KR20150093834A - Dna 항체 작제물 및 그 이용 방법 - Google Patents
Dna 항체 작제물 및 그 이용 방법 Download PDFInfo
- Publication number
- KR20150093834A KR20150093834A KR1020157018712A KR20157018712A KR20150093834A KR 20150093834 A KR20150093834 A KR 20150093834A KR 1020157018712 A KR1020157018712 A KR 1020157018712A KR 20157018712 A KR20157018712 A KR 20157018712A KR 20150093834 A KR20150093834 A KR 20150093834A
- Authority
- KR
- South Korea
- Prior art keywords
- ser
- acid sequence
- nucleic acid
- val
- gly
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 104
- 108020004414 DNA Proteins 0.000 title claims description 44
- 150000007523 nucleic acids Chemical group 0.000 claims abstract description 385
- 239000012634 fragment Substances 0.000 claims abstract description 103
- 239000000203 mixture Substances 0.000 claims abstract description 73
- 201000010099 disease Diseases 0.000 claims abstract description 27
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims abstract description 27
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 300
- 239000000427 antigen Substances 0.000 claims description 234
- 108091007433 antigens Proteins 0.000 claims description 218
- 102000036639 antigens Human genes 0.000 claims description 217
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 197
- 241000725303 Human immunodeficiency virus Species 0.000 claims description 186
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 185
- 229920001184 polypeptide Polymers 0.000 claims description 180
- 239000013612 plasmid Substances 0.000 claims description 94
- 108010076504 Protein Sorting Signals Proteins 0.000 claims description 59
- 241000700605 Viruses Species 0.000 claims description 59
- 238000003776 cleavage reaction Methods 0.000 claims description 47
- 230000007017 scission Effects 0.000 claims description 47
- 238000001727 in vivo Methods 0.000 claims description 41
- 102000039446 nucleic acids Human genes 0.000 claims description 39
- 108020004707 nucleic acids Proteins 0.000 claims description 39
- 108091005804 Peptidases Proteins 0.000 claims description 38
- 239000004365 Protease Substances 0.000 claims description 35
- 241000701022 Cytomegalovirus Species 0.000 claims description 31
- 241001502567 Chikungunya virus Species 0.000 claims description 24
- 208000015181 infectious disease Diseases 0.000 claims description 22
- 125000003729 nucleotide group Chemical group 0.000 claims description 21
- 239000002773 nucleotide Substances 0.000 claims description 20
- 108060003951 Immunoglobulin Proteins 0.000 claims description 18
- 230000028993 immune response Effects 0.000 claims description 18
- 102000018358 immunoglobulin Human genes 0.000 claims description 18
- 241000725619 Dengue virus Species 0.000 claims description 15
- 238000011282 treatment Methods 0.000 claims description 15
- 244000052769 pathogen Species 0.000 claims description 9
- 230000001717 pathogenic effect Effects 0.000 claims description 8
- 101150029707 ERBB2 gene Proteins 0.000 claims description 5
- 230000002265 prevention Effects 0.000 claims description 2
- 230000008569 process Effects 0.000 claims description 2
- 102100037486 Reverse transcriptase/ribonuclease H Human genes 0.000 claims 6
- 125000003275 alpha amino acid group Chemical group 0.000 claims 5
- 230000014509 gene expression Effects 0.000 abstract description 56
- 230000001851 biosynthetic effect Effects 0.000 abstract 1
- 150000001413 amino acids Chemical group 0.000 description 156
- 229940027941 immunoglobulin g Drugs 0.000 description 120
- 241000725643 Respiratory syncytial virus Species 0.000 description 106
- 210000004027 cell Anatomy 0.000 description 88
- 108090000623 proteins and genes Proteins 0.000 description 75
- 241000282414 Homo sapiens Species 0.000 description 68
- 241000699670 Mus sp. Species 0.000 description 64
- 239000013598 vector Substances 0.000 description 62
- 235000018102 proteins Nutrition 0.000 description 57
- 102000004169 proteins and genes Human genes 0.000 description 57
- 238000004520 electroporation Methods 0.000 description 44
- 210000002966 serum Anatomy 0.000 description 42
- 238000004519 manufacturing process Methods 0.000 description 39
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical compound N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 34
- 206010057190 Respiratory tract infections Diseases 0.000 description 34
- 241000880493 Leptailurus serval Species 0.000 description 33
- 102000035195 Peptidases Human genes 0.000 description 32
- 230000027455 binding Effects 0.000 description 31
- 235000001014 amino acid Nutrition 0.000 description 30
- 210000001519 tissue Anatomy 0.000 description 27
- 108020004705 Codon Proteins 0.000 description 26
- 229940024606 amino acid Drugs 0.000 description 26
- 238000006386 neutralization reaction Methods 0.000 description 26
- 235000019419 proteases Nutrition 0.000 description 26
- 239000013604 expression vector Substances 0.000 description 23
- 241000701806 Human papillomavirus Species 0.000 description 22
- 241000894006 Bacteria Species 0.000 description 20
- 108091026890 Coding region Proteins 0.000 description 20
- 238000005457 optimization Methods 0.000 description 20
- 230000003472 neutralizing effect Effects 0.000 description 19
- 230000008488 polyadenylation Effects 0.000 description 19
- 108010017391 lysylvaline Proteins 0.000 description 17
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 16
- 241000711920 Human orthopneumovirus Species 0.000 description 16
- 238000004458 analytical method Methods 0.000 description 16
- 208000006454 hepatitis Diseases 0.000 description 16
- 231100000283 hepatitis Toxicity 0.000 description 16
- 208000035896 Twin-reversed arterial perfusion sequence Diseases 0.000 description 15
- 230000002163 immunogen Effects 0.000 description 15
- 230000000295 complement effect Effects 0.000 description 14
- 238000010586 diagram Methods 0.000 description 14
- 108010050848 glycylleucine Proteins 0.000 description 14
- 230000004048 modification Effects 0.000 description 14
- 238000012986 modification Methods 0.000 description 14
- 101100038180 Caenorhabditis briggsae rpb-1 gene Proteins 0.000 description 13
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 13
- 206010028980 Neoplasm Diseases 0.000 description 13
- 101800001494 Protease 2A Proteins 0.000 description 13
- 101800001066 Protein 2A Proteins 0.000 description 13
- 108010089804 glycyl-threonine Proteins 0.000 description 13
- 108010015792 glycyllysine Proteins 0.000 description 13
- 230000003612 virological effect Effects 0.000 description 13
- 101710132601 Capsid protein Proteins 0.000 description 12
- 241000699666 Mus <mouse, genus> Species 0.000 description 12
- 108020001507 fusion proteins Proteins 0.000 description 12
- 102000037865 fusion proteins Human genes 0.000 description 12
- 244000045947 parasite Species 0.000 description 12
- 108010031719 prolyl-serine Proteins 0.000 description 12
- 230000004044 response Effects 0.000 description 12
- 229960005486 vaccine Drugs 0.000 description 12
- JBVSSSZFNTXJDX-YTLHQDLWSA-N Ala-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)N JBVSSSZFNTXJDX-YTLHQDLWSA-N 0.000 description 11
- 238000002965 ELISA Methods 0.000 description 11
- 101710154606 Hemagglutinin Proteins 0.000 description 11
- 102000018697 Membrane Proteins Human genes 0.000 description 11
- 108010052285 Membrane Proteins Proteins 0.000 description 11
- MNNKPHGAPRUKMW-BPUTZDHNSA-N Met-Asp-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCSC)C(O)=O)=CNC2=C1 MNNKPHGAPRUKMW-BPUTZDHNSA-N 0.000 description 11
- 101710093908 Outer capsid protein VP4 Proteins 0.000 description 11
- 101710135467 Outer capsid protein sigma-1 Proteins 0.000 description 11
- IHCXPSYCHXFXKT-DCAQKATOSA-N Pro-Arg-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O IHCXPSYCHXFXKT-DCAQKATOSA-N 0.000 description 11
- 101710176177 Protein A56 Proteins 0.000 description 11
- 239000000185 hemagglutinin Substances 0.000 description 11
- 238000002347 injection Methods 0.000 description 11
- 239000007924 injection Substances 0.000 description 11
- 108010061238 threonyl-glycine Proteins 0.000 description 11
- 108010073969 valyllysine Proteins 0.000 description 11
- OHLLDUNVMPPUMD-DCAQKATOSA-N Cys-Leu-Val Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CS)N OHLLDUNVMPPUMD-DCAQKATOSA-N 0.000 description 10
- 208000001490 Dengue Diseases 0.000 description 10
- 206010012310 Dengue fever Diseases 0.000 description 10
- 108091006027 G proteins Proteins 0.000 description 10
- 102000030782 GTP binding Human genes 0.000 description 10
- 108091000058 GTP-Binding Proteins 0.000 description 10
- BRTVHXHCUSXYRI-CIUDSAMLSA-N Leu-Ser-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O BRTVHXHCUSXYRI-CIUDSAMLSA-N 0.000 description 10
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 10
- HNDMFDBQXYZSRM-IHRRRGAJSA-N Ser-Val-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HNDMFDBQXYZSRM-IHRRRGAJSA-N 0.000 description 10
- 108010092854 aspartyllysine Proteins 0.000 description 10
- 208000025729 dengue disease Diseases 0.000 description 10
- 108010078428 env Gene Products Proteins 0.000 description 10
- 230000008713 feedback mechanism Effects 0.000 description 10
- 108010078144 glutaminyl-glycine Proteins 0.000 description 10
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 10
- 108010000434 glycyl-alanyl-leucine Proteins 0.000 description 10
- 206010022000 influenza Diseases 0.000 description 10
- 201000004792 malaria Diseases 0.000 description 10
- 230000000638 stimulation Effects 0.000 description 10
- 230000004083 survival effect Effects 0.000 description 10
- 230000014616 translation Effects 0.000 description 10
- 102000001301 EGF receptor Human genes 0.000 description 9
- FOBUGKUBUJOWAD-IHPCNDPISA-N Leu-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FOBUGKUBUJOWAD-IHPCNDPISA-N 0.000 description 9
- 108010079364 N-glycylalanine Proteins 0.000 description 9
- 108010068265 aspartyltyrosine Proteins 0.000 description 9
- 108010050475 glycyl-leucyl-tyrosine Proteins 0.000 description 9
- 108010051110 tyrosyl-lysine Proteins 0.000 description 9
- 238000011144 upstream manufacturing Methods 0.000 description 9
- MNZHHDPWDWQJCQ-YUMQZZPRSA-N Ala-Leu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O MNZHHDPWDWQJCQ-YUMQZZPRSA-N 0.000 description 8
- SNDBKTFJWVEVPO-WHFBIAKZSA-N Asp-Gly-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SNDBKTFJWVEVPO-WHFBIAKZSA-N 0.000 description 8
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 8
- 102000000018 Chemokine CCL2 Human genes 0.000 description 8
- 108060006698 EGF receptor Proteins 0.000 description 8
- 102100038132 Endogenous retrovirus group K member 6 Pro protein Human genes 0.000 description 8
- QDMVXRNLOPTPIE-WDCWCFNPSA-N Glu-Lys-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QDMVXRNLOPTPIE-WDCWCFNPSA-N 0.000 description 8
- ZYRXTRTUCAVNBQ-GVXVVHGQSA-N Glu-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N ZYRXTRTUCAVNBQ-GVXVVHGQSA-N 0.000 description 8
- SOEGEPHNZOISMT-BYPYZUCNSA-N Gly-Ser-Gly Chemical compound NCC(=O)N[C@@H](CO)C(=O)NCC(O)=O SOEGEPHNZOISMT-BYPYZUCNSA-N 0.000 description 8
- LCRDMSSAKLTKBU-ZDLURKLDSA-N Gly-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN LCRDMSSAKLTKBU-ZDLURKLDSA-N 0.000 description 8
- 241000711549 Hepacivirus C Species 0.000 description 8
- 241000700721 Hepatitis B virus Species 0.000 description 8
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 description 8
- 102000004889 Interleukin-6 Human genes 0.000 description 8
- 108090001005 Interleukin-6 Proteins 0.000 description 8
- VUBIPAHVHMZHCM-KKUMJFAQSA-N Leu-Tyr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CC1=CC=C(O)C=C1 VUBIPAHVHMZHCM-KKUMJFAQSA-N 0.000 description 8
- 241001465754 Metazoa Species 0.000 description 8
- SJRQWEDYTKYHHL-SLFFLAALSA-N Phe-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC3=CC=CC=C3)N)C(=O)O SJRQWEDYTKYHHL-SLFFLAALSA-N 0.000 description 8
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 8
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 description 8
- RHAPJNVNWDBFQI-BQBZGAKWSA-N Ser-Pro-Gly Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O RHAPJNVNWDBFQI-BQBZGAKWSA-N 0.000 description 8
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 8
- SGAOHNPSEPVAFP-ZDLURKLDSA-N Thr-Ser-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SGAOHNPSEPVAFP-ZDLURKLDSA-N 0.000 description 8
- HGJRMXOWUWVUOA-GVXVVHGQSA-N Val-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N HGJRMXOWUWVUOA-GVXVVHGQSA-N 0.000 description 8
- 239000003623 enhancer Substances 0.000 description 8
- 230000006870 function Effects 0.000 description 8
- 238000009396 hybridization Methods 0.000 description 8
- 229940100601 interleukin-6 Drugs 0.000 description 8
- 229930182817 methionine Natural products 0.000 description 8
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 description 8
- 108010024654 phenylalanyl-prolyl-alanine Proteins 0.000 description 8
- 239000002953 phosphate buffered saline Substances 0.000 description 8
- 108010070643 prolylglutamic acid Proteins 0.000 description 8
- 239000000523 sample Substances 0.000 description 8
- 230000028327 secretion Effects 0.000 description 8
- 108010069117 seryl-lysyl-aspartic acid Proteins 0.000 description 8
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 7
- 108010068327 4-hydroxyphenylpyruvate dioxygenase Proteins 0.000 description 7
- MDNAVFBZPROEHO-UHFFFAOYSA-N Ala-Lys-Val Natural products CC(C)C(C(O)=O)NC(=O)C(NC(=O)C(C)N)CCCCN MDNAVFBZPROEHO-UHFFFAOYSA-N 0.000 description 7
- JSNWZMFSLIWAHS-HJGDQZAQSA-N Asp-Thr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O JSNWZMFSLIWAHS-HJGDQZAQSA-N 0.000 description 7
- 101710155857 C-C motif chemokine 2 Proteins 0.000 description 7
- 241001115402 Ebolavirus Species 0.000 description 7
- JXFLPKSDLDEOQK-JHEQGTHGSA-N Gln-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCC(N)=O JXFLPKSDLDEOQK-JHEQGTHGSA-N 0.000 description 7
- ZFBBMCKQSNJZSN-AUTRQRHGSA-N Gln-Val-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZFBBMCKQSNJZSN-AUTRQRHGSA-N 0.000 description 7
- HAOUOFNNJJLVNS-BQBZGAKWSA-N Gly-Pro-Ser Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O HAOUOFNNJJLVNS-BQBZGAKWSA-N 0.000 description 7
- 241000238631 Hexapoda Species 0.000 description 7
- JHNJNTMTZHEDLJ-NAKRPEOUSA-N Ile-Ser-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O JHNJNTMTZHEDLJ-NAKRPEOUSA-N 0.000 description 7
- 101710128560 Initiator protein NS1 Proteins 0.000 description 7
- NTBFKPBULZGXQL-KKUMJFAQSA-N Lys-Asp-Tyr Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NTBFKPBULZGXQL-KKUMJFAQSA-N 0.000 description 7
- QLFAPXUXEBAWEK-NHCYSSNCSA-N Lys-Val-Asp Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O QLFAPXUXEBAWEK-NHCYSSNCSA-N 0.000 description 7
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 7
- 101710144127 Non-structural protein 1 Proteins 0.000 description 7
- FDMKYQQYJKYCLV-GUBZILKMSA-N Pro-Pro-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 FDMKYQQYJKYCLV-GUBZILKMSA-N 0.000 description 7
- MKGIILKDUGDRRO-FXQIFTODSA-N Pro-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 MKGIILKDUGDRRO-FXQIFTODSA-N 0.000 description 7
- ZKOKTQPHFMRSJP-YJRXYDGGSA-N Ser-Thr-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZKOKTQPHFMRSJP-YJRXYDGGSA-N 0.000 description 7
- 108091081024 Start codon Proteins 0.000 description 7
- 108020005038 Terminator Codon Proteins 0.000 description 7
- XKWABWFMQXMUMT-HJGDQZAQSA-N Thr-Pro-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O XKWABWFMQXMUMT-HJGDQZAQSA-N 0.000 description 7
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 7
- HJSLDXZAZGFPDK-ULQDDVLXSA-N Val-Phe-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C(C)C)N HJSLDXZAZGFPDK-ULQDDVLXSA-N 0.000 description 7
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 7
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 7
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 7
- 108010087924 alanylproline Proteins 0.000 description 7
- 238000003556 assay Methods 0.000 description 7
- 201000011510 cancer Diseases 0.000 description 7
- 239000003795 chemical substances by application Substances 0.000 description 7
- 238000010790 dilution Methods 0.000 description 7
- 239000012895 dilution Substances 0.000 description 7
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 7
- 108010013768 glutamyl-aspartyl-proline Proteins 0.000 description 7
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 7
- 238000002649 immunization Methods 0.000 description 7
- 230000003053 immunization Effects 0.000 description 7
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 7
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 7
- 238000004246 ligand exchange chromatography Methods 0.000 description 7
- 239000002502 liposome Substances 0.000 description 7
- 238000006467 substitution reaction Methods 0.000 description 7
- 108010071097 threonyl-lysyl-proline Proteins 0.000 description 7
- 230000005030 transcription termination Effects 0.000 description 7
- MJIJBEYEHBKTIM-BYULHYEWSA-N Asn-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N MJIJBEYEHBKTIM-BYULHYEWSA-N 0.000 description 6
- 101710158312 DNA-binding protein HU-beta Proteins 0.000 description 6
- 101710091045 Envelope protein Proteins 0.000 description 6
- 241000233866 Fungi Species 0.000 description 6
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 6
- CKOFNWCLWRYUHK-XHNCKOQMSA-N Glu-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N)C(=O)O CKOFNWCLWRYUHK-XHNCKOQMSA-N 0.000 description 6
- 102100041003 Glutamate carboxypeptidase 2 Human genes 0.000 description 6
- PABFFPWEJMEVEC-JGVFFNPUSA-N Gly-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)CN)C(=O)O PABFFPWEJMEVEC-JGVFFNPUSA-N 0.000 description 6
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 6
- 208000037262 Hepatitis delta Diseases 0.000 description 6
- 241000724709 Hepatitis delta virus Species 0.000 description 6
- 241000709721 Hepatovirus A Species 0.000 description 6
- 241000701044 Human gammaherpesvirus 4 Species 0.000 description 6
- IOVUXUSIGXCREV-DKIMLUQUSA-N Ile-Leu-Phe Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 IOVUXUSIGXCREV-DKIMLUQUSA-N 0.000 description 6
- 102100034353 Integrase Human genes 0.000 description 6
- WSGXUIQTEZDVHJ-GARJFASQSA-N Leu-Ala-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(O)=O WSGXUIQTEZDVHJ-GARJFASQSA-N 0.000 description 6
- PVMPDMIKUVNOBD-CIUDSAMLSA-N Leu-Asp-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O PVMPDMIKUVNOBD-CIUDSAMLSA-N 0.000 description 6
- DRWMRVFCKKXHCH-BZSNNMDCSA-N Leu-Phe-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CC=CC=C1 DRWMRVFCKKXHCH-BZSNNMDCSA-N 0.000 description 6
- XOWMDXHFSBCAKQ-SRVKXCTJSA-N Leu-Ser-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C XOWMDXHFSBCAKQ-SRVKXCTJSA-N 0.000 description 6
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 6
- LJBVRCDPWOJOEK-PPCPHDFISA-N Leu-Thr-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O LJBVRCDPWOJOEK-PPCPHDFISA-N 0.000 description 6
- MVJRBCJCRYGCKV-GVXVVHGQSA-N Leu-Val-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O MVJRBCJCRYGCKV-GVXVVHGQSA-N 0.000 description 6
- 241000124008 Mammalia Species 0.000 description 6
- 101100519207 Mus musculus Pdcd1 gene Proteins 0.000 description 6
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 6
- 101710144128 Non-structural protein 2 Proteins 0.000 description 6
- 101710199667 Nuclear export protein Proteins 0.000 description 6
- QARPMYDMYVLFMW-KKUMJFAQSA-N Phe-Pro-Glu Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(O)=O)C1=CC=CC=C1 QARPMYDMYVLFMW-KKUMJFAQSA-N 0.000 description 6
- 101710188315 Protein X Proteins 0.000 description 6
- QEDMOZUJTGEIBF-FXQIFTODSA-N Ser-Arg-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O QEDMOZUJTGEIBF-FXQIFTODSA-N 0.000 description 6
- UQFYNFTYDHUIMI-WHFBIAKZSA-N Ser-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CO UQFYNFTYDHUIMI-WHFBIAKZSA-N 0.000 description 6
- XNCUYZKGQOCOQH-YUMQZZPRSA-N Ser-Leu-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O XNCUYZKGQOCOQH-YUMQZZPRSA-N 0.000 description 6
- MUJQWSAWLLRJCE-KATARQTJSA-N Ser-Leu-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MUJQWSAWLLRJCE-KATARQTJSA-N 0.000 description 6
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 6
- SNXUIBACCONSOH-BWBBJGPYSA-N Ser-Thr-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CO)C(O)=O SNXUIBACCONSOH-BWBBJGPYSA-N 0.000 description 6
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 6
- 238000000692 Student's t-test Methods 0.000 description 6
- KGKWKSSSQGGYAU-SUSMZKCASA-N Thr-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KGKWKSSSQGGYAU-SUSMZKCASA-N 0.000 description 6
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 6
- JMBRNXUOLJFURW-BEAPCOKYSA-N Thr-Phe-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N)O JMBRNXUOLJFURW-BEAPCOKYSA-N 0.000 description 6
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 6
- PKZIWSHDJYIPRH-JBACZVJFSA-N Trp-Tyr-Gln Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O PKZIWSHDJYIPRH-JBACZVJFSA-N 0.000 description 6
- JJNXZIPLIXIGBX-HJPIBITLSA-N Tyr-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N JJNXZIPLIXIGBX-HJPIBITLSA-N 0.000 description 6
- MQGGXGKQSVEQHR-KKUMJFAQSA-N Tyr-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 MQGGXGKQSVEQHR-KKUMJFAQSA-N 0.000 description 6
- KRAHMIJVUPUOTQ-DCAQKATOSA-N Val-Ser-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N KRAHMIJVUPUOTQ-DCAQKATOSA-N 0.000 description 6
- ZLNYBMWGPOKSLW-LSJOCFKGSA-N Val-Val-Asp Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLNYBMWGPOKSLW-LSJOCFKGSA-N 0.000 description 6
- JVGDAEKKZKKZFO-RCWTZXSCSA-N Val-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C(C)C)N)O JVGDAEKKZKKZFO-RCWTZXSCSA-N 0.000 description 6
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 6
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 6
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 6
- 108010077245 asparaginyl-proline Proteins 0.000 description 6
- 239000003814 drug Substances 0.000 description 6
- 238000009472 formulation Methods 0.000 description 6
- 108010049041 glutamylalanine Proteins 0.000 description 6
- 108010010147 glycylglutamine Proteins 0.000 description 6
- 238000003119 immunoblot Methods 0.000 description 6
- 108010064235 lysylglycine Proteins 0.000 description 6
- 238000005259 measurement Methods 0.000 description 6
- 239000013642 negative control Substances 0.000 description 6
- 108010051242 phenylalanylserine Proteins 0.000 description 6
- 239000000047 product Substances 0.000 description 6
- 108010048397 seryl-lysyl-leucine Proteins 0.000 description 6
- 108010080629 tryptophan-leucine Proteins 0.000 description 6
- 108010079202 tyrosyl-alanyl-cysteine Proteins 0.000 description 6
- BRPMXFSTKXXNHF-IUCAKERBSA-N (2s)-1-[2-[[(2s)-pyrrolidine-2-carbonyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound OC(=O)[C@@H]1CCCN1C(=O)CNC(=O)[C@H]1NCCC1 BRPMXFSTKXXNHF-IUCAKERBSA-N 0.000 description 5
- OYJCVIGKMXUVKB-GARJFASQSA-N Ala-Leu-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N OYJCVIGKMXUVKB-GARJFASQSA-N 0.000 description 5
- IORKCNUBHNIMKY-CIUDSAMLSA-N Ala-Pro-Glu Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O IORKCNUBHNIMKY-CIUDSAMLSA-N 0.000 description 5
- WQLDNOCHHRISMS-NAKRPEOUSA-N Ala-Pro-Ile Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WQLDNOCHHRISMS-NAKRPEOUSA-N 0.000 description 5
- XWFWAXPOLRTDFZ-FXQIFTODSA-N Ala-Pro-Ser Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O XWFWAXPOLRTDFZ-FXQIFTODSA-N 0.000 description 5
- XQNRANMFRPCFFW-GCJQMDKQSA-N Ala-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C)N)O XQNRANMFRPCFFW-GCJQMDKQSA-N 0.000 description 5
- HQIZDMIGUJOSNI-IUCAKERBSA-N Arg-Gly-Arg Chemical compound N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O HQIZDMIGUJOSNI-IUCAKERBSA-N 0.000 description 5
- COXMUHNBYCVVRG-DCAQKATOSA-N Arg-Leu-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O COXMUHNBYCVVRG-DCAQKATOSA-N 0.000 description 5
- 108010021064 CTLA-4 Antigen Proteins 0.000 description 5
- 101100512078 Caenorhabditis elegans lys-1 gene Proteins 0.000 description 5
- 102000013816 Cytotoxic T-lymphocyte antigen 4 Human genes 0.000 description 5
- 101710118188 DNA-binding protein HU-alpha Proteins 0.000 description 5
- DHNWZLGBTPUTQQ-QEJZJMRPSA-N Gln-Asp-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)N)N DHNWZLGBTPUTQQ-QEJZJMRPSA-N 0.000 description 5
- WPJDPEOQUIXXOY-AVGNSLFASA-N Gln-Tyr-Asn Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O WPJDPEOQUIXXOY-AVGNSLFASA-N 0.000 description 5
- QQLBPVKLJBAXBS-FXQIFTODSA-N Glu-Glu-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O QQLBPVKLJBAXBS-FXQIFTODSA-N 0.000 description 5
- AAJHGGDRKHYSDH-GUBZILKMSA-N Glu-Pro-Gln Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O AAJHGGDRKHYSDH-GUBZILKMSA-N 0.000 description 5
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 5
- FFJQHWKSGAWSTJ-BFHQHQDPSA-N Gly-Thr-Ala Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O FFJQHWKSGAWSTJ-BFHQHQDPSA-N 0.000 description 5
- SYOJVRNQCXYEOV-XVKPBYJWSA-N Gly-Val-Glu Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SYOJVRNQCXYEOV-XVKPBYJWSA-N 0.000 description 5
- FULZDMOZUZKGQU-ONGXEEELSA-N Gly-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)CN FULZDMOZUZKGQU-ONGXEEELSA-N 0.000 description 5
- 241000724675 Hepatitis E virus Species 0.000 description 5
- MAABHGXCIBEYQR-XVYDVKMFSA-N His-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N MAABHGXCIBEYQR-XVYDVKMFSA-N 0.000 description 5
- VGSPNSSCMOHRRR-BJDJZHNGSA-N Ile-Ser-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N VGSPNSSCMOHRRR-BJDJZHNGSA-N 0.000 description 5
- 108010065920 Insulin Lispro Proteins 0.000 description 5
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 5
- TYYLDKGBCJGJGW-UHFFFAOYSA-N L-tryptophan-L-tyrosine Natural products C=1NC2=CC=CC=C2C=1CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 TYYLDKGBCJGJGW-UHFFFAOYSA-N 0.000 description 5
- OIARJGNVARWKFP-YUMQZZPRSA-N Leu-Asn-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O OIARJGNVARWKFP-YUMQZZPRSA-N 0.000 description 5
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 5
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 5
- AIQWYVFNBNNOLU-RHYQMDGZSA-N Leu-Thr-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O AIQWYVFNBNNOLU-RHYQMDGZSA-N 0.000 description 5
- CLBGMWIYPYAZPR-AVGNSLFASA-N Lys-Arg-Arg Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O CLBGMWIYPYAZPR-AVGNSLFASA-N 0.000 description 5
- MWVUEPNEPWMFBD-SRVKXCTJSA-N Lys-Cys-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CCCCN MWVUEPNEPWMFBD-SRVKXCTJSA-N 0.000 description 5
- ODUQLUADRKMHOZ-JYJNAYRXSA-N Lys-Glu-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCCCN)N)O ODUQLUADRKMHOZ-JYJNAYRXSA-N 0.000 description 5
- RFQATBGBLDAKGI-VHSXEESVSA-N Lys-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCCCN)N)C(=O)O RFQATBGBLDAKGI-VHSXEESVSA-N 0.000 description 5
- YKBSXQFZWFXFIB-VOAKCMCISA-N Lys-Thr-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCCCN)C(O)=O YKBSXQFZWFXFIB-VOAKCMCISA-N 0.000 description 5
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 5
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 5
- JOXIIFVCSATTDH-IHPCNDPISA-N Phe-Asn-Trp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N JOXIIFVCSATTDH-IHPCNDPISA-N 0.000 description 5
- UNBFGVQVQGXXCK-KKUMJFAQSA-N Phe-Ser-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O UNBFGVQVQGXXCK-KKUMJFAQSA-N 0.000 description 5
- ZLXKLMHAMDENIO-DCAQKATOSA-N Pro-Lys-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O ZLXKLMHAMDENIO-DCAQKATOSA-N 0.000 description 5
- MHHQQZIFLWFZGR-DCAQKATOSA-N Pro-Lys-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O MHHQQZIFLWFZGR-DCAQKATOSA-N 0.000 description 5
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 5
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 5
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 5
- YUJLIIRMIAGMCQ-CIUDSAMLSA-N Ser-Leu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YUJLIIRMIAGMCQ-CIUDSAMLSA-N 0.000 description 5
- BMKNXTJLHFIAAH-CIUDSAMLSA-N Ser-Ser-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O BMKNXTJLHFIAAH-CIUDSAMLSA-N 0.000 description 5
- PYTKULIABVRXSC-BWBBJGPYSA-N Ser-Ser-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PYTKULIABVRXSC-BWBBJGPYSA-N 0.000 description 5
- 210000001744 T-lymphocyte Anatomy 0.000 description 5
- LIXBDERDAGNVAV-XKBZYTNZSA-N Thr-Gln-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O LIXBDERDAGNVAV-XKBZYTNZSA-N 0.000 description 5
- SIMKLINEDYOTKL-MBLNEYKQSA-N Thr-His-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](C)C(=O)O)N)O SIMKLINEDYOTKL-MBLNEYKQSA-N 0.000 description 5
- FIFDDJFLNVAVMS-RHYQMDGZSA-N Thr-Leu-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(O)=O FIFDDJFLNVAVMS-RHYQMDGZSA-N 0.000 description 5
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 5
- ZOCJFNXUVSGBQI-HSHDSVGOSA-N Thr-Trp-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N)O ZOCJFNXUVSGBQI-HSHDSVGOSA-N 0.000 description 5
- GJOBRAHDRIDAPT-NGTWOADLSA-N Thr-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H]([C@@H](C)O)N GJOBRAHDRIDAPT-NGTWOADLSA-N 0.000 description 5
- OGOYMQWIWHGTGH-KZVJFYERSA-N Thr-Val-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O OGOYMQWIWHGTGH-KZVJFYERSA-N 0.000 description 5
- 102100040247 Tumor necrosis factor Human genes 0.000 description 5
- ANHVRCNNGJMJNG-BZSNNMDCSA-N Tyr-Tyr-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CS)C(=O)O)N)O ANHVRCNNGJMJNG-BZSNNMDCSA-N 0.000 description 5
- QHDXUYOYTPWCSK-RCOVLWMOSA-N Val-Asp-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)NCC(=O)O)N QHDXUYOYTPWCSK-RCOVLWMOSA-N 0.000 description 5
- BMGOFDMKDVVGJG-NHCYSSNCSA-N Val-Asp-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N BMGOFDMKDVVGJG-NHCYSSNCSA-N 0.000 description 5
- LHADRQBREKTRLR-DCAQKATOSA-N Val-Cys-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](C(C)C)N LHADRQBREKTRLR-DCAQKATOSA-N 0.000 description 5
- UEHRGZCNLSWGHK-DLOVCJGASA-N Val-Glu-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UEHRGZCNLSWGHK-DLOVCJGASA-N 0.000 description 5
- XTDDIVQWDXMRJL-IHRRRGAJSA-N Val-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N XTDDIVQWDXMRJL-IHRRRGAJSA-N 0.000 description 5
- BGTDGENDNWGMDQ-KJEVXHAQSA-N Val-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N)O BGTDGENDNWGMDQ-KJEVXHAQSA-N 0.000 description 5
- 238000013459 approach Methods 0.000 description 5
- 108010008355 arginyl-glutamine Proteins 0.000 description 5
- 108010062796 arginyllysine Proteins 0.000 description 5
- 238000004364 calculation method Methods 0.000 description 5
- 108010027668 glycyl-alanyl-valine Proteins 0.000 description 5
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 5
- 238000011534 incubation Methods 0.000 description 5
- 230000006698 induction Effects 0.000 description 5
- 108010053037 kyotorphin Proteins 0.000 description 5
- 210000003205 muscle Anatomy 0.000 description 5
- 229920000447 polyanionic polymer Polymers 0.000 description 5
- 108010090894 prolylleucine Proteins 0.000 description 5
- 239000000758 substrate Substances 0.000 description 5
- 238000013518 transcription Methods 0.000 description 5
- 238000013519 translation Methods 0.000 description 5
- 108010044292 tryptophyltyrosine Proteins 0.000 description 5
- 108010071635 tyrosyl-prolyl-arginine Proteins 0.000 description 5
- YYGNTYWPHWGJRM-UHFFFAOYSA-N (6E,10E,14E,18E)-2,6,10,15,19,23-hexamethyltetracosa-2,6,10,14,18,22-hexaene Chemical compound CC(C)=CCCC(C)=CCCC(C)=CCCC=C(C)CCC=C(C)CCC=C(C)C YYGNTYWPHWGJRM-UHFFFAOYSA-N 0.000 description 4
- RLMISHABBKUNFO-WHFBIAKZSA-N Ala-Ala-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O RLMISHABBKUNFO-WHFBIAKZSA-N 0.000 description 4
- CXRCVCURMBFFOL-FXQIFTODSA-N Ala-Ala-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O CXRCVCURMBFFOL-FXQIFTODSA-N 0.000 description 4
- NCQMBSJGJMYKCK-ZLUOBGJFSA-N Ala-Ser-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O NCQMBSJGJMYKCK-ZLUOBGJFSA-N 0.000 description 4
- ARHJJAAWNWOACN-FXQIFTODSA-N Ala-Ser-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O ARHJJAAWNWOACN-FXQIFTODSA-N 0.000 description 4
- BVLIJXXSXBUGEC-SRVKXCTJSA-N Asn-Asn-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O BVLIJXXSXBUGEC-SRVKXCTJSA-N 0.000 description 4
- PUUPMDXIHCOPJU-HJGDQZAQSA-N Asn-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O PUUPMDXIHCOPJU-HJGDQZAQSA-N 0.000 description 4
- KBQOUDLMWYWXNP-YDHLFZDLSA-N Asn-Val-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CC(=O)N)N KBQOUDLMWYWXNP-YDHLFZDLSA-N 0.000 description 4
- DTNUIAJCPRMNBT-WHFBIAKZSA-N Asp-Gly-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](C)C(O)=O DTNUIAJCPRMNBT-WHFBIAKZSA-N 0.000 description 4
- 208000023275 Autoimmune disease Diseases 0.000 description 4
- 102100021277 Beta-secretase 2 Human genes 0.000 description 4
- 101710150190 Beta-secretase 2 Proteins 0.000 description 4
- 241000283690 Bos taurus Species 0.000 description 4
- 206010006187 Breast cancer Diseases 0.000 description 4
- 208000026310 Breast neoplasm Diseases 0.000 description 4
- 102100025248 C-X-C motif chemokine 10 Human genes 0.000 description 4
- 208000035473 Communicable disease Diseases 0.000 description 4
- SZQCDCKIGWQAQN-FXQIFTODSA-N Cys-Arg-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O SZQCDCKIGWQAQN-FXQIFTODSA-N 0.000 description 4
- 201000011001 Ebola Hemorrhagic Fever Diseases 0.000 description 4
- 241000196324 Embryophyta Species 0.000 description 4
- ZHNUHDYFZUAESO-UHFFFAOYSA-N Formamide Chemical compound NC=O ZHNUHDYFZUAESO-UHFFFAOYSA-N 0.000 description 4
- XOKGKOQWADCLFQ-GARJFASQSA-N Gln-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XOKGKOQWADCLFQ-GARJFASQSA-N 0.000 description 4
- IKFZXRLDMYWNBU-YUMQZZPRSA-N Gln-Gly-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N IKFZXRLDMYWNBU-YUMQZZPRSA-N 0.000 description 4
- BETSEXMYBWCDAE-SZMVWBNQSA-N Gln-Trp-Lys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N BETSEXMYBWCDAE-SZMVWBNQSA-N 0.000 description 4
- SGVGIVDZLSHSEN-RYUDHWBXSA-N Gln-Tyr-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O SGVGIVDZLSHSEN-RYUDHWBXSA-N 0.000 description 4
- NJCALAAIGREHDR-WDCWCFNPSA-N Glu-Leu-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NJCALAAIGREHDR-WDCWCFNPSA-N 0.000 description 4
- HZISRJBYZAODRV-XQXXSGGOSA-N Glu-Thr-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O HZISRJBYZAODRV-XQXXSGGOSA-N 0.000 description 4
- WGYHAAXZWPEBDQ-IFFSRLJSSA-N Glu-Val-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WGYHAAXZWPEBDQ-IFFSRLJSSA-N 0.000 description 4
- VSVZIEVNUYDAFR-YUMQZZPRSA-N Gly-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN VSVZIEVNUYDAFR-YUMQZZPRSA-N 0.000 description 4
- JRDYDYXZKFNNRQ-XPUUQOCRSA-N Gly-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN JRDYDYXZKFNNRQ-XPUUQOCRSA-N 0.000 description 4
- KSOBNUBCYHGUKH-UWVGGRQHSA-N Gly-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN KSOBNUBCYHGUKH-UWVGGRQHSA-N 0.000 description 4
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 4
- TTYKEFZRLKQTHH-MELADBBJSA-N His-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O TTYKEFZRLKQTHH-MELADBBJSA-N 0.000 description 4
- 101000892862 Homo sapiens Glutamate carboxypeptidase 2 Proteins 0.000 description 4
- QQFSKBMCAKWHLG-UHFFFAOYSA-N Ile-Phe-Pro-Pro Chemical compound C1CCC(C(=O)N2C(CCC2)C(O)=O)N1C(=O)C(NC(=O)C(N)C(C)CC)CC1=CC=CC=C1 QQFSKBMCAKWHLG-UHFFFAOYSA-N 0.000 description 4
- 241000712431 Influenza A virus Species 0.000 description 4
- ZGUMORRUBUCXEH-AVGNSLFASA-N Leu-Lys-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZGUMORRUBUCXEH-AVGNSLFASA-N 0.000 description 4
- UHNQRAFSEBGZFZ-YESZJQIVSA-N Leu-Phe-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N UHNQRAFSEBGZFZ-YESZJQIVSA-N 0.000 description 4
- UWKNTTJNVSYXPC-CIUDSAMLSA-N Lys-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN UWKNTTJNVSYXPC-CIUDSAMLSA-N 0.000 description 4
- YTJFXEDRUOQGSP-DCAQKATOSA-N Lys-Pro-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YTJFXEDRUOQGSP-DCAQKATOSA-N 0.000 description 4
- XABXVVSWUVCZST-GVXVVHGQSA-N Lys-Val-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN XABXVVSWUVCZST-GVXVVHGQSA-N 0.000 description 4
- JPCHYAUKOUGOIB-HJGDQZAQSA-N Met-Glu-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O JPCHYAUKOUGOIB-HJGDQZAQSA-N 0.000 description 4
- 239000000020 Nitrocellulose Substances 0.000 description 4
- 101710141454 Nucleoprotein Proteins 0.000 description 4
- ZJPGOXWRFNKIQL-JYJNAYRXSA-N Phe-Pro-Pro Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(O)=O)C1=CC=CC=C1 ZJPGOXWRFNKIQL-JYJNAYRXSA-N 0.000 description 4
- TUYWCHPXKQTISF-LPEHRKFASA-N Pro-Cys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)N2CCC[C@@H]2C(=O)O TUYWCHPXKQTISF-LPEHRKFASA-N 0.000 description 4
- UIMCLYYSUCIUJM-UWVGGRQHSA-N Pro-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 UIMCLYYSUCIUJM-UWVGGRQHSA-N 0.000 description 4
- FMLRRBDLBJLJIK-DCAQKATOSA-N Pro-Leu-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]1CCCN1 FMLRRBDLBJLJIK-DCAQKATOSA-N 0.000 description 4
- PRKWBYCXBBSLSK-GUBZILKMSA-N Pro-Ser-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O PRKWBYCXBBSLSK-GUBZILKMSA-N 0.000 description 4
- 108020005091 Replication Origin Proteins 0.000 description 4
- UEJYSALTSUZXFV-SRVKXCTJSA-N Rigin Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O UEJYSALTSUZXFV-SRVKXCTJSA-N 0.000 description 4
- YQHZVYJAGWMHES-ZLUOBGJFSA-N Ser-Ala-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YQHZVYJAGWMHES-ZLUOBGJFSA-N 0.000 description 4
- UGJRQLURDVGULT-LKXGYXEUSA-N Ser-Asn-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O UGJRQLURDVGULT-LKXGYXEUSA-N 0.000 description 4
- FPCGZYMRFFIYIH-CIUDSAMLSA-N Ser-Lys-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O FPCGZYMRFFIYIH-CIUDSAMLSA-N 0.000 description 4
- BHEOSNUKNHRBNM-UHFFFAOYSA-N Tetramethylsqualene Natural products CC(=C)C(C)CCC(=C)C(C)CCC(C)=CCCC=C(C)CCC(C)C(=C)CCC(C)C(C)=C BHEOSNUKNHRBNM-UHFFFAOYSA-N 0.000 description 4
- LAFLAXHTDVNVEL-WDCWCFNPSA-N Thr-Gln-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N)O LAFLAXHTDVNVEL-WDCWCFNPSA-N 0.000 description 4
- VRUFCJZQDACGLH-UVOCVTCTSA-N Thr-Leu-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VRUFCJZQDACGLH-UVOCVTCTSA-N 0.000 description 4
- DXPURPNJDFCKKO-RHYQMDGZSA-N Thr-Lys-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)[C@@H](C)O)C(O)=O DXPURPNJDFCKKO-RHYQMDGZSA-N 0.000 description 4
- FYBFTPLPAXZBOY-KKHAAJSZSA-N Thr-Val-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O FYBFTPLPAXZBOY-KKHAAJSZSA-N 0.000 description 4
- UKINEYBQXPMOJO-UBHSHLNASA-N Trp-Asn-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N UKINEYBQXPMOJO-UBHSHLNASA-N 0.000 description 4
- DQDXHYIEITXNJY-BPUTZDHNSA-N Trp-Gln-Gln Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N DQDXHYIEITXNJY-BPUTZDHNSA-N 0.000 description 4
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 4
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 4
- JFAWZADYPRMRCO-UBHSHLNASA-N Val-Ala-Phe Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JFAWZADYPRMRCO-UBHSHLNASA-N 0.000 description 4
- ZIGZPYJXIWLQFC-QTKMDUPCSA-N Val-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](C(C)C)N)O ZIGZPYJXIWLQFC-QTKMDUPCSA-N 0.000 description 4
- VCIYTVOBLZHFSC-XHSDSOJGSA-N Val-Phe-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N VCIYTVOBLZHFSC-XHSDSOJGSA-N 0.000 description 4
- KSFXWENSJABBFI-ZKWXMUAHSA-N Val-Ser-Asn Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O KSFXWENSJABBFI-ZKWXMUAHSA-N 0.000 description 4
- BZDGLJPROOOUOZ-XGEHTFHBSA-N Val-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](C(C)C)N)O BZDGLJPROOOUOZ-XGEHTFHBSA-N 0.000 description 4
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 4
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 4
- 108010039538 alanyl-glycyl-aspartyl-valine Proteins 0.000 description 4
- 108010044940 alanylglutamine Proteins 0.000 description 4
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 4
- 150000001768 cations Chemical class 0.000 description 4
- 238000012790 confirmation Methods 0.000 description 4
- CVSVTCORWBXHQV-UHFFFAOYSA-N creatine Chemical compound NC(=[NH2+])N(C)CC([O-])=O CVSVTCORWBXHQV-UHFFFAOYSA-N 0.000 description 4
- 230000034994 death Effects 0.000 description 4
- 238000002716 delivery method Methods 0.000 description 4
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 4
- PRAKJMSDJKAYCZ-UHFFFAOYSA-N dodecahydrosqualene Natural products CC(C)CCCC(C)CCCC(C)CCCCC(C)CCCC(C)CCCC(C)C PRAKJMSDJKAYCZ-UHFFFAOYSA-N 0.000 description 4
- 230000000694 effects Effects 0.000 description 4
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 4
- 108010081551 glycylphenylalanine Proteins 0.000 description 4
- 108010037850 glycylvaline Proteins 0.000 description 4
- 238000003018 immunoassay Methods 0.000 description 4
- 230000016784 immunoglobulin production Effects 0.000 description 4
- 230000001939 inductive effect Effects 0.000 description 4
- 239000012678 infectious agent Substances 0.000 description 4
- 230000005764 inhibitory process Effects 0.000 description 4
- 230000000670 limiting effect Effects 0.000 description 4
- 150000002632 lipids Chemical class 0.000 description 4
- 239000000463 material Substances 0.000 description 4
- 230000001404 mediated effect Effects 0.000 description 4
- 230000007935 neutral effect Effects 0.000 description 4
- 229920001220 nitrocellulos Polymers 0.000 description 4
- -1 pH 7.0 to 8.3 Chemical compound 0.000 description 4
- 239000000546 pharmaceutical excipient Substances 0.000 description 4
- 229920002643 polyglutamic acid Polymers 0.000 description 4
- 108010077112 prolyl-proline Proteins 0.000 description 4
- 230000001681 protective effect Effects 0.000 description 4
- 230000001105 regulatory effect Effects 0.000 description 4
- 108010026333 seryl-proline Proteins 0.000 description 4
- 229940031439 squalene Drugs 0.000 description 4
- TUHBEKDERLKLEC-UHFFFAOYSA-N squalene Natural products CC(=CCCC(=CCCC(=CCCC=C(/C)CCC=C(/C)CC=C(C)C)C)C)C TUHBEKDERLKLEC-UHFFFAOYSA-N 0.000 description 4
- 238000010186 staining Methods 0.000 description 4
- 238000007619 statistical method Methods 0.000 description 4
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 4
- 230000035897 transcription Effects 0.000 description 4
- 238000012546 transfer Methods 0.000 description 4
- 108010038745 tryptophylglycine Proteins 0.000 description 4
- 241000712461 unidentified influenza virus Species 0.000 description 4
- 238000002255 vaccination Methods 0.000 description 4
- 238000001262 western blot Methods 0.000 description 4
- 108010027345 wheylin-1 peptide Proteins 0.000 description 4
- 108010082808 4-1BB Ligand Proteins 0.000 description 3
- 102000002627 4-1BB Ligand Human genes 0.000 description 3
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 3
- 208000030507 AIDS Diseases 0.000 description 3
- 241000238876 Acari Species 0.000 description 3
- KUDREHRZRIVKHS-UWJYBYFXSA-N Ala-Asp-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KUDREHRZRIVKHS-UWJYBYFXSA-N 0.000 description 3
- MEFILNJXAVSUTO-JXUBOQSCSA-N Ala-Leu-Thr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MEFILNJXAVSUTO-JXUBOQSCSA-N 0.000 description 3
- MDNAVFBZPROEHO-DCAQKATOSA-N Ala-Lys-Val Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O MDNAVFBZPROEHO-DCAQKATOSA-N 0.000 description 3
- BTRULDJUUVGRNE-DCAQKATOSA-N Ala-Pro-Lys Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O BTRULDJUUVGRNE-DCAQKATOSA-N 0.000 description 3
- WQKAQKZRDIZYNV-VZFHVOOUSA-N Ala-Ser-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WQKAQKZRDIZYNV-VZFHVOOUSA-N 0.000 description 3
- 241000224489 Amoeba Species 0.000 description 3
- RTDZQOFEGPWSJD-AVGNSLFASA-N Arg-Leu-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O RTDZQOFEGPWSJD-AVGNSLFASA-N 0.000 description 3
- XYOVHPDDWCEUDY-CIUDSAMLSA-N Asn-Ala-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O XYOVHPDDWCEUDY-CIUDSAMLSA-N 0.000 description 3
- GXMSVVBIAMWMKO-BQBZGAKWSA-N Asn-Arg-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CCCN=C(N)N GXMSVVBIAMWMKO-BQBZGAKWSA-N 0.000 description 3
- HPBNLFLSSQDFQW-WHFBIAKZSA-N Asn-Ser-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O HPBNLFLSSQDFQW-WHFBIAKZSA-N 0.000 description 3
- MKJBPDLENBUHQU-CIUDSAMLSA-N Asn-Ser-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O MKJBPDLENBUHQU-CIUDSAMLSA-N 0.000 description 3
- MRQQMVZUHXUPEV-IHRRRGAJSA-N Asp-Arg-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MRQQMVZUHXUPEV-IHRRRGAJSA-N 0.000 description 3
- HSWYMWGDMPLTTH-FXQIFTODSA-N Asp-Glu-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HSWYMWGDMPLTTH-FXQIFTODSA-N 0.000 description 3
- KTTCQQNRRLCIBC-GHCJXIJMSA-N Asp-Ile-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O KTTCQQNRRLCIBC-GHCJXIJMSA-N 0.000 description 3
- NVFSJIXJZCDICF-SRVKXCTJSA-N Asp-Lys-Lys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N NVFSJIXJZCDICF-SRVKXCTJSA-N 0.000 description 3
- NJLLRXWFPQQPHV-SRVKXCTJSA-N Asp-Tyr-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O NJLLRXWFPQQPHV-SRVKXCTJSA-N 0.000 description 3
- 101100505161 Caenorhabditis elegans mel-32 gene Proteins 0.000 description 3
- 241000222122 Candida albicans Species 0.000 description 3
- 241000283707 Capra Species 0.000 description 3
- 108090000565 Capsid Proteins Proteins 0.000 description 3
- 102100023321 Ceruloplasmin Human genes 0.000 description 3
- 241000242722 Cestoda Species 0.000 description 3
- VIRYODQIWJNWNU-NRPADANISA-N Cys-Glu-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CS)N VIRYODQIWJNWNU-NRPADANISA-N 0.000 description 3
- 101710204837 Envelope small membrane protein Proteins 0.000 description 3
- 101001065501 Escherichia phage MS2 Lysis protein Proteins 0.000 description 3
- 238000012413 Fluorescence activated cell sorting analysis Methods 0.000 description 3
- 102000004961 Furin Human genes 0.000 description 3
- 108090001126 Furin Proteins 0.000 description 3
- ZNZPKVQURDQFFS-FXQIFTODSA-N Gln-Glu-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZNZPKVQURDQFFS-FXQIFTODSA-N 0.000 description 3
- IULKWYSYZSURJK-AVGNSLFASA-N Gln-Leu-Lys Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(O)=O IULKWYSYZSURJK-AVGNSLFASA-N 0.000 description 3
- HMIXCETWRYDVMO-GUBZILKMSA-N Gln-Pro-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O HMIXCETWRYDVMO-GUBZILKMSA-N 0.000 description 3
- WIMVKDYAKRAUCG-IHRRRGAJSA-N Gln-Tyr-Glu Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O WIMVKDYAKRAUCG-IHRRRGAJSA-N 0.000 description 3
- ITYRYNUZHPNCIK-GUBZILKMSA-N Glu-Ala-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O ITYRYNUZHPNCIK-GUBZILKMSA-N 0.000 description 3
- JJKKWYQVHRUSDG-GUBZILKMSA-N Glu-Ala-Lys Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O JJKKWYQVHRUSDG-GUBZILKMSA-N 0.000 description 3
- CLROYXHHUZELFX-FXQIFTODSA-N Glu-Gln-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O CLROYXHHUZELFX-FXQIFTODSA-N 0.000 description 3
- INGJLBQKTRJLFO-UKJIMTQDSA-N Glu-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O INGJLBQKTRJLFO-UKJIMTQDSA-N 0.000 description 3
- YRMZCZIRHYCNHX-RYUDHWBXSA-N Glu-Phe-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O YRMZCZIRHYCNHX-RYUDHWBXSA-N 0.000 description 3
- BFEZQZKEPRKKHV-SRVKXCTJSA-N Glu-Pro-Lys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CCCCN)C(=O)O BFEZQZKEPRKKHV-SRVKXCTJSA-N 0.000 description 3
- ALMBZBOCGSVSAI-ACZMJKKPSA-N Glu-Ser-Asn Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ALMBZBOCGSVSAI-ACZMJKKPSA-N 0.000 description 3
- 108090000369 Glutamate Carboxypeptidase II Proteins 0.000 description 3
- RJIVPOXLQFJRTG-LURJTMIESA-N Gly-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N RJIVPOXLQFJRTG-LURJTMIESA-N 0.000 description 3
- XCLCVBYNGXEVDU-WHFBIAKZSA-N Gly-Asn-Ser Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O XCLCVBYNGXEVDU-WHFBIAKZSA-N 0.000 description 3
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 3
- WDXLKVQATNEAJQ-BQBZGAKWSA-N Gly-Pro-Asp Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O WDXLKVQATNEAJQ-BQBZGAKWSA-N 0.000 description 3
- UVTSZKIATYSKIR-RYUDHWBXSA-N Gly-Tyr-Glu Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O UVTSZKIATYSKIR-RYUDHWBXSA-N 0.000 description 3
- 241000285387 HBV genotype A Species 0.000 description 3
- 241000285452 HBV genotype B Species 0.000 description 3
- 241000285424 HBV genotype C Species 0.000 description 3
- 241000285366 HBV genotype D Species 0.000 description 3
- 241000285370 HBV genotype E Species 0.000 description 3
- 241000285563 HBV genotype F Species 0.000 description 3
- 241000285576 HBV genotype G Species 0.000 description 3
- 241000285579 HBV genotype H Species 0.000 description 3
- WMKXFMUJRCEGRP-SRVKXCTJSA-N His-Asn-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N WMKXFMUJRCEGRP-SRVKXCTJSA-N 0.000 description 3
- TVMNTHXFRSXZGR-IHRRRGAJSA-N His-Lys-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O TVMNTHXFRSXZGR-IHRRRGAJSA-N 0.000 description 3
- JVEKQAYXFGIISZ-HOCLYGCPSA-N His-Trp-Gly Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)NCC(O)=O)C1=CN=CN1 JVEKQAYXFGIISZ-HOCLYGCPSA-N 0.000 description 3
- ZNTSGDNUITWTRA-WDSOQIARSA-N His-Trp-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C(C)C)C(O)=O ZNTSGDNUITWTRA-WDSOQIARSA-N 0.000 description 3
- PFPUFNLHBXKPHY-HTFCKZLJSA-N Ile-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(=O)O)N PFPUFNLHBXKPHY-HTFCKZLJSA-N 0.000 description 3
- OWSWUWDMSNXTNE-GMOBBJLQSA-N Ile-Pro-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N OWSWUWDMSNXTNE-GMOBBJLQSA-N 0.000 description 3
- HJDZMPFEXINXLO-QPHKQPEJSA-N Ile-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N HJDZMPFEXINXLO-QPHKQPEJSA-N 0.000 description 3
- ZGKVPOSSTGHJAF-HJPIBITLSA-N Ile-Tyr-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CO)C(=O)O)N ZGKVPOSSTGHJAF-HJPIBITLSA-N 0.000 description 3
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 3
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 3
- 108091092195 Intron Proteins 0.000 description 3
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 3
- KFKWRHQBZQICHA-STQMWFEESA-N L-leucyl-L-phenylalanine Natural products CC(C)C[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KFKWRHQBZQICHA-STQMWFEESA-N 0.000 description 3
- DBVWMYGBVFCRBE-CIUDSAMLSA-N Leu-Asn-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O DBVWMYGBVFCRBE-CIUDSAMLSA-N 0.000 description 3
- GPICTNQYKHHHTH-GUBZILKMSA-N Leu-Gln-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GPICTNQYKHHHTH-GUBZILKMSA-N 0.000 description 3
- QVFGXCVIXXBFHO-AVGNSLFASA-N Leu-Glu-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O QVFGXCVIXXBFHO-AVGNSLFASA-N 0.000 description 3
- NRFGTHFONZYFNY-MGHWNKPDSA-N Leu-Ile-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 NRFGTHFONZYFNY-MGHWNKPDSA-N 0.000 description 3
- VCHVSKNMTXWIIP-SRVKXCTJSA-N Leu-Lys-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O VCHVSKNMTXWIIP-SRVKXCTJSA-N 0.000 description 3
- AMSSKPUHBUQBOQ-SRVKXCTJSA-N Leu-Ser-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N AMSSKPUHBUQBOQ-SRVKXCTJSA-N 0.000 description 3
- LINKCQUOMUDLKN-KATARQTJSA-N Leu-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N)O LINKCQUOMUDLKN-KATARQTJSA-N 0.000 description 3
- LCNASHSOFMRYFO-WDCWCFNPSA-N Leu-Thr-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O LCNASHSOFMRYFO-WDCWCFNPSA-N 0.000 description 3
- ILDSIMPXNFWKLH-KATARQTJSA-N Leu-Thr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ILDSIMPXNFWKLH-KATARQTJSA-N 0.000 description 3
- AIMGJYMCTAABEN-GVXVVHGQSA-N Leu-Val-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O AIMGJYMCTAABEN-GVXVVHGQSA-N 0.000 description 3
- QESXLSQLQHHTIX-RHYQMDGZSA-N Leu-Val-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QESXLSQLQHHTIX-RHYQMDGZSA-N 0.000 description 3
- 108060001084 Luciferase Proteins 0.000 description 3
- 239000005089 Luciferase Substances 0.000 description 3
- FZIJIFCXUCZHOL-CIUDSAMLSA-N Lys-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN FZIJIFCXUCZHOL-CIUDSAMLSA-N 0.000 description 3
- MPGHETGWWWUHPY-CIUDSAMLSA-N Lys-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN MPGHETGWWWUHPY-CIUDSAMLSA-N 0.000 description 3
- YKIRNDPUWONXQN-GUBZILKMSA-N Lys-Asn-Gln Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N YKIRNDPUWONXQN-GUBZILKMSA-N 0.000 description 3
- OIQSIMFSVLLWBX-VOAKCMCISA-N Lys-Leu-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OIQSIMFSVLLWBX-VOAKCMCISA-N 0.000 description 3
- WQDKIVRHTQYJSN-DCAQKATOSA-N Lys-Ser-Arg Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N WQDKIVRHTQYJSN-DCAQKATOSA-N 0.000 description 3
- SQXZLVXQXWILKW-KKUMJFAQSA-N Lys-Ser-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SQXZLVXQXWILKW-KKUMJFAQSA-N 0.000 description 3
- IEVXCWPVBYCJRZ-IXOXFDKPSA-N Lys-Thr-His Chemical compound NCCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 IEVXCWPVBYCJRZ-IXOXFDKPSA-N 0.000 description 3
- CAVRAQIDHUPECU-UVOCVTCTSA-N Lys-Thr-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAVRAQIDHUPECU-UVOCVTCTSA-N 0.000 description 3
- SUZVLFWOCKHWET-CQDKDKBSSA-N Lys-Tyr-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O SUZVLFWOCKHWET-CQDKDKBSSA-N 0.000 description 3
- 101710145006 Lysis protein Proteins 0.000 description 3
- 101150039699 M2-1 gene Proteins 0.000 description 3
- 101150103632 M2-2 gene Proteins 0.000 description 3
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 3
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 3
- 108091034117 Oligonucleotide Proteins 0.000 description 3
- HNFUGJUZJRYUHN-JSGCOSHPSA-N Phe-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 HNFUGJUZJRYUHN-JSGCOSHPSA-N 0.000 description 3
- KNYPNEYICHHLQL-ACRUOGEOSA-N Phe-Leu-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 KNYPNEYICHHLQL-ACRUOGEOSA-N 0.000 description 3
- IWZRODDWOSIXPZ-IRXDYDNUSA-N Phe-Phe-Gly Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)NCC(O)=O)C1=CC=CC=C1 IWZRODDWOSIXPZ-IRXDYDNUSA-N 0.000 description 3
- BPCLGWHVPVTTFM-QWRGUYRKSA-N Phe-Ser-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)NCC(O)=O BPCLGWHVPVTTFM-QWRGUYRKSA-N 0.000 description 3
- 101710177166 Phosphoprotein Proteins 0.000 description 3
- 241000223960 Plasmodium falciparum Species 0.000 description 3
- CGBYDGAJHSOGFQ-LPEHRKFASA-N Pro-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 CGBYDGAJHSOGFQ-LPEHRKFASA-N 0.000 description 3
- VCYJKOLZYPYGJV-AVGNSLFASA-N Pro-Arg-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O VCYJKOLZYPYGJV-AVGNSLFASA-N 0.000 description 3
- JMVQDLDPDBXAAX-YUMQZZPRSA-N Pro-Gly-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 JMVQDLDPDBXAAX-YUMQZZPRSA-N 0.000 description 3
- AFXCXDQNRXTSBD-FJXKBIBVSA-N Pro-Gly-Thr Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O AFXCXDQNRXTSBD-FJXKBIBVSA-N 0.000 description 3
- KBUAPZAZPWNYSW-SRVKXCTJSA-N Pro-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 KBUAPZAZPWNYSW-SRVKXCTJSA-N 0.000 description 3
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 3
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 3
- HZWAHWQZPSXNCB-BPUTZDHNSA-N Ser-Arg-Trp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HZWAHWQZPSXNCB-BPUTZDHNSA-N 0.000 description 3
- FTVRVZNYIYWJGB-ACZMJKKPSA-N Ser-Asp-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O FTVRVZNYIYWJGB-ACZMJKKPSA-N 0.000 description 3
- KNCJWSPMTFFJII-ZLUOBGJFSA-N Ser-Cys-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(O)=O KNCJWSPMTFFJII-ZLUOBGJFSA-N 0.000 description 3
- MOVJSUIKUNCVMG-ZLUOBGJFSA-N Ser-Cys-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O)N)O MOVJSUIKUNCVMG-ZLUOBGJFSA-N 0.000 description 3
- ZOHGLPQGEHSLPD-FXQIFTODSA-N Ser-Gln-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZOHGLPQGEHSLPD-FXQIFTODSA-N 0.000 description 3
- FMDHKPRACUXATF-ACZMJKKPSA-N Ser-Gln-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O FMDHKPRACUXATF-ACZMJKKPSA-N 0.000 description 3
- JFWDJFULOLKQFY-QWRGUYRKSA-N Ser-Gly-Phe Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JFWDJFULOLKQFY-QWRGUYRKSA-N 0.000 description 3
- XXXAXOWMBOKTRN-XPUUQOCRSA-N Ser-Gly-Val Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O XXXAXOWMBOKTRN-XPUUQOCRSA-N 0.000 description 3
- CLKKNZQUQMZDGD-SRVKXCTJSA-N Ser-His-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CC1=CN=CN1 CLKKNZQUQMZDGD-SRVKXCTJSA-N 0.000 description 3
- PPNPDKGQRFSCAC-CIUDSAMLSA-N Ser-Lys-Asp Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)CO)C(=O)N[C@@H](CC(O)=O)C(O)=O PPNPDKGQRFSCAC-CIUDSAMLSA-N 0.000 description 3
- XUDRHBPSPAPDJP-SRVKXCTJSA-N Ser-Lys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CO XUDRHBPSPAPDJP-SRVKXCTJSA-N 0.000 description 3
- GDUZTEQRAOXYJS-SRVKXCTJSA-N Ser-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GDUZTEQRAOXYJS-SRVKXCTJSA-N 0.000 description 3
- CUXJENOFJXOSOZ-BIIVOSGPSA-N Ser-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CO)N)C(=O)O CUXJENOFJXOSOZ-BIIVOSGPSA-N 0.000 description 3
- JURQXQBJKUHGJS-UHFFFAOYSA-N Ser-Ser-Ser-Ser Chemical compound OCC(N)C(=O)NC(CO)C(=O)NC(CO)C(=O)NC(CO)C(O)=O JURQXQBJKUHGJS-UHFFFAOYSA-N 0.000 description 3
- PCJLFYBAQZQOFE-KATARQTJSA-N Ser-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CO)N)O PCJLFYBAQZQOFE-KATARQTJSA-N 0.000 description 3
- AXKJPUBALUNJEO-UBHSHLNASA-N Ser-Trp-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC(N)=O)C(O)=O AXKJPUBALUNJEO-UBHSHLNASA-N 0.000 description 3
- VVKVHAOOUGNDPJ-SRVKXCTJSA-N Ser-Tyr-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(O)=O VVKVHAOOUGNDPJ-SRVKXCTJSA-N 0.000 description 3
- 241000700584 Simplexvirus Species 0.000 description 3
- 102100036011 T-cell surface glycoprotein CD4 Human genes 0.000 description 3
- ASJDFGOPDCVXTG-KATARQTJSA-N Thr-Cys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O ASJDFGOPDCVXTG-KATARQTJSA-N 0.000 description 3
- KWQBJOUOSNJDRR-XAVMHZPKSA-N Thr-Cys-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N1CCC[C@@H]1C(=O)O)N)O KWQBJOUOSNJDRR-XAVMHZPKSA-N 0.000 description 3
- CYVQBKQYQGEELV-NKIYYHGXSA-N Thr-His-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O CYVQBKQYQGEELV-NKIYYHGXSA-N 0.000 description 3
- MROIJTGJGIDEEJ-RCWTZXSCSA-N Thr-Pro-Pro Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 MROIJTGJGIDEEJ-RCWTZXSCSA-N 0.000 description 3
- MBLJBGZWLHTJBH-SZMVWBNQSA-N Trp-Val-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 MBLJBGZWLHTJBH-SZMVWBNQSA-N 0.000 description 3
- QJBWZNTWJSZUOY-UWJYBYFXSA-N Tyr-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N QJBWZNTWJSZUOY-UWJYBYFXSA-N 0.000 description 3
- JWHOIHCOHMZSAR-QWRGUYRKSA-N Tyr-Asp-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 JWHOIHCOHMZSAR-QWRGUYRKSA-N 0.000 description 3
- YYLHVUCSTXXKBS-IHRRRGAJSA-N Tyr-Pro-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YYLHVUCSTXXKBS-IHRRRGAJSA-N 0.000 description 3
- ZLFHAAGHGQBQQN-AEJSXWLSSA-N Val-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N ZLFHAAGHGQBQQN-AEJSXWLSSA-N 0.000 description 3
- ZLFHAAGHGQBQQN-GUBZILKMSA-N Val-Ala-Pro Natural products CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O ZLFHAAGHGQBQQN-GUBZILKMSA-N 0.000 description 3
- XLDYBRXERHITNH-QSFUFRPTSA-N Val-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)C(C)C XLDYBRXERHITNH-QSFUFRPTSA-N 0.000 description 3
- OXVPMZVGCAPFIG-BQFCYCMXSA-N Val-Gln-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N OXVPMZVGCAPFIG-BQFCYCMXSA-N 0.000 description 3
- RKIGNDAHUOOIMJ-BQFCYCMXSA-N Val-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 RKIGNDAHUOOIMJ-BQFCYCMXSA-N 0.000 description 3
- RWOGENDAOGMHLX-DCAQKATOSA-N Val-Lys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C(C)C)N RWOGENDAOGMHLX-DCAQKATOSA-N 0.000 description 3
- DIOSYUIWOQCXNR-ONGXEEELSA-N Val-Lys-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O DIOSYUIWOQCXNR-ONGXEEELSA-N 0.000 description 3
- SBJCTAZFSZXWSR-AVGNSLFASA-N Val-Met-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N SBJCTAZFSZXWSR-AVGNSLFASA-N 0.000 description 3
- FMQGYTMERWBMSI-HJWJTTGWSA-N Val-Phe-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C(C)C)N FMQGYTMERWBMSI-HJWJTTGWSA-N 0.000 description 3
- VHIZXDZMTDVFGX-DCAQKATOSA-N Val-Ser-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N VHIZXDZMTDVFGX-DCAQKATOSA-N 0.000 description 3
- SDHZOOIGIUEPDY-JYJNAYRXSA-N Val-Ser-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CO)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 SDHZOOIGIUEPDY-JYJNAYRXSA-N 0.000 description 3
- GVNLOVJNNDZUHS-RHYQMDGZSA-N Val-Thr-Lys Chemical compound [H]N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O GVNLOVJNNDZUHS-RHYQMDGZSA-N 0.000 description 3
- QPJSIBAOZBVELU-BPNCWPANSA-N Val-Tyr-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N QPJSIBAOZBVELU-BPNCWPANSA-N 0.000 description 3
- 208000008383 Wilms tumor Diseases 0.000 description 3
- 108010081404 acein-2 Proteins 0.000 description 3
- 239000002671 adjuvant Substances 0.000 description 3
- 108010041407 alanylaspartic acid Proteins 0.000 description 3
- 108010047495 alanylglycine Proteins 0.000 description 3
- 108010050025 alpha-glutamyltryptophan Proteins 0.000 description 3
- 230000005875 antibody response Effects 0.000 description 3
- 238000003491 array Methods 0.000 description 3
- 230000001580 bacterial effect Effects 0.000 description 3
- 230000004071 biological effect Effects 0.000 description 3
- 239000003153 chemical reaction reagent Substances 0.000 description 3
- 238000010276 construction Methods 0.000 description 3
- 108010060199 cysteinylproline Proteins 0.000 description 3
- 238000011161 development Methods 0.000 description 3
- 229940079593 drug Drugs 0.000 description 3
- 239000000499 gel Substances 0.000 description 3
- 230000002068 genetic effect Effects 0.000 description 3
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 3
- 108010018006 histidylserine Proteins 0.000 description 3
- 230000005745 host immune response Effects 0.000 description 3
- 230000028996 humoral immune response Effects 0.000 description 3
- 230000005847 immunogenicity Effects 0.000 description 3
- 108010025153 lysyl-alanyl-alanine Proteins 0.000 description 3
- 210000004962 mammalian cell Anatomy 0.000 description 3
- 239000002105 nanoparticle Substances 0.000 description 3
- 210000000056 organ Anatomy 0.000 description 3
- 108010084525 phenylalanyl-phenylalanyl-glycine Proteins 0.000 description 3
- 239000013641 positive control Substances 0.000 description 3
- 238000002360 preparation method Methods 0.000 description 3
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 3
- 108010053725 prolylvaline Proteins 0.000 description 3
- 235000019833 protease Nutrition 0.000 description 3
- 238000000159 protein binding assay Methods 0.000 description 3
- 238000011160 research Methods 0.000 description 3
- 108091008146 restriction endonucleases Proteins 0.000 description 3
- 108010091078 rigin Proteins 0.000 description 3
- 150000003839 salts Chemical class 0.000 description 3
- 238000012216 screening Methods 0.000 description 3
- 239000003381 stabilizer Substances 0.000 description 3
- 239000006228 supernatant Substances 0.000 description 3
- 230000001629 suppression Effects 0.000 description 3
- 238000003786 synthesis reaction Methods 0.000 description 3
- 230000002123 temporal effect Effects 0.000 description 3
- 230000001225 therapeutic effect Effects 0.000 description 3
- 238000002560 therapeutic procedure Methods 0.000 description 3
- 201000008827 tuberculosis Diseases 0.000 description 3
- 108010052774 valyl-lysyl-glycyl-phenylalanyl-tyrosine Proteins 0.000 description 3
- KIUKXJAPPMFGSW-DNGZLQJQSA-N (2S,3S,4S,5R,6R)-6-[(2S,3R,4R,5S,6R)-3-Acetamido-2-[(2S,3S,4R,5R,6R)-6-[(2R,3R,4R,5S,6R)-3-acetamido-2,5-dihydroxy-6-(hydroxymethyl)oxan-4-yl]oxy-2-carboxy-4,5-dihydroxyoxan-3-yl]oxy-5-hydroxy-6-(hydroxymethyl)oxan-4-yl]oxy-3,4,5-trihydroxyoxane-2-carboxylic acid Chemical compound CC(=O)N[C@H]1[C@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O[C@H]1[C@H](O)[C@@H](O)[C@H](O[C@H]2[C@@H]([C@@H](O[C@H]3[C@@H]([C@@H](O)[C@H](O)[C@H](O3)C(O)=O)O)[C@H](O)[C@@H](CO)O2)NC(C)=O)[C@@H](C(O)=O)O1 KIUKXJAPPMFGSW-DNGZLQJQSA-N 0.000 description 2
- PKOHVHWNGUHYRE-ZFWWWQNUSA-N (2s)-1-[2-[[(2s)-2-amino-3-(1h-indol-3-yl)propanoyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound O=C([C@H](CC=1C2=CC=CC=C2NC=1)N)NCC(=O)N1CCC[C@H]1C(O)=O PKOHVHWNGUHYRE-ZFWWWQNUSA-N 0.000 description 2
- UHPMCKVQTMMPCG-UHFFFAOYSA-N 5,8-dihydroxy-2-methoxy-6-methyl-7-(2-oxopropyl)naphthalene-1,4-dione Chemical compound CC1=C(CC(C)=O)C(O)=C2C(=O)C(OC)=CC(=O)C2=C1O UHPMCKVQTMMPCG-UHFFFAOYSA-N 0.000 description 2
- 102000007469 Actins Human genes 0.000 description 2
- 108010085238 Actins Proteins 0.000 description 2
- SVBXIUDNTRTKHE-CIUDSAMLSA-N Ala-Arg-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O SVBXIUDNTRTKHE-CIUDSAMLSA-N 0.000 description 2
- UCIYCBSJBQGDGM-LPEHRKFASA-N Ala-Arg-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N UCIYCBSJBQGDGM-LPEHRKFASA-N 0.000 description 2
- BTYTYHBSJKQBQA-GCJQMDKQSA-N Ala-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C)N)O BTYTYHBSJKQBQA-GCJQMDKQSA-N 0.000 description 2
- KXEVYGKATAMXJJ-ACZMJKKPSA-N Ala-Glu-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O KXEVYGKATAMXJJ-ACZMJKKPSA-N 0.000 description 2
- VBRDBGCROKWTPV-XHNCKOQMSA-N Ala-Glu-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N VBRDBGCROKWTPV-XHNCKOQMSA-N 0.000 description 2
- SUMYEVXWCAYLLJ-GUBZILKMSA-N Ala-Leu-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O SUMYEVXWCAYLLJ-GUBZILKMSA-N 0.000 description 2
