JP7532455B2 - 連続性を維持した転位 - Google Patents
連続性を維持した転位 Download PDFInfo
- Publication number
- JP7532455B2 JP7532455B2 JP2022129859A JP2022129859A JP7532455B2 JP 7532455 B2 JP7532455 B2 JP 7532455B2 JP 2022129859 A JP2022129859 A JP 2022129859A JP 2022129859 A JP2022129859 A JP 2022129859A JP 7532455 B2 JP7532455 B2 JP 7532455B2
- Authority
- JP
- Japan
- Prior art keywords
- nucleic acid
- target nucleic
- sequence
- transposome
- bases
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 150000007523 nucleic acids Chemical class 0.000 claims description 291
- 239000011324 bead Substances 0.000 claims description 223
- 102000039446 nucleic acids Human genes 0.000 claims description 221
- 108020004707 nucleic acids Proteins 0.000 claims description 221
- 108020004414 DNA Proteins 0.000 claims description 175
- 238000000034 method Methods 0.000 claims description 151
- 239000007787 solid Substances 0.000 claims description 108
- 108010020764 Transposases Proteins 0.000 claims description 77
- 102000008579 Transposases Human genes 0.000 claims description 76
- 239000012634 fragment Substances 0.000 claims description 59
- 239000000203 mixture Substances 0.000 claims description 44
- 239000000178 monomer Substances 0.000 claims description 36
- 108090000623 proteins and genes Proteins 0.000 claims description 23
- 210000004027 cell Anatomy 0.000 claims description 22
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 18
- 102000040430 polynucleotide Human genes 0.000 claims description 12
- 108091033319 polynucleotide Proteins 0.000 claims description 12
- 239000002157 polynucleotide Substances 0.000 claims description 12
- 238000012217 deletion Methods 0.000 claims description 10
- 230000037430 deletion Effects 0.000 claims description 10
- 230000015572 biosynthetic process Effects 0.000 claims description 9
- 239000002299 complementary DNA Substances 0.000 claims description 8
- 206010028980 Neoplasm Diseases 0.000 claims description 7
- 230000004927 fusion Effects 0.000 claims description 7
- 102000054766 genetic haplotypes Human genes 0.000 claims description 5
- 230000003426 interchromosomal effect Effects 0.000 claims description 5
- 210000003463 organelle Anatomy 0.000 claims description 5
- 230000008826 genomic mutation Effects 0.000 claims description 3
- 230000008707 rearrangement Effects 0.000 claims description 2
- 238000006243 chemical reaction Methods 0.000 description 81
- 238000012163 sequencing technique Methods 0.000 description 80
- 108091034117 Oligonucleotide Proteins 0.000 description 73
- LSNNMFCWUKXFEE-UHFFFAOYSA-M Bisulfite Chemical compound OS([O-])=O LSNNMFCWUKXFEE-UHFFFAOYSA-M 0.000 description 55
- 230000000295 complement effect Effects 0.000 description 36
- 239000000523 sample Substances 0.000 description 33
- 230000017105 transposition Effects 0.000 description 32
- 239000002773 nucleotide Substances 0.000 description 31
- 125000003729 nucleotide group Chemical group 0.000 description 31
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 28
- 210000002381 plasma Anatomy 0.000 description 24
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 22
- 238000001514 detection method Methods 0.000 description 20
- 230000003321 amplification Effects 0.000 description 19
- 238000003556 assay Methods 0.000 description 19
- 238000003199 nucleic acid amplification method Methods 0.000 description 19
- 239000000047 product Substances 0.000 description 19
- 108010090804 Streptavidin Proteins 0.000 description 18
- 238000010586 diagram Methods 0.000 description 18
- 230000008569 process Effects 0.000 description 18
- 238000011282 treatment Methods 0.000 description 18
- 238000009396 hybridization Methods 0.000 description 17
- 238000002360 preparation method Methods 0.000 description 17
- 102100033215 DNA nucleotidylexotransferase Human genes 0.000 description 16
- 230000011987 methylation Effects 0.000 description 16
- 238000007069 methylation reaction Methods 0.000 description 16
- 102000053602 DNA Human genes 0.000 description 14
- 229960002685 biotin Drugs 0.000 description 14
- 239000011616 biotin Substances 0.000 description 14
- 230000008901 benefit Effects 0.000 description 12
- 239000000243 solution Substances 0.000 description 12
- 108091035707 Consensus sequence Proteins 0.000 description 11
- 235000020958 biotin Nutrition 0.000 description 11
- 210000004369 blood Anatomy 0.000 description 10
- 239000008280 blood Substances 0.000 description 10
- 210000000349 chromosome Anatomy 0.000 description 10
- 238000009826 distribution Methods 0.000 description 10
- 201000004283 Shwachman-Diamond syndrome Diseases 0.000 description 9
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical compound [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 9
- 108010012306 Tn5 transposase Proteins 0.000 description 9
- 238000004458 analytical method Methods 0.000 description 9
- 238000013467 fragmentation Methods 0.000 description 9
- 238000006062 fragmentation reaction Methods 0.000 description 9
- 102100034343 Integrase Human genes 0.000 description 8
- 108010061833 Integrases Proteins 0.000 description 8
- 102000057361 Pseudogenes Human genes 0.000 description 8
- 108091008109 Pseudogenes Proteins 0.000 description 8
- 239000000872 buffer Substances 0.000 description 8
- 239000004005 microsphere Substances 0.000 description 8
- 238000005580 one pot reaction Methods 0.000 description 8
- 108020004635 Complementary DNA Proteins 0.000 description 7
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 7
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 7
- 238000012408 PCR amplification Methods 0.000 description 7
- 238000013459 approach Methods 0.000 description 7
- 238000010804 cDNA synthesis Methods 0.000 description 7
- 229920001519 homopolymer Polymers 0.000 description 7
- 238000003780 insertion Methods 0.000 description 7
- 230000035772 mutation Effects 0.000 description 7
- 235000018102 proteins Nutrition 0.000 description 7
- 102000004169 proteins and genes Human genes 0.000 description 7
- 101150116023 TNP1 gene Proteins 0.000 description 6
- 230000000694 effects Effects 0.000 description 6
- 230000007614 genetic variation Effects 0.000 description 6
- 230000003100 immobilizing effect Effects 0.000 description 6
- 230000037431 insertion Effects 0.000 description 6
- 230000001404 mediated effect Effects 0.000 description 6
- 238000002156 mixing Methods 0.000 description 6
- 239000011541 reaction mixture Substances 0.000 description 6
- 101150031434 tnp2 gene Proteins 0.000 description 6
- 238000012546 transfer Methods 0.000 description 6
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 5
- 108700024394 Exon Proteins 0.000 description 5
- 108010033040 Histones Proteins 0.000 description 5
- 125000000539 amino acid group Chemical group 0.000 description 5
- 210000001124 body fluid Anatomy 0.000 description 5
- 238000000338 in vitro Methods 0.000 description 5
- 230000005291 magnetic effect Effects 0.000 description 5
- 238000013507 mapping Methods 0.000 description 5
- 238000000926 separation method Methods 0.000 description 5
- 239000000126 substance Substances 0.000 description 5
- 239000004971 Cross linker Substances 0.000 description 4
- 108010008286 DNA nucleotidylexotransferase Proteins 0.000 description 4
- 102000006947 Histones Human genes 0.000 description 4
- 239000011543 agarose gel Substances 0.000 description 4
- 238000000246 agarose gel electrophoresis Methods 0.000 description 4
- 239000012472 biological sample Substances 0.000 description 4
- 239000010839 body fluid Substances 0.000 description 4
- 235000018417 cysteine Nutrition 0.000 description 4
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 4
- 239000000539 dimer Substances 0.000 description 4
- 238000002474 experimental method Methods 0.000 description 4
- 230000007246 mechanism Effects 0.000 description 4
- 108010009127 mu transposase Proteins 0.000 description 4
- 239000002105 nanoparticle Substances 0.000 description 4
- 229920000642 polymer Polymers 0.000 description 4
- 238000000746 purification Methods 0.000 description 4
- 239000007790 solid phase Substances 0.000 description 4
- LRSASMSXMSNRBT-UHFFFAOYSA-N 5-methylcytosine Chemical compound CC1=CNC(=O)N=C1N LRSASMSXMSNRBT-UHFFFAOYSA-N 0.000 description 3
- 102000004190 Enzymes Human genes 0.000 description 3
- 108090000790 Enzymes Proteins 0.000 description 3
- 102000012330 Integrases Human genes 0.000 description 3
- 108010092799 RNA-directed DNA polymerase Proteins 0.000 description 3
- DWAQJAXMDSEUJJ-UHFFFAOYSA-M Sodium bisulfite Chemical compound [Na+].OS([O-])=O DWAQJAXMDSEUJJ-UHFFFAOYSA-M 0.000 description 3
- 235000001014 amino acid Nutrition 0.000 description 3
- 230000001413 cellular effect Effects 0.000 description 3
- 239000007795 chemical reaction product Substances 0.000 description 3
- 230000029087 digestion Effects 0.000 description 3
- 238000011049 filling Methods 0.000 description 3
- 239000012530 fluid Substances 0.000 description 3
- 230000010354 integration Effects 0.000 description 3
- 230000003993 interaction Effects 0.000 description 3
- 239000000463 material Substances 0.000 description 3
- 238000005457 optimization Methods 0.000 description 3
- 230000036961 partial effect Effects 0.000 description 3
- 239000002245 particle Substances 0.000 description 3
- 229920001184 polypeptide Polymers 0.000 description 3
- 108090000765 processed proteins & peptides Proteins 0.000 description 3
- 102000004196 processed proteins & peptides Human genes 0.000 description 3
- 230000002829 reductive effect Effects 0.000 description 3
- 230000008439 repair process Effects 0.000 description 3
- 238000001542 size-exclusion chromatography Methods 0.000 description 3
- 235000010267 sodium hydrogen sulphite Nutrition 0.000 description 3
- 238000000527 sonication Methods 0.000 description 3
- 241000894007 species Species 0.000 description 3
- 239000000758 substrate Substances 0.000 description 3
- 210000001519 tissue Anatomy 0.000 description 3
- RYVNIFSIEDRLSJ-UHFFFAOYSA-N 5-(hydroxymethyl)cytosine Chemical compound NC=1NC(=O)N=CC=1CO RYVNIFSIEDRLSJ-UHFFFAOYSA-N 0.000 description 2
- YBJHBAHKTGYVGT-ZXFLCMHBSA-N 5-[(3ar,4r,6as)-2-oxo-1,3,3a,4,6,6a-hexahydrothieno[3,4-d]imidazol-4-yl]pentanoic acid Chemical compound N1C(=O)N[C@H]2[C@@H](CCCCC(=O)O)SC[C@H]21 YBJHBAHKTGYVGT-ZXFLCMHBSA-N 0.000 description 2
- 108700028369 Alleles Proteins 0.000 description 2
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 2
- 102000012410 DNA Ligases Human genes 0.000 description 2
- 108010061982 DNA Ligases Proteins 0.000 description 2
- 230000005778 DNA damage Effects 0.000 description 2
- 231100000277 DNA damage Toxicity 0.000 description 2
- WSFSSNUMVMOOMR-UHFFFAOYSA-N Formaldehyde Chemical compound O=C WSFSSNUMVMOOMR-UHFFFAOYSA-N 0.000 description 2
- 108091092584 GDNA Proteins 0.000 description 2
- 101000690100 Homo sapiens U1 small nuclear ribonucleoprotein 70 kDa Proteins 0.000 description 2
- 108010047956 Nucleosomes Proteins 0.000 description 2
- 240000007019 Oxalis corniculata Species 0.000 description 2
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 2
- 239000012506 Sephacryl® Substances 0.000 description 2
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 2
- 108020004682 Single-Stranded DNA Proteins 0.000 description 2
- GWEVSGVZZGPLCZ-UHFFFAOYSA-N Titan oxide Chemical compound O=[Ti]=O GWEVSGVZZGPLCZ-UHFFFAOYSA-N 0.000 description 2
- 102100024121 U1 small nuclear ribonucleoprotein 70 kDa Human genes 0.000 description 2
- 125000003275 alpha amino acid group Chemical group 0.000 description 2
- 150000001412 amines Chemical class 0.000 description 2
- 150000001413 amino acids Chemical class 0.000 description 2
- 125000003277 amino group Chemical group 0.000 description 2
- 230000001580 bacterial effect Effects 0.000 description 2
- 239000006227 byproduct Substances 0.000 description 2
- 201000011510 cancer Diseases 0.000 description 2
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 2
- 238000004925 denaturation Methods 0.000 description 2
- 230000036425 denaturation Effects 0.000 description 2
- 238000010790 dilution Methods 0.000 description 2
- 239000012895 dilution Substances 0.000 description 2
- 201000010099 disease Diseases 0.000 description 2
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 2
- 238000006073 displacement reaction Methods 0.000 description 2
- 238000006911 enzymatic reaction Methods 0.000 description 2
- 230000001747 exhibiting effect Effects 0.000 description 2
- 230000006870 function Effects 0.000 description 2
- 238000012224 gene deletion Methods 0.000 description 2
- 238000005304 joining Methods 0.000 description 2
- 239000012528 membrane Substances 0.000 description 2
- 108020004999 messenger RNA Proteins 0.000 description 2
- 229910052751 metal Inorganic materials 0.000 description 2
- 239000002184 metal Substances 0.000 description 2
- 150000002739 metals Chemical class 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- -1 morpholino nucleic acid Chemical class 0.000 description 2
- 210000001623 nucleosome Anatomy 0.000 description 2
- 239000013610 patient sample Substances 0.000 description 2
- 230000003169 placental effect Effects 0.000 description 2
- 239000013615 primer Substances 0.000 description 2
- 239000002987 primer (paints) Substances 0.000 description 2
- 230000001177 retroviral effect Effects 0.000 description 2
- 230000002441 reversible effect Effects 0.000 description 2
- 210000002966 serum Anatomy 0.000 description 2
- JJAHTWIKCUJRDK-UHFFFAOYSA-N succinimidyl 4-(N-maleimidomethyl)cyclohexane-1-carboxylate Chemical compound C1CC(CN2C(C=CC2=O)=O)CCC1C(=O)ON1C(=O)CCC1=O JJAHTWIKCUJRDK-UHFFFAOYSA-N 0.000 description 2
- 239000000725 suspension Substances 0.000 description 2
- 238000012360 testing method Methods 0.000 description 2
- 238000004448 titration Methods 0.000 description 2
- 230000005945 translocation Effects 0.000 description 2
- 239000013598 vector Substances 0.000 description 2
- HNXRLRRQDUXQEE-ALURDMBKSA-N (2s,3r,4s,5r,6r)-2-[[(2r,3s,4r)-4-hydroxy-2-(hydroxymethyl)-3,4-dihydro-2h-pyran-3-yl]oxy]-6-(hydroxymethyl)oxane-3,4,5-triol Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)OC=C[C@H]1O HNXRLRRQDUXQEE-ALURDMBKSA-N 0.000 description 1
- VYMHBQQZUYHXSS-UHFFFAOYSA-N 2-(3h-dithiol-3-yl)pyridine Chemical group C1=CSSC1C1=CC=CC=N1 VYMHBQQZUYHXSS-UHFFFAOYSA-N 0.000 description 1
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 description 1
- JLBJTVDPSNHSKJ-UHFFFAOYSA-N 4-Methylstyrene Chemical compound CC1=CC=C(C=C)C=C1 JLBJTVDPSNHSKJ-UHFFFAOYSA-N 0.000 description 1
- ZLAQATDNGLKIEV-UHFFFAOYSA-N 5-methyl-2-sulfanylidene-1h-pyrimidin-4-one Chemical compound CC1=CNC(=S)NC1=O ZLAQATDNGLKIEV-UHFFFAOYSA-N 0.000 description 1
- TVICROIWXBFQEL-UHFFFAOYSA-N 6-(ethylamino)-1h-pyrimidin-2-one Chemical compound CCNC1=CC=NC(=O)N1 TVICROIWXBFQEL-UHFFFAOYSA-N 0.000 description 1
- 229920000936 Agarose Polymers 0.000 description 1
- 241000589158 Agrobacterium Species 0.000 description 1
- 241000203069 Archaea Species 0.000 description 1
- 241000193830 Bacillus <bacterium> Species 0.000 description 1
- 241000589968 Borrelia Species 0.000 description 1
- 241000244203 Caenorhabditis elegans Species 0.000 description 1
- 102000014914 Carrier Proteins Human genes 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- 241000606161 Chlamydia Species 0.000 description 1
- 108010077544 Chromatin Proteins 0.000 description 1
- 208000005443 Circulating Neoplastic Cells Diseases 0.000 description 1
- 241000193403 Clostridium Species 0.000 description 1
- 208000035473 Communicable disease Diseases 0.000 description 1
- 241001137853 Crenarchaeota Species 0.000 description 1
- 108010001237 Cytochrome P-450 CYP2D6 Proteins 0.000 description 1
