KR20110036638A - 단백질 스크리닝 방법 - Google Patents
단백질 스크리닝 방법 Download PDFInfo
- Publication number
- KR20110036638A KR20110036638A KR1020117004624A KR20117004624A KR20110036638A KR 20110036638 A KR20110036638 A KR 20110036638A KR 1020117004624 A KR1020117004624 A KR 1020117004624A KR 20117004624 A KR20117004624 A KR 20117004624A KR 20110036638 A KR20110036638 A KR 20110036638A
- Authority
- KR
- South Korea
- Prior art keywords
- nucleic acid
- ligand
- complex
- high affinity
- receptor
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 207
- 108090000623 proteins and genes Proteins 0.000 title claims description 113
- 102000004169 proteins and genes Human genes 0.000 title claims description 108
- 238000012216 screening Methods 0.000 title description 12
- 108090000765 processed proteins & peptides Proteins 0.000 claims abstract description 112
- 102000004196 processed proteins & peptides Human genes 0.000 claims abstract description 94
- 229920001184 polypeptide Polymers 0.000 claims abstract description 92
- 239000003446 ligand Substances 0.000 claims description 246
- 102000039446 nucleic acids Human genes 0.000 claims description 186
- 108020004707 nucleic acids Proteins 0.000 claims description 186
- 150000007523 nucleic acids Chemical class 0.000 claims description 183
- 108020004414 DNA Proteins 0.000 claims description 124
- 102000005962 receptors Human genes 0.000 claims description 109
- 108020003175 receptors Proteins 0.000 claims description 109
- 230000027455 binding Effects 0.000 claims description 86
- 238000009739 binding Methods 0.000 claims description 85
- 108020004999 messenger RNA Proteins 0.000 claims description 77
- 108010011903 peptide receptors Proteins 0.000 claims description 70
- 102000014187 peptide receptors Human genes 0.000 claims description 70
- 108010090804 Streptavidin Proteins 0.000 claims description 61
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 claims description 58
- 108091032973 (ribonucleotides)n+m Proteins 0.000 claims description 58
- 229960002685 biotin Drugs 0.000 claims description 35
- 239000011616 biotin Substances 0.000 claims description 35
- RXWNCPJZOCPEPQ-NVWDDTSBSA-N puromycin Chemical group C1=CC(OC)=CC=C1C[C@H](N)C(=O)N[C@H]1[C@@H](O)[C@H](N2C3=NC=NC(=C3N=C2)N(C)C)O[C@@H]1CO RXWNCPJZOCPEPQ-NVWDDTSBSA-N 0.000 claims description 30
- 235000020958 biotin Nutrition 0.000 claims description 29
- 230000000295 complement effect Effects 0.000 claims description 27
- 239000000427 antigen Substances 0.000 claims description 21
- 108091007433 antigens Proteins 0.000 claims description 21
- 102000036639 antigens Human genes 0.000 claims description 21
- 239000002299 complementary DNA Substances 0.000 claims description 18
- 238000013519 translation Methods 0.000 claims description 18
- 108700022150 Designed Ankyrin Repeat Proteins Proteins 0.000 claims description 17
- 229920001223 polyethylene glycol Polymers 0.000 claims description 17
- 238000010839 reverse transcription Methods 0.000 claims description 17
- -1 ZFVp (O) F Chemical compound 0.000 claims description 16
- 229950010131 puromycin Drugs 0.000 claims description 16
- 210000003705 ribosome Anatomy 0.000 claims description 16
- 102000053602 DNA Human genes 0.000 claims description 11
- 108010088751 Albumins Proteins 0.000 claims description 10
- 102000014914 Carrier Proteins Human genes 0.000 claims description 10
- 108091008324 binding proteins Proteins 0.000 claims description 10
- 239000003161 ribonuclease inhibitor Substances 0.000 claims description 10
- 238000010804 cDNA synthesis Methods 0.000 claims description 9
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 8
- 239000002202 Polyethylene glycol Substances 0.000 claims description 8
- 239000002253 acid Substances 0.000 claims description 8
- QJJXYPPXXYFBGM-LFZNUXCKSA-N Tacrolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1\C=C(/C)[C@@H]1[C@H](C)[C@@H](O)CC(=O)[C@H](CC=C)/C=C(C)/C[C@H](C)C[C@H](OC)[C@H]([C@H](C[C@H]2C)OC)O[C@@]2(O)C(=O)C(=O)N2CCCC[C@H]2C(=O)O1 QJJXYPPXXYFBGM-LFZNUXCKSA-N 0.000 claims description 7
- 102000005367 Carboxypeptidases Human genes 0.000 claims description 5
- 108010006303 Carboxypeptidases Proteins 0.000 claims description 5
- 102000007625 Hirudins Human genes 0.000 claims description 5
- 108010007267 Hirudins Proteins 0.000 claims description 5
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 claims description 5
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 claims description 5
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 claims description 5
- 102100027913 Peptidyl-prolyl cis-trans isomerase FKBP1A Human genes 0.000 claims description 5
- 108010006877 Tacrolimus Binding Protein 1A Proteins 0.000 claims description 5
- 108010022394 Threonine synthase Proteins 0.000 claims description 5
- 108090000190 Thrombin Proteins 0.000 claims description 5
- QBDVVYNLLXGUGN-XGTBZJOHSA-N [(3r,4s,5s,6r)-5-methoxy-4-[(2r,3r)-2-methyl-3-(3-methylbut-2-enyl)oxiran-2-yl]-1-oxaspiro[2.5]octan-6-yl] n-[(2r)-1-amino-3-methyl-1-oxobutan-2-yl]carbamate Chemical compound C([C@H]([C@H]([C@@H]1[C@]2(C)[C@H](O2)CC=C(C)C)OC)OC(=O)N[C@H](C(C)C)C(N)=O)C[C@@]21CO2 QBDVVYNLLXGUGN-XGTBZJOHSA-N 0.000 claims description 5
- 150000001348 alkyl chlorides Chemical class 0.000 claims description 5
- 102000004419 dihydrofolate reductase Human genes 0.000 claims description 5
- WQPDUTSPKFMPDP-OUMQNGNKSA-N hirudin Chemical compound C([C@@H](C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C=CC(OS(O)(=O)=O)=CC=1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CCCCN)NC(=O)[C@H]1N(CCC1)C(=O)[C@@H](NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](NC(=O)[C@H]1NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(O)=O)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)CNC(=O)[C@H](CC(C)C)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H]2CSSC[C@@H](C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(=O)N[C@H](C(NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N2)=O)CSSC1)C(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]1NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)CNC(=O)[C@H](CO)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=2C=CC(O)=CC=2)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)C(C)C)[C@@H](C)O)CSSC1)C(C)C)[C@@H](C)O)[C@@H](C)O)C1=CC=CC=C1 WQPDUTSPKFMPDP-OUMQNGNKSA-N 0.000 claims description 5
- 229940006607 hirudin Drugs 0.000 claims description 5
- 229960000485 methotrexate Drugs 0.000 claims description 5
- 229960004072 thrombin Drugs 0.000 claims description 5
- 108020004705 Codon Proteins 0.000 claims description 4
- 101710181812 Methionine aminopeptidase Proteins 0.000 claims description 4
- 108010027179 Tacrolimus Binding Proteins Proteins 0.000 claims description 4
- 102000018679 Tacrolimus Binding Proteins Human genes 0.000 claims description 4
- 239000003623 enhancer Substances 0.000 claims description 4
- 230000002194 synthesizing effect Effects 0.000 claims description 4
- 108020004635 Complementary DNA Proteins 0.000 claims description 3
- 150000001350 alkyl halides Chemical class 0.000 claims description 3
- 239000002131 composite material Substances 0.000 claims description 3
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 claims description 3
- 102000040650 (ribonucleotides)n+m Human genes 0.000 claims description 2
- 108010055015 haloalcohol dehalogenase Proteins 0.000 claims description 2
- 102000009027 Albumins Human genes 0.000 claims 4
- 210000004602 germ cell Anatomy 0.000 claims 1
- 239000000203 mixture Substances 0.000 abstract description 64
- 238000000338 in vitro Methods 0.000 abstract description 37
- 125000005647 linker group Chemical group 0.000 description 118
- 235000018102 proteins Nutrition 0.000 description 97
- 239000013615 primer Substances 0.000 description 59
- 230000004927 fusion Effects 0.000 description 50
- 101100519161 Arabidopsis thaliana PCR5 gene Proteins 0.000 description 40
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 38
- 150000001875 compounds Chemical class 0.000 description 27
- 101000716149 Homo sapiens T-cell surface glycoprotein CD1b Proteins 0.000 description 26
- 102100024219 T-cell surface glycoprotein CD1a Human genes 0.000 description 26
- 125000003729 nucleotide group Chemical group 0.000 description 24
- 239000000872 buffer Substances 0.000 description 23
- 239000002773 nucleotide Substances 0.000 description 23
- 238000005516 engineering process Methods 0.000 description 21
- 238000000746 purification Methods 0.000 description 21
- 239000001913 cellulose Substances 0.000 description 20
- 229920002678 cellulose Polymers 0.000 description 20
- 239000000499 gel Substances 0.000 description 20
- 238000004519 manufacturing process Methods 0.000 description 20
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 19
- 239000011780 sodium chloride Substances 0.000 description 19
- 230000014616 translation Effects 0.000 description 19
- 239000012148 binding buffer Substances 0.000 description 18
- 230000001225 therapeutic effect Effects 0.000 description 18
- 210000004027 cell Anatomy 0.000 description 15
- 230000006870 function Effects 0.000 description 15
- 239000008188 pellet Substances 0.000 description 15
- 241000894007 species Species 0.000 description 15
- 150000003839 salts Chemical class 0.000 description 14
- 235000001014 amino acid Nutrition 0.000 description 13
- 238000006243 chemical reaction Methods 0.000 description 13
- 108060003951 Immunoglobulin Proteins 0.000 description 12
- 239000007983 Tris buffer Substances 0.000 description 12
- 150000001413 amino acids Chemical class 0.000 description 12
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 12
- 102000018358 immunoglobulin Human genes 0.000 description 12
- 150000003384 small molecules Chemical class 0.000 description 12
- 239000006228 supernatant Substances 0.000 description 12
- 238000013518 transcription Methods 0.000 description 12
- 230000035897 transcription Effects 0.000 description 12
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 12
- 229920000936 Agarose Polymers 0.000 description 11
- 102000004190 Enzymes Human genes 0.000 description 11
- 108090000790 Enzymes Proteins 0.000 description 11
- 201000010099 disease Diseases 0.000 description 11
- 230000003993 interaction Effects 0.000 description 11
- 239000000047 product Substances 0.000 description 11
- 230000002441 reversible effect Effects 0.000 description 11
- 239000011230 binding agent Substances 0.000 description 10
- 230000037396 body weight Effects 0.000 description 10
- 239000003795 chemical substances by application Substances 0.000 description 10
- 238000010276 construction Methods 0.000 description 10
- 239000003814 drug Substances 0.000 description 10
- 230000008569 process Effects 0.000 description 10
- 239000000376 reactant Substances 0.000 description 10
- 238000012163 sequencing technique Methods 0.000 description 10
- 239000011534 wash buffer Substances 0.000 description 10
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 9
- 230000015572 biosynthetic process Effects 0.000 description 9
- 238000010828 elution Methods 0.000 description 9
- 229940088598 enzyme Drugs 0.000 description 9
- 230000014509 gene expression Effects 0.000 description 9
- 229940099472 immunoglobulin a Drugs 0.000 description 9
- 229920000233 poly(alkylene oxides) Polymers 0.000 description 9
- 238000002360 preparation method Methods 0.000 description 9
- 238000009987 spinning Methods 0.000 description 9
- 239000000126 substance Substances 0.000 description 9
- 238000011282 treatment Methods 0.000 description 9
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 8
- 239000004480 active ingredient Substances 0.000 description 8
- 238000013459 approach Methods 0.000 description 8
- 230000003197 catalytic effect Effects 0.000 description 8
- 238000001962 electrophoresis Methods 0.000 description 8
- 238000001727 in vivo Methods 0.000 description 8
- KWGKDLIKAYFUFQ-UHFFFAOYSA-M lithium chloride Chemical compound [Li+].[Cl-] KWGKDLIKAYFUFQ-UHFFFAOYSA-M 0.000 description 8
- 238000011068 loading method Methods 0.000 description 8
- 239000000463 material Substances 0.000 description 8
- 239000000243 solution Substances 0.000 description 8
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 8
- 102100037362 Fibronectin Human genes 0.000 description 7
- 108010067306 Fibronectins Proteins 0.000 description 7
- 206010028980 Neoplasm Diseases 0.000 description 7
- 108091034117 Oligonucleotide Proteins 0.000 description 7
- 238000007792 addition Methods 0.000 description 7
- 230000008901 benefit Effects 0.000 description 7
- 238000011161 development Methods 0.000 description 7
- 229940079593 drug Drugs 0.000 description 7
- 230000000694 effects Effects 0.000 description 7
- 238000001802 infusion Methods 0.000 description 7
- 238000002703 mutagenesis Methods 0.000 description 7
- 231100000350 mutagenesis Toxicity 0.000 description 7
- 238000002823 phage display Methods 0.000 description 7
- 239000008194 pharmaceutical composition Substances 0.000 description 7
- 102100027211 Albumin Human genes 0.000 description 6
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 6
- 102000019298 Lipocalin Human genes 0.000 description 6
- 108050006654 Lipocalin Proteins 0.000 description 6
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 6
- 239000013504 Triton X-100 Substances 0.000 description 6
- 229920004890 Triton X-100 Polymers 0.000 description 6
- 239000003153 chemical reaction reagent Substances 0.000 description 6
- 238000013461 design Methods 0.000 description 6
- 238000002955 isolation Methods 0.000 description 6
- 230000000670 limiting effect Effects 0.000 description 6
- 229920001427 mPEG Polymers 0.000 description 6
- 239000007787 solid Substances 0.000 description 6
- 238000003786 synthesis reaction Methods 0.000 description 6
- GPRLSGONYQIRFK-MNYXATJNSA-N triton Chemical compound [3H+] GPRLSGONYQIRFK-MNYXATJNSA-N 0.000 description 6
- 238000005406 washing Methods 0.000 description 6
- YVGGHNCTFXOJCH-UHFFFAOYSA-N DDT Chemical compound C1=CC(Cl)=CC=C1C(C(Cl)(Cl)Cl)C1=CC=C(Cl)C=C1 YVGGHNCTFXOJCH-UHFFFAOYSA-N 0.000 description 5
- 241000588724 Escherichia coli Species 0.000 description 5
- 238000003556 assay Methods 0.000 description 5
- 239000003054 catalyst Substances 0.000 description 5
- 238000000576 coating method Methods 0.000 description 5
- 238000004132 cross linking Methods 0.000 description 5
- 238000002474 experimental method Methods 0.000 description 5
- 239000012634 fragment Substances 0.000 description 5
- 230000006872 improvement Effects 0.000 description 5
- 238000011534 incubation Methods 0.000 description 5
- 238000002347 injection Methods 0.000 description 5
- 239000007924 injection Substances 0.000 description 5
- 239000002502 liposome Substances 0.000 description 5
- 230000004048 modification Effects 0.000 description 5
- 238000012986 modification Methods 0.000 description 5
- 150000003904 phospholipids Chemical group 0.000 description 5
- 229920005989 resin Polymers 0.000 description 5
- 239000011347 resin Substances 0.000 description 5
- 238000010187 selection method Methods 0.000 description 5
- 125000006850 spacer group Chemical group 0.000 description 5
- 208000024891 symptom Diseases 0.000 description 5
- OHOQEZWSNFNUSY-UHFFFAOYSA-N Cy3-bifunctional dye zwitterion Chemical compound O=C1CCC(=O)N1OC(=O)CCCCCN1C2=CC=C(S(O)(=O)=O)C=C2C(C)(C)C1=CC=CC(C(C1=CC(=CC=C11)S([O-])(=O)=O)(C)C)=[N+]1CCCCCC(=O)ON1C(=O)CCC1=O OHOQEZWSNFNUSY-UHFFFAOYSA-N 0.000 description 4
- 108091005804 Peptidases Proteins 0.000 description 4
- 102000035195 Peptidases Human genes 0.000 description 4
- ISWSIDIOOBJBQZ-UHFFFAOYSA-N Phenol Chemical compound OC1=CC=CC=C1 ISWSIDIOOBJBQZ-UHFFFAOYSA-N 0.000 description 4
- NBIIXXVUZAFLBC-UHFFFAOYSA-N Phosphoric acid Chemical compound OP(O)(O)=O NBIIXXVUZAFLBC-UHFFFAOYSA-N 0.000 description 4
- 239000004365 Protease Substances 0.000 description 4
- 238000010521 absorption reaction Methods 0.000 description 4
- 238000003314 affinity selection Methods 0.000 description 4
- 238000005119 centrifugation Methods 0.000 description 4
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 description 4
- 238000010367 cloning Methods 0.000 description 4
- 238000001784 detoxification Methods 0.000 description 4
- 239000003937 drug carrier Substances 0.000 description 4
- 238000012377 drug delivery Methods 0.000 description 4
- 239000012636 effector Substances 0.000 description 4
- 230000002209 hydrophobic effect Effects 0.000 description 4
- 230000005847 immunogenicity Effects 0.000 description 4
- 239000003112 inhibitor Substances 0.000 description 4
- 238000001990 intravenous administration Methods 0.000 description 4
- 239000007788 liquid Substances 0.000 description 4
- 239000002245 particle Substances 0.000 description 4
- 238000001556 precipitation Methods 0.000 description 4
- 238000011084 recovery Methods 0.000 description 4
- 239000002002 slurry Substances 0.000 description 4
- 239000002904 solvent Substances 0.000 description 4
- 238000003860 storage Methods 0.000 description 4
- 238000007920 subcutaneous administration Methods 0.000 description 4
- 239000000758 substrate Substances 0.000 description 4
- 239000003826 tablet Substances 0.000 description 4
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 3
- 102000000844 Cell Surface Receptors Human genes 0.000 description 3
- 108010001857 Cell Surface Receptors Proteins 0.000 description 3
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 3
- 239000007995 HEPES buffer Substances 0.000 description 3
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 3
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 3
- 108091005461 Nucleic proteins Proteins 0.000 description 3
- 108090000279 Peptidyltransferases Proteins 0.000 description 3
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 description 3
- 238000012181 QIAquick gel extraction kit Methods 0.000 description 3
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical compound [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 3
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 3
- 150000007513 acids Chemical class 0.000 description 3
- OIRDTQYFTABQOQ-KQYNXXCUSA-N adenosine Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OIRDTQYFTABQOQ-KQYNXXCUSA-N 0.000 description 3
- 238000001042 affinity chromatography Methods 0.000 description 3
- 150000001408 amides Chemical class 0.000 description 3
- 230000003321 amplification Effects 0.000 description 3
- 210000003719 b-lymphocyte Anatomy 0.000 description 3
- 230000001580 bacterial effect Effects 0.000 description 3
- 229910052799 carbon Inorganic materials 0.000 description 3
- OGEBRHQLRGFBNV-RZDIXWSQSA-N chembl2036808 Chemical compound C12=NC(NCCCC)=NC=C2C(C=2C=CC(F)=CC=2)=NN1C[C@H]1CC[C@H](N)CC1 OGEBRHQLRGFBNV-RZDIXWSQSA-N 0.000 description 3
- 230000001149 cognitive effect Effects 0.000 description 3
- 239000002270 dispersing agent Substances 0.000 description 3
- 239000006185 dispersion Substances 0.000 description 3
- 239000002612 dispersion medium Substances 0.000 description 3
- 150000002148 esters Chemical class 0.000 description 3
- 238000009472 formulation Methods 0.000 description 3
- 239000007943 implant Substances 0.000 description 3
- 239000004615 ingredient Substances 0.000 description 3
- 238000007918 intramuscular administration Methods 0.000 description 3
- 239000007951 isotonicity adjuster Substances 0.000 description 3
- 230000007246 mechanism Effects 0.000 description 3
- 239000012528 membrane Substances 0.000 description 3
- 238000010369 molecular cloning Methods 0.000 description 3
- 231100000252 nontoxic Toxicity 0.000 description 3
- 230000003000 nontoxic effect Effects 0.000 description 3
- 238000003199 nucleic acid amplification method Methods 0.000 description 3
- 229910052698 phosphorus Inorganic materials 0.000 description 3
- 239000011574 phosphorus Substances 0.000 description 3
- 229920000642 polymer Polymers 0.000 description 3
- 238000006116 polymerization reaction Methods 0.000 description 3
- 239000000843 powder Substances 0.000 description 3
- 230000000069 prophylactic effect Effects 0.000 description 3
- 230000002829 reductive effect Effects 0.000 description 3
- 238000003757 reverse transcription PCR Methods 0.000 description 3
- 125000002652 ribonucleotide group Chemical group 0.000 description 3
- 238000000926 separation method Methods 0.000 description 3
- 230000009870 specific binding Effects 0.000 description 3
- 239000000725 suspension Substances 0.000 description 3
- 230000008685 targeting Effects 0.000 description 3
- 210000001519 tissue Anatomy 0.000 description 3
- VLUUFBLAENSMJV-AEKHSPFPSA-N (2s)-2-amino-1-[(2s,3r,4s,5s)-4-amino-2-(6-aminopurin-9-yl)-3-hydroxy-5-(hydroxymethyl)oxolan-2-yl]propan-1-one Chemical compound C1=NC2=C(N)N=CN=C2N1[C@]1(C(=O)[C@@H](N)C)O[C@H](CO)[C@@H](N)[C@H]1O VLUUFBLAENSMJV-AEKHSPFPSA-N 0.000 description 2
- IIZPXYDJLKNOIY-JXPKJXOSSA-N 1-palmitoyl-2-arachidonoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCC\C=C/C\C=C/C\C=C/C\C=C/CCCCC IIZPXYDJLKNOIY-JXPKJXOSSA-N 0.000 description 2
- 102000008102 Ankyrins Human genes 0.000 description 2
- DPNWSMBUYCLEDG-CIUDSAMLSA-N Asp-Lys-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O DPNWSMBUYCLEDG-CIUDSAMLSA-N 0.000 description 2
- 239000002126 C01EB10 - Adenosine Substances 0.000 description 2
- 102000000905 Cadherin Human genes 0.000 description 2
- 108050007957 Cadherin Proteins 0.000 description 2
- 101100170001 Caenorhabditis elegans ddb-1 gene Proteins 0.000 description 2
- 239000003155 DNA primer Substances 0.000 description 2
- 230000006820 DNA synthesis Effects 0.000 description 2
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 2
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 2
- 108010010803 Gelatin Proteins 0.000 description 2
- 102000053187 Glucuronidase Human genes 0.000 description 2
- 108010060309 Glucuronidase Proteins 0.000 description 2
- IRJWAYCXIYUHQE-WHFBIAKZSA-N Gly-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)CN IRJWAYCXIYUHQE-WHFBIAKZSA-N 0.000 description 2
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 2
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 2
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 2
- 102000016844 Immunoglobulin-like domains Human genes 0.000 description 2
- 108050006430 Immunoglobulin-like domains Proteins 0.000 description 2
- 150000008575 L-amino acids Chemical class 0.000 description 2
- 108091000080 Phosphotransferase Proteins 0.000 description 2
- 241000235648 Pichia Species 0.000 description 2
- 108020004511 Recombinant DNA Proteins 0.000 description 2
- 108091028664 Ribonucleotide Proteins 0.000 description 2
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 2
- WTWGOQRNRFHFQD-JBDRJPRFSA-N Ser-Ala-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WTWGOQRNRFHFQD-JBDRJPRFSA-N 0.000 description 2
- BRKHVZNDAOMAHX-BIIVOSGPSA-N Ser-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N BRKHVZNDAOMAHX-BIIVOSGPSA-N 0.000 description 2
- FUMGHWDRRFCKEP-CIUDSAMLSA-N Ser-Leu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O FUMGHWDRRFCKEP-CIUDSAMLSA-N 0.000 description 2
- 241000270295 Serpentes Species 0.000 description 2
- 101000677856 Stenotrophomonas maltophilia (strain K279a) Actin-binding protein Smlt3054 Proteins 0.000 description 2
- QAOWNCQODCNURD-UHFFFAOYSA-N Sulfuric acid Chemical compound OS(O)(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-N 0.000 description 2
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 description 2
- 102100034922 T-cell surface glycoprotein CD8 alpha chain Human genes 0.000 description 2
- DCLBXIWHLVEPMQ-JRQIVUDYSA-N Thr-Asp-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 DCLBXIWHLVEPMQ-JRQIVUDYSA-N 0.000 description 2
- 241000700605 Viruses Species 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 229960005305 adenosine Drugs 0.000 description 2
- 230000009824 affinity maturation Effects 0.000 description 2
- 239000011543 agarose gel Substances 0.000 description 2
- 230000002776 aggregation Effects 0.000 description 2
- 238000004220 aggregation Methods 0.000 description 2
- 230000004075 alteration Effects 0.000 description 2
- 229910000147 aluminium phosphate Inorganic materials 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 2
- 238000004873 anchoring Methods 0.000 description 2
- 239000003242 anti bacterial agent Substances 0.000 description 2
- 230000000844 anti-bacterial effect Effects 0.000 description 2
- 230000000692 anti-sense effect Effects 0.000 description 2
- 239000003429 antifungal agent Substances 0.000 description 2
- 229940121375 antifungal agent Drugs 0.000 description 2
- 239000008346 aqueous phase Substances 0.000 description 2
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 2
- 210000004369 blood Anatomy 0.000 description 2
- 239000008280 blood Substances 0.000 description 2
- 239000006227 byproduct Substances 0.000 description 2
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 2
- 239000012876 carrier material Substances 0.000 description 2
- 230000015556 catabolic process Effects 0.000 description 2
- OSASVXMJTNOKOY-UHFFFAOYSA-N chlorobutanol Chemical compound CC(C)(O)C(Cl)(Cl)Cl OSASVXMJTNOKOY-UHFFFAOYSA-N 0.000 description 2
- 235000012000 cholesterol Nutrition 0.000 description 2
- 239000011248 coating agent Substances 0.000 description 2
- 238000002648 combination therapy Methods 0.000 description 2
- 238000007796 conventional method Methods 0.000 description 2
- 238000001816 cooling Methods 0.000 description 2
- 108010057085 cytokine receptors Proteins 0.000 description 2
- 102000003675 cytokine receptors Human genes 0.000 description 2
- 238000000354 decomposition reaction Methods 0.000 description 2
- 238000006731 degradation reaction Methods 0.000 description 2
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 2
- 238000010790 dilution Methods 0.000 description 2
- 239000012895 dilution Substances 0.000 description 2
- 239000002552 dosage form Substances 0.000 description 2
- 230000009977 dual effect Effects 0.000 description 2
- 239000000975 dye Substances 0.000 description 2
- 239000003480 eluent Substances 0.000 description 2
- 230000002349 favourable effect Effects 0.000 description 2
- 238000005194 fractionation Methods 0.000 description 2
- 238000001502 gel electrophoresis Methods 0.000 description 2
- 239000008273 gelatin Substances 0.000 description 2
- 229920000159 gelatin Polymers 0.000 description 2
- 235000019322 gelatine Nutrition 0.000 description 2
- 235000011852 gelatine desserts Nutrition 0.000 description 2
- 239000011521 glass Substances 0.000 description 2
- 108010082286 glycyl-seryl-alanine Proteins 0.000 description 2
- 239000005090 green fluorescent protein Substances 0.000 description 2
- 238000010438 heat treatment Methods 0.000 description 2
- 238000009396 hybridization Methods 0.000 description 2
- 230000028993 immune response Effects 0.000 description 2
- 229940072221 immunoglobulins Drugs 0.000 description 2
- 238000003364 immunohistochemistry Methods 0.000 description 2
- 230000005764 inhibitory process Effects 0.000 description 2
- 108010044426 integrins Proteins 0.000 description 2
- 102000006495 integrins Human genes 0.000 description 2
- 230000003834 intracellular effect Effects 0.000 description 2
- 230000002427 irreversible effect Effects 0.000 description 2
- 239000000787 lecithin Substances 0.000 description 2
- 229940067606 lecithin Drugs 0.000 description 2
- 235000010445 lecithin Nutrition 0.000 description 2
- 238000002898 library design Methods 0.000 description 2
- 239000006166 lysate Substances 0.000 description 2
- 108010003700 lysyl aspartic acid Proteins 0.000 description 2
- 238000002824 mRNA display Methods 0.000 description 2
- 210000004962 mammalian cell Anatomy 0.000 description 2
- 239000003550 marker Substances 0.000 description 2
- 125000000325 methylidene group Chemical group [H]C([H])=* 0.000 description 2
- 238000002156 mixing Methods 0.000 description 2
- 230000035772 mutation Effects 0.000 description 2
- 239000012038 nucleophile Substances 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 230000003204 osmotic effect Effects 0.000 description 2
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 2
- 239000012071 phase Substances 0.000 description 2
- 102000020233 phosphotransferase Human genes 0.000 description 2
- 239000013612 plasmid Substances 0.000 description 2
- 230000008488 polyadenylation Effects 0.000 description 2
- 229920005862 polyol Polymers 0.000 description 2
- 150000003077 polyols Chemical class 0.000 description 2
- 230000003389 potentiating effect Effects 0.000 description 2
- 230000002265 prevention Effects 0.000 description 2
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 230000002035 prolonged effect Effects 0.000 description 2
- 238000001243 protein synthesis Methods 0.000 description 2
- 230000004850 protein–protein interaction Effects 0.000 description 2
- 230000002797 proteolythic effect Effects 0.000 description 2
- 239000011541 reaction mixture Substances 0.000 description 2
- 230000004044 response Effects 0.000 description 2
- 239000002336 ribonucleotide Substances 0.000 description 2
- 229940126586 small molecule drug Drugs 0.000 description 2
- 210000004988 splenocyte Anatomy 0.000 description 2
- 238000010561 standard procedure Methods 0.000 description 2
- 235000000346 sugar Nutrition 0.000 description 2
- 150000008163 sugars Chemical class 0.000 description 2
- 239000004094 surface-active agent Substances 0.000 description 2
- 238000013268 sustained release Methods 0.000 description 2
- 238000012360 testing method Methods 0.000 description 2
- 238000002560 therapeutic procedure Methods 0.000 description 2
- 230000004797 therapeutic response Effects 0.000 description 2
- 125000003396 thiol group Chemical group [H]S* 0.000 description 2
- 108010033670 threonyl-aspartyl-tyrosine Proteins 0.000 description 2
- 230000000699 topical effect Effects 0.000 description 2
- 230000004614 tumor growth Effects 0.000 description 2
- 239000013598 vector Substances 0.000 description 2
- 230000003612 virological effect Effects 0.000 description 2
- JPNBVWIRDQVGAC-UHFFFAOYSA-N (2-nitrophenyl) hydrogen carbonate Chemical class OC(=O)OC1=CC=CC=C1[N+]([O-])=O JPNBVWIRDQVGAC-UHFFFAOYSA-N 0.000 description 1
- CTFJATOFOZBFPT-UCTKEYDRSA-N (2s)-2-amino-1-[(2s,3r,4s,5r)-2-(6-aminopurin-9-yl)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-3-phenylpropan-1-one Chemical compound C([C@H](N)C(=O)[C@@]1([C@@H]([C@H](O)[C@@H](CO)O1)O)N1C2=NC=NC(N)=C2N=C1)C1=CC=CC=C1 CTFJATOFOZBFPT-UCTKEYDRSA-N 0.000 description 1
- BLOMDWFVDQMXKC-GFYCOGQESA-N (2s)-2-amino-1-[(2s,3r,4s,5r)-2-(6-aminopurin-9-yl)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]propan-1-one Chemical compound C1=NC2=C(N)N=CN=C2N1[C@]1(C(=O)[C@@H](N)C)O[C@H](CO)[C@@H](O)[C@H]1O BLOMDWFVDQMXKC-GFYCOGQESA-N 0.000 description 1
- BMYNFMYTOJXKLE-UHFFFAOYSA-N 3-azaniumyl-2-hydroxypropanoate Chemical compound NCC(O)C(O)=O BMYNFMYTOJXKLE-UHFFFAOYSA-N 0.000 description 1
- LMEHJKJEPRYEEB-UHFFFAOYSA-N 5-prop-1-ynylpyrimidine Chemical compound CC#CC1=CN=CN=C1 LMEHJKJEPRYEEB-UHFFFAOYSA-N 0.000 description 1
- XZLIYCQRASOFQM-UHFFFAOYSA-N 5h-imidazo[4,5-d]triazine Chemical compound N1=NC=C2NC=NC2=N1 XZLIYCQRASOFQM-UHFFFAOYSA-N 0.000 description 1
- 241000242759 Actiniaria Species 0.000 description 1
- 229930024421 Adenine Natural products 0.000 description 1
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 1
- 108091093088 Amplicon Proteins 0.000 description 1
- 108010049777 Ankyrins Proteins 0.000 description 1
- 101001007348 Arachis hypogaea Galactose-binding lectin Proteins 0.000 description 1
- 241000239290 Araneae Species 0.000 description 1
- 241000228212 Aspergillus Species 0.000 description 1
- 241000972773 Aulopiformes Species 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- 241000282836 Camelus dromedarius Species 0.000 description 1
- 108010078791 Carrier Proteins Proteins 0.000 description 1
- 102000053642 Catalytic RNA Human genes 0.000 description 1
- 108090000994 Catalytic RNA Proteins 0.000 description 1
- ZAMOUSCENKQFHK-UHFFFAOYSA-N Chlorine atom Chemical compound [Cl] ZAMOUSCENKQFHK-UHFFFAOYSA-N 0.000 description 1
- 241000251730 Chondrichthyes Species 0.000 description 1
- 102000008186 Collagen Human genes 0.000 description 1
- 108010035532 Collagen Proteins 0.000 description 1
- 102100024203 Collagen alpha-1(XIV) chain Human genes 0.000 description 1
- 101710106877 Collagen alpha-1(XIV) chain Proteins 0.000 description 1
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 1
- 239000004971 Cross linker Substances 0.000 description 1
- 101150097493 D gene Proteins 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- 230000004544 DNA amplification Effects 0.000 description 1
- 238000007400 DNA extraction Methods 0.000 description 1
- 102000052510 DNA-Binding Proteins Human genes 0.000 description 1
- 230000004568 DNA-binding Effects 0.000 description 1
- 101710096438 DNA-binding protein Proteins 0.000 description 1
- 108091027757 Deoxyribozyme Proteins 0.000 description 1
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 1
- 238000002965 ELISA Methods 0.000 description 1
- VGGSQFUCUMXWEO-UHFFFAOYSA-N Ethene Chemical compound C=C VGGSQFUCUMXWEO-UHFFFAOYSA-N 0.000 description 1
- 239000005977 Ethylene Substances 0.000 description 1
- IAYPIBMASNFSPL-UHFFFAOYSA-N Ethylene oxide Chemical compound C1CO1 IAYPIBMASNFSPL-UHFFFAOYSA-N 0.000 description 1
- PIICEJLVQHRZGT-UHFFFAOYSA-N Ethylenediamine Chemical compound NCCN PIICEJLVQHRZGT-UHFFFAOYSA-N 0.000 description 1
- XZWYTXMRWQJBGX-VXBMVYAYSA-N FLAG peptide Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(O)=O)CC1=CC=C(O)C=C1 XZWYTXMRWQJBGX-VXBMVYAYSA-N 0.000 description 1
- 108010020195 FLAG peptide Proteins 0.000 description 1
- 241000233866 Fungi Species 0.000 description 1
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 1
- 108700007698 Genetic Terminator Regions Proteins 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 102100039619 Granulocyte colony-stimulating factor Human genes 0.000 description 1
- 102100020948 Growth hormone receptor Human genes 0.000 description 1
- 102000001554 Hemoglobins Human genes 0.000 description 1
- 108010054147 Hemoglobins Proteins 0.000 description 1
- 241000545744 Hirudinea Species 0.000 description 1
- 108010088652 Histocompatibility Antigens Class I Proteins 0.000 description 1
- 102000008949 Histocompatibility Antigens Class I Human genes 0.000 description 1
- 101001027128 Homo sapiens Fibronectin Proteins 0.000 description 1
- 101000746367 Homo sapiens Granulocyte colony-stimulating factor Proteins 0.000 description 1
- 101000980827 Homo sapiens T-cell surface glycoprotein CD1a Proteins 0.000 description 1
- 101000716124 Homo sapiens T-cell surface glycoprotein CD1c Proteins 0.000 description 1
- 101000716102 Homo sapiens T-cell surface glycoprotein CD4 Proteins 0.000 description 1
- 101000946843 Homo sapiens T-cell surface glycoprotein CD8 alpha chain Proteins 0.000 description 1
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 1
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 1
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 1
- 206010062717 Increased upper airway secretion Diseases 0.000 description 1
- 102100034343 Integrase Human genes 0.000 description 1
- 102100037872 Intercellular adhesion molecule 2 Human genes 0.000 description 1
- 101710148794 Intercellular adhesion molecule 2 Proteins 0.000 description 1
- 102000014150 Interferons Human genes 0.000 description 1
- 108010050904 Interferons Proteins 0.000 description 1
- 241000235649 Kluyveromyces Species 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- STECJAGHUSJQJN-USLFZFAMSA-N LSM-4015 Chemical compound C1([C@@H](CO)C(=O)OC2C[C@@H]3N([C@H](C2)[C@@H]2[C@H]3O2)C)=CC=CC=C1 STECJAGHUSJQJN-USLFZFAMSA-N 0.000 description 1
- 101500020502 Lachesis muta muta Bradykinin-potentiating peptide 4 Proteins 0.000 description 1
- 108090001090 Lectins Proteins 0.000 description 1
- 102000004856 Lectins Human genes 0.000 description 1
- 108010006444 Leucine-Rich Repeat Proteins Proteins 0.000 description 1
- FYYHWMGAXLPEAU-UHFFFAOYSA-N Magnesium Chemical compound [Mg] FYYHWMGAXLPEAU-UHFFFAOYSA-N 0.000 description 1
- PEEHTFAAVSWFBL-UHFFFAOYSA-N Maleimide Chemical compound O=C1NC(=O)C=C1 PEEHTFAAVSWFBL-UHFFFAOYSA-N 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- 108010052285 Membrane Proteins Proteins 0.000 description 1
- 102100023174 Methionine aminopeptidase 2 Human genes 0.000 description 1
- 108090000192 Methionyl aminopeptidases Proteins 0.000 description 1
- 108010085220 Multiprotein Complexes Proteins 0.000 description 1
- 102000007474 Multiprotein Complexes Human genes 0.000 description 1
- 108010083674 Myelin Proteins Proteins 0.000 description 1
- 102000006386 Myelin Proteins Human genes 0.000 description 1
- 102100030626 Myosin-binding protein H Human genes 0.000 description 1
- 101710139548 Myosin-binding protein H Proteins 0.000 description 1
- GXCLVBGFBYZDAG-UHFFFAOYSA-N N-[2-(1H-indol-3-yl)ethyl]-N-methylprop-2-en-1-amine Chemical compound CN(CCC1=CNC2=C1C=CC=C2)CC=C GXCLVBGFBYZDAG-UHFFFAOYSA-N 0.000 description 1
- 108050000637 N-cadherin Proteins 0.000 description 1
- MBBZMMPHUWSWHV-BDVNFPICSA-N N-methylglucamine Chemical compound CNC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO MBBZMMPHUWSWHV-BDVNFPICSA-N 0.000 description 1
- 108010069196 Neural Cell Adhesion Molecules Proteins 0.000 description 1
- 102100027347 Neural cell adhesion molecule 1 Human genes 0.000 description 1
- 101710089162 Neuroglian Proteins 0.000 description 1
- GRYLNZFGIOXLOG-UHFFFAOYSA-N Nitric acid Chemical compound O[N+]([O-])=O GRYLNZFGIOXLOG-UHFFFAOYSA-N 0.000 description 1
- 101710163270 Nuclease Proteins 0.000 description 1
- GEYBMYRBIABFTA-VIFPVBQESA-N O-methyl-L-tyrosine Chemical compound COC1=CC=C(C[C@H](N)C(O)=O)C=C1 GEYBMYRBIABFTA-VIFPVBQESA-N 0.000 description 1
- 108700026244 Open Reading Frames Proteins 0.000 description 1
- 108091093037 Peptide nucleic acid Proteins 0.000 description 1
- 229920002352 Peptidyl-tRNA Polymers 0.000 description 1
- 229920002732 Polyanhydride Polymers 0.000 description 1
- 229920000954 Polyglycolide Polymers 0.000 description 1
- 239000004642 Polyimide Substances 0.000 description 1
- 229920001710 Polyorthoester Polymers 0.000 description 1
- 239000004721 Polyphenylene oxide Substances 0.000 description 1
- ZLMJMSJWJFRBEC-UHFFFAOYSA-N Potassium Chemical compound [K] ZLMJMSJWJFRBEC-UHFFFAOYSA-N 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- 108010002519 Prolactin Receptors Proteins 0.000 description 1
- 102100029000 Prolactin receptor Human genes 0.000 description 1
- 108010029485 Protein Isoforms Proteins 0.000 description 1
- 102000001708 Protein Isoforms Human genes 0.000 description 1
- 102000001253 Protein Kinase Human genes 0.000 description 1
- 108010076504 Protein Sorting Signals Proteins 0.000 description 1
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 1
- 230000010799 Receptor Interactions Effects 0.000 description 1
- 241000235070 Saccharomyces Species 0.000 description 1
- 241000239226 Scorpiones Species 0.000 description 1
- 229920002684 Sepharose Polymers 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- BLRPTPMANUNPDV-UHFFFAOYSA-N Silane Chemical group [SiH4] BLRPTPMANUNPDV-UHFFFAOYSA-N 0.000 description 1
- VMHLLURERBWHNL-UHFFFAOYSA-M Sodium acetate Chemical compound [Na+].CC([O-])=O VMHLLURERBWHNL-UHFFFAOYSA-M 0.000 description 1
- 108010068542 Somatotropin Receptors Proteins 0.000 description 1
- 241000191940 Staphylococcus Species 0.000 description 1
- 101000874347 Streptococcus agalactiae IgA FC receptor Proteins 0.000 description 1
- 108091008874 T cell receptors Proteins 0.000 description 1
- 108010092262 T-Cell Antigen Receptors Proteins 0.000 description 1
- 102100036011 T-cell surface glycoprotein CD4 Human genes 0.000 description 1
- 210000001744 T-lymphocyte Anatomy 0.000 description 1
- 108010006785 Taq Polymerase Proteins 0.000 description 1
- 108060008539 Transglutaminase Proteins 0.000 description 1
- 241000223259 Trichoderma Species 0.000 description 1
- 108090000848 Ubiquitin Proteins 0.000 description 1
- 102000044159 Ubiquitin Human genes 0.000 description 1
- 108020004417 Untranslated RNA Proteins 0.000 description 1
- 102000039634 Untranslated RNA Human genes 0.000 description 1
- 108010000134 Vascular Cell Adhesion Molecule-1 Proteins 0.000 description 1
- 102100023543 Vascular cell adhesion protein 1 Human genes 0.000 description 1
- NXALGSLCQTXAKO-UHFFFAOYSA-N [Cu].[Cu].[Cu].[Cu].[Cu].[Cu].[Cu].[Cu].[Cu].[Cu].[Cu].[Cu].[Cu].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn] Chemical compound [Cu].[Cu].[Cu].[Cu].[Cu].[Cu].[Cu].[Cu].[Cu].[Cu].[Cu].[Cu].[Cu].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Ag].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn].[Sn] NXALGSLCQTXAKO-UHFFFAOYSA-N 0.000 description 1
- AZJLCKAEZFNJDI-DJLDLDEBSA-N [[(2r,3s,5r)-5-(4-aminopyrrolo[2,3-d]pyrimidin-7-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl] phosphono hydrogen phosphate Chemical compound C1=CC=2C(N)=NC=NC=2N1[C@H]1C[C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O1 AZJLCKAEZFNJDI-DJLDLDEBSA-N 0.000 description 1
- 239000003070 absorption delaying agent Substances 0.000 description 1
- 239000013543 active substance Substances 0.000 description 1
- 229960000643 adenine Drugs 0.000 description 1
- 150000003838 adenosines Chemical class 0.000 description 1
- 239000002671 adjuvant Substances 0.000 description 1
- 238000001261 affinity purification Methods 0.000 description 1
- 125000001931 aliphatic group Chemical group 0.000 description 1
- 229910052784 alkaline earth metal Inorganic materials 0.000 description 1
- 150000001342 alkaline earth metals Chemical class 0.000 description 1
- 230000008850 allosteric inhibition Effects 0.000 description 1
- 229910052782 aluminium Inorganic materials 0.000 description 1
- XAGFODPZIPBFFR-UHFFFAOYSA-N aluminium Chemical compound [Al] XAGFODPZIPBFFR-UHFFFAOYSA-N 0.000 description 1
- 230000001668 ameliorated effect Effects 0.000 description 1
- 150000001412 amines Chemical class 0.000 description 1
- 125000003277 amino group Chemical group 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 238000000137 annealing Methods 0.000 description 1
- 230000030741 antigen processing and presentation Effects 0.000 description 1
- 239000008365 aqueous carrier Substances 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- 159000000032 aromatic acids Chemical class 0.000 description 1
- 239000011324 bead Substances 0.000 description 1
- JUHORIMYRDESRB-UHFFFAOYSA-N benzathine Chemical compound C=1C=CC=CC=1CNCCNCC1=CC=CC=C1 JUHORIMYRDESRB-UHFFFAOYSA-N 0.000 description 1
- 108010005774 beta-Galactosidase Proteins 0.000 description 1
- 102000005936 beta-Galactosidase Human genes 0.000 description 1
- 230000003115 biocidal effect Effects 0.000 description 1
- 239000002551 biofuel Substances 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 239000007844 bleaching agent Substances 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 239000001045 blue dye Substances 0.000 description 1
- 210000001124 body fluid Anatomy 0.000 description 1
- 239000010839 body fluid Substances 0.000 description 1
- 238000006664 bond formation reaction Methods 0.000 description 1
- 210000001185 bone marrow Anatomy 0.000 description 1
- 210000002798 bone marrow cell Anatomy 0.000 description 1
- DQXBYHZEEUGOBF-UHFFFAOYSA-N but-3-enoic acid;ethene Chemical compound C=C.OC(=O)CC=C DQXBYHZEEUGOBF-UHFFFAOYSA-N 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- 201000011510 cancer Diseases 0.000 description 1
- 239000002775 capsule Substances 0.000 description 1
- 239000004202 carbamide Substances 0.000 description 1
- 150000001720 carbohydrates Chemical class 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 238000006555 catalytic reaction Methods 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 230000007910 cell fusion Effects 0.000 description 1
- 230000010261 cell growth Effects 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- 238000001311 chemical methods and process Methods 0.000 description 1
- 238000007385 chemical modification Methods 0.000 description 1
- 239000000460 chlorine Substances 0.000 description 1
- 229910052801 chlorine Inorganic materials 0.000 description 1
- 229960004926 chlorobutanol Drugs 0.000 description 1
- ZYWFEOZQIUMEGL-UHFFFAOYSA-N chloroform;3-methylbutan-1-ol;phenol Chemical compound ClC(Cl)Cl.CC(C)CCO.OC1=CC=CC=C1 ZYWFEOZQIUMEGL-UHFFFAOYSA-N 0.000 description 1
- VDANGULDQQJODZ-UHFFFAOYSA-N chloroprocaine Chemical compound CCN(CC)CCOC(=O)C1=CC=C(N)C=C1Cl VDANGULDQQJODZ-UHFFFAOYSA-N 0.000 description 1
- 229960002023 chloroprocaine Drugs 0.000 description 1
- 229920001436 collagen Polymers 0.000 description 1
- 238000004440 column chromatography Methods 0.000 description 1
- 210000001520 comb Anatomy 0.000 description 1
- 230000002860 competitive effect Effects 0.000 description 1
- 230000009918 complex formation Effects 0.000 description 1
- 238000013329 compounding Methods 0.000 description 1
- 238000013270 controlled release Methods 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 1
- 235000018417 cysteine Nutrition 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- CYQFCXCEBYINGO-IAGOWNOFSA-N delta1-THC Chemical compound C1=C(C)CC[C@H]2C(C)(C)OC3=CC(CCCCC)=CC(O)=C3[C@@H]21 CYQFCXCEBYINGO-IAGOWNOFSA-N 0.000 description 1
- 238000000432 density-gradient centrifugation Methods 0.000 description 1
- 239000005547 deoxyribonucleotide Substances 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 150000001991 dicarboxylic acids Chemical class 0.000 description 1
- ZBCBWPMODOFKDW-UHFFFAOYSA-N diethanolamine Chemical compound OCCNCCO ZBCBWPMODOFKDW-UHFFFAOYSA-N 0.000 description 1
- UGMCXQCYOVCMTB-UHFFFAOYSA-K dihydroxy(stearato)aluminium Chemical compound CCCCCCCCCCCCCCCCCC(=O)O[Al](O)O UGMCXQCYOVCMTB-UHFFFAOYSA-K 0.000 description 1
- 208000035475 disorder Diseases 0.000 description 1
- 150000002019 disulfides Chemical class 0.000 description 1
- 239000008298 dragée Substances 0.000 description 1
- 239000006196 drop Substances 0.000 description 1
- 238000009510 drug design Methods 0.000 description 1
- 238000007876 drug discovery Methods 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 238000005538 encapsulation Methods 0.000 description 1
- 239000002702 enteric coating Substances 0.000 description 1
- 238000009505 enteric coating Methods 0.000 description 1
- BEFDCLMNVWHSGT-UHFFFAOYSA-N ethenylcyclopentane Chemical compound C=CC1CCCC1 BEFDCLMNVWHSGT-UHFFFAOYSA-N 0.000 description 1
- 239000005038 ethylene vinyl acetate Substances 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 230000005284 excitation Effects 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 239000013604 expression vector Substances 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 239000003889 eye drop Substances 0.000 description 1
- 238000000684 flow cytometry Methods 0.000 description 1
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 1
- 239000007850 fluorescent dye Substances 0.000 description 1
- 239000011888 foil Substances 0.000 description 1
- 238000004108 freeze drying Methods 0.000 description 1
- 238000007710 freezing Methods 0.000 description 1
- 230000008014 freezing Effects 0.000 description 1
- 238000007499 fusion processing Methods 0.000 description 1
- 150000004676 glycans Chemical class 0.000 description 1
- 239000003316 glycosidase inhibitor Substances 0.000 description 1
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 1
- 239000010931 gold Substances 0.000 description 1
- 229910052737 gold Inorganic materials 0.000 description 1
- 239000008187 granular material Substances 0.000 description 1
- 230000003394 haemopoietic effect Effects 0.000 description 1
- 125000001475 halogen functional group Chemical group 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 108091008039 hormone receptors Proteins 0.000 description 1
- 229940096329 human immunoglobulin a Drugs 0.000 description 1
- XMBWDFGMSWQBCA-UHFFFAOYSA-N hydrogen iodide Chemical compound I XMBWDFGMSWQBCA-UHFFFAOYSA-N 0.000 description 1
- 229940071870 hydroiodic acid Drugs 0.000 description 1
- 230000007062 hydrolysis Effects 0.000 description 1
- 238000006460 hydrolysis reaction Methods 0.000 description 1
- 125000004356 hydroxy functional group Chemical group O* 0.000 description 1
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 230000003053 immunization Effects 0.000 description 1
- 238000002649 immunization Methods 0.000 description 1
- 238000003018 immunoassay Methods 0.000 description 1
- 230000002163 immunogen Effects 0.000 description 1
- 238000012750 in vivo screening Methods 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 239000007972 injectable composition Substances 0.000 description 1
- 229940079322 interferon Drugs 0.000 description 1
- 108010085650 interferon gamma receptor Proteins 0.000 description 1
- 230000000968 intestinal effect Effects 0.000 description 1
- 210000000936 intestine Anatomy 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 239000012948 isocyanate Substances 0.000 description 1
- 150000002513 isocyanates Chemical class 0.000 description 1
- 150000002576 ketones Chemical class 0.000 description 1
- 238000011031 large-scale manufacturing process Methods 0.000 description 1
- 150000002611 lead compounds Chemical class 0.000 description 1
- 239000002523 lectin Substances 0.000 description 1
- 239000012669 liquid formulation Substances 0.000 description 1
- 239000012160 loading buffer Substances 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 108010054155 lysyllysine Proteins 0.000 description 1
- 239000011777 magnesium Substances 0.000 description 1
- 229910052749 magnesium Inorganic materials 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- MYWUZJCMWCOHBA-VIFPVBQESA-N methamphetamine Chemical compound CN[C@@H](C)CC1=CC=CC=C1 MYWUZJCMWCOHBA-VIFPVBQESA-N 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 238000007069 methylation reaction Methods 0.000 description 1
- 239000004530 micro-emulsion Substances 0.000 description 1
- 238000001471 micro-filtration Methods 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 239000004005 microsphere Substances 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- 150000007522 mineralic acids Chemical class 0.000 description 1
- 210000005087 mononuclear cell Anatomy 0.000 description 1
- 108091005763 multidomain proteins Proteins 0.000 description 1
- 231100000219 mutagenic Toxicity 0.000 description 1
- 230000003505 mutagenic effect Effects 0.000 description 1
- 210000005012 myelin Anatomy 0.000 description 1
- 102000025599 myosin binding proteins Human genes 0.000 description 1
- 108091014719 myosin binding proteins Proteins 0.000 description 1
- 210000004897 n-terminal region Anatomy 0.000 description 1
- 229910017604 nitric acid Inorganic materials 0.000 description 1
- 230000009871 nonspecific binding Effects 0.000 description 1
- 238000007344 nucleophilic reaction Methods 0.000 description 1
- 229940049964 oleate Drugs 0.000 description 1
- ZQPPMHVWECSIRJ-KTKRTIGZSA-N oleic acid Chemical compound CCCCCCCC\C=C/CCCCCCCC(O)=O ZQPPMHVWECSIRJ-KTKRTIGZSA-N 0.000 description 1
- 238000002515 oligonucleotide synthesis Methods 0.000 description 1
- 235000008390 olive oil Nutrition 0.000 description 1
- 239000004006 olive oil Substances 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 150000007524 organic acids Chemical class 0.000 description 1
- 235000005985 organic acids Nutrition 0.000 description 1
- 150000002895 organic esters Chemical class 0.000 description 1
- 229910052760 oxygen Inorganic materials 0.000 description 1
- 239000001301 oxygen Substances 0.000 description 1
- 238000007911 parenteral administration Methods 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 108010091617 pentalysine Proteins 0.000 description 1
- 239000000813 peptide hormone Substances 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 239000000546 pharmaceutical excipient Substances 0.000 description 1
- 230000003285 pharmacodynamic effect Effects 0.000 description 1
- 125000001997 phenyl group Chemical group [H]C1=C([H])C([H])=C(*)C([H])=C1[H] 0.000 description 1
- 208000026435 phlegm Diseases 0.000 description 1
- 239000006187 pill Substances 0.000 description 1
- 229920001200 poly(ethylene-vinyl acetate) Polymers 0.000 description 1
- 229920000747 poly(lactic acid) Polymers 0.000 description 1
- 229920000570 polyether Polymers 0.000 description 1
- 239000004633 polyglycolic acid Substances 0.000 description 1
- 229920001721 polyimide Polymers 0.000 description 1
- 239000004626 polylactic acid Substances 0.000 description 1
- 102000040430 polynucleotide Human genes 0.000 description 1
- 108091033319 polynucleotide Proteins 0.000 description 1
- 239000002157 polynucleotide Substances 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 239000011591 potassium Substances 0.000 description 1
- 229910052700 potassium Inorganic materials 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- MFDFERRIHVXMIY-UHFFFAOYSA-N procaine Chemical compound CCN(CC)CCOC(=O)C1=CC=C(N)C=C1 MFDFERRIHVXMIY-UHFFFAOYSA-N 0.000 description 1
- 229960004919 procaine Drugs 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 238000000159 protein binding assay Methods 0.000 description 1
- 108020001580 protein domains Proteins 0.000 description 1
- 108060006633 protein kinase Proteins 0.000 description 1
- 230000012743 protein tagging Effects 0.000 description 1
- 239000011535 reaction buffer Substances 0.000 description 1
- 230000035484 reaction time Effects 0.000 description 1
- 238000005215 recombination Methods 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 230000009467 reduction Effects 0.000 description 1
- 230000001172 regenerating effect Effects 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 210000001995 reticulocyte Anatomy 0.000 description 1
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical compound [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 1
- 239000002342 ribonucleoside Substances 0.000 description 1
- 238000002702 ribosome display Methods 0.000 description 1
- 108091092562 ribozyme Proteins 0.000 description 1
- 235000019515 salmon Nutrition 0.000 description 1
- 238000003118 sandwich ELISA Methods 0.000 description 1
- 238000007480 sanger sequencing Methods 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 230000019491 signal transduction Effects 0.000 description 1
- 229910052710 silicon Inorganic materials 0.000 description 1
- 239000010703 silicon Substances 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- 239000011734 sodium Substances 0.000 description 1
- 229910052708 sodium Inorganic materials 0.000 description 1
- 239000007909 solid dosage form Substances 0.000 description 1
- 229940075582 sorbic acid Drugs 0.000 description 1
- 235000010199 sorbic acid Nutrition 0.000 description 1
- 239000004334 sorbic acid Substances 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 210000000278 spinal cord Anatomy 0.000 description 1
- 230000003068 static effect Effects 0.000 description 1
- 230000001954 sterilising effect Effects 0.000 description 1
- 238000004659 sterilization and disinfection Methods 0.000 description 1
- 238000010254 subcutaneous injection Methods 0.000 description 1
- 239000007929 subcutaneous injection Substances 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 150000005846 sugar alcohols Polymers 0.000 description 1
- 229910052717 sulfur Inorganic materials 0.000 description 1
- 230000002459 sustained effect Effects 0.000 description 1
- 239000012730 sustained-release form Substances 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical group [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 description 1
- 238000011200 topical administration Methods 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 238000000844 transformation Methods 0.000 description 1
- 102000003601 transglutaminase Human genes 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
- 230000014621 translational initiation Effects 0.000 description 1
- 238000011269 treatment regimen Methods 0.000 description 1
- 229960005486 vaccine Drugs 0.000 description 1
- 238000001291 vacuum drying Methods 0.000 description 1
- 238000009777 vacuum freeze-drying Methods 0.000 description 1
- 235000015112 vegetable and seed oil Nutrition 0.000 description 1
- 239000008158 vegetable oil Substances 0.000 description 1
- 239000003981 vehicle Substances 0.000 description 1
- 125000000391 vinyl group Chemical group [H]C([*])=C([H])[H] 0.000 description 1
- 239000013603 viral vector Substances 0.000 description 1
- 238000012800 visualization Methods 0.000 description 1
- 239000001993 wax Substances 0.000 description 1
- 238000001262 western blot Methods 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
- 230000037303 wrinkles Effects 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
Images






















Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/1034—Isolating an individual clone by screening libraries
- C12N15/1086—Preparation or screening of expression libraries, e.g. reporter assays
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K19/00—Hybrid peptides, i.e. peptides covalently bound to nucleic acids, or non-covalently bound protein-protein complexes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/1034—Isolating an individual clone by screening libraries
- C12N15/1062—Isolating an individual clone by screening libraries mRNA-Display, e.g. polypeptide and encoding template are connected covalently
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/5308—Immunoassay; Biospecific binding assay; Materials therefor for analytes not provided for elsewhere, e.g. nucleic acids, uric acid, worms, mites
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/543—Immunoassay; Biospecific binding assay; Materials therefor with an insoluble carrier for immobilising immunochemicals
- G01N33/54366—Apparatus specially adapted for solid-phase testing
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/68—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids
- G01N33/6803—General methods of protein analysis not limited to specific proteins or families of proteins
- G01N33/6845—Methods of identifying protein-protein interactions in protein mixtures
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/68—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids
- G01N33/6854—Immunoglobulins
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/10—Immunoglobulins specific features characterized by their source of isolation or production
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/40—Immunoglobulins specific features characterized by post-translational modification
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/1034—Isolating an individual clone by screening libraries
- C12N15/1075—Isolating an individual clone by screening libraries by coupling phenotype to genotype, not provided for in other groups of this subclass
Abstract
본 발명은 시험관내에서 바람직한 특성을 갖는 폴리펩타이드를 확인하는데 유용한 방법 및 조성물에 관한 것이다.
Description
본 발명은 단백질 및 핵산의 바람직한 특성을 선택하여 개발하기 위한 조성물 및 방법을 제공한다.
관련 출원
본 출원은, 이의 내용이 본원에 참조로 인용된, 2008년 7월 25일자로 출원된 미국 가특허원 제61/083813호, 2008년 8월 19일자로 출원된 미국 가특허원 제61/090111호, 및 2009년 4월 16일자로 출원된 미국 가특허원 제61/170029호에 대한 우선권을 주장한다.
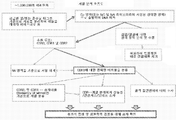
디스플레이 및 선택 기술의 사용시, 보다 큰 다양성으로의 접근은 보다 큰 친화성, 특이성, 안정성 및/또는 기타 바람직한 특성을 갖는 분자를 보다 효과적으로 선택하도록 한다는 것이 잘 공지되어 있다.
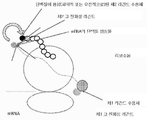
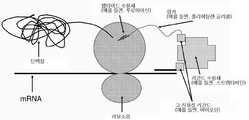
개발되어온 과거의 방법은 파아지 디스플레이, 리보소옴 디스플레이, CIS 디스플레이 및 mRNA 디스플레이를 포함한다. 최근에, 생체내 스크리닝을 사용하여 분자를 확인하는데 관심이 증가되고 있다[참조: J Control Release. 2003 Aug 28;91(1-2):183-6]. 당해 시도는 파아지 디스플레이의 사용으로 가능하게 달성되어 왔지만, 파아지 디스플레이 기술에 의해 제한된 다양성을 겪게 된다. 리보소옴 또는 mRNA 디스플레이는 RNA 종의 불안정성으로 인하여 이러한 적용에 실패할 수 있다. 따라서, DNA-단백질 융합체의 개발이 당해 종의 증가된 안정성으로 인해, 매우 바람직할 수 있다.
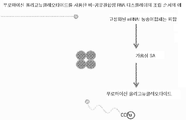
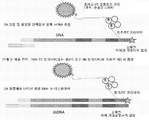
3가지 유형의 DNA-단백질 융합체가 기술되어 있다. CIS 디스플레이는 시험관내 전사/해독시 커플링되는 부위를 사용하여 전사 및 해독되는 동안 DNA에 공유 결합하는 dsDNA 결합 단백질을 생성하는 하나의 방법이다[참조: PNAS, 101(9): 2806-2810]. 그러나, 당해 기술의 주요 한계 중 하나는, 합성된 단백질이 전사/해독 과정 동안 근처에 있는 특정의 이웃하는 DNA에 결합함으로써 미스-태그된(mis-tagged) 융합체를 생성할 수 있다는 것이다. 두번째 방법은, 쿠르츠(Kurz) 및 로쎄(Lohse)의 방법이다[참조: Chembiochem. 2001 Sep 3;2(9):666-72]. 당해 방법은 해독된 단백질과 공유결합하여 RNA상의 공유결합성 부가물에서 리보소옴 휴지기(ribosome pause)를 생성하며, 역 전사용 프라이머로서 제공될 수 있는 다기능성 종을 사용하여 mRNA와의 공유결합성 부가물을 형성하는 것을 포함한다. 당해 방법의 한계는 소랄렌을 사용한 RNA와의 공유결합성 연결 단계의 비효율성이다. 세번째 방법은 요네자와(Yonezawa) 등의 방법[참조: Nucleic Acids Res. 2003 October 1; 31(19): e118.]이다. 당해 방법에서, 스트렙타비딘을 암호화하는 DNA 및 다양한 펩타이드의 영역은 바이오티닐화되어, 해독 머신을 가진 합성 미세구내에 위치되고 해독됨으로써 스트렙타비딘(사합체)이 바이오티닐화된 DNA에 결합하게 될 것이다. 당해 방법의 한계는, 수득되는 종이 사합체이며, 이것이 하나의 입자 상에서의 다수의 결합 종으로 인해 친화성 선택에 문제가 있을 수 있다는 것이다(재결합 효과).
본원에서는 핵산 및 단백질 사이에 비공유결합성 부착을 사용할 수 있고 DNA-단백질 융합체를 형성하도록 할, 요구되는 핵산 단백질 융합체를 생성하기 위한 간단하고, 효율적인 방법이 기술되어 있다.
발명의 요약
본 발명은 단백질 및 핵산의 바람직한 특성을 선택하여 개발하기 위한 조성물 및 방법을 제공한다. 각종 양태에서, 본 발명은 핵산 또는 변형된 핵산에 연결된 소 분자를 포함한다. 다른 양태는 아미노산이 변형된 펩타이드를 포함하는, 폴리펩타이드를 생산하는 방법, 바람직한 특성을 가진 집단의 개개의 구성원을 선택할 수 있는 검정, 및 특성이 개선된 폴리펩타이드의 새로운 변이를 생성하는 방법을 포함한다.
하나의 측면에서 본 발명은
(a) 폴리펩타이드-암호화 서열을 포함하는 제1 핵산 분자;
(b) 제1 핵산 분자에 의해 암호화된 폴리펩타이드; 및
(c) 제1 핵산 분자의 일부에 대해 상보성인 핵산 서열을 포함하는 제2 핵산 분자를 포함하며, 여기서, 제1 핵산 분자는 제2 핵산 분자에 상보성 핵산 염기 짝짓기(pairing)을 통해 결합되고, 제2 핵산 분자는 폴리펩타이드에 비-공유결합으로 결합된 이종양기능성 복합체(heterobifunctional complex)를 제공한다.
일부 양태에서, 당해 이종양기능성 복합체는 추가로:
(a) 제2 핵산 분자에 공유결합으로 결합된 고 친화성 리간드; 및
(b) 펩타이드 수용체에 결합된 리간드 수용체를 포함하며, 여기서, 고 친화성 리간드는 리간드 수용체에 결합되고 펩타이드 수용체는 폴리펩타이드에 공유결합으로 결합된다. 일부 양태에서, 당해 이종양기능성 복합체는 또한 제2 고 친화성 리간드를 포함하며, 여기서, 제2 고 친화성 리간드는 펩타이드 수용체에 공유결합으로 결합되고, 여기서, 제2 고 친화성 리간드는 리간드 수용체에 결합된다. 일부 양태에서, 당해 이종양기능성 복합체내 펩타이드 수용체는 제2 고 친화성 리간드에 링커를 통해 결합된다. 하나의 바람직한 양태에서, 링커는 폴리에틸렌 글리콜을 포함한다. 다른 바람직한 양태에서, 링커는 또한 폴리시알산 링커를 포함한다. 일부 양태에서, 당해 이종양기능성 복합체내 리간드 수용체는 펩타이드 수용체에 공유결합으로 결합된다.
일부 양태에서, 당해 이종양기능성 복합체는 추가로:
(a) 제2 핵산 분자에 공유결합으로 결합된 리간드 수용체; 및
(b) 펩타이드 수용체에 결합된 고 친화성 리간드를 포함하며, 여기서, 리간드 수용체는 고 친화성 리간드에 결합되고 펩타이드 수용체는 폴리펩타이드의 C-말단에 공유결합으로 결합된다.
다른 양태에서, 당해 이종양기능성 복합체는 추가로 제2 핵산 분자의 일부에 대해 상보성인 핵산 서열을 포함하는, 제3 핵산 분자를 포함하며, 여기서, 제3 핵산 분자는 제2 핵산 분자에 상보성 핵산 염기 짝짓기를 통해 결합되며, 여기서, 제3 핵산 분자는 펩타이드 수용체에 공유결합으로 결합되고, 여기서, 펩타이드 수용체는 폴리펩타이드에 공유결합으로 결합된다.
일부 양태에서, 위에서 기술된 복합체내 제2 핵산 분자는 측쇄 핵산 분자이다. 일부 양태에서, 위에서 기술된 복합체내 제2 핵산 분자는 제1 핵산 분자의 역 전사용 프라이머로서 작용할 수 있다.
다른 측면에서, 본 발명은
(a) 제1 고 친화성 리간드에 공유결합으로 결합된 폴리펩타이드-암호화 서열을 포함하는 핵산 분자;
(b) 핵산 분자에 의해 암호화된 폴리펩타이드;
(c) 펩타이드 수용체에 결합된 리간드 수용체를 포함하며, 여기서, 고 친화성 리간드가 리간드 수용체에 결합되고 펩타이드 수용체가 폴리펩타이드의 C-말단에 공유결합으로 결합된 X-디스플레이 복합체(예를 들면, 핵산 폴리펩타이드 복합체)를 제공한다.
일부 양태에서, 당해 X-디스플레이 복합체내 리간드 수용체는 펩타이드 수용체에 공유결합으로 결합된다. 일부 양태에서, 당해 X-디스플레이 복합체는 추가로 제2 고 친화성 리간드를 포함하며, 여기서, 제2 고 친화성 리간드는 펩타이드 수용체에 공유결합으로 결합되고, 여기서, 제2 고 친화성 리간드는 리간드 수용체에 결합된다.
다른 측면에서, 본 발명은
(a) 제1 고 친화성 리간드에 공유결합으로 결합된, 폴리펩타이드-암호화 서열을 포함하는 핵산 분자;
(b) 제2 고 친화성 리간드에 공유결합으로 결합된 제1 리간드 수용체; 및
(c) 제1 핵산 분자에 의해 암호화된 폴리펩타이드(여기서, 폴리펩타이드는 제2 리간드 수용체를 포함한다)를 포함하고, 여기서, 제1 고 친화성 리간드는 제1 리간드 수용체에 결합되며, 제2 고 친화성 리간드는 제2 리간드 수용체에 결합된 X-디스플레이 복합체를 제공한다.
일부 양태에서, 위에서 기술된 복합체에 결합된 제1 또는 제2 고 친화성 리간드는 바이오틴이다.
일부 양태에서, 위에서 기술된 복합체에 결합된 제1 또는 제2 고 친화성 리간드는 FK506, 메토트렉세이트, PPI-2458, 바이오틴, 히루딘, ZFVp(O)F, 글루오레세인-바이오틴, ABD(알부민 결합 도메인), 18bp DNA, RNAse A, 클로로알칸, 아릴(베타-아미노 에틸)케톤, 및 단백질 A를 포함하는 그룹 중에서 선택된다.
일부 양태에서, 위에서 기술된 복합체내 제1 또는 제2 리간드 수용체는 FKBP12, 디하이드로폴레이트 리덕타제, 메티오닌 아미노펩티다제, 이합체성 스트렙타비딘, 스트렙타비딘 사합체, 트롬빈, 카복시펩티다제, 1가 Ab, HSA(알부민), Zn 핑거(finger), hRI(RNase 억제제), 돌연변이된 할로알칸 데할로게나제, 할로태그, 및 소르타제를 포함하는 그룹 중에서 선택된다.
일부 양태에서, 위에서 기술된 복합체내 제1 또는 제2 리간드 수용체는 스프렙타비딘이다.
일부 양태에서, 위에서 기술된 폴리펩타이드는 항체, VH 도메인, VL 도메인, Fab 단편, 일본쇄 항체, 나노바디(nanobody), 유니바디(unibody), 아드넥틴, 아피바디(affibody), DARPin, 안티칼린, 아비머, 10Fn3 도메인, 및 베르사바디를 포함하는 그룹 중에서 선택된다.
다른 측면에서, 본 발명은
(a) 리간드에 공유결합으로 부착된, 폴리펩타이드-암호화 서열을 포함하는 핵산 분자; 및
(b) 제1 핵산 분자에 의해 암호화된 폴리펩타이드(여기서, 폴리펩타이드는 리간드 수용체를 포함한다)를 포함하고, 여기서, 리간드는 리간드 수용체에 결합된 X-디스플레이 복합체를 제공한다.
일부 양태에서, X-디스플레이 복합체에 결합된 리간드는 FK506이고 핵산-폴리펩타이드 복합체내 리간드 수용체는 FKBP의 FK506-결합 도메인이다.
일부 양태에서, 위에서 기술된 복합체에 결합된 제1 핵산 분자는 ssRNA, ssDNA, ssDNA/RNA 하이브리드 dsDNA, 및 dsDNA/RNA 하이브리드로 이루어진 그룹 중에서 선택된다.
일부 양태에서, 위에서 기술된 복합체에 결합된 제1 핵산 분자의 폴리펩타이드-암호화 서열은 골격내(in-frame) 정지 코돈을 함유하지 않는다.
일부 양태에서, 위에서 기술된 폴리펩타이드는 결합 단백질이다. 하나의 바람직한 양태에서, 결합 단백질은 항체의 VH 또는 VL 도메인이다.
일부 양태에서, 위에서 기술된 핵산-폴리펩타이드 복합체는 리보소옴을 함유하지 않는다.
다른 측면에서, 본 발명은 또한 위에서 기술된 X-디스플레이 복합체 다수를 포함하는 라이브러리를 제공하며, 여기서, 복합체의 적어도 일부는 상이한 폴리펩타이드-암호화 서열을 함유한다.
다른 측면에서, 본 발명은
- 제1 핵산 링커에 대해 상보성인 서열 성분을 포함하는 mRNA 서열의 라이브러리를 제공하는 단계
- 제1 고 친화성 리간드에 공유결합으로 연결된 제1 핵산 링커를 제공함으로써 제1 핵산 링커가 상보성 핵산 염기 짝짓기를 통해 mRNA에 결합하도록 하는 단계
- 펩타이드 수용체에 작동적으로 연결된 제2 고 친화성 리간드를 제공하는 단계
- 적어도 2개의 결합 부위를 가진 리간드 수용체를 제공함으로써 리간드 수용체가 제1 고 친화성 리간드 및 제2 고 친화성 리간드에 결합하도록 하는 단계
- mRNA의 해독이 일어나도록 함으로써 펩타이드 수용체가 해독된 단백질에 결합하여 mRNA를 단백질에 연결시키는 핵산-폴리펩타이드 복합체를 형성하는 단계를 포함하는, 핵산-폴리펩타이드 복합체의 라이브러리 방법을 제공한다.
일부 양태에서, 당해 방법은 추가로 X-디스플레이 복합체내 제1 핵산 링커를 프라이머로서 사용하여 mRNA가 역전사되도록 함으로써 DNA/RNA 하이브리드를 형성시킴을 포함한다.
하나의 바람직한 양태에서, 당해 방법은 또한
- mRNA를 분해하고 상보성 DNA 쇄를 합성함으로써 핵산-폴리펩타이드 복합체내에 DNA/DNA 하이브리드를 형성하는 단계를 포함한다.
일부 양태에서, 라이브러리내 mRNA는 TMV 인핸서를 추가로 포함한다.
일부 양태에서, 라이브러리내 mRNA는 Cμ 서열을 추가로 포함한다.
일부 양태에서, 라이브러리내 mRNA는 FLAG 태그를 추가로 포함한다.
일부 양태에서, 라이브러리내 mRNA는 SA 디스플레이 서열을 추가로 포함한다.
일부 양태에서, 라이브러리내 mRNA는 A20 테일을 추가로 포함한다.
다른 측면에서, 본 발명은 또한 본 발명에 기술된 방법에 의해 생산된 핵산-폴리펩타이드 복합체의 라이브러리를 제공한다.
다른 측면에서, 본 발명은 또한
(a) 본 발명에 기술된 X-디스플레이 복합체의 라이브러리를 제공하는 단계;
(b) 라이브러리를 목적한 항원과 접촉시키는 단계;
(c) 라이브러리로부터 목적한 항원에 결합하는 적어도 하나의 X-디스플레이를 선택하는 단계; 및
(d) 선택된 X-디스플레이 복합체의 서열을 암호화하는 폴리펩타이드를 분리하는 단계를 포함하여, 목적하는 항원에 결합할 수 있는 폴리펩타이드를 암호화하는 분리된 핵산 분자를 선택하는 방법을 제공한다.
다른 측면에서, 본 발명은 또한 본 발명에 기술된 방법에 의해 확인된 서열을 암호화하는 폴리펩타이드를 발현 환경내로 도입함으로써 암호화된 폴리펩타이드를 생산함을 포함하여, 목적한 항원에 결합할 수 있는 폴리펩타이드를 생산하는 방법을 제공한다.
다른 측면에서, 본 발명은 또한 본 발명에 기술된 방법에 의해 선택된, 목적한 항원에 결합할 수 있는 폴리펩타이드를 암호화하는 분리된 핵산을 제공한다.
다른 측면에서, 본 발명은 또한
(a) 폴리펩타이드-암호화 서열을 포함하는 제1 핵산 분자;
(b) 제1 핵산 분자에 의해 암호화된 폴리펩타이드;
(c) 제1 핵산 분자의 일부에 대해 상보성인 핵산 서열을 포함하는 제2 핵산 분자;
(d) 제2 핵산 분자에 공유결합으로 결합된 제1 고 친화성 리간드;
(e) 제1 리간드 수용체; 및
(f) 하나 이상의 연결 분자를 통해 펩타이드 수용체에 공유결합으로 결합된 제2 고 친화성 리간드를 포함하며, 여기서, 제1 핵산 분자가 제2 핵산 분자에 상보성 핵산 염기 짝짓기를 통해 결합되고, 여기서, 제1 고친화성 리간드가 제1 결합 부위에서 리간드 수용체에 비공유결합으로 결합되며, 여기서, 제2 리간드가 제2 결합 부위에서 리간드 수용체에 비공유결합으로 결합되고, 여기서, 하나 이상의 연결 분자가 폴리에틸렌 글리콜 분자인 X-디스플레이 복합체를 제공한다.
일부 양태에서, 당해 복합체내 제1 고 친화성 리간드는 바이오틴이고, 리간드 수용체는 스트렙타비딘, 이합체성 스트렙타비딘, 및 사합체성 스트렙타비딘을 포함하는 그룹 중에서 선택된다.
일부 양태에서, 당해 복합체내 제2 고 친화성 리간드는 바이오틴이고, 리간드 수용체는 스트렙타비딘, 이합체성 스트렙타비딘, 및 사합체성 스트렙타비딘을 포함하는 그룹 중에서 선택된다.
일부 양태에서, 당해 복합체내 제1 또는 제2 고 친화성 리간드는 FK506, 메토트렉세이트, PPI-2458, 바이오틴, 히루딘, ZFVp(O)F, 플루오레세인-바이오틴, ABD(알부민 결합 도메인), 18bp DNA, RNAse A, 클로로알칸, 아릴(베타-아미노 에틸)케톤 및 단백질 A를 포함하는 그룹 중에서 선택된다.
일부 양태에서, 당해 복합체는 제2 리간드 수용체를 추가로 포함한다.
일부 양태에서, 위에서 기술된 복합체내 제2 리간드 수용체는 FKBP12, 디하이드로폴레이트 리덕타제, 메티오닌 아미노펩티다제, 이합체성 스트렙타비딘, 스트렙타비딘 사합체, 트롬빈, 카복시펩티다제, 1가 Ab, HSA(알부민), Zn 핑거, hRI(RNase 억제제), 돌연변이된 할로알칼 데할로게나제, 할로태그, 및 소르타제를 포함하는 그룹 중에서 선택된다.
일부 양태에서, 당해 복합체내 펩타이드 수용체는 푸로마이신이다.
일부 양태에서, 당해 복합체내 제1 또는 제2 핵산 분자는 소랄렌을 추가로 포함한다.
일부 양태에서, 폴리펩타이드는 항체, VH 도메인, VL 도메인, Fab 단편, 일본쇄 항체, 나노바디, 유니바디, 아드넥틴, 아피바디, DARPin, 안티칼린, 아비머, 10Fn3 도메인, 및 베르사바디를 포함하는 그룹 중에서 선택된다.
다른 측면에서, 본 발명은
(a) 핵산 분자에 공유결합으로 결합된 제1 고 친화성 리간드;
(b) 펩타이드 수용체에 공유결합으로 결합된 제2 고 친화성 리간드; 및
(c) 2개 이상의 리간드 결합 부위를 포함하는 리간드 수용체를 포함하며; 여기서, 제1 및 제2 리간드가 인접한 리간드 결합 부위에서 리간드 수용체에 결합된 이종양기능성 복합체를 제공한다.
일부 양태에서, 당해 복합체내 제1 및 제2 고 친화성 리간드는 동일하다.
일부 양태에서, 당해 복합체내 제1 및 제2 고 친화성 리간드는 바이오틴이다.
일부 양태에서, 당해 복합체내 핵산 분자는 소랄렌 잔기를 포함한다.
일부 양태에서, 당해 복합체내 펩타이드 수용체는 푸로마이신이다.
일부 양태에서, 당해 복합체내 리간드 수용체는 다합체성 단백질이다.
일부 양태에서, 당해 복합체내 리간드 수용체는 스트렙타비딘이다.
본 발명은 단백질 및 핵산의 바람직한 특성을 선택하여 발전시키기 위한 조성물 및 방법을 제공한다. 당해 방법은 본원에서 "X-디스플레이"로서 언급되거나 스트렙타비딘이 사용되는 일부 양태에서 "SA 디스플레이"로 언급될 수 있다. 각종 양태에서, 본 발명은 핵산 또는 변형된 핵산에 연결된 소 분자를 포함한다. 다른 양태는 변형된 아미노산을 가진 펩타이드를 포함하는 폴리펩타이드를 생산하는 방법, 바람직한 특성을 가진 집단의 개개의 구성원을 선택할 수 있는 검정, 및 특성이 개선된 폴리펩타이드의 새로운 변이를 생성하는 방법을 포함한다.
"선택"은 집단내 다른 분자들로부터 분자를 실질적으로 분할함을 의미한다. 본원에 사용된 것으로서, "선택" 단계는 선택 단계 후 집단내 바람직하지 않은 분자에 비해 바람직한 분자를 적어도 2-배, 일부 양태에서, 3-배, 5-배, 10-배, 20-배, 바람직하게는 30-배, 보다 바람직하게는 100-배 및 가장 바람직하게는 1000-배로 풍부하게 제공한다. 선택 단계는 특정 수의 횟수만큼 반복할 수 있으며, 상이한 유형의 선택 단계를 제공된 시도내에서 조합시킬 수 있다.
"단백질"은 하나 이상의 펩타이드 결합에 의해 결합된 특정의 2개 이상의 천연적으로 존재하거나 변형된 아미노산을 의미한다. "단백질" 및 "펩타이드"는 본원에서 상호교환적으로 사용된다.
"RNA"는 2개 이상의 공유결합으로 결합된, 천연적으로 존재하거나 변형된 리보뉴클레오타이드의 서열을 의미한다. 당해 용어내에 포함된 변형된 RNA의 하나의 예는 포스포로티오에이트 RNA이다.
"DNA"는 2개 이상의 공유결합으로 결합된, 천연적으로 존재하거나 변형된 데옥시리보뉴클레오타이드의 서열을 의미한다.
"핵산"은 특정의 2개 이상의 공유결합으로 결합된 뉴클레오타이드 또는 뉴클레오타이드 유사체 또는 유도체를 의미한다. 본원에 사용된 것으로서, 당해 용어는 제한없이, DNA, RNA 및 PNA를 포함한다. 용어 "핵산"은 변형된 핵산을 포함할 수 있으며, 따라서, 핵산 및 변형된 핵산은 상호교환적으로 사용될 수 있다.
본원에 사용된 것으로서, 용어 "뉴클레오타이드 유사체" 또는 "뉴클레오타이드 유도체" 또는 "변형된 핵산"은 5-프로피닐 피리미딘(즉, 5-프로피닐-dTTP 및 5-프로피닐-dTCP), 7-데아자 푸린(즉, 7-데아자-dATP 및 7-데아자-dGTP)를 말한다. 뉴클레오타이드 유사체는 염기 유사체를 포함하며 데옥시리보뉴클레오타이드 및 리보뉴클레오타이드의 변형된 형태를 포함한다.
"펩타이드 수용체"는 리보소옴 펩티딜 트랜스퍼라제 기능의 촉매 활성에 의해 자라는 단백질 쇄의 C-말단에 가해질 수 있는 특정 분자를 의미한다. 통상적으로 이러한 분자는 (i) 뉴클레오타이드 또는 뉴클레오타이드-유사 잔기[예를 들면, 아데노신 또는 아데노신 유사체(N-6 아미노 위치에서 디-메틸화가 허용될 수 있다)], (ii) 아미노산 또는 아미노산-유사 잔기[예를 들면, 특정의 20D- 또는 L-아미노산 또는 이의 특정의 아미노산 유사체(예를 들면, O-메틸 타이로신 또는 Ellman et al., Meth. Enzymol. 202:301, 1991에 기술된 특정 유사체), 및 (iii) 2개(예를 들면, 3' 위치에서 또는 적어도 바람직하게는 2' 위치에서 에스테르, 아미드 또는 케톤 연결)사이의 연결을 함유하며; 바람직하게는, 당해 연결은 천연의 리보뉴클레오타이드 구조로부터 환의 주름을 현저히 교란하지 않는다. 펩타이드 수용체는 또한 친핵제를 소유할 수 있으며, 당해 친핵제는 아미노 그룹, 하이드록실 그룹 또는 설프하이드릴 그룹일 수 있으나, 이에 한정되지 않는다. 또한, 펩타이드 수용체는 뉴클레오타이드 모사체, 아미노산 모사체 또는 결합된 뉴클레오타이드-아미노산 구조의 모사체로 구성될 수 있다.
본원에 사용된 것으로서, 용어 "X-디스플레이 복합체", "핵산-폴리펩타이드 복합체" 및 "핵산-단백질 융합체"는 상호교환가능하며, 직접 또는 간접적으로 핵산 및 핵산에 의해 암호화된 단백질(또는 펩타이드 또는 이의 단편)의 상호작용으로부터 형성된 복합체를 언급함을 의미한다. 일부 예에서, X-디스플레이 복합체는 "디스플레이 복합체" 또는 "디스플레이 융합체"로 언급될 수 있으며 당해 분야의 숙련가들은, 이것이 본원에서 언급될 수 있는 다른 유형의 디스플레이 시스템과 혼돈되지 않을 수 있는 사용 측면에서 이해될 것이다. 일부 양태에서, 핵산은 RNA, 예를 들면, mRNA이다. 다른 바람직한 양태에서, 핵산은 DNA 또는 cDNA이다. 따라서, 목표가 DNA를 함유하는 복합체를 디스플레이하는 것인 일부 양태에서, X-디스플레이 복합체는 "DNA-단백질 융합체" 또는 "DNA-디스플레이 융합체"로 불릴 수 있다. 용어 "융합체"의 사용은, 핵산이 펩타이드 또는 단백질에 공유결합으로 부착되어 있음을 암시하거나 제한하지 않음을 주목하는 것이 중요하다. 일부 양태에서, RNA 또는 DNA는 변형되거나 변경될 수 있다. 바람직한 양태에서, 핵산과 단백질사이의 상호작용은 비공유결합성(예를 들면, 상호작용은 본원에 기술된 바와 같은 바이오틴/스트렙타비딘 상호작용, 링커 분자 등에 의해 중재될 수 있다)이다. 바람직한 양태에서, 핵산은 mRNA 또는 변형된 mRNA이다.
"변경된 기능"은 분자의 기능에 있어서 정성적이거나 정량적인 변화를 의미한다.
본원에 사용된 것으로서, "결합 파트너"는 목적한 DNA-단백질 융합체의 일부에 대해 특이적인, 공유결합 또는 비-공유결합 친화성을 갖는 특정 분자를 의미한다. 결합 파트너의 예는 항원/항체 쌍, 단백질/억제제 쌍, 수용체/리간드 쌍(예를 들면, 호르몬 수용체/펩타이드 호르몬 쌍과 같은 세포 표면 수용체/리간드 쌍), 효소/기질 쌍(예를 들면, 키나제/기질 쌍), 렉틴/탄수화물 쌍, 올리고머 또는 헤테로올리고머성 단백질 응집체, DNA 결합 단백질/DNA 결합 부위 쌍, RNA/단백질 쌍, 및 핵산 중복체, 헤테로중복체 또는 연결된 쇄, 및 X-디스플레이 복합체의 특정의 일부와 하나 이상의 공유결합성 또는 비-공유결합성 결합(예를 들면, 디설파이드 결합)을 형성할 수 있는 특정 분자를 포함하나, 이에 한정되지 않는다.
"고체 지지체"는, 친화성 복합체가 직접 또는 간접적으로(예를 들면, 다른 항체 또는 단백질 A와 같은 다른 결합 파트너 중간체를 통해) 결합될 수 있거나, 친화성 복합체가 봉매될 수 있는(예를 들면, 수용체 또는 채널을 통해), 특정 컬럼(또는 컬럼 물질), 비드, 시험 튜브, 미세역가 디쉬, 고체 입자(예를 들면, 아가로즈 또는 세파로즈), 미세칩(예를 들면, 규소, 규소-유리 또는 금 칩) 또는 막(예를 들면, 리포좀 또는 비히클의 막)을 의미하나, 이에 한정되지 않는다.
X-디스플레이 복합체를 중재하기 위한 핵산 또는 변형된 핵산 링커
본 발명의 하나의 측면에서 핵산(예를 들면, 천연의 mRNA 또는 변형된 mRNA)는 핵산의 3' 말단에서 하이브리드화되는 핵산 또는 변형된 핵산 링커("NA 링커")의 사용에 의해 해독 말단에서 자체의 암호화된 단백질에 부착될 수 있다. 이러한 양태에서, NA 링커는 링커내에서 역전된 극성을 지님으로써 효과적으로 2개의 3' 말단을 가지며, 이중 비-하이브리드화된 말단은 폴리펩타이드 단백질에 고 친화성으로 공유결합 또는 비공유결합으로 결합할 수 있는 푸로마이신 또는 관련 유사체 또는 소 분자에 부착되어 있다. 따라서, 일부 양태에서, X-디스플레이 복합체는 단백질 및 핵산과 NA 링커의 상호작용에 의해 형성된다.
일부 양태에서, NA 링커는 소랄렌 링커이다. 일부 바람직한 양태에서, 링커는 XB-PBI이다. 일부 양태에서, XB-DDB가 사용될 수 있다. 일부 바람직한 양태에서, 링커(예를 들면, PBI 링커 또는 DDB 링커)는 고 친화성 리간드(예를 들면, 바이오틴)에 부착되는데, 즉, 링커는 고 친화성 리간드를 포함한다.
일부 양태에서, 핵산(예를 들면, 천연의 mRNA 또는 변형된 mRNA)은 펩타이드 수용체 또는 고 친화성 리간드에 추가로 부착된 NA 링커에 가교 결합될 수 있다. 이러한 가교-결합은 당해 분야에 공지된 어떠한 방법에 의해서도 달성될 수 있다. 예를 들어, 본원에 이의 전문이 참조로 인용된 미국 특허 제6416950호는 이러한 가교결합을 제조하는 방법을 기술하고 있다(참조: 예를 들면, 미국 특허 제6416950호의 도 9 내지 13).
추가의 양태에서, 본 발명은 링커내에 역전된 5'-3' 극성을 가진 이중 기능 NA 링커를 포함함으로써, 핵산, 예를 들면, mRNA 또는 변형된 mRNA 주형에 하이브리드화할 수 있으며, 여기서, 하이브리드화는 암호화 영역의 mRNA 외부의 한쪽 3' 말단에서 일어나고, 여기서, 핵산/변형된 링커는 폴리펩타이드 단백질에 대해 공유결합으로 또는 고 친화성으로 결합할 수 있는 소 분자, 또는 푸로마이신 또는 이의 기능성 유사체(예를 들면, 이에 한정되지 않는, 피라졸로피리미딘)과 같은 펩타이드 수용체를 이의 다른 3' 말단상에서 수반한다.
몇몇 양태에서, 핵산, 바람직하게는, mRNA 또는 변형된 mRNA는 3' 말단에서 NA 링커에 대해 하이브리드화되며, NA 링커 자체는 펩타이드(또는 변형된 폴리펩타이드)에 공유결합성 결합 또는 고 친화성 비공유결합성 결합을 통해 공유결합으로 또는 고 친화성으로 결합되어 있다.
추가의 양태에서, NA 링커는 mRNA를 역전사하기 위한 프라이머로서 제공될 수 있다.
추가의 양태는 자체의 "5' 말단"(인용에서, 이는 3' 극성을 효과적으로 가짐으로써 중합화를 지시하기 때문이다)에서 역 극성 핵산 부위를 수반하는 NA 링커에 작동적으로 연결된 암호화 핵산을 포함함으로써, 이는 줄기 루프(stem loop) 구조를 통해 자체의 3' 말단상에 푸로마이신 또는 관련 유사체 또는 소 분자를 수반하는 NA 링커에 결합하는 자체의 능력 외에, 암호화 핵산 주형상에 중합화용 프라이머로서 제공될 수 있다.(참조: 도 2 및 3).
일부 양태에서, 암호화 핵산은 측쇄 NA 링커에 작동적으로 연결되며, 여기서, NA 링커 중 일부는 암호화 핵산의 3' 말단에 대해 상보성이다(참조: 도 5). 측쇄 NA 링커를 생성하는 어떠한 분야의 인지된 수단도 고려된다. 측쇄 점은 NA 링커내 어떠한 위치에서도 존재할 수 있다. 이러한 측쇄 NA 링커는 또한 이들이 결합되는 암호화 핵산, 예를 들면, mRNA의 역 전사용 프라이머로서 제공될 수 있다.
일부 양태에서, 암호화 핵산은 측쇄 NA 링커에 작동적으로 연결되며, 여기서, 링커는 펩타이드 수용체에 공유결합으로 부착된다(참조: 도 6).
일부 양태에서, NA 링커는 잠겨진(locked) 핵산(LNA), 예를 들면, 리보뉴클레오사이드가 2'-산소 및 4'-탄소 원자사이에 메틸렌 단위와 연결된 비사이클릭 핵산을 포함한다. 특수 양태에서, 암호화 핵산에 대해 상보성인 NA 링커의 영역은 LNA를 포함함으로써, 적어도 부분적으로, 핵산 이본쇄 안정성을 증가시킨다[참조: Kaur et al. (2006). Biochemistry 45 (23): 7347-55].
리간드
/수용체 연결
다른 측면에서, X-디스플레이 복합체(예를 들면, 암호화 핵산 및 암호화된 폴리펩타이드)는 자체의 인지체 결합 파트너(리간드 수용체)에 대해 고 친화성 또는 고 친화성 리간드의 공유결합성 결합을 통해 형성된다. 이러한 양태에서, 핵산은 고 친화성 리간드에 공유결합 또는 비공유결합으로 연결되어, 최종적으로 리간드 수용체에 비공유결합 또는 공유결합으로 결합할 수 있다. 바람직한 양태에서, 상호작용은 비공유결합성이다. 일부 양태에서, 리간드 수용체는 또한 제2의 고 친화성 리간드와 연합되며, 이는 최종적으로 펩타이드 수용체에 연결된다.
고 친화성 리간드/리간드 수용체 쌍의 비-제한적 예는 FK506/FKBP12, 메토트렉세이트/디하이드로폴레이트 리덕타제, 및 PPI-2458/메티오닌 아미노펩티다제 2를 포함하나, 이에 한정되지 않는다. 리간드/리간드 수용체 쌍의 추가의 비-제한적인 예는 표 1에 나타낸다. 일부 양태에서, 리간드/리간드 수용체 쌍은 바이오틴/스트렙타비딘이다. 단합체성 스트렙타비딘, 이합체성 스트렙타비딘, 사합체성 스트렙타비딘 및 화학적으로 또는 유전적으로 변형된 이의 변이체를 포함하나, 이에 한정되지 않는 어떠한 형태의 스트렙타비딘도 본 발명의 방법에서 사용하기 위해 고려된다. 일부 양태에서, 리간드 수용체는 사합체성 스트렙타비딘이다. 특수 양태에서, 사합체성 스트렙타비딘은 화학적으로 가교-결합되어 안정성을 증가시킨다.
| 고 친화성 리간드 |
리간드 크기 | 리간드 수용체 |
수용체 크기 |
Kd 또는 Ki | 참조 |
| 바이오틴 | 소 분자 | 스트렙타비딘 사합체 | 53kDa | 1-20fM | |
| 히루딘 | 65aa 펩타이드 | 트롬빈 | 36kDa | 20fM | |
| ZFVp(O)F | 트리펩타이드 | 카복시펩티다제 | 10-27fM | Biochemistry 1991, 30:8165-70 | |
| 플루오레세인-바이오틴 | 1가 Ab | 48fM | PNAS 2000, 97:10701-5 | ||
| ABD(알부민 결합 도메인) | 46aa | HSA(알부민) | 50-500fM | Prot. Eng. Des. Select. 2008, 21:515-27 | |
| 18bp DNA | Zn 핑거 | 6 Zn 핑거 도메인 | 2fM | PNAS 1998, 95:2812-17 | |
| RNAse A | 13kDa | hRI(RNase 억제제) | 50kDa | 290 aM-1 fM | JMB 2007, 368:434-449 |
| 클로로알칸 | 돌연변이된 할로알칸 데할로게나제, 할로태그 | 프로메가 | 비가역성 | ACS Chem.Bio 2008, 3:373-82 |
|
| 억제제 아릴(베타-아미노 에틸) 케톤 |
소 분자 | 소르타제 | 비가역성 | JBC 2007, 282:23129 소르타제 유전자의 확인 미국 특허 제7101692호 |
|
| 단백질 A | 항체 Fc 도메인 | 1fM |
일부 양태에서, 고 친화성 리간드는 핵산(리간드/핵산 분자)에 공유결합으로 연결된다. 핵산에 고 친화성 리간드를 연결하는 어떠한 분야의 인지된 방법도 고려된다. 하나의 양태에서, 고 친화성 리간드는 mRNA 분자의 3' 말단에 공유결합으로 연결된다
일부 양태에서, 고 친화성 리간드 수용체 분자는 펩타이드 수용체에 공유결합으로 연결되며, 이는 최종적으로 리보소옴의 펩티딜 트랜스퍼라제 활성에 의해 해독된 단백질에 공유결합으로 연결될 수 있다(참도: 도 8). 펩타이드 수용체에 대한 고 친화성 리간드 수용체의 연결은 직접적일 수 있거나 링커 분자를 통할 수 있다. 링커 분자를 인지하는 어떠한 분야도 본 발명의 방법에서 사용하기 위해 고려된다. 하나의 양태에서, 고 친화성 리간드 수용체는 폴리에틸렌 글리콜 링커 분자를 사용하여 펩타이드 수용체에 연결된다.
일부 양태에서, 고 친화성 리간드는 펩타이드 수용체에 공유결합으로 연결되며, 이는 최종적으로 리보소옴의 펩티딜 트랜스퍼라제 활성에 의해 해독된 단백질에 공유결합으로 연결될 수 있다(참조: 도 9). 일부 바람직한 양태에서, 이러한 리간드/펩타이드 수용체 분자는 다량체성 리간드 수용체, 예를 들면, 사합체성 스트렙타비딘을 통해 리간드/핵산 분자에 비-공유결합으로 연결될 수 있다. 펩타이드 수용체에 대한 고 친화성 리간드의 공유결합성 연결은 직접적일 수 있거나 링커 분자를 통할 수 있다. 어떠한 분야의 인지된 링커도 본 발명의 방법에서 사용하기 위해 고려된다. 특수 양태에서, 고 친화성 리간드는 펩타이드 수용체에 폴리에틸렌 글리콜 링커 분자를 사용하여 연결된다.
일부 양태에서, 리간드 수용체 분자는 핵산에 의해 암호화된 폴리펩타이드에 융합된다(참조: 도 4 및 10). 이러한 융합은 화학적 가교결합제를 사용하여 화학적으로 또는 유전적으로 수행될 수 있다. 리간드 수용체 분자는 어떠한 영역에서도 암호화된 폴리펩타이드에 융합될 수 있다. 특수 양태에서, 리간드 수용체 분자는 암호화된 폴리펩타이드의 N 말단 영역에 유전적으로 융합된다.
일부 양태에서, 제1 리간드 수용체 분자는 제2(비-인지체) 고 친화성 리간드에 공유결합으로 연결되어 있다. 이러한 양태에서, 제1 리간드 수용체 분자는 핵산에 공유결합으로 연결된 인지체 제1 고 친화성 리간드에 결합될 수 있다. 제2 고 친화성 리간드는 핵산에 의해 암호화된 폴리펩타이드에 융합된 인지체 제2 리간드 수용체에 결합될 수 있다.
바람직한 양태에서, 리간드 수용체 분자, 바람직하게는 다가 리간드 수용체(예를 들면, 다가 스트렙타비딘)은 mRNA 분자에 대해 상보성인 핵산에 공유결합으로 연결된, 제1 고 친화성 리간드(예를 들면, 바이오틴)에 비공유결합으로 결합한다. 다가 리간드 수용체는 또한 펩타이드 수용체(예를 들면, 푸로마이신)에 공유결합으로 연결된, 제2 고 친화성 리간드(예를 들면, 바이오틴)에 공유결합으로 결합한다. 제2 고 친화성 리간드는 펩타이드 수용체에 직접적으로 또는 링커(하기 기술한 바와 같이, 예를 들면, 폴리에틸렌 글리콜)를 통해 연결될 수 있다. 바람직한 양태에서, 제1 고 친화성 리간드에 부착된 핵산은 mRNA의 3' 말단에 대해 상보성이다. 핵산(예를 들어, NA 링커내 핵산)은 X-디스플레이 복합체의 핵산(예를 들면, mRNA)을 암호화하는 단백질에 안정하게 결합하기에 적어도 충분히 길 수 있다. 일부 양태에서, 제1 고 친화성 리간드에 부착된 핵산은, 길이가 15 내지 100개 뉴클레오타이드, 길이가 15 내지 80개 뉴클레오타이드, 길이가 15 내지 50개 뉴클레오타이드, 길이가 5 내지 40개 뉴클레오타이드, 길이가 15 내지 30개 뉴클레오타이드, 길이가 15 내지 20개 뉴클레오타이드, 길이가 10 내지 20개 뉴클레오타이드, 또는 길이가 15 내지 18개 뉴클레오타이드이다. 일부 양태에서, 제1 고 친화성 리간드에 부착된 핵산은, 길이가 15개 뉴클레오타이드, 길이가 18개 뉴클레오타이드, 길이가 20개 뉴클레오타이드, 길이가 30개 뉴클레오타이드, 길이가 50개 뉴클레오타이드, 길이가 70개 뉴클레오타이드, 길이가 80개 뉴클레오타이드 또는 길이가 87개 뉴클레오타이드이다.
본 발명의 몇몇 양태는 mRNA 또는 변형된 mRNA, 푸로마이신 또는 유사체 또는 소 분자에 작동적으로 연결된 NA, 및 함께 mRNA에 의해 암호화되어 연결된 mRNA-폴리펩타이드 복합체를 형성하는 폴리펩타이드를 안정하게 연결하는 방법을 포함한다.
바람직한 양태에서, NA 링커는 mRNA-폴리펩타이드 복합체 상에서 핵산의 제2 쇄를 중합시켜 폴리펩타이드에 연결된 핵산 이본쇄를 형성하기 위한 프라이머로서 사용된다. 바람직한 양태에서, 중합화는 DNA(또는 변형된 DNA) 하이브리드를 형성하기 위한 역 전사이다.
본 발명의 몇가지 양태는 바람직한 결합 특성을 가진 리간드를 제공하고, 복합체를 리간드와 접촉시키며, 결합하지 않은 복합체를 제거하고, 리간드에 결합된 복합체를 회수하는 다수의 명백한 X-디스플레이 복합체를 포함하는 방법을 포함한다.
본 발명의 몇가지 방법은 핵산 분자 및/또는 단백질의 발전을 포함한다. 하나의 양태에서, 본 발명은 회수된 복합체의 핵산 성분을 증폭시켜 핵산의 서열에 변이를 도입시킴을 포함한다. 다른 양태에서, 당해 방법은 또한 증폭되고 변화된 핵산으로부터 폴리펩타이드를 해독하고, 이들을 함께 핵산/변형된 링커를 사용하여 연결시키고, 이들을 리간드와 접촉시켜 결합된 복합체의 다른 새로운 집단을 선택함을 포함한다. 본 발명의 몇가지 양태는, 선택된 mRNA를 변이를 지니도록 재생산하고, 해독하며 다시 선택용 인지체 단백질에 연결시키는 시험관내 발전의 과정, 특히 반복된 과정에서 선택된 단백질-mRNA 복합체를 사용한다.
링커
잔기
일부 양태에서, 본 발명은 하나 이상의 링커 잔기(위에서 기술한 NA 링커와는 별개로)를 사용한다. 일부 양태에서, 링커 잔기를 사용하여 핵산을 펩타이드 수용체에 연결할 수 있다. 다른 양태에서, 링커 잔기를 사용하여 고 친화성 리간드(예를 들면, 바이오틴) 또는 리간드 수용체(예를 들면, 스트렙타비딘)를 펩타이드 수용체에 연결할 수 있다. 다른 양태에서, 링커 잔기를 사용하여 핵산을 고 친화성 리간드에 연결할 수 있다. 본원에 사용된 것으로서, 용어 "링커 잔기"는 하나 이상의 잔기 또는 소단위를 포함할 수 있다.
일부 바람직한 양태에서, 링커 잔기는 폴리에테르 골격을 갖는 화합물의 종인 폴리(알킬렌 옥사이드) 잔기이다. 본 발명에서 사용하는 폴리(알킬렌 옥사이드) 종은 예를 들면, 직쇄- 및 측쇄- 종을 포함할 수 있다. 예를 들면, 폴리(에틸렌 글리콜)은 말단에 추가의 반응성, 활성화가능하거나 불활성인 잔기를 포함하거나 포함하지 않을 수 있는, 반복된 에틸렌 옥사이드 소단위로 이루어진 폴리(알킬렌 옥사이드)이다. 이종양기능성인 직쇄 폴리(알킬렌 옥사이드) 종의 유도체는 또한 당해 분야에 공지되어 있다. 일부 양태에서, 링커 잔기는 5 내지 50개 소단위의 폴리(알킬렌 옥사이드), 10 내지 30개 소단위의 폴리(알킬렌 옥사이드), 10 내지 20개 단위의 폴리(알킬렌 옥사이드), 15 내지 20개 단위의 폴리(알킬렌 옥사이드), 또는 일부 양태에서, 18개 소단위의 폴리(알킬렌 옥사이드)로 구성될 수 있다. 당해 분야의 숙련가는, 특정 수의 링커 잔기가 여전히 X-디스플레이 복합체를 형성할 수 있는 한 사용될 수 있음을 인지할 것이다.
폴리(에틸렌 글리콜)링커는 폴리(에틸렌 글리콜)("PEG") 및 메톡시-PEG("mPEG") 유도체를 포함하는, PEG 골격 또는 mPEG 골격을 가진 잔기이다. 광범위한 PEG 및 mPEG 유도체가 단해 분야에 공지되어 있으며 상업적으로 시판된다. 예를 들어, 넥타르 인코포레이션(Nektar, Inc., 미국 알라바바 헌트스빌 소재)은 친핵성 반응 그룹, 카복실 반응 그룹, 친핵적으로 활성화된 그룹(예를 들면, 활성 에스테르, 니트로페닐 카보네이트, 이소시아네이트, 등), 설프하이드릴 선택성 그룹(예를 들면, 말레이미드), 및 헤테로작용성(PEG 또는 mPEG의 양쪽 말단에 2개의 반응성 그룹을 갖는), 바이오틴 그룹, 비닐 반응성 그룹, 실란 그룹, 인지질 그룹 등을 임의로 갖는 개질 그룹 또는 링커로서 유용한 PEG 및 mPEG 화합물을 제공한다.
다른 양태에서, 링커 잔기는 당해 분야에 인지된 핵산 또는 다른 어떠한 링커일 수 있다. 예를 들면, 폴리시알산(PSA) 및 PSA 유도체가 사용될 수 있다(참조: 미국 특허 제5,846,951호, 미국 특허 공보 제US20080262209호 및 PCT 특허원 WO2005/016973호 및 WO-A-01879221호, 이들 모두는, 전문이 본원에 참조로 인용되어 있다).
비록 바람직한 펩타이드 수용체가 푸로마이신이라고 해도, 푸로마이신과 유사한 방식으로 작용하는 다른 화합물도 사용될 수 있다. 단백질 수용체용으로 다른 가능한 선택은 피라졸로피리미딘 또는 어떠한 관련된 유도체 및 tRNA-유사 구조, 및 당해 분야에 공지된 다른 화합물을 포함한다. 이러한 화합물은 아미노산 뉴클레오타이드, 페닐알라닐-아데노신(A-Phe), 타이로실 아데노신(A-Tyr), 및 알라닐 아데노신(A-Ala)과 같은 아데닌 또는 아데닌-유사 화합물에 연결된 아미노산, 및 페닐알라닐 3' 데옥시 3' 아미노 아데노신, 알라닐 3' 데옥시 3' 아미노 아데노신 및 타이로실 3' 데옥시 3' 아미노 아데노신과 같은 아미드-연결된 구조를 지닌 어떠한 화합물도 포함하나, 이에 한정되지 않으며; 이들 화합물 중 어느 것에서도, 어떠한 천연적으로-존재하는 L-아미노산 또는 이들의 유사체가 사용될 수 있다. 또한, 결합된 tRNA-유사 3' 구조-푸로마이신 접합체를 또한 본 발명에서 사용할 수 있다.
해독 시스템
본 발명의 몇가지 양태는, mRNA가 방출 인자들을 결여한 시험관내 해독 시스템내에서 해독되는 바람직한 방법을 이용한다. 이에 의해, 리보소옴은 정지 코돈에서 지체되어, 푸로마이신 또는 유사체 또는 소 분자가 폴리펩타이드 단백질에 공유결합으로 또는 고 친화성으로 결합하도록 하는 시간을 허용한다.
본 발명의 일부 양태에서, mRNA는, 적어도 하나의 방출 인자의 기능이 방출 인자 억제제에 의해 억제되는 시험관내 해독 시스템에서 해독된다. 적합한 억제제는 항-방출 인자 항체를 포함하나, 이에 한정되지 않는다.
당해 방법은 바람직하게는 시험관내 해독 시스템을 사용하여 수행되므로, 변형된 아미노산이 해독 기관내로 도입되어 화학적 변형을 지닌 폴리펩타이드를 창조할 수 있다는 것이 당해 분야에 공지되어 있다.
망상적혈구 용해질 시스템, 맥아 추출 시스템 또는 기타 적합한 시험관내 전사 시스템과 같은 각종의 시험관내 해독 시스템을 사용할 수 있다. 하나의 바람직한 양태에서 PURESystem(cosmobio.co.jp/export_e/products/proteins/products_ PGM_20060907_06.asp)이 사용된다. 세포-유리된 연속-유동(CFCF) 해독 시스템[참조: Spirin et al. (1988) Science 242: 1162]을 사용하여 라이브러리 구성원의 총 수율, 또는 경우에 따라, 사용 편의성을 증가시킬 수 있다. 정적인 시험관내 단백질 합성 시스템을 사용할 수 있다. 당해 시스템에서, 단백질 합성은 일반적으로 1시간 후에 중지하므로 라이브러리의 창조를 위한 시간 간격을 제한한다. CFCF 기술의 장점은, 단백질의 높은 수준 및 장기간 합성이 보다 크고 보다 다양한 단백질-RNA 복합체의 라이브러리를 생성할 수 있다는 것이다. CFCF 기술은 연장된 기간, 24시간 또는 그 이상에 걸쳐 단백질의 고-수준 합성을 위한 방법으로서 스피린(Spirin) 및 공동-연구자에 의해 기술되었다. 또한, CFCF 기술은 해독된 장치로부터 새로이-합성된 단백질의 분획화를 초래함으로써 이것이 단백질-핵산 복합체를 신속하게 봉쇄하도록 한다. CFCF 기술의 다른 적용은 펩타이드를 합성하기 위한 효율적인 방법을 포함한다. 예를 들어, 고-친화성으로 표적에 결합하는 펩타이드-융합체의 확인 후, 유리 펩타이드를 CFCF 기술을 사용하여 직접 합성하고 결합 검정에 사용할 수 있다.
폴리뉴클레오타이드를 폴리펩타이드(즉, 표현형)에 연결시키기 위한 다른 세포-유리된 기술, 예를 들면, ProfusionTM(참조: 예를 들면, 본원에 참조로 인용된 미국 특허 제6,348,315호; 제6,261,804호; 제6,258,558호; 및 제6,214,553호)을 또한 사용할 수 있다.
프로모터 서열, 터미네이터 서열, 폴리아데닐화 서열, 인핸서 서열, 마커 유전자 및 적절하게는 다른 서열을 포함하는 적절한 조절 서열을 함유하는 적합한 벡터를 선택하거나 작제할 수 있다. 벡터는 경우에 따라, 특수 발현 또는 시험관내 해독 시스템용의 플라스미드, 바이러스, 예를 들면, 파아지, 또는 파아지미드일 수 있다. 추가의 세부사항은 예를 들면, Molecular Cloning: a Laboratory Manual: 2nd edition, Sambrook et al., 1989, Cold Spring Harbor Laboratory Press를 참조한다. 예를 들면, 핵산 작제물의 제조, 돌연변이유발, 서열분석, DNA의 세포내로의 도입 및 유전자 발현, 및 단백질의 분석시 핵산의 조작을 위한 많은 공지된 기술 및 프로토콜이 문헌[참조: Current Protocols in Molecular Biology, Second Edition, Ausubel et al. eds., John Wiley & Sons, 1992]에 상세히 기술되어 있다. 삼브룩(Sambrook) 등 및 아우스벨(Ausubel) 등의 기술내용은 본원에 참조로 인용된다.
일부 양태에서, 플라스미드 또는 바이러스 벡터와 같은 발현 벡터는, 예를 들면, 발현될 DNA가 PCR 증폭된 DNA 쇄 내에서만 존재하는 경우, 사용되지 않는다.
일부 양태에서, 본 발명의 방법은, 모두 이의 전문이 본원에 참조로 인용된 미국 특허 제7,078,197호, 제6,429,300호, 제5,922,545호, 제7,195,880호, 제6,416,950호, 제6,602,685호, 제6,623,926호, 제6,951,725호, 또는 미국 특허원 제11/543,316호, 제10/208,357호에 기술된 방법 및/또는 조성물을 사용할 수 있다.
하나의 바람직한 양태에서, 올리고뉴클레오타이드 프라이머를 결합시키기에 충분한 3' 해독되지 않은 RNA의 영역 및 완전한 정지 코돈을 함유하는 mRNA는 방출 인자를 결여하는 시험관내 해독 시스템(예를 들면, PURESystem, cosmobio.co.jp/export_e/products/proteins/products_PGM_20060907_06.asp)에서 해독된다. 방출 인자는 펩티딜-tRNA에서 에스테르 결합의 가수분해 및 리보소옴으로부터 새로이 합성된 단백질의 방출을 개시한다. 방출 인자의 부재하에서, 리보소옴은 여전히 mRNA 상에서 지체될 것이다. 다음 DNA 올리고뉴클레오타이드를 혼합물에 가한다. 당해 올리고뉴클레오타이드는 mRNA의 3' 말단에 상보성이며 펩타이드 수용체 종을 리보소옴내로 전달하여 결합된 해독된 단백질과의 공유 부가물을 형성할 수 있는 링커와 함께 기능화된다. 일부 양태에서, 이는 가해진 NA 링커이다. 링커의 부착 부위는 3' 말단을 제외한 올리고뉴클레오타이드를 따라 어느곳에도 존재할 수 있다. 링커는 리보소옴내로 이르기에 충분한 길이가 되어야 할 필요가 있다. 부가물을 형성하는 종은 바람직하게는 푸로마이신 또는 피라졸로피리미딘 또는 어떠한 관련된 유도체이다.
링커의 신생(nascent) 단백질에 대한 공유결합성 첨가 후, EDTA를 가하여 리보소옴을 방출시키고, mRNA-올리고뉴클레오타이드-단백질 종을 후속적으로 분리하여, 역 전사에 적용시켜 DNA-단백질 융합체를 창조한다. 최종적으로 DNA의 제2 쇄를 특정 DNA 폴리머라제를 사용하여 가한다. 이러한 양태에서, 비록 mRNA-올리고뉴클레오타이드(예를 들면, NA 링커) 종이 공유결합으로 부착될 수 있다고 해도, NA 링커는 X-디스플레이 복합체내 어떠한 중재자 종에 공유결합으로 부착될 필요가 없다(예를 들어, 바이오틴/스트렙타비딘이 mRNA를 단백질에 브릿지하는데 사용되는 경우).
수득되는 DNA-단백질 융합체는 생체내 또는 시험관내 스크리닝 또는 진단 적용에 사용될 수 있다.
용도
본 발명의 방법 및 조성물은, 단백질 기술이 사용되어 치료학적, 진단학적 또는 산업적 문제를 해결하는 어떠한 영역에서도 상업적 적용을 갖는다. 당해 X-디스플레이 기술은 존재하는 단백질을 개선시키거나 변경시키고 바람직한 기능을 가진 신규 단백질을 분리하는데 유용하다. 이들 단백질은 천연적으로 존재하는 서열일 수 있거나, 천연적으로 존재하는 서열의 변경된 형태일 수 있거나, 부분적으로 또는 완전한 합성 서열일 수 있다.
본 발명의 방법을 사용하여 면역결합제, 예를 들면, 항체, 이의 결합 단편 또는 유사체, 일본쇄 항체, 촉매 항체, VL 및/또는 VH 영역, Fab 단편, Fv 단편, Fab' 단편, Dab 등과 같은 폴리펩타이드를 개발하거나 또는 개선시킬 수 있다. 일부 양태에서, 개선시킬 폴리펩타이드는 면역글로불린 또는 면역글로불린-유사 도메인을 갖는 특정의 폴리펩타이드, 예를 들면, 인터페론, 단백질 A, 안키린, A-도메인, T-세포 수용체, 피브로넥틴 III, 감마-크리스탈린, MHC 부류 분자의 항원 결합 도메인(예를 들면, CD8의 알파 및 베타 항원 결합 도메인), 유비퀴틴, 면역글로불린 상과의 구성원, 및 본원에서 참조로 인용된, 문헌[참조: Binz, A. et al. (2005) Nature Biotechnology 23:1257 및 Barclay (2003) Semin Immunol. 15(4):215-223]에서 고찰되는 바와 같은 많은 다른 것들을 지닌 특정 폴리펩타이드일 수 있다. 일부 양태에서, 사람 면역 레퍼토리로 부터 기원한 면역글로불린 라이브러리와 유사하게, 단일 라이브러리는 스캐폴드로서 많은 상이한 V-영역 서열을 사용하지만, 이들은 보두 기본적인 면역글로불린 폴딩을 공유한다. 일부 양태에서, 면역글로불린 또는 면역글로불린-유사 폴딩은 이황화물 결합에 의해 함께 유지된 몇가지(예를 들면, IgG의 경쇄 C-도메인의 경우에 7개)의 항-평행한 β-쇄를 포함하는 2개의 β-시트(sheet)를 포함하는 장벽 유형(barrel shape)의 단백질 구조이다. 따라서, 특정의 면역글로불린 또는 면역글로불린-유사 단백질, 이의 부위 또는 단편의 개선 또는 선택이 고려된다.
다른 적용에서, 본원에 기술된 X-디스플레이 기술은 면역글로불린 또는 면역글로불린-유사 도메인을 가지거나 가지지 않을 수 있는 특수 결합(예를 들면, 리간드 결합) 특성을 가진 단백질의 분리에 유용하다. 고도의 특수한 결합 상호작용을 나타내는 단백질은 비-항체 인지 시약으로서 사용되어 X-디스플레이 기술이 전통적인 모노클로날 항체 기술을 능가하도록 할 수 있다. 당해 방법에 의해 분리된 항체-유형의 시약은, 전통적인 항체가 이용되는, 진단 및 치료학적 적용을 포함하는 어떠한 영역에서도 사용될 수 있다.
바람직한 양태에서, 당해 방법은 면역결합제, 예를 들면, 항체 분자의 가변 영역 및/또는 CDR의 영역, 즉, 중쇄(VH)로부터의 쇄 및 경쇄(VL)로부터의 쇄인, 2개 쇄의 가변 영역으로 이루어진 항원 결합 활성에 관여하는 구조의 개선을 목표로 할 것이다. 바람직한 항원-결합 특성이 확인되면, 가변 영역(들)을 IgG, IgM, IgA, IgD, 또는 IgE와 같은 적절한 항체 부류로 가공할 수 있다. 당해 방법을 사용하여 사람 면역결합제 및/또는 다른 종으로부터의 면역결합제, 예를 들면, 특정의 포유동물 또는 비-포유동물 면역결합제, 낙타 항체, 상어 항체 등을 개선시키고/시키거나 선택할 수 있다.
본 발명을 사용하여 특정의 다수 질병을 치료하기 위한 사람 또는 사람화된 항체(또는 이의 단편)을 개선시킬 수 있다. 당해 적용에서, 항체 라이브러리를 개발하여 시험관내에서 스크리닝하여, 세포-융합 또는 파아지 디스플레이와 같은 기술에 대한 요구도를 제거한다. 하나의 중요한 적용에서, 본 발명은 일본쇄 항체 라이브러리를 개선시키는데 유용하다[참조: Ward et al., Nature 341:544 (1989); 및 Goulot et al., J. Mol. Biol. 213:617 (1990)]. 당해 적용을 위해, 다양한 영역을 사람 공급원(수용체의 가능한 역 면역 반응을 최소화시키기 위하여)으로부터 작제할 수 있거나 전체적으로 무작위처리된 카세트(라이브러리의 복잡성을 최대화하기 위하여)를 함유할 수 있다. 개선된 항체 분자를 스크리닝하기 위해, 후보물 분자의 혼주물을 표적 분자에 대한 결합에 대해 시험한다. 이후에, 선택이 하나의 라운드에서 다음 라운드로 진행되면서 보다 높은 수준의 스트링전시(stringency)를 결합 단계에 적용한다. 스트링전시를 증가시키기 위하여, 다수의 세척 단계, 과량의 경쟁자 농도, 완충제 조건, 결합 반응 시간의 길이, 및 면역화 매트릭스의 선택을 변경시킬 수 있다. 일본쇄 항체를 표준 항체를 설계하기 위해 간접적으로 또는 치료요법을 위해 직접적으로 사용할 수 있다. 이러한 항체는 항-자가면역 항체의 분리, 면역 제어, 및 AIDA와 같은 바이러스 질병용 백신의 개발시 다수의 강력한 적용을 갖는다.
하기에 상세한 바와 같이, 광범위한 항체 단편 및 항체 모사체 기술이 현재 개발되어 있고 당해 분야에 광범위하게 공지되어 있다. 도메인 항체, 나노바디 및 유니바디와 같은 다수의 이들 기술이 전통적인 항체 구조의 단편 또는 이에 대한 다른 변형을 사용한다 해도, 이들이 전통적인 항체 결합을 모사하면서, 이로부터 생성되고 명백한 메카니즘을 통해 기능하는 결합 구조를 사용하는, 아드넥틴, 아피바디, DARPin, 안티칼린, 아비머 및 베르사바디와 같은 변형 기술이 또한 존재한다. 이들 변형 구조 중 일부는 본원에 참조로 인용된 문헌[참조: Gill and Damle (2006) 17: 653-658]에서 고찰된다. 위에서 언급한 항체 유도체 및 결합제 모두는 본 발명의 방법에 의해 개선되고/되거나 선택될 수 있다. 일부 양태에서, 나노바디, 유니바디, 아드넥틴, 아피바디, DARPin, 안티칼린, 아비머 및 베르사바디를 생성하기 위한 당해 분야에 공지된 방법을 사용하여 초기 결합 단백질을 발견하여 이후 이를 본 발명에 따른 방법에 따라 이로부터 생산하여 선택할 수 있는 라이브러리의 생성을 위한 기본으로 제공할 수 있다. 달리는, 당해 분야에 이미 공지된 결합제를 직접 사용하여 본원에 기술된 방법과 함께 사용하기 위한 새로운 라이브러리를 창조할 수 있다.
일부 양태에서, 본원에 기술된 방법은 도메인 항체(dAb)의 개선을 표적으로 할 것이다. 도메인 항체는 사람 항체의 중쇄(VH) 또는 경쇄(VL)의 가변 영역에 상응하는, 항체의 가장 작은 작용적 결합 단위이다. 도메인 항체는, 분자량이 대략 13kDa이다. 도만티스(domantis)는 완전한 사람 VH 및 VH dAb의 일련의 거대하고 고도로 작용성인 라이브러리(각각의 라이브러리에서 백억개 이상의 상이한 서열)를 개발하여, 당해 라이브러리를 치료학적 표적에 대해 특이적인 dAb를 선택하는데 사용한다. 많은 통상적인 항체와는 대조적으로, 도메인 항체는 세균, 효모 및 포유동물 세포 시스템에서 잘 발현된다. 도메인 항체 및 이의 생산 방법의 추가의 세부사항은, 각각 이의 전문이 본원에 참조로 인용된, 미국 특허 제6,291,158호; 제6,582,915호; 제6,593,081호; 제6,172,197호; 제6,696,245호; 미국 특허원 일련 번호 제2004/0110941호; 유럽 특허원 제1433846호 및 유럽 특허 제0368684호 및 제0616640호; WO05/035572호, WO04/101790호, WO04/081026호, WO04/058821호, WO04/003019호 및 WO03/002609호를 참조로 하여 수득할 수 있다.
다른 양태에서, 본원에 기술된 방법은 나노바디의 개선을 표적으로 할 것이다. 나노바디는 천연적으로 존재하는 중쇄 항체의 독특한 구조 및 기능적 특성을 함유하는 항체-기원한 치료학적 단백질이다. 당해 중쇄 항체는 단일의 가변 도메인(VHH) 및 2개의 고정 도메인(CH2 및 CH3)를 함유한다. 중요하게는, 클로닝되고 분리된 VHH 도메인은 원래의 중쇄 항체의 완전한 항원-결합 특성을 지닌 완벽하게 안정한 폴리펩타이드이다. 나노바디는 사람 항체의 VH 도메인과 고도로 상동성을 가지며 또한 활성의 어떠한 손실없이 추가로 사람화될 수 있다. 중요하게는, 나노바디는 낮은 면역원성 효능을 가지며, 이는 나노바디 납 화합물을 사용한 영장류 연구에서 확인되었다.
나노바디는 소 분자 약물의 중합한 특성을 갖는 통상의 항체의 장점을 결합한다. 통상의 항체와 유사하게, 나노바디는 높은 표적 특이성, 이들의 표적에 대해 높은 친화성 및 낮은 고유 독성을 나타낸다. 그러나, 소 분자 약물과 유사하게 이들은 효소를 억제하고 수용체 틈(cleft)에 용이하게 접근할 수 있다. 또한, 나노바디는 극도로 안정하여, 주사 외의 수단으로 투여할 수 있으며(참조: 이의 본문이 본원에 참조로 인용된 WO 04/041867호) 제조하기 용이하다. 나노바디의 다른 장점은 이들의 작은 크기의 결과로서 일반적이지 않거나 숨겨진 에피토프를 인지하고, 이들의 독특하고 3-차원적인 약물 체재 유연성으로 인하여 단백질 표적의 강(cavity) 또는 활성 부위내로 고 친화성 및 선택성으로 결합하고, 반감기 및 약물 발견의 용이성 및 속도를 조절하는 것을 포함한다.
나노바디는 단일 유전자에 의해 암호화되며 대부분의 모든 원핵 및 진핵 숙주, 예를 들면, 이. 콜라이(E. coli)(참조: 이의 전문이 본원에 참조로 인용된 미국 특허 제6,765,087호), 곰팡이[예를 들면, 아스퍼길러스(Aspergillus) 또는 트리코데르마(Trichoderma)] 및 효모[예를 들면, 사카로마이세스(Saccharomyces), 클루이베로마이세스(Kluyveromyces), 한세눌라(Hansenula) 또는 피키아(Pichia)](참조: 예를 들면, 이의 전문이 본원에서 참조로 인용된 미국 특허 제6,838,254호)에서 효율적으로 생산된다. 생산 과정은 조절가능(scalable)하며 다수-킬로그람의 양의 나노바디가 생산된다. 나노바디는 통상의 항체와 비교하여 보다 우수한 안정성을 나타내므로, 이들은 긴 반감기, 즉시 사용 용액으로 제형화될 수 있다. 따라서, 본 발명의 방법을 사용하여 이들의 표적 분자에 대한 나노바디의 친화성을 개선시킬 수 있다.
당해 분야에 공지된 방법을 사용하여 나노바디(또는 본원에 기술된 다른 결합제/면역결합제)를 생성할 수 있다. 이러한 결합제는 이후에 본 발명의 방법에 따라 생산되고 선택될 수 있는 라이브러리의 생성을 위한 기본으로서 제공될 수 있다. 예를 들면, 나노클론 방법(참조: 예를 들면, 이의 전문이 본원에 참조로 인용된 WO06/079372호)은 B-세포의 자동화된 고-배출 선택을 기초로 하는, 바람직한 표적에 대한 나노바디를 생성하기 위한 독점적인 방법이며 본 발명의 내용에서 사용될 수 있다. 나노클론 방법으로부터 나노바디의 성공적인 선택은 본원에 기술된 방법에 의해 추가로 개선될 수 있는 초기 세트의 나노바디를 제공할 수 있다.
다른 양태에서, 본원에 기술된 방법은 유니바디의 개선을 표적으로 할 것이다. 유니바디는 다른 항체 단편 기술이지만, 이는 IgG4 항체의 힌지 영역의 제거를 기초로 한다. 힌지 영역의 제거는 필수적으로 전통적인 IgG4 항체의 크기의 1/2이고 IgG4 항체의 2가 결합 영역이 아닌 1가 결합 영역을 갖는 분자를 초래한다. IgG4 항체가 불활성이어서 면역 시스템과 상호작용하지 않으며, 이는, 면역 반응이 요구되지 않는 질병의 치료에 유리할 수 있고 이러한 장점은 유니바디에 인계되어 있음이 잘 공지되어 있다. 예를 들어, 유니바디는 이들이 결합한 세포를 억제하거나 무반응(silence)이도록 기능하나 사멸시키지 않을 수 있다. 또한, 암 세포에 대한 유니바디 결합은 이들이 증식하도록 자극하지 않는다. 또한, 유니바디는 전통적인 IgG4 항체의 크기의 약 1/2이므로, 이들은 매우 유리한 효능으로 보다 큰 고형 종양 전체에 우수하게 분포될 수 있다. 유니바디는 전체 IgG4 항체와 유사한 비율로 항체로부터 청소되며 이들의 항체에 대해 전체 항체와 유사한 친화성으로 결합할 수 있다. 유니바디의 추가의 세부사항은, 이의 전문이 본원에 참조로 인용된 특허공개 WO2007/059782호를 참조하여 수득할 수 있다.
다른 양태에서, 본원에 기술된 방법은 피브로넥틴 또는 아드넥틴 분자의 개선을 표적으로 할 것이다. 아드넥틴 분자는 피브로넥틴 단백질의 하나 이상의 도메인으로부터 기원한 가공된 결합 단백질이다(참조: Ward M., and Marcey, D., callutheran.edu/Academic_Programs/Departments/BioDev/omm/fibro/fibro.htm). 통상적으로, 피브로넥틴은 3개의 상이한 단백질 모듈, 제I형, 제II형, 및 제III형 모듈로 이루어진다. 피브로넥틴의 기능의 구조를 참조하기 위해서는, 본원에 참조로 인용된, 문헌[참조: Pankov and Yamada (2002) J Cell Sci. 115(Pt 20):3861-3, Hohenester and Engel (2002) 21:115-128, 및 Lucena et al. (2007) Invest Clin.48:249-262]을 참조한다.
기원하는 조직에 따라서, 피브로넥틴은 예를 들면, 1Fn3, 2Fn3, 3Fn3, 등으로 주목될 수 있는 다수의 제III형 도메인을 함유할 수 있다. 10Fn3 도메인은 인테그린 결합 모티프를 함유하며 또한 베터 쇄를 연결하는 3개의 루프를 함유한다. 이들 루프는 IgG 중쇄의 항원 결합 루프에 상응하는 것으로 고려될 수 있으며, 이들은 본원에서 하기 논의된 방법에 의해 변경되어 목적한 표적에 특이적으로 결합하는 피브로넥틴 및 아드넥틴 분자를 선택할 수 있다. 개발될 아드넥틴 분자는 또한 단순한 단합체성 10Fn3 구조 외에 10Fn3 관련 분자의 중합체로부터 기원할 수 있다.
비록 천연의 10Fn3 도메인이 통상적으로 인테그린에 결합한다고 해도, 아드넥틴 분자가 되도록 채택된 10Fn3 단백질은 목적한 항원에 결합하도록 변경된다. 따라서, 당해 분야의 숙련가에게 이용가능한 방법을 사용하여 본 발명의 방법과 혼용성인 10Fn3 변이체 및 돌연변이체 서열(이에 의해 라이브러리 형성)을 창조할 수 있다. 예를 들어, 10Fn3내 변경을 오류 빈발(error prone) PCR, 부위-지시된 돌연변이유발, DNA 셔플링(shuffling) 또는 본원에 언급된 다른 유형의 재조합적 돌연변이유발을 포함하나, 이에 한정되지 않는 당해 분야에 공지된 어떠한 방법에 의해서도 제조할 수 있다. 하나의 예에서, 10Fn3 서열을 암호화하는 DNA의 변이체를 시험관내에서 직접 합성할 수 있다. 달리는, 천연의 10Fn3 서열을 표준 방법을 사용하여 게놈으로부터 분리하거나 클로닝할 수 있으며(예를 들면, 본원에 참조로 인용된 미국 특허원 제20070082365호에서와 같이 수행), 이후에 당해 분야에 공지된 돌연변이유발 방법을 사용하여 돌연변이시킬 수 있다.
하나의 양태에서, 표적 단백질은 컬럼 수지 또는 미세역가 플레이트내 웰과 같은 고체 지지체 상에 고정시킬 수 있다. 이후에, 표적을 본원에 기술한 것으로서 강력한 결합 단백질 또는 X-디스플레이 복합체의 라이브러리와 접촉시킨다. 라이브러리는 10Fn3 서열의 돌연변이유발/무작위화 또는 10Fn3 루프 영역(베타 쇄는 아님)의 돌연변이유발/무작위화에 의해 야생형 10Fn3로 부터 기원한 10Fn3 클론 또는 아드넥틴 분자를 포함할 수 있다. 선택/돌연변이유발 과정은, 표적에 대해 충분한 친화성을 갖는 결합제가 수득될 때까지 반복할 수 있다. 본 발명에서 사용하기 위한 아드넥틴 분자는 아드넥서스(Adnexus)에 의해 사용된 PROfusionTM 기술[브리스톤-마이어스 스퀴브 캄파니(Briston-Myers Squibb company) 제공]을 사용하여 가공할 수 있다. PROfusion 기술은 위에서 언급한 기술을 기초로 하여 창조되었다[참조: 예를 들면, Roberts & Szostak (1997) 94:12297-12302]. 변경된 10Fn3 도메인의 라이브러리를 생성하고 본 발명으로 사용될 수 있는 적절한 결합제를 선택하는 방법은 다음 미국 특허 및 특허원 서류에 완전히 기술되어 있고 본원에서 참조로 인용되어 있다: 미국 특허 제7,115,396호; 제6,818,418호; 제6,537,749호; 제6,660,473호; 제7,195,880호; 제6,416,950호; 제6,214,553호; 제6623926호; 제6,312,927호; 제6,602,685호; 제6,518,018호; 제6,207,446호; 제6,258,558호; 제6,436,665호; 제6,281,344호; 제7,270,950호; 제6,951,725호; 제6,846,655호; 제7,078,197호; 제6,429,300호; 제7,125,669호; 제6,537,749호; 제6,660,473호; 및 미국 특허원 제20070082365호; 제20050255548호; 제20050038229호; 제20030143616호; 제20020182597호; 제20020177158호; 제20040086980호; 제20040253612호; 제20030022236호; 제20030013160호; 제20030027194호; 제20030013110호; 제20040259155호; 제20020182687호; 제20060270604호; 제20060246059호; 제20030100004호; 제20030143616호; 및 제20020182597호. 또한 이의 전문이 본원에 참조로 인용된 다음 문헌의 방법을 참조한다: Lipovsek et al. (2007) Journal of Molecular Biology 368: 1024-1041; Sergeeva et al. (2006) Adv Drug Deliv Rev. 58:1622-1654; Petty et al. (2007) Trends Biotechnol. 25: 7-15; Rothe et al. (2006) Expert Opin Biol Ther. 6:177-187; 및 Hoogenboom (2005) Nat Biotechnol. 23:1105-1116.
본 발명의 방법을 사용하여 개선시킬 수 있는 추가의 분자는 사람 피브로넥틴 모듈 1Fn3-9Fn3 및 11Fn3-17Fn3 및 비-사람 동물 및 원핵세포로부터의 관련 Fn3 모듈을 포함하나, 이에 한정되지 않는다. 또한, 테나신 및 운둘린과 같이, 10Fn3에 대해 서열 상동성을 갖는 다른 단백질로부터의 Fn3 모듈도 또한 사용할 수 있다. 면역글로불린-유사 폴딩을 갖는(그러나 VH 도메인과 관련되지 않는 서열을 갖는) 다른 예시적인 단백질은 N-카드헤린, ICAM-2, 티틴, GCSF 수용체, 사이토킨 수용체, 글리코시다제 억제제, E-카드헤린 및 항생제 색단백질을 포함한다. 관련 구조를 갖는 추가의 도메인은 마이엘린 막 부착 분자 P0, CD8, CD4, CD2, 제I 부류 MHC, T-세포 항원 수용체, CD1, C2 및 VCAM-1의 I-세트 도메인, 마이오신-결합 단백질 C의 I-세트 면역글로불린 폴딩, 마이오신-결합 단백질 H의 I-세트 면역글로불린 폴딩, 텔로킨의 I-세트 면역글로불린-폴딩, 텔리킨, NCAM, 트위친, 뉴로글리안, 성장 호르몬 수용체, 적혈구형성인자 수용체, 프롤락틴 수용체, GC-SF 수용체, 인터페론-감마 수용체, 베타-갈락토시다제/글루쿠로니다제, 베타-글루쿠로니다제 및 트랜스글루타미나제로부터 기원할 수 있다. 달리는, 하나 이상의 면역글로불린-유사 폴딩을 포함하는 어떠한 다른 단백질을 이용하여 본원에 기술된 방법에 의해 개선시킬 수 있는 아드넥틴-유사 결합 잔기를 생성시킬 수 있다. 이러한 단백질은 예를 들면, 프로그랜 SCOP를 사용하여 확인할 수 있다[참조: Murzin et al., J. Mol. Biol. 247:536 (1995); Lo Conte et al., Nucleic Acids Res. 25:257 (2000)].
다른 양태에서, 본 발명의 방법을 사용하여 아피바디 분자를 개선시킬 수 있다. 아피바디 분자는 스타필로코쿠스 단백질 A의 IgG-결합 도메인 중 하나로부터 기원한, 58개-아미노 잔기 단백질 도메인을 기초로 하는 친화성 단백질의 신규 부류를 나타낸다. 이들 3개의 나선 다발 도메인은, 이로부터 목적한 분자를 표적화하는 아피바디 변이체가 파아지 디스플레이 기술을 사용하여 선택될 수 있는, 조합 파아지미드 라이브러리의 작제를 위한 스캐폴드(scaffold)로서 사용되어 왔다[참조: Nord K, Gunneriusson E, Ringdahl J, Stahl S, Uhlen M, Nygren PA, Binding proteins selected from combinatorial libraries of an α-helical bacterial receptor domain, Nat Biotechnol 1997;15:772-7. Ronmark J, Gronlund H, Uhlen M, Nygren PA, Human immunoglobulin A (IgA)-specific ligands from combinatorial engineering of protein A, Eur J Biochem 2002;269:2647-55]. 당해 분야에 공지된 방법으로 생산될 수 있는 유사한 라이브러리는 본원에 기술된 X-디스플레이 기술을 사용하여 선택할 수 있다. 이들의 낮은 분자량(6kDa)과 조합된 아피바디 분자의 단순하고 강한 구조는 예를 들면, 검출 시약(참조: Ronmark J, Hansson M, Nguyen T, et al, Construction and characterization of affibody-Fc chimeras produced in Escherichia coli, J Immunol Methods 2002;261:199-211)으로서 및 수용체 상호작용을 억제(참조: Sandstorm K, Xu Z, Forsberg G, Nygren PA, Inhibition of the CD28-CD80 co-stimulation signal by a CD28-binding Affibody ligand developed by combinatorial protein engineering, Protein Eng 2003;16:691-7)하기 위한 광범위한 적용에 적합하도록 한다. 아피바디 및 이의 생산 방법의 추가의 세부사항은, 이의 전문이 본원에 참조로 인용된 미국 특허 제5,831,012호를 참조로 수득할 수 있다.
다른 양태에서, 본 발명의 방법은 DARPin을 개선시키는데 사용될 수 있다. DARPin(설계된 안키린 반복 단백질)은 비-항체 폴리펩타이드의 결합능을 발휘하도록 개발된 항체 모사체 DRP(설계된 반복 단백질) 기술의 하나의 예이다. 안키린 또는 루이신-풍부한 반복 단백질과 같은 반복 단백질은 항체와는 달리 세포내 및 세포외에서 발생하는 편재된 결합 분자이다. 이들의 독특한 모듈 구조는 반복 구조 단위(반복물)을 특징으로 하며, 이들은 함께 쌓여서 다양한 모듈성 표적-결합 표면을 나타내는 연장된 반복 도메인을 형성한다. 이러한 모듈방식을 기초로 하여, 고도로 다양화된 결합 특이성을 갖는 폴리펩타이드의 조합 라이브러리가 생성될 수 있다. 당해 방법은 가변적인 표면 잔기 및 반복 도메인내로의 이들의 무작위적인 조립을 나타내는 자가-혼용성 반복물의 컨센서스(consensus) 설계를 포함한다.
DARPins은 세균 발현 시스템내에서 매우 고 수율로 생산될 수 있으며, 이들은 대부분의 공지된 적합한 단백질에 속한다. 사람 수용체, 사이토킨, 키나제, 사람 프로테아제, 바이러스 및 막 단백질을 포함하는 광범위한 표적 단백질에 대한 고도의 특이적이고, 고-친화성인 DARPin을 선택한다. 단일-자리 나노몰 내지 피코몰 범위의 친화성을 갖는 DARPin을 수득할 수 있다.
DARPins은 ELISA, 샌드위치 ELISA, 유동 세포측정 검정(FACS), 면역조직화학(IHC), 칩 적용, 친화성 정제 또는 웨스턴 블롯팅(Western blotting)을 포함하는 광법위한 적용에서 사용되어 왔다. DARPins은 또한 예를 들면, 녹색 형광 단백질(GFP)에 융합된 세포내 마커 단백질로서 세포내 구획에서 고도로 활성인 것으로 입증되었다. DARPin은 또한 바이러스 도입을 pM 범위의 IC50으로 억제하는데 사용되었다. DARPin은 단백질-단백질 상호작용을 차단하는데 이상적일 뿐만 아니라, 효소로 억제한다. 프로테아제, 키나제 및 전달체가 가장 흔히 알로스테릭(allosteric) 억제 모드로 성공적으로 억제되어 왔다. 종양에서 매우 빠르고 특이적인 농축 및 혈액에 대한 매우 유리한 종양 비는, DARPin이 생체내 진단학적 또는 치료학적 시도에 적합하도록 한다.
DARPin 및 기타 DRP 기술에 관한 추가의 정보는 미국 특허원 공보 제2004/0132028호 및 국제 특허공개공보 WO 02/20565호서 찾을 수 있으며, 이들 둘다는, 본원에서 이의 전문이 참조로 인용된다.
다른 양태에서, 본 발명의 방법은 안티칼린을 개선시키는데 사용될 수 있다. 안티칼린은 추가의 항체 모사체 기술이지만, 당해 경우에 결합 특이성은 사람 조직 및 체액에서 천연적으로 및 풍부하게 발현되는 저 분자량 단백질의 계열인, 리포칼린으로부터 기원한다. 리포칼린은 화학적으로 민감하거나 불용성인 단백질의 생리학적 수송 및 저장과 관련한 생체내 기능 범위를 수행하기 위해 발전되어 왔다. 리포칼린은 단백질의 하나의 말단에서 4개의 루프를 지지하는 고도로 보존된 β-장벽을 포함하는 강한 고유 구조를 갖는다. 이들 루프는 개개 리포칼린사이에 결합 특이성에 있어서 변화를 고려한 분자의 당해 부분에서 결합 포켓(pocket) 및 구조적 차이에 대한 입구를 형성한다.
보존된 β-시트 구조에 의해 지지된 고가변성 루프의 전체 구조는 면역글로불린을 상기시키나, 리포칼린은 단일 면역글로불린 도메인보다 제한적으로 보다 큰 160 내지 180개 아미노산의 단일 폴리펩타이드 쇄로 구성된, 크기의 측면에서 항체와는 현저히 상이하다.
리포칼린을 클로닝하여 이들의 루프를 가공함으로써 안티칼린을 창조한다. 구조적으로 다양한 안티칼린의 라이브러리가 생성되었으며 안티칼린 디스플레이는 결합 기능의 선택 및 스크리닝에 이은, 원핵 또는 진핵세포 시스템에서 추가의 분석을 위한 가용성 단백질의 발현 및 생산을 허용한다. 이러한 안티칼린 라이브러리는 본 발명의 X-디스플레이 기술에 따라 사용될 수 있다. 연구들은, 사실상 특정 사람 표적 단백질에 대해 특이적인 안티칼린이 개발되어 분리되고 나노몰 이상 범위의 결합 친화성이 수득될 수 있음을 성공적으로 입증하여 왔다.
안티칼린은 또한 이중 표적화 단백질, 소위, 듀오칼린으로 체재화될 수 있다. 듀오칼린은 표준 제조 과정을 사용하여 하나의 용이하게 생산된 단합체성 단백질내에 2개의 별도의 치료학적 표적을 결합시키는 한편 이의 2개의 결합 도메인의 구조적 배향에 관계없이 표적 특이성 및 친화성을 유지한다. 본 발명의 방법에 의해 선택된 안티칼린은 듀오칼린 분자로 조립될 수 있다.
단일 분자를 통한 다수 표적의 모듈화는 하나 이상의 원인 인자를 포함하는 것으로 공지된 질병에서 특히 유리할 수 있다. 또한, 듀오칼린과 같은 2- 또는 1-가 결합 체재는 질병에서 세포 표면 분자를 표적화하거나, 신호 전달 경로에 있어 작용 효과를 중재하거나, 세포 표면 수용체의 결합 및 집단화를 통해 증가된 내재화 효과를 유도하는데 있어서 매우 강력하다. 또한, 듀오칼린의 높은 고유 안정성은 단합체성 안티칼린에 대해 혼용성이어서 듀오칼린에 대한 유연한 제형 및 전달 효능을 제공한다. 안티칼린에 대한 추가의 정보는, 이의 전문이 본원에 참조로 인용된 미국 특허 제7,250,297호 및 국제 특허출원 공보 WO 99/16873호에서 찾을 수 있다.
다른 양태에서, 본 발명의 방법은 아비머를 개선시키는데 사용될 수 있다. 본 발명의 내용에서 유용한 다른 항체 모사체 기술은 아비머이다. 아비머는 결합 및 억제 특성을 갖는 멀티도메인 단백질을 생성하는, 시험관내 엑손 셔플링 및 파아지 디스플레이에 의해 사람 세포외 수용체 도메인의 거대 계열로부터 발전된다. 다수의 독립적인 결합 도메인의 연결은 통상의 단일-에피토프 결합 단백질과 비교하여 항원항체결합력을 창조하고 개선된 친화성 및 특이성을 초래하는 것으로 밝혀졌다. 다른 강력한 장점은 에스케리키아 콜라이내에서 다중표적-특이적인 분자의 단순하고 효율적인 생산, 개선된 열안정성 및 프로테아제에 대한 내성을 포함한다. 소-나노몰 친화성을 갖는 아피머가 각종 표적에 대해 수득되었으며, 이들은 또한 본원에 기술된 방법에 의해 개선될 수 있다.
아비머에 대한 추가의 정보는, 이들 모두 이의 전문이 본원에 참조로 인용된, 미국 특허원 공보 제2006/0286603호, 제2006/0234299호, 제2006/0223114호, 제2006/0177831호, 제2006/0008844호, 제2005/0221384호, 제2005/0164301호, 제2005/0089932호, 제2005/0053973호, 제2005/0048512호, 제2004/0175756호에서 찾을 수 있다.
다른 양태에서, 본 발명의 방법은 베르사바디를 개선시키는데 사용될 수 있다. 베르사바디는 본 발명의 내용에서 사용될 수 있는 다른 항체 모사체 기술이다. 베르사바디는, 시스테인이 >15%인 3 내지 5 kDa의 소 단백질이며, 통상의 단백질이 가진 소수성 코어를 대체하여 고 이황화물 밀도의 스캐폴드를 형성한다. 소수성 코어를 포함하는, 다수의 소수성 아미노산을 소수의 이황화물로 대체하면 보다 작고, 보다 친수성(응집 및 비-특이적인 결합 없이)이며, 프로테아제 및 열에 대해 보다 내성이고, MHC 발현에 대부분 기여하는 잔기가 소수성이기 때문에 보다 낮은 밀도의 T-세포 에피토프를 갖는 단백질이 생성된다. 이들 특성 4개 모두는 면역원성에 영향을 미치는 것으로 잘 공지되어 있으며, 함께 이들은 면역원성에 있어서 큰 감소를 유발하는 것으로 예측된다.
베르사바디의 관찰은 예측하지 않은 낮은 면역원성을 나타내는 것으로 알려진 거머리, 뱀, 거미, 전갈, 뱀 및 아네모네에 의해 생산된 천연의 주사가능한 생약제로부터 기원한다. 선택된 천연의 단백질 계열로부터 출발하여, 크기를 설계하고 스크리닝함에 의해, 소수성, 단백질분해성 항원 프로세싱 및 에피토프 밀도가 천연의 주사가능한 단백질에 대한 평균보다 더욱 낮은 수준으로 최소화된다.
베르사바디의 구조가 제공되면서, 이들 항체 모사체는 다중-원자가, 다중-특이성, 반감기 메카니즘의 다양성, 조직 표적화 모듈 및 항체 Fc 영역의 부재를 포함하는 다재다능한 체재를 부여한다. 또한, 베르사바디는 이. 콜라이내에서 고 수율로 제조될 수 있으며, 이들의 친수성 및 작은 크기로 인하여, 베르사바디는 고도로 가용성이고 고 농도로 제형화될 수 있다. 베르사바디는 예상치못하게 열 안정성(이들은 비등할 수 있다)이며 연장된 반감기를 부여한다. 본원에 기술된 결합제의 품질 모두(예를 들면, 열 안정성, 염 안정성, 반감기, 면역원성, 표적 친화성 등)은 본원에 기술된 디스플레이 및 선택 방법(X-디스플레이 방법)에 의해 개선될 수 있다.
베르사바디에 관한 추가의 정보는, 이의 전문이 본원에 참조로 인용된 미국 특허원 공보 제2007/0191272호에서 찾을 수 있다.
다른 양태에서, 본 발명의 방법은 SMIPTM 분자를 개선시키는데 사용될 수 있다. SMIPsTM[소 모듈러 면역약제-트루비온 약제(Trubion Pharmaceuticals)]는 표적 결합, 효과기 작용, 생체내 반감기, 및 발현 수준을 유지하고 최적화하기 위해 가공되었다. SMIPS는 3개의 명백한 모듈러 도메인으로 이루어진다. 첫째로, 이들은 특이성을 부여하는 특정 단백질(예를 들면, 세포 표면 수용체, 일본쇄 항체, 가용성 단백질 등)로 이루어질 수 있는 결합 도메인을 함유한다. 둘째로, 이들은 결합 도메인과 효과기 도메인사이에 유연성 링커로서 제공되고, 또한 SMIP 약물의 다합체화를 조절하는데 도움을 주는 힌지 도메인을 함유한다. 최종적으로, SMIPS는 Fc 도메인 또는 다른 특이적으로 설계된 단백질을 포함하는 각종 분자로부터 기원할 수 있는 효과기 도메인을 함유한다. 상이한 결합, 힌지 및 효과기 도메인의 다양성을 갖는 SMIP의 단순한 작제를 허용하는 설계의 모듈 방식은 신속하고 통상화된 약물 설계를 제공한다. SMIPTM 분자의 결합 도메인은 또한 본원에 기술된 방법(예를 들면, X-디스플레이 방법)에 따른 디스플레이 및 선택에 적합한 라이브러리에 대한 기초로서 제공될 수 있다.
이들을 설계하는 방법의 예를 포함하는 SMIP에 대한 추가의 정보는 문헌[참조: Zhao et al. (2007) Blood 110:2569-77] 및 다음 미국 특허원 제20050238646호; 제20050202534호; 제20050202028호; 제20050202023호; 제20050202012호; 제20050186216호; 제20050180970호; 및 제20050175614호에서 찾을 수 있다.
위에서 제공된 항체 단편 및 항체 모사체 기술의 상세한 기술은 본 명세서의 내용에서 사용될 수 있는 모든 기술들의 포괄적인 목록인 것으로 의도되지 않는다. 예를 들어, 및 또한 제한하지 않고, 이의 전문이 본원에 의해 참조로 인용된 문헌[참조: Qui et al., Nature Biotechnology, 25(8) 921-929 (2007)]에 요약된 것으로서 상보성 결정 영역의 융합과 같은 대체 폴리펩타이드-계 기술을 포함하는 각종의 추가의 기술을 본 발명의 내용에서 사용할 수 있다.
본원에 기술된 X-디스플레이 복합체(예를 들면, 핵산-단백질 융합체 또는 DNA-단백질 융합체)를 앞서 기술된 특정 적용에 사용할 수 있거나 RNA-단백질 융합을 위해 고려할 수 있다. 상업적 용도는 시험관내 발전 기술[참조: 예를 들면, Szostak et al., 미국 특허원 제09/007,005호 및 미국 특허원 제09/247,190호; Szostak et al., WO98/31700호; Roberts & Szostak, Proc. Natl. Acad. Sci. USA (1997) vol. 94, p. 12297-12302)], 세포 mRNA로부터 기원한 cDNA 라이브러리의 스크리닝(참조: 예를 들면, Lipovsek et al., 1998년 8월 17일자로 출원된 미국 특허원 제60/096,818호), 및 단백질-단백질 상호작용을 기초로 한 새로윤 유전자의 클로닝(참조: Szostak et al., 미국 특허원 제09/007,005호 및 미국 특허원 제09,247,190호; Szostak et al., WO98/31700호), 및 단백질 디스플레이 실험에서 이들 융합체의 용도(참조: Kuimelis et al., 미국 특허원 제60/080,686호 및 미국 특허원 제09/282,734호)를 통한 바람직한 특성을 갖는 폴리펩타이드의 분리를 포함한다. 본 발명의 X-디스플레이 복합체(예를 들면, DNA-단백질 융합체)는 이미 기술되어 있거나, 이의 전문이 모두 본원에 참조로 인용된, 미국 특허 제6,416,950호; 제6,429,300호; 제6,194,550호; 제6,207,446호; 및 제6,214,553호에 기술된 것들과 같은 앞서 기술된 디스플레이 기술을 위해 고려된 어떠한 적용을 위해서도 사용될 수 있다. 이들 X-디스플레이 복합체(예를 들면, DNA-단백질 융합체)는 특히 약제 및 농업 분야에서 어떠한 적절한 치료학적, 진단학적 또는 조사 목적을 위해 사용될 수 있다.
새로운 촉매의 분리
본 발명은 또한 신규 촉매 단백질을 선택하는데 사용될 수 있다. 시험관내에서 선택 및 발전이 신규한 촉매 RNA 및 DNA의 분리를 위해 이미 사용되어 왔고, 본 발명에서, 신규 단백질 효소의 분리를 위해 사용된다(비-제한적인 예로서, 다당류를 보다 유용한 생연료로 전환시키는 것과 같이, 중합체의 보다 작고 보다 즉시 유용한 부산물로의 도입 메카니즘을 수행하기에 적합한 효소가 단순히 나열을 위해 제공된다). 당해 시도의 하나의 특수 예에서, 촉매는 촉매 전이 상태의 화학적 동족체에 결합시키기 위해 선택함으로써 간접적으로 분리할 수 있다. 다른 특수 예에서, 직접적인 분리는 기질과의 공유 결합 형성(예를 들면, 친화성 태그에 대해 연결된 기질을 사용하여)에 대해 선택하거나 분해(예를 들면, 특이적인 결합을 파괴하는 능력에 대해 선택함으로써 고체 지지체로부터 라이브러리의 촉매 구성원을 유리시킴에 의해)에 의해 수행할 수 있다.
새로운 촉매의 분리에 대한 당해 시도는 촉매 항체 기술보다 적어도 2개의 중요한 장점을 갖는다[참조: Schultz et al., J. Chem. Engng. News 68:26 (1990)]. 첫째로, 촉매 항체 기술에서, 초기 혼주물은 일반적으로 면역글로불린 폴딩에 제한되며; 대조적으로 X-디스플레이 복합체(DNA-단백질 융합체)의 개시 라이브러리는 복잡하게 무작위적일 수 있거나 제한없이, 공지된 효소 구조 또는 단백질 스캐폴드의 변이체로 이루어질 수 있다. 또한, 촉매 항체의 분리는 일반적으로 해독 상태 반응 유사체에 대한 결합에 이어 활성 항체에 대한 시험실적 스크리닝에 의해 초기 선택에 의존하며; 다시 대조적으로, 촉매작용에 대한 직접적인 선택은 RNA 라이브러리를 사용하여 앞서 입증된 바와 같이, X-디스플레이 라이브러리 시도를 사용하여 가능하다. 단백질 효소를 분리하기 위한 대체 시도에서, 해독-상태-동족체 및 직접적인 선택 시도가 결합될 수 있다.
당해 방법에 의해 수득된 효소는 매우 가치가 있다. 예를 들어, 개발될 개선된 화학적 과정을 허용하는 신규의 효과적인 산업적 촉매에 대한 강력한 요구가 현재 존재한다. 본 발명의 주요 장점은, 선택이 임의 조건에서 수행될 수 있고, 예를 들면, 생체내 상태에 제한되지 않는다는 것이다. 따라서, 본 발명은 예정된 환경, 예를 들면, 승온, 승압 또는 용매 농도의 환경에서 작용화하면서, 고도로 특이적인 형질전환(및 이에 의해 바람직하지 않은 부산물의 형성을 최소화시킬 수 있는)을 수행할 수 있는 신규 효소 또는 존재하는 효소의 개선된 변이체의 분리를 용이하게 한다.
시험관내
상호반응 트랩
X-디스플레이 기술은 또한 cDNA 라이브러리를 스크리닝하고 단백질-단백질 상호작용을 기초로 새로운 유전자를 스크리닝하는데 유용하다. 당해 방법에 의해, cDNA 라이브러리를 바람직한 공급원(예를 들면, 문헌: Ausubel et al., Current Protocols in Molecular Biology, John Wiley & Sons and Greene Publishing Company, 1994의 방법에 의해; 특히 5과 참조)으로부터 생성된다. 후보물 cDNA 각각은 X-디스플레이 복합체(예를 들면, DNA-단백질 융합체)로 본원에 기술된 기술을 사용하여 제형화할 수 있으며, 특수 분자와 상호작용하는 이들 복합체의 능력(또는 이들 융합체의 개선된 버젼)을 이후에 시험한다.
상호작용 단계가 시험관내에서 발생한다는 사실은 비특이적인 경쟁인자, 온도 및 이온 조건을 사용하여 반응 스트링전시의 조심스런 조절을 허용한다. 가수분해가능하지 않은 유사체(예를 들면, ATP 대 ATPgS)를 사용한 정상의 소 분자의 변경은 동일한 분자의 상이한 이형태체를 구별하는 선택을 제공한다. 당해 시도는, 선택된 결합 파트너의 핵산 서열이 관련되어 있으므로 용이하게 분리될 수 있기 때문에 많은 단백질의 클로닝 및 기능적 확인 둘다에 유용하다. 또한, 당해 기술은 특정의 사람 유전자의 기능 및 상호작용을 확인하는데 유용하다.
당해 방법을 또한 사용하여 개선된 반감기, 친화성 또는 가용성을 위해 폴리펩타이드 리간드를 개발하거나 개선시킬 수 있다. 본원에 기술된 X-디스플레이 복합체(예를 들면, DNA-단백질 융합체)는 분자 발전 및 인지 시도를 포함하는 바람직한 단백질에 대한 어떠한 선택 방법에서도 사용될 수 있다. 예시적인 선택 방법은, 모두 본원에 참조로 인용된, 초스탁(Szostak) 등의 미국 특허원 제09/007,005호 및 미국 특허원 제09/247,190호; 초스탁 등의 WO98/31700호; 문헌[참조: Roberts & Szostak, Proc. Natl. Acad. Sci. USA (1997) vol. 94, p. 12297-12302]; 리포브섹(Lipovsek) 등의 미국 특허원 제60/096,818호 및 미국 특허원 제09/374,962호; 및 쿠이멜리스(Kuimelis) 등의 미국 특허원 제60/080,686호 및 미국 특허원 제09/282,734호에 기술되어 있다.
라이브러리 생성, 스크리닝 및 친화성 성숙
일부 양태에서, 펩타이드 또는 유전자 라이브러리를 스크리닝하여 바람직한 품질(예를 들면, 특수 항원에 대한 결합)을 갖거나 본 발명의 방법에 따라 개선되거나 변형된 펩타이드를 확인할 수 있다. 관련 양태에서, 본원에 기술된 방법으로 생산되거나 선택된 특수 펩타이드는 또한 친화성 성숙 또는 돌연변이유발에 의해 관련 펩타이드 또는 핵산의 라이브러리를 생산하도록 변경될 수 있다. 자체로서, 본 발명의 하나의 측면은 항원에 결합하는 능력, 보다 높은 결합 친화성 등과 같은 바람직한 품질을 갖는 강력한 펩타이드(또는 이러한 펩타이드를 암호화하는 핵산)을 확인하기 위한 거대 라이브러리의 스크리닝을 포함할 수 있다. 당해 분야에 공지되거나 본원에 기술된 라이브러리 생성 및 표적 선택을 위한 어떠한 방법도 본 발명에 따라 사용될 수 있다.
본원에 기술된 방법에 따라(예를 들면, 적절한 태그, 상보성 서열 등을 가하기 위한), 당해 분야에 공지된 라이브러리 생성 방법을 사용하여 본원에 기술된 방법과 함께 사용하기에 적합한 라이브러리를 창조할 수 있다. 라이브러리 생성을 위한 일부 방법은, 본원에 참조로 인용된, 미국 특허원 제09/007,005호 및 제09/247,190호; 초스탁 등의 WO989/31700호; 문헌[참조: Roberts & Szostak (1997) 94:12297-12302]; 미국 특허원 제60/110,549호, 미국 특허원 제09/459,190호, 및 WO 00/32823호에 기술되어 있다.
하나의 양태에서, 라이브러리는 VH 도메인, 바람직하게는 사람 VH 도메인을 포함할 것이다. 특정 세포를 라이브러리 공급원으로서 사용할 수 있다. 일부 바람직한 양태에서, 라이브러리용 세포 공급원은 말초 혈액 단핵 세포(PBMC), 비장세포 또는 골수 세포(예를 들면, 특정 유형의 공여자 세포로부터의 라이브러리에서 수득할 수 있는 VH 라이브러리 다양성을 기술하는 도 36 참조)일 수 있다.
본 발명의 방법이 대체 양식으로 사용될 수 있음은 당해 분야의 숙련가에 의해 이해될 것이다. 예를 들어, 본원에 기술된 방법 중 하나에 의해 선택된 핵산 또는 단백질은 이로부터 과정을 다시 시작할 수 있는 신규 라이브러리의 생성을 위한 기초로서 제공될 수 있다. 이러한 순서도의 예는 도 22에 나타나 있으며, 여기서, 선택의 1회 라운드의 생성물이 새로운 라이브러리를 재생하기 위해 사용된다.
본원에 기술된 X-디스플레이 방법론은, 분자내 이황화물 결합이 선택 동안 펩타이드내에 존재하는 조건하에서 수행될 수 있다. 다른 양태에서, 이황화물 결합의 형성은 경우에 따라, 방지될 수 있다. 출발 라이브러리는 예를 들면, 직접적인 DNA 합성에 의해, 시험관내 또는 생체내 돌연변이 유발을 통해 수득할 수 있거나, 당해 분야에 공지된 어떠한 유용한 개시 라이브러리를 사용할 수 있다. 예를 들면, 본원에 인용된 문헌들 및 모두 본원에 이의 전문이 참조로 인용된 다음 문헌들에 기술된 라이브러리 및 상기 라이브러리의 제조 방법을 본 발명에 따라 사용할 수 있다: 미국 특허 제5,922,545호, 제7,074,557호.
바람직한 양태에서, 라이브러리는 VH 또는 VL 라이브러리이다. 표 2는 VH 도메인을 증폭시키기 위해 사용될 수 있는 예시적인 프라이머의 비-제한적인 세트를 제공한다.
| 표적 영역 | 프라이머 세부사항 | 프라이머 서열 | 서열 번호 |
| CD1 | IgM, cDNA 합성, 21mer | ACAGGAGACGAGGGGGAAAAG | 1 |
| CD1 | IgG, cDNA 합성, 20mer | GCCAGGGGGAAGACCGATGG | 2 |
| CD1 | IgA, cDNA 합성, 22mer | GAGGCTCAGCGGGAAGACCTTG | 3 |
| CD1 | Vk, cDNA 합성, 21mer | CAACTGCTCATCAGATGGCGG | 4 |
| CD1 | Vl, cDNA 합성, 21mer | CAGTGTGGCCTTGTTGGCTTG | 5 |
| CD2 | PCR 3' IgM, 21mer | GGTTGGGGCGGATGCACTCCC | 6 |
| CD2 | PCR 3' IgG, 21mer | CGATGGGCCCTTGGTGGARGC | 7 |
| CD2 | PCR 3' IgA, 21mer | CTTGGGGCTGGTCGGGGATGC | 8 |
| CD2 | PCR 3' Vk, 21mer | AGATGGTGCAGCCACAGTTCG | 9 |
| JD1-3CD2 | PCR 3' Vl, 42mer | AGATGGTGCAGCCACAGTTCGTAGGACGGTSASCTTGGTCCC | 10 |
| JD7CD2 | PCR 3' Vl, 42mer | AGATGGTGCAGCCACAGTTCGGAGGACGGTCAGCTGGGTGCC | 11 |
| VH1a | PCR5' VH1, 46mer | CAATTACTATTTACAATTACAATGCAGGTKCAGCTGGTGCAGTCTG | 12 |
| VH1b | PCR5' VH1, 46mer | CAATTACTATTTACAATTACAATGCAGGTCCAGCTTGTGCAGTCTG | 13 |
| VH1c | PCR5' VH1, 46mer | CAATTACTATTTACAATTACAATGSAGGTCCAGCTGGTACAGTCTG | 14 |
| VH1d | PCR5' VH1, 46mer | CAATTACTATTTACAATTACAATGCARATGCAGCTGGTGCAGTCTG | 15 |
| VH2 | PCR5' VH2, 46mer | CAATTACTATTTACAATTACAATGCAGRTCACCTTGAAGGAGTCTG | 16 |
| VH3a | PCR5' VH3, 46mer | CAATTACTATTTACAATTACAATGGARGTGCAGCTGGTGGAGTCTG | 17 |
| VH3b | PCR5' VH3, 46mer | CAATTACTATTTACAATTACAATGCAGGTGCAGCTGGTGGAGTCTG | 18 |
| VH3c | PCR5' VH3, 46mer | CAATTACTATTTACAATTACAATGGAGGTGCAGCTGTTGGAGTCTG | 19 |
| VH4a | PCR5' VH4, 42mer | CAATTACTATTTACAATTACAATGCAGSTGCAGCTGCAGGAG | 20 |
| VH4b | PCR5' VH4, 45mer | CAATTACTATTTACAATTACAATGCAGGTGCAGCTACAGCAGTGG | 21 |
| VH5 | PCR5' VH5, 46mer | CAATTACTATTTACAATTACAATGGARGTGCAGCTGGTGCAGTCTG | 22 |
| VH6 | PCR5' VH6, 46mer | CAATTACTATTTACAATTACAATGCAGGTACAGCTGCAGCAGTCAG | 23 |
| VH7 | PCR5' VH7, 46mer | CAATTACTATTTACAATTACAATGCAGGTGCAGCTGGTGCAATCTG | 24 |
| linkVk1a | PCR5' VK1, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGRACATCCAGATGACCCAG | 25 |
| linkVk1b | PCR5' VK1, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGGMCATCCAGTTGACCCAG | 26 |
| linkVk1c | PCR5' VK1, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGGCCATCCRGATGACCCAG | 27 |
| linkVk1d | PCR5' VK1, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGGTCATCTGGATGACCCAG | 28 |
| linkVk2a | PCR5' VK2, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGGATATTGTGATGACCCAG | 29 |
| linkVk2b | PCR5' VK2, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGGATRTTGTGATGACTCAG | 30 |
| linkVk3a | PCR5' VK3, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGGAAATTGTGTTGACRCAG | 31 |
| linkVk3a | PCR5' VK3, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGGAAATAGTGATGACGCAG | 32 |
| linkVk3a | PCR5' VK3, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGGAAATTGTAATGACACAG | 33 |
| linkVk4 | PCR5' VK4, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGGACATCGTGATGACCCAG | 34 |
| linkVk5 | PCR5' VK5, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGGAAACGACACTCACGCAG | 35 |
| linkVk6a | PCR5' VK6, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGGAAATTGTGCTGACTCAG | 36 |
| linkVk6b | PCR5' VK6, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGGATGTTGTGATGACACAG | 37 |
| linkVL1a | PCR5' VL1, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGCAGTCTGTGCTGACKCAG | 38 |
| linkVL1b | PCR5' VL1, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGCAGTCTGTGYTGACGCAG | 39 |
| linkVL2 | PCR5' VL2, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGCAGTCTGCCCTGACTCAG | 40 |
| linkVL3a | PCR5' VL3, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGTCCTATGWGCTGACTCAG | 41 |
| linkVL3b | PCR5' VL3, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGTCCTATGAGCTGACACAG | 42 |
| linkVL3c | PCR5' VL3, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGTCTTCTGAGCTGACTCAG | 43 |
| linkVL3d | PCR5' VL3, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGTCCTATGAGCTGATGCAG | 44 |
| linkVL4 | PCR5' VL4, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGCAGCYTGTGCTGACTCAA | 45 |
| linkVL5 | PCR5' VL5, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGCAGSCTGTGCTGACTCAG | 46 |
| linkVL6 | PCR5' VL6, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGAATTTTATGCTGACTCAG | 47 |
| linkVL7 | PCR5' VL7, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGCAGRCTGTGGTGACTCAG | 48 |
| linkVL8 | PCR5' VL8, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGCAGACTGTGGTGACCCAG | 49 |
| linkVL4/9 | PCR5' VL4/9, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGCWGCCTGTGCTGACTCAG | 50 |
| linkVL10 | PCR5' VL10, 48mer | GGCGGAGGTGGCTCTGGCGGTGGCGGATCGCAGGCAGGGCTGACTCAG | 51 |
바람직한 양태에서, 라이브러리의 핵산 작제물은 T7 프로모터를 함유한다. 라이브러리내 핵산은 당해 분야에 공지된 어떠한 방법에 의해 조작하여 핵산, 이의 해독 생성물, 또는 X-디스플레이 복합체의 생산, 선택 또는 정제에 유용한 적절한 프로모터, 인핸서, 스페이서 또는 태그를 가할 수 있다. 예를 들어, 일부 양태에서, 라이브러리내 서열은 TMV 인핸서, FLAG 태그를 암호화하는 서열, SA 디스플레이 서열 또는 폴리아데닐화 서열 또는 시그날을 포함할 수 있다. 일부 양태에서, 핵산 라이브러리 서열은 또한 RNA 또는 DNA 서열의 공급원을 확인하기 위한 독특한 공급원 태그를 포함할 수 있다. 일부 양태에서, 핵산 라이브러리 서열은 혼주물 태그를 포함할 수 있다. 혼주물 태그는 특수 라운드의 선택 동안 선택된 서열을 확인하는데 사용될 수 있다. 이는 예를 들면, 다수의 선택 라운드로부터의 서열이 이들이 기원하는 선택 라운드의 트랙의 손실없이 단일 수행에서 혼주되어 서열분석되도록 할 것이다.
이후에, 이본쇄 DNA 라이브러리를 시험관내에서 전사시켜 본원에 기술된 바와 같이, 펩타이드 수용체에 연합시킨다. 하나의 바람직한 양태에서, NA 링커 또는 고 친화성 리간드에 부착된 NA 링커(예를 들면, 바이오티닐화된 NA 링커)를 어닐링(예를 들면, DDB-1)시킨다. 일부 양태에서, NA 링커는 mRNA에 광가교결합된다. 특수 양태에서, 리간드 수용체, 예를 들어, 스트렙타비딘을 이후에 로딩한다. 추가의 양태에서, 펩타이드 수용체에 부착된 제2 고 친화성 리간드는 스트렙타비딘에 결합된다. 일부 양태에서, 제2의 고 친화성 리간드/펩타이드 수용체는 바이오틴-푸로마이신 링커, 예를 들면, BPP이다.
이후에, 시험관내 해독을 수행하며 여기서, 펩타이드 수용체는 인접한 해독 생성물과 반응한다.
정제 후 결과는 펩타이드-핵산 X-디스플레이 복합체의 라이브러리이다. 이러한 X-디스플레이 복합체는 이후에 바람직한 양태에서, 정제된 후 역 전사될 수 있다. X-디스플레이 복합체는 당해 분야에 공지된 어떠한 방법, 예를 들면, 친화성 크로마토그래피, 컬럼 크로마토그래피, 밀도 구배 원심분리, 친화성 태그 포획 등에 의해 정제될 수 있다. 바람직한 양태에서, 올리고-dT 셀룰로즈 정제가 사용되며, 여기서, X-디스플레이 복합체는 폴리-A 테일을 갖는 mRNA를 포함하도록 설계된다. 이러한 양태에서, 올리고-dT는 컬럼 또는 정제 장치내에서 셀롤로즈에 공유결합된다. 올리고-dT는 X-디스플레이 복합체내 mRNA의 폴리-A 테일과 상보성 염기 짝짓기에 관여함으로써 정제 장치를 통해 이의 진행을 방해한다. X-디스플레이 복합체는 물 또는 완충제로 후에 용출시킬 수 있다.
역 전사는 바람직한 양태에서, NA 링커, 고 친화성 리간드, 리간드 수용체, 펩타이드 수용체(가능하게는 제2의 고 친화성 리간드에 연결된) 또는 이의 일부 작동가능한 조합과의 연합을 통해 전사된 펩타이드에 비공유결합으로 연결된다.
이후에, 수득되는 정제된 X-디스플레이 복합체는 RNAse로 처리하여 나머지 mRNA를 분해한 후, 제2 쇄 DNA 합성에 의해 완전한 cDNA를 생성한다. 바람직한 양태에서, NA 링커내 핵산은 역 전사용 프라이머로서 제공될 수 있음에 주목한다. 따라서, cDNA는 고 친화성 리간드 및 X-디스플레이 복합체의 일부에 부착된 채로 잔존한다.
X-디스플레이 복합체는 또한, 고려되는 경우로서, X-디스플레이 복합체가 가공되어 태그를 함유하는 경우, 추가로 정제될 수 있다. 당해 분야에 공지된 어떠한 태그도 X-디스플레이 복합체를 정제하는데 사용할 수 있다. 예를 들면, 다른 것들 중에서 FLAG 태그, myc tac, 히스티딘 태그(His 태그), 또는 HA 태그를 사용하는 것이 가능하다. 바람직한 양태에서, FLAG 태그를 암호화하는 서열을 원래의 DNA 서열내로 가공함으로써 최종의 전사된 단백질은 FLAG 태그를 함유한다.
이후에, 수득되는 X-디스플레이 복합체를 당해 분야에 공지된 어떠한 선택 방법을 사용하여 선택한다. 바람직한 양태에서, 친화성 선택이 사용된다. 예를 들면, 바람직한 결합 표적 또는 항원을 친화성 컬럼에서 사용하기 위한 고체 지지체상에 고정시킬 수 있다. 친화성 크로마토그래피에 유용한 방법의 예는, 모두 이의 전문이 본원에 참조로 인용된, 미국 특허 제4,431,546호, 제4,431,544호, 제4,385,991호, 제4,213,860호, 제4,175,182호, 제3,983,001호, 제5,043,062호에 기술되어 있다. 결합 활성은 표준 면역검정 및/또는 친화성 크로마토그래피로 평가할 수 있다. 촉매적 기능, 예를 들면, 단백질분해적 기능을 위한 X-디스플레이 복합체의 스크리닝은 예를 들면, 미국 특허 제5,798,208호에 기술된 표준 헤모글로빈 플라크 검정을 사용하여 달성할 수 있다. 치료학적 표적에 결합하는 후보물 펩타이드(예를 들면, 항체, 일본 쇄 항체 등)의 능력의 측정은 예를 들면, 제공된 표적 또는 항원에 대한 항체의 결합 속도를 측정하는, 비아코어 장치를 사용하여 시험관내에서 검정할 수 있다.
바람직한 양태에서, 선택된 X-디스플레이 복합체는 DNA 성분의 서열분석에 의해 확인할 수 있다. 당해 분야에 공지된 어떠한 서열분석 기술, 예를 들면, 454 서열분석, 상거(Sanger) 서열분석, 합성에 의한 서열 분석, 또는 모두 이의 전문이 본원에 참조로 인용된 미국 특허 제5547835호, 제5171534호, 제5622824호, 제5674743호, 제4811218호, 제5846727호, 제5075216호, 제5405746호, 제5858671호, 제5374527호, 제5409811호, 제5707804호, 제5821058호, 제6087095호, 제5876934호, 제6258533호, 제5149625호에 기술된 방법을 사용할 수 있다.
일부 양태에서, 선택을 수회 수행하여 보다 높은 친화성 결합체를 확인하고 또한 경쟁적 결합제 또는 보다 강력한 스트링전시 세척 조건을 사용하여 실행할 수 있다. 당해 분야의 숙련가는, 본원에 기술된 과정의 변형을 사용할 수 있음을 인지할 것이다.
바람직한 양태에서, 본 발명의 방법은 도 14에 요약된 바와 같이 수행된다.
다른 바람직한 양태에서, X-디스플레이 복합체는 도 13 또는 도 16에 묘사된 바와 같이 설계된다.
본 발명의
펩타이드
또는 이의
모사체를
함유하는 약제학적 조성물
다른 측면에서, 본 발명은 본 발명의 방법에 의해 생성되고, 약제학적으로 허용되는 담쳬와 함께 제형화된, 펩타이드 하나 또는 이들의 조합(예를 들면, 2개 이상의 상이한 펩타이드)를 함유하는 조성물, 예를 들면, 약제학적 조성물을 제공한다. 본 발명의 약제학적 조성물은 또한 조합 치료요법에서 투여될 수 있는데, 즉, 다른 제제와 조합될 수 있다. 예를 들어, 조합 치료요법은 특수 질병 또는 증상을 치료하는데 유용한 다른 적절한 약제와 조합된 본 발명의 펩타이드 또는 이의 모사체를 포함할 수 있다.
본원에 사용된 것으로서, "약제학적으로 허용되는 담체"는 생리학적으로 혼용성인 특정의 및 모든 용매, 분산 매질, 피복제, 항세균제 및 항진균제, 등장성 및 흡수 지연제 등을 포함한다. 바람직하게는 담체는 정맥내, 근육내, 피하, 비경구, 척수 또는 상피 투여(예를 들면, 주사 또는 주입에 의해)에 적합하다. 투여 경로에 따라, 활성 화합물, 즉, 본 발명의 펩타이드 또는 이의 모사체를 물질내에 피복하여 화합물을 불활성화시킬 수 있는 산 및 다른 천연 조건의 작용으로부터 화합물을 보호할 수 있다.
본 발명의 약제학적 화합물은 하나 이상의 약제학적으로 허용되는 염을 포함할 수 있다. "약제학적으로 허용되는 염"은 모 화합물의 바람직한 생물학적 활성을 보유하며 어떠한 바람직하지 않는 독성 효과를 부여하지 않는 염을 말한다[참조: 예를 들면, Berge, S.M., et al.(1977) J. Pharm. Sci. 66:1-19]. 이러한 염의 예는 산 부가 염 및 염기 부가 염을 포함한다. 산 부가 염은 염산, 질산, 인산, 황산, 브롬화수소산, 요오드화수소산, 인산 등과 같은 비독성 무기산, 및 지방족 모노- 및 디카복실산, 페닐-치환된 알카노산, 하이드록시 알카노산, 방향족산, 지방족 및 방향족 설폰산 등과 같은 비독성 유기산으로부터 기원한 것들을 포함한다. 염기 부가 염은 나트륨, 칼륨, 마그네슘, 칼슘 등과 같은 알칼리 토 금속으로부터 기원한 것들 및 N,N'-디벤질에틸렌디아민, N-메틸글루카민, 클로로프로카인, 클로린, 디에탄올아민, 에틸렌디아민, 프로카인 등과 같은 비독성 유기 아민으로부터 기원한 것들을 포함한다.
특수 양태에서, 본 발명의 방법에 의해 선택된 펩타이드 또는 이의 모사체는 물 속에 염화나트륨과 함께 용해시켜 생리학적 등장 염 조건을 달성할 수 있다.
본 발명의 약제학적 조성물에서 사용될 수 있는 적합한 수성 및 비수성 담체의 예는 물, 에탄올, 폴리올(글리세롤, 프로필렌 글리콜, 폴리에틸렌 글리콜 등과 같은), 및 이의 적합한 혼합물, 올리브 오일과 같은 야채 오일, 및 에틸렌 올레이트와 같은 주사가능한 유기 에스테르를 포함한다. 적절한 유동성은 예를 들면, 레시틴과 같은 피복 물질을 사용하고, 분산제의 경우에 요구되는 입자 크기를 유지하고, 표면활성제를 사용함으로써 유지시킬 수 있다.
이들 조성물은 또한 방부제, 습윤제, 유화제 및 분산제와 같은 항원보강제를 함유할 수 있다. 미생물의 존재의 예방은 멸균 공정 및 각종 항세균제 및 항진균제, 예를 들면, 파라벤, 클로로부탄올, 페놀 소르브산 등의 혼입 둘다에 의해 보증할 수 있다. 당, 염화나트륨 등과 같은 등장성 제제를 조성물내로 포함시키는 것이 바람직할 수 있다. 또한, 주사가능한 약제 형태의 연장된 흡수도 알루미늄 모노스테아레이트 및 젤라틴과 같은 흡수를 지연시키는 제제의 혼합에 의해 가져올 수 있다.
약제학적으로 허용되는 담체는 멸균 수용액 또는 분산액 및 멸균 주사가능한 용액 또는 분산액의 일시적인 제조를 위한 멸균 분말을 포함한다. 약제학적 활성 물질을 위한 이러한 매질 및 제제의 사용은 당해 분야에 공지되어 있다. 특정의 통상적인 매질 또는 제제가 활성 화합물과 비혼용성인 경우를 제외하고는, 본 발명의 약제학적 조성물에서 이의 사용이 고려된다. 보체 활성 화합물을 또한 조성물내로 혼입시킬 수 있다.
정제, 당의정, 캅셀제, 환제 및 과립제의 고체 용량형은 장 피복물 또는 약제학적 제형 분야에 잘-공지된 다른 피복물과 같은 피복물 및 외층(shell)으로 제조할 수 있다. 이들은 임의로 유백화제를 함유할 수 있거나 이들이 활성 성분(들) 만을 또는 바람직하게는 장관의 특정 부위에 임의로, 지연된 방식으로 방출하는 조성물일 수 있다. 사용될 수 있는 봉입 조성물의 예는 중합체 물질 및 왁스를 포함한다. 펩타이드는 또한 경우에 따라 하나 이상의 부형제로 미세-봉입된 형태일 수 있다.
치료학적 조성물은 통상적으로 멸균성이어야 하고 제조 및 저장 조건하에서 안정하여야 한다. 조성물은 액제, 미세유제, 리포좀 또는 고 약물 농도에 적합한 다른 주문된 구조로 제형화될 수 있다. 담체는 예를 들면, 물, 에탄올, 폴리올(예를 들면, 글리세롤, 프로필렌 글리콜 및 액체 폴리에틸렌 글리콜 등)을 함유하는 용매 또는 분산 매질, 및 이의 적합한 혼합물일 수 있다. 적절한 유동성은 예를 들면, 레시틴과 같은 피복물을 사용하고, 분산액의 경우에 요구된 입자 크기를 유지시키고 표면활성제를 사용함으로써 유지시킬 수 있다. 많은 경우에, 등장성 제제, 예를 들면, 당, 만니톨, 소르비톨과 같은 다가알코올, 또는 염화나트륨을 포함할 것이다. 주사가능한 조성물의 연장된 흡수는 조성물내에 흡수를 지연시키는 제제, 예를 들면, 모노스테아레이트 염 및 젤라틴을 포함시킴으로써 달성할 수 있다.
액제로서 제형화된 조성물은 예를 들면, 적절한 양의 염을 함유하도록 액제를 제조함으로써 눈에 점적기로 투여하기에 적합하도록 제조할 수 있다.
본 발명의 방법으로 선택된 펩타이드 또는 이의 모사체를 함유하는 리포좀은 문헌[참조: Epstein et al., Proc. Natl. Acad. Sci. USA 82: 3688-3692 (1985), Hwang et al., Proc. Natl. Acad. Sci. USA 77: 4030-4034 (1980), EP 제52,322호, EP 제36,676호; EP 제88,046호; EP 제143,949호; EP 제142,641호; 일본 특허원 제83-118008호, 및 EP 제102,324호, 및 미국 특허 제4,485,045호 및 제4,544,545호, 이의 내용은 이의 전문이 본원에 참조로 인용된다]에 기술된 바와 같이 잘 공지된 방법 중 어느 것에 따라 제조할 수 있다. 리포좀은, 액체 함량이 약 10mol 퍼센트의 콜레스테롤, 바람직하게는 10 내지 40몰 퍼센트 콜레스테롤 범위인 작은(약 200 내지 800 Å) 단층(unilamellar) 유형일 수 있으며, 선택된 비율은 최적 펩타이드 치료요법에 대해 조절된다. 그러나, 본 기재내용을 읽으면, 리포좀 외에 인지질 소포를 또한 사용할 수 있음이 당해 분야의 숙련가에 의해 이해될 것이다.
멸균 주사가능한 액제는 상기 열거한 성분들 중 하나 또는 이들의 조합과 함께 적절한 용매 속에서 요구되는 양의 활성 화합물을 혼입시킨 후, 경우에 따라, 멸균 미세여과함으로써 제조할 수 있다. 일반적으로, 분산제는 활성 화합물을 기본 분산 매질 및 상기 열거한 것들로 부터의 요구되는 다른 성분들을 함유하는 멸균 소포내로 혼입함으로써 제조한다. 멸균 주사가능한 액제를 제조하기 위한 멸균 산제의 경우에, 바람직한 제조 방법은 활성 성분과 이의 앞서 멸균-여과된 용액으로부터의 추가의 바람직한 성분의 분말을 수득하는 진공 건조 및 냉동-건조(동결건조: lyophilization)이다.
단일 용량형을 생산하기 위해 담체 물질과 합해질 수 있는 활성 성분의 양은 치료하는 대상체, 및 특수 투여 방식에 따라 변할 것이다. 담체 물질과 합하여 단일 용량형을 생산할 수 있는 활성 성분의 양은 일반적으로 치료학적 효과를 생산하는 조성물의 양일 것이다. 일반적으로, 100% 중에서, 당해 양은 약제학적으로 허용되는 담체와 함께, 약 0.01 내지 약 99%의 활성 성분, 바람직하게는, 약 0.1 내지 약 70%, 가장 바람직하게는 약 1 내지 약 30%의 활성 성분의 범위일 것이다.
용량 섭생은 최적의 바람직한 반응(예를 들면, 치료학적 반응)을 제공하도록 조절된다. 예를 들어, 단일의 거환을 투여할 수 있거나, 몇개의 분할된 투여량을 시간에 걸쳐 투여할 수 있거나 치료 상황의 급박성에 의해 처방되는 바와 같이 비례적으로 감소되거나 증가될 수 있다. 투여 용이성 및 용량의 균일성을 위해 비경구 조성물을 용량 단위 형태로 제형화하는 것이 특히 유리하다. 본원에 사용된 용량 단위 형은 치료되는 대상체에 대해 단일의 용량으로 적합한 생리학적으로 구별되는 단위를 말하며; 각각의 단위는 요구된 약제학적 담체와 연합된 바람직한 치료학적 효과를 생산하도록 교정된 활성 화합물의 예정된 양을 함유한다. 본 발명의 용량 단위 형을 위한 명세는 (a) 활성 화합물의 독특한 특성 및 달성할 특수 치료학적 효과 및 (b) 개인에서 민감성을 치료하기 위한 활성 화합물과 같은 화합 분야에서 고유한 제한에 의해 및 이에 따라 직접 좌우된다.
본 발명의 펩타이드 또는 이의 모사체의 투여를 위해, 용량은 약 0.0001 내지 100 mg/kg, 및 보다 일반적으로 0.01 내지 5 mg/kg의 숙주 체중의 범위이다. 예를 들어, 용량은 0.3 mg/kg의 체중, 1 mg/kg의 체중, 3 mg/kg의 체중, 5 mg/kg의 체중 또는 10 mg/kg의 체중 또는 1 내지 10 mg/kg의 범위일 수 있다. 예시적인 치료 섭생은 주당 1회 투여, 매 2주당 1회, 매 3주당 1회, 매 4주당 1회, 1개월에 1회, 매 3개월당 1회 또는 매 3 내지 6개월당 1회 투여를 포함한다. 본 발명의 잔기를 위한 바람직한 용량 섭생은 정맥내 투여를 통해 1 mg/kg의 체중 또는 3 mg/kg의 체중을 포함하며, 항체는 다음 투여 계획중 하나를 사용하여 제공된다: (i) 6회의 투여에 대해 매 4주마다, 이후 매 3개월마다; (ii) 매 3주마다; (iii) 3 mg/kg의 체중으로 1회 이후 1 mg/kg의 체중으로 매 3주마다.
달리는, 본 발명의 방법에 의해 선택된 펩타이드 또는 이의 모사체를 서방성 제형으로 투여할 수 있으며, 이 경우 보다 적은 투여 횟수가 요구된다. 용량 및 횟수는 환자에서 투여된 물질의 반감기에 따라 변한다. 투여 용량 및 횟수는, 치료가 예방학적인지 또는 치료학적인지에 따라 변할 것이다. 예방학적 적용의 경우, 비교적 적은 용량을 장기간의 기간에 걸쳐 비교적 흔하지않은 간격으로 투여한다. 일부 환자는 이들의 나머지 생애동안 치료를 계속 제공받는다. 치료학적 적용시, 질병의 진행이 감소되거나 종결되고, 바람직하게는 환자가 질병의 증상의 부분적이거나 완전한 완화를 나타낼 때까지, 비교적 짧은 기간에 비교적 고 용량이 때때로 요구된다. 이후에, 환자에게 예방학적 섭생으로 투여될 수 있다.
본 발명의 약제학적 조성물 중 활성 성분 및 소 분자의 실제 용량 수준은 환자에게 유해함이 없이, 특수 환자, 조성물 및 투여 모드에 대한 바람직한 치료학적 반응을 달성하기에 효과적인 활성 성분의 양을 수득하도록 변할 수 있다. 선택된 용량 수준은 사용된 본 발명의 특수 조성물, 또는 이의 에스테르, 염 또는 아미드의 활성, 투여 경로, 투여 시간, 사용되는 특수 화합물의 배출 속도, 치료 기간, 사용된 특수 조성물과 함께 사용된 기타 약물, 화합물 및/또는 물질, 치료하는 환자의 연령, 성별, 체중, 상태, 일반적인 건강상태 및 이전 의학 기록, 및 의학 분야에 잘 공지된 유사 인자를 포함하는 각종 약력학적 인자에 의존할 것이다.
본 발명의 방법에 의해 선택된 펩타이드 또는 이의 모사체의 "치료학적 유효 용량"은 바람직하게는 질병 증상의 중증도에 있어서의 감소, 질병 증상이 없는 기간의 횟수 및 기간에 있어서의 증가, 또는 질병 고통으로 인한 장애 또는 곤란의 예방을 초래한다. 예를 들어, 종양의 치료의 경우, "치료학적 유효 용량"은 바람직하게는 치료하지 않는 대상체에 비해 세포 성장 또는 종양 성장을 적어도 약 10% 또는 20%, 보다 바람직하게는 적어도 약 40%, 심지어 보다 바람직하게는 적어도 약 60%, 및 여전히 보다 바람직하게는 적어도 약 80% 억제한다. 종양 성장을 억제하기 위한 화합물의 능력은 사람 종양에 있어서 효능의 예측치인 동물 모델 시스템에서 평가할 수 있다. 달리는, 조성물의 이러한 특성은 숙련가에게 공지된 검정에 의한 시험관내 억제와 같은, 억제하는 화합물의 능력을 시험함으로써 평가할 수 있다. 치료학적 유효량의 치료학적 화합물은 대상체에서 종양 크기를 감소시키거나, 또한 증상을 완화시킬 수 있다. 당해 분야의 숙련가는 대상체의 체격, 대상체의 증상의 중증도, 및 선택된 특수 조성물 또는 투여 경로와 같은 인자들을 기초로 하여 이러한 양을 측정할 수 있을 것이다.
본 발명의 조성물은 당해 분야에 공지된 하나 이상의 각종 방법을 사용하여 하나 이상의 투여 경로를 통해 투여할 수 있다. 숙련가에 의해 인지되는 바와 같이, 투여 경로 및/또는 유형은 바람직한 결과에 따라 변할 것이다. 본 발명의 결합 잔기에 대한 바람직한 투여 경로는 정맥내, 근육내, 피내, 복강내, 피하, 척수 또는 예를 들면, 주사 또는 주입에 의한 다른 비경구 투여 경로를 포함한다. 본원에 사용된 것으로서, 어절 "비경구 투여"는 장 및 국소 투여 이외의 투여 방식, 일반적으로 주사에 의한 방식을 의미하며, 정맥내, 근육내, 동맥내, 경막내, 관절강내, 안와내, 심장내, 피내, 경피내, 경기관, 피하, 피부밑, 관절내, 피막밑, 지주막하, 척주관속, 경막외 및 흉골내 주사 및 주입을 포함하나, 이에 한정되지 않는다.
달리는, 본 발명의 펩타이드 또는 이의 모사체를 국소, 표피와 같은, 비-경구 경로 또는 점막내 투여 경로, 예를 들면, 비강내, 경구, 질내, 직장내, 설하 또는 국소를 통해 투여할 수 있다.
활성 화합물은 삽입물(implant), 경피 패취 및 미세캅셀화 전달 시스템을 포함하는, 신속한 방출에 대해 화합물을 보호할 담체와 함께 제조될 수 있다. 생분해가능한, 생혼화성 중합체, 예를 들면, 에틸렌 비닐 아세테이트, 다가무수물, 폴리글리콜산, 콜라겐, 폴리오르토에스테르 및 폴리락트산을 사용할 수 있다. 이러한 제형의 많은 제조 방법은 특허되어 있거나 당해 분야의 숙련가에게 일반적으로 공지되어 있다[참조: 예를 들면, Sustained and Controlled Release Drug Delivery Systems, J.R. Robinson, ed., Marcel Dekker, Inc., New York, 1978].
치료학적 조성물은 당해 분야에 공지된 의학 장치를 사용하여 투여할 수 있다. 예를 들어, 바람직한 양태에서, 본 발명의 치료학적 조성물은 미국 특허 제5,399,163호; 제5,383,851호; 제5,312,335호; 제5,064,413호; 제4,941,880호; 제4,790,824호; 또는 제4,596,556호에 기술된 장치와 같은, 침이 없는 피하 주사 장치로 투여할 수 있다. 본 발명에 유용한 잘-공지된 이식물 및 모듈의 예는 의약을 조절된 속도로 조제하기 위한 이식가능한 미세-주입 펌프를 기술하고 있는 미국 특허 제4,487,603호, 의약을 피부를 통해 투여하기 위한 치료학적 장치를 기술하고 있는 미국 특허 제4,486,194호; 의약을 정밀한 주입 속도로 전달하기 위한 의약 주입 펌프를 기술하고 있는 미국 특허 제4,447,233호; 연속적인 약물 전달을 위한 다양한 유동 이식가능한 주입 장치를 기술하고 있는 미국 특허 제4,447,224호; 다중-챔버 구획을 갖는 삼투압 약물 전달 시스템을 기술하고 있는 미국 특허 제4,439,196호; 및 삼투압 약물 전달 시스템을 기술하고 있는, 미국 특허 제4,475,196호를 포함한다. 이들 특허들은 본원에 참조로 인용된다. 이식물, 전달 시스템 및 모듈과 같은 많은 다른 것들은 당해 분야의 숙련가에게 공지되어 있다.
도 1은 본원에 기술된 방법론의 하나의 양태를 나타낸다.
도 2는 cDNA를 편리하게 프리임(prime) 할 수 있고 반대쪽 말단상에 푸로마이신 또는 유도체 또는 소 분자를 수반할 수 있는 2개의 3' 말단을 갖는 역전된 극성 프라이머인 진전된 프라이머를 사용하는 방법론을 나타낸다.
도 3은 줄기 루프 다양성이 있고 역으로 중복되어 cDNA를 편리하게 프라임할 수 있는 진전된 프라이머를 사용하는 방법론을 나타낸다.
도 4는, FK506 소 분자가 연결된 핵산에 비 공유결합으로 결합함으로써 개선된(발전된) 표현형(폴리펩타이드)를 이의 암호화 유전형(핵산)과 연결시킬 수 있는 FK12BP 단백질에 폴리펩타이드가 융합된, 항체 중쇄 가변 영역의 구조/기능을 개선시키거나 발전시키는데 사용되는 방법론의 하나의 양태를 나타낸다.
도 5는 측쇄 올리고뉴클레오타이드 링커 및 공유결합으로 부착된 펩타이드 수용체를 포함하는 상보성 올리고뉴클레오타이드를 사용하는 시험관내 디스플레이 방법론의 하나의 양태를 나타낸다.
도 6은 펩타이드 수용체에 공유결합으로 부착된, 측쇄 올리고뉴클레오타이드 링커를 사용하는 시험관내 디스플레이의 방법론의 하나의 양태를 나타낸다.
도 7은 고 친화성 리간드 및 리간드 수용체를 사용하는 시험관내 디스플레이의 방법론의 하나의 양태를 나타낸다.
도 8은, 리간드 수용체가 펩타이드 수용체에 공유결합으로 연결된, 고 친화성 리간드 및 리간드 수용체를 사용하는 시험관내 디스플레이의 방법론의 하나의 양태를 나타낸다.
도 9는, 리간드 수용체가 펩타이드 수용체에 비-공유결합으로 연결된, 고 친화성 리간드 및 리간드 수용체를 사용하는 시험관내 디스플레이의 방법론의 하나의 양태를 나타낸다.
도 10은 고 친화성 리간드 및 리간드 수용체를 사용하는 시험관내 디스플레이의 방법론의 하나의 양태를 나타내며, 여기서, 제1 리간드 수용체 분자는 제2(비-인지체) 고 친화성 리간드에 공유결합으로 연결되어 있고, 여기서, 제1 리간드 수용체 분자는 핵산에 공유결합으로 연결된 인지체 제1 고 친화성 리간드에 결합할 수 있으며, 여기서, 제2 고 친화성 리간드는 핵산에 의해 암호화된 폴리펩타이드에 융합된 인지체 제2 리간드 수용체에 결합할 수 있다.
도 11은 고 친화성 리간드 및 리간드 수용체를 사용하는 시험관내 디스플레이의 방법론의 하나의 양태에서 사용된 개개 성분들의 비-제한적 예를 나타낸다.
도 12는 고 친화성 리간드 및 리간드 수용체를 사용한 시험관내 디스플레이의 방법론의 하나의 양태를 위한 핵산/단백질 복합체의 비-제한적인 조립 순서를 나타낸다.
도 13은 바람직한 X-디스플레이 복합체의 설계를 나타낸다.
도 14는 VH 라이브러리를 제조하고, 디스플레이 복합체를 조립하며, 디스플레이 복합체를 선택하고 정제하기 위한 예시적인 개략도를 나타낸다.
도 15는 VH 라이브러리를 위한 시료 단일 클론을 나타낸다. 나열은 전사 및 해독 개시 서열, VH 서열, Cu 서열, FLAG 태그 서열, 링커(예를 들면, NA 링커)에 대해 상보성인 DNA 분절을 나타낸다.
도 16은 디스플레이 방법론의 바람직한 양태의 단계들을 나타낸다.
도 16A는 우선 상보성 쇄 짝짓기 및 소랄렌 연결을 통해 링커/RT 프라이머(NA 링커)에 부착된 mRNA 분자(적절한 링커, 태그, 상보성 영역 및 폴리-A 테일을 함유)를 포함하는 X-디스플레이 복합체를 묘사한다. NA 링커는 또한 스트렙타비딘 분자와 연합된 바이오틴(B) 분자에 공유결합으로 결합되어 있다. 스트렙타비딘은 해독된 단백질에 부착된 푸로마이신에 공유결합으로 자체 결합된, 제2 바이오틴 분자와 연합되어 있다.
도 16A는 역 전사(단계 1) 및 RNA 분해(단계 2)를 묘사한다. 도 16B는 DNA/RNA 하이브리드를 창조하기 위한 제2 쇄 합성(단계 4)를 묘사한다. 도 16B의 최종 묘사는 최종의 dsDNA X-디스플레이 복합체(즉, X-디스플레이 복합체)이다.
도 17은 강력한 라이브러리 구성원 및 일부 양태에서, 프라이머가 454 서열분석과 함께 사용될 수 있는 방법을 나타낸다.
도 18은 VH 라이브러리 구성원의 예시적인 분절을 나타낸다.
도 19는 디스플레이 라이브러리 구성원의 예시적인 분절을 나타내며 프라이머로부터의 말단 서열을 추가로 나타낸다(참조: 도 17).
도 20은 디스플레이 라이브러리 구성원의 예시적인 분절을 나타내며 또한 프라이머로부터 TMV UTR 및 C-mu 영역의 예시적인 서열을 제공한다.
도 21은 서열분석을 위해 선택된 클론을 증폭시키기 위한 프라이머의 가능한 정렬을 나타낸다.
도 22는 선택을 통해 라이브러리로부터 본 발명의 하나의 양태의 진행을 나타내며, 당해 방법을 반복함으로써 하나의 라운드에서 선택된 핵산/단백질이 X-디스플레이 복합체 형성 및 선택의 후속적인 라운드들을 위한 라이브러리를 생성하는데 사용될 수 있음을 나타낸다.
도 23은 수회의 선택 라운드를 라이브러리를 재생하거나 선택 생성물을 증폭하지 않고 사용하는 본 발명의 하나의 양태를 나타낸다.
도 24는 mRNA로부터 VH 및 VL 라이브러리 설계의 하나의 방법을 나타낸다.
도 25는, 친화성 선택시 사용된 표적 분자가 고체 지지체 상에 고정되는 선택 방법의 하나의 예시적인 양태을 나타낸다.
도 26은, 친화성 선택에 사용된 표적 분자가 세포 표면상에서 발현되는 선택 방법의 하나의 예시적인 양태를 나타낸다. 당해 양태에서, 디스플레이 복합체는 복합체를 발현하지 않는 세포에 대해 선택되며(예를 들면, 세포에 결합하지만 목적한 표적에 결합하지 않는 복합체를 제거하기 위하여), 이후 목적한 표적(즉, 특이적인 결합인자를 확인하기 위해)을 발현하는 세포에 대해 선택된다.
도 27은, 공급원 태그가 핵산(예를 들면, 암호화된 DNA의 공급원을 확인하기 위하여) 및 상이한 선택 라운드들로부터 핵산을 태그하기 위해 사용된 암호화 고정 공급원(예를 들면, 하나의 서열분석 수행을 위한 상이한 선택 라운드들로부터 핵산을 혼주하는 경우 유용한)내로 혼입되는 DNA X-디스플레이 복합체(즉, DNA-단백질 융합체)를 나타낸다.
도 28은 DNA X-디스플레이 복합체(즉, DNA-단백질 융합체) 및 N6 프라이머의 첨가를 나타낸다.
도 29는 서열 분석 개략도의 하나의 양태를 나타내는 흐름도 챠트를 나타낸다.
도 30은 mRNA 전사, 정제 및 가교결합 과정의 예시적인 결과를 나타낸다.
도 31은 mRNA 전사, 정제 및 스트렙타비딘 로딩 과정의 예시적인 결과를 나타낸다.
도 32는 RNaseH 처리 및 용출 과정 후 예시적인 결과를 나타낸다.
도 33은 RNaseH 처리 및 용출 과정 후 예시적인 결과를 나타낸다.
도 34는 RT-PCR 및 2nd 쇄 합성 과정 후 예시적인 결과를 나타낸다.
도 35는 하나의 서열분석 수행내로 다수의 선택 라운드를 혼주하도록 하는 라이브러리 설계에 사용될 수 있는 혼주물 태그화를 나타낸다.
도 36은 VH 라이브러리의 제조를 위한 예시적인 공여자 세포를 나타낸다.
도 2는 cDNA를 편리하게 프리임(prime) 할 수 있고 반대쪽 말단상에 푸로마이신 또는 유도체 또는 소 분자를 수반할 수 있는 2개의 3' 말단을 갖는 역전된 극성 프라이머인 진전된 프라이머를 사용하는 방법론을 나타낸다.
도 3은 줄기 루프 다양성이 있고 역으로 중복되어 cDNA를 편리하게 프라임할 수 있는 진전된 프라이머를 사용하는 방법론을 나타낸다.
도 4는, FK506 소 분자가 연결된 핵산에 비 공유결합으로 결합함으로써 개선된(발전된) 표현형(폴리펩타이드)를 이의 암호화 유전형(핵산)과 연결시킬 수 있는 FK12BP 단백질에 폴리펩타이드가 융합된, 항체 중쇄 가변 영역의 구조/기능을 개선시키거나 발전시키는데 사용되는 방법론의 하나의 양태를 나타낸다.
도 5는 측쇄 올리고뉴클레오타이드 링커 및 공유결합으로 부착된 펩타이드 수용체를 포함하는 상보성 올리고뉴클레오타이드를 사용하는 시험관내 디스플레이 방법론의 하나의 양태를 나타낸다.
도 6은 펩타이드 수용체에 공유결합으로 부착된, 측쇄 올리고뉴클레오타이드 링커를 사용하는 시험관내 디스플레이의 방법론의 하나의 양태를 나타낸다.
도 7은 고 친화성 리간드 및 리간드 수용체를 사용하는 시험관내 디스플레이의 방법론의 하나의 양태를 나타낸다.
도 8은, 리간드 수용체가 펩타이드 수용체에 공유결합으로 연결된, 고 친화성 리간드 및 리간드 수용체를 사용하는 시험관내 디스플레이의 방법론의 하나의 양태를 나타낸다.
도 9는, 리간드 수용체가 펩타이드 수용체에 비-공유결합으로 연결된, 고 친화성 리간드 및 리간드 수용체를 사용하는 시험관내 디스플레이의 방법론의 하나의 양태를 나타낸다.
도 10은 고 친화성 리간드 및 리간드 수용체를 사용하는 시험관내 디스플레이의 방법론의 하나의 양태를 나타내며, 여기서, 제1 리간드 수용체 분자는 제2(비-인지체) 고 친화성 리간드에 공유결합으로 연결되어 있고, 여기서, 제1 리간드 수용체 분자는 핵산에 공유결합으로 연결된 인지체 제1 고 친화성 리간드에 결합할 수 있으며, 여기서, 제2 고 친화성 리간드는 핵산에 의해 암호화된 폴리펩타이드에 융합된 인지체 제2 리간드 수용체에 결합할 수 있다.
도 11은 고 친화성 리간드 및 리간드 수용체를 사용하는 시험관내 디스플레이의 방법론의 하나의 양태에서 사용된 개개 성분들의 비-제한적 예를 나타낸다.
도 12는 고 친화성 리간드 및 리간드 수용체를 사용한 시험관내 디스플레이의 방법론의 하나의 양태를 위한 핵산/단백질 복합체의 비-제한적인 조립 순서를 나타낸다.
도 13은 바람직한 X-디스플레이 복합체의 설계를 나타낸다.
도 14는 VH 라이브러리를 제조하고, 디스플레이 복합체를 조립하며, 디스플레이 복합체를 선택하고 정제하기 위한 예시적인 개략도를 나타낸다.
도 15는 VH 라이브러리를 위한 시료 단일 클론을 나타낸다. 나열은 전사 및 해독 개시 서열, VH 서열, Cu 서열, FLAG 태그 서열, 링커(예를 들면, NA 링커)에 대해 상보성인 DNA 분절을 나타낸다.
도 16은 디스플레이 방법론의 바람직한 양태의 단계들을 나타낸다.
도 16A는 우선 상보성 쇄 짝짓기 및 소랄렌 연결을 통해 링커/RT 프라이머(NA 링커)에 부착된 mRNA 분자(적절한 링커, 태그, 상보성 영역 및 폴리-A 테일을 함유)를 포함하는 X-디스플레이 복합체를 묘사한다. NA 링커는 또한 스트렙타비딘 분자와 연합된 바이오틴(B) 분자에 공유결합으로 결합되어 있다. 스트렙타비딘은 해독된 단백질에 부착된 푸로마이신에 공유결합으로 자체 결합된, 제2 바이오틴 분자와 연합되어 있다.
도 16A는 역 전사(단계 1) 및 RNA 분해(단계 2)를 묘사한다. 도 16B는 DNA/RNA 하이브리드를 창조하기 위한 제2 쇄 합성(단계 4)를 묘사한다. 도 16B의 최종 묘사는 최종의 dsDNA X-디스플레이 복합체(즉, X-디스플레이 복합체)이다.
도 17은 강력한 라이브러리 구성원 및 일부 양태에서, 프라이머가 454 서열분석과 함께 사용될 수 있는 방법을 나타낸다.
도 18은 VH 라이브러리 구성원의 예시적인 분절을 나타낸다.
도 19는 디스플레이 라이브러리 구성원의 예시적인 분절을 나타내며 프라이머로부터의 말단 서열을 추가로 나타낸다(참조: 도 17).
도 20은 디스플레이 라이브러리 구성원의 예시적인 분절을 나타내며 또한 프라이머로부터 TMV UTR 및 C-mu 영역의 예시적인 서열을 제공한다.
도 21은 서열분석을 위해 선택된 클론을 증폭시키기 위한 프라이머의 가능한 정렬을 나타낸다.
도 22는 선택을 통해 라이브러리로부터 본 발명의 하나의 양태의 진행을 나타내며, 당해 방법을 반복함으로써 하나의 라운드에서 선택된 핵산/단백질이 X-디스플레이 복합체 형성 및 선택의 후속적인 라운드들을 위한 라이브러리를 생성하는데 사용될 수 있음을 나타낸다.
도 23은 수회의 선택 라운드를 라이브러리를 재생하거나 선택 생성물을 증폭하지 않고 사용하는 본 발명의 하나의 양태를 나타낸다.
도 24는 mRNA로부터 VH 및 VL 라이브러리 설계의 하나의 방법을 나타낸다.
도 25는, 친화성 선택시 사용된 표적 분자가 고체 지지체 상에 고정되는 선택 방법의 하나의 예시적인 양태을 나타낸다.
도 26은, 친화성 선택에 사용된 표적 분자가 세포 표면상에서 발현되는 선택 방법의 하나의 예시적인 양태를 나타낸다. 당해 양태에서, 디스플레이 복합체는 복합체를 발현하지 않는 세포에 대해 선택되며(예를 들면, 세포에 결합하지만 목적한 표적에 결합하지 않는 복합체를 제거하기 위하여), 이후 목적한 표적(즉, 특이적인 결합인자를 확인하기 위해)을 발현하는 세포에 대해 선택된다.
도 27은, 공급원 태그가 핵산(예를 들면, 암호화된 DNA의 공급원을 확인하기 위하여) 및 상이한 선택 라운드들로부터 핵산을 태그하기 위해 사용된 암호화 고정 공급원(예를 들면, 하나의 서열분석 수행을 위한 상이한 선택 라운드들로부터 핵산을 혼주하는 경우 유용한)내로 혼입되는 DNA X-디스플레이 복합체(즉, DNA-단백질 융합체)를 나타낸다.
도 28은 DNA X-디스플레이 복합체(즉, DNA-단백질 융합체) 및 N6 프라이머의 첨가를 나타낸다.
도 29는 서열 분석 개략도의 하나의 양태를 나타내는 흐름도 챠트를 나타낸다.
도 30은 mRNA 전사, 정제 및 가교결합 과정의 예시적인 결과를 나타낸다.
도 31은 mRNA 전사, 정제 및 스트렙타비딘 로딩 과정의 예시적인 결과를 나타낸다.
도 32는 RNaseH 처리 및 용출 과정 후 예시적인 결과를 나타낸다.
도 33은 RNaseH 처리 및 용출 과정 후 예시적인 결과를 나타낸다.
도 34는 RT-PCR 및 2nd 쇄 합성 과정 후 예시적인 결과를 나타낸다.
도 35는 하나의 서열분석 수행내로 다수의 선택 라운드를 혼주하도록 하는 라이브러리 설계에 사용될 수 있는 혼주물 태그화를 나타낸다.
도 36은 VH 라이브러리의 제조를 위한 예시적인 공여자 세포를 나타낸다.
본 발명을 또한 다음 실시예에서 나타내며, 이는 제한하는 것으로 고려되지 않아야 한다.
예시
실시예 전체에서, 다음 물질 및 방법이 달리 기술하지 않는 한 사용된다.
물질 및 방법
일반적으로, 본 발명의 실시는 달리 나타내지 않는 한, 당해 분야의 기술내에 있고 문헌[참조: 예를 들면, Sambrook, Fritsch and Maniatis, Molecular Cloning: Cold Spring Harbor Laboratory Press (1989); DNA Cloning, Vols. 1 and 2, (D.N. Glover, Ed. 1985); Oligonucleotide Synthesis (M.J. Gait, Ed. 1984); PCR Handbook Current Protocols in Nucleic Acid Chemistry, Beaucage, Ed. John Wiley & Sons (1999) (Editor); Oxford Handbook of Nucleic Acid Structure, Neidle, Ed., Oxford Univ Press (1999); PCR Protocols: A Guide to Methods and Applications, Innis et al., Academic Press (1990); PCR Essential Techniques: Essential Techniques, Burke, Ed., John Wiley & Son Ltd (1996); Ike PCR Technique: RT-PCR, Siebert, Ed., Eaton Pub. Co. (1998); Antibody Engineering Protocols (Methods in Molecular Bioogy), 510, Paul, S., Humana Pr (1996); Antibody Engineering: A Practical Approach (Practical Approach Series, 169), McCafferty, Ed., Irl Pr (1996); Antibodies: A Laboratory Manual, Harlow et al., C.S.H.L. Press, Pub. (1999); Current Protocols in Molecular Biology, eds. Ausubel et al., John Wiley & Sons (1992); Large-Scale Mammalian Cell; Culture Technology, Lubiniecki, A., Ed., Marcel Dekker, Pub., (1990)]에 설명된 화학, 분자 생물학, 재조합체 DNA 기술, PCR 기술, 면역학(특히, 예를 들면, 항체 기술), 발현 시스템(예를 들면, 세포-유리된 발현, 파아지 디스플레이, 리보소옴 디스플레이, 및 대량화), 및 모든 필수적인 세포 배양의 통상의 기술을 사용한다.
본 발명의 조성물 및 방법은 일부 양태에서, 예를 들면, 본원에 참조로 인용된, 미국 특허 제7,195,880호; 제6,951,725호; 제7,078,197호; 제7,022,479호, 제6,518,018호; 제7,125,669호; 제6,846,655호; 제6,281,344호; 제6,207,446호; 제6,214,553호; 제6,258,558호; 제6,261,804호; 제6,429,300호; 제6,489,116호; 제6,436,665호; 제6,537,749호; 제6,602,685호; 제6,623,926호; 제6,416,950호; 제6,660,473호; 제6,312,927호; 제5,922,545호; 제6,194,550호; 제6,207,446호; 제6,214,553호; 및 제6,348,315호에 기술되어 있다.
실시예
본 기술내용을 추가로 제한하는 것으로 고려되지 않는, 다음 실시예로 또한 나타낸다.
실시예
1: 미가공(
naive
) 항체 라이브러리의 설계 및
작제
세포 공급원
mRNA는 라이브러리의 다양성을 보증하기 위하여, 총 624명의 상이한 건강한 개인의 전 골수(10명의 공여자), 비장세포(13명의 공여자) 및 말초 단핵 세포(601명의 공여자)로부터 수득하였다. VH 라이브러리의 교정된 다양성은 109 내지 1010이고 VL 라이브러리는 106 내지 107이다.
라이브러리
작제
RT-PCR을 VH 및 VL 라이브러리 작제에 사용하였다.
제1 쇄 cDNA를 IgM, IgG 및 IgA(CD1, CD1 및 CD1)의 H 쇄 고정 영역, 및 카파 및 람다(CD1 및 CD1)의 L 쇄 고정 영역으로부터의 특수 프라이머를 사용하여 합성하였다.
가변 H 쇄 라이브러리 작제를 위해, 다수의 센스 프라이머(변성 프라이머)를 VH1-7 계열 구성원의 FR1 영역으로부터 상부 UTR 서열(VH1-7UTR)을 사용하여 설계하였다. VH에 대한 안티-센스 프라이머를 cDNA 합성을 위한 프라이머(CD2, CD2 및 CD2)에 대해 찾은 고정 영역으로부터 설계하였다. 가변 경쇄 라이브러리 작제를 위해, 다수의 센스 프라이머를 링커 서열의 상부 12개 아미노산을 지닌 각각의 계열의 VD및 VD FR1 영역으로부터 설계하여 일본쇄 Fv 셔플링을 허용하였다. D 및 D 유전자 증폭용 항-센스 프라이머를 동일한 CD2 하부를 지닌 CD1(CD2) 또는 JD에 대해 찾은 고정 영역으로부터 설계하였다. 모든 IgM 및 IgG 계열의 조립된 scFv는 경우에 따라 하부 말단에서 동일한 CD2를 가질 것이다.
VH 라이브러리 작제를 위해, PCR을 CD2, CD2, CD2 및 VH1-7 UTR을 B 세포의 모든 3개의 공급원에 대한 개개의 쌍으로 사용하여 수행하고 겔 정제하였다. 정제한 후, 3개의 공급원으로부터 증폭시킨 개개의 계열을 혼주시키고 7개(VH1-7)의 IgM 라이브러리, 7개(VH1-7)의 IgG 라이브러리 및 7개의 IgA 라이브러리(VH1-7)를 생성하였다. VL 라이브러리 작제를 위해, PCR을 CD2 및 VD 또는 JDCD2 혼합물 및 3개의 B 세포 공급원에 대해 VD을 사용하여 수행하였다. 겔 정제 후, 상이한 공급원으로부터의 VD 및 VD 라이브러리를 혼주하여 VD 및 VD 라이브러리를 생성하였다.
라이브러리 변형
IgM, IgG, IgA VH 라이브러리 및 VL 라이브러리를 또한 변형시켜 5' 말단에서 시험관내 전사, 해독 시그날 서열 및 3' 말단에서 태그 서열을 수반하도록 하였다. 이들 VH 라이브러리를 스트렙타비딘 디스플레이 라이브러리로 제조하도록 준비하였다.
라이브러리
작제용
올리고 서열
표 2에 설정된 올리고뉴클레오타이드 프라이머를 사용하여 VH 및 VL X-디스플레이 라이브러리를 생성하였다.
실시예
2:
스트렙타비딘
디스플레이 라이브러리의 생산 및 사용
당해 실시예는 본 발명의 스트렙타비딘 디스플레이 라이브러리의 생산 및 사용을 기술한다.
물질 및 방법
일반적으로, 본 발명의 실시는, 달리 나타내지 않는 한, 화학, 분자 생물학, 재조합체 DNA 기술, 면역학(특히, 예를 들면, 항체 기술)의 통상의 기술, 및 폴리펩타이드 제조의 표준 기술을 사용할 수 있다[참조: 예를 들면, Sambrook, Fritsch and Maniatis, Molecular Cloning: Cold Spring Harbor Laboratory Press (1989); Antibody Engineering Protocols (Methods in Molecular Biology), 510, Paul, S., Humana Pr (1996); Antibody Engineering: A Practical Approach (Practical Approach Series, 169), McCafferty, Ed., Irl Pr (1996); Antibodies: A Laboratory Manual, Harlow et al., C.S.H.L. Press, Pub. (1999); 및 Current Protocols in Molecular Biology, eds. Ausubel et al., John Wiley & Sons (1992)].
완충제
10X 화학적 연결 완충제: 250 mM 트리스 pH7 및 1M NaCl
1X 올리고 dT 결합 완충제: 100 mM 트리스 pH8, 1M NaCl, 및 0.05% 트리톤 X-100
2X 올리고 dT 결합 완충제: 200 mM 트리스 pH8, 2M NaCl, 및 0.1% 트리톤 X-100
1X flag 결합 완충제: 50 mM HEPES, 150 mM NaCl, 및 0.025% 트리톤 X-100 또는
1X PBS 및 0.025% 트리톤 X-100
5X flag 결합 완충제: 250 mM HEPES, 750 mM NaCl, 및 0.125% 트리톤 X-100 또는 5X PBS 및 0.125% 트리톤 X-100
사용된 시약의 공급원
메가스크립트(Megascript) T7: 암비온(Ambion)[제조원 오스틴(Austin), 텍사스 소재] PH 1334
레틱 분해물(Retic lysate) IVT: 암비온(오스틴, 텍사스 소재) PH1200
UC 마스터 혼합물-met: 암비온(오스틴, 텍사스 소재) PH 1223G
슈퍼스크립트(Superscript) II RNaseH-RT: 인비트로겐(Invitrogen)(미국 캘리포니아 칼스바드 소재) #18064-014
NAP-25 컬럼: 아머샴 파마시아 바이오테크(Amersham Pharmacia Biotech)(미국 캘리포니아 서니베일 소재) #17-0852-01
올리고 dT 셀룰로즈 제7형: 아머샴 파마시아 바이오테크(미국 캘리포니아 서니베일 소재) #27-5543-03
항-flag M2 아가로즈 친화성 겔: 시그마(Sigma)(미국 미네소타 세인트 루이스 소재) #A2220
flag 펩타이드: 시그마(미국 미네소타 세인트 루이스 소재) #F3290
dNTP: 아머샴 파마시아 바이오테크(미국 캘리포니아 서니베일 소재) #27-2035-01
허큘라제 핫스타트(Herculase Hotstart) DNA 폴리머라제: 스트라타젠(Stratagene)(미국 캘리포니아 라 졸라 소재) 600312-51
미니 스핀 컬럼: 바이오라드(Biorad)(미국 캘리포니아주 허쿨레스 소재) #732-6204
초순수(Ultrapure) BSA: 암비온(미국 캘리포니아 포스터 시티 소재) #2616
쉐어드(Sheared) 연어 정자 DNA: 암비온(미국 캘리포니아 포스터 시티 소재) #9680
링커: PBI, DDB, BPP: 트리링크 바이오테크놀로지스, 인코포레이티드(Trilink BioTechnologies, Inc.)(미국 캘리포니아 산 디에고 소재)
H2O: 옴니퓨어(OmniPur)(미국 뉴저지 깁스타운 소재) #9610
2M KCl: Usb(미국 오하이오 클리브랜드 소재) #75896
1M MgCl2: Usb(미국 오하이오 클리브랜드 소재) #78641
0.5M EDTA: Usb(미국 오하이오 클리브랜드 소재) #15694
1M 트리스 pH8: Usb(미국 오하이오 클리브랜드 소재) #22638
1M 트리스 pH7: Usb(미국 오하이오 클리브랜드 소재) #22637
5M NaCl: Usb(미국 오하이오 클리브랜드 소재) #75888
1M HEPES: Usb(미국 오하이오 클리브랜드 소재) #16924
퀴아퀵 겔 추출 키트: 퀴아겐(Qiagen)(미국 캘리포니아 발렌시아가 소재) #28706
6% TBE-우레아 겔: 인비트로겐(Invitrogen)(미국 캘리포니아 칼스바드 소재) EC6865BOX
4-16% NativePAGE 겔: 인비트로겐(미국 캘리포니아 칼스바드)
특수 시약 제조
올리고
dT
셀룰로즈(최종 농도: 100
mg
/
ml
)
2.5 g의 올리고 dT 셀룰로즈를 25 ml의 0.1N NaOH와 50 ml의 튜브 속에서 혼합하였다. 혼합물을 1500 rpm에서 3분 동안 회전시킨 후, 수득되는 상층액을 버린다. 올리고 dT 셀룰로즈를 함유하는 수득되는 펠렛을 25 ml의 1X 올리고 dT 결합 완충제로 세척한 후 1500 rpm에서 3분 동안 회전시켜 다시 침전시켰다. 수득되는 상층액을 다시 펠렛으로부터 분리하여 버렸다. 이 세척 단계를 3회 이상 반복하였다. 마지막 세척 후, 수득되는 상층액의 pH를 측정하였다. pH는 세척 완충제(~ pH 8.5)과 동일하여야 한다. 이후에, 올리고 dT 셀룰로즈를 함유하는 펠렛을 상층액으로부터 분리하고 25 ml의 1X 올리고 dT 결합 완충제 속에 4℃에서 저장하기 전에 재-현탁시켰다.
M2
아가로즈
제조
25 ml의 M2 아가로즈 슬러리를 50 ml의 튜브로 이전시켰다. 5분 동안 1000 RPM에서 벡크만 원심분리기(Beckman centrifuge) 속에서 회전시킨 후, 상층액을 분리하여 버렸다. M2 아가로즈를 함유하는 수득되는 펠렛을 하나의 컬럼 용적의 글리신 10mM pH 3.5으로 재-현탁시키고 5분 동안 1000 RPM에서 회전시켰다. 수득되는 현탁액을 다시 버렸다. 이후에, 아가로즈 펠렛을 하나의 컬럼 용적의 1X flag 결합 완충제으로 재-현탁시켰다. 혼합물을 5 분동안 1000 RPM에서 회전시키고 수득되는 현탁액을 버렸다. 당해 세척 단계를 3회 반복한 후, 펠렛을 하나의 컬럼 용적의 1X 결합 완충제(1 mg/ml의 BSA 및 100㎍/ml의 sssDNA 함유)와 함께 재-현탁하였다. 혼합물을 1시간 동안 또는 밤새 4℃에서 텀블링시켜 2ml 분획 중 분취량으로 분리하고 4℃에서 저장하였다.
VH
라이브러리의 증폭
VH 라이브러리를 증폭시키기 위한 예시적인 방법을 하기에 제공한다:
프라이머
:
5' 프라이머: S7(T7TMVUTR)
5'-TAATACGACTCACTATAGGGACAATTACTATTTACAATTACA-3'(서열 번호: 52)
5'-프라이머: S7a(T7TMVUTR AUG)
5'-TAATACGACTCACTATAGGGACAATTACTATTTACAATTACAATG-3'(서열 번호: 53)
3'프라이머: XB-S5-1(CμflagA20 + 서열이 가해진 SA 디스플레이)
5'-TTTTTTTTTTTTTTTTTTTTAAAT AGC GGA TGC TAA GGA CGA CTTGTCGTCGTCGTCCTTGTAGTC GGTTGGGGCGGATGCACTCCC-3'(서열 번호: 54)
역 프레임 1(프라이머에 대해 상보성인 암호화 쇄의 해독):
1 G S A S A P T D Y K D D D D K S S L A S A I (정지) K K K K K K (서열 번호: 55)
반응물 설정:
10X 헤르쿨라제 완충제(제조원: 스트라타젠) 50 ㎕
10 mM dNTP 10 ㎕
S7 (5 μM) 20 ㎕
S5-1 (5 μM) 20 ㎕
VH 라이브러리 (1 내지 6 계열) 40 ng
H2O X ㎕
헤르쿨라제(제조원: 스트라타젠) 10 ㎕
------------------------
500 ㎕ (50 ㎕/반응물)
온도 주기 프로그램:
95℃/3분 1 주기
95℃/30분 ┓
50℃/30초 ┃ 20 주기
72℃/1분 ┛
72℃/10분 1 주기
50℃의 Tm은 대략치이며 PCR 프라이머의 선택에 의존한다.
라이브러리 정제:
증폭된 VH 라이브러리 DNA를 2% 아가로즈 겔상에서 분리하였다. 400bp 밴드를 겔 단면으로부터 퀴아퀵 겔 추출 키트(Qiaquick Gel Extraction Kit)(제조원: 퀴아젠 #28706, 캘리포니아 발렌시아가 소재)를 사용하여 DNA 추출용 UV 광하에서 절단하고 300㎕의 H2O 속에서 재구성하였다. 5 ㎕의 정제된 DNA를 2% E-겔 상에서 전기영동에 적용하였다. 당해 회수율은 ~80%로 예측되었다.
전사
반응물 설정(MEGAscript kitTM, 암비온 PH 1334, 미국 캘리포니아 포스터 시티 소재)
제1 라운드의 라이브러리 생산을 위해, 완전한 규모의 RNA 전사(500 ㎕)가 추천된다. 반응 용적은 후기 라운드에서 규모 축소될 수 있다.
PCR 생성물 (5 내지 10 ㎍) 200 ㎕
10X 반응 완충제 50 ㎕
ATP (75 mM) 50 ㎕
CTP (75 mM) 50 ㎕
GTP (75 mM) 50 ㎕
UTP (75 mM) 50 ㎕
T7 폴리머라제 50 ㎕
------------------------------------------------------- 총 500 ㎕
항온처리
상기와 같은 반응 혼합물을 37℃에서 1 내지 2시간 동안, 또는 바람직하게는 밤새 항온처리하였다.
정제
예시적인 정제 방법은 하기 제공된 NAP-25 컬럼상에서의 분획화이다. NAP 10 및 NAP 5 컬럼을 소 규모 생산의 정제를 위해 사용할 수 있으며, 이 경우, 분획 용적은 상응하게 변할 수 있다.
NAP-25 컬럼을 사용하는 정제 과정의 경우, 25 ㎕의 Dnase I을 매 500 ㎕의 전사 반응물에 가할 수 있다. 혼합물은 37℃에서 5분 동안 항온처리 한 후, 500 ㎕의 페놀-클로로포름-이소아밀알코올을 혼합물에 가한 경우, 페놀 추출할 것이다. 이후에, 혼합물을 30초 동안 와동시킬 수 있다. 혼합물을 5분 동안 원심분리한 후, 수성 상을 회수할 수 있다. 당해 수성 상의 로딩 전에, NAP-25 컬럼은 10 mL dH2O 점적을 컬럼에 떨어뜨려 예비-세척할 수 있다. 이후에, 추출된 전사 혼합물을 세척 컬럼에 로딩하고 컬럼내로 수행할 수 있다. 이후에, 800 ㎕의 dH2O을 컬럼에 가하고 통과액을 수집할 수 있다. 당해 용출 과정을 5회(E1-E5) 반복하고 수집된 시료내 RNA 농도를 분광광도계 상에서 A260으로 측정할 수 있다. 2 ㎕의 시료를 2% E-겔 내지 QC 상에서 전기영동에 적용시킬 수 있다. 대부분의 RNA를 함유하는 분획을 연결(E3는 소량을 함유하고, E4는 피크 분획이며, E5는 RNA 및 유리된 NTP의 혼합물을 함유한다)에 사용할 수 있다.
RNA의 농도를 교정하기 위해, 5 ㎕의 각각의 용출물을 995 ㎕의 H2O과 혼합물의 OD를 측정하기 전에 혼합할 수 있다.
OD X 40 X 800㎕ X 1000
RNA의 nmol = ---------------------------
330 X 400 X 5 ㎕
대체 RNA 정제 과정(LiCl 침전)은 하기에 예시한다:
500 ㎕의 10 M LiCl을 매 500 ㎕의 전사 반응물에 가한 후 당해 혼합물을 -20℃에서 30분 내지 1시간 동안 냉동시켰다. 이후에, 혼합물을 원심분리에 최대 속도로 20분 동안 적용시킬 수 있다. 수득되는 상층액은 버려질 것이며, 펠렛은 50 ㎕의 3M NaOAc 및 50 ㎕의 dH2O 속에 재현탁시킬 수 있다. 표준 EtOH 침전을 수행할 수 있다. 수득되는 펠렛을 100 ㎕의 dH2O 속에 용해하고 RNA 농도를 퀴빗(Qubit)을 사용하여 측정할 수 있다.
광가교연결
2개 유형의 소랄렌 연결인자를 사용한다: 스트렙타비딘 조립에 사용될 바이오틴 잔기를 함유하는 2'O-Me RNA 링커 PBI 및 DNA 링커 DDB-1.
XB-PBI (SA/DNA 디스플레이 링커 OMe RNA/DNA):
5'-(소랄렌 C6) u agc gga (바이오틴-dT)gc uaa ggA CGA -3'
XB-DDB-1 (DNA 디스플레이 링커):
5'-(소랄렌 C6) (C7-NH2-EZ 바이오틴) T AGC GGA TGC TAA GGA CGA -3'
소랄렌 C6
u,a,g,c = 2-MeO-RNA
A,C,G = 표준 데옥시 아미디트
C7-NH2-아미노 스페이서 7
EZ-바이오틴, 피어스 EZ-연결 TFP-스페이서-바이오틴
역 프레임 1(암호화 쇄내에서 나타나는 것으로서 링커 영역의 해독): S S L A S A
**링커는 광-민감성이며 알루미늄 호일 등으로 광으로부터 보호될 필요가 있다.
반응물 설정에서, 링커/RNA의 비는 1.5:1(최대) 내지 1.1:1(충분)일 수 있다.
1 라운드 반응에서, 대규모 생산(1 내지 2 nmol의 RNA)이 충분한 다양성을 회수하기 위해 제안된다. 말기 라운드에서, RNA 도입은 100 내지 600 pmol로 감소될 수 있다.
RNA 1 nmol
링커 (1mM) 1.1㎕
10 X 화학적 연결 완충제 10㎕
------------------------------------------------------------
첨가된 dH2O 100㎕가 되도록 하는 양(10 pmol RNA /최종 ㎕)
(연결 반응물 중 RNA의 최종 농도는 3 내지 15 pmol/㎕에서 작업한다. 연결 반응물 용적은 변할 수 있다.)
PCR 열순환기내에서 어닐링하기 위해, 시료를 85℃에서 30초 동안 및 4℃에서 0.3℃/초의 속도로 항온처리할 수 있다.
조사를 위해, 1 ㎕의 100 mM DTT를 어닐링된 연결 혼합물에 가할 수 있다. 혼합물을 0.5 ml의 에펜도르프 튜브(eppendorf tube)의 얇은 벽에 이전시키거나 동일한 PCR 튜브 속에 유지시킬 수 있다. 조사 과정은 수동유지된 다중파장 UV 램프[제조원: 유브리피 닷 컴(Uvp.com), 캘리포니아 업랜드 소재, #UVGL-25]를 사용하여 "장 파장"(365 nm)에서 6분 동안 실온으로 수행할 수 있다. 약 50 내지 90%의 RNA가 정제 요구도로 연결될 것으로 예측될 것이다.
연결된 RNA의 QC를 위해, 시료를 전기 영동을 위해 6% TBU 겔에 적용시켜 연결 효능을 점검할 수 있다. 상세하게는, 6% TBU 겔을 300V하에 15분 동안 예비-수행한 후, 콤브(comb)를 제거하고 웰을 완전히 플러싱할 수 있다. 이후에, 각각의 웰의 경우 약 10 내지 15pmol의 유리되거나 연결된 RNA를 2X 로딩 완충제(전사 키트로부터의)과 혼합하고 함께 90℃에서 3분 동안 가열한 후, 빙상에서 급냉시킬 수 있다. 이후에, 예비-가열된 유리 및 연결된 RNA 둘다를 전기영동을 위해 300V에서 예비-가열된 겔의 벽에 청색 염료가 바닥에 도달할 때까지 로딩시킬 수 있다.
예시적인 실험을 도 30에서와 같이 수행하였다. 상세하게는, KDR mRNA를 시험관내 전사시키고 LiCl 침전에 의해 반응물로부터 정제하였다. 1 당량의 PBI 링커를 mRNA 시료에 85℃로 가열한 후 X-연결 완충제 속에서 4℃까지 서서히 냉각시킴으로써 어닐링하였다. DTT를 1 mM의 최종 농도로 가하였다. 시료를 365 nm의 파장에서 상이한 양의 시간 동안 항온처리한 후, 6% TBU 변성 겔 상에서 분해하였다. 상은 겔의 UV 음영이다. 도 30에 나타낸 바와 같이, 가교결합은 5분 조사 후 관측된다(레인 7). 추가로 6분 조사를 광교차연결에 사용하였다.
스트렙타비딘의
로딩
스트렙타비딘은 이의 리간드 바이오틴을 예상외의 고 친화성, 10-15 M의 Kd로 결합시키는 현저힌 안정한 사합체 단백질이다.
A. PBI 링커 사용
RNA에 대한 PBI 링커의 O-Me RNA 일부의 고 Tm으로 인하여, 원래의 100 mM NaCl 완충제(1x X-연결 완충제에서와 같이)를, 물로 5 내지 10x 희석시킨, 10 내지 20 mM 염에 대해 희석하는 것이 추천된다. 1/2 내지 1/4 당량의 스트렙타비딘[제조원: 프로자임(Prozyme), 미국 캘리포니아 산 렌드로 소재] 용액을 PBS 또는 1x X-연결 완충제, 예를 들면, 4 μM X-연결된 RNA에 대해 1 내지 2μM의 최종 농도의 스트렙타비딘 속에 가할 수 있다. 이후에, 1 ㎕의 RNAsine을 가하고 혼합물을 48℃에서 가열 블록 속에서 1시간 동안 항온처리할 수 있다.
B. DDB 링커 사용
DDB 링커는 모든-DNA 분자이며, 1x X-연결 완충제(100 mM NaCl)의 희석이 요구되지 않는다. DDB 링커는 우수한 SA 로딩에 추천될 수 있으며 단지 1.5 내지 2x 과량의 가교결합된 mRNA 만을 스트렙타비딘에 대해 사용하는 것이 가능하다. 1/2 또는 1:1.5 당량의 스트렙타비딘(제조원: 프로자임, 미국 캘리포니아 산 린드로 소재) 용액을 PBS 또는 1x X-연결 완충제 속에, 예를 들면, 4 μM X-연결된 RNA에 대해 2 내지 2.5 μM의 최종 농도의 스트렙타비딘을 가할 수 있다. 이후에, 1 ㎕의 RNAsine를 가하고 혼합물을 48℃에서 열 블록 속에서 1시간 동안 항온처리할 수 있다.
각각의 경우(A 또는 B), 적어도 50% 초과 및 80% 이하의 스트렙타비딘이 로딩되는 것으로 예측될 수 있다.
푸로마이신
링커
BPP
의 로딩
BPP: 5' 바이오틴-BB Cy3-(스페이서 18)4-CC Pu
BPP-8: 5' 바이오틴-BB Cy3-(스페이서 18)8-CC Pu
Cy3 염료
4 또는 8 단위의 스페이서 18
Pu = 푸로마이신-CPG
A BPP 링커는 3' 말단에서 푸로마이신, 펩타이드 수용체 분자를 함유한다(펩타이드 수용체는 리보소옴의 A 부위로 도입되어 인접한 폴리펩타이드 쇄의 COOH 말단에 공유결합으로 커플링된다). 링커는 각각의 X-연결된 mRNA 분자상에 로딩된 스트렙타비딘 분자에 결합하는 5' 말단에서 바이오틴을 갖는다. 당해 펩타이드 수용체는 당해 mRNA(표현형)에 의해 암호화된 단백질에 대해 궁극적으로 mRNA(유전자형)의 비-공유결합으로 강력히 연합할 수 있을 것이다. 각각의 버젼의 BPP 링커(보다 짧은 4x 스페이서-18 또는 보다 긴 8x 스페이서-18)는 가시화를 위해 형광성 Cy-3 염료 잔기(여기: 550, 방사: 570 nm)를 함유한다. 다른 형광성 염료, 예를 들면, 플루오레세인, BODIPY, Cy-5, 로다민 등을 Cy-3 대신 사용할 수 있다.
상세하게는, 1 당량의 상응하는 BPP 링커(스트렙타비딘의 양에 상대적인 양)을 로딩된 트렙타비딘-mRNA 조립에 가할 수 있다. 혼합물을 15분 동안 실온에서 항온처리할 수 있다. 스트렙타비딘에 대해 거의 100%의 BPP 링커가 결합에 대해 예측될 수 있다.
예시적인 실험을 도 31에서와 같이 수행하였다. 상세하게는, KDR mRNA를 시험관내 전사하고 LiCl 침전에 의해 반응물로부터 정제하였다. 1 당량의 PBI 또는 DDB 링커를 mRNA 시료에 85℃로 가열한 후, 100 mM NaCl을 함유하는 1x X-연결 완충제 속에서 4℃로 서서히 냉각시켜 어닐링하였다. PBI-x-연결된 mRNA의 시료를 이후에 5x 희석시켜 20 mM의 최종 NaCl 농도가 되도록 하였다. DDB-x-연결된 mRNA의 시료를 희석하지 않고 사용하였다. 스트렙타비딘 로딩을 위해, 약 1/2 당량의 스트렙타비딘을 각각의 시료에 가한 후, 실온 또는 50℃에서 1시간 동안 항온처리하였다. 이후에, BPP-Cy3 링커를 각각의 시료에 스트렙타비딘과 동일한 양으로 가하였다. 실온에서 15분 항온처리한 후, 수득되는 조립을 4 내지 16% NativePage 상에서 분해하였다.
임의 단계: 올리고
dT
컬럼상에서
SA
조립의 정제
mRNA는 20 As의 테일을 함유하므로, 이는 당해 단계에서 올리고 dT 컬럼 상에서 정제할 수 있다. 당해 정제는 절대적으로 필수적이지 않으나, 다음 단계에서 융합 수율을 어느 정도 개선시킬 수 있다.
조립 정제
등 용적의 2X 올리고 dT 결합 완충제(200 mM 트리스, pH 8, 2 M NaCl, 20 mM EDTA, 0.1% 트리톤)를 제조된 mRNA-SA 조립에 가할 수 있다. 이후에, 올리고-dT 셀룰로즈를 혼합물(100 mg의 처리된/세척된 올리고 dT 셀룰로즈(1 mL의 슬러리)가 1 nmol까지의 RNA 도입을 포획하는데 충분하다)에 가한 후 4℃에서 30 내지 60분 동안 록킹(roking)할 수 있다. 혼합물을 벤치 톱(bench top) 원심분리기 속에서 1500 rpm으로 3분 동안 4℃에서 회전시킬 수 있다. 수득되는 상층액을 버릴 것이다. 수득되는 펠렛은 700 ㎕의 올리고 dT 세척 완충제(100 mM 트리스 pH 8, 1M NaCl, EDTA 비함유, 0.05% 트리톤 x-100) 속에 재현탁시키고, 점적/회전 컬럼[제조원: 바이오라드(BioRad) #732-6204, 미국 캘리포니아 헤르쿨레스 소재] 상에 로딩한 후 원심분리기 속에서 1000 rpm으로 10초 동안 회전시켰다. 컬럼을 700㎕의 올리고 dT 세척 완충제로 세척하고 1000 rpm에서 10초 이상 동안 회전시킬 수 있다. 세척 단계는 8회 반복할 수 있다(각각의 세척 동안, 원심분리 rpm 및 시간은, 이것이 세척 완충제를 통해 회전시키기 어려운 경우 증가시킬 수 있으나 1500rpm을 초과하지는 않는다). 5㎕의 최종 세척액을 계수를 위해 수집할 수 있다. 이후에, mRNA-SA 조립을 dH2O로 용출시킬 수 있다. 60 ㎕의 dH2O를 E1에 대해, 이후 1500 rpm에서 10초 동안(계수를 위해 5㎕ 사용) 회전시켜 사용할 수 있다. E2의 경우, 500 ㎕의 dH2O를 컬럼에 가할 수 있다. 실온에서 5분 동안 항온처리한 후, E2를 4000 rpm에서 20초(계수를 위해 5㎕ 사용) 동안 회전시킨 후 수집할 수 있다. E3의 경우, 300 ㎕의 dH2O를 가하고 컬럼과 함께 5분 동안 실온에서 항온처리할 수 있다. 이후에, E3를 4000 rpm에서 20초 동안(계수를 위해 5㎕ 사용) 회전시켜 수집할 수 있다. 당해 실시예에서, E2는 80%의 mRNA-SA 조립을 함유한다.
해독
해독 용적은 RNA 도입 양에 따라 변할 수 있다. 예시적인 조건은 다음에 제시된다:
해독 설정 (300 ㎕)
RNA-SA 조립 120 pmol + H2O 82 ㎕ (또는 300 ㎕ 이하)
아미노산 마스타 혼합(-met) 15 ㎕
10 mM 메티오닌 3 ㎕
분해물 200 ㎕
-------------------------------------------------------------
총 용적 300 ㎕
혼합물은 30℃에서 수욕 또는 항온처리기(물 블록) 속에서 45분 내지 1시간 동안 항온처리할 수 있다.
융합체
형성
100 ㎕의 2M KCl (500 mM 최종)을 20 ㎕의 1M MgCl2 (50 mM 최종)과 혼합시키고 실온에서 1시간 동안 항온처리할 수 있다. 수득되는 혼합물을 임의로 냉동시키고 -20℃에서 수일 까지 저장할 수 있다. 또한, 냉동은 어느 정도 융합 수율을 개선시킨다.
이후에, 50 ㎕의 0.5M EDTA를 당해 혼합물에 가하여 리보소옴을 분해하고 리보소옴-유리된 융합체(QC의 경우 10 ㎕ 저장)을 생산할 수 있다.
선택을 위한 예시적인 해독 규모로서, 1 라운드의 경우 1.2 nmol RNA (10 x 300 ㎕), 2 라운드의 경우 600 pmol RNA (5 x 300 ㎕) 및 3 라운드의 경우 120 내지 600 pmol RNA(1 내지 5 x 300 ㎕) 등이다.
올리고
dT
셀룰로즈
:
PBI
링커에 의한
융합체
정제
올리고 dT 정제는 RNA 융합 분자(및 RNA)의 정제를 허용하며 시험관내 해독에 의해 생성된 유리된 단백질 분자를 제거한다. 당해 과정 및 다음 역 전사 단계는, PBI 링커 조립이 해독되는 경우 사용할 수 있다. DDB-링커 조립의 경우에, 상이한 과정이 추천된다.
융합체
정제
동 용적의 2X 올리고 dT 결합 완충제(200 mM 트리스, pH 8, 2 M NaCl, 20 mM EDTA, 0.1% 트리톤)를 해독/융합 혼합물에 가할 수 있다. 올리고-dT 셀룰로즈 [100 mg 처리된/세척된 올리고 dT 셀룰로즈(1 mL의 슬러리)는 해독/융합물을 1 nmol 이하의 RNA 도입까지 포획하는데 충분하다]를 이후에 혼합물에 가한 후 4℃에서 30 내지 60분 동안 가할 수 있다. 벤치 탑 원심분리 속에서 1500 rpm으로 3분 동안 4℃에서 회전시킨 후, 수득되는 상층액을 버릴 것이다. 수득되는 펠렛은 700 ㎕의 올리고 dT 세척 완충제(100 mM 트리스 pH 8, 1M NaCl, EDTA 비함유, 0.05% 트리톤 x-100) 속에 재현탁시키고 점적/회전 컬럼(제조원: 바이오라드 #732-6204, 미국 캘리포니아 헤르쿨레스 소재)상에 로딩한 후, 원심분리기 속에서 1000 rpm으로 10초 동안 회전시켰다. 수득되는 펠렛은 700㎕의 올리고 dT 세척 완충제 속에 재현탁시킨 후 1000 rpm에서 10초 동안 회전시켜 펠렛을 재침전시킬 수 있다. 당해 세척 단계는 8회(각각의 세척 동안, 원심분리 rpm 및 시간은, 세척 완충체를 통한 회전이 어려울 경우 증가시킬 수 있으나, 1500rpm을 초과하지 않는다) 반복할 수 있다. 5㎕의 최종 세척액을 계수를 위해 수집할 수 있다. 세척 후, dH2O를 용출에 사용할 수 있다. 예를 들면, 60 ㎕의 dH2O를 E1에 대해 사용한 후, 1500 rpm에서 10초(계수를 위해 5㎕ 사용) 동안 회전시킬 수 있다. E2의 경우, 500 ㎕의 dH2O를 컬럼에 가할 수 있다. 실온에서 5분 동안 항온처리한 후, E2를 4000 rpm에서 20초(계수를 위해 5㎕ 사용) 동안 회전시킬 수 있다. E3의 경우, 300 ㎕의 dH2O를 컬럼에 가하고 컬럼과 함께 5분 동안 실온에서 항온처리할 수 있다. 이후에, E3를 4000 rpm에서 20초(계수를 위해 5㎕ 사용) 동안 회전시킨 후 수집할 수 있다. 당해 실시예에서, E2는 80%의 mRNA-SA 조립을 함유한다.
융합 과정의 평가:
올리고 dT 셀룰로즈로부터의 융합체의 용출은 또한 당해 분야에 공지된 방법, 예를 들면, 겔-전기영동, 플루오레세인 밀도계 또는 방사표지된 계수 등에 의해 분석할 수 있다.
역 전사:
PBI
링커
RNA-cDNA 하이브리드를 RNA의 2차 구조를 안정화시키고 감소시키며 선택 후 PCR용 주형으로서 제공하기 위해 제조한다. PBI 링커의 경우에, 역전사가 외부 프라이머(S6)로서 바람직하나, 링커의 4개의 3' 뉴클레오타이드가 DNA이므로, 보다 낮은 효능이 PBI 링커 자체로부터 수행될 수 있다. 비록, 본 발명자가 이러한 목적을 위해, 상이한 모든-DNA 링커, DDB를 사용하지만, 이는 조립을 DNA-디스플레이된 양식으로 강력하게 전환시킬 수 있다.
외부
RT
프라이머
:
XB-S6-1: 5'-TTAAAT AGC GGA TGC TAA GGA CGA CTTGTCGTCGTCGTCCTTGTAGTC GGTTGGGGCGGATGCACTCCC-3'(서열 번호: 56)
역 프레임 1: G S A S A P T D Y K D D D D K S S L A S A I (정지)(서열 번호: 57)
반응물 설정: (인비트로겐 역 전사 키트)
올리고-dT 용출물을 10000 rpm에서 30초 동안 회전시켜 잔류성 셀룰로즈를 제거할 수 있다.㎕
회전으로부터 E2 + E3 상층액: 800㎕ (총 <1000 pmol)
(겔 상에서 전기영동을 위해 수집된 10 내지 20㎕의 E2)
RT 프라이머 (S6-1) 1mM 1㎕ (1000 pmol)
5x 제1 쇄 완충제 220㎕
0.1 M DTT 11㎕(최종 1 mM)
25 mM dNTPs 22㎕ (각각 최종 0.5 mM)
슈퍼스크립트(Superscript) II 25㎕
H2O 21㎕
---------------------------------------------------------------
총 1100 ㎕
37℃에서 45 내지 60분 동안 항온처리(겔 상에서 수행하기 위해 10㎕ 제거).
QC: cDNA 합성은 NativePage를 사용한 겔 전기영동에 의해 모니터링할 수 있으며 Cy-3 염료의 형광성으로 검출할 수 있다.
역 전사 및
RNAseH
분해물과
커플링된
, 올리고
dT
셀룰로즈에
의한
융합체
정제:
DDB
링커
올리고 dT 정제 및 역 전사를 mRNA-SA 조립과 DDB 링커 속에서 컬럼 상에서 수행함으로써 본 발명자는 DNA-디스플레이된 융합체를 생성한다. 당해 경우에, DDB는 RT 프라이머로서 제공된다. 동일한 과정을 내부 RT 프라이머로서 제공되도록 설계되나, DDB에 비해 효능이 보다 낮은 것으로 입증된, PBI 링커에 적용시킬 수 있다.
DNA-디스플레이된 융합체는 뉴클레아제 분해에 대해 큰 안정성을 입증하며 세포-계 및 생체내 선택을 위해 사용된다.
올리고
dT
셀룰로즈
상에서
융합체
고정화
등 용적의 2X 올리고 dT 결합 완충제(200 mM 트리스, pH 8, 2 M NaCl, 20 mM EDTA, 0.1% 트리톤)를 해독/융합체 혼합물에 가할 수 있다. 올리고-dT 셀룰로즈[100 mg의 처리된/세척된 올리고 dT 셀룰로즈(1 mL의 슬러리)가 해독/융합체를 1 nmol RNA 도입물까지 포획하는데 충분하다]를 4℃에서 30 내지 60분 동안 로킹하기 전에 가할 수 있다. 벤치 탑 원심분리 속에서 1500 rpm으로 3분 동안 4℃에서 회전시킨 후, 수득되는 상층액을 버릴 것이다. 수득되는 펠렛은 700 ㎕의 올리고 dT 세척 완충제(100 mM 트리스 pH 8, 1M NaCl, EDTA 비함유, 0.05% 트리톤 x-100) 속에 재현탁시키고 점적/회전 컬럼(제조원: 바이오라드 #732-6204, 미국 캘리포니아 헤르쿨레스 소재)상에 로딩한 후, 원심분리기 속에서 1000 rpm으로 10초 동안 회전시킨다. 컬럼을 700㎕의 올리고 dT 세척 완충제로 세척한 후, 1000 rpm에서 10초 동안 회전시킨다. 수득되는 펠렛을 8회(각각의 세척 동안, 원심분리 rpm 및 시간은, 세척 완충제를 통한 회전이 어려울 경우 증가시킬 수 있으나, 1500rpm을 초과하지 않는다) 반복할 수 있다. 5㎕의 최종 세척물을 계수를 위해 수집할 것이다.
올리고
dT
셀룰로즈
상에서 역 전사
고정된 융합체를 갖는 올리고 dT 수지를 1x 제1 쇄 완충제(별도로 제조) 속에서 평형화시킬 수 있다. 완충제는 수지로부터 융합체의 용출을 방지하는, 75 mM KCl 및 3 mM MgCl2를 함유한다.
혼합물을 역 전사를 위해 다음과 같이 제조한 후 37 내지 39℃에서 60 내지 75분 동안 항온처리할 수 있다.
물 695 ㎕
5x 제1 쇄 완충제 200 ㎕
0.1 M DTT 10㎕(최종 1mM)
25 mM dNTP 40㎕(각각 최종 1mM)
슈퍼스크립트 II 50 ㎕
RNasin 5㎕
-----------------------------------------
총 1000 ㎕
(당해 실시예에서, 외부 RT 프라이머는 가하지 않는다. dNTPs 및 SSII 역전사 효소의 양은 증가된다)
당해 단계에서, 바이오틴 잔기에 공유결합으로 결합되어 최종적으로 스트렙타비딘-BPP-융합체 샌드위치에 비-공유결합으로 강력하게 부착된 cDNA의 쇄를 제조하여 DNA-디스플레이된 융합체에 대한 전구체를 형성시킨다.
RNA
쇄의
RNAse
H 분해 및 올리고
dT
셀룰로즈로부터
용출
역 전사 단계 후, 동일한 컬럼에 상응하는 양의 RNAse H를 가할 수 있다[1000 ㎕의 상기 기술된 반응물에 대해 10 ㎕의 RNAse H (2 U/㎕, 제조원: 인비트로겐, 미국 캘리포니아 칼스바드 소재)를 가할 수 있다]. 37℃에서 추가로 1시간 동안 항온처리한다.
일-본쇄 DNA-융합체를 올리고 dT 컬럼을 2000 rpm에서 1시간 동안 회전시킴으로써 용출시킨 후 500 ㎕의 1x 제1 쇄 완충제로 세척할 수 있다. 당해 실시예에서, 대략 80 내지 95%의 물질이 컬럼으로부터 용출될 수 있다.
예시적인 실험을 도 32 및 33에서와 같이 수행하였다. 도 32에 나타낸 바와 같이, DNA 디스플레이 조립(DDB 링커와 연결된 mRNA-x)를 RRL 속에서 1시간 동안 30℃에서 200nM의 mRNA 농도로 해독하였다. 생성물을 올리고-dT 컬럼(레인 2 내지 3) 상에 로딩하였다. 컬럼을 1x 올리고-dT 완충제로 수회 세척한 후 1x RT 완충제로 2회 세척하고, dNTPs 및 SSII RT를 1시간 동안 37℃에서 첨가하였다. RNaseH 처리를 또한 다른 1시간 동안 37℃에서 수행하였다. 컬럼을 회전(회전 여과기)하여 용출시켰다. 레인 4 및 5에서, PBI 링커와 함께 조립된 mRNA를 상기와 유사하게 해독한 후, 올리고 dT 수지로 처리하고 5 mM 트리스 pH 7.0으로 용출하였다.
도 33에서, DNA 디스플레이 조립[DDB 링커와 연결된 mRNA-x, 레인 1, 2, 및 3, 또는 BPP 링커와 연결된 mRNA-x, 레인 4 및 5(BPP-8 링커)]를 RRL 속에서 1시간 동안 30℃에서 200 nM의 mRNA 농도에서 해독하였다. 생성물을 올리고-dT 컬럼상에 로딩하였다. 당해 컬럼을 1x 올리고-dT 완충제로 수회 세척한 후 1x RT 완충제로 2회 세척하고, 이어서 dNTP 및 SSII RT를 1시간 동안 37℃에서 가하였다. RNaseH 처리를 또한 다른 1시간 동안 37℃에서 수행하였다. 이후에, 컬럼을 회전(회전 여과기)시켜 용출하였다. 융합체를 항 Flag M2 아가로즈(레인 2, 3 및 5) 상에서 정제하였다.
2
nd
쇄 합성 및
DNA
-디스플레이
융합체
조립의 완성
XB_S7 (T7TMVUTR2 42-mer; VH IgM, IgG 라이브러리 둘다에 대한 5'-PCR 프라이머):
5'-TAATACGACTCACTATAGGGACAATTACTATTTACAATTACA-3'(서열 번호: 52)
XB_S7a(추가의 ATG를 갖는 T7TMV 프라이머 45 mer는 Tm을 3℃까지 개선시킨다):
5'-TAATACGACTCACTATAGGGACAATTACTATTTACAATTACAATG-3'(서열 번호: 58)
앞서의 단계로부터의 용출물에, 추가의 dNTPs 및 SSII RT를 1 내지 1.5 당량의 TMV-T7 프라이머 S7 또는 S7a와 함께 가할 수 있다.
예시적인 반응물은 위에서 기술한 바와 같이, 1500 ㎕ 반응물 당 추가의 시약을 혼합함을 포함한다:
S7 또는 S7a 1 내지 1.5 당량
SSII RT 10 ㎕
dNTP 10 ㎕
혼합물을 추가로 1시간 동안 37 내지 39℃에서 항온처리할 수 있다. 2nd 쇄를 합성한 후, DNA 디스플레이된 융합체 조립을 완성한 후 항 FLAG 항체 수지상에서 추가로 정제하고, 융합체를 세포-계 또는 생체내 선택을 위해 사용할 수 있다.
예시적인 실험을 도 34에 나타낸다. mRNA 조립은 다음과 같이 수행하였다: 4 μM RNA 및 4 μM 링커(DDB 또는 PBI)를 85 내지 4℃에서 1x X-연결 완충제 속에서 어닐링한 후; DTT를 1 mM 및 UV 365에 6분 동안 가하였다. 이후에, SA를 0.67x X-연결 완충제 중 1:2의 비(2 μM에서 최종 mRNA 및 1 μM에서 SA)로 48℃에서 1시간 동안 로딩하였다. 푸로마이신 Cy3 링커(BPP-4 xC18 스페이서)를 1μM에서 조립에 10분 동안 실온에서 가하였다. 올리고 dT 정제는 수행하지 않았다. 다음 RT 반응을 다음과 같이 수행하였다: 슈퍼스크립트 II(SSII)를 42℃에서 3개 조건을 사용하는 표준 RT: 단지 PBI 조립 중 RT 프라이머로서 DDB, RT 프라이머로서 PBI 및 S6(외부 프라이머).
각각의 RT 반응물을 RNAse H (2 U)로 1시간 동안 37℃에서 처리하였다. 또한 제2 쇄를 Y7 프라이머(T7-TMV) 1:1 및 추가의 SSII RT 효소 및 추가의 dNTP를 1시간 동안 42℃[쿠르츠(Kurtz)로부터 취한 조건, Chembiochem 2001]에서 가하여 합성하였다.
FLAG
-태그 정제
Flag 정제로 완전한 길이의 단백질 분자 만이 회수되며 시험관내 해독에 의해 생성된 어떠한 유리된 RNA 및 트렁케이트된(truncated) 단백질 분자도 제거된다.
결합 및 세척:
500 ㎕의 M2 아가로즈(1x 결합 완충제 속에서 예비-스트리핑되고 예비-차단된 10 mM Gly pH 3.5) 현탁액을 2 ml의 튜브에 이전시킬 수 있다. 원심분리기 속에서 1500 rpm으로 1분 동안 회전시킨 후, 수득되는 상층액을 버릴 것이다. 아가로즈는 또한 1 mL의 flag 결합 완충제로 2회 세척할 수 있다. 이후에, 세척된 M2-아가로즈를 제조된 화학적으로 변형된 라이브러리(계수를 위해 5㎕ 사용) 및 1/4 라이브러리 용적의 5X flag 결합 완충제와 혼합하고 4℃에서 1시간 동안 밤새 록킹하였다. 원심분리기 속에서 1500 rpm에서 1분 동안 회전시킨 후, 수득되는 상층액을 신선한 튜브로 이전시키며, 수득되는 M2 아가로즈 펠렛은 0.7 mL의 flag 결합 완충제 속에 재현탁시키고 점적 회전 컬럼 상에 로딩할 것이다. 로딩된 컬럼을 원심분리기 속에서 1000 rpm으로 10초 동안 회전시킨 후 0.7 ml의 flag 결합 완충제로 6회 세척한 후, 1000 rpm에서 10초 동안 회전시킬 것이다. 이후에, 컬럼을 0.7 ml의 1x 결합 완충제로 2회 세척한 후, 1000 rpm에서 10초(5㎕의 최종 세척액을 계수를 위해 수집할 수 있다) 동안 회전시킬 수 있다.
용출:
1X 결합 완충제 중 100㎍/mL FLAG 펩타이드 500 ㎕를 컬럼에 가할 수 있다. 5분 동안 항온처리한 후, 컬럼을 3000 rpm에서 회전시킨 후 용출물을 수집할 수 있다. 용출 과정을 300 ㎕의 flag 펩타이드(5㎕의 각각의 용출물을 계수를 위해 수집할 수 있다)를 사용하여 반복할 수 있다.
회수의 평가:
통상적으로 회수율은 대략 10 내지 30%일 수 있다. 회수는 형광성 또는 당해 분야에 공지된 다른 방법으로 측정할 수 있다.
PCR
목적에 따라, Taq 폴리머라제 또는 고 정확성 폴리머라제를 증폭에 사용할 수 있다. 소규모의 PCR이 증폭에 걸쳐서 일반적으로 유발된 PCR 인공물을 방지하기 위한 PCR 주기 점검용으로 추천된다.
반응물 설정:
10X 헤르쿨라제 완충제(제조원: 스트라타젠) 2.5 ㎕
10 mM dNTP 0.5 ㎕
T7 TMV UTR (5 μM) 1 ㎕
Cμ2flagA20 (5 μM) 1 ㎕
주형 2.5 ㎕
H2O 17 ㎕
헤르쿨라제(제조원: 스트라타젠) 0.5 ㎕
--------------------------------
25 ㎕
주목: 앞서의 단계에서, 예를 들면, 유동-통과, 최종 세척에서 수집된 분획, 용출물 1 및 용출물 2를 PCR용 주형으로서 사용할 수 있다. 상세하게는, 2.5 내지 5 ㎕의 주형을 당해 PCR 반응에, 특히 조기 선택 라운드(예를 들면, 라운드 1 내지 3)에 대해 사용할 수 있다. 그러나, 이는 사용하지 않는 것이 유리할 수 있다. 예시적인 PCR 조건은 하기 나열한다:
95℃로 3분 동안 1 주기
95℃로 30초 동안 ┓
50℃로 30초 동안 ┃ X 주기 (X= 시그날에 따라 15, 20, 또는 25)
72℃로 1분 동안 ┛
72℃로 5분 동안 1 주기
Tm에서 주목: Tm은 프라이머에 대해 교정된다. 당해 실시예에서, 프라이머는 50 ℃ 보다 높거나 52 내지 65 ℃의 Tm을 가질 수 있다.
PCR 반응 후, 5 ㎕의 반응 혼합물을 2% E-겔 상에서 전기영동을 위해 사용할 수 있다. 크기가 ~400 bp인 주요 밴드가 겔 상에 있는 것으로 예측될 수 있다. 소-규모 PCR의 품질이 허용될 경우, 나머지 용출물을 유사한 조건하에서 대규모 PCR용 주형으로서 사용할 수 있다.
DNA
정제:
때때로, PCR 생성물을 정제하는 것이 요구될 수 있다. 전기영동 후, PCR 생성물(400bp 밴드)를 함유하는 2% 아가로즈 겔상에서 겔 단면을 UV 광하에 절단할 수 있다. 이후에, DNA를 Qiaquick 겔 추출 키트(제조원: 퀴아젠 #28706, 미국 캘리포니아 발렌시아가 소재)을 사용하여 겔 단면으로부터 추출할 수 있다. 5 ㎕의 정제된 DNA를 2% E-겔 상에서 전기영동을 위해 사용할 수 있다. 일반적으로 ~80%의 회수율이 예측될 수 있다.
454 서열분석용
태그화
:
DNA
디스플레이
비-증폭 선택 단계에서 개개의 분자의 태그화를 위해, 다음 2nd 쇄 프라이머를 사용한다:
GCCTCCCTCGCGCCATCAGNNNNNNGGGACAATTACTATTTACAATTACA ATG (서열 번호: 59)
당해 프라이머는 TMV 서열, 454 연결인자 서열 및 N6 무작위 태그를 함유한다. 3' 말단(제2의 454 연결인자를 함유, 유전자-특이적인 부분의 Tm은 50.4℃이다)용의 상응하는 PCR 프라이머 GCCTTGCCAGCCCGCTCAGTAGCGGATGCTAAGCACGA (서열 번호: 60)
암플리콘 제제는 연결인자 프라이머 만을 사용하여 수행한다:
전방: Tm 64.7 ℃
GCCTCCCTCGCGCCATCAG (서열 번호: 61)
역방: Tm 65.7 ℃
GCCTTGCCAGCCCGCTCAG (서열 번호: 62)
둘다의 Tm은 대략 65 ℃이므로, RACE 유형의 PCR이 3'프라이머에 대해 가능하다.
등량체
본 발명의 다수의 변형 및 변경 양태가 앞서의 기술의 측면에서 당해 분야의 숙련가에게 익숙할 것이다. 따라서, 당해 기술은 당해 분야의 숙련가에게 본 발명을 수행하기 위한 최상 방식을 교시하려는 목적 및 나열의 목적 만으로 간주되어야 한다. 구조의 세부사항은 본 발명의 취지를 벗어남이 없이 실질적으로 변할 수 있으며, 첨부된 청구의 범위내에 있는 모든 변형의 배타적인 사용도 보존된다. 본 발명은 첨부된 청구의 범위에 의해 요구되는 정도 및 적용가능한 법률의 정도로만 한정되어야 한다.
특허, 특허원, 문헌, 도서, 논문, 학위논문, 웹 페이지, 도면 및/또는 첨부물을 포함하는, 본 출원에 인용된 모든 문헌 및 유사 물질은, 이러한 문헌 및 유사 물질의 체제에 상관없이, 이의 전문이 참조로 표현하여 인용된다. 정의된 용어, 용어 용도, 기술된 기술 등을 포함하는, 하나 이상의 인용된 문헌 및 유사한 물질이 본 출원과 상이하거나 배치되는 경우, 본 출원이 조절한다. 이러한 등량체는 다음 청구의 범위에 포함되는 것으로 의도된다.
<110> WAGNER, Richard, W.
<120> Protein Screening Methods
<130> IPA110084
<150> US61/083,813
<151> 2008-07-25
<150> US61/090,111
<151> 2008-08-19
<150> US61/170,029
<151> 2009-04-16
<160> 62
<170> KopatentIn 1.71
<210> 1
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> IgM cDNA
<400> 1
acaggagacg agggggaaaa g 21
<210> 2
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> IgG cDNA
<400> 2
gccaggggga agaccgatgg 20
<210> 3
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<223> IgA cDNA
<400> 3
gaggctcagc gggaagacct tg 22
<210> 4
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> Vk cDNA
<400> 4
caactgctca tcagatggcg g 21
<210> 5
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> Vl cDNA
<400> 5
cagtgtggcc ttgttggctt g 21
<210> 6
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR 3' IgM
<400> 6
ggttggggcg gatgcactcc c 21
<210> 7
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR 3' IgG
<400> 7
cgatgggccc ttggtggarg c 21
<210> 8
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR 3' IgA
<400> 8
cttggggctg gtcggggatg c 21
<210> 9
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR 3' Vk
<400> 9
agatggtgca gccacagttc g 21
<210> 10
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> J 1-3C
<400> 10
agatggtgca gccacagttc gtaggacggt sascttggtc cc 42
<210> 11
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> J 7C
<400> 11
agatggtgca gccacagttc ggaggacggt cagctgggtg cc 42
<210> 12
<211> 46
<212> DNA
<213> Artificial Sequence
<220>
<223> VH1a
<400> 12
caattactat ttacaattac aatgcaggtk cagctggtgc agtctg 46
<210> 13
<211> 46
<212> DNA
<213> Artificial Sequence
<220>
<223> VH1b
<400> 13
caattactat ttacaattac aatgcaggtc cagcttgtgc agtctg 46
<210> 14
<211> 46
<212> DNA
<213> Artificial Sequence
<220>
<223> VH1c
<400> 14
caattactat ttacaattac aatgsaggtc cagctggtac agtctg 46
<210> 15
<211> 46
<212> DNA
<213> Artificial Sequence
<220>
<223> VH1d
<400> 15
caattactat ttacaattac aatgcaratg cagctggtgc agtctg 46
<210> 16
<211> 46
<212> DNA
<213> Artificial Sequence
<220>
<223> VH2
<400> 16
caattactat ttacaattac aatgcagrtc accttgaagg agtctg 46
<210> 17
<211> 46
<212> DNA
<213> Artificial Sequence
<220>
<223> VH3a
<400> 17
caattactat ttacaattac aatggargtg cagctggtgg agtctg 46
<210> 18
<211> 46
<212> DNA
<213> Artificial Sequence
<220>
<223> VH3b
<400> 18
caattactat ttacaattac aatgcaggtg cagctggtgg agtctg 46
<210> 19
<211> 46
<212> DNA
<213> Artificial Sequence
<220>
<223> VH3c
<400> 19
caattactat ttacaattac aatggaggtg cagctgttgg agtctg 46
<210> 20
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> VH4a
<400> 20
caattactat ttacaattac aatgcagstg cagctgcagg ag 42
<210> 21
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<223> VH4b
<400> 21
caattactat ttacaattac aatgcaggtg cagctacagc agtgg 45
<210> 22
<211> 46
<212> DNA
<213> Artificial Sequence
<220>
<223> VH5
<400> 22
caattactat ttacaattac aatggargtg cagctggtgc agtctg 46
<210> 23
<211> 46
<212> DNA
<213> Artificial Sequence
<220>
<223> VH6
<400> 23
caattactat ttacaattac aatgcaggta cagctgcagc agtcag 46
<210> 24
<211> 46
<212> DNA
<213> Artificial Sequence
<220>
<223> VH7
<400> 24
caattactat ttacaattac aatgcaggtg cagctggtgc aatctg 46
<210> 25
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVk1a
<400> 25
ggcggaggtg gctctggcgg tggcggatcg racatccaga tgacccag 48
<210> 26
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVk1b
<400> 26
ggcggaggtg gctctggcgg tggcggatcg gmcatccagt tgacccag 48
<210> 27
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVk1c
<400> 27
ggcggaggtg gctctggcgg tggcggatcg gccatccrga tgacccag 48
<210> 28
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVk1d
<400> 28
ggcggaggtg gctctggcgg tggcggatcg gtcatctgga tgacccag 48
<210> 29
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVk2a
<400> 29
ggcggaggtg gctctggcgg tggcggatcg gatattgtga tgacccag 48
<210> 30
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVk2b
<400> 30
ggcggaggtg gctctggcgg tggcggatcg gatrttgtga tgactcag 48
<210> 31
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVk3a
<400> 31
ggcggaggtg gctctggcgg tggcggatcg gaaattgtgt tgacrcag 48
<210> 32
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVk3a
<400> 32
ggcggaggtg gctctggcgg tggcggatcg gaaatagtga tgacgcag 48
<210> 33
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVk3a
<400> 33
ggcggaggtg gctctggcgg tggcggatcg gaaattgtaa tgacacag 48
<210> 34
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVk4
<400> 34
ggcggaggtg gctctggcgg tggcggatcg gacatcgtga tgacccag 48
<210> 35
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVk5
<400> 35
ggcggaggtg gctctggcgg tggcggatcg gaaacgacac tcacgcag 48
<210> 36
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVk6a
<400> 36
ggcggaggtg gctctggcgg tggcggatcg gaaattgtgc tgactcag 48
<210> 37
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVk6b
<400> 37
ggcggaggtg gctctggcgg tggcggatcg gatgttgtga tgacacag 48
<210> 38
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVL1a
<400> 38
ggcggaggtg gctctggcgg tggcggatcg cagtctgtgc tgackcag 48
<210> 39
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVL1b
<400> 39
ggcggaggtg gctctggcgg tggcggatcg cagtctgtgy tgacgcag 48
<210> 40
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVL2
<400> 40
ggcggaggtg gctctggcgg tggcggatcg cagtctgccc tgactcag 48
<210> 41
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVL3a
<400> 41
ggcggaggtg gctctggcgg tggcggatcg tcctatgwgc tgactcag 48
<210> 42
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVL3b
<400> 42
ggcggaggtg gctctggcgg tggcggatcg tcctatgagc tgacacag 48
<210> 43
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVL3c
<400> 43
ggcggaggtg gctctggcgg tggcggatcg tcttctgagc tgactcag 48
<210> 44
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVL3d
<400> 44
ggcggaggtg gctctggcgg tggcggatcg tcctatgagc tgatgcag 48
<210> 45
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVL4
<400> 45
ggcggaggtg gctctggcgg tggcggatcg cagcytgtgc tgactcaa 48
<210> 46
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVL5
<400> 46
ggcggaggtg gctctggcgg tggcggatcg cagsctgtgc tgactcag 48
<210> 47
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVL6
<400> 47
ggcggaggtg gctctggcgg tggcggatcg aattttatgc tgactcag 48
<210> 48
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVL7
<400> 48
ggcggaggtg gctctggcgg tggcggatcg cagrctgtgg tgactcag 48
<210> 49
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVL8
<400> 49
ggcggaggtg gctctggcgg tggcggatcg cagactgtgg tgacccag 48
<210> 50
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVL4/9
<400> 50
ggcggaggtg gctctggcgg tggcggatcg cwgcctgtgc tgactcag 48
<210> 51
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<223> linkVL10
<400> 51
ggcggaggtg gctctggcgg tggcggatcg caggcagggc tgactcag 48
<210> 52
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> primer
<400> 52
taatacgact cactataggg acaattacta tttacaatta ca 42
<210> 53
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<223> primer
<400> 53
taatacgact cactataggg acaattacta tttacaatta caatg 45
<210> 54
<211> 87
<212> DNA
<213> Artificial Sequence
<220>
<223> primer
<400> 54
tttttttttt tttttttttt aaatagcgga tgctaaggac gacttgtcgt cgtcgtcctt 60
gtagtcggtt ggggcggatg cactccc 87
<210> 55
<211> 28
<212> PRT
<213> Artificial Sequence
<220>
<223> Reverse Frame 1
<400> 55
Gly Ser Ala Ser Ala Pro Thr Asp Tyr Lys Asp Asp Asp Asp Lys Ser
1 5 10 15
Ser Leu Ala Ser Ala Ile Lys Lys Lys Lys Lys Lys
20 25
<210> 56
<211> 69
<212> DNA
<213> Artificial Sequence
<220>
<223> XB-S6-1
<400> 56
ttaaatagcg gatgctaagg acgacttgtc gtcgtcgtcc ttgtagtcgg ttggggcgga 60
tgcactccc 69
<210> 57
<211> 22
<212> PRT
<213> Artificial Sequence
<220>
<223> Reverse Frame 1
<400> 57
Gly Ser Ala Ser Ala Pro Thr Asp Tyr Lys Asp Asp Asp Asp Lys Ser
1 5 10 15
Ser Leu Ala Ser Ala Ile
20
<210> 58
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<223> XB_S7a
<400> 58
taatacgact cactataggg acaattacta tttacaatta caatg 45
<210> 59
<211> 53
<212> DNA
<213> Artificial Sequence
<220>
<223> primer
<400> 59
gcctccctcg cgccatcagn nnnnngggac aattactatt tacaattaca atg 53
<210> 60
<211> 38
<212> DNA
<213> Artificial Sequence
<220>
<223> primer
<400> 60
gccttgccag cccgctcagt agcggatgct aagcacga 38
<210> 61
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> Forward
<400> 61
gcctccctcg cgccatcag 19
<210> 62
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> Reverse
<400> 62
gccttgccag cccgctcag 19
Claims (56)
- (a) 폴리펩타이드-암호화 서열을 포함하는 제1 핵산 분자;
(b) 제1 핵산 분자에 의해 암호화된 폴리펩타이드; 및
(c) 제1 핵산 분자의 일부에 대해 상보성인 핵산 서열을 포함하는 제2 핵산 분자를 포함하고, 여기서, 제1 핵산 분자는 제2 핵산 분자에 상보성 핵산 염기 짝짓기(pairing)를 통해 결합되고, 여기서, 제2 핵산 분자는 폴리펩타이드에 비-공유결합으로 결합된 X-디스플레이 복합체.
- 제1항에 있어서,
(a) 제2 핵산 분아에 공유결합으로 결합된 고 친화성 리간드; 및
(b) 펩타이드 수용체에 결합된 리간드 수용체를 추가로 포함하며, 여기서, 고 친화성 리간드는 리간드 수용체에 결합되고 펩타이드 수용체는 폴리펩타이드에 공유결합으로 결합된 복합체.
- 제2항에 있어서, 제2 고 친화성 리간드를 추가로 포함하며, 여기서, 제2 고 친화성 리간드가 펩타이드 수용체에 공유결합으로 결합되고, 여기서, 제2 고 친화성 리간드가 리간드 수용체에 결합된 복합체.
- 제3항에 있어서, 펩타이드 수용체가 제2 고 친화성 리간드에 링커를 통해 결합된 복합체.
- 제4항에 있어서, 링커가 폴리에틸렌 글리콜을 포함하는 복합체.
- 제4항에 있어서, 링커가 폴리시알산 링커를 포함하는 복합체.
- 제2항에 있어서, 리간드 수용체가 펩타이드 수용체에 공유결합으로 결합된 복합체.
- 제1항에 있어서,
(a) 제2 핵산 분자에 공유결합으로 결합된 리간드 수용체; 및
(b) 펩타이드 수용체에 결합된 고 친화성 리간드를 추가로 포함하며, 여기서, 리간드 수용체가 고 친화성 리간드에 결합되어 있고 펩타이드 수용체가 폴리펩타이드의 C-말단에 공유결합으로 결합된 복합체.
- 제1항에 있어서, 제2 핵산 분자의 일부에 대해 상보성인 핵산 서열을 포함하는, 제3 핵산 분자를 추가로 포함하며, 여기서, 제3 핵산 분자가 제2 핵산 분자에 상보성 핵산 염기 짝짓기를 통해 결합되고, 여기서, 제3 핵산 분자가 펩타이드 수용체에 공유결합으로 결합되며, 여기서, 펩타이드 수용체가 폴리펩타이드에 공유결합으로 결합된 복합체.
- 제1항 내지 제9항 중 어느 한 항에 있어서, 제2 핵산 분자가 측쇄된 핵산 분자인 복합체.
- 제1항 내지 제9항 중 어느 한 항에 있어서, 제2 핵산 분자가 제1 핵산 분자의 역 전사용 프라이머로서 작용할 수 있는 복합체.
- (a) 제1 고 친화성 리간드에 공유결합으로 결합된, 폴리펩타이드-암호화 서열을 포함하는 핵산 분자;
(b) 핵산 분자에 의해 암호화된 폴리펩타이드;
(c) 펩타이드 수용체에 결합된 리간드 수용체를 포함하며, 여기서, 고 친화성 리간드가 리간드 수용체에 결합되고 펩타이드 수용체가 폴리펩타이드의 C-말단에 공유결합으로 결합된 X-디스플레이 복합체.
- 제12항에 있어서, 리간드 수용체가 펩타이드 수용체에 공유결합으로 결합된 복합체.
- 제12항에 있어서, 제2 고 친화성 리간드를 추가로 포함하며, 여기서, 제2 고 친화성 리간드가 펩타이드 수용체에 공유결합으로 결합되고, 여기서, 제2 고 친화성 리간드가 리간드 수용체에 결합된 복합체.
- (a) 제1 고 친화성 리간드에 공유결합으로 결합된, 폴리펩타이드-암호화 서열을 포함하는 핵산 분자;
(b) 제2 고 친화성 리간드에 공유결합으로 결합된 제1 리간드; 및
(c) 제1 핵산 분자에 의해 암호화된 폴리펩타이드(여기서, 폴리펩타이드는 제2 리간드 수용체를 포함한다)를 포함하며, 여기서, 제1 고 친화성 리간드가 제1 리간드 수용체에 결합되고, 제2 고 친화성 리간드가 제2 리간드 수용체에 결합된 X-디스플레이 복합체.
- 제1항 내지 제15항 중 어느 한 항에 있어서, 제1 고 친화성 리간드 또는 제2 고 친화성 리간드가 바이오틴인 복합체.
- 제1항 내지 제16항 중 어느 한 항에 있어서, 제1 고 친화성 리간드 또는 제2 고 친화성 리간드가 FK506, 메토트렉세이트, PPI-2458, 바이오틴, 히루딘, ZFVp(O)F, 플루오레세인-바이오틴, ABD(알부민 결합 도메인), 18bp DNA, RNAse A, 클로로알칸, 아릴(베타-아미노 에틸)케톤, 및 단백질 A를 포함하는 그룹 중에서 선택되는 복합체.
- 제1항 내지 제17항 중 어느 한 항에 있어서, 제1 리간드 수용체 또는 제2 리간드 수용체가 FKBP12, 디하이드로폴레이트 리덕타제, 메티오닌 아미노펩티다제, 이합체성 스트렙타비딘, 스트렙타비딘 사합체, 트롬빈, 카복시펩티다제, 1가 Ab, HSA(알부민), Zn 핑거(finger), hRI(RNase 억제제), 돌연변이된 할로알칸 데할로게나제, 할로태그, 및 소르타제를 포함하는 그룹 중에서 선택되는 복합체.
- 제1항 내지 제18항 중 어느 한 항에 있어서, 제1 리간드 수용체 또는 제2 리간드 수용체가 스프렙타비딘인 복합체.
- 제1항 내지 제19항 중 어느 한 항에 있어서, 폴리펩타이드가 항체, VH 도메인, VL 도메인, Fab 단편, 일본쇄 항체, 나노바디(nanobody), 유니바디(unibody), 아드넥틴, 아피바디(affibody), DARPin, 안티칼린, 아비머, 10Fn3 도메인, 및 베르사바디를 포함하는 그룹 중에서 선택되는 복합체.
- (a) 고 친화성 리간드에 공유결합으로 부착된, 폴리펩타이드-암호화 서열을 포함하는 핵산 분자; 및
(b) 제1 핵산 분자에 의해 암호화된 폴리펩타이드(여기서, 폴리펩타이드는 리간드 수용체를 포함한다)를 포함하고, 여기서, 리간드는 리간드 수용체에 결합된 X-디스플레이 복합체.
- 제21항에 있어서, 리간드가 FK506이고 리간드 수용체가 FKBP의 FK506-결합 도메인인 복합체.
- 제1항 내지 제22항 중 어느 한 항에 있어서, 제1 핵산 분자가 ssRNA, ssDNA, ssDNA/RNA 하이브리드 dsDNA, 및 dsDNA/RNA 하이브리드로 이루어진 그룹 중에서 선택되는 복합체.
- 제1항 내지 제22항 중 어느 한 항에 있어서, 제1 핵산 분자의 폴리펩타이드-암호화 서열이 골격내(in-frame) 정지 코돈을 함유하지 않는 복합체.
- 제1항 내지 제22항 중 어느 한 항에 있어서, 폴리펩타이드가 결합 단백질인 복합체.
- 제1항 내지 제25항 중 어느 한 항에 있어서, 결합 단백질이 항체의 VH 또는 VL 도메인인 복합체.
- 제1항 내지 제22항 중 어느 한 항에 있어서, 복합체가 리보소옴을 함유하지 않는 복합체.
- 복합체의 적어도 일부가 상이한 폴리펩타이드-암호화 서열을 함유하는, 제1항 내지 제27항 중 어느 한 항에 따른 X-디스플레이 복합체 다수를 포함하는 라이브러리.
- (a) 제1 핵산 링커에 대해 상보성인 서열 성분을 포함하는 mRNA 서열의 라이브러리를 제공하는 단계;
(b) 제1 고 친화성 리간드에 작동적으로 연결된 제1 핵산 링커를 제공함으로써 제1 핵산 링커가 상보성 핵산 염기 짝짓기를 통해 mRNA에 결합하도록 하는 단계;
(c) 펩타이드 수용체에 작동적으로 연결된 제2 고 친화성 리간드를 제공하는 단계;
(d) 적어도 2개의 결합 부위를 가진 리간드 수용체를 제공함으로써 리간드 수용체가 제1 고 친화성 리간드 및 제2 고 친화성 리간드에 결합하도록 하는 단계; 및
(e) mRNA의 해독이 일어나도록 함으로써 펩타이드 수용체가 해독된 단백질에 결합하여 mRNA를 단백질에 연결시키는 핵산-폴리펩타이드 복합체를 형성하는 단계를 포함하는, X-디스플레이 복합체의 라이브러리를 생산하는 방법.
- 제29항에 있어서, mRNA를 핵산-폴리펩타이드내 복합체내 제1 핵산 링커를 프라이머로서 사용하여 역 전사시킴으로써 DNA/DNA 하이브리드가 형성되도록 하는 단계를 추가로 포함하는 방법.
- 제30항에 있어서, mRNA를 분해하고 상보성 DNA 쇄를 합성함으로써 핵산-폴리펩타이드 복합체내에 DNA/DNA 하이브리드를 형성시킴을 추가로 포함하는 방법.
- 제29항에 있어서, mRNA가 TMV 인핸서를 추가로 포함하는 방법.
- 제29항에 있어서, mRNA가 Cμ 서열을 추가로 포함하는 방법.
- 제29항에 있어서, mRNA가 FLAG 태그를 추가로 포함하는 방법.
- 제29항에 있어서, mRNA가 SA 디스플레이 서열을 추가로 포함하는 방법.
- 제29항에 있어서, mRNA가 A20 테일을 추가로 포함하는 방법.
- 제29항 내지 제35항 중 어느 한 항에 따른 방법에 의해 생산된 핵산-폴리펩타이드 복합체의 라이브러리.
- (a) 제29항에 따른 핵산-폴리펩타이드 복합체의 라이브러리를 제공하는 단계;
(b) 라이브러리와 목적한 항원을 접촉시키는 단계;
(c) 라이브러리로부터 목적한 항원과 결합하는 적어도 하나의 핵산-폴리펩타이드 복합체를 선택하는 단계; 및
(d) 선택된 핵산-폴리펩타이드 복합체의 폴리펩타이드-암호화 서열을 분리하는 단계를 포함하여, 목적하는 항원에 결합할 수 있는 폴리펩타이드를 암호화하는 분리된 핵산 분자를 선택하는 방법.
- (a) 제38항에 따른 방법을 사용하여 선택된 폴리펩타이드-암호화 서열을 제공하는 단계; 및
(b) 폴리펩타이드-암호화 서열에 의해 암호화된 폴리펩타이드를 발현시키는 단계를 포함하는, 목적한 항원에 결합할 수 있는 폴리펩타이드를 생산하는 방법.
- 제29항에 따른 방법에 의해 선택된, 목적한 항원에 결합할 수 있는 폴리펩타이드를 암호화하는 분리된 핵산 분자.
- (a) 폴리펩타이드-암호화 서열을 포함하는 제1 핵산 분자;
(b) 제1 핵산 분자에 의해 암호화된 폴리펩타이드;
(c) 제1 핵산 분자의 일부에 대해 상보성인 핵산 서열을 포함하는 제2 핵산 분자;
(d) 제2 핵산 분자에 공유결합으로 결합된 제1 고 친화성 리간드;
(e) 제1 리간드 수용체; 및
(f) 하나 이상의 연결 분자를 통해 펩타이드 수용체에 공유결합으로 결합된 제2 고 친화성 리간드를 포함하며, 여기서, 제1 핵산 분자가 제2 핵산 분자에 상보성 핵산 염기 짝짓기를 통해 결합되고, 여기서, 제1 고 친화성 리간드가 제1 결합 부위에서 리간드 수용체에 비공유결합으로 결합되며, 여기서, 제2 리간드가 제2 결합 부위에서 리간드 수용체에 비공유결합으로 결합되고, 여기서, 하나 이상의 연결 분자가 폴리에틸렌 글리콜 분자인 X-디스플레이 복합체.
- 제41항에 있어서, 제1 고 친화성 리간드가 바이오틴이고, 리간드 수용체가 스트렙타비딘, 이합체성 스트렙타비딘, 및 사합체성 스트렙타비딘을 포함하는 그룹 중에서 선택되는 복합체.
- 제41항에 있어서, 제2 고 친화성 리간드가 바이오틴이고, 리간드 수용체가 스트렙타비딘, 이합체성 스트렙타비딘, 및 사합체성 스트렙타비딘을 포함하는 그룹 중에서 선택되는 복합체.
- 제41항에 있어서, 제1 고 친화성 리간드 또는 제2 고 친화성 리간드가 FK506, 메토트렉세이트, PPI-2458, 바이오틴, 히루딘, ZFVp(O)F, 플루오레세인-바이오틴, ABD (알부민 결합 도메인), 18bp DNA, RNAse A, 클로로알칸, 아릴(베타-아미노 에틸)케톤 및 단백질 A를 포함하는 그룹 중에서 선택되는 복합체.
- 제41항에 있어서, 제2 리간드 수용체를 추가로 포함하는 복합체.
- 제45항에 있어서, 제2 리간드 수용체가 FKBP12, 디하이드로폴레이트 리덕타제, 메티오닌 아미노펩티다제, 이합체성 스트렙타비딘, 스트렙타비딘 사합체, 트롬빈, 카복시펩티다제, 1가 Ab, HSA(알부민), Zn 핑거, hRI(RNase 억제제), 돌연변이된 할로알칼 데할로게나제, 할로태그, 및 소르타제를 포함하는 그룹 중에서 선택되는 복합체.
- 제41항에 있어서, 펩타이드 수용체가 푸로마이신인 복합체.
- 제41항에 있어서, 제1 또는 제2 핵산 분자가 소랄렌을 추가로 포함하는 복합체.
- 제41항에 있어서, 폴리펩타이드가 항체, VH 도메인, VL 도메인, Fab 단편, 일본쇄 항체, 나노바디, 유니바디, 아드넥틴, 아피바디, DARPin, 안티칼린, 아비머, 10Fn3 도메인, 및 베르사바디를 포함하는 그룹 중에서 선택되는 복합체.
- (a) 핵산 분자에 공유결합으로 결합된 제1 고 친화성 리간드;
(b) 펩타이드 수용체에 공유결합으로 결합된 제2 고 친화성 리간드; 및
(c) 2개 이상의 리간드 결합 부위를 포함하는 리간드 수용체를 포함하며; 여기서, 제1 및 제2 리간드는 인접한 리간드 결합 부위에서 리간드 수용체에 결합되는 이종양기능성(heterobifunctional) 복합체.
- 제50항에 있어서, 제1 고 친화성 리간드 및 제2 고 친화성 리간드가 동일한 복합체.
- 제50항에 있어서, 제1 고친화성 리간드 및 제2 고 친화성 리간드가 바이오틴인 복합체.
- 제50항에 있어서, 핵산 분자가 소랄렌 잔기를 포함하는 복합체.
- 제50항에 있어서, 펩타이드 수용체가 푸로마이신인 복합체.
- 제50항에 있어서, 리간드 수용체가 다합체성 단백질인 복합체.
- 제50항에 있어서, 리간드 수용체가 스트렙타비딘인 복합체.
Applications Claiming Priority (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US8381308P | 2008-07-25 | 2008-07-25 | |
| US61/083,813 | 2008-07-25 | ||
| US9011108P | 2008-08-19 | 2008-08-19 | |
| US61/090,111 | 2008-08-19 | ||
| US17002909P | 2009-04-16 | 2009-04-16 | |
| US61/170,029 | 2009-04-16 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20110036638A true KR20110036638A (ko) | 2011-04-07 |
Family
ID=41570886
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020117004624A KR20110036638A (ko) | 2008-07-25 | 2009-07-24 | 단백질 스크리닝 방법 |
Country Status (7)
| Country | Link |
|---|---|
| US (4) | US9134304B2 (ko) |
| EP (2) | EP2316030B1 (ko) |
| JP (4) | JP5924937B2 (ko) |
| KR (1) | KR20110036638A (ko) |
| CN (1) | CN102177438A (ko) |
| ES (1) | ES2752025T3 (ko) |
| WO (1) | WO2010011944A2 (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20210108830A (ko) * | 2020-02-26 | 2021-09-03 | 포항공과대학교 산학협력단 | 나노구조체, 나노구조체를 포함하는 바이오센서, 및 스크리닝 방법 |
Families Citing this family (39)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP2316030B1 (en) * | 2008-07-25 | 2019-08-21 | Wagner, Richard W. | Protein screeing methods |
| GB2467704B (en) * | 2008-11-07 | 2011-08-24 | Mlc Dx Inc | A method for determining a profile of recombined DNA sequences in T-cells and/or B-cells |
| US8628927B2 (en) | 2008-11-07 | 2014-01-14 | Sequenta, Inc. | Monitoring health and disease status using clonotype profiles |
| PT2387627E (pt) | 2009-01-15 | 2016-06-03 | Adaptive Biotechnologies Corp | Determinação do perfil de imunidade adaptativa e métodos de geração de anticorpos monoclonais |
| KR20170119729A (ko) | 2009-02-13 | 2017-10-27 | 엑스-켐, 인크. | Dna―코딩된 라이브러리의 생성 및 스크리닝 방법 |
| US20100330571A1 (en) | 2009-06-25 | 2010-12-30 | Robins Harlan S | Method of measuring adaptive immunity |
| ES2926988T3 (es) | 2011-03-15 | 2022-10-31 | X Body Inc | Métodos de cribado de anticuerpos |
| WO2013036810A1 (en) | 2011-09-07 | 2013-03-14 | X-Chem, Inc. | Methods for tagging dna-encoded libraries |
| US10385475B2 (en) | 2011-09-12 | 2019-08-20 | Adaptive Biotechnologies Corp. | Random array sequencing of low-complexity libraries |
| TWI640537B (zh) | 2011-12-05 | 2018-11-11 | X 染色體有限公司 | PDGF受體β結合多肽 |
| US10077478B2 (en) | 2012-03-05 | 2018-09-18 | Adaptive Biotechnologies Corp. | Determining paired immune receptor chains from frequency matched subunits |
| SG11201407107VA (en) | 2012-05-08 | 2014-11-27 | Adaptive Biotechnologies Corp | Compositions and method for measuring and calibrating amplification bias in multiplexed pcr reactions |
| IL236633B (en) | 2012-07-13 | 2022-07-01 | X Chem Inc | DNA-encoded libraries containing a conjugate containing conjugated oligonucleotide links |
| US20140128275A1 (en) * | 2012-08-21 | 2014-05-08 | Syndecion, LLC | Complex of non-covalently bound protein with encoding nucleic acids and uses thereof |
| AU2013327423B2 (en) | 2012-10-01 | 2017-06-22 | Adaptive Biotechnologies Corporation | Immunocompetence assessment by adaptive immune receptor diversity and clonality characterization |
| EP2952582A4 (en) * | 2013-01-30 | 2016-11-16 | Peptidream Inc | FLEXIBLE DISPLAY METHOD |
| EP2975121A4 (en) * | 2013-03-13 | 2016-07-20 | Univ Tokyo | NUCLEIC ACID BINDING SEQUENCE |
| EP3739336B1 (en) * | 2013-06-28 | 2022-05-11 | X-Body, Inc. | Target antigen discovery, phenotypic screens and use thereof for identification of target cell specific target epitopes |
| US9708657B2 (en) | 2013-07-01 | 2017-07-18 | Adaptive Biotechnologies Corp. | Method for generating clonotype profiles using sequence tags |
| CN105705947B (zh) | 2013-09-23 | 2019-04-02 | X博迪公司 | 用于生成对抗细胞表面抗原的结合剂的方法和组合物 |
| US11390921B2 (en) | 2014-04-01 | 2022-07-19 | Adaptive Biotechnologies Corporation | Determining WT-1 specific T cells and WT-1 specific T cell receptors (TCRs) |
| US10066265B2 (en) | 2014-04-01 | 2018-09-04 | Adaptive Biotechnologies Corp. | Determining antigen-specific t-cells |
| EP3132059B1 (en) | 2014-04-17 | 2020-01-08 | Adaptive Biotechnologies Corporation | Quantification of adaptive immune cell genomes in a complex mixture of cells |
| TWI751102B (zh) | 2014-08-28 | 2022-01-01 | 美商奇諾治療有限公司 | 對cd19具專一性之抗體及嵌合抗原受體 |
| WO2016069886A1 (en) | 2014-10-29 | 2016-05-06 | Adaptive Biotechnologies Corporation | Highly-multiplexed simultaneous detection of nucleic acids encoding paired adaptive immune receptor heterodimers from many samples |
| US10246701B2 (en) | 2014-11-14 | 2019-04-02 | Adaptive Biotechnologies Corp. | Multiplexed digital quantitation of rearranged lymphoid receptors in a complex mixture |
| WO2016086029A1 (en) | 2014-11-25 | 2016-06-02 | Adaptive Biotechnologies Corporation | Characterization of adaptive immune response to vaccination or infection using immune repertoire sequencing |
| EP3262196B1 (en) | 2015-02-24 | 2020-12-09 | Adaptive Biotechnologies Corp. | Method for determining hla status using immune repertoire sequencing |
| WO2016161273A1 (en) | 2015-04-01 | 2016-10-06 | Adaptive Biotechnologies Corp. | Method of identifying human compatible t cell receptors specific for an antigenic target |
| JP7283727B2 (ja) | 2016-06-16 | 2023-05-30 | ヘイスタック サイエンシィズ コーポレーション | コードプローブ分子のコンビナトリアル合成が指令されかつ記録されたオリゴヌクレオチド |
| CA3028002A1 (en) | 2016-06-27 | 2018-01-04 | Juno Therapeutics, Inc. | Method of identifying peptide epitopes, molecules that bind such epitopes and related uses |
| MA45491A (fr) | 2016-06-27 | 2019-05-01 | Juno Therapeutics Inc | Épitopes à restriction cmh-e, molécules de liaison et procédés et utilisations associés |
| US10428325B1 (en) | 2016-09-21 | 2019-10-01 | Adaptive Biotechnologies Corporation | Identification of antigen-specific B cell receptors |
| EP3601321A1 (en) * | 2017-03-29 | 2020-02-05 | Yissum Research and Development Company of the Hebrew University of Jerusalem Ltd. | Purification of an agent of interest |
| US11795580B2 (en) | 2017-05-02 | 2023-10-24 | Haystack Sciences Corporation | Molecules for verifying oligonucleotide directed combinatorial synthesis and methods of making and using the same |
| US11254980B1 (en) | 2017-11-29 | 2022-02-22 | Adaptive Biotechnologies Corporation | Methods of profiling targeted polynucleotides while mitigating sequencing depth requirements |
| WO2020095985A1 (ja) * | 2018-11-07 | 2020-05-14 | 公益財団法人川崎市産業振興財団 | ペプチド-核酸複合体 |
| WO2020205426A1 (en) * | 2019-03-29 | 2020-10-08 | The Regents Of The University Of California | Comprehensive identification of interacting protein targets using mrna display of uniform libraries |
| EP4114943A4 (en) * | 2020-03-05 | 2024-04-24 | Univ Columbia | IN VIVO DISPLAY OF MRNA: LARGE-SCALE PROTEOMICS BY NEXT-GENERATION SEQUENCING |
Family Cites Families (141)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US1316003A (en) | 1919-09-16 | William clair toll | ||
| US40307A (en) | 1863-10-13 | Improvement in steam-engines | ||
| US1311003A (en) | 1919-07-22 | Planooraph co | ||
| US700501A (en) | 1901-06-17 | 1902-05-20 | Willard C James | Apartment-house. |
| US2223603A (en) | 1938-07-15 | 1940-12-03 | William A Darrah | Equipment for heat treating |
| US2719403A (en) | 1951-07-14 | 1955-10-04 | Gisiger Armin | Tight container |
| US3983001A (en) | 1972-05-10 | 1976-09-28 | Ceskoslovenska Akademie Ved | Isolation of biologically active compounds by affinity chromatography |
| US4213860A (en) | 1976-06-30 | 1980-07-22 | Board of Regents, State of Florida for and on behalf of the University of Florida | Affinity chromatography and substrate useful therefor |
| GB1602432A (en) | 1976-12-15 | 1981-11-11 | Atomic Energy Authority Uk | Affinity chromatography |
| US4263428A (en) | 1978-03-24 | 1981-04-21 | The Regents Of The University Of California | Bis-anthracycline nucleic acid function inhibitors and improved method for administering the same |
| US4175182A (en) | 1978-07-03 | 1979-11-20 | Research Corporation | Separation of high-activity heparin by affinity chromatography on supported protamine |
| ATE12348T1 (de) | 1980-11-10 | 1985-04-15 | Gersonde Klaus Prof Dr | Verfahren zur herstellung von lipid-vesikeln durch ultraschallbehandlung, anwendung des verfahrens und vorrichtung zur durchfuehrung des verfahrens. |
| US4475196A (en) | 1981-03-06 | 1984-10-02 | Zor Clair G | Instrument for locating faults in aircraft passenger reading light and attendant call control system |
| US4447233A (en) | 1981-04-10 | 1984-05-08 | Parker-Hannifin Corporation | Medication infusion pump |
| US4431544A (en) | 1981-04-27 | 1984-02-14 | The Public Health Laboratory Service Board | High pressure liquid affinity chromatography |
| US4431546A (en) | 1981-04-27 | 1984-02-14 | The Public Health Laboratory Services Board | Affinity chromatography using metal ions |
| US4485045A (en) | 1981-07-06 | 1984-11-27 | Research Corporation | Synthetic phosphatidyl cholines useful in forming liposomes |
| EP0088046B1 (de) | 1982-02-17 | 1987-12-09 | Ciba-Geigy Ag | Lipide in wässriger Phase |
| US4439196A (en) | 1982-03-18 | 1984-03-27 | Merck & Co., Inc. | Osmotic drug delivery system |
| EP0102324A3 (de) | 1982-07-29 | 1984-11-07 | Ciba-Geigy Ag | Lipide und Tenside in wässriger Phase |
| US4447224A (en) | 1982-09-20 | 1984-05-08 | Infusaid Corporation | Variable flow implantable infusion apparatus |
| US4487603A (en) | 1982-11-26 | 1984-12-11 | Cordis Corporation | Implantable microinfusion pump system |
| US4486194A (en) | 1983-06-08 | 1984-12-04 | James Ferrara | Therapeutic device for administering medicaments through the skin |
| US4544545A (en) | 1983-06-20 | 1985-10-01 | Trustees University Of Massachusetts | Liposomes containing modified cholesterol for organ targeting |
| DE3486459D1 (de) | 1983-09-26 | 1997-12-11 | Udo Dr Med Ehrenfeld | Mittel und Erzeugnis für die Diagnose und Therapie von Tumoren sowie zur Behandlung von Schwächen der zelligen und humoralen Immunabwehr |
| DE3474511D1 (en) | 1983-11-01 | 1988-11-17 | Terumo Corp | Pharmaceutical composition containing urokinase |
| US5171534A (en) | 1984-01-16 | 1992-12-15 | California Institute Of Technology | Automated DNA sequencing technique |
| US5821058A (en) | 1984-01-16 | 1998-10-13 | California Institute Of Technology | Automated DNA sequencing technique |
| US4596556A (en) | 1985-03-25 | 1986-06-24 | Bioject, Inc. | Hypodermic injection apparatus |
| US4811218A (en) | 1986-06-02 | 1989-03-07 | Applied Biosystems, Inc. | Real time scanning electrophoresis apparatus for DNA sequencing |
| US4941880A (en) | 1987-06-19 | 1990-07-17 | Bioject, Inc. | Pre-filled ampule and non-invasive hypodermic injection device assembly |
| US4790824A (en) | 1987-06-19 | 1988-12-13 | Bioject, Inc. | Non-invasive hypodermic injection device |
| US5149625A (en) | 1987-08-11 | 1992-09-22 | President And Fellows Of Harvard College | Multiplex analysis of DNA |
| SE8801070D0 (sv) | 1988-03-23 | 1988-03-23 | Pharmacia Ab | Method for immobilizing a dna sequence on a solid support |
| US4962020A (en) | 1988-07-12 | 1990-10-09 | President And Fellows Of Harvard College | DNA sequencing |
| US5075216A (en) | 1988-09-23 | 1991-12-24 | Cetus Corporation | Methods for dna sequencing with thermus aquaticus dna polymerase |
| KR0184860B1 (ko) | 1988-11-11 | 1999-04-01 | 메디칼 리써어치 카운실 | 단일영역 리간드와 이를 포함하는 수용체 및 이들의 제조방법과 이용(법) |
| US5043062A (en) | 1989-02-21 | 1991-08-27 | Eastman Kodak Company | High performance affinity chromatography column comprising non-porous, nondisperse polymeric packing material |
| US6291158B1 (en) | 1989-05-16 | 2001-09-18 | Scripps Research Institute | Method for tapping the immunological repertoire |
| ES2118066T3 (es) | 1989-10-05 | 1998-09-16 | Optein Inc | Sintesis y aislamiento, exentos de celulas, de nuevos genes y polipeptidos. |
| US5312335A (en) | 1989-11-09 | 1994-05-17 | Bioject Inc. | Needleless hypodermic injection device |
| US5064413A (en) | 1989-11-09 | 1991-11-12 | Bioject, Inc. | Needleless hypodermic injection device |
| CA2079802C (en) | 1990-04-05 | 2001-09-18 | Roberto Crea | Walk-through mutagenesis |
| GB9015198D0 (en) | 1990-07-10 | 1990-08-29 | Brien Caroline J O | Binding substance |
| US6172197B1 (en) | 1991-07-10 | 2001-01-09 | Medical Research Council | Methods for producing members of specific binding pairs |
| US5843701A (en) | 1990-08-02 | 1998-12-01 | Nexstar Pharmaceticals, Inc. | Systematic polypeptide evolution by reverse translation |
| US5846951A (en) | 1991-06-06 | 1998-12-08 | The School Of Pharmacy, University Of London | Pharmaceutical compositions |
| DK1024191T3 (da) | 1991-12-02 | 2008-12-08 | Medical Res Council | Fremstilling af autoantistoffer fremvist på fag-overflader ud fra antistofsegmentbiblioteker |
| DE69233408T2 (de) | 1991-12-02 | 2005-09-22 | Cambridge Antibody Technology Ltd., Melbourn | Herstellung von Antikörpern auf Phagenoberflächen ausgehend von Antikörpersegmentbibliotheken. |
| GB9208733D0 (en) | 1992-04-22 | 1992-06-10 | Medical Res Council | Dna sequencing method |
| US5383851A (en) | 1992-07-24 | 1995-01-24 | Bioject Inc. | Needleless hypodermic injection device |
| US6765087B1 (en) | 1992-08-21 | 2004-07-20 | Vrije Universiteit Brussel | Immunoglobulins devoid of light chains |
| EP1262564A3 (en) | 1993-01-07 | 2004-03-31 | Sequenom, Inc. | Dna sequencing by mass spectrometry |
| US5374527A (en) | 1993-01-21 | 1994-12-20 | Applied Biosystems, Inc. | High resolution DNA sequencing method using low viscosity medium |
| IL108497A0 (en) | 1993-02-01 | 1994-05-30 | Seq Ltd | Methods and apparatus for dna sequencing |
| CA2158642A1 (en) | 1993-03-19 | 1994-09-29 | Hubert Koster | Dna sequencing by mass spectrometry via exonuclease degradation |
| AU6796094A (en) | 1993-04-29 | 1994-11-21 | Raymond Hamers | Production of antibodies or (functionalized) fragments thereof derived from heavy chain immunoglobulins of (camelidae) |
| US5922545A (en) | 1993-10-29 | 1999-07-13 | Affymax Technologies N.V. | In vitro peptide and antibody display libraries |
| SE9400088D0 (sv) | 1994-01-14 | 1994-01-14 | Kabi Pharmacia Ab | Bacterial receptor structures |
| US5654419A (en) | 1994-02-01 | 1997-08-05 | The Regents Of The University Of California | Fluorescent labels and their use in separations |
| UA71889C2 (uk) | 1996-04-02 | 2005-01-17 | Йєда Рісерч Енд Дівелопмент Ко. Лтд. | Модулятори зв'язаного з рецептором tnf фактора (traf), їх одержання та застосування |
| US5846727A (en) | 1996-06-06 | 1998-12-08 | Board Of Supervisors Of Louisiana State University And Agricultural & Mechanical College | Microsystem for rapid DNA sequencing |
| EP1477561B1 (en) | 1996-10-17 | 2008-12-10 | Mitsubishi Chemical Corporation | Molecule assigning genotype to phenotype and use thereof |
| US6258533B1 (en) | 1996-11-01 | 2001-07-10 | The University Of Iowa Research Foundation | Iterative and regenerative DNA sequencing method |
| US5858671A (en) | 1996-11-01 | 1999-01-12 | The University Of Iowa Research Foundation | Iterative and regenerative DNA sequencing method |
| US5876934A (en) | 1996-12-18 | 1999-03-02 | Pharmacia Biotech Inc. | DNA sequencing method |
| US6261804B1 (en) | 1997-01-21 | 2001-07-17 | The General Hospital Corporation | Selection of proteins using RNA-protein fusions |
| AU776478B2 (en) | 1997-01-21 | 2004-09-09 | General Hospital Corporation, The | Selection of proteins using RNA-protein fusions |
| WO1998031700A1 (en) | 1997-01-21 | 1998-07-23 | The General Hospital Corporation | Selection of proteins using rna-protein fusions |
| GB9703369D0 (en) | 1997-02-18 | 1997-04-09 | Lindqvist Bjorn H | Process |
| US6090800A (en) * | 1997-05-06 | 2000-07-18 | Imarx Pharmaceutical Corp. | Lipid soluble steroid prodrugs |
| JP4086325B2 (ja) | 1997-04-23 | 2008-05-14 | プリュックテュン,アンドレアス | 標的分子と相互作用する(ポリ)ペプチドをコードする核酸分子の同定方法 |
| EP0985032B2 (en) | 1997-05-28 | 2009-06-03 | Discerna Limited | Ribosome complexes as selection particles for in vitro display and evolution of proteins |
| DE19742706B4 (de) | 1997-09-26 | 2013-07-25 | Pieris Proteolab Ag | Lipocalinmuteine |
| GB9722131D0 (en) | 1997-10-20 | 1997-12-17 | Medical Res Council | Method |
| US6153383A (en) * | 1997-12-09 | 2000-11-28 | Verdine; Gregory L. | Synthetic transcriptional modulators and uses thereof |
| EP1040501A1 (en) | 1997-12-15 | 2000-10-04 | E.I. Du Pont De Nemours And Company | Ion-bombarded graphite electron emitters |
| EP1068356B8 (en) | 1998-04-03 | 2007-01-03 | Adnexus Therapeutics, Inc. | Addressable protein arrays |
| EP1073730A1 (en) | 1998-04-17 | 2001-02-07 | Whitehead For Biomedical Research | Use of a ribozyme to join nucleic acids and peptides |
| US6846655B1 (en) | 1998-06-29 | 2005-01-25 | Phylos, Inc. | Methods for generating highly diverse libraries |
| AU5551299A (en) * | 1998-08-13 | 2000-03-06 | Trustees Of The University Of Pennsylvania, The | Method of identifying proteins |
| US6312927B1 (en) | 1998-08-17 | 2001-11-06 | Phylos, Inc. | Methods for producing nucleic acids lacking 3'-untranslated regions and optimizing cellular RNA-protein fusion formation |
| DE69941193D1 (de) | 1998-08-17 | 2009-09-10 | Bristol Myers Squibb Co | Identifizierung von verbindung-protein wechselwirkungen mit bibliotheken von gekoppelten protein-nukleinsäure-molekülen |
| WO2000032823A1 (en) | 1998-12-02 | 2000-06-08 | Phylos, Inc. | Dna-protein fusions and uses thereof |
| US7115396B2 (en) | 1998-12-10 | 2006-10-03 | Compound Therapeutics, Inc. | Protein scaffolds for antibody mimics and other binding proteins |
| US6818418B1 (en) | 1998-12-10 | 2004-11-16 | Compound Therapeutics, Inc. | Protein scaffolds for antibody mimics and other binding proteins |
| US6413720B1 (en) * | 1999-01-11 | 2002-07-02 | Signal Pharmaceuticals, Inc. | Method for the affinity isolation of newly synthesized RNA |
| EP1187626A4 (en) | 1999-06-01 | 2006-07-19 | Compound Therapeutics Inc | PROCESS FOR THE PREPARATION OF 5'-NUCLEIC ACID PROTEIN CONJUGATES |
| CA2372795A1 (en) | 1999-07-12 | 2001-01-18 | Robert G. Kuimelis | C-terminal protein tagging |
| ES2383332T3 (es) | 1999-07-27 | 2012-06-20 | Bristol-Myers Squibb Company | Procedimiento de ligación de aceptores de péptidos |
| WO2001016352A1 (en) | 1999-08-27 | 2001-03-08 | Phylos, Inc. | Methods for encoding and sorting in vitro translated proteins |
| EP1211514A4 (en) | 1999-08-31 | 2005-03-09 | Mitsubishi Chem Corp | METHOD OF ANALYZING A MUTUAL INTERACTION BETWEEN A PROTEIN AND A MOLECULE |
| US20010046680A1 (en) | 1999-10-01 | 2001-11-29 | Zhongping Yu | Identification of polypeptides and nucleic acid molecules using linkage between DNA and polypeptide |
| US6794132B2 (en) | 1999-10-02 | 2004-09-21 | Biosite, Inc. | Human antibodies |
| WO2001053539A1 (en) | 2000-01-24 | 2001-07-26 | Phylos, Inc. | Sensitive, multiplexed diagnostic assays for protein analysis |
| US7022479B2 (en) | 2000-01-24 | 2006-04-04 | Compound Therapeutics, Inc. | Sensitive, multiplexed diagnostic assays for protein analysis |
| AU3944401A (en) | 2000-03-31 | 2001-10-15 | Cambridge Antibody Tech | Improvements to ribosome display |
| AU2001253410A1 (en) | 2000-04-12 | 2001-10-30 | Genaissance Pharmaceuticals, Inc. | Haplotypes of the il8rb gene |
| CA2409705A1 (en) | 2000-05-16 | 2001-11-22 | Merck & Co., Inc. | Gene responsible for stargardt-like dominant macular dystrophy |
| EP1332209B1 (en) | 2000-09-08 | 2009-11-11 | Universität Zürich | Collections of repeat proteins comprising repeat modules |
| JP3750020B2 (ja) * | 2000-12-07 | 2006-03-01 | 学校法人慶應義塾 | C末端修飾タンパク質およびその製造方法、ならびに、c末端修飾タンパク質の製造に用いる修飾剤および翻訳テンプレート、ならびに、c末端修飾タンパク質を用いたタンパク質相互作用の検出方法 |
| JP4963142B2 (ja) * | 2000-12-14 | 2012-06-27 | 学校法人慶應義塾 | 遺伝子型と表現型の対応付け分子とその構成要素、および対応付け分子の製造方法と利用方法 |
| US20030133939A1 (en) | 2001-01-17 | 2003-07-17 | Genecraft, Inc. | Binding domain-immunoglobulin fusion proteins |
| US20060223114A1 (en) | 2001-04-26 | 2006-10-05 | Avidia Research Institute | Protein scaffolds and uses thereof |
| CA2444854A1 (en) | 2001-04-26 | 2002-11-07 | Avidia Research Institute | Combinatorial libraries of monomer domains |
| US20030157561A1 (en) | 2001-11-19 | 2003-08-21 | Kolkman Joost A. | Combinatorial libraries of monomer domains |
| US20050053973A1 (en) | 2001-04-26 | 2005-03-10 | Avidia Research Institute | Novel proteins with targeted binding |
| US20050089932A1 (en) | 2001-04-26 | 2005-04-28 | Avidia Research Institute | Novel proteins with targeted binding |
| US20050048512A1 (en) | 2001-04-26 | 2005-03-03 | Avidia Research Institute | Combinatorial libraries of monomer domains |
| US20040175756A1 (en) | 2001-04-26 | 2004-09-09 | Avidia Research Institute | Methods for using combinatorial libraries of monomer domains |
| EP1394250A1 (en) | 2001-05-11 | 2004-03-03 | Kazunari Taira | Method of forming stable complex of transcription product of dna encoding arbitrary peptide with translation product, nucleic acid construct to be used in the method, complex formed by the method ; and screening of functional protein and mrna or dna encoding the protein using the method |
| US6951725B2 (en) | 2001-06-21 | 2005-10-04 | Compound Therapeutics, Inc. | In vitro protein interaction detection systems |
| WO2004058821A2 (en) | 2002-12-27 | 2004-07-15 | Domantis Limited | Dual specific single domain antibodies specific for a ligand and for the receptor of the ligand |
| DE60237282D1 (de) | 2001-06-28 | 2010-09-23 | Domantis Ltd | Doppelspezifischer ligand und dessen verwendung |
| JP2004537312A (ja) | 2001-07-31 | 2004-12-16 | フィロス インク. | 核酸−蛋白質融合多量体のモジュラーアッセンブリ |
| AU2002365404A1 (en) | 2001-11-27 | 2003-06-10 | Compound Therapeutics, Inc. | Solid-phase immobilization of proteins and peptides |
| PT1517921E (pt) | 2002-06-28 | 2006-09-29 | Domantis Ltd | Ligandos duplamente especificos com semi-vida no soro aumentada |
| US20060002935A1 (en) | 2002-06-28 | 2006-01-05 | Domantis Limited | Tumor Necrosis Factor Receptor 1 antagonists and methods of use therefor |
| US20040043384A1 (en) * | 2002-08-28 | 2004-03-04 | Oleinikov Andrew V. | In vitro protein translation microarray device |
| DE60335000D1 (de) | 2002-09-06 | 2010-12-30 | Isogenica Ltd | In vitro peptid-expressionsbank |
| US20040259155A1 (en) | 2002-09-30 | 2004-12-23 | Compound Therapeutics, Inc. | Methods of engineering spatially conserved motifs in polypeptides |
| AU2003286003B2 (en) | 2002-11-08 | 2011-05-26 | Ablynx N.V. | Stabilized single domain antibodies |
| US20060183885A1 (en) * | 2002-12-11 | 2006-08-17 | Etsuko Miyamoto | Protein forming complex with c-fos protein, nucleic acid encoding the same and method of using the same |
| EP1604044B1 (en) | 2003-03-19 | 2009-05-13 | Discerna Limited | Recovery of dna |
| AU2004239065B2 (en) | 2003-05-14 | 2008-05-15 | Domantis Limited | A process for recovering polypeptides that unfold reversibly from a polypeptide repertoire |
| PT1639011E (pt) | 2003-06-30 | 2009-01-20 | Domantis Ltd | Anticorpos (dab) de domínio único peguilados |
| JP2007501888A (ja) | 2003-08-12 | 2007-02-01 | リポクセン テクノロジーズ リミテッド | ポリシアル酸誘導体 |
| ATE386113T1 (de) | 2003-10-01 | 2008-03-15 | Eth Zuerich | Verfahren zur in vitro evolution von polypeptiden |
| CA2543360A1 (en) | 2003-10-24 | 2005-05-06 | Joost A. Kolkman | Ldl receptor class a and egf domain monomers and multimers |
| US20060008844A1 (en) | 2004-06-17 | 2006-01-12 | Avidia Research Institute | c-Met kinase binding proteins |
| AU2005307789A1 (en) | 2004-11-16 | 2006-05-26 | Avidia Research Institute | Protein scaffolds and uses thereof |
| EP1844073A1 (en) | 2005-01-31 | 2007-10-17 | Ablynx N.V. | Method for generating variable domain sequences of heavy chain antibodies |
| WO2006081623A1 (en) * | 2005-02-04 | 2006-08-10 | The Australian National University | Double-stranded oligonucleotides and uses therefor |
| US8217154B2 (en) | 2005-02-23 | 2012-07-10 | Lipoxen Technologies Limited | Activated sialic acid derivatives for protein derivatisation and conjugation |
| AU2006294644A1 (en) | 2005-09-27 | 2007-04-05 | Amunix, Inc. | Proteinaceous pharmaceuticals and uses thereof |
| EP1973576B1 (en) | 2005-11-28 | 2019-05-15 | Genmab A/S | Recombinant monovalent antibodies and methods for production thereof |
| JP4616237B2 (ja) | 2006-11-07 | 2011-01-19 | 日本電信電話株式会社 | シリコン化合物薄膜の形成方法 |
| US8236508B2 (en) | 2008-01-29 | 2012-08-07 | Drexel University | Detecting and measuring live pathogens utilizing a mass detection device |
| EP2316030B1 (en) * | 2008-07-25 | 2019-08-21 | Wagner, Richard W. | Protein screeing methods |
| US8698004B2 (en) | 2008-10-27 | 2014-04-15 | Ibiden Co., Ltd. | Multi-piece board and fabrication method thereof |
| US8876866B2 (en) | 2010-12-13 | 2014-11-04 | Globus Medical, Inc. | Spinous process fusion devices and methods thereof |
-
2009
- 2009-07-24 EP EP09801086.1A patent/EP2316030B1/en active Active
- 2009-07-24 WO PCT/US2009/051716 patent/WO2010011944A2/en active Application Filing
- 2009-07-24 EP EP19192666.6A patent/EP3629022A1/en not_active Withdrawn
- 2009-07-24 ES ES09801086T patent/ES2752025T3/es active Active
- 2009-07-24 KR KR1020117004624A patent/KR20110036638A/ko not_active Application Discontinuation
- 2009-07-24 JP JP2011520232A patent/JP5924937B2/ja active Active
- 2009-07-24 CN CN200980137939XA patent/CN102177438A/zh active Pending
-
2011
- 2011-01-19 US US13/009,500 patent/US9134304B2/en active Active
-
2015
- 2015-07-10 US US14/796,480 patent/US9803193B2/en active Active
-
2016
- 2016-01-28 JP JP2016014207A patent/JP6239654B2/ja active Active
-
2017
- 2017-09-13 US US15/703,710 patent/US10519438B2/en active Active
- 2017-11-01 JP JP2017211730A patent/JP6725473B2/ja active Active
-
2019
- 2019-11-08 US US16/678,220 patent/US11268090B2/en active Active
-
2020
- 2020-06-25 JP JP2020109269A patent/JP7123092B2/ja active Active
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20210108830A (ko) * | 2020-02-26 | 2021-09-03 | 포항공과대학교 산학협력단 | 나노구조체, 나노구조체를 포함하는 바이오센서, 및 스크리닝 방법 |
| US11827920B2 (en) | 2020-02-26 | 2023-11-28 | POSTECH Research and Business Development Foundation | Nanostructure, a biosensor including the nanostructure, and a screening method |
Also Published As
| Publication number | Publication date |
|---|---|
| US9134304B2 (en) | 2015-09-15 |
| US9803193B2 (en) | 2017-10-31 |
| EP3629022A1 (en) | 2020-04-01 |
| EP2316030A2 (en) | 2011-05-04 |
| US11268090B2 (en) | 2022-03-08 |
| JP2018015013A (ja) | 2018-02-01 |
| EP2316030A4 (en) | 2011-10-12 |
| US10519438B2 (en) | 2019-12-31 |
| WO2010011944A2 (en) | 2010-01-28 |
| JP6239654B2 (ja) | 2017-11-29 |
| WO2010011944A3 (en) | 2010-05-06 |
| JP2020178697A (ja) | 2020-11-05 |
| ES2752025T3 (es) | 2020-04-02 |
| JP6725473B2 (ja) | 2020-07-22 |
| US20160040158A1 (en) | 2016-02-11 |
| US20200172897A1 (en) | 2020-06-04 |
| ES2752025T8 (es) | 2021-11-11 |
| JP7123092B2 (ja) | 2022-08-22 |
| US20110183863A1 (en) | 2011-07-28 |
| EP2316030B1 (en) | 2019-08-21 |
| CN102177438A (zh) | 2011-09-07 |
| JP2011528912A (ja) | 2011-12-01 |
| US20180094256A1 (en) | 2018-04-05 |
| JP2016127845A (ja) | 2016-07-14 |
| JP5924937B2 (ja) | 2016-05-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7123092B2 (ja) | タンパク質スクリーニング法 | |
| Zielonka et al. | Shark attack: high affinity binding proteins derived from shark vNAR domains by stepwise in vitro affinity maturation | |
| Reverdatto et al. | Peptide aptamers: development and applications | |
| Rich et al. | Survey of the 2009 commercial optical biosensor literature | |
| EP3103478B1 (en) | Stabilized fibronectin domain compositions, methods and uses | |
| Stern et al. | Titratable avidity reduction enhances affinity discrimination in mammalian cellular selections of yeast-displayed ligands | |
| Valeur et al. | New modalities, technologies, and partnerships in probe and lead generation: enabling a mode-of-action centric paradigm | |
| Lau et al. | Evolution and protein packaging of small-molecule RNA aptamers | |
| Chen et al. | Discovery of aptamer ligands for hepatic stellate cells using SELEX | |
| JP2018064573A (ja) | ハイスループットペプチドミメティックを調製するための方法、経口バイオアベイラブルな薬物およびそれを含有する組成物 | |
| Shraim et al. | Therapeutic Potential of Aptamer–Protein Interactions | |
| JP5809687B2 (ja) | Rnf8−fhaドメイン改変タンパク質及びその製造方法 | |
| JP4953046B2 (ja) | ランダムペプチドライブラリーもしくは抗体超可変領域を模倣したペプチドライブラリーと、rna結合タンパク質を用いる試験管内ペプチド選択法を組み合わせた、新規の機能性ペプチド創製システム | |
| WO2018222433A2 (en) | Circulating tumor cell enrichment using neoepitopes | |
| WO2022221505A2 (en) | Cd71 binding fibronectin type iii domains | |
| Song et al. | Review of phage display: A jack-of-all-trades and master of most biomolecule display | |
| Gao et al. | A phage-displayed disulfide constrained peptide discovery platform yields novel human plasma protein binders | |
| Brango-Vanegas et al. | From exploring cancer and virus targets to discovering active peptides through mRNA display | |
| Gordon | Developing Methods for Discovering Non-Natural and pH Switching Aptamers | |
| Lown | Engineering Cell-Based Selections for Translatable Ligand Discovery | |
| Rosch | Improving Aptamer Specificity with Novel Counterselection Strategies | |
| Rosch | Graduate Student | |
| Shum et al. | RNA Nanotechnology approach for targeted delivery of RNA therapeutics using cell-internalizing aptamers |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| N231 | Notification of change of applicant | ||
| WITN | Application deemed withdrawn, e.g. because no request for examination was filed or no examination fee was paid |