KR20140033018A - 항 b7-h3항체 - Google Patents
항 b7-h3항체 Download PDFInfo
- Publication number
- KR20140033018A KR20140033018A KR1020137027860A KR20137027860A KR20140033018A KR 20140033018 A KR20140033018 A KR 20140033018A KR 1020137027860 A KR1020137027860 A KR 1020137027860A KR 20137027860 A KR20137027860 A KR 20137027860A KR 20140033018 A KR20140033018 A KR 20140033018A
- Authority
- KR
- South Korea
- Prior art keywords
- seq
- amino acid
- antibody
- acid sequence
- nucleotide
- Prior art date
Links
Images

































































Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2803—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily
- C07K16/2827—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the immunoglobulin superfamily against B7 molecules, e.g. CD80, CD86
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
- A61K39/39533—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals
- A61K39/39558—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum against materials from animals against tumor tissues, cells, antigens
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K45/00—Medicinal preparations containing active ingredients not provided for in groups A61K31/00 - A61K41/00
- A61K45/06—Mixtures of active ingredients without chemical characterisation, e.g. antiphlogistics and cardiaca
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/42—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against immunoglobulins
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/40—Immunoglobulins specific features characterized by post-translational modification
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
- C07K2317/732—Antibody-dependent cellular cytotoxicity [ADCC]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
- C07K2317/734—Complement-dependent cytotoxicity [CDC]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
Abstract
본 발명은 종양에 대해 치료 효과를 갖는 항체에 관한 것이다. 즉, 본 발명은 B7-H3 에 결합하여 항종양 활성을 나타내는 항체에 관한 것이다. 본 발명의 과제는 종양에 대해 치료 효과를 갖는 의약품을 제공하는 것이다. B7-H3 에 결합하여 항종양 활성을 나타내는 항 B7-H3 항체를 얻고, 당해 항체를 함유하는 종양 치료용 의약 조성물 등을 얻는다.
Description
본 발명은 종양의 치료 및/또는 예방제로서 유용한 B7-H3 에 결합하는 항체, 그리고 당해 항체를 사용한 종양의 치료 및/또는 예방법에 관한 것이다.
B7-H3 은 1 회 막관통 구조를 갖는 단백질이다 (비특허문헌 1). B7-H3 의 N 말단측의 세포 외 영역에는 2 개의 베리언트가 존재하고, 베리언트 1 에는 각 2 지점의 V 또는 C 형 Ig 도메인이 존재하고, 베리언트 2 에는 각 1 지점의 V 또는 C 형 Ig 도메인이 존재한다. C 말단측의 세포 내 영역에는 45 아미노산이 존재하고 있다.
B7-H3 의 수용체로는, 1 회 막관통 구조를 갖는 TLT-2 가 보고되어 있다 (비특허문헌 2). 그러나, TLT-2 는 B7-H3 의 수용체는 아니라고 주장하는 논문도 있다 (비특허문헌 3). 전자의 보고에 의하면, 수용체가 B7-H3 에 결합함으로써, CD8 양성 T 세포의 활성화를 항진한다.
B7-H3 은 임상적으로 많은 암, 특히 비소세포 폐암, 신장암, 요로상피암, 대장암, 전립선암, 다형 신경 교아종, 난소암, 췌장암에서의 고발현이 보고되어 있다 (비특허문헌 4 ∼ 비특허문헌 11). 또, 전립선암에서는 B7-H3 발현 강도와 종양 체적, 전립선외 침윤, 글리슨 스코어 등의 임상 병리학적인 악성도와 정 (正) 으로 상관이 있는 것, 암의 진행과 상관이 있는 것이 보고되어 있다 (비특허문헌 8). 동일하게 다형 신경 교아종에 있어서 B7-H3 발현과 무재발 생존율이 부 (負) 로 상관이 있고 (비특허문헌 9), 췌장암에서는 B7-H3 발현과 림프절 전이 및 병리학적 진행도와 상관이 있다 (비특허문헌 11). 난소암에 있어서는 B7-H3 발현과 림프절 전이 및 병리학적 진행도와 상관이 있다.
또, B7-H3 유전자에 대한 siRNA 를 B7-H3 양성 암 세포주에 도입함으로써, 파이브로넥틴에 대한 접착성이 저하되고, 세포 유주능이나 마트리겔 침윤능이 저하되는 것을 보고하고 있다 (비특허문헌 12). 또, 다형 신경 교아종에 있어서, B7-H3 의 발현에 의해, NK 세포에 의한 세포사로부터 도피하고 있다는 보고가 있다 (비특허문헌 13).
한편 B7-H3 은 암 세포뿐만 아니라 종양 내 또는 주위의 혈관에도 발현되고 있는 것이 보고되어 있다 (비특허문헌 5, 비특허문헌 14). 난소암 혈관에 B7-H3 이 발현되어 있으면, 생존율이 저하되는 것이 보고되어 있다.
B7 패밀리 분자는 면역계와의 관련성이 시사되어 있다. B7-H3 은 단구 (單球), 수상 (樹狀) 세포나 활성화 T 세포에서 발현되는 것이 보고되어 있다 (비특허문헌 15). B7-H3 은 세포 상해성 T 세포의 활성화에 수반하여, CD4 양성, 또는 CD8 양성 T 세포의 증식을 공자극한다고 보고되어 있다. 그러나, B7-H3 은 공자극을 하지 않는다는 보고도 이루어지고 있다 (비특허문헌 1).
B7-H3 분자가 자기 면역 질환과 관련이 있다는 보고가 있다. 류머티즘이나 다른 자기 면역 질환에 있어서, 섬유아 세포형의 활막 세포와 활성화 T 세포의 상호 작용에 B7-H3 이 중요하다는 보고 (비특허문헌 16) 나 B7-H3 이 활성화 매크로파지로부터의 사이토카인 릴리스시의 보조 자극 인자로 되어 있어, 패혈증 발증에 관련이 있다는 보고가 있다 (비특허문헌 17). 또한, 마우스 천식 모델에 대해 유도상으로 항 B7-H3 항체를 투여함으로써, 소속 림프절에 있어서의 Th2 세포 유도성의 사이토카인 산생이 항마우스 B7-H3 항체를 투여함으로써 억제되어 천식이 개선되었다는 보고가 있다 (비특허문헌 18).
B7-H3 에 관해서는 마우스 B7-H3 에 대한 항체가 종양 내에 침윤하는 CD8 양성 T 세포를 촉진시켜, 종양 증식을 억제하는 것이 보고되어 있다 (비특허문헌 24). 또, B7-H3 의 베리언트 1 을 인식하는 항체가 아데노카시노마 in vivo 항종양 효과를 나타낸다는 특허가 기재되어 있다 (특허문헌 1).
이러한 연구에도 불구하고 현재까지 in vivo 에서 항종양 효과를 나타내는 항 B7-H3 항체의 에피토프에 대해서는 명확하게 되어 있지 않고, B7-H3 의 세포 외 영역 중의 특정한 아미노산 배열이 암 치료를 목적으로 한 모노클로날 항체의 에피토프로서 유용하다는 보고는 없다.
동일한 항원에 대한 항체이어도 에피토프나 항체의 배열이 상이함으로써, 항체의 성질은 상이하다. 그리고, 이들 성질이 상이함으로써, 임상에서 인간에게 투여했을 경우에 약제의 유효성이나 치료 응답성의 빈도, 부작용이나 약제 내성의 발생 빈도 등의 점에서 상이한 반응을 나타내게 된다.
B7-H3 에 대한 항체에 대해서도 종래와는 상이한 특성을 갖는 항체의 창출이 강하게 요구되고 있었다.
The Journal of Immunology 2004년, 제 172 권, p.2352-2359
Proceedings of the national Academy of Sciences of the United States of America 2008년, 제 105 권, p.10495-10500
European Journal of Immunology 2009년, 제 39 권, p.1754-1764
Lung Cancer, 2009년, 제 66 권, p.245-249
Clinical Cancer Research 2008년, 제 14 권, p.5150-5157
Clinical Cancer Research 2008년, 제 14 권, p.4800-4808
Cancer Immunology, Immunotherapy 2010년, 제 59 권, p.1163-1171
Cancer Research 2007년, 제 67 권, p.7893-7900
Histopathology 2008년, 제 53 권, p.73-80
Modern Pathology 2010년, 제 23 권, p.1104-1112
British Journal of Cancer 2009년, 제 101 권, p.1709-1716
Current Cancer Drug Targets 2008년, 제 8 권, p.404-413
Proceedings of the national Academy of Sciences of the United States of America 2004년, 제 101 권, p.12640-12645
Modern Pathology 2010년, 제 23 권, p.1104-1112
Nature Immunology 2001년, 제 2 권, p.269-274
The Journal of Immunology 2008년, 제 180 권, p.2989-2998
The Journal of Immunology 2010년, 제 185 권, p.3677-3684
The Journal of Immunology 2008년, 제 181 권, p.4062-4071
본 발명의 과제는 종양에 대해 치료 효과를 갖는 의약품이 되는 항체 및 당해 항체의 기능성 단편, 그리고 당해 항체 또는 당해 항체의 기능성 단편을 사용한 종양의 치료 방법 등을 제공하는 것이다.
본 발명자들은 상기 과제를 해결하기 위해 예의 검토를 실시한 결과, B7-H3 에 특이적으로 결합하여 항종양 활성을 나타내는 항체를 알아내어 본 발명을 완성시켰다. 즉, 본 발명은 이하의 발명을 포함한다.
(1) 이하의 특성을 갖는 것을 특징으로 하는 항체 또는 당해 항체의 기능성 단편 ;
(a) B7-H3 에 특이적으로 결합한다
(b) 항체 의존성 세포 매개 식작용 (ADCP) 활성을 갖는다
(c) in vivo 에서 항종양 활성을 갖는다
(2) B7-H3 이 배열 번호 6 또는 10 에 기재된 아미노산 배열로 이루어지는 분자인 상기 (1) 에 기재된 항체 또는 당해 항체의 기능성 단편.
(3) B7-H3 의 도메인인 IgC1 및/또는 IgC2 에 결합하는 상기 (1) 또는 (2) 에 기재된 항체 또는 당해 항체의 기능성 단편.
(4) IgC1 이 배열 번호 6 에 있어서 아미노산 번호 140 내지 244 에 기재된 아미노산 배열로 이루어지는 도메인이고, IgC2 가 배열 번호 6 에 있어서 아미노산 번호 358 내지 456 에 기재된 아미노산 배열로 이루어지는 도메인인 상기 (3) 에 기재된 항체 또는 당해 항체의 기능성 단편.
(5) B7-H3 에 대한 결합에 대해 M30 항체와 경합 저해 활성을 갖는 상기 (1) 내지 (4) 중 어느 한 항에 기재된 항체 또는 당해 항체의 기능성 단편.
(6) 항체 의존성 세포 상해 (ADCC) 활성 및/또는 보체 의존성 세포 상해 (CDC) 활성을 갖는 상기 (1) 내지 (5) 중 어느 한 항에 기재된 항체 또는 당해 항체의 기능성 단편.
(7) 종양이 암인 상기 (1) 내지 (6) 중 어느 한 항에 기재된 항체 또는 당해 항체의 기능성 단편.
(8) 암이 폐암, 유방암, 전립선암, 췌장암, 대장암, 멜라노마, 간암, 난소암, 방광암, 위암, 식도암 또는 신장암인 상기 (7) 에 기재된 항체 또는 당해 항체의 기능성 단편.
(9) 중사슬에 있어서의 상보성 결정 영역으로서 배열 번호 92 에 기재된 아미노산 배열로 이루어지는 CDRH1, 배열 번호 93 에 기재된 아미노산 배열로 이루어지는 CDRH2 및 배열 번호 94 에 기재된 아미노산 배열로 이루어지는 CDRH3, 그리고 경사슬에 있어서의 상보성 결정 영역으로서 배열 번호 95 에 기재된 아미노산 배열로 이루어지는 CDRL1, 배열 번호 96 에 기재된 아미노산 배열로 이루어지는 CDRL2 및 배열 번호 97 에 기재된 아미노산 배열로 이루어지는 CDRL3 을 갖는 상기 (1) 내지 (8) 중 어느 한 항에 기재된 항체 또는 당해 항체의 기능성 단편.
(10) 배열 번호 51 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 53 에 있어서 아미노산 번호 23 내지 130 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역을 갖는 상기 (1) 내지 (9) 중 어느 한 항에 기재된 항체 또는 당해 항체의 기능성 단편.
(11) 정상 영역이 인간 유래 정상 영역인 상기 (1) 내지 (10) 중 어느 한 항에 기재된 항체 또는 당해 항체의 기능성 단편.
(12) 배열 번호 63 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 59 에 기재된 아미노산 배열로 이루어지는 경사슬을 갖는 상기 (11) 에 기재된 항체 또는 당해 항체의 기능성 단편.
(13) 인간화되어 있는 상기 (1) 내지 (12) 중 어느 한 항에 기재된 항체 또는 당해 항체의 기능성 단편.
(14) (a) 배열 번호 85 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열, (b) 배열 번호 87 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열, (c) 배열 번호 89 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열, (d) 배열 번호 91 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열, (e) (a) 내지 (d) 의 배열에 대해 적어도 95 % 이상의 상동성을 갖는 아미노산 배열, 및 (f) (a) 내지 (d) 의 배열에 있어서 1 또는 수 개의 아미노산이 결실, 치환 또는 부가된 아미노산 배열로 이루어지는 군에서 선택된 아미노산 배열로 이루어지는 중사슬의 가변 영역, 그리고 (g) 배열 번호 71 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열, (h) 배열 번호 73 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열, (i) 배열 번호 75 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열, (j) 배열 번호 77 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열, (k) 배열 번호 79 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열, (l) 배열 번호 81 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열, (m) 배열 번호 83 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열, (n) (g) 내지 (m) 의 배열에 대해 적어도 95 % 이상의 상동성을 갖는 아미노산 배열, 및 (o) (g) 내지 (m) 의 배열에 있어서 1 또는 수 개의 아미노산이 결실, 치환 또는 부가된 아미노산 배열로 이루어지는 군에서 선택된 아미노산 배열로 이루어지는 경사슬의 가변 영역을 갖는 상기 (13) 에 기재된 항체 또는 당해 항체의 기능성 단편.
(15) 배열 번호 85 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 71 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역, 배열 번호 85 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 73 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역, 배열 번호 85 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 75 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역, 배열 번호 85 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 77 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역, 배열 번호 85 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 79 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역, 배열 번호 85 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 81 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역, 배열 번호 85 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 83 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역, 배열 번호 91 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 71 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역, 배열 번호 91 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 73 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역, 배열 번호 91 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 75 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역, 그리고 배열 번호 91 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 77 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역으로 이루어지는 군에서 선택되는 중사슬의 가변 영역 및 경사슬의 가변 영역을 갖는 상기 (14) 에 기재된 항체 또는 항체의 기능성 단편.
(16) 배열 번호 85 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 71 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 73 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 75 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 77 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 79 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 81 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 83 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 91 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 71 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 91 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 73 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 91 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 75 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬, 그리고 배열 번호 91 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 77 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬로 이루어지는 군에서 선택되는 중사슬 및 경사슬을 갖는 상기 (14) 또는 (15) 에 기재된 항체 또는 당해 항체의 기능성 단편.
(17) 배열 번호 85 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 71 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 73 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 75 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 77 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 79 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 81 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 83 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 91 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 71 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 91 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 73 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 91 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 75 에 기재된 아미노산 배열로 이루어지는 경사슬, 그리고 배열 번호 91 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 77 에 기재된 아미노산 배열로 이루어지는 경사슬로 이루어지는 군에서 선택되는 중사슬 및 경사슬을 갖는 상기 (14) 내지 (16) 중 어느 한 항에 기재된 항체 또는 당해 항체의 기능성 단편.
(18) 기능성 단편이 Fab, F(ab)2, Fab' 및 Fv 로 이루어지는 군에서 선택되는 상기 (1) 내지 (17) 중 어느 한 항에 기재된 항체의 기능성 단편.
(19) 상기 (1) 내지 (18) 중 어느 한 항에 기재된 항체 또는 당해 항체의 기능성 단편을 코드하는 폴리뉴클레오티드.
(20) 배열 번호 50 에 있어서의 58 내지 423 의 뉴클레오티드 배열, 및 배열 번호 52 에 있어서의 67 내지 390 의 뉴클레오티드 배열을 갖는 상기 (19) 에 기재된 폴리뉴클레오티드.
(21) 배열 번호 62 의 뉴클레오티드 배열, 및 배열 번호 58 의 뉴클레오티드 배열인 상기 (19) 또는 (20) 에 기재된 폴리뉴클레오티드.
(22) (a) 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열, (b) 배열 번호 86 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열, (c) 배열 번호 88 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열, (d) 배열 번호 90 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열, 및 (e) (a) 내지 (d) 에 기재된 뉴클레오티드 배열과 상보적인 뉴클레오티드 배열로 이루어지는 폴리뉴클레오티드와 스트린젠트한 조건에서 하이브리다이즈하는 폴리뉴클레오티드가 갖는 뉴클레오티드 배열로 이루어지는 군에서 선택된 뉴클레오티드 배열, 그리고 (f) 배열 번호 70 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, (g) 배열 번호 72 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, (h) 배열 번호 74 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, (i) 배열 번호 76 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, (j) 배열 번호 78 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, (k) 배열 번호 80 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, (l) 배열 번호 82 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 및 (m) (f) 내지 (l) 에 기재된 뉴클레오티드 배열과 상보적인 뉴클레오티드 배열로 이루어지는 폴리뉴클레오티드와 스트린젠트한 조건에서 하이브리다이즈하는 폴리뉴클레오티드가 갖는 뉴클레오티드 배열로 이루어지는 군에서 선택되는 뉴클레오티드 배열을 갖는 상기 (19) 또는 (20) 에 기재된 폴리뉴클레오티드.
(23) 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 70 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 72 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 74 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 76 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 78 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 80 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 82 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 배열 번호 90 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 70 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 배열 번호 90 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 72 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 배열 번호 90 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 74 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 그리고 배열 번호 90 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 76 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열로 이루어지는 군에서 선택되는 뉴클레오티드 배열을 갖는 상기 (22) 에 기재된 폴리뉴클레오티드.
(24) 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 70 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 72 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 74 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 76 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 78 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 80 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 82 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열, 배열 번호 90 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 70 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열, 배열 번호 90 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 72 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열, 배열 번호 90 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 74 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열, 그리고 배열 번호 90 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 76 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열로 이루어지는 군에서 선택되는 뉴클레오티드 배열을 갖는 상기 (22) 또는 (23) 에 기재된 폴리뉴클레오티드.
(25) 배열 번호 84 에 기재된 뉴클레오티드 배열 및 배열 번호 70 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 기재된 뉴클레오티드 배열 및 배열 번호 72 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 기재된 뉴클레오티드 배열 및 배열 번호 74 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 기재된 뉴클레오티드 배열 및 배열 번호 76 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 기재된 뉴클레오티드 배열 및 배열 번호 78 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 기재된 뉴클레오티드 배열 및 배열 번호 80 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 기재된 뉴클레오티드 배열 및 배열 번호 82 에 기재된 뉴클레오티드 배열, 배열 번호 90 에 기재된 뉴클레오티드 배열 및 배열 번호 70 에 기재된 뉴클레오티드 배열, 배열 번호 90 에 기재된 뉴클레오티드 배열 및 배열 번호 72 에 기재된 뉴클레오티드 배열, 배열 번호 90 에 기재된 뉴클레오티드 배열 및 배열 번호 74 에 기재된 뉴클레오티드 배열, 그리고 배열 번호 90 에 기재된 뉴클레오티드 배열 및 배열 번호 76 에 기재된 뉴클레오티드 배열로 이루어지는 군에서 선택되는 뉴클레오티드 배열인 상기 (22) 내지 (24) 중 어느 한 항에 기재된 폴리뉴클레오티드.
(26) 상기 (19) 내지 (25) 중 어느 한 항에 기재된 폴리뉴클레오티드를 함유하는 발현 벡터.
(27) 상기 (26) 에 기재된 발현 벡터에 의해 형질 전환된 숙주 세포.
(28) 숙주 세포가 진핵 세포인 상기 (27) 에 기재된 숙주 세포.
(29) 상기 (27) 또는 (28) 에 기재된 숙주 세포를 배양하는 공정, 및 당해 공정에서 얻어진 배양물로부터 목적으로 하는 항체 또는 당해 항체의 기능성 단편을 채취하는 공정을 포함하는 것을 특징으로 하는 당해 항체 또는 당해 단편의 제조 방법.
(30) 상기 (29) 의 제조 방법에 의해 얻어지는 것을 특징으로 하는 항체 또는 당해 항체의 기능성 단편.
(31) 기능성 단편이 Fab, F(ab)2, Fab' 및 Fv 로 이루어지는 군에서 선택되는 상기 (30) 에 기재된 항체의 기능성 단편.
(32) 항체 의존성 세포 상해 활성을 증강시키기 위해 당 사슬 수식이 조절되어 있는 상기 (1) 내지 (18), (30), (31) 중 어느 한 항에 기재된 항체 또는 당해 항체의 기능성 단편.
(33) 상기 (1) 내지 (18), (30) 내지 (32) 에 기재된 항체 또는 당해 항체의 기능성 단편의 적어도 하나를 함유하는 것을 특징으로 하는 의약 조성물.
(34) 종양 치료용인 상기 (33) 에 기재된 의약 조성물.
(35) 상기 (1) 내지 (18), (30) 내지 (32) 에 기재된 항체 또는 당해 항체의 기능성 단편의 적어도 하나, 및 적어도 하나의 암 치료제를 함유하는 것을 특징으로 하는 종양 치료용 의약 조성물.
(36) 종양이 암인 상기 (34) 또는 (35) 에 기재된 의약 조성물.
(37) 암이 폐암, 유방암, 전립선암, 췌장암, 대장암, 멜라노마, 간암, 난소암, 방광암, 위암, 식도암 또는 신장암인 상기 (36) 에 기재된 의약 조성물.
(38) 상기 (1) 내지 (18), (30) 내지 (32) 에 기재된 항체 또는 당해 항체의 기능성 단편의 적어도 하나를 개체에 투여하는 것을 특징으로 하는 종양의 치료 방법.
(39) 상기 (1) 내지 (18), (30) 내지 (32) 에 기재된 항체 또는 당해 항체의 기능성 단편의 적어도 하나, 및 적어도 하나의 암 치료제를 동시에, 따로따로, 또는 연속해서 개체에 투여하는 것을 특징으로 하는 종양의 치료 방법.
(40) 종양이 암인 상기 (38) 또는 (39) 에 기재된 치료 방법.
(41) 암이 폐암, 유방암, 전립선암, 췌장암, 대장암, 멜라노마, 간암, 난소암, 방광암, 위암, 식도암 또는 신장암인 상기 (40) 에 기재된 치료 방법.
본 발명에 의하면, B7-H3 에 결합하여 암 세포에 대해 항종양 활성을 갖는 항체를 함유하는 암의 치료제 등을 얻을 수 있다.
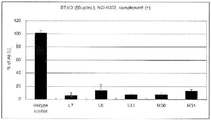
도 1 은 항 B7-H3 항체의 NCI-H322 세포에 대한 ADCP 활성의 유무를 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 3) 를 나타낸다.
도 2 는 시판 항 B7-H3 항체의 NCI-H322 세포에 대한 ADCP 활성의 유무를 나타내는 도면이다.
도 3 은 M30 항체의 공 (空) 벡터 및 B7-H3 발현 293 세포에 대한 ADCC 활성의 유무를 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 3) 를 나타낸다. 또한, 도면 내의 「mock」 는 공 벡터를 발현한 293 세포에 대한 M30 의 ADCC 활성을 의미하고, 「B7H3」은 B7-H3 발현 293 세포에 대한 M30 의 ADCC 활성을 의미한다.
도 4 는 항 B7-H3 항체의 NCI-H322 세포에 대한 CDC 활성의 유무를 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 3) 를 나타낸다.
도 5a 는 M30 항체의 B7-H3 결손 변이체 (B7-H3 IgV1) 에 대한 반응성을 나타내는 도면이다. 컨트롤 항체의 결합성을 점선으로, M30 하이브리도마 배양 상청의 결합성을 실선으로 나타낸다.
도 5b 는 M30 항체의 B7-H3 결손 변이체 (B7-H3 IgC1) 에 대한 반응성을 나타내는 도면이다. 컨트롤 항체의 결합성을 점선으로, M30 하이브리도마 배양 상청의 결합성을 실선으로 나타낸다.
도 5c 는 M30 항체의 B7-H3 결손 변이체 (B7-H3 IgV2) 에 대한 반응성을 나타내는 도면이다. 컨트롤 항체의 결합성을 점선으로, M30 하이브리도마 배양 상청의 결합성을 실선으로 나타낸다.
도 5d 는 M30 항체의 B7-H3 결손 변이체 (B7-H3 IgC2) 에 대한 반응성을 나타내는 도면이다. 컨트롤 항체의 결합성을 점선으로, M30 하이브리도마 배양 상청의 결합성을 실선으로 나타낸다.
도 5e 는 M30 항체의 B7-H3 결손 변이체 (B7-H3 IgC1-V2-C2) 에 대한 반응성을 나타내는 도면이다. 컨트롤 항체의 결합성을 점선으로, M30 하이브리도마 배양 상청의 결합성을 실선으로 나타낸다.
도 5f 는 M30 항체의 B7-H3 결손 변이체 (B7-H3 IgV2-C2) 에 대한 반응성을 나타내는 도면이다. 컨트롤 항체의 결합성을 점선으로, M30 하이브리도마 배양 상청의 결합성을 실선으로 나타낸다.
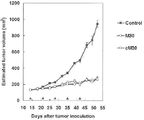
도 6 은 NCI-H322 세포가 이식된 마우스에 대한 항 B7-H3 항체의 항종양 활성을 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 10) 를 나타낸다.
도 7 은 생체 내로부터 탐식 세포를 제거했을 경우의 M30 항체의 항종양 효과를 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 8) 를 나타낸다. 또한, 「mm^3」 은 「㎣」을 의미한다.
도 8 은 M30 항체 및 cM30 항체의 NCI-H322 세포에 대한 ADCP 활성을 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 4) 를 나타낸다.
도 9 는 MDA-MB-231 세포가 이식된 마우스에 대한 M30 항체 및 cM30 항체의 항종양 효과를 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 9) 를 나타낸다.
도 10a 는 M30 의 B7-H3 베리언트 1 항원의 세포 외 영역 폴리펩티드 항원 결합에 대한 cM30 항체 및 M30-H1-L4 항체의 경합 저해 활성을 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 3) 를 나타낸다.
도 10b 는 M30 의 B7-H3 베리언트 2 항원의 세포 외 영역 폴리펩티드 항원 결합에 대한 cM30 항체 및 M30-H1-L4 항체의 경합 저해 활성을 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 3) 를 나타낸다.
도 11 은 M30 항체 및 cM30 항체, M30-H1-L4 항체의 NCI-H322 세포에 대해 ADCP 활성을 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 4) 를 나타낸다.
도 12 는 cM30 항체 및 M30-H1-L4 항체의 NCI-H322 세포에 대해 ADCC 활성을 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 3) 를 나타낸다.
도 13a 는 B7-H3 베리언트 1 의 뉴클레오티드 배열 (배열 번호 5) 을 나타낸다.
도 13b 는 B7-H3 베리언트 1 의 아미노산 배열 (배열 번호 6) 을 나타낸다.
도 14a 는 B7-H3 베리언트 2 의 뉴클레오티드 배열 (배열 번호 9) 을 나타낸다.
도 14b 는 B7-H3 베리언트 2 의 아미노산 배열 (배열 번호 10) 을 나타낸다.
도 15a 는 B7-H3 IgV1 의 뉴클레오티드 배열 (배열 번호 20) 을 나타낸다.
도 15b 는 B7-H3 IgV1 의 아미노산 배열 (배열 번호 21) 을 나타낸다.
도 16a 는 B7-H3 IgC1 의 뉴클레오티드 배열 (배열 번호 22) 을 나타낸다.
도 16b 는 B7-H3 IgC1 의 아미노산 배열 (배열 번호 23) 을 나타낸다.
도 17a 는 B7-H3 IgV2 의 뉴클레오티드 배열 (배열 번호 24) 을 나타낸다.
도 17b 는 B7-H3 IgV2 의 아미노산 배열 (배열 번호 25) 을 나타낸다.
도 18a 는 B7-H3 IgC2 의 뉴클레오티드 배열 (배열 번호 26) 을 나타낸다.
도 18b 는 B7-H3 IgC2 의 아미노산 배열 (배열 번호 27) 을 나타낸다.
도 19a 는 B7-H3 IgC1-V2-C2 의 뉴클레오티드 배열 (배열 번호 28) 을 나타낸다.
도 19b 는 B7-H3 IgC1-V2-C2 의 아미노산 배열 (배열 번호 29) 을 나타낸다.
도 20a 는 B7-H3 IgV2-C2 의 뉴클레오티드 배열 (배열 번호 30) 을 나타낸다.
도 20b 는 B7-H3 IgV2-C2 의 아미노산 배열 (배열 번호 31) 을 나타낸다.
도 21a 는 M30 항체 중사슬의 뉴클레오티드 배열 (배열 번호 50) 을 나타낸다.
도 21b 는 M30 항체 중사슬의 아미노산 배열 (배열 번호 51) 을 나타낸다.
도 22a 는 M30 항체 경사슬의 뉴클레오티드 배열 (배열 번호 52) 을 나타낸다.
도 22b 는 M30 항체 경사슬의 아미노산 배열 (배열 번호 53) 을 나타낸다.
도 23 은 인간 κ 사슬 분비 시그널, 인간 κ 사슬 정상 영역 및 인간 polyA 부가 시그널의 뉴클레오티드 배열 (배열 번호 56) 을 나타낸다.
도 24 는 인간 IgG1 시그널 배열 및 정상 영역의 뉴클레오티드 배열 (배열 번호 57) 을 나타낸다.
도 25a 는 M30 항체 키메라 타입 경사슬의 뉴클레오티드 배열 (배열 번호 58) 을 나타낸다.
도 25b 는 M30 항체 키메라 타입 경사슬의 아미노산 배열 (배열 번호 59) 을 나타낸다.
도 26a 는 M30 항체 키메라 타입 중사슬의 뉴클레오티드 배열 (배열 번호 62) 을 나타낸다.
도 26b 는 M30 항체 키메라 타입 중사슬의 아미노산 배열 (배열 번호 63) 을 나타낸다.
도 27a 는 M30-L1 타입 경사슬의 뉴클레오티드 배열 (배열 번호 70) 을 나타낸다.
도 27b 는 M30-L1 타입 경사슬의 아미노산 배열 (배열 번호 71) 을 나타낸다.
도 28a 는 M30-L2 타입 경사슬의 뉴클레오티드 배열 (배열 번호 72) 을 나타낸다.
도 28b 는 M30-L2 타입 경사슬의 아미노산 배열 (배열 번호 73) 을 나타낸다.
도 29a 는 M30-L3 타입 경사슬의 뉴클레오티드 배열 (배열 번호 74) 을 나타낸다.
도 29b 는 M30-L3 타입 경사슬의 아미노산 배열 (배열 번호 75) 을 나타낸다.
도 30a 는 M30-L4 타입 경사슬의 뉴클레오티드 배열 (배열 번호 76) 을 나타낸다.
도 30b 는 M30-L4 타입 경사슬의 아미노산 배열 (배열 번호 77) 을 나타낸다.
도 31a 는 M30-L5 타입 경사슬의 뉴클레오티드 배열 (배열 번호 78) 을 나타낸다.
도 31b 는 M30-L5 타입 경사슬의 아미노산 배열 (배열 번호 79) 을 나타낸다.
도 32a 는 M30-L6 타입 경사슬의 뉴클레오티드 배열 (배열 번호 80) 을 나타낸다.
도 32b 는 M30-L6 타입 경사슬의 아미노산 배열 (배열 번호 81) 을 나타낸다.
도 33a 는 M30-L7 타입 경사슬의 뉴클레오티드 배열 (배열 번호 82) 을 나타낸다.
도 33b 는 M30-L7 타입 경사슬의 아미노산 배열 (배열 번호 83) 을 나타낸다.
도 34a 는 M30-H1 타입 중사슬의 뉴클레오티드 배열 (배열 번호 84) 을 나타낸다.
도 34b 는 M30-H1 타입 중사슬의 아미노산 배열 (배열 번호 85) 을 나타낸다.
도 35a 는 M30-H2 타입 중사슬의 뉴클레오티드 배열 (배열 번호 86) 을 나타낸다.
도 35b 는 M30-H2 타입 중사슬의 아미노산 배열 (배열 번호 87) 을 나타낸다.
도 36a 는 M30-H3 타입 중사슬의 뉴클레오티드 배열 (배열 번호 88) 을 나타낸다.
도 36b 는 M30-H3 타입 중사슬의 아미노산 배열 (배열 번호 89) 을 나타낸다.
도 37a 는 M30-H4 타입 중사슬의 뉴클레오티드 배열 (배열 번호 90) 을 나타낸다.
도 37b 는 M30-H4 타입 중사슬의 아미노산 배열 (배열 번호 91) 을 나타낸다.
도 38 은 MDA-MB-231 세포가 이식된 마우스에 대한 인간화 M30 (M30-H1-L4) 항체의 항종양 효과를 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 6) 를 나타낸다.
도 2 는 시판 항 B7-H3 항체의 NCI-H322 세포에 대한 ADCP 활성의 유무를 나타내는 도면이다.
도 3 은 M30 항체의 공 (空) 벡터 및 B7-H3 발현 293 세포에 대한 ADCC 활성의 유무를 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 3) 를 나타낸다. 또한, 도면 내의 「mock」 는 공 벡터를 발현한 293 세포에 대한 M30 의 ADCC 활성을 의미하고, 「B7H3」은 B7-H3 발현 293 세포에 대한 M30 의 ADCC 활성을 의미한다.
도 4 는 항 B7-H3 항체의 NCI-H322 세포에 대한 CDC 활성의 유무를 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 3) 를 나타낸다.
도 5a 는 M30 항체의 B7-H3 결손 변이체 (B7-H3 IgV1) 에 대한 반응성을 나타내는 도면이다. 컨트롤 항체의 결합성을 점선으로, M30 하이브리도마 배양 상청의 결합성을 실선으로 나타낸다.
도 5b 는 M30 항체의 B7-H3 결손 변이체 (B7-H3 IgC1) 에 대한 반응성을 나타내는 도면이다. 컨트롤 항체의 결합성을 점선으로, M30 하이브리도마 배양 상청의 결합성을 실선으로 나타낸다.
도 5c 는 M30 항체의 B7-H3 결손 변이체 (B7-H3 IgV2) 에 대한 반응성을 나타내는 도면이다. 컨트롤 항체의 결합성을 점선으로, M30 하이브리도마 배양 상청의 결합성을 실선으로 나타낸다.
도 5d 는 M30 항체의 B7-H3 결손 변이체 (B7-H3 IgC2) 에 대한 반응성을 나타내는 도면이다. 컨트롤 항체의 결합성을 점선으로, M30 하이브리도마 배양 상청의 결합성을 실선으로 나타낸다.
도 5e 는 M30 항체의 B7-H3 결손 변이체 (B7-H3 IgC1-V2-C2) 에 대한 반응성을 나타내는 도면이다. 컨트롤 항체의 결합성을 점선으로, M30 하이브리도마 배양 상청의 결합성을 실선으로 나타낸다.
도 5f 는 M30 항체의 B7-H3 결손 변이체 (B7-H3 IgV2-C2) 에 대한 반응성을 나타내는 도면이다. 컨트롤 항체의 결합성을 점선으로, M30 하이브리도마 배양 상청의 결합성을 실선으로 나타낸다.
도 6 은 NCI-H322 세포가 이식된 마우스에 대한 항 B7-H3 항체의 항종양 활성을 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 10) 를 나타낸다.
도 7 은 생체 내로부터 탐식 세포를 제거했을 경우의 M30 항체의 항종양 효과를 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 8) 를 나타낸다. 또한, 「mm^3」 은 「㎣」을 의미한다.
도 8 은 M30 항체 및 cM30 항체의 NCI-H322 세포에 대한 ADCP 활성을 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 4) 를 나타낸다.
도 9 는 MDA-MB-231 세포가 이식된 마우스에 대한 M30 항체 및 cM30 항체의 항종양 효과를 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 9) 를 나타낸다.
도 10a 는 M30 의 B7-H3 베리언트 1 항원의 세포 외 영역 폴리펩티드 항원 결합에 대한 cM30 항체 및 M30-H1-L4 항체의 경합 저해 활성을 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 3) 를 나타낸다.
도 10b 는 M30 의 B7-H3 베리언트 2 항원의 세포 외 영역 폴리펩티드 항원 결합에 대한 cM30 항체 및 M30-H1-L4 항체의 경합 저해 활성을 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 3) 를 나타낸다.
도 11 은 M30 항체 및 cM30 항체, M30-H1-L4 항체의 NCI-H322 세포에 대해 ADCP 활성을 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 4) 를 나타낸다.
도 12 는 cM30 항체 및 M30-H1-L4 항체의 NCI-H322 세포에 대해 ADCC 활성을 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 3) 를 나타낸다.
도 13a 는 B7-H3 베리언트 1 의 뉴클레오티드 배열 (배열 번호 5) 을 나타낸다.
도 13b 는 B7-H3 베리언트 1 의 아미노산 배열 (배열 번호 6) 을 나타낸다.
도 14a 는 B7-H3 베리언트 2 의 뉴클레오티드 배열 (배열 번호 9) 을 나타낸다.
도 14b 는 B7-H3 베리언트 2 의 아미노산 배열 (배열 번호 10) 을 나타낸다.
도 15a 는 B7-H3 IgV1 의 뉴클레오티드 배열 (배열 번호 20) 을 나타낸다.
도 15b 는 B7-H3 IgV1 의 아미노산 배열 (배열 번호 21) 을 나타낸다.
도 16a 는 B7-H3 IgC1 의 뉴클레오티드 배열 (배열 번호 22) 을 나타낸다.
도 16b 는 B7-H3 IgC1 의 아미노산 배열 (배열 번호 23) 을 나타낸다.
도 17a 는 B7-H3 IgV2 의 뉴클레오티드 배열 (배열 번호 24) 을 나타낸다.
도 17b 는 B7-H3 IgV2 의 아미노산 배열 (배열 번호 25) 을 나타낸다.
도 18a 는 B7-H3 IgC2 의 뉴클레오티드 배열 (배열 번호 26) 을 나타낸다.
도 18b 는 B7-H3 IgC2 의 아미노산 배열 (배열 번호 27) 을 나타낸다.
도 19a 는 B7-H3 IgC1-V2-C2 의 뉴클레오티드 배열 (배열 번호 28) 을 나타낸다.
도 19b 는 B7-H3 IgC1-V2-C2 의 아미노산 배열 (배열 번호 29) 을 나타낸다.
도 20a 는 B7-H3 IgV2-C2 의 뉴클레오티드 배열 (배열 번호 30) 을 나타낸다.
도 20b 는 B7-H3 IgV2-C2 의 아미노산 배열 (배열 번호 31) 을 나타낸다.
도 21a 는 M30 항체 중사슬의 뉴클레오티드 배열 (배열 번호 50) 을 나타낸다.
도 21b 는 M30 항체 중사슬의 아미노산 배열 (배열 번호 51) 을 나타낸다.
도 22a 는 M30 항체 경사슬의 뉴클레오티드 배열 (배열 번호 52) 을 나타낸다.
도 22b 는 M30 항체 경사슬의 아미노산 배열 (배열 번호 53) 을 나타낸다.
도 23 은 인간 κ 사슬 분비 시그널, 인간 κ 사슬 정상 영역 및 인간 polyA 부가 시그널의 뉴클레오티드 배열 (배열 번호 56) 을 나타낸다.
도 24 는 인간 IgG1 시그널 배열 및 정상 영역의 뉴클레오티드 배열 (배열 번호 57) 을 나타낸다.
도 25a 는 M30 항체 키메라 타입 경사슬의 뉴클레오티드 배열 (배열 번호 58) 을 나타낸다.
도 25b 는 M30 항체 키메라 타입 경사슬의 아미노산 배열 (배열 번호 59) 을 나타낸다.
도 26a 는 M30 항체 키메라 타입 중사슬의 뉴클레오티드 배열 (배열 번호 62) 을 나타낸다.
도 26b 는 M30 항체 키메라 타입 중사슬의 아미노산 배열 (배열 번호 63) 을 나타낸다.
도 27a 는 M30-L1 타입 경사슬의 뉴클레오티드 배열 (배열 번호 70) 을 나타낸다.
도 27b 는 M30-L1 타입 경사슬의 아미노산 배열 (배열 번호 71) 을 나타낸다.
도 28a 는 M30-L2 타입 경사슬의 뉴클레오티드 배열 (배열 번호 72) 을 나타낸다.
도 28b 는 M30-L2 타입 경사슬의 아미노산 배열 (배열 번호 73) 을 나타낸다.
도 29a 는 M30-L3 타입 경사슬의 뉴클레오티드 배열 (배열 번호 74) 을 나타낸다.
도 29b 는 M30-L3 타입 경사슬의 아미노산 배열 (배열 번호 75) 을 나타낸다.
도 30a 는 M30-L4 타입 경사슬의 뉴클레오티드 배열 (배열 번호 76) 을 나타낸다.
도 30b 는 M30-L4 타입 경사슬의 아미노산 배열 (배열 번호 77) 을 나타낸다.
도 31a 는 M30-L5 타입 경사슬의 뉴클레오티드 배열 (배열 번호 78) 을 나타낸다.
도 31b 는 M30-L5 타입 경사슬의 아미노산 배열 (배열 번호 79) 을 나타낸다.
도 32a 는 M30-L6 타입 경사슬의 뉴클레오티드 배열 (배열 번호 80) 을 나타낸다.
도 32b 는 M30-L6 타입 경사슬의 아미노산 배열 (배열 번호 81) 을 나타낸다.
도 33a 는 M30-L7 타입 경사슬의 뉴클레오티드 배열 (배열 번호 82) 을 나타낸다.
도 33b 는 M30-L7 타입 경사슬의 아미노산 배열 (배열 번호 83) 을 나타낸다.
도 34a 는 M30-H1 타입 중사슬의 뉴클레오티드 배열 (배열 번호 84) 을 나타낸다.
도 34b 는 M30-H1 타입 중사슬의 아미노산 배열 (배열 번호 85) 을 나타낸다.
도 35a 는 M30-H2 타입 중사슬의 뉴클레오티드 배열 (배열 번호 86) 을 나타낸다.
도 35b 는 M30-H2 타입 중사슬의 아미노산 배열 (배열 번호 87) 을 나타낸다.
도 36a 는 M30-H3 타입 중사슬의 뉴클레오티드 배열 (배열 번호 88) 을 나타낸다.
도 36b 는 M30-H3 타입 중사슬의 아미노산 배열 (배열 번호 89) 을 나타낸다.
도 37a 는 M30-H4 타입 중사슬의 뉴클레오티드 배열 (배열 번호 90) 을 나타낸다.
도 37b 는 M30-H4 타입 중사슬의 아미노산 배열 (배열 번호 91) 을 나타낸다.
도 38 은 MDA-MB-231 세포가 이식된 마우스에 대한 인간화 M30 (M30-H1-L4) 항체의 항종양 효과를 나타내는 도면이다. 도면 내의 에러바는 표준 오차 (n = 6) 를 나타낸다.
본 명세서 중에 있어서, 「암」 과 「종양」 은 동일한 의미로 사용하고 있다.
본 명세서 중에 있어서, 「유전자」라는 단어에는 DNA 뿐만 아니라 그 mRNA, cDNA 및 그 cRNA 도 포함된다.
본 명세서 중에 있어서, 「폴리뉴클레오티드」라고 하는 단어는 핵산과 동일한 의미로 사용하고 있으며, DNA, RNA, 프로브, 올리고 뉴클레오티드, 및 프라이머도 포함된다.
본 명세서 중에 있어서는, 「폴리펩티드」 와 「단백질」 은 구별하지 않고 사용하고 있다.
본 명세서 중에 있어서, 「세포」 에는 동물 개체 내의 세포, 배양 세포도 포함하고 있다.
본 명세서 중에 있어서, 「B7-H3」 은 B7-H3 단백질과 동일한 의미로 사용하고 있으며, 또한 B7-H3 베리언트 1 및/또는 B7-H3 베리언트 2 를 의미한다.
본 명세서 중에 있어서의 「세포 상해」란, 어떠한 형태로 세포에 병리적인 변화를 가져오는 것을 말하고, 직접적인 외상에 머무르지 않고, DNA 의 절단이나 염기의 이량체의 형성, 염색체의 절단, 세포 분열 장치의 손상, 각종 효소 활성의 저하 등 모든 세포의 구조나 기능상의 손상을 말한다.
본 명세서 중에 있어서의 「세포 상해 활성」이란, 상기 세포 상해를 일으키는 것을 말한다.
본 명세서 중에 있어서의 「항체 의존성 세포 매개 식작용 활성」이란, 「antibody dependent cell phagocytosis (ADCP) 활성」 이고, 단구나 매크로파지 세포가 항체를 통해서 종양 세포 등의 표적 세포를 탐식하는 작용 활성을 의미한다. 「항체 의존적 탐식 작용 활성」이라고도 한다.
본 명세서 중에 있어서의 「항체 의존성 세포 상해 활성」이란, 「antibody dependent cellular cytotoxicity (ADCC) 활성」 이고, NK 세포가 항체를 통해서 종양 세포 등의 표적 세포를 상해하는 작용 활성을 의미한다.
본 명세서 중에 있어서의 「보체 의존성 세포 상해 작용 활성」이란, 「complement dependent cytotoxicity (CDC) 활성」이고, 보체가 항체를 통해서 종양 세포 등의 표적 세포를 상해하는 작용 활성을 의미한다.
본 명세서 중에 있어서의 「항체의 기능성 단편」이란, 항원과의 결합 활성을 갖는 항체의 부분 단편으로서, 당해 항체가 갖는 기능의 모두 또는 일부를 유지하고 있는 단편을 의미하고 있고, Fab, F(ab')2, scFv 등을 포함한다. 또한, F(ab')2 를 환원 조건하에서 처리한 항체의 가변 영역의 1 가의 단편인 Fab' 도 항체의 기능성 단편에 포함된다. 단, 항원과의 결합능을 갖고 있는 한 이들 분자에 한정되지 않는다. 또한, 이들 기능성 단편에는 항체 단백질의 전체 길이 분자를 적당한 효소로 처리한 것뿐만 아니라, 유전자 공학적으로 개변된 항체 유전자를 사용하여 적당한 숙주 세포에 있어서 산생된 단백질도 포함된다.
본 발명에 있어서의 「Fab'」란, 상기와 같이 F(ab')2 를 환원 조건하에서 처리한 항체의 가변 영역의 1 가의 단편이다. 단, 유전자 공학적으로 개변된 항체 유전자를 사용하여 산생되는 Fab' 도 본 발명에 있어서의 Fab' 에 포함된다.
본 명세서에 있어서의 「에피토프」란, 특정한 항 B7-H3 항체가 결합하는 B7-H3 의 부분 펩티드 또는 부분 입체 구조를 의미한다. 상기 B7-H3 의 부분 펩티드인 에피토프는 면역 어세이법 등 당업자에게 잘 알려져 있는 방법, 예를 들어 이하의 방법에 의해 결정할 수 있다. 먼저, 항원의 다양한 부분 구조를 제조한다. 부분 구조의 제조에 있어서는, 공지된 올리고 펩티드 합성 기술을 사용할 수 있다. 예를 들어, B7-H7 의 C 말단 혹은 N 말단으로부터 적당한 길이로 순차적으로 짧게 한 일련의 폴리펩티드를 당업자에게 주지의 유전자 재조합 기술을 사용하여 제조한 후, 그들에 대한 항체의 반응성을 검토하여, 대략적인 인식 부위를 결정한 후, 더욱 짧은 펩티드를 합성하여 그들 펩티드와의 반응성을 검토함으로써 에피토프를 결정할 수 있다. 또한, 특정한 항체가 결합하는 항원의 부분 입체 구조인 에피토프는 X 선 구조 해석에 의해 상기의 항체와 인접하는 항원의 아미노산 잔기를 특정함으로써 결정할 수 있다.
본 명세서에 있어서의 「동일한 에피토프에 결합하는 항체」란, 공통의 에피토프에 결합하는 상이한 항체를 의미하고 있다. 제 1 항체가 결합하는 부분 펩티드 또는 부분 입체 구조에 제 2 항체가 결합하면, 제 1 항체와 제 2 항체가 동일한 에피토프에 결합한다고 판정할 수 있다. 또, 제 1 항체의 항원에 대한 결합에 대해 제 2 항체가 경합하는 (즉, 제 2 항체가 제 1 항체와 항원의 결합을 방해하는) 것을 확인함으로써, 구체적인 에피토프의 배열 또는 구조가 결정되어 있지 않아도 제 1 항체와 제 2 항체가 동일한 에피토프에 결합한다고 판정할 수 있다. 또한, 제 1 항체와 제 2 항체가 동일한 에피토프에 결합하고, 또한 제 1 항체가 항종양 활성 등의 특수한 효과를 갖는 경우, 제 2 항체도 동일한 활성을 갖는 것을 기대할 수 있다. 따라서, 제 1 항 B7-H3 항체가 결합하는 부분 펩티드에 제 2 항 B7-H3 항체가 결합하면, 제 1 항체와 제 2 항체가 B7-H3 이 동일한 에피토프에 결합한다고 판정할 수 있다. 또, 제 1 항 B7-H3 항체의 B7-H3 에 대한 결합에 대해 제 2 항 B7-H3 항체가 경합하는 것을 확인함으로써, 제 1 항체와 제 2 항체가 B7-H3 이 동일한 에피토프에 결합하는 항체라고 판정할 수 있다.
본 명세서에 있어서의 「CDR」 이란, 상보성 결정 영역 (CDR : Complemetarity deterring region) 을 의미한다. 항체 분자의 중사슬 및 경사슬에는 각각 3 지점의 CDR 이 있는 것이 알려져 있다. CDR 은 초가변 영역 (hypervariable domain) 이라고도 불리고, 항체의 중사슬 및 경사슬의 가변 영역 내에 있어서, 일차 구조의 변이성이 특히 높은 부위이며, 중사슬 및 경사슬의 폴리펩티드 사슬의 일차 구조 상에 있어서, 각각 3 지점으로 분리되어 있다. 본 명세서 중에 있어서는, 항체의 CDR 에 대해, 중사슬의 CDR 을 중사슬 아미노산 배열의 아미노 말단측으로부터 CDRH1, CDRH2, CDRH3 이라고 표기하고, 경사슬의 CDR 을 경사슬 아미노산 배열의 아미노 말단측으로부터 CDRL1, CDRL2, CDRL3 이라고 표기한다. 이들 부위는 입체 구조 상에서 서로 근접하여, 결합하는 항원에 대한 특이성을 결정하고 있다.
본 발명에 있어서, 「스트린젠트한 조건하에서 하이브리다이즈한다」란, 시판되는 하이브리다이제이션 용액 ExpressHyb Hybridization Solution (클론텍사 제조) 중, 68 ℃ 에서 하이브리다이즈하는 것, 또는 DNA 를 고정시킨 필터를 사용하여 0.7 - 1.0 M 의 NaCl 존재하 68 ℃ 에서 하이브리다이제이션을 실시한 후, 0.1 - 2 배 농도의 SSC 용액 (1 배 농도 SSC 란 150 mM NaCl, 15 mM 시트르산나트륨으로 이루어진다) 을 사용하여, 68 ℃ 에서 세정함으로써 동정할 수 있는 조건 또는 그것과 동등한 조건으로 하이브리다이즈하는 것을 말한다.
1. B7-H3
B7-H3 은 항원 제시 세포에 보조 자극 분자로서 발현하는 B7 패밀리의 하나로, T 세포 상의 리셉터에 작용하여 면역 작용을 촉진하거나 또는 억제한다고 생각되고 있다.
B7-H3 은 1 회 막관통 구조를 갖는 단백질이지만, B7-H3 의 N 말단측의 세포 외 영역에는 2 개의 베리언트가 존재한다. B7-H3 베리언트 1 (4Ig-B7-H3) 에는 각 2 지점의 V 또는 C 형 Ig 도메인이 존재하고, B7-H3 베리언트 2 (2Ig-B7-H3) 에는 각 1 지점의 V 또는 C 형 Ig 도메인이 존재한다.
본 발명에서 사용하는 B7-H3 은 인간, 비인간 포유 동물 (래트, 마우스 등) 의 B7-H3 발현 세포로부터 직접 정제하여 사용하거나, 혹은 당해 세포의 세포막 획분을 조제하여 사용할 수 있고, 또한 B7-H3 을 in vitro 에서 합성하거나, 혹은 유전자 조작에 의해 숙주 세포에 산생시킴으로써 얻을 수 있다. 유전자 조작에서는, 구체적으로는 B7-H3 cDNA 를 발현 가능한 벡터에 삽입한 후, 전사와 번역에 필요한 효소, 기질 및 에너지 물질을 함유하는 용액 중에서 합성하거나, 혹은 다른 원핵 생물, 또는 진핵 생물의 숙주 세포를 형질 전환시킴으로써 B7-H3 을 발현시키는 것에 의해, 그 단백질을 얻을 수 있다.
인간 B7-H3 베리언트 1 유전자의 오픈 리딩 프레임 (ORF) 의 뉴클레오티드 배열은 배열표의 배열 번호 5 에 기재되어 있고, 그 아미노산 배열은 배열표의 배열 번호 6 에 기재되어 있다. 또한, 배열 번호 5 및 6 의 배열은 도 13 에 기재되어 있다.
인간 B7-H3 베리언트 2 유전자의 ORF 의 뉴클레오티드 배열은 배열표의 배열 번호 9 에 기재되어 있고, 그 아미노산 배열은 배열표의 배열 번호 10 에 기재되어 있다. 또한, 배열 번호 9 및 10 의 배열은 도 14 에 기재되어 있다.
또한, 상기 각 B7-H3 의 아미노산 배열에 있어서, 1 또는 수 개의 아미노산이 치환, 결실 및/또는 부가된 아미노산 배열로 이루어지고, 당해 단백질과 동등한 생물 활성을 갖는 단백질도 B7-H3 에 포함된다.
시그널 배열이 제거된 성숙 인간 B7-H3 베리언트 1 은 배열 번호 6 에 나타내는 아미노산 배열의 27 번째 내지 534 번째의 아미노산 잔기로 이루어지는 아미노산 배열에 상당한다. 또한, 시그널 배열이 제거된 성숙 인간 B7-H3 베리언트 2 는 배열 번호 6 에 나타내는 아미노산 배열의 27 번째 내지 316 번째의 아미노산 잔기로 이루어지는 아미노산 배열에 상당한다.
B7-H3 베리언트 1 에 있어서, 각 도메인은 N 말단으로부터 IgV1-IgC1-IgV2-IgC2 의 순서로 존재하고 있고, 배열표의 배열 번호 6 에 있어서 IgV1 은 아미노산 번호 27 내지 139 에 상당하고, IgC1 은 아미노산 번호 140 내지 244 에 상당하고, IgV2 는 아미노산 번호 245 내지 357 에 상당하고, IgC2 는 아미노산 번호 358 내지 456 에 상당한다. 또한, B7-H3 베리언트 2 에 있어서, 각 도메인은 N 말단으로부터 IgV1-IgC2 의 순서로 존재하고 있고, 배열표의 배열 번호 10 에 있어서 IgV1 은 아미노산 번호 27 내지 140 에 상당하고, IgC2 는 아미노산 번호 141 내지 243 에 상당한다.
B7-H3 의 cDNA 는 예를 들어 B7-H3 의 cDNA 를 발현하고 있는 cDNA 라이브러리를 주형으로 하여, B7-H3 의 cDNA 를 특이적으로 증폭시키는 프라이머를 사용하여 폴리머라아제 연쇄 반응 (이하 「PCR」이라고 한다) (Saiki, R. K., et al., Science, (1988) 239, 487-49) 을 실시하는, 이른바 PCR 법에 의해 취득할 수 있다. 또한, 배열표의 배열 번호 5 또는 9 에 나타내는 뉴클레오티드 배열과 상보적인 뉴클레오티드 배열로 이루어지는 폴리뉴클레오티드와 스트린젠트한 조건에서 하이브리다이즈하고, 또한 B7-H3 과 동등한 생물 활성을 갖는 단백질을 코드하는 폴리뉴클레오티드도 B7-H3 의 cDNA 에 포함된다. 또한, 인간 혹은 마우스 B7-H3 유전자좌 (座) 로부터 전사되는 스플라이싱 베리언트 또는 이것에 스트린젠트한 조건에서 하이브리다이즈하는 폴리뉴클레오티드이고, 또한 B7-H3 과 동등한 생물 활성을 갖는 단백질을 코드하는 폴리뉴클레오티드도 B7-H3 의 cDNA 에 포함된다.
또한, 배열표의 배열 번호 6 또는 10 에 나타내는 아미노산 배열, 또는 이들 배열로부터 시그널 배열이 제거된 아미노산 배열에 있어서, 1 혹은 수 개의 아미노산이 치환, 결실, 또는 부가된 아미노산 배열로 이루어지고, B7-H3 과 동등한 생물 활성을 갖는 단백질도 B7-H3 에 포함된다. 또한, 인간 혹은 마우스 B7-H3 유전자좌로부터 전사되는 스플라이싱 베리언트로 코드되는 아미노산 배열 또는 그 아미노산 배열에 있어서, 1 혹은 수 개의 아미노산이 치환, 결실, 또는 부가된 아미노산 배열로 이루어지고, 또한 B7-H3 과 동등한 생물 활성을 갖는 단백질도 B7-H3 에 포함된다.
2. 항 B7-H3 항체의 제조
본 발명의 B7-H3 에 대한 항체는 통상적인 방법을 사용하여 B7-H3 또는 B7-H3 의 아미노산 배열에서 선택되는 임의의 폴리펩티드를 동물에게 면역시키고, 생체 내에 산생되는 항체를 채취, 정제함으로써 얻을 수 있다. 항원이 되는 B7-H3 의 생물종은 인간에 한정되지 않고, 마우스, 래트 등의 인간 이외의 동물에서 유래하는 B7-H3 을 동물에게 면역시킬 수도 있다. 이 경우에는, 취득된 이종 (異種) B7-H3 에 결합하는 항체와 인간 B7-H3 의 교차성을 시험함으로써, 인간의 질환에 적용 가능한 항체를 선별할 수 있다.
또, 공지된 방법 (예를 들어, Kohler and Milstein, Nature (1975) 256, p.495-497, Kennet, R. ed., Monoclonal Antibodies, p.365-367, Plenum Press, N.Y. (1980)) 에 따라, B7-H3 에 대한 항체를 산생하는 항체 산생 세포와 미엘로마 세포를 융합시킴으로써 하이브리도마를 수립하여, 모노클로날 항체를 얻을 수도 있다.
또한, 항원이 되는 B7-H3 은 B7-H3 유전자를 유전자 조작에 의해 숙주 세포에 산생시킴으로써 얻을 수 있다.
구체적으로는, B7-H3 유전자를 발현 가능한 벡터를 제조하고, 이것을 숙주 세포에 도입하여 그 유전자를 발현시키며, 발현된 B7-H3 을 정제하면 된다. 이하, 구체적으로 B7-H3 에 대한 항체의 취득 방법을 설명한다.
(1) 항원의 조제
항 B7-H3 항체를 제조하기 위한 항원으로는, B7-H3 또는 그 적어도 6 개의 연속된 부분 아미노산 배열로 이루어지는 폴리펩티드, 혹은 이들에 임의의 아미노산 배열이나 담체가 부가된 유도체를 들 수 있다.
B7-H3 은 인간의 종양 조직 혹은 종양 세포로부터 직접 정제하여 사용할 수 있고, 또한 B7-H3 을 in vitro 에서 합성하거나, 혹은 유전자 조작에 의해 숙주 세포에 산생시킴으로써 얻을 수 있다.
유전자 조작에서는 구체적으로는 B7-H3 의 cDNA 를 발현 가능한 벡터에 삽입한 후, 전사와 번역에 필요한 효소, 기질 및 에너지 물질을 함유하는 용액 중에서 합성하거나, 혹은 다른 원핵 생물 또는 진핵 생물의 숙주 세포를 형질 전환시킴으로써 B7-H3 을 발현시키는 것에 의해, 항원을 얻을 수 있다.
또한, 막 단백질인 B7-H3 의 세포 외 영역과 항체의 정상 영역을 연결한 융합 단백질을 적절한 숙주·벡터계에 있어서 발현시킴으로써, 분비 단백질로서 항원을 얻는 것도 가능하다.
B7-H3 의 cDNA 는, 예를 들어, B7-H3 의 cDNA 를 발현하고 있는 cDNA 라이브러리를 주형으로 하여, B7-H3 cDNA 를 특이적으로 증폭시키는 프라이머를 사용하여 폴리머라아제 연쇄 반응 (이하 「PCR」이라고 한다) (Saiki, R. K., et al. Science (1988) 239, p.487-489 참조) 을 실시하는, 이른바 PCR 법에 의해 취득할 수 있다.
폴리펩티드의 인·비트로 (in vitro) 합성으로는, 예를 들어 로슈·다이아그노스틱스사 제조의 래피드 트랜스레이션 시스템 (RTS) 을 들 수 있지만, 이것에 한정되지 않는다.
원핵 세포의 숙주로는, 예를 들어 대장균 (Escherichia coli) 이나 고초균 (Bacillus subtilis) 등을 들 수 있다. 목적으로 하는 유전자를 이들 숙주 세포 내에서 형질 전환시키려면, 숙주와 적합할 수 있는 종 유래의 레플리콘 즉 복제 기점과, 조절 배열을 포함하고 있는 플라스미드 벡터로 숙주 세포를 형질 전환시킨다. 또한, 벡터로는, 형질 전환 세포에 표현 형질 (표현형) 의 선택성을 부여할 수 있는 배열을 갖는 것이 바람직하다.
진핵 세포의 숙주 세포에는, 척추 동물, 곤충, 효모 등의 세포가 포함되고, 척추 동물 세포로는, 예를 들어 원숭이의 세포인 COS 세포 (Gluzman, Y. Cell (1981) 23, p.175-182, ATCC CRL-1650), 마우스 선유아 세포 NIH3T3 (ATCC No. CRL-1658) 이나 차이니즈·햄스터 난소 세포 (CHO 세포, ATCC CCL-61) 의 디하이드로 엽산 환원 효소 결손주 (Urlaub, G. and Chasin, L. A. Proc. Natl. Acad. Sci. USA (1980) 77, p.4126-4220) 등이 자주 사용되고 있지만, 이들에 한정되지 않는다.
상기와 같이 하여 얻어지는 형질 전환체는 통상적인 방법에 따라 배양할 수 있고, 그 배양에 의해 세포 내, 또는 세포 외에 목적으로 하는 폴리펩티드가 산생된다.
그 배양에 사용되는 배지로는, 채용한 숙주 세포에 따라 관용되는 각종의 것을 적절히 선택할 수 있고, 대장균이면, 예를 들어 LB 배지에 필요에 따라 암피실린 등의 항생 물질이나 IPMG 를 첨가하여 사용할 수 있다.
상기 배양에 의해, 형질 전환체의 세포 내 또는 세포 외에 산생되는 재조합 단백질은 그 단백질의 물리적 성질이나 화학적 성질 등을 이용한 각종 공지된 분리 조작법에 의해 분리·정제할 수 있다.
그 방법으로는, 구체적으로는 예를 들어, 통상적인 단백질 침전제에 의한 처리, 한외 여과, 분자 체 크로마토그래피 (겔 여과), 흡착 크로마토그래피, 이온 교환 크로마토그래피, 어피니티 크로마토그래피 등의 각종 액체 크로마토그래피, 투석법, 이들의 조합 등을 예시할 수 있다.
또한, 발현시키는 재조합 단백질에 6 잔기로 이루어지는 히스티딘 태그를 연결함으로써, 니켈 어피니티 칼럼으로 효율적으로 정제할 수 있다. 혹은, 발현시키는 재조합 단백질에 IgG 의 Fc 영역을 연결함으로써, 프로테인 A 칼럼으로 효율적으로 정제할 수 있다.
상기 방법을 조합함으로써 용이하게 고수율, 고순도로 목적으로 하는 폴리펩티드를 대량으로 제조할 수 있다.
(2) 항 B7-H3 모노클로날 항체의 제조
B7-H3 과 특이적으로 결합하는 항체의 예로서, B7-H3 과 특이적으로 결합하는 모노클로날 항체를 들 수 있지만, 그 취득 방법은 이하에 기재하는 바와 같다.
모노클로날 항체의 제조에 있어서는, 일반적으로 하기와 같은 작업 공정이 필요하다.
즉,
(a) 항원으로서 사용하는 생체 고분자의 정제,
(b) 항원을 동물에게 주사함으로써 면역시킨 후, 혈액을 채취하여 그 항체가를 검정하여 비장 적출의 시기를 결정하고 나서, 항체 산생 세포를 조제하는 공정,
(c) 골수종 세포 (이하 「미엘로마」라고 한다) 의 조제,
(d) 항체 산생 세포와 미엘로마의 세포 융합,
(e) 목적으로 하는 항체를 산생하는 하이브리도마군의 선별,
(f) 단일 세포 클론으로의 분할 (클로닝),
(g) 경우에 따라서는, 모노클로날 항체를 대량으로 제조하기 위한 하이브리도마의 배양, 또는 하이브리도마를 이식한 동물의 사육,
(h) 이와 같이 하여 제조된 모노클로날 항체의 생리 활성, 및 그 결합 특이성의 검토, 혹은 표지 시약으로서의 특성의 검정 등이다.
이하, 모노클로날 항체의 제조법을 상기 공정에 따라 상세히 서술하지만, 그 항체의 제조법은 이것에 제한되지 않고, 예를 들어 비세포 이외의 항체 산생 세포 및 미엘로마를 사용할 수도 있다.
(a) 항원의 정제
항원으로는, 상기한 바와 같은 방법으로 조제한 B7-H3 또는 그 일부를 사용할 수 있다.
또한, B7-H3 발현 재조합체 세포로부터 조제한 막 획분, 또는 B7-H3 발현 재조합체 세포 자신, 또한 당업자에게 주지된 방법을 사용하여 화학 합성한 본 발명의 단백질의 부분 펩티드를 항원으로서 사용할 수도 있다.
(b) 항체 산생 세포의 조제
공정 (a) 에서 얻어진 항원과, 프로인트의 완전 또는 불완전 아쥬반트, 또는 칼리 명반과 같은 보조제를 혼합하고, 면역원으로서 실험 동물에게 면역시킨다. 실험 동물은 공지된 하이브리도마 제조법에 사용되는 동물을 지장없이 사용할 수 있다. 구체적으로는, 예를 들어 마우스, 래트, 염소, 양, 소, 말 등을 사용할 수 있다. 단, 적출한 항체 산생 세포와 융합시키는 미엘로마 세포의 입수 용이성 등의 관점에서, 마우스 또는 래트를 피면역 동물로 하는 것이 바람직하다.
또한, 실제로 사용하는 마우스 및 래트의 계통에는 특별히 제한은 없고, 마우스의 경우에는, 예를 들어 각 계통 A, AKR, BALB/c, BDP, BA, CE, C3H, 57BL, C57BL, C57L, DBA, FL, HTH, HT1, LP, NZB, NZW, RF, R III, SJL, SWR, WB, 129 등을, 또한 래트의 경우에는, 예를 들어 Wistar, Low, Lewis, Sprague, Dawley, ACI, BN, Fischer 등을 사용할 수 있다.
이들 마우스 및 래트는 예를 들어 닛폰 클레아, 닛폰 찰스 리버 등 실험 동물 사육 판매 업자로부터 입수할 수 있다.
이 중, 후술하는 미엘로마 세포와의 융합 적합성을 감안하면, 마우스에서는 BALB/c 계통이 래트에서는 Wistar 및 Low 계통이 피면역 동물로서 특히 바람직하다.
또한, 항원인 인간과 마우스에서의 상동성을 고려하여, 자기 항체를 제거하는 생체 기구를 저하시킨 마우스, 즉 자기 면역 질환 마우스를 사용하는 것도 바람직하다.
또한, 이들 마우스 또는 래트의 면역시의 주령은 바람직하게는 5 ∼ 12 주령, 더욱 바람직하게는 6 ∼ 8 주령이다.
B7-H3 또는 이 재조합체에 의해 동물을 면역시키기 위해서는, 예를 들어 Weir, D. M., Handbook of Experimental Immunology Vol.Ⅰ. Ⅱ. Ⅲ., Blackwell Scientific Publications, Oxford (1987), Kabat, E. A. and Mayer, M. M., Experimental Immunochemistry, Charles C Thomas Publisher Springfield, Illinois (1964) 등에 상세하게 기재되어 있는 공지된 방법을 사용할 수 있다.
이들 면역법 중, 본 발명에 있어서 바람직한 방법을 구체적으로 나타내면, 예를 들어 이하와 같다.
즉, 먼저 항원인 막 단백질 획분, 혹은 항원을 발현시킨 세포를 동물의 피내 (皮內) 또는 복강 내에 투여한다.
단, 면역 효율을 높이기 위해서는 양자의 병용이 바람직하고, 전반은 피내 투여를 실시하고, 후반 또는 최종회에만 복강 내 투여를 실시하면, 특히 면역 효율을 높일 수 있다.
항원의 투여 스케줄은 피면역 동물의 종류, 개체차 등에 따라 상이하지만, 일반적으로는 항원 투여 횟수 3 ∼ 6 회, 투여 간격 2 ∼ 6 주가 바람직하고, 투여 횟수 3 ∼ 4 회, 투여 간격 2 ∼ 4 주가 더욱 바람직하다.
또한, 항원의 투여량은 동물의 종류, 개체차 등에 따라 상이하지만, 일반적으로는 0.05 ∼ 5 ㎎, 바람직하게는 0.1 ∼ 0.5 ㎎ 정도로 한다.
추가 면역은 이상과 같은 항원 투여의 1 ∼ 6 주 후, 바람직하게는 2 ∼ 4 주 후, 더욱 바람직하게는 2 ∼ 3 주 후에 실시한다.
또한, 추가 면역을 실시할 때의 항원 투여량은 동물의 종류, 크기 등에 따라 상이하지만, 일반적으로 예를 들어 마우스의 경우에는 0.05 ∼ 5 ㎎, 바람직하게는 0.1 ∼ 0.5 ㎎, 더욱 바람직하게는 0.1 ∼ 0.2 ㎎ 정도로 한다.
상기 추가 면역으로부터 1 ∼ 10 일 후, 바람직하게는 2 ∼ 5 일 후, 더욱 바람직하게는 2 ∼ 3 일 후에 피면역 동물로부터 항체 산생 세포를 포함하는 비장 세포 또는 림프구를 무균적으로 취출한다. 그 때에 항체가를 측정하여, 항체가가 충분히 높아진 동물을 항체 산생 세포의 공급원으로서 사용하면, 이후의 조작 효율을 높일 수 있다.
여기서 사용되는 항체가의 측정법으로는, 예를 들어 RIA 법 또는 ELISA 법을 들 수 있지만, 이들 방법에 제한되지 않는다.
본 발명에 있어서의 항체가의 측정은, 예를 들어 ELISA 법에 의하면, 이하에 기재하는 바와 같은 순서에 의해 실시할 수 있다.
먼저, 정제 또는 부분 정제한 항원을 ELISA 용 96 구멍 플레이트 등의 고상 표면에 흡착시키고, 또한 항원이 흡착되어 있지 않은 고상 표면을 항원과 무관계한 단백질, 예를 들어 소 혈청 알부민 (이하 「BSA」라고 한다) 에 의해 덮고, 그 표면을 세정 후, 제 1 항체로서 단계 희석시킨 시료 (예를 들어 마우스 혈청) 에 접촉시켜, 상기 항원에 시료 중의 항체를 결합시킨다.
또한, 제 2 항체로서 효소 표지된 마우스 항체에 대한 항체를 첨가하여 마우스 항체에 결합시키고, 세정 후 그 효소의 기질을 첨가하여, 기질 분해에 기초하는 발색에 의한 흡광도의 변화 등을 측정함으로써 항체가를 산출한다.
피면역 동물의 비장 세포 또는 림프구로부터의 항체 산생 세포의 분리는 공지된 방법 (예를 들어, Kohler et al., Nature (1975) 256, p.495, ; Kohler et al., Eur. J. Immunol. (1977) 6, p.511, ; Milstein et al., Nature (1977), 266, p.550, ; Walsh, Nature, (1977) 266, p.495) 에 따라 실시할 수 있다. 예를 들어, 비장 세포의 경우에는, 비장을 가늘게 절단하고 세포를 스테인리스 메시로 여과한 후, 이글 최소 필수 배지 (MEM) 에 부유시켜 항체 산생 세포를 분리하는 일반적 방법을 채용할 수 있다.
(c) 골수종 세포 (이하, 「미엘로마」라고 한다) 의 조제
세포 융합에 사용하는 미엘로마 세포에는 특별한 제한은 없고, 공지된 세포주로부터 적절히 선택하여 사용할 수 있다. 단, 융합 세포로부터 하이브리도마를 선택할 때의 편리성을 고려하여, 그 선택 수속이 확립되어 있는 HGPRT (Hypoxanthine-guanine phosphoribosyl transferase) 결손주를 사용하는 것이 바람직하다.
즉, 마우스 유래의 X63-Ag8 (X63), NS1-ANS/1 (NS1), P3X63-Ag8.U1 (P3U1), X63-Ag8.653 (X63.653), SP2/0-Ag14 (SP2/0), MPC11-45.6TG1.7 (45.6TG), FO, S149/5XXO, BU.1 등, 래트 유래의 210.RSY3.Ag.1.2.3 (Y3) 등, 인간 유래의 U266AR (SKO-007), GM1500·GTG-A12 (GM1500), UC729-6, LICR-LOW-HMy2 (HMy2), 8226AR/NIP4-1 (NP41) 등이다. 이들 HGPRT 결손주는, 예를 들어, American Type Culture Collection (ATCC) 등으로부터 입수할 수 있다.
이들 세포주는 적당한 배지, 예를 들어 8-아자구아닌 배지 [RPMI-1640 배지에 글루타민, 2-메르캅토에탄올, 겐타마이신, 및 소 태아 혈청 (이하 「FCS」라고 한다) 을 첨가한 배지에 8-아자구아닌을 첨가한 배지], 이스코브 개변 둘베코 배지 (Iscove's Modified Dulbecco's Medium ; 이하 「IMDM」이라고 한다), 또는 둘베코 개변 이글 배지 (Dulbecco's Modified Eagle Medium ; 이하 「DMEM」이라고 한다) 에서 계대 배양하지만, 세포 융합의 3 내지 4 일 전에 정상 배지 [예를 들어, 10 % FCS 를 함유하는 ASF104 배지 (아지노모토 (주) 사 제조)] 에서 계대 배양하여, 융합 당일에 2 × 107 이상의 세포수를 확보해 둔다.
(d) 세포 융합
항체 산생 세포와 미엘로마 세포의 융합은 공지된 방법 (Weir, D. M., Handbook of Experimental Immunology Vol.Ⅰ. Ⅱ. Ⅲ., Blackwell Scientific Publications, Oxford (1987), Kabat, E. A. and Mayer, M. M., Experimental Immunochemistry, Charles C Thomas Publisher Springfield, Illinois (1964) 등) 에 따라, 세포의 생존율을 극도로 저하시키지 않을 정도의 조건하에서 적절히 실시할 수 있다.
그러한 방법은, 예를 들어, 폴리에틸렌글리콜 등의 고농도 폴리머 용액 중에서 항체 산생 세포와 미엘로마 세포를 혼합하는 화학적 방법, 전기적 자극을 이용하는 물리적 방법 등을 사용할 수 있다. 이 중, 상기 화학적 방법의 구체예를 나타내면 이하와 같다.
즉, 고농도 폴리머 용액으로서 폴리에틸렌글리콜을 사용하는 경우에는, 분자량 1500 ∼ 6000, 바람직하게는 2000 ∼ 4000 의 폴리에틸렌글리콜 용액 중에서, 30 ∼ 40 ℃, 바람직하게는 35 ∼ 38 ℃ 의 온도에서 항체 산생 세포와 미엘로마 세포를 1 ∼ 10 분간, 바람직하게는 5 ∼ 8 분간 혼합한다.
(e) 하이브리도마군의 선택
상기 세포 융합에 의해 얻어지는 하이브리도마의 선택 방법은 특별히 제한은 없지만, 통상적으로 HAT (히포크산틴·아미노프테린·티미딘) 선택법 (Kohler et al., Nature (1975) 256, p.495 ; Milstein et al., Nature (1977) 266, p.550) 이 사용된다.
이 방법은 아미노프테린에서 생존할 수 없는 HGPRT 결손주의 미엘로마 세포를 사용하여 하이브리도마를 얻는 경우에 유효하다.
즉, 미융합 세포 및 하이브리도마를 HAT 배지에서 배양함으로써, 아미노프테린에 대한 내성을 가진 하이브리도마만을 선택적으로 잔존시키고, 또한 증식시킬 수 있다.
(f) 단일 세포 클론으로의 분할 (클로닝)
하이브리도마의 클로닝법으로는, 예를 들어 메틸셀룰로오스법, 연 (軟) 아가로오스법, 한계 희석법 등의 공지된 방법을 사용할 수 있다 (예를 들어 Barbara, B. M. and Stanley, M. S. : Selected Methods in Cellular Immunology, W. H. Freeman and Company, San Francisco (1980) 참조). 이들 방법 중, 특히 메틸셀룰로오스법 등의 삼차원 배양법이 바람직하다. 예를 들어, 세포 융합에 의해 형성된 하이브리도마군을 ClonaCell-HY Selection Medium D (StemCell Technologies 사 제조 #03804) 등의 메틸셀룰로오스 배지에 현탁하여 배양하고, 형성된 하이브리도마 콜로니를 회수함으로써 모노클론 하이브리도마의 취득이 가능하다. 회수된 각 하이브리도마 콜로니를 배양하여, 얻어진 하이브리도마 배양 상청 중에 안정적으로 항체가가 관찰된 것을 B7-H3 모노클로날 항체 산생 하이브리도마주로서 선택한다.
이와 같이 하여 수립된 하이브리도마주의 예로는, B7-H3 하이브리도마 M30 을 들 수 있다. 또한, 본 명세서 중에 있어서는, B7-H3 하이브리도마 M30 이 산생하는 항체를 「M30 항체」 또는 간단히 「M30」이라고 기재한다.
M30 항체의 중사슬은 배열표의 배열 번호 51 에 나타내는 아미노산 배열을 갖는다. 또, M30 항체의 경사슬은 배열표의 배열 번호 53 에 나타내는 아미노산 배열을 갖는다. 또한, 배열표의 배열 번호 51 에 나타내는 중사슬 아미노산 배열 중에서, 1 내지 19 번째의 아미노산 잔기로 이루어지는 아미노산 배열은 시그널 배열이고, 20 내지 141 번째의 아미노산 잔기로 이루어지는 아미노산 배열은 가변 영역이고, 142 내지 471 번째의 아미노산 잔기로 이루어지는 아미노산 배열은 정상 영역이다. 또한, 배열표의 배열 번호 53 에 나타내는 경사슬 아미노산 배열 중에서, 1 내지 22 번째의 아미노산 잔기로 이루어지는 아미노산 배열은 시그널 배열이고, 23 내지 130 번째의 아미노산 잔기로 이루어지는 아미노산 배열은 가변 영역이고, 131 내지 235 번째의 아미노산 잔기로 이루어지는 아미노산 배열은 정상 영역이다.
배열표의 배열 번호 51 에 나타내는 중사슬 아미노산 배열은 배열표의 배열 번호 50 에 나타내는 뉴클레오티드 배열에 의해 코드되어 있다. 배열표의 배열 번호 50 에 나타내는 뉴클레오티드 배열의 1 내지 57 번째의 뉴클레오티드로 이루어지는 뉴클레오티드 배열은 항체의 중사슬 시그널 배열을 코드하고 있고, 58 내지 423 번째의 뉴클레오티드로 이루어지는 뉴클레오티드 배열은 항체의 중사슬 가변 영역을 코드하고 있고, 그리고 424 내지 1413 번째의 뉴클레오티드로 이루어지는 뉴클레오티드 배열은 항체의 중사슬 정상 영역을 코드하고 있다.
배열표의 배열 번호 53 에 나타내는 경사슬 아미노산 배열은 배열표의 배열 번호 52 에 나타내는 뉴클레오티드 배열에 의해 코드되어 있다. 배열표의 배열 번호 52 에 나타내는 뉴클레오티드 배열의 1 내지 66 번째의 뉴클레오티드로 이루어지는 뉴클레오티드 배열은 항체의 경사슬 시그널 배열을 코드하고 있고, 67 내지 390 번째의 뉴클레오티드로 이루어지는 뉴클레오티드 배열은 항체의 경사슬 가변 영역을 코드하고 있고, 그리고 391 내지 705 번째의 뉴클레오티드로 이루어지는 뉴클레오티드 배열은 항체의 경사슬 정상 영역을 코드하고 있다.
(g) 하이브리도마의 배양에 의한 모노클로날 항체의 조제
이와 같이 하여 선택된 하이브리도마는 이것을 배양함으로써 모노클로날 항체를 효율적으로 얻을 수 있지만, 배양에 앞서, 목적으로 하는 모노클로날 항체를 산생하는 하이브리도마를 스크리닝하는 것이 바람직하다.
이 스크리닝에는 그 자체가 이미 알려진 방법을 채용할 수 있다.
본 발명에 있어서의 항체가의 측정은 예를 들어 상기 (b) 의 항목에서 설명한 ELISA 법에 의해 실시할 수 있다.
이상의 방법에 의해 얻은 하이브리도마는 액체 질소 중 또는 -80 ℃ 이하의 냉동고 중에 동결 상태로 보존할 수 있다.
클로닝을 완료한 하이브리도마는 배지를 HT 배지에서 정상 배지로 바꾸어 배양된다.
대량 배양은 대형 배양병을 사용한 회전 배양, 혹은 스피너 배양으로 실시된다. 이 대량 배양에 있어서의 상청으로부터, 겔 여과 등, 당업자에게 주지된 방법을 사용하여 정제함으로써, 본 발명의 단백질에 특이적으로 결합하는 모노클로날 항체를 얻을 수 있다.
또한, 동 계통의 마우스 (예를 들어, 상기의 BALB/c), 혹은 Nu/Nu 마우스의 복강 내에 하이브리도마를 주사하고, 그 하이브리도마를 증식시킴으로써, 본 발명의 모노클로날 항체를 대량으로 함유하는 복수를 얻을 수 있다.
복강 내에 투여하는 경우에는, 사전 (3 ∼ 7 일 전) 에 2,6,10,14-테트라메틸펜타데칸 (2,6,10,14-tetramethyl pentadecane) (프리스탄) 등의 광물유를 투여하면, 보다 다량의 복수가 얻어진다.
예를 들어, 하이브리도마와 동 계통의 마우스의 복강 내에 미리 면역 억제제를 주사하여, T 세포를 불활성화시킨 후, 20 일 후에 106 ∼ 107 개의 하이브리도마·클론 세포를 혈청을 함유하지 않는 배지 중에 부유 (0.5 ㎖) 시켜 복강 내에 투여하고, 통상적으로 복부가 팽만하여, 복수가 고인 시점에서 마우스로부터 복수를 채취한다. 이 방법에 의해, 배양액 중에 비해 약 100 배 이상의 농도의 모노클로날 항체가 얻어진다.
상기 방법에 의해 얻은 모노클로날 항체는 예를 들어 Weir, D. M. : Handbook of Experimental Immunology, Vol.Ⅰ, Ⅱ, Ⅲ, Blackwell Scientific Publications, Oxford (1978) 에 기재되어 있는 방법으로 정제할 수 있다.
이렇게 하여 얻어지는 모노클로날 항체는 B7-H3 에 대해 높은 항원 특이성을 갖는다.
(h) 모노클로날 항체의 검정
이렇게 하여 얻어진 모노클로날 항체의 아이소 타입 및 서브 클래스의 결정은 이하와 같이 실시할 수 있다.
먼저, 동정법으로는 옥털로니 (Ouchterlony) 법, ELISA 법, 또는 RIA 법을 들 수 있다.
옥털로니법은 간편하기는 하지만, 모노클로날 항체의 농도가 낮은 경우에는 농축 조작이 필요하다.
한편, ELISA 법 또는 RIA 법을 사용한 경우에는, 배양 상청을 그대로 항원 흡착 고상과 반응시키고, 추가로 제 2 차 항체로서 각종 이뮤노글로블린 아이소 타입, 서브 클래스에 대응하는 항체를 사용함으로써, 모노클로날 항체의 아이소 타입, 서브 클래스를 동정하는 것이 가능하다.
또한, 더욱 간편한 방법으로서, 시판되는 동정용 키트 (예를 들어, 마우스 타이퍼 키트 ; 바이오래드사 제조) 등을 이용할 수도 있다.
또한, 단백질의 정량은 폴린로리법, 및 280 ㎚ 에 있어서의 흡광도 [1.4 (OD280) = 이뮤노글로블린 1 ㎎/㎖] 로부터 산출하는 방법에 의해 실시할 수 있다.
또한, (2) 의 (a) 내지 (h) 의 공정을 다시 실시하여 별도로 독립적으로 모노클로날 항체를 취득한 경우에 있어서도, M30 항체와 동등한 세포 상해 활성을 갖는 항체를 취득하는 것이 가능하다. 이와 같은 항체의 일례로서, M30 항체와 동일한 에피토프에 결합하는 항체를 들 수 있다. M30 은 B7-H3 의 세포 외 영역 중의 도메인인 IgC1 도메인 또는 IgC2 도메인에 있어서의 에피토프를 인식하여, IgC1 도메인 혹은 IgC2 도메인 또는 양자에 결합하므로, 특히 당해 에피토프로는 B7-H3 의 IgC1 도메인 또는 IgC2 도메인에 존재하는 에피토프를 들 수 있다. 새롭게 제조된 모노클로날 항체가 M30 항체가 결합하는 부분 펩티드 또는 부분 입체 구조에 결합하면, 그 모노클로날 항체가 M30 항체와 동일한 에피토프에 결합한다고 판정할 수 있다. 또, M30 항체의 B7-H3 에 대한 결합에 대해 그 모노클로날 항체가 경합하는 (즉, 그 모노클로날 항체가 M30 항체와 B7-H3 의 결합을 방해하는) 것을 확인함으로써, 구체적인 에피토프의 배열 또는 구조가 결정되어 있지 않아도, 그 모노클로날 항체가 M30 항체와 동일한 에피토프에 결합한다고 판정할 수 있다. 에피토프가 동일하다는 것이 확인된 경우, 그 모노클로날 항체가 M30 항체와 동등한 세포 상해 활성을 갖고 있을 것이 크게 기대된다.
(3) 그 밖의 항체
본 발명의 항체에는, 상기 B7-H3 에 대한 모노클로날 항체에 더하여, 인간에 대한 이종 항원성을 저하시키는 것 등을 목적으로 하여 인위적으로 개변한 유전자 재조합형 항체, 예를 들어 키메라 (Chimeric) 항체, 인간화 (Humanized) 항체, 인간 항체 등도 포함된다. 이들 항체는 이미 알려진 방법을 사용하여 제조할 수 있다.
키메라 항체로는, 항체의 가변 영역과 정상 영역이 서로 이종인 항체, 예를 들어 마우스 또는 래트 유래 항체의 가변 영역을 인간 유래의 정상 영역에 접합시킨 키메라 항체를 들 수 있다 (Proc. Natl. Acad. Sci. U.S.A., 81, 6851-6855, (1984) 참조). 마우스 항인간 B7-H3 항체 M30 유래의 키메라 항체는 배열 번호 51 의 20 내지 141 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 중사슬 가변 영역을 포함하는 중사슬 및 배열 번호 53 의 23 내지 130 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 경사슬 가변 영역을 포함하는 경사슬로 이루어지는 항체이며, 임의의 인간 유래의 정상 영역을 갖고 있어도 된다. 이와 같은 키메라 항체의 일례로서 배열표의 배열 번호 63 의 1 내지 471 번째의 아미노산 잔기로 이루어지는 아미노산 배열을 갖는 중사슬, 및 배열 번호 59 의 1 내지 233 번째의 아미노산 잔기로 이루어지는 아미노산 배열을 갖는 경사슬로 이루어지는 항체를 들 수 있다. 또한, 배열표의 배열 번호 63 에 나타내는 중사슬 배열 중에서, 1 내지 19 번째의 아미노산 잔기로 이루어지는 아미노산 배열은 시그널 배열이고, 20 내지 141 번째의 아미노산 잔기로 이루어지는 아미노산 배열은 가변 영역이고, 142 내지 471 번째의 아미노산 잔기로 이루어지는 아미노산 배열은 정상 영역이다. 또한, 배열표의 배열 번호 59 에 나타내는 경사슬 배열 중에서, 1 내지 20 번째의 아미노산 잔기로 이루어지는 아미노산 배열은 시그널 배열이고, 21 내지 128 번째의 아미노산 잔기로 이루어지는 아미노산 배열은 가변 영역이고, 129 내지 233 번째의 아미노산 잔기로 이루어지는 아미노산 배열은 정상 영역이다.
배열표의 배열 번호 63 에 나타내는 중사슬 아미노산 배열은 배열표의 배열 번호 62 에 나타내는 뉴클레오티드 배열에 의해 코드되어 있다. 배열표의 배열 번호 62 에 나타내는 뉴클레오티드 배열의 1 내지 57 번째의 뉴클레오티드로 이루어지는 뉴클레오티드 배열은 항체의 중사슬 시그널 배열을 코드하고 있고, 58 내지 423 번째의 뉴클레오티드로 이루어지는 뉴클레오티드 배열은 항체의 중사슬 가변 영역을 코드하고 있고, 그리고 424 내지 1413 번째의 뉴클레오티드로 이루어지는 뉴클레오티드 배열은 항체의 중사슬 정상 영역을 코드하고 있다.
배열표의 배열 번호 59 에 나타내는 경사슬 아미노산 배열은 배열표의 배열 번호 58 에 나타내는 뉴클레오티드 배열에 의해 코드되어 있다. 배열표의 배열 번호 58 에 나타내는 뉴클레오티드 배열의 1 내지 60 번째의 뉴클레오티드로 이루어지는 뉴클레오티드 배열은 항체의 경사슬 시그널 배열을 코드하고 있고, 61 내지 384 번째의 뉴클레오티드로 이루어지는 뉴클레오티드 배열은 항체의 경사슬 가변 영역을 코드하고 있고, 그리고 385 내지 699 번째의 뉴클레오티드로 이루어지는 뉴클레오티드 배열은 항체의 경사슬 정상 영역을 코드하고 있다.
인간화 항체로는, 상보성 결정 영역 (CDR ; complementarity determining region) 만을 인간 유래의 항체에 삽입한 항체 (Nature (1986) 321, p.522-525 참조), CDR 이식법에 의해 CDR 의 배열에 더하여 일부의 프레임 워크의 아미노산 잔기도 인간 항체에 이식한 항체 (국제 공개 팜플렛 WO90/07861) 를 들 수 있다.
단, M30 항체 유래의 인간화 항체로는, M30 항체의 6 종 모두의 CDR 배열을 유지하고, 항종양 활성을 갖는 한, 특정한 인간화 항체에 한정되지 않는다. 또한, M30 항체의 중사슬 가변 영역은 배열표의 배열 번호 92 에 나타내는 아미노산 배열로 이루어지는 CDRH1 (NYVMH), 배열 번호 93 에 나타내는 아미노산 배열로 이루어지는 CDRH2 (YINPYNDDVKYNEKFKG), 및 배열 번호 94 에 나타내는 아미노산 배열로 이루어지는 CDRH3 (WGYYGSPLYYFDY) 을 보유하고 있다. 또한, M30 항체의 경사슬 가변 영역은 배열표의 배열 번호 95 에 나타내는 아미노산 배열로 이루어지는 CDRL1 (RASSRLIYMH), 배열 번호 96 에 나타내는 아미노산 배열로 이루어지는 CDRL2 (ATSNLAS), 및 배열 번호 97 에 나타내는 아미노산 배열로 이루어지는 CDRL3 (QQWNSNPPT) 을 보유하고 있다.
마우스 항체 M30 의 인간화 항체의 실례로는, (1) 배열표의 배열 번호 85, 87, 89 또는 91 의 20 내지 141 번째의 아미노산 잔기로 이루어지는 아미노산 배열, (2) 상기 (1) 의 아미노산 배열에 대해 적어도 95 % 이상의 상동성을 갖는 아미노산 배열, 및 (3) 상기 (1) 의 아미노산 배열에 있어서 1 또는 수 개의 아미노산이 결실, 치환 또는 부가된 아미노산 배열 중 어느 하나로 이루어지는 중사슬 가변 영역을 포함하는 중사슬, 그리고 (4) 배열 번호 71, 73, 75, 77, 79, 81 또는 83 의 21 내지 128 번째의 아미노산 잔기로 이루어지는 아미노산 배열, (5) 상기 (4) 의 아미노산 배열에 대해 적어도 95 % 이상의 상동성을 갖는 아미노산 배열, 및 (6) 상기 (4) 의 아미노산 배열에 있어서 1 또는 수 개의 아미노산이 결실, 치환 또는 부가된 아미노산 배열 중 어느 하나로 이루어지는 경사슬 가변 영역을 포함하는 경사슬의 임의의 조합을 들 수 있다.
또한, 본 명세서 중에 있어서의 「수 개」란, 1 내지 10 개, 1 내지 9 개, 1 내지 8 개, 1 내지 7 개, 1 내지 6 개, 1 내지 5 개, 1 내지 4 개, 1 내지 3 개, 또는 1 혹은 2 개를 의미한다.
또한, 본 명세서 중에 있어서의 아미노산의 치환으로는 보존적 아미노산 치환이 바람직하다. 보존적 아미노산 치환이란, 아미노산 측사슬에 관련이 있는 아미노산 그룹 내에서 생기는 치환이다. 바람직한 아미노산 그룹은 이하와 같다 : 산성 그룹 = 아스파르트산, 글루탐산 ; 염기성 그룹 = 리신, 아르기닌, 히스티딘 ; 비극성 그룹 = 알라닌, 발린, 류신, 이소류신, 프롤린, 페닐알라닌, 메티오닌, 트립토판 ; 및 비대전 극성 패밀리 = 글리신, 아스파라긴, 글루타민, 시스테인, 세린, 트레오닌, 티로신. 다른 바람직한 아미노산 그룹은 다음과 같다 : 지방족 하이드록시 그룹 = 세린 및 트레오닌 ; 아미드 함유 그룹 = 아스파라긴 및 글루타민 ; 지방족 그룹 = 알라닌, 발린, 류신 및 이소류신 ; 그리고 방향족 그룹 = 페닐알라닌, 트립토판 및 티로신. 이러한 아미노산 치환은 원래의 아미노산 배열을 갖는 물질의 특성을 저하시키지 않는 범위에서 실시하는 것이 바람직하다.
상기 중사슬 및 경사슬의 바람직한 조합으로는, 배열 번호 85 의 20 내지 141 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 중사슬 가변 영역을 포함하는 중사슬 및 배열 번호 71 의 21 내지 128 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 경사슬 가변 영역을 포함하는 경사슬로 이루어지는 항체, 배열 번호 85 의 20 내지 141 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 중사슬 가변 영역을 포함하는 중사슬 및 배열 번호 73 의 21 내지 128 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 경사슬 가변 영역을 포함하는 경사슬로 이루어지는 항체, 배열 번호 85 의 20 내지 141 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 중사슬 가변 영역을 포함하는 중사슬 및 배열 번호 75 의 21 내지 128 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 경사슬 가변 영역을 포함하는 경사슬로 이루어지는 항체, 배열 번호 85 의 20 내지 141 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 중사슬 가변 영역을 포함하는 중사슬 및 배열 번호 77 의 21 내지 128 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 경사슬 가변 영역을 포함하는 경사슬로 이루어지는 항체, 배열 번호 85 의 20 내지 141 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 중사슬 가변 영역을 포함하는 중사슬 및 배열 번호 79 의 21 내지 128 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 경사슬 가변 영역을 포함하는 경사슬로 이루어지는 항체, 배열 번호 85 의 20 내지 141 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 중사슬 가변 영역을 포함하는 중사슬 및 배열 번호 81 의 21 내지 128 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 경사슬 가변 영역을 포함하는 경사슬로 이루어지는 항체, 배열 번호 85 의 20 내지 141 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 중사슬 가변 영역을 포함하는 중사슬 및 배열 번호 83 의 21 내지 128 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 경사슬 가변 영역을 포함하는 경사슬로 이루어지는 항체, 배열 번호 91 의 20 내지 141 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 중사슬 가변 영역을 포함하는 중사슬 및 배열 번호 71 의 21 내지 128 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 경사슬 가변 영역을 포함하는 경사슬로 이루어지는 항체, 배열 번호 91 의 20 내지 141 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 중사슬 가변 영역을 포함하는 중사슬 및 배열 번호 73 의 21 내지 128 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 경사슬 가변 영역을 포함하는 경사슬로 이루어지는 항체, 배열 번호 91 의 20 내지 141 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 중사슬 가변 영역을 포함하는 중사슬 및 배열 번호 75 의 21 내지 128 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 경사슬 가변 영역을 포함하는 경사슬로 이루어지는 항체, 그리고 배열 번호 91 의 20 내지 141 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 중사슬 가변 영역을 포함하는 중사슬 및 배열 번호 77 의 21 내지 128 번째의 아미노산 잔기로 이루어지는 아미노산 배열로 이루어지는 경사슬 가변 영역을 포함하는 경사슬로 이루어지는 항체를 들 수 있다.
더욱 바람직한 조합으로는, 배열 번호 85 의 아미노산 배열을 갖는 중사슬 및 배열 번호 71 의 아미노산 배열을 갖는 경사슬로 이루어지는 항체, 배열 번호 85 의 아미노산 배열을 갖는 중사슬 및 배열 번호 73 의 아미노산 배열을 갖는 경사슬로 이루어지는 항체, 배열 번호 85 의 아미노산 배열을 갖는 중사슬 및 배열 번호 75 의 아미노산 배열을 갖는 경사슬로 이루어지는 항체, 배열 번호 85 의 아미노산 배열을 갖는 중사슬 및 배열 번호 77 의 아미노산 배열을 갖는 경사슬로 이루어지는 항체, 배열 번호 85 의 아미노산 배열을 갖는 중사슬 및 배열 번호 79 의 아미노산 배열을 갖는 경사슬로 이루어지는 항체, 배열 번호 85 의 아미노산 배열을 갖는 중사슬 및 배열 번호 81 의 아미노산 배열을 갖는 경사슬로 이루어지는 항체, 배열 번호 85 의 아미노산 배열을 갖는 중사슬 및 배열 번호 83 의 아미노산 배열을 갖는 경사슬로 이루어지는 항체, 배열 번호 91 의 아미노산 배열을 갖는 중사슬 및 배열 번호 71 의 아미노산 배열을 갖는 경사슬로 이루어지는 항체, 배열 번호 91 의 아미노산 배열을 갖는 중사슬 및 배열 번호 73 의 아미노산 배열을 갖는 경사슬로 이루어지는 항체, 배열 번호 91 의 아미노산 배열을 갖는 중사슬 및 배열 번호 75 의 아미노산 배열을 갖는 경사슬로 이루어지는 항체, 그리고 배열 번호 91 의 아미노산 배열을 갖는 중사슬 및 배열 번호 77 의 아미노산 배열을 갖는 경사슬로 이루어지는 항체를 들 수 있다.
상기의 중사슬 아미노산 배열 및 경사슬 아미노산 배열과 높은 상동성을 나타내는 배열을 조합함으로써, 상기의 각 항체와 동등한 세포 상해성 활성을 갖는 항체를 선택하는 것이 가능하다. 이와 같은 상동성은 일반적으로는 80 % 이상의 상동성이고, 바람직하게는 90 % 이상의 상동성이고, 보다 바람직하게는 95 % 이상의 상동성이며, 가장 바람직하게는 99 % 이상의 상동성이다. 또한, 중사슬 또는 경사슬의 아미노산 배열에 1 내지 수 개의 아미노산 잔기가 치환, 결실 또는 부가된 아미노산 배열을 조합하는 것에 의해서도, 상기의 각 항체와 동등한 세포 상해성 활성을 갖는 항체를 선택하는 것이 가능하다.
2 종류의 아미노산 배열 사이의 상동성은 Blast algorithm version 2.2.2 (Altschul, Stephen F., Thomas L. Madden, Alejandro A. Schaffer, Jinghui Zhang, Zheng Zhang, Webb Miller, and David J. Lipman (1997), 「Gapped BLAST and PSI-BLAST : a new generation of protein database search programs」, Nucleic Acids Res. 25 : 3389-3402) 의 디폴트 파라미터를 사용함으로써 결정할 수 있다. Blast algorithm 은 인터넷으로
1334907992153_0
에 액세스하는 것에 의해서도 사용할 수 있다.
또한, 배열표의 배열 번호 85, 87, 89 또는 91 에 나타내는 중사슬 아미노산 배열 중에서, 1 내지 19 번째의 아미노산 잔기로 이루어지는 아미노산 배열은 시그널 배열이고, 20 내지 141 번째의 아미노산 잔기로 이루어지는 아미노산 배열은 가변 영역이고, 142 내지 471 번째의 아미노산 잔기로 이루어지는 아미노산 배열은 정상 영역이다.
또한, 배열표의 배열 번호 71, 73, 75, 77, 79, 81 또는 83 에 나타내는 경사슬 아미노산 배열 중에서, 1 내지 20 번째의 아미노산 잔기로 이루어지는 아미노산 배열은 시그널 배열이고, 21 내지 128 번째의 아미노산 잔기로 이루어지는 아미노산 배열은 가변 영역이고, 129 내지 233 번째의 아미노산 잔기로 이루어지는 아미노산 배열은 정상 영역이다.
배열표의 배열 번호 85, 87, 89 또는 91 에 나타내는 중사슬 아미노산 배열은 각각 배열표의 배열 번호 84, 86, 88 또는 90 에 나타내는 뉴클레오티드 배열에 의해 코드되어 있다. 또한, 배열 번호 84 및 85 의 배열은 도 34 에, 배열 번호 86 및 87 의 배열은 도 35 에, 배열 번호 88 및 89 의 배열은 도 36 에, 배열 번호 90 및 91 의 배열은 도 37 에 각각 기재되어 있다. 각 뉴클레오티드 배열의 1 내지 57 번째의 뉴클레오티드로 이루어지는 뉴클레오티드 배열은 항체의 중사슬 시그널 배열을 코드하고 있고, 58 내지 423 번째의 뉴클레오티드로 이루어지는 뉴클레오티드 배열은 항체의 중사슬 가변 영역을 코드하고 있고, 그리고 424 내지 1413 번째의 뉴클레오티드로 이루어지는 뉴클레오티드 배열은 항체의 중사슬 정상 영역을 코드하고 있다.
배열표의 배열 번호 71, 73, 75, 77, 79, 81 또는 83 에 나타내는 경사슬 아미노산 배열은 각각 배열표의 배열 번호 70, 72, 74, 76, 78, 80 또는 82 에 나타내는 뉴클레오티드 배열에 의해 코드되어 있다. 또한, 배열 번호 70 및 71 의 배열은 도 27 에, 배열 번호 72 및 73 의 배열은 도 28 에, 배열 번호 74 및 75 의 배열은 도 29 에, 배열 번호 76 및 77 의 배열은 도 30 에, 배열 번호 78 및 79 의 배열은 도 31 에, 배열 번호 80 및 81 의 배열은 도 32 에, 배열 번호 82 및 83 의 배열은 도 33 에 각각 기재되어 있다. 각 뉴클레오티드 배열의 1 내지 60 번째의 뉴클레오티드로 이루어지는 뉴클레오티드 배열은 항체의 경사슬 시그널 배열을 코드하고 있고, 61 내지 384 번째의 뉴클레오티드로 이루어지는 뉴클레오티드 배열은 항체의 경사슬 가변 영역을 코드하고 있고, 그리고 385 내지 699 번째의 뉴클레오티드로 이루어지는 뉴클레오티드 배열은 항체의 경사슬 정상 영역을 코드하고 있다.
이들 뉴클레오티드 배열과 다른 항체의 뉴클레오티드 배열 사이의 상동성에 대해서도 Blast algorithm 에 의해 결정할 수 있다.
본 발명의 항체로는, 또한 M30 항체와 동일한 에피토프에 결합하는 인간 항체를 들 수 있다. 항 B7-H3 인간 항체란, 인간 염색체 유래 항체의 유전자 배열만을 갖는 인간 항체를 의미한다. 항 B7-H3 인간 항체는 인간 항체의 중사슬과 경사슬의 유전자를 포함하는 인간 염색체 단편을 갖는 인간 항체 산생 마우스를 사용한 방법 (Tomizuka, K. et al., Nature Genetics (1997) 16, p.133-143, ; Kuroiwa, Y. et. al., Nucl. Acids Res. (1998) 26, p.3447-3448 ; Yoshida, H. et. al., Animal Cell Technology : Basic and Applied Aspects vol.10, p.69-73 (Kitagawa, Y., Matsuda, T. and Iijima, S. eds.), Kluwer Academic Publishers, 1999. ; Tomizuka, K. et. al., Proc. Natl. Acad. Sci. USA (2000) 97, p.722-727 등을 참조) 에 의해 취득할 수 있다.
이와 같은 인간 항체 산생 마우스는 구체적으로는 내재성 면역 글로블린 중사슬 및 경사슬의 유전자좌가 파괴되고, 대신에 효모 인공 염색체 (Yeast artificial chromosome, YAC) 벡터 등을 개재하여 인간 면역 글로블린 중사슬 및 경사슬의 유전자좌가 도입된 유전자 재조합 동물을 녹아웃 동물 및 트랜스제닉 동물의 제조, 및 이들 동물끼리를 교배시킴으로써 만들어 낼 수 있다.
또한, 유전자 재조합 기술에 의해, 그러한 인간 항체의 중사슬 및 경사슬의 각각을 코드하는 cDNA, 바람직하게는 그 cDNA 를 포함하는 벡터에 의해 진핵 세포를 형질 전환하고, 유전자 재조합 인간 모노클로날 항체를 산생하는 형질 전환 세포를 배양함으로써, 이 항체를 배양 상청 중에서 얻을 수도 있다.
여기서, 숙주로는 예를 들어 진핵 세포, 바람직하게는 CHO 세포, 림프구나 미엘로마 등의 포유 동물 세포를 사용할 수 있다.
또한, 인간 항체 라이브러리로부터 선별한 파지 디스플레이 유래의 인간 항체를 취득하는 방법 (Wormstone, I. M. et. al, Investigative Ophthalmology & Visual Science. (2002) 43 (7), p.2301-2308 ; Carmen, S. et. al., Briefings in Functional Genomics and Proteomics (2002), 1 (2), p.189-203 ; Siriwardena, D. et. al., Ophthalmology (2002) 109 (3), p.427-431 등 참조) 도 알려져 있다.
예를 들어, 인간 항체의 가변 영역을 1 개 사슬 항체 (scFv) 로서 파지 표면에 발현시키고, 항원에 결합하는 파지를 선택하는 파지 디스플레이법 (Nature Biotechnology (2005), 23, (9), p.1105-1116) 을 사용할 수 있다.
항원에 결합함으로써 선택된 파지의 유전자를 해석함으로써, 항원에 결합하는 인간 항체의 가변 영역을 코드하는 DNA 배열을 결정할 수 있다.
항원에 결합하는 scFv 의 DNA 배열이 밝혀지면, 당해 배열을 갖는 발현 벡터를 제조하고, 적당한 숙주에 도입하여 발현시킴으로써 인간 항체를 취득할 수 있다 (WO92/01047, WO92/20791, WO93/06213, WO93/11236, WO93/19172, WO95/01438, WO95/15388, Annu. Rev. Immunol (1994) 12, p.433-455, Nature Biotechnology (2005) 23 (9), p.1105-1116).
새롭게 제조된 인간 항체가 M30 항체가 결합하는 부분 펩티드 또는 부분 입체 구조에 결합하면, 그 인간 항체가 M30 항체와 동일한 에피토프에 결합한다고 판정할 수 있다. 또한, M30 항체의 B7-H3 에 대한 결합에 대해 그 인간 항체가 경합하는 (즉, 그 인간 항체가 M30 항체와 B7-H3 의 결합을 방해하는) 것을 확인함으로써, 구체적인 에피토프의 배열 또는 구조가 결정되어 있지 않아도, 그 인간 항체가 M30 항체와 동일한 에피토프에 결합한다고 판정할 수 있다. 에피토프가 동일하다는 것이 확인된 경우, 그 인간 항체가 M30 항체와 동등한 세포 상해 활성을 갖고 있을 것이 강하게 기대된다.
이상의 방법에 의해 얻어진 키메라 항체, 인간화 항체, 또는 인간 항체는, 실시예 3 에 나타낸 방법 등에 의해 항원에 대한 결합성을 평가하여, 바람직한 항체를 선발할 수 있다.
항체의 성질을 비교할 때의 다른 지표의 일례로는, 항체의 안정성을 들 수 있다. 시차 주사 칼로리메트리 (DSC) 는 단백의 상대적 구조 안정성이 양호한 지표가 되는 열변성 중점 (Tm) 을 빠르고, 또한 정확하게 측정할 수 있는 장치이다. DSC 를 사용하여 Tm 치를 측정하고, 그 값을 비교함으로써, 열 안정성의 차를 비교할 수 있다. 항체의 보존 안정성은 항체의 열 안정성과 어느 정도의 상관을 나타내는 것이 알려져 있고 (Lori Burton, et. al., Pharmaceutical Development and Technology (2007) 12, p.265-273), 열 안정성을 지표로, 바람직한 항체를 선발할 수 있다. 항체를 선발하기 위한 다른 지표로는, 적절한 숙주 세포에 있어서의 수량이 높은 것, 및 수용액 중에서의 응집성이 낮은 것을 들 수 있다. 예를 들어 수량이 가장 높은 항체가 가장 높은 열 안정성을 나타낸다고는 할 수 없기 때문에, 이상에 서술한 지표에 기초하여 종합적으로 판단하여, 인간에 대한 투여에 가장 적합한 항체를 선발할 필요가 있다.
또한, 항체의 중사슬 및 경사슬의 전체 길이 배열을 적절한 링커를 사용하여 연결하고, 1 개 사슬 이뮤노글로블린 (single chain immunoglobulin) 을 취득하는 방법도 알려져 있다 (Lee, H-S, et. al., Molecular Immunology (1999) 36, p.61-71 ; Shirrmann, T. et. al., mAbs (2010), 2, (1) p.1-4). 이와 같은 1 개 사슬 이뮤노글로블린은 이량체화함으로써, 본래는 사량체인 항체와 유사한 구조와 활성을 유지하는 것이 가능하다. 또한, 본 발명의 항체는 단일의 중사슬 가변 영역을 갖고, 경사슬 배열을 갖지 않는 항체이어도 된다. 이와 같은 항체는 단일 도메인 항체 (single domain antibody : sdAb) 또는 나노바디 (nanobody) 라고 불리고 있으며, 실제로 낙타 또는 라마에서 관찰되고, 항원 결합능이 유지되고 있는 것이 보고되어 있다 (Muyldemans S. et. al., Protein Eng. (1994) 7 (9), 1129-35, Hamers-Casterman C. et. al., Nature (1993) 363 (6428) 446-8). 상기 항체는 본 발명에 있어서의 항체의 기능성 단편의 일종으로 해석할 수도 있다.
본 발명에는 항체 또는 당해 항체의 기능성 단편의 수식체도 포함된다. 당해 수식체란, 본 발명의 항체 또는 당해 항체의 기능성 단편에 화학적 또는 생물학적인 수식이 실시되어 이루어지는 것을 의미한다. 화학적인 수식체에는, 아미노산 골격에 대한 화학 부분의 결합, N-결합 또는 O-결합 탄수화물 사슬의 화학 수식체 등이 포함된다. 생물학적인 수식체에는, 번역 후 수식 (예를 들어, N-결합 또는 O-결합에 대한 당 사슬 부가, N 말 또는 C 말의 프로세싱, 탈아미드화, 아스파르트산의 이성화, 메티오닌의 산화) 된 것, 원핵 생물 숙주 세포를 사용하여 발현시킴으로써 N 말에 메티오닌 잔기가 부가된 것 등이 포함된다. 또한, 본 발명의 항체 또는 항원의 검출 또는 단리를 가능하게 하기 위해서 표지된 것, 예를 들어, 효소 표지체, 형광 표지체, 어피니티 표지체도 이러한 수식물의 의미에 포함된다. 이와 같은 본 발명의 항체 또는 당해 항체의 기능성 단편의 수식물은 원래의 본 발명의 항체 또는 당해 항체의 기능성 단편의 안정성 및 혈중 체류성의 개선, 항원성의 저감, 이러한 항체 또는 항원의 검출 또는 단리 등에 유용하다.
또한, 본 발명의 항체에 결합되어 있는 당 사슬 수식을 조절하는 것 (글리코실화, 탈푸코오스화 등) 에 의해, 항체 의존성 세포 상해 활성을 증강시키는 것이 가능하다. 항체의 당 사슬 수식의 조절 기술로는, WO99/54342, WO00/61739, WO02/31140 등이 알려져 있지만, 이들에 한정되는 것은 아니다. 본 발명의 항체 및 당해 항체의 기능성 단편에는 당해 당 사슬 수식이 조절된 항체 및 당해 항체의 기능성 단편도 포함된다.
항체 유전자를 일단 단리한 후, 적당한 숙주에 도입하여 항체를 제조하는 경우에는 적당한 숙주와 발현 벡터의 조합을 사용할 수 있다. 항체 유전자의 구체예로는, 본 명세서에 기재된 항체의 중사슬 배열을 코드하는 유전자, 및 경사슬 배열을 코드하는 유전자를 조합한 것을 들 수 있다. 숙주 세포를 형질 전환할 때에는, 중사슬 배열 유전자와 경사슬 배열 유전자는 동일한 발현 벡터에 삽입되어 있는 것이 가능하고, 또한 다른 발현 벡터에 삽입되어 있는 것도 가능하다.
진핵 세포를 숙주로서 사용하는 경우, 동물 세포, 식물 세포, 진핵 미생물을 사용할 수 있다. 특히 동물 세포로는, 포유류 세포, 예를 들어 원숭이의 세포인 COS 세포 (Gluzman, Y. Cell (1981) 23, p.175-182, ATCC CRL-1650), 마우스 선유아 세포 NIH3T3 (ATCC No.CRL-1658) 이나 차이니즈·햄스터 난소 세포 (CHO 세포, ATCC CCL-61) 의 디하이드로엽산 환원 효소 결손주 (Urlaub, G. and Chasin, L. A. Proc. Natl. Acad. Sci. U.S.A. (1980) 77, p.4126-4220) 를 들 수 있다.
원핵 세포를 사용하는 경우에는, 예를 들어 대장균, 고초균을 들 수 있다.
이들 세포에 목적으로 하는 항체 유전자 또는 당해 항체의 기능성 단편을 형질 전환에 의해 도입하고, 형질 전환된 세포를 in vitro 에서 배양함으로써 항체가 얻어진다. 당해 배양에 있어서는 항체의 배열에 따라 수량이 상이한 경우가 있어, 동등한 결합 활성을 갖는 항체 중에서 수량을 지표로 의약으로서의 생산이 용이한 것을 선별하는 것이 가능하다. 따라서, 본 발명의 항체 및 당해 항체의 기능성 단편에는, 상기 형질 전환된 숙주 세포를 배양하는 공정, 및 당해 공정에서 얻어진 배양물로부터 목적으로 하는 항체 또는 당해 항체의 기능성 단편을 채취하는 공정을 포함하는 것을 특징으로 하는 당해 항체 또는 당해 단편의 제조 방법에 의해 얻어지는 항체 또는 당해 항체의 기능성 단편도 포함된다.
또한, 포유류 배양 세포로 생산되는 항체의 중사슬의 카르복실 말단의 리신 잔기가 결실되는 것이 알려져 있고 (Journal of Chromatography A, 705 : 129-134 (1995)), 또한 동일하게 중사슬 카르복실 말단의 글리신, 리신의 2 아미노산 잔기가 결실되어, 새롭게 카르복실 말단에 위치하는 프롤린 잔기가 아미드화되는 것이 알려져 있다 (Analytical Biochemistry, 360 : 75-83 (2007)). 그러나, 이들 중사슬 배열의 결실 및 수식은 항체의 항원 결합능 및 이펙터 기능 (보체 (補體) 의 활성화나 항체 의존성 세포 장해 작용 등) 에는 영향을 미치지 않는다. 따라서, 본 발명에는 당해 수식을 받은 항체 및 당해 항체의 기능성 단편도 포함되고, 중사슬 카르복실 말단에 있어서 1 또는 2 개의 아미노산이 결실된 결실체, 및 아미드화된 당해 결실체 (예를 들어, 카르복실 말단 부위의 프롤린 잔기가 아미드화된 중사슬) 등을 들 수 있다. 단, 항원 결합능 및 이펙터 기능이 유지되고 있는 한, 본 발명에 관련된 항체의 중사슬의 카르복실 말단의 결실체는 상기의 종류에 한정되지 않는다. 본 발명에 관련된 항체를 구성하는 2 개의 중사슬은 완전 길이 및 상기의 결실체로 이루어지는 군에서 선택되는 중사슬 중 어느 1 종이어도 되고, 어느 2 종을 조합한 것이어도 된다. 각 결실체의 양비는 본 발명에 관련된 항체를 산생하는 포유류 배양 세포의 종류 및 배양 조건에 영향을 받을 수 있지만, 본 발명에 관련된 항체의 주성분으로는 2 개의 중사슬의 쌍방에서 카르복실 말단의 1 개의 아미노산 잔기가 결실되어 있는 경우를 들 수 있다. 본 발명의 항체의 아이소 타입으로서의 제한은 없고, 예를 들어 IgG (IgG1, IgG2, IgG3, IgG4), IgM, IgA (IgA1, IgA2), IgD 혹은 IgE 등을 들 수 있지만, 바람직하게는 IgG 또는 IgM, 더욱 바람직하게는 IgG1 또는 IgG2 를 들 수 있다.
또한 본 발명의 항체는 항체의 항원 결합부를 갖는 항체의 기능성 단편 또는 그 수식물이어도 된다. 항체를 파파인, 펩신 등의 단백질 분해 효소로 처리하거나, 혹은 항체 유전자를 유전자 공학적 수법에 의해 개변하여 적당한 배양 세포에서 발현시킴으로써, 그 항체의 단편을 얻을 수 있다. 이와 같은 항체 단편 중에서, 항체가 갖는 기능의 모두 또는 일부를 유지하고 있는 단편을 항체의 기능성 단편이라고 부를 수 있다.
항체의 기능으로는, 일반적으로는 항원 결합 활성, 항원의 활성을 중화시키는 활성, 항원의 활성을 증강시키는 활성, 항체 의존성 세포 상해 (ADCC) 활성 및 보체 의존성 세포 상해 (CDC) 활성을 들 수 있지만, 본 발명에 관련된 항체 및 그 기능성 단편이 갖는 기능은 B7-H3 에 대한 결합 활성이고, 바람직하게는 항체 의존성 세포 매개 식작용 (ADCP) 활성이고, 보다 바람직하게는 종양 세포에 대한 ADCP 활성을 통한 세포 상해 활성 (항종양 활성) 이다. 또한, 본 발명의 항체는, ADCP 활성에 더하여, ADCC 활성 및/또는 CDC 활성을 겸비하고 있어도 된다. 특히 기존의 항종양 항체를 함유하는 의약에 대해서는, 종양 세포에 직접적으로 작용하여 증식 시그널을 차단하는 것, 종양 세포에 직접적으로 작용하여 세포사 시그널을 유도하는 것, 혈관 신생을 억제하는 것, NK 세포를 통해서 ADCC 활성을 일으키는 것, 및 보체를 통해서 CDC 활성을 유도함으로써 종양 세포의 증식을 억제하는 것이 보고되고 있지만 (J Clin Oncol 28 : 4390-4399. (2010), Clin Cancer Res ; 16 (1) ; 11-20. (2010)), 본원 발명에 관련된 항 B7-H3 항체가 갖는 ADCP 활성에 대해서는, 기존의 항종양 항체를 함유하는 의약의 활성으로서 보고되고 있는 것을 적어도 본 발명자들은 모른다.
항체의 단편으로는, 예를 들어 Fab, F(ab')2, Fv, 또는 중사슬 및 경사슬의 Fv 를 적당한 링커로 연결시킨 싱글 체인 Fv (scFv), diabody (diabodies), 선상 항체, 및 항체 단편으로부터 형성된 다특이성 항체 등을 들 수 있다. 또한, F(ab')2 를 환원 조건하에서 처리한 항체의 가변 영역의 1 가의 단편인 Fab' 도 항체의 단편에 포함된다.
또한, 본 발명의 항체는 적어도 2 종류의 상이한 항원에 대해 특이성을 갖는 다특이성 항체이어도 된다. 통상적으로 이와 같은 분자는 2 종류의 항원에 결합하는 것이지만 (즉, 이중 특이성 항체 (bispecific antibody)), 본 발명에 있어서의 「다특이성 항체」는 그 이상 (예를 들어, 3 종류) 의 항원에 대해 특이성을 갖는 항체를 포함하는 것이다.
본 발명의 다특이성 항체는 전체 길이로 이루어지는 항체, 또는 그러한 항체의 단편 (예를 들어, F(ab')2 이중 특이성 항체) 이어도 된다. 이중 특이성 항체는 2 종류의 항체의 중사슬과 경사슬 (HL 쌍) 을 결합시켜 제조할 수도 있고, 상이한 모노클로날 항체를 산생하는 하이브리도마를 융합시켜, 이중 특이성 항체 산생 융합 세포를 제조하는 것에 의해서도 제조할 수 있다 (Millstein et al., Nature (1983) 305, p.537-539).
본 발명의 항체는 1 개 사슬 항체 (scFv 라고도 기재한다) 이어도 된다. 1 개 사슬 항체는 항체의 중사슬 가변 영역과 경사슬 가변 영역을 폴리펩티드의 링커로 연결함으로써 얻어진다 (Pluckthun, The Pharmacology of Monoclonal Antibodies, 113 (Rosenberg 및 Moore 편, Springer Verlag, New York, p.269-315 (1994), Nature Biotechnology (2005), 23, p.1126-1136). 또한, 2 개의 scFv 를 폴리펩티드 링커로 결합시켜 제조되는 BiscFv 단편을 이중 특이성 항체로서 사용할 수도 있다.
1 개 사슬 항체를 제조하는 방법은 당 기술 분야에 있어서 주지이다 (예를 들어, 미국 특허 제4,946,778호, 미국 특허 제5,260,203호, 미국 특허 제5,091,513호, 미국 특허 제5,455,030호 등을 참조). 이 scFv 에 있어서, 중사슬 가변 영역과 경사슬 가변 영역은 콘주게이트를 만들지 않는 링커, 바람직하게는 폴리펩티드 링커를 통해서 연결된다 (Huston, J. S. et al., Proc. Natl. Acad. Sci. U.S.A. (1988), 85, p.5879-5883). scFv 에 있어서의 중사슬 가변 영역 및 경사슬 가변 영역은 동일한 항체에서 유래해도 되고, 다른 항체에서 유래해도 된다.
가변 영역을 연결하는 폴리펩티드 링커로는, 예를 들어 12 ∼ 19 잔기로 이루어지는 임의의 1 개 사슬 펩티드가 사용된다.
scFv 를 코드하는 DNA 는, 상기 항체의 중사슬 또는 중사슬 가변 영역을 코드하는 DNA, 및 경사슬 또는 경사슬 가변 영역을 코드하는 DNA 중, 그들 배열 중 전부 또는 원하는 아미노산 배열을 코드하는 DNA 부분을 주형으로 하고, 그 양단을 규정하는 프라이머쌍을 사용하여 PCR 법에 의해 증폭시키고, 이어서, 추가로 폴리펩티드 링커 부분을 코드하는 DNA, 및 그 양단이 각각 중사슬, 경사슬과 연결되도록 규정하는 프라이머쌍을 조합하여 증폭시킴으로써 얻어진다.
또한, 일단 scFv 를 코드하는 DNA 가 제조되면, 그들을 함유하는 발현 벡터, 및 그 발현 벡터에 의해 형질 전환된 숙주를 통상적인 방법에 따라 얻을 수 있고, 또한 그 숙주를 사용함으로써, 통상적인 방법에 따라 scFv 를 얻을 수 있다. 이들 항체 단편은 상기와 동일하게 하여 유전자를 취득하고 발현시켜, 숙주에 의해 산생시킬 수 있다.
본 발명의 항체는 다량화하여 항원에 대한 친화성을 높인 것이어도 된다. 다량화하는 항체로는 1 종류의 항체이어도 되고, 동일한 항원의 복수의 에피토프를 인식하는 복수의 항체이어도 된다. 항체를 다량화하는 방법으로는, IgG CH3 도메인과 2 개의 scFv 의 결합, 스트렙토아비딘과의 결합, 헬릭스-턴-헬릭스 모티프의 도입 등을 들 수 있다.
본 발명의 항체는 아미노산 배열이 상이한 복수 종류의 항 B7-H3 항체의 혼합물인 폴리클로날 항체이어도 된다. 폴리클로날 항체의 일례로는, CDR 이 상이한 복수 종류의 항체의 혼합물을 들 수 있다. 그러한 폴리클로날 항체로는, 상이한 항체를 산생하는 세포의 혼합물을 배양하고, 그 배양물로부터 정제된 항체를 사용할 수 있다 (WO2004/061104호 참조).
항체의 수식물로서 폴리에틸렌글리콜 (PEG) 등의 각종 분자와 결합한 항체를 사용할 수도 있다.
본 발명의 항체는 또한 이들 항체와 다른 약제가 콘주게이트를 형성하고 있는 것 (Immunoconjugate) 이어도 된다. 이와 같은 항체의 예로는, 그 항체가 방사성 물질이나 약리 작용을 갖는 화합물과 결합되어 있는 것을 들 수 있고 (Nature Biotechnology (2005) 23, p.1137-1146), 예를 들어, 인듐 (111In) 카프로마브 펜데타이드 (Indium (111In) Capromab pendetide), 테크네튬 (99 mTc) 노페투모마브 메르펜탄 (Technetium (99 mTc) Nofetumomab merpentan), 인듐 (111In) 이브리투모마브 (Indium (111In) Ibritumomab), 이트륨 (90Y) 이브리투모마브 (Yttrium (90Y) Ibritumomab), 요오드 (131I) 토시투모마브 (Iodine (131I) Tositumomab) 등을 들 수 있다.
얻어진 항체는 균일하게까지 정제할 수 있다. 항체의 분리, 정제는 통상적인 단백질에서 사용되고 있는 분리, 정제 방법을 사용하면 된다. 예를 들어, 칼럼 크로마토그래피, 필터 여과, 한외 여과, 염석, 투석, 조제용 폴리아크릴아미드 겔 전기 영동, 등전점 전기 영동 등을 적절히 선택, 조합하면, 항체를 분리, 정제할 수 있지만 (Strategies for Protein Purification and Characterization : A Laboratory Course Manual, Daniel R. Marshak et al. eds., Cold Spring Harbor Laboratory Press (1996) ; Antibodies : A Laboratory Manual. Ed Harlow and David Lane, Cold Spring Harbor Laboratory (1988)), 이들에 한정되는 것은 아니다.
크로마토그래피로는, 어피니티 크로마토그래피, 이온 교환 크로마토그래피, 소수성 크로마토그래피, 겔 여과 크로마토그래피, 역상 크로마토그래피, 흡착 크로마토그래피 등을 들 수 있다.
이들 크로마토그래피는 HPLC 나 FPLC 등의 액체 크로마토그래피를 사용하여 실시할 수 있다.
어피니티 크로마토그래피에 사용하는 칼럼으로는, 프로테인 A 칼럼, 프로테인 G 칼럼을 들 수 있다. 예를 들어 프로테인 A 칼럼을 사용한 칼럼으로서 Hyper D, POROS, Sepharose F. F. (파르마시아) 등을 들 수 있다.
또한, 항원을 고정화시킨 담체를 사용하여, 항원에 대한 결합성을 이용하여 항체를 정제할 수도 있다.
3. 항 B7-H3 항체를 함유하는 의약
상기 서술한 「2. 항 B7-H3 항체의 제조」 의 항에 기재된 방법으로 얻어지는 항체는, 암 세포에 대해 세포 상해 활성을 나타내는 점에서, 의약으로서 특히 암에 대한 치료제 및/또는 예방제로서 사용할 수 있다.
in vitro 에서의 항체에 의한 살세포 활성은 세포 증식의 억제 활성으로 측정할 수 있다.
예를 들어, B7-H3 을 과잉 발현하고 있는 암 세포주를 배양하고, 배양계에 다양한 농도로 항체를 첨가하여, 포커스 형성, 콜로니 형성 및 스페로이드 증식에 대한 억제 활성을 측정할 수 있다.
in vivo 에서의 실험 동물을 이용한 항체의 암에 대한 치료 효과는, 예를 들어, B7-H3 을 고발현하고 있는 종양 세포주를 이식한 누드 마우스에 항체를 투여하고, 암 세포의 변화를 측정할 수 있다.
암의 종류로는, 폐암, 신장암, 요로상피암, 대장암, 전립선암, 다형 신경 교아종, 난소암, 췌장암, 유방암, 멜라노마, 간암, 방광암, 위암, 식도암 등을 들 수 있지만, 치료 대상이 되는 암 세포가 B7-H3 을 발현하고 있는 한 이들에 한정되지 않는다.
본 발명의 의약 조성물에 있어서 허용되는 제제에 사용하는 물질로는 투여량이나 투여 농도에 있어서, 의약 조성물이 투여되는 자에 대해 비독성인 것이 바람직하다.
본 발명의 의약 조성물은 pH, 침투압, 점도, 투명도, 색, 등장성, 무균성, 안정성, 용해율, 서방률, 흡수율, 침투율을 바꾸거나, 유지하거나 하기 위한 제제용 물질을 함유할 수 있다. 제제용 물질로서 이하의 것을 들 수 있지만, 이들에 제한되지 않는다 : 글리신, 알라닌, 글루타민, 아스파라긴, 아르기닌 또는 리신 등의 아미노산류, 항균제, 아스코르브산, 황산나트륨 또는 아황산수소나트륨 등의 항산화제, 인산, 시트르산, 붕산 버퍼, 탄산수소나트륨, 트리스-염산 (Tris-HCl) 용액 등의 완충제, 만니톨이나 글리신 등의 충전제, 에틸렌디아민사아세트산 (EDTA) 등의 킬레이트제, 카페인, 폴리비닐피롤리딘, β-시클로덱스트린이나 하이드록시프로필-β-시클로덱스트린 등의 착화제, 글루코오스, 만노오스 또는 덱스트린 등의 증량제, 단당류, 이당류 등의 다른 탄수화물, 착색제, 향미제, 희석제, 유화제나 폴리비닐피롤리딘 등의 친수 폴리머, 저분자량 폴리펩티드, 염 형성 카운터 이온, 염화벤즈알코늄, 벤조산, 살리실산, 티메로살, 페네틸알코올, 메틸파라벤, 프로필파라벤, 클로렉시딘, 소르브산 또는 과산화수소 등의 방부제, 글리세린, 프로필렌·글리콜 또는 폴리에틸렌글리콜 등의 용매, 만니톨 또는 소르비톨 등의 당 알코올, 현탁제, 소르비탄에스테르, 폴리소르베이트 20 이나 폴리소르베이트 80 등의 폴리소르베이트, 트리톤 (triton), 트로메타민 (tromethamine), 레시틴 또는 콜레스테롤 등의 계면 활성제, 수크로오스나 소르비톨 등의 안정화 증강제, 염화나트륨, 염화칼륨이나 만니톨·소르비톨 등의 탄성 증강제, 수송제, 부형제 및/또는 약학상의 보조제. 이들 제제용 물질의 첨가량은 항 B7-H3 항체의 중량에 대해 0.001 ∼ 100 배, 특히 0.1 ∼ 10 배 첨가하는 것이 바람직하다. 제제 중의 바람직한 의약 조성물의 조성은 당업자에 의해 적용 질환, 적용 투여 경로 등에 따라 적절히 결정할 수 있다.
의약 조성물 중의 부형제나 담체는 액체이어도 되고 고체이어도 된다. 적당한 부형제나 담체는 주사용 물이나 생리 식염수, 인공 뇌척수액이나 비경구 투여에 통상적으로 사용되고 있는 다른 물질이어도 된다. 중성의 생리 식염수나 혈청 알부민을 함유하는 생리 식염수를 담체에 사용할 수도 있다. 의약 조성물에는 pH 7.0 - 8.5 의 Tris 버퍼, pH 4.0 - 5.5 의 아세트산 버퍼, pH 3.0 - 6.2 의 시트르산 버퍼를 함유할 수 있다. 또한, 이들 버퍼에 소르비톨이나 다른 화합물을 함유할 수도 있다.
본 발명의 의약 조성물에는 항 B7-H3 항체를 함유하는 의약 조성물, 그리고 항 B7-H3 항체 및 적어도 하나의 암 치료제를 함유하는 의약 조성물을 들 수 있고, 본 발명의 의약 조성물은 선택된 조성과 필요한 순도를 갖는 약제로서, 동결 건조품 혹은 액체로서 준비된다. 항 B7-H3 항체를 함유하는 의약 조성물, 그리고 항 B7-H3 항체 및 적어도 하나의 암 치료약제를 함유하는 의약 조성물은 수크로오스와 같은 적당한 부형제를 사용한 동결 건조품으로서 성형될 수도 있다.
상기의 의약 조성물에 있어서, 항 B7-H3 항체와 함께 함유되는 암 치료제는 항 B7-H3 항체와 동시에, 따로따로, 혹은 연속해서 개체에 투여되어도 되고, 각각의 투여 간격을 바꾸어 투여해도 된다. 이와 같은 암 치료제로서 abraxane, carboplatin, cisplatin, gemcitabine, irinotecan (CPT-11), paclitaxel, pemetrexed, sorafenib, vinblastin 또는 국제 공개 제WO2003/038043호 팜플렛에 기재된 약제, 또한 LH-RH 아날로그 (류프로렐린, 고세렐린 등), 에스트라무스틴·포스페이트, 에스트로겐 길항약 (타목시펜, 랄록시펜 등), 아로마타아제 저해제 (아나스트로졸, 레트로졸, 엑스메스탄 등) 등을 들 수 있지만, 항종양 활성을 갖는 약제이면, 상기의 약제에 한정되지 않는다.
투여 대상이 되는 개체로는 특별히 한정되는 것은 아니지만, 바람직하게는 포유 동물, 더욱 바람직하게는 인간을 들 수 있다.
본 발명의 의약 조성물은 비경구 투여용으로 조제할 수도 있고, 경구에 의한 소화관 흡수용으로 조제할 수도 있다. 제제의 조성 및 농도는 투여 방법에 따라 결정할 수 있고, 본 발명의 의약 조성물에 함유되는 항 B7-H3 항체의 B7-H3 에 대한 친화성, 즉, B7-H3 에 대한 해리 정수 (定數) (Kd 치) 에 대해, 친화성이 높을 (Kd 치가 낮을) 수록 인간에 대한 투여량을 적게 해도 약효를 발휘할 수 있기 때문에, 이 결과에 기초하여 본 발명의 의약 조성물의 인간에 대한 투여량을 결정할 수도 있다. 투여량은 인간형 항 B7-H3 항체를 인간에 대해 투여할 때에는 약 0.001 ∼ 100 ㎎/㎏ 을 1 회 혹은 1 ∼ 180 일 사이에 1 회의 간격으로 복수회 투여하면 된다. 본 발명의 의약 조성물의 형태로는, 점적을 포함하는 주사제, 좌제, 경비제 (經鼻劑), 설하제, 경피 흡수제 등을 들 수 있다.
이하, 실시예를 나타내어 본 발명을 구체적으로 설명하지만, 본 발명은 이들 실시예에 한정되는 것은 아니다. 또한, 하기 실시예에 있어서 유전자 조작에 관한 각 조작은 특별히 명시가 없는 한, 「몰레큘러 클로닝 (Molecular Cloning)」 (Sambrook, J., Fritsch, E. F. 및 Maniatis, T. 저, Cold Spring Harbor Laboratory Press 로부터 1989년에 발간) 에 기재된 방법에 의해 실시하거나, 또는 시판되는 시약이나 키트를 사용하는 경우에는 시판품의 지시서에 따라 사용하였다.
실시예
이하, 실시예에 있어서 본 발명을 더욱 상세하게 설명하지만, 본 발명은 이들에 한정되지 않는다.
또한, 하기 실시예에 있어서 유전자 조작에 관한 각 조작은 특별히 명시가 없는 한, 「몰레큘러 클로닝 (Molecular Cloning)」 (Sambrook, J., Fritsch, E. F. 및 Maniatis, T. 저, Cold SpringHarbor Laboratory Press 로부터 1989년 발간) 에 기재된 방법 및 그 밖의 당업자가 사용하는 실험서에 기재된 방법에 의해 실시하거나, 또는 시판되는 시약이나 키트를 사용하는 경우에는 시판품의 지시서에 따라 실시하였다.
실시예 1. 플라스미드 제조
1)-1 인간 B7-H3 발현 벡터의 제조
1)-1-1 전체 길이 인간 B7-H3 베리언트 1 발현 벡터의 제조
LNCaP 세포 (American Type Culture Collection : ATCC) total RNA 로부터 합성한 cDNA 를 주형으로 프라이머 세트 :

