ES2786633T3 - Enzimas CAR y producción mejorada de alcoholes grasos - Google Patents
Enzimas CAR y producción mejorada de alcoholes grasos Download PDFInfo
- Publication number
- ES2786633T3 ES2786633T3 ES18160746T ES18160746T ES2786633T3 ES 2786633 T3 ES2786633 T3 ES 2786633T3 ES 18160746 T ES18160746 T ES 18160746T ES 18160746 T ES18160746 T ES 18160746T ES 2786633 T3 ES2786633 T3 ES 2786633T3
- Authority
- ES
- Spain
- Prior art keywords
- fatty
- mutations
- polypeptide
- host cell
- fatty alcohol
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/0004—Oxidoreductases (1.)
- C12N9/0008—Oxidoreductases (1.) acting on the aldehyde or oxo group of donors (1.2)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/10—Transferases (2.)
- C12N9/1025—Acyltransferases (2.3)
- C12N9/1029—Acyltransferases (2.3) transferring groups other than amino-acyl groups (2.3.1)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P7/00—Preparation of oxygen-containing organic compounds
- C12P7/02—Preparation of oxygen-containing organic compounds containing a hydroxy group
- C12P7/04—Preparation of oxygen-containing organic compounds containing a hydroxy group acyclic
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P7/00—Preparation of oxygen-containing organic compounds
- C12P7/64—Fats; Fatty oils; Ester-type waxes; Higher fatty acids, i.e. having at least seven carbon atoms in an unbroken chain bound to a carboxyl group; Oxidised oils or fats
- C12P7/6409—Fatty acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y102/00—Oxidoreductases acting on the aldehyde or oxo group of donors (1.2)
- C12Y102/01—Oxidoreductases acting on the aldehyde or oxo group of donors (1.2) with NAD+ or NADP+ as acceptor (1.2.1)
- C12Y102/0105—Long-chain-fatty-acyl-CoA reductase (1.2.1.50)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y102/00—Oxidoreductases acting on the aldehyde or oxo group of donors (1.2)
- C12Y102/99—Oxidoreductases acting on the aldehyde or oxo group of donors (1.2) with other acceptors (1.2.99)
- C12Y102/99006—Carboxylate reductase (1.2.99.6)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y203/00—Acyltransferases (2.3)
- C12Y203/01—Acyltransferases (2.3) transferring groups other than amino-acyl groups (2.3.1)
- C12Y203/01041—Beta-ketoacyl-acyl-carrier-protein synthase I (2.3.1.41)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y301/00—Hydrolases acting on ester bonds (3.1)
- C12Y301/02—Thioester hydrolases (3.1.2)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P2203/00—Fermentation products obtained from optionally pretreated or hydrolyzed cellulosic or lignocellulosic material as the carbon source
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02E—REDUCTION OF GREENHOUSE GAS [GHG] EMISSIONS, RELATED TO ENERGY GENERATION, TRANSMISSION OR DISTRIBUTION
- Y02E50/00—Technologies for the production of fuel of non-fossil origin
- Y02E50/10—Biofuels, e.g. bio-diesel
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02P—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN THE PRODUCTION OR PROCESSING OF GOODS
- Y02P20/00—Technologies relating to chemical industry
- Y02P20/50—Improvements relating to the production of bulk chemicals
- Y02P20/52—Improvements relating to the production of bulk chemicals using catalysts, e.g. selective catalysts
Landscapes
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Genetics & Genomics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- Biochemistry (AREA)
- General Health & Medical Sciences (AREA)
- Biotechnology (AREA)
- Microbiology (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- Medicinal Chemistry (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Oil, Petroleum & Natural Gas (AREA)
- Biophysics (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Enzymes And Modification Thereof (AREA)
Abstract
Un polipéptido de ácido carboxílico reductasa (CAR) variante que comprende una secuencia de aminoácidos que tiene una identidad de secuencia de al menos el 80% con el polipéptido de CAR natural de la SEQ ID NO: 7 y que tiene al menos una sustitución de aminoácido seleccionada del grupo que consiste en S3R, D18R, D18L, D18T, D18P, E20V, E20S, E20R, S22R, S22N, S22G, L80R, R87G, R87E, V191S, F288R, F288S, F288G, Q473L, Q473W, Q473Y, Q473I, Q473H, A535S, D750A, R827C, R827A, I870L, R873S, V926A, V926E, S927K, S927G, M930K, M930R y L1128W, en la que (i) la expresión de dicho polipéptido de CAR variante en una célula hospedadora recombinante da como resultado un título más alto de aldehídos grasos en comparación con una célula hospedadora recombinante que expresa el polipéptido de CAR natural de SEQ ID NO: 7 o, (ii) la expresión de dicho polipéptido de CAR variante en una célula hospedadora recombinante da como resultado un título más alto de alcoholes grasos en comparación con una célula hospedadora recombinante que expresa el polipéptido de CAR natural de SEQ ID NO: 7.
Description
DESCRIPCIÓN
Enzimas CAR y producción mejorada de alcoholes grasos
Campo de la divulgación
La divulgación se refiere a enzimas de ácido carboxílico reductasa (CAR) variantes para la producción mejorada de alcoholes grasos en células hospedadoras recombinantes. La divulgación se refiere además a ácidos nucleicos y polipéptidos de CAR variantes así como a células hospedadoras recombinantes y cultivos celulares. Se engloban además métodos de preparación de composiciones de alcoholes grasos.
Antecedentes de la divulgación
Los alcoholes grasos constituyen una categoría importante de productos bioquímicos industriales. Estas moléculas y sus derivados tienen numerosos usos, incluyendo como tensioactivos, lubricantes, plastificantes, disolventes, emulsionantes, emolientes, espesantes, sabores, fragancias y combustibles. En la industria, los alcoholes grasos se producen por medio de hidrogenación catalítica de ácidos grasos producidos a partir de fuentes naturales, tales como aceite de coco, aceite de palma, aceite de palmiste, sebo y manteca de cerdo, o mediante hidratación química de alfaolefinas producidas a partir de materias primas petroquímicas. Los alcoholes grasos derivados de fuentes naturales tienen longitudes de cadena variables. La longitud de cadena de los alcoholes grasos es importante con respecto a aplicaciones particulares. En la naturaleza, los alcoholes grasos también se preparan mediante enzimas que pueden reducir moléculas de acil-ACP o acil-CoA a los correspondientes alcoholes primarios (véanse, por ejemplo, las publicaciones de patente estadounidense n.°s 20100105955, 20100105963 y 20ll0250663).
El documento US 2010/0298612 describe la producción de alcoholes grasos de cadena larga mediante células hospedadoras recombinantes que expresan enzimas de ácido carboxílico reductasa heterólogas. El documento US 2010/0105963 describe métodos para producir alcoholes grasos expresando una ácido carboxílico reductasa en una célula hospedadora. El documento WO 20111047101 describe microorganismos recombinantes para la producción de 1,2-butanodiol y otros alcoholes, pero no usos específicos para la producción de alcoholes grasos.
Las tecnologías actuales para producir alcoholes grasos implican la reducción mediada por catalizador inorgánico de ácidos grasos a los correspondientes alcoholes primarios, lo que es costoso, requiere mucho tiempo y es engorroso. Los ácidos grasos usados en este procedimiento derivan de fuentes naturales (por ejemplo, grasas y aceites animales y vegetales, citados anteriormente). La deshidratación de alcoholes grasos para dar alfa-olefinas también puede lograrse mediante catálisis química. Sin embargo, esta técnica no es renovable y está asociada con un alto coste de funcionamiento y desechos químicos peligrosos para el medio ambiente. Por tanto, existe la necesidad de métodos mejorados para la producción de alcoholes grasos y la presente divulgación aborda esta necesidad.
Sumario
Un aspecto de la divulgación proporciona un polipéptido de ácido carboxílico reductasa (CAR) variante que comprende una secuencia de aminoácidos que tiene una identidad de secuencia de al menos el 80 % con SEQ ID NO: 7, en el que el polipéptido de CAR variante se modifica por ingeniería genética para que tenga al menos una mutación en una posición de aminoácido seleccionada del grupo de S3R, D18R, D18L, D18 T, D18P, E20V, E20S, E20R, S22R, S22N, S22G, L80R, R87G, R87E, V191S, F288R, F288S, F288G, Q473L, Q473W, Q473Y, Q473I, Q473H, A535S, D750A, R827C, R827A, I870L, R873S, V926A, V926E, S927K, S927G, M930K, M930R y L1128W en el que, la expresión del polipéptido de CAR variante en una célula hospedadora recombinante, da como resultado un título más alto de las composiciones de aldehídos grasos o de alcoholes grasos en comparación con una célula hospedadora recombinante que expresa un polipéptido natural correspondiente de SEQ ID NO: 7 El polipéptido de CAR es un polipéptido de CARB. En realizaciones preferidas, el polipéptido de CAR incluye la mutación A535S; o las mutaciones E20R, F288G, Q473I y A535S; o las mutaciones E20R, f288G, Q473H, A535S, R827A y S927G; o las mutaciones E20R, S22R, F288G, Q473H, A535S, R827A y S927G; o las mutaciones S3R, E20R, S22R, F288G, Q473H, A535S, R873S, S927G, M930R y L1128W; o E20R, S22R, F288G, Q473H, A535S, R873S, S927G, M930R y L1128W; o las mutaciones D18R, E20R, S22R, F288G, Q473I, A535S, S927G, M930K y L1128W; o las mutaciones E20R, S22R, F288G, Q473I, A535S, R827C, V926E, S927K y M930R; o las mutaciones D18R, E20R, 288G, Q473I, A535S, R827C, V926E, M930K y L1128W; o las mutaciones E20R, S22R, F288G, Q473H, A535S, R827C, V926A, S927K y M930R; o las mutaciones E20R, S22R, F288G, Q473H, A535S y R827C; o las mutaciones E20R, S22R, F288G, Q473I, A535S, R827C y M930R; o las mutaciones E20R, S22R, F288G, Q473I, A535S, I870L, S927G y M930R; o las mutaciones E20R, S22R, F288G, Q473I, A535S, I870L y S927G; o las mutaciones D18R, E20R, S22R, F288G, Q473I, A535S, R827C, I870L, V926A y S927G; o las mutaciones E20R, S22R, F288G, Q473H, A535S, R827C, I870L y L1128W; o las mutaciones D18R, E20R, S22R, F288G, Q473H, A535S, R827C, I870L, S927G y L1128W; o las mutaciones E20R, S22R, F288G, Q473I, A535S, R827C, I870L, S927G y L1128W; o las mutaciones E20R, S22R, F288G, Q473I, A535S, R827C, I870L, S927G, M930K y L1128W; o las mutaciones E20R, S22R, F288G, Q473H, A535S, I870L, S927G y M930K; o las mutaciones E20R, F288G, Q473I, A535S, I870L, M930K; o las mutaciones E20R, S22R, F288G, Q473H, A535S, S927G, M930K y L1128W; o las mutaciones D18R, E20R, S22R, F288G, Q473I, A535S, S927G y L1128W; o las mutaciones E20R, S22R, F288G, Q473I, A535S, R827C, I870L y S927G; o las mutaciones D18R, E20R, S22R,
F288G, Q473I, A535S, R827C, I870L, S927G y L1128W; o las mutaciones D18R, E20R, S22R, F288G, Q473I, A535S, S927G, M930R y L1128W; o las mutaciones E20R, S22R, F288G, Q473H, A535S, V926E, S927G y M930R; o las mutaciones E20R, S22R, F288G, Q473H, A535S, R827C, I870L, V926A y L1128W; o combinaciones de las mismas.
Otro aspecto de la divulgación proporciona una célula hospedadora que incluye una secuencia de polinucleótido que codifica un polipéptido de ácido carboxílico reductasa (CAR) variante que tiene una identidad de secuencia de al menos el 80 % con SEQ ID NO: 7 y que tiene al menos una mutación en una posición de aminoácido seleccionada del grupo de S3R, D18R, D18L, D18T, D18P, E20V, E20S, E20R, S22R, S22N, S22G, L80R, R87G, R87E, V191S, F288R, F288S, F288G, Q473L, Q473W, Q473Y, Q473I, Q473H, A535S, D750A, R827C, R827A, I870L, R873S, V926A, V926E, S927K, S927G, M930K, M930R y L1128W, en la que la célula hospedadora modificada por ingeniería genética produce una composición de alcohol graso con un rendimiento o título superior que una célula hospedadora que expresa un polipéptido de CAR natural correspondiente cuando se cultiva en un medio que contiene una fuente de carbono en condiciones eficaces para expresar el polipéptido de CAR variante, y en donde la SEQ ID NO: 7 es el correspondiente polipéptido de CAR natural. En una realización preferida, la célula hospedadora recombinante incluye además un polinucleótido que codifica un polinucleótido de tioesterasa. En otra realización preferida, la célula hospedadora recombinante incluye además un polinucleótido que codifica un polipéptido de FabB y un polipéptido de FadR. En otra realización preferida, la célula hospedadora recombinante incluye además un polinucleótido que codifica una reductasa de aldehído graso, por ejemplo, AlrA, y un cultivo celular que lo contiene.
En otra realización preferida, la célula hospedadora modificada por ingeniería genética tiene un título que es al menos 3 veces mayor que el título de una célula hospedadora que expresa el polipéptido de CAR natural correspondiente cuando se cultiva en las mismas condiciones que la célula hospedadora modificada por ingeniería genética. En una realización preferida, la célula hospedadora modificada por ingeniería genética tiene un título de desde 30 g/l hasta 250 g/l. En otra realización preferida, la célula hospedadora modificada por ingeniería genética tiene un título de desde 90 g/l hasta 120 g/l.
En otra realización preferida, la célula hospedadora modificada por ingeniería genética tiene un rendimiento que es al menos 3 veces mayor que el rendimiento de una célula hospedadora que expresa el polipéptido de CAR natural correspondiente cuando se cultiva en las mismas condiciones que la célula hospedadora modificada por ingeniería genética. En una realización preferida, la célula hospedadora modificada por ingeniería genética tiene un rendimiento de desde el 10% hasta el 40%.
La divulgación engloba además un cultivo celular que incluye la célula hospedadora recombinante tal como se describe en el presente documento. En una realización preferida, el cultivo celular tiene una productividad que es al menos aproximadamente 3 veces mayor que la productividad de un cultivo celular que expresa el polipéptido de CAR natural correspondiente. En otra realización preferida, la productividad oscila entre 0,7 mg/l/h y 3 g/l/h. En otra realización preferida, el medio de cultivo comprende una composición de alcohol graso. La composición de alcohol graso se produce de manera extracelular. La composición de alcohol graso puede incluir uno o más de un alcohol graso C6, C8, C10, C12, C13, C14, C15, C16, C17 o C18; o un alcohol graso insaturado C10:1, C12:1, C14:1, C16:1 o C18:1. En otra realización preferida, la composición de alcohol graso comprende alcoholes grasos C12 y C14. En aún otra realización preferida, la composición de alcohol graso comprende alcoholes grasos C12 y C14 a una razón de aproximadamente 3:1. En todavía otra realización preferida, la composición de alcohol graso engloba alcoholes grasos insaturados. Además, la composición de alcohol graso puede incluir un alcohol graso que tiene un doble enlace en la posición 7 en la cadena de carbono entre C7 y C8 desde el extremo reducido del alcohol graso. En otra realización preferida, la composición de alcohol graso incluye alcoholes grasos saturados. En otra realización preferida, la composición de alcohol graso incluye alcoholes grasos de cadena ramificada.
La divulgación contempla además un método de preparación de una composición de alcohol graso a un alto título, rendimiento o productividad, que incluye las etapas de modificar por ingeniería genética la célula hospedadora recombinante de la divulgación; cultivar la célula hospedadora recombinante en un medio que incluye una fuente de carbono; y opcionalmente aislar la composición de alcohol graso del medio.
Breve descripción de los dibujos
La presente divulgación se entiende mejor cuando se lee junto con las figuras adjuntas, que sirven para ilustrar las realizaciones preferidas. Sin embargo, se entiende que la divulgación no se limita a las realizaciones específicas dadas a conocer en las figuras.
La figura 1 es una visión general esquemática de una ruta de biosíntesis a modo de ejemplo para su uso en la producción de acil-CoA como precursor para dar derivados de ácido graso en una célula hospedadora recombinante. El ciclo se inicia mediante la condensación de malonil-ACP y acetil-CoA.
La figura 2 es una visión general esquemática de un ciclo de biosíntesis de ácidos grasos a modo de ejemplo, en el que se produce malonil-ACP mediante la transacilación de malonil-CoA con malonil-ACP (catalizada por malonil-CoAACP transacilasa; fabD), luego la p-cetoacil-ACP sintasa III (fabH) inicia la condensación de malonil-ACP con acetil-CoA. Los ciclos de elongación comienzan con la condensación de malonil-ACP y una acil-ACP catalizada
por p-cetoacil-ACP sintasa I (fabB) y p-cetoacil-ACP sintasa II (fabF) para producir una p-ceto-acil-ACP, luego la p-ceto-acil-ACP se reduce por una p-cetoacil-ACP reductasa dependiente de NADPH (fabG) para producir una phidroxi-acil-ACP, que se deshidrata para dar una trans-2-enoil-acil-ACP por p-hidroxiacil-ACP deshidratasa (fabA o fabZ). FabA también puede isomerizar trans-2-enoil-acil-ACP para dar c/s-3-enoil-acil-ACP, que puede sortear a fabI y puede usarse por fabB (normalmente para una longitud de cadena alifática de hasta C16) para producir pceto-acil-ACP. La etapa final en cada ciclo está catalizada por una enoil-ACP reductasa dependiente de NADH o NADHPH (fabI) que convierte trans-2-enoil-acil-ACP en acil-ACP. En los métodos descritos en el presente documento, se produce la terminación de la síntesis de ácidos grasos mediante la retirada por tioesterasa del grupo acilo de acil-ACP para liberar ácidos grasos libres (FFA, free fatty ac/d). Las tioesterasas (por ejemplo, tesA) hidrolizan enlaces tioéster, que aparecen entre cadenas de acilo y ACP a través de enlaces sulfhidrilo.
La figura 3 ilustra la estructura y función del complejo enzimático de acetil-CoA carboxilasa (accABCD). La biotina carboxilasa está codificada por el gen accC, mientras que la proteína transportadora de biotina y carboxilo (BCCP) está codificada por el gen accB. Las dos subunidades implicadas en la actividad carboxiltransferasa están codificadas por los genes accA y accD. La biotina de BCCP unida covalentemente, transporta el resto carboxilato. El gen b/rA (no mostrado) biotinila holo-accB.
La figura 4 presenta una visión general esquemática de una ruta de biosíntesis a modo de ejemplo para la producción de alcohol graso partiendo de acil-ACP, en la que la producción de aldehído graso está catalizada por la actividad enzimática de acil-ACP reductasa (AAR) o tioesterasa y ácido carboxílico reductasa (Car). El aldehído graso se convierte en alcohol graso por aldehído reductasa (también denominada alcohol deshidrogenasa). Esta ruta no incluye acil graso-CoA sintetasa (fadD).
La figura 5 ilustra la producción de derivados de ácido graso (especie grasa total) por la cepa de E. col/ MG1655 con el gen de fadE atenuado (es decir, delecionado) en comparación con la producción de derivados de ácido graso por E. col/ MG1655. Los datos presentados en la figura 5 muestran que la atenuación del gen de fadE no afectó a la producción de derivados de ácido graso.
Las figuras 6A y 6B muestran datos para la producción de “especie grasa total” a partir de exámenes en placa por duplicado cuando se transformó el plásmido pCL-WT TRC WT TesA en cada una de las cepas mostradas en las figuras y se realizó una fermentación en medios FA2 con 20 horas desde la inducción hasta la recogida a 32° C (figura 6a ) y a 37° C (figura 6B).
Las figuras 7A y 7B proporcionan una representación esquemática del locus iFAB138, que incluye un diagrama del promotor cat-loxP-T5 integrado en frente de FAB138 (7A); y un diagrama de iT5_138 (7B). La secuencia del promotor cat-loxP-T5 integrado en frente de FAB138 con homología de 50 pares de bases mostrada en cada lado de la región promotora cat-loxP-T5 se proporciona como SEQ ID NO: 1 y la secuencia de la región promotora iT5_138 con homología de 50 pares de bases en cada lado se proporciona como SEQ ID NO: 2.
La figura 8 muestra el efecto de corregir los genes de rph e ilvG. Se transformaron EG149 (rph- ilvg-) y V668 (EG149 rph+ ilvG+) con pCL-tesA (un plásmido pCL1920 que contiene PTRC-'tesA) obtenido a partir de D191. La figura muestra que corregir los genes de rph e ilvG en la cepa EG149 permite un nivel superior de producción de FFA que en la cepa V668 en la que los genes de rph e ilvG no se corrigieron.
La figura 9 es una representación esquemática de una inserción de casete de transposón en el gen de yijP de la cepa LC535 (acierto de transposón 68F11). Se muestran los promotores internos para el casete de transposón, y pueden tener efectos sobre la expresión de genes adyacentes.
La figura 10 muestra la conversión de ácidos grasos libres en alcoholes grasos mediante CarB60 en la cepa V324. Las figuras muestran que las células que expresan CarB60 a partir del cromosoma (barras oscuras) convierten una mayor fracción de ácidos grasos libres C12 y C14 en alcohol graso en comparación con CarB (barras claras).
La figura 11 muestra que las células que expresan CarB60 a partir del cromosoma convierten una mayor fracción de ácidos grasos libres C12 y C14 en alcohol graso en comparación con CarB.
La figura 12 muestra la producción de alcohol graso tras la fermentación de mutantes en bibliotecas de combinación.
La figura 13 muestra la producción de alcohol graso por variantes de carB en plásmido de producción (carB1 y CarB2) tras la fermentación en matraz de agitación.
La figura 14 muestra la producción de alcohol graso por variantes de carB integradas de copia única (icarB1, icarB2, icarB3 e icarB4) tras la fermentación en matraz de agitación.
La figura 15 muestra los resultados del sistema de examen de doble plásmido para variantes de CarB mejoradas tal como se valida mediante fermentación en matraz de agitación.
La figura 16 muestra variantes de CarB novedosas para la producción mejorada de alcoholes grasos en biorreactores.
Descripción detallada
Visión general
La presente divulgación se refiere a enzimas ácido carboxílico reductasa (CAR) variantes novedosas así como a sus secuencias de ácido nucleico y proteína. Se engloban además en la divulgación células hospedadoras recombinantes y cultivos celulares que incluyen las enzimas CAR variantes para la producción de alcoholes grasos. La presente invención se define por las reivindicaciones.
Con el fin de que la producción de alcoholes grasos a partir de biomasa o azúcares fermentables sea comercialmente viable, el procedimiento debe optimizarse para lograr una conversión y recuperación eficaces del producto. La presente divulgación aborda esta necesidad proporcionando composiciones y métodos para la producción mejorada de alcoholes grasos usando enzimas variantes modificadas por ingeniería genética y células hospedadoras recombinantes modificadas por ingeniería genética. Las células hospedadoras sirven como biocatalizadores que dan como resultado la producción de alto título de alcoholes grasos usando procedimientos de fermentación. Como tales, se dan a conocer en el presente documento métodos para crear células hospedadoras fotosintéticas y heterotróficas que producen alcoholes grasos y alfa-olefinas de longitudes de cadena específicas directamente de manera que no es necesaria la conversión catalítica de ácidos grasos purificados. Este nuevo método proporciona ventajas de coste y calidad del producto.
Más específicamente, la producción de una composición de alcohol graso deseada puede potenciarse modificando la expresión de uno o más genes implicados en una ruta de biosíntesis para la producción, degradación y/o secreción de alcohol graso. La divulgación proporciona células hospedadoras recombinantes, que se han modificado por ingeniería genética para proporcionar una biosíntesis de alcohol graso potenciada en relación con células hospedadoras nativas o no modificadas por ingeniería genética (por ejemplo, mejoras de cepas). La divulgación también proporciona polinucleótidos útiles en las células hospedadoras recombinantes, métodos y composiciones de la divulgación. Sin embargo se reconocerá que no es necesaria la identidad de secuencia absoluta para tales polinucleótidos. Por ejemplo, pueden hacerse cambios en una secuencia de polinucleótido particular el polipéptido codificado puede evaluarse para determinar su actividad. Tales cambios comprenden normalmente mutaciones conservativas y mutaciones silenciosas (por ejemplo, optimización de codones). Pueden examinarse polinucleótidos modificados o mutados (es decir, mutantes) y polipéptidos variantes codificados para detectar una función deseada, tal como, una función mejorada en comparación con el polipéptido parental, incluyendo pero sin limitarse a actividad catalítica aumentada, estabilidad aumentada o inhibición disminuida (por ejemplo, inhibición por retroalimentación disminuida), usando métodos conocidos en la técnica.
La divulgación identifica actividades enzimáticas implicadas en diversas etapas (es decir, reacciones) de las rutas de biosíntesis de ácidos grasos descritas en el presente documento según el número de clasificación de enzimas (EC), y proporciona polipéptidos a modo de ejemplo (es decir, enzimas) clasificadas mediante tales números de EC, y polinucleótidos a modo de ejemplo que codifican para tales polipéptidos. Tales polipéptidos y polinucleótidos a modo de ejemplo, que se identifican en el presente documento mediante números de registro y/o números de identificador de secuencia (SEQ ID NO), son útiles para modificar por ingeniería genética rutas de ácidos grasos en células hospedadorasparentales para obtener las células hospedadoras recombinantes descritas en el presente documento. Sin embargo, debe entenderse que los polipéptidos y polinucleótidos descritos en el presente documento son a modo de ejemplo y no limitativos. Las secuencias de homólogos de polipéptidos a modo de ejemplo descritas en el presente documento están disponibles para los expertos en la técnica usando bases de datos (por ejemplo, las bases de datos Entrez proporcionadas por el Centro Nacional para la Información Biotecnológica (NCBI), las bases de datos ExPasy proporcionadas por el Instituto Suizo de Bioinformática, la base de datos BRENDA proporcionada por la Universidad Técnica de Braunschweig, y la base de datos KEGG proporcionada por el Centro de Bioinformática de la Universidad de Kyoto y la Universidad de Tokyo, todas las cuales están disponibles en Internet).
Una variedad de células hospedadoras pueden modificarse para contener enzimas de biosíntesis de alcoholes grasos tales como las descritas en el presente documento, dando como resultado células hospedadoras recombinantes adecuadas para la producción de composiciones de alcoholes grasos. Se entiende que una variedad de células pueden proporcionar fuentes de material genético, incluyendo secuencias de polinucleótido que codifican para polipéptidos adecuados para su uso en una célula hospedadora recombinante proporcionada en el presente documento.
Definiciones
A menos que se defina otra cosa, todos los términos técnicos y científicos usados en el presente documento tienen el mismo significado que entiende comúnmente un experto habitual en la técnica a la que pertenece la divulgación. Aunque pueden usarse otros métodos y materiales similares, o equivalentes, a los descritos en el presente documento en la práctica de la presente divulgación, los materiales y métodos preferidos se describen en el presente documento.
En la descripción y reivindicación de la presente divulgación, se usará la siguiente terminología según las definiciones expuestas a continuación.
Números de registro: Los números de registro de secuencias en la totalidad de esta descripción se obtuvieron de bases de datos proporcionadas por el NCBI (Centro Nacional para la Información Biotecnológica) mantenidas por los Institutos Nacionales de Salud, EE.UU. (que se identifican en el presente documento como “números de registro de NCBI” o alternativamente como “números de registro de GenBank”), y de las bases de datos UniProt Knowledgebase (UniProtKB) y Swiss-Prot proporcionadas por el Instituto Suizo de Bioinformática (que se identifican en el presente documento como “números de registro de UniProtKB”).
Números de clasificación de enzimas (EC): Se establecen los números de clasificación de enzimas (EC) por el Comité de Nomenclatura de la Unión Internacional de Bioquímica y Biología Molecular (IUBMB), cuya descripción está disponible en el sitio web de Nomenclatura de Enzimas del IUBMB en Internet. Los números EC clasifican las enzimas según la reacción que catalizan.
Tal como se usa en el presente documento, el término “nucleótido” se refiere a una unidad monomérica de un polinucleótido que consiste en una base heterocíclica, un azúcar y uno o más grupos fosfato. Las bases que se producen de manera natural (guanina, (G), adenina, (A), citosina, (C), timina, (T) y uracilo (U)) son normalmente derivados de purina o pirimidina, aunque debe entenderse que también están incluidos análogos de bases que se producen de manera natural y no natural. El azúcar que se produce de manera natural es la pentosa (azúcar de cinco carbonos), la desoxirribosa (que forma ADN) o la ribosa (que forma ARN), aunque debe entenderse que también están incluidos análogos de azúcares que se producen de manera natural y no natural. Los ácidos nucleicos se unen normalmente mediante enlaces fosfato para formar ácidos nucleicos o polinucleótidos, aunque se conocen en la técnica muchas otras uniones (por ejemplo, fosforotioatos, boranofosfatos, y similares).
Tal como se usa en el presente documento, el término “polinucleótido” se refiere a un polímero de ribonucleótidos (ARN) o desoxirribonucleótidos (ADN), que puede ser monocatenario o bicatenario y que puede contener nucleótidos no naturales o alterados. Los términos “polinucleótido”, “secuencia de ácido nucleico” y “secuencia de nucleótidos” se usan de manera intercambiable en el presente documento para referirse a una forma polimérica de nucleótidos de cualquier longitud, o bien ARN o bien ADN. Estos términos se refieren a la estructura primaria de la molécula, y por tanto incluyen ADN bi y monocatenario y ARN bi y monocatenario. Los términos incluyen, como equivalentes, análogos de o bien ARN o bien ADN producidos a partir de análogos de nucleótidos y polinucleótidos modificados tales como, aunque no limitados a polinucleótidos metilados y/o de extremos ocupados. El polinucleótido puede estar en cualquier forma, incluyendo pero sin limitarse a, plásmido, viral, cromosómico, EST, ADNc, ARNm y ARNr.
Tal como se usa en el presente documento, los términos “polipéptido” y “proteína” se usan de manera intercambiable para referirse a un polímero de residuos de aminoácido. El término “polipéptido recombinante” se refiere a un polipéptido que se produce mediante técnicas recombinantes, en las que generalmente se inserta ADN o ARN que codifica para la proteína expresada en un vector de expresión adecuado que se usa a su vez para transformar una célula hospedadora para producir el polipéptido.
Tal como se usan en el presente documento, los términos “homólogo” y “homólogo/a” se refieren a un polinucleótido o un polipéptido que comprende una secuencia que es idéntica en al menos aproximadamente el 50% a la secuencia de polinucleótido o polipéptido correspondiente. Preferiblemente, los polinucleótidos o polipéptidos homólogos tienen secuencias de polinucleótido o secuencias de aminoácidos que tienen una homología de al menos aproximadamente el 80%, el 81%, el 82%, el 83%, el 84%, el 85%, el 86%, el 87%, el 88%, el 89%, el 90%, el 91%, el 92%, el 93%, el 94%, el 95%, el 96%, el 97%, el 98% o al menos aproximadamente el 99% con la secuencia de aminoácidos o secuencia de polinucleótido correspondiente. Tal como se usa en el presente documento los términos “homología” de secuencia e “identidad” de secuencia se usan de manera intercambiable.
Un experto habitual en la técnica conoce métodos para determinar la homología entre dos o más secuencias. En resumen, pueden realizarse cálculos de “homología” entre dos secuencias de la siguiente manera. Las secuencias se alinean para fines de comparación óptima (por ejemplo, pueden introducirse huecos en una o ambas de una primera y una segunda secuencias de aminoácidos o de ácido nucleico para la alineación óptima y pueden excluirse las secuencias no homólogas para fines de comparación). En una realización preferida, la longitud de una primera secuencia que se alinea para fines de comparación es de al menos aproximadamente el 30%, preferiblemente al menos aproximadamente el 40%, más preferiblemente al menos aproximadamente el 50%, incluso más preferiblemente al menos aproximadamente el 60%, e incluso más preferiblemente al menos aproximadamente el 70%, al menos aproximadamente el 80%, al menos aproximadamente el 90% o aproximadamente el 100% de la longitud de una segunda secuencia. Se comparan entonces los residuos de aminoácido o nucleótidos en posiciones de aminoácido o posiciones de nucleótido correspondientes de las secuencias primera y segunda. Cuando una posición en la primera secuencia está ocupada por el mismo residuo de aminoácido o nucleótido que la posición correspondiente en la segunda secuencia, entonces las moléculas son idénticas en esa posición. El tanto por ciento de homología entre las dos secuencias es una función del número de posiciones idénticas compartidas por las secuencias, teniendo en cuenta el número de huecos y la longitud de cada hueco, que es necesario introducir para la alineación óptima de las dos secuencias.
La comparación de secuencias y determinación del tanto por ciento de homología entre dos secuencias puede lograrse usando un algoritmo matemático, tal como BLAST (Altschul et al. J. Mol. Biol. 215(3):403-410 (1990)). El tanto por ciento de homología entre dos secuencias de aminoácidos también puede determinarse usando el algoritmo de Needleman y Wunsch que se ha incorporado en el programa GAP en el paquete de software de GCG, usando o bien una matriz Blossum 62 o bien una matriz PAM250, y un peso de hueco de 16, 14, 12, 10, 8, 6 ó 4 y un peso de longitud de 1, 2, 3, 4, 5 ó 6 (Needleman y Wunsch (1970) J. Mol. Biol. 48:444-453). El tanto por ciento de homología entre dos secuencias de nucleótidos también puede determinarse usando el programa GAP en el paquete de software de GCG, usando una matriz NWSgapdna.CMP y un peso de hueco de 40, 50, 60, 70 u 80 y un peso de longitud de 1,2, 3, 4, 5 ó 6. Un experto habitual en la técnica puede realizar cálculos de homología inicial y ajustar los parámetros del algoritmo en consecuencia. Un conjunto preferido de parámetros (y el que debe usarse si un profesional no está seguro de qué parámetros deben aplicarse para determinar si una molécula está dentro de una limitación de homología de las reivindicaciones) son una matriz de puntuación Blossum 62 con una penalización por hueco de 12, penalización por extensión de hueco de 4 y penalización por hueco con desplazamiento del marco de lectura de 5. Se conocen métodos adicionales de alineación de secuencias en las técnicas biotecnológicas (véanse, por ejemplo, Rosenberg (2005) BMC Bioinformatics 6:278; Altschul et al. (2005) FEBS J. 272(20):5101-5109) (2005).
Tal como se usa en el presente documento, el término “se hibrida en condiciones de rigurosidad baja, rigurosidad media, rigurosidad alta o condiciones de rigurosidad muy alta” describe condiciones para la hibridación y el lavado. Puede encontrarse orientación para realizar reacciones de hibridación en Current Protocols in Molecular Biology, John Wiley & Sons, N.Y. (1989), 6.3.1 - 6.3.6. Se describen métodos acuosos y no acuosos en esa referencia y puede usarse cualquier método. Condiciones de hibridación específicas a las que se hace referencia en el presente documento son de la siguiente manera: (1) condiciones de hibridación de rigurosidad baja -- 6X cloruro de sodio/citrato de sodio (SSC) a aproximadamente 45°C, seguido por dos lavados en 0,2X SSC, SDS al 0,1% al menos a 50°C (la temperatura de los lavados puede aumentarse hasta 55°C para condiciones de rigurosidad baja); (2) condiciones de hibridación de rigurosidad media -- 6X SSC a aproximadamente 45°C, seguido por uno o más lavados en 0,2X SSC, SDS al 0,1% a 60°C; (3) condiciones de hibridación de rigurosidad alta -- 6X SSC a aproximadamente 45°C, seguido por uno o más lavados en 0,2X SSC, SDS al 0,1% a 65°C; y (4) condiciones de hibridación de rigurosidad muy alta - fosfato de sodio 0,5 M, 7% SDS a 65°C, seguido por uno o más lavados a 0,2X SSC, SDS al 1% a 65°C. Las condiciones de rigurosidad muy alta (4) son las condiciones preferidas a menos que se especifique de otro modo.
Un polipéptido “endógeno” se refiere a un polipéptido codificado por el genoma de la célula parental (también denominada “célula hospedadora”) a partir de la cual se modifica por ingeniería genética la célula recombinante (o “derivada”).
Un polipéptido “exógeno” se refiere a un polipéptido que no está codificado por el genoma de la célula parental. Un polipéptido (es decir, mutante) es un ejemplo de un polipéptido exógeno.
El término “heterólogo” significa en general derivados de una especie diferente o derivados de un organismo diferente. Tal como se usa en el presente documento, se refiere a una secuencia de nucleótidos o una secuencia de polinucleótido que no está presente de manera natural en un organismo particular. Expresión heteróloga significa que una proteína o polipéptido se añade experimentalmente a una célula que no expresa normalmente esa proteína. Como tal, heterólogo se refiere al hecho de que una proteína transferida se derivó inicialmente a partir de un tipo celular diferente o una especie diferente del receptor. Por ejemplo, puede introducirse una secuencia de polinucleótido endógena para una célula vegetal en una célula hospedadora bacteriana mediante métodos recombinantes, y el polinucleótido vegetal es entonces un polinucleótido heterólogo en una célula hospedadora bacteriana recombinante.
Tal como se usa en el presente documento, el término “fragmento” de un polipéptido se refiere a una parte más corta de un polipéptido o una proteína de longitud completa cuyo tamaño oscila entre cuatro residuos de aminoácido y toda la secuencia de aminoácidos menos un residuo de aminoácido. En determinadas realizaciones de la divulgación, un fragmento se refiere a toda la secuencia de aminoácidos de un dominio de un polipéptido o una proteína (por ejemplo, un dominio de unión a sustrato o un dominio catalítico).
Tal como se usa en el presente documento, el término “mutagénesis” se refiere a un procedimiento mediante el cual se cambia la información genética de un organismo de manera estable. La mutagénesis de una secuencia de ácido nucleico que codifica para proteína produce una proteína mutante. Mutagénesis también se refiere a cambios en secuencias de ácido nucleico no codificantes que dan como resultado actividad de proteína modificada.
Tal como se usa en el presente documento, el término “gen” se refiere a secuencias de ácido nucleico que codifican para o bien un producto de ARN o bien un producto de proteína, así como secuencias de ácido nucleico operativamente unidas que afectan a la expresión del ARN o la proteína (por ejemplo, tales secuencias incluyen pero no se limitan a secuencias promotoras o potenciadoras) o secuencias de ácido nucleico operativamente unidas que codifican para secuencias que afectan a la expresión del ARN o la proteína (por ejemplo, tales secuencias incluyen pero no se limitan a sitios de unión al ribosoma o secuencias de control de la traducción).
Se conocen en la técnica secuencias de control de la expresión e incluyen, por ejemplo, promotores, potenciadores,
señales de poliadenilación, terminadores de la transcripción, sitios internos de entrada al ribosoma (IRES), y similares, que proporcionan la expresión de la secuencia de polinucleótido en una célula hospedadora. Las secuencias de control de la expresión interaccionan específicamente con proteínas celulares implicadas en la transcripción (Maniatis et al. (1987) Science 236:1237-1245 (1987)). Se describen secuencias de control de la expresión a modo de ejemplo, por ejemplo, en Goeddel, Gene Expression Technology: Methods in Enzymology, vol. 185, Academic Press, San Diego, Calif. (1990).
En los métodos de la divulgación, una secuencia de control de la expresión está operativamente unida a una secuencia de polinucleótido. Por “operativamente unida” quiere decirse que una secuencia de polinucleótido y una(s) secuencia(s) de control de la expresión se conectan de tal manera que se permita la expresión génica cuando se unen las moléculas apropiadas (por ejemplo, proteínas activadoras de la transcripción) a la(s) secuencia(s) de control de la expresión. Están ubicados promotores operativamente unidos en el sentido de 5' de la secuencia de polinucleótido seleccionada en cuanto a la dirección de transcripción y traducción. Pueden estar ubicados potenciadores operativamente unidos en el sentido de 5', dentro de o en el sentido de 3' del polinucleótido seleccionado.
Tal como se usa en el presente documento, el término “vector” se refiere a una molécula de ácido nucleico que puede transportar otro ácido nucleico, es decir, una secuencia de polinucleótido, a la que se ha unido. Un tipo de vector útil es un episoma (es decir, un ácido nucleico que puede dar replicación extracromosómica). Los vectores útiles son aquéllos que pueden dar replicación y/o expresión autónoma de ácidos nucleicos a los que se unen. Los vectores que pueden dirigir la expresión de genes a los que se unen operativamente se denominan en el presente documento “vectores de expresión”. En general, los vectores de expresión de utilidad en técnicas de ADN recombinante están a menudo en forma de “plásmidos”, que se refieren en general a bucles de ADN bicatenario circular que, en su forma de vector, no se unen al cromosoma. Los términos “plásmido” y “vector” se usan de manera intercambiable en el presente documento, en la medida en que un plásmido es la forma más comúnmente usada de vector. Sin embargo, también se incluyen otras de tales formas de vectores de expresión que sirven para funciones equivalentes y que se han conocido en la técnica posteriormente al presente documento. En algunas realizaciones, vector recombinante comprende al menos una secuencia que incluye (a) una secuencia de control de la expresión acoplada operativamente a la secuencia de polinucleótido; (b) un marcador de selección acoplado operativamente a la secuencia de polinucleótido; (c) una secuencia de marcador acoplada operativamente a la secuencia de polinucleótido; (d) un resto de purificación acoplado operativamente a la secuencia de polinucleótido; (e) una secuencia de secreción acoplada operativamente a la secuencia de polinucleótido; y (f) una secuencia de selección como diana acoplada operativamente a la secuencia de polinucleótido. Los vectores de expresión descritos en el presente documento incluyen una secuencia de polinucleótido descrita en el presente documento en una forma adecuada para la expresión de la secuencia de polinucleótido en una célula hospedadora. Los expertos en la técnica apreciarán que el diseño del vector de expresión puede depender de factores tales como la elección de la célula hospedadora que va transformarse, el nivel de expresión de polipéptido deseado, etc. Los vectores de expresión descritos en el presente documento pueden introducirse en células hospedadoras para producir polipéptidos, incluyendo polipéptidos de fusión, codificados por las secuencias de polinucleótido tal como se describe en el presente documento.
La expresión de genes que codifican para polipéptidos en procariotas, por ejemplo, E. coli, se lleva a cabo con la mayor frecuencia con vectores que contienen promotores constitutivos o inducibles que dirigen la expresión de polipéptidos o bien de fusión o bien de no fusión. Los vectores de fusión añaden un número de aminoácidos a un polipéptido codificado en el mismo, habitualmente al extremo amino-terminal o carboxi-terminal del polipéptido recombinante. Tales vectores de fusión sirven normalmente para uno o más de los tres propósitos siguientes: (1) aumentar expresión del polipéptido recombinante; (2) aumentar la solubilidad del polipéptido recombinante; y (3) ayudar en la purificación del polipéptido recombinante actuando como ligando en purificación por afinidad. A menudo, en los vectores de expresión de fusión, se introduce un sitio de escisión proteolítica en la unión del resto de fusión y el polipéptido recombinante. Esto permite la separación del polipéptido recombinante del resto de fusión después de la purificación del polipéptido de fusión. En determinadas realizaciones, una secuencia de polinucleótido de la divulgación está operativamente unida a un promotor derivado del bacteriófago T5. En determinadas realizaciones, la célula hospedadora es una célula de levadura, y el vector de expresión es un vector de expresión de levadura. Los ejemplos de vectores para la expresión en la levadura S. cerevisiae incluyen pYepSec1 (Baldari et al. (1987) EMBO J. 6:229-234 (1987)); pMFa (Kurjan et al. (1982) Cell 30:933-943 (1982)); pJRY88 (Schultz et al. (1987) Gene 54: 113 123 (1987)); pYES2 (Invitrogen Corp., San Diego, CA) y picZ (Invitrogen Corp., San Diego, CA). En otras realizaciones, la célula hospedadora es una célula de insecto, y el vector de expresión es un vector de expresión de baculovirus. Los vectores de baculovirus disponibles para la expresión de proteínas en células de insecto en cultivo (por ejemplo, células Sf9) incluyen, por ejemplo, la serie de pAc (Smith et al. Mol. Cell Biol. 3:2156-2165 (1983)) y la serie de pVL (Lucklow et al. (1989) Virology 170:31-39 (1989)). En aún otra realización, las secuencias de polinucleótido descritas en el presente documento pueden expresarse en células de mamífero usando un vector de expresión de mamífero. Se conocen bien en la técnica otros sistemas de expresión adecuados para células tanto procariotas como eucariotas; véase, por ejemplo, Sambrook et al., “Molecular Cloning: A Laboratory Manual”, segunda edición, Cold Spring Harbor Laboratory, (1989).
Tal como se usa en el presente documento, el término “acil-CoA” se refiere a un acil-tioéster formado entre el carbono de carbonilo de la cadena de alquilo y el grupo sulfhidrilo del resto 4'-fosfopantetionilo de la coenzima A (CoA), que tiene la fórmula R-C(O)S-CoA, en la que R es cualquier grupo alquilo que tiene al menos 4 átomos de carbono.
Tal como se usa en el presente documento, “acil-ACP” se refiere a un acil-tioéster formado entre el carbono de carbonilo de una cadena de alquilo y el grupo sulfhidrilo del resto fosfopanteteinilo de una proteína transportadora de acilo (ACP). El resto de fosfopanteteinilo se une de manera postraduccional a un residuo de serina conservado en la
ACP mediante la acción de la proteína transportadora de holo-acilo sintasa (ACPS), una fosfopanteteinilo transferasa.
En algunas realizaciones, una acil-ACP es un producto intermedio en la síntesis de acil-ACP totalmente saturadas. En otras realizaciones, una acil-ACP es un producto intermedio en la síntesis de acil-ACP insaturadas. En algunas realizaciones, la cadena de carbonos tendrá aproximadamente 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20,
21, 22, 23, 24, 25 ó 26 carbonos. Cada una de estas acil-ACP son sustratos para enzimas que las convierten en derivados de ácido graso.
Tal como se usa en el presente documento, el término “ácido graso o derivado del mismo” significa un “ácido graso” o un “derivado de ácido graso”. El término “ácido graso” significa un ácido carboxílico que tiene la fórmula RCOOH. R representa un grupo alifático, preferiblemente un grupo alquilo. R puede comprender entre aproximadamente 4 y aproximadamente 22 átomos de carbono. Los ácidos grasos pueden ser saturados, monoinsaturados o poliinsaturados. En una realización preferida, el ácido graso se prepara a partir de una ruta de biosíntesis de ácidos grasos. El término “derivado de ácido graso” significa productos producidos en parte a partir de la ruta de biosíntesis de ácidos grasos del organismo hospedador de producción. “Derivado de ácido graso” también incluye productos producidos en parte a partir de acil-ACP o derivados de acil-ACP. Los derivados de ácido graso a modo de ejemplo incluyen, por ejemplo, acil-CoA, aldehídos grasos, alcoholes de cadena corta y larga, hidrocarburos y ésteres (por ejemplo, ceras, ésteres de ácidos grasos o ésteres grasos).
Tal como se usa en el presente documento, el término “ruta de biosíntesis de ácidos grasos” significa una ruta de biosíntesis que produce derivados de ácido graso, por ejemplo, alcoholes grasos. La ruta de biosíntesis de ácidos grasos incluye ácido graso sintasas que pueden modificarse por ingeniería genética para producir ácidos grasos y en algunas realizaciones pueden expresarse con enzimas adicionales para producir derivados de ácido graso, tales como alcoholes grasos que tienen características deseadas.
Tal como se usa en el presente documento, “aldehído graso” significa un aldehído que tiene la fórmula RCHO caracterizada por un grupo carbonilo (C=O). En algunas realizaciones, el aldehído graso es cualquier aldehído producido a partir de un alcohol graso. En determinadas realizaciones, el grupo R tiene al menos 5, al menos 6, al menos 7, al menos 8, al menos 9, al menos 10, al menos 11, al menos 12, al menos 13, al menos 14, al menos 15, al menos 16, al menos 17, al menos 18 o al menos 19, carbonos de longitud. Alternativamente, o además, el grupo R tiene 20 o menos, 19 o menos, 18 o menos, 17 o menos, 16 o menos, 15 o menos, 14 o menos, 13 o menos, 12 o menos, 11 o menos, 10 o menos, 9 o menos, 8 o menos, 7 o menos o 6 o menos carbonos de longitud. Por tanto, el grupo R puede tener un grupo R delimitado por dos cualesquiera de los extremos anteriores. Por ejemplo, el grupo R puede tener 6-16 carbonos de longitud, 10-14 carbonos de longitud o 12-18 carbonos de longitud. En algunas realizaciones, el aldehído graso es un aldehído graso C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C20, C21, C22, C23, C24, C25, o uno C26. En determinadas realizaciones, el aldehído graso es un aldehído graso C6,
C8, C10, C12, C13, C14, C15, C16, C17 o C18.
Tal como se usa en el presente documento, “alcohol graso” significa un alcohol que tiene la fórmula ROH. En algunas realizaciones, el grupo R tiene al menos 5, al menos 6, al menos 7, al menos 8, al menos 9, al menos 10, al menos
11, al menos 12, al menos 13, al menos 14, al menos 15, al menos 16, al menos 17, al menos 18 o al menos 19, carbonos de longitud. Alternativamente, o además, el grupo R tiene 20 o menos, 19 o menos, 18 o menos, 17 o menos,
16 o menos, 15 o menos, 14 o menos, 13 o menos, 12 o menos, 11 o menos, 10 o menos, 9 o menos, 8 o menos, 7 o menos o 6 o menos carbonos de longitud. Por tanto, el grupo R puede tener un grupo R delimitado por dos cualesquiera de los extremos anteriores. Por ejemplo, el grupo R puede tener 6-16 carbonos de longitud, 10-14 carbonos de longitud o 12-18 carbonos. En algunas realizaciones, el alcohol graso es un alcohol graso C6, C7, C8, C9,
C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C20, C21, C22, C23, C24, C25, o uno C26. En determinadas realizaciones, el alcohol graso es un alcohol graso C6, C8, C10, C12, C13, C14, C15, C16, C17 o C18.
Una “composición de alcohol graso” tal como se hace referencia en el presente documento se produce por una célula hospedadora recombinante y comprende normalmente una mezcla de alcoholes grasos. En algunos casos, la mezcla incluye más de un tipo de producto (por ejemplo, alcoholes grasos y ácidos grasos). En otros casos, las composiciones de derivado de ácido graso pueden comprender, por ejemplo, una mezcla de alcoholes grasos con diversas longitudes de cadena y características de saturación o ramificación. En todavía otros casos, la composición de alcohol graso comprende una mezcla de tanto más de un tipo de producto como de productos con diversas longitudes de cadena y características de saturación o ramificación.
Una célula hospedadora modificada por ingeniería para producir un aldehído graso convertirá normalmente parte del aldehído graso en un alcohol graso. Cuando una célula hospedadora que produce alcoholes grasos se modifica por ingeniería genética para expresar un polinucleótido que codifica para una éster sintasa, se producen ésteres de cera.
En una realización, se producen alcoholes grasos a partir de una ruta de biosíntesis de ácidos grasos. Como ejemplo, puede convertirse acil-ACP en ácidos grasos por medio de la acción de una tioesterasa (por ejemplo, TesA de E. coli), que se convierten en aldehídos grasos y alcoholes grasos por medio de la acción de una ácido carboxílico reductasa
(por ejemplo, CarB de E. coli). La conversión de aldehidos grasos en alcoholes grasos puede verse facilitada además, por ejemplo, por medio de la acción de un polipéptido de biosíntesis de alcoholes grasos. En algunas realizaciones, un gen que codifica para un polipéptido de biosíntesis de alcoholes grasos se expresa o sobreexpresa en la célula hospedadora. En determinadas realizaciones, el polipéptido de biosíntesis de alcoholes grasos tiene actividad aldehído reductasa o alcohol deshidrogenasa. Los ejemplos de polipéptidos de alcohol deshidrogenasa útiles según la divulgación incluyen, pero no se limitan a AlrA de Acinetobacter sp. M-1 (SEQ ID NO: 3) u homólogos de AlrA, tales como AlrAadp1 (SEQ ID NO: 4) y alcohol deshidrogenasas de E. coli endógenas tales como YjgB, (AAC77226) (SEQ ID NO: 5), DkgA (NP_417485), DkgB (NP_414743), YdjL (AAC74846), YdjJ (NP_416288), AdhP (NP_415995), YhdH (NP_417719), YahK (NP_414859), YphC (AAC75598), YqhD (446856) e YbbO [AAC73595.1]. Se describen ejemplos adicionales en las publicaciones de solicitud de patente internacional n.os WO2007/136762, WO2008/119082 y WO2010/062480. En determinadas realizaciones, el polipéptido de biosíntesis de alcoholes grasos tiene actividad aldehído reductasa o alcohol deshidrogenasa (EC 1.1.1.1).
Tal como se usa en el presente documento, el término “alcohol deshidrogenasa” se refiere a un polipéptido que puede catalizar la conversión de un aldehído graso en un alcohol (por ejemplo, alcohol graso). Un experto habitual en la técnica apreciará que determinadas alcohol deshidrogenasas pueden catalizar otras reacciones también, y estas alcohol deshidrogenasas no específicas se abarcan también por el término “alcohol deshidrogenasa”. El grupo R de un ácido graso, aldehído graso o alcohol graso puede ser una cadena lineal o una cadena ramificada. Las cadenas ramificadas pueden tener más de un punto de ramificación y pueden incluir ramificaciones cíclicas. En algunas realizaciones, el ácido graso ramificado, aldehído graso ramificado o alcohol graso ramificado es un ácido graso ramificado, aldehído graso ramificado o alcohol graso ramificado C6, C7, C8, C9, C10, C11, C12, C13, C14, C15, C16, C17, C18, C19, C20, C21, C22, C23, C24, C25, o uno C26. En realizaciones particulares, el ácido graso ramificado, aldehído graso ramificado o alcohol graso ramificado es un ácido graso ramificado, aldehído graso ramificado o alcohol graso ramificado C6, C8, C10, C12, C13, C14, C15, C16, C17 o C18. En determinadas realizaciones, el grupo hidroxilo del ácido graso ramificado, aldehído graso ramificado o alcohol graso ramificado está en la posición primaria (C1). En determinadas realizaciones, el ácido graso ramificado, aldehído graso ramificado o alcohol graso ramificado es un ácido graso iso, aldehído graso iso o alcohol graso iso, o un ácido graso anteiso, un aldehído graso anteiso o alcohol graso anteiso. En realizaciones a modo de ejemplo, el ácido graso ramificado, aldehído graso ramificado o alcohol graso ramificado se selecciona de ácido graso ramificado, aldehído graso ramificado o alcohol graso ramificado iso -C7:0, iso-C8 :0 , iso-C9:0, iso-C10:0, iso-C11:0, iso-C12:0 , iso-C13:0, iso-C14:0, iso-C15:0, iso-C16:0 , iso-C17:0, iso-C18:0, iso-C19:0, anteiso-C7:0, anteiso-C8:0 , anteiso-C9:0, anteiso-C10:0 , anteiso-C11;0 , anteiso-C12:0, anteiso-C13:0, anteiso-C14:0, anteiso-C15:0, anteiso-C16:0, anteiso-C17:0, anteiso-C18:0, and anteiso-C19:0. El grupo R de un ácido graso ramificado o no ramificado, aldehído graso ramificado o no ramificado o alcohol graso ramificado o no ramificado puede ser saturado o insaturado. Si es insaturado, el grupo R puede tener uno o más de un punto de insaturación. En algunas realizaciones, el ácido graso insaturado, aldehído graso insaturado o alcohol graso insaturado es un ácido graso monoinsaturado, aldehído graso monoinsaturado o alcohol graso monoinsaturado. En determinadas realizaciones, el ácido graso insaturado, aldehído graso insaturado o alcohol graso insaturado es un ácido graso insaturado, aldehído graso insaturado o alcohol graso insaturado C6:1, C7:1, C8:1, C9:1, C10:1, C11:1, C12:1, C13:1, C14:1, C15:1, C16:1, C17:1, C18:1, C19:1, C20:1, C21:1, C22:1, C23:1, C24:1, C25:1, o uno C26:1. En determinadas realizaciones preferidas, el ácido graso insaturado, aldehído graso insaturado o alcohol graso insaturado es C10:1, C12:1, C14:1, C16:1 o C18:1. En aún otras realizaciones, el ácido graso insaturado, aldehído graso insaturado o alcohol graso insaturado es insaturado en la posición omega-7. En determinadas realizaciones, el ácido graso insaturado, aldehído graso insaturado o alcohol graso insaturado comprende un doble enlace cis.
Tal como se usa en el presente documento, una “célula hospedadora” recombinante o modificada por ingeniería genética es una célula hospedadora, por ejemplo, un microorganismo que se ha modificado de manera que produce alcoholes grasos. En algunas realizaciones, la célula hospedadora recombinante comprende uno o más polinucleótidos, codificando cada polinucleótido para un polipéptido que tiene actividad enzimática de biosíntesis de aldehídos grasos y/o alcoholes grasos, en la que la célula hospedadora recombinante produce una composición de alcohol graso cuando se cultiva en presencia de una fuente de carbono en condiciones eficaces para expresar los polinucleótidos.
Tal como se usa en el presente documento, el término “clon” se refiere normalmente a una célula o un grupo de células que descienden de y esencialmente idénticas genéticamente a un único ancestro común, por ejemplo, las bacterias de una colonia bacteriana clonada surgida a partir de una única célula bacteriana.
Tal como se usa en el presente documento, el término “cultivo” se refiere normalmente a un medio líquido que comprende células viables. En una realización, un cultivo comprende células que se reproducen en medios de cultivo predeterminados en condiciones controladas, por ejemplo, un cultivo de células hospedadoras recombinantes hechas crecer en medios líquidos que comprenden una fuente de carbono y nitrógeno seleccionada. “Cultivar” o “cultivo” se refieren al crecimiento de una población de células de células microbianas en condiciones adecuadas en un medio líquido o sólido. En realizaciones particulares, cultivar se refiere a la bioconversión fermentativa de un sustrato en un producto final. Se conocen bien medios de cultivo y los componentes individuales de tales medios de cultivo están disponibles de fuentes comerciales, por ejemplo, con las marcas comerciales DIFCOTM y BBLTM. En un ejemplo no limitativo, el medio de nutrientes acuoso es un “medio rico” que comprende fuentes complejas de nitrógeno, sales y carbono, tal como el medio YP, que comprende 10 g/l de peptona y 10 g/l de extracto de levadura de un medio de este
tipo. La célula hospedadora puede modificarse por ingeniería genética adicionalmente para asimilar el carbono eficazmente y usar materiales celulósicos como fuentes de carbono según los métodos descritos, por ejemplo, en las patentes estadounidenses 5.000.000; 5.028.539; 5.424.202; 5.482.846; 5.602.030 y en el documento WO2010127318.
Además, la célula hospedadora puede modificarse por ingeniería para expresar una invertasa de modo que pueda
usarse sacarosa como fuente de carbono.
Tal como se usa en el presente documento, el término “en condiciones eficaces para expresar dichas secuencias de nucleótidos heterólogas” significa cualesquiera condiciones que permiten que una célula hospedadora produzca un aldehído graso o alcohol graso deseado. Las condiciones adecuadas incluyen, por ejemplo, condiciones de fermentación.
Tal como se usa en el presente documento, un “nivel modificado” o “alterado de” actividad de una proteína, por ejemplo
una enzima, en una célula hospedadora recombinante se refiere a una diferencia en una o más características en la actividad determinadas con relación a la célula hospedadora parental o nativa. Normalmente se determinan diferencias
en actividad entre una célula hospedadora recombinante, que tiene actividad modificada, y la célula hospedadora
natural correspondiente (por ejemplo, comparación de un cultivo de una célula hospedadora recombinante con relación
a la célula hospedadora natural). Actividades modificadas pueden ser el resultado de, por ejemplo, cantidades modificadas de proteína expresada por una célula hospedadora recombinante (por ejemplo, como resultado de un aumento o una disminución del número de copias de secuencias de ADN que codifican para la proteína, un aumento
o una disminución del número de transcritos de ARNm que codifican para la proteína, y/o un aumento o una disminución de las cantidades de traducción de proteína de la proteína a partir del ARNm); cambios en la estructura
de la proteína (por ejemplo, cambios en la estructura primaria, tales como cambios en la secuencia codificante de la proteína que dan como resultado cambios en la especificidad de sustrato, cambios en parámetros cinéticos observados); y cambios en la estabilidad de la proteína (por ejemplo, un aumento o una disminución de la degradación
de la proteína). En algunas realizaciones, el polipéptido es un mutante o una variante de cualquiera de los polipéptidos descritos en el presente documento. En determinados casos, las secuencias codificantes para los polipéptidos tal como se describe en el presente documento se someten a optimización de codones para la expresión en una célula hospedadora particular. Por ejemplo, para la expresión en E. coli, pueden optimizarse uno o más codones tal como se describe, por ejemplo, en Grosjean et al. Gene 18:199-209 (1982).
El término “secuencias reguladoras” tal como se usa en el presente documento se refiere normalmente a una secuencia de bases en ADN, operativamente unida a secuencias de ADN que codifican para una proteína que controla
en última instancia la expresión de la proteína. Los ejemplos de secuencias reguladoras incluyen, pero no se limitan
a, secuencias promotoras de ARN, secuencias de unión a factor de transcripción, secuencias de terminación de la transcripción, moduladores de la transcripción (tales como elementos potenciadores), secuencias de nucleótidos que
afectan a la estabilidad del ARN y secuencias reguladoras de la traducción (tales como sitios de unión al ribosoma
(por ejemplo, secuencias de Shine-Dalgarno en procariotas o secuencias de Kozak en eucariotas), codones de iniciación, codones de terminación).
Tal como se usa en el presente documento, la frase “la expresión de dicha secuencia de nucleótidos se modifica con
relación a la secuencia de nucleótidos natural”, significa un aumento o una disminución en el nivel de expresión y/o actividad de una secuencia de nucleótidos endógena o la expresión y/o actividad de una secuencia de nucleótidos que codifica para polipéptido heterólogo o no nativo. Tal como se usa en el presente documento, el término “sobreexpresar” significa expresar o hacer que se exprese un polinucleótido o polipéptido en una célula a una mayor concentración de
lo que se expresa normalmente en una célula natural correspondiente en las mismas condiciones.
Los términos “nivel alterado de expresión” y “nivel modificado de expresión” se usan de manera intercambiable y significan que está presente un polinucleótido, polipéptido o hidrocarburo en una concentración diferente en una célula hospedadora modificada por ingeniería genética en comparación con su concentración en una célula natural correspondiente en las mismas condiciones.
Tal como se usa en el presente documento, el término “título” se refiere a la cantidad de aldehído graso o alcohol graso producido por volumen unitario de cultivo de células hospedadoras. En cualquier aspecto de las composiciones
y los métodos descritos en el presente documento, un alcohol graso se produce a un título de 25 mg/l, 50 mg/l, 75
mg/l, 100 mg/l, 125 mg/l, 150 mg/l, 175 mg/l, 200 mg/l, 225 mg/l, 250 mg/l, 275 mg/l, 300 mg/l, 325 mg/l, 350 mg/l, 375
mg/l, 400 mg/l, 425 mg/l, 450 mg/l, 475 mg/l, 500 mg/l, 525 mg/l, 550 mg/l, 575 mg/l, 600 mg/l, 625 mg/l, 650 mg/l, 675
mg/l, 700 mg/l, 725 mg/l, 750 mg/l, 775 mg/l, 800 mg/l, 825 mg/l, 850 mg/l, 875 mg/l, 900 mg/l, 925 mg/l, 950 mg/l, 975
mg/l, 1000 mg/l, 1050 mg/l, 1075 mg/l, 1100 mg/l, 1125 mg/l, 1150 mg/l, 1175 mg/l, 1200 mg/l, 1225 mg/l, 1250 1275 mg/l, 1300 mg/l, 1325 mg/l, 1350 mg/l, 1375 mg/l, 1400 mg/l, 1425 mg/l, 1450 mg/l, 1475 mg/l, 1500 mg/l, mg/l, 1550 mg/l, 1575 mg/l, 1600 mg/l, 1625 mg/l, 1650 mg/l, 1675 mg/l, 1700 mg/l, 1725 mg/l, 1750 mg/l, 1775 1800 mg/l, 1825 mg/l, 1850 mg/l, 1875 mg/l, 1900 mg/l, 1925 mg/l, 1950 mg/l, 1975 mg/l, 2000 mg/l (2 g/l), 3 g/l, 10 g/l, 20 g/l, 30 g/l, 40 g/l, 50 g/l, 60 g/l, 70 g/l, 80 g/l, 90 g/l, 100 g/l o un intervalo delimitado por dos cualesquiera de
los valores anteriores. En otras realizaciones, se produce un aldehído graso o alcohol graso a un título de más de 100
g/l, más de 200 g/l, más de 300 g/l, o mayor, tal como 500 g/l, 700 g/l, 1000 g/l, 1200 g/l, 1500 g/l o 2000 g/l. El título preferido de aldehído graso o alcohol graso producido por una célula hospedadora recombinante según los métodos
de la divulgación es de desde 5 g/l hasta 200 g/l, de 10 g/l a 150 g/l, de 20 g/l a 120 g/l y de 30 g/l a 100 g/l.
Tal como se usa en el presente documento, el término “rendimiento del aldehido graso o alcohol graso producido por una célula hospedadora” se refiere a la eficacia mediante la que una fuente de carbono de entrada se convierte en producto (es decir, alcohol graso o aldehído graso) en una célula hospedadora. Células hospedadoras modificadas por ingeniería genética para producir alcoholes grasos y/o aldehídos grasos según los métodos de la divulgación tienen un rendimiento de al menos el 3%, al menos el 4%, al menos el 5%, al menos el 6%, al menos el 7%, al menos el 8%, al menos el 9%, al menos el 10%, al menos el 11%, al menos el 12%, al menos el 13%, al menos el 14%, al menos el 15%, al menos el 16%, al menos el 17%, al menos el 18%, al menos el 19%, al menos el 20%, al menos el 21%, al menos el 22%, al menos el 23%, al menos el 24%, al menos el 25%, al menos el 26%, al menos el 27%, al menos el 28%, al menos el 29%, o al menos el 30% o un intervalo delimitado por dos cualesquiera de los valores anteriores. En otras realizaciones, se produce un aldehído graso o alcohol graso con un rendimiento de más del 30%, el 40%, el 50%, el 60%, el 70%, el 80%, el 90% o más. Alternativamente, o además, el rendimiento es de aproximadamente el 30% o menos, aproximadamente el 27% o menos, aproximadamente el 25% o menos o aproximadamente el 22% o menos. Por tanto, el rendimiento puede estar delimitado por dos cualesquiera de los extremos anteriores. Por ejemplo, el rendimiento del alcohol graso o aldehído graso producido por la célula hospedadora recombinante según los métodos de la divulgación puede ser del 5% al 15%, del 10% al 25%, del 10% al 22%, del 15% al 27%, del 18% al 22%, del 20% al 28% o del 20% al 30%. El rendimiento preferido de alcohol graso producido por la célula hospedadora recombinante según los métodos de la divulgación es de desde el 10% hasta el 30%.
Tal como se usa en el presente documento, el término “productividad” se refiere a la cantidad de aldehído graso o alcohol graso producido por volumen unitario de cultivo de células hospedadoras por tiempo unitario. En cualquier aspecto de las composiciones y los métodos descritos en el presente documento, la productividad de aldehído graso o alcohol graso producido por una célula hospedadora recombinante es de al menos 100 mg/l/hora, al menos 200 mg/l/hora, al menos 300 mg/l/hora, al menos 400 mg/l/hora, al menos 500 mg/l/hora, al menos 600 mg/l/hora, al menos 700 mg/l/hora, al menos 800 mg/l/hora, al menos 900 mg/l/hora, al menos 1000 mg/l/hora, al menos 1100 mg/l/hora, al menos 1200 mg/l/hora, al menos 1300 mg/l/hora, al menos 1400 mg/l/hora, al menos 1500 mg/l/hora, al menos 1600 mg/l/hora, al menos 1700 mg/l/hora, al menos 1800 mg/l/hora, al menos 1900 mg/l/hora, al menos 2000 mg/l/hora, al menos 2100 mg/l/hora, al menos 2200 mg/l/hora, al menos 2300 mg/l/hora, al menos 2400 mg/l/hora o al menos 2500 mg/l/hora. Alternativamente, o además, la productividad es de 2500 mg/l/hora o menos, 2000 mg/l/DO600 o menos, 1500 mg/l/DO600 o menos, 120 mg/l/hora o menos, 1000 mg/l/hora o menos, 800 mg/l/hora o menos o 600 mg/l/hora o menos. Por tanto, la productividad puede estar delimitada por dos cualesquiera de los extremos anteriores. Por ejemplo, la productividad puede ser de 3 a 30 mg/l/hora, de 6 a 20 mg/l/hora o de 15 a 30 mg/l/hora. La productividad preferida de un aldehído graso o alcohol graso producido por una célula hospedadora recombinante según los métodos de la divulgación se selecciona de 500 mg/l/hora a 2500 mg/l/hora, o desde 700 mg/l/hora hasta 2000 mg/l/hora.
Los términos “especie grasa total” y “producto de ácido graso total” pueden usarse de manera intercambiable en el presente documento con referencia a la cantidad total de alcoholes grasos, aldehídos grasos, ácidos grasos libres y ésteres grasos presentes en una muestra tal como se evalúa mediante CG-FID tal como se describe en la publicación de solicitud de patente internacional WO 2008/119082. Las muestras pueden contener uno, dos, tres o cuatro de estos compuestos dependiendo del contexto.
Tal como se usa en el presente documento, el término “tasa de utilización de glucosa” significa la cantidad de glucosa usada por el cultivo por tiempo unitario, notificada como gramos/litro/hora (g/l/h).
Tal como se usa en el presente documento, el término “fuente de carbono” se refiere a un sustrato o compuesto adecuado para usarse como fuente de carbono para el crecimiento de células procariotas o eucariotas simples. Las fuentes de carbono pueden estar en diversas formas, incluyendo, pero sin limitarse a polímeros, hidratos de carbono, ácidos, alcoholes, aldehídos, cetonas, aminoácidos, péptidos y gases (por ejemplo, CO y CO2). Las fuentes de carbono a modo de ejemplo incluyen, pero no se limitan a, monosacáridos, tales como glucosa, fructosa, manosa, galactosa, xilosa y arabinosa; oligosacáridos, tales como fructo-oligosacárido y galacto-oligosacárido; polisacáridos tales como almidón, celulosa, pectina y xilano; disacáridos, tales como sacarosa, maltosa, celobiosa y turanosa; material celulósico y variantes tales como hemicelulosas, metilcelulosa y carboximetilcelulosa sódica; ácidos grasos saturados o insaturados, succinato, lactato y acetato; alcoholes, tales como etanol, metanol y glicerol, o mezclas de los mismos. La fuente de carbono también puede ser un producto de fotosíntesis, tal como glucosa. En determinadas realizaciones preferidas, la fuente de carbono es biomasa. En otras realizaciones preferidas, la fuente de carbono es glucosa. En otras realizaciones preferidas, la fuente de carbono es sacarosa.
Tal como se usa en el presente documento, el término “biomasa” se refiere a cualquier material biológico del que se derive una fuente de carbono. En algunas realizaciones, se procesa una biomasa para dar una fuente de carbono, que es adecuada para la bioconversión. En otras realizaciones, la biomasa no requiere procesamiento adicional para dar una fuente de carbono. La fuente de carbono puede convertirse en un biocombustible. Una fuente de biomasa a modo de ejemplo es vegetación o materia vegetal, tal como maíz, caña de azúcar o césped de pradera. Otra fuente de biomasa a modo de ejemplo es productos de desecho metabólicos, tales como materia animal (por ejemplo, estiércol de vaca). Las fuentes de biomasa a modo de ejemplo adicionales incluyen algas y otras plantas marinas. La biomasa también incluye productos de desecho de la industria, la agricultura, silvicultura y domésticos, incluyendo, pero sin
limitarse a, residuo de fermentación, ensilado, paja, madera, aguas cloacales, basura, desechos urbanos celulósicos y restos de comidas. El término “biomasa” también puede referirse a fuentes de carbono, tales como hidratos de carbono (por ejemplo, monosacáridos, disacáridos o polisacáridos).
Tal como se usa en el presente documento, el término “aislados”, con respecto a productos (tales como ácidos grasos y derivados de los mismos) se refiere a productos que están separados de componentes celulares, medios de cultivo celular, o precursores químicos o sintéticos. Los ácidos grasos y derivados de los mismos producidos mediante los métodos descritos en el presente documento pueden ser relativamente inmiscibles en el caldo de fermentación, así como en el citoplasma. Por tanto, los ácidos grasos y derivados de los mismos pueden recogerse en una fase orgánica o bien de manera intracelular o bien de manera extracelular.
Tal como se usa en el presente documento, los términos “purificar”, “purificado” o “purificación” significan la retirada o el aislamiento de una molécula de su entorno, por ejemplo, mediante aislamiento o separación. Las moléculas “sustancialmente purificadas” están libres en al menos aproximadamente el 60% (por ejemplo, libres en al menos aproximadamente el 70%, libres en al menos aproximadamente el 75%, libres en al menos aproximadamente el 85%, libres en al menos aproximadamente el 90%, libres en al menos aproximadamente el 95%, libres en al menos aproximadamente el 97%, libres en al menos aproximadamente el 99%) de otros componentes con los que se asocian. Tal como se usa en el presente documento, estos términos también se refieren a la retirada de contaminantes de una muestra. Por ejemplo, la retirada de contaminantes puede dar como resultado un aumento en el porcentaje de un aldehído graso o un alcohol graso en una muestra. Por ejemplo, cuando se produce un aldehído graso o un alcohol graso en una célula hospedadora recombinante, el aldehído graso o alcohol graso puede purificarse mediante la retirada de proteínas de la célula hospedadora. Después de la purificación, el porcentaje de un aldehído graso o un alcohol graso en la muestra aumenta. Los términos “purificar”, “purificado” y “purificación” son términos relativos que no requieren pureza absoluta. Por tanto, por ejemplo, cuando se produce un aldehído graso o un alcohol graso en células hospedadoras recombinantes, un aldehído graso purificado o un alcohol graso purificado es un aldehído graso o un alcohol graso que está sustancialmente separado de otros componentes celulares (por ejemplo, ácidos nucleicos, polipéptidos, lípidos, hidratos de carbono u otros hidrocarburos).
Mejoras de cepas
Con el fin de cumplir los objetivos muy altos para el título, el rendimiento y/o la productividad de alcoholes grasos, se hicieron varias modificaciones en las células hospedadoras de producción. FadR es un factor regulador clave implicado en las rutas de biosíntesis de ácidos grasos y degradación de ácidos grasos (Cronan et al., Mol. Microbiol., 29(4): 937 943 (1998)). La enzima ACS de E. coli FadD y la proteína de transporte de ácidos grasos FadL son componentes esenciales de un sistema de captación de ácidos grasos. FadL media en el transporte de ácidos grasos al interior de la célula bacteriana, y FadD media en la formación de ésteres de acil-CoA. Cuando no está disponible ninguna otra fuente de carbono, la bacteria capta ácidos grasos exógenos y los convierte en ésteres de acil-CoA, que pueden unirse al factor de transcripción FadR y desreprimir la expresión de los genes fad que codifican para proteínas responsables del transporte (FadL), activación (FadD) y p-oxidación (FadA, FadB, FadE y FadH) de ácidos grasos. Cuando están disponibles fuentes de carbono alternativas, las bacterias sintetizan ácidos grasos como acil-ACP, que se usan para la síntesis de fosfolípidos, pero no son sustratos para la p-oxidación. Por tanto, acil-CoA y acil-ACP son ambas fuentes independientes de ácidos grasos que pueden dar como resultado diferentes productos finales (Caviglia et al., J. Biol. Chem., 279(12): 1163-1169 (2004)). La solicitud provisional estadounidense n.° 611470.989 describe métodos mejorados de producción de derivados de ácido graso en una célula hospedadora que se modifica por ingeniería genética para tener un nivel de expresión alterado de un polipéptido de FadR en comparación con el nivel de expresión del polipéptido de FadR en una célula hospedadora natural correspondiente.
Hay especulaciones contradictorias en la técnica en cuanto a los factores limitantes de la biosíntesis de ácidos grasos en células hospedadoras, tales como E. coli. Un enfoque para aumentar el flujo a través de la biosíntesis de ácidos grasos es manipular diversas enzimas en la ruta (figuras 1 y 2). El suministro de acil-ACP a partir de acetil-CoA por medio del complejo de acetil-CoA carboxilasa (acc) (figura 3) y la ruta de biosíntesis de ácidos grasos (fab) puede limitar la tasa de producción de alcohol graso. En un enfoque a modo de ejemplo detallado en el ejemplo 2, el efecto de la sobreexpresión de Corynebacterium glutamicum accABCD (±birA) demostró que tales modificaciones genéticas pueden conducir a un aumento de acetil-coA y malonil-CoA en E. coli. Un posible motivo de una baja tasa de flujo a través de la biosíntesis de ácidos grasos es un suministro limitado de precursores, concretamente acetil-CoA y, en particular, malonil-CoA, y los principales precursores para la biosíntesis de ácidos grasos. El ejemplo 3 describe la construcción de operones de fab que codifican para enzimas en la ruta de biosíntesis para la conversión de malonil-CoA en acil-ACP y su integración en el cromosoma de una célula hospedadora de E. coli. En aún otro enfoque detallado en el ejemplo 4, se mostró que mutaciones en los genes de rph e ilvG en la célula hospedadora de E. coli daban como resultado una producción superior de ácido graso libre (FFA), que se tradujo en una producción superior de alcohol graso. En todavía otro enfoque, se realizaron mutagénesis de transposones y examen de alto rendimiento para encontrar mutaciones beneficiosas que aumentaran el título o rendimiento. El ejemplo 5 describe cómo una inserción de transposón en el gen de yijP puede mejorar el rendimiento de alcohol graso en fermentaciones semicontinuas y en matraz de agitación.
Ácido carboxílico reductasa (CAR)
Se han modificado por ingeniería genética células hospedadoras recombinantes para producir alcoholes grasos expresando una tioesterasa, que cataliza la conversión de acil-ACP en ácidos grasos libres (FFA) y una ácido carboxílico reductasa (CAR), que convierte ácidos grasos libres en aldehídos grasos. Aldehído reductasas nativas (endógenas) presentes en la célula hospedadora (por ejemplo, E. coli) pueden convertir aldehídos grasos en alcoholes grasos. Se describen tioesterasas a modo de ejemplo por ejemplo en la publicación de patente estadounidense n.° 20100154293. CarB es una ácido carboxílico reductasa a modo de ejemplo, una enzima clave en la ruta de producción de alcohol graso. El documento WO2010/062480 describe una búsqueda con BLAST usando la secuencia de aminoácidos NRRL 5646 CAR (registro de Genpept AAR91681) (SEQ ID nO: 6) como secuencia de consulta, y el uso de la misma en la identificación de aproximadamente 20 secuencias homólogas.
Los términos “ácido carboxílico reductasa”, “CAR” y “polipéptido de biosíntesis de aldehídos grasos” se usan de manera intercambiable en el presente documento. En la práctica de la divulgación, se expresa o sobreexpresa un gen que codifica para un polipéptido de ácido carboxílico reductasa en la célula hospedadora. En algunas realizaciones, el polipéptido de CarB tiene la secuencia de aminoácidos de SEQ ID NO: 7. En otras realizaciones, el polipéptido de CarB es una variante o un mutante de SEQ ID NO: 7. En determinadas realizaciones, el polipéptido de CarB es de una célula de mamífero, célula vegetal, célula de insecto, célula de levadura, célula fúngica, célula de hongos filamentosos, una célula bacteriana o cualquier otro organismo. En algunas realizaciones, la célula bacteriana es una micobacteria seleccionada del grupo que consiste en Mycobacterium smegmatis, Mycobacterium abscessus, Mycobacterium avium, Mycobacterium bovis, Mycobacterium tuberculosis, Mycobacterium leprae, Mycobacterium marinum y Mycobacterium ulcerans. En otras realizaciones, la célula bacteriana es de una especie de Nocardia, por ejemplo, Nocardia NRRL 5646, Nocardia farcinica, Streptomyces griseus, Salinispora arenicola o Clavibacter michiganenesis. En otras realizaciones, el polipéptido de CarB es un homólogo de CarB que tiene una secuencia de aminoácidos que es al menos el 90%, el 91%, el 92%, el 93%, el 94%, el 95%, el 96%, el 97%, el 98% o el 99% idéntica a la secuencia de aminoácidos de SEQ ID NO: 7. Un experto habitual en la técnica puede identificar fácilmente homólogos de CarB derivados de E. coli MG1566 y determinar su función usando los métodos descritos en el presente documento. En otras realizaciones, el polipéptido de CarB contiene una mutación en el número de aminoácido 3, 12, 20, 28, 46, 74, 103, 191, 288, 473, 827, 926, 927, 930 ó 1128 de SEQ ID NO: 7. Se detallan mutaciones a modo de ejemplo en la tabla 10. Los fragmentos o mutantes preferidos de un polipéptido conservan parte o toda la función biológica (por ejemplo, actividad enzimática) del polipéptido natural correspondiente. En algunas realizaciones, el fragmento o mutante conserva al menos aproximadamente el 75%, al menos aproximadamente el 80%, al menos aproximadamente el 90%, al menos aproximadamente el 95% o al menos aproximadamente el 98% o más de la función biológica del polipéptido natural correspondiente. En otras realizaciones, el fragmento o mutante conserva aproximadamente el 100% de la función biológica del polipéptido natural correspondiente. Puede encontrarse orientación para determinar qué residuos de aminoácido pueden sustituirse, insertarse o delecionarse sin afectar a la actividad biológica usando programas informáticos bien conocidos en la técnica, por ejemplo, el software LASERGENE™ (DNASTAR, Inc., Madison, WI).
En aún otras realizaciones, un fragmento o mutante presenta una función biológica aumentada en comparación con un polipéptido natural correspondiente. Por ejemplo, un fragmento o mutante puede presentar una mejora de al menos aproximadamente el 10%, al menos aproximadamente el 25%, al menos aproximadamente el 50%, al menos aproximadamente el 75% o al menos aproximadamente el 90% en la actividad enzimática en comparación con el polipéptido natural correspondiente. En otras realizaciones, el fragmento o mutante presenta una mejora de al menos aproximadamente el 100% (por ejemplo, al menos aproximadamente el 200%, o al menos aproximadamente el 500%) en la actividad enzimática en comparación con el polipéptido natural correspondiente. Se entiende que los polipéptidos descritos en el presente documento pueden tener sustituciones de aminoácidos no esenciales o conservativas adicionales, que no tienen un efecto sustancial sobre la función del polipéptido. Puede determinarse si se tolerará o no una sustitución particular (es decir, no afectará de manera adversa a la función biológica deseada, tal como unión al ADN o actividad enzimática) tal como se describe en Bowie et al. (Science, 247: 1306-1310 (1990)).
Como resultado de los métodos y las enzimas variantes de la presente divulgación, uno o más del título, el rendimiento y/o la productividad del ácido graso o derivado del mismo producido por la célula hospedadora modificada por ingeniería genética que tiene un nivel de expresión alterado de un polipéptido de CarB se aumenta en relación con el de la célula hospedadora natural correspondiente. Para permitir una conversión máxima de ácidos grasos C12 y C14 en alcoholes grasos, CarB debe expresarse a actividad suficiente. Una célula hospedadora recombinante mejorada tendría una enzima CAR que se expresa a partir de, por ejemplo, el cromosoma de E. coli. Tal como se muestra en el ejemplo 6, las células que expresan la enzima CarB a partir del cromosoma tienen más actividad ácido carboxílico reductasa en relación con la CarB original y pueden convertir más ácidos grasos C12 y C14 en alcoholes grasos. CarB es un gen grande (3,5 kb) y aumenta el tamaño del plásmido considerablemente, lo que hace difícil usar un plásmido pCL para someter a prueba nuevos genes durante el desarrollo de cepas. Los enfoques para aumentar la actividad de CarB incluyen aumentar su solubilidad, estabilidad, expresión y/o funcionalidad. En un enfoque a modo de ejemplo, se produce una proteína de fusión que contiene 6 histidinas y un sitio de escisión de trombina en el extremo N-terminal de CarB. Esta enzima difiere de CarB en 60 nucleótidos adicionales en el extremo N-terminal, y se denomina CarB60. Cuando se expresan CarB o CarB60 a partir del cromosoma de E. coli bajo el control del promotor pTRC, las células que contienen CarB60 tienen una actividad ácido carboxílico reductasa celular total aumentada y convierten más ácidos grasos libres (FFA) C12 y C14 en alcoholes grasos. Un experto en la técnica apreciará que esto es un ejemplo
de modificación por ingeniería genética molecular con el fin de lograr una mayor conversión de ácidos grasos libres (FFA) C12 y C14 en alcoholes grasos tal como se ilustra en el ejemplo 6 (citado anteriormente). Se engloban enfoques similares en el presente documento (véase el ejemplo 7).
Las fosfopanteteína transferasas (PPTasas) (EC 2.7.8.7) catalizan la transferencia de 4'-fosfopanteteína desde CoA hasta un sustrato. Car, CarB de Nocardia y varios homólogos de las mismas contienen un sitio de unión supuesto para 4'-fosfopanteteína (PPT) (He et al., Appl. Enviran. Microbiol., 70(3): 1874-1881 (2004)). En algunas realizaciones de la divulgación, se expresa o sobreexpresa una PPTasa en una célula hospedadora modificada por ingeniería genética. En determinadas realizaciones, la PPTasa es EntD de E. coli MG1655 (SEQ ID NO: 8). En algunas realizaciones, se expresan o sobreexpresan una tioesterasa y una ácido carboxílico reductasa en una célula hospedadora modificada por ingeniería genética. En determinadas realizaciones, la tioesterasa es tesA y la ácido carboxílico reductasa es carB. En otras realizaciones, se expresan o sobreexpresan una tioesterasa, una ácido carboxílico reductasa y una alcohol deshidrogenasa en una célula hospedadora modificada por ingeniería genética. En determinadas realizaciones, la tioesterasa es tesA, la ácido carboxílico reductasa es carB y la alcohol deshidrogenasa es alrAadp1 (número de registro de GenPept CAG70248.1) de Acinetobacter baylyi ADP1 (SEQ ID NO: 4). En todavía otras realizaciones, se expresan o sobreexpresan una tioesterasa, una ácido carboxílico reductasa una PPTasa y una alcohol deshidrogenasa en la célula hospedadora modificada por ingeniería genética. En determinadas realizaciones, la tioesterasa es tesA, la ácido carboxílico reductasa es carB, la PPTasa es entD y la alcohol deshidrogenasa es alrAadp1. En realizaciones todavía adicionales, una célula hospedadora modificada que expresa una o más de una tioesterasa, una CAR, una PPTasa y una alcohol deshidrogenasa tiene también una o más mejoras de cepas. Las mejoras de cepas a modo de ejemplo incluyen, pero no se limitan a la expresión o sobreexpresión de un polipéptido de acetil-CoA carboxilasa, sobreexpresión de un polipéptido de FadR, expresión o sobreexpresión de un operón de iFAB heterólogo o la inserción de un transposón en el gen de yijP u otro gen, o enfoques similares. También se describe en el presente documento una composición de alcohol graso producida mediante cualquiera de los métodos descritos en el presente documento. Una composición de alcohol graso producida mediante cualquiera de los métodos descritos en el presente documento puede usarse directamente como materiales de partida para la producción de otros compuestos químicos (por ejemplo, polímeros, tensioactivos, plásticos, textiles, disolventes, adhesivos, etc.) o aditivos para el cuidado personal. Estos compuestos pueden usarse también como materia prima para reacciones posteriores, por ejemplo, hidrogenación, craqueo catalítico (por ejemplo, por medio de hidrogenación, pirólisis o ambas) para preparar otros productos.
Mutantes o variantes
En algunas realizaciones, el polipéptido expresado en una célula hospedadora recombinante es un mutante o una variante de cualquiera de los polipéptidos descritos en el presente documento. Los términos “mutante” y “variante” tal como se usan en el presente documento se refieren a un polipéptido que tiene una secuencia de aminoácidos que difiere de un polipéptido natural en al menos un aminoácido. Por ejemplo, el mutante puede comprender una o más de las siguientes sustituciones de aminoácidos conservativas: reemplazo de un aminoácido alifático, tal como alanina, valina, leucina e isoleucina, por otro aminoácido alifático; reemplazo de una serina por una treonina; reemplazo de una treonina por una serina; reemplazo de un residuo ácido, tal como ácido aspártico y ácido glutámico, por otro residuo ácido; reemplazo de un residuo que porta un grupo amida, tal como asparagina y glutamina, por otro residuo que porta un grupo amida; intercambio de un residuo básico, tal como lisina y arginina, por otro residuo básico; y reemplazo de un residuo aromático, tal como fenilalanina y tirosina, por otro residuo aromático. En algunas realizaciones, el polipéptido mutante tiene aproximadamente 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 30, 40, 50, 60, 70, 80, 90, 100 o más sustituciones, adiciones, inserciones o deleciones de aminoácidos. Algunos fragmentos o mutantes preferidos de un polipéptido conservan parte o la totalidad de la función biológica (por ejemplo, actividad enzimática) del polipéptido natural correspondiente. En algunas realizaciones, el fragmento conserva al menos aproximadamente el 75%, al menos aproximadamente el 80%, al menos aproximadamente el 90%, al menos aproximadamente el 95% o al menos aproximadamente el 98% o más de la función biológica del polipéptido natural correspondiente. En otras realizaciones, el fragmento o mutante conserva aproximadamente el 100% de la función biológica del polipéptido natural correspondiente. Puede encontrarse orientación sobre la determinación de qué residuos de aminoácido pueden sustituirse, insertarse o delecionarse sin afectar a la biológica actividad usando programas informáticos bien conocidos en la técnica, por ejemplo, el software LASERGENE™ (DNASTAR, Inc., Madison, WI).
En aún otras realizaciones, un fragmento o mutante presenta un aumento de la función biológica en comparación con un polipéptido natural correspondiente. Por ejemplo, un fragmento o mutante puede presentar una mejora de al menos un 10%, al menos un 25%, al menos un 50%, al menos un 75% o al menos un 90% de la actividad enzimática en comparación con el polipéptido natural correspondiente. En otras realizaciones, el fragmento o mutante presenta una mejora de al menos el 100%, (por ejemplo, al menos el 200%, o al menos el 500%) de la actividad enzimática en comparación con el polipéptido natural correspondiente. Se entiende que los polipéptidos descritos en el presente documento pueden tener sustituciones de aminoácidos no esenciales o conservativas adicionales que no tienen un efecto sustancial sobre la función del polipéptido. Puede determinarse si se tolerará o no una sustitución particular (es decir, no afectará de manera adversa a la función biológica deseada, tal como actividad ácido carboxílico reductasa) tal como se describe en Bowie et al. (Science, 247:1306-1310 (1990)). Una sustitución de aminoácidos conservativa es una en la que el residuo de aminoácido se reemplaza por un residuo de aminoácido que tiene una cadena lateral similar. Se han definido en la técnica familias de residuos de aminoácido que tienen cadenas laterales similares. Estas familias incluyen aminoácidos con cadenas laterales básicas (por ejemplo, lisina, arginina, histidina), cadenas laterales
ácidas (por ejemplo, ácido aspártico, ácido glutámico), cadenas laterales polares no cargadas (por ejemplo, glicina, asparagina, glutamina, serina, treonina, tirosina, cisteína), cadenas laterales apolares (por ejemplo, alanina, valina, leucina, isoleucina, prolina, fenilalanina, metionina, triptófano), cadenas laterales con ramificación beta (por ejemplo, treonina, valina, isoleucina) y cadenas laterales aromáticas (por ejemplo, tirosina, fenilalanina, triptófano, histidina). Las variantes pueden producirse de manera natural o crearse in vitro. En particular, tales variantes pueden crearse usando técnicas de ingeniería genética, tales como mutagénesis dirigida al sitio, mutagénesis química al azar, procedimientos de deleción con exonucleasa III o técnicas de clonación convencionales. Alternativamente, tales variantes, mutantes, fragmentos, análogos o derivados pueden crearse usando procedimientos de modificación o síntesis química.
Se conocen bien en la técnica métodos de producción de variantes. Estos incluyen procedimientos en los que secuencias de ácido nucleico obtenidas a partir de aislados naturales se modifican para generar ácidos nucleicos que codifican para polipéptidos que tienen características que potencian su valor en aplicaciones industriales o de laboratorio. En tales procedimientos, se generan y caracterizan un gran número de secuencias variantes que tienen una o más diferencias de nucleótidos con respecto a la secuencia obtenida a partir del aislado natural. Normalmente, estas diferencias de nucleótidos dan como resultado cambios de aminoácidos con respecto a los polipéptidos codificados por los ácidos nucleicos de los aislados naturales. Por ejemplo, pueden prepararse variantes usando mutagénesis al azar y dirigida al sitio. La mutagénesis al azar y dirigida al sitio se describen, por ejemplo, en Arnold Curr. Opin. Biotech. 4:450-455 (1993). Puede lograrse la mutagénesis al azar usando PCR propensa a error (véanse, por ejemplo, Leung et al. Technique 1:11-15 (1989); y Caldwell et al. PCR Methods Applic. 2: 28-33 (1992)). En la PCR propensa a error, la se realiza PCR en condiciones en las que la fidelidad de copiado de la ADN polimerasa es baja, de manera que se obtiene una alta tasa de mutaciones puntuales a lo largo de toda la longitud del producto de PCR. En resumen, en tales procedimientos, se mezclan ácidos nucleicos que van a mutagenizarse (por ejemplo, una secuencia de polinucleótido que codifica para una enzima ácido carboxílico reductasa) con cebadores de PCR, tampón de reacción, MgCl2, MnCl2, Taq polimerasa, y una concentración apropiada de dNTP para lograr una alta tasa de mutaciones puntuales a lo largo de toda la longitud del producto de PCR. Por ejemplo, la reacción puede realizarse usando 20 fmoles de ácido nucleico que va a mutagenizarse, 30 pmoles de cada cebador de PCR, un tampón de reacción que comprende KCl 50 mM, Tris HCl 10 mM (pH 8,3), gelatina al 0,01%, MgCh 7 mM, MnCh 0,5 mM, 5 unidades de Taq polimerasa, dGTP 0,2 mM, dATP 0,2 mM, dCTP 1 mM y dTTP 1 mM. Puede realizarse PCR durante 30 ciclos de 94°C durante 1 min, 45°C durante 1 min y 72°C durante 1 min. Sin embargo, los expertos en la técnica apreciarán que estos parámetros pueden variarse según sea apropiado. Los ácidos nucleicos mutagenizados se clonan entonces en un vector apropiado, y se evalúan las actividades de los polipéptidos codificados por los ácidos nucleicos mutagenizados (véase el ejemplo 7). Puede lograrse la mutagénesis dirigida al sitio usando mutagénesis dirigida por oligonucleótidos para generar mutaciones específicas de sitio en cualquier ADN clonado de interés. La mutagénesis por oligonucleótidos se describe, por ejemplo, en Reidhaar-Olson et al. Science 241:53-57 (1988). En resumen, en tales procedimientos, se sintetizan una pluralidad de oligonucleótidos bicatenarios que portan una o más mutaciones que van a introducirse en el ADN clonado, y se insertan en el ADN clonado que va a mutagenizarse (por ejemplo, una secuencia de polinucleótido que codifica para un polipéptido de CAR). Se recuperan los clones que contienen el ADN mutagenizado, y se evalúan las actividades de los polipéptidos para los que codifican. Otro método para generar variantes es la PCR de ensamblaje. La PCR de ensamblaje implica el ensamblaje de un producto de PCR de una mezcla de fragmentos de ADN pequeños. Un gran número de diferentes reacciones PCR se producen en paralelo en el mismo vial, cebando con los productos de una reacción los productos de otra reacción. La PCR de ensamblaje se describe, por ejemplo, en la patente estadounidense 5.965.408. Todavía otro método de generación de variantes es la mutagénesis por PCR sexual. En la mutagénesis por PCR sexual, se produce recombinación homóloga forzada entre moléculas de ADN de diferentes secuencias de ADN, pero altamente relacionadas, in vitro como resultado de fragmentación al azar de la molécula de ADN basándose en la homología de secuencia. Esto va seguido por fijación del cruzamiento mediante extensión de cebadores en una reacción PCR. La mutagénesis por PCR sexual se describe, por ejemplo, en Stemmer Proc. Natl. Acad. Sci. U.S.A. 91:10747-10751 (1994).
También pueden crearse variantes mediante mutagénesis in vivo. En algunas realizaciones, se generan mutaciones al azar en una secuencia de ácido nucleico propagando la secuencia en una cepa bacteriana, tal como una cepa de E. coli, que porta mutaciones en una o más de las rutas de reparación de ADN. Tales cepas “mutadoras” tienen una mayor tasa de mutación al azar que la de una cepa natural. La propagación de una secuencia de ADN (por ejemplo, una secuencia de polinucleótido que codifica para un polipéptido de CAR) en una de estas cepas generará eventualmente mutaciones al azar dentro del ADN. Se describen cepas mutadoras adecuadas para su uso para mutagénesis in vivo en, por ejemplo, la publicación de solicitud de patente internacional n.° WO1991/016427). También pueden generarse variantes usando mutagénesis de casete. En la mutagénesis de casete, una pequeña región de una molécula de ADN bicatenario se reemplaza por un “casete” de oligonucleótido sintético que difiere de la secuencia nativa. El oligonucleótido contiene a menudo una secuencia nativa completa y/o parcialmente aleatorizada. También puede usarse mutagénesis de conjunto recursivo para generar variantes. La mutagénesis de conjunto recursivo es un algoritmo para la modificación por ingeniería de proteínas (es decir, mutagénesis de proteínas) desarrollado para producir diversas poblaciones de mutantes relacionados fenotípicamente cuyos miembros difieren en la secuencia de aminoácidos. Este método usa un mecanismo de realimentación para controlar tandas sucesivas de mutagénesis de casete combinatoria. La mutagénesis de conjunto recursivo se describe, por ejemplo, en Arkin et al. Proc. Natl. Acad. Sci., U.S.A. 89:7811-7815 (1992). En algunas realizaciones, se crean variantes usando mutagénesis de conjunto exponencial. La mutagénesis de conjunto exponencial es un procedimiento para generar bibliotecas combinatorias
con un alto porcentaje de mutantes únicos y funcionales, en los que se aleatorizan pequeños grupos de residuos en paralelo para identificar, en cada posición alterada, aminoácidos que conducen a proteínas funcionales (véase, por ejemplo, Delegrave et al. (1993) Biotech. Res. 11:1548-1552). En algunas realizaciones, se crean variantes usando procedimientos de intercambio en los que se fusionan entre sí partes de una pluralidad de ácidos nucleicos que codifican distintos polipéptidos para crear secuencias de ácido nucleico quiméricas que codifican polipéptidos quiméricos tal como se describe, por ejemplo, en las patentes estadounidenses 5.965.408 y 5.939.250.
La mutagénesis por inserción es una mutagénesis de ADN mediante la inserción de una o más bases. Las mutaciones por inserción pueden producirse de manera natural, mediadas por virus o transposón, o pueden crearse artificialmente para fines de investigación en el laboratorio, por ejemplo, mediante mutagénesis de transposones. Cuando se integra ADN exógeno en el del hospedador, la gravedad de cualquier mutación consiguiente depende totalmente de la ubicación dentro del genoma del hospedador en el que se inserta el ADN. Por ejemplo, pueden ser evidentes efectos significativos si se inserta un transposón en el medio de un gen esencial, en una región promotora o en una región represora o potenciadora. Se realizaron mutagénesis de transposones y examen de alto rendimiento para encontrar mutaciones beneficiosas que aumentaran el título o rendimiento de alcohol graso. Se describen en el presente documento células hospedadoras recombinantes que comprenden (a) una secuencia de polinucleótido que codifica para una ácido carboxílico reductasa que comprende una secuencia de aminoácidos que tiene una identidad de secuencia de al menos el 80%, el 81%, el 82%, el 83%, el 84%, el 85%, el 86%, el 87%, el 88%, el 89%, el 90%, el 91%, el 92%, el 93%, el 94%, el 95%, el 96%, el 97%, el 98% o el 99% con la secuencia de aminoácidos de SEQ ID NO: 7 y (b) un polinucleótido que codifica para un polipéptido que tiene actividad ácido carboxílico reductasa, en las que la célula hospedadora recombinante puede producir un aldehído graso o un alcohol graso.
Modificación por ingeniería genética de células hospedadoras
En algunas realizaciones, se proporciona una secuencia de polinucleótido (o gen) a una célula hospedadora por medio de un vector recombinante, que comprende un promotor operativamente unido a la secuencia de polinucleótido. En determinadas realizaciones, el promotor es un promotor regulado por el desarrollo, uno específico de orgánulo, uno específico de tejido, uno inducible, uno constitutivo o uno específico de célula. En algunas realizaciones, el vector recombinante incluye (a) una secuencia de control de la expresión acoplada operativamente a la secuencia de polinucleótido; (b) un marcador de selección acoplado operativamente a la secuencia de polinucleótido; (c) una secuencia de marcador acoplada operativamente a la secuencia de polinucleótido; (d) un resto de purificación acoplado operativamente a la secuencia de polinucleótido; (e) una secuencia de secreción acoplada operativamente a la secuencia de polinucleótido; y (f) una secuencia de direccionamiento acoplada operativamente a la secuencia de polinucleótido. Los vectores de expresión descritos en el presente documento incluyen una secuencia de polinucleótido descrita en el presente documento en una forma adecuada para la expresión de la secuencia de polinucleótido en una célula hospedadora. Los expertos en la técnica apreciarán que el diseño del vector de expresión puede depender de factores tales como la elección de la célula hospedadora que va a transformarse, el nivel de expresión del polipéptido deseado, etc. Los vectores de expresión descritos en el presente documento pueden introducirse en las células hospedadoras para producir polipéptidos, incluyendo polipéptidos de fusión, codificados por las secuencias de polinucleótido descritas en el presente documento. La expresión de genes que codifican para polipéptidos en procariotas, por ejemplo, E. coli, se lleva a cabo lo más a menudo con vectores que contienen promotores constitutivos o inducibles que dirigen la expresión de polipéptidos o bien de fusión o bien de no fusión. Los vectores de fusión añaden un número de aminoácidos a un polipéptido codificado en el mismo, habitualmente al extremo amino-terminal o carboxi-terminal del polipéptido recombinante. Tales vectores de fusión sirven normalmente para uno o más de los tres propósitos siguientes: (1) aumentar la expresión del polipéptido recombinante; (2) aumentar la solubilidad del polipéptido recombinante; y (3) ayudar en la purificación del polipéptido recombinante actuando como ligando en purificación por afinidad. A menudo, en los vectores de expresión de fusión, se introduce un sitio de escisión proteolítica en la unión del resto de fusión y el polipéptido recombinante. Esto permite la separación del polipéptido recombinante del resto de fusión después de la purificación del polipéptido de fusión. Los ejemplos de tales enzimas, y sus secuencias de reconocimiento relacionadas, incluyen factor Xa, trombina y enterocinasa. Los vectores de expresión de fusión a modo de ejemplo incluyen pGEX (Pharmacia Biotech, lnc., Piscataway, NJ; Smith et al., Gene, 67: 31-40 (1988)), pMAL (New England Biolabs, Beverly, MA) y pRITS (Pharmacia Biotech, Inc., Piscataway, N.J.), que fusionan glutatión-S-transferasa (GST), proteína de unión a maltosa E o proteína A, respectivamente, al polipéptido recombinante diana.
Los ejemplos de vectores de expresión de E. coli de no fusión, inducibles incluyen pTrc (Amann et al., Gene (1988) 69:301-315) y pET 11d (Studier et al., Gene Expression Technology: Methods in Enzymology 185, Academic Press, San Diego, Calif. (1990) 60-89). La expresión del gen diana a partir del vector pTrc se basa en la transcripción por la ARN polimerasa del hospedador a partir de un promotor de fusión trp-lac híbrido. La expresión del gen diana a partir del vector pET 11d se basa en la transcripción a partir de un promotor de fusión T7 gn10-lac mediada por una ARN polimerasa viral coexpresada (T7 gn1). Esta polimerasa viral la suministran cepas hospedadoras BL21(DE3) o HMS174(DE3) a partir de un profago l residente que alberga un gen de T7 gn1 bajo el control transcripcional del promotor lacUV 5. Se conocen bien en la técnica sistemas de expresión adecuados para células tanto procariotas como eucariotas; véase, por ejemplo, Sambrook et al., “Molecular Cloning: A Laboratory Manual”, segunda edición, Cold Spring Harbor Laboratory, (1989). Los ejemplos de vectores de expresión de E. coli de no fusión, inducibles incluyen pTrc (Amann et al., Gene, 69: 301-315 (1988)) y PET 11d (Studier et al., Gene Expression Technology:
Methods in Enzymology 185, Acadernic Press, San Diego, CA, págs. 60-89 (1990)). En determinadas realizaciones, una secuencia de polinucleótido de la divulgación está operativamente unida a un promotor derivado del bacteriófago T5. En una realización, la célula hospedadora es una célula de levadura. En esta realización, el vector de expresión es un vector de expresión de levadura. Pueden introducirse vectores en células procariotas o eucariotas por medio de técnicas reconocidas en la técnica para introducir ácido nucleico exógeno (por ejemplo, ADN) en una célula hospedadora. Pueden encontrarse métodos adecuados para transformar o transfectar células hospedadoras, por ejemplo, en Sambrook et al. (citado anteriormente). Para la transformación estable de células bacterianas, se sabe que, dependiendo del vector de expresión y la técnica de transformación usados, sólo una pequeña fracción de células captará y replicará el vector de expresión. En algunas realizaciones, con el fin de identificar y seleccionar estos transformantes, se introduce un gen que codifica para un marcador seleccionable (por ejemplo, resistencia a un antibiótico) en las células hospedadoras junto con el gen de interés. Los marcadores seleccionables incluyen los que confieren resistencia a fármacos tales como, pero sin limitarse a, ampicilina, kanamicina, cloranfenicol o tetraciclina. Pueden introducirse ácidos nucleicos que codifican para un marcador seleccionable en una célula hospedadora en el mismo vector que el que codifica para un polipéptido descrito en el presente documento o pueden introducirse en un vector separado. Las células transformadas de manera estable con el ácido nucleico introducido pueden identificarse mediante crecimiento en presencia de un fármaco de selección apropiado.
Producción de composiciones de alcoholes grasos por células hospedadoras recombinantes
Las estrategias para aumentar la producción de alcoholes grasos por células hospedadoras recombinantes incluyen el aumento del flujo a través de la ruta de biosíntesis de ácidos grasos mediante la sobreexpresión de genes de biosíntesis de ácidos grasos nativos y la expresión de genes de biosíntesis de ácidos grasos exógenos de diferentes organismos en un hospedador de producción modificado por ingeniería genética. También pueden emplearse actividad potenciada de enzimas relevantes en la ruta de biosíntesis de alcoholes grasos, por ejemplo, CAR, así como otras estrategias para optimizar el crecimiento y la productividad de la célula hospedadora para maximizar la producción. En algunas realizaciones, la célula hospedadora recombinante comprende un polinucleótido que codifica para un polipéptido (una enzima) que tiene una actividad de biosíntesis de alcoholes grasos (es decir, un polipéptido de biosíntesis de alcoholes grasos o una enzima de biosíntesis de alcoholes grasos), y se produce un alcohol graso por la célula hospedadora recombinante. Puede producirse una composición que comprende alcoholes grasos (una composición de alcohol graso) cultivando la célula hospedadora recombinante en presencia de una fuente de carbono en condiciones eficaces para expresar una enzima de biosíntesis de alcoholes grasos. En algunas realizaciones, la composición de alcohol graso comprende alcoholes grasos, sin embargo, una composición de alcohol graso puede comprender otros derivados de ácido graso. Normalmente, la composición de alcohol graso se recupera del entorno extracelular de la célula hospedadora recombinante, es decir, el medio de cultivo celular. En un enfoque, se han modificado por ingeniería genética células hospedadoras recombinantes para producir alcoholes grasos expresando una tioesterasa, que cataliza la conversión de acil-ACP en ácidos grasos libres (FFA) y una ácido carboxílico reductasa (CAR), que convierte ácidos grasos libres en aldehídos grasos. Las aldehído reductasas nativas (endógenas) presentes en la célula hospedadora (por ejemplo, E. coli) pueden convertir los aldehídos grasos en alcoholes grasos. En algunas realizaciones, el alcohol graso se produce expresando o sobreexpresando en la célula hospedadora recombinante un polinucleótido que codifica para un polipéptido que tiene actividad de biosíntesis de alcoholes grasos que convierte un aldehído graso en un alcohol graso. Por ejemplo, puede usarse una alcohol deshidrogenasa (también denominada en el presente documento aldehído reductasa, por ejemplo, EC 1.1.1.1), en la práctica de la divulgación. Tal como se usa en el presente documento, el término “alcohol deshidrogenasa” se refiere a un polipéptido que puede catalizar la conversión de un aldehído graso en un alcohol (por ejemplo, un alcohol graso). Un experto habitual en la técnica apreciará que determinadas alcohol deshidrogenasas también pueden catalizar otras reacciones, y estas alcohol deshidrogenasas no específicas también se engloban mediante el término “alcohol deshidrogenasa”. Los ejemplos de polipéptidos de alcohol deshidrogenasa útiles según la divulgación incluyen, pero no se limitan a AlrAadp1 (SEQ ID NO: 4) u homólogos de AlrA y alcohol deshidrogenasas de E. coli endógenas tales como YjgB, (AAC77226) (SEQ ID NO: 5), DkgA (NP_417485), DkgB (NP_414743), YdjL (AAC74846), YdjJ (NP_416288), AdhP (NP_415995), YhdH (NP_417719), YahK (NP_414859), YphC (AAC75598), YqhD (446856) e YbbO [AAC73595.1]. Se describen ejemplos adicionales en las publicaciones de solicitud de patente internacional n.os WO2007/136762, WO2008/119082 y w O 2010/062480. En determinadas realizaciones el polipéptido de biosíntesis de alcoholes grasos tiene actividad aldehído reductasa o alcohol deshidrogenasa (EC 1.1.1.1). En otro enfoque, se han modificado por ingeniería genética células hospedadoras recombinantes para producir alcoholes grasos expresando acil-CoA reductasas o acilo graso reductasas (FAR) que forman alcoholes grasos que convierten sustratos de acil graso-tioéster (por ejemplo, acil graso-CoA o acil graso-ACP) en alcoholes grasos. En algunas realizaciones, el alcohol graso se produce expresando o sobreexpresando un polinucleótido que codifica para un polipéptido que tiene actividad acil-CoA reductasa (FAR) que forma alcoholes grasos en una célula hospedadora recombinante. Se describen ejemplos de polipéptidos de FAR útiles según esta realización en la publicación PCT n.° WO2010/062480.
El alcohol graso puede producirse por medio de una ruta dependiente de acil-CoA que utiliza productos intermedios de acil graso-ACP y acil graso-CoA y una ruta independiente de acil-CoA que utiliza productos intermedios de acil graso-ACP pero no un producto intermedio de acil graso-CoA. En realizaciones particulares, la enzima codificada por el gen sobreexpresado se selecciona de una ácido graso sintasa, una acil-ACP tioesterasa, una acil graso-CoA sintasa y una acetil-CoA carboxilasa. En algunas realizaciones, la proteína codificada por el gen sobreexpresado es endógena para la célula hospedadora. En otras realizaciones la proteína codificada por el gen sobreexpresado es heteróloga
para la célula hospedadora. Se preparan también alcoholes grasos en la naturaleza por enzimas que pueden reducir diversas moléculas de acil-ACP o acil-CoA hasta los correspondientes alcoholes primarios. Véanse también las publicaciones de patente estadounidense n.os 20100105963 y 20110206630 y la patente estadounidense n.° 8097439. Tal como se usa en el presente documento, una célula hospedadora recombinante o una célula hospedadora modificada por ingeniería genética se refiere a una célula hospedadora cuya constitución genética se ha alterado en relación con la célula hospedadora natural correspondiente, por ejemplo, mediante la introducción deliberada de nuevos elementos genéticos y/o la modificación deliberada de elementos genéticos presentes de manera natural en la célula hospedadora. La descendencia de tales células hospedadoras recombinantes también contiene estos elementos genéticos nuevos y/o modificados. En cualquiera de los aspectos de la divulgación descrita en el presente documento, la célula hospedadora puede seleccionarse del grupo que consiste en una célula vegetal, célula de insecto, célula fúngica (por ejemplo, un hongo filamentoso, tales como Candida sp., o una levadura gemante, tal como Saccharomyces sp.), una célula algal y una célula bacteriana. En una realización preferida, las células hospedadoras recombinantes son células microbianas recombinantes. Los ejemplos de células hospedadoras que son células microbianas incluyen pero no se limitan a células del género Escherichia, Bacillus, Lactobacillus, Zymomonas, Rhodococcus, Pseudomonas, Aspergillus, Trichoderma, Neurospora, Fusarium, Humicola, Rhizomucor, Kluyveromyces, Pichia, Mucor, Myceliophtora, Penicillium, Phanerochaete, Pleurotus, Trametes, Chrysosporium, Saccharomyces, Stenotrophamonas, Schizosaccharomyces, Yarrowia o Streptomyces. En algunas realizaciones, la célula hospedadora es una célula bacteriana Gram-positiva. En otras realizaciones, la célula hospedadora es una célula bacteriana Gram-negativa. En algunas realizaciones, la célula hospedadora es una célula de E. coli. En otras realizaciones, la célula hospedadora es una célula de Bacillus lentus, una célula de Bacillus brevis, una célula de Bacillus stearothermophilus, una célula de Bacillus lichenoformis, una célula de Bacillus alkalophilus, una célula de Bacillus coagulans, una célula de Bacillus circulans, una célula de Bacillus pumilis, una célula de Bacillus thuringiensis, una célula de Bacillus clausii, una célula de Bacillus megaterium, una célula de Bacillus subtilis o una célula de Bacillus amyloliquefaciens. En otras realizaciones la célula hospedadora es una célula de Trichoderma koningii, una célula de Trichoderma viride, una célula de Trichoderma reesei, una célula de Trichoderma longibrachiatum, una célula de Aspergillus awamori, una célula de Aspergillus fumigates, una célula de Aspergillus foetidus, una célula de Aspergillus nidulans, una célula de Aspergillus niger, una célula de Aspergillus oryzae, una célula de Humicola insolens, una célula de Humicola lanuginose, una célula de Rhodococcus opacus, una célula de Rhizomucor miehei o una célula de Mucor michei.
En aún otras realizaciones, la célula hospedadora es una célula de Streptomyces lividans o una célula de Streptomyces murinus. En aún otras realizaciones, la célula hospedadora es una célula de Actinomycetes. En algunas realizaciones la célula hospedadora es una célula de Saccharomyces cerevisiae. En algunas realizaciones, la célula hospedadora es una célula de Saccharomyces cerevisiae. En otras realizaciones, la célula hospedadora es una célula de una planta eucariota, alga, cianobacteria, bacteria verde del azufre, bacteria verde no del azufre, bacteria púrpura del azufre, bacteria púrpura no del azufre, extremófilo, levadura, hongo, un organismo modificado por ingeniería genética de los mismos, o un organismo sintético. En algunas realizaciones, la célula hospedadora depende de la luz o fija carbono. En algunas realizaciones, la célula hospedadora depende de la luz o fija carbono. En algunas realizaciones, la célula hospedadora tiene actividad autótrofa. En algunas realizaciones, la célula hospedadora tiene actividad fotoautótrofa, tal como en presencia de luz. En algunas realizaciones, la célula hospedadora es heterótrofa o mixótrofa en ausencia de luz. En determinadas realizaciones, la célula hospedadora es una célula de Arabidopsis thaliana, Panicum virgatum, Miscanthus giganteus, Zea mays, Botryococcus braunii, Chlamydomonas reinhardtii, Dunaliela salina, Synechococcus Sp. PCC 7002, Synechococcus Sp. PCC 7942, Synechocystis Sp. PCC 6803, Thermosynechococcus elongates BP-1, Chlorobium tepidum, Chlorojlexus auranticus, Chromatium vinosum, Rhodospirillum rubrum, Rhodobacter capsulatus, Rhodopseudomonas palusris, Clostridium ljungdahlii, Clostridium thermocellum, Penicillium chrysogenum, Pichia pastoris, Saccharomyces cerevisiae, Schizosaccharomyces pombe, Pseudomonas fluorescens o Zymomonas mobilis.
Cultivo de células hospedadoras recombinantes y fermentación
Tal como se usa en el presente documento, el término fermentación se refiere ampliamente a la conversión de materiales orgánicos en sustancias diana por células hospedadoras, por ejemplo, la conversión de una fuente de carbono por células hospedadoras recombinantes en ácidos grasos o derivados de los mismos mediante la propagación de un cultivo de las células hospedadoras recombinantes en un medio que comprende la fuente de carbono. Tal como se usa en el presente documento, las condiciones permisivas para la producción significan cualesquiera condiciones que permiten que una célula hospedadora produzca un producto deseado, tal como un ácido graso o derivado de ácido graso. De manera similar, las condiciones en las que se expresa la secuencia de polinucleótido de un vector significan cualesquiera condiciones que permiten que una célula hospedadora sintetice un polipéptido. Las condiciones adecuadas incluyen, por ejemplo, condiciones de fermentación. Las condiciones de fermentación pueden comprender muchos parámetros incluyendo, pero sin limitarse a, intervalos de temperatura, niveles de aireación, tasas de alimentación y composición de medios. Cada una de estas condiciones, individualmente y en combinación, permiten que crezca la célula hospedadora. La fermentación puede ser aerobia, anaerobia, o variaciones de las mismas (tales como microaerobias). Los medios de cultivo a modo de ejemplo incluyen caldos o geles. Generalmente, el medio incluye una fuente de carbono que puede metabolizarse por una célula hospedadora directamente. Además, pueden usarse enzimas en el medio para facilitar la movilización (por ejemplo, la despolimerización de almidón o celulosa para dar azúcares fermentables) y el metabolismo posterior de la fuente de
carbono. Para la producción a pequeña escala, las células hospedadoras modificadas por ingeniería genética pueden hacerse crecer en lotes de, por ejemplo, aproximadamente 100 ml, 500 ml, 1 l, 2 l, 5 l o 10 l; fermentarse; e inducirse para expresar una secuencia de polinucleótido deseada, tal como una secuencia de polinucleótido que codifica para un polipéptido de CAR. Para la producción a gran escala, las células hospedadoras modificadas por ingeniería genética pueden hacerse crecer en lotes de aproximadamente 10 l, 100 l, 1000 l, 10.000 l, 100.000 l y 1.000.000 l o más; fermentarse; e inducirse para expresar una secuencia de polinucleótido deseada. Alternativamente, puede llevarse a cabo fermentación semicontinua a gran escala.
Composiciones de alcoholes grasos
Las composiciones de alcoholes grasos descritas en el presente documento se encuentran en el entorno extracelular del cultivo de células hospedadoras recombinantes y pueden aislarse fácilmente del medio de cultivo. Una composición de alcohol graso puede secretarse por la célula hospedadora recombinante, transportarse al entorno extracelular o transferirse de manera pasiva al entorno extracelular del cultivo de células hospedadoras recombinantes. La composición de alcohol graso se aísla de un cultivo de células hospedadoras recombinantes usando métodos de rutina conocidos en la técnica. Se describen en el presente documento composiciones producidas por células hospedadoras recombinantes o modificadas por ingeniería genética (bioproductos) que incluyen uno más aldehídos grasos y/o alcoholes grasos. Aunque un componente de alcohol graso con una longitud de cadena y grado de saturación particulares puede constituir la mayoría del bioproducto producido por una célula hospedadora recombinante o modificada por ingeniería genética cultivada, la composición incluye normalmente una mezcla de aldehídos grasos y/o alcoholes grasos que varían con respecto a la longitud de cadena y/o grado de saturación. Tal como se usa en el presente documento, fracción de carbono moderno o fM tiene el mismo significado definido por los materiales de referencia patrón del Instituto Nacional de Normas y Tecnología (NIST) (SRM 4990B y 4990C, conocidos como patrones de ácido oxálico HOxI y HOxII, respectivamente). La definición fundamental se refiere a 0,95 veces la razón isotópica 14C/12C HOxl (con referencia a AD 1950). Esto es aproximadamente equivalente a la madera antes de la Revolución Industrial corregida para la desintegración. Para la biosfera viva actual (material vegetal), fM es aproximadamente 1,1.
Los bioproductos (por ejemplo, los alcoholes y aldehídos grasos producidos según la presente divulgación) que comprenden compuestos orgánicos producidos biológicamente y, en particular, los alcoholes y aldehídos grasos producidos biológicamente usando la ruta de biosíntesis de ácidos grasos en el presente documento, no se han producido a partir de fuentes renovables y, como tal, son nuevas composiciones de materia. Estos nuevos bioproductos pueden distinguirse de compuestos orgánicos derivados de carbono petroquímico basándose en la obtención de huella isotópica de carbono dual o la datación mediante 14C. Adicionalmente, la fuente específica de carbono de fuente biológica (por ejemplo, glucosa frente a glicerol) puede determinarse mediante obtención de huella isotópica de carbono dual (véase, por ejemplo, la patente estadounidense n.° 7.169.588). La capacidad para distinguir bioproductos de compuestos orgánicos basados en el petróleo es beneficiosa en la trazabilidad de estos materiales en el comercio. Por ejemplo, pueden distinguirse compuestos orgánicos o químicos que comprenden perfiles isotópicos de carbono tanto de base biológica como de base en el petróleo de compuestos orgánicos y químicos que se componen sólo de materiales basados en el petróleo. Así, los bioproductos en el presente documento pueden someterse a seguimiento o trazabilidad en el comercio basándose en su perfil isotópico de carbono único. Los bioproductos pueden distinguirse de compuestos orgánicos basados en el petróleo comparando la razón isotópica de carbono estable (13C/12C) en cada muestra. La razón 13C/12C en un bioproducto dado es consecuencia de la razón 13C/12C en el dióxido de carbono atmosférico en el momento en que se fija el dióxido de carbono. También refleja la ruta metabólica precisa. También se producen variaciones regionales. El petróleo, las plantas C3 (las de hoja caduca), las plantas C4 (las hierbas) y carbonatos marinos muestran todos diferencias significativas en 13C/12C y los valores de 513C correspondientes. Además, la materia lipídica de plantas C3 y C4 se analiza de manera diferente que en materiales derivados de los componentes de hidrato de carbono de las mismas plantas como consecuencia de la ruta metabólica. Dentro de la precisión de medición, 13C muestra grandes variaciones debido a efectos de fraccionamiento isotópico, siendo el más significativo de ellos para bioproductos el mecanismo de fotosíntesis. La principal causa de las diferencias en la razón isotópica de carbono en plantas se asocia estrechamente con diferencias en la ruta de metabolismo de carbono por fotosíntesis en las plantas, particularmente la reacción que se produce durante la carboxilación primaria (es decir, la fijación inicial de CO2 atmosférico). Dos grandes clases de vegetación son las que incorporan el ciclo de fotosíntesis C3 (o de Calvin-Benson) y las que incorporan el ciclo de fotosíntesis C4 (o de Hatch-Slack). En plantas C3, la fijación primaria de CO2 o reacción de carboxilación implica la enzima ribulosa-1,5-difosfato carboxilasa, y el primer producto estable es un compuesto de 3 carbonos. Las plantas C3, tales como frondosas y coníferas, son predominantes en las zonas de climas templados. En plantas C4, una reacción de carboxilación adicional que implica otra enzima, fosfoenol-piruvato carboxilasa, es la reacción de carboxilación primaria. El primer compuesto carbonado estable es un ácido de 4 carbonos que se descarboxila posteriormente. El CO2 así liberado vuelve a fijarse mediante el ciclo C3. Ejemplos de plantas C4 son hierbas tropicales, maíz y caña de azúcar. Las plantas tanto C4 como C3 muestran un intervalo de razones isotópicas 13C/12C, pero valores típicos son de aproximadamente -7 a aproximadamente -13 por cada mil para plantas C4 y de aproximadamente -19 a aproximadamente -27 por cada mil para plantas C3 (véase, por ejemplo, Stuiver et al. (1977) Radiocarbon 19:355 (1977)). El carbón y el petróleo se encuentran generalmente en este último intervalo. La escala de medición de 13C se definió originariamente por un cero establecido por la piedra caliza belemnita de Pee Dee (PDB), facilitándose los valores en partes por mil desviaciones con respecto a este material. Los valores de “513C” se expresan en partes por miles (por mil), abreviado como, %o, y
se calculan de la siguiente manera:
513C (<%) = [(13C/12C)muestra - (13C/12C)patrón]/ (13C/12C)patrón X 1000
Puesto que el material de referencia (RM) de PDB se ha agotado, una serie de RM alternativos se ha desarrollado en cooperación con IAEA, USGS, NIST, y otros laboratorios de isótopos internacionales seleccionados. Las notaciones para las desviaciones por mil con respecto a PDB es 513C. Se realizan las mediciones con CO2 mediante espectrometría de masas de razón estable de alta precisión (IRMS) con iones moleculares de masas 44, 45 y 46. Las composiciones descritas en el presente documento incluyen bioproductos producidos mediante cualquiera de los métodos descritos en el presente documento, incluyendo, por ejemplo, productos de alcohol y aldehido graso. Específicamente, el bioproducto puede tener un 513C de aproximadamente -28 o mayor, aproximadamente -27 o mayor, -20 o mayor, -18 o mayor, -15 o mayor, -13 o mayor, -10 o mayor, o -8 o mayor. Por ejemplo, el bioproducto puede tener un 513C de -30 a -15, de -27 a -19, de -25 a -21, de -15 a -5, de -13 a -7 o de -13 a -10. En otros casos, el bioproducto puede tener un 513C de aproximadamente -10, -11, -12 o -12,3. Los bioproductos, incluyendo los bioproductos producidos según la divulgación en el presente documento, también pueden distinguirse de compuestos orgánicos basados en el petróleo comparando la cantidad de 14C en cada compuesto. Dado que el 14C tiene una semivida nuclear de 5730 años, los combustibles basados en el petróleo que contienen carbono más “antiguo” pueden distinguirse de bioproductos que contienen carbono “más nuevo” (véanse, por ejemplo, Currie, “Source Apportionment of Atmospheric Particles”, Characterization of Environmental Particles, J. Buffle y H. P. van Leeuwen, eds., 1 de vol. I de IUPAC Environmental Analytical Chemical Series (Lewis Publishers, Inc.) 3-74, (1992)).
La suposición básica en la datación por radiocarbono es que la constancia de la concentración de 14C en la atmósfera conduce a la constancia de 14C en organismos vivos. Sin embargo, debido a las pruebas nucleares atmosféricas desde 1950 y el quemado de combustibles fósiles desde 1850, el 14C ha adquirido una segunda característica temporal geoquímica. Su concentración en el CO2 atmosférico, y así en la biosfera viva, se duplicó aproximadamente en el apogeo de las pruebas nucleares, a mediados de los años 1960. Desde entonces se ha vuelto gradualmente a la tasa isotópica (14C/12C) inicial cosmogénica (atmosférica) de estado estacionario de aproximadamente 1,2 x 1012, con una “semivida” de relajación aproximada de 7-10 años. (Esta última semivida no ha de tomarse literalmente; más bien, debe usarse la función de entrada/desintegración nuclear atmosférica detallada para rastrear la variación de 14C atmosférico y de la biosfera desde el comienzo de la era nuclear). Es esta última característica temporal de 14C de la biosfera la que mantiene la promesa de datación anual de carbono reciente de la biosfera. Puede medirse el 14C mediante espectrometría de masas con acelerador (AMS), facilitándose los resultados en unidades de “fracción de carbono moderno” (fM). La fM se define por los materiales de referencia patrón 4990B y 4990C del Instituto Nacional de Normas y Tecnología (NIST). Tal como se usa en el presente documento, la fracción de carbono moderno (fM) tiene el mismo significado definido por los materiales de referencia patrón (SRM) 4990B y 4990C del Instituto Nacional de Normas y Tecnología (NIST), conocidos como patrones de ácidos oxálicos HOxI y HOxII, respectivamente). La definición fundamental se refiere a 0,95 veces la razón isotópica 14C/12C HOxI (con referencia a 1950). Esto es aproximadamente equivalente a la madera anterior a la Revolución Industrial corregida para la desintegración. Para la biosfera viva actual (material vegetal), fM es de aproximadamente 1,1. Esto es aproximadamente equivalente a la madera anterior a la Revolución Industrial corregida para la desintegración. Para la biosfera viva actual (material vegetal), fM es de aproximadamente 1,1.
Las composiciones descritas en el presente documento incluyen bioproductos que pueden tener una fM14C de al menos aproximadamente 1. Por ejemplo, el bioproducto de la divulgación puede tener una fM14C de al menos 1,01, una fM14C de 1 a 1,5, una fM14C de 1,04 a 1,18, o una fM14C de 1,111 a 1,124. Otra medición de 14C se conoce como el tanto por ciento de carbono moderno (pMC). Para un arqueólogo o geólogo que usa dataciones por 14C, 1950 es igual a una edad de “cero años”. Esto también representa 100 pMC. El “carbono de bombas” en la atmósfera alcanzó casi el doble del nivel normal en 1963 en el apogeo de las armas termonucleares. Su distribución dentro de la atmósfera se ha aproximado desde su aparición, mostrando valores que son mayores de 100 pMC para plantas y animales que viven desde 1950. Ha disminuido gradualmente a lo largo del tiempo, siendo el valor de hoy en día próximo a 107,5 pMC. Esto significa que un material de biomasa reciente, tal como maíz, proporcionaría una firma de 14C próxima a 107,5 pMC. Los compuestos basados en el petróleo tendrán un valor de pMC de cero. La combinación de carbono fósil con carbono de hoy en día dará como resultado una dilución del contenido de pMC de hoy en día. Suponiendo que 107,5 pMC representa el contenido de 14C de materiales de biomasa de hoy en día y 0 pMC representa el contenido de 14C de productos basados en el petróleo, el valor de pMC medido para ese material reflejará las proporciones de los dos tipos de componente. Por ejemplo, un material derivado al 100% de soja de hoy en día proporcionará una firma de radiocarbono próxima a 107,5 pMC. Si ese material se diluyera al 50% con productos basados en el petróleo, proporcionaría una firma de radiocarbono de aproximadamente 54 pMC. Se deriva un contenido de carbono de base biológica asignando el “100%” igual a 107,5 pMC y el “0%” igual a 0 pMC. Por ejemplo, una muestra que mide 99 pMC proporcionará un contenido de carbono de base biológica equivalente del 93%. Este valor se denomina el resultado de carbono de base biológica medio y supone que todos los componentes dentro del material analizado se originan o bien a partir de material biológico de hoy en día o bien a partir de material basado en el petróleo. Un bioproducto que comprende uno o más derivados de ácido graso tal como se describe en el presente documento puede tener un pMC de al menos 50, 60, 70, 75, 80, 85, 90, 95, 96, 97, 98, 99 ó 100. En otros casos, un bioproducto descrito en el presente documento puede tener un pMC de entre 50 y 100; entre 60 y 100; entre 70 y 100; entre 80 y 100; entre 85 y 100; entre 87 y 98; o entre 90 y 95. En aún otros casos, un bioproducto descrito en el
presente documento puede tener un pMC de 90, 91, 92, 93, 94 ó 94,2.
Examen de composiciones de alcoholes grasos producidas por la célula hospedadora recombinante
Para determinar si las condiciones son suficientes para permitir la expresión, se cultiva una célula hospedadora recombinante que comprende un gen heterólogo o un gen nativo modificado, por ejemplo, durante aproximadamente 4, 8, 12, 24, 36 ó 48 horas. Durante y/o después del cultivo, pueden obtenerse muestras y analizarse para determinar si el nivel de producción de alcohol graso (título, rendimiento o productividad) es diferente del de la célula parental natural correspondiente que no se ha modificado. Por ejemplo, el medio en el que las células hospedadoras se hicieron crecer puede someterse a prueba para detectar la presencia de un producto deseado. Cuando se somete a prueba para detectar la presencia de un producto, pueden usarse ensayos, tales como, pero sin limitarse a, CCF, HPLC, CG/FID, CG/EM, CL/EM, EM. Pueden cultivarse cepas de células hospedadoras recombinantes en volúmenes pequeños (de 0,001 l a 1 l) de medio en placas o matraces de agitación con el fin de examinar para detectar un nivel alterado de producción de especies grasas o alcohol graso. Una vez identificadas las cepas candidatas o “aciertos” a pequeña escala, estas cepas se cultivan en volúmenes más grandes (de 1 l a 1000 l) de medio en biorreactores, tanques y plantas piloto para determinar el nivel preciso de producción de especies grasas o alcohol graso. Estas condiciones de cultivo de volumen grande las usan los expertos en la técnica para optimizar las condiciones de cultivo para obtener la producción deseada de especies grasas o alcohol graso.
Utilidad de composiciones de alcoholes grasos y aldehídos grasos
Los aldehídos se utilizan para producir muchos productos químicos especializados. Por ejemplo, los aldehídos se utilizan para producir polímeros, resinas (por ejemplo, baquelita), tintes, aromatizantes, plastificantes, perfumes, productos farmacéuticos, y otros productos químicos, algunos de los cuales se pueden usar como disolventes, conservantes, o desinfectantes. Además, determinados compuestos naturales y sintéticos, tales como vitaminas y hormonas, son aldehídos, y muchos azúcares contienen grupos aldehído. Los aldehídos grasos pueden convertirse en alcoholes grasos mediante reducción química o enzimática. Los alcoholes grasos tienen muchos usos comerciales. Las ventas anuales a nivel mundial de alcoholes grasos y sus derivados son superiores a mil millones de dólares U.S. Los alcoholes grasos de cadena más corta se usan en las industrias cosmética y alimentaria como emulsionantes, emolientes, y espesantes. Debido a su naturaleza anfifílica, los alcoholes grasos se comportan como tensioactivos no iónicos, que son útiles en productos de higiene personal y para el cuidado del hogar, tales como, por ejemplo, detergentes. Además, los alcoholes grasos se utilizan en ceras, gomas, resinas, pomadas y lociones farmacéuticas, aditivos para aceite lubricante, textiles antiestáticos y agentes de acabado, plastificantes, cosméticos, disolventes industriales, y disolventes para grasas. También se describe en el presente documento una composición tensioactiva o una composición detergente que comprende un alcohol graso producido mediante cualquiera de los métodos descritos en el presente documento. El experto en la técnica apreciará que, dependiendo del uso previsto de la composición tensioactiva o detergente, se pueden producir y utilizar diferentes alcoholes grasos. Por ejemplo, cuando los alcoholes grasos descritos en el presente documento se usan como materia prima para la producción de tensioactivos o detergentes, el experto en la técnica apreciará que las características de la materia prima de alcohol graso afectarán las características de la composición tensioactiva o detergente producida. Por tanto, las características de la composición tensioactiva o detergente producida se pueden seleccionar mediante la producción de alcoholes grasos concretos para usar como materia prima. Una composición tensioactiva o detergente basada en alcohol graso descrita en el presente documento se puede mezclar con otros tensioactivos y/u otros detergentes bien conocidos en la técnica. En algunas realizaciones, la mezcla puede incluir al menos el 10%, al menos el 15%, al menos el 20%, al menos el 30%, al menos el 40%, al menos el 50%, al menos el 60%, o un intervalo delimitado por dos cualesquiera de los valores anteriores, en peso del alcohol graso. En otros ejemplos, puede producirse una composición tensioactiva o detergente que incluye al menos el 5%, al menos el 10%, al menos el 20%, al menos el 30%, al menos el 40%, al menos el 50%, al menos el 60%, al menos el 70%, al menos el 80%, al menos el 85%, al menos el 90%, al menos el 95%, o un intervalo delimitado por dos cualesquiera de los valores anteriores, en peso de un alcohol graso que incluye una cadena de átomos de carbono que tiene 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, o 22 carbonos de longitud. Dichas composiciones tensioactivas o detergentes también pueden incluir al menos un aditivo, tal como una microemulsión o un tensioactivo o detergente de origen no microbiológico tales como aceites vegetales o petróleo, que pueden estar presentes en la cantidad de al menos el 5%, al menos el 10%, al menos el 15%, al menos el 20%, al menos el 30%, al menos el 40%, al menos el 50%, al menos el 60%, al menos el 70%, al menos el 80%, al menos el 85%, al menos el 90%, al menos el 95%, o un intervalo delimitado por dos cualesquiera de los valores anteriores, en peso del alcohol graso. La divulgación se ilustrará adicionalmente mediante los siguientes Ejemplos. Los ejemplos se proporcionan solo con fines ilustrativos. De ninguna manera deben interpretarse como una limitación del alcance o del contenido de la divulgación.
Ejemplos
EJEMPLO 1
Modificaciones del hospedador de producción - Atenuación de Acil-CoA deshidrogenasa
Este ejemplo describe la construcción de una célula hospedadora modificada por ingeniería genética en la que la
expresión de una enzima de degradación de ácidos grasos está atenuada. Se delecionó el gen de fadE de Escherichia coli MG1655 (una cepa de E. coli K) usando el sistema Lambda Red (también conocido como Red-Driven Integration) descrito por Datsenko et al., Proc. Natl. Acad. Sci. USA 97: 6640- 6645 (2000), con las siguientes modificaciones:
Se usaron los siguientes cebadores para crear la deleción de fadE:
Del-fadE-
FS’-AAAAACAGCAACAATGTGAGCTTTGTTGTAATTATATTGTAAACATATTGATTCC
GGGGATCCGTCGACC (SEQ ID NO: 9); y
Del-fadE-
RS’-AAACGGAGCCTTTCGGCTCCGTTATTCATTTACGCGGCTTCAACTTTCCTGTA
GGCTGGAGCTGCTTC (SEQ ID NO: 10)
Se usaron los cebadores Del-fadE-F y Del-fadE-R para amplificar el casete de resistencia a kanamicina (KmR) del plásmido pKD13 (descrito por Datsenko et al., citado anteriormente) mediante PCR. Entonces se usó el producto de PCR para transformar células de E. coli MG1655 electrocompetentes que contenían pKD46 (descrito en Datsenko et al., citado anteriormente) que se habían inducido previamente con arabinosa durante 3-4 horas. Tras un crecimiento de 3 horas en un caldo súper óptimo con medio de represión de catabolitos (SOC) a 37°C, se sembraron en placa las células en placas de agar Luria que contenían 50 mg/ml de kanamicina. Se identificaron colonias resistentes y se aislaron tras una incubación durante la noche a 37°C. Se confirmó la alteración del gen de fadE mediante amplificación por PCR usando los cebadores fadE-L2 y fadE-R1, que se diseñaron para flanquear el gen de fadE de E. coli.
Los cebadores de confirmación de la deleción de fadE fueron:
fadE-L2 5 ’-CGGGCAGGTGCTATGACCAGGAC (SEQ ID NO: 11); y
fadE-Rl 5’-CGCGGCGTTGACCGGCAGCCTGG (SEQ ID NO: 12)
Tras confirmarse la deleción de fadE, se usó una única colonia para eliminar el marcador KmR usando el plásmido pCP20 tal como se describe por Datsenko et al., citado anteriormente. La cepa de E. coli MG1655 con el gen de fadE delecionado y el marcador KmR eliminado resultante se denominó E. coli MG1655 DfadE, o E. coli MG1655 D1. Se comparó la producción de derivados de ácido graso (“especie grasa total”) por la cepa de E. coli MG1655 con el gen fadE delecionado con la producción de derivados de ácido graso por E. coli MG1655. Se transformaron las células con el plásmido de producción pDG109 (pCL1920_PTRc_carBopt_12H08_alrAadp1_fabB[A329G]_fadR) y se fermentaron en medio mínimo de glucosa. Los datos presentados en la figura 5 muestran que la deleción del gen fadE no afectó a la producción de derivados de ácido graso.
EJEMPLO 2
Aumento del flujo a través de la ruta de síntesis de ácidos grasos - mediada por acetil CoA carboxilasa
Los principales precursores para la biosíntesis de ácidos grasos son malonil-CoA y acetil-CoA (figura 1). Se ha sugerido que estos precursores limitan la velocidad de biosíntesis de ácidos grasos (figura 2) en E. coli. En este ejemplo, se sobreexpresaron operones de acc sintéticos [accABCD de Corynebacterium glutamicum (±birA)] y las modificaciones genéticas condujeron a un aumento de la producción de acetil-coA y malonil-CoA en E. coli. En un enfoque, con el fin de aumentar los niveles de malonil-CoA, se sobreexpresó un complejo enzimático de acetil-CoA carboxilasa de Corynebacterium glutamicum (C. glutamicum) en E. coli. Acetil-CoA carboxilasa (acc) consiste en cuatro subunidades diferenciadas, accA, accB, accC y accD (figura 3). La ventaja de acc de C. glutamicum es que dos subunidades se expresan como proteínas de fusión, accCB y accDA, respectivamente, lo que facilita su expresión equilibrada. Adicionalmente, se sobreexpresó birA de C. glutamicum, que biotinila la subunidad accB (figura 3). El ejemplo 3 describe la coexpresión de genes de acc junto con operones de fab completos.
EJEMPLO 3
Aumento del flujo a través de la ruta de biosíntesis de ácidos grasos - iFAB
Producción de derivados de ácido graso:
Las estrategias para aumentar el flujo a través de la ruta de síntesis de ácidos grasos en células hospedadoras recombinantes incluyen tanto la sobreexpresión de genes de biosíntesis de ácidos grasos de E. coli nativos como la expresión de genes de biosíntesis de ácidos grasos endógenos de diferentes organismos en E. coli. En este estudio,
se combinaron genes de biosíntesis de ácidos grasos de diferentes organismos en el genoma de E. coli DV2. Se evaluaron dieciséis cepas que contienen iFAB 130 - 145. Se presenta la estructura detallada de iFAB 130 - 145 en la tabla 1 de iFAB, a continuación.
Tabla 1. Com onentes encontrados en iFAB 130-145.

Cada “iFAB” incluía diversos genes de fab en el siguiente orden: 1) una enoil-ACP reductasa (BS_fabI, BS_FabL, Vc_FabV o Ec_FabI); 2) una b-cetoacil-ACP sintetasa III (St_fabH); 3) una malonil-CoA-ACP transacilasa (St_fabD); 4) una b-cetoacil-ACP reductasa (St_fabG); 5) una 3-hidroxi-acil-ACP deshidratasa (St_fabA o St_fabZ); 6) una bcetoacil-ACP sintetasa II (Cac_fabF). Obsérvese que St_fabA tiene también actividad trans-2, cis-3-decenoil-ACP isomerasa (ref) y que Cac_fabF tiene actividades b-cetoacil-ACP sintetasa II y b-cetoacil-ACP sintetasa I (Zhu et al., BMC Microbiology 9:119 (2009)). Véase la tabla 2, a continuación para la composición específica de iFAB 130 - 145. Véanse las figuras 7A y B que proporcionan la representación esquemática del locus iFAB138, incluyendo un diagrama del promotor cat-loxP-T5 integrado en frente de FAB138 (7A); y un diagrama de iT5_138 (7B).

El plásmido pCL_Ptrc_tesA se transformó en cada una de las cepas y se realizó una fermentación en medio FA2 con 20 horas desde la inducción hasta la recogida tanto a 32° C como a 37° C. En las Figs. 6A y 6B se muestran los datos de producción de Especies grasas totales procedentes de exámenes en placa por duplicado. A partir de este examen de la biblioteca, se determinó que la mejor construcción era DV2 con ífAB138. La construcción iFAB138 se transfirió a la cepa D178 para preparar la cepa EG149. Esta cepa se utilizó para una modificación genética adicional. La secuencia de iFAB138 en el genoma de EG149 se presenta como la SEQ ID NO:13. La Tabla 3 presenta la caracterización genética de diversas cepas de E. coli en las que se introdujeron plásmidos que contenían las
construcciones de expresión descritas en el presente documento tal como se describe a continuación. Estas cepas y plásmidos se usaron para demostrar las células hospedadoras recombinantes, los cultivos, y los métodos de determinadas realizaciones de la presente divulgación. Las designaciones genéticas de la Tabla 3 son designaciones estándar conocidas por los expertos en la técnica.
Tabla 3: Caracterización enética de ce as de E. coli

EJEMPLO 4
Aumento de la cantidad de producto de ácido graso libre (FFA) reparando las mutaciones de rph e ilvG
Se corrigieron las mutaciones de ilvG y rph en esta cepa dando como resultado una producción superior de FFA. Se transformaron las cepas D178, EG149 y V668 (tabla 3) con pCL_Ptrc_tesA. Se realizó una fermentación a 32° C en medio FA2 durante 40 horas para comparar la producción de FFA de las cepas D178, EG149 y V668 con pCL_Ptrc_tesA. La corrección de las mutaciones de rph e ilvG dio como resultado un aumento del 116% en la producción de FFA de la cepa base con pCL_Ptrc_tesA. Tal como se observa en la figura 8, V668/pCL_Ptrc_tesA produce más FFA que la D178/pCL_Ptrc_tesA, o el control EG149/pCL_Ptrc_tesA. Puesto que FFA es un precursor para los productos de LS9, una producción de FFA superior es un buen indicador de que la nueva cepa puede producir niveles superiores de productos de LS9. Se ejecutó la fermentación y extracción según el protocolo de fermentación de FALC convencional ejemplificado por lo siguiente.
Se usó un vial de banco de células congelado de la cepa de E. coli seleccionada para inocular 20 ml de caldo LB en un matraz de agitación con deflectores de 125 ml que contenía antibiótico espectinomicina a una concentración de 115 pg/ml. Se incubó este matraz de agitación en un agitador orbital a 32°C durante aproximadamente seis horas, luego se transfirieron 1,25 ml del caldo a 125 ml de medio de siembra FA2 con bajo contenido en P (NELCl 2 g/l, NaCl 0,5 g/l, KH2PO4 3 g/l, MgSÜ4-7H2O 0,25 g/l, CaCl2-2H2Ü 0,015 g/l mM, glucosa 30 g/l, 1 ml/l de disolución de oligoelementos (2 g/l de ZnCh • 4 H2O, 2 g/l de CaCh • 6 H2O, 2 g/l de Na2MoÜ4 • 2 H2O, 1,9 g/l de CuSÜ4 • 5 H2O, 0,5 g/l de H3BO3 y 10 ml/l de HCl concentrado), 10 mg/l de citrato férrico, 100 mM de tampón Bis-Tris (pH 7,0) y 115 m/ml de espectinomicina), en un matraz de agitación Erlenmeyer con deflectores de 500 ml, y se incubó en un agitador durante la noche a 32°C. Se usaron 100 ml de este cultivo de siembra de FA2 con bajo contenido en P para inocular un biorreactor Biostat Aplus de 5 l (Sartorius BBI), que contenía inicialmente 1,9 l de medio de fermentación de biorreactor F1 esterilizado. Este medio se compone inicialmente de 3,5 g/l de KH2PO4, 0,5 g/l de (NH4)2SO4, 0,5 g/l de MgSO4 heptahidratado, 10 g/l de glucosa filtrada estéril, citrato férrico 80 mg/l, casaminoácidos 5 g/l, 10 ml/l de la disolución de oligoelementos filtrada estéril, 1,25 ml/l de una disolución de vitaminas filtrada estéril (0,42 g/l de riboflavina, 5,4 g/l de ácido pantoténico, 6 g/l de niacina, 1,4 g/l de piridoxina, 0,06 g/l de biotina y 0,04 g/l de ácido fólico), y la espectinomicina a la concentración que se utilizó en el medio de siembra. Se mantuvo el pH del cultivo a 6,9 usando agua amoniacal al 28% p/v, la temperatura a 33°C, la velocidad de aireación 1 lpm (0,5 v/v/m), y la tensión de oxígeno disuelto al 30% de saturación, utilizando el bucle de agitación en cascada con el controlador de DO y complementación de oxígeno. Se controló la formación de espuma mediante la adición automatizada de un antiespumante basado en emulsión de silicona (Dow Corning 1410).
Se inició una alimentación de nutrientes compuesta por MgSO4 heptahidratado 3,9 g/l y glucosa 600 g/l cuando la glucosa en el medio inicial casi se había agotado (aproximadamente 4-6 horas tras la inoculación) bajo una velocidad de alimentación exponencial de 0,3 h-1 hasta una velocidad de alimentación de glucosa máxima constante de 10-12 g/l/h, basándose en el volumen de fermentación nominal de 2 l. Se indujo la producción de alcohol graso en el biorreactor cuando el cultivo alcanzó una DO de 5 AU (aproximadamente 3-4 horas tras la inoculación) mediante la adición de una disolución madre de IPTG 1 M hasta una concentración final de 1 mM. Se tomaron muestras del biorreactor dos veces al día después de eso, y se cosechó aproximadamente 72 horas tras la inoculación. Se transfirió una muestra de 0,5 ml del caldo de fermentación bien mezclado a un tubo cónico de 15 ml (VWR), y se mezcló
concienzudamente con 5 ml de acetato de butilo. Se invirtió el tubo varias veces para mezclar, entonces se agitó con vórtex vigorosamente durante aproximadamente dos minutos. Entonces se centrifugó el tubo durante cinco minutos para separar las fases acuosa y orgánica, y se transfirió una parte de la fase orgánica a un vial de vidrio para el análisis por cromatografía de gases.
EJEMPLO 5
Aumento de la producción de Alcohol graso mediante mutagénesis de transposón - yijP
Para mejorar el título, el rendimiento, la productividad de la producción de alcohol graso por E. coli, se llevaron a cabo mutagénesis de transposón y examen de alto rendimiento y se secuenciaron mutaciones beneficiosas. Se mostró que una inserción de transposón en la cepa yijP mejoraba el rendimiento de alcohol graso de la cepa en fermentaciones tanto en matraz de agitación como semicontinuas. La cepa SL313 produce alcoholes grasos. El genotipo de esta cepa se proporciona en la tabla 3. Se sometieron los clones de transposón a examen de alto rendimiento para medir la producción de alcoholes grasos. En resumen, se recogieron colonias en placas de pocillos profundos que contenían LB, se hicieron crecer durante la noche, se inocularon en LB nuevo y se hicieron crecer durante 3 horas, se inocularon en medio FA2.1 nuevo, se hicieron crecer durante 16 horas, luego se extrajeron usando acetato de butilo. Se derivatizó el extracto en bruto con BSTFA (N,O-bis[Trimetilsilil]trifluoroacetamida) y se analizó usando CG/FID. Se incluyó espectinomicina (100 mg/l) en todos los medios para mantener la selección del plásmido pDG109. Se seleccionaron aciertos eligiendo clones que producían una especie grasa total similar que la cepa control SL313, pero que tenían un mayor porcentaje de especies de alcohol graso y un menor porcentaje de ácidos grasos libres que el control. Se identificó la cepa 68F11 como un acierto y se validó en una fermentación en matraz de agitación usando el medio FA2.1. Una comparación del acierto de transposón 68F11 con la cepa control SL313 indica que 68F11 produce un mayor porcentaje de especies de alcohol graso que el control, mientras que ambas cepas producen títulos similares de especie grasa total. Se secuenció una única colonia del acierto 68F11, denominada LC535, para identificar la ubicación de la inserción del transposón. En resumen, se purificó el ADN genómico a partir de un cultivo en LB durante la noche de 10 ml usando el kit z R Fungal/Bacterial DNA MiniPrep™ (Zymo Research Corporation, Irvine, CA) según las instrucciones del fabricante. Se secuenció el ADN genómico purificado fuera del transposón usando cebadores internos para el transposón:
DG150 5 ’ -GCAGTTATTGGTGCCCTTAAACGCCTGGTTGCTACGCCTG-3 ’
(SEQ ID NO: 14)
DG131 5’- GAGCCAATATGCGAGAACACCCGAGAA-3’ (SEQ ID NO:15)
Se determinó que la cepa LC535 tiene una inserción de transposón en el gen de yijP (figura 18). yijP codifica para una proteína de la membrana interna conservada cuya función no está clara. El gen de yijP está en un operón y se transcribe conjuntamente con el gen de ppc, que codifica para fosfoenolpiruvato carboxilasa, y el gen de yijO, que codifica para un regulador de la transcripción de unión a ADN predicho de función desconocida. Los promotores internos para el transposón probablemente tienen efectos sobre el nivel y el momento de la transcripción de yijP, ppc e yijO, y también pueden tener efectos sobre genes adyacentes, frwD, pflC, pfld y argE. En la figura 18 se muestran los promotores internos para el casete de transposón, y pueden tener efectos sobre la expresión génica adyacente. Se evaluó la cepa LC535 en una fermentación semicontinua en dos fechas diferentes. Ambas fermentaciones demostraron que LC535 producía alcoholes grasos con un rendimiento mayor que SL313 de control, y la mejora era del 1,3-1,9% del rendimiento absoluto basándose en la entrada de carbono. Se evaluó adicionalmente el casete de transposón de yijP en una cepa diferente, V940, que produce alcohol graso a un rendimiento mayor que la cepa SL313. Se amplificó el casete yijP::Tn5-cat de la cepa LC535 usando los cebadores:
LC277 5’-
CGCTGAACGTATTGCAGGCCGAGTTGCTGCACCGCTCCCGCCAGGCAG-3’
(SEQ ID NO: 16)
LC278 5’-
GGAATTGCCACGGTGCGGCAGGCTCCATACGCGAGGCCAGGTTATCCAACG-3’
(SEQ ID NO: 17)
Se introdujo por electroporación este ADN lineal en la cepa SL571 y se integró en el cromosoma usando el sistema de recombinación Lambda Red. Se examinaron colonias usando los cebadores fuera de la región del transposón:

Se transformó una colonia con el casete de transposón de yijP correcto (figura 9) con el plásmido de producción pV171.1 para producir la cepa D851. Se sometió a prueba D851 (V940 yijP::Tn5-cat) en una fermentación en matraz de agitación frente a la cepa isogénica V940 que no contiene el casete de transposón de yijP. El resultado de esta fermentación mostró que el casete de transposón de yijP confiere la producción de un mayor porcentaje de alcohol graso por la cepa D851 en relación con la cepa V940 y produce títulos similares de especie grasa total que la cepa de control V940. Se evaluó la cepa D851 en una fermentación semicontinua en dos fechas diferentes. En la tabla 4 se muestran los datos de estas fermentaciones, que ilustra que en fermentaciones semicontinuas de 5 l, las cepas con la inserción del transposón yijP::Tn5-cat tenían un rendimiento de especie grasa total (“FAS”) aumentado y un aumento en el porcentaje de alcohol graso (“FALC”). Las “especies grasas” incluyen FALC y FFA.
Tabla 4: Efecto de la inserción del trans osón de i sobre el título rendimiento de FAS FALC

Método de fermentación en tanque:
Para evaluar la producción de ésteres de ácidos grasos en tanque, se usó un vial en glicerol de la cepa deseada para inocular 20 ml de LB espectinomicina en matraz de agitación y se incubó a 32°C durante aproximadamente seis horas. Se usaron 4 ml de cultivo en LB para inocular 125 ml de medio de siembra con bajo contenido en PFA (a continuación), que entonces se incubó a 32°C en un agitador durante la noche. Se usaron 50 ml del cultivo durante la noche para inocular 1 l de medio de tanque. Se hicieron funcionar los tanques a pH 7,2 y 30,5°C en condiciones de pH estacionario con una velocidad de alimentación máxima de 16 g/l/h (glucosa o metanol).
Tabla 5: Medio de siembra con bao contenido en PFA


EJEMPLO 6
Adición de una etiqueta de fusión de 60 pb N-terminal a CarB (CarB60)
Hay muchos modos de aumentar la solubilidad, estabilidad, expresión o funcionalidad de una proteína. En un enfoque
para aumentar la solubilidad de CarB, pudo clonarse una etiqueta de fusión antes del gen. En otro enfoque para aumentar la expresión de CarB, pudo alterarse el promotor o sitio de unión al ribosoma (RBS) del gen. En este estudio, se modificó carB (SEQ ID NO: 7) mediante la adición de una etiqueta de fusión de 60 pb N-terminal. Para generar la proteína modificada (denominada en el presente documento “CarB60”), se clonó el primer lugar carB en el vector pET15b usando los cebadores:
5’- GCAATTCCATATGACGAGCGATGTTCACGA-3’ (SEQ ID NO:20); y
5’- CCGCTCGAGTAAATCAGACCGAACTCGCG (SEQ ID NO:21).
La construcción de pET15b-carB contenía 60 nucleótidos directamente en el sentido de 5' del gen carB: 5'-ATGGGCAGCAGCCATCATCATCATCATCACAGCAGCGGCCTGGTGCCGCGCGGCAG CCAT (SEQ ID NO:22)
La versión con etiqueta de fusión de carB se renombró carB60. Entonces se digirió el pET15b_carB60 usando las enzimas de restricción NcoI y HindIII y se subclonó en el vector derivado de pCL1920 OP80 que se cortó con las mismas enzimas. Se transformó este plásmido en la cepa V324 (MG1655 AfadE::FRT AfhuA::FRT fabB::A329V entD::T5-entD lacIZ::PTC-'TesA) para evaluar la producción de FALC. Se fermentaron las cepas según un procedimiento convencional (resumido más adelante) y se cuantificaron el título de especie grasa total y el título de alcohol graso total. La figura 10 muestra que CarB60 aumenta los títulos de alcohol graso y por tanto la enzima CarB60 tiene una actividad celular total mayor que CarB cuando se expresa a partir de un plásmido de múltiples copias.
Para evaluar la producción de alcoholes grasos en cepas de producción, se hicieron crecer transformantes en 2 ml de caldo LB complementado con antibióticos (100 mg/l) a 37°C. Tras el crecimiento durante la noche, se transfirieron 40 ul de cultivo a 2 ml de LB nuevo complementado con antibióticos. Tras 3 horas de crecimiento, se transfirieron 2 ml de cultivo a un matraz de 125 ml que contenía 20 ml de medio M9 con glucosa al 3% complementado con 20 ml de disolución de oligoelementos, citrato de hierro 10 mg/l, tiamina 1 mg/l, y antibióticos (medio FA2). Cuando la DO600 del cultivo alcanzó 1,0, se añadió 1 mM de IPTG a cada matraz. Tras 20 horas de crecimiento a 37°C, se retiraron muestras de 400 ml de cada matraz y se extrajeron los alcoholes grasos con 400 ml de acetato de butilo. Para entender adicionalmente el mecanismo de la actividad de CarB mejorada, se purificó CarB60 a partir de la cepa D178 que no contiene 'TesA (MG1655 DfadE::FRT AfhuA::FRT fabB::A329V entD::PT5-entD). En resumen, se transformó pCL1920_carB60 en la cepa D178, que se había modificado por ingeniería genética para la producción de alcohol graso, y se llevó a cabo la fermentación a 37°C en medio FA-2 complementado con espectinomicina (100 mg/ml). Cuando el cultivo alcanzó una DO600 de 1,6, se indujeron las células con isopropil-p-D-tiogalactopiranósido (IPTG) 1 mM y se incubaron durante 23 h adicionales a 37°C. Para la purificación de CarB60, las células se recogieron mediante centrifugación durante 20 min a 4°C a 4.500 rpm. Se suspendió la pasta celular (10 g) en 12 ml de mezcla maestra BugBuster (Novagen) y disolución de cóctel inhibidor de proteasas. Se rompieron las células mediante prensa francesa y se centrifugó el homogenado resultante a 10.000 rpm para eliminar los residuos celulares. Se añadió Ni-NTA a la mezcla resultante, y se agitó la suspensión a 4°C a 100 rpm durante 1 hora en un agitador rotatorio. Se vertió la suspensión en una columna, y se recogió la fracción no retenida. Se lavó la resina de Ni-NTA con imidazol 10 mM en tampón fosfato de sodio 50 mM pH 8,0 que contenía NaCl 300 mM, y se lavó adicionalmente con imidazol 20 mM en tampón fosfato de sodio 50 mM pH 8,0 que contenía NaCl 300 mM. Se eluyó la proteína CarB60 con imidazol 250 mM en tampón fosfato de sodio 50 mM pH 8,0 que contenía NaCl 300 mM, y se analizó mediante SDS-PAGE. Se dializó la proteína frente a glicerol al 20% (v/v) en tampón fosfato de sodio 50 mM pH 7,5 produciendo aproximadamente 10 mg de CarB60 por litro de cultivo. Se congeló inmediatamente la proteína y se almacenó a -80°C hasta que se necesitó.
La proteína CarB60 se expresaba abundantemente a partir de un plásmido de múltiples copias. El análisis de SDS-PAGe adicional mostró que la expresión de CarB60 era superior a la de CarB. El nivel de expresión superior de CarB60 sugirió que el gen de carB60 integrado en el cromosoma de E. coli produciría más proteína que el gen de carB en la misma ubicación. Para someter a prueba esta hipótesis, se integró el gen de carB60 en el cromosoma de E. coli. En resumen, se amplificó en primer lugar el gen de carB60 a partir de pCL_carB60 usando el cebador directo:
5'-ACGGATCCCCGGAATGCGCAACGCAATTAATGTaAGTTAGCGC-3' (SEQ ID NO:23);y el cebador inverso: 5'-TGCGTCATCGCCATTGAATTCCTAAATCAGACCGAACTCGCGCAGG-3' (SEQ ID NO:24).
Se amplificó un segundo producto de PCR a partir del vector pAH56 usando el cebador directo:
5'-ATTCCGGGGATCCGTCGACC-3' (SEQ ID NO:25); y el cebador inverso:
5'-AATGGCGATGACGCATCCTCACG-3' (SEQ ID NO:26)
Este fragmento contiene un casete de resistencia a kanamicina, el sitio lattP, y un origen de replicación gR6k. Se unieron los dos productos de PCR usando el kit InFusion (Clontech) para crear el plásmido pSL116-126. Se transformó una cepa de producción de alcohol graso que contenía una forma integrada de 'TesA12H08 y un plásmido auxiliar pINT con o bien pSL116-126 que contenía el gen de carB60 o bien el plásmido F27 que contenía el gen de carB. Se fermentaron estas cepas en medio FA2 según procedimientos convencionales para fermentaciones en matraz de agitación, tal como se describió anteriormente. Para caracterizar y cuantificar los alcoholes grasos y ésteres de ácidos grasos, se usó la detección por cromatografía de gases acoplada con ionización de llama (“FID”). Se derivatizó
el extracto en bruto con BSTFA (N,O-bis[Trimetilsilil]trifluoroacetamida) y se analizó usando una CG/FID. Se llevó a cabo la cuantificación inyectando diversas concentraciones de las referencias auténticas apropiadas usando el método de CG descrito anteriormente así como ensayos que incluyen, pero no se limitan a, cromatografía de gases (CG), espectrometría de masas (EM), cromatografía en capa fina (CCF), cromatografía de líquidos de alta resolución (HPLC), cromatografía de líquidos (CL), CG acoplada con un detector de ionización de llama (CG-FID), CG-EM y CL-EM. Cuando se somete a prueba para detectar la expresión de un polipéptido, pueden usarse técnicas tales como inmunotransferencia de tipo Western y transferencia puntual.
En la figura 11 se muestran los resultados de la fermentación tras 20 horas. Los títulos de productos grasos totales de las dos cepas son similares (especie grasa total 2,4 g/l), sin embargo CarB60 integrada convierte una mayor fracción de ácidos grasos libres de longitud de cadena C12 y C14 en alcoholes grasos, en comparación con CarB sin la etiqueta N-terminal. Estos datos sugieren que células que expresan CarB60 tienen una actividad ácido carboxílico reductasa celular total superior, y pueden convertir más FFA en alcoholes grasos. Por tanto, carB60, cuando se integra en el cromosoma, es un molde de carB mejorado que proporciona la actividad deseada para hacer evolucionar el gen de carB para identificar variantes de carB mejoradas.
EJEMPLO 7
Generación de mutantes de CarB
La enzima CarB es una etapa limitante de la velocidad en la producción de alcoholes grasos en determinadas condiciones del procedimiento. Para producir alcoholes grasos de manera económica, se hicieron esfuerzos para aumentar la actividad de la enzima CarB.
Examen de la biblioteca de PCR propensa a error:
Se realizó mutagénesis al azar usando PCR propensa a error en condiciones en las que la fidelidad de copiado de la ADN polimerasa es baja. Se clonaron los ácidos nucleicos mutagenizados en un vector, y se realizó PCR propensa a error seguido por examen de alto rendimiento para encontrar mutaciones beneficiosas que aumentaran la conversión de ácidos grasos libres en alcoholes grasos (tal como se detalla a continuación). Se mutaron adicionalmente residuos importantes para dar otros aminoácidos. Varias mutaciones de aminoácidos individuales y combinaciones de mutaciones aumentaron la fracción de especies grasas que se convertían en alcoholes grasos. En resumen, se generaron mutaciones al azar en el gen de carB60opt mediante PCR propensa a error usando el kit Genemorph II (Stratagene). Se generaron mutaciones en sólo uno de dos dominios de carB60opt por separado, para facilitar la clonación. La biblioteca 1 contenía los primeros 759 residuos de carB60opt y se generó mediante PCR propensa a error usando los cebadores:
HZ117 5’- ACGGAAAGGAGCTAGCACATGGGCAGCAGCCATCATCAT-3’
(SEQ ID NO:27); y
DG264 5’- GTAAAGGATGGACGGCGGTCACCCGCC-3’ (SEQ ID NO:28).
El vector para la biblioteca 1 era el plásmido pDG115 digerido con las enzimas NheI y PshAI. La biblioteca 2 contenía los últimos 435 residuos de carB60opt y se generó mediante PCR propensa a error usando los cebadores:
DG263 5’- CACGGCGGGTGACCGCCGTCCATCC-3’(SEQ ID NO:29); y
HZ118 5’- TTAATTCCGGGGATCCCTAAATCAGACCGAACTCGCGCAGGTC-3’ (SEQ ID
NO;30).
El vector para la biblioteca 2 era el plásmido pDG115 digerido con las enzimas PshAI y BamHI. Se clonaron los insertos propensos a error en los vectores usando InFusion Advantage (Clontech) y se hicieron pasar a través de la cepa de clonación NEB Turbo (New England Biolabs). Entonces se transformaron las bibliotecas en la cepa EG442 (EG149 Tn7::PTRC-ABR lacIZ::PT50-ABR). Entonces se sometieron los clones de carB60opt propensos a error a examen de alto rendimiento para medir la producción de alcoholes grasos. En resumen, se recogieron colonias en placas de pocillos profundos que contenían LB, se hicieron crecer durante la noche, se inocularon en LB nuevo y se hicieron crecer durante 3 horas, se inocularon en medio FA-2.1 nuevo, se hicieron crecer durante 16 horas, luego se extrajeron usando acetato de butilo. Se derivatizó el extracto en bruto con BSTFA (N,O-bis[Trimetilsilil]trifluoroacetamida) y se analizó usando un método de CG/FID convencional. Se incluyó espectinomicina (100 mg/l) en todos los medios para mantener la selección del plásmido pDG115. Se seleccionaron aciertos eligiendo clones que producían un título de ácidos grasos libres más pequeño y un título de ácidos grasos totales más grande en comparación con la cepa de control. Para comparar aciertos de diferentes exámenes de fermentación, se normalizó la conversión de ácidos grasos libres en
alcoholes grasos calculando un porcentaje de ácidos grasos libres normalizado NORM FFA = porcentaje de FFA mutante / porcentaje de FFA de control en donde “porcentaje de FFA” es el título de la especie de ácidos grasos totales dividido entre el título de la especie grasa total. Se sometieron los aciertos a verificación adicional usando fermentaciones en matraz de agitación, tal como se describe a continuación.
Se secuenciaron los aciertos para identificar mutaciones beneficiosas. Se realizó la secuenciación mediante PCR de colonias de todo el gen de carB60opt usando los cebadores
SL595'- CAGCCGTTTATTGCCGACTGGATG-3'(SEQ ID NO:31); y
EG479 5'- CTGTTTTATCAGACCGCTTCTGCGTTC-3' (SEQ ID NO:32), y se secuenciaron usando cebadores internos para la enzima carB60opt.
En la tabla 7 se muestran las mutaciones beneficiosas que mejoran la enzima CarB60opt. La columna de ácidos grasos libres normalizados (NORM FFA) indica la mejora en la enzima, indicando los valores inferiores la mejor mejora “Pocillo n.°” indica el pocillo de examen primario en el que se encontró esta mutación. Todos los números de residuos se refieren a la secuencia de proteína CarB, que no incluye la etiqueta de 60 pb. Las mutaciones indicadas con el prefijo “Tag:” indican mutaciones en la etiqueta N-terminal de 60 pb/20 residuos.
Tabla 7: Mutaciones beneficiosas en la enzima CarB identificada durante el examen propenso a error (mutaciones d TAG eliminadas

Mutagénesis de saturación (biblioteca conjunta 1 y 2 generada):
Se sometieron posiciones de aminoácidos que se consideraban beneficiosas para la producción de alcohol graso tras la PCR propensa a error a mutagénesis adicional. Se usaron cebadores que contenían los nucleótidos degenerados NNK o NNS para mutar estas posiciones para dar otros aminoácidos. Se examinaron las “bibliotecas de mutagénesis de saturación” resultantes tal como se describió anteriormente para las bibliotecas propensas a error, y se identificaron aciertos que mejoraban adicionalmente la conversión en alcohol graso (un título de ácidos grasos libres total más pequeño y un título de alcoholes grasos total más grande en comparación con la cepa “control” parental). En la tabla 8 se muestran cambios de codones/aminoácidos individuales en nueve posiciones diferentes que mejoran la producción de alcoholes grasos. Se sometieron los aciertos a verificación adicional usando fermentaciones en matraz de agitación, tal como se describe en el presente documento.
Tabla 8: M i n n fi i n l nzim rB i n ifi r n m n i r i n minoácidos


A continuación se combinaron sustituciones de aminoácidos que se consideraban beneficiosas para la producción de alcohol graso. Se usó PCR para amplificar partes del gen de carBopt que contenía diversas mutaciones deseadas, y se unieron las partes entre sí usando un método basado en PCR (Horton, R.M., Hunt, H.D., Ho, S.N., Pullen, J.K. y Pease, L.R. 1989). Se examinó el gen de carBopt sin la etiqueta N-terminal de 60 pb. Las mutaciones combinadas en esta biblioteca de combinación se muestran en la tabla 9.
Tabla 9: mbinación
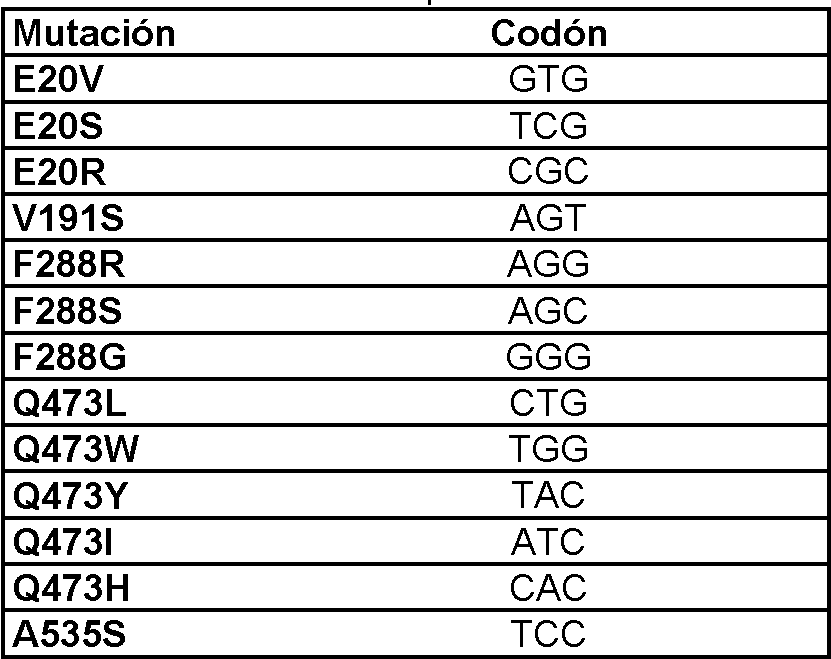
Para facilitar el examen, se integró entonces la biblioteca de combinación de CarB resultante en el cromosoma de la cepa V668 en el locus lacZ. La secuencia del gen de carBopt en este locus se presenta como SEQ ID NO: 7. El genotipo de la cepa V668 es MG1655 (AfadE::FRT DfhuA::FRT AfabB::A329V AentD::T5-entD AinsH-11:: Placuv5fab138 rph+ ilvG+) (tal como se muestra en la tabla 3 y la figura 16). Entonces se transformaron las cepas con el plásmido pVA3, que contiene TesA, una enzima CarB catalíticamente inactiva CarB[S693A] que destruye el sitio de unión de fosfopanteteína, y otros genes que aumentan la producción de ácidos grasos libres. Se examinó la biblioteca de combinación tal como se describió anteriormente para la biblioteca propensa a error. Se usó como control V668 con carB opt (A535S) integrado en la región lacZ y que contenía pVA3. Se seleccionaron aciertos que aumentaban la producción de alcoholes grasos y se sometieron a verificación adicional usando fermentaciones en matraz de agitación, tal como se describe en el ejemplo 5. En la figura 12 se muestra el porcentaje mejorado de producción de alcohol graso tras la fermentación en matraz de agitación de células hospedadoras recombinantes que expresan mutantes de combinación de CarB.
Se amplificaron los mutantes de combinación de CarB integrados a partir de los aciertos de carB integrados mediante PCR usando los cebadores:
EG58 5 ’ - GCACTCGACCGGAATTATCG (SEQ ID NO:33); y
EG626 5’- GCACTACGCGTACTGTGAGCCAGAG (SEQ ID NO:34).
Se reamplificaron estos insertos usando los cebadores:
DG2435’- GAGGAATAAACCATGACGAGCGATGTTCACGACGCGACCGACGGC
(SEQ ID NO:35); y
DG2105’- CTAAATCAGACCGAACTCGCGCAGG (SEQ ID NO:36).
Usando clonación InFusion, se clonaron los mutantes de carB agrupados en un plásmido de producción, pV869, que se amplificó por PCR usando los cebadores:
DG228 5’- CATGGTTTATTCCTCCITATTTAATCGATAC(SEQ ID NO:37); y
DG318 5’- TGACCTGCGCGAGTTCGGTCTGATTTAG (SEQ ID NO:38).
El muíante de carB que tenía el mejor rendimiento en el examen de plásmido de fermentación en matraz de agitación (carB2; tabla 11) se designó VA101 y la cepa de control que portaba carBopt [A535S] se designó VA82. Véase la figura 13.
Se combinaron sustituciones de aminoácidos en el dominio de reducción de carB consideradas beneficiosas para la producción de alcohol graso con uno de los mejores aciertos de la biblioteca de combinación de carB-L, “carB3” (tabla 11). Se usó PCR para amplificar partes del gen de carBopt que contenían diversas mutaciones deseadas en el domino de reducción, y se unieron las partes entre sí usando SOE PCR. En la tabla 10 se muestran las mutaciones combinadas en esta biblioteca de combinación.
Tabla 10: M i n rB rir l n i li ombinación

Se examinó la biblioteca de combinación tal como se describió anteriormente para la biblioteca propensa a error. Se usó como control V668 con carB3 integrado en la región de lacZ y que contenía pVA3. Se seleccionaron aciertos que presentaban producción aumentada de alcoholes grasos y se sometieron a verificación adicional usando fermentaciones en matraz de agitación, tal como se describió anteriormente. En la tabla 11 se muestran los resultados de una fermentación en matraz de agitación que muestra un porcentaje mejorado de producción de alcohol graso usando una mutación de combinación de CarB adicional (carB4). En la figura 4 se presenta una representación gráfica de la eficacia de conversión relativa de variantes de CarB de bajo número de copias. Los resultados notificados en la tabla 11 son de ejecuciones en biorreactor llevadas a cabo en condiciones idénticas.
Tabla 11: Variantes de CAR

identificación de mutaciones beneficiosas adicionales en la enzima CarB mediante mutagénesis de saturación:
Se desarrolló posteriormente un sistema de examen de plásmido doble y se validó para identificar variantes de CarB mejoradas con respecto a CarB4 para la producción de FALC. Este sistema de plásmido doble cumplía los siguientes criterios: 1) Los clones mutantes producen un alto título de FA para proporcionar flujo de ácidos grasos en exceso de la actividad de CarB. Esto se logra transformando una cepa base (V668 con dos copias de TE cromosómico) con un plásmido (pLYC4, pCL1920_PTRC_carDead_tesA_alrAadp1_fabB[A329G]_fadR) que porta el operón de FALC con una enzima CarB catalíticamente inactiva CarB[S693A] para potenciar la producción de ácidos grasos libres; 2) el plásmido de examen con molde de mutante de carB, preferiblemente menor de 9 kb, es propenso a procedimientos de mutagénesis de saturación y es compatible para la expresión con pLYC4; 3) el intervalo dinámico de actividad de CarB puede ajustarse. Esto se logra combinando un promotor más débil (Pt r c 1) y codones de iniciación alternativos (GTG o TTG) para ajustar los niveles de expresión de CarB4. 3) Se introdujo una buena estabilidad del plásmido, un módulo de toxina/antitoxina (operón de ccdBA) para mantener la estabilidad del plásmido.
En resumen, se construyó el plásmido de examen pBZ1 (pACYCDuet-1-PTRC1-carB4GTG_rrnBter_ccdAB) a partir de cuatro partes usando el método de clonación In-Fusion HD (Clontech) mezclando razones molares iguales de cuatro partes (P trc 1, carB4 con codones de iniciación ATG/TTG/GTG, terminadores rrnB T1T2 con ccdAB y vector pACYCDuet-1). Se amplificaron por PCR las partes (1 a 4) mediante los siguientes pares de cebadores: (1) P trc 1 -cebador directo 5'CGGTTCTGGCAAATATTCTGAAATGAGCTGTTGACAATTAATCAAATCCGGCTCGTATAATGTGTG-3' (SEQ ID NO:45 ) y cebador inverso 5'-GGTTTATTCCTCCTTATTTAATCGATACAT-3' (SEQ ID NO:46) usando el plásmido pVA232 (pCL1920_PTRc_carB4_tesA_alrAadp1_fabB[A329G]_fadR) como molde. (1) carB4 con codones de iniciación ATG/TTG/GTG - cebador directo carB4 ATG 5'ATGTATCGATTAAATAAGGAGGAATAAACCATGGGCACGAGCGATGTTCACGACG CGAC-3' (SEQ ID NO:47); carB4 GTG 5'A TGTATCGATTAAATAAGGAGGAATAAACCGTGGGCACGAGCGATGTTCACGACG CGAC-3' (SEQ ID NO:48); y carB4 TTG 5'-AT GT ATCGATT AAAT AAGGAGGAAT AAACCTT GGGCACGAGCGAT GTT CACGACGCGAC-3' (SEQ ID NO:49); y cebador inverso carB4 inv 5'-TTCTAAATCAGACCGAACTCGCGCAG-3' (SEQ ID NO:50), usando como molde el plásmido pVA232. (3) Los terminadores de rrnB T1T2 con ccdAB - Cebador inverso rrnB T1T2 term 5'-CTGCGCGAGTTCGGTCTGATTTAGAATTCCTCGAGGATGGTAGTGTGG-3' (SEQ ID NO:51 ) y cebador inverso ccdAB inv 5'-CAGTCGACATACGAAACGGGAATGCGG-3' (SEQ ID NO:52), usando el plásmido pAH008 (operón pV171 de ccdBA). (4) El vector estructural pACYCDuet-1 - Cebador inverso del vector pACYC para 5'CCGCATTCCCGTTTCGTATGTCGACTGAAACCTCAGGCATTGAGAAGCACACGGTC-3' (SEQ ID NO:53 ) y el cebador inverso del vector pACYC inv
5'-CTCATTTCAGAATATTTGCCAGAACCGTTAATTTCCTAATGCAGGAGTCGCATAAG-3' (SEQ ID NO:54).
Se coexpresó el plásmido pBZ1 con pLYC4 en la cepa descrita anteriormente y se validó mediante fermentación en matraz de agitación y placa de pocillos profundos. Se optimizaron las condiciones de fermentación de manera que el molde de CarB4_GTG tenía de manera reproducible una conversión de FALC de aproximadamente 65 % en ambas plataformas de fermentación tal como se describe en el ejemplo 5. En la figura 15 se muestran los resultados para la fermentación en matraz de agitación.
Se sometieron sitios adicionales (18, 19, 22, 28, 80, 87, 90, 143, 212, 231, 259, 292, 396, 416, 418, 530, 541, 574, 612, 636, 677, 712, 750, 799, 809, 810, 870, 936, 985, 986, 1026, 1062, 1080, 1134, 1149, 1158, 1161, 1170) que contenían mutaciones en las variantes de CarB mejoradas (tabla 7) a mutagénesis de saturación completa. Se usaron cebadores que contenían los nucleótidos degenerados NNK o NNS para mutar estas posiciones para dar otros aminoácidos mediante un método basado en PCR (Sawano y Miyawaki 2000, Nucl. Acids Res. 28: e78). Se construyó la biblioteca de saturación usando el molde de plásmido pBZ1 (pACYCDuet-1_PTRC1-carB4GTG_rrnBter_ccdAB). Se transformaron clones mutantes en cepas de clonación NEB Turbo (New England Biolab) y se aislaron y se agruparon plásmidos. Entonces se transformaron los plásmidos agrupados en una cepa basada en V668 que portaba el plásmido pLYC4 y se seleccionaron los transformantes en placas de agar LB complementado con antibióticos (espectinomicina 100 mg/l y cloranfenicol 34 mg/l).
Entonces se examinaron las variantes de CarB de la biblioteca de saturación para determinar la producción de alcoholes grasos. Se recogieron colonias individuales directamente en placas de 96 pocillos según un protocolo de fermentación en placa de pocillos profundos modificado tal como se describe en el ejemplo 5. Se seleccionaron aciertos eligiendo clones que producían un título de ácidos grasos libres total más pequeño y un título de alcoholes grasos total más grande en comparación con la cepa de control. Para comparar los aciertos de diferentes lotes de fermentación, se normalizó la conversión de ácidos grasos libres en alcoholes grasos calculando un porcentaje de ácidos grasos libres normalizado. También se usó NORM FFA (%) en la validación de aciertos tal como se describe en el ejemplo 5. NORM FFA (%) = porcentaje de FFA mutante / porcentaje de FFA de control; en donde “porcentaje de FFA” es el título de la especie de ácidos grasos totales dividido entre el título de la especie grasa total. Se sometieron los aciertos a verificación adicional usando fermentaciones en matraz de agitación tal como se describe en el ejemplo 5. La columna de ácido graso libre normalizado (NORM FFA) indica la mejora en la enzima, indicando los valores inferiores la mejor mejora. “ID de acierto” indica la posición de pocillo de placa de selección primaria en donde se encontró el fenotipo de NORM FFA inferior. Se identificaron mutaciones de aciertos secuenciando productos
de PCR amplificados a partir de “aciertos” que contenían plásmidos pBZ1 usando cebadores específicos de gen de carB mutante (BZ1 para 5'-GGATCTCGACGCTCTCCCTT-3' (SEQ ID NO:55 ) y cebador único BZ12_ccdAB 5 -TCAAAAACGCCA i"IAACCTGATG1TCTG-3 (SEQ ID NO;56) En la tabla 12 se resumen los valores de NORM FFA y las mutaciones identificadas en aciertos validados.
Tabla 12: Mutaciones beneficiosas en la enzima CarB4 identificadas durante la mutagénesis de saturación de aminoácidos
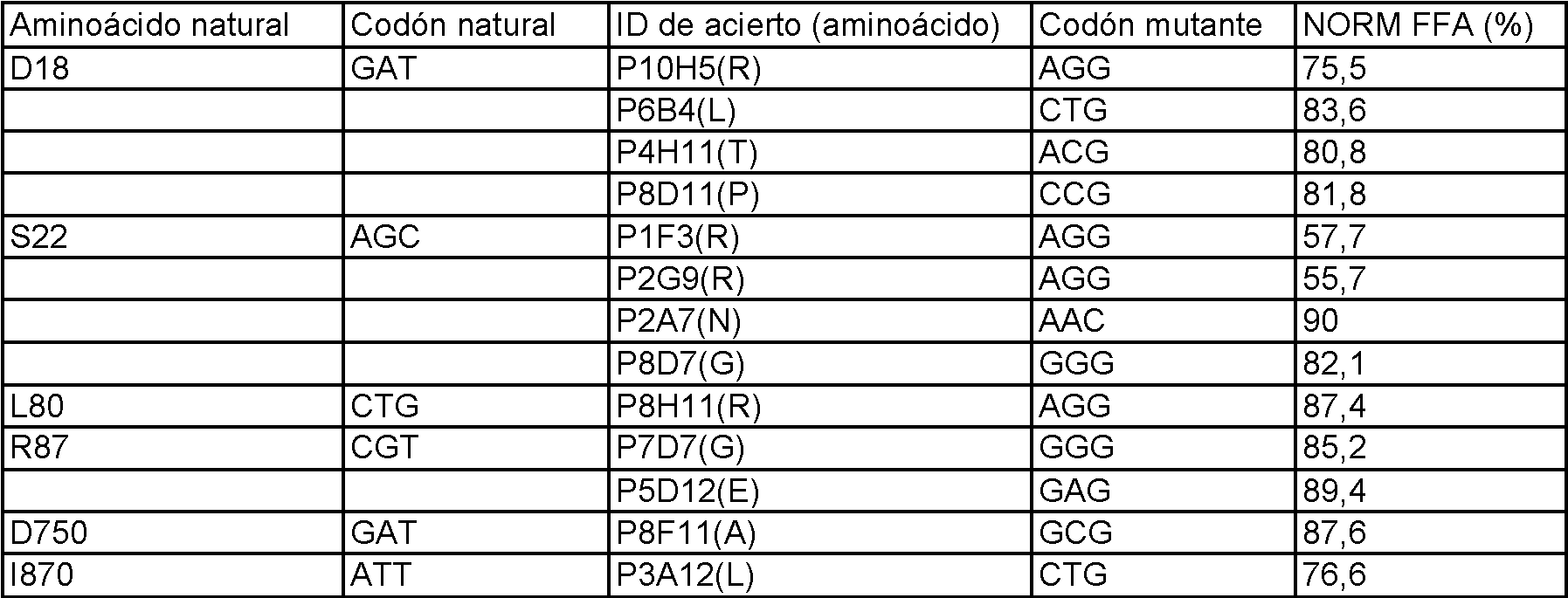
Identificación de variantes novedosas de la enzima CarB mediante mutagénesis combinatoria completa:
Se construyó una biblioteca combinatoria completa para incluir los siguientes residuos de aminoácido: 18D, 18R, 22S, 22R, 473H, 473I, 827R, 827C, 870I, 870L, 926V, 926A, 926E, 927S, 927K, 9270, 930M, 930K, 930R, 1128L y 1128W. Se diseñaron cebadores que contenían codones nativos y mutantes en todas las posiciones para la construcción de la biblioteca mediante un método basado en PCR (Horton, R.M., Hunt, H.D., Ho, S.N., Pullen, J.K. y Pease, L.R. 1989). Las mutaciones beneficiosas conservadas en CarB2, CarB3 y CarB4 (20R, 288G y 535S) no se cambiaron, por tanto, se usó carB2GTG clonado en pBZ1 (pBZ1_PTRC1_carB2GTG_ccdAB modificado) como molde de PCR. Se completó la construcción de la biblioteca ensamblando fragmentos de PCR en los ORF de CarB que contenían las mutaciones combinatorias anteriores. Entonces se clonaron los ORF de CarB mutantes en la estructura principal de pBZ1 mediante el método In-Fusion (Clontech). Se precipitó el producto de In-Fusion y se introdujo por electroporación directamente en la cepa de examen que portaba el plásmido pLYC4. Se llevaron a cabo el examen de la biblioteca, la fermentación en matraz de agitación y placa de pocillos profundos tal como se describe en el ejemplo 5. En la tabla 13 se resumen las actividades (NORM FFA normalizado por CarB2, 100%) de mutantes de CarB con mutaciones combinatorias específicas. Se incluyen CarB2, CarB4 y CarB5 (CarB4-S22R) como controles. La columna de NORM FFA indica la mejora en la enzima CarB, indicando los valores inferiores la mejor mejora. También se muestra la mejora en veces (X-FIOC) del control (CarB2). Todas las mutaciones enumeradas son en relación con la secuencia de polipéptido de CarB natural (SEQ ID NO: 7). Por ejemplo, CarB1 tiene la mutación A535S, y la CarBDead (una enzima CarB catalíticamente inactiva) porta la mutación S693A que destruye el sitio de unión de fosfopanteteína.
Variantes de CarB novedosas para la producción mejorada de alcohol graso en biorreactores:
El fin de identificar variantes de CarB novedosas enumeradas en la tabla 13 es usarlas para la producción mejorada de alcohol graso. La variante de CarB superior (P06B6 - S3R, E20R, S22R, F288G, Q473H, A535S, R873S, S927G, M930R, L1128W) de la tabla 13 porta una mutación espontánea (AGC natural a AGA) en la posición 3. Ambas variantes de CarB P06B6, concretamente CarB7 (aminoácido R por AGA en la posición 3 - S3R, e20R, S22R, F288G, Q473H, A535S, R873S, S927G, M930R, L1128W), y CarB8 (aminoácido natural S por AGC en la posición 3 - E20R, S22R, F288G, Q473H, A535S, R873S, S927G, M930R, L1128W) se prepararon y clonaron en la estructura principal del plásmido de producción de alcohol graso de bajo número de copias pCL1920 para generar los siguientes operones de alcohol graso que difieren sólo en CarB. Se revirtió el codón de iniciación de la traducción (GTG) para todas las variantes de CarB (CarB2, CarB7 y carB8) a ATG para maximizar la expresión.
pCL1920_PTRC_carB2_tesA_alrAadp1_fabB[A329G]_fadR pCL1920_PTRC_carB7_tesA_alrAadp1_fabB[A329G]_fadR pCL1920_PTRC_carB8_tesA_alrAadp1_fabB[A329G]_fadR
Se transformaron los plásmidos descritos anteriormente en una cepa basada en V668 con una copia de TE cromosómico, y se examinaron las cepas resultantes en biorreactores tal como se describe en el ejemplo 4. En la figura 16 se muestra la mejora (medida en % de alcoholes grasos en el producto de fermentación del biorreactor) de CarB7 y CarB8 con respecto a CarB2. El orden de actividad es CarB7 > CarB8 > CarB2. La mutación de la posición 3 de CarB7 (AGC a un codón poco común AGA R) confería actividad mayor que CarB8, además, el análisis de SDSPAGE de proteínas solubles totales reveló expresión mayor de CarB7 que CarB8 y CarB2. Los niveles de expresión de CarB2 y CarB8 eran similares. Esto concuerda con los datos de CarB60 descritos en el ejemplo 6, tanto la mutación de la posición 3 de codón poco común AGA R como la etiqueta de CarB60 en su extremo N-terminal pueden mejorar la expresión de CarB. Se entiende que CarB7 y CarB8 tendrán un mejor rendimiento que CarB2 en cepas con flujo de ácidos grasos libres aumentado o bien modificando por ingeniería genética las cepas hospedadoras y/o bien modificando por ingeniería genética los otros componentes del operón de producción de alcohol graso.
Tabla 13: Sumario de variantes de CarB identificadas a partir de la biblioteca combinatoria en sistema de plásmido doble.

Todos los métodos descritos en el presente documento pueden realizarse en cualquier orden adecuado a menos que se indique lo contrario en el presente documento o se contradiga claramente por el contexto de otra forma. El uso de todos y cada uno de los ejemplos, o una expresión a modo de ejemplo (por ejemplo, “tal como”) proporcionados en el presente documento, pretende meramente iluminar mejor la divulgación y no supone una limitación en el alcance de la divulgación a menos que se reivindique lo contrario. Ninguna expresión en la memoria descriptiva debe interpretarse que indica que cualquier elemento no reivindicado sea esencial para la práctica de la divulgación. Debe entenderse que la terminología usada en el presente documento es para el fin de describir realizaciones particulares sólo, y no pretende ser limitativa. Se describen en el presente documento realizaciones preferidas de esta divulgación.
Variaciones de esas realizaciones preferidas pueden resultar evidentes para los expertos habituales en la técnica tras la lectura de la descripción anterior.
Tabla 14: Secuencias











Claims (13)
1. Un polipéptido de ácido carboxílico reductasa (CAR) variante que comprende una secuencia de aminoácidos que tiene una identidad de secuencia de al menos el 80% con el polipéptido de CAR natural de la SEQ ID NO: 7 y que tiene al menos una sustitución de aminoácido seleccionada del grupo que consiste en S3R, D18R, D18L, D18T, D18p , E20V, E20S, E20R, S22R, S22N, S22G, L80R, R87G, R87E, V191S, F288R, F288S, F288G, Q473L, Q473W, Q473Y, Q473I, Q473H, A535S, D750A, R827C, R827A, I870L, R873S, V926A, V926E, S927K, S927G, M930K, M930R y L1128W, en la que (i) la expresión de dicho polipéptido de CAR variante en una célula hospedadora recombinante da como resultado un título más alto de aldehídos grasos en comparación con una célula hospedadora recombinante que expresa el polipéptido de CAR natural de SEQ ID NO: 7 o, (ii) la expresión de dicho polipéptido de CAR variante en una célula hospedadora recombinante da como resultado un título más alto de alcoholes grasos en comparación con una célula hospedadora recombinante que expresa el polipéptido de CAR natural de SEQ ID NO: 7.
2. El polipéptido de CAR variante de la reivindicación 1, en el que dicho polipéptido variante comprende:
(a) la mutación A535S;
(b) las mutaciones E20R; F288G, Q473I y A535S;
(c) las mutaciones E20R; F288G, Q473H, A535S, R827A y S927G;
(d) las mutaciones E20R; S22R, F288G, Q473H, A535S, R827A y S927G;
(e) las mutaciones S3R; E20R, S22R, F288G, Q473H, A535S, R873S, S927G, M930R y L1128W;
(f) las mutaciones E20R; S22R, F288G, Q473H, A535S, R873S, S927G, M930R y LI128W;
(g) las mutaciones D18R; E20R, S22R, F288G, Q473I, A535S, S927G, M930K y L1128W;
(h) las mutaciones E20R; S22R, F288G, Q473I, A535S, R827C, V926E, S927K y M930R;
(i) las mutaciones D18R; E20R, 288G, Q473I, A535S, R827C, V926E, M930K y L1128W;
(j) las mutaciones E20R; S22R, F288G, Q473H, A535S, R827C, V926A, S927K y M930R;
(k) las mutaciones E20R; S22R, F288G, Q473H, A535S y R827C;
(l) las mutaciones E20R; S22R, F288G, Q473I, A535S, R827C y M930R;
(m) las mutaciones E20R; S22R, F288G, Q473I, A535S, I870L, S927G y M930R;
(n) las mutaciones E20R; S22R, F288G, Q473I, A535S, I870L y S927G;
(o) las mutaciones D18R; E20R, S22R, F288G, Q473I, A535S, R827C, I870L, V926A y S927G;
(p) las mutaciones E20R; S22R, F288G, Q473H, A535S, R827C, I870L y L1128W;
(q) las mutaciones D18R; E20R, S22R, F288G, Q473H, A535S, R827C, I870L, S927G y L1128W;
(r) las mutaciones E20R; S22R, F288G, Q473I, A535S, R827C, I870L, S927G y L1128W;
(s) las mutaciones E20R; S22R, F288G, Q473I, A535S, R827C, I870L, S927G, M930K y L1128W;
(t) las mutaciones E20R; S22R, F288G, Q473H, A535S, I870L, S927G y M930K;
(u) las mutaciones E20R; F288G, Q473I, A535S, I870L y M930K;
(v) las mutaciones E20R; S22R, F288G, Q473H, A535S, S927G, M930K y L1128W;
(w) las mutaciones D18R; E20R, S22R, F288G, Q473I, A535S, S927G y L1128W;
(x) las mutaciones E20R; S22R, F288G, Q473I, A535S, R827C, I870L y S927G;
(y) las mutaciones D18R; E20R, S22R, F288G, Q473I, A535S, R827C, I870L, S927G y L1128W;
(z) las mutaciones D18R; E20R, S22R, F288G, Q473I, A535S, S927G, M930R y L1128W;
(xx) las mutaciones E20R; S22R, F288G, Q473H, A535S, V926E, S927G y M930R; o
(zz) las mutaciones E20R, S22R, F288G, Q473H, A535S, R827C, I870L, V926A y L1128W.
3. Una célula hospedadora recombinante que comprende una secuencia de polinucleótido que codifica un polipéptido de ácido carboxílico reductasa (CAR) variante que tiene una identidad de secuencia de al menos el 80% con el polipéptido de CAR natural de SEQ ID NO: 7 y que tiene al menos una sustitución de aminoácido seleccionada del grupo que consiste en S3R, D18R, D18L, D18T, D18P, E20V, E20S, E20R, S22R, S22N, S22G, L80R, R87G, R87E, V191S, F288R, F288S, F288G, Q473L, Q473W, Q473Y, Q473I, Q473H, A535S, D750A, R827C, R827A, I870L, R873S, V926A, V926E, S927K, S927G, M930K, M930R y L1128W, en la que la célula hospedadora recombinante produce un aldehído graso o un alcohol graso con un título o rendimiento más alto que una célula hospedadora que expresa el polipéptido de CAR natural de SEQ ID NO: 7, cuando se cultiva en un medio que contiene una fuente de carbono en condiciones eficaces para expresar dicho polipéptido de CAR variante.
4. La célula hospedadora recombinante de la reivindicación 3, que comprende además un polinucleótido que codifica un polipéptido de tioesterasa.
5. La célula hospedadora recombinante de la reivindicación 4, que comprende además un polinucleótido que codifica
(i) un polipéptido de FabB y un polipéptido de FadR, o
(ii) una aldehído graso reductasa.
6. Un cultivo celular que comprende la célula hospedadora recombinante de una cualquiera de las reivindicaciones 3 5.
7. El cultivo celular de la reivindicación 6, en el que dicho cultivo celular tiene una productividad que es al menos 3
veces mayor que la productividad de un cultivo celular que expresa el correspondiente polipéptido de CAR natural.
8. El cultivo celular de la reivindicación 7, en el que dicha productividad varía de 0,7 mg/l/h a 3 g/l/h.
9. El cultivo celular de la reivindicación 8, en el que el medio de cultivo comprende una composición de aldehído graso o de alcohol graso.
10. El cultivo celular de acuerdo con una cualquiera de la reivindicación 9, en el que la composición de aldehído graso o de alcohol graso se recoge extracelularmente en una fase orgánica.
11. El cultivo celular de la reivindicación 10, en el que la composición de alcohol graso comprende uno o más de un alcohol graso C6, C8, C10, C12, C13, C14, C15, C16, C17 o C18.
12. El cultivo celular de la reivindicación 10, en el que la composición de alcohol graso comprende un alcohol graso insaturado C10:1, C12:1, C14:1, C16:1 o C18:1.
13. El cultivo celular de la reivindicación 10, en el que la composición de alcohol graso comprende alcoholes grasos C12 y C14.
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201261619309P | 2012-04-02 | 2012-04-02 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2786633T3 true ES2786633T3 (es) | 2020-10-13 |
Family
ID=49237582
Family Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES18160746T Active ES2786633T3 (es) | 2012-04-02 | 2013-04-02 | Enzimas CAR y producción mejorada de alcoholes grasos |
| ES13766728.3T Active ES2613553T3 (es) | 2012-04-02 | 2013-04-02 | Enzimas CAR y producción mejorada de alcoholes grasos |
| ES16198810.0T Active ES2666157T3 (es) | 2012-04-02 | 2013-04-02 | Enzimas CAR y producción mejorada de alcoholes grasos |
Family Applications After (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES13766728.3T Active ES2613553T3 (es) | 2012-04-02 | 2013-04-02 | Enzimas CAR y producción mejorada de alcoholes grasos |
| ES16198810.0T Active ES2666157T3 (es) | 2012-04-02 | 2013-04-02 | Enzimas CAR y producción mejorada de alcoholes grasos |
Country Status (14)
| Country | Link |
|---|---|
| US (4) | US9340801B2 (es) |
| EP (6) | EP3674399B1 (es) |
| JP (1) | JP6230594B2 (es) |
| KR (6) | KR102282677B1 (es) |
| CN (1) | CN104704113B (es) |
| AU (2) | AU2013243602B2 (es) |
| BR (2) | BR112014024674B1 (es) |
| CA (1) | CA2883064A1 (es) |
| CO (1) | CO7170148A2 (es) |
| ES (3) | ES2786633T3 (es) |
| MX (2) | MX358177B (es) |
| MY (1) | MY170889A (es) |
| SI (1) | SI3385374T1 (es) |
| WO (1) | WO2013152052A2 (es) |
Families Citing this family (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AP2011005673A0 (en) * | 2008-10-28 | 2011-04-30 | Ls9 Inc | Methods and composition for producing fatty alcohols. |
| EP3674399B1 (en) * | 2012-04-02 | 2021-09-22 | Genomatica, Inc. | Car enzymes and improved production of fatty alcohols |
| CA2883968C (en) | 2012-04-02 | 2022-08-23 | REG Life Sciences, LLC | Improved production of fatty acid derivatives |
| IN2015DN01858A (es) | 2012-08-10 | 2015-05-29 | Opx Biotechnologies Inc | |
| US20150057465A1 (en) | 2013-03-15 | 2015-02-26 | Opx Biotechnologies, Inc. | Control of growth-induction-production phases |
| WO2014145334A1 (en) * | 2013-03-15 | 2014-09-18 | Opx Biotechnologies, Inc. | Acetyl-coa carboxylase mutations |
| JP6603658B2 (ja) | 2013-07-19 | 2019-11-06 | カーギル インコーポレイテッド | 脂肪酸及び脂肪酸誘導体の製造のための微生物及び方法 |
| US11408013B2 (en) | 2013-07-19 | 2022-08-09 | Cargill, Incorporated | Microorganisms and methods for the production of fatty acids and fatty acid derived products |
| ES2920511T3 (es) | 2014-07-18 | 2022-08-04 | Genomatica Inc | Producción microbiana de 1,3-dioles |
| EP2993228B1 (en) | 2014-09-02 | 2019-10-09 | Cargill, Incorporated | Production of fatty acid esters |
| CN105985987B (zh) * | 2015-03-02 | 2020-01-31 | 苏州安捷生物科技有限公司 | 一种生物法制备脂肪醇的方法 |
| US10538746B2 (en) | 2016-03-17 | 2020-01-21 | INVISTA North America S.à r.l. | Polypeptides and variants having improved activity, materials and processes relating thereto |
| CN110494566A (zh) | 2017-02-02 | 2019-11-22 | 嘉吉公司 | 产生c6-c10脂肪酸衍生物的经遗传修饰的细胞 |
| JP2020515293A (ja) | 2017-04-03 | 2020-05-28 | ジェノマティカ, インコーポレイテッド | 中鎖脂肪酸誘導体の生産のための改良された活性を有するチオエステラーゼ変種 |
| JPWO2022209763A1 (es) | 2021-03-30 | 2022-10-06 | ||
| WO2023178193A1 (en) | 2022-03-16 | 2023-09-21 | Genomatica, Inc. | Acyl-acp thioesterase variants and uses thereof |
Family Cites Families (28)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5000000A (en) | 1988-08-31 | 1991-03-19 | University Of Florida | Ethanol production by Escherichia coli strains co-expressing Zymomonas PDC and ADH genes |
| US5482846A (en) | 1988-08-31 | 1996-01-09 | University Of Florida | Ethanol production in Gram-positive microbes |
| US5424202A (en) | 1988-08-31 | 1995-06-13 | The University Of Florida | Ethanol production by recombinant hosts |
| US5028539A (en) | 1988-08-31 | 1991-07-02 | The University Of Florida | Ethanol production using engineered mutant E. coli |
| EP0528881A4 (en) | 1990-04-24 | 1993-05-26 | Stratagene | Methods for phenotype creation from multiple gene populations |
| US5602030A (en) | 1994-03-28 | 1997-02-11 | University Of Florida Research Foundation | Recombinant glucose uptake system |
| US6428767B1 (en) | 1995-05-12 | 2002-08-06 | E. I. Du Pont De Nemours And Company | Method for identifying the source of carbon in 1,3-propanediol |
| US5965408A (en) | 1996-07-09 | 1999-10-12 | Diversa Corporation | Method of DNA reassembly by interrupting synthesis |
| US5939250A (en) | 1995-12-07 | 1999-08-17 | Diversa Corporation | Production of enzymes having desired activities by mutagenesis |
| US7056714B2 (en) * | 2003-03-11 | 2006-06-06 | University Of Iowa Research Foundation, Inc. | Carboxylic acid reductase polypeptide, nucleotide sequence encoding same and methods of use |
| DE102004052115A1 (de) | 2004-10-26 | 2006-04-27 | Westfälische Wilhelms-Universität Münster | Mikroorganismen zur Herstellung von Fettsäureestern, Verfahren zu deren Herstellung und deren Verwendung |
| MX2008014603A (es) | 2006-05-19 | 2009-02-06 | Ls9 Inc | Produccion de acidos grasos y derivados de los mismos. |
| KR20100015763A (ko) | 2007-03-28 | 2010-02-12 | 엘에스9, 인코포레이티드 | 지방산 유도체의 생산 증가 |
| WO2008147781A2 (en) | 2007-05-22 | 2008-12-04 | Ls9, Inc. | Hydrocarbon-producing genes and methods of their use |
| TWI351779B (en) | 2007-12-03 | 2011-11-01 | Advance Smart Ind Ltd | Apparatus and method for correcting residual capac |
| WO2009085278A1 (en) | 2007-12-21 | 2009-07-09 | Ls9, Inc. | Methods and compositions for producing olefins |
| ES2550467T3 (es) | 2008-10-07 | 2015-11-10 | REG Life Sciences, LLC | Métodos y composiciones para producir aldehídos grasos |
| AP2011005673A0 (en) | 2008-10-28 | 2011-04-30 | Ls9 Inc | Methods and composition for producing fatty alcohols. |
| CN105647842A (zh) | 2008-12-23 | 2016-06-08 | Reg生命科学有限责任公司 | 硫酯酶相关的方法和组合物 |
| CN102482676A (zh) | 2009-05-01 | 2012-05-30 | 加州大学评议会 | 来源于生物质聚合物的脂肪酸脂产物 |
| BRPI1010920B1 (pt) * | 2009-05-22 | 2020-04-28 | Codexis Inc | processo para a produção biológica de álcoois graxos |
| CN105441374A (zh) * | 2009-10-13 | 2016-03-30 | 基因组股份公司 | 生产1,4-丁二醇、4-羟基丁醛、4-羟基丁酰-coa、腐胺和相关化合物的微生物及其相关方法 |
| WO2011100667A1 (en) | 2010-02-14 | 2011-08-18 | Ls9, Inc. | Surfactant and cleaning compositions comprising microbially produced branched fatty alcohols |
| WO2011127409A2 (en) | 2010-04-08 | 2011-10-13 | Ls9, Inc. | Methods and compositions related to fatty alcohol biosynthetic enzymes |
| WO2012154329A1 (en) * | 2011-04-01 | 2012-11-15 | Ls9, Inc. | Methods and compositions for improved production of fatty acids and derivatives thereof |
| KR20140027195A (ko) * | 2011-04-01 | 2014-03-06 | 게노마티카 인코포레이티드 | 메타크릴산 및 메타크릴레이트 에스테르 생산용 미생물 및 관련 방법 |
| US8617862B2 (en) * | 2011-06-22 | 2013-12-31 | Genomatica, Inc. | Microorganisms for producing propylene and methods related thereto |
| EP3674399B1 (en) * | 2012-04-02 | 2021-09-22 | Genomatica, Inc. | Car enzymes and improved production of fatty alcohols |
-
2013
- 2013-04-02 EP EP19212944.3A patent/EP3674399B1/en active Active
- 2013-04-02 EP EP16198810.0A patent/EP3153579B1/en active Active
- 2013-04-02 AU AU2013243602A patent/AU2013243602B2/en not_active Ceased
- 2013-04-02 MX MX2016013852A patent/MX358177B/es unknown
- 2013-04-02 BR BR112014024674-2A patent/BR112014024674B1/pt active Search and Examination
- 2013-04-02 EP EP13766728.3A patent/EP2834350B1/en active Active
- 2013-04-02 ES ES18160746T patent/ES2786633T3/es active Active
- 2013-04-02 EP EP22202380.6A patent/EP4186974A1/en active Pending
- 2013-04-02 KR KR1020207009760A patent/KR102282677B1/ko active IP Right Grant
- 2013-04-02 KR KR1020197017717A patent/KR102185762B1/ko active IP Right Grant
- 2013-04-02 KR KR1020217023277A patent/KR20210095226A/ko not_active Application Discontinuation
- 2013-04-02 CA CA2883064A patent/CA2883064A1/en active Pending
- 2013-04-02 CN CN201380026546.8A patent/CN104704113B/zh active Active
- 2013-04-02 MX MX2014011903A patent/MX343296B/es active IP Right Grant
- 2013-04-02 EP EP18160746.6A patent/EP3385374B1/en active Active
- 2013-04-02 EP EP21191034.4A patent/EP3985108A1/en not_active Withdrawn
- 2013-04-02 WO PCT/US2013/035040 patent/WO2013152052A2/en active Application Filing
- 2013-04-02 KR KR1020197005741A patent/KR102114841B1/ko active IP Right Grant
- 2013-04-02 JP JP2015504688A patent/JP6230594B2/ja active Active
- 2013-04-02 ES ES13766728.3T patent/ES2613553T3/es active Active
- 2013-04-02 KR KR1020147030704A patent/KR101831331B1/ko active IP Right Grant
- 2013-04-02 KR KR1020177026945A patent/KR20170113710A/ko active Search and Examination
- 2013-04-02 US US14/390,350 patent/US9340801B2/en active Active
- 2013-04-02 BR BR122019026987-4A patent/BR122019026987B1/pt active IP Right Grant
- 2013-04-02 ES ES16198810.0T patent/ES2666157T3/es active Active
- 2013-04-02 SI SI201331706T patent/SI3385374T1/sl unknown
- 2013-04-02 MY MYPI2014002838A patent/MY170889A/en unknown
-
2014
- 2014-10-29 CO CO14240039A patent/CO7170148A2/es unknown
-
2016
- 2016-05-13 US US15/154,636 patent/US9758769B2/en active Active
- 2016-09-20 AU AU2016231497A patent/AU2016231497B2/en active Active
-
2017
- 2017-09-05 US US15/695,205 patent/US10301603B2/en active Active
-
2019
- 2019-05-16 US US16/414,550 patent/US11034937B2/en active Active
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| ES2786633T3 (es) | Enzimas CAR y producción mejorada de alcoholes grasos | |
| US20210348173A1 (en) | Production Of Fatty Acid Derivatives | |
| AU2017200596B2 (en) | Acyl-ACP reductase with improved properties | |
| ES2920511T3 (es) | Producción microbiana de 1,3-dioles | |
| EP2931742A2 (en) | Acp-mediated production of fatty acid derivatives | |
| KR20160049016A (ko) | 개선된 아세틸-coa 카르복실라아제 변이체 |