- 102100021704 Cytochrome P450 2D6 Human genes 0.000 description 1
- 230000007118 DNA alkylation Effects 0.000 description 1
- 230000007067 DNA methylation Effects 0.000 description 1
- 102000016911 Deoxyribonucleases Human genes 0.000 description 1
- 108010053770 Deoxyribonucleases Proteins 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- 241000255581 Drosophila <fruit fly, genus> Species 0.000 description 1
- 238000008157 ELISA kit Methods 0.000 description 1
- 241000196324 Embryophyta Species 0.000 description 1
- 241000588698 Erwinia Species 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- 241001137858 Euryarchaeota Species 0.000 description 1
- 241000233866 Fungi Species 0.000 description 1
- 208000034826 Genetic Predisposition to Disease Diseases 0.000 description 1
- 108091093094 Glycol nucleic acid Proteins 0.000 description 1
- 208000031886 HIV Infections Diseases 0.000 description 1
- 241000589989 Helicobacter Species 0.000 description 1
- 241000405147 Hermes Species 0.000 description 1
- 241000238631 Hexapoda Species 0.000 description 1
- 101000786334 Homo sapiens Zinc finger BED domain-containing protein 5 Proteins 0.000 description 1
- 241000713772 Human immunodeficiency virus 1 Species 0.000 description 1
- 241000713340 Human immunodeficiency virus 2 Species 0.000 description 1
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 1
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 1
- 241000589248 Legionella Species 0.000 description 1
- 208000007764 Legionnaires' Disease Diseases 0.000 description 1
- 102000003960 Ligases Human genes 0.000 description 1
- 108090000364 Ligases Proteins 0.000 description 1
- 208000016604 Lyme disease Diseases 0.000 description 1
- PEEHTFAAVSWFBL-UHFFFAOYSA-N Maleimide Chemical compound O=C1NC(=O)C=C1 PEEHTFAAVSWFBL-UHFFFAOYSA-N 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 241001465754 Metazoa Species 0.000 description 1
- 241000713869 Moloney murine leukemia virus Species 0.000 description 1
- 241000186359 Mycobacterium Species 0.000 description 1
- 241000204031 Mycoplasma Species 0.000 description 1
- 241001437658 Nanoarchaeota Species 0.000 description 1
- 241000588653 Neisseria Species 0.000 description 1
- 241000244206 Nematoda Species 0.000 description 1
- 102000007999 Nuclear Proteins Human genes 0.000 description 1
- 108010089610 Nuclear Proteins Proteins 0.000 description 1
- 239000004677 Nylon Substances 0.000 description 1
- 235000016499 Oxalis corniculata Nutrition 0.000 description 1
- 102000035195 Peptidases Human genes 0.000 description 1
- 108091005804 Peptidases Proteins 0.000 description 1
- 108091093037 Peptide nucleic acid Proteins 0.000 description 1
- 101100029173 Phaeosphaeria nodorum (strain SN15 / ATCC MYA-4574 / FGSC 10173) SNP2 gene Proteins 0.000 description 1
- 108020005120 Plant DNA Proteins 0.000 description 1
- 208000020584 Polyploidy Diseases 0.000 description 1
- 239000004793 Polystyrene Substances 0.000 description 1
- 206010036790 Productive cough Diseases 0.000 description 1
- 241000589516 Pseudomonas Species 0.000 description 1
- 241000910071 Pyrobaculum filamentous virus 1 Species 0.000 description 1
- 241000589180 Rhizobium Species 0.000 description 1
- 101100094821 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) SMX2 gene Proteins 0.000 description 1
- 241000607142 Salmonella Species 0.000 description 1
- 229920002684 Sepharose Polymers 0.000 description 1
- 241000607720 Serratia Species 0.000 description 1
- 241000191940 Staphylococcus Species 0.000 description 1
- 241000191967 Staphylococcus aureus Species 0.000 description 1
- 241000194017 Streptococcus Species 0.000 description 1
- 241000187747 Streptomyces Species 0.000 description 1
- 239000004809 Teflon Substances 0.000 description 1
- 229920006362 Teflon® Polymers 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-N Thiophosphoric acid Chemical group OP(O)(S)=O RYYWUUFWQRZTIU-UHFFFAOYSA-N 0.000 description 1
- 108091046915 Threose nucleic acid Proteins 0.000 description 1
- 241000589886 Treponema Species 0.000 description 1
- 102100025791 Zinc finger BED domain-containing protein 5 Human genes 0.000 description 1
- 230000005856 abnormality Effects 0.000 description 1
- 239000002253 acid Substances 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 230000004931 aggregating effect Effects 0.000 description 1
- 210000004381 amniotic fluid Anatomy 0.000 description 1
- IVRMZWNICZWHMI-UHFFFAOYSA-N azide group Chemical group [N-]=[N+]=[N-] IVRMZWNICZWHMI-UHFFFAOYSA-N 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 108091008324 binding proteins Proteins 0.000 description 1
- 238000001369 bisulfite sequencing Methods 0.000 description 1
- 238000006664 bond formation reaction Methods 0.000 description 1
- 239000004202 carbamide Substances 0.000 description 1
- 229910052799 carbon Inorganic materials 0.000 description 1
- 230000024245 cell differentiation Effects 0.000 description 1
- 239000013592 cell lysate Substances 0.000 description 1
- 230000019522 cellular metabolic process Effects 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 239000000919 ceramic Substances 0.000 description 1
- 210000001175 cerebrospinal fluid Anatomy 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000010382 chemical cross-linking Methods 0.000 description 1
- 238000002144 chemical decomposition reaction Methods 0.000 description 1
- 239000003153 chemical reaction reagent Substances 0.000 description 1
- 210000003483 chromatin Anatomy 0.000 description 1
- 239000003086 colorant Substances 0.000 description 1
- 238000004440 column chromatography Methods 0.000 description 1
- 230000021615 conjugation Effects 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 239000000356 contaminant Substances 0.000 description 1
- 238000011109 contamination Methods 0.000 description 1
- 239000013256 coordination polymer Substances 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- 239000005546 dideoxynucleotide Substances 0.000 description 1
- 239000012470 diluted sample Substances 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 230000001973 epigenetic effect Effects 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 239000000499 gel Substances 0.000 description 1
- 230000004077 genetic alteration Effects 0.000 description 1
- 231100000118 genetic alteration Toxicity 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 238000013412 genome amplification Methods 0.000 description 1
- 239000011521 glass Substances 0.000 description 1
- 229930195712 glutamate Natural products 0.000 description 1
- 150000004676 glycans Chemical class 0.000 description 1
- 239000010439 graphite Substances 0.000 description 1
- 229910002804 graphite Inorganic materials 0.000 description 1
- 239000012145 high-salt buffer Substances 0.000 description 1
- 108091008039 hormone receptors Proteins 0.000 description 1
- 238000011534 incubation Methods 0.000 description 1
- 230000009319 interchromosomal translocation Effects 0.000 description 1
- 230000001788 irregular Effects 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 239000004816 latex Substances 0.000 description 1
- 229920000126 latex Polymers 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 210000002751 lymph Anatomy 0.000 description 1
- 239000006166 lysate Substances 0.000 description 1
- 230000014759 maintenance of location Effects 0.000 description 1
- 102000016470 mariner transposase Human genes 0.000 description 1
- 108060004631 mariner transposase Proteins 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 1
- 239000000693 micelle Substances 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 238000001000 micrograph Methods 0.000 description 1
- 210000003470 mitochondria Anatomy 0.000 description 1
- 238000007837 multiplex assay Methods 0.000 description 1
- 239000013642 negative control Substances 0.000 description 1
- 210000004940 nucleus Anatomy 0.000 description 1
- 229920001778 nylon Polymers 0.000 description 1
- 210000000056 organ Anatomy 0.000 description 1
- 230000003647 oxidation Effects 0.000 description 1
- 238000007254 oxidation reaction Methods 0.000 description 1
- 239000012188 paraffin wax Substances 0.000 description 1
- 230000005298 paramagnetic effect Effects 0.000 description 1
- 239000002907 paramagnetic material Substances 0.000 description 1
- 244000045947 parasite Species 0.000 description 1
- 238000005192 partition Methods 0.000 description 1
- 239000012071 phase Substances 0.000 description 1
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 1
- 239000004033 plastic Substances 0.000 description 1
- 210000004910 pleural fluid Anatomy 0.000 description 1
- 229920000058 polyacrylate Polymers 0.000 description 1
- 229920001282 polysaccharide Polymers 0.000 description 1
- 239000005017 polysaccharide Substances 0.000 description 1
- 229920002223 polystyrene Polymers 0.000 description 1
- 239000002244 precipitate Substances 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 238000004321 preservation Methods 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000003252 repetitive effect Effects 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 238000003757 reverse transcription PCR Methods 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 210000003296 saliva Anatomy 0.000 description 1
- 239000012488 sample solution Substances 0.000 description 1
- 238000004062 sedimentation Methods 0.000 description 1
- 210000000582 semen Anatomy 0.000 description 1
- 238000010008 shearing Methods 0.000 description 1
- 239000000377 silicon dioxide Substances 0.000 description 1
- 229910052708 sodium Inorganic materials 0.000 description 1
- 239000011734 sodium Substances 0.000 description 1
- 210000003802 sputum Anatomy 0.000 description 1
- 208000024794 sputum Diseases 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 239000011550 stock solution Substances 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 230000000946 synaptic effect Effects 0.000 description 1
- 210000001138 tear Anatomy 0.000 description 1
- 239000004408 titanium dioxide Substances 0.000 description 1
- 230000013819 transposition, DNA-mediated Effects 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 210000002700 urine Anatomy 0.000 description 1
- 238000005406 washing Methods 0.000 description 1
Images

























































Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/1034—Isolating an individual clone by screening libraries
- C12N15/1065—Preparation or screening of tagged libraries, e.g. tagged microorganisms by STM-mutagenesis, tagged polynucleotides, gene tags
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/1034—Isolating an individual clone by screening libraries
- C12N15/1082—Preparation or screening gene libraries by chromosomal integration of polynucleotide sequences, HR-, site-specific-recombination, transposons, viral vectors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/10—Processes for the isolation, preparation or purification of DNA or RNA
- C12N15/1034—Isolating an individual clone by screening libraries
- C12N15/1093—General methods of preparing gene libraries, not provided for in other subgroups
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6806—Preparing nucleic acids for analysis, e.g. for polymerase chain reaction [PCR] assay
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6813—Hybridisation assays
- C12Q1/6834—Enzymatic or biochemical coupling of nucleic acids to a solid phase
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6869—Methods for sequencing
- C12Q1/6874—Methods for sequencing involving nucleic acid arrays, e.g. sequencing by hybridisation
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
-
- C—CHEMISTRY; METALLURGY
- C40—COMBINATORIAL TECHNOLOGY
- C40B—COMBINATORIAL CHEMISTRY; LIBRARIES, e.g. CHEMICAL LIBRARIES
- C40B50/00—Methods of creating libraries, e.g. combinatorial synthesis
- C40B50/06—Biochemical methods, e.g. using enzymes or whole viable microorganisms
-
- C—CHEMISTRY; METALLURGY
- C40—COMBINATORIAL TECHNOLOGY
- C40B—COMBINATORIAL CHEMISTRY; LIBRARIES, e.g. CHEMICAL LIBRARIES
- C40B70/00—Tags or labels specially adapted for combinatorial chemistry or libraries, e.g. fluorescent tags or bar codes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2525/00—Reactions involving modified oligonucleotides, nucleic acids, or nucleotides
- C12Q2525/10—Modifications characterised by
- C12Q2525/191—Modifications characterised by incorporating an adaptor
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2563/00—Nucleic acid detection characterized by the use of physical, structural and functional properties
- C12Q2563/179—Nucleic acid detection characterized by the use of physical, structural and functional properties the label being a nucleic acid
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2565/00—Nucleic acid analysis characterised by mode or means of detection
- C12Q2565/50—Detection characterised by immobilisation to a surface
- C12Q2565/514—Detection characterised by immobilisation to a surface characterised by the use of the arrayed oligonucleotides as identifier tags, e.g. universal addressable array, anti-tag or tag complement array
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/154—Methylation markers
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/156—Polymorphic or mutational markers
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/172—Haplotypes
Landscapes
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biochemistry (AREA)
- Molecular Biology (AREA)
- Microbiology (AREA)
- Biomedical Technology (AREA)
- General Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Physics & Mathematics (AREA)
- Analytical Chemistry (AREA)
- Plant Pathology (AREA)
- Crystallography & Structural Chemistry (AREA)
- Immunology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Medicinal Chemistry (AREA)
- Virology (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Immobilizing And Processing Of Enzymes And Microorganisms (AREA)
- Glass Compositions (AREA)
- Inorganic Insulating Materials (AREA)
- Transition And Organic Metals Composition Catalysts For Addition Polymerization (AREA)
Description
本願は、その全体が参照により本明細書に組み込まれる、2014年10月17日出願
の米国仮特許出願第62/065,544号及び2015年5月5日出願の米国仮特許出
願第62/157,396号の優先権を主張する。
する方法及び組成物の実施形態は、核酸鋳型の調製及び核酸鋳型からの配列データの取得
に関する。
症の診断、遺伝子異常の検出及び特徴付け、癌に関連した遺伝子変化の同定、疾患への遺
伝的感受性の研究、並びに様々な種類の治療に対する反応の測定を行う方法として用いら
れてきた。生体試料中の特定の核酸配列を検出する一般的な技術は、核酸シークエンシン
グである。
Sangerが用いた鎖伸長法から著しく発展してきた。今日、核酸の並列処理を全て1
回のシークエンシングランで行うことを可能にする、いくつかのシークエンシング法が用
いられている。従って、1回のシークエンシングランから生成される情報は、膨大なもの
となる可能性がある。
ブラリーを調製する方法について記載する。当該方法は、標的核酸を複数のトランスポソ
ーム複合体と接触させることを含むものであり、各トランスポソーム複合体は、トランス
ポゾン及びトランスポザーゼを含み、トランスポゾンは転移鎖及び非転移鎖を含む。トラ
ンスポソーム複合体の少なくとも1つのトランスポゾンは、相補的な捕捉配列にハイブリ
ダイズすることが可能なアダプター配列を含む。標的核酸を複数のフラグメントにフラグ
メント化し、標的核酸の連続性(contiguity)を維持しながらフラグメントの
少なくとも1つの鎖の5’末端に複数の転移鎖を挿入する。標的核酸の複数のフラグメン
トを複数の固体支持体と接触させる。複数の固体支持体の各々は複数の固定化オリゴヌク
レオチドを含み、各オリゴヌクレオチドは相補的な捕捉配列及び第1のバーコード配列を
含み、複数の固体支持体中の各固体支持体からの第1のバーコード配列は、複数の固体支
持体中の他の固体支持体からの第1のバーコード配列とは異なる。バーコード配列の情報
を標的核酸のフラグメントに転移させ、それにより、同じ標的核酸の少なくとも2つのフ
ラグメントが同一のバーコード情報を受け取るように、少なくとも1つの鎖が第1のバー
コード配列で5’タグ化された、二本鎖フラグメントの固定化ライブラリーを作製する。
記載する。当該方法は、標的核酸を複数のトランスポソーム複合体と接触させることを含
むものであり、各トランスポソーム複合体は、トランスポゾン及びトランスポザーゼを含
み、トランスポゾンは転移鎖及び非転移鎖を含み、トランスポソーム複合体のトランスポ
ゾンの少なくとも1つは、相補的な捕捉配列にハイブリダイズすることが可能なアダプタ
ー配列を含む。標的核酸を複数のフラグメントにフラグメント化し、標的核酸の連続性を
維持しながら複数の転移鎖を複数のフラグメントに挿入する。標的核酸の複数のフラグメ
ントを複数の固体支持体と接触させる。複数の固体支持体の各々は複数の固定化オリゴヌ
クレオチドを含み、各オリゴヌクレオチドは相補的な捕捉配列及び第1のバーコード配列
を含み、複数の固体支持体中の各固体支持体からの第1のバーコード配列は、複数の固体
支持体中の他の固体支持体からの第1のバーコード配列とは異なる。バーコード配列情報
を、同じ標的核酸の少なくとも2つのフラグメントが同一のバーコード情報を受け取るよ
うに、標的核酸フラグメントに転移させる。標的核酸フラグメントの配列及びバーコード
配列を決定する。標的核酸の連続性情報を、バーコード配列を識別することにより決定す
る。いくつかの実施形態において、トランスポソーム複合体のトランスポザーゼを転位(
transposition)後に除去し、続いて、トランスポゾンのアダプター配列を