및,

를 사용하여 PCR 반응을 실시하여, 인간 B7-H3 베리언트 1 을 코드하는 cDNA 를 증폭시켰다.
다음으로, 얻어진 PCR 산물을 MagExtractor PCR & Gel cleanup (TOYOBO 사) 으로 정제하였다. 또한, 제한 효소 (NheI/NotI) 로 소화한 후, MagExtractor PCR & Gel cleanup (TOYOBO 사) 으로 정제하였다. pcDNA3.1 (+) 플라스미드 DNA 를 동일한 제한 효소 (NheI/NotI) 로 소화한 후, MagExtractor PCR & Gel cleanup (TOYOBO 사) 으로 정제하였다.
상기 정제 DNA 용액을 혼합하고, 추가로 Ligation high (TOYOBO 사) 를 첨가하여, 16 ℃ 에서 8 시간 인큐베이트하고, 라이게이션하였다.
상기 반응물을 대장균 DH5α 컴피턴트 셀 (인비트로젠사) 에 첨가하여 형질 전환하였다.
상기로 얻어진 콜로니에 대해, PCR 프라이머와 BGH reverse Primer 로 콜로니 다이렉트 PCR 을 실시하여, 후보 클론을 셀렉션하였다.
얻어진 후보 클론을 액체 배지 (LB/Amp) 에서 배양하고, MagExtractor-Plasmid- (TOYOBO 사) 로 플라스미드 DNA 를 추출하였다.
얻어진 플라스미드 DNA 를 주형으로

및

사이의 시퀀스 해석을 실시하여, 취득 클론과 제공 CDS 배열을 비교하였다.
배열을 확인 후, 얻어진 클론을 200 ㎖ 의 LB/Amp 배지에서 배양하고, VioGene 사 Plasmid Midi V-100 키트를 사용하여, 플라스미드 DNA 의 추출을 실시하였다.
본 벡터를 pcDNA3.1-B7-H3 이라고 명명하였다. 본 벡터에 클로닝된 B7-H3 베리언트 1 유전자의 ORF 부분의 배열은 배열표의 배열 번호 5 의 뉴클레오티드 번호 1 내지 1602 에 나타나 있다. 또한, B7-H3 베리언트 1 의 아미노산 배열은 배열표의 배열 번호 6 에 나타나 있다.
1)-1-2 전체 길이 인간 B7-H3 베리언트 2 발현 벡터의 제조
LNCaP 세포 total RNA 로부터 합성한 cDNA 를 주형으로, 이하에 기재하는 프라이머 세트 :


를 사용하여 PCR 을 실시하여, 인간 B7-H3 베리언트 2 를 코드하는 cDNA 를 증폭시켰다.
실시예 1)-1-1 과 동일하게 정제를 실시하고, 정제 후의 PCR 산물을 Gateway BP 반응에 의해 pDONR221 vector (인비트로젠사) 에 삽입하여, 대장균 TOP10 (인비트로젠사) 을 형질 전환하였다.
형질 전환 후에 얻어진 클론에 대해 콜로니 PCR 로 인서트 사이즈의 확인을 실시하였다. 각각 인서트의 길이를 확인한 8 개의 클론에 대해 벡터측으로부터 인서트 방향으로 1 반응씩의 시퀀스 반응을 실시하여, 인서트의 3' 및 5' 의 말단 DNA 배열의 확인을 실시하였다. 배열을 확인한 엔트리 클론과 Gateway 데스티네이션 벡터 pcDNA-DEST40 (인비트로젠사) 에서 Gateway LR 반응을 실시하였다. 대장균 TOP10 의 형질 전환 후에 얻어진 클론에 대해 콜로니 PCR 로 인서트 사이즈의 확인을 실시하였다. 인서트의 길이를 확인한 클론에 대해 인서트의 3' 및 5' 의 말단 DNA 배열의 해석을 실시하여, 목적 인서트가 올바르게 삽입된 것을 확인하였다. 제조한 클론의 플라스미드를 인비트로젠사 PureLink HiPure Plasmid Megaprep Kit 를 사용하여 1 ㎎ 이상 정제하였다.
본 벡터를 pcDNA-DEST40-B7-H3 베리언트 2 라고 명명하였다. 본 벡터에 클로닝된 B7-H3 베리언트 2 유전자의 ORF 부분의 배열은 배열표의 배열 번호 9 의 뉴클레오티드 번호 1 내지 948 에 나타나 있다. 또한, B7-H3 베리언트 2 의 아미노산 배열은 배열표의 배열 번호 10 에 나타나 있다.
1)-2 B7-H3 부분 단백질 발현 벡터의 제조
실시예 1)-1-1 의 B7-H3 베리언트 1 에 관련된 B7-H3 전체 길이 플라스미드를 템플레이트로 하여, 이하에 기재하는 영역을 각각 PCR 에 의해 증폭시켰다. 목적으로 하는 영역 번호는 배열 번호 5 로 나타내는 B7-H3 의 뉴클레오티드 번호에 상당한다. 프라이머는 Gateway att 배열에 더하고, 3' 측은 Stop 코돈을 포함하도록 설계하였다.
하기 1), 2), 3) 은 2 영역을 증폭 후, PCR 로 연결하여 1 단편으로 하였다. 즉, 1) 은 프라이머 7 및 12 와 프라이머 15 및 11 에서 증폭시키고, PCR 산물을 또한 프라이머 7 및 11 에서 증폭시켰다. 2) 는 프라이머 8 및 13 과 프라이머 15 및 11 에서 증폭시키고, PCR 산물을 또한 프라이머 8 및 11 에서 증폭시켰다. 3) 은 프라이머 9 및 14 와 프라이머 15 및 11 에서 증폭시키고, PCR 산물을 또한 프라이머 9 및 11 에서 증폭시켰다. 4) 는 프라이머 10 및 11 에서 증폭시켰다. 5) 는 프라이머 8 및 11 에서 증폭시켰다. 6) 은 프라이머 9 및 11 에서 증폭시켰다.
·목적 영역
1) B7-H3 베리언트 1 ORF : 79 ∼ 417 및 1369 ∼ 1602 (573 bp)
2) B7-H3 베리언트 1 ORF : 418 ∼ 732 및 1369 ∼ 1602 (549 bp)
3) B7-H3 베리언트 1 ORF : 733 ∼ 1071 및 1369 ∼ 1602 (573 bp)
4) B7-H3 베리언트 1 ORF : 1072 ∼ 1602 (531 bp)
5) B7-H3 베리언트 1 ORF : 418 ∼ 1602 (1185 bp)
6) B7-H3 베리언트 1 ORF : 733 ∼ 1602 (870 bp)
·프라이머 번호 및 염기 배열
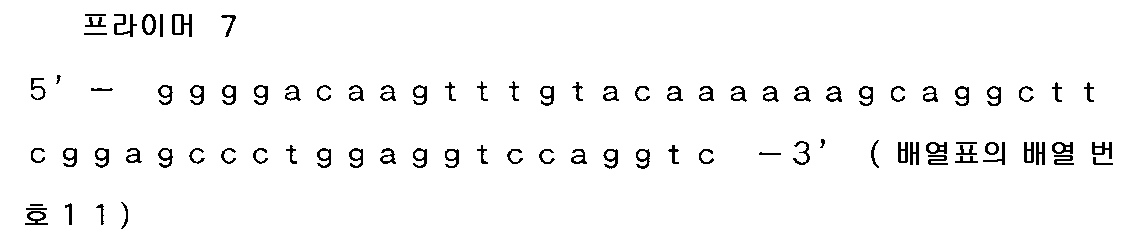

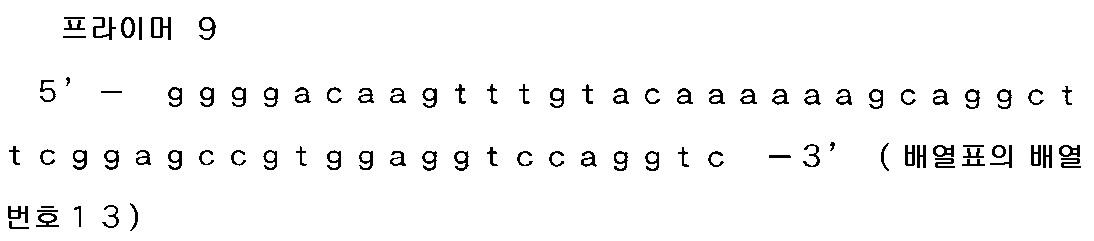

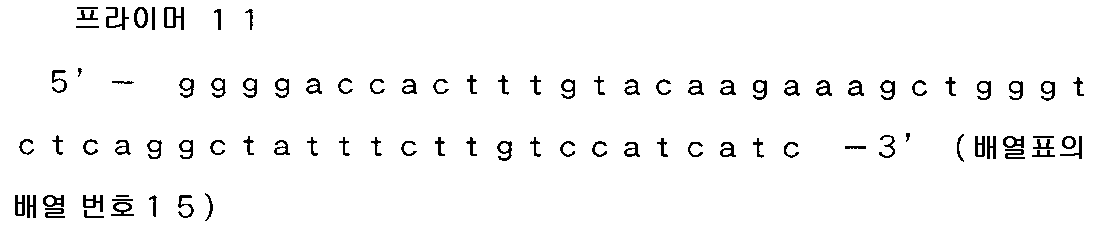




실시예 1)-1-1 과 동일하게 정제를 실시하고, 정제 후의 각 증폭물을 Gateway BP 반응에 의해 pDONR221 vector 에 삽입하여, 대장균 TOP10 을 형질 전환하였다. 형질 전환 후에 얻어진 클론에 대해 콜로니 PCR 로 인서트 사이즈의 확인을 실시하였다.
인서트의 길이를 확인한 각 클론에 대해, 벡터측으로부터 인서트 방향으로 1 반응씩의 시퀀스 반응을 실시하여, 인서트의 3' 및 5' 의 말단 DNA 배열의 확인을 실시하였다.
목적으로 하는 인서트가 확인된 클론에 대해, 하기 프라이머를 사용하여 인서트의 전체 DNA 배열에 대해서도 확인을 실시하였다. 배열 해석의 결과, 모두 목적 배열 정보와 완전하게 일치했던 것이 확인되었다.
배열을 확인한 각 엔트리 클론과 pFLAG-myc-CMV-19-DEST (인비트로젠사) 에서 Gateway LR 반응을 실시하였다. 대장균 DH10B (인비트로젠사) 의 형질 전환 후에 얻어진 클론에 대해 콜로니 PCR 로 인서트 사이즈의 확인을 실시하였다.
인서트의 길이를 확인한 각 클론에 대해, 인서트의 3' 및 5' 의 말단 DNA 배열의 해석을 실시하여, 목적 인서트가 올바르게 삽입된 것을 확인하였다. 이하, 상기 1) 내지 6) 을 삽입한 발현 벡터를 각각 B7-H3 IgV1, B7-H3 IgC1, B7-H3 IgV2, B7-H3 IgC2, B7-H3 IgC1-V2-C2, B7-H3 IgV2-C2 라고 기재한다.
본 벡터에 클로닝된 B7-H3 IgV1, B7-H3 IgC1, B7-H3 IgV2, B7-H3 IgC2, B7-H3 IgC1-V2-C2, B7-H3 IgV2-C2 유전자의 ORF 부분의 뉴클레오티드 배열은 각각 배열표의 배열 번호 20, 22, 24, 26, 28, 30 에 나타나 있다. 또한, B7-H3 IgV1, B7-H3 IgC1, B7-H3 IgV2, B7-H3 IgC2, B7-H3 IgC1-V2-C2, B7-H3 IgV2-C2 의 아미노산 배열은 배열표의 배열 번호 21, 23, 25, 27, 29, 31 에 나타나 있다. 또한, 배열 번호 20 및 21 의 배열은 도 15 에, 배열 번호 22 및 23 의 배열은 도 16 에, 배열 번호 24 및 25 의 배열은 도 17 에, 배열 번호 26 및 27 의 배열은 도 18 에, 배열 번호 28 및 29 의 배열은 도 19 에, 배열 번호 30 및 31 의 배열은 도 20 에 각각 기재되어 있다.
1)-3 B7 패밀리 유전자 발현 벡터의 제조
B7 패밀리 유전자인 B7RP-1, B7-H1, B7-DC 를 발현 벡터 pCMV6-XL-4 에 삽입한 유전자 발현 벡터, pCMV6-XL-4-B7RP-1, pCMV6-XL-4-B7-H1, pCMV6-XL-4-B7-DC 는 모두 Origene 사로부터 구입하였다.
B7 패밀리 유전자인 CD80, CD86, B7-H4 를 발현하는 벡터는 이하와 같이 제조하였다.
CD80, CD86, B7-H4 를 엔트리 벡터 pENTR/221 에 삽입한 클론인 pENTR/221-CD80, pENTR/221-CD86, pENTR/221-B7-H4 를 인비트로젠사로부터 구입하였다.
배열을 확인한 각 엔트리 클론과 pcDNA3.1-DEST (인비트로젠사) 에서 Gateway LR 반응을 실시하였다. 대장균 DH10B 의 형질 전환 후에 얻어진 클론에 대해 콜로니 PCR 로 인서트 사이즈의 확인을 실시하였다. 인서트의 길이를 확인한 각 클론에 대해 인서트의 3' 및 5' 의 말단 DNA 배열의 해석을 실시하여, 목적 인서트가 올바르게 삽입된 것을 확인하였다.
본 벡터에 클로닝된 B7RP-1, B7-H1, B7-DC, CD80, CD86, B7-H4 유전자의 ORF 부분의 뉴클레오티드 배열은 각각 배열표의 배열 번호 32, 34, 36, 38, 40, 42 에 나타나 있다. 또한, B7RP-1, B7-H1, B7-DC, CD80, CD86, B7-H4 의 아미노산 배열은 배열표의 배열 번호 33, 35, 37, 39, 41, 43 에 나타나 있다.
실시예 2. 모노클로날 항체 제조 및 항체 스크리닝
2)-1 면역
4 ∼ 6 주령의 BALB/cAnNCrlCrlj 마우스 (닛폰 찰스·리버사), FcgRⅡ KO 마우스 (타코닉사, 면역 생물학 연구소) 또는 GANP 마우스 (Transgenic 사) 를 사용하였다. 0 일째, 7 일째, 15 일째, 24 일째에 베르센 (인비트로젠) 으로 벗긴 LNCaP 세포, MCF7 세포 (ATCC) 또는 AsPC1 세포 (ATCC) 를 5 × 106 세포/마우스를 마우스 등부 피하에 투여하였다. 31 일째에 동일한 세포를 5 × 106 세포 각 마우스에 정맥 투여하고, 34 일째에 마우스 비장을 채취하여 하이브리도마 제조에 사용하였다.
2)-2 하이브리도마의 제조
비장 세포와 마우스 미엘로마 P3X63Ag8U. 1 세포 (ATCC) 를 PEG4000 (IBL 사 제조) 을 사용하여 세포 융합하여 하이브리도마를 제조하였다.
그 결과, LNCaP 세포 면역 마우스로부터 합계 9639 클론, MCF7 세포 면역 마우스로부터 4043 클론, AsPC1 세포 면역 마우스로부터 3617 클론의 하이브리도마를 수립하였다. 얻어진 하이브리도마 배양 상청을 사용하여 항체 산생 하이브리도마의 CDC 어세이에 의한 스크리닝을 실시하였다.
2)-3 항체 스크리닝 : CDC 어세이
0 일째에 5000 cells/80 ㎕ 가 되도록 LNCaP 세포 또는 MCF7 세포를 희석시키고, 96 well plate 에 80 ㎕/well 첨가하고 하룻밤 배양하였다. 하이브리도마 배양 상청을 세포를 파종한 plate 에 20 ㎕/well 첨가하고, 4 ℃ 에서 1 시간 가만히 정지시켰다. 토끼 보체의 희석 동결 건조품 (Cedarlane 사) 에 1 바이알당 1 ㎖ 의 멸균수를 빙상에서 첨가하였다. 1 분간 가만히 정지, 혼합한 후, 19 ㎖ 의 0.1 % BSA/RPMI 1640 배지 (BSA Sigma 사) 와 혼합하였다. 37 ℃ 에서 1 시간 반응을 실시하였다.
플레이트를 실온에서 30 분간 방치하여 실온으로 되돌렸다. CellTiter-Glo 시약 (Promega 사) 을 각 웰에 120 ㎕ 첨가하고, 실온에서 10 분간 반응하였다. 플레이트 리더 (ARVO HTS Prekin Elmer 사) 로 발광량을 측정하였다. 발광량이 적은 웰은 보체 의존적인 세포사를 유도했다고 판단되었다. 그러한 보체 의존적인 세포사를 유도한 배양 상청을 산생하는 하이브리도마를 선택하였다.
그 결과, 각각 LNCaP 면역 유래 클론으로부터 24 클론, MCF7 면역 유래 클론으로부터 36 클론, AsPC1 면역 유래 클론으로부터 3 클론의 스크리닝 양성 클론이 얻어졌다.
실시예 3. 항원 동정
3)-1 면역 침강물의 동정
3)-1-1 면역 침강
MCF7 세포를 5 - 10 × 108 세포 배양하였다. 이들 세포는 셀 스크레이퍼로 박리, 회수한 후, -80 도로 동결 보존을 실시하였다. 4 ℃ 로 식힌 1 % NP-40 (시그마 알드리치사) 과 Protease inhibitor (로슈사) 함유 Lysis buffer 10 ㎖ 를 동결 세포에 첨가하고, 빙상에서 거품이 일어나지 않도록 피펫으로 펠릿을 용해시켰다. 완전하게 펠릿이 용해되면, 빙상에서 30 분 방치하였다. 가용화된 샘플은 4 ℃, 10000 - 15000 회전, 20 분 원심 분리하여 상청을 15 ㎖ 팔콘 튜브로 옮겼다.
Protein G sepharose 4FF beads (아머샴 파마시아사) 500 ㎕ 를 3 회 세정하고, Lysis buffer 로 치환하였다. 빙상에서 protein G sepharose 4FF beads 500 ㎕ 를 가용화한 샘플 상청에 첨가하고, 하룻밤 4 ℃ 에서 회전 교반하였다.
샘플을 Polyprep column chromatography columns (Biorad 사) 에 통과시켜, 플로우 스루를 면역 침강 샘플로서 사용하였다.
면역 침강에 사용하는 항체액 3 ㎍ 을 인산 완충 생리 식염수 (PBS) 로 치환한 50 ㎕ 의 protein G sepharose 4FF beads 에 첨가하고 (1.5 ㎖ tube), 4 ℃ 에서 1 시간 내지 16 시간 회전 교반하여 항체를 beads 에 결합시켰다. 면역 침강 샘플에 항체가 결합한 beads 를 첨가하고, 4 ℃, 3 시간 회전 교반하였다.
칼럼을 비어있는 15 ㎖ 팔콘 튜브로 옮기고, 6.5 ㎖ Lysis buffer 를 첨가하였다. 이 조작을 4 회 반복하였다.
칼럼의 출구에 뚜껑을 덮고, 500 ㎕ Lysis buffer 로 피펫팅하여, 1.5 ㎖ 튜브에 beads 를 회수하였다. 이 조작을 2 회 반복하였다.
5000 회전으로 1 분간, 4 ℃ 원심 후, 상청을 천천히 제거하고, 90 ㎕ 의 Elution buffer (10 mM Glycine-HCl pH 2.0) 를 첨가하고, voltex 후 원심하였다. 1.5 ㎖ spin culmn 의 칼럼을 떼어내고, 10 ㎕ 1 M Tris-HCL, pH 8.5 를 첨가하였다. 칼럼을 원래대로 되돌려, 용출 분획을 옮기고, 10000 회전으로 1 분간 원심하였다. 100 ㎕ 의 샘플을 얻었다.
이 샘플을 이하의 3)-1-2 에 나타내는 바와 같이, 액층 소화법에 의한 MS 해석을 실시하였다.
3)-1-2 질량 분석법에 의한 항원 동정
면역 침강법에 의해 얻어진 획분을 통상적인 방법에 따라, 액층 소화법으로 트립신 (모디파이드트립신, 프로메가사) 을 첨가하고, 37 ℃ 에서 16 시간 소화 반응을 실시하였다. 생성한 소화 펩티드는 액체 크로마토그래피 (LC)/탠덤 질량 분석 장치 (MS/MS) (서모 피셔 사이언스사) 에 제공하였다. 얻어진 질량 스펙트럼 데이터는 데이터베이스 검색 소프트웨어 (Mascot, 매트릭스 사이언스사) 에 의해 분석하였다. 데이터베이스는 International Protein Index (IPI) 를 사용하였다. 그 결과, 34 종류의 항원이 동정되었다.
동정된 항원 정보 중에서 세포막 단백질인 것을 고려한 문헌 정보 검색을 실시하고, B7-H3 (CD296) 항원 (B7-H3 베리언트 1) 에 주목하여 이하의 3)-2 및 3)-3 의 실험을 실시하였다.
3)-2 항원 유전자 발현 세포의 조제
NIH-3T3 세포 (ATCC) 를 5 × 104 세포/㎠ 가 되도록 collagen type I 코트 플라스크 (IWAKI 사 제조) 에 파종하고, 10 % 소 태아 혈청 (FBS) 함유 DMEM 배지 (인비트로젠사) 중에서 37 ℃, 5 % CO2 의 조건하에서 하룻밤 배양하였다.
다음날, 실시예 1)-1-1 로 제조된 pcDNA3.1-B7-H3, 1)-1-2 로 제조된 pcDNA-DEST40-B7-H3 베리언트 2, 및 공 벡터인 pcDNA-DEST40 을 각각 NIH-3T3 세포에 Lipofectamine 2000 (인비트로젠사 제조) 을 사용하여 트랜스펙션하고, 37 ℃, 5 % CO2 의 조건하에서 추가로 하룻밤 배양하였다.
다음날, 트랜스펙션된 NIH-3T3 세포를 트립신 처리하여, 10 % FBS 함유 DMEM 으로 세포를 세정한 후, 5 % FBS 함유 PBS 에 현탁하였다. 얻어진 세포 현탁액을 플로우 사이토메트리 해석에 사용하였다.
3)-3 플로우 사이토메트리 해석
MS 로 B7-H3 베리언트 1 을 면역 침강한 하이브리도마가 산생하는 항체의 B7-H3 에 대한 결합 특이성을 플로우 사이토메트리법에 의해 확인하였다. 실시예 3)-2 로 조제한 세포 현탁액을 원심하여 상청을 제거한 후, 각 벡터를 트랜스펙트한 NIH-3T3 세포에 대해 하이브리도마 배양 상청을 첨가하여 현탁하고, 4 ℃ 에서 1 시간 가만히 정지시켰다.
5 % FBS 함유 PBS 로 2 회 세정한 후, 5 % FBS 함유 PBS 로 1000 배로 희석시킨 Fluorescein-conjugated goat IgG fraction to mouse IgG (Whole Molecule) (ICN Pharmaceuticals 사 제조 #55493) 를 첨가하여 현탁하고, 4 ℃ 에서 1 시간 가만히 정지시켰다.
5 % FBS 함유 PBS 로 2 회 세정한 후, 2 ㎍/㎖ 7-aminoactinomycin D (인비트로젠 (Molecular Probes) 사 제조) 를 함유하는 5 % FBS 함유 PBS 에 재현탁하고, 플로우 사이토미터 (FC500 : BeckmanCoulter 사) 로 검출을 실시하였다. 데이터 해석은 Flowjo (TreeStar 사) 로 실시하였다.
7-aminoactinomycin D 양성의 사세포를 게이트로 제외한 후, 생세포의 FITC 형광 강도의 히스토그램을 제조하였다.
컨트롤인 공 벡터를 도입한 NIH-3T3 세포의 형광 강도 히스토그램에 대해 B7-H3 베리언트 1 발현 NIH-3T3 세포 및 B7-H3 베리언트 2 발현 NIH-3T3 세포의 히스토그램이 강형광 강도측으로 시프트하고 있는 샘플을 산생하는 하이브리도마를 항 B7-H3 항체 산생 하이브리도마로서 취득하였다.
그 결과, L7, L8, L11, M30, M31 의 5 클론의 항 B7-H3 항체 산생 하이브리도마 유래의 항체가 B7-H3 베리언트 1 및 B7-H3 베리언트 2 와 교차 반응성을 나타내는 것이 분명해졌다.
3)-4 모노클로날 항체의 암 세포주에 대한 결합성의 확인
실시예 3)-3 에서 B7-H3 베리언트 1 및 B7-H3 베리언트 2 에 대한 결합이 확인된 모노클로날 항체가 B7-H3 베리언트 1 및 B7-H3 베리언트 2 를 고발현하는 암 세포에 결합하는가 여부를 실시예 3)-3 과 동일한 플로우 사이토메트리법으로 검토하였다.
트랜스펙션한 NIH-3T3 세포 대신에 인간 유방암 세포주 (MDA-MB-231) (ATCC), 인간 폐암 세포주 (NCI-H322) (ATCC) 가 사용되었다. 그 결과, 수립한 모노클로날 항체는 모두 이들 암 세포주에 결합하는 것이 확인되었다.
3)-5 모노클로날 항체의 아이소 타입 결정
모노클로날 항체의 아이소 타입은 Mouse monoclonal isotyping kit (Serotec 사 제조) 에 의해 결정되었다. 그 결과, 항 B7-H3 항체 산생 하이브리도마 (L7, L8, L11, M30, M31) 유래의 항체의 아이소 타입은 모두 IgG2a 였다.
3)-6 모노클로날 항체의 조제
모노클로날 항체는 하이브리도마 이식 마우스의 복수 또는 하이브리도마 배양 상청 (이하 「항체 정제 원료」라고 한다) 으로부터 정제하였다.
마우스 복수는 이하와 같이 조제하였다. 먼저, 7 - 8 주령의 BALB/cAJcl-nu/nu (닛폰 클레아) 를 프리스탄 (Sigma 사 제조) 처리하고, 약 3 주 후에 생리 식염수로 세정한 하이브리도마를 마우스 1 마리당 1 × 107 세포로 복강 내에 이식하였다. 1 - 2 주 후에 복강 내에 저류한 복수를 채취하고, 0.22 ㎛ 의 필터를 통과시키고 멸균하여 항체 정제 원료로서 사용하였다.
하이브리도마 배양 상청은 CELLine (BD Biosciences 사 제조) 을 사용하여 조제하였다. 배지에 ClonaCell-HY Growth Medium E (StemCell Technologies 사 제조 #03805) 를 사용하는 점 이외에는 메이커의 지시서에 따라 배양하였다. 회수된 배양 상청은 0.45 ㎛ 필터로 여과하여, 항체 정제 원료로서 사용하였다.
항체는 Recombinat Protein A rPA50 (RepliGen 사 제조) 을 포르밀-셀루로파인 (생화학 공업사 제조) 에 고정화시킨 어피니티 칼럼 (이하 「포르밀셀루로파인 Protein A」라고 약기한다) 또는 Hitrap MabSelect SuRe (GE Healthcare Bio-Sciences 사 제조) 로 정제되었다. 포르밀셀루로파인 Protein A 에서는 항체 정제 원료를 결합 버퍼 (3 M NaCl, 1.5 M Glycine pH 8.9) 로 3 배 희석시킨 것을 칼럼에 첨가하고, 결합 버퍼로 세정 후, 0.1 M 시트르산 pH 4.0 으로 용출하였다.
한편, Hitrap MabSelect SuRe (GE 헬스케어사) 에서는, 항체 정제 원료를 칼럼에 첨가하고 PBS 로 세정 후, 2 M Arginine-HCl pH 4.0 으로 용출하였다.
용출된 항체 용액은 중화 후, PBS 에 버퍼 치환되었다.
항체의 농도는 POROS G 20 ㎛ Column, PEEK, 4.6 ㎜ × 100 ㎜, 1.7 ㎖ (Applied Biosystems) 에 결합시킨 항체를 용출하고, 용출액의 흡광도 (O.D. 280 ㎚) 를 측정함으로써 구하였다. 구체적으로는, 평형화 버퍼 (30.6 mM 인산2수소나트륨·12 물, 19.5 mM 인산1칼륨, 0.15 M NaCl, pH 7.0) 로 평형화한 POROS G 20 ㎛ 에 PBS 로 희석시킨 항체 샘플을 첨가하고, 평형화 버퍼로 칼럼을 세정 후, 칼럼에 결합한 항체를 용리액 (0.1 % (v/v) HCl, 0.15 M NaCl) 으로 용출하였다. 용출액의 흡광도 (O.D. 280 ㎚) 의 피크 면적을 측정하고, 다음 식으로 농도를 산출하였다.
항체 샘플 농도 (㎎/㎖) = (항체 샘플의 피크 면적)/(표준품 (인간 IgG1) 의 피크 면적) × 표준품의 농도 (㎎ /㎖) × 샘플의 희석 배율
또한, 얻어진 항체에 함유되는 엔도톡신 농도를 엔도스페시 ES-50M 세트 (생화학 공업 #020150) 와 엔도톡신 표준품 CSE-L 세트 (생화학 공업 #020055) 를 사용하여 측정하고, 1 EU/㎎ 이하인 것을 확인하여 이하의 실험에 사용하였다.
실시예 4. 항 B7-H3 항체의 성질
4)-1 ADCP 활성
Balb/c-nu/nu 마우스 (♀, 6 - 10 wk) (닛폰 찰스 리버사) 에 1.5 ㎖ 의 티오 글리콜레이트를 복강 내 투여하였다. 5 일 후에 복강 중의 매크로파지 세포를 회수하였다. 500 ㎕/well (1 × 105 cell/well) 을 24 well plate 에 첨가하고, 37 ℃ 에서 하룻밤 배양하였다. 본 세포를 이펙터 세포로 하였다.
타겟 세포가 되는 NCI-H322 세포의 라벨링을 PKH26 dye labeling kit (Sigma 사) 를 사용하여 실시하였다. 타겟 세포를 TrypLE (인비트로젠사) 로 박리하고, PBS 로 2 회 세정하였다. 세포를 Diluent C 로 1 × 107 cells/㎖ 가 되도록 현탁하였다. PKH26 dye stock (1 mM) 을 Diluent C 로 8 μM 으로 희석시키고, 바로 세포 부유액과 등량의 dye 희석액을 첨가하였다. 실온에 5 분간 방치하였다. 혈청 1 ㎖ 를 첨가하고, 추가로 혈청 함유 배지를 첨가하고 2 회 세정을 실시하였다. 본 세포를 타겟 세포로 하였다.
실시예 3)-6 으로 얻어진 항체를 배양액으로 20 ㎍/㎖ 로 희석시켰다. 다음으로 실시예 4)-1-1 로 얻어진 타겟 세포를 2 × 106/100 ㎕/tube 에 분주하고, 혼합하였다. 빙상에서 30 분간 가만히 정지시켰다. 상청을 버리고, 배양액으로 2 회 세정하였다. 배양액 500 ㎕ 에 현탁하였다. 이펙터 세포로부터 상청을 제거하고, 항체를 처리하여 배양액에 서스펜드한 세포를 첨가하고 혼합하였다. CO2 인큐베이터 내에서 3 시간 배양하였다. Trypsin-EDTA 로 세포를 박리하여, 세포를 회수하였다. 회수한 세포에 FITC 표지 항마우스 CD11b 항체 (벡톤 디킨슨사) 를 첨가하고, 빙상에서 30 분간 가만히 정지시켰다. 상청을 버리고, 배양액으로 2 회 세정하였다. 회수한 세포를 300 ㎕ 의 배양액으로 현탁하고, FACS Calibur (벡톤 디킨슨사) 로 측정을 실시하였다. CD11b 양성의 매크로파지 세포에 있어서, PKH26 양성 획분을 탐식 양성 세포로 하여 평가를 실시하였다 (n = 3).
그 결과, 도 1 에 나타내는 바와 같이, L7, L8, L11, M30, M31 은 각각 매크로파지에 의한 NCI-H322 세포의 탐식률을 48.0 ± 0.9 %, 52.3 ± 1.1 %, 57.1 ± 2.5 %, 61.9 ± 2.1 %, 57.7 ± 3.0 % 유도한 점에서, L7, L8, L11, M30, M31 항체는 NCI-H322 세포에 대해 ADCP 활성을 갖는 것이 나타났다.
동일하게, 시판되는 항 B7-H3 항체를 입수하여 그 ADCP 활성을 측정하였다. 래트 항인간 B7-H3 항체 MIH35 (eBioscience 사), 마우스 항인간 B7-H3 항체 185504 (R & D Systems 사), MIH42 (Serotec 사), DCN70 (Biolegend 사) 을 각각 입수하였다. 이들 항체가 B7-H3 과 결합하는 것을 실시예 3)-3 과 동일한 방법으로 확인하였다. 이들 항체를 사용하여 상기의 방법으로 ADCP 활성을 측정하였다.
그 결과, 도 2 에 나타내는 바와 같이 MIH35, MIH42, DCN70 을 1 ㎍/㎖ 첨가했을 때, 각각 매크로파지에 의한 NCI-H322 세포의 탐식을 4.2 %, 8.2 %, 10.8 % 유도하였다. 이런 점에서, MIH35, MIH42, DCN70 은 거의 ADCP 활성을 나타내지 않는 것이 분명해졌다.
이런 점에서, 이번 스크리닝에 의해 얻어진 B7-H3 인식 클론 M30 은 시판 B7-H3 항체와 비교하여 특히 강한 ADCP 활성을 갖는 것이 나타났다.
4)-2 ADCC 활성
4)-2-1 이펙터 세포의 조제
누드 마우스인 CAnN.Cg-Foxn1nu/CrlCrlj (닛폰 찰스·리버사) 로부터 무균적으로 비장을 채취하였다. 채취한 비장을 2 장의 슬라이드 글라스로 호모게나이즈하고, BD Pharm Lyse (BD Biosciences 사 제조 #555899) 를 사용하여 용혈 처리를 실시하였다. 얻어진 비장 세포를 Fetal Bovine Serum, Ultra-low IgG (인비트로젠사 제조) 를 10 % 함유하는 페놀레드 불함 RPMI1640 (인비트로젠사 제조) (이하 「ADCC 용 배지」라고 약기한다) 에 현탁하고, 셀 스트레이너 (포아 사이즈 40 ㎛ : BD Biosciences 사 제조) 를 통과시킨 후, 생세포수를 트리판 블루 색소 배제 시험으로 계측하였다. 비장 세포 현탁액을 원심 후, 배지를 제거하고, 생세포 밀도로 1.5 × 107 세포/㎖ 가 되도록 ADCC 용 배지로 재현탁하여 이펙터 세포로 하였다.
4)-2-2 표적 세포의 조제
실시예 3)-3 과 동일한 방법으로 제조한 B7-H3 발현 293 세포 (ATCC) 및 공 벡터를 발현한 293 세포를 트립신 처리하고, 10 % FBS 함유 RPMI1640 (인비트로젠사) 으로 세포를 세정 후, 10 % FBS 함유 RPMI1640 에 재현탁하여, 각 세포 4 × 106 개를 0.22 ㎛ 필터로 멸균한 Chromium-51 (5550 kBq) 과 혼합하고, 37 ℃, 5 % CO2 의 조건하에서 1 시간 라벨하였다. 라벨한 세포를 10 % FBS 함유 RPMI1640 (인비트로젠사) 으로 3 회 세정하고, ADCC 용 배지로 2 × 105 세포/㎖ 가 되도록 재현탁하여 표적 세포로 하였다.
4)-2-3 51Cr 릴리스 어세이
2 × 105 세포/㎖ 의 표적 세포를 50 ㎕/웰로 96 구멍 U 바닥 마이크로 플레이트에 분주하였다. 거기에 이펙터 세포 첨가 후의 최종농도로 2.5 ㎍/㎖ 가 되도록 ADCC 용 배지로 희석시킨 M30, 아이소 타입 컨트롤 항체 (mIgG2a) (eBioscience 사) 를 50 ㎕ 첨가하고, 4 ℃ 에서 1 시간 가만히 정지시켰다. 거기에 1.5 × 107 세포/㎖ 의 이펙터 세포를 100 ㎕ 첨가하고, 37 ℃, 5 % CO2 의 조건하에서 하룻밤 배양하였다. 다음날, 상청을 LumaPlate (PerkinElmer 사 제조) 에 회수하고, 감마 카운터로 방출된 감마선량을 측정하였다. ADCC 활성에 의한 세포 용해율은 다음 식으로 산출하였다.
세포 용해율 (%) = (A - B)/(C - B) × 100
A : 샘플 웰의 카운트
B : 자연 방출 (항체·이펙터 세포 비첨가 웰) 카운트의 평균치 (n = 3). 항체 첨가시와 이펙터 세포 첨가시에 각각 ADCC 용 배지를 50 ㎕, 100 ㎕ 첨가하였다. 그 이외에는 샘플 웰과 동일한 조작을 실시하였다.
C : 최대 방출 (표적 세포를 계면활성제로 용해시킨 웰) 카운트의 평균치 (n = 3). 항체 첨가시에 ADCC 용 배지를 50 ㎕, 이펙터 세포 첨가시에 Triton-X100 을 2 % (v/v) 함유하는 ADCC 용 배지를 100 ㎕ 를 첨가하였다. 그 이외에는 샘플 웰과 동일한 조작을 실시하였다.
3 회 실험의 평균치이고, 에러바는 표준 편차를 나타내고, P 치는 Student's t-test 에 의해 산출하였다. 측정 결과를 도 3 에 나타냈다.
그 결과, M30 은 B7-H3 발현 293 세포에 대해 31.6 ± 3.3 % 의 세포 용해 활성을 나타내는 점에서, M30 항체는 B7-H3 발현 293 세포에 대해 ADCC 활성을 갖는 것이 나타났다.
4)-3 CDC 활성
실시예 2)-3-1 에 나타내는 방법과 동일한 수법으로 실험을 실시하였다. 평가 세포에는 NCI-H322 세포를 사용하였다. 보체 첨가 후의 최종농도로 25 ㎍/㎖ 가 되도록 10 % FBS 함유 RPMI1640 (항생 물질 함유 : 페니실린, 스트렙토마이신) 으로 희석시킨 실시예 3)-6 으로 얻어진 항 B7-H3 항체 (L7, L8, L11, M30, M31) 및 아이소 타입 컨트롤 항체 (mIgG2a) 를 첨가하고, 4 ℃ 에서 1 시간 가만히 정지시켰다. 거기에 RPMI1640 으로 30 % 로 희석시킨 토끼 보체 (CEDARLANE 사 제조 #CL3051) 를 최종농도로 5 % 가 되도록 첨가하고, 37 ℃, 5 % CO2 의 조건하에서 1 시간 인큐베이트하고, 추가로 실온에서 30 분간 가만히 정지시켰다. 세포 생존율을 측정하기 위해, 배양액과 등량의 CellTiter-Glo Luminescent Cell Viability Assay (Promega 사 제조) 를 첨가하고, 실온에서 10 분간 교반한 후, 플레이트 리더로 발광량을 계측하였다. 세포 생존율은 다음 식으로 산출하였다.
세포 생존율 (%) = (a - b)/(c - b) × 100
a : 샘플 웰의 발광량
b : 백그라운드 (세포·항체 비첨가 웰) 발광량의 평균치 (n = 3). 세포 파종시에 세포 현탁액 대신에 등량의 10 % FBS 함유 RPMI1640 (항생 물질 함유 : 페니실린, 스트렙토마이신) 을 첨가하고, 항체 첨가시에 항체 희석액과 등량의 10 % FBS 함유 RPMI1640 (항생 물질 함유 : 페니실린, 스트렙토마이신) 을 첨가하였다. 그 이외에는 샘플 웰과 동일한 조작을 실시하였다.
c : 항체 비첨가 웰의 발광량의 평균치 (n = 3). 항체 첨가시에 항체 희석액과 등량의 10 % FBS 함유 RPMI1640 (항생 물질 함유 : 페니실린, 스트렙토마이신) 을 첨가하였다. 그 이외에는 샘플 웰과 동일한 조작을 실시하였다.
측정 결과를 도 4 에 나타냈다. 3 회의 실험의 평균치이고, 에러바는 표준 편차를 나타내고 있다. 그 결과, 컨트롤 항체, L7, L8, L11, M30, M31 은 각각 보체 존재하에서 NCI-H322 세포에 대해 101.5 ± 3.3 %, 6.3 ± 4.2 %, 13.6 ± 9.1 %, 7.2 ± 1.4 %, 7.5 ± 1.8 %, 12.8 ± 2.0 % 의 세포 생존율의 저하를 유도한 점에서, L7, L8, L11, M30, M31 항체는 NCI-H322 세포에 대해 CDC 활성을 갖는 것이 나타났다.
4)-4 결합 도메인의 결정
M30 이 B7-H3 의 어느 도메인에 결합하는지를 실시예 3)-3 과 동일한 플로우 사이토메트리법으로 검토하였다. 실시예 1)-1-3 에서 조정된 각 B7-H3 부분 단백질 발현 벡터를 트랜스펙션한 NIH-3T3 세포가 사용되었다.
그 결과, 도 5 에 나타내는 바와 같이 M30 은 B7-H3 IgC1, B7-H3 IgC2, B7-H3 IgC1-V2-C2, B7-H3 IgV2-C2 에 결합하는 것이 확인되었다. B7-H3 IgV1, B7-H3 IgV2 에는 결합하지 않았다.
이런 점에서, M30 은 B7-H3 의 C1 도메인 (배열 번호 6 의 아미노산 번호 140 내지 244 에 나타내는 아미노산 배열) 및 C2 도메인 (배열 번호 6 의 아미노산 번호 358 내지 456 에 나타내는 아미노산 배열) 에 결합하는 것이 나타났다. 동일하게 하여, L8, L11 및 M31 도 C1 도메인 및 C2 도메인에 결합하는 것이 나타나고, L7 은 V1 도메인 (배열 번호 6 의 아미노산 번호 27 내지 139 에 나타내는 아미노산 배열) 및 V2 도메인 (배열 번호 6 의 아미노산 번호 245 내지 357 에 나타내는 아미노산 배열) 에 결합하는 것이 나타났다.
따라서, M30 은 B7-H3 의 세포 외 영역 중의 도메인인 IgC1 도메인 및/또는 IgC2 도메인에 있어서의 에피토프를 인식하여, IgC1 도메인 혹은 IgC2 도메인 또는 양자에 결합하는 것이 나타났다.
4)-5 항원 특이성
M30 의 항원 특이성을 실시예 3)-3 과 동일한 플로우 사이토메트리법으로 검토하였다.
실시예 1)-1-4 로 조정된 B7 패밀리 단백질인 CD80, CD86, B7-RP-1, B7-H1, B7-DC, B7-H4 단백질 발현 벡터를 각각 트랜스펙션한 293T 세포가 사용되었다.
그 결과, M30 은 B7 패밀리 분자인 CD80, CD86, B7-RP-1, B7-H1, B7-DC, B7-H4 에 결합하지 않는 것이 나타났다.
실시예 5. in vivo 항종양 효과
5)-1 항 B7-H3 항체의 in vivo 항종양 효과
NCI-H322 세포를 트립신 처리하여 배양 플라스크로부터 벗긴 후, 10 % FBS 함유 RPMI1640 (인비트로젠사) 에 현탁 후 원심하여 상청을 제거하였다. 세포를 동 배지에서 2 회 세정한 후, 생리 식염수 (오오츠카 제약 공장 제조) 에 현탁하고, 6 주령의 BALB/cAJcl-nu/nu (닛폰 클레아사) 에 1 × 107 세포/마우스로 액와부 피하에 이식하였다. 이식일을 0 일째로 하여 10, 17, 24, 31, 38 일째에 L7, L8, L11, M30, M31 항체를 500 ㎍/마우스 (약 25 ㎎/㎏) 로 복강 내 투여하였다. 컨트롤에는 항체와 동 체적 (500 ㎕) 의 PBS 를 복강 내 투여하였다. 종양 체적을 10, 17, 24, 31, 38, 45 일째에 측정하고, 항체 투여에 의한 항종양 효과를 검토하였다.
그 결과, M30, M31 투여군에서는 PBS 투여군에 비해 유의하게 종양 증식이 억제되었다 (45 일째 시점의 종양 체적에 대해 PBS 투여군과의 비교에서 M30, M31 의 P 치는 각각 P < 0.05, P < 0.01 이었다. P 치는 Student's t-test 에 의해 산출). 또한, 45 일째 시점에서의 종양 증식 저해율 (= 100 - (항체 투여군의 종양 체적의 평균치)/(PBS 투여군의 종양 체적의 평균치) × 100) 은 L7, L8, L11, M30, M31 에서 각각 -16.1 %, 0.2 %, 25.5 %, 47.2 %, 58.2 % 였다. M30, M31 항체에서 in vivo 에서 매우 강한 항종양 효과가 관찰되었다 (도 6).
이상의 결과로부터, M30 및 M31 항체가 B7-H3 항원을 인식하여 항종양 효과를 나타내는 항체인 것이 분명해졌다.
5)-2 탐식 세포를 제거했을 경우의 in vivo 항종양 효과
생체 내의 탐식 세포를 제거하기 위해, 클로드로네이트 봉입 리포솜을 제조하였다. 즉, 클로드로네이트 봉입 리포솜을 생체 내에 투여함으로써, 생체 내의 탐식 세포 (매크로파지) 가 제거되는 것이 보고되어 있고 (Journal of immunological methods 1994년, 제 174 권, p.83-93), 당해 보고의 방법에 따라 클로드로네이트 봉입 리포솜을 제조하여 이하의 실험에 제공하였다.
NCI-H322 세포를 트립신 처리하여 배양 플라스크로부터 벗긴 후, 10 % FBS 함유 RPMI1640 (인비트로젠사) 에 현탁 후 원심하여 상청을 제거하였다. 당해 세포를 동 배지에서 2 회 세정한 후, 생리 식염수 (PBS, 오오츠카 제약 공장 제조) 에 현탁하고, 6 주령의 BALB/cAJcl-nu/nu (닛폰 클레아사) 에 1 × 107 세포/마우스로 액와부 피하에 이식하였다. 이식일을 -14 일째로 하여 0 일째에 군 나누기를 실시하였다.
마우스 생체 내의 매크로파지를 제거하는 군에는, 클로드로네이트 봉입 리포솜을 0, 4, 7, 11, 14, 18, 21, 25, 28, 32 일째에 0.2 ㎖/마우스로 정맥 주사하였다. 또한, 음성 대조군에는 PBS 를 동일한 날 (0, 4, 7, 11, 14, 18, 21, 25, 28, 32 일째) 에 0.2 ㎖/마우스로 정맥 주사하였다.
다음으로, 상기 양 군에 M30 항체를 1, 8, 15, 22, 29 일째에 500 ㎍/마우스 (약 25 ㎎/㎏) 로 복강 내 투여하였다. 또한, 음성 대조로서 M30 항체와 동 체적 (500 ㎕) 의 PBS 를 동일한 날 (1, 8, 15, 22, 29 일째) 에 상기 양 군에 복강 내 투여하였다.
종양 체적을 0, 8, 15, 22, 29, 36 일째에 측정하고, 항체 투여에 의한 항종양 효과를 검토하였다 (n = 8).
그 결과를 표 1, 표 2 및 도 7 에 나타낸다.
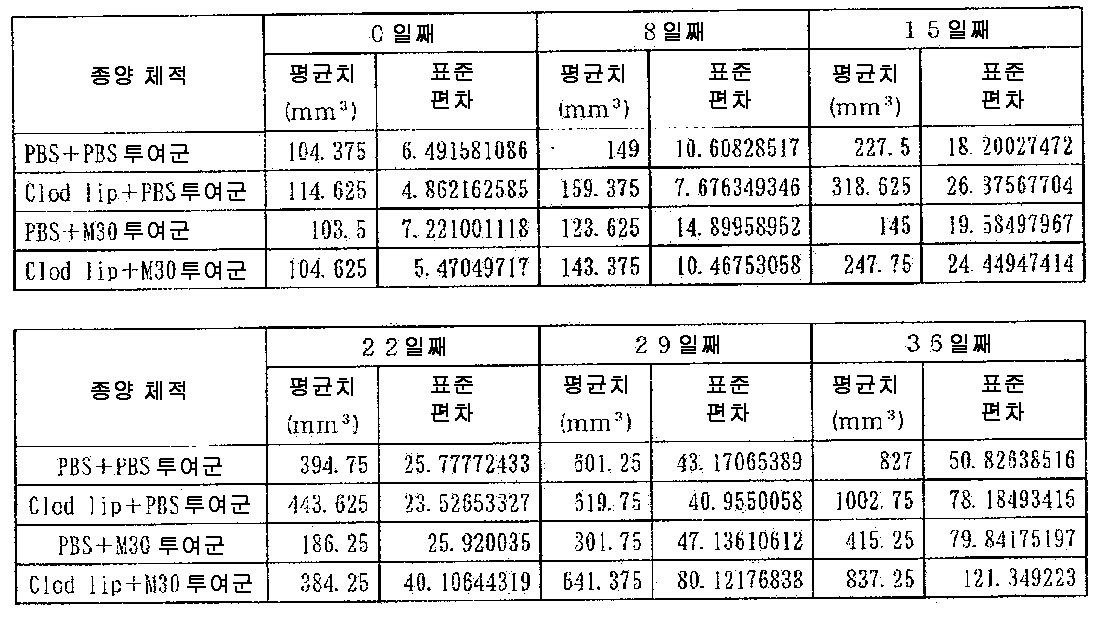
PBS 정맥 투여 + M30 항체 복강 내 투여군 (PBS + M30 투여군) 에서는, 음성 대상이 되는 PBS 정맥 투여 + PBS 복강 내 투여군 (PBS + PBS 투여군) 에 비해 유의하게 종양 증식이 억제되었다. 즉, 36 일째 시점의 종양 체적에 대해 PBS + PBS 투여군과의 비교에서, PBS + M30 투여군의 P 치는 P < 0.05 였다 (P 치는 Student's t-test 에 의해 산출). 또한, 36 일째 시점에서의 종양 증식 저해율 (= 100 - (PBS + M30 투여군의 종양 체적의 평균치)/(PBS + PBS 투여군의 종양 체적의 평균치) × 100) 은 49.8 % 였다 (표 2).
한편, 클로드로네이트 봉입 리포솜 정맥 투여 + PBS 복강 내 투여군 (Clod lip + PBS 투여군) 및 클로드로네이트 봉입 리포솜 정맥 투여 + M30 항체 복강 내 투여군 (Clod lip + M30 투여군) 에서는 종양 증식의 억제는 관찰되지 않았다. 즉, 36 일째 시점의 종양 체적에 대해 PBS + PBS 투여군과의 비교에서, Clod lip + PBS 투여군 및 Clod lip + M30 투여군의 P 치는 각각 P = 0.52, P = 1 이었다 (P 치는 Student's t-test 에 의해 산출). 또한, 36 일째 시점에서의 종양 증식 저해율 (= 100 - (Clod lip + PBS 투여군 또는 Clod lip + M30 투여군의 종양 체적의 평균치)/(PBS + PBS 투여군의 종양 체적의 평균치) × 100) 은 각각 -21.2 %, -1.4 % 였다 (표 2).

이상의 결과로부터, M30 항체의 항종양 효과는 클로드로네이트 봉입 리포솜 투여에 의해 억제된 것이 나타난 점에서, M30 항체의 항종양 효과는 주로 매크로파지를 통한 효과인 것이 분명해졌다.
실시예 6. 마우스 항체 M30 의 cDNA 의 클로닝과 배열의 결정
6)-1 마우스 항체 M30 의 중사슬 및 경사슬의 N 말단 아미노산 배열의 결정
마우스 항체 M30 의 중사슬 및 경사슬의 N 말단 아미노산 배열을 결정하기 위해, 실시예 3)-6 으로 정제한 마우스 항체 M30 을 SDS-PAGE 로 분리하였다. 분리 후의 겔로부터 PVDF 막 (포아 사이즈 0.45 ㎛ ; 인비트로젠사 제조) 에 겔 중의 단백질을 전사하고, 세정 버퍼 (25 mM NaCl, 10 mM 붕산나트륨 버퍼 pH 8.0) 로 세정한 후, 염색액 (50 % 메탄올, 20 % 아세트산, 0.05 % 쿠마시브릴리언트블루) 에 5 분간 담그어 염색하고 나서 90 % 메탄올로 탈색하였다.
PVDF 막 상에서 가시화된 중사슬 (이동도가 작은 쪽의 밴드) 및 경사슬 (이동도가 큰 쪽의 밴드) 에 상당하는 밴드 부분을 절취하였다.
경사슬에 상당하는 밴드에 대해서는 소량의 0.5 % 폴리비닐피롤리돈/100 mM 아세트산 용액 중에서 37 ℃ 에서 30 분간 보온한 후, 물로 잘 세정하고, 다음으로, Pfu 피로글루탐산아미노펩티다아제 키트 (타카라 바이오 주식회사) 를 사용하여 수식 N 말단 잔기를 제거하고, 물로 세정한 후 바람 건조시켰다. Procise (등록상표) cLC 프로테인 시퀸서 Model492cLC (Applied Biosystems) 를 사용하여, 자동 에드먼법 (Edman et al. (1967) Eur. J. Biochem. 1, 80 참조) 에 의해 각각의 N 말단 아미노산 배열의 동정을 시도하였다.
그 결과, 마우스 항체 M30 의 중사슬에 상당하는 밴드의 N 말단의 아미노산 배열은
EVQLQQSGPE (배열표의 배열 번호 44)
이고, 경사슬에 상당하는 밴드의 N 말단 아미노산 배열은
IVLSQSPTILSASP (배열표의 배열 번호 45)
였다.
6-2) 마우스 항체 M30 산생 하이브리도마로부터의 mRNA 의 조제
마우스 항체 M30 의 중사슬 및 경사슬을 코드하는 cDNA 를 클로닝하기 위해, 마우스 항체 M30 산생 하이브리도마로부터 Quick Prep mRNA Purification Kit (GE Healthcare 사) 를 사용하여 mRNA 를 조제하였다.
6-3) 마우스 항체 M30 의 cDNA 의 클로닝과 배열의 결정
마우스 항체 M30 의 중사슬 및 경사슬의 아이소 타입이 γ2a 와 κ 인 것 (실시예 3)-5), 실시예 1-1) 에서 결정한 중사슬 및 경사슬의 N 말단 아미노산 배열, 및 항체의 아미노산 배열 데이터베이스 (Kabat, E. A. et al., (1991) in Sequences of Proteins of Immunological Interest Vol.Ⅰ 및 Ⅱ, U.S. Department of Health and Human Services 참조) 를 참고로 하여, 항체 유전자 번역 영역의 5' 말단측과 종지 코돈을 포함하는 3' 말단 부분에 각각 하이브리다이즈하는 올리고 뉴클레오티드 프라이머를 몇 개 합성하고, 실시예 6-2) 에서 조제한 mRNA 와 TaKaRa One Step RNA PCR Kit (AMV) (타카라 바이오사) 를 사용하여 중사슬, 및 경사슬을 코드하는 cDNA 를 증폭시킨 결과, 하기의 프라이머 세트로 항체의 중사슬, 및 경사슬을 코드하는 cDNA 를 증폭시킬 수 있었다.
중사슬용 프라이머 세트

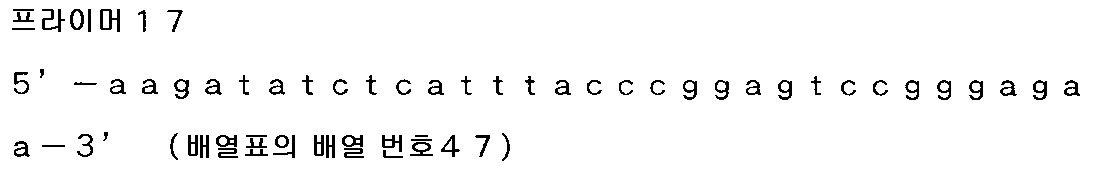
경사슬용 프라이머 세트


PCR 로 증폭된 중사슬, 및 경사슬의 cDNA 를 각각 pEF6/V5-His TOPO TA Expression Kit (인비트로젠사) 를 사용하여 클로닝하고, 클로닝된 중사슬, 경사슬의 각 뉴클레오티드 배열을 유전자 배열 해석 장치 (「ABI PRISM 3700 DNA Analyzer ; Applied Biosystems」 또는 「Applied Biosystems 3730 × l Analyzer ; Applied Biosystems」) 를 사용하여 결정하였다. 시퀀스의 반응은 GeneAmp 9700 (Applied Biosystems 사) 을 사용하였다.
결정된 마우스 항체 M30 의 중사슬을 코드하는 cDNA 의 뉴클레오티드 배열을 배열표의 배열 번호 50 에 나타내고, 아미노산 배열을 배열 번호 51 에 나타냈다. 또한, 배열 번호 50 및 51 의 배열은 도 21 에 기재되어 있다.
결정된 마우스 항체 M30 의 경사슬을 코드하는 cDNA 의 뉴클레오티드 배열을 배열표의 배열 번호 52 에 나타내고, 아미노산 배열을 배열표의 배열 번호 53 에 나타냈다. 또한, 배열 번호 52 및 53 의 배열은 도 22 에 기재되어 있다.
또한, 중사슬 및 경사슬의 아미노산 배열을 항체의 아미노산 배열의 데이터베이스인 KabatMan (PROTEINS : Structure, Function and Genetics, 25 (1996), 130-133. 참조) 을 사용하여 비교 검토한 결과, 마우스 항체 M30 의 중사슬에 대해서는, 배열표의 배열 번호 51 의 아미노산 번호 20 내지 141 에 나타내는 아미노산 배열이 가변 영역인 것이 분명해졌다. 또한, 마우스 항체 M30 의 경사슬에 대해서는, 배열표의 배열 번호 53 의 아미노산 번호 23 내지 130 에 나타내는 아미노산 배열이 가변 영역인 것이 분명해졌다.
실시예 7. 키메라 항체 M30 (cM30 항체) 의 제조
7)-1 범용 발현 벡터 pEF6KCL 및 pEF1FCCU 의 제조
7)-1-1 키메라 및 인간화 경사슬 발현 벡터 pEF6KCL 의 구축
플라스미드 pEF6/V5-HisB (인비트로젠사) 를 주형으로 하고, 하기 프라이머를 사용하여 PCR 을 실시함으로써, BGHpA 의 직후 (Sequence Position 2174) 부터 Sma I (Sequence Position 2958) 까지의 DNA 단편 (f1 origin of replication 및 SV40 promotor and origin 을 포함하는 DNA 프래그먼트, 이하,「프래그먼트 A」라고 한다) 을 취득하였다.


얻어진 프래그먼트 A 와, 인간 κ 사슬 분비 시그널 및 인간 κ 사슬 정상 영역 및 인간 polyA 부가 시그널을 코드하는 DNA 배열을 포함하는 DNA 프래그먼트 (배열 번호 56 : 이하, 「프래그먼트 B」라고 한다. 배열 번호 56 의 배열은 도 23 에 기재되어 있다) 를 Overlap Extension PCR 에 의해 결합하였다. 얻어진 프래그먼트 A 와 프래그먼트 B 가 결합한 DNA 단편을 제한 효소 KpnI 및 SmaI 로 소화하고, 제한 효소 KpnI 및 SmaI 로 소화한 플라스미드 pEF6/V5-HisB (인비트로젠사) 와 라이게이션하여, EF1 프로모터의 하류에 시그널 배열, 클로닝 사이트, 인간 κ 사슬 정상 영역, 및 인간 polyA 부가 시그널 배열을 갖는 키메라 및 인간화 경사슬 발현 벡터 pEF6KCL 을 구축하였다.
7)-2 pEF1KCL 의 구축
상기의 방법으로 얻어진 pEF6KCL 로부터 제한 효소 KpnI 및 SmaI 로 잘라낸 DNA 단편을 KpnI 및 SmaI 로 소화한 pEF1/myc-HisB (인비트로젠사) 와 라이게이션하여, 플라스미드 pEF1KCL 을 구축하였다.
7)-3 키메라 및 인간화 중사슬 발현 벡터 pEF1FCCU 의 구축
인간 IgG1 시그널 배열 및 정상 영역의 아미노산을 코드하는 DNA 배열을 포함하는 DNA 단편 (배열 번호 57 : 배열 번호 57 의 배열은 도 24 에 기재되어 있다) 을 제한 효소 NheI 및 PmeI 로 소화하고, NheI 및 PmeI 로 소화한 플라스미드 pEF1KCL 과 결합하여, EF1 프로모터의 하류에 시그널 배열, 클로닝 사이트, 인간 중사슬 정상 영역, 및 인간 polyA 부가 시그널 배열을 갖는 키메라 및 인간화 중사슬 발현 벡터 pEF1FCCU 를 구축하였다.
7)-4 M30 키메라 타입 경사슬 발현 벡터의 구축
마우스 항체 M30 의 경사슬을 코드하는 cDNA 를 템플레이트로 하여, KOD-Plus- (TOYOBO 사) 와 하기의 프라이머 세트로 경사슬의 가변 영역을 코드하는 cDNA 를 포함하는 부분을 증폭시키고, 제한 효소 NdeI 및 BsiWI 로 잘리는 DNA 단편을 키메라 및 인간화 항체 경사슬 발현 범용 벡터 (pEF6KCL) 를 제한 효소 NdeI 및 BsiWI 로 절단한 지점에 삽입함으로써, M30 키메라 타입 경사슬 발현 벡터를 구축하였다. 얻어진 발현 벡터를 「pEF6KCL/M30L」이라고 명명하였다. M30 키메라 타입 경사슬의 뉴클레오티드 배열을 배열표의 배열 번호 58 에 나타내고, 아미노산 배열을 배열 번호 59 에 나타냈다. 또한, 배열 번호 58 및 59 의 배열은 도 25 에 기재되어 있다. 또한, 배열표의 배열 번호 59 에 기재된 cM30 항체 경사슬의 아미노산 배열에 있어서 128 번째의 트레오닌 잔기는 경사슬 가변 영역의 카르복실 말단이고, 배열표의 배열 번호 53 에 기재된 M30 항체 경사슬의 아미노산 배열에 있어서 130 번째의 알라닌 잔기에 대응하지만, 배열 번호 59 에 기재된 아미노산 배열에 있어서는 이미 인간 항체 경사슬 유래의 트레오닌 잔기로 치환되어 있다.
경사슬용 프라이머 세트


7)-5 M30 키메라 타입 중사슬 발현 벡터의 구축
마우스 항체 M30 의 중사슬을 코드하는 cDNA 를 템플레이트로 하여, KOD-Plus- (TOYOBO 사) 와 하기의 프라이머 세트 A 를 사용하여 PCR 을 실시함으로써 얻어진 DNA 단편과 하기의 프라이머 세트 B 를 사용하여 PCR 을 실시함으로써 얻어진 DNA 단편을 하기의 프라이머 세트 C 를 사용한 Overlap Extension PCR 에 의해 결합함으로써, 가변 영역 중에 있는 BlpI 를 제거함과 함께 중사슬의 가변 영역을 코드하는 cDNA 를 포함하는 부분을 증폭시켰다. 제한 효소 BlpI 로 잘리는 DNA 단편을 키메라 및 인간화 항체 중사슬 발현 범용 벡터 (pEF1FCCU) 를 제한 효소 BlpI 로 절단한 지점에 삽입함으로써, M30 키메라 타입 중사슬 발현 벡터를 구축하였다. 얻어진 발현 벡터를 「pEF1FCCU/M30H」라고 명명하였다.
M30 키메라 타입 중사슬의 뉴클레오티드 배열을 배열표의 배열 번호 62 에 나타내고, 아미노산 배열을 배열 번호 63 에 나타냈다. 또한, 배열 번호 62 및 63 의 배열은 도 26 에 기재되어 있다.
프라이머 세트 A


프라이머 세트 B


프라이머 세트 C


7)-6 키메라 항체 M30 조제
7)-6-1 키메라 항체 M30 의 생산
1.2 × 109 개의 대수 증식기의 FreeStyle 293F 세포 (인비트로젠사) 를 신선한 1.2 ℓ 의 FreeStyle 293 expression medium (인비트로젠사) 에 파종하고, 37 ℃, 8 % CO2 인큐베이터 내에서 90 rpm 으로 1 시간 진탕 배양하였다. Polyethyleneimine (Polyscience #24765) 3.6 ㎎ 을 Opti-Pro SFM 배지 (인비트로젠사) 20 ㎖ 에 용해시키고, 다음으로 PureLink HiPure Plasmid 키트 (인비트로젠사) 를 사용하여 조제한 pEF1FCCU/M30H (0.4 ㎎) 및 pEF6KCL/M30L (0.8 ㎎) 를 20 ㎖ 의 Opti-Pro SFM 배지에 현탁하였다. Polyethyleneimine/Opti-Pro SFM 혼합액 20 ㎖ 에 발현 벡터/Opti-Pro SFM 혼합액 20 ㎖ 를 첨가하여 조심스럽게 교반하고, 추가로 5 분간 방치한 후에 FreeStyle 293F 세포에 첨가하였다. 37℃, 8 % CO2 인큐베이터에서 7 일간, 90 rpm 으로 진탕 배양하여 얻어진 배양 상청을 Disposable Capsule Filter (Advantec #CCS-045-E1H) 로 여과하였다.
pEF1FCCU/M30H 와 pEF6KCL/M30L 의 조합에 의해 취득된 키메라 항체 M30 을 「cM30」 또는 「cM30 항체」라고 명명하였다.
7)-6-2 cM30 의 정제
실시예 7-1) 로 얻어진 배양 상청을 rProteinA 어피니티 크로마토그래피 (4 - 6 ℃ 하) (GE 헬스케어·재팬사) 와 세라믹하이드록실아파타이트 (실온하) 의 2 단계 공정으로 정제하였다. rProteinA 어피니티 크로마토그래피 정제 후와 세라믹하이드록실아파타이트 정제 후의 버퍼 치환 공정은 실온하에서 실시하였다.
최초로 배양 상청 1100 - 1200 ㎖ 를 PBS 로 평형화한 MabSelectSuRe (GE Healthcare Bioscience 사 제조, HiTrap 칼럼 : 용적 1 ㎖ × 2 연결) 에 어플라이하였다. 배양액이 칼럼에 모두 들어간 후, PBS 15 - 30 ㎖ 로 칼럼을 세정하였다. 다음으로 2 M 아르기닌염산염 용액 (pH 4.0) 으로 용출하여, 항체가 포함되는 획분을 모았다. 그 획분을 탈염 칼럼 (GE Healthcare Bioscience 사 제조, HiTrap Desalting 칼럼 : 용적 5 ㎖ × 2 연결) 으로 5 mM 인산나트륨/50 mM MES/20 mM NaCl/pH 6.5 의 버퍼로 치환을 실시하였다.
또한, 그 치환된 항체 용액을 5 mM NaPi/50 mM MES/20 mM NaCl/pH 6.5 의 버퍼로 평형화된 세라믹하이드록실아파타이트 칼럼 (닛폰 바이오래드, Bio-Scale CHT2-1 Hydroxyapatite Column : 용적 2 ㎖) 에 어플라이하였다. 염화나트륨에 의한 직선적 농도 구배 용출을 실시하여, 항체가 포함되는 획분을 모았다. 당해 획분을 탈염 칼럼 (GE Healthcare Bioscience 사 제조, HiTrap Desalting 칼럼 : 용적 5 ㎖ × 2 연결) 으로 CBS (10 mM 시트르산 완충액/140 mM 염화나트륨, pH 6.0) 로의 액 치환을 실시하였다.
마지막으로 Centrifugal UF Filter Device VIVASPIN20 (분획 분자량 30 K, Sartorius 사, 4 ℃ 하) 으로 농축하고, IgG 농도를 1.0 ㎎/㎖ 이상으로 조제하여 정제 샘플로 하였다.
실시예 8. cM30 항체의 활성
8)-1 cM30 항체의 B7-H3 에 대한 결합 활성
M30 항체 및 cM30 항체의 B7-H3 항원과의 친화성은 표면 플라스몬 공명 (SPR) 장치 (GE Healthcare 사) 에 의해 측정하였다. 정법에 의해, 항마우스 IgG 또는 항인간 IgG 항체를 센서 칩에 고정화시키고, 거기에 M30 항체 샘플 또는 cM30 항체를 결합한 후에, 각 농도의 리컴비넌트 B7-H3 베리언트 2 항원의 세포 외 영역 폴리펩티드 (R & D Systems 사 제조 : #2318-B3-050/CF) 를 첨가하고, 런닝 버퍼 (인산 버퍼, 0.05 % SP20) 중에서의 항체에 대한 결합량을 시간 경과적으로 측정하였다. 측정한 결합량을 전용 소프트웨어 (BIAevaluation Version4.1, GE 헬스케어사) 에 의해 해석하여 해리 정수를 산출하였다.
그 결과, M30 항체 및 cM30 항체는 각각 5.89 nM 및 3.43 nM 의 해리 정수로 리컴비넌트 B7-H3 항원에 결합하였다. 이런 점에서, M30 항체 및 cM30 항체는 B7-H3 항원에 결합하고, 그 결합 강도는 거의 동등하다는 것이 확인되었다.
8)-2 cM30 항체의 ADCP 활성
정상인의 말초혈 단핵구 (PBMC) 를 정법에 따라 분리하였다. RPMI-10 % FCS (인비트로젠사) 중에 현탁하고, 플라스크 중에 파종하였다. CO2 인큐베이터에서 하룻밤 배양을 실시하였다. 배양 상청을 버리고, 플라스크에 부착된 세포에 M-CSF 및 GM-CSF (PeproTech 사) 를 첨가한 RPMI-10 % FCS 를 첨가하고, 2 주간 배양하였다. 세포를 TrypLE 로 박리하여 회수하였다. 500 ㎕/well (1 × 105 cell/well) 을 24 well plate 에 첨가하고, 37 ℃ 에서 하룻밤 배양하였다. 본 세포를 이펙터 세포로 하였다.
타겟 세포가 되는 NCI-H322 세포의 라벨링을 PKH26 dye labeling kit (Sigma 사) 를 사용하여 실시하였다. 타겟 세포를 TrypLE 로 박리하고, PBS 로 2 회 세정하였다. 세포를 Diluent C 로 1 × 107 cells/㎖ 가 되도록 현탁하였다. PKH26 dye stock (1 mM) 을 Diluent C 로 8 μM 으로 희석시키고, 바로 세포 부유액과 등량의 dye 희석액을 첨가하였다. 실온에 5 분간 방치하였다. 혈청 1 ㎖ 를 첨가하고, 추가로 혈청 함유 배지를 첨가하고 2 회 세정을 실시하였다.
M30 및 cM30 항체를 배양액으로 20 ㎍/㎖ 에 희석시켰다. 타겟 세포를 2 × 106/100 ㎕/tube 분주, 혼합하였다. 빙상에서 30 분간 가만히 정지시켰다. 상청을 버리고, 배양액으로 2 회 세정하였다. 배양액 500 ㎕ 에 현탁하였다. 이펙터 세포로부터 상청을 제거하고, 항체를 처리하여 배양액에 서스펜드한 세포를 첨가하고 혼합하였다. CO2 인큐베이터 내에서 3 시간 배양하였다. Trypsin-EDTA 로 세포를 박리하여, 세포를 회수하였다. 회수한 세포에 FITC 표지 항마우스 CD11b 항체 (벡톤 디킨슨사) 를 첨가하고, 빙상에서 30 분간 가만히 정지시켰다. 상청을 버리고, 배양액으로 2 회 세정하였다. 회수한 세포를 300 ㎕ 의 배지에서 현탁하고, FACS Calibur (벡톤 디킨슨사) 로 측정을 실시하였다. CD11b 양성의 매크로파지 세포에 있어서, PKH26 양성 획분을 탐식 양성 세포로 하여 평가를 실시하였다.
그 결과, 도 8 에 나타내는 바와 같이 10 ㎍/㎖ 의 M30 및 cM30 항체를 첨가했을 때, 각각 매크로파지에 의한 NCI-H322 세포의 탐식을 33 ± 1 % 및 35 ± 2 % 유도하였다. 이런 점에서, cM30 항체는 M30 항체와 동일하게 NCI-H322 세포에 대해 ADCP 활성을 갖는 것이 나타났다. 동일한 실험 결과가 MDA-MB-231 세포 (ATCC) 에 대한 ADCP 활성에 있어서도 얻어졌다.
8)-3 cM30 항체의 in vivo 항종양 효과
MDA-MB-231 세포를 트립신 처리하여 배양 플라스크로부터 벗긴 후, 10 % FBS 함유 RPMI1640 배지 (인비트로젠사) 에 현탁 후 원심하여 상청을 제거하였다. 세포를 동 배지에서 2 회 세정한 후, BD 마트리겔 기저막 매트릭스 (BD Biosciences 사 제조) 에 현탁하고, 6 주령의 마우스 (CB17/Icr-Prkdc[scid]/CrlCrlj, 닛폰 찰스·리버 주식회사) 에 5 × 106 세포/마우스로 액와부 피하에 이식하였다. 이식일을 0 일째로 하여, 14, 21, 28, 35, 42 일째에 M30 항체, cM30 항체를 500 ㎍/마우스 (약 25 ㎎/㎏) 로 복강 내 투여하였다. 종양 체적을 14, 18, 21, 25, 28, 32, 35, 39, 42, 46, 49, 52 일째에 측정하고, 항체 투여에 의한 항종양 효과를 검토하였다.
그 결과, M30 항체, cM30 항체 투여군에서는 항체를 투여하지 않은 무처치군에 비해 유의하게 종양 증식이 억제되었다. 52 일째 시점의 종양 중량에 대해 무처치군과의 비교에서 M30 항체, cM30 항체의 P 치는 모두 P < 0.001 이었다. P 치는 Dunnett 형 다중 비교에 의해 산출하였다.
또한, 52 일째 시점에서의 종양 증식 저해율 (= 100 - (항체 투여군의 종양 체적의 평균치)/(무처치군의 종양 체적의 평균치) × 100) 은 M30 항체에서 71.3 %, cM30 항체에서 71.7 % 이고, cM30 항체는 M30 항체와 동일하게 in vivo 에서 매우 강한 항종양 효과가 관찰되었다 (도 9).
실시예 9. 마우스 항인간 B7-H3 항체 #M30 의 인간화 항체의 설계
9)-1 M30 의 인간화 버젼의 설계
9)-1-1 M30 의 가변 영역의 분자 모델링
M30 의 가변 영역의 분자 모델링은 상동성 모델링으로서 일반적으로 공지된 방법 (Methods in Enzymology, 203, 121-153, (1991)) 에 의해 실행되었다. Protein Data Bank (Nuc. Acid Res. 35, D301-D303 (2007)) 에 등록되는 인간 면역 글로블린의 가변 영역의 1 차 배열 (X 선 결정 구조로부터 유도되는 삼차원 구조가 입수 가능하다) 을 실시예 6-3) 에서 결정된 M30 의 가변 영역과 비교하였다.
결과적으로, 3BKY 가 M30 의 경사슬의 가변 영역에 대해 동일하게 프레임 워크 중에 결손이 있는 항체 중에서, 가장 높은 배열 상동성을 갖는 것으로서 선택되었다. 또한, 3DGG 가 M30 의 중사슬의 가변 영역에 대해 가장 높은 배열 상동성을 갖는 것으로서 선택되었다.
프레임 워크 영역의 삼차원 구조는 M30 의 경사슬 및 중사슬에 대응하는 3BKY 및 3DGG 의 좌표를 조합하여 「프레임 워크 모델」을 얻음으로써 제조되었다. M30 의 CDR 은 Thornton et al. (J. Mol. Biol., 263, 800-815, (1996)) 의 분류, 및 H3 룰 (FEBS letter 399, 1-8 (1996)) 에 따라, CDRH1 (배열 번호 92), CDRH2 (배열 번호 93) 및 CDRH3 (배열 번호 94), CDRL1 (배열 번호 95), CDRL2 (배열 번호 96), CDRL3 (배열 번호 97) 에 대해 가장 가까운 컨포메이션을 갖는 좌표로서 각각 2HOJ, 1BBD, 1Q9O, 2FBJ, 1LNK, 1TET 를 선택하여 프레임 워크 모델에 삽입되었다.
마지막으로, 에너지의 점에서 M30 의 가변 영역의 가능성이 있는 분자 모델을 얻기 위해, 불리한 원자간 접촉을 제거하기 위한 에너지 계산을 실시하였다. 상기 순서를 시판되는 단백질 입체 구조 예측 프로그램 Prime 및 배좌 탐색 프로그램 MacroModel (Schrodinger, LLC) 을 사용하여 실시하였다.
9)-1-2 인간화 M30 에 대한 아미노산 배열의 설계
인간화 M30 항체의 구축을 CDR 그래프팅 (Proc. Natl. Acad. Sci. USA 86, 10029 - 10033 (1989)) 으로서 일반적으로 공지된 방법에 의해 실시하였다.
억셉터 항체는 프레임 워크 영역 내의 아미노산 상동성에 기초하여 선택되었다. M30 의 프레임 워크 영역의 배열을 항체의 아미노산 배열의 Kabat 데이터베이스 (Nuc. Acid Res. 29, 205 - 206 (2001)) 의 모든 인간 프레임 워크와 비교하고, 결과로서, mAb49 'CL 항체 (NCBI 의 GenBank : D16838.1 및 D16837.1) 가 프레임 워크 영역에 대한 70 % 의 배열 상동성에서 기인하여 억셉터로서 선택되었다.
mAb49 'CL 에 대한 프레임 워크 영역의 아미노산 잔기를 M30 에 대한 아미노산 잔기와 정렬시키고, 상이한 아미노산이 사용되는 위치를 동정하였다. 이들 잔기의 위치는 위에서 구축된 M30 의 삼차원 모델을 사용하여 분석되고, 그리고 억셉터 상에 그래프팅되어야 할 도너 잔기가 Queen et al. (Proc. Natl. Acad. Sci. USA 86, 10029 - 10033 (1989)) 에 의해 부여되는 기준에 의해 선택되었다. 선택된 몇 개의 도너 잔기를 억셉터 항체에 이입함으로써, 인간화 #32A1 배열을 이하의 실시예에 기재하는 바와 같이 구축하였다.
9)-2 M30 중사슬의 인간화
9)-2-1 M30-H1 타입 중사슬 :
배열표의 배열 번호 63 에 나타내는 cM30 중사슬의 아미노산 번호 20 (글루탐산), 24 (글루타민), 28 (프롤린), 30 (류신), 31 (발린), 35 (알라닌), 39 (메티오닌), 57 (리신), 59 (리신), 67 (이소류신), 86 (리신), 87 (알라닌), 89 (글루타민), 91 (세린), 93 (리신), 95 (세린), 106 (트레오닌), 110 (세린), 136 (트레오닌), 137 (류신) 을 각각 글루타민, 발린, 알라닌, 발린, 리신, 세린, 발린, 아르기닌, 알라닌, 메티오닌, 아르기닌, 발린, 이소류신, 알라닌, 글루탐산, 트레오닌, 아르기닌, 트레오닌, 류신, 발린으로 치환하는 것을 따라 설계된 인간화 M30 중사슬을 「M30-H1 타입 중사슬」이라고 명명하였다.
M30-H1 타입 중사슬의 아미노산 배열을 배열 번호 85 에 나타냈다.
9)-2-2 M30-H2 타입 중사슬 :
배열표의 배열 번호 63 에 나타내는 cM30 중사슬의 아미노산 번호 20 (글루탐산), 24 (글루타민), 28 (프롤린), 30 (류신), 31 (발린), 35 (알라닌), 39 (메티오닌), 57 (리신), 59 (리신), 86 (리신), 87 (알라닌), 89 (글루타민), 91 (세린), 93 (리신), 95 (세린), 106 (트레오닌), 110 (세린), 136 (트레오닌), 137 (류신) 을 각각 글루타민, 발린, 알라닌, 발린, 리신, 세린, 발린, 아르기닌, 알라닌, 아르기닌, 발린, 이소류신, 알라닌, 글루탐산, 트레오닌, 아르기닌, 트레오닌, 류신, 발린으로 치환하는 것을 따라 설계된 인간화 M30 중사슬을 「M30-H2 타입 중사슬」이라고 명명하였다.
M30-H2 타입 중사슬의 아미노산 배열을 배열 번호 87 에 나타냈다.
9)-2-3 M30-H3 타입 중사슬 :
배열표의 배열 번호 63 에 나타내는 cM30 중사슬의 아미노산 번호 24 (글루타민), 28 (프롤린), 30 (류신), 31 (발린), 35 (알라닌), 39 (메티오닌), 59 (리신), 89 (글루타민), 91 (세린), 93 (리신), 95 (세린), 106 (트레오닌), 110 (세린), 136 (트레오닌), 137 (류신) 을 각각 발린, 알라닌, 발린, 리신, 세린, 발린, 알라닌, 이소류신, 알라닌, 글루탐산, 트레오닌, 아르기닌, 트레오닌, 류신, 발린으로 치환하는 것을 따라 설계된 인간화 M30 중사슬을 「M30-H3 타입 중사슬」이라고 명명하였다.
M30-H3 타입 중사슬의 아미노산 배열을 배열 번호 89 에 나타냈다.
9)-2-4 M30-H4 타입 중사슬 :
배열표의 배열 번호 63 에 나타내는 cM30 중사슬의 아미노산 번호 24 (글루타민), 28 (프롤린), 30 (류신), 31 (발린), 35 (알라닌), 39 (메티오닌), 59 (리신), 95 (세린), 106 (트레오닌), 110 (세린), 136 (트레오닌), 137 (류신) 을 각각 발린, 알라닌, 발린, 리신, 세린, 발린, 알라닌, 트레오닌, 아르기닌, 트레오닌, 류신, 발린으로 치환하는 것을 따라 설계된 인간화 M30 중사슬을 「M30-H4 타입 중사슬」이라고 명명하였다.
M30-H4 타입 중사슬의 아미노산 배열을 배열 번호 91 에 나타냈다.
9)-3 M30 경사슬의 인간화
9)-3-1 M30-L1 타입 경사슬 :
배열표의 배열 번호 59 에 나타내는 cM30 경사슬의 아미노산 번호 21 (글루타민), 25 (세린), 29 (트레오닌), 30 (이소류신), 33 (알라닌), 38 (리신), 39 (발린), 41 (메티오닌), 42 (트레오닌), 61 (세린), 62 (세린), 64 (리신), 65 (프롤린), 66 (트립토판), 77 (발린), 89 (세린), 90 (티로신), 91 (세린), 97 (발린), 99 (알라닌), 102 (알라닌), 104 (트레오닌), 119 (트레오닌), 123 (류신), 125 (류신) 를 각각 글루탐산, 트레오닌, 알라닌, 트레오닌, 류신, 아르기닌, 알라닌, 류신, 세린, 글루타민, 알라닌, 아르기닌, 류신, 류신, 이소류신, 아스파르트산, 페닐알라닌, 트레오닌, 류신, 프롤린, 페닐알라닌, 발린, 글루타민, 발린, 이소류신으로 치환하는 것을 따라 설계된 인간화 M30 경사슬을 「M30-L1 타입 경사슬」이라고 명명하였다.
M30-L1 타입 경사슬의 아미노산 배열을 배열 번호 71 에 나타냈다.
9)-3-2 M30-L2 타입 경사슬 :
배열표의 배열 번호 59 에 나타내는 cM30 경사슬의 아미노산 번호 21 (글루타민), 25 (세린), 29 (트레오닌), 30 (이소류신), 33 (알라닌), 38 (리신), 39 (발린), 41 (메티오닌), 42 (트레오닌), 61 (세린), 62 (세린), 64 (리신), 65 (프롤린), 77 (발린), 89 (세린), 91 (세린), 97 (발린), 99 (알라닌), 102 (알라닌), 104 (트레오닌), 119 (트레오닌), 123 (류신), 125 (류신) 를 각각 글루탐산, 트레오닌, 알라닌, 트레오닌, 류신, 아르기닌, 알라닌, 류신, 세린, 글루타민, 알라닌, 아르기닌, 류신, 이소류신, 아스파르트산, 트레오닌, 류신, 프롤린, 페닐알라닌, 발린, 글루타민, 발린, 이소류신으로 치환하는 것을 따라 설계된 인간화 M30 경사슬을 「M30-L2 타입 경사슬」이라고 명명하였다.
M30-L2 타입 경사슬의 아미노산 배열을 배열 번호 73 에 나타냈다.
9)-3-3 M30-L3 타입 경사슬 :
배열표의 배열 번호 59 에 나타내는 cM30 경사슬의 아미노산 번호 29 (트레오닌), 30 (이소류신), 33 (알라닌), 38 (리신), 39 (발린), 41 (메티오닌), 62 (세린), 65 (프롤린), 77 (발린), 91 (세린), 97 (발린), 99 (알라닌), 102 (알라닌), 104 (트레오닌), 119 (트레오닌), 123 (류신), 125 (류신) 를 각각 알라닌, 트레오닌, 류신, 아르기닌, 알라닌, 류신, 알라닌, 류신, 이소류신, 트레오닌, 류신, 프롤린, 페닐알라닌, 발린, 글루타민, 발린, 이소류신으로 치환하는 것을 따라 설계된 인간화 M30 경사슬을 「M30-L3 타입 경사슬」이라고 명명하였다.
M30-L3 타입 경사슬의 아미노산 배열을 배열 번호 75 에 나타냈다.
9)-3-4 M30-L4 타입 경사슬 :
배열표의 배열 번호 59 에 나타내는 cM30 경사슬의 아미노산 번호 21 (글루타민), 25 (세린), 29 (트레오닌), 30 (이소류신), 33 (알라닌), 38 (리신), 39 (발린), 41 (메티오닌), 42 (트레오닌), 61 (세린), 62 (세린), 64 (리신), 66 (트립토판), 77 (발린), 89 (세린), 90 (티로신), 91 (세린), 96 (아르기닌), 97 (발린), 99 (알라닌), 102 (알라닌), 104 (트레오닌), 119 (트레오닌), 123 (류신), 125 (류신) 를 각각 글루탐산, 트레오닌, 알라닌, 트레오닌, 류신, 아르기닌, 알라닌, 류신, 세린, 글루타민, 알라닌, 아르기닌, 류신, 이소류신, 아스파르트산, 페닐알라닌, 트레오닌, 세린, 류신, 프롤린, 페닐알라닌, 발린, 글루타민, 발린, 이소류신으로 치환하는 것을 따라 설계된 인간화 M30 경사슬을 「M30-L4 타입 경사슬」이라고 명명하였다.
M30-L4 타입 경사슬의 아미노산 배열을 배열 번호 77 에 나타냈다.
9)-3-5 M30-L5 타입 경사슬 :
배열표의 배열 번호 59 에 나타내는 cM30 경사슬의 아미노산 번호 29 (트레오닌), 30 (이소류신), 33 (알라닌), 38 (리신), 39 (발린), 41 (메티오닌), 62 (세린), 77 (발린), 91 (세린), 97 (발린), 99 (알라닌), 102 (알라닌), 104 (트레오닌), 119 (트레오닌), 123 (류신), 125 (류신) 를 각각 알라닌, 트레오닌, 류신, 아르기닌, 알라닌, 류신, 알라닌, 이소류신, 트레오닌, 류신, 프롤린, 페닐알라닌, 발린, 글루타민, 발린, 이소류신으로 치환하는 것을 따라 설계된 인간화 M30 경사슬을 「M30-L5 타입 경사슬」이라고 명명하였다.
M30-L5 타입 경사슬의 아미노산 배열을 배열 번호 79 에 나타냈다.
9)-3-6 M30-L6 타입 경사슬 :
배열표의 배열 번호 59 에 나타내는 cM30 경사슬의 아미노산 번호 21 (글루타민), 25 (세린), 29 (트레오닌), 30 (이소류신), 33 (알라닌), 38 (리신), 39 (발린), 41 (메티오닌), 42 (트레오닌), 61 (세린), 62 (세린), 64 (리신), 66 (트립토판), 77 (발린), 89 (세린), 90 (티로신), 91 (세린), 97 (발린), 99 (알라닌), 102 (알라닌), 104 (트레오닌), 119 (트레오닌), 123 (류신), 125 (류신) 를 각각 글루탐산, 트레오닌, 알라닌, 트레오닌, 류신, 아르기닌, 알라닌, 류신, 세린, 글루타민, 알라닌, 아르기닌, 류신, 이소류신, 아스파르트산, 페닐알라닌, 트레오닌, 류신, 프롤린, 페닐알라닌, 발린, 글루타민, 발린, 이소류신으로 치환하는 것을 따라 설계된 인간화 M30 경사슬을 「M30-L6 타입 경사슬」이라고 명명하였다.
M30-L6 타입 경사슬의 아미노산 배열을 배열 번호 81 에 나타냈다.
9)-3-7 M30-L7 타입 경사슬 :
배열표의 배열 번호 59 에 나타내는 cM30 경사슬의 아미노산 번호 21 (글루타민), 25 (세린), 29 (트레오닌), 30 (이소류신), 33 (알라닌), 38 (리신), 39 (발린), 41 (메티오닌), 42 (트레오닌), 61 (세린), 62 (세린), 64 (리신), 66 (트립토판), 77 (발린), 89 (세린), 91 (세린), 97 (발린), 99 (알라닌), 102 (알라닌), 104 (트레오닌), 119 (트레오닌), 123 (류신), 125 (류신) 를 각각 글루탐산, 트레오닌, 알라닌, 트레오닌, 류신, 아르기닌, 알라닌, 류신, 세린, 글루타민, 알라닌, 아르기닌, 류신, 이소류신, 아스파르트산, 트레오닌, 류신, 프롤린, 페닐알라닌, 발린, 글루타민, 발린, 이소류신으로 치환하는 것을 따라 설계된 인간화 M30 경사슬을 「M30-L7 타입 경사슬」이라고 명명하였다.
M30-L7 타입 경사슬의 아미노산 배열을 배열 번호 83 에 나타냈다.
(실시예 10) 인간화 항체의 제조
10)-1 M30-L1, M30-L2, M30-L3, M30-L4, M30-L5, M30-L6, 및 M30-L7 타입 경사슬 발현 벡터의 구축
배열표의 배열 번호 71 의 아미노산 번호 21 내지 128, 배열 번호 73 의 아미노산 번호 21 내지 128, 배열 번호 75 의 아미노산 번호 21 내지 128, 배열 번호 77 의 아미노산 번호 21 내지 128, 배열 번호 79 의 아미노산 번호 21 내지 128, 배열 번호 81 의 아미노산 번호 21 내지 128, 및 배열 번호 83 의 아미노산 번호 21 내지 128 에 각각 나타내는 M30-L1, M30-L2, M30-L3, M30-L4, M30-L5, M30-L6, 및 M30-L7 타입 경사슬 가변 영역을 코드하는 유전자를 포함하는 DNA 를 상기 아미노산 배열에 관련된 배열 번호에 대응하는 뉴클레오티드 배열에 관련된 배열 번호 70, 72, 74, 76, 78, 80 및 82 에 기초하여 합성하고 (GENEART 사, 인공 유전자 합성 서비스), 제한 효소 NdeI 및 BsiWI 로 잘리는 DNA 단편을 키메라 및 인간화 항체 경사슬 발현 범용 벡터 (pEF6KCL) 를 제한 효소 NdeI 및 BsiWI 로 절단한 지점에 삽입함으로써, M30-L1, M30-L2, M30-L3, M30-L4, M30-L5, M30-L6, 및 M30-L7 타입 경사슬 발현 벡터를 구축하였다.
얻어진 발현 벡터를 각각 「pEF6KCL/M30-L1」, 「pEF6KCL/M30-L2」, 「pEF6KCL/M30-L3」, 「pEF6KCL/M30-L4」, 「pEF6KCL/M30-L5」, 「pEF6KCL/M30-L6」, 및 「pEF6KCL/M30-L7」 이라고 명명하였다.
10)-2 M30-H1, M30-H2, M30-H3, 및 M30-H4 타입 중사슬 발현 벡터의 구축
배열표의 배열 번호 85 의 아미노산 번호 20 내지 141, 배열 번호 87 의 아미노산 번호 20 내지 141, 배열 번호 89 의 아미노산 번호 20 내지 141, 및 배열 번호 91 의 아미노산 번호 20 내지 141 에 각각 나타내는 M30-H1, M30-H2, M30-H3, 및 M30-H4 타입 중사슬 가변 영역을 코드하는 유전자를 포함하는 DNA 를 상기 아미노산 배열에 관련된 배열 번호에 대응하는 뉴클레오티드 배열에 관련된 배열 번호 84, 86, 88 및 90 에 기초하여 합성하고 (GENEART 사 인공 유전자 합성 서비스), 제한 효소 BlpI 로 잘리는 DNA 단편을 인간화 항체 중사슬 발현 범용 벡터 (pEF1FCCU) 를 제한 효소 BlpI 로 절단한 지점에 삽입함으로써, M30-H1, M30-H2, M30-H3, 및 M30-H4 타입 중사슬 발현 벡터를 구축하였다.
얻어진 발현 벡터를 각각 「pEF1FCCU/M30-H1」, 「pEF1FCCU/M30-H2」, 「pEF1FCCU/M30-H3」, 및 「pEF1FCCU/M30-H4」라고 명명하였다.
10)-3 인간화 항체의 생산
1.2 × 109 개의 대수 증식기의 FreeStyle 293F 세포 (인비트로젠사) 를 신선한 1.2 ℓ 의 FreeStyle293 expression medium (인비트로젠사) 에 파종하고, 37 ℃, 8 % CO2 인큐베이터 내에서 90 rpm 으로 1 시간 진탕 배양하였다. Polyethyleneimine (Polyscience #24765) 3.6 ㎎ 을 Opti-Pro SFM 배지 (인비트로젠사) 20 ㎖ 에 용해시키고, 다음으로 PureLink HiPure Plasmid 키트 (인비트로젠사) 를 사용하여 조제한 중사슬 발현 벡터 (0.4 ㎎) 및 경사슬 발현 벡터 (0.8 ㎎) 를 20 ㎖ 의 Opti-Pro SFM 배지에 현탁하였다. Polyethyleneimine/Opti-Pro SFM 혼합액 20 ㎖ 에 발현 벡터/Opti-Pro SFM 혼합액 20 ㎖ 를 첨가하여 조심스럽게 교반하고, 추가로 5 분간 방치한 후에 FreeStyle 293F 세포에 첨가하였다. 37 ℃, 8 % CO2 인큐베이터에서 7 일간, 90 rpm 으로 진탕 배양하여 얻어진 배양 상청을 Disposable Capsule Filter (Advantec #CCS-045-E1H) 로 여과하였다.
pEF1FCCU/M30-H1 과 pEF6KCL/M30-L1 의 조합에 의해 취득된 M30 의 인간화 항체를 「M30-H1-L1」, pEF1FCCU/M30-H1 과 pEF6KCL/M30-L2 의 조합에 의해 취득된 M30 의 인간화 항체를 「M30-H1-L2」, pEF1FCCU/M30-H1 과 pEF6KCL/M30-L3 의 조합에 의해 취득된 M30 의 인간화 항체를 「M30-H1-L3」, pEF1FCCU/M30-H1 과 pEF6KCL/M30-L4 의 조합에 의해 취득된 M30 의 인간화 항체를 「M30-H1-L4」, pEF1FCCU/M30-H4 와 pEF6KCL/M30-L1 의 조합에 의해 취득된 M30 의 인간화 항체를 「M30-H4-L1」, pEF1FCCU/M30-H4 와 pEF6KCL/M30-L2 의 조합에 의해 취득된 M30 의 인간화 항체를 「M30-H4-L2」, pEF1FCCU/M30-H4 와 pEF6KCL/M30-L3 의 조합에 의해 취득된 M30 의 인간화 항체를 「M30-H4-L3」, pEF1FCCU/M30-H4 와 pEF6KCL/M30-L4 의 조합에 의해 취득된 M30 의 인간화 항체를 「M30-H4-L4」, pEF1FCCU/M30-H1 과 pEF6KCL/M30-L5 의 조합에 의해 취득된 M30 의 인간화 항체를 「M30-H1-L5」, pEF1FCCU/M30-H1 과 pEF6KCL/M30-L6 의 조합에 의해 취득된 M30 의 인간화 항체를 「M30-H1-L6」, 및 pEF1FCCU/M30-H1 과 pEF6KCL/M30-L7 의 조합에 의해 취득된 M30 의 인간화 항체를 「M30-H1-L7」 이라고 명명하였다.
10)-4 인간화 항체의 정제
실시예 6-1) 로 얻어진 배양 상청을 rProteinA 어피니티 크로마토그래피 (4 - 6 ℃ 하) 와 세라믹하이드록실아파타이트 (실온하) 의 2 단계 공정으로 정제하였다. rProteinA 어피니티 크로마토그래피 정제 후와 세라믹하이드록실아파타이트 정제 후의 버퍼 치환 공정은 실온하에서 실시하였다.
최초로, 배양 상청 1100 - 1200 ㎖ 를 PBS 로 평형화한 MabSelectSuRe (GE Healthcare Bioscience 사 제조, HiTrap 칼럼 : 용적 1 ㎖ × 2 연결) 에 어플라이하였다. 배양액이 칼럼에 모두 들어간 후, PBS 15 - 30 ㎖ 로 칼럼을 세정하였다. 다음으로 2 M 아르기닌염산염 용액 (pH 4.0) 으로 용출하여, 항체가 포함되는 획분을 모았다. 당해 획분을 탈염 칼럼 (GE Healthcare Bioscience 사 제조, HiTrap Desalting 칼럼 : 용적 5 ㎖ × 2 연결) 으로 5 mM 인산나트륨/50 mM MES/20 mM NaCl/pH 6.5 의 버퍼로 치환을 실시하였다.
또한, 그 치환한 항체 용액을 5 mM NaPi/50 mM MES/20 mM NaCl/pH 6.5 의 버퍼로 평형화된 세라믹하이드록실아파타이트 칼럼 (닛폰 바이오래드, Bio-Scale CHT2-1 Hydroxyapatite Column : 용적 2 ㎖) 에 어플라이하였다. 염화나트륨에 의한 직선적 농도 구배 용출을 실시하여, 항체가 포함되는 획분을 모았다.
당해 획분을 탈염 칼럼 (GE Healthcare Bioscience 사 제조, HiTrap Desalting 칼럼 : 용적 5 ㎖ × 2 연결) 으로 CBS (10 mM 시트르산 완충액/140 mM 염화나트륨, pH 6.0) 로의 액 치환을 실시하였다.
마지막으로 Centrifugal UF Filter Device VIVASPIN20 (분획 분자량 30 K, Sartorius 사, 4 ℃ 하) 에서 농축하고, IgG 농도를 1.0 ㎎/㎖ 이상으로 조제하여 정제 샘플로 하였다.
10)-5 인간화 항체의 B7-H3 항원에 대한 결합성
항원인 인간 B7-H3 과 인간화 M30 항체의 결합성은 표면 플라스몬 공명 (SPR) 장치 (BIACORE 사) 에 의해 측정하였다. 정법에 의해, 항인간 IgG 항체를 센서 칩에 고정화시키고, 거기에 상기 10)-4 로 얻어진 인간화 M30 항체의 정제 샘플을 결합한 후에, 각 농도의 B7-H3 베리언트 2 항원의 세포 외 영역 폴리펩티드 (R & D Systems 사 제조 : #2318-B3-050/CF) 를 첨가하고, 런닝 버퍼 (인산 버퍼, 0.05 % SP20) 중에서의 항체에 대한 결합량을 시간 경과적으로 측정하였다. 측정한 결합량을 전용 소프트웨어 (BIA evaluation) 에 의해 해석하여 해리 정수 (KD [M]) 를 산출하였다. cM30 항체를 측정회마다 양성 대조로 하여 측정을 실시하였다. 그 결과는 표 3 과 같고, 인간화 M30 항체는 모두 B7-H3 항원에 대해 결합 활성을 갖고 있었다.

실시예 11. M30 항체, cM30 항체 및 인간화 M30 항체의 B7-H3 항원 결합에 대한 경합 저해 활성의 측정
M30 항체의 B7-H3 베리언트 1 및 베리언트 2 에 대한 결합에 대한 cM30 항체, 인간화 M30 항체 (M30-H1-L4 항체) 의 경합 저해 활성을 이하의 방법으로 측정하였다.
EZ-Link Sulfo-NHS-LC Biotinylation Kit (Thermo scientific 사 제조 #21435) 를 사용하여 첨부된 프로토콜에 따라, 마우스 모노클로날 항체 M30 을 각각 비오틴화하였다 (이하, 비오틴화 M30 을 각각 「bM30」이라고 표기한다). 또한, 하기 ELISA 법에 사용하는 버퍼는 모두 BD OPTI EIA (BD Biosciences #550536) 를 사용하였다.
B7-H3 베리언트 1 의 세포 외 영역 폴리펩티드 (R & D Systems 사 제조 : #1949-B3-050/CF) 및 B7-H3 베리언트 2 의 세포 외 영역 폴리펩티드 (R & D Systems 사 제조 : #2318-B3-050/CF) 를 Coating buffer 로 0.5 ㎍/㎖ 로 희석시켜 이뮤노플레이트 (Nunc 사 제조 #442404) 에 100 ㎕/웰로 분주하고, 4 ℃ 에서 하룻밤 가만히 정지시킴으로써 플레이트에 단백질을 흡착시켰다. 다음날, 웰을 assay diluent 를 200 ㎕/웰로 분주하고, 실온에서 4 시간 가만히 정지시켰다.
웰 중의 액을 제거 후, 5 ㎍/㎖ 의 비오틴화 항체와 각종 농도 (0 ㎍/㎖, 1 ㎍/㎖, 5 ㎍/㎖, 25 ㎍/㎖, 50 ㎍/㎖, 125 ㎍/㎖) 의 비표지 항체의 혼합 용액을 assay diluent 에 각각 100 ㎕/웰로 분주하고, 1 시간 실온에서 가만히 정지시켰다.
Wash buffer 로 2 회 웰을 세정한 후, assay diluent 로 500 배로 희석시킨 Streptavidin-horseradish Peroxidase Conjugate (GE Healthcare Bio-Sciences 사 제조 #RPN1231V) 를 100 ㎕/웰로 첨가하고, 실온에서 1 시간 가만히 정지시켰다.
웰 중의 액을 제거하고, wash buffer 로 2 회 웰을 세정한 후, Substrate Solution 을 100 ㎕/웰로 첨가하여, 교반하면서 발색 반응을 실시하였다. 발색 후, blocking buffer 를 100 ㎕/웰로 첨가하여 발색 반응을 멈추게 하고, 플레이트 리더로 450 ㎚ 의 흡광도를 측정하였다.
그 결과, bM30 만을 첨가한 웰의 흡광도는 B7-H3 베리언트 1 의 세포 외 영역 폴리펩티드 및 B7-H3 베리언트 2 의 세포 외 영역 폴리펩티드를 부착시킨 플레이트에서 각각 2.36 ± 0.05, 1.90 ± 0.20 (평균치 ± 표준 편차 (n = 12)) 이었다.
도 10 의 그래프 중의 흡광도는 각각 평균치±표준 편차 (n = 3) 로 나타내고 있다. 컨트롤 IgG 는 bM30 의 B7-H3 에 대한 결합을 저해하지 않았다.
한편, bM30 의 B7-H3 에 대한 결합은 B7-H3 베리언트 1 의 세포 외 영역 폴리펩티드 및 B7-H3 베리언트 2 의 세포 외 영역 폴리펩티드를 부착시킨 플레이트 중 어느 것에 있어서도 M30 항체 자신 또는 그 키메라 항체인 cM30 항체 및 인간화 항체인 M30-H1-L4 에 의해 저해되는 것이 나타났다.
즉, cM30 항체 및 인간화 항체 (M30-H1-L4 항체) 는 M30 항체와 동일한 B7-H3 항원 에피토프를 인식하고 있는 것이 나타났다.
실시예 12. 인간화 M30 항체의 활성
12)-1 인간화 M30 항체의 ADCP 활성
정상인 PBMC 를 정법에 따라 분리하였다. RPMI-10 % FCS 중에 현탁하고, 플라스크 중에 파종하였다. CO2 인큐베이터에서 하룻밤 배양을 실시하였다. 배양 상청을 버리고, 플라스크에 부착된 세포에 M-CSF 및 GM-CSF (PeproTech 사) 를 첨가한 RPMI-10 % FCS 를 첨가하고, 2 주간 배양하였다. 세포를 TrypLE 로 박리하여 회수하였다. 500 ㎕/well (1 × 105 cell/well) 을 24 well plate 에 첨가하고, 37 ℃ 에서 하룻밤 배양하였다. 본 세포를 이펙터 세포로 하였다.
타겟 세포가 되는 NCI-H322 세포의 라벨링을 PKH26 dye labeling kit (Sigma 사) 를 사용하여 실시하였다. 타겟 세포를 TrypLE 로 박리하고, PBS 로 2 회 세정하였다. 세포를 Diluent C 로 1 × 107 cells/㎖ 가 되도록 현탁하였다. PKH26 dye stock (1 mM) 을 Diluent C 로 8 μM 에 희석시키고, 바로 세포 부유액과 등량의 dye 희석액을 첨가하였다. 실온에 5 분간 방치하였다. 혈청 1 ㎖ 를 첨가하고, 추가로 혈청 함유 배지를 첨가하고 2 회 세정을 실시하였다.
M30 항체, cM30 항체 및 인간화 M30 항체 (M30-H1-L4 항체) 를 RPMI-10 % FCS (인비트로젠사) 로 20 ㎍/㎖ 에 희석시켰다. 타겟 세포 (NCI-H322 세포) 를 2 × 106 cells/100 ㎕/tube 분주, 혼합하였다. 빙상에서 30 분간 가만히 정지시켰다. 상청을 버리고, 배양액으로 2 회 세정하였다. 배양액 500 ㎕ 에 현탁하였다.
이펙터 세포로부터 상청을 제거하고, M30 항체, cM30 항체 및 인간화 M30 항체 (M30-H1-L4 항체) 를 처리하여 배양액에 서스펜드한 세포를 첨가하여 혼합하였다. CO2 인큐베이터 내에서 3 시간 배양하였다.
Trypsin-EDTA 로 세포를 박리하여, 세포를 회수하였다.
회수한 세포에 FITC 표지 항마우스 CD11b 항체 (벡톤 디킨슨사) 를 첨가하고, 빙상에서 30 분간 가만히 정지시켰다.
상청을 버리고, 배양액으로 2 회 세정하였다.
회수한 세포를 300 uℓ 의 배지에서 현탁하고, FACS Calibur (벡톤 디킨슨사) 로 측정을 실시하였다. CD11b 양성의 매크로파지 세포에 있어서, PKH26 양성 획분을 탐식 양성 세포로서 평가를 실시하였다.
그 결과를 도 11 에 나타낸다.
인간화 M30 항체 (M30-H1-L4 항체) 를 첨가한 군에서는, M30 항체 및 cM30 항체를 첨가한 군과 동일하게, NCI-H322 세포에 대해 ADCP 활성이 관찰되었다.
12)-2 인간화 M30 항체의 ADCC 활성
정상인 PBMC 를 정법에 따라 분리하였다. RPMI-10 % FCS 중에 현탁하고, 플라스크 중에 파종하였다. CO2 인큐베이터에서 하룻밤 배양을 실시하였다.
부유 세포를 회수하고, 세정 조작을 실시하여 말초혈 림프구 (PBL) 로 하였다. 얻어진 PBL 을 Fetal Bovine Serum (인비트로젠사 제조) 을 10 % 함유하는 페놀레드 불함 RPMI1640 (인비트로젠사 제조) (이하 「ADCC 용 배지」라고 약기한다) 에 현탁하고, 셀 스트레이너 (포아 사이즈 40 ㎛ : BD Biosciences 사 제조) 를 통과시킨 후, 생세포수를 트리판 블루 색소 배제 시험으로 계측하였다. 비장 세포 현탁액을 원심 후, 배지를 제거하고, 생세포 밀도로 2.5 × 106 세포/㎖ 가 되도록 ADCC 용 배지에서 재현탁하여 이펙터 세포로 하였다.
NCI-H322 세포를 트립신 처리하고, 10 % FBS 함유 RPMI1640 으로 세포를 세정 후, 10 % FBS 함유 RPMI1640 에 재현탁하고, 각 세포 4 × 106 개를 0.22 ㎛ 필터로 멸균한 Chromium-51 (5550 kBq) 과 혼합하여, 37 ℃, 5 % CO2 의 조건하에서 1 시간 라벨하였다. 라벨한 세포를 ADCC 용 배지에서 3 회 세정하고, ADCC 용 배지에서 2 × 105 세포/㎖ 가 되도록 재현탁하여 표적 세포로 하였다.
2 × 105 세포/㎖ 의 표적 세포를 50 ㎕/웰로 96 구멍 U 바닥 마이크로 플레이트에 분주하였다. 거기에 이펙터 세포 첨가 후의 최종농도로 1, 10, 100, 1000 ng/㎖ 가 되도록 ADCC 용 배지로 희석시킨 cM30 항체 그리고 인간화 M30 항체 (M30-H1-L4, M30-H4-L4, M30-H1-L5, M30-H1-L6, M30-H1-L7) 의 각 항체를 50 ㎕ 첨가하였다. 거기에 2.5 × 106 세포/㎖ 의 이펙터 세포를 100 ㎕ 첨가하고, 37 ℃, 5 % CO2 의 조건하에서 4 시간 배양하였다. 상청을 LumaPlate (PerkinElmer 사 제조) 에 회수하고, 감마 카운터에서 방출된 감마선량을 측정하였다. ADCC 활성에 의한 세포 용해율은 다음 식으로 산출하였다.
세포 용해율 (%) = (A - B)/(C - B) × 100
A : 샘플 웰의 카운트
B : 자연 방출 (항체·이펙터 세포 비첨가 웰) 카운트의 평균치 (n = 3). 항체 첨가시와 이펙터 세포 첨가시에 각각 ADCC 용 배지를 50 ㎕, 100 ㎕ 첨가하였다. 그 이외에는 샘플 웰과 동일한 조작을 실시하였다.
C : 최대 방출 (표적 세포를 계면활성제로 용해시킨 웰) 카운트의 평균치 (n = 3). 항체 첨가시에 ADCC 용 배지를 50 ㎕, 이펙터 세포 첨가시에 Triton-X100 을 2 % (v/v) 함유하는 ADCC 용 배지를 100 ㎕ 를 첨가하였다. 그 이외에는 샘플 웰과 동일한 조작을 실시하였다.
그 결과를 표 4 및 도 12 에 나타낸다.
3 회의 실험의 평균치이고, 에러바는 표준 편차를 나타내고, P 치는 Student's t-test 에 의해 산출하였다.
M30-H1-L4 항체 첨가군에서는 cM30 항체 첨가군과 동일하게, ADCC 활성이 관찰되었다. 그 밖의 인간화 M30 항체 (M30-H4-L4, M30-H1-L5, M30-H1-L6, M30-H1-L7) 에 대해서도 동일하게 ADCC 활성이 관찰되었다.

12)-3 인간화 M30 항체의 in vivo 항종양 효과
MDA-MB-231 세포를 트립신 처리하여 배양 플라스크로부터 벗긴 후, 10 % FBS 함유 RPMI1640 배지 (라이프 테크놀로지스사) 에 현탁 후 원심하고, 상청을 제거하였다. 세포를 동 배지에서 2 회 세정한 후, BD 마트리겔 기저막 매트릭스 (BD Biosciences 사 제조) 에 현탁하고, 6 주령의 마우스 (FOX CHASE SCID C.B. 17/Icr-scid/scidJcl, 닛폰 클레아 주식회사) 에 5 × 106 세포/마우스로 액와부 피하에 이식하였다. 이식일을 0 일째로 하여 14, 21, 28, 35, 42 일째에 인간화 M30 항체 (M30-H1-L4 항체) 를 10, 1, 0.1, 0.01 ㎎/㎏ (각 약 200, 20, 2, 0.2 ㎍/마우스) 으로 복강 내 투여하였다. 종양 체적을 14, 18, 21, 25, 28, 31, 35, 39, 42, 45, 49 일째에 측정하고, 항체 투여에 의한 항종양 효과를 검토하였다.
그 결과, 인간화 M30 항체 (M30-H1-L4 항체) 의 10, 1, 0.1 ㎎/㎏ 투여군에서는, 항체를 투여하지 않은 무처치군에 비해 유의하게 종양 증식이 억제되었다. 49 일째 시점의 종양 중량에 대해 무처치군과의 비교에서, 인간화 M30 항체 (M30-H1-L4 항체) 의 10, 1 및 0.1 ㎎/㎏ 투여군의 종양 증식 저해율 (%) (= 100 - (항체 투여군의 종양 중량의 평균치)/(무처치군의 종양 중량의 평균치) × 100) 은 각각 67, 54, 51 % 이고, P 치는 모두 P < 0.0001 이었다. P 치는 Dunnett 형 다중 비교에 의해 산출하였다.
또한, 49 일째 시점에서의 M30-H1-L4 항체의 종양 증식 저해율 (%) (= 100 - (항체 투여군의 종양 체적의 평균치)/(무처치군의 종양 체적의 평균치) × 100) 은 10, 1, 0.1, 0.01 ㎎/㎏ 투여군에서 각각 84, 68, 61, 30 % 이고, 인간화 M30 항체 (M30-H1-L4 항체) 는 M30 항체 및 cM30 항체와 동일하게, in vivo 에서 매우 강한 항종양 효과가 관찰되고, 그 효과에는 용량 반응성이 확인되었다 (도 38).
산업상의 이용가능성
본 발명의 항 B7-H3 항체는 항종양 활성을 갖고, 그 항 B7-H3 항체를 함유하는 의약 조성물은 항암제가 될 수 있다.
배열표 프리 텍스트
배열 번호 1 - PCR 프라이머 1
배열 번호 2 - PCR 프라이머 2
배열 번호 3 - CMV promoter 프라이머 : 프라이머 3
배열 번호 4 - BGH reverse 프라이머 : 프라이머 4
배열 번호 5 - B7-H3 베리언트 1 의 뉴클레오티드 배열
배열 번호 6 - B7-H3 베리언트 1 의 아미노산 배열
배열 번호 7 - PCR 프라이머 5
배열 번호 8 - PCR 프라이머 6
배열 번호 9 - B7-H3 베리언트 2 의 뉴클레오티드 배열
배열 번호 10 - B7-H3 베리언트 2 의 아미노산 배열
배열 번호 11 - PCR 프라이머 7
배열 번호 12 - PCR 프라이머 8
배열 번호 13 - PCR 프라이머 9
배열 번호 14 - PCR 프라이머 10
배열 번호 15 - PCR 프라이머 11
배열 번호 16 - PCR 프라이머 12
배열 번호 17 - PCR 프라이머 13
배열 번호 18 - PCR 프라이머 14
배열 번호 19 - PCR 프라이머 15
배열 번호 20 - B7-H3 IgV1 의 뉴클레오티드 배열
배열 번호 21 - B7-H3 IgV1 의 아미노산 배열
배열 번호 22 - B7-H3 IgC1 의 뉴클레오티드 배열
배열 번호 23 - B7-H3 IgC1 의 아미노산 배열
배열 번호 24 - B7-H3 IgV2 의 뉴클레오티드 배열
배열 번호 25 - B7-H3 IgV2 의 아미노산 배열
배열 번호 26 - B7-H3 IgC2 의 뉴클레오티드 배열
배열 번호 27 - B7-H3 IgC2 의 아미노산 배열
배열 번호 28 - B7-H3 IgC1-V2-C2 의 뉴클레오티드 배열
배열 번호 29 - B7-H3 IgC1-V2-C2 의 아미노산 배열
배열 번호 30 - B7-H3 IgV2-C2 의 뉴클레오티드 배열
배열 번호 31 - B7-H3 IgV2-C2 의 아미노산 배열
배열 번호 32 - B7RP-1 의 뉴클레오티드 배열
배열 번호 33 - B7RP-1 의 아미노산 배열
배열 번호 34 - B7-H1 의 뉴클레오티드 배열
배열 번호 35 - B7-H1 의 아미노산 배열
배열 번호 36 - B7-DC 의 뉴클레오티드 배열
배열 번호 37 - B7-DC 의 아미노산 배열
배열 번호 38 - CD80 의 뉴클레오티드 배열
배열 번호 39 - CD80 의 아미노산 배열
배열 번호 40 - CD86 의 뉴클레오티드 배열
배열 번호 41 - CD86 의 아미노산 배열
배열 번호 42 - B7-H4 의 뉴클레오티드 배열
배열 번호 43 - B7-H4 의 아미노산 배열
배열 번호 44 - 마우스 항체 M30 중사슬의 N 말단의 아미노산 배열
배열 번호 45 - 마우스 항체 M30 경사슬의 N 말단의 아미노산 배열
배열 번호 46 - PCR 프라이머 16
배열 번호 47 - PCR 프라이머 17
배열 번호 48 - PCR 프라이머 18
배열 번호 49 - PCR 프라이머 19
배열 번호 50 - M30 항체 중사슬을 코드하는 cDNA 의 뉴클레오티드 배열
배열 번호 51 - M30 항체 중사슬의 아미노산 배열
배열 번호 52 - M30 항체 경사슬을 코드하는 cDNA 의 뉴클레오티드 배열
배열 번호 53 - M30 항체 경사슬의 아미노산 배열
배열 번호 54 - PCR 프라이머 20
배열 번호 55 - PCR 프라이머 21
배열 번호 56 - 인간 κ 사슬 분비 시그널, 인간 κ 사슬 정상 영역 및 인간 polyA 부가 시그널을 코드하는 DNA 배열
배열 번호 57 - 인간 IgG1 시그널 배열 및 정상 영역의 아미노산을 코드하는 DNA 배열을 포함하는 DNA 단편
배열 번호 58 - M30 항체 키메라 타입 경사슬을 코드하는 cDNA 의 뉴클레오티드 배열
배열 번호 59 - M30 항체 키메라 타입 경사슬의 아미노산 배열
배열 번호 60 - PCR 프라이머 22
배열 번호 61 - PCR 프라이머 23
배열 번호 62 - M30 항체 키메라 타입 중사슬을 코드하는 cDNA 의 뉴클레오티드 배열
배열 번호 63 - M30 항체 키메라 타입 중사슬의 아미노산 배열
배열 번호 64 - PCR 프라이머 24
배열 번호 65 - PCR 프라이머 25
배열 번호 66 - PCR 프라이머 26
배열 번호 67 - PCR 프라이머 27
배열 번호 68 - PCR 프라이머 28
배열 번호 69 - PCR 프라이머 29
배열 번호 70 - M30-L1 타입 경사슬의 뉴클레오티드 배열
배열 번호 71 - M30-L1 타입 경사슬의 아미노산 배열
배열 번호 72 - M30-L2 타입 경사슬의 뉴클레오티드 배열
배열 번호 73 - M30-L2 타입 경사슬의 아미노산 배열
배열 번호 74 - M30-L3 타입 경사슬의 뉴클레오티드 배열
배열 번호 75 - M30-L3 타입 경사슬의 아미노산 배열
배열 번호 76 - M30-L4 타입 경사슬의 뉴클레오티드 배열
배열 번호 77 - M30-L4 타입 경사슬의 아미노산 배열
배열 번호 78 - M30-L5 타입 경사슬의 뉴클레오티드 배열
배열 번호 79 - M30-L5 타입 경사슬의 아미노산 배열
배열 번호 80 - M30-L6 타입 경사슬의 뉴클레오티드 배열
배열 번호 81 - M30-L6 타입 경사슬의 아미노산 배열
배열 번호 82 - M30-L7 타입 경사슬의 뉴클레오티드 배열
배열 번호 83 - M30-L7 타입 경사슬의 아미노산 배열
배열 번호 84 - M30-H1 타입 중사슬의 뉴클레오티드 배열
배열 번호 85 - M30-H1 타입 중사슬의 아미노산 배열
배열 번호 86 - M30-H2 타입 중사슬의 뉴클레오티드 배열
배열 번호 87 - M30-H2 타입 중사슬의 아미노산 배열
배열 번호 88 - M30-H3 타입 중사슬의 뉴클레오티드 배열
배열 번호 89 - M30-H3 타입 중사슬의 아미노산 배열
배열 번호 90 - M30-H4 타입 중사슬의 뉴클레오티드 배열
배열 번호 91 - M30-H4 타입 중사슬의 아미노산 배열
배열 번호 92 - M30 항체의 CDRH1 의 아미노산 배열
배열 번호 93 - M30 항체의 CDRH2 의 아미노산 배열
배열 번호 94 - M30 항체의 CDRH3 의 아미노산 배열
배열 번호 95 - M30 항체의 CDRL1 의 아미노산 배열
배열 번호 96 - M30 항체의 CDRL2 의 아미노산 배열
배열 번호 97 - M30 항체의 CDRL3 의 아미노산 배열
SEQUENCE LISTING
<110> Daiichi Sankyo Company, Limited
<120> Anti B7-H3 antibody
<130> DSPCT-FP1214
<150>?JP 2011-097645
<151>?2011-04-25
<150>?US 61/478878
<151>?2011-04-25
<160> 97
<170> PatentIn version 3.4
<210> 1
<211> 46
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 1
ctatagggag acccaagctg gctagcatgc tgcgtcggcg gggcag 46
<210> 2
<211> 66
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 2
aacgggccct ctagactcga gcggccgctc aggctatttc ttgtccatca tcttctttgc 60
tgtcag 66
<210> 3
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 3
cgcaaatggg cggtaggcgt g 21
<210> 4
<211> 18
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 4
tagaaggcac agtcgagg 18
<210> 5
<211> 1815
<212> DNA
<213> Homo sapiens
<400> 5
atgctgcgtc ggcggggcag ccctggcatg ggtgtgcatg tgggtgcagc cctgggagca 60
ctgtggttct gcctcacagg agccctggag gtccaggtcc ctgaagaccc agtggtggca 120
ctggtgggca ccgatgccac cctgtgctgc tccttctccc ctgagcctgg cttcagcctg 180
gcacagctca acctcatctg gcagctgaca gataccaaac agctggtgca cagctttgct 240
gagggccagg accagggcag cgcctatgcc aaccgcacgg ccctcttccc ggacctgctg 300
gcacagggca acgcatccct gaggctgcag cgcgtgcgtg tggcggacga gggcagcttc 360
acctgcttcg tgagcatccg ggatttcggc agcgctgccg tcagcctgca ggtggccgct 420
ccctactcga agcccagcat gaccctggag cccaacaagg acctgcggcc aggggacacg 480
gtgaccatca cgtgctccag ctaccagggc taccctgagg ctgaggtgtt ctggcaggat 540
gggcagggtg tgcccctgac tggcaacgtg accacgtcgc agatggccaa cgagcagggc 600
ttgtttgatg tgcacagcat cctgcgggtg gtgctgggtg caaatggcac ctacagctgc 660
ctggtgcgca accccgtgct gcagcaggat gcgcacagct ctgtcaccat cacaccccag 720
agaagcccca caggagccgt ggaggtccag gtccctgagg acccggtggt ggccctagtg 780
ggcaccgatg ccaccctgcg ctgctccttc tcccccgagc ctggcttcag cctggcacag 840
ctcaacctca tctggcagct gacagacacc aaacagctgg tgcacagttt caccgaaggc 900
cgggaccagg gcagcgccta tgccaaccgc acggccctct tcccggacct gctggcacaa 960
ggcaatgcat ccctgaggct gcagcgcgtg cgtgtggcgg acgagggcag cttcacctgc 1020
ttcgtgagca tccgggattt cggcagcgct gccgtcagcc tgcaggtggc cgctccctac 1080
tcgaagccca gcatgaccct ggagcccaac aaggacctgc ggccagggga cacggtgacc 1140
atcacgtgct ccagctaccg gggctaccct gaggctgagg tgttctggca ggatgggcag 1200
ggtgtgcccc tgactggcaa cgtgaccacg tcgcagatgg ccaacgagca gggcttgttt 1260
gatgtgcaca gcgtcctgcg ggtggtgctg ggtgcgaatg gcacctacag ctgcctggtg 1320
cgcaaccccg tgctgcagca ggatgcgcac ggctctgtca ccatcacagg gcagcctatg 1380
acattccccc cagaggccct gtgggtgacc gtggggctgt ctgtctgtct cattgcactg 1440
ctggtggccc tggctttcgt gtgctggaga aagatcaaac agagctgtga ggaggagaat 1500
gcaggagctg aggaccagga tggggaggga gaaggctcca agacagccct gcagcctctg 1560
aaacactctg acagcaaaga agatgatgga caagaaatag cctgagcggc cgccactgtg 1620
ctggatatct gcagaattcc accacactgg actagtggat ccgagctcgg taccaagctt 1680
aagtttaaac cgctgatcag cctcgactgt gccttctagt tgccagccat ctgttgtttg 1740
cccctccccc gtgccttcct tgaccctgga aggtgccact cccactgtcc tttcctaata 1800
aaatgaggaa attgc 1815
<210> 6
<211> 534
<212> PRT
<213> Homo sapiens
<400> 6
Met Leu Arg Arg Arg Gly Ser Pro Gly Met Gly Val His Val Gly Ala
1 5 10 15
Ala Leu Gly Ala Leu Trp Phe Cys Leu Thr Gly Ala Leu Glu Val Gln
20 25 30
Val Pro Glu Asp Pro Val Val Ala Leu Val Gly Thr Asp Ala Thr Leu
35 40 45
Cys Cys Ser Phe Ser Pro Glu Pro Gly Phe Ser Leu Ala Gln Leu Asn
50 55 60
Leu Ile Trp Gln Leu Thr Asp Thr Lys Gln Leu Val His Ser Phe Ala
65 70 75 80
Glu Gly Gln Asp Gln Gly Ser Ala Tyr Ala Asn Arg Thr Ala Leu Phe
85 90 95
Pro Asp Leu Leu Ala Gln Gly Asn Ala Ser Leu Arg Leu Gln Arg Val
100 105 110
Arg Val Ala Asp Glu Gly Ser Phe Thr Cys Phe Val Ser Ile Arg Asp
115 120 125
Phe Gly Ser Ala Ala Val Ser Leu Gln Val Ala Ala Pro Tyr Ser Lys
130 135 140
Pro Ser Met Thr Leu Glu Pro Asn Lys Asp Leu Arg Pro Gly Asp Thr
145 150 155 160
Val Thr Ile Thr Cys Ser Ser Tyr Gln Gly Tyr Pro Glu Ala Glu Val
165 170 175
Phe Trp Gln Asp Gly Gln Gly Val Pro Leu Thr Gly Asn Val Thr Thr
180 185 190
Ser Gln Met Ala Asn Glu Gln Gly Leu Phe Asp Val His Ser Ile Leu
195 200 205
Arg Val Val Leu Gly Ala Asn Gly Thr Tyr Ser Cys Leu Val Arg Asn
210 215 220
Pro Val Leu Gln Gln Asp Ala His Ser Ser Val Thr Ile Thr Pro Gln
225 230 235 240
Arg Ser Pro Thr Gly Ala Val Glu Val Gln Val Pro Glu Asp Pro Val
245 250 255
Val Ala Leu Val Gly Thr Asp Ala Thr Leu Arg Cys Ser Phe Ser Pro
260 265 270
Glu Pro Gly Phe Ser Leu Ala Gln Leu Asn Leu Ile Trp Gln Leu Thr
275 280 285
Asp Thr Lys Gln Leu Val His Ser Phe Thr Glu Gly Arg Asp Gln Gly
290 295 300
Ser Ala Tyr Ala Asn Arg Thr Ala Leu Phe Pro Asp Leu Leu Ala Gln
305 310 315 320
Gly Asn Ala Ser Leu Arg Leu Gln Arg Val Arg Val Ala Asp Glu Gly
325 330 335
Ser Phe Thr Cys Phe Val Ser Ile Arg Asp Phe Gly Ser Ala Ala Val
340 345 350
Ser Leu Gln Val Ala Ala Pro Tyr Ser Lys Pro Ser Met Thr Leu Glu
355 360 365
Pro Asn Lys Asp Leu Arg Pro Gly Asp Thr Val Thr Ile Thr Cys Ser
370 375 380
Ser Tyr Arg Gly Tyr Pro Glu Ala Glu Val Phe Trp Gln Asp Gly Gln
385 390 395 400
Gly Val Pro Leu Thr Gly Asn Val Thr Thr Ser Gln Met Ala Asn Glu
405 410 415
Gln Gly Leu Phe Asp Val His Ser Val Leu Arg Val Val Leu Gly Ala
420 425 430
Asn Gly Thr Tyr Ser Cys Leu Val Arg Asn Pro Val Leu Gln Gln Asp
435 440 445
Ala His Gly Ser Val Thr Ile Thr Gly Gln Pro Met Thr Phe Pro Pro
450 455 460
Glu Ala Leu Trp Val Thr Val Gly Leu Ser Val Cys Leu Ile Ala Leu
465 470 475 480
Leu Val Ala Leu Ala Phe Val Cys Trp Arg Lys Ile Lys Gln Ser Cys
485 490 495
Glu Glu Glu Asn Ala Gly Ala Glu Asp Gln Asp Gly Glu Gly Glu Gly
500 505 510
Ser Lys Thr Ala Leu Gln Pro Leu Lys His Ser Asp Ser Lys Glu Asp
515 520 525
Asp Gly Gln Glu Ile Ala
530
<210> 7
<211> 59
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 7
ggggacaagt ttgtacaaaa aagcaggctt caccatgctg cgtcggcggg gcagccctg 59
<210> 8
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 8
ggggaccact ttgtacaaga aagctgggtc ggctatttct tgt 43
<210> 9
<211> 948
<212> DNA
<213> Homo sapiens
<400> 9
atgctgcgtc ggcggggcag ccctggcatg ggtgtgcatg tgggtgcagc cctgggagca 60
ctgtggttct gcctcacagg agccctggag gtccaggtcc ctgaagaccc agtggtggca 120
ctggtgggca ccgatgccac cctgtgctgc tccttctccc ctgagcctgg cttcagcctg 180
gcacagctca acctcatctg gcagctgaca gataccaaac agctggtgca cagctttgct 240
gagggccagg accagggcag cgcctatgcc aaccgcacgg ccctcttccc ggacctgctg 300
gcacagggca acgcatccct gaggctgcag cgcgtgcgtg tggcggacga gggcagcttc 360
acctgcttcg tgagcatccg ggatttcggc agcgctgccg tcagcctgca ggtggccgct 420
ccctactcga agcccagcat gaccctggag cccaacaagg acctgcggcc aggggacacg 480
gtgaccatca cgtgctccag ctaccggggc taccctgagg ctgaggtgtt ctggcaggat 540
gggcagggtg tgcccctgac tggcaacgtg accacgtcgc agatggccaa cgagcagggc 600
ttgtttgatg tgcacagcgt cctgcgggtg gtgctgggtg cgaatggcac ctacagctgc 660
ctggtgcgca accccgtgct gcagcaggat gcgcacggct ctgtcaccat cacagggcag 720
cctatgacat tccccccaga ggccctgtgg gtgaccgtgg ggctgtctgt ctgtctcatt 780
gcactgctgg tggccctggc tttcgtgtgc tggagaaaga tcaaacagag ctgtgaggag 840
gagaatgcag gagctgagga ccaggatggg gagggagaag gctccaagac agccctgcag 900
cctctgaaac actctgacag caaagaagat gatggacaag aaatagcc 948
<210> 10
<211> 316
<212> PRT
<213> Homo sapiens
<400> 10
Met Leu Arg Arg Arg Gly Ser Pro Gly Met Gly Val His Val Gly Ala
1 5 10 15
Ala Leu Gly Ala Leu Trp Phe Cys Leu Thr Gly Ala Leu Glu Val Gln
20 25 30
Val Pro Glu Asp Pro Val Val Ala Leu Val Gly Thr Asp Ala Thr Leu
35 40 45
Cys Cys Ser Phe Ser Pro Glu Pro Gly Phe Ser Leu Ala Gln Leu Asn
50 55 60
Leu Ile Trp Gln Leu Thr Asp Thr Lys Gln Leu Val His Ser Phe Ala
65 70 75 80
Glu Gly Gln Asp Gln Gly Ser Ala Tyr Ala Asn Arg Thr Ala Leu Phe
85 90 95
Pro Asp Leu Leu Ala Gln Gly Asn Ala Ser Leu Arg Leu Gln Arg Val
100 105 110
Arg Val Ala Asp Glu Gly Ser Phe Thr Cys Phe Val Ser Ile Arg Asp
115 120 125
Phe Gly Ser Ala Ala Val Ser Leu Gln Val Ala Ala Pro Tyr Ser Lys
130 135 140
Pro Ser Met Thr Leu Glu Pro Asn Lys Asp Leu Arg Pro Gly Asp Thr
145 150 155 160
Val Thr Ile Thr Cys Ser Ser Tyr Arg Gly Tyr Pro Glu Ala Glu Val
165 170 175
Phe Trp Gln Asp Gly Gln Gly Val Pro Leu Thr Gly Asn Val Thr Thr
180 185 190
Ser Gln Met Ala Asn Glu Gln Gly Leu Phe Asp Val His Ser Val Leu
195 200 205
Arg Val Val Leu Gly Ala Asn Gly Thr Tyr Ser Cys Leu Val Arg Asn
210 215 220
Pro Val Leu Gln Gln Asp Ala His Gly Ser Val Thr Ile Thr Gly Gln
225 230 235 240
Pro Met Thr Phe Pro Pro Glu Ala Leu Trp Val Thr Val Gly Leu Ser
245 250 255
Val Cys Leu Ile Ala Leu Leu Val Ala Leu Ala Phe Val Cys Trp Arg
260 265 270
Lys Ile Lys Gln Ser Cys Glu Glu Glu Asn Ala Gly Ala Glu Asp Gln
275 280 285
Asp Gly Glu Gly Glu Gly Ser Lys Thr Ala Leu Gln Pro Leu Lys His
290 295 300
Ser Asp Ser Lys Glu Asp Asp Gly Gln Glu Ile Ala
305 310 315
<210> 11
<211> 52
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 11
ggggacaagt ttgtacaaaa aagcaggctt cggagccctg gaggtccagg tc 52
<210> 12
<211> 55
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 12
ggggacaagt ttgtacaaaa aagcaggctt cgctccctac tcgaagccca gcatg 55
<210> 13
<211> 52
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 13
ggggacaagt ttgtacaaaa aagcaggctt cggagccgtg gaggtccagg tc 52
<210> 14
<211> 55
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 14
ggggacaagt ttgtacaaaa aagcaggctt cgctccctac tcgaagccca gcatg 55
<210> 15
<211> 54
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 15
ggggaccact ttgtacaaga aagctgggtc tcaggctatt tcttgtccat catc 54
<210> 16
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 16
gggaatgtca taggctgccc ggccacctgc aggctgacgg cag 43
<210> 17
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 17
gggaatgtca taggctgccc tgtggggctt ctctggggtg tg 42
<210> 18
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 18
gggaatgtca taggctgccc ggccacctgc aggctgacgg cag 43
<210> 19
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 19
gggcagccta tgacattccc cccagag 27
<210> 20
<211> 576
<212> DNA
<213> Homo sapiens
<400> 20
ggagccctgg aggtccaggt ccctgaagac ccagtggtgg cactggtggg caccgatgcc 60
accctgtgct gctccttctc ccctgagcct ggcttcagcc tggcacagct caacctcatc 120
tggcagctga cagataccaa acagctggtg cacagctttg ctgagggcca ggaccagggc 180
agcgcctatg ccaaccgcac ggccctcttc ccggacctgc tggcacaggg caacgcatcc 240
ctgaggctgc agcgcgtgcg tgtggcggac gagggcagct tcacctgctt cgtgagcatc 300
cgggatttcg gcagcgctgc cgtcagcctg caggtggccg ggcagcctat gacattcccc 360
ccagaggccc tgtgggtgac cgtggggctg tctgtctgtc tcattgcact gctggtggcc 420
ctggctttcg tgtgctggag aaagatcaaa cagagctgtg aggaggagaa tgcaggagct 480
gaggaccagg atggggaggg agaaggctcc aagacagccc tgcagcctct gaaacactct 540
gacagcaaag aagatgatgg acaagaaata gcctga 576
<210> 21
<211> 191
<212> PRT
<213> Homo sapiens
<400> 21
Gly Ala Leu Glu Val Gln Val Pro Glu Asp Pro Val Val Ala Leu Val
1 5 10 15
Gly Thr Asp Ala Thr Leu Cys Cys Ser Phe Ser Pro Glu Pro Gly Phe
20 25 30
Ser Leu Ala Gln Leu Asn Leu Ile Trp Gln Leu Thr Asp Thr Lys Gln
35 40 45
Leu Val His Ser Phe Ala Glu Gly Gln Asp Gln Gly Ser Ala Tyr Ala
50 55 60
Asn Arg Thr Ala Leu Phe Pro Asp Leu Leu Ala Gln Gly Asn Ala Ser
65 70 75 80
Leu Arg Leu Gln Arg Val Arg Val Ala Asp Glu Gly Ser Phe Thr Cys
85 90 95
Phe Val Ser Ile Arg Asp Phe Gly Ser Ala Ala Val Ser Leu Gln Val
100 105 110
Ala Gly Gln Pro Met Thr Phe Pro Pro Glu Ala Leu Trp Val Thr Val
115 120 125
Gly Leu Ser Val Cys Leu Ile Ala Leu Leu Val Ala Leu Ala Phe Val
130 135 140
Cys Trp Arg Lys Ile Lys Gln Ser Cys Glu Glu Glu Asn Ala Gly Ala
145 150 155 160
Glu Asp Gln Asp Gly Glu Gly Glu Gly Ser Lys Thr Ala Leu Gln Pro
165 170 175
Leu Lys His Ser Asp Ser Lys Glu Asp Asp Gly Gln Glu Ile Ala
180 185 190
<210> 22
<211> 552
<212> DNA
<213> Homo sapiens
<400> 22
gctccctact cgaagcccag catgaccctg gagcccaaca aggacctgcg gccaggggac 60
acggtgacca tcacgtgctc cagctaccag ggctaccctg aggctgaggt gttctggcag 120
gatgggcagg gtgtgcccct gactggcaac gtgaccacgt cgcagatggc caacgagcag 180
ggcttgtttg atgtgcacag catcctgcgg gtggtgctgg gtgcaaatgg cacctacagc 240
tgcctggtgc gcaaccccgt gctgcagcag gatgcgcaca gctctgtcac catcacaccc 300
cagagaagcc ccacagggca gcctatgaca ttccccccag aggccctgtg ggtgaccgtg 360
gggctgtctg tctgtctcat tgcactgctg gtggccctgg ctttcgtgtg ctggagaaag 420
atcaaacaga gctgtgagga ggagaatgca ggagctgagg accaggatgg ggagggagaa 480
ggctccaaga cagccctgca gcctctgaaa cactctgaca gcaaagaaga tgatggacaa 540
gaaatagcct ga 552
<210> 23
<211> 183
<212> PRT
<213> Homo sapiens
<400> 23
Ala Pro Tyr Ser Lys Pro Ser Met Thr Leu Glu Pro Asn Lys Asp Leu
1 5 10 15
Arg Pro Gly Asp Thr Val Thr Ile Thr Cys Ser Ser Tyr Gln Gly Tyr
20 25 30
Pro Glu Ala Glu Val Phe Trp Gln Asp Gly Gln Gly Val Pro Leu Thr
35 40 45
Gly Asn Val Thr Thr Ser Gln Met Ala Asn Glu Gln Gly Leu Phe Asp
50 55 60
Val His Ser Ile Leu Arg Val Val Leu Gly Ala Asn Gly Thr Tyr Ser
65 70 75 80
Cys Leu Val Arg Asn Pro Val Leu Gln Gln Asp Ala His Ser Ser Val
85 90 95
Thr Ile Thr Pro Gln Arg Ser Pro Thr Gly Gln Pro Met Thr Phe Pro
100 105 110
Pro Glu Ala Leu Trp Val Thr Val Gly Leu Ser Val Cys Leu Ile Ala
115 120 125
Leu Leu Val Ala Leu Ala Phe Val Cys Trp Arg Lys Ile Lys Gln Ser
130 135 140
Cys Glu Glu Glu Asn Ala Gly Ala Glu Asp Gln Asp Gly Glu Gly Glu
145 150 155 160
Gly Ser Lys Thr Ala Leu Gln Pro Leu Lys His Ser Asp Ser Lys Glu
165 170 175
Asp Asp Gly Gln Glu Ile Ala
180
<210> 24
<211> 576
<212> DNA
<213> Homo sapiens
<400> 24
ggagccgtgg aggtccaggt ccctgaggac ccggtggtgg ccctagtggg caccgatgcc 60
accctgcgct gctccttctc ccccgagcct ggcttcagcc tggcacagct caacctcatc 120
tggcagctga cagacaccaa acagctggtg cacagtttca ccgaaggccg ggaccagggc 180
agcgcctatg ccaaccgcac ggccctcttc ccggacctgc tggcacaagg caatgcatcc 240
ctgaggctgc agcgcgtgcg tgtggcggac gagggcagct tcacctgctt cgtgagcatc 300
cgggatttcg gcagcgctgc cgtcagcctg caggtggccg ggcagcctat gacattcccc 360
ccagaggccc tgtgggtgac cgtggggctg tctgtctgtc tcattgcact gctggtggcc 420
ctggctttcg tgtgctggag aaagatcaaa cagagctgtg aggaggagaa tgcaggagct 480
gaggaccagg atggggaggg agaaggctcc aagacagccc tgcagcctct gaaacactct 540
gacagcaaag aagatgatgg acaagaaata gcctga 576
<210> 25
<211> 191
<212> PRT
<213> Homo sapiens
<400> 25
Gly Ala Val Glu Val Gln Val Pro Glu Asp Pro Val Val Ala Leu Val
1 5 10 15
Gly Thr Asp Ala Thr Leu Arg Cys Ser Phe Ser Pro Glu Pro Gly Phe
20 25 30
Ser Leu Ala Gln Leu Asn Leu Ile Trp Gln Leu Thr Asp Thr Lys Gln
35 40 45
Leu Val His Ser Phe Thr Glu Gly Arg Asp Gln Gly Ser Ala Tyr Ala
50 55 60
Asn Arg Thr Ala Leu Phe Pro Asp Leu Leu Ala Gln Gly Asn Ala Ser
65 70 75 80
Leu Arg Leu Gln Arg Val Arg Val Ala Asp Glu Gly Ser Phe Thr Cys
85 90 95
Phe Val Ser Ile Arg Asp Phe Gly Ser Ala Ala Val Ser Leu Gln Val
100 105 110
Ala Gly Gln Pro Met Thr Phe Pro Pro Glu Ala Leu Trp Val Thr Val
115 120 125
Gly Leu Ser Val Cys Leu Ile Ala Leu Leu Val Ala Leu Ala Phe Val
130 135 140
Cys Trp Arg Lys Ile Lys Gln Ser Cys Glu Glu Glu Asn Ala Gly Ala
145 150 155 160
Glu Asp Gln Asp Gly Glu Gly Glu Gly Ser Lys Thr Ala Leu Gln Pro
165 170 175
Leu Lys His Ser Asp Ser Lys Glu Asp Asp Gly Gln Glu Ile Ala
180 185 190
<210> 26
<211> 534
<212> DNA
<213> Homo sapiens
<400> 26
gctccctact cgaagcccag catgaccctg gagcccaaca aggacctgcg gccaggggac 60
acggtgacca tcacgtgctc cagctaccgg ggctaccctg aggctgaggt gttctggcag 120
gatgggcagg gtgtgcccct gactggcaac gtgaccacgt cgcagatggc caacgagcag 180
ggcttgtttg atgtgcacag cgtcctgcgg gtggtgctgg gtgcgaatgg cacctacagc 240
tgcctggtgc gcaaccccgt gctgcagcag gatgcgcacg gctctgtcac catcacaggg 300
cagcctatga cattcccccc agaggccctg tgggtgaccg tggggctgtc tgtctgtctc 360
attgcactgc tggtggccct ggctttcgtg tgctggagaa agatcaaaca gagctgtgag 420
gaggagaatg caggagctga ggaccaggat ggggagggag aaggctccaa gacagccctg 480
cagcctctga aacactctga cagcaaagaa gatgatggac aagaaatagc ctga 534
<210> 27
<211> 177
<212> PRT
<213> Homo sapiens
<400> 27
Ala Pro Tyr Ser Lys Pro Ser Met Thr Leu Glu Pro Asn Lys Asp Leu
1 5 10 15
Arg Pro Gly Asp Thr Val Thr Ile Thr Cys Ser Ser Tyr Arg Gly Tyr
20 25 30
Pro Glu Ala Glu Val Phe Trp Gln Asp Gly Gln Gly Val Pro Leu Thr
35 40 45
Gly Asn Val Thr Thr Ser Gln Met Ala Asn Glu Gln Gly Leu Phe Asp
50 55 60
Val His Ser Val Leu Arg Val Val Leu Gly Ala Asn Gly Thr Tyr Ser
65 70 75 80
Cys Leu Val Arg Asn Pro Val Leu Gln Gln Asp Ala His Gly Ser Val
85 90 95
Thr Ile Thr Gly Gln Pro Met Thr Phe Pro Pro Glu Ala Leu Trp Val
100 105 110
Thr Val Gly Leu Ser Val Cys Leu Ile Ala Leu Leu Val Ala Leu Ala
115 120 125
Phe Val Cys Trp Arg Lys Ile Lys Gln Ser Cys Glu Glu Glu Asn Ala
130 135 140
Gly Ala Glu Asp Gln Asp Gly Glu Gly Glu Gly Ser Lys Thr Ala Leu
145 150 155 160
Gln Pro Leu Lys His Ser Asp Ser Lys Glu Asp Asp Gly Gln Glu Ile
165 170 175
Ala
<210> 28
<211> 1188
<212> DNA
<213> Homo sapiens
<400> 28
gctccctact cgaagcccag catgaccctg gagcccaaca aggacctgcg gccaggggac 60
acggtgacca tcacgtgctc cagctaccag ggctaccctg aggctgaggt gttctggcag 120
gatgggcagg gtgtgcccct gactggcaac gtgaccacgt cgcagatggc caacgagcag 180
ggcttgtttg atgtgcacag catcctgcgg gtggtgctgg gtgcaaatgg cacctacagc 240
tgcctggtgc gcaaccccgt gctgcagcag gatgcgcaca gctctgtcac catcacaccc 300
cagagaagcc ccacaggagc cgtggaggtc caggtccctg aggacccggt ggtggcccta 360
gtgggcaccg atgccaccct gcgctgctcc ttctcccccg agcctggctt cagcctggca 420
cagctcaacc tcatctggca gctgacagac accaaacagc tggtgcacag tttcaccgaa 480
ggccgggacc agggcagcgc ctatgccaac cgcacggccc tcttcccgga cctgctggca 540
caaggcaatg catccctgag gctgcagcgc gtgcgtgtgg cggacgaggg cagcttcacc 600
tgcttcgtga gcatccggga tttcggcagc gctgccgtca gcctgcaggt ggccgctccc 660
tactcgaagc ccagcatgac cctggagccc aacaaggacc tgcggccagg ggacacggtg 720
accatcacgt gctccagcta ccggggctac cctgaggctg aggtgttctg gcaggatggg 780
cagggtgtgc ccctgactgg caacgtgacc acgtcgcaga tggccaacga gcagggcttg 840
tttgatgtgc acagcgtcct gcgggtggtg ctgggtgcga atggcaccta cagctgcctg 900
gtgcgcaacc ccgtgctgca gcaggatgcg cacggctctg tcaccatcac agggcagcct 960
atgacattcc ccccagaggc cctgtgggtg accgtggggc tgtctgtctg tctcattgca 1020
ctgctggtgg ccctggcttt cgtgtgctgg agaaagatca aacagagctg tgaggaggag 1080
aatgcaggag ctgaggacca ggatggggag ggagaaggct ccaagacagc cctgcagcct 1140
ctgaaacact ctgacagcaa agaagatgat ggacaagaaa tagcctga 1188
<210> 29
<211> 395
<212> PRT
<213> Homo sapiens
<400> 29
Ala Pro Tyr Ser Lys Pro Ser Met Thr Leu Glu Pro Asn Lys Asp Leu
1 5 10 15
Arg Pro Gly Asp Thr Val Thr Ile Thr Cys Ser Ser Tyr Gln Gly Tyr
20 25 30
Pro Glu Ala Glu Val Phe Trp Gln Asp Gly Gln Gly Val Pro Leu Thr
35 40 45
Gly Asn Val Thr Thr Ser Gln Met Ala Asn Glu Gln Gly Leu Phe Asp
50 55 60
Val His Ser Ile Leu Arg Val Val Leu Gly Ala Asn Gly Thr Tyr Ser
65 70 75 80
Cys Leu Val Arg Asn Pro Val Leu Gln Gln Asp Ala His Ser Ser Val
85 90 95
Thr Ile Thr Pro Gln Arg Ser Pro Thr Gly Ala Val Glu Val Gln Val
100 105 110
Pro Glu Asp Pro Val Val Ala Leu Val Gly Thr Asp Ala Thr Leu Arg
115 120 125
Cys Ser Phe Ser Pro Glu Pro Gly Phe Ser Leu Ala Gln Leu Asn Leu
130 135 140
Ile Trp Gln Leu Thr Asp Thr Lys Gln Leu Val His Ser Phe Thr Glu
145 150 155 160
Gly Arg Asp Gln Gly Ser Ala Tyr Ala Asn Arg Thr Ala Leu Phe Pro
165 170 175
Asp Leu Leu Ala Gln Gly Asn Ala Ser Leu Arg Leu Gln Arg Val Arg
180 185 190
Val Ala Asp Glu Gly Ser Phe Thr Cys Phe Val Ser Ile Arg Asp Phe
195 200 205
Gly Ser Ala Ala Val Ser Leu Gln Val Ala Ala Pro Tyr Ser Lys Pro
210 215 220
Ser Met Thr Leu Glu Pro Asn Lys Asp Leu Arg Pro Gly Asp Thr Val
225 230 235 240
Thr Ile Thr Cys Ser Ser Tyr Arg Gly Tyr Pro Glu Ala Glu Val Phe
245 250 255
Trp Gln Asp Gly Gln Gly Val Pro Leu Thr Gly Asn Val Thr Thr Ser
260 265 270
Gln Met Ala Asn Glu Gln Gly Leu Phe Asp Val His Ser Val Leu Arg
275 280 285
Val Val Leu Gly Ala Asn Gly Thr Tyr Ser Cys Leu Val Arg Asn Pro
290 295 300
Val Leu Gln Gln Asp Ala His Gly Ser Val Thr Ile Thr Gly Gln Pro
305 310 315 320
Met Thr Phe Pro Pro Glu Ala Leu Trp Val Thr Val Gly Leu Ser Val
325 330 335
Cys Leu Ile Ala Leu Leu Val Ala Leu Ala Phe Val Cys Trp Arg Lys
340 345 350
Ile Lys Gln Ser Cys Glu Glu Glu Asn Ala Gly Ala Glu Asp Gln Asp
355 360 365
Gly Glu Gly Glu Gly Ser Lys Thr Ala Leu Gln Pro Leu Lys His Ser
370 375 380
Asp Ser Lys Glu Asp Asp Gly Gln Glu Ile Ala
385 390 395
<210> 30
<211> 873
<212> DNA
<213> Homo sapiens
<400> 30
ggagccgtgg aggtccaggt ccctgaggac ccggtggtgg ccctagtggg caccgatgcc 60
accctgcgct gctccttctc ccccgagcct ggcttcagcc tggcacagct caacctcatc 120
tggcagctga cagacaccaa acagctggtg cacagtttca ccgaaggccg ggaccagggc 180
agcgcctatg ccaaccgcac ggccctcttc ccggacctgc tggcacaagg caatgcatcc 240
ctgaggctgc agcgcgtgcg tgtggcggac gagggcagct tcacctgctt cgtgagcatc 300
cgggatttcg gcagcgctgc cgtcagcctg caggtggccg ctccctactc gaagcccagc 360
atgaccctgg agcccaacaa ggacctgcgg ccaggggaca cggtgaccat cacgtgctcc 420
agctaccggg gctaccctga ggctgaggtg ttctggcagg atgggcaggg tgtgcccctg 480
actggcaacg tgaccacgtc gcagatggcc aacgagcagg gcttgtttga tgtgcacagc 540
gtcctgcggg tggtgctggg tgcgaatggc acctacagct gcctggtgcg caaccccgtg 600
ctgcagcagg atgcgcacgg ctctgtcacc atcacagggc agcctatgac attcccccca 660
gaggccctgt gggtgaccgt ggggctgtct gtctgtctca ttgcactgct ggtggccctg 720
gctttcgtgt gctggagaaa gatcaaacag agctgtgagg aggagaatgc aggagctgag 780
gaccaggatg gggagggaga aggctccaag acagccctgc agcctctgaa acactctgac 840
agcaaagaag atgatggaca agaaatagcc tga 873
<210> 31
<211> 290
<212> PRT
<213> Homo sapiens
<400> 31
Gly Ala Val Glu Val Gln Val Pro Glu Asp Pro Val Val Ala Leu Val
1 5 10 15
Gly Thr Asp Ala Thr Leu Arg Cys Ser Phe Ser Pro Glu Pro Gly Phe
20 25 30
Ser Leu Ala Gln Leu Asn Leu Ile Trp Gln Leu Thr Asp Thr Lys Gln
35 40 45
Leu Val His Ser Phe Thr Glu Gly Arg Asp Gln Gly Ser Ala Tyr Ala
50 55 60
Asn Arg Thr Ala Leu Phe Pro Asp Leu Leu Ala Gln Gly Asn Ala Ser
65 70 75 80
Leu Arg Leu Gln Arg Val Arg Val Ala Asp Glu Gly Ser Phe Thr Cys
85 90 95
Phe Val Ser Ile Arg Asp Phe Gly Ser Ala Ala Val Ser Leu Gln Val
100 105 110
Ala Ala Pro Tyr Ser Lys Pro Ser Met Thr Leu Glu Pro Asn Lys Asp
115 120 125
Leu Arg Pro Gly Asp Thr Val Thr Ile Thr Cys Ser Ser Tyr Arg Gly
130 135 140
Tyr Pro Glu Ala Glu Val Phe Trp Gln Asp Gly Gln Gly Val Pro Leu
145 150 155 160
Thr Gly Asn Val Thr Thr Ser Gln Met Ala Asn Glu Gln Gly Leu Phe
165 170 175
Asp Val His Ser Val Leu Arg Val Val Leu Gly Ala Asn Gly Thr Tyr
180 185 190
Ser Cys Leu Val Arg Asn Pro Val Leu Gln Gln Asp Ala His Gly Ser
195 200 205
Val Thr Ile Thr Gly Gln Pro Met Thr Phe Pro Pro Glu Ala Leu Trp
210 215 220
Val Thr Val Gly Leu Ser Val Cys Leu Ile Ala Leu Leu Val Ala Leu
225 230 235 240
Ala Phe Val Cys Trp Arg Lys Ile Lys Gln Ser Cys Glu Glu Glu Asn
245 250 255
Ala Gly Ala Glu Asp Gln Asp Gly Glu Gly Glu Gly Ser Lys Thr Ala
260 265 270
Leu Gln Pro Leu Lys His Ser Asp Ser Lys Glu Asp Asp Gly Gln Glu
275 280 285
Ile Ala
290
<210> 32
<211> 909
<212> DNA
<213> Homo sapiens
<400> 32
atgcggctgg gcagtcctgg actgctcttc ctgctcttca gcagccttcg agctgatact 60
caggagaagg aagtcagagc gatggtaggc agcgacgtgg agctcagctg cgcttgccct 120
gaaggaagcc gttttgattt aaatgatgtt tacgtatatt ggcaaaccag tgagtcgaaa 180
accgtggtga cctaccacat cccacagaac agctccttgg aaaacgtgga cagccgctac 240
cggaaccgag ccctgatgtc accggccggc atgctgcggg gcgacttctc cctgcgcttg 300
ttcaacgtca ccccccagga cgagcagaag tttcactgcc tggtgttgag ccaatccctg 360
ggattccagg aggttttgag cgttgaggtt acactgcatg tggcagcaaa cttcagcgtg 420
cccgtcgtca gcgcccccca cagcccctcc caggatgagc tcaccttcac gtgtacatcc 480
ataaacggct accccaggcc caacgtgtac tggatcaata agacggacaa cagcctgctg 540
gaccaggctc tgcagaatga caccgtcttc ttgaacatgc ggggcttgta tgacgtggtc 600
agcgtgctga ggatcgcacg gacccccagc gtgaacattg gctgctgcat agagaacgtg 660
cttctgcagc agaacctgac tgtcggcagc cagacaggaa atgacatcgg agagagagac 720
aagatcacag agaatccagt cagtaccggc gagaaaaacg cggccacgtg gagcatcctg 780
gctgtcctgt gcctgcttgt ggtcgtggcg gtggccatag gctgggtgtg cagggaccga 840
tgcctccaac acagctatgc aggtgcctgg gctgtgagtc cggagacaga gctcactggc 900
cacgtttga 909
<210> 33
<211> 302
<212> PRT
<213> Homo sapiens
<400> 33
Met Arg Leu Gly Ser Pro Gly Leu Leu Phe Leu Leu Phe Ser Ser Leu
1 5 10 15
Arg Ala Asp Thr Gln Glu Lys Glu Val Arg Ala Met Val Gly Ser Asp
20 25 30
Val Glu Leu Ser Cys Ala Cys Pro Glu Gly Ser Arg Phe Asp Leu Asn
35 40 45
Asp Val Tyr Val Tyr Trp Gln Thr Ser Glu Ser Lys Thr Val Val Thr
50 55 60
Tyr His Ile Pro Gln Asn Ser Ser Leu Glu Asn Val Asp Ser Arg Tyr
65 70 75 80
Arg Asn Arg Ala Leu Met Ser Pro Ala Gly Met Leu Arg Gly Asp Phe
85 90 95
Ser Leu Arg Leu Phe Asn Val Thr Pro Gln Asp Glu Gln Lys Phe His
100 105 110
Cys Leu Val Leu Ser Gln Ser Leu Gly Phe Gln Glu Val Leu Ser Val
115 120 125
Glu Val Thr Leu His Val Ala Ala Asn Phe Ser Val Pro Val Val Ser
130 135 140
Ala Pro His Ser Pro Ser Gln Asp Glu Leu Thr Phe Thr Cys Thr Ser
145 150 155 160
Ile Asn Gly Tyr Pro Arg Pro Asn Val Tyr Trp Ile Asn Lys Thr Asp
165 170 175
Asn Ser Leu Leu Asp Gln Ala Leu Gln Asn Asp Thr Val Phe Leu Asn
180 185 190
Met Arg Gly Leu Tyr Asp Val Val Ser Val Leu Arg Ile Ala Arg Thr
195 200 205
Pro Ser Val Asn Ile Gly Cys Cys Ile Glu Asn Val Leu Leu Gln Gln
210 215 220
Asn Leu Thr Val Gly Ser Gln Thr Gly Asn Asp Ile Gly Glu Arg Asp
225 230 235 240
Lys Ile Thr Glu Asn Pro Val Ser Thr Gly Glu Lys Asn Ala Ala Thr
245 250 255
Trp Ser Ile Leu Ala Val Leu Cys Leu Leu Val Val Val Ala Val Ala
260 265 270
Ile Gly Trp Val Cys Arg Asp Arg Cys Leu Gln His Ser Tyr Ala Gly
275 280 285
Ala Trp Ala Val Ser Pro Glu Thr Glu Leu Thr Gly His Val
290 295 300
<210> 34
<211> 873
<212> DNA
<213> Homo sapiens
<400> 34
atgaggatat ttgctgtctt tatattcatg acctactggc atttgctgaa cgcatttact 60
gtcacggttc ccaaggacct atatgtggta gagtatggta gcaatatgac aattgaatgc 120
aaattcccag tagaaaaaca attagacctg gctgcactaa ttgtctattg ggaaatggag 180
gataagaaca ttattcaatt tgtgcatgga gaggaagacc tgaaggttca gcatagtagc 240
tacagacaga gggcccggct gttgaaggac cagctctccc tgggaaatgc tgcacttcag 300
atcacagatg tgaaattgca ggatgcaggg gtgtaccgct gcatgatcag ctatggtggt 360
gccgactaca agcgaattac tgtgaaagtc aatgccccat acaacaaaat caaccaaaga 420
attttggttg tggatccagt cacctctgaa catgaactga catgtcaggc tgagggctac 480
cccaaggccg aagtcatctg gacaagcagt gaccatcaag tcctgagtgg taagaccacc 540
accaccaatt ccaagagaga ggagaagctt ttcaatgtga ccagcacact gagaatcaac 600
acaacaacta atgagatttt ctactgcact tttaggagat tagatcctga ggaaaaccat 660
acagctgaat tggtcatccc agaactacct ctggcacatc ctccaaatga aaggactcac 720
ttggtaattc tgggagccat cttattatgc cttggtgtag cactgacatt catcttccgt 780
ttaagaaaag ggagaatgat ggatgtgaaa aaatgtggca tccaagatac aaactcaaag 840
aagcaaagtg atacacattt ggaggagacg taa 873
<210> 35
<211> 290
<212> PRT
<213> Homo sapiens
<400> 35
Met Arg Ile Phe Ala Val Phe Ile Phe Met Thr Tyr Trp His Leu Leu
1 5 10 15
Asn Ala Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr
20 25 30
Gly Ser Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu
35 40 45
Asp Leu Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile
50 55 60
Ile Gln Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser
65 70 75 80
Tyr Arg Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn
85 90 95
Ala Ala Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr
100 105 110
Arg Cys Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val
115 120 125
Lys Val Asn Ala Pro Tyr Asn Lys Ile Asn Gln Arg Ile Leu Val Val
130 135 140
Asp Pro Val Thr Ser Glu His Glu Leu Thr Cys Gln Ala Glu Gly Tyr
145 150 155 160
Pro Lys Ala Glu Val Ile Trp Thr Ser Ser Asp His Gln Val Leu Ser
165 170 175
Gly Lys Thr Thr Thr Thr Asn Ser Lys Arg Glu Glu Lys Leu Phe Asn
180 185 190
Val Thr Ser Thr Leu Arg Ile Asn Thr Thr Thr Asn Glu Ile Phe Tyr
195 200 205
Cys Thr Phe Arg Arg Leu Asp Pro Glu Glu Asn His Thr Ala Glu Leu
210 215 220
Val Ile Pro Glu Leu Pro Leu Ala His Pro Pro Asn Glu Arg Thr His
225 230 235 240
Leu Val Ile Leu Gly Ala Ile Leu Leu Cys Leu Gly Val Ala Leu Thr
245 250 255
Phe Ile Phe Arg Leu Arg Lys Gly Arg Met Met Asp Val Lys Lys Cys
260 265 270
Gly Ile Gln Asp Thr Asn Ser Lys Lys Gln Ser Asp Thr His Leu Glu
275 280 285
Glu Thr
290
<210> 36
<211> 909
<212> DNA
<213> Homo sapiens
<400> 36
atgcggctgg gcagtcctgg actgctcttc ctgctcttca gcagccttcg agctgatact 60
caggagaagg aagtcagagc gatggtaggc agcgacgtgg agctcagctg cgcttgccct 120
gaaggaagcc gttttgattt aaatgatgtt tacgtatatt ggcaaaccag tgagtcgaaa 180
accgtggtga cctaccacat cccacagaac agctccttgg aaaacgtgga cagccgctac 240
cggaaccgag ccctgatgtc accggccggc atgctgcggg gcgacttctc cctgcgcttg 300
ttcaacgtca ccccccagga cgagcagaag tttcactgcc tggtgttgag ccaatccctg 360
ggattccagg aggttttgag cgttgaggtt acactgcatg tggcagcaaa cttcagcgtg 420
cccgtcgtca gcgcccccca cagcccctcc caggatgagc tcaccttcac gtgtacatcc 480
ataaacggct accccaggcc caacgtgtac tggatcaata agacggacaa cagcctgctg 540
gaccaggctc tgcagaatga caccgtcttc ttgaacatgc ggggcttgta tgacgtggtc 600
agcgtgctga ggatcgcacg gacccccagc gtgaacattg gctgctgcat agagaacgtg 660
cttctgcagc agaacctgac tgtcggcagc cagacaggaa atgacatcgg agagagagac 720
aagatcacag agaatccagt cagtaccggc gagaaaaacg cggccacgtg gagcatcctg 780
gctgtcctgt gcctgcttgt ggtcgtggcg gtggccatag gctgggtgtg cagggaccga 840
tgcctccaac acagctatgc aggtgcctgg gctgtgagtc cggagacaga gctcactggc 900
cacgtttga 909
<210> 37
<211> 302
<212> PRT
<213> Homo sapiens
<400> 37
Met Arg Leu Gly Ser Pro Gly Leu Leu Phe Leu Leu Phe Ser Ser Leu
1 5 10 15
Arg Ala Asp Thr Gln Glu Lys Glu Val Arg Ala Met Val Gly Ser Asp
20 25 30
Val Glu Leu Ser Cys Ala Cys Pro Glu Gly Ser Arg Phe Asp Leu Asn
35 40 45
Asp Val Tyr Val Tyr Trp Gln Thr Ser Glu Ser Lys Thr Val Val Thr
50 55 60
Tyr His Ile Pro Gln Asn Ser Ser Leu Glu Asn Val Asp Ser Arg Tyr
65 70 75 80
Arg Asn Arg Ala Leu Met Ser Pro Ala Gly Met Leu Arg Gly Asp Phe
85 90 95
Ser Leu Arg Leu Phe Asn Val Thr Pro Gln Asp Glu Gln Lys Phe His
100 105 110
Cys Leu Val Leu Ser Gln Ser Leu Gly Phe Gln Glu Val Leu Ser Val
115 120 125
Glu Val Thr Leu His Val Ala Ala Asn Phe Ser Val Pro Val Val Ser
130 135 140
Ala Pro His Ser Pro Ser Gln Asp Glu Leu Thr Phe Thr Cys Thr Ser
145 150 155 160
Ile Asn Gly Tyr Pro Arg Pro Asn Val Tyr Trp Ile Asn Lys Thr Asp
165 170 175
Asn Ser Leu Leu Asp Gln Ala Leu Gln Asn Asp Thr Val Phe Leu Asn
180 185 190
Met Arg Gly Leu Tyr Asp Val Val Ser Val Leu Arg Ile Ala Arg Thr
195 200 205
Pro Ser Val Asn Ile Gly Cys Cys Ile Glu Asn Val Leu Leu Gln Gln
210 215 220
Asn Leu Thr Val Gly Ser Gln Thr Gly Asn Asp Ile Gly Glu Arg Asp
225 230 235 240
Lys Ile Thr Glu Asn Pro Val Ser Thr Gly Glu Lys Asn Ala Ala Thr
245 250 255
Trp Ser Ile Leu Ala Val Leu Cys Leu Leu Val Val Val Ala Val Ala
260 265 270
Ile Gly Trp Val Cys Arg Asp Arg Cys Leu Gln His Ser Tyr Ala Gly
275 280 285
Ala Trp Ala Val Ser Pro Glu Thr Glu Leu Thr Gly His Val
290 295 300
<210> 38
<211> 867
<212> DNA
<213> Homo sapiens
<400> 38
atgggccaca cacggaggca gggaacatca ccatccaagt gtccatacct caatttcttt 60
cagctcttgg tgctggctgg tctttctcac ttctgttcag gtgttatcca cgtgaccaag 120
gaagtgaaag aagtggcaac gctgtcctgt ggtcacaatg tttctgttga agagctggca 180
caaactcgca tctactggca aaaggagaag aaaatggtgc tgactatgat gtctggggac 240
atgaatatat ggcccgagta caagaaccgg accatctttg atatcactaa taacctctcc 300
attgtgatcc tggctctgcg cccatctgac gagggcacat acgagtgtgt tgttctgaag 360
tatgaaaaag acgctttcaa gcgggaacac ctggctgaag tgacgttatc agtcaaagct 420
gacttcccta cacctagtat atctgacttt gaaattccaa cttctaatat tagaaggata 480
atttgctcaa cctctggagg ttttccagag cctcacctct cctggttgga aaatggagaa 540
gaattaaatg ccatcaacac aacagtttcc caagatcctg aaactgagct ctatgctgtt 600
agcagcaaac tggatttcaa tatgacaacc aaccacagct tcatgtgtct catcaagtat 660
ggacatttaa gagtgaatca gaccttcaac tggaatacaa ccaagcaaga gcattttcct 720
gataacctgc tcccatcctg ggccattacc ttaatctcag taaatggaat ttttgtgata 780
tgctgcctga cctactgctt tgccccaaga tgcagagaga gaaggaggaa tgagagattg 840
agaagggaaa gtgtacgccc tgtatag 867
<210> 39
<211> 288
<212> PRT
<213> Homo sapiens
<400> 39
Met Gly His Thr Arg Arg Gln Gly Thr Ser Pro Ser Lys Cys Pro Tyr
1 5 10 15
Leu Asn Phe Phe Gln Leu Leu Val Leu Ala Gly Leu Ser His Phe Cys
20 25 30
Ser Gly Val Ile His Val Thr Lys Glu Val Lys Glu Val Ala Thr Leu
35 40 45
Ser Cys Gly His Asn Val Ser Val Glu Glu Leu Ala Gln Thr Arg Ile
50 55 60
Tyr Trp Gln Lys Glu Lys Lys Met Val Leu Thr Met Met Ser Gly Asp
65 70 75 80
Met Asn Ile Trp Pro Glu Tyr Lys Asn Arg Thr Ile Phe Asp Ile Thr
85 90 95
Asn Asn Leu Ser Ile Val Ile Leu Ala Leu Arg Pro Ser Asp Glu Gly
100 105 110
Thr Tyr Glu Cys Val Val Leu Lys Tyr Glu Lys Asp Ala Phe Lys Arg
115 120 125
Glu His Leu Ala Glu Val Thr Leu Ser Val Lys Ala Asp Phe Pro Thr
130 135 140
Pro Ser Ile Ser Asp Phe Glu Ile Pro Thr Ser Asn Ile Arg Arg Ile
145 150 155 160
Ile Cys Ser Thr Ser Gly Gly Phe Pro Glu Pro His Leu Ser Trp Leu
165 170 175
Glu Asn Gly Glu Glu Leu Asn Ala Ile Asn Thr Thr Val Ser Gln Asp
180 185 190
Pro Glu Thr Glu Leu Tyr Ala Val Ser Ser Lys Leu Asp Phe Asn Met
195 200 205
Thr Thr Asn His Ser Phe Met Cys Leu Ile Lys Tyr Gly His Leu Arg
210 215 220
Val Asn Gln Thr Phe Asn Trp Asn Thr Thr Lys Gln Glu His Phe Pro
225 230 235 240
Asp Asn Leu Leu Pro Ser Trp Ala Ile Thr Leu Ile Ser Val Asn Gly
245 250 255
Ile Phe Val Ile Cys Cys Leu Thr Tyr Cys Phe Ala Pro Arg Cys Arg
260 265 270
Glu Arg Arg Arg Asn Glu Arg Leu Arg Arg Glu Ser Val Arg Pro Val
275 280 285
<210> 40
<211> 990
<212> DNA
<213> Homo sapiens
<400> 40
atggatcccc agtgcactat gggactgagt aacattctct ttgtgatggc cttcctgctc 60
tctggtgctg ctcctctgaa gattcaagct tatttcaatg agactgcaga cctgccatgc 120
caatttgcaa actctcaaaa ccaaagcctg agtgagctag tagtattttg gcaggaccag 180
gaaaacttgg ttctgaatga ggtatactta ggcaaagaga aatttgacag tgttcattcc 240
aagtatatgg gccgcacaag ttttgattcg gacagttgga ccctgagact tcacaatctt 300
cagatcaagg acaagggctt gtatcaatgt atcatccatc acaaaaagcc cacaggaatg 360
attcgcatcc accagatgaa ttctgaactg tcagtgcttg ctaacttcag tcaacctgaa 420
atagtaccaa tttctaatat aacagaaaat gtgtacataa atttgacctg ctcatctata 480
cacggttacc cagaacctaa gaagatgagt gttttgctaa gaaccaagaa ttcaactatc 540
gagtatgatg gtattatgca gaaatctcaa gataatgtca cagaactgta cgacgtttcc 600
atcagcttgt ctgtttcatt ccctgatgtt acgagcaata tgaccatctt ctgtattctg 660
gaaactgaca agacgcggct tttatcttca cctttctcta tagagcttga ggaccctcag 720
cctcccccag accacattcc ttggattaca gctgtacttc caacagttat tatatgtgtg 780
atggttttct gtctaattct atggaaatgg aagaagaaga agcggcctcg caactcttat 840
aaatgtggaa ccaacacaat ggagagggaa gagagtgaac agaccaagaa aagagaaaaa 900
atccatatac ctgaaagatc tgatgaagcc cagcgtgttt ttaaaagttc gaagacatct 960
tcatgcgaca aaagtgatac atgtttttag 990
<210> 41
<211> 329
<212> PRT
<213> Homo sapiens
<400> 41
Met Asp Pro Gln Cys Thr Met Gly Leu Ser Asn Ile Leu Phe Val Met
1 5 10 15
Ala Phe Leu Leu Ser Gly Ala Ala Pro Leu Lys Ile Gln Ala Tyr Phe
20 25 30
Asn Glu Thr Ala Asp Leu Pro Cys Gln Phe Ala Asn Ser Gln Asn Gln
35 40 45
Ser Leu Ser Glu Leu Val Val Phe Trp Gln Asp Gln Glu Asn Leu Val
50 55 60
Leu Asn Glu Val Tyr Leu Gly Lys Glu Lys Phe Asp Ser Val His Ser
65 70 75 80
Lys Tyr Met Gly Arg Thr Ser Phe Asp Ser Asp Ser Trp Thr Leu Arg
85 90 95
Leu His Asn Leu Gln Ile Lys Asp Lys Gly Leu Tyr Gln Cys Ile Ile
100 105 110
His His Lys Lys Pro Thr Gly Met Ile Arg Ile His Gln Met Asn Ser
115 120 125
Glu Leu Ser Val Leu Ala Asn Phe Ser Gln Pro Glu Ile Val Pro Ile
130 135 140
Ser Asn Ile Thr Glu Asn Val Tyr Ile Asn Leu Thr Cys Ser Ser Ile
145 150 155 160
His Gly Tyr Pro Glu Pro Lys Lys Met Ser Val Leu Leu Arg Thr Lys
165 170 175
Asn Ser Thr Ile Glu Tyr Asp Gly Ile Met Gln Lys Ser Gln Asp Asn
180 185 190
Val Thr Glu Leu Tyr Asp Val Ser Ile Ser Leu Ser Val Ser Phe Pro
195 200 205
Asp Val Thr Ser Asn Met Thr Ile Phe Cys Ile Leu Glu Thr Asp Lys
210 215 220
Thr Arg Leu Leu Ser Ser Pro Phe Ser Ile Glu Leu Glu Asp Pro Gln
225 230 235 240
Pro Pro Pro Asp His Ile Pro Trp Ile Thr Ala Val Leu Pro Thr Val
245 250 255
Ile Ile Cys Val Met Val Phe Cys Leu Ile Leu Trp Lys Trp Lys Lys
260 265 270
Lys Lys Arg Pro Arg Asn Ser Tyr Lys Cys Gly Thr Asn Thr Met Glu
275 280 285
Arg Glu Glu Ser Glu Gln Thr Lys Lys Arg Glu Lys Ile His Ile Pro
290 295 300
Glu Arg Ser Asp Glu Ala Gln Arg Val Phe Lys Ser Ser Lys Thr Ser
305 310 315 320
Ser Cys Asp Lys Ser Asp Thr Cys Phe
325
<210> 42
<211> 849
<212> DNA
<213> Homo sapiens
<400> 42
atggcttccc tggggcagat cctcttctgg agcataatta gcatcatcat tattctggct 60
ggagcaattg cactcatcat tggctttggt atttcaggga gacactccat cacagtcact 120
actgtcgcct cagctgggaa cattggggag gatggaatcc tgagctgcac ttttgaacct 180
gacatcaaac tttctgatat cgtgatacaa tggctgaagg aaggtgtttt aggcttggtc 240
catgagttca aagaaggcaa agatgagctg tcggagcagg atgaaatgtt cagaggccgg 300
acagcagtgt ttgctgatca agtgatagtt ggcaatgcct ctttgcggct gaaaaacgtg 360
caactcacag atgctggcac ctacaaatgt tatatcatca cttctaaagg caaggggaat 420
gctaaccttg agtataaaac tggagccttc agcatgccgg aagtgaatgt ggactataat 480
gccagctcag agaccttgcg gtgtgaggct ccccgatggt tcccccagcc cacagtggtc 540
tgggcatccc aagttgacca gggagccaac ttctcggaag tctccaatac cagctttgag 600
ctgaactctg agaatgtgac catgaaggtt gtgtctgtgc tctacaatgt tacgatcaac 660
aacacatact cctgtatgat tgaaaatgac attgccaaag caacagggga tatcaaagtg 720
acagaatcgg agatcaaaag gcggagtcac ctacagctgc taaactcaaa ggcttctctg 780
tgtgtctctt ctttctttgc catcagctgg gcacttctgc ctctcagccc ttacctgatg 840
ctaaaatag 849
<210> 43
<211> 282
<212> PRT
<213> Homo sapiens
<400> 43
Met Ala Ser Leu Gly Gln Ile Leu Phe Trp Ser Ile Ile Ser Ile Ile
1 5 10 15
Ile Ile Leu Ala Gly Ala Ile Ala Leu Ile Ile Gly Phe Gly Ile Ser
20 25 30
Gly Arg His Ser Ile Thr Val Thr Thr Val Ala Ser Ala Gly Asn Ile
35 40 45
Gly Glu Asp Gly Ile Leu Ser Cys Thr Phe Glu Pro Asp Ile Lys Leu
50 55 60
Ser Asp Ile Val Ile Gln Trp Leu Lys Glu Gly Val Leu Gly Leu Val
65 70 75 80
His Glu Phe Lys Glu Gly Lys Asp Glu Leu Ser Glu Gln Asp Glu Met
85 90 95
Phe Arg Gly Arg Thr Ala Val Phe Ala Asp Gln Val Ile Val Gly Asn
100 105 110
Ala Ser Leu Arg Leu Lys Asn Val Gln Leu Thr Asp Ala Gly Thr Tyr
115 120 125
Lys Cys Tyr Ile Ile Thr Ser Lys Gly Lys Gly Asn Ala Asn Leu Glu
130 135 140
Tyr Lys Thr Gly Ala Phe Ser Met Pro Glu Val Asn Val Asp Tyr Asn
145 150 155 160
Ala Ser Ser Glu Thr Leu Arg Cys Glu Ala Pro Arg Trp Phe Pro Gln
165 170 175
Pro Thr Val Val Trp Ala Ser Gln Val Asp Gln Gly Ala Asn Phe Ser
180 185 190
Glu Val Ser Asn Thr Ser Phe Glu Leu Asn Ser Glu Asn Val Thr Met
195 200 205
Lys Val Val Ser Val Leu Tyr Asn Val Thr Ile Asn Asn Thr Tyr Ser
210 215 220
Cys Met Ile Glu Asn Asp Ile Ala Lys Ala Thr Gly Asp Ile Lys Val
225 230 235 240
Thr Glu Ser Glu Ile Lys Arg Arg Ser His Leu Gln Leu Leu Asn Ser
245 250 255
Lys Ala Ser Leu Cys Val Ser Ser Phe Phe Ala Ile Ser Trp Ala Leu
260 265 270
Leu Pro Leu Ser Pro Tyr Leu Met Leu Lys
275 280
<210> 44
<211> 10
<212> PRT
<213> Mus musculus
<400> 44
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu
1 5 10
<210> 45
<211> 14
<212> PRT
<213> Mus musculus
<400> 45
Ile Val Leu Ser Gln Ser Pro Thr Ile Leu Ser Ala Ser Pro
1 5 10
<210> 46
<211> 26
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 46
aagaattcat ggaatggagt tggata 26
<210> 47
<211> 32
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 47
aagatatctc atttacccgg agtccgggag aa 32
<210> 48
<211> 26
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 48
aagaattcat ggattttctg gtgcag 26
<210> 49
<211> 32
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 49
aagatatctt aacactcatt cctgttgaag ct 32
<210> 50
<211> 1413
<212> DNA
<213> Mus musculus
<400> 50
atggaatgga gttggatatt tctctttctc ctgtcaggaa ctgcaggtgt ccactctgag 60
gtccagctgc agcagtctgg acctgagctg gtaaagcctg gggcttcagt gaagatgtcc 120
tgcaaggctt ctggatacac attcactaac tatgttatgc actgggtgaa gcagaagcct 180
gggcagggcc ttgagtggat tggatatatt aatccttaca atgatgatgt taagtacaat 240
gagaagttca aaggcaaggc cacacagact tcagacaaat cctccagcac agcctacatg 300
gagctcagca gcctgacctc tgaggactct gcggtctatt actgtgcaag atgggggtac 360
tacggtagtc ccttatacta ctttgactac tggggccaag gcaccactct cacagtctcc 420
tcagccaaaa caacagcccc atcggtctat ccactggccc ctgtgtgtgg agatacaact 480
ggctcctcgg tgactctagg atgcctggtc aagggttatt tccctgagcc agtgaccttg 540
acctggaact ctggatccct gtccagtggt gtgcacacct tcccagctgt cctgcagtct 600
gacctctaca ccctcagcag ctcagtgact gtaacctcga gcacctggcc cagccagtcc 660
atcacctgca atgtggccca cccggcaagc agcaccaagg tggacaagaa aattgagccc 720
agagggccca caatcaagcc ctgtcctcca tgcaaatgcc cagcacctaa cctcttgggt 780
ggaccatccg tcttcatctt ccctccaaag atcaaggatg tactcatgat ctccctgagc 840
cccatagtca catgtgtggt ggtggatgtg agcgaggatg acccagatgt ccagatcagc 900
tggtttgtga acaacgtgga agtacacaca gctcagacac aaacccatag agaggattac 960
aacagtactc tccgggtggt cagtgccctc cccatccagc accaggactg gatgagtggc 1020
aaggagttca aatgcaaggt caacaacaaa gacctcccag cgcccatcga gagaaccatc 1080
tcaaaaccca aagggtcagt aagagctcca caggtatatg tcttgcctcc accagaagaa 1140
gagatgacta agaaacaggt cactctgacc tgcatggtca cagacttcat gcctgaagac 1200
atttacgtgg agtggaccaa caacgggaaa acagagctaa actacaagaa cactgaacca 1260
gtcctggact ctgatggttc ttacttcatg tacagcaagc tgagagtgga aaagaagaac 1320
tgggtggaaa gaaatagcta ctcctgttca gtggtccacg agggtctgca caatcaccac 1380
acgactaaga gcttctcccg gactccgggt aaa 1413
<210> 51
<211> 471
<212> PRT
<213> Mus musculus
<400> 51
Met Glu Trp Ser Trp Ile Phe Leu Phe Leu Leu Ser Gly Thr Ala Gly
1 5 10 15
Val His Ser Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys
20 25 30
Pro Gly Ala Ser Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe
35 40 45
Thr Asn Tyr Val Met His Trp Val Lys Gln Lys Pro Gly Gln Gly Leu
50 55 60
Glu Trp Ile Gly Tyr Ile Asn Pro Tyr Asn Asp Asp Val Lys Tyr Asn
65 70 75 80
Glu Lys Phe Lys Gly Lys Ala Thr Gln Thr Ser Asp Lys Ser Ser Ser
85 90 95
Thr Ala Tyr Met Glu Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Trp Gly Tyr Tyr Gly Ser Pro Leu Tyr Tyr Phe
115 120 125
Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser Ala Lys Thr
130 135 140
Thr Ala Pro Ser Val Tyr Pro Leu Ala Pro Val Cys Gly Asp Thr Thr
145 150 155 160
Gly Ser Ser Val Thr Leu Gly Cys Leu Val Lys Gly Tyr Phe Pro Glu
165 170 175
Pro Val Thr Leu Thr Trp Asn Ser Gly Ser Leu Ser Ser Gly Val His
180 185 190
Thr Phe Pro Ala Val Leu Gln Ser Asp Leu Tyr Thr Leu Ser Ser Ser
195 200 205
Val Thr Val Thr Ser Ser Thr Trp Pro Ser Gln Ser Ile Thr Cys Asn
210 215 220
Val Ala His Pro Ala Ser Ser Thr Lys Val Asp Lys Lys Ile Glu Pro
225 230 235 240
Arg Gly Pro Thr Ile Lys Pro Cys Pro Pro Cys Lys Cys Pro Ala Pro
245 250 255
Asn Leu Leu Gly Gly Pro Ser Val Phe Ile Phe Pro Pro Lys Ile Lys
260 265 270
Asp Val Leu Met Ile Ser Leu Ser Pro Ile Val Thr Cys Val Val Val
275 280 285
Asp Val Ser Glu Asp Asp Pro Asp Val Gln Ile Ser Trp Phe Val Asn
290 295 300
Asn Val Glu Val His Thr Ala Gln Thr Gln Thr His Arg Glu Asp Tyr
305 310 315 320
Asn Ser Thr Leu Arg Val Val Ser Ala Leu Pro Ile Gln His Gln Asp
325 330 335
Trp Met Ser Gly Lys Glu Phe Lys Cys Lys Val Asn Asn Lys Asp Leu
340 345 350
Pro Ala Pro Ile Glu Arg Thr Ile Ser Lys Pro Lys Gly Ser Val Arg
355 360 365
Ala Pro Gln Val Tyr Val Leu Pro Pro Pro Glu Glu Glu Met Thr Lys
370 375 380
Lys Gln Val Thr Leu Thr Cys Met Val Thr Asp Phe Met Pro Glu Asp
385 390 395 400
Ile Tyr Val Glu Trp Thr Asn Asn Gly Lys Thr Glu Leu Asn Tyr Lys
405 410 415
Asn Thr Glu Pro Val Leu Asp Ser Asp Gly Ser Tyr Phe Met Tyr Ser
420 425 430
Lys Leu Arg Val Glu Lys Lys Asn Trp Val Glu Arg Asn Ser Tyr Ser
435 440 445
Cys Ser Val Val His Glu Gly Leu His Asn His His Thr Thr Lys Ser
450 455 460
Phe Ser Arg Thr Pro Gly Lys
465 470
<210> 52
<211> 705
<212> DNA
<213> Mus musculus
<400> 52
atggattttc tggtgcagat tttcagcttc ctgctaatca gtgcttcagt cataatgtcc 60
agaggacaaa ttgttctctc ccagtctcca acaatcctgt ctgcatctcc aggggagaag 120
gtcacaatga cttgcagggc cagctcaaga ctaatttaca tgcattggta tcagcagaag 180
ccaggatcct cccccaaacc ctggatttat gccacatcca acctggcttc tggagtccct 240
gctcgcttca gtggcagtgg gtctgggacc tcttactctc tcacaatcag cagagtggag 300
gctgaagatg ctgccactta ttactgccag cagtggaata gtaacccacc cacgttcggt 360
actgggacca agctggagct gaaacgggct gatgctgcac caactgtatc catcttccca 420
ccatccagtg agcagttaac atctggaggt gcctcagtcg tgtgcttctt gaacaacttc 480
taccccaaag acatcaatgt caagtggaag attgatggca gtgaacgaca aaatggcgtc 540
ctgaacagtt ggactgatca ggacagcaaa gacagcacct acagcatgag cagcaccctc 600
acgttgacca aggacgagta tgaacgacat aacagctata cctgtgaggc cactcacaag 660
acatcaactt cacccattgt caagagcttc aacaggaatg agtgt 705
<210> 53
<211> 235
<212> PRT
<213> Mus musculus
<400> 53
Met Asp Phe Leu Val Gln Ile Phe Ser Phe Leu Leu Ile Ser Ala Ser
1 5 10 15
Val Ile Met Ser Arg Gly Gln Ile Val Leu Ser Gln Ser Pro Thr Ile
20 25 30
Leu Ser Ala Ser Pro Gly Glu Lys Val Thr Met Thr Cys Arg Ala Ser
35 40 45
Ser Arg Leu Ile Tyr Met His Trp Tyr Gln Gln Lys Pro Gly Ser Ser
50 55 60
Pro Lys Pro Trp Ile Tyr Ala Thr Ser Asn Leu Ala Ser Gly Val Pro
65 70 75 80
Ala Arg Phe Ser Gly Ser Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile
85 90 95
Ser Arg Val Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp
100 105 110
Asn Ser Asn Pro Pro Thr Phe Gly Thr Gly Thr Lys Leu Glu Leu Lys
115 120 125
Arg Ala Asp Ala Ala Pro Thr Val Ser Ile Phe Pro Pro Ser Ser Glu
130 135 140
Gln Leu Thr Ser Gly Gly Ala Ser Val Val Cys Phe Leu Asn Asn Phe
145 150 155 160
Tyr Pro Lys Asp Ile Asn Val Lys Trp Lys Ile Asp Gly Ser Glu Arg
165 170 175
Gln Asn Gly Val Leu Asn Ser Trp Thr Asp Gln Asp Ser Lys Asp Ser
180 185 190
Thr Tyr Ser Met Ser Ser Thr Leu Thr Leu Thr Lys Asp Glu Tyr Glu
195 200 205
Arg His Asn Ser Tyr Thr Cys Glu Ala Thr His Lys Thr Ser Thr Ser
210 215 220
Pro Ile Val Lys Ser Phe Asn Arg Asn Glu Cys
225 230 235
<210> 54
<211> 28
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 54
ccacgcgccc tgtagcggcg cattaagc 28
<210> 55
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 55
aaacccggga gctttttgca aaagcctagg 30
<210> 56
<211> 1704
<212> DNA
<213> Artificial Sequence
<220>
<223> human kappa chain secretion signal, human kappa chain constant
region and human poly A additional signal
<400> 56
ggtaccaccc aagctggcta ggtaagcttg ctagcgccac catggtgctg cagacccagg 60
tgttcatctc cctgctgctg tggatctccg gcgcatatgg cgatatcgtg atgattaaac 120
gtacggtggc cgccccctcc gtgttcatct tccccccctc cgacgagcag ctgaagtccg 180
gcaccgcctc cgtggtgtgc ctgctgaata acttctaccc cagagaggcc aaggtgcagt 240
ggaaggtgga caacgccctg cagtccggga actcccagga gagcgtgacc gagcaggaca 300
gcaaggacag cacctacagc ctgagcagca ccctgaccct gagcaaagcc gactacgaga 360
agcacaaggt gtacgcctgc gaggtgaccc accagggcct gagctccccc gtcaccaaga 420
gcttcaacag gggggagtgt taggggcccg tttaaacggg tggcatccct gtgacccctc 480
cccagtgcct ctcctggccc tggaagttgc cactccagtg cccaccagcc ttgtcctaat 540
aaaattaagt tgcatcattt tgtctgacta ggtgtccttc tataatatta tggggtggag 600
gggggtggta tggagcaagg ggcaagttgg gaagacaacc tgtagggcct gcggggtcta 660
ttgggaacca agctggagtg cagtggcaca atcttggctc actgcaatct ccgcctcctg 720
ggttcaagcg attctcctgc ctcagcctcc cgagttgttg ggattccagg catgcatgac 780
caggctcacc taatttttgt ttttttggta gagacggggt ttcaccatat tggccaggct 840
ggtctccaac tcctaatctc aggtgatcta cccaccttgg cctcccaaat tgctgggatt 900
acaggcgtga accactgctc cacgcgccct gtagcggcgc attaagcgcg gcgggtgtgg 960
tggttacgcg cagcgtgacc gctacacttg ccagcgccct agcgcccgct cctttcgctt 1020
tcttcccttc ctttctcgcc acgttcgccg gctttccccg tcaagctcta aatcgggggc 1080
tccctttagg gttccgattt agtgctttac ggcacctcga ccccaaaaaa cttgattagg 1140
gtgatggttc acgtagtggg ccatcgccct gatagacggt ttttcgccct ttgacgttgg 1200
agtccacgtt ctttaatagt ggactcttgt tccaaactgg aacaacactc aaccctatct 1260
cggtctattc ttttgattta taagggattt tgccgatttc ggcctattgg ttaaaaaatg 1320
agctgattta acaaaaattt aacgcgaatt aattctgtgg aatgtgtgtc agttagggtg 1380
tggaaagtcc ccaggctccc cagcaggcag aagtatgcaa agcatgcatc tcaattagtc 1440
agcaaccagg tgtggaaagt ccccaggctc cccagcaggc agaagtatgc aaagcatgca 1500
tctcaattag tcagcaacca tagtcccgcc cctaactccg cccatcccgc ccctaactcc 1560
gcccagttcc gcccattctc cgccccatgg ctgactaatt ttttttattt atgcagaggc 1620
cgaggccgcc tctgcctctg agctattcca gaagtagtga ggaggctttt ttggaggcct 1680
aggcttttgc aaaaagctcc cggg 1704
<210> 57
<211> 1120
<212> DNA
<213> Artificial Sequence
<220>
<223> human IgG1 signal sequence and constant region
<400> 57
tgctagcgcc accatgaaac acctgtggtt cttcctcctg ctggtggcag ctcccagatg 60
ggtgctgagc caggtgcaat tgtgcaggcg gttagctcag cctccaccaa gggcccaagc 120
gtcttccccc tggcaccctc ctccaagagc acctctggcg gcacagccgc cctgggctgc 180
ctggtcaagg actacttccc cgaacccgtg accgtgagct ggaactcagg cgccctgacc 240
agcggcgtgc acaccttccc cgctgtcctg cagtcctcag gactctactc cctcagcagc 300
gtggtgaccg tgccctccag cagcttgggc acccagacct acatctgcaa cgtgaatcac 360
aagcccagca acaccaaggt ggacaagaga gttgagccca aatcttgtga caaaactcac 420
acatgcccac cctgcccagc acctgaactc ctggggggac cctcagtctt cctcttcccc 480
ccaaaaccca aggacaccct catgatctcc cggacccctg aggtcacatg cgtggtggtg 540
gacgtgagcc acgaagaccc tgaggtcaag ttcaactggt acgtggacgg cgtggaggtg 600
cataatgcca agacaaagcc ccgggaggag cagtacaaca gcacgtaccg ggtggtcagc 660
gtcctcaccg tcctgcacca ggactggctg aatggcaagg agtacaagtg caaggtctcc 720
aacaaagccc tcccagcccc catcgagaaa accatctcca aagccaaagg ccagccccgg 780
gaaccacagg tgtacaccct gcccccatcc cgggaggaga tgaccaagaa ccaggtcagc 840
ctgacctgcc tggtcaaagg cttctatccc agcgacatcg ccgtggagtg ggagagcaat 900
ggccagcccg agaacaacta caagaccacc cctcccgtgc tggactccga cggctccttc 960
ttcctctaca gcaagctcac cgtggacaag agcaggtggc agcagggcaa cgtcttctca 1020
tgctccgtga tgcatgaggc tctgcacaac cactacaccc agaagagcct ctccctgtct 1080
cccggcaaat gagatatcgg gcccgtttaa acgggtggca 1120
<210> 58
<211> 699
<212> DNA
<213> Artificial Sequence
<220>
<223> Light chain of chimeric M30
<400> 58
atggtgctgc agacccaggt gttcatctcc ctgctgctgt ggatctccgg cgcatatggc 60
caaattgttc tctcccagtc tccaacaatc ctgtctgcat ctccagggga gaaggtcaca 120
atgacttgca gggccagctc aagactaatt tacatgcatt ggtatcagca gaagccagga 180
tcctccccca aaccctggat ttatgccaca tccaacctgg cttctggagt ccctgctcgc 240
ttcagtggca gtgggtctgg gacctcttac tctctcacaa tcagcagagt ggaggctgaa 300
gatgctgcca cttattactg ccagcagtgg aatagtaacc cacccacgtt cggtactggg 360
accaagctgg agctgaaacg tacggtggcc gccccctccg tgttcatctt ccccccctcc 420
gacgagcagc tgaagtccgg caccgcctcc gtggtgtgcc tgctgaataa cttctacccc 480
agagaggcca aggtgcagtg gaaggtggac aacgccctgc agtccgggaa ctcccaggag 540
agcgtgaccg agcaggacag caaggacagc acctacagcc tgagcagcac cctgaccctg 600
agcaaagccg actacgagaa gcacaaggtg tacgcctgcg aggtgaccca ccagggcctg 660
agctcccccg tcaccaagag cttcaacagg ggggagtgt 699
<210> 59
<211> 233
<212> PRT
<213> Artificial Sequence
<220>
<223> Light chain of chimeric M30
<400> 59
Met Val Leu Gln Thr Gln Val Phe Ile Ser Leu Leu Leu Trp Ile Ser
1 5 10 15
Gly Ala Tyr Gly Gln Ile Val Leu Ser Gln Ser Pro Thr Ile Leu Ser
20 25 30
Ala Ser Pro Gly Glu Lys Val Thr Met Thr Cys Arg Ala Ser Ser Arg
35 40 45
Leu Ile Tyr Met His Trp Tyr Gln Gln Lys Pro Gly Ser Ser Pro Lys
50 55 60
Pro Trp Ile Tyr Ala Thr Ser Asn Leu Ala Ser Gly Val Pro Ala Arg
65 70 75 80
Phe Ser Gly Ser Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Arg
85 90 95
Val Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Asn Ser
100 105 110
Asn Pro Pro Thr Phe Gly Thr Gly Thr Lys Leu Glu Leu Lys Arg Thr
115 120 125
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
130 135 140
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
145 150 155 160
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
165 170 175
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
180 185 190
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
195 200 205
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
210 215 220
Thr Lys Ser Phe Asn Arg Gly Glu Cys
225 230
<210> 60
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 60
aaacatatgg ccaaattgtt ctctcccagt ctccaacaat cc 42
<210> 61
<211> 37
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 61
aaacgtacgt ttcagctcca gcttggtccc agtaccg 37
<210> 62
<211> 1413
<212> DNA
<213> Artificial Sequence
<220>
<223> Heavy chain of chimeric M30
<400> 62
atgaaacacc tgtggttctt cctcctgctg gtggcagctc ccagatgggt gctgagcgag 60
gtccagctgc agcagtctgg acctgagctg gtaaagcctg gggcttcagt gaagatgtcc 120
tgcaaggctt ctggatacac attcactaac tatgttatgc actgggtgaa gcagaagcct 180
gggcagggcc ttgagtggat tggatatatt aatccttaca atgatgatgt taagtacaat 240
gagaagttca aaggcaaggc cacacagact tcagacaaat cctccagcac agcctacatg 300
gaactcagca gcctgacctc tgaggactct gcggtctatt actgtgcaag atgggggtac 360
tacggtagtc ccttatacta ctttgactac tggggccaag gcaccactct cacagtcagc 420
tcagcctcca ccaagggccc aagcgtcttc cccctggcac cctcctccaa gagcacctct 480
ggcggcacag ccgccctggg ctgcctggtc aaggactact tccccgaacc cgtgaccgtg 540
agctggaact caggcgccct gaccagcggc gtgcacacct tccccgctgt cctgcagtcc 600
tcaggactct actccctcag cagcgtggtg accgtgccct ccagcagctt gggcacccag 660
acctacatct gcaacgtgaa tcacaagccc agcaacacca aggtggacaa gagagttgag 720
cccaaatctt gtgacaaaac tcacacatgc ccaccctgcc cagcacctga actcctgggg 780
ggaccctcag tcttcctctt ccccccaaaa cccaaggaca ccctcatgat ctcccggacc 840
cctgaggtca catgcgtggt ggtggacgtg agccacgaag accctgaggt caagttcaac 900
tggtacgtgg acggcgtgga ggtgcataat gccaagacaa agccccggga ggagcagtac 960
aacagcacgt accgggtggt cagcgtcctc accgtcctgc accaggactg gctgaatggc 1020
aaggagtaca agtgcaaggt ctccaacaaa gccctcccag cccccatcga gaaaaccatc 1080
tccaaagcca aaggccagcc ccgggaacca caggtgtaca ccctgccccc atcccgggag 1140
gagatgacca agaaccaggt cagcctgacc tgcctggtca aaggcttcta tcccagcgac 1200
atcgccgtgg agtgggagag caatggccag cccgagaaca actacaagac cacccctccc 1260
gtgctggact ccgacggctc cttcttcctc tacagcaagc tcaccgtgga caagagcagg 1320
tggcagcagg gcaacgtctt ctcatgctcc gtgatgcatg aggctctgca caaccactac 1380
acccagaaga gcctctccct gtctcccggc aaa 1413
<210> 63
<211> 471
<212> PRT
<213> Artificial Sequence
<220>
<223> Heavy chain of chimeric M30
<400> 63
Met Lys His Leu Trp Phe Phe Leu Leu Leu Val Ala Ala Pro Arg Trp
1 5 10 15
Val Leu Ser Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys
20 25 30
Pro Gly Ala Ser Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe
35 40 45
Thr Asn Tyr Val Met His Trp Val Lys Gln Lys Pro Gly Gln Gly Leu
50 55 60
Glu Trp Ile Gly Tyr Ile Asn Pro Tyr Asn Asp Asp Val Lys Tyr Asn
65 70 75 80
Glu Lys Phe Lys Gly Lys Ala Thr Gln Thr Ser Asp Lys Ser Ser Ser
85 90 95
Thr Ala Tyr Met Glu Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Trp Gly Tyr Tyr Gly Ser Pro Leu Tyr Tyr Phe
115 120 125
Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser Ala Ser Thr
130 135 140
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
145 150 155 160
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
165 170 175
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
180 185 190
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
195 200 205
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
210 215 220
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu
225 230 235 240
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
245 250 255
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
260 265 270
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
275 280 285
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
290 295 300
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
305 310 315 320
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
325 330 335
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
340 345 350
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
355 360 365
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys
370 375 380
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
385 390 395 400
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
405 410 415
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
420 425 430
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
435 440 445
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
450 455 460
Leu Ser Leu Ser Pro Gly Lys
465 470
<210> 64
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 64
aaagctgagc gaggtccagc tgcagcagtc tggacctgag 40
<210> 65
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 65
gaggtcaggc tgctgagttc catgtaggct gtgctg 36
<210> 66
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 66
cagcacagcc tacatggaac tcagcagcct gacctc 36
<210> 67
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 67
aaagctgagc tgactgtgag agtggtgcct tggccccag 39
<210> 68
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 68
aaagctgagc gaggtccagc tgcagcagtc tggacctgag 40
<210> 69
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> PCR primer
<400> 69
aaagctgagc tgactgtgag agtggtgcct tggccccag 39
<210> 70
<211> 699
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized light chain of M30
<400> 70
atggtgctgc agacccaggt gttcatctcc ctgctgctgt ggatctccgg cgcatatggc 60
gagatcgtgc tgacccagag ccccgccacc ctgtctctga gccctggcga gagagccacc 120
ctgagctgca gagccagcag ccgcctgatc tacatgcact ggtatcagca gaagcccggc 180
caggccccca gactgctgat ctacgccacc agcaacctgg ccagcggcat ccccgccaga 240
ttttctggca gcggcagcgg caccgacttc accctgacca tctctcggct ggaacccgag 300
gacttcgccg tgtactactg ccagcagtgg aacagcaacc cccccacctt cggccagggc 360
accaaggtcg aaatcaagcg tacggtggcc gccccctccg tgttcatctt ccccccctcc 420
gacgagcagc tgaagtccgg caccgcctcc gtggtgtgcc tgctgaataa cttctacccc 480
agagaggcca aggtgcagtg gaaggtggac aacgccctgc agtccgggaa ctcccaggag 540
agcgtgaccg agcaggacag caaggacagc acctacagcc tgagcagcac cctgaccctg 600
agcaaagccg actacgagaa gcacaaggtg tacgcctgcg aggtgaccca ccagggcctg 660
agctcccccg tcaccaagag cttcaacagg ggggagtgt 699
<210> 71
<211> 233
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized light chain of M30
<400> 71
Met Val Leu Gln Thr Gln Val Phe Ile Ser Leu Leu Leu Trp Ile Ser
1 5 10 15
Gly Ala Tyr Gly Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser
20 25 30
Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Ser Arg
35 40 45
Leu Ile Tyr Met His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg
50 55 60
Leu Leu Ile Tyr Ala Thr Ser Asn Leu Ala Ser Gly Ile Pro Ala Arg
65 70 75 80
Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg
85 90 95
Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Trp Asn Ser
100 105 110
Asn Pro Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr
115 120 125
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
130 135 140
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
145 150 155 160
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
165 170 175
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
180 185 190
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
195 200 205
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
210 215 220
Thr Lys Ser Phe Asn Arg Gly Glu Cys
225 230
<210> 72
<211> 699
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized light chain of M30
<400> 72
atggtgctgc agacccaggt gttcatctcc ctgctgctgt ggatctccgg cgcatatggc 60
gagatcgtgc tgacccagag ccccgccacc ctgtctctga gccctggcga gagagccacc 120
ctgagctgca gagccagcag caggctgatc tacatgcact ggtatcagca gaagcccggc 180
caggccccca gactgtggat ctacgccacc agcaacctgg ccagcggcat ccccgccaga 240
ttttctggca gcggcagcgg caccgactac accctgacca tcagccgcct ggaacccgag 300
gacttcgccg tgtactactg ccagcagtgg aacagcaacc cccccacctt cggccagggc 360
accaaggtcg aaatcaagcg tacggtggcc gccccctccg tgttcatctt ccccccctcc 420
gacgagcagc tgaagtccgg caccgcctcc gtggtgtgcc tgctgaataa cttctacccc 480
agagaggcca aggtgcagtg gaaggtggac aacgccctgc agtccgggaa ctcccaggag 540
agcgtgaccg agcaggacag caaggacagc acctacagcc tgagcagcac cctgaccctg 600
agcaaagccg actacgagaa gcacaaggtg tacgcctgcg aggtgaccca ccagggcctg 660
agctcccccg tcaccaagag cttcaacagg ggggagtgt 699
<210> 73
<211> 233
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized light chain of M30
<400> 73
Met Val Leu Gln Thr Gln Val Phe Ile Ser Leu Leu Leu Trp Ile Ser
1 5 10 15
Gly Ala Tyr Gly Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser
20 25 30
Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Ser Arg
35 40 45
Leu Ile Tyr Met His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg
50 55 60
Leu Trp Ile Tyr Ala Thr Ser Asn Leu Ala Ser Gly Ile Pro Ala Arg
65 70 75 80
Phe Ser Gly Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Arg
85 90 95
Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Trp Asn Ser
100 105 110
Asn Pro Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr
115 120 125
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
130 135 140
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
145 150 155 160
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
165 170 175
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
180 185 190
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
195 200 205
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
210 215 220
Thr Lys Ser Phe Asn Arg Gly Glu Cys
225 230
<210> 74
<211> 699
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized light chain of M30
<400> 74
atggtgctgc agacccaggt gttcatctcc ctgctgctgt ggatctccgg cgcatatggc 60
cagatcgtgc tgtcccagag ccccgccacc ctgtctctga gccctggcga gagagccacc 120
ctgacctgca gagccagcag caggctgatc tacatgcact ggtatcagca gaagcccggc 180
agcgccccca agctgtggat ctacgccacc agcaacctgg ccagcggcat ccccgccaga 240
ttttctggca gcggcagcgg caccagctac accctgacca tctcccgcct ggaacccgag 300
gacttcgccg tgtactactg ccagcagtgg aacagcaacc cccccacctt cggccagggc 360
accaaggtcg aaatcaagcg tacggtggcc gccccctccg tgttcatctt ccccccctcc 420
gacgagcagc tgaagtccgg caccgcctcc gtggtgtgcc tgctgaataa cttctacccc 480
agagaggcca aggtgcagtg gaaggtggac aacgccctgc agtccgggaa ctcccaggag 540
agcgtgaccg agcaggacag caaggacagc acctacagcc tgagcagcac cctgaccctg 600
agcaaagccg actacgagaa gcacaaggtg tacgcctgcg aggtgaccca ccagggcctg 660
agctcccccg tcaccaagag cttcaacagg ggggagtgt 699
<210> 75
<211> 233
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized light chain of M30
<400> 75
Met Val Leu Gln Thr Gln Val Phe Ile Ser Leu Leu Leu Trp Ile Ser
1 5 10 15
Gly Ala Tyr Gly Gln Ile Val Leu Ser Gln Ser Pro Ala Thr Leu Ser
20 25 30
Leu Ser Pro Gly Glu Arg Ala Thr Leu Thr Cys Arg Ala Ser Ser Arg
35 40 45
Leu Ile Tyr Met His Trp Tyr Gln Gln Lys Pro Gly Ser Ala Pro Lys
50 55 60
Leu Trp Ile Tyr Ala Thr Ser Asn Leu Ala Ser Gly Ile Pro Ala Arg
65 70 75 80
Phe Ser Gly Ser Gly Ser Gly Thr Ser Tyr Thr Leu Thr Ile Ser Arg
85 90 95
Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Trp Asn Ser
100 105 110
Asn Pro Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr
115 120 125
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
130 135 140
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
145 150 155 160
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
165 170 175
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
180 185 190
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
195 200 205
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
210 215 220
Thr Lys Ser Phe Asn Arg Gly Glu Cys
225 230
<210> 76
<211> 699
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized light chain of M30
<400> 76
atggtgctgc agacccaggt gttcatctcc ctgctgctgt ggatctccgg cgcatatggc 60
gagatcgtgc tgacccagag ccccgccacc ctgtctctga gccctggcga gagagccacc 120
ctgagctgca gagccagcag ccgcctgatc tacatgcact ggtatcagca gaagcccggc 180
caggccccca gacctctgat ctacgccacc agcaacctgg ccagcggcat ccccgccaga 240
ttttctggca gcggcagcgg caccgacttc accctgacca tcagcagcct ggaacccgag 300
gacttcgccg tgtactactg ccagcagtgg aacagcaacc cccccacctt cggccagggc 360
accaaggtcg aaatcaagcg tacggtggcc gccccctccg tgttcatctt ccccccctcc 420
gacgagcagc tgaagtccgg caccgcctcc gtggtgtgcc tgctgaataa cttctacccc 480
agagaggcca aggtgcagtg gaaggtggac aacgccctgc agtccgggaa ctcccaggag 540
agcgtgaccg agcaggacag caaggacagc acctacagcc tgagcagcac cctgaccctg 600
agcaaagccg actacgagaa gcacaaggtg tacgcctgcg aggtgaccca ccagggcctg 660
agctcccccg tcaccaagag cttcaacagg ggggagtgt 699
<210> 77
<211> 233
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized light chain of M30
<400> 77
Met Val Leu Gln Thr Gln Val Phe Ile Ser Leu Leu Leu Trp Ile Ser
1 5 10 15
Gly Ala Tyr Gly Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser
20 25 30
Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Ser Arg
35 40 45
Leu Ile Tyr Met His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg
50 55 60
Pro Leu Ile Tyr Ala Thr Ser Asn Leu Ala Ser Gly Ile Pro Ala Arg
65 70 75 80
Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser
85 90 95
Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Trp Asn Ser
100 105 110
Asn Pro Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr
115 120 125
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
130 135 140
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
145 150 155 160
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
165 170 175
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
180 185 190
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
195 200 205
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
210 215 220
Thr Lys Ser Phe Asn Arg Gly Glu Cys
225 230
<210> 78
<211> 699
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized light chain of M30
<400> 78
atggtgctgc agacccaggt gttcatctcc ctgctgctgt ggatctccgg cgcatatggc 60
cagatcgtgc tgtcccagag ccccgccacc ctgtctctga gccctggcga gagagccacc 120
ctgacctgca gagccagcag caggctgatc tacatgcact ggtatcagca gaagcccggc 180
agcgccccca agccttggat ctacgccacc agcaacctgg ccagcggcat ccccgccaga 240
ttttctggca gcggcagcgg caccagctac accctgacca tctcccgcct ggaacccgag 300
gacttcgccg tgtactactg ccagcagtgg aacagcaacc cccccacctt cggccagggc 360
accaaggtcg aaatcaagcg tacggtggcc gccccctccg tgttcatctt ccccccctcc 420
gacgagcagc tgaagtccgg caccgcctcc gtggtgtgcc tgctgaataa cttctacccc 480
agagaggcca aggtgcagtg gaaggtggac aacgccctgc agtccgggaa ctcccaggag 540
agcgtgaccg agcaggacag caaggacagc acctacagcc tgagcagcac cctgaccctg 600
agcaaagccg actacgagaa gcacaaggtg tacgcctgcg aggtgaccca ccagggcctg 660
agctcccccg tcaccaagag cttcaacagg ggggagtgt 699
<210> 79
<211> 233
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized light chain of M30
<400> 79
Met Val Leu Gln Thr Gln Val Phe Ile Ser Leu Leu Leu Trp Ile Ser
1 5 10 15
Gly Ala Tyr Gly Gln Ile Val Leu Ser Gln Ser Pro Ala Thr Leu Ser
20 25 30
Leu Ser Pro Gly Glu Arg Ala Thr Leu Thr Cys Arg Ala Ser Ser Arg
35 40 45
Leu Ile Tyr Met His Trp Tyr Gln Gln Lys Pro Gly Ser Ala Pro Lys
50 55 60
Pro Trp Ile Tyr Ala Thr Ser Asn Leu Ala Ser Gly Ile Pro Ala Arg
65 70 75 80
Phe Ser Gly Ser Gly Ser Gly Thr Ser Tyr Thr Leu Thr Ile Ser Arg
85 90 95
Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Trp Asn Ser
100 105 110
Asn Pro Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr
115 120 125
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
130 135 140
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
145 150 155 160
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
165 170 175
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
180 185 190
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
195 200 205
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
210 215 220
Thr Lys Ser Phe Asn Arg Gly Glu Cys
225 230
<210> 80
<211> 699
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized light chain of M30
<400> 80
atggtgctgc agacccaggt gttcatctcc ctgctgctgt ggatctccgg cgcatatggc 60
gagatcgtgc tgacccagag ccccgccacc ctgtctctga gccctggcga gagagccacc 120
ctgagctgca gagccagcag ccgcctgatc tacatgcact ggtatcagca gaagcccggc 180
caggccccca gacctctgat ctacgccacc agcaacctgg ccagcggcat ccccgccaga 240
ttttctggca gcggcagcgg caccgacttc accctgacca tcagccgcct ggaacccgag 300
gacttcgccg tgtactactg ccagcagtgg aacagcaacc cccccacctt cggccagggc 360
accaaggtcg aaatcaagcg tacggtggcc gccccctccg tgttcatctt ccccccctcc 420
gacgagcagc tgaagtccgg caccgcctcc gtggtgtgcc tgctgaataa cttctacccc 480
agagaggcca aggtgcagtg gaaggtggac aacgccctgc agtccgggaa ctcccaggag 540
agcgtgaccg agcaggacag caaggacagc acctacagcc tgagcagcac cctgaccctg 600
agcaaagccg actacgagaa gcacaaggtg tacgcctgcg aggtgaccca ccagggcctg 660
agctcccccg tcaccaagag cttcaacagg ggggagtgt 699
<210> 81
<211> 233
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized light chain of M30
<400> 81
Met Val Leu Gln Thr Gln Val Phe Ile Ser Leu Leu Leu Trp Ile Ser
1 5 10 15
Gly Ala Tyr Gly Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser
20 25 30
Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Ser Arg
35 40 45
Leu Ile Tyr Met His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg
50 55 60
Pro Leu Ile Tyr Ala Thr Ser Asn Leu Ala Ser Gly Ile Pro Ala Arg
65 70 75 80
Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Arg
85 90 95
Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Trp Asn Ser
100 105 110
Asn Pro Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr
115 120 125
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
130 135 140
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
145 150 155 160
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
165 170 175
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
180 185 190
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
195 200 205
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
210 215 220
Thr Lys Ser Phe Asn Arg Gly Glu Cys
225 230
<210> 82
<211> 699
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized light chain of M30
<400> 82
atggtgctgc agacccaggt gttcatctcc ctgctgctgt ggatctccgg cgcatatggc 60
gagatcgtgc tgacccagag ccccgccacc ctgtctctga gccctggcga gagagccacc 120
ctgagctgca gagccagcag ccgcctgatc tacatgcact ggtatcagca gaagcccggc 180
caggccccca gacctctgat ctacgccacc agcaacctgg ccagcggcat ccccgccaga 240
ttttctggca gcggcagcgg caccgactac accctgacca tcagccgcct ggaacccgag 300
gacttcgccg tgtactactg ccagcagtgg aacagcaacc cccccacctt cggccagggc 360
accaaggtcg aaatcaagcg tacggtggcc gccccctccg tgttcatctt ccccccctcc 420
gacgagcagc tgaagtccgg caccgcctcc gtggtgtgcc tgctgaataa cttctacccc 480
agagaggcca aggtgcagtg gaaggtggac aacgccctgc agtccgggaa ctcccaggag 540
agcgtgaccg agcaggacag caaggacagc acctacagcc tgagcagcac cctgaccctg 600
agcaaagccg actacgagaa gcacaaggtg tacgcctgcg aggtgaccca ccagggcctg 660
agctcccccg tcaccaagag cttcaacagg ggggagtgt 699
<210> 83
<211> 233
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized light chain of M30
<400> 83
Met Val Leu Gln Thr Gln Val Phe Ile Ser Leu Leu Leu Trp Ile Ser
1 5 10 15
Gly Ala Tyr Gly Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser
20 25 30
Leu Ser Pro Gly Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Ser Arg
35 40 45
Leu Ile Tyr Met His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg
50 55 60
Pro Leu Ile Tyr Ala Thr Ser Asn Leu Ala Ser Gly Ile Pro Ala Arg
65 70 75 80
Phe Ser Gly Ser Gly Ser Gly Thr Asp Tyr Thr Leu Thr Ile Ser Arg
85 90 95
Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Trp Asn Ser
100 105 110
Asn Pro Pro Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr
115 120 125
Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu
130 135 140
Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro
145 150 155 160
Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly
165 170 175
Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr
180 185 190
Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His
195 200 205
Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val
210 215 220
Thr Lys Ser Phe Asn Arg Gly Glu Cys
225 230
<210> 84
<211> 1413
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized heavy chain of M30
<400> 84
atgaaacacc tgtggttctt cctcctgctg gtggcagctc ccagatgggt gctgagccag 60
gtgcagctgg tgcagtctgg cgccgaagtg aagaaacccg gcagcagcgt gaaggtgtcc 120
tgcaaggcca gcggctacac cttcaccaac tacgtgatgc actgggtgcg ccaggcccct 180
gggcagggac tggaatggat gggctacatc aacccctaca acgacgacgt gaagtacaac 240
gagaagttca agggcagagt gaccatcacc gccgacgaga gcaccagcac cgcctacatg 300
gaactgagca gcctgcggag cgaggacacc gccgtgtact actgcgccag atggggctac 360
tacggcagcc ccctgtacta cttcgactac tggggccagg gcaccctggt gacagtcagc 420
tcagcctcca ccaagggccc aagcgtcttc cccctggcac cctcctccaa gagcacctct 480
ggcggcacag ccgccctggg ctgcctggtc aaggactact tccccgaacc cgtgaccgtg 540
agctggaact caggcgccct gaccagcggc gtgcacacct tccccgctgt cctgcagtcc 600
tcaggactct actccctcag cagcgtggtg accgtgccct ccagcagctt gggcacccag 660
acctacatct gcaacgtgaa tcacaagccc agcaacacca aggtggacaa gagagttgag 720
cccaaatctt gtgacaaaac tcacacatgc ccaccctgcc cagcacctga actcctgggg 780
ggaccctcag tcttcctctt ccccccaaaa cccaaggaca ccctcatgat ctcccggacc 840
cctgaggtca catgcgtggt ggtggacgtg agccacgaag accctgaggt caagttcaac 900
tggtacgtgg acggcgtgga ggtgcataat gccaagacaa agccccggga ggagcagtac 960
aacagcacgt accgggtggt cagcgtcctc accgtcctgc accaggactg gctgaatggc 1020
aaggagtaca agtgcaaggt ctccaacaaa gccctcccag cccccatcga gaaaaccatc 1080
tccaaagcca aaggccagcc ccgggaacca caggtgtaca ccctgccccc atcccgggag 1140
gagatgacca agaaccaggt cagcctgacc tgcctggtca aaggcttcta tcccagcgac 1200
atcgccgtgg agtgggagag caatggccag cccgagaaca actacaagac cacccctccc 1260
gtgctggact ccgacggctc cttcttcctc tacagcaagc tcaccgtgga caagagcagg 1320
tggcagcagg gcaacgtctt ctcatgctcc gtgatgcatg aggctctgca caaccactac 1380
acccagaaga gcctctccct gtctcccggc aaa 1413
<210> 85
<211> 471
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized heavy chain of M30
<400> 85
Met Lys His Leu Trp Phe Phe Leu Leu Leu Val Ala Ala Pro Arg Trp
1 5 10 15
Val Leu Ser Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys
20 25 30
Pro Gly Ser Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe
35 40 45
Thr Asn Tyr Val Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu
50 55 60
Glu Trp Met Gly Tyr Ile Asn Pro Tyr Asn Asp Asp Val Lys Tyr Asn
65 70 75 80
Glu Lys Phe Lys Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser
85 90 95
Thr Ala Tyr Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Trp Gly Tyr Tyr Gly Ser Pro Leu Tyr Tyr Phe
115 120 125
Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr
130 135 140
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
145 150 155 160
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
165 170 175
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
180 185 190
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
195 200 205
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
210 215 220
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu
225 230 235 240
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
245 250 255
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
260 265 270
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
275 280 285
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
290 295 300
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
305 310 315 320
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
325 330 335
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
340 345 350
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
355 360 365
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys
370 375 380
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
385 390 395 400
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
405 410 415
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
420 425 430
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
435 440 445
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
450 455 460
Leu Ser Leu Ser Pro Gly Lys
465 470
<210> 86
<211> 1413
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized heavy chain of M30
<400> 86
atgaaacacc tgtggttctt cctcctgctg gtggcagctc ccagatgggt gctgagccag 60
gtgcagctgg tgcagtctgg cgccgaagtg aagaaacccg gcagcagcgt gaaggtgtcc 120
tgcaaggcca gcggctacac cttcaccaac tacgtgatgc actgggtgcg ccaggcccct 180
gggcagggac tggaatggat cggctacatc aacccctaca acgacgacgt gaagtacaac 240
gagaagttca agggcagagt gaccatcacc gccgacgaga gcaccagcac cgcctacatg 300
gaactgagca gcctgcggag cgaggacacc gccgtgtact actgcgccag atggggctac 360
tacggcagcc ccctgtacta cttcgactac tggggccagg gcaccctggt gacagtcagc 420
tcagcctcca ccaagggccc aagcgtcttc cccctggcac cctcctccaa gagcacctct 480
ggcggcacag ccgccctggg ctgcctggtc aaggactact tccccgaacc cgtgaccgtg 540
agctggaact caggcgccct gaccagcggc gtgcacacct tccccgctgt cctgcagtcc 600
tcaggactct actccctcag cagcgtggtg accgtgccct ccagcagctt gggcacccag 660
acctacatct gcaacgtgaa tcacaagccc agcaacacca aggtggacaa gagagttgag 720
cccaaatctt gtgacaaaac tcacacatgc ccaccctgcc cagcacctga actcctgggg 780
ggaccctcag tcttcctctt ccccccaaaa cccaaggaca ccctcatgat ctcccggacc 840
cctgaggtca catgcgtggt ggtggacgtg agccacgaag accctgaggt caagttcaac 900
tggtacgtgg acggcgtgga ggtgcataat gccaagacaa agccccggga ggagcagtac 960
aacagcacgt accgggtggt cagcgtcctc accgtcctgc accaggactg gctgaatggc 1020
aaggagtaca agtgcaaggt ctccaacaaa gccctcccag cccccatcga gaaaaccatc 1080
tccaaagcca aaggccagcc ccgggaacca caggtgtaca ccctgccccc atcccgggag 1140
gagatgacca agaaccaggt cagcctgacc tgcctggtca aaggcttcta tcccagcgac 1200
atcgccgtgg agtgggagag caatggccag cccgagaaca actacaagac cacccctccc 1260
gtgctggact ccgacggctc cttcttcctc tacagcaagc tcaccgtgga caagagcagg 1320
tggcagcagg gcaacgtctt ctcatgctcc gtgatgcatg aggctctgca caaccactac 1380
acccagaaga gcctctccct gtctcccggc aaa 1413
<210> 87
<211> 471
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized heavy chain of M30
<400> 87
Met Lys His Leu Trp Phe Phe Leu Leu Leu Val Ala Ala Pro Arg Trp
1 5 10 15
Val Leu Ser Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys
20 25 30
Pro Gly Ser Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe
35 40 45
Thr Asn Tyr Val Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu
50 55 60
Glu Trp Ile Gly Tyr Ile Asn Pro Tyr Asn Asp Asp Val Lys Tyr Asn
65 70 75 80
Glu Lys Phe Lys Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser
85 90 95
Thr Ala Tyr Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Trp Gly Tyr Tyr Gly Ser Pro Leu Tyr Tyr Phe
115 120 125
Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr
130 135 140
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
145 150 155 160
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
165 170 175
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
180 185 190
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
195 200 205
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
210 215 220
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu
225 230 235 240
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
245 250 255
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
260 265 270
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
275 280 285
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
290 295 300
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
305 310 315 320
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
325 330 335
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
340 345 350
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
355 360 365
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys
370 375 380
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
385 390 395 400
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
405 410 415
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
420 425 430
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
435 440 445
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
450 455 460
Leu Ser Leu Ser Pro Gly Lys
465 470
<210> 88
<211> 1413
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized heavy chain of M30
<400> 88
atgaaacacc tgtggttctt cctcctgctg gtggcagctc ccagatgggt gctgagcgag 60
gtgcagctgg tgcagtctgg cgccgaagtg aagaaacccg gcagcagcgt gaaggtgtcc 120
tgcaaggcca gcggctacac cttcaccaac tacgtgatgc actgggtgaa acaggcccct 180
gggcagggcc tggaatggat cggctacatc aacccctaca acgacgacgt gaagtacaac 240
gagaagttca agggcaaggc caccatcacc gccgacgaga gcaccagcac cgcctacatg 300
gaactgagca gcctgcggag cgaggacacc gccgtgtact actgcgccag atggggctac 360
tacggcagcc ccctgtacta cttcgactac tggggccagg gcaccctggt gacagtcagc 420
tcagcctcca ccaagggccc aagcgtcttc cccctggcac cctcctccaa gagcacctct 480
ggcggcacag ccgccctggg ctgcctggtc aaggactact tccccgaacc cgtgaccgtg 540
agctggaact caggcgccct gaccagcggc gtgcacacct tccccgctgt cctgcagtcc 600
tcaggactct actccctcag cagcgtggtg accgtgccct ccagcagctt gggcacccag 660
acctacatct gcaacgtgaa tcacaagccc agcaacacca aggtggacaa gagagttgag 720
cccaaatctt gtgacaaaac tcacacatgc ccaccctgcc cagcacctga actcctgggg 780
ggaccctcag tcttcctctt ccccccaaaa cccaaggaca ccctcatgat ctcccggacc 840
cctgaggtca catgcgtggt ggtggacgtg agccacgaag accctgaggt caagttcaac 900
tggtacgtgg acggcgtgga ggtgcataat gccaagacaa agccccggga ggagcagtac 960
aacagcacgt accgggtggt cagcgtcctc accgtcctgc accaggactg gctgaatggc 1020
aaggagtaca agtgcaaggt ctccaacaaa gccctcccag cccccatcga gaaaaccatc 1080
tccaaagcca aaggccagcc ccgggaacca caggtgtaca ccctgccccc atcccgggag 1140
gagatgacca agaaccaggt cagcctgacc tgcctggtca aaggcttcta tcccagcgac 1200
atcgccgtgg agtgggagag caatggccag cccgagaaca actacaagac cacccctccc 1260
gtgctggact ccgacggctc cttcttcctc tacagcaagc tcaccgtgga caagagcagg 1320
tggcagcagg gcaacgtctt ctcatgctcc gtgatgcatg aggctctgca caaccactac 1380
acccagaaga gcctctccct gtctcccggc aaa 1413
<210> 89
<211> 471
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized heavy chain of M30
<400> 89
Met Lys His Leu Trp Phe Phe Leu Leu Leu Val Ala Ala Pro Arg Trp
1 5 10 15
Val Leu Ser Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys
20 25 30
Pro Gly Ser Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe
35 40 45
Thr Asn Tyr Val Met His Trp Val Lys Gln Ala Pro Gly Gln Gly Leu
50 55 60
Glu Trp Ile Gly Tyr Ile Asn Pro Tyr Asn Asp Asp Val Lys Tyr Asn
65 70 75 80
Glu Lys Phe Lys Gly Lys Ala Thr Ile Thr Ala Asp Glu Ser Thr Ser
85 90 95
Thr Ala Tyr Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Trp Gly Tyr Tyr Gly Ser Pro Leu Tyr Tyr Phe
115 120 125
Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr
130 135 140
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
145 150 155 160
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
165 170 175
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
180 185 190
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
195 200 205
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
210 215 220
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu
225 230 235 240
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
245 250 255
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
260 265 270
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
275 280 285
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
290 295 300
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
305 310 315 320
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
325 330 335
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
340 345 350
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
355 360 365
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys
370 375 380
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
385 390 395 400
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
405 410 415
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
420 425 430
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
435 440 445
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
450 455 460
Leu Ser Leu Ser Pro Gly Lys
465 470
<210> 90
<211> 1413
<212> DNA
<213> Artificial Sequence
<220>
<223> Humanized heavy chain of M30
<400> 90
atgaaacacc tgtggttctt cctcctgctg gtggcagctc ccagatgggt gctgagcgag 60
gtgcagctgg tgcagtctgg cgccgaagtg aagaaacccg gcagcagcgt gaaggtgtcc 120
tgcaaggcca gcggctacac cttcaccaac tacgtgatgc actgggtcaa gcaggcccct 180
gggcagggcc tggaatggat cggctacatc aacccctaca acgacgacgt gaagtacaac 240
gagaagttca agggcaaggc cacccagacc agcgacaaga gcaccagcac cgcctacatg 300
gaactgagca gcctgcggag cgaggacacc gccgtgtact actgcgccag atggggctac 360
tacggcagcc ccctgtacta cttcgactac tggggccagg gcaccctggt caccgtcagc 420
tcagcctcca ccaagggccc aagcgtcttc cccctggcac cctcctccaa gagcacctct 480
ggcggcacag ccgccctggg ctgcctggtc aaggactact tccccgaacc cgtgaccgtg 540
agctggaact caggcgccct gaccagcggc gtgcacacct tccccgctgt cctgcagtcc 600
tcaggactct actccctcag cagcgtggtg accgtgccct ccagcagctt gggcacccag 660
acctacatct gcaacgtgaa tcacaagccc agcaacacca aggtggacaa gagagttgag 720
cccaaatctt gtgacaaaac tcacacatgc ccaccctgcc cagcacctga actcctgggg 780
ggaccctcag tcttcctctt ccccccaaaa cccaaggaca ccctcatgat ctcccggacc 840
cctgaggtca catgcgtggt ggtggacgtg agccacgaag accctgaggt caagttcaac 900
tggtacgtgg acggcgtgga ggtgcataat gccaagacaa agccccggga ggagcagtac 960
aacagcacgt accgggtggt cagcgtcctc accgtcctgc accaggactg gctgaatggc 1020
aaggagtaca agtgcaaggt ctccaacaaa gccctcccag cccccatcga gaaaaccatc 1080
tccaaagcca aaggccagcc ccgggaacca caggtgtaca ccctgccccc atcccgggag 1140
gagatgacca agaaccaggt cagcctgacc tgcctggtca aaggcttcta tcccagcgac 1200
atcgccgtgg agtgggagag caatggccag cccgagaaca actacaagac cacccctccc 1260
gtgctggact ccgacggctc cttcttcctc tacagcaagc tcaccgtgga caagagcagg 1320
tggcagcagg gcaacgtctt ctcatgctcc gtgatgcatg aggctctgca caaccactac 1380
acccagaaga gcctctccct gtctcccggc aaa 1413
<210> 91
<211> 471
<212> PRT
<213> Artificial Sequence
<220>
<223> Humanized heavy chain of M30
<400> 91
Met Lys His Leu Trp Phe Phe Leu Leu Leu Val Ala Ala Pro Arg Trp
1 5 10 15
Val Leu Ser Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys
20 25 30
Pro Gly Ser Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe
35 40 45
Thr Asn Tyr Val Met His Trp Val Lys Gln Ala Pro Gly Gln Gly Leu
50 55 60
Glu Trp Ile Gly Tyr Ile Asn Pro Tyr Asn Asp Asp Val Lys Tyr Asn
65 70 75 80
Glu Lys Phe Lys Gly Lys Ala Thr Gln Thr Ser Asp Lys Ser Thr Ser
85 90 95
Thr Ala Tyr Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val
100 105 110
Tyr Tyr Cys Ala Arg Trp Gly Tyr Tyr Gly Ser Pro Leu Tyr Tyr Phe
115 120 125
Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ser Thr
130 135 140
Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser
145 150 155 160
Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu
165 170 175
Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His
180 185 190
Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser
195 200 205
Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys
210 215 220
Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu
225 230 235 240
Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro
245 250 255
Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
260 265 270
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
275 280 285
Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp
290 295 300
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr
305 310 315 320
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
325 330 335
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu
340 345 350
Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
355 360 365
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu Met Thr Lys
370 375 380
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
385 390 395 400
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
405 410 415
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
420 425 430
Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser
435 440 445
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
450 455 460
Leu Ser Leu Ser Pro Gly Lys
465 470
<210> 92
<211> 5
<212> PRT
<213> Mus musculus
<400> 92
Asn Tyr Val Met His
1 5
<210> 93
<211> 17
<212> PRT
<213> Mus musculus
<400> 93
Tyr Ile Asn Pro Tyr Asn Asp Asp Val Lys Tyr Asn Glu Lys Phe Lys
1 5 10 15
Gly
<210> 94
<211> 13
<212> PRT
<213> Mus musculus
<400> 94
Trp Gly Tyr Tyr Gly Ser Pro Leu Tyr Tyr Phe Asp Tyr
1 5 10
<210> 95
<211> 10
<212> PRT
<213> Mus musculus
<400> 95
Arg Ala Ser Ser Arg Leu Ile Tyr Met His
1 5 10
<210> 96
<211> 7
<212> PRT
<213> Mus musculus
<400> 96
Ala Thr Ser Asn Leu Ala Ser
1 5
<210> 97
<211> 9
<212> PRT
<213> Mus musculus
<400> 97
Gln Gln Trp Asn Ser Asn Pro Pro Thr
1 5
Claims (41)
- 이하의 특성을 갖는 것을 특징으로 하는 항체 또는 당해 항체의 기능성 단편 :
(a) B7-H3 에 특이적으로 결합한다
(b) 항체 의존성 세포 매개 식작용 (ADCP) 활성을 갖는다
(c) in vivo 에서 항종양 활성을 갖는다 - 제 1 항에 있어서,
B7-H3 이 배열 번호 6 또는 10 에 기재된 아미노산 배열로 이루어지는 분자인 항체 또는 당해 항체의 기능성 단편. - 제 1 항 또는 제 2 항에 있어서,
B7-H3 의 도메인인 IgC1 및/또는 IgC2 에 결합하는 항체 또는 당해 항체의 기능성 단편. - 제 3 항에 있어서,
IgC1 이 배열 번호 6 에 있어서 아미노산 번호 140 내지 244 에 기재된 아미노산 배열로 이루어지는 도메인이고, IgC2 가 배열 번호 6 에 있어서 아미노산 번호 358 내지 456 에 기재된 아미노산 배열로 이루어지는 도메인인 항체 또는 당해 항체의 기능성 단편. - 제 1 항 내지 제 4 항 중 어느 한 항에 있어서,
B7-H3 에 대한 결합에 대해 M30 항체와 경합 저해 활성을 갖는 항체 또는 당해 항체의 기능성 단편. - 제 1 항 내지 제 5 항 중 어느 한 항에 있어서,
항체 의존성 세포 상해 (ADCC) 활성 및/또는 보체 의존성 세포 상해 (CDC) 활성을 갖는 항체 또는 당해 항체의 기능성 단편. - 제 1 항 내지 제 6 항 중 어느 한 항에 있어서,
종양이 암인 항체 또는 당해 항체의 기능성 단편. - 제 7 항에 있어서,
암이 폐암, 유방암, 전립선암, 췌장암, 대장암, 멜라노마, 간암, 난소암, 방광암, 위암, 식도암 또는 신장암인 항체 또는 당해 항체의 기능성 단편. - 제 1 항 내지 제 8 항 중 어느 한 항에 있어서,
중사슬에 있어서의 상보성 결정 영역으로서 배열 번호 92 에 기재된 아미노산 배열로 이루어지는 CDRH1, 배열 번호 93 에 기재된 아미노산 배열로 이루어지는 CDRH2 및 배열 번호 94 에 기재된 아미노산 배열로 이루어지는 CDRH3, 그리고 경사슬에 있어서의 상보성 결정 영역으로서 배열 번호 95 에 기재된 아미노산 배열로 이루어지는 CDRL1, 배열 번호 96 에 기재된 아미노산 배열로 이루어지는 CDRL2 및 배열 번호 97 에 기재된 아미노산 배열로 이루어지는 CDRL3 을 갖는 항체 또는 당해 항체의 기능성 단편. - 제 1 항 내지 제 9 항 중 어느 한 항에 있어서,
배열 번호 51 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 53 에 있어서 아미노산 번호 23 내지 130 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역을 갖는 항체 또는 당해 항체의 기능성 단편. - 제 1 항 내지 제 10 항 중 어느 한 항에 있어서,
정상 영역이 인간 유래 정상 영역인 항체 또는 당해 항체의 기능성 단편. - 제 11 항에 있어서,
배열 번호 63 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 59 에 기재된 아미노산 배열로 이루어지는 경사슬을 갖는 항체 또는 당해 항체의 기능성 단편. - 제 1 항 내지 제 12 항 중 어느 한 항에 있어서,
인간화되어 있는 항체 또는 당해 항체의 기능성 단편. - 제 13 항에 있어서,
(a) 배열 번호 85 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열, (b) 배열 번호 87 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열, (c) 배열 번호 89 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열, (d) 배열 번호 91 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열, (e) (a) 내지 (d) 의 배열에 대해 적어도 95 % 이상의 상동성을 갖는 아미노산 배열, 및 (f) (a) 내지 (d) 의 배열에 있어서 1 또는 수 개의 아미노산이 결실, 치환 또는 부가된 아미노산 배열로 이루어지는 군에서 선택된 아미노산 배열로 이루어지는 중사슬의 가변 영역, 그리고 (g) 배열 번호 71 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열, (h) 배열 번호 73 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열, (i) 배열 번호 75 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열, (j) 배열 번호 77 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열, (k) 배열 번호 79 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열, (l) 배열 번호 81 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열, (m) 배열 번호 83 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열, (n) (g) 내지 (m) 의 배열에 대해 적어도 95 % 이상의 상동성을 갖는 아미노산 배열, 및 (o) (g) 내지 (m) 의 배열에 있어서 1 또는 수 개의 아미노산이 결실, 치환 또는 부가된 아미노산 배열로 이루어지는 군에서 선택된 아미노산 배열로 이루어지는 경사슬의 가변 영역을 갖는 항체 또는 당해 항체의 기능성 단편. - 제 14 항에 있어서,
배열 번호 85 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 71 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역, 배열 번호 85 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 73 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역, 배열 번호 85 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 75 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역, 배열 번호 85 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 77 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역, 배열 번호 85 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 79 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역, 배열 번호 85 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 81 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역, 배열 번호 85 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 83 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역, 배열 번호 91 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 71 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역, 배열 번호 91 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 73 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역, 배열 번호 91 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 75 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역, 그리고 배열 번호 91 에 있어서 아미노산 번호 20 내지 141 에 기재된 아미노산 배열로 이루어지는 중사슬의 가변 영역 및 배열 번호 77 에 있어서 아미노산 번호 21 내지 128 에 기재된 아미노산 배열로 이루어지는 경사슬의 가변 영역으로 이루어지는 군에서 선택되는 중사슬의 가변 영역 및 경사슬의 가변 영역을 갖는 항체 또는 항체의 기능성 단편. - 제 14 항 또는 제 15 항에 있어서,
배열 번호 85 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 71 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 73 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 75 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 77 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 79 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 81 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 83 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 91 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 71 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 91 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 73 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 91 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 75 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬, 그리고 배열 번호 91 에 있어서 아미노산 번호 20 내지 471 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 77 에 있어서 아미노산 번호 21 내지 233 에 기재된 아미노산 배열로 이루어지는 경사슬로 이루어지는 군에서 선택되는 중사슬 및 경사슬을 갖는 항체 또는 당해 항체의 기능성 단편. - 제 14 항 내지 제 16 항 중 어느 한 항에 있어서,
배열 번호 85 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 71 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 73 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 75 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 77 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 79 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 81 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 85 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 83 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 91 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 71 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 91 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 73 에 기재된 아미노산 배열로 이루어지는 경사슬, 배열 번호 91 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 75 에 기재된 아미노산 배열로 이루어지는 경사슬, 그리고 배열 번호 91 에 기재된 아미노산 배열로 이루어지는 중사슬 및 배열 번호 77 에 기재된 아미노산 배열로 이루어지는 경사슬로 이루어지는 군에서 선택되는 중사슬 및 경사슬을 갖는 항체 또는 당해 항체의 기능성 단편. - 제 1 항 내지 제 17 항 중 어느 한 항에 있어서,
기능성 단편이 Fab, F(ab)2, Fab' 및 Fv 로 이루어지는 군에서 선택되는 항체의 기능성 단편. - 제 1 항 내지 제 18 항 중 어느 한 항에 기재된 항체 또는 당해 항체의 기능성 단편을 코드하는 폴리뉴클레오티드.
- 제 19 항에 있어서,
배열 번호 50 에 있어서의 58 내지 423 의 뉴클레오티드 배열, 및 배열 번호 52 에 있어서의 67 내지 390 의 뉴클레오티드 배열을 갖는 폴리뉴클레오티드. - 제 19 항 또는 제 20 항에 있어서,
배열 번호 62 의 뉴클레오티드 배열, 및 배열 번호 58 의 뉴클레오티드 배열인 폴리뉴클레오티드. - 제 19 항 또는 제 20 항에 있어서,
(a) 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열, (b) 배열 번호 86 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열, (c) 배열 번호 88 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열, (d) 배열 번호 90 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열, 및 (e) (a) 내지 (d) 에 기재된 뉴클레오티드 배열과 상보적인 뉴클레오티드 배열로 이루어지는 폴리뉴클레오티드와 스트린젠트한 조건에서 하이브리다이즈하는 폴리뉴클레오티드가 갖는 뉴클레오티드 배열로 이루어지는 군에서 선택된 뉴클레오티드 배열, 그리고 (f) 배열 번호 70 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, (g) 배열 번호 72 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, (h) 배열 번호 74 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, (i) 배열 번호 76 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, (j) 배열 번호 78 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, (k) 배열 번호 80 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, (l) 배열 번호 82 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 및 (m) (f) 내지 (l) 에 기재된 뉴클레오티드 배열과 상보적인 뉴클레오티드 배열로 이루어지는 폴리뉴클레오티드와 스트린젠트한 조건에서 하이브리다이즈하는 폴리뉴클레오티드가 갖는 뉴클레오티드 배열로 이루어지는 군에서 선택되는 뉴클레오티드 배열을 갖는 폴리뉴클레오티드. - 제 22 항에 있어서,
배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 70 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 72 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 74 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 76 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 78 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 80 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 82 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 배열 번호 90 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 70 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 배열 번호 90 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 72 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 배열 번호 90 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 74 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열, 그리고 배열 번호 90 에 있어서 뉴클레오티드 번호 58 내지 423 에 기재된 뉴클레오티드 배열 및 배열 번호 76 에 있어서 뉴클레오티드 번호 61 내지 384 에 기재된 뉴클레오티드 배열로 이루어지는 군에서 선택되는 뉴클레오티드 배열을 갖는 폴리뉴클레오티드. - 제 22 항 또는 제 23 항에 있어서,
배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 70 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 72 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 74 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 76 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 78 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 80 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 82 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열, 배열 번호 90 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 70 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열, 배열 번호 90 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 72 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열, 배열 번호 90 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 74 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열, 그리고 배열 번호 90 에 있어서 뉴클레오티드 번호 58 내지 1413 에 기재된 뉴클레오티드 배열 및 배열 번호 76 에 있어서 뉴클레오티드 번호 61 내지 699 에 기재된 뉴클레오티드 배열로 이루어지는 군에서 선택되는 뉴클레오티드 배열을 갖는 폴리뉴클레오티드. - 제 22 항 내지 제 24 항 중 어느 한 항에 있어서,
배열 번호 84 에 기재된 뉴클레오티드 배열 및 배열 번호 70 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 기재된 뉴클레오티드 배열 및 배열 번호 72 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 기재된 뉴클레오티드 배열 및 배열 번호 74 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 기재된 뉴클레오티드 배열 및 배열 번호 76 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 기재된 뉴클레오티드 배열 및 배열 번호 78 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 기재된 뉴클레오티드 배열 및 배열 번호 80 에 기재된 뉴클레오티드 배열, 배열 번호 84 에 기재된 뉴클레오티드 배열 및 배열 번호 82 에 기재된 뉴클레오티드 배열, 배열 번호 90 에 기재된 뉴클레오티드 배열 및 배열 번호 70 에 기재된 뉴클레오티드 배열, 배열 번호 90 에 기재된 뉴클레오티드 배열 및 배열 번호 72 에 기재된 뉴클레오티드 배열, 배열 번호 90 에 기재된 뉴클레오티드 배열 및 배열 번호 74 에 기재된 뉴클레오티드 배열, 그리고 배열 번호 90 에 기재된 뉴클레오티드 배열 및 배열 번호 76 에 기재된 뉴클레오티드 배열로 이루어지는 군에서 선택되는 뉴클레오티드 배열인 폴리뉴클레오티드. - 제 19 항 내지 제 25 항 중 어느 한 항에 기재된 폴리뉴클레오티드를 함유하는 발현 벡터.
- 제 26 항에 기재된 발현 벡터에 의해 형질 전환된 숙주 세포.
- 제 27 항에 있어서,
숙주 세포가 진핵 세포인 숙주 세포. - 제 27 항 또는 제 28 항에 기재된 숙주 세포를 배양하는 공정, 및 당해 공정에서 얻어진 배양물로부터 목적으로 하는 항체 또는 당해 항체의 기능성 단편을 채취하는 공정을 포함하는 것을 특징으로 하는 당해 항체 또는 당해 단편의 제조 방법.
- 제 29 항의 제조 방법에 의해 얻어지는 것을 특징으로 하는 항체 또는 당해 항체의 기능성 단편.
- 제 30 항에 있어서,
기능성 단편이 Fab, F(ab)2, Fab' 및 Fv 로 이루어지는 군에서 선택되는 항체의 기능성 단편. - 제 1 항 내지 제 18 항, 제 30 항, 제 31 항 중 어느 한 항에 있어서,
항체 의존성 세포 상해 활성을 증강시키기 위해 당 사슬 수식이 조절되어 있는 항체 또는 당해 항체의 기능성 단편. - 제 1 항 내지 제 18 항, 제 30 항 내지 제 32 항에 기재된 항체 또는 당해 항체의 기능성 단편의 적어도 하나를 함유하는 것을 특징으로 하는 의약 조성물.
- 제 33 항에 있어서,
종양 치료용인 의약 조성물. - 제 1 항 내지 제 18 항, 제 30 항 내지 제 32 항에 기재된 항체 또는 당해 항체의 기능성 단편의 적어도 하나, 및 적어도 하나의 암 치료제를 함유하는 것을 특징으로 하는 종양 치료용 의약 조성물.
- 제 34 항 또는 제 35 항에 있어서,
종양이 암인 의약 조성물. - 제 36 항에 있어서,
암이 폐암, 유방암, 전립선암, 췌장암, 대장암, 멜라노마, 간암, 난소암, 방광암, 위암, 식도암 또는 신장암인 의약 조성물. - 제 1 항 내지 제 18 항, 제 30 항 내지 제 32 항에 기재된 항체 또는 당해 항체의 기능성 단편의 적어도 하나를 개체에 투여하는 것을 특징으로 하는 종양의 치료 방법.
- 제 1 항 내지 제 18 항, 제 30 항 내지 제 32 항에 기재된 항체 또는 당해 항체의 기능성 단편의 적어도 하나, 및 적어도 하나의 암 치료제를 동시에, 따로따로 또는 연속해서 개체에 투여하는 것을 특징으로 하는 종양의 치료 방법.
- 제 38 항 또는 제 39 항에 있어서,
종양이 암인 치료 방법. - 제 40 항에 있어서,
암이 폐암, 유방암, 전립선암, 췌장암, 대장암, 멜라노마, 간암, 난소암, 방광암, 위암, 식도암 또는 신장암인 치료 방법.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201161478878P | 2011-04-25 | 2011-04-25 | |
| US61/478,878 | 2011-04-25 | ||
| JP2011097645 | 2011-04-25 | ||
| JPJP-P-2011-097645 | 2011-04-25 | ||
| PCT/JP2012/060904 WO2012147713A1 (ja) | 2011-04-25 | 2012-04-24 | 抗b7-h3抗体 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020197029164A Division KR102125672B1 (ko) | 2011-04-25 | 2012-04-24 | 항 b7-h3항체 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20140033018A true KR20140033018A (ko) | 2014-03-17 |
| KR102030987B1 KR102030987B1 (ko) | 2019-11-11 |
Family
ID=47072232
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020137027860A KR102030987B1 (ko) | 2011-04-25 | 2012-04-24 | 항 b7-h3항체 |
Country Status (26)
| Country | Link |
|---|---|
| US (2) | US9371395B2 (ko) |
| EP (1) | EP2703486B1 (ko) |
| JP (2) | JP5917498B2 (ko) |
| KR (1) | KR102030987B1 (ko) |
| CN (1) | CN103687945B (ko) |
| AU (1) | AU2012248470B2 (ko) |
| CA (1) | CA2834136C (ko) |
| CO (1) | CO6811812A2 (ko) |
| DK (1) | DK2703486T3 (ko) |
| ES (1) | ES2667568T3 (ko) |
| HR (1) | HRP20180640T1 (ko) |
| HU (1) | HUE038685T2 (ko) |
| IL (1) | IL229061B (ko) |
| LT (1) | LT2703486T (ko) |
| MX (1) | MX344773B (ko) |
| MY (1) | MY173377A (ko) |
| PL (1) | PL2703486T3 (ko) |
| PT (1) | PT2703486T (ko) |
| RS (1) | RS57279B1 (ko) |
| RU (1) | RU2668170C2 (ko) |
| SG (1) | SG194620A1 (ko) |
| SI (1) | SI2703486T1 (ko) |
| TR (1) | TR201808018T4 (ko) |
| TW (1) | TWI561531B (ko) |
| WO (1) | WO2012147713A1 (ko) |
| ZA (1) | ZA201307983B (ko) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20190015755A (ko) * | 2016-06-08 | 2019-02-14 | 애브비 인코포레이티드 | 항-b7-h3 항체 및 항체 약물 콘쥬게이트 |
| WO2019225787A1 (ko) * | 2018-05-24 | 2019-11-28 | 에이비엘바이오 주식회사 | 항-b7-h3 항체 및 그 용도 |
Families Citing this family (72)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| RS57279B1 (sr) * | 2011-04-25 | 2018-08-31 | Daiichi Sankyo Co Ltd | Anti-b7-h3 antitelo |
| US9790282B2 (en) | 2013-03-25 | 2017-10-17 | The United States Of America, As Represented By The Secretary, Department Of Health And Human Services | Anti-CD276 polypeptides, proteins, and chimeric antigen receptors |
| CA2947660C (en) | 2014-05-29 | 2021-06-29 | Spring Bioscience Corporation | Anti-b7-h3 antibodies and diagnostic uses thereof |
| ES2875057T3 (es) | 2014-09-17 | 2021-11-08 | Us Health | Anticuerpos anti-CD276 (B7H3) |
| CN113150165A (zh) * | 2014-12-22 | 2021-07-23 | 西雅图免疫公司 | 双特异性四价抗体及其制造和使用方法 |
| KR20180021723A (ko) * | 2015-06-29 | 2018-03-05 | 다이이찌 산쿄 가부시키가이샤 | 항체-약물 콘주게이트의 선택적 제조 방법 |
| IL288784B2 (en) * | 2015-09-24 | 2023-10-01 | Daiichi Sankyo Co Ltd | Antibodies against GARP, nucleotides encoding them, and vectors, cells and preparations containing them, methods for their preparation and uses thereof |
| WO2017062619A2 (en) | 2015-10-08 | 2017-04-13 | Macrogenics, Inc. | Combination therapy for the treatment of cancer |
| CR20180318A (es) | 2015-12-14 | 2018-09-19 | Macrogenics Inc | Moléculas biespecíficas que tienen inmunorreactividad con pd-1 y ctla-4, y métodos de uso de las mismas |
| SG10201601719RA (en) | 2016-03-04 | 2017-10-30 | Agency Science Tech & Res | Anti-LAG-3 Antibodies |
| MY198114A (en) | 2016-04-15 | 2023-08-04 | Macrogenics Inc | Novel b7-h3-binding molecules, antibody drug conjugates thereof and methods of use thereof |
| SG10201603721TA (en) | 2016-05-10 | 2017-12-28 | Agency Science Tech & Res | Anti-CTLA-4 Antibodies |
| SG10201913326UA (en) | 2016-06-07 | 2020-02-27 | Macrogenics Inc | Combination therapy |
| CA3027103A1 (en) * | 2016-06-08 | 2017-12-14 | Abbvie Inc. | Anti-b7-h3 antibodies and antibody drug conjugates |
| CN109563167A (zh) * | 2016-06-08 | 2019-04-02 | 艾伯维公司 | 抗b7-h3抗体和抗体药物偶联物 |
| TW201825524A (zh) * | 2016-09-20 | 2018-07-16 | 中國大陸商上海藥明生物技術有限公司 | 新型抗-pcsk9抗體 |
| US11459394B2 (en) | 2017-02-24 | 2022-10-04 | Macrogenics, Inc. | Bispecific binding molecules that are capable of binding CD137 and tumor antigens, and uses thereof |
| WO2018156180A1 (en) | 2017-02-24 | 2018-08-30 | Kindred Biosciences, Inc. | Anti-il31 antibodies for veterinary use |
| CN109843927B (zh) * | 2017-03-06 | 2022-06-21 | 江苏恒瑞医药股份有限公司 | 抗b7-h3抗体、其抗原结合片段及其医药用途 |
| JP7158403B2 (ja) * | 2017-03-31 | 2022-10-21 | ジエンス ヘンルイ メデイシンカンパニー リミテッド | B7-h3抗体、その抗原結合フラグメント、及びそれらの医学的使用 |
| CN109963591B (zh) * | 2017-08-04 | 2023-04-04 | 江苏恒瑞医药股份有限公司 | B7h3抗体-药物偶联物及其医药用途 |
| WO2019040780A1 (en) | 2017-08-25 | 2019-02-28 | Five Prime Therapeutics Inc. | ANTI-B7-H4 ANTIBODIES AND METHODS OF USE |
| RU2020122822A (ru) | 2017-12-12 | 2022-01-13 | Макродженикс, Инк. | Биспецифичные связывающие cd16 молекулы и их применение при лечении заболеваний |
| CN110090306B (zh) * | 2018-01-31 | 2023-04-07 | 江苏恒瑞医药股份有限公司 | 双醛连接臂的配体-药物偶联物、其制备方法及其应用 |
| US11685781B2 (en) | 2018-02-15 | 2023-06-27 | Macrogenics, Inc. | Variant CD3-binding domains and their use in combination therapies for the treatment of disease |
| BR112020017925A2 (pt) | 2018-03-02 | 2020-12-22 | Five Prime Therapeutics, Inc. | Anticorpos contra b7-h4 e métodos de uso dos mesmos |
| EP3806848A2 (en) | 2018-06-15 | 2021-04-21 | Flagship Pioneering Innovations V, Inc. | Increasing immune activity through modulation of postcellular signaling factors |
| WO2020013170A1 (ja) * | 2018-07-10 | 2020-01-16 | 国立大学法人神戸大学 | 抗SIRPα抗体 |
| WO2020018964A1 (en) | 2018-07-20 | 2020-01-23 | Fred Hutchinson Cancer Research Center | Compositions and methods for controlled expression of antigen-specific receptors |
| EP3833686A4 (en) * | 2018-08-08 | 2023-01-11 | Dragonfly Therapeutics, Inc. | NKG2D, CD16 AND TUMOR ASSOCIATED ANTIGEN BINDING PROTEINS |
| US11401324B2 (en) | 2018-08-30 | 2022-08-02 | HCW Biologics, Inc. | Single-chain chimeric polypeptides and uses thereof |
| JP7397874B2 (ja) | 2018-08-30 | 2023-12-13 | エイチシーダブリュー バイオロジックス インコーポレイテッド | 多鎖キメラポリペプチドおよびその使用 |
| AU2019328575A1 (en) | 2018-08-30 | 2021-02-25 | HCW Biologics, Inc. | Single-chain and multi-chain chimeric polypeptides and uses thereof |
| CN110950953B (zh) * | 2018-09-26 | 2022-05-13 | 福州拓新天成生物科技有限公司 | 抗b7-h3的单克隆抗体及其在细胞治疗中的应用 |
| AU2019351427A1 (en) | 2018-09-30 | 2021-04-15 | Changzhou Hansoh Pharmaceutical Co., Ltd. | Anti-B7H3 antibody-exatecan analog conjugate and medicinal use thereof |
| CN112239502A (zh) * | 2019-07-18 | 2021-01-19 | 上海复旦张江生物医药股份有限公司 | 一种抗b7-h3抗体及其制备方法、其偶联物和应用 |
| CN110305213B (zh) * | 2018-11-09 | 2023-03-10 | 泰州复旦张江药业有限公司 | 一种抗b7-h3抗体及其制备方法、其偶联物和应用 |
| WO2020140094A1 (en) * | 2018-12-27 | 2020-07-02 | Gigagen, Inc. | Anti-b7-h3 binding proteins and methods of use thereof |
| CN109851673B (zh) * | 2019-01-22 | 2023-07-25 | 苏州旭光科星抗体生物科技有限公司 | 一种抗人b7-h3单克隆抗体的制备方法及其免疫组化检测方法及其应用及其试剂盒 |
| MA55805A (fr) | 2019-05-03 | 2022-03-09 | Flagship Pioneering Innovations V Inc | Métodes de modulation de l'activité immunitaire |
| US11738052B2 (en) | 2019-06-21 | 2023-08-29 | HCW Biologics, Inc. | Multi-chain chimeric polypeptides and uses thereof |
| WO2021003075A1 (en) * | 2019-07-03 | 2021-01-07 | Crystal Bioscience Inc. | Anti-b7-h3 antibody and methods of use thereof |
| KR20210006637A (ko) * | 2019-07-09 | 2021-01-19 | 주식회사 와이바이오로직스 | B7-h3(cd276)에 특이적으로 결합하는 항체 및 그의 용도 |
| EP4023245A4 (en) | 2019-08-28 | 2023-08-30 | Azusapharma Sciences, Inc. | BIFIDOBACTERIUM SPP. WITH EXPRESSION AND SECRETION OF DIABODY-TYPE BSAB |
| US20220332829A1 (en) * | 2019-09-16 | 2022-10-20 | Nanjing Sanhome Pharmaceutical Co., Ltd. | Anti-b7-h3 antibody and application thereof |
| CN110642948B (zh) * | 2019-10-09 | 2021-06-29 | 达石药业(广东)有限公司 | B7-h3纳米抗体、其制备方法及用途 |
| EP3822288A1 (en) * | 2019-11-18 | 2021-05-19 | Deutsches Krebsforschungszentrum, Stiftung des öffentlichen Rechts | Antibodies targeting, and other modulators of, the cd276 antigen, and uses thereof |
| WO2021097800A1 (en) * | 2019-11-22 | 2021-05-27 | Abl Bio Inc. | Anti-pd-l1/anti-b7-h3 multispecific antibodies and uses thereof |
| JP2023509359A (ja) | 2019-12-17 | 2023-03-08 | フラグシップ パイオニアリング イノベーションズ ブイ,インコーポレーテッド | 鉄依存性細胞分解の誘導物質との併用抗癌療法 |
| IL295077A (en) | 2020-02-11 | 2022-09-01 | Hcw Biologics Inc | Methods for treating age-related and inflammatory diseases |
| IL295084A (en) | 2020-02-11 | 2022-09-01 | Hcw Biologics Inc | Chromatography resin and its uses |
| IL295083A (en) | 2020-02-11 | 2022-09-01 | Hcw Biologics Inc | Methods for activating regulatory t cells |
| CN113527487A (zh) * | 2020-04-22 | 2021-10-22 | 复星凯特生物科技有限公司 | 抗人b7-h3的单克隆抗体及其应用 |
| CN115836087A (zh) | 2020-04-29 | 2023-03-21 | Hcw生物科技公司 | 抗cd26蛋白及其用途 |
| WO2021247003A1 (en) | 2020-06-01 | 2021-12-09 | HCW Biologics, Inc. | Methods of treating aging-related disorders |
| JP2023527869A (ja) | 2020-06-01 | 2023-06-30 | エイチシーダブリュー バイオロジックス インコーポレイテッド | 加齢関連障害の治療法 |
| CN113754766A (zh) * | 2020-06-02 | 2021-12-07 | 明慧医药(上海)有限公司 | 抗b7-h3抗体及其制备和应用 |
| JP2023532339A (ja) | 2020-06-29 | 2023-07-27 | フラグシップ パイオニアリング イノベーションズ ブイ,インコーポレーテッド | サノトランスミッションを促進するためにエンジニアリングされたウイルス及び癌の処置におけるそれらの使用 |
| CN111662384B (zh) * | 2020-06-30 | 2021-04-09 | 广州百暨基因科技有限公司 | 抗b7h3抗体及其应用 |
| CN116761635A (zh) | 2020-11-24 | 2023-09-15 | 诺华股份有限公司 | Bcl-xl抑制剂抗体药物缀合物及其使用方法 |
| CA3203257A1 (en) * | 2020-12-23 | 2022-06-30 | Li Li | Anti-b7-h3 antibody and uses thereof |
| KR20230145038A (ko) | 2021-02-09 | 2023-10-17 | 메디링크 테라퓨틱스 (쑤저우) 컴퍼니, 리미티드 | 생물활성 물질 접합체, 이의 제조방법 및 이의 용도 |
| JP2024512669A (ja) | 2021-03-31 | 2024-03-19 | フラグシップ パイオニアリング イノベーションズ ブイ,インコーポレーテッド | タノトランスミッションポリペプチド及び癌の処置におけるそれらの使用 |
| WO2023278641A1 (en) | 2021-06-29 | 2023-01-05 | Flagship Pioneering Innovations V, Inc. | Immune cells engineered to promote thanotransmission and uses thereof |
| AU2022314735A1 (en) | 2021-07-19 | 2024-02-22 | Regeneron Pharmaceuticals, Inc. | Combination of checkpoint inhibitors and an oncolytic virus for treating cancer |
| CN114380910B (zh) * | 2022-01-07 | 2023-04-28 | 苏州旭光科星抗体生物科技有限公司 | 靶向人b7-h3分子的人源化单克隆抗体及其应用 |
| WO2023159102A1 (en) | 2022-02-17 | 2023-08-24 | Regeneron Pharmaceuticals, Inc. | Combinations of checkpoint inhibitors and oncolytic virus for treating cancer |
| WO2023168363A1 (en) | 2022-03-02 | 2023-09-07 | HCW Biologics, Inc. | Method of treating pancreatic cancer |
| WO2023221975A1 (zh) * | 2022-05-18 | 2023-11-23 | 苏州宜联生物医药有限公司 | 包含蛋白降解剂类生物活性化合物的抗体药物偶联物及其制备方法和用途 |
| WO2023223097A1 (en) | 2022-05-20 | 2023-11-23 | Novartis Ag | Antibody drug conjugates |
| WO2023225359A1 (en) | 2022-05-20 | 2023-11-23 | Novartis Ag | Antibody-drug conjugates of antineoplastic compounds and methods of use thereof |
| WO2024077191A1 (en) | 2022-10-05 | 2024-04-11 | Flagship Pioneering Innovations V, Inc. | Nucleic acid molecules encoding trif and additionalpolypeptides and their use in treating cancer |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2008066691A2 (en) | 2006-11-08 | 2008-06-05 | Macrogenics West, Inc. | Tes7 and antibodies that bind thereto |
Family Cites Families (24)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5260203A (en) | 1986-09-02 | 1993-11-09 | Enzon, Inc. | Single polypeptide chain binding molecules |
| US4946778A (en) | 1987-09-21 | 1990-08-07 | Genex Corporation | Single polypeptide chain binding molecules |
| US5091513A (en) | 1987-05-21 | 1992-02-25 | Creative Biomolecules, Inc. | Biosynthetic antibody binding sites |
| IL162181A (en) | 1988-12-28 | 2006-04-10 | Pdl Biopharma Inc | A method of producing humanized immunoglubulin, and polynucleotides encoding the same |
| GB9015198D0 (en) | 1990-07-10 | 1990-08-29 | Brien Caroline J O | Binding substance |
| DK0585287T3 (da) | 1990-07-10 | 2000-04-17 | Cambridge Antibody Tech | Fremgangsmåde til fremstilling af specifikke bindingsparelementer |
| DK0605522T3 (da) | 1991-09-23 | 2000-01-17 | Medical Res Council | Fremgangsmåde til fremstilling af humaniserede antistoffer |
| DK1024191T3 (da) | 1991-12-02 | 2008-12-08 | Medical Res Council | Fremstilling af autoantistoffer fremvist på fag-overflader ud fra antistofsegmentbiblioteker |
| CA2131151A1 (en) | 1992-03-24 | 1994-09-30 | Kevin S. Johnson | Methods for producing members of specific binding pairs |
| GB9313509D0 (en) | 1993-06-30 | 1993-08-11 | Medical Res Council | Chemisynthetic libraries |
| CA2177367A1 (en) | 1993-12-03 | 1995-06-08 | Andrew David Griffiths | Recombinant binding proteins and peptides |
| AU3657899A (en) * | 1998-04-20 | 1999-11-08 | James E. Bailey | Glycosylation engineering of antibodies for improving antibody-dependent cellular cytotoxicity |
| EP2275540B1 (en) | 1999-04-09 | 2016-03-23 | Kyowa Hakko Kirin Co., Ltd. | Method for controlling the activity of immunologically functional molecule |
| WO2002010187A1 (en) | 2000-07-27 | 2002-02-07 | Mayo Foundation For Medical Education And Research | B7-h3 and b7-h4, novel immunoregulatory molecules |
| CA2424602C (en) | 2000-10-06 | 2012-09-18 | Kyowa Hakko Kogyo Co., Ltd. | Antibody composition-producing cell |
| WO2002036142A2 (en) * | 2000-11-03 | 2002-05-10 | University Of Vermont And State Agricultural College | Compositions for inhibiting grb7 |
| PL216750B1 (pl) | 2001-11-01 | 2014-05-30 | Uab Research Foundation | Zastosowanie przeciwciał selektywnych dla receptora liganda indukującego apoptozę pokrewnego czynnikowi martwicy nowotworu i innych czynników terapeutycznych do leczenia nowotworu oraz kompozycja zawierająca takie przeciwciała i inne czynniki terapeutyczne |
| BRPI0406678A (pt) | 2003-01-07 | 2005-12-20 | Symphogen As | Método para produzir proteìnas policlonais recombinantes |
| US20050002935A1 (en) * | 2003-04-17 | 2005-01-06 | Vincent Ling | Use of B7-H3 as an immunoregulatory agent |
| ES2534288T3 (es) * | 2004-08-03 | 2015-04-21 | Innate Pharma | Composiciones terapéuticas contra el cáncer que seleccionan como objetivo 4Ig-B7-H3 |
| US7592429B2 (en) | 2005-05-03 | 2009-09-22 | Ucb Sa | Sclerostin-binding antibody |
| CN101104639A (zh) * | 2006-07-10 | 2008-01-16 | 苏州大学 | 抗人b7-h3单克隆抗体的制备及其应用 |
| EP2121008A4 (en) * | 2007-03-22 | 2010-03-31 | Sloan Kettering Inst Cancer | USES OF MONOCLONAL ANTIBODY 8H9 |
| RS57279B1 (sr) * | 2011-04-25 | 2018-08-31 | Daiichi Sankyo Co Ltd | Anti-b7-h3 antitelo |
-
2012
- 2012-04-24 RS RS20180646A patent/RS57279B1/sr unknown
- 2012-04-24 MY MYPI2013003891A patent/MY173377A/en unknown
- 2012-04-24 KR KR1020137027860A patent/KR102030987B1/ko active Application Filing
- 2012-04-24 HU HUE12776528A patent/HUE038685T2/hu unknown
- 2012-04-24 SG SG2013079199A patent/SG194620A1/en unknown
- 2012-04-24 CN CN201280030835.0A patent/CN103687945B/zh active Active
- 2012-04-24 PT PT127765287T patent/PT2703486T/pt unknown
- 2012-04-24 ES ES12776528.7T patent/ES2667568T3/es active Active
- 2012-04-24 WO PCT/JP2012/060904 patent/WO2012147713A1/ja active Application Filing
- 2012-04-24 US US13/455,021 patent/US9371395B2/en active Active
- 2012-04-24 CA CA2834136A patent/CA2834136C/en active Active
- 2012-04-24 LT LTEP12776528.7T patent/LT2703486T/lt unknown
- 2012-04-24 TW TW101114495A patent/TWI561531B/zh active
- 2012-04-24 RU RU2013152164A patent/RU2668170C2/ru active
- 2012-04-24 PL PL12776528T patent/PL2703486T3/pl unknown
- 2012-04-24 TR TR2018/08018T patent/TR201808018T4/tr unknown
- 2012-04-24 EP EP12776528.7A patent/EP2703486B1/en active Active
- 2012-04-24 SI SI201231272T patent/SI2703486T1/en unknown
- 2012-04-24 JP JP2013512363A patent/JP5917498B2/ja active Active
- 2012-04-24 MX MX2013012285A patent/MX344773B/es active IP Right Grant
- 2012-04-24 DK DK12776528.7T patent/DK2703486T3/en active
- 2012-04-24 AU AU2012248470A patent/AU2012248470B2/en active Active
-
2013
- 2013-10-18 ZA ZA2013/07983A patent/ZA201307983B/en unknown
- 2013-10-24 IL IL229061A patent/IL229061B/en active IP Right Grant
- 2013-11-22 CO CO13275282A patent/CO6811812A2/es active IP Right Grant
-
2016
- 2016-04-06 JP JP2016076911A patent/JP6224759B2/ja active Active
- 2016-06-20 US US15/187,209 patent/US20160368990A1/en not_active Abandoned
-
2018
- 2018-04-23 HR HRP20180640TT patent/HRP20180640T1/hr unknown
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2008066691A2 (en) | 2006-11-08 | 2008-06-05 | Macrogenics West, Inc. | Tes7 and antibodies that bind thereto |
Non-Patent Citations (18)
| Title |
|---|
| Abstract 2555, AACR Annual Meeting, Apr 12-16, 2008* * |
| British Journal of Cancer 2009년, 제 101 권, p.1709-1716 |
| Cancer Immunology, Immunotherapy 2010년, 제 59 권, p.1163-1171 |
| Cancer Research 2007년, 제 67 권, p.7893-7900 |
| Clinical Cancer Research 2008년, 제 14 권, p.4800-4808 |
| Clinical Cancer Research 2008년, 제 14 권, p.5150-5157 |
| Current Cancer Drug Targets 2008년, 제 8 권, p.404-413 |
| European Journal of Immunology 2009년, 제 39 권, p.1754-1764 |
| Histopathology 2008년, 제 53 권, p.73-80 |
| Lung Cancer, 2009년, 제 66 권, p.245-249 |
| Modern Pathology 2010년, 제 23 권, p.1104-1112 |
| Nature Immunology 2001년, 제 2 권, p.269-274 |
| Proceedings of the national Academy of Sciences of the United States of America 2004년, 제 101 권, p.12640-12645 |
| Proceedings of the national Academy of Sciences of the United States of America 2008년, 제 105 권, p.10495-10500 |
| The Journal of Immunology 2004년, 제 172 권, p.2352-2359 |
| The Journal of Immunology 2008년, 제 180 권, p.2989-2998 |
| The Journal of Immunology 2008년, 제 181 권, p.4062-4071 |
| The Journal of Immunology 2010년, 제 185 권, p.3677-3684 |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20190015755A (ko) * | 2016-06-08 | 2019-02-14 | 애브비 인코포레이티드 | 항-b7-h3 항체 및 항체 약물 콘쥬게이트 |
| WO2019225787A1 (ko) * | 2018-05-24 | 2019-11-28 | 에이비엘바이오 주식회사 | 항-b7-h3 항체 및 그 용도 |
| US11891445B1 (en) | 2018-05-24 | 2024-02-06 | Abl Bio Inc. | Anti-B7-H3 antibody and use thereof |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102030987B1 (ko) | 항 b7-h3항체 | |
| AU2020230256B2 (en) | Anti-LAG3 antibodies and antigen-binding fragments | |
| AU2020200866B2 (en) | Anti-GARP antibody | |
| JP6985252B2 (ja) | ネクチン−4に対する特異性を有する抗体及びその使用 | |
| KR101814852B1 (ko) | 신규 항 dr5 항체 | |
| JP6755866B2 (ja) | Cd73特異的結合分子及びその使用 | |
| KR101690340B1 (ko) | 항 Siglec-15 항체 | |
| DK2412728T3 (en) | Therapeutic compositions for cancer, that target 4Ig-B7-H3 | |
| KR20180086502A (ko) | 항-lag3 항체 및 항원-결합 단편 | |
| KR20180030899A (ko) | Pd-l1 (“프로그램화된 사멸-리간드 1”) 항체 | |
| KR20120035145A (ko) | 인간화 axl 항체 | |
| KR20210007959A (ko) | Hhla2 수용체로서의 kir3dl3, 항-hhla2 항체, 및 이들의 용도 | |
| CN113164780A (zh) | 抗lap抗体变体及其用途 | |
| CA3176257A1 (en) | Methods of treating multiple myeloma | |
| AU2018307292A1 (en) | Anti-CD147 antibody | |
| KR102125672B1 (ko) | 항 b7-h3항체 | |
| CA3150807A1 (en) | Anti-vsig4 antibody or antigen binding fragment and uses thereof | |
| EP3693012A1 (en) | Composition for cytotoxic t cell depletion | |
| KR20230154981A (ko) | 항-인간 cxcr5 항체 및 이의 용도 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AMND | Amendment | ||
| AMND | Amendment | ||
| AMND | Amendment | ||
| E902 | Notification of reason for refusal | ||
| AMND | Amendment | ||
| AMND | Amendment | ||
| E601 | Decision to refuse application | ||
| AMND | Amendment | ||
| X701 | Decision to grant (after re-examination) | ||
| A107 | Divisional application of patent |