JP4046893B2 - データベース複写装置及びデータベース複写方法並びにデータベース複写プログラムを記録したコンピュータ読み取り可能な記録媒体 - Google Patents
データベース複写装置及びデータベース複写方法並びにデータベース複写プログラムを記録したコンピュータ読み取り可能な記録媒体 Download PDFInfo
- Publication number
- JP4046893B2 JP4046893B2 JP14923199A JP14923199A JP4046893B2 JP 4046893 B2 JP4046893 B2 JP 4046893B2 JP 14923199 A JP14923199 A JP 14923199A JP 14923199 A JP14923199 A JP 14923199A JP 4046893 B2 JP4046893 B2 JP 4046893B2
- Authority
- JP
- Japan
- Prior art keywords
- database
- data
- records
- update
- copying
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images








Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/27—Replication, distribution or synchronisation of data between databases or within a distributed database system; Distributed database system architectures therefor
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F11/00—Error detection; Error correction; Monitoring
- G06F11/07—Responding to the occurrence of a fault, e.g. fault tolerance
- G06F11/14—Error detection or correction of the data by redundancy in operations
- G06F11/1402—Saving, restoring, recovering or retrying
- G06F11/1415—Saving, restoring, recovering or retrying at system level
- G06F11/1441—Resetting or repowering
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/953—Organization of data
- Y10S707/954—Relational
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/964—Database arrangement
- Y10S707/966—Distributed
- Y10S707/967—Peer-to-peer
- Y10S707/968—Partitioning
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/99931—Database or file accessing
- Y10S707/99933—Query processing, i.e. searching
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/99951—File or database maintenance
- Y10S707/99952—Coherency, e.g. same view to multiple users
- Y10S707/99953—Recoverability
Landscapes
- Engineering & Computer Science (AREA)
- Databases & Information Systems (AREA)
- Theoretical Computer Science (AREA)
- Computing Systems (AREA)
- Data Mining & Analysis (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
【発明の属する技術分野】
本発明は、データベースの複写技術に関し、特に、汎用性を高める技術に関する。
【0002】
【従来の技術】
近年では、業務の国際化や24時間サービスにより、業務プログラムを実行するコンピュータシステムを無停止で運用する必要性が高まっている。
【0003】
ところで、コンピュータシステムでは、ハードウエア等の保守のために、システムを停止させる必要がある。コンピュータシステムの無停止運用では、システムを停止できないため、保守を行うことができない。このため、コンピュータシステムを2セット用意し、交互に運用を切り替えることにより、一方のシステムを停止させて保守を行う運用形態が考えられる。
【0004】
しかしながら、保守作業には、ディスク装置の保守も含まれるため、2つのコンピュータシステム間で同一ディスク装置を共用することはできない。従って、システム毎に別のディスク装置とする必要があり、運用の切り替え時に、データベース(以下「DB」という)の複写が必要となる。DBの複写は、コンピュータシステムの利用者に対するサービスが停止しない程度に、充分速くなければならない。
【0005】
このような課題を解決するために、本出願人は、更新系データベースの複写方式(特開平10−207754号公報参照)を提案した。この技術は、業務プログラムが抽出済みデータに対してDBを更新した場合にだけ、更新差分を取得,反映してDBの等価性を保証するものである。そして、データ抽出時には、抽出対象範囲を排他占有し、その範囲内のレコード及びレコード間の接続関係(以下「セット関係」という)を一気に抽出する。
【0006】
【発明が解決しようとする課題】
しかしながら、DB構造によっては、セット関係がDB全体に及ぶ可能性があり、次のような不具合が発生するおそれがある。即ち、セット関係がDB全体に及ぶ場合には、DB全体を排他占有してデータを抽出することとなり、実質的にDB更新が不可能となってしまう。従って、従来技術では、DBの複写に関してDB構造上の制約があり、汎用性が低いものであった。
【0007】
そこで、本発明は以上のような従来の問題点に鑑み、DB構造の如何にかかわらずDB複写を効率的に行えるようにし、汎用性を高めたデータベース複写技術を提供することを目的とする。
【0008】
【課題を解決するための手段】
このため、請求項1記載の発明は、複写元データベースを所定領域に分割し、各領域に含まれるレコード及び該レコード間の接続関係を複写先データベースに複写するデータ複写手段と、前記複写元データベースから、異なった領域に夫々含まれるレコード間の接続関係を抽出する接続関係抽出手段と、該接続関係抽出手段により抽出された接続関係に基づいて、前記データ複写手段により複写先データベースに複写されたレコード間の接続関係を再現する接続関係再現手段と、を含んでデータベース複写装置を構成したことを特徴とする。
【0009】
かかる構成によれば、データベースの複写は、次のようにして行われる。
(1)複写元データベースが所定領域に分割され、各領域に含まれるレコード及びレコード間の接続関係が複写先データベースに複写される。
【0010】
(2)複写元データベースから、異なった領域に夫々含まれるレコード間の接続関係が抽出される。
(3)抽出された接続関係に基づいて、複写先データベースに複写されたレコード間の接続関係が再現される。
【0011】