相補的な捕捉配列にハイブリダイズさせる。いくつかの実施形態において、トランスポザ
ーゼをSDS処理により除去する。いくつかの実施形態において、トランスポザーゼをタ
ンパク質分解酵素処理により除去する。
を同時に測定する方法について記載する。当該方法は、標的核酸を複数のトランスポソー
ム複合体と接触させることを含むものであり、各トランスポソーム複合体は、トランスポ
ゾン及びトランスポザーゼを含み、トランスポゾンは転移鎖及び非転移鎖を含み、トラン
スポソーム複合体のトランスポゾンの少なくとも1つは、相補的な捕捉配列にハイブリダ
イズすることが可能なアダプター配列を含む。標的核酸を複数のフラグメントにフラグメ
ント化し、標的核酸の連続性を維持しながら複数の転移鎖を標的核酸フラグメントに挿入
する。標的核酸の複数のフラグメントを複数の固体支持体と接触させ、複数の固体支持体
の各々は複数の固定化オリゴヌクレオチドを含み、各オリゴヌクレオチドは相補的な捕捉
配列及び第1のバーコード配列を含み、複数の固体支持体中の各固体支持体からの第1の
バーコード配列は、複数の固体支持体中の他の固体支持体からの第1のバーコード配列と
は異なる。バーコード配列情報を、同じ標的核酸の少なくとも2つのフラグメントが同一
のバーコード情報を受け取るように、標的核酸フラグメントに転移させる。バーコードを
含む標的核酸フラグメントを亜硫酸水素塩処理に付し、それにより、バーコードを含む亜
硫酸水素塩処理標的核酸フラグメントを生成する。亜硫酸水素塩処理標的核酸フラグメン
トの配列及びバーコード配列を決定する。標的核酸の連続性情報を、バーコード配列を識
別することにより決定する。
調製する方法について記載する。当該方法は、それに固定化されたトランスポソーム複合
体を有する複数の固体支持体を提供することを含み、トランスポソーム複合体は多量体で
あり、同じトランスポソーム複合体のトランスポソーム単量体単位は互いに結合し、トラ
ンスポソーム単量体単位は第1のポリヌクレオチドに結合したトランスポザーゼを含み、
第1のポリヌクレオチドは、(i)トランスポゾン末端配列を含む3’部分、及び(ii
)第1のバーコードを含む第1のアダプターを含む。標的DNAを、標的DNAがトラン
スポソーム複合体によりフラグメント化され、第1のポリヌクレオチドの3’トランスポ
ゾン末端配列がフラグメントの少なくとも1つの鎖の5’末端に転移する条件下で、複数
の固体支持体に適用する。それにより、少なくとも1つの鎖が第1のバーコードで5’タ
グ付けされた二本鎖フラグメントの固定化ライブラリーを作製する。
ンシングライブラリーを調製する方法について記載する。当該方法は、標的核酸を2つ又
はそれ以上のフラグメントにフラグメント化することを含む。第1の共通アダプター配列
を標的核酸のフラグメントの5’末端に組み込み、アダプター配列は、第1のプライマー
結合配列及び親和性部分を含み、親和性部分は、結合ペアの1つのメンバーに存在する。
標的核酸フラグメントを変性させる。標的核酸フラグメントを固体支持体に固定化する。
固体支持体は、結合ペアの他のメンバーを含み、標的核酸の固定化は、結合ペアの結合に
より行う。固定化標的核酸フラグメントを亜硫酸水素塩処理に付す。第2の共通アダプタ
ー配列を亜硫酸水素塩処理した固定化標的核酸フラグメントに組み込み、第2の共通アダ
プターは、第2のプライマー結合部位を含む。固体支持体に固定化された亜硫酸水素塩処
理固定化標的核酸フラグメントを増幅し、それにより、標的核酸のメチル化状態を決定す
るためのシークエンシングライブラリーを作製する。
ンシングライブラリーを調製する方法について記載する。当該方法は、それに固定化され
た固定化トランスポソーム複合体を含む複数の固体支持体を提供することを含む。トラン
スポソーム複合体は、トランスポゾン及びトランスポザーゼを含み、トランスポゾンは、
転移鎖及び非転移鎖を含む。転移鎖は、(i)トランスポザーゼ認識配列を含む3’末端
の第1の部分及び(ii)第1のアダプター配列及び結合ペアの第1のメンバーを含む5
’から第1の部分に位置する第2の部分を含む。結合ペアの第1のメンバーは、固体支持
体上で結合ペアの第2のメンバーに結合し、それにより、トランスポゾンを固体支持体に
固定化する。第1のアダプターはまた、第1のプライマー結合配列を含む。非転移鎖は、
(i)トランスポザーゼ認識配列を含む5’末端の第1の部分及び(ii)3’末端の末
端ヌクレオチドがブロックされている第2のアダプター配列を含む3’から第1の部分に
位置する第2の部分を含む。第2のアダプターはまた、第2のプライマー結合配列を含む
。標的核酸を、固定化トランスポソーム複合体を含む複数の固体支持体と接触させる。標
的核酸を複数のフラグメントにフラグメント化し、複数の転移鎖をフラグメントの少なく
とも1つの鎖の5’末端に挿入し、それにより、標的核酸フラグメントを固体支持体に固
定化する。フラグメント化された標的核酸の3’末端を、DNAポリメラーゼで伸長させ
る。非転移鎖を、フラグメント化された標的核酸の3’末端にライゲートする。固定化標
的核酸フラグメントを亜硫酸水素塩処理に付す。亜硫酸水素塩処理中に損傷を受けた固定
化標的核酸フラグメントの3’末端を、固定化標的核酸フラグメントの3’末端がホモポ
リマーテイルを含むように、DNAポリメラーゼを用いて伸長させる。第2のアダプター
配列を、亜硫酸水素塩処理中に損傷を受けた固定化標的核酸フラグメントの3’末端に導
入する。固体支持体に固定化された亜硫酸水素塩処理標的核酸フラグメントを、第1及び
第2のプライマーを用いて増幅し、それにより、標的核酸のメチル化状態を決定するため
のシークエンシングライブラリーを作製する。
ンシングライブラリーを調製する方法について記載する。当該方法は、標的核酸をトラン
スポソーム複合体と接触させることを含むものであり、トランスポソーム複合体は、トラ
ンスポゾン及びトランスポザーゼを含む。トランスポゾンは、転移鎖及び非転移鎖を含む
。転移鎖は、(i)トランスポザーゼ認識配列を含む3’末端の第1の部分及び(ii)
第1のアダプター配列及び結合ペアの第1のメンバーを含む5’から第1の部分に位置す
る第2の部分を含み、結合ペアの第1のメンバーは、結合ペアの第2のメンバーに結合す
る。非転移鎖は、(i)トランスポザーゼ認識配列を含む5’末端の第1の部分及び(i
i)3’末端の末端ヌクレオチドがブロックされている第2のアダプター配列を含む3’
から第1の部分に位置する第2の部分を含み、第2のアダプターは、第2のプライマー結
合配列を含む。標的核酸を複数のフラグメントにフラグメント化し、複数の転移鎖をフラ
グメントの少なくとも1つの鎖の5’末端に挿入し、それにより、標的核酸フラグメント
を固体支持体に固定化する。トランスポゾン末端を含む標的核酸フラグメントを結合ペア
の第2のメンバーを含む複数の固体支持体に接触させ、結合ペアの第1のメンバーと結合
ペアの第2のメンバーとの結合により、標的核酸を固体支持体に固定化する。フラグメン
ト化された標的核酸の3’末端を、DNAポリメラーゼで伸長させる。非転移鎖を、フラ
グメント化された標的核酸の3’末端にライゲートする。固定化標的核酸フラグメントを
亜硫酸水素塩処理に付す。亜硫酸水素塩処理中に損傷を受けた固定化標的核酸フラグメン
トの3’末端を、固定化標的核酸フラグメントの3’末端がホモポリマーテイルを含むよ
うに、DNAポリメラーゼを用いて伸長させる。第2のアダプター配列を、亜硫酸水素塩
処理中に損傷を受けた固定化標的核酸フラグメントの3’末端に導入する。固体支持体に
固定化された亜硫酸水素塩処理標的核酸フラグメントを、第1及び第2のプライマーを用
いて増幅し、それにより、標的核酸のメチル化状態を決定するためのシークエンシングラ
イブラリーを作製する。
デオキシヌクレオチド、リン酸基、チオリン酸基、及びアジド基からなる群から選択され
る1つのメンバーによりブロックする。
いくつかのケースにおいて、修飾された核酸は、結合ペアの第1のメンバーを含んでいて
もよく、捕捉プローブは、結合ペアの第2のメンバーを含んでいてもよい。いくつかのケ
ースにおいて、捕捉プローブを固体表面に固定化してもよく、修飾された核酸は、結合ペ
アの第1のメンバーを含んでいてもよく、捕捉プローブは、結合ペアの第2のメンバーを
含んでいてもよい。そのようなケースでは、結合ペアの第1及び第2のメンバーの結合に
より、修飾された標的核酸を固体表面に固定化する。結合ペアの例としては、これに限定
されないが、ビオチン-アビジン、ビオチン-ストレプトアビジン、ビオチン-ニュート
ラアビジン、リガンド-受容体、ホルモン-受容体、レクチン-糖タンパク質、オリゴヌ
クレオチド-相補的オリゴヌクレオチド、及び抗原-抗体が挙げられる。
d)転位により標的核酸の5’末端フラグメントに組み込む。いくつかの実施形態におい
て、第1の共通アダプター配列を、ライゲーションにより標的核酸の5’末端フラグメン
トに組み込む。いくつかの実施形態において、第2の共通アダプター配列を亜硫酸水素塩
処理固定化標的核酸フラグメントに組み込むステップは、(i)固定化標的核酸フラグメ
ントの3’末端を、ターミナルトランスフェラーゼを用いて伸長し、ホモポリマーテイル
を含ませるステップ、(ii)一本鎖ホモポリマー部分を含むオリゴヌクレオチドと、第
2の共通アダプター配列を含む二本鎖部分とをハイブリダイズさせるステップであって、
一本鎖ホモポリマー部分がホモポリマーテイルに相補的である、ステップ、及び(iii
)第2の共通アダプター配列を固定化標的核酸フラグメントにライゲートし、それにより
、第2の共通アダプター配列を亜硫酸水素塩処理固定化標的核酸フラグメントに組み込む
ステップを含む。
態において、標的核酸は、単一の細胞小器官に由来する。いくつかの実施形態において、
標的核酸は、ゲノムDNAである。いくつかの実施形態において、標的核酸は、他の核酸
と架橋する。いくつかの実施形態において、標的核酸は、ホルマリン固定パラフィン包埋
(FFPE:formarin fixed paraffin embedded)サ
ンプルに由来する。いくつかの実施形態において、標的核酸は、タンパク質と架橋する。
いくつかの実施形態において、標的核酸は、DNAと架橋する。いくつかの実施形態にお
いて、標的核酸は、ヒストンに保護されたDNAである。いくつかの実施形態において、
ヒストンを標的核酸から除去する。いくつかの実施形態において、標的核酸は、無細胞腫
瘍DNAである。いくつかの実施形態において、無細胞腫瘍DNAは、胎盤液から得る。
いくつかの実施形態において、無細胞腫瘍DNAは、血漿から得る。いくつかの実施形態
において、血漿は、血漿用採取ゾーンを有する膜分離装置を用いて全血から採取する。い
くつかの実施形態において、血漿用採取ゾーンは、固体支持体に固定化されたトランスポ
ソーム複合体を含む。いくつかの実施形態において、標的核酸は、cDNAである。いく
つかの実施形態において、固体支持体は、ビーズである。いくつかの実施形態において、
複数の固体支持体は、複数のビーズであり、複数のビーズは、様々なサイズである。
の固定化オリゴヌクレオチドに存在する。いくつかの実施形態において、異なるバーコー
ド配列が、各個々の固体支持体上の複数の固定化オリゴヌクレオチドに存在する。いくつ
かの実施形態において、標的核酸フラグメントへのバーコード配列情報の転移は、ライゲ
ーションによる。いくつかの実施形態において、標的核酸フラグメントへのバーコード配
列情報の転移は、ポリメラーゼ伸長による。いくつかの実施形態において、標的核酸フラ
グメントへのバーコード配列情報の転移は、ライゲーション及びポリメラーゼ伸長の両方
による。いくつかの実施形態において、ポリメラーゼ伸長は、ライゲートした固定化オリ
ゴヌクレオチドを鋳型として用い、非ライゲートトランスポゾン鎖の3’末端をDNAポ
リメラーゼで伸長させることによる。いくつかの実施形態において、アダプター配列の少
なくとも一部は、第2のバーコード配列をさらに含む。
位のトランスポゾンのアダプター配列は、同じトランスポソーム複合体の他の単量体単位
とは異なる。いくつかの実施形態において、アダプター配列は、第1のプライマー結合配
列をさらに含む。いくつかの実施形態において、第1のプライマー結合部位は、捕捉配列
又は捕捉配列の相補体に対して、配列相同性を持たない。いくつかの実施形態において、
固体支持体上の固定化オリゴヌクレオチドは、第2のプライマー結合配列をさらに含む。
ソーム単量体単位は、同じトランスポソーム複合体内で互いに結合する。いくつかの実施
形態において、トランスポソーム単量体単位のトランスポザーゼは、同じトランスポソー
ム複合体の別のトランスポソーム単量体単位のトランスポザーゼに結合する。いくつかの
実施形態において、トランスポソーム単量体単位のトランスポゾンは、同じトランスポソ
ーム複合体の別のトランスポソーム単量体単位のトランスポゾンに結合する。いくつかの
実施形態において、トランスポソーム単量体単位のトランスポザーゼは、同じトランスポ
ソーム複合体の別のトランスポソーム単量体単位のトランスポザーゼに共有結合により結
合する。いくつかの実施形態において、1つの単量体単位のトランスポザーゼは、同じト
ランスポソーム複合体の別のトランスポソーム単量体単位のトランスポザーゼにジスルフ
ィド結合により結合する。いくつかの実施形態において、トランスポソーム単量体単位の
トランスポゾンは、同じトランスポソーム複合体の別のトランスポソーム単量体単位のト
ランスポゾンに共有結合により結合する。
。いくつかの実施形態において、標的核酸配列の連続性情報は、ゲノム変異を示す。いく
つかの実施形態において、ゲノム変異は、欠損、転位(translocations)
、染色体間の遺伝子融合、重複、及びパラログからなる群から選択される。いくつかの実
施形態において、固体支持体に固定化されたオリゴヌクレオチドは、部分的二本鎖領域及
び部分的一本鎖領域を含む。いくつかの実施形態において、オリゴヌクレオチドの部分的
一本鎖領域は、第2のバーコード配列及び第2のプライマー結合配列を含む。いくつかの
実施形態において、バーコードを含む標的核酸フラグメントを、標的核酸フラグメントの
配列を決定する前に増幅する。いくつかの実施形態において、後続の増幅を、標的核酸フ
ラグメントの配列を決定する前に、単一の反応区画で行う。いくつかの実施形態において
、第3のバーコード配列を、増幅中に標的核酸フラグメントに導入する。
、複数の第1のセットの反応区画から、バーコードを含む標的核酸フラグメントのプール
にまとめるステップ、バーコードを含む標的核酸フラグメントの前記プールを複数の第2
のセットの反応区画に再分配するステップ、及び標的核酸フラグメントを第2のセットの
反応区画内でシークエンシング前に増幅することにより、第3のバーコードを標的核酸フ
ラグメントに導入するステップをさらに含んでいてもよい。
させる前にプレフラグメント化するステップをさらに含んでいてもよい。いくつかの実施
形態において、標的核酸のプレフラグメント化は、超音波処理及び制限消化からなる群か
ら選択される方法により行われる。
する方法及び組成物の実施形態は、核酸鋳型の調製及び核酸鋳型からの配列データの取得
に関する。
核酸ライブラリーを構築するために、固体支持体上で標的核酸をタグメント化する方法に
関する。1つの実施形態において、固体支持体は、ビーズである。1つの実施形態におい
て、標的核酸は、DNAである。
支持体、トランスポザーゼに基づく方法の、方法及び組成物に関する。いくつかの実施形
態において、組成物及び方法は、アセンブリ/フェージング情報を引き出すことができる
。
により、連続性情報を引き出す方法及び組成物に関する。
る。例示的なゲノム変異としては、これに限定されないが、欠損、染色体間転位、重複、
パラログ、染色体間遺伝子融合が挙げられる。いくつかの実施形態において、本明細書に
開示する方法及び組成物は、ゲノム変異のフェージング情報の決定に関する。
フェージングに関する。1つの実施形態において、標的核酸は、DNAである。1つの実
施形態において、標的核酸は、ゲノムDNAである。いくつかの実施形態において、標的
核酸は、RNAである。いくつかの実施形態において、RNAは、mRNAである。いく
つかの実施形態において、標的核酸は、相補的DNA(cDNA:compliment
ary DNA)である。いくつかの実施形態において、標的核酸は、単一の細胞に由来
する。いくつかの実施形態において、標的核酸は、循環腫瘍細胞に由来する。いくつかの
実施形態において、標的核酸は、無細胞DNAである。いくつかの実施形態において、標
的核酸は、無細胞腫瘍DNAである。いくつかの実施形態において、標的核酸は、ホルマ
リン固定パラフィン包埋組織サンプルに由来する。いくつかの実施形態において、標的核
酸は、架橋標的核酸である。いくつかの実施形態において、標的核酸は、タンパク質に架
橋する。いくつかの実施形態において、標的核酸は、核酸に架橋する。いくつかの実施形
態において、標的核酸は、ヒストンに保護されたDNAである。いくつかの実施形態にお
いて、ヒストンに保護されたDNAを、ヒストンに対する抗体を用いて細胞溶解物から沈
殿させ、ヒストンを除去する。
きビーズを用いて、標的核酸から作製する。いくつかの実施形態において、タグメント化
標的核酸は、トランスポザーゼが標的DNAに結合したままで、クローンインデックス付
きビーズを用いて捕捉することができる。いくつかの実施形態において、特異的な捕捉プ
ローブを用いて、標的核酸中の目的の特異的な領域を捕捉する。標的核酸の捕捉された領
域は、種々のストリンジェンシーで洗浄し、任意選択的に増幅し、その後シークエンシン
グすることができる。いくつかの実施形態において、捕捉プローブは、ビオチン化しても
よい。ビオチン化捕捉プローブがインデックス付き標的核酸の特異的な領域にハイブリダ
イズした複合体は、ストレプトアビジンビーズを用いて分離することができる。標的フェ
ージングの例示的なスキームを図41に示す。
ジングに用いることができる。いくつかの実施形態において、エクソン、プロモーターを
濃縮することができる。マーカー、例えば、エクソン領域間のヘテロ接合SNPは、特に
エクソン間の距離が大きい場合に、エクソンのフェージングに役立つ可能性がある。例示
的なエクソームのフェージングを図42に示す。いくつかの実施形態において、インデッ
クス付き結合リードは、隣接しているエクソンのヘテロ接合SNPに同時に及ぶ(カバー
する)ことができない。従って、2つ又はそれ以上のエクソンをフェージングすることは
困難である。本明細書に開示する組成物及び方法はまた、エクソン間のヘテロ接合SNP
を濃縮し、例えば、エクソン1をSNP1に、SNP2をエクソン2にフェージングする
。従って、SNP1の使用を通じて、エクソン1及びエクソン2を、図42に示すように
フェージングすることができる。
メチル化の検出に用いることができる。亜硫酸水素塩変換(BSC:bisulfite
conversion)によるメチル化検出は、BSC反応がDNAに対して厳しい(
harsh)ものであり、DNAをフラグメント化し、それにより連続性/フェージング
情報を除去するため、困難である。また、本願に開示する方法は、従来のBSCアプロー
チで必要とされるのとは対照的に、更なる精製ステップを必要としないことにより、収率
を改善するため、さらに利点がある。
イブラリーを1つのアッセイで調製することができる。いくつかの実施形態において、異
なるサイズのクローンインデックス付きビーズを用いて、異なるサイズのライブラリーを
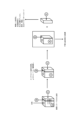
調製することができる。図1は、トランスポザーゼをビーズ表面に結合させる方法100
の一例のフローチャートを示す。トランスポザーゼは、トランスポゾンオリゴヌクレオチ
ド、トランスポザーゼ、及び固相に加えてもよい任意の化学物質を用いて、ビーズ表面に
結合させてもよい。1つの例において、トランスポソームを、ビオチン-ストレプトアビ
ジン結合複合体を介してビーズ表面に結合させる。方法100は、これに限定されないが
、以下のステップを含む。
含んでいてもよい。シークエンス結合部位の例示的な配列としては、これに限定されない
が、AATGATACGGCGACCACCGAGATCTACAC(P5配列)及びC
AAGCAGAAGACGGCATACGAGAT(P7配列)が挙げられる。いくつか
の実施形態において、トランスポゾンをビオチン化してもよい。
トランスポゾンはまた、1つ又はそれ以上のインデックス配列(固有の識別子)を含んで
いてもよい。例示的なインデックス配列としては、これに限定されないが、TAGATC
GC、CTCTCTAT、TATCCTCT、AGAGTAGA、GTAAGGAG、A
CTGCATA、AAGGAGTA、CTAAGCCTが挙げられる。別の例では、P5
トランスポゾンのみ又はP7トランスポゾンのみをビオチン化する。さらに別の例では、
トランスポゾンは、モザイク末端(ME:mosaic end)配列のみ、又はME配
列に加えてP5及びP7配列ではない追加の配列を含む。この例では、P5及びP7配列
は、後続のPCR増幅ステップで付加する。
トランスポソームは、P5及びP7トランスポソームの混合物である。P5及びP7トラ
ンスポソームの混合物は、図11及び12と関連してより詳細に説明する。
結合させる。この例では、ビーズは、ストレプトアビジン被覆ビーズであり、トランスポ
ソームを、ビオチン-ストレプトアビジン結合複合体を介してビーズ表面に結合させる。
ビーズは、種々のサイズであってもよい。1つの例において、ビーズは、2.8μmビー
ズであってもよい。別の例において、1μmビーズであってもよい。1μmビーズの懸濁
液(例えば、1μL)は、体積当たり大きな表面積をトランスポソーム結合にもたらす。
トランスポソーム結合に用いることができる表面積により、反応当たりのタグメント化生
成物の数が増加する。
では、トランスポゾンを二本鎖で示す。別の例(図示しない)では、ヘアピン等の別の構
造、即ち、二本鎖を形成することができる自己相補的な領域を有する単一のオリゴヌクレ
オチドを用いてもよい。
及び複数のP7トランスポゾン210bを生成する。P5トランスポゾン210a及びP
7トランスポゾン210bをビオチン化する。
ポゾン210bをトランスポザーゼTn5 215と混合し、複数のアセンブルしたトラ
ンスポソーム220を形成する。
合させる。ビーズ225は、ストレプトアビジン被覆ビーズである。トランスポソーム2
20を、ビオチン-ストレプトアビジン結合複合体を介してビーズ225に結合させる。
3に示すように、ビーズ表面等の固体支持体上で形成してもよい。この例では、P5及び
P7オリゴヌクレオチドを、トランスポソーム複合体のアセンブリ前に、初めにビーズ表
面に結合させる。
0において、トランスポソーム220が結合した図2のビーズ225を示す。DNA31
0の溶液をビーズ225の懸濁液に加える。DNA310がトランスポソーム220に接
触すると、DNAがタグメント化(フラグメント化及びタグ化)され、トランスポソーム
220を介してビーズ225に結合する。結合及びタグメント化されたDNA310をP
CR増幅して、溶液中(ビーズを含まない)で増幅産物315のプールを生成してもよい
。増幅産物315は、フローセル320の表面に転移させてもよい。クラスター生成プロ
トコル(例えば、ブリッジ増幅プロトコル、又はクラスター生成に使用することができる
任意のその他の増幅プロトコル)を用いて、複数のクラスター325をフローセル320
の表面上に生成してもよい。クラスター325は、タグメント化DNA310のクローン
増幅産物である。これでクラスター325は、シークエンシングプロトコルの次のステッ
プ用に準備できたことになる。
体表面に結合してもよい。
リゴヌクレオチドは、トランスポソームのアセンブリ前に、初めにビーズ表面に結合させ
る。図10は、ビーズ表面上でトランスポソーム複合体を形成する方法1000の一例の
フローチャートを示す。方法1000は、これに限定されないが、以下のステップを含む
。
せる。1つの例において、P5及びP7オリゴヌクレオチドは、ビオチン化し、ビーズは
、ストレプトアビジン被覆ビーズである。このステップはまた、図11の模式図1100
に絵で示す。ここで、図11を参照すると、P5オリゴヌクレオチド1110及びP7オ
リゴヌクレオチド1115は、ビーズ1120の表面に結合する。この例においては、1
つのP5オリゴヌクレオチド1110及び1つのP7オリゴヌクレオチド1115が、ビ
ーズ1120の表面に結合しているが、任意の数のP5オリゴヌクレオチド1110及び
/又はP7オリゴヌクレオチド1115が、複数のビーズ1120の表面に結合してもよ
い。1つの例において、P5オリゴヌクレオチド1110は、P5プライマー配列、イン
デックス配列(固有の識別子)、リード1シークエンシングプライマー配列、及びモザイ
ク末端(ME)配列を含む。この例において、P7オリゴヌクレオチド1115は、P7
プライマー配列、インデックス配列(固有の識別子)、リード2シークエンシングプライ
マー配列、及びME配列を含む。別の例(図示せず)において、インデックス配列は、P
5オリゴヌクレオチド1110のみに存在する。さらに別の例(図示せず)において、イ
ンデックス配列は、P7オリゴヌクレオチド1115のみに存在する。さらに別の例(図
示せず)において、インデックス配列は、P5オリゴヌクレオチド1110及びP7オリ
ゴヌクレオチド1115のいずれにも存在しない。
ーズ結合P5及びP7オリゴヌクレオチドにハイブリダイズさせる。このステップはまた
、図12の模式図1200に絵で示す。ここで、図12を参照すると、相補的ME配列(
ME’)1125は、P5オリゴヌクレオチド1110及びP7オリゴヌクレオチド11
15にハイブリダイズする。相補的ME配列(ME’)1125(例えば、相補的ME配
列(ME’)1125a及び相補的ME配列(ME’)1125b)は、P5オリゴヌク
レオチド1110及びP7オリゴヌクレオチド1115のME配列にそれぞれハイブリダ
イズする。相補的ME配列(ME’)1125は、典型的には、約15塩基長であり、5
’末端でリン酸化されている。
添加し、ビーズ結合トランスポソーム複合体の混合物を形成する。このステップはまた、
図13の模式図1300に絵で示す。ここで図13を参照すると、トランスポザーゼ酵素
が添加されて、複数のトランスポソーム複合体1310を形成する。この例において、ト
ランスポソーム複合体1310は、トランスポザーゼ酵素、2つの表面結合オリゴヌクレ
オチド配列、及びそれらにハイブリダイズした相補的ME配列(ME’)1125を含む
二本鎖構造である。例えば、トランスポソーム複合体1310aは、相補的ME配列(M
E’)1125にハイブリダイズしたP5オリゴヌクレオチド1110及び相補的ME配
列(ME’)1125にハイブリダイズしたP7オリゴヌクレオチド1115(即ち、P
5:P7)を含み、トランスポソーム複合体1310bは、相補的ME配列(ME’)1
125にハイブリダイズした2つのP5オリゴヌクレオチド1110(即ち、P5:P5
)含み、トランスポソーム複合体1310cは、相補的ME配列(ME’)1125にハ
イブリダイズした2つのP7オリゴヌクレオチド1115(即ち、P7:P7)含む。P
5:P5、P7:P7、及びP5:P7トランスポソーム複合体の割合は、例えば、25
:25:50であってもよい。
例示的な模式図1400を示す。この例において、トランスポソーム複合体1310を有
するビーズ1120を、タグメント化バッファー中のDNA1410の溶液に加え、タグ
メント化を生じさせ、DNAをビーズ1120の表面にトランスポソーム1310を介し
て結合させる。DNA1410の連続したタグメント化により、トランスポソーム131
0間に複数のブリッジ分子1415が生じる。ブリッジ分子1415の長さは、ビーズ1
120の表面におけるトランスポソーム複合体1310の密度に依存する可能性がある。
1つの例において、ビーズ1120の表面上のトランスポソーム複合体1310の密度は
、図10の方法100のステップ1010においてビーズ1120の表面に結合するP5
及びP7オリゴヌクレオチドの量を変化させることにより調整してもよい。別の例におい
て、ビーズ1120の表面上のトランスポソーム複合体1310の密度は、図10の方法
1000のステップ1015において、P5及びP7オリゴヌクレオチドにハイブリダイ
ズする相補的ME配列(ME’)の量を変化させることにより、調整してもよい。さらに
別の例において、ビーズ1120の表面上のトランスポソーム複合体1310の密度は、
図1の方法1000のステップ1020において加えるトランポザーゼ酵素の量を変化さ
せることにより、調整してもよい。
合体1310が結合したビーズ1120の量に依存しない。同様に、タグメント化反応に
おいてより多い又はより少ないDNA1410を加えることは、最終的なタグメント化産
物のサイズを変えないが、反応の収率に影響を与える可能性がある。
化反応の精製は、ビーズ1120を磁石で固定化し、洗浄することにより容易に行うこと
ができる。従って、タグメント化及びその後のPCR増幅を、単一の反応区画(「ワンポ
ット(one-pot)」)での反応で実施してもよい。
が可能なトランスポザーゼに基づく方法の、方法及び組成物に関する。いくつかの実施形
態において、組成物及び方法は、アセンブリ/フェーズ情報を引き出すことができる。1
つの実施形態において、固体支持体は、ビーズである。1つの実施形態において、標的核
酸は、DNAである。1つの実施形態において、標的核酸は、ゲノムDNAである。いく
つかの実施形態において、標的核酸は、RNAである。いくつかの実施形態において、R
NAは、mRNAである。いくつかの実施形態において、標的核酸は、相補的DNA(c
DNA)である。
て固定化し、その後トランスポザーゼをトランスポゾンに結合してトランスポソームを形
成してもよい。
る、固相でのトランスポソームの形成に特に関連して、2つのトランスポゾンを、固体支
持体において互いにごく近接して(好ましくは、一定の距離で)固定化してもよい。この
アプローチには、いくつかの利点がある。1つ目としては、好ましくは、2つのトランス
ポゾンがトランスポソームを効率良く形成するのに最適なリンカー長及び方向で、2つの
トランスポゾンが、常に同時に固定化されることになる。2つ目としては、トランスポソ
ームの形成効率が、トランスポゾン密度の関数とはならないであろうことである。2つの
トランスポゾンが、トランスポソームを形成するのに適切な方向及び両者間の距離で、常
に利用できることになる。3つ目としては、表面上のランダムな固定化トランスポゾンに
より、トランスポゾン間に種々の距離が形成され、それにより、1つの画分のみがトラン
スポソームを効率良く形成するのに最適な方向及び距離を有する。結果として、全てのト
ランスポゾンがトランスポソームに変換するのではなく、固相化非複合体化トランスポゾ
ンが存在することになる。これらのトランスポゾンは、ME部分が二本鎖DNAであるた
め、転位の標的となり易い。これにより、転位効率の低下をもたらし、望ましくない副産
物を形成する可能性がある。従って、続けて使用して、タグメント化及びシークエンシン
グを通じて連続性情報を導き出すことができる固体支持体上に、トランスポソームを調製
してもよい。例示的なスキームを図15に示す。いくつかの実施形態において、トランス
ポゾンは、化学的結合以外の手法で固体支持体に固定化してもよい。固体支持体上にトラ
ンスポゾンを固定化する例示的な方法としては、これに限定されないが、ストレプトアビ
ジン-ビオチン、マルトース-マルトース結合タンパク質、抗原-抗体、DNA-DNA
又はDNA-RNAハイブリダイゼーション等の親和結合が挙げられる。
体に固定化することができる。いくつかの実施形態において、トランスポゾンは、固有の
インデックス、バーコード、及び増幅プライマー結合部位を含む。トランスポザーゼを、
トランスポゾンを含む溶液に添加し、固体支持体上に固定化することが可能なトランスポ
ソーム二量体を形成することができる。1つの実施形態において、各セットが固定化トラ
ンスポゾンに由来する同じインデックスを有し、それによりインデックス付きビーズを生
成する、複数のビーズセットを生成することができる。図29Aに示すように、標的核酸
を、インデックス付きビーズの各セットに添加することができる。
することができ、タグメント化及びその後のPCR増幅を別々に行ってもよい。
ームは、多くの液滴が、1つのビーズと1つ又はそれ以上のDNA分子及び十分なトラン
スポソームとを含むように、液滴内で組み合わせることができる。
ルに標的核酸を加えることができ、タグメント化及びその後のPCR増幅を単一の反応区
画(「ワンポット」)で行ってもよい。
り、連続性情報を引き出す方法及び組成物に関する。いくつかの実施形態において、連続
性保存転位(CPT:contiguity preserving transpos
ition)をDNA上で行うが、DNAは、無傷(intact)のままであり(CP
T-DNA)、従って、連結ライブラリーを形成する。連続性情報は、トランスポザーゼ
を用いて標的核酸に隣接した鋳型核酸フラグメントの関連性(association)
を維持することにより、保存することができる。CPT-DNAは、固体支持体、例えば
、ビーズに固定化された、固有のインデックス又はバーコードを有する相補的オリゴヌク
レオチドのハイブリダイゼーションにより捕捉することができる(図29B)。いくつか
の実施形態において、固体支持体に固定化されたオリゴヌクレオチドは、バーコードに加
えて、プライマー結合部位、固有分子インデックス(UMI:unique molec
ular indices)をさらに含んでいてもよい。
理的近接性を保つことにより、同じ起源の分子、例えば、染色体からのフラグメント化さ
れた核酸が、同じ固有のバーコード及びインデックス情報を固体支持体に固定化されたオ
リゴヌクレオチドから受け取る可能性が増える。これにより、固有のバーコードを有する
連結シークエンシングライブラリーが得られることになる。連結シークエンシングライブ
ラリーをシークエンスして、連続配列情報を引き出すことができる。
製する本発明の上記態様の、例示的な実施形態の模式図を示す。例示的な方法は、CPT
-DNAと、固有のインデックス及びバーコードを有する固体支持体上の固定化オリゴヌ
クレオチドとのライゲーション、及び鎖置換PCRを活用して、シークエンシングライブ
ラリーを生成する。1つの実施形態において、クローンインデックス付きビーズは、ラン
ダム又は特定のプライマー及びインデックス等の固定化DNA配列で生成してもよい。連
結ライブラリーは、固定化オリゴヌクレオチドへのハイブリダイゼーションとその後のラ
イゲーションにより、クローンインデックス付きビーズ上に捕捉することができる。分子
内ハイブリダイゼーション捕捉は、分子間ハイブリダイゼーションよりもはるかに速いた
め、連続転位ライブラリーが、ビーズに「巻き付く(wrap around)」ことに
なる。図18及び19は、クローンインデックス付きビーズ上でのCPT-DNAの捕捉
及び連続性情報の保存を示す。鎖置換PCRは、クローンビーズインデックス情報を個々
の分子に転移することができる。従って、各連結ライブラリーは、特異的にインデックス
付けされることになる。
の鎖は固体支持体に固定化され、もう一方の鎖は、固定化された鎖に部分的に相補的であ
ることによりY-アダプターとなるような、部分的二本鎖構造を含むことができる。いく
つかの実施形態において、固体支持体に固定化されたY-アダプターは、ライゲーション
及びギャップ充填により連結タグメント化DNAに結合する。図20に示す。
/インデックスを用いた、CPT-DNAのハイブリダイゼーション捕捉を通じて、形成
