JP2005538428A - 日本語仮想辞書 - Google Patents
日本語仮想辞書 Download PDFInfo
- Publication number
- JP2005538428A JP2005538428A JP2003531361A JP2003531361A JP2005538428A JP 2005538428 A JP2005538428 A JP 2005538428A JP 2003531361 A JP2003531361 A JP 2003531361A JP 2003531361 A JP2003531361 A JP 2003531361A JP 2005538428 A JP2005538428 A JP 2005538428A
- Authority
- JP
- Japan
- Prior art keywords
- character string
- string
- character
- dictionary
- target
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000000034 method Methods 0.000 claims abstract description 105
- 238000006243 chemical reaction Methods 0.000 claims description 42
- 238000012545 processing Methods 0.000 claims description 11
- 230000003993 interaction Effects 0.000 claims description 10
- 230000000877 morphologic effect Effects 0.000 claims description 8
- 230000009466 transformation Effects 0.000 claims description 5
- 238000013519 translation Methods 0.000 claims description 4
- 238000010586 diagram Methods 0.000 description 13
- 235000016496 Panda oleosa Nutrition 0.000 description 10
- 240000000220 Panda oleosa Species 0.000 description 10
- 239000002245 particle Substances 0.000 description 5
- 230000008569 process Effects 0.000 description 5
- 238000011156 evaluation Methods 0.000 description 3
- 238000004364 calculation method Methods 0.000 description 2
- 238000007796 conventional method Methods 0.000 description 2
- 230000002093 peripheral effect Effects 0.000 description 2
- 241000699670 Mus sp. Species 0.000 description 1
- 238000005273 aeration Methods 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 235000021268 hot food Nutrition 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
Images











Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/40—Processing or translation of natural language
- G06F40/53—Processing of non-Latin text
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Health & Medical Sciences (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- Document Processing Apparatus (AREA)
- Machine Translation (AREA)
- Character Discrimination (AREA)
Abstract
Description
入力: inthehouse
出力1: INTHEHOUSE
出力2: i NTHEHOUSE
出力3: in THEHOUSE
出力4: int HEHOUSE
出力5: inth EHOUSE
出力6: inthe HOUSE − (正しい候補)
出力7: intheh OUSE
出力8: intheho USE
出力9: inthehou SE
出力10: inthehous E
出力11: inthehouse
上で説明したように、この変換方法では、ユーザが、入力テキストの訂正される部分を選択した後に多数の候補が生成される。それは、その候補中に正しい選択肢が含まれる場合であっても、最終的な選択での混乱につながる可能性がある。もう1つの変換方法では、接尾辞を認識できるアナライザが用いられる。このアナライザは、末尾からの範囲を、それ以上接尾辞を見つけられなくなるまで分析する。しかし、普通の方法では、正確な結果を達成するために、ユーザが対話する必要があり、これによって、潜在的に効率が低い。
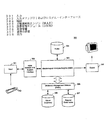
図1Aは、平仮名文字、片仮名文字、および漢字文字を含む日本語文字の例を示す図である。
図1Bは、平仮名テキストを日本語テキストに変換する変換方法を示す図である。
図2は、本発明と共に使用することができるコンピュータ・システムを示す図である。
図3は、本発明の仮名漢字変換システムの一実施形態を示す図である。
図4は、本発明の一実施形態によって使用される片仮名文字のコスト値の計算の例を示す図である。
図5は、本発明のユーザ対話を伴う仮名漢字変換システムのもう1つの例を示す図である。
図6Aは、本発明の平仮名文字セットから片仮名文字セットへの変換処理の実施形態を示す図である。
図6Bは、本発明の例に対する普通の方法の処理を示す図である。
図7は、本発明の平仮名文字を片仮名文字に変換する方法を示す図である。
図8は、本発明の平仮名文字セットから片仮名文字セットへの変換処理のもう1つの実施形態を示す図である。
図9A、9Bは、本発明の平仮名文字から片仮名文字への変換のもう1つの方法を示す図である。
A−Ka−Ma−I POS:名詞、優先順位:100
A−Ka−Ma−I POS:動詞として働くことができる名詞、優先順位:100
A−Ka−Ma−I POS:形容詞、優先順位:100
他の実装が可能である。
コスト値1=f1+f2+f3+c1+c2
である。同様に、第2の選択は、
コスト値2=fa+f3+ca
のコスト値を有する。一実施形態では、コスト値は、意味論的要因または文法的要因を含む。評価ユニット303によって、2つの選択のコスト値が評価され、最小のコスト値、この例ではコスト値2を有する選択が変換の最終出力として選択される。
Claims (117)
- ソース文字列をターゲット文字列に変換する機械で実施される方法であって、
前記ソース文字列を有する第1文字列を受け取ることと、
前記第1文字列を複数の部分列に分割することと、
前記複数の部分列を辞書を介して第2文字列に変換することと、
前記複数の部分列に対応する第3文字列を作成することと、
前記第2文字列と前記第3文字列を分析することと、
前記分析に基づいて、前記第2文字列と前記第3文字列から第4文字列を構成することと、
前記第4文字列に基づいて候補リストを作成することと、
前記候補リストから前記ターゲット文字列を選択することと、
前記ターゲット文字列を出力することと
を含む方法。 - 前記第1文字列が日本語平仮名文字を含み、前記辞書が前記受取の前に機械読取可能な形で格納されている請求項1に記載の方法。
- 前記第2文字列が日本語単語を含む請求項1に記載の方法。
- 前記第3文字列が片仮名文字を含む請求項1に記載の方法。
- 前記第2文字列が前記第1文字列に対応する文字列を含む場合に、前記第2文字列から前記第4文字列を構成することと、
前記第2文字列が前記第1文字列に対応する文字列を含まない場合に、前記第3文字列から前記第4文字列を構成することと
をさらに含む請求項1に記載の方法。 - 前記第2文字列と前記第3文字列に関連する優先順位情報に基づいて、前記第2文字列と前記第3文字列に優先順位を付けることをさらに含む請求項1に記載の方法。
- 前記優先順位情報が、
前記第2文字列のそれぞれの使用頻度と、
文字セグメント長と、
前記第2文字列の間の接続関係情報と
を含む請求項6に記載の方法。 - 前記優先順位情報に基づいて、前記第2文字列と前記第3文字列のそれぞれの優先順位値を計算することをさらに含む請求項6に記載の方法。
- 前記辞書から前記第2文字列の優先順位情報を検索することをさらに含む請求項1に記載の方法。
- 前記辞書が複数の辞書を含む請求項1に記載の方法。
- 前記第2文字列と前記第3文字列の前記分析が規則の組に基づいて実行される請求項1に記載の方法。
- 前記規則の組が、前記文字列の使用頻度と前記文字列の間の接続関係の情報を含む請求項11に記載の方法。
- 前記規則の組が、文字セグメント長と意味論的/文法的規則の情報をさらに含む請求項12に記載の方法。
- 前記第2文字列と前記第3文字列からの前記第4文字列の前記構成が前記規則の組に基づく請求項11に記載の方法。
- 前記第4文字列のそれぞれの優先順位値を計算することをさらに含む請求項1に記載の方法。
- 前記候補リストが、前記第4文字列の前記優先順位値に基づいて作成される請求項15に記載の方法。
- 最高の優先順位値を有する候補が、前記候補リストからの前記ターゲット文字列として選択される請求項16に記載の方法。
- 前記ターゲット文字列が正しいかどうかを判定するために、前記ターゲット文字列の前記出力を検査することと、
前記出力が正しくない場合に、代替文字列の候補リストを検索することと、
前記候補リストから最終出力として文字列を選択することと
をさらに含む請求項1に記載の方法。 - ユーザが前記ターゲット文字列の前記出力を検査する請求項18に記載の方法。
- 前記候補リストをユーザ・インターフェースに表示することをさらに含む請求項18に記載の方法。
- 前記候補リストから最終出力としての文字列をユーザが選択する請求項18に記載の方法。
- 前記候補リストからの前記最終出力の前記選択に基づいて、最終出力文字列の前記優先順位情報に関してデータベースを更新することをさらに含む請求項18に記載の方法。
- 前記ユーザ・インターフェースがポップアップ・ウィンドウを含む請求項20に記載の方法。
- 前記候補リストが正しいターゲット文字列を含まない場合に、前記方法が、さらに、
ユーザによって前記ターゲット文字列を供給することと、
前記第1文字列を前記ターゲット文字列に手動で変換することと、
前記ユーザによって供給された前記ターゲット文字列をデータベースに格納することと
を含む請求項18に記載の方法。 - 前記ターゲット文字列が前記ユーザによってユーザ・インターフェースを介して入力される請求項24に記載の方法。
- 前記規則の組がユーザによってユーザ・インターフェースを介して定義される請求項11に記載の方法。
- 前記第3文字列の前記作成がルックアップ・テーブルを介して実行される請求項1に記載の方法。
- 前記第3文字列の前記作成がアルゴリズムを介して実行される請求項1に記載の方法。
- 前記第3文字列のそれぞれに優先順位値を割り当てることをさらに含む請求項8に記載の方法。
- 前記第3文字列の前記優先順位が前記第2文字列の前記優先順位より低い請求項29に記載の方法。
- 第1日本語文字入力列を第2日本語文字列に変換するデータ処理システムで実施される方法であって、
平仮名入力を受け取ることと、
前記平仮名入力に基づいて、複数の可能な片仮名候補を自動的に判定することと、
前記平仮名入力を片仮名文字に変換するために前記複数の可能な片仮名候補を分析することと、
前記分析に応答して前記片仮名候補の1つを選択することと、
前記片仮名候補の前記1つを含む変換されたテキストを出力することと
を含む方法。 - 前記変換されたテキストが、さらに、漢字文字を含む請求項31に記載の方法。
- ソース文字列をターゲット文字列に変換する装置であって、
前記ソース文字列を有する第1文字列を受け取る手段と、
前記第1文字列を複数の部分列に分割する手段と、
前記複数の部分列を辞書を介して第2文字列に変換する手段と、
前記複数の部分列に対応する第3文字列を作成する手段と、
前記第2文字列と前記第3文字列を分析する手段と、
前記分析に基づいて、前記第2文字列と前記第3文字列から第4文字列を構成する手段と、
前記第4文字列に基づいて候補リストを作成する手段と、
前記候補リストから前記ターゲット文字列を選択する手段と、
前記ターゲット文字列を出力する手段と
を含む装置。 - 前記第1文字列が日本語平仮名文字を含み、前記辞書が前記受取の前に機械読取可能な形で格納されている請求項33に記載の装置。
- 前記第2文字列が日本語単語を含む請求項33に記載の装置。
- 前記第3文字列が片仮名文字を含む請求項33に記載の装置。
- 前記第2文字列が前記第1文字列に対応する文字列を含む場合に、前記第2文字列から前記第4文字列を構成する手段と、
前記第2文字列が前記第1文字列に対応する文字列を含まない場合に、前記第3文字列から前記第4文字列を構成する手段と
をさらに含む請求項33に記載の装置。 - 前記第2文字列と前記第3文字列に関連する優先順位情報に基づいて、前記第2文字列と前記第3文字列に優先順位を付ける手段をさらに含む請求項33に記載の装置。
- 前記優先順位情報が、
前記第2文字列のそれぞれの使用頻度と、
文字セグメント長と、
前記第2文字列の間の接続関係情報と
を含む請求項38に記載の装置。 - 前記優先順位情報に基づいて、前記第2文字列と前記第3文字列のそれぞれの優先順位値を計算する手段をさらに含む請求項39に記載の装置。
- 前記辞書から前記第2文字列の優先順位情報を検索する手段をさらに含む請求項33に記載の装置。
- 前記辞書が複数の辞書を含む請求項33に記載の装置。
- 前記第2文字列と前記第3文字列の前記分析が規則の組に基づいて実行される請求項33に記載の装置。
- 前記規則の組が前記文字列の使用頻度と前記文字列の間の接続関係の情報を含む請求項43に記載の装置。
- 前記規則の組が文字セグメント長と意味論的/文法的規則の情報をさらに含む請求項44に記載の装置。
- 前記第2文字列と前記第3文字列からの前記第4文字列の前記構成が前記規則の組に基づく請求項43に記載の装置。
- 前記第4文字列のそれぞれの優先順位値を計算する手段をさらに含む請求項33に記載の装置。
- 前記候補リストが前記第4文字列の前記優先順位値に基づいて作成される請求項47に記載の装置。
- 最高の優先順位値を有する候補が前記候補リストからの前記ターゲット文字列として選択される請求項48に記載の装置。
- 前記ターゲット文字列が正しいかどうかを判定するために、前記ターゲット文字列の前記出力を検査する手段と、
前記出力が正しくない場合に、代替文字列の候補リストを検索する手段と、
前記候補リストから最終出力として文字列を選択する手段と
をさらに含む請求項33に記載の装置。 - ユーザが前記ターゲット文字列の前記出力を検査する請求項50に記載の装置。
- 前記候補リストをユーザ・インターフェースに表示する手段をさらに含む請求項50に記載の装置。
- 前記候補リストから、最終出力としての文字列をユーザが選択する請求項50に記載の装置。
- 前記候補リストからの前記最終出力の前記選択に基づいて、最終出力文字列の前記優先順位情報に関してデータベースを更新する手段をさらに含む請求項50に記載の装置。
- 前記ユーザ・インターフェースがポップアップ・ウィンドウを含む請求項52に記載の装置。
- 前記候補リストが正しいターゲット文字列を含まない場合に、前記装置が、さらに、
ユーザによって前記ターゲット文字列を供給する手段と、
前記第1文字列を前記ターゲット文字列に手動で変換する手段と、
前記ユーザによって供給された前記ターゲット文字列をデータベースに格納する手段と
を含む請求項50に記載の装置。 - 前記ターゲット文字列が前記ユーザによってユーザ・インターフェースを介して入力される請求項56に記載の装置。
- 前記規則の組がユーザによってユーザ・インターフェースを介して定義される請求項43に記載の装置。
- 前記第3文字列の前記作成がルックアップ・テーブルを介して実行される請求項33に記載の装置。
- 前記第3文字列の作成がアルゴリズムを介して実行される請求項33に記載の装置。
- 前記第3文字列のそれぞれに優先順位値を割り当てる手段をさらに含む請求項40に記載の装置。
- 前記第3文字列の前記優先順位が前記第2文字列の前記優先順位より低い請求項61に記載の装置。
- 第1日本語文字入力列を第2日本語文字列に変換する装置であって、
平仮名入力を受け取る手段と、
前記平仮名入力に基づいて、複数の可能な片仮名候補を自動的に判定する手段と、
前記平仮名入力を片仮名文字に変換するために前記複数の可能な片仮名候補を分析する手段と、
前記分析に応答して前記片仮名候補の1つを選択する手段と、
前記片仮名候補の前記1つを含む変換されたテキストを出力することと
を含む装置。 - 前記変換されたテキストが、さらに、漢字文字を含む請求項63に記載の装置。
- ソース文字列をターゲット文字列に変換する方法を機械に実行させる実行可能コードを格納する機械可読媒体であって、その方法が、
前記ソース文字列を有する第1文字列を受け取ることと、
前記第1文字列を複数の部分列に分割することと、
前記複数の部分列を辞書を介して第2文字列に変換することと、
前記複数の部分列に対応する第3文字列を作成することと、
前記第2文字列と前記第3文字列を分析することと、
前記分析に基づいて、前記第2文字列と前記第3文字列から第4文字列を構成することと、
前記第4文字列に基づいて候補リストを作成することと、
前記候補リストから前記ターゲット文字列を選択することと、
前記ターゲット文字列を出力することと
を含む機械可読媒体。 - 前記第1文字列が日本語平仮名文字を含み、前記辞書が前記受取の前に機械読取可能な形で格納されている請求項65に記載の機械可読媒体。
- 前記第2文字列が日本語単語を含む請求項65に記載の機械可読媒体。
- 前記第3文字列が片仮名文字を含む請求項65に記載の機械可読媒体。
- 前記方法が、
前記第2文字列が前記第1文字列に対応する文字列を含む場合に、前記第2文字列から前記第4文字列を構成することと、
前記第2文字列が前記第1文字列に対応する文字列を含まない場合に、前記第3文字列から前記第4文字列を構成することと
をさらに含む請求項65に記載の機械可読媒体。 - 前記方法が、前記第2文字列と前記第3文字列に関連する優先順位情報に基づいて、前記第2文字列と前記第3文字列に優先順位を付けることをさらに含む請求項65に記載の機械可読媒体。
- 前記優先順位情報が、
前記第2文字列のそれぞれの使用頻度と、
文字セグメント長と、
前記第2文字列の間の接続関係情報と
を含む請求項70に記載の機械可読媒体。 - 前記方法が、前記優先順位情報に基づいて、前記第2文字列と前記第3文字列のそれぞれの優先順位値を計算することをさらに含む請求項70に記載の機械可読媒体。
- 前記方法が前記辞書から前記第2文字列の優先順位情報を検索することをさらに含む請求項65に記載の機械可読媒体。
- 前記辞書が複数の辞書を含む請求項65に記載の機械可読媒体。
- 前記第2文字列と前記第3文字列の前記分析が規則の組に基づいて実行される請求項65に記載の機械可読媒体。
- 前記規則の組が、前記文字列の使用頻度と前記文字列の間の接続関係の情報を含む請求項75に記載の機械可読媒体。
- 前記規則の組が文字セグメント長と意味論的/文法的規則の情報をさらに含む請求項76に記載の機械可読媒体。
- 前記第2文字列と前記第3文字列からの前記第4文字列の前記構成が前記規則の組に基づく請求項75に記載の機械可読媒体。
- 前記方法が、前記第4文字列のそれぞれの優先順位値を計算することをさらに含む請求項65に記載の機械可読媒体。
- 前記候補リストが、前記第4文字列の前記優先順位値に基づいて作成される請求項79に記載の機械可読媒体。
- 最高の優先順位値を有する候補が前記候補リストからの前記ターゲット文字列として選択される請求項80に記載の機械可読媒体。
- 前記方法が、
前記ターゲット文字列が正しいかどうかを判定するために、前記ターゲット文字列の前記出力を検査することと、
前記出力が正しくない場合に、代替文字列の候補リストを検索することと、
前記候補リストから最終出力として文字列を選択することと
をさらに含む請求項65に記載の機械可読媒体。 - ユーザが、前記ターゲット文字列の前記出力を検査する請求項82に記載の機械可読媒体。
- 前記方法が、前記候補リストをユーザ・インターフェースに表示することをさらに含む請求項82に記載の機械可読媒体。
- ユーザが、前記候補リストから、最終出力としての文字列を選択する請求項82に記載の機械可読媒体。
- 前記方法が、前記候補リストからの前記最終出力の前記選択に基づいて、最終出力文字列の前記優先順位情報に関してデータベースを更新することをさらに含む請求項82に記載の機械可読媒体。
- 前記ユーザ・インターフェースがポップアップ・ウィンドウを含む請求項84に記載の機械可読媒体。
- 前記候補リストが正しいターゲット文字列を含まない場合に、前記方法が、さらに、
ユーザによって前記ターゲット文字列を供給することと、
前記第1文字列を前記ターゲット文字列に手動で変換することと、
前記ユーザによって供給された前記ターゲット文字列をデータベースに格納することと
を含む請求項82に記載の機械可読媒体。 - 前記ターゲット文字列が前記ユーザによってユーザ・インターフェースを介して入力される請求項88に記載の機械可読媒体。
- 前記規則の組がユーザによってユーザ・インターフェースを介して定義される請求項75に記載の機械可読媒体。
- 前記第3文字列の前記作成がルックアップ・テーブルを介して実行される請求項65に記載の機械可読媒体。
- 前記第3文字列の前記作成がアルゴリズムを介して実行される請求項65に記載の機械可読媒体。
- 前記方法が、前記第3文字列のそれぞれに優先順位値を割り当てることをさらに含む請求項72に記載の機械可読媒体。
- 前記第3文字列の前記優先順位が前記第2文字列の前記優先順位より低い請求項93に記載の機械可読媒体。
- 第1日本語文字入力列を第2日本語文字列に変換する方法を機械に実行させる実行可能コードを格納する機械可読媒体であって、その方法が、
平仮名入力を受け取ることと、
前記平仮名入力に基づいて、複数の可能な片仮名候補を自動的に判定することと、
前記平仮名入力を片仮名文字に変換するために前記複数の可能な片仮名候補を分析することと、
前記分析に応答して前記片仮名候補の1つを選択することと、
前記片仮名候補の前記1つを含む変換されたテキストを出力することと
を含む機械可読媒体。 - 前記変換されたテキストが、さらに、漢字文字を含む請求項95に記載の機械可読媒体。
- ソース文字列をターゲット文字列に変換する装置であって、
前記ソース文字列を有する第1文字列を受け取る入力メソッドと、
前記第1文字列を第2文字列に変換するように結合された通常の辞書と、
前記第1文字列に基づいて第3文字列を生成するように結合された仮想辞書と、
前記入力メソッドに結合された形態素解析エンジン(MAE)であって、前記MAEが前記第1文字列に対する形態素解析を実行し、前記第2文字列と前記第3文字列に基づいて前記第1文字列を前記ターゲット文字列に変換する形態素解析エンジンと、
前記MAEに結合された出力ユニットと
を含む装置。 - 前記入力メソッドが、前記第1文字列を受け取るアプリケーション・プログラミング・インターフェース(API)を含む請求項97に記載の装置。
- 前記入力メソッドが、キーボードから前記第1文字列を受け取る請求項97に記載の装置。
- 前記入力メソッドが携帯情報端末(PDA)から前記第1文字列を受け取る請求項97に記載の装置。
- 前記第1文字列が日本語平仮名文字を含む請求項97に記載の装置。
- 前記ターゲット文字列が日本語文字を含み、前記日本語文字が
平仮名文字と、
片仮名文字と、
漢字文字と
を含む請求項97に記載の装置。 - 前記MAEが、前記第1文字列を複数の部分列に分割し、前記複数の文字列を前記通常の辞書を介して前記第2文字列に変換する請求項97に記載の装置。
- 前記MAEが、前記第1文字列を複数の部分列に分割し、前記仮想辞書を介して前記複数の部分列に対応する前記第3文字列を生成する請求項97に記載の装置。
- 前記仮想辞書が前記第3文字列のそれぞれについて品詞情報を提供する請求項104に記載の装置。
- 前記仮想辞書が前記第3文字列のそれぞれに優先順位値を割り当てる請求項104に記載の装置。
- 前記第3文字列の前記優先順位が前記通常の辞書からの前記文字列の前記優先順位より低い請求項106に記載の装置。
- 前記通常の辞書が複数の辞書を含む請求項97に記載の装置。
- 前記MAEが前記通常の辞書の出力から候補を選択し、前記MAEが前記通常の辞書が正しい変換を含まない場合に、前記仮想辞書の出力から前記候補を選択する請求項104に記載の装置。
- 前記MAEに結合された辞書管理モジュール(DMM)をさらに含み、前記辞書管理モジュールが、前記通常の辞書と前記仮想辞書を管理する請求項97に記載の装置。
- 前記MAEが前記DMMを介して前記通常の辞書と前記仮想辞書にアクセスする請求項110に記載の装置。
- 前記MAEから生成される前記変換へのユーザ対話を提供するように結合されたユーザ・インターフェースをさらに含む請求項97に記載の装置。
- 前記MAEから生成される前記変換が正しくない場合に、前記MAEによって生成された候補リストから、ユーザが前記ユーザ・インターフェースを介して最終出力を選択する請求項112に記載の装置。
- 前記出力ユニットがディスプレイ・デバイスに前記変換を送る請求項97に記載の装置。
- 前記出力ユニットがAPIを介してアプリケーションに前記変換を送る請求項97に記載の装置。
- 請求項97に記載の装置を有するコンピュータ・システム。
- 前記コンピュータ・システムがネットワーク・コンピュータであり、前記通常の辞書がネットワーク・ストレージ位置に格納される請求項116に記載のコンピュータ・システム。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US09/965,333 US7136803B2 (en) | 2001-09-25 | 2001-09-25 | Japanese virtual dictionary |
| PCT/US2002/029768 WO2003027895A2 (en) | 2001-09-25 | 2002-09-18 | Character string conversion |
Related Child Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2007104626A Division JP4286299B2 (ja) | 2001-09-25 | 2007-04-12 | 日本語仮想辞書 |
| JP2010042126A Division JP5364617B2 (ja) | 2001-09-25 | 2010-02-26 | 日本語仮想辞書 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2005538428A true JP2005538428A (ja) | 2005-12-15 |
Family
ID=25509820
Family Applications (5)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2003531361A Pending JP2005538428A (ja) | 2001-09-25 | 2002-09-18 | 日本語仮想辞書 |
| JP2007104626A Expired - Fee Related JP4286299B2 (ja) | 2001-09-25 | 2007-04-12 | 日本語仮想辞書 |
| JP2008101299A Pending JP2008204476A (ja) | 2001-09-25 | 2008-04-09 | 日本語仮想辞書 |
| JP2010042126A Expired - Fee Related JP5364617B2 (ja) | 2001-09-25 | 2010-02-26 | 日本語仮想辞書 |
| JP2013147026A Expired - Fee Related JP5535379B2 (ja) | 2001-09-25 | 2013-07-12 | 日本語仮想辞書 |
Family Applications After (4)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2007104626A Expired - Fee Related JP4286299B2 (ja) | 2001-09-25 | 2007-04-12 | 日本語仮想辞書 |
| JP2008101299A Pending JP2008204476A (ja) | 2001-09-25 | 2008-04-09 | 日本語仮想辞書 |
| JP2010042126A Expired - Fee Related JP5364617B2 (ja) | 2001-09-25 | 2010-02-26 | 日本語仮想辞書 |
| JP2013147026A Expired - Fee Related JP5535379B2 (ja) | 2001-09-25 | 2013-07-12 | 日本語仮想辞書 |
Country Status (5)
| Country | Link |
|---|---|
| US (2) | US7136803B2 (ja) |
| JP (5) | JP2005538428A (ja) |
| AU (1) | AU2002339951A1 (ja) |
| TW (1) | TWI223165B (ja) |
| WO (1) | WO2003027895A2 (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010165369A (ja) * | 2001-09-25 | 2010-07-29 | Apple Inc | 日本語仮想辞書 |
| JP2013235117A (ja) * | 2012-05-08 | 2013-11-21 | Yahoo Japan Corp | 単語分割装置、及び単語分割方法 |
Families Citing this family (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7403888B1 (en) * | 1999-11-05 | 2008-07-22 | Microsoft Corporation | Language input user interface |
| US8200865B2 (en) * | 2003-09-11 | 2012-06-12 | Eatoni Ergonomics, Inc. | Efficient method and apparatus for text entry based on trigger sequences |
| JP2007133033A (ja) * | 2005-11-08 | 2007-05-31 | Nec Corp | 音声テキスト化システム、音声テキスト化方法および音声テキスト化用プログラム |
| US7899664B2 (en) * | 2006-05-22 | 2011-03-01 | Sharp Kabushiki Kaisha | Information processing apparatus, computer, information processing system, information processing method, and program for receiving a character string and returning conversion candidates |
| JP5309480B2 (ja) * | 2007-06-14 | 2013-10-09 | 沖電気工業株式会社 | 文字列入力装置、文字列入力方法およびプログラム |
| JP4226049B1 (ja) | 2007-08-27 | 2009-02-18 | 日本インスツルメンツ株式会社 | 炭化水素を主成分とする試料中の水銀を測定する水銀測定装置 |
| US8275601B2 (en) | 2008-05-11 | 2012-09-25 | Research In Motion Limited | Mobile electronic device and associated method enabling transliteration of a text input |
| JP2010055235A (ja) * | 2008-08-27 | 2010-03-11 | Fujitsu Ltd | 翻訳支援プログラム、及び該システム |
| JP2010282507A (ja) * | 2009-06-05 | 2010-12-16 | Casio Computer Co Ltd | 辞書機能を備えた電子機器およびプログラム |
| US7721222B1 (en) | 2009-06-10 | 2010-05-18 | Cheman Shaik | Dynamic language text generation system and method |
| US9471560B2 (en) * | 2011-06-03 | 2016-10-18 | Apple Inc. | Autocorrecting language input for virtual keyboards |
| US8386926B1 (en) * | 2011-10-06 | 2013-02-26 | Google Inc. | Network-based custom dictionary, auto-correction and text entry preferences |
| JP6742692B2 (ja) * | 2015-01-30 | 2020-08-19 | 富士通株式会社 | 符号化プログラムおよび伸長プログラム |
| JP6677415B2 (ja) * | 2016-03-03 | 2020-04-08 | 富士通コネクテッドテクノロジーズ株式会社 | 文字入力装置及び文字入力プログラム |
| US10628522B2 (en) * | 2016-06-27 | 2020-04-21 | International Business Machines Corporation | Creating rules and dictionaries in a cyclical pattern matching process |
| KR20200029162A (ko) | 2018-09-10 | 2020-03-18 | (주)시스템배관 | 탄성 재질의 탄성 공간링을 이용한 내진용 배관 연결장치 |
Family Cites Families (28)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS59168533A (ja) * | 1983-03-16 | 1984-09-22 | Fujitsu Ltd | 文字列変換方式 |
| JPS61120276A (ja) * | 1984-11-16 | 1986-06-07 | Sanyo Electric Co Ltd | 片仮名・平仮名変換装置及び変換方法 |
| JPS6231467A (ja) | 1985-08-01 | 1987-02-10 | Toshiba Corp | 文章作成装置 |
| JPH0193861A (ja) | 1987-10-05 | 1989-04-12 | Brother Ind Ltd | 日本語処理機能を備えた電子翻訳機 |
| JP2836159B2 (ja) * | 1990-01-30 | 1998-12-14 | 株式会社日立製作所 | 同時通訳向き音声認識システムおよびその音声認識方法 |
| JPH0594431A (ja) | 1991-10-02 | 1993-04-16 | Sharp Corp | 仮名変換装置 |
| JPH05113968A (ja) * | 1991-10-23 | 1993-05-07 | Nec Corp | 日本語入力装置 |
| US5432948A (en) * | 1993-04-26 | 1995-07-11 | Taligent, Inc. | Object-oriented rule-based text input transliteration system |
| JPH07129562A (ja) * | 1993-10-28 | 1995-05-19 | Toshiba Corp | 文書作成装置およびその方法 |
| US5675817A (en) * | 1994-12-05 | 1997-10-07 | Motorola, Inc. | Language translating pager and method therefor |
| JPH08287060A (ja) * | 1995-04-19 | 1996-11-01 | Canon Inc | 文字処理装置および文字処理方法 |
| JP3728789B2 (ja) * | 1996-02-19 | 2005-12-21 | オムロン株式会社 | 日本語文解析装置および日本語文解析方法 |
| JP3895797B2 (ja) * | 1996-02-22 | 2007-03-22 | 株式会社東芝 | 変換候補生成方法 |
| US5963893A (en) * | 1996-06-28 | 1999-10-05 | Microsoft Corporation | Identification of words in Japanese text by a computer system |
| US5999950A (en) | 1997-08-11 | 1999-12-07 | Webtv Networks, Inc. | Japanese text input method using a keyboard with only base kana characters |
| JPH1166061A (ja) * | 1997-08-22 | 1999-03-09 | Sharp Corp | 情報処理装置および情報処理プログラムを記録したコンピュータ読み取り可能な記録媒体 |
| JP3272288B2 (ja) * | 1997-12-24 | 2002-04-08 | 日本アイ・ビー・エム株式会社 | 機械翻訳装置および機械翻訳方法 |
| US6401060B1 (en) * | 1998-06-25 | 2002-06-04 | Microsoft Corporation | Method for typographical detection and replacement in Japanese text |
| US6707571B1 (en) * | 1998-08-28 | 2004-03-16 | Seiko Epson Corporation | Character printing method and device as well as image forming method and device |
| JP2000122768A (ja) * | 1998-10-14 | 2000-04-28 | Microsoft Corp | 文字入力装置、方法および記録媒体 |
| JP4302326B2 (ja) * | 1998-11-30 | 2009-07-22 | コーニンクレッカ フィリップス エレクトロニクス エヌ ヴィ | テキストの自動区分 |
| US6275789B1 (en) * | 1998-12-18 | 2001-08-14 | Leo Moser | Method and apparatus for performing full bidirectional translation between a source language and a linked alternative language |
| US6556984B1 (en) * | 1999-01-19 | 2003-04-29 | International Business Machines Corporation | Hierarchical string matching using multi-path dynamic programming |
| US6278969B1 (en) * | 1999-08-18 | 2001-08-21 | International Business Machines Corp. | Method and system for improving machine translation accuracy using translation memory |
| JP2001101185A (ja) * | 1999-09-24 | 2001-04-13 | Internatl Business Mach Corp <Ibm> | 辞書の自動切り換えが可能な機械翻訳方法および装置並びにそのような機械翻訳方法を実行するためのプログラムを記憶したプログラム記憶媒体 |
| WO2002001401A1 (en) * | 2000-06-26 | 2002-01-03 | Onerealm Inc. | Method and apparatus for normalizing and converting structured content |
| US20040205671A1 (en) * | 2000-09-13 | 2004-10-14 | Tatsuya Sukehiro | Natural-language processing system |
| US7136803B2 (en) * | 2001-09-25 | 2006-11-14 | Apple Computer, Inc. | Japanese virtual dictionary |
-
2001
- 2001-09-25 US US09/965,333 patent/US7136803B2/en not_active Expired - Lifetime
-
2002
- 2002-09-18 AU AU2002339951A patent/AU2002339951A1/en not_active Abandoned
- 2002-09-18 WO PCT/US2002/029768 patent/WO2003027895A2/en active Application Filing
- 2002-09-18 JP JP2003531361A patent/JP2005538428A/ja active Pending
- 2002-09-24 TW TW091121867A patent/TWI223165B/zh not_active IP Right Cessation
-
2006
- 2006-11-13 US US11/598,869 patent/US7630880B2/en not_active Expired - Lifetime
-
2007
- 2007-04-12 JP JP2007104626A patent/JP4286299B2/ja not_active Expired - Fee Related
-
2008
- 2008-04-09 JP JP2008101299A patent/JP2008204476A/ja active Pending
-
2010
- 2010-02-26 JP JP2010042126A patent/JP5364617B2/ja not_active Expired - Fee Related
-
2013
- 2013-07-12 JP JP2013147026A patent/JP5535379B2/ja not_active Expired - Fee Related
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2010165369A (ja) * | 2001-09-25 | 2010-07-29 | Apple Inc | 日本語仮想辞書 |
| JP2013242895A (ja) * | 2001-09-25 | 2013-12-05 | Apple Inc | 日本語仮想辞書 |
| JP2013235117A (ja) * | 2012-05-08 | 2013-11-21 | Yahoo Japan Corp | 単語分割装置、及び単語分割方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP5364617B2 (ja) | 2013-12-11 |
| WO2003027895A2 (en) | 2003-04-03 |
| US7136803B2 (en) | 2006-11-14 |
| AU2002339951A1 (en) | 2003-04-07 |
| WO2003027895A3 (en) | 2003-10-23 |
| TWI223165B (en) | 2004-11-01 |
| JP2013242895A (ja) | 2013-12-05 |
| JP4286299B2 (ja) | 2009-06-24 |
| US20070061131A1 (en) | 2007-03-15 |
| JP2010165369A (ja) | 2010-07-29 |
| JP2008204476A (ja) | 2008-09-04 |
| JP2007220138A (ja) | 2007-08-30 |
| US7630880B2 (en) | 2009-12-08 |
| US20030061031A1 (en) | 2003-03-27 |
| JP5535379B2 (ja) | 2014-07-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4286299B2 (ja) | 日本語仮想辞書 | |
| US8005662B2 (en) | Translation method, translation output method and storage medium, program, and computer used therewith | |
| US6073146A (en) | System and method for processing chinese language text | |
| US20050216253A1 (en) | System and method for reverse transliteration using statistical alignment | |
| JP2016186805A5 (ja) | ||
| JPH0724056B2 (ja) | コンピュータによる形態論的テキスト解析方法 | |
| US7328404B2 (en) | Method for predicting the readings of japanese ideographs | |
| JPH11238051A (ja) | 中国語入力変換処理装置、中国語入力変換処理方法、中国語入力変換処理プログラムを記録した記録媒体 | |
| JP2004118461A (ja) | 言語モデルのトレーニング方法、かな漢字変換方法、言語モデルのトレーニング装置、かな漢字変換装置、コンピュータプログラムおよびコンピュータ読み取り可能な記録媒体 | |
| JP2009258887A (ja) | 機械翻訳装置及び機械翻訳プログラム | |
| Garabık | Levenshtein Edit Operations as a Base for a Morphology Analyzer | |
| JPH03225462A (ja) | ローマ字漢字変換装置 | |
| JPH07210571A (ja) | 単語検索処理装置及び単語検索処理方法 | |
| JPH06149791A (ja) | 漢字文章入力装置 | |
| JP2009223704A (ja) | 翻訳装置及び翻訳プログラム | |
| JPH04305769A (ja) | 機械翻訳装置 | |
| Bernard | Machine translation: Success or failure using MT in an IT research and development environment | |
| Asahiah et al. | A survey of approaches to diacritic restoration | |
| JP2003242145A (ja) | 言語処理プログラム、言語処理装置、その方法および記録媒体 | |
| JPH0816569A (ja) | 文書処理装置 | |
| JP2002351869A (ja) | 文書処理装置 | |
| JPH09204429A (ja) | 機械翻訳装置 | |
| JPH02224065A (ja) | 機械翻訳システム | |
| JPH0916603A (ja) | 翻訳装置及び同装置に用いられる翻訳処理方法 | |
| JP2010211640A (ja) | 機械翻訳装置 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20060627 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20060704 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20060922 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20070116 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20070412 |
|
| A911 | Transfer to examiner for re-examination before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20070525 |
|
| A912 | Re-examination (zenchi) completed and case transferred to appeal board |
Free format text: JAPANESE INTERMEDIATE CODE: A912 Effective date: 20070727 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090928 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20100120 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20100125 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20100222 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20100225 |