- DPNZTBKGAUAZQU-DLOVCJGASA-N Ala-Leu-His Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N DPNZTBKGAUAZQU-DLOVCJGASA-N 0.000 description 2
- SOBIAADAMRHGKH-CIUDSAMLSA-N Ala-Leu-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SOBIAADAMRHGKH-CIUDSAMLSA-N 0.000 description 2
- OINVDEKBKBCPLX-JXUBOQSCSA-N Ala-Lys-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OINVDEKBKBCPLX-JXUBOQSCSA-N 0.000 description 2
- XRUJOVRWNMBAAA-NHCYSSNCSA-N Ala-Phe-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 XRUJOVRWNMBAAA-NHCYSSNCSA-N 0.000 description 2
- YJHKTAMKPGFJCT-NRPADANISA-N Ala-Val-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O YJHKTAMKPGFJCT-NRPADANISA-N 0.000 description 2
- ZDILXFDENZVOTL-BPNCWPANSA-N Ala-Val-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZDILXFDENZVOTL-BPNCWPANSA-N 0.000 description 2
- 102000013455 Amyloid beta-Peptides Human genes 0.000 description 2
- 108010090849 Amyloid beta-Peptides Proteins 0.000 description 2
- GIVATXIGCXFQQA-FXQIFTODSA-N Arg-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCN=C(N)N GIVATXIGCXFQQA-FXQIFTODSA-N 0.000 description 2
- FEZJJKXNPSEYEV-CIUDSAMLSA-N Arg-Gln-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O FEZJJKXNPSEYEV-CIUDSAMLSA-N 0.000 description 2
- AUFHLLPVPSMEOG-YUMQZZPRSA-N Arg-Gly-Glu Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O AUFHLLPVPSMEOG-YUMQZZPRSA-N 0.000 description 2
- FSNVAJOPUDVQAR-AVGNSLFASA-N Arg-Lys-Arg Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FSNVAJOPUDVQAR-AVGNSLFASA-N 0.000 description 2
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 2
- XSPKAHFVDKRGRL-DCAQKATOSA-N Arg-Pro-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O XSPKAHFVDKRGRL-DCAQKATOSA-N 0.000 description 2
- HGKHPCFTRQDHCU-IUCAKERBSA-N Arg-Pro-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O HGKHPCFTRQDHCU-IUCAKERBSA-N 0.000 description 2
- ATABBWFGOHKROJ-GUBZILKMSA-N Arg-Pro-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O ATABBWFGOHKROJ-GUBZILKMSA-N 0.000 description 2
- LRPZJPMQGKGHSG-XGEHTFHBSA-N Arg-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)O LRPZJPMQGKGHSG-XGEHTFHBSA-N 0.000 description 2
- ZJBUILVYSXQNSW-YTWAJWBKSA-N Arg-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O ZJBUILVYSXQNSW-YTWAJWBKSA-N 0.000 description 2
- INOIAEUXVVNJKA-XGEHTFHBSA-N Arg-Thr-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O INOIAEUXVVNJKA-XGEHTFHBSA-N 0.000 description 2
- XRNXPIGJPQHCPC-RCWTZXSCSA-N Arg-Thr-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CCCNC(N)=N)[C@@H](C)O)C(O)=O XRNXPIGJPQHCPC-RCWTZXSCSA-N 0.000 description 2
- ZUVMUOOHJYNJPP-XIRDDKMYSA-N Arg-Trp-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZUVMUOOHJYNJPP-XIRDDKMYSA-N 0.000 description 2
- ULBHWNVWSCJLCO-NHCYSSNCSA-N Arg-Val-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCN=C(N)N ULBHWNVWSCJLCO-NHCYSSNCSA-N 0.000 description 2
- QLSRIZIDQXDQHK-RCWTZXSCSA-N Arg-Val-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QLSRIZIDQXDQHK-RCWTZXSCSA-N 0.000 description 2
- NVGWESORMHFISY-SRVKXCTJSA-N Asn-Asn-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O NVGWESORMHFISY-SRVKXCTJSA-N 0.000 description 2
- SRUUBQBAVNQZGJ-LAEOZQHASA-N Asn-Gln-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)N)N SRUUBQBAVNQZGJ-LAEOZQHASA-N 0.000 description 2
- WONGRTVAMHFGBE-WDSKDSINSA-N Asn-Gly-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N WONGRTVAMHFGBE-WDSKDSINSA-N 0.000 description 2
- QUAWOKPCAKCHQL-SRVKXCTJSA-N Asn-His-Lys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N QUAWOKPCAKCHQL-SRVKXCTJSA-N 0.000 description 2
- WQLJRNRLHWJIRW-KKUMJFAQSA-N Asn-His-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC(=O)N)N)O WQLJRNRLHWJIRW-KKUMJFAQSA-N 0.000 description 2
- HDHZCEDPLTVHFZ-GUBZILKMSA-N Asn-Leu-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O HDHZCEDPLTVHFZ-GUBZILKMSA-N 0.000 description 2
- ORJQQZIXTOYGGH-SRVKXCTJSA-N Asn-Lys-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O ORJQQZIXTOYGGH-SRVKXCTJSA-N 0.000 description 2
- YXVAESUIQFDBHN-SRVKXCTJSA-N Asn-Phe-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O YXVAESUIQFDBHN-SRVKXCTJSA-N 0.000 description 2
- GKKUBLFXKRDMFC-BQBZGAKWSA-N Asn-Pro-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O GKKUBLFXKRDMFC-BQBZGAKWSA-N 0.000 description 2
- JWQWPRCDYWNVNM-ACZMJKKPSA-N Asn-Ser-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N JWQWPRCDYWNVNM-ACZMJKKPSA-N 0.000 description 2
- HNXWVVHIGTZTBO-LKXGYXEUSA-N Asn-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O HNXWVVHIGTZTBO-LKXGYXEUSA-N 0.000 description 2
- YNQIDCRRTWGHJD-ZLUOBGJFSA-N Asp-Asn-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(O)=O YNQIDCRRTWGHJD-ZLUOBGJFSA-N 0.000 description 2
- KNMRXHIAVXHCLW-ZLUOBGJFSA-N Asp-Asn-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N)C(=O)O KNMRXHIAVXHCLW-ZLUOBGJFSA-N 0.000 description 2
- DPNWSMBUYCLEDG-CIUDSAMLSA-N Asp-Lys-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O DPNWSMBUYCLEDG-CIUDSAMLSA-N 0.000 description 2
- DONWIPDSZZJHHK-HJGDQZAQSA-N Asp-Lys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N)O DONWIPDSZZJHHK-HJGDQZAQSA-N 0.000 description 2
- GYWQGGUCMDCUJE-DLOVCJGASA-N Asp-Phe-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(O)=O GYWQGGUCMDCUJE-DLOVCJGASA-N 0.000 description 2
- USNJAPJZSGTTPX-XVSYOHENSA-N Asp-Phe-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O USNJAPJZSGTTPX-XVSYOHENSA-N 0.000 description 2
- KESWRFKUZRUTAH-FXQIFTODSA-N Asp-Pro-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O KESWRFKUZRUTAH-FXQIFTODSA-N 0.000 description 2
- VNXQRBXEQXLERQ-CIUDSAMLSA-N Asp-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)O)N VNXQRBXEQXLERQ-CIUDSAMLSA-N 0.000 description 2
- KNDCWFXCFKSEBM-AVGNSLFASA-N Asp-Tyr-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O KNDCWFXCFKSEBM-AVGNSLFASA-N 0.000 description 2
- ALMIMUZAWTUNIO-BZSNNMDCSA-N Asp-Tyr-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ALMIMUZAWTUNIO-BZSNNMDCSA-N 0.000 description 2
- QOJJMJKTMKNFEF-ZKWXMUAHSA-N Asp-Val-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC(O)=O QOJJMJKTMKNFEF-ZKWXMUAHSA-N 0.000 description 2
- 241000714230 Avian leukemia virus Species 0.000 description 2
- 241000193738 Bacillus anthracis Species 0.000 description 2
- 241000283724 Bison bonasus Species 0.000 description 2
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 2
- 108700013048 CCL2 Proteins 0.000 description 2
- BHPQYMZQTOCNFJ-UHFFFAOYSA-N Calcium cation Chemical compound [Ca+2] BHPQYMZQTOCNFJ-UHFFFAOYSA-N 0.000 description 2
- 241000282472 Canis lupus familiaris Species 0.000 description 2
- 102000000844 Cell Surface Receptors Human genes 0.000 description 2
- 108010001857 Cell Surface Receptors Proteins 0.000 description 2
- 241000282693 Cercopithecidae Species 0.000 description 2
- 201000009182 Chikungunya Diseases 0.000 description 2
- 241000193449 Clostridium tetani Species 0.000 description 2
- 101710094648 Coat protein Proteins 0.000 description 2
- 241000223935 Cryptosporidium Species 0.000 description 2
- TVYMKYUSZSVOAG-ZLUOBGJFSA-N Cys-Ala-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O TVYMKYUSZSVOAG-ZLUOBGJFSA-N 0.000 description 2
- NDUSUIGBMZCOIL-ZKWXMUAHSA-N Cys-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CS)N NDUSUIGBMZCOIL-ZKWXMUAHSA-N 0.000 description 2
- YMBAVNPKBWHDAW-CIUDSAMLSA-N Cys-Asp-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N YMBAVNPKBWHDAW-CIUDSAMLSA-N 0.000 description 2
- XRTISHJEPHMBJG-SRVKXCTJSA-N Cys-Asp-Tyr Chemical compound SC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 XRTISHJEPHMBJG-SRVKXCTJSA-N 0.000 description 2
- BMHBJCVEXUBGFI-BIIVOSGPSA-N Cys-Cys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CS)NC(=O)[C@H](CS)N)C(=O)O BMHBJCVEXUBGFI-BIIVOSGPSA-N 0.000 description 2
- SFRQEQGPRTVDPO-NRPADANISA-N Cys-Gln-Val Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O SFRQEQGPRTVDPO-NRPADANISA-N 0.000 description 2
- WVLZTXGTNGHPBO-SRVKXCTJSA-N Cys-Leu-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O WVLZTXGTNGHPBO-SRVKXCTJSA-N 0.000 description 2
- KSMSFCBQBQPFAD-GUBZILKMSA-N Cys-Pro-Pro Chemical compound SC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 KSMSFCBQBQPFAD-GUBZILKMSA-N 0.000 description 2
- NDNZRWUDUMTITL-FXQIFTODSA-N Cys-Ser-Val Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NDNZRWUDUMTITL-FXQIFTODSA-N 0.000 description 2
- CLEFUAZULXANBU-MELADBBJSA-N Cys-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CS)N)C(=O)O CLEFUAZULXANBU-MELADBBJSA-N 0.000 description 2
- MHYHLWUGWUBUHF-GUBZILKMSA-N Cys-Val-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CS)N MHYHLWUGWUBUHF-GUBZILKMSA-N 0.000 description 2
- 102000004127 Cytokines Human genes 0.000 description 2
- 108090000695 Cytokines Proteins 0.000 description 2
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 description 2
- 108010090461 DFG peptide Proteins 0.000 description 2
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 2
- 238000008157 ELISA kit Methods 0.000 description 2
- 208000030820 Ebola disease Diseases 0.000 description 2
- 101150039808 Egfr gene Proteins 0.000 description 2
- 241000701832 Enterobacteria phage T3 Species 0.000 description 2
- 101710121417 Envelope glycoprotein Proteins 0.000 description 2
- 241000710198 Foot-and-mouth disease virus Species 0.000 description 2
- 241000223218 Fusarium Species 0.000 description 2
- WUAYFMZULZDSLB-ACZMJKKPSA-N Gln-Ala-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O WUAYFMZULZDSLB-ACZMJKKPSA-N 0.000 description 2
- WLODHVXYKYHLJD-ACZMJKKPSA-N Gln-Asp-Ser Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N WLODHVXYKYHLJD-ACZMJKKPSA-N 0.000 description 2
- CXFUMJQFZVCETK-FXQIFTODSA-N Gln-Cys-Gln Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O CXFUMJQFZVCETK-FXQIFTODSA-N 0.000 description 2
- NVEASDQHBRZPSU-BQBZGAKWSA-N Gln-Gln-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O NVEASDQHBRZPSU-BQBZGAKWSA-N 0.000 description 2
- FGYPOQPQTUNESW-IUCAKERBSA-N Gln-Gly-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N FGYPOQPQTUNESW-IUCAKERBSA-N 0.000 description 2
- QQAPDATZKKTBIY-YUMQZZPRSA-N Gln-Gly-Met Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CCSC)C(O)=O QQAPDATZKKTBIY-YUMQZZPRSA-N 0.000 description 2
- ZXGLLNZQSBLQLT-SRVKXCTJSA-N Gln-Met-Lys Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N ZXGLLNZQSBLQLT-SRVKXCTJSA-N 0.000 description 2
- FQCILXROGNOZON-YUMQZZPRSA-N Gln-Pro-Gly Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O FQCILXROGNOZON-YUMQZZPRSA-N 0.000 description 2
- OSCLNNWLKKIQJM-WDSKDSINSA-N Gln-Ser-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O OSCLNNWLKKIQJM-WDSKDSINSA-N 0.000 description 2
- LPIKVBWNNVFHCQ-GUBZILKMSA-N Gln-Ser-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LPIKVBWNNVFHCQ-GUBZILKMSA-N 0.000 description 2
- YRHZWVKUFWCEPW-GLLZPBPUSA-N Gln-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O YRHZWVKUFWCEPW-GLLZPBPUSA-N 0.000 description 2
- XKPACHRGOWQHFH-IRIUXVKKSA-N Gln-Thr-Tyr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O XKPACHRGOWQHFH-IRIUXVKKSA-N 0.000 description 2
- FITIQFSXXBKFFM-NRPADANISA-N Gln-Val-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FITIQFSXXBKFFM-NRPADANISA-N 0.000 description 2
- UTKUTMJSWKKHEM-WDSKDSINSA-N Glu-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O UTKUTMJSWKKHEM-WDSKDSINSA-N 0.000 description 2
- HUFCEIHAFNVSNR-IHRRRGAJSA-N Glu-Gln-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HUFCEIHAFNVSNR-IHRRRGAJSA-N 0.000 description 2
- MUSGDMDGNGXULI-DCAQKATOSA-N Glu-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCC(O)=O MUSGDMDGNGXULI-DCAQKATOSA-N 0.000 description 2
- ZGKXAUIVGIBISK-SZMVWBNQSA-N Glu-His-Trp Chemical compound N[C@@H](CCC(O)=O)C(=O)N[C@@H](Cc1c[nH]cn1)C(=O)N[C@@H](Cc1c[nH]c2ccccc12)C(O)=O ZGKXAUIVGIBISK-SZMVWBNQSA-N 0.000 description 2
- MWMJCGBSIORNCD-AVGNSLFASA-N Glu-Leu-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O MWMJCGBSIORNCD-AVGNSLFASA-N 0.000 description 2
- YGLCLCMAYUYZSG-AVGNSLFASA-N Glu-Lys-His Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 YGLCLCMAYUYZSG-AVGNSLFASA-N 0.000 description 2
- AQNYKMCFCCZEEL-JYJNAYRXSA-N Glu-Lys-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 AQNYKMCFCCZEEL-JYJNAYRXSA-N 0.000 description 2
- NNQDRRUXFJYCCJ-NHCYSSNCSA-N Glu-Pro-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O NNQDRRUXFJYCCJ-NHCYSSNCSA-N 0.000 description 2
- DMYACXMQUABZIQ-NRPADANISA-N Glu-Ser-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O DMYACXMQUABZIQ-NRPADANISA-N 0.000 description 2
- BPCLDCNZBUYGOD-BPUTZDHNSA-N Glu-Trp-Glu Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O)=CNC2=C1 BPCLDCNZBUYGOD-BPUTZDHNSA-N 0.000 description 2
- QSDKBRMVXSWAQE-BFHQHQDPSA-N Gly-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN QSDKBRMVXSWAQE-BFHQHQDPSA-N 0.000 description 2
- IXKRSKPKSLXIHN-YUMQZZPRSA-N Gly-Cys-Leu Chemical compound [H]NCC(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O IXKRSKPKSLXIHN-YUMQZZPRSA-N 0.000 description 2
- CQZDZKRHFWJXDF-WDSKDSINSA-N Gly-Gln-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CCC(N)=O)NC(=O)CN CQZDZKRHFWJXDF-WDSKDSINSA-N 0.000 description 2
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 2
- BUEFQXUHTUZXHR-LURJTMIESA-N Gly-Gly-Pro zwitterion Chemical compound NCC(=O)NCC(=O)N1CCC[C@H]1C(O)=O BUEFQXUHTUZXHR-LURJTMIESA-N 0.000 description 2
- OLPPXYMMIARYAL-QMMMGPOBSA-N Gly-Gly-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)CNC(=O)CN OLPPXYMMIARYAL-QMMMGPOBSA-N 0.000 description 2
- NSTUFLGQJCOCDL-UWVGGRQHSA-N Gly-Leu-Arg Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N NSTUFLGQJCOCDL-UWVGGRQHSA-N 0.000 description 2
- CLNSYANKYVMZNM-UWVGGRQHSA-N Gly-Lys-Arg Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CCCN=C(N)N CLNSYANKYVMZNM-UWVGGRQHSA-N 0.000 description 2
- GMTXWRIDLGTVFC-IUCAKERBSA-N Gly-Lys-Glu Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O GMTXWRIDLGTVFC-IUCAKERBSA-N 0.000 description 2
- YOBGUCWZPXJHTN-BQBZGAKWSA-N Gly-Ser-Arg Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YOBGUCWZPXJHTN-BQBZGAKWSA-N 0.000 description 2
- IALQAMYQJBZNSK-WHFBIAKZSA-N Gly-Ser-Asn Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O IALQAMYQJBZNSK-WHFBIAKZSA-N 0.000 description 2
- CQMFNTVQVLQRLT-JHEQGTHGSA-N Gly-Thr-Gln Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O CQMFNTVQVLQRLT-JHEQGTHGSA-N 0.000 description 2
- YJDALMUYJIENAG-QWRGUYRKSA-N Gly-Tyr-Asn Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)CN)O YJDALMUYJIENAG-QWRGUYRKSA-N 0.000 description 2
- GWCJMBNBFYBQCV-XPUUQOCRSA-N Gly-Val-Ala Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O GWCJMBNBFYBQCV-XPUUQOCRSA-N 0.000 description 2
- 102100021181 Golgi phosphoprotein 3 Human genes 0.000 description 2
- HVLSXIKZNLPZJJ-TXZCQADKSA-N HA peptide Chemical compound C([C@@H](C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@H]1N(CCC1)C(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 HVLSXIKZNLPZJJ-TXZCQADKSA-N 0.000 description 2
- 108010054147 Hemoglobins Proteins 0.000 description 2
- 102000001554 Hemoglobins Human genes 0.000 description 2
- HVCRQRQPIIRNLY-IUCAKERBSA-N His-Gln-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)NCC(=O)O)N HVCRQRQPIIRNLY-IUCAKERBSA-N 0.000 description 2
- HIAHVKLTHNOENC-HGNGGELXSA-N His-Glu-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O HIAHVKLTHNOENC-HGNGGELXSA-N 0.000 description 2
- AKEDPWJFQULLPE-IUCAKERBSA-N His-Glu-Gly Chemical compound N[C@@H](Cc1cnc[nH]1)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O AKEDPWJFQULLPE-IUCAKERBSA-N 0.000 description 2
- KRBMQYPTDYSENE-BQBZGAKWSA-N His-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](N)CC1=CNC=N1 KRBMQYPTDYSENE-BQBZGAKWSA-N 0.000 description 2
- HZWWOGWOBQBETJ-CUJWVEQBSA-N His-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N)O HZWWOGWOBQBETJ-CUJWVEQBSA-N 0.000 description 2
- 101000858088 Homo sapiens C-X-C motif chemokine 10 Proteins 0.000 description 2
- 101000889276 Homo sapiens Cytotoxic T-lymphocyte protein 4 Proteins 0.000 description 2
- 108010000521 Human Growth Hormone Proteins 0.000 description 2
- 102000002265 Human Growth Hormone Human genes 0.000 description 2
- 239000000854 Human Growth Hormone Substances 0.000 description 2
- 241001135569 Human adenovirus 5 Species 0.000 description 2
- 241000713772 Human immunodeficiency virus 1 Species 0.000 description 2
- MKWSZEHGHSLNPF-NAKRPEOUSA-N Ile-Ala-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)O)N MKWSZEHGHSLNPF-NAKRPEOUSA-N 0.000 description 2
- FADXGVVLSPPEQY-GHCJXIJMSA-N Ile-Cys-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)N)C(=O)O)N FADXGVVLSPPEQY-GHCJXIJMSA-N 0.000 description 2
- DFJJAVZIHDFOGQ-MNXVOIDGSA-N Ile-Glu-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N DFJJAVZIHDFOGQ-MNXVOIDGSA-N 0.000 description 2
- FFJQAEYLAQMGDL-MGHWNKPDSA-N Ile-Lys-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 FFJQAEYLAQMGDL-MGHWNKPDSA-N 0.000 description 2
- IVXJIMGDOYRLQU-XUXIUFHCSA-N Ile-Pro-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O IVXJIMGDOYRLQU-XUXIUFHCSA-N 0.000 description 2
- JZNVOBUNTWNZPW-GHCJXIJMSA-N Ile-Ser-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)O)C(=O)O)N JZNVOBUNTWNZPW-GHCJXIJMSA-N 0.000 description 2
- FBGXMKUWQFPHFB-JBDRJPRFSA-N Ile-Ser-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N FBGXMKUWQFPHFB-JBDRJPRFSA-N 0.000 description 2
- ZLFNNVATRMCAKN-ZKWXMUAHSA-N Ile-Ser-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N ZLFNNVATRMCAKN-ZKWXMUAHSA-N 0.000 description 2
- UYODHPPSCXBNCS-XUXIUFHCSA-N Ile-Val-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(C)C UYODHPPSCXBNCS-XUXIUFHCSA-N 0.000 description 2
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 2
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 2
- 108020005350 Initiator Codon Proteins 0.000 description 2
- 102000014150 Interferons Human genes 0.000 description 2
- 108010050904 Interferons Proteins 0.000 description 2
- IBMVEYRWAWIOTN-UHFFFAOYSA-N L-Leucyl-L-Arginyl-L-Proline Natural products CC(C)CC(N)C(=O)NC(CCCN=C(N)N)C(=O)N1CCCC1C(O)=O IBMVEYRWAWIOTN-UHFFFAOYSA-N 0.000 description 2
- RCFDOSNHHZGBOY-UHFFFAOYSA-N L-isoleucyl-L-alanine Natural products CCC(C)C(N)C(=O)NC(C)C(O)=O RCFDOSNHHZGBOY-UHFFFAOYSA-N 0.000 description 2
- UCOCBWDBHCUPQP-DCAQKATOSA-N Leu-Arg-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O UCOCBWDBHCUPQP-DCAQKATOSA-N 0.000 description 2
- FEHQLKKBVJHSEC-SZMVWBNQSA-N Leu-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FEHQLKKBVJHSEC-SZMVWBNQSA-N 0.000 description 2
- HYMLKESRWLZDBR-WEDXCCLWSA-N Leu-Gly-Thr Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HYMLKESRWLZDBR-WEDXCCLWSA-N 0.000 description 2
- BTNXKBVLWJBTNR-SRVKXCTJSA-N Leu-His-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(O)=O BTNXKBVLWJBTNR-SRVKXCTJSA-N 0.000 description 2
- IAJFFZORSWOZPQ-SRVKXCTJSA-N Leu-Leu-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IAJFFZORSWOZPQ-SRVKXCTJSA-N 0.000 description 2
- LXKNSJLSGPNHSK-KKUMJFAQSA-N Leu-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N LXKNSJLSGPNHSK-KKUMJFAQSA-N 0.000 description 2
- HWMQRQIFVGEAPH-XIRDDKMYSA-N Leu-Ser-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 HWMQRQIFVGEAPH-XIRDDKMYSA-N 0.000 description 2
- QWWPYKKLXWOITQ-VOAKCMCISA-N Leu-Thr-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(C)C QWWPYKKLXWOITQ-VOAKCMCISA-N 0.000 description 2
- KLSUAWUZBMAZCL-RHYQMDGZSA-N Leu-Thr-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(O)=O KLSUAWUZBMAZCL-RHYQMDGZSA-N 0.000 description 2
- YQFZRHYZLARWDY-IHRRRGAJSA-N Leu-Val-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN YQFZRHYZLARWDY-IHRRRGAJSA-N 0.000 description 2
- WSXTWLJHTLRFLW-SRVKXCTJSA-N Lys-Ala-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O WSXTWLJHTLRFLW-SRVKXCTJSA-N 0.000 description 2
- KNKHAVVBVXKOGX-JXUBOQSCSA-N Lys-Ala-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KNKHAVVBVXKOGX-JXUBOQSCSA-N 0.000 description 2
- GAOJCVKPIGHTGO-UWVGGRQHSA-N Lys-Arg-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O GAOJCVKPIGHTGO-UWVGGRQHSA-N 0.000 description 2
- FUKDBQGFSJUXGX-RWMBFGLXSA-N Lys-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCCCN)N)C(=O)O FUKDBQGFSJUXGX-RWMBFGLXSA-N 0.000 description 2
- SWWCDAGDQHTKIE-RHYQMDGZSA-N Lys-Arg-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SWWCDAGDQHTKIE-RHYQMDGZSA-N 0.000 description 2
- NRQRKMYZONPCTM-CIUDSAMLSA-N Lys-Asp-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O NRQRKMYZONPCTM-CIUDSAMLSA-N 0.000 description 2
- FGMHXLULNHTPID-KKUMJFAQSA-N Lys-His-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCCN)C(O)=O)CC1=CN=CN1 FGMHXLULNHTPID-KKUMJFAQSA-N 0.000 description 2
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 2
- CTJUSALVKAWFFU-CIUDSAMLSA-N Lys-Ser-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N CTJUSALVKAWFFU-CIUDSAMLSA-N 0.000 description 2
- SBQDRNOLGSYHQA-YUMQZZPRSA-N Lys-Ser-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SBQDRNOLGSYHQA-YUMQZZPRSA-N 0.000 description 2
- IOQWIOPSKJOEKI-SRVKXCTJSA-N Lys-Ser-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O IOQWIOPSKJOEKI-SRVKXCTJSA-N 0.000 description 2
- UGCIQUYEJIEHKX-GVXVVHGQSA-N Lys-Val-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O UGCIQUYEJIEHKX-GVXVVHGQSA-N 0.000 description 2
- GILLQRYAWOMHED-DCAQKATOSA-N Lys-Val-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCCN GILLQRYAWOMHED-DCAQKATOSA-N 0.000 description 2
- 101710125418 Major capsid protein Proteins 0.000 description 2
- 101710085938 Matrix protein Proteins 0.000 description 2
- 241000712079 Measles morbillivirus Species 0.000 description 2
- XUMBMVFBXHLACL-UHFFFAOYSA-N Melanin Chemical compound O=C1C(=O)C(C2=CNC3=C(C(C(=O)C4=C32)=O)C)=C2C4=CNC2=C1C XUMBMVFBXHLACL-UHFFFAOYSA-N 0.000 description 2
- 101710127721 Membrane protein Proteins 0.000 description 2
- PWPBGAJJYJJVPI-PJODQICGSA-N Met-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)CCSC)C(O)=O)=CNC2=C1 PWPBGAJJYJJVPI-PJODQICGSA-N 0.000 description 2
- CAODKDAPYGUMLK-FXQIFTODSA-N Met-Asn-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O CAODKDAPYGUMLK-FXQIFTODSA-N 0.000 description 2
- RKIIYGUHIQJCBW-SRVKXCTJSA-N Met-His-Glu Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O RKIIYGUHIQJCBW-SRVKXCTJSA-N 0.000 description 2
- FWAHLGXNBLWIKB-NAKRPEOUSA-N Met-Ile-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCSC FWAHLGXNBLWIKB-NAKRPEOUSA-N 0.000 description 2
- KSIPKXNIQOWMIC-RCWTZXSCSA-N Met-Thr-Arg Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCNC(N)=N KSIPKXNIQOWMIC-RCWTZXSCSA-N 0.000 description 2
- QAVZUKIPOMBLMC-AVGNSLFASA-N Met-Val-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(C)C QAVZUKIPOMBLMC-AVGNSLFASA-N 0.000 description 2
- 102000003505 Myosin Human genes 0.000 description 2
- 108060008487 Myosin Proteins 0.000 description 2
- 101710144111 Non-structural protein 3 Proteins 0.000 description 2
- 102100034574 P protein Human genes 0.000 description 2
- 101710181008 P protein Proteins 0.000 description 2
- 241001494479 Pecora Species 0.000 description 2
- 108090000284 Pepsin A Proteins 0.000 description 2
- 102000057297 Pepsin A Human genes 0.000 description 2
- GYEPCBNTTRORKW-PCBIJLKTSA-N Phe-Ile-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O GYEPCBNTTRORKW-PCBIJLKTSA-N 0.000 description 2
- MSHZERMPZKCODG-ACRUOGEOSA-N Phe-Leu-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 MSHZERMPZKCODG-ACRUOGEOSA-N 0.000 description 2
- JDMKQHSHKJHAHR-UHFFFAOYSA-N Phe-Phe-Leu-Tyr Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)CC1=CC=CC=C1 JDMKQHSHKJHAHR-UHFFFAOYSA-N 0.000 description 2
- JLLJTMHNXQTMCK-UBHSHLNASA-N Phe-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 JLLJTMHNXQTMCK-UBHSHLNASA-N 0.000 description 2
- WWPAHTZOWURIMR-ULQDDVLXSA-N Phe-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 WWPAHTZOWURIMR-ULQDDVLXSA-N 0.000 description 2
- IIEOLPMQYRBZCN-SRVKXCTJSA-N Phe-Ser-Cys Chemical compound N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O IIEOLPMQYRBZCN-SRVKXCTJSA-N 0.000 description 2
- OOLOTUZJUBOMAX-GUBZILKMSA-N Pro-Ala-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O OOLOTUZJUBOMAX-GUBZILKMSA-N 0.000 description 2
- UAYHMOIGIQZLFR-NHCYSSNCSA-N Pro-Gln-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O UAYHMOIGIQZLFR-NHCYSSNCSA-N 0.000 description 2
- LGSANCBHSMDFDY-GARJFASQSA-N Pro-Glu-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)O)C(=O)N2CCC[C@@H]2C(=O)O LGSANCBHSMDFDY-GARJFASQSA-N 0.000 description 2
- ZTVCLZLGHZXLOT-ULQDDVLXSA-N Pro-Glu-Trp Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O ZTVCLZLGHZXLOT-ULQDDVLXSA-N 0.000 description 2
- OWQXAJQZLWHPBH-FXQIFTODSA-N Pro-Ser-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O OWQXAJQZLWHPBH-FXQIFTODSA-N 0.000 description 2
- 101710083689 Probable capsid protein Proteins 0.000 description 2
- 108010079005 RDV peptide Proteins 0.000 description 2
- WDXYVIIVDIDOSX-DCAQKATOSA-N Ser-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N WDXYVIIVDIDOSX-DCAQKATOSA-N 0.000 description 2
- OOKCGAYXSNJBGQ-ZLUOBGJFSA-N Ser-Asn-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O OOKCGAYXSNJBGQ-ZLUOBGJFSA-N 0.000 description 2
- VAUMZJHYZQXZBQ-WHFBIAKZSA-N Ser-Asn-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O VAUMZJHYZQXZBQ-WHFBIAKZSA-N 0.000 description 2
- QPFJSHSJFIYDJZ-GHCJXIJMSA-N Ser-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CO QPFJSHSJFIYDJZ-GHCJXIJMSA-N 0.000 description 2
- BPMRXBZYPGYPJN-WHFBIAKZSA-N Ser-Gly-Asn Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O BPMRXBZYPGYPJN-WHFBIAKZSA-N 0.000 description 2
- MUARUIBTKQJKFY-WHFBIAKZSA-N Ser-Gly-Asp Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MUARUIBTKQJKFY-WHFBIAKZSA-N 0.000 description 2
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 2
- FUMGHWDRRFCKEP-CIUDSAMLSA-N Ser-Leu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O FUMGHWDRRFCKEP-CIUDSAMLSA-N 0.000 description 2
- QYSFWUIXDFJUDW-DCAQKATOSA-N Ser-Leu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYSFWUIXDFJUDW-DCAQKATOSA-N 0.000 description 2
- GZSZPKSBVAOGIE-CIUDSAMLSA-N Ser-Lys-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O GZSZPKSBVAOGIE-CIUDSAMLSA-N 0.000 description 2
- BYCVMHKULKRVPV-GUBZILKMSA-N Ser-Lys-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O BYCVMHKULKRVPV-GUBZILKMSA-N 0.000 description 2
- HHJFMHQYEAAOBM-ZLUOBGJFSA-N Ser-Ser-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O HHJFMHQYEAAOBM-ZLUOBGJFSA-N 0.000 description 2
- OZPDGESCTGGNAD-CIUDSAMLSA-N Ser-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CO OZPDGESCTGGNAD-CIUDSAMLSA-N 0.000 description 2
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 2
- DYEGLQRVMBWQLD-IXOXFDKPSA-N Ser-Thr-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CO)N)O DYEGLQRVMBWQLD-IXOXFDKPSA-N 0.000 description 2
- BDMWLJLPPUCLNV-XGEHTFHBSA-N Ser-Thr-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O BDMWLJLPPUCLNV-XGEHTFHBSA-N 0.000 description 2
- RCOUFINCYASMDN-GUBZILKMSA-N Ser-Val-Met Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(O)=O RCOUFINCYASMDN-GUBZILKMSA-N 0.000 description 2
- JGUWRQWULDWNCM-FXQIFTODSA-N Ser-Val-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O JGUWRQWULDWNCM-FXQIFTODSA-N 0.000 description 2
- HSWXBJCBYSWBPT-GUBZILKMSA-N Ser-Val-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CO)C(C)C)C(O)=O HSWXBJCBYSWBPT-GUBZILKMSA-N 0.000 description 2
- 241000258242 Siphonaptera Species 0.000 description 2
- PXIPVTKHYLBLMZ-UHFFFAOYSA-N Sodium azide Chemical compound [Na+].[N-]=[N+]=[N-] PXIPVTKHYLBLMZ-UHFFFAOYSA-N 0.000 description 2
- FKNQFGJONOIPTF-UHFFFAOYSA-N Sodium cation Chemical compound [Na+] FKNQFGJONOIPTF-UHFFFAOYSA-N 0.000 description 2
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 2
- 241000191967 Staphylococcus aureus Species 0.000 description 2
- 241001115374 Tai Forest ebolavirus Species 0.000 description 2
- 206010043376 Tetanus Diseases 0.000 description 2
- NJEMRSFGDNECGF-GCJQMDKQSA-N Thr-Ala-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O NJEMRSFGDNECGF-GCJQMDKQSA-N 0.000 description 2
- BSNZTJXVDOINSR-JXUBOQSCSA-N Thr-Ala-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O BSNZTJXVDOINSR-JXUBOQSCSA-N 0.000 description 2
- XSLXHSYIVPGEER-KZVJFYERSA-N Thr-Ala-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O XSLXHSYIVPGEER-KZVJFYERSA-N 0.000 description 2
- JVTHIXKSVYEWNI-JRQIVUDYSA-N Thr-Asn-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JVTHIXKSVYEWNI-JRQIVUDYSA-N 0.000 description 2
- KRPKYGOFYUNIGM-XVSYOHENSA-N Thr-Asp-Phe Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N)O KRPKYGOFYUNIGM-XVSYOHENSA-N 0.000 description 2
- DIPIPFHFLPTCLK-LOKLDPHHSA-N Thr-Gln-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N)O DIPIPFHFLPTCLK-LOKLDPHHSA-N 0.000 description 2
- VOHWDZNIESHTFW-XKBZYTNZSA-N Thr-Glu-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N)O VOHWDZNIESHTFW-XKBZYTNZSA-N 0.000 description 2
- GKWNLDNXMMLRMC-GLLZPBPUSA-N Thr-Glu-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O GKWNLDNXMMLRMC-GLLZPBPUSA-N 0.000 description 2
- SXAGUVRFGJSFKC-ZEILLAHLSA-N Thr-His-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SXAGUVRFGJSFKC-ZEILLAHLSA-N 0.000 description 2
- PRNGXSILMXSWQQ-OEAJRASXSA-N Thr-Leu-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PRNGXSILMXSWQQ-OEAJRASXSA-N 0.000 description 2
- BDGBHYCAZJPLHX-HJGDQZAQSA-N Thr-Lys-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O BDGBHYCAZJPLHX-HJGDQZAQSA-N 0.000 description 2
- JLNMFGCJODTXDH-WEDXCCLWSA-N Thr-Lys-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O JLNMFGCJODTXDH-WEDXCCLWSA-N 0.000 description 2
- SPVHQURZJCUDQC-VOAKCMCISA-N Thr-Lys-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O SPVHQURZJCUDQC-VOAKCMCISA-N 0.000 description 2
- DEGCBBCMYWNJNA-RHYQMDGZSA-N Thr-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O DEGCBBCMYWNJNA-RHYQMDGZSA-N 0.000 description 2
- ZESGVALRVJIVLZ-VFCFLDTKSA-N Thr-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O ZESGVALRVJIVLZ-VFCFLDTKSA-N 0.000 description 2
- COYHRQWNJDJCNA-NUJDXYNKSA-N Thr-Thr-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O COYHRQWNJDJCNA-NUJDXYNKSA-N 0.000 description 2
- LECUEEHKUFYOOV-ZJDVBMNYSA-N Thr-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)[C@@H](C)O LECUEEHKUFYOOV-ZJDVBMNYSA-N 0.000 description 2
- RPECVQBNONKZAT-WZLNRYEVSA-N Thr-Tyr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H]([C@@H](C)O)N RPECVQBNONKZAT-WZLNRYEVSA-N 0.000 description 2
- XVHAUVJXBFGUPC-RPTUDFQQSA-N Thr-Tyr-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O XVHAUVJXBFGUPC-RPTUDFQQSA-N 0.000 description 2
- CYCGARJWIQWPQM-YJRXYDGGSA-N Thr-Tyr-Ser Chemical compound C[C@@H](O)[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CO)C([O-])=O)CC1=CC=C(O)C=C1 CYCGARJWIQWPQM-YJRXYDGGSA-N 0.000 description 2
- BKVICMPZWRNWOC-RHYQMDGZSA-N Thr-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)[C@@H](C)O BKVICMPZWRNWOC-RHYQMDGZSA-N 0.000 description 2
- 201000005485 Toxoplasmosis Diseases 0.000 description 2
- 108700009124 Transcription Initiation Site Proteins 0.000 description 2
- ZCPCXVJOMUPIDD-IHPCNDPISA-N Trp-Asp-Phe Chemical compound C([C@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)N)C(O)=O)C1=CC=CC=C1 ZCPCXVJOMUPIDD-IHPCNDPISA-N 0.000 description 2
- UDCHKDYNMRJYMI-QEJZJMRPSA-N Trp-Glu-Ser Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O UDCHKDYNMRJYMI-QEJZJMRPSA-N 0.000 description 2
- XGFGVFMXDXALEV-XIRDDKMYSA-N Trp-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N XGFGVFMXDXALEV-XIRDDKMYSA-N 0.000 description 2
- NLWCSMOXNKBRLC-WDSOQIARSA-N Trp-Lys-Val Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O NLWCSMOXNKBRLC-WDSOQIARSA-N 0.000 description 2
- 108090000631 Trypsin Proteins 0.000 description 2
- 102000004142 Trypsin Human genes 0.000 description 2
- AKFLVKKWVZMFOT-IHRRRGAJSA-N Tyr-Arg-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(O)=O AKFLVKKWVZMFOT-IHRRRGAJSA-N 0.000 description 2
- QYSBJAUCUKHSLU-JYJNAYRXSA-N Tyr-Arg-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O QYSBJAUCUKHSLU-JYJNAYRXSA-N 0.000 description 2
- WPVGRKLNHJJCEN-BZSNNMDCSA-N Tyr-Asp-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 WPVGRKLNHJJCEN-BZSNNMDCSA-N 0.000 description 2
- QOIKZODVIPOPDD-AVGNSLFASA-N Tyr-Cys-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O QOIKZODVIPOPDD-AVGNSLFASA-N 0.000 description 2
- OSXNCKRGMSHWSQ-ACRUOGEOSA-N Tyr-His-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OSXNCKRGMSHWSQ-ACRUOGEOSA-N 0.000 description 2
- NKUGCYDFQKFVOJ-JYJNAYRXSA-N Tyr-Leu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NKUGCYDFQKFVOJ-JYJNAYRXSA-N 0.000 description 2
- NSGZILIDHCIZAM-KKUMJFAQSA-N Tyr-Leu-Ser Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N NSGZILIDHCIZAM-KKUMJFAQSA-N 0.000 description 2
- GZUIDWDVMWZSMI-KKUMJFAQSA-N Tyr-Lys-Cys Chemical compound NCCCC[C@@H](C(=O)N[C@@H](CS)C(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 GZUIDWDVMWZSMI-KKUMJFAQSA-N 0.000 description 2
- SINRIKQYQJRGDQ-MEYUZBJRSA-N Tyr-Lys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 SINRIKQYQJRGDQ-MEYUZBJRSA-N 0.000 description 2
- WURLIFOWSMBUAR-SLFFLAALSA-N Tyr-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CC3=CC=C(C=C3)O)N)C(=O)O WURLIFOWSMBUAR-SLFFLAALSA-N 0.000 description 2
- AUZADXNWQMBZOO-JYJNAYRXSA-N Tyr-Pro-Arg Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)C1=CC=C(O)C=C1 AUZADXNWQMBZOO-JYJNAYRXSA-N 0.000 description 2
- NHOVZGFNTGMYMI-KKUMJFAQSA-N Tyr-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NHOVZGFNTGMYMI-KKUMJFAQSA-N 0.000 description 2
- PWKMJDQXKCENMF-MEYUZBJRSA-N Tyr-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O PWKMJDQXKCENMF-MEYUZBJRSA-N 0.000 description 2
- GZWPQZDVTBZVEP-BZSNNMDCSA-N Tyr-Tyr-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O GZWPQZDVTBZVEP-BZSNNMDCSA-N 0.000 description 2
- GNWUWQAVVJQREM-NHCYSSNCSA-N Val-Asn-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N GNWUWQAVVJQREM-NHCYSSNCSA-N 0.000 description 2
- IQQYYFPCWKWUHW-YDHLFZDLSA-N Val-Asn-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N IQQYYFPCWKWUHW-YDHLFZDLSA-N 0.000 description 2
- CGGVNFJRZJUVAE-BYULHYEWSA-N Val-Asp-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CGGVNFJRZJUVAE-BYULHYEWSA-N 0.000 description 2
- VFOHXOLPLACADK-GVXVVHGQSA-N Val-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N VFOHXOLPLACADK-GVXVVHGQSA-N 0.000 description 2
- WDIGUPHXPBMODF-UMNHJUIQSA-N Val-Glu-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N WDIGUPHXPBMODF-UMNHJUIQSA-N 0.000 description 2
- NXRAUQGGHPCJIB-RCOVLWMOSA-N Val-Gly-Asn Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O NXRAUQGGHPCJIB-RCOVLWMOSA-N 0.000 description 2
- OACSGBOREVRSME-NHCYSSNCSA-N Val-His-Asn Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1cnc[nH]1)C(=O)N[C@@H](CC(N)=O)C(O)=O OACSGBOREVRSME-NHCYSSNCSA-N 0.000 description 2
- KTEZUXISLQTDDQ-NHCYSSNCSA-N Val-Lys-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)O)C(=O)O)N KTEZUXISLQTDDQ-NHCYSSNCSA-N 0.000 description 2
- CKTMJBPRVQWPHU-JSGCOSHPSA-N Val-Phe-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)O)N CKTMJBPRVQWPHU-JSGCOSHPSA-N 0.000 description 2
- JQTYTBPCSOAZHI-FXQIFTODSA-N Val-Ser-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N JQTYTBPCSOAZHI-FXQIFTODSA-N 0.000 description 2
- NZYNRRGJJVSSTJ-GUBZILKMSA-N Val-Ser-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NZYNRRGJJVSSTJ-GUBZILKMSA-N 0.000 description 2
- UVHFONIHVHLDDQ-IFFSRLJSSA-N Val-Thr-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N)O UVHFONIHVHLDDQ-IFFSRLJSSA-N 0.000 description 2
- TVGWMCTYUFBXAP-QTKMDUPCSA-N Val-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](C(C)C)N)O TVGWMCTYUFBXAP-QTKMDUPCSA-N 0.000 description 2
- QHSSPPHOHJSTML-HOCLYGCPSA-N Val-Trp-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)NCC(=O)O)N QHSSPPHOHJSTML-HOCLYGCPSA-N 0.000 description 2
- PGBMPFKFKXYROZ-UFYCRDLUSA-N Val-Tyr-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O)N PGBMPFKFKXYROZ-UFYCRDLUSA-N 0.000 description 2
- IECQJCJNPJVUSB-IHRRRGAJSA-N Val-Tyr-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](CO)C(O)=O IECQJCJNPJVUSB-IHRRRGAJSA-N 0.000 description 2
- OWFGFHQMSBTKLX-UFYCRDLUSA-N Val-Tyr-Tyr Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O)N OWFGFHQMSBTKLX-UFYCRDLUSA-N 0.000 description 2
- ZHWZDZFWBXWPDW-GUBZILKMSA-N Val-Val-Cys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(O)=O ZHWZDZFWBXWPDW-GUBZILKMSA-N 0.000 description 2
- 108010067390 Viral Proteins Proteins 0.000 description 2
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 2
- 239000000654 additive Substances 0.000 description 2
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 2
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 2
- 230000036436 anti-hiv Effects 0.000 description 2
- 230000000890 antigenic effect Effects 0.000 description 2
- 108010013835 arginine glutamate Proteins 0.000 description 2
- 108010068380 arginylarginine Proteins 0.000 description 2
- 108010060035 arginylproline Proteins 0.000 description 2
- 210000004436 artificial bacterial chromosome Anatomy 0.000 description 2
- 210000001106 artificial yeast chromosome Anatomy 0.000 description 2
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 2
- 108010038633 aspartylglutamate Proteins 0.000 description 2
- 108010047857 aspartylglycine Proteins 0.000 description 2
- 230000001363 autoimmune Effects 0.000 description 2
- 230000009286 beneficial effect Effects 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- 230000003115 biocidal effect Effects 0.000 description 2
- 230000008827 biological function Effects 0.000 description 2
- 230000015572 biosynthetic process Effects 0.000 description 2
- 230000037396 body weight Effects 0.000 description 2
- 108010006025 bovine growth hormone Proteins 0.000 description 2
- 239000000872 buffer Substances 0.000 description 2
- 229910001424 calcium ion Inorganic materials 0.000 description 2
- 229940095731 candida albicans Drugs 0.000 description 2
- 230000032823 cell division Effects 0.000 description 2
- 210000000170 cell membrane Anatomy 0.000 description 2
- 238000012512 characterization method Methods 0.000 description 2
- ZPUCINDJVBIVPJ-LJISPDSOSA-N cocaine Chemical compound O([C@H]1C[C@@H]2CC[C@@H](N2C)[C@H]1C(=O)OC)C(=O)C1=CC=CC=C1 ZPUCINDJVBIVPJ-LJISPDSOSA-N 0.000 description 2
- 108010063333 cocaine receptor Proteins 0.000 description 2
- 239000002299 complementary DNA Substances 0.000 description 2
- 150000001875 compounds Chemical class 0.000 description 2
- 230000000875 corresponding effect Effects 0.000 description 2
- 229960003624 creatine Drugs 0.000 description 2
- 239000006046 creatine Substances 0.000 description 2
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 2
- 230000001419 dependent effect Effects 0.000 description 2
- 230000004069 differentiation Effects 0.000 description 2
- 230000006806 disease prevention Effects 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 230000002708 enhancing effect Effects 0.000 description 2
- 238000001976 enzyme digestion Methods 0.000 description 2
- 239000012091 fetal bovine serum Substances 0.000 description 2
- 238000000684 flow cytometry Methods 0.000 description 2
- 230000002538 fungal effect Effects 0.000 description 2
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 2
- 108010010096 glycyl-glycyl-tyrosine Proteins 0.000 description 2
- 108010077515 glycylproline Proteins 0.000 description 2
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 2
- 208000002672 hepatitis B Diseases 0.000 description 2
- 108010050343 histidyl-alanyl-glutamine Proteins 0.000 description 2
- 230000008348 humoral response Effects 0.000 description 2
- 229920002674 hyaluronan Polymers 0.000 description 2
- 229960003160 hyaluronic acid Drugs 0.000 description 2
- 210000000987 immune system Anatomy 0.000 description 2
- 230000036039 immunity Effects 0.000 description 2
- 230000003308 immunostimulating effect Effects 0.000 description 2
- 238000000338 in vitro Methods 0.000 description 2
- 208000037797 influenza A Diseases 0.000 description 2
- 208000037798 influenza B Diseases 0.000 description 2
- 239000004615 ingredient Substances 0.000 description 2
- 230000000977 initiatory effect Effects 0.000 description 2
- 238000011081 inoculation Methods 0.000 description 2
- 229940079322 interferon Drugs 0.000 description 2
- DRAVOWXCEBXPTN-UHFFFAOYSA-N isoguanine Chemical compound NC1=NC(=O)NC2=C1NC=N2 DRAVOWXCEBXPTN-UHFFFAOYSA-N 0.000 description 2
- 108010027338 isoleucylcysteine Proteins 0.000 description 2
- 108010091871 leucylmethionine Proteins 0.000 description 2
- 108010057821 leucylproline Proteins 0.000 description 2
- 239000003446 ligand Substances 0.000 description 2
- 238000004020 luminiscence type Methods 0.000 description 2
- 108010054155 lysyllysine Proteins 0.000 description 2
- 239000003550 marker Substances 0.000 description 2
- 108020004999 messenger RNA Proteins 0.000 description 2
- 210000001616 monocyte Anatomy 0.000 description 2
- 229940035032 monophosphoryl lipid a Drugs 0.000 description 2
- 230000035772 mutation Effects 0.000 description 2
- 230000002018 overexpression Effects 0.000 description 2
- 239000002245 particle Substances 0.000 description 2
- 102000013415 peroxidase activity proteins Human genes 0.000 description 2
- 108040007629 peroxidase activity proteins Proteins 0.000 description 2
- 108010073101 phenylalanylleucine Proteins 0.000 description 2
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 2
- 102000040430 polynucleotide Human genes 0.000 description 2
- 108091033319 polynucleotide Proteins 0.000 description 2
- 239000002157 polynucleotide Substances 0.000 description 2
- 230000003389 potentiating effect Effects 0.000 description 2
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 2
- 108010079317 prolyl-tyrosine Proteins 0.000 description 2
- 238000000746 purification Methods 0.000 description 2
- 102000005962 receptors Human genes 0.000 description 2
- 108020003175 receptors Proteins 0.000 description 2
- 230000009467 reduction Effects 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 230000000717 retained effect Effects 0.000 description 2
- 108010048818 seryl-histidine Proteins 0.000 description 2
- 108010071207 serylmethionine Proteins 0.000 description 2
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 2
- 229910001415 sodium ion Inorganic materials 0.000 description 2
- 239000000243 solution Substances 0.000 description 2
- 230000009870 specific binding Effects 0.000 description 2
- 230000004936 stimulating effect Effects 0.000 description 2
- 239000000126 substance Substances 0.000 description 2
- 239000004094 surface-active agent Substances 0.000 description 2
- 229940113082 thymine Drugs 0.000 description 2
- 238000001890 transfection Methods 0.000 description 2
- 239000013638 trimer Substances 0.000 description 2
- 239000012588 trypsin Substances 0.000 description 2
- 229960001322 trypsin Drugs 0.000 description 2
- 210000004881 tumor cell Anatomy 0.000 description 2
- 108010003137 tyrosyltyrosine Proteins 0.000 description 2
- 241001515965 unidentified phage Species 0.000 description 2
- 229940035893 uracil Drugs 0.000 description 2
- 108010009962 valyltyrosine Proteins 0.000 description 2
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 2
- 230000004580 weight loss Effects 0.000 description 2
- GJLXVWOMRRWCIB-MERZOTPQSA-N (2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-[[(2S)-2-acetamido-5-(diaminomethylideneamino)pentanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-3-(4-hydroxyphenyl)propanoyl]amino]-5-(diaminomethylideneamino)pentanoyl]amino]-3-(1H-indol-3-yl)propanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanoyl]amino]-6-aminohexanamide Chemical compound C([C@H](NC(=O)[C@H](CCCN=C(N)N)NC(=O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(N)=O)C1=CC=C(O)C=C1 GJLXVWOMRRWCIB-MERZOTPQSA-N 0.000 description 1
- MZOFCQQQCNRIBI-VMXHOPILSA-N (3s)-4-[[(2s)-1-[[(2s)-1-[[(1s)-1-carboxy-2-hydroxyethyl]amino]-4-methyl-1-oxopentan-2-yl]amino]-5-(diaminomethylideneamino)-1-oxopentan-2-yl]amino]-3-[[2-[[(2s)-2,6-diaminohexanoyl]amino]acetyl]amino]-4-oxobutanoic acid Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN MZOFCQQQCNRIBI-VMXHOPILSA-N 0.000 description 1
- IIZPXYDJLKNOIY-JXPKJXOSSA-N 1-palmitoyl-2-arachidonoyl-sn-glycero-3-phosphocholine Chemical compound CCCCCCCCCCCCCCCC(=O)OC[C@H](COP([O-])(=O)OCC[N+](C)(C)C)OC(=O)CCC\C=C/C\C=C/C\C=C/C\C=C/CCCCC IIZPXYDJLKNOIY-JXPKJXOSSA-N 0.000 description 1
- NHBKXEKEPDILRR-UHFFFAOYSA-N 2,3-bis(butanoylsulfanyl)propyl butanoate Chemical compound CCCC(=O)OCC(SC(=O)CCC)CSC(=O)CCC NHBKXEKEPDILRR-UHFFFAOYSA-N 0.000 description 1
- MJZJYWCQPMNPRM-UHFFFAOYSA-N 6,6-dimethyl-1-[3-(2,4,5-trichlorophenoxy)propoxy]-1,6-dihydro-1,3,5-triazine-2,4-diamine Chemical compound CC1(C)N=C(N)N=C(N)N1OCCCOC1=CC(Cl)=C(Cl)C=C1Cl MJZJYWCQPMNPRM-UHFFFAOYSA-N 0.000 description 1
- 241000580482 Acidobacteria Species 0.000 description 1
- 241001156739 Actinobacteria <phylum> Species 0.000 description 1
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 1
- 229930024421 Adenine Natural products 0.000 description 1
- 241000701242 Adenoviridae Species 0.000 description 1
- 241000256111 Aedes <genus> Species 0.000 description 1
- 208000000230 African Trypanosomiasis Diseases 0.000 description 1
- YYSWCHMLFJLLBJ-ZLUOBGJFSA-N Ala-Ala-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O YYSWCHMLFJLLBJ-ZLUOBGJFSA-N 0.000 description 1
- XQGIRPGAVLFKBJ-CIUDSAMLSA-N Ala-Asn-Lys Chemical compound N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)O XQGIRPGAVLFKBJ-CIUDSAMLSA-N 0.000 description 1
- BUDNAJYVCUHLSV-ZLUOBGJFSA-N Ala-Asp-Ser Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O BUDNAJYVCUHLSV-ZLUOBGJFSA-N 0.000 description 1
- WCBVQNZTOKJWJS-ACZMJKKPSA-N Ala-Cys-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O WCBVQNZTOKJWJS-ACZMJKKPSA-N 0.000 description 1
- ROLXPVQSRCPVGK-XDTLVQLUSA-N Ala-Glu-Tyr Chemical compound N[C@@H](C)C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O ROLXPVQSRCPVGK-XDTLVQLUSA-N 0.000 description 1
- SUHLZMHFRALVSY-YUMQZZPRSA-N Ala-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)NCC(O)=O SUHLZMHFRALVSY-YUMQZZPRSA-N 0.000 description 1
- MAEQBGQTDWDSJQ-LSJOCFKGSA-N Ala-Met-His Chemical compound C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N MAEQBGQTDWDSJQ-LSJOCFKGSA-N 0.000 description 1
- GFEDXKNBZMPEDM-KZVJFYERSA-N Ala-Met-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GFEDXKNBZMPEDM-KZVJFYERSA-N 0.000 description 1
- 108010011667 Ala-Phe-Ala Proteins 0.000 description 1
- CJQAEJMHBAOQHA-DLOVCJGASA-N Ala-Phe-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CJQAEJMHBAOQHA-DLOVCJGASA-N 0.000 description 1
- ZBLQIYPCUWZSRZ-QEJZJMRPSA-N Ala-Phe-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CC1=CC=CC=C1 ZBLQIYPCUWZSRZ-QEJZJMRPSA-N 0.000 description 1
- MAZZQZWCCYJQGZ-GUBZILKMSA-N Ala-Pro-Arg Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MAZZQZWCCYJQGZ-GUBZILKMSA-N 0.000 description 1
- RTZCUEHYUQZIDE-WHFBIAKZSA-N Ala-Ser-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RTZCUEHYUQZIDE-WHFBIAKZSA-N 0.000 description 1
- HOVPGJUNRLMIOZ-CIUDSAMLSA-N Ala-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](C)N HOVPGJUNRLMIOZ-CIUDSAMLSA-N 0.000 description 1
- IOFVWPYSRSCWHI-JXUBOQSCSA-N Ala-Thr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C)N IOFVWPYSRSCWHI-JXUBOQSCSA-N 0.000 description 1
- IETUUAHKCHOQHP-KZVJFYERSA-N Ala-Thr-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@H](C)N)[C@@H](C)O)C(O)=O IETUUAHKCHOQHP-KZVJFYERSA-N 0.000 description 1
- QDGMZAOSMNGBLP-MRFFXTKBSA-N Ala-Trp-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)N QDGMZAOSMNGBLP-MRFFXTKBSA-N 0.000 description 1
- PGNNQOJOEGFAOR-KWQFWETISA-N Ala-Tyr-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=C(O)C=C1 PGNNQOJOEGFAOR-KWQFWETISA-N 0.000 description 1
- XKXAZPSREVUCRT-BPNCWPANSA-N Ala-Tyr-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](C)N)CC1=CC=C(O)C=C1 XKXAZPSREVUCRT-BPNCWPANSA-N 0.000 description 1
- 108010088751 Albumins Proteins 0.000 description 1
- 102000009027 Albumins Human genes 0.000 description 1
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 1
- 241000710929 Alphavirus Species 0.000 description 1
- 208000024827 Alzheimer disease Diseases 0.000 description 1
- 208000004881 Amebiasis Diseases 0.000 description 1
- 206010001935 American trypanosomiasis Diseases 0.000 description 1
- 206010001980 Amoebiasis Diseases 0.000 description 1
- 244000303258 Annona diversifolia Species 0.000 description 1
- 235000002198 Annona diversifolia Nutrition 0.000 description 1
- 206010059313 Anogenital warts Diseases 0.000 description 1
- 241000272814 Anser sp. Species 0.000 description 1
- 101100067974 Arabidopsis thaliana POP2 gene Proteins 0.000 description 1
- 241000712892 Arenaviridae Species 0.000 description 1
- 241000712891 Arenavirus Species 0.000 description 1
- UISQLSIBJKEJSS-GUBZILKMSA-N Arg-Arg-Ser Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CO)C(O)=O UISQLSIBJKEJSS-GUBZILKMSA-N 0.000 description 1
- OZNSCVPYWZRQPY-CIUDSAMLSA-N Arg-Asp-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O OZNSCVPYWZRQPY-CIUDSAMLSA-N 0.000 description 1
- VXXHDZKEQNGXNU-QXEWZRGKSA-N Arg-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N VXXHDZKEQNGXNU-QXEWZRGKSA-N 0.000 description 1
- VNFWDYWTSHFRRG-SRVKXCTJSA-N Arg-Gln-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O VNFWDYWTSHFRRG-SRVKXCTJSA-N 0.000 description 1
- HPKSHFSEXICTLI-CIUDSAMLSA-N Arg-Glu-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O HPKSHFSEXICTLI-CIUDSAMLSA-N 0.000 description 1
- PNQWAUXQDBIJDY-GUBZILKMSA-N Arg-Glu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNQWAUXQDBIJDY-GUBZILKMSA-N 0.000 description 1
- CYXCAHZVPFREJD-LURJTMIESA-N Arg-Gly-Gly Chemical compound NC(=N)NCCC[C@H](N)C(=O)NCC(=O)NCC(O)=O CYXCAHZVPFREJD-LURJTMIESA-N 0.000 description 1
- PHHRSPBBQUFULD-UWVGGRQHSA-N Arg-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCCN=C(N)N)N PHHRSPBBQUFULD-UWVGGRQHSA-N 0.000 description 1
- WVNFNPGXYADPPO-BQBZGAKWSA-N Arg-Gly-Ser Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O WVNFNPGXYADPPO-BQBZGAKWSA-N 0.000 description 1
- KRQSPVKUISQQFS-FJXKBIBVSA-N Arg-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCN=C(N)N KRQSPVKUISQQFS-FJXKBIBVSA-N 0.000 description 1
- NKNILFJYKKHBKE-WPRPVWTQSA-N Arg-Gly-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O NKNILFJYKKHBKE-WPRPVWTQSA-N 0.000 description 1
- GXXWTNKNFFKTJB-NAKRPEOUSA-N Arg-Ile-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O GXXWTNKNFFKTJB-NAKRPEOUSA-N 0.000 description 1
- KZXPVYVSHUJCEO-ULQDDVLXSA-N Arg-Phe-Lys Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCCN)C(O)=O)CC1=CC=CC=C1 KZXPVYVSHUJCEO-ULQDDVLXSA-N 0.000 description 1
- KMFPQTITXUKJOV-DCAQKATOSA-N Arg-Ser-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O KMFPQTITXUKJOV-DCAQKATOSA-N 0.000 description 1
- FRBAHXABMQXSJQ-FXQIFTODSA-N Arg-Ser-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O FRBAHXABMQXSJQ-FXQIFTODSA-N 0.000 description 1
- XEOXPCNONWHHSW-AVGNSLFASA-N Arg-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N XEOXPCNONWHHSW-AVGNSLFASA-N 0.000 description 1
- 206010003399 Arthropod bite Diseases 0.000 description 1
- 241000244185 Ascaris lumbricoides Species 0.000 description 1
- JJGRJMKUOYXZRA-LPEHRKFASA-N Asn-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)N)N)C(=O)O JJGRJMKUOYXZRA-LPEHRKFASA-N 0.000 description 1
- VWJFQGXPYOPXJH-ZLUOBGJFSA-N Asn-Cys-Asp Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)C(=O)N VWJFQGXPYOPXJH-ZLUOBGJFSA-N 0.000 description 1
- RAQMSGVCGSJKCL-FOHZUACHSA-N Asn-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC(N)=O RAQMSGVCGSJKCL-FOHZUACHSA-N 0.000 description 1
- RCFGLXMZDYNRSC-CIUDSAMLSA-N Asn-Lys-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O RCFGLXMZDYNRSC-CIUDSAMLSA-N 0.000 description 1
- RBOBTTLFPRSXKZ-BZSNNMDCSA-N Asn-Phe-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RBOBTTLFPRSXKZ-BZSNNMDCSA-N 0.000 description 1
- UGXYFDQFLVCDFC-CIUDSAMLSA-N Asn-Ser-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O UGXYFDQFLVCDFC-CIUDSAMLSA-N 0.000 description 1
- WLVLIYYBPPONRJ-GCJQMDKQSA-N Asn-Thr-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O WLVLIYYBPPONRJ-GCJQMDKQSA-N 0.000 description 1
- UPAGTDJAORYMEC-VHWLVUOQSA-N Asn-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC(=O)N)N UPAGTDJAORYMEC-VHWLVUOQSA-N 0.000 description 1
- LGCVSPFCFXWUEY-IHPCNDPISA-N Asn-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N LGCVSPFCFXWUEY-IHPCNDPISA-N 0.000 description 1
- JPPLRQVZMZFOSX-UWJYBYFXSA-N Asn-Tyr-Ala Chemical compound NC(=O)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=C(O)C=C1 JPPLRQVZMZFOSX-UWJYBYFXSA-N 0.000 description 1
- QNNBHTFDFFFHGC-KKUMJFAQSA-N Asn-Tyr-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N)O QNNBHTFDFFFHGC-KKUMJFAQSA-N 0.000 description 1
- WSOKZUVWBXVJHX-CIUDSAMLSA-N Asp-Arg-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O WSOKZUVWBXVJHX-CIUDSAMLSA-N 0.000 description 1
- DZQKLNLLWFQONU-LKXGYXEUSA-N Asp-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(=O)O)N)O DZQKLNLLWFQONU-LKXGYXEUSA-N 0.000 description 1
- VFUXXFVCYZPOQG-WDSKDSINSA-N Asp-Glu-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O VFUXXFVCYZPOQG-WDSKDSINSA-N 0.000 description 1
- PDECQIHABNQRHN-GUBZILKMSA-N Asp-Glu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC(O)=O PDECQIHABNQRHN-GUBZILKMSA-N 0.000 description 1
- LBOVBQONZJRWPV-YUMQZZPRSA-N Asp-Lys-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O LBOVBQONZJRWPV-YUMQZZPRSA-N 0.000 description 1
- GWIJZUVQVDJHDI-AVGNSLFASA-N Asp-Phe-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O GWIJZUVQVDJHDI-AVGNSLFASA-N 0.000 description 1
- RPUYTJJZXQBWDT-SRVKXCTJSA-N Asp-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC(=O)O)N RPUYTJJZXQBWDT-SRVKXCTJSA-N 0.000 description 1
- CUQDCPXNZPDYFQ-ZLUOBGJFSA-N Asp-Ser-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O CUQDCPXNZPDYFQ-ZLUOBGJFSA-N 0.000 description 1
- MGSVBZIBCCKGCY-ZLUOBGJFSA-N Asp-Ser-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MGSVBZIBCCKGCY-ZLUOBGJFSA-N 0.000 description 1
- YIDFBWRHIYOYAA-LKXGYXEUSA-N Asp-Ser-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O YIDFBWRHIYOYAA-LKXGYXEUSA-N 0.000 description 1
- JSHWXQIZOCVWIA-ZKWXMUAHSA-N Asp-Ser-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O JSHWXQIZOCVWIA-ZKWXMUAHSA-N 0.000 description 1
- GCACQYDBDHRVGE-LKXGYXEUSA-N Asp-Thr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC(O)=O GCACQYDBDHRVGE-LKXGYXEUSA-N 0.000 description 1
- PLNJUJGNLDSFOP-UWJYBYFXSA-N Asp-Tyr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O PLNJUJGNLDSFOP-UWJYBYFXSA-N 0.000 description 1
- SQIARYGNVQWOSB-BZSNNMDCSA-N Asp-Tyr-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SQIARYGNVQWOSB-BZSNNMDCSA-N 0.000 description 1
- BPAUXFVCSYQDQX-JRQIVUDYSA-N Asp-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC(=O)O)N)O BPAUXFVCSYQDQX-JRQIVUDYSA-N 0.000 description 1
- PLOKOIJSGCISHE-BYULHYEWSA-N Asp-Val-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O PLOKOIJSGCISHE-BYULHYEWSA-N 0.000 description 1
- XMKXONRMGJXCJV-LAEOZQHASA-N Asp-Val-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O XMKXONRMGJXCJV-LAEOZQHASA-N 0.000 description 1
- XWKPSMRPIKKDDU-RCOVLWMOSA-N Asp-Val-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O XWKPSMRPIKKDDU-RCOVLWMOSA-N 0.000 description 1
- GYNUXDMCDILYIQ-QRTARXTBSA-N Asp-Val-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC(=O)O)N GYNUXDMCDILYIQ-QRTARXTBSA-N 0.000 description 1
- 241000228212 Aspergillus Species 0.000 description 1
- 201000001320 Atherosclerosis Diseases 0.000 description 1
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 description 1
- 108010074708 B7-H1 Antigen Proteins 0.000 description 1
- 241000193830 Bacillus <bacterium> Species 0.000 description 1
- 241001235572 Balantioides coli Species 0.000 description 1
- 206010004194 Bed bug infestation Diseases 0.000 description 1
- 208000009137 Behcet syndrome Diseases 0.000 description 1
- 241000228405 Blastomyces dermatitidis Species 0.000 description 1
- 208000019838 Blood disease Diseases 0.000 description 1
- 241000282817 Bovidae Species 0.000 description 1
- 241000884921 Bundibugyo ebolavirus Species 0.000 description 1
- 102100035875 C-C chemokine receptor type 5 Human genes 0.000 description 1
- 101710149870 C-C chemokine receptor type 5 Proteins 0.000 description 1
- 102100021943 C-C motif chemokine 2 Human genes 0.000 description 1
- 101710098275 C-X-C motif chemokine 10 Proteins 0.000 description 1
- 102000001902 CC Chemokines Human genes 0.000 description 1
- 108010040471 CC Chemokines Proteins 0.000 description 1
- 241000244203 Caenorhabditis elegans Species 0.000 description 1
- 101100314454 Caenorhabditis elegans tra-1 gene Proteins 0.000 description 1
- 241000714198 Caliciviridae Species 0.000 description 1
- 241001493160 California encephalitis virus Species 0.000 description 1
- 241000282832 Camelidae Species 0.000 description 1
- 241000222120 Candida <Saccharomycetales> Species 0.000 description 1
- 101000898643 Candida albicans Vacuolar aspartic protease Proteins 0.000 description 1
- 206010007134 Candida infections Diseases 0.000 description 1
- 101000898783 Candida tropicalis Candidapepsin Proteins 0.000 description 1
- 241000700198 Cavia Species 0.000 description 1
- 241000282994 Cervidae Species 0.000 description 1
- 206010008342 Cervix carcinoma Diseases 0.000 description 1
- 241000283153 Cetacea Species 0.000 description 1
- 208000024699 Chagas disease Diseases 0.000 description 1
- 108010008978 Chemokine CXCL10 Proteins 0.000 description 1
- 201000006082 Chickenpox Diseases 0.000 description 1
- 241000191368 Chlorobi Species 0.000 description 1
- 108090000317 Chymotrypsin Proteins 0.000 description 1
- 241000223782 Ciliophora Species 0.000 description 1
- 241001414835 Cimicidae Species 0.000 description 1
- 241000222290 Cladosporium Species 0.000 description 1
- 206010009344 Clonorchiasis Diseases 0.000 description 1
- 241000193163 Clostridioides difficile Species 0.000 description 1
- 101100532584 Clostridium perfringens (strain 13 / Type A) sspC1 gene Proteins 0.000 description 1
- 241000223203 Coccidioides Species 0.000 description 1
- 241000202814 Cochliomyia hominivorax Species 0.000 description 1
- 108700010070 Codon Usage Proteins 0.000 description 1
- 108020004635 Complementary DNA Proteins 0.000 description 1
- 208000000907 Condylomata Acuminata Diseases 0.000 description 1
- 241000711573 Coronaviridae Species 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- 241000699802 Cricetulus griseus Species 0.000 description 1
- 101000898784 Cryphonectria parasitica Endothiapepsin Proteins 0.000 description 1
- 201000007336 Cryptococcosis Diseases 0.000 description 1
- 241001522864 Cryptococcus gattii VGI Species 0.000 description 1
- 241000221204 Cryptococcus neoformans Species 0.000 description 1
- 241000192700 Cyanobacteria Species 0.000 description 1
- PRXCTTWKGJAPMT-ZLUOBGJFSA-N Cys-Ala-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O PRXCTTWKGJAPMT-ZLUOBGJFSA-N 0.000 description 1
- BYALSSDCQYHKMY-XGEHTFHBSA-N Cys-Arg-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CS)N)O BYALSSDCQYHKMY-XGEHTFHBSA-N 0.000 description 1
- BPHKULHWEIUDOB-FXQIFTODSA-N Cys-Gln-Gln Chemical compound SC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O BPHKULHWEIUDOB-FXQIFTODSA-N 0.000 description 1
- HHABWQIFXZPZCK-ACZMJKKPSA-N Cys-Gln-Ser Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N HHABWQIFXZPZCK-ACZMJKKPSA-N 0.000 description 1
- GUKYYUFHWYRMEU-WHFBIAKZSA-N Cys-Gly-Asp Chemical compound [H]N[C@@H](CS)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O GUKYYUFHWYRMEU-WHFBIAKZSA-N 0.000 description 1
- NIXHTNJAGGFBAW-CIUDSAMLSA-N Cys-Lys-Ser Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N NIXHTNJAGGFBAW-CIUDSAMLSA-N 0.000 description 1
- SMEYEQDCCBHTEF-FXQIFTODSA-N Cys-Pro-Ala Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O SMEYEQDCCBHTEF-FXQIFTODSA-N 0.000 description 1
- NITLUESFANGEIW-BQBZGAKWSA-N Cys-Pro-Gly Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O NITLUESFANGEIW-BQBZGAKWSA-N 0.000 description 1
- YWEHYKGJWHPGPY-XGEHTFHBSA-N Cys-Thr-Arg Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CS)N)O YWEHYKGJWHPGPY-XGEHTFHBSA-N 0.000 description 1
- SAEVTQWAYDPXMU-KATARQTJSA-N Cys-Thr-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O SAEVTQWAYDPXMU-KATARQTJSA-N 0.000 description 1
- ALTQTAKGRFLRLR-GUBZILKMSA-N Cys-Val-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CS)N ALTQTAKGRFLRLR-GUBZILKMSA-N 0.000 description 1
- 108010005843 Cysteine Proteases Proteins 0.000 description 1
- 102000005927 Cysteine Proteases Human genes 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- 102100026233 DAN domain family member 5 Human genes 0.000 description 1
- 102000053602 DNA Human genes 0.000 description 1
- 108010041986 DNA Vaccines Proteins 0.000 description 1
- 229940021995 DNA vaccine Drugs 0.000 description 1
- 230000004568 DNA-binding Effects 0.000 description 1
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 1
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 1
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 1
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 1
- 241000710829 Dengue virus group Species 0.000 description 1
- 101710088335 Diacylglycerol acyltransferase/mycolyltransferase Ag85A Proteins 0.000 description 1
- 101710088334 Diacylglycerol acyltransferase/mycolyltransferase Ag85B Proteins 0.000 description 1
- 108010044266 Dopamine Plasma Membrane Transport Proteins Proteins 0.000 description 1
- 241000255581 Drosophila <fruit fly, genus> Species 0.000 description 1
- 108010031111 EBV-encoded nuclear antigen 1 Proteins 0.000 description 1
- 102000005593 Endopeptidases Human genes 0.000 description 1
- 108010059378 Endopeptidases Proteins 0.000 description 1
- 241000991587 Enterovirus C Species 0.000 description 1
- 102000004190 Enzymes Human genes 0.000 description 1
- 108090000790 Enzymes Proteins 0.000 description 1
- 101800003838 Epidermal growth factor Proteins 0.000 description 1
- 102400001368 Epidermal growth factor Human genes 0.000 description 1
- 241000283086 Equidae Species 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- 241000306559 Exserohilum Species 0.000 description 1
- 108050001049 Extracellular proteins Proteins 0.000 description 1
- 241000723648 Fabavirus Species 0.000 description 1
- 241000242711 Fasciola hepatica Species 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 241000711950 Filoviridae Species 0.000 description 1
- 241000192125 Firmicutes Species 0.000 description 1
- 241000710831 Flavivirus Species 0.000 description 1
- 206010016952 Food poisoning Diseases 0.000 description 1
- 208000019331 Foodborne disease Diseases 0.000 description 1
- 201000003741 Gastrointestinal carcinoma Diseases 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- 241000726221 Gemma Species 0.000 description 1
- 108700023863 Gene Components Proteins 0.000 description 1
- 241000224467 Giardia intestinalis Species 0.000 description 1
- RZSLYUUFFVHFRQ-FXQIFTODSA-N Gln-Ala-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O RZSLYUUFFVHFRQ-FXQIFTODSA-N 0.000 description 1
- HHWQMFIGMMOVFK-WDSKDSINSA-N Gln-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O HHWQMFIGMMOVFK-WDSKDSINSA-N 0.000 description 1
- UWZLBXOBVKRUFE-HGNGGELXSA-N Gln-Ala-His Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)N)N UWZLBXOBVKRUFE-HGNGGELXSA-N 0.000 description 1
- LJEPDHWNQXPXMM-NHCYSSNCSA-N Gln-Arg-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O LJEPDHWNQXPXMM-NHCYSSNCSA-N 0.000 description 1
- IXFVOPOHSRKJNG-LAEOZQHASA-N Gln-Asp-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O IXFVOPOHSRKJNG-LAEOZQHASA-N 0.000 description 1
- GPISLLFQNHELLK-DCAQKATOSA-N Gln-Gln-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N GPISLLFQNHELLK-DCAQKATOSA-N 0.000 description 1
- KVXVVDFOZNYYKZ-DCAQKATOSA-N Gln-Gln-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O KVXVVDFOZNYYKZ-DCAQKATOSA-N 0.000 description 1
- MADFVRSKEIEZHZ-DCAQKATOSA-N Gln-Gln-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N MADFVRSKEIEZHZ-DCAQKATOSA-N 0.000 description 1
- LVNILKSSFHCSJZ-IHRRRGAJSA-N Gln-Gln-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N LVNILKSSFHCSJZ-IHRRRGAJSA-N 0.000 description 1
- XKBASPWPBXNVLQ-WDSKDSINSA-N Gln-Gly-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O XKBASPWPBXNVLQ-WDSKDSINSA-N 0.000 description 1
- SMLDOQHTOAAFJQ-WDSKDSINSA-N Gln-Gly-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SMLDOQHTOAAFJQ-WDSKDSINSA-N 0.000 description 1
- ZEEPYMXTJWIMSN-GUBZILKMSA-N Gln-Lys-Ser Chemical compound NCCCC[C@@H](C(=O)N[C@@H](CO)C(O)=O)NC(=O)[C@@H](N)CCC(N)=O ZEEPYMXTJWIMSN-GUBZILKMSA-N 0.000 description 1
- MSHXWFKYXJTLEZ-CIUDSAMLSA-N Gln-Met-Asn Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N MSHXWFKYXJTLEZ-CIUDSAMLSA-N 0.000 description 1
- XUMFMAVDHQDATI-DCAQKATOSA-N Gln-Pro-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O XUMFMAVDHQDATI-DCAQKATOSA-N 0.000 description 1
- KUBFPYIMAGXGBT-ACZMJKKPSA-N Gln-Ser-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O KUBFPYIMAGXGBT-ACZMJKKPSA-N 0.000 description 1