される。図21は、このようなY-アダプターを作製する例示的なスキームを示す。これ
らのY-アダプターを使用することにより、潜在的に各フラグメントがシークエンシング
ライブラリーになる可能性があることを確かにする。これにより、シークエンシング当た
りの適用範囲(coverage)が増加する。
もよい。いくつかの実施形態において、遊離トランスポソームの分離は、サイズ排除クロ
マトグラフィーによる。1つの実施形態において、分離は、MicroSpin S-4
00 HR Columns(ペンシルバニア州ピッツバーグ、GE Healthca
re Life Sciences社)により行ってもよい。図22は、遊離トランスポ
ソームから分離したCPT-DNAのアガロースゲル電気泳動を示す。
つかの特有の利点がある。1つ目としては、方法は、ハイブリダイゼーションに基づくも
のであり、転位に基づくものではない。分子内ハイブリダイゼーション率>>分子間ハイ
ブリダイゼーション率である。従って、単一の標的DNA分子の連続転位ライブラリーが
固有インデックス付きビーズに巻き付く可能性は、2つ又はそれ以上の異なる単一の標的
DNA分子が固有インデックス付きビーズに巻き付くのに比べてはるかに高い。2つ目と
しては、DNAの転位及び転位したDNAのバーコード化は、2つの別個のステップで生
じる。3つ目としては、ビーズ上の活性化トランスポソームのアセンブリ及び固体表面上
のトランスポゾンの表面密度の最適化に関連した課題を、回避することができる。4つ目
としては、自己転位産物をカラム精製により除去することができる。5つ目としては、連
結転位DNAがギャップを含むため、DNAがより柔軟であり、それ故、トランスポソー
ムをビーズに固定化する方法に比べて、転位密度(挿入サイズ)への負荷が少ない。6つ
目としては、方法に、組み合わせ(combinatorial)バーコードスキームを
用いることができる。7つ目としては、インデックス付きオリゴをビーズに共有結合させ
るのが容易である。従って、インデックス交換の可能性が少ない。8つ目としては、タグ
メント化及びその後のPCR増幅を多重化してもよく、単一反応区画(「ワンポット」)
反応で行うことができるため、各インデックス配列に対して個々の反応を行う必要がなく
なる。
わたって挿入してもよい。いくつかの実施形態において、各バーコードは、間にフラグメ
ント化部位が配置された第1のバーコード配列及び第2のバーコード配列を含む。第1の
バーコード配列及び第2のバーコード配列は、互いにペアとなるように同定又は設計する
ことができる。第1のバーコードと第2のバーコードとが関連するようにペアを作ること
は、有益(informative)である可能性がある。有利なことに、ペアとなった
バーコード配列を用いて、シークエンシングデータを鋳型核酸のライブラリーからアセン
ブルすることができる。例えば、第1のバーコード配列を含む第1の鋳型核酸、及び第1
のバーコード配列とペアとなる第2のバーコード配列含む第2の鋳型核酸を同定すること
は、第1及び第2の鋳型核酸が、標的核酸の配列表示において互いに隣接した配列を表す
ことを意味する。このような方法を用いて、参照ゲノムを必要とすることなく、標的核酸
の配列表示をデノボで(新たに)アセンブルすることができる。
ラリーを生成する方法及び組成物に関する。
クレオチド配列:ランダム又は特異的なプライマー及び固有のインデックスで生成する。
標的核酸を、クローンインデックス付きビーズに加える。いくつかの実施形態において、
標的核酸は、DNAである。1つの実施形態において、標的DNAを変性させる。標的D
NAは、固体表面(例えば、ビーズ)に固定化された固有のインデックスを含むプライマ
ーにハイブリダイズし、続いて、同じインデックスを有する別のプライマーにハイブリダ
イズする。ビーズ上のプライマーは、DNAを増幅させる。1つ又はそれ以上の更なる増
幅ラウンドを行ってもよい。1つの実施形態において、増幅は、3’ランダムn量体配列
を有するビーズ固定化プライマーを用いて、全ゲノム増幅により行ってもよい。好ましい
実施形態において、ランダムn量体は、増幅中のプライマー-プライマー相互作用を防ぐ
ために、疑似相補的塩基(2-チオチミン、2-アミノdA、N4-エチルシトシン等)
を含む(Hoshika,S;Chen,F;Leal,NA;Benner,SA,A
ngew.Chem.Int.Ed.49(32)5554-5557(2010))。
図23は、特定のDNAフラグメントのショットガン配列ライブラリーを生成する例示的
なスキームを示す。クローンインデックス付きシークエンシングライブラリー及び増幅産
物のライブラリーを生成することができる。1つの実施形態において、このようなライブ
ラリーは、転位により生成することができる。インデックス情報を指針として用いること
により、クローンインデックス付きライブラリーの配列情報を用いて、連続性情報をアセ
ンブルすることができる。図24は、クローンインデックス付きシークエンシングライブ
ラリーから配列情報をアセンブルする例示的なスキームを示す。
間増幅よりもはるかに速い。従って、ビーズ上の生成物は、同じインデックスを有するこ
とになる。特定のDNAフラグメントのショットガンライブラリーを、作製することがで
きる。ランダムプライマーは、ランダムな場所で鋳型を増幅するため、同じインデックス
を有するショットガンライブラリーを特定の分子から生成することができ、インデックス
付き配列を用いて配列情報をアセンブルすることができる。上記実施形態の方法の大きな
利点は、反応を単一の反応(ワンポット反応)で多重化することができ、多くの個別のウ
ェルを用いる必要がなくなることである。多くのインデックス付きクローンビーズを調製
することができ、そのため、多くの異なるフラグメントを固有にラベルすることができ、
同じゲノム領域に対して親対立遺伝子を識別することができる。多数のインデックスを用
いることにより、父親のDNAコピー及び母親のDNAコピーが同じゲノム領域に対して
同じインデックスを受け取る可能性は低い。当該方法は、内(intra)反応が間(i
nter)反応よりもはるかに速いという事実を利用するものであり、ビーズは、大きな
物理的区画において実質的な仕切りを基本的に作り出す。
(cfDNA:cell free DNA)アッセイにおいてcfDNAに用いてもよ
い。いくつかの実施形態において、cfDNAは、血漿、胎盤液から得る。
血から得ることができる(Liu et al.Anal Chem.2013 Nov
5;85(21):10463-70)。1つの実施形態において、血漿分離器におけ
る血漿採取ゾーンは、トランスポソームを含む固体支持体を含んでいてもよい。トランス
ポソームを含む固体支持体は、血漿が全血から分離される時に、単離された血漿からcf
DNAを捕捉してもよく、cfDNAの濃縮及び/又はDNAのタグメント化を行うこと
ができる。いくつかの実施形態において、タグメント化は、固有のバーコードをさらに導
入することにより、続いて分離(demultiplexing)を、ライブラリープー
ルのシークエンシング後に行うことを可能にするであろう。
イマー、ヌクレオチド、バッファー、金属)及びポリメラーゼを含んでいてもよい。1つ
の実施形態において、マスターミックスは、血漿が分離器から出てくる時に再構成される
ように、乾燥状態であってもよい。いくつかの実施形態において、プライマーは、ランダ
ムプライマーである。いくつかの実施形態において、プライマーは、特定の遺伝子に対す
る特異的プライマーであってもよい。cfDNAのPCR増幅の結果として、分離された
血漿から直接ライブラリーを生成することになる。
(プライマー、ヌクレオチド、バッファー、金属)、逆転写酵素、及びポリメラーゼを含
んでいてもよい。いくつかの実施形態において、プライマーは、ランダムプライマー又は
オリゴdTプライマーである。いくつかの実施形態において、プライマーは、特定の遺伝
子に対する特異的プライマーであってもよい。得られたcDNAは、シークエンシングに
用いることができる。或いは、cDNAは、配列ライブラリー調製のために、固体支持体
に固定化されたトランスポソームで処理してもよい。
を含んでいてもよい。いくつかの実施形態において、分離装置は、採血装置を有していて
もよい。これにより、血液を血漿分離器及びライブラリー調製装置に直接送ることになる
。いくつかの実施形態において、装置は、下流配列分析器を有していてもよい。いくつか
の実施形態において、配列分析器は、単回使用シークエンサーである。いくつかの実施形
態において、シークエンサーは、まとめてシークエンシングする前に、サンプルの列を作
ることができる。或いは、シークエンサーは、サンプルがシークエンシング領域に送達さ
れる、ランダムアクセス機能を有していてもよい。
、シリカ基質を含んでいてもよい。
5-メチルシトシン(5-Me-C)及び5-ヒドロキシメチルシトシン(5-ヒドロ
キシ-C)は、エピジェネティック(Epi)修飾としても知られ、細胞代謝、分化、及
び癌増殖において重要な役割を果たす。本願の発明者らは、驚くべきことに、且つ予想外
にも、フェージング及び同時のメチル化の検出が、本願の方法及び組成物を用いて可能で
あることを見出した。本願の方法は、ビーズ上でのCPTシークエンシング(CPT-s
eq)(インデックス付き連結ライブラリー)とDNAメチル化検出とを組み合わせるこ
とを可能にするものである。例えば、ビーズ上に生成された個々のライブラリーを亜硫酸
水素塩で処理して、非メチル化CをUに変換するが、メチル化CはUに変換しないことに
より、5-Me-Cの検出を可能にすることができる。ヘテロ接合SNPを用いた更なる
フェージング分析を通じて、Epi-メチル化-フェージングブロックを複数のメガ塩基
領域で確立することができる。
ガ塩基まで可能である。いくつかの実施形態において、分析されるDNAのサイズは、約
100塩基、200塩基、300塩基、400塩基、500塩基、600塩基、700塩
基、800塩基、900塩基、1000塩基、1200塩基、1300塩基、1500塩
基、2000塩基、3000塩基、3500塩基、4000塩基、4500塩基、500
0塩基、5500塩基、6000塩基、6500塩基、7000塩基、7500塩基、8
000塩基、8500塩基、9000塩基、9500塩基、10,000塩基、10,5
00塩基、11,000塩基、11,500塩基、12,000塩基、12,500塩基
、13,000塩基、14,000塩基、14,500塩基、15,000塩基、15,
500塩基、16,000塩基、16,500塩基、17,000塩基、17,500塩
基、18,000塩基、18,500塩基、19,000塩基、19,500塩基、20
,000塩基、20,500塩基、21,000塩基、21,500塩基、22,000
塩基、22,500塩基、23,000塩基、23,500塩基、24,000塩基、2
4,500塩基、25,000塩基、25,500塩基、26,000塩基、26,50
0塩基、27,000塩基、27,500塩基、28,000塩基、28,500塩基、
29,500塩基、30,000塩基、30,500塩基、31,000塩基、31,5
00塩基、32,000塩基、33,000塩基、34,000塩基、35,000塩基
、36,000塩基、37,000塩基、38,000塩基、39,000塩基、40,
000塩基、42,000塩基、45,000塩基、50,000塩基、55,000塩
基、60,000塩基、65,000塩基、70,000塩基、75,000塩基、80
,000塩基、85,000塩基、90,000塩基、95,000塩基、100,00
0塩基、110,000塩基、120,000塩基、130,000塩基、140,00
0塩基、150,000塩基、160,000塩基、170,000塩基、180,00
0塩基、200,000塩基、225,000塩基、250,000塩基、300,00
0塩基、350,000塩基、400,000塩基、450,000塩基、500,00
0塩基、550,000塩基、600,000塩基、650,000塩基、700,00
0塩基、750,000塩基、800,000塩基、850,000塩基、900,00
0塩基、1,000,000塩基、1,250,000塩基、1,500,000塩基、
2,000,000塩基、2,500,000塩基、3,000,000塩基、4,00
0,000塩基、5,000,000塩基、6,000,000塩基、7,000,00
0塩基、8,000,000塩基、9,000,000塩基、10,000,000塩基
、15,000,000塩基、20,000,000塩基、30,000,000塩基、
40,000,000塩基、50,000,000塩基、75,000,000塩基、1
00,000,000塩基、又はそれ以上である。
istone-foot)プリンティング等の他のEpi修飾はまた、本願に開示する方
法及び組成物を用いてフェージングの中で分析することもできる。
合ライブラリーに変換される。元のDNAよりもはるかに小さい個々のインデックス付き
ライブラリーは、個々のライブラリーがより小さいため、フラグメント化され難い。イン
デックス付きライブラリーの小画分が消失したとしても、フェージング情報は、インデッ
クス付きDNA分子の全長にわたって依然として維持される。例えば、100kbの分子
の場合、従来の亜硫酸水素塩変換(BSC)では半分にフラグメント化され、連続性はも
はや50kbに制限される。本明細書に開示する方法では、100kbのライブラリーは
、初めにインデックス化され、個々のライブラリーの画分が消失しても、連続性は、依然
として~100kbである(全ライブラリーがDNA分子の一端から消失する稀な事態を
除いて)。また、本明細書に開示する方法は、従来の亜硫酸水素塩変換アプローチでは必
要とされるのとは対照的に、更なる精製ステップが必要とされないことにより、収率が上
がるため、さらに利点を有する。本明細書に開示する方法では、ビーズは、亜硫酸水素塩
変換の後に洗浄するだけである。さらに、DNAが固相に結合しているままで、DNA(
インデックス付きライブラリー)の最小限の消失及び少ない手間でバッファー交換を容易
に行うことができる。
は、ビーズ上でのDNAのタグメント化、9塩基対の反復領域のギャップ充填ライゲーシ
ョン、SDSによるTn5の除去、及びビーズ上の個々のライブラリーの亜硫酸水素塩変
換からなる。隣接する相補的ライブラリーが再アニールしないことを確実にするために、
亜硫酸水素塩変換を変性条件下で行い、それにより、亜硫酸水素塩変換効率を低下させる
。BSCは、非メチル化CをUに変換し、メチル化Cは、変換されない。
後にシークエンシングライブラリーを調製した後、一本鎖鋳型を調製するために、ギャッ
プ充填ライゲーションしたライブラリーの画分を分解する。一本鎖鋳型は、既に鋳型が、
ライブラリーの消失を低減すること又は亜硫酸水素塩変換効率を改善することができる一
本鎖であるため、亜硫酸水素塩変換に対してより穏やかな条件を必要とする。1つの実施
形態において、3’チオ保護トランスポゾン(Exo抵抗性)及び非保護トランスポゾン
の混合物を、同じビーズ上で用いる。酵素、例えば、Exo Iを用いて、非チオ保護ラ
イブラリーを分解し、それらを一本鎖ライブラリーに変換することができる。チオ保護ト
ランスポゾン:非保護トランスポゾンが50:50である混合物を用いることにより、ラ
イブラリーの50%を一本鎖ライブラリーに変換し(50%では、ライブラリーの1つの
トランスポゾンは保護されており、1つのトランスポゾン(相補鎖)は保護されていない
)、25%は変換せず(両方のトランスポゾンがチオ保護されている)、25%は両方と
も変換してライブラリー全体を除去する(両方のトランスポゾンが保護されていない)。
での1つの課題は、DNAが結合したビーズを、亜硫酸水素ナトリウムにより高温で長時
間処理することで、DNA及びビーズの両方に損傷を与えることである。DNA損傷の回
復を助けるため、キャリアDNA(即ち、ラムダDNA)を亜硫酸水素塩処理前に反応混
合物に加える。キャリアDNAが存在しても、当初のDNAの約80%が消失することが
予測された。結果として、CPTSeq連続性ブロックは、従来のCPTSeqプロトコ
ルよりも少ないメンバーを有する。
ためのいくつかのストラテジーを提案する。第1のストラテジーは、ストレプトアビジン
ビーズにトランスポソーム複合体をより密集させることで、ライブラリー挿入サイズを小
さくすることに依拠する。ライブラリーサイズを小さくすることにより、より少ない割合
のライブラリーエレメントが亜硫酸水素塩処理により分解される。
、破損したライブラリーエレメントを酵素により回復させることである。回復ストラテジ
ーの目的は、ライブラリー増幅に必要な3’共通配列を、亜硫酸水素塩処理中に3’部分
が分解及び消失したビーズ結合ライブラリーエレメントに再び加えることである。3’共
通配列を加えた後は、これらのエレメントをPCR増幅及びシークエンシングすることが
できる。図67及び68は、このストラテジーの例示的なスキームを示す。二本鎖CPT
Seqライブラリーエレメントを変性し、亜硫酸水素塩変換する(上段)。亜硫酸水素塩
変換の間に、DNA鎖の1つが損傷を受け(中段)、3’末端上のPCR共通配列が消失
する。鋳型救出ストラテジーにより、PCR増幅に必要な3’共通配列(緑色)を回復さ
せる(下段)。1つの例において、3’リン酸化アテニュエーターオリゴ、即ち、シーク
エンシングアダプターとそれに続くオリゴdTストレッチを含む配列の存在下で、ターミ
ナルトランスフェラーゼを使用する(図68A)。簡単に言えば、TdTが、10~15
dAのストレッチを、アテニュエーターオリゴのオリゴdT部分にアニールする破損ライ
ブラリーエレメントの3’末端に、加える。このDNAハイブリッドの形成により、Td
T反応が停止し、破損ライブラリーエレメントの3’末端をDNAポリメラーゼにより結
果的に伸長させるための鋳型をもたらす。
び5’リン酸化二本鎖シークエンシングアダプター部分を有する部分的二本鎖アテニュエ
ーターオリゴの存在下で行う。TdT反応の終結時、最後に付加されたdAと5’リン酸
化アテニュエーターオリゴとの間のニックを、DNAリガーゼで封止する。
拠しており、米国特許出願公開第2015/0087027号明細書に記載されている。
共通シークエンシングアダプターはまた、近年導入されたMMLV RTのssDNA鋳
型スイッチング活性により、破損ライブラリーエレメントの3’末端に付加することがで
きる。つまり、MMLV RT及び鋳型スイッチオリゴ(TSオリゴ:template
switch_oligo)を、損傷DNAに加える(図68C)。この反応の最初の
ステップにおいて、逆転写酵素は、一本鎖DNAフラグメントの3’末端にいくつかの追
加のヌクレオチドを付加し、これらの塩基は、TSオリゴの1つの3’末端に存在するオ
リゴ(N)配列とペアを作る。次いで、逆転写酵素の鋳型スイッチング活性により、アニ
ールされた共通プライマーの配列をBSC破損ライブラリーエレメントの3’末端に付加
し、共通シークエンシングプライマーによるPCRで増幅される能力を回復させる。
「ポスト亜硫酸水素塩変換」ライブラリー構築法を用いて、亜硫酸水素塩変換中に3’末
端の共通配列を消失したライブラリーエレメントを救出することができる。図69に示す
ように、このライブラリー救出法は、共通配列及びそれに続く短いストレッチのランダム
配列を有する3’リン酸化オリゴを利用する。これらの短いランダム配列は、亜硫酸水素
塩処理一本鎖DNAにハイブリダイズし、続いて共通配列が、DNAポリメラーゼにより
破損ライブラリー鎖に複製される。
ーを示す。捕捉タグを含む第1の共通配列を、DNAの5’末端に共有結合させる。第1
の共通配列は、片側転位(図示する)、アダプターライゲーション、又は米国特許出願公
開第2015/0087027号明細書に記載されたターミナルトランスフェラーゼ(T
dT)アダプターライゲーションを含む、種々の方法を用いてDNAに結合させることが
できる。
させる。ビオチンをCS1上の捕捉タグとして使用する場合は、例えば、DNAは、スト
レプトアビジン磁性ビーズ(図示する)を用いて結合させることができる。固体支持体に
結合してしまえば、バッファー交換を容易に行うことができる。
Aは、亜硫酸水素塩変換に容易に利用できるはずであり、Promega社のMethy
l Edge BSCキットの改良版を用いて変換効率95%まで観察した(図75)。
に共有結合させる。オリゴをssDNAに共有結合させるためのいくつかの方法を、上述
してきた。TdTアテニュエーター/アダプターライゲーション法を用いて、>95%の
ライゲーション効率を達成した。結果として、提案したメチルシークエンシング(Met
hylSeq)操作フローを用いた最終ライブラリーの収量は、既存の方法よりも高くな
るはずである。
持体から除去する。PCRプライマーは、シークエンシングアダプター等の追加の共通配
列を、MethylSeqライブラリーの末端に付加するようにデザインすることができ
る。
ゲノムのアセンブリの精度は、様々な長さスケールの技術の使用次第である。例えば、
ショットガン(数百bp)-メイトペア(~3Kb)から-Hi-C(Mbスケール)は
全て、アセンブリ及びコンティグ長を経時的に改良する方法である。課題は、これを行う
ために多重アッセイが必要であり、多層アプローチを扱い難く且つ費用が掛かるものとし
ていることである。本明細書に開示する組成物及び方法は、単一のアッセイで複数の長さ
スケールに対応することができる。
ば、ビーズを用いて単一アッセイで達成することができる。各ビーズのサイズは、ビーズ
の物理的サイズがライブラリーサイズを決定し、特定のライブラリーサイズ又はサイズ範
囲をもたらすことになる。様々なサイズのビーズは全て、ライブラリーに転移する固有の
クローンインデックスを有する。従って、様々なサイズのライブラリーが、固有にインデ
ックス付けされた異なる各ライブラリースケール長で生成される。様々な長さスケールの
ライブラリーを同じ物理的区画で同時に調製するため、コストが減り、操作フロー全体を
改善する。いくつかの実施形態において、各特定の固体支持体サイズ、例えば、ビーズサ
イズは、固有のインデックスを受け取る。いくつかの他の実施形態において、同じ固体支
持体サイズ、例えば、同じビーズサイズの複数の異なるインデックスもまた調製すること
で、複数のDNA分子をそのサイズ範囲に対してインデックス区分することができる。図
45は、単一アッセイで、様々なサイズのクローンインデックス付きビーズを用いて様々
なサイズのライブラリーを生成する例示的なスキームを示す。
塩基、100塩基、150塩基、200塩基、250塩基、300塩基、350塩基、4
00塩基、500塩基、600塩基、700塩基、800塩基、900塩基、1000塩
基、1200塩基、1300塩基、1500塩基、2000塩基、3000塩基、350
0塩基、4000塩基、4500塩基、5000塩基、5500塩基、6000塩基、6
500塩基、7000塩基、7,500塩基、8000塩基、8500塩基、9000塩
基、9500塩基、10,000塩基、10,500塩基、11,000塩基、11,5
00塩基、12,000塩基、12,500塩基、13,000塩基、14,000塩基
、14,500塩基、15,000塩基、15,500塩基、16,000塩基、16,
500塩基、17,000塩基、17,500塩基、18,000塩基、18,500塩
基、19,000塩基、19,500塩基、20,000塩基、20,500塩基、21
,000塩基、21,500塩基、22,000塩基、22,500塩基、23,000
塩基、23,500塩基、24,000塩基、24,500塩基、25,000塩基、2
5,500塩基、26,000塩基、26,500塩基、27,000塩基、27,50
0塩基、28,000塩基、28,500塩基、29,500塩基、30,000塩基、
30,500塩基、31,000塩基、31,500塩基、32,000塩基、33,0
00塩基、34,000塩基、35,000塩基、36,000塩基、37,000塩基
、38,000塩基、39,000塩基、40,000塩基、42,000塩基、45,
000塩基、50,000塩基、55,000塩基、60,000塩基、65,000塩
基、70,000塩基、75,000塩基、80,000塩基、85,000塩基、90
,000塩基、95,000塩基、100,000塩基、110,000塩基、120,
000塩基、130,000塩基、140,000塩基、150,000塩基、160,
000塩基、170,000塩基、180,000塩基、200,000塩基、225,
000塩基、250,000塩基、300,000塩基、350,000塩基、400,
000塩基、450,000塩基、500,000塩基、550,000塩基、600,
000塩基、650,000塩基、700,000塩基、750,000塩基、800,
000塩基、850,000塩基、900,000塩基、1,000,000塩基、1,
250,000塩基、1,500,000塩基、2,000,000塩基、2,500,
000塩基、3,000,000塩基、4,000,000塩基、5,000,000塩
基、6,000,000塩基、7,000,000塩基、8,000,000塩基、9,
000,000塩基、10,000,000塩基、15,000,000塩基、20,0
00,000塩基、30,000,000塩基、40,000,000塩基、50,00
0,000塩基、75,000,000塩基、100,000,000塩基、又はそれ以
上である。
きな長さスケールを有する代わりに、疑似遺伝子、パラログ等のアセンブリに用いること
ができる。いくつかの実施形態において、複数の長さスケールのライブラリーを、単一ア
ッセイで同時に調製する。利点は、少なくとも1つの長さスケールが、疑似遺伝子又は遺
伝子のみを有し、両方は有さない固有領域に結合することである。従って、この長さスケ
ールで検出される変異は、遺伝子又は疑似遺伝子のどちらかに変異を一意的に決めること
ができる。同じことがコピー数の変異、パラログ等にも当てはまる。アセンブリの長所は
、異なる長さスケールの使用である。本明細書に開示する方法を用いることにより、異な
る長さスケールのインデックス付き結合ライブラリーを、異なる長さスケールのための個
々の異なるライブラリー調製を行わずに、単一のアッセイで生成することができる。図4
6は、異なる長さスケールのライブラリーで遺伝子変異を決定する例示的なスキームを示
す。
本明細書に開示する組成物及び方法は、遺伝子変異の分析に関する。例示的な遺伝子変
異としては、これに限定されないが、欠損、染色体間転位、重複、パラログ、染色体間遺
伝子融合が挙げられる。いくつかの実施形態において、本明細書に開示する組成物及び方
法は、遺伝子変異のフェージング情報の決定に関する。以下の表は、例示的な染色体間遺
伝子融合を示す。


ラグメント化することができる。例示的なフラグメント化法としては、これに限定されな
いが、超音波処理、機械的剪断、及び制限消化が挙げられる。タグメント化(フラグメン
ト化及びタグ化)前の標的核酸のフラグメント化は、疑似遺伝子(例えば、CYP2D6
)のアセンブリ/フェージングに有利である。インデックス付き結合リードの長い島(>
30kb)は、図64に示すように、疑似遺伝子A及びA’に及ぶであろう。高い配列相
同性のため、どの変異が遺伝子A及び遺伝子A’に属するのかを決定することが課題とな
るであろう。より短い変異は、固有の周囲配列で疑似遺伝子の1つの変異に結合するであ
ろう。そのようなより短い島は、タグメント化前に標的核酸をフラグメント化することに
より達成することができる。
いくつかの実施形態において、トランスポザーゼは、トランスポソーム複合体中で多量
体であり、例えば、二量体、四量体等をトランスポソーム複合体中で形成する。本願の発
明者らは、驚くべきことに、且つ予想外にも、多量体トランスポソーム複合体中の単量体
トランスポザーゼを結合させること、又は多量体トランスポソーム複合体中のトランスポ
ソーム単量体のトランスポゾン末端を結合させることには、いくつかの利点があることを
見出した。1つ目としては、トランスポザーゼ又はトランスポゾンの結合は、より安定し
た複合体をもたらし、大きな画分が活性化状態にある。2つ目としては、より低い濃度の
トランスポソームを、転位反応によるフラグメント化において用いることができる可能性
がある。3つ目としては、結合により、トランスポソーム複合体のモザイク末端(ME)
の交換が少なくなり、それにより、バーコード又はアダプター分子の混合が少なくなる。
そのようなME末端の交換は、複合体がバラバラになり、再編成する場合、又は、トラン
スポソームがストレプトアビジン/ビオチンにより固体支持体上に固定化され、ストレプ
トアビジン/ビオチン相互作用が壊れて再編成する場合、又は、コンタミネーションの可
能性がある場合に、生じる可能性がある。本願の発明者らは、種々の反応条件下で、ME
末端の重大な交換(swap又はexchange)があることに気付いた。いくつかの
実施形態において、交換は、15%にまで達する可能性がある。交換は、高塩濃度バッフ
ァーで顕著であり、グルタミン酸バッファーでは低下する。図57及び58は、ME交換
のいくつかの考え得るメカニズムを示す。
ニットは、共有及び非共有手段により互いに結合させることができる。いくつかの実施形
態において、トランスポザーゼ単量体は、トランスポソーム複合体を形成する前に(トラ
ンスポゾンが加わる前に)結合させることができる。いくつかの実施形態において、トラ
ンスポザーゼ単量体は、トランスポソームの形成後に結合させることができる。
アミノ酸で置換し、ジスルフィド結合の形成を促進していてもよい。例えば、Tn5トラ
ンスポザーゼにおいて、Asp468、Tyr407、Asp461、Lys459、S
er458、Gly462、Ala466、Met470をCysで置換して、単量体サ
ブユニット間のジスルフィド結合を促進していてもよい。図59及び60に示す。Mos
-1トランスポザーゼに関して、システインで置換することができる例示的なアミノ酸と
しては、これに限定されないが、Leu21、Leu32、Ala35、His20、P
he17、Phe36、Ile16、Thr13、Arg12、Gln10、Glu9が
挙げられる。図61に示す。いくつかの実施形態において、システインで置換されたアミ
ノ酸残基を有する修飾トランスポザーゼは、マレイミド又はピリジルジチオール反応基を
用いた化学架橋剤を用いて、互いに化学的に架橋させることができる。例示的な化学架橋
剤は、Pierce Protein Biology/ThermoFisher S
cientific社(米国ニューヨーク州グランドアイランド)から市販されている。
合させることができる。例示的な固体支持体としては、これに限定されないが、ナノ粒子
、ビーズ、フローセル表面、カラムマトリックスが挙げられる。いくつかの実施形態にお
いて、固体表面は、アミン基で被覆されていてもよい。システインで置換されたアミノ酸
残基を有する修飾トランスポザーゼは、そのようなアミン基に対し、アミン-スルフヒド
リル架橋剤(即ち、スクシンイミジル-4-(N-マレイミドメチル)シクロヘキサン-
1-カルボキシレート(SMCC))を用いて、化学的に架橋させることができる。例示
的なスキームを図62に示す。いくつかの実施形態において、マレイミド-PEG-ビオ
チン架橋剤を用いて、dTnpをストレプトアビジン被覆固体表面に結合させてもよい。
体タンパク質を発現するように、修飾することができる。例えば、Tn5又はMos-1
遺伝子は、単一のポリペプチドで、2つのTn5又はMos-1タンパク質を発現するよ
うに修飾することができる。同様に、Muトランスポザーゼ遺伝子は、単一のポリペプチ
ドで、4つのmuトランスポザーゼユニットをコードするように修飾することができる。
合させて、結合トランスポソーム多量体複合体を形成することができる。トランスポゾン
末端を結合させることにより、プライマー部位を挿入することができ、シークエンシング
プライマー、増幅プライマー、又は任意のロール(role)DNAが、標的DNAをフ
ラグメント化することなくgDNAに働くことができる。そのような機能性の挿入は、情
報を無傷分子から抽出する必要があるか又はサブサンプリングが重要である、ハプロタイ
プアッセイ又は結合部タグ化アッセイにおいて、利点である。いくつかの実施形態におい
て、Muトランスポソームのトランスポゾン末端は、「ループ状の」Muトランスポザー
ゼ/トランスポゾン構造に結合させることができる。Muは四量体であるため、これに制
限されないが、R2UJ及び/又はR1UJをR2J及び/又はR1Jに結合させること
により、種々の構造が可能である。これらの構造において、R2UJ及びR1UJは、R
2J及びR1Jと、それぞれ結合することができる又は結合しない。図63は、トランス
ポゾン末端が結合したMuトランスポソーム複合体を示す。いくつかの実施形態において
、Tn5のトランスポゾン末端又はMos-1トランスポソームのトランスポゾン末端を
、結合させることができる。
て機能するトランスポザーゼ又はインテグラーゼ酵素と複合体を形成するのに必要なヌク
レオチド配列(「トランスポゾン末端配列」)のみを示す、二本鎖DNAを意味する。ト
ランスポゾンは、トランスポゾンを認識し、且つ結合するトランスポザーゼ又はインテグ
ラーゼとともに、「複合体」又は「シナプス複合体」又は「トランスポソーム複合体」又
は「トランスポソーム組成物」を形成する。複合体は、in vitro転位反応におい
て一緒にインキュベートする標的DNAに、トランスポゾンを挿入又は転位することが可
能である。トランスポゾンは、「転移トランスポゾン配列」すなわち「転移鎖」、及び「
非転移トランスポゾン配列」すなわち「非転移鎖」からなる2つの相補的配列を示す。例
えば、in vitro転位反応において活性がある機能亢進性Tn5トランスポザーゼ
(例えば、EZ-Tn5(商標)トランスポザーゼ、米国ウィスコンシン州マディソン、
EPICENTRE Biotechnologies社)とともに複合体を形成する1
つのトランスポゾンは、以下の「転移トランスポゾン配列」を示す転移鎖:
5’AGATGTGTATAAGAGACAG3’
及び以下の「非転移トランスポゾン配列」を示す非転移鎖:
5’CTGTCT CTTATACACATCT3’
を含む。
する。非転移鎖は、転移トランスポゾン末端配列に相補的なトランスポゾン配列を示し、
in vitro転位反応において、標的DNAに結合又は転移しない。いくつかの実施
形態において、トランスポゾン配列は、以下の配列うちの1つ又はそれ以上を含んでいて
もよい:バーコード、アダプター配列、タグ配列、プライマー結合配列、捕捉配列、固有
分子識別(UMI:unique molecular identifier)配列。
捉配列、捕捉配列に相補的な配列、固有分子識別(UMI)配列、親和性部分、制限部位
を含むことができる核酸配列を意味する。
上のDNAフラグメント間の空間的関係を指す。情報の共有態様は、隣接関係、区画関係
、及び距離空間関係に関するものとすることができる。これらの関係に関する情報は、順
に、DNAフラグメントに由来する配列リードの階層的なアセンブリ又はマッピングを容
易にする。この連続性情報は、そのようなアセンブリ又はマッピングの効率及び精度を改
善する。なぜなら、従来のショットガンシークエンシングと関連して用いられる伝統的な
アセンブリ又はマッピング法では、個々の配列リードが由来した2つ又はそれ以上のDN
Aフラグメントの空間的関係に関して、個々の配列リードの相対的なゲノム起源又は座標
を考慮に入れないからである。従って、本明細書に記載する実施形態によれば、連続性情
報を捕捉する方法を、隣接空間関係を決定する短距離連続性法、区画空間関係を決定する
中距離連続性法、又は距離空間関係を決定する長距離連続性法により行ってもよい。これ
らの方法は、DNA配列アセンブリ又はマッピングの精度及び質を高める。また、これら
の方法は、上述のシークエンシング法等の任意のシークエンシング法とともに用いてもよ
い。
空間的関係に関して、個々の配列リードの相対的なゲノム起源又は座標を含む。いくつか
の実施形態において、連続性情報は、非重複配列リードからの配列情報を含む。
。いくつかの実施形態において、標的核酸配列の連続性情報は、ゲノム変異を示す。
の関連において、同じ標的核酸からのフラグメントの核酸配列の順番を維持することを意
味する。
のうちの任意の分量を指すことができる。例えば、「少なくとも一部」は、全量の少なく
とも約1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、15%、20
%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70
%、75%、80%、85%、90%、95%、99%、99.9%、又は100%を指
すことができる。
は、ポリマー中の単量体の順序を示すシグナルを得るために行われる物理的又は化学的ス
テップの繰り返し工程を指すことができる。シグナルは、単一の単量体解像度又はより低
い解像度で単量体の順序を示すことができる。特定の実施形態において、ステップを、核
酸標的に対して開始し、核酸標的中の塩基の順序を示すシグナルを得るために行うことが
できる。工程は、典型的な完了まで行うことができ、典型的な完了とは、通常、工程から
のシグナルが、合理的なレベルの確実性で、標的の塩基をそれ以上区別することができな
い時点までと定義される。所望する場合、例えば、所望の配列情報量が得られるまで等、
より早く完了することができる。シークエンシングリードは、単一の標的核酸分子に対し
て、又は同じ配列を有する標的核酸分子群に対して同時に、又は異なる配列を有する標的
核酸群に対して同時に行うことができる。いくつかの実施形態において、シークエンシン
グリードは、シグナルが、シグナル取得が開始された1つ又はそれ以上の標的核酸分子か
らそれ以上は得られない時点で、終了する。例えば、シークエンシングリードは、固相基
質上に存在する1つ又はそれ以上の標的核酸分子に対して開始し、1つ又はそれ以上の標
的核酸分子を基質から除去した時点で終了させることができる。或いは、シークエンシン
グは、シークエンシングランを開始した時に基質上に存在していた標的核酸の検出を中止
することにより、終了することができる。例示的なシークエンシング方法は、その全体が
参照により本明細書に組み込まれる、米国特許第9,029,103号明細書に記載され
ている。
、ポリマー中の単量体単位の順序及び種類を示す情報を指すことができる。例えば、情報
は、核酸中のヌクレオチドの順序及び種類を示すことができる。情報は、例えば、描写、
画像、電子メディア、一連の記号、一連の数字、一連の文字、一連の色等を含む、任意の
種々の形式であってよい。情報は、単一の単量体解像度又はより低い解像度であってもよ
い。例示的なポリマーは、ヌクレオチド単位を有するDNA又はRNA等の核酸である。
一連の「A」、「T」、「G」、及び「C」文字は、単一のヌクレオチド解像度でDNA
分子の実際の配列と相関性があるDNAに対する周知の配列表示である。その他の例示的
なポリマーは、アミノ酸単位を有するタンパク質、及び糖単位を有する多糖類である。
本明細書全体を通じて、固体支持体及び固体表面は、交換可能に用いられる。いくつか
の実施形態において、固体支持体又はその表面は、管又は容器の内表面又は外表面等、非
平面である。いくつかの実施形態において、固体支持体は、ミクロスフェア又はビーズを
含む。本明細書において、「ミクロスフェア」又は「ビーズ」又は「粒子」又はその文法
的等価物は、小さな分散粒子を意味する。適切なビーズ組成物としては、これに限定され
ないが、プラスチック、セラミック、ガラス、ポリスチレン、メチルスチレン、アクリル
ポリマー、常磁性物質、トリアゾル(thoria sol)、カーボングラファイト、
二酸化チタン、ラテックス、又は、セファロース等の架橋デキストラン、セルロース、ナ
イロン、架橋ミセル、及びテフロンが挙げられ、同様に、固形支持体として本明細書で概
説する任意の他の材料を全て使用することができる。Bangs Laboratori
es社(インディアナ州フィッシャーズ)の「ミクロスフェア検出ガイド(Micros
phere Detection Guide)」は、役立つガイドである。特定の実施
態様において、ミクロスフェアは、磁性ミクロスフェア又はビーズである。いくつかの実
施形態において、ビーズは、色分けされていてもよい。例えば、Luminex社(テキ
サス州オースティン)のMicroPlex(登録商標)ミクロスフェアを用いてもよい
。
ーズは多孔質であってもよい。ビーズのサイズは、直径で、ナノメートル即ち約10nm
から、ミリメートル即ち1mmに及び、約0.2ミクロン~約200ミクロンのビーズが
好ましく、約0.5~約5ミクロンのビーズが特に好ましいが、いくつかの実施態様にお
いて、より小さい又はより大きいビーズを用いてもよい。いくつかの実施態様において、
ビーズは、直径が約0.1μm、0.2μm、0.3μm、0.4μm、0.5μm、0
.6μm、0.7μm、0.8μm、0.9μm、1μm、1.5μm、2μm、2.5
μm、2.8μm、3μm、3.5μm、4μm、4.5μm、5μm、5.5μm、6
μm、6.5μm、7μm、7.5μm、8μm、8.5μm、9μm、9.5μm、1
0μm、10.5μm、15μm、20μm、25μm、30μm、35μm、40μm
、45μm、50μm、55μm、60μm、65μm、70μm、75μm、80μm
、85μm、90μm、95μm、100μm、150μm、又は200μmであっても
よい。
「トランスポソーム」は、インテグラーゼ又はトランスポザーゼ等の組み込み(インテ
グレーション)酵素、及びトランスポザーゼ認識部位等の組み込み認識部位を含む核酸を
含む。本明細書で提供する実施形態において、トランスポザーゼは、転位反応を触媒する
ことが可能なトランスポザーゼ認識部位とともに機能的複合体を形成することができる。
トランスポザーゼは、「タグメント化」と称することもある工程において、トランスポザ
ーゼ認識部位に結合し、トランスポザーゼ認識部位を標的核酸に挿入する可能性がある。
いくつかのそのような組み込み事象において、トランスポザーゼ認識部位の1つの鎖が、
標的核酸に転移してもよい。1つの例において、トランスポソームは、2つのサブユニッ
トを含む二量体トランスポザーゼ、及び2つの非連続トランスポゾン配列を含む。別の例
において、トランスポソームは、2つのサブユニットを含む二量体トランスポザーゼを含
むトランスポザーゼ、及び連続トランスポゾン配列を含む。
ーゼ認識部位(Goryshin and Reznikoff,J.Biol.Che
m.,273:7367(1998))、又は、MuAトランスポザーゼ、及びR1及び
R2末端配列を含むMuトランスポザーゼ認識部位(Mizuuchi,K.,Cell
,35:785,1983;Savilahti,H,etal.,EMBOJ.,14
:4893,1995)の使用を含めることができる。機能亢進性Tn5トランスポザー
ゼと複合体を形成する例示的なトランスポザーゼ認識部位(例えば、EZ-Tn5(商標
)トランスポザーゼ、ウィスコンシン州マディソン、Epicentre Biotec
hnologies社)は、以下の19塩基の転移鎖(時に、「M」又は「ME」)及び
非転移鎖:それぞれ、5′AGATGTGTATAAGAGACAG3′、5′CTGT
CTCTTATACACATCT3′を含む。ME配列はまた、当業者により最適化され
て、使用されてもよい。
位システムの更なる例としては、黄色ブドウ球菌(Staphylococcus au
reus)Tn552(Colegio et al.,J.Bacteriol.,1
83:2384-8,2001;Kirby C et al.,Mol.Microb
iol.,43:173-86,2002)、Ty1(Devine&Boeke,Nu
cleic Acids Res.,22:3765-72,1994、及び国際公開第
95/23875号)、トランスポゾンTn7(Craig,N L,Science.
271:1512,1996;Craig,N L,Review in:Curr T
op Microbiol Immunol.,204:27-48,1996)、Tn
/O及びIS10(Kleckner N,et al.,Curr Top Micr
obiol Immunol.,204:49-82,1996)、マリナートランスポ
ザーゼ(Lampe D J,et al.,EMBO J.,15:5470-9,1
996)、Tc1(Plasterk R H,Curr.Topics Microb
iol.Immunol.,204:125-43,1996)、Pエレメント(Glo
or,G B,Methods Mol.Biol.,260:97-114,2004
)、Tn3(Ichikawa & Ohtsubo,J Biol.Chem.265
:18829-32,1990)、細菌挿入配列(Ohtsubo&Sekine,Cu
rr.Top.Microbiol.Immunol.204:1-26,1996)、
レトロウイルス(Brown,et al.,Proc Natl Acad Sci
USA,86:2525-9,1989)、及び酵母のレトロトランスポゾン(Boek
e&Corces,Annu Rev Microbiol.43:403-34,19
89)が挙げられる。更なる例としては、IS5、Tn10、Tn903、IS911、
カタバミ(Sleeping Beauty)、SPIN、hAT、ピギーバック(Pi
ggyBac)、ハーミス(Hermes)、Tcバスター(TcBuster)、Ae
バスター1(AeBuster1)、Tol2、及び改変型トランスポザーゼファミリー
酵素(Zhang et al.,(2009)PLoS Genet.5:e1000
689.Epub 2009 Oct 16;Wilson C.et al(2007
)J.Microbiol.Methods 71:332-5)が挙げられる。
なる例としては、レトロウイルスインテグラーゼ、及びレトロウイルスインテグラーゼに
対するインテグラーゼ認識配列が挙げられ、例えば、HIV-1、HIV-2、SIV、
PFV-1、RSVのインテグラーゼが挙げられる。
一般に、バーコードは、1つ又はそれ以上の特定の核酸を同定するために使用すること
ができる1つ又はそれ以上のヌクレオチド配列を含むことができる。バーコードは、人工
配列であってもよく、或いは、転位の際に生成する自然発生配列、例えば、以前に並置さ
れたDNAフラグメントの末端にある同一のフランキングゲノムDNA配列(gコード)
等であってもよい。いくつかの実施形態において、バーコードは、標的核酸配列にはない
人工配列であり、1つ又はそれ以上の標的核酸配列を同定するのに用いることができる。
、10個、11個、12個、13個、14個、15個、16個、17個、18個、19個
、20個、又はそれ以上の連続したヌクレオチドを含んでいてもよい。いくつかの実施形
態において、バーコードは、少なくとも約10個、20個、30個、40個、50個、6
0個、70個、80個、90個、100個、又はそれ以上の連続したヌクレオチドを含む
。いくつかの実施形態において、バーコードを含む核酸群におけるバーコードの少なくと
も一部は、異なっている。いくつかの実施形態において、バーコードの少なくとも約10
%、20%、30%、40%、50%、60%、70%、80%、90%、95%、99
%が、異なっている。更なるそのような実施形態において、バーコードの全てが異なって
いる。バーコードを含む核酸群において、異なるバーコードの多様性は、ランダムに又は
非ランダムに生成することができる。
含む。2つの非連続トランスポゾン配列を含むトランスポソーム等、いくつかの実施形態
において、第1のトランスポゾン配列は、第1のバーコードを含み、第2のトランスポゾ
ン配列は、第2のバーコードを含む。いくつかの実施形態において、トランスポゾン配列
は、第1のバーコード配列及び第2のバーコード配列を含むバーコードを含む。前述の実
施形態のいくつかにおいて、第1のバーコード配列は、第2のバーコード配列とペアにな
るように同定又は設計することができる。例えば、互いにペアとなることが知られている
複数の第1及び第2のバーコード配列を含む参照表を用いて、既知の第1のバーコード配
列が既知の第2のバーコード配列とペアになることを知ることができる。
いてもよい。別の例において、第1のバーコード配列は、第2のバーコード配列の逆相補
配列を含んでいてもよい。いくつかの実施形態において、第1のバーコード配列及び第2
のバーコード配列は、異なる。第1及び第2のバーコード配列は、バイコード(bi-c
ode)を含んでいてもよい。
型核酸の調製に用いる。当然のことながら、膨大な数の利用可能なバーコードにより、各
鋳型核酸分子は、固有の識別を含むことができる。鋳型核酸の混合物における各分子の固
有の識別は、いくつかの用途に用いることができる。例えば、固有に識別された分子は、
例えば、ハプロタイプシークエンシング、親対立遺伝子の識別、メタゲノムシークエンシ
ング、及びゲノムのサンプルシークエンシングにおいて、複数の染色体を有するサンプル
、ゲノム、細胞、細胞型、細胞の病状、及び種における、個々の核酸分子の同定に応用す
ることができる。
GAGGC、CCTATCCT、GGCTCTGA、AGGCGAAG、TAATCTT
A、CAGGACGT、及びGTACTGACが挙げられる。
いくつかの実施形態において、トランスポゾン配列は、「シークエンシングアダプター
」又は「シークエンシングアダプター部位」、言い換えれば、プライマーにハイブリダイ
ズすることができる1つ又はそれ以上の部位を含む領域を含むことができる。いくつかの
実施形態において、トランスポゾン配列は、増幅及びシークエンシング等に有用な少なく
とも第1のプライマー部位を含むことができる。配列結合部位の例示的な配列としては、
これに限定されないが、AATGATACGGCGACCACCGAGATCTACAC
(P5配列)及びCAAGCAGAAGACGGCATACGAGAT(P7配列)が挙
げられる。
標的核酸としては、任意の目的の核酸を挙げることができる。標的核酸としては、DN
A、RNA、ペプチド核酸、モルフォリノ核酸、ロックド核酸、グリコール核酸、トレオ
ース核酸、核酸の混合サンプル、倍数性DNA(即ち、植物DNA)、これらの混合物、
及びこれらのハイブリッドを挙げることができる。好ましい実施形態において、ゲノムD
NA又はその増幅コピーを、標的核酸として用いる。別の好ましい実施形態において、c
DNA、ミトコンドリアDNA、又は葉緑体DNAを用いる。いくつかの実施形態におい
て、標的核酸は、mRNAである。
来である。いくつかの実施形態において、標的核酸は、単一の細胞小器官由来である。例
示的な単一の細胞小器官としては、これに限定されないが、単一の核、単一のミトコンド
リア、及び単一のリボソームが挙げられる。いくつかの実施形態において、標的核酸は、
ホルマリン固定パラフィン包埋(FFPE)サンプルに由来する。いくつかの実施形態に
おいて、標的核酸は、架橋核酸である。いくつかの実施形態において、標的核酸は、タン
パク質と架橋する。いくつかの実施形態において、標的核酸は、架橋DNAである。いく
つかの実施形態において、標的核酸は、ヒストンに保護されたDNAである。いくつかの
実施形態において、ヒストンは、標的核酸から除去される。いくつかの実施形態において
、標的核酸は、ヌクレオソーム由来である。いくつかの実施形態において、標的核酸は、
核タンパク質が除去されたヌクレオソーム由来である。
て、標的核酸は、ホモポリマー配列を含む。標的核酸はまた、繰り返し配列を含むことが
できる。繰り返し配列は、例えば、2ヌクレオチド、5ヌクレオチド、10ヌクレオチド
、20ヌクレオチド、30ヌクレオチド、40ヌクレオチド、50ヌクレオチド、100
ヌクレオチド、250ヌクレオチド、500ヌクレオチド、1000ヌクレオチド、又は
それ以上を含めた任意の種々の長さとすることができる。繰り返し配列は、連続又は非連
続して、例えば、2回、3回、4回、5回、6回、7回、8回、9回、10回、15回、
20回、又はそれ以上を含めた、任意の種々の回数の繰り返しとすることができる。
他の実施形態は、複数の標的核酸を使用することができる。そのような実施形態において
、複数の標的核酸としては、複数の同じ標的核酸、いくつかの標的核酸は同じである複数
の異なる標的核酸、又は全ての標的核酸が異なる複数の標的核酸を挙げることができる。
複数の標的核酸を使用する実施形態は、例えば、1つ又はそれ以上のチャンバー又はアレ
イ表面で試薬が標的核酸に同時に送られるように、多重型式で行うことができる。いくつ
かの実施形態において、複数の標的核酸としては、実質的に全ての特定の生命体のゲノム
を挙げることができる。複数の標的核酸としては、例えば、ゲノムの少なくとも約1%、
5%、10%、25%、50%、75%、80%、85%、90%、95%,又は99%
を含めた、特定の生命体のゲノムの少なくとも一部を挙げることができる。特定の実施形
態において、当該一部は、ゲノムの最大で約1%、5%、10%、25%、50%、75
%、80%、85%、90%、95%,又は99%である上限を有することができる。
体から得られる核酸分子、又は1つ又はそれ以上の生命体を含む自然源から得られる核酸
分子群から調製してもよい。核酸分子の供給源としては、これに限定されないが、細胞小
器官、細胞、組織、臓器、又は生命体が挙げられる。標的核酸分子の供給源として用いら
れてもよい細胞は、原核細胞(バクテリア細胞、例えば、大腸菌(Escherichi
a)、バチルス(Bacillus)、セラチア(Serratia)、サルモネア(S
almonella)、ブドウ球菌(Staphylococcus)、連鎖球菌(St
reptococcus)、クロストリジウム(Clostridium)、クラミジア
(Chlamydia)、ナイセリア(Neisseria)、トレポネーマ(Trep
onema)、マイコプラズマ(Mycoplasma)、ボレリア(Borrelia
)、レジオネラ(Legionella)、シュードモナス(Pseudomonas)
、マイコバクテリウム(Mycobacterium)、ヘリコバクター(Helico
bacter)、エルウィニア(Erwinia)、アグロバクテリウム(Agroba
cterium)、根粒菌(Rhizobium)、及びStreptomyces g
enera);クレン古細菌門(crenarchaeota)、ナノ古細菌門(nan
oarchaeota)、又はユリ古細菌門(euryarchaeotia)等の古細
菌細胞;又は真菌(例えば、酵母)、植物、原生動物や他の寄生生物、及び動物(昆虫(
例えば、ショウジョウバエ(Drosophila spp.)、線形動物(例えば、線
虫(Caenorhabditis elegans)、及び哺乳動物(例えば、ラット
、マウス、サル、非ヒト霊長類、及びヒト)を含む)等の真核細胞であってもよい。標的
核酸及び鋳型核酸は、当該技術分野でよく知られている種々の方法を用いて、目的とする
特定の配列を濃縮することができる。そのような方法の例は、その全体が参照により本明
細書に組み込まれる国際公開第2012/108864号において提供されている。いく
つかの実施形態において、核酸は、鋳型ライブラリーの調製方法の間に、さらに濃縮させ
てもよい。例えば、核酸は、トランスポソームの挿入前、トランスポソームの挿入後、及
び/又は核酸の増幅後に、特定の配列について濃縮させてもよい。
ことができ、例えば、核酸は、本明細書で提供する方法で用いる前に、混入物を少なくと
も約70%、80%、90%、95%、96%、97%、98%、99%、又は100%
含まないものとすることができる。いくつかの実施形態において、当該技術分野で知られ
ている標的核酸の質及びサイズを維持する方法を用いることは有益であり、例えば、標的
DNAの単離及び/又は直接転位を、アガロースプラグを用いて行ってもよい。転位はま
た、細胞群、ライセート、及び未精製DNAを用いて、細胞で直接行うことができる。
よい。本明細書で用いる場合、用語「生体サンプル」又は「患者サンプル」は、組織及び
体液等のサンプルを含む。「体液」としては、これに限定されないが、血液、血清、血漿
、唾液、脳脊髄液、胸膜液、涙液、乳管液(lactal duct fluid)、リ
ンパ液、喀痰、尿、羊水、及び精液が挙げられる。サンプルは、「無細胞」である体液を
含んでいてもよい。「無細胞体液」は、約1%(質量/質量)未満の全細胞物質を含む。
血漿又は血清は、無細胞体液の例である。サンプルは、天然又は合成由来(即ち、無細胞
となるように調製された細胞サンプル)の標本を含んでいてもよい。
ポソームに曝す前に、(例えば、超音波処理、制限消化、他の機械的手段により)フラグ
メント化することができる。
は、当技術分野で知られている方法(例えば、遠心分離及びろ過等)により、血液から全
細胞物質を除去することにより、血液から得てもよい。
はそれ以上」を意味する。
h as)」、「含む(include)」、「含めて(including)」、又は
それらの変形が本明細書で用いられる場合、これらの用語は、限定の用語であるとは見な
されないものであり、「これに限定されるものではないが」又は「限定されずに」を意味
すると解釈されるものである。
る発明を制限するものではない。
図3のビーズベースタグメント化工程からのDNAクラスターの収量を評価し、図4の
表に示した。本実施例において、50ng、250ng、1000ngのヒトNA128
78 DNAを、同じバッチのタグメント化ビーズ(2.8μmビーズ)を用いてタグメ
ント化した。第2の50ng分量のNA12878 DNAを、第2のバッチのタグメン
ト化ビーズ(完全リピート:2.8μmビーズ)を用いてタグメント化した。ビーズ結合
タグメント化DNAサンプルをPCR増幅し、精製した。一定分量(5.4μL)の各精
製PCR産物(未定量)を270倍希釈し、約50pMのストックサンプル溶液を作製し
た。各サンプルに対し、50pMストック溶液を15pM、19pM、21pM、及び2
4pMに希釈した。希釈したサンプルを、クラスター生成及びシークエンシングのために
フローセルにロードした。データによれば、同じ希釈液(~50pM)から始めて、クラ
スター数は、同じセットのビーズを用いた3つの異なるインプットレベル(即ち、50n
g、250ng、1000ng)に対して、100~114%の間であることが分かる。
50ng完全リピートでのクラスター数(異なるバッチのビーズを用いた)は、81%で
あった。異なる希釈液(15pM、19pM、21pM、及び24pM)は、約10%以
内の同数のクラスターを産生する。データによれば、ビーズが収量を大きく制御し、収量
は、異なるDNAインプット及び異なるリピートで再現性があることが分かる。
図3のビーズベースタグメント化工程の再現性を図5に示す。本実施例において、「同
じ」トランスポソーム密度で作製した6種類の異なるインデックス付きビーズ(インデッ
クス1~6;2.8μmビーズ)調製物を、50ng及び500ngのインプットNA1
2878 DNAを用いたタグメント化DNAの調製に用いた。タグメント化DNAをP
CR増幅し、精製した。2つのHiSeqレーン用に、12種類の精製PCR産物をプー
ルして、6種類ずつの2つの混合物(プール1及びプール2)にした。各プールは、1レ
ーン当たり3~50ng及び3~500ngのサンプルを含む。データ表500は、各イ
ンデックス付きサンプルの挿入サイズ中央値及び挿入サイズ平均値を示す。
図5のインデックス付きサンプルのプール1の挿入サイズ及びプール2の挿入サイズを
、それぞれ図6A(プロット600)及び図6B(プロット650)に示す。データはま
た、挿入サイズが、6種類の異なるインデックス付きビーズ調製物の間で均一であること
を示す。ビーズベースタグメント化は、挿入サイズ及びDNA収量を制御するメカニズム
をもたらす。
図5に記載の実験に関して、リードの合計数及びアラインされたリードの割合の再現性
を図7(棒グラフ700)に示す。両方のインプット(50ng及び500ng)で、リ
ードの合計数は、同じインデックス付きビーズ調製物に対して同様である。6種類のイン
デックス付きビーズ調製物のうちの4種類(インデックス1、2、3、及び6)で、極め
て近い収量を示し、インデックス付きビーズ調製物4及び5では、インデックス配列によ
るものである可能性がある、幾分のばらつきが見られた。
エクソーム濃縮アッセイ、例えば、Illumina社のNextera(登録商標)急
速捕捉濃縮プロトコルに用いてもよい。現在のエクソーム濃縮アッセイ(即ち、Illu
mina社のNextera(登録商標)急速捕捉濃縮プロトコル)では、溶液ベースの
タグメント化(Nextera)をゲノムDNAのフラグメント化に用いる。その後、遺
伝子特異的プライマーを用いて、目的とする特異的遺伝子フラグメントをプルダウンする
。2回の濃縮サイクルを行った後、プルダウンしたフラグメントをPCR及びシークエン
シングにより濃縮する。
、ヒトNA12878 DNAを、25ng、50ng、100ng、150ng、20
0ng、及び500ngのインプットDNAを用いてタグメント化した。コントロールラ
イブラリー(NA00536)を、標準プロトコルに従って、50ngのインプットDN
Aから調製した。各DNAインプットは、異なるインデックス(固有識別子)を有した。
標準方法に合わせるため、且つ、十分な量のフラグメントがプルダウン用に存在すること
を確実にするために、濃縮ポリメラーゼマスターミックス(EPM:enhanced
polymerase mastermix)を用いた10サイクルのPCRを行った。
増幅プロトコルは、72℃で3分、98℃で30秒、続いて98℃で10秒を10サイク
ル、65℃で30秒、及び72℃で1分とした。その後、サンプルを10℃で保持した。
次に、サンプルを、エクソーム濃縮プルダウン工程及びシークエンシングを通じて処理し
た。
タグメント化ライブラリーの挿入サイズ
図8A、8B、及び8Cは、それぞれ、エクソーム濃縮アッセイにおける、コントロー
ルライブラリーでの挿入サイズのプロット800、ビーズベースタグメント化ライブラリ
ーでの挿入サイズのプロット820、及びサマリーデータ表840を示す。データによれ
ば、ビーズベースタグメント化ライブラリーは、コントロールライブラリーに比べて、広
い挿入サイズ分布を有するが、挿入サイズは、サンプルのDNAインプットに関係なく極
めて近いことが分かる。
図9A、9B、及び9Cは、それぞれ、図8A、8B、及び8Cのエクソーム濃縮アッ
セイにおける、フィルターを通過した複製物(dups PF:duplicates
passing filters)の割合の棒グラフ900、PCT selected
basesの棒グラフ920、及びPCT usable bases on tar
getの棒グラフ940を示す。図9Aを参照すると、dups PFの割合(%)は、
いくつのリードがフローセルの他の部分で複製されているかを示す尺度である。この数値
は、全てのクラスターが結果に対して有益なデータをもたらすことを確実にするためには
、理想的には、(ここで示すように)低くなるものである。
いたはずの目的の部位に又はその近くに配列するリードの割合の尺度である。理想的には
、この数値は、濃縮工程の成功を反映して1に近くなるものである。また、この数値は、
濃縮されるべきではないリードが工程を終えていないことを示す。
た領域内で目的とする特定の塩基上に実際に配列しているリードの割合の尺度である。理
想的には、全ての濃縮リードが濃縮されたリード内の目的とする塩基上に配列するもので
あるが、タグメント化のランダム性及び様々な挿入長さのために、目的とする領域上で配
列し終えていないリードが濃縮される可能性がある。
クリーンアップを用いて小さ過ぎる又は大き過ぎるフラグメントを除去してもよい。SP
RIクリーンアップは、サイズ及び所望の沈澱又は非沈澱DNAの保持(即ち、第1ステ
ップは、所望のサイズよりも大きいDNAのみを沈澱させ、可溶な小さいフラグメントを
保持する)に基づいた選択的DNA沈澱により、所望のサイズよりも大きい又は小さいフ
ラグメントを除去する工程である。その後、小さいフラグメントをさらに沈澱させ、この
時、望まない極めて小さいフラグメント(まだ溶液中にある)を除去し、沈澱したDNA
を保持し、洗浄した後、再可溶化して所望のサイズ範囲のDNAを得る。別の例を挙げれ
ば、ビーズ表面上の活性化トランスポソームのスペーシングを用いて、挿入サイズ分布を
制御してもよい。例えば、ビーズ表面上のギャップを不活性トランスポソーム(例えば、
不活性トランスポゾンを有するトランスポソーム)で充填してもよい。
る1000bpウィンドウ内で0回、1回、2回、又は3回のリードが起きた回数を示す
。ビーズを9種類の異なるインデックス付きトランスポソームで生成し、少量のヒトDN
Aのタグメント化に用いた。リードを生成させ、アラインし、同じインデックスを共有す
る1000bp又は10Kbウィンドウ内のリードの数について分析した。インデックス
を共有する小さいウィンドウ内のリードの中には、偶然生成するものがあってもよく、こ
れが何回起こる可能性があるかという予測を、表3及び表4の「ランダム」列に示す。「
ビーズ」列の数は、インデックスを共有する1000bp(表3)又は10Kp(表4)
ウィンドウの実際の数を示す。表3及び表4に示すように、同じインデックスが1000
bp又は10Kpウィンドウ内で見つかった実際の回数は、ランダムケースでの予測より
も顕著に多い。「0」枠は、特定の1000bpウィンドウがそれにマッピングするイン
デックスリードを有さない全ての回数を示す。数値は、極少量のヒトゲノムのみがシーク
エンシングされ、大半のウィンドウがそれらにアラインされるリードを有さないため、こ
こでは最も大きい。「1」は、ただ1つのリードが1000bp(又は10Kp)ウィン
ドウにマップする回数であり、「2」は、1000bp(又は10Kp)ウィンドウ内で
2つのリードがインデックスを共有する回数である、等である。このデータは、1400
超のケースにおいて、同じピースのDNA(10Kp超)が、約15000回のタグメン
ト化事象の中で、同じビーズにより、少なくとも2回から5回までタグメント化されてい
ることを示唆している。フラグメントは、インデックスを共有しているため、それらが偶
然にそこに存在する可能性は低く、同じビーズに由来している。
。
転位の後、CPT-DNA及び遊離トランスポソームを含む反応混合物を、Sepha
cryl S-400及びSephacryl S-200サイズ排除クロマトグラフィ
ーを用いたカラムクロマトグラフィーにかけた。図22に示す。CPT-DNAは、NC
P DNAと表示する。
捕捉プローブA7及びB7の密度を、1μmビーズ上で最適化し、結果を図25に示し
た。レーン1(A7)及びレーン3(B7)は、高いプローブ密度を有し、レーン2(A
7)及びレーン4(B7)は、1umビーズ当たり推定10,000~100,000の
プローブ密度を有した。標的分子に対する捕捉プローブのライゲーション産物を、アガロ
ースゲルで評価した。ビーズ当たり約10,000~100,000のプローブ密度は、
より高いプローブ密度よりも良好なライゲーション効率を有した。
クス付きシークエンシングライブラリーの調製の実現性試験
トランスポソームを、ビーズ上のA7及びB7捕捉配列に相補的なA7’及びB7’捕
捉配列を有するトランスポゾンと機能亢進性Tn5トランスポザーゼとを混合することに
より、調製した。高分子量ゲノムDNAをトランスポソームと混合し、CPT-DNAを
生成する。それとは別に、ビーズを、固定化オリゴヌクレオチド:P5-A7、P7-B
7、又はP5-A7+P7-B7で調製する。ここで、P5及びP7は、プライマー結合
配列であり、A7及びB7は、それぞれA7’及びB7’配列に相補的な捕捉配列である
。P5-A7単独、P7-B7単独、P5-A7+P7-B7、又はP5-A7ビーズ及
びP7-B7ビーズの混合物を含むビーズを、CPT-DNAで処理し、反応混合物にリ
ガーゼを添加して、固定化オリゴの転位DNAに対するハイブリダイゼーションの効率を
決定した。結果を図26に示す。シークエンシングライブラリーは、アガロースゲル上で
高分子量バンドにより示されるように、P5-A7及びP7-B7がともに1つのビーズ
上に固定化されている場合(レーン4)のみで作製される。結果は、高効率の分子内ハイ
ブリダイゼーションを示し、また、分子内ハイブリダイゼーションによるビーズ上でのC
PT-DNAのインデックス付きシークエンシングライブラリーの調製の実現性を証明し
た。
いくつかのトランスポソームセットを調製した。1つのセットにおいて、機能亢進性T
n5トランスポザーゼを、5’ビオチンを有するトランスポゾン配列Tnp1と混合し、
トランスポソーム1を調製する。別のセットにおいて、5’ビオチンを有する固有インデ
ックス2を有するTnp2で、トランスポソーム2を調製する。別のセットにおいて、ト
ランスポソーム3の調製のため、機能亢進性Tn5トランスポザーゼを、5’ビオチンを
有するトランスポゾン配列Tnp3と混合する。別のセットにおいて、固有インデックス
4及び5’ビオチンを有するTnp4でトランスポソーム4を調製する。トランスポソー
ム1及び2、並びにトランスポソーム3及び4を、それぞれ別々にストレプトアビジンビ
ーズと混合し、ビーズセット1及びビーズセット2を生成する。次に、2つのセットのビ
ーズを混合し、ゲノムDNA及びタグメント化バッファーとともにインキュベートして、
ゲノムDNAのタグメント化を促進する。この後、タグメント化配列のPCR増幅を行う
。増幅したDNAをシークエンシングし、インデックス配列の挿入を分析する。タグメン
ト化がビーズに限定される場合、大多数のフラグメントは、Tnp1/Tnp2及びTn
p3/Tnp4インデックスでコードされることになる。分子内ハイブリダイゼーション
がある場合には、フラグメントは、Tnp1/Tnp4、Tnp2/Tnp3、Tnp1
/Tnp3、及びTnp2/Tnp4インデックスでコードされることになる。5サイク
ル及び10サイクルのPCR後のシークエンシング結果を図27に示した。コントロール
は、混合され、ビーズ上に固定化された、4種類全てのトランスポゾンを有する。結果は
、大多数の配列がTnp1/Tnp2又はTnp3/Tnp4インデックスを有すること
を示し、クローンインデックス化が実現可能であることを示している。コントロールは、
インデックスを区別しないことを示す。
96種類のインデックス付きトランスポソームビーズを調製する。個々のインデックス
付きトランスポソームは、5’末端のTn5モザイク末端配列(ME)及びインデックス
配列を有するオリゴヌクレオチドを含むトランスポゾンを混合して、調製した。個々のイ
ンデックス付きトランスポソームを、ストレプトアビジン-ビオチン相互作用によりビー
ズ上に固定化した。ビーズ上のトランスポソームを洗浄し、ビーズ上の96種類全ての個
々にインデックス化されたトランスポソームをプールした。ME配列に相補的でインデッ
クス配列を有するオリゴヌクレオチドを、固定化オリゴヌクレオチドにアニールし、固有