従って、レコード間の接続関係がデータベース全体に及ぶ場合であっても、分割された領域単位でのデータベース複写が行われ、その後、異なる領域に夫々含まれるレコード間の接続関係が再現される。このため、従来技術のように、広範囲に亘るデータベースの排他占有が不要となり、例えば、オンラインシステムの稼動中にデータベース複写を行うことが可能となる。
【0012】
請求項2記載の発明は、前記データ複写手段によりレコード及び該レコード間の接続関係が複写された複写元データベースの領域に対してデータベース更新要求があったときに、該データベース更新要求による更新差分を取得する更新差分取得手段と、該更新差分取得手段により取得された更新差分に基づいて、前記データ複写手段により複写先データベースに複写されたレコード及び該レコード間の接続関係を更新するデータ更新手段と、当該更新差分取得手段により取得された更新差分に基づいて、前記接続関係抽出手段により抽出された接続関係を更新する接続関係更新手段と、を含んだ構成であることを特徴とする。
【0013】
かかる構成によれば、レコード及びレコード間の接続関係が複写された複写元データベースの領域に対してデータベース更新要求があったときには、データベース更新要求による更新差分が取得される。即ち、複写元データベースにおけるレコード等が複写済みである領域に対して更新を行っても、その更新が複写先データベースに反映されないことから、更新差分が取得されるのである。そして、取得された更新差分に基づいて、複写先データベースに複写されたレコード及びレコード間の接続関係、並びに、異なる領域に夫々含まれるレコード間の接続関係が更新される。その後、更新された異なる領域に含まれるレコード間の接続関係に基づいて、複写先データベースに複写されたレコード間の接続関係が再現される。
【0014】
請求項3記載の発明は、前記データ複写手段及び前記接続関係抽出手段による複写元データベースに対する処理が完了したか否かを判定する処理完了判定手段と、前記データ複写手段によりレコード及び該レコード間の接続関係が複写された複写元データベースの領域に対してデータベース更新要求があったときに、該データベース更新要求による更新差分を取得する更新差分取得手段と、を備え、前記接続関係再現手段は、前記処理完了判定手段により複写元データベースに対する処理が完了したと判定されたときに、前記接続関係抽出手段により抽出された接続関係及び前記更新差分取得手段により取得された更新差分に基づいて、前記データ複写手段により複写先データベースに複写されたレコード間の接続関係を再現及び更新する構成であることを特徴とする。
【0015】
かかる構成によれば、レコード及びレコード間の接続関係が複写された複写元データベースの領域に対してデータベース更新要求があったときには、データベース更新要求による更新差分が取得される。そして、複写元データベースに対する処理が完了すると、接続関係及び更新差分に基づいて、複写先データベースに複写されたレコード間の接続関係が再現及び更新される。従って、請求項2記載の発明のような抽出された接続関係の更新処理が不要となる。
【0016】
請求項4記載の発明は、前記接続関係抽出手段により抽出された接続関係は、不揮発性記憶媒体上に保持される構成であることを特徴とする。
ここで、「不揮発性記憶媒体」とは、例えば、ハードディスク装置のように、電源が遮断されたときであってもその内容が保持される記憶媒体をいう。
【0017】
かかる構成によれば、接続関係抽出手段により抽出された接続関係が大きくなっても、コンピュータシステムのメモリ消費が抑制される。また、データベースの複写中にコンピュータシステムがダウンしても、接続関係が保持されているので,再起動時にデータベースの回復が可能となる。
【0018】
請求項5記載の発明は、複写元データベースを所定領域に分割し、各領域に含まれるレコード及び該レコード間の接続関係を複写先データベースに複写するデータ複写工程と、前記複写元データベースから、異なった領域に夫々含まれるレコード間の接続関係を抽出する接続関係抽出工程と、該接続関係抽出工程により抽出された接続関係に基づいて、前記データ複写工程により複写先データベースに複写されたレコード間の接続関係を再現する接続関係再現工程と、を含んでデータベース複写方法を構成したことを特徴とする。
【0019】
かかる構成によれば、データベースの複写は、次のようにして行われる。
(1)複写元データベースが所定領域に分割され、各領域に含まれるレコード及びレコード間の接続関係が複写先データベースに複写される。
【0020】
(2)複写元データベースから、異なった領域に夫々含まれるレコード間の接続関係が抽出される。
(3)抽出された接続関係に基づいて、複写先データベースに複写されたレコード間の接続関係が再現される。
【0021】
従って、レコード間の接続関係がデータベース全体に及ぶ場合であっても、分割された領域単位でのデータベース複写が行われ、その後、異なる領域に夫々含まれるレコード間の接続関係が再現される。このため、従来技術のように、広範囲に亘るデータベースの排他占有が不要となり、例えば、オンラインシステムの稼動中にデータベース複写を行うことが可能となる。
【0022】
請求項6記載の発明は、複写元データベースを所定領域に分割し、各領域に含まれるレコード及び該レコード間の接続関係を複写先データベースに複写するデータ複写機能と、前記複写元データベースから、異なった領域に夫々含まれるレコード間の接続関係を抽出する接続関係抽出機能と、該接続関係抽出機能により抽出された接続関係に基づいて、前記データ複写機能により複写先データベースに複写されたレコード間の接続関係を再現する接続関係再現機能と、を実現するためのデータベース複写プログラムを記録媒体に記録したことを特徴とする。
【0023】
ここで、「記録媒体」とは、各種情報を確実に記録でき、かつ、必要に応じて確実に取り出し可能なものをいい、磁気テープ,磁気ディスク,磁気ドラム,ICカード,CD−ROM等の可搬記録媒体が該当する。
【0024】
かかる構成によれば、データ複写機能と、接続関係抽出機能と、接続関係再現機能と、を実現するためのデータベース複写プログラムが記録媒体に記録される。従って、かかるプログラムを記録した記録媒体があれば、一般的なコンピュータシステムを利用して、本発明に係るデータベース複写装置を容易に構築することが可能となる。
【0025】
【発明の実施の形態】
以下、添付された図面を参照して本発明を詳述する。
本発明を詳述する前に、従来技術の問題点を再度説明する。
【0026】
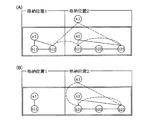
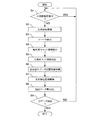
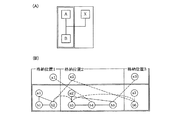
図20は、オンラインシステムの運用形態の一例を示す。従来の運用例では、図20(A)に示すように、オンラインサービスの停止時間内(図では、22時〜翌日7時)に、保守等のシステム停止を前提とした作業が行われていた。しかし、24時間サービス等によりオンラインシステムを無停止で運用するようになると、1つのコンピュータシステムでは、図20(B)に示すように、システム停止を前提とした作業ができなくなってしまう。このため、図20(C)に示すように、2つのコンピュータシステムを用いて、システムを交互に運用を切り替えることにより、システム停止を前提とした作業が可能になる。
【0027】
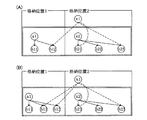
2つのコンピュータシステムを交互に切り替えるためには、前述したように、DBの複写が必要となる。DBの複写処理について、図21を参照しつつ説明すると、次のようになる。なお、DB複写は、システム1のDBからシステム2のDBへ行うものとする。
【0028】
(1)システム切り替えに先立って、システム1のDBからデータを抽出する。
(2)DB抽出と連動して、システム1に対するサービス要求の更新差分の取得を開始する。
【0029】
(3)抽出したデータを、システム2のDBに複写する。
(4)システム1のサービスを停止する。この時点まで、システム1ではサービスを行っており、更新差分が取得される。
【0030】
(5)更新差分を反映して、システム1のDBとシステム2のDBとを等価にする。この場合、DB抽出後の更新分を反映するだけであるので、処理は短時間で終了し、オンラインシステムの停止は利用者に分からない程度になる。
【0031】
(6)システム1とシステム2とのDBが等価状態になったので、システム2のDBを使用してサービスを再開する。
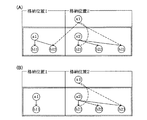
以上説明した従来技術によるDB複写では、データ抽出範囲を排他占有し、その範囲内のデータ及びセット関係を一気に抽出するため、セット関係がDB全体に及ぶ場合には、短時間でのDB更新が不可能となってしまう。即ち、図22に示すような「n:1型」のDBの場合であって、図23に示すようなデータ格納構造である場合には、異なった格納位置に跨ったセット関係があるため、DB全体を排他占有しなければならない。オンラインシステム等におけるDBは、一般的に大規模であるため、DB全体を排他占有した場合には、短時間でのDB複写は到底望めないこととなる。従って、コンピュータシステムを短時間で切り替えることは不可能となる。
【0032】
次に、このような従来技術の問題点を解決するための方法について説明する。
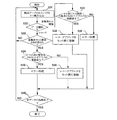
図1は、DB複写中にDB更新がない場合のDB複写方法を示す。
複写元DBが図1(A)に示すようなデータ格納構造である場合、複写元DBから図1(B)に示すような抽出データを抽出する。抽出データは、夫々の格納位置毎に、レコード,解決済みセット情報及び未解決セット情報を含んで構成される。レコードとは、複写元DBに格納されているデータ本体、即ち、図22のようなデータ構造であれば、「野球部」,「一課」,「山田」というようなデータそのものをいう。解決済みセット情報とは、異なった格納位置間に跨ったセット関係があり得ないセット関係を特定する情報をいう。未解決セット情報とは、異なった格納位置間に跨ったセット関係があり得るセット関係を特定する情報をいう。抽出データが抽出できたら、未解決セット情報から、図1(C)に示すようなセット表(詳細は後述する)を生成する。
【0033】
そして、レコードを複写先DBに複写し、図1(D)に示すように、解決済みセット情報に基づいて複写されたレコード間のセット関係を再現する。その後、セット表に基づいて未解決セット関係を再現すると、複写先DB上に、図1(A)と同一の論理構造を有するDB構造が再現される。
【0034】
また、DB複写中にDB更新がある場合には、図2及び図3に示すようなDB複写方法となる。
複写元DBが図2(A)に示すようなデータ格納構造である場合、先の例と同様にして、複写元DBから図3(A)に示すような抽出データを抽出する。ここで、複写元DBの格納位置1のデータを抽出後、格納位置2のデータ抽出前に、図2(B)に示すように、格納位置1にレコード「b13」が追加された場合を考える。この場合には、図3(B)に示すような更新差分を取得する。更新差分は、DB更新情報及び未解決セット情報を含んで構成される。また、未解決セット情報に基づいて、図3(C)に示すようなセット表を生成する。
【0035】
そして、先の例と同様にして、レコードを複写先DBに複写し、図2(C)に示すように、解決済みセット情報に基づいて複写されたレコード間のセット関係を再現する。
【0036】
ところで、格納位置1にレコード「b13」の追加があったので、これを複写先DBに反映しなければならない。即ち、更新差分のDB更新情報に基づいて複写先DBに対して更新を行うと、図2(D)のようになる。また、DB更新によりセット表にも変更の必要性が生じたので、更新差分の未解決セット情報に基づいてセット表を更新すると、セット表は図3(D)のようになる。その後、セット表に基づいて未解決セット関係を再現すると、複写先DB上に、図2(A)と同一の論理構造を有するDB構造が再現される。
【0037】
なお、本発明は、以上説明した2つの場合だけではなく、図4〜図6に示すような場合にも適用が可能である。夫々の場合を簡単に説明すると、次のようになる。
【0038】
図4は、DB更新としてデータ削除がある場合を示す。即ち、図4(A)に示すようなDB格納構造において、複写元DBの格納位置1のデータを抽出後、格納位置2のデータ抽出前に、図4(B)に示すように、格納位置1のレコード「b12」が削除された場合である。
【0039】
図5は、セット関係をポインタリストで管理する構造のDBにおいて、DB更新としてデータ追加がある場合を示す。即ち、図5(A)に示すようなDB格納構造において、複写元DBの格納位置1のデータを抽出後、格納位置2のデータ抽出前に、図5(B)に示すように、格納位置1にレコード「b13」が追加された場合である。
【0040】
図6は、セット関係をポインタリストで管理する構造のDBにおいて、DB更新としてデータ削除がある場合を示す。即ち、図6(A)に示すようなDB格納構造において、複写元DBの格納位置1のデータを抽出後、格納位置2のデータ抽出前に、図6(B)に示すように、格納位置1のレコード「b12」が削除された場合である。
【0041】
次に、以上説明した方法を実現するための具体的な構成について説明する。
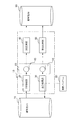
図7は、本発明に係るDB複写装置の全体構成を示す。DB複写装置は、少なくとも、中央処理装置(CPU)とメモリとを備えたコンピュータ上に構築され、メモリにロードされたプログラムに従ってソフトウエア的に動作する。
【0042】
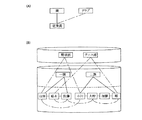
DB複写装置10は、図7に示すように、DB抽出部20と、差分取得部30と、DB反映部40と、差分反映部50と、不揮発性記憶媒体としてのハードディスク装置等からなるファイル記憶部60と、を含んで構成される。
【0043】
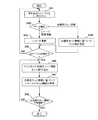
DB抽出部20は、図8に示すフローチャートに従って、複写元DB70から抽出データを抽出し、抽出データを抽出データファイル62としてファイル記憶部60に書き出す。なお、DB抽出部20が、データ複写手段,データ複写工程,データ複写機能,接続関係抽出手段,接続関係抽出工程及び接続関係抽出機能の一部として作用する。
【0044】
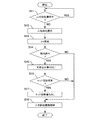
ステップ1(図では「S1」と略記する。以下同様)では、差分取得部30により複写元DB70のデータ抽出対象範囲が占有排他獲得されているか否かが判定される。そして、データ抽出対象範囲が占有排他獲得されていると判定されれば、占有排他獲得が解除されるまで待機する(Yes)。一方、データ抽出対象範囲が独占排他獲得されていないと判定されれば、ステップ2へと進む(No)。ここで、データ抽出対象範囲とは、例えば、図2(A)における矩形で表したDBの部分的範囲のことをいう。また、複写元DB70のデータ抽出対象範囲が占有排他獲得されている間待機する理由は、業務プログラム80により複写元DB70の更新が行われているときにデータ抽出が行われないようにすることで、複写元DB70及び複写先DB90のデータ不一致を防止するためである。
【0045】
ステップ2では、複写元DB70のデータ抽出対象範囲が占有排他獲得される。
ステップ3では、複写元DB70からレコードが抽出される。
【0046】
ステップ4では、複写元DB70から解決済みセット情報が抽出される。
ここで、ステップ3及びステップ4の処理が、データ複写手段,データ複写工程及びデータ複写機能の一部に相当する。
【0047】
