는 서열번호 21과 적어도 90% 동일한 아미노산 서열; 또는 g) 서열번호 22인 아미노산 서열 또는 서열번호 22와 적어도 90% 동일한 아미노산 서열; 또는 h) 서열번호 23인 아미노산 서열 또는 서열번호 23과 적어도 90% 동일한 아미노산 서열; 또는 i) 서열번호 24인 아미노산 서열 또는 서열번호 24와 적어도 90% 동일한 아미노산 서열; 또는 j) 서열번호 25인 아미노산 서열 또는 서열번호 25와 적어도 90% 동일한 아미노산 서열; 또는 k) 서열번호 26인 아미노산 서열 또는 서열번호 26과 적어도 90% 동일한 아미노산 서열; 또는 l) 서열번호 27인 아미노산 서열 또는 서열번호 27과 적어도 90% 동일한 아미노산 서열 또는 m) 서열번호 28인 아미노산 서열 또는 서열번호 28과 적어도 90% 동일한 아미노산 서열을 포함하는 내인성 Gag 폴리펩티드이다.
특정 실시양태에서, 재조합 Arc 폴리펩티드 또는 재조합 내인성 Gag 폴리펩티드를 코딩하는 DNA를 포함하는 벡터가 본원에 개시된다. 일부 실시양태에서, 벡터는 치료제를 추가로 코딩한다. 일부 실시양태에서, 치료제는 핵산이다. 일부 실시양태에서, 핵산은 RNA이다. 일부 실시양태에서, 재조합 Arc 폴리펩티드는 서열번호 1인 아미노산 서열 또는 서열번호 1과 적어도 90% 동일한 아미노산 서열을 포함하는 인간 Arc 폴리펩티드이다. 일부 실시양태에서, 재조합 Arc 폴리펩티드는 a) 서열번호 2인 아미노산 서열 또는 서열번호 2와 적어도 90% 동일한 아미노산 서열; b) 서열번호 3인 아미노산 서열 또는 서열번호 3과 적어도 90% 동일한 아미노산 서열; c) 서열번호 4인 아미노산 서열 또는 서열번호 4와 적어도 90% 동일한 아미노산 서열; d) 서열번호 5인 아미노산 서열 또는 서열번호 5와 적어도 90% 동일한 아미노산 서열; e) 서열번호 6인 아미노산 서열 또는 서열번호 6과 적어도 90% 동일한 아미노산 서열; f) 서열번호 7인 아미노산 서열 또는 서열번호 7과 적어도 90% 동일한 아미노산 서열; g) 서열번호 8인 아미노산 서열 또는 서열번호 8과 적어도 90% 동일한 아미노산 서열; h) 서열번호 9인 아미노산 서열 또는 서열번호 9와 적어도 90% 동일한 아미노산 서열; i) 서열번호 10인 아미노산 서열 또는 서열번호 10과 적어도 90% 동일한 아미노산 서열; 또는 j) 서열번호 11인 아미노산 서열 또는 서열번호 11과 적어도 90% 동일한 아미노산 서열; 또는 k) 서열번호 12인 아미노산 서열 또는 서열번호 12와 적어도 90% 동일한 아미노산 서열; 또는 l) 서열번호 13인 아미노산 서열 또는 서열번호 13과 적어도 90% 동일한 아미노산 서열; 또는 m) 서열번호 14인 아미노산 서열 또는 서열번호 14과 적어도 90% 동일한 아미노산 서열; 또는 n) 서열번호 15인 아미노산 서열 또는 서열번호 15와 적어도 90% 동일한 아미노산 서열을 포함하는 Arc 폴리펩티드이다. 일부 실시양태에서, 재조합 내인성 Gag 폴리펩티드는 인간 내인성 Gag 폴리펩티드이다. 일부 실시양태에서, 재조합 내인성 Gag 폴리펩티드는 a) 서열번호 16인 아미노산 서열 또는 서열번호 16과 적어도 90% 동일한 아미노산 서열; b) 서열번호 17인 아미노산 서열 또는 서열번호 17과 적어도 90% 동일한 아미노산 서열; c) 서열번호 18인 아미노산 서열 또는 서열번호 18과 적어도 90% 동일한 아미노산 서열; d) 서열번호 19인 아미노산 서열 또는 서열번호 19와 적어도 90% 동일한 아미노산 서열; e) 서열번호 20인 아미노산 서열 또는 서열번호 20과 적어도 90% 동일한 아미노산 서열; f) 서열번호 21인 아미노산 서열 또는 서열번호 21과 적어도 90% 동일한 아미노산 서열; 또는 g) 서열번호 22인 아미노산 서열 또는 서열번호 22와 적어도 90% 동일한 아미노산 서열; 또는 h) 서열번호 23인 아미노산 서열 또는 서열번호 23과 적어도 90% 동일한 아미노산 서열; 또는 i) 서열번호 24인 아미노산 서열 또는 서열번호 24와 적어도 90% 동일한 아미노산 서열; 또는 j) 서열번호 25인 아미노산 서열 또는 서열번호 25와 적어도 90% 동일한 아미노산 서열; 또는 k) 서열번호 26인 아미노산 서열 또는 서열번호 26과 적어도 90% 동일한 아미노산 서열; 또는 l) 서열번호 27인 아미노산 서열 또는 서열번호 27과 적어도 90% 동일한 아미노산 서열 또는 m) 서열번호 28인 아미노산 서열 또는 서열번호 28과 적어도 90% 동일한 아미노산 서열을 포함하는 내인성 Gag 폴리펩티드이다.
특정 실시양태에서, 재조합 Arc 폴리펩티드 또는 재조합 내인성 Gag 폴리펩티드를 코딩하는 DNA를 포함하고, 여기서 재조합 Arc 폴리펩티드는 래트 Arc 폴리펩티드 또는 인간 Arc 폴리펩티드가 아닌, 벡터가 본원에 개시된다. 일부 실시양태에서, 벡터는 카고를 추가로 코딩한다. 일부 실시양태에서, 카고는 핵산이다. 일부 실시양태에서, 카고는 RNA이다. 일부 실시양태에서, 카고는 치료제이다. 일부 실시양태에서, 재조합 Arc 폴리펩티드는 a) 서열번호 2인 아미노산 서열 또는 서열번호 2와 적어도 90% 동일한 아미노산 서열; b) 서열번호 3인 아미노산 서열 또는 서열번호 3과 적어도 90% 동일한 아미노산 서열; c) 서열번호 4인 아미노산 서열 또는 서열번호 4와 적어도 90% 동일한 아미노산 서열; d) 서열번호 5인 아미노산 서열 또는 서열번호 5와 적어도 90% 동일한 아미노산 서열; e) 서열번호 6인 아미노산 서열 또는 서열번호 6과 적어도 90% 동일한 아미노산 서열; f) 서열번호 7인 아미노산 서열 또는 서열번호 7과 적어도 90% 동일한 아미노산 서열; g) 서열번호 8인 아미노산 서열 또는 서열번호 8과 적어도 90% 동일한 아미노산 서열; h) 서열번호 9인 아미노산 서열 또는 서열번호 9와 적어도 90% 동일한 아미노산 서열; i) 서열번호 10인 아미노산 서열 또는 서열번호 10과 적어도 90% 동일한 아미노산 서열; 또는 j) 서열번호 11인 아미노산 서열 또는 서열번호 11과 적어도 90% 동일한 아미노산 서열; 또는 k) 서열번호 12인 아미노산 서열 또는 서열번호 12와 적어도 90% 동일한 아미노산 서열; 또는 l) 서열번호 13인 아미노산 서열 또는 서열번호 13과 적어도 90% 동일한 아미노산 서열; 또는 m) 서열번호 14인 아미노산 서열 또는 서열번호 14와 적어도 90% 동일한 아미노산 서열; 또는 n) 서열번호 15인 아미노산 서열 또는 서열번호 15와 적어도 90% 동일한 아미노산 서열을 포함하는 Arc 폴리펩티드이다. 일부 실시양태에서, 재조합 내인성 Gag 폴리펩티드는 a) 서열번호 16인 아미노산 서열 또는 서열번호 16과 적어도 90% 동일한 아미노산 서열; b) 서열번호 17인 아미노산 서열 또는 서열번호 17과 적어도 90% 동일한 아미노산 서열; c) 서열번호 18인 아미노산 서열 또는 서열번호 18과 적어도 90% 동일한 아미노산 서열; d) 서열번호 19인 아미노산 서열 또는 서열번호 19와 적어도 90% 동일한 아미노산 서열; e) 서열번호 20인 아미노산 서열 또는 서열번호 20과 적어도 90% 동일한 아미노산 서열; f) 서열번호 21인 아미노산 서열 또는 서열번호 21과 적어도 90% 동일한 아미노산 서열; 또는 g) 서열번호 22인 아미노산 서열 또는 서열번호 22와 적어도 90% 동일한 아미노산 서열; 또는 h) 서열번호 23인 아미노산 서열 또는 서열번호 23과 적어도 90% 동일한 아미노산 서열; 또는 i) 서열번호 24인 아미노산 서열 또는 서열번호 24와 적어도 90% 동일한 아미노산 서열; 또는 j) 서열번호 25인 아미노산 서열 또는 서열번호 25와 적어도 90% 동일한 아미노산 서열; 또는 k) 서열번호 26인 아미노산 서열 또는 서열번호 26과 적어도 90% 동일한 아미노산 서열; 또는 l) 서열번호 27인 아미노산 서열 또는 서열번호 27과 적어도 90% 동일한 아미노산 서열 또는 m) 서열번호 28인 아미노산 서열 또는 서열번호 28과 적어도 90% 동일한 아미노산 서열을 포함하는 내인성 Gag 폴리펩티드이다.
특정 실시양태에서, 재조합 Arc 폴리펩티드 또는 재조합 내인성 Gag 폴리펩티드 및 치료제를 포함하는 캡시드를 세포에 투여하는 단계를 포함하는, 카고를 세포에 전달하는 방법이 본원에 개시된다. 일부 실시양태에서, 치료제는 핵산이다. 일부 실시양태에서, 핵산은 RNA이다. 일부 실시양태에서, 재조합 Arc 폴리펩티드는 서열번호 1인 아미노산 서열 또는 서열번호 1과 적어도 90% 동일한 아미노산 서열을 포함하는 인간 Arc 폴리펩티드이다. 일부 실시양태에서, 재조합 Arc 폴리펩티드는a) 서열번호 2인 아미노산 서열 또는 서열번호 2와 적어도 90% 동일한 아미노산 서열; b) 서열번호 3인 아미노산 서열 또는 서열번호 3과 적어도 90% 동일한 아미노산 서열; c) 서열번호 4인 아미노산 서열 또는 서열번호 4와 적어도 90% 동일한 아미노산 서열; d) 서열번호 5인 아미노산 서열 또는 서열번호 5와 적어도 90% 동일한 아미노산 서열; e) 서열번호 6인 아미노산 서열 또는 서열번호 6과 적어도 90% 동일한 아미노산 서열; f) 서열번호 7인 아미노산 서열 또는 서열번호 7과 적어도 90% 동일한 아미노산 서열; g) 서열번호 8인 아미노산 서열 또는 서열번호 8과 적어도 90% 동일한 아미노산 서열; h) 서열번호 9인 아미노산 서열 또는 서열번호 9와 적어도 90% 동일한 아미노산 서열; i) 서열번호 10인 아미노산 서열 또는 서열번호 10과 적어도 90% 동일한 아미노산 서열; 또는 j) 서열번호 11인 아미노산 서열 또는 서열번호 11과 적어도 90% 동일한 아미노산 서열; 또는 k) 서열번호 12인 아미노산 서열 또는 서열번호 12와 적어도 90% 동일한 아미노산 서열; 또는 l) 서열번호 13인 아미노산 서열 또는 서열번호 13과 적어도 90% 동일한 아미노산 서열; 또는 m) 서열번호 14인 아미노산 서열 또는 서열번호 14와 적어도 90% 동일한 아미노산 서열; 또는 n) 서열번호 15인 아미노산 서열 또는 서열번호 15와 적어도 90% 동일한 아미노산 서열을 포함하는 Arc 폴리펩티드이다. 일부 실시양태에서, 재조합 내인성 Gag 폴리펩티드는 인간 내인성 Gag 폴리펩티드이다. 일부 실시양태에서, 재조합 내인성 Gag 폴리펩티드는 a) 서열번호 16인 아미노산 서열 또는 서열번호 16과 적어도 90% 동일한 아미노산 서열; b) 서열번호 17인 아미노산 서열 또는 서열번호 17과 적어도 90% 동일한 아미노산 서열; c) 서열번호 18인 아미노산 서열 또는 서열번호 18과 적어도 90% 동일한 아미노산 서열; d) 서열번호 19인 아미노산 서열 또는 서열번호 19와 적어도 90% 동일한 아미노산 서열; e) 서열번호 20인 아미노산 서열 또는 서열번호 20과 적어도 90% 동일한 아미노산 서열; f) 서열번호 21인 아미노산 서열 또는 서열번호 21과 적어도 90% 동일한 아미노산 서열; 또는 g) 서열번호 22인 아미노산 서열 또는 서열번호 22와 적어도 90% 동일한 아미노산 서열; 또는 h) 서열번호 23인 아미노산 서열 또는 서열번호 23과 적어도 90% 동일한 아미노산 서열; 또는 i) 서열번호 24인 아미노산 서열 또는 서열번호 24와 적어도 90% 동일한 아미노산 서열; 또는 j) 서열번호 25인 아미노산 서열 또는 서열번호 25와 적어도 90% 동일한 아미노산 서열; 또는 k) 서열번호 26인 아미노산 서열 또는 서열번호 26과 적어도 90% 동일한 아미노산 서열; 또는 l) 서열번호 27인 아미노산 서열 또는 서열번호 27과 적어도 90% 동일한 아미노산 서열 또는 m) 서열번호 28인 아미노산 서열 또는 서열번호 28과 적어도 90% 동일한 아미노산 서열을 포함하는 내인성 Gag 폴리펩티드이다. 일부 실시양태에서, 세포는 진핵 세포이다. 일부 실시양태에서, 세포는 척추동물 세포이다. 일부 실시양태에서, 세포는 포유동물 세포이다. 일부 실시양태에서, 세포는 인간 세포이다. 일부 실시양태에서, 카고는 핵산이다. 일부 실시양태에서, 세포는 핵산에 의해 코딩되는 유전자를 발현한다. 일부 실시양태에서, 카고는 치료제이다.
특정 실시양태에서, 재조합 Arc 폴리펩티드 또는 재조합 내인성 Gag 폴리펩티드를 포함하는 캡시드를 세포에 투여하는 단계를 포함하고, 여기서 재조합 Arc 폴리펩티드는 래트 Arc 폴리펩티드 또는 인간 Arc 폴리펩티드가 아닌, 카고를 세포에 전달하는 방법이 본원에 개시된다. 일부 실시양태에서, 캡시드는 카고를 추가로 포함한다. 일부 실시양태에서, 카고는 핵산이다. 일부 실시양태에서, 카고는 RNA이다. 일부 실시양태에서, 카고는 치료제이다. 일부 실시양태에서, 재조합 Arc 폴리펩티드는 a) 서열번호 2인 아미노산 서열 또는 서열번호 2와 적어도 90% 동일한 아미노산 서열; b) 서열번호 3인 아미노산 서열 또는 서열번호 3과 적어도 90% 동일한 아미노산 서열; c) 서열번호 4인 아미노산 서열 또는 서열번호 4와 적어도 90% 동일한 아미노산 서열; d) 서열번호 5인 아미노산 서열 또는 서열번호 5와 적어도 90% 동일한 아미노산 서열; e) 서열번호 6인 아미노산 서열 또는 서열번호 6과 적어도 90% 동일한 아미노산 서열; f) 서열번호 7인 아미노산 서열 또는 서열번호 7과 적어도 90% 동일한 아미노산 서열; g) 서열번호 8인 아미노산 서열 또는 서열번호 8과 적어도 90% 동일한 아미노산 서열; h) 서열번호 9인 아미노산 서열 또는 서열번호 9와 적어도 90% 동일한 아미노산 서열; i) 서열번호 10인 아미노산 서열 또는 서열번호 10과 적어도 90% 동일한 아미노산 서열; 또는 j) 서열번호 11인 아미노산 서열 또는 서열번호 11과 적어도 90% 동일한 아미노산 서열; 또는 k) 서열번호 12인 아미노산 서열 또는 서열번호 12와 적어도 90% 동일한 아미노산 서열; 또는 l) 서열번호 13인 아미노산 서열 또는 서열번호 13과 적어도 90% 동일한 아미노산 서열; 또는 m) 서열번호 14인 아미노산 서열 또는 서열번호 14와 적어도 90% 동일한 아미노산 서열; 또는 n) 서열번호 15인 아미노산 서열 또는 서열번호 15와 적어도 90% 동일한 아미노산 서열을 포함하는 Arc 폴리펩티드이다. 일부 실시양태에서, 재조합 내인성 Gag 폴리펩티드는 a) 서열번호 16인 아미노산 서열 또는 서열번호 16과 적어도 90% 동일한 아미노산 서열; b) 서열번호 17인 아미노산 서열 또는 서열번호 17과 적어도 90% 동일한 아미노산 서열; c) 서열번호 18인 아미노산 서열 또는 서열번호 18과 적어도 90% 동일한 아미노산 서열; d) 서열번호 19인 아미노산 서열 또는 서열번호 19와 적어도 90% 동일한 아미노산 서열; e) 서열번호 20인 아미노산 서열 또는 서열번호 20과 적어도 90% 동일한 아미노산 서열; f) 서열번호 21인 아미노산 서열 또는 서열번호 21과 적어도 90% 동일한 아미노산 서열; 또는 g) 서열번호 22인 아미노산 서열 또는 서열번호 22와 적어도 90% 동일한 아미노산 서열; 또는 h) 서열번호 23인 아미노산 서열 또는 서열번호 23과 적어도 90% 동일한 아미노산 서열; 또는 i) 서열번호 24인 아미노산 서열 또는 서열번호 24와 적어도 90% 동일한 아미노산 서열; 또는 j) 서열번호 25인 아미노산 서열 또는 서열번호 25와 적어도 90% 동일한 아미노산 서열; 또는 k) 서열번호 26인 아미노산 서열 또는 서열번호 26과 적어도 90% 동일한 아미노산 서열; 또는 l) 서열번호 27인 아미노산 서열 또는 서열번호 27과 적어도 90% 동일한 아미노산 서열 또는 m) 서열번호 28인 아미노산 서열 또는 서열번호 28과 적어도 90% 동일한 아미노산 서열을 포함하는 내인성 Gag 폴리펩티드이다. 일부 실시양태에서, 세포는 진핵 세포이다. 일부 실시양태에서, 세포는 척추동물 세포이다. 일부 실시양태에서, 세포는 포유동물 세포이다. 일부 실시양태에서, 세포는 인간 세포이다. 일부 실시양태에서, 카고는 핵산이다. 일부 실시양태에서, 세포는 핵산에 의해 코딩되는 유전자를 발현한다. 일부 실시양태에서, 카고는 치료제이다.
특정 실시양태에서, 재조합 Arc 폴리펩티드 또는 재조합 내인성 Gag 폴리펩티드 및 치료제를 포함하는 캡시드를 세포에 투여하는 단계를 포함하는, 핵산을 세포로 형질감염시키는 방법이 본원에 개시된다. 일부 실시양태에서, 치료제는 핵산이다. 일부 실시양태에서, 핵산은 RNA이다. 일부 실시양태에서, 재조합 Arc 폴리펩티드는 서열번호 1인 아미노산 서열 또는 서열번호 1과 적어도 90% 동일한 아미노산 서열을 포함하는 인간 Arc 폴리펩티드이다. 일부 실시양태에서, 재조합 Arc 폴리펩티드는 a) 서열번호 2인 아미노산 서열 또는 서열번호 2와 적어도 90% 동일한 아미노산 서열; b) 서열번호 3인 아미노산 서열 또는 서열번호 3과 적어도 90% 동일한 아미노산 서열; c) 서열번호 4인 아미노산 서열 또는 서열번호 4와 적어도 90% 동일한 아미노산 서열; d) 서열번호 5인 아미노산 서열 또는 서열번호 5와 적어도 90% 동일한 아미노산 서열; e) 서열번호 6인 아미노산 서열 또는 서열번호 6과 적어도 90% 동일한 아미노산 서열; f) 서열번호 7인 아미노산 서열 또는 서열번호 7과 적어도 90% 동일한 아미노산 서열; g) 서열번호 8인 아미노산 서열 또는 서열번호 8과 적어도 90% 동일한 아미노산 서열; h) 서열번호 9인 아미노산 서열 또는 서열번호 9와 적어도 90% 동일한 아미노산 서열; i) 서열번호 10인 아미노산 서열 또는 서열번호 10과 적어도 90% 동일한 아미노산 서열; 또는 j) 서열번호 11인 아미노산 서열 또는 서열번호 11과 적어도 90% 동일한 아미노산 서열; 또는 k) 서열번호 12인 아미노산 서열 또는 서열번호 12와 적어도 90% 동일한 아미노산 서열; 또는 l) 서열번호 13인 아미노산 서열 또는 서열번호 13과 적어도 90% 동일한 아미노산 서열; 또는 m) 서열번호 14인 아미노산 서열 또는 서열번호 14와 적어도 90% 동일한 아미노산 서열; 또는 n) 서열번호 15인 아미노산 서열 또는 서열번호 15와 적어도 90% 동일한 아미노산 서열을 포함하는 Arc 폴리펩티드이다. 일부 실시양태에서, 재조합 내인성 Gag 폴리펩티드는 인간 내인성 Gag 폴리펩티드이다. 일부 실시양태에서, 재조합 내인성 Gag 폴리펩티드는 a) 서열번호 16인 아미노산 서열 또는 서열번호 16과 적어도 90% 동일한 아미노산 서열; b) 서열번호 17인 아미노산 서열 또는 서열번호 17과 적어도 90% 동일한 아미노산 서열; c) 서열번호 18인 아미노산 서열 또는 서열번호 18과 적어도 90% 동일한 아미노산 서열; d) 서열번호 19인 아미노산 서열 또는 서열번호 19와 적어도 90% 동일한 아미노산 서열; e) 서열번호 20인 아미노산 서열 또는 서열번호 20과 적어도 90% 동일한 아미노산 서열; f) 서열번호 21인 아미노산 서열 또는 서열번호 21과 적어도 90% 동일한 아미노산 서열; 또는 g) 서열번호 22인 아미노산 서열 또는 서열번호 22와 적어도 90% 동일한 아미노산 서열; 또는 h) 서열번호 23인 아미노산 서열 또는 서열번호 23과 적어도 90% 동일한 아미노산 서열; 또는 i) 서열번호 24인 아미노산 서열 또는 서열번호 24와 적어도 90% 동일한 아미노산 서열; 또는 j) 서열번호 25인 아미노산 서열 또는 서열번호 25와 적어도 90% 동일한 아미노산 서열; 또는 k) 서열번호 26인 아미노산 서열 또는 서열번호 26과 적어도 90% 동일한 아미노산 서열; 또는 l) 서열번호 27인 아미노산 서열 또는 서열번호 27과 적어도 90% 동일한 아미노산 서열 또는 m) 서열번호 8인 아미노산 서열 또는 서열번호 28과 적어도 90% 동일한 아미노산 서열을 포함하는 내인성 Gag 폴리펩티드이다.
특정 실시양태에서, 재조합 Arc 폴리펩티드 또는 재조합 내인성 Gag 폴리펩티드를 포함하는 캡시드를 세포에 투여하는 단계를 포함하고, 여기서 재조합 Arc 폴리펩티드는 래트 Arc 폴리펩티드 또는 인간 Arc 폴리펩티드가 아닌, 핵산을 세포로 형질감염시키는 방법이 본원에 개시된다. 일부 실시양태에서, 캡시드는 카고를 추가로 포함한다. 일부 실시양태에서, 카고는 핵산이다. 일부 실시양태에서, 카고는 RNA이다. 일부 실시양태에서, 카고는 치료제이다. 일부 실시양태에서, 재조합 Arc 폴리펩티드는 a) 서열번호 2인 아미노산 서열 또는 서열번호 2와 적어도 90% 동일한 아미노산 서열; b) 서열번호 3인 아미노산 서열 또는 서열번호 3과 적어도 90% 동일한 아미노산 서열; c) 서열번호 4인 아미노산 서열 또는 서열번호 4와 적어도 90% 동일한 아미노산 서열; d) 서열번호 5인 아미노산 서열 또는 서열번호 5와 적어도 90% 동일한 아미노산 서열; e) 서열번호 6인 아미노산 서열 또는 서열번호 6과 적어도 90% 동일한 아미노산 서열; f) 서열번호 7인 아미노산 서열 또는 서열번호 7과 적어도 90% 동일한 아미노산 서열; g) 서열번호 8인 아미노산 서열 또는 서열번호 8과 적어도 90% 동일한 아미노산 서열; h) 서열번호 9인 아미노산 서열 또는 서열번호 9와 적어도 90% 동일한 아미노산 서열; i) 서열번호 10인 아미노산 서열 또는 서열번호 10과 적어도 90% 동일한 아미노산 서열; 또는 j) 서열번호 11인 아미노산 서열 또는 서열번호 11과 적어도 90% 동일한 아미노산 서열; 또는 k) 서열번호 12인 아미노산 서열 또는 서열번호 12와 적어도 90% 동일한 아미노산 서열; 또는 l) 서열번호 13인 아미노산 서열 또는 서열번호 13과 적어도 90% 동일한 아미노산 서열; 또는 m) 서열번호 14인 아미노산 서열 또는 서열번호 14와 적어도 90% 동일한 아미노산 서열; 또는 n) 서열번호 15인 아미노산 서열 또는 서열번호 15와 적어도 90% 동일한 아미노산 서열을 포함하는 Arc 폴리펩티드이다. 일부 실시양태에서, 재조합 내인성 Gag 폴리펩티드는 a) 서열번호 12인 아미노산 서열 또는 서열번호 12와 적어도 90% 동일한 아미노산 서열; b) 서열번호 13인 아미노산 서열 또는 서열번호 13과 적어도 90% 동일한 아미노산 서열; c) 서열번호 14인 아미노산 서열 또는 서열번호 14와 적어도 90% 동일한 아미노산 서열; d) 서열번호 15인 아미노산 서열 또는 서열번호 15와 적어도 90% 동일한 아미노산 서열; e) 서열번호 16인 아미노산 서열 또는 서열번호 16과 적어도 90% 동일한 아미노산 서열; f) 서열번호 17인 아미노산 서열 또는 서열번호 17과 적어도 90% 동일한 아미노산 서열; g) 서열번호 18인 아미노산 서열 또는 서열번호 18과 적어도 90% 동일한 아미노산 서열; g) 서열번호 19인 아미노산 서열 또는 서열번호 19와 적어도 90% 동일한 아미노산 서열; g) 서열번호 20인 아미노산 서열 또는 서열번호 20과 적어도 90% 동일한 아미노산 서열; g) 서열번호 21인 아미노산 서열 또는 서열번호 21과 적어도 90% 동일한 아미노산 서열; 또는 h) 서열번호 22인 아미노산 서열 또는 서열번호 22와 적어도 90% 동일한 아미노산 서열을 포함하는 내인성 Gag 폴리펩티드이다.
특정 실시양태에서, 카고 결합 도메인 및 Arc 또는 endo-Gag 폴리펩티드로부터의 적어도 하나의 캡시드 형성 서브유닛을 포함하는 조작된 Arc 또는 endo-Gag 폴리펩티드가 본원에 개시된다. 일부 실시양태에서, 카고 결합 도메인은 핵산 결합 도메인을 포함한다. 일부 실시양태에서, 카고 결합 도메인은 소분자에 결합하는 폴리펩티드를 포함한다. 일부 실시양태에서, 카고 결합 도메인은 단백질, 펩티드, 또는 항체 또는 이의 결합 단편에 결합하는 폴리펩티드를 포함한다. 일부 실시양태에서, 카고 결합 도메인은 펩티드모방체 또는 뉴클레오티드모방체에 결합하는 폴리펩티드를 포함한다. 일부 실시양태에서, 적어도 하나의 캡시드 형성 서브유닛은 서열번호 1의 CA N-로브(lobe) 및/또는 CA C-로브에 상응하는 폴리펩티드를 포함한다. 일부 실시양태에서, 조작된 Arc 또는 endo-Gag 폴리펩티드는 상이한 종의 Arc 또는 endo-Gag 폴리펩티드로부터의 제2 캡시드 형성 서브유닛을 추가포 포함한다. 일부 실시양태에서, 제2 캡시드 형성 서브유닛은 서열번호 1의 N-로브 및/또는 C-로브에 상응하는 폴리펩티드를 포함한다. 일부 실시양태에서, 적어도 하나의 캡시드 형성 서브유닛 및 제2 캡시드 형성 서브유닛은 포유동물, 설치류, 조류, 파충류, 어류, 곤충, 진균 또는 식물로부터 선택되는 Arc 또는 endo-Gag의 종으로부터 각각 독립적으로 선택된다. 일부 실시양태에서, 적어도 하나의 캡시드 형성 서브유닛 및 제2 캡시드 형성 서브유닛은 2개의 상이한 종으로부터의 것이다. 일부 실시양태에서, 카고 결합 도메인은 직접적으로 또는 링커를 통해 적어도 하나의 캡시드 형성 서브유닛의 C-말단에 융합된다. 일부 실시양태에서, 카고 결합 도메인은 직접적으로 또는 링커를 통해 적어도 하나의 캡시드 형성 서브유닛의 N-말단에 융합된다. 일부 실시양태에서, 제2 캡시드 형성 서브유닛은 직접적으로 또는 링커를 통해 적어도 하나의 캡시드 형성 서브유닛의 C-말단에 융합된다. 일부 실시양태에서, 제2 캡시드 형성 서브유닛은 직접적으로 또는 링커를 통해 적어도 하나의 캡시드 형성 서브유닛의 N-말단에 융합된다. 일부 실시양태에서, 카고 결합 도메인은 직접적으로 또는 링커를 통해 적어도 하나의 캡시드 형성 서브유닛의 N-말단에 융합되고 제2 캡시드 형성 서브유닛은 직접적으로 또는 링커를 통해 적어도 하나의 캡시드 형성 서브유닛의 C-말단에 융합된다. 실시양태에서, 카고 결합 도메인은 직접적으로 또는 링커를 통해 적어도 하나의 캡시드 형성 서브유닛의 C-말단에 융합되고 제2 캡시드 형성 서브유닛은 직접적으로 또는 링커를 통해 적어도 하나의 캡시드 형성 서브유닛의 N-말단에 융합된다. 일부 실시양태에서, 조작된 Arc 또는 endo-Gag 폴리펩티드는 제2 폴리펩티드를 추가로 포함한다. 일부 실시양태에서, 제2 폴리펩티드는 직접적으로 또는 링커를 통해 적어도 하나의 캡시드 형성 서브유닛에 융합된다. 일부 실시양태에서, 제2 폴리펩티드는 직접적으로 또는 링커를 통해 카고 결합 도메인에 융합된다. 일부 실시양태에서, 제2 폴리펩티드는 단백질 또는 항체 또는 이의 결합 단편이다. 일부 실시양태에서, 단백질은 인간 단백질 또는 바이러스 단백질이다. 일부 실시양태에서, 단백질은 인간 Gag-유사 단백질이다. 일부 실시양태에서, 단백질은 관심 표적 수용체에 결합하도록 설계된 드 노보 조작된 단백질이다. 일부 실시양태에서, 제2 폴리펩티드는 조작된 Arc 또는 endo-Gag 폴리펩티드에 의해 형성된 캡시드의 관심 표적 부위로의 전달을 안내한다.
특정 실시양태에서, 캡시드 형성, 핵산 결합 또는 전달과 관련되지 않은 부분이 제거된 말단절단된 Arc 또는 endo-Gag 폴리펩티드가 본원에 개시된다. 일부 실시양태에서, 부분은 뉴클레오티드 결합 도메인이 인간 Arc RNA 결합 도메인이 아니라면 매트릭스(MA) 도메인, 역전사효소(RT) 도메인, 뉴클레오티드 결합 도메인, 또는 이들의 조합을 포함한다. 일부 실시양태에서, 부분은 CA C-로브 도메인을 포함한다. 일부 실시양태에서, 부분은 N-말단 결실, C-말단 결실, 또는 이들의 조합을 포함한다. 일부 실시양태에서, N-말단 결실은 최대 10개 아미노산, 20개 아미노산, 30개 아미노산 또는 50개 아미노산의 결실을 포함한다. 일부 실시양태에서, C-말단 결실은 최대 10개 아미노산, 20개 아미노산, 30개 아미노산 또는 50개 아미노산의 결실을 포함한다.
특정 실시양태에서, 말단절단된 Arc 또는 endo-Gag 폴리펩티드일 수 있는 조작된 Arc 또는 endo-Gag 폴리펩티드 및 조작된 Arc 또는 endo-Gag에 의해 형성되는 캡시드에 의해 캡슐화되는 카고를 포함하는 Arc 또는 endo-Gag 기반 캡시드가 본원에 개시된다. 일부 실시양태에서, 카고는 핵산 분자이다. 일부 실시양태에서, 핵산 분자는 DNA, RNA, 또는 DNA와 RNA의 혼합물이다. 일부 실시양태에서, DNA 및 RNA는 각각 독립적으로 단일 가닥, 이중 가닥, 또는 단일 및 이중 가닥의 혼합물이다. 일부 실시양태에서, 카고는 소분자이다. 일부 실시양태에서, 카고는 단백질이다. 일부 실시양태에서, 카고는 펩티드이다. 일부 실시양태에서, 카고는 항체 또는 이의 결합 단편이다. 일부 실시양태에서, 카고는 펩티드모방체 또는 뉴클레오티드모방체이다. 일부 실시양태에서, Arc 또는 endo-Gag 기반 캡시드는 조작된 Arc 또는 endo-Gag 폴리펩티드와 상이한 Arc 또는 endo-Gag 단백질의 하나 이상의 종으로부터의 하나 이상의 추가의 캡시드 서브유닛을 포함한다. 일부 실시양태에서, Arc 기반 또는 endo-Gag 기반 캡시드는 비-Arc 단백질로부터의 하나 이상의 추가의 캡시드 서브유닛을 포함한다. 일부 실시양태에서, 하나 이상의 추가의 캡시드 서브유닛은 코피아(Copia) 단백질, ASPRV1 단백질, SCAN 도메인 패밀리로부터의 단백질, 부신생물성 Ma 항원 패밀리에 의해 코딩되는 단백질(예컨대, PNMA5, PNMA6, PNMA6A 및 PNMA6B), 레트로트랜스포존 Gag-유사 패밀리로부터의 단백질(예컨대, RTL3, RTL6, RTL8A, RTL8B), 또는 이들의 조합을 포함한다. 일부 실시양태에서, 하나 이상의 추가의 캡시드 서브유닛은 BOP, LDOC1, MOAP1, PEG10, PNMA3, PNMA5, PNMA6A, PNMA6B, RTL3, RTL6, RTL8A, RTL8B, 및 ZNF18을 포함한다. 일부 실시양태에서, 캡시드는 적어도 1 nm, 2 nm, 3 nm, 4 nm, 5 nm, 10nm, 15 nm, 20 nm, 25 nm, 30 nm, 50 nm, 80 nm, 100 nm, 120 nm, 150 nm, 200 nm, 250 nm, 300 nm, 500 nm, 600 nm, 또는 그 초과의 직경을 갖는다. 일부 실시양태에서, 캡시드는 약 1 nm 내지 약 600 nm, 약 1 nm 내지 약 500 nm, 약 1 nm 내지 약 200 nm, 약 1 nm 내지 약 100 nm, 약 1 nm 내지 약 50 nm, 또는 약 1 nm 내지 약 30 nm의 직경을 갖는다. 일부 실시양태에서, 캡시드는 감소된 표적외(off-target) 효과를 갖는다. 일부 실시양태에서, 캡시드는 표적외 효과를 갖지 않는다. 일부 실시양태에서, 캡시드는 생체외에서 형성된다. 일부 실시양태에서, 캡시드는 시험관내에서 형성된다.
특정 실시양태에서, 본원에 기재된 재조합 또는 조작된 Arc 폴리펩티드 또는 재조합 또는 조작된 내인성 Gag 폴리펩티드를 코딩하는 핵산 중합체가 본원에 개시된다.
특정 실시양태에서, 본원에 기재된 재조합 또는 조작된 Arc 폴리펩티드 또는 재조합 또는 조작된 내인성 Gag 폴리펩티드를 코딩하는 핵산 중합체를 포함하는 벡터가 본원에 개시된다.
특정 실시양태에서, 복수의 재조합 또는 조작된 Arc 폴리펩티드 또는 복수의 재조합 또는 조작된 endo-Gag 폴리펩티드를 로딩된 캡시드를 생성하기에 충분한 시간 동안 용액에서 카고와 함께 인큐베이션하는 단계를 포함하는, 로딩된 Arc 기반 또는 endo-Gag 기반 캡시드를 제조하는 방법이 본원에 개시된다. 일부 실시양태에서, 방법은 카고와 함께 인큐베이션하기 전에 복수의 조작된 Arc 또는 endo-Gag 폴리펩티드를 포함하는 용액을 복수의 비-Arc 또는 비-endo-Gag 캡시드 형성 서브유닛과 혼합하는 단계를 추가로 포함한다. 일부 실시양태에서, 복수의 비-Arc 또는 비-endo-Gag 캡시드 형성 서브유닛은 복수의 재조합 또는 조작된 Arc 또는 endo-Gag 폴리펩티드와 1:1, 2:1, 3:1, 4:1, 5:1, 6:1, 7:1, 8:1, 9:1, 또는 10:1의 비로 혼합된다. 일부 실시양태에서, 복수의 비-Arc 또는 비-endo-Gag 캡시드 형성 서브유닛은 복수의 조작된 Arc 또는 endo-Gag 폴리펩티드와 1:2, 1:3, 1:4, 1:5, 1:6, 1:7, 1:8, 1:9, 또는 1:10의 비로 혼합된다. 일부 실시양태에서, 방법은 카고와 함께 인큐베이션하기 전에 복수의 말단절단된 Arc 또는 endo-Gag 폴리펩티드를 포함하는 용액을 복수의 비-Arc 또는 endo-Gag 캡시드 형성 서브유닛과 혼합하는 단계를 추가로 포함한다. 일부 실시양태에서, 복수의 비-Arc 또는 endo-Gag 캡시드 형성 서브유닛은 복수의 말단절단된 Arc 또는 endo-Gag 폴리펩티드와 1:1, 2:1, 3:1, 4:1, 5:1, 6:1, 7:1, 8:1, 9:1, 또는 10:1의 비로 혼합된다. 일부 실시양태에서, 복수의 비-Arc 또는 비-endo-Gag 캡시드 형성 서브유닛은 복수의 말단절단된 Arc 또는 endo-Gag 폴리펩티드와 1:2, 1:3, 1:4, 1:5, 1:6, 1:7, 1:8, 1:9, 또는 1:10의 비로 혼합된다. 일부 실시양태에서, 복수의 조작된 Arc 또는 endo-Gag 폴리펩티드는 박테리아 세포 시스템, 곤충 세포 시스템, 또는 포유동물 세포 시스템으로부터 수득된다. 일부 실시양태에서, 복수의 조작된 Arc 또는 endo-Gag 폴리펩티드는 무세포 시스템으로부터 수득된다. 일부 실시양태에서, 복수의 말단절단된 Arc 또는 endo-Gag 폴리펩티드는 박테리아 세포 시스템, 곤충 세포 시스템, 또는 포유동물 세포 시스템으로부터 수득된다. 일부 실시양태에서, 복수의 말단절단된 Arc 또는 endo-Gag 폴리펩티드는 무세포 시스템으로부터 수득된다. 일부 실시양태에서, 로딩된 Arc 기반 또는 endo-Gag 캡시드는 전신 투여용으로 제제화된다. 일부 실시양태에서, 로딩된 Arc 또는 endo-Gag 기반 캡시드는 국소 투여용으로 제제화된다. 일부 실시양태에서, 로딩된 Arc 또는 endo-Gag 기반 캡시드는 비경구 투여용으로 제제화된다. 일부 실시양태에서, 로딩된 Arc 또는 endo-Gag 기반 캡시드는 경구 투여용으로 제제화된다. 일부 실시양태에서, 로딩된 Arc 또는 endo-Gag 기반 캡시드는 국부 투여용으로 제제화된다. 일부 실시양태에서, 로딩된 Arc 또는 endo-Gag 기반 캡시드는 설하 또는 에어로졸 투여용으로 제제화된다.
특정 실시양태에서, 관심 부위의 세포를 Arc 기반 또는 Arc 기반 캡시드의 세포 흡수를 촉진하기에 충분한 시간 동안 Arc 기반 또는 Arc 기반 캡시드와 접촉시키는 단계를 포함하는, 카고를 관심 부위에 전달하기 위한 조작된 또는 재조합 Arc 기반 또는 endo-Gag 기반 캡시드의 용도가 본원에 개시된다. 일부 실시양태에서, 세포는 종양 세포이다. 일부 실시양태에서, 종양 세포는 고형 종양 세포이다. 일부 실시양태에서, 고형 종양 세포는 방광암, 유방암, 뇌암, 결장직장암, 신장암, 간암, 폐암, 췌장암, 전립선암, 피부암, 위암 또는 갑상선암으로부터의 세포이다. 일부 실시양태에서, 종양 세포는 혈액 악성종양으로부터의 것이다. 일부 실시양태에서, 혈액 악성종양은 B 세포 악성종양, 또는 T 세포 악성종양이다. 일부 실시양태에서, 혈액 악성종양은 만성 림프구성 백혈병(CLL), 소 림프구성 림프종(SLL), 미만성 거대 B 세포 림프종(DLBCL), 소포 림프종, 맨틀 세포 림프종, 버킷 림프종, 피부 T 세포 림프종, 또는 말초 T 세포 림프종이다. 일부 실시양태에서, 세포는 체세포이다. 일부 실시양태에서, 세포는 줄기 세포 또는 전구 세포이다. 일부 실시양태에서, 세포는 중간엽 줄기 또는 전구 세포이다. 일부 실시양태에서, 세포는 조혈 줄기 또는 전구 세포이다. 일부 실시양태에서, 세포는 근육 세포, 피부 세포, 혈액 세포, 또는 면역 세포이다. 일부 실시양태에서, 표적 단백질은 과발현되거나 세포에서 고갈된다. 일부 실시양태에서, 세포의 표적 유전자는 하나 이상의 돌연변이를 갖는다. 일부 실시양태에서, 세포는 손상된 스플라이싱 메커니즘을 포함한다. 일부 실시양태에서, 용도는 생체내 용도이다. 일부 실시양태에서, Arc 기반 캡시드는 대상체에게 전신 투여된다. 일부 실시양태에서, Arc 기반 또는 endo-Gag 기반 캡시드는 대상체에게 국소 투여를 통해 투여된다. 일부 실시양태에서, Arc 기반 또는 endo-Gag 기반 캡시드는 대상체에게 비경구 투여된다. 일부 실시양태에서, Arc 기반 캡시드는 대상체에게 경구적으로 투여된다. 일부 실시양태에서, Arc 기반 또는 endo-Gag 기반 캡시드는 대상체에게 국부로 투여된다. 일부 실시양태에서, Arc 기반 또는 endo-Gag 기반 캡시드는 대상체에게 설하 또는 에어로졸 투여를 통해 투여된다. 일부 실시양태에서, 용도는 시험관내 또는 생체외 용도이다.
특정 실시양태에서, 조작된 Arc 또는 endo-Gag 폴리펩티드, 말단절단된 Arc 또는 endo-Gag 폴리펩티드, 재조합 또는 조작된 Arc 또는 endo-Gag 폴리펩티드를 코딩하는 벡터, 또는 Arc 기반 또는 endo-Gag 기반 캡시드를 포함하는 키트가 본원에 개시된다.
본 개시내용의 다양한 측면은 첨부된 청구범위에서 구체적으로 설명된다. 본 개시내용의 특징 및 이점에 대한 더 나은 이해는 본 개시내용의 원리가 활용되는 예시적인 실시양태를 설명하는 하기의 상세한 설명 및 하기 첨부 도면을 참조함으로써 얻어질 것이다.
도 1은 예시적인 Arc 폴리펩티드의 표현이다.
도 2는 예시적인 조작된 Arc 폴리펩티드의 표현이다.
도 3은 (A) 특정 카고(예컨대, RNA 페이로드)을 운반하거나 (B) 기능외(off-function) 효과를 제거하기 위해 Arc 폴리펩티드를 조작하는 예시적인 방법을 예시한다.
도 4a는 HisTrap 컬럼으로부터 이미다졸 구배로의 용출에 의한 6xHis 태그부착된 인간 Arc의 단리를 도시한다.
도 4b는 NaCl 구배로 용출된 모노 Q 컬럼 상의 잔류 핵산으로부터 6xHis 태그부착된 인간 Arc의 분리를 도시한다.
도 5는 네거티브 염색된 인간 Arc 캡시드의 투과 전자 현미경 이미지를 도시한다.
도 6은 재조합적으로 발현된 Arc 동원체(ortholog)로부터 형성된 네거티브 염색된 캡시드의 투과 전자 현미경 이미지를 도시한다.
도 7은 재조합적으로 발현된 endo-Gag 단백질로부터 형성된 네거티브 염색된 캡시드의 투과 전자 현미경 이미지를 도시한다.
도 8은 HeLa 세포에 의한 Alexa594 표지된 Arc 캡시드의 선택적 내재화를 도시한다.
도 9는 Arc 캡시드에 의한 Cre RNA의 HeLa 세포로의 전달을 도시한다.
도 10은 이종 RNA 페이로드를 전달하는 능력에 대해 Arc 및 endo-Gag 유전자 후보를 스크리닝하는 방법을 예시한다.
도 1은 예시적인 Arc 폴리펩티드의 표현이다.
도 2는 예시적인 조작된 Arc 폴리펩티드의 표현이다.
도 3은 (A) 특정 카고(예컨대, RNA 페이로드)을 운반하거나 (B) 기능외(off-function) 효과를 제거하기 위해 Arc 폴리펩티드를 조작하는 예시적인 방법을 예시한다.
도 4a는 HisTrap 컬럼으로부터 이미다졸 구배로의 용출에 의한 6xHis 태그부착된 인간 Arc의 단리를 도시한다.
도 4b는 NaCl 구배로 용출된 모노 Q 컬럼 상의 잔류 핵산으로부터 6xHis 태그부착된 인간 Arc의 분리를 도시한다.
도 5는 네거티브 염색된 인간 Arc 캡시드의 투과 전자 현미경 이미지를 도시한다.
도 6은 재조합적으로 발현된 Arc 동원체(ortholog)로부터 형성된 네거티브 염색된 캡시드의 투과 전자 현미경 이미지를 도시한다.
도 7은 재조합적으로 발현된 endo-Gag 단백질로부터 형성된 네거티브 염색된 캡시드의 투과 전자 현미경 이미지를 도시한다.
도 8은 HeLa 세포에 의한 Alexa594 표지된 Arc 캡시드의 선택적 내재화를 도시한다.
도 9는 Arc 캡시드에 의한 Cre RNA의 HeLa 세포로의 전달을 도시한다.
도 10은 이종 RNA 페이로드를 전달하는 능력에 대해 Arc 및 endo-Gag 유전자 후보를 스크리닝하는 방법을 예시한다.
진단 또는 치료제를 관심 부위에 정밀하게 투여하는 것은 지속적인 도전을 제시하였다. 핵산을 세포에 전달하는 이용 가능한 방법은 무수한 한계를 갖는다. 예컨대, 유전자 요법에 자주 사용되는 AAV 바이러스 벡터는 면역원성이고, < 3kb의 제한된 페이로드 용량을 갖고, 열악한 생체 분포를 겪고, 직접 주사로만 투여할 수 있으며, 통합에 의해 숙주 유전자를 파괴할 위험이 있다. 비-바이러스 방법은 상이한 한계를 갖는다. 리포솜은 주로 간에 전달된다. 세포외 소포는 < 1 kb의 제한된 페이로드 용량, 제한된 확장성 및 정제 어려움을 갖는다. 따라서, 치료 페이로드를 전달하는 새로운 방법에 대한 필요성이 인식된다.
대부분의 분자는 신체에 고유한 친화력을 가지고 있지 않다. 다른 경우에서, 투여된 작용제는 청소를 위해 간 및 신장에 축적되거나 의도하지 않은 조직 또는 세포 유형에 축적된다. 전달을 개선하는 방법은 소수성 화합물 또는 중합체로 선택한 작용제를 코팅하는 것을 포함한다. 이러한 접근법은 순환에서 상기 작용제의 지속기간을 증가시키고 세포 흡수를 위한 소수성을 증대시킨다. 반면에, 이 접근법은 카고를 전달을 위한 관심 부위로 적극적으로 보내지 않는다.
요법이 필요한 부위를 명확하게 표적으로 하기 위해, 치료 화합물은 임의적으로 표적 세포의 표면에 디스플레이되는 수용체를 인식하고 결합하는 리간드, 항체 및 압타머와 같은 모이어티에 융합된다. 관심 세포에 도달하면, 치료 화합물은 임의적으로 세포내 표적에 추가로 전달된다. 예컨대, 치료 RNA는 세포의 세포질의 리보솜과 접촉하면 단백질로 번역될 수 있다.
Arc(활성 조절되는 세포골격 관련된 단백질)는 α-아미노-3-히드록시-5-메틸이속사졸-4-프로피온산(AMPA) 유형 글루타메이트 수용체의 세포내이입 트래피킹을 조절한다. Arc 활성은 시냅스 강도 및 뉴런 가소성과 관련이 있다. 실험 뮤린 모델에서 Arc 손실의 표현형은 결손이 있는 장기 기억 형성 및 감소된 뉴런 활성 및 가소성을 포함하였다.
Arc는 레트로바이러스 Gag 단백질과 유사한 분자 특성을 나타낸다. Arc 유전자는 Ty3/gypsy 레트로트랜스포존으로부터 유래되었을 수 있다. 내인성 Gag(endo-Gag) 단백질은 Arc를 포함하여 진핵 유기체에 내인성인 임의의 단백질이며, 바이러스 Gag 단백질에 대해 예측된 주석이 달린 유사성을 갖는다. 예시적인 endo-Gag 단백질은 문헌(Campillos M, Doerks T, Shah PK, and Bork P, Computational characterization of multiple Gag-like human proteins, Trends Genet. 2006 Nov;22(11):585-9)에 개시되어 있다. endo-Gag 단백질은 임의적으로 원핵 또는 진핵 세포, 또는 박테리아, 효모, 곤충, 척추동물, 포유동물 또는 인간 세포를 포함하는 임의의 숙주 세포에 의해 재조합적으로 발현된다. 본원에서 기재되는 바와 같이, 일부 실시양태에서 endo-Gag 단백질은 endo-Gag 캡시드로 조립된다.
특정 실시양태에서, 관심 카고의 전달을 위해 캡시드로 조립되는 Arc 및 endo-Gag 폴리펩티드가 본원에 개시된다. 일부 실시양태에서, 또한 관심 카고의 전달을 위해 캡시드로 조립되는 조작된 Arc 및 endo-Gag 폴리펩티드가 본원에 기재된다. 추가의 실시양태에서, 관심 카고의 전달을 위한 캡시드, 예컨대 Arc 기반 또는 endo-Gag 기반 캡시드가 본원에 기재된다.
Arc 폴리펩티드 및 내인성 Gag 폴리펩티드
특정 실시양태에서, Arc 폴리펩티드가 본원에 개시된다. 특정 실시양태에서, endo-Gag 폴리펩티드가 본원에 개시된다. endo-Gag 서열은 이 섹션에 기재된 임의의 유형의 조작된 Arc 폴리펩티드를 형성하기 위한 Arc 서열에 대한 임의적 대체물이라는 것을 이해해야 한다.
일부 예에서, Arc는 비-인간 Arc 폴리펩티드이다. 일부 예에서, Arc 폴리펩티드는 전장 Arc 폴리펩티드(예컨대, 전장 비-인간 Arc 폴리펩티드)를 포함한다. 다른 예에서, Arc 폴리펩티드는 캡시드의 형성에 참여하는 말단절단된 Arc 폴리펩티드와 같은 비-인간 Arc의 단편을 포함한다. 추가의 예에서, Arc 폴리펩티드는 비-인간 Arc 폴리펩티드의 하나 이상의 도메인을 포함하고, 여기서 도메인 중 적어도 하나는 캡시드의 형성에 참여한다. 추가의 예에서, Arc 폴리펩티드는 재조합 Arc 폴리펩티드이다.
일부 예에서, endo-Gag는 비-인간 endo-Gag 폴리펩티드이다. 일부 예에서, endo-Gag 폴리펩티드는 전장 endo-Gag 폴리펩티드(예컨대, 전장 비-인간 endo-Gag 폴리펩티드)를 포함한다. 다른 예에서, endo-Gag 폴리펩티드는 캡시드의 형성에 참여하는 말단절단된 endo-Gag 폴리펩티드와 같은 비-인간 endo-Gag의 단편을 포함한다. 추가의 예에서, endo-Gag 폴리펩티드는 비-인간 endo-Gag 폴리펩티드의 하나 이상의 도메인을 포함하고, 여기서 도메인 중 적어도 하나는 캡시드의 형성에 참여한다. 추가의 예에서, endo-Gag 폴리펩티드는 재조합 endo-Gag 폴리펩티드이다.
일부 실시양태에서, Arc는 인간 Arc에 고유하지 않은 카고에 결합하도록 변형된 적어도 그의 RNA 결합 도메인을 갖는 인간 Arc 폴리펩티드이다. 일부 예에서, Arc 폴리펩티드는 인간 Arc 단백질에 고유하지 않은 카고에 결합하도록 변형된 적어도 그의 RNA 결합 도메인을 갖는 전장 인간 Arc 폴리펩티드를 포함한다. 다른 예에서, Arc 폴리펩티드는 적어도 그의 RNA 결합 도메인에 변형(들)을 포함하는 인간 Arc 단편을 포함한다. 추가의 예에서, Arc 폴리펩티드는 인간 Arc 폴리펩티드의 하나 이상의 도메인을 포함하고, 여기서 도메인 중 적어도 하나는 캡시드의 형성에 참여하고, 여기서 RNA 결합 도메인은 천연 인간 Arc 단백질은 결합하지 않는 카고에 결합하도록 변형된다. 추가의 예에서, Arc 폴리펩티드는 재조합 인간 Arc 폴리펩티드이며, 적어도 RNA 결합 도메인은 인간 Arc 단백질에 고유하지 않은 카고를 로딩할 수 있도록 변형된다.
일부 실시양태에서, Endo-Gag는 인간 endo-Gag에 고유하지 않은 카고에 결합하도록 변형된 적어도 그의 RNA 결합 도메인을 갖는 인간 Endo-Gag 폴리펩티드이다. 일부 예에서, endo-Gag 폴리펩티드는 인간 endo-Gag 단백질에 고유하지 않은 카고에 결합하도록 변형된 적어도 그의 RNA 결합 도메인을 갖는 전장 인간 endo-Gag 폴리펩티드를 포함한다. 다른 예에서, endo-Gag 폴리펩티드는 천연 인간 endo-Gag 단백질이 결합하지 않는 카고에 결합하도록 적어도 그의 RNA 결합 도메인에 변형(들)을 포함하는 인간 endo-Gag 단편을 포함한다. 추가의 예에서, endo-Gag 폴리펩티드는 인간 endo-Gag 폴리펩티드의 하나 이상의 도메인을 포함하고, 여기서 도메인 중 적어도 하나는 캡시드의 형성에 참여하고 여기서 RNA 결합 도메인은 인간 endo-Gag 단백질에 고유하지 않은 카고에 결합하도록 변형된다. 추가의 예에서, endo-Gag 폴리펩티드는 재조합 인간 endo-Gag 폴리펩티드이고, 적어도 RNA 결합 도메인은 인간 endo-Gag 단백질에 고유하지 않은 카고를 로딩할 수 있도록 변형된다.
일부 예에서, Arc 또는 endo-Gag 폴리펩티드는 조작된 Arc 또는 endo-Gag 폴리펩티드이다. 본원에서 사용되는 바와 같이, 조작된 폴리펩티드는 전장 야생형 폴리펩티드와 서열이 동일하지 않은 재조합 폴리펩티드이다. 일부 예에서, 조작된 Arc 또는 endo-Gag 폴리펩티드는 제1 종으로부터의 Arc 또는 endo-Gag 폴리펩티드의 단편 및 제2 종의 Arc 또는 endo-Gag 폴리펩티드로부터의 적어도 추가의 단편을 포함한다. 일부 경우에서, 제1 Arc 또는 endo-Gag 폴리펩티드는 동물계, 식물계, 진균 또는 원생생물계의 계의 구성원으로부터 선택된다. 일부 경우에서, 제1 종은 포유동물, 설치류, 조류, 파충류, 어류, 척추동물, 진핵생물, 곤충, 진균, 또는 식물로부터 선택된다. 일부 경우에서, 제2 Arc 폴리펩티드는 제1 Arc 또는 endo-Gag 폴리펩티드와 동일하거나 상이한 동물계, 식물계, 진균 또는 원생생물계의 계의 구성원으로부터 선택된다. 일부 경우에서, 제2 종은 제1 종과 상이한 포유동물, 설치류, 조류, 파충류, 어류, 척추동물, 진핵생물, 곤충, 진균, 또는 식물로부터 선택된다.
일부 실시양태에서, 재조합 또는 조작된 Arc 폴리펩티드로서의 발현하기 위한 예시적인 포유동물 Arc 또는 endo-Gag 단백질은 호모 사피엔스(homo sapiens) 종으로부터 것이다. 재조합 또는 조작된 Arc 폴리펩티드로서의 발현을 위한 영장류 Arc 또는 endo-Gag 단백질의 추가의 예시적인 종은 고릴라(gorilla), 판고 아벨리(pongo abelii), 판 파니쿠스(pan paniscus), 마카카 네메스트리나(macaca nemestrina), 클로로세부스 사바에우스(chlorocebus sabaeus), 파피오 아누비스(papio anubis), 리노피테쿠스 록셀라나(rhinopithecus roxellana), 마카카 파시쿨라리스(macaca fascicularis), 노마스쿠스 류코게니스(nomascus leucogenys), 칼리트릭스 자쿠스(callithrix jacchus), 아오투스 난시마에(aotus nancymaae), 세부스 카푸시누스 이미타토르(cebus capucinus imitator), 사이미리 볼리비엔시스 볼리베엔시스(saimiri boliviensis boliviensis), 오톨레무르 가르네티이(otolemur garnettii), 마카카 물라타(macaca mulatta), 및 마카카 파시쿨라리스(macaca fascicularis)를 포함한다.
재조합 또는 조작된 Arc 또는 endo-Gag 폴리펩티드로서의 발현을 위한 설치류 Arc 또는 endo-Gag 단백질의 예시적인 종 목록은 푸코미스 다마렌시스(fukomys damarensis), 미크로세버스 무리누스(microcebus murinus), 헤테로세팔루스 글라베르(heterocephalus glaber), 프로피테쿠스 코퀘렐리(propithecus coquereli), 마르모타 마르모타 마르모타(marmota marmota marmota), 갈레오프테루스 바리에가투스(galeopterus variegatus), 카비아 포르셀루스(cavia porcellus), 디포도미스 오르디이(dipodomys ordii), 옥토돈 데구스(octodon degus), 카스토르 카나덴시스 나노스팔락스 갈릴리(castor canadensis nannospalax galili), 카를리토 시리차(carlito syrichta), 친칠라 라니게라(chinchilla lanigera), 무스 무스쿨루스(mus musculus), 익티도미스 트리데셈리네아투스(ictidomys tridecemlineatus), 라투스 노르베기쿠스(rattus norvegicus), 미크로투스 오크로가스테르(microtus ochrogaster), 오톨레무르 가르네티이(otolemur garnettii), 메리오네스 운구이쿨라투스(meriones unguiculatus), 크리세툴루스 그리세우스(cricetulus griseus), 라투스 노르베기쿠스(rattus norvegicus), 네오토마 레피다(neotoma lepida), 자쿨루스 자쿨루스(jaculus jaculus), 무스텔라 푸토리우스 푸로(mustela putorius furo), 메소크리세투스 아우라투스(mesocricetus auratus), 투파이아 치넨시스(tupaia chinensis), 크리세툴루스 그리세우스(cricetulus griseus), 크리소클로리스 아시아티카(chrysochloris asiatica), 엘레판툴루스 에드와르디이(elephantulus edwardii), 에리나세우스 에우로파에우스(erinaceus europaeus), 오초토나 프린셉스(ochotona princeps), 소렉스 아라네우스(sorex araneus), 모노델피스 도메스티카(monodelphis domestica), 에키노프스 텔파이리(echinops telfairi), 및 콘딜루라 크리스타타(condylura cristata)를 포함한다.
재조합 또는 조작된 Arc 또는 endo-Gag 폴리펩티드로서의 발현을 위한 Arc 또는 endo-Gag 단백질의 예시적인 종 목록은 불페스 불페스(vulpes vulpes), 카니스 루푸스 딘고(canis lupus dingo), 펠리스 카투스(felis catus), 판테라 파르두스(panthera pardus), 칼로리누스 우르시누스(callorhinus ursinus), 오도베누스 로스마루스 디베르겐스(odobenus rosmarus divergens), 에쿠우 아시누스(equus asinus), 수스 스크로파(sus scrofa), 마니스 자바이카(manis javanica), 세라토테리움 시뭄 시뭄(ceratotherium simum simum), 렙토니코테스 웨델리이(leptonychotes weddellii), 엔히드라 루트리스 케뇨니(enhydra lutris kenyoni), 리포테스 복실리페르(lipotes vexillifer), 보스 그룬니엔스(bos grunniens), 부발루스 부발리스(bubalus bubalis), 카멜루스 드로메다리우스(camelus dromedarius), 비쿠그나 파코스(vicugna pacos), 오르시누스 오르카(orcinus orca), 네오모나쿠스 샤우인슬란디(neomonachus schauinslandi), 투르시오프스 트룬카투스(tursiops truncatus), 보스 타우루스(bos taurus), 카프라 히르쿠스(capra hircus), 델피나프테루스 레우카스(delphinapterus leucas), 오비스 아리에스 무시몬(ovis aries musimon), 발라에노프테라 아쿠토로스트라타 스캄모니(balaenoptera acutorostrata scammoni), 네오포카에나 아시아에오리엔탈리스 아시아에오리엔탈리스(neophocaena asiaeorientalis asiaeorientalis), 미니오프테루스 나탈렌스시(miniopterus natalensis), 프테로푸스 알렉토(pteropus alecto), 피세테르 카토돈(physeter catodon), 록소돈타 아프리카나(loxodonta africana), 오릭테로푸스 아페르 아페르(orycteropus afer afer), 보스 무투스(bos mutus), 데스모두스 로툰두스(desmodus rotundus), 히포시데로스 아르미게르(hipposideros armiger), 아일루로포다 멜라노레우카(ailuropoda melanoleuca), 트리케쿠스 마나투스 라티로스트리스(trichechus manatus latirostris), 로우세투스 라티로스트리스(rousettus latirostris), 로우세투스 아에집티아쿠스(rousettus aegyptiacus), 에프테시쿠스 푸스쿠스(eptesicus fuscus), 리놀로푸스 시니쿠스(rhinolophus sinicus), 세르부스 엘라푸스 히펠라푸스(cervus elaphus hippelaphus), 오도코일레우스 비르기니아누스 텍사누스(odocoileus virginianus texanus), 판톨로프스 호드그소니이(pantholops hodgsonii), 카멜루스 박트리아누스(camelus bactrianus), 사르코필루스 하리시이(sarcophilus harrisii), 파스콜락토스 시네레우스(phascolarctos cinereus), 및 오르니토린쿠스 아나티누스(ornithorhynchus anatinus)를 포함한다.
재조합 또는 조작된 Arc 또는 endo-Gag 폴리펩티드로서의 발현을 위한 조류 Arc 또는 endo-Gag 단백질의 예시적인 종 목록은 갈루스 갈루스(gallus gallus), 코르부스 코르닉스(corvus cornix), 코르닉스(cornix), 파루스 메이저(parus major), 코르부스 브라키린코스(corvus brachyrhynchos), 드로마이우스 노바에홀란디아에(dromaius novaehollandiae), 및 아프테릭스 로위(apteryx rowi)를 포함한다.
재조합 또는 조작된 Arc 또는 endo-Gag 폴리펩티드로서의 발현을 위한 파충류 Arc 단백질의 예시적인 종 목록은 피톤 비비타투스(python bivittatus), 포고나 비티셉스(pogona vitticeps), 아놀리스 카롤리넨시스(anolis carolinensis), 프로토보트로프스 무크로스쿠아마투스(protobothrops mucrosquamatus), 앨리게이터 시넨시스(alligator sinensis), 크로코딜루스 포로수스(crocodylus porosus), 가비알리스 간게티쿠스(gavialis gangeticus), 앨리게이터 미시시피엔시스(alligator mississippiensis), 펠로디스쿠스 시넨시스(pelodiscus sinensis), 테라페네 멕시카나 트리운구이스(terrapene mexicana triunguis), 크리세미스 픽타 벨리이(chrysemys picta bellii), 첼로니아 미다스(chelonia mydas), 나노라나 파케리(nanorana parkeri), 제노푸스 트로피칼리스(xenopus tropicalis), 제노푸스 라에비스(xenopus laevis), 및 라티메리아 칼룸나에(latimeria chalumnae)를 포함한다.
재조합 또는 조작된 Arc 또는 endo-Gag 폴리펩티드로서의 발현을 위한 어류 Arc 단백질의 예시적인 종 목록은 온코린쿠스 미키스(oncorhynchus mykiss), 아칸토크로미스 폴리아칸투스(acanthochromis polyacanthus), 온코린쿠스 키수치(oncorhynchus kisutch), 카라시우스 아우라투스(carassius auratus), 및 아우스트로푼둘루스 림나에우스(austrofundulus limnaeus)를 포함한다.
재조합 또는 조작된 Arc 또는 endo-Gag 폴리펩티드로서의 발현을 위한 곤충 Arc 또는 endo-Gag 단백질의 예시적인 종 목록은 드로소필라 세라타(drosophila serrata), 드로소필라 비펙티나타(drosophila bipectinata), 솔레놉시스 인빅타(solenopsis invicta), 템노토락스 쿠르비스피노수스(temnothorax curvispinosus), 드로소필라 멜라노가스테르(drosophila melanogaster), 아그릴루스 플라니페니스(agrilus planipennis), 캄포노투스 플로리다누스(camponotus floridanus), 포고노미르멕스 바르바투스(pogonomyrmex barbatus), 닐라파르바타 루겐스(nilaparvata lugens), 봄빅스 모리(bombyx mori), 트리볼리움 카스타네움(tribolium castaneum), 및 렙티노타르사 데셈리네아타(leptinotarsa decemlineata)를 포함한다.
재조합 또는 조작된 Arc 또는 endo-Gag 폴리펩티드로서의 발현을 위한 식물 Arc 또는 endo-Gag 단백질의 예시적인 종 목록은 스피나시아 올레라세아(spinacia oleracea) 및 에리트란테 구타타(erythranthe guttata)를 포함한다.
재조합 또는 조작된 Arc 또는 endo-Gag 폴리펩티드로서의 발현을 위한 진균 단백질의 예시적인 종 목록은 사카로미세스 세레비시아에(Saccharomyces cerevisiae), 리조푸스 델레마르(rhizopus delemar), 푸사리움 옥시스포룸(fusarium oxysporum), 크립토코쿠스 네오포르만스(cryptococcus neoformans), 리조파구스 일레굴라리스(rhizophagus irregularis), 푸사리움 푸지쿠로이(fusarium fujikuroi), 칸디다 알비칸스(candida albicans), 트리코피톤 루브룸(trichophyton rubrum), 피레노포라 트리티시-레펜티스(pyrenophora tritici-repentis), 리조푸스 미크로스포루스(rhizopus microsporus), 리족토니아 솔라니(rhizoctonia solani), 아스페르길루스 플라부스(aspergillus flavus), 베르티실리움 달리아에(verticillium dahliae), 푸사리움 베르티실리오이데스(fusarium verticillioides), 아스페르길루스 니게르(aspergillus niger), 푸사리움 그라미네아룸(fusarium graminearum), 아스페르길루스 푸미가투스(aspergillus fumigatus), 지모셉토리아 트리티시(zymoseptoria tritici), 및 트리코데르마 하르지아눔(trichoderma harzianum)을 포함한다.
재조합 또는 조작된 Arc 또는 endo-Gag 폴리펩티드로서의 발현을 위한 원생생물 Arc 또는 endo-Gag 단백질의 예시적인 종 목록은 엔타모에바 히스톨리티카(entamoeba histolytica), 파울리넬라 미크로포라(paulinella micropora), 구일라르디아 테타(guillardia theta), 옥시르히스 마리나(oxyrrhis marina), 세미나비스 로부스타(seminavis robusta), 유글레나 론가(euglena longa), 나에글레리아 그루베리(naegleria gruberi), 및 트리코모나스 바기날리스(trichomonas vaginalis)를 포함한다.
일부 예에서, Arc 또는 endo-Gag는 캡시드 조립/형성(CA) 도메인, 카고 결합 도메인(예컨대, RNA 결합 도메인) 및 임의적으로 매트릭스(MA) 도메인, 역전사효소(RT) 도메인, 또는 이들의 조합을 포함한다. 일부 경우에서, CA 도메인은 N-로브 도메인 및 C-로브 도메인으로 더 나뉜다. 일부 경우에서, 카고 결합 도메인은 RNA 결합 도메인, DNA 결합 도메인, 단백질 결합 도메인, 펩티드 결합 도메인, 항체 결합 도메인, 소분자 결합 도메인, 또는 펩티드모방체/뉴클레오티드모방체 결합 도메인을 포함한다. 예시적인 카고 결합 도메인은 GPCR, 항체 또는 이의 결합 단편, 지단백질, 인테그린, 티로신 키나제, DNA 결합 단백질, RNA 결합 단백질, 뉴클레아제, 리가제, 프로테아제, 인테그라제, 이소머라제, 포스파타제, GTPase, 아로마타제, 에스테라제, 어댑터 단백질, G-단백질, GEF, 사이토카인, 인터류킨, 인터류킨 수용체, 인터페론, 인터페론 수용체, 카스파제, 전사 인자, 신경영양 인자 및 그들의 수용체, 성장 인자 및 그들의 수용체, 신호 인식 입자 및 수용체 성분, 세포외 매트릭스 단백질, 막의 통합 성분, 리보솜 단백질, 번역 신장 인자, 번역 개시 인자, GPI 고정된 단백질, 조직 인자, 디스트로핀, 우트로핀, 디스트로브레빈, 이들의 임의의 융합, 조합, 서브유닛, 유도체 또는 도메인으로부터의 도메인을 포함하지만 이에 제한되지 않는다.
일부 실시양태에서, 캡시드 형성 또는 핵산 결합에 관여하지 않는 하나 이상의 비-필수 영역은 Arc 또는 endo-Gag 폴리펩티드를 생성하기 위해 Arc 또는 endo-Gag 단백질로부터 제거된다. 이러한 경우에서, 하나 이상의 비-필수 영역, 예컨대 N-말단 영역(예컨대, 최대 10개 아미노산, 최대 20개 아미노산, 최대 30개 아미노산, 또는 최대 50개 아미노산), C-말단 영역(예컨대, 최대 10개 아미노산, 최대 20개 아미노산, 최대 30개 아미노산, 또는 최대 50개 아미노산), RT 도메인, MA 도메인, 또는 이들의 조합이 Arc 또는 endo-Gag 폴리펩티드를 생성하기 위해 Arc 또는 endo-Gag 단백질로부터 삭제된다. 일부 경우에서, 캡시드 조립/형성 및 카고 결합과 관련된 필수 영역만 Arc 또는 endo-Gag 폴리펩티드에 잔류한다. 추가의 경우에서, 캡시드 조립/형성에 관여하는 필수 영역(예컨대, N-로브 및/또는 C-로브)만 Arc 폴리펩티드에 잔류한다.
특정 실시양태에서, RT 도메인, MA 도메인, 및/또는 내인성 RNA 결합 도메인은 다른 카고 결합 도메인으로 대체된다: 예컨대, DNA 결합 도메인, 단백질 결합 도메인, 펩티드 결합 도메인, 항체 결합 도메인, 소분자 결합 도메인, 펩티드모방체 결합 도메인, 또는 뉴클레오티드모방체 결합 도메인으로 대체된다. 일부 실시양태에서, Arc 또는 endo-Gag 폴리펩티드는 캡시드 형성, 핵산 결합, 또는 전달에 관여하는 도메인의 말단절단 또는 변형을 포함한다.
일부 실시양태에서, Arc 또는 endo-Gag 폴리펩티드는 MA 도메인, CA N-로브, CA C-로브, 카고 결합 도메인, 및 RT 도메인을 포함한다. 일부 예에서, Arc 폴리펩티드는 N-말단에서 C-말단으로 MA 도메인, CA N-로브, CA C-로브, RT 도메인 및 카고 결합 도메인을 포함한다. 일부 예에서, Arc 또는 endo-Gag 폴리펩티드는 N-말단에서 C-말단으로 MA 도메인, RT 도메인, 카고 결합 도메인, CA N-로브 및 CA C-로브를 포함한다. 일부 예에서, Arc 또는 endo-Gag 폴리펩티드는 N-말단에서 C-말단으로 카고 결합 도메인, MA 도메인, RT 도메인, CA N-로브 및 CA C-로브를 포함한다. 일부 예에서, 도메인은 캡시드 조립 및 카고 결합을 방해하지 않는 순서로 배열된다. 일부 예에서, 각각의 도메인은 각각의 2개의 플랭킹 도메인에 직접 또는 간접적으로 융합된다.
일부 실시양태에서, Arc 또는 endo-Gag 폴리펩티드는 MA 도메인, CA N-로브, CA C-로브, 및 카고 결합 도메인을 포함한다. 일부 예에서, Arc 또는 endo-Gag 폴리펩티드는 N-말단에서 C-말단으로 MA 도메인, CA N-로브, CA C-로브, 및 카고 결합 도메인을 포함한다. 일부 경우에서, Arc 폴리펩티드는 N-말단에서 C-말단으로 MA 도메인, 카고 결합 도메인, CA N-로브 및 CA C-로브 도메인을 포함한다. 일부 예에서, Arc 또는 endo-Gag 폴리펩티드는 N-말단에서 C-말단으로 카고 결합 도메인, MA 도메인, CA N-로브, 및 CA C-로브를 포함한다. 일부 예에서, 도메인은 캡시드 조립 및 카고 결합을 방해하지 않는 순서로 배열된다. 일부 예에서, 각각의 도메인은 각각의 2개의 플랭킹 도메인에 직접 또는 간접적으로 융합된다.
일부 실시양태에서, Arc 또는 endo-Gag 폴리펩티드는 CA N-로브, CA C-로브 및 카고 결합 도메인을 포함한다. 일부 예에서, Arc 또는 endo-Gag 폴리펩티드는 N-말단에서 C-말단으로 CA N-로브, CA C-로브 및 카고 결합 도메인을 포함한다. 일부 예에서, Arc 또는 endo-Gag 폴리펩티드는 N-말단에서 C-말단으로 카고 결합 도메인, CA N-로브 및 CA C-로브를 포함한다. 일부 예에서, 도메인은 캡시드 조립 및 카고 결합을 방해하지 않는 순서로 배열된다. 일부 예에서, 각각의 도메인은 각각의 2개의 플랭킹 도메인에 직접 또는 간접적으로 융합된다.
일부 실시양태에서, Arc 또는 endo-Gag 폴리펩티드는 CA N-로브 및 카고 결합 도메인을 포함한다. 일부 예에서, Arc 또는 endo-Gag 폴리펩티드는 N-말단에서 C-말단으로 CA N-로브 및 카고 결합 도메인을 포함한다. 일부 예에서, Arc 또는 endo-Gag 폴리펩티드는 N-말단에서 C-말단으로 카고 결합 도메인 및 CA N-로브를 포함한다. 일부 예에서, 도메인은 캡시드 조립 및 카고 결합을 방해하지 않는 순서로 배열된다. 일부 경우에서, 2개의 도메인은 직접 또는 간접적으로 서로 융합된다.
일부 실시양태에서, Arc 또는 endo-Gag 폴리펩티드는 조작된 Arc 폴리펩티드를 생성하기 위해 하나 이상의 추가의 종으로부터의 카고 결합 도메인, CA 도메인, MA 도메인, 또는 RT 도메인을 포함하도록 조작된다. 예컨대, 조작된 Arc 또는 endo-Gag 폴리펩티드는 제1 종으로부터의 카고 결합 도메인, CA 도메인, MA 도메인, 또는 RT 도메인 및 제2 종으로부터의 카고 결합 도메인, CA 도메인, MA 도메인, 또는 RT 도메인을 포함한다. 일부 경우에서, 제1 종은 진핵생물, 척추동물, 인간, 포유동물, 설치류, 조류, 파충류, 어류, 곤충, 진균, 또는 식물로부터 선택된다. 일부 경우에서, 제2 종은 제1 종과 상이한 진핵생물, 척추동물, 인간, 포유동물, 설치류, 조류, 파충류, 어류, 곤충, 진균, 또는 식물로부터 선택된다.
일부 예에서, 조작된 또는 endo-Gag Arc 폴리펩티드는 제1 종으로부터의 카고 결합 도메인 및 제2 종으로부터의 CA 도메인(예컨대, CA N-로브 및 임의적으로 CA C-로브)을 포함한다. 조작된 Arc 또는 endo-Gag 폴리펩티드는 임의적으로 제1 종 또는 제2 종으로부터의 MA 도메인 및 RT 도메인을 포함한다. 일부 경우에서, 제1 종은 진핵생물, 척추동물, 인간, 포유동물, 설치류, 조류, 파충류, 어류, 곤충, 진균, 또는 식물로부터 선택된다. 일부 경우에서, 제2 종은 제1 종과 상이한 진핵생물, 척추동물, 인간, 포유동물, 설치류, 조류, 파충류, 어류, 곤충, 진균, 또는 식물로부터 선택된다.
일부 예에서, 조작된 Arc 또는 endo-Gag 폴리펩티드는 카고 결합 도메인, 제1 CA 도메인, 제2 CA 도메인, 및 임의적으로 MA 도메인 및/또는 RT 도메인을 포함한다. 일부 경우에서, 카고 결합 도메인, 제1 CA 도메인, 및 임의적으로 MA 도메인 및/또는 RT 도메인은 제1 종으로부터의 것이고 제2 CA 도메인은 제2 종으로부터의 것이다. 일부 경우에서, 제1 CA 도메인은 제1 종으로부터의 것이고 카고 결합 도메인, 제2 CA 도메인, 및 임의적으로 MA 도메인 및/또는 RT 도메인은 제2 종으로부터의 것이다. 일부 예에서, 도메인은 캡시드 조립 및 카고 결합을 방해하지 않는 순서로 배열된다. 일부 예에서, 각각의 도메인은 각각의 2개의 인접한 도메인에 직접 또는 간접적으로 융합된다.
일부 예에서, 조작된 Arc 또는 endo-Gag 폴리펩티드는 카고 결합 도메인, 제1 CA 도메인 및 제2 CA 도메인을 포함한다. 일부 경우에서, 카고 결합 도메인 및 제1 CA 도메인은 제1 종으로부터의 것이고 제2 CA 도메인은 제2 종으로부터의 것이다. 일부 경우에서, 제1 CA 도메인은 제1 종으로부터의 것이고 카고 결합 도메인 및 제2 CA 도메인은 제2 종으로부터의 것이다. 이러한 경우에서, 조작된 Arc 또는 endo-Gag 폴리펩티드는 N-말단에서 C-말단으로 카고 결합 도메인, 제1 CA 도메인 및 제2 CA 도메인을 포함한다. 이러한 경우에서, 조작된 Arc 또는 endo-Gag 폴리펩티드는 N-말단에서 C-말단으로 제1 CA 도메인, 카고 결합 도메인, 및 제2 CA 도메인을 포함한다. 이러한 경우에서, 조작된 Arc 또는 endo-Gag 폴리펩티드는 N-말단에서 C-말단으로 제1 CA 도메인, 제2 CA 도메인, 및 카고 결합 도메인을 포함한다. 일부 예에서, 도메인은 캡시드 조립 및 카고 결합을 방해하지 않는 순서로 배열된다. 일부 예에서, 각각의 도메인은 각각의 2개의 플랭킹 도메인에 직접 또는 간접적으로 융합된다.
일부 예에서, 조작된 Arc 또는 endo-Gag 폴리펩티드는 제2 폴리펩티드를 추가로 포함한다. 일부 예에서, 제2 폴리펩티드는 링커를 통해 카고 결합 도메인, 제1 CA 도메인, 제2 CA 도메인, 존재하는 경우 MA 도메인, 또는 존재하는 경우 RT 도메인 중 하나 이상에 직접 또는 간접적으로 융합된다. 일부 경우에서, 제2 폴리펩티드는 단백질(예컨대, 인간 단백질), 항체 또는 이의 결합 단편, 바이러스 단백질, Gag-유사 단백질(예컨대, 인간 Gag-유사 단백질), 또는 관심 표적 수용체에 결합하도록 설계된 드 노보 조작된 단백질을 포함한다. 일부 예에서, 항체 또는 이의 결합 단편은 인간화 항체 또는 이의 결합 단편, 뮤린 항체 또는 이의 결합 단편, 키메라 항체 또는 이의 결합 단편, 모노클로날 항체 또는 이의 결합 단편, 다중특이적 항체 또는 이의 단편 결합, 이중특이적 항체 또는 이의 결합 단편, 1가 Fab', 2가 Fab2, F(ab)'3 단편, 단일 쇄 가변 단편(scFv), 비스-scFv, (scFv)2, 디아바디, 미니바디, 나노바디, 트리아바디, 테트라바디, 디술파이드 안정화된 Fv 단백질(dsFv), 단일 도메인 항체(sdAb), Ig NAR, 낙타류 항체 또는 이의 결합 단편, 또는 이의 화학적으로 변형된 유도체를 포함한다. 일부 예에서, 제2 폴리펩티드는 조작된 Arc 폴리펩티드에 의해 형성된 캡시드를 관심 표적 부위에 전달하는 것을 안내한다.
일부 실시양태에서, (예컨대, Arc 폴리펩티드 또는 endo-Gag 폴리펩티드를 코딩하는) 본 개시 내용의 핵산 서열 또는 아미노산 서열은 본원에 제공된 아미노산 서열과 적어도 70% 상동성, 적어도 71% 상동성, 적어도 72% 상동성, 적어도 73% 상동성, 적어도 74% 상동성, 적어도 75% 상동성, 적어도 76% 상동성, 적어도 77% 상동성, 적어도 78% 상동성, 적어도 79% 상동성, 적어도 80% 상동성, 적어도 81% 상동성, 적어도 82% 상동성, 적어도 83% 상동성, 적어도 84% 상동성, 적어도 85% 상동성, 적어도 86% 상동성, 적어도 87% 상동성, 적어도 88% 상동성, 적어도 89% 상동성, 적어도 90% 상동성, 적어도 91% 상동성, 적어도 92% 상동성, 적어도 93% 상동성, 적어도 94% 상동성, 적어도 95% 상동성, 적어도 96% 상동성, 적어도 97% 상동성, 적어도 98% 상동성, 적어도 99% 상동성, 적어도 99.1% 상동성, 적어도 99.2% 상동성, 적어도 99.3% 상동성, 적어도 99.4% 상동성, 적어도 99.5% 상동성, 적어도 99.6% 상동성, 적어도 99.7% 상동성, 적어도 99.8% 상동성, 적어도 99.9% 또는 적어도 99.99% 상동성을 갖는다. NCBI BLAST, 클루스탈(Clustal) W, MAFFT, 클루스탈 오메가(Clustal Omega), AlignMe, 프랄린(Praline) 또는 또 다른 적절한 방법 또는 알고리즘과 같은 2개 이상의 서열 간의 상동성을 결정하기 위해 다양한 방법 및 소프트웨어 프로그램이 사용된다.
특정 실시양태에서, Arc 폴리펩티드는 서열번호 1의 아미노산 서열 또는 서열번호 1과 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 인간 폴리펩티드이다.
특정 실시양태에서, Arc 폴리펩티드는 서열번호 2의 아미노산 서열 또는 서열번호 2와 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 범고래 폴리펩티드이다.
특정 실시양태에서, Arc 폴리펩티드는 서열번호 3의 아미노산 서열 또는 서열번호 3과 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 흰꼬리 사슴 폴리펩티드이다.
특정 실시양태에서, Arc 폴리펩티드는 서열번호 4의 아미노산 서열 또는 서열번호 4와 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 오리너구리 폴리펩티드이다.
특정 실시양태에서, Arc 폴리펩티드는 서열번호 5의 아미노산 서열 또는 서열번호 5와 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 거위 폴리펩티드이다.
특정 실시양태에서, Arc 폴리펩티드는 서열번호 6의 아미노산 서열 또는 서열번호 6과 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 달마티안 펠리칸(Dalmatian pelican) 폴리펩티드이다.
특정 실시양태에서, Arc 폴리펩티드는 서열번호 7의 아미노산 서열 또는 서열번호 7과 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 흰꼬리 수리 폴리펩티드이다.
특정 실시양태에서, Arc 폴리펩티드는 서열번호 8의 아미노산 서열 또는 서열번호 8과 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 킹 코브라 폴리펩티드이다.
특정 실시양태에서, Arc 폴리펩티드는 서열번호 9의 아미노산 서열 또는 서열번호 9와 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 조기어류(Ray finned fish) 폴리펩티드이다.
특정 실시양태에서, Arc 폴리펩티드는 서열번호 10의 아미노산 서열 또는 서열번호 10과 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 향유 고래 폴리펩티드이다.
특정 실시양태에서, Arc 폴리펩티드는 서열번호 11의 아미노산 서열 또는 서열번호 11과 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 칠면조 폴리펩티드이다.
특정 실시양태에서, Arc 폴리펩티드는 서열번호 12의 아미노산 서열 또는 서열번호 12와 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 중앙 턱수염 도마뱀(central bearded dragon) 폴리펩티드이다.
특정 실시양태에서, Arc 폴리펩티드는 서열번호 13의 아미노산 서열 또는 서열번호 13과 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 양쯔강 악어(chinese alligator) 폴리펩티드이다.
특정 실시양태에서, Arc 폴리펩티드는 서열번호 14의 아미노산 서열 또는 서열번호 14와 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 미국 악어(American alligator) 폴리펩티드이다.
특정 실시양태에서, Arc 폴리펩티드는 서열번호 15의 아미노산 서열 또는 서열번호 15와 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 일본 게코(Japanese gekko) 폴리펩티드이다.
특정 실시양태에서, endo-Gag 폴리펩티드는 서열번호 16의 아미노산 서열 또는 서열번호 16과 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 인간 PNMA3 폴리펩티드이다.
특정 실시양태에서, endo-Gag 폴리펩티드는 서열번호 17의 아미노산 서열 또는 서열번호 17과 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 인간 PNMA5 폴리펩티드이다.
특정 실시양태에서, endo-Gag 폴리펩티드는 서열번호 18의 아미노산 서열 또는 서열번호 18과 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 인간 PNMA6A 폴리펩티드이다.
특정 실시양태에서, endo-Gag 폴리펩티드는 서열번호 19의 아미노산 서열 또는 서열번호 19와 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 인간 PNMA6B 폴리펩티드이다.
특정 실시양태에서, endo-Gag 폴리펩티드는 서열번호 20의 아미노산 서열 또는 서열번호 20과 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 인간 RTL3 폴리펩티드이다.
특정 실시양태에서, endo-Gag 폴리펩티드는 서열번호 21의 아미노산 서열 또는 서열번호 21과 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 인간 RTL6 폴리펩티드이다.
특정 실시양태에서, endo-Gag 폴리펩티드는 서열번호 22의 아미노산 서열 또는 서열번호 22와 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 인간 RTL8A 폴리펩티드이다.
특정 실시양태에서, endo-Gag 폴리펩티드는 서열번호 23의 아미노산 서열 또는 서열번호 23과 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 인간 RTL8B 폴리펩티드이다.
특정 실시양태에서, endo-Gag 폴리펩티드는 서열번호 24의 아미노산 서열 또는 서열번호 24와 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 인간 BOP 폴리펩티드이다.
특정 실시양태에서, endo-Gag 폴리펩티드는 서열번호 25의 아미노산 서열 또는 서열번호 25와 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 인간 LDOC1 폴리펩티드이다.
특정 실시양태에서, endo-Gag 폴리펩티드는 서열번호 26의 아미노산 서열 또는 서열번호 26과 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 인간 ZNF18 폴리펩티드이다.
특정 실시양태에서, endo-Gag 폴리펩티드는 서열번호 27의 아미노산 서열 또는 서열번호 27과 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 인간 MOAP1 폴리펩티드이다.
특정 실시양태에서, endo-Gag 폴리펩티드는 서열번호 28의 아미노산 서열 또는 서열번호 28과 적어도 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99% 동일성을 갖는 서열을 갖는 인간 PEG10 폴리펩티드이다.
일부 경우에서, 재조합 Arc 또는 endo-Gag 폴리펩티드는 도 1에 예시되는 Arc 폴리펩티드이다.
일부 경우에서, 조작된 Arc 또는 endo-Gag 폴리펩티드는 도 2에 예시되는 조작된 Arc 폴리펩티드이다.
링커
특정 실시양태에서, 본 개시 내용의 폴리펩티드는 링커를 포함한다. 일부 실시양태에서, 링커는 펩티드 링커이다. 일부 예에서, 링커는 경성 링커이다. 다른 예에서, 링커는 연성 링커이다. 일부 경우에서, 링커는 비-절단 가능한 링커이다. 다른 경우에서, 링커는 절단 가능한 링커이다. 추가의 경우에서, 링커는 선형 구조 또는 비-선형 구조(예컨대, 사이클릭 구조)를 포함한다.
특정 실시양태에서, 비-절단 가능한 링커는 다양한 길이의 짧은 펩티드를 포함한다. 예시적인 비-절단 가능한 링커는 (EAAAK)n(서열번호 70) 또는 (EAAAR)n(서열번호 71)을 포함하며, 여기서 n은 1 내지 5이고, 글루탐산-프롤린 잔기 또는 리신-프롤린 반복의 최대 30개 잔기이다. 일부 실시양태에서, 비-절단 가능한 링커는 (GGGGS)n(서열번호 72) 또는 (GGGS)n(서열번호 73)을 포함하며, 여기서 n은 1 내지 10이고; KESGSVSSEQLAQFRSLD(서열번호 74); 또는 EGKSSGSGSESKST(서열번호 75)이다. 일부 실시양태에서, 비-절단 가능한 링커는 폴리-Gly/Ala 중합체를 포함한다.
특정 실시양태에서, 링커는 절단 가능한 링커, 예컨대 세포외 절단 가능한 링커 또는 세포내 절단 가능한 링커이다. 일부 예에서, 링커는 특정 조건의 존재 또는 특정 환경(예컨대, 생리적 조건 하)에서의 절단을 위해 설계된다. 예컨대, 특정 효소에 의하는 것과 같은 특정 조건에 의한 절단을 위한 링커의 설계는 특정 위치에 대한 세포 흡수의 표적화를 가능하게 한다.
일부 실시양태에서, 링커는 pH 민감성 링커이다. 한 예에서, 링커는 염기성 pH 조건 하에서 절단된다. 다른 예에서, 링커는 산성 pH 조건 하에서 절단된다.
일부 실시양태에서, 링커는 트롬빈, 메탈로프로테아제, 푸린, 카텝신 B, 괴사 효소(예컨대, 칼파인) 등을 포함하지만 이에 제한되지 않는 세린 프로테아제와 같은 내인성 효소(예컨대, 프로테아제)에 의해 생체내에서 절단된다. 예시적인 절단 가능한 링커는 GGAANLVRGG(서열번호 76); SGRIGFLRTA(서열번호 77); SGRSA(서열번호 78); GFLG(서열번호 79); ALAL(서열번호 80); FK; PIC(Et)F-F(서열번호 81)(여기서 C(Et)는 S-에틸시스테인을 나타냄); PR(S/T)(L/I)(S/T)(서열번호 82); DEVD(서열번호 83); GWEHDG열번호 84); RPLALWRS(서열번호 85); 또는 이들의 조합을 포함하지만 이에 제한되지 않는다.
캡시드
일부 실시양태에서, 캡시드가 본원에 개시된다. 일부 예에서, 캡시드는 Arc 폴리펩티드 및/또는 endo-Gag 폴리펩티드, 예컨대 코피아 단백질, ASPRV1 단백질, SCAN 도메인 패밀리로부터의 단백질, 부신생물성 Ma 항원 패밀리에 의해 코딩되는 단백질, 레트로트랜스포존 Gag-유사 패밀리로부터 선택되는 단백질 또는 단백질의 조합, 또는 이들의 조합을 포함한다. 예시적인 endo-Gag 폴리펩티드는 BOP, LDOC1, MOAP1, PEG10, PNMA3, PNMA5, PNMA6A, PNMA6B, RTL3, RTL6, RTL8A, RTL8B, 및 ZNF18이다. 일부 예에서, Arc 폴리펩티드, 코피아 단백질, ASPRV1 단백질, SCAN 도메인 패밀리로부터의 단백질, 부신생물성 Ma 항원 패밀리에 의해 코딩되는 단백질, 및 레트로트랜스포존 Gag-유사 패밀리로부터 선택되는 단백질 또는 단백질의 조합은 각각 독립적으로 전장 폴리펩티드이다. 다른 예에서, Arc 폴리펩티드, 코피아 단백질, ASPRV1 단백질, SCAN 도메인 패밀리로부터의 단백질, 부신생물성 Ma 항원 패밀리에 의해 코딩되는 단백질, 및 레트로트랜스포존 Gag-유사 패밀리로부터 선택되는 단백질 또는 단백질의 조합은 각각 독립적으로, 예컨대 캡시드의 서브유닛을 형성할 수 있는, 이의 기능적 단편이다.
Arc 기반 캡시드 및 endo-Gag 기반 캡시드
일부 실시양태에서, 캡시드는 Arc 기반 캡시드를 포함한다. 일부 실시양태에서, 캡시드는 endo-Gag 기반 캡시드를 포함한다. 일부 예에서, Arc 기반 및/또는 endo-Gag 캡시드는 상술된 복수의 재조합 Arc 폴리펩티드 및/또는 endo-Gag 폴리펩티드, 상술된 복수의 조작된 Arc 폴리펩티드 및/또는 endo-Gag 폴리펩티드, 또는 이들의 조합을 포함한다. 일부 경우에서, Arc 기반 캡시드는 복수의 재조합 Arc 폴리펩티드를 포함한다. 다른 경우에서, Arc 기반 캡시드는 복수의 조작된 Arc 폴리펩티드를 포함한다. 일부 경우에서, endo-Gag 기반 캡시드는 복수의 재조합 endo-Gag 폴리펩티드를 포함한다. 다른 경우에서, endo-Gag 기반 캡시드는 복수의 조작된 endo-Gag 폴리펩티드를 포함한다.
일부 실시양태에서, Arc 기반 또는 endo-Gag 기반 캡시드는 제1 종으로부터의 제1 복수의 Arc 및/또는 endo-Gag 폴리펩티드 및 적어도 제2 종으로부터의 제2 복수의 Arc 및/또는 endo-Gag 폴리펩티드를 포함한다. 일부 경우에서, 제1 종은 진핵생물, 척추동물, 인간, 포유동물, 설치류, 조류, 파충류, 어류, 곤충, 진균, 또는 식물로부터 선택된다. 일부 경우에서, 제2 종은 제1 종과 상이한 진핵생물, 척추동물, 인간, 포유동물, 설치류, 조류, 파충류, 어류, 곤충, 진균, 또는 식물로부터 선택된다.
일부 예에서, 제1 복수의 Arc 또는 endo-Gag 폴리펩티드 대 제2 복수의 Arc 또는 endo-Gag 폴리펩티드의 비는 1:1, 2:1, 3:1, 4:1, 5:1, 6:1, 7:1, 8:1, 9:1, 10:1, 20:1, 50:1, 또는 100:1이다. 일부 경우에서, 제1 복수의 Arc 또는 endo-Gag 폴리펩티드 대 제2 복수의 Arc 또는 endo-Gag 폴리펩티드의 비는 1:1이다. 일부 경우에서, 제1 복수의 Arc 또는 endo-Gag 폴리펩티드 대 제2 복수의 Arc 또는 endo-Gag 폴리펩티드의 비는 2:1이다. 일부 경우에서, 제1 복수의 Arc 또는 endo-Gag 폴리펩티드 대 제2 복수의 Arc 또는 endo-Gag 폴리펩티드의 비는 4:1이다. 일부 경우에서, 복수의 제1 Arc 또는 endo-Gag 폴리펩티드 대 제2 복수의 Arc 또는 endo-Gag 폴리펩티드의 비는 5:1이다. 일부 경우에서, 제1 복수의 Arc 또는 endo-Gag 폴리펩티드 대 제2 복수의 Arc 또는 endo-Gag 폴리펩티드의 비는 8:1이다. 일부 경우에서, 제1 복수의 Arc 또는 endo-Gag 폴리펩티드 대 복수의 제2 Arc 폴리펩티드의 비는 10:1이다. 일부 경우에서, 제1 복수의 Arc 또는 endo-Gag 폴리펩티드 대 제2 복수의 Arc 또는 endo-Gag 폴리펩티드의 비는 20:1이다. 일부 경우에서, 제1 복수의 Arc 또는 endo-Gag 폴리펩티드 대 제2 복수의 Arc 또는 endo-Gag 폴리펩티드의 비는 50:1이다. 일부 경우에서, 제1 복수의 Arc 또는 endo-Gag 폴리펩티드 대 제2 복수의 Arc 또는 endo-Gag 폴리펩티드의 비는 100:1이다. 일부 예에서, 비는 몰 농도의 비교이다. 일부 예에서, 비는 캡시드 형성 서브유닛의 수의 비교이다(예컨대, 각각의 또는 조작된 Arc 폴리펩티드는 캡시드 서브유닛을 형성함).
일부 예에서, 제1 복수의 Arc 또는 endo-Gag 폴리펩티드 대 제2 복수의 Arc 또는 endo-Gag 폴리펩티드의 비는 1:2, 1:3, 1:4, 1 : 5, 1:6, 1:7, 1:8, 1:9, 1:10, 1:20, 또는 1:50이다. 일부 경우에서, 제1 복수의 Arc 또는 endo-Gag 폴리펩티드 대 제2 복수의 Arc 또는 endo-Gag 폴리펩티드의 비는 1:2이다. 일부 경우에서, 제1 복수의 Arc 또는 endo-Gag 폴리펩티드 대 제2 복수의 Arc 또는 endo-Gag 폴리펩티드의 비는 1 : 5이다. 일부 경우에서, 제1 복수의 Arc 또는 endo-Gag 폴리펩티드 대 제2 복수의 Arc 또는 endo-Gag 폴리펩티드의 비는 1:8이다. 일부 경우에서, 제1 복수의 Arc 또는 endo-Gag 폴리펩티드 대 제2 복수의 Arc 또는 endo-Gag 폴리펩티드의 비는 1:10이다. 일부 경우에서, 제1 복수의 Arc 또는 endo-Gag 폴리펩티드 대 제2 복수의 Arc 또는 endo-Gag 폴리펩티드의 비는 1:20이다. 일부 경우에서, 제1 복수의 Arc 또는 endo-Gag 폴리펩티드 대 제2 복수의 Arc 또는 endo-Gag 폴리펩티드의 비는 1:50이다. 일부 예에서, 비는 몰 농도의 비교이다. 일부 예에서, 비는 캡시드 형성 서브유닛의 수의 비교이다(예컨대, 각각의 재조합 또는 조작된 Arc 또는 endo-Gag 폴리펩티드는 캡시드 서브유닛을 형성함).
일부 실시양태에서, Arc 기반 캡시드 또는 endo-Gag 기반 캡시드는 복수의 재조합 또는 조작된 Arc 폴리펩티드 및 복수의 비-Arc 단백질을 포함한다. 비-Arc 단백질의 예시적인 종은 코피아, ASPRV1, SCAN 도메인 패밀리로부터 선택되는 단백질 또는 단백질의 조합, 부신생물성 Ma 항원 패밀리로부터 선택되는 단백질 또는 단백질의 조합, 및 레트로트랜스포존 Gag-유사 패밀리로부터 선택되는 단백질 또는 단백질의 조합을 포함하지만 이에 제한되지 않는다. 비-Arc 단백질의 예시적인 종은 BOP, LDOC1, MOAP1, PEG10, PNMA3, PNMA5, PNMA6A, PNMA6B, RTL3, RTL6, RTL8A, RTL8B, 및 ZNF18을 포함한다.
일부 예에서, 복수의 재조합 또는 조작된 Arc 폴리펩티드 대 복수의 비-Arc 단백질의 비는 1:1, 2:1, 3:1, 4:1, 5:1, 6:1이다. 7:1, 8:1, 9:1, 10:1, 20:1, 50:1 또는 100:1이다. 일부 경우에서, 복수의 재조합 또는 조작된 Arc 폴리펩티드 대 복수의 비-Arc 단백질의 비는 1:1이다. 일부 경우에서, 복수의 재조합 또는 조작된 Arc 폴리펩티드 대 복수의 비-Arc 단백질의 비는 2:1이다. 일부 경우에서, 복수의 재조합 또는 조작된 Arc 폴리펩티드 대 복수의 비-Arc 단백질의 비는 4:1이다. 일부 경우에서, 복수의 재조합 또는 조작된 Arc 폴리펩티드 대 복수의 비-Arc 단백질의 비는 5:1이다. 일부 경우에서, 복수의 재조합 또는 조작된 Arc 폴리펩티드 대 복수의 비-Arc 단백질의 비는 8:1이다. 일부 경우에서, 복수의 재조합 또는 조작된 Arc 폴리펩티드 대 복수의 비-Arc 단백질의 비는 10:1이다. 일부 경우에서, 복수의 재조합 또는 조작된 Arc 폴리펩티드 대 복수의 비-Arc 단백질의 비는 20:1이다. 일부 경우에서, 복수의 재조합 또는 조작된 Arc 폴리펩티드 대 복수의 비-Arc 단백질의 비는 50:1이다. 일부 경우에서, 복수의 재조합 또는 조작된 Arc 폴리펩티드 대 복수의 비-Arc 단백질의 비는 100:1이다. 일부 예에서, 비는 몰 농도의 비교이다. 일부 예에서, 비는 캡시드 형성 서브유닛의 수의 비교이다(예컨대, 각각의 재조합 또는 조작된 Arc 폴리펩티드는 캡시드 서브유닛을 형성함).
일부 예에서, 복수의 재조합 또는 조작된 Arc 폴리펩티드 대 복수의 비-Arc 단백질의 비는 1:2, 1:3, 1:4, 1:5, 1:6, 1:7, 1:8, 1:9, 1:10, 1:20, 또는 1:50이다. 일부 경우에서, 복수의 재조합 또는 조작된 Arc 폴리펩티드 대 복수의 비-Arc 단백질의 비는 1:2이다. 일부 경우에서, 복수의 재조합 또는 조작된 Arc 폴리펩티드 대 복수의 비-Arc 단백질의 비는 1:5이다. 일부 경우에서, 복수의 재조합 또는 조작된 Arc 폴리펩티드 대 복수의 비-Arc 단백질의 비는 1:8이다. 일부 경우에서, 복수의 재조합 또는 조작된 Arc 폴리펩티드 대 복수의 비-Arc 단백질의 비는 1:10이다. 일부 경우에서, 복수의 재조합 또는 조작된 Arc 폴리펩티드 대 복수의 비-Arc 단백질의 비는 1:20이다. 일부 경우에서, 복수의 재조합 또는 조작된 Arc 폴리펩티드 대 복수의 비-Arc 단백질의 비는 1:50이다. 일부 예에서, 비는 몰 농도의 비교이다. 일부 예에서, 비는 캡시드 형성 서브유닛의 수의 비교이다(예컨대, 각각의 재조합 또는 조작된 Arc 폴리펩티드는 캡시드 서브유닛을 형성함).
일부 실시양태에서, 캡시드는 적어도 1 nm의 직경을 갖는다. 일부 예에서, 캡시드는 적어도 2 nm, 3 nm, 4 nm, 5 nm, 10 nm, 15 nm, 20 nm, 25 nm, 30 nm, 40 nm, 50 nm, 60 nm, 70 nm, 80 nm, 90 nm, 100 nm, 150 nm, 200 nm, 300 nm, 400 nm, 500 nm, 600 nm, 또는 그 초과의 직경을 갖는다. 일부 예에서, 캡시드는 적어도 5 nm, 또는 그 초과의 직경을 갖는다. 일부 예에서, 캡시드는 적어도 10 nm, 또는 그 초과의 직경을 갖는다. 일부 경우에서, 캡시드는 적어도 20 nm, 또는 그 초과의 직경을 갖는다. 일부 경우에서, 캡시드는 적어도 30 nm, 또는 그 초과의 직경을 갖는다. 일부 경우에서, 캡시드는 적어도 40 nm, 또는 그 초과의 직경을 갖는다. 일부 경우에서, 캡시드는 적어도 50 nm, 또는 그 초과의 직경을 갖는다. 일부 경우에서, 캡시드는 적어도 80 nm, 또는 그 초과의 직경을 갖는다. 일부 경우에서, 캡시드는 적어도 100 nm, 또는 그 초과의 직경을 갖는다. 일부 경우에서, 캡시드는 적어도 200 nm, 또는 그 초과의 직경을 갖는다. 일부 경우에서, 캡시드는 적어도 300 nm, 또는 그 초과의 직경을 갖는다. 일부 경우에서, 캡시드는 적어도 400 nm, 또는 그 초과의 직경을 갖는다. 일부 경우에서, 캡시드는 적어도 500 nm, 또는 그 초과의 직경을 갖는다. 일부 경우에서, 캡시드는 적어도 600 nm, 또는 그 초과의 직경을 갖는다.
일부 실시양태에서, 캡시드는 최대 1 nm, 또는 그 미만의 직경을 갖는다. 일부 예에서, 캡시드는 최대 2 nm, 3 nm, 4 nm, 5 nm, 10 nm, 15 nm, 20 nm, 25 nm, 30 nm, 40 nm, 50 nm, 60 nm, 70 nm, 80 nm, 90 nm, 100 nm, 150 nm, 200 nm, 300 nm, 400 nm, 500 nm, 600 nm, 또는 그 미만의 직경을 갖는다. 일부 예에서, 캡시드는 최대 5 nm, 또는 그 미만의 직경을 갖는다. 일부 경우에서, 캡시드는 최대 10 nm, 또는 그 미만의 직경을 갖는다. 일부 예에서, 캡시드는 최대 20 nm, 또는 그 미만의 직경을 갖는다. 일부 예에서, 캡시드는 최대 30 nm, 또는 그 미만의 직경을 갖는다. 일부 예에서, 캡시드는 최대 40 nm, 또는 그 미만의 직경을 갖는다. 일부 예에서, 캡시드는 최대 50 nm, 또는 그 미만의 직경을 갖는다. 일부 예에서, 캡시드는 최대 80 nm, 또는 그 미만의 직경을 갖는다. 일부 예에서, 캡시드는 최대 100 nm, 또는 그 미만의 직경을 갖는다. 일부 예에서, 캡시드는 최대 200 nm, 또는 그 미만의 직경을 갖는다. 일부 예에서, 캡시드는 최대 400 nm, 또는 그 미만의 직경을 갖는다. 일부 예에서, 캡시드는 최대 500 nm, 또는 그 미만의 직경을 갖는다. 일부 예에서, 캡시드는 최대 600 nm, 또는 그 미만의 직경을 갖는다.
일부 실시양태에서, 캡시드는 약 1 nm, 2 nm, 3 nm, 4 nm, 5 nm, 10 nm, 15 nm, 20 nm, 25 nm, 30 nm, 40 nm, 50 nm, 60 nm, 70 nm, 80 nm, 90 nm, 100 nm, 150 nm, 200 nm, 300 nm, 400 nm, 500 nm, 또는 600 nm의 직경을 갖는다. 일부 예에서, 캡시드는 약 5 nm의 직경을 갖는다. 일부 경우에서, 캡시드는 약 10 nm의 직경을 갖는다. 일부 예에서, 캡시드는 약 20 nm의 직경을 갖는다. 일부 예에서, 캡시드는 약 30 nm의 직경을 갖는다. 일부 예에서, 캡시드는 약 40 nm의 직경을 갖는다. 일부 예에서, 캡시드는 약 50 nm의 직경을 갖는다. 일부 예에서, 캡시드는 약 80 nm의 직경을 갖는다. 일부 예에서, 캡시드는 약 100 nm의 직경을 갖는다. 일부 예에서, 캡시드는 약 200 nm의 직경을 갖는다. 일부 예에서, 캡시드는 약 300 nm의 직경을 갖는다. 일부 예에서, 캡시드는 약 400 nm의 직경을 갖는다. 일부 예에서, 캡시드는 약 500 nm의 직경을 갖는다. 일부 예에서, 캡시드는 약 600 nm의 직경을 갖는다.
일부 실시양태에서, 캡시드는 약 1 nm 내지 약 600 nm의 직경을 갖는다. 일부 예에서, 캡시드는 약 2 nm 내지 약 500 nm, 약 2 nm 내지 약 400 nm, 약 2 nm 내지 약 300 nm, 약 2 nm 내지 약 200 nm, 약 2 nm 내지 약 100 nm, 약 2 nm 내지 약 50 nm, 약 2 nm 내지 약 30 nm, 약 20 nm 내지 약 400 nm, 약 20 nm 내지 약 300 nm, 약 20 nm 내지 약 200 nm, 약 20 nm 내지 약 100 nm, 약 20 nm 내지 약 50 nm, 약 20 nm 내지 약 30 nm, 약 30 nm 내지 약 500 nm, 약 30 nm 내지 약 400 nm, 약 30 nm 내지 약 300 nm, 약 30 nm 내지 약 200 nm, 약 30 nm 내지 약 100 nm, 약 30 nm 내지 약 50 nm, 약 50 nm 내지 약 300 nm, 약 50 nm 내지 약 200 nm, 약 50 nm 내지 약 100 nm, 약 2 nm 내지 약 25 nm, 약 2 nm 내지 약 20 nm, 약 2 nm 내지 약 10 nm, 약 5 nm 내지 약 25 nm, 약 5 nm 내지 약 20 nm, 약 5 nm 내지 약 10 nm, 약 10 nm 내지 약 25 nm, 또는 약 10 nm 내지 약 20 nm의 직경을 갖는다.
일부 실시양태에서, 캡시드는 감소된 표적외 효과를 갖는다. 일부 경우에서, 표적외 효과는 10%, 5%, 4%, 3%, 2%, 1% 또는 0.5% 미만이다. 일부 경우에서, 표적외 효과는 10%, 5%, 4%, 3%, 2%, 1% 또는 0.5% 이하이다.
일부 경우에 캡시드는 표적외 효과를 갖지 않는다.
특정 실시양태에서, Arc 및/또는 endo-Gag 기반 캡시드의 형성은 생체외 또는 시험관내에서 발생한다.
일부 예에서, Arc 및/또는 endo-Gag 기반 캡시드는 생체내에서 조립된다.
일부 예에서, Arc 및/또는 endo-Gag 기반 캡시드는 실온에서 안정하다. 일부 경우에서, Arc 및/또는 endo-Gag 기반 캡시드는 비어 있다. 다른 경우에서, Arc 및/또는 endo-Gag 기반 캡시드는 로딩된다(예컨대, 카고 및/또는 치료제, 예컨대 DNA 또는 RNA가 로딩됨).
일부 예에서, Arc 및/또는 endo-Gag 기반 캡시드는 약 2℃ 내지 약 37℃의 온도에서 안정하다. 일부 예에서, Arc 및/또는 endo-Gag 기반 캡시드는 약 2℃ 내지 약 8℃, 약 2℃ 내지 약 4℃, 약 20℃ 내지 약 37℃, 약 25℃ 내지 약 37℃, 약 20℃ 내지 약 30℃, 약 25℃ 내지 약 30℃, 또는 약 30℃ 내지 약 37℃의 온도에서 안정하다. 일부 경우에서, Arc 및/또는 endo-Gag 기반 캡시드는 비어 있다. 다른 경우에서, Arc 및/또는 endo-Gag 기반 캡시드는 로딩된다(예컨대, 카고 및/또는 치료제, 예컨대 DNA 또는 RNA가 로딩됨).
일부 예에서, Arc 및/또는 endo-Gag 기반 캡시드는 적어도 약 1일, 2일, 4일, 5일, 7일, 14일, 28일, 30일, 60일, 2개월, 3개월, 4개월, 5개월, 6개월, 12개월, 18개월, 24개월, 3년, 5년, 또는 그 초과 동안 안정하다. 일부 경우에서, Arc 및/또는 endo-Gag 기반 캡시드는 최소 분해, 예컨대 분해되는 Arc 및/또는 endo-Gag 기반 캡시드의 총 집단을 기준으로 하여 10%, 5%, 4%, 3%, 2%, 1%, 0.5% 미만을 갖는다. 일부 경우에서, Arc 및/또는 endo-Gag 기반 캡시드는 비어 있다. 다른 경우에서, Arc 및/또는 endo-Gag 기반 캡시드는 로딩된다(예컨대, 치료제, 예컨대 DNA 또는 RNA가 로딩됨).
추가의 캡시드
일부 실시양태에서, 캡시드는 코피아 단백질을 포함한다. 일부 예에서, 코피아 단백질은 드로소필라 멜라노가스테르(Drosophila melanogaster)(UniProtKB-P04146), 세라티티스 카피타테(Ceratitis capitate)(UniProtKB-W8BHY5) 또는 드로소필라 시물란스(Drosophila simulans)(UniProtKB-Q08461)로부터의 것이다.
일부 실시양태에서, 캡시드는 단백질 ASPRV1을 포함한다. ASPRV1 단백질은 피부 장벽의 발달 및 유지에 참여하는 구조 단백질이다. 일부 예에서, 단백질 ASPRV1은 호모 사피엔스(UniProtKB-Q53RT3)로부터의 것이다.
일부 실시양태에서, 캡시드는 SCAN 도메인 패밀리로부터의 단백질을 포함한다. SCAN 도메인은 징크 핑거 전사 인자의 슈퍼패밀리이다. SCAN 도메인은 루이신 풍부 영역(LeR)으로도 알려져 있으며 자가-회합 또는 다른 단백질과의 선택적 회합을 매개하는 단백질 상호 작용 도메인으로 기능한다.
일부 실시양태에서, 캡시드는 부신생물성 Ma 항원 패밀리로부터의 단백질을 포함한다. 부신생물성 Ma 항원 패밀리는 neurO- 및 고환-특이적 단백질의 약 14개의 구성원을 포함한다.
일부 실시양태에서, 캡시드는 레트로트랜스포존 Gag-유사 유전자에 의해 코딩되는 단백질을 포함한다.
일부 실시양태에서, 캡시드는 BOP, LDOC1, MOAP1, PEG10, PNMA3, PNMA5, PNMA6A, PNMA6B, RTL3, RTL6, RTL8A, RTL8B, 및/또는 ZNF18을 포함한다.
카고
일부 실시양태에서, 본 개시 내용의 조성물(예컨대, 캡시드)은 카고를 포함한다. 일부 실시양태에서, 카고는 치료제이다. 일부 실시양태에서, 카고는 핵산 분자, 소분자, 단백질, 펩티드, 항체 또는 이의 결합 단편, 펩티드모방체, 또는 뉴클레오티드모방체이다. 일부 예에서, 카고는, 예컨대 하나 이상의 약물을 포함하는 치료 카고이다. 일부 예에서, 카고는 프로파일링을 위한 진단 도구, 예컨대 하나 이상의 마커(예컨대, 하나 이상의 질환 표현형과 관련된 마커)를 포함한다. 추가의 예에서, 카고는 이미징 도구를 포함한다.
일부 예에서, 카고는 핵산 분자이다. 예시적인 핵산 분자는 DNA, RNA, 또는 DNA와 RNA의 혼합물을 포함한다. 일부 예에서, 핵산 분자는 DNA 중합체이다. 일부 경우에서, DNA는 단일 가닥 DNA 중합체이다. 다른 경우에서, DNA는 이중 가닥 DNA 중합체이다. 추가의 경우에서, DNA는 단일 및 이중 가닥 DNA 중합체의 하이브리드이다.
일부 실시양태에서, 핵산 분자는 RNA 중합체, 예컨대 단일 가닥 RNA 중합체, 이중 가닥 RNA 중합체, 또는 단일 및 이중 가닥 RNA 중합체의 하이브리드이다. 일부 예에서, RNA는 안티센스 올리고리보뉴클레오티드, siRNA, mRNA, tRNA, rRNA, snRNA, shRNA, 마이크로RNA 또는 비-코딩 RNA를 포함하고/하거나 코딩한다.
일부 실시양태에서, 핵산 분자는 DNA와 RNA의 하이브리드를 포함한다.
일부 실시양태에서, 핵산 분자는 임의적으로 DNA, RNA, 또는 DNA와 RNA의 하이브리드를 포함하는 안티센스 올리고뉴클레오티드이다.
일부 예에서, 핵산 분자는 mRNA 분자를 포함하고/하거나 코딩한다.
일부 실시양태에서, 핵산 분자는 RNAi 분자를 포함하고/하거나 코딩한다. 일부 경우에서, RNAi 분자는 마이크로RNA(miRNA) 분자이다. 다른 경우에서, RNAi 분자가 siRNA 분자이다. miRNA 및/또는 siRNA는 임의적으로 이중 가닥 또는 헤어핀으로서 또한 임의적으로 전구체 분자로 캡슐화된다.
일부 실시양태에서, 핵산 분자는 핵산 기반 요법에 사용하기 위한 것이다. 일부 예에서, 핵산 분자는 유전자 발현 조절(예컨대, mRNA 번역 또는 분해 조정), RNA 스플라이싱 조정 또는 RNA 간섭을 위한 것이다. 일부 경우에서, 핵산 분자는 유전자 발현 조절, RNA 스플라이싱 조정, 또는 RNA 간섭에 사용하기 위한 안티센스 올리고뉴클레오티드, 마이크로RNA 분자, siRNA 분자, mRNA 분자를 포함하고/하거나 코딩한다.
일부 예에서, 핵산 분자는 유전자 편집에 사용하기 위한 것이다. 예시적인 유전자 편집 시스템은 CRISPR-Cas 시스템, 징크 핑거 뉴클레아제(ZFN) 시스템, 및 전사 활성화제-유사 이펙터 뉴클레아제(TALEN) 시스템을 포함하지만 이에 제한되지 않는다. 일부 경우에서, 핵산 분자는 CRISPR-Cas 시스템, ZFN 시스템, 또는 TALEN 시스템에 관여하는 성분을 포함하고/하거나 코딩한다.
일부 경우에서, 핵산 분자는 치료 및/또는 예방 백신 생성을 위한 항원 생성에 사용하기 위한 것이다. 예컨대, 핵산 분자는 발현되고 바람직한 면역 반응(예컨대, 전염증 면역 반응, 항염증 면역 반응, B 세포 반응, 항체 반응, T 세포 반응, CD4+ T 세포 반응, CD8+ T 세포 반응, Th1 면역 반응, Th2 면역 반응, Th17 면역 반응, Treg 면역 반응, 또는 이들의 조합)을 유도하는 항원을 코딩한다.
일부 경우에서, 핵산 분자는 핵산 효소를 포함한다. 핵산 효소는 촉매 활성을 갖는 RNA 분자(예컨대, 리보자임) 또는 DNA 분자(예컨대, 데옥시리보자임)이다. 일부 예에서, 핵산 분자는 리보자임이다. 다른 예에서, 핵산 분자는 데옥시리보자임이다. 일부 경우에서, 핵산 분자는 바이오센서 및/또는 분자 스위치로 기능하는 MNAzyme이다(예컨대, 문헌(Mokany, et al., "MNAzymes, a versatile new class of nucleic acid enzymes that can function as biosensors and molecular switches," JACS 132(2): 1051-1059 (2010)) 참조).
일부 예에서, 핵산 분자의 예시적인 표적은 UL123(인간 시토메갈로바이러스), APOB, AR(안드로겐 수용체) 유전자, KRAS, PCSK9, CFTR, 및 SMN(예컨대, SMN2)을 포함하지만 이에 제한되지 않는다.
일부 실시양태에서, 핵산 분자는 길이가 적어도 5개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 35, 40, 50, 60, 70, 80, 90, 100, 150, 200, 250, 300, 400, 500, 1000, 1500, 2000, 3000, 4000, 5000, 6000, 7000, 8000, 9000개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 10개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 12개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 15개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 18개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 19개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 20개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 21개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 22개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 23개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 24개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 25개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 26개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 27개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 28개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 29개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 30개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 40개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 50개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 100개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 200개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 300개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 500개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 1000개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 2000개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 3000개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 4000개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 5000개 뉴클레오티드 또는 그 초과이다. 일부 예에서, 핵산 분자는 길이가 적어도 8000개 뉴클레오티드 또는 그 초과이다.
일부 실시양태에서, 핵산 분자는 길이가 최대 12개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 35, 40, 50, 60, 70, 80, 90, 100, 150, 200, 250, 300, 400, 500, 1000, 1500, 2000, 3000, 4000, 5000, 6000, 7000, 8000, 9000개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 15개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 18개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 19개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 20개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 21개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 22개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 23개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 24개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 25개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 26개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 27개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 28개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 29개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 30개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 40개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 50개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 100개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 200개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 300개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 500개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 1000개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 2000개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 3000개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 4000개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 5000개 뉴클레오티드 또는 그 미만이다. 일부 예에서, 핵산 분자는 길이가 최대 8000개 뉴클레오티드 또는 그 미만이다.
일부 실시양태에서, 핵산 분자는 길이가 약 5개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 35, 40, 50, 60, 70, 80, 90, 100, 150, 200, 250, 300, 400, 500, 1000, 1500, 2000, 3000, 4000, 5000, 6000, 7000, 8000, 9000개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 10개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 12개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 15개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 18개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 19개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 20개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 21개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 22개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 23개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 24개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 25개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 26개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 27개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 28개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 29개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 30개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 40개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 50개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 100개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 200개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 300개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 500개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 1000개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 2000개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 3000개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 4000개 뉴클레오티드이다. 일부 예에서, 핵산 분자는 길이가 약 5000개 뉴클레오티드이다.
일부 실시양태에서, 핵산 분자는 약 5개 내지 약 10,000개 뉴클레오티드 길이다. 일부 예에서, 핵산 분자는 약 5 내지 약 9000개 뉴클레오티드 길이, 약 5 내지 약 8000개 뉴클레오티드 길이, 약 5 내지 약 7000개 뉴클레오티드 길이, 약 5 내지 약 6000개 뉴클레오티드 길이, 약 5 내지 약 5000개 뉴클레오티드 길이, 약 5 내지 약 4000개 뉴클레오티드 길이, 약 5 내지 약 3000개 뉴클레오티드 길이, 약 5 내지 약 2000개 뉴클레오티드 길이, 약 5 내지 약 1000개 뉴클레오티드 길이, 약 5 내지 약 500개 뉴클레오티드 길이, 약 5 내지 약 100개 뉴클레오티드 길이, 약 5 내지 약 50개 뉴클레오티드 길이, 약 5 내지 약 40개 뉴클레오티드 길이, 약 5 내지 약 30개 뉴클레오티드 길이, 약 5 내지 약 25개 뉴클레오티드 길이, 약 5 내지 약 20개 뉴클레오티드 길이, 약 10 내지 약 8000개 뉴클레오티드 길이, 약 10 내지 약 7000개 뉴클레오티드 길이, 약 10 내지 약 6000개 뉴클레오티드 길이, 약 10 내지 약 5000개 뉴클레오티드 길이, 약 10 내지 약 4000개 뉴클레오티드 길이, 약 10 내지 약 3000개 뉴클레오티드 길이, 약 10 내지 약 2000개 뉴클레오티드 길이, 약 10 내지 약 1000개 뉴클레오티드 길이, 약 10 내지 약 500개 뉴클레오티드 길이, 약 10 내지 약 100개 뉴클레오티드 길이, 약 10 내지 약 50개 뉴클레오티드 길이, 약 10 내지 약 40개 뉴클레오티드 길이, 약 10 내지 약 30개 뉴클레오티드 길이, 약 10 내지 약 25개 뉴클레오티드 길이, 약 10 내지 약 20개 뉴클레오티드 길이, 약 18 내지 약 8000개 뉴클레오티드 길이, 약 18 내지 약 7000개 뉴클레오티드 길이, 약 18 내지 약 6000개 뉴클레오티드 길이, 약 18 내지 약 5000개 뉴클레오티드 길이, 약 18 내지 약 4000개 뉴클레오티드 길이, 약 18 내지 약 3000개 뉴클레오티드 길이, 약 18 내지 약 2000개 뉴클레오티드 길이, 약 18 내지 약 1000개 뉴클레오티드 길이, 약 18 내지 약 500개 뉴클레오티드 길이, 약 18 내지 약 100개 뉴클레오티드 길이, 약 18 내지 약 50개 뉴클레오티드 길이, 약 18 내지 약 40개 뉴클레오티드 길이, 약 18 내지 약 30개 뉴클레오티드 길이, 약 18 내지 약 25개 뉴클레오티드 길이, 약 12 내지 약 50개 뉴클레오티드 길이, 약 20 내지 약 40개 뉴클레오티드 길이, 약 20 내지 약 30개 뉴클레오티드 길이, 또는 약 25 내지 약 30개 뉴클레오티드 길이이다.
일부 실시양태에서, 핵산 분자는 천연, 합성, 또는 인공 뉴클레오티드 유사체 또는 염기를 포함한다. 일부 경우에서, 핵산 분자는 DNA, RNA 및/또는 뉴클레오티드 유사체의 조합을 포함한다. 일부 경우에서, 합성 또는 인공 뉴클레오티드 유사체 또는 염기는 리보스 모이어티, 포스페이트 모이어티, 뉴클레오시드 모이어티, 또는 이들의 조합 중 하나 이상에서 변형을 포함한다.
일부 실시양태에서, 상술된 뉴클레오티드 유사체 또는 인공 뉴클레오티드 염기는 리보스 모이어티의 2' 히드록실기에서 변형을 갖는 핵산을 포함한다. 일부 예에서, 변형은 H, OR, R, 할로, SH, SR, NH2, NHR, NR2 또는 CN을 포함하며, 여기서 R은 알킬 모이어티이다. 예시적인 알킬 모이어티는 할로겐, 황, 티올, 티오에테르, 티오에스테르, 아민(1차, 2차 또는 3차), 아미드, 에테르, 에스테르, 알콜 및 산소를 포함하지만 이에 제한되지 않는다. 일부 예에서, 알킬 모이어티는 변형을 추가로 포함한다. 일부 예에서, 변형은 아조기, 케토기, 알데히드기, 카르복실기, 니트로기, 니트로소기, 니트릴기, 헤테로사이클(예컨대, 이미다졸, 히드라지노 또는 히드록실아미노)기, 및 이소시아네이트 또는 시아네이트기, 또는 황 함유 기(예컨대, 술폭사이드, 술폰, 술파이드 또는 디술파이드)를 포함하지만 이에 제한되지 않는다. 일부 경우에서, 알킬 모이어티는 헤테로 치환을 추가로 포함한다. 일부 예에서, 헤테로사이클릭기의 탄소는 질소, 산소 또는 황으로 치환된다. 일부 예에서, 헤테로사이클릭 치환은 모르폴리노, 이미다졸, 및 피롤리디노를 포함하지만 이에 제한되지 않는다.
일부 예에서, 2' 히드록실기에서의 변형은 2'-O-메틸 변형 또는 2'-O-메톡시 에틸(2'-O-MOE) 변형이다. 일부 경우에서, 2'-O-메틸 변형은 리보스 모이어티의 2' 히드록실기에 메틸기를 추가하는 반면, 2'O-메톡시에틸 변형은 리보스 모이어티의 2' 히드록실기에 메톡시에틸기를 추가한다.
일부 예에서, 2' 히드록실기에서의 변형은 프로필 링커를 포함하는 연장된 아민기가 아민기를 2'산소에 결합하는 2'-O-아미노프로필 변형이다. 일부 예에서, 이 변형은 슈가당 아민기로부터 하나의 양전하를 도입함으로써 올리고뉴클레오티드 분자의 포스페이트 유래된 전체 음전하를 중화시키고 그에 따라 양쪽성 이온 특성으로 인해 세포 흡수 특성을 개선한다.
일부 예에서, 2' 히드록실기에서의 변형은 2' 탄소에 결합된 산소 분자가 메텔린기에 의해 4' 탄소에 연결됨으로써 2'-C,4'-C-옥시-메틸렌 연결된 비사이클릭 리보뉴클레오티드 단량체를 형성하는 잠금 또는 브리징된 리보스 변형(예컨대, 잠금 핵산 또는 LNA)이다.
일부 실시양태에서, 2' 히드록실기에서의 추가의 변형은 2'-데옥시, T-데옥시-2'-플루오로, 2'-O-아미노프로필(2'-O-AP), 2'-O-디메틸아미노에틸(2'-O-DMAOE), 2'-O-디메틸아미노프로필(2'-O-DMAP), T-O-디메틸아미노에틸옥시에틸(2'-O-DMAEOE), 또는 2'-ON-메틸아세트아미도(2'-O-NMA)를 포함한다.
일부 실시양태에서, 뉴클레오티드 유사체는 변형된 염기, 예컨대 5-프로피 닐우리딘, 5-프로피닐시티딘, 6-메틸아데닌, 6-메틸구아닌, N,N,-디메틸아데닌, 2-프로필아데닌, 2 프로필구아닌, 2-아미노아데닌, 1-메틸이노신, 3-메틸우리딘, 5-메틸시티딘, 5-메틸우리딘 및 5 위치에 변형을 갖는 다른 뉴클레오티드, 5-(2-아미노) 프로필 우리딘, 5-할로시티딘, 5-할로우리딘, 4-아세틸시티딘, 1-메틸아데노신, 2-메틸아데노신, 3-메틸시티딘, 6-메틸우리딘, 2-메틸구아노신, 7-메틸구아노신, 2,2-디메틸구아노신, 5-메틸아미노에틸우리딘, 5-메틸옥시우리딘, 데아자뉴클레오티드(예컨대, 7-데아자-아데노신, 6-아조우리딘, 6-아조시티딘, 또는 6-아조티미딘), 5-메틸-2-티오우리딘, 다른 티오 염기(예컨대, 2-티오우리딘, 4-티오우리딘, 및 2-티오시티딘), 디히드로우리딘, 슈도우리딘, 큐오신, 아르케오신, 나프틸 및 치환된 나프틸기, 임의의 O- 및 N-알킬화 퓨린 및 피리미딘(예컨대, N6-메틸아데노신, 5-메틸카르보닐메틸우리딘, 우리딘 5-옥시아세트산, 피리딘-4-온, 또는 피리딘-2-온), 페닐 및 변형된 페닐기, 예컨대 아미노페놀 또는 2,4,6-트리메톡시 벤젠, G-클램프 뉴클레오티드로 작용하는 변형된 시토신, 8-치환된 아데닌 및 구아닌, 5-치환된 우라실 및 티민, 아자피리미딘, 카르복시히드록시알킬 뉴클레오티드, 카르복시알킬아미노알킬 뉴클레오티드, 및 알킬카르보닐알킬화 뉴클레오티드를 포함하지만 이에 제한되지 않는다. 변형된 뉴클레오티드는 또한 슈가 모이어티와 관련하여 변형된 뉴클레오티드 뿐만 아니라 리보실이 아닌 슈가 또는 이의 유사체를 갖는 뉴클레오티드를 포함한다. 예컨대, 슈가 모이어티는 일부 경우에서 만노스, 아라비노스, 글루코피라노스, 갈락토피라노스, 4'-티오리보스, 및 다른 슈가, 헤테로사이클, 또는 카르보사이클이거나 이에 기초한다. 용어 뉴클레오티드는 또한 범용 염기를 포함한다. 예로서, 범용 염기는 3-니트로피롤, 5-니트로인돌, 또는 네불라린을 포함하지만 이에 제한되지 않는다.
일부 실시양태에서, 뉴클레오티드 유사체는 모르폴리노, 펩티드 핵산(PNA), 메틸포스포네이트 뉴클레오티드, 티올포스포네이트 뉴클레오티드, 2'-플루오로 N3-P5'-포스포르아미다이트, 또는 1',5'-안히드로헥시톨 핵산(HNA)을 추가로 포함한다. 모르폴리노 또는 포스포로디아미데이트 모르폴리노 올리고(PMO)는 구조가 천연 핵산 구조를 모방하지만 정상적인 슈가 및 포스페이트 구조와는 다른 합성 분자를 포함한었다. 일부 예에서, 5원 리보스 고리는 4개의 탄소, 1개의 질소 및 1개의 산소를 함유하는 6원 모르폴리노 고리로 치환된다. 일부 경우에서, 리보스 단량체는 포스페이트기 대신 포스포르디아미데이트기에 의해 연결된다. 이러한 경우에서, 골격 변경은 모든 양전하 및 음전하를 제거하여 하전된 올리고뉴클레오티드에 사용되는 것과 같은 세포 전달제의 도움 없이 세포막을 통과할 수 있는 모르폴리노 중성 분자를 만든다.
일부 실시양태에서, 펩티드 핵산(PNA)은 슈가 고리 또는 포스페이트 결합을 함유하지 않으며 염기는 올리고글리신-유사 분자에 의해 부착되고 적절하게 이격되어 골격 전하를 제거한다.
일부 실시양태에서, 하나 이상의 변형은 임의적으로 뉴클레오티드간 결합에서 발생한다. 일부 예에서, 변형된 뉴클레오티드간 결합은 포스포로티오에이트; 포스포로디티오에이트; 메틸포스포네이트; 5'-알킬렌포스포네이트; 5'-메틸포스포네이트; 3'-알킬렌 포스포네이트; 보론트리플루오리데이트; 3'-5' 결합 또는 2'-5' 결합의 보라노포스페이트 에스테르 및 셀레포스페이트; 포스포트리에스테르; 티오노알킬포스포트리에스테르; 수소 포스포네이트 결합; 알킬 포스포네이트; 알킬포 포노티오에이트; 아릴포스포노티오에이트; 포스포로셀레노에이트; 포스포로디셀레노에이트; 포스피네이트; 포스포르아데이트; 3'-알킬포스포르아미데이트; 아미노알킬포스포르아미데이트; 티오노포스포르아미데이트; 포스포로피페라지데이트; 포스포로아닐로 티오에이트; 포스포로아닐리데이트; 케톤; 술폰; 술폰아미드; 카르보네이트; 카르바메이트; 메틸렌히드라조; 메틸렌디메틸히드라조; 포름아세탈; 티오포름아세탈; 옥심; 메틸렌이미노; 메틸렌메틸이미노; 티오아미데이트; 리보아세틸기와의 결합; 아미노에틸 글리신; 실릴 또는 실록산 결합; 예컨대, 포화 또는 불포화 및/또는 치환 및/또는 헤테로 원자를 함유하는 1 내지 10개의 탄소의 헤테로 원자가 있거나 없는 알킬 또는 시클로알킬 결합; 모르폴리노 구조, 아미드 또는 폴리아미드와의 결합(여기서 염기는 골격의 아자 질소에 직접 또는 간접적으로 부착됨); 및 이들의 조합을 포함하지만 이에 제한되지 않는다.
일부 실시양태에서, 하나 이상의 변형은 변형이 중성 또는 하전되지 않은 골격을 생성하는 변형된 포스페이트 골격을 포함한다. 일부 예에서, 포스페이트 골격은 알킬화에 의해 변형되어 하전되지 않은 또는 중성 포스페이트 골격을 생성한다. 본원에서 사용되는 바와 같이, 알킬화는 메틸화, 에틸화 및 프로필화를 포함한다. 일부 경우에서, 알킬화와 관련하여 본원에서 사용되는 알킬기는 1 내지 6개의 탄소 원자를 함유하는 선형 또는 분지형 포화 탄화수소기를 지칭한다. 일부 예에서, 예시적인 알킬기는 메틸, 에틸, N-프로필, 이소프로필, N-부틸, 이소부틸, sec-부틸, tert-부틸, N-펜틸, 이소펜틸, 네오펜틸, 헥실, 이소헥실, 1,1-디메틸부틸, 2,2-디메틸부틸, 3,3-디메틸부틸, 및 2-에틸부틸기를 포함하지만 이에 제한되지 않는다. 일부 경우에서, 변형된 포스페이트는 미국 특허 번호 9481905에 기재된 포스페이트기이다.
일부 실시양태에서, 추가의 변형된 포스페이트 골격은 메틸 포스포네이트, 에틸 포스포네이트, 메틸티오포스포네이트, 또는 메톡시 포스포네이트를 포함한다. 일부 경우에서, 변형된 포스페이트는 메틸포스포네이트이다. 일부 경우에서, 변형된 포스페이트는 에틸포스포네이트이다. 일부 경우에서, 변형된 포스페이트는 메틸 티오포스포네이트이다. 일부 경우에서, 변형된 포스페이트는 메톡시포스포네이트이다.
일부 실시양태에서, 하나 이상의 변형은 임의적으로 리보스 모이어티, 포스페이트 골격 및 뉴클레오시드의 변형, 또는 3' 또는 5' 말단에서 뉴클레오티드 유사체의 변형을 추가로 포함한다. 예컨대, 3' 말단은 임의적으로 3' 양이온 기를 포함하거나 3'-3'연결로 3'-말단에서 뉴클레오시드를 반전시킨다. 또 다른 대안에서, 3'-말단은 임의적으로 아미노알킬기, 예컨대 3'C 5-아미노 알킬 dT와 접합된다. 추가의 대안에서, 3'-말단은 임의적으로 비염기 부위, 예컨대 비퓨린 또는 비피리미딘 부위와 접합된다. 일부 예에서, 5'-말단은 아미노알킬기, 예컨대 5'-O-알킬아미노 치환체와 접합된다. 일부 경우에서, 5'-말단은 비염기 부위, 예컨대 비퓨린 또는 비피리미딘 부위와 접합된다.
일부 실시양태에서, 예시적인 핵산 카고는 포미비르센, 미포메르센, AZD5312(AstraZeneca), 누시네르센 및 SB010(Sterna Biologicals)을 포함하지만 이에 제한되지 않는다.
소분자
일부 실시양태에서, 카고는 소분자이다. 일부 예에서, 소분자는 억제제(예컨대, 팬(pan) 억제제 또는 선택적 억제제)이다. 다른 예에서, 소분자는 활성화제이다. 추가의 경우에서, 소분자는 효능제, 길항제, 부분 효능제, 혼합 효능제/길항제 또는 경쟁적 길항제이다.
일부 실시양태에서, 소분자는 진통제, 항불안제, 항부정맥제, 항박테리아제, 항생제, 항응고제 및 혈전용해제, 항경련제, 항우울제, 지사제, 항구토제, 항진균제, 항히스타민제, 항고혈압제, 항염증제, 항신생물제, 항정신병제, 해열제, 항바이러스제, 바르비투레이트, 베타 차단제, 기관지 확장제, 감기 치료제, 코르티코스테로이드, 기침 억제제, 세포독성제, 충혈제거제, 이뇨제, 거담제, 호르몬, 혈당강하제, 면역억제제, 완하제, 근육 이완제, 성 호르몬, 수면제, 또는 신경안정제의 부류에 속하는 약물이다.
일부 실시양태에서, 소분자는 억제제, 예컨대 티로신 키나제 경로 또는 세린/트레오닌 키나제 경로와 같은 키나제 경로의 억제제이다. 일부 경우에서, 소분자는 이중 단백질 키나제 억제제이다. 일부 경우에서, 소분자는 지질 키나제 억제제이다.
일부 경우에서, 소분자는 뉴라미니다제 억제제이다.
일부 경우에서, 소분자는 탄산 안히드라제 억제제이다.
일부 실시양태에서, 소분자의 예시적인 표적은 혈관 내피 성장 인자 수용체 1(VEGFR1), 혈관 내피 성장 인자 수용체 2(VEGFR2), 혈관 내피 성장 인자 수용체 3(VEGFR3), 섬유모세포 성장 인자 수용체 1(FGFR1), 섬유모세포 성장 인자 수용체 2(FGFR2), 섬유모세포 성장 인자 수용체 3(FGFR3), 섬유모세포 성장 인자 수용체 4(FGFR4), 사이클린 의존적 키나제 4(CDK4), 사이클린 의존적 키나제 6(CDK6), 수용체 티로신 키나제, 포스포이노시티드 3-키나제(PI3K) 이소형(예컨대, PI3Kδ, p110δ로도 알려짐), 야누스 키나제 1(JAK1), 야누스 키나제 3(JAK3), 혈소판 유래된 성장 인자 수용체(PDFG-R) 패밀리로부터의 수용체, 및 탄산 안히드라제(예컨대, 탄산 안히드라제 I)를 포함하지만 이에 제한되지 않는다.
일부 실시양태에서, 소분자는 바이러스 단백질, 예컨대 바이러스 외피 단백질을 표적으로 한다. 일부 실시양태에서, 소분자는 숙주 세포에 대한 바이러스 흡착을 감소시킨다. 일부 실시양태에서, 소분자는 숙주 세포로의 바이러스 진입을 감소시킨다. 일부 실시양태에서, 소분자는 숙주 또는 숙주 세포에서 바이러스 복제를 감소시킨다. 일부 실시양태에서, 소분자는 바이러스 조립을 감소시킨다.
일부 실시양태에서, 예시적인 소분자 카고는 렌바티닙, 팔보시클립, 레고라페닙, 이델랄리십, 토파시티닙, 닌테다닙, 자나미비르, 에톡졸아미드, 및 아르테미시닌을 포함하지만 이에 제한되지 않는다.
단백질
일부 실시양태에서, 카고는 단백질이다. 일부 예에서, 단백질이 전장 단백질이다. 다른 예에서, 단백질은 단편, 예컨대 기능적 단편이다. 일부 경우에서, 단백질이 자연 발생 단백질이다. 추가의 경우에서, 단백질은 드 노보 조작된 단백질이다. 추가의 경우에서, 단백질은 융합 단백질이다. 추가의 경우에서, 단백질은 재조합 단백질이다. 예시적인 단백질은 Fc 융합 단백질, 항응고제, 혈액 인자, 골 형태형성 단백질, 효소, 성장 인자, 호르몬, 인터페론, 인터류킨, 및 혈전용해제를 포함하지만 이에 제한되지 않는다.
일부 예에서, 단백질은 효소 대체 요법에 사용하기 위한 것이다.
일부 경우에서, 단백질은 치료 및/또는 예방 백신 생성을 위한 항원 생성에 사용하기 위한 것이다. 예컨대, 단백질은 바람직한 면역 반응(예컨대, 전염증 면역 반응, 항염증 면역 반응, B 세포 반응, 항체 반응, T 세포 반응, CD4+ T 세포 반응, CD8+ T 세포 반응, Th1 면역 반응, Th2 면역 반응, Th17 면역 반응, Treg 면역 반응, 또는 이들의 조합)을 유도하는 항원을 포함한다.
일부 예에서, 예시적인 단백질 카고는 로미플로스팀, 리라글루타이드, 인간 성장 호르몬(rHGH), 인간 인슐린(BHI), 난포 자극 호르몬(FSH), 인자 VIII, 에리트로포이에틴(EPO), 과립구 콜로니 자극 인자(G-CSF), 알파-갈락토시다제 A, 알파-L-이두로니다제, N-아세틸갈락토스아민-4-술파타제, 도르나제 알파, 조직 플라스미노겐 활성화제(TPA), 글루코세레브로시다제, 인터페론-베타-1a, 인슐린-유사 성장 인자 1(IGF-1) 또는 라스부리카제를 포함하지만 이에 제한되지 않는다.
펩티드
일부 실시양태에서, 카고는 펩티드이다. 일부 경우에서, 펩티드는 자연 발생 펩티드이다. 다른 예에서, 펩티드는 인공적으로 조작된 펩티드 또는 재조합 펩티드이다. 일부 경우에서, 펩티드는 G-단백질 커플링된 수용체, 이온 채널, 미생물, 항 미생물 표적, 촉매 또는 다른 Ig 패밀리 수용체, 세포내 표적, 막 고정된 표적 또는 세포외 표적을 표적으로 한다.
일부 경우에서, 펩티드는 적어도 2개의 아미노산을 포함한다. 일부 경우에서, 펩티드는 적어도 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100개의 아미노산을 포함한다. 일부 경우에서, 펩티드는 적어도 10개의 아미노산을 포함한다. 일부 경우에서, 펩티드는 적어도 15개의 아미노산을 포함한다. 일부 경우에서, 펩티드는 적어도 20개의 아미노산을 포함한다. 일부 경우에서, 펩티드는 적어도 30개의 아미노산을 포함한다. 일부 경우에서, 펩티드는 적어도 40개의 아미노산을 포함한다. 일부 경우에서, 펩티드는 적어도 50개의 아미노산을 포함한다. 일부 경우에서, 펩티드는 적어도 60개의 아미노산을 포함한다. 일부 경우에서, 펩티드는 적어도 70개의 아미노산을 포함한다. 일부 경우에서, 펩티드는 적어도 80개의 아미노산을 포함한다. 일부 경우에서, 펩티드는 적어도 90개의 아미노산을 포함한다. 일부 경우에서, 펩티드는 적어도 100개의 아미노산을 포함한다.
일부 경우에서, 펩티드는 최대 3개의 아미노산을 포함한다. 일부 경우에서, 펩티드는 최대 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100개의 아미노산을 포함한다. 일부 경우에서, 펩티드가 최대 10개의 아미노산을 포함한다. 일부 경우에서, 펩티드가 최대 15개의 아미노산을 포함한다. 일부 경우에서, 펩티드가 최대 20개의 아미노산을 포함한다. 일부 경우에서, 펩티드가 최대 30개의 아미노산을 포함한다. 일부 경우에서, 펩티드가 최대 40개의 아미노산을 포함한다. 일부 경우에서, 펩티드가 최대 50개의 아미노산을 포함한다. 일부 경우에서, 펩티드가 최대 60개의 아미노산을 포함한다. 일부 경우에서, 펩티드가 최대 70개의 아미노산을 포함한다. 일부 경우에서, 펩티드가 최대 80개의 아미노산을 포함한다. 일부 경우에서, 펩티드가 최대 90개의 아미노산을 포함한다. 일부 경우에서, 펩티드가 최대 100개의 아미노산을 포함한다.
일부 경우에서, 펩티드는 약 1 내지 약 10 kDa를 포함한다. 일부 경우에서, 펩티드는 약 1 내지 약 9 kDa, 약 1 내지 약 6 kDa, 약 1 내지 약 5 kDa, 약 1 내지 약 4 kDa, 약 1 내지 약 3 kDa, 약 2 내지 약 8 kDa, 약 2 내지 약 6 kDa, 약 2 내지 약 4 kDa, 약 1.2 내지 약 2.8 kDa, 약 1.5 내지 약 2.5 kDa, 또는 약 1.5 내지 약 2 kDa를 포함한다.
일부 실시양태에서, 펩티드는 사이클릭 펩티드이다. 일부 예에서, 사이클릭 펩티드는 마크로사이클릭 펩티드이다. 다른 예에서, 사이클릭 펩티드는 제한된 펩티드이다. 사이클릭 펩티드는, 예컨대 헤드-대-테일, 헤드-대-측쇄, 측쇄-대-테일 및 측쇄-대-측쇄 결합과 같은 다양한 결합으로 조립된다. 일부 예에서, 사이클릭 펩티드(예컨대, 마크로사이클릭 또는 제한된 펩티드)는 분자량이 약 500 달톤 내지 약 2000 달톤이다. 다른 예에서, 사이클릭 펩티드(예컨대, 마크로사이클릭 또는 제한된 펩티드)는 약 10개 아미노산 내지 약 100개 아미노산, 약 10개 아미노산 내지 약 70개 아미노산, 또는 약 10개 아미노산 내지 약 50개 아미노산 범위이다.
일부 경우에서, 펩티드는 치료 및/또는 예방 백신 생성을 위한 항원 생성에 사용하기 위한 것이다. 예컨대, 펩티드는 바람직한 면역 반응(예컨대, 전염증 면역 반응, 항염증 면역 반응, B 세포 반응, 항체 반응, T 세포 반응, CD4+ T 세포 반응, CD8+ T 세포 반응, Th1 면역 반응, Th2 면역 반응, Th17 면역 반응, Treg 면역 반응, 또는 이들의 조합)을 유도하는 항원을 포함한다.
일부 실시양태에서, 펩티드는 천연 아미노산, 비천연 아미노산, 또는 이들의 조합을 포함한다. 일부 예에서, 아미노산 잔기는 아미노기 및 카르복실기를 모두 함유하는 분자를 지칭한다. 적합한 아미노산은 제한 없이 자연 발생 아미노산의 D- 및 L-이성체 뿐만 아니라 유기 합성 또는 다른 대사 경로에 의해 제조되는 비-자연 발생 아미노산을 포함한다. 본원에서 사용되는 바와 같이 용어 아미노산은 제한 없이 α-아미노산, 천연 아미노산, 비-천연 아미노산, 및 아미노산 유사체를 포함한다.
일부 예에서, α-아미노산은 α-탄소로 지정된 탄소에 결합된 아미노기 및 카르복실기를 모두 함유하는 분자를 지칭한다.
일부 예에서, β-아미노산은 β 배치의 아미노기 및 카르복실기를 모두 함유하는 분자를 지칭한다.
일부 실시양태에서, 아미노산 유사체는 라세미 혼합물이다. 일부 예에서, 아미노산 유사체의 D 이성체가 사용된다. 일부 경우에서, 아미노산 유사체의 L 이성체가 사용된다. 일부 예에서, 아미노산 유사체는 R 또는 S 배치의 키랄 중심을 포함한다.
일부 실시양태에서, 예시적인 펩티드 카고는 페기네사티드, 인슐린, 부신피질자극 호르몬(ACTH), 칼시토닌, 옥시토신, 바소프레신, 옥트레올리드 및 류프로렐린을 포함하지만 이에 제한되지 않는다.
일부 실시양태에서, 예시적인 펩티드 카고는 텔라반신, 달바반신, 오리타반신, 아니둘라푼진, 란레오티드, 파시레오티드, 로미뎁신, 리나클로티드 및 페기네사티드를 포함하지만 이에 제한되지 않는다.
항체
일부 실시양태에서, 카고는 항체 또는 이의 결합 단편이다. 일부 경우에서, 항체 또는 이의 결합 단편은 인간화 항체 또는 이의 결합 단편, 뮤린 항체 또는 이의 결합 단편, 키메라 항체 또는 이의 결합 단편, 모노클로날 항체 또는 이의 결합 단편, 이중특이적 항체 또는 이의 결합 단편, 1가 Fab', 2가 Fab2, F(ab)'3 단편, 단일 쇄 가변 단편(scFv), 비스-scFv, (scFv)2, 디아바디, 미니바디, 나노바디, 트리아바디, 테트라바디, 디술파이드 안정화된 Fv 단백질(dsFv), 단일 도메인 항체(sdAb), Ig NAR, 낙타류 항체 또는 이의 결합 단편, 또는 이의 화학적으로 변형된 유도체를 포함한다.
일부 예에서, 항체 또는 결합 단편은 세포 표면 단백질을 인식한다. 일부 예에서, 세포 표면 단백질은 암 세포에 의해 발현되는 항원이다. 일부 예에서, 세포 표면 단백질은 네오에피토프이다. 일부 예에서, 세포 표면 단백질은 야생형 단백질과 비교하여 하나 이상의 돌연변이를 포함한다. 예시적인 암 항원은 알파 태아단백질, ASLG659, B7-H3, BAFF-R, 브레비칸, CA125(MUC16), CA15-3, CA19-9, 암배아 항원(CEA), CA242, CRIPTO(CR, CR1, CRGF, CRIPTO, TDGF1, 기형암종 유래된 성장 인자), CTLA-4, CXCR5, E16(LAT1, SLC7A5), FcRH2(IFGP4, IRTA4, SPAP1A(SH2 도메인 함유 포스파타제 앵커 단백질 1a), SPAP1B, SPAP1C)), 표피 성장 인자, ETBR, Fc 수용체-유사 단백질 1(FCRH1), GEDA, HLA-DOB(MHC 부류 II 분자의 베타 서브유닛(Ia 항원), 인간 융모 성선자극 호르몬, ICOS, IL-2 수용체, IL20Rα, 면역 글로불린 슈퍼패밀리 수용체 전위 관련된 2(IRTA2), L6, 루이스 Y, 루이스 X, MAGE-1, MAGE-2, MAGE-3, MAGE 4, MART1, 메소텔린, MDP, MPF(SMR, MSLN), MCP1(CCL2), 대식구 억제 인자(MIF), MPG, MSG783, 뮤신, MUC1-KLH, Napi3b(SLC34A2), 넥틴-4, Neu 온코진 산물, NCA, 태반 알칼리성 포스파타제, 전립선 특이적 막 항원(PMSA), 전립선 산 포스파타제, PSCA hlg , 항-트랜스페린 수용체, p97, 퓨린성 수용체 P2X 리간드 게이팅된 이온 채널 5(P2X5), LY64(림프구 항원 64(RP105), gp100, P21, 전립선의 6개의 막횡단 상피 항원(STEAP1), STEAP2, Sema 5b, 종양 관련된 당단백질 72(TAG-72), TrpM4(BR22450, FLJ20041, TRPM4, TRPM4B, 일시적 수용체 전위 양이온 채널, 서브패밀리 M, 멤버 4) 등을 포함하지만 이에 제한되지 않는다.
일부 예에서, 세포 표면 단백질은 분화 클러스터(CD) 세포 표면 마커를 포함한다. 예시적인 CD 세포 표면 마커는 CD1, CD2, CD3, CD4, CD5, CD6, CD7, CD8, CD9, CD10, CD11a, CD11b, CD11c, CD11d, CDw12, CD13, CD14, CD15, CD15s, CD16, CDw17, CD18, CD19, CD20, CD21, CD22, CD23, CD24, CD25, CD26, CD27, CD28, CD29, CD30, CD31, CD32, CD33, CD34, CD35, CD36, CD37, CD38, CD39, CD40, CD41, CD42, CD43, CD44, CD45, CD45RO, CD45RA, CD45RB, CD46, CD47, CD48, CD49a, CD49b, CD49c, CD49d, CD49e, CD49f, CD50, CD51, CD52, CD53, CD54, CD55, CD56, CD57, CD58, CD59, CDw60, CD61, CD62E, CD62L(L-셀렉틴), CD62P, CD63, CD64, CD65, CD66a, CD66b, CD66c, CD66d, CD66e, CD71, CD79(예컨대, CD79a, CD79b), CD90, CD95(Fas), CD103, CD104, CD125(IL5RA), CD134(OX40), CD137(4-1BB), CD152(CTLA-4), CD221, CD274, CD279(PD-1), CD319(SLAMF7), CD326(EpCAM) 등을 포함하지만 이에 제한되지 않는다.
일부 실시양태에서, 예시적인 항체 또는 이의 결합 단편은 잘루투무맙(HuMax-EFGr, Genmab), 아바고보맙(Menarini), 아비투주맙(Merck), 아데카투무맙(MT201), 알라시주맙 페골, 알레투주맙(Campath®, 맙캄파쓰, 또는 캄파쓰-1H; 류코시트), 알로무네(BioTransplant), 아마툭시맙(Morphotek, Inc.), 항-VEGF(Genetech), 아나투모맙 마페나톡스, 아폴리주맙(hu1D10), 아스크린바쿠맙(Pfizer Inc.), 아테졸리주맙(MPDL3280A; Genentech/Roche), B43.13(오바렉스, AltaRex Corporation), 바실릭시맙(Simulect®, Novartis), 벨리무맙(Benlysta®, GlaxoSmithKline), 베바시주맙(Avastin®, Genentech), 블리나투모맙(블린시토, AMG103; Amgen), BEC2(ImGlone Systems Inc.), 카를루맙(Janssen Biotech), 카투막소맙(Removab, Trion Pharma), CEAcide(Immunomedics), 세툭시맙(Erbitux®, ImClone), 시타투주맙 보가톡스(VB6-845), 시툭투무맙(IMC-A12, ImClone Systems Inc.), 코나투무맙(AMG 655, Amgen), 다세투주맙(SGN-40, huS2C6; Seattle Genetics, Inc.), 다라투무맙(Darzalex®, Janssen Biotech), 데투모맙, 드로지투맙(Genentech), 두르발루맙(MedImmune), 두시기투맙(MedImmune), 에드레콜로맙(MAb17-1A, 파노렉스, Glaxo Wellcome), 엘로투주맙(EmplicitiTM, Bristol-Myers Squibb), 에미베투주맙(Eli Lilly), 에나바투주맙(Facet Biotech Corp.), 엔포르투맙 보도틴(Seattle Genetics, Inc.), 에노블리투주맙(MGA271, MacroGenics, Inc.), 엔시툭수맙(Neogenix Oncology, Inc.), 에프라투주맙(림포시드, Immunomedics, Inc.), 에르투막소맙(Rexomun®, Trion Pharma), 에타라시주맙(아베그린, MedImmune), 파를레투주맙(MORAb-003, Morphotek, Inc), FBTA05(림포문, Trion Pharma), 피클라투주맙(AVEO Pharmaceuticals), 피기투무맙(CP-751871, Pfizer), 플란보투맙(ImClone Systems), 프레솔리무맙(GC1008, Aanofi-Aventis), 푸툭시맙, 글락시맙, 가니투맙(Amgen), 기렌툭시맙(Rencarex®, Wilex AG), IMAB362(클라우딕시맙, Ganymed Pharmaceuticals AG), 이말루맙(Baxalta), IMC-1C11(ImClone Systems), IMC-C225(Imclone Systems Inc.), 임가투주맙(Genentech/Roche), 인테투무맙(Centocor, Inc.), 이필리무맙(Yervoy®, Bristol-Myers Squibb), 이라투무맙(Medarex, Inc.), 이사툭시맙(SAR650984, Sanofi-Aventis), 라베투주맙(CEA-CIDE, Immunomedics), 렉사투무맙(ETR2-ST01, Cambridge Antibody Technology), 린투주맙(SGN-33, Seattle Genetics), 루카투무맙(Novartis), 루밀릭시맙, 마파투무맙(HGS-ETR1, Human Genome Sciences), 마투주맙(EMD 72000, Merck), 밀라투주맙(hLL1, Immunomedics, Inc.), 미투모맙(BEC-2, ImClone Systems), 나르나투맙(ImClone Systems), 네시투무맙(PortrazzaTM, Eli Lilly), 네스바쿠맙(Regeneron Pharmaceuticals), 니모투주맙(h-R3, BIOMAb EGFR, TheraCIM, 테랄록, 또는 CIMAher; Biotech Pharmaceutical Co.), 니볼루맙(Opdivo®, Bristol-Myers Squibb), 오비누투주맙(가지바 또는 가지바로; Hoffmann-La Roche), 오카라투주맙(AME-133v, LY2469298; Mentrik Biotech, LLC), 오파투무맙(Arzerra®, Genmab), 오나르투주맙(Genentech), 온툭시주맙(Morphotek, Inc.), 오레고보맙(오바렉스®, AltaRex Corp.), 오틀레르투주맙(Emergent BioSolutions), 파니투무맙(ABX-EGF, Amgen), 판코맙(Glycotope GMBH), 파르사투주맙(Genentech), 파트리투맙, 펨브롤리주맙(Keytruda®, Merck), 펨투모맙(테라긴, Antisoma), 페르투주맙(페르제타, Genentech), 피딜리주맙(CT-011, Medivation), 폴라투주맙 보도틴(Genentech/Roche), 프리투무맙, 라코투모맙(Vaxira®, Recombio), 라무시루맙(Cyramza®, ImClone Systems Inc.), 리툭시맙(Rituxan®, Genentech), 로바투무맙(Schering-Plough), 세리반투맙(Sanofi/Merrimack Pharmaceuticals, Inc.), 시브로투주맙, 실툭시맙(SylvantTM, Janssen Biotech), 스마트 MI95(Protein Design Labs, Inc.), 스마트 ID10(Protein Design Labs, Inc.), 타발루맙(LY2127399, Eli Lilly), 타플리투모맙 팝톡스, 테나투모맙, 테프로투무맙(Roche), 테툴로맙, TGN1412(CD28-SuperMAB 또는 TAB08), 티가투주맙(CD-1008, Daiichi Sankyo), 토시투모맙, 트라스투주맙(Herceptin®), 트레멜리무맙(CP-672,206; Pfizer), 투코투주맙 셀몰류킨(EMD Pharmaceuticals), 우블리툭시맙, 우렐루맙(BMS-663513, Bristol-Myers Squibb), 볼로식시맙(M200, Biogen Idec), 및 자툭시맙을 포함하지만 이에 제한되지 않는다.
일부 예에서, 항체 또는 이의 결합 단편은 항체-약물 접합체(ADC)이다. 일부 경우에서, ADC의 페이로드는, 예컨대 아우리스타틴 유도체, 메이탄신, 메이탄시노이드, 탁산, 칼리케아미신, 세마도틴, 두오카르마이신, 피롤로벤조디아제핀(PDB) 또는 투불리신을 포함하지만 이에 제한되지 않는다. 일부 예에서, 페이로드는 모노 메틸 아우리스타틴 E(MMAE) 또는 모노메틸 아우리스타틴 F(MMAF)를 포함한다. 일부 예에서, 페이로드는 DM2(메르탄신) 또는 DM4를 포함한다. 일부 예에서, 페이로드는 피롤로벤조디아제핀 이량체를 포함한다.
추가의 카고
일부 실시양태에서, 카고는 펩티드모방체이다. 펩티드모방체는 펩티드를 모방하도록 설계된 작은 단백질-유사 중합체이다. 일부 예에서, 펩티드모방체에는 D- 펩티드를 포함한다. 다른 예에서, 펩티드모방체는 L-펩티드를 포함한다. 예시적인 펩티드모방체는 펩토이드 및 β-펩티드를 포함한다.
일부 실시양태에서, 카고는 뉴클레오티드모방체이다.
벡터 및 발현 시스템
특정 실시양태에서, 상술된 Arc 폴리펩티드, endo-Gag 폴리펩티드, 조작된 Arc 및 조작된 endo-Gag 폴리펩티드는 플라스미드 벡터에 의해 코딩된다. 일부 실시양태에서, 벡터는 진핵 또는 원핵 공급원으로부터 유래된 임의의 적합한 벡터를 포함한다. 일부 경우에서, 벡터는 박테리아(예컨대, 이. 콜라이(E. coli)), 곤충, 효모(예컨대, 피키아 파스토리스(Pichia pastoris)), 조류, 또는 포유동물 공급원으로부터 수득된다.
예시적인 박테리아 벡터는 pACYC177, pASK75, pBAD 벡터 시리즈, pBADM 벡터 시리즈, pET 벡터 시리즈, pETM 벡터 시리즈, pGEX 벡터 시리즈, pHAT, pHAT2, pMal-c2, pMal-p2, pQE 벡터 시리즈, pRSET A, pRSET B, pRSET C, pTrcHis2 series, pZA31-Luc, pZE21-MCS-1, pFLAG ATS, pFLAG CTS, pFLAG MAC, pFLAG Shift-12c, pTAC-MAT-1, pFLAG CTC, 또는 pTAC-MAT-2를 포함한다.
예시적인 곤충 벡터는 pFastBac1, pFastBac DUAL, pFastBac ET, pFastBac HTa, pFastBac HTb, pFastBac HTc, pFastBac M30a, pFastBact M30b, pFastBac, M30c, pVL1392, pVL1393, pVL1393 M10, pVL1393 M11, pVL1393 M12, FLAG 벡터, 예컨대 pPolh-FLAG1 또는 pPolh-MAT 2, 또는 MAT 벡터, 예컨대 pPolh-MAT1, 또는 pPolh-MAT2를 포함한다.
일부 경우에서, 효모 벡터는 Gateway® pDESTTM 14 벡터, Gateway® pDESTTM 15 벡터, Gateway® pDESTTM 17 벡터, Gateway® pDESTTM 24 벡터, Gateway® pYES-DEST52 벡터, pBAD-DEST49 Gateway® 목표 벡터, pAO815 피키아 벡터, pFLD1 피키 파스토리스(Pichi pastoris) 벡터, pGAPZA,B, & C 피키아 파스토리스 벡터, pPIC3.5K 피키아 벡터, pPIC6 A, B, & C 피키아 벡터, pPIC9K 피키아 벡터, pTEF1/Zeo, pYES2 효모 벡터, pYES2/CT 효모 벡터, pYES2/NT A, B, & C 효모 벡터, 또는 pYES3/CT 효모 벡터를 포함한다.
예시적인 조류 벡터는 pChlamy-4 벡터 또는 MCS 벡터를 포함한다.
포유동물 벡터의 예는 일시적 발현 벡터 또는 안정한 발현 벡터를 포함한다. 포유동물 일시적 발현 벡터는 p3xFLAG-CMV 8, pFLAG-Myc-CMV 19, pFLAG-Myc-CMV 23, pFLAG-CMV 2, pFLAG-CMV 6a,b,c, pFLAG-CMV 5.1, pFLAG-CMV 5a,b,c, p3xFLAG-CMV 7.1, pFLAG-CMV 20, p3xFLAG-Myc-CMV 24, pCMV-FLAG-MAT1, pCMV-FLAG-MAT2, pBICEP-CMV 3, 또는 pBICEP-CMV 4를 포함한다. 포유동물 안정한 발현 벡터는 pFLAG-CMV 3, p3xFLAG-CMV 9, p3xFLAG-CMV 13, pFLAG-Myc-CMV 21, p3xFLAG-Myc-CMV 25, pFLAG-CMV 4, p3xFLAG-CMV 10, p3xFLAG-CMV 14, pFLAG-Myc-CMV 22, p3xFLAG-Myc-CMV 26, pBICEP-CMV 1, 또는 pBICEP-CMV 2를 포함한다.
일부 예에서, 무세포 시스템은 세포로부터의 세포질 및/또는 핵 성분의 혼합물이며 시험관내 핵산 합성에 사용된다. 일부 경우에서, 무세포 시스템은 원핵 세포 성분 또는 진핵 세포 성분을 사용한다. 때때로, 핵산 합성은, 예컨대 드로소필라 세포, 제노푸스 난자, 또는 HeLa 세포(ATCC® CCL-2™)를 기반으로 하는 무세포 시스템에서 수득된다. 예시적인 무세포 시스템은 이. 콜라이 S30 추출물 시스템, 이. 콜라이 T7 S30 시스템, 또는 PURExpress®를 포함하지만 이에 제한되지 않는다.
숙주 세포
일부 실시양태에서, 숙주 세포는 천연 유래 세포 또는 유전자조작으로 변형된 세포와 같은 임의의 적합한 세포를 포함한다. 일부 예에서, 숙주 세포는 생성 숙주 세포이다. 일부 예에서, 숙주 세포는 진핵 세포이다. 다른 예에서 숙주 세포는 원핵 세포이다. 일부 경우에서, 진핵 세포는 진균(예컨대, 효모 세포), 동물 세포, 또는 식물 세포를 포함한다. 일부 경우에서, 원핵 세포가 박테리아 세포이다. 박테리아 세포의 예는 그람 양성 박테리아 또는 그람 음성 박테리아를 포함한다. 일부 실시양태에서 그람 음성 박테리아는 혐기성, 막대형, 또는 둘 다이다.
일부 경우에서, 그람 양성 박테리아는 악티노박테리아(Actinobacteria), 피르미쿠테스(Firmicutes), 또는 테네리쿠테스(Tenericutes)를 포함한다. 일부 경우에서, 그람 음성 박테리아는 아퀴피카에(Aquificae), 데이노코쿠스-페르무스(Deinococcus-Thermus), 피브로박테레스-클로로비/박테로이데테스(Fibrobacteres-Chlorobi/Bacteroidetes)(FCB군), 푸소박테리아(Fusobacteria), 겜마티모나데테스(Gemmatimonadetes), 니트로스피라에(Nitrospirae), 플란크토미세테스-베루코미크로비아/클라미디아에(Planctomycetes-Verrucomicrobia/Chlamydiae)(PVC군), 프로테오박테리아(Proteobacteria), 스피로카에테스(Spirochaetes) 또는 시네르기스테테스(Synergistetes). 일부 실시양태에서, 박테리아는 아시도박테리아(Acidobacteria), 클로로플렉시(Chloroflexi), 크리시오게네테스(Chrysiogenetes), 시아노박테리아(Cyanobacteria), 데페리박테레스(Deferribacteres), 딕티오글로미(Dictyoglomi), 테르모데술포박테리아(Thermodesulfobacteria) 또는 테르모토가에(Thermotogae)를 포함한다. 일부 실시양태에서, 박테리아 세포는 에스케리키아 콜라이(Escherichia coli), 클로스트리디움 보툴리눔(Clostridium botulinum) 또는 콜라이 바실리(Coli bacilli)이다.
예시적인 원핵 숙주 세포는 BL21, Mach1TM, DH10BTM, TOP10, DH5α, DH10BacTM, OmniMaxTM, MegaXTM, DH12STM, INV110, TOP10F', INVαF, TOP10/P3, ccdB 서바이벌(Survival), PIR1, PIR2, Stbl2TM, Stbl3TM, 또는 Stbl4TM을 포함하지만 이에 제한되지 않는다.
일부 예에서, 동물 세포는 척추동물 또는 무척추동물로부터의 세포를 포함한다. 일부 경우에서, 동물 세포는 해양 무척추동물, 어류, 곤충, 양서류, 파충류, 포유동물, 또는 인간으로부터의 세포를 포함한다. 일부 경우에서, 진균 세포는 맥주 효모, 빵 효모 또는 와인 효모와 같은 효모 세포를 포함한다.
진균은 효모, 몰드(mold), 사상균, 담자균 또는 접합균과 같은 자낭균을 포함한다. 일부 예에서, 효모는 아스코미코타(Ascomycota) 또는 바시디오미코타(Basidiomycota)를 포함한다. 일부 경우에서, 아스코미코타는 사카로미코티나(Saccharomycotina)(진정한 효모, 예컨대 사카로미세스 세레비시아에(빵 효모)) 또는 타프리노미코티나(Taphrinomycotina)(예컨대, 쉬조사카로미세테스(Schizosaccharomycetes)(분열 효모))를 포함한다. 일부 경우에서, 바시디오미코타(Basidiomycota)는 아가리코미코티나(Agaricomycotina)(예컨대, 트레멜로미세테스(Tremellomycetes)) 또는 푸시니오미코티나(Pucciniomycotina)(예컨대, 미크로보트리요미세테스(Microbotryomycetes))를 포함한다.
예시적 효모 또는 사상균은, 예컨대 사카로미세스, 쉬조사카로미세스, 칸디다, 피키아, 한세눌라(Hansenula), 클루이베로미세스(Kluyveromyces), 지고사카로미세스(Zygosaccharomyces), 야로위아(Yarrowia), 트리코스포론(Trichosporon), 로도스포리디(Rhodosporidi), 아스페르길루스(Aspergillus), 푸사리움(Fusarium), 또는 트리코데르마(Trichoderma) 속을 포함한다. 예시적 효모 또는 사상균은, 예컨대 사카로미세스 세레비시아에, 쉬조사카로미세스 폼베(Schizosaccharomyces pombe), 칸디다 우틸리스(Candida utilis), 칸디다 보이디니(Candida boidini), 칸디다 알비카스(Candida albicans), 칸디다 트로피칼리스(Candida tropicalis), 칸디다 스텔라토이데아(Candida stellatoidea), 칸디다 글라블라타(Candida glabrata), 칸디다 크루세이(Candida krusei), 칸디다 파라프실로시스(Candida parapsilosis), 칸디다 구일리에르몬디이(Candida guilliermondii), 칸디다 비스와나티이(Candida viswanathii), 칸디다 루시타니아에(Candida lusitaniae), 로도토룰라 무실라기노사(Rhodotorula mucilaginosa), 피키아 메타놀리카(Pichia metanolica), 피키아 안구스타(Pnichia angusta), 피키아 파스토리스(Pichia pastoris), 피키아 아노말라(Pichia anomala), 한세눌라 폴리모르파(Hansenula polymorpha), 클루이베로미세스 락티스(Kluyveromyces lactis), 지고사카로미세스 로욱시이(Zygosaccharomyces rouxii), 야로위아 리폴리티카(Yarrowia lipolytica), 트리코스포론 풀루란스(Trichosporon pullulans), 로도스로리디움 토루-아스페르길루스 니거(Rhodosporidium toru-Aspergillus niger), 아스페르길루스 니둘란스(Aspergillus nidulans), 아스페르길루스 아와모리(Aspergillus awamori), 아스페르길루스 오리자에(Aspergillus oryzae), 트리코데르마 레세이(Trichoderma reesei), 야로위아 리폴리티카(Yarrowia lipolytica), 브레타노미세스 브룩셀렌시스(Brettanomyces bruxellensis), 칸디다 스텔라타(Candida stellata), 쉬조사카로미세스 폼베(Schizosaccharomyces pombe), 토룰라스포라 델브루엑키이(Torulaspora delbrueckii), 지고사카로미세스 바일리이(Zygosaccharomyces bailii), 크립토코쿠스 네오포르만스(Cryptococcus neoformans), 크립토코쿠스 가티이(Cryptococcus gattii), 또는 사카로미세스 보울라르디이(Saccharomyces boulardii) 종을 포함한다.
예시적인 효모 숙주 세포는 GS115, KM71H, SMD1168, SMD1168H 및 X-33과 같은 피키아 파스토리스 효모 균주; 및 INVSc1과 같은 사카로미세스 세레비시아에 효모 균주를 포함하지만 이에 제한되지 않는다.
일부 예에서, 추가의 동물 세포는 연체동물, 절지동물, 환형동물 또는 해면동물로부터 수득되는 세포를 포함한다. 일부 경우에서, 추가의 동물 세포는 포유동물 세포, 예컨대 인간, 영장류, 유인원, 말, 소, 돼지, 개, 고양이 또는 설치류로부터의 세포이다. 일부 경우에서, 설치류는 마우스, 래트, 햄스터, 게르빌, 햄스터, 친칠라, 팬시 래트 또는 기니피그를 포함한다.
예시적인 포유동물 숙주 세포는 293A 세포주, 293FT 세포주, 293F 세포 , 293 H 세포, CHO DG44 세포, CHO-S 세포, CHO-K1 세포, Expi293FTM 세포, Flp-InTM T-RExTM 293 세포주, Flp-InTM-293 세포주, Flp-InTM-3T3 세포주, Flp-InTM-BHK 세포주, Flp-InTM-CHO 세포주, Flp-InTM-CV-1 세포주, Flp-InTM-Jurkat 세포주, FreeStyleTM 293-F 세포, FreeStyleTM CHO-S 세포, GripTiteTM 293 MSR 세포주, GS-CHO 세포주, HepaRGTM 세포, T-RExTM Jurkat 세포주, Per.C6 세포, T-RExTM-293 세포주, T-RExTM-CHO 세포주, 및 T-RExTM-HeLa 세포주를 포함하지만 이에 제한되지 않는다.
일부 예에서, 포유동물 숙주 세포는 1차 세포이다. 일부 예에서, 포유동물 숙주 세포는 안정한 세포주, 또는 관심 유전 물질을 자체 게놈에 통합하고 여러 세대의 세포 분열 후에 유전 물질의 산물을 발현할 수 있는 능력을 가진 세포주이다. 일부 경우에서, 포유동물 숙주 세포는 일시적 세포주, 또는 관심 유전 물질을 자체 게놈에 통합하지 않고 여러 세대의 세포 분열 후에 유전 물질의 산물을 발현할 능력이 없는 세포주이다.
예시적인 곤충 숙주 세포는 드로소필라 S2 세포, Sf9 세포, Sf21 세포, High Five™ 세포 및 expresSF+® 세포를 포함하지만 이에 제한되지 않는다.
일부 예에서, 식물 세포는 조류로부터의 세포를 포함한다. 예시적인 곤충 세포주는 클라미도모나스 레이하르드티이(Chlamydomonas reinhardtii), 또는 시네코코쿠스 엘론가투스 PPC 7942(Synechococcus elongatus PPC 7942)로부터의 스트레인을 포함한다.
사용 방법
특정 실시양태에서, 카고를 캡슐화하는 캡시드를 제조하는 방법이 본원에 개시된다. 일부 실시양태에서, 방법은 복수의 Arc 또는 endo-Gag 폴리펩티드, 조작된 Arc 또는 endo-Gag 폴리펩티드, 및/또는 재조합 Arc 또는 endo-Gag 폴리펩티드를 로딩된 Arc 기반 캡시드 또는 endo-Gag 기반 캡시드를 생성하기에 충부한 시간 동안 용액에서 카고와 함께 인큐베이션하는 단계를 포함한다.
일부 예에서, 방법은 카고와 함께 인큐베이션하기 전에 복수의 조작된 및/또는 재조합 Arc 폴리펩티드를 포함하는 용액을 복수의 비-Arc 캡시드 형성 서브유닛과 혼합하는 단계를 포함한다. 일부 경우에서, 복수의 비-Arc 캡시드 형성 서브유닛은 복수의 조작된 및/또는 재조합 Arc 폴리펩티드와 1:1, 2:1, 3:1, 4:1, 5:1, 6:1, 7:1, 8:1, 9:1, 또는 10:1의 비로 혼합된다. 다른 경우에서, 복수의 비-Arc 캡시드 형성 서브유닛은 복수의 조작된 및/또는 재조합 Arc 폴리펩티드와 1:2, 1:3, 1:4, 1:5, 1:6, 1:7, 1:8, 1:9, 또는 1:10의 비로 혼합된다.
일부 경우에서, 로딩된 Arc 기반 캡시드 또는 endo-Gag 기반 캡시드를 생성하기에 충분한 시간은 적어도 약 5분, 적어도 약 10분, 적어도 약 20분, 적어도 약 30분, 적어도 약 1시간, 적어도 약 2시간, 적어도 약 4시간, 적어도 약 6시간, 적어도 약 10시간, 적어도 약 12시간, 적어도 약 24시간, 또는 그 초과이다.
일부 경우에서, Arc 기반 캡시드 또는 endo-Gag 기반 캡시드는 약 2℃ 내지 약 37℃의 온도에서 제조된다. 일부 예에서, Arc 기반 캡시드 또는 endo-Gag 기반 캡시드는 약 2℃ 내지 약 8℃, 약 2℃ 내지 약 4℃, 약 20℃ 내지 약 37℃, 약 25℃ 내지 약 37℃, 약 20℃ 내지 약 30℃, 약 25℃ 내지 약 30℃, 또는 약 30℃ 내지 약 37℃의 온도에서 제조된다.
일부 경우에서, Arc 기반 캡시드 또는 endo-Gag 기반 캡시드는 실온에서 제조된다.
일부 예에서, Arc 기반 캡시드 또는 endo-Gag 기반 캡시드는 전신 투여용으로 추가로 제제화된다.
일부 예에서, Arc 기반 캡시드 또는 endo-Gag 기반 캡시드는 국소 투여용으로 추가로 제제화된다.
일부 예에서, Arc 기반 캡시드 또는 endo-Gag 기반 캡시드는 비경구(예컨대, 동맥내, 관절내, 피내, 병변내, 근육내, 안내, 골내 주입, 복강내, 척추강내, 정맥내, 유리체내, 또는 피하) 투여용으로 추가로 제제화된다.
일부 예에서, Arc 기반 캡시드 또는 endo-Gag 기반 캡시드는 국부 투여용으로 추가로 제제화된다.
일부 예에서, Arc 기반 캡시드 또는 endo-Gag 기반 캡시드는 경구 투여용으로 추가로 제제화된다.
일부 예에서, Arc 기반 캡시드 또는 endo-Gag 기반 캡시드는 설하 투여용으로 추가로 제제화된다.
일부 예에서, Arc 기반 캡시드 또는 endo-Gag 기반 캡시드는 에어로졸 투여용으로 추가로 제제화된다.
특정 실시양태에서, 또한 관심 부위로 카고를 전달하기 위한 Arc 기반 캡시드 또는 endo-Gag 기반 캡시드의 용도가 본원에 기재된다. 일부 예에서, 방법은 관심 부위의 세포를 캡시드의 세포 흡수를 촉진하기에 충분한 시간 동안 Arc 기반 캡시드 또는 endo-Gag 기반 캡시드와 접촉시키는 단계를 포함한다.
일부 경우에서, 세포는 근육 세포, 피부 세포, 혈액 세포, 또는 면역 세포(예컨대, T 세포 또는 B 세포)이다.
일부 예에서, 세포는 종양 세포, 예컨대 고형 종양 세포 또는 혈액 악성종양으로부터의 세포이다. 일부 경우에서, 고형 종양 세포는 방광암, 유방암, 뇌암, 결장직장암, 신장암, 간암, 폐암, 췌장암, 전립선암, 피부암, 위암, 또는 갑상선암으로부터의 세포이다. 일부 경우에서, 혈액 악성종양으로부터의 세포는 B 세포 악성종양 또는 T 세포 악성종양으로부터의 것이다. 일부 경우에서, 세포는 백혈병, 림프종, 골수종, 만성 림프구성 백혈병(CLL), 소 림프구성 림프종(SLL), 미만성 거대 B 세포 림프종(DLBCL), 소포 림프종, 맨틀 세포 림프종, 버킷 림프종, 피부 T 세포 림프종, 말초 T 세포 림프종, 다발성 골수종, 형질세포종, 급성 림프아구성 백혈병(ALL), 급성 골수성 백혈병(AML) 또는 만성 골수성 백혈병(CML)으로부터의 것이다.
일부 실시양태에서, 세포는 체세포이다. 일부 예에서, 세포는 혈액 세포, 피부 세포, 결합 조직 세포, 뼈 세포, 근육 세포, 또는 기관으로부터의 세포이다.
일부 실시양태에서, 세포는 상피 세포, 결합 조직 세포, 근육 세포, 또는 뉴런이다.
일부 예에서, 세포는 내배엽 세포, 중배엽 세포, 또는 외배엽이다. 일부 예에서, 내배엽은 호흡기, 장, 간, 담낭, 췌장, 랑게르한스섬, 갑상선 또는 후장의 세포를 포함한다. 일부 경우에서, 중배엽은 골연골전구세포, 근육 세포, 소화계로부터의 세포, 신장 줄기 세포, 생식계로부터의 세포, 순환계로부터의 세포(예컨대, 내피 세포)를 포함한다. 외배엽으로부터의 예시적인 세포는 상피 세포, 뇌하수체 전엽 세포, 말초 신경계 세포, 신경내분비계 세포, 눈 세포, 중추 신경계 세포, 뇌실막 세포, 또는 송과체 세포를 포함한다. 일부 경우에서, 중추 및 말초 신경계로부터 유래되는 세포는 뉴런, 슈반 세포, 위성 아교 세포, 희돌기아교세포 또는 성상 세포를 포함한다. 일부 경우에서, 뉴런은 인터뉴런, 피라미드 뉴런, 가바성(gabaergic) 뉴런, 도파민성 뉴런, 세로토닌성 뉴런, 글루타메이트성 뉴런, 척수로부터의 운동 뉴런, 또는 억제성 척수 뉴런을 추가로 포함한다.
일부 실시양태에서, 세포는 줄기 세포 또는 전구 세포이다. 일부 경우에서, 세포가 중간엽 줄기 또는 전구 세포이다. 다른 경우에서, 세포는 조혈 줄기 또는 전구 세포이다.
일부 경우에서, 표적 단백질은 세포에서 과발현되거나 세포에서 고갈된다. 일부 경우에서, 표적 단백질은 세포에서 과발현된다. 추가의 경우에서, 표적 단백질은 세포에서 고갈된다.
일부 경우에서, 세포의 표적 유전자는 하나 이상의 돌연변이를 갖는다.
일부 경우에서, 세포는 손상된 스플라이싱 메커니즘을 포함한다.
일부 예에서, Arc 기반 캡시드는 이를 필요로 하는 대상체에게 전신 투여된다.
다른 예에서, Arc 기반 캡시드 또는 endo-Gag 기반 캡시드는 이를 필요로 하는 대상체에게 국소적으로 투여된다.
일부 실시양태에서, Arc 기반 캡시드 또는 endo-Gag 기반 캡시드는 이를 필요로 하는 대상체에게 비경구적으로, 경구적으로, 국부적으로, 설하를 통해, 또는 에어로졸에 의해 투여된다. 일부 경우에서, Arc 기반 캡시드 또는 endo-Gag 기반 캡시드는 이를 필요로 하는 대상체에게 비경구적으로 투여된다. 다른 경우에서, Arc 기반 캡시드 또는 endo-Gag 기반 캡시드는 이를 필요로 하는 대상체에게 경구적으로 투여된다. 추가의 경우에서, Arc 기반 캡시드 또는 endo-Gag 기반 캡시드는 이를 필요로 하는 대상체에게 국부적으로, 설하를 통해, 또는 에어로졸에 의해 투여된다.
일부 실시양태에서, 전달 성분은 관심 부위로의 표적 전달을 위해 Arc 기반 캡시드 또는 endo-Gag 기반 캡시드와 조합된다. 일부 예에서, 전달 성분은 담체, 예컨대 미셀, 리포솜, 또는 미세소포와 같은 세포외 소포; 또는 바이러스 외피를 포함한다.
일부 예에서, 전달 성분은 자체 전달 성분을 포함하지 않는(예컨대, 제2 폴리펩티드가 존재하지 않는) Arc 기반 캡시드 또는 endo-Gag 기반 캡시드에 대한 1차 전달 비히클의 역할을 한다. 이러한 경우에서, 전달 성분은 Arc 기반 캡시드 또는 endo-Gag 기반 캡시드를 관심 표적 부위로 유도하고 임의적으로 세포내 흡수를 촉진한다.
다른 예에서, 전달 성분은 Arc 기반 캡시드의 제2 폴리펩티드의 표적 특이성 및/또는 민감도를 향상시킨다. 이러한 경우에서, 전달 성분은 표적 부위에 대한 Arc 기반 캡시드 또는 endo-Gag 기반 캡시드의 특이성 및/또는 친화성을 향상시킨다. 추가의 경우에서, 전달 성분은 특이성 및/또는 친화성을 약 2배, 3배, 4배, 5배, 6배, 7배, 8배, 9배, 10배, 20배, 30배, 50배, 100배, 200배, 500배, 또는 그 초과로 향상시킨다. 추가의 경우에서, 전달 성분은 특이성 및/또는 친화성을 약 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100%, 200%, 500%, 또는 그 초과로 향상시킨다. 또한, 전달 성분은 임의적으로 표적외 효과를 약 2배, 3배, 4배, 5배, 6배, 7배, 8배, 9배, 10배, 20배, 30배, 50배, 100배, 200배, 500배, 또는 그 초과로 감소시킨다. 또한, 전달 성분은 임의적으로 표적외 효과를 약 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100%, 200%, 500%, 또는 그 초과로 감소시킨다.
추가의 예에서, 전달 성분은 Arc 기반 캡시드를 일반적인 표적 영역(예컨대, 종양 미세환경)으로 수송하는 제1 비히클의 역할을 하고 Arc 기반 또는 endo-Gag 기반 캡시드의 제2 폴리펩티드는 Arc 기반 캡시드 또는 endo-Gag 기반 캡시드를 특정 표적 부위로 유도하고 임의적으로 세포내 흡수를 촉진하는 제2 전달 분자의 역할을 한다. 이러한 경우에서, 전달 성분은 표적외 효과를 약 2배, 3배, 4배, 5배, 6배, 7배, 8배, 9배, 10배, 20배, 30배, 50배, 100배, 200배, 500배, 또는 그 초과로 감소시킨다. 이러한 경우에서, 전달 성분은 표적외 효과를 약 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100%, 200%, 500%, 또는 그 초과로 감소시킨다.
추가의 예에서, 전달 성분은 Arc 기반 캡시드를 관심 표적 부위로 수송하는 제1 비히클의 역할을 하고, Arc 기반 또는 endo-Gag 기반 캡시드의 제2 폴리펩티드는 세포내 흡수를 촉진하는 제2 전달 분자의 역할을 한다.
일부 실시양태에서, 전달 성분은 세포외 소포를 포함한다. 일부 예에서, 세포외 소포는 미세소포, 리포솜 또는 미셀을 포함한다. 일부 예에서, 세포외 소포는 약 10 nm 내지 약 2000 nm, 약 10 nm 내지 약 1000 nm, 약 10 nm 내지 약 800 nm, 약 20 nm 내지 약 600 nm, 약 30 nm 내지 약 500 nm, 약 50 nm 내지 약 200 nm, 또는 약 80 nm 내지 약 100 nm의 직경을 갖는다.
일부 실시양태에서, 전달 성분은 미세소포를 포함한다. 순환하는 미세소포 또는 미세입자로도 알려진 미세소포는 인지질을 포함하는 막 결합된 소포이다. 일부 예에서, 미세소포는 약 50 nm 내지 약 1000 nm, 약 100 nm 내지 약 800 nm, 약 200 nm 내지 약 500 nm, 또는 약 50 nm 내지 약 400 nm의 직경을 갖는다.
일부 예에서, 미세소포는 세포막 역전, 세포외배출, 흘림(shedding), 블레빙(blebbing), 또는 출아(budding)로부터 유래된다. 일부 경우에서, 미세소포는 분화된 세포로부터 생성된다. 다른 예에서, 미세소포는 미분화된 세포로부터, 예컨대 모세포, 전구 세포 또는 줄기 세포에 의해 생성된다.
일부 실시양태에서, 전달 성분은 리포솜을 포함한다. 일부 예에서, 리포솜은 관심 부위 또는 영역으로의 표적 전달을 위해 리포솜의 표면에 존재하는 복수의 리포펩티드를 포함한다. 일부 경우에서, 리포솜이 표적 세포와 융합되어 리포솜의 내용물이 표적 세포로 비워진다. 일부 경우에서, 리포솜이 식세포성 세포에 의해 세포내이입된다. 세포내이입은 리소좀 지질의 리소좀내 분해 및 캡슐화된 작용제의 방출로 이어진다.
통합에 적합한 예시적인 리포솜은 다층 소포(MLV), 올리고층 소포(OLV), 단층 소포(UV), 작은 단층 소포(SUV), 중간 크기 단층 소포(MUV), 큰(large) 단층 소포(LUV), 거대(giant) 단층 소포(GUV), 다낭(multivesicular) 소포(MVV), 역상 증발법으로 제조된 단일 또는 올리고층 소포(REV), 역상 증발법으로 제조된 다층 소포(MLV-REV), 안정한 다수층(plurilamellar) 소포(SPLV), 냉동 및 해동된 MLV(FATMLV), 압출 방법으로 제조된 소포(VET), 프렌치 프레스에 의해 제조된 소포(FPV), 융합에 의해 제조된 소포(FUV), 탈수-재수화 소포(DRV), 및 버블솜(BSV)을 포함하지만 이에 제한되지 않는다. 일부 예에서, 리포솜은 알피폴(Amphipol)(A8-35)을 포함한다. 리포솜 제조 기술은, 예컨대 문헌(COLLOIDAL DRUG DELIVERY SYSTEMS, vol. 66 (J. Kreuter ed., Marcel Dekker, Inc. (1994)))에 기재되어 있다.
제조 방법에 따라, 리포솜은 단층 또는 다층이고, 직경이 약 20 nm부터 약 1000 nm 초과로 크기가 다양하다.
일부 예에서, 본원에 제공된 리포솜은 또한 담체 지질을 포함한다. 일부 실시양태에서, 담체 지질은 인지질이다. 리포솜을 형성할 수 있는 담체 지질은 디팔미토일포스파티딜콜린(DPPC), 포스파티딜콜린(PC; 레시틴), 포스파티드산(PA), 포스파티딜글리세롤(PG), 포스파티딜에탄올아민(PE), 또는 포스파티딜세린(PS)을 포함하지만 이에 제한되지 않는다. 다른 적합한 인지질은 추가로 디스테아로일포스파티딜콜린(DSPC), 디미리스토일포스파티딜콜린(DMPC), 디팔미토일포스파티딜글리세롤(DPPG), 디스테아로일포스파티딜글리세롤(DSPG), 디미리스토일포스파티딜글리세롤(DMPCG); 디미리스토일포스파티드산(DMPA), 디스테아로일포스파티드산(DSPA), 디팔미토일포스파티딜세린(DPSP), 디미리스토일포스파티딜세린(ASD), 디스테아로일포스파티딜세린(DSPS), 디팔미토일포스파티딜에탄올아민(DPPE), 디미리스토일포스파티딜에탄올아민(DMPE), 디스테아로일포스파티틸에탄올아민(DSPE) 등을 포함하지만 이에 제한되지 않는다. 일부 실시양태에서, 리포솜은 리포솜 형성을 조정하는 스테롤(예컨대, 콜레스테롤)을 추가로 포함한다. 담체 지질은 임의적으로 비-포스페이트 극성 지질이다.
일부 실시양태에서, 전달 성분은 미셀을 포함한다. 일부 예에서, 미셀은 약 2 nm 내지 약 250 nm, 약 20 nm 내지 약 200 nm, 약 20 nm 내지 약 100 nm, 또는 약 50 내지 약 100 nm의 직경을 갖는다.
일부 경우에서, 미셀은 소수성 코어가 친수성 쉘로 둘러싸여진 코어 쉘 구조를 특징으로 하는 중합체 미셀이다. 일부 경우에서, 친수성 쉘은 친수성 중합체 또는 공중합체 및 pH 민감성 성분을 추가로 포함한다.
예시적인 친수성 중합체 또는 공중합체는 폴리(N-치환된 아크릴아미드), 폴리(N-아크릴로일 피롤리딘), 폴리(N-아크릴로일 피페리딘), 폴리(N-아크릴-L-아미노산 아미드), 폴리(에틸 옥사졸린), 메틸셀룰로스, 히드록시프로필 아크릴레이트, 히드록시알킬 셀룰로스 유도체 및 폴리(비닐 알콜), 폴리(N-이소프로필 아크릴아미드), 폴리(N-비닐-2-피롤리돈), 폴리에틸렌글리콜 유도체, 및 이들의 조합을 포함하지만 이에 제한되지 않는다.
pH 민감성 모이어티는 알킬아크릴산, 예컨대 메타크릴산, 에틸아크릴산, 프로필 아크릴산 및 부틸 아크릴산과 같은 알킬 아크릴산, 또는 아미노산, 예컨대 글루탐산을 포함하지만 이에 제한되지 않는다.
일부 경우에서, 소수성 모이어티는 미셀의 코어를 구성하고, 예컨대 옥타 데실 아크릴레이트와 같은 단일 알킬 쇄 또는 포스파티딜에탄올아민 또는 디옥타데실아민과 같은 이중 쇄 알킬 화합물을 포함한다. 일부 경우에서, 소수성 모이어티는 임의적으로 폴리(락트산) 또는 폴리(e-카프롤락톤)와 같은 수불용성 중합체이다.
pH 민감성을 나타내는 중합체성 미셀도 고려되며, 예컨대 메타크릴산, 메타크릴산 에스테르 및 아크릴산 에스테르, 폴리비닐 아세테이트 프탈레이트, 히드록시프로필 메틸 셀룰로스 프탈레이트, 셀룰로스 아세테이트 프탈레이트, 또는 셀룰로스 아세테이트 트리멜리테이트로부터의 공중합체를 포함하지만 이에 제한되지 않는 pH-민감성 중합체를 사용하여 형성된다.
일부 실시양태에서, 전달 성분은 바이러스 외피를 포함한다. 바이러스 외피는 당단백질, 인지질, 및 숙주로부터 수득되는 추가의 단백질을 포함한다. 일부 예에서, 바이러스 외피는 광범위한 표적 세포에 대해 허용된다. 다른 경우에서, 바이러스 외피는 허용되지 않으며 관심 표적 세포에 특이적이다. 일부 경우에서, 바이러스 외피는 세포-특이적 결합 단백질 및 임의적으로 표적 세포로의 카고의 융합을 돕는 융합형성 분자를 포함한다. 일부 경우에서, 바이러스 외피는 내인성 바이러스 외피를 포함한다. 다른 경우에서, 바이러스 외피는 하나 이상의 외래 단백질을 포함하는 변형된 외피이다.
일부 예에서, 바이러스 외피는 DNA 바이러스로부터 유래된다. 예시적인 외피 DNA 바이러스는 헤르페스비리다에(Herpesviridae), 폭스비리다에(Poxviridae), 및 헤파드나비리다에(Hepadnavirdae) 과로부터의 바이러스를 포함한다.
다른 경우에서, 바이러스 외피는 RNA 바이러스로부터 유래된다. 예시적인 외피 RNA 바이러스는 부냐비리다에(Bunyaviridae), 코로나비리다에(Coronaviridae), 필로비리다에(Filoviridae), 플라비비리다에(Flaviviridae), 오르토믹소비리다에(Orthomyxoviridae), 파라믹소비리다에(Paramyxoviridae), 라브도비리다에(Rhabdoviridae) 및 토가비리다에(Togaviridae) 과로부터의 바이러스를 포함한다.
추가의 예에서, 바이러스 외피는 레트로비리다에(Retroviridae) 과로부터의 바이러스로부터 유래된다.
일부 실시양태에서, 바이러스 외피는 종양용해성 바이러스, 예컨대 헤르페스비리다에(Herpesviridae)(예컨대, HSV1) 또는 폭스비리다에(Poxviridae)(예컨대, 박시니아 바이러스 및 믹소마 바이러스) 과로부터의 종양용해성 DNA 바이러스; 또는 라브도비리다에(Rhabdoviridae)(예컨대, VSV) 또는 파라믹소비리다에(Paramyxoviridae)(예컨대, MV 및 NDV) 과로부터의 종양용해성 RNA 바이러스로부터의 것이다.
일부 예에서, 바이러스 외피는 항원 또는 세포 표면 분자에 결합하는 외래 또는 조작된 단백질을 추가로 포함한다. 표적화를 위한 예시적인 항원 및 세포 표면 분자는 P-당단백질, Her2/Neu, 에리트로포이에틴(EPO), 표피 성장 인자 수용체(EGFR), 혈관 내피 성장 인자 수용체(VEGF-R), 카드헤린, 암배아 항원(CEA), CD4. CD8, CD19. CD20, CD33, CD34, CD45, CD117(c-kit), CD133, HLA-A. HLA-B, HLA-C, 케모카인 수용체 5(CCRS), 줄기 세포 마커 ABCG2 수송체, 난소암 항원 CA125, 면역글로불린, 인테그린, 전립선 특이적 항원(PSA), 전립선 줄기 세포 항원(PSCA), 수지상 세포 특이적 세포간 부착 분자 3-그래빙 비-인테그린(DC-SIGN), 티로글로불린, 과립구-대식구 콜로니 자극 인자(GM-CSF), 근원성 분화 촉진 인자-1(MyoD-1), Leu-7(CD57), LeuM-1, 모노클로날 항체 Ki-67(Ki-67)에 의해 정의되는 세포 증식 관련된 인간 핵 항원, 바이러스 외피 단백질, HIV gp120 또는 트랜스페린 수용체를 포함하지만 이에 제한되지 않는다.
일부 실시양태에서, Arc 기반 캡시드 또는 endo-Gag 기반 캡시드는 시험관 내 사용을 위한 것이다.
일부 예에서, Arc 기반 캡시드 또는 endo-Gag 기반 캡시드는 생체외 사용을 위한 것이다.
일부 경우에서, Arc 기반 캡시드 또는 endo-Gag 기반 캡시드는 생체내 사용을 위한 것이다.
키트/제조 물품
특정 실시양태에서, 본원에 기재된 하나 이상의 방법과 함께 사용하기 위한 키트 및 제조 물품이 본원에 개시된다. 이러한 키트는 바이알, 튜브 등과 같은 하나 이상의 용기를 수용하도록 구획화된 캐리어, 패키지 또는 용기를 포함하며, 각각의 용기(들)는 본원에 기재된 방법에 사용되는 개별 요소 중 하나를 포함한다. 적합한 용기는, 예컨대 병, 바이알, 주사기 및 시험관을 포함한다. 일 실시양태에서, 용기는 유리 또는 플라스틱과 같은 다양한 물질로부터 형성된다.
예컨대, 용기(들)는 상술된 재조합 또는 조작된 Arc 또는 endo-Gag 폴리펩티드를 포함한다. 이러한 키트는 임의적으로 본원에 기재된 방법에서의 사용과 관련된 식별 설명 또는 라벨 또는 지침을 포함한다. 예컨대, 키트는 전형적으로 내용물이 나열된 라벨 및/또는 사용 지침, 및 사용 지침을 갖는 패키지 삽입물을 포함한다. 전형적으로 지침 세트도 포함될 것이다.
특정 용어
달리 정의되지 않는 한, 본원 사용된 모든 기술 및 과학 용어는 일반적으로 이해되는 것과 동일한 의미를 갖는다. 상세한 설명은 단지 예시적이고 설명적인 것이며 청구된 임의의 주제를 제한하지 않는다는 것을 이해해야 한다. 본 출원에서, 단수의 사용은 특별히 달리 언급되지 않는 한 복수를 포함한다. 명세서에서 사용되는 바와 같이, 단수 형태는 문맥이 달리 명확하게 지시하지 않는 한 복수 지시 대상을 포함한다는 점에 유의해야 한다. 본 출원에서 "또는"의 사용은 달리 명시되지 않는 한 "및/또는"을 의미한다. 또한, 용어 "포함하는" 뿐만 아니라 "포함한다" 및 "포함되는"과 같은 다른 형태의 사용은 제한적이지 않다.
본 발명의 다양한 특징이 단일 실시양태의 맥락에서 설명될 수 있지만, 특징은 또한 개별적으로 또는 임의의 적절한 조합으로 제공될 수 있다. 반대로, 본 발명은 명확성을 위해 별도의 실시양태의 맥락에서 본원에서 설명될 수 있지만, 본 발명은 또한 단일 실시양태로 구현될 수 있다.
본 명세서에서 "일부 실시양태", "일 실시양태", "한 실시양태" 또는 "다른 실시양태"에 대한 언급은, 실시양태와 관련하여 설명된 특정 특징, 구조 또는 특성이 본 발명의 적어도 일부 실시양태에 포함되며 반드시 모든 실시양태에 필요한 것은 아니라는 것을 의미한다.
본원에서 사용되는 바와 같이, 범위 및 양은 "약" 특정 값 또는 범위로 표현될 수 있다. 약은 또한 정확한 양을 포함한다. 따라서, "약 5 μL"는 "약 5 μL" 및 "5 μL"을 의미한다. 일반적으로, 용어 "약"은 실험 오차 내에 있을 것으로 예상되는 양을 포함한다.
본원에 사용된 섹션 제목은 조직화 목적으로만 사용되며 기재된 주제를 제한하는 것으로 해석되어서는 안된다.
본원에서 사용되는 바와 같이, 본원에 기재된 CA N-로브의 서열은 인간 CA N-로브에 상응한다. 일부 예에서, 인간 CA N-로브는 서열번호 1의 잔기 207-278을 포함한다. 일부 예에서, 본원에 기재된 CA N-로브는 서열번호 1의 잔기 207-278과 약 30%, 40%, 50%, 60%, 70%, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97% 98% 또는 99% 서열 동일성을 포함한다. 일부 경우에서, 본원에 기재된 CA N-로브는 인간 CA N-로브와 구조적 유사성을 공유한다. 예컨대, 본원에 기재된 CA N-로브는 인간 CA N-로브와 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97% 98% 또는 99% 구조적 유사성을 공유한다. 일부 경우에서, CA N-로브는 높은 구조적 유사성(예컨대, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97% 98% 또는 99% 구조적 유사성)을 공유하지만 높은 서열 동일성은 공유하지 않는다(예컨대, 서열 동일성은 80% 미만, 70% 미만, 60% 미만, 50% 미만, 40% 미만 또는 30% 미만임). 일부 경우에서, CA N-로브는 서열번호 1의 잔기 207-278을 포함한다.
본원에서 사용되는 바와 같이, 본원에 기재된 CA C-로브의 서열은 인간 CA C-로브에 상응한다. 일부 예에서, 인간 CA C-로브는 서열번호 1의 잔기 278-370을 포함한다. 일부 예에서, 본원에 기재된 CA C-로브는 서열번호 1의 잔기 278-370과 약 30%, 40%, 50%, 60%, 70%, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97% 98% 또는 99% 서열 동일성을 포함한다. 일부 경우에서, 본원에 기재된 CA C-로브는 인간 CA C-로브와 구조적 유사성을 공유한다. 예컨대, 본원에 기재된 CA C-로브는 인간 CA C-로브와 약 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97% 98% 또는 99% 구조적 유사성을 공유한다. 일부 경우에서, CA C-로브는 높은 구조적 유사성(예컨대, 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97% 98% 또는 99% 구조적 유사성)을 공유하지만 높은 서열 동일성은 공유하지 않는다(예컨대, 서열 동일성은 80% 미만, 70% 미만, 60% 미만, 50% 미만, 40% 미만 또는 30% 미만임). 일부 경우에서, CA C-로브는 서열번호 1의 잔기 278-370을 포함한다.
본원에 사용된 용어 "개체(들)", "대상체(들)" 및 "환자(들)"는 임의의 포유동물을 의미한다. 일부 실시양태에서, 포유동물은 인간이다. 일부 실시양태에서, 포유동물은 비-인간이다. 어떠한 용어도 의료 종사자(예컨대, 의사, 등록 간호사, 임상 간호사, 의사 보조원, 잡역부 또는 호스피스 작업자)의 감독(예컨대, 지속적 또는 간헐적)에 의해 특징지어지는 상황에 요구되거나 이에 제한되지 않는다.
실시예
이들 실시예는 예시 목적으로만 제공되며 본원에 제공된 청구범위의 범위를 제한하지 않는다.
실시예 1 - 재조합 Arc 단백질 및 조작된 Arc 단백질을 코딩하는 DNA 벡터의 구축
Arc 발현을 위한 재조합 DNA 벡터를 구축하기 위해, 개시 메티오닌을 제외한 전장 cDNA 오픈 리딩 프레임을 클로닝 벡터에 삽입한 후 표준 방법에 따라 발현 벡터에 전달한다. endo-Gag 단백질을 발현하기 위한 재조합 DNA 벡터를 구축하는 데에도 동일한 접근법이 이용된다. 인간 Arc cDNA는 주석이 달린 매트릭스 도메인(MA) 및 캡시드 도메인을 포함한다. 캡시드 도메인은 N-말단 로브(NTD) 및 C-말단 로브(CTD)를 갖는다. 도 1은 인간 Arc 단백질의 구조 및 비단뱀, 오리너구리 및 오르카(Orca)의 예측되는 Arc 구조를 예시한다.
조작된 Arc 단백질을 코딩하는 cDNA는 임의적으로 상이한 종으로부터의 Arc 서열을 재조합함으로써(도 2), 다른 단백질로부터의 기능 도메인을 Arc 단백질에 삽입함으로써(도 3a), Arc 단백질의 서열을 변형함으로써(도 3b), 및/또는 도 2-3에 예시된 접근법의 임의의 조합에 의해 생성된다. 조작된 endo-Gag 단백질을 코딩하는 cDNA도 마찬가지로 상이한 종으로부터의 endo-Gag 서열을 재조합함으로써, 다른 단백질로부터의 기능 도메인을 endo-Gag 단백질에 삽입함으로써, endo-Gag 단백질의 서열을 변형함으로써, 및/또는 이들 접근법의 임의의 조합에 의해 생성된다. 또한, 조작된 endo-Gag 단백질은 임의적으로 Arc 서열을 함유하고 조작된 Arc 단백질은 임의적으로 endo-Gag 서열을 함유한다. 조작된 Arc 및 endo-Gag 단백질 단량체는 캡시드로 조립된다.
표 1의 Arc 및 endo-Gag 단백질을 코딩하는 cDNA를 pET-41 a(+)(EMD Millipore (Novagen) Cat# 70566) 로부터 유래되는 발현 벡터에 삽입하였다. pET-41 a (+)의 전체 클로닝 부위를 제거하고, 서열번호 58의 아미노산 서열을 갖는 대안적 N-말단 태그를 코딩하는 서열번호 57의 뉴클레오티드 서열을 갖고 6xHis 태그(서열번호 59), 6개 아미노산 스페이서(서열번호 60), 및 AcTEV™ 절단 부위(서열번호 61)를 포함하는 DNA로 대체하였다. 시작 메티오닌 코돈이 없는 Arc 및 endo-Gag 오픈 리딩 프레임을 깁슨(Gibson) 조립에 의해 AcTEV™ 절단 부위 뒤에 삽입하였다(Gibson DG, Young L, Chuang RY, Venter JC, Hutchison CA 3rd, Smith HO (2009). "Enzymatic assembly of DNA molecules up to several hundred kilobases". Nature Methods. 6 (5): 343-345). 발현 및 AcTEV™ 절단 후, 생성된 Arc 또는 endo-Gag 단백질의 N-말단은 AcTEV™ 절단 부위로부터 단일 잔기 글리신을 갖는다.
서열번호 57
서열번호 58 
서열번호 59 
서열번호 60 
서열번호 61 


실시예 2 - Arc 및 endo-Gag 단백질의 발현 및 정제
Arc 및 endo-Gag 오픈 리딩 프레임을 포함하는 발현 벡터 구축물을 Rosetta 2 (DE3)pLysS 이. 콜라이 균주(Millipore Sigma, Cat# 71403)로 형질전환시켰다. Arc 또는 endo-Gag 발현을 0.1mM IPTG로 유도된 후 16℃에서 16시간 인큐베이션하였다. 세포 펠렛을 20mM 인산나트륨 pH 7.4, 0.1M NaCl, 40mM 이미다졸, 1mM DTT, 및 10% 글리세롤에서 초음파 처리에 의해 용해시켰다. 용해물을 과량의 TURBO DNase(Thermo Fisher Scientific, Cat# AM2238), RNase 칵테일(Thermo Fisher Scientific, Cat# AM2286) 및 벤조나제 뉴클레아제(Millipore Sigma, Cat# 71205)로 처리하여 핵산을 제거하였다. NaCl 농도를 0.5M로 조정하기 위해 NaCl을 용해물에 첨가한 다음 원심분리 및 여과하여 세포 파편을 제거하였다. 6xHis 태그부착된 재조합 단백질을 HisTrap HP 컬럼(GE Healthcare, Cat# 17-5247-01)에 로딩하고, 버퍼 A(20mM 인산나트륨 pH 7.4, 0.5M NaCl, 40mM 이미다졸 및 10% 글리세롤)로 세척하고, 버퍼 B의 선형 구배(20mM 인산나트륨 pH 7.4, 0.5M NaCl, 500mM 이미다졸, 및 10% 글리세롤)로 용출하였다. 수집 튜브에 용출물 1ml당 10μl의 0.5M EDTA pH 8.0을 미리 보충하였다. 생성된 Arc 또는 endo-Gag 단백질은 SDS-PAGE 분석에 의해 나타나는 바와 같이 일반적으로 95% 초과로 순수하며, 1L의 박테리아 배양물당 최대 50mg의 수율을 갖는다(도 4a).
모노 Q 5/50 GL 컬럼(GE Healthcare, Cat# 17516601)에서 음이온 교환 크로마토그래피로 잔류 핵산을 제거하였다. 컬럼에 로딩하기 전에, 재조합 단백질을 제조업자의 프로토콜에 따라 "피어스(Pierce) 단백질 농축기 PES, 10K MWCO, 5-20 ml"(Thermo Scientific, Cat#88528)를 사용하여 버퍼 C(20 mM Tris-HCl pH 8.0, 100 mM NaCl, 및 10% 글리세롤)로 버퍼 교환하였다. 로딩 후, 모노 Q 수지를 2ml의 버퍼 C로 세척하였다. Arc 및 endo-Gag 단백질을 버퍼 D의 선형 구배(20mM Tris-HCl pH 8.0, 500mM NaCl 및 10% 글리세롤)를 사용하여 용출하였다. RNA는 Arc로부터 효율적으로 분리되고 600mM NaCl에서 용출되었다(도 4b).
N-말단 6xHis 태그 및 스페이서를 10kDa MWCO PES 농축기를 사용하여 모노 Q 정제된 Arc의 농축 피크 분획으로부터 제거한 다음 10% v/v의 AcTEV™ 프로테아제(Invitrogen™ #12575023)로 처리하였다. 절단 효율은 SDS-PAGE 검정에 의해 나타나는 바와 같이 99% 초과이다. 이어서, 단백질을 HisTrap 버퍼 A로 희석하고 HisTrap HP 수지로 세척한다. 생성된 정제된 Arc는 N-말단 글리신 잔기를 가지며 개시 메티오닌을 함유하지 않는다.
실시예 3 - 캡시드 조립
절단된 Arc 단백질(1mg/mL)을 20kDa MWCO 투석 카세트에 로딩하고 실온에서 1M 인산나트륨(pH 7.5)에서 밤새 투석하였다. 다음날, 용액을 카세트로부터 꺼내고 마이크로원심분리기 튜브로 옮기고 탁상용 원심분리기에서 5분 동안 최대 속도로 회전시켰다. 상청액을 100kDa MWCO 재생 셀룰로스 아미콘 한외여과 원심 농축기로 옮겼다. 버퍼를 PBS pH 7.5로 교환하고 부피를 20배 감소시켰다.
캡시드 조립을 투과 전자 현미경으로 검정하였다. EM 그리드(탄소 지지 필름, 사각 그리드, 400 메쉬 5-6 nm, 구리, CF400-Cu-UL)는 글로 방전에 의해 제조되었다. 정제된 Arc의 5 μL 샘플을 20초 동안 그리드에 적용한 다음 여과지를 사용하여 빨아들였다. 이어서, 그리드를 MilliQ H2O로 세척하고 H2O 중의 1% 우라닐 아세테이트 5μL로 30초 동안 염색한 다음 1분 동안 공기 건조시켰다. Arc 캡시드의 이미지를 가탄(Gatan) 4k x 4k 원뷰(OneView) 카메라가 장착된 FEI Talos L120C TEM을 사용하여 획득하였다. 도 5는 농축된 인간 Arc 캡시드를 도시한다. 도 6은 다른 척추동물 종으로부터 재조합적으로 발현된 Arc 동원체로부터 형성된 캡시드를 도시한다. 도 7은 다른 척추동물 종으로부터 재조합적으로 발현된 endo-Gag 유전자로부터 형성된 캡시드를 도시한다.
실시예 4 - Arc 캡시드의 선택적 세포 내재화
단리된 재조합 인간 Arc 단백질(0.5mg/ml)로부터 조립된 캡시드를 PBS(pH 8.5) 중의 NHS 에스테르 Alexa Fluor™ 594-NHS 염료(Invitrogen™ #A20004)(DMSO에 용해됨) 50몰 과량과 반응시켜 형광 표지하였다. 어둠 속에서 2시간 동안 반응을 진행시켰다. Alexa594 표지된 캡시드를 PBS(pH 7.5)로 밤새 어둠 속에서 실온에서 적어도 2회의 버퍼 교환과 함께 투석하여 임의의 표지되지 않은 염료를 제거하였다.
HeLa 세포(ATCC® CCL-2™)를 실험 24시간 전에 96 웰 플레이트에 시딩하여 처리를 위해 ~80% 합류에 도달하였다. 이어서, 표지된 캡시드를 0.05mg/ml의 최종 캡시드 농도로 완전한 조직 배양 배지에 스파이킹하였다. 처리를 37℃에서 4시간 동안 진행된 다음, 이미징 전에 10ug/ml 훽스트(Hoechst) 핵 염료를 함유하는 이미징 배지(DMEM, 페놀 레드 없음, 10% FBS 및 20mM HEPES 포함)로 세포를 3회 세척한다. 형광 현미경 검사에서 점상 염색 패턴을 나타내었으며, 이는 Arc 캡시드가 HeLa 세포에 의해 내재화되었음을 시사한다(도 8). 동일한 조건 하에 Alexa Fluor™ 594 표지된 소 혈청 알부민(BSA)(최종 농도 0.05 mg/ml) 또는 45.6 μM Alexa Fluor™ 594를 투여한 후 세포내 염색이 거의 또는 전혀 관찰되지 않았다.
실시예 5 - Arc 캡시드에 의한 이종 RNA 전달
(1M 인산나트륨으로의 투석에 의한) 캡시드 형성 동안 과량의 RNA에서 스파이킹함으로써 인간 Arc 캡시드에 Cre RNA를 로딩하였다. Cre RNA 로딩된 캡시드를 37℃에서 4시간 동안 0.05 mg/ml의 최종 캡시드 농도로 생물학적 삼중으로 HeLa 세포에 투여하였다. 이어서, RNA 추출 전에 세포를 얼음 냉각된 1xPBS로 3회 세척하였다(Invitrogen™ TRIzol™ 시약 # 15596026). 정제된 세포 관련된 RNA를 qPCR에 의해 기술적 삼중으로 정량화하고, 값을 세포 GAPDH 수준으로 정규화하고, 단백질 정제로부터 이어질 수 있는 에쉐리키아 콜라이 rrsA mRNA 및 Arc RNA와 비교하였다. 표 2는 PCR 반응에 사용된 프라이머를 나타낸다. 검출된 세포 관련된 Cre RNA의 양은 Arc 캡시드에 Cre RNA를 로딩한 경우 Cre RNA가 로딩되지 않은 대조군 캡시드와 비교하여 >27배 더 높았다(도 9).

도 10은 Arc 또는 endo-Gag 캡시드에 의한 이종 RNA의 전달을 입증하는 대안적인 방법을 예시한다. 6xHis-태그부착된 Arc 또는 endo-Gag 유전자를 숙주 세포에서 발현시킨다. 생성된 Arc 단량체를 캡시드 형성 조건 하에서 번역 가능한 Cre mRNA와 혼합하여 Cre mRNA 로딩된 캡시드를 형성한다. Cre 로딩된 캡시드를 LoxP-루시페라제 리포터 마우스에 투여한다. Cre mRNA가 마우스 세포에 성공적으로 전달되고 Cre 리컴비나제 단백질이 후속 번역되면 리포터의 LoxP 부위가 재조합되어 임의적으로 루시페린 투여 시 생물발광 이미징에 의해 검출되는 루시페라제 발현이 유도된다. 이 방법은 후보 Arc 및 endo-Gag 유전자의 전달 가능성을 시험하는 데 이용된다. 양성 루시퍼라제 신호는 후보 Arc 또는 endo-Gag 유전자가 이종 카고를 통합하고 그 카고를 표적 세포에 전달하는 캡시드로 조립할 수 있는 Arc 또는 endo-Gag 단백질을 코딩함을 나타낸다.
본 발명의 바람직한 실시양태가 본원에 제시되고 설명되었지만, 이러한 실시양태는 단지 예로서 제공된다는 것이 당업자에게 명백할 것이다. 이제 본 발명을 벗어나지 않고 다양한 변형, 변화 및 대체가 당업자에게 떠오를 것이다. 본원에 기재된 본 발명의 실시양태에 대한 다양한 대안이 본 발명을 실시하는 데 사용될 수 있음을 이해해야 한다. 하기의 청구범위는 본 발명의 범위를 정의하고, 이들 청구범위 내의 방법 및 구조 및 그 균등물이 이에 의해 커버되는 것으로 의도된다.


















SEQUENCE LISTING
<110> VNV NEWCO INC.
<120> ARC-BASED CAPSIDS AND USES THEREOF
<130> 54838-702.601
<140> PCT/US2019/051786
<141> 2019-09-18
<150> 62/733,015
<151> 2018-09-18
<160> 85
<170> PatentIn version 3.5
<210> 1
<211> 396
<212> PRT
<213> Homo sapiens
<400> 1
Gly Glu Leu Asp His Arg Thr Ser Gly Gly Leu His Ala Tyr Pro Gly
1 5 10 15
Pro Arg Gly Gly Gln Val Ala Lys Pro Asn Val Ile Leu Gln Ile Gly
20 25 30
Lys Cys Arg Ala Glu Met Leu Glu His Val Arg Arg Thr His Arg His
35 40 45
Leu Leu Ala Glu Val Ser Lys Gln Val Glu Arg Glu Leu Lys Gly Leu
50 55 60
His Arg Ser Val Gly Lys Leu Glu Ser Asn Leu Asp Gly Tyr Val Pro
65 70 75 80
Thr Ser Asp Ser Gln Arg Trp Lys Lys Ser Ile Lys Ala Cys Leu Cys
85 90 95
Arg Cys Gln Glu Thr Ile Ala Asn Leu Glu Arg Trp Val Lys Arg Glu
100 105 110
Met His Val Trp Arg Glu Val Phe Tyr Arg Leu Glu Arg Trp Ala Asp
115 120 125
Arg Leu Glu Ser Thr Gly Gly Lys Tyr Pro Val Gly Ser Glu Ser Ala
130 135 140
Arg His Thr Val Ser Val Gly Val Gly Gly Pro Glu Ser Tyr Cys His
145 150 155 160
Glu Ala Asp Gly Tyr Asp Tyr Thr Val Ser Pro Tyr Ala Ile Thr Pro
165 170 175
Pro Pro Ala Ala Gly Glu Leu Pro Gly Gln Glu Pro Ala Glu Ala Gln
180 185 190
Gln Tyr Gln Pro Trp Val Pro Gly Glu Asp Gly Gln Pro Ser Pro Gly
195 200 205
Val Asp Thr Gln Ile Phe Glu Asp Pro Arg Glu Phe Leu Ser His Leu
210 215 220
Glu Glu Tyr Leu Arg Gln Val Gly Gly Ser Glu Glu Tyr Trp Leu Ser
225 230 235 240
Gln Ile Gln Asn His Met Asn Gly Pro Ala Lys Lys Trp Trp Glu Phe
245 250 255
Lys Gln Gly Ser Val Lys Asn Trp Val Glu Phe Lys Lys Glu Phe Leu
260 265 270
Gln Tyr Ser Glu Gly Thr Leu Ser Arg Glu Ala Ile Gln Arg Glu Leu
275 280 285
Asp Leu Pro Gln Lys Gln Gly Glu Pro Leu Asp Gln Phe Leu Trp Arg
290 295 300
Lys Arg Asp Leu Tyr Gln Thr Leu Tyr Val Asp Ala Asp Glu Glu Glu
305 310 315 320
Ile Ile Gln Tyr Val Val Gly Thr Leu Gln Pro Lys Leu Lys Arg Phe
325 330 335
Leu Arg His Pro Leu Pro Lys Thr Leu Glu Gln Leu Ile Gln Arg Gly
340 345 350
Met Glu Val Gln Asp Asp Leu Glu Gln Ala Ala Glu Pro Ala Gly Pro
355 360 365
His Leu Pro Val Glu Asp Glu Ala Glu Thr Leu Thr Pro Ala Pro Asn
370 375 380
Ser Glu Ser Val Ala Ser Asp Arg Thr Gln Pro Glu
385 390 395
<210> 2
<211> 396
<212> PRT
<213> Orcinus orca
<400> 2
Gly Glu Leu Asp Gln Arg Thr Thr Gly Gly Leu His Ala Tyr Pro Ala
1 5 10 15
Pro Arg Gly Gly Pro Val Ala Lys Pro Asn Val Ile Leu Gln Ile Gly
20 25 30
Lys Cys Arg Ala Glu Met Leu Glu His Val Arg Arg Thr His Arg His
35 40 45
Leu Leu Thr Glu Val Ser Lys Gln Val Glu Arg Glu Leu Lys Gly Leu
50 55 60
His Arg Ser Val Gly Lys Leu Glu Ser Asn Leu Asp Gly Tyr Val Pro
65 70 75 80
Thr Gly Asp Ser Gln Arg Trp Arg Lys Ser Ile Lys Ala Cys Leu Cys
85 90 95
Arg Cys Gln Glu Thr Ile Ala Asn Leu Glu Arg Trp Val Lys Arg Glu
100 105 110
Met His Val Trp Arg Glu Val Phe Tyr Arg Leu Glu Arg Trp Ala Asp
115 120 125
Arg Leu Glu Ser Met Gly Gly Lys Tyr Pro Val Gly Ser Asn Pro Ser
130 135 140
Arg His Thr Thr Ser Val Gly Val Gly Gly Pro Glu Ser Tyr Gly His
145 150 155 160
Glu Ala Asp Thr Tyr Asp Tyr Thr Val Ser Pro Tyr Ala Ile Thr Pro
165 170 175
Pro Pro Ala Ala Gly Glu Leu Pro Gly Gln Glu Ala Val Glu Ala Gln
180 185 190
Gln Tyr Pro Pro Trp Gly Leu Gly Glu Asp Gly Gln Pro Ser Pro Gly
195 200 205
Val Asp Thr Gln Ile Phe Glu Asp Pro Arg Glu Phe Leu Ser His Leu
210 215 220
Glu Glu Tyr Leu Arg Gln Val Gly Gly Ser Glu Glu Tyr Trp Leu Ser
225 230 235 240
Gln Ile Gln Asn His Met Asn Gly Pro Ala Lys Lys Trp Trp Glu Tyr
245 250 255
Lys Gln Gly Ser Val Lys Asn Trp Val Glu Phe Lys Lys Glu Phe Leu
260 265 270
Gln Tyr Ser Glu Gly Ala Leu Ser Arg Glu Ala Val Gln Arg Glu Leu
275 280 285
Asp Leu Pro Gln Lys Gln Gly Glu Pro Leu Asp Gln Phe Leu Trp Arg
290 295 300
Lys Arg Asp Leu Tyr Gln Thr Leu Tyr Val Asp Ala Asp Glu Glu Glu
305 310 315 320
Ile Ile Gln Tyr Val Val Gly Thr Leu Gln Pro Lys Leu Lys Arg Phe
325 330 335
Leu Arg Pro Pro Leu Pro Lys Thr Leu Glu Gln Leu Ile Gln Lys Gly
340 345 350
Met Glu Val Glu Asp Gly Leu Glu Gln Val Ala Glu Pro Ala Ser Pro
355 360 365
His Leu Pro Thr Glu Glu Glu Ser Glu Ala Leu Thr Pro Ala Leu Thr
370 375 380
Ser Glu Ser Val Ala Ser Asp Arg Thr Gln Pro Glu
385 390 395
<210> 3
<211> 390
<212> PRT
<213> Odocoileus virginianus texanus
<400> 3
Gly Glu Leu Asp His Arg Thr Thr Gly Gly Leu His Ala Tyr Pro Ala
1 5 10 15
Pro Arg Gly Gly Pro Ala Ala Lys Pro Asn Val Ile Leu Gln Ile Gly
20 25 30
Lys Cys Arg Ala Glu Met Leu Glu His Val Arg Arg Thr His Arg His
35 40 45
Leu Leu Ala Glu Val Ser Lys Gln Val Glu Arg Glu Leu Lys Gly Leu
50 55 60
His Arg Ser Val Gly Lys Leu Glu Ser Asn Leu Asp Gly Tyr Val Pro
65 70 75 80
Thr Gly Asp Ser Gln Arg Trp Lys Lys Ser Ile Lys Ala Cys Leu Ser
85 90 95
Arg Cys Gln Glu Thr Ile Ala Asn Leu Glu Arg Trp Val Lys Arg Glu
100 105 110
Met His Val Trp Arg Glu Val Phe Tyr Arg Leu Glu Arg Trp Ala Asp
115 120 125
Arg Leu Glu Ser Gly Gly Gly Lys Tyr Pro Val Gly Ser Asp Pro Ala
130 135 140
Arg His Thr Val Ser Val Gly Val Gly Gly Pro Glu Ser Tyr Cys Gln
145 150 155 160
Asp Ala Asp Asn Tyr Asp Tyr Thr Val Ser Pro Tyr Ala Ile Thr Pro
165 170 175
Pro Pro Ala Ala Gly Gln Leu Pro Gly Gln Glu Glu Val Glu Ala Gln
180 185 190
Gln Tyr Pro Pro Trp Ala Pro Gly Glu Asp Gly Gln Leu Ser Pro Gly
195 200 205
Val Asp Thr Gln Val Phe Glu Asp Pro Arg Glu Phe Leu Arg His Leu
210 215 220
Glu Asp Tyr Leu Arg Gln Val Gly Gly Ser Glu Glu Tyr Trp Leu Ser
225 230 235 240
Gln Ile Gln Asn His Met Asn Gly Pro Ala Lys Lys Trp Trp Glu Tyr
245 250 255
Lys Gln Gly Ser Val Lys Asn Trp Val Glu Phe Lys Lys Glu Phe Leu
260 265 270
Gln Tyr Ser Glu Gly Thr Leu Ser Arg Glu Ala Ile Gln Arg Glu Leu
275 280 285
Asp Leu Pro Gln Lys Gln Gly Glu Pro Leu Asp Gln Phe Leu Trp Arg
290 295 300
Lys Arg Asp Leu Tyr Gln Thr Leu Tyr Val Asp Ala Glu Glu Glu Glu
305 310 315 320
Ile Ile Gln Tyr Val Val Gly Thr Leu Gln Pro Lys Leu Lys Arg Phe
325 330 335
Leu Arg Pro Pro Leu Pro Lys Thr Leu Glu Gln Leu Ile Gln Lys Gly
340 345 350
Met Glu Val Gln Asp Gly Leu Glu Gln Ala Ala Glu Pro Ala Ala Glu
355 360 365
Glu Ala Glu Ala Leu Thr Pro Ala Leu Thr Asn Glu Ser Val Ala Ser
370 375 380
Asp Arg Thr Gln Pro Glu
385 390
<210> 4
<211> 401
<212> PRT
<213> Ornithorhynchus anatinus
<400> 4
Gly Glu Leu Asp Arg Leu Asn Pro Ser Ser Gly Leu His Pro Ser Ser
1 5 10 15
Gly Leu His Pro Tyr Pro Gly Leu Arg Gly Gly Ala Thr Ala Lys Pro
20 25 30
Asn Val Ile Leu Gln Ile Gly Lys Cys Arg Ala Glu Met Leu Glu His
35 40 45
Val Arg Lys Thr His Arg His Leu Leu Thr Glu Val Ser Arg Gln Val
50 55 60
Glu Arg Glu Leu Lys Gly Leu His Lys Ser Val Gly Lys Leu Glu Ser
65 70 75 80
Asn Leu Asp Gly Tyr Val Pro Ser Ser Asp Ser Gln Arg Trp Lys Lys
85 90 95
Ser Ile Lys Ala Cys Leu Ser Arg Cys Gln Glu Thr Ile Ala His Leu
100 105 110
Glu Arg Trp Val Lys Arg Glu Met Asn Val Trp Arg Glu Val Phe Tyr
115 120 125
Arg Leu Glu Arg Trp Ala Asp Arg Leu Glu Ala Met Gly Gly Lys Tyr
130 135 140
Pro Ala Gly Glu Gln Ala Arg Arg Thr Val Ser Val Gly Val Gly Gly
145 150 155 160
Pro Glu Thr Cys Cys Pro Gly Asp Glu Ser Tyr Asp Cys Pro Ile Ser
165 170 175
Pro Tyr Ala Val Pro Pro Ser Thr Gly Glu Ser Pro Glu Ser Leu Asp
180 185 190
Gln Gly Asp Gln His Tyr Gln Gln Trp Phe Ala Leu Pro Glu Glu Ser
195 200 205
Pro Val Ser Pro Gly Val Asp Thr Gln Ile Phe Glu Asp Pro Arg Glu
210 215 220
Phe Leu Arg His Leu Glu Lys Tyr Leu Lys Gln Val Gly Gly Thr Glu
225 230 235 240
Glu Asp Trp Leu Ser Gln Ile Gln Asn His Met Asn Gly Pro Ala Lys
245 250 255
Lys Trp Trp Glu Tyr Lys Gln Gly Ser Val Lys Asn Trp Leu Glu Phe
260 265 270
Lys Lys Glu Phe Leu Gln Tyr Ser Glu Gly Thr Leu Thr Arg Asp Ala
275 280 285
Leu Lys Arg Glu Leu Asp Leu Pro Gln Lys Gln Gly Glu Pro Leu Asp
290 295 300
Gln Phe Leu Trp Arg Lys Arg Asp Leu Tyr Gln Thr Leu Tyr Val Asp
305 310 315 320
Ala Asp Glu Glu Glu Ile Ile Gln Tyr Val Val Gly Thr Leu Gln Pro
325 330 335
Lys Leu Lys Arg Phe Leu His His Pro Leu Pro Lys Thr Leu Glu Gln
340 345 350
Leu Ile Gln Arg Gly Gln Glu Val Gln Asn Gly Leu Glu Pro Thr Asp
355 360 365
Asp Pro Ala Gly Gln Arg Thr Gln Ser Glu Asp Asn Asp Glu Ser Leu
370 375 380
Thr Pro Ala Val Thr Asn Glu Ser Thr Ala Ser Glu Gly Thr Leu Pro
385 390 395 400
Glu
<210> 5
<211> 404
<212> PRT
<213> Anser cygnoides domesticus
<400> 5
Gly Gln Leu Asp Asn Val Thr Asn Ala Gly Ile His Ser Phe Gln Gly
1 5 10 15
His Arg Gly Val Ala Asn Lys Pro Asn Val Ile Leu Gln Ile Gly Lys
20 25 30
Cys Arg Ala Glu Met Leu Glu His Val Arg Arg Thr His Arg His Leu
35 40 45
Leu Ser Glu Val Ser Lys Gln Val Glu Arg Glu Leu Lys Gly Leu Gln
50 55 60
Lys Ser Val Gly Lys Leu Glu Asn Asn Leu Glu Asp His Val Pro Thr
65 70 75 80
Asp Asn Gln Arg Trp Lys Lys Ser Ile Lys Ala Cys Leu Ala Arg Cys
85 90 95
Gln Glu Thr Ile Ala His Leu Glu Arg Trp Val Lys Arg Glu Met Asn
100 105 110
Val Trp Lys Glu Val Phe Phe Arg Leu Glu Lys Trp Ala Asp Arg Leu
115 120 125
Glu Ser Met Gly Gly Lys Tyr Cys Pro Gly Glu His Gly Lys Gln Thr
130 135 140
Val Ser Val Gly Val Gly Gly Pro Glu Ile Arg Pro Ser Glu Gly Glu
145 150 155 160
Ile Tyr Asp Tyr Ala Leu Asp Met Ser Gln Met Tyr Ala Leu Thr Pro
165 170 175
Pro Pro Gly Glu Met Pro Ser Ile Pro Gln Ala His Asp Ser Tyr Gln
180 185 190
Trp Val Ser Val Ser Glu Asp Ala Pro Ala Ser Pro Val Glu Thr Gln
195 200 205
Val Phe Glu Asp Pro Arg Glu Phe Leu Ser His Leu Glu Glu Tyr Leu
210 215 220
Lys Gln Val Gly Gly Thr Glu Glu Tyr Trp Leu Ser Gln Ile Gln Asn
225 230 235 240
His Met Asn Gly Pro Ala Lys Lys Trp Trp Glu Tyr Lys Gln Asp Ser
245 250 255
Val Lys Asn Trp Val Glu Phe Lys Lys Glu Phe Leu Gln Tyr Ser Glu
260 265 270
Gly Thr Leu Thr Arg Asp Ala Ile Lys Arg Glu Leu Asp Leu Pro Gln
275 280 285
Lys Glu Gly Glu Pro Leu Asp Gln Phe Leu Trp Arg Lys Arg Asp Leu
290 295 300
Tyr Gln Thr Leu Tyr Val Asp Ala Asp Glu Glu Glu Ile Ile Gln Tyr
305 310 315 320
Val Val Gly Thr Leu Gln Pro Lys Leu Lys Arg Phe Leu Ser Tyr Pro
325 330 335
Leu Pro Lys Thr Leu Glu Gln Leu Ile Gln Arg Gly Lys Glu Val Gln
340 345 350
Gly Asn Met Asp His Ser Asp Glu Pro Ser Pro Gln Arg Thr Pro Glu
355 360 365
Ile Gln Ser Gly Asp Ser Val Glu Ser Met Pro Pro Ser Thr Thr Ala
370 375 380
Ser Pro Val Pro Ser Asn Gly Thr Gln Pro Glu Pro Pro Ser Pro Pro
385 390 395 400
Ala Thr Val Ile
<210> 6
<211> 395
<212> PRT
<213> Pelecanus crispus
<400> 6
Gly Gln Leu Asp Asn Val Thr Asn Ala Gly Ile His Ser Phe Gln Gly
1 5 10 15
His Arg Gly Val Ala Asn Lys Pro Asn Val Ile Leu Gln Ile Gly Lys
20 25 30
Cys Arg Ala Glu Met Leu Glu His Val Arg Arg Thr His Arg His Leu
35 40 45
Leu Ser Glu Val Ser Lys Gln Val Glu Arg Glu Leu Lys Gly Leu Gln
50 55 60
Lys Ser Val Gly Lys Leu Glu Asn Asn Leu Glu Asp His Val Pro Thr
65 70 75 80
Asp Asn Gln Arg Trp Lys Lys Ser Ile Lys Ala Cys Leu Ala Arg Cys
85 90 95
Gln Glu Thr Ile Ala His Leu Glu Arg Trp Val Lys Arg Glu Met Asn
100 105 110
Val Trp Lys Glu Val Phe Phe Arg Leu Glu Lys Trp Ala Asp Arg Leu
115 120 125
Glu Ser Met Gly Gly Lys Tyr Cys Pro Gly Glu His Gly Lys Gln Thr
130 135 140
Val Ser Val Gly Val Gly Gly Pro Glu Ile Arg Pro Ser Glu Gly Glu
145 150 155 160
Ile Tyr Asp Tyr Ala Leu Asp Met Ser Gln Met Tyr Ala Leu Thr Pro
165 170 175
Pro Pro Gly Glu Val Pro Ser Ile Pro Gln Ala His Asp Ser Tyr Gln
180 185 190
Trp Val Ser Val Ser Glu Asp Ala Pro Ala Ser Pro Val Glu Thr Gln
195 200 205
Val Phe Glu Asp Pro Arg Glu Phe Leu Ser His Leu Glu Glu Tyr Leu
210 215 220
Lys Gln Val Gly Gly Thr Glu Glu Tyr Trp Leu Ser Gln Ile Gln Asn
225 230 235 240
His Met Asn Gly Pro Ala Lys Lys Trp Trp Glu Tyr Lys Gln Asp Ser
245 250 255
Val Lys Asn Trp Val Glu Phe Lys Lys Glu Phe Leu Gln Tyr Ser Glu
260 265 270
Gly Thr Leu Thr Arg Asp Ala Ile Lys Arg Glu Leu Asp Leu Pro Gln
275 280 285
Lys Glu Gly Glu Pro Leu Asp Gln Phe Leu Trp Arg Lys Arg Asp Leu
290 295 300
Tyr Gln Thr Leu Tyr Val Asp Ala Asp Glu Glu Glu Ile Ile Gln Tyr
305 310 315 320
Val Val Gly Thr Leu Gln Pro Lys Leu Lys Arg Phe Leu Ser Tyr Pro
325 330 335
Leu Pro Lys Thr Leu Glu Gln Leu Ile Gln Arg Gly Lys Glu Val Gln
340 345 350
Gly Asn Met Asp His Ser Glu Glu Pro Ser Pro Gln Arg Thr Pro Glu
355 360 365
Ile Gln Ser Gly Asp Ser Val Asp Ser Val Pro Pro Ser Thr Thr Ala
370 375 380
Ser Pro Val Pro Ser Asn Gly Thr Gln Pro Glu
385 390 395
<210> 7
<211> 395
<212> PRT
<213> Haliaeetus albicilla
<400> 7
Gly Gln Leu Asp Asn Val Thr Asn Ala Gly Ile His Ser Phe Gln Gly
1 5 10 15
His Arg Gly Val Ala Asn Lys Pro Asn Val Ile Leu Gln Ile Gly Lys
20 25 30
Cys Arg Ala Glu Met Leu Glu His Val Arg Arg Thr His Arg His Leu
35 40 45
Leu Ser Glu Val Ser Lys Gln Val Glu Arg Glu Leu Lys Gly Leu Gln
50 55 60
Lys Ser Val Gly Lys Leu Glu Asn Asn Leu Glu Asp His Val Pro Thr
65 70 75 80
Asp Asn Gln Arg Trp Lys Lys Ser Ile Lys Ala Cys Leu Ala Arg Cys
85 90 95
Gln Glu Thr Ile Ala His Leu Glu Arg Trp Val Lys Arg Glu Met Asn
100 105 110
Val Trp Lys Glu Val Phe Phe Arg Leu Glu Lys Trp Ala Asp Arg Leu
115 120 125
Glu Ser Met Gly Gly Lys Tyr Cys Pro Gly Asp His Gly Lys Gln Thr
130 135 140
Val Ser Val Gly Val Gly Gly Pro Glu Ile Arg Pro Ser Glu Gly Glu
145 150 155 160
Ile Tyr Asp Tyr Ala Leu Asp Met Ser Gln Met Tyr Ala Leu Thr Pro
165 170 175
Pro Pro Gly Glu Val Pro Ser Ile Pro Gln Ala His Asp Ser Tyr Gln
180 185 190
Trp Val Ser Thr Ser Glu Asp Ala Pro Ala Ser Pro Val Glu Thr Gln
195 200 205
Val Phe Glu Asp Pro Arg Glu Phe Leu Ser His Leu Glu Glu Tyr Leu
210 215 220
Lys Gln Val Gly Gly Thr Glu Glu Tyr Trp Leu Ser Gln Ile Gln Asn
225 230 235 240
His Met Asn Gly Pro Ala Lys Lys Trp Trp Glu Tyr Lys Gln Asp Ser
245 250 255
Val Lys Asn Trp Val Glu Phe Lys Lys Glu Phe Leu Gln Tyr Ser Glu
260 265 270
Gly Thr Leu Thr Arg Asp Ala Ile Lys Arg Glu Leu Asp Leu Pro Gln
275 280 285
Lys Glu Gly Glu Pro Leu Asp Gln Phe Leu Trp Arg Lys Arg Asp Leu
290 295 300
Tyr Gln Thr Leu Tyr Val Asp Ala Asp Glu Glu Glu Ile Ile Gln Tyr
305 310 315 320
Val Val Gly Thr Leu Gln Pro Lys Leu Lys Arg Phe Leu Ser Tyr Pro
325 330 335
Leu Pro Lys Thr Leu Glu Gln Leu Ile Gln Arg Gly Lys Glu Val Gln
340 345 350
Gly Asn Met Asp His Ser Glu Glu Pro Ser Pro Gln Arg Thr Pro Glu
355 360 365
Ile Gln Ser Gly Asp Ser Val Asp Ser Val Pro Pro Ser Thr Thr Ala
370 375 380
Ser Pro Val Pro Ser Asn Gly Thr Gln Pro Glu
385 390 395
<210> 8
<211> 465
<212> PRT
<213> Ophiophagus hannah
<400> 8
Gly Ser Trp Gly Leu Gln Arg His Val Ala Asp Glu Arg Arg Gly Leu
1 5 10 15
Ala Thr Pro Thr Tyr Gly Ala Val Cys Ser Ile Arg Glu Lys Lys Ala
20 25 30
Ser Gln Leu Ser Gly Gln Ser Cys Leu Glu Lys Glu Leu Leu Gly Trp
35 40 45
Lys Cys Thr Glu Ala Ile Val Glu Met Met Gln Val Asp Asn Phe Asn
50 55 60
His Gly Asn Leu His Ser Cys Gln Gly His Arg Gly Met Ala Asn His
65 70 75 80
Lys Pro Asn Val Ile Leu Gln Ile Gly Lys Cys Arg Ala Glu Met Leu
85 90 95
Asp His Val Arg Arg Thr His Arg His Leu Leu Thr Glu Val Ser Lys
100 105 110
Gln Val Glu Arg Glu Leu Lys Ser Leu Gln Lys Ser Val Gly Lys Leu
115 120 125
Glu Asn Asn Leu Glu Asp His Val Pro Ser Ala Ala Glu Asn Gln Arg
130 135 140
Trp Lys Lys Ser Ile Lys Ala Cys Leu Ala Arg Cys Gln Glu Thr Ile
145 150 155 160
Ala His Leu Glu Arg Trp Val Lys Arg Glu Ile Asn Val Trp Lys Glu
165 170 175
Val Phe Phe Arg Leu Glu Lys Trp Ala Asp Arg Leu Glu Ser Gly Gly
180 185 190
Gly Lys Tyr Gly Pro Gly Asp Gln Ser Arg Gln Thr Val Ser Val Gly
195 200 205
Val Gly Ala Pro Glu Ile Gln Pro Arg Lys Glu Glu Ile Tyr Asp Tyr
210 215 220
Ala Leu Asp Met Ser Gln Met Tyr Ala Leu Thr Pro Pro Pro Met Gly
225 230 235 240
Glu Asp Pro Asn Val Pro Gln Ser His Asp Ser Tyr Gln Trp Ile Thr
245 250 255
Ile Ser Asp Asp Ser Pro Pro Ser Pro Val Glu Thr Gln Ile Phe Glu
260 265 270
Asp Pro Arg Glu Phe Leu Thr His Leu Glu Asp Tyr Leu Lys Gln Val
275 280 285
Gly Gly Thr Glu Glu Tyr Trp Leu Ser Gln Ile Gln Asn His Met Asn
290 295 300
Gly Pro Ala Lys Lys Trp Trp Glu Tyr Lys Gln Asp Ser Val Lys Asn
305 310 315 320
Trp Leu Glu Phe Lys Lys Glu Phe Leu Gln Tyr Ser Glu Gly Thr Leu
325 330 335
Thr Arg Asp Ala Ile Lys Gln Glu Leu Asp Leu Pro Gln Lys Asp Gly
340 345 350
Glu Pro Leu Asp Gln Phe Leu Trp Arg Lys Arg Asp Leu Tyr Gln Thr
355 360 365
Leu Tyr Ile Asp Ala Glu Glu Glu Glu Val Ile Gln Tyr Val Val Gly
370 375 380
Thr Leu Gln Pro Lys Leu Lys Arg Phe Leu Ser His Pro Tyr Pro Lys
385 390 395 400
Thr Leu Glu Gln Leu Ile Gln Arg Gly Lys Glu Val Glu Gly Asn Leu
405 410 415
Asp Asn Ser Glu Glu Pro Ser Pro Gln Arg Ser Pro Lys His Gln Leu
420 425 430
Gly Gly Ser Val Glu Ser Leu Pro Pro Ser Ser Thr Ala Ser Pro Val
435 440 445
Ala Ser Asp Glu Thr His Pro Asp Val Ser Ala Pro Pro Val Thr Val
450 455 460
Ile
465
<210> 9
<211> 451
<212> PRT
<213> Austrofundulus limnaeus
<400> 9
Gly Asp Gly Glu Thr Gln Ala Glu Asn Pro Ser Thr Ser Leu Asn Asn
1 5 10 15
Thr Asp Glu Asp Ile Leu Glu Gln Leu Lys Lys Ile Val Met Asp Gln
20 25 30
Gln His Leu Tyr Gln Lys Glu Leu Lys Ala Ser Phe Glu Gln Leu Ser
35 40 45
Arg Lys Met Phe Ser Gln Met Glu Gln Met Asn Ser Lys Gln Thr Asp
50 55 60
Leu Leu Leu Glu His Gln Lys Gln Thr Val Lys His Val Asp Lys Arg
65 70 75 80
Val Glu Tyr Leu Arg Ala Gln Phe Asp Ala Ser Leu Gly Trp Arg Leu
85 90 95
Lys Glu Gln His Ala Asp Ile Thr Thr Lys Ile Ile Pro Glu Ile Ile
100 105 110
Gln Thr Val Lys Glu Asp Ile Ser Leu Cys Leu Ser Thr Leu Cys Ser
115 120 125
Ile Ala Glu Asp Ile Gln Thr Ser Arg Ala Thr Thr Val Thr Gly His
130 135 140
Ala Ala Val Gln Thr His Pro Val Asp Leu Leu Gly Glu His His Leu
145 150 155 160
Gly Thr Thr Gly His Pro Arg Leu Gln Ser Thr Arg Val Gly Lys Pro
165 170 175
Asp Asp Val Pro Glu Ser Pro Val Ser Leu Phe Met Gln Gly Glu Ala
180 185 190
Arg Ser Arg Ile Val Gly Lys Ser Pro Ile Lys Leu Gln Phe Pro Thr
195 200 205
Phe Gly Lys Ala Asn Asp Ser Ser Asp Pro Leu Gln Tyr Leu Glu Arg
210 215 220
Cys Glu Asp Phe Leu Ala Leu Asn Pro Leu Thr Asp Glu Glu Leu Met
225 230 235 240
Ala Thr Leu Arg Asn Val Leu His Gly Thr Ser Arg Asp Trp Trp Asp
245 250 255
Val Ala Arg His Lys Ile Gln Thr Trp Arg Glu Phe Asn Lys His Phe
260 265 270
Arg Ala Ala Phe Leu Ser Glu Asp Tyr Glu Asp Glu Leu Ala Glu Arg
275 280 285
Val Arg Asn Arg Ile Gln Lys Glu Asp Glu Ser Ile Arg Asp Phe Ala
290 295 300
Tyr Met Tyr Gln Ser Leu Cys Lys Arg Trp Asn Pro Ala Ile Cys Glu
305 310 315 320
Gly Asp Val Val Lys Leu Ile Leu Lys Asn Ile Asn Pro Gln Leu Pro
325 330 335
Ser Gln Leu Arg Ser Arg Val Thr Thr Val Asp Glu Leu Val Arg Leu
340 345 350
Gly Gln Gln Leu Glu Lys Asp Arg Gln Asn Gln Leu Gln Tyr Glu Leu
355 360 365
Arg Lys Ser Ser Gly Lys Ile Ile Gln Lys Ser Ser Ser Cys Glu Thr
370 375 380
Ser Ala Leu Pro Asn Thr Lys Ser Thr Pro Asn Gln Gln Asn Pro Ala
385 390 395 400
Thr Ser Asn Arg Pro Pro Gln Val Tyr Cys Trp Arg Cys Lys Gly His
405 410 415
His Ala Pro Ala Ser Cys Pro Gln Trp Lys Ala Asp Lys His Arg Ala
420 425 430
Gln Pro Ser Arg Ser Ser Gly Pro Gln Thr Leu Thr Asn Leu Gln Ala
435 440 445
Gln Asp Ile
450
<210> 10
<211> 396
<212> PRT
<213> Physeter catodon
<400> 10
Gly Glu Leu Asp Gln Arg Ala Ala Gly Gly Leu Arg Ala Tyr Pro Ala
1 5 10 15
Pro Arg Gly Gly Pro Val Ala Lys Pro Ser Val Ile Leu Gln Ile Gly
20 25 30
Lys Cys Arg Ala Glu Met Leu Glu His Val Arg Arg Thr His Arg His
35 40 45
Leu Leu Thr Glu Val Ser Lys Gln Val Glu Arg Glu Leu Lys Gly Leu
50 55 60
His Arg Ser Val Gly Lys Leu Glu Gly Asn Leu Asp Gly Tyr Val Pro
65 70 75 80
Thr Gly Asp Ser Gln Arg Trp Lys Lys Ser Ile Lys Ala Cys Leu Cys
85 90 95
Arg Cys Gln Glu Thr Ile Ala Asn Leu Glu Arg Trp Val Lys Arg Glu
100 105 110
Met His Val Trp Arg Glu Val Phe Tyr Arg Leu Glu Arg Trp Ala Asp
115 120 125
Arg Leu Glu Ser Met Gly Gly Lys Tyr Pro Val Gly Thr Asn Pro Ser
130 135 140
Arg His Thr Val Ser Val Gly Val Gly Gly Pro Glu Gly Tyr Ser His
145 150 155 160
Glu Ala Asp Thr Tyr Asp Tyr Thr Val Ser Pro Tyr Ala Ile Thr Pro
165 170 175
Pro Pro Ala Ala Gly Glu Leu Pro Gly Gln Glu Ala Val Glu Ala Gln
180 185 190
Gln Tyr Pro Pro Trp Gly Leu Gly Glu Asp Gly Gln Pro Gly Pro Gly
195 200 205
Val Asp Thr Gln Ile Phe Glu Asp Pro Arg Glu Phe Leu Ser His Leu
210 215 220
Glu Glu Tyr Leu Arg Gln Val Gly Gly Ser Glu Glu Tyr Trp Leu Ser
225 230 235 240
Gln Ile Gln Asn His Met Asn Gly Pro Ala Lys Lys Trp Trp Glu Phe
245 250 255
Lys Gln Gly Ser Val Lys Asn Trp Val Glu Phe Lys Lys Glu Phe Leu
260 265 270
Gln Tyr Ser Glu Gly Thr Leu Ser Arg Glu Ala Ile Gln Arg Glu Leu
275 280 285
Asp Leu Pro Gln Lys Gln Gly Glu Pro Leu Asp Gln Phe Leu Trp Arg
290 295 300
Lys Arg Asp Leu Tyr Gln Thr Leu Tyr Val Asp Ala Glu Glu Glu Glu
305 310 315 320
Ile Ile Gln Tyr Val Val Gly Thr Leu Gln Pro Lys Leu Lys Arg Phe
325 330 335
Leu Arg Pro Pro Leu Pro Lys Thr Leu Glu Gln Leu Ile Gln Lys Gly
340 345 350
Met Glu Val Gln Asp Gly Leu Glu Gln Ala Ala Glu Pro Ala Ser Pro
355 360 365
Arg Leu Pro Pro Glu Glu Glu Ser Glu Ala Leu Thr Pro Ala Leu Thr
370 375 380
Ser Glu Ser Val Ala Ser Asp Arg Thr Gln Pro Glu
385 390 395
<210> 11
<211> 404
<212> PRT
<213> Meleagris gallopavo
<400> 11
Gly Gln Leu Asp Asn Val Thr Asn Ala Gly Ile His Ser Phe Gln Gly
1 5 10 15
His Arg Gly Val Ala Asn Lys Pro Asn Val Ile Leu Gln Ile Gly Lys
20 25 30
Cys Arg Ala Glu Met Leu Glu His Val Arg Arg Thr His Arg His Leu
35 40 45
Leu Ser Glu Val Ser Lys Gln Val Glu Arg Glu Leu Lys Gly Leu Gln
50 55 60
Lys Ser Val Gly Lys Leu Glu Asn Asn Leu Glu Asp His Val Pro Thr
65 70 75 80
Asp Asn Gln Arg Trp Lys Lys Ser Ile Lys Ala Cys Leu Ala Arg Cys
85 90 95
Gln Glu Thr Ile Ala His Leu Glu Arg Trp Val Lys Arg Glu Met Asn
100 105 110
Val Trp Lys Glu Val Phe Phe Arg Leu Glu Lys Trp Ala Asp Arg Leu
115 120 125
Glu Ser Met Gly Gly Lys Tyr Cys Pro Gly Glu His Gly Lys Gln Thr
130 135 140
Val Ser Val Gly Val Gly Gly Pro Glu Ile Arg Pro Ser Glu Gly Glu
145 150 155 160
Ile Tyr Asp Tyr Ala Leu Asp Met Ser Gln Met Tyr Ala Leu Thr Pro
165 170 175
Gly Pro Gly Glu Val Pro Ser Ile Pro Gln Ala His Asp Ser Tyr Gln
180 185 190
Trp Val Ser Val Ser Glu Asp Ala Pro Ala Ser Pro Val Glu Thr Gln
195 200 205
Ile Phe Glu Asp Pro His Glu Phe Leu Ser His Leu Glu Glu Tyr Leu
210 215 220
Lys Gln Val Gly Gly Thr Glu Glu Tyr Trp Leu Ser Gln Ile Gln Asn
225 230 235 240
His Met Asn Gly Pro Ala Lys Lys Trp Trp Glu Tyr Lys Gln Asp Ser
245 250 255
Val Lys Asn Trp Val Glu Phe Lys Lys Glu Phe Leu Gln Tyr Ser Glu
260 265 270
Gly Thr Leu Thr Arg Asp Ala Ile Lys Arg Glu Leu Asp Leu Pro Gln
275 280 285
Lys Glu Gly Glu Pro Leu Asp Gln Phe Leu Trp Arg Lys Arg Asp Leu
290 295 300
Tyr Gln Thr Leu Tyr Val Asp Ala Asp Glu Glu Glu Ile Ile Gln Tyr
305 310 315 320
Val Val Gly Thr Leu Gln Pro Lys Leu Lys Arg Phe Leu Ser Tyr Pro
325 330 335
Leu Pro Lys Thr Leu Glu Gln Leu Ile Gln Arg Gly Lys Glu Val Gln
340 345 350
Gly Asn Met Asp His Ser Glu Glu Pro Ser Pro Gln Arg Thr Pro Glu
355 360 365
Ile Gln Ser Gly Asp Ser Val Glu Ser Met Pro Pro Ser Thr Thr Ala
370 375 380
Ser Pro Val Pro Ser Asn Gly Thr Gln Pro Glu Pro Pro Ser Pro Pro
385 390 395 400
Ala Thr Val Ile
<210> 12
<211> 409
<212> PRT
<213> Pogona vitticeps
<400> 12
Gly Gln Leu Glu Asn Ile Asn Gln Gly Ser Leu His Ala Phe Gln Gly
1 5 10 15
His Arg Gly Val Val His Asn Asn Lys Pro Asn Val Ile Leu Gln Ile
20 25 30
Gly Lys Cys Arg Ala Glu Met Leu Glu His Val Arg Arg Thr His Arg
35 40 45
His Leu Leu Thr Glu Val Ser Lys Gln Val Glu Arg Glu Leu Lys Gly
50 55 60
Leu Gln Lys Ser Val Gly Lys Leu Glu Asn Asn Leu Glu Asp His Val
65 70 75 80
Pro Ser Ala Ala Glu Asn Gln Arg Trp Lys Lys Ser Ile Lys Ala Cys
85 90 95
Leu Ala Arg Cys Gln Glu Thr Ile Ala Asn Leu Glu Arg Trp Val Lys
100 105 110
Arg Glu Met Asn Val Trp Lys Glu Val Phe Phe Arg Leu Glu Arg Trp
115 120 125
Ala Asp Arg Leu Glu Ser Gly Gly Gly Lys Tyr Cys His Ala Asp Gln
130 135 140
Gly Arg Gln Thr Val Ser Val Gly Val Gly Gly Pro Glu Val Arg Pro
145 150 155 160
Ser Glu Gly Glu Ile Tyr Asp Tyr Ala Leu Asp Met Ser Gln Met Tyr
165 170 175
Ala Leu Thr Pro Pro Pro Met Gly Asp Val Pro Val Ile Pro Gln Pro
180 185 190
His Asp Ser Tyr Gln Trp Val Thr Asp Pro Glu Glu Ala Pro Pro Ser
195 200 205
Pro Val Glu Thr Gln Ile Phe Glu Asp Pro Arg Glu Phe Leu Thr His
210 215 220
Leu Glu Asp Tyr Leu Lys Gln Val Gly Gly Thr Glu Glu Tyr Trp Leu
225 230 235 240
Ser Gln Ile Gln Asn His Met Asn Gly Pro Ala Lys Lys Trp Trp Glu
245 250 255
Tyr Lys Gln Asp Ser Val Lys Asn Trp Leu Glu Phe Lys Lys Glu Phe
260 265 270
Leu Gln Tyr Ser Glu Gly Thr Leu Thr Arg Asp Ala Ile Lys Gln Glu
275 280 285
Leu Asp Leu Pro Gln Lys Glu Gly Glu Pro Leu Asp Gln Phe Leu Trp
290 295 300
Arg Lys Arg Asp Leu Tyr Gln Thr Leu Tyr Val Glu Ala Glu Glu Glu
305 310 315 320
Glu Val Ile Gln Tyr Val Val Gly Thr Leu Gln Pro Lys Leu Lys Arg
325 330 335
Phe Leu Ser His Pro Tyr Pro Lys Thr Leu Glu Gln Leu Ile Gln Arg
340 345 350
Gly Lys Glu Val Glu Gly Asn Leu Asp Asn Ser Glu Glu Pro Ser Pro
355 360 365
Gln Arg Thr Pro Glu His Gln Leu Gly Asp Ser Val Glu Ser Leu Pro
370 375 380
Pro Ser Thr Thr Ala Ser Pro Ala Gly Ser Asp Lys Thr Gln Pro Glu
385 390 395 400
Ile Ser Leu Pro Pro Thr Thr Val Ile
405
<210> 13
<211> 404
<212> PRT
<213> Alligator sinensis
<400> 13
Gly Gln Leu Asp Ser Val Thr Asn Ala Gly Val His Thr Tyr Gln Gly
1 5 10 15
His Arg Ser Val Ala Asn Lys Pro Asn Val Ile Leu Gln Ile Gly Lys
20 25 30
Cys Arg Thr Glu Met Leu Glu His Val Arg Arg Thr His Arg His Leu
35 40 45
Leu Thr Glu Val Ser Lys Gln Val Glu Arg Glu Leu Lys Gly Leu Gln
50 55 60
Lys Ser Val Gly Lys Leu Glu Asn Asn Leu Glu Asp His Val Pro Thr
65 70 75 80
Asp Asn Gln Arg Trp Lys Lys Ser Ile Lys Ala Cys Leu Ala Arg Cys
85 90 95
Gln Glu Thr Ile Ala His Leu Glu Arg Trp Val Lys Arg Glu Met Asn
100 105 110
Val Trp Lys Glu Val Phe Phe Arg Leu Glu Arg Trp Ala Asp Arg Leu
115 120 125
Glu Ser Met Gly Gly Lys Tyr Cys Pro Thr Asp Ser Ala Arg Gln Thr
130 135 140
Val Ser Val Gly Val Gly Gly Pro Glu Ile Arg Pro Ser Glu Gly Glu
145 150 155 160
Ile Tyr Asp Tyr Ala Leu Asp Met Ser Gln Met Tyr Ala Leu Thr Pro
165 170 175
Ser Pro Gly Glu Leu Pro Ser Val Pro Gln Pro His Asp Ser Tyr Gln
180 185 190
Trp Val Thr Ser Pro Glu Asp Ala Pro Ala Ser Pro Val Glu Thr Gln
195 200 205
Val Phe Glu Asp Pro Arg Glu Phe Leu Cys His Leu Glu Glu Tyr Leu
210 215 220
Lys Gln Val Gly Gly Thr Glu Glu Tyr Trp Leu Ser Gln Ile Gln Asn
225 230 235 240
His Met Asn Gly Pro Ala Lys Lys Trp Trp Glu Tyr Lys Gln Asp Thr
245 250 255
Val Lys Asn Trp Val Glu Phe Lys Lys Glu Phe Leu Gln Tyr Ser Glu
260 265 270
Gly Thr Leu Thr Arg Asp Ala Ile Lys Arg Glu Leu Asp Leu Pro Gln
275 280 285
Lys Asp Gly Glu Pro Leu Asp Gln Phe Leu Trp Arg Lys Arg Asp Leu
290 295 300
Tyr Gln Thr Leu Tyr Ile Asp Ala Asp Glu Glu Gln Ile Ile Gln Tyr
305 310 315 320
Val Val Gly Thr Leu Gln Pro Lys Leu Lys Arg Phe Leu Ser Tyr Pro
325 330 335
Leu Pro Lys Thr Leu Glu Gln Leu Ile Gln Lys Gly Lys Glu Val Gln
340 345 350
Gly Ser Leu Asp His Ser Glu Glu Pro Ser Pro Gln Arg Ala Ser Glu
355 360 365
Ala Arg Thr Gly Asp Ser Val Glu Thr Leu Pro Pro Ser Thr Thr Thr
370 375 380
Ser Pro Asn Thr Ser Ser Gly Thr Gln Pro Glu Ala Pro Ser Pro Pro
385 390 395 400
Ala Thr Val Ile
<210> 14
<211> 404
<212> PRT
<213> Alligator mississippiensis
<400> 14
Gly Gln Leu Asp Ser Val Thr Asn Ala Gly Val His Thr Tyr Gln Gly
1 5 10 15
His Arg Gly Val Ala Asn Lys Pro Asn Val Ile Leu Gln Ile Gly Lys
20 25 30
Cys Arg Thr Glu Met Leu Glu His Val Arg Arg Thr His Arg His Leu
35 40 45
Leu Thr Glu Val Ser Lys Gln Val Glu Arg Glu Leu Lys Gly Leu Gln
50 55 60
Lys Ser Val Gly Lys Leu Glu Asn Asn Leu Glu Asp His Val Pro Thr
65 70 75 80
Asp Asn Gln Arg Trp Lys Lys Ser Ile Lys Ala Cys Leu Ala Arg Cys
85 90 95
Gln Glu Thr Ile Ala His Leu Glu Arg Trp Val Lys Arg Glu Met Asn
100 105 110
Val Trp Lys Glu Val Phe Phe Arg Leu Glu Arg Trp Ala Asp Arg Leu
115 120 125
Glu Ser Met Gly Gly Lys Tyr Cys Pro Thr Asp Ser Ala Arg Gln Thr
130 135 140
Val Ser Val Gly Val Gly Gly Pro Glu Ile Arg Pro Ser Glu Gly Glu
145 150 155 160
Ile Tyr Asp Tyr Ala Leu Asp Met Ser Gln Met Tyr Ala Leu Thr Pro
165 170 175
Ser Pro Gly Glu Leu Pro Ser Ile Pro Gln Pro His Asp Ser Tyr Gln
180 185 190
Trp Val Thr Ser Pro Glu Asp Ala Pro Ala Ser Pro Val Glu Thr Gln
195 200 205
Val Phe Glu Asp Pro Arg Glu Phe Leu Cys His Leu Glu Glu Tyr Leu
210 215 220
Lys Gln Val Gly Gly Thr Glu Glu Tyr Trp Leu Ser Gln Ile Gln Asn
225 230 235 240
His Met Asn Gly Pro Ala Lys Lys Trp Trp Glu Tyr Lys Gln Asp Thr
245 250 255
Val Lys Asn Trp Val Glu Phe Lys Lys Glu Phe Leu Gln Tyr Ser Glu
260 265 270
Gly Thr Leu Thr Arg Asp Ala Ile Lys Arg Glu Leu Asp Leu Pro Gln
275 280 285
Lys Asp Gly Glu Pro Leu Asp Gln Phe Leu Trp Arg Lys Arg Asp Leu
290 295 300
Tyr Gln Thr Leu Tyr Ile Asp Ala Asp Glu Glu Gln Ile Ile Gln Tyr
305 310 315 320
Val Val Gly Thr Leu Gln Pro Lys Leu Lys Arg Phe Leu Ser Tyr Pro
325 330 335
Leu Pro Lys Thr Leu Glu Gln Leu Ile Gln Lys Gly Lys Glu Val Gln
340 345 350
Gly Ser Leu Asp His Ser Glu Glu Pro Ser Pro Gln Arg Ala Ser Glu
355 360 365
Ala Arg Thr Gly Asp Ser Val Glu Ser Leu Pro Pro Ser Thr Thr Thr
370 375 380
Ser Pro Asn Ala Ser Ser Gly Thr Gln Pro Glu Ala Pro Ser Pro Pro
385 390 395 400
Ala Thr Val Ile
<210> 15
<211> 408
<212> PRT
<213> Gekko japonicus
<400> 15
Gly Gln Leu Glu Asn Val Asn His Gly Asn Leu His Ser Phe Gln Gly
1 5 10 15
His Arg Gly Gly Val Ala Asn Lys Pro Asn Val Ile Leu Gln Ile Gly
20 25 30
Lys Cys Arg Ala Glu Met Leu Asp His Val Arg Arg Thr His Arg His
35 40 45
Leu Leu Thr Glu Val Ser Lys Gln Val Glu Arg Glu Leu Lys Gly Leu
50 55 60
Gln Lys Ser Val Gly Lys Leu Glu Asn Asn Leu Glu Asp His Val Pro
65 70 75 80
Ser Ala Val Glu Asn Gln Arg Trp Lys Lys Ser Ile Lys Ala Cys Leu
85 90 95
Ser Arg Cys Gln Glu Thr Ile Ala His Leu Glu Arg Trp Val Lys Arg
100 105 110
Glu Met Asn Val Trp Lys Glu Val Phe Phe Arg Leu Glu Arg Trp Ala
115 120 125
Asp Arg Leu Glu Ser Gly Gly Gly Lys Tyr Cys His Gly Asp Asn His
130 135 140
Arg Gln Thr Val Ser Val Gly Val Gly Gly Pro Glu Val Arg Pro Ser
145 150 155 160
Glu Gly Glu Ile Tyr Asp Tyr Ala Leu Asp Met Ser Gln Met Tyr Ala
165 170 175
Leu Thr Pro Pro Ser Pro Gly Asp Val Pro Val Val Ser Gln Pro His
180 185 190
Asp Ser Tyr Gln Trp Val Thr Val Pro Glu Asp Thr Pro Pro Ser Pro
195 200 205
Val Glu Thr Gln Ile Phe Glu Asp Pro Arg Glu Phe Leu Thr His Leu
210 215 220
Glu Asp Tyr Leu Lys Gln Val Gly Gly Thr Glu Glu Tyr Trp Leu Ser
225 230 235 240
Gln Ile Gln Asn His Met Asn Gly Pro Ala Lys Lys Trp Trp Glu Tyr
245 250 255
Lys Gln Asp Ser Val Lys Asn Trp Leu Glu Phe Lys Lys Glu Phe Leu
260 265 270
Gln Tyr Ser Glu Gly Thr Leu Thr Arg Asp Ala Ile Lys Glu Glu Leu
275 280 285
Asp Leu Pro Gln Lys Asp Gly Glu Pro Leu Asp Gln Phe Leu Trp Arg
290 295 300
Lys Arg Asp Leu Tyr Gln Thr Leu Tyr Val Glu Ala Asp Glu Glu Glu
305 310 315 320
Val Ile Gln Tyr Val Val Gly Thr Leu Gln Pro Lys Leu Lys Arg Phe
325 330 335
Leu Ser His Pro Tyr Pro Lys Thr Leu Glu Gln Leu Ile Gln Arg Gly
340 345 350
Lys Glu Val Glu Gly Asn Leu Asp Asn Ser Glu Glu Pro Thr Pro Gln
355 360 365
Arg Thr Pro Glu His Gln Leu Cys Gly Ser Val Glu Ser Leu Pro Pro
370 375 380
Ser Ser Thr Val Ser Pro Val Ala Ser Asp Gly Thr Gln Pro Glu Thr
385 390 395 400
Ser Pro Leu Pro Ala Thr Val Ile
405
<210> 16
<211> 455
<212> PRT
<213> Homo sapiens
<400> 16
Gly Pro Leu Thr Leu Leu Gln Asp Trp Cys Arg Gly Glu His Leu Asn
1 5 10 15
Thr Arg Arg Cys Met Leu Ile Leu Gly Ile Pro Glu Asp Cys Gly Glu
20 25 30
Asp Glu Phe Glu Glu Thr Leu Gln Glu Ala Cys Arg His Leu Gly Arg
35 40 45
Tyr Arg Val Ile Gly Arg Met Phe Arg Arg Glu Glu Asn Ala Gln Ala
50 55 60
Ile Leu Leu Glu Leu Ala Gln Asp Ile Asp Tyr Ala Leu Leu Pro Arg
65 70 75 80
Glu Ile Pro Gly Lys Gly Gly Pro Trp Glu Val Ile Val Lys Pro Arg
85 90 95
Asn Ser Asp Gly Glu Phe Leu Asn Arg Leu Asn Arg Phe Leu Glu Glu
100 105 110
Glu Arg Arg Thr Val Ser Asp Met Asn Arg Val Leu Gly Ser Asp Thr
115 120 125
Asn Cys Ser Ala Pro Arg Val Thr Ile Ser Pro Glu Phe Trp Thr Trp
130 135 140
Ala Gln Thr Leu Gly Ala Ala Val Gln Pro Leu Leu Glu Gln Met Leu
145 150 155 160
Tyr Arg Glu Leu Arg Val Phe Ser Gly Asn Thr Ile Ser Ile Pro Gly
165 170 175
Ala Leu Ala Phe Asp Ala Trp Leu Glu His Thr Thr Glu Met Leu Gln
180 185 190
Met Trp Gln Val Pro Glu Gly Glu Lys Arg Arg Arg Leu Met Glu Cys
195 200 205
Leu Arg Gly Pro Ala Leu Gln Val Val Ser Gly Leu Arg Ala Ser Asn
210 215 220
Ala Ser Ile Thr Val Glu Glu Cys Leu Ala Ala Leu Gln Gln Val Phe
225 230 235 240
Gly Pro Val Glu Ser His Lys Ile Ala Gln Val Lys Leu Cys Lys Ala
245 250 255
Tyr Gln Glu Ala Gly Glu Lys Val Ser Ser Phe Val Leu Arg Leu Glu
260 265 270
Pro Leu Leu Gln Arg Ala Val Glu Asn Asn Val Val Ser Arg Arg Asn
275 280 285
Val Asn Gln Thr Arg Leu Lys Arg Val Leu Ser Gly Ala Thr Leu Pro
290 295 300
Asp Lys Leu Arg Asp Lys Leu Lys Leu Met Lys Gln Arg Arg Lys Pro
305 310 315 320
Pro Gly Phe Leu Ala Leu Val Lys Leu Leu Arg Glu Glu Glu Glu Trp
325 330 335
Glu Ala Thr Leu Gly Pro Asp Arg Glu Ser Leu Glu Gly Leu Glu Val
340 345 350
Ala Pro Arg Pro Pro Ala Arg Ile Thr Gly Val Gly Ala Val Pro Leu
355 360 365
Pro Ala Ser Gly Asn Ser Phe Asp Ala Arg Pro Ser Gln Gly Tyr Arg
370 375 380
Arg Arg Arg Gly Arg Gly Gln His Arg Arg Gly Gly Val Ala Arg Ala
385 390 395 400
Gly Ser Arg Gly Ser Arg Lys Arg Lys Arg His Thr Phe Cys Tyr Ser
405 410 415
Cys Gly Glu Asp Gly His Ile Arg Val Gln Cys Ile Asn Pro Ser Asn
420 425 430
Leu Leu Leu Ala Lys Glu Thr Lys Glu Ile Leu Glu Gly Gly Glu Arg
435 440 445
Glu Ala Gln Thr Asn Ser Arg
450 455
<210> 17
<211> 448
<212> PRT
<213> Homo sapiens
<400> 17
Gly Ala Leu Thr Leu Leu Glu Asp Trp Cys Lys Gly Met Asp Met Asp
1 5 10 15
Pro Arg Lys Ala Leu Leu Ile Val Gly Ile Pro Met Glu Cys Ser Glu
20 25 30
Val Glu Ile Gln Asp Thr Val Lys Ala Gly Leu Gln Pro Leu Cys Ala
35 40 45
Tyr Arg Val Leu Gly Arg Met Phe Arg Arg Glu Asp Asn Ala Lys Ala
50 55 60
Val Phe Ile Glu Leu Ala Asp Thr Val Asn Tyr Thr Thr Leu Pro Ser
65 70 75 80
His Ile Pro Gly Lys Gly Gly Ser Trp Glu Val Val Val Lys Pro Arg
85 90 95
Asn Pro Asp Asp Glu Phe Leu Ser Arg Leu Asn Tyr Phe Leu Lys Asp
100 105 110
Glu Gly Arg Ser Met Thr Asp Val Ala Arg Ala Leu Gly Cys Cys Ser
115 120 125
Leu Pro Ala Glu Ser Leu Asp Ala Glu Val Met Pro Gln Val Arg Ser
130 135 140
Pro Pro Leu Glu Pro Pro Lys Glu Ser Met Trp Tyr Arg Lys Leu Lys
145 150 155 160
Val Phe Ser Gly Thr Ala Ser Pro Ser Pro Gly Glu Glu Thr Phe Glu
165 170 175
Asp Trp Leu Glu Gln Val Thr Glu Ile Met Pro Ile Trp Gln Val Ser
180 185 190
Glu Val Glu Lys Arg Arg Arg Leu Leu Glu Ser Leu Arg Gly Pro Ala
195 200 205
Leu Ser Ile Met Arg Val Leu Gln Ala Asn Asn Asp Ser Ile Thr Val
210 215 220
Glu Gln Cys Leu Asp Ala Leu Lys Gln Ile Phe Gly Asp Lys Glu Asp
225 230 235 240
Phe Arg Ala Ser Gln Phe Arg Phe Leu Gln Thr Ser Pro Lys Ile Gly
245 250 255
Glu Lys Val Ser Thr Phe Leu Leu Arg Leu Glu Pro Leu Leu Gln Lys
260 265 270
Ala Val His Lys Ser Pro Leu Ser Val Arg Ser Thr Asp Met Ile Arg
275 280 285
Leu Lys His Leu Leu Ala Arg Val Ala Met Thr Pro Ala Leu Arg Gly
290 295 300
Lys Leu Glu Leu Leu Asp Gln Arg Gly Cys Pro Pro Asn Phe Leu Glu
305 310 315 320
Leu Met Lys Leu Ile Arg Asp Glu Glu Glu Trp Glu Asn Thr Glu Ala
325 330 335
Val Met Lys Asn Lys Glu Lys Pro Ser Gly Arg Gly Arg Gly Ala Ser
340 345 350
Gly Arg Gln Ala Arg Ala Glu Ala Ser Val Ser Ala Pro Gln Ala Thr
355 360 365
Val Gln Ala Arg Ser Phe Ser Asp Ser Ser Pro Gln Thr Ile Gln Gly
370 375 380
Gly Leu Pro Pro Leu Val Lys Arg Arg Arg Leu Leu Gly Ser Glu Ser
385 390 395 400
Thr Arg Gly Glu Asp His Gly Gln Ala Thr Tyr Pro Lys Ala Glu Asn
405 410 415
Gln Thr Pro Gly Arg Glu Gly Pro Gln Ala Ala Gly Glu Glu Leu Gly
420 425 430
Asn Glu Ala Gly Ala Gly Ala Met Ser His Pro Lys Pro Trp Glu Thr
435 440 445
<210> 18
<211> 399
<212> PRT
<213> Homo sapiens
<400> 18
Gly Ala Val Thr Met Leu Gln Asp Trp Cys Arg Trp Met Gly Val Asn
1 5 10 15
Ala Arg Arg Gly Leu Leu Ile Leu Gly Ile Pro Glu Asp Cys Asp Asp
20 25 30
Ala Glu Phe Gln Glu Ser Leu Glu Ala Ala Leu Arg Pro Met Gly His
35 40 45
Phe Thr Val Leu Gly Lys Ala Phe Arg Glu Glu Asp Asn Ala Thr Ala
50 55 60
Ala Leu Val Glu Leu Asp Arg Glu Val Asn Tyr Ala Leu Val Pro Arg
65 70 75 80
Glu Ile Pro Gly Thr Gly Gly Pro Trp Asn Val Val Phe Val Pro Arg
85 90 95
Cys Ser Gly Glu Glu Phe Leu Gly Leu Gly Arg Val Phe His Phe Pro
100 105 110
Glu Gln Glu Gly Gln Met Val Glu Ser Val Ala Gly Ala Leu Gly Val
115 120 125
Gly Leu Arg Arg Val Cys Trp Leu Arg Ser Ile Gly Gln Ala Val Gln
130 135 140
Pro Trp Val Glu Ala Val Arg Cys Gln Ser Leu Gly Val Phe Ser Gly
145 150 155 160
Arg Asp Gln Pro Ala Pro Gly Glu Glu Ser Phe Glu Val Trp Leu Asp
165 170 175
His Thr Thr Glu Met Leu His Val Trp Gln Gly Val Ser Glu Arg Glu
180 185 190
Arg Arg Arg Arg Leu Leu Glu Gly Leu Arg Gly Thr Ala Leu Gln Leu
195 200 205
Val His Ala Leu Leu Ala Glu Asn Pro Ala Arg Thr Ala Gln Asp Cys
210 215 220
Leu Ala Ala Leu Ala Gln Val Phe Gly Asp Asn Glu Ser Gln Ala Thr
225 230 235 240
Ile Arg Val Lys Cys Leu Thr Ala Gln Gln Gln Ser Gly Glu Arg Leu
245 250 255
Ser Ala Phe Val Leu Arg Leu Glu Val Leu Leu Gln Lys Ala Met Glu
260 265 270
Lys Glu Ala Leu Ala Arg Ala Ser Ala Asp Arg Val Arg Leu Arg Gln
275 280 285
Met Leu Thr Arg Ala His Leu Thr Glu Pro Leu Asp Glu Ala Leu Arg
290 295 300
Lys Leu Arg Met Ala Gly Arg Ser Pro Ser Phe Leu Glu Met Leu Gly
305 310 315 320
Leu Val Arg Glu Ser Glu Ala Trp Glu Ala Ser Leu Ala Arg Ser Val
325 330 335
Arg Ala Gln Thr Gln Glu Gly Ala Gly Ala Arg Ala Gly Ala Gln Ala
340 345 350
Val Ala Arg Ala Ser Thr Lys Val Glu Ala Val Pro Gly Gly Pro Gly
355 360 365
Arg Glu Pro Glu Gly Leu Leu Gln Ala Gly Gly Gln Glu Ala Glu Glu
370 375 380
Leu Leu Gln Glu Gly Leu Lys Pro Val Leu Glu Glu Cys Asp Asn
385 390 395
<210> 19
<211> 399
<212> PRT
<213> Homo sapiens
<400> 19
Gly Ala Val Thr Met Leu Gln Asp Trp Cys Arg Trp Met Gly Val Asn
1 5 10 15
Ala Arg Arg Gly Leu Leu Ile Leu Gly Ile Pro Glu Asp Cys Asp Asp
20 25 30
Ala Glu Phe Gln Glu Ser Leu Glu Ala Ala Leu Arg Pro Met Gly His
35 40 45
Phe Thr Val Leu Gly Lys Val Phe Arg Glu Glu Asp Asn Ala Thr Ala
50 55 60
Ala Leu Val Glu Leu Asp Arg Glu Val Asn Tyr Ala Leu Val Pro Arg
65 70 75 80
Glu Ile Pro Gly Thr Gly Gly Pro Trp Asn Val Val Phe Val Pro Arg
85 90 95
Cys Ser Gly Glu Glu Phe Leu Gly Leu Gly Arg Val Phe His Phe Pro
100 105 110
Glu Gln Glu Gly Gln Met Val Glu Ser Val Ala Gly Ala Leu Gly Val
115 120 125
Gly Leu Arg Arg Val Cys Trp Leu Arg Ser Ile Gly Gln Ala Val Gln
130 135 140
Pro Trp Val Glu Ala Val Arg Tyr Gln Ser Leu Gly Val Phe Ser Gly
145 150 155 160
Arg Asp Gln Pro Ala Pro Gly Glu Glu Ser Phe Glu Val Trp Leu Asp
165 170 175
His Thr Thr Glu Met Leu His Val Trp Gln Gly Val Ser Glu Arg Glu
180 185 190
Arg Arg Arg Arg Leu Leu Glu Gly Leu Arg Gly Thr Ala Leu Gln Leu
195 200 205
Val His Ala Leu Leu Ala Glu Asn Pro Ala Arg Thr Ala Gln Asp Cys
210 215 220
Leu Ala Ala Leu Ala Gln Val Phe Gly Asp Asn Glu Ser Gln Ala Thr
225 230 235 240
Ile Arg Val Lys Cys Leu Thr Ala Gln Gln Gln Ser Gly Glu Arg Leu
245 250 255
Ser Ala Phe Val Leu Arg Leu Glu Val Leu Leu Gln Lys Ala Met Glu
260 265 270
Lys Glu Ala Leu Ala Arg Ala Ser Ala Asp Arg Val Arg Leu Arg Gln
275 280 285
Met Leu Thr Arg Ala His Leu Thr Glu Pro Leu Asp Glu Ala Leu Arg
290 295 300
Lys Leu Arg Met Ala Gly Arg Ser Pro Ser Phe Leu Glu Met Leu Gly
305 310 315 320
Leu Val Arg Glu Ser Glu Ala Trp Glu Ala Ser Leu Ala Arg Ser Val
325 330 335
Arg Ala Gln Thr Gln Glu Gly Ala Gly Ala Arg Ala Gly Ala Gln Ala
340 345 350
Val Ala Arg Ala Ser Thr Lys Val Glu Ala Val Pro Gly Gly Pro Gly
355 360 365
Arg Glu Pro Glu Gly Leu Arg Gln Ala Gly Gly Gln Glu Ala Glu Glu
370 375 380
Leu Leu Gln Glu Gly Leu Lys Pro Val Leu Glu Glu Cys Asp Asn
385 390 395
<210> 20
<211> 475
<212> PRT
<213> Homo sapiens
<400> 20
Gly Val Glu Asp Leu Ala Ala Ser Tyr Ile Val Leu Lys Leu Glu Asn
1 5 10 15
Glu Ile Arg Gln Ala Gln Val Gln Trp Leu Met Glu Glu Asn Ala Ala
20 25 30
Leu Gln Ala Gln Ile Pro Glu Leu Gln Lys Ser Gln Ala Ala Lys Glu
35 40 45
Tyr Asp Leu Leu Arg Lys Ser Ser Glu Ala Lys Glu Pro Gln Lys Leu
50 55 60
Pro Glu His Met Asn Pro Pro Ala Ala Trp Glu Ala Gln Lys Thr Pro
65 70 75 80
Glu Phe Lys Glu Pro Gln Lys Pro Pro Glu Pro Gln Asp Leu Leu Pro
85 90 95
Trp Glu Pro Pro Ala Ala Trp Glu Leu Gln Glu Ala Pro Ala Ala Pro
100 105 110
Glu Ser Leu Ala Pro Pro Ala Thr Arg Glu Ser Gln Lys Pro Pro Met
115 120 125
Ala His Glu Ile Pro Thr Val Leu Glu Gly Gln Gly Pro Ala Asn Thr
130 135 140
Gln Asp Ala Thr Ile Ala Gln Glu Pro Lys Asn Ser Glu Pro Gln Asp
145 150 155 160
Pro Pro Asn Ile Glu Lys Pro Gln Glu Ala Pro Glu Tyr Gln Glu Thr
165 170 175
Ala Ala Gln Leu Glu Phe Leu Glu Leu Pro Pro Pro Gln Glu Pro Leu
180 185 190
Glu Pro Ser Asn Ala Gln Glu Phe Leu Glu Leu Ser Ala Ala Gln Glu
195 200 205
Ser Leu Glu Gly Leu Ile Val Val Glu Thr Ser Ala Ala Ser Glu Phe
210 215 220
Pro Gln Ala Pro Ile Gly Leu Glu Ala Thr Asp Phe Pro Leu Gln Tyr
225 230 235 240
Thr Leu Thr Phe Ser Gly Asp Ser Gln Lys Leu Pro Glu Phe Leu Val
245 250 255
Gln Leu Tyr Ser Tyr Met Arg Val Arg Gly His Leu Tyr Pro Thr Glu
260 265 270
Ala Ala Leu Val Ser Phe Val Gly Asn Cys Phe Ser Gly Arg Ala Gly
275 280 285
Trp Trp Phe Gln Leu Leu Leu Asp Ile Gln Ser Pro Leu Leu Glu Gln
290 295 300
Cys Glu Ser Phe Ile Pro Val Leu Gln Asp Thr Phe Asp Asn Pro Glu
305 310 315 320
Asn Met Lys Asp Ala Asn Gln Cys Ile His Gln Leu Cys Gln Gly Glu
325 330 335
Gly His Val Ala Thr His Phe His Leu Ile Ala Gln Glu Leu Asn Trp
340 345 350
Asp Glu Ser Thr Leu Trp Ile Gln Phe Gln Glu Gly Leu Ala Ser Ser
355 360 365
Ile Gln Asp Glu Leu Ser His Thr Ser Pro Ala Thr Asn Leu Ser Asp
370 375 380
Leu Ile Thr Gln Cys Ile Ser Leu Glu Glu Lys Pro Asp Pro Asn Pro
385 390 395 400
Leu Gly Lys Ser Ser Ser Ala Glu Gly Asp Gly Pro Glu Ser Pro Pro
405 410 415
Ala Glu Asn Gln Pro Met Gln Ala Ala Ile Asn Cys Pro His Ile Ser
420 425 430
Glu Ala Glu Trp Val Arg Trp His Lys Gly Arg Leu Cys Leu Tyr Cys
435 440 445
Gly Tyr Pro Gly His Phe Ala Arg Asp Cys Pro Val Lys Pro His Gln
450 455 460
Ala Leu Gln Ala Gly Asn Ile Gln Ala Cys Gln
465 470 475
<210> 21
<211> 239
<212> PRT
<213> Homo sapiens
<400> 21
Gly Val Gln Pro Gln Thr Ser Lys Ala Glu Ser Pro Ala Leu Ala Ala
1 5 10 15
Ser Pro Asn Ala Gln Met Asp Asp Val Ile Asp Thr Leu Thr Ser Leu
20 25 30
Arg Leu Thr Asn Ser Ala Leu Arg Arg Glu Ala Ser Thr Leu Arg Ala
35 40 45
Glu Lys Ala Asn Leu Thr Asn Met Leu Glu Ser Val Met Ala Glu Leu
50 55 60
Thr Leu Leu Arg Thr Arg Ala Arg Ile Pro Gly Ala Leu Gln Ile Thr
65 70 75 80
Pro Pro Ile Ser Ser Ile Thr Ser Asn Gly Thr Arg Pro Met Thr Thr
85 90 95
Pro Pro Thr Ser Leu Pro Glu Pro Phe Ser Gly Asp Pro Gly Arg Leu
100 105 110
Ala Gly Phe Leu Met Gln Met Asp Arg Phe Met Ile Phe Gln Ala Ser
115 120 125
Arg Phe Pro Gly Glu Ala Glu Arg Val Ala Phe Leu Val Ser Arg Leu
130 135 140
Thr Gly Glu Ala Glu Lys Trp Ala Ile Pro His Met Gln Pro Asp Ser
145 150 155 160
Pro Leu Arg Asn Asn Tyr Gln Gly Phe Leu Ala Glu Leu Arg Arg Thr
165 170 175
Tyr Lys Ser Pro Leu Arg His Ala Arg Arg Ala Gln Ile Arg Lys Thr
180 185 190
Ser Ala Ser Asn Arg Ala Val Arg Glu Arg Gln Met Leu Cys Arg Gln
195 200 205
Leu Ala Ser Ala Gly Thr Gly Pro Cys Pro Val His Pro Ala Ser Asn
210 215 220
Gly Thr Ser Pro Ala Pro Ala Leu Pro Ala Arg Ala Arg Asn Leu
225 230 235
<210> 22
<211> 113
<212> PRT
<213> Homo sapiens
<400> 22
Gly Asp Gly Arg Val Gln Leu Met Lys Ala Leu Leu Ala Gly Pro Leu
1 5 10 15
Arg Pro Ala Ala Arg Arg Trp Arg Asn Pro Ile Pro Phe Pro Glu Thr
20 25 30
Phe Asp Gly Asp Thr Asp Arg Leu Pro Glu Phe Ile Val Gln Thr Ser
35 40 45
Ser Tyr Met Phe Val Asp Glu Asn Thr Phe Ser Asn Asp Ala Leu Lys
50 55 60
Val Thr Phe Leu Ile Thr Arg Leu Thr Gly Pro Ala Leu Gln Trp Val
65 70 75 80
Ile Pro Tyr Ile Arg Lys Glu Ser Pro Leu Leu Asn Asp Tyr Arg Gly
85 90 95
Phe Leu Ala Glu Met Lys Arg Val Phe Gly Trp Glu Glu Asp Glu Asp
100 105 110
Phe
<210> 23
<211> 113
<212> PRT
<213> Homo sapiens
<400> 23
Gly Glu Gly Arg Val Gln Leu Met Lys Ala Leu Leu Ala Arg Pro Leu
1 5 10 15
Arg Pro Ala Ala Arg Arg Trp Arg Asn Pro Ile Pro Phe Pro Glu Thr
20 25 30
Phe Asp Gly Asp Thr Asp Arg Leu Pro Glu Phe Ile Val Gln Thr Ser
35 40 45
Ser Tyr Met Phe Val Asp Glu Asn Thr Phe Ser Asn Asp Ala Leu Lys
50 55 60
Val Thr Phe Leu Ile Thr Arg Leu Thr Gly Pro Ala Leu Gln Trp Val
65 70 75 80
Ile Pro Tyr Ile Lys Lys Glu Ser Pro Leu Leu Ser Asp Tyr Arg Gly
85 90 95
Phe Leu Ala Glu Met Lys Arg Val Phe Gly Trp Glu Glu Asp Glu Asp
100 105 110
Phe
<210> 24
<211> 364
<212> PRT
<213> Homo sapiens
<400> 24
Gly Pro Arg Gly Arg Cys Arg Gln Gln Gly Pro Arg Ile Pro Ile Trp
1 5 10 15
Ala Ala Ala Asn Tyr Ala Asn Ala His Pro Trp Gln Gln Met Asp Lys
20 25 30
Ala Ser Pro Gly Val Ala Tyr Thr Pro Leu Val Asp Pro Trp Ile Glu
35 40 45
Arg Pro Cys Cys Gly Asp Thr Val Cys Val Arg Thr Thr Met Glu Gln
50 55 60
Lys Ser Thr Ala Ser Gly Thr Cys Gly Gly Lys Pro Ala Glu Arg Gly
65 70 75 80
Pro Leu Ala Gly His Met Pro Ser Ser Arg Pro His Arg Val Asp Phe
85 90 95
Cys Trp Val Pro Gly Ser Asp Pro Gly Thr Phe Asp Gly Ser Pro Trp
100 105 110
Leu Leu Asp Arg Phe Leu Ala Gln Leu Gly Asp Tyr Met Ser Phe His
115 120 125
Phe Glu His Tyr Gln Asp Asn Ile Ser Arg Val Cys Glu Ile Leu Arg
130 135 140
Arg Leu Thr Gly Arg Ala Gln Ala Trp Ala Ala Pro Tyr Leu Asp Gly
145 150 155 160
Asp Leu Pro Leu Pro Asp Asp Tyr Glu Leu Phe Cys Gln Asp Leu Lys
165 170 175
Glu Val Val Gln Asp Pro Asn Ser Phe Ala Glu Tyr His Ala Val Val
180 185 190
Thr Cys Pro Leu Pro Leu Ala Ser Ser Gln Leu Pro Val Ala Pro Gln
195 200 205
Leu Pro Val Val Arg Gln Tyr Leu Ala Arg Phe Leu Glu Gly Leu Ala
210 215 220
Leu Asp Met Gly Thr Ala Pro Arg Ser Leu Pro Ala Ala Met Ala Thr
225 230 235 240
Pro Ala Val Ser Gly Ser Asn Ser Val Ser Arg Ser Ala Leu Phe Glu
245 250 255
Gln Gln Leu Thr Lys Glu Ser Thr Pro Gly Pro Lys Glu Pro Pro Val
260 265 270
Leu Pro Ser Ser Thr Cys Ser Ser Lys Pro Gly Pro Val Glu Pro Ala
275 280 285
Ser Ser Gln Pro Glu Glu Ala Ala Pro Thr Pro Val Pro Arg Leu Ser
290 295 300
Glu Ser Ala Asn Pro Pro Ala Gln Arg Pro Asp Pro Ala His Pro Gly
305 310 315 320
Gly Pro Lys Pro Gln Lys Thr Glu Glu Glu Val Leu Glu Thr Glu Gly
325 330 335
Asp Gln Glu Val Ser Leu Gly Thr Pro Gln Glu Val Val Glu Ala Pro
340 345 350
Glu Thr Pro Gly Glu Pro Pro Leu Ser Pro Gly Phe
355 360
<210> 25
<211> 146
<212> PRT
<213> Homo sapiens
<400> 25
Gly Val Asp Glu Leu Val Leu Leu Leu His Ala Leu Leu Met Arg His
1 5 10 15
Arg Ala Leu Ser Ile Glu Asn Ser Gln Leu Met Glu Gln Leu Arg Leu
20 25 30
Leu Val Cys Glu Arg Ala Ser Leu Leu Arg Gln Val Arg Pro Pro Ser
35 40 45
Cys Pro Val Pro Phe Pro Glu Thr Phe Asn Gly Glu Ser Ser Arg Leu
50 55 60
Pro Glu Phe Ile Val Gln Thr Ala Ser Tyr Met Leu Val Asn Glu Asn
65 70 75 80
Arg Phe Cys Asn Asp Ala Met Lys Val Ala Phe Leu Ile Ser Leu Leu
85 90 95
Thr Gly Glu Ala Glu Glu Trp Val Val Pro Tyr Ile Glu Met Asp Ser
100 105 110
Pro Ile Leu Gly Asp Tyr Arg Ala Phe Leu Asp Glu Met Lys Gln Cys
115 120 125
Phe Gly Trp Asp Asp Asp Glu Asp Asp Asp Asp Glu Glu Glu Glu Asp
130 135 140
Asp Tyr
145
<210> 26
<211> 549
<212> PRT
<213> Homo sapiens
<400> 26
Gly Pro Val Asp Leu Gly Gln Ala Leu Gly Leu Leu Pro Ser Leu Ala
1 5 10 15
Lys Ala Glu Asp Ser Gln Phe Ser Glu Ser Asp Ala Ala Leu Gln Glu
20 25 30
Glu Leu Ser Ser Pro Glu Thr Ala Arg Gln Leu Phe Arg Gln Phe Arg
35 40 45
Tyr Gln Val Met Ser Gly Pro His Glu Thr Leu Lys Gln Leu Arg Lys
50 55 60
Leu Cys Phe Gln Trp Leu Gln Pro Glu Val His Thr Lys Glu Gln Ile
65 70 75 80
Leu Glu Ile Leu Met Leu Glu Gln Phe Leu Thr Ile Leu Pro Gly Glu
85 90 95
Ile Gln Met Trp Val Arg Lys Gln Cys Pro Gly Ser Gly Glu Glu Ala
100 105 110
Val Thr Leu Val Glu Ser Leu Lys Gly Asp Pro Gln Arg Leu Trp Gln
115 120 125
Trp Ile Ser Ile Gln Val Leu Gly Gln Asp Ile Leu Ser Glu Lys Met
130 135 140
Glu Ser Pro Ser Cys Gln Val Gly Glu Val Glu Pro His Leu Glu Val
145 150 155 160
Val Pro Gln Glu Leu Gly Leu Glu Asn Ser Ser Ser Gly Pro Gly Glu
165 170 175
Leu Leu Ser His Ile Val Lys Glu Glu Ser Asp Thr Glu Ala Glu Leu
180 185 190
Ala Leu Ala Ala Ser Gln Pro Ala Arg Leu Glu Glu Arg Leu Ile Arg
195 200 205
Asp Gln Asp Leu Gly Ala Ser Leu Leu Pro Ala Ala Pro Gln Glu Gln
210 215 220
Trp Arg Gln Leu Asp Ser Thr Gln Lys Glu Gln Tyr Trp Asp Leu Met
225 230 235 240
Leu Glu Thr Tyr Gly Lys Met Val Ser Gly Ala Gly Ile Ser His Pro
245 250 255
Lys Ser Asp Leu Thr Asn Ser Ile Glu Phe Gly Glu Glu Leu Ala Gly
260 265 270
Ile Tyr Leu His Val Asn Glu Lys Ile Pro Arg Pro Thr Cys Ile Gly
275 280 285
Asp Arg Gln Glu Asn Asp Lys Glu Asn Leu Asn Leu Glu Asn His Arg
290 295 300
Asp Gln Glu Leu Leu His Ala Ser Cys Gln Ala Ser Gly Glu Val Pro
305 310 315 320
Ser Gln Ala Ser Leu Arg Gly Phe Phe Thr Glu Asp Glu Pro Gly Cys
325 330 335
Phe Gly Glu Gly Glu Asn Leu Pro Glu Ala Leu Gln Asn Ile Gln Asp
340 345 350
Glu Gly Thr Gly Glu Gln Leu Ser Pro Gln Glu Arg Ile Ser Glu Lys
355 360 365
Gln Leu Gly Gln His Leu Pro Asn Pro His Ser Gly Glu Met Ser Thr
370 375 380
Met Trp Leu Glu Glu Lys Arg Glu Thr Ser Gln Lys Gly Gln Pro Arg
385 390 395 400
Ala Pro Met Ala Gln Lys Leu Pro Thr Cys Arg Glu Cys Gly Lys Thr
405 410 415
Phe Tyr Arg Asn Ser Gln Leu Ile Phe His Gln Arg Thr His Thr Gly
420 425 430
Glu Thr Tyr Phe Gln Cys Thr Ile Cys Lys Lys Ala Phe Leu Arg Ser
435 440 445
Ser Asp Phe Val Lys His Gln Arg Thr His Thr Gly Glu Lys Pro Cys
450 455 460
Lys Cys Asp Tyr Cys Gly Lys Gly Phe Ser Asp Phe Ser Gly Leu Arg
465 470 475 480
His His Glu Lys Ile His Thr Gly Glu Lys Pro Tyr Lys Cys Pro Ile
485 490 495
Cys Glu Lys Ser Phe Ile Gln Arg Ser Asn Phe Asn Arg His Gln Arg
500 505 510
Val His Thr Gly Glu Lys Pro Tyr Lys Cys Ser His Cys Gly Lys Ser
515 520 525
Phe Ser Trp Ser Ser Ser Leu Asp Lys His Gln Arg Ser His Leu Gly
530 535 540
Lys Lys Pro Phe Gln
545
<210> 27
<211> 351
<212> PRT
<213> Homo sapiens
<400> 27
Gly Thr Leu Arg Leu Leu Glu Asp Trp Cys Arg Gly Met Asp Met Asn
1 5 10 15
Pro Arg Lys Ala Leu Leu Ile Ala Gly Ile Ser Gln Ser Cys Ser Val
20 25 30
Ala Glu Ile Glu Glu Ala Leu Gln Ala Gly Leu Ala Pro Leu Gly Glu
35 40 45
Tyr Arg Leu Leu Gly Arg Met Phe Arg Arg Asp Glu Asn Arg Lys Val
50 55 60
Ala Leu Val Gly Leu Thr Ala Glu Thr Ser His Ala Leu Val Pro Lys
65 70 75 80
Glu Ile Pro Gly Lys Gly Gly Ile Trp Arg Val Ile Phe Lys Pro Pro
85 90 95
Asp Pro Asp Asn Thr Phe Leu Ser Arg Leu Asn Glu Phe Leu Ala Gly
100 105 110
Glu Gly Met Thr Val Gly Glu Leu Ser Arg Ala Leu Gly His Glu Asn
115 120 125
Gly Ser Leu Asp Pro Glu Gln Gly Met Ile Pro Glu Met Trp Ala Pro
130 135 140
Met Leu Ala Gln Ala Leu Glu Ala Leu Gln Pro Ala Leu Gln Cys Leu
145 150 155 160
Lys Tyr Lys Lys Leu Arg Val Phe Ser Gly Arg Glu Ser Pro Glu Pro
165 170 175
Gly Glu Glu Glu Phe Gly Arg Trp Met Phe His Thr Thr Gln Met Ile
180 185 190
Lys Ala Trp Gln Val Pro Asp Val Glu Lys Arg Arg Arg Leu Leu Glu
195 200 205
Ser Leu Arg Gly Pro Ala Leu Asp Val Ile Arg Val Leu Lys Ile Asn
210 215 220
Asn Pro Leu Ile Thr Val Asp Glu Cys Leu Gln Ala Leu Glu Glu Val
225 230 235 240
Phe Gly Val Thr Asp Asn Pro Arg Glu Leu Gln Val Lys Tyr Leu Thr
245 250 255
Thr Tyr His Lys Asp Glu Glu Lys Leu Ser Ala Tyr Val Leu Arg Leu
260 265 270
Glu Pro Leu Leu Gln Lys Leu Val Gln Arg Gly Ala Ile Glu Arg Asp
275 280 285
Ala Val Asn Gln Ala Arg Leu Asp Gln Val Ile Ala Gly Ala Val His
290 295 300
Lys Thr Ile Arg Arg Glu Leu Asn Leu Pro Glu Asp Gly Pro Ala Pro
305 310 315 320
Gly Phe Leu Gln Leu Leu Val Leu Ile Lys Asp Tyr Glu Ala Ala Glu
325 330 335
Glu Glu Glu Ala Leu Leu Gln Ala Ile Leu Glu Gly Asn Phe Thr
340 345 350
<210> 28
<211> 708
<212> PRT
<213> Homo sapiens
<400> 28
Gly Thr Glu Arg Arg Arg Asp Glu Leu Ser Glu Glu Ile Asn Asn Leu
1 5 10 15
Arg Glu Lys Val Met Lys Gln Ser Glu Glu Asn Asn Asn Leu Gln Ser
20 25 30
Gln Val Gln Lys Leu Thr Glu Glu Asn Thr Thr Leu Arg Glu Gln Val
35 40 45
Glu Pro Thr Pro Glu Asp Glu Asp Asp Asp Ile Glu Leu Arg Gly Ala
50 55 60
Ala Ala Ala Ala Ala Pro Pro Pro Pro Ile Glu Glu Glu Cys Pro Glu
65 70 75 80
Asp Leu Pro Glu Lys Phe Asp Gly Asn Pro Asp Met Leu Ala Pro Phe
85 90 95
Met Ala Gln Cys Gln Ile Phe Met Glu Lys Ser Thr Arg Asp Phe Ser
100 105 110
Val Asp Arg Val Arg Val Cys Phe Val Thr Ser Met Met Thr Gly Arg
115 120 125
Ala Ala Arg Trp Ala Ser Ala Lys Leu Glu Arg Ser His Tyr Leu Met
130 135 140
His Asn Tyr Pro Ala Phe Met Met Glu Met Lys His Val Phe Glu Asp
145 150 155 160
Pro Gln Arg Arg Glu Val Ala Lys Arg Lys Ile Arg Arg Leu Arg Gln
165 170 175
Gly Met Gly Ser Val Ile Asp Tyr Ser Asn Ala Phe Gln Met Ile Ala
180 185 190
Gln Asp Leu Asp Trp Asn Glu Pro Ala Leu Ile Asp Gln Tyr His Glu
195 200 205
Gly Leu Ser Asp His Ile Gln Glu Glu Leu Ser His Leu Glu Val Ala
210 215 220
Lys Ser Leu Ser Ala Leu Ile Gly Gln Cys Ile His Ile Glu Arg Arg
225 230 235 240
Leu Ala Arg Ala Ala Ala Ala Arg Lys Pro Arg Ser Pro Pro Arg Ala
245 250 255
Leu Val Leu Pro His Ile Ala Ser His His Gln Val Asp Pro Thr Glu
260 265 270
Pro Val Gly Gly Ala Arg Met Arg Leu Thr Gln Glu Glu Lys Glu Arg
275 280 285
Arg Arg Lys Leu Asn Leu Cys Leu Tyr Cys Gly Thr Gly Gly His Tyr
290 295 300
Ala Asp Asn Cys Pro Ala Lys Ala Ser Lys Ser Ser Pro Ala Gly Lys
305 310 315 320
Leu Pro Gly Pro Ala Val Glu Gly Pro Ser Ala Thr Gly Pro Glu Ile
325 330 335
Ile Arg Ser Pro Gln Asp Asp Ala Ser Ser Pro His Leu Gln Val Met
340 345 350
Leu Gln Ile His Leu Pro Gly Arg His Thr Leu Phe Val Arg Ala Met
355 360 365
Ile Asp Ser Gly Ala Ser Gly Asn Phe Ile Asp His Glu Tyr Val Ala
370 375 380
Gln Asn Gly Ile Pro Leu Arg Ile Lys Asp Trp Pro Ile Leu Val Glu
385 390 395 400
Ala Ile Asp Gly Arg Pro Ile Ala Ser Gly Pro Val Val His Glu Thr
405 410 415
His Asp Leu Ile Val Asp Leu Gly Asp His Arg Glu Val Leu Ser Phe
420 425 430
Asp Val Thr Gln Ser Pro Phe Phe Pro Val Val Leu Gly Val Arg Trp
435 440 445
Leu Ser Thr His Asp Pro Asn Ile Thr Trp Ser Thr Arg Ser Ile Val
450 455 460
Phe Asp Ser Glu Tyr Cys Arg Tyr His Cys Arg Met Tyr Ser Pro Ile
465 470 475 480
Pro Pro Ser Leu Pro Pro Pro Ala Pro Gln Pro Pro Leu Tyr Tyr Pro
485 490 495
Val Asp Gly Tyr Arg Val Tyr Gln Pro Val Arg Tyr Tyr Tyr Val Gln
500 505 510
Asn Val Tyr Thr Pro Val Asp Glu His Val Tyr Pro Asp His Arg Leu
515 520 525
Val Asp Pro His Ile Glu Met Ile Pro Gly Ala His Ser Ile Pro Ser
530 535 540
Gly His Val Tyr Ser Leu Ser Glu Pro Glu Met Ala Ala Leu Arg Asp
545 550 555 560
Phe Val Ala Arg Asn Val Lys Asp Gly Leu Ile Thr Pro Thr Ile Ala
565 570 575
Pro Asn Gly Ala Gln Val Leu Gln Val Lys Arg Gly Trp Lys Leu Gln
580 585 590
Val Ser Tyr Asp Cys Arg Ala Pro Asn Asn Phe Thr Ile Gln Asn Gln
595 600 605
Tyr Pro Arg Leu Ser Ile Pro Asn Leu Glu Asp Gln Ala His Leu Ala
610 615 620
Thr Tyr Thr Glu Phe Val Pro Gln Ile Pro Gly Tyr Gln Thr Tyr Pro
625 630 635 640
Thr Tyr Ala Ala Tyr Pro Thr Tyr Pro Val Gly Phe Ala Trp Tyr Pro
645 650 655
Val Gly Arg Asp Gly Gln Gly Arg Ser Leu Tyr Val Pro Val Met Ile
660 665 670
Thr Trp Asn Pro His Trp Tyr Arg Gln Pro Pro Val Pro Gln Tyr Pro
675 680 685
Pro Pro Gln Pro Pro Pro Pro Pro Pro Pro Pro Pro Pro Pro Pro Ser
690 695 700
Tyr Ser Thr Leu
705
<210> 29
<211> 1188
<212> DNA
<213> Homo sapiens
<400> 29
ggggagctgg accaccggac cagcggcggg ctccacgcct accccgggcc gcggggcggg 60
caggtggcca agcccaacgt gatcctgcag atcgggaagt gccgggccga gatgctggag 120
cacgtgcggc ggacgcaccg gcacctgctg gccgaggtgt ccaagcaggt ggagcgcgag 180
ctgaaggggc tgcaccggtc ggtcgggaag ctggagagca acctggacgg ctacgtgccc 240
acgagcgact cgcagcgctg gaagaagtcc atcaaggcct gcctgtgccg ctgccaggag 300
accatcgcca acctggagcg ctgggtcaag cgcgagatgc acgtgtggcg cgaggtgttc 360
taccgcctgg agcgctgggc cgaccgcctg gagtccacgg gcggcaagta cccggtgggc 420
agcgagtcag cccgccacac cgtttccgtg ggcgtggggg gtcccgagag ctactgccac 480
gaggcagacg gctacgacta caccgtcagc ccctacgcca tcaccccgcc cccagccgct 540
ggcgagctgc ccgggcagga gcccgccgag gcccagcagt accagccgtg ggtccccggc 600
gaggacgggc agcccagccc cggcgtggac acgcagatct tcgaggaccc tcgagagttc 660
ctgagccacc tagaggagta cttgcggcag gtgggcggct ctgaggagta ctggctgtcc 720
cagatccaga atcacatgaa cgggccggcc aagaagtggt gggagttcaa gcagggctcc 780
gtgaagaact gggtggagtt caagaaggag ttcctgcagt acagcgaggg cacgctgtcc 840
cgagaggcca tccagcgcga gctggacctg ccgcagaagc agggcgagcc gctggaccag 900
ttcctgtggc gcaagcggga cctgtaccag acgctctacg tggacgcgga cgaggaggag 960
atcatccagt acgtggtggg caccctgcag cccaagctca agcgtttcct gcgccacccc 1020
ctgcccaaga ccctggagca gctcatccag aggggcatgg aggtgcagga tgacctggag 1080
caggcggccg agccggccgg cccccacctc ccggtggagg atgaggcgga gaccctcacg 1140
cccgccccca acagcgagtc cgtggccagt gaccggaccc agcccgag 1188
<210> 30
<211> 1188
<212> DNA
<213> Orcinus orca
<400> 30
ggggaattgg atcaacgtac taccggtggc cttcacgcat accctgcacc acgcgggggc 60
cctgtcgcga agccaaatgt catcctgcag attgggaagt gccgggctga gatgctggag 120
cacgtccgtc ggacgcatcg tcatcttctt actgaggtgt caaaacaggt ggagcgtgaa 180
ctcaaaggct tgcaccgcag cgttgggaaa cttgaaagca acttagatgg ctatgtgccg 240
actggcgaca gccagcgttg gcgtaagtcc atcaaagcat gtttgtgtcg ttgccaggaa 300
acgattgcaa acctggagcg ttgggtcaaa cgggagatgc atgtctggcg tgaagtattt 360
tatcgtttag agcgttgggc cgatcgttta gagagcatgg gtggtaagta ccctgtgggg 420
agcaaccctt ctcggcatac gacgtcagtc ggtgttggcg ggccggagtc ctacggtcat 480
gaagcggaca cctacgacta taccgtaagc ccttatgcta ttaccccacc acctgcggcc 540
ggcgaattac ctggccagga agccgttgag gctcaacaat accctccttg ggggctgggc 600
gaggatggtc aacctagccc aggggtagac acgcaaatct ttgaggaccc acgggagttt 660
ctttcccacc tggaagaata cctgcgtcag gttggtggga gcgaagaata ctggctgtca 720
caaattcaaa accatatgaa tggtcctgca aaaaaatggt gggaatataa acagggttcc 780
gtgaaaaact gggttgagtt taaaaaggag tttcttcaat attccgaggg cgccctcagt 840
cgggaggcgg tccaacgcga gttggacttg ccacagaaac agggggaacc actcgatcaa 900
ttcctttggc ggaaacgtga cctttaccag acattgtacg tggatgcaga tgaggaagaa 960
attatccaat atgttgtggg gaccctgcag ccgaaactga aacgtttcct tcgcccgccg 1020
ctgcctaaaa cgttggaaca acttattcag aaaggtatgg aggtcgagga tggcttagaa 1080
caagtcgcag agccggcctc gccacacttg cctacagagg aggaatcgga ggcgctgacc 1140
ccagcactta catcagagtc agtggcatca gaccggacac aaccagag 1188
<210> 31
<211> 1170
<212> DNA
<213> Odocoileus virginianus texanus
<400> 31
ggggagttag atcaccgtac aacggggggg ttgcacgcat accctgctcc acgtggcggg 60
ccggcagcta agccaaacgt aatcctgcag attgggaagt gccgggcaga gatgttggag 120
cacgtccggc ggacccaccg gcacctcctg gctgaagtgt ctaaacaagt agaacgggaa 180
ctcaaaggtc ttcatcgtag cgtcgggaaa ttggaatcga atttggacgg gtatgttcct 240
acaggcgact cacagcggtg gaaaaagagc atcaaggcct gcctgagtcg ctgccaggag 300
acgattgcta acctcgaacg ctgggttaag cgggagatgc acgtttggcg cgaagtcttc 360
taccggctgg agcgttgggc tgatcggctc gaatctggtg ggggtaagta tccagttggg 420
tccgaccctg ctcgccacac agtctcagtt ggcgtaggtg ggccggagtc gtattgccaa 480
gatgcggaca actatgatta tacagtttcc ccatacgcga tcacaccacc gccggcagca 540
gggcagctgc caggtcagga agaggttgag gcccagcagt atccaccatg ggccccaggg 600
gaagacggcc agctttctcc tggggtggac actcaagttt ttgaagatcc gcgtgaattt 660
ctgcggcatt tagaagatta tctccgccag gtcggggggt ctgaagagta ttggttaagc 720
caaattcaaa accatatgaa cggcccggcc aagaagtggt gggagtacaa gcaagggtct 780
gtgaaaaatt gggtggagtt taagaaagaa ttcttgcaat attctgaggg cactctttcg 840
cgtgaagcca tccaacgcga actcgactta ccgcagaaac aaggggaacc tctcgaccaa 900
tttctgtggc gcaaacgcga cctgtaccag actctttacg tcgatgctga ggaggaagaa 960
attattcaat acgtagttgg cacactgcag cctaagctta aacggttttt acgtccacca 1020
ttgccgaaga cgcttgaaca actcatccag aagggtatgg aggttcaaga tggtctggaa 1080
caggcagcgg aaccagcggc ggaggaggca gaagccctga cacctgcgtt aactaacgag 1140
tctgtcgcga gcgaccgcac ccagccggaa 1170
<210> 32
<211> 1203
<212> DNA
<213> Ornithorhynchus anatinus
<400> 32
ggggaattag accgcctgaa cccaagctca ggcctgcatc catcctctgg tttgcatcca 60
tacccaggtc tccggggcgg ggcaaccgcg aagcctaatg tcattttgca aattggcaaa 120
tgccgtgcgg aaatgcttga acacgtccgc aaaactcacc gtcatctcct cacagaagta 180
tcgcgccaag tagaacgcga gctcaaaggc cttcacaaaa gtgttggcaa gttggaatca 240
aatcttgatg ggtacgtacc gtcaagcgac tcccaacgct ggaagaaaag cattaaggcg 300
tgcttatccc gttgccaaga gacgattgcg catttagaac gctgggttaa acgtgaaatg 360
aatgtatggc gtgaggtgtt ctaccgtttg gaacgttggg cggaccgtct ggaggctatg 420
ggcggtaagt atcctgccgg tgagcaggcc cggcgtacag tttcagtggg cgttgggggc 480
cctgagacat gttgtccagg ggatgaaagt tatgattgtc cgatttctcc gtatgcagtt 540
ccaccttcca ccggcgagtc tccggaatcc ttagaccaag gggatcagca ctatcagcag 600
tggtttgccc tcccggagga gtcccctgtt agccctgggg ttgataccca gatctttgaa 660
gatcctcgcg agtttttacg tcatctggag aagtacctga aacaagtcgg cgggacagag 720
gaagactggc tttctcaaat ccagaatcac atgaatgggc cggcgaagaa gtggtgggag 780
tacaagcaag ggagtgttaa gaattggctt gaatttaaga aggaattttt acagtattcg 840
gagggcacac tgacgcggga cgcgttgaaa cgtgaactgg atctcccaca gaaacaaggc 900
gaaccacttg atcaattttt atggcggaag cgcgacttat atcagacact ctacgttgac 960
gccgatgaag aggaaatcat tcagtacgtc gtgggcactc ttcagccgaa attaaaacgc 1020
tttctccatc acccactccc taagacgctt gagcagctta tccaacgggg ccaagaagtt 1080
cagaatggtc tggagcctac cgacgatcct gcaggccaac gcactcaatc ggaggacaac 1140
gacgaaagcc ttacccctgc cgtcaccaat gagagtactg caagcgaggg caccctgcca 1200
gag 1203
<210> 33
<211> 1212
<212> DNA
<213> Anser cygnoides domesticus
<400> 33
gggcagcttg ataacgttac aaacgcgggc atccactcct tccaggggca tcgtggcgta 60
gcgaataagc caaatgtcat tctgcaaatt ggtaaatgtc gtgcggaaat gctggagcac 120
gttcgccgca cccaccgcca tttattatct gaagtatcta agcaggtaga acgtgagctg 180
aaagggctgc aaaagtccgt gggcaagctc gagaataact tggaggatca tgtccctaca 240
gataaccaac gctggaagaa gtccattaaa gcgtgcttgg ctcgttgtca agagactatc 300
gcgcatttag agcgttgggt gaaacgcgaa atgaacgtct ggaaggaggt gtttttccgg 360
ctggaaaagt gggcagaccg gctggagtca atgggtggca agtactgccc gggcgaacac 420
gggaaacaaa ccgtcagtgt aggcgtgggg ggtcctgaaa tccggccttc ggagggggaa 480
atttatgatt atgctctgga tatgagccag atgtatgcac tcaccccacc tccaggcgaa 540
atgccatcaa tcccacaagc ccatgacagc tatcagtggg ttagtgtctc agaagatgcc 600
ccggcgagcc ctgtcgaaac ccaggtattt gaggaccctc gggaattcct gtctcacctg 660
gaggaatacc tgaagcaggt aggcggcacg gaggagtatt ggttgtccca gatccagaat 720
cacatgaatg gtccggcaaa aaaatggtgg gaatataaac aggactccgt taaaaactgg 780
gttgagttta aaaaggaatt cttgcaatac tctgaaggta ctttaactcg ggatgctatt 840
aagcgtgaac tcgacttgcc gcaaaaggaa ggtgaacctc ttgaccaatt cctttggcgg 900
aagcgggacc tctatcagac actttacgtg gacgcggatg aggaggagat cattcagtat 960
gtggtcggta ccctgcagcc gaagctcaag cgtttcctga gctatcctct cccaaagact 1020
ttagaacagc tcatccagcg cggtaaagaa gtgcagggta acatggatca ctccgatgag 1080
ccttcgccgc agcgtacacc tgaaattcaa tcaggtgact ccgtagaatc tatgccacct 1140
tcaacaacgg catctccggt tccatctaat ggtacccaac ctgagccgcc gagcccgcca 1200
gccaccgtta tc 1212
<210> 34
<211> 1185
<212> DNA
<213> Pelecanus crispus
<400> 34
gggcaacttg acaacgtaac aaacgctggg attcactcct ttcagggcca ccgcggtgtc 60
gccaacaagc caaacgtaat cttgcaaatt ggcaaatgcc gtgcggagat gttggaacac 120
gttcgtcgta cacatcgtca cttgctgtcg gaagtctcta aacaagtaga acgtgaactt 180
aaagggcttc aaaagtcagt cggcaaattg gaaaacaacc ttgaagacca tgtaccaacc 240
gacaatcagc gttggaaaaa gtctatcaaa gcttgcctgg cccgttgtca agagacgatt 300
gctcacctgg agcggtgggt aaagcgcgag atgaatgtgt ggaaagaggt cttcttccgc 360
ttggaaaaat gggccgaccg tttggagtcc atgggcggta aatattgtcc gggtgaacat 420
ggtaagcaaa cagtctctgt gggcgttggt gggccggaga ttcggccttc tgaaggcgag 480
atttacgatt atgcgctcga catgtcccag atgtatgcgc ttacaccacc accgggcgag 540
gtaccaagca ttcctcaagc gcatgacagt tatcagtggg ttagcgtatc cgaagacgct 600
cctgcctcgc cggtagagac ccaggttttt gaagatcctc gtgaattttt aagccacttg 660
gaggagtatt tgaagcaggt aggggggaca gaggaatatt ggctgtctca gatccagaac 720
cacatgaatg gcccggctaa aaagtggtgg gaatacaaac aagattcggt aaagaattgg 780
gtagaattta aaaaggagtt tttacagtac tcagagggga ctctcacgcg tgatgcgatc 840
aaacgcgagt tggatcttcc tcaaaaagag ggggagccac tcgatcagtt cctctggcgc 900
aagcgggatc tctaccaaac actctacgta gacgcagacg aagaagagat catccagtac 960
gtggtgggta cgctccagcc gaaactcaaa cgtttcctca gctacccact tcctaagact 1020
ctggaacaac tgattcagcg gggcaaagag gtccagggta acatggacca ttcagaggaa 1080
cctagtccgc aacgtacacc tgagatccaa tctggggatt ctgtcgattc ggttccacct 1140
tctacaacag cgtctccggt gccgtcaaat gggacccaac cagag 1185
<210> 35
<211> 1185
<212> DNA
<213> Haliaeetus albicilla
<400> 35
gggcagcttg ataatgtaac caatgcaggt atccactctt tccagggtca ccgcggtgtg 60
gcaaacaagc caaatgttat tctgcaaatt ggtaagtgtc gcgctgagat gttagaacac 120
gtccggcgca cgcatcggca tctcctgtca gaggtttcaa agcaggtaga gcgtgaatta 180
aagggcctcc agaagtccgt aggtaaactc gaaaataatc ttgaagacca cgttcctacc 240
gataatcaac ggtggaaaaa gtcaatcaag gcgtgcttag cacggtgtca ggaaacgatc 300
gcgcacctcg aacgttgggt gaagcgcgaa atgaatgtct ggaaagaagt gttcttccgg 360
cttgagaagt gggctgatcg gctcgaatcc atgggtggca aatattgtcc aggtgatcat 420
ggcaagcaaa cggtctccgt cggtgttggt ggtccggaaa tccggccgag cgagggtgaa 480
atctatgact acgctcttga tatgtcccag atgtatgcac tcactcctcc gccgggtgag 540
gtcccgtcga tcccgcaggc gcatgactca taccaatggg tgtcgactag cgaagacgca 600
ccagcctccc ctgttgaaac tcaagtattc gaggacccgc gtgagttcct gagccattta 660
gaggagtacc ttaagcaggt tggtggtacc gaggaatact ggttgagcca gattcagaat 720
cacatgaacg ggccggctaa gaaatggtgg gaatacaagc aggattcagt caagaattgg 780
gtcgaattta agaaggagtt tttgcagtac agtgagggga cgctcacacg cgacgctatc 840
aaacgggagc tggacctgcc acaaaaggag ggtgaaccgc ttgatcagtt tctttggcgc 900
aagcgtgatc tgtatcaaac cctgtatgtg gacgctgacg aagaagagat cattcagtac 960
gtggttggga ctctgcaacc aaagctgaag cgttttcttt cttatcctct ccctaagaca 1020
ctggaacagt taatccaacg tggcaaggag gtccagggta atatggacca ctctgaggaa 1080
ccgagcccgc aacgtactcc tgaaattcag agcggggata gtgtcgactc agttcctcca 1140
agtacgaccg catccccggt cccaagtaac ggtacccaac cagag 1185
<210> 36
<211> 1395
<212> DNA
<213> Ophiophagus hannah
<400> 36
gggtcttggg gcttgcaacg tcacgtggct gatgaacgtc gtggcctcgc tacgcctacc 60
tacggcgcgg tttgttccat tcgggagaaa aaagcctccc aactgagcgg ccagagctgt 120
ttggagaaag agttgcttgg ttggaaatgt acggaggcaa tcgtggaaat gatgcaagtc 180
gataacttta accacggtaa cttacatagc tgccaaggcc atcgggggat ggcaaatcac 240
aaaccgaacg taatccttca aatcgggaaa tgtcgcgcag aaatgttaga ccacgtgcgt 300
cgcacccacc gccatctctt gacggaggtt tcgaagcagg tagaacgcga attgaagtct 360
ctccaaaagt cggttggcaa gctcgagaat aatctggaag accacgtgcc atcggcagcg 420
gagaaccaac gttggaagaa atcaattaaa gcctgcctgg cccggtgcca agaaacaatt 480
gctcacctcg aacgctgggt taaacgcgaa atcaacgtct ggaaagaagt attctttcgt 540
ctggagaagt gggcggaccg ccttgagtcg ggtgggggca agtatgggcc tggtgaccaa 600
agtcgtcaaa ctgtaagtgt cggtgttggg gccccagaaa tccaaccgcg gaaagaagaa 660
atctatgact acgctctcga catgtcgcag atgtatgcct taacaccacc gccgatgggt 720
gaagacccaa acgtacctca atcccacgat agctaccagt ggattaccat ctcagacgat 780
tcacctccgt cgccagtgga aactcaaatt ttcgaggatc cacgcgaatt ccttacccat 840
ctcgaggatt atcttaagca agtgggcggg actgaagaat attggttgag tcagattcaa 900
aatcatatga acggtccggc caagaaatgg tgggagtaca aacaagattc cgtgaaaaac 960
tggttggaat tcaagaagga attccttcaa tactctgagg gtactttgac acgtgacgca 1020
attaaacaag aacttgactt accgcagaag gacggcgagc cattggatca atttctttgg 1080
cggaagcggg acctgtatca gacgctctat attgatgcag aggaggaaga agtaatccaa 1140
tacgttgttg gcacactcca accgaaatta aaacgtttcc tttcccaccc gtatccgaaa 1200
actttggaac agttaatcca acgtgggaaa gaggtggaag gcaacctcga taactctgag 1260
gagcctagcc cgcaacggag tccaaagcac caattgggtg gtagcgtcga gagcctccca 1320
ccttcgtcga ccgcaagtcc tgttgcgtca gacgagactc acccagacgt gagcgcacct 1380
ccggtaacgg tgatt 1395
<210> 37
<211> 1353
<212> DNA
<213> Austrofundulus limnaeus
<400> 37
ggggacggcg agactcaagc tgagaatcca tctaccagct tgaacaacac tgacgaagat 60
atcttggaac agctcaagaa aattgtcatg gatcaacaac acctgtatca gaaagaatta 120
aaggcatctt ttgaacaact cagtcgcaaa atgttttccc agatggaaca aatgaatagc 180
aagcaaacgg atctgctttt agaacatcaa aaacagactg tcaaacatgt agacaagcgc 240
gtggagtatt tgcgggcgca attcgatgca tcgttaggct ggcggttgaa agagcaacac 300
gcggatatta cgaccaaaat cattcctgag atcatccaaa cggtgaagga agatattagc 360
ctgtgtcttt ctacgctctg cagtatcgct gaagatatcc agacatcacg ggctaccact 420
gtcacagggc atgctgccgt acaaacccat cctgtggatc ttttgggtga acaccattta 480
gggaccacgg ggcacccacg cttacagtcg acccgtgtag ggaaaccaga cgacgtacct 540
gagtcgccgg taagcctgtt tatgcaaggt gaggcgcgtt cccggatcgt tggcaagagt 600
ccgattaaac tgcaatttcc gacgttcggc aaagcaaacg attcttccga cccactccaa 660
tatctggagc ggtgtgagga ctttcttgct cttaaccctt taactgatga ggaacttatg 720
gctactttgc ggaatgtgtt acatggcacc tctcgggatt ggtgggatgt cgcacgtcat 780
aaaatccaaa cttggcgtga gtttaataaa cacttccggg cggctttcct cagcgaggat 840
tatgaagatg agttggctga gcgcgtccgt aaccgcatcc aaaaagaaga tgagtctatc 900
cgcgatttcg cttatatgta tcagtccttg tgcaagcggt ggaaccctgc tatctgcgaa 960
ggtgatgtag taaagctcat cctgaagaac atcaatccac aactgccgtc tcagttacgc 1020
tcccgggtca cgaccgtgga tgagcttgtt cgcttgggcc agcagcttga aaaagatcgt 1080
cagaatcagc tccaatatga gcttcggaag agttccggca aaattatcca aaaatctagt 1140
tcgtgcgaaa cttcagcgct cccgaacacg aagagtacac ctaatcaaca aaaccctgct 1200
accagtaacc gtcctccaca ggtgtattgc tggcggtgta agggtcacca tgcccctgcc 1260
tcttgtccgc aatggaaagc tgataagcac cgtgcgcaac cttcgcggag ttctgggcca 1320
caaactctga ctaatctcca agctcaagac atc 1353
<210> 38
<211> 1188
<212> DNA
<213> Physeter catodon
<400> 38
ggggaattgg atcaacgtgc ggcagggggc ttgcgcgcgt acccggcgcc gcgtggtggt 60
ccagttgcca aaccgagcgt aattcttcag attggtaagt gccgcgctga gatgctggaa 120
cacgtccgcc gcacgcatcg ccatcttctg acggaggtaa gtaaacaagt ggagcgcgaa 180
ctcaaggggt tacatcggtc tgtcggtaag ttggagggca atttagacgg ctatgtgcct 240
accggtgatt cccaacgctg gaaaaaaagt atcaaggcgt gtctctgccg gtgtcaggaa 300
acaattgcaa atctcgagcg ttgggtgaaa cgtgagatgc atgtttggcg tgaggtattc 360
tatcgtttgg aacggtgggc agaccgtttg gagtctatgg ggggcaagta tccggtgggc 420
actaacccgt cgcggcacac agtaagtgtc ggggtagggg gcccggaagg ctattctcat 480
gaagcggata cttatgacta cacggtgtct ccgtatgcta tcacgccacc gcctgccgcg 540
ggtgagttgc ctggtcaaga ggctgtcgag gcacaacagt accctccatg gggtctgggg 600
gaggacgggc aaccaggtcc gggcgtggac acgcagattt ttgaggaccc tcgcgaattt 660
ttgagccact tagaggagta cctgcggcaa gtagggggga gtgaagagta ctggttatcg 720
caaattcaaa atcatatgaa tggccctgcg aagaaatggt gggagttcaa acaggggtca 780
gtcaagaatt gggtcgagtt taagaaagaa tttttgcaat acagtgaggg tacgttgagt 840
cgcgaggcca tccaacgtga actggacctc cctcagaagc agggggagcc gttagatcaa 900
tttttatggc ggaaacgtga cttataccaa accctctacg ttgacgctga ggaagaagaa 960
attattcaat atgttgtcgg tacgctgcag ccaaagctga agcggttcct ccgtcctcca 1020
ctccctaaaa ccttagaaca attaatccaa aaaggcatgg aagttcagga cgggttagaa 1080
caagcggccg aaccggcctc tccgcgtctg ccgccggaag aggagagtga ggctcttacg 1140
cctgcgctca cgagcgaatc agtagcctcc gatcggacac agccagag 1188
<210> 39
<211> 1212
<212> DNA
<213> Meleagris gallopavo
<400> 39
gggcagcttg acaatgtgac gaacgcgggg attcacagct ttcaagggca ccgcggcgtc 60
gccaacaaac cgaatgtcat tctgcaaatc ggtaaatgtc gtgctgaaat gcttgagcac 120
gttcgtcgta cccatcgtca cttgctttct gaagtatcaa aacaagtgga gcgggaactc 180
aaaggcctgc aaaagtcagt gggtaaattg gagaataacc tcgaagacca tgtacctaca 240
gacaaccagc ggtggaaaaa atctatcaag gcatgcctcg ctcgttgcca ggagactatt 300
gcccatcttg agcggtgggt gaaacgtgaa atgaacgtat ggaaggaagt attttttcgc 360
ttagagaagt gggctgatcg tcttgaatcg atgggcggca agtactgtcc tggggaacac 420
ggcaaacaaa ctgtatctgt cggcgtgggg ggcccggaga tccggccatc ggaaggggaa 480
atttatgatt atgctctcga catgtcccaa atgtatgctc tcacaccagg gccaggggaa 540
gtaccgtcaa ttccgcaagc acacgacagc taccaatggg tatctgtgag cgaggacgcg 600
cctgcctctc cggttgagac gcaaatcttt gaggacccac atgaattttt gtctcatctt 660
gaagaatatc tcaaacaggt tggcggcaca gaagaatact ggttatctca gatccagaat 720
cacatgaacg gcccggctaa aaagtggtgg gagtataagc aagattccgt aaagaactgg 780
gtcgaattca agaaagagtt tcttcaatac tctgagggta ctctgacgcg cgatgcaatt 840
aagcgggagt tagaccttcc acaaaaagag ggggagcctc ttgaccagtt cctgtggcgt 900
aagcgcgacc tctatcagac actttacgtc gacgctgatg aagaagagat tattcaatat 960
gttgtgggta ccctgcagcc aaagcttaag cgtttcctta gctacccact tccgaaaact 1020
ctggagcagc tcattcaacg cggtaaggaa gtgcagggca acatggacca ctctgaagag 1080
cctagcccgc agcgcactcc tgaaatccaa tcaggtgaca gtgtggagtc aatgccgccg 1140
tcaaccaccg cttctccggt acctagcaac gggacgcaac cagagcctcc aagcccaccg 1200
gctacagtca tc 1212
<210> 40
<211> 1227
<212> DNA
<213> Pogona vitticeps
<400> 40
gggcaacttg agaatattaa ccaaggttcc ctgcacgcgt ttcagggtca tcgcggcgtg 60
gtccataaca acaagcctaa cgttattctc cagatcggga agtgccgcgc cgaaatgctg 120
gagcatgtgc ggcgcaccca tcgccatttg ctcactgaag tatcaaaaca ggtggagcgt 180
gagttgaagg ggttgcagaa aagtgtaggc aaacttgaaa ataatttaga agaccacgta 240
ccaagtgcgg ctgagaacca acgctggaag aagtcgatta aagcctgctt agcgcgttgt 300
caggagacca ttgcgaactt ggaacgctgg gttaaacgtg agatgaatgt ttggaaggag 360
gtctttttcc gcttagagcg ctgggcagat cgcctcgaat ccgggggtgg caagtactgc 420
catgcagacc agggtcgcca aactgtcagc gtaggtgttg gtggtcctga agtgcgtccg 480
tctgaaggtg aaatttacga ttacgcgttg gatatgagcc aaatgtacgc cttgactccg 540
ccgcctatgg gtgatgttcc agtaattcct cagccgcatg acagttatca gtgggtgaca 600
gatccggaag aagcgccacc aagtccggtt gagacacaaa ttttcgagga ccctcgggag 660
tttctgaccc atcttgagga ttatttaaaa caagtcggcg ggacagagga atattggctc 720
tcacagatcc aaaatcatat gaatgggcca gcgaaaaagt ggtgggaata taaacaggat 780
agtgtgaaga actggcttga gttcaaaaaa gaattcttgc agtactcaga aggcacgtta 840
acgcgggacg ctattaaaca ggaacttgac cttccacaaa aagaagggga accgctggat 900
caattcctct ggcgcaaacg cgatttgtac caaactctct acgtcgaggc agaagaagag 960
gaggtcatcc aatatgtagt tggcacactg caaccaaaac tgaagcggtt tctttctcat 1020
ccgtacccta aaaccctgga gcaactcatc cagcgcggga aggaagttga ggggaatttg 1080
gacaatagtg aagaaccgtc tccacagcgg accccagaac atcagctggg ggacagtgtg 1140
gaatctttgc cgcctagtac tacggcttcg cctgccggtt cggataaaac gcaacctgag 1200
attagcttac ctccaactac agtcatt 1227
<210> 41
<211> 1212
<212> DNA
<213> Alligator sinensis
<400> 41
gggcaattag attcggtaac caatgcgggc gtccacacct accagggcca tcggagcgtc 60
gccaataaac ctaacgtcat tcttcaaatc gggaaatgtc ggactgagat gctggagcat 120
gtccgtcgga ctcatcgcca cctgctcaca gaagtgtcaa agcaagtgga acgtgaactc 180
aagggcttac agaagagcgt gggcaaactg gaaaacaatc ttgaagacca tgtcccaact 240
gacaatcagc ggtggaagaa gtcaatcaag gcatgtctcg cgcgttgcca agagaccatt 300
gctcaccttg agcggtgggt gaaacgtgaa atgaacgtgt ggaaggaggt gttcttccgg 360
ttagaacgct gggccgaccg ccttgaatca atgggtggta aatactgccc gacggactct 420
gcacgtcaga cagttagcgt tggggtgggg ggcccggaaa ttcggcctag tgaaggcgaa 480
atctatgact acgcgctcga tatgagccaa atgtacgctc ttacgccgtc accgggcgaa 540
ttgccgtccg tccctcaacc gcatgattca taccagtggg tcactagtcc ggaagacgct 600
ccggcgtcac cagttgaaac gcaggtattc gaggatcctc gggagttctt gtgtcatttg 660
gaagagtacc tgaagcaggt tggcggtaca gaggaatatt ggctgagcca gattcagaat 720
catatgaatg gtcctgcaaa aaagtggtgg gaatataaac aagacacggt taagaattgg 780
gtggaattca agaaggagtt cttacaatac agtgagggta cacttacccg tgatgcgatt 840
aagcgggaat tagacctccc gcaaaaggac ggtgagcctc tggatcaatt tttatggcgt 900
aagcgtgacc tctatcagac attatacatt gatgccgatg aagaacagat cattcagtac 960
gtcgtgggga cattgcaacc taaactcaag cggttcttgt cctatccact tccaaaaact 1020
cttgaacaat taatccagaa agggaaggag gtgcagggtt cacttgacca cagcgaggag 1080
ccgagtcctc aacgtgcgag cgaggctcgg acgggcgata gtgtggaaac cttgccgcct 1140
tctaccacta catcaccaaa tacgtcatct ggtacacagc cagaggcacc atcgcctcca 1200
gcgacggtaa tc 1212
<210> 42
<211> 1212
<212> DNA
<213> Alligator mississippiensis
<400> 42
gggcagttag acagtgtgac taacgccggg gtgcatacgt accaggggca ccgcggggtc 60
gccaataagc caaatgtaat tctccagatt gggaagtgtc gtacagagat gttggaacat 120
gtccgtcgca ctcatcgcca cttgctcacc gaggtctcca aacaagtaga acgcgaactc 180
aaggggctcc agaagagtgt tgggaagttg gagaataacc tcgaagacca cgttccgaca 240
gataaccaac ggtggaaaaa gtctattaaa gcctgtctcg cccgttgtca agagacaatc 300
gcacacttgg aacgctgggt caaacgggag atgaatgtgt ggaaggaagt cttcttccgt 360
ctcgagcggt gggcggatcg tttagaaagt atgggcggta aatattgccc aactgactcg 420
gctcgtcaaa cggtgtcggt tggcgtaggc ggcccggaaa ttcgccctag cgagggtgag 480
atctatgact atgcacttga catgagtcag atgtatgcgt taactccgtc gccaggggag 540
cttccaagta ttccacagcc tcacgatagt tatcaatggg taacttctcc tgaagacgcc 600
ccagcatccc cagttgagac acaagtattc gaggaccctc gtgagtttct ctgtcacctc 660
gaggagtacc ttaaacaggt aggcgggacc gaagagtact ggttatcgca aatccaaaac 720
catatgaatg gtcctgccaa aaagtggtgg gagtataaac aagatactgt gaagaattgg 780
gtagagttca agaaagagtt cttacagtac tctgagggga cgttaactcg tgatgcgatc 840
aagcgcgaat tggatttacc tcagaaggac ggcgagccac tcgaccagtt cttatggcgc 900
aagcgtgact tgtatcaaac cctttatatc gatgctgacg aggaacaaat tatccagtac 960
gtagtcggta cgttgcaacc aaaacttaaa cgctttctga gctacccatt acctaaaacg 1020
ttggagcaac tgatccagaa aggtaaagag gtgcaaggga gcctggatca tagtgaagaa 1080
ccgagccctc agcgggcttc tgaagctcgg accggtgata gcgtcgaatc tttaccacct 1140
agtaccacaa ccagcccgaa tgcgtcatct ggtacccaac ctgaagcgcc ttccccacct 1200
gctacagtca tt 1212
<210> 43
<211> 1224
<212> DNA
<213> Gekko japonicus
<400> 43
gggcagctcg agaatgtcaa ccatgggaac ctccattctt ttcaaggtca tcgcggcggc 60
gtcgccaaca agccaaacgt tatcttgcag atcggtaaat gtcgtgcaga gatgctggac 120
cacgtccggc ggacccaccg gcatttactg acagaggtat cgaaacaggt tgaacgtgag 180
ttgaaggggt tacagaaatc agtagggaaa ttagaaaata acttagaaga ccatgtccct 240
tcagccgttg aaaaccagcg ttggaaaaaa tcgatcaagg cctgcctttc ccgctgccaa 300
gagaccattg cccaccttga gcgttgggtg aagcgcgaga tgaacgtatg gaaagaggtt 360
ttcttccgct tagagcggtg ggcagatcgg ttggaatctg ggggcgggaa atattgtcac 420
ggtgataatc atcgtcaaac agtatcagtc ggtgttggcg gccctgaggt acgtccatct 480
gaaggcgaaa tttacgatta cgctctcgac atgtcgcaaa tgtacgcttt aacaccgcct 540
agcccagggg atgtgcctgt agttagccag ccgcacgaca gctatcagtg ggttacggtt 600
ccggaggata cccctccatc cccggtggag acgcaaatct tcgaggaccc acgggagttc 660
ttgacccact tagaggatta cttaaagcaa gtggggggta cagaggaata ttggttatct 720
cagatccaga atcacatgaa cgggccagcc aagaagtggt gggagtataa gcaagactca 780
gtaaaaaatt ggctcgagtt taagaaggaa ttccttcagt attccgaggg gacacttacg 840
cgcgacgcta tcaaggaaga acttgacctc ccgcaaaagg acggggaacc tcttgatcag 900
ttcctgtggc gcaagcgcga cttgtaccag accctgtacg tggaggcgga tgaggaggag 960
gtgatccagt atgttgtggg gactttacaa cctaaattaa agcgttttct ctcacaccct 1020
tacccgaaaa cgttagagca acttatccaa cggggcaaag aggtggaagg gaacctcgac 1080
aattcagagg aaccaacacc tcagcgtact ccagaacacc aactgtgtgg ttctgtagaa 1140
tcgctgcctc cttcctctac cgtcagtcca gtggctagcg atggtactca acctgagact 1200
tcgccattgc cagcgactgt tatt 1224
<210> 44
<211> 1365
<212> DNA
<213> Homo sapiens
<400> 44
gggccattga cgttgttaca agactggtgt cgtggtgaac atttaaacac ccgccggtgc 60
atgttgatcc tcggtatccc agaagattgc ggcgaggatg agttcgaaga gacacttcag 120
gaggcgtgtc gccatttagg gcggtaccgc gtgatcggcc gcatgttccg tcgtgaggaa 180
aatgcccaag cgatcctctt ggaattggcg caggatattg actatgcctt actccctcgg 240
gaaatccctg ggaaaggcgg gccttgggag gtaattgtga agccgcgtaa ttccgacggc 300
gaattcttaa atcggcttaa tcgctttctt gaagaggagc gccgtacggt ctccgatatg 360
aaccgtgttt tgggctcgga tactaactgt tcagctcctc gtgtcaccat tagtcctgaa 420
ttctggactt gggcacagac gctgggcgca gctgtccaac cattgctcga acagatgctc 480
taccgggagt tacgggtctt cagtggcaat acgatttcca tcccaggtgc tctcgctttt 540
gacgcgtggc tggagcatac cacggaaatg cttcaaatgt ggcaggtgcc tgaaggggag 600
aaacggcggc gcttgatgga gtgtttgcgg gggccagccc tgcaagtcgt tagtgggtta 660
cgtgcatcga atgccagtat cactgtcgaa gagtgtcttg ctgcactgca gcaggtattc 720
ggtccagtgg aaagtcataa gattgcccaa gtaaagttat gcaaagctta ccaggaggct 780
ggggaaaaag taagcagctt cgttttgcgt ttggagccac tgcttcagcg tgctgtagaa 840
aacaacgtgg tcagtcgccg caatgtcaac caaacacgtc ttaagcgtgt tctgtcgggc 900
gccacccttc ctgacaagct gcgtgataaa ttgaagttaa tgaaacagcg ccgtaaaccg 960
ccgggtttct tggcgttggt taaactgtta cgtgaagagg aggagtggga ggccacctta 1020
gggccagacc gcgagtcatt ggaggggtta gaagtggcac cgcgcccgcc agcacggatt 1080
acgggtgttg gcgcagtacc tcttccggca tccgggaatt catttgatgc ccgtccttcg 1140
caagggtacc ggcgccgtcg gggtcgtggt cagcaccgtc ggggcggcgt tgctcgtgca 1200
ggctctcgtg gctctcgtaa gcggaaacgg cacaccttct gctattcctg tggtgaggat 1260
ggccatattc gtgtccaatg cattaaccct agcaatctcc tgttggctaa ggagaccaaa 1320
gagattttgg aagggggaga acgtgaagcg caaacgaatt cacgt 1365
<210> 45
<211> 1344
<212> DNA
<213> Homo sapiens
<400> 45
ggggctctta cgctcttaga agactggtgt aagggtatgg acatggaccc gcggaaggct 60
ctcctgattg taggtattcc gatggaatgc agtgaggtgg aaatccagga tacagttaaa 120
gctggtcttc aacctctgtg cgcttatcgt gtactcggcc gtatgttccg gcgggaggat 180
aatgcgaagg ctgttttcat tgagctggca gacaccgtga attacaccac gttaccgtct 240
cacattccgg gtaaaggggg ttcctgggaa gtcgttgtta aacctcggaa ccctgacgac 300
gagttccttt ctcggcttaa ctacttcttg aaagatgagg gccgctcgat gacggatgtc 360
gcccgggcac tggggtgctg tagcttacct gcggaatcac tggacgcgga agtaatgcca 420
caggtccgct ccccaccatt agaacctcca aaagagagta tgtggtaccg taagttaaaa 480
gtgtttagtg gtaccgcgtc gccttcgccg ggggaggaga catttgagga ctggttagag 540
caagtcaccg agatcatgcc tatctggcaa gtatctgaag ttgaaaagcg ccgtcggtta 600
ctggagtcac tccggggccc ggcactctca attatgcgcg tgttacaagc caataacgat 660
agcattaccg ttgaacagtg tttggatgca ttaaagcaga tctttggcga caaggaagac 720
ttccgtgcct ctcaatttcg ttttcttcaa acgtccccta aaattgggga gaaggtgagt 780
acgttcctgc tgcgtttaga gccactcttg caaaaggccg ttcacaagag cccactttcg 840
gtacgtagta ctgatatgat tcggttaaag cacctgttgg cacgcgtagc catgaccccg 900
gcactgcgtg gtaaactcga attactcgac caacgcgggt gcccacctaa ttttcttgag 960
ctgatgaagc tgatccggga tgaggaagag tgggagaata ctgaagctgt gatgaaaaat 1020
aaagagaaac cttcaggtcg tggccgcggt gcatcaggcc gtcaagctcg cgccgaggcc 1080
agtgtaagtg ctccgcaagc aacagtccaa gcacgtagct tctctgattc tagcccgcag 1140
acgattcagg ggggcttacc acctcttgtc aagcgtcggc gccttttggg ttcggagagc 1200
acacgtgggg aagaccacgg gcaagctact tatccgaaag cagagaatca gactccaggg 1260
cgtgagggcc cgcaggcggc tggggaggaa cttggtaatg aggccggggc cggcgcgatg 1320
tcccacccga aaccgtggga aacc 1344
<210> 46
<211> 1197
<212> DNA
<213> Homo sapiens
<400> 46
ggggctgtga caatgctcca ggactggtgc cgttggatgg gcgtgaacgc tcggcggggg 60
ctgttaatct taggtatccc tgaagactgt gacgatgcag agttccaaga gtcgttagaa 120
gctgcactcc gtcctatggg tcactttact gtactcggta aggccttccg cgaggaagac 180
aacgctaccg ctgcgctggt ggaattagat cgcgaggtta attacgcact tgttccacgc 240
gaaattccgg gcaccggcgg gccttggaac gtcgtgttcg ttcctcggtg ctccggcgag 300
gaattcctgg ggttaggccg cgtgttccac tttcctgaac aggagggcca aatggtagaa 360
tcggttgcgg gggcactggg ggtaggtctg cgccgcgtgt gttggttacg ctcgatcggg 420
caagctgtac aaccatgggt agaagctgtt cgctgccaaa gcttaggggt atttagtggt 480
cgtgatcaac ctgcacctgg tgaagaaagc ttcgaggtct ggttggatca tacgaccgag 540
atgttgcatg tgtggcaagg cgtgtcggaa cgggaacggc gccgtcgtct gctggaaggg 600
ctgcgtggca cagccttaca acttgtacat gccttactgg cagaaaatcc ggcacggaca 660
gcacaagatt gcttggctgc attagcccaa gtttttggtg ataacgaaag ccaggcaacg 720
attcgtgtta aatgtttgac agcccaacag cagagtggcg aacgcctctc tgcgttcgtt 780
ctccgcttag aagtacttct gcaaaaggct atggagaagg aagcattggc gcgcgcgtca 840
gcggatcggg tgcgtcttcg tcagatgctg acacgcgcac atctcacaga gccgttggat 900
gaagccttac ggaaattgcg tatggcaggg cgttctccgt cttttttgga aatgctcggc 960
ttagtacgcg agtcagaggc ctgggaggca agtctggctc ggtccgtccg ggcgcaaacc 1020
caggagggtg caggggcccg ggcgggggcc caagcagttg cgcgtgccag cactaaggtt 1080
gaagctgtac ctggtggccc tggccgggag ccagaaggtc tcctccaagc cgggggccaa 1140
gaagcggaag aacttctcca agagggctta aagccggttt tagaggaatg tgacaat 1197
<210> 47
<211> 1197
<212> DNA
<213> Homo sapiens
<400> 47
ggggcggtca ccatgttgca agactggtgt cggtggatgg gcgtgaatgc tcggcggggt 60
ttattgatct tgggtatccc agaagactgt gacgacgccg agtttcagga gtcgctcgag 120
gccgcccttc gtccaatggg gcattttacg gttctgggca aggtgttccg tgaagaggat 180
aacgctacag cagctcttgt ggagcttgac cgtgaggtga attatgcgtt agtacctcgc 240
gagattccag gtaccggtgg gccatggaac gtagtcttcg tcccacgttg ctcgggggag 300
gaatttctgg ggcttgggcg cgtattccac tttccagaac aggaagggca gatggtcgaa 360
agcgtagcag gcgctcttgg cgttggtctc cggcgcgtgt gctggttacg ctccatcggc 420
caagcagtcc aaccatgggt tgaagccgta cgctatcaat ctttaggtgt cttctcaggc 480
cgtgaccagc cggcgcctgg tgaggaatcc ttcgaagtct ggctcgatca tacaactgag 540
atgctgcatg tatggcaagg tgtctcagag cgggaacggc ggcggcggtt attagagggg 600
ctccgtggga ctgcgctcca attagtacat gcgcttttgg ccgaaaatcc agcccgtact 660
gcccaagatt gtctggcagc actcgcccaa gtattcggcg acaacgaatc gcaggcaaca 720
atccgcgtaa agtgtcttac agcacagcag cagtcagggg aacgtcttag tgcgttcgtt 780
ctgcggctgg aagtgttact ccagaaagcc atggaaaagg aggcattggc tcgcgcgagc 840
gctgaccgtg tacgtctgcg gcaaatgctt actcgcgcac atctcaccga gcctctcgat 900
gaagcactgc ggaaactgcg catggcaggc cgcagcccgt ctttcctgga aatgttaggc 960
ttagtccggg agtccgaagc ctgggaggcc agtctggcac ggtcagtgcg ggcacaaacg 1020
caagagggtg caggggcacg ggcgggtgca caagcagttg cacgtgcctc cactaaagtt 1080
gaggcagtgc cgggtgggcc aggccgtgaa ccggagggtt tgcgccaagc cggcgggcag 1140
gaagccgaag aattactcca agaaggttta aaaccggttt tggaggaatg cgataac 1197
<210> 48
<211> 1425
<212> DNA
<213> Homo sapiens
<400> 48
ggggtggaag atttggcggc atcttacatc gtattaaagc ttgagaacga aatccggcag 60
gcgcaggtcc aatggttaat ggaggaaaac gccgccctgc aggcccagat ccctgaactt 120
caaaagtcgc aagccgcgaa ggagtatgat cttctgcgta aatcttcgga ggcgaaggag 180
ccgcaaaaac tgccagaaca tatgaatcca ccggccgctt gggaagcaca aaagactcca 240
gagtttaagg aaccacagaa acctcctgaa ccacaggatt tgcttccttg ggagccgcct 300
gctgcctggg agttgcaaga agcaccggct gcccctgagt cactggctcc gcctgcaacc 360
cgtgagtctc agaaaccacc tatggcgcat gaaatcccta ctgtattgga ggggcaaggg 420
cctgccaaca cacaagacgc tacgattgct caagaaccaa agaatagcga gccgcaagac 480
cctccaaata tcgagaaacc tcaggaagct ccggaatatc aagaaacagc ggcacagttg 540
gagtttttag aacttcctcc acctcaggag ccactcgaac cgagcaatgc gcaagaattt 600
ctcgagttgt cggctgccca ggagtcctta gaaggcctca ttgtagttga aacgtccgcg 660
gcttcggagt tcccacaggc tcctatcggg cttgaagcca ccgactttcc gctgcagtac 720
acgcttacct tctctggcga cagccagaag ttgccagaat ttttggtcca actctacagt 780
tatatgcggg tacgtgggca cttataccct accgaggcgg cgttagtgtc gtttgtaggc 840
aattgtttct cagggcgcgc gggctggtgg tttcagttgc ttttggatat ccagtcgcct 900
ctgttagaac agtgtgaaag ttttatcccg gttctccaag acacatttga caatccggaa 960
aacatgaagg acgcaaacca atgcatccac cagctttgtc agggcgaggg tcatgtggcc 1020
acacacttcc acctcattgc acaagagctt aattgggatg aaagcacgct gtggatccag 1080
ttccaggaag gcctggcctc atccatccag gatgaacttt cccatacatc gcctgctacc 1140
aacctgagtg atctgattac tcaatgcatc tcattagagg aaaagcctga cccaaacccg 1200
ttagggaagt cctcctcggc ggagggggat ggcccggaaa gtccgccagc agaaaaccaa 1260
cctatgcaag ctgcgatcaa ttgtcctcac atttccgaag cagagtgggt tcgttggcac 1320
aaaggccggc tttgtctcta ttgcggctat ccgggtcact tcgcacgtga ttgcccagtg 1380
aagccacacc aggcgttaca ggcagggaac attcaggctt gccaa 1425
<210> 49
<211> 717
<212> DNA
<213> Homo sapiens
<400> 49
ggggtgcagc cgcagactag caaagctgaa tcgccggctc tcgctgcctc accgaacgca 60
caaatggatg acgttattga tacattaacc tccctgcgtc tgacgaattc ggctctgcgg 120
cgggaggcta gcactcttcg ggccgagaaa gcaaatttaa ctaatatgct cgagtcagtg 180
atggccgagt taacgctgtt acggacccgt gcgcggattc cgggggccct gcagattacg 240
ccaccaattt cgtctattac tagcaacggt actcgcccga tgacgactcc tccaactagt 300
ttacctgaac cgttttctgg cgatcctggc cggttagctg gtttccttat gcagatggac 360
cgttttatga tctttcaagc tagccggttt ccaggggagg cagagcgtgt tgcgttcctg 420
gtgtcgcgct taactggcga agcagaaaaa tgggccattc ctcacatgca accagactct 480
cctttgcgta acaactatca aggcttctta gcagagttac ggcggaccta taagagcccg 540
ttgcgtcacg cccggcgggc gcaaatccgg aagacatcgg cctcgaaccg ggcagtccgt 600
gaacgccaaa tgctttgccg gcaacttgca tcagcaggta caggcccatg cccggtacac 660
cctgctagta acgggacttc cccggcaccg gcattaccag cacgggcgcg taactta 717
<210> 50
<211> 339
<212> DNA
<213> Homo sapiens
<400> 50
ggggacggtc gggtacagtt gatgaaggct ttattggctg gccctttacg tccggcggca 60
cgccgttggc ggaatcctat tccatttcca gagacttttg atggggatac tgatcgcctc 120
ccggagttta tcgtccaaac ttcgtcctac atgttcgttg acgaaaatac tttctctaac 180
gacgctctga aagtgacatt tctcattacc cggctgacag gtccagcctt gcaatgggtc 240
attccgtaca ttcgtaaaga aagcccgctt cttaacgact atcggggttt cctggccgag 300
atgaagcggg tttttgggtg ggaagaggac gaggacttt 339
<210> 51
<211> 339
<212> DNA
<213> Homo sapiens
<400> 51
ggggaaggtc gggtgcaact tatgaaagcg ttgcttgccc gcccgcttcg tccagcagca 60
cgtcgctggc ggaatccaat tcctttcccg gagacttttg acggggacac cgatcggctc 120
ccagagttca ttgtgcagac gtcaagctat atgttcgtgg atgagaacac gttctctaac 180
gacgcgttga aagtgacttt cttaattacg cgtttgactg gcccggcttt acaatgggtg 240
attccataca ttaagaaaga gtcaccgctt ctcagtgatt atcgcggttt tttagccgag 300
atgaagcggg tcttcgggtg ggaagaagac gaagacttt 339
<210> 52
<211> 1092
<212> DNA
<213> Homo sapiens
<400> 52
gggccgcgtg ggcgttgccg tcaacaaggt cctcggattc cgatttgggc agcggccaac 60
tatgccaacg cccacccgtg gcaacaaatg gataaggctt cgccaggcgt tgcttacaca 120
cctttggttg atccttggat tgagcggcct tgttgcggtg acacggtttg tgtgcgcacc 180
acaatggaac agaagagcac agcgtcaggc acttgtggtg gtaagcctgc tgagcgtggt 240
cctctcgcgg ggcatatgcc gagctcacgc ccacatcggg ttgatttctg ttgggttcct 300
ggtagcgacc caggcacatt cgacggcagt ccatggctct tagatcgctt tttggcgcaa 360
cttggtgatt acatgagttt tcactttgaa cactaccagg acaatatcag ccgtgtctgc 420
gagattcttc gtcggttaac gggccgcgct caggcatggg ctgctcctta cctggacggg 480
gaccttccac tgccagacga ctacgaattg ttttgtcaag accttaagga ggtagtacag 540
gaccctaaca gtttcgccga gtatcacgcc gtggtgactt gtccactccc tcttgcttcg 600
tcccaacttc ctgtagctcc tcagcttccg gtggtacgcc aataccttgc gcgcttcttg 660
gagggccttg ctttggatat gggtacggcg cctcggtcac tcccggccgc tatggccaca 720
ccggcagtct ccggctcgaa ctccgtttct cgttctgcct tatttgaaca acaactcaca 780
aaggaatcca ctccaggccc gaaagagcca cctgttctcc ctagctcgac ttgctctagc 840
aaaccgggtc ctgtcgaacc agccagttca caacctgaag aggctgctcc taccccggtg 900
ccgcgtttgt cagagtcggc taacccaccg gctcagcgtc cagaccctgc tcaccctggt 960
ggtcctaaac cacaaaaaac cgaagaggaa gttttagaaa ctgaggggga ccaggaagtt 1020
agcctgggga cgccgcagga ggtcgtagaa gcgccggaaa caccaggtga accaccgctc 1080
agccctgggt tc 1092
<210> 53
<211> 438
<212> DNA
<213> Homo sapiens
<400> 53
ggggttgatg aattggtgct cttgttgcac gcgctgttaa tgcgccatcg ggcgctttcc 60
attgaaaatt ctcagttgat ggagcaactt cgcttgttgg tctgcgaacg ggcgagcctt 120
cttcgtcagg tacgtccgcc gagctgtcca gtgccatttc ctgagacttt taacggggag 180
tcatcacggt tacctgagtt catcgtccaa accgcaagct atatgttagt taatgaaaat 240
cgcttttgca atgacgcaat gaaagtcgct tttttgatta gccttcttac tggtgaagca 300
gaagaatggg tcgtcccata cattgagatg gattcaccaa ttcttgggga ctaccgtgcg 360
ttcttggatg agatgaagca gtgttttggg tgggacgatg atgaagatga cgacgatgag 420
gaagaggagg atgactat 438
<210> 54
<211> 1647
<212> DNA
<213> Homo sapiens
<400> 54
gggcctgtgg atttaggtca ggctttgggg ttgttgccat ccctcgctaa ggccgaagat 60
tcccaattta gcgaaagcga tgcagcttta caggaggaat tgtcttctcc ggaaaccgca 120
cggcaacttt ttcgtcaatt tcgctatcaa gtcatgtcgg ggcctcatga aacactgaaa 180
cagttacgga agttatgttt tcagtggctg caacctgaag tccatacaaa ggaacaaatc 240
ctcgaaattc tgatgctgga acagttcttg accattctgc ctggtgaaat tcagatgtgg 300
gtccgcaagc agtgccctgg tagtggggag gaggcggtta cgttagtaga atccctgaaa 360
ggtgatccac aacggctctg gcaatggatc tccatccaag tcctgggtca ggatatcctg 420
tctgagaaaa tggagtcacc ttcttgccag gtgggcgaag tggagccaca cctggaagtt 480
gtacctcagg aactggggtt agagaattca tcttcagggc cgggggaact tctttcgcac 540
atcgtgaaag aggagtctga cactgaagca gagttggcgt tagcggcatc ccagccagct 600
cgtttggaag aacggctgat tcgggatcag gaccttgggg cgtccctcct cccggcagca 660
ccgcaggagc aatggcgtca attagacagc actcaaaaag aacaatattg ggacctgatg 720
ctggagacct acggcaaaat ggtatccggc gcgggtatct cacacccgaa gtccgattta 780
acgaactcaa ttgagttcgg tgaagagttg gcaggtattt atttacatgt aaacgaaaag 840
attccgcggc ctacctgcat tggtgaccgc caagaaaacg acaaagaaaa ccttaatttg 900
gaaaaccatc gtgaccagga attattacat gccagctgcc aggcctcggg cgaagtgcca 960
tcccaggcat cgttacgtgg cttctttacc gaggacgaac ctggttgctt cggcgaaggg 1020
gagaaccttc ctgaggcact tcagaatatc caggatgagg ggactggcga acagctgagc 1080
ccgcaagaac gcattagtga aaaacagttg ggtcaacatt tgccaaatcc gcactcgggg 1140
gagatgtcga cgatgtggct tgaagaaaaa cgggagacca gccagaaagg ccaaccacgt 1200
gcaccaatgg cgcagaaatt gccaacgtgc cgcgaatgtg gcaaaacgtt ttatcgcaat 1260
agtcaactta tctttcacca acgcacacac accggtgaga catattttca atgcaccatc 1320
tgcaaaaagg cgtttctccg gtcatctgat ttcgtgaaac atcagcggac tcatactggc 1380
gaaaaacctt gtaaatgtga ctattgtggc aagggcttta gtgattttag cgggcttcgg 1440
catcacgaga agatccatac cggcgagaag ccatacaagt gtccaatctg tgagaaatct 1500
ttcatccagc gcagtaattt taaccgccac caacgggttc acaccggtga aaagccttat 1560
aaatgctcgc attgtggcaa gagcttcagc tggagctcct cgctcgataa gcatcaacgt 1620
tcacatctgg ggaagaagcc gttccaa 1647
<210> 55
<211> 1053
<212> DNA
<213> Homo sapiens
<400> 55
gggactctcc gcttacttga ggattggtgt cgggggatgg acatgaaccc acgtaaggcc 60
cttcttatcg ccgggatttc ccagtcatgt tcagtcgccg agattgaaga ggcgctccaa 120
gccgggcttg ctcctttagg cgagtatcgt ctccttgggc ggatgtttcg ccgcgatgaa 180
aatcgcaaag tagcgttggt tggtctcaca gctgaaacta gccatgcgct tgtacctaaa 240
gaaattcctg gtaaaggcgg gatctggcgg gttattttta aaccaccgga cccggacaat 300
acgtttcttt ctcgtttgaa tgagttcctc gcgggcgagg ggatgacggt gggggaactt 360
agtcgtgctc ttggtcacga aaatgggtca ttagaccctg aacagggtat gattccggaa 420
atgtgggcgc cgatgctggc acaggctctg gaggctctcc aaccggcttt acagtgcctt 480
aagtacaaga agctgcgcgt tttttcaggg cgcgagtctc cagagccggg tgaggaggaa 540
ttcggccgtt ggatgttcca taccacccag atgatcaaag cgtggcaggt gccggatgtc 600
gagaaacgcc gccggctgtt ggaatcactc cgcgggccgg cacttgacgt tattcgggtt 660
ctgaaaatta acaacccgtt aattacggta gatgaatgtt tgcaagcact tgaagaggtc 720
tttggggtga ctgacaatcc tcgggaattg caagtaaaat acttaacgac ctaccataag 780
gacgaggaga aattatcagc ctacgtactg cggctggaac cgctgctgca gaagctcgtc 840
cagcgggggg ctattgaacg ggacgctgtt aatcaggctc gcctggatca ggtaatcgct 900
ggggcggtac ataaaactat ccgccgtgag ctgaacctgc ctgaagacgg gccggcgcca 960
ggctttcttc aactcctcgt tttgattaag gattacgagg cagctgaaga ggaggaagca 1020
ttacttcagg ccattcttga agggaacttt act 1053
<210> 56
<211> 2124
<212> DNA
<213> Homo sapiens
<400> 56
gggacagaac ggcgtcgcga cgaattaagt gaagaaatta ataatcttcg tgaaaaggtt 60
atgaaacaga gtgaggaaaa caacaatctt caatcccaag tccagaaact cactgaggag 120
aatactacac tccgtgagca agttgaacct acacctgaag atgaagatga cgacattgag 180
ttgcggggcg cagcagccgc agccgcgcct ccgccgccga tcgaggagga atgcccggag 240
gatttaccgg aaaaatttga tggtaatccg gacatgttag cgccattcat ggcccagtgc 300
caaattttta tggaaaagtc tacgcgcgat tttagtgtag atcgcgtacg tgtatgtttt 360
gtgacgagca tgatgactgg tcgcgcagcc cgttgggcgt cagcgaaatt ggagcggtcg 420
cactacctga tgcataatta cccggcgttc atgatggaga tgaaacacgt gtttgaagac 480
ccgcagcggc gggaggtggc caaacgcaag atccggcggt tgcggcaggg catgggcagc 540
gtaattgatt atagtaatgc gtttcaaatg attgcgcagg atctggattg gaatgaacct 600
gctctcattg atcaatatca tgaagggctt agtgaccata ttcaagagga actctctcac 660
ctggaagtgg ctaaatctct ctccgccctt attggccaat gcattcatat tgagcgccgt 720
cttgcacgtg ctgctgccgc tcggaaaccg cgtagtccac cacgggcttt agtgctccca 780
catatcgcgt cacaccatca agtagatcct actgagccag tggggggtgc acgcatgcgc 840
ttaacccaag aagaaaagga acgtcgtcgt aagctgaatt tatgcctgta ctgcggcact 900
ggtggccatt atgccgataa ctgtcctgcc aaagccagta agtcaagccc ggctgggaaa 960
cttccaggtc ctgccgtcga gggcccttct gctaccggcc cagagattat ccgctccccg 1020
caagacgatg cgtcgtcgcc tcatctccag gtaatgctcc aaatccacct ccctggccgg 1080
cacacactct ttgtccgggc gatgattgac tctggggcgt ctggtaattt tattgatcac 1140
gagtatgttg ctcaaaatgg tatccctctc cggatcaaag actggcctat tctggttgaa 1200
gccatcgatg gccgtccgat cgcgagcggt cctgtggttc atgaaacgca tgacctcatc 1260
gttgatctgg gtgaccaccg tgaagtatta tcctttgatg tgactcagtc accgtttttt 1320
ccagttgttt tgggcgtccg ttggctttcg actcacgatc ctaacatcac gtggtcgaca 1380
cggtcgattg tcttcgattc ggaatattgt cgttatcatt gccgcatgta ttcaccaatt 1440
ccgccgtctc tcccgccgcc tgcgccgcaa cctcctctgt attacccggt ggacggttac 1500
cgtgtttacc agccagttcg ctactactac gtacaaaacg tgtacacgcc tgttgatgaa 1560
cacgtgtacc cagatcaccg cctggtcgac cctcatattg agatgatccc gggtgcgcac 1620
tcgatcccat cgggccatgt ttattccttg tctgagccag aaatggccgc cttacgggat 1680
tttgtggccc ggaatgtcaa agacggcctg attaccccga caattgcacc aaacggtgct 1740
caggtgttgc aggtgaagcg gggctggaag ttgcaagtca gctatgattg tcgtgcgcca 1800
aacaacttca ctattcagaa ccaatatcca cgtctcagca tccctaatct cgaggaccag 1860
gcacatcttg caacatatac tgaatttgta cctcagattc ctggctatca gacttatcct 1920
acgtatgctg cctacccaac atacccggta ggtttcgcat ggtacccagt aggccgggac 1980
gggcagggcc gctctttata tgttcctgtc atgattacat ggaacccgca ttggtaccgc 2040
cagcctccgg tcccacagta cccacctcct caacctccac cacctccgcc gcctcctcca 2100
ccgccacctt cttactcgac atta 2124
<210> 57
<211> 60
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
oligonucleotide
<400> 57
atgcatcacc atcaccatca cggctcaggg tctggtagcg aaaatctgta cttccagggg 60
<210> 58
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 58
Met His His His His His His Gly Ser Gly Ser Gly Ser Glu Asn Leu
1 5 10 15
Tyr Phe Gln Gly
20
<210> 59
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
6xHis tag
<400> 59
His His His His His His
1 5
<210> 60
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 60
Gly Ser Gly Ser Gly Ser
1 5
<210> 61
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 61
Glu Asn Leu Tyr Phe Gln Gly
1 5
<210> 62
<211> 26
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
primer
<400> 62
aagctcattt cctggtatga caacga 26
<210> 63
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
primer
<400> 63
agggtctctc tcttcctctt gtgct 25
<210> 64
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
primer
<400> 64
gctcaacctg ggaactgcat ctgat 25
<210> 65
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
primer
<400> 65
taatcctgtt tgctccccac gcttt 25
<210> 66
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
primer
<400> 66
ggcccctcag ctccagtgat tc 22
<210> 67
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
primer
<400> 67
cctgttgtca ctctcctggc tctga 25
<210> 68
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
primer
<400> 68
gccaagacat aagaaacctc gcct 24
<210> 69
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
primer
<400> 69
gtgaatcaac atcctccctc cgtc 24
<210> 70
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
Peptide
<220>
<221> MISC_FEATURE
<222> (1)..(25)
<223> This sequence may encompass 1-5 "Glu Ala Ala Ala Lys"
repeating units
<400> 70
Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Glu
1 5 10 15
Ala Ala Ala Lys Glu Ala Ala Ala Lys
20 25
<210> 71
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
Peptide
<220>
<221> MISC_FEATURE
<222> (1)..(25)
<223> This sequence may encompass 1-5 "Glu Ala Ala Ala Arg"
repeating units
<400> 71
Glu Ala Ala Ala Arg Glu Ala Ala Ala Arg Glu Ala Ala Ala Arg Glu
1 5 10 15
Ala Ala Ala Arg Glu Ala Ala Ala Arg
20 25
<210> 72
<211> 50
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
Polypeptide
<220>
<221> MISC_FEATURE
<222> (1)..(50)
<223> This sequence may encompass 1-10 "Gly Gly Gly Gly Ser"
repeating units
<400> 72
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
35 40 45
Gly Ser
50
<210> 73
<211> 40
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
Polypeptide
<220>
<221> MISC_FEATURE
<222> (1)..(40)
<223> This sequence may encompass 1-10 "Gly Gly Gly Ser"
repeating units
<400> 73
Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser
20 25 30
Gly Gly Gly Ser Gly Gly Gly Ser
35 40
<210> 74
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
Peptide
<400> 74
Lys Glu Ser Gly Ser Val Ser Ser Glu Gln Leu Ala Gln Phe Arg Ser
1 5 10 15
Leu Asp
<210> 75
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 75
Glu Gly Lys Ser Ser Gly Ser Gly Ser Glu Ser Lys Ser Thr
1 5 10
<210> 76
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 76
Gly Gly Ala Ala Asn Leu Val Arg Gly Gly
1 5 10
<210> 77
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 77
Ser Gly Arg Ile Gly Phe Leu Arg Thr Ala
1 5 10
<210> 78
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 78
Ser Gly Arg Ser Ala
1 5
<210> 79
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 79
Gly Phe Leu Gly
1
<210> 80
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 80
Ala Leu Ala Leu
1
<210> 81
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
Peptide
<220>
<221> MOD_RES
<222> (3)..(3)
<223> S-ethylcysteine
<400> 81
Pro Ile Cys Phe Phe
1 5
<210> 82
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<220>
<221> MOD_RES
<222> (3)..(3)
<223> Ser or Thr
<220>
<221> MOD_RES
<222> (4)..(4)
<223> Leu or Ile
<220>
<221> MOD_RES
<222> (5)..(5)
<223> Ser or Thr
<400> 82
Pro Arg Xaa Xaa Xaa
1 5
<210> 83
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 83
Asp Glu Val Asp
1
<210> 84
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 84
Gly Trp Glu His Asp Gly
1 5
<210> 85
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 85
Arg Pro Leu Ala Leu Trp Arg Ser
1 5
Claims (24)
- 재조합 Arc 폴리펩티드 또는 재조합 내인성 Gag 폴리펩티드 및 치료제를 포함하는 캡시드.
- 제1항에 있어서, 치료제가 핵산인 캡시드.
- 제2항에 있어서, 핵산이 RNA인 캡시드.
- 제1항 내지 제3항 중 어느 한 항에 있어서, 재조합 Arc 폴리펩티드가 서열번호 1인 아미노산 서열 또는 서열번호 1과 적어도 90% 동일한 아미노산 서열을 포함하는 인간 Arc 폴리펩티드인 캡시드.
- 제1항 내지 제3항 중 어느 한 항에 있어서, 재조합 Arc 폴리펩티드가
a) 서열번호 2인 아미노산 서열 또는 서열번호 2와 적어도 90% 동일한 아미노산 서열;
b) 서열번호 3인 아미노산 서열 또는 서열번호 3과 적어도 90% 동일한 아미노산 서열;
c) 서열번호 4인 아미노산 서열 또는 서열번호 4와 적어도 90% 동일한 아미노산 서열;
d) 서열번호 5인 아미노산 서열 또는 서열번호 5와 적어도 90% 동일한 아미노산 서열;
e) 서열번호 6인 아미노산 서열 또는 서열번호 6과 적어도 90% 동일한 아미노산 서열;
f) 서열번호 7인 아미노산 서열 또는 서열번호 7과 적어도 90% 동일한 아미노산 서열;
g) 서열번호 8인 아미노산 서열 또는 서열번호 8과 적어도 90% 동일한 아미노산 서열; 또는
h) 서열번호 9인 아미노산 서열 또는 서열번호 9와 적어도 90% 동일한 아미노산 서열; 또는
i) 서열번호 10인 아미노산 서열 또는 서열번호 10과 적어도 90% 동일한 아미노산 서열; 또는
j 서열번호 11인 아미노산 서열 또는 서열번호 11과 적어도 90% 동일한 아미노산 서열; 또는
k) 서열번호 12인 아미노산 서열 또는 서열번호 12와 적어도 90% 동일한 아미노산 서열; 또는
l) 서열번호 13인 아미노산 서열 또는 서열번호 13과 적어도 90% 동일한 아미노산 서열; 또는
m) 서열번호 14인 아미노산 서열 또는 서열번호 14와 적어도 90% 동일한 아미노산 서열; 또는
n) 서열번호 15인 아미노산 서열 또는 서열번호 15와 적어도 90% 동일한 아미노산 서열
을 포함하는 Arc 폴리펩티드인 캡시드. - 제1항 내지 제3항 중 어느 한 항에 있어서, 재조합 내인성 Gag 폴리펩티드가 인간 내인성 Gag 폴리펩티드인 캡시드.
- 제6항에 있어서, 재조합 인간 내인성 Gag 폴리펩티드가
a) 서열번호 16인 아미노산 서열 또는 서열번호 16과 적어도 90% 동일한 아미노산 서열;
b) 서열번호 17인 아미노산 서열 또는 서열번호 17과 적어도 90% 동일한 아미노산 서열;
c) 서열번호 18인 아미노산 서열 또는 서열번호 18과 적어도 90% 동일한 아미노산 서열;
d) 서열번호 19인 아미노산 서열 또는 서열번호 19와 적어도 90% 동일한 아미노산 서열;
e) 서열번호 20인 아미노산 서열 또는 서열번호 20과 적어도 90% 동일한 아미노산 서열;
f) 서열번호 21인 아미노산 서열 또는 서열번호 21과 적어도 90% 동일한 아미노산 서열;
g) 서열번호 22인 아미노산 서열 또는 서열번호 22와 적어도 90% 동일한 아미노산 서열;
h) 서열번호 23인 아미노산 서열 또는 서열번호 23과 적어도 90% 동일한 아미노산 서열;
i) 서열번호 24인 아미노산 서열 또는 서열번호 24와 적어도 90% 동일한 아미노산 서열;
j) 서열번호 25인 아미노산 서열 또는 서열번호 25와 적어도 90% 동일한 아미노산 서열; 또는
k) 서열번호 26인 아미노산 서열 또는 서열번호 26과 적어도 90% 동일한 아미노산 서열; 또는
l) 서열번호 27인 아미노산 서열 또는 서열번호 27과 적어도 90% 동일한 아미노산 서열; 또는
m) 서열번호 28인 아미노산 서열 또는 서열번호 28과 적어도 90% 동일한 아미노산 서열
을 포함하는 내인성 Gag 폴리펩티드인 캡시드. - 재조합 Arc 폴리펩티드 또는 재조합 내인성 Gag 폴리펩티드를 포함하고, 재조합 Arc 폴리펩티드는 래트 Arc 폴리펩티드 또는 인간 Arc 폴리펩티드가 아닌, 캡시드.
- 제8항에 있어서, 카고(cargo)를 추가로 포함하는 캡시드.
- 제9항에 있어서, 카고가 핵산인 캡시드.
- 제10항에 있어서, 카고가 RNA인 캡시드.
- 제9항에 있어서, 카고가 치료제인 캡시드.
- 제8항 내지 제12항 중 어느 한 항에 있어서, 재조합 Arc 폴리펩티드가
a) 서열번호 2인 아미노산 서열 또는 서열번호 2와 적어도 90% 동일한 아미노산 서열;
b) 서열번호 3인 아미노산 서열 또는 서열번호 3과 적어도 90% 동일한 아미노산 서열;
c) 서열번호 4인 아미노산 서열 또는 서열번호 4와 적어도 90% 동일한 아미노산 서열;
d) 서열번호 5인 아미노산 서열 또는 서열번호 5와 적어도 90% 동일한 아미노산 서열;
e) 서열번호 6인 아미노산 서열 또는 서열번호 6과 적어도 90% 동일한 아미노산 서열;
f) 서열번호 7인 아미노산 서열 또는 서열번호 7과 적어도 90% 동일한 아미노산 서열;
g) 서열번호 8인 아미노산 서열 또는 서열번호 8과 적어도 90% 동일한 아미노산 서열;
h) 서열번호 9인 아미노산 서열 또는 서열번호 9와 적어도 90% 동일한 아미노산 서열;
i) 서열번호 10인 아미노산 서열 또는 서열번호 10과 적어도 90% 동일한 아미노산 서열; 또는
j) 서열번호 11인 아미노산 서열 또는 서열번호 11과 적어도 90% 동일한 아미노산 서열; 또는
k) 서열번호 12인 아미노산 서열 또는 서열번호 12와 적어도 90% 동일한 아미노산 서열; 또는
l) 서열번호 13인 아미노산 서열 또는 서열번호 13과 적어도 90% 동일한 아미노산 서열; 또는
m) 서열번호 14인 아미노산 서열 또는 서열번호 14와 적어도 90% 동일한 아미노산 서열; 또는
n) 서열번호 15인 아미노산 서열 또는 서열번호 15와 적어도 90% 동일한 아미노산 서열
을 포함하는 Arc 폴리펩티드인 캡시드. - 제8항 내지 제12항 중 어느 한 항에 있어서, 재조합 내인성 Gag 폴리펩티드가
a) 서열번호 16인 아미노산 서열 또는 서열번호 16과 적어도 90% 동일한 아미노산 서열;
b) 서열번호 17인 아미노산 서열 또는 서열번호 17과 적어도 90% 동일한 아미노산 서열;
c) 서열번호 18인 아미노산 서열 또는 서열번호 18과 적어도 90% 동일한 아미노산 서열;
d) 서열번호 19인 아미노산 서열 또는 서열번호 19와 적어도 90% 동일한 아미노산 서열;
e) 서열번호 20인 아미노산 서열 또는 서열번호 20과 적어도 90% 동일한 아미노산 서열;
f) 서열번호 21인 아미노산 서열 또는 서열번호 21과 적어도 90% 동일한 아미노산 서열; 또는
g) 서열번호 22인 아미노산 서열 또는 서열번호 22와 적어도 90% 동일한 아미노산 서열; 또는
h) 서열번호 23인 아미노산 서열 또는 서열번호 23과 적어도 90% 동일한 아미노산 서열; 또는
i) 서열번호 24인 아미노산 서열 또는 서열번호 24와 적어도 90% 동일한 아미노산 서열; 또는
j) 서열번호 25인 아미노산 서열 또는 서열번호 25와 적어도 90% 동일한 아미노산 서열; 또는
k) 서열번호 26인 아미노산 서열 또는 서열번호 26과 적어도 90% 동일한 아미노산 서열; 또는
l) 서열번호 27인 아미노산 서열 또는 서열번호 27과 적어도 90% 동일한 아미노산 서열; 또는
m) 서열번호 28인 아미노산 서열 또는 서열번호 28과 적어도 90% 동일한 아미노산 서열
을 포함하는 내인성 Gag 폴리펩티드인 캡시드. - 제1항 내지 제14항 중 어느 한 항의 재조합 Arc 폴리펩티드 또는 재조합 내인성 Gag 폴리펩티드를 코딩하는 DNA를 포함하는 벡터.
- 제1항 내지 제14항 중 어느 한 항의 캡시드를 세포에 투여하는 단계를 포함하는, 카고를 세포에 전달하는 방법.
- 제16항에 있어서, 세포가 진핵 세포인 방법.
- 제16항에 있어서, 세포가 척추동물 세포인 방법.
- 제16항에 있어서, 세포가 포유동물 세포인 방법.
- 제16항에 있어서, 세포가 인간 세포인 방법.
- 제16항 내지 제20항 중 어느 한 항에 있어서, 카고가 핵산인 방법.
- 제21항에 있어서, 세포가 핵산에 의해 코딩되는 유전자를 발현하는 것인 방법.
- 제16항 내지 제20항 중 어느 한 항에 있어서, 카고가 치료제인 방법.
- 제1항 내지 제14항 중 어느 한 항의 캡시드를 세포에 투여하는 단계를 포함하는, 핵산을 세포로 형질감염시키는 방법.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020247017429A KR20240093924A (ko) | 2018-09-18 | 2019-09-18 | Arc 기반 캡시드 및 이의 용도 |
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201862733015P | 2018-09-18 | 2018-09-18 | |
| US62/733,015 | 2018-09-18 | ||
| PCT/US2019/051786 WO2020061229A2 (en) | 2018-09-18 | 2019-09-18 | Arc-based capsids and uses thereof |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020247017429A Division KR20240093924A (ko) | 2018-09-18 | 2019-09-18 | Arc 기반 캡시드 및 이의 용도 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20210070305A true KR20210070305A (ko) | 2021-06-14 |
Family
ID=69888834
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020217011429A KR20210070305A (ko) | 2018-09-18 | 2019-09-18 | Arc 기반 캡시드 및 이의 용도 |
| KR1020247017429A KR20240093924A (ko) | 2018-09-18 | 2019-09-18 | Arc 기반 캡시드 및 이의 용도 |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020247017429A KR20240093924A (ko) | 2018-09-18 | 2019-09-18 | Arc 기반 캡시드 및 이의 용도 |
Country Status (8)
| Country | Link |
|---|---|
| US (3) | US20220088224A1 (ko) |
| EP (1) | EP3852813A4 (ko) |
| JP (2) | JP7344300B2 (ko) |
| KR (2) | KR20210070305A (ko) |
| CN (1) | CN113164623A (ko) |
| AU (1) | AU2019343045A1 (ko) |
| CA (1) | CA3113095A1 (ko) |
| WO (1) | WO2020061229A2 (ko) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20210403907A1 (en) * | 2018-09-18 | 2021-12-30 | Vnv Newco Inc. | Arc-based capsids and uses thereof |
| US20220088224A1 (en) | 2018-09-18 | 2022-03-24 | Vnv Newco Inc. | Arc-based capsids and uses thereof |
| US20200347100A1 (en) * | 2019-03-15 | 2020-11-05 | The Broad Institute, Inc. | Non-naturally occurring capsids for delivery of nucleic acids and/or proteins |
| US11129892B1 (en) * | 2020-05-18 | 2021-09-28 | Vnv Newco Inc. | Vaccine compositions comprising endogenous Gag polypeptides |
| CA3205477A1 (en) * | 2021-01-27 | 2022-08-04 | Aera Therapeutics, Inc. | Pnma2-based capsids and uses thereof |
| EP4334445A1 (en) * | 2021-05-04 | 2024-03-13 | Cornell University | Engineered extracellular vesicles |
| WO2024006988A2 (en) * | 2022-06-30 | 2024-01-04 | The Broad Institute, Inc. | Engineered delivery vesicles and uses thereof |
| WO2024026295A1 (en) * | 2022-07-27 | 2024-02-01 | Aera Therapeutics, Inc. | Endogenous gag-based and pnma family capsids and uses thereof |
Family Cites Families (119)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4510245A (en) | 1982-11-18 | 1985-04-09 | Chiron Corporation | Adenovirus promoter system |
| US4897355A (en) | 1985-01-07 | 1990-01-30 | Syntex (U.S.A.) Inc. | N[ω,(ω-1)-dialkyloxy]- and N-[ω,(ω-1)-dialkenyloxy]-alk-1-yl-N,N,N-tetrasubstituted ammonium lipids and uses therefor |
| US5168062A (en) | 1985-01-30 | 1992-12-01 | University Of Iowa Research Foundation | Transfer vectors and microorganisms containing human cytomegalovirus immediate-early promoter-regulatory DNA sequence |
| US4968615A (en) | 1985-12-18 | 1990-11-06 | Ciba-Geigy Corporation | Deoxyribonucleic acid segment from a virus |
| US4737323A (en) | 1986-02-13 | 1988-04-12 | Liposome Technology, Inc. | Liposome extrusion method |
| US4837028A (en) | 1986-12-24 | 1989-06-06 | Liposome Technology, Inc. | Liposomes with enhanced circulation time |
| US5000960A (en) | 1987-03-13 | 1991-03-19 | Micro-Pak, Inc. | Protein coupling to lipid vesicles |
| US5989886A (en) | 1991-01-02 | 1999-11-23 | The Johns Hopkins University | Method for the inhibition and prevention of viral replication using fusions of a virus protein and a destructive enzyme |
| US5260065A (en) | 1991-09-17 | 1993-11-09 | Micro Vesicular Systems, Inc. | Blended lipid vesicles |
| US5543158A (en) | 1993-07-23 | 1996-08-06 | Massachusetts Institute Of Technology | Biodegradable injectable nanoparticles |
| US6007845A (en) | 1994-07-22 | 1999-12-28 | Massachusetts Institute Of Technology | Nanoparticles and microparticles of non-linear hydrophilic-hydrophobic multiblock copolymers |
| US5985309A (en) | 1996-05-24 | 1999-11-16 | Massachusetts Institute Of Technology | Preparation of particles for inhalation |
| US5855913A (en) | 1997-01-16 | 1999-01-05 | Massachusetts Instite Of Technology | Particles incorporating surfactants for pulmonary drug delivery |
| US5944710A (en) | 1996-06-24 | 1999-08-31 | Genetronics, Inc. | Electroporation-mediated intravascular delivery |
| US5869326A (en) | 1996-09-09 | 1999-02-09 | Genetronics, Inc. | Electroporation employing user-configured pulsing scheme |
| GB9710049D0 (en) | 1997-05-19 | 1997-07-09 | Nycomed Imaging As | Method |
| GB9710809D0 (en) | 1997-05-23 | 1997-07-23 | Medical Res Council | Nucleic acid binding proteins |
| JP4303418B2 (ja) | 1997-10-24 | 2009-07-29 | ライフ テクノロジーズ コーポレーション | 組換え部位を有する核酸を使用する組換えクローニング |
| ES2341926T3 (es) | 1998-03-02 | 2010-06-29 | Massachusetts Institute Of Technology | Poliproteinas con dedos de cinc que tienen enlazadores mejorados. |
| FR2780069B1 (fr) | 1998-06-23 | 2002-06-28 | Inst Nat Sante Rech Med | Famille de sequences nucleiques et de sequences proteiques deduites presentant des motifs retroviraux endogenes humains et leurs applications |
| US7013219B2 (en) | 1999-01-12 | 2006-03-14 | Sangamo Biosciences, Inc. | Regulation of endogenous gene expression in cells using zinc finger proteins |
| US6534261B1 (en) | 1999-01-12 | 2003-03-18 | Sangamo Biosciences, Inc. | Regulation of endogenous gene expression in cells using zinc finger proteins |
| US7030215B2 (en) | 1999-03-24 | 2006-04-18 | Sangamo Biosciences, Inc. | Position dependent recognition of GNN nucleotide triplets by zinc fingers |
| US6794136B1 (en) | 2000-11-20 | 2004-09-21 | Sangamo Biosciences, Inc. | Iterative optimization in the design of binding proteins |
| US20030104526A1 (en) | 1999-03-24 | 2003-06-05 | Qiang Liu | Position dependent recognition of GNN nucleotide triplets by zinc fingers |
| FR2797889A1 (fr) | 1999-09-01 | 2001-03-02 | Bio Merieux | Procede de detection de l'expression d'une proteine d'enveloppe d'un retrovirus endogene humain et utilisations d'un gene codant pour cette proteine |
| WO2002080851A2 (en) | 2001-04-05 | 2002-10-17 | The Johns Hopkins University | Chimeric vaccines |
| US7776321B2 (en) | 2001-09-26 | 2010-08-17 | Mayo Foundation For Medical Education And Research | Mutable vaccines |
| EP1532161B1 (en) | 2002-06-13 | 2012-02-15 | Novartis Vaccines and Diagnostics, Inc. | Vectors for expression of hml-2 polypeptides |
| ATE551353T1 (de) | 2003-04-04 | 2012-04-15 | Centre Nat Rech Scient | Protein mit fusogener wirkung, nukleinsäuresequenzen, die für dieses protein codieren und pharmazeutische zusammensetzungen, die dieses enthalten |
| EP1732585B1 (en) | 2004-03-30 | 2010-06-30 | Institut Gustave Roussy | Polypeptide sequence involved in the modulation of the immunosuppresive effect of viral proteins |
| GB0418651D0 (en) | 2004-08-20 | 2004-09-22 | Medical Res Council | Method |
| EP2327774A3 (en) | 2005-10-18 | 2011-09-28 | Precision Biosciences | Rationally-designed meganucleases with altered sequence specificity and DNA-binding affinity |
| JP2008078613A (ja) | 2006-08-24 | 2008-04-03 | Rohm Co Ltd | 窒化物半導体の製造方法及び窒化物半導体素子 |
| WO2008149176A1 (en) | 2007-06-06 | 2008-12-11 | Cellectis | Meganuclease variants cleaving a dna target sequence from the mouse rosa26 locus and uses thereof |
| WO2009042727A1 (en) | 2007-09-24 | 2009-04-02 | The Johns Hopkins University | Immediate early gene arc interacts with endocytic machinery and regulates the trafficking and function of presenilin |
| KR101164602B1 (ko) | 2008-01-09 | 2012-07-10 | 주식회사 케이알바이오텍 | 배큘로바이러스?기반 백신 |
| MX2011004859A (es) | 2008-11-07 | 2011-08-03 | Massachusetts Inst Technology | Lipidoides de aminoalcohol y usos de los mismos. |
| US20110027239A1 (en) | 2009-07-29 | 2011-02-03 | Tissue Genesis, Inc. | Adipose-derived stromal cells (asc) as delivery tool for treatment of cancer |
| US8927807B2 (en) | 2009-09-03 | 2015-01-06 | The Regents Of The University Of California | Nitrate-responsive promoter |
| PL2510096T5 (pl) | 2009-12-10 | 2018-06-29 | Regents Of The University Of Minnesota | Modyfikacja DNA zależna od efektora TAL |
| US9567573B2 (en) | 2010-04-26 | 2017-02-14 | Sangamo Biosciences, Inc. | Genome editing of a Rosa locus using nucleases |
| EP2609135A4 (en) | 2010-08-26 | 2015-05-20 | Massachusetts Inst Technology | POLY (BETA-AMINO ALCOHOLS), THEIR PREPARATION AND USES THEREOF |
| CA2831392C (en) | 2011-03-28 | 2020-04-28 | Massachusetts Institute Of Technology | Conjugated lipomers and uses thereof |
| CA2853316C (en) | 2011-10-25 | 2018-11-27 | The University Of British Columbia | Limit size lipid nanoparticles and related methods |
| WO2013086373A1 (en) | 2011-12-07 | 2013-06-13 | Alnylam Pharmaceuticals, Inc. | Lipids for the delivery of active agents |
| US9303079B2 (en) | 2012-04-02 | 2016-04-05 | Moderna Therapeutics, Inc. | Modified polynucleotides for the production of cytoplasmic and cytoskeletal proteins |
| AU2013243955B2 (en) | 2012-04-02 | 2018-02-22 | Modernatx, Inc. | Modified polynucleotides for the production of oncology-related proteins and peptides |
| CA2842041A1 (en) | 2012-04-18 | 2013-10-24 | Arrowhead Research Corporation | Poly(acrylate) polymers for in vivo nucleic acid delivery |
| PL3494997T3 (pl) | 2012-07-25 | 2020-04-30 | The Broad Institute, Inc. | Indukowalne białka wiążące dna i narzędzia perturbacji genomu oraz ich zastosowania |
| US8697359B1 (en) | 2012-12-12 | 2014-04-15 | The Broad Institute, Inc. | CRISPR-Cas systems and methods for altering expression of gene products |
| EP2931899A1 (en) | 2012-12-12 | 2015-10-21 | The Broad Institute, Inc. | Functional genomics using crispr-cas systems, compositions, methods, knock out libraries and applications thereof |
| ES2701749T3 (es) | 2012-12-12 | 2019-02-25 | Broad Inst Inc | Métodos, modelos, sistemas y aparatos para identificar secuencias diana para enzimas Cas o sistemas CRISPR-Cas para secuencias diana y transmitir resultados de los mismos |
| KR20150105634A (ko) | 2012-12-12 | 2015-09-17 | 더 브로드 인스티튜트, 인코퍼레이티드 | 서열 조작을 위한 개선된 시스템, 방법 및 효소 조성물의 유전자 조작 및 최적화 |
| PT2896697E (pt) | 2012-12-12 | 2015-12-31 | Massachusetts Inst Technology | Engenharia de sistemas, métodos e composições guia otimizadas para a manipulação de sequências |
| US8993233B2 (en) | 2012-12-12 | 2015-03-31 | The Broad Institute Inc. | Engineering and optimization of systems, methods and compositions for sequence manipulation with functional domains |
| CN110982844B (zh) | 2012-12-12 | 2024-08-13 | 布罗德研究所有限公司 | 用于序列操纵的crispr-cas组分系统、方法以及组合物 |
| MX2015007550A (es) | 2012-12-12 | 2017-02-02 | Broad Inst Inc | Suministro, modificación y optimización de sistemas, métodos y composiciones para la manipulación de secuencias y aplicaciones terapéuticas. |
| DK2784162T3 (en) | 2012-12-12 | 2015-07-13 | Broad Inst Inc | Design of systems, methods and optimized control manipulations for sequence manipulation |
| US20140310830A1 (en) | 2012-12-12 | 2014-10-16 | Feng Zhang | CRISPR-Cas Nickase Systems, Methods And Compositions For Sequence Manipulation in Eukaryotes |
| WO2014118272A1 (en) | 2013-01-30 | 2014-08-07 | Santaris Pharma A/S | Antimir-122 oligonucleotide carbohydrate conjugates |
| US9481905B2 (en) | 2013-02-19 | 2016-11-01 | Orizhan Bioscience Limited | Method of using neutrilized DNA (N-DNA) as surface probe for high throughput detection platform |
| US9693958B2 (en) | 2013-03-15 | 2017-07-04 | Cureport, Inc. | Methods and devices for preparation of lipid nanoparticles |
| US11332719B2 (en) | 2013-03-15 | 2022-05-17 | The Broad Institute, Inc. | Recombinant virus and preparations thereof |
| EP3725885A1 (en) | 2013-06-17 | 2020-10-21 | The Broad Institute, Inc. | Functional genomics using crispr-cas systems, compositions methods, screens and applications thereof |
| MX2015017312A (es) | 2013-06-17 | 2017-04-10 | Broad Inst Inc | Suministro y uso de composiciones, vectores y sistemas crispr-cas para la modificación dirigida y terapia hepáticas. |
| EP3011035B1 (en) | 2013-06-17 | 2020-05-13 | The Broad Institute, Inc. | Assay for quantitative evaluation of target site cleavage by one or more crispr-cas guide sequences |
| CN105492611A (zh) | 2013-06-17 | 2016-04-13 | 布罗德研究所有限公司 | 用于序列操纵的优化的crispr-cas双切口酶系统、方法以及组合物 |
| CN105793425B (zh) | 2013-06-17 | 2021-10-26 | 布罗德研究所有限公司 | 使用病毒组分靶向障碍和疾病的crispr-cas系统和组合物的递送、用途和治疗应用 |
| SG10201710488TA (en) | 2013-06-17 | 2018-01-30 | Broad Inst Inc | Delivery, Engineering and Optimization of Systems, Methods and Compositions for Targeting and Modeling Diseases and Disorders of Post Mitotic Cells |
| ES2777217T3 (es) | 2013-06-17 | 2020-08-04 | Broad Inst Inc | Suministro, modificación y optimización de sistemas de guía en tándem, métodos y composiciones para la manipulación de secuencias |
| US10655173B2 (en) | 2013-10-18 | 2020-05-19 | The Broad Institute, Inc. | Spatial and cellular mapping of biomolecules in situ by high-throughput sequencing |
| KR102523466B1 (ko) | 2013-11-07 | 2023-04-20 | 에디타스 메디신, 인코포레이티드 | 지배적인 gRNA를 이용하는 CRISPR-관련 방법 및 조성물 |
| CN106536729A (zh) | 2013-12-12 | 2017-03-22 | 布罗德研究所有限公司 | 使用粒子递送组分靶向障碍和疾病的crispr‑cas系统和组合物的递送、用途和治疗应用 |
| WO2015089462A1 (en) | 2013-12-12 | 2015-06-18 | The Broad Institute Inc. | Delivery, use and therapeutic applications of the crispr-cas systems and compositions for genome editing |
| EP3080271B1 (en) | 2013-12-12 | 2020-02-12 | The Broad Institute, Inc. | Systems, methods and compositions for sequence manipulation with optimized functional crispr-cas systems |
| SG10201804975PA (en) | 2013-12-12 | 2018-07-30 | Broad Inst Inc | Delivery, Use and Therapeutic Applications of the Crispr-Cas Systems and Compositions for HBV and Viral Diseases and Disorders |
| WO2015089364A1 (en) | 2013-12-12 | 2015-06-18 | The Broad Institute Inc. | Crystal structure of a crispr-cas system, and uses thereof |
| JP6625055B2 (ja) | 2013-12-12 | 2020-01-08 | ザ・ブロード・インスティテュート・インコーポレイテッド | 組成物、及びヌクレオチドリピート障害におけるcrispr−cas系の使用方法 |
| WO2015089473A1 (en) | 2013-12-12 | 2015-06-18 | The Broad Institute Inc. | Engineering of systems, methods and optimized guide compositions with new architectures for sequence manipulation |
| EP3080260B1 (en) | 2013-12-12 | 2019-03-06 | The Broad Institute, Inc. | Crispr-cas systems and methods for altering expression of gene products, structural information and inducible modular cas enzymes |
| WO2016049258A2 (en) | 2014-09-25 | 2016-03-31 | The Broad Institute Inc. | Functional screening with optimized functional crispr-cas systems |
| WO2016094874A1 (en) | 2014-12-12 | 2016-06-16 | The Broad Institute Inc. | Escorted and functionalized guides for crispr-cas systems |
| WO2016094867A1 (en) | 2014-12-12 | 2016-06-16 | The Broad Institute Inc. | Protected guide rnas (pgrnas) |
| WO2016094872A1 (en) | 2014-12-12 | 2016-06-16 | The Broad Institute Inc. | Dead guides for crispr transcription factors |
| WO2016106236A1 (en) | 2014-12-23 | 2016-06-30 | The Broad Institute Inc. | Rna-targeting system |
| WO2016106244A1 (en) | 2014-12-24 | 2016-06-30 | The Broad Institute Inc. | Crispr having or associated with destabilization domains |
| WO2016149426A1 (en) | 2015-03-16 | 2016-09-22 | The Broad Institute, Inc. | Constructs for continuous monitoring of live cells |
| US9738687B2 (en) | 2015-04-10 | 2017-08-22 | Feldan Bio Inc. | Polypeptide-based shuttle agents for improving the transduction efficiency of polypeptide cargos to the cytosol of target eukaryotic cells, uses thereof, methods and kits relating to same |
| WO2016185125A1 (fr) * | 2015-05-15 | 2016-11-24 | Vectalys | Particule rétrovirale comportant au moins deux arn non viraux encapsidés |
| US10624849B2 (en) | 2015-09-28 | 2020-04-21 | Northwestern University | Targeted extracellular vesicles comprising membrane proteins with engineered glycosylation sites |
| US10968253B2 (en) | 2015-10-20 | 2021-04-06 | Institut National De La Sante Et De La Recherche Medicale (Inserm) | Methods and products for genetic engineering |
| EP3235828A1 (en) | 2016-04-21 | 2017-10-25 | Genethon | Stable pseudotyped lentiviral particles and uses thereof |
| WO2017191274A2 (en) | 2016-05-04 | 2017-11-09 | Curevac Ag | Rna encoding a therapeutic protein |
| JP7355382B2 (ja) | 2017-05-10 | 2023-10-03 | ユニヴァーシティー オブ ユタ リサーチ ファウンデーション | Arcカプシドの組成物及び使用方法 |
| EP3625342B1 (en) | 2017-05-18 | 2022-08-24 | The Broad Institute, Inc. | Systems, methods, and compositions for targeted nucleic acid editing |
| WO2018213708A1 (en) | 2017-05-18 | 2018-11-22 | The Broad Institute, Inc. | Systems, methods, and compositions for targeted nucleic acid editing |
| JP2020530438A (ja) | 2017-06-22 | 2020-10-22 | アンスティテュ ギュスタフ ルッシーInstitut Gustave Roussy | ヒト内在性レトロウイルスタンパク質 |
| CN111328290A (zh) | 2017-06-26 | 2020-06-23 | 博德研究所 | 用于靶向核酸编辑的基于crispr/cas-腺嘌呤脱氨酶的组合物、系统和方法 |
| US20200248169A1 (en) | 2017-06-26 | 2020-08-06 | The Broad Institute, Inc. | Crispr/cas-cytidine deaminase based compositions, systems, and methods for targeted nucleic acid editing |
| EP3655530A4 (en) | 2017-07-17 | 2021-07-28 | The Broad Institute, Inc. | NEW TYPE VI CRISPR ORTHOLOGIST AND SYSTEMS |
| CN111630060B (zh) | 2017-09-01 | 2024-01-23 | 盈珀治疗有限公司 | 用于在疾病的预防和/或治疗中使用的疫苗 |
| CA3073848A1 (en) | 2017-09-21 | 2019-03-28 | The Broad Institute, Inc. | Systems, methods, and compositions for targeted nucleic acid editing |
| US20190096250A1 (en) | 2017-09-28 | 2019-03-28 | Uber Technologies, Inc. | Systems and Methods for Determining Whether an Autonomous Vehicle Can Provide a Requested Service for a Rider |
| WO2019071048A1 (en) | 2017-10-04 | 2019-04-11 | The Broad Institute, Inc. | SYSTEMS, METHODS AND COMPOSITIONS FOR TARGETED NUCLEIC ACID EDITION |
| WO2019077150A1 (en) | 2017-10-20 | 2019-04-25 | Genethon | USE OF SYNCYTIN TO TARGET A MEDICINAL PRODUCT AND GENE ADMINISTRATION TO PULMONARY TISSUE |
| JP2021501137A (ja) | 2017-10-20 | 2021-01-14 | ジェネトン | 再生筋組織への標的化薬物及び遺伝子送達のためのシンシチンの使用 |
| US20210163933A1 (en) | 2017-12-11 | 2021-06-03 | University Of Massachusetts | Arc protein extracellular vesicle nucleic acid delivery platform |
| WO2019126709A1 (en) | 2017-12-22 | 2019-06-27 | The Broad Institute, Inc. | Cas12b systems, methods, and compositions for targeted dna base editing |
| WO2019126762A2 (en) | 2017-12-22 | 2019-06-27 | The Broad Institute, Inc. | Cas12a systems, methods, and compositions for targeted rna base editing |
| WO2019213257A1 (en) | 2018-05-01 | 2019-11-07 | Wake Forest University Health Sciences | Lentiviral-based vectors and related systems and methods for eukaryotic gene editing |
| CA3105925A1 (en) | 2018-07-10 | 2020-01-16 | Alia Therapeutics S.R.L. | Vesicles for traceless delivery of guide rna molecules and/or guide rna molecule/rna-guided nuclease complex(es) and a production method thereof |
| US20220088224A1 (en) | 2018-09-18 | 2022-03-24 | Vnv Newco Inc. | Arc-based capsids and uses thereof |
| US20210403907A1 (en) | 2018-09-18 | 2021-12-30 | Vnv Newco Inc. | Arc-based capsids and uses thereof |
| AU2019406778A1 (en) | 2018-12-17 | 2021-07-22 | Massachusetts Institute Of Technology | Crispr-associated transposase systems and methods of use thereof |
| US20200347100A1 (en) | 2019-03-15 | 2020-11-05 | The Broad Institute, Inc. | Non-naturally occurring capsids for delivery of nucleic acids and/or proteins |
| JP2022536364A (ja) | 2019-06-13 | 2022-08-15 | ザ ジェネラル ホスピタル コーポレイション | 操作されたヒト内在性ウイルス様粒子および細胞への送達のためのその使用方法 |
| KR20220083688A (ko) | 2019-09-20 | 2022-06-20 | 더 브로드 인스티튜트, 인코퍼레이티드 | 표적 세포로 카고 전달을 위한 조성물 및 방법 |
| US11129892B1 (en) | 2020-05-18 | 2021-09-28 | Vnv Newco Inc. | Vaccine compositions comprising endogenous Gag polypeptides |
-
2019
- 2019-09-18 US US17/277,119 patent/US20220088224A1/en not_active Abandoned
- 2019-09-18 AU AU2019343045A patent/AU2019343045A1/en active Pending
- 2019-09-18 WO PCT/US2019/051786 patent/WO2020061229A2/en unknown
- 2019-09-18 JP JP2021539499A patent/JP7344300B2/ja active Active
- 2019-09-18 KR KR1020217011429A patent/KR20210070305A/ko not_active IP Right Cessation
- 2019-09-18 EP EP19862077.5A patent/EP3852813A4/en active Pending
- 2019-09-18 KR KR1020247017429A patent/KR20240093924A/ko unknown
- 2019-09-18 CN CN201980075900.3A patent/CN113164623A/zh active Pending
- 2019-09-18 CA CA3113095A patent/CA3113095A1/en active Pending
-
2021
- 2021-07-21 US US17/382,102 patent/US11505578B2/en active Active
- 2021-07-21 US US17/382,092 patent/US11447527B2/en active Active
-
2023
- 2023-08-31 JP JP2023141593A patent/JP2024007554A/ja active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| US20210347829A1 (en) | 2021-11-11 |
| EP3852813A4 (en) | 2022-06-22 |
| WO2020061229A2 (en) | 2020-03-26 |
| US11447527B2 (en) | 2022-09-20 |
| US11505578B2 (en) | 2022-11-22 |
| US20220002358A1 (en) | 2022-01-06 |
| CA3113095A1 (en) | 2020-03-26 |
| JP2024007554A (ja) | 2024-01-18 |
| CN113164623A (zh) | 2021-07-23 |
| US20220088224A1 (en) | 2022-03-24 |
| WO2020061229A3 (en) | 2020-04-30 |
| JP2022502077A (ja) | 2022-01-11 |
| AU2019343045A1 (en) | 2021-05-13 |
| KR20240093924A (ko) | 2024-06-24 |
| EP3852813A2 (en) | 2021-07-28 |
| JP7344300B2 (ja) | 2023-09-13 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11447527B2 (en) | Endogenous Gag-based capsids and uses thereof | |
| US20210403907A1 (en) | Arc-based capsids and uses thereof | |
| US11110180B2 (en) | Nucleic acid-polypeptide compositions and uses thereof | |
| CN108473555B (zh) | 条件活性多肽 | |
| US20210095283A1 (en) | Heteroduplex nucleic acid molecules and uses thereof | |
| AU2016401692A1 (en) | Compositions and methods for the treatment of wounds, disorders, and diseases of the skin | |
| EP2811023A1 (en) | Vector simultaneously expressing dodecameric trail and hsv-tk suicide genes, and anticancer stem cell therapeutic agent using same | |
| CN113727720A (zh) | 用于治疗表达cldn6的癌症的嵌合抗原受体修饰的细胞 | |
| KR20230005865A (ko) | 전위-기반 요법 | |
| US20240102052A1 (en) | Pnma2-based capsids and uses thereof | |
| WO2024026295A1 (en) | Endogenous gag-based and pnma family capsids and uses thereof | |
| RU2757502C1 (ru) | Генетическая кассета, содержащая кодон-оптимизированные нуклеотидные последовательности генов TRAIL, PTEN и IFNβ-1, и фармацевтическая композиция для лечения онкологических заболеваний | |
| US20220177548A1 (en) | Methods and Compositions for Treating Melanoma | |
| US20240189247A1 (en) | Minimal Human-Derived Virus-Like Particles and Methods of Use Thereof for Delivery of Biomolecules | |
| WO2024050551A2 (en) | Compositions and methods for in vivo expression of chimeric antigen receptors | |
| WO2024159175A2 (en) | Compositions, systems, and methods for reducing adipose tissue | |
| CN117916379A (zh) | 用于生物分子的稳定表达及递送的质粒平台 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AMND | Amendment | ||
| AMND | Amendment | ||
| E902 | Notification of reason for refusal | ||
| AMND | Amendment | ||
| E601 | Decision to refuse application | ||
| AMND | Amendment | ||
| X601 | Decision of rejection after re-examination |