- OKARHJKJTKFQBM-ACZMJKKPSA-N Gln-Ser-Asn Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N OKARHJKJTKFQBM-ACZMJKKPSA-N 0.000 description 1
- HGBHRZBXOOHRDH-JBACZVJFSA-N Gln-Tyr-Trp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HGBHRZBXOOHRDH-JBACZVJFSA-N 0.000 description 1
- HNAUFGBKJLTWQE-IFFSRLJSSA-N Gln-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCC(=O)N)N)O HNAUFGBKJLTWQE-IFFSRLJSSA-N 0.000 description 1
- AVZHGSCDKIQZPQ-CIUDSAMLSA-N Glu-Arg-Ala Chemical compound C[C@H](NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCC(O)=O)C(O)=O AVZHGSCDKIQZPQ-CIUDSAMLSA-N 0.000 description 1
- GLWXKFRTOHKGIT-ACZMJKKPSA-N Glu-Asn-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O GLWXKFRTOHKGIT-ACZMJKKPSA-N 0.000 description 1
- XXCDTYBVGMPIOA-FXQIFTODSA-N Glu-Asp-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XXCDTYBVGMPIOA-FXQIFTODSA-N 0.000 description 1
- KVBPDJIFRQUQFY-ACZMJKKPSA-N Glu-Cys-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O KVBPDJIFRQUQFY-ACZMJKKPSA-N 0.000 description 1
- KIMXNQXJJWWVIN-AVGNSLFASA-N Glu-Cys-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCC(=O)O)N)O KIMXNQXJJWWVIN-AVGNSLFASA-N 0.000 description 1
- PVBBEKPHARMPHX-DCAQKATOSA-N Glu-Gln-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CCC(O)=O PVBBEKPHARMPHX-DCAQKATOSA-N 0.000 description 1
- MIQCYAJSDGNCNK-BPUTZDHNSA-N Glu-Gln-Trp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O MIQCYAJSDGNCNK-BPUTZDHNSA-N 0.000 description 1
- MTAOBYXRYJZRGQ-WDSKDSINSA-N Glu-Gly-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MTAOBYXRYJZRGQ-WDSKDSINSA-N 0.000 description 1
- VSRCAOIHMGCIJK-SRVKXCTJSA-N Glu-Leu-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O VSRCAOIHMGCIJK-SRVKXCTJSA-N 0.000 description 1
- DNPCBMNFQVTHMA-DCAQKATOSA-N Glu-Leu-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O DNPCBMNFQVTHMA-DCAQKATOSA-N 0.000 description 1
- IRXNJYPKBVERCW-DCAQKATOSA-N Glu-Leu-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IRXNJYPKBVERCW-DCAQKATOSA-N 0.000 description 1
- SJJHXJDSNQJMMW-SRVKXCTJSA-N Glu-Lys-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O SJJHXJDSNQJMMW-SRVKXCTJSA-N 0.000 description 1
- DXVOKNVIKORTHQ-GUBZILKMSA-N Glu-Pro-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O DXVOKNVIKORTHQ-GUBZILKMSA-N 0.000 description 1
- RFTVTKBHDXCEEX-WDSKDSINSA-N Glu-Ser-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RFTVTKBHDXCEEX-WDSKDSINSA-N 0.000 description 1
- GUOWMVFLAJNPDY-CIUDSAMLSA-N Glu-Ser-Met Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(O)=O GUOWMVFLAJNPDY-CIUDSAMLSA-N 0.000 description 1
- ZSIDREAPEPAPKL-XIRDDKMYSA-N Glu-Trp-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCC(=O)O)N ZSIDREAPEPAPKL-XIRDDKMYSA-N 0.000 description 1
- MIWJDJAMMKHUAR-ZVZYQTTQSA-N Glu-Trp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCC(=O)O)N MIWJDJAMMKHUAR-ZVZYQTTQSA-N 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- 102000003958 Glutamate Carboxypeptidase II Human genes 0.000 description 1
- QIZJOTQTCAGKPU-KWQFWETISA-N Gly-Ala-Tyr Chemical compound [NH3+]CC(=O)N[C@@H](C)C(=O)N[C@H](C([O-])=O)CC1=CC=C(O)C=C1 QIZJOTQTCAGKPU-KWQFWETISA-N 0.000 description 1
- KRRMJKMGWWXWDW-STQMWFEESA-N Gly-Arg-Phe Chemical compound NC(=N)NCCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KRRMJKMGWWXWDW-STQMWFEESA-N 0.000 description 1
- WKJKBELXHCTHIJ-WPRPVWTQSA-N Gly-Arg-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N WKJKBELXHCTHIJ-WPRPVWTQSA-N 0.000 description 1
- CIMULJZTTOBOPN-WHFBIAKZSA-N Gly-Asn-Asn Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O CIMULJZTTOBOPN-WHFBIAKZSA-N 0.000 description 1
- GRIRDMVMJJDZKV-RCOVLWMOSA-N Gly-Asn-Val Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O GRIRDMVMJJDZKV-RCOVLWMOSA-N 0.000 description 1
- TZOVVRJYUDETQG-RCOVLWMOSA-N Gly-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CN TZOVVRJYUDETQG-RCOVLWMOSA-N 0.000 description 1
- GNPVTZJUUBPZKW-WDSKDSINSA-N Gly-Gln-Ser Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GNPVTZJUUBPZKW-WDSKDSINSA-N 0.000 description 1
- QPDUVFSVVAOUHE-XVKPBYJWSA-N Gly-Gln-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)CN)C(O)=O QPDUVFSVVAOUHE-XVKPBYJWSA-N 0.000 description 1
- IEFJWDNGDZAYNZ-BYPYZUCNSA-N Gly-Glu Chemical compound NCC(=O)N[C@H](C(O)=O)CCC(O)=O IEFJWDNGDZAYNZ-BYPYZUCNSA-N 0.000 description 1
- DHDOADIPGZTAHT-YUMQZZPRSA-N Gly-Glu-Arg Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DHDOADIPGZTAHT-YUMQZZPRSA-N 0.000 description 1
- QSVCIFZPGLOZGH-WDSKDSINSA-N Gly-Glu-Ser Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O QSVCIFZPGLOZGH-WDSKDSINSA-N 0.000 description 1
- CCQOOWAONKGYKQ-BYPYZUCNSA-N Gly-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)CN CCQOOWAONKGYKQ-BYPYZUCNSA-N 0.000 description 1
- KMSGYZQRXPUKGI-BYPYZUCNSA-N Gly-Gly-Asn Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC(N)=O KMSGYZQRXPUKGI-BYPYZUCNSA-N 0.000 description 1
- QPTNELDXWKRIFX-YFKPBYRVSA-N Gly-Gly-Gln Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O QPTNELDXWKRIFX-YFKPBYRVSA-N 0.000 description 1
- TWTPDFFBLQEBOE-IUCAKERBSA-N Gly-Leu-Gln Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O TWTPDFFBLQEBOE-IUCAKERBSA-N 0.000 description 1
- ULZCYBYDTUMHNF-IUCAKERBSA-N Gly-Leu-Glu Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ULZCYBYDTUMHNF-IUCAKERBSA-N 0.000 description 1
- NNCSJUBVFBDDLC-YUMQZZPRSA-N Gly-Leu-Ser Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O NNCSJUBVFBDDLC-YUMQZZPRSA-N 0.000 description 1
- BXICSAQLIHFDDL-YUMQZZPRSA-N Gly-Lys-Asn Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O BXICSAQLIHFDDL-YUMQZZPRSA-N 0.000 description 1
- WNGHUXFWEWTKAO-YUMQZZPRSA-N Gly-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN WNGHUXFWEWTKAO-YUMQZZPRSA-N 0.000 description 1
- JSLVAHYTAJJEQH-QWRGUYRKSA-N Gly-Ser-Phe Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 JSLVAHYTAJJEQH-QWRGUYRKSA-N 0.000 description 1
- ABPRMMYHROQBLY-NKWVEPMBSA-N Gly-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)CN)C(=O)O ABPRMMYHROQBLY-NKWVEPMBSA-N 0.000 description 1
- JQFILXICXLDTRR-FBCQKBJTSA-N Gly-Thr-Gly Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)NCC(O)=O JQFILXICXLDTRR-FBCQKBJTSA-N 0.000 description 1
- XHVONGZZVUUORG-WEDXCCLWSA-N Gly-Thr-Lys Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN XHVONGZZVUUORG-WEDXCCLWSA-N 0.000 description 1
- MYXNLWDWWOTERK-BHNWBGBOSA-N Gly-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN)O MYXNLWDWWOTERK-BHNWBGBOSA-N 0.000 description 1
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 1
- PYFIQROSWQERAS-LBPRGKRZSA-N Gly-Trp-Gly Chemical compound C1=CC=C2C(C[C@H](NC(=O)CN)C(=O)NCC(O)=O)=CNC2=C1 PYFIQROSWQERAS-LBPRGKRZSA-N 0.000 description 1
- SFOXOSKVTLDEDM-HOTGVXAUSA-N Gly-Trp-Leu Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)CN)=CNC2=C1 SFOXOSKVTLDEDM-HOTGVXAUSA-N 0.000 description 1
- GNNJKUYDWFIBTK-QWRGUYRKSA-N Gly-Tyr-Asp Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O GNNJKUYDWFIBTK-QWRGUYRKSA-N 0.000 description 1
- BAYQNCWLXIDLHX-ONGXEEELSA-N Gly-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN BAYQNCWLXIDLHX-ONGXEEELSA-N 0.000 description 1
- YGHSQRJSHKYUJY-SCZZXKLOSA-N Gly-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN YGHSQRJSHKYUJY-SCZZXKLOSA-N 0.000 description 1
- 108090000288 Glycoproteins Proteins 0.000 description 1
- 102000003886 Glycoproteins Human genes 0.000 description 1
- 244000060234 Gmelina philippensis Species 0.000 description 1
- 208000031886 HIV Infections Diseases 0.000 description 1
- 208000037357 HIV infectious disease Diseases 0.000 description 1
- 206010061192 Haemorrhagic fever Diseases 0.000 description 1
- 101710165610 Heat-stable 19 kDa antigen Proteins 0.000 description 1
- 241000700739 Hepadnaviridae Species 0.000 description 1
- 208000005176 Hepatitis C Diseases 0.000 description 1
- 241000700586 Herpesviridae Species 0.000 description 1
- 108010026764 High-Temperature Requirement A Serine Peptidase 2 Proteins 0.000 description 1
- 102000018980 High-Temperature Requirement A Serine Peptidase 2 Human genes 0.000 description 1
- KZTLOHBDLMIFSH-XVYDVKMFSA-N His-Ala-Asp Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O KZTLOHBDLMIFSH-XVYDVKMFSA-N 0.000 description 1
- FYVHHKMHFPMBBG-GUBZILKMSA-N His-Gln-Asp Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N FYVHHKMHFPMBBG-GUBZILKMSA-N 0.000 description 1
- SDTPKSOWFXBACN-GUBZILKMSA-N His-Glu-Asp Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O SDTPKSOWFXBACN-GUBZILKMSA-N 0.000 description 1
- BCZFOHDMCDXPDA-BZSNNMDCSA-N His-Lys-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC2=CN=CN2)N)O BCZFOHDMCDXPDA-BZSNNMDCSA-N 0.000 description 1
- QCBYAHHNOHBXIH-UWVGGRQHSA-N His-Pro-Gly Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)NCC(O)=O)C1=CN=CN1 QCBYAHHNOHBXIH-UWVGGRQHSA-N 0.000 description 1
- STGQSBKUYSPPIG-CIUDSAMLSA-N His-Ser-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 STGQSBKUYSPPIG-CIUDSAMLSA-N 0.000 description 1
- PLCAEMGSYOYIPP-GUBZILKMSA-N His-Ser-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 PLCAEMGSYOYIPP-GUBZILKMSA-N 0.000 description 1
- JMSONHOUHFDOJH-GUBZILKMSA-N His-Ser-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 JMSONHOUHFDOJH-GUBZILKMSA-N 0.000 description 1
- CSTDQOOBZBAJKE-BWAGICSOSA-N His-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CC2=CN=CN2)N)O CSTDQOOBZBAJKE-BWAGICSOSA-N 0.000 description 1
- 241000228404 Histoplasma capsulatum Species 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 description 1
- 101000912351 Homo sapiens DAN domain family member 5 Proteins 0.000 description 1
- 101100118549 Homo sapiens EGFR gene Proteins 0.000 description 1
- 101500025419 Homo sapiens Epidermal growth factor Proteins 0.000 description 1
- 101000899111 Homo sapiens Hemoglobin subunit beta Proteins 0.000 description 1
- 101100095550 Homo sapiens SENP7 gene Proteins 0.000 description 1
- 101001041393 Homo sapiens Serine protease HTRA1 Proteins 0.000 description 1
- 101000611183 Homo sapiens Tumor necrosis factor Proteins 0.000 description 1
- 206010020460 Human T-cell lymphotropic virus type I infection Diseases 0.000 description 1
- 241000714260 Human T-lymphotropic virus 1 Species 0.000 description 1
- 241000714259 Human T-lymphotropic virus 2 Species 0.000 description 1
- 241000701024 Human betaherpesvirus 5 Species 0.000 description 1
- 101100540311 Human papillomavirus type 16 E6 gene Proteins 0.000 description 1
- 101000767631 Human papillomavirus type 16 Protein E7 Proteins 0.000 description 1
- 102000004157 Hydrolases Human genes 0.000 description 1
- 108090000604 Hydrolases Proteins 0.000 description 1
- 206010020751 Hypersensitivity Diseases 0.000 description 1
- XQFRJNBWHJMXHO-RRKCRQDMSA-N IDUR Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C(I)=C1 XQFRJNBWHJMXHO-RRKCRQDMSA-N 0.000 description 1
- WECYRWOMWSCWNX-XUXIUFHCSA-N Ile-Arg-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(C)C)C(O)=O WECYRWOMWSCWNX-XUXIUFHCSA-N 0.000 description 1
- WNQKUUQIVDDAFA-ZPFDUUQYSA-N Ile-Gln-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCSC)C(=O)O)N WNQKUUQIVDDAFA-ZPFDUUQYSA-N 0.000 description 1
- NZOCIWKZUVUNDW-ZKWXMUAHSA-N Ile-Gly-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O NZOCIWKZUVUNDW-ZKWXMUAHSA-N 0.000 description 1
- RWYCOSAAAJBJQL-KCTSRDHCSA-N Ile-Gly-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N RWYCOSAAAJBJQL-KCTSRDHCSA-N 0.000 description 1
- VOBYAKCXGQQFLR-LSJOCFKGSA-N Ile-Gly-Val Chemical compound CC[C@H](C)[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O VOBYAKCXGQQFLR-LSJOCFKGSA-N 0.000 description 1
- GLYJPWIRLBAIJH-FQUUOJAGSA-N Ile-Lys-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(=O)O)N GLYJPWIRLBAIJH-FQUUOJAGSA-N 0.000 description 1
- GLYJPWIRLBAIJH-UHFFFAOYSA-N Ile-Lys-Pro Natural products CCC(C)C(N)C(=O)NC(CCCCN)C(=O)N1CCCC1C(O)=O GLYJPWIRLBAIJH-UHFFFAOYSA-N 0.000 description 1
- PXKACEXYLPBMAD-JBDRJPRFSA-N Ile-Ser-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PXKACEXYLPBMAD-JBDRJPRFSA-N 0.000 description 1
- RKQAYOWLSFLJEE-SVSWQMSJSA-N Ile-Thr-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)O)N RKQAYOWLSFLJEE-SVSWQMSJSA-N 0.000 description 1
- YBKKLDBBPFIXBQ-MBLNEYKQSA-N Ile-Thr-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)O)N YBKKLDBBPFIXBQ-MBLNEYKQSA-N 0.000 description 1
- FXJLRZFMKGHYJP-CFMVVWHZSA-N Ile-Tyr-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N FXJLRZFMKGHYJP-CFMVVWHZSA-N 0.000 description 1
- OMDWJWGZGMCQND-CFMVVWHZSA-N Ile-Tyr-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N OMDWJWGZGMCQND-CFMVVWHZSA-N 0.000 description 1
- PRTZQMBYUZFSFA-XEGUGMAKSA-N Ile-Tyr-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)NCC(=O)O)N PRTZQMBYUZFSFA-XEGUGMAKSA-N 0.000 description 1
- JZBVBOKASHNXAD-NAKRPEOUSA-N Ile-Val-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N JZBVBOKASHNXAD-NAKRPEOUSA-N 0.000 description 1
- 206010061598 Immunodeficiency Diseases 0.000 description 1
- 208000029462 Immunodeficiency disease Diseases 0.000 description 1
- 108700005091 Immunoglobulin Genes Proteins 0.000 description 1
- 206010061218 Inflammation Diseases 0.000 description 1
- 241000713196 Influenza B virus Species 0.000 description 1
- UGQMRVRMYYASKQ-KQYNXXCUSA-N Inosine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C2=NC=NC(O)=C2N=C1 UGQMRVRMYYASKQ-KQYNXXCUSA-N 0.000 description 1
- 229930010555 Inosine Natural products 0.000 description 1
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 1
- LHSGPCFBGJHPCY-UHFFFAOYSA-N L-leucine-L-tyrosine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LHSGPCFBGJHPCY-UHFFFAOYSA-N 0.000 description 1
- LZDNBBYBDGBADK-UHFFFAOYSA-N L-valyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C(C)C)C(O)=O)=CNC2=C1 LZDNBBYBDGBADK-UHFFFAOYSA-N 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- 208000004554 Leishmaniasis Diseases 0.000 description 1
- KSZCCRIGNVSHFH-UWVGGRQHSA-N Leu-Arg-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O KSZCCRIGNVSHFH-UWVGGRQHSA-N 0.000 description 1
- USTCFDAQCLDPBD-XIRDDKMYSA-N Leu-Asn-Trp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N USTCFDAQCLDPBD-XIRDDKMYSA-N 0.000 description 1
- VQPPIMUZCZCOIL-GUBZILKMSA-N Leu-Gln-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O VQPPIMUZCZCOIL-GUBZILKMSA-N 0.000 description 1
- DPWGZWUMUUJQDT-IUCAKERBSA-N Leu-Gln-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O DPWGZWUMUUJQDT-IUCAKERBSA-N 0.000 description 1
- AXZGZMGRBDQTEY-SRVKXCTJSA-N Leu-Gln-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O AXZGZMGRBDQTEY-SRVKXCTJSA-N 0.000 description 1
- APFJUBGRZGMQFF-QWRGUYRKSA-N Leu-Gly-Lys Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCCN APFJUBGRZGMQFF-QWRGUYRKSA-N 0.000 description 1
- YFBBUHJJUXXZOF-UWVGGRQHSA-N Leu-Gly-Pro Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O YFBBUHJJUXXZOF-UWVGGRQHSA-N 0.000 description 1
- VGPCJSXPPOQPBK-YUMQZZPRSA-N Leu-Gly-Ser Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O VGPCJSXPPOQPBK-YUMQZZPRSA-N 0.000 description 1
- BKTXKJMNTSMJDQ-AVGNSLFASA-N Leu-His-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N BKTXKJMNTSMJDQ-AVGNSLFASA-N 0.000 description 1
- ORWTWZXGDBYVCP-BJDJZHNGSA-N Leu-Ile-Cys Chemical compound SC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CC(C)C ORWTWZXGDBYVCP-BJDJZHNGSA-N 0.000 description 1
- OMHLATXVNQSALM-FQUUOJAGSA-N Leu-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(C)C)N OMHLATXVNQSALM-FQUUOJAGSA-N 0.000 description 1
- HRTRLSRYZZKPCO-BJDJZHNGSA-N Leu-Ile-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HRTRLSRYZZKPCO-BJDJZHNGSA-N 0.000 description 1
- IEWBEPKLKUXQBU-VOAKCMCISA-N Leu-Leu-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IEWBEPKLKUXQBU-VOAKCMCISA-N 0.000 description 1
- RTIRBWJPYJYTLO-MELADBBJSA-N Leu-Lys-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N1CCC[C@@H]1C(=O)O)N RTIRBWJPYJYTLO-MELADBBJSA-N 0.000 description 1
- KIZIOFNVSOSKJI-CIUDSAMLSA-N Leu-Ser-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N KIZIOFNVSOSKJI-CIUDSAMLSA-N 0.000 description 1
- AKVBOOKXVAMKSS-GUBZILKMSA-N Leu-Ser-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O AKVBOOKXVAMKSS-GUBZILKMSA-N 0.000 description 1
- DAYQSYGBCUKVKT-VOAKCMCISA-N Leu-Thr-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(O)=O DAYQSYGBCUKVKT-VOAKCMCISA-N 0.000 description 1
- HOMFINRJHIIZNJ-HOCLYGCPSA-N Leu-Trp-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)NCC(O)=O HOMFINRJHIIZNJ-HOCLYGCPSA-N 0.000 description 1
- YLMIDMSLKLRNHX-HSCHXYMDSA-N Leu-Trp-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O YLMIDMSLKLRNHX-HSCHXYMDSA-N 0.000 description 1
- JGKHAFUAPZCCDU-BZSNNMDCSA-N Leu-Tyr-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CC=C(O)C=C1 JGKHAFUAPZCCDU-BZSNNMDCSA-N 0.000 description 1
- TUIOUEWKFFVNLH-DCAQKATOSA-N Leu-Val-Cys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(O)=O TUIOUEWKFFVNLH-DCAQKATOSA-N 0.000 description 1
- VKVDRTGWLVZJOM-DCAQKATOSA-N Leu-Val-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O VKVDRTGWLVZJOM-DCAQKATOSA-N 0.000 description 1
- 241001541121 Linguatula Species 0.000 description 1
- 241001541122 Linguatula serrata Species 0.000 description 1
- 241000406668 Loxodonta cyclotis Species 0.000 description 1
- PNPYKQFJGRFYJE-GUBZILKMSA-N Lys-Ala-Glu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNPYKQFJGRFYJE-GUBZILKMSA-N 0.000 description 1
- KCXUCYYZNZFGLL-SRVKXCTJSA-N Lys-Ala-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O KCXUCYYZNZFGLL-SRVKXCTJSA-N 0.000 description 1
- IXHKPDJKKCUKHS-GARJFASQSA-N Lys-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N IXHKPDJKKCUKHS-GARJFASQSA-N 0.000 description 1
- NTSPQIONFJUMJV-AVGNSLFASA-N Lys-Arg-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O NTSPQIONFJUMJV-AVGNSLFASA-N 0.000 description 1
- WLCYCADOWRMSAJ-CIUDSAMLSA-N Lys-Asn-Cys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(O)=O WLCYCADOWRMSAJ-CIUDSAMLSA-N 0.000 description 1
- KWUKZRFFKPLUPE-HJGDQZAQSA-N Lys-Asp-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWUKZRFFKPLUPE-HJGDQZAQSA-N 0.000 description 1
- AFAFFVKJJYBBTC-UHFFFAOYSA-N Lys-Gln-Ala-Gly-Asp-Val Chemical compound CC(C)C(C(O)=O)NC(=O)C(CC(O)=O)NC(=O)CNC(=O)C(C)NC(=O)C(CCC(N)=O)NC(=O)C(N)CCCCN AFAFFVKJJYBBTC-UHFFFAOYSA-N 0.000 description 1
- GQZMPWBZQALKJO-UWVGGRQHSA-N Lys-Gly-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O GQZMPWBZQALKJO-UWVGGRQHSA-N 0.000 description 1
- XNKDCYABMBBEKN-IUCAKERBSA-N Lys-Gly-Gln Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O XNKDCYABMBBEKN-IUCAKERBSA-N 0.000 description 1
- GQFDWEDHOQRNLC-QWRGUYRKSA-N Lys-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN GQFDWEDHOQRNLC-QWRGUYRKSA-N 0.000 description 1
- PRSBSVAVOQOAMI-BJDJZHNGSA-N Lys-Ile-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCCCN PRSBSVAVOQOAMI-BJDJZHNGSA-N 0.000 description 1
- MYZMQWHPDAYKIE-SRVKXCTJSA-N Lys-Leu-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O MYZMQWHPDAYKIE-SRVKXCTJSA-N 0.000 description 1
- ODTZHNZPINULEU-KKUMJFAQSA-N Lys-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N ODTZHNZPINULEU-KKUMJFAQSA-N 0.000 description 1
- AFLBTVGQCQLOFJ-AVGNSLFASA-N Lys-Pro-Arg Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O AFLBTVGQCQLOFJ-AVGNSLFASA-N 0.000 description 1
- QBHGXFQJFPWJIH-XUXIUFHCSA-N Lys-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCCN QBHGXFQJFPWJIH-XUXIUFHCSA-N 0.000 description 1
- LUTDBHBIHHREDC-IHRRRGAJSA-N Lys-Pro-Lys Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O LUTDBHBIHHREDC-IHRRRGAJSA-N 0.000 description 1
- MIFFFXHMAHFACR-KATARQTJSA-N Lys-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CCCCN MIFFFXHMAHFACR-KATARQTJSA-N 0.000 description 1
- YQAIUOWPSUOINN-IUCAKERBSA-N Lys-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](N)CCCCN YQAIUOWPSUOINN-IUCAKERBSA-N 0.000 description 1
- HMZPYMSEAALNAE-ULQDDVLXSA-N Lys-Val-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O HMZPYMSEAALNAE-ULQDDVLXSA-N 0.000 description 1
- IKXQOBUBZSOWDY-AVGNSLFASA-N Lys-Val-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CCCCN)N IKXQOBUBZSOWDY-AVGNSLFASA-N 0.000 description 1
- 241000282560 Macaca mulatta Species 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- 241001115401 Marburgvirus Species 0.000 description 1
- ZEDVFJPQNNBMST-CYDGBPFRSA-N Met-Arg-Ile Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZEDVFJPQNNBMST-CYDGBPFRSA-N 0.000 description 1
- FVKRQMQQFGBXHV-QXEWZRGKSA-N Met-Asp-Val Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O FVKRQMQQFGBXHV-QXEWZRGKSA-N 0.000 description 1
- MHQXIBRPDKXDGZ-ZFWWWQNUSA-N Met-Gly-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)CNC(=O)[C@@H](N)CCSC)C(O)=O)=CNC2=C1 MHQXIBRPDKXDGZ-ZFWWWQNUSA-N 0.000 description 1
- HAQLBBVZAGMESV-IHRRRGAJSA-N Met-Lys-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(O)=O HAQLBBVZAGMESV-IHRRRGAJSA-N 0.000 description 1
- 108010006035 Metalloproteases Proteins 0.000 description 1
- 102000005741 Metalloproteases Human genes 0.000 description 1
- RJQXTJLFIWVMTO-TYNCELHUSA-N Methicillin Chemical compound COC1=CC=CC(OC)=C1C(=O)N[C@@H]1C(=O)N2[C@@H](C(O)=O)C(C)(C)S[C@@H]21 RJQXTJLFIWVMTO-TYNCELHUSA-N 0.000 description 1
- 241000713333 Mouse mammary tumor virus Species 0.000 description 1
- 241000761989 Mucoromycotina Species 0.000 description 1
- 208000034578 Multiple myelomas Diseases 0.000 description 1
- 101100407308 Mus musculus Pdcd1lg2 gene Proteins 0.000 description 1
- 241000187479 Mycobacterium tuberculosis Species 0.000 description 1
- 108010066427 N-valyltryptophan Proteins 0.000 description 1
- 241000244206 Nematoda Species 0.000 description 1
- 206010029113 Neovascularisation Diseases 0.000 description 1
- 101100068676 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) gln-1 gene Proteins 0.000 description 1
- 208000015914 Non-Hodgkin lymphomas Diseases 0.000 description 1
- 241000243985 Onchocerca volvulus Species 0.000 description 1
- 108700026244 Open Reading Frames Proteins 0.000 description 1
- 241000712464 Orthomyxoviridae Species 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 241000283903 Ovis aries Species 0.000 description 1
- 241000282579 Pan Species 0.000 description 1
- 108010067372 Pancreatic elastase Proteins 0.000 description 1
- 102000016387 Pancreatic elastase Human genes 0.000 description 1
- 108090000526 Papain Proteins 0.000 description 1
- 241001631646 Papillomaviridae Species 0.000 description 1
- 241001480234 Paragonimus westermani Species 0.000 description 1
- 208000030852 Parasitic disease Diseases 0.000 description 1
- 241000701945 Parvoviridae Species 0.000 description 1
- 241000150350 Peribunyaviridae Species 0.000 description 1
- 241000710778 Pestivirus Species 0.000 description 1
- VHWOBXIWBDWZHK-IHRRRGAJSA-N Phe-Arg-Asp Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H](CC(O)=O)C(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 VHWOBXIWBDWZHK-IHRRRGAJSA-N 0.000 description 1
- HXSUFWQYLPKEHF-IHRRRGAJSA-N Phe-Asn-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N HXSUFWQYLPKEHF-IHRRRGAJSA-N 0.000 description 1
- CUMXHKAOHNWRFQ-BZSNNMDCSA-N Phe-Asp-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 CUMXHKAOHNWRFQ-BZSNNMDCSA-N 0.000 description 1
- PSBJZLMFFTULDX-IXOXFDKPSA-N Phe-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC1=CC=CC=C1)N)O PSBJZLMFFTULDX-IXOXFDKPSA-N 0.000 description 1
- OWCLJDXHHZUNEL-IHRRRGAJSA-N Phe-Cys-Val Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O OWCLJDXHHZUNEL-IHRRRGAJSA-N 0.000 description 1
- ZZVUXQCQPXSUFH-JBACZVJFSA-N Phe-Glu-Trp Chemical compound C([C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CC=CC=C1 ZZVUXQCQPXSUFH-JBACZVJFSA-N 0.000 description 1
- YYKZDTVQHTUKDW-RYUDHWBXSA-N Phe-Gly-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N YYKZDTVQHTUKDW-RYUDHWBXSA-N 0.000 description 1
- BWTKUQPNOMMKMA-FIRPJDEBSA-N Phe-Ile-Phe Chemical compound C([C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 BWTKUQPNOMMKMA-FIRPJDEBSA-N 0.000 description 1
- CWFGECHCRMGPPT-MXAVVETBSA-N Phe-Ile-Ser Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O CWFGECHCRMGPPT-MXAVVETBSA-N 0.000 description 1
- KDYPMIZMXDECSU-JYJNAYRXSA-N Phe-Leu-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 KDYPMIZMXDECSU-JYJNAYRXSA-N 0.000 description 1
- YTILBRIUASDGBL-BZSNNMDCSA-N Phe-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 YTILBRIUASDGBL-BZSNNMDCSA-N 0.000 description 1
- AXIOGMQCDYVTNY-ACRUOGEOSA-N Phe-Phe-Leu Chemical compound C([C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 AXIOGMQCDYVTNY-ACRUOGEOSA-N 0.000 description 1
- BSJCSHIAMSGQGN-BVSLBCMMSA-N Phe-Pro-Trp Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)N)C(=O)N[C@@H](CC3=CNC4=CC=CC=C43)C(=O)O BSJCSHIAMSGQGN-BVSLBCMMSA-N 0.000 description 1
- WEDZFLRYSIDIRX-IHRRRGAJSA-N Phe-Ser-Arg Chemical compound NC(=N)NCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=CC=C1 WEDZFLRYSIDIRX-IHRRRGAJSA-N 0.000 description 1
- FGWUALWGCZJQDJ-URLPEUOOSA-N Phe-Thr-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FGWUALWGCZJQDJ-URLPEUOOSA-N 0.000 description 1
- 241000709664 Picornaviridae Species 0.000 description 1
- 206010035226 Plasma cell myeloma Diseases 0.000 description 1
- 108010051456 Plasminogen Proteins 0.000 description 1
- 102000013566 Plasminogen Human genes 0.000 description 1
- 241000242594 Platyhelminthes Species 0.000 description 1
- 241000142787 Pneumocystis jirovecii Species 0.000 description 1
- 101710182846 Polyhedrin Proteins 0.000 description 1
- 229920001213 Polysorbate 20 Polymers 0.000 description 1
- 239000004793 Polystyrene Substances 0.000 description 1
- 241000700625 Poxviridae Species 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- BNBBNGZZKQUWCD-IUCAKERBSA-N Pro-Arg-Gly Chemical compound NC(N)=NCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H]1CCCN1 BNBBNGZZKQUWCD-IUCAKERBSA-N 0.000 description 1
- KDIIENQUNVNWHR-JYJNAYRXSA-N Pro-Arg-Phe Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O KDIIENQUNVNWHR-JYJNAYRXSA-N 0.000 description 1
- FUVBEZJCRMHWEM-FXQIFTODSA-N Pro-Asn-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O FUVBEZJCRMHWEM-FXQIFTODSA-N 0.000 description 1
- JARJPEMLQAWNBR-GUBZILKMSA-N Pro-Asp-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JARJPEMLQAWNBR-GUBZILKMSA-N 0.000 description 1
- KIPIKSXPPLABPN-CIUDSAMLSA-N Pro-Glu-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1 KIPIKSXPPLABPN-CIUDSAMLSA-N 0.000 description 1
- MGDFPGCFVJFITQ-CIUDSAMLSA-N Pro-Glu-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O MGDFPGCFVJFITQ-CIUDSAMLSA-N 0.000 description 1
- VPEVBAUSTBWQHN-NHCYSSNCSA-N Pro-Glu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O VPEVBAUSTBWQHN-NHCYSSNCSA-N 0.000 description 1
- DMKWYMWNEKIPFC-IUCAKERBSA-N Pro-Gly-Arg Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O DMKWYMWNEKIPFC-IUCAKERBSA-N 0.000 description 1
- FEPSEIDIPBMIOS-QXEWZRGKSA-N Pro-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 FEPSEIDIPBMIOS-QXEWZRGKSA-N 0.000 description 1
- DXTOOBDIIAJZBJ-BQBZGAKWSA-N Pro-Gly-Ser Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CO)C(O)=O DXTOOBDIIAJZBJ-BQBZGAKWSA-N 0.000 description 1
- XYHMFGGWNOFUOU-QXEWZRGKSA-N Pro-Ile-Gly Chemical compound OC(=O)CNC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H]1CCCN1 XYHMFGGWNOFUOU-QXEWZRGKSA-N 0.000 description 1
- GURGCNUWVSDYTP-SRVKXCTJSA-N Pro-Leu-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GURGCNUWVSDYTP-SRVKXCTJSA-N 0.000 description 1
- ULWBBFKQBDNGOY-RWMBFGLXSA-N Pro-Lys-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCCN)C(=O)N2CCC[C@@H]2C(=O)O ULWBBFKQBDNGOY-RWMBFGLXSA-N 0.000 description 1
- HBBBLSVBQGZKOZ-GUBZILKMSA-N Pro-Met-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O HBBBLSVBQGZKOZ-GUBZILKMSA-N 0.000 description 1
- NTXFLJULRHQMDC-GUBZILKMSA-N Pro-Met-Asp Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@@H]1CCCN1 NTXFLJULRHQMDC-GUBZILKMSA-N 0.000 description 1
- HWLKHNDRXWTFTN-GUBZILKMSA-N Pro-Pro-Cys Chemical compound C1C[C@H](NC1)C(=O)N2CCC[C@H]2C(=O)N[C@@H](CS)C(=O)O HWLKHNDRXWTFTN-GUBZILKMSA-N 0.000 description 1
- PCWLNNZTBJTZRN-AVGNSLFASA-N Pro-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 PCWLNNZTBJTZRN-AVGNSLFASA-N 0.000 description 1
- GMJDSFYVTAMIBF-FXQIFTODSA-N Pro-Ser-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O GMJDSFYVTAMIBF-FXQIFTODSA-N 0.000 description 1
- SXJOPONICMGFCR-DCAQKATOSA-N Pro-Ser-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O SXJOPONICMGFCR-DCAQKATOSA-N 0.000 description 1
- KWMZPPWYBVZIER-XGEHTFHBSA-N Pro-Ser-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWMZPPWYBVZIER-XGEHTFHBSA-N 0.000 description 1
- CWZUFLWPEFHWEI-IHRRRGAJSA-N Pro-Tyr-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O CWZUFLWPEFHWEI-IHRRRGAJSA-N 0.000 description 1
- QKWYXRPICJEQAJ-KJEVXHAQSA-N Pro-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@@H]2CCCN2)O QKWYXRPICJEQAJ-KJEVXHAQSA-N 0.000 description 1
- OQSGBXGNAFQGGS-CYDGBPFRSA-N Pro-Val-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O OQSGBXGNAFQGGS-CYDGBPFRSA-N 0.000 description 1
- KHRLUIPIMIQFGT-AVGNSLFASA-N Pro-Val-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O KHRLUIPIMIQFGT-AVGNSLFASA-N 0.000 description 1
- 108700030875 Programmed Cell Death 1 Ligand 2 Proteins 0.000 description 1
- 102100024216 Programmed cell death 1 ligand 1 Human genes 0.000 description 1
- 102100024213 Programmed cell death 1 ligand 2 Human genes 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- 206010060862 Prostate cancer Diseases 0.000 description 1
- 208000000236 Prostatic Neoplasms Diseases 0.000 description 1
- 101710118538 Protease Proteins 0.000 description 1
- 241000192142 Proteobacteria Species 0.000 description 1
- 201000004681 Psoriasis Diseases 0.000 description 1
- 206010037660 Pyrexia Diseases 0.000 description 1
- 206010037742 Rabies Diseases 0.000 description 1
- 241000711798 Rabies lyssavirus Species 0.000 description 1
- 101710100963 Receptor tyrosine-protein kinase erbB-4 Proteins 0.000 description 1
- 208000015634 Rectal Neoplasms Diseases 0.000 description 1
- 241000702247 Reoviridae Species 0.000 description 1
- 108700008625 Reporter Genes Proteins 0.000 description 1
- 206010061603 Respiratory syncytial virus infection Diseases 0.000 description 1
- 241000712907 Retroviridae Species 0.000 description 1
- 241000711931 Rhabdoviridae Species 0.000 description 1
- 101000933133 Rhizopus niveus Rhizopuspepsin-1 Proteins 0.000 description 1
- 101000910082 Rhizopus niveus Rhizopuspepsin-2 Proteins 0.000 description 1
- 101000910079 Rhizopus niveus Rhizopuspepsin-3 Proteins 0.000 description 1
- 101000910086 Rhizopus niveus Rhizopuspepsin-4 Proteins 0.000 description 1
- 101000910088 Rhizopus niveus Rhizopuspepsin-5 Proteins 0.000 description 1
- 241000220010 Rhode Species 0.000 description 1
- 108091028664 Ribonucleotide Proteins 0.000 description 1
- 241000714474 Rous sarcoma virus Species 0.000 description 1
- 101150098865 SSP2 gene Proteins 0.000 description 1
- 101100123851 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) HER1 gene Proteins 0.000 description 1
- 101000898773 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) Saccharopepsin Proteins 0.000 description 1
- 241000607142 Salmonella Species 0.000 description 1
- 102100031406 Sentrin-specific protease 7 Human genes 0.000 description 1
- HRNQLKCLPVKZNE-CIUDSAMLSA-N Ser-Ala-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O HRNQLKCLPVKZNE-CIUDSAMLSA-N 0.000 description 1
- OBXVZEAMXFSGPU-FXQIFTODSA-N Ser-Asn-Arg Chemical compound C(C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CO)N)CN=C(N)N OBXVZEAMXFSGPU-FXQIFTODSA-N 0.000 description 1
- UBRXAVQWXOWRSJ-ZLUOBGJFSA-N Ser-Asn-Asp Chemical compound C([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CO)N)C(=O)N UBRXAVQWXOWRSJ-ZLUOBGJFSA-N 0.000 description 1
- FIDMVVBUOCMMJG-CIUDSAMLSA-N Ser-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO FIDMVVBUOCMMJG-CIUDSAMLSA-N 0.000 description 1
- VGNYHOBZJKWRGI-CIUDSAMLSA-N Ser-Asn-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CO VGNYHOBZJKWRGI-CIUDSAMLSA-N 0.000 description 1
- FFOKMZOAVHEWET-IMJSIDKUSA-N Ser-Cys Chemical compound OC[C@H](N)C(=O)N[C@@H](CS)C(O)=O FFOKMZOAVHEWET-IMJSIDKUSA-N 0.000 description 1
- BLPYXIXXCFVIIF-FXQIFTODSA-N Ser-Cys-Arg Chemical compound C(C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CO)N)CN=C(N)N BLPYXIXXCFVIIF-FXQIFTODSA-N 0.000 description 1
- ZHYMUFQVKGJNRM-ZLUOBGJFSA-N Ser-Cys-Asn Chemical compound OC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CC(N)=O ZHYMUFQVKGJNRM-ZLUOBGJFSA-N 0.000 description 1
- WTPKKLMBNBCCNL-ACZMJKKPSA-N Ser-Cys-Glu Chemical compound C(CC(=O)O)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CO)N WTPKKLMBNBCCNL-ACZMJKKPSA-N 0.000 description 1
- VDVYTKZBMFADQH-AVGNSLFASA-N Ser-Gln-Tyr Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 VDVYTKZBMFADQH-AVGNSLFASA-N 0.000 description 1
- BRGQQXQKPUCUJQ-KBIXCLLPSA-N Ser-Glu-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BRGQQXQKPUCUJQ-KBIXCLLPSA-N 0.000 description 1
- ZOPISOXXPQNOCO-SVSWQMSJSA-N Ser-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CO)N ZOPISOXXPQNOCO-SVSWQMSJSA-N 0.000 description 1
- VMLONWHIORGALA-SRVKXCTJSA-N Ser-Leu-Leu Chemical compound CC(C)C[C@@H](C([O-])=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CO VMLONWHIORGALA-SRVKXCTJSA-N 0.000 description 1
- HDBOEVPDIDDEPC-CIUDSAMLSA-N Ser-Lys-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O HDBOEVPDIDDEPC-CIUDSAMLSA-N 0.000 description 1
- RQXDSYQXBCRXBT-GUBZILKMSA-N Ser-Met-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@H](C(O)=O)CCCN=C(N)N RQXDSYQXBCRXBT-GUBZILKMSA-N 0.000 description 1
- ZKBKUWQVDWWSRI-BZSNNMDCSA-N Ser-Phe-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZKBKUWQVDWWSRI-BZSNNMDCSA-N 0.000 description 1
- CKDXFSPMIDSMGV-GUBZILKMSA-N Ser-Pro-Val Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O CKDXFSPMIDSMGV-GUBZILKMSA-N 0.000 description 1
- KQNDIKOYWZTZIX-FXQIFTODSA-N Ser-Ser-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCNC(N)=N KQNDIKOYWZTZIX-FXQIFTODSA-N 0.000 description 1
- WLJPJRGQRNCIQS-ZLUOBGJFSA-N Ser-Ser-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O WLJPJRGQRNCIQS-ZLUOBGJFSA-N 0.000 description 1
- GYDFRTRSSXOZCR-ACZMJKKPSA-N Ser-Ser-Glu Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O GYDFRTRSSXOZCR-ACZMJKKPSA-N 0.000 description 1
- OLKICIBQRVSQMA-SRVKXCTJSA-N Ser-Ser-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OLKICIBQRVSQMA-SRVKXCTJSA-N 0.000 description 1
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 1
- RXUOAOOZIWABBW-XGEHTFHBSA-N Ser-Thr-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N RXUOAOOZIWABBW-XGEHTFHBSA-N 0.000 description 1
- SQHKXWODKJDZRC-LKXGYXEUSA-N Ser-Thr-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O SQHKXWODKJDZRC-LKXGYXEUSA-N 0.000 description 1
- RTXKJFWHEBTABY-IHPCNDPISA-N Ser-Trp-Tyr Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CC=C(C=C3)O)C(=O)O)NC(=O)[C@H](CO)N RTXKJFWHEBTABY-IHPCNDPISA-N 0.000 description 1
- PIQRHJQWEPWFJG-UWJYBYFXSA-N Ser-Tyr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O PIQRHJQWEPWFJG-UWJYBYFXSA-N 0.000 description 1
- 102000012479 Serine Proteases Human genes 0.000 description 1
- 108010022999 Serine Proteases Proteins 0.000 description 1
- 102100021119 Serine protease HTRA1 Human genes 0.000 description 1
- 108020004459 Small interfering RNA Proteins 0.000 description 1
- 102100033928 Sodium-dependent dopamine transporter Human genes 0.000 description 1
- 101001039853 Sonchus yellow net virus Matrix protein Proteins 0.000 description 1
- 241001149963 Sporothrix schenckii Species 0.000 description 1
- 241000191940 Staphylococcus Species 0.000 description 1
- 108010090804 Streptavidin Proteins 0.000 description 1
- 241000194017 Streptococcus Species 0.000 description 1
- 241000244177 Strongyloides stercoralis Species 0.000 description 1
- 241000282887 Suidae Species 0.000 description 1
- 230000006044 T cell activation Effects 0.000 description 1
- 230000024932 T cell mediated immunity Effects 0.000 description 1
- 208000000389 T-cell leukemia Diseases 0.000 description 1
- 208000028530 T-cell lymphoblastic leukemia/lymphoma Diseases 0.000 description 1
- 108700026226 TATA Box Proteins 0.000 description 1
- 244000269722 Thea sinensis Species 0.000 description 1
- 241000204652 Thermotoga Species 0.000 description 1
- DWYAUVCQDTZIJI-VZFHVOOUSA-N Thr-Ala-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O DWYAUVCQDTZIJI-VZFHVOOUSA-N 0.000 description 1
- DGDCHPCRMWEOJR-FQPOAREZSA-N Thr-Ala-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 DGDCHPCRMWEOJR-FQPOAREZSA-N 0.000 description 1
- GLQFKOVWXPPFTP-VEVYYDQMSA-N Thr-Arg-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O GLQFKOVWXPPFTP-VEVYYDQMSA-N 0.000 description 1
- TWLMXDWFVNEFFK-FJXKBIBVSA-N Thr-Arg-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O TWLMXDWFVNEFFK-FJXKBIBVSA-N 0.000 description 1
- DSLHSTIUAPKERR-XGEHTFHBSA-N Thr-Cys-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O DSLHSTIUAPKERR-XGEHTFHBSA-N 0.000 description 1
- DJDSEDOKJTZBAR-ZDLURKLDSA-N Thr-Gly-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O DJDSEDOKJTZBAR-ZDLURKLDSA-N 0.000 description 1
- KBBRNEDOYWMIJP-KYNKHSRBSA-N Thr-Gly-Thr Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KBBRNEDOYWMIJP-KYNKHSRBSA-N 0.000 description 1
- JKGGPMOUIAAJAA-YEPSODPASA-N Thr-Gly-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O JKGGPMOUIAAJAA-YEPSODPASA-N 0.000 description 1
- WPSDXXQRIVKBAY-NKIYYHGXSA-N Thr-His-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O WPSDXXQRIVKBAY-NKIYYHGXSA-N 0.000 description 1
- IMDMLDSVUSMAEJ-HJGDQZAQSA-N Thr-Leu-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IMDMLDSVUSMAEJ-HJGDQZAQSA-N 0.000 description 1
- IJVNLNRVDUTWDD-MEYUZBJRSA-N Thr-Leu-Tyr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O IJVNLNRVDUTWDD-MEYUZBJRSA-N 0.000 description 1
- XSEPSRUDSPHMPX-KATARQTJSA-N Thr-Lys-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O XSEPSRUDSPHMPX-KATARQTJSA-N 0.000 description 1
- KPNSNVTUVKSBFL-ZJDVBMNYSA-N Thr-Met-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KPNSNVTUVKSBFL-ZJDVBMNYSA-N 0.000 description 1
- MXNAOGFNFNKUPD-JHYOHUSXSA-N Thr-Phe-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MXNAOGFNFNKUPD-JHYOHUSXSA-N 0.000 description 1
- MXDOAJQRJBMGMO-FJXKBIBVSA-N Thr-Pro-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O MXDOAJQRJBMGMO-FJXKBIBVSA-N 0.000 description 1
- YGCDFAJJCRVQKU-RCWTZXSCSA-N Thr-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O YGCDFAJJCRVQKU-RCWTZXSCSA-N 0.000 description 1
- FWTFAZKJORVTIR-VZFHVOOUSA-N Thr-Ser-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O FWTFAZKJORVTIR-VZFHVOOUSA-N 0.000 description 1
- STUAPCLEDMKXKL-LKXGYXEUSA-N Thr-Ser-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O STUAPCLEDMKXKL-LKXGYXEUSA-N 0.000 description 1
- VGNKUXWYFFDWDH-BEMMVCDISA-N Thr-Trp-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N3CCC[C@@H]3C(=O)O)N)O VGNKUXWYFFDWDH-BEMMVCDISA-N 0.000 description 1
- YOPQYBJJNSIQGZ-JNPHEJMOSA-N Thr-Tyr-Tyr Chemical compound C([C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 YOPQYBJJNSIQGZ-JNPHEJMOSA-N 0.000 description 1
- 102000035100 Threonine proteases Human genes 0.000 description 1
- 108091005501 Threonine proteases Proteins 0.000 description 1
- 241000710924 Togaviridae Species 0.000 description 1
- 241000223997 Toxoplasma gondii Species 0.000 description 1
- 102000040945 Transcription factor Human genes 0.000 description 1
- 108091023040 Transcription factor Proteins 0.000 description 1
- 102100023935 Transmembrane glycoprotein NMB Human genes 0.000 description 1
- 101800001690 Transmembrane protein gp41 Proteins 0.000 description 1
- 241000242541 Trematoda Species 0.000 description 1
- 239000007983 Tris buffer Substances 0.000 description 1
- HQJOVVWAPQPYDS-ZFWWWQNUSA-N Trp-Gly-Arg Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O HQJOVVWAPQPYDS-ZFWWWQNUSA-N 0.000 description 1
- YRXXUYPYPHRJPB-RXVVDRJESA-N Trp-Gly-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)NCC(=O)N[C@@H](CC3=CNC4=CC=CC=C43)C(=O)O)N YRXXUYPYPHRJPB-RXVVDRJESA-N 0.000 description 1
- WSGPBCAGEGHKQJ-BBRMVZONSA-N Trp-Gly-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC1=CNC2=CC=CC=C21)N WSGPBCAGEGHKQJ-BBRMVZONSA-N 0.000 description 1
- GQHAIUPYZPTADF-FDARSICLSA-N Trp-Ile-Arg Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 GQHAIUPYZPTADF-FDARSICLSA-N 0.000 description 1
- UJRIVCPPPMYCNA-HOCLYGCPSA-N Trp-Leu-Gly Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N UJRIVCPPPMYCNA-HOCLYGCPSA-N 0.000 description 1
- RRVUOLRWIZXBRQ-IHPCNDPISA-N Trp-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N RRVUOLRWIZXBRQ-IHPCNDPISA-N 0.000 description 1
- NLLARHRWSFNEMH-NUTKFTJISA-N Trp-Lys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N NLLARHRWSFNEMH-NUTKFTJISA-N 0.000 description 1
- RERRMBXDSFMBQE-ZFWWWQNUSA-N Trp-Met-Gly Chemical compound CSCC[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N RERRMBXDSFMBQE-ZFWWWQNUSA-N 0.000 description 1
- ZZDFLJFVSNQINX-HWHUXHBOSA-N Trp-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N)O ZZDFLJFVSNQINX-HWHUXHBOSA-N 0.000 description 1
- SUGLEXVWEJOCGN-ONUFPDRFSA-N Trp-Thr-Trp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC3=CNC4=CC=CC=C43)N)O SUGLEXVWEJOCGN-ONUFPDRFSA-N 0.000 description 1
- SSSDKJMQMZTMJP-BVSLBCMMSA-N Trp-Tyr-Val Chemical compound C([C@@H](C(=O)N[C@@H](C(C)C)C(O)=O)NC(=O)[C@@H](N)CC=1C2=CC=CC=C2NC=1)C1=CC=C(O)C=C1 SSSDKJMQMZTMJP-BVSLBCMMSA-N 0.000 description 1
- UGFOSENEZHEQKX-PJODQICGSA-N Trp-Val-Ala Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)Cc1c[nH]c2ccccc12)C(=O)N[C@@H](C)C(O)=O UGFOSENEZHEQKX-PJODQICGSA-N 0.000 description 1
- 241000223109 Trypanosoma cruzi Species 0.000 description 1
- 102000044209 Tumor Suppressor Genes Human genes 0.000 description 1
- 108700025716 Tumor Suppressor Genes Proteins 0.000 description 1
- 102000001742 Tumor Suppressor Proteins Human genes 0.000 description 1
- 108010040002 Tumor Suppressor Proteins Proteins 0.000 description 1
- 241001584775 Tunga penetrans Species 0.000 description 1
- DYEGCOJHFNJBKB-UFYCRDLUSA-N Tyr-Arg-Tyr Chemical compound C([C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 DYEGCOJHFNJBKB-UFYCRDLUSA-N 0.000 description 1
- AYHSJESDFKREAR-KKUMJFAQSA-N Tyr-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 AYHSJESDFKREAR-KKUMJFAQSA-N 0.000 description 1
- IUQDEKCCHWRHRW-IHPCNDPISA-N Tyr-Asn-Trp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O IUQDEKCCHWRHRW-IHPCNDPISA-N 0.000 description 1
- NSTPFWRAIDTNGH-BZSNNMDCSA-N Tyr-Asn-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O NSTPFWRAIDTNGH-BZSNNMDCSA-N 0.000 description 1
- VFJIWSJKZJTQII-SRVKXCTJSA-N Tyr-Asp-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O VFJIWSJKZJTQII-SRVKXCTJSA-N 0.000 description 1
- UABYBEBXFFNCIR-YDHLFZDLSA-N Tyr-Asp-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UABYBEBXFFNCIR-YDHLFZDLSA-N 0.000 description 1
- SMLCYZYQFRTLCO-UWJYBYFXSA-N Tyr-Cys-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O SMLCYZYQFRTLCO-UWJYBYFXSA-N 0.000 description 1
- FFCRCJZJARTYCG-KKUMJFAQSA-N Tyr-Cys-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)O)N)O FFCRCJZJARTYCG-KKUMJFAQSA-N 0.000 description 1
- SLCSPPCQWUHPPO-JYJNAYRXSA-N Tyr-Glu-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 SLCSPPCQWUHPPO-JYJNAYRXSA-N 0.000 description 1
- HDSKHCBAVVWPCQ-FHWLQOOXSA-N Tyr-Glu-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O HDSKHCBAVVWPCQ-FHWLQOOXSA-N 0.000 description 1
- ZMKDQRJLMRZHRI-ACRUOGEOSA-N Tyr-Phe-His Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N ZMKDQRJLMRZHRI-ACRUOGEOSA-N 0.000 description 1
- GQVZBMROTPEPIF-SRVKXCTJSA-N Tyr-Ser-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O GQVZBMROTPEPIF-SRVKXCTJSA-N 0.000 description 1
- QPOUERMDWKKZEG-HJPIBITLSA-N Tyr-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 QPOUERMDWKKZEG-HJPIBITLSA-N 0.000 description 1
- RIVVDNTUSRVTQT-IRIUXVKKSA-N Tyr-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O RIVVDNTUSRVTQT-IRIUXVKKSA-N 0.000 description 1
- KRXFXDCNKLANCP-CXTHYWKRSA-N Tyr-Tyr-Ile Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(O)=O)NC(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 KRXFXDCNKLANCP-CXTHYWKRSA-N 0.000 description 1
- SQUMHUZLJDUROQ-YDHLFZDLSA-N Tyr-Val-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O SQUMHUZLJDUROQ-YDHLFZDLSA-N 0.000 description 1
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 description 1
- 241000700618 Vaccinia virus Species 0.000 description 1
- VJOWWOGRNXRQMF-UVBJJODRSA-N Val-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 VJOWWOGRNXRQMF-UVBJJODRSA-N 0.000 description 1
- LABUITCFCAABSV-UHFFFAOYSA-N Val-Ala-Tyr Natural products CC(C)C(N)C(=O)NC(C)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LABUITCFCAABSV-UHFFFAOYSA-N 0.000 description 1
- JIODCDXKCJRMEH-NHCYSSNCSA-N Val-Arg-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N JIODCDXKCJRMEH-NHCYSSNCSA-N 0.000 description 1
- QPZMOUMNTGTEFR-ZKWXMUAHSA-N Val-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](C(C)C)N QPZMOUMNTGTEFR-ZKWXMUAHSA-N 0.000 description 1
- XQVRMLRMTAGSFJ-QXEWZRGKSA-N Val-Asp-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N XQVRMLRMTAGSFJ-QXEWZRGKSA-N 0.000 description 1
- HZYOWMGWKKRMBZ-BYULHYEWSA-N Val-Asp-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N HZYOWMGWKKRMBZ-BYULHYEWSA-N 0.000 description 1
- PWRITNSESKQTPW-NRPADANISA-N Val-Gln-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N PWRITNSESKQTPW-NRPADANISA-N 0.000 description 1
- SZTTYWIUCGSURQ-AUTRQRHGSA-N Val-Glu-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SZTTYWIUCGSURQ-AUTRQRHGSA-N 0.000 description 1
- VCAWFLIWYNMHQP-UKJIMTQDSA-N Val-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N VCAWFLIWYNMHQP-UKJIMTQDSA-N 0.000 description 1
- OQWNEUXPKHIEJO-NRPADANISA-N Val-Glu-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N OQWNEUXPKHIEJO-NRPADANISA-N 0.000 description 1
- DJEVQCWNMQOABE-RCOVLWMOSA-N Val-Gly-Asp Chemical compound CC(C)[C@@H](C(=O)NCC(=O)N[C@@H](CC(=O)O)C(=O)O)N DJEVQCWNMQOABE-RCOVLWMOSA-N 0.000 description 1
- PIFJAFRUVWZRKR-QMMMGPOBSA-N Val-Gly-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)NCC(=O)NCC([O-])=O PIFJAFRUVWZRKR-QMMMGPOBSA-N 0.000 description 1
- LAYSXAOGWHKNED-XPUUQOCRSA-N Val-Gly-Ser Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O LAYSXAOGWHKNED-XPUUQOCRSA-N 0.000 description 1
- OPGWZDIYEYJVRX-AVGNSLFASA-N Val-His-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N OPGWZDIYEYJVRX-AVGNSLFASA-N 0.000 description 1
- MJXNDRCLGDSBBE-FHWLQOOXSA-N Val-His-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N MJXNDRCLGDSBBE-FHWLQOOXSA-N 0.000 description 1
- SDUBQHUJJWQTEU-XUXIUFHCSA-N Val-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](C(C)C)N SDUBQHUJJWQTEU-XUXIUFHCSA-N 0.000 description 1
- OVBMCNDKCWAXMZ-NAKRPEOUSA-N Val-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](C(C)C)N OVBMCNDKCWAXMZ-NAKRPEOUSA-N 0.000 description 1
- BZWUSZGQOILYEU-STECZYCISA-N Val-Ile-Tyr Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 BZWUSZGQOILYEU-STECZYCISA-N 0.000 description 1
- DJQIUOKSNRBTSV-CYDGBPFRSA-N Val-Ile-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](C(C)C)N DJQIUOKSNRBTSV-CYDGBPFRSA-N 0.000 description 1
- KISFXYYRKKNLOP-IHRRRGAJSA-N Val-Phe-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)O)N KISFXYYRKKNLOP-IHRRRGAJSA-N 0.000 description 1
- UGFMVXRXULGLNO-XPUUQOCRSA-N Val-Ser-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O UGFMVXRXULGLNO-XPUUQOCRSA-N 0.000 description 1
- QTPQHINADBYBNA-DCAQKATOSA-N Val-Ser-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN QTPQHINADBYBNA-DCAQKATOSA-N 0.000 description 1
- USXYVSTVPHELAF-RCWTZXSCSA-N Val-Thr-Met Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](C(C)C)N)O USXYVSTVPHELAF-RCWTZXSCSA-N 0.000 description 1
- 206010046980 Varicella Diseases 0.000 description 1
- 241000700647 Variola virus Species 0.000 description 1
- 102000005789 Vascular Endothelial Growth Factors Human genes 0.000 description 1
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 description 1
- 241001416177 Vicugna pacos Species 0.000 description 1
- 241000405217 Viola <butterfly> Species 0.000 description 1
- 230000010530 Virus Neutralization Effects 0.000 description 1
- 241000244005 Wuchereria bancrofti Species 0.000 description 1
- 241000607734 Yersinia <bacteria> Species 0.000 description 1
- 241000607479 Yersinia pestis Species 0.000 description 1
- HCHKCACWOHOZIP-UHFFFAOYSA-N Zinc Chemical compound [Zn] HCHKCACWOHOZIP-UHFFFAOYSA-N 0.000 description 1
- 206010061418 Zygomycosis Diseases 0.000 description 1
- SXEHKFHPFVVDIR-UHFFFAOYSA-N [4-(4-hydrazinylphenyl)phenyl]hydrazine Chemical compound C1=CC(NN)=CC=C1C1=CC=C(NN)C=C1 SXEHKFHPFVVDIR-UHFFFAOYSA-N 0.000 description 1
- 230000035508 accumulation Effects 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- 230000003213 activating effect Effects 0.000 description 1
- 230000006786 activation induced cell death Effects 0.000 description 1
- 239000004480 active ingredient Substances 0.000 description 1
- 230000000996 additive effect Effects 0.000 description 1
- 229960000643 adenine Drugs 0.000 description 1
- 108700010877 adenoviridae proteins Proteins 0.000 description 1
- 241001148470 aerobic bacillus Species 0.000 description 1
- 108010005233 alanylglutamic acid Proteins 0.000 description 1
- 108010070944 alanylhistidine Proteins 0.000 description 1
- 108010011559 alanylphenylalanine Proteins 0.000 description 1
- 230000007815 allergy Effects 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- 208000025009 anogenital human papillomavirus infection Diseases 0.000 description 1
- 201000004201 anogenital venereal wart Diseases 0.000 description 1
- 230000000507 anthelmentic effect Effects 0.000 description 1
- PYKYMHQGRFAEBM-UHFFFAOYSA-N anthraquinone Natural products CCC(=O)c1c(O)c2C(=O)C3C(C=CC=C3O)C(=O)c2cc1CC(=O)OC PYKYMHQGRFAEBM-UHFFFAOYSA-N 0.000 description 1
- 150000004056 anthraquinones Chemical class 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 201000007201 aphasia Diseases 0.000 description 1
- 108010069926 arginyl-glycyl-serine Proteins 0.000 description 1
- 206010003246 arthritis Diseases 0.000 description 1
- 208000006673 asthma Diseases 0.000 description 1
- 108010088716 attachment protein G Proteins 0.000 description 1
- 230000003190 augmentative effect Effects 0.000 description 1
- 229940120638 avastin Drugs 0.000 description 1
- 229940065181 bacillus anthracis Drugs 0.000 description 1
- 208000007456 balantidiasis Diseases 0.000 description 1
- 230000004888 barrier function Effects 0.000 description 1
- 235000015278 beef Nutrition 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 229960000397 bevacizumab Drugs 0.000 description 1
- 239000003124 biologic agent Substances 0.000 description 1
- 210000004369 blood Anatomy 0.000 description 1
- 239000008280 blood Substances 0.000 description 1
- 229910021538 borax Inorganic materials 0.000 description 1
- 238000004422 calculation algorithm Methods 0.000 description 1
- 230000036952 cancer formation Effects 0.000 description 1
- 201000003984 candidiasis Diseases 0.000 description 1
- 210000000234 capsid Anatomy 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 230000036755 cellular response Effects 0.000 description 1
- 201000010881 cervical cancer Diseases 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 229960001231 choline Drugs 0.000 description 1
- OEYIOHPDSNJKLS-UHFFFAOYSA-N choline Chemical compound C[N+](C)(C)CCO OEYIOHPDSNJKLS-UHFFFAOYSA-N 0.000 description 1
- 239000003593 chromogenic compound Substances 0.000 description 1
- 210000000349 chromosome Anatomy 0.000 description 1
- 229960002376 chymotrypsin Drugs 0.000 description 1
- 229960003920 cocaine Drugs 0.000 description 1
- 230000000112 colonic effect Effects 0.000 description 1
- 238000002648 combination therapy Methods 0.000 description 1
- 229940001442 combination vaccine Drugs 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 230000000052 comparative effect Effects 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 239000013068 control sample Substances 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 239000013078 crystal Substances 0.000 description 1
- 239000012228 culture supernatant Substances 0.000 description 1
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 1
- 108010004073 cysteinylcysteine Proteins 0.000 description 1
- 230000016396 cytokine production Effects 0.000 description 1
- 210000005220 cytoplasmic tail Anatomy 0.000 description 1
- 229940104302 cytosine Drugs 0.000 description 1
- 231100000433 cytotoxic Toxicity 0.000 description 1
- 238000011393 cytotoxic chemotherapy Methods 0.000 description 1
- 230000001472 cytotoxic effect Effects 0.000 description 1
- 230000002950 deficient Effects 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 210000004443 dendritic cell Anatomy 0.000 description 1
- 238000001514 detection method Methods 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- 206010012601 diabetes mellitus Diseases 0.000 description 1
- RAABOESOVLLHRU-UHFFFAOYSA-N diazene Chemical compound N=N RAABOESOVLLHRU-UHFFFAOYSA-N 0.000 description 1
- 229910000071 diazene Inorganic materials 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- 239000000539 dimer Substances 0.000 description 1
- 206010013023 diphtheria Diseases 0.000 description 1
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 238000005553 drilling Methods 0.000 description 1
- 230000005520 electrodynamics Effects 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 229940066758 endopeptidases Drugs 0.000 description 1
- 210000002889 endothelial cell Anatomy 0.000 description 1
- 229940088598 enzyme Drugs 0.000 description 1
- 229940116977 epidermal growth factor Drugs 0.000 description 1
- 210000003527 eukaryotic cell Anatomy 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 238000002474 experimental method Methods 0.000 description 1
- 238000010195 expression analysis Methods 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 238000000855 fermentation Methods 0.000 description 1
- 230000004151 fermentation Effects 0.000 description 1
- 210000002950 fibroblast Anatomy 0.000 description 1
- 238000007667 floating Methods 0.000 description 1
- 229940014144 folate Drugs 0.000 description 1
- 235000019152 folic acid Nutrition 0.000 description 1
- 239000011724 folic acid Substances 0.000 description 1
- 230000000855 fungicidal effect Effects 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 230000004077 genetic alteration Effects 0.000 description 1
- 231100000118 genetic alteration Toxicity 0.000 description 1
- 229940085435 giardia lamblia Drugs 0.000 description 1
- 229930195712 glutamate Natural products 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 150000004676 glycans Chemical class 0.000 description 1
- 108010075431 glycyl-alanyl-phenylalanine Proteins 0.000 description 1
- 108010078326 glycyl-glycyl-valine Proteins 0.000 description 1
- 108010074027 glycyl-seryl-phenylalanine Proteins 0.000 description 1
- 108010084389 glycyltryptophan Proteins 0.000 description 1
- 201000009277 hairy cell leukemia Diseases 0.000 description 1
- 201000010536 head and neck cancer Diseases 0.000 description 1
- 208000014829 head and neck neoplasm Diseases 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 208000014951 hematologic disease Diseases 0.000 description 1
- 208000018706 hematopoietic system disease Diseases 0.000 description 1
- 208000005252 hepatitis A Diseases 0.000 description 1
- 229940022353 herceptin Drugs 0.000 description 1
- 239000000833 heterodimer Substances 0.000 description 1
- 108010085325 histidylproline Proteins 0.000 description 1
- 208000029080 human African trypanosomiasis Diseases 0.000 description 1
- 229940116978 human epidermal growth factor Drugs 0.000 description 1
- 208000033519 human immunodeficiency virus infectious disease Diseases 0.000 description 1
- 229940048921 humira Drugs 0.000 description 1
- 230000005934 immune activation Effects 0.000 description 1
- 230000008004 immune attack Effects 0.000 description 1
- 230000007813 immunodeficiency Effects 0.000 description 1
- 238000010166 immunofluorescence Methods 0.000 description 1
- 238000003125 immunofluorescent labeling Methods 0.000 description 1
- 229940072221 immunoglobulins Drugs 0.000 description 1
- 238000009169 immunotherapy Methods 0.000 description 1
- 230000001976 improved effect Effects 0.000 description 1
- 239000000411 inducer Substances 0.000 description 1
- 230000002458 infectious effect Effects 0.000 description 1
- 230000002757 inflammatory effect Effects 0.000 description 1
- 230000004054 inflammatory process Effects 0.000 description 1
- 238000001802 infusion Methods 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 229960003786 inosine Drugs 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 239000000543 intermediate Substances 0.000 description 1
- 201000002313 intestinal cancer Diseases 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 150000002500 ions Chemical class 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 1
- 108010078274 isoleucylvaline Proteins 0.000 description 1
- 239000000644 isotonic solution Substances 0.000 description 1
- 206010023332 keratitis Diseases 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- 238000011031 large-scale manufacturing process Methods 0.000 description 1
- 229940067606 lecithin Drugs 0.000 description 1
- 235000010445 lecithin Nutrition 0.000 description 1
- 239000000787 lecithin Substances 0.000 description 1
- 108010034529 leucyl-lysine Proteins 0.000 description 1
- 108010090333 leucyl-lysyl-proline Proteins 0.000 description 1
- 108010044056 leucyl-phenylalanine Proteins 0.000 description 1
- 108010012058 leucyltyrosine Proteins 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 238000003670 luciferase enzyme activity assay Methods 0.000 description 1
- 239000006166 lysate Substances 0.000 description 1
- 108010003700 lysyl aspartic acid Proteins 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 238000002483 medication Methods 0.000 description 1
- 201000001441 melanoma Diseases 0.000 description 1
- 238000002844 melting Methods 0.000 description 1
- 230000008018 melting Effects 0.000 description 1
- 239000012528 membrane Substances 0.000 description 1
- 210000003071 memory t lymphocyte Anatomy 0.000 description 1
- 230000003340 mental effect Effects 0.000 description 1
- 229910021645 metal ion Inorganic materials 0.000 description 1
- 108010056582 methionylglutamic acid Proteins 0.000 description 1
- 108010005942 methionylglycine Proteins 0.000 description 1
- 229960003085 meticillin Drugs 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 201000007524 mucormycosis Diseases 0.000 description 1
- 125000001446 muramyl group Chemical group N[C@@H](C=O)[C@@H](O[C@@H](C(=O)*)C)[C@H](O)[C@H](O)CO 0.000 description 1
- 201000008026 nephroblastoma Diseases 0.000 description 1
- GVUGOAYIVIDWIO-UFWWTJHBSA-N nepidermin Chemical compound C([C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)NC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](NC(=O)[C@H](CS)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CS)NC(=O)[C@H](C)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CCSC)NC(=O)[C@H](CS)NC(=O)[C@@H](NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CS)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CS)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O)C(C)C)[C@@H](C)CC)C(C)C)C(C)C)C1=CC=C(O)C=C1 GVUGOAYIVIDWIO-UFWWTJHBSA-N 0.000 description 1
- 230000003448 neutrophilic effect Effects 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 235000016709 nutrition Nutrition 0.000 description 1
- 230000035764 nutrition Effects 0.000 description 1
- 208000002042 onchocerciasis Diseases 0.000 description 1
- 238000011275 oncology therapy Methods 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 210000001672 ovary Anatomy 0.000 description 1
- 230000001575 pathological effect Effects 0.000 description 1
- 230000007170 pathology Effects 0.000 description 1
- 230000035515 penetration Effects 0.000 description 1
- 229940111202 pepsin Drugs 0.000 description 1
- 229940021222 peritoneal dialysis isotonic solution Drugs 0.000 description 1
- 238000002823 phage display Methods 0.000 description 1
- 239000008194 pharmaceutical composition Substances 0.000 description 1
- 108010012581 phenylalanylglutamate Proteins 0.000 description 1
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 1
- 238000000053 physical method Methods 0.000 description 1
- 230000009894 physiological stress Effects 0.000 description 1
- 239000004033 plastic Substances 0.000 description 1
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 1
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 1
- 229920000136 polysorbate Polymers 0.000 description 1
- 229920002223 polystyrene Polymers 0.000 description 1
- 239000000843 powder Substances 0.000 description 1
- 108010029020 prolylglycine Proteins 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 230000004853 protein function Effects 0.000 description 1
- 230000001823 pruritic effect Effects 0.000 description 1
- 150000003212 purines Chemical class 0.000 description 1
- 239000002510 pyrogen Substances 0.000 description 1
- JFINOWIINSTUNY-UHFFFAOYSA-N pyrrolidin-3-ylmethanesulfonamide Chemical compound NS(=O)(=O)CC1CCNC1 JFINOWIINSTUNY-UHFFFAOYSA-N 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 150000004053 quinones Chemical class 0.000 description 1
- 102000027426 receptor tyrosine kinases Human genes 0.000 description 1
- 108091008598 receptor tyrosine kinases Proteins 0.000 description 1
- 238000010188 recombinant method Methods 0.000 description 1
- 206010038038 rectal cancer Diseases 0.000 description 1
- 201000001275 rectum cancer Diseases 0.000 description 1
- 230000022532 regulation of transcription, DNA-dependent Effects 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 206010039073 rheumatoid arthritis Diseases 0.000 description 1
- 239000002336 ribonucleotide Substances 0.000 description 1
- 125000002652 ribonucleotide group Chemical group 0.000 description 1
- 210000003705 ribosome Anatomy 0.000 description 1
- 229960004641 rituximab Drugs 0.000 description 1
- 201000004409 schistosomiasis Diseases 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 208000007056 sickle cell anemia Diseases 0.000 description 1
- 230000019491 signal transduction Effects 0.000 description 1
- 229940068638 simponi Drugs 0.000 description 1
- 235000020183 skimmed milk Nutrition 0.000 description 1
- 201000002612 sleeping sickness Diseases 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 239000004328 sodium tetraborate Substances 0.000 description 1
- 235000010339 sodium tetraborate Nutrition 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 125000006850 spacer group Chemical group 0.000 description 1
- 241000894007 species Species 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 229940071598 stelara Drugs 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 125000001424 substituent group Chemical group 0.000 description 1
- 229940036185 synagis Drugs 0.000 description 1
- 208000006379 syphilis Diseases 0.000 description 1
- 201000000596 systemic lupus erythematosus Diseases 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- 230000008646 thermal stress Effects 0.000 description 1
- 208000037816 tissue injury Diseases 0.000 description 1
- 230000005026 transcription initiation Effects 0.000 description 1
- 230000014621 translational initiation Effects 0.000 description 1
- 108091007466 transmembrane glycoproteins Proteins 0.000 description 1
- 102000035160 transmembrane proteins Human genes 0.000 description 1
- 108091005703 transmembrane proteins Proteins 0.000 description 1
- 230000001960 triggered effect Effects 0.000 description 1
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 1
- 208000037972 tropical disease Diseases 0.000 description 1
- 230000005740 tumor formation Effects 0.000 description 1
- 229940046728 tumor necrosis factor alpha inhibitor Drugs 0.000 description 1
- 239000002451 tumor necrosis factor inhibitor Substances 0.000 description 1
- 238000002604 ultrasonography Methods 0.000 description 1
- 241001148471 unidentified anaerobic bacterium Species 0.000 description 1
- 241000701447 unidentified baculovirus Species 0.000 description 1
- VBEQCZHXXJYVRD-GACYYNSASA-N uroanthelone Chemical compound C([C@@H](C(=O)N[C@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)C(C)C)[C@@H](C)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H](CCSC)NC(=O)[C@H](CS)NC(=O)[C@@H](NC(=O)CNC(=O)CNC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CS)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@H](CO)NC(=O)[C@H]1N(CCC1)C(=O)[C@H](CS)NC(=O)CNC(=O)[C@H]1N(CCC1)C(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O)C(C)C)[C@@H](C)CC)C1=CC=C(O)C=C1 VBEQCZHXXJYVRD-GACYYNSASA-N 0.000 description 1
- 210000002229 urogenital system Anatomy 0.000 description 1
- 229960003824 ustekinumab Drugs 0.000 description 1
- 239000005526 vasoconstrictor agent Substances 0.000 description 1
- 230000029812 viral genome replication Effects 0.000 description 1
- 238000005406 washing Methods 0.000 description 1
- 229940055760 yervoy Drugs 0.000 description 1
- 229910052725 zinc Inorganic materials 0.000 description 1
- 239000011701 zinc Substances 0.000 description 1
Images




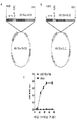

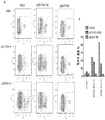



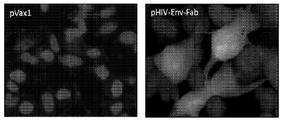

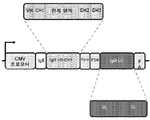









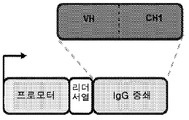


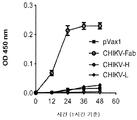
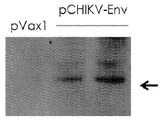
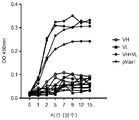


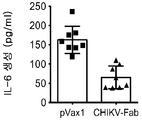
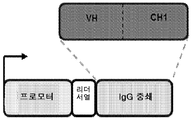
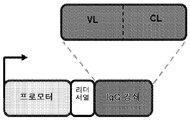








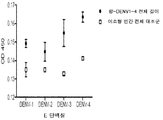









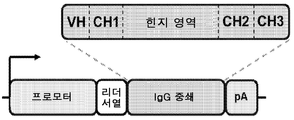












Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/08—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses
- C07K16/10—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses from RNA viruses
- C07K16/1081—Togaviridae, e.g. flavivirus, rubella virus, hog cholera virus
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/70—Carbohydrates; Sugars; Derivatives thereof
- A61K31/7088—Compounds having three or more nucleosides or nucleotides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/12—Viral antigens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/12—Viral antigens
- A61K39/21—Retroviridae, e.g. equine infectious anemia virus
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
- A61K39/42—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum viral
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/463—Cellular immunotherapy characterised by recombinant expression
- A61K39/4633—Antibodies or T cell engagers
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
- A61P31/14—Antivirals for RNA viruses
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
- A61P31/14—Antivirals for RNA viruses
- A61P31/18—Antivirals for RNA viruses for HIV
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P31/00—Antiinfectives, i.e. antibiotics, antiseptics, chemotherapeutics
- A61P31/12—Antivirals
- A61P31/20—Antivirals for DNA viruses
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/08—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/08—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses
- C07K16/10—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses from RNA viruses
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/08—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses
- C07K16/10—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from viruses from RNA viruses
- C07K16/1036—Retroviridae, e.g. leukemia viruses
- C07K16/1045—Lentiviridae, e.g. HIV, FIV, SIV
- C07K16/1063—Lentiviridae, e.g. HIV, FIV, SIV env, e.g. gp41, gp110/120, gp160, V3, PND, CD4 binding site
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/32—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against translation products of oncogenes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N7/00—Viruses; Bacteriophages; Compositions thereof; Preparation or purification thereof
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/51—Medicinal preparations containing antigens or antibodies comprising whole cells, viruses or DNA/RNA
- A61K2039/53—DNA (RNA) vaccination
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2121/00—Preparations for use in therapy
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2300/00—Mixtures or combinations of active ingredients, wherein at least one active ingredient is fully defined in groups A61K31/00 - A61K41/00
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
- A61K48/005—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'active' part of the composition delivered, i.e. the nucleic acid delivered
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61M—DEVICES FOR INTRODUCING MEDIA INTO, OR ONTO, THE BODY; DEVICES FOR TRANSDUCING BODY MEDIA OR FOR TAKING MEDIA FROM THE BODY; DEVICES FOR PRODUCING OR ENDING SLEEP OR STUPOR
- A61M37/00—Other apparatus for introducing media into the body; Percutany, i.e. introducing medicines into the body by diffusion through the skin
- A61M2037/0007—Other apparatus for introducing media into the body; Percutany, i.e. introducing medicines into the body by diffusion through the skin having means for enhancing the permeation of substances through the epidermis, e.g. using suction or depression, electric or magnetic fields, sound waves or chemical agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/10—Immunoglobulins specific features characterized by their source of isolation or production
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/10—Immunoglobulins specific features characterized by their source of isolation or production
- C07K2317/14—Specific host cells or culture conditions, e.g. components, pH or temperature
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/21—Immunoglobulins specific features characterized by taxonomic origin from primates, e.g. man
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/55—Fab or Fab'
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/60—Immunoglobulins specific features characterized by non-natural combinations of immunoglobulin fragments
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2740/00—Reverse transcribing RNA viruses
- C12N2740/00011—Details
- C12N2740/10011—Retroviridae
- C12N2740/16011—Human Immunodeficiency Virus, HIV
- C12N2740/16034—Use of virus or viral component as vaccine, e.g. live-attenuated or inactivated virus, VLP, viral protein
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2740/00—Reverse transcribing RNA viruses
- C12N2740/00011—Details
- C12N2740/10011—Retroviridae
- C12N2740/16011—Human Immunodeficiency Virus, HIV
- C12N2740/16111—Human Immunodeficiency Virus, HIV concerning HIV env
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2740/00—Reverse transcribing RNA viruses
- C12N2740/00011—Details
- C12N2740/10011—Retroviridae
- C12N2740/16011—Human Immunodeficiency Virus, HIV
- C12N2740/16111—Human Immunodeficiency Virus, HIV concerning HIV env
- C12N2740/16134—Use of virus or viral component as vaccine, e.g. live-attenuated or inactivated virus, VLP, viral protein
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2770/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses positive-sense
- C12N2770/00011—Details
- C12N2770/24011—Flaviviridae
- C12N2770/24111—Flavivirus, e.g. yellow fever virus, dengue, JEV
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2770/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses positive-sense
- C12N2770/00011—Details
- C12N2770/24011—Flaviviridae
- C12N2770/24111—Flavivirus, e.g. yellow fever virus, dengue, JEV
- C12N2770/24134—Use of virus or viral component as vaccine, e.g. live-attenuated or inactivated virus, VLP, viral protein
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2770/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses positive-sense
- C12N2770/00011—Details
- C12N2770/36011—Togaviridae
- C12N2770/36034—Use of virus or viral component as vaccine, e.g. live-attenuated or inactivated virus, VLP, viral protein
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2770/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssRNA viruses positive-sense
- C12N2770/00011—Details
- C12N2770/36011—Togaviridae
- C12N2770/36111—Alphavirus, e.g. Sindbis virus, VEE, EEE, WEE, Semliki
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02A—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE
- Y02A50/00—TECHNOLOGIES FOR ADAPTATION TO CLIMATE CHANGE in human health protection, e.g. against extreme weather
- Y02A50/30—Against vector-borne diseases, e.g. mosquito-borne, fly-borne, tick-borne or waterborne diseases whose impact is exacerbated by climate change
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Virology (AREA)
- Medicinal Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Immunology (AREA)
- Molecular Biology (AREA)
- Genetics & Genomics (AREA)
- Biochemistry (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biophysics (AREA)
- Oncology (AREA)
- Epidemiology (AREA)
- Engineering & Computer Science (AREA)
- Microbiology (AREA)
- Communicable Diseases (AREA)
- Mycology (AREA)
- Hematology (AREA)
- Biotechnology (AREA)
- AIDS & HIV (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Biomedical Technology (AREA)
- General Engineering & Computer Science (AREA)
- Tropical Medicine & Parasitology (AREA)
- Cell Biology (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Peptides Or Proteins (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
Abstract
생체 내 합성 항체의 발현을 위한 항체 및 이들의 기능적 단편을 인코딩하는 최적화된 핵산 서열을 포함하는 조성물, 및 대상체에서 합성 항체의 생성 방법이 본원에 개시된다. 본 개시는 또한 상기 조성물 및 방법을 이용하는 대상체에서의 질환 예방 및/또는 치료 방법을 제공한다.
Description
관련 출원에 대한 교차 참조
본 출원은 2012.12.13.에 출원된 미국 가출원 번호 61/737,094, 2013.09.23.에 출원된 미국 가출원 번호 61/881,376, 및 2013.10.28.에 출원된 미국 가출원 번호 61/896,646을 우선권으로 청구하며, 이는 모두 본원에 참조로 도입된다.
정부 이해관계의 언급
본 발명은 국립위생연구소(National Institutes of Health)에서 부여하는 계약 번호 HHSN272200800063C 및 5-P30-AI-045008-13 하의 정부 지원으로 수행되었다. 정부는 본 발명에 일정한 권리를 갖는다.
기술 분야
본 발명은 생체 내 합성 항체, 또는 그의 단편의 생성을 위한 재조합 핵산 서열을 포함하는 조성물, 및 상기 조성물의 투여에 의한 대상체에서의 질환의 예방 및/또는 치료 방법에 관한 것이다.
면역글로불린 분자는 시스테인 잔기 간의 디설파이드 결합(S-S로 나타냄)에 의해 공유 연결된 각 유형의 두 경쇄(L) 및 중쇄(H)를 포함한다. 중쇄(VH) 및 경쇄(VL)의 가변 도메인은 항체 분자의 결합 부위에 기여한다. 중쇄 불변 영역은 최대 3개의 불변 도메인(CH1, CH2 및 CH3) 및 (가요성) 힌지 영역으로 이루어진다. 경쇄는 또한 불변 도메인(CL)을 갖는다. 중쇄 및 경쇄의 가변 영역은 4개의 틀 영역(FR; FR1, FR2, FR3 및 FR4) 및 3개의 상보성 결정 영역(CDR; CDR1, CDR2 및 CDR3)을 포함한다. 따라서 이들은 생체 내에서 조립하기 어려웠던 매우 복잡한 유전적 시스템이다.
표적화된 모노클로날 항체(mAb)는 지난 25년 간 가장 중요한 의학적 치료 진보 중 하나를 나타낸다. 상기 유형의 면역 기반 치료법은 이제 수많은 자가면역 질환, 암뿐만 아니라 감염성 질환의 치료를 위해 일상적으로 이용된다. 암에 있어서, 현재 이용되는 여러 면역글로불린(Ig) 기반 치료법은 종양에 대한 세포독성 화학치료법 요법과 조합된다. 상기 조합 접근은 전체적 생존을 크게 개선시켰다. 비호지킨성 림프종의 치료를 위해 CD20을 표적화하는 키메라 mAb인 리툭시맙(Rituxan), 및 CTLA-4를 차단하고 흑색종 및 다른 암의 치료에 이용된 인간 mAb인 이필리무맙(Yervoy)을 포함하는 여러 mAb 제조물이 특정 암에 대한 이용을 위해 허가받았다. 추가적으로, 베바시주맙(Avastin)은 VEGF 및 종양 신혈관형성을 표적화하고 결직장암의 치료에 이용된 또 다른 유명한 인간화된 mAb이다. 암 치료를 위해 가장 높은 프로필의 mAb는 환자 서브세트에서 유방암에 대해 상당한 유효성을 가진 것으로 나타난, Her2/neu를 표적화하는 인간화된 제조물인 트라스투주맙(Herceptin)일 것이다. 또한 수많은 mAb가 자가면역 및 특정 혈액 장애의 치료를 위해 이용되고 있다.
암 치료에 부가하여, 폴리클로날 Ig의 수동 전달은 디프테리아, A형 및 B형 간염, 광견병, 파상풍, 수두 및 호흡기 세포융합 바이러스(RSV)를 포함하는 여러 감염성 질환에 대한 보호 효능을 매개한다. 실제로, 몇몇 폴리클로날 Ig 제조물은 능동 백신접종을 통해 생성될 보호적 Ig를 위한 충분한 시간이 없는 상황에서, 질환 유행 지역으로 여행하는 개인에서 특정 감염 제제에 대한 일시적 보호를 제공한다. 또한 면역 결핍증이 있는 어린이에서, RSV 감염을 표적으로 하는 mAb인 팔리비주맙(Synagis)이 RSV에 대해 임상적으로 보호하는 것으로 나타났다.
mAb 치료법의 임상적 영향은 인상적이다. 그러나 상기 치료적 접근의 이용 및 전파를 제한하는 문제가 여전히 존재한다. 이들 중 일부에는 더 넓은 모집단에서, 특히 큰 영향을 가질 수 있는 개발도상국에서 이들의 이용을 제한할 수 있는 이들 복잡한 생물학적 제제의 높은 생산 비용이 포함된다. 또한 유효성을 확보하고 유지하기 위한 mAb의 반복 투여에 대한 빈번한 요구는 물류 및 환자 순응성의 관점에서 장애일 수 있다. 추가적으로, 이들 항체 제형물의 장기 안정성이 빈번하게 짧고 최적이 아니다. 따라서 안전하고 비용 효율적인 방식으로 대상체에 전달될 수 있는 합성 항체 분자에 대한 당분야의 필요성이 남아 있다. 또한, 합성 항체 확인 및 발현 방법이 논의되었다; 그러나, 단백질 생산은 여전히 어렵고 비용이 높다.
면역치료법 및 면역조정은 병원체와 싸우거나 이환 세포를 사멸시키기 위해 대상체의 면역계와 협력하거나 이를 조정하거나 자극함으로써 질환의 치료를 허용하는 치료 방식을 제공한다. 백신은 질환의 예방, 그리고 일부 경우에는 치료법을 위해 세포성 및 체액성 면역 반응을 모두 자극할 수 있는 약물의 한 클래스를 제공한다. 예를 들어, 인플루엔자에 대한 백신은 대상체가 독감 바이러스에 대해 기억 반응을 생성하는 것을 돕고 이후 감염을 예방하는 것을 도울 수 있다. 그러나 예를 들어 치쿤군야 또는 뎅기, 또는 에볼라와 같은 열대 바이러스와 같이 빠른 중화 항체 반응이 유익할 경우, 신속한 발병을 유발하는 병원체에 대한 우려가 존재한다. 이러한 상황에서, 대상체가 확립되고 효과적인 기억 반응을 갖지 않는 경우, 숙주 체액성 반응의 지연은 치명적인 것으로 입증될 수 있다. 더욱이, 바이러스가 숙주를 완전 감염시키고 안정화되기 전에 HIV와 같이 문제가 되는 바이러스의 감염 저지를 돕는 중화 항체의 즉각적 생산이 유익할 것이다. 즉각적 기억 반응, 또는 보다 바람직하게는 중화 항체 반응을 제공할 수 있는 백신; 이어서 필요한 경우, 조합 치료법을 위해 숙주 면역 반응을 자극하는 백신과 조합될 수 있는 백신이 필요하다.
요약
본 발명은 대상체에서 합성 항체의 생성 방법에 대한 것이다. 이 방법은 대상체에 항체 또는 그의 단편을 인코딩하는 재조합 핵산 서열을 포함하는 조성물을 투여하는 단계를 포함할 수 있다. 재조합 핵산 서열은 합성 항체를 생성하기 위해 대상체에서 발현될 수 있다.
항체는 중쇄 폴리펩티드, 또는 그의 단편, 및 경쇄 폴리펩티드, 또는 그의 단편을 포함할 수 있다. 중쇄 폴리펩티드, 또는 그의 단편은 제1 핵산 서열에 의해 인코딩될 수 있고, 경쇄 폴리펩티드, 또는 그의 단편은 제2 핵산 서열에 의해 인코딩될 수 있다. 재조합 핵산 서열은 제1 핵산 서열 및 제2 핵산 서열을 포함할 수 있다. 재조합 핵산 서열은 대상체에서 단일 전사체로 제1 핵산 서열 및 제2 핵산 서열을 발현하기 위한 프로모터를 추가로 포함할 수 있다. 프로모터는 사이토메갈로바이러스(CMV) 프로모터일 수 있다.
재조합 핵산 서열은 프로테아제 절단 부위를 인코딩하는 제3 핵산 서열을 추가로 포함할 수 있다. 제3 핵산 서열은 제1 핵산 서열 및 제2 핵산 서열 간에 배치될 수 있다. 대상체의 프로테아제는 프로테아제 절단 부위를 인식하고 절단할 수 있다.
재조합 핵산 서열은 항체 폴리펩티드 서열을 생성하기 위해 대상체에서 발현될 수 있다. 항체 폴리펩티드 서열은 중쇄 폴리펩티드, 또는 그의 단편, 프로테아제 절단 부위, 및 경쇄 폴리펩티드, 또는 그의 단편을 포함할 수 있다. 대상체에 의해 생산된 프로테아제는 항체 폴리펩티드 서열의 프로테아제 절단 부위를 인식하고 절단하여 절단된 중쇄 폴리펩티드 및 절단된 경쇄 폴리펩티드를 생성할 수 있다. 합성 항체는 절단된 중쇄 폴리펩티드 및 절단된 경쇄 폴리펩티드에 의해 생성될 수 있다.
재조합 핵산 서열은 제1 전사체로 제1 핵산 서열을 발현하기 위한 제1 프로모터 및 제2 전사체로 제2 핵산 서열을 발현하기 위한 제2 프로모터를 포함할 수 있다. 제1 전사체는 제1 폴리펩티드로 번역될 수 있고, 제2 전사체는 제2 폴리펩티드로 번역될 수 있다. 합성 항체는 제1 및 제2 폴리펩티드에 의해 생성될 수 있다. 제1 프로모터 및 제2 프로모터는 동일할 수 있다. 프로모터는 사이토메갈로바이러스(CMV) 프로모터일 수 있다.
중쇄 폴리펩티드는 가변 중쇄 영역 및 불변 중쇄 영역 1을 포함할 수 있다. 중쇄 폴리펩티드는 가변 중쇄 영역, 불변 중쇄 영역 1, 힌지 영역, 불변 중쇄 영역 2 및 불변 중쇄 영역 3을 포함할 수 있다. 경쇄 폴리펩티드는 가변 경쇄 영역 및 불변 경쇄 영역을 포함할 수 있다.
재조합 핵산 서열은 코작(Kozak) 서열을 추가로 포함할 수 있다. 재조합 핵산 서열은 면역글로불린(Ig) 신호 펩티드를 추가로 포함할 수 있다. Ig 신호 펩티드는 IgE 또는 IgG 신호 펩티드를 포함할 수 있다.
재조합 핵산 서열은 서열 식별 번호 1, 2, 5, 41, 43, 45, 46, 47, 48, 49, 51, 53, 55, 57, 59, 및 61 중 적어도 하나의 아미노산 서열을 인코딩하는 핵산 서열을 포함할 수 있다. 재조합 핵산 서열은 서열 식별 번호 3, 4, 6, 7, 40, 42, 44, 50, 52, 54, 56, 58, 60, 62, 및 63 중 적어도 하나의 핵산 서열을 포함할 수 있다.
본 발명은 또한 대상체에서 합성 항체의 생성 방법에 대한 것이다. 이 방법은 중쇄 폴리펩티드, 또는 그의 단편을 인코딩하는 제1 재조합 핵산 서열, 및 경쇄 폴리펩티드, 또는 그의 단편을 인코딩하는 제2 재조합 핵산 서열을 포함하는 조성물을 대상체에 투여하는 단계를 포함할 수 있다. 제1 재조합 핵산 서열은 제1 폴리펩티드를 생성하기 위해 대상체에서 발현될 수 있고, 제2 재조합 핵산 서열은 제2 폴리펩티드를 생성하기 위해 대상체에서 발현될 수 있다. 합성 항체는 제1 및 제2 폴리펩티드에 의해 생성될 수 있다.
제1 재조합 핵산 서열은 대상체에서 제1 폴리펩티드를 발현하기 위한 제1 프로모터를 추가로 포함할 수 있다. 제2 재조합 핵산 서열은 대상체에서 제2 폴리펩티드를 발현하기 위한 제2 프로모터를 추가로 포함할 수 있다. 제1 프로모터 및 제2 프로모터는 동일할 수 있다. 프로모터는 사이토메갈로바이러스(CMV) 프로모터일 수 있다.
중쇄 폴리펩티드는 가변 중쇄 영역 및 불변 중쇄 영역 1을 포함할 수 있다. 중쇄 폴리펩티드는 가변 중쇄 영역, 불변 중쇄 영역 1, 힌지 영역, 불변 중쇄 영역 2 및 불변 중쇄 영역 3을 포함할 수 있다. 경쇄 폴리펩티드는 가변 경쇄 영역 및 불변 경쇄 영역을 포함할 수 있다.
제1 재조합 핵산 서열 및 제2 재조합 핵산 서열은 코작 서열을 추가로 포함할 수 있다. 제1 재조합 핵산 서열 및 제2 재조합 핵산 서열은 면역글로불린(Ig) 신호 펩티드를 추가로 포함할 수 있다. Ig 신호 펩티드는 IgE 또는 IgG 신호 펩티드를 포함할 수 있다.
본 발명은 또한 대상체에서 질환의 예방 또는 치료 방법에 대한 것이다. 이 방법은 상기 방법 중 하나에 따른 대상체에서의 합성 항체의 생성 단계를 포함할 수 있다. 합성 항체는 외래 항원에 대해 특이적일 수 있다. 외래 항원은 바이러스에서 유래될 수 있다. 바이러스는 인간 면역결핍 바이러스(HIV), 치쿤군야 바이러스(CHIKV) 또는 뎅기 바이러스일 수 있다.
바이러스는 HIV일 수 있다. 재조합 핵산 서열은 서열 식별 번호 1, 2, 5, 46, 47, 48, 49, 51, 53, 55, 및 57 중 적어도 하나의 아미노산 서열을 인코딩하는 핵산 서열을 포함할 수 있다. 재조합 핵산 서열은 서열 식별 번호 3, 4, 6, 7, 50, 52, 55, 56, 62, 및 63 중 적어도 하나의 핵산 서열을 포함할 수 있다.
바이러스는 CHIKV일 수 있다. 재조합 핵산 서열은 서열 식별 번호 59 및 61 중 적어도 하나의 아미노산 서열을 인코딩하는 핵산 서열을 포함할 수 있다. 재조합 핵산 서열은 서열 식별 번호 58 및 60 중 적어도 하나의 핵산 서열을 포함할 수 있다.
바이러스는 뎅기 바이러스일 수 있다. 재조합 핵산 서열은 서열 식별 번호 45 중 적어도 하나의 아미노산 서열을 인코딩하는 핵산 서열을 포함할 수 있다. 재조합 핵산 서열은 서열 식별 번호 44 중 적어도 하나의 핵산 서열을 포함한다.
합성 항체는 자가-항원에 대해 특이적일 수 있다. 자가-항원은 Her2일 수 있다. 재조합 핵산 서열은 서열 식별 번호 41 및 43 중 적어도 하나의 아미노산 서열을 인코딩하는 핵산 서열을 포함할 수 있다. 재조합 핵산 서열은 서열 식별 번호 40 및 42 중 적어도 하나의 핵산 서열을 포함할 수 있다.
본원에 기재된 본 발명의 한 측면에는 본원에 기재된 뉴클레오티드 산물이 포함되며, 일부 예에서는 하나의 뉴클레오티드 작제물로 이루어지며, 일부 예에서는 다른 두 뉴클레오티드 작제물로 이루어진다.
본 발명의 하나의 측면은 병원체에 특이적인 합성 항체를 인코딩하는 뉴클레오티드 서열을 투여하는 단계를, 그리고 일부 예에서는 또한 대상체에 면역 반응을 생성하기 위해 병원체의 항원을 투여하는 단계를 포함하는, 병원체에 의한 감염의 치료 방법에 관한 것이다.
도면의 간략한 설명
도 1은 실시예 1에 기재된 바와 같은 IgG 중쇄를 인코딩하는 핵산 서열을 나타낸다.
도 2는 실시예 1에 기재된 바와 같은 IgG 경쇄를 인코딩하는 핵산 서열을 나타낸다.
도 3은 시간(hr) 대 OD 450nm(조직 배양 상청액의 1:100 희석액)를 도시한 그래프를 나타낸다.
도 4는 웨스턴 블롯 이미지를 나타낸다.
도 5는 pHIV-1Env-Fab의 생성 및 발현 확인을 나타낸다. (A & B) pHIV-1 Env Fab 항-gp120 Fab를 발현하는 작제물의 원형 플라스미드 맵이 VRC01 중쇄(H) 및 경쇄(L) 가변 Ig 유전자를 이용해서 설계되었다. 발현 수준을 증가시키기 위해 Fab 플라스미드의 구축 시 몇몇 개질이 포함되었다. 나타낸 바와 같은 Fab VL 및 VH 단편 유전자는 pVax1 벡터의 BamH1 및 Xho1 제한효소 부위 사이에 별도로 클로닝되었다. (C) pHIV-1 Env Fab의 시험관 내 발현. 이 그래프는 293T 세포의 전달감염 후 pHIV-1 Env Fab 발현의 경시적 역학을 나타내었다. 발현을 시사하는 나타낸 값은 3개 웰의 평균 OD450nm±SD이다. 대조군으로 293T 세포도 pVax1 골격으로 전달감염되었다.
도 6은 pHIV-1 Env Fab에 의한 항-HIV Env 특이적 Fab의 경시적 생성 측정을 나타낸다. (A) 항-HIV1 Fab의 생성 시간 경과. pHIV-1 Env Fab의 투여 후, 특이적 Fab의 생산을 ELISA로 1:100의 최종 희석도에서 혈청 중에 10일에 걸쳐 측정하고 OD450nm로 나타내었다. pVax1이 투여된 마우스로부터의 혈청을 음성 대조군으로 이용하였다. (B) 재조합 gp120(rgp120)으로의 면역접종 후 항-gp120 항체 반응의 비교 측정. 실시예 2에 나타낸 바와 같이, rgp120의 단회 주사로 마우스를 면역접종한 뒤 항-gp120 항체 생산을 최대 10일에 걸쳐 측정하고 OD450nm 값으로 나타내었다. 이 연구에 대해서는 음성 대조군 주사로 PBS를 이용하였다. (C) 면역블롯 분석에 의한 HIV1Env-Fab 결합의 확인. 실시예에 나타낸 바와 같이, 5 또는 10㎍의 gp120을 SDS-PAGE 및 니트로셀룰로오스 블롯팅을 거친 후 블롯을 pHIV-1 Env Fab 투여 마우스로부터의 혈청과 인큐베이션하였다. 면역블롯은 실험 혈청이 결합된 rgp120을 인식함을 나타내어, 생성된 Fab의 특이성을 확인시켰다. (D) pHIV-1Env-Fab 투여 후 마우스 혈청에서 IgG1로 측정된 인간 IgG1Fab의 경시적 정량. IgG1을 나타낸 시점에 표준 ELISA 키트로 측정하고 Fab(㎍/mL)±SD로 표시하였다. pVax1-투여 마우스로부터의 혈청을 음성 대조군으로 이용하였다. 혈청 표본을 x축에 나타낸 시점에 분석하였다. (A), (B) 및 (D)에 디스플레이한 그래프에 나타낸 화살표는 DNA 플라스미드 투여 시점을 나타낸다.
도 7은 A군 HIV Env 당단백질에 대한 HIV1 Env Fab의 FACS 결합 분석을 나타낸다. (A) HIV-1 A군 Env 당단백질에 대한 항-HIV1Env-Fab의 결합을 나타내는 FACS 스캔. 공통(pCon-Env-A) 또는 "최적화된"(pOpt-Env-A) HIV-1 A군 외피를 발현하는 DNA를 293T 세포 내로 전달감염시켰다. 전달감염 2일 후, 세포를 정제된 천연 VRC01 Ig, pHIV-1 Env Fab로부터 생성된 혈청(단회 플라스미드 투여 48시간 후 수집됨) 또는 pIgG-E1M2 투여로 생성된 대조군 Ig로 염색하였다. 혈청 및 VRC01 항체를 PBS 50μl 중에 각각 1:4 또는 1:100으로 희석하고 실온에서 30분 동안 인큐베이션하였다. 이어서 세포를 적절한 이차 피코에리트리틴(PE) 콘주게이트된 Ig로 염색한 뒤 단일선 및 살아있는 세포로 FACS 분석에 대해 관문화하였다. 양성 세포의 결합 백분율을 각 스캔에서 나타내었다. (B) FACS 결합 데이터의 그래픽 표시. 각각의 Ig/혈청 시험군에서 염색된 세포의 수(즉 발현 수준을 시사함)를 배경 염색값으로 나누고 평가된 상이한 HIV A군 Env 제조물의 함수로서 y축 상에서 특이적 결합 백분율로 나타내었다.
도 8은 pHIV-1Env-Fab 투여 마우스로부터의 혈청에 의한 HIV-1의 중화 시간 경과를 나타낸다. 중화 활성 혈청의 분석에 이용된 혈청을 그래프에 나타낸 시점에 수집하였다. 중화 분석을 HIV-1 가유형 바이러스 패널을 이용해서 TZM-BL 세포에서 수행하였다: Bal26(패널 A; B군, 티어 1), Q23Env17(패널 B; A군, 티어 1), SF162S(패널 C; B군, 티어 1), 및 ZM53M(패널 D; C군, 티어 2). 세포를 실시예 2에 묘사된 0.01의 MOI로 감염시키고, pHIV-1 Env Fab 투여로 생성된 Fab를 함유하는 혈청(최종 희석도 1:50)의 존재 하에 인큐베이션하였다. 중화값 백분율을 나타내고, 그 계산을 실시예 2에 기재하였다. 또한 실험 혈청이 50% 바이러스 중화를 매개한 근사 시점을 시사하는 수평선이 각 그래프에 제공된다.
도 9는 실시예 2-7에 기재된 HIV-1 Env Fab의 중쇄(VH-CH1)를 인코딩하는 핵산 서열을 나타낸다.
도 10은 실시예 2-7에 기재된 HIV-1 Env Fab의 경쇄(VL-CL)를 인코딩하는 핵산 서열을 나타낸다.
도 11은 HIV Env를 인코딩하는 플라스미드로 전달감염된 세포의 면역형광도를 나타낸다. 세포를 pVAX1(왼쪽 패널) 또는 pHIV-Env-Fab(오른쪽 패널)로부터의 제조물로 염색하였다.
도 12는 항원 유형 대 혈청 농도(ng/mL)를 도시하는 그래프를 나타낸다.
도 13은 합성 인간 IgG1 항체를 인코딩하는 작제물의 모식도를 나타낸다.
도 14는 도 13의 작제물에 의해 인코딩되는 조립된 항체(발현 시)의 모식도를 나타낸다.
도 15는 VRC01 IgG의 아미노산 서열을 나타낸다.
도 16은 (A) HIV-1 Env-PG9 Ig를 인코딩하는 작제물의 모식도; (B) (A)의 작제물을 함유하는 벡터의 모식도; 및 (C) 염색된 겔의 이미지를 나타낸다.
도 17은 (A) HIV-1 Env-4E10 Ig를 인코딩하는 작제물의 모식도; (B) (A)의 작제물을 함유하는 벡터의 모식도; 및 (C) 염색된 겔의 이미지를 나타낸다.
도 18은 퓨린에 의한 절단 전의 HIV-1 Env-PG9 Ig의 아미노산 서열을 나타낸다.
도 19는 퓨린에 의한 절단 전의 HIV-1 Env-4E10 Ig의 아미노산 서열을 나타낸다.
도 20은 (A) CHIKV-Env-Fab의 중쇄(VH-CH1)를 인코딩하는 작제물의 모식도; (B) CHIKV-Env-Fab의 중쇄(VL-CL)를 인코딩하는 작제물의 모식도를 나타낸다.
도 21은 CHIKV-Env-Fab의 중쇄(VH-CH1) 또는 경쇄(VL-CL)를 인코딩하는 작제물을 함유하는 발현 벡터의 모식도를 나타낸다.
도 22는 시간(hr) 대 OD450nm를 도시하는 그래프를 나타낸다.
도 23은 면역블롯(immunoblot) 이미지를 나타낸다.
도 24는 DNA 투여 및 채혈 전 및 채혈 수득 시점의 모식도를 나타낸다.
도 25는 시간(일) 대 OD450nm를 도시하는 그래프를 나타낸다.
도 26은 유발접종 후 일수 대 생존 백분율을 도시하는 그래프를 나타낸다.
도 27은 마우스군 대 TNF-α(pg/mL)를 도시하는 그래프를 나타낸다.
도 28은 마우스군 대 IL-6(pg/mL)을 도시하는 그래프를 나타낸다.
도 29는 VH-CH1을 인코딩하고 프로모터의 제어 하인 작제물을 예시하는 모식도를 나타낸다.
도 30은 VL-CL을 인코딩하고 프로모터의 제어 하인 작제물을 예시하는 모식도를 나타낸다.
도 31은 발현 벡터 내로 클로닝된 항-Her-2 Fab의 VH-CH1 또는 VL-CL을 인코딩하는 작제물을 예시하는 모식도를 나타낸다.
도 32는 항-Her-2 Fab의 VH-CH1을 인코딩하는 핵산 서열을 나타낸다.
도 33은 도 32의 핵산 서열에 의해 인코딩되는 아미노산 서열(즉, 항-Her-2 Fab의 VH-CH1의 아미노산 서열)을 나타낸다.
도 34는 항-Her-2 Fab의 VL-CL을 인코딩하는 핵산 서열을 나타낸다.
도 35는 도 34의 핵산 서열에 의해 인코딩되는 아미노산 서열(즉, 항-Her-2 Fab의 VL-CL의 아미노산 서열)을 나타낸다.
도 36은 전달감염된 세포 유형 대 IgG 농도(㎍/mL)를 도시하는 그래프를 나타낸다.
도 37은 면역글로불린 G(IgG) 중쇄의 가변 중쇄 영역(VH), 가변 중쇄 불변 영역 1(CH1), 힌지 영역, 가변 중쇄 불변 영역 2(CH2), 가변 중쇄 불변 3(CH3)을 인코딩하고, IgG 경쇄의 가변 경쇄 영역(VL) 및 가변 경쇄 불변 영역(CL)을 인코딩하는 작제물을 예시하는 모식도를 나타낸다. IgG의 중쇄 및 경쇄는 프로테아제 절단 부위에 의해 분리되며, 각각에는 신호 펩티드(리더 서열에 의해 인코딩됨)가 선행된다.
도 38은 항-뎅기 바이러스(DENV) 인간 IgG를 인코딩하는 핵산 서열을 나타낸다.
도 39는 도 39의 핵산 서열에 의해 인코딩된 아미노산 서열(즉, 항-DENV 인간 IgG의 아미노산 서열)을 나타낸다. 상기 아미노산 서열에서, 중쇄 및 경쇄를 두 개별 폴리펩티드로 분리하기 위한 프로테아제 절단은 아직 일어나지 않았다.
도 40은 마우스군 대 OD 450nm를 도시하는 그래프를 나타낸다.
도 41은 주사 후 일수 대 인간 IgG 농도(ng/mL)를 도시하는 그래프를 나타낸다.
도 42는 도 1의 핵산 서열(즉, 서열 식별 번호 6)에 의해 인코딩된 아미노산 서열을 나타낸다. 상기 아미노산 서열은 아래 실시예 1에 기재된 IgG 중쇄의 아미노산 서열이다.
도 43은 도 2의 핵산 서열(즉, 서열 식별 번호 7)에 의해 인코딩된 아미노산 서열을 나타낸다. 상기 아미노산 서열은 아래 실시예 1에 기재된 IgG 경쇄의 아미노산 서열이다.
도 44는 도 9의 핵산 서열(즉, 서열 식별 번호 3)에 의해 인코딩된 아미노산 서열을 나타낸다. 상기 아미노산 서열은 실시예 2-7에 기재된 HIV-1 Env-Fab 중쇄(VH-CH1)의 아미노산 서열이다.
도 45는 도 10의 핵산 서열(즉, 서열 식별 번호 4)에 의해 인코딩된 아미노산 서열을 나타낸다. 상기 아미노산 서열은 실시예 2-7에 기재된 HIV-1 Env-Fab 경쇄(VL-CL)의 아미노산 서열이다.
도 46은 아래 실시예 11에 기재된 HIV-1 PG9 단일쇄 Fab(scFab)를 인코딩하는 핵산 서열이다.
도 47은 도 46의 핵산 서열(즉, 서열 식별 번호 50)에 의해 인코딩된 아미노산 서열을 나타낸다. 상기 아미노산 서열은 아래 실시예 11에 기재된 HIV-1 PG9 scFab의 아미노산 서열이다.
도 48은 아래 실시예 13에 기재된 HIV-1 4E10 단일쇄 Fab(scFab)를 인코딩하는 핵산 서열이다.
도 49는 도 48의 핵산 서열(즉, 서열 식별 번호 52)에 의해 인코딩된 아미노산 서열을 나타낸다. 상기 아미노산 서열은 아래 실시예 13에 기재된 HIV-1 4E10 scFab의 아미노산 서열이다.
도 50은 면역글로불린 G(IgG) 중쇄의 가변 중쇄 영역(VH), 가변 중쇄 불변 영역 1(CH1), 힌지 영역, 가변 중쇄 불변 영역 2(CH2), 가변 중쇄 불변 3(CH3)을 인코딩하는 작제물을 예시하는 모식도를 나타낸다. IgG 중쇄를 인코딩하는 핵산 서열에는 리더 서열이 선행된다.
도 51은 IgG 경쇄의 가변 경쇄 영역(VL) 및 가변 경쇄 불변 영역(CL)을 인코딩하는 작제물을 예시하는 모식도를 나타낸다. IgG 경쇄를 인코딩하는 핵산 서열에는 리더 서열이 선행된다.
도 52는 아래 실시예 9에 기재된 HIV-1 VRC01 IgG1 중쇄를 인코딩하는 핵산 서열을 나타낸다.
도 53은 도 52의 핵산 서열(즉, 서열 식별 번호 54)에 의해 인코딩된 아미노산 서열을 나타낸다. 상기 아미노산 서열은 아래 실시예 9에 기재된 HIV-1 VRC01 IgG1 중쇄의 아미노산 서열이다.
도 54는 아래 실시예 9에 기재된 HIV-1 VRC01 IgG1 경쇄를 인코딩하는 핵산 서열이다.
도 55는 도 54의 핵산 서열(즉, 서열 식별 번호 56)에 의해 인코딩된 아미노산 서열을 나타낸다. 상기 아미노산 서열은 실시예 9에서 아래 기재된 HIV-1 VRC01 IgG1 경쇄의 아미노산 서열이다.
도 56은 실시예 14에서 아래 기재된 CHIKV-Env-Fab의 중쇄(VH-CH1)를 인코딩하는 핵산 서열을 나타낸다.
도 57은 도 56의 핵산 서열(즉, 서열 식별 번호 58)에 의해 인코딩된 아미노산 서열을 나타낸다. 상기 아미노산 서열은 아래 실시예 14에 기재된 CHIKV-Env-Fab의 중쇄(VH-CH1)의 아미노산 서열이다.
도 58은 아래 실시예 14에서 기재된 CHIKV-Env-Fab의 경쇄(VL-CL)를 인코딩하는 핵산 서열이다.
도 59는 도 58의 핵산 서열(즉, 서열 식별 번호 60)에 의해 인코딩된 아미노산 서열을 나타낸다. 상기 아미노산 서열은 아래 실시예 14에 기재된 CHIKV-Env-Fab의 경쇄(VL-CL)의 아미노산 서열이다.
도 60은 아래 실시예 12에 기재된 HIV-1 Env-4E10 Ig를 인코딩하는 핵산 서열을 나타낸다.
도 61은 아래 실시예 10에 기재된 HIV-1 Env-PG9 Ig를 인코딩하는 핵산 서열을 나타낸다.
도 62는 VRC01 IgG를 인코딩하는 핵산 서열(서열 식별 번호 64)을 나타낸다.
상세한 설명
본 발명은 항체, 그의 단편, 이들의 변이체, 또는 이들의 조합을 인코딩하는 재조합 핵산 서열을 포함하는 조성물에 관한 것이다. 조성물은 합성 항체의 생체 내 발현 및 형성을 촉진하기 위해 이를 필요로 하는 대상체에 투여될 수 있다.
특히, 재조합 핵산 서열로부터 발현된 중쇄 및 경쇄 폴리펩티드는 합성 항체로 조립될 수 있다. 중쇄 폴리펩티드 및 경쇄 폴리펩티드는 조립으로 항원과 결합할 수 있고, 본원에 기재된 조립되지 않은 항체에 비해 면역원성이 더 크며, 항원에 대해 면역 반응을 야기하거나 유도할 수 있는 합성 항체를 생성하도록 서로 상호작용할 수 있다.
추가적으로, 이들 합성 항체는 항체 유도된 면역 반응에 반응하여 생산되는 항체에 비해 대상체에서 보다 신속히 생성된다. 합성 항체는 광범위한 항원에 효과적으로 결합하고 이를 중화시킬 수 있다. 합성 항체는 또한 질환에 대해 효과적으로 보호하고/하거나 생존을 촉진할 수 있다.
1. 정의
달리 정의되지 않는 한, 본원에서 이용된 모든 기술적 및 과학적 용어는 당업자가 일반적으로 이해하는 바와 동일한 의미를 갖는다. 상충 시, 정의를 포함하여 본 문서가 우선이 될 것이다. 바람직한 방법 및 재료가 아래 기재되지만, 본원에 기재된 것과 유사하거나 동등한 방법 및 재료가 본 발명의 실시 또는 평가에서 이용될 수 있다. 본원에서 언급된 모든 공보, 특허 출원, 특허 및 다른 참고문헌은 이들의 전문이 참조로 도입된다. 본원에 개시된 재료, 방법, 및 실시예는 단지 예시적인 것이며 제한하려는 것이 아니다.
본원에서 이용되는 용어 "포함한다", "포함된다", "갖는", "갖는다", "수 있다", "함유한다" 및 이들의 변형은 추가적인 행위 또는 구조의 가능성을 배제하지 않는 개방형 전이 어구, 용어 또는 단어로 의도된다. 문맥 상 뚜렷이 달리 나타내지 않는 한, 단수 형태에는 복수 참조물이 포함된다. 본 개시는 또한 명시적으로 나타내건 나타내지 않건, 본원에 제시된 구현예 또는 요소를 "포함하는", "이로 구성된" 및 "본질적으로 이로 구성된" 다른 구현예를 고려한다.
"항체"는 Fab, F(ab')2, Fd, 및 단일쇄 항체, 및 이들의 유도체를 포함하는 클래스 IgG, IgM, IgA, IgD 또는 IgE의 항체, 또는 단편, 그의 단편 또는 유도체를 의미할 수 있다. 항체는 원하는 에피토프 또는 이로부터 유래된 서열에 충분한 결합 특이성을 나타내는 포유류 혈청 표본에서 단리된 항체, 폴리클로날 항체, 친화도 정제된 항체, 또는 이들의 혼합물일 수 있다.
본원에서 상호 교환적으로 이용되는 "항체 단편" 또는 "항체의 단편"은 항원-결합 부위 또는 가변 영역을 포함하는 온전한 항체의 일부를 나타낸다. 이 일부에는 온전한 항체의 Fc 영역의 불변 중쇄 도메인(즉, 항체 이소형에 따라 CH2, CH3, 또는 CH4)이 포함되지 않는다. 항체 단편의 예에는 비제한적으로 Fab 단편, Fab' 단편, Fab'-SH 단편, F(ab')2 단편, Fd 단편, Fv 단편, 디아바디, 단일쇄 Fv(scFv) 분자, 하나의 경쇄 가변 도메인만 함유하는 단일쇄 폴리펩티드, 경쇄 가변 도메인의 세 CDR을 함유하는 단일쇄 폴리펩티드, 하나의 중쇄 가변 영역만 함유하는 단일쇄 폴리펩티드, 및 중쇄 가변 영역의 세 CDR을 함유하는 단일쇄 폴리펩티드가 포함된다.
"항원"은 숙주에서 면역 반응을 생성하는 능력을 갖는 단백질을 나타낸다. 항원은 항체에 의해 인식되고 이에 결합될 수 있다. 항원은 체내에서 또는 외부 환경에서 유래될 수 있다.
본원에서 이용되는 "코딩 서열" 또는 "인코딩 핵산"은 본원에 나타낸 바와 같은 항체를 인코딩하는 뉴클레오티드 서열을 포함하는 핵산(RNA 또는 DNA 분자)을 의미할 수 있다. 코딩 서열에는 핵산이 투여되는 개인 또는 포유류의 세포에서 발현을 지시할 수 있는 프로모터 및 폴리아데닐화 신호를 포함하는 조절 요소에 작동 가능하게 연결된 개시 및 종결 신호가 추가로 포함될 수 있다. 코딩 서열에는 신호 펩티드를 인코딩하는 서열이 추가로 포함될 수 있다.
본원에서 이용되는 "상보체" 또는 "상보적인"은 핵산이 핵산 분자의 뉴클레오티드 또는 뉴클레오티드 유사체 간 왓슨-크릭(예로, A-T/U 및 C-G) 또는 후그스틴(Hoogsteen) 염기쌍 형성을 의미할 수 있음을 의미할 수 있다.
본원에서 이용되는 "정전류"는 조직 또는 상기 조직을 정의하는 세포가 동일한 조직에 전달되는 전기 자극 기간에 걸쳐 수신하거나 경험하는 전류를 정의하기 위한 것이다. 전기 자극은 본원에 기재된 전기천공 장치로부터 전달된다. 상기 전류는 본원에 제공된 전기천공 장치가 피드백 요소, 바람직하게는 즉각적인 피드백을 가지므로, 전기 자극의 수명에 걸쳐 상기 조직에서 정전류량으로 유지된다. 피드백 요소는 자극 기간에 걸쳐 조직(또는 세포)의 저항을 측정하고, 전기천공장치가 그 전기 에너지 출력을 변경하도록(예로 전압을 증가하도록) 유도하여 동일한 조직에서의 전류가 전기 자극 동안(마이크로초 수준) 그리고 자극 별로 변하지 않고 유지될 수 있다. 일부 구현예에서, 피드백 요소는 컨트롤러를 포함한다.
본원에서 이용되는 "전류 피드백" 또는 "피드백"은 상호 교환적으로 이용될 수 있고 제공된 전기천공 장치의 능동 반응을 의미할 수 있으며, 이는 전극 간에 조직에서 전류를 측정하는 단계 및 전류를 불변 수준으로 유지하기 위해 이에 따라 EP 장치에 의해 전달되는 에너지 출력을 변경하는 단계를 포함한다. 상기 불변 수준은 자극 순서 또는 전기 처리의 개시 전에 사용자에 의해 사전 설정된다. 내부 전기 회로가 전극 간에 조직 내 전류를 연속적으로 모니터링하고 이 모니터링된 전류(또는 조직 내 전류)를 사전 설정된 전류와 비교하여 모니터링된 전류를 사전 설정된 수준으로 유지하기 위해 연속적으로 에너지-출력 조정을 수행할 수 있으므로, 피드백은 전기천공 장치의 전기천공 성분, 예로 컨트롤러에 의해 수행될 수 있다. 피드백 루프는 이것이 아날로그 폐쇄 루프 피드백이므로, 즉각적일 수 있다.
본원에서 이용되는 "분산된 전류"는 본원에 기재된 전기천공 장치의 다양한 바늘 전극 어레이로부터 전달되는 전기적 전류 패턴을 의미할 수 있고, 여기서 이 패턴은 조직이 전기천공되는 임의 영역 상에서 전기천공 관련된 열 스트레스의 발생을 최소화하거나 바람직하게는 제거한다.
본원에서 상호 교환적으로 이용되는 "전기천공", "전기-투과화", 또는 "전기-역학 증강"("EP")은 생체막에서 미시적 경로(구멍)을 유도하기 위한 막통과 전기장 자극의 이용을 나타낼 수 있다; 이들의 존재는 생체분자, 예컨대 플라스미드, 올리고뉴클레오티드, siRNA, 약물, 이온, 및 물이 세포막의 한 쪽에서 다른 쪽으로 이동할 수 있게 한다.
본원에서 이용되는 "내인성 항체"는 체액성 면역 반응의 유도를 위해 유효 용량의 항원이 투여되는 대상체에서 생성되는 항체를 나타낼 수 있다.
본원에서 이용되는 "피드백 기전"은 소프트웨어 또는 하드웨어(또는 펌웨어)에 의해 수행되는 절차를 나타낼 수 있고, 이 절차는 본 발명의 값, 바람직하게는 전류로 원하는 조직의 임피던스를 (에너지 자극 전달 이전, 동안, 및/또는 이후) 수신하고 비교하며, 사전 설정된 값을 달성하기 위해 전달된 에너지 자극을 조정한다. 피드백 기전은 아날로그 폐쇄 루프 회로에 의해 수행될 수 있다.
"단편"은 기능하고, 즉 원하는 표적에 결합할 수 있고, 전장 항체와 동일한 목적 효과를 갖는 항체의 폴리펩티드 단편을 의미할 수 있다. 항체의 단편은 N 및/또는 C 말단에서 적어도 하나의 아미노산이 없는 것을 제외하고는 전장과 100% 동일할 수 있고, 각각의 경우 위치 1에 신호 펩티드 및/또는 메티오닌을 갖거나 갖지 않는다. 단편은 부가된 임의의 이종성 신호 펩티드를 제외하고, 특정한 전장 항체 길이의 20% 이상, 25% 이상, 30% 이상, 35% 이상, 40% 이상, 45% 이상, 50% 이상, 55% 이상, 60% 이상, 65% 이상, 70% 이상, 75% 이상, 80% 이상, 85% 이상, 90% 이상, 91% 이상, 92% 이상, 93% 이상, 94% 이상, 95% 이상, 96% 이상, 97% 이상, 98% 이상, 99% 이상 백분율을 포함할 수 있다. 단편은 항체와 95% 이상, 96% 이상, 97% 이상, 98% 이상 또는 99% 이상 동일한 폴리펩티드의 단편을 포함하며, 추가적으로 동일성 백분율 계산 시 포함되지 않는 N 말단 메티오닌 또는 이종성 신호 펩티드를 포함할 수 있다. 단편은 추가로 N 말단 메티오닌 및/또는 신호 펩티드, 예컨대 면역글로불린 신호 펩티드, 예를 들어 IgE 또는 IgG 신호 펩티드를 포함할 수 있다. N 말단 메티오닌 및/또는 신호 펩티드는 항체의 단편에 연결될 수 있다.
항체를 인코딩하는 핵산 서열의 단편은 5' 및/또는 3' 말단에서 적어도 하나의 뉴클레오티드가 없는 것을 제외하고는 전장과 100% 동일할 수 있고, 각각의 경우 위치 1에 신호 펩티드 및/또는 메티오닌을 인코딩하는 서열을 갖거나 갖지 않는다. 단편은 부가된 임의의 이종성 신호 펩티드를 제외하고, 특정한 전장 코딩 서열 길이의 20% 이상, 25% 이상, 30% 이상, 35% 이상, 40% 이상, 45% 이상, 50% 이상, 55% 이상, 60% 이상, 65% 이상, 70% 이상, 75% 이상, 80% 이상, 85% 이상, 90% 이상, 91% 이상, 92% 이상, 93% 이상, 94% 이상, 95% 이상, 96% 이상, 97% 이상, 98% 이상, 99% 이상 백분율을 포함할 수 있다. 단편은 항체와 95% 이상, 96% 이상, 97% 이상, 98% 이상 또는 99% 이상 동일한 폴리펩티드를 인코딩하는 단편을 포함하고 선택적으로는 동일성 백분율 계산 시 포함되지 않는 N 말단 메티오닌 또는 이종성 신호 펩티드를 인코딩하는 서열을 추가로 포함할 수 있다. 단편은 추가로 N 말단 메티오닌 및/또는 신호 펩티드, 예컨대 면역글로불린 신호 펩티드, 예를 들어 IgE 또는 IgG 신호 펩티드에 대한 코딩 서열을 포함할 수 있다. N 말단 메티오닌 및/또는 신호 펩티드를 인코딩하는 코딩 서열이 항체 서열의 단편에 연결될 수 있다.
본원에서 이용되는 "유전적 작제물"은 단백질, 예컨대 항체를 인코딩하는 뉴클레오티드 서열을 포함하는 DNA 또는 RNA 분자를 나타낸다. 코딩 서열에는 핵산 분자가 투여되는 개인의 세포에서 발현을 지시할 수 있는 프로모터 및 폴리아데닐화 신호를 포함하는 조절 요소에 작동 가능하게 연결된 개시 및 종결 신호가 포함된다. 본원에서 이용되는 용어 "발현 가능한 형태"는 개인의 세포에 존재하는 경우, 코딩 서열이 발현되도록 단백질을 인코딩하는 코딩 서열에 작동 가능하게 연결된 필요한 조절 요소를 함유하는 유전자 작제물을 나타낸다.
둘 이상의 핵산 또는 폴리펩티드 서열의 맥락에서 본원에서 이용되는 "동일한" 또는 "동일성"은 서열이 명시된 영역에 걸쳐 동일한 명시된 잔기 백분율을 가짐을 의미할 수 있다. 백분율은 두 서열을 최적 정렬하고, 명시된 영역에 걸쳐 두 서열을 비교하고, 두 서열에서 동일한 잔기가 나오는 위치의 수를 결정하여 매치된 위치의 수를 산출하고, 매치된 위치의 수를 명시된 영역에서 위치의 총 수로 나누고, 그 결과에 100을 곱해서 서열 동일성 백분율을 산출함으로써 계산될 수 있다. 두 서열이 상이한 길이이거나 정렬로 하나 이상의 엇갈린 말단이 생성되고 명시된 비교 영역에 하나의 서열만 포함되는 경우, 단일 서열의 잔기는 계산의 분모에는 포함되지만 분자에는 포함되지 않는다. DNA 및 RNA를 비교하는 경우, 티민(T) 및 우라실(U)은 동등한 것으로 간주될 수 있다. 동일성은 수동으로 또는 BLAST 또는 BLAST 2.0과 같은 컴퓨터 서열 알고리즘을 이용하여 수행될 수 있다.
본원에서 이용되는 "임피던스"는 피드백 기전을 논의할 때 이용될 수 있고, 옴의 법칙에 따라 전류값으로 전환되어 사전 설정된 전류와의 비교를 가능케 할 수 있다.
본원에서 이용되는 "면역 반응"은 하나 이상의 핵산 및/또는 펩티드의 도입에 반응하는 숙주의 면역계, 예로 포유류의 면역계 활성화를 의미할 수 있다. 면역 반응은 세포성 또는 체액성 반응의 형태 또는 둘 다일 수 있다.
본원에서 이용되는 "핵산" 또는 "올리고뉴클레오티드" 또는 "폴리뉴클레오티드"는 서로 공유 연결된 적어도 2개의 뉴클레오티드를 의미할 수 있다. 단일쇄의 도시는 또한 상보쇄의 서열을 정의한다. 따라서 핵산은 또한 도시된 단일쇄의 상보쇄를 포괄한다. 핵산의 여러 변이체가 주어진 핵산과 동일한 목적을 위해 이용될 수 있다. 따라서 핵산은 또한 실질적으로 동일한 핵산 및 이들의 상보체를 포괄한다. 단일쇄는 엄격한 혼성화 조건 하에 표적 서열에 혼성화할 수 있는 탐침을 제공한다. 따라서 핵산은 또한 엄격한 혼성화 조건 하에 혼성화하는 탐침을 포괄한다.
핵산은 단일쇄 또는 이중쇄일 수도 있고, 또는 이중쇄 및 단일쇄 서열을 모두 일부 함유할 수도 있다. 핵산은 DNA, 게놈 및 cDNA 둘 다, RNA, 또는 하이브리드일 수 있고, 여기서 핵산은 데옥시리보- 및 리보-뉴클레오티드의 조합 및 우라실, 아데닌, 티민, 시토신, 구아닌, 이노신, 잔틴 하이포잔틴, 이소시토신 및 이소구아닌을 포함하는 염기의 조합을 함유할 수 있다. 핵산은 화학적 합성 방법에 의해 또는 재조합 방법에 의해 수득될 수 있다.
본원에서 이용되는 "작동 가능하게 연결된"은 유전자의 발현이 이것이 공간적으로 연결된 프로모터의 제어 하에 있음을 의미할 수 있다. 프로모터는 그 제어 하 유전자의 5'(상류) 또는 3'(하류)에 배치될 수 있다. 프로모터 및 유전자 간 거리는 프로모터가 유래된 유전자에서 이것이 제어하는 유전자 및 프로모터 간 거리와 대략 동일할 수 있다. 당분야에 공지된 바와 같이, 상기 거리의 변동은 프로모터 기능의 손실 없이 수용될 수 있다.
본원에서 이용되는 "펩티드", "단백질", 또는 "폴리펩티드"는 아미노산의 연결된 서열을 의미할 수 있고, 천연, 합성, 또는 천연 및 합성의 개질 또는 조합일 수 있다.
본원에서 이용되는 "프로모터"는 세포 내 핵산의 발현을 부여하거나, 활성화하거나, 증강시킬 수 있는 합성 또는 천연 유래 분자를 의미할 수 있다. 프로모터는 발현을 추가 증강시키고/시키거나 그 공간적 발현 및/또는 시간적 발현을 변경시키기 위해 하나 이상의 특정 전사 조절 서열을 포함할 수 있다. 프로모터는 또한 원위 인핸서 또는 억제유전자 요소를 포함할 수 있고, 이는 전사 개시 부위에서 수천 개 염기쌍만큼 떨어져 배치될 수 있다. 프로모터는 바이러스, 박테리아, 진균, 식물, 곤충, 및 동물을 포함하는 원천에서 유래될 수 있다. 프로모터는 발현이 일어나는 세포, 조직 또는 기관에 대해, 발현이 일어나는 발생 단계에 대해, 또는 외부 자극, 예컨대 생리적 스트레스, 병원체, 금속 이온 또는 유도제에 반응하여 항상적으로 또는 차별적으로 유전자 성분의 발현을 조절할 수 있다. 프로모터의 대표예에는 박테리오파지 T7 프로모터, 박테리오파지 T3 프로모터, SP6 프로모터, lac 작동유전자-프로모터, tac 프로모터, SV40 후기 프로모터, SV40 조기 프로모터, RSV-LTR 프로모터, CMV IE 프로모터, SV40 조기 프로모터 또는 SV 40 후기 프로모터 및 CMV IE 프로모터가 포함된다.
"신호 펩티드" 및 "리더 서열"은 본원에서 상호 교환적으로 이용되며, 본원에 나타낸 단백질의 아미노 말단에 연결될 수 있는 아미노산 서열을 나타낸다. 신호 펩티드/리더 서열은 전형적으로 단백질의 위치선정을 지시한다. 본원에서 이용된 신호 펩티드/리더 서열은 바람직하게는 이것이 생산되는 세포로부터 단백질의 분비를 촉진한다. 신호 펩티드/리더 서열은 종종 세포로부터의 분비 시, 종종 성숙 단백질로 불리는 단백질의 나머지로부터 절단된다. 신호 펩티드/리더 서열은 단백질의 N 말단에 연결된다.
본원에서 이용되는 "엄격한 혼성화 조건"은 제1 핵산 서열(예로, 탐침)이 제2 핵산 서열(예로, 표적)에, 예컨대 핵산의 복합 혼합물로 혼성화할 조건을 의미할 수 있다. 엄격한 조건은 서열 의존적이며, 상이한 상황에서 상이할 것이다. 엄격한 조건은 정의된 이온 강도 pH에서 특정 서열에 대한 열 용융점(Tm)보다 약 5-10℃ 더 낮게 선택될 수 있다. Tm은 표적에 상보적인 탐침의 50%가 평형 시(표적 서열이 과량으로 존재하므로, Tm에서 탐침의 50%가 평형 시 점유됨) 표적 서열에 혼성화하는 온도(정의된 이온 강도, pH 및 핵산 농도 하에)일 수 있다. 엄격한 조건은 염 농도가 약 1.0M 나트륨 이온 미만, 예컨대 pH 7.0 내지 8.3에서 약 0.01-1.0M 나트륨 이온 농도(또는 다른 염)이고 온도가 짧은 탐침(예로 약 10-50개 뉴클레오티드)에 대해 적어도 약 30℃이고 긴 탐침(예로 약 50개 초과 뉴클레오티드)에 대해 적어도 약 60℃인 것들일 수 있다. 엄격한 조건은 또한 탈안정화 제제, 예컨대 포름아미드의 첨가로 달성될 수 있다. 선택적 또는 특이적 혼성화를 위해, 양성 신호는 배경 혼성화의 적어도 2 내지 10배일 수 있다. 예시적인 엄격한 혼성화 조건에는 하기가 포함된다: 50% 포름아미드, 5xSSC, 및 1% SDS, 42℃에서 인큐베이션하거나, 또는 5xSSC, 1% SDS, 65℃에서 인큐베이션하고, 65℃에서 0.2xSSC, 및 0.1% SDS 중에 세척.
본원에서 상호 교환적으로 이용되는 "대상체" 및 "환자"는 비제한적으로 포유류(예로, 소, 돼지, 낙타, 라마, 말, 염소, 토끼, 양, 햄스터, 기니아픽, 고양이, 개, 래트 및 마우스, 비인간 영장류(예를 들어, 원숭이, 예컨대 게잡이 또는 붉은털 원숭이, 침팬지 등) 및 인간)를 포함하는 임의의 척추동물을 나타낸다. 일부 구현예에서, 대상체는 인간 또는 비-인간일 수 있다. 대상체 또는 환자는 다른 형태의 치료를 거치고 있을 수 있다.
본원에서 이용되는 "실질적으로 상보적인"은 제1 서열이 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100개 또는 그 초과의 뉴클레오티드 또는 아미노산 영역에 걸쳐 제2 서열의 상보체에 적어도 60%, 65%, 70%, 75%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% 또는 99% 동일함을, 또는 두 서열이 엄격한 혼성화 조건 하에 혼성화함을 의미할 수 있다.
본원에서 이용되는 "실질적으로 동일한"은 제1 서열이 제2 서열의 상보체에 실질적으로 상보적인 경우, 제1 및 제2 서열이 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100개 또는 그 초과의 뉴클레오티드 또는 아미노산 영역에 걸쳐 또는 핵산에 대해 적어도 60%, 65%, 70%, 75%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99%임을 의미할 수 있다.
본원에서 이용되는 "합성 항체"는 본원에서 기재된 재조합 핵산 서열에 의해 인코딩되고 대상체에서 생성되는 항체를 나타낸다.
본원에서 이용되는 "치료" 또는 "치료하는"은 질환의 예방, 억제, 진압 또는 완전 제거 수단을 통한 대상체의 질환으로부터의 보호를 의미할 수 있다. 질환의 예방에는 질환의 개시 전에 대상체에 대한 본 발명의 백신 투여가 관여된다. 질환의 억제에는 질환의 유도 후 그러나 그 임상적 출현 전에 대상체에 대한 본 발명의 백신 투여가 관여된다. 질환의 진압에는 질환의 임상적 출현 후 대상체에 대한 본 발명의 백신 투여가 관여된다.
핵산에 대해 본원에서 이용되는 "변이체"는 (i) 참조된 뉴클레오티드 서열의 일부 또는 단편; (ii) 참조된 뉴클레오티드 서열 또는 이들의 일부의 상보체; (iii) 참조된 핵산 또는 이들의 상보체와 실질적으로 동일한 핵산; 또는 (iv) 참조된 핵산, 이들의 상보체, 또는 이들과 실질적으로 동일한 서열에 엄격한 조건 하에 혼성화하는 핵산을 의미할 수 있다.
펩티드 또는 폴리펩티드에 대한 "변이체"는 아미노산의 삽입, 결실, 또는 보존적 치환에 의해 아미노산 서열이 상이하지만 적어도 하나의 생물학적 활성을 보유한다. 변이체는 또한 적어도 하나의 생물학적 활성을 보유하는 아미노산 서열을 갖는 참조된 단백질과 실질적으로 동일한 아미노산 서열을 갖는 단백질을 의미할 수 있다. 아미노산의 보존적 치환, 즉 유사한 특성(예로, 친수성, 하전된 영역의 정도 및 분포)의 상이한 아미노산을 이용한 아미노산 대체는 당분야에서 전형적으로 작은 변화가 관여되는 것으로 인식된다. 이러한 작은 변화는, 부분적으로 당분야에 이해되는 바와 같이 아미노산의 수치 지수를 고려하여 확인될 수 있다[Kyte et al., J. Mol. Biol. 157:105-132(1982)]. 아미노산의 수치 지수는 그 소수성 및 전하의 고려에 기반한다. 유사한 수치 지수의 아미노산이 치환되고 여전히 단백질 기능을 보유할 수 있음이 당분야에 공지되어 있다. 하나의 측면에서, ±2의 수치 지수를 갖는 아미노산이 치환된다. 아미노산의 친수성은 또한 생물학적 기능을 보유하는 단백질을 생성할 치환을 드러내기 위해 이용될 수 있다. 펩티드의 맥락에서 아미노산의 친수성 고려는 항원성 및 면역원성과 잘 연관되는 것으로 보고된 유용한 척도인 해당 펩티드의 가장 큰 국소 평균 친수성 계산을 허용한다(본원에 전체가 참조로 도입된 미국 특허 No. 4,554,101). 당분야에서 이해되는 바와 같은, 유사한 친수성값을 갖는 아미노산의 치환은 생물학적 활성, 예를 들어 면역원성을 보유하는 펩티드를 생성할 수 있다. 치환은 서로 ±2 내의 친수성값을 갖는 아미노산으로 수행될 수 있다. 아미노산의 소수성 지수 및 친수성값은 모두 아미노산의 특정 측쇄에 의해 영향을 받는다. 그 관찰과 일치하게, 생물학적 기능과 상용성인 아미노산 치환은 아미노산의 상대적 유사성, 특히 소수성, 친수성, 전하, 크기 및 다른 특성으로 드러나는 바와 같은 이들 아미노산의 측쇄에 근거하는 것으로 이해된다.
변이체는 전체 유전자 서열의 전장 또는 그의 단편에 걸쳐 실질적으로 동일한 핵산 서열일 수 있다. 핵산 서열은 유전자 서열의 전장 또는 그의 단편에 걸쳐 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 또는 100% 동일할 수 있다. 변이체는 아미노산 서열의 전장 또는 그의 단편에 걸쳐 실질적으로 동일한 아미노산 서열일 수 있다. 아미노산 서열은 아미노산 서열의 전장 또는 그의 단편에 걸쳐 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 또는 100% 동일할 수 있다.
본원에서 이용되는 "벡터"는 복제 기원을 함유하는 핵산 서열을 의미할 수 있다. 벡터는 플라스미드, 박테리오파지, 박테리아 인공 염색체 또는 효모 인공 염색체일 수 있다. 벡터는 DNA 또는 RNA 벡터일 수 있다. 벡터는 자가-복제 염색체외 벡터 또는 숙주 게놈 내로 통합되는 벡터일 수 있다.
본원에서 수치 범위의 언급에 있어서, 동일한 정도의 정밀도를 갖는 그 사이의 각각의 개입 숫자가 명시적으로 고려된다. 예를 들어, 6-9의 범위에 있어서, 숫자 7 및 8은 6 및 9에 부가하여 고려되며, 범위 6.0-7.0에 있어서, 숫자 6.0, 6.1, 6.2, 6.3, 6.4, 6.5, 6.6, 6.7, 6.8, 6.9, 및 7.0이 명시적으로 고려된다.
2. 조성물
본 발명은 항체, 그의 단편, 이들의 변이체, 또는 이들의 조합을 인코딩하는 재조합 핵산 서열을 포함하는 조성물에 관한 것이다. 이를 필요로 하는 대상체에 투여되는 경우, 조성물은 대상체에서 합성 항체의 생성을 일으킬 수 있다. 합성 항체는 대상체에 존재하는 표적 분자(즉, 항원)에 결합할 수 있다. 이러한 결합은 항원을 중화시키거나, 다른 분자, 예를 들어 단백질 또는 핵산에 의한 항원의 인식을 차단하거나, 항원에 대한 면역 반응을 야기 또는 유도할 수 있다.
합성 항체는 조성물이 투여된 대상체에서 질환에 대해 치료, 예방 및/또는 보호할 수 있다. 항원에 결합함으로써, 합성 항체는 조성물이 투여된 대상체에서 질환에 대해 치료, 예방 및/또는 보호할 수 있다. 합성 항체는 조성물이 투여된 대상체에서 질환 생존을 촉진할 수 있다. 합성 항체는 조성물이 투여된 대상체에서 적어도 약 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 또는 100%의 질환 생존을 제공할 수 있다. 다른 구현예에서, 합성 항체는 조성물이 투여된 대상체에서 적어도 약 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 또는 80%의 질환 생존을 제공할 수 있다.
조성물은 대상체에 대한 조성물 투여의 적어도 약 1시간, 2시간, 3시간, 4시간, 5시간, 6시간, 7시간, 8시간, 9시간, 10시간, 11시간, 12시간, 13시간, 14시간, 15시간, 20시간, 25시간, 30시간, 35시간, 40시간, 45시간, 50시간, 또는 60시간 내에 대상체에서 합성 항체의 생성을 일으킬 수 있다. 조성물은 대상체에 대한 조성물 투여의 적어도 약 1일, 2일, 3일, 4일, 5일, 6일, 7일, 8일, 9일, 또는 10일 내에 대상체에서 합성 항체의 생성을 일으킬 수 있다. 조성물은 대상체에 대한 조성물 투여의 약 1시간 내지 약 6일, 약 1시간 내지 약 5일, 약 1시간 내지 약 4일, 약 1시간 내지 약 3일, 약 1시간 내지 약 2일, 약 1시간 내지 약 1일, 약 1시간 내지 약 72시간, 약 1시간 내지 약 60시간, 약 1시간 내지 약 48시간, 약 1시간 내지 약 36시간, 약 1시간 내지 약 24시간, 약 1시간 내지 약 12시간, 또는 약 1시간 내지 약 6시간 내에 대상체에서 합성 항체의 생성을 일으킬 수 있다.
이를 필요로 하는 대상체에 투여되는 경우, 조성물은 체액성 면역 반응을 유도하기 위해 항원이 투여된 대상체에서 내인성 항체의 생성보다 더 신속하게 대상체에서 합성 항체의 생성을 일으킬 수 있다. 조성물은 체액성 면역 반응을 유도하기 위해 항원이 투여된 대상체에서 내인성 항체 생성의 적어도 약 1일, 2일, 3일, 4일, 5일, 6일, 7일, 8일, 9일, 또는 10일 전에 합성 항체의 생성을 일으킬 수 있다.
본 발명의 조성물은 조성물이 질병 또는 사망을 유도하지 않으므로 안전하고; 질병에 대해 보호하며; 투여 용이성, 적은 부작용, 생물학적 안정성 및 낮은 용량 별 비용을 제공하는 것과 같이 효과적인 조성물에 요구되는 특징을 가질 수 있다.
3. 재조합 핵산 서열
상술된 바와 같이, 조성물은 재조합 핵산 서열을 포함할 수 있다. 재조합 핵산 서열은 항체, 그의 단편, 이들의 변이체, 또는 이들의 조합을 인코딩할 수 있다. 항체는 아래에 보다 상세히 기재된다.
재조합 핵산 서열은 이종성 핵산 서열일 수 있다. 재조합 핵산 서열에는 적어도 하나의 이종성 핵산 서열 또는 하나 이상의 이종성 핵산 서열이 포함될 수 있다.
재조합 핵산 서열은 최적화된 핵산 서열일 수 있다. 이러한 최적화는 항체의 면역원성을 증가시키거나 변경할 수 있다. 최적화는 또한 전사 및/또는 번역을 개선할 수 있다. 최적화에는 하기 중 하나 이상이 포함될 수 있다: 전사를 증가시키기 위한 낮은 GC 함량의 리더 서열; mRNA 안정성 및 코돈 최적화; 증가된 번역을 위한 코작 서열(예로, GCC ACC)의 부가; 신호 펩티드를 인코딩하는 면역글로불린(Ig) 리더 서열의 부가; 및 시스-작용 서열 모티프(즉 내부 TATA 박스)가 작용 가능한 범위까지의 제거.
a. 재조합 핵산 서열 작제물
재조합 핵산 서열에는 하나 이상의 재조합 핵산 서열 작제물이 포함될 수 있다. 재조합 핵산 서열 작제물에는 하나 이상의 성분이 포함될 수 있고, 이는 아래에 보다 상세히 기재된다.
재조합 핵산 서열 작제물에는 중쇄 폴리펩티드, 그의 단편, 이들의 변이체, 또는 이들의 조합을 인코딩하는 이종성 핵산 서열이 포함될 수 있다. 재조합 핵산 서열 작제물에는 경쇄 폴리펩티드, 그의 단편, 이들의 변이체, 또는 이들의 조합을 인코딩하는 이종성 핵산 서열이 포함될 수 있다. 재조합 핵산 서열 작제물에는 또한 프로테아제 또는 펩티다아제 절단 부위를 인코딩하는 이종성 핵산 서열이 포함될 수 있다. 재조합 핵산 서열 작제물에는 하나 이상의 리더 서열이 포함될 수 있고, 여기서 각각의 리더 서열은 신호 펩티드를 인코딩한다. 재조합 핵산 서열 작제물에는 하나 이상의 프로모터, 하나 이상의 인트론, 하나 이상의 전사 종결 영역, 하나 이상의 개시 코돈, 하나 이상의 종결 또는 정지 코돈, 및/또는 하나 이상의 폴리아데닐화 신호가 포함될 수 있다. 재조합 핵산 서열 작제물에는 또한 하나 이상의 링커 또는 태그 서열이 포함될 수 있다. 태그 서열은 헤마글루티닌(HA) 태그를 인코딩할 수 있다.
(1) 중쇄 폴리펩티드
재조합 핵산 서열 작제물에는 중쇄 폴리펩티드, 그의 단편, 이들의 변이체, 또는 이들의 조합을 인코딩하는 이종성 핵산이 포함될 수 있다. 중쇄 폴리펩티드에는 가변 중쇄(VH) 영역 및/또는 적어도 하나의 불변 중쇄(CH) 영역이 포함될 수 있다. 적어도 하나의 불변 중쇄 영역에는 불변 중쇄 영역 1(CH1), 불변 중쇄 영역 2(CH2), 및 불변 중쇄 영역 3(CH3), 및/또는 힌지 영역이 포함될 수 있다.
일부 구현예에서, 중쇄 폴리펩티드에는 VH 영역 및 CH1 영역이 포함될 수 있다. 다른 구현예에서, 중쇄 폴리펩티드에는 VH 영역, CH1 영역, 힌지 영역, CH2 영역, 및 CH3 영역이 포함될 수 있다.
중쇄 폴리펩티드에는 상보성 결정 영역("CDR") 세트가 포함될 수 있다. CDR 세트는 VH 영역의 세 고가변 영역을 함유할 수 있다. 중쇄 폴리펩티드의 N-말단에서 시작하여, 이들 CDR은 각각 "CDR1", "CDR2", 및 "CDR3"으로 표시된다. 중쇄 폴리펩티드의 CDR1, CDR2, 및 CDR3은 항원의 결합 또는 인식에 기여할 수 있다.
(2) 경쇄 폴리펩티드
재조합 핵산 서열 작제물에는 경쇄 폴리펩티드, 그의 단편, 이들의 변이체, 또는 이들의 조합을 인코딩하는 이종성 핵산 서열이 포함될 수 있다. 경쇄 폴리펩티드에는 가변 경쇄(VL) 영역 및/또는 불변 경쇄(CL) 영역이 포함될 수 있다.
경쇄 폴리펩티드에는 상보성 결정 영역("CDR") 세트가 포함될 수 있다. CDR 세트는 VL 영역의 세 고가변 영역을 함유할 수 있다. 경쇄 폴리펩티드의 N-말단에서 시작하여, 이들 CDR은 각각 "CDR1", "CDR2", 및 "CDR3"으로 표시된다. 경쇄 폴리펩티드의 CDR1, CDR2, 및 CDR3은 항원의 결합 또는 인식에 기여할 수 있다.
(3) 프로테아제 절단 부위
재조합 핵산 서열 작제물에는 프로테아제 절단 부위를 인코딩하는 이종성 핵산 서열이 포함될 수 있다. 프로테아제 절단 부위는 프로테아제 또는 펩티다아제에 의해 인식될 수 있다. 프로테아제는 엔도펩티다아제 또는 엔도프로테아제, 예를 들어 비제한적으로 퓨린, 엘라스타아제, HtrA, 칼파인, 트립신, 키모트립신, 트립신, 및 펩신일 수 있다. 프로테아제는 퓨린일 수 있다. 다른 구현예에서, 프로테아제는 세린 프로테아제, 트레오닌 프로테아제, 시스테인 프로테아제, 아스파르테이트 프로테아제, 메탈로프로테아제, 글루탐산 프로테아제, 또는 내부 펩티드 결합을 절단하는(즉, N-말단 또는 C-말단 펩티드 결합을 절단하지 않는) 임의의 프로테아제일 수 있다.
프로테아제 절단 부위에는 절단 효율을 촉진하거나 증가시키는 하나 이상의 아미노산 서열이 포함될 수 있다. 하나 이상의 아미노산 서열은 별도의 폴리펩티드를 형성 또는 생성하는 효율을 촉진하거나 증가시킬 수 있다. 하나 이상의 아미노산 서열에는 2A 펩티드 서열이 포함될 수 있다.
(4) 링커 서열
재조합 핵산 서열 작제물에는 하나 이상의 링커 서열이 포함될 수 있다. 링커 서열은 본원에 기재된 하나 이상의 성분을 공간적으로 분리하거나 연결할 수 있다. 다른 구현예에서, 링커 서열은 두 개 이상의 폴리펩티드를 공간적으로 분리하거나 연결하는 아미노산 서열을 인코딩할 수 있다.
(5) 프로모터
재조합 핵산 서열 작제물에는 하나 이상의 프로모터가 포함될 수 있다. 하나 이상의 프로모터는 유전자 발현을 유도하고 유전자 발현을 조절할 수 있는 임의의 프로모터일 수 있다. 이러한 프로모터는 DNA 의존적 RNA 폴리머라아제를 통해 전사에 필요한 시스-작용 서열 요소이다. 유전자 발현을 지시하기 위해 이용된 프로모터의 선택은 구체적 용도에 의존한다. 프로모터는 이것이 그 천연 설정에서 전사 개시 부위로부터 유래되므로, 재조합 핵산 서열 작제물에서 전사 개시로부터 대략 동일한 거리에 배치될 수 있다. 그러나 상기 거리의 변동이 프로모터의 기능의 손실 없이 수용될 수 있다.
프로모터는 중쇄 폴리펩티드 및/또는 경쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열에 작동 가능하게 연결될 수 있다. 프로모터는 진핵 세포에서 발현에 효과적으로 나타난 프로모터일 수 있다. 코딩 서열에 작동 가능하게 연결된 프로모터는 CMV 프로모터, 원숭이 바이러스 40(SV40)에서 유래된 프로모터, 예컨대 SV40 조기 프로모터 및 SV40 후기 프로모터, 마우스 유방암 바이러스(MMTV) 프로모터, 인간 면역결핍 바이러스(HIV) 프로모터, 예컨대 소 면역결핍 바이러스(BIV) 긴 말단 반복서열(LTR) 프로모터, 몰로니 바이러스 프로모터, 조류 백혈증 바이러스(ALV) 프로모터, 사이토메갈로바이러스(CMV) 프로모터, 예컨대 CMV 최조기 프로모터, 엡스타인 바 바이러스(EBV) 프로모터, 또는 라우스 육종 바이러스(RSV) 프로모터일 수 있다. 프로모터는 또한 인간 유전자, 예컨대 인간 액틴, 인간 미오신, 인간 헤모글로빈, 인간 근육 크레아틴, 인간 폴리헤드린, 또는 인간 메탈로티오나인에서 유래된 프로모터일 수 있다.
프로모터는 항상적 프로모터 또는 숙주 세포가 일부 특정 외부 자극에 노출되는 경우에만 전사를 개시하는 유도 가능한 프로모터일 수 있다. 다세포 개체의 경우, 프로모터는 또한 특정 조직 또는 기관 또는 발달 단계에 특이적일 수 있다. 프로모터는 또한 천연 또는 합성의 조직 특이적 프로모터, 예컨대 근육 또는 피부 특이적 프로모터일 수 있다. 이러한 프로모터의 예는 미국 특허 출원 공개 번호 US20040175727에 기재되며, 그 내용은 전문이 본원에 도입된다.
프로모터는 인핸서와 연관될 수 있다. 인핸서는 코딩 서열의 상류에 배치될 수 있다. 인핸서는 인간 액틴, 인간 미오신, 인간 헤모글로빈, 인간 근육 크레아틴 또는 바이러스 인핸서, 예컨대 CMV, FMDV, RSV 또는 EBV 유래의 인핸서일 수 있다. 폴리뉴클레오티드 기능 증강은 미국 특허 번호 5,593,972, 5,962,428, 및 WO94/016737에 기재되며, 각각의 내용은 전체가 참조로 도입된다.
(6) 인트론
재조합 핵산 서열 작제물에는 하나 이상의 인트론이 포함될 수 있다. 각각의 인트론에는 기능적 스플라이스 공여체 및 수신체 부위가 포함될 수 있다. 인트론에는 스플라이싱 인핸서가 포함될 수 있다. 인트론에는 효율적인 스플라이싱을 위해 필요한 하나 이상의 신호가 포함될 수 있다.
(7) 전사 종결 영역
재조합 핵산 서열 작제물에는 하나 이상의 전사 종결 영역이 포함될 수 있다. 전사 종결 영역은 효율적인 종결을 제공하기 위해 코딩 서열의 하류일 수 있다. 전사 종결 영역은 상술된 프로모터와 동일한 유전자에서 수득될 수도 있고, 또는 하나 이상의 상이한 유전자에서 수득될 수도 있다.
(8) 개시 코돈
재조합 핵산 서열 작제물에는 하나 이상의 개시 코돈이 포함될 수 있다. 개시 코돈은 코딩 서열의 상류에 배치될 수 있다. 개시 코돈은 코딩 서열과 같은 틀에 있을 수 있다. 개시 코돈은 효율적인 번역 개시를 위해 필요한 하나 이상의 신호, 예를 들어 비제한적으로 리보솜 결합 부위에 연합될 수 있다.
(9) 종결 코돈
재조합 핵산 서열 작제물에는 하나 이상의 종결 또는 정지 코돈이 포함될 수 있다. 종결 코돈은 코딩 서열의 하류일 수 있다. 종결 코돈은 코딩 서열과 같은 틀에 있을 수 있다. 종결 코돈은 효율적인 번역 종결을 위해 필요한 하나 이상의 신호에 연합될 수 있다.
(10) 폴리아데닐화 신호
재조합 핵산 서열 작제물에는 하나 이상의 폴리아데닐화 신호가 포함될 수 있다. 폴리아데닐화 신호에는 전사체의 효율적인 폴리아데닐화를 위해 필요한 하나 이상의 신호가 포함될 수 있다. 폴리아데닐화 신호는 코딩 서열의 하류에 배치될 수 있다. 폴리아데닐화 신호는 SV40 폴리아데닐화 신호, LTR 폴리아데닐화 신호, 소 성장 호르몬(bGH) 폴리아데닐화 신호, 인간 성장 호르몬(hGH) 폴리아데닐화 신호, 또는 인간 β-글로빈 폴리아데닐화 신호일 수 있다. SV40 폴리아데닐화 신호는 pCEP4 플라스미드(Invitrogen, San Diego, CA)로부터의 폴리아데닐화 신호일 수 있다.
(11) 리더 서열
재조합 핵산 서열 작제물에는 하나 이상의 리더 서열이 포함될 수 있다. 리더 서열은 신호 펩티드를 인코딩할 수 있다. 신호 펩티드는 면역글로불린(Ig) 신호 펩티드, 예를 들어 비제한적으로 IgG 신호 펩티드 및 IgE 신호 펩티드일 수 있다. 일부 예에서, 리더 서열은 서열 식별 번호 65의 IgE 리더 IgE 리더 서열: atggactgga cttggattct gttcctggtc gccgccgcaa ctcgcgtgca tagc이며, 이는 서열 식별 번호 66의 단백질: Met Asp Trp Thr Trp Ile Leu Phe Leu Val Ala Ala Ala Thr Arg Val His Ser을 인코딩한다.
b. 재조합 핵산 서열 작제물의 배열
상술된 바와 같이, 재조합 핵산 서열에는 하나 이상의 재조합 핵산 서열 작제물이 포함될 수 있으며, 여기서 각각의 재조합 핵산 서열 작제물에는 하나 이상의 성분이 포함될 수 있다. 하나 이상의 성분이 상기에 상세히 기재된다. 재조합 핵산 서열 작제물에 포함되는 경우, 하나 이상의 성분은 서로에 대해 임의 순서로 배열될 수 있다. 일부 구현예에서, 하나 이상의 성분은 아래 기재된 바와 같이 재조합 핵산 서열 작제물에 배열될 수 있다.
(1) 배열 1
하나의 배열에서, 제1 재조합 핵산 서열 작제물에는 중쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열이 포함될 수 있고, 제2 재조합 핵산 서열 작제물에는 경쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열이 포함될 수 있다.
제1 재조합 핵산 서열 작제물은 벡터에 배치될 수 있다. 제2 재조합 핵산 서열 작제물은 제2 또는 별도의 벡터에 배치될 수 있다. 재조합 핵산 서열 작제물의 벡터 내로의 배치는 아래에 보다 상세히 기재된다.
제1 재조합 핵산 서열 작제물에는 또한 프로모터, 인트론, 전사 종결 영역, 개시 코돈, 종결 코돈, 및/또는 폴리아데닐화 신호가 포함될 수 있다. 제1 재조합 핵산 서열 작제물에는 추가로 리더 서열이 포함될 수 있고, 여기서 리더 서열은 중쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열의 상류(또는 5')에 배치된다. 따라서 리더 서열에 의해 인코딩된 신호 펩티드는 중쇄 폴리펩티드에 펩티드 결합에 의해 연결될 수 있다.
제2 재조합 핵산 서열 작제물에는 또한 프로모터, 개시 코돈, 종결 코돈, 및 폴리아데닐화 신호가 포함될 수 있다. 제2 재조합 핵산 서열 작제물에는 추가로 리더 서열이 포함될 수 있고, 여기서 리더 서열은 경쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열의 상류(또는 5')에 배치된다. 따라서 리더 서열에 의해 인코딩된 신호 펩티드는 경쇄 폴리펩티드에 펩티드 결합에 의해 연결될 수 있다.
따라서 배열 1의 하나의 예에는 VH 및 CH1이 포함되는 중쇄 폴리펩티드를 인코딩하는 제1 벡터(및 이에 따른 제1 재조합 핵산 서열 작제물), 및 VL 및 CL이 포함되는 경쇄 폴리펩티드를 인코딩하는 제2 벡터(및 이에 따른 제2 재조합 핵산 서열 작제물)가 포함될 수 있다. 배열 1의 제2 예에는 VH, CH1, 힌지 영역, CH2, 및 CH3이 포함되는 중쇄 폴리펩티드를 인코딩하는 제1 벡터(및 이에 따른 제1 재조합 핵산 서열 작제물), 및 VL 및 CL이 포함되는 경쇄 폴리펩티드를 인코딩하는 제2 벡터(및 이에 따른 제2 재조합 핵산 서열 작제물)가 포함될 수 있다.
(2) 배열 2
제2 배열에서, 재조합 핵산 서열 작제물에는 중쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열 및 경쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열이 포함될 수 있다. 중쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열은 경쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열의 상류(또는 5')에 배치될 수 있다. 대안적으로, 경쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열은 중쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열의 상류(또는 5')에 배치될 수 있다.
재조합 핵산 서열 작제물은 아래에 보다 상세히 기재된 바와 같이 벡터에 배치될 수 있다.
재조합 핵산 서열 작제물에는 프로테아제 절단 부위 및/또는 링커 서열을 인코딩하는 이종성 핵산 서열이 포함될 수 있다. 재조합 핵산 서열 작제물에 포함되는 경우, 프로테아제 절단 부위를 인코딩하는 이종성 핵산 서열은 중쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열 및 경쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열 간에 배치될 수 있다. 따라서 프로테아제 절단 부위는 발현 시 중쇄 폴리펩티드 및 경쇄 폴리펩티드의 다른 폴리펩티드로의 분리를 허용한다. 다른 구현예에서, 링커 서열이 재조합 핵산 서열 작제물에 포함되는 경우, 링커 서열은 중쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열 및 경쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열 간에 배치될 수 있다.
재조합 핵산 서열 작제물에는 또한 프로모터, 인트론, 전사 종결 영역, 개시 코돈, 종결 코돈, 및/또는 폴리아데닐화 신호가 포함될 수 있다. 재조합 핵산 서열 작제물에는 하나 이상의 프로모터가 포함될 수 있다. 재조합 핵산 서열 작제물에는 하나의 프로모터가 중쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열에 연관될 수 있고 제2 프로모터가 경쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열에 연관될 수 있도록 두 프로모터가 포함될 수 있다. 다른 구현예에서, 재조합 핵산 서열 작제물에는 중쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열 및 경쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열에 연관된 하나의 프로모터가 포함될 수 있다.
재조합 핵산 서열 작제물에는 2개의 리더 서열이 추가로 포함될 수 있고, 여기서 제1 리더 서열은 중쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열의 상류(또는 5')에 배치되고 제2 리더 서열은 경쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열의 상류(또는 5')에 배치된다. 따라서 제1 리더 서열에 의해 인코딩된 제1 신호 펩티드가 중쇄 폴리펩티드에 펩티드 결합에 의해 연결될 수 있고, 제2 리더 서열에 의해 인코딩된 제2 신호 펩티드가 경쇄 폴리펩티드에 펩티드 결합에 의해 연결될 수 있다.
따라서 배열 2의 하나의 예에는 VH 및 CH1이 포함되는 중쇄 폴리펩티드 및 VL 및 CL이 포함되는 경쇄 폴리펩티드를 인코딩하는 벡터(및 이에 따른 재조합 핵산 서열 작제물)가 포함될 수 있고, 여기서 링커 서열은 중쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열 및 경쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열 간에 배치된다.
배열 2의 제2 예에는 VH 및 CH1이 포함되는 중쇄 폴리펩티드 및 VL 및 CL이 포함되는 경쇄 폴리펩티드를 인코딩하는 벡터(및 이에 따른 재조합 핵산 서열 작제물)가 포함될 수 있고, 여기서 프로테아제 절단 부위를 인코딩하는 이종성 핵산 서열은 중쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열 및 경쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열 간에 배치된다.
배열 2의 제3 예에는 VH, CH1, 힌지 영역, CH2, 및 CH3이 포함되는 중쇄 폴리펩티드 및 VL 및 CL이 포함되는 경쇄 폴리펩티드를 인코딩하는 벡터(및 이에 따른 재조합 핵산 서열 작제물)가 포함될 수 있고, 여기서 링커 서열은 중쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열 및 경쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열 간에 배치된다.
배열 2의 제4 예에는 VH, CH1, 힌지 영역, CH2, 및 CH3이 포함되는 중쇄 폴리펩티드 및 VL 및 CL이 포함되는 경쇄 폴리펩티드를 인코딩하는 벡터(및 이에 따른 재조합 핵산 서열 작제물)가 포함될 수 있고, 여기서 프로테아제 절단 부위를 인코딩하는 이종성 핵산 서열은 중쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열 및 경쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열 간에 배치된다.
c. 재조합 핵산 서열 작제물로부터의 발현
상술된 바와 같이, 재조합 핵산 서열 작제물에는 하나 이상의 성분 가운데, 중쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열 및/또는 경쇄 폴리펩티드를 인코딩하는 이종성 핵산 서열이 포함될 수 있다. 따라서 재조합 핵산 서열 작제물은 중쇄 폴리펩티드 및/또는 경쇄 폴리펩티드의 발현을 촉진할 수 있다.
상술된 바와 같은 배열 1이 이용되는 경우, 제1 재조합 핵산 서열 작제물은 중쇄 폴리펩티드의 발현을 촉진할 수 있고, 제2 재조합 핵산 서열 작제물은 경쇄 폴리펩티드의 발현을 촉진할 수 있다. 상술된 바와 같은 배열 2가 이용되는 경우, 재조합 핵산 서열 작제물은 중쇄 폴리펩티드 및 경쇄 폴리펩티드의 발현을 촉진할 수 있다.
예를 들어 비제한적으로 세포, 개체 또는 포유류에서의 발현 시, 중쇄 폴리펩티드 및 경쇄 폴리펩티드는 합성 항체로 조립될 수 있다. 특히, 중쇄 폴리펩티드 및 경쇄 폴리펩티드는 조립으로 항원에 결합할 수 있는 합성 항체가 생성되도록 서로 상호작용할 수 있다. 다른 구현예에서, 중쇄 폴리펩티드 및 경쇄 폴리펩티드는 조립으로 본원에 기재된 바와 같이 조립되지 않은 항체에 비해 더 면역원성이 높은 합성 항체를 생성하도록 서로 상호작용할 수 있다. 다른 구현예에서, 중쇄 폴리펩티드 및 경쇄 폴리펩티드는 조립으로 항원에 대해 면역 반응을 야기하거나 유도할 수 있는 합성 항체를 생성하도록 서로 상호작용할 수 있다.
d. 벡터
상술된 재조합 핵산 서열 작제물은 하나 이상의 벡터에 배치될 수 있다. 하나 이상의 벡터는 복제 기원을 함유할 수 있다. 하나 이상의 벡터는 플라스미드, 박테리오파지, 박테리아 인공 염색체 또는 효모 인공 염색체일 수 있다. 하나 이상의 벡터는 자가 복제 염색체외 벡터, 또는 숙주 게놈 내로 통합되는 벡터일 수 있다.
하나 이상의 벡터는 이종성 발현 작제물일 수 있고, 이는 일반적으로 표적 세포 내로 특정 유전자를 도입하기 위해 이용되는 플라스미드이다. 일단 발현 벡터가 세포 내로 들어가면, 재조합 핵산 서열 작제물에 의해 인코딩되는 중쇄 폴리펩티드 및/또는 경쇄 폴리펩티드가 세포-전사 및 번역 기전 리보솜 복합체에 의해 생성된다. 하나 이상의 벡터는 다량의 안정한 메신저 RNA, 그리고 이에 따라 단백질을 발현할 수 있다.
(1) 발현 벡터
하나 이상의 벡터는 원형 플라스미드 또는 선행 핵산일 수 있다. 원형 플라스미드 및 선형 핵산은 적절한 대상체 세포에서 특정 뉴클레오티드 서열의 발현을 지시할 수 있다. 재조합 핵산 서열 작제물을 포함하는 하나 이상의 벡터는 키메라일 수 있다, 즉 그 성분의 적어도 하나가 그 다른 성분의 적어도 하나에 대해 이종성이다.
(2) 플라스미드
하나 이상의 벡터는 플라스미드일 수 있다. 플라스미드는 재조합 핵산 서열 작제물로 세포를 전달감염하기 위해 유용할 수 있다. 플라스미드는 대상체 내로 재조합 핵산 서열 작제물을 도입하기 위해 유용할 수 있다. 플라스미드는 또한 조절 서열을 포함할 수 있고, 이는 플라스미드가 투여되는 세포에서 유전자 발현에 매우 적합할 수 있다.
플라스미드는 또한 염색체외로 플라스미드를 유지하고 세포에서 복수의 플라스미드 사본을 생산하기 위해 포유류 복제 기원을 포함할 수 있다. 플라스미드는 Invitrogen(San Diego, CA)의 pVAXI, pCEP4 또는 pREP4일 수 있고, 이는 엡스타인 바 바이러스 복제 기원 및 핵 항원 EBNA-1 코딩 영역을 포함할 수 있고, 이는 통합 없이 고사본 에피솜 복제를 생산할 수 있다. 플라스미드 골격은 pAV0242일 수 있다. 플라스미드는 복제 결함 아데노바이러스 유형 5(Ad5) 플라스미드일 수 있다.
플라스미드는 pSE420(Invitrogen, San Diego, Calif.)일 수 있고, 이는 대장균(E.coli)에서 단백질 생산을 위해 이용될 수 있다. 플라스미드는 또한 pYES2(Invitrogen, San Diego, Calif.)일 수 있으며, 이는 효모의 사카로마이세스 세레비시애 균주에서 단백질 생산을 위해 이용될 수 있다. 플라스미드는 또한 MAXBAC™ 완전 배큘로바이러스 발현 시스템(Invitrogen, San Diego, Calif.)일 수 있고, 이는 곤충 세포에서 단백질 생산을 위해 이용될 수 있다. 플라스미드는 또한 pcDNAI 또는 pcDNA3(Invitrogen, San Diego, Calif.)일 수 있고, 이는 포유류 세포, 예컨대 중국 햄스터 난소(CHO) 세포에서 단백질 생산을 위해 이용될 수 있다.
(3) 원형 및 선형 벡터
하나 이상의 벡터는 원형 플라스미드일 수 있고, 이는 세포 게놈 내로의 통합에 의해 표적 세포를 형질전환시키거나 염색체외(예로 복제 기원이 있는 자가 복제 플라스미드)로 존재할 수 있다. 벡터는 pVAX, pcDNA3.0, 또는 provax, 또는 재조합 핵산 서열 작제물에 의해 인코딩된 중쇄 폴리펩티드 및/또는 경쇄 폴리펩티드를 발현할 수 있는 임의의 다른 발현 벡터일 수 있다.
또한 선형 핵산, 또는 선형 발현 카세트("LEC")가 본원에 제공되며, 이는 전기천공을 통해 대상체에 효율적으로 전달되고 핵산 서열 작제물에 의해 인코딩된 중쇄 폴리펩티드 및/또는 경쇄 폴리펩티드를 발현할 수 있다. LEC는 임의의 인산염 골격이 없는 임의의 선형 DNA일 수 있다. LEC는 임의의 항생제 내성 유전자 및/또는 인산염 골격을 함유하지 않을 수 있다. LEC는 원하는 유전자 발현에 관련되지 않은 다른 핵산 서열을 함유하지 않을 수 있다.
LEC는 선형화될 수 있는 임의의 플라스미드에서 유래될 수 있다. 플라스미드는 재조합 핵산 서열 작제물에 의해 인코딩된 중쇄 폴리펩티드 및/또는 경쇄 폴리펩티드를 발현할 수 있다. 플라스미드는 pNP(Puerto Rico/34) 또는 pM2(New Caledonia/99)일 수 있다. 플라스미드는 WLV009, pVAX, pcDNA3.0, 또는 provax, 또는 재조합 핵산 서열 작제물에 의해 인코딩된 중쇄 폴리펩티드 및/또는 경쇄 폴리펩티드를 발현할 수 있는 임의의 다른 발현 벡터일 수 있다.
LEC는 pcrM2일 수 있다. LEC는 pcrNP일 수 있다. pcrNP 및 pcrMR은 각각 pNP(Puerto Rico/34) 및 pM2(New Caledonia/99)에서 유래될 수 있다.
(4) 벡터의 제조 방법
재조합 핵산 서열 작제물이 배치된 하나 이상의 벡터의 제조 방법이 본원에 제공된다. 최종 서브클로닝 단계 후, 벡터는 당분야에 공지된 방법을 이용하여 대규모 발효 탱크에서 세포 배양에 접종하기 위해 이용될 수 있다.
다른 구현예에서, 최종 서브클로닝 단계 후, 벡터는 하나 이상의 전기천공(EP) 장치와 함께 이용될 수 있다. EP 장치는 아래에 보다 상세히 기재된다.
하나 이상의 벡터는 공지된 장치 및 기법의 조합을 이용하여 제형화되거나 제조될 수 있지만, 바람직하게는 2007. 5. 23.에 출원된, 라이센스 받고 공동 계류중인 미국 가출원 미국 일련 번호 60/939,792에 기재된 플라스미드 제조 기법을 이용하여 제조된다. 일부 예에서, 본원에 기재된 DNA 플라스미드는 10mg/mL 이상의 농도로 제형화될 수 있다. 제조 기법에는 또한 미국 일련 번호 60/939792에 기재된 것에 더하여, 2007. 7. 3.에 허여된 라이센스 받은 특허, 미국 특허 번호 7,238,522에 기재된 것들을 포함하는 당업자에게 일반적으로 공지된 다양한 장치 및 프로토콜이 포함되거나 도입된다. 상기-참조된 출원 및 특허, 미국 일련 번호 60/939,792 및 미국 특허 번호 7,238,522는 각각 이들의 전문이 본원에 도입된다.
4. 항체
상술된 바와 같이, 재조합 핵산 서열은 항체, 그의 단편, 이들의 변이체, 또는 이들의 조합을 인코딩할 수 있다. 항체는 항원에 결합하거나 이와 반응할 수 있고, 이는 아래에 보다 상세히 기재된다.
항체는 CDR에 대한 지지를 제공하고 서로에 대해 CDR의 공간적 관계를 정의하는 중쇄 및 경쇄 틀("FR") 세트 사이에 각각 배치된 중쇄 및 경쇄 상보성 결정 영역("CDR") 세트를 포함할 수 있다. CDR 세트는 중쇄 또는 경쇄 V 영역의 세 고가변 영역을 함유할 수 있다. 중쇄 또는 경쇄의 N-말단에서 시작하여, 이들 영역은 각각 "CDR1", "CDR2" 및 "CDR3"으로 표시된다. 따라서 항원-결합 부위에는 중쇄 또는 경쇄 V 영역 각각으로부터의 CDR 세트를 포함하는 6개의 CDR이 포함될 수 있다.
단백분해 효소 파파인은 우선적으로 IgG 분자를 절단하여 몇몇 단편을 생성하며, 그 중 둘(F(ab) 단편)은 각각 온전한 항원-결합 부위가 포함되는 공유 이종이량체를 포함한다. 효소 펩신은 IgG 분자를 절단하여 F(ab')2 단편을 포함하는 몇몇 단편을 제공할 수 있고, 이는 두 항원-결합 부위를 모두 포함한다. 따라서 항체는 Fab 또는 F(ab')2일 수 있다. Fab에는 중쇄 폴리펩티드 및 경쇄 폴리펩티드가 포함될 수 있다. Fab의 중쇄 폴리펩티드에는 VH 영역 및 CH1 영역이 포함될 수 있다. Fab의 경쇄에는 VL 영역 및 CL 영역이 포함될 수 있다.
항체는 면역글로불린(Ig)일 수 있다. Ig는, 예를 들어 IgA, IgM, IgD, IgE, 및 IgG일 수 있다. 면역글로불린에는 중쇄 폴리펩티드 및 경쇄 폴리펩티드가 포함될 수 있다. 면역글로불린의 중쇄 폴리펩티드에는 VH 영역, CH1 영역, 힌지 영역, CH2 영역, 및 CH3 영역이 포함될 수 있다. 면역글로불린의 경쇄 폴리펩티드에는 VL 영역 및 CL 영역이 포함될 수 있다.
항체는 폴리클로날 또는 모노클로날 항체일 수 있다. 항체는 키메라 항체, 단일쇄 항체, 친화도 성숙된 항체, 인간 항체, 인간화된 항체, 또는 완전 인간 항체일 수 있다. 인간화된 항체는 비인간 종으로부터의 하나 이상의 상보성 결정 영역(CDR) 및 인간 면역글로불린 분자로부터의 틀 영역을 갖고 원하는 항원에 결합하는 비인간 종으로부터의 항체일 수 있다.
5. 항원
합성 항체는 항원 또는 그의 단편 또는 변이체에 대한 것이다. 항원은 핵산 서열, 아미노산 서열, 또는 이들의 조합일 수 있다. 핵산 서열은 DNA, RNA, cDNA, 이들의 변이체, 그의 단편, 또는 이들의 조합일 수 있다. 아미노산 서열은 단백질, 펩티드, 이들의 변이체, 그의 단편, 또는 이들의 조합일 수 있다.
항원은 임의 수의 개체, 예를 들어 바이러스, 기생충, 박테리아, 진균, 또는 포유류에서 유래될 수 있다. 항원은 자가면역 질환, 알러지, 또는 천식에 연관될 수 있다. 다른 구현예에서, 항원은 암, 헤르페스, 독감, B형 간염, C형 간염, 인간 유두종 바이러스(HPV), 또는 인간 면역결핍 바이러스(HIV)에 연관될 수 있다.
일부 구현예에서, 항원은 외래의 것이다. 일부 구현예에서, 항원은 자가-항원이다.
a. 외래 항원
일부 구현예에서, 항원은 외래의 것이다. 외래 항원은, 체내로 도입되는 경우 면역 반응을 자극할 수 있는 임의의 비-자가 물질(즉, 대상체 외부에서 유래됨)이다.
(1) 바이러스 항원
외래 항원은 바이러스 항원, 또는 그의 단편, 또는 이들의 변이체일 수 있다. 바이러스 항원은 하기 패밀리 중 하나로부터의 바이러스에서 유래될 수 있다: 아데노바이러스과(Adenoviridae), 아레나바이러스과(Arenaviridae), 부냐바이러스과(Bunyaviridae), 칼리시바이러스과(Caliciviridae), 코로나바이러스과(Coronaviridae), 필로바이러스과(Filoviridae), 헤파드나바이러스과(Hepadnaviridae), 헤르페스바이러스과(Herpesviridae), 오르소믹소바이러스과(Orthomyxoviridae), 파포바바이러스과(Papovaviridae), 파라믹소바이러스과(ramyxoviridae), 파르보바이러스과(Parvoviridae), 피코나바이러스과(Picornaviridae), 폭스바이러스과(Poxviridae), 레오바이러스과(Reoviridae), 레트로바이러스과(Retroviridae), 랩도바이러스과(Rhabdoviridae), 또는 토가바이러스과(Togaviridae). 바이러스 항원은 인간 면역결핍 바이러스(HIV), 치쿤군야 바이러스(CHIKV), 뎅기열 바이러스, 유두종 바이러스, 예를 들어 인간 유두종 바이러스(HPV), 폴리오 바이러스, 간염 바이러스, 예를 들어 A형 간염 바이러스(HAV), B형 간염 바이러스(HBV), C형 간염 바이러스(HCV), D형 간염 바이러스(HDV), 및 E형 간염 바이러스(HEV), 천연두 바이러스(바리올라 메이저 및 마이너), 백시니아 바이러스, 인플루엔자 바이러스, 리노바이러스, 말 뇌염 바이러스, 루벨라 바이러스, 황열 바이러스, 노워크 바이러스, A형 간염 바이러스, 인간 T-세포 백혈병 바이러스(HTLV-I), 털세포 백혈병 바이러스(HTLV-II), 캘리포니아 뇌염 바이러스, 한타 바이러스(출혈열), 광견병 바이러스, 에볼라열 바이러스, 마르부르크 바이러스, 홍역 바이러스, 볼거리 바이러스, 호흡기 세포융합 바이러스(RSV), 단순 헤르페스 1(구강 헤르페스), 단순 헤르페스 2(생식기 헤르페스), 헤르페스 조스터(바리셀라-조스터, 수두로도 알려짐), 사이토메갈로바이러스(CMV), 예를 들어 인간 CMV, 엡스타인-바 바이러스(EBV), 플라비바이러스, 구제역 질환 바이러스, 라사 바이러스, 아레나바이러스, 또는 암 유발 바이러스에서 유래될 수 있다.
(a) 인간 면역결핍 바이러스(HIV) 항원
바이러스 항원은 인간 면역결핍 바이러스(HIV) 바이러스에서 유래될 수 있다. 일부 구현예에서, HIV 항원은 서브타입 A 외피 단백질, 서브타입 B 외피 단백질, 서브타입 C 외피 단백질, 서브타입 D 외피 단백질, 서브타입 B Nef-Rev 단백질, Gag 서브타입 A, B, C, 또는 D 단백질, MPol 단백질, Env A, Env B, Env C, Env D, B Nef-Rev, Gag의 핵산 또는 아미노산 서열, 또는 임의의 이들의 조합일 수 있다.
HIV에 특이적인 합성 항체에는 서열 식별 번호 3의 핵산 서열에 의해 인코딩되는 서열 식별 번호 48의 아미노산 서열 및 서열 식별 번호 4의 핵산 서열에 의해 인코딩되는 서열 식별 번호 49의 아미노산 서열을 포함하는 Fab 단편이 포함될 수 있다. 합성 항체는 서열 식별 번호 6의 핵산 서열에 의해 인코딩되는 서열 식별 번호 46의 아미노산 서열 및 서열 식별 번호 7의 핵산 서열에 의해 인코딩되는 서열 식별 번호 47의 아미노산 서열을 포함할 수 있다. Fab 단편은 서열 식별 번호 50의 핵산 서열에 의해 인코딩되는 서열 식별 번호 51의 아미노산 서열을 포함할 수 있다. Fab는 서열 식별 번호 52의 핵산 서열에 의해 인코딩되는 서열 식별 번호 53의 아미노산 서열을 포함할 수 있다.
HIV에 특이적인 합성 항체에는 서열 식별 번호 5의 아미노산 서열을 포함하는 Ig가 포함될 수 있다. Ig는 서열 식별 번호 62의 핵산 서열에 의해 인코딩되는 서열 식별 번호 1의 아미노산 서열을 포함할 수 있다. Ig는 서열 식별 번호 63의 핵산 서열에 의해 인코딩되는 서열 식별 번호 2의 아미노산 서열을 포함할 수 있다. Ig는 서열 식별 번호 54의 핵산 서열에 의해 인코딩되는 서열 식별 번호 55의 아미노산 서열, 및 서열 식별 번호 56의 핵산 서열에 의해 인코딩되는 서열 식별 번호 57의 아미노산 서열을 포함할 수 있다.
(b) 치쿤군야 바이러스
바이러스 항원은 치쿤군야 바이러스에서 유래될 수 있다. 치쿤군야 바이러스는 토가바이러스과의 알파바이러스속에 속한다. 치쿤군야 바이러스는 아에데스(Aedes)속과 같은 감염된 모기가 물어서 인간으로 전파된다.
CHIKV에 특이적인 합성 항체에는 서열 식별 번호 58의 핵산 서열에 의해 인코딩되는 서열 식별 번호 59의 아미노산 서열, 및 서열 식별 번호 60의 핵산 서열에 의해 인코딩되는 서열 식별 번호 61의 아미노산 서열을 포함하는 Fab 단편이 포함될 수 있다.
(c) 뎅기 바이러스
바이러스 항원은 뎅기 바이러스 유래일 수 있다. 뎅기 바이러스 항원은 바이러스 입자를 형성하는 3가지 단백질 또는 폴리펩티드(C, prM, 및 E) 중 하나일 수 있다. 뎅기 바이러스 항원은 바이러스 복제에 관여되는 7가지 다른 단백질 또는 폴리펩티드(NS1, NS2a, NS2b, NS3, NS4a, NS4b, NS5) 중 하나일 수 있다. 뎅기 바이러스는 DENV-1, DENV-2, DENV-3 및 DENV-4를 포함하는 바이러스의 5가지 계통 또는 혈청형 중 하나일 수 있다. 항원은 복수의 뎅기 바이러스 항원의 임의 조합일 수 있다.
뎅기 바이러스에 특이적인 합성 항체에는 서열 식별 번호 44의 핵산 서열에 의해 인코딩되는 서열 식별 번호 45의 아미노산 서열을 포함하는 Ig가 포함될 수 있다.
(d) 간염 항원
바이러스 항원에는 간염 바이러스 항원(즉, 간염 항원), 또는 그의 단편, 또는 이들의 변이체가 포함될 수 있다. 간염 항원은 A형 간염 바이러스(HAV), B형 간염 바이러스(HBV), C형 간염 바이러스(HCV), D형 간염 바이러스(HDV), 및/또는 E형 간염 바이러스(HEV) 중 하나 이상으로부터의 항원 또는 면역원일 수 있다.
간염 항원은 HAV로부터의 항원일 수 있다. 간염 항원은 HAV 캡시드 단백질, HAV 비구조 단백질, 그의 단편, 이들의 변이체, 또는 이들의 조합일 수 있다.
간염 항원은 HCV로부터의 항원일 수 있다. 간염 항원은 HCV 핵캡시드 단백질(즉, 핵심 단백질), HCV 외피 단백질(예로, E1 및 E2), HCV 비구조 단백질(예로, NS1, NS2, NS3, NS4a, NS4b, NS5a, 및 NS5b), 그의 단편, 이들의 변이체, 또는 이들의 조합일 수 있다.
간염 항원은 HDV로부터의 항원일 수 있다. 간염 항원은 HDV 델타 항원, 그의 단편, 또는 이들의 변이체일 수 있다.
간염 항원은 HEV로부터의 항원일 수 있다. 간염 항원은 HEV 캡시드 단백질, 그의 단편, 또는 이들의 변이체일 수 있다.
간염 항원은 HBV로부터의 항원일 수 있다. 간염 항원은 HBV 핵심 단백질, HBV 표면 단백질, HBV DNA 폴리머라아제, 유전자 X에 의해 인코딩된 HBV 단백질, 그의 단편, 이들의 변이체, 또는 이들의 조합일 수 있다. 간염 항원은 HBV 유전형 A 핵심 단백질, HBV 유전형 B 핵심 단백질, HBV 유전형 C 핵심 단백질, HBV 유전형 D 핵심 단백질, HBV 유전형 E 핵심 단백질, HBV 유전형 F 핵심 단백질, HBV 유전형 G 핵심 단백질, HBV 유전형 H 핵심 단백질, HBV 유전형 A 표면 단백질, HBV 유전형 B 표면 단백질, HBV 유전형 C 표면 단백질, HBV 유전형 D 표면 단백질, HBV 유전형 E 표면 단백질, HBV 유전형 F 표면 단백질, HBV 유전형 G 표면 단백질, HBV 유전형 H 표면 단백질, 그의 단편, 이들의 변이체, 또는 이들의 조합일 수 있다.
일부 구현예에서, 간염 항원은 HBV 유전형 A, HBV 유전형 B, HBV 유전형 C, HBV 유전형 D, HBV 유전형 E, HBV 유전형 F, HBV 유전형 G, 또는 HBV 유전형 H로부터의 항원일 수 있다.
(e) 인간 유두종 바이러스(HPV) 항원
바이러스 항원은 HPV로부터의 항원을 포함할 수 있다. HPV 항원은 자궁경부암, 직장암, 및/또는 다른 암을 유도하는 HPV 유형 16, 18, 31, 33, 35, 45, 52, 및 58에서 유래될 수 있다. HPV 항원은 생식기 사마귀를 유도하며 두부암 및 경부암의 원인으로 알려져 있는 HPV 유형 6 및 11에서 유래될 수 있다.
HPV 항원은 각각의 HPV 유형으로부터의 HPV E6 또는 E7 도메인일 수 있다. 예를 들어 HPV 유형 16(HPV16)에 있어서, HPV16 항원에는 HPV16 E6 항원, HPV16 E7 항원, 단편, 변이체, 또는 이들의 조합이 포함될 수 있다. 유사하게는, HPV 항원은 HPV 6 E6 및/또는 E7, HPV 11 E6 및/또는 E7, HPV 18 E6 및/또는 E7, HPV 31 E6 및/또는 E7, HPV 33 E6 및/또는 E7, HPV 52 E6 및/또는 E7, 또는 HPV 58 E6 및/또는 E7, 그의 단편, 변이체, 또는 조합일 수 있다.
(f) RSV 항원
바이러스 항원은 RSV 항원을 포함할 수 있다. RSV 항원은 인간 RSV 융합 단백질(본원에서 "RSV F", "RSV F 단백질" 및 "F 단백질"로도 불림), 또는 그의 단편 또는 변이체일 수 있다. 인간 RSV 융합 단백질은 RSV 서브타입 A 및 B 간에 보존될 수 있다. RSV 항원은 RSV Long 계통(GenBank AAX23994.1)의 RSV F 단백질, 또는 그의 단편 또는 변이체일 수 있다. RSV 항원은 RSV A2 계통(GenBank AAB59858.1)의 RSV F 단백질, 또는 그의 단편 또는 변이체일 수 있다. RSV 항원은 RSV F 단백질의 단량체, 이량체, 또는 삼량체, 또는 그의 단편 또는 변이체일 수 있다.
RSV F 단백질은 융합-전 형태 또는 융합-후 형태일 수 있다. RSV F의 융합-후 형태는 면역화된 동물에서 높은 역가의 중화 항체를 생성하고 동물을 RSV 유발접종으로부터 보호한다.
RSV 항원은 또한 인간 RSV 부착 당단백질(본원에서 "RSV G", "RSV G 단백질" 및 "G 단백질"로도 불림), 또는 그의 단편 또는 변이체일 수 있다. 인간 RSV G 단백질은 RSV 서브타입 A 및 B 간에 상이하다. 항원은 RSV Long 계통(GenBank AAX23993)으로부터의 RSV G 단백질, 또는 그의 단편 또는 변이체일 수 있다. RSV 항원은 RSV 서브타입 B 단리체 H5601, RSV 서브타입 B 단리체 H1068, RSV 서브타입 B 단리체 H5598, RSV 서브타입 B 단리체 H1123으로부터의 RSV G 단백질, 또는 그의 단편 또는 변이체일 수 있다.
다른 구현예에서, RSV 항원은 인간 RSV 비구조 단백질 1("NS1 단백질"), 또는 그의 단편 또는 변이체일 수 있다. 예를 들어, RSV 항원은 RSV Long 계통(GenBank AAX23987.1)으로부터의 RSV NS1 단백질, 또는 그의 단편 또는 변이체일 수 있다. 인간 RSV 항원은 또한 RSV 비구조 단백질 2("NS2 단백질"), 또는 그의 단편 또는 변이체일 수 있다. 예를 들어, RSV 항원은 RSV Long 계통(GenBank AAX23988.1)으로부터의 RSV NS2 단백질, 또는 그의 단편 또는 변이체일 수 있다. RSV 항원은 추가로 인간 RSV 핵캡시드("N") 단백질, 또는 그의 단편 또는 변이체일 수 있다. 예를 들어, RSV 항원은 RSV Long 계통(GenBank AAX23989.1)으로부터의 RSV N 단백질, 또는 그의 단편 또는 변이체일 수 있다. RSV 항원은 인간 RSV 인단백질("P") 단백질, 또는 그의 단편 또는 변이체일 수 있다. 예를 들어, RSV 항원은 RSV Long 계통(GenBank AAX23990.1)으로부터의 RSV P 단백질, 또는 그의 단편 또는 변이체일 수 있다. RSV 항원은 또한 인간 RSV 기질 단백질("M") 단백질, 또는 그의 단편 또는 변이체일 수 있다. 예를 들어, RSV 항원은 RSV Long 계통(GenBank AAX23991.1)으로부터의 RSV M 단백질, 또는 그의 단편 또는 변이체일 수 있다.
또 다른 구현예에서, RSV 항원은 인간 RSV 작은 소수성("SH") 단백질, 또는 그의 단편 또는 변이체일 수 있다. 예를 들어, RSV 항원은 RSV Long 계통(GenBank AAX23992.1)으로부터의 RSV SH 단백질, 또는 그의 단편 또는 변이체일 수 있다. RSV 항원은 또한 인간 RSV 기질 단백질2-1("M2-1") 단백질, 또는 그의 단편 또는 변이체일 수 있다. 예를 들어, RSV 항원은 RSV Long 계통(GenBank AAX23995.1)으로부터의 RSV M2-1 단백질, 또는 그의 단편 또는 변이체일 수 있다. RSV 항원은 추가로 인간 RSV 기질 단백질 2-2("M2-2") 단백질, 또는 그의 단편 또는 변이체일 수 있다. 예를 들어, RSV 항원은 RSV Long 계통(GenBank AAX23997.1)으로부터의 RSV M2-2 단백질, 또는 그의 단편 또는 변이체일 수 있다. 인간 RSV 항원은 RSV 폴리머라아제 L("L") 단백질, 또는 그의 단편 또는 변이체일 수 있다. 예를 들어, RSV 항원은 RSV Long 계통(GenBank AAX23996.1)으로부터의 RSV L 단백질, 또는 그의 단편 또는 변이체일 수 있다.
추가 구현예에서, RSV 항원은 NS1, NS2, N, P, M, SH, M2-1, M2-2, 또는 L 단백질의 최적화된 아미노산 서열을 가질 수 있다. RSV 항원은 인간 RSV 단백질 또는 재조합 항원, 예컨대 인간 RSV 게놈에 의해 인코딩된 단백질 중 임의의 하나일 수 있다.
다른 구현예에서, RSV 항원은 비제한적으로 RSV Long 계통으로부터의 RSV F 단백질, RSV Long 계통으로부터의 RSV G 단백질, 최적화된 아미노산 RSV G 아미노산 서열, RSV Long 계통의 인간 RSV 게놈, 최적화된 아미노산 RSV F 아미노산 서열, RSV Long 계통으로부터의 RSV NS1 단백질, RSV Long 계통으로부터의 RSV NS2 단백질, RSV Long 계통으로부터의 RSV N 단백질, RSV Long 계통으로부터의 RSV P 단백질, RSV Long 계통으로부터의 RSV M 단백질, RSV Long 계통으로부터의 RSV SH 단백질, RSV Long 계통으로부터의 RSV M2-1 단백질, RSV Long 계통으로부터의 RSV M2-2 단백질, RSV Long 계통으로부터의 RSV L 단백질, RSV 서브타입 B 단리체 H5601로부터의 RSV G 단백질, RSV 서브타입 B 단리체 H1068로부터의 RSV G 단백질, RSV 서브타입 B 단리체 H5598로부터의 RSV G 단백질, RSV 서브타입 B 단리체 H1123으로부터의 RSV G 단백질, 또는 그의 단편, 또는 이들의 변이체일 수 있다.
(g) 인플루엔자 항원
바이러스 항원은 인플루엔자 바이러스로부터의 항원을 포함할 수 있다. 인플루엔자 항원은 하나 이상의 인플루엔자 혈청형에 대해 포유류에서 면역 반응을 일으킬 수 있는 것들이다. 항원은 전장 번역 산물 HA0, 서브유닛 HA1, 서브유닛 HA2, 이들의 변이체, 그의 단편 또는 이들의 조합을 포함할 수 있다. 인플루엔자 헤마글루티닌 항원은 여러 계통의 인플루엔자 A 혈청형 H1, 혈청형 H2, 여러 계통의 인플루엔자 A 혈청형 H1의 상이한 세트로부터 유래되거나 여러 계통의 인플루엔자 B로부터 유래된 하이브리드 서열로부터 유래될 수 있다. 인플루엔자 헤마글루티닌 항원은 인플루엔자 B로부터 유래될 수 있다.
인플루엔자 항원은 또한 면역 반응이 유도될 수 있는 특정 인플루엔자 면역원에 대해 효과적일 수 있는 적어도 하나의 항원성 에피토프를 함유할 수 있다. 항원은 온전한 인플루엔자 바이러스에 존재하는 면역원성 부위 및 에피토프의 전체 레퍼토리를 제공할 수 있다. 항원은 한 혈청형의 복수의 인플루엔자 A 바이러스 계통, 예컨대 혈청형 H1 또는 혈청형 H2의 복수의 인플루엔자 A 바이러스 계통으로부터의 헤마글루티닌 항원 서열에서 유래될 수 있다. 항원은 두 상이한 헤마글루티닌 항원 서열 또는 이들의 일부의 조합으로부터 유래되는 하이브리드 헤마글루티닌 항원 서열일 수 있다. 각각의 두 상이한 헤마글루티닌 항원 서열은 한 혈청형의 복수의 인플루엔자 A 바이러스 계통, 예컨대 혈청형 H1의 복수의 인플루엔자 A 바이러스 계통의 상이한 세트로부터 유래될 수 있다. 항원은 복수의 인플루엔자 B 바이러스 계통으로부터의 헤마글루티닌 항원 서열에서 유래된 헤마글루티닌 항원 서열일 수 있다.
일부 구현예에서, 인플루엔자 항원은 H1 HA, H2 HA, H3 HA, H5 HA, 또는 BHA 항원일 수 있다.
(h) 에볼라 바이러스
바이러스 항원은 에볼라 바이러스에서 유래될 수 있다. 에볼라 바이러스 질환(EVD) 또는 에볼라 출혈열(EHF)에는 분디부교 바이러스(BDBV), 에볼라 바이러스(EBOV), 수단 바이러스(SUDV), 및 타이 숲 바이러스(TAFV, 또한 코트디부아르 에볼라 바이러스(아이보리 해안 에볼라바이러스, CIEBOV)로도 불림)를 포함하는 5가지 공지된 에볼라 바이러스 중 임의의 4가지가 포함된다.
(2) 박테리아 항원
외래 항원은 박테리아 항원 또는 그의 단편 또는 변이체일 수 있다. 박테리아는 하기 문 중 임의 하나에서 유래될 수 있다: 아시도박테리아, 액티노박테리아, 아쿠이피캐, 박테로이데티스, 칼디세리카, 클라미디애, 클로로비, 클로로플렉시, 크리시오제네티스, 시아노박테리아, 데페리박테리스, 다이노코커스-써무스, 딕티오글로미, 엘루시마이크로비아, 파이브로박테리스, 퍼미큐티스, 푸소박테리아, 젬마티모나데티스, 렌티스패래, 니트로스피라, 플랑크토마이세티스, 프로테오박테리아, 스피로캐테스, 시너지스테티스, 테네리큐티스, 써모데설포박테리아, 써모토개 및 베루코마이크로비아.
박테리아는 그람 양성 박테리아 또는 그람 음성 박테리아일 수 있다. 박테리아는 호기성 박테리아 또는 혐기성 박테리아일 수 있다. 박테리아는 자력영양 박테리아 또는 종속영양 박테리아일 수 있다. 박테리아는 중온균, 중성친화균, 극한서식균, 호산균, 호염기균, 호열균, 한냉균, 호염균, 또는 호삼투균일 수 있다.
박테리아는 탄저병 박테리아, 항생제 내성 박테리아, 질환 유도 박테리아, 식중독 박테리아, 감염성 박테리아, 살모넬라 박테리아, 스타필로코커스 박테리아, 스트렙토코커스 박테리아, 또는 파상풍 박테리아일 수 있다. 박테리아는 미코박테리아, 클로스트리디움 테타니(Clostridium tetani), 예르시니아 페스티스(Yersinia pestis), 바실러스 안트라시스(Bacillus anthracis), 메티실린 내성 스타필로코커스 아우레우스(Staphylococcus aureus(MRSA)), 또는 클로스트리디움 디피실(Clostridium difficile)일 수 있다. 박테리아는 미코박테리아 투베르쿨로시스(Mycobacteria tuberculosis)일 수 있다.
(a) 미코박테리아 투베르쿨로시스 항원
박테리아 항원은 미코박테리아 투베르쿨로시스(Mycobacteria tuberculosis) 항원(즉, TB 항원 또는 TB 면역원), 또는 그의 단편, 또는 이들의 변이체일 수 있다. TB 항원은 TB 항원의 Ag85 패밀리, 예를 들어 Ag85A 및 Ag85B에서 유래될 수 있다. TB 항원은 TB 항원의 Esx 패밀리, 예를 들어 EsxA, EsxB, EsxC, EsxD, EsxE, EsxF, EsxH, EsxO, EsxQ, EsxR, EsxS, EsxT, EsxU, EsxV, 및 EsxW에서 유래될 수 있다.
(3) 기생충 항원
외래 항원은 기생충 항원 또는 그의 단편 또는 변이체일 수 있다. 기생충은 원충, 연충, 또는 외부기생충일 수 있다. 연충(즉, 벌레)은 편형충(예로, 흡충 및 촌충), 구두충, 또는 회충(예로, 요충)일 수 있다. 외부기생충은 이, 벼룩, 진드기 및 응애류 진드기(mite)일 수 있다.
기생충은 하기 질환 중 임의 하나를 유도하는 임의의 기생충일 수 있다: 가시아메바 각막염, 아메바증, 회충증, 바베스열원충증, 대장섬모충증, 아메리카너구리회충증, 샤가스 질환, 간흡충증, 코클리오미아 호미니보락스, 와포자충증, 긴촌충증, 용선충증, 포충증, 코끼리피부병, 요충증, 간질증, 비대흡충증, 사상충증, 편모충증, 턱구충증, 왜소조충증, 포자충증, 카타야마열, 리슈만편모충증, 라임 질환, 말라리아, 요코가와흡충증, 구더기증, 회선사상충증, 이감염증, 옴, 주혈흡충증, 수면병, 분선충증, 조충증, 개회충증, 톡소포자충증, 손모충증, 및 편충증.
기생충은 아칸스아메바, 고래회충, 아스카리스 룸브리코이데스(Ascaris lumbricoides), 쇠파리, 발란티디움 콜라이(Balantidium coli), 빈대, 세스토다(촌충), 양충, 코클리오마이아 호미니보락스(Cochliomyia hominivorax), 엔트아메바 히스톨리티카, 파시올라 헤파티카(Fasciola hepatica), 기아디아 람블리아(Giardia lamblia), 구충, 리슈만편모충증, 링구아툴라 세라타(Linguatula serrata), 간흡충, 로아 사상충, 폐흡충속-폐 흡충, 요충, 플라스모디움 팔시파룸(Plasmodium falciparum), 주혈흡충속, 스트롱길로이데스 스테르코랄리스(Strongyloides stercoralis), 응애류 진드기, 촌충, 톡소플라즈마 곤디이(Toxoplasma gondii), 파동편모충, 편충, 또는 부체레리아 반크로프티(Wuchereria bancrofti)일 수 있다.
(a) 말라리아 항원
외래 항원은 말라리아 항원(즉, PF 항원 또는 PF 면역원), 또는 그의 단편, 또는 이들의 변이체일 수 있다. 항원은 말라리아를 유도하는 기생충에서 유래될 수 있다. 말라리아 유도 기생충은 플라스모디움 팔시파룸(Plasmodium falciparum)일 수 있다. 플라스모디움 팔시파룸(Plasmodium falciparum) 항원에는 포자소체(CS) 항원이 포함될 수 있다.
일부 구현예에서, 말라리아 항원은 P. 팔시파룸 면역원 CS; LSA1; TRAP; CelTOS; 및 Ama1 중 하나일 수 있다. 면역원은 전장 또는 전장 단백질의 면역원성 단편일 수 있다.
다른 구현예에서, 말라리아 항원은 SSP2로도 불리는 TRAP일 수 있다. 다른 구현예에서, 말라리아 항원은 Ag2로도 불리며 고도로 보존된 플라스모디움 항원인 CelTOS일 수 있다. 추가 구현예에서, 말라리아 항원은 고도로 보존된 플라스모디움 항원인 Ama1일 수 있다. 일부 구현예에서, 말라리아 항원은 CS 항원일 수 있다.
다른 구현예에서, 말라리아 항원은 본원에 나타낸 PF 단백질의 둘 이상의 조합을 포함하는 융합 단백질일 수 있다. 예를 들어, 융합 단백질은 서로 직접 인접하여 연결되거나 그 사이에 스페이서 또는 하나 이상의 아미노산으로 연결된 CS 면역원, ConLSA1 면역원, ConTRAP 면역원, ConCelTOS 면역원, 및 ConAma1 면역원 중 둘 이상을 포함할 수 있다. 일부 구현예에서, 융합 단백질은 2개의 PF 면역원을 포함한다; 일부 구현예에서 융합 단백질은 3개의 PF 면역원을 포함하며, 일부 구현예에서 융합 단백질은 4개의 PF 면역원을 포함하고, 일부 구현예에서 융합 단백질은 5개의 PF 면역원을 포함한다. 2개의 PF 면역원을 갖는 융합 단백질은 하기를 포함할 수 있다: CS 및 LSA1; CS 및 TRAP; CS 및 CelTOS; CS 및 Ama1; LSA1 및 TRAP; LSA1 및 CelTOS; LSA1 및 Ama1; TRAP 및 CelTOS; TRAP 및 Ama1; 또는 CelTOS 및 Ama1. 3개의 PF 면역원을 갖는 융합 단백질은 하기를 포함할 수 있다: CS, LSA1 및 TRAP; CS, LSA1 및 CelTOS; CS, LSA1 및 Ama1; LSA1, TRAP 및 CelTOS; LSA1, TRAP 및 Ama1; 또는 TRAP, CelTOS 및 Ama1. 4개의 PF 면역원을 갖는 융합 단백질은 하기를 포함할 수 있다: CS, LSA1, TRAP 및 CelTOS; CS, LSA1, TRAP 및 Ama1; CS, LSA1, CelTOS 및 Ama1; CS, TRAP, CelTOS 및 Ama1; 또는 LSA1, TRAP, CelTOS 및 Ama1. 5개의 PF 면역원을 갖는 융합 단백질은 CS 또는 CS-alt, LSA1, TRAP, CelTOS 및 Ama1을 포함할 수 있다.
(4) 진균 항원
외래 항원은 진균 항원 또는 그의 단편 또는 변이체일 수 있다. 진균은 아스페르길러스 종, 블라스토마이세스 더마티티디스(Blastomyces dermatitidis), 칸디다(Candida) 효모(예로, 칸디다 알비칸스(Candida albicans)), 코키디오이데스(Coccidioides), 크립토코커스 네오포르만스(Cryptococcus neoformans), 크립토코커스 가티이(Cryptococcus gattii), 피부사상균, 푸사리움(Fusarium)종, 히스토플라즈마 캡술라툼(Histoplasma capsulatum), 뮤코로마이코티나(Mucoromycotina), 뉴모시스티스 지로베시이(Pneumocystis jirovecii), 스포로트릭스 슈켄키이(Sporothrix schenckii), 엑세로힐럼(Exserohilum), 또는 클라스포리움( Cladosporium) 일 수 있다.
b. 자가 항원
일부 구현예에서, 항원은 자가 항원이다. 자가 항원은 면역 반응을 자극할 수 있는 대상체 자신의 몸의 구성성분일 수 있다. 일부 구현예에서, 자가 항원은 대상체가 질환 상태, 예로 자가면역 질환에 있지 않는 한, 면역 반응을 유발하지 않는다.
자가 항원에는 비제한적으로 시토카인, 바이러스, 예컨대 HIV 및 뎅기를 포함하여 상술된 것들에 대한 항체, 암 진행 또는 발생에 영향을 미치는 항원, 및 세포 표면 수용체 또는 막통과 단백질이 포함될 수 있다.
(1) WT-1
자가-항원 항원은 윌름 종양 억제인자 유전자 1(WT1), 그의 단편, 이들의 변이체, 또는 이들의 조합일 수 있다. WT1은 N-말단에 프롤린/글루타민-풍부 DNA-결합 도메인을, 그리고 C-말단에 4개의 아연 핑거 모티프를 함유하는 전사 인자이다. WT1은 비뇨생식계의 정상 발달에서 역할을 수행하며, 여러 인자, 예를 들어 공지된 종양 억제인자인 p53 및 세포독성 약물의 처리 후 여러 부위에서 WT1을 절단하는 세린 프로테아제 HtrA2와 상호작용한다. WT1의 돌연변이는 종양 또는 암 형성, 예를 들어 윌름 종양 또는 WT1을 발현하는 종양을 야기할 수 있다.
(2) EGFR
자가-항원에는 표피 성장 인자 수용체(EGFR) 또는 그의 단편 또는 변이체가 포함될 수 있다. EGFR(ErbB-1 및 HER1로도 불림)은 세포외 단백질 리간드의 표피 성장 인자 패밀리(EGF-패밀리)의 구성원에 대한 세포-표면 수용체이다. EGFR은 ErbB 수용체 패밀리의 구성원이며, 여기에는 4가지 밀접하게 관련된 수용체 티로신 키나아제가 포함된다: EGFR(ErbB-1), HER2/c-neu(ErbB-2), Her 3(ErbB-3), 및 Her 4(ErbB-4). EGFR 발현 또는 활성에 영향을 미치는 돌연변이는 암을 일으킬 수 있다.
항원에는 ErbB-2 항원이 포함될 수 있다. Erb-2(인간 표피 성장 인자 수용체 2)는 Neu, HER2, CD340(분화 클러스터 340), 또는 p185로도 알려져 있고, ERBB2 유전자에 의해 인코딩된다. 상기 유전자의 증폭 또는 과발현은 특정한 공격적 유형의 유방암의 발생 및 진행에 역할을 담당하는 것으로 나타났다. 유방암 여성의 대략 25-30%에서, ERBB2 유전자에 유전적 변형이 일어나서 종양 세포 표면 상에 증가된 양의 HER2 생성을 유도한다. 이러한 HER2의 과발현은 신속한 세포 분열을 촉진하고, 이에 따라 HER2는 종양 세포를 표시한다.
HER2에 특이적인 합성 항체에는 서열 식별 번호 40의 핵산 서열에 의해 인코딩되는 서열 식별 번호 41의 아미노산 서열, 및 서열 식별 번호 42의 핵산 서열에 의해 인코딩되는 서열 식별 번호 43의 아미노산 서열을 포함하는 Fab 단편이 포함될 수 있다.
(3) 코카인
자가-항원은 코카인 수용체 항원일 수 있다. 코카인 수용체에는 도파민 수송체가 포함된다.
(4) PD-1
자가-항원에는 프로그래밍된 사멸 1(PD-1)이 포함될 수 있다. 프로그래밍된 사멸 1(PD-1) 및 그 리간드, PD-L1 및 PD-L2는 T 세포 활성화, 내성 및 면역병리 간 균형을 조절하는 저해 신호를 전달한다. PD-1은 세포외 IgV 도메인에 이어 막통과 영역 및 세포내 꼬리를 포함하는 288개 아미노산의 세포 표면 단백질 분자이다.
(5) 4-1BB
자가-항원에는 4-1BB 리간드가 포함될 수 있다. 4-1BB 리간드는 TNF 수퍼패밀리에 속하는 유형 2 막통과 당단백질이다. 4-1BB 리간드는 활성화된 T 림프구 상에서 발현될 수 있다. 4-1BB는 활성화-유도된 T-세포 공-자극 분자이다. 4-1BB를 통한 신호전달은 생존 유전자를 상향조절하고, 세포 분열을 증강시키고, 시토카인 생산을 유도하고, T 세포에서 활성화-유도된 세포사를 예방한다.
(6) CTLA4
자가-항원에는 CD152(분화 클러스터 152)로도 알려져 있는 CTLA-4(세포독성 T-림프구 항원 4)가 포함될 수 있다. CTLA-4는 T 세포 표면 상에서 발견되는 단백질 수용체로, 항원 상에서 세포성 면역 공격을 일으킨다. 항원은 CTLA-4의 단편, 예컨대 세포외 V 도메인, 막통과 도메인, 및 세포질 꼬리, 또는 이들의 조합일 수 있다.
(7) IL-6
자가-항원에는 인터류킨 6(IL-6)이 포함될 수 있다. IL-6은 비제한적으로 당뇨병, 죽상경화, 우울증, 알츠하이머 질환, 전신성 홍반성 루푸스, 다중 골수종, 암, 베체트 질환 및 류마티스성 관절염을 포함하는 여러 질환에서 염증 및 자가-면역 절차를 자극한다.
(8) MCP-1
자가-항원에는 단핵구 화학주성 단백질-1(MCP-1)이 포함될 수 있다. MCP-1은 케모카인(C-C 모티프) 리간드 2(CCL2) 또는 작은 유도 가능한 시토카인 A2로도 불린다. MCP-1은 CC 케모카인 패밀리에 속하는 시토카인이다. MCP-1은 조직 부상 또는 감염에 의해 생산되는 염증 부위로 단핵구, 메모리 T 세포 및 수지상 세포를 모집한다.
(9) 아밀로이드 베타
자가-항원에는 아밀로이드 베타(Aβ) 또는 그의 단편 또는 변이체가 포함될 수 있다. Aβ 항원은 Aβ(X-Y) 펩티드를 포함할 수 있고, 여기서 인간 서열 Aβ 단백질의 아미노산 위치 X부터 아미노산 Y까지의 아미노산 서열은 X 및 Y 둘 다, 특히 아미노산 서열  (아미노산 위치 1 내지 47에 대응; 인간 조회 서열)의 아미노산 위치 X부터 아미노산 Y까지의 아미노산 서열 또는 이들의 변이체를 포함한다. Aβ 항원은 Aβ(X-Y) 폴리펩티드의 Aβ 폴리펩티드를 포함할 수 있고, 여기서 X는 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 또는 32일 수 있고, Y는 47, 46, 45, 44, 43, 42, 41, 40, 39, 38, 37, 36, 35, 34, 33, 32, 31, 30, 29, 28, 27, 26, 25, 24, 23, 22, 21, 20, 19, 18, 17, 16, 또는 15일 수 있다. Aβ 폴리펩티드는 적어도 15, 적어도 16, 적어도 17, 적어도 18, 적어도 19, 적어도 20, 적어도 21, 적어도 22, 적어도 23, 적어도 24, 적어도 25, 적어도 30, 적어도 35, 적어도 36, 적어도 37, 적어도 38, 적어도 39, 적어도 40, 적어도 41, 적어도 42, 적어도 43, 적어도 44, 적어도 45, 또는 적어도 46 아미노산인 단편을 포함할 수 있다.
(아미노산 위치 1 내지 47에 대응; 인간 조회 서열)의 아미노산 위치 X부터 아미노산 Y까지의 아미노산 서열 또는 이들의 변이체를 포함한다. Aβ 항원은 Aβ(X-Y) 폴리펩티드의 Aβ 폴리펩티드를 포함할 수 있고, 여기서 X는 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 또는 32일 수 있고, Y는 47, 46, 45, 44, 43, 42, 41, 40, 39, 38, 37, 36, 35, 34, 33, 32, 31, 30, 29, 28, 27, 26, 25, 24, 23, 22, 21, 20, 19, 18, 17, 16, 또는 15일 수 있다. Aβ 폴리펩티드는 적어도 15, 적어도 16, 적어도 17, 적어도 18, 적어도 19, 적어도 20, 적어도 21, 적어도 22, 적어도 23, 적어도 24, 적어도 25, 적어도 30, 적어도 35, 적어도 36, 적어도 37, 적어도 38, 적어도 39, 적어도 40, 적어도 41, 적어도 42, 적어도 43, 적어도 44, 적어도 45, 또는 적어도 46 아미노산인 단편을 포함할 수 있다.
(10) IP-10
자가-항원에는 인터페론(IFN)-감마-유도된 단백질 10(IP-10)이 포함될 수 있다. IP-10은 작은-유도 가능한 시토카인 B10 또는 C-X-C 모티프 케모카인 10(CXCL10)으로도 알려져 있다. CXCL10은 IFN-γ에 반응하여 몇몇 세포 유형, 예컨대 단핵구, 내피 세포 및 섬유아세포에 의해 분비된다.
(11) PSMA
자가-항원에는 전립선-특이적 막 항원(PSMA)이 포함될 수 있다. PSMA는 글루타메이트 카르복시펩티다아제 II(GCPII), N-아세틸-L-아스파르틸-L-글루타메이트 펩티다아제 I(NAALADase I), NAAG 펩티다아제, 또는 폴레이트 가수분해효소(FOLH)로도 알려져 있다. PMSA는 전립선암 세포에 의해 고도 발현되는 통합 막 단백질이다.
c. 다른 항원
일부 구현예에서, 항원은 외래 항원 및/또는 자가-항원 이외의 항원이다.
(a) HIV-1 VRC01
다른 항원은 HIV-1 VRC01일 수 있다. HIV-1 VCR01은 HIV에 대한 중화 CD4-결합 부위-항체이다. HIV-1 VCR01은 HIV-1의 gp120 루프 D, CD4 결합 루프, 및 V5 영역 내를 포함하는 HIV-1의 부분들과 접촉한다.
(b) HIV-1 PG9
다른 항원은 HIV-1 PG9일 수 있다. HIV-1 PG9는 HIV(HIV-1) 외피(Env) 당단백질(gp) 삼량체에 우선적으로 결합하고 바이러스를 광범위하게 중화시키는 글리칸-의존적 인간 항체의 확장된 패밀리의 시조 구성원이다.
(c) HIV-1 4E10
다른 항원은 HIV-1 4E10일 수 있다. HIV-1 4E10은 중화 항-HIV 항체이다. HIV-1 4E10은 gp41 외-도메인의 C 말단에 위치하는 HIV-1의 막-근처 외부 영역(MPER)에 맵핑된 선형 에피토프에 대한 것이다.
(d) DV-SF1
다른 항원은 DV-SF1일 수 있다. DV-SF1은 4가지 뎅기 바이러스 혈청형의 외피 단백질에 결합하는 중화 항체이다.
(e) DV-SF2
다른 항원은 DV-SF2일 수 있다. DV-SF2는 뎅기 바이러스의 에피토프에 결합하는 중화 항체이다. DV-SF2은 DENV4 혈청형에 특이적일 수 있다.
(f) DV-SF3
다른 항원은 DV-SF3일 수 있다. DV-SF3은 뎅기 바이러스 외피 단백질의 EDIII A 가닥에 결합하는 중화 항체이다.
6. 조성물의 부형제 및 다른 성분
조성물은 약학적으로 허용 가능한 부형제를 추가로 포함할 수 있다. 약학적으로 허용 가능한 부형제는 기능적 분자, 예컨대 운반체, 담체, 또는 희석제일 수 있다. 약학적으로 허용 가능한 부형제는 전달감염 촉진 제제일 수 있고, 여기에는 표면 활성 제제, 예컨대 면역 자극 복합체(ISCOMS), 프로인트 불완전 보강제, LPS 유사체, 예컨대 모노포스포릴 지질 A, 무라밀 펩티드, 퀴논 유사체, 소포체, 예컨대 스쿠알렌 및 스쿠알렌, 히알루론산, 지질, 리포좀, 칼슘 이온, 바이러스 단백질, 다중 음이온, 다중 양이온, 또는 나노입자, 또는 다른 공지된 전달감염 촉진 제제가 포함될 수 있다.
전달감염 촉진 제제는 다중 음이온, 다중 양이온, 예컨대 폴리-L-글루타메이트(LGS), 또는 지질이다. 전달감염 촉진 제제는 폴리-L-글루타메이트이고, 폴리-L-글루타메이트는 6mg/ml 미만의 농도로 조성물에 존재할 수 있다. 전달감염 촉진 제제에는 또한 표면 활성 제제, 예컨대 면역-자극 복합체(ISCOMS), 프로인트 불완전 보강제, LPS 유사체, 예컨대 모노포스포릴 지질 A, 무라밀 펩티드, 퀴논 유사체 및 소포체, 예컨대 스쿠알렌 및 스쿠알렌이 포함될 수 있고, 히알루론산이 또한 조성물과 함께 투여되어 이용될 수 있다. 조성물에는 또한 전달감염 촉진 제제, 예컨대 지질, 리포좀, 예컨대 레시틴 리포좀 또는 당분야에 공지된 다른 리포좀, 예컨대 DNA-리포좀 혼합물(예를 들어 WO9324640 참고), 칼슘 이온, 바이러스 단백질, 다중 음이온, 다중 양이온, 또는 나노입자, 또는 다른 공지된 전달감염 촉진 제제가 포함될 수 있다. 전달감염 촉진 제제는 다중 음이온, 다중 양이온, 예컨대 폴리-L-글루타메이트(LGS), 또는 지질이다. 백신 중 전달감염 제제의 농도는 4mg/ml 미만, 2mg/ml 미만, 1mg/ml 미만, 0.750mg/ml 미만, 0.500mg/ml 미만, 0.250mg/ml 미만, 0.100mg/ml 미만, 0.050mg/ml 미만, 또는 0.010mg/ml 미만이다.
조성물은 전문이 참조로 도입되는 1994. 4. 1.에 출원된 미국 일련 번호 021,579에 기재된 바와 같은 유전적 촉진 제제를 추가로 포함할 수 있다.
조성물은 약 1나노그램 내지 100밀리그램; 약 1마이크로그램 내지 약 10밀리그램; 또는 바람직하게는 약 0.1마이크로그램 내지 약 10밀리그램; 또는 보다 바람직하게는 약 1밀리그램 내지 약 2밀리그램인 양으로 DNA를 포함할 수 있다. 일부 바람직한 구현예에서, 본 발명에 따른 조성물은 약 5나노그램 내지 약 1000마이크로그램의 DNA를 포함한다. 일부 바람직한 구현예에서, 조성물은 약 10나노그램 내지 약 800마이크로그램의 DNA를 함유할 수 있다. 일부 바람직한 구현예에서, 조성물은 약 0.1 내지 약 500마이크로그램의 DNA를 함유할 수 있다. 일부 바람직한 구현예에서, 조성물은 약 1 내지 약 350마이크로그램의 DNA를 함유할 수 있다. 일부 바람직한 구현예에서, 조성물은 약 25 내지 약 250마이크로그램, 약 100 내지 약 200마이크로그램, 약 1나노그램 내지 100밀리그램; 약 1마이크로그램 내지 약 10밀리그램; 약 0.1마이크로그램 내지 약 10밀리그램; 약 1밀리그램 내지 약 2밀리그램, 약 5나노그램 내지 약 1000마이크로그램, 약 10나노그램 내지 약 800마이크로그램, 약 0.1 내지 약 500마이크로그램, 약 1 내지 약 350마이크로그램, 약 25 내지 약 250마이크로그램, 약 100 내지 약 200마이크로그램의 DNA를 함유할 수 있다.
조성물은 사용될 투여 경로에 따라 제형화될 수 있다. 주사 가능한 약학 조성물은 멸균이며, 발열원이 없고 입자가 없을 수 있다. 등장성 제형물 또는 용액이 이용될 수 있다. 등장성을 위한 첨가제에는 나트륨 클로라이드, 덱스트로스, 만니톨, 소르비톨, 및 락토오스가 포함될 수 있다. 조성물은 혈관수축 제제를 포함할 수 있다. 등장성 용액에는 인산염 완충 식염수가 포함될 수 있다. 조성물은 젤라틴 및 알부민을 포함하는 안정화제를 추가로 포함할 수 있다. LGS 또는 다중 양이온 또는 다중 음이온을 포함하는 안정화제는 제형이 연장된 시기 동안 실온 또는 상온에서 안정하도록 할 수 있다.
7. 합성 항체의 생성 방법
본 발명은 또한 합성 항체의 생성 방법에 대한 것이다. 방법에는 아래에 보다 상세히 기재된 전달 방법을 이용함으로써 이를 필요로 하는 대상체에 조성물을 투여하는 단계가 포함될 수 있다. 따라서 합성 항체는 대상체에 대한 조성물의 투여 시 생체 내 또는 대상체에서 생성된다.
방법에는 또한 하나 이상의 세포 내로 조성물을 투여하는 단계가 포함될 수 있고, 이에 따라 합성 항체는 하나 이상의 세포에서 생성되거나 생산될 수 있다. 방법에는 하나 이상의 조직, 예를 들어 비제한적으로 피부 및 근육 내로 조성물을 도입하는 단계를 추가로 포함할 수 있고, 이에 따라 합성 항체는 하나 이상의 조직에서 생성되거나 생산될 수 있다.
8. 항체에 대한 확인 또는 스크리닝 방법
본 발명은 추가로 상술된 항원에 반응성이거나 이에 결합하는 상술된 항체의 확인 또는 스크리닝 방법에 관한 것이다. 항체의 확인 또는 스크리닝 방법은 항체를 확인하거나 스크리닝하기 위해 당분야 숙련가에게 공지된 방법론으로 항원을 이용할 수 있다. 이러한 방법론에는 비제한적으로 라이브러리(예로 파지 디스플레이)로부터의 항체 선택 및 동물의 면역화 이후 항체의 단리 및/또는 정제가 포함될 수 있다. 이용 가능한 방법은, 예를 들어 본원에 그 전문이 도입된 [Rajan, S., and Sidhu, S., Methods in Enzymology, vol 502, Chapter One "Simplified Synthetic Antibody Libraries(2012)]에서 참고하라.
9. 조성물의 전달 방법
본 발명은 또한 이를 필요로 하는 대상체에 조성물을 전달하는 방법에 관한 것이다. 전달 방법에는 대상체에 조성물을 투여하는 단계가 포함될 수 있다. 투여에는 비제한적으로 생체 내 전기천공을 포함하는 및 포함하지 않는 DNA 주입, 리포좀 매개된 전달 및 나노입자 촉진된 전달이 포함될 수 있다.
조성물 전달을 수신하는 포유류는 인간, 영장류, 비인간 영장류, 젖소, 육우, 양, 염소, 영양, 유럽들소, 물소, 유럽들소, 소과, 사슴, 고슴도치, 코끼리, 라마, 알파카, 마우스, 래트 및 닭일 수 있다.
조성물은 경구, 비경구, 설하, 경피, 직장, 경점막, 국소, 흡입을 통해, 협측 투여를 통해, 흉막내, 정맥내, 동맥내, 복강내, 피하, 근육내, 비강내 경막내, 및 관절내 또는 이들의 조합을 포함하는 상이한 경로에 의해 투여될 수 있다. 수의학적 용도를 위해, 조성물은 정상적인 수의학적 관례에 따라 적합하게 허용 가능한 제형으로 투여될 수 있다. 수의사는 특정 동물에 가장 적절한 투여 방식 및 투여 경로를 쉽게 결정할 수 있다. 조성물은 전통적인 주사기, 무바늘 주입 장치, "마이크로돌출형 폭탄 곤 건", 또는 다른 물리적 방법, 예컨대 전기천공("EP"), "수력학적 방법", 또는 초음파에 의해 투여될 수 있다.
a. 전기천공
전기천공을 통한 조성물의 투여는 가역적 구멍을 세포막에 형성하기 위해 효과적인 에너지 자극을 원하는 포유류 조직으로 전달하도록 배치될 수 있는 전기천공 장치를 이용해서 달성될 수 있고, 바람직한 에너지 자극은 사용자에 의해 사전 설정된 전류 입력과 유사한 정전류이다. 전기천공 장치는 전기천공 성분 및 전극 어셈블리 또는 핸들 어셈블리를 포함한다. 전기천공 성분에는 하기를 포함하는 전기천공 장치의 다양한 요소의 하나 이상이 포함되고 도입될 수 있다: 컨트롤러, 전류 파형 생성기, 임피던스 평가기, 파형 로거, 입력 요소, 상태 보고 요소, 커뮤니케이션 포트, 메모리 성분, 전원 및 전력 스위치. 전기천공은 플라스미드에 의한 세포의 전달감염을 촉진하기 위해, 생체 내 전기천공 장치, 예를 들어 CELLECTRA EP 시스템(VGX Pharmaceuticals, Blue Bell, PA) 또는 Elgen 전기천공기(Genetronics, San Diego, CA)를 이용해서 달성될 수 있다.
전기천공 성분은 전기천공 장치의 하나의 요소로 기능할 수 있고, 다른 요소가 전기천공 성분과 커뮤니케이션하는 별도의 요소(또는 성분)이다. 전기천공 성분은 전기천공 장치의 둘 이상의 요소로 기능할 수 있고, 이는 전기천공 성분과 별도의 전기천공 장치의 다른 요소와 여전히 커뮤니케이션할 수 있다. 하나의 전기기계적 또는 기계적 장치의 일부로 존재하는 전기천공 장치의 요소는 요소가 하나의 장치로 또는 서로 커뮤니케이션하는 별도 요소로서 기능할 수 있는 것으로 제한되지 않을 수 있다. 전기천공 성분은 원하는 조직에서 정전류를 생성하는 에너지 자극을 전달할 수 있고, 피드백 기전이 포함된다. 전극 어셈블리에는 복수 전극을 공간적 배열로 갖는 전극 어레이가 포함될 수 있고, 여기서 전극 어셈블리는 전기천공 성분으로부터 에너지 자극을 수신하고, 이를 전극을 통해 원하는 조직으로 전달한다. 적어도 하나의 복수 전극은 에너지 자극의 전달 동안 중성이고, 원하는 조직에서 임피던스를 측정하고 전기천공 성분으로 임피던스를 커뮤니케이션한다. 피드백 기전은 측정된 임피던스를 수신할 수 있고, 정전류를 유지하기 위해 전기천공 성분에 의해 전달된 에너지 자극을 조정할 수 있다.
복수의 전극은 분산된 패턴으로 에너지 자극을 전달할 수 있다. 복수의 전극은 프로그래밍된 순서로 전극 제어를 통해 분산된 패턴으로 에너지 자극을 전달할 수 있고, 프로그래밍된 순서는 전기천공 성분으로 사용자에 의해 입력된다. 프로그래밍된 순서는 순서대로 전달된 복수의 자극을 포함할 수 있고, 여기서 복수 자극의 각각의 자극은 임피던스를 측정하는 하나의 중성 전극을 갖는 적어도 2개의 활성 전극에 의해 전달되며, 복수 자극의 후속 자극은 임피던스를 측정하는 하나의 중성 전극을 갖는 적어도 2개의 활성 전극 중 다른 것에 의해 전달된다.
피드백 기전은 하드웨어 또는 소프트웨어에 의해 수행될 수 있다. 피드백 기전은 아날로그 폐쇄-루프 회로에 의해 수행될 수 있다. 피드백은 50㎲, 20㎲, 10㎲ 또는 1㎲마다 일어나지만, 바람직하게는 실시간 피드백이거나 순간적이다(즉, 반응 시간을 결정하기 위해 이용 가능한 기법에 의해 결정되는 바에 따라 실질적으로 순간적임). 중성 전극은 원하는 조직에서 임피던스를 측정하고 피드백 기전으로 임피던스를 커뮤니케이션할 수 있고, 피드백 기전은 임피던스에 반응하여 정전류를 사전 설정된 전류와 유사한 값으로 유지하기 위해 에너지 자극을 조정한다. 피드백 기전은 에너지 자극의 전달 동안 연속적으로 및 순간적으로 정전류를 유지할 수 있다.
본 발명의 조성물 전달을 촉진할 수 있는 전기천공 장치 및 전기천공 방법의 예에는 그 내용의 전문이 본원에 참조로 도입된 미국 특허 번호 7,245,963(Draghia-Akli et al.), 미국 특허 공보 2005/0052630(Smith et al.)에 기재된 것들이 포함된다. 조성물의 전달을 촉진하기 위해 이용될 수 있는 다른 전기천공 장치 및 전기천공 방법에는 2006. 10. 17.에 출원된 미국 가출원 일련 번호 60/852,149 및 2007. 10. 10.에 출원된 60/978,982에 대해 35 USC 119(e) 하에 이익을 청구하는, 2007. 10. 17.에 출원된 공동 계류중이고 공동 소유된 미국 특허 출원 일련 번호 11/874072에 제공된 것들이 포함되며, 모두 본원에 이들의 전문이 도입된다.
미국 특허 번호 7,245,963(Draghia-Akli et al.)은 체내 또는 식물에서 선택된 조직 세포 내 생체분자의 도입을 촉진하기 위한 모듈형 전극 시스템 및 이들의 용도를 기재한다. 모듈형 전극 시스템은 복수의 바늘 전극; 피하 바늘; 프로그래밍 가능한 정전류 자극 컨트롤러로부터 복수의 바늘 전극으로 전도성 링크를 제공하는 전기 커넥터; 및 전원을 포함할 수 있다. 운영는 지지 구조 상에 실장된 복수의 바늘 전극을 쥐고 이들을 체내 또는 식물에서 선택된 조직 내로 단단히 삽입할 수 있다. 이어서 생체분자는 피하 바늘을 통해 선택된 조직 내로 전달된다. 프로그래밍 가능한 정전류 자극 컨트롤러가 활성화되며 정전류 전기 자극이 복수의 바늘 전극에 적용된다. 적용된 정전류 전기 자극은 복수의 전극 간에서 세포 내로 생체분자의 도입을 촉진한다. 미국 특허 번호 7,245,963의 전체 내용이 본원에 참조로 도입된다.
미국 특허 공보 2005/0052630(Smith, et al.)은 체내 또는 식물에서 선택된 조직 세포 내로 생체분자의 도입을 효과적으로 촉진하기 위해 이용될 수 있는 전기천공 장치를 기재한다. 전기천공 장치는 그 작동이 소프트웨어 또는 펌웨어에 의해 특정되는 전기-역학 장치("EKD 장치")를 포함한다. EKD 장치는 자극 파라미터의 입력 및 사용자 제어에 기반하여 어레이 내 전극 간에 일련의 프로그래밍 가능한 정전류 자극 패턴을 생성하며, 전류 파형 데이터의 저장 및 획득을 허용한다. 전기천공 장치는 또한 바늘 전극 어레이, 주입 바늘을 위한 중심 주입 채널, 및 제거 가능한 가이드 디스크를 갖는 대체 가능한 전극 디스크를 포함한다. 미국 특허 공보 2005/0052630의 전체 내용이 본원에 참조로 도입된다.
미국 특허 번호 7,245,963 및 미국 특허 공보 2005/0052630에 기재된 전극 어레이 및 방법은 근육과 같은 조직뿐만 아니라 다른 조직 또는 기관 내로의 심부 침투를 위해 채택될 수 있다. 전극 어레이의 구조로 인해, 주입 바늘(선택한 생체분자의 전달을 위한)도 표적 기관 내로 완전 삽입되고, 주입은 전극에 의해 사전-서술된 영역에서 해당 표적에 수직으로 투여된다. 미국 특허 번호 7,245,963 및 미국 특허 공보 2005/005263에 기재된 전극은 바람직하게는 20mm 길이 및 21게이지이다.
추가적으로, 전기천공 장치 및 이들의 용도를 도입하는 일부 구현예에, 하기 특허에 기재된 것들인 전기천공 장치가 고려된다: 1993. 12. 28.에 허여된 미국 특허 5,273,525, 2000. 8. 29.에 허여된 미국 특허 6,110,161, 2001. 7. 17.에 허여된 6,261,281, 및 2005. 10. 25.에 허여된 6,958,060, 및 2005. 9. 6.에 허여된 미국 특허 6,939,862. 또한, 임의의 다양한 장치를 이용한 DNA 전달에 관한 2004. 2. 24.에 허여된 미국 특허 6,697,669, 및 DNA의 주입 방법에 대한 2008. 2. 5.에 허여된 미국 특허 7,328,064에서 제공된 요지를 포괄하는 특허가 본원에서 고려된다. 상기-특허는 이들의 전문이 참조로 도입된다.
10. 치료 방법
또한 대상체에서 합성 항체를 생성함으로써 이를 필요로 하는 대상체에서 질환의 치료, 보호 및/또는 예방 방법이 본원에 제공된다. 방법에는 대상체에 대한 조성물의 투여 단계가 포함될 수 있다. 대상체에 대한 조성물의 투여는 상술된 전달 방법을 이용하여 수행될 수 있다.
대상체에서 합성 항체의 생성 시, 합성 항체는 항원에 결합하거나 이와 반응할 수 있다. 이러한 결합은 항원을 중화시키거나, 다른 분자, 예를 들어 단백질 또는 핵산에 의한 항원의 인식을 차단하거나, 항원에 대한 면역 반응을 야기 또는 유도하여 대상체에서 항원에 연관된 질환을 치료, 보호 및/또는 예방할 수 있다.
조성물 용량은 1㎍ 내지 10mg의 활성 성분/체중kg/시간일 수 있고, 20㎍ 내지 10mg 성분/체중kg/시간일 수 있다. 조성물은 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 또는 31일마다 투여될 수 있다. 효과적인 치료를 위한 조성물 투여 횟수는 1, 2, 3, 4, 5, 6, 7, 8, 9, 또는 10일 수 있다.
하나의 치료 방법에서, 합성 항체, 또는 이들의 기능적 단편은 바이러스 또는 박테리아, 또는 암성 세포인지와 무관하게, 감염에 대해 치료를 필요로 하는 대상체에 투여될 수 있다. 본원에 기재된 합성 항체의 투여는 생체 내 발현 시 신체의 이환 영역에서 스스로를 신속히 제시하고 표적(결합하고, 바람직하게는 중화하도록 설계된 것)에 대해 중화 반응을 일으킬 수 있는 기능적 항체를 제공할 수 있다. 상기 신속한 제시는 다소 신속하고/하거나 기존 메모리 면역성을 갖지 않는 개인에서 질환 병리를 위해 중요할 수 있다. 감염된 대상체에 대해 신속한 중화가 중요한 일부 구체 사례는 열대 질환, 예컨대 뎅기, 치쿤군야 및 에볼라에서이다. 이러한 감염은 바이러스로의 감염 순간부터 신속한 중화를 필요로 한다. 실시예 5 및 도 6a 및 6b는 기재된 방법으로 생성된 발현 작제물을 이용한 항체의 신속한 생성을 나타낸다. 도 6a는 플라스미드 DNA 작제물 투여 1일 내에 항체가 발현됨을 나타낸다; 반면 도 6b에서는 단백질/항원의 투여가 약 8일에 항체 발현을 일으킨다.
상기 치료 방법은 단독일 수도 있고, 또는 표적에 대해 숙주 면역 반응을 생성하기 위해 대상체를 유도할 항원을 이용한 일반 백신접종과 조합될 수도 있다. 조합 백신은 의도된 표적에 대해 2상 면역반응의 이익을 제공할 것이다: 1) 합성 항체, 및 이들의 기능적 단편을 인코딩하는 뉴클레오티드 서열에 의해 제공되는 첫 번째 신속 반응, 및 2) 숙주가 표적에 대해 그 자신의 면역 반응을 일으킬 수 있을 때까지의 지체 기간을 가질 전통적 백신(DNA 백신 또는 합성 면역원이 포함될 수 있음)에 의해 유발되는 두 번째 숙주 면역 반응.
본 발명은 하기 비제한적 실시예에 의해 예시되는 여러 측면을 갖는다.
11. 실시예
본 발명이 하기 실시예에서 추가로 예시된다. 이들 실시예는 본 발명의 바람직한 구현예를 나타내는 반면, 단지 예로서 주어짐이 이해되어야 한다. 상기 논의 및 이들 실시예로부터, 당분야 숙련가는 본 발명의 본질적 특징을 확인할 수 있고, 이들의 요지 및 범위에서 벗어나지 않고 다양한 이용 및 조건에 이를 채택하기 위해 본 발명의 다양한 변화 및 개질을 수행할 수 있다. 따라서 본원에 나타내고 기재된 것들에 부가하여 본 발명의 다양한 개질이 상기 기재로부터 당분야 숙련가에게 자명할 것이다. 이러한 개질은 또한 첨부된 특허청구범위의 범위 내에 속하는 것이다.
실시예 1
생체 내 면역글로불린(Ig) 생성을 위한 고발현 시스템을 구축하였다. 특히 2개의 중쇄 및 2개의 경쇄 폴리펩티드가 포함된 완전 조립된 Ig 분자의 생체 내 발현을 개선하기 위해 Ig 중쇄 및 경쇄 서열을 개질하였다. gp120IgG-중쇄 및 경쇄 분자의 작제물을 생성하고, 별도로 pVAX1 벡터(Life Technologies, Carlsbad, CA)에 삽입하였다. 상기 항체는 아래에 기재된 바와 같은 특징분석 연구에 이용할 수 있도록 정의된 특성을 갖는다. 생체 내 Ig 발현을 최적화하기 위한 작제물 생성 시 몇몇 개질을 포함시켰다. 최적화에는 코돈 최적화 및 코작 서열(GCC ACC)의 도입이 포함되었다. Ig의 중쇄 및 경쇄에 대한 최적화된 작제물의 핵산 서열을 각각 서열 식별 번호 6 및 서열 식별 번호 7에 나타낸다(각각 도 1 및 2). 도 1 및 2에서, 밑줄 및 이중 밑줄은 작제물을 pVAX1 벡터 내로 클로닝하기 위해 이용된 BamHI(GGA TCC) 및 XhoI(CTC GAG) 제한 효소 부위를 나타내는 반면, 진한 글씨는 시작(ATG) 및 정지(TGA TAA) 코돈을 나타낸다. 서열 식별 번호 6은 서열 식별 번호 46에 나타낸 아미노산 서열, 즉 IgG 중쇄의 아미노산 서열(도 42)을 인코딩한다. 서열 식별 번호 7은 서열 식별 번호 47에 나타낸 아미노산 서열, 즉 IgG 경쇄의 아미노산 서열(도 43)을 인코딩한다.
세포를 천연 Ig 작제물(즉, 최적화되지 않은 것) 또는 서열 식별 번호 6 및 7을 함유하는 작제물(즉, 최적화된 것)로 전달감염시켰다. 전달감염 후, IgG 분비를 전달감염된 세포로부터 측정하고, IgG 합성 역학을 도 3에 나타낸다. 도 3에 나타낸 바와 같이, 최적화되지 않은 및 최적화된 작제물 모두 Ig의 중쇄 및 경쇄를 발현하여 IgG를 형성하였으나, 최적화된 작제물이 더 빠른 IgG 항체 축적을 일으켰다. 서열 식별 번호 6 및 7(즉, 최적화된 Ig 서열)을 함유하는 플라스미드로 전달감염된 세포는 최적화되지 않은 Ig 서열을 함유하는 플라스미드로 전달감염된 세포보다 완전 조립된 Ig 분자의 더 많은 생산을 나타내었다. 따라서 작제물의 최적화 또는 개질은 실질적으로 Ig 발현을 증가시켰다. 다시 말하면, 서열 식별 번호 6 및 7을 함유하는 작제물은 서열 식별 번호 6 및 7을 생성하기 위해 이용된 최적화 또는 개질로 인해 천연 작제물에 비해 실질적으로 더 큰 Ig 발현을 제공하였다. 이들 데이터는 또한 Ig의 중쇄 및 경쇄가 플라스미드 시스템으로부터 생체 내에서 효율적으로 조립될 수 있음을 나타내었다.
서열 식별 번호 6 및 7을 함유하는 작제물을 추가 조사하기 위해, 마우스에 서열 식별 번호 6 및 7에 나타낸 서열을 함유하는 플라스미드를 투여하였다. 특히 플라스미드를 전기천공을 이용하여 투여하였다. 투여 후, 면역접종된 마우스에서 면역 반응(즉, IgG 수준)의 유도를 웨스턴 블롯으로 평가하였다(즉, 마우스의 혈청을 이용하여 gp120 항원을 검출하였다). 도 4에 나타낸 바와 같이, 서열 식별 번호 6 및 7을 함유하는 플라스미드가 투여된 마우스는 웨스턴 블롯 분석에서 항체 결합이 관찰되었으므로, 강한 항체 생산을 일으켰다. 상기 항체 생산을 관찰하기 위해서는 1회 투여만 필요하였다.
요약하면, 이들 데이터는 Ig 중쇄 및 경쇄를 인코딩하는 핵산 서열이 발현 벡터, 예컨대 pVAX1에 포함되는 경우, 전달감염된 세포 및 발현 벡터가 투여된 마우스에서 조립된 IgG의 발현을 일으킴을(즉 중쇄 및 경쇄가 함께 모여 그 항원에 결합하는 항체를 형성함을) 나타내었다. 이들 데이터는 또한 Ig 중쇄 및 경쇄를 인코딩하는 핵산 서열의 최적화 또는 개질이 Ig 생산을 유의미하게 증가시킴을 나타내었다.
실시예 2
실시예 3-7에 대한 재료 및 방법
세포 및 시약. 293T 및 TZM-Bl 세포를 10% 소 태아 혈청(FBS) 및 항생제가 보강된 Dulbecco 개질 Eagle 배지(DMEM; Gibco-Invitrogen, CA) 중에 유지하고 융합 시 계대하였다. 재조합 HIV-1 p24 및 gp120 Env(rgp120) 단백질을 Protein Science Inc.에서 입수하고 페록시다아제-콘주게이트된 스트렙타비딘을 Jackson Laboratory에서 입수하였다. 기재된 세포주 및 다른 시약은 AIDS Research and Reference Reagent Program(Division of AIDS, NIAID, NIH)에서 입수하였다.
동물 및 단백질 및 플라스미드 투여 및 전달. 암컷 BALB/c 마우스(8주령)를 Taconic Farms(Germantown, NY)에서 구입하였다. 이들 투여를 위해, 50㎕ 부피(pVax1 또는 pHIV-1Env-Fab) 중 25㎍의 플라스미드 DNA를 근육내(IM) 주사한 뒤 MID-EP 시스템(CELLECTRA®; Inovio Pharmaceuticals, Blue Bell, PA)에 의해 EP 매개된 증강 전달을 이용하였다. 전달을 위한 펄스화 파라미터는 다음과 같았다: 0.5Amp 정전류 3회 자극, 1초 간격 및 52ms 길이. 각 동물은 실험 또는 대조군 플라스미드 제형물의 단회 투여를 받았다. 단백질 면역화 분석을 위해, JRFL 계통의 HIV-1 재조합 gp120(rgp120)(Immune Technology Corp, NY에서 구매)을 이용하였다. 단백질 면역화 연구에서, 단회 25㎍ 용량의 rgp120을 TiterMax 보강제와 혼합하고 피하 주사하였다. pHIV-1 Env Fab 또는 rgp120-투여된 마우스로부터의 혈청을 구체적 분석에 따라 상이한 시점에 수집하였다.
HIV-1Env-Fab 플라스미드 DNA의 구축. 항-Env VRC01 인간 mAb로부터의 HIV-1 Env-Fab 서열(VH 및 VL)을 몇몇 개질을 포함하는 합성 올리고뉴클레오티드의 이용에 의해 생성하였다. 중쇄(VH-CH1)는 서열 식별 번호 3에 나타낸 핵산 서열에 의해 인코딩되며, 경쇄(VL-CL)는 서열 식별 번호 4에 나타낸 핵산에 의해 인코딩된다(각각 도 9 및 10). 도 9 및 10에서, 밑줄 및 이중 밑줄은 인코딩 핵산 서열을 pVAX1 벡터 내로 클로닝하기 위해 이용된 HindIII(AAG CTT) 및 XhoI(CTC GAG) 제한 효소 부위를 나타내는 반면, 진한 글씨는 시작(ATG) 및 정지(TGA 또는 TAA) 코돈을 나타낸다. 서열 식별 번호 3은 서열 식별 번호 48에 나타낸 아미노산 서열, 즉 HIV-1 Env-Fab의 VH-CH1의 아미노산 서열(도 44)을 인코딩한다. 서열 식별 번호 4는 서열 식별 번호 49에 나타낸 아미노산 서열, 즉 HIV-1 Env-Fab의 VL-CL의 아미노산 서열(도 45)을 인코딩한다.
효율적인 IgE 리더 서열(서열 식별 번호 66 단백질을 인코딩하는 서열 식별 번호 65 뉴클레오티드)을 발현을 개선하기 위해 Env 항원 유전자 서열 내로 도입하였다. 생성된 개질되고 증강된 HIV-1Env-Fab DNA 면역원은 코돈- 및 RNA-최적화되었으며, 이어서 GenScript(Piscataway, NJ)에 의해 pVax1 발현 벡터 내로 클로닝되고 이들 작제물의 대규모 생산이 이어졌다. VH 및 VL 유전자(각각 서열 식별 번호 3 및 4)를 BamH1 및 Xho1 제한 효소 부위 간에 삽입하였다. 이어서 정제된 플라스미드 DNA를 마우스로의 후속 투여를 위해 수중 제형화하였다. 음성 대조군 플라스미드로서, "미관련"/대조군 Ig를 생성하는 pIgG-E1M2를 이용하였다.
HIV-1Env-Fab 발현 및 면역블롯 분석. 293T 세포주를 제조업체에서 권장된 바와 같은 방법에 의해 비-리포좀 FuGENE6 전달감염 시약(Promega, WI)을 이용하여 발현 분석을 위해 이용하였다. 간략하게, 세포를 5㎍의 pVax1 대조군 또는 pHIV-1Env-Fab를 이용한 후속 전달감염 24시간 전에 50-70% 융합성으로 접종하였다(35mm 배양 디쉬의 웰 당 1-3x105세포/2mL). 상청액을 70시간까지 다양한 시점에 수집하고, 표준 ELISA 방법에 의해 특정 Fab 분자 수준에 대해 평가하였다. pVax1 전달감염된 세포로부터의 상청액을 음성 대조군으로 이용하였다. 또한, 293T 세포를 HIV gp160 Env 단백질에 대한 유전자로 전달감염시켰다.
생성된 Fab에 의한 천연 HIV-1 Env 단백질 인식의 추가 확인을 면역블롯 분석으로 수행하였다. 상기 연구를 위해, 상술된 rgp120을 12% SDS-PAGE 상에서 전기영동하였다. 겔을 니트로셀룰로오스 막 상에 블롯팅하고(Millipore, Bedford, MA) PBS-T(0.05%) 중 5% w/v 탈지 분유로 차단하였다. 이어서 니트로셀룰로오스를 분석을 위해 개별 스트립으로 후속 절단하였다. pHIV-1 Env Fab 투여된 마우스로부터의 혈청을 투여 48시간 후 수집하고, PBS 중 1:100으로 희석하고, 1시간 동안 개별 니트로셀룰로오스 스트립과 반응시켰다. 이어서 스트립을 Tris-완충 식염수-0.2% Tween으로 4회 세척하고, 마우스 IgG에 대한 페록시다아제-커플링된 항혈청(Jackson Laboratories, ME)과 반응시키고, 디아미노벤지딘 기질(Sigma, St. Louis, MO)과 인큐베이션하여 생성된 HIV-1 Env Fab의 gp120에 대한 적절한 결합을 가시화하였다.
Ig 결합 분석 - ELISA. ELISA에 의해 DNA 플라스미드 생성된 Fab 또는 항-rgp120 항체의 rgp120에 대한 결합 확인을 평가하였다. Ig 결합 분석을 pHIV-1 Env Fab, pVax1 또는 rgp120 단백질이 투여된 개별 동물로부터의 혈청으로 수행하였다. 다시, 상기 기본 Ig 면역분석을 위해, 혈청 표본을 단회 DNA 플라스미드 투여 48시간 후 수집하였다. 간략하게, 96-웰 고결합 폴리스티렌 플레이트(Corning, NY)를 하룻밤 동안 4℃에서 PBS 중에 희석된 B군 HIV MN rgp120(2㎍/mL)으로 코팅하였다. 다음 날, 플레이트를 PBS-T(PBS, 0.05% Tween 20)로 세척하고, 1시간 동안 PBS-T 중의 3% BSA로 차단하고, 1시간 동안 37℃에서 면역화된 및 면역화되지 않은 마우스로부터의 혈청의 1:100 희석액과 함께 인큐베이션하였다. 결합된 IgG를 1:5,000의 희석도로 염소 항-마우스 IgG-HRP(Research Diagnostics, NJ)를 이용해서 검출하였다. 결합된 효소를 발색원 기질 용액 TMB(R&D Systems)의 첨가에 의해 검출하고, Biotek EL312e Bio-Kinetics 판독기 상에서 450nm에서 판독하였다. 모든 혈청 표본을 2회씩 평가하였다. 시판 IgG1 정량 ELISA 키트를 이용해서 pHIV-1 Env Fab 투여된 마우스로부터의 혈청 중 Fab 농도를 정량하는 추가 면역 분석을 수행하였다. 상기 분석은 제조업체의 명세에 따라 수행하였다.
유세포 측정 분석(FACS). 유세포 측정 분석(FACS)을 위해, 293T 세포를 공통 A군 Env 플라스미드(pCon-Env-A) 또는 일차 바이러스 단리체(Q23Env17)로부터 Env를 발현하는 최적화된 A군 플라스미드(pOpt-Env-A)로 전달감염시켰다. 전달감염을 표준 방법에 의해 수행하였다. 전달감염 확인 후, 세포를 빙냉 완충액 A(PBS/0.1% BSA/0.01% NaN3)로 세척하고 20분 동안 4℃에서 일차 Ig의 1:100 희석액(플라스미드 투여 48시간 후 수집된, pHIV-1 Env Fab 또는 대조군 pIgG-E1M2 플라스미드가 주사된 마우스로부터의 혈청 또는 정제된 VRC01)과 인큐베이션하였다. 이어서 세척하고, 다시 20분 동안 피코에리트리틴(PE)에 콘주게이트된 1:100 희석된 형광-표지된 이차 Ig 50㎕과 인큐베이션하였다. 이어서 세포를 세척하고, 즉시 유세포 측정기(Becton Dickinson FACS) 상에서 분석하였다. 모든 인큐베이션 및 세척은 4℃에서 빙냉 완충액 A로 수행하였다. 세포를 단선 상에서 살아있는 세포에 대해 관문화하였다. GFP 발현을 평가하기 위해, GFP-양성 세포를 CellQuest 소프트웨어(BD Bioscience)를 이용하여 FACS-LSR 기구로 수행하였다. 데이터를 Flow Jo 소프트웨어로 분석하였다.
단회-사이클 HIV-1 중화 분석. 실험 또는 대조군 혈청의 존재 또는 부재 하 Env-가유형 바이러스를 이용한 단회 감염 후 중화 종결점으로 루시퍼라아제 유전자 발현 감소가 이용되는 TZM-Bl(HeLa 세포 유래)기반 분석으로 Fab 매개된 HIV-1 중화 분석을 측정하였다. TZM-Bl 세포를 조작하여 CD4 및 CCR5를 발현시키고, 초파리 루시퍼라아제에 대한 리포터 유전자를 포함시켰다. 상기 분석에서, pVax1만 또는 pHIV-1Env Fab가 투여된 마우스로부터의 혈청을 웰 당 1:50으로 희석한 뒤 다중 감염도 0.01로 가유형 HIV-1 Bal26, Q23Env17, SF162S 또는 ZM53M 무세포 바이러스를 첨가하였다. Bal26 및 SF162S는 모두 B군 티어 1 바이러스이고, 상기 티어 상태는 바이러스가 중화에 대해 높거나 평균을 초과하는 감수성을 가졌음을 나타낸다. Q23Env17 및 ZM53M은 각각 A군, 티어 1 및 C군, 티어 2 바이러스이다. 티어 2 상태는 바이러스가 중화에 대해 평균 또는 중등 감수성을 가짐을 나타내었다. 상기 분석에 이어, 104 TZM-BL 세포를 각 웰에 첨가하고, 48시간 동안 인큐베이션하고, 용해시킨 뒤 100㎕의 Bright-Glo 기질(루시퍼라아제 분석 시스템, Promega, WI)을 첨가하고, 이어서 발광측정계를 이용하여 루시퍼라아제를 정량하였다. 상기 분석의 판독치는 RLU(상대 광 단위)였다. RLU 감소 백분율을 다음과 같이 계산하였다: (1-(실험 표본의 평균 RLU-대조군)/대조군으로부터의 평균 RLU-무첨가 대조군 웰)) x 100. 이어서 HIV-1 중화를 RLU 감소 백분율로 표시하였고, 이는 감염 저해 백분율을 나타낸다.
실시예 3
항-HIV-1 Env-Fab 발현 작제물의 생성
인간 mAb VRC01을 광범위하게 중화하는 항-HIV-1 외피에 대한 VH 및 VL-Ig(면역글로불린) 사슬 코딩 서열 둘 다에 대한 cDNA를 NIH AIDS Research and Reference Reagent Program을 통해 VRC(Vaccine Research Center, NIH)에서 수득한 뒤 pVax1 벡터 내로 클로닝하였다. 상기 실시예 2에 나타낸 바와 같이, 몇몇 개질을 생물학적 활성 Ig 분자의 생산을 최대화 및 최적화하기 위해 발현 벡터 내에 도입하였다. 특히, 이들 개질에는 코돈 및 RNA 최적화 및 안정화가 포함되었고, 리더 서열 이용, 고농도에서의 플라스미드 생산이 증강되었으며, EP를 통해 생체 내 플라스미드 전달을 촉진하였다. 생성된 작제물을 포유류 세포 및 조직에서의 적절하고 효율적인 발현을 위해 중요한 인간 사이토메갈로바이러스(CMV)로부터의 최조기 프로모터의 제어 하에 배치하였다. 이 연구에 이용된 작제물의 모식적 지도를 도 5a 및 5b에 나타낸다.
추가적으로, 항-HIV-1 Env Fab를 pHIV-Env-Fab로부터 제조하고, HIV Env를 인코딩하는 플라스미드로 전달감염된 세포를 염색하기 위해 이용하였다. pVAX1을 대조군으로 이용하였다. 도 11에 나타낸 바와 같이, 면역형광 염색은 항-HIV-1 Env Fab가 HIV Env을 인코딩하는 플라스미드로 전달감염된 세포를 염색시켰으므로, 벡터 pHIV-Env-Fab가 항-HIV-1 Env Fab의 제조를 허용함을 나타내었다. 따라서 항-HIV-1 Env Fab는 HIV Env 당단백질에 대한 결합에 특이적이었다.
실시예 4
전달감염된 세포에 의한 Ig 생산
pHIV-1Env-Fab의 발현을 평가하기 위해, 작제물을 293T 세포 내에 전달감염시켰다. 공통 HIV-1 B군 gp120 단백질을 이용하는 ELISA 면역분석은 전달감염 후 24시간만큼 빨리, 전달감염된 293 T 세포로부터의 상청액 중 항-HIV-1 Env-Fab의 존재를 확인시켰다(도 5c). 높은 OD450nm값(즉 약 0.5 내지 0.8 범위)이 전달감염 후 24 내지 72시간에 세포 추출물에서 검출되었고, 이어서 48시간에 피크 및 정체기에 도달하였다. 이들 결과는 HIV Env 당단백질에 대한 항-HIV-1 Env Fab의 특이성을 확인시켰다. 도 5c에 나타낸 데이터의 통계적 분석은 다음과 같았다: pHIV-1 Env-Fab 주사된 마우스로부터의 혈청에 대한 OD450nm값은 22 내지 72 시간 시점의 측정에서 pVax1 대조군에 비해 유의미하였다(p<0.05, 스튜던트 t 시험).
실시예 5
HIV-1 Env Fab의 생체 내 특징분석
DNA 플라스미드로부터 생체 내 Fab 생산을 나타내기 위해, 마우스에 근육내 경로에 의해 pHIV-1 Env Fab를 투여한 뒤 EP를 통해 전달을 증강시켰다. DNA 플라스미드의 단회 주사를 전달하고, 혈청을 투여 후 12시간 및 1, 2, 3, 4 7 및 10일에 수집하였다. 이어서 혈청(1:100 희석도로)을 도 6a에 나타낸 바와 같이 ELISA 분석에 의해 Ig/Fab 수준에 대해 후속 평가하였다. 도 6a의 데이터를 OD450nm으로 나타내며, Ig/Fab 수준과 비례하였다(pVax1 및 HIV-1 Env-Fab군 모두에서 개별 마우스로부터). 이들 데이터는 pHIV-1Env-Fab의 단회 투여 후 Fab의 상대 수준이 1일에 검출 가능해지고, 이어서 경시적으로 증가하였음을 나타내었다. 비교 목적으로, 실시예 2에 상술된 바와 같이 rgp120의 단회 투여/면역화를 Balb/C 마우스 내로 수행하고, 이어서 특이적 항-gp120 항체 수준의 범위 및 수명을 결정하기 위해 후속 혈청 수집 및 ELISA에 의한 경시적인 분석(1:100 희석도로)을 수행하였다. 도 6b는 결과를 나타낸다.
상기 단백질 전달 연구에서, 배경 대비 항원 특이적인 Ig 수준은 면역화 후 10일에서야 검출 가능하였다. 이는 OD450nm값이 투여 후 1일째에 적어도 0.1의 OD450nm 단위로 확보되고 10일째에 0.28 내지 0.35OD 단위 사이 수준에서 정체한 pHIV-1 Env Fab 투여에 의해 야기된 Fab 수준과 대조적이었다(도 6a). 따라서 pHIV-1 Env Fab의 전달은 통상적인 단백질 면역화에 비해 특이적 Fab의 보다 신속한 생성을 일으켰다. 상기 발견은 생물학적 활성 Ig의 생성을 위한 상기 DNA 플라스미드 전달 방법의 잠재적인 임상적 유용성을 강조하였다.
DNA 전달 기술에 의해 생산된 재조합 Fab의 양뿐만 아니라 품질을 확인하기 위해 추가 분석을 수행하였다. 구체적으로, 전기영동되고 블롯팅된 재조합 HIV-1 gp120 단백질을 이용해서 면역블롯 분석을 수행하고, 투여 48시간 후에 pHIV-1Env-Fab 마우스로부터의 혈청을 탐침으로 이용하였다(도 6c). 블롯은 gp120 단백질의 분자량에 적절한 밴드를 나타내어, 이것이 기능적이며 gp120에 결합할 수 있음을 확인시켰다. 마찬가지로, ELISA에 의한 인간 Fab 정량을 수행하고, 플라스미드 투여 후 시간(즉 일수)의 함수로 나타내었다(도 6d). 결과는 생성된 Fab의 수준이 2-3㎍/ml를 피크로 하였음을 나타낸다. 이들 결과는 HIV-1 Env 단백질을 특이적으로 인식하고 결합하는 능력뿐만 아니라 생성된 VRC01 기반 Fab의 VH 및 VL의 사슬의 정확한 폴리펩티드 조립을 나타내었다.
도 6에 나타낸 데이터의 통계 분석은 다음과 같다. 도 6a에 요약된 데이터에 있어서, pHIV-1 Env-Fab 주사된 마우스로부터의 혈청에 대한 OD450nm값은 1 내지 10일의 측정 시점에 pVax1 주사된 마우스로부터의 혈청에 비해 통계적으로 상승하였다(p<0.05, 스튜던트 t 시험). 도 6b에 요약된 데이터에 있어서, rpg120군으로부터의 OD450nm값은 10 내지 14일 시점의 측정에서 PBS 대조군에 비해 유의미하게 상승하였다(p<0.05, 스튜던트 t 시험). 도 6d에 요약된 데이터에 있어서, pHIV-1 Env-Fab 주사된 마우스로부터의 OD450nm값은 2 내지 10일 시점의 측정에서 유의미하게 상승하였다(p<0.05, 스튜던트 t 시험).
실시예 6
상이한 HIV-1 Env 단백질을 발현하는 세포에 대한 Fab/Ig의 결합: FACS 기반 분석
pHIV-1Env-Fab가 투여된 마우스로부터의 혈청을 또한 293T 세포에 의해 일시적으로 발현된 상이한 HIV-Env 단백질에 대한 생성된 Fab의 결합을 평가하기 위해 이용하였다. 천연형 VRC01-mAb를 양성 대조군으로 이용하여 세포 표면 상에서 Env 단백질의 적절한 발현 및 검출을 확인하였다. 앞서 나타낸 바와 같이, "미관련/연관되지 않은" Ig(Ig-E1M2)를 음성 대조군으로 이용하였다. 도 7a 및 7b에 나타낸 바와 같이, pVax1(즉 Env 삽입물이 없는) 전달감염된 세포에 대해 상이한 Ig/Fab에 의해 본질적으로 배경 염색만 존재하였다. 그러나 정제된 VRC01 mAb 및 pHIV-1Env-Fab 투여된 마우스로부터의 혈청에 있어서 모두, 일차 HIV-1 단리체 pQ23Env17로부터의 Env를 발현하는 최적화된 C군 플라스미드(pOpt-Env-A)뿐만 아니라 공통 A군 Env 플라스미드(pCon-Env-A)를 발현하는 전달감염된 세포의 유의미한 양성 염색이 존재하였다. 더욱이, pIg-E1M2 투여된 마우스로부터의 혈청은 배경 수준을 초과하는 임의의 HIV1 Env 전달감염된 세포의 염색을 나타내지 못했다. 이들 결과를 나타내는 FACS 분석이 도 7a에 제공된다. 상기 실험에 대해 FACS 분석으로부터의 데이터(즉 도 7a)를 나타내는 대표 그래프를 도 7b에 제공한다.
도 7b에 나타낸 데이터의 통계 분석은 다음과 같다. pCon-Env-A에 의해 생성된 외피 당단백질에 대해 천연 VRC01 항체 및 pHIV-1 Env-Fab 주사된 마우스로부터의 혈청 간에는 특이적 결합의 유의차가 존재하지 않았다(p<0.05, 스튜던트 t 시험). 그러나 pOpt-Env-A에 의해 생성된 외피 당단백질에 대한 VRC01 항체의 결합이 pHIV-1 Env-Fab 주사된 마우스로부터의 혈청에 의한 결합보다 유의미하게 더 높았다(p<0.05, 스튜던트 t 시험).
실시예 7
pHIV-1 Env Fab에 의해 생산된 Ig의 HIV 중화 활성
pHIV-1Env-Fab가 투여된 마우스로부터의 혈청을 일시적으로 전달감염된 293T 세포에서 발현되는 HIV-1 Env 단백질에 대한 HIV-Env Fab의 결합을 평가하기 위해 이용하였다. 혈청은 pHIV-1Env-Fab의 투여 6일 후에 마우스로부터 수득하였다. 구체적으로, 세포를 A군, B군 또는 C군 계통으로부터의 HIV-1 Env가 발현되는 플라스미드로 전달감염시켰다. A군, B군, 및 C군 계통은 92RW020, SF162, 및 ZM197이었다. 도 12에 나타낸 바와 같이, pHIV-1Env-Fab가 투여된 마우스로부터의 혈청은 A군, B군, 및 C군 HIV-1 계통으로부터의 HIV-1 Env에 결합하였고, 이에 따라 혈청이 여러 서브타입의 HIV-1로부터의 HIV-1 Env과 교차반응하는 항체(즉, HIV-Env Fab)를 함유함을 나타내었다.
이 연구에서 생산된 HIV-Env Fab의 잠재적인 HIV-1 중화 활성을 평가하기 위해, TZM-Bl 표적 세포의 이용에 기반한 발광 기반 중화 분석을 수행하였다. TZM-Bl 표적 세포를 상기 실시예 2에 기재된 바와 같이 실험 혈청 및 대조군의 부재 또는 존재 하에 4가지 상이한 가유형 HIV 바이러스 단리체로 감염시켰다.
도 8은 HIV 가유형 바이러스에 대해 pHIV-1 Env Fab 주사된 마우스로부터의 혈청에 대한 중화 곡선을 도시한다. HIV-1 티어 1 바이러스 Q23Env(A군)뿐만 아니라 Bal26 및 SF162S(둘 다 B군)가 구체적으로 평가되었다. 또한, 혈청을 HIV-1 C군 티어 2 바이러스 ZM53M에 대해서도 평가하였다. 데이터는 HIV 감염의 중화/저해 백분율로 나타낸다. 그래프에서 평행선으로 그린 수평성은 분석에서의 50% 중화/저해 수준을 나타내었다. 양성 중화 대조군 mAb(데이터는 나타내지 않음)를 이 연구에서 이용하여 상기 분석 방법의 유용성 및 타당성을 확인하였다. 간략하게, 양성 대조군 중화 mAb는 모든 4가지 바이러스 가유형의 감염을 적어도 50% 저해할 수 있었다.
pHIV-1 Env Fab 투여된 마우스로부터의 혈청은 플라스미드 투여 후 경시적으로 HIV 중화 활성의 증가를 나타내었고, 중화 백분율은 Bal25, Q23Env17 및 SF162S에 있어서 2일째에 50%에 도달하였다. 또한 이들 3가지 바이러스에 대한 정체기 중화 백분율은 각각 약 62, 60 및 70%였다. ZM53M에 있어서, 50% 중화 역치는 3일까지 도달되지 않았고, 정체기 중화는 50%를 초과하지 않았다. 평가된 다른 3가지에 비해 이러한 덜 강력한 중화 프로필은 이것이 덜 중화 가능한 티어 2 바이러스임을 반영하기 때문일 수 있다. 종합하면, 상기 연구에서 생성된 Fab는 다양한 HIV 단리체를 효과적으로 중화시킬 수 있었다. 도 8에 나타낸 데이터의 통계적 분석은 다음과 같다. 크루스칼-왈리스(Kruskal-Wallis) 비-파라미터 분석에 기반하여, pHIV-1 Env-Fab 주사된 마우스로부터의 혈청에 의해 유도된 ZM53M C군 바이러스에 대한 HIV 중화 수준(도 8d)만이 평가된 다른 바이러스와 유의미하게 상이하였다(도 8a, 8b 및 8c). 상기 차이는 최대로 달성 가능한 중화 수준뿐만 아니라 50% 중화를 달성하는데 필요한 시간(일수)에 있었다.
실시예 3-7을 요약하면, pHIV-1 Env Fab 투여된 마우스에서 VRC01 Fab의 혈청 농도는 주사 후 12일째에 2-3㎍/mL로 피크였다. 상기 범위는 현재 FDA에 의해 허가받은 여러 모노클로날 항체에 필적하여, 본 발명자들의 항체 접근이 상기 소동물 모델에서 유의미하고 생물학적으로 관련된 수준의 항체를 생산함을 시사하였다. 특히, 우스테키누맙(상표명: Stelara) 및 골리무맙(Simponi)에 있어서, 판 건선 및 관절염과 같은 자가면역 질환에 대한 이용에 대해 제시되는 두 항체는 각각 0.31±0.33㎍/mL 및 1.8±1.1㎍/mL의 평균±SD 혈청 농도를 갖는다. 또한, TNF 저해제 아달리무맙(Humira)은 약 6㎍/mL의 평균 조(rough) 혈청 농도를 갖는다. 이에 관해, 실시예 4-8에 기재된 데이터는 개체에 대해 항체를 인코딩하는 DNA의 전달이 유의미하고 생물학적으로 관련된 수준의 항체가 개체에 존재하도록 생체 내 조립을 일으켰음을 나타내었다.
이들 데이터는 또한 통상적 단백질 투여에 의해 생산된 Ig에 비해 pHIV-1Env Fab의 단회 EP 증강된 투여 후 생체 내에서 Fab를 보다 신속히 생산하는 능력을 나타내었다(도 6a 및 6b). 또한, 어려운 백신 표적에 대해 기능적인 보호 Ig 유사 분자를 생성하는 능력이 나타났다. 현재까지 능동 백신접종 후 HIV-1 중화 항체의 유도는 매우 어려웠으며, 일차 감염 동안 전파 후 수년 까지도 중화 항체가 발생하지 않는다. 상기 DNA 플라스미드 접근으로, 중화 역가는 전달 후 1-2일 내에 관찰되었고, 피크 중화 Fab 혈청 농도(3.31±0.13㎍/mL)는 투여 후 1주에 일어났다(도 6d). 상기 수준의 Ig는 현재 연구에서 감염으로부터 완전 보호를 제공하는 것으로 나타난 8.3㎍/mL 농도와 비교적 유사하였다. 이들 데이터는 생물학적 활성 Ig 단편의 신속한 유도를 나타내었다.
이들 데이터는 또한 HIV-1Env-Fab DNA 투여에 의해 야기된 HIV-1 일차 단리체에 대한 중화 항체 역가 및 반응을 나타내었다. 혈청을 A군, B군 및 C군으로부터의 예를 나타낸 상이한 바이러스 티어 1, 및 2 바이러스 단리체 패널에 대해 평가하였다. 결과는 이들 바이러스에 대한 강력한 중화 활성의 생성을 나타내었다(도 8).
따라서 상기 DNA 플라스미드 기반 방법은 생체 내에서 특이적이고 생물학적으로 활성이 있는 Fab 또는 Ig 분자를 생성하였고, 항체 생성을 위한 통상적 항원-기반 백신접종의 이용 필요성을 배제하였고, 시험관 내 제조된 Ig를 생성하고 정제할 필요성을 제거하였다.
실시예 8
인간 Ig 항체를 인코딩하는 플라스미드의 구축
상술된 바와 같이, 인코딩 핵산의 대상체로의 투여 시 생체 내 생성된 VRC01 항체, 즉 HIV-Env Fab로부터 Fab를 생성하였다. 이들 연구를 추가 확장하기 위해, VRC01 항체에서 유래된 IgG1 항체를 인코딩하는 핵산 서열을 생성하였다. 도 13의 모식도에 나타낸 바와 같이, 상기 핵산 서열은 퓨린 절단 부위 및 P2A 펩티드 서열을 인코딩하는 핵산 서열에 의해 분리된 IgG 중쇄 및 경쇄를 인코딩하였다. P2A 펩티드 서열은 프로테아제에 의한 절단의 효율을 증가시키며, 이에 따라 절단 후 별도의 폴리펩티드를 생성한다.
IgG 중쇄에는 가변 중쇄(VH), 불변 중쇄 1(CH1), 힌지, 불변 중쇄 2(CH2), 및 불변 중쇄 3(CH3) 영역이 포함되었다. IgG 경쇄에는 가변 경쇄(VL) 및 불변 경쇄(CL) 영역이 포함되었다. 상기 작제물을 사이토메갈로바이러스(CMV) 프로모터의 제어 하에, 예를 들어 발현 벡터 pVAX1에 배치하였다. 상기 작제물은 반응성 gp120(즉, VRC01 항체에 의해 인식되는 항원)인 완전 조립된 IgG 항체의 생산을 일으켰다(도 14에 나타낸 바와 같음). 이러한 완전 조립된 IgG를 본원에서 VRC01 IgG로 나타낸다. VRC01 IgG의 아미노산 서열(퓨린에 의한 절단 전)을 도 15에 나타내고 서열 식별 번호 64를 인코딩하는 핵산 서열에 의해 인코딩되는 서열 식별 번호 5에 나타낸다(도 62 참고).
특히, VRC01 IgG의 아미노산 서열(퓨린에 의한 절단 전; 서열 식별 번호 64의 뉴클레오티드 서열에 의해 인코딩되는 서열 식별 번호 5 및 도 15)은 하기 구조를 갖는다: 면역글로불린 E1(IgE1) 신호 펩티드, 가변 중쇄 영역(VH), 불변 중쇄 영역 1(CH1), 힌지 영역, 불변 중쇄 영역 2(CH2), 불변 중쇄 영역 3(CH3), 퓨린 절단 부위, GSG 링커, P2A 펩티드, IgE1 신호 펩티드, 가변 경쇄 영역(VL), 및 불변 경쇄 영역(CL, 특히 카파). 구조의 각 부분의 서열(모두 상술되고 도 13에 나타낸 순서로 서열 식별 번호 15 내에 포함됨)을 아래에 제공한다.
VRC-1 IgG의 IgE1 신호 펩티드 -
VRC01 IgG의 가변 중쇄 영역 -

VRC01 IgG의 불변 중쇄 영역 1(CH1) -
VRC01 IgG의 힌지 영역 - 
VRC01 IgG의 불변 중쇄 영역 2(CH2) -

VRC01 IgG의 불변 중쇄 영역 3(CH3) -

VRC01 IgG의 퓨린 절단 부위 - 
VRC01 IgG의 GSG 링커 및 P2A 펩티드- 
VRC01 IgG의 IgE1 신호 펩티드 - 
VRC01 IgG의 가변 경쇄 영역(VL) -

VRC01 IgG의 불변 경쇄 영역(CL, 카파) -

실시예 9
두 플라스미드에 의해 인코딩된 HIV-1 VRC01 IgG
실시예 2-8에 상술된 바와 같이, Fab(각각의 사슬이 별도의 플라스미드에서 발현됨)를 VRC01 항체, 즉 HIV-Env Fab로부터 생성하였고, IgG(단일 플라스미드에서 발현됨)를 VRC01 항체, 즉 VRC01 IgG로부터 생성하였다. 이들 연구를 추가 확장시키기 위해, IgG를 VRC01 항체로부터 생성하였고, 여기서 중쇄(즉, 가변 중쇄 영역(VH), 불변 중쇄 영역 1(CH1), 힌지 영역, 불변 중쇄 영역 2(CH2), 및 불변 중쇄 영역 3(CH3)) 및 경쇄(즉, 가변 경쇄 영역(VL) 및 불변 경쇄 영역(CL))는 별도의 작제물에 의해 인코딩되었다(도 50 및 51). 상기 IgG를 본원에서 HIV-1 VRC01 IgG로 나타낸다.
또한 각각의 작제물에는 일단 생체 내 생성된 항체의 분비를 최적화하기 위한 리더 서열이 포함되었다. 각각의 작제물을 pVAX1 벡터의 BamHI 및 XhoI 부위 내에 클로닝하고, 이에 따라 작제물을 사이토메갈로바이러스(CMV) 프로모터의 제어 하에 배치하였다(도 50 및 51). 따라서 생체 내에서 VRC01 IgG를 형성하거나 생성하기 위해, 플라스미드 혼합물, 즉 중쇄를 인코딩하는 작제물을 함유하는 플라스미드 및 경쇄를 인코딩하는 작제물을 함유하는 플라스미드를 대상체에 투여해야 한다.
추가적으로, 각각의 작제물을 추가로 최적화하였다. 최적화에는 코작 서열(GCC ACC)의 부가 및 코돈 최적화가 포함되었다. HIV-1 VRC01 IgG의 IgG1 중쇄를 인코딩하는 핵산 서열을 서열 식별 번호 54 및 도 52에 나타낸다. 도 52에서, 밑줄 및 이중 밑줄은 핵산 서열을 pVAX1 벡터 내로 클로닝하기 위해 이용된 BamHI(GGA TCC) 및 XhoI(CTC GAG) 제한 효소 부위를 나타내는 반면, 진한 글씨는 시작(ATG) 및 정지(TGA TAA) 코돈을 나타낸다. 서열 식별 번호 54는 서열 식별 번호 55 및 도 53에 나타낸 아미노산 서열, 즉 HIV-1 VRC01 IgG의 IgG1 중쇄의 아미노산 서열을 인코딩한다.
HIV-1 VRC01 IgG의 IgG 경쇄를 인코딩하는 핵산 서열을 서열 식별 번호 56 및 도 54에 나타낸다. 도 54에서, 밑줄 및 이중 밑줄은 핵산 서열을 pVAX1 벡터 내로 클로닝하기 위해 이용된 BamHI(GGA TCC) 및 XhoI(CTC GAG) 제한 효소 부위를 나타내는 반면, 진한 글씨는 시작(ATG) 및 정지(TGA 또는 TAA) 코돈을 나타낸다. 서열 식별 번호 56은 서열 식별 번호 57 및 도 55에 나타낸 아미노산 서열, 즉 HIV-1 VRC01 IgG의 IgG 경쇄의 아미노산 서열을 나타낸다.
실시예 10
HIV-1 Env-PG9 Ig
VRC01 IgG에 부가하여, HIV-1 Env에 반응성인 IgG를 인코딩하는 다른 작제물을 생성하였다. 상기 작제물은 HIV-1 Env-PG9로, 최적화되고 발현 벡터 내로 클로닝되었다(도 16a 및 16b). 최적화에는 코작 서열(예로, GCC ACC), 리더 서열, 및 코돈 최적화가 포함되었다. HIV-1 Env-PG9 Ig를 인코딩하는 핵산 서열을 함유하는 발현 벡터의 생성을 도 16c에 나타낸 바와 같이 제한 효소 소화에 의해 확인하였다. 도 16c에서, 레인 1은 소화되지 않은 발현 벡터이고, 레인 2는 BamHI 및 XhoI로 소화된 발현 벡터이고, 레인 M은 마커였다.
HIV-1 Env-PG9 Ig를 인코딩하는 핵산 서열을 서열 식별 번호 63 및 도 61에 나타낸다. 도 61에서, 밑줄 및 이중 밑줄은 핵산 서열을 pVAX1 벡터 내로 클로닝하기 위해 이용된 BamHI(GGA TCC) 및 XhoI(CTC GAG) 제한 효소 부위를 나타내는 반면, 진한 글씨는 시작(ATG) 및 정지(TGA 또는 TAA) 코돈을 나타낸다. 서열 식별 번호 63은 서열 식별 번호 2 및 도 18에 나타낸 아미노산 서열, 즉 HIV-1 ENv-PG9 Ig의 아미노산 서열(퓨린에 의한 절단 전)을 나타낸다.
상기 아미노산 서열에서, 신호 펩티드는 생체 내 생성된 항체의 분비를 개선하기 위해 각각의 중쇄 및 경쇄에 펩티드 결합에 의해 연결된다. 추가적으로, 번역된 폴리펩티드의 중쇄 또는 경쇄를 함유하는 별도의 폴리펩티드로의 보다 효율적인 절단을 허용하기 위해, P2A 펩티드를 인코딩하는 핵산 서열이 중쇄 및 경쇄를 인코딩하는 핵산 서열 간에 배치된다
특히, HIV-1 Env-PG9 Ig의 아미노산 서열(퓨린에 의한 절단 전; 서열 식별 번호 2 및 도 18)은 하기 구조를 갖는다: 인간 IgG 중쇄 신호 펩티드, 가변 중쇄 영역(VH), 불변 중쇄 영역 1(CH1), 힌지 영역, 불변 중쇄 영역 2(CH2), 불변 중쇄 영역 3(CH3), 퓨린 절단 부위, GSG 링커, P2A 펩티드, 인간 람다 경쇄 신호 펩티드, 가변 경쇄 영역(VL), 및 불변 경쇄 영역(CL, 특히 람다). 구조의 각 부분의 서열(모두 상술된 순서로 서열 식별 번호 2 내에 포함됨)을 아래에 제공한다.
HIV-1 Env-PG9 Ig의 인간 IgG 중쇄 신호 펩티드-
HIV-1 Env-PG9 Ig의 가변 중쇄 영역 -

HIV-1 Env-PG9 Ig의 불변 중쇄 영역 1(CH1) -
HIV-1 Env-PG9 Ig의 힌지 영역 - 
HIV-1 Env-PG9 Ig의 불변 중쇄 영역 2(CH2) -

HIV-1 Env-PG9 Ig의 불변 중쇄 영역 3(CH3) -

HIV-1 Env-PG9 Ig의 퓨린 절단 부위 - 
HIV-1 Env-PG9 Ig의 GSG 링커 및 P2A 펩티드 -
HIV-1 Env-PG9 Ig의 인간 람다 경쇄 신호 펩티드 -
HIV-1 Env-PG9 Ig의 가변 경쇄 영역(VL) -
HIV-1 Env-PG9 Ig의 불변 경쇄 영역(CL, 람다) -

실시예 11
HIV-1 PG9 단일쇄 Fab(scFab)
상술된 HIV-1 Env-PG9 Ig에 부가하여, 단일쇄 Fab(즉, 단일 전사체로 전사되고 단일 폴리펩티드로 번역되는 핵산 서열에 의해 인코딩된 VH/CH1 및 VL/CL)를 PG9 항체(본원에서 HIV-1 PG9 scFab로 나타냄)에 기반하여 생성하였다. HIV-1 PG9 scFab를 인코딩하는 핵산 서열을 서열 식별 번호 50 및 도 46에 나타낸다. 도 46에서, 밑줄 및 이중 밑줄은 상기 핵산 서열을 pVAX1 벡터 내로 클로닝하기 위해 이용된 BamHI(GGA TCC) 및 XhoI(CTC GAG)을 나타내는 반면, 진한 글씨는 시작(ATG) 및 정지(TGA 또는 TAA) 코돈을 나타낸다. 서열 식별 번호 50에 나타낸 핵산 서열은 최적화된 핵산 서열이다, 즉 코작 서열(GCC ACC), 코돈 최적화, 및 리더 서열을 포함하였다. 리더 서열은 작제물의 5' 말단, 즉 단일쇄 Fab 앞에 배치하였고, 이에 따라 링커 서열에 의해 인코딩된 신호 펩티드가 단일쇄 Fab의 아미노 말단에 펩티드 결합에 의해 연결되었다. 서열 식별 번호 50에 나타낸 핵산 서열에는 또한 VH/CH1을 인코딩하는 핵산 서열 및 VL/CL을 인코딩하는 핵산 서열 간에 배치된 링커 서열이 포함되었다. 따라서 서열 식별 번호 50에 의해 인코딩된 폴리펩티드에서, 링커 서열에 의해 인코딩된 아미노산 서열은 VH/CH1 및 VL/CL을 함께 유지하였다. 서열 식별 번호 50은 서열 식별 번호 51 및 도 47에 나타낸 아미노산 서열, 즉 HIV-1 PG9 scFab의 아미노산 서열을 인코딩하였다.
실시예 12
HIV-1 Env-4E10 Ig
VRC01 IgG 및 HIV-1 Env-PG9 Ig에 부가하여, HIV-1 Env에 반응성인 IgG를 인코딩하는 다른 작제물을 생성하였다. 상기 작제물은 최적화되고 발현 벡터 내로 클로닝된 HIV-1 Env-4E10이었다(도 17a 및 17b). 최적화에는 코작 서열(예로, GCC ACC), 리더 서열의 도입, 및 코돈 최적화가 포함되었다. HIV-1 Env-4E10 Ig를 인코딩하는 핵산 서열을 함유하는 발현 벡터의 생성을 도 17c에 나타낸 바와 같이 제한 효소 소화에 의해 확인하였다. 도 17c에서, 레인 1은 소화되지 않은 발현 벡터이고, 레인 2는 BamHI 및 XhoI로 소화된 발현 벡터이고, 레인 M은 마커였다.
HIV-1 Env-4E10 Ig를 인코딩하는 핵산 서열을 서열 식별 번호 62 및 도 60에 나타낸다. 도 60에서, 밑줄 및 이중 밑줄은 핵산 서열을 pVAX1 벡터 내로 클로닝하기 위해 이용된 BamHI(GGA TCC) 및 XhoI(CTC GAG) 제한 효소 부위를 나타내는 반면, 진한 글씨는 시작(ATG) 및 정지(TGA TAA) 코돈을 나타낸다. 서열 식별 번호 62는 서열 식별 번호 1 및 도 19에 나타낸 아미노산 서열, 즉 HIV-1 ENv-4E10 Ig의 아미노산 서열(퓨린에 의한 절단 전)을 인코딩한다.
상기 아미노산 서열에서, 신호 펩티드는 생체 내 생성된 항체의 분비를 개선하기 위해 각각의 중쇄 및 경쇄에 펩티드 결합에 의해 연결된다. 추가적으로, 번역된 폴리펩티드의 중쇄 또는 경쇄를 함유하는 별도의 폴리펩티드로의 보다 효율적인 절단을 허용하기 위해, P2A 펩티드를 인코딩하는 핵산 서열이 중쇄 및 경쇄를 인코딩하는 핵산 서열 간에 배치된다.
특히, HIV-1 Env-4E10 Ig의 아미노산 서열(퓨린에 의한 절단 전; 서열 식별 번호 1 및 도 19)은 하기 구조를 갖는다: 인간 IgG 중쇄 신호 펩티드, 가변 중쇄 영역(VH), 불변 중쇄 영역 1(CH1), 힌지 영역, 불변 중쇄 영역 2(CH2), 불변 중쇄 영역 3(CH3), 퓨린 절단 부위, GSG 링커, P2A 펩티드, 인간 카파 경쇄 신호 펩티드, 가변 경쇄 영역(VL), 및 불변 경쇄 영역(CL, 특히 카파). 구조의 각 부분의 서열(모두 상술된 순서로 서열 식별 번호 1 내에 함유됨)을 아래에 제공한다.
HIV-1 Env-4E10 Ig의 인간 IgG 중쇄 신호 펩티드-
HIV-1 Env-4E10 Ig의 가변 중쇄 영역 -

HIV-1 Env-4E10 Ig의 불변 중쇄 영역 1(CH1) -
HIV-1 Env-4E10 Ig의 힌지 영역 - 
HIV-1 Env-4E10 Ig의 불변 중쇄 영역 2(CH2) -

HIV-1 Env-4E10 Ig의 불변 중쇄 영역 3(CH3) -

HIV-1 Env-4E10 Ig의 퓨린 절단 부위 - 
HIV-1 Env-4E10 Ig의 GSG 링커 및 P2A 펩티드 -
HIV-1 Env-4E10 Ig의 인간 카파 경쇄 신호 펩티드 -
HIV-1 Env-4E10 Ig의 가변 경쇄 영역(VL) -

HIV-1 Env-4E10 Ig의 불변 경쇄 영역(CL, 카파) -

실시예 13
HIV-1 4E10 ScFab
상술된 HIV-1 Env-PG9 Ig에 부가하여, 단일쇄 Fab(즉, 단일 전사체로 전사되고 단일 폴리펩티드로 번역되는 핵산 서열에 의해 인코딩된 VH/CH1 및 VL/CL)를 4E10 항체(본원에서 HIV-1 4E10 scFab로 나타냄)에 기반하여 생성하였다. HIV-1 4E10 scFab를 인코딩하는 핵산 서열을 서열 식별 번호 52 및 도 48에 나타낸다. 도 48에서, 밑줄 및 이중 밑줄은 상기 핵산 서열을 pVAX1 벡터 내로 클로닝하기 위해 이용된 BamHI(GGA TCC) 및 XhoI(CTC GAG)을 나타내는 반면, 진한 글씨는 시작(ATG) 및 정지(TGA 또는 TAA) 코돈을 나타낸다. 서열 식별 번호 52에 나타낸 핵산 서열은 최적화된 핵산 서열이다, 즉 코작 서열(GCC ACC), 코돈 최적화, 및 리더 서열을 포함하였다. 리더 서열은 작제물의 5' 말단, 즉 단일쇄 Fab 앞에 배치하였고, 이에 따라 링커 서열에 의해 인코딩된 신호 펩티드는 단일쇄 Fab의 아미노 말단에 펩티드 결합에 의해 연결되었다. 서열 식별 번호 52에 나타낸 핵산 서열에는 또한 VH/CH1을 인코딩하는 핵산 서열 및 VL/CL을 인코딩하는 핵산 서열 간에 배치된 링커 서열이 포함되었다. 따라서 서열 식별 번호 52에 의해 인코딩된 폴리펩티드에서, 링커 서열에 의해 인코딩된 아미노산 서열은 VH/CH1 및 VL/CL을 함께 유지하였다. 서열 식별 번호 52은 서열 식별 번호 53 및 도 49에 나타낸 아미노산 서열, 즉 HIV-1 4E10 scFab의 아미노산 서열을 인코딩하였다.
실시예 14
CHIKV-Env-Fab
상술된 바와 같이, HIV-1 Env에 반응성인 Fab는 세포 또는 마우스로 HIV-1Env Fab의 중쇄(VH-CH1) 및 경쇄(VL-CL)를 인코딩하는 핵산 서열의 전달 시 생체 내 조립되거나 생성되었다. 다른 항원에 반응성인 Fab가 세포 또는 대상체에 대한 인코딩 핵산 서열의 전달 시 생체 내 생성될 수 있는지를 결정하기 위해, 치쿤군야 바이러스(CHIKV)의 외피 단백질(Env)에 반응성인 항체의 중쇄(VH-CH1) 및 경쇄(VL-CL, 람다 유형)를 인코딩하는 작제물을 생성하였다. 각각의 작제물에는 도 20a, 20b 및 21에 나타낸 바와 같은 리더 서열 및 코작 서열이 포함되었다. VH-CH1 및 VL-CL을 인코딩하는 작제물을 발현 벡터 내로 클로닝하고, 이에 따라 사이토메갈로바이러스(CMV) 프로모터의 제어 하에 배치하였다(도 21). VH-CH1 및 VL-CL을 인코딩하는 작제물을 함유하는 발현 벡터는 각각 CHIKV-H 및 CHIV-L로 알려진다. 더불어, CHIKV-H 및 CHIKV-L 벡터의 혼합물은 pCHIKV-Env-Fab로 알려지며, 이는 생체 내 CHIKV-Env-Fab를 생성하였다(즉, 세포 또는 대상체 내로의 도입 시). 다시 말하면, 두 벡터가 모두 아래에 보다 상세히 기재된 바와 같이 생체 내에서 CHIKV-Env-Fab를 생성하기 위해 필요하였다.
작제물은 또한 발현을 위해 최적화되었다. 특히, 생체 내에서 CHIKV-Env-Fab의 생성 시 CHIKV-Env-Fab의 분비 효율을 증가시키기 위해 각 작제물에 리더 서열을 포함시켰다. 각각의 작제물을 또한 코돈 최적화하고 코작 서열(GCC ACC)을 포함시켰다. CHIKV-Env-Fab의 중쇄(VH-CH1)를 인코딩하는 핵산 서열을 서열 식별 번호 58 및 도 56에 나타낸다. 도 56에서, 밑줄 및 이중 밑줄은 핵산 서열을 pVAX1 벡터 내로 클로닝하기 위해 이용된 BamHI(GGA TCC) 및 XhoI(CTC GAG) 제한 효소 부위를 나타내는 반면, 진한 글씨는 시작(ATG) 및 정지(TGA TAA) 코돈을 나타낸다. 서열 식별 번호 58은 서열 식별 번호 59 및 도 57에 나타낸 아미노산 서열, 즉 CHIKV-Env-Fab의 중쇄(VH-CH1)의 아미노산 서열을 인코딩한다.
CHIKV-Env-Fab의 경쇄(VL-CL)를 인코딩하는 핵산 서열을 서열 식별 번호 60 및 도 58에 나타낸다. 도 58에서, 밑줄 및 이중 밑줄은 핵산 서열을 pVAX1 벡터 내로 클로닝하기 위해 이용된 BamHI(GGA TCC) 및 XhoI(CTC GAG) 제한 효소 부위를 나타내는 반면, 진한 글씨는 시작(ATG) 및 정지(TGA TAA) 코돈을 나타낸다. 서열 식별 번호 60은 서열 식별 번호 61 및 도 59에 나타낸 아미노산 서열, 즉 CHIKV-Env-Fab의 경쇄(VL-CL)의 아미노산 서열을 인코딩한다.
생체 내 CHIKV-Env-Fab 생성의 경시적 역학을 측정하기 위해, 세포를 pVAX1, CHIKV-H, CHIKV-L, 또는 pCHIKV-Env-Fab로 전달감염시켰다. 전달감염 후, ELISA를 이용하여 경시적인 CHIKV-Env-Fab 생성 수준을 측정하였다. 도 22에 나타낸 바와 같이, pVAX1, CHIKV-H, 또는 CHIKV-L로 전달감염된 세포는 CHIKV Env 항원에 반응성인 항체를 생산하지 않았다. 대조적으로, pCHIKV-Env-Fab로 전달감염된 세포는 CHIKV Env 항원에 반응성인 항체(즉, CHIKV-Env-Fab, CHIKV-Fab로도 알려져 있음)를 생산하였다. 따라서 이들 데이터는 CHIKV-Env-Fab의 중쇄(VH-CH1) 및 경쇄(VL-CL)를 인코딩하는 핵산 서열의 전달이 CHIKV-Env 항원에 결합하거나 반응성인 Fab의 생성을 일으킴을 나타내었다.
추가적으로, CHIKV-Env-Fab를 CHIKV-Env 항원을 인코딩하는 플라스미드인 pCHIKV-Env로 전달감염된 세포에서 수득된 용해액의 웨스턴 블롯에 이용하였다. 도 23에 나타낸 바와 같이, CHIKV-Env 항원이 CHIKV-Env-Fab를 통해 검출되어 상기 Fab가 항원에 결합함을 시사하였다.
생체 내 CHIKV-Env-Fab의 생성 또는 조립을 추가 조사하기 위해, 마우스에 pCHIKV-Env-Fab(즉, 12.5㎍ CHIKV-H 및 12.5㎍ CHIKV-L)를 투여하였다. 추가적으로, 제2, 제3, 및 제4군의 마우스에 각각 25㎍의 pVAX1, CHIKV-H, 및 CHIKV-L을 투여하여, 대조군으로 이용하였다. 특히 플라스미드를 채혈-전 표본의 수득 후 0일에 각 군의 마우스에 투여하였다. 1일, 2일, 3일, 5일, 7일 및 10일에 채혈하였다(도 24). 이들 혈액 상에서 ELISA 측정을 수행하여 CHIKV-Env 항원에 반응성인 항체 수준을 결정하였다. 도 25에 나타낸 바와 같이, pCHIKV-Env-Fab가 투여된 마우스는 CHIKV-Env 항원에 반응성인 항체(즉, CHIKV-Env-Fab) 생성을 일으켰다. pVAX1, CHIKV-H 또는 CHIKV-L이 투여된 마우스는 CHIKV-Env 항원과 유의미하게 반응성을 갖는 항체를 생성하지 않았다. 따라서 이들 데이터는 CHIKV-Env-Fab의 중쇄(VH-CH1) 및 경쇄(VL-CL)를 인코딩하는 핵산 서열의 전달 시, 상기 Fab가 생체 내(즉 마우스에서) 생성되었으며, 그 항원(즉, CHIKV-Env)에 반응성임을 추가로 나타내었으며, 이에 따라 Fab가 생체 내에서 정확히 조립됨을 나타내었다.
CHIKV-Env-Fab가 CHIKV 감염에 대해 보호할 수 있는지를 결정하기 위해, C57BL/6 마우스(2-3주령; 약 20-25g 체중)에 0일에 pCHIKV-Env-Fab(50㎍) 또는 pVAX1을 투여하였다. pCHIKV-Env-Fab의 투여 6시간 후, 각 마우스에 비강내 경로로 총 부피 25㎕ 중 7 log 10 PFU를 접종하였다. 다음 날마다 각 마우스에 대해 체중을 측정하고, 체중 손실이 30% 초과인 경우 마우스를 희생시켰다.
도 26에 나타낸 바와 같이, pCHIKV-Env-Fab가 투여된 마우스의 약 75%가 연구 14일째에 CHIKV 감염에 생존한 반면, pVAX1이 투여된 마우스는 14일째에 모두 사망하였다. 추가적으로, pCHIKV-Env-Fab가 투여된 마우스는 pVAX1이 투여된 마우스에 비해 더 낮은 수준의 시토카인 TNF-α 및 IL-6에 연관되었다(도 27 및 28). TNF-α 및 IL-6 수준을 마우스에서 수득한 혈청에서 측정하였다. 이들 생존 마우스는 병리 징후, 체중 손실을 나타내지 않았고, 더 낮은 수준의 시토카인 TNF-α 및 IL-6을 가졌다. 따라서 이들 데이터는 pCHIKV-Env-Fab 투여가 마우스를 CHIKV 감염으로부터 보호하고 CHIKV 감염 시 생존을 촉진함을 나타내었다. 다시 말하면, 마우스에서 CHIKV-Env-Fab의 생체 내 생성은 CHIKV 감염에 대해 보호하고 생존을 촉진하였다.
실시예 15
항-Her-2 Fab
상술된 바와 같이, HIV-1 Env 또는 CHIKV Env에 반응성인 Fab(즉, VH/CH1 및 VL/CL)가 세포 또는 마우스로 HIV-1Env Fab 또는 CHIKV Env-Fab의 중쇄(VH-CH1) 및 경쇄(VL-CL)를 인코딩하는 핵산 서열의 전달 시 생체 내 조립되거나 생성되었다. 자가 항원(즉, Fab를 인코딩하는 핵산 서열이 투여된 대상체에 내인성인 항원)에 반응성인 Fab가 세포 또는 마우스로의 인코딩 핵산의 전달 시 생체 내 생성될 수 있는지를 결정하기 위해, 인간 표피 성장 인자 수용체 2(Her-2; Erb2로도 알려져 있음)에 반응성인 항체의 중쇄(VH-CH1) 및 경쇄(VL-CL)를 인코딩하는 작제물을 생성하였다. 각각의 작제물에는 도 28, 30 및 31에 나타낸 바와 같이 항-Her-2 Fab의 VH-CH1 또는 VL-CL을 인코딩하는 핵산 서열에 선행하여 리더 서열 및 코작 서열(GCC ACC)이 포함되었다. 따라서 이들 작제물은 리더 서열 및 코작 서열의 도입으로 인해 최적화되었고, 코돈 이용에 대해 추가로 최적화되었다.
VH-CH1 및 VL-CL을 인코딩하는 작제물을 pVAX1 발현 벡터 내로, 즉 BamHI 및 XhoI 제한 효소 부위 사이에 클로닝하고, 이에 따라 사이토메갈로바이러스(CMV) 프로모터의 제어 하에 배치하였다. 특히, VH-CH1 및 VL-CL을 인코딩하는 작제물을 두 별도의 pVAX1 벡터 내로 클로닝하였고, 이에 따라 생체 내에서 항-Her-2 Fab를 생성하기 위해서는 생성된 두 플라스미드가 필요하였다.
항-Her-2 Fab의 VH-CH1을 인코딩하는 핵산 서열을 서열 식별 번호 40 및 도 32에 나타낸다. 도 32에서, 밑줄 및 이중 밑줄은 각각 핵산 서열을 pVAX1 벡터 내로 클로닝하기 위해 이용된 BamHI(GGA TCC) 및 XhoI(CTC GAG) 제한 효소 부위를 나타내는 반면, 진한 글씨는 시작(ATG) 및 정지(TGA TAA) 코돈을 나타낸다. 서열 식별 번호 40은 서열 식별 번호 41에 나타낸 아미노산 서열, 즉 항-Her-2 Fab의 VH-CH1의 아미노산 서열을 인코딩한다(도 32 및 33).
항-Her-2 Fab의 VL-CL을 인코딩하는 핵산 서열을 서열 식별 번호 42 및 도 34에 나타낸다. 도 34에서, 밑줄 및 이중 밑줄은 각각 핵산 서열을 pVAX1 벡터 내로 클로닝하기 위해 이용된 BamHI(GGA TCC) 및 XhoI(CTC GAG) 제한 효소 부위를 나타내는 반면, 진한 글씨는 시작(ATG) 및 정지(TGA TAA) 코돈을 나타낸다. 서열 식별 번호 42는 서열 식별 번호 43에 나타낸 아미노산 서열, 즉 항-Her-2 Fab의 VL-CL의 아미노산 서열을 인코딩한다(도 34 및 35).
항-Her-2 Fab의 VH-CH1 및 VL-CL을 인코딩하는 플라스미드의 혼합물이 생체 내에서 항-Her-2 Fab를 생성하는지를 결정하기 위해, 293T 세포를 항-Her-2 Fab 또는 pVAX1의 중쇄(VH-CH1) 및 경쇄(VL 및 CL)를 인코딩하는 플라스미드 혼합물로 전달감염시켰다. 전달감염 후, 전체 IgG 농도를 도 36에 나타낸 바와 같이 측정하였다. 도 36에서, 오차 막내는 표준 편차를 나타내었다. 이들 데이터는 각각 항-Her-2 Fab의 VH-CH1 또는 VL-CL을 인코딩하는 두 플라스미드의 도입 시 항-Her-2 Fab가 생체 내 생성됨을 나타내었다.
실시예 16
항-뎅기 바이러스 인간 IgG
생체 내에서 항-뎅기 바이러스(DENV) 인간 IgG 항체를 생성하기 위해 단일 플라스미드 시스템을 생성하였다. 특히, 도 37의 모식도에 나타낸 바와 같이 작제물을 생성하였다. 구체적으로, 리더 서열을 IgG 중쇄(즉, 가변 중쇄 영역(VH), 불변 중쇄 영역 1(CH1), 힌지 영역, 불변 중쇄 영역 2(CH2), 및 불변 중쇄 영역 3(CH3))를 인코딩하는 핵산 서열의 상류에 배치하였다. 다시 프로테아제 절단 부위를 인코딩하는 서열을 IgG 중쇄를 인코딩하는 핵산 서열의 하류에 배치하였다. IgG 경쇄(즉, 가변 경쇄 영역(VL) 및 불변 경쇄 영역(CL))를 인코딩하는 핵산 서열을 프로테아제 절단 부위(즉, 퓨린 절단 부위)를 인코딩하는 서열 뒤에 배치하였다. 상기 작제물에 의해 인코딩된 신호 펩티드는 인지체 신호 펩티드였으므로, 이에 따라 발현 시 항체의 적절한 분비를 제공하였다. 추가적으로, 발현 시 단일 전사체가 단일 폴리펩티드로 번역되고, 이어서 프로테아제에 의해 항-DENV 인간 IgG의 중쇄 및 경쇄에 해당하는 폴리펩티드로 가공된다. 이어서 이들 중쇄 및 경쇄 폴리펩티드는 기능적 항-DENV 인간 IgG로, 즉 그 인지체 항원에 결합하는 항체로 조립된다.
상기 작제물을 발현 벡터 pVAX1(즉 BamHI 및 XhoI 부위) 내에 클로닝하고, 이에 따라 프로모터의 제어 하에 배치하였다. 항-뎅기 바이러스 인간 IgG를 인코딩하는 상기 작제물은 서열 식별 번호 44에 나타낸 핵산 서열을 가지며(도 38), 발현을 위해 최적화되었다. 도 38에서, 밑줄 및 이중 밑줄은 작제물을 pVAX1 벡터 내로 클로닝하기 위해 이용된 BamHI(GGA TCC) 및 XhoI(CTC GAG) 제한 효소 부위를 나타내는 반면, 진한 글씨는 시작(ATG) 및 정지(TGA 또는 TAA) 코돈을 나타낸다. 최적화에는 코작 서열(GCC ACC)의 도입 및 코돈 최적화가 포함되었다. 서열 식별 번호 44는 서열 식별 번호 45 및 도 39에 나타낸 아미노산 서열, 즉 프로테아제에 의해 별도의 중쇄 및 경쇄의 두 별도의 폴리펩티드로의 절단 전 항-DENV 인간 IgG의 아미노산 서열을 인코딩한다.
항-뎅기 바이러스 인간 IgG가 생체 내(즉 마우스에서) 생성되는지를 결정하기 위해, 항-뎅기 바이러스 인간 IgG를 인코딩하는 핵산 서열을 함유하는 플라스미드를 마우스에 투여하였다. 플라스미드 투여 후, 마우스로부터 혈청을 수득하고 ELISA를 통해 분석하여 혈청이 4가지 뎅기 바이러스 혈청형, 즉 DENV-1, DENV-2, DENV-3, 및 DENV-4로부터의 뎅기 E 단백질에 반응성인 항체를 함유하는지를 결정하였다. 도 40에 나타낸 바와 같이, 항-DENV 인간 IgG를 인코딩하는 핵산 서열을 함유하는 플라스미드가 투여된 마우스로부터의 혈청은 혈청형 DENV-1, -2, -3, 및 -4로부터의 DENV E 단백질에 반응성이었다. 이소형 항체를 양성 대조군으로 이용하였다. 따라서 이들 데이터는 마우스 내로의 플라스미드 도입 시, 항-DENV 인간 IgG를 인코딩하는 핵산 서열이 항-DENV 인간 IgG의 중쇄 및 경쇄를 함유하는 폴리펩티드를 산출하도록 가공되는 폴리펩티드로 전사되고 번역됨을 나타내었다. 이들 폴리펩티드는 항-DENV 인간 IgG로 조립되었고, 이에 따라 DENV E 단백질에 결합하거나 반응성인 기능적 항체를 제공하였다.
단일 플라스미드의 투여에 의한 생체 내 항-DENV 인간 IgG의 생성을 추가 조사하기 위해, 마우스에 항-DENV 인간 IgG를 인코딩하는 핵산 서열을 함유하는 플라스미드를 주사를 통해 투여하였다. 구체적으로, 마우스에 50㎍ 또는 100㎍의 플라스미드를 투여하였고, 각 군 당 마우스는 5마리씩이었다. 주사 후 3일 및 6일에, 마우스를 혈청전환에 대해 조사하였다. 도 41에 나타낸 바와 같이, 두 군의 마우스가 모두 항-DENV IgG 항체에 대해 혈청양성이었다. 특히 50㎍의 플라스미드가 투여된 마우스는 약 110ng/mL의 인간 IgG를 가졌고, 100㎍의 플라스미드가 투여된 마우스는 약 170ng/mL의 인간 IgG를 가졌다. 따라서 이들 데이터는 항-DENV 인간 IgG를 인코딩하는 플라스미드의 투여 후 생체 내 항-DENV 인간 IgG의 생성을 추가로 나타내었다. 이들 데이터는 또한 항-DENV 인간 IgG 항체 생산이 1주 이내에 일어나며, 이에 따라 항-DENV 인간 IgG 항체의 신속한 생산을 허용함을 나타내었다.
상기 상세한 설명 및 동반 실시예는 단지 예시적인 것이며, 오로지 첨부된 특허청구범위 및 이들의 균등부에 의해 정의되는 본 발명의 범위를 제한하는 것으로 간주되어서는 안 됨이 이해된다.
개시된 구현예에 대한 다양한 변화 및 개질은 당분야 숙련가에게 자명할 것이다. 비제한적으로 본 발명의 화학적 구조, 치환체, 유도체, 중간체, 합성, 조성물, 제형 또는 이용 방법에 관한 것들을 포함하는 이러한 변화 및 개질이 발명의 요지 및 범위에서 벗어나지 않고 수행될 수 있다.
<110> THE TRUSTEES OF THE UNIVERSITY OF PENNSYLVANIA
WEINER, DAVID
MUTHUMANI, Karupiah
WALTERS, Jewell
SARDESAI, Niranjan
<120> DNA ANTIBODY CONSTRUCTS AND METHOD OF USING SAME
<130> UPVG0053 WO
<150> PCT/US 13/075137
<151> 2013-12-13
<150> US 61/737,094
<151> 2012-12-13
<150> US 61/881,376
<151> 2012-09-23
<150> US 61/896,646
<151> 2012-10-28
<160> 64
<170> KopatentIn 2.0
<210> 1
<211> 738
<212> PRT
<213> Artificial Sequence
<220>
<223> Amino Acid Sequence of HIV-1 Env-4E10 Ig
<400> 1
Met Asp Trp Thr Trp Arg Ile Leu Phe Leu Val Ala Ala Ala Thr Gly
1 5 10 15
Thr His Ala Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Arg
20 25 30
Pro Gly Ser Ser Val Thr Val Ser Cys Lys Ala Ser Gly Gly Ser Phe
35 40 45
Ser Thr Tyr Ala Leu Ser Trp Val Arg Gln Ala Pro Gly Arg Gly Leu
50 55 60
Glu Trp Met Gly Gly Val Ile Pro Leu Leu Thr Ile Thr Asn Tyr Ala
65 70 75 80
Pro Arg Phe Gln Gly Arg Ile Thr Ile Thr Ala Asp Arg Ser Thr Ser
85 90 95
Thr Ala Tyr Leu Glu Leu Asn Ser Leu Arg Pro Glu Asp Thr Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Glu Gly Thr Thr Gly Trp Gly Trp Leu Gly Lys
115 120 125
Pro Ile Gly Ala Phe Ala His Trp Gly Gln Gly Thr Leu Val Thr Val
130 135 140
Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser
145 150 155 160
Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys
165 170 175
Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu
180 185 190
Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu
195 200 205
Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr
210 215 220
Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val
225 230 235 240
Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro
245 250 255
Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe
260 265 270
Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
275 280 285
Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe
290 295 300
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
305 310 315 320
Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
325 330 335
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
340 345 350
Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala
355 360 365
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg
370 375 380
Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly
385 390 395 400
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
405 410 415
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
420 425 430
Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln
435 440 445
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
450 455 460
Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys Arg Gly Arg Lys
465 470 475 480
Arg Arg Ser Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala
485 490 495
Gly Asp Val Glu Glu Asn Pro Gly Pro Met Val Leu Gln Thr Gln Val
500 505 510
Phe Ile Ser Leu Leu Leu Trp Ile Ser Gly Ala Tyr Gly Glu Ile Val
515 520 525
Leu Thr Gln Ser Pro Gly Thr Gln Ser Leu Ser Pro Gly Glu Arg Ala
530 535 540
Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Gly Asn Asn Lys Leu Ala
545 550 555 560
Trp Tyr Gln Gln Arg Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr Gly
565 570 575
Ala Ser Ser Arg Pro Ser Gly Val Ala Asp Arg Phe Ser Gly Ser Gly
580 585 590
Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu Pro Glu Asp
595 600 605
Phe Ala Val Tyr Tyr Cys Gln Gln Tyr Gly Gln Ser Leu Ser Thr Phe
610 615 620
Gly Gln Gly Thr Lys Val Glu Lys Arg Thr Val Ala Ala Pro Ser Val
625 630 635 640
Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr Ala Ser
645 650 655
Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys Val Gln
660 665 670
Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu Ser Val
675 680 685
Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu
690 695 700
Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala Cys Glu
705 710 715 720
Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe Asn Arg
725 730 735
Gly Glu
<210> 2
<211> 768
<212> PRT
<213> Artificial Sequence
<220>
<223> Amino Acid Sequence of HIV-1 Env-PG9 Ig
<400> 2
Met Asp Trp Thr Trp Arg Ile Leu Phe Leu Val Ala Ala Ala Thr Gly
1 5 10 15
Thr His Ala Glu Phe Gly Leu Ser Trp Val Phe Leu Val Ala Phe Leu
20 25 30
Arg Gly Val Gln Cys Gln Arg Leu Val Glu Ser Gly Gly Gly Val Val
35 40 45
Gln Pro Gly Ser Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asp
50 55 60
Phe Ser Arg Gln Gly Met His Trp Val Arg Gln Ala Pro Gly Gln Gly
65 70 75 80
Leu Glu Trp Val Ala Phe Ile Lys Tyr Asp Gly Ser Glu Lys Tyr His
85 90 95
Ala Asp Ser Val Trp Gly Arg Leu Ser Ile Ser Arg Asp Asn Ser Lys
100 105 110
Asp Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Val Glu Asp Thr Ala
115 120 125
Thr Tyr Phe Cys Val Arg Glu Ala Gly Gly Pro Asp Tyr Arg Asn Gly
130 135 140
Tyr Asn Tyr Tyr Asp Phe Tyr Asp Gly Tyr Tyr Asn Tyr His Tyr Met
145 150 155 160
Asp Val Trp Gly Lys Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr
165 170 175
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
180 185 190
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
195 200 205
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
210 215 220
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
225 230 235 240
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
245 250 255
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu
260 265 270
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
275 280 285
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
290 295 300
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
305 310 315 320
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
325 330 335
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
340 345 350
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
355 360 365
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
370 375 380
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
385 390 395 400
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys
405 410 415
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
420 425 430
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
435 440 445
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
450 455 460
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
465 470 475 480
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
485 490 495
Leu Ser Leu Ser Pro Gly Lys Arg Gly Arg Lys Arg Arg Ser Gly Ser
500 505 510
Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val Glu Glu
515 520 525
Asn Pro Gly Pro Met Ala Trp Thr Pro Leu Phe Leu Phe Leu Leu Thr
530 535 540
Cys Cys Pro Gly Gly Ser Asn Ser Gln Ser Ala Leu Thr Gln Pro Ala
545 550 555 560
Ser Val Ser Gly Ser Pro Gly Gln Ser Ile Thr Ile Ser Cys Asn Gly
565 570 575
Thr Ser Asn Asp Val Gly Gly Tyr Glu Ser Val Ser Trp Tyr Gln Gln
580 585 590
His Pro Gly Lys Ala Pro Lys Val Val Ile Tyr Asp Val Ser Lys Arg
595 600 605
Pro Ser Gly Val Ser Asn Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr
610 615 620
Ala Ser Leu Thr Ile Ser Gly Leu Gln Ala Glu Asp Glu Gly Asp Tyr
625 630 635 640
Tyr Cys Lys Ser Leu Thr Ser Thr Arg Arg Arg Val Phe Gly Thr Gly
645 650 655
Thr Lys Leu Thr Val Leu Gly Gln Pro Lys Ala Ala Pro Ser Val Thr
660 665 670
Leu Phe Pro Pro Ser Ser Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu
675 680 685
Val Cys Leu Ile Ser Asp Phe Tyr Pro Gly Ala Val Thr Val Ala Trp
690 695 700
Lys Ala Asp Ser Ser Pro Val Lys Ala Gly Val Glu Thr Thr Thr Pro
705 710 715 720
Ser Lys Gln Ser Asn Asn Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu
725 730 735
Thr Pro Glu Gln Trp Lys Ser His Lys Ser Tyr Ser Cys Gln Val Thr
740 745 750
His Glu Gly Ser Thr Val Glu Lys Thr Val Ala Pro Thr Glu Cys Ser
755 760 765
<210> 3
<211> 792
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleic Acid Sequence Encoding the Heavy Chain (VH-CH1) of HIV-1
Env Fab
<400> 3
aagcttgccg ccaccatgga gactgataca ctgctgctgt gggtgctgct gctgtgggtg 60
ccagggtcaa ccggagatgg ggctcaggtc cagctggtcc agagcggcgg acagatgaag 120
aaacccggcg agagcatgag gatctcctgc agagcatctg gatacgagtt catcgactgt 180
accctgaact ggattaggct ggctcctgga aagagaccag agtggatggg gtggctgaaa 240
ccacgagggg gagcagtgaa ttacgcccgg cccctgcagg gacgagtgac catgaccagg 300
gacgtgtaca gcgataccgc cttcctggag ctgcggtccc tgacagtgga cgatactgct 360
gtctacttct gcacacgcgg aaagaactgt gactataatt gggattttga acactggggc 420
cggggaacac ccgtgatcgt cagctccccc agtactaagg gaccttcagt gtttccactg 480
gccccctcta gtaaatccac ctctggaggg acagccgctc tgggatgcct ggtgaaagat 540
tatttccccg aacctgtgac cgtcagttgg aactcagggg ctctgacttc tggcgtgcac 600
acctttcctg cagtcctgca gtcaagcggg ctgtacagtc tgtcctctgt ggtcactgtg 660
cctagttcaa gcctgggcac tcagacctat atttgtaacg tgaatcataa gccatccaat 720
acaaaagtgg acaaaaaagc cgaacccaaa tcctgttacc cttatgatgt gcccgactac 780
gcctgactcg ag 792
<210> 4
<211> 756
<212> DNA
<213> Artificial Sequence
<220>
<223> Light Chain (VL-CL) of HIV-1 Env Fab
<400> 4
aagcttgccg ccaccatgga aaccgataca ctgctgctgt gggtgctgct gctgtgggtg 60
ccaggaagta ccggggatgg ggctcaggtc cagattgtgc tgactcagtc ccctgggacc 120
ctgtctctga gtccaggcga gacagctatc atttcatgcc gaactagcca gtacggcagc 180
ctggcttggt atcagcagcg accaggacag gcaccacgac tggtcatcta ctcaggcagc 240
acaagggccg ctggcatccc cgacaggttc tccggcagca ggtgggggcc tgattacaac 300
ctgactatct ctaatctgga gagtggggac tttggcgtgt actattgcca gcagtatgag 360
ttcttcggcc agggaactaa ggtgcaggtg gacatcaaaa gaaccgtggc agccccatcc 420
gtcttcattt ttcccccttc tgatgagcag ctgaagtcag gcaccgccag cgtggtctgt 480
ctgctgaaca atttctaccc ccgggaagcc aaggtgcagt ggaaagtgga caacgctctg 540
cagagtggaa attcacagga gagcgtgacc gaacaggact ccaaggattc tacatatagt 600
ctgagcagca ccctgaccct gagtaaagca gattacgaga agcacaaagt gtatgcctgt 660
gaagtcacac atcagggcct gaggagcccc gtgactaaaa gtttcaaccg aggagagtgc 720
tacccttatg atgtgcccga ctacgcctaa ctcgag 756
<210> 5
<211> 731
<212> PRT
<213> Artificial Sequence
<220>
<223> VRC01 IgG
<400> 5
Met Asp Trp Thr Trp Ile Leu Phe Leu Val Ala Ala Ala Thr Arg Val
1 5 10 15
His Ser Gln Val Gln Leu Val Gln Ser Gly Gly Gln Met Lys Lys Pro
20 25 30
Gly Glu Ser Met Arg Ile Ser Cys Arg Ala Ser Gly Tyr Glu Phe Ile
35 40 45
Asp Cys Thr Leu Asn Trp Ile Arg Leu Ala Pro Gly Lys Arg Pro Glu
50 55 60
Trp Met Gly Trp Leu Lys Pro Arg Gly Gly Ala Val Asn Tyr Ala Arg
65 70 75 80
Pro Leu Gln Gly Arg Val Thr Met Thr Arg Asp Val Tyr Ser Asp Thr
85 90 95
Ala Phe Leu Glu Leu Arg Ser Leu Thr Val Asp Asp Thr Ala Val Tyr
100 105 110
Phe Cys Thr Arg Gly Lys Asn Cys Asp Tyr Asn Trp Asp Phe Glu His
115 120 125
Trp Gly Arg Gly Thr Pro Val Ile Val Ser Ser Pro Ser Thr Lys Gly
130 135 140
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
145 150 155 160
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
165 170 175
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
180 185 190
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
195 200 205
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
210 215 220
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Ala Glu Pro Lys
225 230 235 240
Ser Cys Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys Arg Gly Arg Lys Arg Arg
465 470 475 480
Ser Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp
485 490 495
Val Glu Glu Asn Pro Gly Pro Met Asp Trp Thr Trp Ile Leu Phe Leu
500 505 510
Val Ala Ala Ala Thr Arg Val His Ser Glu Ile Val Leu Thr Gln Ser
515 520 525
Pro Gly Thr Leu Ser Leu Ser Pro Gly Glu Thr Ala Ile Ile Ser Cys
530 535 540
Arg Thr Ser Gln Tyr Gly Ser Leu Ala Trp Tyr Gln Gln Arg Pro Gly
545 550 555 560
Gln Ala Pro Arg Leu Val Ile Tyr Ser Gly Ser Thr Arg Ala Ala Gly
565 570 575
Ile Pro Asp Arg Phe Ser Gly Ser Arg Trp Gly Pro Asp Tyr Asn Leu
580 585 590
Thr Ile Ser Asn Leu Glu Ser Gly Asp Phe Gly Val Tyr Tyr Cys Gln
595 600 605
Gln Tyr Glu Phe Phe Gly Gln Gly Thr Lys Val Gln Val Asp Ile Lys
610 615 620
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
625 630 635 640
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
645 650 655
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
660 665 670
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
675 680 685
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
690 695 700
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Arg Ser
705 710 715 720
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
725 730
<210> 6
<211> 819
<212> DNA
<213> Artificial Sequence
<220>
<223> Optimized Nucleic Acid Sequence Encoding IgG Heavy Chain
<400> 6
ggatccgcca ccatggaaac cgacactctg ctgctgtggg tgctgctgct gtgggtgccc 60
ggctcaacag gcgacggcgc tcaggtccag ctggtccagt ctggagctgt gatcaagacc 120
cctggcagct ccgtcaaaat ttcttgcaga gcaagtggct acaacttccg ggactatagc 180
atccactggg tgcggctgat tcctgataag ggatttgagt ggatcggctg gatcaagcca 240
ctgtggggcg ctgtgtccta cgcaaggcag ctgcaggggc gcgtctccat gacacgacag 300
ctgtctcagg acccagacga tcccgattgg ggggtggcct acatggagtt cagtggactg 360
actcccgcag acaccgccga atatttttgc gtgcggagag gctcctgcga ctactgtggg 420
gatttcccat ggcagtattg gtgtcaggga actgtggtcg tggtctctag tgcatcaacc 480
aagggcccca gcgtgtttcc tctggcccca tcaagcaaaa gtacatcagg aggaactgca 540
gctctgggat gtctggtgaa ggattacttc cccgagcctg tgaccgtcag ctggaactcc 600
ggagcactga cctccggagt gcacacattt cccgctgtcc tgcagtcctc tgggctgtac 660
tctctgagtt cagtggtcac agtgcctagc tcctctctgg gcacccagac atatatctgc 720
aacgtcaatc ataagccaag taatactaaa gtggacaaga aagtcgaacc caaatcatgt 780
tacccctatg acgtgcctga ttatgcttga taactcgag 819
<210> 7
<211> 753
<212> DNA
<213> Artificial Sequence
<220>
<223> Optimized Nucleic Acid Sequence Encoding IgG Light Chain
<400> 7
ggatccgcca ccatggagac tgatacactg ctgctgtggg tgctgctgct gtgggtgcct 60
ggctcaaccg gcgacggggc tcaggtccag attgtgctga cccagagccc tggcatcctg 120
tcactgagcc caggagagac cgcaacactg ttctgcaagg cctcccaggg cgggaacgct 180
atgacatggt accagaaacg gagaggacag gtgccccgac tgctgatcta tgacacttca 240
aggcgagcaa gcggagtgcc tgatcgattt gtcggcagcg gctctgggac agacttcttt 300
ctgactatta ataagctgga cagagaggat ttcgctgtgt actattgcca gcagtttgaa 360
ttctttggac tgggcagcga gctggaagtg cacaggaccg tcgccgctcc aagtgtgttc 420
atttttcccc ctagcgatga gcagctgaaa tccgggacag cctctgtggt ctgtctgctg 480
aacaatttct acccccgcga agcaaaggtg cagtggaaag tcgacaacgc cctgcagagt 540
ggcaattcac aggagagcgt gaccgaacag gactccaagg attctacata tagtctgagc 600
tccactctga ccctgtctaa agctgattac gagaagcaca aagtgtatgc atgcgaagtc 660
actcatcagg gcctgtctag tcctgtgacc aagagcttta accgagggga gtgttaccca 720
tatgacgtcc ccgattacgc ctgataactc gag 753
<210> 8
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> IgE1 Signal Peptide of VRC-1 IgG
<400> 8
Met Asp Trp Thr Trp Ile Leu Phe Leu Val Ala Ala Ala Thr Arg Val
1 5 10 15
His Ser
<210> 9
<211> 126
<212> PRT
<213> Artificial Sequence
<220>
<223> Variable Heavy Region of VRC01 IgG
<400> 9
Gln Val Gln Leu Val Gln Ser Gly Gly Gln Met Lys Lys Pro Gly Glu
1 5 10 15
Ser Met Arg Ile Ser Cys Arg Ala Ser Gly Tyr Glu Phe Ile Asp Cys
20 25 30
Thr Leu Asn Trp Ile Arg Leu Ala Pro Gly Lys Arg Pro Glu Trp Met
35 40 45
Gly Trp Leu Lys Pro Arg Gly Gly Ala Val Asn Tyr Ala Arg Pro Leu
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Val Tyr Ser Asp Thr Ala Phe
65 70 75 80
Leu Glu Leu Arg Ser Leu Thr Val Asp Asp Thr Ala Val Tyr Phe Cys
85 90 95
Thr Arg Gly Lys Asn Cys Asp Tyr Asn Trp Asp Phe Glu His Trp Gly
100 105 110
Arg Gly Thr Pro Val Ile Val Ser Ser Pro Ser Thr Lys Gly
115 120 125
<210> 10
<211> 98
<212> PRT
<213> Artificial Sequence
<220>
<223> Constant Heavy region 1 (CH1) of VRC01 IgG
<400> 10
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
1 5 10 15
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
20 25 30
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
35 40 45
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
50 55 60
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
65 70 75 80
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Ala Glu Pro Lys
85 90 95
Ser Cys
<210> 11
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Hinge Region of VRC01 IgG
<400> 11
Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro
1 5 10 15
<210> 12
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<223> Constant Heavy Region 2 (CH2) of VRC01 IgG
<400> 12
Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
1 5 10 15
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
20 25 30
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
35 40 45
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
50 55 60
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
65 70 75 80
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
85 90 95
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys
100 105 110
<210> 13
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Constant Heavy Region 3 (CH3) of VRC01 IgG
<400> 13
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
1 5 10 15
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
20 25 30
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
35 40 45
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
50 55 60
Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
65 70 75 80
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
85 90 95
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
100 105
<210> 14
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Furin Cleavage Site of VRC01 IgG
<400> 14
Arg Gly Arg Lys Arg Arg Ser
1 5
<210> 15
<211> 22
<212> PRT
<213> Artificial Sequence
<220>
<223> GSG Linker and P2A Peptide of VRC01 IgG
<400> 15
Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val
1 5 10 15
Glu Glu Asn Pro Gly Pro
20
<210> 16
<211> 104
<212> PRT
<213> Artificial Sequence
<220>
<223> Variable Light Region (VL) of VRC01 IgG
<400> 16
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Thr Ala Ile Ile Ser Cys Arg Thr Ser Gln Tyr Gly Ser Leu Ala
20 25 30
Trp Tyr Gln Gln Arg Pro Gly Gln Ala Pro Arg Leu Val Ile Tyr Ser
35 40 45
Gly Ser Thr Arg Ala Ala Gly Ile Pro Asp Arg Phe Ser Gly Ser Arg
50 55 60
Trp Gly Pro Asp Tyr Asn Leu Thr Ile Ser Asn Leu Glu Ser Gly Asp
65 70 75 80
Phe Gly Val Tyr Tyr Cys Gln Gln Tyr Glu Phe Phe Gly Gln Gly Thr
85 90 95
Lys Val Gln Val Asp Ile Lys Arg
100
<210> 17
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> Constant Light Region (CL, kappa) of VRC01 IgG
<400> 17
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
1 5 10 15
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
20 25 30
Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
35 40 45
Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr
50 55 60
Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys
65 70 75 80
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Arg Ser Pro
85 90 95
Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
100 105
<210> 18
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> Human IgG Heavy Chain Signal Peptide of HIV-1 Env-PG9 Ig
<400> 18
Met Asp Trp Thr Trp Arg Ile Leu Phe Leu Val Ala Ala Ala Thr Gly
1 5 10 15
Thr His Ala
<210> 19
<211> 154
<212> PRT
<213> Artificial Sequence
<220>
<223> Variable Heavy Region of HIV-1 Env-PG9 Ig
<400> 19
Glu Phe Gly Leu Ser Trp Val Phe Leu Val Ala Phe Leu Arg Gly Val
1 5 10 15
Gln Cys Gln Arg Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly
20 25 30
Ser Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Asp Phe Ser Arg
35 40 45
Gln Gly Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp
50 55 60
Val Ala Phe Ile Lys Tyr Asp Gly Ser Glu Lys Tyr His Ala Asp Ser
65 70 75 80
Val Trp Gly Arg Leu Ser Ile Ser Arg Asp Asn Ser Lys Asp Thr Leu
85 90 95
Tyr Leu Gln Met Asn Ser Leu Arg Val Glu Asp Thr Ala Thr Tyr Phe
100 105 110
Cys Val Arg Glu Ala Gly Gly Pro Asp Tyr Arg Asn Gly Tyr Asn Tyr
115 120 125
Tyr Asp Phe Tyr Asp Gly Tyr Tyr Asn Tyr His Tyr Met Asp Val Trp
130 135 140
Gly Lys Gly Thr Thr Val Thr Val Ser Ser
145 150
<210> 20
<211> 98
<212> PRT
<213> Artificial Sequence
<220>
<223> Constant Heavy region 1 (CH1) of HIV-1 Env-PG9 Ig
<400> 20
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Arg Val
<210> 21
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Hinge Region of HIV-1 Env-PG9 Ig
<400> 21
Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro
1 5 10 15
<210> 22
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<223> Constant Heavy Region 2 (CH2) of HIV-1 Env-PG9 Ig
<400> 22
Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
1 5 10 15
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
20 25 30
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
35 40 45
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
50 55 60
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
65 70 75 80
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
85 90 95
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys
100 105 110
<210> 23
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Constant Heavy Region 3 (CH3) of HIV-1 Env-PG9 Ig
<400> 23
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
1 5 10 15
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
20 25 30
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
35 40 45
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
50 55 60
Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
65 70 75 80
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
85 90 95
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
100 105
<210> 24
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Furin Cleavage Site of HIV-1 Env-PG9 Ig
<400> 24
Arg Gly Arg Lys Arg Arg Ser
1 5
<210> 25
<211> 22
<212> PRT
<213> Artificial Sequence
<220>
<223> GSG Linker and P2A Peptide of HIV-1 Env-PG9 Ig
<400> 25
Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val
1 5 10 15
Glu Glu Asn Pro Gly Pro
20
<210> 26
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Human Lamba Light Chain Signal Peptide of HIV-1 Env-PG9 Ig
<400> 26
Met Ala Trp Thr Pro Leu Phe Leu Phe Leu Leu Thr Cys Cys Pro Gly
1 5 10 15
Gly Ser Asn Ser
20
<210> 27
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<223> Variable Light Region (VL) of HIV-1 Env-PG9 Ig
<400> 27
Gln Ser Ala Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro Gly Gln
1 5 10 15
Ser Ile Thr Ile Ser Cys Asn Gly Thr Ser Asn Asp Val Gly Gly Tyr
20 25 30
Glu Ser Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro Lys Val
35 40 45
Val Ile Tyr Asp Val Ser Lys Arg Pro Ser Gly Val Ser Asn Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Gly Asp Tyr Tyr Cys Lys Ser Leu Thr Ser Thr
85 90 95
Arg Arg Arg Val Phe Gly Thr Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 28
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> Constant Light Region (CL, lamba) of HIV-1 Env-PG9 Ig
<400> 28
Gly Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser
1 5 10 15
Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp
20 25 30
Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro
35 40 45
Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn
50 55 60
Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys
65 70 75 80
Ser His Lys Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val
85 90 95
Glu Lys Thr Val Ala Pro Thr Glu Cys Ser
100 105
<210> 29
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> Human IgG Heavy Chain Signal Peptide of HIV-1 Env-4E10 Ig
<400> 29
Met Asp Trp Thr Trp Arg Ile Leu Phe Leu Val Ala Ala Ala Thr Gly
1 5 10 15
Thr His Ala
<210> 30
<211> 127
<212> PRT
<213> Artificial Sequence
<220>
<223> Variable Heavy Region of HIV-1 Env-4E10 Ig
<400> 30
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Arg Pro Gly Ser
1 5 10 15
Ser Val Thr Val Ser Cys Lys Ala Ser Gly Gly Ser Phe Ser Thr Tyr
20 25 30
Ala Leu Ser Trp Val Arg Gln Ala Pro Gly Arg Gly Leu Glu Trp Met
35 40 45
Gly Gly Val Ile Pro Leu Leu Thr Ile Thr Asn Tyr Ala Pro Arg Phe
50 55 60
Gln Gly Arg Ile Thr Ile Thr Ala Asp Arg Ser Thr Ser Thr Ala Tyr
65 70 75 80
Leu Glu Leu Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Gly Thr Thr Gly Trp Gly Trp Leu Gly Lys Pro Ile Gly
100 105 110
Ala Phe Ala His Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 31
<211> 98
<212> PRT
<213> Artificial Sequence
<220>
<223> Constant Heavy region 1 (CH1) of HIV-1 Env-4E10 Ig
<400> 31
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Lys Val
<210> 32
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Hinge Region of HIV-1 Env-4E10 Ig
<400> 32
Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro
1 5 10 15
<210> 33
<211> 110
<212> PRT
<213> Artificial Sequence
<220>
<223> Constant Heavy Region 2 (CH2) of HIV-1 Env-4E10 Ig
<400> 33
Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
1 5 10 15
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
20 25 30
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
35 40 45
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
50 55 60
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
65 70 75 80
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
85 90 95
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys
100 105 110
<210> 34
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Constant Heavy Region 3 (CH3) of HIV-1 Env-4E10 Ig
<400> 34
Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp
1 5 10 15
Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe
20 25 30
Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu
35 40 45
Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe
50 55 60
Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly
65 70 75 80
Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr
85 90 95
Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
100 105
<210> 35
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Furin Cleavage Site of HIV-1 Env-4E10 Ig
<400> 35
Arg Gly Arg Lys Arg Arg Ser
1 5
<210> 36
<211> 22
<212> PRT
<213> Artificial Sequence
<220>
<223> GSG Linker and P2A Peptide of HIV-1 Env-4E10 Ig
<400> 36
Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val
1 5 10 15
Glu Glu Asn Pro Gly Pro
20
<210> 37
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Human Kappa Light Chain Signal Peptide of HIV-1 Env-4E10 Ig
<400> 37
Met Val Leu Gln Thr Gln Val Phe Ile Ser Leu Leu Leu Trp Ile Ser
1 5 10 15
Gly Ala Tyr Gly
20
<210> 38
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> Variable Light Region (VL) of HIV-1 Env-4E10 Ig
<400> 38
Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Gln Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Gly Asn Asn
20 25 30
Lys Leu Ala Trp Tyr Gln Gln Arg Pro Gly Gln Ala Pro Arg Leu Leu
35 40 45
Ile Tyr Gly Ala Ser Ser Arg Pro Ser Gly Val Ala Asp Arg Phe Ser
50 55 60
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg Leu Glu
65 70 75 80
Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Tyr Gly Gln Ser Leu
85 90 95
Ser Thr Phe Gly Gln Gly Thr Lys Val Glu
100 105
<210> 39
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Constant Light Region (CL, kappa) of HIV-1 Env-4E10 Ig
<400> 39
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
1 5 10 15
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
20 25 30
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
35 40 45
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
50 55 60
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
65 70 75 80
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
85 90 95
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu
100 105
<210> 40
<211> 744
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleic Acid Sequence Encoding the VH-CH1 of anti-Her-2 Fab
<400> 40
ggatccgcca ccatggactg gacatggatt ctgtttctgg tcgccgccgc tacaagagtg 60
cattccgaag tgcagctggt cgagagtgga gggggactgg tgcagcccgg cggatctctg 120
cgactgagtt gcgccgcttc aggcttcacc tttacagact acaccatgga ttgggtgaga 180
caggcacctg gcaagggact ggagtgggtg gctgatgtca acccaaatag tgggggctca 240
atctacaacc agaggttcaa gggcaggttc accctgagcg tggacaggtc caaaaacact 300
ctgtatctgc agatgaattc tctgcgggct gaagataccg cagtctacta ttgcgcccgc 360
aatctgggcc caagcttcta ctttgactat tgggggcagg gcacactggt gactgtcagc 420
tccgcttcta caaagggacc aagcgtgttc ccactggcac cctctagtaa atccacctct 480
ggagggacag cagccctggg ctgtctggtg aaagactatt tccccgagcc tgtgactgtc 540
agctggaact ccggagcact gactagcgga gtgcacacct ttccagccgt cctgcagtca 600
agcggcctgt actccctgtc ctctgtggtc acagtgccta gttcaagcct gggaactcag 660
acctatattt gtaatgtgaa ccataaacca agcaatacaa aggtggacaa gaaggtggaa 720
ccaaaatcct gctgataact cgag 744
<210> 41
<211> 240
<212> PRT
<213> Artificial Sequence
<220>
<223> Amino Acid Sequence of the VH-CH1 of anti-Her-2 Fab
<400> 41
Met Asp Trp Thr Trp Ile Leu Phe Leu Val Ala Ala Ala Thr Arg Val
1 5 10 15
His Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro
20 25 30
Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Thr
35 40 45
Asp Tyr Thr Met Asp Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu
50 55 60
Trp Val Ala Asp Val Asn Pro Asn Ser Gly Gly Ser Ile Tyr Asn Gln
65 70 75 80
Arg Phe Lys Gly Arg Phe Thr Leu Ser Val Asp Arg Ser Lys Asn Thr
85 90 95
Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr
100 105 110
Tyr Cys Ala Arg Asn Leu Gly Pro Ser Phe Tyr Phe Asp Tyr Trp Gly
115 120 125
Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
130 135 140
Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
145 150 155 160
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
165 170 175
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
180 185 190
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
195 200 205
Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His
210 215 220
Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
225 230 235 240
<210> 42
<211> 720
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleic Acid Sequence Encoding the VL-CL of anti-Her-2 Fab
<400> 42
ggatccgcca ccatggattg gacttggatt ctgttcctgg tcgccgccgc tacccgcgtg 60
cattccgata ttcagatgac tcagagcccc tcctcactgt cagccagcgt gggcgaccga 120
gtcaccatca catgcaaagc ttctcaggat gtgagtattg gggtcgcatg gtaccagcag 180
aagccaggca aagcacccaa gctgctgatc tattccgcct cttacaggta tacaggagtg 240
cccagcagat tcagtggctc aggaagcggg actgacttta ctctgaccat cagctccctg 300
cagcctgagg atttcgctac ctactattgc cagcagtact atatctaccc atataccttt 360
ggccagggaa caaaagtgga gatcaagcgg accgtggccg ctccctccgt cttcattttt 420
cccccttctg acgaacagct gaagagcgga acagcaagcg tggtctgtct gctgaacaat 480
ttctaccctc gcgaggccaa agtgcagtgg aaggtcgata acgctctgca gtccgggaat 540
tctcaggaga gtgtgactga acaggactca aaagatagca cctattccct gtctagtaca 600
ctgactctga gcaaggcaga ctacgaaaag cacaaagtgt atgcctgtga ggtcacccac 660
caggggctgt caagtcccgt caccaagtcc ttcaatagag gcgaatgctg ataactcgag 720
720
<210> 43
<211> 232
<212> PRT
<213> Artificial Sequence
<220>
<223> Amino Acid Sequence of the VL-CL of anti-Her-2 Fab
<400> 43
Met Asp Trp Thr Trp Ile Leu Phe Leu Val Ala Ala Ala Thr Arg Val
1 5 10 15
His Ser Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser
20 25 30
Val Gly Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Val Ser
35 40 45
Ile Gly Val Ala Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
50 55 60
Leu Ile Tyr Ser Ala Ser Tyr Arg Tyr Thr Gly Val Pro Ser Arg Phe
65 70 75 80
Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu
85 90 95
Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Gln Gln Tyr Tyr Ile Tyr
100 105 110
Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val
115 120 125
Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys
130 135 140
Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg
145 150 155 160
Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn
165 170 175
Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser
180 185 190
Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys
195 200 205
Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr
210 215 220
Lys Ser Phe Asn Arg Gly Glu Cys
225 230
<210> 44
<211> 2241
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleic Acid Sequence Encoding anti-DENV Human IgG
<400> 44
ggatccgcca ccatggactg gacttggagg attctgtttc tggtcgccgc cgctactggg 60
actcacgctc aggcacatct ggtcgaatct ggaggaggag tggtccagcc tggccgatcc 120
ctgcgactgt cttgcgcagc tagcgccttc aacttcagca caaacgcaat gcactgggtg 180
cgacaggcac caggcaaggg actggagtgg gtcgctgtga tctcatacga cggaagccat 240
aagtactatg cagattctgt gaaaggccgg ttcaccattt ccagggacaa ttctaagaac 300
accctgtatc tgcagatgaa tagcctgcgc gcagccgata ccgcagtgta ctattgcgca 360
actgtcggcg tgctgacctg gccagtgaac gccgaatact ttcaccattg gggacagggc 420
agtctggtct cagtgagctc cgcaagtact aagggaccat cagtgttccc actggcaccc 480
tctagtaaat ctactagtgg cgggaccgct gcactgggat gtctggtgaa ggactatttc 540
cccgagcctg tcaccgtgag ctggaattcc ggagccctga caagcggcgt ccacactttt 600
cccgctgtgc tgcagtcaag cggactgtac tccctgtcct ctgtggtcac tgtgcctagt 660
tcaagcctgg gcactcagac ctatatctgc aatgtgaacc acaagccctc taacaccaaa 720
gtcgacaaga aagtggaacc taagagctgt gataaaacac atacttgccc accttgtcca 780
gcaccagagc tgctgggagg accaagcgtg ttcctgtttc cacccaagcc taaagacaca 840
ctgatgatta gccggacacc tgaagtcact tgcgtggtcg tggacgtgtc ccacgaggac 900
cccgaagtca agtttaattg gtacgtggat ggcgtcgagg tgcataacgc caagaccaaa 960
ccccgggagg aacagtacaa tagcacatat agagtcgtgt ccgtcctgac tgtgctgcat 1020
caggattggc tgaatgggaa ggagtataag tgcaaagtgt ctaacaaggc tctgcctgca 1080
ccaatcgaga aaaccattag caaggctaaa ggccagccta gggaaccaca ggtgtacaca 1140
ctgcctccaa gtcgcgacga gctgaccaag aatcaggtct ccctgacatg tctggtgaaa 1200
ggcttctatc catcagatat cgccgtggag tgggaaagca acgggcagcc cgaaaacaat 1260
tacaagacca caccccctgt gctggactct gatggcagtt tctttctgta ttctaagctg 1320
accgtggaca aaagtagatg gcagcagggg aatgtctttt catgtagcgt gatgcacgag 1380
gccctgcaca accattacac acagaagtcc ctgtctctga gtcccggaaa gaggggccgc 1440
aaacggagat cagggagcgg agctactaat ttcagcctgc tgaaacaggc aggggatgtg 1500
gaggaaaacc ccggacctat ggcttggacc ccactgttcc tgtttctgct gacatgctgt 1560
cccgggggca gcaattctca gagtgtcctg acacagccac catcagtgag cggagcacca 1620
ggacagaggg tgaccatctc ctgcacaggc agcagcagca acattggcgc cgggtacgac 1680
gtgcattggt atcagcagct gcccggcacc gctcctaagc tgctgatctg tggcaacaat 1740
aaccgcccat ctggggtgcc cgatcgattc tccggctcta aaagtgggac ttcagccagc 1800
ctggctatta ccggcctgca ggccgaggac gaagctgatt actattgcca gagctacgac 1860
tcaagcctga ccggagtcgt gttcggagga ggaaccaagc tgacagtcct gggacagcct 1920
aaagccgctc caagcgtgac actgtttcct ccatcctctg aggaactgca ggcaaacaag 1980
gccaccctgg tgtgcctgat ttccgacttc taccccgggg cagtcactgt ggcttggaag 2040
gcagatagtt cacctgtcaa agccggagtg gagactacca caccatcaaa gcagagcaat 2100
aacaaatacg cagccagctc ctatctgtcc ctgacccctg agcagtggaa gtctcacaaa 2160
tcctattctt gccaggtcac tcacgaagga agcactgtgg agaaaactgt cgcaccaacc 2220
gaatgtagtt gataactcga g 2241
<210> 45
<211> 739
<212> PRT
<213> Artificial Sequence
<220>
<223> Amino Acid Sequence of anti-DENV Human IgG
<400> 45
Met Asp Trp Thr Trp Arg Ile Leu Phe Leu Val Ala Ala Ala Thr Gly
1 5 10 15
Thr His Ala Gln Ala His Leu Val Glu Ser Gly Gly Gly Val Val Gln
20 25 30
Pro Gly Arg Ser Leu Arg Leu Ser Cys Ala Ala Ser Ala Phe Asn Phe
35 40 45
Ser Thr Asn Ala Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu
50 55 60
Glu Trp Val Ala Val Ile Ser Tyr Asp Gly Ser His Lys Tyr Tyr Ala
65 70 75 80
Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn
85 90 95
Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Ala Asp Thr Ala Val
100 105 110
Tyr Tyr Cys Ala Thr Val Gly Val Leu Thr Trp Pro Val Asn Ala Glu
115 120 125
Tyr Phe His His Trp Gly Gln Gly Ser Leu Val Ser Val Ser Ser Ala
130 135 140
Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser
145 150 155 160
Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe
165 170 175
Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly
180 185 190
Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu
195 200 205
Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr
210 215 220
Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys
225 230 235 240
Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro
245 250 255
Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys
260 265 270
Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val
275 280 285
Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr
290 295 300
Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu
305 310 315 320
Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His
325 330 335
Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys
340 345 350
Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln
355 360 365
Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu
370 375 380
Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro
385 390 395 400
Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn
405 410 415
Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu
420 425 430
Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val
435 440 445
Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln
450 455 460
Lys Ser Leu Ser Leu Ser Pro Gly Lys Arg Gly Arg Lys Arg Arg Ser
465 470 475 480
Gly Ser Gly Ala Thr Asn Phe Ser Leu Leu Lys Gln Ala Gly Asp Val
485 490 495
Glu Glu Asn Pro Gly Pro Met Ala Trp Thr Pro Leu Phe Leu Phe Leu
500 505 510
Leu Thr Cys Cys Pro Gly Gly Ser Asn Ser Gln Ser Val Leu Thr Gln
515 520 525
Pro Pro Ser Val Ser Gly Ala Pro Gly Gln Arg Val Thr Ile Ser Cys
530 535 540
Thr Gly Ser Ser Ser Asn Ile Gly Ala Gly Tyr Asp Val His Trp Tyr
545 550 555 560
Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu Ile Cys Gly Asn Asn
565 570 575
Asn Arg Pro Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Lys Ser Gly
580 585 590
Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu Gln Ala Glu Asp Glu Ala
595 600 605
Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser Leu Thr Gly Val Val Phe
610 615 620
Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln Pro Lys Ala Ala Pro
625 630 635 640
Ser Val Thr Leu Phe Pro Pro Ser Ser Glu Glu Leu Gln Ala Asn Lys
645 650 655
Ala Thr Leu Val Cys Leu Ile Ser Asp Phe Tyr Pro Gly Ala Val Thr
660 665 670
Val Ala Trp Lys Ala Asp Ser Ser Pro Val Lys Ala Gly Val Glu Thr
675 680 685
Thr Thr Pro Ser Lys Gln Ser Asn Asn Lys Tyr Ala Ala Ser Ser Tyr
690 695 700
Leu Ser Leu Thr Pro Glu Gln Trp Lys Ser His Lys Ser Tyr Ser Cys
705 710 715 720
Gln Val Thr His Glu Gly Ser Thr Val Glu Lys Thr Val Ala Pro Thr
725 730 735
Glu Cys Ser
<210> 46
<211> 265
<212> PRT
<213> Artificial Sequence
<220>
<223> IgG Heavy Chain
<400> 46
Met Glu Thr Asp Thr Leu Leu Leu Trp Val Leu Leu Leu Trp Val Pro
1 5 10 15
Gly Ser Thr Gly Asp Gly Ala Gln Val Gln Leu Val Gln Ser Gly Ala
20 25 30
Val Ile Lys Thr Pro Gly Ser Ser Val Lys Ile Ser Cys Arg Ala Ser
35 40 45
Gly Tyr Asn Phe Arg Asp Tyr Ser Ile His Trp Val Arg Leu Ile Pro
50 55 60
Asp Lys Gly Phe Glu Trp Ile Gly Trp Ile Lys Pro Leu Trp Gly Ala
65 70 75 80
Val Ser Tyr Ala Arg Gln Leu Gln Gly Arg Val Ser Met Thr Arg Gln
85 90 95
Leu Ser Gln Asp Pro Asp Asp Pro Asp Trp Gly Val Ala Tyr Met Glu
100 105 110
Phe Ser Gly Leu Thr Pro Ala Asp Thr Ala Glu Tyr Phe Cys Val Arg
115 120 125
Arg Gly Ser Cys Asp Tyr Cys Gly Asp Phe Pro Trp Gln Tyr Trp Cys
130 135 140
Gln Gly Thr Val Val Val Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
145 150 155 160
Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
165 170 175
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
180 185 190
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
195 200 205
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
210 215 220
Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His
225 230 235 240
Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
245 250 255
Tyr Pro Tyr Asp Val Pro Asp Tyr Ala
260 265
<210> 47
<211> 243
<212> PRT
<213> Artificial Sequence
<220>
<223> IgG Light Chain
<400> 47
Met Glu Thr Asp Thr Leu Leu Leu Trp Val Leu Leu Leu Trp Val Pro
1 5 10 15
Gly Ser Thr Gly Asp Gly Ala Gln Val Gln Ile Val Leu Thr Gln Ser
20 25 30
Pro Gly Ile Leu Ser Leu Ser Pro Gly Glu Thr Ala Thr Leu Phe Cys
35 40 45
Lys Ala Ser Gln Gly Gly Asn Ala Met Thr Trp Tyr Gln Lys Arg Arg
50 55 60
Gly Gln Val Pro Arg Leu Leu Ile Tyr Asp Thr Ser Arg Arg Ala Ser
65 70 75 80
Gly Val Pro Asp Arg Phe Val Gly Ser Gly Ser Gly Thr Asp Phe Phe
85 90 95
Leu Thr Ile Asn Lys Leu Asp Arg Glu Asp Phe Ala Val Tyr Tyr Cys
100 105 110
Gln Gln Phe Glu Phe Phe Gly Leu Gly Ser Glu Leu Glu Val His Arg
115 120 125
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
130 135 140
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
145 150 155 160
Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
165 170 175
Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr
180 185 190
Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys
195 200 205
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro
210 215 220
Val Thr Lys Ser Phe Asn Arg Gly Glu Cys Tyr Pro Tyr Asp Val Pro
225 230 235 240
Asp Tyr Ala
<210> 48
<211> 256
<212> PRT
<213> Artificial Sequence
<220>
<223> Amino Acid Sequence of the Heavy Chain (VH-CH1) of HIV-1 Env Fab
<400> 48
Met Glu Thr Asp Thr Leu Leu Leu Trp Val Leu Leu Leu Trp Val Pro
1 5 10 15
Gly Ser Thr Gly Asp Gly Ala Gln Val Gln Leu Val Gln Ser Gly Gly
20 25 30
Gln Met Lys Lys Pro Gly Glu Ser Met Arg Ile Ser Cys Arg Ala Ser
35 40 45
Gly Tyr Glu Phe Ile Asp Cys Thr Leu Asn Trp Ile Arg Leu Ala Pro
50 55 60
Gly Lys Arg Pro Glu Trp Met Gly Trp Leu Lys Pro Arg Gly Gly Ala
65 70 75 80
Val Asn Tyr Ala Arg Pro Leu Gln Gly Arg Val Thr Met Thr Arg Asp
85 90 95
Val Tyr Ser Asp Thr Ala Phe Leu Glu Leu Arg Ser Leu Thr Val Asp
100 105 110
Asp Thr Ala Val Tyr Phe Cys Thr Arg Gly Lys Asn Cys Asp Tyr Asn
115 120 125
Trp Asp Phe Glu His Trp Gly Arg Gly Thr Pro Val Ile Val Ser Ser
130 135 140
Pro Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
145 150 155 160
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
165 170 175
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
180 185 190
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
195 200 205
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
210 215 220
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
225 230 235 240
Lys Ala Glu Pro Lys Ser Cys Tyr Pro Tyr Asp Val Pro Asp Tyr Ala
245 250 255
<210> 49
<211> 244
<212> PRT
<213> Artificial Sequence
<220>
<223> Amino Acid Sequence of the Light Chain (VL-CL) of HIV-1 Env Fab
<400> 49
Met Glu Thr Asp Thr Leu Leu Leu Trp Val Leu Leu Leu Trp Val Pro
1 5 10 15
Gly Ser Thr Gly Asp Gly Ala Gln Val Gln Ile Val Leu Thr Gln Ser
20 25 30
Pro Gly Thr Leu Ser Leu Ser Pro Gly Glu Thr Ala Ile Ile Ser Cys
35 40 45
Arg Thr Ser Gln Tyr Gly Ser Leu Ala Trp Tyr Gln Gln Arg Pro Gly
50 55 60
Gln Ala Pro Arg Leu Val Ile Tyr Ser Gly Ser Thr Arg Ala Ala Gly
65 70 75 80
Ile Pro Asp Arg Phe Ser Gly Ser Arg Trp Gly Pro Asp Tyr Asn Leu
85 90 95
Thr Ile Ser Asn Leu Glu Ser Gly Asp Phe Gly Val Tyr Tyr Cys Gln
100 105 110
Gln Tyr Glu Phe Phe Gly Gln Gly Thr Lys Val Gln Val Asp Ile Lys
115 120 125
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
130 135 140
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
145 150 155 160
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
165 170 175
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
180 185 190
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
195 200 205
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Arg Ser
210 215 220
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys Tyr Pro Tyr Asp Val
225 230 235 240
Pro Asp Tyr Ala
<210> 50
<211> 1536
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleic Acid Sequence Encoding HIV-1 PG9 Fab
<400> 50
ggatccgcca ccatggcaag acccctgtgc accctgctgc tgctgatggc aaccctggcc 60
ggagccctgg cacagagcgc cctgacccag cccgcaagcg tctccggctc accaggccag 120
agcatcacta ttagttgcaa cgggactagc aacgacgtgg gaggctatga gagtgtcagc 180
tggtaccagc agcatcccgg aaaagcacca aaagtggtca tctacgatgt cagtaaaagg 240
ccaagtgggg tctcaaatag gttctcaggg agtaaatctg ggaatacagc atctctgacc 300
atctccggac tgggcgcaga agatgaaggc gactactatt gcaaaagcct gacctcaacc 360
agacggcgag tctttgggac aggcaccaag ctgacagtcc tgacagtcgc tgccccctcc 420
gtcttcattt ttccaccttc agatgagcag ctgaaatctg gcactgcatc tgtggtctgc 480
ctgctgaaca acttctatcc acgagaggcc aaggtgcagt ggaaagtgga taacgcactg 540
cagtccggca atagtcagga aagcgtgact gagcaggatt ccaaggacag tacctatagc 600
ctgtccagta cactgaccct gtccaaggct gactacgaaa aacataaggt gtatgcatgt 660
gaagtgactc accagggact gaggtcacca gtcactaagt cttttaacag gggagagtgc 720
ggcgggggag gatctggagg cggcggctct ggagggggag gctcaggggg cggaggaagc 780
ggcggaggag ggtccggagg aggaggcagt cagagactgg tcgaaagcgg gggaggagtg 840
gtgcagcctg ggtcctcact gagactgtca tgcgctgcca gtggctttga tttttcacga 900
cagggaatgc attgggtcag gcaggcaccc ggacagggcc tggaatgggt cgccttcatt 960
aagtacgacg gaagcgagaa gtaccatgcc gactcagtgt ggggaaggct gagcatctca 1020
agggacaact caaaggacac cctgtacctg cagatgaata gcctgagagt ggaagatacc 1080
gctacttatt tctgcgtgcg agaggccgga gggccagatt accggaacgg gtacaattac 1140
tatgatttct acgacggcta ctacaattac cattatatgg atgtctgggg caaaggaact 1200
acagtcaccg tgagctccgc aagtactaag ggaccttccg tgtttcctct ggctcccagt 1260
tccaaaagta catccggagg aacagccgct ctgggatgtc tggtcaagga ctattttccc 1320
gagcccgtga ctgtctcctg gaacagcggg gctctgacaa gcggggtgca cacctttcct 1380
gccgtgctgc agtccagtgg gctgtacagt ctgtctagtg tcgtcactgt gccaagctca 1440
agtctgggga cccagacata catttgtaat gtgaaccata aaccctcaaa caccaaagtg 1500
gacaagaaag tggaacctaa aagctgataa ctcgag 1536
<210> 51
<211> 504
<212> PRT
<213> Artificial Sequence
<220>
<223> Amino Acid Sequence of HIV-1 PG9 Fab
<400> 51
Met Ala Arg Pro Leu Cys Thr Leu Leu Leu Leu Met Ala Thr Leu Ala
1 5 10 15
Gly Ala Leu Ala Gln Ser Ala Leu Thr Gln Pro Ala Ser Val Ser Gly
20 25 30
Ser Pro Gly Gln Ser Ile Thr Ile Ser Cys Asn Gly Thr Ser Asn Asp
35 40 45
Val Gly Gly Tyr Glu Ser Val Ser Trp Tyr Gln Gln His Pro Gly Lys
50 55 60
Ala Pro Lys Val Val Ile Tyr Asp Val Ser Lys Arg Pro Ser Gly Val
65 70 75 80
Ser Asn Arg Phe Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr
85 90 95
Ile Ser Gly Leu Gly Ala Glu Asp Glu Gly Asp Tyr Tyr Cys Lys Ser
100 105 110
Leu Thr Ser Thr Arg Arg Arg Val Phe Gly Thr Gly Thr Lys Leu Thr
115 120 125
Val Leu Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
130 135 140
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
145 150 155 160
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
165 170 175
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
180 185 190
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
195 200 205
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Arg
210 215 220
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys Gly Gly Gly Gly
225 230 235 240
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
245 250 255
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Arg Leu Val Glu Ser
260 265 270
Gly Gly Gly Val Val Gln Pro Gly Ser Ser Leu Arg Leu Ser Cys Ala
275 280 285
Ala Ser Gly Phe Asp Phe Ser Arg Gln Gly Met His Trp Val Arg Gln
290 295 300
Ala Pro Gly Gln Gly Leu Glu Trp Val Ala Phe Ile Lys Tyr Asp Gly
305 310 315 320
Ser Glu Lys Tyr His Ala Asp Ser Val Trp Gly Arg Leu Ser Ile Ser
325 330 335
Arg Asp Asn Ser Lys Asp Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg
340 345 350
Val Glu Asp Thr Ala Thr Tyr Phe Cys Val Arg Glu Ala Gly Gly Pro
355 360 365
Asp Tyr Arg Asn Gly Tyr Asn Tyr Tyr Asp Phe Tyr Asp Gly Tyr Tyr
370 375 380
Asn Tyr His Tyr Met Asp Val Trp Gly Lys Gly Thr Thr Val Thr Val
385 390 395 400
Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser
405 410 415
Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys
420 425 430
Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu
435 440 445
Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu
450 455 460
Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr
465 470 475 480
Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val
485 490 495
Asp Lys Lys Val Glu Pro Lys Ser
500
<210> 52
<211> 1503
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleic Acid Sequence Encoding HIV-1 4E10 Fab
<400> 52
ggatccgcca ccatggcaag acctctgtgc actctgctgc tgctgatggc tactctggcc 60
ggggctctgg ctgagattgt cctgacccag tcccctggca ctcagtcact gtcccccggc 120
gagcgcgcaa ctctgtcctg cagagcaagc cagtccgtcg ggaacaacaa gctggcatgg 180
taccagcagc gcccaggaca ggcacccagg ctgctgatct acggagcaag ctcccggcct 240
agcggagtcg ctgatagatt ctccggaagc ggctccggga ccgatttcac tctgaccatc 300
tccaggctgg aacctgagga ttttgccgtg tattactgtc agcagtacgg gcagagcctg 360
tcaactttcg gccagggaac taaagtcgaa aagagaaccg tggccgcacc aagcgtcttt 420
atttttcccc ctagcgatga acagctgaaa tccgggactg cttccgtggt ctgcctgctg 480
aataacttct atccaagaga ggcaaaggtg cagtggaaag tggacaacgc cctgcagagc 540
ggaaactcac aggaatctgt gacagagcag gactccaagg atagcacata cagtctgtcc 600
tcaactctga ccctgtccaa agctgactat gagaagcata aagtctacgc atgtgaggtg 660
acccaccagg gactgaggtc ccccgtcact aagtccttca atagaggcga gtgcgggggc 720
gggggcagtg gcggaggggg aagtgggggc ggagggagtg gcggcggcgg gagtggcggc 780
ggcggctcag ggggcggcgg ctcccaggtc cagctggtcc agagcggagc cgaggtcaag 840
agaccaggct cttcagtcac cgtgagctgc aaagccagcg gaggctcctt tagcacttac 900
gccctgtcat gggtgcggca ggccccaggc cgaggcctgg agtggatggg cggcgtgatc 960
cccctgctga ccattactaa ctatgcccct agatttggag gccggatcac catcacagct 1020
gacagatcca catccacagc ttacctggag ctgaacagtc tgaggcccga ggacactgca 1080
gtctactact gtgcacgaga aggcaccact ggatgggggt ggctggggaa gcccatcggg 1140
gcttttgcac attggggcgg agggacactg gtgactgtga gctctgccag cactaaaggg 1200
cccagtgtct tccctctggc cccaagttcc aagagtacat cagggggcac cgccgcactg 1260
gggtgtctgg tgaaggatta cttcccagag cccgtgacag tcagttggaa cagcggcgct 1320
ctgaccagtg gggtgcacac tttcccagcc gtgctgcaga gttcagggct gtactccctg 1380
tcctcagtgg tgactgtgcc ctcaagcagt ctggggactc agacttacat ttgtaatgtg 1440
aaccataaac cctcaaatac taaagtggac aaaaaagtgg aaccaaagag ctgataactc 1500
gag 1503
<210> 53
<211> 493
<212> PRT
<213> Artificial Sequence
<220>
<223> Amino Acid Sequence of HIV-1 4E10 Fab
<400> 53
Met Ala Arg Pro Leu Cys Thr Leu Leu Leu Leu Met Ala Thr Leu Ala
1 5 10 15
Gly Ala Leu Ala Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Gln Ser
20 25 30
Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser
35 40 45
Val Gly Asn Asn Lys Leu Ala Trp Tyr Gln Gln Arg Pro Gly Gln Ala
50 55 60
Pro Arg Leu Leu Ile Tyr Gly Ala Ser Ser Arg Pro Ser Gly Val Ala
65 70 75 80
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile
85 90 95
Ser Arg Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Tyr
100 105 110
Gly Gln Ser Leu Ser Thr Phe Gly Gln Gly Thr Lys Val Glu Lys Arg
115 120 125
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
130 135 140
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
145 150 155 160
Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
165 170 175
Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr
180 185 190
Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys
195 200 205
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Arg Ser Pro
210 215 220
Val Thr Lys Ser Phe Asn Arg Gly Glu Cys Gly Gly Gly Gly Ser Gly
225 230 235 240
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
245 250 255
Gly Gly Ser Gly Gly Gly Gly Ser Gln Val Gln Leu Val Gln Ser Gly
260 265 270
Ala Glu Val Lys Arg Pro Gly Ser Ser Val Thr Val Ser Cys Lys Ala
275 280 285
Ser Gly Gly Ser Phe Ser Thr Tyr Ala Leu Ser Trp Val Arg Gln Ala
290 295 300
Pro Gly Arg Gly Leu Glu Trp Met Gly Gly Val Ile Pro Leu Leu Thr
305 310 315 320
Ile Thr Asn Tyr Ala Pro Arg Phe Gly Gly Arg Ile Thr Ile Thr Ala
325 330 335
Asp Arg Ser Thr Ser Thr Ala Tyr Leu Glu Leu Asn Ser Leu Arg Pro
340 345 350
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Glu Gly Thr Thr Gly Trp
355 360 365
Gly Trp Leu Gly Lys Pro Ile Gly Ala Phe Ala His Trp Gly Gly Gly
370 375 380
Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
385 390 395 400
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
405 410 415
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
420 425 430
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
435 440 445
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
450 455 460
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
465 470 475 480
Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser
485 490
<210> 54
<211> 1446
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleic Acid Sequence Encoding the HIV-1 VRC01 IgG1 Heavy Chain
(VH/CH1/Hinge/CH2/CH3)
<400> 54
ggatccgcca ccatggattg gacatggatt ctgttcctgg tcgccgccgc aactagagtg 60
cattcacagg tgcagctggt gcagtcaggc gggcagatga agaaacccgg cgagagtatg 120
cgaatctcat gccgggctag cgggtacgaa ttcatcgact gtaccctgaa ctggattaga 180
ctggcacctg ggaagaggcc agagtggatg ggatggctga aacctagagg cggggcagtg 240
aattacgcca gaccactgca gggcagggtc actatgaccc gcgacgtgta ttctgatacc 300
gcattcctgg agctgcgaag tctgacagtc gacgatactg ccgtgtactt ctgcacacgg 360
ggcaagaact gtgactataa ttgggatttt gaacactggg gcagggggac acctgtcatt 420
gtgagctccc caagtactaa gggaccctca gtgtttcccc tggccccttc tagtaaaagt 480
acctcaggag gcacagccgc tctgggatgc ctggtgaagg attacttccc tgagccagtc 540
accgtgagtt ggaactcagg cgccctgaca agcggggtcc atacttttcc agctgtgctg 600
cagtcaagcg ggctgtactc cctgtcctct gtggtcacag tgcccagttc aagcctggga 660
acacagactt atatctgtaa cgtcaatcac aagcctagca atactaaagt ggacaagaaa 720
gccgagccta agagctgcga accaaagtcc tgtgataaaa cccatacatg ccctccctgt 780
ccagctcctg aactgctggg cggcccatcc gtgttcctgt ttccacccaa gcccaaagac 840
accctgatga ttagcaggac tcctgaggtc acctgcgtgg tcgtggacgt gtcccacgag 900
gaccccgaag tcaagtttaa ctggtacgtg gatggcgtcg aagtgcataa tgccaagaca 960
aaaccccggg aggaacagta caactctacc tatagagtcg tgagtgtcct gacagtgctg 1020
caccaggact ggctgaacgg gaaggagtat aagtgcaaag tgtctaataa ggccctgcca 1080
gctcccatcg agaaaacaat ttccaaggca aaaggccagc caagggaacc ccaggtgtac 1140
actctgcctc catcccgcga cgagctgact aagaaccagg tctctctgac ctgtctggtg 1200
aaaggattct atccaagcga tatcgccgtg gagtgggaat ccaatggcca gcccgagaac 1260
aattacaaga ccacaccccc tgtgctggac agcgatggct ccttctttct gtattcaaag 1320
ctgaccgtgg ataaaagccg ctggcagcag gggaacgtct ttagctgctc cgtgatgcac 1380
gaagctctgc acaatcatta cacccagaag tctctgagtc tgtcacctgg caagtgataa 1440
ctcgag 1446
<210> 55
<211> 474
<212> PRT
<213> Artificial Sequence
<220>
<223> Amino Acid Sequence of the HIV-1 VRC01 IgG1 Heavy Chain
(VH/CH1/CH2/CH3)
<400> 55
Met Asp Trp Thr Trp Ile Leu Phe Leu Val Ala Ala Ala Thr Arg Val
1 5 10 15
His Ser Gln Val Gln Leu Val Gln Ser Gly Gly Gln Met Lys Lys Pro
20 25 30
Gly Glu Ser Met Arg Ile Ser Cys Arg Ala Ser Gly Tyr Glu Phe Ile
35 40 45
Asp Cys Thr Leu Asn Trp Ile Arg Leu Ala Pro Gly Lys Arg Pro Glu
50 55 60
Trp Met Gly Trp Leu Lys Pro Arg Gly Gly Ala Val Asn Tyr Ala Arg
65 70 75 80
Pro Leu Gln Gly Arg Val Thr Met Thr Arg Asp Val Tyr Ser Asp Thr
85 90 95
Ala Phe Leu Glu Leu Arg Ser Leu Thr Val Asp Asp Thr Ala Val Tyr
100 105 110
Phe Cys Thr Arg Gly Lys Asn Cys Asp Tyr Asn Trp Asp Phe Glu His
115 120 125
Trp Gly Arg Gly Thr Pro Val Ile Val Ser Ser Pro Ser Thr Lys Gly
130 135 140
Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly
145 150 155 160
Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val
165 170 175
Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe
180 185 190
Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val
195 200 205
Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val
210 215 220
Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Ala Glu Pro Lys
225 230 235 240
Ser Cys Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
465 470
<210> 56
<211> 708
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleic Acid Sequence Encoding the HIV-1 VRC01 IgG Light Chain
(VL/CL)
<400> 56
ggatccgcca ccatggattg gacttggatt ctgttcctgg tggcagccgc taccagagtc 60
cattccgaaa ttgtgctgac ccagtctccc ggaacactgt ctctgagtcc tggcgagaca 120
gccatcattt cctgtaggac ttctcagtac gggagtctgg catggtatca gcagcgacca 180
ggacaggctc ctcgactggt catctactca ggaagcactc gggcagccgg cattcccgac 240
cgattctccg ggtctcggtg gggacctgat tacaacctga ccatctcaaa tctggaaagc 300
ggagactttg gcgtgtacta ttgccagcag tatgagttct ttgggcaggg aaccaaggtc 360
caggtggaca tcaaacgcac agtcgctgca ccaagcgtgt tcatctttcc accctcagat 420
gaacagctga agtccggcac cgcctctgtg gtgtgcctgc tgaacaattt ctacccccgg 480
gaggcaaagg tccagtggaa agtggacaac gccctgcagt ctggcaatag tcaggagtca 540
gtgactgaac aggacagcaa ggattccacc tattctctgt cctctactct gaccctgagc 600
aaagctgatt acgagaagca caaagtgtat gcatgtgagg tcacccacca gggactgcgg 660
tcacccgtca ccaagagctt caatcgcgga gagtgttgat aactcgag 708
<210> 57
<211> 228
<212> PRT
<213> Artificial Sequence
<220>
<223> Amino Acid Sequence of the HIV-1 VRC01 IgG Light Chain (VL/CL)
<400> 57
Met Asp Trp Thr Trp Ile Leu Phe Leu Val Ala Ala Ala Thr Arg Val
1 5 10 15
His Ser Glu Ile Val Leu Thr Gln Ser Pro Gly Thr Leu Ser Leu Ser
20 25 30
Pro Gly Glu Thr Ala Ile Ile Ser Cys Arg Thr Ser Gln Tyr Gly Ser
35 40 45
Leu Ala Trp Tyr Gln Gln Arg Pro Gly Gln Ala Pro Arg Leu Val Ile
50 55 60
Tyr Ser Gly Ser Thr Arg Ala Ala Gly Ile Pro Asp Arg Phe Ser Gly
65 70 75 80
Ser Arg Trp Gly Pro Asp Tyr Asn Leu Thr Ile Ser Asn Leu Glu Ser
85 90 95
Gly Asp Phe Gly Val Tyr Tyr Cys Gln Gln Tyr Glu Phe Phe Gly Gln
100 105 110
Gly Thr Lys Val Gln Val Asp Ile Lys Arg Thr Val Ala Ala Pro Ser
115 120 125
Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr Ala
130 135 140
Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys Val
145 150 155 160
Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu Ser
165 170 175
Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser Thr
180 185 190
Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala Cys
195 200 205
Glu Val Thr His Gln Gly Leu Arg Ser Pro Val Thr Lys Ser Phe Asn
210 215 220
Arg Gly Glu Cys
225
<210> 58
<211> 744
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleic Acid Sequence Encoding the Heavy Chain (VH-CH1) of the
CHIKV-Env-Fab
<400> 58
ggatccgcca ccatggattg gacatggagg attctgtttc tggtcgccgc cgctactgga 60
actcacgctc aggtgcagct ggtgcagtca gggtccgaac tgaagaaacc aggggcatct 120
gtgaaggtca gttgcaaagc ctcaggctac accctgacac ggtatgccat gacttgggtg 180
cgccaggctc ctggacaggg actggagtgg atgggctgga tcaacactta caccggaaat 240
ccaacttatg tgcaggggtt caccggccga ttcgtgtttt ctctggacac ttccgtctct 300
accgcctttc tgcacattac aagtctgaag gcagaggaca ctgccgtgta cttctgcgct 360
agggaaggcg gagcaagagg ctttgattat tggggccagg gaaccctggt gacagtcagc 420
tccgccagca caaagggacc ctccgtgttc ccactggctc cctctagtaa aagtacatca 480
gggggcactg ccgctctggg atgtctggtc aaagattact tccccgaacc tgtgaccgtc 540
agctggaact ccggagctct gaccagcggg gtgcatacat ttcccgcagt cctgcagtca 600
agcggactgt actccctgtc ctctgtggtc acagtgccta gttcaagcct ggggacacag 660
acttatatct gtaatgtgaa ccataagcca agcaacacca aagtggacaa aaaagtggaa 720
cctaagagct gctgataact cgag 744
<210> 59
<211> 240
<212> PRT
<213> Artificial Sequence
<220>
<223> Amino Acid Sequence of the Heavy Chain (VH-CH1) of the
CHIKV-Env-Fab
<400> 59
Met Asp Trp Thr Trp Arg Ile Leu Phe Leu Val Ala Ala Ala Thr Gly
1 5 10 15
Thr His Ala Gln Val Gln Leu Val Gln Ser Gly Ser Glu Leu Lys Lys
20 25 30
Pro Gly Ala Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Leu
35 40 45
Thr Arg Tyr Ala Met Thr Trp Val Arg Gln Ala Pro Gly Gln Gly Leu
50 55 60
Glu Trp Met Gly Trp Ile Asn Thr Tyr Thr Gly Asn Pro Thr Tyr Val
65 70 75 80
Gln Gly Phe Thr Gly Arg Phe Val Phe Ser Leu Asp Thr Ser Val Ser
85 90 95
Thr Ala Phe Leu His Ile Thr Ser Leu Lys Ala Glu Asp Thr Ala Val
100 105 110
Tyr Phe Cys Ala Arg Glu Gly Gly Ala Arg Gly Phe Asp Tyr Trp Gly
115 120 125
Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser
130 135 140
Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala
145 150 155 160
Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val
165 170 175
Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala
180 185 190
Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val
195 200 205
Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His
210 215 220
Lys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys
225 230 235 240
<210> 60
<211> 738
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleic Acid Sequence Encoding the Light Chain (VL-CL) of the
CHIKV-Env-Fab
<400> 60
ggatccgcca ccatggcatg gaccccactg ttcctgttcc tgctgacttg ttgtcctggc 60
gggagcaatt cacagagcgt cctgacccag cccccttctg tgtccggagc accaggacag 120
cgagtcacaa tctcttgcac tggaagctcc tctaacattg gggccagcca cgacgtgcat 180
tggtaccagc agctgccagg gaccgctccc acactgctga tctatgtgaa ctctaatagg 240
cctagtggcg tcccagatag attttcaggg agcaagtccg gcacctctgc tagtctggca 300
attacaggac tgcaggctga ggacgaagca gattactatt gccagagtta cgactcaaac 360
ctgtcaggca gcgcagtgtt cggaggagga actaagctga ccgtcctggg acagcccaaa 420
gccgctcctt ctgtgaccct gtttccccct agttcagagg aactgcaggc caacaaggct 480
actctggtgt gtctgatctc cgacttctac cctggagcag tgaccgtcgc atggaaggcc 540
gatagctccc cagtgaaagc tggggtcgag accacaactc ccagcaagca gtccaacaac 600
aagtacgcag cctctagtta tctgtcactg acacctgaac agtggaagag ccacaaatcc 660
tattcttgcc aagtgactca tgagggcagt accgtggaaa agacagtcgc cccaactgag 720
tgttcctgat aactcgag 738
<210> 61
<211> 238
<212> PRT
<213> Artificial Sequence
<220>
<223> Amino Acid Sequence of the Light Chain (VL-CL) of the
CHIKV-Env-Fab
<400> 61
Met Ala Trp Thr Pro Leu Phe Leu Phe Leu Leu Thr Cys Cys Pro Gly
1 5 10 15
Gly Ser Asn Ser Gln Ser Val Leu Thr Gln Pro Pro Ser Val Ser Gly
20 25 30
Ala Pro Gly Gln Arg Val Thr Ile Ser Cys Thr Gly Ser Ser Ser Asn
35 40 45
Ile Gly Ala Ser His Asp Val His Trp Tyr Gln Gln Leu Pro Gly Thr
50 55 60
Ala Pro Thr Leu Leu Ile Tyr Val Asn Ser Asn Arg Pro Ser Gly Val
65 70 75 80
Pro Asp Arg Phe Ser Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala
85 90 95
Ile Thr Gly Leu Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser
100 105 110
Tyr Asp Ser Asn Leu Ser Gly Ser Ala Val Phe Gly Gly Gly Thr Lys
115 120 125
Leu Thr Val Leu Gly Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe
130 135 140
Pro Pro Ser Ser Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys
145 150 155 160
Leu Ile Ser Asp Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala
165 170 175
Asp Ser Ser Pro Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys
180 185 190
Gln Ser Asn Asn Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro
195 200 205
Glu Gln Trp Lys Ser His Lys Ser Tyr Ser Cys Gln Val Thr His Glu
210 215 220
Gly Ser Thr Val Glu Lys Thr Val Ala Pro Thr Glu Cys Ser
225 230 235
<210> 62
<211> 2238
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleic Acid Sequence Encoding HIV-1 Env-4E10 Ig
<400> 62
ggatccgcca ccatggattg gacatggagg attctgtttc tggtcgccgc cgctacagga 60
actcacgccc aggtgcagct ggtgcagtca ggagccgaag tgaagcgacc aggcagctcc 120
gtcactgtgt cctgcaaagc atctggcgga tcattcagca cctacgccct gagctgggtg 180
agacaggctc ctggacgagg actggaatgg atgggaggcg tcatcccact gctgacaatt 240
actaactacg ccccccgatt tcagggcagg atcaccatta cagcagaccg ctccacttct 300
accgcctatc tggagctgaa tagcctgaga ccagaagata ccgcagtgta ctattgcgcc 360
cgggagggaa ccacaggatg gggatggctg ggaaagccca tcggggcttt cgcacactgg 420
ggccagggaa ccctggtcac agtgtctagt gccagcacaa agggcccctc cgtgtttccc 480
ctggctcctt caagcaaaag tacttcagga gggaccgccg ctctgggatg tctggtgaag 540
gactacttcc ctgagccagt caccgtgtcc tggaactctg gcgctctgac ctccggagtg 600
catacatttc ccgcagtcct gcagtcctct gggctgtact ctctgagttc agtggtcact 660
gtgcctagct cctctctggg cacacagact tatatctgca acgtgaatca caagccctcc 720
aataccaaag tcgacaagaa agtggaacct aagtcttgtg ataaaaccca tacatgccca 780
ccttgtccag cacctgagct gctgggcgga ccttccgtgt tcctgtttcc acccaagcca 840
aaagacacac tgatgattag ccggacacct gaagtgactt gtgtggtcgt ggacgtcagc 900
cacgaggacc ccgaagtgaa gttcaactgg tacgtggatg gcgtcgaggt gcataatgcc 960
aagaccaaac ccagggagga acagtacaac tctacttata gggtcgtgag tgtcctgacc 1020
gtgctgcacc aggactggct gaacgggaag gagtataagt gcaaagtgtc caataaggcc 1080
ctgccagctc ccatcgagaa aacaatttct aaggctaaag gccagccacg cgaaccccag 1140
gtgtacactc tgcctcccag cagggacgag ctgaccaaga accaggtgag tctgacatgt 1200
ctggtcaaag gcttctatcc aagcgatatc gccgtggagt gggaatccaa tggacagccc 1260
gaaaacaatt acaagactac cccccctgtg ctggacagtg atggatcatt ctttctgtat 1320
tccaagctga ccgtggacaa atctcgctgg cagcagggga acgtctttag ctgctccgtg 1380
atgcacgagg ccctgcacaa tcattacaca cagaagtctc tgagtctgtc accaggcaag 1440
cggggacgca aaaggagaag cgggtccggc gctactaact tcagcctgct gaaacaggca 1500
ggggatgtgg aggaaaatcc tggcccaatg gtcctgcaga cccaggtgtt tatctcactg 1560
ctgctgtgga ttagcggggc ttatggcgaa atcgtgctga ctcagagccc cggaacccag 1620
tctctgagtc ctggggagcg cgctacactg agctgtcgag catcacagag cgtggggaac 1680
aataagctgg catggtacca gcagaggcct ggccaggctc caagactgct gatctatggc 1740
gcaagttcac ggcctagcgg agtggcagac cgcttctccg gatctgggag tggcaccgat 1800
tttactctga ccattagcag gctggagcca gaagacttcg ctgtgtacta ttgccagcag 1860
tacggccagt cactgagcac atttggacag gggactaagg tcgaaaaaag aaccgtggca 1920
gccccaagtg tcttcatttt tccaccctca gacgagcagc tgaagagtgg aacagcctca 1980
gtcgtgtgtc tgctgaacaa tttctacccc agggaggcca aggtccagtg gaaagtggat 2040
aacgctctgc agagcggcaa ttcccaggag tctgtgacag aacaggacag taaggattca 2100
acttatagcc tgagctccac actgactctg tccaaagcag attacgagaa gcacaaagtg 2160
tatgcctgcg aagtcaccca tcagggactg tctagtcctg tgacaaagtc ttttaacaga 2220
ggggagtgat aactcgag 2238
<210> 63
<211> 2328
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleic Acid Sequence Encoding HIV-1 Env-PG9 Ig
<400> 63
ggatccgcca ccatggactg gacttggagg attctgtttc tggtcgccgc cgcaactgga 60
actcacgctg aatttggact gtcatgggtc tttctggtgg cctttctgcg aggggtccag 120
tgccagaggc tggtggagtc cggaggagga gtggtccagc caggcagctc cctgcgactg 180
agttgtgccg cttcagggtt cgacttttct agacagggca tgcactgggt gcggcaggca 240
ccaggacagg gactggagtg ggtggctttc atcaagtacg acggaagtga aaaatatcat 300
gccgattcag tgtgggggcg gctgtcaatt agccgcgaca actccaagga taccctgtac 360
ctgcagatga attctctgag ggtcgaggac acagctactt atttctgcgt gagggaagca 420
ggcggacctg attacagaaa cgggtataat tactatgact tttacgatgg ctactataac 480
taccactata tggacgtgtg gggcaaggga accacagtca cagtgtctag tgcatcaact 540
aaaggcccaa gcgtgtttcc cctggcccct tcaagcaagt ccacttctgg aggaaccgca 600
gcactgggat gtctggtgaa ggattacttc cctgagccag tcaccgtgag ttggaactca 660
ggcgccctga ctagcggagt ccataccttt cctgctgtgc tgcagtcctc tgggctgtac 720
agcctgagtt cagtggtcac agtgccaagc tcctctctgg gcacccagac atatatctgc 780
aacgtgaatc acaagcctag caatactaag gtcgacaaaa gagtggaacc aaagagctgt 840
gataaaactc atacctgccc accttgtcca gcacctgagc tgctgggagg gccttccgtg 900
ttcctgtttc cacccaagcc aaaagacacc ctgatgatta gccggacacc agaagtcact 960
tgcgtggtcg tggacgtgag ccacgaggac cccgaagtca agtttaactg gtacgtggat 1020
ggcgtcgagg tgcataatgc taagacaaaa ccacgggagg aacagtacaa ctccacatat 1080
cgcgtcgtgt ctgtcctgac tgtgctgcac caggactggc tgaacggcaa ggagtataag 1140
tgcaaagtgt ccaataaggc actgccagcc cccatcgaga aaaccatttc taaggccaaa 1200
ggccagccac gagaacccca ggtgtacaca ctgcctccaa gtagggacga gctgactaag 1260
aaccaggtct ctctgacctg tctggtgaaa ggcttctatc cctctgatat cgctgtggag 1320
tgggaaagta atggacagcc tgaaaacaat tacaagacta ccccccctgt gctggacagc 1380
gatggcagct tcttcctgta tagcaagctg accgtggaca aatccagatg gcagcagggg 1440
aacgtcttta gttgctcagt gatgcacgag gcactgcaca atcattacac ccagaaaagc 1500
ctgtccctgt ctcctggcaa gaggggaaga aaaaggagaa gtgggtcagg cgcaacaaac 1560
ttcagcctgc tgaagcaggc cggagatgtg gaggaaaatc ctgggccaat ggcttggacc 1620
cccctgttcc tgtttctgct gacatgctgt cctggcggaa gcaactccca gtctgcactg 1680
acacagccag caagtgtgtc agggagccca ggacagagca tcaccatttc ctgtaacggc 1740
acaagcaatg acgtcggggg ctacgagtcc gtgtcttggt atcagcagca tcctggaaag 1800
gccccaaaag tcgtgatcta cgatgtcagc aaacgcccct ctggggtgag taaccgattc 1860
agtggatcaa agagcgggaa taccgcttct ctgacaatta gtggcctgca ggcagaggac 1920
gaaggagatt actattgcaa atcactgaca agcactcggc gccgagtctt cggaaccggg 1980
acaaagctga ctgtgctggg ccagcccaaa gctgcaccta gcgtgaccct gtttccaccc 2040
agttcagagg aactgcaggc taataaggca acactggtgt gtctgatctc cgacttctac 2100
cctggcgctg tcactgtggc ctggaaggct gatagctccc cagtcaaagc aggagtggaa 2160
acaactaccc cctccaagca gtctaacaac aagtacgccg cttctagtta tctgtcactg 2220
actcccgagc agtggaagag ccacaaatcc tattcttgcc aggtgaccca tgagggctcc 2280
actgtcgaaa agaccgtggc ccctacagag tgttcttgat aactcgag 2328
<210> 64
<211> 2217
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleic Acid Sequence Encoding VRC01 IgG
<400> 64
ggatccgcca ccatggattg gacatggatt ctgttcctgg tcgccgccgc aactagagtg 60
cattcacagg tgcagctggt gcagtcaggc gggcagatga agaaacccgg cgagagtatg 120
cgaatctcat gccgggctag cgggtacgaa ttcatcgact gtaccctgaa ctggattaga 180
ctggcacctg ggaagaggcc agagtggatg ggatggctga aacctagagg cggggcagtg 240
aattacgcca gaccactgca gggcagggtc actatgaccc gcgacgtgta ttctgatacc 300
gcattcctgg agctgcgaag tctgacagtc gacgatactg ccgtgtactt ctgcacacgg 360
ggcaagaact gtgactataa ttgggatttt gaacactggg gcagggggac acctgtcatt 420
gtgagctccc caagtactaa gggaccctca gtgtttcccc tggccccttc tagtaaaagt 480
acctcaggag gcacagccgc tctgggatgc ctggtgaagg attacttccc tgagccagtc 540
accgtgagtt ggaactcagg cgccctgaca agcggggtcc atacttttcc agctgtgctg 600
cagtcaagcg ggctgtactc cctgtcctct gtggtcacag tgcccagttc aagcctggga 660
acacagactt atatctgtaa cgtcaatcac aagcctagca atactaaagt ggacaagaaa 720
gccgagccta agagctgcga accaaagtcc tgtgataaaa cccatacatg ccctccctgt 780
ccagctcctg aactgctggg cggcccatcc gtgttcctgt ttccacccaa gcccaaagac 840
accctgatga ttagcaggac tcctgaggtc acctgcgtgg tcgtggacgt gtcccacgag 900
gaccccgaag tcaagtttaa ctggtacgtg gatggcgtcg aagtgcataa tgccaagaca 960
aaaccccggg aggaacagta caactctacc tatagagtcg tgagtgtcct gacagtgctg 1020
caccaggact ggctgaacgg gaaggagtat aagtgcaaag tgtctaataa ggccctgcca 1080
gctcccatcg agaaaacaat ttccaaggca aaaggccagc caagggaacc ccaggtgtac 1140
actctgcctc catcccgcga cgagctgact aagaaccagg tctctctgac ctgtctggtg 1200
aaaggattct atccaagcga tatcgccgtg gagtgggaat ccaatggcca gcccgagaac 1260
aattacaaga ccacaccccc tgtgctggac agcgatggct ccttctttct gtattcaaag 1320
ctgaccgtgg ataaaagccg ctggcagcag gggaacgtct ttagctgctc cgtgatgcac 1380
gaagctctgc acaatcatta cacccagaag tctctgagtc tgtcacctgg caagagggga 1440
cgaaaacgga gaagcggcag cggagctaca aacttcagcc tgctgaaaca ggcaggcgac 1500
gtggaggaaa atcctgggcc aatggattgg acttggattc tgttcctggt ggcagccgct 1560
accagagtcc attccgaaat tgtgctgacc cagtctcccg gaacactgtc tctgagtcct 1620
ggcgagacag ccatcatttc ctgtaggact tctcagtacg ggagtctggc atggtatcag 1680
cagcgaccag gacaggctcc tcgactggtc atctactcag gaagcactcg ggcagccggc 1740
attcccgacc gattctccgg gtctcggtgg ggacctgatt acaacctgac catctcaaat 1800
ctggaaagcg gagactttgg cgtgtactat tgccagcagt atgagttctt tgggcaggga 1860
accaaggtcc aggtggacat caaacgcaca gtcgctgcac caagcgtgtt catctttcca 1920
ccctcagatg aacagctgaa gtccggcacc gcctctgtgg tgtgcctgct gaacaatttc 1980
tacccccggg aggcaaaggt ccagtggaaa gtggacaacg ccctgcagtc tggcaatagt 2040
caggagtcag tgactgaaca ggacagcaag gattccacct attctctgtc ctctactctg 2100
accctgagca aagctgatta cgagaagcac aaagtgtatg catgtgaggt cacccaccag 2160
ggactgcggt cacccgtcac caagagcttc aatcgcggag agtgttgata actcgag 2217
Claims (52)
- 대상체에서 합성 항체의 생성 방법으로서, 상기 방법은 항체 또는 그의 단편을 인코딩하는 재조합 핵산 서열을 포함하는 조성물을 상기 대상체에 투여하는 단계를 포함하며, 여기서 상기 재조합 핵산 서열은 상기 대상체에서 발현되어 상기 합성 항체를 생성하는, 방법.
- 제1항에 있어서, 상기 항체는 중쇄 폴리펩티드, 또는 그의 단편, 및 경쇄 폴리펩티드, 또는 그의 단편을 포함하는, 방법.
- 제2항에 있어서, 상기 중쇄 폴리펩티드, 또는 그의 단편은 제1 핵산 서열에 의해 인코딩되고, 상기 경쇄 폴리펩티드, 또는 그의 단편은 제2 핵산 서열에 의해 인코딩되는, 방법.
- 제3항에 있어서, 상기 재조합 핵산 서열은 상기 제1 핵산 서열 및 상기 제2 핵산 서열을 포함하는, 방법.
- 제4항에 있어서, 상기 재조합 핵산 서열은 상기 대상체에서 단일 전사체로 상기 제1 핵산 서열 및 상기 제2 핵산 서열을 발현하기 위한 프로모터를 추가로 포함하는, 방법.
- 제5항에 있어서, 상기 프로모터는 사이토메갈로바이러스(CMV) 프로모터인, 방법.
- 제5항에 있어서, 상기 재조합 핵산 서열은 프로테아제 절단 부위를 인코딩하는 제3 핵산 서열을 추가로 포함하며, 여기서 상기 제3 핵산 서열은 상기 제1 핵산 서열 및 상기 제2 핵산 서열 사이에 배치되는, 방법.
- 제7항에 있어서, 상기 대상체의 상기 프로테아제는 상기 프로테아제 절단 부위를 인식하고 절단하는, 방법.
- 제8항에 있어서, 상기 재조합 핵산 서열은 상기 대상체에서 발현되어 항체 폴리펩티드 서열을 생성하며, 여기서 상기 항체 폴리펩티드 서열은 상기 중쇄 폴리펩티드, 또는 그의 단편, 상기 프로테아제 절단 부위, 및 상기 경쇄 폴리펩티드, 또는 그의 단편을 포함하고, 상기 대상체에 의해 생산된 상기 프로테아제는 상기 항체 폴리펩티드 서열의 상기 프로테아제 절단 부위를 인식하고 절단하여 절단된 중쇄 폴리펩티드 및 절단된 경쇄 폴리펩티드를 생성하고, 상기 합성 항체는 상기 절단된 중쇄 폴리펩티드 및 상기 절단된 경쇄 폴리펩티드에 의해 생성되는, 방법.
- 제4항에 있어서, 상기 재조합 핵산 서열은 제1 전사체로서 상기 제1 핵산 서열을 발현하기 위한 제1 프로모터 및 제2 전사체로서 상기 제2 핵산 서열을 발현하기 위한 제2 프로모터를 포함하며, 여기서 상기 제1 전사체는 제1 폴리펩티드로 번역되고 상기 제2 전사체는 제2 폴리펩티드로 번역되며, 상기 합성 항체는 상기 제1 및 제2 폴리펩티드에 의해 생성되는, 방법.
- 제10항에 있어서, 상기 제1 프로모터 및 상기 제2 프로모터는 동일한, 방법.
- 제11항에 있어서, 상기 프로모터는 사이토메갈로바이러스(CMV) 프로모터인, 방법.
- 제2항에 있어서, 상기 중쇄 폴리펩티드는 가변 중쇄 영역 및 불변 중쇄 영역 1을 포함하는, 방법.
- 제2항에 있어서, 상기 중쇄 폴리펩티드는 가변 중쇄 영역, 불변 중쇄 영역 1, 힌지 영역, 불변 중쇄 영역 2 및 불변 중쇄 영역 3을 포함하는, 방법.
- 제2항에 있어서, 상기 경쇄 폴리펩티드는 가변 경쇄 영역 및 불변 경쇄 영역을 포함하는, 방법.
- 제1항에 있어서, 상기 재조합 핵산 서열은 코작(Kozak) 서열을 추가로 포함하는, 방법.
- 제1항에 있어서, 상기 재조합 핵산 서열은 면역글로불린(Ig) 신호 펩티드를 추가로 포함하는, 방법.
- 제17항에 있어서, 상기 Ig 신호 펩티드는 IgE 또는 IgG 신호 펩티드를 포함하는, 방법.
- 제1항에 있어서, 상기 재조합 핵산 서열은 서열 식별 번호 1, 2, 5, 41, 43, 45, 46, 47, 48, 49, 51, 53, 55, 57, 59, 및 61의 아미노산 서열 중 적어도 하나를 인코딩하는 핵산 서열을 포함하는, 방법.
- 제1항에 있어서, 상기 재조합 핵산 서열은 서열 식별 번호 3, 4, 6, 7, 40, 42, 44, 50, 52, 54, 56, 58, 60, 62 및 63 중 적어도 하나의 핵산 서열을 포함하는, 방법.
- 대상체에서 합성 항체의 생성 방법으로서, 상기 방법은 중쇄 폴리펩티드, 또는 그의 단편을 인코딩하는 제1 재조합 핵산 서열, 및 경쇄 폴리펩티드, 또는 그의 단편을 인코딩하는 제2 재조합 핵산 서열을 포함하는 조성물을 상기 대상체에 투여하는 단계를 포함하며, 여기서 상기 제1 재조합 핵산 서열은 상기 대상체에서 발현되어 제1 폴리펩티드를 생성하고 상기 제2 재조합 핵산은 상기 대상체에서 발현되어 제2 폴리펩티드를 생성하며, 상기 합성 항체는 상기 제1 및 제2 폴리펩티드에 의해 생성되는, 방법.
- 제21항에 있어서, 상기 제1 재조합 핵산 서열은 상기 대상체에서 상기 제1 폴리펩티드를 발현하기 위한 제1 프로모터를 추가로 포함하고, 상기 제2 재조합 핵산 서열은 상기 대상체에서 상기 제2 폴리펩티드를 발현하기 위한 제2 프로모터를 추가로 포함하는, 방법.
- 제22항에 있어서, 상기 제1 프로모터 및 제2 프로모터는 동일한, 방법.
- 제23항에 있어서, 상기 프로모터는 사이토메갈로바이러스(CMV) 프로모터인, 방법.
- 제21항에 있어서, 상기 중쇄 폴리펩티드는 가변 중쇄 영역 및 불변 중쇄 영역 1을 포함하는 방법.
- 제21항에 있어서, 상기 중쇄 폴리펩티드는 가변 중쇄 영역, 불변 중쇄 영역 1, 힌지 영역, 불변 중쇄 영역 2 및 불변 중쇄 영역 3을 포함하는, 방법.
- 제21항에 있어서, 상기 경쇄 폴리펩티드는 가변 경쇄 영역 및 불변 경쇄 영역을 포함하는, 방법.
- 제21항에 있어서, 상기 제1 재조합 핵산 서열 및 상기 제2 재조합 핵산 서열은 코작 서열을 추가로 포함하는, 방법.
- 제21항에 있어서, 상기 제1 재조합 핵산 서열 및 상기 제2 재조합 핵산 서열은 면역글로불린(Ig) 신호 펩티드를 추가로 포함하는, 방법.
- 제29항에 있어서, 상기 Ig 신호 펩티드는 IgE 또는 IgG 신호 펩티드를 포함하는, 방법.
- 대상체에서 질환의 예방 또는 치료 방법으로서, 상기 방법은 제1항 또는 제21항의 방법에 따라 대상체에서 합성 항체를 생성하는 단계를 포함하는, 방법.
- 제31항에 있어서, 상기 합성 항체는 외래 항원에 대해 특이적인, 방법.
- 제32항에 있어서, 상기 외래 항원은 바이러스로부터 유래되는, 방법.
- 제33항에 있어서, 상기 바이러스는 인간 면역결핍 바이러스(HIV), 치쿤군야(Chikungunya) 바이러스(CHIKV) 또는 뎅기 바이러스인, 방법.
- 제34항에 있어서, 상기 바이러스는 HIV인, 방법.
- 제35항에 있어서, 상기 재조합 핵산 서열은 서열 식별 번호 1, 2, 5, 46, 47, 48, 49, 51, 53, 55, 및 57 중 적어도 하나의 아미노산 서열을 인코딩하는 핵산 서열을 포함하는, 방법.
- 제35항에 있어서, 상기 재조합 핵산 서열은 서열 식별 번호 3, 4, 6, 7, 50, 52, 55, 56, 62, 63 및 64 중 적어도 하나의 핵산 서열을 포함하는, 방법.
- 제34항에 있어서, 상기 바이러스는 CHIKV인, 방법.
- 제38항에 있어서, 상기 재조합 핵산 서열은 서열 식별 번호 59 및 61 중 적어도 하나의 아미노산 서열을 인코딩하는 핵산 서열을 포함하는, 방법.
- 제38항에 있어서, 상기 재조합 핵산 서열은 서열 식별 번호 58 및 60 중 적어도 하나의 핵산 서열을 포함하는, 방법.
- 제34항에 있어서, 상기 바이러스는 뎅기 바이러스인, 방법.
- 제41항에 있어서, 상기 재조합 핵산 서열은 서열 식별 번호 45 중 적어도 하나의 아미노산 서열을 인코딩하는 핵산 서열을 포함하는, 방법.
- 제41항에 있어서, 상기 재조합 핵산 서열은 서열 식별 번호 44 중 적어도 하나의 핵산 서열을 포함하는, 방법.
- 제31항에 있어서, 상기 합성 항체는 자가-항원에 특이적인, 방법.
- 제44항에 있어서, 상기 자가-항원은 Her2인, 방법.
- 제45항에 있어서, 상기 재조합 핵산 서열은 서열 식별 번호 41 및 43 중 적어도 하나의 아미노산 서열을 인코딩하는 핵산 서열을 포함하는, 방법.
- 제45항에 있어서, 상기 재조합 핵산 서열은 서열 식별 번호 40 및 42 중 적어도 하나의 핵산 서열을 포함하는, 방법.
- 제1항 내지 제47항 중 어느 한 항의 방법에 의해 생산되는, 산물.
- 제48항에 있어서, 상기 산물은 기능적 항체를 발현할 수 있는 단일 DNA 플라스미드인, 산물.
- 제48항에 있어서, 상기 산물은 생체 내에서 조합하여 기능적 항체를 형성하는 기능적 항체의 성분을 발현할 수 있는 두 별개의 DNA 플라스미드로 이루어지는, 산물.
- 병원체에 의한 감염으로부터의 대상체의 치료 방법으로서, 상기 방법은:
상기 병원체에 특이적인 합성 항체를 인코딩하는 뉴클레오티드 서열을 투여하는 단계를 포함하는, 방법. - 제51항에 있어서, 상기 방법은:
상기 병원체의 항원을 투여하여 상기 대상체에서 면역 반응을 생성하는 단계를 추가로 포함하는, 방법.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020217020972A KR20210088741A (ko) | 2012-12-13 | 2013-12-13 | Dna 항체 작제물 및 그 이용 방법 |
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201261737094P | 2012-12-13 | 2012-12-13 | |
| US61/737,094 | 2012-12-13 | ||
| US201361881376P | 2013-09-23 | 2013-09-23 | |
| US61/881,376 | 2013-09-23 | ||
| US201361896646P | 2013-10-28 | 2013-10-28 | |
| US61/896,646 | 2013-10-28 | ||
| PCT/US2013/075137 WO2014093894A2 (en) | 2012-12-13 | 2013-12-13 | Dna antibody constructs and method of using same |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020217020972A Division KR20210088741A (ko) | 2012-12-13 | 2013-12-13 | Dna 항체 작제물 및 그 이용 방법 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20150093834A true KR20150093834A (ko) | 2015-08-18 |
Family
ID=50935092
Family Applications (4)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020157018712A KR20150093834A (ko) | 2012-12-13 | 2013-12-13 | Dna 항체 작제물 및 그 이용 방법 |
| KR1020237036307A KR20230156146A (ko) | 2012-12-13 | 2013-12-13 | Dna 항체 작제물 및 그 이용 방법 |
| KR1020217020972A KR20210088741A (ko) | 2012-12-13 | 2013-12-13 | Dna 항체 작제물 및 그 이용 방법 |
| KR1020167018560A KR102454610B1 (ko) | 2012-12-13 | 2014-12-13 | Dna 항체 작제물 및 그 이용 방법 |
Family Applications After (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237036307A KR20230156146A (ko) | 2012-12-13 | 2013-12-13 | Dna 항체 작제물 및 그 이용 방법 |
| KR1020217020972A KR20210088741A (ko) | 2012-12-13 | 2013-12-13 | Dna 항체 작제물 및 그 이용 방법 |
| KR1020167018560A KR102454610B1 (ko) | 2012-12-13 | 2014-12-13 | Dna 항체 작제물 및 그 이용 방법 |
Country Status (15)
| Country | Link |
|---|---|
| US (4) | US9994629B2 (ko) |
| EP (1) | EP2931318A4 (ko) |
| JP (6) | JP6898060B2 (ko) |
| KR (4) | KR20150093834A (ko) |
| CN (1) | CN104853782A (ko) |
| AU (7) | AU2013358944B2 (ko) |
| BR (2) | BR112015013700A8 (ko) |
| CA (1) | CA2889723A1 (ko) |
| EA (1) | EA201591131A1 (ko) |
| HK (1) | HK1213481A1 (ko) |
| MX (4) | MX2015007575A (ko) |
| MY (1) | MY175708A (ko) |
| SG (1) | SG10202002718RA (ko) |
| WO (1) | WO2014093894A2 (ko) |
| ZA (1) | ZA201503583B (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20190033047A (ko) * | 2016-05-05 | 2019-03-28 | 더 트러스티스 오브 더 유니버시티 오브 펜실바니아 | 관문 분자를 표적으로 하는 dna 단클론성 항체 |
Families Citing this family (26)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7078350B2 (ja) | 2013-10-28 | 2022-05-31 | ザ トラスティーズ オブ ザ ユニバーシティ オブ ペンシルバニア | Dna抗体構築物及びその使用方法 |
| KR20150093834A (ko) | 2012-12-13 | 2015-08-18 | 더 트러스티스 오브 더 유니버시티 오브 펜실바니아 | Dna 항체 작제물 및 그 이용 방법 |
| EP3080159A4 (en) * | 2013-12-13 | 2017-08-02 | The Trustees Of The University Of Pennsylvania | Dna antibody constructs and method of using same |
| CA2962799A1 (en) * | 2014-10-01 | 2016-04-07 | The Trustees Of The University Of Pennsylvania | Vaccines having an antigen and interleukin-21 as an adjuvant |
| CA2969214A1 (en) * | 2014-12-01 | 2016-06-09 | The Trustees Of The University Of Pennsylvania | Dna antibody constructs and method of using same |
| CN117069855A (zh) | 2015-10-25 | 2023-11-17 | 赛诺菲 | 用于预防或治疗hiv感染的三特异性和/或三价结合蛋白 |
| US20180363000A1 (en) * | 2015-12-14 | 2018-12-20 | The Trustees Of The University Of Pennsylvania | Aav-anti pcsk9 antibody constructs and uses thereof |
| SG11201808152PA (en) * | 2016-03-21 | 2018-10-30 | David Weiner | Dna antibody constructs and method of using same |
| KR20240036142A (ko) | 2016-04-13 | 2024-03-19 | 사노피 | 3특이성 및/또는 3가 결합 단백질 |
| KR20220035288A (ko) | 2016-05-05 | 2022-03-21 | 더 트러스티스 오브 더 유니버시티 오브 펜실바니아 | 인플루엔자 바이러스를 표적으로 하는 dna 단일 클론 항체 |
| CN110072554A (zh) * | 2016-05-05 | 2019-07-30 | 宾夕法尼亚大学理事会 | 用于抗铜绿假单胞菌的dna抗体构建体 |
| US20190192692A1 (en) * | 2016-05-05 | 2019-06-27 | The Trustees Of The University Of Pennsylvania | DNA Monoclonal Antibodies Targeting IL-6 and CD126 |
| JP2019533993A (ja) * | 2016-09-19 | 2019-11-28 | ザ トラスティーズ オブ ザ ユニバーシティ オブ ペンシルバニア | ジカウイルスに対する新規ワクチンとジカウイルスに対する使用に向けたdna抗体構築物との組み合わせ |
| US11286295B2 (en) | 2016-10-20 | 2022-03-29 | Sanofi | Anti-CHIKV monoclonal antibodies directed against the E2 structural protein |
| WO2018085801A1 (en) * | 2016-11-07 | 2018-05-11 | Weiner David B | Dna antibody constructs for use against lyme disease |
| EP3606552A4 (en) * | 2017-04-07 | 2020-08-05 | The Rockefeller University | COMPOSITIONS AND PROCEDURES RELATED TO HUMAN NEUTRALIZING ANTIBODIES AGAINST ZIKA AND DENGUE-1 VIRUS |
| CN111032077A (zh) * | 2017-05-22 | 2020-04-17 | 叶才明 | 抗-登革热病毒抗体、包含该抗体的药学组合物及其用途 |
| US11230592B2 (en) | 2017-09-27 | 2022-01-25 | The Wistar Institute Of Anatomy And Biology | DNA antibody constructs for use against middle east respiratory syndrome coronavirus |
| WO2019152602A1 (en) * | 2018-01-31 | 2019-08-08 | The Wistar Institute Of Anatomy And Biology | Structurally modified flavivirus dmabs |
| US11613576B2 (en) | 2019-04-09 | 2023-03-28 | Sanofi | Trispecific binding proteins, methods, and uses thereof |
| WO2021022107A1 (en) * | 2019-07-31 | 2021-02-04 | The Wistar Institute Of Anatomy And Biology | Multivalent dna antibody constructs and use thereof |
| JP2022549138A (ja) | 2019-09-18 | 2022-11-24 | インターガラクティック セラピューティクス インコーポレイテッド | 合成dnaベクターおよびその使用法 |
| SE544001C2 (en) * | 2020-03-17 | 2021-10-26 | Xbrane Biopharma Ab | Novel combination of tis sequences, signal peptide sequences and nucleic acid sequences encoding heavy and light chains of an antibody |
| SE544000C2 (en) * | 2020-03-17 | 2021-10-26 | Xbrane Biopharma Ab | Novel combination of tis sequence, signal peptide sequence and nucleic acid sequence encoding a recombinant protein |
| US20230136960A1 (en) * | 2020-03-19 | 2023-05-04 | Nature's Toolbox, Inc. | Novel MRNA-Based COVID-19 Multi-Valent Vaccine and Methods of Scaled Production of the Same |
| KR20230142829A (ko) * | 2020-12-02 | 2023-10-11 | 토마스 제퍼슨 유니버시티 | 데스모글레인 2 지정 키메라 항원 수용체(car) 작제물및 사용 방법 |
Family Cites Families (42)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| FI46572C (fi) * | 1972-04-07 | 1973-04-10 | Stroemberg Oy Ab | Jännitemuuntaja. |
| US7276488B2 (en) | 1997-06-04 | 2007-10-02 | Oxford Biomedica (Uk) Limited | Vector system |
| US20030039635A1 (en) | 1998-09-30 | 2003-02-27 | Corixa Corporation | Compositions and methods for WT1 specific immunotherapy |
| CN1334343A (zh) * | 2000-07-14 | 2002-02-06 | 中国医学科学院肿瘤医院肿瘤研究所 | 抑制肿瘤生长的新抗体、其衍生物及其应用 |
| US20070037165A1 (en) | 2000-09-08 | 2007-02-15 | Applera Corporation | Polymorphisms in known genes associated with human disease, methods of detection and uses thereof |
| WO2004013278A2 (en) * | 2002-08-02 | 2004-02-12 | Yuhan Corporation | Expression vectors |
| JP4644663B2 (ja) * | 2003-06-03 | 2011-03-02 | セル ジェネシス インコーポレイテッド | ペプチド開裂部位を用いた単一ベクターからの組換えポリペプチドの高められた発現のための構成と方法 |
| CN1480215A (zh) | 2003-07-07 | 2004-03-10 | 叶新新 | Sars病毒抗原抗体复合疫苗及实验动物模型与方法 |
| SI1753871T1 (sl) * | 2004-05-28 | 2016-01-29 | Agensys, Inc. | Protitelesa in sorodne molekule, ki se vežejo na psca proteine |
| EP2583981A3 (en) | 2004-05-28 | 2013-07-31 | Agensys, Inc. | Antibodies and related molecules that bind to PSCA proteins |
| EP1765846A4 (en) | 2004-07-13 | 2010-02-17 | Cell Genesys Inc | AAV VECTOR COMPOSITIONS AND ITS USE IN PROCESSES FOR INCREASING IMMUNOGLOBULIN EXPRESSION |
| KR20150043558A (ko) | 2004-07-22 | 2015-04-22 | 제넨테크, 인크. | Her2 항체 조성물 |
| JO3000B1 (ar) * | 2004-10-20 | 2016-09-05 | Genentech Inc | مركبات أجسام مضادة . |
| BRPI0607796A2 (pt) | 2005-02-18 | 2009-06-13 | Medarex Inc | composto ou um sal farmaceuticamente aceitável do mesmo, processo para preparação e uso do mesmo, e, composição farmacêutica |
| US20060216722A1 (en) | 2005-03-25 | 2006-09-28 | Christer Betsholtz | Glomerular expression profiling |
| JP2009508470A (ja) * | 2005-07-21 | 2009-03-05 | アボット・ラボラトリーズ | Sorf構築物並びにポリタンパク質、プロタンパク質及びタンパク質分解による方法を含む複数の遺伝子発現 |
| EP2185188B1 (en) | 2007-08-22 | 2014-08-06 | Medarex, L.L.C. | Site-specific attachment of drugs or other agents to engineered antibodies with c-terminal extensions |
| CA2598966A1 (en) | 2007-09-07 | 2009-03-07 | Institut Pasteur | Anti-chikungunya monoclonal antibodies and uses thereof |
| JP2009171880A (ja) | 2008-01-23 | 2009-08-06 | Yokohama City Univ | アルツハイマー病における次世代遺伝子治療法・免疫治療法の開発 |
| CN101970496B (zh) | 2008-03-14 | 2014-04-16 | 特朗斯吉有限公司 | 针对csf-1r的抗体 |
| CN101990580A (zh) | 2008-04-04 | 2011-03-23 | 宾夕法尼亚州立大学托管会 | 屈曲病毒蛋白共有序列、编码该屈曲病毒蛋白共有序列的核酸分子和组合物及其使用方法 |
| CN102272155B (zh) * | 2008-10-13 | 2018-05-25 | 生物医学研究所 | 登革热病毒中和抗体及其用途 |
| CN102481367B (zh) * | 2009-07-06 | 2015-04-29 | 弗·哈夫曼-拉罗切有限公司 | 结合地高辛配基的双特异性抗体 |
| EP2453917B1 (en) | 2009-07-13 | 2015-07-22 | Bharat Biotech International Limited | A composition useful as rotavirus vaccine and a method therefor. |
| US20110045534A1 (en) | 2009-08-20 | 2011-02-24 | Cell Signaling Technology, Inc. | Nucleic Acid Cassette For Producing Recombinant Antibodies |
| EP2480572B1 (en) * | 2009-09-25 | 2019-01-30 | The United States of America, as represented by The Secretary, Department of Health and Human Services | Neutralizing antibodies to hiv-1 and their use |
| DK2488867T3 (da) * | 2009-10-14 | 2020-11-09 | Janssen Biotech Inc | Fremgangsmåder til affinitetsmodning af antistoffer |
| US8298820B2 (en) * | 2010-01-26 | 2012-10-30 | The Trustees Of The University Of Pennsylvania | Influenza nucleic acid molecules and vaccines made therefrom |
| JP5744196B2 (ja) | 2010-07-09 | 2015-07-08 | クルセル ホランド ベー ヴェー | 抗ヒト呼吸器多核体ウイルス(rsv)抗体および使用の方法 |
| CN103097413A (zh) * | 2010-07-09 | 2013-05-08 | Jv生物公司 | 脂质缀合抗体 |
| US8637035B2 (en) | 2010-07-16 | 2014-01-28 | Academia Sinica | Anti-dengue virus antibodies |
| US8927692B2 (en) | 2010-11-12 | 2015-01-06 | The Trustees Of The University Of Pennsylvania | Consensus prostate antigens, nucleic acid molecule encoding the same and vaccine and uses comprising the same |
| KR20140007404A (ko) * | 2011-01-31 | 2014-01-17 | 더 트러스티스 오브 더 유니버시티 오브 펜실바니아 | 신규 허피스 항원을 암호화하는 핵산 분자, 이것을 포함하는 백신 및 이것의 사용 방법 |
| WO2012106578A1 (en) | 2011-02-04 | 2012-08-09 | The United States Of America, As Represented By The Secretary, Department Of Health And Human Services | HIV NEUTRALIZING ANTIBODIES HAVING MUTATIONS IN CONSTANT DOMAIN (Fc) |
| WO2012115980A1 (en) * | 2011-02-22 | 2012-08-30 | California Institute Of Technology | Delivery of proteins using adeno-associated virus (aav) vectors |
| CN102199218A (zh) * | 2011-04-29 | 2011-09-28 | 中国人民解放军军事医学科学院基础医学研究所 | 一种抗Her2抗体-白细胞介素2融合蛋白及其用途 |
| WO2013177533A1 (en) | 2012-05-25 | 2013-11-28 | California Institute Of Technology | Expression of secreted and cell-surface polypeptides |
| JP7078350B2 (ja) * | 2013-10-28 | 2022-05-31 | ザ トラスティーズ オブ ザ ユニバーシティ オブ ペンシルバニア | Dna抗体構築物及びその使用方法 |
| CN104812401B (zh) | 2012-12-13 | 2017-10-13 | 宾夕法尼亚大学理事会 | Wt1疫苗 |
| KR20150093834A (ko) | 2012-12-13 | 2015-08-18 | 더 트러스티스 오브 더 유니버시티 오브 펜실바니아 | Dna 항체 작제물 및 그 이용 방법 |
| WO2014100490A1 (en) | 2012-12-19 | 2014-06-26 | Adimab, Llc | Multivalent antibody analogs, and methods of their preparation and use |
| EP3080159A4 (en) | 2013-12-13 | 2017-08-02 | The Trustees Of The University Of Pennsylvania | Dna antibody constructs and method of using same |
-
2013
- 2013-12-13 KR KR1020157018712A patent/KR20150093834A/ko active Application Filing
- 2013-12-13 MX MX2015007575A patent/MX2015007575A/es unknown
- 2013-12-13 EP EP13863143.7A patent/EP2931318A4/en active Pending
- 2013-12-13 BR BR112015013700A patent/BR112015013700A8/pt not_active Application Discontinuation
- 2013-12-13 JP JP2015548014A patent/JP6898060B2/ja active Active
- 2013-12-13 KR KR1020237036307A patent/KR20230156146A/ko active Application Filing
- 2013-12-13 US US14/651,740 patent/US9994629B2/en active Active
- 2013-12-13 CN CN201380065674.3A patent/CN104853782A/zh active Pending
- 2013-12-13 EA EA201591131A patent/EA201591131A1/ru unknown
- 2013-12-13 AU AU2013358944A patent/AU2013358944B2/en active Active
- 2013-12-13 WO PCT/US2013/075137 patent/WO2014093894A2/en active Application Filing
- 2013-12-13 KR KR1020217020972A patent/KR20210088741A/ko not_active IP Right Cessation
- 2013-12-13 CA CA2889723A patent/CA2889723A1/en active Pending
-
2014
- 2014-12-13 SG SG10202002718RA patent/SG10202002718RA/en unknown
- 2014-12-13 BR BR112016013493-1A patent/BR112016013493B1/pt active IP Right Grant
- 2014-12-13 MY MYPI2016702163A patent/MY175708A/en unknown
- 2014-12-13 AU AU2014361811A patent/AU2014361811B2/en active Active
- 2014-12-13 KR KR1020167018560A patent/KR102454610B1/ko active IP Right Grant
- 2014-12-13 MX MX2016007722A patent/MX2016007722A/es unknown
-
2015
- 2015-05-21 ZA ZA2015/03583A patent/ZA201503583B/en unknown
- 2015-06-12 MX MX2022016002A patent/MX2022016002A/es unknown
-
2016
- 2016-02-05 HK HK16101459.4A patent/HK1213481A1/zh unknown
- 2016-06-13 MX MX2021015971A patent/MX2021015971A/es unknown
- 2016-11-18 AU AU2016259451A patent/AU2016259451A1/en not_active Abandoned
-
2018
- 2018-04-30 AU AU2018202997A patent/AU2018202997A1/en not_active Abandoned
- 2018-06-12 US US16/005,997 patent/US20180346554A1/en active Pending
- 2018-09-26 US US16/142,457 patent/US11208470B2/en active Active
-
2019
- 2019-03-27 JP JP2019061531A patent/JP2019115355A/ja active Pending
- 2019-04-04 AU AU2019202343A patent/AU2019202343B2/en active Active
-
2020
- 2020-03-02 JP JP2020035240A patent/JP2020108381A/ja active Pending
- 2020-03-13 AU AU2020201853A patent/AU2020201853B2/en active Active
-
2021
- 2021-02-04 JP JP2021016537A patent/JP2021087433A/ja not_active Withdrawn
- 2021-06-03 AU AU2021203643A patent/AU2021203643A1/en active Pending
- 2021-12-17 US US17/554,642 patent/US20220112273A1/en not_active Abandoned
-
2023
- 2023-03-15 JP JP2023040876A patent/JP2023080085A/ja active Pending
- 2023-06-30 JP JP2023108341A patent/JP2023138998A/ja active Pending
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20190033047A (ko) * | 2016-05-05 | 2019-03-28 | 더 트러스티스 오브 더 유니버시티 오브 펜실바니아 | 관문 분자를 표적으로 하는 dna 단클론성 항체 |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| AU2019202343B2 (en) | DNA antibody constructs and method of using same | |
| JP2021166534A (ja) | Dna抗体構築物及びその使用方法 | |
| US20230023093A1 (en) | Dna antibody constructs and method of using same | |
| JP2017500030A (ja) | Dna抗体構築物及びその使用方法 | |
| EA042816B1 (ru) | Днк-конструкции антитела и способ их применения |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| E902 | Notification of reason for refusal | ||
| AMND | Amendment | ||
| E601 | Decision to refuse application | ||
| AMND | Amendment | ||
| X601 | Decision of rejection after re-examination | ||
| A107 | Divisional application of patent |