のインデックスを有するトランスポゾンを作製した。96種類のクローンインデックス付
きトランスポソームビーズセットを混ぜ合わせ、高分子量(HMW:high mole
cular weight)ゲノムDNAとともに、Nexteraタグメント化バッフ
ァーの存在下、単一のチューブでインキュベートした。
ゼを除去する。タグメント化DNAをインデックス付きプライマーで増幅し、PE Hi
Seqフローセルv2で、TrueSeq v3クラスターキットを用いてシークエンシ
ングし、シークエンシングデータを分析する。
プロットは、主要なピーク、1つはクラスター内からのもの(近位)ともう1つはクラス
ター間からのもの(遠位)、を基本的に示す。方法及び結果の模式図を、図30及び31
に示す。島のサイズは、約3~10kbの範囲である。カバーされた塩基の割合は、約5
%~10%である。ゲノムDNAの挿入サイズは、約200~300塩基である。
初めに、ME’配列を有する第1のオリゴヌクレオチド、ME-バーコード-P5/P
7配列を有する第2のオリゴヌクレオチド、及びTn5トランスポザーゼを混合すること
により、トランスポソームを溶液中にアセンブルした。第1のセットにおいて、ME’配
列を有する第1のオリゴヌクレオチドを、3’末端でビオチン化する。第2のケースにお
いて、ME-バーコード-P5/P7配列を有するオリゴヌクレオチドを、5’末端でビ
オチン化する。種々の濃度(10nM、50nM、及び200NM)の得られた各トラン
スポソームセットに対し、ストレプトアビジンビーズを添加して、トランスポソームがス
トレプトアビジンビーズに固定化されるようにする。ビーズを洗浄し、HMWゲノムDN
Aを加え、タグメント化を行う。いくつかのケースでは、タグメント化DNAを0.1%
SDSで処理し、他のケースでは、タグメント化DNAを処理しない。タグメント化DN
Aを5~8サイクルでPCR増幅し、シークエンシングする。模式図を図32に示す。
る。3’ビオチンを有するオリゴヌクレオチドは、トランスポソームに対してより良いラ
イブラリーサイズを有する。
を有するトランスポソームは、より小さいサイズのライブラリー及びより多くの自己挿入
副産物を示す。
種々の量の標的HMW DNAを、50mMのTn5:トランスポゾン密度を有するク
ローンインデックス付きビーズに加え、37℃で15分間若しくは60分間、又は室温で
60分間インキュベートした。トランスポソームは、3’ビオチンを有するオリゴヌクレ
オチドを含んだ。タグメント化を行い、反応混合物を0.1%SDSで処理し、PCR増
幅させた。増幅したDNAをシークエンシングした。図35は、サイズ分布に対するイン
プットDNAの影響を示す。10pgのインプットDNAによる反応は、最小シグナルを
示した。サイズ分布パターンは、20pg、40pg、及び200pgのDNAインプッ
トで同様であった。
溶液ベース及びビーズベースの方法を用いて、島のサイズ及び分布を比較した。溶液ベ
ースアプローチにおいて、トランスポゾンにそれぞれ固有のインデックスを有する96種
類のトランスポソームを、96穴プレートにアセンブルする。HMWゲノムDNAを添加
し、タグメント化反応を行う。反応生成物を0.1%SDSで処理し、PCR増幅させる
。増幅したDNAをシークエンシングした。
る96種類のトランスポソームを、96穴プレートにアセンブルした。オリゴヌクレオチ
ドは、3’末端ビオチンを含んだ。ストレプトアビジンビーズを96穴プレートの各々に
添加し、トランスポソームがストレプトアビジンビーズに固定化されるようにインキュベ
ートする。ビーズをそれぞれ洗浄してプールし、HMWゲノムDNAを添加し、タグメン
ト化反応を単一反応容器(ワンポット)内で行う。反応生成物を0.1%SDSで処理し
、PCR増幅させる。増幅産物をシークエンシングした。
全てのトランスポゾン配列を混合する。オリゴヌクレオチドは、3’末端ビオチンを含ん
だ。トランスポソームを個々の混合インデックス付きトランスポゾンから調製する。スト
レプトアビジンビーズを混合物に添加する。HMWゲノムDNAを添加し、タグメント化
反応を行う。反応生成物を0.1%SDSで処理し、PCR増幅させる。増幅産物をシー
クエンシングした。
ード)が、溶液ベースの方法と同様に、ワンポットクローンインデックス付きビーズで観
られることを示している。インデックス付きトランスポゾンをトランスポソーム形成前に
混合した場合、島(近位リード)は観られなかった。トランスポソーム形成前にトランス
ポゾンを混合することにより、ビーズ当たり異なるインデックス/トランスポソームを有
する、即ちクローンではないビーズが得られる。
60kbヘテロ接合欠損の検出
シークエンシングデータをfastqファイルとして抽出し、分離(デマルチプレック
ス)工程を行って、各バーコードに対する個々のfastqファイルを生成する。CPT
シークエンシングからのfastqファイルを、インデックスに従って分離し、重複を除
去した参照ゲノムにアラインする。スキャンウィンドウ内の任意のリードを示すインデッ
クスの数を記録する、5kb/1kbウィンドウにより、染色体をスキャンする。統計的
には、ヘテロ接合欠損領域のため、隣接領域と比較して、半量のDNAしかライブラリー
生成に利用できない。従って、インデックスの数も隣接領域の約半分となるべきである。
NA12878 chr1の60kbヘテロ接合欠損を、9216個のインデックス付き
CPTシークエンシングデータから5kbウィンドウにスキャンすることにより、図47
A及び47Bに示す。
CPTシークエンシングからのfastqファイルを、インデックスに従って分離し、
重複を除去した参照ゲノムにアラインする。染色体を2kbウィンドウにスキャンする。
各2kbウィンドウは、36864ベクターであり、固有インデックスからのリードがこ
の2kbウィンドウでいくつ見つかったかを各エレメントが記録する。ゲノムにわたり、
2kbウィンドウペア(X、Y)毎に、重み付けジャッカード(weighted-Ja
ccard)インデックスを計算する。このインデックスは、事実上、サンプルの(X、
Y)間の距離を示す。これらのインデックスを、図48に示すヒートマップとして表示す
る。各データポイントは、2kbスキャンウィンドウのペアを表わし、左上の四角は、と
もに領域1からのX、Yであり、右下は、ともに領域2からのX、Yであり、右上は、領
域1から領域2にわたる領域からのX、Yである。遺伝子融合シグナルは、このケースで
は中央の横線として示される。
CPTシークエンシングからのfastqファイルを、インデックスに従って分離し、
重複を除去した参照ゲノムにアラインする。染色体を1kbウィンドウにスキャンする。
図49は、遺伝子欠損の検出結果を示す。
亜硫酸水素塩変換効率の最適化
ビーズ上のインデックス付き結合CPT-seqライブラリーに対して、ME(モザイ
クエレメント領域)及びgDNA領域で、変換を評価した。Promega社のMeth
ylEdge亜硫酸水素塩変換システムを最適化して、効率を改善した。
に付着したインデックス付き結合ライブラリーのうち、95%が亜硫酸水素塩変換(BS
C)した。亜硫酸水素塩条件間で、同様のPCR収量が観察された。>より厳しい亜硫酸
水素塩処理でも、ライブラリーを分解しないように思われた。図51に示す。ビーズ上の
インデックス付き結合ライブラリーの約95%でBSCが観察された。BSCを改良(C
>U)するために研究した変数は、温度及びNaOH濃度(変性)であった。60℃及び
1MのNaOH、又は℃及び0.3MのNaOHで良い結果となった。
ークエンシングリード構造が観察された。塩基の割合(%)の計測値を、IVCプロット
とともに図52に示す。
アガロースゲル電気泳動の画像を示す。200~500bpの期待したサイズ範囲のライ
ブラリーが観察された。DNA無しでの反応では、インデックス付き結合ライブラリーを
産生しない。
全ゲノムインデックス付き結合CPT-seqライブラリーを濃縮した。図54は、サ
イズ選択をしない濃縮前の全ゲノムインデックス付き結合CPT-seqライブラリーの
バイオアナライザートレースを示す。図55は、濃縮後のライブラリーのアガロースゲル
分析を示す。
。全ゲノムインデックス付き結合リードライブラリーの濃縮の図解を左に示す。小さいバ
ーは、各々インデックス付き短ライブラリーを示す。インデックス付きライブラリーのク
ラスターは、単一ビーズ上で同じインデックスでクローンインデックス付けされた領域で
ある「島」であり、従って、ゲノムスケール上でリードの近位性(「島」性)を示す。標
的領域におけるライブラリーの濃縮(国際公開第2012/108864号「核酸の選択
的濃縮(Selective enrichment of nucleic acid
s)」を参照)を右に示す。リードは、HLA領域で濃縮される。さらに、リードがイン
デックスで選別され、ゲノムにアラインされる場合、リードは、インデックス付き結合リ
ードから連続性情報が維持されていることを示す「島」構造を再び示す。
トランスポソーム複合体のモザイク末端(ME)の交換を評価するため、異なるインデ
ックスを有するビーズを調製した。混合後、ライブラリーをシークエンシングし、各ライ
ブラリーのインデックスをレポートすることにより、インデックス交換を決定した。「交
換(swapped)」の割合(%)を、(D4+D5+E3+E5+f4)/(全96
種の合計)で計算した。図65に示す。
によるライブラリー挿入サイズの縮小
ストレプトアビジン磁性ビーズを、1倍、6倍、及び12倍濃度のTsTn5トランス
ポソーム複合体とともにロードした。各ビーズタイプに対して、Epi-CPTSeqプ
ロトコルを実施した。分析のため、最終PCR産物をAgilent BioAnaly
zer上にロードした。図に示す。Epi-CPTSeqライブラリーフラグメントは、
比較的小さく、ビーズ上にTsTn5を多くロードするほど多く産生した。
亜硫酸水素塩変換後、DNAは損傷を受け、結果としてPCR増幅に必要な共通配列(
CS2)が減少する。DNAフラグメントCPTSeq及びEpi-CPTSeq(Me
-CPTSeq)ライブラリーを、BioAnalyzerで分析した。亜硫酸水素塩変
換中のDNA損傷により、Epi-CPTSeqライブラリーは、図70に示すように、
CPTSeqライブラリーと比較して、5倍低い収量であり、小さいライブラリーサイズ
分布を有する。
ターミナルトランスフェラーゼ(TdT)媒介ライゲーションによるDNA末端修復の
実現性を試験した。簡単には、5pmolのssDNA鋳型を,TdT(10/50U)
、アテニュエーター/アダプター二本鎖(0/15/25pmol)、及びDNAリガー
ゼ(0/10U)とともに、37℃で15分間インキュベートした。伸長/ライゲーショ
ンのDNA産物を、TBE-Ureaゲルで分析し、結果を図71に示した。全ての反応
成分を添加した結果、アダプター分子のほぼ完全なライゲーションが行われた(レーン5
~8)。
実現性を、亜硫酸水素ナトリウム変換ビーズ結合ライブラリーに対して試験した。図72
に示す。簡単には、DNAをビーズ上でタグメント化し(最初の2レーン)、Prome
ga社のMethylEdge亜硫酸水素塩変換キットで処理し(レーン3及び4)、D
NA救出プロトコルを行った(レーン5及び6)。救出反応後のDNAライブラリーの収
量及びサイズは、明らかに増加している。また、挿入トランスポゾン(SI)の存在量も
増加しており、アダプター分子の効率的なライゲーションを示している。
Claims (20)
- (a)それぞれその上に複数のトランスポソーム複合体を固定化している複数の固体支持体を提供するステップであって、前記トランスポソーム複合体の各々は2つ以上のトランスポソームの単量体単位を含み、前記トランスポソームの単量体単位が互いに結合してトランスポソーム複合体を形成しており、前記トランスポソームの各単量体単位が、ポリヌクレオチドに結合したトランスポザーゼを含み、前記ポリヌクレオチドは、
(i)トランスポゾン末端配列を含む3’部分と、
(ii)第1のバーコード配列を含む第1のアダプターと
を含む、ステップと、
(b)二本鎖の標的核酸を、前記二本鎖の標的核酸が前記トランスポソーム複合体により二本鎖の標的核酸フラグメントにフラグメント化され、前記ポリヌクレオチドの前記トランスポゾン末端配列が前記二本鎖の標的核酸フラグメントの少なくとも1つの鎖の5’末端に転移される条件下で、前記複数の固体支持体に適用し、それにより、少なくとも1つの鎖が前記第1のバーコード配列で5’タグ化されている二本鎖の標的核酸フラグメントの固定化ライブラリーを作製するステップと、
を含む、タグ化核酸フラグメントの固定化ライブラリーを調製する方法。 - (a)それぞれその上に複数のトランスポソーム複合体を固定化している複数の固体支持体を提供するステップであって、前記トランスポソーム複合体の各々は2つ以上のトランスポソームの単量体単位を含み、前記トランスポソームの単量体単位が互いに結合してトランスポソーム複合体を形成しており、前記トランスポソームの各単量体単位が、ポリヌクレオチドに結合したトランスポザーゼを含み、前記ポリヌクレオチドは、
(i)トランスポゾン末端配列を含む3’部分と、
(ii)第1のバーコード配列を含む第1のアダプターと
を含む、ステップと、
(b)二本鎖の標的核酸を、前記標的核酸の連続性を維持しながら、前記二本鎖の標的核酸が前記トランスポソーム複合体により二本鎖の標的核酸フラグメントにフラグメント化され、前記ポリヌクレオチドの前記トランスポゾン末端配列が前記二本鎖の標的核酸フラグメントの少なくとも1つの鎖の5’末端に転移される条件下で、前記複数の固体支持体に適用し、それにより、少なくとも1つの鎖が前記第1のバーコード配列で5’タグ化されている二本鎖の標的核酸フラグメントの固定化ライブラリーを作製するステップであり、ある固体支持体上の前記第1のバーコード配列は同じ核酸配列を含み、前記複数の固体支持体中のある固体支持体からの第1のバーコードの核酸配列は、前記複数の固体支持体中の他の固体支持体からの第1のバーコードの核酸配列とは異なる、ステップと、
(c)前記標的核酸のフラグメントの配列及び関連した前記第1のバーコード配列を決定するステップと、
(d)前記第1のバーコード配列を識別することにより、前記標的核酸の連続性情報を決定するステップと
を含む、標的核酸配列の連続性情報を決定する方法。 - トランスポソーム単量体単位の前記トランスポザーゼが、同じ前記トランスポソーム複合体の別のトランスポソーム単量体単位の別のトランスポザーゼに結合している、請求項1又は2に記載の方法。
- トランスポソーム単量体単位の前記トランスポゾン末端配列が、同じ前記トランスポソーム複合体の別のトランスポソーム単量体単位の別のトランスポゾン末端配列に結合している、請求項1又は2に記載の方法。
- 前記トランスポソーム複合体中の前記トランスポザーゼのサブユニットが、共有及び非共有結合により互いに結合している、請求項1又は2に記載の方法。
- 前記トランスポソーム単量体単位の前記トランスポザーゼが、トランスポゾンが加わってトランスポソーム複合体が形成される前に互いに結合する、請求項1又は2に記載の方法。
- 前記トランスポソーム単量体単位の前記トランスポザーゼが、トランスポソーム複合体の形成後に互いに結合する、請求項1又は2に記載の方法。
- 前記第1のアダプターが、第1のプライマー結合配列をさらに含む、請求項1又は2に記載の方法。
- 標的核酸配列の前記連続性情報が、ハプロタイプ情報を示す、請求項2に記載の方法。
- 標的核酸配列の前記連続性情報が、欠損、転位、染色体間遺伝子融合、重複、及びパラログからなる群から選択されるゲノム変異を示す、請求項2~9のいずれか一項に記載の方法。
- 前記バーコードを含む標的核酸フラグメントが、前記標的核酸フラグメントの配列を決定する前に増幅される、請求項2~10のいずれか一項に記載の方法。
- 前記標的核酸をトランスポソーム複合体と接触させる前に、前記標的核酸をプレフラグメント化するステップをさらに含む、請求項1~11のいずれか一項に記載の方法。
- 前記標的核酸が単一の細胞から得られる、請求項1~12のいずれか一項に記載の方法。
- 前記標的核酸が単一の細胞小器官から得られる、請求項1~13のいずれか一項に記載の方法。
- 前記標的核酸がゲノムDNAを含む、請求項1~14のいずれか一項に記載の方法。
- 前記標的核酸が他の核酸に架橋する、請求項1~15のいずれか一項に記載の方法。
- 前記標的核酸が無細胞腫瘍DNAを含む、請求項1~16のいずれか一項に記載の方法。
- 前記標的核酸がcDNAを含む、請求項1~17のいずれか一項に記載の方法。
- 前記固体支持体がビーズを含む、請求項1~18のいずれか一項に記載の方法。
- (a)それぞれその上に複数のトランスポソーム複合体を固定化している複数の固体支持体であって、前記トランスポソーム複合体の各々は2つ以上のトランスポソームの単量体単位を含み、前記トランスポソームの単量体単位が互いに結合してトランスポソーム複合体を形成しており、前記トランスポソームの各単量体単位が、ポリヌクレオチドに結合したトランスポザーゼを含み、前記ポリヌクレオチドは、
(i)トランスポゾン末端配列を含む3’部分と、
(ii)第1のバーコード配列を含む第1のアダプターと
を含む、複数の固体支持体と、
(b)前記固体支持体に固定化された二本鎖の標的核酸であって、前記二本鎖の標的核酸は前記トランスポソーム複合体により二本鎖の標的核酸フラグメントにフラグメント化されており、前記ポリヌクレオチドの前記トランスポゾン末端配列が前記二本鎖の標的核酸フラグメントの少なくとも1つの鎖の5’末端に転移され、少なくとも1つの鎖が前記第1のバーコード配列で5’タグ化されている、二本鎖の標的核酸と、
を含む、標的核酸のバーコード化核酸フラグメントのライブラリーを調製するための組成物。
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201462065544P | 2014-10-17 | 2014-10-17 | |
| US62/065,544 | 2014-10-17 | ||
| US201562157396P | 2015-05-05 | 2015-05-05 | |
| US62/157,396 | 2015-05-05 | ||
| US201562242880P | 2015-10-16 | 2015-10-16 | |
| US62/242,880 | 2015-10-16 | ||
| JP2020204004A JP7127104B2 (ja) | 2014-10-17 | 2020-12-09 | 連続性を維持した転位 |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2020204004A Division JP7127104B2 (ja) | 2014-10-17 | 2020-12-09 | 連続性を維持した転位 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2022172158A JP2022172158A (ja) | 2022-11-15 |
| JP7532455B2 true JP7532455B2 (ja) | 2024-08-13 |
Family
ID=55747561
Family Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017520884A Active JP6808617B2 (ja) | 2014-10-17 | 2015-10-16 | 連続性を維持した転位 |
| JP2020204004A Active JP7127104B2 (ja) | 2014-10-17 | 2020-12-09 | 連続性を維持した転位 |
| JP2022129859A Active JP7532455B2 (ja) | 2014-10-17 | 2022-08-17 | 連続性を維持した転位 |
Family Applications Before (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017520884A Active JP6808617B2 (ja) | 2014-10-17 | 2015-10-16 | 連続性を維持した転位 |
| JP2020204004A Active JP7127104B2 (ja) | 2014-10-17 | 2020-12-09 | 連続性を維持した転位 |
Country Status (10)
| Country | Link |
|---|---|
| US (3) | US11873480B2 (ja) |
| JP (3) | JP6808617B2 (ja) |
| KR (2) | KR102643955B1 (ja) |
| AU (2) | AU2015331739B2 (ja) |
| BR (2) | BR122021026779B1 (ja) |
| CA (1) | CA2964799A1 (ja) |
| IL (3) | IL299976B1 (ja) |
| RU (2) | RU2736728C2 (ja) |
| SG (2) | SG10201903408VA (ja) |
| WO (1) | WO2016061517A2 (ja) |
Families Citing this family (145)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8835358B2 (en) | 2009-12-15 | 2014-09-16 | Cellular Research, Inc. | Digital counting of individual molecules by stochastic attachment of diverse labels |
| US9074251B2 (en) | 2011-02-10 | 2015-07-07 | Illumina, Inc. | Linking sequence reads using paired code tags |
| JP6017458B2 (ja) | 2011-02-02 | 2016-11-02 | ユニヴァーシティ・オブ・ワシントン・スルー・イッツ・センター・フォー・コマーシャリゼーション | 大量並列連続性マッピング |
| CN104364392B (zh) | 2012-02-27 | 2018-05-25 | 赛卢拉研究公司 | 用于分子计数的组合物和试剂盒 |
| US10323279B2 (en) | 2012-08-14 | 2019-06-18 | 10X Genomics, Inc. | Methods and systems for processing polynucleotides |
| US10400280B2 (en) | 2012-08-14 | 2019-09-03 | 10X Genomics, Inc. | Methods and systems for processing polynucleotides |
| US10752949B2 (en) | 2012-08-14 | 2020-08-25 | 10X Genomics, Inc. | Methods and systems for processing polynucleotides |
| US9951386B2 (en) | 2014-06-26 | 2018-04-24 | 10X Genomics, Inc. | Methods and systems for processing polynucleotides |
| US11591637B2 (en) | 2012-08-14 | 2023-02-28 | 10X Genomics, Inc. | Compositions and methods for sample processing |
| CN113528634A (zh) | 2012-08-14 | 2021-10-22 | 10X基因组学有限公司 | 微胶囊组合物及方法 |
| US10273541B2 (en) | 2012-08-14 | 2019-04-30 | 10X Genomics, Inc. | Methods and systems for processing polynucleotides |
| US9701998B2 (en) | 2012-12-14 | 2017-07-11 | 10X Genomics, Inc. | Methods and systems for processing polynucleotides |
| US10533221B2 (en) | 2012-12-14 | 2020-01-14 | 10X Genomics, Inc. | Methods and systems for processing polynucleotides |
| EP3567116A1 (en) | 2012-12-14 | 2019-11-13 | 10X Genomics, Inc. | Methods and systems for processing polynucleotides |
| KR20200140929A (ko) | 2013-02-08 | 2020-12-16 | 10엑스 제노믹스, 인크. | 폴리뉴클레오티드 바코드 생성 |
| DK3553175T3 (da) | 2013-03-13 | 2021-08-23 | Illumina Inc | Fremgangsmåde til fremstilling af et nukleinsyresekvenseringsbibliotek |
| US9328382B2 (en) | 2013-03-15 | 2016-05-03 | Complete Genomics, Inc. | Multiple tagging of individual long DNA fragments |
| KR102536833B1 (ko) | 2013-08-28 | 2023-05-26 | 벡톤 디킨슨 앤드 컴퍼니 | 대량의 동시 단일 세포 분석 |
| US9824068B2 (en) | 2013-12-16 | 2017-11-21 | 10X Genomics, Inc. | Methods and apparatus for sorting data |
| AU2015243445B2 (en) | 2014-04-10 | 2020-05-28 | 10X Genomics, Inc. | Fluidic devices, systems, and methods for encapsulating and partitioning reagents, and applications of same |
| CN113249435B (zh) | 2014-06-26 | 2024-09-03 | 10X基因组学有限公司 | 分析来自单个细胞或细胞群体的核酸的方法 |
| CA2956925C (en) | 2014-08-01 | 2024-02-13 | Dovetail Genomics, Llc | Tagging nucleic acids for sequence assembly |
| AU2015339148B2 (en) | 2014-10-29 | 2022-03-10 | 10X Genomics, Inc. | Methods and compositions for targeted nucleic acid sequencing |
| US9975122B2 (en) | 2014-11-05 | 2018-05-22 | 10X Genomics, Inc. | Instrument systems for integrated sample processing |
| WO2016114970A1 (en) | 2015-01-12 | 2016-07-21 | 10X Genomics, Inc. | Processes and systems for preparing nucleic acid sequencing libraries and libraries prepared using same |
| CA2976902A1 (en) | 2015-02-17 | 2016-08-25 | Dovetail Genomics Llc | Nucleic acid sequence assembly |
| US10697000B2 (en) | 2015-02-24 | 2020-06-30 | 10X Genomics, Inc. | Partition processing methods and systems |
| WO2016138148A1 (en) | 2015-02-24 | 2016-09-01 | 10X Genomics, Inc. | Methods for targeted nucleic acid sequence coverage |
| EP3262192B1 (en) | 2015-02-27 | 2020-09-16 | Becton, Dickinson and Company | Spatially addressable molecular barcoding |
| GB2554572B (en) * | 2015-03-26 | 2021-06-23 | Dovetail Genomics Llc | Physical linkage preservation in DNA storage |
| US11535882B2 (en) | 2015-03-30 | 2022-12-27 | Becton, Dickinson And Company | Methods and compositions for combinatorial barcoding |
| WO2016172373A1 (en) | 2015-04-23 | 2016-10-27 | Cellular Research, Inc. | Methods and compositions for whole transcriptome amplification |
| US11453875B2 (en) | 2015-05-28 | 2022-09-27 | Illumina Cambridge Limited | Surface-based tagmentation |
| CN107922959A (zh) | 2015-07-02 | 2018-04-17 | 阿瑞玛基因组学公司 | 混合物样品的精确分子去卷积 |
| WO2017034970A1 (en) * | 2015-08-21 | 2017-03-02 | The General Hospital Corporation | Combinatorial single molecule analysis of chromatin |
| US10619186B2 (en) | 2015-09-11 | 2020-04-14 | Cellular Research, Inc. | Methods and compositions for library normalization |
| KR20180096586A (ko) | 2015-10-19 | 2018-08-29 | 더브테일 제노믹스 엘엘씨 | 게놈 어셈블리, 하플로타입 페이징 및 표적 독립적 핵산 검출을 위한 방법 |
| US11371094B2 (en) | 2015-11-19 | 2022-06-28 | 10X Genomics, Inc. | Systems and methods for nucleic acid processing using degenerate nucleotides |
| WO2017096158A1 (en) | 2015-12-04 | 2017-06-08 | 10X Genomics, Inc. | Methods and compositions for nucleic acid analysis |
| WO2017120531A1 (en) | 2016-01-08 | 2017-07-13 | Bio-Rad Laboratories, Inc. | Multiple beads per droplet resolution |
| US20190169602A1 (en) * | 2016-01-12 | 2019-06-06 | Seqwell, Inc. | Compositions and methods for sequencing nucleic acids |
| EP3414341A4 (en) | 2016-02-11 | 2019-10-09 | 10X Genomics, Inc. | SYSTEMS, METHODS, AND MEDIA FOR ASSEMBLING NOVO OF GENOME SEQUENCE DATA OVERALL |
| SG11201807117WA (en) | 2016-02-23 | 2018-09-27 | Dovetail Genomics Llc | Generation of phased read-sets for genome assembly and haplotype phasing |
| US20170283864A1 (en) | 2016-03-31 | 2017-10-05 | Agilent Technologies, Inc. | Use of transposase and y adapters to fragment and tag dna |
| JP7120630B2 (ja) | 2016-05-02 | 2022-08-17 | エンコディア, インコーポレイテッド | 核酸エンコーディングを使用した巨大分子解析 |
| EP3954771A1 (en) | 2016-05-13 | 2022-02-16 | Dovetail Genomics, LLC | Recovering long-range linkage information from preserved samples |
| WO2017197338A1 (en) | 2016-05-13 | 2017-11-16 | 10X Genomics, Inc. | Microfluidic systems and methods of use |
| US10894990B2 (en) | 2016-05-17 | 2021-01-19 | Shoreline Biome, Llc | High throughput method for identification and sequencing of unknown microbial and eukaryotic genomes from complex mixtures |
| US10301677B2 (en) | 2016-05-25 | 2019-05-28 | Cellular Research, Inc. | Normalization of nucleic acid libraries |
| US10640763B2 (en) | 2016-05-31 | 2020-05-05 | Cellular Research, Inc. | Molecular indexing of internal sequences |
| US10202641B2 (en) | 2016-05-31 | 2019-02-12 | Cellular Research, Inc. | Error correction in amplification of samples |
| WO2018013724A1 (en) * | 2016-07-12 | 2018-01-18 | Kapa Biosystems, Inc. | System and method for transposase-mediated amplicon sequencing |
| KR102475710B1 (ko) * | 2016-07-22 | 2022-12-08 | 오레곤 헬스 앤드 사이언스 유니버시티 | 단일 세포 전체 게놈 라이브러리 및 이의 제조를 위한 조합 인덱싱 방법 |
| EP3497219A4 (en) * | 2016-08-10 | 2020-08-19 | President and Fellows of Harvard College | NOVO ASSEMBLY PROCESSES FROM GENOMIC DNA BARCODE FRAGMENTS |
| WO2018057779A1 (en) * | 2016-09-23 | 2018-03-29 | Jianbiao Zheng | Compositions of synthetic transposons and methods of use thereof |
| CA3034924A1 (en) | 2016-09-26 | 2018-03-29 | Cellular Research, Inc. | Measurement of protein expression using reagents with barcoded oligonucleotide sequences |
| US11021738B2 (en) | 2016-12-19 | 2021-06-01 | Bio-Rad Laboratories, Inc. | Droplet tagging contiguity preserved tagmented DNA |
| US10550429B2 (en) | 2016-12-22 | 2020-02-04 | 10X Genomics, Inc. | Methods and systems for processing polynucleotides |
| US10815525B2 (en) | 2016-12-22 | 2020-10-27 | 10X Genomics, Inc. | Methods and systems for processing polynucleotides |
| GB201622219D0 (en) | 2016-12-23 | 2017-02-08 | Cs Genetics Ltd | Methods and reagents for molecular barcoding |
| EP4310183A3 (en) | 2017-01-30 | 2024-02-21 | 10X Genomics, Inc. | Methods and systems for droplet-based single cell barcoding |
| EP3577232A1 (en) | 2017-02-01 | 2019-12-11 | Cellular Research, Inc. | Selective amplification using blocking oligonucleotides |
| US10995333B2 (en) | 2017-02-06 | 2021-05-04 | 10X Genomics, Inc. | Systems and methods for nucleic acid preparation |
| DK3452621T3 (da) * | 2017-02-21 | 2022-12-12 | Illumina Inc | Tagmentation ved brug af immobiliserede transposomer med linkere |
| GB2577214B (en) | 2017-05-05 | 2021-10-06 | Scipio Bioscience | Methods for trapping and barcoding discrete biological units in hydrogel |
| CN109526228B (zh) | 2017-05-26 | 2022-11-25 | 10X基因组学有限公司 | 转座酶可接近性染色质的单细胞分析 |
| US20180340169A1 (en) * | 2017-05-26 | 2018-11-29 | 10X Genomics, Inc. | Single cell analysis of transposase accessible chromatin |
| CA3059559A1 (en) | 2017-06-05 | 2018-12-13 | Becton, Dickinson And Company | Sample indexing for single cells |
| RU2770879C2 (ru) * | 2017-06-07 | 2022-04-22 | Орегон Хэлт Энд Сайенс Юниверсити | Полногеномные библиотеки отдельных клеток для бисульфитного секвенирования |
| WO2019060722A2 (en) | 2017-09-22 | 2019-03-28 | X Gen Us Co. | METHODS AND COMPOSITIONS FOR USE IN PREPARING POLYNUCLEOTIDES |
| US10837047B2 (en) | 2017-10-04 | 2020-11-17 | 10X Genomics, Inc. | Compositions, methods, and systems for bead formation using improved polymers |
| WO2019076768A1 (en) * | 2017-10-16 | 2019-04-25 | Tervisetehnoloogiate Arenduskeskus As | METHOD AND KIT FOR PREPARING DNA BANK |
| WO2019084043A1 (en) | 2017-10-26 | 2019-05-02 | 10X Genomics, Inc. | METHODS AND SYSTEMS FOR NUCLEIC ACID PREPARATION AND CHROMATIN ANALYSIS |
| CN111479631B (zh) | 2017-10-27 | 2022-02-22 | 10X基因组学有限公司 | 用于样品制备和分析的方法和系统 |
| CA3081441C (en) | 2017-10-31 | 2023-08-29 | Encodia, Inc. | Kits for analysis using nucleic acid encoding and/or label |
| EP3704247B1 (en) | 2017-11-02 | 2023-01-04 | Bio-Rad Laboratories, Inc. | Transposase-based genomic analysis |
| CN111051523B (zh) | 2017-11-15 | 2024-03-19 | 10X基因组学有限公司 | 功能化凝胶珠 |
| US10829815B2 (en) | 2017-11-17 | 2020-11-10 | 10X Genomics, Inc. | Methods and systems for associating physical and genetic properties of biological particles |
| US11873481B2 (en) | 2017-11-21 | 2024-01-16 | Arima Genomics, Inc. | Preserving spatial-proximal contiguity and molecular contiguity in nucleic acid templates |
| WO2019108851A1 (en) | 2017-11-30 | 2019-06-06 | 10X Genomics, Inc. | Systems and methods for nucleic acid preparation and analysis |
| CN111712579B (zh) | 2017-12-22 | 2024-10-15 | 10X基因组学有限公司 | 用于处理来自一个或多个细胞的核酸分子的系统和方法 |
| WO2019157529A1 (en) | 2018-02-12 | 2019-08-15 | 10X Genomics, Inc. | Methods characterizing multiple analytes from individual cells or cell populations |
| US11639928B2 (en) | 2018-02-22 | 2023-05-02 | 10X Genomics, Inc. | Methods and systems for characterizing analytes from individual cells or cell populations |
| WO2019169028A1 (en) | 2018-02-28 | 2019-09-06 | 10X Genomics, Inc. | Transcriptome sequencing through random ligation |
| WO2019195166A1 (en) | 2018-04-06 | 2019-10-10 | 10X Genomics, Inc. | Systems and methods for quality control in single cell processing |
| US11365409B2 (en) | 2018-05-03 | 2022-06-21 | Becton, Dickinson And Company | Molecular barcoding on opposite transcript ends |
| ES2945191T3 (es) * | 2018-05-03 | 2023-06-29 | Becton Dickinson Co | Análisis de muestras multiómicas de alto rendimiento |
| CN112639094A (zh) * | 2018-05-08 | 2021-04-09 | 深圳华大智造科技股份有限公司 | 用于准确且经济高效的测序、单体型分型和组装的基于单管珠粒的dna共条形码化 |
| WO2019217758A1 (en) | 2018-05-10 | 2019-11-14 | 10X Genomics, Inc. | Methods and systems for molecular library generation |
| AU2019270185A1 (en) * | 2018-05-17 | 2020-01-16 | Illumina, Inc. | High-throughput single-cell sequencing with reduced amplification bias |
| US11932899B2 (en) | 2018-06-07 | 2024-03-19 | 10X Genomics, Inc. | Methods and systems for characterizing nucleic acid molecules |
| US11703427B2 (en) | 2018-06-25 | 2023-07-18 | 10X Genomics, Inc. | Methods and systems for cell and bead processing |
| US20200032335A1 (en) | 2018-07-27 | 2020-01-30 | 10X Genomics, Inc. | Systems and methods for metabolome analysis |
| US11479816B2 (en) | 2018-08-20 | 2022-10-25 | Bio-Rad Laboratories, Inc. | Nucleotide sequence generation by barcode bead-colocalization in partitions |
| US12065688B2 (en) | 2018-08-20 | 2024-08-20 | 10X Genomics, Inc. | Compositions and methods for cellular processing |
| WO2020061903A1 (zh) * | 2018-09-27 | 2020-04-02 | 深圳华大生命科学研究院 | 测序文库的构建方法和得到的测序文库及测序方法 |
| WO2020072380A1 (en) | 2018-10-01 | 2020-04-09 | Cellular Research, Inc. | Determining 5' transcript sequences |
| JP7528067B2 (ja) * | 2018-10-25 | 2024-08-05 | イルミナ インコーポレイテッド | インデックス及びバーコードを使用してアレイ上のリガンドを識別するための方法及び組成物 |
| WO2020097315A1 (en) | 2018-11-08 | 2020-05-14 | Cellular Research, Inc. | Whole transcriptome analysis of single cells using random priming |
| US11459607B1 (en) | 2018-12-10 | 2022-10-04 | 10X Genomics, Inc. | Systems and methods for processing-nucleic acid molecules from a single cell using sequential co-partitioning and composite barcodes |
| WO2020123384A1 (en) | 2018-12-13 | 2020-06-18 | Cellular Research, Inc. | Selective extension in single cell whole transcriptome analysis |
| US11845983B1 (en) | 2019-01-09 | 2023-12-19 | 10X Genomics, Inc. | Methods and systems for multiplexing of droplet based assays |
| IL281664B2 (en) | 2019-01-11 | 2024-07-01 | Illumina Cambridge Ltd | A complex bound to the surface of transposome complexes |
| WO2020154247A1 (en) | 2019-01-23 | 2020-07-30 | Cellular Research, Inc. | Oligonucleotides associated with antibodies |
| KR20210120820A (ko) | 2019-01-29 | 2021-10-07 | 일루미나, 인코포레이티드 | 플로우 셀 |
| WO2020159795A2 (en) | 2019-01-29 | 2020-08-06 | Illumina, Inc. | Sequencing kits |
| WO2020157684A1 (en) | 2019-01-29 | 2020-08-06 | Mgi Tech Co., Ltd. | High coverage stlfr |
| TW202100247A (zh) | 2019-01-29 | 2021-01-01 | 美商伊路米納有限公司 | 流通槽 |
| US11467153B2 (en) | 2019-02-12 | 2022-10-11 | 10X Genomics, Inc. | Methods for processing nucleic acid molecules |
| WO2020168013A1 (en) | 2019-02-12 | 2020-08-20 | 10X Genomics, Inc. | Methods for processing nucleic acid molecules |
| US11851683B1 (en) | 2019-02-12 | 2023-12-26 | 10X Genomics, Inc. | Methods and systems for selective analysis of cellular samples |
| EP3924504A1 (en) | 2019-02-14 | 2021-12-22 | Max-Planck-Gesellschaft zur Förderung der Wissenschaften e.V. | Haplotagging - haplotype phasing and single-tube combinatorial barcoding of nucleic acid molecules using bead-immobilized tn5 transposase |
| WO2020167920A1 (en) | 2019-02-14 | 2020-08-20 | Cellular Research, Inc. | Hybrid targeted and whole transcriptome amplification |
| US11655499B1 (en) | 2019-02-25 | 2023-05-23 | 10X Genomics, Inc. | Detection of sequence elements in nucleic acid molecules |
| EP3938537A1 (en) | 2019-03-11 | 2022-01-19 | 10X Genomics, Inc. | Systems and methods for processing optically tagged beads |
| JP2022530966A (ja) | 2019-04-30 | 2022-07-05 | エンコディア, インコーポレイテッド | 分析物を調製するための方法および関連キット |
| BR112021012751A2 (pt) | 2019-07-12 | 2021-12-14 | Illumina Cambridge Ltd | Preparação de biblioteca de ácidos nucleicos usando eletroforese |
| CN113260711A (zh) * | 2019-07-12 | 2021-08-13 | Illumina剑桥有限公司 | 使用固定在固体载体上的crispr/cas9制备核酸测序文库的组合物和方法 |
| WO2021011803A1 (en) | 2019-07-16 | 2021-01-21 | Omniome, Inc. | Synthetic nucleic acids having non-natural structures |
| EP4004231A1 (en) | 2019-07-22 | 2022-06-01 | Becton, Dickinson and Company | Single cell chromatin immunoprecipitation sequencing assay |
| US20220298545A1 (en) * | 2019-08-19 | 2022-09-22 | Universal Sequencing Technology Corporation | Methods and Compositions for Tracking Nucleic Acid Fragment Origin for Nucleic Acid Sequencing |
| US20210087613A1 (en) * | 2019-09-20 | 2021-03-25 | Illumina, Inc. | Methods and compositions for identifying ligands on arrays using indexes and barcodes |
| US20220389412A1 (en) * | 2019-10-25 | 2022-12-08 | Changping National Laboratory | Methylation detection and analysis of mammalian dna |
| WO2021092386A1 (en) | 2019-11-08 | 2021-05-14 | Becton Dickinson And Company | Using random priming to obtain full-length v(d)j information for immune repertoire sequencing |
| US11714848B2 (en) * | 2019-12-02 | 2023-08-01 | Illumina Cambridge Limited | Time-based cluster imaging of amplified contiguity-preserved library fragments of genomic DNA |
| CA3134746A1 (en) | 2019-12-19 | 2021-06-24 | Illumina, Inc. | High-throughput single-cell libraries and methods of making and of using |
| CN115244184A (zh) | 2020-01-13 | 2022-10-25 | 贝克顿迪金森公司 | 用于定量蛋白和rna的方法和组合物 |
| US20230081062A1 (en) * | 2020-02-12 | 2023-03-16 | Universal Sequencing Technology Corporation | Methods for intracellular barcoding and spatial barcoding |
| US11211144B2 (en) | 2020-02-18 | 2021-12-28 | Tempus Labs, Inc. | Methods and systems for refining copy number variation in a liquid biopsy assay |
| US11475981B2 (en) | 2020-02-18 | 2022-10-18 | Tempus Labs, Inc. | Methods and systems for dynamic variant thresholding in a liquid biopsy assay |
| US11211147B2 (en) | 2020-02-18 | 2021-12-28 | Tempus Labs, Inc. | Estimation of circulating tumor fraction using off-target reads of targeted-panel sequencing |
| US11851700B1 (en) | 2020-05-13 | 2023-12-26 | 10X Genomics, Inc. | Methods, kits, and compositions for processing extracellular molecules |
| WO2021231779A1 (en) | 2020-05-14 | 2021-11-18 | Becton, Dickinson And Company | Primers for immune repertoire profiling |
| US11932901B2 (en) | 2020-07-13 | 2024-03-19 | Becton, Dickinson And Company | Target enrichment using nucleic acid probes for scRNAseq |
| EP4232600A2 (en) * | 2020-10-21 | 2023-08-30 | Illumina, Inc. | Sequencing templates comprising multiple inserts and compositions and methods for improving sequencing throughput |
| US12084715B1 (en) | 2020-11-05 | 2024-09-10 | 10X Genomics, Inc. | Methods and systems for reducing artifactual antisense products |
| CN116635533A (zh) | 2020-11-20 | 2023-08-22 | 贝克顿迪金森公司 | 高表达的蛋白和低表达的蛋白的谱分析 |
| EP4298244A1 (en) | 2021-02-23 | 2024-01-03 | 10X Genomics, Inc. | Probe-based analysis of nucleic acids and proteins |
| CN112950101B (zh) * | 2021-05-13 | 2021-08-17 | 北京富通东方科技有限公司 | 一种基于产量预测的汽车工厂混流线排产方法 |
| US11753677B2 (en) | 2021-11-10 | 2023-09-12 | Encodia, Inc. | Methods for barcoding macromolecules in individual cells |
| EP4272764A1 (en) | 2022-05-03 | 2023-11-08 | Scipio Bioscience | Method of complexing biological units with particles |
| WO2023230551A2 (en) * | 2022-05-26 | 2023-11-30 | Illumina, Inc. | Preparation of long read nucleic acid libraries |
| WO2023239907A1 (en) * | 2022-06-09 | 2023-12-14 | The Regents Of The University Of California | Single cell co-sequencing of dna methylation and rna |
| WO2024089953A1 (ja) | 2022-10-27 | 2024-05-02 | 住友化学株式会社 | オリゴヌクレオチドの製造方法 |
| WO2024137703A1 (en) * | 2022-12-20 | 2024-06-27 | Illumina, Inc. | Multivalent assemblies for enhanced target hybridization |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20120053063A1 (en) | 2010-08-27 | 2012-03-01 | Illumina Cambridge Limited | Methods for sequencing polynucleotides |
| JP2013150611A (ja) | 2007-01-19 | 2013-08-08 | Epigenomics Ag | 細胞増殖性障害の検出のための方法及び核酸 |
| WO2013131962A1 (en) | 2012-03-06 | 2013-09-12 | Illumina Cambridge Limited | Improved methods of nucleic acid sequencing |
| JP2013535986A (ja) | 2010-08-27 | 2013-09-19 | ジェネンテック, インコーポレイテッド | 核酸の捕捉法および配列決定法 |
| JP2014506788A (ja) | 2011-02-02 | 2014-03-20 | ユニヴァーシティ・オブ・ワシントン・スルー・イッツ・センター・フォー・コマーシャリゼーション | 大量並列連続性マッピング |
| WO2014108810A2 (en) | 2013-01-09 | 2014-07-17 | Lumina Cambridge Limited | Sample preparation on a solid support |
| WO2014124338A1 (en) | 2013-02-08 | 2014-08-14 | 10X Technologies, Inc. | Polynucleotide barcode generation |
Family Cites Families (113)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA1323293C (en) | 1987-12-11 | 1993-10-19 | Keith C. Backman | Assay using template-dependent nucleic acid probe reorganization |
| GB8810400D0 (en) | 1988-05-03 | 1988-06-08 | Southern E | Analysing polynucleotide sequences |
| CA1341584C (en) | 1988-04-06 | 2008-11-18 | Bruce Wallace | Method of amplifying and detecting nucleic acid sequences |
| AU3539089A (en) | 1988-04-08 | 1989-11-03 | Salk Institute For Biological Studies, The | Ligase-based amplification method |
| EP0379559B1 (en) | 1988-06-24 | 1996-10-23 | Amgen Inc. | Method and reagents for detecting nucleic acid sequences |
| US5130238A (en) | 1988-06-24 | 1992-07-14 | Cangene Corporation | Enhanced nucleic acid amplification process |
| DE68926504T2 (de) | 1988-07-20 | 1996-09-12 | David Segev | Verfahren zur amplifizierung und zum nachweis von nukleinsäuresequenzen |
| US5185243A (en) | 1988-08-25 | 1993-02-09 | Syntex (U.S.A.) Inc. | Method for detection of specific nucleic acid sequences |
| CA2044616A1 (en) | 1989-10-26 | 1991-04-27 | Roger Y. Tsien | Dna sequencing |
| AU635105B2 (en) | 1990-01-26 | 1993-03-11 | Abbott Laboratories | Improved method of amplifying target nucleic acids applicable to both polymerase and ligase chain reactions |
| US5573907A (en) | 1990-01-26 | 1996-11-12 | Abbott Laboratories | Detecting and amplifying target nucleic acids using exonucleolytic activity |
| US5223414A (en) | 1990-05-07 | 1993-06-29 | Sri International | Process for nucleic acid hybridization and amplification |
| US5455166A (en) | 1991-01-31 | 1995-10-03 | Becton, Dickinson And Company | Strand displacement amplification |
| CA2182517C (en) | 1994-02-07 | 2001-08-21 | Theo Nikiforov | Ligase/polymerase-mediated primer extension of single nucleotide polymorphisms and its use in genetic analysis |
| US5677170A (en) | 1994-03-02 | 1997-10-14 | The Johns Hopkins University | In vitro transposition of artificial transposons |
| KR100230718B1 (ko) | 1994-03-16 | 1999-11-15 | 다니엘 엘. 캐시앙, 헨리 엘. 노르호프 | 등온 가닥 변위 핵산 증폭법 |
| US5552278A (en) | 1994-04-04 | 1996-09-03 | Spectragen, Inc. | DNA sequencing by stepwise ligation and cleavage |
| US5641658A (en) | 1994-08-03 | 1997-06-24 | Mosaic Technologies, Inc. | Method for performing amplification of nucleic acid with two primers bound to a single solid support |
| PT889120E (pt) | 1994-12-09 | 2002-09-30 | Microscience Ltd | Genes de virulencia no grupo vgc2 de salmonella |
| US5750341A (en) | 1995-04-17 | 1998-05-12 | Lynx Therapeutics, Inc. | DNA sequencing by parallel oligonucleotide extensions |
| US5965443A (en) | 1996-09-09 | 1999-10-12 | Wisconsin Alumni Research Foundation | System for in vitro transposition |
| US5925545A (en) | 1996-09-09 | 1999-07-20 | Wisconsin Alumni Research Foundation | System for in vitro transposition |
| GB9620209D0 (en) | 1996-09-27 | 1996-11-13 | Cemu Bioteknik Ab | Method of sequencing DNA |
| US5858671A (en) | 1996-11-01 | 1999-01-12 | The University Of Iowa Research Foundation | Iterative and regenerative DNA sequencing method |
| GB9626815D0 (en) | 1996-12-23 | 1997-02-12 | Cemu Bioteknik Ab | Method of sequencing DNA |
| AU6846698A (en) | 1997-04-01 | 1998-10-22 | Glaxo Group Limited | Method of nucleic acid amplification |
| AU6846798A (en) | 1997-04-01 | 1998-10-22 | Glaxo Group Limited | Method of nucleic acid sequencing |
| FI103809B (fi) | 1997-07-14 | 1999-09-30 | Finnzymes Oy | In vitro -menetelmä templaattien tuottamiseksi DNA-sekventointia varten |
| AR021833A1 (es) | 1998-09-30 | 2002-08-07 | Applied Research Systems | Metodos de amplificacion y secuenciacion de acido nucleico |
| US20010046669A1 (en) | 1999-02-24 | 2001-11-29 | Mccobmie William R. | Genetically filtered shotgun sequencing of complex eukaryotic genomes |
| US20050181440A1 (en) | 1999-04-20 | 2005-08-18 | Illumina, Inc. | Nucleic acid sequencing using microsphere arrays |
| US6355431B1 (en) | 1999-04-20 | 2002-03-12 | Illumina, Inc. | Detection of nucleic acid amplification reactions using bead arrays |
| US6274320B1 (en) | 1999-09-16 | 2001-08-14 | Curagen Corporation | Method of sequencing a nucleic acid |
| US7244559B2 (en) | 1999-09-16 | 2007-07-17 | 454 Life Sciences Corporation | Method of sequencing a nucleic acid |
| BR0015382B1 (pt) | 1999-11-08 | 2014-04-29 | Eiken Chemical | Processos e kits para sintetizacao e amplificação do acido nucleico bem como, processos para detectar uma sequencia de nucleotideo alvo e de uma mutacao da dita sequencia |
| US7955794B2 (en) | 2000-09-21 | 2011-06-07 | Illumina, Inc. | Multiplex nucleic acid reactions |
| US7582420B2 (en) | 2001-07-12 | 2009-09-01 | Illumina, Inc. | Multiplex nucleic acid reactions |
| US7611869B2 (en) | 2000-02-07 | 2009-11-03 | Illumina, Inc. | Multiplexed methylation detection methods |
| US7001792B2 (en) | 2000-04-24 | 2006-02-21 | Eagle Research & Development, Llc | Ultra-fast nucleic acid sequencing device and a method for making and using the same |
| EP1290225A4 (en) | 2000-05-20 | 2004-09-15 | Univ Michigan | METHOD FOR PRODUCING A DNA BANK BY POSITIONAL REPRODUCTION |
| CN101525660A (zh) | 2000-07-07 | 2009-09-09 | 维西根生物技术公司 | 实时序列测定 |
| US6846658B1 (en) | 2000-10-12 | 2005-01-25 | New England Biolabs, Inc. | Method for cloning and producing the Msel restriction endonuclease |
| EP1354064A2 (en) | 2000-12-01 | 2003-10-22 | Visigen Biotechnologies, Inc. | Enzymatic nucleic acid synthesis: compositions and methods for altering monomer incorporation fidelity |
| AR031640A1 (es) | 2000-12-08 | 2003-09-24 | Applied Research Systems | Amplificacion isotermica de acidos nucleicos en un soporte solido |
| US20040110191A1 (en) | 2001-01-31 | 2004-06-10 | Winkler Matthew M. | Comparative analysis of nucleic acids using population tagging |
| US7138267B1 (en) | 2001-04-04 | 2006-11-21 | Epicentre Technologies Corporation | Methods and compositions for amplifying DNA clone copy number |
| US6777187B2 (en) | 2001-05-02 | 2004-08-17 | Rubicon Genomics, Inc. | Genome walking by selective amplification of nick-translate DNA library and amplification from complex mixtures of templates |
| GB0115194D0 (en) | 2001-06-21 | 2001-08-15 | Leuven K U Res & Dev | Novel technology for genetic mapping |
| US7057026B2 (en) | 2001-12-04 | 2006-06-06 | Solexa Limited | Labelled nucleotides |
| US7399590B2 (en) | 2002-02-21 | 2008-07-15 | Asm Scientific, Inc. | Recombinase polymerase amplification |
| US20040002090A1 (en) | 2002-03-05 | 2004-01-01 | Pascal Mayer | Methods for detecting genome-wide sequence variations associated with a phenotype |
| DK3363809T3 (da) | 2002-08-23 | 2020-05-04 | Illumina Cambridge Ltd | Modificerede nukleotider til polynukleotidsekvensering |
| US7595883B1 (en) | 2002-09-16 | 2009-09-29 | The Board Of Trustees Of The Leland Stanford Junior University | Biological analysis arrangement and approach therefor |
| WO2004042078A1 (en) | 2002-11-05 | 2004-05-21 | The University Of Queensland | Nucleotide sequence analysis by quantification of mutagenesis |
| US7575865B2 (en) | 2003-01-29 | 2009-08-18 | 454 Life Sciences Corporation | Methods of amplifying and sequencing nucleic acids |
| JP2006517104A (ja) | 2003-02-10 | 2006-07-20 | マックス−デルブルック−セントラム フユール モレクラーレ メディツィン(エムディーシー) | トランスポゾンに基づく標的化システム |
| US20050053980A1 (en) | 2003-06-20 | 2005-03-10 | Illumina, Inc. | Methods and compositions for whole genome amplification and genotyping |
| WO2005042781A2 (en) | 2003-10-31 | 2005-05-12 | Agencourt Personal Genomics Corporation | Methods for producing a paired tag from a nucleic acid sequence and methods of use thereof |
| US20110059865A1 (en) | 2004-01-07 | 2011-03-10 | Mark Edward Brennan Smith | Modified Molecular Arrays |
| US7595160B2 (en) | 2004-01-13 | 2009-09-29 | U.S. Genomics, Inc. | Analyte detection using barcoded polymers |
| US7727744B2 (en) | 2004-03-30 | 2010-06-01 | Epicentre Technologies Corporation | Methods for obtaining directionally truncated polypeptides |
| WO2006047183A2 (en) | 2004-10-21 | 2006-05-04 | New England Biolabs, Inc. | Recombinant dna nicking endonuclease and uses thereof |
| US7319142B1 (en) | 2004-08-31 | 2008-01-15 | Monsanto Technology Llc | Nucleotide and amino acid sequences from Xenorhabdus and uses thereof |
| EP1790202A4 (en) | 2004-09-17 | 2013-02-20 | Pacific Biosciences California | APPARATUS AND METHOD FOR ANALYZING MOLECULES |
| US7449297B2 (en) | 2005-04-14 | 2008-11-11 | Euclid Diagnostics Llc | Methods of copying the methylation pattern of DNA during isothermal amplification and microarrays |
| US7601499B2 (en) | 2005-06-06 | 2009-10-13 | 454 Life Sciences Corporation | Paired end sequencing |
| CA2611671C (en) | 2005-06-15 | 2013-10-08 | Callida Genomics, Inc. | Single molecule arrays for genetic and chemical analysis |
| US7405281B2 (en) | 2005-09-29 | 2008-07-29 | Pacific Biosciences Of California, Inc. | Fluorescent nucleotide analogs and uses therefor |
| GB0522310D0 (en) | 2005-11-01 | 2005-12-07 | Solexa Ltd | Methods of preparing libraries of template polynucleotides |
| US20070128610A1 (en) | 2005-12-02 | 2007-06-07 | Buzby Philip R | Sample preparation method and apparatus for nucleic acid sequencing |
| WO2007087312A2 (en) | 2006-01-23 | 2007-08-02 | Population Genetics Technologies Ltd. | Molecular counting |
| EP2021503A1 (en) | 2006-03-17 | 2009-02-11 | Solexa Ltd. | Isothermal methods for creating clonal single molecule arrays |
| CA2648149A1 (en) | 2006-03-31 | 2007-11-01 | Solexa, Inc. | Systems and devices for sequence by synthesis analysis |
| EP2038429B1 (en) | 2006-06-30 | 2013-08-21 | Nugen Technologies, Inc. | Methods for fragmentation and labeling of nucleic acids |
| US7754429B2 (en) | 2006-10-06 | 2010-07-13 | Illumina Cambridge Limited | Method for pair-wise sequencing a plurity of target polynucleotides |
| EP2089517A4 (en) | 2006-10-23 | 2010-10-20 | Pacific Biosciences California | POLYMERASEENZYME AND REAGENTS FOR ADVANCED NUCKIC ACID SEQUENCING |
| US20090088331A1 (en) | 2006-11-07 | 2009-04-02 | Government Of The United States Of America, As Represented By The Secretary, Dept. Of Health And | Influenza virus nucleic acid microarray and method of use |
| US20080242560A1 (en) | 2006-11-21 | 2008-10-02 | Gunderson Kevin L | Methods for generating amplified nucleic acid arrays |
| US8262900B2 (en) | 2006-12-14 | 2012-09-11 | Life Technologies Corporation | Methods and apparatus for measuring analytes using large scale FET arrays |
| US8349167B2 (en) | 2006-12-14 | 2013-01-08 | Life Technologies Corporation | Methods and apparatus for detecting molecular interactions using FET arrays |
| EP2653861B1 (en) | 2006-12-14 | 2014-08-13 | Life Technologies Corporation | Method for sequencing a nucleic acid using large-scale FET arrays |
| AU2008276308A1 (en) | 2007-07-13 | 2009-01-22 | The Board Of Trustees Of The Leland Stanford Junior University | Method and apparatus using electric field for improved biological assays |
| CN101802223A (zh) | 2007-08-15 | 2010-08-11 | 香港大学 | 用于高通量亚硫酸氢盐dna-测序的方法和组合物及其用途 |
| US8415099B2 (en) | 2007-11-05 | 2013-04-09 | Complete Genomics, Inc. | Efficient base determination in sequencing reactions |
| US8852864B2 (en) | 2008-01-17 | 2014-10-07 | Sequenom Inc. | Methods and compositions for the analysis of nucleic acids |
| US20090325169A1 (en) | 2008-04-30 | 2009-12-31 | Integrated Dna Technologies, Inc. | Rnase h-based assays utilizing modified rna monomers |
| KR20110025993A (ko) | 2008-06-30 | 2011-03-14 | 바이오나노매트릭스, 인크. | 단일-분자 전체 게놈 분석용 장치 및 방법 |
| US8383345B2 (en) | 2008-09-12 | 2013-02-26 | University Of Washington | Sequence tag directed subassembly of short sequencing reads into long sequencing reads |
| US20100137143A1 (en) | 2008-10-22 | 2010-06-03 | Ion Torrent Systems Incorporated | Methods and apparatus for measuring analytes |
| US9080211B2 (en) | 2008-10-24 | 2015-07-14 | Epicentre Technologies Corporation | Transposon end compositions and methods for modifying nucleic acids |
| EP2508529B1 (en) * | 2008-10-24 | 2013-08-28 | Epicentre Technologies Corporation | Transposon end compositions and methods for modifying nucleic acids |
| US20110311506A1 (en) | 2009-02-25 | 2011-12-22 | The Johns Hopkins University | Piggybac transposon variants and methods of use |
| WO2010115122A2 (en) | 2009-04-03 | 2010-10-07 | Illumina, Inc. | Generation of uniform fragments of nucleic acids using patterned substrates |
| WO2011106314A2 (en) | 2010-02-25 | 2011-09-01 | Advanced Liquid Logic, Inc. | Method of making nucleic acid libraries |
| DK2625320T3 (da) * | 2010-10-08 | 2019-07-01 | Harvard College | High-throughput enkeltcellestregkodning |
| WO2012058096A1 (en) | 2010-10-27 | 2012-05-03 | Illumina, Inc. | Microdevices and biosensor cartridges for biological or chemical analysis and systems and methods for the same |
| US9074251B2 (en) | 2011-02-10 | 2015-07-07 | Illumina, Inc. | Linking sequence reads using paired code tags |
| US8829171B2 (en) * | 2011-02-10 | 2014-09-09 | Illumina, Inc. | Linking sequence reads using paired code tags |
| EP2635679B1 (en) | 2010-11-05 | 2017-04-19 | Illumina, Inc. | Linking sequence reads using paired code tags |
| US8951781B2 (en) | 2011-01-10 | 2015-02-10 | Illumina, Inc. | Systems, methods, and apparatuses to image a sample for biological or chemical analysis |
| ES2568910T3 (es) | 2011-01-28 | 2016-05-05 | Illumina, Inc. | Reemplazo de oligonucleótidos para bibliotecas etiquetadas en dos extremos y direccionadas |
| WO2012108864A1 (en) | 2011-02-08 | 2012-08-16 | Illumina, Inc. | Selective enrichment of nucleic acids |
| WO2012149042A2 (en) | 2011-04-25 | 2012-11-01 | Bio-Rad Laboratories, Inc. | Methods and compositions for nucleic acid analysis |
| US20130017978A1 (en) | 2011-07-11 | 2013-01-17 | Finnzymes Oy | Methods and transposon nucleic acids for generating a dna library |
| AU2013232131B2 (en) | 2012-03-13 | 2018-09-20 | Integrated Dna Technologies, Inc. | Methods and compositions for size-controlled homopolymer tailing of substrate polynucleotides by a nucleic acid polymerase |
| CN104736722B (zh) | 2012-05-21 | 2018-08-07 | 斯克利普斯研究所 | 样品制备方法 |
| US9012022B2 (en) | 2012-06-08 | 2015-04-21 | Illumina, Inc. | Polymer coatings |
| US8895249B2 (en) | 2012-06-15 | 2014-11-25 | Illumina, Inc. | Kinetic exclusion amplification of nucleic acid libraries |
| US9644199B2 (en) | 2012-10-01 | 2017-05-09 | Agilent Technologies, Inc. | Immobilized transposase complexes for DNA fragmentation and tagging |
| CN105074010B (zh) | 2013-03-07 | 2018-04-17 | 积水医疗株式会社 | 甲基化dna 的检测方法 |
| DK3553175T3 (da) * | 2013-03-13 | 2021-08-23 | Illumina Inc | Fremgangsmåde til fremstilling af et nukleinsyresekvenseringsbibliotek |
| KR102536833B1 (ko) | 2013-08-28 | 2023-05-26 | 벡톤 디킨슨 앤드 컴퍼니 | 대량의 동시 단일 세포 분석 |
| CN114717291A (zh) | 2013-12-30 | 2022-07-08 | 阿特雷卡公司 | 使用核酸条形码分析与单细胞缔合的核酸 |
-
2015
- 2015-10-16 KR KR1020227041250A patent/KR102643955B1/ko active IP Right Grant
- 2015-10-16 RU RU2019138705A patent/RU2736728C2/ru active
- 2015-10-16 CA CA2964799A patent/CA2964799A1/en active Pending
- 2015-10-16 SG SG10201903408VA patent/SG10201903408VA/en unknown
- 2015-10-16 RU RU2017116989A patent/RU2709655C2/ru active
- 2015-10-16 IL IL299976A patent/IL299976B1/en unknown
- 2015-10-16 SG SG11201703139VA patent/SG11201703139VA/en unknown
- 2015-10-16 WO PCT/US2015/056040 patent/WO2016061517A2/en active Application Filing
- 2015-10-16 JP JP2017520884A patent/JP6808617B2/ja active Active
- 2015-10-16 AU AU2015331739A patent/AU2015331739B2/en active Active
- 2015-10-16 BR BR122021026779-0A patent/BR122021026779B1/pt active IP Right Grant
- 2015-10-16 BR BR122021026781-2A patent/BR122021026781B1/pt active IP Right Grant
- 2015-10-16 KR KR1020177013242A patent/KR102472027B1/ko active IP Right Grant
- 2015-10-16 US US15/519,482 patent/US11873480B2/en active Active
-
2017
- 2017-04-13 IL IL251737A patent/IL251737B/en unknown
-
2018
- 2018-10-29 US US16/173,202 patent/US20190048332A1/en not_active Abandoned
-
2020
- 2020-12-09 JP JP2020204004A patent/JP7127104B2/ja active Active
-
2021
- 2021-11-04 IL IL287853A patent/IL287853B2/en unknown
-
2022
- 2022-02-22 AU AU2022201205A patent/AU2022201205A1/en active Pending
- 2022-04-12 US US17/719,276 patent/US20220282242A1/en active Pending
- 2022-08-17 JP JP2022129859A patent/JP7532455B2/ja active Active
Patent Citations (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2013150611A (ja) | 2007-01-19 | 2013-08-08 | Epigenomics Ag | 細胞増殖性障害の検出のための方法及び核酸 |
| US20120053063A1 (en) | 2010-08-27 | 2012-03-01 | Illumina Cambridge Limited | Methods for sequencing polynucleotides |
| JP2013535986A (ja) | 2010-08-27 | 2013-09-19 | ジェネンテック, インコーポレイテッド | 核酸の捕捉法および配列決定法 |
| JP2014506788A (ja) | 2011-02-02 | 2014-03-20 | ユニヴァーシティ・オブ・ワシントン・スルー・イッツ・センター・フォー・コマーシャリゼーション | 大量並列連続性マッピング |
| WO2013131962A1 (en) | 2012-03-06 | 2013-09-12 | Illumina Cambridge Limited | Improved methods of nucleic acid sequencing |
| WO2014108810A2 (en) | 2013-01-09 | 2014-07-17 | Lumina Cambridge Limited | Sample preparation on a solid support |
| JP2016508715A (ja) | 2013-01-09 | 2016-03-24 | イルミナ ケンブリッジ リミテッド | 固形支持体でのサンプル調製 |
| WO2014124338A1 (en) | 2013-02-08 | 2014-08-14 | 10X Technologies, Inc. | Polynucleotide barcode generation |
| US20140235506A1 (en) | 2013-02-08 | 2014-08-21 | 10X Technologies, Inc. | Polynucleotide barcode generation |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7532455B2 (ja) | 連続性を維持した転位 | |
| US11584959B2 (en) | Compositions and methods for selection of nucleic acids | |
| CN107969137B (zh) | 接近性保留性转座 | |
| AU2015296029A1 (en) | Tagging nucleic acids for sequence assembly | |
| US11807896B2 (en) | Physical linkage preservation in DNA storage | |
| AU2018256358B2 (en) | Nucleic acid characteristics as guides for sequence assembly | |
| AU2021411520A1 (en) | Methods and compositions for sequencing library preparation | |
| BR112017007912B1 (pt) | Transposon de preservação de contiguidade |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20220914 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20220914 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20230905 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20231204 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20240206 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20240425 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20240702 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20240731 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7532455 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |