KR20190091264A - 다량체 il-15 기반 분자 - Google Patents
다량체 il-15 기반 분자 Download PDFInfo
- Publication number
- KR20190091264A KR20190091264A KR1020197014404A KR20197014404A KR20190091264A KR 20190091264 A KR20190091264 A KR 20190091264A KR 1020197014404 A KR1020197014404 A KR 1020197014404A KR 20197014404 A KR20197014404 A KR 20197014404A KR 20190091264 A KR20190091264 A KR 20190091264A
- Authority
- KR
- South Korea
- Prior art keywords
- fusion protein
- cells
- ser
- cell
- txm
- Prior art date
Links
- 102000003812 Interleukin-15 Human genes 0.000 title claims abstract description 149
- 108090000172 Interleukin-15 Proteins 0.000 title claims abstract description 149
- 230000027455 binding Effects 0.000 claims abstract description 162
- 239000000427 antigen Substances 0.000 claims abstract description 77
- 108091007433 antigens Proteins 0.000 claims abstract description 76
- 102000036639 antigens Human genes 0.000 claims abstract description 76
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims abstract description 76
- 201000010099 disease Diseases 0.000 claims abstract description 61
- 230000011664 signaling Effects 0.000 claims abstract description 17
- 102000007474 Multiprotein Complexes Human genes 0.000 claims abstract description 12
- 108010085220 Multiprotein Complexes Proteins 0.000 claims abstract description 11
- 210000004027 cell Anatomy 0.000 claims description 221
- 108090000623 proteins and genes Proteins 0.000 claims description 207
- 108020001507 fusion proteins Proteins 0.000 claims description 202
- 102000037865 fusion proteins Human genes 0.000 claims description 199
- 102000004169 proteins and genes Human genes 0.000 claims description 190
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 151
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 136
- 229920001184 polypeptide Polymers 0.000 claims description 130
- 238000000034 method Methods 0.000 claims description 110
- 150000007523 nucleic acids Chemical group 0.000 claims description 103
- 206010028980 Neoplasm Diseases 0.000 claims description 94
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 62
- 239000013598 vector Substances 0.000 claims description 56
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 54
- 108020004414 DNA Proteins 0.000 claims description 51
- 210000002865 immune cell Anatomy 0.000 claims description 44
- 210000004881 tumor cell Anatomy 0.000 claims description 37
- 101000889276 Homo sapiens Cytotoxic T-lymphocyte protein 4 Proteins 0.000 claims description 34
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 claims description 29
- 230000009826 neoplastic cell growth Effects 0.000 claims description 29
- 208000023275 Autoimmune disease Diseases 0.000 claims description 28
- 108060003951 Immunoglobulin Proteins 0.000 claims description 28
- 102000018358 immunoglobulin Human genes 0.000 claims description 28
- 230000004927 fusion Effects 0.000 claims description 27
- 239000000203 mixture Substances 0.000 claims description 26
- 239000003446 ligand Substances 0.000 claims description 24
- 206010035226 Plasma cell myeloma Diseases 0.000 claims description 21
- 102000053602 DNA Human genes 0.000 claims description 20
- 208000015181 infectious disease Diseases 0.000 claims description 20
- 239000008194 pharmaceutical composition Substances 0.000 claims description 19
- 210000001744 T-lymphocyte Anatomy 0.000 claims description 18
- 229940045513 CTLA4 antagonist Drugs 0.000 claims description 17
- 208000035473 Communicable disease Diseases 0.000 claims description 17
- 102000009109 Fc receptors Human genes 0.000 claims description 17
- 108010087819 Fc receptors Proteins 0.000 claims description 17
- 101000934338 Homo sapiens Myeloid cell surface antigen CD33 Proteins 0.000 claims description 17
- 102100025243 Myeloid cell surface antigen CD33 Human genes 0.000 claims description 17
- 230000028993 immune response Effects 0.000 claims description 16
- 241000725303 Human immunodeficiency virus Species 0.000 claims description 14
- 206010033128 Ovarian cancer Diseases 0.000 claims description 14
- 206010061535 Ovarian neoplasm Diseases 0.000 claims description 14
- 230000002147 killing effect Effects 0.000 claims description 13
- 230000004936 stimulating effect Effects 0.000 claims description 13
- 108010064548 Lymphocyte Function-Associated Antigen-1 Proteins 0.000 claims description 12
- 201000001441 melanoma Diseases 0.000 claims description 12
- 108010000499 Thromboplastin Proteins 0.000 claims description 11
- 230000009870 specific binding Effects 0.000 claims description 11
- 206010006187 Breast cancer Diseases 0.000 claims description 10
- 208000026310 Breast neoplasm Diseases 0.000 claims description 10
- 206010009944 Colon cancer Diseases 0.000 claims description 10
- 208000034578 Multiple myelomas Diseases 0.000 claims description 10
- 230000035772 mutation Effects 0.000 claims description 10
- 102100033553 Delta-like protein 4 Human genes 0.000 claims description 9
- 101710112728 Delta-like protein 4 Proteins 0.000 claims description 9
- 206010058467 Lung neoplasm malignant Diseases 0.000 claims description 9
- 206010061902 Pancreatic neoplasm Diseases 0.000 claims description 9
- 206010060862 Prostate cancer Diseases 0.000 claims description 9
- 230000001413 cellular effect Effects 0.000 claims description 9
- 201000002528 pancreatic cancer Diseases 0.000 claims description 9
- 208000031261 Acute myeloid leukaemia Diseases 0.000 claims description 8
- 208000003950 B-cell lymphoma Diseases 0.000 claims description 8
- 208000017604 Hodgkin disease Diseases 0.000 claims description 8
- 101000801234 Homo sapiens Tumor necrosis factor receptor superfamily member 18 Proteins 0.000 claims description 8
- 108010017535 Interleukin-15 Receptors Proteins 0.000 claims description 8
- 102000004556 Interleukin-15 Receptors Human genes 0.000 claims description 8
- 208000000236 Prostatic Neoplasms Diseases 0.000 claims description 8
- 102100033728 Tumor necrosis factor receptor superfamily member 18 Human genes 0.000 claims description 8
- 210000003719 b-lymphocyte Anatomy 0.000 claims description 8
- 230000004663 cell proliferation Effects 0.000 claims description 8
- 201000005202 lung cancer Diseases 0.000 claims description 8
- 208000020816 lung neoplasm Diseases 0.000 claims description 8
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 claims description 8
- 208000008443 pancreatic carcinoma Diseases 0.000 claims description 8
- 208000001333 Colorectal Neoplasms Diseases 0.000 claims description 7
- 208000010747 Hodgkins lymphoma Diseases 0.000 claims description 7
- 208000033776 Myeloid Acute Leukemia Diseases 0.000 claims description 6
- 208000005718 Stomach Neoplasms Diseases 0.000 claims description 6
- 108060008683 Tumor Necrosis Factor Receptor Proteins 0.000 claims description 6
- 206010017758 gastric cancer Diseases 0.000 claims description 6
- 201000011549 stomach cancer Diseases 0.000 claims description 6
- 230000014621 translational initiation Effects 0.000 claims description 6
- 102000003298 tumor necrosis factor receptor Human genes 0.000 claims description 6
- 230000003213 activating effect Effects 0.000 claims description 5
- 230000004069 differentiation Effects 0.000 claims description 5
- 206010005003 Bladder cancer Diseases 0.000 claims description 4
- 208000021519 Hodgkin lymphoma Diseases 0.000 claims description 4
- 102000006496 Immunoglobulin Heavy Chains Human genes 0.000 claims description 4
- 108010019476 Immunoglobulin Heavy Chains Proteins 0.000 claims description 4
- 208000006265 Renal cell carcinoma Diseases 0.000 claims description 4
- 108020004682 Single-Stranded DNA Proteins 0.000 claims description 4
- 206010042971 T-cell lymphoma Diseases 0.000 claims description 4
- 208000027585 T-cell non-Hodgkin lymphoma Diseases 0.000 claims description 4
- 201000001531 bladder carcinoma Diseases 0.000 claims description 4
- 238000004132 cross linking Methods 0.000 claims description 4
- 102220311640 rs1382779104 Human genes 0.000 claims description 4
- 208000010570 urinary bladder carcinoma Diseases 0.000 claims description 4
- 208000010839 B-cell chronic lymphocytic leukemia Diseases 0.000 claims description 3
- 208000028564 B-cell non-Hodgkin lymphoma Diseases 0.000 claims description 3
- 102000013463 Immunoglobulin Light Chains Human genes 0.000 claims description 3
- 108010065825 Immunoglobulin Light Chains Proteins 0.000 claims description 3
- 208000031422 Lymphocytic Chronic B-Cell Leukemia Diseases 0.000 claims description 3
- 208000032852 chronic lymphocytic leukemia Diseases 0.000 claims description 3
- 230000002496 gastric effect Effects 0.000 claims description 3
- 208000005017 glioblastoma Diseases 0.000 claims description 3
- 201000005787 hematologic cancer Diseases 0.000 claims description 3
- 208000002154 non-small cell lung carcinoma Diseases 0.000 claims description 3
- 208000000461 Esophageal Neoplasms Diseases 0.000 claims description 2
- 206010030155 Oesophageal carcinoma Diseases 0.000 claims description 2
- 208000031673 T-Cell Cutaneous Lymphoma Diseases 0.000 claims description 2
- 201000007241 cutaneous T cell lymphoma Diseases 0.000 claims description 2
- 201000004101 esophageal cancer Diseases 0.000 claims description 2
- 239000003862 glucocorticoid Substances 0.000 claims description 2
- 201000003911 head and neck carcinoma Diseases 0.000 claims description 2
- 201000005962 mycosis fungoides Diseases 0.000 claims description 2
- 208000025638 primary cutaneous T-cell non-Hodgkin lymphoma Diseases 0.000 claims description 2
- 210000001635 urinary tract Anatomy 0.000 claims description 2
- 102000002262 Thromboplastin Human genes 0.000 claims 2
- 230000006450 immune cell response Effects 0.000 claims 1
- 102000008616 interleukin-15 receptor activity proteins Human genes 0.000 claims 1
- 108040002039 interleukin-15 receptor activity proteins Proteins 0.000 claims 1
- 102100024216 Programmed cell death 1 ligand 1 Human genes 0.000 description 227
- 108010074708 B7-H1 Antigen Proteins 0.000 description 226
- 235000018102 proteins Nutrition 0.000 description 171
- 206010039509 Scab Diseases 0.000 description 117
- 241000282414 Homo sapiens Species 0.000 description 95
- 241000699666 Mus <mouse, genus> Species 0.000 description 53
- 239000012636 effector Substances 0.000 description 48
- 108010076504 Protein Sorting Signals Proteins 0.000 description 43
- 102000039446 nucleic acids Human genes 0.000 description 43
- 108020004707 nucleic acids Proteins 0.000 description 43
- 235000001014 amino acid Nutrition 0.000 description 42
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 41
- 230000000694 effects Effects 0.000 description 41
- 239000012634 fragment Substances 0.000 description 41
- 238000011282 treatment Methods 0.000 description 37
- 230000014509 gene expression Effects 0.000 description 36
- 101001055157 Homo sapiens Interleukin-15 Proteins 0.000 description 33
- 229940024606 amino acid Drugs 0.000 description 33
- 201000009030 Carcinoma Diseases 0.000 description 32
- 108091006020 Fc-tagged proteins Proteins 0.000 description 32
- 150000001413 amino acids Chemical class 0.000 description 32
- 239000013604 expression vector Substances 0.000 description 32
- 102000056003 human IL15 Human genes 0.000 description 32
- 108010057840 ALT-803 Proteins 0.000 description 30
- 150000001875 compounds Chemical class 0.000 description 30
- -1 CD86 Proteins 0.000 description 29
- 101000868279 Homo sapiens Leukocyte surface antigen CD47 Proteins 0.000 description 28
- 102000005962 receptors Human genes 0.000 description 28
- 108020003175 receptors Proteins 0.000 description 28
- 230000001404 mediated effect Effects 0.000 description 26
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 25
- 101001117317 Homo sapiens Programmed cell death 1 ligand 1 Proteins 0.000 description 24
- 108091008874 T cell receptors Proteins 0.000 description 24
- 102100032913 Leukocyte surface antigen CD47 Human genes 0.000 description 23
- 102000048776 human CD274 Human genes 0.000 description 23
- 239000002609 medium Substances 0.000 description 23
- 241000700605 Viruses Species 0.000 description 21
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 description 20
- 230000015572 biosynthetic process Effects 0.000 description 20
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 description 19
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 description 19
- 201000011510 cancer Diseases 0.000 description 19
- 210000000822 natural killer cell Anatomy 0.000 description 19
- 230000004071 biological effect Effects 0.000 description 18
- 230000001419 dependent effect Effects 0.000 description 18
- 230000035755 proliferation Effects 0.000 description 18
- 238000006467 substitution reaction Methods 0.000 description 18
- 101001117316 Mus musculus Programmed cell death 1 ligand 1 Proteins 0.000 description 17
- 241000699670 Mus sp. Species 0.000 description 17
- 230000000903 blocking effect Effects 0.000 description 16
- 239000002773 nucleotide Substances 0.000 description 16
- 125000003729 nucleotide group Chemical group 0.000 description 16
- 102000001301 EGF receptor Human genes 0.000 description 15
- 230000037396 body weight Effects 0.000 description 15
- 208000035475 disorder Diseases 0.000 description 15
- 230000001965 increasing effect Effects 0.000 description 15
- 208000024891 symptom Diseases 0.000 description 15
- 102000004127 Cytokines Human genes 0.000 description 14
- 108090000695 Cytokines Proteins 0.000 description 14
- 206010025323 Lymphomas Diseases 0.000 description 14
- 241000124008 Mammalia Species 0.000 description 14
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 14
- 108060006698 EGF receptor Proteins 0.000 description 13
- 238000001042 affinity chromatography Methods 0.000 description 13
- 230000005888 antibody-dependent cellular phagocytosis Effects 0.000 description 13
- 238000004113 cell culture Methods 0.000 description 13
- 239000012228 culture supernatant Substances 0.000 description 13
- 238000009396 hybridization Methods 0.000 description 13
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 description 12
- 102100037877 Intercellular adhesion molecule 1 Human genes 0.000 description 12
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 12
- 102100034922 T-cell surface glycoprotein CD8 alpha chain Human genes 0.000 description 12
- 238000002360 preparation method Methods 0.000 description 12
- 239000011780 sodium chloride Substances 0.000 description 12
- 101100519207 Mus musculus Pdcd1 gene Proteins 0.000 description 11
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 description 11
- 239000000556 agonist Substances 0.000 description 11
- 230000003993 interaction Effects 0.000 description 11
- 239000003550 marker Substances 0.000 description 11
- 201000000050 myeloid neoplasm Diseases 0.000 description 11
- 238000003752 polymerase chain reaction Methods 0.000 description 11
- 230000028327 secretion Effects 0.000 description 11
- 239000001509 sodium citrate Substances 0.000 description 11
- 230000001225 therapeutic effect Effects 0.000 description 11
- 238000005406 washing Methods 0.000 description 11
- ZHNUHDYFZUAESO-UHFFFAOYSA-N Formamide Chemical compound NC=O ZHNUHDYFZUAESO-UHFFFAOYSA-N 0.000 description 10
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical group NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 10
- 108010064593 Intercellular Adhesion Molecule-1 Proteins 0.000 description 10
- 108010053727 Interleukin-15 Receptor alpha Subunit Proteins 0.000 description 10
- 102100034256 Mucin-1 Human genes 0.000 description 10
- 102000001759 Notch1 Receptor Human genes 0.000 description 10
- 108010029755 Notch1 Receptor Proteins 0.000 description 10
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 10
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 10
- 102100030859 Tissue factor Human genes 0.000 description 10
- 238000004458 analytical method Methods 0.000 description 10
- 239000003814 drug Substances 0.000 description 10
- 208000032839 leukemia Diseases 0.000 description 10
- HRXKRNGNAMMEHJ-UHFFFAOYSA-K trisodium citrate Chemical compound [Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O HRXKRNGNAMMEHJ-UHFFFAOYSA-K 0.000 description 10
- 229940038773 trisodium citrate Drugs 0.000 description 10
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 description 9
- 230000003013 cytotoxicity Effects 0.000 description 9
- 231100000135 cytotoxicity Toxicity 0.000 description 9
- 230000004048 modification Effects 0.000 description 9
- 238000012986 modification Methods 0.000 description 9
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 9
- 230000008685 targeting Effects 0.000 description 9
- 230000014616 translation Effects 0.000 description 9
- 102100024222 B-lymphocyte antigen CD19 Human genes 0.000 description 8
- 108010066687 Epithelial Cell Adhesion Molecule Proteins 0.000 description 8
- 102000018651 Epithelial Cell Adhesion Molecule Human genes 0.000 description 8
- 102100034458 Hepatitis A virus cellular receptor 2 Human genes 0.000 description 8
- 101000980825 Homo sapiens B-lymphocyte antigen CD19 Proteins 0.000 description 8
- 101001068133 Homo sapiens Hepatitis A virus cellular receptor 2 Proteins 0.000 description 8
- 101000716102 Homo sapiens T-cell surface glycoprotein CD4 Proteins 0.000 description 8
- 102100036011 T-cell surface glycoprotein CD4 Human genes 0.000 description 8
- 230000000259 anti-tumor effect Effects 0.000 description 8
- 230000004186 co-expression Effects 0.000 description 8
- 230000021615 conjugation Effects 0.000 description 8
- 230000006870 function Effects 0.000 description 8
- 238000001727 in vivo Methods 0.000 description 8
- 239000000463 material Substances 0.000 description 8
- 210000002307 prostate Anatomy 0.000 description 8
- 239000000126 substance Substances 0.000 description 8
- 108700012359 toxins Proteins 0.000 description 8
- 238000013519 translation Methods 0.000 description 8
- 102100025475 Carcinoembryonic antigen-related cell adhesion molecule 5 Human genes 0.000 description 7
- 101000914324 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 5 Proteins 0.000 description 7
- 101001133056 Homo sapiens Mucin-1 Proteins 0.000 description 7
- 101000851376 Homo sapiens Tumor necrosis factor receptor superfamily member 8 Proteins 0.000 description 7
- 108010002350 Interleukin-2 Proteins 0.000 description 7
- 102000000588 Interleukin-2 Human genes 0.000 description 7
- 102100036857 Tumor necrosis factor receptor superfamily member 8 Human genes 0.000 description 7
- 230000004913 activation Effects 0.000 description 7
- 239000003795 chemical substances by application Substances 0.000 description 7
- 238000004587 chromatography analysis Methods 0.000 description 7
- 238000012217 deletion Methods 0.000 description 7
- 230000037430 deletion Effects 0.000 description 7
- 238000011161 development Methods 0.000 description 7
- 230000018109 developmental process Effects 0.000 description 7
- 238000009472 formulation Methods 0.000 description 7
- 230000013595 glycosylation Effects 0.000 description 7
- 238000006206 glycosylation reaction Methods 0.000 description 7
- 239000003102 growth factor Substances 0.000 description 7
- 210000001165 lymph node Anatomy 0.000 description 7
- 210000004962 mammalian cell Anatomy 0.000 description 7
- 238000004519 manufacturing process Methods 0.000 description 7
- 239000013641 positive control Substances 0.000 description 7
- 230000012743 protein tagging Effects 0.000 description 7
- 230000009467 reduction Effects 0.000 description 7
- 210000000952 spleen Anatomy 0.000 description 7
- 238000007920 subcutaneous administration Methods 0.000 description 7
- 230000004083 survival effect Effects 0.000 description 7
- 210000001519 tissue Anatomy 0.000 description 7
- 230000009466 transformation Effects 0.000 description 7
- 230000003612 virological effect Effects 0.000 description 7
- 102100031585 ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Human genes 0.000 description 6
- 102100038078 CD276 antigen Human genes 0.000 description 6
- 102000004190 Enzymes Human genes 0.000 description 6
- 108090000790 Enzymes Proteins 0.000 description 6
- 241000588724 Escherichia coli Species 0.000 description 6
- 101000777636 Homo sapiens ADP-ribosyl cyclase/cyclic ADP-ribose hydrolase 1 Proteins 0.000 description 6
- 241001465754 Metazoa Species 0.000 description 6
- 239000005557 antagonist Substances 0.000 description 6
- 230000001580 bacterial effect Effects 0.000 description 6
- 238000012258 culturing Methods 0.000 description 6
- 239000000412 dendrimer Substances 0.000 description 6
- 229920000736 dendritic polymer Polymers 0.000 description 6
- 239000000539 dimer Substances 0.000 description 6
- 238000006471 dimerization reaction Methods 0.000 description 6
- 238000005516 engineering process Methods 0.000 description 6
- 229940088598 enzyme Drugs 0.000 description 6
- 238000000684 flow cytometry Methods 0.000 description 6
- 239000001963 growth medium Substances 0.000 description 6
- 230000002401 inhibitory effect Effects 0.000 description 6
- 239000002105 nanoparticle Substances 0.000 description 6
- 102000040430 polynucleotide Human genes 0.000 description 6
- 108091033319 polynucleotide Proteins 0.000 description 6
- 239000002157 polynucleotide Substances 0.000 description 6
- 239000000047 product Substances 0.000 description 6
- 150000003839 salts Chemical class 0.000 description 6
- 239000003053 toxin Substances 0.000 description 6
- 231100000765 toxin Toxicity 0.000 description 6
- 238000013518 transcription Methods 0.000 description 6
- 239000003981 vehicle Substances 0.000 description 6
- 102100024217 CAMPATH-1 antigen Human genes 0.000 description 5
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 description 5
- 101150013553 CD40 gene Proteins 0.000 description 5
- 108010065524 CD52 Antigen Proteins 0.000 description 5
- 108091026890 Coding region Proteins 0.000 description 5
- 108020004705 Codon Proteins 0.000 description 5
- 239000004471 Glycine Substances 0.000 description 5
- 101000623901 Homo sapiens Mucin-16 Proteins 0.000 description 5
- 101000611936 Homo sapiens Programmed cell death protein 1 Proteins 0.000 description 5
- 108010031794 IGF Type 1 Receptor Proteins 0.000 description 5
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 5
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 5
- 239000004472 Lysine Substances 0.000 description 5
- 102100023123 Mucin-16 Human genes 0.000 description 5
- 108091005461 Nucleic proteins Proteins 0.000 description 5
- 206010039491 Sarcoma Diseases 0.000 description 5
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 5
- 102100040247 Tumor necrosis factor Human genes 0.000 description 5
- 102100040112 Tumor necrosis factor receptor superfamily member 10B Human genes 0.000 description 5
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 description 5
- 238000003556 assay Methods 0.000 description 5
- 230000001363 autoimmune Effects 0.000 description 5
- 230000008901 benefit Effects 0.000 description 5
- 230000000295 complement effect Effects 0.000 description 5
- 230000004540 complement-dependent cytotoxicity Effects 0.000 description 5
- 102000044459 human CD47 Human genes 0.000 description 5
- 229940044680 immune agonist Drugs 0.000 description 5
- 239000012651 immune agonist Substances 0.000 description 5
- 229940072221 immunoglobulins Drugs 0.000 description 5
- 230000003308 immunostimulating effect Effects 0.000 description 5
- 238000000338 in vitro Methods 0.000 description 5
- 239000003112 inhibitor Substances 0.000 description 5
- 210000004698 lymphocyte Anatomy 0.000 description 5
- 210000002540 macrophage Anatomy 0.000 description 5
- 238000002156 mixing Methods 0.000 description 5
- 238000007911 parenteral administration Methods 0.000 description 5
- 239000002904 solvent Substances 0.000 description 5
- 241000894007 species Species 0.000 description 5
- 239000006228 supernatant Substances 0.000 description 5
- 238000012360 testing method Methods 0.000 description 5
- 229940124597 therapeutic agent Drugs 0.000 description 5
- 230000035897 transcription Effects 0.000 description 5
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 4
- 101710185679 CD276 antigen Proteins 0.000 description 4
- 108010012236 Chemokines Proteins 0.000 description 4
- 102000019034 Chemokines Human genes 0.000 description 4
- 108091035707 Consensus sequence Proteins 0.000 description 4
- 238000002965 ELISA Methods 0.000 description 4
- 241000196324 Embryophyta Species 0.000 description 4
- 102000003886 Glycoproteins Human genes 0.000 description 4
- 108090000288 Glycoproteins Proteins 0.000 description 4
- 241000238631 Hexapoda Species 0.000 description 4
- 241000282412 Homo Species 0.000 description 4
- 101000914321 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 7 Proteins 0.000 description 4
- 101001057504 Homo sapiens Interferon-stimulated gene 20 kDa protein Proteins 0.000 description 4
- 101001055144 Homo sapiens Interleukin-2 receptor subunit alpha Proteins 0.000 description 4
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 description 4
- 101000914484 Homo sapiens T-lymphocyte activation antigen CD80 Proteins 0.000 description 4
- 101000635804 Homo sapiens Tissue factor Proteins 0.000 description 4
- 101000597779 Homo sapiens Tumor necrosis factor ligand superfamily member 18 Proteins 0.000 description 4
- 101000610604 Homo sapiens Tumor necrosis factor receptor superfamily member 10B Proteins 0.000 description 4
- 101000851370 Homo sapiens Tumor necrosis factor receptor superfamily member 9 Proteins 0.000 description 4
- 102000038455 IGF Type 1 Receptor Human genes 0.000 description 4
- 108010073807 IgG Receptors Proteins 0.000 description 4
- 102000009490 IgG Receptors Human genes 0.000 description 4
- 102100039688 Insulin-like growth factor 1 receptor Human genes 0.000 description 4
- 102100027268 Interferon-stimulated gene 20 kDa protein Human genes 0.000 description 4
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical group C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 4
- 108020004511 Recombinant DNA Proteins 0.000 description 4
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 4
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 4
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 description 4
- 102100027222 T-lymphocyte activation antigen CD80 Human genes 0.000 description 4
- 102100036856 Tumor necrosis factor receptor superfamily member 9 Human genes 0.000 description 4
- 235000004279 alanine Nutrition 0.000 description 4
- 230000002494 anti-cea effect Effects 0.000 description 4
- 238000013459 approach Methods 0.000 description 4
- 229950002916 avelumab Drugs 0.000 description 4
- 230000000975 bioactive effect Effects 0.000 description 4
- 230000003115 biocidal effect Effects 0.000 description 4
- 238000012512 characterization method Methods 0.000 description 4
- 238000010367 cloning Methods 0.000 description 4
- 239000002299 complementary DNA Substances 0.000 description 4
- 230000000875 corresponding effect Effects 0.000 description 4
- 230000001461 cytolytic effect Effects 0.000 description 4
- 238000001514 detection method Methods 0.000 description 4
- 210000003527 eukaryotic cell Anatomy 0.000 description 4
- 230000007717 exclusion Effects 0.000 description 4
- 102000043321 human CTLA4 Human genes 0.000 description 4
- 102000053830 human TNFSF18 Human genes 0.000 description 4
- 238000009169 immunotherapy Methods 0.000 description 4
- 230000000977 initiatory effect Effects 0.000 description 4
- 238000007918 intramuscular administration Methods 0.000 description 4
- 238000007912 intraperitoneal administration Methods 0.000 description 4
- 230000002601 intratumoral effect Effects 0.000 description 4
- 238000001990 intravenous administration Methods 0.000 description 4
- 230000003389 potentiating effect Effects 0.000 description 4
- 230000001105 regulatory effect Effects 0.000 description 4
- 238000000926 separation method Methods 0.000 description 4
- 210000002966 serum Anatomy 0.000 description 4
- 238000010186 staining Methods 0.000 description 4
- 101150047061 tag-72 gene Proteins 0.000 description 4
- 230000009258 tissue cross reactivity Effects 0.000 description 4
- 238000001890 transfection Methods 0.000 description 4
- 238000012546 transfer Methods 0.000 description 4
- 210000003932 urinary bladder Anatomy 0.000 description 4
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 3
- MZOFCQQQCNRIBI-VMXHOPILSA-N (3s)-4-[[(2s)-1-[[(2s)-1-[[(1s)-1-carboxy-2-hydroxyethyl]amino]-4-methyl-1-oxopentan-2-yl]amino]-5-(diaminomethylideneamino)-1-oxopentan-2-yl]amino]-3-[[2-[[(2s)-2,6-diaminohexanoyl]amino]acetyl]amino]-4-oxobutanoic acid Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN MZOFCQQQCNRIBI-VMXHOPILSA-N 0.000 description 3
- 102100022749 Aminopeptidase N Human genes 0.000 description 3
- 239000004475 Arginine Substances 0.000 description 3
- 102100038080 B-cell receptor CD22 Human genes 0.000 description 3
- 235000014469 Bacillus subtilis Nutrition 0.000 description 3
- 241000894006 Bacteria Species 0.000 description 3
- 102100032412 Basigin Human genes 0.000 description 3
- 108700012439 CA9 Proteins 0.000 description 3
- 102100025221 CD70 antigen Human genes 0.000 description 3
- 102100024423 Carbonic anhydrase 9 Human genes 0.000 description 3
- 102100032768 Complement receptor type 2 Human genes 0.000 description 3
- 102000016607 Diphtheria Toxin Human genes 0.000 description 3
- 108010053187 Diphtheria Toxin Proteins 0.000 description 3
- 108010008165 Etanercept Proteins 0.000 description 3
- 102100030595 HLA class II histocompatibility antigen gamma chain Human genes 0.000 description 3
- 101000884305 Homo sapiens B-cell receptor CD22 Proteins 0.000 description 3
- 101000798441 Homo sapiens Basigin Proteins 0.000 description 3
- 101000934356 Homo sapiens CD70 antigen Proteins 0.000 description 3
- 101000941929 Homo sapiens Complement receptor type 2 Proteins 0.000 description 3
- 101001082627 Homo sapiens HLA class II histocompatibility antigen gamma chain Proteins 0.000 description 3
- 101001034652 Homo sapiens Insulin-like growth factor 1 receptor Proteins 0.000 description 3
- 101001046677 Homo sapiens Integrin alpha-V Proteins 0.000 description 3
- 101000878605 Homo sapiens Low affinity immunoglobulin epsilon Fc receptor Proteins 0.000 description 3
- 101000917858 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 description 3
- 101000917839 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-B Proteins 0.000 description 3
- 101000617725 Homo sapiens Pregnancy-specific beta-1-glycoprotein 2 Proteins 0.000 description 3
- 101000863873 Homo sapiens Tyrosine-protein phosphatase non-receptor type substrate 1 Proteins 0.000 description 3
- 241000701806 Human papillomavirus Species 0.000 description 3
- 206010021245 Idiopathic thrombocytopenic purpura Diseases 0.000 description 3
- 108010091135 Immunoglobulin Fc Fragments Proteins 0.000 description 3
- 102000018071 Immunoglobulin Fc Fragments Human genes 0.000 description 3
- 102100022337 Integrin alpha-V Human genes 0.000 description 3
- 108010074328 Interferon-gamma Proteins 0.000 description 3
- 102000004889 Interleukin-6 Human genes 0.000 description 3
- 108090001005 Interleukin-6 Proteins 0.000 description 3
- 241000235058 Komagataella pastoris Species 0.000 description 3
- 102100038007 Low affinity immunoglobulin epsilon Fc receptor Human genes 0.000 description 3
- 102000000440 Melanoma-associated antigen Human genes 0.000 description 3
- 108050008953 Melanoma-associated antigen Proteins 0.000 description 3
- 101000597780 Mus musculus Tumor necrosis factor ligand superfamily member 18 Proteins 0.000 description 3
- 108091034117 Oligonucleotide Proteins 0.000 description 3
- 102100040678 Programmed cell death protein 1 Human genes 0.000 description 3
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 3
- 101000762949 Pseudomonas aeruginosa (strain ATCC 15692 / DSM 22644 / CIP 104116 / JCM 14847 / LMG 12228 / 1C / PRS 101 / PAO1) Exotoxin A Proteins 0.000 description 3
- 101710100969 Receptor tyrosine-protein kinase erbB-3 Proteins 0.000 description 3
- 102100029986 Receptor tyrosine-protein kinase erbB-3 Human genes 0.000 description 3
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 3
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical compound [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 3
- 230000005867 T cell response Effects 0.000 description 3
- 102100022153 Tumor necrosis factor receptor superfamily member 4 Human genes 0.000 description 3
- 102100029948 Tyrosine-protein phosphatase non-receptor type substrate 1 Human genes 0.000 description 3
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 description 3
- 102100023543 Vascular cell adhesion protein 1 Human genes 0.000 description 3
- 102100033177 Vascular endothelial growth factor receptor 2 Human genes 0.000 description 3
- 239000002253 acid Substances 0.000 description 3
- 208000009956 adenocarcinoma Diseases 0.000 description 3
- 125000000539 amino acid group Chemical group 0.000 description 3
- 210000004102 animal cell Anatomy 0.000 description 3
- 239000002246 antineoplastic agent Substances 0.000 description 3
- 230000006907 apoptotic process Effects 0.000 description 3
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 3
- 201000003710 autoimmune thrombocytopenic purpura Diseases 0.000 description 3
- 238000002869 basic local alignment search tool Methods 0.000 description 3
- 230000002051 biphasic effect Effects 0.000 description 3
- 210000004369 blood Anatomy 0.000 description 3
- 239000008280 blood Substances 0.000 description 3
- 239000000872 buffer Substances 0.000 description 3
- 230000030833 cell death Effects 0.000 description 3
- 230000008859 change Effects 0.000 description 3
- 239000013599 cloning vector Substances 0.000 description 3
- 231100000433 cytotoxic Toxicity 0.000 description 3
- 229940127089 cytotoxic agent Drugs 0.000 description 3
- 230000001472 cytotoxic effect Effects 0.000 description 3
- 239000002552 dosage form Substances 0.000 description 3
- 231100000673 dose–response relationship Toxicity 0.000 description 3
- 238000004520 electroporation Methods 0.000 description 3
- 230000002708 enhancing effect Effects 0.000 description 3
- 229960000403 etanercept Drugs 0.000 description 3
- 230000005714 functional activity Effects 0.000 description 3
- 230000012010 growth Effects 0.000 description 3
- 208000024200 hematopoietic and lymphoid system neoplasm Diseases 0.000 description 3
- 238000004128 high performance liquid chromatography Methods 0.000 description 3
- 230000006698 induction Effects 0.000 description 3
- 230000001939 inductive effect Effects 0.000 description 3
- 238000002347 injection Methods 0.000 description 3
- 239000007924 injection Substances 0.000 description 3
- 238000003780 insertion Methods 0.000 description 3
- 230000037431 insertion Effects 0.000 description 3
- 239000002502 liposome Substances 0.000 description 3
- 230000036210 malignancy Effects 0.000 description 3
- 239000012528 membrane Substances 0.000 description 3
- 229960005558 mertansine Drugs 0.000 description 3
- 238000012737 microarray-based gene expression Methods 0.000 description 3
- 238000010369 molecular cloning Methods 0.000 description 3
- 238000012243 multiplex automated genomic engineering Methods 0.000 description 3
- 239000013642 negative control Substances 0.000 description 3
- 230000003472 neutralizing effect Effects 0.000 description 3
- 229960003301 nivolumab Drugs 0.000 description 3
- 210000000056 organ Anatomy 0.000 description 3
- 230000001717 pathogenic effect Effects 0.000 description 3
- 230000037361 pathway Effects 0.000 description 3
- 239000000546 pharmaceutical excipient Substances 0.000 description 3
- 239000013612 plasmid Substances 0.000 description 3
- 230000036515 potency Effects 0.000 description 3
- 210000001236 prokaryotic cell Anatomy 0.000 description 3
- 238000000746 purification Methods 0.000 description 3
- 230000002829 reductive effect Effects 0.000 description 3
- 108091008146 restriction endonucleases Proteins 0.000 description 3
- 238000012216 screening Methods 0.000 description 3
- 208000000587 small cell lung carcinoma Diseases 0.000 description 3
- 239000000243 solution Substances 0.000 description 3
- 238000010561 standard procedure Methods 0.000 description 3
- 230000000638 stimulation Effects 0.000 description 3
- 208000011580 syndromic disease Diseases 0.000 description 3
- 241000701161 unidentified adenovirus Species 0.000 description 3
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 3
- PUPZLCDOIYMWBV-UHFFFAOYSA-N (+/-)-1,3-Butanediol Chemical compound CC(O)CCO PUPZLCDOIYMWBV-UHFFFAOYSA-N 0.000 description 2
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 2
- QZDDFQLIQRYMBV-UHFFFAOYSA-N 2-[3-nitro-2-(2-nitrophenyl)-4-oxochromen-8-yl]acetic acid Chemical compound OC(=O)CC1=CC=CC(C(C=2[N+]([O-])=O)=O)=C1OC=2C1=CC=CC=C1[N+]([O-])=O QZDDFQLIQRYMBV-UHFFFAOYSA-N 0.000 description 2
- KZMAWJRXKGLWGS-UHFFFAOYSA-N 2-chloro-n-[4-(4-methoxyphenyl)-1,3-thiazol-2-yl]-n-(3-methoxypropyl)acetamide Chemical compound S1C(N(C(=O)CCl)CCCOC)=NC(C=2C=CC(OC)=CC=2)=C1 KZMAWJRXKGLWGS-UHFFFAOYSA-N 0.000 description 2
- HVCOBJNICQPDBP-UHFFFAOYSA-N 3-[3-[3,5-dihydroxy-6-methyl-4-(3,4,5-trihydroxy-6-methyloxan-2-yl)oxyoxan-2-yl]oxydecanoyloxy]decanoic acid;hydrate Chemical compound O.OC1C(OC(CC(=O)OC(CCCCCCC)CC(O)=O)CCCCCCC)OC(C)C(O)C1OC1C(O)C(O)C(O)C(C)O1 HVCOBJNICQPDBP-UHFFFAOYSA-N 0.000 description 2
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 2
- 102100030310 5,6-dihydroxyindole-2-carboxylic acid oxidase Human genes 0.000 description 2
- 102000000412 Annexin Human genes 0.000 description 2
- 108050008874 Annexin Proteins 0.000 description 2
- 101100067974 Arabidopsis thaliana POP2 gene Proteins 0.000 description 2
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 2
- 102100026008 Breakpoint cluster region protein Human genes 0.000 description 2
- 102100031650 C-X-C chemokine receptor type 4 Human genes 0.000 description 2
- 108010049990 CD13 Antigens Proteins 0.000 description 2
- 102100027207 CD27 antigen Human genes 0.000 description 2
- 102100032912 CD44 antigen Human genes 0.000 description 2
- 241000282472 Canis lupus familiaris Species 0.000 description 2
- 241000701489 Cauliflower mosaic virus Species 0.000 description 2
- 102000016289 Cell Adhesion Molecules Human genes 0.000 description 2
- 108010067225 Cell Adhesion Molecules Proteins 0.000 description 2
- 108010001857 Cell Surface Receptors Proteins 0.000 description 2
- 102000000844 Cell Surface Receptors Human genes 0.000 description 2
- 102000009410 Chemokine receptor Human genes 0.000 description 2
- 108050000299 Chemokine receptor Proteins 0.000 description 2
- 108010069112 Complement System Proteins Proteins 0.000 description 2
- 102000000989 Complement System Proteins Human genes 0.000 description 2
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 2
- 101100481408 Danio rerio tie2 gene Proteins 0.000 description 2
- 108010049207 Death Domain Receptors Proteins 0.000 description 2
- 102000009058 Death Domain Receptors Human genes 0.000 description 2
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 2
- 101150084967 EPCAM gene Proteins 0.000 description 2
- 102100037241 Endoglin Human genes 0.000 description 2
- 108010036395 Endoglin Proteins 0.000 description 2
- 102100032031 Epidermal growth factor-like protein 7 Human genes 0.000 description 2
- 241000283074 Equus asinus Species 0.000 description 2
- 108091008794 FGF receptors Proteins 0.000 description 2
- 102100041003 Glutamate carboxypeptidase 2 Human genes 0.000 description 2
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 2
- 229930186217 Glycolipid Natural products 0.000 description 2
- 102000009465 Growth Factor Receptors Human genes 0.000 description 2
- 108010009202 Growth Factor Receptors Proteins 0.000 description 2
- 208000009889 Herpes Simplex Diseases 0.000 description 2
- 101000773083 Homo sapiens 5,6-dihydroxyindole-2-carboxylic acid oxidase Proteins 0.000 description 2
- 101000933320 Homo sapiens Breakpoint cluster region protein Proteins 0.000 description 2
- 101000922348 Homo sapiens C-X-C chemokine receptor type 4 Proteins 0.000 description 2
- 101000914511 Homo sapiens CD27 antigen Proteins 0.000 description 2
- 101000884279 Homo sapiens CD276 antigen Proteins 0.000 description 2
- 101000868273 Homo sapiens CD44 antigen Proteins 0.000 description 2
- 101100118549 Homo sapiens EGFR gene Proteins 0.000 description 2
- 101000921195 Homo sapiens Epidermal growth factor-like protein 7 Proteins 0.000 description 2
- 101000892862 Homo sapiens Glutamate carboxypeptidase 2 Proteins 0.000 description 2
- 101001078133 Homo sapiens Integrin alpha-2 Proteins 0.000 description 2
- 101000935040 Homo sapiens Integrin beta-2 Proteins 0.000 description 2
- 101000599852 Homo sapiens Intercellular adhesion molecule 1 Proteins 0.000 description 2
- 101000998120 Homo sapiens Interleukin-3 receptor subunit alpha Proteins 0.000 description 2
- 101000581981 Homo sapiens Neural cell adhesion molecule 1 Proteins 0.000 description 2
- 101000622137 Homo sapiens P-selectin Proteins 0.000 description 2
- 101000874179 Homo sapiens Syndecan-1 Proteins 0.000 description 2
- 101000801433 Homo sapiens Trophoblast glycoprotein Proteins 0.000 description 2
- 101000801254 Homo sapiens Tumor necrosis factor receptor superfamily member 16 Proteins 0.000 description 2
- 101000666896 Homo sapiens V-type immunoglobulin domain-containing suppressor of T-cell activation Proteins 0.000 description 2
- 101000851007 Homo sapiens Vascular endothelial growth factor receptor 2 Proteins 0.000 description 2
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 2
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 2
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 2
- 102100025305 Integrin alpha-2 Human genes 0.000 description 2
- 102100025390 Integrin beta-2 Human genes 0.000 description 2
- 102100037850 Interferon gamma Human genes 0.000 description 2
- 108010050904 Interferons Proteins 0.000 description 2
- 102000014150 Interferons Human genes 0.000 description 2
- 102000000589 Interleukin-1 Human genes 0.000 description 2
- 108010002352 Interleukin-1 Proteins 0.000 description 2
- 108090000176 Interleukin-13 Proteins 0.000 description 2
- 102000003816 Interleukin-13 Human genes 0.000 description 2
- 108010038453 Interleukin-2 Receptors Proteins 0.000 description 2
- 102000010789 Interleukin-2 Receptors Human genes 0.000 description 2
- 102100033493 Interleukin-3 receptor subunit alpha Human genes 0.000 description 2
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 2
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 2
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 2
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 2
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical group CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 2
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical group CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 2
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 2
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 2
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 2
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical group CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 2
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Chemical group CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 2
- 102000003960 Ligases Human genes 0.000 description 2
- 108090000364 Ligases Proteins 0.000 description 2
- 102100029185 Low affinity immunoglobulin gamma Fc region receptor III-B Human genes 0.000 description 2
- 102100039373 Membrane cofactor protein Human genes 0.000 description 2
- 108090000015 Mesothelin Proteins 0.000 description 2
- 102000003735 Mesothelin Human genes 0.000 description 2
- 108010008707 Mucin-1 Proteins 0.000 description 2
- 108010063954 Mucins Proteins 0.000 description 2
- 102000015728 Mucins Human genes 0.000 description 2
- 101100222220 Mus musculus Ctla4 gene Proteins 0.000 description 2
- 101000859077 Mus musculus Cytotoxic T-lymphocyte protein 4 Proteins 0.000 description 2
- 101100481410 Mus musculus Tek gene Proteins 0.000 description 2
- 241000202889 Mycoplasma salivarium Species 0.000 description 2
- SUHQNCLNRUAGOO-UHFFFAOYSA-N N-glycoloyl-neuraminic acid Natural products OCC(O)C(O)C(O)C(NC(=O)CO)C(O)CC(=O)C(O)=O SUHQNCLNRUAGOO-UHFFFAOYSA-N 0.000 description 2
- FDJKUWYYUZCUJX-UHFFFAOYSA-N N-glycolyl-beta-neuraminic acid Natural products OCC(O)C(O)C1OC(O)(C(O)=O)CC(O)C1NC(=O)CO FDJKUWYYUZCUJX-UHFFFAOYSA-N 0.000 description 2
- FDJKUWYYUZCUJX-KVNVFURPSA-N N-glycolylneuraminic acid Chemical compound OC[C@H](O)[C@H](O)[C@@H]1O[C@](O)(C(O)=O)C[C@H](O)[C@H]1NC(=O)CO FDJKUWYYUZCUJX-KVNVFURPSA-N 0.000 description 2
- 102100035486 Nectin-4 Human genes 0.000 description 2
- 101710043865 Nectin-4 Proteins 0.000 description 2
- 102100027347 Neural cell adhesion molecule 1 Human genes 0.000 description 2
- 102000004473 OX40 Ligand Human genes 0.000 description 2
- 108010042215 OX40 Ligand Proteins 0.000 description 2
- 102100023472 P-selectin Human genes 0.000 description 2
- 206010033701 Papillary thyroid cancer Diseases 0.000 description 2
- 241001494479 Pecora Species 0.000 description 2
- 108091005804 Peptidases Proteins 0.000 description 2
- 102000035195 Peptidases Human genes 0.000 description 2
- 241000288906 Primates Species 0.000 description 2
- 239000004365 Protease Substances 0.000 description 2
- 241000711798 Rabies lyssavirus Species 0.000 description 2
- 241000283984 Rodentia Species 0.000 description 2
- 101100123851 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) HER1 gene Proteins 0.000 description 2
- 241000242677 Schistosoma japonicum Species 0.000 description 2
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 2
- 206010041067 Small cell lung cancer Diseases 0.000 description 2
- 108010090804 Streptavidin Proteins 0.000 description 2
- 102100035721 Syndecan-1 Human genes 0.000 description 2
- 230000006044 T cell activation Effects 0.000 description 2
- 208000000389 T-cell leukemia Diseases 0.000 description 2
- 208000028530 T-cell lymphoblastic leukemia/lymphoma Diseases 0.000 description 2
- 208000024313 Testicular Neoplasms Diseases 0.000 description 2
- 206010057644 Testis cancer Diseases 0.000 description 2
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 2
- 239000004473 Threonine Substances 0.000 description 2
- 208000031981 Thrombocytopenic Idiopathic Purpura Diseases 0.000 description 2
- 102000002689 Toll-like receptor Human genes 0.000 description 2
- 108020000411 Toll-like receptor Proteins 0.000 description 2
- 101710120037 Toxin CcdB Proteins 0.000 description 2
- 102100033579 Trophoblast glycoprotein Human genes 0.000 description 2
- 101710165473 Tumor necrosis factor receptor superfamily member 4 Proteins 0.000 description 2
- 102100038282 V-type immunoglobulin domain-containing suppressor of T-cell activation Human genes 0.000 description 2
- 241000700618 Vaccinia virus Species 0.000 description 2
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Chemical group CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 2
- 102000009524 Vascular Endothelial Growth Factor A Human genes 0.000 description 2
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 2
- 230000001154 acute effect Effects 0.000 description 2
- 238000007792 addition Methods 0.000 description 2
- 230000002411 adverse Effects 0.000 description 2
- 125000003295 alanine group Chemical group N[C@@H](C)C(=O)* 0.000 description 2
- 238000010171 animal model Methods 0.000 description 2
- 235000009582 asparagine Nutrition 0.000 description 2
- 229960001230 asparagine Drugs 0.000 description 2
- 210000003651 basophil Anatomy 0.000 description 2
- 229960002685 biotin Drugs 0.000 description 2
- 235000020958 biotin Nutrition 0.000 description 2
- 239000011616 biotin Substances 0.000 description 2
- 229960000455 brentuximab vedotin Drugs 0.000 description 2
- 230000010261 cell growth Effects 0.000 description 2
- 230000007969 cellular immunity Effects 0.000 description 2
- 230000036755 cellular response Effects 0.000 description 2
- 239000003153 chemical reaction reagent Substances 0.000 description 2
- 238000002512 chemotherapy Methods 0.000 description 2
- 230000002759 chromosomal effect Effects 0.000 description 2
- 238000004440 column chromatography Methods 0.000 description 2
- 230000024203 complement activation Effects 0.000 description 2
- 108010047295 complement receptors Proteins 0.000 description 2
- 102000006834 complement receptors Human genes 0.000 description 2
- 230000004154 complement system Effects 0.000 description 2
- 108091008034 costimulatory receptors Proteins 0.000 description 2
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 2
- 102000003675 cytokine receptors Human genes 0.000 description 2
- 108010057085 cytokine receptors Proteins 0.000 description 2
- 239000002254 cytotoxic agent Substances 0.000 description 2
- 231100000599 cytotoxic agent Toxicity 0.000 description 2
- 230000003247 decreasing effect Effects 0.000 description 2
- 210000004443 dendritic cell Anatomy 0.000 description 2
- 238000003745 diagnosis Methods 0.000 description 2
- 230000006806 disease prevention Effects 0.000 description 2
- 229940079593 drug Drugs 0.000 description 2
- 238000001962 electrophoresis Methods 0.000 description 2
- 239000000839 emulsion Substances 0.000 description 2
- 210000003979 eosinophil Anatomy 0.000 description 2
- 208000037828 epithelial carcinoma Diseases 0.000 description 2
- 238000002270 exclusion chromatography Methods 0.000 description 2
- 102000052178 fibroblast growth factor receptor activity proteins Human genes 0.000 description 2
- 238000002825 functional assay Methods 0.000 description 2
- 229960003297 gemtuzumab ozogamicin Drugs 0.000 description 2
- 230000002068 genetic effect Effects 0.000 description 2
- 235000013922 glutamic acid Nutrition 0.000 description 2
- 239000004220 glutamic acid Substances 0.000 description 2
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 2
- 235000004554 glutamine Nutrition 0.000 description 2
- 210000003630 histaminocyte Anatomy 0.000 description 2
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 2
- 102000048362 human PDCD1 Human genes 0.000 description 2
- 230000002209 hydrophobic effect Effects 0.000 description 2
- 239000012642 immune effector Substances 0.000 description 2
- 229940121354 immunomodulator Drugs 0.000 description 2
- 230000002458 infectious effect Effects 0.000 description 2
- 230000002757 inflammatory effect Effects 0.000 description 2
- 238000001802 infusion Methods 0.000 description 2
- 229940079322 interferon Drugs 0.000 description 2
- 230000003834 intracellular effect Effects 0.000 description 2
- 229960005386 ipilimumab Drugs 0.000 description 2
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Chemical group CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 2
- 229960000310 isoleucine Drugs 0.000 description 2
- 108020001756 ligand binding domains Proteins 0.000 description 2
- 230000000670 limiting effect Effects 0.000 description 2
- 239000007788 liquid Substances 0.000 description 2
- 210000004072 lung Anatomy 0.000 description 2
- 230000003211 malignant effect Effects 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- ANZJBCHSOXCCRQ-FKUXLPTCSA-N mertansine Chemical compound CO[C@@H]([C@@]1(O)C[C@H](OC(=O)N1)[C@@H](C)[C@@H]1O[C@@]1(C)[C@@H](OC(=O)[C@H](C)N(C)C(=O)CCS)CC(=O)N1C)\C=C\C=C(C)\CC2=CC(OC)=C(Cl)C1=C2 ANZJBCHSOXCCRQ-FKUXLPTCSA-N 0.000 description 2
- 229910021645 metal ion Inorganic materials 0.000 description 2
- 230000001394 metastastic effect Effects 0.000 description 2
- 206010061289 metastatic neoplasm Diseases 0.000 description 2
- 239000003094 microcapsule Substances 0.000 description 2
- 239000004005 microsphere Substances 0.000 description 2
- 210000003205 muscle Anatomy 0.000 description 2
- 210000000440 neutrophil Anatomy 0.000 description 2
- 238000002515 oligonucleotide synthesis Methods 0.000 description 2
- 230000002018 overexpression Effects 0.000 description 2
- 230000005298 paramagnetic effect Effects 0.000 description 2
- 239000002245 particle Substances 0.000 description 2
- 230000001575 pathological effect Effects 0.000 description 2
- 229960002087 pertuzumab Drugs 0.000 description 2
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 2
- 229920001481 poly(stearyl methacrylate) Polymers 0.000 description 2
- 238000002264 polyacrylamide gel electrophoresis Methods 0.000 description 2
- 229920000768 polyamine Polymers 0.000 description 2
- 238000001556 precipitation Methods 0.000 description 2
- 239000003755 preservative agent Substances 0.000 description 2
- 238000002203 pretreatment Methods 0.000 description 2
- 230000002265 prevention Effects 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 230000001737 promoting effect Effects 0.000 description 2
- 230000001902 propagating effect Effects 0.000 description 2
- QELSKZZBTMNZEB-UHFFFAOYSA-N propylparaben Chemical compound CCCOC(=O)C1=CC=C(O)C=C1 QELSKZZBTMNZEB-UHFFFAOYSA-N 0.000 description 2
- 231100000654 protein toxin Toxicity 0.000 description 2
- 210000001938 protoplast Anatomy 0.000 description 2
- 238000001959 radiotherapy Methods 0.000 description 2
- 238000010188 recombinant method Methods 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 230000004044 response Effects 0.000 description 2
- 125000003607 serino group Chemical group [H]N([H])[C@]([H])(C(=O)[*])C(O[H])([H])[H] 0.000 description 2
- 230000019491 signal transduction Effects 0.000 description 2
- 239000007787 solid Substances 0.000 description 2
- 210000004989 spleen cell Anatomy 0.000 description 2
- 210000000130 stem cell Anatomy 0.000 description 2
- 239000000725 suspension Substances 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 201000003120 testicular cancer Diseases 0.000 description 2
- 238000002560 therapeutic procedure Methods 0.000 description 2
- 208000030045 thyroid gland papillary carcinoma Diseases 0.000 description 2
- 230000005026 transcription initiation Effects 0.000 description 2
- 229960000575 trastuzumab Drugs 0.000 description 2
- 229950007217 tremelimumab Drugs 0.000 description 2
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 2
- 241000701447 unidentified baculovirus Species 0.000 description 2
- 241001515965 unidentified phage Species 0.000 description 2
- VBEQCZHXXJYVRD-GACYYNSASA-N uroanthelone Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)C(C)C)[C@@H](C)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CCSC)NC(=O)[C@H](CS)NC(=O)[C@@H](NC(=O)CNC(=O)CNC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CS)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CS)NC(=O)CNC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O)C(C)C)[C@@H](C)CC)C1=CC=C(O)C=C1 VBEQCZHXXJYVRD-GACYYNSASA-N 0.000 description 2
- 239000004474 valine Chemical group 0.000 description 2
- 230000029812 viral genome replication Effects 0.000 description 2
- FFILOTSTFMXQJC-QCFYAKGBSA-N (2r,4r,5s,6s)-2-[3-[(2s,3s,4r,6s)-6-[(2s,3r,4r,5s,6r)-5-[(2s,3r,4r,5r,6r)-3-acetamido-4,5-dihydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-2-[(2r,3s,4r,5r,6r)-4,5-dihydroxy-2-(hydroxymethyl)-6-[(e)-3-hydroxy-2-(octadecanoylamino)octadec-4-enoxy]oxan-3-yl]oxy-3-hy Chemical compound O[C@@H]1[C@@H](O)[C@H](OCC(NC(=O)CCCCCCCCCCCCCCCCC)C(O)\C=C\CCCCCCCCCCCCC)O[C@H](CO)[C@H]1O[C@H]1[C@H](O)[C@@H](O[C@]2(O[C@@H]([C@@H](N)[C@H](O)C2)C(O)C(O)CO[C@]2(O[C@@H]([C@@H](N)[C@H](O)C2)C(O)C(O)CO)C(O)=O)C(O)=O)[C@@H](O[C@H]2[C@@H]([C@@H](O)[C@@H](O)[C@@H](CO)O2)NC(C)=O)[C@@H](CO)O1 FFILOTSTFMXQJC-QCFYAKGBSA-N 0.000 description 1
- BXTJCSYMGFJEID-XMTADJHZSA-N (2s)-2-[[(2r,3r)-3-[(2s)-1-[(3r,4s,5s)-4-[[(2s)-2-[[(2s)-2-[6-[3-[(2r)-2-amino-2-carboxyethyl]sulfanyl-2,5-dioxopyrrolidin-1-yl]hexanoyl-methylamino]-3-methylbutanoyl]amino]-3-methylbutanoyl]-methylamino]-3-methoxy-5-methylheptanoyl]pyrrolidin-2-yl]-3-met Chemical compound C([C@H](NC(=O)[C@H](C)[C@@H](OC)[C@@H]1CCCN1C(=O)C[C@H]([C@H]([C@@H](C)CC)N(C)C(=O)[C@@H](NC(=O)[C@H](C(C)C)N(C)C(=O)CCCCCN1C(C(SC[C@H](N)C(O)=O)CC1=O)=O)C(C)C)OC)C(O)=O)C1=CC=CC=C1 BXTJCSYMGFJEID-XMTADJHZSA-N 0.000 description 1
- TZCPCKNHXULUIY-RGULYWFUSA-N 1,2-distearoyl-sn-glycero-3-phosphoserine Chemical compound CCCCCCCCCCCCCCCCCC(=O)OC[C@H](COP(O)(=O)OC[C@H](N)C(O)=O)OC(=O)CCCCCCCCCCCCCCCCC TZCPCKNHXULUIY-RGULYWFUSA-N 0.000 description 1
- BJHCYTJNPVGSBZ-YXSASFKJSA-N 1-[4-[6-amino-5-[(Z)-methoxyiminomethyl]pyrimidin-4-yl]oxy-2-chlorophenyl]-3-ethylurea Chemical compound CCNC(=O)Nc1ccc(Oc2ncnc(N)c2\C=N/OC)cc1Cl BJHCYTJNPVGSBZ-YXSASFKJSA-N 0.000 description 1
- GZCWLCBFPRFLKL-UHFFFAOYSA-N 1-prop-2-ynoxypropan-2-ol Chemical compound CC(O)COCC#C GZCWLCBFPRFLKL-UHFFFAOYSA-N 0.000 description 1
- PNDPGZBMCMUPRI-HVTJNCQCSA-N 10043-66-0 Chemical compound [131I][131I] PNDPGZBMCMUPRI-HVTJNCQCSA-N 0.000 description 1
- WUAPFZMCVAUBPE-NJFSPNSNSA-N 188Re Chemical compound [188Re] WUAPFZMCVAUBPE-NJFSPNSNSA-N 0.000 description 1
- LKKMLIBUAXYLOY-UHFFFAOYSA-N 3-Amino-1-methyl-5H-pyrido[4,3-b]indole Chemical compound N1C2=CC=CC=C2C2=C1C=C(N)N=C2C LKKMLIBUAXYLOY-UHFFFAOYSA-N 0.000 description 1
- WEVYNIUIFUYDGI-UHFFFAOYSA-N 3-[6-[4-(trifluoromethoxy)anilino]-4-pyrimidinyl]benzamide Chemical compound NC(=O)C1=CC=CC(C=2N=CN=C(NC=3C=CC(OC(F)(F)F)=CC=3)C=2)=C1 WEVYNIUIFUYDGI-UHFFFAOYSA-N 0.000 description 1
- 102100033400 4F2 cell-surface antigen heavy chain Human genes 0.000 description 1
- 102100040079 A-kinase anchor protein 4 Human genes 0.000 description 1
- 101710109924 A-kinase anchor protein 4 Proteins 0.000 description 1
- 102100033793 ALK tyrosine kinase receptor Human genes 0.000 description 1
- 102000013563 Acid Phosphatase Human genes 0.000 description 1
- 108010051457 Acid Phosphatase Proteins 0.000 description 1
- 206010000830 Acute leukaemia Diseases 0.000 description 1
- 208000024893 Acute lymphoblastic leukemia Diseases 0.000 description 1
- 208000014697 Acute lymphocytic leukaemia Diseases 0.000 description 1
- 208000036762 Acute promyelocytic leukaemia Diseases 0.000 description 1
- 102100040149 Adenylyl-sulfate kinase Human genes 0.000 description 1
- 108010054404 Adenylyl-sulfate kinase Proteins 0.000 description 1
- 101150051188 Adora2a gene Proteins 0.000 description 1
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 1
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 1
- 102100025677 Alkaline phosphatase, germ cell type Human genes 0.000 description 1
- 102100024321 Alkaline phosphatase, placental type Human genes 0.000 description 1
- 102100035248 Alpha-(1,3)-fucosyltransferase 4 Human genes 0.000 description 1
- 102100023635 Alpha-fetoprotein Human genes 0.000 description 1
- 102100032187 Androgen receptor Human genes 0.000 description 1
- 102100022014 Angiopoietin-1 receptor Human genes 0.000 description 1
- 201000003076 Angiosarcoma Diseases 0.000 description 1
- 102100030988 Angiotensin-converting enzyme Human genes 0.000 description 1
- 102100023003 Ankyrin repeat domain-containing protein 30A Human genes 0.000 description 1
- 208000008958 Anti-N-Methyl-D-Aspartate Receptor Encephalitis Diseases 0.000 description 1
- 208000002267 Anti-neutrophil cytoplasmic antibody-associated vasculitis Diseases 0.000 description 1
- 102000006306 Antigen Receptors Human genes 0.000 description 1
- 108010083359 Antigen Receptors Proteins 0.000 description 1
- 241000269350 Anura Species 0.000 description 1
- 102100021569 Apoptosis regulator Bcl-2 Human genes 0.000 description 1
- 102100024003 Arf-GAP with SH3 domain, ANK repeat and PH domain-containing protein 1 Human genes 0.000 description 1
- 102000016904 Armadillo Domain Proteins Human genes 0.000 description 1
- 108010014223 Armadillo Domain Proteins Proteins 0.000 description 1
- 240000003291 Armoracia rusticana Species 0.000 description 1
- 206010003571 Astrocytoma Diseases 0.000 description 1
- 241000972773 Aulopiformes Species 0.000 description 1
- 206010069002 Autoimmune pancreatitis Diseases 0.000 description 1
- 108090001008 Avidin Proteins 0.000 description 1
- 102100029822 B- and T-lymphocyte attenuator Human genes 0.000 description 1
- 208000004736 B-Cell Leukemia Diseases 0.000 description 1
- 102100025218 B-cell differentiation antigen CD72 Human genes 0.000 description 1
- 208000032791 BCR-ABL1 positive chronic myelogenous leukemia Diseases 0.000 description 1
- 229940125565 BMS-986016 Drugs 0.000 description 1
- 241000223838 Babesia bovis Species 0.000 description 1
- 241000193830 Bacillus <bacterium> Species 0.000 description 1
- 244000063299 Bacillus subtilis Species 0.000 description 1
- 101000840545 Bacillus thuringiensis L-isoleucine-4-hydroxylase Proteins 0.000 description 1
- 208000035143 Bacterial infection Diseases 0.000 description 1
- 102100021663 Baculoviral IAP repeat-containing protein 5 Human genes 0.000 description 1
- 102100027522 Baculoviral IAP repeat-containing protein 7 Human genes 0.000 description 1
- 206010004146 Basal cell carcinoma Diseases 0.000 description 1
- 108010006654 Bleomycin Proteins 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 1
- 241000589567 Brucella abortus Species 0.000 description 1
- 206010006500 Brucellosis Diseases 0.000 description 1
- 108050005711 C Chemokine Proteins 0.000 description 1
- 102000017483 C chemokine Human genes 0.000 description 1
- 102100035875 C-C chemokine receptor type 5 Human genes 0.000 description 1
- 102100025618 C-X-C chemokine receptor type 6 Human genes 0.000 description 1
- 102100028668 C-type lectin domain family 4 member C Human genes 0.000 description 1
- 102100032957 C5a anaphylatoxin chemotactic receptor 1 Human genes 0.000 description 1
- 102100037917 CD109 antigen Human genes 0.000 description 1
- 102100035893 CD151 antigen Human genes 0.000 description 1
- 102100024210 CD166 antigen Human genes 0.000 description 1
- 102100021992 CD209 antigen Human genes 0.000 description 1
- 102000053028 CD36 Antigens Human genes 0.000 description 1
- 108010045374 CD36 Antigens Proteins 0.000 description 1
- 102100032937 CD40 ligand Human genes 0.000 description 1
- 102100036008 CD48 antigen Human genes 0.000 description 1
- 102100022002 CD59 glycoprotein Human genes 0.000 description 1
- 102100025222 CD63 antigen Human genes 0.000 description 1
- 102100027221 CD81 antigen Human genes 0.000 description 1
- 102100027217 CD82 antigen Human genes 0.000 description 1
- 102100035793 CD83 antigen Human genes 0.000 description 1
- 102100029761 Cadherin-5 Human genes 0.000 description 1
- 101100123850 Caenorhabditis elegans her-1 gene Proteins 0.000 description 1
- 101100504320 Caenorhabditis elegans mcp-1 gene Proteins 0.000 description 1
- 102100025570 Cancer/testis antigen 1 Human genes 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- 102100025466 Carcinoembryonic antigen-related cell adhesion molecule 3 Human genes 0.000 description 1
- 102000014914 Carrier Proteins Human genes 0.000 description 1
- 208000005024 Castleman disease Diseases 0.000 description 1
- 206010008342 Cervix carcinoma Diseases 0.000 description 1
- 102000001327 Chemokine CCL5 Human genes 0.000 description 1
- 108010055166 Chemokine CCL5 Proteins 0.000 description 1
- 201000006082 Chickenpox Diseases 0.000 description 1
- 102000009016 Cholera Toxin Human genes 0.000 description 1
- 108010049048 Cholera Toxin Proteins 0.000 description 1
- 208000005243 Chondrosarcoma Diseases 0.000 description 1
- 201000009047 Chordoma Diseases 0.000 description 1
- 208000006332 Choriocarcinoma Diseases 0.000 description 1
- 102000011022 Chorionic Gonadotropin Human genes 0.000 description 1
- 108010062540 Chorionic Gonadotropin Proteins 0.000 description 1
- 208000010833 Chronic myeloid leukaemia Diseases 0.000 description 1
- KRKNYBCHXYNGOX-UHFFFAOYSA-K Citrate Chemical compound [O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O KRKNYBCHXYNGOX-UHFFFAOYSA-K 0.000 description 1
- 241000284156 Clerodendrum quadriloculare Species 0.000 description 1
- 102100035167 Coiled-coil domain-containing protein 54 Human genes 0.000 description 1
- 102100025680 Complement decay-accelerating factor Human genes 0.000 description 1
- 102100030886 Complement receptor type 1 Human genes 0.000 description 1
- 206010010356 Congenital anomaly Diseases 0.000 description 1
- 239000004971 Cross linker Substances 0.000 description 1
- 201000007336 Cryptococcosis Diseases 0.000 description 1
- 241000221204 Cryptococcus neoformans Species 0.000 description 1
- 102000002427 Cyclin B Human genes 0.000 description 1
- 108010068150 Cyclin B Proteins 0.000 description 1
- 201000003808 Cystic echinococcosis Diseases 0.000 description 1
- 241000701022 Cytomegalovirus Species 0.000 description 1
- 238000001712 DNA sequencing Methods 0.000 description 1
- 241000289632 Dasypodidae Species 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 1
- 102100025012 Dipeptidyl peptidase 4 Human genes 0.000 description 1
- 102100024364 Disintegrin and metalloproteinase domain-containing protein 8 Human genes 0.000 description 1
- 241001269524 Dura Species 0.000 description 1
- 102100023471 E-selectin Human genes 0.000 description 1
- 101150049307 EEF1A2 gene Proteins 0.000 description 1
- 102000012804 EPCAM Human genes 0.000 description 1
- 102100025137 Early activation antigen CD69 Human genes 0.000 description 1
- 241000244170 Echinococcus granulosus Species 0.000 description 1
- 229940126626 Ektomab Drugs 0.000 description 1
- 206010072378 Encephalitis autoimmune Diseases 0.000 description 1
- 102100038132 Endogenous retrovirus group K member 6 Pro protein Human genes 0.000 description 1
- 241000991587 Enterovirus C Species 0.000 description 1
- 101710091045 Envelope protein Proteins 0.000 description 1
- 108010055196 EphA2 Receptor Proteins 0.000 description 1
- 102100030340 Ephrin type-A receptor 2 Human genes 0.000 description 1
- 101800003838 Epidermal growth factor Proteins 0.000 description 1
- 241000283086 Equidae Species 0.000 description 1
- 241000283073 Equus caballus Species 0.000 description 1
- 241000206602 Eukaryota Species 0.000 description 1
- 208000006168 Ewing Sarcoma Diseases 0.000 description 1
- 206010015866 Extravasation Diseases 0.000 description 1
- 229940126611 FBTA05 Drugs 0.000 description 1
- 201000003542 Factor VIII deficiency Diseases 0.000 description 1
- 241000714165 Feline leukemia virus Species 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 108010003471 Fetal Proteins Proteins 0.000 description 1
- 102000004641 Fetal Proteins Human genes 0.000 description 1
- 102100035139 Folate receptor alpha Human genes 0.000 description 1
- 102000003817 Fos-related antigen 1 Human genes 0.000 description 1
- 108090000123 Fos-related antigen 1 Proteins 0.000 description 1
- 102100020997 Fractalkine Human genes 0.000 description 1
- 102000005698 Frizzled receptors Human genes 0.000 description 1
- 108010045438 Frizzled receptors Proteins 0.000 description 1
- 241000233866 Fungi Species 0.000 description 1
- 102100031351 Galectin-9 Human genes 0.000 description 1
- 241000287828 Gallus gallus Species 0.000 description 1
- 101100229077 Gallus gallus GAL9 gene Proteins 0.000 description 1
- 101001077417 Gallus gallus Potassium voltage-gated channel subfamily H member 6 Proteins 0.000 description 1
- 108700004714 Gelonium multiflorum GEL Proteins 0.000 description 1
- 208000032612 Glial tumor Diseases 0.000 description 1
- 201000010915 Glioblastoma multiforme Diseases 0.000 description 1
- 206010018338 Glioma Diseases 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- ZWZWYGMENQVNFU-UHFFFAOYSA-N Glycerophosphorylserin Natural products OC(=O)C(N)COP(O)(=O)OCC(O)CO ZWZWYGMENQVNFU-UHFFFAOYSA-N 0.000 description 1
- 102100035716 Glycophorin-A Human genes 0.000 description 1
- 108010017080 Granulocyte Colony-Stimulating Factor Proteins 0.000 description 1
- 102100039619 Granulocyte colony-stimulating factor Human genes 0.000 description 1
- 108010017213 Granulocyte-Macrophage Colony-Stimulating Factor Proteins 0.000 description 1
- 102100039620 Granulocyte-macrophage colony-stimulating factor Human genes 0.000 description 1
- 208000003084 Graves Ophthalmopathy Diseases 0.000 description 1
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 1
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 1
- 101150069554 HIS4 gene Proteins 0.000 description 1
- 108010058597 HLA-DR Antigens Proteins 0.000 description 1
- 102000006354 HLA-DR Antigens Human genes 0.000 description 1
- 108010036449 HLA-DR10 antigen Proteins 0.000 description 1
- 206010066476 Haematological malignancy Diseases 0.000 description 1
- 102000002812 Heat-Shock Proteins Human genes 0.000 description 1
- 108010004889 Heat-Shock Proteins Proteins 0.000 description 1
- 241000125500 Hedypnois rhagadioloides Species 0.000 description 1
- 208000001258 Hemangiosarcoma Diseases 0.000 description 1
- 208000002250 Hematologic Neoplasms Diseases 0.000 description 1
- 102100031573 Hematopoietic progenitor cell antigen CD34 Human genes 0.000 description 1
- 208000009292 Hemophilia A Diseases 0.000 description 1
- 241000711549 Hepacivirus C Species 0.000 description 1
- 101710083479 Hepatitis A virus cellular receptor 2 homolog Proteins 0.000 description 1
- 241000700721 Hepatitis B virus Species 0.000 description 1
- 102100026122 High affinity immunoglobulin gamma Fc receptor I Human genes 0.000 description 1
- 241000228404 Histoplasma capsulatum Species 0.000 description 1
- 241001272567 Hominoidea Species 0.000 description 1
- 101000800023 Homo sapiens 4F2 cell-surface antigen heavy chain Proteins 0.000 description 1
- 101000779641 Homo sapiens ALK tyrosine kinase receptor Proteins 0.000 description 1
- 101000574440 Homo sapiens Alkaline phosphatase, germ cell type Proteins 0.000 description 1
- 101001022185 Homo sapiens Alpha-(1,3)-fucosyltransferase 4 Proteins 0.000 description 1
- 101000753291 Homo sapiens Angiopoietin-1 receptor Proteins 0.000 description 1
- 101000757191 Homo sapiens Ankyrin repeat domain-containing protein 30A Proteins 0.000 description 1
- 101000971171 Homo sapiens Apoptosis regulator Bcl-2 Proteins 0.000 description 1
- 101000864344 Homo sapiens B- and T-lymphocyte attenuator Proteins 0.000 description 1
- 101000934359 Homo sapiens B-cell differentiation antigen CD72 Proteins 0.000 description 1
- 101000936083 Homo sapiens Baculoviral IAP repeat-containing protein 7 Proteins 0.000 description 1
- 101000856683 Homo sapiens C-X-C chemokine receptor type 6 Proteins 0.000 description 1
- 101000766907 Homo sapiens C-type lectin domain family 4 member C Proteins 0.000 description 1
- 101000867983 Homo sapiens C5a anaphylatoxin chemotactic receptor 1 Proteins 0.000 description 1
- 101000897416 Homo sapiens CD209 antigen Proteins 0.000 description 1
- 101000716130 Homo sapiens CD48 antigen Proteins 0.000 description 1
- 101000897400 Homo sapiens CD59 glycoprotein Proteins 0.000 description 1
- 101000934368 Homo sapiens CD63 antigen Proteins 0.000 description 1
- 101000914479 Homo sapiens CD81 antigen Proteins 0.000 description 1
- 101000914469 Homo sapiens CD82 antigen Proteins 0.000 description 1
- 101000946856 Homo sapiens CD83 antigen Proteins 0.000 description 1
- 101000856237 Homo sapiens Cancer/testis antigen 1 Proteins 0.000 description 1
- 101000914337 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 3 Proteins 0.000 description 1
- 101000737052 Homo sapiens Coiled-coil domain-containing protein 54 Proteins 0.000 description 1
- 101000856022 Homo sapiens Complement decay-accelerating factor Proteins 0.000 description 1
- 101000727061 Homo sapiens Complement receptor type 1 Proteins 0.000 description 1
- 101000908391 Homo sapiens Dipeptidyl peptidase 4 Proteins 0.000 description 1
- 101000622123 Homo sapiens E-selectin Proteins 0.000 description 1
- 101000934374 Homo sapiens Early activation antigen CD69 Proteins 0.000 description 1
- 101001023230 Homo sapiens Folate receptor alpha Proteins 0.000 description 1
- 101000854520 Homo sapiens Fractalkine Proteins 0.000 description 1
- 101001074244 Homo sapiens Glycophorin-A Proteins 0.000 description 1
- 101001021491 Homo sapiens HERV-H LTR-associating protein 2 Proteins 0.000 description 1
- 101000777663 Homo sapiens Hematopoietic progenitor cell antigen CD34 Proteins 0.000 description 1
- 101000913074 Homo sapiens High affinity immunoglobulin gamma Fc receptor I Proteins 0.000 description 1
- 101001019455 Homo sapiens ICOS ligand Proteins 0.000 description 1
- 101000878602 Homo sapiens Immunoglobulin alpha Fc receptor Proteins 0.000 description 1
- 101001055308 Homo sapiens Immunoglobulin heavy constant epsilon Proteins 0.000 description 1
- 101001037256 Homo sapiens Indoleamine 2,3-dioxygenase 1 Proteins 0.000 description 1
- 101000994378 Homo sapiens Integrin alpha-3 Proteins 0.000 description 1
- 101001046687 Homo sapiens Integrin alpha-E Proteins 0.000 description 1
- 101001078143 Homo sapiens Integrin alpha-IIb Proteins 0.000 description 1
- 101001046686 Homo sapiens Integrin alpha-M Proteins 0.000 description 1
- 101000935043 Homo sapiens Integrin beta-1 Proteins 0.000 description 1
- 101001015004 Homo sapiens Integrin beta-3 Proteins 0.000 description 1
- 101001003140 Homo sapiens Interleukin-15 receptor subunit alpha Proteins 0.000 description 1
- 101001002657 Homo sapiens Interleukin-2 Proteins 0.000 description 1
- 101001018097 Homo sapiens L-selectin Proteins 0.000 description 1
- 101000605020 Homo sapiens Large neutral amino acids transporter small subunit 1 Proteins 0.000 description 1
- 101000777628 Homo sapiens Leukocyte antigen CD37 Proteins 0.000 description 1
- 101000980823 Homo sapiens Leukocyte surface antigen CD53 Proteins 0.000 description 1
- 101000608935 Homo sapiens Leukosialin Proteins 0.000 description 1
- 101000917826 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor II-a Proteins 0.000 description 1
- 101000917824 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor II-b Proteins 0.000 description 1
- 101001063392 Homo sapiens Lymphocyte function-associated antigen 3 Proteins 0.000 description 1
- 101000916644 Homo sapiens Macrophage colony-stimulating factor 1 receptor Proteins 0.000 description 1
- 101000934372 Homo sapiens Macrosialin Proteins 0.000 description 1
- 101000961414 Homo sapiens Membrane cofactor protein Proteins 0.000 description 1
- 101000694615 Homo sapiens Membrane primary amine oxidase Proteins 0.000 description 1
- 101000628547 Homo sapiens Metalloreductase STEAP1 Proteins 0.000 description 1
- 101000946889 Homo sapiens Monocyte differentiation antigen CD14 Proteins 0.000 description 1
- 101000577540 Homo sapiens Neuropilin-1 Proteins 0.000 description 1
- 101000736088 Homo sapiens PC4 and SFRS1-interacting protein Proteins 0.000 description 1
- 101000613490 Homo sapiens Paired box protein Pax-3 Proteins 0.000 description 1
- 101000601724 Homo sapiens Paired box protein Pax-5 Proteins 0.000 description 1
- 101001043564 Homo sapiens Prolow-density lipoprotein receptor-related protein 1 Proteins 0.000 description 1
- 101001136592 Homo sapiens Prostate stem cell antigen Proteins 0.000 description 1
- 101001136981 Homo sapiens Proteasome subunit beta type-9 Proteins 0.000 description 1
- 101000880770 Homo sapiens Protein SSX2 Proteins 0.000 description 1
- 101000738771 Homo sapiens Receptor-type tyrosine-protein phosphatase C Proteins 0.000 description 1
- 101000633784 Homo sapiens SLAM family member 7 Proteins 0.000 description 1
- 101000650817 Homo sapiens Semaphorin-4D Proteins 0.000 description 1
- 101000884271 Homo sapiens Signal transducer CD24 Proteins 0.000 description 1
- 101000824971 Homo sapiens Sperm surface protein Sp17 Proteins 0.000 description 1
- 101000873927 Homo sapiens Squamous cell carcinoma antigen recognized by T-cells 3 Proteins 0.000 description 1
- 101000831007 Homo sapiens T-cell immunoreceptor with Ig and ITIM domains Proteins 0.000 description 1
- 101000596234 Homo sapiens T-cell surface protein tactile Proteins 0.000 description 1
- 101000800116 Homo sapiens Thy-1 membrane glycoprotein Proteins 0.000 description 1
- 101001010792 Homo sapiens Transcriptional regulator ERG Proteins 0.000 description 1
- 101000835093 Homo sapiens Transferrin receptor protein 1 Proteins 0.000 description 1
- 101000904724 Homo sapiens Transmembrane glycoprotein NMB Proteins 0.000 description 1
- 101000638154 Homo sapiens Transmembrane protease serine 2 Proteins 0.000 description 1
- 101000611183 Homo sapiens Tumor necrosis factor Proteins 0.000 description 1
- 101000638251 Homo sapiens Tumor necrosis factor ligand superfamily member 9 Proteins 0.000 description 1
- 101000795167 Homo sapiens Tumor necrosis factor receptor superfamily member 13B Proteins 0.000 description 1
- 101000801232 Homo sapiens Tumor necrosis factor receptor superfamily member 1B Proteins 0.000 description 1
- 101000611023 Homo sapiens Tumor necrosis factor receptor superfamily member 6 Proteins 0.000 description 1
- 101000760337 Homo sapiens Urokinase plasminogen activator surface receptor Proteins 0.000 description 1
- 241000701074 Human alphaherpesvirus 2 Species 0.000 description 1
- 241000701085 Human alphaherpesvirus 3 Species 0.000 description 1
- 241000701044 Human gammaherpesvirus 4 Species 0.000 description 1
- 102000004157 Hydrolases Human genes 0.000 description 1
- 108090000604 Hydrolases Proteins 0.000 description 1
- 206010020880 Hypertrophy Diseases 0.000 description 1
- 102100034980 ICOS ligand Human genes 0.000 description 1
- 101150106931 IFNG gene Proteins 0.000 description 1
- 101710123134 Ice-binding protein Proteins 0.000 description 1
- 101710082837 Ice-structuring protein Proteins 0.000 description 1
- 108010073816 IgE Receptors Proteins 0.000 description 1
- 102000009438 IgE Receptors Human genes 0.000 description 1
- 102100026120 IgG receptor FcRn large subunit p51 Human genes 0.000 description 1
- 101710177940 IgG receptor FcRn large subunit p51 Proteins 0.000 description 1
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 1
- 229940076838 Immune checkpoint inhibitor Drugs 0.000 description 1
- 208000004187 Immunoglobulin G4-Related Disease Diseases 0.000 description 1
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 1
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 1
- 102100038005 Immunoglobulin alpha Fc receptor Human genes 0.000 description 1
- 102100026212 Immunoglobulin heavy constant epsilon Human genes 0.000 description 1
- 206010062016 Immunosuppression Diseases 0.000 description 1
- 102100040061 Indoleamine 2,3-dioxygenase 1 Human genes 0.000 description 1
- 108091008026 Inhibitory immune checkpoint proteins Proteins 0.000 description 1
- 102000037984 Inhibitory immune checkpoint proteins Human genes 0.000 description 1
- 108090000723 Insulin-Like Growth Factor I Proteins 0.000 description 1
- 102000004218 Insulin-Like Growth Factor I Human genes 0.000 description 1
- 102100032819 Integrin alpha-3 Human genes 0.000 description 1
- 102100022341 Integrin alpha-E Human genes 0.000 description 1
- 102100025306 Integrin alpha-IIb Human genes 0.000 description 1
- 102100022338 Integrin alpha-M Human genes 0.000 description 1
- 102100022297 Integrin alpha-X Human genes 0.000 description 1
- 102100025304 Integrin beta-1 Human genes 0.000 description 1
- 102100032999 Integrin beta-3 Human genes 0.000 description 1
- 102000008070 Interferon-gamma Human genes 0.000 description 1
- 108010066719 Interleukin Receptor Common gamma Subunit Proteins 0.000 description 1
- 102000018682 Interleukin Receptor Common gamma Subunit Human genes 0.000 description 1
- 102000003814 Interleukin-10 Human genes 0.000 description 1
- 108090000174 Interleukin-10 Proteins 0.000 description 1
- 102100020789 Interleukin-15 receptor subunit alpha Human genes 0.000 description 1
- 108050003558 Interleukin-17 Proteins 0.000 description 1
- 102000013691 Interleukin-17 Human genes 0.000 description 1
- 108090000978 Interleukin-4 Proteins 0.000 description 1
- 102000010781 Interleukin-6 Receptors Human genes 0.000 description 1
- 108010038501 Interleukin-6 Receptors Proteins 0.000 description 1
- 102100037792 Interleukin-6 receptor subunit alpha Human genes 0.000 description 1
- 102100021593 Interleukin-7 receptor subunit alpha Human genes 0.000 description 1
- 108090001007 Interleukin-8 Proteins 0.000 description 1
- 102000002698 KIR Receptors Human genes 0.000 description 1
- 108010043610 KIR Receptors Proteins 0.000 description 1
- 101100288095 Klebsiella pneumoniae neo gene Proteins 0.000 description 1
- 241001138401 Kluyveromyces lactis Species 0.000 description 1
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 1
- 102100031413 L-dopachrome tautomerase Human genes 0.000 description 1
- 101710093778 L-dopachrome tautomerase Proteins 0.000 description 1
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 1
- 102100033467 L-selectin Human genes 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- 101150073396 LTA gene Proteins 0.000 description 1
- 241000589248 Legionella Species 0.000 description 1
- 208000007764 Legionnaires' Disease Diseases 0.000 description 1
- 208000018142 Leiomyosarcoma Diseases 0.000 description 1
- 241000222736 Leishmania tropica Species 0.000 description 1
- 102100031586 Leukocyte antigen CD37 Human genes 0.000 description 1
- 102100024221 Leukocyte surface antigen CD53 Human genes 0.000 description 1
- 102100020943 Leukocyte-associated immunoglobulin-like receptor 1 Human genes 0.000 description 1
- 102100039564 Leukosialin Human genes 0.000 description 1
- 108090001030 Lipoproteins Proteins 0.000 description 1
- 102000004895 Lipoproteins Human genes 0.000 description 1
- 102100029204 Low affinity immunoglobulin gamma Fc region receptor II-a Human genes 0.000 description 1
- 208000016604 Lyme disease Diseases 0.000 description 1
- 102100030984 Lymphocyte function-associated antigen 3 Human genes 0.000 description 1
- 102220639870 Lysine-specific demethylase RSBN1L_N65A_mutation Human genes 0.000 description 1
- 102000016200 MART-1 Antigen Human genes 0.000 description 1
- 108010010995 MART-1 Antigen Proteins 0.000 description 1
- 108700012912 MYCN Proteins 0.000 description 1
- 101150022024 MYCN gene Proteins 0.000 description 1
- 102100028198 Macrophage colony-stimulating factor 1 receptor Human genes 0.000 description 1
- 102100025136 Macrosialin Human genes 0.000 description 1
- 108700018351 Major Histocompatibility Complex Proteins 0.000 description 1
- 206010025538 Malignant ascites Diseases 0.000 description 1
- 102100027754 Mast/stem cell growth factor receptor Kit Human genes 0.000 description 1
- 241000712079 Measles morbillivirus Species 0.000 description 1
- 208000000172 Medulloblastoma Diseases 0.000 description 1
- 108010061593 Member 14 Tumor Necrosis Factor Receptors Proteins 0.000 description 1
- 102000012750 Membrane Glycoproteins Human genes 0.000 description 1
- 108010090054 Membrane Glycoproteins Proteins 0.000 description 1
- 102100027159 Membrane primary amine oxidase Human genes 0.000 description 1
- 201000009906 Meningitis Diseases 0.000 description 1
- 208000002030 Merkel cell carcinoma Diseases 0.000 description 1
- 241000520674 Mesocestoides corti Species 0.000 description 1
- 206010027406 Mesothelioma Diseases 0.000 description 1
- 102100026712 Metalloreductase STEAP1 Human genes 0.000 description 1
- 206010027480 Metastatic malignant melanoma Diseases 0.000 description 1
- 206010050513 Metastatic renal cell carcinoma Diseases 0.000 description 1
- QPJVMBTYPHYUOC-UHFFFAOYSA-N Methyl benzoate Natural products COC(=O)C1=CC=CC=C1 QPJVMBTYPHYUOC-UHFFFAOYSA-N 0.000 description 1
- 102100035877 Monocyte differentiation antigen CD14 Human genes 0.000 description 1
- 241000711386 Mumps virus Species 0.000 description 1
- 241000711408 Murine respirovirus Species 0.000 description 1
- 101001128134 Mus musculus NACHT, LRR and PYD domains-containing protein 5 Proteins 0.000 description 1
- 101100407308 Mus musculus Pdcd1lg2 gene Proteins 0.000 description 1
- 101100369989 Mus musculus Tnfaip3 gene Proteins 0.000 description 1
- 208000007101 Muscle Cramp Diseases 0.000 description 1
- 241000186362 Mycobacterium leprae Species 0.000 description 1
- 241000187479 Mycobacterium tuberculosis Species 0.000 description 1
- 241000204028 Mycoplasma arginini Species 0.000 description 1
- 241000202956 Mycoplasma arthritidis Species 0.000 description 1
- 241000202938 Mycoplasma hyorhinis Species 0.000 description 1
- 241000202894 Mycoplasma orale Species 0.000 description 1
- 241000202934 Mycoplasma pneumoniae Species 0.000 description 1
- 208000033761 Myelogenous Chronic BCR-ABL Positive Leukemia Diseases 0.000 description 1
- 201000002481 Myositis Diseases 0.000 description 1
- 108700026495 N-Myc Proto-Oncogene Proteins 0.000 description 1
- 102100030124 N-myc proto-oncogene protein Human genes 0.000 description 1
- 208000032580 NMDA receptor encephalitis Diseases 0.000 description 1
- 241000588652 Neisseria gonorrhoeae Species 0.000 description 1
- 241000588650 Neisseria meningitidis Species 0.000 description 1
- 108090000028 Neprilysin Proteins 0.000 description 1
- 102000003729 Neprilysin Human genes 0.000 description 1
- 206010029260 Neuroblastoma Diseases 0.000 description 1
- 206010029266 Neuroendocrine carcinoma of the skin Diseases 0.000 description 1
- 208000005890 Neuroma Diseases 0.000 description 1
- 208000029067 Neuromyelitis optica spectrum disease Diseases 0.000 description 1
- 102100028762 Neuropilin-1 Human genes 0.000 description 1
- 101710163270 Nuclease Proteins 0.000 description 1
- 206010030113 Oedema Diseases 0.000 description 1
- 241000243985 Onchocerca volvulus Species 0.000 description 1
- 101710160107 Outer membrane protein A Proteins 0.000 description 1
- 238000010222 PCR analysis Methods 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 102100040891 Paired box protein Pax-3 Human genes 0.000 description 1
- 102100037504 Paired box protein Pax-5 Human genes 0.000 description 1
- 241000282322 Panthera Species 0.000 description 1
- 108090000526 Papain Proteins 0.000 description 1
- 108010033276 Peptide Fragments Proteins 0.000 description 1
- 102000007079 Peptide Fragments Human genes 0.000 description 1
- 102000015439 Phospholipases Human genes 0.000 description 1
- 108010064785 Phospholipases Proteins 0.000 description 1
- 102000004160 Phosphoric Monoester Hydrolases Human genes 0.000 description 1
- 108090000608 Phosphoric Monoester Hydrolases Proteins 0.000 description 1
- 108010004729 Phycoerythrin Proteins 0.000 description 1
- 241000223960 Plasmodium falciparum Species 0.000 description 1
- 241000223810 Plasmodium vivax Species 0.000 description 1
- 102100024616 Platelet endothelial cell adhesion molecule Human genes 0.000 description 1
- 108010051742 Platelet-Derived Growth Factor beta Receptor Proteins 0.000 description 1
- 102100026547 Platelet-derived growth factor receptor beta Human genes 0.000 description 1
- 102100029740 Poliovirus receptor Human genes 0.000 description 1
- 208000008601 Polycythemia Diseases 0.000 description 1
- 206010036105 Polyneuropathy Diseases 0.000 description 1
- 102100022807 Potassium voltage-gated channel subfamily H member 2 Human genes 0.000 description 1
- 208000006664 Precursor Cell Lymphoblastic Leukemia-Lymphoma Diseases 0.000 description 1
- 102100033237 Pro-epidermal growth factor Human genes 0.000 description 1
- 108700030875 Programmed Cell Death 1 Ligand 2 Proteins 0.000 description 1
- 102100024213 Programmed cell death 1 ligand 2 Human genes 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- 102100021923 Prolow-density lipoprotein receptor-related protein 1 Human genes 0.000 description 1
- 102100040120 Prominin-1 Human genes 0.000 description 1
- 208000033826 Promyelocytic Acute Leukemia Diseases 0.000 description 1
- 102100036735 Prostate stem cell antigen Human genes 0.000 description 1
- 108010072866 Prostate-Specific Antigen Proteins 0.000 description 1
- 102100038358 Prostate-specific antigen Human genes 0.000 description 1
- 102220479509 Proteasome inhibitor PI31 subunit_D8A_mutation Human genes 0.000 description 1
- 102100035764 Proteasome subunit beta type-9 Human genes 0.000 description 1
- 102100037686 Protein SSX2 Human genes 0.000 description 1
- 101710188315 Protein X Proteins 0.000 description 1
- 241000125945 Protoparvovirus Species 0.000 description 1
- 241000589516 Pseudomonas Species 0.000 description 1
- 241000589517 Pseudomonas aeruginosa Species 0.000 description 1
- 206010037660 Pyrexia Diseases 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 230000010799 Receptor Interactions Effects 0.000 description 1
- 102100020718 Receptor-type tyrosine-protein kinase FLT3 Human genes 0.000 description 1
- 102100037422 Receptor-type tyrosine-protein phosphatase C Human genes 0.000 description 1
- 102100037421 Regulator of G-protein signaling 5 Human genes 0.000 description 1
- 101710140403 Regulator of G-protein signaling 5 Proteins 0.000 description 1
- 241000725643 Respiratory syncytial virus Species 0.000 description 1
- 201000000582 Retinoblastoma Diseases 0.000 description 1
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 description 1
- 241000710799 Rubella virus Species 0.000 description 1
- 102100029198 SLAM family member 7 Human genes 0.000 description 1
- 108010017324 STAT3 Transcription Factor Proteins 0.000 description 1
- 108010029477 STAT5 Transcription Factor Proteins 0.000 description 1
- 102000001712 STAT5 Transcription Factor Human genes 0.000 description 1
- 101001037255 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) Indoleamine 2,3-dioxygenase Proteins 0.000 description 1
- 108010084592 Saporins Proteins 0.000 description 1
- 241000242680 Schistosoma mansoni Species 0.000 description 1
- 102100027744 Semaphorin-4D Human genes 0.000 description 1
- 108010079723 Shiga Toxin Proteins 0.000 description 1
- 101710173694 Short transient receptor potential channel 2 Proteins 0.000 description 1
- 108010047827 Sialic Acid Binding Immunoglobulin-like Lectins Proteins 0.000 description 1
- 102000007073 Sialic Acid Binding Immunoglobulin-like Lectins Human genes 0.000 description 1
- 102100038081 Signal transducer CD24 Human genes 0.000 description 1
- 102100024040 Signal transducer and activator of transcription 3 Human genes 0.000 description 1
- 241000710960 Sindbis virus Species 0.000 description 1
- 208000021386 Sjogren Syndrome Diseases 0.000 description 1
- 208000005392 Spasm Diseases 0.000 description 1
- 241000589973 Spirochaeta Species 0.000 description 1
- 102100035748 Squamous cell carcinoma antigen recognized by T-cells 3 Human genes 0.000 description 1
- 241000191967 Staphylococcus aureus Species 0.000 description 1
- 241000193985 Streptococcus agalactiae Species 0.000 description 1
- 101100309436 Streptococcus mutans serotype c (strain ATCC 700610 / UA159) ftf gene Proteins 0.000 description 1
- 241000193996 Streptococcus pyogenes Species 0.000 description 1
- 241000282887 Suidae Species 0.000 description 1
- 108010002687 Survivin Proteins 0.000 description 1
- 230000024932 T cell mediated immunity Effects 0.000 description 1
- 230000006052 T cell proliferation Effects 0.000 description 1
- 229940126547 T-cell immunoglobulin mucin-3 Drugs 0.000 description 1
- 102100024834 T-cell immunoreceptor with Ig and ITIM domains Human genes 0.000 description 1
- 102100035268 T-cell surface protein tactile Human genes 0.000 description 1
- 101150057140 TACSTD1 gene Proteins 0.000 description 1
- 108010000449 TNF-Related Apoptosis-Inducing Ligand Receptors Proteins 0.000 description 1
- 108010014401 TWEAK Receptor Proteins 0.000 description 1
- 241001672171 Taenia hydatigena Species 0.000 description 1
- 241000244154 Taenia ovis Species 0.000 description 1
- 241000244159 Taenia saginata Species 0.000 description 1
- 241000223779 Theileria parva Species 0.000 description 1
- 206010043561 Thrombocytopenic purpura Diseases 0.000 description 1
- 102100026966 Thrombomodulin Human genes 0.000 description 1
- 201000007023 Thrombotic Thrombocytopenic Purpura Diseases 0.000 description 1
- 102100033523 Thy-1 membrane glycoprotein Human genes 0.000 description 1
- 241000223997 Toxoplasma gondii Species 0.000 description 1
- 102100026144 Transferrin receptor protein 1 Human genes 0.000 description 1
- 102000004887 Transforming Growth Factor beta Human genes 0.000 description 1
- 108090001012 Transforming Growth Factor beta Proteins 0.000 description 1
- 102000009618 Transforming Growth Factors Human genes 0.000 description 1
- 108010009583 Transforming Growth Factors Proteins 0.000 description 1
- 102100023935 Transmembrane glycoprotein NMB Human genes 0.000 description 1
- 102100031989 Transmembrane protease serine 2 Human genes 0.000 description 1
- 101800001690 Transmembrane protein gp41 Proteins 0.000 description 1
- 241000589886 Treponema Species 0.000 description 1
- 241000589884 Treponema pallidum Species 0.000 description 1
- 241000243777 Trichinella spiralis Species 0.000 description 1
- 244000250129 Trigonella foenum graecum Species 0.000 description 1
- 235000001484 Trigonella foenum graecum Nutrition 0.000 description 1
- 241000223104 Trypanosoma Species 0.000 description 1
- 241000223105 Trypanosoma brucei Species 0.000 description 1
- 241000223109 Trypanosoma cruzi Species 0.000 description 1
- 241000223097 Trypanosoma rangeli Species 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 1
- 102100032101 Tumor necrosis factor ligand superfamily member 9 Human genes 0.000 description 1
- 102100028786 Tumor necrosis factor receptor superfamily member 12A Human genes 0.000 description 1
- 102100029675 Tumor necrosis factor receptor superfamily member 13B Human genes 0.000 description 1
- 102100028785 Tumor necrosis factor receptor superfamily member 14 Human genes 0.000 description 1
- 102100033725 Tumor necrosis factor receptor superfamily member 16 Human genes 0.000 description 1
- 102100040403 Tumor necrosis factor receptor superfamily member 6 Human genes 0.000 description 1
- 206010067584 Type 1 diabetes mellitus Diseases 0.000 description 1
- 102000014384 Type C Phospholipases Human genes 0.000 description 1
- 108010079194 Type C Phospholipases Proteins 0.000 description 1
- 108091005906 Type I transmembrane proteins Proteins 0.000 description 1
- 101710107540 Type-2 ice-structuring protein Proteins 0.000 description 1
- 102100039094 Tyrosinase Human genes 0.000 description 1
- 108060008724 Tyrosinase Proteins 0.000 description 1
- 102100024689 Urokinase plasminogen activator surface receptor Human genes 0.000 description 1
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 description 1
- 208000002495 Uterine Neoplasms Diseases 0.000 description 1
- 108010079206 V-Set Domain-Containing T-Cell Activation Inhibitor 1 Proteins 0.000 description 1
- 102100038929 V-set domain-containing T-cell activation inhibitor 1 Human genes 0.000 description 1
- 206010046980 Varicella Diseases 0.000 description 1
- 108010000134 Vascular Cell Adhesion Molecule-1 Proteins 0.000 description 1
- 108010073929 Vascular Endothelial Growth Factor A Proteins 0.000 description 1
- 108010053096 Vascular Endothelial Growth Factor Receptor-1 Proteins 0.000 description 1
- 108010053099 Vascular Endothelial Growth Factor Receptor-2 Proteins 0.000 description 1
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 description 1
- 102100033178 Vascular endothelial growth factor receptor 1 Human genes 0.000 description 1
- 206010047115 Vasculitis Diseases 0.000 description 1
- 241001416177 Vicugna pacos Species 0.000 description 1
- JXLYSJRDGCGARV-WWYNWVTFSA-N Vinblastine Natural products O=C(O[C@H]1[C@](O)(C(=O)OC)[C@@H]2N(C)c3c(cc(c(OC)c3)[C@]3(C(=O)OC)c4[nH]c5c(c4CCN4C[C@](O)(CC)C[C@H](C3)C4)cccc5)[C@@]32[C@H]2[C@@]1(CC)C=CCN2CC3)C JXLYSJRDGCGARV-WWYNWVTFSA-N 0.000 description 1
- 208000036142 Viral infection Diseases 0.000 description 1
- 108700020467 WT1 Proteins 0.000 description 1
- 101150084041 WT1 gene Proteins 0.000 description 1
- 208000033559 Waldenström macroglobulinemia Diseases 0.000 description 1
- 208000000260 Warts Diseases 0.000 description 1
- 241000710886 West Nile virus Species 0.000 description 1
- 102100022748 Wilms tumor protein Human genes 0.000 description 1
- 208000027418 Wounds and injury Diseases 0.000 description 1
- 108010093038 XCL-2 calpain Proteins 0.000 description 1
- VWQVUPCCIRVNHF-OUBTZVSYSA-N Yttrium-90 Chemical compound [90Y] VWQVUPCCIRVNHF-OUBTZVSYSA-N 0.000 description 1
- 238000002679 ablation Methods 0.000 description 1
- 230000001133 acceleration Effects 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 239000013543 active substance Substances 0.000 description 1
- 229950009084 adecatumumab Drugs 0.000 description 1
- 239000002671 adjuvant Substances 0.000 description 1
- 229940009456 adriamycin Drugs 0.000 description 1
- 229950008459 alacizumab pegol Drugs 0.000 description 1
- 229960000548 alemtuzumab Drugs 0.000 description 1
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 229950001537 amatuximab Drugs 0.000 description 1
- 229960000723 ampicillin Drugs 0.000 description 1
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 1
- 239000012491 analyte Substances 0.000 description 1
- 229950006061 anatumomab mafenatox Drugs 0.000 description 1
- 108010080146 androgen receptors Proteins 0.000 description 1
- 208000007502 anemia Diseases 0.000 description 1
- 238000000137 annealing Methods 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 208000029188 anti-NMDA receptor encephalitis Diseases 0.000 description 1
- 230000002424 anti-apoptotic effect Effects 0.000 description 1
- 230000003172 anti-dna Effects 0.000 description 1
- 230000003432 anti-folate effect Effects 0.000 description 1
- 230000036436 anti-hiv Effects 0.000 description 1
- 230000001064 anti-interferon Effects 0.000 description 1
- 230000000118 anti-neoplastic effect Effects 0.000 description 1
- 230000005809 anti-tumor immunity Effects 0.000 description 1
- 230000000840 anti-viral effect Effects 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 229940127074 antifolate Drugs 0.000 description 1
- 210000000612 antigen-presenting cell Anatomy 0.000 description 1
- 229940034982 antineoplastic agent Drugs 0.000 description 1
- 229950003145 apolizumab Drugs 0.000 description 1
- 239000013011 aqueous formulation Substances 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 229960003852 atezolizumab Drugs 0.000 description 1
- 208000022362 bacterial infectious disease Diseases 0.000 description 1
- 210000000227 basophil cell of anterior lobe of hypophysis Anatomy 0.000 description 1
- 239000011324 bead Substances 0.000 description 1
- 229960003270 belimumab Drugs 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 229960000397 bevacizumab Drugs 0.000 description 1
- 230000001588 bifunctional effect Effects 0.000 description 1
- 108091008324 binding proteins Proteins 0.000 description 1
- 238000002306 biochemical method Methods 0.000 description 1
- 239000012472 biological sample Substances 0.000 description 1
- 229960000074 biopharmaceutical Drugs 0.000 description 1
- 238000001574 biopsy Methods 0.000 description 1
- JCXGWMGPZLAOME-AKLPVKDBSA-N bismuth-212 Chemical compound [212Bi] JCXGWMGPZLAOME-AKLPVKDBSA-N 0.000 description 1
- 229960001561 bleomycin Drugs 0.000 description 1
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 1
- 210000001754 blood buffy coat Anatomy 0.000 description 1
- 238000006664 bond formation reaction Methods 0.000 description 1
- 210000001185 bone marrow Anatomy 0.000 description 1
- 238000010322 bone marrow transplantation Methods 0.000 description 1
- 210000000481 breast Anatomy 0.000 description 1
- 229940056450 brucella abortus Drugs 0.000 description 1
- 229940126608 cBR96-doxorubicin immunoconjugate Drugs 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- 244000309466 calf Species 0.000 description 1
- 238000002619 cancer immunotherapy Methods 0.000 description 1
- 239000012830 cancer therapeutic Substances 0.000 description 1
- 230000000711 cancerogenic effect Effects 0.000 description 1
- 229950007296 cantuzumab mertansine Drugs 0.000 description 1
- 239000007963 capsule composition Substances 0.000 description 1
- 231100000357 carcinogen Toxicity 0.000 description 1
- 239000003183 carcinogenic agent Substances 0.000 description 1
- 229950000771 carlumab Drugs 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 239000012876 carrier material Substances 0.000 description 1
- 229960000419 catumaxomab Drugs 0.000 description 1
- 229950006754 cedelizumab Drugs 0.000 description 1
- 230000021164 cell adhesion Effects 0.000 description 1
- 238000010366 cell biology technique Methods 0.000 description 1
- 230000006037 cell lysis Effects 0.000 description 1
- 230000012292 cell migration Effects 0.000 description 1
- 230000003833 cell viability Effects 0.000 description 1
- 230000005754 cellular signaling Effects 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 201000010881 cervical cancer Diseases 0.000 description 1
- 210000003679 cervix uteri Anatomy 0.000 description 1
- 229960005395 cetuximab Drugs 0.000 description 1
- 239000013043 chemical agent Substances 0.000 description 1
- 238000009614 chemical analysis method Methods 0.000 description 1
- 238000010382 chemical cross-linking Methods 0.000 description 1
- 125000003636 chemical group Chemical group 0.000 description 1
- 238000007385 chemical modification Methods 0.000 description 1
- 239000012707 chemical precursor Substances 0.000 description 1
- 229940044683 chemotherapy drug Drugs 0.000 description 1
- 235000013330 chicken meat Nutrition 0.000 description 1
- 208000006990 cholangiocarcinoma Diseases 0.000 description 1
- 230000001684 chronic effect Effects 0.000 description 1
- 208000024207 chronic leukemia Diseases 0.000 description 1
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 1
- 229960004316 cisplatin Drugs 0.000 description 1
- 238000003776 cleavage reaction Methods 0.000 description 1
- 238000000975 co-precipitation Methods 0.000 description 1
- 238000012761 co-transfection Methods 0.000 description 1
- 210000001072 colon Anatomy 0.000 description 1
- 208000029742 colonic neoplasm Diseases 0.000 description 1
- 238000002648 combination therapy Methods 0.000 description 1
- 230000009918 complex formation Effects 0.000 description 1
- 239000002131 composite material Substances 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 239000000356 contaminant Substances 0.000 description 1
- 239000002872 contrast media Substances 0.000 description 1
- 238000013270 controlled release Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 239000011258 core-shell material Substances 0.000 description 1
- 238000012937 correction Methods 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 239000013078 crystal Substances 0.000 description 1
- 208000017763 cutaneous neuroendocrine carcinoma Diseases 0.000 description 1
- 125000004122 cyclic group Chemical group 0.000 description 1
- 235000018417 cysteine Nutrition 0.000 description 1
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 1
- 230000009089 cytolysis Effects 0.000 description 1
- 239000002619 cytotoxin Substances 0.000 description 1
- 229950007409 dacetuzumab Drugs 0.000 description 1
- 229960002806 daclizumab Drugs 0.000 description 1
- 229940126590 dalatumumab Drugs 0.000 description 1
- 229960002482 dalotuzumab Drugs 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 230000018044 dehydration Effects 0.000 description 1
- 238000006297 dehydration reaction Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 239000003599 detergent Substances 0.000 description 1
- 229950008962 detumomab Drugs 0.000 description 1
- 238000002405 diagnostic procedure Methods 0.000 description 1
- 238000000502 dialysis Methods 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 230000000916 dilatatory effect Effects 0.000 description 1
- 239000002270 dispersing agent Substances 0.000 description 1
- 238000010494 dissociation reaction Methods 0.000 description 1
- 230000005593 dissociations Effects 0.000 description 1
- 238000004090 dissolution Methods 0.000 description 1
- 239000003651 drinking water Substances 0.000 description 1
- 235000020188 drinking water Nutrition 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 210000001951 dura mater Anatomy 0.000 description 1
- 229950009791 durvalumab Drugs 0.000 description 1
- 229950000006 ecromeximab Drugs 0.000 description 1
- 229960001776 edrecolomab Drugs 0.000 description 1
- 210000003162 effector t lymphocyte Anatomy 0.000 description 1
- 229940056913 eftilagimod alfa Drugs 0.000 description 1
- 238000005868 electrolysis reaction Methods 0.000 description 1
- 229950003048 enavatuzumab Drugs 0.000 description 1
- 230000003511 endothelial effect Effects 0.000 description 1
- 238000001976 enzyme digestion Methods 0.000 description 1
- 229940116977 epidermal growth factor Drugs 0.000 description 1
- 108010087914 epidermal growth factor receptor VIII Proteins 0.000 description 1
- 229950001757 epitumomab Drugs 0.000 description 1
- 229950009760 epratuzumab Drugs 0.000 description 1
- 125000001495 ethyl group Chemical group [H]C([H])([H])C([H])([H])* 0.000 description 1
- 230000017188 evasion or tolerance of host immune response Effects 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 108010052305 exodeoxyribonuclease III Proteins 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 238000003804 extraction from natural source Methods 0.000 description 1
- 238000013213 extrapolation Methods 0.000 description 1
- 230000036251 extravasation Effects 0.000 description 1
- 239000012091 fetal bovine serum Substances 0.000 description 1
- 210000002950 fibroblast Anatomy 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- MHMNJMPURVTYEJ-UHFFFAOYSA-N fluorescein-5-isothiocyanate Chemical compound O1C(=O)C2=CC(N=C=S)=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 MHMNJMPURVTYEJ-UHFFFAOYSA-N 0.000 description 1
- IJJVMEJXYNJXOJ-UHFFFAOYSA-N fluquinconazole Chemical compound C=1C=C(Cl)C=C(Cl)C=1N1C(=O)C2=CC(F)=CC=C2N=C1N1C=NC=N1 IJJVMEJXYNJXOJ-UHFFFAOYSA-N 0.000 description 1
- 102000006815 folate receptor Human genes 0.000 description 1
- 108020005243 folate receptor Proteins 0.000 description 1
- 239000004052 folic acid antagonist Substances 0.000 description 1
- 238000005194 fractionation Methods 0.000 description 1
- 125000002446 fucosyl group Chemical group C1([C@@H](O)[C@H](O)[C@H](O)[C@@H](O1)C)* 0.000 description 1
- 125000000524 functional group Chemical group 0.000 description 1
- 230000002538 fungal effect Effects 0.000 description 1
- UIWYJDYFSGRHKR-UHFFFAOYSA-N gadolinium atom Chemical compound [Gd] UIWYJDYFSGRHKR-UHFFFAOYSA-N 0.000 description 1
- 230000005021 gait Effects 0.000 description 1
- 229950004896 ganitumab Drugs 0.000 description 1
- 210000001035 gastrointestinal tract Anatomy 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 238000005227 gel permeation chromatography Methods 0.000 description 1
- 238000002523 gelfiltration Methods 0.000 description 1
- 229950002026 girentuximab Drugs 0.000 description 1
- 229950009672 glembatumumab vedotin Drugs 0.000 description 1
- 150000004676 glycans Chemical class 0.000 description 1
- 208000027096 gram-negative bacterial infections Diseases 0.000 description 1
- 208000027136 gram-positive bacterial infections Diseases 0.000 description 1
- 239000005090 green fluorescent protein Substances 0.000 description 1
- 210000003128 head Anatomy 0.000 description 1
- 201000010536 head and neck cancer Diseases 0.000 description 1
- 208000014829 head and neck neoplasm Diseases 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 201000002222 hemangioblastoma Diseases 0.000 description 1
- 230000002489 hematologic effect Effects 0.000 description 1
- 210000003958 hematopoietic stem cell Anatomy 0.000 description 1
- 230000002440 hepatic effect Effects 0.000 description 1
- 206010073071 hepatocellular carcinoma Diseases 0.000 description 1
- 231100000844 hepatocellular carcinoma Toxicity 0.000 description 1
- 239000000833 heterodimer Substances 0.000 description 1
- 208000010726 hind limb paralysis Diseases 0.000 description 1
- 102000051957 human ERBB2 Human genes 0.000 description 1
- 102000049109 human HAVCR2 Human genes 0.000 description 1
- 102000043323 human PSIP1 Human genes 0.000 description 1
- 229940084986 human chorionic gonadotropin Drugs 0.000 description 1
- 210000004408 hybridoma Anatomy 0.000 description 1
- 229950006359 icrucumab Drugs 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 229950005646 imgatuzumab Drugs 0.000 description 1
- 230000006303 immediate early viral mRNA transcription Effects 0.000 description 1
- 230000005965 immune activity Effects 0.000 description 1
- 230000005931 immune cell recruitment Effects 0.000 description 1
- 230000008073 immune recognition Effects 0.000 description 1
- 230000008629 immune suppression Effects 0.000 description 1
- 230000037451 immune surveillance Effects 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 230000006058 immune tolerance Effects 0.000 description 1
- 239000012274 immune-checkpoint protein inhibitor Substances 0.000 description 1
- 238000003119 immunoblot Methods 0.000 description 1
- 229940127121 immunoconjugate Drugs 0.000 description 1
- 229940127130 immunocytokine Drugs 0.000 description 1
- 230000001506 immunosuppresive effect Effects 0.000 description 1
- 239000007943 implant Substances 0.000 description 1
- 238000002513 implantation Methods 0.000 description 1
- 230000001976 improved effect Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 239000012535 impurity Substances 0.000 description 1
- 230000005918 in vitro anti-tumor Effects 0.000 description 1
- 238000000099 in vitro assay Methods 0.000 description 1
- 238000005462 in vivo assay Methods 0.000 description 1
- 229950009230 inclacumab Drugs 0.000 description 1
- 239000012678 infectious agent Substances 0.000 description 1
- 208000037798 influenza B Diseases 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 230000005764 inhibitory process Effects 0.000 description 1
- 108091008042 inhibitory receptors Proteins 0.000 description 1
- 208000014674 injury Diseases 0.000 description 1
- 229950004101 inotuzumab ozogamicin Drugs 0.000 description 1
- 229960004717 insulin aspart Drugs 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 102000006495 integrins Human genes 0.000 description 1
- 108010044426 integrins Proteins 0.000 description 1
- 229960003130 interferon gamma Drugs 0.000 description 1
- 108040006858 interleukin-6 receptor activity proteins Proteins 0.000 description 1
- 229950001014 intetumumab Drugs 0.000 description 1
- 230000009545 invasion Effects 0.000 description 1
- 238000005342 ion exchange Methods 0.000 description 1
- 238000004255 ion exchange chromatography Methods 0.000 description 1
- 229950010939 iratumumab Drugs 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 229960000318 kanamycin Drugs 0.000 description 1
- 229930027917 kanamycin Natural products 0.000 description 1
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 1
- 229930182823 kanamycin A Natural products 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 238000011005 laboratory method Methods 0.000 description 1
- 239000004816 latex Substances 0.000 description 1
- 229920000126 latex Polymers 0.000 description 1
- 231100000518 lethal Toxicity 0.000 description 1
- 230000001665 lethal effect Effects 0.000 description 1
- 125000001909 leucine group Chemical group [H]N(*)C(C(*)=O)C([H])([H])C(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- 108010025001 leukocyte-associated immunoglobulin-like receptor 1 Proteins 0.000 description 1
- 229950002950 lintuzumab Drugs 0.000 description 1
- 150000002632 lipids Chemical class 0.000 description 1
- 238000001638 lipofection Methods 0.000 description 1
- 206010024627 liposarcoma Diseases 0.000 description 1
- 244000144972 livestock Species 0.000 description 1
- 230000004807 localization Effects 0.000 description 1
- 230000033001 locomotion Effects 0.000 description 1
- 229950004563 lucatumumab Drugs 0.000 description 1
- 201000005296 lung carcinoma Diseases 0.000 description 1
- 208000012804 lymphangiosarcoma Diseases 0.000 description 1
- 230000000527 lymphocytic effect Effects 0.000 description 1
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 229950001869 mapatumumab Drugs 0.000 description 1
- 229950003135 margetuximab Drugs 0.000 description 1
- 229950008001 matuzumab Drugs 0.000 description 1
- 210000003071 memory t lymphocyte Anatomy 0.000 description 1
- 206010027191 meningioma Diseases 0.000 description 1
- 229910052751 metal Inorganic materials 0.000 description 1
- 239000002184 metal Substances 0.000 description 1
- 208000021039 metastatic melanoma Diseases 0.000 description 1
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 229960000485 methotrexate Drugs 0.000 description 1
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 238000000520 microinjection Methods 0.000 description 1
- 230000005012 migration Effects 0.000 description 1
- 238000013508 migration Methods 0.000 description 1
- 229950003734 milatuzumab Drugs 0.000 description 1
- 229950002142 minretumomab Drugs 0.000 description 1
- 229950005674 modotuximab Drugs 0.000 description 1
- 229950007699 mogamulizumab Drugs 0.000 description 1
- 238000001823 molecular biology technique Methods 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 201000006417 multiple sclerosis Diseases 0.000 description 1
- 238000002887 multiple sequence alignment Methods 0.000 description 1
- 229950009793 naptumomab estafenatox Drugs 0.000 description 1
- 229950008353 narnatumab Drugs 0.000 description 1
- 229960000513 necitumumab Drugs 0.000 description 1
- 210000003739 neck Anatomy 0.000 description 1
- 230000001338 necrotic effect Effects 0.000 description 1
- 230000001613 neoplastic effect Effects 0.000 description 1
- 208000008795 neuromyelitis optica Diseases 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 229950010203 nimotuzumab Drugs 0.000 description 1
- 231100000252 nontoxic Toxicity 0.000 description 1
- 230000003000 nontoxic effect Effects 0.000 description 1
- VOMXSOIBEJBQNF-UTTRGDHVSA-N novorapid Chemical group C([C@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@H](CS)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@H](CO)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CS)NC(=O)[C@H](CS)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](NC(=O)CN)[C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(O)=O)C1=CC=C(O)C=C1.C([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O)C(C)C)NC(=O)[C@H](CO)NC(=O)CNC(=O)[C@H](CS)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC=1C=CC=CC=1)C(C)C)C1=CN=CN1 VOMXSOIBEJBQNF-UTTRGDHVSA-N 0.000 description 1
- GYCKQBWUSACYIF-UHFFFAOYSA-N o-hydroxybenzoic acid ethyl ester Natural products CCOC(=O)C1=CC=CC=C1O GYCKQBWUSACYIF-UHFFFAOYSA-N 0.000 description 1
- 229960003347 obinutuzumab Drugs 0.000 description 1
- 239000003921 oil Substances 0.000 description 1
- 229950000846 onartuzumab Drugs 0.000 description 1
- 230000014207 opsonization Effects 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 239000003960 organic solvent Substances 0.000 description 1
- 201000008968 osteosarcoma Diseases 0.000 description 1
- 210000001672 ovary Anatomy 0.000 description 1
- 229960001972 panitumumab Drugs 0.000 description 1
- 235000019834 papain Nutrition 0.000 description 1
- 229940055729 papain Drugs 0.000 description 1
- 229950004260 parsatuzumab Drugs 0.000 description 1
- 229950011485 pascolizumab Drugs 0.000 description 1
- 244000052769 pathogen Species 0.000 description 1
- 229950010966 patritumab Drugs 0.000 description 1
- 229960002621 pembrolizumab Drugs 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 208000033808 peripheral neuropathy Diseases 0.000 description 1
- 230000035699 permeability Effects 0.000 description 1
- 210000001539 phagocyte Anatomy 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 230000004962 physiological condition Effects 0.000 description 1
- 239000002504 physiological saline solution Substances 0.000 description 1
- 229950010773 pidilizumab Drugs 0.000 description 1
- 229950010074 pinatuzumab vedotin Drugs 0.000 description 1
- 229940126620 pintumomab Drugs 0.000 description 1
- 108010031345 placental alkaline phosphatase Proteins 0.000 description 1
- 229950009416 polatuzumab vedotin Drugs 0.000 description 1
- 108010048507 poliovirus receptor Proteins 0.000 description 1
- 229920001606 poly(lactic acid-co-glycolic acid) Polymers 0.000 description 1
- 229920000642 polymer Polymers 0.000 description 1
- 230000007824 polyneuropathy Effects 0.000 description 1
- 108040000983 polyphosphate:AMP phosphotransferase activity proteins Proteins 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 239000011148 porous material Substances 0.000 description 1
- 230000024834 positive regulation of antibody-dependent cellular cytotoxicity Effects 0.000 description 1
- 239000000843 powder Substances 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 230000002335 preservative effect Effects 0.000 description 1
- 229950009904 pritumumab Drugs 0.000 description 1
- 230000000770 proinflammatory effect Effects 0.000 description 1
- 238000011321 prophylaxis Methods 0.000 description 1
- 238000012342 propidium iodide staining Methods 0.000 description 1
- 201000001514 prostate carcinoma Diseases 0.000 description 1
- 208000023958 prostate neoplasm Diseases 0.000 description 1
- 235000019833 protease Nutrition 0.000 description 1
- 235000019419 proteases Nutrition 0.000 description 1
- 238000000159 protein binding assay Methods 0.000 description 1
- 235000004252 protein component Nutrition 0.000 description 1
- 230000004853 protein function Effects 0.000 description 1
- 230000009145 protein modification Effects 0.000 description 1
- 238000001742 protein purification Methods 0.000 description 1
- 239000002096 quantum dot Substances 0.000 description 1
- 229950003033 quilizumab Drugs 0.000 description 1
- 239000012857 radioactive material Substances 0.000 description 1
- 238000002708 random mutagenesis Methods 0.000 description 1
- 230000009257 reactivity Effects 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 238000005215 recombination Methods 0.000 description 1
- 102000037983 regulatory factors Human genes 0.000 description 1
- 108091008025 regulatory factors Proteins 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 238000004007 reversed phase HPLC Methods 0.000 description 1
- 201000009410 rhabdomyosarcoma Diseases 0.000 description 1
- 206010039073 rheumatoid arthritis Diseases 0.000 description 1
- 229960004641 rituximab Drugs 0.000 description 1
- 229920002477 rna polymer Polymers 0.000 description 1
- 238000005096 rolling process Methods 0.000 description 1
- 102220053806 rs121918461 Human genes 0.000 description 1
- 101150025220 sacB gene Proteins 0.000 description 1
- 235000019515 salmon Nutrition 0.000 description 1
- 229950000106 samalizumab Drugs 0.000 description 1
- 239000000523 sample Substances 0.000 description 1
- 230000002000 scavenging effect Effects 0.000 description 1
- 230000007017 scission Effects 0.000 description 1
- 201000008407 sebaceous adenocarcinoma Diseases 0.000 description 1
- 201000007321 sebaceous carcinoma Diseases 0.000 description 1
- 229950008684 sibrotuzumab Drugs 0.000 description 1
- 229960003323 siltuximab Drugs 0.000 description 1
- 238000001542 size-exclusion chromatography Methods 0.000 description 1
- 238000004513 sizing Methods 0.000 description 1
- 208000017520 skin disease Diseases 0.000 description 1
- 201000010153 skin papilloma Diseases 0.000 description 1
- 229910052708 sodium Inorganic materials 0.000 description 1
- 239000011734 sodium Substances 0.000 description 1
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 1
- JUJBNYBVVQSIOU-UHFFFAOYSA-M sodium;4-[2-(4-iodophenyl)-3-(4-nitrophenyl)tetrazol-2-ium-5-yl]benzene-1,3-disulfonate Chemical compound [Na+].C1=CC([N+](=O)[O-])=CC=C1N1[N+](C=2C=CC(I)=CC=2)=NC(C=2C(=CC(=CC=2)S([O-])(=O)=O)S([O-])(=O)=O)=N1 JUJBNYBVVQSIOU-UHFFFAOYSA-M 0.000 description 1
- 229950006551 sontuzumab Drugs 0.000 description 1
- 210000004988 splenocyte Anatomy 0.000 description 1
- 206010041823 squamous cell carcinoma Diseases 0.000 description 1
- 239000003381 stabilizer Substances 0.000 description 1
- 230000000087 stabilizing effect Effects 0.000 description 1
- 238000011301 standard therapy Methods 0.000 description 1
- 101150050955 stn gene Proteins 0.000 description 1
- 208000003265 stomatitis Diseases 0.000 description 1
- 125000001424 substituent group Chemical group 0.000 description 1
- 235000000346 sugar Nutrition 0.000 description 1
- 150000008163 sugars Chemical class 0.000 description 1
- 230000002483 superagonistic effect Effects 0.000 description 1
- 231100000617 superantigen Toxicity 0.000 description 1
- 230000001502 supplementing effect Effects 0.000 description 1
- 238000001356 surgical procedure Methods 0.000 description 1
- 239000000375 suspending agent Substances 0.000 description 1
- 210000000225 synapse Anatomy 0.000 description 1
- 206010042863 synovial sarcoma Diseases 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 238000010189 synthetic method Methods 0.000 description 1
- 238000007910 systemic administration Methods 0.000 description 1
- 201000000596 systemic lupus erythematosus Diseases 0.000 description 1
- 239000007916 tablet composition Substances 0.000 description 1
- 238000002626 targeted therapy Methods 0.000 description 1
- 229950010259 teprotumumab Drugs 0.000 description 1
- 230000002381 testicular Effects 0.000 description 1
- MPLHNVLQVRSVEE-UHFFFAOYSA-N texas red Chemical compound [O-]S(=O)(=O)C1=CC(S(Cl)(=O)=O)=CC=C1C(C1=CC=2CCCN3CCCC(C=23)=C1O1)=C2C1=C(CCC1)C3=[N+]1CCCC3=C2 MPLHNVLQVRSVEE-UHFFFAOYSA-N 0.000 description 1
- 230000003582 thrombocytopenic effect Effects 0.000 description 1
- 229950004742 tigatuzumab Drugs 0.000 description 1
- 238000011200 topical administration Methods 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 201000007363 trachea carcinoma Diseases 0.000 description 1
- 238000010361 transduction Methods 0.000 description 1
- 230000026683 transduction Effects 0.000 description 1
- 238000003151 transfection method Methods 0.000 description 1
- 239000012581 transferrin Substances 0.000 description 1
- 238000011426 transformation method Methods 0.000 description 1
- 230000001131 transforming effect Effects 0.000 description 1
- 230000005945 translocation Effects 0.000 description 1
- 108091005703 transmembrane proteins Proteins 0.000 description 1
- 102000035160 transmembrane proteins Human genes 0.000 description 1
- 230000032258 transport Effects 0.000 description 1
- 229950010086 tregalizumab Drugs 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- 229940096911 trichinella spiralis Drugs 0.000 description 1
- 230000004614 tumor growth Effects 0.000 description 1
- 108010087967 type I signal peptidase Proteins 0.000 description 1
- 238000000108 ultra-filtration Methods 0.000 description 1
- 238000002604 ultrasonography Methods 0.000 description 1
- 241000712461 unidentified influenza virus Species 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 229950005972 urelumab Drugs 0.000 description 1
- 230000002485 urinary effect Effects 0.000 description 1
- 206010046766 uterine cancer Diseases 0.000 description 1
- BNJNAEJASPUJTO-DUOHOMBCSA-N vadastuximab talirine Chemical compound COc1ccc(cc1)C2=CN3[C@@H](C2)C=Nc4cc(OCCCOc5cc6N=C[C@@H]7CC(=CN7C(=O)c6cc5OC)c8ccc(NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)CCCCCN9C(=O)C[C@@H](SC[C@H](N)C(=O)O)C9=O)C(C)C)cc8)c(OC)cc4C3=O BNJNAEJASPUJTO-DUOHOMBCSA-N 0.000 description 1
- 229950008718 vantictumab Drugs 0.000 description 1
- 229960001183 venetoclax Drugs 0.000 description 1
- LQBVNQSMGBZMKD-UHFFFAOYSA-N venetoclax Chemical compound C=1C=C(Cl)C=CC=1C=1CC(C)(C)CCC=1CN(CC1)CCN1C(C=C1OC=2C=C3C=CNC3=NC=2)=CC=C1C(=O)NS(=O)(=O)C(C=C1[N+]([O-])=O)=CC=C1NCC1CCOCC1 LQBVNQSMGBZMKD-UHFFFAOYSA-N 0.000 description 1
- 229960003048 vinblastine Drugs 0.000 description 1
- JXLYSJRDGCGARV-XQKSVPLYSA-N vincaleukoblastine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 JXLYSJRDGCGARV-XQKSVPLYSA-N 0.000 description 1
- 229960004528 vincristine Drugs 0.000 description 1
- OGWKCGZFUXNPDA-XQKSVPLYSA-N vincristine Chemical compound C([N@]1C[C@@H](C[C@]2(C(=O)OC)C=3C(=CC4=C([C@]56[C@H]([C@@]([C@H](OC(C)=O)[C@]7(CC)C=CCN([C@H]67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)C[C@@](C1)(O)CC)CC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-XQKSVPLYSA-N 0.000 description 1
- OGWKCGZFUXNPDA-UHFFFAOYSA-N vincristine Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(OC(C)=O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-UHFFFAOYSA-N 0.000 description 1
- 230000009385 viral infection Effects 0.000 description 1
- 230000004584 weight gain Effects 0.000 description 1
- 235000019786 weight gain Nutrition 0.000 description 1
- 229950008250 zalutumumab Drugs 0.000 description 1
- 229950009002 zanolimumab Drugs 0.000 description 1
- 229950007157 zolbetuximab Drugs 0.000 description 1
Images










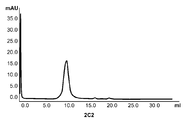







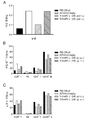

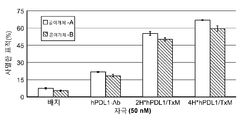


















Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
- A61K39/39533—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals
- A61K39/3955—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals against proteinaceous materials, e.g. enzymes, hormones, lymphokines
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/005—Enzyme inhibitors
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/19—Cytokines; Lymphokines; Interferons
- A61K38/20—Interleukins [IL]
- A61K38/2086—IL-13 to IL-16
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
- A61P31/14—Antivirals for RNA viruses
- A61P31/18—Antivirals for RNA viruses for HIV
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/52—Cytokines; Lymphokines; Interferons
- C07K14/54—Interleukins [IL]
- C07K14/5443—IL-15
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/715—Receptors; Cell surface antigens; Cell surface determinants for cytokines; for lymphokines; for interferons
- C07K14/7155—Receptors; Cell surface antigens; Cell surface determinants for cytokines; for lymphokines; for interferons for interleukins [IL]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/08—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses
- C07K16/10—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses from RNA viruses
- C07K16/1036—Retroviridae, e.g. leukemia viruses
- C07K16/1045—Lentiviridae, e.g. HIV, FIV, SIV
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2818—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against CD28 or CD152
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2827—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against B7 molecules, e.g. CD80, CD86
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/36—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against blood coagulation factors
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
- C07K2317/62—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments comprising only variable region components
- C07K2317/622—Single chain antibody (scFv)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/035—Fusion polypeptide containing a localisation/targetting motif containing a signal for targeting to the external surface of a cell, e.g. to the outer membrane of Gram negative bacteria, GPI- anchored eukaryote proteins
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/30—Non-immunoglobulin-derived peptide or protein having an immunoglobulin constant or Fc region, or a fragment thereof, attached thereto
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/70—Fusion polypeptide containing domain for protein-protein interaction
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Immunology (AREA)
- Medicinal Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Molecular Biology (AREA)
- Genetics & Genomics (AREA)
- Biophysics (AREA)
- Biochemistry (AREA)
- Virology (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Gastroenterology & Hepatology (AREA)
- Zoology (AREA)
- Engineering & Computer Science (AREA)
- Epidemiology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Oncology (AREA)
- AIDS & HIV (AREA)
- Hematology (AREA)
- Toxicology (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Tropical Medicine & Parasitology (AREA)
- Communicable Diseases (AREA)
- Cell Biology (AREA)
- Mycology (AREA)
- Microbiology (AREA)
- Endocrinology (AREA)
- Peptides Or Proteins (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Medicinal Preparation (AREA)
Abstract
본 발명은, IL-15 또는 이의 기능성 변이체를 포함하는 하나의 도메인과, 질환 항원, 면역 관문 분자 또는 신호전달 분자에 특이적인 결합 도메인을 가지는 다중 특이적 단백질 복합체를 특징으로 한다.
Description
관련 출원에 관한 상호 참조
본 출원은 미국 가명세서 특허출원 제62/513,964호(2017년 6월 1일 출원) 및 미국 가명세서 특허출원 제62/411,216호(2016년 10월 21일 출원)의 이익을 주장한다. 상기 출원들의 전체 내용은 전체로서 본원에 참조로 인용되어 있다.
본 발명의 분야
본 발명은, 일반적으로 다량체 융합 분자 분야에 관한 것이다.
본원에 기술된 발명이 있기 전까지만 해도 비 특이 면역 활성과 연관된 부작용이 일어나지 않으면서 다양한 효과기 분자를 질환이 발병한 부위에 표적화하여 치료적 이익을 제공하고자 하는 신규 전략 개발에 대한 필요가 절실하였다.
본 발명은 적어도 부분적으로, 다중 특이 IL-15 기반 단백질 복합체가, 면역 세포의 자극을 증진시키고, 이 면역 세포의 질환 세포에 대한 활성을 촉진함으로써 질환의 완화 또는 예방을 초래한다는 놀라운 발견을 바탕으로 한다. 이러한 IL-15 기반 단백질 복합체는 또한 질환 항원(disease antigen) 및 표적 항원에 대한 결합의 증가를 보이기도 한다. 본원에는 IL-15 또는 기능성 변이체를 포함하는 하나의 도메인과, 질환 항원, 면역 관문 또는 신호전달 분자에 특이적인 결합 도메인을 가지는 다중 특이적 단백질 복합체가 제공된다. 구체적으로 본원에는, 프로그래밍된 사멸 리간드 1(PD-L1), 프로그래밍된 사멸 1(PD-1), 세포독성 T 림프구 연관 단백질 4(CTLA-4), 분화 클러스터 47(CD47), TIM-3(T-cell immunoglobulin and mucin-domain containing-3; TIM3), 또는 글루코코르티코이드 유도성 종양 괴사 인자 수용체(TNFR) 과 관련 유전자(GITR)를 인지하는 결합 도메인에 융합된 IL-15N72D:IL-15RαSu-Ig Fc 스캐폴드(scaffold)를 포함하는 단백질 복합체가 기술되어 있다. 이 복합체는 IL-15 활성을 통하여 NK 세포 반응 및 T 세포 반응을 유도하고, 나아가 항 PD-L1, PD-1, CTLA-4, CD47, TIM3 또는 GITR 결합 도메인에 의한 면역 관문 봉쇄를 통하여 면역 반응을 증가시킨다(도 1). 몇몇 경우에 있어서, 이 복합체는 또한 질환 세포에 발현되는 항원, 예컨대 PD-L1, 단일 가닥 데옥시리보핵산(ssDNA), CD20, 인간 표피 성장 인자 수용체 2(HER2), 표피 성장 인자 수용체(EGFR), CD19, CD38, CD52, 디시알로강글리오사이드(GD2), CD33, Notch1, 세포간 부착 분자 1(ICAM-1), 조직 인자 또는 HIV 외피를 인지하고, Fc 결합 도메인을 통해 질환 세포에 대한 항체 의존적 세포 매개 세포독성(ADCC) 및 보체 의존적 세포독성(CDC)을 자극한다.
적어도 2개의 가용성 단백질을 포함하는, 단리된 가용성 융합 단백질 복합체가 제공된다. 예를 들어 제1 단백질은 인터루킨-15(IL-15) 폴리펩티드, 예컨대 N72D 돌연변이를 포함하는 변이체 IL-15 폴리펩티드(IL-15N72D)를 포함한다. 제2 단백질은 가용성 IL-15 수용체 알파 스시(sushi)-결합 도메인(IL-15RαSu)에 면역글로불린 Fc 도메인이 융합된 것(IL-15RαSu/Fc)을 포함한다. 단리된 가용성 융합 단백질 복합체의 제3 성분은 질환 항원, 면역 관문 분자 또는 신호전달 분자, 예컨대 PD-L1, PD-1, CTLA-4, CD47, TIM3 또는 GITR을 인지하는 결합 도메인을 포함하는데, 다만 이 결합 도메인은 IL-15N72D 단백질 또는 IL-15RαSu/Fc 단백질 중 어느 하나에 융합된다. 몇몇 경우에 있어서, 이러한 결합 도메인은 IL-15N72D 단백질 및 IL-15RαSu/Fc 단백질 둘 다에 융합된다. 다른 경우에 있어서, 이러한 결합 도메인들 중 하나는 IL-15N72D 단백질 또는 IL-15RαSu/Fc 단백질에 결합하고, 제2의 결합 도메인, 즉 면역 관문 분자 또는 신호전달 분자 또는 질환 항원에 특이적인 결합 도메인은 또 다른 단백질에 융합된다. 일 양태에서, 질환 항원은 신생물형성, 또는 자가면역성 질환과 연관되어 있다. 몇몇 경우에 있어서, 제1 가용성 단백질 또는 제2 가용성 단백질은 질환 세포상에 발현되는 질환 항원, 예컨대 PD-L1, ssDNA, CD20, HER2, EGFR, CD19, CD38, CD52, GD2, CD33, Notch1, 세포간 부착 분자 1(ICAM-1), 조직 인자 또는 HIV 외피 또는 기타 공지의 항원을 인지하는 결합 도메인을 추가로 포함한다. 대안적으로 IL-15N72D 단백질 또는 IL-15RαSu/Fc 단백질 중 어느 하나는 질환 항원, 면역 관문 분자 또는 신호전달 분자에 특이적인 결합 도메인을 포함하고, 또 다른 단백질(IL-15RαSu/Fc 또는 IL-15N72D 단백질 각각)은 융합된 추가의 결합 도메인을 포함하지 않는다. 제1 단백질의 IL-15N72D 도메인은 제2 단백질의 가용성 IL-15RαSu 도메인과 결합하여, 가용성 융합 단백질 복합체를 형성한다. 예시적 융합 단백질 복합체는 IL-15N72D 및/또는 IL-15RαSu/Fc 융합 단백질에 공유 결합된 항 PD-L1 항체를 포함한다(도 1 및 도 2). 대안적으로 제1 단백질은 면역글로불린 Fc 도메인에 융합된 가용성 IL-15 수용체 알파 스시 결합 도메인(IL-15RαSu)에 공유 결합된 항 PD-L1 항체를 포함하는 반면에, 제2 단백질은 N72D 돌연변이를 포함하는 변이체 인터루킨-15(IL-15) 폴리펩티드(IL-15N72D)와 공유 결합된 질환 항원을 인지하는 결합 도메인을 포함한다.
몇몇 경우에 있어서, 결합 도메인은 단일 사슬 항체(scAb 또는 scFv)를 포함하는데, 이 경우 면역글로불린 경쇄 가변 도메인은 폴리펩티드 링커 서열에 의해 면역글로불린 중쇄 가변 도메인에 공유 결합되어 있다. 대안적으로 결합 도메인은 면역 관문 억제제 또는 면역 효현제로서의 역할을 할 수 있는 가용성 또는 세포 외 리간드나 수용체 도메인을 포함한다.
예시적 제1 단백질은 서열 번호 2, 6, 10, 18, 20, 24, 28, 32 또는 38에 제시된 아미노산 서열을 포함한다. 예시적 제2 단백질은 서열 번호 4, 8, 12, 14, 16, 22, 26, 30, 34, 36, 40, 42, 44, 46, 51, 52, 53 또는 54에 제시된 아미노산 서열을 포함한다. 제1 단백질을 암호화하는 예시적 핵산 서열은 서열 번호 1, 5, 9, 17, 19, 23, 27, 31 또는 37에 제시된 서열을 포함한다. 제2 단백질을 암호화하는 예시적 핵산 서열은 서열 번호 3, 7, 11, 13, 15, 21, 25, 29, 33, 35, 39, 41, 43, 45, 47, 48, 49 또는 50에 제시된 서열을 포함한다. 일 양태에서, 핵산 서열(들)은 융합 단백질을 암호화하는 서열에 작동가능하도록 결합된 리더 서열, 번역 개시 신호 및 촉진인자를 추가로 포함한다. 본원에 기술된 핵산 서열을 포함하는 DNA 벡터(들)도 또한 제공된다. 예를 들어 핵산 서열은 복제용 벡터, 발현용 벡터, 아니면 이들 벡터 둘 다의 내부에 있다.
제2 가용성 융합 단백질 복합체에 공유 결합된 제1 가용성 융합 단백질 복합체를 포함하는 가용성 융합 단백질 복합체도 또한 제공된다. 예를 들어 본 발명의 가용성 융합 단백질 복합체는 다량체화, 예컨대 이량체화, 삼량체화되거나, 또는 다중 복합체화된다(예컨대 4 복합체 형성, 5 복합체 형성 등). 예를 들어 다량체는 동종다량체 또는 이종다량체이다. 가용성 융합 단백질 복합체는 공유 결합, 예컨대 이황화 결합 형성 화학 가교제에 의해 연결된다. 몇몇 경우들에서, 하나의 가용성 융합 단백질은 이황화 결합에 의해 또 다른 가용성 융합 단백질에 공유 결합되고, 그 결과 제1 가용성 단백질의 Fc 도메인과 제2 가용성 단백질의 Fc 도메인이 연결된다.
Fc 도메인 또는 이의 기능성 단편은, IgG Fc 도메인, 인간 IgG1 Fc 도메인, 인간 IgG2 Fc 도메인, 인간 IgG3 Fc 도메인, 인간 IgG4 Fc 도메인, IgA Fc 도메인, IgD Fc 도메인, IgE Fc 도메인 및 IgM Fc 도메인; 마우스 IgG2A 도메인; 또는 이것들의 임의의 조합으로 이루어진 군으로부터 선택된 Fc 도메인을 포함한다. 선택적으로 Fc 도메인은 변경된 보체 또는 Fc 수용체 결합 특성 또는 변경된 이량체화 또는 당화 프로필을 보이는 Fc 도메인을 초래하는 아미노산 변화를 포함한다. 변경된 보체 또는 Fc 수용체 결합 특성 또는 변경된 이량체화 또는 당화 프로필을 보이는 Fc 도메인을 제조하기 위한 아미노산 변화는 당 분야에 공지되어 있다. 예를 들어 IgG1 CH2의 234번 및 235번 위치 루신 잔기들(번호매김은 항체 공통 서열을 기반으로 함)(즉 … P E L L G G …)의, 알라닌 잔기들(즉 … P E A A G G …)로의 치환은 Fc 감마 수용체 결합능의 상실을 초래하는 한편, IgG1 CH2의 322번 위치 리신 잔기(번호매김은 항체 공통 서열을 기반으로 함)(즉 … K C K S L …)의, 알라닌 잔기(즉 … K C A S L …)로의 치환은 보체 활성화 능력의 상실을 초래한다. 몇몇 예들에서, 이러한 돌연변이는 조합되어 발생한다.
몇몇 양태들에서, 결합 도메인은 폴리펩티드 링커 서열에 의해 IL-15 폴리펩티드(또는 이의 기능성 단편)에 공유 결합된다. 이와 유사하게, 결합 도메인은 폴리펩티드 링커 서열에 의해 IL-15Rα 폴리펩티드(또는 이의 기능성 단편)에 공유 결합된다. 선택적으로 IL-15Rα 폴리펩티드(또는 이의 기능성 단편)는 폴리펩티드 링커 서열에 의해 Fc 도메인(또는 이의 기능성 단편)에 공유 결합된다. 각각의 폴리펩티드 링커 서열은 독립적으로 선택될 수 있다. 선택적으로 폴리펩티드 링커 서열은 동일하다. 대안적으로 폴리펩티드 링커 서열은 상이하다.
선택적으로 가용성 융합 단백질 중 적어도 하나가 검출 가능한 표지를 포함하는, 본 발명의 가용성 융합 단백질 복합체가 제공된다. 검출 가능한 표지로서는 바이오틴, 스트렙타비딘, 효소 또는 이의 촉매 활성 단편, 방사성핵종, 나노입자, 상자성 금속 이온 또는 형광 분자, 인광 분자 또는 화학발광 분자, 아니면 이것들의 임의의 조합을 포함하나, 이에 한정되는 것은 아니다.
몇몇 양태들에서, 제1 가용성 단백질을 암호화하는 핵산 서열은 서열 번호 1, 5, 9, 17, 19, 23, 27, 31 또는 37 중 하나에 제시된 서열을 포함한다. 몇몇 구현예에서, 제2 가용성 단백질을 암호화하는 핵산 서열은 서열 번호 3, 7, 11, 13, 15, 21, 25, 29, 33, 35, 39, 41, 43, 45, 47, 48, 49 또는 50 중 하나에 제시된 서열을 포함한다.
몇몇 구현예에서, 핵산 서열은 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 35, 39, 41, 43,45, 47, 48, 49 또는 50을 포함한다.
본 핵산 서열은 가용성 단백질을 암호화하는 서열에 작동가능하도록 결합된 리더 서열, 번역 개시 신호 및 촉진인자를 추가로 포함한다.
다른 구현예에서, 펩티드는 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 51, 52, 53 또는 54를 포함한다.
본 발명은 본 발명의 가용성 융합 단백질 복합체를 제조하기 위한 방법을 제공한다. 이 방법은, a) 적당한 제어 서열을 가져 제1 단백질을 암호화하는 DNA 벡터를 제1 숙주 세포에 도입하는 단계; b) 세포 또는 배지 중 제1 단백질이 발현되기 충분한 조건 하에서 제1 숙주 세포를 배지 중에서 배양하는 단계; c) 숙주 세포나 배지로부터 제1 단백질을 정제하는 단계; d) 적당한 제어 서열을 가져 제2 단백질을 암호화하는 DNA 벡터를 제2 숙주 세포에 도입하는 단계; e) 세포 또는 배지 중 제2 단백질이 발현되기 충분한 조건 하에서 제2 숙주 세포를 배지 중에서 배양하는 단계; f) 숙주 세포 또는 배지로부터 제2 단백질을 정제하는 단계, 그리고 g) 제1 단백질의 IL-15 도메인과, 제2 단백질의 가용성 IL-15Rα 도메인 사이의 결합을 허용하여 가용성 융합 단백질 복합체 형성을 달성하기 충분한 조건 하에서 제1 단백질과 제2 단백질을 혼합하는 단계를 포함한다.
몇몇 경우들에 있어서, 본 방법은 발현 벡터로부터 발현되는 폴리펩티드들 간에 이황화 결합의 형성을 허용하기 충분한 조건 하에서 제1 단백질과 제2 단백질을 혼합하는 단계를 추가로 포함한다.
대안적으로, 본 발명의 가용성 융합 단백질 복합체를 제조하기 위한 방법은, a) 적당한 제어 서열을 가져 제1 단백질을 암호화하는 DNA 벡터와, 적당한 제어 서열을 가져 제2 단백질을 암호화하는 DNA 벡터를 숙주 세포에 도입하는 단계; b) 단백질을 세포나 배지에서 발현시키고, 제1 단백질의 IL-15 도메인과 제2 단백질의 가용성 IL-15Rα 도메인 간 결합을 허용하여, 가용성 융합 단백질 복합체의 형성을 달성하기 충분한 조건 하에 숙주 세포를 배지 중에서 배양하는 단계; 및 c) 숙주 세포나 배지로부터 가용성 융합 단백질 복합체를 정제하는 단계에 의해 수행된다.
일 양태에서, 본 방법은 발현 벡터로부터 발현된 폴리펩티드들 간 이황화 결합의 형성을 허용하기에 충분한 조건 하에 제1 단백질과 제2 단백질을 혼합하는 단계를 추가로 포함한다.
가용성 융합 단백질 복합체를 제조하기 위한 방법으로서, a) 적당한 제어 서열을 가져 제1 단백질 및 제2 단백질을 암호화하는 DNA 벡터를 숙주 세포에 도입하는 단계; b) 단백질을 세포나 배지에서 발현시키고, 제1 단백질의 IL-15 도메인과 제2 단백질의 가용성 IL-15Rα 도메인 간 결합을 허용하여, 가용성 융합 단백질 복합체의 형성을 달성하고, 폴리펩티드들 간 이황화 결합 형성을 허용하기 충분한 조건 하에 숙주 세포를 배지 중에서 배양하는 단계; 및 c) 숙주 세포나 배지로부터 가용성 융합 단백질 복합체를 정제하는 단계를 포함하는 방법도 또한 제공된다.
선택적으로 본 방법은, 발현 벡터로부터 발현된 폴리펩티드들 간 이황화 결합의 형성을 허용하기에 충분한 조건 하에 제1 단백질과 제2 단백질을 혼합하는 단계를 추가로 포함한다.
신생물형성, 감염성 질환 또는 자가면역성 질환을, 이 질환들의 치료를 필요로 하는 대상체에서 치료하기 위한 방법은, 본원에 기술된 가용성 융합 단백질 복합체, 예컨대 가용성 항 PD-L1 scAb/IL-15N72D:항 PD-L1 scAb/IL-15RαSu/Fc 융합 단백질 복합체를 포함하는 약학 조성물 유효량을 대상체에 투여하여, 신생물형성, 감염성 질환 또는 자가면역성 질환을 치료함으로써 수행된다. 예를 들어 고형 악성종양 또는 혈액학적 악성종양의 치료를 필요로 하는 대상체 내에서 이 고형 악성종양 또는 혈액학적 악성종양을 치료하기 위한 방법은, 가용성 항 인간 PD-L1 scAb/huIL-15N72D:항 인간 PD-L1 scAb/huIL-15RαSu/huIgG1 Fc 융합 단백질 복합체를 포함하는 약학 조성물 유효량을 대상체에 투여하여, 이 악성종양을 치료함으로써 수행된다. 예시적 항 인간 PD-L1 scAb/huIL-15N72D 단백질은 서열 번호 2 및 6에 제시된 아미노산 서열을 포함한다. 예시적 항 인간 PD-L1 scAb/huIL-15RαSu/huIgG1 Fc 단백질은 서열 번호 4 및 8에 제시된 아미노산 서열을 포함한다.
본원에 기술된 방법으로 치료하는데 적합한 신생물형성은, 교모세포종, 전립선암, 급성 골수성 백혈병, B 세포 신생물형성, 다발성 골수종, B 세포 림프종, B 세포 비호지킨 림프종, 호지킨 림프종, 만성 림프구성 백혈병, 급성 골수성 백혈병, 피부 T 세포 림프종, T 세포 림프종, 고형 종양, 요로상피/방광 암종, 흑색종, 폐암, 신세포 암종, 유방암, 위 및 식도 암, 두경부암, 전립선암, 췌장암, 결장직장암, 난소암, 비 소세포 폐 암종 및 편평 세포 두경부 암종을 포함한다.
본원에 기술된 방법을 사용하여 치료될 예시적 감염으로서는 인간 면역결핍증 바이러스(HIV) 감염이 있다. 예시적 핵산 서열은 서열 번호 47, 48, 49 또는 50을 포함한다. 예시적 아미노산 서열은 서열 번호 51, 52, 53 또는 54를 포함한다. 본원에 기술된 방법은 또한 세균 감염(예컨대 그램 양성 또는 그램 음성 세균 감염)을 치료하는데 유용하다(Oleksiewicz et al. 2012. Arch Biochem Biophys. 526:124-31). 본원에 기술된 방법을 사용하여 치료될 예시적 자가면역성 질환으로서는 B 세포에 의해 매개되는 자가면역성 질환이 있다. 이러한 자가면역성 질환으로서는 류머티즘성 관절염, 다발성 경화증, 특발성 혈소판감소증, IgM 매개 말초신경병증, VIII 인자 결핍증, 전신홍반성루프스, 쇼그렌 증후군, 염증성 근염, 심상성천포창, 시속척수염, ANCA 연관 혈관염, 만성 염증성 탈수초성 다발신경병증, 자가면역성 빈혈, 진성적혈구무형성증, 혈전성혈소판감소성자반(TTP), 특발성 혈소판감소성자반(ITP), 에반증후군, 혈관염(예컨대 육아종증다발혈관염, 구 베게너증), 수포성 피부 장애(예컨대 천포창, 유천포창), 제1형 진성당뇨병, 항 NMDA 수용체 뇌염, 데빅병, 그레이브스 안구병증, 자가면역성 췌장염, 안구간대경련-근간대경련 증후군(OMS) 및 IgG4 관련 질환을 포함한다.
융합 단백질 복합체를 포함하는 약학 조성물이 유효량만큼 투여된다. 예를 들어 약학 조성물의 유효량은 약 1 μg/kg 내지 약 100 μg/kg, 예컨대 1, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95 또는 100 μg/kg이다. 대안적으로 TxM은 고정 용량으로 투여되거나, 체표면적을 기반으로(즉 1 ㎡ 당) 투여된다.
융합 단백질 복합체를 포함하는 약학 조성물은 1개월에 적어도 1회 투여되는데, 예컨대 1 개월에 2회, 1 주일에 1회, 1 주일에 2회, 1 일 1회, 1 일 2회, 8 시간 마다, 4 시간 마다, 2 시간 마다 또는 매시간 투여된다. 본 약학 조성물에 적합한 투여 방식은 전신 투여, 정맥내 투여, 국소 투여, 피하 투여, 근육내 투여, 종양내 투여, 흡입 및 복막내 투여를 포함한다.
바람직하게 본 융합 단백질 복합체는 인터페론 감마(IFN-γ)의 혈청 중 수준을 상승시키고/상승시키거나, CD4+ 및 CD8+ T 세포 및 NK 세포가 대상체 내 발병 세포 또는 종양 세포를 사멸시키도록 자극한다.
본 발명의 가용성 융합 단백질 복합체에 관한 임의의 양태들에서, IL-15 폴리펩티드는 원산(native) IL-15 폴리펩티드의 아미노산 서열과 상이한 아미노산 서열을 가지는 IL-15 변이체이다. 인간 IL-15 폴리펩티드는 본원에서 huIL-15, hIL-15, huIL15, hIL15, IL-15 야생형(wt)이라 지칭되고, 이의 변이체는 원산 아미노산, 성숙 서열 중 이의 위치 및 변이체 아미노산을 이용하여 지칭된다. 예를 들어 huIL15N72D는, 72번 위치에 N → D의 치환을 포함하는 인간 IL-15를 지칭한다. 일 양태에서, IL-15 변이체는, 예컨대 원산 IL-15 폴리펩티드의 IL-15/IL-2βγC 수용체(IL-15R)와의 결합 활성보다 증가한, IL-15/IL-2βγC 수용체와의 결합 활성으로 입증되는 바와 같이, IL-15 효현제로서의 역할을 한다. 대안적으로 IL-15 변이체는, 예컨대 원산 IL-15 폴리펩티드의 IL-15R과의 결합 활성보다 감소한, IL-15R과의 결합 활성으로 입증되는 바와 같이, IL-15 길항제로서의 역할을 한다.
표적 세포를 사멸하기 위한 방법은, a) 본 발명의 가용성 융합 단백질 복합체를 다수의 세포와 접촉시키는 단계[다만 이 다수의 세포는 IL-15 도메인에 의해 인지되는 IL-15R 사슬을 보유하는 면역 세포, 또는 관문 억제제 또는 면역 효현제 결합 도메인에 의해 조정되는 관문 또는 신호전달 분자를 보유하는 면역 세포, 그리고 표적 질환 세포를 추가로 포함함]; b) IL-15R 또는 신호전달 분자나, 관문 분자의 봉쇄를 통하여 면역 세포를 활성화하는 단계; 그리고 c) 활성화된 면역 세포에 의해 표적 질환 세포를 사멸하는 단계에 의해 수행된다. 예를 들어 표적 질환 세포는 종양 세포, 자가면역 세포 또는 바이러스 감염 세포이다. 몇몇 경우에 있어서, 결합 도메인은 항 PD-L1 항체를 포함한다.
표적 세포를 사멸하기 위한 방법은 a) 본 발명의 가용성 융합 단백질 복합체와 다수의 세포를 접촉시키는 단계[다만 이 다수의 세포는 Fc 도메인에 의해 인지되는 Fc 수용체 사슬을 보유하는 면역 세포와, 항원 특이적 scAb와 같은 결합 도메인에 의해 인지되는 항원을 보유하는 표적 질환 세포를 추가로 포함함]; b) 면역 세포에 결합하여 이를 활성화하기에 충분한, 표적 질환 세포상 항원 및 면역 세포상 Fc 수용체 사슬 간의 특이적 결합 복합체(가교)를 형성하는 단계; 그리고 c) 결합되어 활성화된 면역 세포에 의해 표적 질환 세포를 사멸하는 단계를 추가로 포함한다. 예를 들어 표적 질환 세포는 종양 세포, 자가면역 세포 또는 바이러스 감염 세포이다. 몇몇 경우에 있어서, 결합 도메인은 항 PD-L1 항체를 포함한다.
환자에서 질환을 예방 또는 치료하기 위한 방법도 또한 제공되는데, 이 방법은 a) 본 발명의 가용성 융합 단백질 복합체를 환자에 투여하는 단계; b) 환자에서 면역 세포를 활성화하는 단계; 그리고 c) 환자에서 질환을 예방 또는 치료하기 충분하게 활성화된 면역 세포를 통해 질환 세포를 손상 또는 사멸시키는 단계를 포함한다.
본 발명은 또한 환자(발병된 세포)에서 질환을 예방 또는 치료하기 위한 방법을 제공하는데, 이 방법은 a) IL-15R 사슬, 또는 관문 또는 신호전달 분자를 보유하는 면역 세포를, 본 발명의 가용성 융합 단백질 복합체와 혼합하는 단계; b) 이 면역 세포를 활성화하는 단계; c) 환자에게 이 활성화된 면역 세포를 투여하는 단계; 그리고 d) 환자에서 질환을 예방 또는 치료하기 충분하게 활성화된 면역 세포를 통하여 질환 세포를 손상 또는 사멸시키는 단계를 포함한다.
본 발명의 융합 단백질 복합체 투여는 대상체 내에서 면역 반응을 유도한다. 예를 들어 본 발명의 융합 단백질 복합체 투여는 신생물형성, 감염성 질환 또는 자가면역성 질환과 연관된 세포에 대해 면역 반응을 유도한다. 일 양태에서, 본 발명의 융합 단백질 복합체는 면역 세포 증식을 증가시킨다.
본 발명은 본 발명의 가용성 융합 단백질 복합체 유효량을 포유동물에 투여함으로써 포유동물 내에서 면역 반응을 자극하는 방법을 제공한다. 본 발명은 또한 본 발명의 임의의 구현예의 가용성 융합 단백질 복합체 유효량만큼을 포유동물에 투여함으로써, 포유동물 내 면역 반응을 억제하는 방법을 제공한다.
달리 정의되지 않는 한, 본원에 사용된 모든 기술 용어와 과학 용어는 본 발명이 속한 분야의 당 업자에 의해 통상적으로 이해되는 의미를 가진다. 이하 참고문헌들은 본 발명에 사용된 다수의 용어에 관한 일반적인 정의와 함께 기술 하나를 제공한다: Singleton et al., Dictionary of Microbiology and Molecular Biology (2nd ed. 1994); The Cambridge Dictionary of Science and Technology (Walker ed., 1988); The Glossary of Genetics, 5th Ed., R. Rieger et al. (eds.), Springer Verlag (1991); 및 Hale & Marham, The Harper Collins Dictionary of Biology (1991). 본원에 사용된 바와 같은 하기 용어들은 달리 명시되지 않는 한 이 용어들에 부여된 하기 의미들을 가진다.
"제제"란, 펩티드, 핵산 분자 또는 소형 화합물을 의미한다.
"TxM"이란, 결합 도메인에 결합된 IL-15N72D:IL-15RαSu/Fc 스캐폴드를 포함하는 복합체를 의미한다(도 2). 예시적 TxM은, PD-L1을 특이적으로 인지하는 결합 도메인에 대한 융합체를 포함하는 IL-15N72D:IL-15RαSu 복합체(PD-L1 TxM)이다.
"완화하다"란, 질환의 발달 또는 진행을 늦추거나, 억제하거나, 경감시키거나, 감소시키거나, 정지시키거나 또는 안정화하는 것을 의미한다.
"유사체"란, 동일하지는 않지만 유사한 기능상 특징 또는 구조상 특징을 가지는 분자를 의미한다. 예를 들어 폴리펩티드 유사체는, 이 유사체의 기능을 자연 발생 폴리펩티드의 기능에 비하여 증진시키는 임의의 생화학적 변형을 가지면서, 이 유사체에 상응하는 자연 발생 폴리펩티드의 생물 활성도 보유한다. 이러한 생화학적 변형은, 예를 들어 리간드 결합능을 변경시키지 않으면서, 유사체의 프로테아제 내성, 막 투과성 또는 반감기를 증가시킬 수 있었다. 유사체는 비 자연 발생 아미노산을 포함할 수 있다.
"결합 도메인"이란 용어는, 당 분야에 공지된 항체, 단일 사슬 항체, Fab, Fv, T 세포 수용체 결합 도메인, 리간드 결합 도메인, 수용체 결합 도메인 또는 기타 항원 특이적 폴리펩티드를 포함하도록 의도된다.
본 발명은 어떤 항체 또는 항체의 단편이 원하는 생물 활성을 보이는 한, 이 항체 또는 항체의 단편을 포함한다. 키메라 항체, 예컨대 인간화 항체도 또한 본 발명에 포함된다. 일반적으로 인간화 항체는, 인간이 아닌 공급원으로부터 유래한 아미노산 잔기 하나 이상이 도입되어 있다. 인간화는, 예를 들어 당 분야에 기술된 방법을 이용하여 인간 항체의 상보성 결정 영역을, 이에 상응하는 설치류의 상보성 결정 영역 최소한의 부분으로 치환함으로써 수행될 수 있다.
"항체" 또는 "면역글로불린"이란 용어는, 폴리클로날 항체와 모노클로날 항체 둘 다를 포함하도록 의도된다. 바람직한 항체는 항원과 반응성인 모노클로날 항체이다. "항체"란 용어는 또한, 항원과 반응성인 항체 하나 초과만큼의 혼합물(예컨대 항원과 반응성인 상이한 유형들의 모노클로날 항체 칵테일)을 포함한다. "항체"란 용어는, 전 항체, 이의 생물 기능성 단편, 단일 사슬 항체, 그리고 유전자 변경된 항체, 예컨대 하나를 초과하는 종으로부터 유래하는 부분들을 포함하는 키메라 항체, 이기능성 항체, 항체 접합체, 인간화 항체 및 인간 항체를 포함하도록 또한 의도된다. 추가로 사용될 수도 있는 생물 기능성 항체 단편으로서는 항원과의 결합에 충분한 항체 유래 펩티드 단편이 있다. 본원에 사용된 바와 같은 "항체"는, 관심 에피토프, 항원 또는 항원 단편과 결합할 수 있는 전체 항체뿐만 아니라, 임의의 항체 단편(예컨대 F(ab')2, Fab', Fab, Fv)을 포함하는 의미이다.
어떤 분자"에 결합하는"이란, 해당 분자에 대하여 물리화학적 친화성을 가지는 것을 의미한다.
"검출하다"란, 검출될 피분석물의 존재, 부재 또는 그 양을 동정하는 것을 의미한다.
"질환"이란, 세포, 조직 또는 장기의 정상 기능을 손상시키거나 방해하는 임의의 병태나 장애를 의미한다. 질환의 예로서는 신생물형성, 자가면역성 질환 및 바이러스 감염을 포함한다.
제제 또는 제제 성분의 "유효량"및 "치료적 유효량"이란 용어는, 해당 제제 또는 성분이 단독으로 또는 조합하여 원하는 효과를 제공하기 충분한 양을 의미한다. 예를 들어 "유효량"이란, 치료전인 환자에 있어서 어떤 질환의 증상들에 비해 해당 질환의 증상을 완화하는데 필요한, 화합물 단독의 양 또는 다른 성분과 합한 양을 의미한다. 어떤 질환의 치료적 처치를 위하여 본 발명을 수행하는데 사용되는 활성 화합물(들)의 유효량은, 투여 방식, 대상체의 나이, 체중 및 전반적 건강 상태에 따라 달라진다. 궁극적으로 참여 전문의나 수의사가 적당한 양과 투여 계획을 결정할 것이다. 이러한 양은 "유효"량이라 지칭된다.
"단편"이란, 폴리펩티드 또는 핵산 분자의 일부를 의미한다. 이 일부는, 바람직하게 기준 핵산 분자 또는 폴리펩티드의 전체 길이의 적어도 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80% 또는 90%를 함유한다. 예를 들어 단편은 10, 20, 30, 40, 50, 60, 70, 80, 90 또는 100, 200, 300, 400, 500, 600, 700, 800, 900, 또는 1000 개의 뉴클레오티드 또는 아미노산을 함유할 수 있다. 그러나, 본 발명은 또한 폴리펩티드 및 핵산 단편이 각각 전장 폴리펩티드 및 핵산의 원하는 생물 활성을 보이는 한, 이 폴리펩티드 및 핵산 단편도 포함한다. 거의 모든 길이를 가지는 핵산 단편이 사용된다. 예를 들어 총 길이가 약 10,000, 약 5,000, 약 3,000, 약 2,000, 약 1,000, 약 500, 약 200, 약 100, 약 50 개 염기쌍(이 중간 길이도 모두 포함)인 예시적 폴리뉴클레오티드 분절이 본 발명의 다수의 실시예에 포함된다. 이와 유사하게, 거의 모든 길이를 가지는 폴리펩티드 단편이 사용된다. 예를 들어 총 길이가 약 10,000, 약 5,000, 약 3,000, 약 2,000, 약 1,000, 약 5,000, 약 1,000, 약 500, 약 200, 약 100 또는 약 50 개 아미노산(이 중간 길이도 모두 포함)인 예시적 폴리펩티드 분절이 본 발명의 다수의 실시예에 포함된다.
"단리된", "정제된" 또는 "생물학적으로 순수한"이란 용어는, 어떤 물질이 자체의 원산 상태로서 발견될 때 보통 수반되는 성분들로부터 다양한 정도로 벗어난 상태를 지칭한다. "단리하다"란, 원래의 공급원이나 주위환경으로부터 어느 정도 분리되는 것을 나타낸다. "정제하다"란, 단리시보다 더 높은 정도로 분리되는 것을 나타낸다.
"정제된" 또는 "생물학적으로 순수한" 단백질은, 어떠한 불순물도 해당 단백질의 생물 특성에 거의 영향을 미치지 않거나 여타의 부정적인 결과를 초래하지 않도록 다른 물질로부터 충분히 벗어나 있다. 즉 만일 본 발명의 핵산이나 펩티드가 재조합 DNA 기술에 의해 생산되었을 때 세포성 물질, 바이러스 물질 또는 배양 배지를 실질적으로 포함하지 않거나, 또는 만일 화학적으로 합성되었을 때 화학 전구체 또는 기타 화학물질을 실질적으로 포함하지 않는다면 해당 핵산이나 펩티드는 정제된 것이다. 순도와 균질성은 통상 분석 화학 기술, 예컨대 폴리아크릴아미드 겔 전기영동 또는 고성능 액체 크로마토그래피가 사용되어 측정된다. "정제된"이란 용어는, 전기영동 겔에서 핵산이나 단백질이 본질적으로 하나의 밴드를 보일 때를 가리킬 수 있다. 변형, 예를 들어 인산화 또는 당화가 일어날 수 있는 단백질의 경우, 상이한 변형은 별도로 정제될 수 있는 상이한 단리 단백질들을 생성할 수 있다.
이와 유사하게 "실질적으로 순수한"이란, 어떤 뉴클레오티드나 폴리펩티드가, 자연에서 이 뉴클레오티드나 폴리펩티드와 함께 발생하는 성분들로부터 분리된 경우를 의미한다. 통상적으로 뉴클레오티드 및 폴리펩티드가, 자연에서 이것과 결합되어 존재하는 단백질 및 자연 발생 유기 분자로부터 적어도 60 중량%, 70 중량%, 80 중량%, 90 중량%, 95 중량% 또는 심지어 99% 중량% 분리되어 있다면, 해당 뉴클레오티드 및 폴리펩티드는 실질적으로 순수한 것이다.
"단리된 핵산"이란, 어떤 핵산의 기원이 된 유기체의 자연 발생 게놈 내 이 핵산에 측접하는 유전자로부터 벗어난 핵산을 의미한다. 이 용어는, 예를 들어 (a) 자연 발생 게놈 DNA 분자의 일부이긴 하지만, 유기체 게놈 내 자연 발생되는 DNA 분자의 해당 일부와 측접하는 핵산 서열이 양쪽으로 측접되어 있지 않은 DNA; (b) 생성될 분자가 임의의 자연 발생 벡터 또는 게놈 DNA와 동일하지 않게 되는 방식으로 원핵생물 또는 진핵생물 게놈 DNA 내 또는 벡터 내에 통합된 핵산; (c) 별도의 분자, 예컨대 cDNA, 게놈 단편, 중합효소 연쇄 반응(PCR)에 의해 생성된 단편, 또는 제한 단편; 그리고 (d) 하이브리드 유전자, 즉 융합 단백질을 암호화하는 유전자의 일부인 재조합 뉴클레오티드 서열을 아우른다. 본 발명에 따른 단리 핵산 분자는 합성에 의해 생산된 분자뿐만 아니라, 화학적으로 변경되었고/변경되었거나 변형 골격을 가지는 임의의 핵산들을 추가로 포함한다. 예를 들어 단리된 핵산은 정제 cDNA 또는 RNA 폴리뉴클레오티드이다. 단리된 핵산 분자는 또한 전령 리보핵산(mRNA) 분자를 포함하기도 한다.
"단리된 폴리펩티드"란, 자연에서 함께 발생하는 성분들로부터 분리된 본 발명의 폴리펩티드를 의미한다. 통상적으로 본 폴리펩티드는, 그것이 자연에서 결합하고 있는 단백질 및 자연 발생 유기 분자로부터 적어도 60 중량% 벗어났을 때 단리된 것이다. 바람직하게 본 제제는 본 발명의 폴리펩티드 적어도 75 중량%, 더욱 바람직하게는 적어도 90 중량%, 그리고 가장 바람직하게는 적어도 99 중량%이다. 본 발명의 단리된 폴리펩티드는, 예를 들어 자연 공급원으로부터의 추출, 이러한 폴리펩티드를 암호화하는 재조합 핵산의 발현, 또는 단백질의 화학 합성에 의해 수득될 수 있다. 순도는 적당한 임의의 방법, 예를 들어 컬럼 크로마토그래피, 폴리아크릴아미드 겔 전기영동 또는 HPLC 분석에 의해 측정될 수 있다.
"마커"란, 어떤 질환이나 장애와 연관된 발현 수준 또는 활성이 변경된 임의의 단백질 또는 폴리뉴클레오티드를 의미한다.
"신생물형성"이란, 과도한 증식 또는 감소한 세포자멸에 의해 특징지어지는 질환이나 장애를 의미한다. 본 발명이 사용될 수 있는 예시적 신생물형성으로서는 백혈병(예컨대 급성 백혈병, 급성 림프구성 백혈병, 급성 골수성 백혈병, 급성 골수아구성 백혈병, 급성 전골수성 백혈병, 급성 골수단핵구성 백혈병, 급성 단핵구성 백혈병, 급성 적백혈병, 만성 백혈병, 만성 골수성 백혈병, 만성 림프구성 백혈병), 진성 다혈구증, 림프종(호지킨 질환, 비호지킨 질환), 발덴스트롬 매크로글로불린혈증, 증쇄병 및 고형 종양, 예컨대 육종 및 암종(예컨대 섬유육종, 점액육종, 지방육종, 연골육종, 골원성 육종, 척색종, 혈관육종, 내피육종, 림프관육종, 림프관내피모세포종, 활막종, 중피종, 유잉 종양, 평활근육종, 횡문근육종, 결장 암종, 췌장암, 유방암, 난소암, 전립선암, 평평세포 암종, 기저세포 암종, 선암종, 한선암종, 피지선암종, 유두갑상선암종, 유두갑상선선암종, 낭샘암종, 수질암종, 기관지원성암종, 신세포암종, 간세포암, 담관암종, 융모막암종, 정상피종, 태생성암종, 빌름 종양, 자궁경부암, 자궁암, 고환암, 폐암종, 소세포 폐암종, 방광 암종, 상피암종, 신경교종, 다형성신경교종, 성상세포종, 수모세포종, 두개인두종, 상의세포종, 송과체부종양, 혈관모세포종, 청신경종, 핍지교종, 신경초종, 뇌수막종, 흑색종, 신경아세포종 및 망막모세포종)을 포함하나, 이에 한정되는 것은 아니다. 특정 구현예들에서, 신생물형성은 다발성 골수종, 베타 세포 림프종, 요로상피/방광 암종 또는 흑색종이다. 본원에 사용된 바와 같이 "제제를 수득하는 것"에서와 같이"수득하는 것"은, 해당 제제를 합성, 구매 또는 취득하는 것을 포함한다.
"감소하다"란, 적어도 5%, 10%, 25%, 50%, 75% 또는 100%만큼의"-"변경을 의미한다.
"기준"이란, 표준 또는 대조군인 조건을 의미한다.
"기준 서열"은, 서열 비교의 기초로서 사용되는 한정된 서열이다. 기준 서열은 지정 서열의 종속 서열 또는 전체 서열일 수 있는데; 예를 들어 전장 cDNA 또는 유전자 서열의 분절, 또는 전체 cDNA 또는 유전자 서열일 수 있다. 폴리펩티드에 있어서, 기준 폴리펩티드 서열의 길이는, 일반적으로 적어도 약 16개 아미노산, 바람직하게 적어도 약 20개 아미노산, 더욱 바람직하게 적어도 약 25개 아미노산, 그리고 더욱더 바람직하게 약 35개 아미노산, 약 50개 아미노산, 또는 약 100개 아미노산일 것이다. 핵산에 있어서, 기준 핵산 서열의 길이는, 일반적으로 적어도 약 50개 뉴클레오티드, 바람직하게 적어도 약 60개 뉴클레오티드, 더욱 바람직하게 적어도 약 75개 뉴클레오티드, 그리고 더욱더 바람직하게 약 100개 뉴클레오티드 또는 약 300개 뉴클레오티드, 또는 이 범위 정도나 이 범위 사이의 임의의 정수만큼의 개수의 뉴클레오티드일 것이다.
"특이적으로 결합하다"란, 어떤 화합물 또는 항체가 본 발명의 폴리펩티드를 인지하고 이에 결합하되, 자연에서 본 발명의 폴리펩티드를 포함하는 시료(예컨대 생물 시료) 중 다른 분자는 실질적으로 인지하지 않고 결합하지 않는 경우를 의미한다.
본 발명의 방법에 유용한 핵산 분자는 본 발명의 폴리펩티드 또는 이의 단편을 암호화하는 임의의 핵산 분자를 포함한다. 이러한 핵산 분자는 내부 핵산 서열과 100% 동일할 필요는 없지만, 통상 실질적인 동일성을 보일 것이다. 내부 서열과의 "실질적 동일성"을 가지는 폴리뉴클레오티드는, 통상 이중 가닥 핵산 분자의 적어도 한 가닥과 잡종화될 수 있다. 본 발명의 방법에 유용한 핵산 분자는 본 발명의 폴리펩티드 또는 이의 단편을 암호화하는 임의의 핵산 분자를 포함한다. 이러한 핵산 분자는 내부 핵산 서열과 100% 동일할 필요는 없지만, 통상 실질적인 동일성을 보일 것이다. 내부 서열과 "실질적 동일성"을 가지는 폴리뉴클레오티드는, 통상 이중 가닥 핵산 분자의 적어도 한 가닥과 잡종화될 수 있다. "잡종화하다"란, 다양한 엄중도 조건(stringency condition) 하에 쌍을 이루어 상보성 폴리뉴클레오티드 서열들(예컨대 본원에 기술된 유전자) 또는 이의 일부들 간에 이중 가닥 분자를 형성하는 경우를 의미한다. 예를 들어 문헌(Wahl, G. M. and S. L. Berger (1987) Methods Enzymol. 152:399; Kimmel, A. R. (1987) Methods Enzymol. 152:507)을 참조한다.
예를 들어 엄중한 염 농도는 보통 약 750 mM 미만 NaCl 및 약 75 mM 미만의 시트르산삼나트륨, 바람직하게 약 500 mM 미만 NaCl 및 약 50 mM 미만의 시트르산삼나트륨, 그리고 더욱 바람직하게 약 250 mM 미만 NaCl 및 약 25 mM 미만의 시트르산삼나트륨일 것이다. 저 엄중도 잡종화는 유기 용매, 예컨대 포름아미드의 부재하에 이루어질 수 있는 반면, 고 엄중도 잡종화는 적어도 약 35%의 포름아미드, 더욱 바람직하게는 적어도 약 50%의 포름아미드의 존재 하에 이루어질 수 있다. 엄중한 온도 조건은 보통 적어도 약 30℃, 더욱 바람직하게는 적어도 약 37℃, 그리고 가장 바람직하게는 적어도 약 42℃의 온도를 포함할 것이다. 추가의 가변적 매개변수, 예컨대 잡종화 시간, 세제(예컨대 도데실황산나트륨(SDS)) 농도, 그리고 운반체 DNA의 포함 또는 배제는 당 업자들에게 널리 공지되어 있다. 다양한 엄중도 수준은 필요에 따라 다양한 조건들을 조합함으로써 달성된다. 바람직한 구현예에서, 잡종화는 30℃ 및 750 mM NaCl, 75 mM 시트르산삼나트륨 및 1% SDS 중에서 일어날 것이다. 더욱 바람직한 구현예에서, 잡종화는 37℃ 및 500 mM NaCl, 50 mM 시트르산삼나트륨 및 1% SDS, 35% 포름아미드 및 100 mu.g/ml 변성 연어 정자 DNA(ssDNA) 중에서 일어날 것이다. 가장 바람직한 구현예에서, 잡종화는 42℃ 및 250 mM NaCl, 25 mM 시트르산삼나트륨 및 1% SDS, 50% 포름아미드 및 200 μg/ml ssDNA 중에서 일어날 것이다. 이러한 조건들에 있어서 유용한 변동은 당 업자들이 용이하게 알 것이다.
대부분의 응용에 있어서, 잡종화에 뒤이어 행해지는 세척 단계도 또한 엄중도가 다양할 것이다. 세척 엄중도 조건은 염의 농도와 온도에 의해 한정될 수 있다. 상기와 같이 세척 엄중도는, 염 농도를 낮추거나 온도를 높임으로써 증가할 수 있다. 예를 들어 세척 단계에 있어 엄중한 염 농도는, 바람직하게 약 30 mM 미만의 NaCl 및 약 3 mM 미만의 시트르산삼나트륨이고, 가장 바람직하게는 약 15 mM 미만의 NaCl 및 약 1.5 mM 미만의 시트르산삼나트륨일 것이다. 세척 단계에 있어 엄중한 온도 조건은, 보통 적어도 약 25℃, 더욱 바람직하게 적어도 약 42℃, 더욱더 바람직하게는 적어도 약 68℃를 포함할 것이다. 바람직한 구현예에서, 세척 단계는 25℃ 및 30 mM NaCl, 3 mM 시트르산삼나트륨 및 0.1% SDS 중에서 진행될 것이다. 더욱 바람직한 구현예에서, 세척 단계는 42℃ 및 15 mM NaCl, 1.5 mM 시트르산삼나트륨 및 0.1% SDS 중에서 진행될 것이다. 더욱 바람직한 구현예에서, 세척 단계는 68℃ 및 15 mM NaCl, 1.5 mM 시트르산삼나트륨 및 0.1% SDS 중에서 진행될 것이다. 이러한 조건에 대한 추가의 변동은 당 업자들이 용이하게 알 것이다. 잡종화 기술은 당 업자들에게 널리 공지되어 있으며, 예를 들어 문헌(Benton and Davis (Science 196:180, 1977); Grunstein and Hogness (Proc. Natl. Acad. Sci., USA 72:3961, 1975); Ausubel et al. (Current Protocols in Molecular Biology, Wiley Interscience, New York, 2001); Berger and Kimmel (Guide to Molecular Cloning Techniques, 1987, Academic Press, New York); and Sambrook et al., Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory Press, New York)에 기술되어 있다.
"실질적으로 동일한"이란, 어떤 폴리펩티드 또는 핵산 분자가 기준 아미노산 서열(예를 들어 본원에 기술된 아미노산 서열들 중 임의의 하나) 또는 핵산 서열(예를 들어 본원에 기술된 핵산 서열들 중 임의의 하나)에 대해 적어도 50%의 동일성을 보이는 경우를 의미한다. 바람직하게 이러한 서열은 비교에 사용된 서열과 아미노산 수준 또는 핵산 수준에서 적어도 60%, 더욱 바람직하게는 80% 또는 85%, 더욱더 바람직하게는 90%, 95% 또는 심지어 99% 동일하다.
서열 동일성은, 통상적으로 서열 분석 소프트웨어(예를 들어 Sequencher(Gene Codes Corporation, 775 Technology Drive, Ann Arbor, MI); Vector NTI(Life Technologies, 3175 Staley Rd. Grand Island, NY)가 사용되어 측정된다. 이러한 소프트웨어는 다양한 치환, 결실 및/또는 기타 변형에 상동성의 정도를 할당함으로써 동일하거나 유사한 서열을 매칭시킨다. 보존적 치환은, 통상적으로 하기 군들, 즉 글리신, 알라닌; 발린, 이소루신, 루신; 아스파르트산, 글루탐산, 아스파라긴, 글루타민; 세린, 트레오닌; 리신, 아르기닌; 및 페닐알라닌, 티로신 내에서의 치환을 포함한다. 동일성의 정도를 측정하기 위한 예시적 접근법에 있어서, BLAST 프로그램이 사용될 수 있는데, 이 프로그램에서 확률 스코어 e-3 내지 e-100이라 함은, 두 서열이 관련성이 매우 큰 서열임을 나타낸다.
"대상체"란, 포유동물, 예컨대 인간 또는 인간 이외의 포유동물, 예컨대 소, 말, 개, 양 또는 고양이(이에 한정되는 것은 아님)를 의미한다. 대상체는, 바람직하게 B 세포 림프종 또는 이에 대한 소인의 치료를 필요로 하는 포유동물로서, 예를 들어 B 세포 림프종이라 진단되었거나 이에 대한 소인이 있는 것으로 진단된 대상체이다. 포유동물은 임의의 포유동물, 예컨대 인간, 영장류, 마우스, 래트, 개, 고양이, 말뿐만 아니라, 식용으로 기른 가축이나 동물, 예컨대 송아지, 양, 돼지, 닭 및 염소이다. 바람직한 구현예에서, 포유동물은 인간이다.
본원에 제공된 범위들은 해당 범위 내의 모든 값들에 대한 약칭인 것으로 이해된다. 예를 들어 "1 내지 50의 범위"는 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49 또는 50으로 이루어진 군에 속하는 임의의 수, 수들의 조합 또는 이 범위의 종속 범위를 포함하는 것으로 이해된다.
본원에 사용된 바와 같은 "치료하는 것" 및 "치료"란 용어는, 어떤 제제(agent)나 제제(formulation)를, 불리한 병태, 장애 또는 질환이 걸린 개체로서, 임상 증상을 보이는 개체에 투여하여, 해당 증상의 중증도 및/또는 발생 빈도의 감소, 해당 증상 및/또는 이 증상의 기저 원인의 제거, 그리고/또는 손상의 개선 또는 교정의 가속화를 달성하는 것을 지칭한다. 어떤 장애나 병태를 치료하는 것은 해당 장애, 병태 또는 이러한 장애나 병태와 연관된 증상이 완전히 없어져야 하는 것은 아니지만, 그렇다고 이처럼 해당 장애, 병태 또는 이러한 장애나 병태와 연관된 증상이 완전히 없어져서는 안 될 것까지는 없음이 이해될 것이다.
"예방하는 것"및 "예방"이란 용어는, 특정의 불리한 병태, 장애 또는 질환에 취약하거나 이의 소인이 있는 임상 무증상 개체에 제제 또는 조성물을 투여하는 것을 지칭하므로, 증상의 발생 및/또는 해당 증상의 기저 원인을 예방하는 것에 관한 것이다.
달리 특별히 진술되거나, 내용으로부터 명백하지 않다면, 본원에 사용된 바와 같은 "또는"이란 용어는, 포괄적인 것으로 이해된다. 특별히 달리 진술되거나, 내용으로부터 명백하지 않다면, 본원에 사용된 바와 같은 "하나", "하나의" 및 "본"이란 용어는 단수 또는 복수를 나타내는 것으로 이해된다.
특별히 진술되거나, 내용으로부터 명백하지 않다면, 본원에 사용된 바와 같은 "약"이란 용어는, 당 분야에서 보통 관용되는 범위 내, 예를 들어 평균의 2 표준 편차 내에 속하는 것으로 이해된다. "약"은 진술된 값의 10%, 9%, 8%, 7%, 6%, 5%, 4%, 3%, 2%, 1%, 0.5%, 0.1%, 0.05% 또는 0.01% 이내인 것으로 이해될 수 있다. 내용으로부터 분명하지 않다면, 본원에 제공된 모든 수치 값은 용어 "약"에 의해 수식된다.
본원의 변인에 관한 임의의 정의에 있어서 화학기의 나열에 대한 설명은 해당 변인의 정의를, 임의의 단일 군 또는 나열된 군들의 조합으로서 포함한다. 본원의 변인 또는 양태에 대한 한 구현예의 설명은, 해당 구현예를 임의의 구현예 하나로서, 또는 또 다른 임의의 구현예들이나 이의 일부와의 조합으로서 포함한다.
본원에 제공된 임의의 조성물 또는 방법은, 본원에 제공된 방법 및 기타 조성물들 중 임의의 것 하나 이상과 조합될 수 있다.
"~를 포함하는(including)", "~를 함유하는" 또는 "~에 의해 특징지어지는"과 밀접한 전이적 용어 "~를 포함하는(comprising)"은 포괄적이거나 개방적인 용어로서, 언급되지 않은 추가의 요소나 방법의 단계들을 배제하지 않는다. 이와는 대조적으로, 전이적 어구 "~으로 이루어진"은, 청구항에 지정되지 않은 임의의 요소, 단계 또는 성분을 베지한다. 전이적 어구 "본질적으로 ~으로 이루어진"은, 지정된 물질이나 단계에 대한 특허청구범위와, 청구된 발명의 "기본적이고 신규한 특징(들)에 실질적으로 영향을 미치지 않는 물질이나 단계"를 한정하는 어구이다.
본 발명의 기타 특징 및 이점은 이하 본 발명의 바람직한 구현예들에 관한 설명과, 특허청구범위로부터 명백할 것이다. 달리 정의되지 않는 한, 본원에 사용된 모든 기술 용어와 과학 용어는 본 발명이 속하는 분야의 당업자에 의해 보통 이해되는 바와 동일한 의미를 가진다. 비록 본원에 기술된 방법 및 물질과 유사하거나 균등한 방법 및 물질이 본 발명의 실시 또는 시험에 사용될 수 있지만, 적합한 방법과 물질이 이하에 기술되어 있다. 본원에 인용된 공개 외국 특허 및 특허출원 모두는 본원에 참조로 인용되어 있다.
본원에 언급된 승인 번호에 의해 표시되는 GenBank 및 NCBI 제출에 관한 사항은 본원에 참조로 인용되어 있다. 본원에 언급된 기타 공표된 모든 참고문헌, 서류, 논문 및 과학 문헌은 본원에 참조로 인용되어 있다. 상충될 경우, 용어의 정의를 포함하는 본 발명의 설명이 이를 조정할 것이다. 또한 물질, 방법 및 실시예는 오로지 예시적인 것일뿐, 본 발명을 제한하고자 하는 것은 아니다.
도 1은, 항 PD-L1 scAb/huIL-15N72D 및 항 PD-L1 scAb/huIL-15RαSu/Fc 융합 단백질을 포함하는 PD-L1 TxM 복합체의 활성과, PD-L1 항원을 발현하는 질환 세포에 대한 이 복합체의 면역 매개 효과를 보여주는 개략적 도해이다.
도 2는, 면역 관문 분자, 면역 신호전달 분자 및/또는 질환 항원을 인지하는 결합 도메인에 융합된, IL-15/IL-15RαSu/Fc 스캐폴드를 포함하는 상이한 TxM 복합체들을 보여주는 개략적 도해이다.
도 3은, 이황화 결합 환원을 거친 TxM 복합체의 황산도데실나트륨 폴리아크릴아미드 겔 전기영동(SDS-PAGE) 분석 결과를 보여주는 사진이다. 우측 레인: PD-L1 TxM; 좌측 레인: 마커.
도 4a는, 인간 IL-15 및 인간 IgG에 특이적인 항체에 대한, 항 인간 PD-L1 TxM 복합체의 결합 활성을 보여주는 선 그래프이다. 도 4b는, 인간 IL-15 및 인간 IgG에 특이적인 항체에 대한, 제2의 항 인간 PD-L1 TxM 복합체의 결합 활성을 보여주는 선 그래프이다. 도 4c는, 인간 IL-15 및 마우스 IgG에 특이적인 항체에 대한, 항 마우스 PD-L1 TxM 복합체의 결합 활성을 보여주는 선 그래프이다.
도 5a는, PD-L1 보유 인간 MB231 종양 세포에 대한, PD-L1 TxM 복합체의 결합 활성을 보여주는 선 그래프이다. 도 5b는, 인간 MB231 종양 세포 상에 발현되는 PD-L1에 대한, PD-L1 TxM 복합체의 차단 활성을 보여주는 선 그래프이다. 도 5c는, PD-L1 보유 인간 MB231 종양 세포에 대한, PD-L1 TxM 복합체의 결합 활성을 보여주는 선 그래프이다.
도 6a는, 마우스 5T33P 종양 세포 상에 발현되는 PD-L1에 대한, PD-L1 TxM 복합체의 차단 활성을 보여주는 선 그래프이다. 도 6b는, 마우스 MB49luc 종양 세포 상에 발현되는 PD-L1에 대한, PD-L1 TxM 복합체의 차단 활성을 보여주는 선 그래프이다.
도 7a 및 도 7b는, 마우스 A20 종양 세포 상에 발현되는 PD-L1에 대한, 항 PD-L1 Ab의 차단 활성 및 PD-L1 TxM 복합체의 차단 활성을 비교하는 선 그래프이다.
도 8은 PD-L1 TxM 복합체에 의해 매개되는 IL-15 의존적 32Dβ 세포의 증식을 보여주는 선 그래프이다.
도 9a는 "4두형(4 headed)" 및 "2두형(2 headed)" PD-L1 TxM 복합체를 보여주는 개략적 도해이다. 도 9b는 이황화 결합 환원을 거친 4두형 및 2두형 마우스 특이적 PD-L1 TxM 복합체의 SDS-PAGE 분석 결과를 보여주는 사진이다. 도 9c 및 도 9d는, 분석용 크기별 배제 컬럼상에서 용리된 이후의 2두형 및 4두형 마우스 특이적 PD-L1 TxM 복합체 각각의 크로마토그래피 프로필을 나타내는 선 그래프르 보여주는 것으로서, 단백질 응집체로부터 TxM 복합체가 분리되었음을 입증한다.
도 10a는 IL-2Rβγ 보유 32Dβ 세포에 대한, 2두형 및 4두형 마우스 특이적 PD-L1 TxM 복합체의 결합 활성을 보여주는 선 그래프이다. 도 10b 및 도 10c는, 5T33P 골수종 세포 상에 발현되는 PD-L1에 대한, 2두형 및 4두형 마우스 특이적 PD-L1 TxM 복합체의 차단 활성을 입증하는 선 그래프를 보여주는 것이다.
도 11a는, ALT-803(IL-15N72D:IL-15Rα/Fc 복합체)에 의해 매개되는 IL-15 의존적 32Dβ 세포의 증식과 비교되는, 2두형 마우스 특이적 PD-L1 TxM 복합체에 의해 매개되는 IL-15 의존적 32Dβ 세포의 증식을 보여주는 선 그래프이다. 도 11b는, ALT-803에 의해 매개되는 IL-15 의존적 32Dβ 세포의 증식과 비교되는, 4두형 마우스 특이적 PD-L1 TxM 복합체에 의해 매개되는 IL-15 의존적 32Dβ 세포의 증식을 보여주는 선 그래프이다.
도 12a는, 이황화 결합 환원을 거친 2두형 및 4두형 인간 특이적 PD-L1 TxM 복합체의 SDS-PAGE 분석 결과를 보여주는 사진이다. 도 12b 및 도 12c는, 분석용 크기별 배제 컬럼상에서 용리된 이후의 2두형 및 4두형 인간 특이적 PD-L1 TxM 복합체 각각의 크로마토그래피 프로필을 나타내는 선 그래프를 보여주는 것으로서, 단백질 응집체로부터 TxM 복합체가 분리되었음을 입증한다.
도 13은, PC-3 인간 전립선 암 세포 상에 발현되는 PD-L1에 대한, 2두형 및 4두형 인간 특이적 PD-L1 TxM 복합체의 차단 활성을 보여주는 선 그래프이다.
도 14a는, ALT-803에 의해 매개되는 IL-15 의존적 32Dβ 세포의 증식과 비교되는, 2두형 인간 특이적 PD-L1 TxM 복합체에 의해 매개되는 IL-15 의존적 32Dβ 세포의 증식을 보여주는 선 그래프이다. 도 14b는, ALT-803에 의해 매개되는 IL-15 의존적 32Dβ 세포의 증식과 비교되는, 4두형 인간 특이적 PD-L1 TxM 복합체에 의해 매개되는 IL-15 의존적 32Dβ 세포의 증식을 보여주는 선 그래프이다.
도 15a는, PBS, ALT-803, 4두형 마우스 특이적 PD-L1 TxM(T4M-mPD-L1) 및 2두형 마우스 특이적 PD-L1 TxM(T2M-mPD-L1)으로 처리된 마우스의 비장 중량을 보여주는 막대 도표이다. 도 15b 및 도 15c는 PBS, ALT-803, 4두형 마우스 특이적 PD-L1 TxM(T4M-mPD-L1) 및 2두형 마우스 특이적 PD-L1 TxM(T2M-mPD-L1)으로 처리된 마우스의 비장 및 림프절 각각에 있어서 상이한 면역 세포 서브세트의 백분율을 나타내는 막대 도표를 보여주는 것이다.
도 16은, PD-L1 TxM, 항 PD-L1 Ab 또는 ALT-803에 의해 유도된, 5T33 골수종 세포에 대한 면역 세포의 세포독성을 나타내는 막대 도표이다.
도 17은, 항 인간 PD-L1 Ab, 2두형 인간 특이적 PD-L1 TxM(T4M-mPD-L1) 또는 4두형 인간 특이적 PD-L1 TxM(T2M-mPD-L1)에 의해 유도되는, PD-L1 양성 SW1990 인간 췌장 암 세포에 대한 인간 면역 세포의 세포독성을, 배지 단독에 의해 유도되는, PD-L1 양성 SW1990 인간 췌장 암 세포에 대한 인간 면역 세포의 세포독성과 비교하여 나타내는 막대 도표이다.
도 18은, PD-L1 TxM 복합체, ALT-803, ALT-803 및 항 PD-L1 Ab, 또는 PBS 처리 후 5T33 골수종 종양을 보유하는 마우스의 생존률을 나타내는 선 그래프이다.
도 19는, 2H PD-L1 TxM 복합체, ALT-803, ALT-803 및 항 PD-L1 Ab, 또는 PBS 처리 후 동소성 MB49luc 방광 종양을 보유하는 마우스의 생존률을 나타내는 선 그래프이다.
도 20은, 분석용 크기별 배제 컬럼상에서 용리된 이후 정제된 상이한 TxM 단백질의 크로마토그래피 프로필을 나타내는 선 그래프로서, 단백질 응집체로부터 TxM 복합체가 분리되었음을 입증한다.
도 21a는 마우스 림프구 상에 발현되는 CTLA-4에 대한, CTLA-4 TxM 복합체의 차단 활성을 보여주는 선 그래프이다. 도 21b는 인간 림프구 상에 발현되는 CTLA-4에 대한, CTLA-4 TxM 복합체의 차단 활성을 보여주는 선 그래프이다.
도 22a는 마우스 5T33P 종양 세포 상에 발현되는 PD-L1에 대한, PD-L1/CTLA-4 TxM 복합체의 차단 활성을 보여주는 선 그래프이다. 도 22b는 마우스 림프구 상에 발현되는 CTLA-4에 대한, PD-L1/CTLA-4 TxM 복합체의 차단 활성을 보여주는 선 그래프이다.
도 23a는 CD47 보유 마우스 B16F10 흑색종 종양 세포에 대한, CD47 TxM 복합체의 결합 활성을 보여주는 선 그래프이다. 도 23b는, CD47 보유 인간 Jurkat T 세포에 대한, CD47 TxM 복합체의 결합 활성을 보여주는 선 그래프이다.
도 24a는, 단일 가닥 DNA에 대한 TNT scAb TxM 복합체의 결합 활성을 나타내는 선 그래프이다. 도 24b는, 단일 가닥 DNA에 대한 TNT scAb/항 PD-L1 scAb TxM 복합체의 결합 활성을 나타내는 선 그래프이다.
도 25a는 투과처리된 인간 MB231 유방암 세포에 대한, TNT scAb TxM, TNT scAb/항 PD-L1 scAb TxM 및 2두형 항 PD-L1 scAb TxM 복합체의 결합 활성을 보여주는 선 그래프이다. 도 25b는, 투과처리된 인간 A549 폐암 세포에 대한, TNT scAb TxM, TNT scAb/항 PD-L1 scAb TxM 및 2두형 항 PD-L1 scAb TxM 복합체의 결합 활성을 보여주는 선 그래프이다.
도 26은 인간 TF 양성-PD-L1 양성 SW1990 인간 췌장암 세포에 대한, 2두형 hOAT scAb TxM, 항 인간 PD-L1 scAb/hOAT scAb TxM, 2두형 항 인간 PD-L1 scAb TxM 복합체 및 Hoat와, 항 인간 PD-L1 대조군 Ab의 결합 활성을 보여주는 선 그래프이다.
도 27a는, 인간 IL-15 및 인간 IgG에 특이적인 항체에 대한 LFA-1 TxM 복합체의 결합 활성을 보여주는 선 그래프이다. 도 27b는 ICAM-1에 대한 LFA-1 TxM 복합체의 결합 활성을 보여주는 막대 그래프이다.
도 28은 인간 IL-15 및 인간 IgG에 특이적인 항체에 대한, Notch1 특이적 TxM 복합체의 결합 활성을 보여주는 선 그래프이다.
도 29는 인간 IL-15 및 인간 IgG에 특이적인 항체에 대한, 항 인간 TIM3 scAb TxM 복합체의 결합 활성을 보여주는 선 그래프이다.
도 30a 및 도 30b는 인간 IL-15 및 인간 IgG에 특이적인 항체에 대한, HIV 특이적 bNAb scFv TxM 복합체의 결합 활성을 보여주는 선 그래프이다. 도 30c 내지 도 30f는 HIV 외피 단백질에 대한, HIV 특이적 bNAb TxM 복합체의 결합 활성을 보여주는 선 그래프를 보여주는 것이다.
도 31은 2두형 hOAT scAb TxM 또는 hOAT 대조군 Ab에 의해 유도되는, 인간 TF 양성 SW1990 인간 췌장암 세포에 대한 인간 면역 세포의 세포독성을, 배지 단독에 의해 유도되는, 인간 TF 양성 SW1990 인간 췌장암 세포에 대한 인간 면역 세포의 세포독성과 비교하여 나타내는 막대 도표이다.
도 2는, 면역 관문 분자, 면역 신호전달 분자 및/또는 질환 항원을 인지하는 결합 도메인에 융합된, IL-15/IL-15RαSu/Fc 스캐폴드를 포함하는 상이한 TxM 복합체들을 보여주는 개략적 도해이다.
도 3은, 이황화 결합 환원을 거친 TxM 복합체의 황산도데실나트륨 폴리아크릴아미드 겔 전기영동(SDS-PAGE) 분석 결과를 보여주는 사진이다. 우측 레인: PD-L1 TxM; 좌측 레인: 마커.
도 4a는, 인간 IL-15 및 인간 IgG에 특이적인 항체에 대한, 항 인간 PD-L1 TxM 복합체의 결합 활성을 보여주는 선 그래프이다. 도 4b는, 인간 IL-15 및 인간 IgG에 특이적인 항체에 대한, 제2의 항 인간 PD-L1 TxM 복합체의 결합 활성을 보여주는 선 그래프이다. 도 4c는, 인간 IL-15 및 마우스 IgG에 특이적인 항체에 대한, 항 마우스 PD-L1 TxM 복합체의 결합 활성을 보여주는 선 그래프이다.
도 5a는, PD-L1 보유 인간 MB231 종양 세포에 대한, PD-L1 TxM 복합체의 결합 활성을 보여주는 선 그래프이다. 도 5b는, 인간 MB231 종양 세포 상에 발현되는 PD-L1에 대한, PD-L1 TxM 복합체의 차단 활성을 보여주는 선 그래프이다. 도 5c는, PD-L1 보유 인간 MB231 종양 세포에 대한, PD-L1 TxM 복합체의 결합 활성을 보여주는 선 그래프이다.
도 6a는, 마우스 5T33P 종양 세포 상에 발현되는 PD-L1에 대한, PD-L1 TxM 복합체의 차단 활성을 보여주는 선 그래프이다. 도 6b는, 마우스 MB49luc 종양 세포 상에 발현되는 PD-L1에 대한, PD-L1 TxM 복합체의 차단 활성을 보여주는 선 그래프이다.
도 7a 및 도 7b는, 마우스 A20 종양 세포 상에 발현되는 PD-L1에 대한, 항 PD-L1 Ab의 차단 활성 및 PD-L1 TxM 복합체의 차단 활성을 비교하는 선 그래프이다.
도 8은 PD-L1 TxM 복합체에 의해 매개되는 IL-15 의존적 32Dβ 세포의 증식을 보여주는 선 그래프이다.
도 9a는 "4두형(4 headed)" 및 "2두형(2 headed)" PD-L1 TxM 복합체를 보여주는 개략적 도해이다. 도 9b는 이황화 결합 환원을 거친 4두형 및 2두형 마우스 특이적 PD-L1 TxM 복합체의 SDS-PAGE 분석 결과를 보여주는 사진이다. 도 9c 및 도 9d는, 분석용 크기별 배제 컬럼상에서 용리된 이후의 2두형 및 4두형 마우스 특이적 PD-L1 TxM 복합체 각각의 크로마토그래피 프로필을 나타내는 선 그래프르 보여주는 것으로서, 단백질 응집체로부터 TxM 복합체가 분리되었음을 입증한다.
도 10a는 IL-2Rβγ 보유 32Dβ 세포에 대한, 2두형 및 4두형 마우스 특이적 PD-L1 TxM 복합체의 결합 활성을 보여주는 선 그래프이다. 도 10b 및 도 10c는, 5T33P 골수종 세포 상에 발현되는 PD-L1에 대한, 2두형 및 4두형 마우스 특이적 PD-L1 TxM 복합체의 차단 활성을 입증하는 선 그래프를 보여주는 것이다.
도 11a는, ALT-803(IL-15N72D:IL-15Rα/Fc 복합체)에 의해 매개되는 IL-15 의존적 32Dβ 세포의 증식과 비교되는, 2두형 마우스 특이적 PD-L1 TxM 복합체에 의해 매개되는 IL-15 의존적 32Dβ 세포의 증식을 보여주는 선 그래프이다. 도 11b는, ALT-803에 의해 매개되는 IL-15 의존적 32Dβ 세포의 증식과 비교되는, 4두형 마우스 특이적 PD-L1 TxM 복합체에 의해 매개되는 IL-15 의존적 32Dβ 세포의 증식을 보여주는 선 그래프이다.
도 12a는, 이황화 결합 환원을 거친 2두형 및 4두형 인간 특이적 PD-L1 TxM 복합체의 SDS-PAGE 분석 결과를 보여주는 사진이다. 도 12b 및 도 12c는, 분석용 크기별 배제 컬럼상에서 용리된 이후의 2두형 및 4두형 인간 특이적 PD-L1 TxM 복합체 각각의 크로마토그래피 프로필을 나타내는 선 그래프를 보여주는 것으로서, 단백질 응집체로부터 TxM 복합체가 분리되었음을 입증한다.
도 13은, PC-3 인간 전립선 암 세포 상에 발현되는 PD-L1에 대한, 2두형 및 4두형 인간 특이적 PD-L1 TxM 복합체의 차단 활성을 보여주는 선 그래프이다.
도 14a는, ALT-803에 의해 매개되는 IL-15 의존적 32Dβ 세포의 증식과 비교되는, 2두형 인간 특이적 PD-L1 TxM 복합체에 의해 매개되는 IL-15 의존적 32Dβ 세포의 증식을 보여주는 선 그래프이다. 도 14b는, ALT-803에 의해 매개되는 IL-15 의존적 32Dβ 세포의 증식과 비교되는, 4두형 인간 특이적 PD-L1 TxM 복합체에 의해 매개되는 IL-15 의존적 32Dβ 세포의 증식을 보여주는 선 그래프이다.
도 15a는, PBS, ALT-803, 4두형 마우스 특이적 PD-L1 TxM(T4M-mPD-L1) 및 2두형 마우스 특이적 PD-L1 TxM(T2M-mPD-L1)으로 처리된 마우스의 비장 중량을 보여주는 막대 도표이다. 도 15b 및 도 15c는 PBS, ALT-803, 4두형 마우스 특이적 PD-L1 TxM(T4M-mPD-L1) 및 2두형 마우스 특이적 PD-L1 TxM(T2M-mPD-L1)으로 처리된 마우스의 비장 및 림프절 각각에 있어서 상이한 면역 세포 서브세트의 백분율을 나타내는 막대 도표를 보여주는 것이다.
도 16은, PD-L1 TxM, 항 PD-L1 Ab 또는 ALT-803에 의해 유도된, 5T33 골수종 세포에 대한 면역 세포의 세포독성을 나타내는 막대 도표이다.
도 17은, 항 인간 PD-L1 Ab, 2두형 인간 특이적 PD-L1 TxM(T4M-mPD-L1) 또는 4두형 인간 특이적 PD-L1 TxM(T2M-mPD-L1)에 의해 유도되는, PD-L1 양성 SW1990 인간 췌장 암 세포에 대한 인간 면역 세포의 세포독성을, 배지 단독에 의해 유도되는, PD-L1 양성 SW1990 인간 췌장 암 세포에 대한 인간 면역 세포의 세포독성과 비교하여 나타내는 막대 도표이다.
도 18은, PD-L1 TxM 복합체, ALT-803, ALT-803 및 항 PD-L1 Ab, 또는 PBS 처리 후 5T33 골수종 종양을 보유하는 마우스의 생존률을 나타내는 선 그래프이다.
도 19는, 2H PD-L1 TxM 복합체, ALT-803, ALT-803 및 항 PD-L1 Ab, 또는 PBS 처리 후 동소성 MB49luc 방광 종양을 보유하는 마우스의 생존률을 나타내는 선 그래프이다.
도 20은, 분석용 크기별 배제 컬럼상에서 용리된 이후 정제된 상이한 TxM 단백질의 크로마토그래피 프로필을 나타내는 선 그래프로서, 단백질 응집체로부터 TxM 복합체가 분리되었음을 입증한다.
도 21a는 마우스 림프구 상에 발현되는 CTLA-4에 대한, CTLA-4 TxM 복합체의 차단 활성을 보여주는 선 그래프이다. 도 21b는 인간 림프구 상에 발현되는 CTLA-4에 대한, CTLA-4 TxM 복합체의 차단 활성을 보여주는 선 그래프이다.
도 22a는 마우스 5T33P 종양 세포 상에 발현되는 PD-L1에 대한, PD-L1/CTLA-4 TxM 복합체의 차단 활성을 보여주는 선 그래프이다. 도 22b는 마우스 림프구 상에 발현되는 CTLA-4에 대한, PD-L1/CTLA-4 TxM 복합체의 차단 활성을 보여주는 선 그래프이다.
도 23a는 CD47 보유 마우스 B16F10 흑색종 종양 세포에 대한, CD47 TxM 복합체의 결합 활성을 보여주는 선 그래프이다. 도 23b는, CD47 보유 인간 Jurkat T 세포에 대한, CD47 TxM 복합체의 결합 활성을 보여주는 선 그래프이다.
도 24a는, 단일 가닥 DNA에 대한 TNT scAb TxM 복합체의 결합 활성을 나타내는 선 그래프이다. 도 24b는, 단일 가닥 DNA에 대한 TNT scAb/항 PD-L1 scAb TxM 복합체의 결합 활성을 나타내는 선 그래프이다.
도 25a는 투과처리된 인간 MB231 유방암 세포에 대한, TNT scAb TxM, TNT scAb/항 PD-L1 scAb TxM 및 2두형 항 PD-L1 scAb TxM 복합체의 결합 활성을 보여주는 선 그래프이다. 도 25b는, 투과처리된 인간 A549 폐암 세포에 대한, TNT scAb TxM, TNT scAb/항 PD-L1 scAb TxM 및 2두형 항 PD-L1 scAb TxM 복합체의 결합 활성을 보여주는 선 그래프이다.
도 26은 인간 TF 양성-PD-L1 양성 SW1990 인간 췌장암 세포에 대한, 2두형 hOAT scAb TxM, 항 인간 PD-L1 scAb/hOAT scAb TxM, 2두형 항 인간 PD-L1 scAb TxM 복합체 및 Hoat와, 항 인간 PD-L1 대조군 Ab의 결합 활성을 보여주는 선 그래프이다.
도 27a는, 인간 IL-15 및 인간 IgG에 특이적인 항체에 대한 LFA-1 TxM 복합체의 결합 활성을 보여주는 선 그래프이다. 도 27b는 ICAM-1에 대한 LFA-1 TxM 복합체의 결합 활성을 보여주는 막대 그래프이다.
도 28은 인간 IL-15 및 인간 IgG에 특이적인 항체에 대한, Notch1 특이적 TxM 복합체의 결합 활성을 보여주는 선 그래프이다.
도 29는 인간 IL-15 및 인간 IgG에 특이적인 항체에 대한, 항 인간 TIM3 scAb TxM 복합체의 결합 활성을 보여주는 선 그래프이다.
도 30a 및 도 30b는 인간 IL-15 및 인간 IgG에 특이적인 항체에 대한, HIV 특이적 bNAb scFv TxM 복합체의 결합 활성을 보여주는 선 그래프이다. 도 30c 내지 도 30f는 HIV 외피 단백질에 대한, HIV 특이적 bNAb TxM 복합체의 결합 활성을 보여주는 선 그래프를 보여주는 것이다.
도 31은 2두형 hOAT scAb TxM 또는 hOAT 대조군 Ab에 의해 유도되는, 인간 TF 양성 SW1990 인간 췌장암 세포에 대한 인간 면역 세포의 세포독성을, 배지 단독에 의해 유도되는, 인간 TF 양성 SW1990 인간 췌장암 세포에 대한 인간 면역 세포의 세포독성과 비교하여 나타내는 막대 도표이다.
본 발명은 최소한 부분적으로 다중 특이적 IL-15 기반 단백질 복합체가 면역 세포의 활성을 증진시키고, 질환 세포에 대한 이 면역 세포의 활성을 촉진함으로써, 질환의 완화 또는 예방을 초래한다는 놀라운 발견에 바탕을 두고 있다. 이러한 단백질 복합체는 또한 질환 항원 및 표적 항원에 대한 증가한 결합을 보이기도 한다. 본원에는 IL-15 또는 기능성 변이체를 포함하는 하나의 도메인과, 질환 특이적 결합 도메인, 면역 관문 억제제 또는 면역 효현제를 포함하는 결합 도메인을 가지는 다중 특이적 단백질 복합체가 제공된다. 이러한 단백질 복합체는 대상체 내 신생물형성, 감염성 질환 또는 자가면역 질환을 치료하기 위한 방법에 사용된다. 구체적으로 이하에 상세히 기술된 바와 같이, 가용성 항 PD-L1 scAb/huIL-15N72D:항 PD-L1 scAb/huIL-15RαSu/huIgG1 Fc 복합체("PD-L1 TxM")는 면역 세포를 자극하여 종양 표적 세포를 사멸시키도록 하였다(도 1). 그러므로 본원에는 PD-L1 TxM을 특징으로 하는 조성물과, 신생물형성(예컨대 고형 종양 및 혈액학적 종양)에 대한 면역 반응을 증진시키기 위해 이러한 조성물을 사용하는 방법이 제공된다.
본원에 기술된 바와 같이, 숙주 면역 인지 및 면역 반응에 대해 발병 세포를 표적화하는 능력을 가지는 단백질을 사용하는 것은, 암, 감염성 질환 및 자가면역성 질환을 치료하는데 유효한 전략이다. 미국 특허 제8,507,222호(본원에 참조로 인용됨)에 기술된 바와 같이, IL-15 및 IL-15 수용체α 도메인을 포함하는 단백질 스캐폴드는 질환 세포상 항원과 면역 세포상 수용체를 인지할 수 있는 다중 특이적 단백질을 제조하는데 사용되었다. 미국특허 제8,507,222호의 실시예 15를 참조한다. 본원에는 면역 관문 분자 또는 신호전달 분자를 인지하는 결합 도메인 하나 이상에 결합된, IL-15 및 IL-15 수용체α를 포함하는 가용성 다중 특이적 단백질 복합체의 제조에 대해 기술되어 있다. 몇몇 경우에 있어서, 이러한 복합체는 또한 질환 세포에 발현되는 항원, 예컨대 PD-L1, ssDNA, CD20, HER2, EGFR, CD19, CD38, CD52, GD2, CD33, Notch1, 세포간 부착 분자 1(ICAM-1), 조직 인자, HIV 외피, 또는 기타 종양 항원을 인지하는 결합 도메인도 포함한다.
몇몇 경우에 있어서, 결합 도메인은 면역글로불린 경쇄 가변 도메인이 폴리펩티드 링커 서열에 의해 면역글로불린 중쇄 가변 도메인에 공유 결합되어 있는 단일 사슬 항체를 포함한다. 단일 사슬 항체 도메인은 VH-링커-VL 형태 또는 VL-링커-VH 형태 중 어느 하나의 형태로 정렬될 수 있다. 대안적으로 결합 도메인은 면역 관문 억제제 또는 면역 효현제로서 작용할 수 있는 가용성 또는 세포외 리간드 또는 수용체 도메인을 포함한다. 면역 관문 분자 또는 신호전달 분자를 인지하는 결합 도메인은 결합 활성이 유지되는 한, 추가의 링커 서열을 통하거나, 아니면 이 추가의 링커 서열 없이 IL-15 또는 IL-15 수용체 α단백질의 N-말단 또는 C-말단 중 어느 하나와 결합한다. 바람직하게 결합 도메인은 인간 IL-15N72D 강력 효현제(superagonist) 단백질(huIL-15N72D)의 N-말단에 결합되어 있다. 대안적으로 결합 도메인은 인간 IL-15N72D 단백질의 C-말단에 결합되어 있다. 바람직하게 결합 도메인은 인간 IL-15 수용체 α 스시 도메인(huIL-15RαSu)의 N-말단에 결합되어 있다. 대안적으로 결합 도메인은 huIL-15RαSuFc 단백질의 C-말단에 결합되어 있다. 몇몇 경우, 본 발명의 다중 특이적 단백질 복합체는 면역 세포 상 CD16 수용체의 인지 및 단백질 이량체화를 위한 IgG Fc 도메인을 추가로 포함한다. 이러한 도메인은 표적 세포에 대하여 항체 의존적 세포성 세포독성(ADCC), 항체 의존적 세포성 식세포작용(ADCP) 및 보체 의존적 세포독성(CDC)의 자극을 매개한다. 몇몇 예에 있어서, 증진 또는 감소한 CD16 결합 활성을 가지는 Fc 도메인을 사용하는 것이 유용하다. 일 양태에서, Fc 도메인은, ADCC 활성은 감소시키지만, 이황화 결합 이량체를 형성하는 능력은 보유하게 하는, 아미노산 치환 L234A 및 L235A(LALA)(번호는 Fc 공통 서열을 바탕으로 함)를 함유한다.
인터루킨-15
인터루킨-15(IL-15)는 효과기 NK 세포와 CD8+ 기억 T 세포의 발달, 증식 및 활성화에 중요한 시토카인이다. IL-15는 IL-15 수용체α(IL-15Rα)에 결합한 후, 이를 경유하여(in trans) 효과기 세포 상 IL-2/IL-15 수용체 β- 공통 γ 사슬(IL-15Rβγc) 복합체에 제시된다. IL-15 및 IL-2는 둘 다 IL-15Rβγc와 결합하고, STAT3 및 STAT5 경로들을 통해 신호를 전달한다. 그러나 IL-2와는 달리, IL-15는 CD4+CD25+FoxP3+ 조절 T(Treg) 세포의 유지를 지원하지 않거나, 또는 활성화된 CD8+ T 세포의 세포 사멸을 유도하지 않기 때문에, 이러한 특성들은 다발성 골수종에 대한 IL-2의 치료 활성을 제한할 수 있다. 뿐만 아니라 IL-15는 항 세포자멸 신호를 효과기 CD8+ T 세포에 제공하는 것으로 알려진 유일한 시토카인이다. 단독으로 투여되거나 또는 IL-15Rα와의 복합체로서 투여된 IL-15는 실험 동물 모델에서 잘 확립된 고형 종양에 강력한 항종양 활성을 보이므로, 잠재적으로 암을 치료할 수 있었던 면역치료 약물로서 가장 촉망받는 것들 중 하나인 것으로 확인되었다.
IL-15 기반 암 치료제의 임상 개발을 가속화하기 위하여, IL-15에 비해 생물 활성이 증가한 IL-15 돌연변이체(IL-15N72D)가 동정되었다(Zhu et al., J Immunol, 183: 3598-3607, 2009). 이 IL-15 강력 효현제(IL-15N72D)의 약동학적 특성과 생물 활성은 IL-15N72D:IL-15Rα/Fc 융합 복합체(ALT-803)를 만듦으로써 더욱 향상되었으며, 그 결과 강력 효현성 복합체는 생체 내에서 원산 시토카인의 활성보다 적어도 25배 큰 활성을 갖게되었다(Han et al., Cytokine, 56: 804-810, 2011).
면역 관문 억제제 및 면역 효현성 도메인
다른 구현예에서, 결합 도메인은 면역 관문 분자나 신호전달 분자, 또는 이의 리간드에 특이적이며, 면역 관문 억제 활성의 억제제 또는 면역 자극 활성의 효현제로서 작용을 한다. 이러한 면역 관문 분자 및 신호전달 분자, 그리고 리간드로서는 PD-1, PD-L1, PD-L2, CTLA-4, CD28, CD80, CD86, B7-H3, B7-H4, B7-H5, ICOS-L, ICOS, BTLA, CD137L, CD137, HVEM, KIR, 4-1BB, OX40L, CD70, CD27, CD47, CIS, OX40, GITR, IDO, TIM3, GAL9, VISTA, CD155, TIGIT, LIGHT, LAIR-1, Siglecs 및 A2aR을 포함한다(Pardoll DM. 2012. Nature Rev Cancer 12:252-264, Thaventhiran T, et al. 2012. J Clin Cell Immunol S12:004). 또한, 본 발명의 바람직한 항체 도메인은 이필리무맙 및/또는 트레멜리무맙(항 CTLA4), 니볼루맙, 펨브롤리주맙, 피딜리주맙, TSR-042, ANB011, AMP-514 및 AMP-224(리간드-Fc 융합체)(항 PD1), 아테졸리주맙(MPDL3280A), 아벨루맙(MSB0010718C), 더발루맙(MEDI4736), MEDI0680 및 BMS-9365569(항 PDL1), MEDI6469(항 OX40 효현제), BMS-986016, IMP701, IMP731, IMP321(항 LAG3) 및 GITR 리간드를 포함할 수 있다.
항원 특이적 결합 도메인
항원 특이적 결합 도메인은 발병 세포상 표적들과 특이적으로 결합하는 폴리펩티드들로 이루어져 있다. 대안적으로 이러한 도메인은 병상(diseased state)을 지원하는 기타 세포상 표적, 예컨대 종양의 성장을 지원하는 기질 세포상 표적 또는 질환 매개성 면역억제를 지원하는 면역세포상 표적에 결합할 수 있다. 항원 특이적 결합 도메인은 당 분야에 공지된 항체, 단일 사슬 항체, Fab, Fv, T 세포 수용체 결합 도메인, 리간드 결합 도메인, 수용체 결합 도메인, 도메인 항체, 단일 도메인 항체, 미니바디, 나노바디, 펩티바디 또는 기타 다양한 항체 모의체(예컨대 아피머, 아피틴, 알파바디, 아트리머, CTLA4 기반 분자, 아드넥틴, 안티칼린, Kunitz 도메인 기반 단백질, 아비머, 노틴, 파이노머, 다르핀, 아피바디, 아필린, 모노바디 및 아르마딜로 반복 단백질 기반 단백질(Weidle, UH, et al. 2013. Cancer Genomics & Proteomics 10: 155-168))을 포함한다.
임의의 구현예들에서, 항원 특이적 결합 도메인에 대한 항원은 세포 표면 수용체 또는 리간드를 포함한다. 추가의 구현예에서, 항원은 CD 항원, 시토카인 또는 케모카인 수용체 또는 리간드, 성장 인자 수용체 또는 리간드, 조직 인자, 세포 부착 분자, MHC/MHC-유사 분자, Fc 수용체, Toll-유사 수용체, NK 수용체, TCR, BCR, 양성/음성 보조자극 수용체 또는 리간드, 사멸 수용체 또는 리간드, 종양 연관 항원, 또는 바이러스 암호화 항원을 포함한다.
바람직하게 항원 특이적 결합 도메인은 종양 세포상 항원과 결합할 수 있다. 종양 특이적 결합 도메인은 암 환자 치료용으로 승인된 항체, 예컨대 리툭시맙, 오파투무맙 및 오비누투주맙(항 CD20 Ab); 트라스투주맙 및 퍼투주맙(항 HER2 Ab); 세툭시맙 및 파니투무맙(항 EGFR Ab); 그리고 알렘투주맙(항 CD52 Ab)로부터 유래할 수 있다. 이와 유사하게, 승인된 항체-효과기 분자 접합체로서, CD20에 특이적인 것(90Y-표지화 이브리투모맙 티욱세탄, 131I-표지화 토시투모맙), HER2에 특이적인 것(아도-트라스투주맙 엠탄신), CD30에 특이적인 것(브렌툭시맙 베도틴) 및 CD33에 특이적인 것(겜투주맙 오조가미신)으로부터 유래하는 결합 도메인이 사용될 수 있었다(Sliwkowski MX, Mellman I. 2013 Science 341:1192).
또한, 본 발명의 바람직한 결합 도메인은 당 분야에 공지된 기타 다양한 종양 특이적 항체 도메인을 포함할 수 있다. 암 치료를 위한 항체와 이의 각각의 표적으로서는 니볼루맙(항 PD-1 Ab), TA99(항 gp75), 3F8(항 GD2), 8H9(항 B7-H3), 아바고보맙(항 CA-125(이미타티온)), 아데카투무맙(항 EpCAM), 아푸투주맙(항 CD20), 알라시주맙 페골(항 VEGFR2), 알투모맙 펜테테이트(항 CEA), 아마툭시맙(항 메소텔린), AME-133(항 CD20), 아나투모맙 마페나톡스(항 TAG-72), 아폴리주맙(항 HLA-DR), 아르시투모맙(항 CEA), 바비툭시맙(항 포스파티딜세린), 벡투모맙(항 CD22), 벨리무맙(항 BAFF), 베실레소맙(항 CEA-관련 항원), 베바시주맙(항 VEGF-A), 비바투주맙 메르탄신(항 CD44 v6), 블리나투모맙(항 CD19), BMS-663513(항 CD137), 브렌툭시맙 베도틴(항 CD30(TNFRSF8)), 칸투주맙 메르탄신(항 뮤신 CanAg), 칸투주맙 라브탄신(항 MUC1), 카프로맙 펜데타이드(항 전립선암종세포), 카를루맙(항 MCP-1), 카투막소맙(항 EpCAM, CD3), cBR96-독소루비신 면역접합체(항 루이-Y 항원), CC49(항 TAG-72), 세델리주맙(항 CD4), Ch.14.18(항 GD2), ch-TNT(항 DNA 연관 항원), 시타투주맙 보가톡스(항 EpCAM), 식수투무맙(항 IGF-1 수용체), 클리바투주맙 테트락세탄(항 MUC1), 코나투무맙(항 TRAIL-R2), CP-870893(항 CD40), 다세투주맙(항 CD40), 다클리주맙(항 CD25), 달로투주맙(항 인슐린 유사 성장 인자 I 수용체), 다라투무맙(항 CD38(사이클릭 ADP 리보스 하이드롤라아제)), 뎀시주맙(항 DLL4), 데투모맙(항 B-림프종 세포), 드로지투맙(항 DR5), 둘리고투맙(항 HER3), 두시기투맙(항 ILGF2), 에크로멕시맙(항 GD3 강글리오사이드), 에드레콜로맙(항 EpCAM), 엘로투주맙(항 SLAMF7), 엘시리모맙(항 IL-6), 에나바투주맙(항 TWEAK 수용체), 에노티쿠맙(항 DLL4), 엔시툭시맙(항 5AC), 에피투모맙 시툭세탄(항 에피시알린), 에프라투주맙(항 CD22), 에르투막소맙(항 HER2/neu, CD3), 에타라시주맙(항 인테그린 αvβ3), 파랄리모맙(항 인터페론 수용체), 파를레투주맙(항 엽산염 수용체 1), FBTA05(항 CD20), 피클라투주맙(항 HGF), 피기투무맙(항 IGF-1 수용체), 플란보투맙(항 TYRP1(당단백질 75)), 프레솔리무맙(항 TGFβ), 푸툭시맙(항 EGFR), 갈릭시맙(항 CD80), 가니투맙(항 IGF-I), 겜투주맙 오조가미신(항 CD33), 기렌툭시맙(항 탄산무수화효소 9(CA-IX)), 글렘바투무맙 베도틴(항 GPNMB), 구셀쿠맙(항 IL13), 이발리주맙(항 CD4), 이브리투모맙 티욱세탄(항 CD20), 이크루쿠맙(항 VEGFR-1), 이고보맙(항 CA-125), IMAB362(항 CLDN18.2), IMC-CS4(항 CSF1R), IMC-TR1(TGFβRII), 임가투주맙(항 EGFR), 인클라쿠맙(항 셀렉틴 P), 인다툭시맙 라브탄신(항 SDC1), 이노투주맙 오조가미신(항 CD22), 인테투무맙(항 CD51), 이필리무맙(항 CD152), 이라투무맙(항 CD30(TNFRSF8)), KM3065(항 CD20), KW-0761(항 CD194), LY2875358(항 MET) 라베투주맙(항 CEA), 람브롤리주맙(항 PDCD1), 렉사투무맙(항 TRAIL-R2), 린투주맙(항 CD33), 리릴루맙(항 KIR2D), 로르보투주맙 메르탄신(항 CD56), 루카투무맙(항 CD40), 루밀릭시맙(항 CD23(IgE 수용체)), 마파투무맙(항 TRAIL-R1), 마르게툭시맙(항 ch4D5), 마투주맙(항 EGFR), 마브릴리무맙(항 GMCSF 수용체 α-사슬), 밀라투주맙(항 CD74), 민레투모맙(항 TAG-72), 미투모맙(항 GD3 강글리오사이드), 모가물리주맙(항 CCR4), 목세투모맙 파수도톡스(항 CD22), 나콜로맙 타페나톡스(항 C242 항원), 납투모맙 에스타페나톡스(항 5T4), 나르나투맙(항 RON), 네시투무맙(항 EGFR), 네스바쿠맙(항 안지오포이에틴 2), 니모투주맙(항 EGFR), 니볼루맙(항 IgG4), 노페투모맙 메르펜탄, 오크렐리주맙(항 CD20), 오카라투주맙(항 CD20), 올라라투맙(항 PDGF-Rα), 오나르투주맙(항 c-MET), 온툭시주맙(항 TEM1), 오포르투주맙 모나톡스(항 EpCAM), 오레고보맙(항 CA-125), 오틀레르투주맙(항 CD37), 판코맙(MUC1의 항 종양 특이적 당화), 파르사투주맙(항 EGFL7), 파스콜리주맙(항 IL-4), 파트리투맙(항 HER3), 펨투모맙(항 MUC1), 페르투주맙(항 HER2/neu), 피딜리주맙(항 PD-1), 피나투주맙 베도틴(항 CD22), 핀투모맙(항 선암종 항원), 폴라투주맙 베도틴(항 CD79B), 프리투무맙(항 비멘틴), PRO131921(항 CD20), 퀼리주맙(항 IGHE), 라코투모맙(항 N-글리콜릴뉴라민산), 라드레투맙(항 피브로넥틴 여분 도메인-B), 라무시루맙(항 VEGFR2), 리로투무맙(항 HGF), 로바투무맙(항 IGF-1 수용체), 로레두맙(항 RHD), 로벨리주맙(항 CD11 및 CD18), 사말리주맙(항 CD200), 사투모맙 펜데타이드(항 TAG-72), 세리반투맙(항 ERBB3), SGN-CD19A(항 CD19), SGN-CD33A(항 CD33), 시브로투주맙(항 FAP), 실툭시맙(항 IL-6), 솔리토맙(항 EpCAM), 손투주맙(항 에피시알린), 타발루맙(항 BAFF), 타카투주맙 테트라제탄(항 알파-태아단백질), 타플리투모맙 팝톡스(항 CD19), 텔리모맙 아리톡스, 테나투모맙(항 테나신 C), 테네릭시맙(항 CD40), 테프로투무맙(항 CD221), TGN1412(항 CD28), 티실리무맙(항 CTLA-4), 티가투주맙(항 TRAIL-R2), TNX-650(항 IL-13), 토시투모맙(항 CS20), 토베투맙(항 CD140a), TRBS07(항 GD2), 트레갈리주맙(항 CD4), 트레멜리무맙(항 CTLA-4), TRU-016(항 CD37), 투코투주맙 셀모루킨(항 EpCAM), 우블리툭시맙(항 CD20), 우렐루맙(항 4-1BB), 반틱투맙(항 프리즐드(Frizzled) 수용체), 바팔릭시맙(항 AOC3(VAP-1)), 바텔리주맙(항 ITGA2), 벨투주맙(항 CD20), 베센쿠맙(항 NRP1), 비실리주맙(항 CD3), 볼로식시맙(항 인테그린 α5β1), 보르세투주맙 마포도틴(항 CD70), 보투무맙(항 종양 항원 CTAA16.88), 잘루투무맙(항 EGFR), 자놀리무맙(항 CD4), 자툭시맙(항 HER1), 지랄리무맙(항 CD147(바시긴)), RG7636(항 ETBR), RG7458(항 MUC16), RG7599(항 NaPi2b), MPDL3280A(항 PD-L1), RG7450(항 STEAP1) 및 GDC-0199(항 Bcl-2)를 포함하나, 이에 한정되는 것은 아니다.
본 발명에 유용한 기타 항체 도메인 또는 종양 결합 단백질(예컨대 TCR 도메인)로서는 하기 항원들과 결합하는 것들을 포함하나, 이에 한정되는 것은 아니다(주의; 명시된 암의 적응증들은 비 제한적 예를 나타냄): 아미노펩티다아제 N(CD13), 어넥신 Al, B7-H3(CD276, 다수의 암), CA125(난소암), CA15-3(암종), CA19-9(암종), L6(암종), 루이 Y(암종), 루이 X(암종), 알파 태아단백질(암종), CA242(결장직장암), 태반 알칼리성 포스파타아제(암종), 전립선 특이 항원(전립선), 전립선산 포스파타아제(전립선), 표피 성장 인자(암종), CD2(호지킨병, NHL 림프종, 다발성 골수종), CD3 엡실론(T 세포 림프종, 폐암, 유방암, 위암, 난소암, 자가면역성 질환, 악성 복수), CD19(B 세포 악성종양), CD20(비호지킨 림프종, B-세포 신생물형성, 자가면역성 질환), CD21(B 세포 림프종), CD22(백혈병, 림프종, 다발성 골수종, SLE), CD30(호지킨 림프종), CD33(백혈병, 자가면역성 질환), CD38(다발성 골수종), CD40(림프종, 다발성 골수종, 백혈병(CLL)), CD51(전이성 흑색종, 육종), CD52(백혈병), CD56(소세포 폐암, 난소암, Merkel 세포 암종, 및 액상 종양, 다발성 골수종), CD66e(암종), CD70(전이성 신세포 암종 및 비호지킨 림프종), CD74(다발성 골수종), CD80(림프종), CD98(암종), CD123(백혈병), 뮤신(암종), CD221(고형 종양), CD227(유방암, 난소암), CD262(NSCLC 및 기타 암), CD309(난소암), CD326(고형 종양), CEACAM3(결장직장암, 위암), CEACAM5(CEA, CD66e)(유방암, 결장직장암, 폐암), DLL4(A-유사-4), EGFR(다수의 암), CTLA4(흑색종), CXCR4(CD 184, 혈액종양, 고형 종양), 엔도글린(CD 105, 고형 종양), EPCAM(상피 세포 부착 분자, 방광, 두부, 경부, 결장, NHL 전립선, 및 난소의 암), ERBB2(폐, 유방 및 전립선의 암), FCGR1(자가면역성 질환), FOLR(엽산염 수용체, 난소암), FGFR(암종), GD2 강글리오사이드(암종), G-28(세포 표면 항원 당지질, 흑색종), GD3 이디오타입(암종), 열충격 단백질(암종), HER1(폐암, 위암), HER2(유방, 폐 및 난소의 암), HLA-DR10(NHL), HLA-DRB(NHL, B 세포 백혈병), 인간 융모막 성선자극호르몬(암종), IGF1R(고형 종양, 혈액암), IL-2 수용체(T 세포 백혈병 및 림프종), IL-6R(다발성 골수종, RA, 캐슬만씨병, IL6 의존성 종양), 인테그린 (다수의 암에 대한 ανβ3, α5β1, α6β4, α11β3, α5β5, ανβ5), MAGE-1(암종), MAGE-2(암종), MAGE-3(암종), MAGE 4(암종), 항 트랜스페린 수용체(암종), p97(흑색종), MS4A1(막 확장성 4-도메인 아과 A 일원 1, 비호지킨 B 세포 림프종, 백혈병), MUC1(유방, 난소, 자궁경부, 기관지 및 위장관의 암), MUC16(CA125)(난소암), CEA(결장직장암), gp100(흑색종), MARTI(흑색종), MPG(흑색종), MS4A1(막 확장성 4-도메인 아과 A, 소세포 폐암, NHL), 뉴클레올린, Neu 발암유전자 생성물(암종), P21(암종), 넥틴-4(암종), 항 (N-글리콜릴뉴라민산, 유방암, 흑색종)의 파라토프, PLAP-유사 고환 알칼리성 포스파타아제(난소암, 고환암), PSMA(전립선 종양), PSA(전립선), ROB04, TAG 72(종양 연관 당단백질 72, AML, 위암, 결장직장암, 난소암), T 세포 경막 단백질(암), Tie(CD202b), 조직 인자, TNFRSF10B(종양 괴사 인자 수용체 상과 일원 10B, 암종), TNFRSF13B(종양 괴사 인자 수용체 상과 일원 13B, 다발성 골수종, NHL, 기타 암, RA 및 SLE), TPBG(세포영양막 당단백질, 신세포 암종), TRAIL-R1(종양 괴사성 세포자멸 유도 리간드 수용체 1, 림프종, NHL, 결장직장암, 폐암), VCAM-1(CD106, 흑색종), VEGF, VEGF-A, VEGF-2(CD309)(다수의 암). 기타 몇몇 종양 연관 항원 표적에 관하여도 검토된 바 있다(Gerber, et al, Mabs 2009 1:247-253; Novellino et al, Cancer Immunol Immunother. 2005 54:187-207, Franke, et al, Cancer Biother Radiopharm. 2000, 15:459-76, Guo, et al., Adv Cancer Res. 2013; 119: 421-475, Parmiani et al. J Immunol. 2007 178:1975-9). 이러한 항원의 예들로서는 분화클러스터들(CD4, CD5, CD6, CD7, CD8, CD9, CD10, CD11a, CD11b, CD11c, CD12w, CD14, CD15, CD16, CDwl7, CD18, CD21, CD23, CD24, CD25, CD26, CD27, CD28, CD29, CD31, CD32, CD34, CD35, CD36, CD37, CD41, CD42, CD43, CD44, CD45, CD46, CD47, CD48, CD49b, CD49c, CD53, CD54, CD55, CD58, CD59, CD61, CD62E, CD62L, CD62P, CD63, CD68, CD69, CD71, CD72, CD79, CD81, CD82, CD83, CD86, CD87, CD88, CD89, CD90, CD91, CD95, CD96, CD100, CD103, CD105, CD106, CD109, CD117, CD120, CD127, CD133, CD134, CD135, CD138, CD141, CD142, CD143, CD144, CD147, CD151, CD152, CD154, CD156, CD158, CD163, CD166, .CD168, CD184, CDw186, CD195, CD202(a, b), CD209, CD235a, CD271, CD303, CD304), 어넥신 Al, 뉴클레올린, 엔도글린(CD105), ROB04, 아미노-펩티다아제 N, -유사-4(DLL4), VEGFR-2(CD309), CXCR4(CD184), Tie2, B7-H3, WT1, MUC1, LMP2, HPV E6 E7, EGFRvIII, HER-2/neu, 이디오타입, MAGE A3, p53 비돌연변이체, NY-ESO-1, GD2, CEA, MelanA/MARTl, Ras 돌연변이체, gp100, p53 돌연변이체, 프로티나아제 3(PR1), bcr-abl, 티로시나아제, 서바이빈, hTERT, 육종 전좌 중단점(sarcoma translocation breakpoint), EphA2, PAP, ML-IAP, AFP, EpCAM, ERG(TMPRSS2 ETS 융합 유전자), NA17, PAX3, ALK, 안드로겐 수용체, 사이클린 B l, 폴리시알산, MYCN, RhoC, TRP-2, GD3, 푸코실 GMl, 메소텔린, PSCA, MAGE Al, sLe(a), CYPIB I, PLACl, GM3, BORIS, Tn, GloboH, ETV6-AML, NY-BR-1, RGS5, SART3, STn, 탄산무수화효소 IX, PAX5, OY-TES1, 정자 단백질 17, LCK, HMWMAA, AKAP-4, SSX2, XAGE 1, B7H3, 레규마인, Tie 2, Page4, VEGFR2, MAD-CT-1, FAP, PDGFR-β, MAD-CT-2, Notch1, ICAM1 및 Fos-관련 항원 1을 포함한다.
추가로 본 발명의 바람직한 결합 도메인으로서는, 당 분야에 공지된, 감염 세포 연관 에피토프 표적 및 항원 표적에 특이적인 것들을 포함한다. 이러한 표적들로서는 하기 관심 감염성 제제로부터 유래하는 것들을 포함하나, 이에 한정되는 것은 아니다:
HIV 바이러스(구체적으로 HIV 외피 스파이크 유래 항원 및/또는 gp120 및 gp41 에피토프), 인유두종바이러스(HPV), 마이코박테리움 투베르큘로시스(Mycobacterium tuberculosis), 스트렙토코커스 아가락티아에(Streptococcus agalactiae), 메티실린 내성 스타필로코커스 아우레우스(Staphylococcus aureus), 레지오넬라 뉴모필리아(Legionella pneumophilia), 스트렙토코커스 피오제네스(Streptococcus pyogenes), 에스케리치아 콜라이(Escherichia coli), 네이세리아 고노로에아에(Neisseria gonorrhoeae), 네이세리아 메닌기티디스(Neisseria meningitidis), 뉴모코커스(Pneumococcus), 크립토코커스 네오포르만스(Cryptococcus neoformans), 히스토플라스마 캡슐라튬(Histoplasma capsulatum), - 인플루엔자 B, 트레포네마 팔리듐(Treponema pallidum), 라임병 스피로헤타, 슈도모나스 아에루기노사(Pseudomonas aeruginosa), 마이코박테리움 레프라에(Mycobacterium leprae), 브루셀라 아보르투스(Brucella abortus), 공수병 바이러스, 인플루엔자 바이러스, 거대세포바이러스, 헤르페스 심플렉스(herpes simplex) 바이러스 I, 헤르페스 심플렉스 바이러스 II, 인간 혈청 파르보 유사 바이러스, 호흡기세포융합 바이러스, 바리셀라-조스터(varicella-zoster) 바이러스, B형 간염 바이러스, C형 간염 바이러스, 홍역 바이러스, 아데노바이러스, 인간 T 세포 백혈병 바이러스, 엡스타인-바(Epstein-Barr) 바이러스, 마우스 백혈병 바이러스, 이하선염 바이러스, 수포성구내염 바이러스, 신드비스(sindbis) 바이러스, 림프구성 맥락수막염 바이러스, 사마귀 바이러스, 청설병 바이러스, 센다이(Sendai) 바이러스, 고양이 백혈병 바이러스, 레오바이러스, 소아마비 바이러스, 유인원 바이러스 40, 마우스 유방 종양 바이러스, 뎅기열 바이러스, 풍진 바이러스, 웨스트 나일(West Nile) 바이러스, 플라스모듐 팔시파륨(Plasmodium falciparum), 플라스모듐 비백스(Plasmodium vivax), 톡소플라스마 곤디이(Toxoplasma gondii), 트리파노소마 란겔리(Trypanosoma rangeli), 트리파노소마 크루지(Trypanosoma cruzi), 트리파노소마 로데시엔세이(Trypanosoma rhodesiensei), 트리파노소마 브루세이(Trypanosoma brucei), 쉬스토소마 만소니(Schistosoma mansoni), 쉬스토소마 자포니큠(Schistosoma japonicum), 바베시아 보비스(Babesia bovis), 엘메리아 테넬라(Elmeria tenella), 온코세르카 볼불루스(Onchocerca volvulus), 레이슈마니아 트로피카(Leishmania tropica), 트리키넬라 스피랄리스(Trichinella spiralis), 테일레리아 파르바(Theileria parva), 타에니아 히단티게나(Taenia hydatigena), 타에니아 오비스(Taenia ovis), 타에니아 사기나타(Taenia saginata), 에키노코커스 그래뉼로서스(Echinococcus granulosus), 메소세스토이데스 코르티(Mesocestoides corti), 마이코플라스마 아르트리티디스(Mycoplasma arthritidis), 엠.하이오리니스(M. hyorhinis), 엠.오랄레(M. orale), 엠.아르기니니(M arginini), 아콜레플라스마 라이드로이이(Acholeplasma laidlawii), 엠. 살리바리움(M. salivarium) 및 엠. 뉴모니아에(M. pneumoniae).
T 세포 수용체(TCR)
T 세포는 기타 면역 세포 유형들(다형핵 세포, 호산구, 호염기구, 비만 세포, B 세포, NK 세포)과 함께 면역계의 세포성 성분을 이루는 세포의 하위군이다. 생리적 조건 하에서 T 세포는 면역 감시와 외래 항원 제거의 역할을 담당한다. 그러나 병리학적 조건 하에서는 T 세포가 질환의 유발과 확산에 중요한 역할을 한다는 강력한 증거가 있다. 이러한 장애에 있어서, T 세포 면역 관용성의 파괴는, 그것이 중심적인 것인지 아니면 주변적인 것인지간에 자가면역성 질환의 유발에 있어 근본적인 과정인 것이다.
TCR 복합체는, 적어도 7개의 경막 단백질로 이루어져 있다. 이황화 결합된 (ab 또는 γδ) 이종이량체는 단형속 항원 인지 단위를 형성하는 한편, e, g, d, z 및 h 사슬들로 이루어져 있는 CD3의 불변 사슬은 신호전달 경로에 리간드 결합을 연계하여, T 세포 활성화와 세포성 면역반응을 도모하는데 관여한다. TCR 사슬의 유전자 다양성에도 불구, 공지된 모든 서브유닛들에는 2가지 구조적 특징이 공통으로 존재한다. 첫 번째 구조적 특징은 이 TCR 사슬이 (아마도 알파-나선형일) 경막 확장성 도메인 하나를 가지는 경막 단백질이라는 점이다. 두 번째 구조적 특징은, 모든 TCR 사슬들은 예측 경막 도메인 내에 하전된 아미노산을 가지는 것과 같은 일반적이지 않은 특징을 가진다는 점이다. 불변 사슬은 하나의 음전하를 가지고, 마우스와 인간 간에 보존되어 있으며, 가변 사슬은 하나의 양전하를 가지거나(TCR-b) 또는 2개의 양전하를 가진다(TCR-a). TCR-a의 경막 서열은 다수의 종들간에 매우 보존적이어서, 계통발생상 중요한 기능상의 역할을 담당할 수 있다. 친수성 아미노산 아르기닌과 리신을 함유하는 옥타펩티드 서열은 종들 간에 동일하다.
T 세포 반응은 TCR에의 항원 결합에 의해 조정된다. TCR의 일 유형은, 면역글로불린 가변 영역(V) 및 불변 영역(C)을 닮은, a 사슬 및 b 사슬로 이루어진 막 결합 이종이량체이다. TCR a 사슬은 공유 결합된 V-a 사슬 및 C-a 사슬을 포함하는 한편, TCR b 사슬은 C-b 사슬에 공유 결합된 V-b 사슬을 포함한다. V-a 사슬 및 V-b 사슬은 주 조직적합성 복합체(MHC)(인간의 경우에는 HLA 복합체로 알려짐)의 환경 중 항원 또는 초항원과 결합할 수 있는 포켓 또는 틈을 형성한다. 문헌(Davis Ann. Rev. of Immunology 3: 537(1985); Fundamental Immunology 3rd Ed., W. Paul Ed. Rsen Press LTD. New York(1993))을 참조한다.
TCR 사슬(ab 또는 γδ)의 세포외 도메인은 또한 세포 표면상 발현을 위해 이종 경막 도메인과의 융합체로서 조작될 수 있다. 이러한 TCR은 CD3, CD28, CD8, 4-1BB 및/또는 키메라 활성화 수용체(CAR) 경막 도메인 또는 활성화 도메인과의 융합체를 포함할 수 있다. TCR은 또한 ab 또는 γδ 사슬의 항원 결합 도메인들 중 하나 이상을 포함하는 가용성 단백질일 수 있다. 이러한 TCR은 TCR 불변 도메인들과 결합되어 있거나 결합되어 있지 않은 TCR 가변 도메인 또는 이의 기능성 단편을 포함할 수 있다. 가용성 TCR은 이종이량체이거나 단일 사슬 분자일 수 있다.
Fc 도메인
본 발명의 단백질 복합체는 Fc 도메인을 함유할 수 있다. 예를 들어 PD-L1 TxM은 항 PD-L1 scAb/huIL-15N72D:항 PD-L1 scAb/huIL-15RαSu/huIgG1 Fc 융합 복합체를 포함한다. IgG의 Fc 영역과, 또 다른 단백질(예컨대 다양한 시토카인)의 도메인 및 가용성 수용체를 합한 융합 단백질이 보고된 바 있다(예컨대 문헌(Capon et al., Nature, 337:525-531, 1989; Chamow et al., Trends Biotechnol., 14:52-60, 1996); 미국특허 제5,116,964호 및 동 제5,541,087호) 참조). 원형 융합 단백질은 IgG Fc의 힌지 영역 내 시스테인 잔기들을 통해 결합되어, 중쇄 가변 도메인과 CH1 도메인, 그리고 경쇄를 포함하지 않는, IgG 분자와 유사한 분자를 이루는 동종이량체 단백질이다. Fc 도메인을 포함하는 융합 단백질의 이량체로서의 성질은, 다른 분자와의 고차원적 상호작용(즉 2가 또는 이중 특이적 결합)을 제공함에 있어서 유리할 수 있다. 구조상의 상동성으로 말미암아, Fc 융합 단백질은, 유사한 이소타입을 보이는 인간 IgG의 생체 내 약동학적 프로필과 거의 동일한 생체 내 약동학적 프로필을 보인다. IgG군의 면역글로불린은 인간 혈액에 가장 많이 존재하는 단백질로서, 이의 혈행 반감기(circulation half-life)는 21일까지에 이를 수 있다. IL-15 또는 IL-15 융합 단벡질의 혈행 반감기를 연장시키고/연장시키거나 이의 생물 활성을 증가시키기 위한, 인간 중쇄 IgG 단백질의 Fc부에 공유 결합된 IL-15Rα와 비공유 결합하고 있는 IL-15 도메인을 함유하는 융합 단백질 복합체가 본원에 기술되어 있다.
"Fc"란 용어는, Fc 수용체라 칭하여지는 세포 표면 수용체와, 보체계의 몇몇 단백질과 상호작용하는 항체의 불변 영역인 결정화가능 단편 영역(fragment crystallizable region)을 지칭한다. 이러한 "Fc"는 이량체 형태를 가진다. 원산 Fc의 원천 면역글로불린 공급원은, 바람직하게 인간 기원 면역글로불린 중 임의의 것일 수 있지만, IgG1 및 IgG2가 바람직하다. 원산 Fc들은 공유 결합(즉 이황화 결합)과 비공유 결합에 의해 이량체 형태 또는 다량체 형태로 결합될 수 있는, 단량체 폴리펩티드들로 이루어져 있다. 원산 Fc 분자들의 단량체 서브유닛들 사이의 분자간 이황화 결합의 수는, 군(예컨대 IgG, IgA, IgE) 또는 하위군(예컨대 IgG1, IgG2, IgG3, IgA1, IgGA2)에 따라서 1개 내지 4개의 범위이다. 원산 Fc의 일례로서는 IgG의 파페인 분해에 의해 생성되는 이황화 결합 이량체가 있다(문헌(Ellison et al.(1982), Nucleic Acids Res. 10: 4071-9) 참조). 본원에 사용된 바와 같은 "원산 Fc"란 용어는, 단량체 형태, 이량체 형태 및 다량체 형태를 총칭하는 것이다. Fc 도메인은 단백질 A, 단백질 G, 다양한 Fc 수용체 및 보체 단백질에 대한 결합 부위들을 함유한다. 몇몇 구현예들에서 복합체의 Fc 도메인은 Fc 수용체와 상호작용하여, 항체 의존적 세포 매개 세포독성(ADCC) 및/또는 항체 의존적 세포성 식세포작용(ADCP)을 매개할 수 있다. 다른 응용예에서, 복합체는 ADCC 또는 ADCP를 효과적으로 매개할 수 없는 Fc 도메인(예컨대 IgG4 Fc)을 포함한다.
몇몇 구현예들에서, "Fc 변이체"란 용어는, 원산 Fc로부터 변형되었지만, 구조 수용체(salvage receptor), 즉 FcRn에 대한 결합 부위를 여전히 포함하는 분자 또는 서열을 지칭한다. 국제특허출원공보 WO 97/34631 및 WO 96/32478는, 예시적 Fc 변이체뿐만 아니라, 구조 수용체와의 상호작용을 기술하고 있으며, 이 문헌들은 본원에 참조로 인용되어 있다. 그러므로 "Fc 변이체"란 용어는, 비인간 원산 Fc로부터 유래하여 인간화된 분자 또는 서열을 포함한다. 게다가 원산 Fc는, 본 발명의 융합 분자에 불필요한 구조적 특징 또는 생물 활성을 제공함으로 말미암아 제거될 수 있는 부위들을 포함한다. 그러므로 임의의 구현예들에서, "Fc 변이체"란 용어는, (1) 이황화 결합 형성, (2) 선택된 숙주 세포와의 양립불가능, (3) 선택된 숙주 세포 내 발현시 N-말단의 이질성, (4) 당화, (5) 보체와의 상호작용, (6) 구조 수용체 이외의 Fc 수용체와의 결합, (7) 항체 의존적 세포성 세포독성(ADCC) 또는 (8) 항체 의존적 세포성 식세포작용(ADCP)에 영향을 미치거나 이에 수반되는 하나 이상의 원산 Fc 부위들 또는 잔기들이 변경된, 분자 또는 서열을 포함한다. 이러한 변경은 이와 같은 Fc의 특성들 중 임의의 것 하나 이상을 증가시킬 수 있거나 감소시킬 수 있다. Fc 변이체는 이하에 더욱 상세히 기술되어 있다.
"Fc 도메인"이란 용어는, 상기 정의된 바와 같이 원산 Fc 및 Fc 변이체 분자들 및 서열들을 포함한다. Fc 변이체 및 원산 Fc와 같이, "Fc 도메인"이란 용어는, 그것이 전 항체로부터 분해되었건, 아니면 재조합 유전자 발현 또는 기타 수단에 의해 생산되었건 간에 단량체 형태 또는 다량체 형태의 분자들을 포함한다.
융합 단백질 복합체
본 발명은 융합 단백질 복합체를 제공한다(도 1 및 도 2). 몇몇 경우들에 있어서, 제1 단백질은, 인터루킨-15(IL-15) 또는 이의 기능성 단편에 공유 결합되는 제1 생물 활성 폴리펩티드를 포함하고; 제2 단백질은 가용성 인터루킨-15 수용체 알파(IL-15Ra) 폴리펩티드 또는 이의 기능성 단편에 공유 결합되는 제2의 생물 활성 폴리펩티드를 포함하는데, 여기서 제1 단백질의 IL-15 도메인은 제2 단백질의 가용성 IL-15Ra 도메인과 결합하여, 가용성 융합 단백질 복합체를 형성한다. 본 발명의 융합 단백질 복합체는 또한 제1 단백질 및 제2 단백질 중 어느 하나 또는 둘다에 결합된 면역글로불린 Fc 도메인 또는 이의 기능성 단편을 포함한다. 바람직하게 융합 단백질에 결합된 Fc 도메인들은 상호작용하여 융합 단백질 복합체를 형성한다. 이러한 복합체는 면역글로불린 Fc 도메인들 간에 이황화 결합을 형성함으로써 안정화될 수 있다. 일 양태에서, 본 발명의 가용성 융합 단백질 복합체는 IL-15 폴리펩티드, IL-15 변이체 또는 이의 기능성 단편과, 가용성 IL-15Rα 폴리펩티드 또는 이의 기능성 단편을 포함하는데, 여기서 IL-15 폴리펩티드 및 IL-15Rα 폴리펩티드 중 어느 하나 또는 둘 다는 면역글로불린 Fc 도메인 또는 이의 기능성 단편을 추가로 포함한다.
임의의 예들에서, 제1 및 제2 단백질 중 어느 하나 또는 둘 다는 항체 또는 이의 기능성 단편을 포함한다. 예를 들어 결합 도메인 중 하나는 가용성 항 PD-L1 단일 사슬 항체 또는 이의 기능성 단편을 포함한다. 다른 예에 있어서, 또 다른 제2 결합 도메인은 항 CTLA4 단일 사슬 항체 또는 질환 항원 특이적 항체 또는 이의 기능성 단편을 포함한다. 일 구현예에서, 본 발명은 가용성 항 PD-L1 scAb/huIL-15N72D:항 PD-L1 scAb/huIL-15RαSu/huIgG1 Fc 융합 단백질 복합체를 포함하는 PD-L1 TxM을 제공한다. 이 복합체에서 huIL-15N72D 도메인 및 huIL-15RαSu 도메인은 2개의 항 PD-L1 scAb/huIL-15RαSu/huIgG1 Fc 융합 단백질상 huIgG1 Fc 도메인과 상호작용하여 다중 사슬 융합 단백질 복합체를 형성한다.
본원에 사용된 바와 같은 "생물 활성 폴리펩티드" 또는 "효과기 분자"란 용어는, 본원에 논의된 바와 같이 원하는 효과를 발휘할 수 있는 아미노산 서열, 예컨대 단백질, 폴리펩티드 또는 펩티드; 당체 또는 다당체; 지질 또는 당지질, 당단백질 또는 지단백질을 의미한다. 효과기 분자는 또한 화학 제제를 포함한다. 생물 활성 단백질, 폴리펩티드 또는 펩티드나, 또는 효과기 단백질, 폴리펩티드 또는 펩티드를 암호화하는 효과기 분자 핵산도 또한 고려된다. 그러므로 적합한 분자로서는 조절 인자, 효소, 항체 또는 약물뿐만 아니라, DNA, RNA 및 올리고뉴클레오티드도 포함한다. 생물 활성 폴리펩티드 또는 효과기 분자는 자연 발생될 수 있거나, 또는, 예컨대 재조합 또는 화학 합성법에 의해 공지의 성분으로부터 합성될 수 있으며, 이종 성분을 포함할 수 있다. 생물 활성 폴리펩티드 또는 효과기 분자는, 일반적으로 표준 분자 크기분석 기술, 예컨대 원심분리나 SDS-폴리아크릴아미드 겔 전기영동에 의해 판단되는 바에 따라 약 0.1 내지 100 KD 또는 이 이상으로부터 약 1000 KD까지이며, 바람직하게는 약 0.1, 0.2, 0.5, 1, 2, 5, 10, 20, 30 내지 50 KD이다. 본 발명의 원하는 효과로서는, 예를 들어 결합 활성이 증가한 본 발명의 융합 단백질 복합체의 형성, 예컨대 질환의 예방 또는 치료에 있어 세포 증식 또는 세포 사멸을 유도하기 위한 표적 세포의 사멸, 면역 반응의 개시, 또는 진단을 목적으로 하는 검출 분자로서의 기능을 포함하나, 이에 한정되는 것은 아니다. 이러한 검출을 위하여, 일련의 단계들을 포함하는 검정법, 예를 들어 세포를 증식시키기 위해 이 세포를 배양하는 단계와, 세포와 본 발명의 융합 복합체를 접촉시키는 단계, 그리고 이후 융합 복합체가 세포의 추후 발달을 억제하는지 여부를 평가하는 단계를 포함하는 검정법이 사용될 수 있었다.
본 발명에 따라 효과기 분자를 본 발명의 융합 단백질 복합체에 공유 결합시키는 것은, 다수의 유의미한 이점을 제공한다. 하나의 효과기 분자, 예컨대 공지의 구조를 가지는 펩티드를 함유하는 본 발명의 융합 단백질 복합체가 제조될 수 있다. 추가로 다양한 효과기 분자가 유사한 DNA 벡터들에서 제조될 수 있다. 다시 말해, 상이한 효과기 분자 라이브러리는 감염 세포 또는 발병 세포의 인지를 위하여 융합 단백질 복합체에 결합될 수 있다. 또한 치료적 응용을 위해서는, 본 발명의 융합 단백질 복합체를 대상체에 투여하기 보다, 이 융합 단백질 복합체를 암호화하는 DNA 발현 벡터를 투여하여 융합 단백질 복합체를 생체 내 발현시킬 수 있다. 이러한 접근법은, 통상적으로 재조합 단백질 제조와 관련된 고비용의 정제 단계들을 수행하지 않고, 항원 흡수의 복잡성을 초래하지 않으며, 종래 접근법과 연관된 처리를 수행하지 않게 해준다.
지적된 바와 같이, 본원에 개시된 융합 단백질의 성분들, 예를 들어 효과기 분자, 예컨대 시토카인, 케모카인, 성장 인자, 단백질 독소, 면역글로불린 도메인 또는 기타 생물 활성 분자와, 임의의 펩티드 링커는 거의 모든 방식으로 조직될 수 있되, 다만 융합 단백질은 의도되었던 기능을 가진다. 구체적으로 융합 단백질의 각 성분은, 원한다면 다른 성분과 적어도 하나의 적합한 펩티드 링커 서열에 의해 이격될 수 있다. 뿐만 아니라, 융합 단백질은, 예컨대 융합 단백질의 변형, 동정 및/또는 정제를 가속화하기 위한 태그를 포함할 수 있다. 더욱 구체적인 융합 단백질은 이하 기술된 실시예에 제시되어 있다.
링커
본 발명의 융합 복합체는 또한, 바람직하게 IL-15 또는 IL-15Ra 도메인들과 생물 활성 폴리펩티드 사이에 놓인 가요성 링커 서열을 포함하기도 한다. 링커 서열은 IL-15 또는 IL-15Ra 도메인들에 대하여 생물 활성 폴리펩티드가 효과적으로 배치되는 것을 허용함으로써, 상기 두 도메인의 기능상의 활성이 발휘될 수 있도록 만들어야 한다.
임의의 경우들에 있어서, 가용성 융합 단백질 복합체는 링커를 가지는데, 이때 제1 생물 활성 폴리펩티드는 폴리펩티드 링커 서열에 의하여 IL-15(또는 이의 기능성 단편)에 공유 결합된다. 다른 양태들에서, 본원에 기술된 바와 같은 가용성 융합 단백질 복합체는 링커를 가지는데, 이때 제2 생물 활성 폴리펩티드는 폴리펩티드 링커 서열에 의하여 IL-15Rα 폴리펩티드(또는 이의 기능성 단편)에 공유 결합된다.
링커 서열은, 바람직하게 뉴클레오티드 서열에 의해 암호화되고, 그로 말미암아 항원을 인지하기 위한 항체 분자의 결합 도메인 또는 제시되는 항원을 인지하기 위한 TCR 분자의 결합 홈(binding groove)을 효과적으로 배치할 수 있는 펩티드가 생성된다. 본원에 사용된 바와 같이 "IL-15 또는 IL-15Ra 도메인에 대하여 생물 활성 폴리펩티드를 효과적으로 배치하는 것"이란 어구 또는 기타 유사한 어구는, IL-15 또는 IL-15Ra 도메인에 결합된 생물 활성 폴리펩티드가, IL-15 또는 IL-15Ra 도메인이 서로간에 상호작용을 하여 단백질 복합체를 형성할 수 있도록 배치되는 것을 의미하도록 의도된다. 예를 들어 IL-15 또는 IL-15Ra 도메인은, 면역 세포와의 상호작용이 면역 반응을 개시 또는 억제하거나, 세포의 발달을 억제 또는 자극하는 것을 허용하도록 효과적으로 배치된다.
본 발명의 융합 복합체는 또한, 바람직하게 IL-15 또는 IL-15Ra 도메인들과 면역글로불린 Fc 도메인 사이에 놓인 가요성 링커 서열을 포함한다. 링커 서열은 Fc 도메인, 생물 활성 폴리펩티드, 그리고 IL-15 또는 IL-15Ra 도메인들의 효과적 배치를 허용함으로써, 각각의 도메인의 기능상 활성을 발휘시킬 수 있어야 한다. 예를 들어 Fc 도메인은 적절한 융합 단백질 복합체의 형성을 허용하고/허용하거나 면역 세포상 Fc 수용체 또는 보체계의 단백질과의 상호작용을 허용하여 옵소닌화, 세포 용해, 비만 세포, 호염기구 및 호산구의 탈과립화와, 기타 Fc 의존적 과정; 보체 경로의 활성화; 및 융합 단백질 복합체의 생체 내 반감기 연장을 비롯한 Fc 매개 효과를 자극하도록 효과적으로 배치된다.
링커 서열은 또한 생물 활성 폴리펩티드의 폴리펩티드 2개 이상을 결합시켜, 원하는 기능상 활성을 가지는 단일 사슬 분자를 제조하는데 사용될 수 있다.
바람직하게 링커 서열은 약 7개 아미노산 내지 약 20개 아미노산, 더욱 바람직하게 약 10개 아미노산 내지 약 20개 아미노산을 포함한다. 링커 서열은 생물 활성 폴리펩티드 또는 효과기 분자가 하나의 원치않는 형상으로 고정되지 않도록 가요성인 것이 바람직하다. 링커 서열은, 예를 들어 융합된 분자로부터 인지 부위를 이격시키는데 사용될 수 있다. 구체적으로 펩티드 링커 서열은 생물 활성 폴리펩티드와 효과기 분자 사이에 배치되어, 예컨대 이 생물 활성 폴리펩티드와 효과기 분자를 화학적으로 가교시키고, 분자 가요성을 제공할 수 있다. 링커는 가요성을 제공하기 위해, 바람직하게 주로 소형 측쇄를 가지는 아미노산, 예컨대 글리신, 알라닌 및 세린을 포함한다. 바람직하게 링커 서열 약 80% 또는 약 90%, 또는 이 이상은 글리신, 알라닌 또는 세린 잔기를 포함하며, 특히 글리신 및 세린 잔기를 포함한다.
항체의 가변 영역들을 하나로 성공적으로 결합시키는데 사용되었던 다수의 가요성 링커 디자인들 중 임의의 것을 비롯한 상이한 링커 서열이 사용될 수 있었다(문헌(Whitlow, M. et al.,(1991) Methods: A Companion to Methods in Enzymology, 2:97-105) 참조).
약학 치료제
본 발명은 치료제로서 사용되기 위한 융합 단백질 복합체를 포함하는 약학 조성물을 제공한다. 일 양태에서, 본 발명의 융합 단백질 복합체는, 예를 들어 약학적으로 허용 가능한 완충제, 예컨대 생리 식염수 중에 제제화되어 전신 투여된다. 환자에 본 조성물 유효 수준만큼을 연속적이면서도 지속적으로 제공하는데 바람직한 투여 경로로서는, 예를 들어 방광에의 점적 주입, 피하, 정맥내, 복막내, 근육내, 종양내 또는 피내 주사를 포함한다. 인간 환자 또는 기타 동물의 치료는, 생리적으로 허용 가능한 담체 중 본원에 동정된 치료제 치료적 유효량이 사용되어 수행된다. 적합한 담체 및 이의 제제는, 예를 들어 문헌(Remington's Pharmaceutical Sciences by E. W. Martin)에 기술되어 있다. 투여될 치료제의 양은, 투여 방식, 환자의 나이와 체중, 그리고 신생물형성의 임상 증상에 따라서 달라진다. 일반적으로 그 양은, 신생물형성, 자가면역성 질환 또는 감염성 질환과 연관된 기타 질환의 치료에 사용되는 기타 제제에 적용되는 양의 범위일 것이지만, 임의의 경우 화합물의 증가한 특이성으로 말미암아 그보다 더 적은 양이 필요할 것이다. 화합물은, 당 업자에게 공지된 방법에 의해 측정되는 바에 따르면, 대상체의 면역 반응을 증진시키거나, 신생물형성, 감염 또는 자가면역 세포의 증식, 생존 또는 침습을 감소시키는 투여량으로 투여된다.
약학 조성물의 제제화
신생물형성, 감염성 질환 또는 자가면역성 질환을 치료하기 위한 본 발명의 융합 단백질 복합체의 투여는, 다른 성분들과 합하여졌을 때 상기 신생물형성, 감염성 질환 또는 자가면역성 질환을 완화, 감소 또는 안정화하기 효과적인 치료제 농도를 달성하는데 적합한 임의의 방법에 의해 이루어진다. 본 발명의 융합 단백질 복합체는 임의의 적당량만큼 임의의 적합한 담체 물질 중에 용해되어 함유될 수 있는데, 일반적으로는 본 조성물 총 중량을 기준으로 1 중량% 내지 95 중량%의 양만큼 존재한다. 본 조성물은 비경구 투여 경로(예컨대 피하, 정맥내, 근육내, 방광내, 종양내 또는 복막내 투여 경로)에 적합한 투여형으로 제공될 수 있다. 예를 들어 본 약학 조성물은 종래의 약학 실무에 따라 제제화된다(예를 들어 문헌(Remington: The Science and Practice of Pharmacy(20th ed.), ed. A. R. Gennaro, Lippincott Williams & Wilkins, 2000 and Encyclopedia of Pharmaceutical Technology, eds. J. Swarbrick and J. C. Boylan, 1988-1999, Marcel Dekker, New York) 참조).
인간에의 투여량은 숙련자가, 동물 모델에 대한 투여량에 비준하여 인간에 대한 투여량을 맞추는 것이 통상적인 일이라 당 업자가 인지하는 바와 같이, 처음에 마우스나 인간 이외의 영장류에 적용되었던 화합물 양으로부터 외삽함으로써 결정된다. 예를 들어 투여량은 체중 1 kg당 화합물 약 1 mg 내지 체중 1 kg당 화합물 약 5000 mg; 또는 체중 1 kg당 화합물 약 5 mg 내지 체중 1 kg당 화합물 약 4000 mg; 또는 체중 1 kg당 화합물 약 10 mg 내지 체중 1 kg당 화합물 약 3000 mg; 또는 체중 1 kg당 화합물 약 50 mg 내지 체중 1 kg당 화합물 약 2000 mg; 또는 체중 1 kg당 화합물 약 100 mg 내지 체중 1 kg당 화합물 약 1000 mg; 또는 체중 1 kg당 화합물 약 150 mg 내지 체중 1 kg당 화합물 약 500 mg으로 다양할 수 있다. 예를 들어 용량은 체중 1 kg당 약 1, 5, 10, 25, 50, 75, 100, 150, 200, 250, 300, 350, 400, 450, 500, 550, 600, 650, 700, 750, 800, 850, 900, 950, 1,000, 1,050, 1,100, 1,150, 1,200, 1,250, 1,300, 1,350, 1,400, 1,450, 1,500, 1,600, 1,700, 1,800, 1,900, 2,000, 2,500, 3,000, 3,500, 4,000, 4,500 또는 5,000 mg이다. 대안적으로, 용량은 체중 1 kg당 화합물 약 5 mg 내지 체중 1 kg당 화합물 약 20 mg의 범위에 있다. 다른 예에서, 용량은 체중 1 kg당 약 8, 10, 12, 14, 16 또는 18 mg이다. 바람직하게 본 융합 단백질 복합체는 0.5 mg/kg 내지 약 10 mg/kg(예컨대 0.5, 1, 3, 5, 10 mg/kg)으로 투여된다. 물론 상기 투여량은, 이러한 치료 프로토콜에서 통상적으로 행하여지는 바와 같이 초기 임상 시험 결과와 특정 환자의 필요에 따라 상향 또는 하향 조정될 수 있다.
약학 조성물은 적당한 부형제와 함께 투여시 제어되는 방식으로 치료제를 방출하는 약학 조성물로 제제화된다. 그 예로서는 단일 또는 다수 단위 정제 또는 캡슐 조성물, 오일 용액, 현탁액, 에멀전, 마이크로캡슐, 미소구, 분자 복합체, 나노입자, 패치 및 리포좀을 포함한다. 바람직하게 본 융합 단백질 복합체는 비경구 투여에 적합한 부형제 중에 제제화된다.
비경구 조성물
본 발명의 융합 단백질 복합체를 포함하는 약학 조성물은 투여형, 제제로서 주사, 주입 또는 이식(피하, 정맥내, 근육내, 종양내, 방광내, 복막내)에 의해 비경구 투여되거나, 또는 종래의 약학적으로 허용 가능한 무독성 담체 및 보조제를 함유하는 적합한 전달 장치나 이식물을 통하여 비경구 투여된다. 이러한 조성물의 제제 및 제조물은 약학 제제 분야의 숙련자들에게 널리 공지되어 있다. 제제에 관하여는 문헌(Remington: The Science and Practice of Pharmacy, 상동)에서 살펴볼 수 있다.
본 발명의 융합 단백질 복합체를 포함하는 비경구 투여용 조성물은 단위 투여형(예컨대 단일 용량 앰플)으로 제공된다. 대안적으로 본 조성물은 수 회의 용량이 담겨 있으며, 적합한 보존제가 첨가될 수 있는 바이알로서 제공된다(하기 참조). 본 조성물은 용액, 현탁액, 에멀전, 주입 장치 또는 이식용 전달 장치의 형태를 가지거나, 또는 사용전 물이나 다른 적합한 비이클로 재구성될 건조 분말로서 제공된다. 신생물형성, 감염성 질환 또는 자가면역성 질환을 감소 또는 완화하는 활성 제제와는 별도로, 본 조성물은 비경구 투여가 허용되는 적합한 담체 및/또는 부형제를 포함한다. 활성 치료제(들)는 제어 방출을 위해 미소구, 마이크로캡슐, 나노입자, 리포좀에 혼입될 수 있다. 더욱이 본 조성물은 현탁제, 가용화제, 안정화제, pH 조정제, 긴장성 조정제 및/또는 분산제를 포함할 수 있다.
상기 명시된 바와 같이, 본 발명의 융합 단백질 복합체를 포함하는 약학 조성물은 멸균 주사에 적합한 형태를 가질 수 있다. 이러한 조성물을 제조하기 위하여, 적합한 활성 치료제(들)가 비경구 투여가 허용되는 액체 비이클에 용해 또는 현탁된다. 사용될 수 있는 허용 가능 비이클 및 용매로서는 물이 있는데, 이 물의 pH는 적당량의 염화수소산, 수산화나트륨 또는 적합한 완충제, 1,3-부탄디올, 링거 용액 및 등장성 염화나트륨 용액 및 덱스트로스 용액을 첨가함으로써 적합하게 조정된다. 수성 제제는 또한 보존제(예컨대 메틸, 에틸 또는 n-프로필 p-하이드록시벤조에이트) 하나 이상을 함유할 수 있다. 화합물들 중 하나가 물에 거의 녹지 않거나 약간만 녹는 경우, 용해촉진제 또는 가용화제가 첨가될 수 있거나, 아니면 용매는 프로필렌글리콜을 10 %w/w 내지 60 %w/w 포함할 수 있다.
본 발명은 신생물형성, 감염성 질환 또는 자가면역성 질환이나 이의 증상들을 치료하는 방법으로서, 본원의 화학식을 가지는 화합물을 포함하는 약학 조성물 치료적 유효량만큼을 대상체(예컨대 포유동물, 예컨대 인간)에 투여하는 단계를 포함하는 방법을 제공한다. 그러므로 일 구현예는, 신생물형성, 감염성 질환 또는 자가면역성 질환이나 이의 증상들을 앓고 있거나 이에 취약한 대상체를 치료하는 방법이다. 이 방법은 질환 또는 장애가 치료되는 조건 하에 해당 질환 또는 장애 또는 이의 증상들을 치료하기 충분한, 본원의 화합물 치료량만큼을 포유동물에 투여하는 단계를 포함한다.
본원의 방법은, 본원에 기술된 화합물 또는 본원에 기술된 조성물 유효량을 대상체(상기와 같은 치료를 필요로 하는 것으로 확인된 대상체 포함)에 투여하여 상기와 같은 효과를 얻는 단계를 포함한다. 상기와 같은 치료를 필요로 하는 대상체를 확인하는 것은, 대상체 또는 건강 관리 전문가의 판단에 의할 수 있으므로, 주관적일 수 있거나(예컨대 의견에 의할 수 있거나) 또는 객관적일 수 있다(예컨대 시험 또는 진단 방법에 의해 확인될 수 있다).
(예방적 치료를 포함하여) 본 발명의 치료 방법은, 일반적으로 본원의 화합물, 예컨대 본원의 화학식을 가지는 화합물 치료적 유효량을, 포유동물, 구체적으로 인간을 포함하여 치료를 필요로 하는 대상체(예컨대 동물, 인간)에 투여하는 단계를 포함한다. 이러한 치료는 신생물형성, 감염성 질환, 자가면역성 질환, 장애 또는 이의 증상들을 앓고 있거나, 발병하였거나, 취약하거나 또는 발병 위험이 있는 대상체, 구체적으로는 인간에게 적합하게 수행될 것이다. 이처럼 "발병 위험이 있는" 대상체인지의 결정은 진단 시험이나, 대상체 또는 건강 관리 제공자의 의견에 따라(예컨대 유전자 시험, 효소 또는 단백질 마커, (본원에 정의된 바와 같은) "마커(Marker)" 및 가족력 등에 따라) 임의의 객관적 결정 또는 주관적 결정에 의해 이루어질 수 있다. 본 발명의 융합 단백질 복합체는 면역 반응의 증가가 요망되는 기타 임의의 장애를 치료하는데 사용될 수 있다.
본 발명은 또한 치료 과정을 모니터링하는 방법도 제공한다. 이 방법은, 본원의 화합물이 어떤 질환 또는 이의 증상을 치료하는데 충분한 치료량만큼 투여된 대상체로서, 신생물형성과 연관된 해당 장애 또는 이의 증상을 앓고 있거나 이에 취약한 대상체를 대상으로, 진단 마커("마커")(예컨대 본원의 화합물, 단백질 또는 이의 지표 등에 의해 조정되는, 본원에 기술된 임의의 표적)의 수준을 측정하는 단계, 또는 진단을 위한 측정 단계(예컨대 스크리닝, 검정)를 포함한다. 본 방법에서 측정된 "마커"의 수준은, 건강한 정상 대조군 또는 다른 발병 환자에 대해 공지된"마커"수준과 비교될 수 있으며, 이로써 대상체의 질환 상태가 확립될 수 있다. 몇몇 경우들에 있어서, 대상체 내 "마커"의 2차 수준은 1차 수준의 측정 시점보다 나중의 시점에 측정되고, 이 두 가지 수준이 비교되어, 해당 질환의 경과와 치료법의 효능이 모니터링된다. 임의의 양태들에서, 대상체 내 "마커"의 치료전 수준은, 본 발명에 따른 치료를 시작하기 전에 측정되고; 추후 "마커"의 이 같은 치료전 수준은 치료 개시후 대상체 내 "마커" 수준과 비교될 수 있으며, 그 결과 치료의 효능이 확인될 수 있다.
병행 치료법
선택적으로 본 발명의 융합 단백질 복합체는 기타 임의의 표준 치료법이 수행됨과 아울러 투여되는데; 이러한 방법은 당 업자에게 공지된 방법으로서, 문헌(Remington's Pharmaceutical Sciences by E. W. Martin)에 기술되어 있다. 원한다면 본 발명의 융합 단백질 복합체는 종래의 임의 항신생물형성 치료법, 예컨대 면역요법, 치료 항체 투여, 표적 치료법, 수술, 방사선 요법 또는 화학 요법(이에 한정되는 것은 아님)이 수행됨과 아울러 투여된다.
키트 또는 약학 시스템
본 발명의 융합 단백질 복합체를 포함하는 약학 조성물은, 신생물형성, 감염성 질환 또는 자가면역성 질환을 완환화하는데 사용되기 위한 키트나 약학 시스템에 통합될 수 있다. 본 발명의 이러한 양태에 따른 키트 또는 약학 시스템은 내부에 하나 이상의 용기 수단, 예컨대 바이알, 튜브, 앰플 및 병 등이 빽빽하게 담겨있는 운반 수단, 예컨대 박스, 갑, 튜브를 포함한다. 본 발명의 키트나 약학 시스템은 본 발명의 융합 단백질 복합체 사용에 관련된 지침을 하나의 구성품으로서 포함할 수 있다.
재조합 단백질 발현
일반적으로 본 발명의 융합 단백질 복합체(예컨대 TxM 복합체의 성분들)의 제조는 본원에 개시된 방법과, 인지된 재조합 DNA 기술에 의해 달성될 수 있다.
일반적으로 재조합 폴리펩티드는 적합한 숙주 세포를, 폴리펩티드 암호화 핵산 분자 또는 이의 단편 전부 또는 일부를 포함하는 적합한 발현 비이클로 형질전환시킴으로써 제조된다. 분자생물학 분야의 숙련자들은, 다양한 발현계들 중 임의의 것이 재조합 단백질을 제공하는데 사용될 수 있음을 이해할 것이다. 사용된 숙주 세포가 정확히 무엇인지는 본 발명에 있어서 중요하지 않다. 재조합 폴리펩티드는 실질적으로 임의의 진핵생물 숙주(예컨대 사카로마이세스 세레비지아에(Saccharomyces cerevisiae), 곤충 세포, 예컨대 Sf21 세포, 또는 포유동물 세포, 예컨대 NIH 3T3, HeLa, 또는 바람직하게 COS 세포) 내에서 생산될 수 있다. 이러한 세포는 다양한 공급처(예컨대 미국 모식균 배양 수집소(American Type Culture Collection)(Rockland, Md.)로부터 입수 가능하다(예를 들어 문헌(Ausubel et al., Current Protocol in Molecular Biology, New York: John Wiley and Sons, 1997)도 참조). 형질감염 방법과 발현 비이클을 선택하는 것은, 선택된 숙주계에 따라 달라질 것이다. 형질전환 방법은, 예컨대 문헌(Ausubel et al. (상동))에 기술되어 있으며; 발현 비이클은, 예컨대 문헌(Cloning Vectors: A Laboratory Manual (P. H. Pouwels et al., 1985, Supp. 1987)에 제공된 것들로부터 선택될 수 있다.
다양한 발현계가 재조합 폴리펩티드의 제조를 위해 존재한다. 이러한 폴리펩티드를 제조하는데 유용한 발현 벡터로서는 염색체, 에피좀 및 바이러스 유래 벡터, 예컨대 세균 플라스미드 유래 벡터, 박테리오파아지 유래 벡터, 트랜스포존 유래 벡터, 효모 에피좀 유래 벡터, 삽입 요소 유래 벡터, 효모 염색체 요소 유래 벡터, 바큘로바이러스, 파포바 바이러스(예컨대 SV40), 백시니아 바이러스, 아데노바이러스, 계두바이러스, 위광견병 바이러스 및 레트로바이러스와 같은 바이러스 유래 벡터, 그리고 이것들의 조합으로부터 유래하는 벡터를 포함하나, 이에 한정되는 것은 아니다.
일단 재조합 폴리펩티드가 발현되면, 이 폴리펩티드는, 예컨대 친화성 크로마토그래피를 사용하여 단리된다. 일례에서, (예컨대 본원에 기술된 바와 같이 제조된) 항체로서, 이 폴리펩티드에 대해 생성된 항체는 컬럼에 부착되어, 재조합 폴리펩티드를 단리하는데 사용될 수 있다. 친화성 크로마토그래피 전 폴리펩티드를 품은 세포의 용해 및 분획화는 표준적 방법에 의해 수행될 수 있다(예컨대 문헌(Ausubel et al., 상동) 참조). 일단 단리되면, 재조합 단백질은 원할 경우, 예컨대 고성능 액체 크로마토그래피에 의해 더 정제될 수 있다(예컨대 문헌(Fisher, Laboratory Techniques In Biochemistry and Molecular Biology, eds., Work and Burdon, Elsevier, 1980) 참조).
본원에 사용된 바와 같이, 본 발명의 생물 활성 폴리펩티드 또는 효곽 분자는 시토카인, 케모카인, 성장 인자, 단백질 독소, 면역글로불린 도메인 또는 기타 생물 활성 단백질, 예컨대 효소와 같은 인자들을 포함할 수 있다. 또한 생물 활성 폴리펩티드는 다른 화합물, 예컨대 비단백질성 독소, 세포독성 제제, 화학요법제, 검출 가능한 표지, 방사성 물질 등과의 접합체를 포함할 수 있다.
본 발명의 시토카인은 다른 세포에 영향을 미치고 세포성 면역의 여러 다효성 중 임의의 것에 관여하는, 세포에 의해 생산되는 임의의 인자에 의해 한정된다. 시토카인의 예들로서는 IL-2 과, 인터페론(IFN), IL-10, IL-1, IL-17, TGF 및 TNF 시토카인 과, 그리고 IL-1 내지 IL-35, IFN-a, IFN-b, IFNg, TGF-b, TNF-a 및 TNFb를 포함하나, 이에 한정되는 것은 아니다.
본 발명의 일 양태에서, 제1 단백질은 인터루킨-15(IL-15) 도메인 또는 이의 기능성 단편에 공유 결합된 제1 생물 활성 폴리펩티드를 포함한다. IL-15는 T 세포 활성화와 증식에 영향을 미치는 시토카인이다. 면역 세포 활성화 및 증식에 영향을 미치는 IL-15 활성은 어떤 면에서 IL-2의 활성과 유사하지만, 근본적인 차이점에 대해서는 특성규명이 잘 되어 있다(Waldmann, T A, 2006, Nature Rev. Immunol. 6:595-601).
본 발명의 또 다른 양태에서, 제1 단백질은, IL-15 변이체(본원에서는 IL-15 돌연변이체라고도 지칭됨)인 인터루킨-15(IL-15) 도메인을 포함한다. IL-15 변이체는, 바람직하게 원산(또는 야생형) IL-15 단백질의 아미노산 서열과 상이한 아미노산 서열을 포함한다. IL-15 변이체는, 바람직하게 IL-15Rα 폴리펩티드와 결합하여, IL-15 효현제 또는 길항제로서 작용한다. 바람직하게 효현제 활성을 가지는 IL-15 변이체는 강력 효현제 활성을 가진다. IL-15 변이체는 IL-15Rα와의 결합 여부에 의존하지 않고 IL-15 효현제 또는 길항제로서의 작용을 할 수 있다. IL-15 효현제는 야생형 IL-15의 생물 활성과 거의 동일하거나 증가한 생물 활성에 의해 실증된다. IL-15 길항제는 야생형 IL-15의 생물 활성에 비하여 감소한 생물 활성 또는 IL-15 매개 반응을 억제하는 능력에 의해 실증된다. 몇몇 예들에 있어서, IL-15 변이체는 IL-15RbgC 수용체에 증가한 활성 또는 감소한 활성으로 결합한다. 몇몇 경우들에 있어서, IL-15 변이체의 서열은 원산 IL-2 서열에 비하여 적어도 하나의 아미노산 변화, 예컨대 치환 또는 결실을 가지고, 이러한 변화는 IL-15 효현제 활성 또는 길항제 활성을 초래한다. 바람직하게 아미노산 치환/결실은, IL-15Rb 및/또는 gC와 상호작용하는 IL-15의 도메인에서 일어난다. 더욱 바람직하게 아미노산 치환/결실은 IL-15Rα 폴리펩티드와의 결합 또는 IL-15 변이체 생산능에 영향을 미치지 않는다. IL-15 변이체를 생산하기 적합한 아미노산 치환/결실은 추정적 또는 공지의 IL-15 구조, 구조가 공지되어 있는 상동성 분자, 예컨대 IL-2와 IL-15의 비교, 합리적이거나 무작위의 돌연변이유발 및 기능 검정법(본원에 제공된 바와 같음) 또는 기타 실험 방법들을 바탕으로 동정될 수 있다. 추가로 적합한 아미노산 치환은 추가 아미노산들의 삽입과 보존적 또는 비보존적 변화일 수 있다. 바람직하게 본 발명의 IL-15 변이체는, 성숙한 인간 IL-15 서열상 6, 8, 10, 61, 65, 72, 92, 101, 104, 105, 108, 109, 111 또는 112번 위치에 1개 또는 1개 초과의 아미노산 치환/결실을 함유하고; 구체적으로 D8N("D8" 은 원산 성숙 인간 IL-15 서열의 아미노산 및 잔기 위치를 나타내고, "N" 은 IL-15 변이체 내 해당 위치에 있는 치환된 아미노산 잔기를 나타냄), I6S, D8A, D61A, N65A, N72R, V104P 또는 Q108A 치환은 길항제 활성을 가지는 IL-15 변이체를 생성하고, N72D 치환은 효현제 활성을 가지는 IL-15 변이체를 생성한다.
케모카인은 시토카인과 유사하게, 다른 세포에 노출되었을 때 세포성 면역의 여러 다효성 중 임의의 것에 관여하는 임의의 화학 인자 또는 분자로서 정의된다. 적합한 케모카인으로서는 CXC, CC, C 및 CX3C 케모카인과, CCL-1 내지 CCL-28, CXC-1 내지 CXC-17, XCL-1, XCL-2, CX3CL1, MIP-1b, IL-8, MCP-1, 및 Rantes를 포함할 수 있으나, 이에 한정되는 것은 아니다.
성장 인자는 특정 세포에 노출될 때 노출된 세포의 증식 및/또는 분화를 유도하는 임의의 분자들을 포함한다. 성장 인자로서는 단백질 및 화학 분자를 포함하고, 이것들 중 몇몇은 GM-CSF, G-CSF, 인간 성장 인자 및 줄기세포 성장 인자를 포함한다. 추가의 성장 인자도 또한 본원에 기술된 용도로서 적합할 수 있다.
독소 또는 세포독성 제제로서는 세포에 노출되었을 때 성장에 치사 효과 또는 억제 효과를 보이는 임의의 물질을 포함한다. 더욱 구체적으로 효과기 분자는, 예컨대 식물이나 세균 기원의 세포 독소, 예컨대 디프테리아 독소(DT), 쉬가 독소, 아브린, 콜레라 독소, 리신, 사포린, 슈도모나스 외독소(PE), 미국자리공 항바이러스 단백질 또는 겔로닌일 수 있다. 이러한 독소의 생물 활성 단편은 당 분야에 널리 공지되어 있으며, 예컨대 DT A 사슬 및 리신 A 사슬을 포함한다. 추가로 독소는 세포 표면에서 활성인 제제, 예컨대 포스포리파아제 효소(예컨대 포스포리파아제 C)일 수 있다.
또한 효과기 분자는 화학요법 약물, 예컨대 빈데신, 빈크리스틴, 빈블라스틴, 메토트렉세이트, 아드리아마이신, 블레오마이신 또는 시스플라틴일 수 있다.
추가로, 효과기 분자는 진단 연구 또는 영상화 연구에 적합한, 검출 가능하게 표지화된 분자일 수 있다. 이러한 표지로서는 바이오틴 또는 스트렙타비딘/아비딘, 검출 가능한 나노입자 또는 결정, 효소 또는 이의 촉매 활성 단편, 형광 표지, 예컨대 녹색 형광 단백질, FITC, 피코에리트린, 사이콤, 텍사스 레드 또는 양자점; 방사성핵종, 예컨대 요오드-131, 이트륨-90, 레늄-188 또는 비스무트-212; 인광 분자, 화학발광 분자, 또는 PET, 초음파 또는 MRI에 의해 검출 가능한 표지, 예컨대 Gd-- 또는 상자성 금속 이온 기반 조영제를 포함한다. 예를 들어 문헌(Moskaug, et al. J. Biol. Chem. 264, 15709 (1989); Pastan, I. et al. Cell 47, 641, 1986; Pastan et al., Recombinant Toxins as Novel Therapeutic Agents, Ann. Rev. Biochem. 61, 331, (1992); "Chimeric Toxins" Olsnes and Phil, Pharmac. Ther., 25, 355 (1982); 공개된 PCT 특허출원공보 WO 94/29350; 공개된 PCT 특허출원공보 WO 94/04689; 공개된 PCT 특허출원공보 WO2005046449 및 미국특허 제5,620,939호(효과기 또는 태그를 포함하는 단백질을 제조 및 사용하는 것에 관하여 개시됨))을 참조한다.
IL-15 및 IL-15Rα 도메인들이 공유 결합되어 포함되어 있는 단백질 융합 또는 접합 복합체는 몇 가지 중요한 용도를 가진다. 예를 들어 항 PD-L1 scAb를 포함하는 단백질 융합 또는 접합 복합체는 IL-15:IL-15Rα복합체를 임의의 세포, 예컨대 PD-L1을 발현하는 종양 세포에 전달하는데 사용될 수 있다. 따라서 이 단백질 융합 또는 접합 복합체는 리간드를 포함하는 세포를 선택적으로 손상 또는 사멸하는 수단을 제공한다. 본 단백질 융합 또는 접합 복합체에 의해 손상 또는 사멸될 수 있는 세포나 조직의 예들로서는 종양 및 바이러스 감염 세포 또는 세균 감염 세포로서, 하나 이상의 리간드를 발현하는 세포를 포함한다. 손상 또는 사멸에 취약한 세포나 조직은 본원에 개시된 방법에 의해 용이하게 검정될 수 있다.
본 발명의 IL-15 및 IL-15Rα 폴리펩티드는 적합하게, 그 아미노산 서열이 자연 발생 IL-15 및 IL-15Rα 분자, 예컨대 인간, 마우스 또는 기타 설치류 또는 기타 포유동물의 IL-15 및 IL-15Rα 분자의 아미노산 서열과 상응한다. 이러한 폴리펩티드 및 이를 암호화하는 핵산의 서열은, 예를 들어 인간 인터루킨 15(IL15) mRNA - GenBank: U14407.1 (본원에 참조로 인용됨), Mus 근육 인터루킨 15(IL15) mRNA - GenBank: U14332.1 (본원에 참조로 인용됨), 인간 인터루킨-15 수용체 알파 사슬 전구체(IL15RA) mRNA - GenBank: U31628.1 (본원에 참고로 인용됨), Mus 근육 인터루킨 15 수용체, 알파 사슬 - GenBank: BC095982.1 (본원에 참고로 인용됨)와 같이 문헌에 공지되어 있다.
몇몇 경우에 있어서, 예를 들어 sc-항체의 역가를 증가시키기 위해 본 발명의 단백질 융합 또는 접합 복합체를 다가로 만드는 것이 유용할 수 있다. 구체적으로 융합 단백질 복합체의 IL-15 도메인 및 IL-15Rα도메인 간 상호작용은 다가 복합체를 제조하는 수단을 제공한다. 또한, 다가 융합 단백질은, 예를 들어 표준 바이오틴-스트렙타비딘 표지화 기술을 사용하거나, 또는 적합한 고형 지지체, 예컨대 라텍스 비드에의 접합을 통해, 1개 내지 4개의 단백질(동일하거나 상이한 단백질들)을 서로 공유 결합 또는 비공유 결합시켜 제조될 수 있다. 화학 가교된 단백질(예컨대 덴드리머에 가교된 단백질)은 또한 적합한 다가 종이다. 예를 들어 단백질은, 변형될 수 있는 태그 서열, 예컨대 바이오틴화 BirA 태그, 또는 Cys 또는 His와 같이 화학 반응성 측쇄를 가지는 아미노산 잔기를 암호화하는 서열을 포함시킴으로써 변형될 수 있다. 이러한 아미노산 태그 또는 화학 반응성 아미노산은 융합 단백질 내 다양한 위치, 바람직하게는 생물 활성 폴리펩티드 또는 효과기 분자의 활성 부위로부터 멀리 떨어진 위치에 배치될 수 있다. 예를 들어 가용성 융합 단백질의 C-말단은, 이처럼 반응성 아미노산(들)을 포함하는 기타 융합 단백질 또는 태그에 공유 결합될 수 있다. 2개 이상의 융합 단백질을 적합한 덴드리머 또는 기타 나노입자에 화학적으로 결합시켜 다가 분자를 제조하기 위해서는 적합한 측쇄가 포함될 수 있다. 덴드리머는 자체의 표면에 다수의 상이한 작용기 중 임의의 것 하나를 가질 수 있는 합성 화학 중합체이다(D. Tomalia, Aldrichimica Acta, 26:91:101 (1993)). 본 발명에 따라 사용되는 예시적 덴드리머로서는, 예컨대 시스테인 잔기들을 결합시킬 수 있는 E9 불꽃형(combust) 폴리아민 덴드리머 및 E9 성상형(starburst) 폴리아민 덴드리머를 포함한다. 예시적 나노입자로서는 리포좀, 코어-외피(core-shell) 입자 또는 PLGA 기반 입자를 포함한다.
다른 양태에서, 융합 단백질 복합체의 폴리펩티드들 중 하나 또는 둘 다는 면역글로불린 도메인을 포함한다. 대안적으로 단백질 결합 도메인-IL-15 융합 단백질은 면역글로불린 도메인에 추가로 결합될 수 있다. 바람직한 면역글로불린 도메인은 다른 면역글로불린 도메인과의 상호작용을 허용하여, 상기 제공된 바와 같은 다중 사슬 단백질을 형성하도록 만들 수 있는 영역들을 포함한다. 예를 들어 면역글로불린 중쇄 영역, 예컨대 IgG1 CH2-CH3은 안정적으로 상호작용하여, Fc 영역을 형성할 수 있다. Fc 도메인을 포함하여 바람직한 면역글로불린 도메인은 또한 효과기 기능, 예컨대 Fc 수용체 또는 보체 단백질 결합 활성을 가지고/가지거나 당화 부위들을 가지는 영역들을 포함한다. 몇몇 양태들에서, 융합 단백질 복합체의 면역글로불린 도메인은, Fc 수용체 또는 보체 결합 활성 또는 당화 또는 이량체화를 감소 또는 증가시켜, 생성되는 단백질의 생물 활성에 영향을 미치는 돌연변이를 함유한다. 예를 들어 Fc 수용체와의 결합을 감소시키는 돌연변이를 함유하는 면역글로불린 도메인이, 특이 항원을 인지 또는 검출하도록 디자인된 시약에 유리할 수 있도록, Fc 수용체 보유 세포에 대한 결합 활성이 낮은 본 발명의 융합 단백질 복합체를 제조하는데 사용될 수 있었다.
핵산 및 벡터
본 발명은 핵산 서열, 구체적으로 본 융합 단백질(예컨대 TxM의 성분들)을 암호화하는 DNA 서열을 추가로 제공한다. 바람직하게 DNA 서열은 염색체외 복제에 적합한 벡터, 예컨대 파아지, 바이러스, 플라스미드, 파지미드, 코스미드, YAC 또는 에피좀에 의해 운반된다. 구체적으로 원하는 융합 단백질을 암호화하는 DNA 벡터는, 본원에 기술된 제조 방법들을 가속화하고, 융합 단백질을 유의미한 양만큼 수득하기 위해 사용될 수 있다. DNA 서열은 적당한 발현 벡터, 즉 삽입된 단백질 암호화 서열의 전사 및 번역에 필요한 요소를 함유하는 벡터로 삽입될 수 있다. 다양한 숙주-벡터계는 단백질 암호화 서열을 발현시키는데 이용될 수 있다. 이러한 계로서는 바이러스(예컨대 백시니아 바이러스, 아데노바이러스 등)으로 감염된 포유동물 세포계; 바이러스(예컨대 바큘로바이러스)로 감염된 곤층 세포계; 미생물, 예컨대 효모 벡터를 함유하는 효모, 또는 박테리오파아지 DNA, 플라스미드 DNA 또는 코스미드 DNA로 형질전환된 세균을 포함한다. 이용된 숙주-벡터계에 따라서, 다수의 적합한 전사 요소 및 번역 요소 중 임의의 하나가 사용될 수 있다. 문헌((Sambrook et al., 상동) 및 (Ausubel et al., 상동))을 참조한다.
가용성 융합 단백질 복합체를 제조하기 위한 방법이 본 발명에 포함되는데, 이 방법은 본원에 기술된 바와 같이 제1 및 제2 단백질들을 암호화하는 DNA 벡터를 숙주 세포에 도입하는 단계, 세포나 배지 중 융합 단백질을 발현하기 충분한 조건 하에 이 숙주 세포를 배지 중에서 배양하여, 제1 단백질의 IL-15 도메인과 제2 단백질의 가용성 IL-15Rα 도메인간 결합을 허용함으로써, 가용성 융합 단백질 복합체를 형성하는 단계, 그리고 숙주 세포나 배지로부터 가용성 융합 단백질 복합체를 정제하는 단계를 포함한다.
일반적으로 본 발명에 따라 바람직한 DNA 벡터에는, 효과기 분자를 암호화하는 서열에 작동가능하도록 결합된, 생물 활성 폴리펩티드를 암호화하는 제1 뉴클레오티드 서열 도입용 제1 클로닝 부위를 5'→ 3' 방향으로 포함하는 뉴클레오티드 서열이 포스포디에스테르 결합에 의해 결합되어 포함되어 있다.
DNA 벡터에 의해 암호화된 융합 단백질 성분들은 카세트 형태로 제공될 수 있다. "카세트"란 용어는, 각각의 성분이 표준 재조합 방법에 의해 다른 성분 대신 용이하게 치환될 수 있는 구조를 의미한다. 구체적으로 카세트 형태로 구성된 DNA 벡터는, 암호화된 융합 복합체가 혈청형을 발생시킬 능력을 가질 수 있거나 가지는 병원체에 맞서 사용될 때 특히 요망된다.
융합 단백질 복합체를 암호화하는 벡터를 제조하기 위하여, 생물 활성 폴리펩티드를 암호화하는 서열은, 적합한 리가아제를 사용하여 효과기 펩티드를 암호화하는 서열에 결합된다. 제시 펩티드를 암호화하는 DNA는, 적합한 세포주와 같은 자연 공급원으로부터 DNA를 단리하거나, 또는 공지의 합성 방법, 예컨대 포스페이트 트리에스테르 방법에 의해 수득될 수 있다. 예컨대 문헌(Oligonucleotide Synthesis, IRL Press (M. J. Gait, ed., 1984))을 참조한다. 합성 올리고뉴클레오티드는 또한 시판되고 있는 자동화 올리고뉴클레오티드 합성기를 사용하여 제조될 수 있다. 생물 활성 폴리펩티드를 암호화하는 유전자가 일단 단리되면, 이 유전자는 중합효소 연쇄 반응(PCR) 또는 기타 당 분야에 공지된 방법에 의해 증폭될 수 있다. 생물 활성 폴리펩티드 유전자를 증폭시키는데 적합한 PCR 프라이머는 PCR 생성물에 제한 부위들을 부가할 수 있다. PCR 생성물은, 바람직하게 효과기 펩티드에 대한 스플라이싱 부위들과, 생물 활성 폴리펩티드-효과기 융합 복합체의 적절한 발현 및 분비에 필요한 선도 서열을 포함한다. PCR 생성물은 또한, 바람직하게 링커 서열을 암호화하는 서열이나, 또는 이러한 서열을 결찰하기 위한 제한 효소 부위를 포함한다.
본원에 기술된 융합 단백질은, 바람직하게 표준 재조합 DNA 기술에 의해 생산된다. 예를 들어 생물 활성 폴리펩티드를 암호화하는 DNA 분자가 일단 단리되면, 이 서열은 효과기 폴리펩티드를 암호화하는 또 다른 DNA 분자에 결찰될 수 있다. 생물 활성 폴리펩티드를 암호화하는 뉴클레오티드 서열은, 효과기 펩티드를 암호화하는 DNA 서열과 직접 연결될 수 있거나, 또는 더욱 통상적으로 본원에 논의된 바와 같은 링커 서열을 암호화하는 DNA 서열은, 생물 활성 폴리펩티드를 암호화하는 서열과, 효과기 펩티드를 암호화하는 서열 사이에 끼워진 후, 적합한 리가아제가 사용되어 연결될 수 있다. 생성된 하이브리드 DNA 분자는 적합한 숙주 세포 내에서 발현되어 융합 단백질 복합체로 생성될 수 있다. DNA 분자는, 결찰 후 암호화되는 폴리펩티드의 번역 틀이 변경되지 않도록 서로 5'→ 3'방향으로 결찰된다(즉 DNA 분자는 서로에 대해 틀 내(in-frame) 결찰된다). 생성된 DNA 분자는 틀 내 융합 단백질을 암호화한다.
또 다른 뉴클레오티드 서열도 또한 유전자 구조체에 포함될 수 있다. 예를 들어 효과기 펩티드에 융합된 생물 활성 폴리펩티드를 암호화하는 서열의 발현을 제어하는 촉진인자 서열, 또는 융합 단백질을 세포 표면이나 배양 배지로 안내하는 선도 서열이, 구조체에 포함될 수 있거나 또는 이 구조체가 삽입된 발현 벡터 내에 존재할 수 있다. 면역글로불린 또는 CMV 촉진인자가 특히 바람직하다.
변이체 생물 활성 폴리펩티드, IL-15, IL-15Rα 또는 Fc 도메인 암호화 서열을 수득함에 있어서, 당 업자들은 생물 활성의 소실 또는 감소가 초래되지 않은 채 폴리펩티드가 임의의 아미노산 치환, 부가, 결실 및 번역후 변형에 의해 변형될 수 있음을 인지할 것이다. 구체적으로 보존적 아미노산 치환이 일어나면, 즉 하나의 아미노산이 유사한 크기, 전하, 극성 및 형태를 가지는 또 다른 아미노산으로 치환되면, 단백질 기능은 유의미하게 변경되지 않을 것임은 널리 공지되어 있다. 단백질의 구성성분인 20개의 표준 아미노산은 넓게 보존적 아미노산으로 이루어진 군 4 가지로 하기와 같이 분류될 수 있다: 비극성(소수성) 군은 알라닌, 이소루신, 루신, 메티오닌, 페닐알라닌, 프롤린, 트립토판 및 발린을 포함하고; 극성(비하전, 중성) 군은 아스파라긴, 시스테인, 글루타민, 글리신, 세린, 트레오닌 및 티로신을 포함하며; 극성 하전(염기성) 군은 아르기닌, 히스티딘 및 리신을 포함하고; 음 하전(산성) 군은 아스파르트산 및 글루탐산을 포함한다. 어떤 단백질에 있어서 하나의 아미노산의, 동일군에 속하는 또 다른 아미노산으로의 치환은 단백질의 생물 활성에 부정적인 영향을 미치지 않을 것이다. 다른 예에서, 단백질의 생물 활성을 감소 또는 증가시키기 위해 아미노산 위치에 대한 변형이 이루어질 수 있다. 이러한 변화는 표적이 된 잔기(들)의 공지되었거나 추정되는 구조적 특성 또는 기능상 특성을 바탕으로 부위 특이적 돌연변이를 통하여 도입될 수 있거나 또는 무작위로 도입될 수 있다. 변이체 단백질이 발현된 후, 변형으로 말미암은 생물 활성 변화는 결합 또는 기능 검정을 사용하여 용이하게 평가될 수 있다.
뉴클레오티드 서열들간의 상동성은 DNA 잡종화 분석에 의해 결정될 수 있는데, 여기서 이중 가닥 DNA 하이브리드의 안정성은 일어난 염기 쌍 형성 정도에 의존적이다. 높은 온도 및/또는 낮은 염 함량의 조건은, 하이브리드의 안정성을 감소시키고, 선택된 상동성 정도에 못미치는 상동성을 가지는 서열의 어닐링(annealing)을 방지하도록 달라질 수 있다. 예를 들어 G-C 함량이 약 55%인 서열에 있어서, 40℃ ~ 50℃, 6 x SSC(염화나트륨/시트르산나트륨 완충제) 및 0.1% SDS(도데실황산나트륨)의 잡종화 및 세척 조건은 약 60% ~ 약 70%의 상동성을 초래하고, 50℃ ~ 65℃, 1 x SSC 및 0.1% SDS의 잡종화 및 세척 조건은 약 82% ~ 약 97%의 상동성을 초래하며, 52℃, 0.1 x SSC 및 0.1% SDS의 잡종화 및 세척 조건은 약 99% ~ 약 100%의 상동성을 초래한다. 뉴클레오티드와 아미노산 서열을 비교하기 위한(그리고 상동성의 정도를 측정하기 위한) 여러 컴퓨터 프로그램도 또한 입수 가능하고, 시판중인 소프트웨어와 무료 소프트웨어 둘 다의 공급처를 제공하는 목록은 문헌(Ausubel et al. (1999))에서 찾아볼 수 있다. 용이하게 입수 가능한 서열 비교 및 다중 서열 정렬 알고리즘으로서는 각각 BLAST(Basic Local Alignment Search Tool)(Altschul et al., 1997) 및 ClustalW 프로그램이 있다. BLAST는 www.ncbi.nlm.nih.gov에서 입수 가능하고, ClustalW 버전은 2.ebi.ac.uk에서 입수 가능하다.
융합 단백질의 성분들은, 각각이 의도로 하는 기능을 수행할 수 있도록 제공된 임의의 순서에 가깝게 조직될 수 있다. 예를 들어 일 구현예에서, 생물 활성 폴리펩티드는 효과기 분자의 C-말단 또는 N-말단에 위치한다.
본 발명의 바람직한 효과기 분자는 도메인들이 의도로 하는 기능을 유도하는 크기를 가질 것이다. 본 발명의 효과기 분자는 제조된 후, 널리 공지된 화학 가교 방법을 비롯한 다양한 방법에 의해 생물 활성 폴리펩티드에 융합될 수 있다. 예를 들어 문헌(Means, G. E. and Feeney, R. E. (1974), Chemical Modification of Proteins, Holden-Day. See also, S. S. Wong (1991), Chemistry of Protein Conjugation and Cross-Linking, CRC Press)을 참조한다. 그러나 일반적으로 틀 내 융합 단백질을 제조하기 위해 재조합 조작법을 사용하는 것이 바람직하다.
언급된 바와 같이, 본 발명에 따른 융합 분자 또는 접합체 분자는 몇 가지 방식으로 조직될 수 있다. 예시적 구성에 있어서, 생물 활성 폴리펩티드의 C-말단은 효과기 분자의 N-말단에 작동 가능하도록 결합된다. 이러한 결합은 원한다면 재조합 방법에 의해 달성될 수 있다. 그러나 다른 구성에 있어서, 생물 활성 폴리펩티드의 N-말단은 효과기 분자의 C-말단에 결합된다.
대안적으로 또는 추가로, 필요에 따라 하나 이상의 추가 효과기 분자가 생물 활성 폴리펩티드 또는 접합 복합체에 삽입될 수 있다.
벡터 및 발현
본 발명의 융합 단백질 복합체(예컨대 TxM)의 성분들을 발현하는데 다수의 전략이 사용될 수 있다. 예를 들어 본 발명의 융합 단백질 복합체 성분 하나 이상을 암호화하는 구조체는, 구조체 삽입을 위해 벡터를 절단하는 제한 효소를 사용하여 적합한 벡터에 통합된 다음 결찰될 수 있다. 이후 유전자 구조체를 함유하는 벡터는 융합 단백질의 발현에 적합한 숙주에 도입된다. 일반적으로 문헌(Sambrook et al., 상동)을 참조한다. 적합한 벡터의 선택은 클로닝 프로토콜에 관한 인자들을 바탕으로 실험을 통하여 이루어질 수 있다. 예를 들어 벡터는 사용되고 있는 숙주와 양립 가능하여야 하며, 이러한 숙주에 적절한 레플리콘(replicon)을 가져야 한다. 벡터는 발현될 융합 단백질 복합체를 암호화하는 DNA 서열을 수용할 수 있어야 한다. 적합한 숙주 세포로서는 진핵생물 및 원핵생물 세포, 바람직하게 용이하게 형질전환되어 배양 배지 중에서 신속한 성장을 보일 수 있는 세포를 포함한다. 특히 바람직한 숙주 세포로서는 원핵생물, 예컨대 이.콜라이, 바실러스 서브틸리스(Bacillus subtilis) 등과, 진핵생물, 예컨대 동물 세포 및 효소 균주, 예컨대 에스.세레비지아에를 포함한다. 포유동물 세포, 특히 J558, NSO, SP2-O 또는 CHO가 일반적으로 바람직하다. 기타 적합한 숙주로서는, 예를 들어 곤충 세포, 예컨대 Sf9를 포함한다. 종래의 배양 조건이 적용된다. 문헌(Sambrook, 상동)을 참조한다. 이후 안정적으로 형질전환되었거나 형질감염된 세포주가 선택될 수 있다. 본 발명의 융합 단백질 복합체를 발현하는 세포는 공지의 방법에 의해 확인될 수 있다. 예를 들어 면역글로불린에 결합된 융합 단백질 복합체의 발현은, 결합된 면역글로불린에 특이적인 ELISA 및/또는 면역 블럿팅(immunoblotting)에 의해 확인될 수 있다. IL-15 또는 IL-15Rα 도메인들에 결합된 생물 활성 폴리펩티드를 포함하는 융합 단백질의 발현을 확인하기 위한 다른 방법들이 실시예들에 개시되어 있다.
상기에서 일반적으로 언급된 바와 같이, 원하는 융합 단백질을 암호화하는 핵산을 증식시키기 위한 예비적 목적으로 숙주 세포가 사용될 수 있다. 그러므로 숙주 세포는 특별히 융합 단백질 생산이 의도되는 원핵생물 또는 진핵생물 세포를 포함할 수 있다. 따라서 숙주 세포는, 구체적으로 융합체를 암호화하는 핵산을 증식시킬 수 있는 효모, 파리, 벌레, 식물, 개구리, 포유동물 세포 및 장기를 포함한다. 사용될 수 있는 포유동물 세포주의 비제한적 예들로서는 CHO dhfr-세포(Urlaub and Chasm, Proc. Natl. Acad. Sci. USA, 77:4216 (1980)), 293 세포(Graham et al., J Gen. Virol., 36:59 (1977)) 또는 골수종 세포, 예컨대 SP2 또는 NSO(Galfre and Milstein, Meth. Enzymol., 73(B):3 (1981))를 포함한다.
원하는 융합 단백질 복합체를 암호화하는 핵산을 증식시킬 수 있는 숙주 세포는 포유동물 이외의 진핵생물 세포, 예컨대 곤충 세포(예컨대 에스피. 프루기페르다(Sp. frugiperda)), 효모(예컨대 에스.세레비지아에, 에스, 폼베(S. pombe), 피.파스토리스(P. pastoris), 케이. 락티스(K. lactis), 에이치. 폴리모르파(H. polymorpha); Fleer, R.에 의해 일반적으로 검토된 바와 같은 것들(Current Opinion in Biotechnology, 3(5):486496 (1992)), 진균 세포 및 식물 세포도 포함한다. 이.콜라이 및 바실러스와 같은 임의의 원핵생물도 또한 고려된다.
세포를 형질감염시키기 위한 표준 기술에 의해 원하는 융합 단백질을 암호화하는 핵산이 숙주 세포에 도입될 수 있다. "형질감염시키는 것" 또는 "형질감염"이란 용어는, 핵산을 숙주 세포에 도입하기 위한 종래의 모든 기술, 예컨대 인산칼슘 공침전법, DEAE-덱스트란 매개 형질감염, 리포펙션(lipofection), 전기영동, 미세주입, 바이러스에 의한 형질도입 및/또는 통합을 포함하는 것으로 의도된다. 숙주 세포를 형질감염시키기 적합한 방법은 문헌(Sambrook et al., 상동) 및 기타 실험 교과서에서 찾아볼 수 있다.
다수의 촉진인자(전사 개시 조절 영역)가 본 발명에 따라 사용될 수 있다. 적당한 촉진인자의 선택은 제안된 발현 숙주에 따라서 달라진다. 이종 공급원으로부터 유래하는 촉진인자는, 그것이 선택된 숙주 내에서 기능을 발휘하는 한, 사용될 수 있다.
촉진인자 선택은 또한 원하는 효능과, 펩티드 또는 단백질 생성 수준에 따라 달라진다. 유도성 촉진인자. 예컨대 tac는 종종 이.콜라이 내 단백질 발현 수준을 극적으로 증가시키기 위해 사용된다. 단백질 과발현은 숙주 세포에 유해할 수 있다. 결과적으로 숙주 세포 성장이 제한될 수 있다. 유도성 촉진인자계가 사용되면, 숙주 세포는 허용 가능한 밀도로 배양된 후 유전자 발현이 유도되고, 이로써 생성물 수율이 더 높아지는 것이 가속화되는 것이다.
본 발명에 따라 다양한 신호 서열이 사용될 수 있다. 생물 활성 폴리펩티드 암호화 서열에 상동성인 신호 서열이 사용될 수 있다. 대안적으로 발현 숙주 내에서의 효율적 분비와 처리를 위해 선택 또는 디자인된 신호 서열도 또한 사용될 수 있다. 예를 들어 적합한 신호 서열/숙주 세포 쌍은 비.서브틸리스 sacB 신호 서열(비.서브틸리스 내 분비용)과, 사카로마이세스 세레비지아에 a-메이팅 인자(mating factor) 또는 피.파스토리스 산 포스파타아제 phoI 신호 서열(피.파스토리스 내 분비용)을 포함한다. 신호 서열은 신호 펩티다아제 절단 부위를 암호화하는 서열, 또는 보통은 10개 이하의 코돈으로 이루어진 짧은 뉴클레오티드 가교를 통하여 단백질 암호화 서열에 직접 연결될 수 있는데, 이 경우 상기 가교는 하류 TCR 서열의 올바른 해독틀을 보장한다.
전사 및 번역을 증진시키기 위한 요소들이 진핵생물 단백질 발현계에 대해 동정되었다. 예를 들어 이종 촉진인자 양쪽 중 어느 한쪽으로부터 1,000 bp 떨어져 꽃양배추 모자이크 바이러스(CaMV) 촉진인자가 배치되면, 식물 세포에서 전사 수준은 10배 ~ 400배까지 증가할 수 있다. 발현 구조체는 또한 적당한 번역 개시 서열을 포함하여야 한다. 적당한 번역 개시를 위하여 Kozak 공통 서열을 포함하도록 발현 구조체가 변형되면, 번역 수준은 10배까지 증가할 수 있다.
발현 구조체의 일부일 수 있거나, 또는 이로부터 분리되어 존재할 수 있는(예를 들어 발현 벡터에 의해 운반될 수 있는) 선택 마커가 종종 사용되므로, 이러한 마커는 관심 유전자 부위와 상이한 부위에 통합될 수 있다. 그 예로서는 항생제에 대한 내성을 부여하는 마커(예컨대 bla는 이.콜라이 숙주 세포에 암피실린에 대한 내성을 부여하고, nptII는 다양한 원핵생물 및 진핵생물 세포에 카나마이신에 대한 내성을 부여함) 또는 숙주가 최소 배지에서 성장하는 것을 허용하는 마커(예컨대 HIS4는 피.파스토리스 또는 His- 에스.세레비지아에가 히스티딘 부재 하에서도 성장할 수 있도록 함)를 포함한다. 선택 마커는 자체만의 전사 및 번역 개시 및 종료 조절 영역을 가져서, 마커의 독립적 발현을 허용한다. 만일 항생제 내성이 마커로서 사용되면, 선택을 위한 항생제의 농도는 항생제에 따라서 달라질 것인데, 일반적으로 항생제 농도는 배지 1 mL당 항생제 10 mg 내지 600 mg의 범위이다.
발현 구조체는, 공지의 재조합 DNA 기술을 이용하여 조립된다(Sambrook et al., 1989; Ausubel et al., 1999). 제한 효소 분해 및 결찰은, 2개의 DNA 단편을 연결하는데 이용되는 기본 단계들이다. DNA 단편의 말단들은 결찰 전에 변형을 필요로 할 수 있는데, 이 변형은 돌출 말단(overhang)을 채우거나, 뉴클레아제(예컨대 ExoIII)로 단편(들)의 말단부를 결실시키거나, 부위 유도적 돌연변이유발법에 의하거나, 또는 PCR에 의해 신규 염기쌍들을 부가함으로써 달성될 수 있다. 선택된 단편들의 연결을 돕기 위해 폴리링커(polylinker)와 어댑터(adaptor)가 사용될 수 있다. 발현 구조체는 통상적으로 이.콜라이의 제한, 결찰 및 형질전환 라운드를 이용하는 단계들에서 조립된다. 발현 구조체를 구성하는데 적합한 클로닝 벡터 다수(lZAP 및 pBLUESCRIPT SK-1(Stratagene, La Jolla, CA), pET(Novagen Inc., Madison, WI); Ausubel et al., 1999에 예시됨) 가 당 분야에 공지되어 있으며, 본 발명에 있어서 벡터에 관한 구체적인 선택은 중요하지 않다. 클로닝 벡터의 선택은 발현 구조체를 숙주 세포에 도입하기 위해 선택된 유전자 이동계에 의해 영향을 받을 것이다. 생성된 구조체는 각 단계의 말미에 제한 분석, DNA 서열 분석, 잡종화 및 PCR 분석에 의해 분석될 수 있다.
발현 구조체는 클로닝 벡터 구조체(선형 또는 환형)로서 숙주를 형질전환시킬 수 있거나, 또는 클로닝 벡터로부터 분리되어 그대로 사용되거나 전달 벡터에 도입되어 사용될 수 있다. 전달 벡터는 선택된 숙주 세포 유형 내에 발현 구조체를 도입하여 이를 유지시키는 것을 돕는다. 발현 구조체는 다수의 공지된 유전자 이동계(예컨대 자연 순응성, 화학물질 매개 형질전환, 원형질체 형질전환, 전기천공, 유전자총 형질전환, 형질감염 또는 접합) 중 임의의 것에 의해 숙주 세포에 도입된다(Ausubel et al., 1999; Sambrook et al., 1989). 선택된 유전자 이동계는 사용된 숙주 세포와 벡터계에 의존적이다.
예를 들어 발현 구조체는 원형질체 형질전환 또는 전기천공에 의해 에스.세레비지아에 세포에 도입될 수 있다. 에스.세레비지아에의 전기천공은 용이하게 달성되며, 그 결과 세포벽불완전제거균(spheroplast) 형질전환과 거의 동일한 형질전환 효율을 보이게 된다.
본 발명은 또한 관심 융합 단백질을 단리하기 위한 제조 방법을 추가로 제공한다. 이 방법에 있어서, 조절 서열에 작동 가능하도록 연결된, 관심 단백질을 암호화하는 핵산이 내부에 도입된 숙주 세포(예컨대 효모, 진균, 곤충, 세균 또는 동물 세포)는 관심 융합 단백질을 암호화하는 뉴클레오티드 서열의 전사가 자극되는 배양 배지 중에서 생산 규모로 성장한다. 이후 관심 융합 단백질은 수득된 숙주 세포 또는 배양 배지로부터 단리된다. 배지 또는 수득된 세포로부터 관심 단백질을 단리하기 위해 표준 단백질 정제 기술이 사용될 수 있다. 구체적으로 정제 기술은 원하는 융합 단백질을 다양한 도구, 예컨대 회전병, 스피너 플라스크, 조직 배양 평판, 생물반응기 또는 발효조로부터 대규모로(즉 적어도 밀리그램 단위의 양만큼) 발현 및 정제하기 위해 사용될 수 있다.
발현된 단백질 융합 복합체는 공지의 방법에 의해 단리 및 정제될 수 있다. 통상적으로 배양 배지는 원심분리 또는 여과되고, 이후 상청액은 발현된 융합 복합체와 결합하는 모노클로날 항체를 사용하는 것을 포함하는 면역친화성 프로토콜, 또는 친화성 또는 면역친화성 크로마토그래피, 예컨대 단백질-A 또는 단백질-G 친화성 크로마토그래피에 의해 정제된다. 본 발명의 융합 단백질은 공지의 기술들을 적당히 병행하여 분리 및 정제될 수 있다. 이러한 방법들로서는, 예를 들어 용해도를 이용하는 방법, 예컨대 염 침전법 및 용매 침전법, 분자량의 차이를 이용하는 방법, 예컨대 투석, 한외여과, 겔여과 및 SDS-폴리아크릴아미드 겔 전기영동법, 전기적 하전량의 차이를 이용하는 방법, 예컨대 이온 교환 컬럼 크로마토그래피, 특이적 친화성을 이용하는 방법, 예컨대 친화성 크로마토그래피, 소수성의 차이를 이용하는 방법, 예컨대 역상 고성능 액체 크로마토그래피, 그리고 등전점 차이를 이용하는 방법, 예컨대 등전점 맞춤 전기영동, 금속 친화성 컬럼, 예컨대 Ni-NTA를 이용하는 방법을 포함한다. 일반적으로 이러한 방법에 관하여 개시되어 있는 문헌(Sambrook et al.(상동) 및 Ausubel et al.(상동))을 참조한다.
본 발명의 융합 단백질은 실질적으로 순수한 것이 바람직하다. 즉, 본 융합 단백질은 자연에서 이를 수반하는 세포 대체물(cell substituent)로부터 분리되고, 이로써 융합 단백질은, 바람직하게 적어도 80%(w/w) 또는 90%(w/w) 또는 95%(w/w)의 균질성을 보이며 존재한다. 적어도 98%(w/w) 내지 99%(w/w)의 균질성을 보이는 융합 단백질이 다수의 약학적 응용, 임상 응용 및 연구적 응용에 가장 바람직하다. 융합 단백질이 일단 실질적으로 정제되면, 이 단백질에는 치료적 응용을 위하여 오염물이 실질적으로 존재하지 않아야 한다. 가용성 융합 단백질이 일단 부분적으로나 실질적으로 순수한 상태로 정제되면, 이 단백질은 치료적으로 사용될 수 있거나, 또는 본원에 개시된 바와 같이 시험관 내 또는 생체 내 검정을 수행하는데 사용될 수 있다. 실질적 순도는, 다양한 표준적 기술, 예컨대 크로마토그래피 및 겔 전기영동에 의해 측정될 수 있다.
본 융합 단백질 복합체는, 암성이거나 감염되었거나 하나 이상의 질환에 의해 감염성을 보이게 될 수 있는 여러 세포와 함께 시험관 내 또는 생체 내에서 사용되기 적합하다.
인간의 인터루킨-15(huIL-15)는, 항원 제시 세포상에 발현되는 인간 IL-15 수용체 α 사슬(huIL-15Rα)에 의하여 면역 효과기 세포에 경유 제시(trans-presenting)된다. IL-15Rα는, 주로 세포외 스시 도메인을 통하여 높은 친화도(38 pM)로 huIL-15와 결합한다(huIL-15RαSu). 본원에 기술된 바와 같이 huIL-15 및 huIL-15RαSu 도메인은 다중 도메인 융합 복합체를 구성하기 위한 스캐폴드로서 사용될 수 있다.
IgG 도메인, 구체적으로 Fc 단편은 승인된 생물의약품을 비롯하여 다수의 치료용 분자에 대한 이량체 스캐폴드로서 성공적으로 사용된 바 있다. 예를 들어 에타너셉트는 가용성 인간 p75 종양 괴사 인자-α(TNF-α) 수용체(sTNFR)가, 인간 IgG1의 Fc 도메인에 결합되어 있는 이량체이다. 이와 같은 이량체화는 TNF-α 활성 억제에 대해 에타너셉트로 하여금 단량체 sTNFR보다 1000배 이하로 더 강력하게 될 수 있도록 만들고, 단량체 형태의 혈청 중 반감기보다 5배 더 긴 혈청 중 반감기를 융합체에 제공한다. 결과적으로 에타너셉트는 TNF-α의 생체 내 전염증 활성을 중화하고, 다수의 상이한 자가면역성 적응증에 대한 환자의 치료결과를 개선하는데 효과적이다.
Fc 단편의 이량체화 활성에 더하여, 이 Fc 단편은 또한 보체 활성화, 그리고 자연살해(NK) 세포, 호중구, 식세포 및 수지상 세포 상에 제시되는 Fcγ 수용체와의 상호작용을 통해 세포독성 효과기 기능도 제공한다. 항암 치료 항체 및 기타 항체 도메인-Fc 융합 단백질에 관한 내용 중, 이러한 활성은 동물 종양 모델 및 암 환자에서 관찰되는 효능에 중요한 역할을 담당할 수 있을 것이다. 그러나 이와 같은 세포독성 효과기 반응은 다수의 치료적 응용에 있어 충분치 못할 수 있다. 그러므로 Fc 도메인의 효과기 활성을 개선 및 증진하고, 세포용해성 면역 반응, 예컨대 T 세포 활성을 표적화된 치료 분자를 통해 질환 부위에 보충하는 기타 수단을 개발하는 것에 상당한 관심이 모아지고 있다. IgG 도메인은 전통적인 하이브리도마 융합 기술에 의해 생성된 생성물의 품질과 양을 개선/증가시키는 이중 특이적 항체를 생성하기 위한 스캐폴드로서 사용되어 왔다. 비록 이 방법은 다른 스캐폴드의 단점들을 우회하지만, 포유동물 세포에서 이중 특이적 항체를 임상 개발 및 사용을 지원하기 충분한 수준으로 제조하는 것은 어려운 일이었다.
인간 유래 면역자극성 다량체 스캐폴드를 개발하고자 하는 노력으로, 인간 IL-15(huIL-15) 및 IL-15 수용체 도메인이 사용되었다. huIL-15는, huIL-15 수용체 α-사슬(huIL-15Rα)과 높은 결합 친화도(평형 해리 상수 (KD) 약 10-11 M)로 결합하는, 시토카인의 소형 4중 α-나선 묶음(bundle) 과의 일원이다. 생성된 복합체는 이후 T 세포 및 NK 세포 표면상에 제시되는 인간 IL-2/15 수용체 β/공통 γ 사슬(huIL-15RβγC) 복합체들에 경유 제시된다. 이 시토카인/수용체 상호작용을 통해 바이러스 감염 세포 및 악성 세포를 근절하는데 중요한 역할을 담당하는 효과기 T 세포와 NK 세포의 증식 및 활성화가 초래된다. 보통 huIL-15 및 huIL-15Rα는 수지상 세포 내에서 함께 생성되어, 추후 세포 내에 이종이량체 분자로서 분비되어 세포 표면에 제시되는 복합체를 이룬다. 그러므로 huIL-15 및 huIL-15Rα 상호작용의 특성들은, 이와 같은 사슬간 결합 도메인이 인간 유래 면역자극 스캐폴드로서 사용되어, 표적 특이적 결합이 가능한 가용성 이량체 분자를 형성함을 암시한다.
이하에 상세히 기술된 바와 같이, huIL-15:huIL-15RαSu 기반 스캐폴드는 PD-L1 TxM을 제조하는데 사용되었다. 이 이량체 융합 단백질 복합체는 이의 huIL-15 도메인들과 결합 도메인들의 면역자극 및 표적 특이적 생물 활성을 보유하였는데, 이 점은 huIL-15 및 huIL-15Rα의 부가가 융합 도메인들의 공간적 배열을 유의미하게 변경시키지 않았고, 시토카인 활성에 영향을 미치지 않으면서 형태상의 가요성을 적당한 정도로 제공하였음을 말해주는 것이다. 그러므로 이 스캐폴드는 다가 융합 복합체, 예컨대 PD-L1 TxM을 형성하여, 분자의 전체 결합 친화성을 증가시키는데 사용될 수 있었다. 가용성 융합 단백질은 재조합 CH0 세포 배양액 중에서 비교적 높은 수준(과도한 세포주 스크리닝 또는 최적화 없이도 세포 배양 상청액 1 리터당 mg 단위)으로 제조되었으며, 세포 배양 상청액으로부터 용이하게 정제될 수 있었다.
본 발명의 실시예는, 달리 명시되지 않은 한, 당 업자의 이해범위 내에서 널리 알려진 종래의 분자 생물학 기술(재조합 기술 포함), 미생물학 기술, 세포 생물학 기술, 생화학 기술 및 면역학 기술이 사용된다. 이러한 기술은 문헌(예컨대 "Molecular Cloning: A Laboratory Manual", second edition (Sambrook, 1989); "Oligonucleotide Synthesis" (Gait, 1984); "Animal Cell Culture" (Freshney, 1987); "Methods in Enzymology" "Handbook of Experimental Immunology" (Weir, 1996); "Gene Transfer Vectors for Mammalian Cells" (Miller and Calos, 1987); "Current Protocols in Molecular Biology" (Ausubel, 1987); "PCR: The Polymerase Chain Reaction", (Mullis, 1994); "Current Protocols in Immunology" (Coligan, 1991))에 상세히 설명되어 있다. 이러한 기술은 본 발명의 폴리뉴클레오티드와 폴리펩티드의 제조에 적용될 수 있으며, 마찬가지로 본 발명을 제조하고 실시하는 데에도 사용될 수 있다. 특정 구현예들에 특히 유용한 기술은 이하 문단들에서 논의될 것이다.
림프종
림프종은 B 림프구 또는 T 림프구가 정상 세포보다 더 빠르게 분열하고, 의도된 시간보다 더 오래 생존할 때 발생하는 혈액 암의 한 유형이다. 예를 들어 B 세포 림프종은 호지킨 림프종과 대부분의 비호지킨 림프종 둘 다를 포함한다. B 세포 림프종은 CD20을 발현한다.
림프종은 림프절, 비장, 골수, 혈액 또는 기타 장기에서 발달할 수 있다. 이러한 악성 세포는 종종 림프절에서 기원하여, 소절의 비대(즉 림프양 세포의 고형 종양)로서 제시하기도 한다. 림프종은 림프절 생검(즉 림프절의 일부 또는 전부를 절개하여 현미경으로 검사하는 것)에 의해 제한적으로 진단된다. 이러한 검사는, 림프종을 나타낼 수 있는 병리조직학적 특징들을 규명할 수 있다. 치료는 화학요법, 방사선요법 및/또는 골수 이식을 수반할 수 있다.
이하 실시예들은 본 발명의 검정, 스크리닝 및 치료 방법이 어떻게 실시되고 이용되는지에 대한 완전한 개시 및 설명을 당업자들에게 제공하기 위해 제시되는 것이지, 본 발명의 발명자들이 자신들의 발명이라고 간주하는 것에 대한 범위를 한정하고자 하는 것은 아니다.
실시예
실시예
1: 항 PD-L1 결합 도메인을 포함하는 IL-15 기반 융합 단백질 복합체(PD-L1 TxM)의 제조 및 특성규명
암 세포는 면역 관문 분자 및 리간드, 예컨대 PD-L1에 의해 조절되는 다양한 면역 억제 경로를 가동시킬 수 있다. 이러한 관문 분자를 차단하는 항체가 항 종양 면역성을 증진시키는 것으로 보였다. IL-15는 NK 및 CD8+ 세포의 세포용해 활성을 증가시키면서 이 세포들을 활성화 및 증식시킨다. Ig 분자의 Fc 영역은 NK 세포 및 대식세포 상 Fcγ 수용체와 상호작용할 수 있으며, 표적 질환 세포에 대한 항체 의존적 세포성 세포독성(ADCC) 또는 항체 의존적 세포성 식세포작용(ADCP)을 매개한다. 하기에 상세히 기술된 바와 같이, 항 PD-L1 결합 도메인에 융합된 IL-15N72D:IL-15RαSu/Fc 스캐폴드를 포함하는 단백질 복합체가 제조되었다. 이 복합체는 항 PD-L1 결합 도메인을 통해 종양 세포를 인지하고, IL-15 활성을 통해 NK 세포 반응 및 T 세포 반응을 유도하며, Fc 결합 도메인을 통해 ADCC 및 CDC를 자극한다.
구체적으로 구조체는 단일 사슬 항 PD-L1 항체를 huIL-15N72D 및 IL-15RαSu/Fc 사슬들에 결합하여 제조되었다. 항 PD-L1 단일 사슬 항체(항 PD-L1 scAb) 서열은 가요성 링커 서열을 통해 결합된, 항체의 중쇄 및 경쇄 V 항체 도메인 암호화 영역을 포함한다. 단일 사슬 항체 도메인은 VH-링커-VL 또는 VL-링커-VH 형태 중 어느 하나의 형태로 배열될 수 있다. 몇몇 경우에 있어서, 항 PD-L1 scAb는 IL-15N72D 및/또는 IL-15RαSu/Fc 사슬의 C-말단에 결합된다. 다른 경우에 있어서, 항 PD-L1은 IL-15N72D 및/또는 IL-15RαSu/Fc 사슬의 N-말단에 결합된다. 마우스 PD-L1 분자 또는 인간 PD-L1 분자 중 어느 하나에 특이적인 항 PD-L1 scAb가 이러한 구조체에 사용되었다.
1) huIL-15N72D 및 huIL-15RαSu/huIgG1 Fc 사슬의 N-말단에 결합된 항 인간 PD-L1 scAb를 포함하는 구조체의 핵산 및 단백질 서열은 이하에 보였다. (신호 펩티드 서열 및 종결 코돈을 포함하는) 항 인간 PD-L1 scAb/IL-15N72D 구조체의 핵산 서열은 하기와 같다(서열 번호 1):


(신호 펩티드 서열을 포함하는) 항 인간 PD-L1 scAb/IL-15N72D 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 2):


몇몇 경우에서, 리더 펩티드는 성숙 폴리펩티드로부터 절단된다.
(리더 서열을 포함하는) 항 인간 PD-L1 scAb/huIL-15RαSu/huIgG1 Fc 구조체의 핵산 서열은 하기와 같다(서열 번호 3):


(리더 서열을 포함하는) 항 인간 PD-L1 scAb/huIL-15RαSu/huIgG1 Fc 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 4):


몇몇 경우에 있어서, 리더 펩티드는 성숙 폴리펩티드로부터 절단된다.
2) huIL-15N72D 및 huIL-15RαSu/huIgG1 Fc 사슬의 N-말단에 결합된 제2 항 인간 PD-L1 scAb(아벨루맙)를 포함하는 구조체의 핵산 및 단백질 서열은 하기에 보였다. (신호 펩티드 서열 및 종결 코돈을 포함하는) 항 인간 PD-L1 scAb/IL-15N72D 구조체의 핵산 서열은 하기와 같다(서열 번호 5):


(신호 펩티드 서열을 포함하는) 항 인간 PD-L1 scAb/IL-15N72D 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 6):


몇몇 경우에 있어서, 리더 펩티드는 성숙 폴리펩티드로부터 절단된다.
(리더 서열을 포함하는) 항 인간 PD-L1 scAb/huIL-15RαSu/huIgG1 Fc 구조체의 핵산 서열은 하기와 같다(서열 번호 7):


(리더 서열을 포함하는) 항 인간 PD-L1 scAb/huIL-15RαSu/huIgG1 Fc 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 8):


몇몇 경우에 있어서, 리더 펩티드는 성숙 폴리펩티드로부터 절단된다.
3) huIL-15N72D 및 huIL-15RαSu/muIgG2A Fc 사슬의 N-말단에 결합된 항 마우스 PD-L1 scAb를 포함하는 구조체의 핵산 및 단백질 서열은 하기에 보였다. (신호 펩티드 서열 및 종결 코돈을 포함하는) 항 마우스 PD-L1 scAb/IL-15N72D 구조체의 핵산 서열은 하기와 같다(서열 번호 9):


(신호 펩티드 서열을 포함하는) 항 마우스 PD-L1 scAb/IL-15N72D 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 10):


몇몇 경우에 있어서, 리더 펩티드는 성숙 폴리펩티드로부터 절단된다.
(리더 서열을 포함하는) 항 마우스 PD-L1 scAb/huIL-15RαSu/muIgG2A Fc 구조체의 핵산 서열은 하기와 같다(서열 번호 11):


(리더 서열을 포함하는) 항 마우스 PD-L1 scAb/huIL-15RαSu/muIgG2A Fc 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 12):


몇몇 경우에 있어서, 리더 펩티드는 성숙 폴리펩티드로부터 절단된다.
항 PD-L1 scAb/IL-15N72D 및 항 PD-L1 scAb/IL-15RαSu/Fc 서열은 앞서(본원에 참조로 인용된 미국 특허 제8,507,222호) 기술된 바와 같이 발현 벡터에 클로닝되었으며, 발현 벡터는 CHO 세포를 형질감염시켰다. CHO 세포 내에서 2개의 구조체의 공동 발현은 가용성 항 PD-L1 scAb/IL-15N72D:항 PD-L1 scAb/IL-15RαSu/Fc 복합체의 형성 및 분비를 허용하였는데, 이 복합체는 단백질 A 친화성 크로마토그래피가 사용되어 CHO 세포 상청액으로부터 정제되었다.
정제된 항 PD-L1 scAb/IL-15N72D:항 PD-L1 scAb/IL-15RαSu/Fc 단백질 복합체의 SDS-PAGE 분석 결과는 도 3에 보였다. 가용성 항 마우스 PD-L1 scAb/huIL-15RαSu/muIgG2A 및 항 마우스 PD-L1 scAb/IL-15N72D 단백질에 해당하는 밴드들은 각각 약 60 kDa 및 약 40 kDa의 위치에서 관찰되었다.
실시예 2: PL-L1 TxM의 시험관 내 특성규명
ELISA 기반 방법은 PD-L1 TxM의 형성을 확인시켜주었다. 도 4a에 있어서, 형질감염된 CHO 세포 유래 배양 상청액 중 항 인간 PD-L1 scAb/IL-15N72D:항 인간 PD-L1 scAb/huIL-15RαSu/huIgG1 Fc 융합 단백질 복합체는 포착 항체, 항 인간 IgG 항체(Jackson ImmunoResearch), 검출 항체, 바이오틴화 항 인간 IL-15 항체(BAM 247, R&D Systems)와 함께 huIgG1/huIL15 특이적 ELISA가 사용되어 검출되었다. 이는, 비형질감염 CHO 세포를 함유하는 배지의 상청액만이 사용되어 대조군 시료와 비교되었다. 형질감염 CHO 세포로부터 유래한 배양 상청액에서 관찰된 신호의 증가는 PD-L1 TxM 복합체가 생성되었음을 확인시켜주는 것이다 제2 항 인간 PD-L1 scAb/IL-15N72D:항 인간 PD-L1 scAb/huIL-15RαSu/huIgG1 Fc 융합 단백질 복합체(아벨루맙 TxM)로부터 유사한 결과가 얻어졌다(도 4b).
마우스 특이적 PD-L1 TxM에 있어서, 융합 단백질 복합체는 포착 항체, Affinipure 당나귀 항 마우스 IgG(Jackson ImmunoResearch) 또는 인간/영장류 IL15 항체(MAB647, R&D system), 그리고 검출 항체 호오스래디시 퍼옥시다아제-Affinipure 당나귀 항 마우스 IgG(Jackson ImmunoResearch) 또는 비이오틴화 항 인간 IL-15 항체(BAM 247, R&D Systems) 각각과 함께, mIgG2a 특이적 또는 huIL15 특이적 ELISA가 사용되어 검출되었다(도 4c). 정제된 마우스 특이적 PD-L1 TxM에 대한 항체 반응성은, 양성 대조군의 경우와 비교되었을 때, 복합체가 형성되었음을 확인시켜주었다.
이러한 융합 단백질 복합체가 종양 세포 상의 PD-L1과 결합하는 능력도 또한 검토되었다. 인간 특이적 PD-L1 TxM의 결합은 MB231 종양 세포를 보유하는 수용체가 사용되는 유새포분석에 의해 평가되었다. 이러한 연구에서, 1 x 105개 세포는 PD-L1 TxM 복합체로 염색되었다. 도 5a에 보인 바와 같이, 유세포분석은, APC 접합 마우스 항 인간 Fc Ab(Biolegend)가 사용되어 검출되었을 때 MB231 세포에 PD-L1 TxM 복합체가 결합하였음을 입증하였다. 도 5b에 있어서, 이러한 결합의 특이성은 PD-L1 TxM 복합체를 사용하여, 시판중인 APC 접합 항 인간 PD-L1 Ab(Biolegend)로 MB231 세포가 염색되는 것을 차단함으로써 시험되었다. 이와 유사하게, 유세포분석은, 아벨루맙 기반 PD-L1 TxM 복합체가 MB231 종양 세포에 결합함을 입증하였다(도 5c).
마우스 특이적 PD-L1 TxM 복합체의 결합을 평가하기 위하여, PD-L1 양성 5T33P 골수종 및 MB49luc 방광 종양 세포(시험당 5 x 105개 세포)는 처음에 PE 또는 Brilliant Violet 표지화 항 마우스 PD-L1 Ab(시험당 100 μL 중 2 μg)로 염색되었다(도 6a 및 도 6b). 이러한 결합의 특이성은 정제된 마우스 특이적 PD-L1 TxM 복합체를 첨가하여, 항체와 PD-L1 리간드의 결합을 차단함으로써 시험되었다. 정제된 항 mPD-L1 Ab(S1-PD-L1)는 양성 대조군으로 사용되었다. 흥미롭게도, PD-L1 TxM 복합체는 종양 세포 상 PD-L1 염색을 동량의 항 PD-L1 Ab보다 더 잘 차단하였음이 발견되었다. 이 점은, A20 B 세포 림프종 세포가 사용되는 차단 연구에서 추가로 평가되었다. 역가 분석은, 종양 세포 표면상에 발현되는 PD-L1과의 상호작용을 차단함에 있어 PD-L1 TxM이 항 PD-L1 Ab보다 적어도 5배 더 유효하였음을 나타내었다(도 7a 및 도 7b).
PD-L1 TxM 복합체의 IL-15 면역 자극 활성을 평가하기 위해, IL-15 의존적 32Dβ세포(마우스 조혈 세포주)의 증식이 평가되었다. PD-L1 TxM의 수준을 높이면서 이 PD-L1 TxM은 32Dβ 세포(104개 세포/웰)에 첨가되었으며, 이로부터 2일 후 WST-1 증식 시약을 이용하여 세포 증식이 확인되었다. 도 8에 보인 바와 같이, 32Dβ 세포 증식의 용량 의존적 증가는 PD-L1 TxM에 의해 매개되었는데, 이는 이 복합체의 면역자극 활성을 입증해준다.
PD-L1 TxM 복합체의 상이한 형태들의 특징과 활성을 평가하기 위해 추가 연구가 수행되었다. 항 PD-L1 scAb/IL-15N72D 및 항 PD-L1 scAb/IL-15RαSu/Fc 단백질을 포함하는 복합체는, 4개의 항 PD-L1 scAb 결합 도메인을 가지는 것으로(즉 4두형(4H)인 것으로) 예상되는 반면에, IL-15N72D 및 항 PD-L1 scAb/IL-15RαSu/Fc 단백질을 포함하는 복합체는 2개의 항 PD-L1 scAb 결합 도메인을 가질 것으로(즉 2두형(2H)인 것으로) 예상된다(도 9a). 이 복합체들은, 2H TxM에 비하여 4H TxM의 표적 세포에 대한 결합성 결합(avidity binding)이 더 크다는 점을 바탕으로 하였을 때, 상이한 활성을 가질 것으로 예상된다. IL-15N72D에 대한 단백질 융합은 또한 IL-15의 생물 활성을 감소시키는 것으로 보이기도 하였다. 그러므로 4H TxM 형태는 2H TxM보다 IL-15 활성이 더 작을 것으로 예상된다. 이러한 차이점은, 큰(항체와 유사한) 표적화 활성 및 더 작은 면역자극 활성이 바람직할 경우(즉 4H TxM 형태일 경우), 아니면 더 작은 표적화 활성 및 더 큰 면역 자극 활성(면역시토카인)이 바람직할 경우에 이점을 제공할 것으로 예상된다.
이러한 형태를 평가하기 위하여, 항 마우스 PD-L1 scAb/IL-15N72D 및 항 마우스 PD-L1 scAb-/IL-15RαSu/Fc 발현 벡터, 또는 IL-15N72D 및 항 마우스 PD-L1 scAb-/IL-15RαSu/Fc 발현 벡터 각각으로 CHO 세포를 형질감염시킴으로써, 4H 마우스 특이적 PD-L1 TxM(2C2) 및 2H 마우스 특이적 PD-L1 TxM(PDN3)이 제조되었다. 그 다음, TxM 복합체는 형질감염 CHO 세포 상청액으로부터 단백질 A 크로마토그래피에 의해 정제되었으며, 정제된 단백질은 환원 SDS-PAGE에 의해 평가되었다(도 9b). 각각 약 60 kDa, 약 40 kDa 및 약 16 kDa의 위치에서 가용성 항 마우스 PD-L1 scAb/huIL-15RαSu/muIgG2A, 항 마우스 PD-L1 scAb/IL-15N72D 및 IL-15N72D 단백질에 해당하는 밴드들이 관찰되었다. 뿐만 아니라, 정제된 4H PD-L1 TxM(2C2) 및 2H PD-L1 TxM(PDN3) 복합체들은 분석용 크기별 배제 크로마토그래피(SEC)에 의해 분석되었을 때 단일 단백질 피크로서 이동하였다(도 9c 및 도 9d). 이러한 결과는, 2개의 상이한 PD-L1 TxM 복합체들이 예상되는 구조적 특성을 가지는 가용성 단백질로서 제조 및 정제될 수 있음을 보여준다.
전술된 연구와 유사하게, 이러한 융합 단백질 복합체가 면역 세포상 IL-2Rβ/γ 및 종양 세포상 PD-L1과 결합하는 능력이 연구되었다. IL-2Rβ/γ 양성 32Dβ 세포는 4H PD-L1 TxM(2C2), 2H PD-L1 TxM(PDN3) 또는 대조군 ALT-803 복합체들과 함께 항온처리되었다. 세척 단계를 거친 후, 유세포분석으로 결합형 TxM/ALT-803 복합체를 검출하기 위해 항 인간 IL-15 Ab-PE(또는 이소타입 대조군 Ab)가 첨가되었다. 도 10a에 보인 바와 같이, 4H PD-L1 TxM(2C2), 2H PD-L1 TxM(PDN3) 및 ALT-803 단백질은 대조군과 달리 32Dβ 세포와 결합할 수 있었다. PD-L1과의 결합을 평가하기 위해, PD-L1 양성 5T33P 골수종 세포는 처음에 Brilliant Violet 421(BV421) 표지화 항 마우스 PD-L1 Ab로 염색되었다(10F.9G2). 이 결합의 특이성은, 정제된 4H PD-L1 TxM(2C2) 및 2H PD-L1 TxM(PDN3) 복합체들을 첨가하여, BV421 항체가 PD-L1 리간드에 결합하는 것을 차단함으로써 시험되었다(도 10b 및 도 10c). 정제된 항 mPD-L1 Ab(NJI6)는 양성 대조군으로 사용되었다. 이의 높은 결합성과 일치되게, 4H PD-L1 TxM 1 μg은 항 PD-L1 Ab 염색을 차단함에 있어 2H PD-L1 TxM 6 μg만큼 유효하였다. 이러한 결과는, 4H PD-L1 및 2H PD-L1 TxM 복합체들이 IL-2Rβ/γ 및 PD-L1 표적 결합 활성을 보유함을 확인시켜주는 것이다.
전술된 바와 같이, 마우스 특이적 4H PD-L1 및 2H PD-L1 TxM 복합체들의 IL-15 면역 자극 활성은 IL-15 의존적 32Dβ 세포의 증식을 바탕으로 분석되었다. 도 11a 및 도 11b에 보인 바와 같이, 32Dβ 세포 증식의 용량 의존적 증가는 4H PD-L1 및 2H PD-L1 TxM 복합체들 중 어느 하나에 의해 매개되었는데, 이 점은 이 TxM 형태들의 면역 자극 활성을 입증해주는 것이다. 2H PD-L1 TxM 복합체(PDN-3)는 ALT-803에 비하여 IL-15 생체활성에 있어 약간의 감소를 보였던 반면에, 4H PD-L1 TxM 복합체(2C2)는 IL-15 생체활성에 있어 대략 30배만큼의 감소를 보였다. 이 점은, 이전의 결합 도메인-IL-15N72D 융합 단백질의 더 작은 IL-15 활성과 일치한다.
4H 인간 특이적 PD-L1 TxM 복합체 및 2H 인간 특이적 PD-L1 TxM 복합체를 대상으로 유사한 연구가 수행되었다. 이 단백질은, CHO 세포를 항 인간 PD-L1 scAb/IL-15N72D 및 항 인간 PD-L1 scAb-/IL-15RαSu/Fc 발현 벡터, 또는 IL-15N72D 및 항 인간 PD-L1 scAb-/IL-15RαSu/Fc 발현 벡터 각각으로 형질감염시킨 다음, 단백질 A 크로마토그래피를 통해 세포 배양 상청액으로부터 정제함으로써 제조되었다. 환원 SDS-PAGE 분석은, 정제된 4H 인간 특이적 PD-L1 TxM 및 2H 인간 특이적 PD-L1 TxM 제제에 있어서 예상되는 단백질 밴드를 확인하였다(도 12a). 이와 유사하게, 분석용 SEC는, 정제된 4H 인간 특이적 PD-L1 TxM 및 2H 인간 특이적 PD-L1 TxM 복합체들이 단일 단백질 피크로서 이동하였음을 나타내었다(도 12b 및 도 12c).
이러한 융합 단백질 복합체가 종양 세포상 PD-L1과 결합하는 능력이 분석되었다. PD-L1 양성 PC-3 인간 전립선암 세포가, 10 nM의 정제 인간 특이적 4H PD-L1 TxM, 2H PD-L1 TxM 또는 대조군 2H 항 CD20 scAb(2B8) TxM 복합체의 존재 또는 부재 하에 APC 표지화 항 마우스 PD-L1 Ab로 염색되었다(도 13). 결과는, 인간 특이적 4H PD-L1 및 2H PD-L1 TxM 복합체들이, 항 PD-L1 Ab와 인간 종양 세포의 결합을 차단할 수 있었던 반면에, 대조군 TxM 복합체는 그렇지 않았음을 보여준다. 이전의 결과들과 일치되게, 4H PD-L1 TxM 복합체는 2H PD-L1 TxM 복합체보다 더 우수한 결합 활성을 보였다. 이러한 결과는, 인간 특이적 4H PD-L1 및 2H PD-L1 TxM 복합체들이 인간 종양 세포 상 PD-L1 표적 결합 활성을 보유함을 확인시켜주는 것이다.
전술된 바와 같이, 인간 특이적 4H PD-L1 TxM 복합체 및 2H PD-L1 TxM 복합체들의 IL-15 면역 자극 활성은, IL-15 의존적 32Dβ 세포의 증식을 기반으로 분석되었다. 도 14a 및 도 14b에 보인 바와 같이, 32Dβ 세포 증식의 용량 의존적 증가는 4H PD-L1 TxM 복합체 및 2H PD-L1 TxM 복합체 중 어느 하나에 의해 매개되었는데, 이 점은 이 TxM 형태들의 면역 자극 활성을 입증하여주는 것이다. 2H PD-L1 TxM 복합체는 ALT-803에 비하여 IL-15 생체활성에 있어 약간의 증가를 보였던 반면에, 4H PD-L1 TxM 복합체는 ALT-803에 비하여 IL-15 생체활성에 있어 대략 5배의 감소를 보였다. 이 점은, 이전 결합 도메인-IL-15N72D 융합 단백질의 더 작은 IL-15 활성과 일치한다.
실시예
3: PD-L1
TxM의
시험관 내 및 생체 내 면역 자극 활성 및
항 종양
활성
PD-L1 TxM이 생체 내에서 면역 반응을 자극하는 능력이 마우스에서 평가되었다. C57BL/6 마우스는 PBS 200 μl, ALT-803(0.4 mg/kg, 대조군), 4H 마우스 특이적 PD-L1 TxM(200 μg, 2C2 (T4M-mPD-L1)), 또는 2H 마우스 특이적 PD-L1 TxM(200 μg, PDN3(T2M-mPD-L1))로 피하 주사되었다. 처리후 3일에, 비장 및 림프절이 수집되었다. 비장 세포와 림프구는 항 CD4, CD8, NK 및 CD19 Ab가 사용되는 면역 세포 하위세트 염색을 거쳐 유세포분석용으로 준비되었다. 도 15a에 보인 바와 같이, ALT-803, 2H PD-L1 TxM 및 4H PD-L1 TxM 처리는, 이 단백질들의 면역 자극 활성과 일치되게, 비장 중량의 증가를 유도하였다. 구체적으로 2H PD-L1 TxM 처리는 4H PD-L1 TxM 처리보다 더 많은 비장 중량 증가를 유도하였는데, 이 점은 이 복합체들로써 관찰되는 IL-15 활성에 있어서의 차이와 일치한다. 2H PD-L1 TxM 및 4H PD-L1 TxM 처리는 또한 PBS 대조군에 비하여 마우스 비장 및 림프절 내 CD8 T 세포 및 NK 세포 백분율의 증가를 초래하였다(도 15b 및 도 15c). 이러한 면역 반응은, 이 TxM 복합체들의 IL-15 생체활성과 일치하였다.
추가로, PD-L1 TxM이 종양 세포에 대해 면역 세포의 세포독성을 자극하는 능력이 시험관 내에서 평가되었다. 제조자의 지침에 따라 PD-L1 양성 세포가 CellTrace Violet(Invitrogen)으로 표지화된 다음, 면역 효과기 세포(즉 비장 세포)와 함께 R10 배지(10% 소 태아 혈청 포함 RPMI-1640) 중에서 효과기:5T33P 골수종 표적 비율 10:1로 배양되었다(37℃, 5% CO2). 효과기 세포는, P-mel 마우스 비장 세포를 3일 동안 항 CD3 Ab(2C11: 4 μg/ml)으로 자극함으로써 준비되었다. 종양 및 효과기 세포는 4일 동안 마우스 특이적 PD-L1 TxM과 함께 항온처리되었으며, 이후 표적 세포 생존률을 확정하기 위해 유세포분석을 통해 분석되었다. PBS는 음성 대조군으로서 사용되었고, ALT-803(IL-15N72D:IL-15Rα/Fc), 항 PD-L1 Ab 및 ALT-803 + 항 PD-L1 Ab는 양성 대조군으로서 사용되었다. 도 16에 보인 바와 같이, PBS 처리 군에 비하여 PD-L1 TxM 2.1 μg 처리 군에서 5T33P 종양 세포의 유의미한 사멸이 관찰되었다.
인간 특이적 2H PD-L1 TxM 및 4H PD-L1 TxM 복합체들이 사용되어 유사한 시험관 내 항 종양 활성이 평가되었다. 2명의 상이한 공여자로부터 유래한 인간 NK 세포는 NK 세포 단리 키트(Stemcell Technologies)에 의해 혈액 백혈구연층(blood buffy coat)으로부터 정제되어, 효과기 세포로서 사용되었다. PD-L1 양성 인간 췌장 종양 세포 SW1990은 Celltrace-Violet으로 표지화되어 표적 세포로서 사용되었다. 인간 NK 세포 및 SW1990 종양 세포는 E:T 비율 5:1로 배지 단독, 또는 50nM 항 인간 PD-L1 Ab(대조군), 인간 특이적 2H PD-L1 TxM 복합체 또는 4H PD-L1 TxM 복합체를 함유하는 배지 중에서 혼합되었다. 40시간 후, Violet 표지화 표적 세포의 요오드화프로피듐 염색을 기반으로 하는 유세포분석에 의해 표적 세포 사멸 %가 평가되었다. 도 17에 보인 바와 같이, 인간 특이적 2H PD-L1 TxM 복합체 또는 4H PD-L1 TxM 복합체 중 어느 하나와 항온처리된 인간 NK 세포는 미처리 NK 세포, 또는 항 인간 PD-L1 Ab로 처리된 NK 세포의 PD-L1 양성 인간 종양 세포에 대한 세포독성(즉 기존의 ADCC)보다 더 큰, PD-L1 양성 인간 종양 세포에 대해 세포독성을 매개할 수 있었다. 이러한 결과는 항 PD-L1 Ab의 면역 세포 매개성 표적화 항 종양 활성에 비하여 PD-L1 TxM 복합체의 면역 세포 매개성 표적화 항 종양 활성이 유의미하게 개선되었음을 나타낸다.
종양 보유 동물 내에서 PD-L1 TxM의 효능을 평가하기 위해 동소성 5T33P 골수종 모델이 사용되었다. 0일에 암컷 C57BL/6NHsd 마우스(군당 4 마리 마우스)에 5T33P 골수종 세포(1 x 107개/마우스)가 정맥내 주사되었다. 그 다음, 7일과 14일에 저용량 PD-L1 TxM(0.11 mg/kg, 0.05 mg/kg ALT-803에 대한 몰 등가 용량) 또는 고용량 PD-L1 TxM(52.5 μg/용량, 25 μg/용량 항 PD-L1 Ab에 대한 몰 등가 용량)가 피하 투여되었다. ALT-803(0.15 mg/kg) 및 ALT-803(0.05 mg/kg) + 항 PD-L1 Ab(25 μg/용량)는 양성 대조군으로 사용되었고, PBS는 음성 대조군으로 사용되었다. 생존률(또는 뒷 다리 마비로 말미암은 이환율)이 연구 종말점(study endpoint)으로서 모니터링되었다. 분명한 점은, 고용량 PD-L1 TxM(52.5 μg/마우스) 처리가 PBS 처리에 비하여 종양 보유 마우스의 생존을 연장시키는 것으로 확인되었다(도 18). 이 효과는, 거의 동일한 ALT-803 + 항 PD-L1 Ab 병용 요법에서 관찰되었던 효과와 동등하였다. 종양 보유 동물에 PD-L1 TxM 처리가 행하여진 후에는 겉으로 드러나는 독성은 관찰되지 않았다.
추가로, 동소성 MB49luc 종양 보유 마우스를 대상으로 PD-L1 TxM 복합체의 항 종양 활성이 평가되었다. 0일에 C57BL/6NHsd 마우스(군당 6마리 마우스)의 방광에 MB49luc 방광 종양 세포(3 x 104개/마우스)가 서서히 주입되었다. 7, 11, 14 및 18 일에 종양 보유 마우스에 마우스 특이적 2H PD-L1 TxM(2.8 mg/kg)이 피하 처리되었다. ALT-803 처리(0.2 mg/kg, 피하) 및 ALT-803(0.2 mg/kg, 피하) + 항 PD-L1 Ab(50 μg/용량, 피하)는 양성 대조군으로 사용되었고, PBS는 음성 대조군으로 사용되었다. 생존률(또는 이환율)이 연구 종말점으로서 모니터링되었다. 도 19에 보인 바와 같이, 2H PD-L1 TxM 처리는 PBS 처리에 비하여 MB49luc 종양 보유 마우스의 생존을 연장시키는 것으로 확인되었다. 2H PD-L1 TxM의 항 종양 효과는 ALT-803 및 ALT-803 + 항 PD-L1 Ab 양성 대조군으로 관찰되는 바만큼 우수하였거나, 그보다 더 우수하였다.
실시예
4: 항
CTLA4
결합 도메인을 포함하는 IL-15 기반 융합 단백질(
CTLA4
TxM) 및 항 PD-1 결합 도메인을 포함하는 IL-15 기반 융합 단백질(PD-1
TxM
)의 제조
본 발명의 융합 단백질이, 실시예 1 ~ 3에 기술된 융합 단백질 복합체와 유사하게 CTLA4 및 PD-1을 인지하는 결합 도메인을 포함하도록 제조되었다. 구체적으로, 단일 사슬 항 CTLA4 항체를 huIL-15N72D 및 IL-15RαSu/Fc 사슬에 결합함으로써 구조체가 제조되었다. 항 CTLA4 단일 사슬 항체(항 CTLA4scAb) 서열은 가요성 링커 서열을 통하여 결합된 항체의 중쇄 및 경쇄 V 항체 도메인의 암호화 영역을 포함한다. 단일 사슬 항체 도메인은 VH-링커-VL 형태 또는 VL-링커-VH 형태 중 어느 하나의 형태로 배열될 수 있다. 몇몇 경우에 있어서, 항 CTLA4scAb는 IL-15N72D 및/또는 IL-15RαSu/Fc 사슬의 C-말단에 결합되어 있다. 다른 경우에 있어서, 항 CTLA4는 IL-15N72D 및/또는 IL-15RαSu/Fc 사슬의 N-말단에 결합되어 있다. 마우스 CTLA4 분자 또는 인간 CTLA4 분자 중 어느 하나에 특이적인 항 CTLA4scAb가 이러한 구조체에 사용되었다.
(리더 서열을 포함하는) 항 인간 CTLA-4 scAb/huIL-15RαSu/huIgG1 Fc 구조체의 핵산 서열은 하기와 같다(서열 번호 13):


(리더 서열을 포함하는) 인간 CTLA-4 scAb/huIL-15RαSu/huIgG1 Fc 단백질의 아미노산 서열은 하기와 같다(서열 번호 14):


몇몇 경우에 있어서, 리더 펩티드는 성숙 폴리펩티드로부터 절단된다.
유사하게, (리더 서열을 포함하는) 항 마우스 CTLA-4 scAb/huIL-15RαSu/mIgG2a 구조체의 핵산 서열은 하기와 같다(서열 번호 15):


(리더 서열을 포함하는) 항 마우스 CTLA-4 scAb/huIL-15RαSu/mIgG2a 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 16):


몇몇 경우에 있어서, 리더 펩티드는 성숙 폴리펩티드로부터 절단된다.
상기 명시된 바와 같이 항 인간 및 마우스 CTLA4 scAb 도메인들은 또한 IL-15N72D 단백질에의 융합체로서 제조되었다.
유사하게, (신호 펩티드 서열 및 종결 코돈을 포함하는) 항 인간 PD1 scAb/IL-15N72D 구조체의 핵산 서열은 하기와 같다(서열 번호 17):


(신호 펩티드 서열을 포함하는) 항 PD1 scAb-IL-15N72D 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 18):


몇몇 경우에 있어서, 리더 펩티드는 성숙 폴리펩티드로부터 절단된다, 상기 명시된 바와 같이, 항 인간 PD-1 scAb 도메인도 또한 huIL-15RαSu/Fc 구조체에 대한 융합체로서 제조되었다.
실시예 1 및 선행 문헌(미국 특허 제8,507,222호의 실시예 1 및 2; 본원에 참조로서 인용됨)에 기술된 바와 같이, 서열은 발현 벡터에 클로닝되었으며, 이 발현 벡터는 CHO를 형질감염시켰다. 몇몇 경우에 있어서, CHO 세포는 동일하거나 상이한(즉 항 PD-L1 및 항 CTLA4 scAb) 결합 도메인을 가지는 huIL-15N72D 및 huIL-15RαSu/Fc 융합 단백질 둘 다를 암호화하는 벡터로 형질감염되었다. 전술된 바와 같이, 단백질 A 친화성 크로마토그래피를 통하여 CHO 세포 배양 상청액으로부터 융합 단백질 복합체가 정제되었다.
전술된 항 인간 PD-1 scAb/항 인간 CTLA-4 scAb TxM 복합체에 더하여, CHO 세포를 항 인간 PD-L1 scAb/IL-15N72D(서열 번호 1) 구조체 및 항 인간 CTLA-4 scAb/huIL-15RαSu/huIgG1 Fc(서열 번호 15) 구조체를 포함하는 발현 벡터로 공동 형질감염시킴으로써, 항 인간 PD-L1 scAb/항 인간 CTLA-4 scAb TxM 복합체가 제조되었다. 이 융합 단백질 복합체는 전술된 바와 같이 단백질 A 친화성 크로마토그래피를 통해 CHO 세포 배양 상청액으로부터 정제되었다.
실시예
5: 다른 결합 도메인을 포함하는 IL-15 기반 융합 단백질 복합체의 제조
실시예 1 ~ 4에 기술된 융합 단백질 복합체와 유사하게, 본 발명의 융합 단백질은 CD47, GITR, ssDNA 및 기타 질환 관련 표적(즉 CD20, CD19 등)을 인지하는 결합 도메인을 포함하도록 제조되었다.
CD47은 대식세포 상 억제 수용체로서 사용되는 신호-조절 단백질 알파(SIRPα)를 차지함으로써 면역 회피를 촉진하는 세포 표면 분자이다. 이 "나를 먹지 말라는 신호"는 CD47 및 SIRPα의 상호작용을 차단하여, 대식세포에 의한 항체 의존적 세포성 식세포작용(ADCP)를 회복시킴으로써 파괴될 수 있다. 본 발명의 IL-15 도메인은, 자체의 세포용해 활성을 증가시키면서 NK 세포 및 CD8+ 세포를 활성화 및 증식시킨다. 본 발명의 Fc 영역이 충분히 고농도일 때, 이 영역은 ADCC 또는 ADCP 각각을 위해 NK 세포 및 대식세포 상 Fcγ 수용체와 상호작용할 수 있다. 본 실시예는 CD47/SIRPα 경로, IL-15 도메인을 통한 NK 세포 및 CD8+ 세포의 활성화를 차단하고, Fc-매개 ADCC/ADCP를 통한 종양 제거를 허용하는, 나노바디 Vh 영역(NbVh; PNAS 2016 113 (19) E2646-E2654)을 포함하는 융합 단백질의 제조 및 초기 특성규명에 관하여 기술하고 있다. 이하에 상세히 기술된 바와 같이, 항 마우스 CD47 NbVh/huIL-15N72D 및 항 마우스 CD47 NbVh/huIL-15RαSu/mIgG2a Fc를 포함하는 단백질 복합체가 제조되었다.
구체적으로, 항 마우스 CD47 NbVh를 huIL-15N72D 사슬에 결합시킴으로써 구조체가 제조되었다. 항 마우스 CD47 NbVh 서열은 알파카 나노바디의 중쇄 가변 도메인의 암호화 영역을 포함한다. 항 마우스 CD47 NbVh는 huIL-15N72D의 N-말단에 결합된다. huIL-15N72D의 N-말단에 결합된 항 마우스 CD47 NbVh를 포함하는 구조체의 핵산 및 단백질 서열이 이하에 제시되어 있다.
(신호 펩티드 서열을 포함하는) 항 마우스 CD47 NbVh/huIL-15N72D 구조체의 핵산 서열은 하기와 같다(서열 번호 19):


(신호 펩티드 서열을 포함하는) 항 마우스 CD47 NbVh/IL-15N72D 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 20):

(리더 서열을 포함하는) 항 마우스 CD47 NbVh/huIL-15RαSu/mIgG2a Fc 구조체의 핵산 서열은 하기와 같다(서열 번호 21):


(리더 서열을 포함하는) 항 마우스 CD47 NbVh/huIL-15RαSu/mIgG2a Fc 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 22):


상기 명시된 바와 같이, 몇몇 경우에 있어서 리더 펩티드는 성숙 폴리펩티드로부터 절단된다.
인간 CD47에 특이적인 항체로부터 유래한 단일 사슬 항체 도메인이 사용되어 유사한 구조체가 제조되었다. (신호 펩티드 서열을 포함하는) 항 인간 CD47 scAb/huIL-15N72D 구조체의 핵산 서열은 하기와 같다(서열 번호 23):


(신호 펩티드 서열을 포함하는) 항 인간 CD47 scAb/huIL-15N72D 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 24):


(리더 서열을 포함하는) 항 인간 CD47 scAb/huIL-15RαSu/hIgG1 Fc 구조체의 핵산 서열은 하기와 같다(서열 번호 25):


(리더 서열을 포함하는) 항 인간 CD47 scAb/huIL-15RαSu/hIgG1 Fc 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 26):


GITR 리간드 및 GITR 간 상호작용은, 면역 세포에 자극 신호 전달을 제공하는 것으로 공지되어 있으므로, GITR 리간드(GITRL)는 IL-15의 면역 자극 활성과 잠재적으로 상승작용을 할 수 있었던 면역 효현제 분자인 것으로 공지되어 있다. 따라서, 구조체는 인간 GIRTL 및 huIL-15N72D 사슬을 결합하여 제조되었다.
(신호 펩티드 서열을 포함하는) 인간 GITRL/huIL-15N72D 구조체의 핵산 서열은 하기와 같다(서열 번호 27):


(신호 펩티드 서열을 포함하는) 인간 GITRL/IL-15N72D 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 28):

(리더 서열을 포함하는) 인간 GITRL/huIL-15RαSu/hIgG1 Fc 구조체의 핵산 서열은 하기와 같다(서열 번호 29):

(리더 서열을 포함하는) 인간 GITRL/huIL-15RαSu/hIgG1 Fc 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 30):


발병 세포에 의해 발현되는 항원을 표적화하는 결합 도메인을 포함하는 본 발명의 융합 단백질 복합체도 또한 제조될 수 있었다. 이러한 항원은 종양 세포를 비롯한 질환 세포에 의해 방출되는 단일 가닥 DNA(ssDNA)를 포함할 수 있었다. 따라서, ssDNA를 인지하는 단일 사슬 Ab 도메인(Hu51-4 항체로부터 유래하는 TNT scAb)을 가지는 본 발명의 융합 단백질 복합체가 제조되었다.
(신호 펩티드 서열을 포함하는) TNT scAb/huIL-15N72D 구조체의 핵산 서열은 하기와 같다(서열 번호 31):


(신호 펩티드 서열을 포함하는) TNT scAb/IL-15N72D 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 32):


(리더 서열을 포함하는) TNT/huIL-15RαSu/hIgG1 Fc 구조체의 핵산 서열은 하기와 같다(서열 번호 33):


(리더 서열을 포함하는) TNT scAb/huIL-15RαSu/hIgG1 Fc 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 34):


발병 세포에 의해 발현되는 기타 항원을 표적화하는 결합 도메인을 포함하는 본 발명의 융합 단백질 복합체도 또한 제조될 수 있었다. 이러한 항원은 종양 세포를 비롯한 질환 세포 상에 발현되는 CD33 또는 조직 인자나, 면역 세포 상에 발현되는 관문 억제 인자를 포함할 수 있었다.
조직 인자(TF)는 몇몇 종양 세포 유형에서 과발현된다고 보고된 경막 당단백질이다. 중요한 점은, 증가한 TF 발현은 암세포 신호전달, 종양 세포 이동 및 감소한 세포자멸에 연루되어, 전이 가능성의 증갈ㄹ 초래한다는 것이다. 그러므로 TF의 표적화는 이 단백질을 과발현하는 종양 세포 유형에 대한 면역 요법 전략에서 유익할 수 있다. 키메라 항 조직 인자 항체인 ALT-836은 이미 제조되어 임상 시험된 바 있다. 이 항체의 인간화된 가변 사슬(hOAT)도 또한 특성규명된 바 있다. 그러므로 인간 조직 인자를 인지하는 단일 사슬 Ab 도메인(hOAT scAb)을 가지는 본 발명의 융합 단백질 복합체가 제조되었다.
(리더 서열을 포함하는) hOAT scAb/huIL-15RαSu/hIgG1 Fc 구조체의 핵산 서열은 하기와 같다(서열 번호 35):


(신호 펩티드 서열을 포함하는) hOAT scAb/huIL-15RαSu/hIgG1 Fc 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 36):

몇몇 경우에 있어서, 리더 펩티드는 성숙 폴리펩티드로부터 절단된다.
hOAT scAb/huIL-15N72D 융합 단백질을 발현하는 유사한 구조체가 제조될 수 있었다.
실시예 1과, 앞서(본원에 참조로서 인용되어 있는 미국 특허출원 제8,507,222호의 실시예 1 및 2) 기술된 바와 같이 서열이 발현 벡터에 클로닝되었으며, 이 발현 벡터는 CHO 세포를 형질감염시켰다. 몇몇 경우에 있어서, CHO 세포는 본 발명의 동일하거나 상이한 결합 도메인들을 가지는 huIL-15N72D 및 huIL-15RαSu/Fc 융합 단백질 둘 다를 암호화하는 벡터로 형질감염되었다. 융합 단백질 복합체는 전술된 바와 같이, 단백질 A 친화성 크로마토그래피가 사용되어 CHO 세포 배양 상청액으로부터 정제되었다.
CD33을 인지하는 단일 사슬 Ab 도메인(CD33 scAb)을 가지는 본 발명의 융합 단백질 복합체도 또한 제조되었다. (신호 펩티드 서열을 포함하는) CD33 scAb/huIL-15N72D 구조체의 핵산 서열은 하기와 같다(서열 번호 37):


(신호 펩티드 서열을 포함하는) CD33 scAb/IL-15N72D 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 38):

몇몇 경우에 있어서, 리더 펩티드는 성숙 폴리펩티드로부터 절단된다.
(리더 서열을 포함하는) CD33 scAb/huIL-15RαSu/hIgG1 Fc 구조체의 핵산 서열은 하기와 같다(서열 번호 39):


(리더 서열을 포함하는) CD33 scAb/huIL-15RαSu/hIgG1 Fc 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 40):

몇몇 경우에 있어서, 리더 펩티드는 성숙 폴리펩티드로부터 절단된다.
실시예 1과, 앞서(본원에 참조로서 인용되어 있는 미국 특허출원 제8,507,222호의 실시예 1 및 2) 기술된 바와 같이, 서열이 발현 벡터에 클로닝되었으며, 이 발현 벡터는 CHO 세포를 형질감염시켰다. 몇몇 경우에 있어서, CHO 세포는, 본 발명의 동일하거나 상이한 결합 도메인들을 가지는 huIL-15N72D 및 huIL-15RαSu/Fc 융합 단백질 둘 다를 암호화하는 벡터로 형질감염되었다. 융합 단백질 복합체는 전술된 바와 같이, 단백질 A 친화성 크로마토그래피가 사용되어 CHO 세포 배양 상청액으로부터 정제되었다.
세포내 부착 분자 1(ICAM-1)은 면역글로불린 상과의 세포 표면 당단백질이다. 세포 표면 상에서의 ICAM-1 단백질 발현 수준은 다양한 고형 종양의 전이 잠재성과 양의 상관관계가 있음이 입증되었다. 림프구 기능 연관 항원 1(LFA-1)은 모든 T 세포와 B 세포, 대식세포, 호중구 및 NK 세포에서 발견된다. 구체적으로 "I 도메인"을 통한 ICAM-1과의 결합은, 세포 부착(면역학/세포용해 시냅스 형성) 또는 (혈관외유출 이전 혈류 중 세포의 이동을 늦추기 위한) 롤링(rolling)을 지탱함이 공지되어 있다. I 도메인은 단독으로 2개의 돌연변이, 즉 K287C 및 K294C가 부가된 ICAM-1과의 큰 친화성 결합을 지원할 수 있다. 따라서 huIL-15N72D: huIL-15RαSu 복합체를 통해 종양을 표적화하고, 효과기 면역 세포의 활성화 및 국소화를 촉진하기 위해, 돌연변이와 함께 LFA-1 I 도메인을 포함하는 TxM이 제조되었다.
(리더 서열을 포함하는) 인간 LFA-1 I 도메인(K287C/K294C)/huIL-15RαSu/huIgG1 Fc 구조체의 핵산 서열은 하기와 같다(서열 번호 41):


(리더 서열을 포함하는) 성숙 인간 LFA-1 I 도메인(K287C/K294C)/huIL-15RαSu/huIgG1 Fc 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 42):

몇몇 경우에 있어서, 리더 펩티드는 성숙 폴리펩티드로부터 절단된다.
인간 LFA-1 I 도메인(K287C/K294C)/huIL-15N72D 융합 단백질을 발현하는 유사한 구조체가 제조될 수 있었다.
실시예 1과, 앞서(본원에 참조로서 인용되어 있는 미국 특허출원 제8,507,222호의 실시예 1 및 2) 기술된 바와 같이, 서열이 발현 벡터에 클로닝되었으며, 이 발현 벡터는 CHO 세포를 형질감염시켰다. 몇몇 경우에 있어서, CHO 세포는, 본 발명의 동일하거나 상이한 결합 도메인들을 가지는 huIL-15N72D 및 huIL-15RαSu/Fc 융합 단백질 둘 다를 암호화하는 벡터로 형질감염되었다. 융합 단백질 복합체는 전술된 바와 같이, 단백질 A 친화성 크로마토그래피가 사용되어 CHO 세포 배양 상청액으로부터 정제되었다.
예를 들어 CHO 세포는 huIL-15N72D 발현 벡터가 형질감염되었다. 세포는 또한 인간 LFA-1 I 도메인(K287C/K294C)/huIL-15RαSu/huIgG1 Fc 구조체를 발현하는 벡터로 형질감염되었다. CHO 세포에서의 두 구조체의 공동 발현은, 가용성 huIL-15N72D: 인간 LFA-1 I 도메인(K287C/K294C)/huIL-15RαSu/huIgG1 Fc 복합체(2*hLFA1/TxM라 지칭됨)의 형성과 분비를 허용하였다.
Notch1은 다수의 표피 성장 인자(EGF) 유사 반복부로 이루어진 세포외 도메인과, 다수의 상이한 도메인 유형으로 이루어진 세포내 도메인을 포함하는, 구조적 특징들을 공유하는 제I형 경막 단백질 과의 일원이다. 이의 과발현이 몇몇 종양 유형에서 입증되었는데, 이 점은 Notch1을 면역 요법에 매력적인 표적으로 만들어준다. 델타 유사 단백질 4(DLL4)는 Notch1에 대한 몇몇 리간드 중 하나로서, Notch1에 대하여 최고의 친화성을 가지는 것으로 보였다. 그러므로 DLL4의 세포외 도메인(27번 ~ 529번)은 TxM 복합체의 생성에 있어 Notch1을 표적화하기 위해 사용되었다.
(리더 서열을 포함하는) hDLL4/huIL-15RαSu/huIgG1 Fc 구조체의 핵산 서열은 하기와 같다(서열 번호 43):


(리더 서열을 포함하는) 성숙 hDLL4/huIL-15RαSu/huIgG1 Fc 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 44):

몇몇 경우에 있어서, 리더 펩티드는 성숙 폴리펩티드로부터 절단된다.
hDLL4 도메인/huIL-15N72D 융합 단백질을 발현하는 유사한 구조체가 제조될 수 있었다.
실시예 1과, 앞서(본원에 참조로서 인용되어 있는 미국 특허출원 제8,507,222호의 실시예 1 및 2) 기술된 바와 같이, 서열이 발현 벡터에 클로닝되었으며, 이 발현 벡터는 CHO 세포를 형질감염시켰다. 몇몇 경우에 있어서, CHO 세포는, 본 발명의 동일하거나 상이한 결합 도메인들을 가지는 huIL-15N72D 및 huIL-15RαSu/Fc 융합 단백질 둘 다를 암호화하는 벡터로 형질감염되었다. 융합 단백질 복합체는 전술된 바와 같이, 단백질 A 친화성 크로마토그래피가 사용되어 CHO 세포 배양 상청액으로부터 정제되었다.
예를 들어 huIL-15N72D 및 hDLL4/huIL-15RαSu/huIgG1 Fc 발현 벡터의 CHO 세포 내 공동 발현은 2*hDLL4/TxM이라 지칭되는 가용성 TxM 복합체의 형성과 분비를 허용하였다.
Tim-3(T-cell immunoglobulin and mucin-domain containing-3)은 IFN-γ 생산 CD4+ T 조력 1(Th1) 및 CD8+ T 세포독성 1(Tc1) T 세포에서 발견되는 면역 관문 수용체이다. 그러므로 이 Tim-3은 암 면역 요법에 매력적인 표적이다. 따라서 인간 Tim-3을 인지하는 단일 사슬 Ab 도메인(haTIM3scFv)을 가지는 본 발명의 융합 단백질 복합체가 제조되었다.
(리더 서열을 포함하는) haTIM3scFv/huIL-15RαSu/huIgG1 Fc 구조체의 핵산 서열은 하기와 같다(서열 번호 45):


(리더 서열을 포함하는) 성숙 haTIM3scFv/huIL-15RαSu/huIgG1 Fc 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 46):


몇몇 경우에 있어서, 리더 펩티드는 성숙 폴리펩티드로부터 절단된다.
haTIM3scFv/huIL-15N72D 융합 단백질을 발현하는 유사한 구조체가 제조될 수 있었다.
실시예 1과, 앞서(본원에 참조로서 인용되어 있는 미국 특허출원 제8,507,222호의 실시예 1 및 2) 기술된 바와 같이, 서열이 발현 벡터에 클로닝되었으며, 이 발현 벡터는 CHO 세포를 형질감염시켰다. 몇몇 경우에 있어서, CHO 세포는, 본 발명의 동일하거나 상이한 결합 도메인들을 가지는 huIL-15N72D 및 huIL-15RαSu/Fc 융합 단백질 둘 다를 암호화하는 벡터로 형질감염되었다. 융합 단백질 복합체는 전술된 바와 같이, 단백질 A 친화성 크로마토그래피가 사용되어 CHO 세포 배양 상청액으로부터 정제되었다.
예를 들어 CHO 세포는 huIL-15N72D 발현 벡터로 형질감염되었다. 이 세포는 또한 haTIM3scFv/huIL-15RαSu/huIgG1 Fc 구조체를 발현하는 벡터로 형질감염되었다. 2개의 구조체의 CHO 세포 내 공동 발현은 가용성 huIL-15N72D: haTIM3scFv/huIL-15RαSu/huIgG1 Fc 복합체(2*haTIM3/TxM이라 지칭됨)의 형성 및 분비를 허용하였다.
종양 표적화 분자 이외에도, 바이러스 감염 세포를 검출하고 이에 맞서 싸우는 역할을 하는 TxM 복합체가 제조될 수 있다. 효능이 크고, 광범위하게 중화하며, HIV에 특이적인 모노클로날 항체(bNAb)의 최근의 발견은, 잠재적 치료제의 신규 군을 제공한다. 중화 항체가 HIV 외피(Env)를 표적화하고, 시험관 내에서 바이러스 복제를 효과적으로 억제한다는 사실은 오랫동안 공지되어 왔다. 이 Ab 매개 억제와, 잠복성 바이러스 복제를 깨워, (IL-15 자극을 통해) 활성화된 효과기 세포로 이를 사멸시키는 "치고 사멸시키는(kick and kill)"접근법을 결합하기 위해, bNAb의 단일 사슬 항체 도메인(scFv)을 포함하는 TxM 복합체가 제조되었다. bNAb N6, 2G12, VRC07 및 10-1074 유래 scFv를 포함하는, 4개의 상이한 항 HIV TxM의 제조 및 특성규명이 이하에 기술되어 있다.
(리더 서열을 포함하는) N6scFv/huIL-15RαSu/huIgG1 Fc 구조체의 핵산 서열은 하기와 같다(서열 번호 47):


(리더 서열을 포함하는) 2G12scFv/huIL-15RαSu/huIgG1 Fc 구조체의 핵산 서열은 하기와 같다(서열 번호 48):



(리더 서열을 포함하는) VRC07(523)scFv/huIL-15RαSu/huIgG1 Fc 구조체의 핵산 서열은 하기와 같다(서열 번호 49):


(리더 서열을 포함하는) 10-1074scFv/huIL-15RαSu/huIgG1 Fc 구조체의 핵산 서열은 하기와 같다(서열 번호 50):


(리더 서열을 포함하는) 성숙 N6scFv/huIL-15RαSu/huIgG1 Fc 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 51):

(리더 서열을 포함하는) 성숙 2G12scFv/huIL-15RαSu/huIgG1 Fc 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 52):


(리더 서열을 포함하는) 성숙 VRC07(523)scFv/huIL-15RαSu/huIgG1 Fc 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 53):


(리더 서열을 포함하는) 성숙 10-1074scFv/huIL-15RαSu/huIgG1 Fc 융합 단백질의 아미노산 서열은 하기와 같다(서열 번호 54):

몇몇 경우에 있어서, 리더 펩티드는 성숙 폴리펩티드로부터 절단된다.
전술된 바와 같이 bNAb scFv/huIL-15N72D 융합 단백질을 발현하는 유사 구조체가 제조될 수 있었다.
실시예 1과, 앞서(본원에 참조로서 인용되어 있는 미국 특허출원 제8,507,222호의 실시예 1 및 2) 기술된 바와 같이, 서열이 발현 벡터에 클로닝되었으며, 이 발현 벡터는 CHO 세포를 형질감염시켰다. 몇몇 경우에 있어서, CHO 세포는, 본 발명의 동일하거나 상이한 결합 도메인들을 가지는 huIL-15N72D 및 huIL-15RαSu/Fc 융합 단백질 둘 다를 암호화하는 벡터로 형질감염되었다. 융합 단백질 복합체는 전술된 바와 같이, 단백질 A 친화성 크로마토그래피가 사용되어 CHO 세포 배양 상청액으로부터 정제되었다.
예를 들어 CHO 세포 내 huIL-15N72D 및 N6scFv/huIL-15RαSu/huIgG1 Fc 발현 벡터의 공동 발현은, 2*hN6/TxM이라 지칭되는 가용성 TxM 복합체의 형성과 분비를 허용하였다. CHO 세포 내 huIL-15N72D 및 2G12scFv/huIL-15RαSu/huIgG1 Fc 발현 벡터의 공동 발현은, 2*h2G12/TxM이라 지칭되는 가용성 TxM 복합체의 형성과 분비를 허용하였다. CHO 세포 내 huIL-15N72D 및 VRC07(523)scFv/huIL-15RαSu/huIgG1 Fc 발현 벡터의 공동 발현은 2*hVRC07(523)/TxM이라 지칭되는 가용성 TxM 복합체의 형성과 분비를 허용하였다. CHO 세포 내 huIL-15N72D 및 10-1074scFv/huIL-15RαSu/huIgG1 Fc 발현 벡터의 공동 발현은 2*h10-1074/TxM이라 지칭되는 가용성 TxM 복합체의 형성과 분비를 허용하였다.
상기 명시된 바와 같이, TxM 단백질은 CHO 세포 상청액으로부터 단백질 A 크로마토그래피 및 기타 분리 방법(즉 이온 교환 크로마토그래피, 소수성 크로마토그래피 및/또는 크기별 배제 크로마토그래피와, 여과 방법)에 의해 정제될 수 있었다. 더욱이 정제된 단백질은 겔 크로마토그래피 및 기타 분석 방법에 의해 특성규명될 수 있었다. 예를 들어 도 20은, 2개의 scAb 또는 결합 도메인을 가지는 것(즉 2두형(2H) IL-15N72D:항 PD-L1 scAb/IL-15RαSu/Fc 복합체) 또는 4개의 scAb 또는 결합 도메인을 가지는 것(즉 4두형(4H) 항 PD-L1 scAb/IL-15N72D:항 PD-L1 scAb/IL-15RαSu/Fc 복합체) 또는 상이한 표적화 도메인의 조합(즉 종양 표적화 도메인/항 PDL1scAb TxM 복합체)을 비롯하여 다양한 TxM 복합체의 크기별 배제 크로마토그래피 분석 결과를 보여준다. SEC 크로마토그래피는, 단백질 A 정제된 TxM 단백질은 주로 IL-15N72D:IL-15RαSu/Fc 복합체의 이동 패턴과 일치하는 이동 패턴을 보이는 주 단백질 피크를 보임을 나타냈다.
scAb 또는 결합 도메인을 포함하는 유사 TxM 구조체는 다른 CD 항원, 시토카인 또는 케모카인 수용체 또는 리간드, 성장 인자 수용체 또는 리간드, 세포 부착 분자, MHC/MHC-유사 분자, Fc 수용체, Toll-유사 수용체, NK 수용체, TCR, BCR, 양성/음성 보조자극 수용체 또는 리간드, 사멸 수용체 또는 리간드, 종양 연관 항원, 바이러스 암호화 항원 및 세균 암호화 항원, 그리고 세균 특이적 에 특이적인 항체 서열로 용이하게 제조될 수 있었다. 특히 관심이 가는 것은, 항원 CD4, CD19, CD20, CD21, CD22, CD23, CD25, CD30, CD33, CD38, CD40, CD44, CD51, CD52, CD70, CD74, CD80, CD123, CD152, CD147, CD221, EGFR, HER-2/neu, HER-1, HER-3, HER-4, CEA, OX40 리간드, cMet, 조직 인자, Nectin-4, PSA, PSMA, EGFL7, FGFR, IL-6 수용체, IGF-1 수용체, GD2, CA-125, EpCam, 사멸 수용체 5, MUC1, VEGFR1, VEGFR2, PDGFR, Trail R2, 엽산염 수용체, 안지오포이에틴-2, 알파베타3 인테그린 수용체, HLA-DR 항원 및 본원에 기술된 기타 질환 표적에 대한 질환 특이적 결합 도메인(예컨대 scAb)을 가지는 TxM이다. HIV, HCV, HBC, CMV, HTLV, HPV, EBV, RSV 및 기타 바이러스 유래 바이러스 항원에 대한 항체 도메인, 특히 HIV 외피 스파이크 및/또는 gp120 및 gp41 에피토프를 인지하는 것도 또한 관심이 간다. 이러한 항체 도메인은 당 분야에 공지된 서열로부터 제조될 수 있거나, 또는 당 분야에 공지된 다양한 공급원(즉 척추동물 숙주 또는 세포, 조합 라이브러리, 무작위 합성 라이브러리, 컴퓨터 모델링 등)으로부터 새로이 단리될 수 있다.
실시예
6: 기타
TxM
활성의 특성규명
CTLA-4 TxM의 결합 활성은, CTLA-4 양성 면역 세포가 사용되어 평가되었다. 마우스 특이적 CTLA-4 TxM에 관한 연구에 있어서, 마우스 림프구 내 CTLA-4의 발현이 처음에 항 CD3 Ab(2C11, 4 μg/ml)에 의해 4일 동안 유도되었다. CTLA-4 발현은, PE 항 마우스 CTLA-4 항체(클론 UC10-4B9) 또는 PE 아르메니아 햄스터 IgG 이소타입 대조군으로 염색함으로써 평가되었다. 도 21a에 보인 바와 같이 유세포 분석은 마우스 CTLA-4가 눈에 띄게 유도되었음을 입증하였다. 마우스 특이적 CTLA-4 TxM(100 μl 상청액)의 첨가는, 양성 대조군 항 mCTLA-4 항체(클론 HB304)가 그러하였듯이, 항 마우스 CTLA-4 항체 결합을 차단할 수 있었다. 인간 특이적 CTLA-4 TxM를 사용하여 연구하기 위해서, 인간 PBMC 내 CTLA-4의 발현이 항 CD3 Ab(OKT3 :4 μg/ml)에 의해 3일 동안 유도되었다. 그 다음, 세포는 PE 항 인간 CTLA-4 항체(클론 BNI3, Biolegend) 또는 PE 마우스 IgG2a, κ 이소타입 대조군으로 염색되었다. 전술된 결과들과 일치되게, 인간 특이적 CTLA-4 TxM(CL-8, 100 ul)은 인간 면역 세포 표면상 CTLA-4를 차단할 수 있었다(도 21b). 이러한 결과는 CTLA-4 TxM 복합체의 특이성을 입증해준다.
이와 유사하게, 마우스 특이적 PD-L1/CTLA-4 TxM 복합체의 결합 활성은 PD-L1 양성 5T33 골수종 종양 세포(실시예 2에 기술된 방법 참조) 및 CTLA-4 양성 면역 세포를 대상으로 평가되었다. 도 22a 및 도 22b에 보인 바와 같이, PD-L1/CTLA-4 TxM(상청액)은 세포 표면에 발현되는 PD-L1 및 CTLA-4 둘 다와의 결합을 차단할 수 있었다. 이 점은 또한 다중 특이적 TxM 복합체가, 결합된 결합 도메인들 각각의 반응성을 보유함을 나타낸다.
CD47 TxM 구조체의 직접 결합은 CD47 양성 세포가 사용되어 평가되었다. 도 23a 및 도 23b에 보인 바와 같이, 마우스 및 인간 특이적 CD47 TxM 복합체는 마우스 B16F10 흑색종과 인간 Jurkat T 세포 각각을 염색할 수 있었다. 이러한 결과는, 이 복합체가 CD47 결합 활성을 보유하였음을 나타낸다.
TNT scAb 도메인을 포함하는 TxM 복합체의 결합을 평가하기 위해 단일 가닥 DNA ELISA 방법(ALPCO ssDNA ELISA 키트 35-SSSHU-E01)이 사용되었다. 요약하면, TNT scAb 도메인을 포함하는 정제 TxM 단백질은 연속 희석되었고, 이 단백질 100 μL가 인간 재조합 단일 가닥 DNA로 코팅된 ELISA 웰에 첨가되었다. 항온처리한지 30분 후, 웰은 세척되었고, 이후 HRP-항 인간 IgG 항체 100 μL가 첨가되었다. 추가 항온처리 및 세척 단계 이후, 결합되었던 TxM 단백질은 TMB 기질로 검출되었다. 웰의 흡광도는 450 nM에서 판독되었다. 도 24a 및 도 24b에 보인 바와 같이, TNT scAb TxM 및 TNT scAb/항 인간 PD-L1 scAb TxM 복합체는 단일 가닥 DNA와 결합할 수 있었는데, 이 경우 TNT scAb TxM의 Kd(188 pM)는 TNT scAb/항 인간 PD-L1 scAb TxM의 Kd(10279 pM)에 비하여 더 낮았는데, 이는 아마도 TNT scAb TxM 중 4H TNT scAb의 결합력이 TNT scAb/항 인간 PD-L1 scAb TxM 중 2H TNT scAb의 결합력보다 더 컸기때문인 것으로 생각된다.
TNT scAb TxM 복합체가 종양 세포와 결합하는 능력도 또한 평가되었는데, 이때 종양 세포 DNA는 이 세포를 고정 및 투과처리함으로써 노출되었다. 초기 연구에서, MB231 유방암 세포는 처음에 1.5% 파라포름알데히드로 고정되었고, 0.1% 사포닌으로 투과처리된 다음, 105개 세포(106개 세포/mL)는 실온에서 30분 동안 0.01 nM ~ 100 nM의 TNT scAb TxM, TNT scAb/항 인간 PD-L1 scAb TxM 또는 2H-항 인간 PD-L1 scAb TxM(음성 대조군)과 함께 항온처리되었다. 세포는 세척되고 나서, 항 인간 IgG Fc-APC로 염색된 다음, 유세포분석에 의해 분석되었다. 도 25a는, 상이한 TxM 농도로 MB231 세포가 염색되었을 때의 평균 형광도 세기(MFI)를 보여주는데, 이는 투과처리된 유방 종양 세포에 대한, TNT scAb TxM 및 TNT scAb/항 인간 PD-L1 scAb TxM의 특이적이고 농도 의존적인 결합을 확인시켜주는 것이다. 음성 대조군 PD-L1 scAb TxM 복합체와는 최소한의 결합이 확인되었는데, 이 점은 MB231 세포주 상 PD-L1의 발현 수준이 낮다는 것과 일치한다. 고정 및 투과처리된 PD-L1 음성 A549 인간 폐 종양 세포를 대상으로 유사한 연구가 수행되었다. 역시, 결과(도 25b)는 투과처리된 폐 종양 세포에 대한, TNT scAb TxM 및 TNT scAb/항 인간 PD-L1 scAb TxM의 특이적이고 농도 의존적인 결합을 확인시켜주었다.
게다가, hOAT scAb 및/또는 항 인간 PD-L1 scAb 도메인을 포함하는 TxM 복합체가 종양 세포와 결합하는 능력이 평가되었다. SW1990 인간 췌장암 세포주는 인간 TF를 높은 수준으로 발현하였고, 인간 PD-L1을 낮은 수준으로 발현하였다. 연구에서, 105개 SW1990 세포(106개 세포/mL)가 실온에서 30분 동안 0.01 nM ~100 nM의 2두형(h2) hOATscAb/TxM, 항 인간 PD-L1scAb/hOATscAb/TxM, h2*항 인간 PD-L1scAb/TxM 또는 대조군 hOAT Ab 또는 대조군 항 인간 PD-L1 Ab(아벨루맙)와 함께 항온처리되었다. 세포는 세척되었고, 항 인간 IgG Fc-APC로 염색된 다음, 유세포분석에 의해 분석되었다. 도 26은, 상이한 단백질 농도에서의 SW1990 세포 염색의 평균 형광도 세기(MFI)를 보여준다. 결과는 hOAT scAb를 포함하는 TxM 복합체(h2*hOATscAb/TxM 및 항 인간 PD-L1scAb/hOATscAb/TxM)가, 대조군 hOAT Ab와 유사하게 높은 수준의 염색을 SW1990 종양 세포 상 인간 TF에 대해 보였음을 확인시켜주었다. 항 인간 PD-L1 scAb를 포함하는 TxM 복합체(h2*항 인간 PD-L1scAb/TxM)는, 대조군 항 인간 PD-L1 Ab(아벨루맙)와 유사하게 더 낮은 수준의 염색을 SW1990 종양 세포 상 인간 PD-L1에 대해 보였다.
huIL-15N72D: 인간 LFA-1 I 도메인(K287C/K294C)/huIL-15RαSu/huIgG1 Fc 복합체 형성을 확인하는데 ELISA 기반 방법이 사용되었다. huIL-15N72D 및 인간 LFA-1 I 도메인(K287C/K294C)/huIL-15RαSu/huIgG1 Fc 발현 벡터가 공동 형질감염된 CHO 세포 유래 배양 상청액 중 결합 활성이 평가되었다. 도 27a에 있어서, 융합 단백질 복합체는 포착 항체, 항 인간 IL-15 항체(R&D Systems) 및 검출 항체, 항 인간 IgG 항체(Jackson ImmunoResearch)가 사용되어 huIL15/huIgG1 특이적 ELISA에 의해 검출되었다. 이러한 결합은, 비형질감염 CHO 세포를 함유하는 배지의 상청액만이 사용되어 대조군 시료의 결합과 비교되었다. 결과는, 2*hLFA1/TxM가 생산되었음과 이의 적당한 복합체 형성이 이루어졌음을 보여준다.
게다가, 2*hLFA1/TxM과 ICAM-1의 결합이 ELISA에 의해 평가되었다(도 27b). 이뮤노플레이트(immunoplate)의 웰을 인간 ICAM-1-Fc(Biolegend) 1 μg으로 코팅하였다. 세척 단계 후, 2*hLFA1/TxM을 함유하는 CHO 배양 상청액이 세포에 첨가되었다. 항온처리와 추가의 세척 단계들 이후, HRP-접합 항 인간 IL-15 항체(R&D Systems)를 사용하여 융합 단백질 복합체의 결합이 확인되었다. 웰의 흡광도는 ABTS와의 항온처리 이후 405 nm에서 판독되었다. 도 27b의 결과는, 이 복합체가 ICAM-1을 인지함을 나타낸다.
유사한 ELISA 기반 방법은, 형질감염된 CHO 세포 배양 상청액 중 huIL-15N72D: hDLL4/huIL-15RαSu/huIgG1 Fc 복합체가 형성되었음을 확인시켜주었다. 도 28에 있어서, 배양 상청액 중 융합 단백질 복합체는 포착 항체, 항 인간 IL-15 항체(R&D Systems) 및 검출 항체, 항 인간 IgG 항체(Jackson ImmunoResearch)가 사용되어 huIL15/huIgG1 특이적 ELISA에 의해 검출되었다. 시료는 비형질감염 CHO 세포를 함유하는 배지의 상청액만이 사용되어 대조군 시료의 경우와 비교되었다. 결과는, 2*hDLL4/TxM 복합체가 생산되었고, 이 복합체의 적당한 복합체 형성이 이루어졌음을 나타낸다.
ELISA 기반 방법도 또한 huIL-15N72D: haTIM3scFv/huIL-15RαSu/huIgG1 Fc 복합체가 형성되었음을 확인시켜주었다. 도 29에 있어서, 형질감염된 CHO 배양 상청액 중 융합 단백질 복합체는 포착 항체, 항 인간 IL-15 항체(R&D Systems) 및 검출 항체, 항 인간 IgG 항체(Jackson ImmunoResearch)가 사용되어 huIL15/huIgG1 특이적 ELISA에 의해 검출되었다. 이러한 결합은, 비형질감염 CHO 세포를 함유하는 배지의 상청액만이 사용되어 대조군 시료의 경우와 비교되었다. 결과는, 2*haTIM3/TxM 복합체가 생산되었고, 이 복합체의 적당한 복합체 형성이 이루어졌음을 나타낸다.
bNAb scFv TxM 발현 벡터가 공동 형질감염된 CHO 세포로부터 유래하는 상청액은 TxM 복합체의 발현 및 결합 능을 측정하기 위해 사용되었다. ELISA 기반 방법은 bNAb scFv TxM 복합체가 형성되었음을 확인시켜주었다. 도 30a 및 도 30b에 있어서, 형질감염된 CHO 배양 상청액 중 융합 단백질 복합체는 포착 항체, 항 인간 IL-15 항체(R&D Systems) 및 검출 항체, 항 인간 IgG 항체(Jackson ImmunoResearch)가 사용되어 huIL15/huIgG1 특이적 ELISA에 의해 검출되었다. 양성 대조군 TxM은 hCD20을 인지하는 것이다. 결과는, 상이한 bNAb scFv TxM 복합체 4개가 생산되었고, 이의 적당한 복합체 형성이 이루어졌음을 나타낸다.
더욱이, bNAb scFv TxM과 HIV 단백질 표적(gp120(SF162.LS) 및 gp140 (SF162.LS))의 결합은 ELISA에 의해 평가되었다. 이 연구를 위해, 이뮤노플레이트 웰이 HIV gp120(SF162.LS) 또는 gp140(SF162.LS)(ProtTech, Inc.) 0.1 μg으로 코팅되었다. 세척 단계 이후, bNAb scFv TxM을 함유하는 CHO 배양 상청액이 세포에 첨가되었다. 음성 대조군 TxM은 hCD20을 인지하는 것이다. 항온처리 및 추가의 세척 단계 이후에, HRP-접합 항 인간 IgG 항체(Jackson ImmunoResearch)가 사용되어 융합 단백질 복합체의 결합이 확인되었다. 웰 내 흡광도는 ABTS와의 항온처리 후에 405 nm에서 판독되었다. 도 30c ~ 도 30f의 결과들은 bNAb scFv TxM 복합체가 HIV 단백질 표적을 인지하였음을 나타낸다.
전반적으로 이러한 결과는, 다양한 면역 관문 분자 및 신호전달 분자에 특이적인 결합 도메인을 가지는 TxM 복합체가 제조될 수 있으며, 이 복합체는 표적 분자에 증진된 결합 활성을 제공할 수 있음을 입증한다. 이러한 복합체는 IL-15 면역자극 활성을 보였고, 세포상 표적 항원에 대해 면역 매개 세포독성을 유도할 수 있었다. 이러한 복합체는 또한 동물 종양 모델에 있어서 매우 효과적이었다.
실시예
7:
TxM
복합체의 면역자극 및
항 종양
활성
실시예 2에 나타낸 바와 같이, TxM 복합체의 IL-15 면역자극 활성은 IL-2Rβ/γ 보유 면역 세포, 예컨대 32Dβ 세포주의 증식을 기반으로 평가되었다. 요약하면, 정제된 TxM 단백질은, 그 농도를 증가시키면서 IMDM:10% FBS 배지 200 μL 중 32Dβ 세포(104개 세포/웰)에 첨가되었고, 이 세포는 37℃에서 3일 동안 항온처리되었다. 그 다음, PrestoBlue 세포 생존능 시약(cell viability reagent)이 첨가되었다(20 μL/웰). 4시간 후, 레자주린 기반 용액인 PrestoBlue의 대사 활성 세포에 의한 환원을 기반으로 세포 증식을 확인하기 위해, 570 nm에서의 흡광도가 측정되었다(다만 이 때 정규화를 위한 기준 파장(reference wavelength)은 600 nm였음). 그 다음, 흡광도와 TxM 단백질 농도 간 관계를 기반으로 TxM 복합체에 대한 IL-15 생체활성의 반수 최대 유효 농도(EC50)가 확정되었다. 표 1은, 본 발명의 결합 도메인들을 포함하는 다양한 TxM 복합체에 대한 IL-15 EC50 값을 보여준다. 결과는, 2개의 scAb/결합 도메인을 가지는 TxM 복합체(즉 2두형(2H) 항 PD-L1 scAb/IL-15N72D:항 PD-L1 scAb/IL-15RαSu/Fc 복합체) 또는 4개의 scAb/결합 도메인을 가지는 TxM 복합체(즉 4두형(4H) 항 PD-L1 scAb/IL-15N72D:항 PD-L1 scAb/IL-15RαSu/Fc 복합체) 또는 상이한 표적화 도메인들의 조합(즉 종양 표적화 도메인/항 PDL1scAb TxM 복합체)을 비롯하여 다양한 정제 TxM 복합체의 면역자극 활성을 확인시켜주었다.

hOAT scAb TxM이 종양 세포에 대한 면역 세포의 세포독성을 자극하는 능력이 시험관 내에서 평가되었다. 인간 NK 세포가 NK 세포 단리 키트(Stemcell Technologies사)가 사용되어 혈액의 백혈구 연층으로부터 정제되어, 효과기 세포로서 사용되었다. TF 양성 인간 췌장 종양 세포인 SW1990은 Celltrace-Violet으로 표지화되어 표적 세포로서 사용되었다. 인간 NK 세포 및 SW1990 종양 세포는 E:T 비율 1:1로, 배지(단독) 중에 또는 10nM hOAT Ab(대조군) 또는 2H hOAT scAb TxM 복합체를 함유하는 배지 중에 혼합되었다. 40시간 후, 표적 세포 사멸%가 바이올렛-표지화 표적 세포의 요오드화프로피듐 염색을 기반으로 유세포분석에 의해 평가되었다. 도 31에 보인 바와 같이, 2H hOAT scAb TxM 복합체와 함께 항온처리된 인간 NK 세포는 미처리 NK 세포 또는 hOAT Ab 처리된 NK 세포(즉 기존의 ADCC)보다 TF 양성 인간 종양 세포에 대해 더 큰 세포독성을 매개할 수 있었다. 이러한 결과는, 항 TF TxM 복합체의 면역 세포 매개 표적화 항 종양 활성이 항 TF Ab의 면역 세포 매개 표적화 항 종양 활성에 비하여 유의미하게 개선되었음을 보여준다.
TxM 복합체가 T 세포 활성의 관문 매개 억제를 극복하는 능력이, 이미 기술된 시험관 내 검정법(Steward, R, et al Cancer Immunol Res 2015 3(9):1052-1062)을 통해 평가되었다. 예를 들어 증가한 면역 세포 증식(BrDU 혼입에 의해 측정됨) 및 IFNγ 방출(ELISA에 의해 측정됨)을 입증하기 위하여, 새로이 단리된 1차 인간 T 세포는 항 CD3 및 항 CD28 코팅 비드와 함께 배양되었다. 비드에 PD-L1 항체가 첨가되었을 때, PD-L1/PD-1 상호작용의 억제 신호전달로 말미암아 T 세포 증식과 IFNγ 방출은 유의미하게 감소하였다. 항 CD3, 항 CD28, PD-L1 코팅 비드 및 T 세포와 같은 환경에 가용성 PD-L1 TxM 또는 PD-1 TxM이 첨가되었을 때, PD-L1/PD-1 상호작용의 봉쇄로 말미암아 T 세포 증식과 IFNγ 방출은 증가하였다. 항 CD3, 항 CD28, 항 CTLA-4 코팅 비드 및 T 세포와 같은 환경에서 CTLA-4 TxM이 사용되는 유사한 검정법은 또한 CTLA-4 TxM의 면역 관문 억제 활성을 입증하였다.
이러한 복합체의 항 종양 활성은 마우스 이종이식편 모델에서 인간 종양 세포주 및 환자 유래 종양 세포가 사용되어 평가되었다(Morton, J.J., et al. Cancer Research 2016 doi: 10.1158/0008-5472). 시판중인 인간화 마우스 모델(즉 Hu-CD34 NSGTM, Jackson laboratory)은 인간 종양 세포주 및 환자 유래 종양 세포로부터 유래하는 종양에 대한 인간 면역 세포 반응의 면역요법 활성을 평가하기 위해 개발되었다. 예를 들어 PD-L1 양성 피하 인간 MDA-MB-231 유방암 종양을 보유하는 Hu-CD34 NSGTM 마우스는 PBS로 처리되었거나, 아니면 PD-L1 TxM 또는 PD-1 TxM으로 그 용량 수준을 증가시키면서 처리되었으며(즉 2주 동안 매주 2회씩 피하 투여), 종양 성장이 평가되었다. 종양 부피의 용량 의존적 감소는 PD-L1 양성 인간 종양에 대한 PD-L1 TxM 및/또는 PD-1 TxM의 치료적 활성에 대한 증거를 제공한다. 고형 종양 마우스 모델은 또한 환자 유래 PD-L1 양성 종양 세포(즉 BR1126(TM00098), LG1306(TM00302))가 사용되어 제작될 수 있었다. BR1126 종양 보유 Hu-CD34 NSGTM 마우스에 있어 PD-L1 TxM 및/또는 PD-1 TxM의 활성은 처리 후 종양 성장 또는 마우스 생존을 평가함으로써 평가될 수 있었다. 뿐만 아니라, 혈액 및 종양 미세환경에서의 T 세포 반응의 처리 의존적 변화가 이 모델에서 평가되었다. PD-L1 TxM 및/또는 PD-1 TxM 처리 후 혈액 또는 종양 중 T 세포 수준 또는 활성(즉 IFNγ 양성 세포)의 증가는, 종양 보유 마우스 내 이 복합체의 면역자극 활성의 증거를 제공한다. 종합하였을 때, 이 연구들은 생체 내 인간 종양에 대한 PD-L1 TxM 및/또는 PD-1 TxM의 면역 세포 매개 활성을 입증하여 주었다.
기타 구현예들
본 발명은, 본 발명의 상세한 설명과 함께 기술되어 있지만, 전술된 기술은 본 발명의 범위를 예시하기 위한 것이지 제한하고자 하는 것은 아니며, 본 발명의 범위는 첨부된 특허청구범위에 의해 한정된다. 다른 양태들, 이점들, 그리고 변형예들은 하기 청구항들의 범위 내에 있다.
본원에 인용된 특허 문헌 및 과학 문헌은, 당 분야의 숙련자들이 이용 가능한 지식을 확립해준다. 본원에 인용된 모든 미국 특허와, 공개 또는 미공개 미국 특허 출원은 참조로 인용되어 있는 것이다. 본원에 인용된 모든 공개 외국 특허 및 특허출원은 본원에 참조로 인용되어 있는 것이다. 본원에 인용된 승인 번호로서 명시된 Genbank 및 NCBI 제출에 관한 사항도 본원에 참조로 인용되어 있는 것이다. 본원에 인용된 기타 모든 공표 참고문헌, 서류, 논문 및 과학 문헌은 본원에 참조로 인용되어 있는 것이다.
본 발명은, 본 발명의 바람직한 구현예를 참고로 하여 구체적으로 보였을 뿐만 아니라 기술되어 있긴 하지만, 그 형태와 세부사항에 대한 다양한 변화가, 첨부된 청구항들에 의해 포함되는 본 발명의 범위로부터 벗어나지 않고 내부적으로 가하여질 수 있음은 당 업자에 의해 이해될 것이다.
SEQUENCE LISTING
<110> ALTOR BIOSCIENCE CORPORATION
NANTCELL, INC.
<120> MULTIMERIC IL-15-BASED MOLECULES
<130> 48277-529001WO
<140> PCT/US2017/057757
<141> 2017-10-21
<150> 62/513,964
<151> 2017-06-01
<150> 62/411,216
<151> 2016-10-21
<160> 58
<170> PatentIn version 3.5
<210> 1
<211> 1125
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 1
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccaacatc 60
cagatgaccc agtcccctag ctccgtgtcc gcctccgtgg gagatcgggt gaccatcacc 120
tgtagggcct cccaggacat ctccaggtgg ctggcctggt accagcagaa gcccggcaag 180
gcccccaagc tgctgatcta cgccgcctcc tccctgcagt ccggagtgcc tagcaggttc 240
tccggctccg gatccggcac agacttcgcc ctgaccatct cctccctgca gcccgaggac 300
ttcgccacct actactgcca gcaggccgac tccaggttct ccatcacctt cggccagggc 360
accaggctgg agatcaagag gggaggtggc ggatccggag gtggaggttc tggtggaggt 420
gggagtgagg tgcagctggt gcagtccgga ggaggactgg tgcagcctgg cggatccctg 480
aggctgtcct gtgccgcttc cggcttcacc ttcagctcct actccatgaa ctgggtgagg 540
caggcccctg gaaagggcct ggagtgggtg tcctacatct ccagctcctc ctccaccatc 600
cagtacgccg actccgtgaa gggcaggttc accatctcca gggacaacgc caagaactcc 660
ctgtacctgc agatgaacag cctgagggac gaggacaccg ccgtgtacta ctgcgccagg 720
ggcgactatt actacggcat ggacgtgtgg ggccagggaa ccaccgtgac cgtgtcctcc 780
aactgggtta acgtaataag tgatttgaaa aaaattgaag atcttattca atctatgcat 840
attgatgcta ctttatatac ggaaagtgat gttcacccca gttgcaaagt aacagcaatg 900
aagtgctttc tcttggagtt acaagttatt tcacttgagt ccggagatgc aagtattcat 960
gatacagtag aaaatctgat catcctagca aacgacagtt tgtcttctaa tgggaatgta 1020
acagaatctg gatgcaaaga atgtgaggaa ctggaggaaa aaaatattaa agaatttttg 1080
cagagttttg tacatattgt ccaaatgttc atcaacactt cttaa 1125
<210> 2
<211> 374
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 2
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Asn Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser
20 25 30
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Ile Ser
35 40 45
Arg Trp Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
50 55 60
Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
65 70 75 80
Ser Gly Ser Gly Ser Gly Thr Asp Phe Ala Leu Thr Ile Ser Ser Leu
85 90 95
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asp Ser Arg
100 105 110
Phe Ser Ile Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys Arg Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
130 135 140
Gln Leu Val Gln Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu
145 150 155 160
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr Ser Met
165 170 175
Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Tyr
180 185 190
Ile Ser Ser Ser Ser Ser Thr Ile Gln Tyr Ala Asp Ser Val Lys Gly
195 200 205
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu Gln
210 215 220
Met Asn Ser Leu Arg Asp Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg
225 230 235 240
Gly Asp Tyr Tyr Tyr Gly Met Asp Val Trp Gly Gln Gly Thr Thr Val
245 250 255
Thr Val Ser Ser Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile
260 265 270
Glu Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu
275 280 285
Ser Asp Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu
290 295 300
Leu Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His
305 310 315 320
Asp Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asp Ser Leu Ser Ser
325 330 335
Asn Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu
340 345 350
Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln
355 360 365
Met Phe Ile Asn Thr Ser
370
<210> 3
<211> 1674
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 3
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccaacatc 60
cagatgaccc agtcccctag ctccgtgtcc gcctccgtgg gagatcgggt gaccatcacc 120
tgtagggcct cccaggacat ctccaggtgg ctggcctggt accagcagaa gcccggcaag 180
gcccccaagc tgctgatcta cgccgcctcc tccctgcagt ccggagtgcc tagcaggttc 240
tccggctccg gatccggcac agacttcgcc ctgaccatct cctccctgca gcccgaggac 300
ttcgccacct actactgcca gcaggccgac tccaggttct ccatcacctt cggccagggc 360
accaggctgg agatcaagag gggaggtggc ggatccggag gtggaggttc tggtggaggt 420
gggagtgagg tgcagctggt gcagtccgga ggaggactgg tgcagcctgg cggatccctg 480
aggctgtcct gtgccgcttc cggcttcacc ttcagctcct actccatgaa ctgggtgagg 540
caggcccctg gaaagggcct ggagtgggtg tcctacatct ccagctcctc ctccaccatc 600
cagtacgccg actccgtgaa gggcaggttc accatctcca gggacaacgc caagaactcc 660
ctgtacctgc agatgaacag cctgagggac gaggacaccg ccgtgtacta ctgcgccagg 720
ggcgactatt actacggcat ggacgtgtgg ggccagggaa ccaccgtgac cgtgtcctcc 780
atcacgtgcc ctccccccat gtccgtggaa cacgcagaca tctgggtcaa gagctacagc 840
ttgtactcca gggagcggta catttgtaac tctggtttca agcgtaaagc cggcacgtcc 900
agcctgacgg agtgcgtgtt gaacaaggcc acgaatgtcg cccactggac aacccccagt 960
ctcaaatgca ttagagagcc gaaatcttgt gacaaaactc acacatgccc accgtgccca 1020
gcacctgaac tcctgggggg accgtcagtc ttcctcttcc ccccaaaacc caaggacacc 1080
ctcatgatct cccggacccc tgaggtcaca tgcgtggtgg tggacgtgag ccacgaagac 1140
cctgaggtca agttcaactg gtacgtggac ggcgtggagg tgcataatgc caagacaaag 1200
ccgcgggagg agcagtacaa cagcacgtac cgtgtggtca gcgtcctcac cgtcctgcac 1260
caggactggc tgaatggcaa ggagtacaag tgcaaggtct ccaacaaagc cctcccagcc 1320
cccatcgaga aaaccatctc caaagccaaa gggcagcccc gagaaccaca ggtgtacacc 1380
ctgcccccat cccgggatga gctgaccaag aaccaggtca gcctgacctg cctggtcaaa 1440
ggcttctatc ccagcgacat cgccgtggag tgggagagca atgggcagcc ggagaacaac 1500
tacaagacca cgcctcccgt gctggactcc gacggctcct tcttcctcta cagcaagctc 1560
accgtggaca agagcaggtg gcagcagggg aacgtcttct catgctccgt gatgcatgag 1620
gctctgcaca accactacac gcagaagagc ctctccctgt ctcctggtaa ataa 1674
<210> 4
<211> 557
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 4
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Asn Ile Gln Met Thr Gln Ser Pro Ser Ser Val Ser Ala Ser
20 25 30
Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Asp Ile Ser
35 40 45
Arg Trp Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
50 55 60
Leu Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe
65 70 75 80
Ser Gly Ser Gly Ser Gly Thr Asp Phe Ala Leu Thr Ile Ser Ser Leu
85 90 95
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asp Ser Arg
100 105 110
Phe Ser Ile Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys Arg Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
130 135 140
Gln Leu Val Gln Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu
145 150 155 160
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr Ser Met
165 170 175
Asn Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Tyr
180 185 190
Ile Ser Ser Ser Ser Ser Thr Ile Gln Tyr Ala Asp Ser Val Lys Gly
195 200 205
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu Gln
210 215 220
Met Asn Ser Leu Arg Asp Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg
225 230 235 240
Gly Asp Tyr Tyr Tyr Gly Met Asp Val Trp Gly Gln Gly Thr Thr Val
245 250 255
Thr Val Ser Ser Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala
260 265 270
Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile
275 280 285
Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu
290 295 300
Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser
305 310 315 320
Leu Lys Cys Ile Arg Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys
325 330 335
Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu
340 345 350
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
355 360 365
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys
370 375 380
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
385 390 395 400
Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu
405 410 415
Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
420 425 430
Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
435 440 445
Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
450 455 460
Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
465 470 475 480
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
485 490 495
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly
500 505 510
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
515 520 525
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
530 535 540
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
545 550 555
<210> 5
<211> 1134
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 5
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcccagtcc 60
gctctgaccc agcctgcttc cgtgtccggc tcccctggac agtccatcac catctcctgt 120
accggcacct cctccgatgt gggcggctac aactacgtgt cctggtacca gcagcacccc 180
ggcaaagccc ccaagctgat gatctatgac gtgtccaacc ggccctccgg cgtgtccaac 240
aggttctccg gctccaagtc cggcaacacc gcctccctga caatctccgg cctgcaggcc 300
gaggatgagg ctgactacta ctgctcctcc tacacctcct cctccaccag ggtgttcggc 360
accggcacca aggtgaccgt gctgggaggt ggcggatccg gaggtggagg ttctggtgga 420
ggtgggagtg aggtgcagct gctggagtcc ggaggcggac tggtgcagcc tggaggatcc 480
ctgaggctgt cctgcgctgc ctccggcttc accttctcct cctacatcat gatgtgggtg 540
aggcaggctc ctggcaaggg cctggagtgg gtgtcctcca tctacccctc cggcggcatc 600
accttctacg ccgataccgt gaagggcagg ttcaccatct cccgggacaa ctccaagaac 660
accctgtacc tgcagatgaa ctccctgagg gctgaggaca ccgccgtgta ctactgcgcc 720
aggatcaagc tgggcaccgt gaccacagtg gactactggg gacagggcac cctggtgacc 780
gtgtcctcca actgggttaa cgtaataagt gatttgaaaa aaattgaaga tcttattcaa 840
tctatgcata ttgatgctac tttatatacg gaaagtgatg ttcaccccag ttgcaaagta 900
acagcaatga agtgctttct cttggagtta caagttattt cacttgagtc cggagatgca 960
agtattcatg atacagtaga aaatctgatc atcctagcaa acgacagttt gtcttctaat 1020
gggaatgtaa cagaatctgg atgcaaagaa tgtgaggaac tggaggaaaa aaatattaaa 1080
gaatttttgc agagttttgt acatattgtc caaatgttca tcaacacttc ttaa 1134
<210> 6
<211> 377
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 6
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Gln Ser Ala Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro
20 25 30
Gly Gln Ser Ile Thr Ile Ser Cys Thr Gly Thr Ser Ser Asp Val Gly
35 40 45
Gly Tyr Asn Tyr Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro
50 55 60
Lys Leu Met Ile Tyr Asp Val Ser Asn Arg Pro Ser Gly Val Ser Asn
65 70 75 80
Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser
85 90 95
Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Thr
100 105 110
Ser Ser Ser Thr Arg Val Phe Gly Thr Gly Thr Lys Val Thr Val Leu
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu
130 135 140
Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser
145 150 155 160
Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr Ile
165 170 175
Met Met Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser
180 185 190
Ser Ile Tyr Pro Ser Gly Gly Ile Thr Phe Tyr Ala Asp Thr Val Lys
195 200 205
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
210 215 220
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
225 230 235 240
Arg Ile Lys Leu Gly Thr Val Thr Thr Val Asp Tyr Trp Gly Gln Gly
245 250 255
Thr Leu Val Thr Val Ser Ser Asn Trp Val Asn Val Ile Ser Asp Leu
260 265 270
Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu
275 280 285
Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys Val Thr Ala Met Lys
290 295 300
Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala
305 310 315 320
Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asp Ser
325 330 335
Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu
340 345 350
Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His
355 360 365
Ile Val Gln Met Phe Ile Asn Thr Ser
370 375
<210> 7
<211> 1683
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 7
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcccagtcc 60
gctctgaccc agcctgcttc cgtgtccggc tcccctggac agtccatcac catctcctgt 120
accggcacct cctccgatgt gggcggctac aactacgtgt cctggtacca gcagcacccc 180
ggcaaagccc ccaagctgat gatctatgac gtgtccaacc ggccctccgg cgtgtccaac 240
aggttctccg gctccaagtc cggcaacacc gcctccctga caatctccgg cctgcaggcc 300
gaggatgagg ctgactacta ctgctcctcc tacacctcct cctccaccag ggtgttcggc 360
accggcacca aggtgaccgt gctgggaggt ggcggatccg gaggtggagg ttctggtgga 420
ggtgggagtg aggtgcagct gctggagtcc ggaggcggac tggtgcagcc tggaggatcc 480
ctgaggctgt cctgcgctgc ctccggcttc accttctcct cctacatcat gatgtgggtg 540
aggcaggctc ctggcaaggg cctggagtgg gtgtcctcca tctacccctc cggcggcatc 600
accttctacg ccgataccgt gaagggcagg ttcaccatct cccgggacaa ctccaagaac 660
accctgtacc tgcagatgaa ctccctgagg gctgaggaca ccgccgtgta ctactgcgcc 720
aggatcaagc tgggcaccgt gaccacagtg gactactggg gacagggcac cctggtgacc 780
gtgtcctcca tcacgtgccc tccccccatg tccgtggaac acgcagacat ctgggtcaag 840
agctacagct tgtactccag ggagcggtac atttgtaact ctggtttcaa gcgtaaagcc 900
ggcacgtcca gcctgacgga gtgcgtgttg aacaaggcca cgaatgtcgc ccactggaca 960
acccccagtc tcaaatgcat tagagagccg aaatcttgtg acaaaactca cacatgccca 1020
ccgtgcccag cacctgaact cctgggggga ccgtcagtct tcctcttccc cccaaaaccc 1080
aaggacaccc tcatgatctc ccggacccct gaggtcacat gcgtggtggt ggacgtgagc 1140
cacgaagacc ctgaggtcaa gttcaactgg tacgtggacg gcgtggaggt gcataatgcc 1200
aagacaaagc cgcgggagga gcagtacaac agcacgtacc gtgtggtcag cgtcctcacc 1260
gtcctgcacc aggactggct gaatggcaag gagtacaagt gcaaggtctc caacaaagcc 1320
ctcccagccc ccatcgagaa aaccatctcc aaagccaaag ggcagccccg agaaccacag 1380
gtgtacaccc tgcccccatc ccgggatgag ctgaccaaga accaggtcag cctgacctgc 1440
ctggtcaaag gcttctatcc cagcgacatc gccgtggagt gggagagcaa tgggcagccg 1500
gagaacaact acaagaccac gcctcccgtg ctggactccg acggctcctt cttcctctac 1560
agcaagctca ccgtggacaa gagcaggtgg cagcagggga acgtcttctc atgctccgtg 1620
atgcatgagg ctctgcacaa ccactacacg cagaagagcc tctccctgtc tcctggtaaa 1680
taa 1683
<210> 8
<211> 560
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 8
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Gln Ser Ala Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro
20 25 30
Gly Gln Ser Ile Thr Ile Ser Cys Thr Gly Thr Ser Ser Asp Val Gly
35 40 45
Gly Tyr Asn Tyr Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro
50 55 60
Lys Leu Met Ile Tyr Asp Val Ser Asn Arg Pro Ser Gly Val Ser Asn
65 70 75 80
Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser
85 90 95
Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Thr
100 105 110
Ser Ser Ser Thr Arg Val Phe Gly Thr Gly Thr Lys Val Thr Val Leu
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu
130 135 140
Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser
145 150 155 160
Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr Ile
165 170 175
Met Met Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser
180 185 190
Ser Ile Tyr Pro Ser Gly Gly Ile Thr Phe Tyr Ala Asp Thr Val Lys
195 200 205
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu
210 215 220
Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala
225 230 235 240
Arg Ile Lys Leu Gly Thr Val Thr Thr Val Asp Tyr Trp Gly Gln Gly
245 250 255
Thr Leu Val Thr Val Ser Ser Ile Thr Cys Pro Pro Pro Met Ser Val
260 265 270
Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu
275 280 285
Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser
290 295 300
Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr
305 310 315 320
Thr Pro Ser Leu Lys Cys Ile Arg Glu Pro Lys Ser Cys Asp Lys Thr
325 330 335
His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser
340 345 350
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
355 360 365
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
370 375 380
Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
385 390 395 400
Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val
405 410 415
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
420 425 430
Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr
435 440 445
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
450 455 460
Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys
465 470 475 480
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
485 490 495
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
500 505 510
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser
515 520 525
Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
530 535 540
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
545 550 555 560
<210> 9
<211> 1131
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 9
atgacatgga ctctactatt ccttgccttc cttcatcact taacagggtc atgtgcccag 60
tttgtgctta ctcagccaaa ctctgtgtct acgaatctcg gaagcacagt caagctgtct 120
tgcaaccgca gcactggtaa cattggaaac aattatgtga actggtacca gcagcatgaa 180
ggaagatctc ccaccactct gatttattgg gatgatagga gaccagatgg agttcctgac 240
aggttctctg gctccattga cagatcttcc aactcagccc tcctgacaat caataatgtg 300
cagactgagg atgaaactga ctacttctgt cagtcttaca gtagtggtat gtatattttc 360
ggcggtggaa ccaagctcac tgtcctagga ggtggcggat ccggaggtgg aggttctggt 420
ggaggtggga gtgaggttca gctgcagcag tctggggctg agctggtgaa gcctggggct 480
tcagtaaagt tgtcctgcaa aacttctggt tacaccttca gcaattacta tatgagttgg 540
ttgaagcaga tgcctggaca gaatattgag tggatcggaa acatttatgg tggaaatggt 600
ggtgctggct ataatcagaa gttcaagggc aaggccacac tgacagtgga caaatcttcc 660
agcacagcgt acatggatct cagcagcctg acatctgagg cctctgcagt ctatttttgt 720
gcaagggtcg gacttcccgg cctttttgat tactggggcc agggagtcat ggtcacagtc 780
tcctcaaact gggtgaatgt aataagtgat ttgaaaaaaa ttgaagatct tattcaatct 840
atgcatattg atgctacttt atatacggaa agtgatgttc accccagttg caaagtaaca 900
gcaatgaagt gctttctctt ggagttacaa gttatttcac ttgagtccgg agatgcaagt 960
attcatgata cagtagaaaa tctgatcatc ctagcaaacg acagtttgtc ttctaatggg 1020
aatgtaacag aatctggatg caaagaatgt gaggaactgg aggaaaaaaa tattaaagaa 1080
tttttgcaga gttttgtaca tattgtccaa atgttcatca acacttctta a 1131
<210> 10
<211> 376
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 10
Met Thr Trp Thr Leu Leu Phe Leu Ala Phe Leu His His Leu Thr Gly
1 5 10 15
Ser Cys Ala Gln Phe Val Leu Thr Gln Pro Asn Ser Val Ser Thr Asn
20 25 30
Leu Gly Ser Thr Val Lys Leu Ser Cys Asn Arg Ser Thr Gly Asn Ile
35 40 45
Gly Asn Asn Tyr Val Asn Trp Tyr Gln Gln His Glu Gly Arg Ser Pro
50 55 60
Thr Thr Leu Ile Tyr Trp Asp Asp Arg Arg Pro Asp Gly Val Pro Asp
65 70 75 80
Arg Phe Ser Gly Ser Ile Asp Arg Ser Ser Asn Ser Ala Leu Leu Thr
85 90 95
Ile Asn Asn Val Gln Thr Glu Asp Glu Thr Asp Tyr Phe Cys Gln Ser
100 105 110
Tyr Ser Ser Gly Met Tyr Ile Phe Gly Gly Gly Thr Lys Leu Thr Val
115 120 125
Leu Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Glu Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Val Lys Pro Gly Ala
145 150 155 160
Ser Val Lys Leu Ser Cys Lys Thr Ser Gly Tyr Thr Phe Ser Asn Tyr
165 170 175
Tyr Met Ser Trp Leu Lys Gln Met Pro Gly Gln Asn Ile Glu Trp Ile
180 185 190
Gly Asn Ile Tyr Gly Gly Asn Gly Gly Ala Gly Tyr Asn Gln Lys Phe
195 200 205
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
210 215 220
Met Asp Leu Ser Ser Leu Thr Ser Glu Ala Ser Ala Val Tyr Phe Cys
225 230 235 240
Ala Arg Val Gly Leu Pro Gly Leu Phe Asp Tyr Trp Gly Gln Gly Val
245 250 255
Met Val Thr Val Ser Ser Asn Trp Val Asn Val Ile Ser Asp Leu Lys
260 265 270
Lys Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr
275 280 285
Thr Glu Ser Asp Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys
290 295 300
Phe Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser
305 310 315 320
Ile His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asp Ser Leu
325 330 335
Ser Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu
340 345 350
Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile
355 360 365
Val Gln Met Phe Ile Asn Thr Ser
370 375
<210> 11
<211> 1683
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 11
atgacatgga ctctactatt ccttgccttc cttcatcact taacagggtc atgtgcccag 60
tttgtgctta ctcagccaaa ctctgtgtct acgaatctcg gaagcacagt caagctgtct 120
tgcaaccgca gcactggtaa cattggaaac aattatgtga actggtacca gcagcatgaa 180
ggaagatctc ccaccactct gatttattgg gatgatagga gaccagatgg agttcctgac 240
aggttctctg gctccattga cagatcttcc aactcagccc tcctgacaat caataatgtg 300
cagactgagg atgaaactga ctacttctgt cagtcttaca gtagtggtat gtatattttc 360
ggcggtggaa ccaagctcac tgtcctagga ggtggcggat ccggaggtgg aggttctggt 420
ggaggtggga gtgaggttca gctgcagcag tctggggctg agctggtgaa gcctggggct 480
tcagtaaagt tgtcctgcaa aacttctggt tacaccttca gcaattacta tatgagttgg 540
ttgaagcaga tgcctggaca gaatattgag tggatcggaa acatttatgg tggaaatggt 600
ggtgctggct ataatcagaa gttcaagggc aaggccacac tgacagtgga caaatcttcc 660
agcacagcgt acatggatct cagcagcctg acatctgagg cctctgcagt ctatttttgt 720
gcaagggtcg gacttcccgg cctttttgat tactggggcc agggagtcat ggtcacagtc 780
tcctcaatca cgtgccctcc ccccatgtcc gtggaacacg cagacatctg ggtcaagagc 840
tacagcttgt actccaggga gcggtacatt tgtaactctg gtttcaagcg taaagccggc 900
acgtccagcc tgacggagtg cgtgttgaac aaggccacga atgtcgccca ctggacaacc 960
cccagtctca aatgcattag agaaccaaga gggcccacaa tcaagccctg tcctccatgc 1020
aaatgcccag cacctaacct cttgggtgga ccatccgtct tcatcttccc tccaaagatc 1080
aaggatgtac tcatgatctc cctgagcccc atagtcacat gtgtggtggt ggatgtgagc 1140
gaggatgacc cagatgtcca gatcagctgg tttgtgaaca acgtggaagt acacacagct 1200
cagacacaaa cccatagaga ggattacaac agtactctcc gggtggtcag tgccctcccc 1260
atccagcacc aggactggat gagtggcaag gagttcaaat gcaaggtcaa caacaaagac 1320
ctcccagcgc ccatcgagag aaccatctca aaacccaaag ggtcagtaag agctccacag 1380
gtatatgtct tgcctccacc agaagaagag atgactaaga aacaggtcac tctgacctgc 1440
atggtcacag acttcatgcc tgaagacatt tacgtggagt ggaccaacaa cgggaaaaca 1500
gagctaaact acaagaacac tgaaccagtc ctggactctg atggttctta cttcatgtac 1560
agcaagctga gagtggaaaa gaagaactgg gtggaaagaa atagctactc ctgttcagtg 1620
gtccacgagg gtctgcacaa tcaccacacg actaagagct tctcccggac tccaggtaaa 1680
taa 1683
<210> 12
<211> 560
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 12
Met Thr Trp Thr Leu Leu Phe Leu Ala Phe Leu His His Leu Thr Gly
1 5 10 15
Ser Cys Ala Gln Phe Val Leu Thr Gln Pro Asn Ser Val Ser Thr Asn
20 25 30
Leu Gly Ser Thr Val Lys Leu Ser Cys Asn Arg Ser Thr Gly Asn Ile
35 40 45
Gly Asn Asn Tyr Val Asn Trp Tyr Gln Gln His Glu Gly Arg Ser Pro
50 55 60
Thr Thr Leu Ile Tyr Trp Asp Asp Arg Arg Pro Asp Gly Val Pro Asp
65 70 75 80
Arg Phe Ser Gly Ser Ile Asp Arg Ser Ser Asn Ser Ala Leu Leu Thr
85 90 95
Ile Asn Asn Val Gln Thr Glu Asp Glu Thr Asp Tyr Phe Cys Gln Ser
100 105 110
Tyr Ser Ser Gly Met Tyr Ile Phe Gly Gly Gly Thr Lys Leu Thr Val
115 120 125
Leu Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Glu Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Val Lys Pro Gly Ala
145 150 155 160
Ser Val Lys Leu Ser Cys Lys Thr Ser Gly Tyr Thr Phe Ser Asn Tyr
165 170 175
Tyr Met Ser Trp Leu Lys Gln Met Pro Gly Gln Asn Ile Glu Trp Ile
180 185 190
Gly Asn Ile Tyr Gly Gly Asn Gly Gly Ala Gly Tyr Asn Gln Lys Phe
195 200 205
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
210 215 220
Met Asp Leu Ser Ser Leu Thr Ser Glu Ala Ser Ala Val Tyr Phe Cys
225 230 235 240
Ala Arg Val Gly Leu Pro Gly Leu Phe Asp Tyr Trp Gly Gln Gly Val
245 250 255
Met Val Thr Val Ser Ser Ile Thr Cys Pro Pro Pro Met Ser Val Glu
260 265 270
His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg
275 280 285
Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu
290 295 300
Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr
305 310 315 320
Pro Ser Leu Lys Cys Ile Arg Glu Pro Arg Gly Pro Thr Ile Lys Pro
325 330 335
Cys Pro Pro Cys Lys Cys Pro Ala Pro Asn Leu Leu Gly Gly Pro Ser
340 345 350
Val Phe Ile Phe Pro Pro Lys Ile Lys Asp Val Leu Met Ile Ser Leu
355 360 365
Ser Pro Ile Val Thr Cys Val Val Val Asp Val Ser Glu Asp Asp Pro
370 375 380
Asp Val Gln Ile Ser Trp Phe Val Asn Asn Val Glu Val His Thr Ala
385 390 395 400
Gln Thr Gln Thr His Arg Glu Asp Tyr Asn Ser Thr Leu Arg Val Val
405 410 415
Ser Ala Leu Pro Ile Gln His Gln Asp Trp Met Ser Gly Lys Glu Phe
420 425 430
Lys Cys Lys Val Asn Asn Lys Asp Leu Pro Ala Pro Ile Glu Arg Thr
435 440 445
Ile Ser Lys Pro Lys Gly Ser Val Arg Ala Pro Gln Val Tyr Val Leu
450 455 460
Pro Pro Pro Glu Glu Glu Met Thr Lys Lys Gln Val Thr Leu Thr Cys
465 470 475 480
Met Val Thr Asp Phe Met Pro Glu Asp Ile Tyr Val Glu Trp Thr Asn
485 490 495
Asn Gly Lys Thr Glu Leu Asn Tyr Lys Asn Thr Glu Pro Val Leu Asp
500 505 510
Ser Asp Gly Ser Tyr Phe Met Tyr Ser Lys Leu Arg Val Glu Lys Lys
515 520 525
Asn Trp Val Glu Arg Asn Ser Tyr Ser Cys Ser Val Val His Glu Gly
530 535 540
Leu His Asn His His Thr Thr Lys Ser Phe Ser Arg Thr Pro Gly Lys
545 550 555 560
<210> 13
<211> 1692
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 13
atgaagtggg tgacctttat ctccctgctg ttcctgtttt cctccgccta cagcatcgtg 60
atgacccagt cccctagctc cctgagcgct agcgtgggag accgggtgac catcacctgt 120
cgggcctccc agagcatttc cagctacctg aactggtacc agcagaagcc cggcaaggcc 180
cctaagctgc tgatttacgc tgccagcagc ctgcagtccg gagtgcctcc caggtttagc 240
ggctccggat ccggcaccga gttcaccctg accatctcct ccctgcagcc cgaggacttc 300
gccacctact actgtcagca ggccaacagc tttcccccca cctttggcca aggaaccaag 360
gtggacatca agaggaccgt ggccggaggc ggaggctccg gcggcggcgg ctccggcggc 420
ggcggctccc tggtgcagtc cggcgctgaa gtgaagaagc ctggcgcctc cgtgaaggtg 480
tcctgcgagg cctccggcta caccttcacc aactactaca tccactggct gaggcaggct 540
cctggacagg gcctggagtg gatgggcatc atcaacccct ccggaggctc caccacctac 600
gcccagaagt tccagggcag gatcaccatg acaagggaca cctccaccaa caccctgtac 660
atggaactgt cctccctccg gtccgaggac accgccatct actactgcgc caggagggat 720
tgcaggggcc ctagctgcta cttcgcttac tggggccagg gaaccaccgt gaccgtgtcc 780
tccgcctcca ccaagggcat cacgtgccct ccccccatgt ccgtggaaca cgcagacatc 840
tgggtcaaga gctacagctt gtactccagg gagcggtaca tttgtaactc tggtttcaag 900
cgtaaagccg gcacgtccag cctgacggag tgcgtgttga acaaggccac gaatgtcgcc 960
cactggacaa cccccagtct caaatgcatt agagagccga aatcttgtga caaaactcac 1020
acatgcccac cgtgcccagc acctgaactc ctggggggac cgtcagtctt cctcttcccc 1080
ccaaaaccca aggacaccct catgatctcc cggacccctg aggtcacatg cgtggtggtg 1140
gacgtgagcc acgaagaccc tgaggtcaag ttcaactggt acgtggacgg cgtggaggtg 1200
cataatgcca agacaaagcc gcgggaggag cagtacaaca gcacgtaccg tgtggtcagc 1260
gtcctcaccg tcctgcacca ggactggctg aatggcaagg agtacaagtg caaggtctcc 1320
aacaaagccc tcccagcccc catcgagaaa accatctcca aagccaaagg gcagccccga 1380
gaaccacagg tgtacaccct gcccccatcc cgggatgagc tgaccaagaa ccaggtcagc 1440
ctgacctgcc tggtcaaagg cttctatccc agcgacatcg ccgtggagtg ggagagcaat 1500
gggcagccgg agaacaacta caagaccacg cctcccgtgc tggactccga cggctccttc 1560
ttcctctaca gcaagctcac cgtggacaag agcaggtggc agcaggggaa cgtcttctca 1620
tgctccgtga tgcatgaggc tctgcacaac cactacacgc agaagagcct ctccctgtct 1680
cctggtaaat aa 1692
<210> 14
<211> 563
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 14
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Val Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val
20 25 30
Gly Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Ser Ser
35 40 45
Tyr Leu Asn Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu
50 55 60
Ile Tyr Ala Ala Ser Ser Leu Gln Ser Gly Val Pro Pro Arg Phe Ser
65 70 75 80
Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln
85 90 95
Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Ala Asn Ser Phe Pro
100 105 110
Pro Thr Phe Gly Gln Gly Thr Lys Val Asp Ile Lys Arg Thr Val Ala
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Leu
130 135 140
Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala Ser Val Lys Val
145 150 155 160
Ser Cys Glu Ala Ser Gly Tyr Thr Phe Thr Asn Tyr Tyr Ile His Trp
165 170 175
Leu Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly Ile Ile Asn
180 185 190
Pro Ser Gly Gly Ser Thr Thr Tyr Ala Gln Lys Phe Gln Gly Arg Ile
195 200 205
Thr Met Thr Arg Asp Thr Ser Thr Asn Thr Leu Tyr Met Glu Leu Ser
210 215 220
Ser Leu Arg Ser Glu Asp Thr Ala Ile Tyr Tyr Cys Ala Arg Arg Asp
225 230 235 240
Cys Arg Gly Pro Ser Cys Tyr Phe Ala Tyr Trp Gly Gln Gly Thr Thr
245 250 255
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Ile Thr Cys Pro Pro Pro
260 265 270
Met Ser Val Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr
275 280 285
Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly
290 295 300
Thr Ser Ser Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala
305 310 315 320
His Trp Thr Thr Pro Ser Leu Lys Cys Ile Arg Glu Pro Lys Ser Cys
325 330 335
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
340 345 350
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
355 360 365
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
370 375 380
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
385 390 395 400
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
405 410 415
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
420 425 430
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
435 440 445
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
450 455 460
Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
465 470 475 480
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
485 490 495
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
500 505 510
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
515 520 525
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
530 535 540
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
545 550 555 560
Pro Gly Lys
<210> 15
<211> 1689
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 15
atgaagtggg taacctttat ttcccttctt tttctcttta gctcggctta ttccgacatc 60
atgatgaccc agtccccttc ctccctgtcc gtgagcgctg gcgagaaggc taccatcagc 120
tgcaagtcct cccagtccct gttcaacagc aacgccaaga ccaactacct gaactggtac 180
ctgcagaagc ccggccagtc ccccaagctg ctgatctatt acgctagcac caggcatacc 240
ggcgtgcccg acaggtttag gggatccggc agcggcaccg acttcaccct gaccatctcc 300
agcgtgcagg acgaggacct cgctttctac tactgccagc aatggtacga ttacccttac 360
accttcggcg ctggcaccaa ggtggagatt aagaggggcg gaggcggatc cggcggcggc 420
ggctccggcg gcggaggctc ccagattcag ctgcaggagt ccggccctgg actggtcaac 480
cctagccagt ccctgagcct gtcctgttcc gtgacaggct atagcatcac cagcggctac 540
ggctggaact ggatcaggca gtttcccggc cagaaagtgg agtggatggg cttcatctac 600
tacgagggct ccacctacta taacccctcc atcaagtccc ggatcagcat caccagggat 660
acctccaaga accagttctt cctgcaagtc aactccgtga ccaccgaaga caccgccacc 720
tactactgcg ccaggcagac aggctacttc gactactggg gccagggcac aatggtgacc 780
gtcagcagcg ccatcacgtg ccctcccccc atgtccgtgg aacacgcaga catctgggtc 840
aagagctaca gcttgtactc cagggagcgg tacatttgta actctggttt caagcgtaaa 900
gccggcacgt ccagcctgac ggagtgcgtg ttgaacaagg ccacgaatgt cgcccactgg 960
acaaccccca gtctcaaatg cattagagaa ccaagagggc ccacaatcaa gccctgtcct 1020
ccatgcaaat gcccagcacc taacctcttg ggtggaccat ccgtcttcat cttccctcca 1080
aagatcaagg atgtactcat gatctccctg agccccatag tcacatgtgt ggtggtggat 1140
gtgagcgagg atgacccaga tgtccagatc agctggtttg tgaacaacgt ggaagtacac 1200
acagctcaga cacaaaccca tagagaggat tacaacagta ctctccgggt ggtcagtgcc 1260
ctccccatcc agcaccagga ctggatgagt ggcaaggagt tcaaatgcaa ggtcaacaac 1320
aaagacctcc cagcgcccat cgagagaacc atctcaaaac ccaaagggtc agtaagagct 1380
ccacaggtat atgtcttgcc tccaccagaa gaagagatga ctaagaaaca ggtcactctg 1440
acctgcatgg tcacagactt catgcctgaa gacatttacg tggagtggac caacaacggg 1500
aaaacagagc taaactacaa gaacactgaa ccagtcctgg actctgatgg ttcttacttc 1560
atgtacagca agctgagagt ggaaaagaag aactgggtgg aaagaaatag ctactcctgt 1620
tcagtggtcc acgagggtct gcacaatcac cacacgacta agagcttctc ccggactcca 1680
ggtaaataa 1689
<210> 16
<211> 562
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 16
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Asp Ile Met Met Thr Gln Ser Pro Ser Ser Leu Ser Val Ser
20 25 30
Ala Gly Glu Lys Ala Thr Ile Ser Cys Lys Ser Ser Gln Ser Leu Phe
35 40 45
Asn Ser Asn Ala Lys Thr Asn Tyr Leu Asn Trp Tyr Leu Gln Lys Pro
50 55 60
Gly Gln Ser Pro Lys Leu Leu Ile Tyr Tyr Ala Ser Thr Arg His Thr
65 70 75 80
Gly Val Pro Asp Arg Phe Arg Gly Ser Gly Ser Gly Thr Asp Phe Thr
85 90 95
Leu Thr Ile Ser Ser Val Gln Asp Glu Asp Leu Ala Phe Tyr Tyr Cys
100 105 110
Gln Gln Trp Tyr Asp Tyr Pro Tyr Thr Phe Gly Ala Gly Thr Lys Val
115 120 125
Glu Ile Lys Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
130 135 140
Gly Gly Ser Gln Ile Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Asn
145 150 155 160
Pro Ser Gln Ser Leu Ser Leu Ser Cys Ser Val Thr Gly Tyr Ser Ile
165 170 175
Thr Ser Gly Tyr Gly Trp Asn Trp Ile Arg Gln Phe Pro Gly Gln Lys
180 185 190
Val Glu Trp Met Gly Phe Ile Tyr Tyr Glu Gly Ser Thr Tyr Tyr Asn
195 200 205
Pro Ser Ile Lys Ser Arg Ile Ser Ile Thr Arg Asp Thr Ser Lys Asn
210 215 220
Gln Phe Phe Leu Gln Val Asn Ser Val Thr Thr Glu Asp Thr Ala Thr
225 230 235 240
Tyr Tyr Cys Ala Arg Gln Thr Gly Tyr Phe Asp Tyr Trp Gly Gln Gly
245 250 255
Thr Met Val Thr Val Ser Ser Ala Ile Thr Cys Pro Pro Pro Met Ser
260 265 270
Val Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg
275 280 285
Glu Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser
290 295 300
Ser Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp
305 310 315 320
Thr Thr Pro Ser Leu Lys Cys Ile Arg Glu Pro Arg Gly Pro Thr Ile
325 330 335
Lys Pro Cys Pro Pro Cys Lys Cys Pro Ala Pro Asn Leu Leu Gly Gly
340 345 350
Pro Ser Val Phe Ile Phe Pro Pro Lys Ile Lys Asp Val Leu Met Ile
355 360 365
Ser Leu Ser Pro Ile Val Thr Cys Val Val Val Asp Val Ser Glu Asp
370 375 380
Asp Pro Asp Val Gln Ile Ser Trp Phe Val Asn Asn Val Glu Val His
385 390 395 400
Thr Ala Gln Thr Gln Thr His Arg Glu Asp Tyr Asn Ser Thr Leu Arg
405 410 415
Val Val Ser Ala Leu Pro Ile Gln His Gln Asp Trp Met Ser Gly Lys
420 425 430
Glu Phe Lys Cys Lys Val Asn Asn Lys Asp Leu Pro Ala Pro Ile Glu
435 440 445
Arg Thr Ile Ser Lys Pro Lys Gly Ser Val Arg Ala Pro Gln Val Tyr
450 455 460
Val Leu Pro Pro Pro Glu Glu Glu Met Thr Lys Lys Gln Val Thr Leu
465 470 475 480
Thr Cys Met Val Thr Asp Phe Met Pro Glu Asp Ile Tyr Val Glu Trp
485 490 495
Thr Asn Asn Gly Lys Thr Glu Leu Asn Tyr Lys Asn Thr Glu Pro Val
500 505 510
Leu Asp Ser Asp Gly Ser Tyr Phe Met Tyr Ser Lys Leu Arg Val Glu
515 520 525
Lys Lys Asn Trp Val Glu Arg Asn Ser Tyr Ser Cys Ser Val Val His
530 535 540
Glu Gly Leu His Asn His His Thr Thr Lys Ser Phe Ser Arg Thr Pro
545 550 555 560
Gly Lys
<210> 17
<211> 1131
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 17
atggaatgga gctgggtgtt cctgttcttt ctgtccgtga ccaccggtgt ccactccctg 60
cctgtgctga ctcaaccacc ctcggtgtct gaagtccccg ggcagagggt caccatttcc 120
tgttctggag gcatctccaa catcggaagc aatgctgtaa actggtacca gcacttccca 180
ggaaaggctc ccaaactcct catctattat aatgatctgc tgccctcagg ggtctctgac 240
cgattctctg cctccaagtc tggcacctca gcctccctgg ccatcagtgg gctccggtcc 300
gaggatgagg ctgattatta ctgtgcagca tgggatgaca atctgagtgc ttatgtcttc 360
gcaactggga ccaaggtcac cgtcctgagt ggaggtggcg gatccggagg tggaggttct 420
ggtggaggtg ggagtcaggt tcagctggtg cagtctgggg ctgaggtgaa gaagcctggg 480
gcctcagtga aggtctcctg caaggcttct ggttacacct ttaccagcta tggtatcagc 540
tgggtgcgac aggcccctgg acaagggctt gagtggatgg gatggatcag cgcttacaat 600
ggtaacacaa actatgcaca gaagctccag ggcagagtca ccatgaccac agacacatcc 660
acgagcacag cctacatgga gctgaggagc ctgagatctg acgacacggc cgtgtattac 720
tgtgcgagag ggttatacgg tgacgaggac tactggggcc agggaaccct ggtcaccgtg 780
agctcaaact gggttaacgt aataagtgat ttgaaaaaaa ttgaagatct tattcaatct 840
atgcatattg atgctacttt atatacggaa agtgatgttc accccagttg caaagtaaca 900
gcaatgaagt gctttctctt ggagttacaa gttatttcac ttgagtccgg agatgcaagt 960
attcatgata cagtagaaaa tctgatcatc ctagcaaacg acagtttgtc ttctaatggg 1020
aatgtaacag aatctggatg caaagaatgt gaggaactgg aggaaaaaaa tattaaagaa 1080
tttttgcaga gttttgtaca tattgtccaa atgttcatca acacttctta a 1131
<210> 18
<211> 376
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 18
Met Glu Trp Ser Trp Val Phe Leu Phe Phe Leu Ser Val Thr Thr Gly
1 5 10 15
Val His Ser Leu Pro Val Leu Thr Gln Pro Pro Ser Val Ser Glu Val
20 25 30
Pro Gly Gln Arg Val Thr Ile Ser Cys Ser Gly Gly Ile Ser Asn Ile
35 40 45
Gly Ser Asn Ala Val Asn Trp Tyr Gln His Phe Pro Gly Lys Ala Pro
50 55 60
Lys Leu Leu Ile Tyr Tyr Asn Asp Leu Leu Pro Ser Gly Val Ser Asp
65 70 75 80
Arg Phe Ser Ala Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser
85 90 95
Gly Leu Arg Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Ala Trp Asp
100 105 110
Asp Asn Leu Ser Ala Tyr Val Phe Ala Thr Gly Thr Lys Val Thr Val
115 120 125
Leu Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
130 135 140
Ser Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly
145 150 155 160
Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser
165 170 175
Tyr Gly Ile Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp
180 185 190
Met Gly Trp Ile Ser Ala Tyr Asn Gly Asn Thr Asn Tyr Ala Gln Lys
195 200 205
Leu Gln Gly Arg Val Thr Met Thr Thr Asp Thr Ser Thr Ser Thr Ala
210 215 220
Tyr Met Glu Leu Arg Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr Tyr
225 230 235 240
Cys Ala Arg Gly Leu Tyr Gly Asp Glu Asp Tyr Trp Gly Gln Gly Thr
245 250 255
Leu Val Thr Val Ser Ser Asn Trp Val Asn Val Ile Ser Asp Leu Lys
260 265 270
Lys Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr
275 280 285
Thr Glu Ser Asp Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys
290 295 300
Phe Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser
305 310 315 320
Ile His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asp Ser Leu
325 330 335
Ser Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu
340 345 350
Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile
355 360 365
Val Gln Met Phe Ile Asn Thr Ser
370 375
<210> 19
<211> 768
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 19
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcccaggtg 60
cagctggtgg agtccggagg aggcctggtg gagcctggag gatccctgag gctgtcctgt 120
gccgccagcg gcatcatctt caagatcaac gacatgggct ggtatcggca ggcccctggc 180
aaaaggaggg agtgggtggc cgcttccaca ggaggcgatg aggccatcta cagggactcc 240
gtgaaggaca ggttcaccat ctccagggac gccaagaact ccgtgttcct gcagatgaac 300
tccctgaagc ccgaggatac cgccgtgtac tactgcaccg ccgtgatctc caccgatagg 360
gacggcaccg agtggaggag gtactggggc cagggcacac aggtgactgt gtcctccggc 420
ggcaactggg ttaacgtaat aagtgatttg aaaaaaattg aagatcttat tcaatctatg 480
catattgatg ctactttata tacggaaagt gatgttcacc ccagttgcaa agtaacagca 540
atgaagtgct ttctcttgga gttacaagtt atttcacttg agtccggaga tgcaagtatt 600
catgatacag tagaaaatct gatcatccta gcaaacgaca gtttgtcttc taatgggaat 660
gtaacagaat ctggatgcaa agaatgtgag gaactggagg aaaaaaatat taaagaattt 720
ttgcagagtt ttgtacatat tgtccaaatg ttcatcaaca cttcttaa 768
<210> 20
<211> 255
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 20
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Glu Pro
20 25 30
Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ile Ile Phe Lys
35 40 45
Ile Asn Asp Met Gly Trp Tyr Arg Gln Ala Pro Gly Lys Arg Arg Glu
50 55 60
Trp Val Ala Ala Ser Thr Gly Gly Asp Glu Ala Ile Tyr Arg Asp Ser
65 70 75 80
Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Ala Lys Asn Ser Val Phe
85 90 95
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys
100 105 110
Thr Ala Val Ile Ser Thr Asp Arg Asp Gly Thr Glu Trp Arg Arg Tyr
115 120 125
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser Gly Gly Asn Trp Val
130 135 140
Asn Val Ile Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met
145 150 155 160
His Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys
165 170 175
Lys Val Thr Ala Met Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser
180 185 190
Leu Glu Ser Gly Asp Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile
195 200 205
Ile Leu Ala Asn Asp Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser
210 215 220
Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe
225 230 235 240
Leu Gln Ser Phe Val His Ile Val Gln Met Phe Ile Asn Thr Ser
245 250 255
<210> 21
<211> 1317
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 21
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcccaggtg 60
cagctggtgg agtccggagg aggcctggtg gagcctggag gatccctgag gctgtcctgt 120
gccgccagcg gcatcatctt caagatcaac gacatgggct ggtatcggca ggcccctggc 180
aaaaggaggg agtgggtggc cgcttccaca ggaggcgatg aggccatcta cagggactcc 240
gtgaaggaca ggttcaccat ctccagggac gccaagaact ccgtgttcct gcagatgaac 300
tccctgaagc ccgaggatac cgccgtgtac tactgcaccg ccgtgatctc caccgatagg 360
gacggcaccg agtggaggag gtactggggc cagggcacac aggtgactgt gtcctccggc 420
ggcatcacgt gtcctcctcc tatgtccgtg gaacacgcag acatctgggt caagagctac 480
agcttgtact ccagggagcg gtacatttgt aactctggtt tcaagcgtaa agccggcacg 540
tccagcctga cggagtgcgt gttgaacaag gccacgaatg tcgcccactg gacaaccccc 600
agtctcaaat gcattagaga accaagaggg cccacaatca agccctgtcc tccatgcaaa 660
tgcccagcac ctaacctctt gggtggacca tccgtcttca tcttccctcc aaagatcaag 720
gatgtactca tgatctccct gagccccata gtcacatgtg tggtggtgga tgtgagcgag 780
gatgacccag atgtccagat cagctggttt gtgaacaacg tggaagtaca cacagctcag 840
acacaaaccc atagagagga ttacaacagt actctccggg tggtcagtgc cctccccatc 900
cagcaccagg actggatgag tggcaaggag ttcaaatgca aggtcaacaa caaagacctc 960
ccagcgccca tcgagagaac catctcaaaa cccaaagggt cagtaagagc tccacaggta 1020
tatgtcttgc ctccaccaga agaagagatg actaagaaac aggtcactct gacctgcatg 1080
gtcacagact tcatgcctga agacatttac gtggagtgga ccaacaacgg gaaaacagag 1140
ctaaactaca agaacactga accagtcctg gactctgatg gttcttactt catgtacagc 1200
aagctgagag tggaaaagaa gaactgggtg gaaagaaata gctactcctg ttcagtggtc 1260
cacgagggtc tgcacaatca ccacacgact aagagcttct cccggactcc aggtaaa 1317
<210> 22
<211> 439
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 22
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Glu Pro
20 25 30
Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ile Ile Phe Lys
35 40 45
Ile Asn Asp Met Gly Trp Tyr Arg Gln Ala Pro Gly Lys Arg Arg Glu
50 55 60
Trp Val Ala Ala Ser Thr Gly Gly Asp Glu Ala Ile Tyr Arg Asp Ser
65 70 75 80
Val Lys Asp Arg Phe Thr Ile Ser Arg Asp Ala Lys Asn Ser Val Phe
85 90 95
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys
100 105 110
Thr Ala Val Ile Ser Thr Asp Arg Asp Gly Thr Glu Trp Arg Arg Tyr
115 120 125
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser Gly Gly Ile Thr Cys
130 135 140
Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp Val Lys Ser Tyr
145 150 155 160
Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg
165 170 175
Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu Asn Lys Ala Thr
180 185 190
Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys Ile Arg Glu Pro
195 200 205
Arg Gly Pro Thr Ile Lys Pro Cys Pro Pro Cys Lys Cys Pro Ala Pro
210 215 220
Asn Leu Leu Gly Gly Pro Ser Val Phe Ile Phe Pro Pro Lys Ile Lys
225 230 235 240
Asp Val Leu Met Ile Ser Leu Ser Pro Ile Val Thr Cys Val Val Val
245 250 255
Asp Val Ser Glu Asp Asp Pro Asp Val Gln Ile Ser Trp Phe Val Asn
260 265 270
Asn Val Glu Val His Thr Ala Gln Thr Gln Thr His Arg Glu Asp Tyr
275 280 285
Asn Ser Thr Leu Arg Val Val Ser Ala Leu Pro Ile Gln His Gln Asp
290 295 300
Trp Met Ser Gly Lys Glu Phe Lys Cys Lys Val Asn Asn Lys Asp Leu
305 310 315 320
Pro Ala Pro Ile Glu Arg Thr Ile Ser Lys Pro Lys Gly Ser Val Arg
325 330 335
Ala Pro Gln Val Tyr Val Leu Pro Pro Pro Glu Glu Glu Met Thr Lys
340 345 350
Lys Gln Val Thr Leu Thr Cys Met Val Thr Asp Phe Met Pro Glu Asp
355 360 365
Ile Tyr Val Glu Trp Thr Asn Asn Gly Lys Thr Glu Leu Asn Tyr Lys
370 375 380
Asn Thr Glu Pro Val Leu Asp Ser Asp Gly Ser Tyr Phe Met Tyr Ser
385 390 395 400
Lys Leu Arg Val Glu Lys Lys Asn Trp Val Glu Arg Asn Ser Tyr Ser
405 410 415
Cys Ser Val Val His Glu Gly Leu His Asn His His Thr Thr Lys Ser
420 425 430
Phe Ser Arg Thr Pro Gly Lys
435
<210> 23
<211> 1119
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 23
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccaacatc 60
cagatgaccc agtccccttc cgccatgagc gcttccgtgg gcgacagggt gaccatcacc 120
tgcaaggcct cccaggacat ccacaggtac ctgtcctggt tccagcagaa gcccggcaag 180
gtgcccaagc acctgatcta cagggctaac aggctggtgt ccggcgtgcc ttccaggttt 240
tccggctccg gctccggcac cgagttcacc ctgaccatct ccagcctgca gcccgaggac 300
ttcgccacct actactgcct gcagtacgac gagttcccct acaccttcgg cggcggcacc 360
aaggtggaga tcaagggagg tggcggatcc ggaggtggag gttctggtgg aggtgggagt 420
cagatgcagc tggtacagtc cggcgccgag gtgaagaaga ccggctccag cgtgaaggtg 480
tcctgcaagg cctccggctt caacatcaag gactactacc tgcactgggt gaggcaggcc 540
cctggacaag ccctggagtg gatgggctgg atcgaccccg acaacggcga caccgagtac 600
gcccagaagt tccaggacag ggtgaccatc accagggaca ggtccatgag caccgcctac 660
atggagctgt cctccctgag gtccgaggac accgccatgt actactgcaa cgccgcctac 720
ggctcctcct cctaccccat ggactactgg ggccagggca ccaccgtgac cgtgaactgg 780
gttaacgtaa taagtgattt gaaaaaaatt gaagatctta ttcaatctat gcatattgat 840
gctactttat atacggaaag tgatgttcac cccagttgca aagtaacagc aatgaagtgc 900
tttctcttgg agttacaagt tatttcactt gagtccggag atgcaagtat tcatgataca 960
gtagaaaatc tgatcatcct agcaaacgac agtttgtctt ctaatgggaa tgtaacagaa 1020
tctggatgca aagaatgtga ggaactggag gaaaaaaata ttaaagaatt tttgcagagt 1080
tttgtacata ttgtccaaat gttcatcaac acttcttaa 1119
<210> 24
<211> 372
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 24
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Asn Ile Gln Met Thr Gln Ser Pro Ser Ala Met Ser Ala Ser
20 25 30
Val Gly Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile His
35 40 45
Arg Tyr Leu Ser Trp Phe Gln Gln Lys Pro Gly Lys Val Pro Lys His
50 55 60
Leu Ile Tyr Arg Ala Asn Arg Leu Val Ser Gly Val Pro Ser Arg Phe
65 70 75 80
Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu
85 90 95
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Glu Phe
100 105 110
Pro Tyr Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Met Gln Leu
130 135 140
Val Gln Ser Gly Ala Glu Val Lys Lys Thr Gly Ser Ser Val Lys Val
145 150 155 160
Ser Cys Lys Ala Ser Gly Phe Asn Ile Lys Asp Tyr Tyr Leu His Trp
165 170 175
Val Arg Gln Ala Pro Gly Gln Ala Leu Glu Trp Met Gly Trp Ile Asp
180 185 190
Pro Asp Asn Gly Asp Thr Glu Tyr Ala Gln Lys Phe Gln Asp Arg Val
195 200 205
Thr Ile Thr Arg Asp Arg Ser Met Ser Thr Ala Tyr Met Glu Leu Ser
210 215 220
Ser Leu Arg Ser Glu Asp Thr Ala Met Tyr Tyr Cys Asn Ala Ala Tyr
225 230 235 240
Gly Ser Ser Ser Tyr Pro Met Asp Tyr Trp Gly Gln Gly Thr Thr Val
245 250 255
Thr Val Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu Asp
260 265 270
Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp
275 280 285
Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu Glu
290 295 300
Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp Thr
305 310 315 320
Val Glu Asn Leu Ile Ile Leu Ala Asn Asp Ser Leu Ser Ser Asn Gly
325 330 335
Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys
340 345 350
Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met Phe
355 360 365
Ile Asn Thr Ser
370
<210> 25
<211> 1668
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 25
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccaacatc 60
cagatgaccc agtccccttc cgccatgagc gcttccgtgg gcgacagggt gaccatcacc 120
tgcaaggcct cccaggacat ccacaggtac ctgtcctggt tccagcagaa gcccggcaag 180
gtgcccaagc acctgatcta cagggctaac aggctggtgt ccggcgtgcc ttccaggttt 240
tccggctccg gctccggcac cgagttcacc ctgaccatct ccagcctgca gcccgaggac 300
ttcgccacct actactgcct gcagtacgac gagttcccct acaccttcgg cggcggcacc 360
aaggtggaga tcaagggagg tggcggatcc ggaggtggag gttctggtgg aggtgggagt 420
cagatgcagc tggtacagtc cggcgccgag gtgaagaaga ccggctccag cgtgaaggtg 480
tcctgcaagg cctccggctt caacatcaag gactactacc tgcactgggt gaggcaggcc 540
cctggacaag ccctggagtg gatgggctgg atcgaccccg acaacggcga caccgagtac 600
gcccagaagt tccaggacag ggtgaccatc accagggaca ggtccatgag caccgcctac 660
atggagctgt cctccctgag gtccgaggac accgccatgt actactgcaa cgccgcctac 720
ggctcctcct cctaccccat ggactactgg ggccagggca ccaccgtgac cgtgatcacg 780
tgtcctcctc ctatgtccgt ggaacacgca gacatctggg tcaagagcta cagcttgtac 840
tccagggagc ggtacatttg taactctggt ttcaagcgta aagccggcac gtccagcctg 900
acggagtgcg tgttgaacaa ggccacgaat gtcgcccact ggacaacccc cagtctcaaa 960
tgcattagag agccgaaatc ttgtgacaaa actcacacat gcccaccgtg cccagcacct 1020
gaactcctgg ggggaccgtc agtcttcctc ttccccccaa aacccaagga caccctcatg 1080
atctcccgga cccctgaggt cacatgcgtg gtggtggacg tgagccacga agaccctgag 1140
gtcaagttca actggtacgt ggacggcgtg gaggtgcata atgccaagac aaagccgcgg 1200
gaggagcagt acaacagcac gtaccgtgtg gtcagcgtcc tcaccgtcct gcaccaggac 1260
tggctgaatg gcaaggagta caagtgcaag gtctccaaca aagccctccc agcccccatc 1320
gagaaaacca tctccaaagc caaagggcag ccccgagaac cacaggtgta caccctgccc 1380
ccatcccggg atgagctgac caagaaccag gtcagcctga cctgcctggt caaaggcttc 1440
tatcccagcg acatcgccgt ggagtgggag agcaatgggc agccggagaa caactacaag 1500
accacgcctc ccgtgctgga ctccgacggc tccttcttcc tctacagcaa gctcaccgtg 1560
gacaagagca ggtggcagca ggggaacgtc ttctcatgct ccgtgatgca tgaggctctg 1620
cacaaccact acacgcagaa gagcctctcc ctgtctcctg gtaaataa 1668
<210> 26
<211> 555
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 26
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Asn Ile Gln Met Thr Gln Ser Pro Ser Ala Met Ser Ala Ser
20 25 30
Val Gly Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Ile His
35 40 45
Arg Tyr Leu Ser Trp Phe Gln Gln Lys Pro Gly Lys Val Pro Lys His
50 55 60
Leu Ile Tyr Arg Ala Asn Arg Leu Val Ser Gly Val Pro Ser Arg Phe
65 70 75 80
Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu
85 90 95
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Leu Gln Tyr Asp Glu Phe
100 105 110
Pro Tyr Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Met Gln Leu
130 135 140
Val Gln Ser Gly Ala Glu Val Lys Lys Thr Gly Ser Ser Val Lys Val
145 150 155 160
Ser Cys Lys Ala Ser Gly Phe Asn Ile Lys Asp Tyr Tyr Leu His Trp
165 170 175
Val Arg Gln Ala Pro Gly Gln Ala Leu Glu Trp Met Gly Trp Ile Asp
180 185 190
Pro Asp Asn Gly Asp Thr Glu Tyr Ala Gln Lys Phe Gln Asp Arg Val
195 200 205
Thr Ile Thr Arg Asp Arg Ser Met Ser Thr Ala Tyr Met Glu Leu Ser
210 215 220
Ser Leu Arg Ser Glu Asp Thr Ala Met Tyr Tyr Cys Asn Ala Ala Tyr
225 230 235 240
Gly Ser Ser Ser Tyr Pro Met Asp Tyr Trp Gly Gln Gly Thr Thr Val
245 250 255
Thr Val Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile
260 265 270
Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn
275 280 285
Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val
290 295 300
Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys
305 310 315 320
Cys Ile Arg Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro
325 330 335
Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro
340 345 350
Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr
355 360 365
Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn
370 375 380
Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg
385 390 395 400
Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val
405 410 415
Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser
420 425 430
Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys
435 440 445
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
450 455 460
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
465 470 475 480
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
485 490 495
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
500 505 510
Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
515 520 525
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
530 535 540
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
545 550 555
<210> 27
<211> 744
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 27
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccaccgcc 60
aaggagccct gcatggccaa gttcggccct ctgccctcca agtggcagat ggcctcctcc 120
gagcctccct gtgtgaacaa ggtgtccgac tggaagctgg agatcctgca gaacggcctg 180
tacctgatct acggccaggt ggcccccaac gccaactaca acgacgtggc ccccttcgag 240
gtgcggctgt acaagaacaa ggacatgatc cagaccctga ccaacaagtc caagatccag 300
aacgtgggcg gcacctatga gctgcacgtg ggcgacacca tcgacctgat cttcaactcc 360
gagcaccagg tgctgaagaa caacacctac tggggcatca actgggttaa cgtaataagt 420
gatttgaaaa aaattgaaga tcttattcaa tctatgcata ttgatgctac tttatatacg 480
gaaagtgatg ttcaccccag ttgcaaagta acagcaatga agtgctttct cttggagtta 540
caagttattt cacttgagtc cggagatgca agtattcatg atacagtaga aaatctgatc 600
atcctagcaa acgacagttt gtcttctaat gggaatgtaa cagaatctgg atgcaaagaa 660
tgtgaggaac tggaggaaaa aaatattaaa gaatttttgc agagttttgt acatattgtc 720
caaatgttca tcaacacttc ttaa 744
<210> 28
<211> 247
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 28
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Thr Ala Lys Glu Pro Cys Met Ala Lys Phe Gly Pro Leu Pro
20 25 30
Ser Lys Trp Gln Met Ala Ser Ser Glu Pro Pro Cys Val Asn Lys Val
35 40 45
Ser Asp Trp Lys Leu Glu Ile Leu Gln Asn Gly Leu Tyr Leu Ile Tyr
50 55 60
Gly Gln Val Ala Pro Asn Ala Asn Tyr Asn Asp Val Ala Pro Phe Glu
65 70 75 80
Val Arg Leu Tyr Lys Asn Lys Asp Met Ile Gln Thr Leu Thr Asn Lys
85 90 95
Ser Lys Ile Gln Asn Val Gly Gly Thr Tyr Glu Leu His Val Gly Asp
100 105 110
Thr Ile Asp Leu Ile Phe Asn Ser Glu His Gln Val Leu Lys Asn Asn
115 120 125
Thr Tyr Trp Gly Ile Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys
130 135 140
Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr
145 150 155 160
Glu Ser Asp Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe
165 170 175
Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile
180 185 190
His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asp Ser Leu Ser
195 200 205
Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu
210 215 220
Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val
225 230 235 240
Gln Met Phe Ile Asn Thr Ser
245
<210> 29
<211> 1293
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 29
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccaccgcc 60
aaggagccct gcatggccaa gttcggccct ctgccctcca agtggcagat ggcctcctcc 120
gagcctccct gtgtgaacaa ggtgtccgac tggaagctgg agatcctgca gaacggcctg 180
tacctgatct acggccaggt ggcccccaac gccaactaca acgacgtggc ccccttcgag 240
gtgcggctgt acaagaacaa ggacatgatc cagaccctga ccaacaagtc caagatccag 300
aacgtgggcg gcacctatga gctgcacgtg ggcgacacca tcgacctgat cttcaactcc 360
gagcaccagg tgctgaagaa caacacctac tggggcatca tcacgtgtcc tcctcctatg 420
tccgtggaac acgcagacat ctgggtcaag agctacagct tgtactccag ggagcggtac 480
atttgtaact ctggtttcaa gcgtaaagcc ggcacgtcca gcctgacgga gtgcgtgttg 540
aacaaggcca cgaatgtcgc ccactggaca acccccagtc tcaaatgcat tagagagccg 600
aaatcttgtg acaaaactca cacatgccca ccgtgcccag cacctgaact cctgggggga 660
ccgtcagtct tcctcttccc cccaaaaccc aaggacaccc tcatgatctc ccggacccct 720
gaggtcacat gcgtggtggt ggacgtgagc cacgaagacc ctgaggtcaa gttcaactgg 780
tacgtggacg gcgtggaggt gcataatgcc aagacaaagc cgcgggagga gcagtacaac 840
agcacgtacc gtgtggtcag cgtcctcacc gtcctgcacc aggactggct gaatggcaag 900
gagtacaagt gcaaggtctc caacaaagcc ctcccagccc ccatcgagaa aaccatctcc 960
aaagccaaag ggcagccccg agaaccacag gtgtacaccc tgcccccatc ccgggatgag 1020
ctgaccaaga accaggtcag cctgacctgc ctggtcaaag gcttctatcc cagcgacatc 1080
gccgtggagt gggagagcaa tgggcagccg gagaacaact acaagaccac gcctcccgtg 1140
ctggactccg acggctcctt cttcctctac agcaagctca ccgtggacaa gagcaggtgg 1200
cagcagggga acgtcttctc atgctccgtg atgcatgagg ctctgcacaa ccactacacg 1260
cagaagagcc tctccctgtc tcctggtaaa taa 1293
<210> 30
<211> 430
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 30
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Thr Ala Lys Glu Pro Cys Met Ala Lys Phe Gly Pro Leu Pro
20 25 30
Ser Lys Trp Gln Met Ala Ser Ser Glu Pro Pro Cys Val Asn Lys Val
35 40 45
Ser Asp Trp Lys Leu Glu Ile Leu Gln Asn Gly Leu Tyr Leu Ile Tyr
50 55 60
Gly Gln Val Ala Pro Asn Ala Asn Tyr Asn Asp Val Ala Pro Phe Glu
65 70 75 80
Val Arg Leu Tyr Lys Asn Lys Asp Met Ile Gln Thr Leu Thr Asn Lys
85 90 95
Ser Lys Ile Gln Asn Val Gly Gly Thr Tyr Glu Leu His Val Gly Asp
100 105 110
Thr Ile Asp Leu Ile Phe Asn Ser Glu His Gln Val Leu Lys Asn Asn
115 120 125
Thr Tyr Trp Gly Ile Ile Thr Cys Pro Pro Pro Met Ser Val Glu His
130 135 140
Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr
145 150 155 160
Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr
165 170 175
Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro
180 185 190
Ser Leu Lys Cys Ile Arg Glu Pro Lys Ser Cys Asp Lys Thr His Thr
195 200 205
Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe
210 215 220
Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro
225 230 235 240
Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val
245 250 255
Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr
260 265 270
Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val
275 280 285
Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys
290 295 300
Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser
305 310 315 320
Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro
325 330 335
Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val
340 345 350
Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly
355 360 365
Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp
370 375 380
Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp
385 390 395 400
Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His
405 410 415
Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
420 425 430
<210> 31
<211> 1131
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 31
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccgagatc 60
gtgctgaccc agtcccctgc taccctgtcc ctgtcccctg gcgagagggc taccctgtcc 120
tgcagggcca ggcaatccat ctccaactac ctgcactggt accagcagaa acctggccag 180
gcccccaggc tgctgatcta ctacgcctcc cagtccatct ccggcatccc tgacaggttc 240
agcggatccg gctccggcac cgacttcacc ctgaccatct ccaggctgga gcctgaggac 300
ttcgccgtgt actactgcca gcagtccaac tcctggcctc tgaccttcgg ccagggcacc 360
aaggtggaga tcaagcgggg aggtggcgga tccggaggtg gaggttctgg tggaggtggg 420
agtgaggtgc agctggtgca gtccggcgcc gaagtgaaga agcccggagc ctccgtgaag 480
gtgtcctgca aggcctccgg ctacaccttc accaggtact ggatgcactg ggtgaggcag 540
gcccctggac agggactgga gtggatcggc gccatctacc ccggcaactc cgacacctcc 600
tacaaccaga agttcaaggg caaggccacc atcaccgccg acacctccac caacaccgcc 660
tacatggagc tgtcctccct gaggtccgag gacaccgccg tgtactactg cgctaggggc 720
gaggagatcg gcgtgaggag gtggttcgcc tactggggac agggcaccct ggtgaccgtg 780
tccagcaact gggttaacgt aataagtgat ttgaaaaaaa ttgaagatct tattcaatct 840
atgcatattg atgctacttt atatacggaa agtgatgttc accccagttg caaagtaaca 900
gcaatgaagt gctttctctt ggagttacaa gttatttcac ttgagtccgg agatgcaagt 960
attcatgata cagtagaaaa tctgatcatc ctagcaaacg acagtttgtc ttctaatggg 1020
aatgtaacag aatctggatg caaagaatgt gaggaactgg aggaaaaaaa tattaaagaa 1080
tttttgcaga gttttgtaca tattgtccaa atgttcatca acacttctta a 1131
<210> 32
<211> 376
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 32
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser
20 25 30
Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg Ala Arg Gln Ser Ile Ser
35 40 45
Asn Tyr Leu His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu
50 55 60
Leu Ile Tyr Tyr Ala Ser Gln Ser Ile Ser Gly Ile Pro Asp Arg Phe
65 70 75 80
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu
85 90 95
Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Ser Asn Ser Trp
100 105 110
Pro Leu Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln
130 135 140
Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala Ser Val Lys
145 150 155 160
Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Arg Tyr Trp Met His
165 170 175
Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile Gly Ala Ile
180 185 190
Tyr Pro Gly Asn Ser Asp Thr Ser Tyr Asn Gln Lys Phe Lys Gly Lys
195 200 205
Ala Thr Ile Thr Ala Asp Thr Ser Thr Asn Thr Ala Tyr Met Glu Leu
210 215 220
Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Gly
225 230 235 240
Glu Glu Ile Gly Val Arg Arg Trp Phe Ala Tyr Trp Gly Gln Gly Thr
245 250 255
Leu Val Thr Val Ser Ser Asn Trp Val Asn Val Ile Ser Asp Leu Lys
260 265 270
Lys Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr
275 280 285
Thr Glu Ser Asp Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys
290 295 300
Phe Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser
305 310 315 320
Ile His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asp Ser Leu
325 330 335
Ser Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu
340 345 350
Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile
355 360 365
Val Gln Met Phe Ile Asn Thr Ser
370 375
<210> 33
<211> 1680
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 33
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccgagatc 60
gtgctgaccc agtcccctgc taccctgtcc ctgtcccctg gcgagagggc taccctgtcc 120
tgcagggcca ggcaatccat ctccaactac ctgcactggt accagcagaa acctggccag 180
gcccccaggc tgctgatcta ctacgcctcc cagtccatct ccggcatccc tgacaggttc 240
agcggatccg gctccggcac cgacttcacc ctgaccatct ccaggctgga gcctgaggac 300
ttcgccgtgt actactgcca gcagtccaac tcctggcctc tgaccttcgg ccagggcacc 360
aaggtggaga tcaagcgggg aggtggcgga tccggaggtg gaggttctgg tggaggtggg 420
agtgaggtgc agctggtgca gtccggcgcc gaagtgaaga agcccggagc ctccgtgaag 480
gtgtcctgca aggcctccgg ctacaccttc accaggtact ggatgcactg ggtgaggcag 540
gcccctggac agggactgga gtggatcggc gccatctacc ccggcaactc cgacacctcc 600
tacaaccaga agttcaaggg caaggccacc atcaccgccg acacctccac caacaccgcc 660
tacatggagc tgtcctccct gaggtccgag gacaccgccg tgtactactg cgctaggggc 720
gaggagatcg gcgtgaggag gtggttcgcc tactggggac agggcaccct ggtgaccgtg 780
tccagcatca cgtgtcctcc tcctatgtcc gtggaacacg cagacatctg ggtcaagagc 840
tacagcttgt actccaggga gcggtacatt tgtaactctg gtttcaagcg taaagccggc 900
acgtccagcc tgacggagtg cgtgttgaac aaggccacga atgtcgccca ctggacaacc 960
cccagtctca aatgcattag agagccgaaa tcttgtgaca aaactcacac atgcccaccg 1020
tgcccagcac ctgaactcct ggggggaccg tcagtcttcc tcttcccccc aaaacccaag 1080
gacaccctca tgatctcccg gacccctgag gtcacatgcg tggtggtgga cgtgagccac 1140
gaagaccctg aggtcaagtt caactggtac gtggacggcg tggaggtgca taatgccaag 1200
acaaagccgc gggaggagca gtacaacagc acgtaccgtg tggtcagcgt cctcaccgtc 1260
ctgcaccagg actggctgaa tggcaaggag tacaagtgca aggtctccaa caaagccctc 1320
ccagccccca tcgagaaaac catctccaaa gccaaagggc agccccgaga accacaggtg 1380
tacaccctgc ccccatcccg ggatgagctg accaagaacc aggtcagcct gacctgcctg 1440
gtcaaaggct tctatcccag cgacatcgcc gtggagtggg agagcaatgg gcagccggag 1500
aacaactaca agaccacgcc tcccgtgctg gactccgacg gctccttctt cctctacagc 1560
aagctcaccg tggacaagag caggtggcag caggggaacg tcttctcatg ctccgtgatg 1620
catgaggctc tgcacaacca ctacacgcag aagagcctct ccctgtctcc tggtaaataa 1680
<210> 34
<211> 559
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 34
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser
20 25 30
Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg Ala Arg Gln Ser Ile Ser
35 40 45
Asn Tyr Leu His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu
50 55 60
Leu Ile Tyr Tyr Ala Ser Gln Ser Ile Ser Gly Ile Pro Asp Arg Phe
65 70 75 80
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu
85 90 95
Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Ser Asn Ser Trp
100 105 110
Pro Leu Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln
130 135 140
Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala Ser Val Lys
145 150 155 160
Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Arg Tyr Trp Met His
165 170 175
Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Ile Gly Ala Ile
180 185 190
Tyr Pro Gly Asn Ser Asp Thr Ser Tyr Asn Gln Lys Phe Lys Gly Lys
195 200 205
Ala Thr Ile Thr Ala Asp Thr Ser Thr Asn Thr Ala Tyr Met Glu Leu
210 215 220
Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Gly
225 230 235 240
Glu Glu Ile Gly Val Arg Arg Trp Phe Ala Tyr Trp Gly Gln Gly Thr
245 250 255
Leu Val Thr Val Ser Ser Ile Thr Cys Pro Pro Pro Met Ser Val Glu
260 265 270
His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg
275 280 285
Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu
290 295 300
Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr
305 310 315 320
Pro Ser Leu Lys Cys Ile Arg Glu Pro Lys Ser Cys Asp Lys Thr His
325 330 335
Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val
340 345 350
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
355 360 365
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu
370 375 380
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
385 390 395 400
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
405 410 415
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
420 425 430
Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile
435 440 445
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
450 455 460
Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
465 470 475 480
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
485 490 495
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
500 505 510
Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg
515 520 525
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
530 535 540
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
545 550 555
<210> 35
<211> 1662
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 35
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccgacatc 60
cagatgaccc agtcccctgc ttccctgtcc gcttccgtgg gcgacagggt gaccatcacc 120
tgcctggcct cccagaccat cgacacctgg ctggcctggt acctgcagaa gcccggcaag 180
tccccccagc tgctgatcta cgccgctacc aacctggccg acggcgtgcc tagcaggttt 240
tccggctccg gctccggcac cgacttctcc ttcaccatct cctccctgca gcccgaggac 300
ttcgccacct actactgcca gcaggtgtac tcctccccct tcaccttcgg ccagggcacc 360
aagctggaga tcaagggagg tggcggatcc ggaggtggag gttctggtgg aggtgggagt 420
cagatccagc tggtgcagtc cggcggcgaa gtgaaaaagc ccggcgccag cgtgagggtg 480
tcctgtaagg cctccggcta ctccttcacc gactacaacg tgtactgggt gaggcagtcc 540
cccggcaagg gactggagtg gatcggctac atcgacccct acaacggcat caccatctac 600
gaccagaact tcaagggcaa ggccaccctg accgtggaca agtccacctc cacagcctac 660
atggagctgt cctccctgag gtccgaggac accgccgtgt acttctgcgc cagggacgtg 720
accaccgctc tggacttctg gggacagggc accaccgtga ccgtgagctc catcacgtgt 780
cctcctccta tgtccgtgga acacgcagac atctgggtca agagctacag cttgtactcc 840
agggagcggt acatttgtaa ctctggtttc aagcgtaaag ccggcacgtc cagcctgacg 900
gagtgcgtgt tgaacaaggc cacgaatgtc gcccactgga caacccccag tctcaaatgc 960
attagagagc cgaaatcttg tgacaaaact cacacatgcc caccgtgccc agcacctgaa 1020
ctcctggggg gaccgtcagt cttcctcttc cccccaaaac ccaaggacac cctcatgatc 1080
tcccggaccc ctgaggtcac atgcgtggtg gtggacgtga gccacgaaga ccctgaggtc 1140
aagttcaact ggtacgtgga cggcgtggag gtgcataatg ccaagacaaa gccgcgggag 1200
gagcagtaca acagcacgta ccgtgtggtc agcgtcctca ccgtcctgca ccaggactgg 1260
ctgaatggca aggagtacaa gtgcaaggtc tccaacaaag ccctcccagc ccccatcgag 1320
aaaaccatct ccaaagccaa agggcagccc cgagaaccac aggtgtacac cctgccccca 1380
tcccgggatg agctgaccaa gaaccaggtc agcctgacct gcctggtcaa aggcttctat 1440
cccagcgaca tcgccgtgga gtgggagagc aatgggcagc cggagaacaa ctacaagacc 1500
acgcctcccg tgctggactc cgacggctcc ttcttcctct acagcaagct caccgtggac 1560
aagagcaggt ggcagcaggg gaacgtcttc tcatgctccg tgatgcatga ggctctgcac 1620
aaccactaca cgcagaagag cctctccctg tctcctggta aa 1662
<210> 36
<211> 554
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 36
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Asp Ile Gln Met Thr Gln Ser Pro Ala Ser Leu Ser Ala Ser
20 25 30
Val Gly Asp Arg Val Thr Ile Thr Cys Leu Ala Ser Gln Thr Ile Asp
35 40 45
Thr Trp Leu Ala Trp Tyr Leu Gln Lys Pro Gly Lys Ser Pro Gln Leu
50 55 60
Leu Ile Tyr Ala Ala Thr Asn Leu Ala Asp Gly Val Pro Ser Arg Phe
65 70 75 80
Ser Gly Ser Gly Ser Gly Thr Asp Phe Ser Phe Thr Ile Ser Ser Leu
85 90 95
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Val Tyr Ser Ser
100 105 110
Pro Phe Thr Phe Gly Gln Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Ile Gln Leu
130 135 140
Val Gln Ser Gly Gly Glu Val Lys Lys Pro Gly Ala Ser Val Arg Val
145 150 155 160
Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Asp Tyr Asn Val Tyr Trp
165 170 175
Val Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Ile Gly Tyr Ile Asp
180 185 190
Pro Tyr Asn Gly Ile Thr Ile Tyr Asp Gln Asn Phe Lys Gly Lys Ala
195 200 205
Thr Leu Thr Val Asp Lys Ser Thr Ser Thr Ala Tyr Met Glu Leu Ser
210 215 220
Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Phe Cys Ala Arg Asp Val
225 230 235 240
Thr Thr Ala Leu Asp Phe Trp Gly Gln Gly Thr Thr Val Thr Val Ser
245 250 255
Ser Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp
260 265 270
Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser
275 280 285
Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu
290 295 300
Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys
305 310 315 320
Ile Arg Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
325 330 335
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
340 345 350
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
355 360 365
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
370 375 380
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
385 390 395 400
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
405 410 415
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
420 425 430
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
435 440 445
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
450 455 460
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
465 470 475 480
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
485 490 495
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
500 505 510
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
515 520 525
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
530 535 540
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
545 550
<210> 37
<211> 1137
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 37
atggattttc aggtgcagat tatcagcttc ctgctaatca gtgcttcagt cataatgtca 60
agaggacagg tgcagctggt tcagagcggt gcggaagtta aaaagccggg ctcttccgtg 120
aaagttagct gcaaagcgtc tggttatacc ttcaccgact acaacatgca ctgggtccgc 180
caggccccag gccagggtct ggaatggatc ggttatattt acccgtacaa cggtggcacg 240
ggatataacc agaaattcaa atccaaagct accatcactg cggacgaaag caccaacacc 300
gcatatatgg aattgtcttc tctgcgtagc gaagataccg cggtttacta ttgcgctcgt 360
ggtcgtccag cgatggatta ctggggtcag ggcaccctgg tgaccgtgag ctctggcgga 420
ggcggatctg gtggtggcgg atccggtgga ggcggaagcg atatccagat gacccagtcc 480
ccgagctccc tgtctgccag cgtgggcgac cgcgtgacta tcacctgccg tgcgtccgaa 540
agcgtggata actacggcat ttcctttatg aactggttcc agcagaaacc gggtaaagcc 600
ccgaaactgc tgatttatgc ggcctctaac cagggcagcg gtgtgccgag ccgcttttcc 660
ggcagcggtt cggggaccga tttcactctg accatttcta gcctgcagcc agatgacttc 720
gcgacctact actgccaaca gtctaaagaa gttccgtgga ccttcggtca gggtaccaaa 780
gttgaaatta aaaactgggt taacgtaata agtgatttga aaaaaattga agatcttatt 840
caatctatgc atattgatgc tactttatat acggaaagtg atgttcaccc cagttgcaaa 900
gtaacagcaa tgaagtgctt tctcttggag ttacaagtta tttcacttga gtccggagat 960
gcaagtattc atgatacagt agaaaatctg atcatcctag caaacgacag tttgtcttct 1020
aatgggaatg taacagaatc tggatgcaaa gaatgtgagg aactggagga aaaaaatatt 1080
aaagaatttt tgcagagttt tgtacatatt gtccaaatgt tcatcaacac ttcttaa 1137
<210> 38
<211> 378
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 38
Met Asp Phe Gln Val Gln Ile Ile Ser Phe Leu Leu Ile Ser Ala Ser
1 5 10 15
Val Ile Met Ser Arg Gly Gln Val Gln Leu Val Gln Ser Gly Ala Glu
20 25 30
Val Lys Lys Pro Gly Ser Ser Val Lys Val Ser Cys Lys Ala Ser Gly
35 40 45
Tyr Thr Phe Thr Asp Tyr Asn Met His Trp Val Arg Gln Ala Pro Gly
50 55 60
Gln Gly Leu Glu Trp Ile Gly Tyr Ile Tyr Pro Tyr Asn Gly Gly Thr
65 70 75 80
Gly Tyr Asn Gln Lys Phe Lys Ser Lys Ala Thr Ile Thr Ala Asp Glu
85 90 95
Ser Thr Asn Thr Ala Tyr Met Glu Leu Ser Ser Leu Arg Ser Glu Asp
100 105 110
Thr Ala Val Tyr Tyr Cys Ala Arg Gly Arg Pro Ala Met Asp Tyr Trp
115 120 125
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly
130 135 140
Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Ile Gln Met Thr Gln Ser
145 150 155 160
Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys
165 170 175
Arg Ala Ser Glu Ser Val Asp Asn Tyr Gly Ile Ser Phe Met Asn Trp
180 185 190
Phe Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Ala Ala
195 200 205
Ser Asn Gln Gly Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser
210 215 220
Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Asp Asp Phe
225 230 235 240
Ala Thr Tyr Tyr Cys Gln Gln Ser Lys Glu Val Pro Trp Thr Phe Gly
245 250 255
Gln Gly Thr Lys Val Glu Ile Lys Asn Trp Val Asn Val Ile Ser Asp
260 265 270
Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr
275 280 285
Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys Val Thr Ala Met
290 295 300
Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp
305 310 315 320
Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asp
325 330 335
Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys
340 345 350
Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val
355 360 365
His Ile Val Gln Met Phe Ile Asn Thr Ser
370 375
<210> 39
<211> 1686
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 39
atggattttc aggtgcagat tatcagcttc ctgctaatca gtgcttcagt cataatgtca 60
agaggacagg tgcagctggt tcagagcggt gcggaagtta aaaagccggg ctcttccgtg 120
aaagttagct gcaaagcgtc tggttatacc ttcaccgact acaacatgca ctgggtccgc 180
caggccccag gccagggtct ggaatggatc ggttatattt acccgtacaa cggtggcacg 240
ggatataacc agaaattcaa atccaaagct accatcactg cggacgaaag caccaacacc 300
gcatatatgg aattgtcttc tctgcgtagc gaagataccg cggtttacta ttgcgctcgt 360
ggtcgtccag cgatggatta ctggggtcag ggcaccctgg tgaccgtgag ctctggcgga 420
ggcggatctg gtggtggcgg atccggtgga ggcggaagcg atatccagat gacccagtcc 480
ccgagctccc tgtctgccag cgtgggcgac cgcgtgacta tcacctgccg tgcgtccgaa 540
agcgtggata actacggcat ttcctttatg aactggttcc agcagaaacc gggtaaagcc 600
ccgaaactgc tgatttatgc ggcctctaac cagggcagcg gtgtgccgag ccgcttttcc 660
ggcagcggtt cggggaccga tttcactctg accatttcta gcctgcagcc agatgacttc 720
gcgacctact actgccaaca gtctaaagaa gttccgtgga ccttcggtca gggtaccaaa 780
gttgaaatta aaatcacgtg tcctcctcct atgtccgtgg aacacgcaga catctgggtc 840
aagagctaca gcttgtactc cagggagcgg tacatttgta actctggttt caagcgtaaa 900
gccggcacgt ccagcctgac ggagtgcgtg ttgaacaagg ccacgaatgt cgcccactgg 960
acaaccccca gtctcaaatg cattagagag ccgaaatctt gtgacaaaac tcacacatgc 1020
ccaccgtgcc cagcacctga actcctgggg ggaccgtcag tcttcctctt ccccccaaaa 1080
cccaaggaca ccctcatgat ctcccggacc cctgaggtca catgcgtggt ggtggacgtg 1140
agccacgaag accctgaggt caagttcaac tggtacgtgg acggcgtgga ggtgcataat 1200
gccaagacaa agccgcggga ggagcagtac aacagcacgt accgtgtggt cagcgtcctc 1260
accgtcctgc accaggactg gctgaatggc aaggagtaca agtgcaaggt ctccaacaaa 1320
gccctcccag cccccatcga gaaaaccatc tccaaagcca aagggcagcc ccgagaacca 1380
caggtgtaca ccctgccccc atcccgggat gagctgacca agaaccaggt cagcctgacc 1440
tgcctggtca aaggcttcta tcccagcgac atcgccgtgg agtgggagag caatgggcag 1500
ccggagaaca actacaagac cacgcctccc gtgctggact ccgacggctc cttcttcctc 1560
tacagcaagc tcaccgtgga caagagcagg tggcagcagg ggaacgtctt ctcatgctcc 1620
gtgatgcatg aggctctgca caaccactac acgcagaaga gcctctccct gtctcctggt 1680
aaataa 1686
<210> 40
<211> 561
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 40
Met Asp Phe Gln Val Gln Ile Ile Ser Phe Leu Leu Ile Ser Ala Ser
1 5 10 15
Val Ile Met Ser Arg Gly Gln Val Gln Leu Val Gln Ser Gly Ala Glu
20 25 30
Val Lys Lys Pro Gly Ser Ser Val Lys Val Ser Cys Lys Ala Ser Gly
35 40 45
Tyr Thr Phe Thr Asp Tyr Asn Met His Trp Val Arg Gln Ala Pro Gly
50 55 60
Gln Gly Leu Glu Trp Ile Gly Tyr Ile Tyr Pro Tyr Asn Gly Gly Thr
65 70 75 80
Gly Tyr Asn Gln Lys Phe Lys Ser Lys Ala Thr Ile Thr Ala Asp Glu
85 90 95
Ser Thr Asn Thr Ala Tyr Met Glu Leu Ser Ser Leu Arg Ser Glu Asp
100 105 110
Thr Ala Val Tyr Tyr Cys Ala Arg Gly Arg Pro Ala Met Asp Tyr Trp
115 120 125
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly
130 135 140
Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Ile Gln Met Thr Gln Ser
145 150 155 160
Pro Ser Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys
165 170 175
Arg Ala Ser Glu Ser Val Asp Asn Tyr Gly Ile Ser Phe Met Asn Trp
180 185 190
Phe Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr Ala Ala
195 200 205
Ser Asn Gln Gly Ser Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser
210 215 220
Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Asp Asp Phe
225 230 235 240
Ala Thr Tyr Tyr Cys Gln Gln Ser Lys Glu Val Pro Trp Thr Phe Gly
245 250 255
Gln Gly Thr Lys Val Glu Ile Lys Ile Thr Cys Pro Pro Pro Met Ser
260 265 270
Val Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg
275 280 285
Glu Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser
290 295 300
Ser Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp
305 310 315 320
Thr Thr Pro Ser Leu Lys Cys Ile Arg Glu Pro Lys Ser Cys Asp Lys
325 330 335
Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro
340 345 350
Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser
355 360 365
Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp
370 375 380
Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn
385 390 395 400
Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val
405 410 415
Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu
420 425 430
Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys
435 440 445
Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr
450 455 460
Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr
465 470 475 480
Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu
485 490 495
Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu
500 505 510
Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys
515 520 525
Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu
530 535 540
Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
545 550 555 560
Lys
<210> 41
<211> 1626
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 41
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccatgaag 60
tgggtgacct tcatcagcct gctgttcctg ttctccagcg cctactccga tttagtgttt 120
ctgttcgacg gctccatgtc tttacagccc gatgagttcc agaagatttt agacttcatg 180
aaggacgtga tgaagaaact gtccaacacc agctaccagt tcgctgccgt gcagttctcc 240
acctcctaca agaccgagtt cgacttctcc gactacgtga agcggaagga ccccgatgct 300
ttactgaagc acgtcaagca catgctgctg ctcaccaaca cctttggcgc catcaactac 360
gtggccaccg aggtgtttcg tgaggaactg ggagctcggc ccgatgccac caaggtgctg 420
attatcatca ccgacggcga agccaccgat agcggaaaca tcgatgccgc caaggacatc 480
atccggtaca ttatcggcat cggcaagcac ttccagacca aggagagcca agagacttta 540
cacaagttcg cctccaagcc cgcttccgag ttcgtgtgca ttttagacac cttcgagtgt 600
ttaaaggatt tatttaccga gctgcagaag aagatctacg tgattgaggg caccagcaag 660
caagatctga cctccttcaa catggagctg tccagcagcg gcatttccgc tgatttatct 720
cgtggccacg ccatcacgtg tcctcctcct atgtccgtgg aacacgcaga catctgggtc 780
aagagctaca gcttgtactc cagggagcgg tacatttgta actctggttt caagcgtaaa 840
gccggcacgt ccagcctgac ggagtgcgtg ttgaacaagg ccacgaatgt cgcccactgg 900
acaaccccca gtctcaaatg cattagagag ccgaaatctt gtgacaaaac tcacacatgc 960
ccaccgtgcc cagcacctga actcctgggg ggaccgtcag tcttcctctt ccccccaaaa 1020
cccaaggaca ccctcatgat ctcccggacc cctgaggtca catgcgtggt ggtggacgtg 1080
agccacgaag accctgaggt caagttcaac tggtacgtgg acggcgtgga ggtgcataat 1140
gccaagacaa agccgcggga ggagcagtac aacagcacgt accgtgtggt cagcgtcctc 1200
accgtcctgc accaggactg gctgaatggc aaggagtaca agtgcaaggt ctccaacaaa 1260
gccctcccag cccccatcga gaaaaccatc tccaaagcca aagggcagcc ccgagaacca 1320
caggtgtaca ccctgccccc atcccgggat gagctgacca agaaccaggt cagcctgacc 1380
tgcctggtca aaggcttcta tcccagcgac atcgccgtgg agtgggagag caatgggcag 1440
ccggagaaca actacaagac cacgcctccc gtgctggact ccgacggctc cttcttcctc 1500
tacagcaagc tcaccgtgga caagagcagg tggcagcagg ggaacgtctt ctcatgctcc 1560
gtgatgcatg aggctctgca caaccactac acgcagaaga gcctctccct gtctcctggt 1620
aaataa 1626
<210> 42
<211> 523
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 42
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Asp Leu Val Phe Leu Phe Asp Gly Ser Met Ser Leu Gln Pro
20 25 30
Asp Glu Phe Gln Lys Ile Leu Asp Phe Met Lys Asp Val Met Lys Lys
35 40 45
Leu Ser Asn Thr Ser Tyr Gln Phe Ala Ala Val Gln Phe Ser Thr Ser
50 55 60
Tyr Lys Thr Glu Phe Asp Phe Ser Asp Tyr Val Lys Arg Lys Asp Pro
65 70 75 80
Asp Ala Leu Leu Lys His Val Lys His Met Leu Leu Leu Thr Asn Thr
85 90 95
Phe Gly Ala Ile Asn Tyr Val Ala Thr Glu Val Phe Arg Glu Glu Leu
100 105 110
Gly Ala Arg Pro Asp Ala Thr Lys Val Leu Ile Ile Ile Thr Asp Gly
115 120 125
Glu Ala Thr Asp Ser Gly Asn Ile Asp Ala Ala Lys Asp Ile Ile Arg
130 135 140
Tyr Ile Ile Gly Ile Gly Lys His Phe Gln Thr Lys Glu Ser Gln Glu
145 150 155 160
Thr Leu His Lys Phe Ala Ser Lys Pro Ala Ser Glu Phe Val Cys Ile
165 170 175
Leu Asp Thr Phe Glu Cys Leu Lys Asp Leu Phe Thr Glu Leu Gln Lys
180 185 190
Lys Ile Tyr Val Ile Glu Gly Thr Ser Lys Gln Asp Leu Thr Ser Phe
195 200 205
Asn Met Glu Leu Ser Ser Ser Gly Ile Ser Ala Asp Leu Ser Arg Gly
210 215 220
His Ala Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile
225 230 235 240
Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn
245 250 255
Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val
260 265 270
Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys
275 280 285
Cys Ile Arg Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro
290 295 300
Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro
305 310 315 320
Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr
325 330 335
Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn
340 345 350
Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg
355 360 365
Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val
370 375 380
Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser
385 390 395 400
Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys
405 410 415
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
420 425 430
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
435 440 445
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
450 455 460
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
465 470 475 480
Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
485 490 495
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
500 505 510
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
515 520
<210> 43
<211> 2457
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 43
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccagcggc 60
gtgttccagc tgcagctgca agagtttatc aacgagaggg gcgtgctggc ttccggtcgt 120
ccttgtgagc ccggttgtag gacctttttc cgggtgtgtt taaagcattt tcaagctgtg 180
gtgtcccccg gaccttgtac cttcggcacc gtgtccaccc ccgttctggg caccaactcc 240
ttcgccgttc gtgacgacag ctccggagga ggtcgtaatc ctttacagct gcctttcaac 300
tttacttggc ccggcacctt ctccctcatc atcgaagctt ggcatgcccc cggtgacgat 360
ctgcggcccg aagctctgcc ccccgatgct ttaatcagca agattgccat tcaaggttct 420
ttagccgtgg gccagaactg gctgctggac gagcagacca gcacactcac tcgtctgagg 480
tactcctatc gtgtgatctg cagcgacaac tactacggcg acaattgcag ccggctgtgc 540
aagaagagga acgaccactt cggccattac gtctgccagc ccgacggcaa tttatcttgt 600
ctgcccggtt ggaccggcga gtactgtcag cagcccatct gtttaagcgg ctgccacgag 660
cagaacggct actgcagcaa gcccgctgag tgtctgtgta ggcccggctg gcaaggtagg 720
ctgtgcaacg agtgcatccc ccacaatggc tgtcggcacg gcacttgttc caccccttgg 780
cagtgcactt gtgacgaggg ctggggaggt ttattctgcg accaagatct gaactactgc 840
acccaccaca gcccttgtaa gaacggagct acttgttcca acagcggcca gaggtcctac 900
acttgtactt gtaggcccgg ttacaccggc gtcgactgcg aactggaact gagcgaatgc 960
gatagcaacc cttgtcgtaa cggcggcagc tgcaaggacc aagaagacgg ctaccactgt 1020
ttatgccctc ccggatacta cggtttacac tgcgagcact ccacactgtc ttgtgccgac 1080
tccccttgtt tcaacggcgg aagctgtcgt gagaggaacc aaggtgccaa ctacgcttgt 1140
gagtgccctc ccaacttcac cggctccaac tgcgagaaga aggtggatcg ttgcacctcc 1200
aacccttgcg ccaacggcgg ccagtgttta aataggggcc cttcccggat gtgtcgttgt 1260
cgtcccggtt ttaccggcac ctactgcgag ctgcacgtca gcgattgcgc ccggaatcct 1320
tgcgctcacg gcggaacttg tcacgattta gagaacggtt taatgtgcac ttgtcccgct 1380
ggattcagcg gtcgtaggtg tgaggtgagg acctccatcg acgcttgtgc cagcagccct 1440
tgcttcaatc gtgccacttg ttacaccgat ttatccaccg acaccttcgt gtgcaactgc 1500
ccctacggct tcgtgggatc tcgttgcgag ttccccgttg gcctgcctcc tagctttccc 1560
tggatcacgt gtcctcctcc tatgtccgtg gaacacgcag acatctgggt caagagctac 1620
agcttgtact ccagggagcg gtacatttgt aactctggtt tcaagcgtaa agccggcacg 1680
tccagcctga cggagtgcgt gttgaacaag gccacgaatg tcgcccactg gacaaccccc 1740
agtctcaaat gcattagaga gccgaaatct tgtgacaaaa ctcacacatg cccaccgtgc 1800
ccagcacctg aactcctggg gggaccgtca gtcttcctct tccccccaaa acccaaggac 1860
accctcatga tctcccggac ccctgaggtc acatgcgtgg tggtggacgt gagccacgaa 1920
gaccctgagg tcaagttcaa ctggtacgtg gacggcgtgg aggtgcataa tgccaagaca 1980
aagccgcggg aggagcagta caacagcacg taccgtgtgg tcagcgtcct caccgtcctg 2040
caccaggact ggctgaatgg caaggagtac aagtgcaagg tctccaacaa agccctccca 2100
gcccccatcg agaaaaccat ctccaaagcc aaagggcagc cccgagaacc acaggtgtac 2160
accctgcccc catcccggga tgagctgacc aagaaccagg tcagcctgac ctgcctggtc 2220
aaaggcttct atcccagcga catcgccgtg gagtgggaga gcaatgggca gccggagaac 2280
aactacaaga ccacgcctcc cgtgctggac tccgacggct ccttcttcct ctacagcaag 2340
ctcaccgtgg acaagagcag gtggcagcag gggaacgtct tctcatgctc cgtgatgcat 2400
gaggctctgc acaaccacta cacgcagaag agcctctccc tgtctcctgg taaataa 2457
<210> 44
<211> 818
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 44
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ser Gly Val Phe Gln Leu Gln Leu Gln Glu Phe Ile Asn Glu
20 25 30
Arg Gly Val Leu Ala Ser Gly Arg Pro Cys Glu Pro Gly Cys Arg Thr
35 40 45
Phe Phe Arg Val Cys Leu Lys His Phe Gln Ala Val Val Ser Pro Gly
50 55 60
Pro Cys Thr Phe Gly Thr Val Ser Thr Pro Val Leu Gly Thr Asn Ser
65 70 75 80
Phe Ala Val Arg Asp Asp Ser Ser Gly Gly Gly Arg Asn Pro Leu Gln
85 90 95
Leu Pro Phe Asn Phe Thr Trp Pro Gly Thr Phe Ser Leu Ile Ile Glu
100 105 110
Ala Trp His Ala Pro Gly Asp Asp Leu Arg Pro Glu Ala Leu Pro Pro
115 120 125
Asp Ala Leu Ile Ser Lys Ile Ala Ile Gln Gly Ser Leu Ala Val Gly
130 135 140
Gln Asn Trp Leu Leu Asp Glu Gln Thr Ser Thr Leu Thr Arg Leu Arg
145 150 155 160
Tyr Ser Tyr Arg Val Ile Cys Ser Asp Asn Tyr Tyr Gly Asp Asn Cys
165 170 175
Ser Arg Leu Cys Lys Lys Arg Asn Asp His Phe Gly His Tyr Val Cys
180 185 190
Gln Pro Asp Gly Asn Leu Ser Cys Leu Pro Gly Trp Thr Gly Glu Tyr
195 200 205
Cys Gln Gln Pro Ile Cys Leu Ser Gly Cys His Glu Gln Asn Gly Tyr
210 215 220
Cys Ser Lys Pro Ala Glu Cys Leu Cys Arg Pro Gly Trp Gln Gly Arg
225 230 235 240
Leu Cys Asn Glu Cys Ile Pro His Asn Gly Cys Arg His Gly Thr Cys
245 250 255
Ser Thr Pro Trp Gln Cys Thr Cys Asp Glu Gly Trp Gly Gly Leu Phe
260 265 270
Cys Asp Gln Asp Leu Asn Tyr Cys Thr His His Ser Pro Cys Lys Asn
275 280 285
Gly Ala Thr Cys Ser Asn Ser Gly Gln Arg Ser Tyr Thr Cys Thr Cys
290 295 300
Arg Pro Gly Tyr Thr Gly Val Asp Cys Glu Leu Glu Leu Ser Glu Cys
305 310 315 320
Asp Ser Asn Pro Cys Arg Asn Gly Gly Ser Cys Lys Asp Gln Glu Asp
325 330 335
Gly Tyr His Cys Leu Cys Pro Pro Gly Tyr Tyr Gly Leu His Cys Glu
340 345 350
His Ser Thr Leu Ser Cys Ala Asp Ser Pro Cys Phe Asn Gly Gly Ser
355 360 365
Cys Arg Glu Arg Asn Gln Gly Ala Asn Tyr Ala Cys Glu Cys Pro Pro
370 375 380
Asn Phe Thr Gly Ser Asn Cys Glu Lys Lys Val Asp Arg Cys Thr Ser
385 390 395 400
Asn Pro Cys Ala Asn Gly Gly Gln Cys Leu Asn Arg Gly Pro Ser Arg
405 410 415
Met Cys Arg Cys Arg Pro Gly Phe Thr Gly Thr Tyr Cys Glu Leu His
420 425 430
Val Ser Asp Cys Ala Arg Asn Pro Cys Ala His Gly Gly Thr Cys His
435 440 445
Asp Leu Glu Asn Gly Leu Met Cys Thr Cys Pro Ala Gly Phe Ser Gly
450 455 460
Arg Arg Cys Glu Val Arg Thr Ser Ile Asp Ala Cys Ala Ser Ser Pro
465 470 475 480
Cys Phe Asn Arg Ala Thr Cys Tyr Thr Asp Leu Ser Thr Asp Thr Phe
485 490 495
Val Cys Asn Cys Pro Tyr Gly Phe Val Gly Ser Arg Cys Glu Phe Pro
500 505 510
Val Gly Leu Pro Pro Ser Phe Pro Trp Ile Thr Cys Pro Pro Pro Met
515 520 525
Ser Val Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser
530 535 540
Arg Glu Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr
545 550 555 560
Ser Ser Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His
565 570 575
Trp Thr Thr Pro Ser Leu Lys Cys Ile Arg Glu Pro Lys Ser Cys Asp
580 585 590
Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly
595 600 605
Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile
610 615 620
Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu
625 630 635 640
Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His
645 650 655
Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg
660 665 670
Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys
675 680 685
Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu
690 695 700
Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr
705 710 715 720
Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu
725 730 735
Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp
740 745 750
Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val
755 760 765
Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp
770 775 780
Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His
785 790 795 800
Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro
805 810 815
Gly Lys
<210> 45
<211> 1701
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 45
atggaatgga gctgggtctt tctcttcttc ctgtcagtaa ccaccggtgt ccactcctcc 60
tatgtgctga ctcagcctcc ctccgcgtcc gggtctcctg gacagtcagt caccatctcc 120
tgcactggaa ccagcagtga cgttggtaat aataactatg tctcctggta ccaacagcac 180
ccaggcaaag cccccaaact catgatttat gatgtcagta atcggccctc aggggtttct 240
actcgcttct ctggctccaa gtctggcaac acggcctccc tgaccatctc tgggctccag 300
gctgaggacg aggctgatta ttactgcagc tcatatacaa ccagcagtac ttatgtcttc 360
ggaactggga ccaagctgac cgtcctgggg cagccaaagg cgggaggtgg cggatccgga 420
ggtggaggtt ctggtggagg tgggagtctg gtgcaatctg gggctgaggt gaagaagcct 480
ggggcctcag tgaaggtctc ctgcaaggct tctggataca ccttcaccgg ctactatatg 540
cactgggtgc gacaggcccc tggacaaggg cttgagtgga tgggatggat caaccctaac 600
agtggtggca caaactatgc acagaagttc cagggcagag tcaccatgac caggaacacc 660
tccataagca cagcctacat ggagttgagc agcctgagat ctgacgacac ggccgtgtat 720
tactgtgcga gagagatgta ttactatggt tcggggtaca actggttcga cccctggggc 780
cagggaaccc tggtcaccgt gagctcaatc acgtgtcctc ctcctatgtc cgtggaacac 840
gcagacatct gggtcaagag ctacagcttg tactccaggg agcggtacat ttgtaactct 900
ggtttcaagc gtaaagccgg cacgtccagc ctgacggagt gcgtgttgaa caaggccacg 960
aatgtcgccc actggacaac ccccagtctc aaatgcatta gagagccgaa atcttgtgac 1020
aaaactcaca catgcccacc gtgcccagca cctgaactcc tggggggacc gtcagtcttc 1080
ctcttccccc caaaacccaa ggacaccctc atgatctccc ggacccctga ggtcacatgc 1140
gtggtggtgg acgtgagcca cgaagaccct gaggtcaagt tcaactggta cgtggacggc 1200
gtggaggtgc ataatgccaa gacaaagccg cgggaggagc agtacaacag cacgtaccgt 1260
gtggtcagcg tcctcaccgt cctgcaccag gactggctga atggcaagga gtacaagtgc 1320
aaggtctcca acaaagccct cccagccccc atcgagaaaa ccatctccaa agccaaaggg 1380
cagccccgag aaccacaggt gtacaccctg cccccatccc gggatgagct gaccaagaac 1440
caggtcagcc tgacctgcct ggtcaaaggc ttctatccca gcgacatcgc cgtggagtgg 1500
gagagcaatg ggcagccgga gaacaactac aagaccacgc ctcccgtgct ggactccgac 1560
ggctccttct tcctctacag caagctcacc gtggacaaga gcaggtggca gcaggggaac 1620
gtcttctcat gctccgtgat gcatgaggct ctgcacaacc actacacgca gaagagcctc 1680
tccctgtctc ctggtaaata a 1701
<210> 46
<211> 566
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 46
Met Glu Trp Ser Trp Val Phe Leu Phe Phe Leu Ser Val Thr Thr Gly
1 5 10 15
Val His Ser Ser Tyr Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Ser
20 25 30
Pro Gly Gln Ser Val Thr Ile Ser Cys Thr Gly Thr Ser Ser Asp Val
35 40 45
Gly Asn Asn Asn Tyr Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala
50 55 60
Pro Lys Leu Met Ile Tyr Asp Val Ser Asn Arg Pro Ser Gly Val Ser
65 70 75 80
Thr Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile
85 90 95
Ser Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr
100 105 110
Thr Thr Ser Ser Thr Tyr Val Phe Gly Thr Gly Thr Lys Leu Thr Val
115 120 125
Leu Gly Gln Pro Lys Ala Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro
145 150 155 160
Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr
165 170 175
Gly Tyr Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu
180 185 190
Trp Met Gly Trp Ile Asn Pro Asn Ser Gly Gly Thr Asn Tyr Ala Gln
195 200 205
Lys Phe Gln Gly Arg Val Thr Met Thr Arg Asn Thr Ser Ile Ser Thr
210 215 220
Ala Tyr Met Glu Leu Ser Ser Leu Arg Ser Asp Asp Thr Ala Val Tyr
225 230 235 240
Tyr Cys Ala Arg Glu Met Tyr Tyr Tyr Gly Ser Gly Tyr Asn Trp Phe
245 250 255
Asp Pro Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ile Thr Cys
260 265 270
Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp Val Lys Ser Tyr
275 280 285
Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg
290 295 300
Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu Asn Lys Ala Thr
305 310 315 320
Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys Ile Arg Glu Pro
325 330 335
Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu
340 345 350
Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp
355 360 365
Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp
370 375 380
Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly
385 390 395 400
Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn
405 410 415
Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp
420 425 430
Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro
435 440 445
Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu
450 455 460
Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn
465 470 475 480
Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile
485 490 495
Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr
500 505 510
Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys
515 520 525
Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys
530 535 540
Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu
545 550 555 560
Ser Leu Ser Pro Gly Lys
565
<210> 47
<211> 1665
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 47
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcctacatc 60
cacgtgaccc agtccccctc ctctttaagc gtgagcatcg gagatcgtgt gaccatcaac 120
tgccagacct cccaaggtgt gggctccgat ttacactggt accagcacaa gcccggtcgg 180
gcccccaagc tgctgatcca ccacaccagc tccgtggagg atggcgtgcc ctctcgtttc 240
tccggctccg gcttccatac ctccttcaat ttaaccatca gcgatttaca agctgacgac 300
atcgccacct actactgcca agttctccag ttcttcggcc ggggctctcg tctgcatatc 360
aagggaggcg gcggatccgg cggcggaggc agcggcggag gcggatctcg tgctcatctg 420
gtgcagagcg gaaccgccat gaagaagccc ggtgctagcg tgcgggtgtc ttgtcagacc 480
agcggataca ccttcaccgc ccacatttta ttctggtttc gtcaagctcc cggtcgtgga 540
ctggaatggg tgggctggat caagccccag tatggcgccg tgaactttgg cggcggcttt 600
cgtgatcggg tgactttaac tcgtgacgtg tatcgggaga tcgcctacat ggacattagg 660
ggtttaaagc ccgacgatac cgccgtgtac tactgcgctc gtgatcgttc ctacggcgat 720
agcagctggg ctttagatgc ttggggccaa ggtaccacag tgtggtccgc catcacgtgt 780
cctcctccta tgtccgtgga acacgcagac atctgggtca agagctacag cttgtactcc 840
agggagcggt acatttgtaa ctctggtttc aagcgtaaag ccggcacgtc cagcctgacg 900
gagtgcgtgt tgaacaaggc cacgaatgtc gcccactgga caacccccag tctcaaatgc 960
attagagagc cgaaatcttg tgacaaaact cacacatgcc caccgtgccc agcacctgaa 1020
ctcctggggg gaccgtcagt cttcctcttc cccccaaaac ccaaggacac cctcatgatc 1080
tcccggaccc ctgaggtcac atgcgtggtg gtggacgtga gccacgaaga ccctgaggtc 1140
aagttcaact ggtacgtgga cggcgtggag gtgcataatg ccaagacaaa gccgcgggag 1200
gagcagtaca acagcacgta ccgtgtggtc agcgtcctca ccgtcctgca ccaggactgg 1260
ctgaatggca aggagtacaa gtgcaaggtc tccaacaaag ccctcccagc ccccatcgag 1320
aaaaccatct ccaaagccaa agggcagccc cgagaaccac aggtgtacac cctgccccca 1380
tcccgggatg agctgaccaa gaaccaggtc agcctgacct gcctggtcaa aggcttctat 1440
cccagcgaca tcgccgtgga gtgggagagc aatgggcagc cggagaacaa ctacaagacc 1500
acgcctcccg tgctggactc cgacggctcc ttcttcctct acagcaagct caccgtggac 1560
aagagcaggt ggcagcaggg gaacgtcttc tcatgctccg tgatgcatga ggctctgcac 1620
aaccactaca cgcagaagag cctctccctg tctcctggta aataa 1665
<210> 48
<211> 1680
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 48
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccgtggtg 60
atgacccagt ccccttccac cctgtccgct tccgtgggcg acaccatcac catcacctgc 120
agggcctccc agtccatcga gacctggctg gcctggtacc agcagaagcc cggcaaggcc 180
cccaagctgc tgatctacaa ggcctccacc ctgaagaccg gcgtgccctc caggttttcc 240
ggatccggct ccggcaccga gttcaccctg accatcagcg gcctgcagtt cgacgacttc 300
gccacctacc actgccagca ctacgccggc tactccgcca cctttggaca gggcaccagg 360
gtggagatca agggaggtgg cggatccgga ggtggaggtt ctggtggagg tgggagtgag 420
gtgcagctgg tggaatccgg aggcggcctg gtgaaagctg gcggaagcct gatcctgagc 480
tgcggcgtgt ccaacttcag gatctccgcc cacaccatga actgggtgag gagggtgcct 540
ggaggaggac tggagtgggt ggccagcatc tccacctcct ccacctacag ggactacgcc 600
gacgccgtga agggcaggtt caccgtgagc agggacgacc tggaggactt cgtgtacctg 660
cagatgcaca agatgcgggt ggaggacacc gccatctact actgcgccag gaagggctcc 720
gacaggctgt ccgacaacga cccctttgac gcctggggcc ctggaaccgt ggtgacagtg 780
tcccccatca cgtgtcctcc tcctatgtcc gtggaacacg cagacatctg ggtcaagagc 840
tacagcttgt actccaggga gcggtacatt tgtaactctg gtttcaagcg taaagccggc 900
acgtccagcc tgacggagtg cgtgttgaac aaggccacga atgtcgccca ctggacaacc 960
cccagtctca aatgcattag agagccgaaa tcttgtgaca aaactcacac atgcccaccg 1020
tgcccagcac ctgaactcct ggggggaccg tcagtcttcc tcttcccccc aaaacccaag 1080
gacaccctca tgatctcccg gacccctgag gtcacatgcg tggtggtgga cgtgagccac 1140
gaagaccctg aggtcaagtt caactggtac gtggacggcg tggaggtgca taatgccaag 1200
acaaagccgc gggaggagca gtacaacagc acgtaccgtg tggtcagcgt cctcaccgtc 1260
ctgcaccagg actggctgaa tggcaaggag tacaagtgca aggtctccaa caaagccctc 1320
ccagccccca tcgagaaaac catctccaaa gccaaagggc agccccgaga accacaggtg 1380
tacaccctgc ccccatcccg ggatgagctg accaagaacc aggtcagcct gacctgcctg 1440
gtcaaaggct tctatcccag cgacatcgcc gtggagtggg agagcaatgg gcagccggag 1500
aacaactaca agaccacgcc tcccgtgctg gactccgacg gctccttctt cctctacagc 1560
aagctcaccg tggacaagag caggtggcag caggggaacg tcttctcatg ctccgtgatg 1620
catgaggctc tgcacaacca ctacacgcag aagagcctct ccctgtctcc tggtaaataa 1680
<210> 49
<211> 1674
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 49
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcctcctcc 60
ctgacccaga gccccggaac actctccctc tcccccggtg agaccgctat catctcttgt 120
aggaccagcc agtacggctc tttagcttgg tatcaacaga ggcccggcca agctcctagg 180
ctggtcattt acagcggcag cacaagggcc gccggcatcc ccgataggtt ctccggctcc 240
cggtggggcc ccgattacaa tttaacaatc tccaatttag agtccggaga cttcggcgtc 300
tactactgcc agcagtacga gttcttcggc caaggtacca aagtgcaagt tgatatcaag 360
ggcggcggag gctccggcgg cggcggatcc ggcggaggag gatcccaagt taggctgtcc 420
cagagcggag gccagatgaa gaagcccggt gactccatgc ggatcagctg tcgtgccagc 480
ggctacgagt tcatcaactg ccccatcaac tggattcgtc tggcccccgg taagcggccc 540
gaatggatgg gctggatgaa acctcgtcac ggcgctgtgt cctacgctcg tcagctgcaa 600
ggtcgtgtga ccatgactcg tgacatgtac agcgagaccg cctttttaga gctgaggtct 660
ttaacctccg acgacaccgc tgtgtacttc tgcacccggg gcaagtactg caccgctcgg 720
gactactaca actgggactt cgagcactgg ggccaaggta cacccgtgac agtgtcctcc 780
atcacgtgtc ctcctcctat gtccgtggaa cacgcagaca tctgggtcaa gagctacagc 840
ttgtactcca gggagcggta catttgtaac tctggtttca agcgtaaagc cggcacgtcc 900
agcctgacgg agtgcgtgtt gaacaaggcc acgaatgtcg cccactggac aacccccagt 960
ctcaaatgca ttagagagcc gaaatcttgt gacaaaactc acacatgccc accgtgccca 1020
gcacctgaac tcctgggggg accgtcagtc ttcctcttcc ccccaaaacc caaggacacc 1080
ctcatgatct cccggacccc tgaggtcaca tgcgtggtgg tggacgtgag ccacgaagac 1140
cctgaggtca agttcaactg gtacgtggac ggcgtggagg tgcataatgc caagacaaag 1200
ccgcgggagg agcagtacaa cagcacgtac cgtgtggtca gcgtcctcac cgtcctgcac 1260
caggactggc tgaatggcaa ggagtacaag tgcaaggtct ccaacaaagc cctcccagcc 1320
cccatcgaga aaaccatctc caaagccaaa gggcagcccc gagaaccaca ggtgtacacc 1380
ctgcccccat cccgggatga gctgaccaag aaccaggtca gcctgacctg cctggtcaaa 1440
ggcttctatc ccagcgacat cgccgtggag tgggagagca atgggcagcc ggagaacaac 1500
tacaagacca cgcctcccgt gctggactcc gacggctcct tcttcctcta cagcaagctc 1560
accgtggaca agagcaggtg gcagcagggg aacgtcttct catgctccgt gatgcatgag 1620
gctctgcaca accactacac gcagaagagc ctctccctgt ctcctggtaa ataa 1674
<210> 50
<211> 1716
<212> DNA
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polynucleotide
<400> 50
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcctccagc 60
tacgtgaggc ctctctccgt ggctctgggc gaaacagctc gtatcagctg cggtcgtcaa 120
gctctgggat ctcgtgctgt gcagtggtac cagcaccggc ccggtcaagc tcccatttta 180
ctgatctaca acaaccaaga tcggccctcc ggcatccccg aaaggtttag cggcaccccc 240
gatatcaact tcggcacaag ggccacttta accattagcg gagtggaggc cggcgacgag 300
gccgactact actgccacat gtgggactcc cggtccggct tttcttggag ctttggcggc 360
gctactcgtc tgacagtgct gggcggaggc ggctccggag gcggcggcag cggaggaggc 420
ggatcccaag ttcagctgca agaatccgga cccggtttag tgaagcccag cgagacttta 480
agcgtgactt gtagcgtgag cggcgacagc atgaacaact actactggac ttggattcgt 540
cagagccccg gtaagggttt agagtggatc ggctacatct ccgaccggga gtccgccacc 600
tacaacccct ctttaaactc ccgggtggtg atctctcgtg acacctccaa gaaccagctg 660
tctttaaagc tgaactccgt gacccccgct gacaccgccg tgtactactg cgctaccgct 720
aggcggggcc agaggatcta cggcgtggtg agcttcggcg agttcttcta ctactacagc 780
atggacgtgt ggggcaaagg caccaccgtg accgtgtcct ccatcacgtg tcctcctcct 840
atgtccgtgg aacacgcaga catctgggtc aagagctaca gcttgtactc cagggagcgg 900
tacatttgta actctggttt caagcgtaaa gccggcacgt ccagcctgac ggagtgcgtg 960
ttgaacaagg ccacgaatgt cgcccactgg acaaccccca gtctcaaatg cattagagag 1020
ccgaaatctt gtgacaaaac tcacacatgc ccaccgtgcc cagcacctga actcctgggg 1080
ggaccgtcag tcttcctctt ccccccaaaa cccaaggaca ccctcatgat ctcccggacc 1140
cctgaggtca catgcgtggt ggtggacgtg agccacgaag accctgaggt caagttcaac 1200
tggtacgtgg acggcgtgga ggtgcataat gccaagacaa agccgcggga ggagcagtac 1260
aacagcacgt accgtgtggt cagcgtcctc accgtcctgc accaggactg gctgaatggc 1320
aaggagtaca agtgcaaggt ctccaacaaa gccctcccag cccccatcga gaaaaccatc 1380
tccaaagcca aagggcagcc ccgagaacca caggtgtaca ccctgccccc atcccgggat 1440
gagctgacca agaaccaggt cagcctgacc tgcctggtca aaggcttcta tcccagcgac 1500
atcgccgtgg agtgggagag caatgggcag ccggagaaca actacaagac cacgcctccc 1560
gtgctggact ccgacggctc cttcttcctc tacagcaagc tcaccgtgga caagagcagg 1620
tggcagcagg ggaacgtctt ctcatgctcc gtgatgcatg aggctctgca caaccactac 1680
acgcagaaga gcctctccct gtctcctggt aaataa 1716
<210> 51
<211> 554
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 51
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Tyr Ile His Val Thr Gln Ser Pro Ser Ser Leu Ser Val Ser
20 25 30
Ile Gly Asp Arg Val Thr Ile Asn Cys Gln Thr Ser Gln Gly Val Gly
35 40 45
Ser Asp Leu His Trp Tyr Gln His Lys Pro Gly Arg Ala Pro Lys Leu
50 55 60
Leu Ile His His Thr Ser Ser Val Glu Asp Gly Val Pro Ser Arg Phe
65 70 75 80
Ser Gly Ser Gly Phe His Thr Ser Phe Asn Leu Thr Ile Ser Asp Leu
85 90 95
Gln Ala Asp Asp Ile Ala Thr Tyr Tyr Cys Gln Val Leu Gln Phe Phe
100 105 110
Gly Arg Gly Ser Arg Leu His Ile Lys Gly Gly Gly Gly Ser Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Gly Ser Arg Ala His Leu Val Gln Ser Gly
130 135 140
Thr Ala Met Lys Lys Pro Gly Ala Ser Val Arg Val Ser Cys Gln Thr
145 150 155 160
Ser Gly Tyr Thr Phe Thr Ala His Ile Leu Phe Trp Phe Arg Gln Ala
165 170 175
Pro Gly Arg Gly Leu Glu Trp Val Gly Trp Ile Lys Pro Gln Tyr Gly
180 185 190
Ala Val Asn Phe Gly Gly Gly Phe Arg Asp Arg Val Thr Leu Thr Arg
195 200 205
Asp Val Tyr Arg Glu Ile Ala Tyr Met Asp Ile Arg Gly Leu Lys Pro
210 215 220
Asp Asp Thr Ala Val Tyr Tyr Cys Ala Arg Asp Arg Ser Tyr Gly Asp
225 230 235 240
Ser Ser Trp Ala Leu Asp Ala Trp Gly Gln Gly Thr Thr Val Trp Ser
245 250 255
Ala Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp
260 265 270
Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser
275 280 285
Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu
290 295 300
Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys
305 310 315 320
Ile Arg Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
325 330 335
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
340 345 350
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
355 360 365
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
370 375 380
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
385 390 395 400
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
405 410 415
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
420 425 430
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
435 440 445
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
450 455 460
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
465 470 475 480
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
485 490 495
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
500 505 510
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
515 520 525
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
530 535 540
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
545 550
<210> 52
<211> 559
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 52
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Val Val Met Thr Gln Ser Pro Ser Thr Leu Ser Ala Ser Val
20 25 30
Gly Asp Thr Ile Thr Ile Thr Cys Arg Ala Ser Gln Ser Ile Glu Thr
35 40 45
Trp Leu Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu
50 55 60
Ile Tyr Lys Ala Ser Thr Leu Lys Thr Gly Val Pro Ser Arg Phe Ser
65 70 75 80
Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Gly Leu Gln
85 90 95
Phe Asp Asp Phe Ala Thr Tyr His Cys Gln His Tyr Ala Gly Tyr Ser
100 105 110
Ala Thr Phe Gly Gln Gly Thr Arg Val Glu Ile Lys Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val
130 135 140
Glu Ser Gly Gly Gly Leu Val Lys Ala Gly Gly Ser Leu Ile Leu Ser
145 150 155 160
Cys Gly Val Ser Asn Phe Arg Ile Ser Ala His Thr Met Asn Trp Val
165 170 175
Arg Arg Val Pro Gly Gly Gly Leu Glu Trp Val Ala Ser Ile Ser Thr
180 185 190
Ser Ser Thr Tyr Arg Asp Tyr Ala Asp Ala Val Lys Gly Arg Phe Thr
195 200 205
Val Ser Arg Asp Asp Leu Glu Asp Phe Val Tyr Leu Gln Met His Lys
210 215 220
Met Arg Val Glu Asp Thr Ala Ile Tyr Tyr Cys Ala Arg Lys Gly Ser
225 230 235 240
Asp Arg Leu Ser Asp Asn Asp Pro Phe Asp Ala Trp Gly Pro Gly Thr
245 250 255
Val Val Thr Val Ser Pro Ile Thr Cys Pro Pro Pro Met Ser Val Glu
260 265 270
His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg
275 280 285
Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu
290 295 300
Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr
305 310 315 320
Pro Ser Leu Lys Cys Ile Arg Glu Pro Lys Ser Cys Asp Lys Thr His
325 330 335
Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val
340 345 350
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
355 360 365
Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu
370 375 380
Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
385 390 395 400
Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser
405 410 415
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
420 425 430
Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile
435 440 445
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
450 455 460
Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
465 470 475 480
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
485 490 495
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
500 505 510
Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg
515 520 525
Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
530 535 540
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
545 550 555
<210> 53
<211> 557
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 53
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ser Ser Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro
20 25 30
Gly Glu Thr Ala Ile Ile Ser Cys Arg Thr Ser Gln Tyr Gly Ser Leu
35 40 45
Ala Trp Tyr Gln Gln Arg Pro Gly Gln Ala Pro Arg Leu Val Ile Tyr
50 55 60
Ser Gly Ser Thr Arg Ala Ala Gly Ile Pro Asp Arg Phe Ser Gly Ser
65 70 75 80
Arg Trp Gly Pro Asp Tyr Asn Leu Thr Ile Ser Asn Leu Glu Ser Gly
85 90 95
Asp Phe Gly Val Tyr Tyr Cys Gln Gln Tyr Glu Phe Phe Gly Gln Gly
100 105 110
Thr Lys Val Gln Val Asp Ile Lys Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gln Val Arg Leu Ser Gln Ser Gly Gly
130 135 140
Gln Met Lys Lys Pro Gly Asp Ser Met Arg Ile Ser Cys Arg Ala Ser
145 150 155 160
Gly Tyr Glu Phe Ile Asn Cys Pro Ile Asn Trp Ile Arg Leu Ala Pro
165 170 175
Gly Lys Arg Pro Glu Trp Met Gly Trp Met Lys Pro Arg His Gly Ala
180 185 190
Val Ser Tyr Ala Arg Gln Leu Gln Gly Arg Val Thr Met Thr Arg Asp
195 200 205
Met Tyr Ser Glu Thr Ala Phe Leu Glu Leu Arg Ser Leu Thr Ser Asp
210 215 220
Asp Thr Ala Val Tyr Phe Cys Thr Arg Gly Lys Tyr Cys Thr Ala Arg
225 230 235 240
Asp Tyr Tyr Asn Trp Asp Phe Glu His Trp Gly Gln Gly Thr Pro Val
245 250 255
Thr Val Ser Ser Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala
260 265 270
Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile
275 280 285
Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu
290 295 300
Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser
305 310 315 320
Leu Lys Cys Ile Arg Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys
325 330 335
Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu
340 345 350
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
355 360 365
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys
370 375 380
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
385 390 395 400
Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu
405 410 415
Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
420 425 430
Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
435 440 445
Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
450 455 460
Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
465 470 475 480
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
485 490 495
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly
500 505 510
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
515 520 525
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
530 535 540
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
545 550 555
<210> 54
<211> 571
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
polypeptide
<400> 54
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ser Ser Tyr Val Arg Pro Leu Ser Val Ala Leu Gly Glu Thr
20 25 30
Ala Arg Ile Ser Cys Gly Arg Gln Ala Leu Gly Ser Arg Ala Val Gln
35 40 45
Trp Tyr Gln His Arg Pro Gly Gln Ala Pro Ile Leu Leu Ile Tyr Asn
50 55 60
Asn Gln Asp Arg Pro Ser Gly Ile Pro Glu Arg Phe Ser Gly Thr Pro
65 70 75 80
Asp Ile Asn Phe Gly Thr Arg Ala Thr Leu Thr Ile Ser Gly Val Glu
85 90 95
Ala Gly Asp Glu Ala Asp Tyr Tyr Cys His Met Trp Asp Ser Arg Ser
100 105 110
Gly Phe Ser Trp Ser Phe Gly Gly Ala Thr Arg Leu Thr Val Leu Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Val
130 135 140
Gln Leu Gln Glu Ser Gly Pro Gly Leu Val Lys Pro Ser Glu Thr Leu
145 150 155 160
Ser Val Thr Cys Ser Val Ser Gly Asp Ser Met Asn Asn Tyr Tyr Trp
165 170 175
Thr Trp Ile Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Ile Gly Tyr
180 185 190
Ile Ser Asp Arg Glu Ser Ala Thr Tyr Asn Pro Ser Leu Asn Ser Arg
195 200 205
Val Val Ile Ser Arg Asp Thr Ser Lys Asn Gln Leu Ser Leu Lys Leu
210 215 220
Asn Ser Val Thr Pro Ala Asp Thr Ala Val Tyr Tyr Cys Ala Thr Ala
225 230 235 240
Arg Arg Gly Gln Arg Ile Tyr Gly Val Val Ser Phe Gly Glu Phe Phe
245 250 255
Tyr Tyr Tyr Ser Met Asp Val Trp Gly Lys Gly Thr Thr Val Thr Val
260 265 270
Ser Ser Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile
275 280 285
Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn
290 295 300
Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val
305 310 315 320
Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys
325 330 335
Cys Ile Arg Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro
340 345 350
Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro
355 360 365
Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr
370 375 380
Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn
385 390 395 400
Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg
405 410 415
Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val
420 425 430
Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser
435 440 445
Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys
450 455 460
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
465 470 475 480
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
485 490 495
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
500 505 510
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
515 520 525
Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
530 535 540
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
545 550 555 560
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
565 570
<210> 55
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 55
Pro Glu Leu Leu Gly Gly
1 5
<210> 56
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 56
Pro Glu Ala Ala Gly Gly
1 5
<210> 57
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 57
Lys Cys Lys Ser Leu
1 5
<210> 58
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Description of Artificial Sequence: Synthetic
peptide
<400> 58
Lys Cys Ala Ser Leu
1 5
Claims (32)
- 적어도 2개의 가용성 단백질을 포함하는 단리된 가용성 융합 단백질 복합체로서,
제1 가용성 단백질은 인터루킨-15(IL-15) 폴리펩티드 도메인을 포함하고, 제2 가용성 단백질은 면역글로불린 Fc 도메인에 융합된 가용성 IL-15 수용체 알파 스시-결합 도메인(IL-15RαSu)을 포함하고,
제1 가용성 단백질 또는 제2 가용성 단백질 중 하나는 질환 항원, 면역 관문 분자 또는 면역 신호전달 분자에 특이적으로 결합하는 결합 도메인을 추가로 포함하며,
제1 가용성 단백질의 IL-15 도메인은 제2 가용성 단백질의 IL-15RαSu 도메인에 결합하여, 가용성 융합 단백질 복합체를 형성하는, 단리된 가용성 융합 단백질 복합체. - 제1항에 있어서, 상기 제1 가용성 단백질 또는 제2 가용성 단백질 중 하나는 질환 항원, 면역 관문 분자 또는 면역 신호전달 분자에 특이적으로 결합하는 제2 결합 도메인을 추가로 포함하는, 가용성 융합 단백질 복합체.
- 제1항 또는 제2항에 있어서, 상기 IL-15 폴리펩티드는 N72D 돌연변이를 포함하는 IL-15 변이체(IL-15N72D)인 가용성 융합 단백질 복합체.
- 제1항 내지 제3항 중 어느 한 항에 있어서, 상기 결합 도메인은 폴리펩티드 링커 서열에 의해 면역글로불린 중쇄 가변 도메인에 공유 결합된 면역글로불린 경쇄 가변 도메인을 포함하는 가용성 융합 단백질 복합체.
- 제1항 내지 제4항 중 어느 한 항에 있어서, 상기 결합 도메인은 프로그래밍된 사멸 리간드 1(PD-L1), 프로그래밍된 사멸 1(PD-1), 세포독성 T 림프구 연관 단백질 4(CTLA-4), 분화 클러스터 33(CD33), 분화 클러스터 47(CD47), 글루코코르티코이드 유도성 종양 괴사 인자 수용체(TNFR) 과 관련 유전자(GITR), 림프구 기능 연관 항원 1(LFA-1), 조직 인자(TF), 델타 유사 단백질 4(DLL4), 단일 가닥 DNA 또는 TIM-3(T-cell immunoglobulin and mucin-domain containing-3)를 포함하는 분자 하나 이상과 특이적으로 결합하는 가용성 융합 단백질 복합체.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 제1 가용성 단백질은 서열 번호 2, 6, 10, 18, 20, 24, 28, 32 또는 38 중 하나에 제시된 아미노산 서열을 포함하는 가용성 융합 단백질 복합체.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 제2 가용성 단백질은 서열 번호 4, 8, 12, 14, 16, 22, 26, 30, 34, 36, 40, 42, 44, 46, 51, 52, 53 또는 54 중 하나에 제시된 아미노산 서열을 포함하는 가용성 융합 단백질 복합체.
- 제1항 내지 제7항 중 어느 한 항에 의한 제2 가용성 융합 단백질 복합체에 공유 결합된, 제1항 내지 제7항 중 어느 한 항에 의한 제1 가용성 융합 단백질 복합체를 포함하는 가용성 융합 단백질 복합체.
- 제8항에 있어서, 상기 제1 가용성 융합 단백질 복합체는 이황화 결합에 의해 제2 가용성 융합 단백질 복합체와 공유 결합하고, 그 결과 제1 가용성 융합 단백질 복합체의 Fc 도메인과 제2 가용성 융합 단백질 복합체의 Fc 도메인이 연결되는 가용성 융합 단백질 복합체.
- 제6항에 의한 제1 가용성 단백질을 암호화하는 핵산 서열로서, 상기 핵산 서열은 서열 번호 1, 5, 9, 17, 19, 23, 27, 31 또는 37 중 하나에 제시된 서열을 포함하는 핵산 서열.
- 제10항에 있어서, 상기 핵산 서열은 가용성 단백질을 암호화하는 서열에 작동가능하도록 결합된 리더 서열, 번역 개시 신호 및 촉진인자를 추가로 포함하는 핵산 서열.
- 제7항에 의한 제2 가용성 단백질을 암호화하는 핵산 서열로서, 상기 핵산 서열은 서열 번호 3, 7, 11, 13, 15, 21, 25, 29, 33, 35, 39, 41, 43, 45, 47, 48, 49 또는 50 중 하나에 제시된 서열을 포함하는 핵산 서열.
- 제12항에 있어서, 상기 핵산 서열은 가용성 단백질을 암호화하는 서열에 작동가능하도록 결합된 리더 서열, 번역 개시 신호 및 촉진인자를 추가로 포함하는 핵산 서열.
- 제11항에 의한 핵산 서열 및/또는 제13항에 의한 핵산 서열을 포함하는 DNA 벡터.
- 제1항 내지 제9항 중 어느 한 항에 있어서, 상기 질환 항원은 신생물형성, 감염성 질환 또는 자가면역성 질환과 연관된 가용성 융합 단백질 복합체.
- a) 제1항에 의한 가용성 융합 단백질 복합체를 다수의 세포와 접촉시키는 단계[다만 이 다수의 세포는 제1항 또는 제2항에 의한 IL-15 도메인에 의해 인지되는 IL-15 수용체(IL-15R) 사슬을 보유하는 면역 세포, 또는 제1항 또는 재2항에 의한 결합 도메인에 의해 인지되는 질환 항원, 관문 분자 또는 신호전달 분자를 보유하는 면역 세포, 그리고 표적 세포를 추가로 포함함];
b) IL-15R 또는 신호전달 분자나, 관문 분자의 봉쇄를 통하여 면역 세포를 활성화하는 단계; 그리고
c) 활성화된 면역 세포에 의해 표적 세포를 사멸하는 단계
를 포함하는, 표적 세포를 사멸하기 위한 방법. - a) 제2항에 의한 가용성 융합 단백질 복합체와 다수의 세포를 접촉시키는 단계[다만 이 다수의 세포는 제1항 또는 제2항에 의한 Fc 도메인에 의해 인지되는 Fc 수용체 사슬을 보유하는 면역 세포와, 제1항 또는 제2항에 의한 항원 특이적 결합 도메인에 의해 인지되는 항원을 보유하는 표적 세포를 추가로 포함함];
b) 면역 세포에 결합하여 이를 활성화하기에 충분한, 표적 세포상 항원 및 면역 세포상 Fc 수용체 사슬 간의 특이적 결합 복합체(가교)를 형성하는 단계; 그리고
c) 결합되어 활성화된 면역 세포에 의해 표적 세포를 사멸하는 단계
를 포함하는, 표적 세포를 사멸하기 위한 방법. - 제16항 또는 제17항에 있어서, 상기 표적 세포는 종양 세포, 감염된 세포 또는 자가면역성 질환 연관 세포인 방법.
- 제16항 또는 제17항에 있어서, 상기 결합 도메인은 항 PD-L1 항체를 포함하는 방법.
- 제1항 내지 제9항 및 제15항 중 어느 한 항에 의한 가용성 융합 단백질 복합체 유효량을 대상체에 투여하는 단계를 포함하는, 대상체에 있어서 면역 반응을 자극하는 방법.
- 신생물형성, 감염성 질환 또는 자가면역성 질환을, 이 질환들의 치료를 필요로 하는 대상체에서 치료하기 위한 방법으로서, 제1항 내지 제15항 및 제17항 중 어느 한 항에 의한 가용성 융합 단백질 복합체를 포함하는 약학 조성물 유효량을 상기 대상체에 투여하여, 상기 신생물형성, 감염성 질환 또는 자가면역성 질환을 치료하는 단계를 포함하는 방법.
- 제21항에 있어서, 상기 신생물형성은 교모세포종, 전립선암, 혈액학적 암, B 세포 신생물형성, 다발성 골수종, B 세포 림프종, B 세포 비호지킨 림프종, 호지킨 림프종, 만성 림프구성 백혈병, 급성 골수성 백혈병, 피부 T 세포 림프종, T 세포 림프종, 고형 종양, 요로상피/방광 암종, 흑색종, 폐암, 신세포 암종, 유방암, 위 및 식도 암, 전립선암, 췌장암, 결장직장암, 난소암, 비 소세포 폐 암종 및 편평 세포 두경부 암종으로 이루어진 군으로부터 선택되는 방법.
- 제21항 또는 제22항에 있어서, 상기 유효량은 상기 융합 단백질 복합체 1 kg당 약 1 μg 내지 약 100 μg인 방법.
- 제21항 또는 제22항에 있어서, 상기 융합 단백질 복합체는 1주일에 적어도 1회 투여되는 방법.
- 제21항 내지 제24항 중 어느 한 항에 있어서, 상기 약학 조성물은 전신, 국소, 정맥내, 피하 또는 종양내 투여되는 방법.
- 제21항 내지 제25항 중 어느 한 항에 있어서, 상기 융합 단백질 복합체는 대상체에서 면역 반응을 유도하는 방법.
- 제21항 내지 제26항 중 어느 한 항에 있어서, 상기 융합 단백질 복합체는 면역 세포 증식을 증가시키는 방법.
- 제21항 내지 제27항 중 어느 한 항에 있어서, 상기 융합 단백질 복합체는 상기 신생물형성, 감염성 질환 또는 자가면역성 질환과 연관된 세포에 대한 면역 세포 반응을 자극하는 방법.
- 서열 번호 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 35, 39, 41, 43,45, 47, 48, 49 또는 50을 포함하는 핵산 서열.
- 서열 번호 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 51, 52, 53 또는 54를 포함하는 펩티드.
- 서열 번호 51, 52, 53 또는 54를 포함하는 가용성 융합 단백질 복합체 치료적 유효량을 포함하는 조성물을 대상체에 투여하는 단계를 포함하는, 인간 면역결핍증 바이러스(HIV) 감염을 예방 또는 치료하는 방법.
- 제1항 내지 제9항 및 제15항 중 어느 한 항에 의한 단리된 가용성 융합 단백질 복합체, 제10항, 제12항 및 제29항 중 어느 한 항에 의한 핵산 서열, 제14항에 의한 DNA 벡터 또는 제30항에 의한 펩티드 서열을 포함하는 약학 조성물.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020217015704A KR102392142B1 (ko) | 2016-10-21 | 2017-10-21 | 다량체 il-15 기반 분자 |
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201662411216P | 2016-10-21 | 2016-10-21 | |
| US62/411,216 | 2016-10-21 | ||
| US201762513964P | 2017-06-01 | 2017-06-01 | |
| US62/513,964 | 2017-06-01 | ||
| PCT/US2017/057757 WO2018075989A1 (en) | 2016-10-21 | 2017-10-21 | Multimeric il-15-based molecules |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020217015704A Division KR102392142B1 (ko) | 2016-10-21 | 2017-10-21 | 다량체 il-15 기반 분자 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20190091264A true KR20190091264A (ko) | 2019-08-05 |
Family
ID=62019612
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020217015704A KR102392142B1 (ko) | 2016-10-21 | 2017-10-21 | 다량체 il-15 기반 분자 |
| KR1020197014404A KR20190091264A (ko) | 2016-10-21 | 2017-10-21 | 다량체 il-15 기반 분자 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020217015704A KR102392142B1 (ko) | 2016-10-21 | 2017-10-21 | 다량체 il-15 기반 분자 |
Country Status (11)
| Country | Link |
|---|---|
| US (3) | US20180200366A1 (ko) |
| EP (1) | EP3529263A4 (ko) |
| KR (2) | KR102392142B1 (ko) |
| CN (1) | CN110799528A (ko) |
| AU (1) | AU2017345791B2 (ko) |
| BR (1) | BR112019007920A2 (ko) |
| CA (2) | CA3200275A1 (ko) |
| IL (1) | IL266100B2 (ko) |
| MX (1) | MX2019004681A (ko) |
| SG (1) | SG11201903306SA (ko) |
| WO (1) | WO2018075989A1 (ko) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11173191B2 (en) | 2014-06-30 | 2021-11-16 | Altor BioScience, LLC. | IL-15-based molecules and methods of use thereof |
| US11318201B2 (en) | 2016-10-21 | 2022-05-03 | Altor BioScience, LLC. | Multimeric IL-15-based molecules |
| US11498950B1 (en) | 2007-05-11 | 2022-11-15 | Altor Bioscience, Llc | Fusion molecules and IL-15 variants |
| US11992516B2 (en) | 2022-10-11 | 2024-05-28 | Altor BioScience, LLC. | Compositions comprising IL-15-based molecules and immune checkpoint inhibitor antibodies |
Families Citing this family (43)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA3024509A1 (en) | 2016-05-18 | 2017-11-23 | Modernatx, Inc. | Mrna combination therapy for the treatment of cancer |
| AU2017283480A1 (en) | 2016-06-13 | 2019-01-24 | Torque Therapeutics, Inc. | Methods and compositions for promoting immune cell function |
| KR102562519B1 (ko) | 2016-10-14 | 2023-08-02 | 젠코어 인코포레이티드 | IL-15/IL-15Rα FC-융합 단백질 및 PD-1 항체 단편을 포함하는 이중특이성 이종이량체 융합 단백질 |
| AU2018237046A1 (en) * | 2017-03-20 | 2019-09-26 | Cancer Therapeutics Laboratories, Inc. | Humanized anti-nuclear antibodies for targeting necrosis in cancer therapy |
| MA49517A (fr) | 2017-06-30 | 2020-05-06 | Xencor Inc | Protéines de fusion fc hétérodimères ciblées contenant il-15/il-15ra et domaines de liaison à l'antigène |
| CN111655716B (zh) | 2017-08-28 | 2024-03-08 | 艾尔特生物科技公司 | 基于il-15的与il-7和il-21的融合体 |
| EP3678701A4 (en) | 2017-09-05 | 2021-12-01 | Torque Therapeutics, Inc. | THERAPEUTIC PROTEIN COMPOSITIONS AND METHOD FOR MANUFACTURING AND USING THEREOF |
| WO2019204665A1 (en) | 2018-04-18 | 2019-10-24 | Xencor, Inc. | Pd-1 targeted heterodimeric fusion proteins containing il-15/il-15ra fc-fusion proteins and pd-1 antigen binding domains and uses thereof |
| CN112437777A (zh) | 2018-04-18 | 2021-03-02 | Xencor股份有限公司 | 包含IL-15/IL-15RA Fc融合蛋白和TIM-3抗原结合结构域的靶向TIM-3的异源二聚体融合蛋白 |
| MX2020013621A (es) | 2018-06-19 | 2021-03-25 | Nantcell Inc | Composiciones y metodos de tratamiento de vih. |
| WO2020023713A1 (en) * | 2018-07-26 | 2020-01-30 | Nantbio, Inc. | Tri-cytokine txm compositions and methods |
| WO2020047299A1 (en) | 2018-08-30 | 2020-03-05 | HCW Biologics, Inc. | Multi-chain chimeric polypeptides and uses thereof |
| US11401324B2 (en) | 2018-08-30 | 2022-08-02 | HCW Biologics, Inc. | Single-chain chimeric polypeptides and uses thereof |
| JP7449292B2 (ja) | 2018-08-30 | 2024-03-13 | エイチシーダブリュー バイオロジックス インコーポレイテッド | 加齢関連障害の治療法 |
| CN112996904A (zh) * | 2018-09-07 | 2021-06-18 | 南特生物公司 | 刺激hank和nk92mi细胞的靶向il-12治疗和方法 |
| BR112021006783A2 (pt) | 2018-10-12 | 2021-07-13 | Xencor, Inc. | proteína de fusão fc heterodimérica de il-15/r¿ direcionada, composição de ácido nucleico, composição de vetor de expressão, célula hospedeira, e, métodos de produção da proteína de fusão fc heterodimérica de il-15/r¿ direcionada e de tratamento de um câncer. |
| JP7092404B2 (ja) * | 2018-10-31 | 2022-06-28 | イミュニティーバイオ、インコーポレイテッド | Pd-l1キメラ抗原受容体を発現するnk細胞によるpd-l1陽性悪性腫瘍の排除 |
| CN113438961A (zh) | 2018-12-20 | 2021-09-24 | Xencor股份有限公司 | 含有IL-15/IL-15Rα和NKG2D抗原结合结构域的靶向异二聚体Fc融合蛋白 |
| CA3142159A1 (en) * | 2019-05-31 | 2020-12-03 | City Of Hope | Cd33 targeted chimeric antigen receptor modified t cells for treatment of cd33 positive malignancies |
| EP3987010A1 (en) | 2019-06-21 | 2022-04-27 | HCW Biologics, Inc. | Multi-chain chimeric polypeptides and uses thereof |
| EP4019536A4 (en) * | 2019-08-19 | 2023-09-06 | Nantong Yichen Biopharma. Co. Ltd. | IMMUNOCYTOTIN, ITS PRODUCTION AND ITS USE |
| CN114787196A (zh) * | 2019-08-29 | 2022-07-22 | 南特生物科学公司 | 修饰的n-810及其方法 |
| RU2753282C2 (ru) * | 2019-09-19 | 2021-08-12 | Закрытое Акционерное Общество "Биокад" | ИММУНОЦИТОКИН, ВКЛЮЧАЮЩИЙ ГЕТЕРОДИМЕРНЫЙ БЕЛКОВЫЙ КОМПЛЕКС НА ОСНОВЕ IL-15/IL-15Rα, И ЕГО ПРИМЕНЕНИЕ |
| CA3151281A1 (en) * | 2019-09-26 | 2021-04-01 | Jeffrey S. Miller | Nk engager compounds that bind viral antigens and methods of use |
| TW202128757A (zh) | 2019-10-11 | 2021-08-01 | 美商建南德克公司 | 具有改善之特性的 PD-1 標靶 IL-15/IL-15Rα FC 融合蛋白 |
| CN114787181A (zh) * | 2019-11-21 | 2022-07-22 | Inserm(法国国家健康医学研究院) | 用抗pd-1/il-15免疫细胞因子靶向pd-1的新型免疫疗法 |
| US20210188933A1 (en) * | 2019-12-18 | 2021-06-24 | Nantcell, Inc | Methods of treating pancytopenia |
| US20220025402A1 (en) | 2020-07-22 | 2022-01-27 | Nantcell, Inc. | Electroporation With Active Compensation |
| WO2022042576A1 (zh) * | 2020-08-27 | 2022-03-03 | 盛禾(中国)生物制药有限公司 | 一种多功能融合蛋白及其用途 |
| WO2022090202A1 (en) * | 2020-10-26 | 2022-05-05 | Cytune Pharma | IL-2/IL-15RBβү AGONIST FOR TREATING NON-MELANOMA SKIN CANCER |
| US20230390361A1 (en) * | 2020-10-26 | 2023-12-07 | Cytune Pharma | Il-2/il-15r-beta-gamma agonist for treating squamous cell carcinoma |
| US20220227867A1 (en) * | 2020-12-24 | 2022-07-21 | Xencor, Inc. | ICOS TARGETED HETERODIMERIC FUSION PROTEINS CONTAINING IL-15/IL-15RA Fc-FUSION PROTEINS AND ICOS ANTIGEN BINDING DOMAINS |
| CN112795543B (zh) * | 2021-02-04 | 2022-09-27 | 华中农业大学 | 杂交瘤细胞株及其分泌的抗草鱼IL-15Rα单克隆抗体和应用 |
| JP2024506292A (ja) * | 2021-02-05 | 2024-02-13 | サルブリス バイオセラピューティクス,インコーポレイティド | Il-15融合タンパク質と、その製造法ならびに利用法 |
| WO2022171196A1 (zh) * | 2021-02-11 | 2022-08-18 | 兰州大学第二医院 | 抗cd87抗体及其特异性嵌合抗原受体 |
| CN113106068A (zh) * | 2021-03-26 | 2021-07-13 | 深圳市先康达生命科学有限公司 | 一种自分泌IL-15与anti-PD1融合蛋白的免疫细胞 |
| EP4351320A1 (en) | 2021-06-09 | 2024-04-17 | ImmunityBio, Inc. | Methods and systems for producing a protein of interest in a plant |
| WO2023049832A1 (en) * | 2021-09-23 | 2023-03-30 | Sagittarius Bio, Inc. | Il-12 and il-15 polypeptides |
| US20230151095A1 (en) | 2021-11-12 | 2023-05-18 | Xencor, Inc. | Bispecific antibodies that bind to b7h3 and nkg2d |
| CN115806629A (zh) * | 2022-08-03 | 2023-03-17 | 深圳市先康达生命科学有限公司 | 一种自分泌IL-15与anti-CTLA4结合的融合蛋白及其应用 |
| CN115806628A (zh) * | 2022-08-03 | 2023-03-17 | 深圳市先康达生命科学有限公司 | 一种自分泌IL-15与anti-TIGIT结合的融合蛋白及其应用 |
| WO2024102636A1 (en) | 2022-11-07 | 2024-05-16 | Xencor, Inc. | Bispecific antibodies that bind to b7h3 and mica/b |
| CN116789837B (zh) * | 2023-03-24 | 2024-02-23 | 山西纳安生物科技股份有限公司 | 一种抗组织因子人源化抗体及制备的抗体偶联药物和应用 |
Family Cites Families (63)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS5291285A (en) | 1976-01-23 | 1977-08-01 | Hitachi Ltd | Escalator |
| JPS5841623B2 (ja) | 1978-12-25 | 1983-09-13 | 株式会社東芝 | 質量分析装置のイオン検出器 |
| JPS5718916A (en) | 1980-07-11 | 1982-01-30 | Iseki Agricult Mach | Shaking table sorter of automatic feeding type thresher |
| JPS5770185A (en) | 1980-10-21 | 1982-04-30 | Kazuo Makino | Preparation of blended oil for coal liquefaction |
| JPS57144287A (en) | 1981-03-02 | 1982-09-06 | Toray Ind Inc | Cyclopentabenzofuran derivative |
| US5116964A (en) | 1989-02-23 | 1992-05-26 | Genentech, Inc. | Hybrid immunoglobulins |
| US5314995A (en) | 1990-01-22 | 1994-05-24 | Oncogen | Therapeutic interleukin-2-antibody based fusion proteins |
| WO1994004689A1 (en) | 1992-08-14 | 1994-03-03 | The Government Of The United States Of America, As Represented By The Secretary Of The Department Of Health And Human Services | Recombinant toxin with increased half-life |
| US5747654A (en) | 1993-06-14 | 1998-05-05 | The United States Of America As Represented By The Department Of Health And Human Services | Recombinant disulfide-stabilized polypeptide fragments having binding specificity |
| JPH09512165A (ja) | 1994-04-06 | 1997-12-09 | イミュネックス・コーポレーション | インターロイキン15 |
| DK0772624T3 (da) | 1994-04-06 | 2000-11-13 | Immunex Corp | Interleukin-15 |
| US5541087A (en) | 1994-09-14 | 1996-07-30 | Fuji Immunopharmaceuticals Corporation | Expression and export technology of proteins as immunofusins |
| US5795966A (en) | 1995-02-22 | 1998-08-18 | Immunex Corp | Antagonists of interleukin-15 |
| US7008624B1 (en) | 1995-02-22 | 2006-03-07 | Immunex Corporation | Antagonists of interleukin-15 |
| US6096871A (en) | 1995-04-14 | 2000-08-01 | Genentech, Inc. | Polypeptides altered to contain an epitope from the Fc region of an IgG molecule for increased half-life |
| US5534592A (en) | 1995-09-22 | 1996-07-09 | The Goodyear Tire & Rubber Company | High performance blend for tire treads |
| DE69731289D1 (de) | 1996-03-18 | 2004-11-25 | Univ Texas | Immunglobulinähnliche domäne mit erhöhten halbwertszeiten |
| EP0927254B1 (en) | 1996-04-26 | 2005-06-22 | Beth Israel Deaconess Medical Center, Inc. | Antagonists of interleukin-15 |
| EP1273304B2 (en) | 1997-02-21 | 2009-07-15 | Amgen Inc. | Use of interleukin-15 |
| RU2270691C2 (ru) | 2000-05-12 | 2006-02-27 | Бет Израел Диконесс Медикал Сентер, Инк. | Композиции и способы достижения иммунной супрессии |
| CN101712721A (zh) | 2000-06-05 | 2010-05-26 | 阿尔托生物科学有限公司 | T细胞受体融合物及共轭物以及其使用方法 |
| DE60138222D1 (de) | 2000-09-14 | 2009-05-14 | Beth Israel Hospital | Modulierung von il-2 und il-15 vermittelten t zellantworten |
| US20030180888A1 (en) | 2000-11-03 | 2003-09-25 | Millennium Pharmaceuticals, Inc. | CD2000 and CD2001 molecules, and uses thereof |
| CA2492671C (en) | 2002-03-22 | 2012-04-17 | Aprogen, Inc. | Humanized antibody and process for preparing same |
| WO2004028339A2 (en) | 2002-09-27 | 2004-04-08 | Brigham And Women's Hospital, Inc. | Treatment of patients with multiple sclerosis based on gene expression changes in central nervous system tissues |
| RS20050724A (en) | 2003-02-26 | 2007-11-15 | Genmab A/S., | Human antibodies specific for interleukin 15(il-15) |
| DE10324708A1 (de) | 2003-05-30 | 2004-12-16 | Ltn Servotechnik Gmbh | Schleifringelement und Verfahren zu dessen Herstellung |
| CN1233822C (zh) | 2003-09-05 | 2005-12-28 | 中国科学技术大学 | 白细胞介素-15基因修饰的自然杀伤细胞株及其制备方法 |
| AU2004289316B2 (en) | 2003-11-10 | 2011-03-31 | Altor Bioscience Corporation | Soluble TCR molecules and methods of use |
| ES2367027T3 (es) | 2004-02-27 | 2011-10-27 | Inserm (Institut National De La Santé Et De La Recherche Medicale) | Sitio de unión de la il-15 para il-15ralfa y mutantes específicos de il-15 que tienen actividad agonista/antagonista. |
| EP1586585A1 (de) | 2004-04-14 | 2005-10-19 | F. Hoffmann-La Roche Ag | Expressionssystem zur Herstellung von IL-15/Fc-Fusionsproteinen und ihre Verwendung |
| CN100334112C (zh) | 2004-10-15 | 2007-08-29 | 上海海欣生物技术有限公司 | 人白细胞介素15与Fc融合蛋白 |
| EP1814580B1 (en) | 2004-11-24 | 2016-08-10 | Fred Hutchinson Cancer Research Center | Methods of using il-21 for adoptive immunotherapy and identification of tumor antigens |
| JP2008523132A (ja) | 2004-12-13 | 2008-07-03 | サイトス バイオテクノロジー アーゲー | Il−15抗原アレイとその使用法 |
| CA2608474C (en) | 2005-05-17 | 2019-11-12 | University Of Connecticut | Compositions and methods for immunomodulation in an organism |
| EP1777294A1 (en) | 2005-10-20 | 2007-04-25 | Institut National De La Sante Et De La Recherche Medicale (Inserm) | IL-15Ralpha sushi domain as a selective and potent enhancer of IL-15 action through IL-15Rbeta/gamma, and hyperagonist (IL15Ralpha sushi -IL15) fusion proteins |
| EP1873166B1 (en) | 2006-06-30 | 2010-09-08 | CONARIS research institute AG | Improved sgp 130Fc dimers |
| US7965180B2 (en) | 2006-09-28 | 2011-06-21 | Semiconductor Energy Laboratory Co., Ltd. | Wireless sensor device |
| NO2856876T3 (ko) | 2007-03-30 | 2018-06-30 | ||
| ES2470772T3 (es) | 2007-05-11 | 2014-06-24 | Altor Bioscience Corporation | Moléculas de fusión y variantes de IL-15 |
| AU2013273643C1 (en) | 2007-05-11 | 2016-08-11 | Altor Bioscience Corporation | Fusion molecules and il-15 variants |
| WO2008157776A2 (en) | 2007-06-21 | 2008-12-24 | Angelica Therapeutics, Inc. | Modified diphtheria toxins |
| JP2010531878A (ja) | 2007-06-27 | 2010-09-30 | マリン ポリマー テクノロジーズ,インコーポレーテッド | IL‐15とIL‐15Rαとの複合体及びその使用 |
| US7837588B2 (en) | 2007-07-20 | 2010-11-23 | American Axle & Manufacturing, Inc. | Pre-load mechanism for helical gear differential |
| US20110070191A1 (en) | 2008-03-19 | 2011-03-24 | Wong Hing C | T cell receptor fusions and conjugates and methods of use there of |
| EP2918607B1 (en) | 2010-09-21 | 2017-11-08 | Altor BioScience Corporation | Multimeric il-15 soluble fusion molecules and methods of making and using same |
| US11053299B2 (en) | 2010-09-21 | 2021-07-06 | Immunity Bio, Inc. | Superkine |
| EP2537933A1 (en) | 2011-06-24 | 2012-12-26 | Institut National de la Santé et de la Recherche Médicale (INSERM) | An IL-15 and IL-15Ralpha sushi domain based immunocytokines |
| US20130302274A1 (en) | 2011-11-25 | 2013-11-14 | Roche Glycart Ag | Combination therapy |
| WO2013163427A1 (en) | 2012-04-25 | 2013-10-31 | The United States Of America, As Represented By The Secretary, Department Of Health & Human Services | Antibodies to treat hiv-1 infection |
| IN2014KN02740A (ko) | 2012-06-18 | 2015-05-08 | Novartis Ag | |
| US9682143B2 (en) | 2012-08-14 | 2017-06-20 | Ibc Pharmaceuticals, Inc. | Combination therapy for inducing immune response to disease |
| WO2014028776A1 (en) | 2012-08-15 | 2014-02-20 | Zyngenia, Inc. | Monovalent and multivalent multispecific complexes and uses thereof |
| IL285049B (en) | 2012-10-18 | 2022-07-01 | California Inst Of Techn | Broad-spectrum neutralizing antibodies against the AIDS virus |
| WO2014066527A2 (en) | 2012-10-24 | 2014-05-01 | Admune Therapeutics Llc | Il-15r alpha forms, cells expressing il-15r alpha forms, and therapeutic uses of il-15r alpha and il-15/il-15r alpha complexes |
| HUE057917T2 (hu) * | 2014-01-15 | 2022-06-28 | Kadmon Corp Llc | Immunmodulátor szerek |
| CN112494646A (zh) | 2014-06-30 | 2021-03-16 | 阿尔托生物科学有限公司 | 基于il-15的分子及其方法和用途 |
| CN104672325A (zh) | 2015-03-11 | 2015-06-03 | 福建农林大学 | 一种用新鲜螺旋藻制备藻蓝蛋白的方法 |
| WO2016154003A1 (en) | 2015-03-20 | 2016-09-29 | The United States Of America, As Represented By The Secretary, Department Of Health & Human Services | Neutralizing antibodies to gp120 and their use |
| CA2999294A1 (en) | 2015-09-25 | 2017-03-30 | Altor Bioscience Corporation | Interleukin-15 superagonist significantly enhances graft-versus-tumor activity |
| US10865230B2 (en) | 2016-05-27 | 2020-12-15 | Altor Bioscience, Llc | Construction and characterization of multimeric IL-15-based molecules with CD3 binding domains |
| AU2017345791B2 (en) | 2016-10-21 | 2020-10-22 | Altor Bioscience Corporation | Multimeric IL-15-based molecules |
| EP3773657A4 (en) | 2018-03-26 | 2021-12-08 | Altor Bioscience LLC | ANTI-PDL1, IL-15 AND TGF BETA RECEPTOR COMBINATION MOLECULES |
-
2017
- 2017-10-21 AU AU2017345791A patent/AU2017345791B2/en active Active
- 2017-10-21 WO PCT/US2017/057757 patent/WO2018075989A1/en unknown
- 2017-10-21 KR KR1020217015704A patent/KR102392142B1/ko active IP Right Grant
- 2017-10-21 CA CA3200275A patent/CA3200275A1/en active Pending
- 2017-10-21 MX MX2019004681A patent/MX2019004681A/es unknown
- 2017-10-21 KR KR1020197014404A patent/KR20190091264A/ko not_active IP Right Cessation
- 2017-10-21 CA CA3041310A patent/CA3041310C/en active Active
- 2017-10-21 EP EP17861811.2A patent/EP3529263A4/en active Pending
- 2017-10-21 SG SG11201903306SA patent/SG11201903306SA/en unknown
- 2017-10-21 BR BR112019007920A patent/BR112019007920A2/pt unknown
- 2017-10-21 US US15/789,985 patent/US20180200366A1/en not_active Abandoned
- 2017-10-21 CN CN201780079905.4A patent/CN110799528A/zh active Pending
-
2019
- 2019-04-17 IL IL266100A patent/IL266100B2/en unknown
-
2020
- 2020-01-24 US US16/752,606 patent/US11369679B2/en active Active
-
2021
- 2021-01-29 US US17/163,239 patent/US11318201B2/en active Active
Cited By (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11498950B1 (en) | 2007-05-11 | 2022-11-15 | Altor Bioscience, Llc | Fusion molecules and IL-15 variants |
| US11673932B2 (en) | 2007-05-11 | 2023-06-13 | Altor BioScience, LLC. | Fusion molecules and IL-15 variants |
| US11173191B2 (en) | 2014-06-30 | 2021-11-16 | Altor BioScience, LLC. | IL-15-based molecules and methods of use thereof |
| US11471511B2 (en) | 2014-06-30 | 2022-10-18 | Altor Bioscience, Llc | IL-15-based molecules and methods of use thereof |
| US11679144B2 (en) | 2014-06-30 | 2023-06-20 | Altor BioScience, LLC. | IL-15-based molecules and methods of use thereof |
| US11890323B2 (en) | 2014-06-30 | 2024-02-06 | Altor Bioscience, Llc | Method of treating cancer with composition comprising IL-15-based molecules and BCG |
| US11925676B2 (en) | 2014-06-30 | 2024-03-12 | Altor BioScience, LLC. | Method for treating neoplasia with an anti-CD38 antibody and an IL-15:IL-15R complex |
| US11318201B2 (en) | 2016-10-21 | 2022-05-03 | Altor BioScience, LLC. | Multimeric IL-15-based molecules |
| US11369679B2 (en) | 2016-10-21 | 2022-06-28 | Altor Bioscience, Llc | Multimeric IL-15-based molecules |
| US11992516B2 (en) | 2022-10-11 | 2024-05-28 | Altor BioScience, LLC. | Compositions comprising IL-15-based molecules and immune checkpoint inhibitor antibodies |
Also Published As
| Publication number | Publication date |
|---|---|
| CA3200275A1 (en) | 2018-04-26 |
| SG11201903306SA (en) | 2019-05-30 |
| US20200261575A1 (en) | 2020-08-20 |
| MX2019004681A (es) | 2019-10-07 |
| AU2017345791A1 (en) | 2019-05-09 |
| JP2019533449A (ja) | 2019-11-21 |
| IL266100A (en) | 2019-06-30 |
| AU2017345791B2 (en) | 2020-10-22 |
| EP3529263A1 (en) | 2019-08-28 |
| CA3041310C (en) | 2023-09-05 |
| BR112019007920A2 (pt) | 2019-10-08 |
| IL266100B (en) | 2022-10-01 |
| KR102392142B1 (ko) | 2022-04-28 |
| WO2018075989A1 (en) | 2018-04-26 |
| CN110799528A (zh) | 2020-02-14 |
| IL266100B2 (en) | 2023-02-01 |
| US11369679B2 (en) | 2022-06-28 |
| KR20210062749A (ko) | 2021-05-31 |
| EP3529263A4 (en) | 2020-07-08 |
| CA3041310A1 (en) | 2018-04-26 |
| US20180200366A1 (en) | 2018-07-19 |
| US20210196821A1 (en) | 2021-07-01 |
| US11318201B2 (en) | 2022-05-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102392142B1 (ko) | 다량체 il-15 기반 분자 | |
| AU2020202688B2 (en) | Therapeutic nuclease compositions and methods | |
| CN110719920B (zh) | 蛋白质异二聚体及其用途 | |
| AU2017202437B2 (en) | Novel immunoconjugates | |
| KR101901458B1 (ko) | Tcr 복합체 면역치료제 | |
| KR101900953B1 (ko) | Cd86 길항제 다중-표적 결합 단백질 | |
| KR101163240B1 (ko) | 결합 구성체 및 이의 사용 방법 | |
| JP2024063050A (ja) | 抗原提示ポリペプチドおよびその使用方法 | |
| CN111051350B (zh) | 包含信号调节蛋白α的免疫缀合物 | |
| KR20180081532A (ko) | 암 치료용 조성물 및 방법 | |
| KR20110044991A (ko) | TNF-α 길항제 다-표적 결합 단백질 | |
| KR20110043643A (ko) | 인터루킨 6 면역치료제 | |
| KR20110044992A (ko) | TGF-β 길항제 다중-표적 결합 단백질 | |
| CN101679497A (zh) | 可溶性il-17ra/rc融合蛋白以及相关方法 | |
| KR20080056241A (ko) | Il-17a 및 il-17f 길항제 및 그것의 사용 방법 | |
| CN101316861A (zh) | Il-17a和il-17f拮抗剂以及使用所述拮抗剂的方法 | |
| KR20200011377A (ko) | 면역 관련 질환의 예방 또는 치료용 조성물 | |
| KR20230165829A (ko) | 이중특이적 분자 및 관련 조성물 및 방법 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| AMND | Amendment | ||
| E902 | Notification of reason for refusal | ||
| AMND | Amendment | ||
| E601 | Decision to refuse application | ||
| A107 | Divisional application of patent | ||
| AMND | Amendment | ||
| X601 | Decision of rejection after re-examination |