ステップ5では、複写元DB70から未解決セット情報が抽出される。ここで、解決済みセット関係と未解決セット関係の区別は、例えば、DB構造定義を解析することで判断することができる。なお、ステップ5の処理が、接続関係抽出手段,接続関係抽出工程及び接続関係抽出機能の一部に相当する。
【0048】
ステップ6では、複写元DB70からデータを抽出した抽出済みデータ位置情報(具体的には、複写元DB70のデータ格納位置を特定するアドレス)が、ファイル記憶部60に書き出される。
【0049】
ステップ7では、複写元DB70のデータ抽出対象範囲の占有排他獲得が解除される。
ステップ8では、複写元DB70から抽出したレコード,解決済みセット情報及び未解決セット情報が、抽出データファイル62としてファイル記憶部60に書き出される。
【0050】
ステップ9では、複写元DB70から全データが抽出されたか否かが判定される。そして、全データが抽出されたと判定されればDB抽出部20における処理を終了し(Yes)、全データが抽出されていないと判定されればステップ1へと戻る(No)。
【0051】
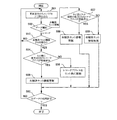
差分取得部30は、業務プログラム80からDB更新要求があったときに起動される。そして、図9に示すフローチャートに従って、データ更新対象範囲が複写元DB70から抽出済みのときに、その更新差分を更新差分ファイル64としてファイル記憶部60に書き出す。また、更新差分ファイル64は、DB複写装置10の起動時に空に初期化される。なお、差分取得部30が、更新差分取得手段として作用する。
【0052】
ステップ11では、DB抽出部20により複写元DB70のデータ更新対象範囲が占有排他獲得されているか否かが判定される。そして、データ更新対象範囲が独占排他獲得されていると判定されれば、占有排他獲得が解除されるまで待機する(Yes)。一方、データ更新対象範囲が占有排他獲得されていないと判定されれば、ステップ12へと進む(No)。ここで、複写元DB70のデータ更新対象範囲が占有排他獲得されている間待機する理由は、先のDB抽出部20における待機理由と同様である。
【0053】
ステップ12では、複写元DB70のデータ更新対象範囲が占有排他獲得される。
ステップ13では、業務プログラム80からのDB更新要求に基づいて、複写元DB70の更新が行われる。
【0054】
ステップ14では、複写元DB70のデータ更新対象範囲のデータが抽出済みであるか否かが判定される。データが抽出済みであるか否かは、ファイル記憶部60に登録された抽出済みデータ位置情報を参照することで判定することができる。そして、データ更新対象範囲のデータが抽出済みであると判定されればステップ15へと進み(Yes)、データが抽出済みでないと判定されればステップ18へと進む(No)。
【0055】
ステップ15では、更新差分ファイル64がファイル記憶部60に書き出される。
ステップ16では、業務プログラム80からのDB更新要求によりセット関係が更新されたか否かが判定される。そして、セット関係が更新されたと判定されればステップ17へと進み(Yes)、セット情報が更新差分ファイル64としてファイル記憶部60に書き出される。一方、セット関係が更新されていないと判定されればステップ18へと進む(No)。
【0056】
ここで、ステップ14〜ステップ17の処理が、更新差分取得手段に相当する。
ステップ18では、複写元DB70のデータ更新対象範囲の占有排他獲得が解除される。
【0057】
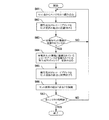
DB反映部40は、図10に示すフローチャートに従って、ファイル記憶部60から抽出データファイル62を読み込み、複写先DB90に対してレコード及び解決済みセット情報を複写すると共に、未解決セット情報を「セット表」に登録する。ここで、セット表は、図11に示すように、複写元DBのアドレス,複写先DBのアドレス及び未解決セット情報を含んで構成される。なお、DB反映部40が、データ複写手段,データ複写工程,データ複写機能,接続関係抽出手段,接続関係抽出工程及び接続関係抽出機能の一部として作用する。
【0058】
ステップ21では、ファイル記憶部60の抽出データファイル62からエントリが1つ読み込まれる。
ステップ22では、読み込まれたデータの種別に応じた分岐処理が行われる。即ち、データがレコードであればステップ23へと進み、レコードが複写先DB90に複写される。また、データが解決済みセット情報であればステップ24へと進み、解決済みセット情報に基づいて、複写先DB90に複写されたレコードのセット関係が再現される。さらに、データが未解決セット情報であればステップ25へと進み、未解決セット情報がセット表に登録される。なお、未解決セット情報のセット表への登録処理の詳細については後述する。
【0059】
ここで、ステップ23及びステップ24の処理が、データ複写手段,データ複写工程及びデータ複写機能の一部に相当する。また、ステップ25の処理が、接続関係抽出手段,接続関係抽出工程及び接続関係抽出機能の一部に相当する。
【0060】
ステップ26では、抽出データファイル62の全データの処理が終了したか否かが判定される。そして、全データの処理が終了したと判定されればDB反映部40における処理を終了し(Yes)、全データの処理が終了していないと判定されればステップ21へと戻り(No)、次のエントリの処理が行われる。
【0061】
ここで、DB反映部40において、未解決セット情報をセット表に登録する処理の詳細について説明する。なお、以下の説明においては、図2及び図3の例を前提とする。
【0062】
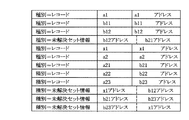
DB抽出部20の機能により、複写元DB70から図12に示すような抽出データが抽出される。抽出データは、データ種別、並びに、レコード名及びレコードアドレス(データ種別がレコードの場合)、又は、セット関係の起点及び終点アドレス(データ種別が未解決セット情報の場合)を含んで構成される。また、解決済みセット情報は、エントリの並びの順序によって表現される。そして、セット表の生成は、図13に示すフローチャートに従って行われる。
【0063】
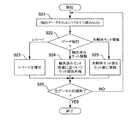
ステップ31では、抽出データファイル62からエントリが1つ読み込まれる。
ステップ32では、データ種別に応じた分岐処理が行われる。即ち、データがレコードであればステップ33へと進み、データが未解決セット情報であればステップ37へと進む。
【0064】
データがレコードである場合の処理を行うステップ33では、未解決セット関係があり得るレコードであるか否かが判定される。そして、未解決セット関係があり得ると判定されればステップ34へと進み(Yes)、未解決セット関係があり得ないと判定されればステップ31へと戻る(No)。
【0065】
ステップ34では、複写元DB70のレコードアドレスをキーとしてセット表が検索され、セット表にレコードアドレスが登録されているか否かが判定される。そして、セット表にレコードアドレスが登録されていると判定されればステップ35へと進み(Yes)、データ矛盾が発生していると判断して、例えば、エラーメッセージ表示等のエラー処理が実行される。一方、セット表にレコードアドレスが登録されていないと判定されればステップ36へと進み(No)、複写元DB70及び複写先DB90のレコードアドレスが、セット表に登録される。
【0066】
データが未解決セット情報である場合の処理を行うステップ37では、セット関係の起点となるレコードアドレス(複写元DBのアドレス)をキーとしてセット表が検索され、セット表にレコードアドレスが登録されているか否かが判定される。そして、セット表にレコードアドレスが登録されていると判定されればステップ38へと進み(Yes)、セット関係の終点となるレコードアドレスがセット表に登録される。一方、セット表にレコードアドレスが登録されていないと判定されればステップ39へと進み(No)、データ矛盾が発生していると判断して、例えば、エラーメッセージ表示等のエラー処理が実行される。
【0067】
ステップ40では、全データの処理が終了したか否かが判定される。そして、全データの処理が終了したと判定されればセット表の生成処理を終了し(Yes)、全データの処理が終了していないと判定されればステップ31へと戻り(No)、次のエントリの処理が行われる。
【0068】
以上説明したステップ31〜ステップ40の処理によれば、図14に示すように、未解決セット情報がセット表に登録される。なお、図14では、複写元DB及び複写先DBのレコードアドレスが同一形式で表現されているが、実際には、レコードが論理複写されるため同一アドレスとは限られない。
【0069】
差分反映部50は、図15に示すフローチャートに従って、ファイル記憶部60から更新差分ファイル64を読み込み、複写先DB90に対してデータ更新を行うと共に、「セット表」に基づいて未解決セット情報を再現する。なお、業務プログラム80からDB更新要求がない場合には、空の更新差分ファイル64に基づくデータ更新が行われる。これにより、DB更新がない場合には、実質的にDBのデータ更新が行われないこととなる。なお、差分反映部50が、接続関係再現手段,接続関係再現工程,接続関係再現機能,データ更新手段,接続関係更新手段として作用する。
【0070】
ステップ41では、更新差分ファイル64からエントリが1つ読み込まれる。
ステップ42では、データ種別に応じた分岐処理が行われる。即ち、データがレコード更新情報であればステップ43へと進み、複写先DB90に対してレコード更新が行われる。一方、データが未解決セット情報であればステップ44へと進み、未解決セット情報に基づいてセット表が更新される。なお、セット表の更新処理の詳細については後述する。
【0071】
ここで、ステップ43の処理が、データ更新手段に相当する。また、ステップ44の処理が、接続関係更新手段に相当する。
ステップ45では、更新差分ファイル64の全データの処理が終了したか否かが判定される。そして、全データの処理が終了したと判定されればステップ46へと進み(Yes)、全データの処理が終了していないと判定されればステップ41へと戻り(No)、次のエントリの処理が行われる。
【0072】
ステップ46では、セット表から未解決セット情報が1つ読み込まれる。
ステップ47では、読み込まれた未解決セット情報に基づいて、複写先DB90に複写されたレコードのセット関係が再現される。なお、レコードのセット関係の再現処理の詳細については後述する。ここで、ステップ47の処理が、接続関係再現手段,接続関係再現工程及び接続関係再現機能に相当する。
【0073】
ステップ48では、全未解決セット情報の処理が終了したか否かが判定される。そして、全未解決セット情報の処理が終了したと判定されれば差分反映部50における処理を終了し(Yes)、全未解決セット情報の処理が終了していないと判定されればステップ46へと戻り(No)、次の未解決セット情報の処理が行われる。
【0074】
ここで、差分反映部50において、セット表を更新する処理の詳細について説明する。なお、以下の説明においては、図2及び図3の例を前提とする。
差分取得部30の機能により、図16に示すような更新差分が生成される。更新差分は、データ種別、並びに、レコード名及びレコードアドレス(データ種別がレコード更新情報の場合)、又は、セット関係の起点及び終点アドレス(データ種別が未解決セット情報の場合)を含んで構成される。そして、セット表の更新は、図17に示すフローチャートに従って行われる。
【0075】
ステップ51では、更新差分ファイル64からエントリが1つ読み込まれる。
ステップ52では、データ種別に応じた分岐処理が行われる。即ち、データがレコードであればステップ53へと進み、データが未解決セット情報であればステップ57へと進む。
【0076】
データがレコードである場合の処理を行うステップ53では、未解決セット関係があり得るレコードであるか否かが判定される。そして、未解決セット関係があり得ると判定されればステップ54へと進み(Yes)、未解決セット関係があり得ないと判定されればステップ51へと戻る(No)。
【0077】
ステップ54では、複写元DB70のレコードアドレスをキーとしてセット表が検索され、セット表にレコードアドレスが登録されているか否かが判定される。そして、セット表にレコードアドレスが登録されていると判定されればステップ55へと進み(Yes)、セット関係の終点となるレコードアドレスにより未解決セット情報が更新される。一方、セット表にレコードアドレスが登録されていないと判定されればステップ56へと進み(No)、複写元DB70及び複写先DB90のレコードアドレスが、セット表に登録される。
【0078】
データが未解決セット情報である場合の処理を行うステップ57では、セット関係の起点となるレコードアドレスをキーとしてセット表が検索され、セット表にレコードアドレスが登録されているか否かが判定される。そして、セット表にレコードアドレスが登録されていると判定されればステップ58へと進み(Yes)、セット関係の終点となるレコードアドレスにより未解決セット情報が更新される。一方、セット表にレコードアドレスが登録されていないと判定されればステップ59へと進み(No)、未解決セット情報が無視される。
【0079】
ステップ60では、全データの処理が終了したか否かが判定される。そして、全データの処理が終了したと判定されればセット表の更新処理を終了し(Yes)、全データの処理が終了していないと判定されればステップ51へと戻り(No)、次のエントリの処理が行われる。
【0080】
以上説明したステップ51〜ステップ60の処理によれば、セット表が図18に示すように更新される。即ち、業務プログラム80によるDB更新内容が、セット表に反映されることとなる。
【0081】
次に、差分反映部50において、セット表に基づくセット関係の再現処理の詳細について、図19のフローチャートを参照して説明する。なお、以下の説明においては、図18のセット表に基づいて、レコード間のセット関係を再現するものとする。
【0082】
ステップ61では、セット表からエントリが1つ読み込まれる。
ステップ62では、複写元DB70のレコードアドレスがセット関係の起点に位置付けられる。
【0083】
ステップ63では、エントリの未解決セット情報が登録されているか否かが判定される。そして、未解決セット情報が登録されていればステップ64へと進み(Yes)、未解決セット情報が登録されていなければステップ61へと戻り、次のエントリの処理が行われる。
【0084】
ステップ64では、未解決セット情報に登録されているレコードアドレスをキーとしてセット表が検索され、このレコードアドレスが登録されている複写元DB70のエントリが読み込まれる。
【0085】
ステップ65では、エントリの複写先DB90のレコードアドレスがセット関係の終点に位置付けられる。
ステップ66では、位置付けられたセット関係の起点と終点とが接続され、レコード間のセット関係が再現される。
【0086】
ステップ67では。セット表の全エントリの処理が終了したか否かが判定される。そして、全エントリの処理が終了したと判定されればセット関係の再現処理を終了し(Yes)、全エントリの処理が終了していないと判定されればステップ61へと戻る(No)。
【0087】
以上説明した構成のDB複写装置によれば、レコード間の接続関係がデータベース全体に及ぶ場合であっても、分割された領域単位でのデータベース複写が行われ、その後、異なる領域に夫々含まれるレコード間の接続関係が再現される。このため、従来技術のように、広範囲に亘るデータベースの排他占有が不要となり、例えば、オンラインシステムの稼動中にデータベース複写を行うことが可能となる。従って、データベース構造の如何にかかわらずデータベース複写が効率的に行われ、データベース複写の係る汎用性を高めることができる。
【0088】
また、レコード及びレコード間の接続関係が複写された複写元データベースの領域に対してデータベース更新要求があったときには、データベース更新要求による更新差分が取得される。そして、取得された更新差分に基づいて、複写先データベースに複写されたレコード及びレコード間の接続関係、並びに、異なる領域に夫々含まれるレコード間の接続関係が更新される。その後、更新された異なる領域に含まれるレコード間の接続関係に基づいて、複写先データベースに複写されたレコード間の接続関係が再現される。従って、データベース複写中であっても、例えば、業務プログラムからのデータベース更新要求を処理することが可能となり、種々のオンラインシステムへ適用することができる。
【0089】
なお、本実施形態では、セット表をファイル記憶部60に登録したが、セット表をメモリ上に登録する構成としてもよい。但し、セット表は、一般的に大規模になること及びシステムダウン時のデータ保証を考慮すると、本実施形態のように、不揮発性記憶媒体に登録することが望ましい。
【0090】
また、本実施形態では、セット関係は、全ての更新差分を反映した後に再現する構成を採用しているが、DB抽出完了後であれば任意の時点で行うことができる。例えば、処理完了判定手段としてDB抽出が完了した旨の情報を更新差分取得中に取得し、差分反映部がこれを認識した時点で行う方法も考えられる。この場合、DB抽出完了後のセット表の更新がなくなるため,本実施形態よりも効率が良いという利点がある。
【0091】
このような機能を実現するプログラムを、例えば、磁気テープ,磁気ディスク,磁気ドラム,ICカード,CD−ROM等の可搬記録媒体に記録しておけば、本発明に係るDB複写プログラムを市場に流通させることができる。そして、かかる記録媒体を取得した者は、一般的なコンピュータシステムを利用して、本発明に係るDB複写装置を容易に構築することができる。
【0092】
【発明の効果】
以上説明したように、請求項1又は請求項5に記載の発明によれば、レコード間の接続関係がデータベース全体に及ぶ場合であっても、分割された領域単位でのデータベース複写が行われ、その後、異なる領域に夫々含まれるレコード間の接続関係が再現される。従って、データベース構造の如何にかかわらずデータベース複写が効率的に行われ、データベース複写の係る汎用性を高めることができる。
【0093】
請求項2記載の発明によれば、データベース複写中にデータベース更新要求があっても、その内容を複写先データベースに反映することができる。従って、データベース複写中であっても、例えば、業務プログラムからのデータベース更新要求を処理することが可能となり、種々のオンラインシステムへ適用することができる。
【0094】
請求項3記載の発明によれば、複写元データベースに対する処理が完了すると、接続関係及び更新差分に基づいて、複写先データベースに複写されたレコード間の接続関係が再現及び更新される。従って、請求項2記載の発明のような抽出された接続関係の更新処理が不要となり、データベース複写効率をさらに向上することができる。
【0095】
請求項4記載の発明によれば、コンピュータシステムのメモリ消費が抑制されるので、コンピュータシステムのハードウエア上の要求を緩和することができる。また、コンピュータシステムがダウンしても接続関係が保持されるので、再起動時にデータベースを回復することができる。
【0096】
請求項6記載の発明によれば、請求項1又は請求項5に記載の発明の効果に加え、本発明に係るデータベース複写プログラムを市場に流通させることができる。そして、かかる記録媒体を取得した者は、一般的なコンピュータシステムを利用して、本発明に係るデータベース複写装置を容易に構築することができる。
【図面の簡単な説明】
【図1】データベースの更新がない場合の本発明の原理を示し、(A)は複写元データベースのデータ格納構造、(B)は複写元データベースから抽出した抽出データ、(C)は抽出データに基づいて生成されたセット表、(D)は複写先データベースに複写されたレコード及び解決済みセット情報を夫々説明する図である。
【図2】データベースの更新がある場合の本発明の原理を示し、(A)は複写元データベースのデータ格納構造、(B)はデータベースの更新内容、(C)は複写先データベースに複写されたレコード及び解決済みセット情報、(D)はデータベースの更新内容を反映した複写先データベースを夫々説明する図である。
【図3】データベースの更新がある場合の本発明の原理を示し、(A)は複写元データベースから抽出した抽出データ、(B)はデータベースの更新内容に応じて生成された更新差分、(C)は抽出データに基づいて生成されたセット表、(D)は更新差分により更新されたセット表を夫々説明する図である。
【図4】本発明が適用可能な他のデータ格納構造の一例を示す図である。
【図5】本発明が適用可能な他のデータ格納構造の一例を示す図である。
【図6】本発明が適用可能な他のデータ格納構造の一例を示す図である。
【図7】本発明に係るデータベース複写装置の全体構成図である。
【図8】DB抽出部における処理内容を示すフローチャートである。
【図9】差分取得部における処理内容を示すフローチャートである。
【図10】DB反映部における処理内容を示すフローチャートである。
【図11】セット表の説明図である。
【図12】抽出データの説明図である。
【図13】セット表の生成処理内容を示すフローチャートである。
【図14】セット表の生成処理によって生成されたセット表の具体例を示す図である。
【図15】差分反映部における処理内容を示すフローチャートである。
【図16】差分取得部によって生成される更新差分の具体例を示す図である。
【図17】セット表の更新処理内容を示すフローチャートである。
【図18】セット表の更新処理によって更新されたセット表の具体例を示す図である。
【図19】セット関係の再現処理内容を示すフローチャートである。
【図20】従来技術の問題点を示し、(A)はシステムを停止して保守等を行う運用形態、(B)はシステムの無停止運用形態、(C)は2つのシステムを交互に切り替えて保守等を行う運用形態を夫々説明する図である。
【図21】システムを切り替えるときのデータベース複写処理の概要説明図である。
【図22】従来技術ではデータベース複写が短時間でできない一例を示し、(A)はn:1型のデータ構造、(B)はn:1型のデータ構造の具体例を夫々説明する図である。
【図23】従来技術ではデータベース複写が短時間でできない一例を示し、(A)は論理構造、(B)はデータ格納構造を夫々説明する図である。
【符号の説明】
10…データベース複写装置
20…DB抽出部
30…差分取得部
40…DB反映部
50…差分反映部
60…ファイル記憶部
64…更新差分ファイル
70…複写元データベース
90…複写先データベース
Claims (6)
- 複写元データベースを所定領域に分割し、各領域に含まれるレコード及び該レコード間の接続関係を複写先データベースに複写するデータ複写手段と、
前記複写元データベースから、異なった領域に夫々含まれるレコード間の接続関係を抽出する接続関係抽出手段と、
該接続関係抽出手段により抽出された接続関係に基づいて、前記データ複写手段により複写先データベースに複写されたレコード間の接続関係を再現する接続関係再現手段と、
を含んで構成されたことを特徴とするデータベース複写装置。 - 前記データ複写手段によりレコード及び該レコード間の接続関係が複写された複写元データベースの領域に対してデータベース更新要求があったときに、該データベース更新要求による更新差分を取得する更新差分取得手段と、
該更新差分取得手段により取得された更新差分に基づいて、前記データ複写手段により複写先データベースに複写されたレコード及び該レコード間の接続関係を更新するデータ更新手段と、
当該更新差分取得手段により取得された更新差分に基づいて、前記接続関係抽出手段により抽出された接続関係を更新する接続関係更新手段と、
を含んだ構成である請求項1記載のデータベース複写装置。 - 前記データ複写手段及び前記接続関係抽出手段による複写元データベースに対する処理が完了したか否かを判定する処理完了判定手段と、
前記データ複写手段によりレコード及び該レコード間の接続関係が複写された複写元データベースの領域に対してデータベース更新要求があったときに、該データベース更新要求による更新差分を取得する更新差分取得手段と、
を備え、
前記接続関係再現手段は、前記処理完了判定手段により複写元データベースに対する処理が完了したと判定されたときに、前記接続関係抽出手段により抽出された接続関係及び前記更新差分取得手段により取得された更新差分に基づいて、前記データ複写手段により複写先データベースに複写されたレコード間の接続関係を再現及び更新する構成である請求項1記載のデータベース複写装置。 - 前記接続関係抽出手段により抽出された接続関係は、不揮発性記憶媒体上に保持される構成である請求項1〜請求項3のいずれか1つに記載のデータベース複写装置。
- データ複写手段が、複写元データベースを所定領域に分割し、各領域に含まれるレコード及び該レコード間の接続関係を複写先データベースに複写するデータ複写工程と、
接続関係抽出手段が、前記複写元データベースから、異なった領域に夫々含まれるレコード間の接続関係を抽出する接続関係抽出工程と、
接続関係再現手段が、該接続関係抽出工程により抽出された接続関係に基づいて、前記データ複写工程により複写先データベースに複写されたレコード間の接続関係を再現する接続関係再現工程と、
を含んで構成されたことを特徴とするデータベース複写方法。 - コンピュータに、
複写元データベースを所定領域に分割し、各領域に含まれるレコード及び該レコード間の接続関係を複写先データベースに複写するデータ複写機能と、
前記複写元データベースから、異なった領域に夫々含まれるレコード間の接続関係を抽出する接続関係抽出機能と、
該接続関係抽出機能により抽出された接続関係に基づいて、前記データ複写機能により複写先データベースに複写されたレコード間の接続関係を再現する接続関係再現機能と、
を実現させるためのデータベース複写プログラムを記録したコンピュータ読み取り可能な記録媒体。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP14923199A JP4046893B2 (ja) | 1999-05-28 | 1999-05-28 | データベース複写装置及びデータベース複写方法並びにデータベース複写プログラムを記録したコンピュータ読み取り可能な記録媒体 |
| US09/427,935 US6636876B1 (en) | 1999-05-28 | 1999-10-27 | Database copy apparatus, database copy method and recording medium recorded with database copy program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP14923199A JP4046893B2 (ja) | 1999-05-28 | 1999-05-28 | データベース複写装置及びデータベース複写方法並びにデータベース複写プログラムを記録したコンピュータ読み取り可能な記録媒体 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2000339210A JP2000339210A (ja) | 2000-12-08 |
| JP4046893B2 true JP4046893B2 (ja) | 2008-02-13 |
Family
ID=15470749
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP14923199A Expired - Fee Related JP4046893B2 (ja) | 1999-05-28 | 1999-05-28 | データベース複写装置及びデータベース複写方法並びにデータベース複写プログラムを記録したコンピュータ読み取り可能な記録媒体 |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US6636876B1 (ja) |
| JP (1) | JP4046893B2 (ja) |
Families Citing this family (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6775423B2 (en) * | 2000-05-03 | 2004-08-10 | Microsoft Corporation | Systems and methods for incrementally updating an image in flash memory |
| US7620665B1 (en) * | 2000-11-21 | 2009-11-17 | International Business Machines Corporation | Method and system for a generic metadata-based mechanism to migrate relational data between databases |
| US7987157B1 (en) * | 2003-07-18 | 2011-07-26 | Symantec Operating Corporation | Low-impact refresh mechanism for production databases |
| US7143117B2 (en) * | 2003-09-25 | 2006-11-28 | International Business Machines Corporation | Method, system, and program for data synchronization by determining whether a first identifier for a portion of data at a first source and a second identifier for a portion of corresponding data at a second source match |
| JP4390618B2 (ja) * | 2004-04-28 | 2009-12-24 | 富士通株式会社 | データベース再編成プログラム、データベース再編成方法、及びデータベース再編成装置 |
| US7492953B2 (en) * | 2004-06-17 | 2009-02-17 | Smith Micro Software, Inc. | Efficient method and system for reducing update requirements for a compressed binary image |
| JP4854973B2 (ja) | 2005-03-09 | 2012-01-18 | 富士通株式会社 | 記憶制御プログラム、記憶制御方法、記憶制御装置および記憶制御システム |
| US7890508B2 (en) * | 2005-08-19 | 2011-02-15 | Microsoft Corporation | Database fragment cloning and management |
| US9547485B2 (en) * | 2006-03-31 | 2017-01-17 | Prowess Consulting, Llc | System and method for deploying a virtual machine |
| US20070234337A1 (en) * | 2006-03-31 | 2007-10-04 | Prowess Consulting, Llc | System and method for sanitizing a computer program |
| US8159775B2 (en) * | 2007-07-27 | 2012-04-17 | Hewlett-Packard Development Company, L.P. | Vibration identification and attenuation system and method |
| US8671166B2 (en) * | 2007-08-09 | 2014-03-11 | Prowess Consulting, Llc | Methods and systems for deploying hardware files to a computer |
| JP2009069941A (ja) * | 2007-09-11 | 2009-04-02 | Honda Motor Co Ltd | データ生成システムおよびデータ生成方法 |
| US8051111B2 (en) | 2008-01-31 | 2011-11-01 | Prowess Consulting, Llc | Method and system for modularizing windows imaging format |
| US20100312805A1 (en) * | 2009-05-08 | 2010-12-09 | Noonan Iii Donal Charles | System and method for capturing, managing, and distributing computer files |
| US9110847B2 (en) | 2013-06-24 | 2015-08-18 | Sap Se | N to M host system copy |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5970502A (en) * | 1996-04-23 | 1999-10-19 | Nortel Networks Corporation | Method and apparatus for synchronizing multiple copies of a database |
| JPH10207754A (ja) * | 1997-01-16 | 1998-08-07 | Fujitsu Ltd | 更新系データベースの複製方式 |
| US6026398A (en) * | 1997-10-16 | 2000-02-15 | Imarket, Incorporated | System and methods for searching and matching databases |
| US6424969B1 (en) * | 1999-07-20 | 2002-07-23 | Inmentia, Inc. | System and method for organizing data |
-
1999
- 1999-05-28 JP JP14923199A patent/JP4046893B2/ja not_active Expired - Fee Related
- 1999-10-27 US US09/427,935 patent/US6636876B1/en not_active Expired - Lifetime
Also Published As
| Publication number | Publication date |
|---|---|
| JP2000339210A (ja) | 2000-12-08 |
| US6636876B1 (en) | 2003-10-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4046893B2 (ja) | データベース複写装置及びデータベース複写方法並びにデータベース複写プログラムを記録したコンピュータ読み取り可能な記録媒体 | |
| US8239356B2 (en) | Methods and apparatuses for data protection | |
| US7991749B2 (en) | Database recovery method applying update journal and database log | |
| JP4199993B2 (ja) | スナップショット取得方法 | |
| JP3180038B2 (ja) | 大容量記憶装置の構成管理のための方法およびシステム | |
| JP2557172B2 (ja) | タイムゼロ・バックアップ・コピー・プロセスにおける副ファイル状態のポーリングのための方法およびシステム | |
| US8117167B2 (en) | Method and data processing system with data replication | |
| JP2003280964A (ja) | スナップショット取得方法、ストレージシステム及びディスク装置 | |
| JP3617437B2 (ja) | データコピー方法およびデータコピー用プログラムを記録したプログラム記録媒体 | |
| JP3042600B2 (ja) | 分散ファイルの同期方式 | |
| WO2021169163A1 (zh) | 一种文件数据存取方法、装置和计算机可读存储介质 | |
| JP2008146408A (ja) | データ記憶装置、そのデータ再配置方法、プログラム | |
| CN120336088A (zh) | 快照回滚方法、装置、电子设备及存储介质 | |
| JP2002318717A (ja) | データベースシステム | |
| JP2005506632A (ja) | 大容量記憶装置用セキュリティ装置 | |
| KR950011056B1 (ko) | 트랜잭션 처리시스템의 로그/회복관리방법 | |
| JPH0385650A (ja) | ディスクボリューム復元方式 | |
| JPH06214839A (ja) | ファイル管理方式 | |
| JP2006189976A (ja) | 記憶装置、そのデータ処理方法、そのデータ処理プログラム及びデータ処理システム | |
| JPH11259519A (ja) | 文書登録検索方法ならびにシステムおよび同方法がプログラムされ記録される記録媒体 | |
| JP2004005524A (ja) | データ記録装置、データ記録方法、当該方法を実行するためのプログラム及びプログラム記録媒体 | |
| JP2001142772A (ja) | メモリの名称による管理方法及び複写方法並びにメモリの名称による管理プログラムを記録した媒体及び複写プログラムを記録した媒体 | |
| JPH04255040A (ja) | データベース処理装置 | |
| JPH04235645A (ja) | ファイルのバックアップ処理方式 | |
| JPH04250563A (ja) | 文書作成・管理システム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20040324 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20070821 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20070927 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20071120 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20071121 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20101130 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |