ES2701406T3 - Anticuerpos que reconocen alfa-sinucleína - Google Patents
Anticuerpos que reconocen alfa-sinucleína Download PDFInfo
- Publication number
- ES2701406T3 ES2701406T3 ES13845625T ES13845625T ES2701406T3 ES 2701406 T3 ES2701406 T3 ES 2701406T3 ES 13845625 T ES13845625 T ES 13845625T ES 13845625 T ES13845625 T ES 13845625T ES 2701406 T3 ES2701406 T3 ES 2701406T3
- Authority
- ES
- Spain
- Prior art keywords
- antibody
- seq
- antibodies
- variable region
- synuclein
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 108090000185 alpha-Synuclein Proteins 0.000 title description 36
- 102000003802 alpha-Synuclein Human genes 0.000 title 1
- NFGXHKASABOEEW-UHFFFAOYSA-N 1-methylethyl 11-methoxy-3,7,11-trimethyl-2,4-dodecadienoate Chemical compound COC(C)(C)CCCC(C)CC=CC(C)=CC(=O)OC(C)C NFGXHKASABOEEW-UHFFFAOYSA-N 0.000 claims abstract description 28
- 150000001413 amino acids Chemical class 0.000 claims description 56
- 208000009829 Lewy Body Disease Diseases 0.000 claims description 40
- 201000002832 Lewy body dementia Diseases 0.000 claims description 35
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 32
- 150000007523 nucleic acids Chemical class 0.000 claims description 31
- 238000011282 treatment Methods 0.000 claims description 23
- 108020004707 nucleic acids Proteins 0.000 claims description 19
- 102000039446 nucleic acids Human genes 0.000 claims description 19
- 239000008194 pharmaceutical composition Substances 0.000 claims description 7
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 claims description 5
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 claims description 5
- 210000004899 c-terminal region Anatomy 0.000 claims description 5
- 238000011321 prophylaxis Methods 0.000 claims description 5
- 101000834898 Homo sapiens Alpha-synuclein Proteins 0.000 claims description 3
- 239000003937 drug carrier Substances 0.000 claims description 2
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 claims 1
- 239000004472 Lysine Substances 0.000 claims 1
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 claims 1
- 238000000034 method Methods 0.000 description 66
- 102100035360 Cerebellar degeneration-related antigen 1 Human genes 0.000 description 62
- 101710117290 Aldo-keto reductase family 1 member C4 Proteins 0.000 description 59
- 235000001014 amino acid Nutrition 0.000 description 58
- 230000027455 binding Effects 0.000 description 55
- 210000004027 cell Anatomy 0.000 description 41
- 102100026882 Alpha-synuclein Human genes 0.000 description 36
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 28
- 241001529936 Murinae Species 0.000 description 27
- 230000035772 mutation Effects 0.000 description 27
- 238000006467 substitution reaction Methods 0.000 description 27
- 238000012360 testing method Methods 0.000 description 26
- 241000699666 Mus <mouse, genus> Species 0.000 description 25
- 201000010099 disease Diseases 0.000 description 25
- 108090000623 proteins and genes Proteins 0.000 description 24
- 108010076504 Protein Sorting Signals Proteins 0.000 description 22
- 210000004558 lewy body Anatomy 0.000 description 22
- 239000012634 fragment Substances 0.000 description 21
- 239000003153 chemical reaction reagent Substances 0.000 description 20
- 230000009467 reduction Effects 0.000 description 18
- 208000018737 Parkinson disease Diseases 0.000 description 15
- 230000003920 cognitive function Effects 0.000 description 15
- 235000018102 proteins Nutrition 0.000 description 15
- 102000004169 proteins and genes Human genes 0.000 description 15
- 108091007433 antigens Proteins 0.000 description 14
- 102000036639 antigens Human genes 0.000 description 14
- 238000001514 detection method Methods 0.000 description 14
- 231100000350 mutagenesis Toxicity 0.000 description 14
- 108090000765 processed proteins & peptides Proteins 0.000 description 14
- 206010067889 Dementia with Lewy bodies Diseases 0.000 description 13
- 239000000427 antigen Substances 0.000 description 13
- 238000003556 assay Methods 0.000 description 13
- 238000002703 mutagenesis Methods 0.000 description 13
- 230000002829 reductive effect Effects 0.000 description 13
- 208000001089 Multiple system atrophy Diseases 0.000 description 12
- 108091028043 Nucleic acid sequence Proteins 0.000 description 12
- 239000013598 vector Substances 0.000 description 12
- 238000010171 animal model Methods 0.000 description 11
- 230000014509 gene expression Effects 0.000 description 11
- 208000024891 symptom Diseases 0.000 description 11
- 230000000946 synaptic effect Effects 0.000 description 11
- 241000699670 Mus sp. Species 0.000 description 10
- 230000000694 effects Effects 0.000 description 10
- 238000004519 manufacturing process Methods 0.000 description 10
- 208000024827 Alzheimer disease Diseases 0.000 description 9
- 238000012347 Morris Water Maze Methods 0.000 description 8
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 8
- 235000004279 alanine Nutrition 0.000 description 8
- 210000004556 brain Anatomy 0.000 description 8
- 230000007423 decrease Effects 0.000 description 8
- 102000005962 receptors Human genes 0.000 description 8
- 108020003175 receptors Proteins 0.000 description 8
- 230000009870 specific binding Effects 0.000 description 8
- 230000001225 therapeutic effect Effects 0.000 description 8
- 108060003951 Immunoglobulin Proteins 0.000 description 7
- 102000004874 Synaptophysin Human genes 0.000 description 7
- 108090001076 Synaptophysin Proteins 0.000 description 7
- 238000009825 accumulation Methods 0.000 description 7
- 238000012867 alanine scanning Methods 0.000 description 7
- 238000004458 analytical method Methods 0.000 description 7
- 239000013604 expression vector Substances 0.000 description 7
- 230000003053 immunization Effects 0.000 description 7
- 102000018358 immunoglobulin Human genes 0.000 description 7
- 230000009261 transgenic effect Effects 0.000 description 7
- 238000002965 ELISA Methods 0.000 description 6
- 241001465754 Metazoa Species 0.000 description 6
- 230000015572 biosynthetic process Effects 0.000 description 6
- 208000010877 cognitive disease Diseases 0.000 description 6
- 238000002474 experimental method Methods 0.000 description 6
- 238000002347 injection Methods 0.000 description 6
- 239000007924 injection Substances 0.000 description 6
- 238000002372 labelling Methods 0.000 description 6
- 239000000203 mixture Substances 0.000 description 6
- 102000004196 processed proteins & peptides Human genes 0.000 description 6
- 230000004044 response Effects 0.000 description 6
- 238000001262 western blot Methods 0.000 description 6
- 241000282412 Homo Species 0.000 description 5
- 208000025535 REM sleep behavior disease Diseases 0.000 description 5
- 102000019355 Synuclein Human genes 0.000 description 5
- 108050006783 Synuclein Proteins 0.000 description 5
- 230000002776 aggregation Effects 0.000 description 5
- 238000004220 aggregation Methods 0.000 description 5
- 125000003295 alanine group Chemical group N[C@@H](C)C(=O)* 0.000 description 5
- 125000000539 amino acid group Chemical group 0.000 description 5
- 238000013459 approach Methods 0.000 description 5
- 230000003376 axonal effect Effects 0.000 description 5
- 210000003719 b-lymphocyte Anatomy 0.000 description 5
- 230000001149 cognitive effect Effects 0.000 description 5
- 230000000295 complement effect Effects 0.000 description 5
- 239000002299 complementary DNA Substances 0.000 description 5
- 238000013461 design Methods 0.000 description 5
- 238000003745 diagnosis Methods 0.000 description 5
- 230000006870 function Effects 0.000 description 5
- 230000002068 genetic effect Effects 0.000 description 5
- 238000002649 immunization Methods 0.000 description 5
- 230000002163 immunogen Effects 0.000 description 5
- 230000001404 mediated effect Effects 0.000 description 5
- 108020004999 messenger RNA Proteins 0.000 description 5
- 239000002773 nucleotide Substances 0.000 description 5
- 125000003729 nucleotide group Chemical group 0.000 description 5
- 229920001184 polypeptide Polymers 0.000 description 5
- 230000000069 prophylactic effect Effects 0.000 description 5
- 230000000717 retained effect Effects 0.000 description 5
- 239000007858 starting material Substances 0.000 description 5
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 5
- 208000028698 Cognitive impairment Diseases 0.000 description 4
- 102220622317 Huntingtin-associated protein 1_T14S_mutation Human genes 0.000 description 4
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 4
- 208000032859 Synucleinopathies Diseases 0.000 description 4
- 108700019146 Transgenes Proteins 0.000 description 4
- 230000008499 blood brain barrier function Effects 0.000 description 4
- 210000001218 blood-brain barrier Anatomy 0.000 description 4
- 239000003795 chemical substances by application Substances 0.000 description 4
- 238000010367 cloning Methods 0.000 description 4
- 238000012217 deletion Methods 0.000 description 4
- 230000037430 deletion Effects 0.000 description 4
- 239000012636 effector Substances 0.000 description 4
- 210000004408 hybridoma Anatomy 0.000 description 4
- 230000001976 improved effect Effects 0.000 description 4
- 230000002401 inhibitory effect Effects 0.000 description 4
- 238000003780 insertion Methods 0.000 description 4
- 230000037431 insertion Effects 0.000 description 4
- 102200055259 rs723044 Human genes 0.000 description 4
- 101100043731 Caenorhabditis elegans syx-3 gene Proteins 0.000 description 3
- 108020004414 DNA Proteins 0.000 description 3
- 206010012289 Dementia Diseases 0.000 description 3
- 102000047174 Disks Large Homolog 4 Human genes 0.000 description 3
- 108700019745 Disks Large Homolog 4 Proteins 0.000 description 3
- 101100535673 Drosophila melanogaster Syn gene Proteins 0.000 description 3
- 102000004190 Enzymes Human genes 0.000 description 3
- 108090000790 Enzymes Proteins 0.000 description 3
- 241000699660 Mus musculus Species 0.000 description 3
- 101100368134 Mus musculus Syn1 gene Proteins 0.000 description 3
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 3
- 230000003321 amplification Effects 0.000 description 3
- 230000000692 anti-sense effect Effects 0.000 description 3
- 230000002567 autonomic effect Effects 0.000 description 3
- 210000004227 basal ganglia Anatomy 0.000 description 3
- 238000009227 behaviour therapy Methods 0.000 description 3
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 3
- 230000001413 cellular effect Effects 0.000 description 3
- 239000000356 contaminant Substances 0.000 description 3
- 230000003013 cytotoxicity Effects 0.000 description 3
- 231100000135 cytotoxicity Toxicity 0.000 description 3
- 208000035475 disorder Diseases 0.000 description 3
- 101150069842 dlg4 gene Proteins 0.000 description 3
- 239000003623 enhancer Substances 0.000 description 3
- 238000011156 evaluation Methods 0.000 description 3
- 229940072221 immunoglobulins Drugs 0.000 description 3
- 238000009169 immunotherapy Methods 0.000 description 3
- 230000006872 improvement Effects 0.000 description 3
- 238000011503 in vivo imaging Methods 0.000 description 3
- 230000001965 increasing effect Effects 0.000 description 3
- 238000007917 intracranial administration Methods 0.000 description 3
- 238000013507 mapping Methods 0.000 description 3
- 238000005259 measurement Methods 0.000 description 3
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 3
- 210000000478 neocortex Anatomy 0.000 description 3
- 230000009871 nonspecific binding Effects 0.000 description 3
- 238000003199 nucleic acid amplification method Methods 0.000 description 3
- 238000004806 packaging method and process Methods 0.000 description 3
- 239000000047 product Substances 0.000 description 3
- 238000000159 protein binding assay Methods 0.000 description 3
- 238000003757 reverse transcription PCR Methods 0.000 description 3
- 102200024710 rs104894942 Human genes 0.000 description 3
- 102220243676 rs1555601019 Human genes 0.000 description 3
- 102220061728 rs369946779 Human genes 0.000 description 3
- 102220047535 rs587783040 Human genes 0.000 description 3
- 238000012163 sequencing technique Methods 0.000 description 3
- 231100000419 toxicity Toxicity 0.000 description 3
- 230000001988 toxicity Effects 0.000 description 3
- 238000001890 transfection Methods 0.000 description 3
- 238000011830 transgenic mouse model Methods 0.000 description 3
- 239000003981 vehicle Substances 0.000 description 3
- 241000251468 Actinopterygii Species 0.000 description 2
- 125000001433 C-terminal amino-acid group Chemical group 0.000 description 2
- 241000282832 Camelidae Species 0.000 description 2
- 108020004705 Codon Proteins 0.000 description 2
- 206010010774 Constipation Diseases 0.000 description 2
- 241000557626 Corvus corax Species 0.000 description 2
- 208000019505 Deglutition disease Diseases 0.000 description 2
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 2
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 2
- 241000713666 Lentivirus Species 0.000 description 2
- 125000000729 N-terminal amino-acid group Chemical group 0.000 description 2
- 241001494479 Pecora Species 0.000 description 2
- 102220468699 Protein arginine N-methyltransferase 3_Y87F_mutation Human genes 0.000 description 2
- 208000009106 Shy-Drager Syndrome Diseases 0.000 description 2
- 102000004584 Somatomedin Receptors Human genes 0.000 description 2
- 108010017622 Somatomedin Receptors Proteins 0.000 description 2
- 108091081024 Start codon Proteins 0.000 description 2
- 230000002159 abnormal effect Effects 0.000 description 2
- 239000002253 acid Substances 0.000 description 2
- 230000004075 alteration Effects 0.000 description 2
- 125000003277 amino group Chemical group 0.000 description 2
- 230000003302 anti-idiotype Effects 0.000 description 2
- 230000006399 behavior Effects 0.000 description 2
- 230000006736 behavioral deficit Effects 0.000 description 2
- 230000003542 behavioural effect Effects 0.000 description 2
- 230000001588 bifunctional effect Effects 0.000 description 2
- 230000003925 brain function Effects 0.000 description 2
- 210000005013 brain tissue Anatomy 0.000 description 2
- 102220352716 c.4A>G Human genes 0.000 description 2
- 230000008859 change Effects 0.000 description 2
- 231100000876 cognitive deterioration Toxicity 0.000 description 2
- 230000008878 coupling Effects 0.000 description 2
- 238000010168 coupling process Methods 0.000 description 2
- 238000005859 coupling reaction Methods 0.000 description 2
- 230000003247 decreasing effect Effects 0.000 description 2
- 230000007850 degeneration Effects 0.000 description 2
- 230000006866 deterioration Effects 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 230000018109 developmental process Effects 0.000 description 2
- VYFYYTLLBUKUHU-UHFFFAOYSA-N dopamine Chemical compound NCCC1=CC=C(O)C(O)=C1 VYFYYTLLBUKUHU-UHFFFAOYSA-N 0.000 description 2
- 230000003291 dopaminomimetic effect Effects 0.000 description 2
- 239000003814 drug Substances 0.000 description 2
- 230000009977 dual effect Effects 0.000 description 2
- 238000004520 electroporation Methods 0.000 description 2
- 230000008030 elimination Effects 0.000 description 2
- 238000003379 elimination reaction Methods 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 230000002349 favourable effect Effects 0.000 description 2
- 125000000524 functional group Chemical group 0.000 description 2
- 238000002599 functional magnetic resonance imaging Methods 0.000 description 2
- 238000003384 imaging method Methods 0.000 description 2
- 238000010324 immunological assay Methods 0.000 description 2
- NOESYZHRGYRDHS-UHFFFAOYSA-N insulin Chemical compound N1C(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(NC(=O)CN)C(C)CC)CSSCC(C(NC(CO)C(=O)NC(CC(C)C)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CCC(N)=O)C(=O)NC(CC(C)C)C(=O)NC(CCC(O)=O)C(=O)NC(CC(N)=O)C(=O)NC(CC=2C=CC(O)=CC=2)C(=O)NC(CSSCC(NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2C=CC(O)=CC=2)NC(=O)C(CC(C)C)NC(=O)C(C)NC(=O)C(CCC(O)=O)NC(=O)C(C(C)C)NC(=O)C(CC(C)C)NC(=O)C(CC=2NC=NC=2)NC(=O)C(CO)NC(=O)CNC2=O)C(=O)NCC(=O)NC(CCC(O)=O)C(=O)NC(CCCNC(N)=N)C(=O)NCC(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC=CC=3)C(=O)NC(CC=3C=CC(O)=CC=3)C(=O)NC(C(C)O)C(=O)N3C(CCC3)C(=O)NC(CCCCN)C(=O)NC(C)C(O)=O)C(=O)NC(CC(N)=O)C(O)=O)=O)NC(=O)C(C(C)CC)NC(=O)C(CO)NC(=O)C(C(C)O)NC(=O)C1CSSCC2NC(=O)C(CC(C)C)NC(=O)C(NC(=O)C(CCC(N)=O)NC(=O)C(CC(N)=O)NC(=O)C(NC(=O)C(N)CC=1C=CC=CC=1)C(C)C)CC1=CN=CN1 NOESYZHRGYRDHS-UHFFFAOYSA-N 0.000 description 2
- 238000001990 intravenous administration Methods 0.000 description 2
- 238000011835 investigation Methods 0.000 description 2
- -1 isocytochrome C Proteins 0.000 description 2
- 210000004962 mammalian cell Anatomy 0.000 description 2
- 239000003550 marker Substances 0.000 description 2
- 230000006996 mental state Effects 0.000 description 2
- 239000013642 negative control Substances 0.000 description 2
- 230000001537 neural effect Effects 0.000 description 2
- 210000002569 neuron Anatomy 0.000 description 2
- 210000004179 neuropil Anatomy 0.000 description 2
- 208000031237 olivopontocerebellar atrophy Diseases 0.000 description 2
- 210000000287 oocyte Anatomy 0.000 description 2
- 230000001575 pathological effect Effects 0.000 description 2
- 238000002823 phage display Methods 0.000 description 2
- 239000013641 positive control Substances 0.000 description 2
- 238000002600 positron emission tomography Methods 0.000 description 2
- 238000000746 purification Methods 0.000 description 2
- 230000010076 replication Effects 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 102200036624 rs104893875 Human genes 0.000 description 2
- 102200036620 rs104893878 Human genes 0.000 description 2
- 102200156936 rs28934878 Human genes 0.000 description 2
- 102220222437 rs764367878 Human genes 0.000 description 2
- 238000002603 single-photon emission computed tomography Methods 0.000 description 2
- 239000000243 solution Substances 0.000 description 2
- 239000002904 solvent Substances 0.000 description 2
- 241000894007 species Species 0.000 description 2
- 208000003755 striatonigral degeneration Diseases 0.000 description 2
- 238000007920 subcutaneous administration Methods 0.000 description 2
- 239000000126 substance Substances 0.000 description 2
- 210000000225 synapse Anatomy 0.000 description 2
- 238000002424 x-ray crystallography Methods 0.000 description 2
- OWEGMIWEEQEYGQ-UHFFFAOYSA-N 100676-05-9 Natural products OC1C(O)C(O)C(CO)OC1OCC1C(O)C(O)C(O)C(OC2C(OC(O)C(O)C2O)CO)O1 OWEGMIWEEQEYGQ-UHFFFAOYSA-N 0.000 description 1
- OSJPPGNTCRNQQC-UWTATZPHSA-N 3-phospho-D-glyceric acid Chemical compound OC(=O)[C@H](O)COP(O)(O)=O OSJPPGNTCRNQQC-UWTATZPHSA-N 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- 102000007698 Alcohol dehydrogenase Human genes 0.000 description 1
- 108010021809 Alcohol dehydrogenase Proteins 0.000 description 1
- 102100028116 Amine oxidase [flavin-containing] B Human genes 0.000 description 1
- 208000007415 Anhedonia Diseases 0.000 description 1
- 206010002653 Anosmia Diseases 0.000 description 1
- 108010032595 Antibody Binding Sites Proteins 0.000 description 1
- 208000019901 Anxiety disease Diseases 0.000 description 1
- 206010002942 Apathy Diseases 0.000 description 1
- 102000013918 Apolipoproteins E Human genes 0.000 description 1
- 108010025628 Apolipoproteins E Proteins 0.000 description 1
- 206010003694 Atrophy Diseases 0.000 description 1
- 102220549033 B-cell linker protein_Y91F_mutation Human genes 0.000 description 1
- 102000000119 Beta-lactoglobulin Human genes 0.000 description 1
- 241000701822 Bovine papillomavirus Species 0.000 description 1
- 206010006100 Bradykinesia Diseases 0.000 description 1
- 101100476210 Caenorhabditis elegans rnt-1 gene Proteins 0.000 description 1
- UXVMQQNJUSDDNG-UHFFFAOYSA-L Calcium chloride Chemical compound [Cl-].[Cl-].[Ca+2] UXVMQQNJUSDDNG-UHFFFAOYSA-L 0.000 description 1
- 102000014914 Carrier Proteins Human genes 0.000 description 1
- 108010047041 Complementarity Determining Regions Proteins 0.000 description 1
- 108091035707 Consensus sequence Proteins 0.000 description 1
- 241000699802 Cricetulus griseus Species 0.000 description 1
- 102000008130 Cyclic AMP-Dependent Protein Kinases Human genes 0.000 description 1
- 108010049894 Cyclic AMP-Dependent Protein Kinases Proteins 0.000 description 1
- 108010001237 Cytochrome P-450 CYP2D6 Proteins 0.000 description 1
- 102100021704 Cytochrome P450 2D6 Human genes 0.000 description 1
- 241000701022 Cytomegalovirus Species 0.000 description 1
- 208000003164 Diplopia Diseases 0.000 description 1
- 241000255925 Diptera Species 0.000 description 1
- 208000007590 Disorders of Excessive Somnolence Diseases 0.000 description 1
- 241000255581 Drosophila <fruit fly, genus> Species 0.000 description 1
- 238000012286 ELISA Assay Methods 0.000 description 1
- YQYJSBFKSSDGFO-UHFFFAOYSA-N Epihygromycin Natural products OC1C(O)C(C(=O)C)OC1OC(C(=C1)O)=CC=C1C=C(C)C(=O)NC1C(O)C(O)C2OCOC2C1O YQYJSBFKSSDGFO-UHFFFAOYSA-N 0.000 description 1
- 241000588724 Escherichia coli Species 0.000 description 1
- 208000034347 Faecal incontinence Diseases 0.000 description 1
- 102000009109 Fc receptors Human genes 0.000 description 1
- 108010087819 Fc receptors Proteins 0.000 description 1
- 241000251152 Ginglymostoma cirratum Species 0.000 description 1
- 208000004547 Hallucinations Diseases 0.000 description 1
- 239000012981 Hank's balanced salt solution Substances 0.000 description 1
- GVGLGOZIDCSQPN-PVHGPHFFSA-N Heroin Chemical compound O([C@H]1[C@H](C=C[C@H]23)OC(C)=O)C4=C5[C@@]12CCN(C)[C@@H]3CC5=CC=C4OC(C)=O GVGLGOZIDCSQPN-PVHGPHFFSA-N 0.000 description 1
- 229920000209 Hexadimethrine bromide Polymers 0.000 description 1
- 238000011993 High Performance Size Exclusion Chromatography Methods 0.000 description 1
- 101000619542 Homo sapiens E3 ubiquitin-protein ligase parkin Proteins 0.000 description 1
- 208000006083 Hypokinesia Diseases 0.000 description 1
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 1
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 1
- 108700005091 Immunoglobulin Genes Proteins 0.000 description 1
- 102000004877 Insulin Human genes 0.000 description 1
- 108090001061 Insulin Proteins 0.000 description 1
- WTDRDQBEARUVNC-LURJTMIESA-N L-DOPA Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C(O)=C1 WTDRDQBEARUVNC-LURJTMIESA-N 0.000 description 1
- WTDRDQBEARUVNC-UHFFFAOYSA-N L-Dopa Natural products OC(=O)C(N)CC1=CC=C(O)C(O)=C1 WTDRDQBEARUVNC-UHFFFAOYSA-N 0.000 description 1
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 1
- 108010060630 Lactoglobulins Proteins 0.000 description 1
- 102000011965 Lipoprotein Receptors Human genes 0.000 description 1
- 108010061306 Lipoprotein Receptors Proteins 0.000 description 1
- 241000829100 Macaca mulatta polyomavirus 1 Species 0.000 description 1
- GUBGYTABKSRVRQ-PICCSMPSSA-N Maltose Natural products O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@@H](CO)OC(O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-PICCSMPSSA-N 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 108010062431 Monoamine oxidase Proteins 0.000 description 1
- 208000016285 Movement disease Diseases 0.000 description 1
- 229940121948 Muscarinic receptor antagonist Drugs 0.000 description 1
- 206010052904 Musculoskeletal stiffness Diseases 0.000 description 1
- 238000005481 NMR spectroscopy Methods 0.000 description 1
- 206010028980 Neoplasm Diseases 0.000 description 1
- 108091034117 Oligonucleotide Proteins 0.000 description 1
- 108700026244 Open Reading Frames Proteins 0.000 description 1
- 206010031127 Orthostatic hypotension Diseases 0.000 description 1
- 208000002192 Parkinson disease 3 Diseases 0.000 description 1
- 208000027089 Parkinsonian disease Diseases 0.000 description 1
- 206010034010 Parkinsonism Diseases 0.000 description 1
- 108091000080 Phosphotransferase Proteins 0.000 description 1
- 206010035226 Plasma cell myeloma Diseases 0.000 description 1
- 208000009144 Pure autonomic failure Diseases 0.000 description 1
- 108020005067 RNA Splice Sites Proteins 0.000 description 1
- 108020004511 Recombinant DNA Proteins 0.000 description 1
- 206010071390 Resting tremor Diseases 0.000 description 1
- 208000005793 Restless legs syndrome Diseases 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- 241000235070 Saccharomyces Species 0.000 description 1
- 206010039424 Salivary hypersecretion Diseases 0.000 description 1
- 241000239226 Scorpiones Species 0.000 description 1
- 206010039792 Seborrhoea Diseases 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- 201000001880 Sexual dysfunction Diseases 0.000 description 1
- 208000008630 Sialorrhea Diseases 0.000 description 1
- 208000013738 Sleep Initiation and Maintenance disease Diseases 0.000 description 1
- 210000001744 T-lymphocyte Anatomy 0.000 description 1
- 102000007238 Transferrin Receptors Human genes 0.000 description 1
- 108010033576 Transferrin Receptors Proteins 0.000 description 1
- 206010044565 Tremor Diseases 0.000 description 1
- 101000980463 Treponema pallidum (strain Nichols) Chaperonin GroEL Proteins 0.000 description 1
- CGWAPUBOXJWXMS-HOTGVXAUSA-N Tyr-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 CGWAPUBOXJWXMS-HOTGVXAUSA-N 0.000 description 1
- 238000005411 Van der Waals force Methods 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- 206010047513 Vision blurred Diseases 0.000 description 1
- 238000012452 Xenomouse strains Methods 0.000 description 1
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 1
- 239000008351 acetate buffer Substances 0.000 description 1
- OIPILFWXSMYKGL-UHFFFAOYSA-N acetylcholine Chemical compound CC(=O)OCC[N+](C)(C)C OIPILFWXSMYKGL-UHFFFAOYSA-N 0.000 description 1
- 229960004373 acetylcholine Drugs 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 238000001042 affinity chromatography Methods 0.000 description 1
- 230000032683 aging Effects 0.000 description 1
- WQZGKKKJIJFFOK-PHYPRBDBSA-N alpha-D-galactose Chemical compound OC[C@H]1O[C@H](O)[C@H](O)[C@@H](O)[C@H]1O WQZGKKKJIJFFOK-PHYPRBDBSA-N 0.000 description 1
- VREFGVBLTWBCJP-UHFFFAOYSA-N alprazolam Chemical compound C12=CC(Cl)=CC=C2N2C(C)=NN=C2CN=C1C1=CC=CC=C1 VREFGVBLTWBCJP-UHFFFAOYSA-N 0.000 description 1
- DKNWSYNQZKUICI-UHFFFAOYSA-N amantadine Chemical compound C1C(C2)CC3CC2CC1(N)C3 DKNWSYNQZKUICI-UHFFFAOYSA-N 0.000 description 1
- 229960003805 amantadine Drugs 0.000 description 1
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 1
- 229960000723 ampicillin Drugs 0.000 description 1
- 230000005875 antibody response Effects 0.000 description 1
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 description 1
- 230000036506 anxiety Effects 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- 125000003118 aryl group Chemical group 0.000 description 1
- 230000037444 atrophy Effects 0.000 description 1
- 208000031326 autosomal dominant parkinson disease 3 Diseases 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- GUBGYTABKSRVRQ-QUYVBRFLSA-N beta-maltose Chemical compound OC[C@H]1O[C@H](O[C@H]2[C@H](O)[C@@H](O)[C@H](O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@@H]1O GUBGYTABKSRVRQ-QUYVBRFLSA-N 0.000 description 1
- 108091008324 binding proteins Proteins 0.000 description 1
- 238000011325 biochemical measurement Methods 0.000 description 1
- 208000029162 bladder disease Diseases 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 230000037396 body weight Effects 0.000 description 1
- 239000000872 buffer Substances 0.000 description 1
- 239000001110 calcium chloride Substances 0.000 description 1
- 229910001628 calcium chloride Inorganic materials 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- 201000011510 cancer Diseases 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 239000005018 casein Substances 0.000 description 1
- BECPQYXYKAMYBN-UHFFFAOYSA-N casein, tech. Chemical compound NCCCCC(C(O)=O)N=C(O)C(CC(O)=O)N=C(O)C(CCC(O)=N)N=C(O)C(CC(C)C)N=C(O)C(CCC(O)=O)N=C(O)C(CC(O)=O)N=C(O)C(CCC(O)=O)N=C(O)C(C(C)O)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=N)N=C(O)C(CCC(O)=O)N=C(O)C(CCC(O)=O)N=C(O)C(COP(O)(O)=O)N=C(O)C(CCC(O)=N)N=C(O)C(N)CC1=CC=CC=C1 BECPQYXYKAMYBN-UHFFFAOYSA-N 0.000 description 1
- 235000021240 caseins Nutrition 0.000 description 1
- 239000003543 catechol methyltransferase inhibitor Substances 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 239000006143 cell culture medium Substances 0.000 description 1
- 230000003727 cerebral blood flow Effects 0.000 description 1
- 230000008455 cerebrovascular function Effects 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 1
- 239000000812 cholinergic antagonist Substances 0.000 description 1
- 239000013611 chromosomal DNA Substances 0.000 description 1
- 238000003759 clinical diagnosis Methods 0.000 description 1
- 230000007278 cognition impairment Effects 0.000 description 1
- 230000003931 cognitive performance Effects 0.000 description 1
- 238000004440 column chromatography Methods 0.000 description 1
- 238000012875 competitive assay Methods 0.000 description 1
- 230000009137 competitive binding Effects 0.000 description 1
- 230000002860 competitive effect Effects 0.000 description 1
- 239000003636 conditioned culture medium Substances 0.000 description 1
- 230000003750 conditioning effect Effects 0.000 description 1
- 238000012258 culturing Methods 0.000 description 1
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 1
- 230000009089 cytolysis Effects 0.000 description 1
- 230000007812 deficiency Effects 0.000 description 1
- 230000006735 deficit Effects 0.000 description 1
- 210000001787 dendrite Anatomy 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000002405 diagnostic procedure Methods 0.000 description 1
- 239000003085 diluting agent Substances 0.000 description 1
- 238000006471 dimerization reaction Methods 0.000 description 1
- 238000000375 direct analysis in real time Methods 0.000 description 1
- 239000002270 dispersing agent Substances 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 229960003638 dopamine Drugs 0.000 description 1
- 229940052760 dopamine agonists Drugs 0.000 description 1
- 239000003136 dopamine receptor stimulating agent Substances 0.000 description 1
- 239000002552 dosage form Substances 0.000 description 1
- 238000005553 drilling Methods 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 238000012063 dual-affinity re-targeting Methods 0.000 description 1
- 210000001671 embryonic stem cell Anatomy 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 206010016256 fatigue Diseases 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 1
- 239000007850 fluorescent dye Substances 0.000 description 1
- 238000009472 formulation Methods 0.000 description 1
- 230000005714 functional activity Effects 0.000 description 1
- 238000002825 functional assay Methods 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 230000005021 gait Effects 0.000 description 1
- 229930182830 galactose Natural products 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 210000004602 germ cell Anatomy 0.000 description 1
- 230000002518 glial effect Effects 0.000 description 1
- 102000034238 globular proteins Human genes 0.000 description 1
- 108091005896 globular proteins Proteins 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 230000002414 glycolytic effect Effects 0.000 description 1
- 230000013595 glycosylation Effects 0.000 description 1
- 238000006206 glycosylation reaction Methods 0.000 description 1
- 230000012010 growth Effects 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 238000004128 high performance liquid chromatography Methods 0.000 description 1
- 210000001320 hippocampus Anatomy 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 206010020765 hypersomnia Diseases 0.000 description 1
- 230000001900 immune effect Effects 0.000 description 1
- 238000003018 immunoassay Methods 0.000 description 1
- 230000005847 immunogenicity Effects 0.000 description 1
- 230000016784 immunoglobulin production Effects 0.000 description 1
- 238000003364 immunohistochemistry Methods 0.000 description 1
- 238000001114 immunoprecipitation Methods 0.000 description 1
- 230000005022 impaired gait Effects 0.000 description 1
- 238000000338 in vitro Methods 0.000 description 1
- 238000001727 in vivo Methods 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 239000003112 inhibitor Substances 0.000 description 1
- 230000005764 inhibitory process Effects 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 206010022437 insomnia Diseases 0.000 description 1
- 229940125396 insulin Drugs 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 238000007913 intrathecal administration Methods 0.000 description 1
- 238000010253 intravenous injection Methods 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 210000003292 kidney cell Anatomy 0.000 description 1
- 102000005861 leptin receptors Human genes 0.000 description 1
- 108010019813 leptin receptors Proteins 0.000 description 1
- 229960004502 levodopa Drugs 0.000 description 1
- 238000001638 lipofection Methods 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 230000033001 locomotion Effects 0.000 description 1
- 210000005075 mammary gland Anatomy 0.000 description 1
- 238000004949 mass spectrometry Methods 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 238000002483 medication Methods 0.000 description 1
- 230000007334 memory performance Effects 0.000 description 1
- 230000003923 mental ability Effects 0.000 description 1
- 230000003924 mental process Effects 0.000 description 1
- 229930182817 methionine Natural products 0.000 description 1
- 238000000520 microinjection Methods 0.000 description 1
- 235000013336 milk Nutrition 0.000 description 1
- 239000008267 milk Substances 0.000 description 1
- 210000004080 milk Anatomy 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000000302 molecular modelling Methods 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 230000000877 morphologic effect Effects 0.000 description 1
- 210000003205 muscle Anatomy 0.000 description 1
- 230000000869 mutational effect Effects 0.000 description 1
- 201000000050 myeloid neoplasm Diseases 0.000 description 1
- 210000002241 neurite Anatomy 0.000 description 1
- 208000011851 neurological alteration Diseases 0.000 description 1
- 230000007996 neuronal plasticity Effects 0.000 description 1
- 230000002981 neuropathic effect Effects 0.000 description 1
- 230000007171 neuropathology Effects 0.000 description 1
- 230000003557 neuropsychological effect Effects 0.000 description 1
- 238000010855 neuropsychological testing Methods 0.000 description 1
- 231100000189 neurotoxic Toxicity 0.000 description 1
- 230000002887 neurotoxic effect Effects 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 238000013364 oligosaccharide-mapping technique Methods 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 230000002018 overexpression Effects 0.000 description 1
- 239000005022 packaging material Substances 0.000 description 1
- 230000005298 paramagnetic effect Effects 0.000 description 1
- 238000007911 parenteral administration Methods 0.000 description 1
- 230000008506 pathogenesis Effects 0.000 description 1
- 239000000863 peptide conjugate Substances 0.000 description 1
- 230000000737 periodic effect Effects 0.000 description 1
- 239000000546 pharmaceutical excipient Substances 0.000 description 1
- 230000003285 pharmacodynamic effect Effects 0.000 description 1
- 102000020233 phosphotransferase Human genes 0.000 description 1
- 230000035790 physiological processes and functions Effects 0.000 description 1
- 239000002504 physiological saline solution Substances 0.000 description 1
- 239000000902 placebo Substances 0.000 description 1
- 229940068196 placebo Drugs 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 230000001144 postural effect Effects 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 238000004321 preservation Methods 0.000 description 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 1
- 238000012545 processing Methods 0.000 description 1
- 230000007425 progressive decline Effects 0.000 description 1
- 230000000750 progressive effect Effects 0.000 description 1
- 210000001236 prokaryotic cell Anatomy 0.000 description 1
- 230000002035 prolonged effect Effects 0.000 description 1
- 230000001902 propagating effect Effects 0.000 description 1
- 238000001742 protein purification Methods 0.000 description 1
- 210000001938 protoplast Anatomy 0.000 description 1
- 230000002285 radioactive effect Effects 0.000 description 1
- 230000036385 rapid eye movement (rem) sleep Effects 0.000 description 1
- 230000035484 reaction time Effects 0.000 description 1
- 238000003259 recombinant expression Methods 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 238000011808 rodent model Methods 0.000 description 1
- 102200036626 rs104893877 Human genes 0.000 description 1
- 102220054995 rs373913704 Human genes 0.000 description 1
- 102220270128 rs781438362 Human genes 0.000 description 1
- 102200036566 rs80356715 Human genes 0.000 description 1
- 239000000523 sample Substances 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 208000008742 seborrheic dermatitis Diseases 0.000 description 1
- 230000003248 secreting effect Effects 0.000 description 1
- 230000035807 sensation Effects 0.000 description 1
- 230000001953 sensory effect Effects 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 239000004017 serum-free culture medium Substances 0.000 description 1
- 231100000872 sexual dysfunction Toxicity 0.000 description 1
- 210000003625 skull Anatomy 0.000 description 1
- 208000019116 sleep disease Diseases 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 125000006850 spacer group Chemical group 0.000 description 1
- 239000003381 stabilizer Substances 0.000 description 1
- 230000000087 stabilizing effect Effects 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 238000012030 stroop test Methods 0.000 description 1
- 210000003523 substantia nigra Anatomy 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 238000011477 surgical intervention Methods 0.000 description 1
- 239000000375 suspending agent Substances 0.000 description 1
- 230000009182 swimming Effects 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 230000009897 systematic effect Effects 0.000 description 1
- 229940124597 therapeutic agent Drugs 0.000 description 1
- 230000004797 therapeutic response Effects 0.000 description 1
- 210000001519 tissue Anatomy 0.000 description 1
- 238000003325 tomography Methods 0.000 description 1
- 230000000699 topical effect Effects 0.000 description 1
- 231100000331 toxic Toxicity 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 238000012549 training Methods 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 230000031998 transcytosis Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 238000012301 transgenic model Methods 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 230000014621 translational initiation Effects 0.000 description 1
- 238000011269 treatment regimen Methods 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- 241000701161 unidentified adenovirus Species 0.000 description 1
- 238000012795 verification Methods 0.000 description 1
- 239000002699 waste material Substances 0.000 description 1
- 230000003442 weekly effect Effects 0.000 description 1
- 230000004584 weight gain Effects 0.000 description 1
- 230000004580 weight loss Effects 0.000 description 1
Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K49/00—Preparations for testing in vivo
- A61K49/0004—Screening or testing of compounds for diagnosis of disorders, assessment of conditions, e.g. renal clearance, gastric emptying, testing for diabetes, allergy, rheuma, pancreas functions
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/14—Drugs for disorders of the nervous system for treating abnormal movements, e.g. chorea, dyskinesia
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/14—Drugs for disorders of the nervous system for treating abnormal movements, e.g. chorea, dyskinesia
- A61P25/16—Anti-Parkinson drugs
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/20—Hypnotics; Sedatives
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/28—Drugs for disorders of the nervous system for treating neurodegenerative disorders of the central nervous system, e.g. nootropic agents, cognition enhancers, drugs for treating Alzheimer's disease or other forms of dementia
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/60—Medicinal preparations containing antigens or antibodies characteristics by the carrier linked to the antigen
- A61K2039/6031—Proteins
- A61K2039/6056—Antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/10—Immunoglobulins specific features characterized by their source of isolation or production
- C07K2317/14—Specific host cells or culture conditions, e.g. components, pH or temperature
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/24—Immunoglobulins specific features characterized by taxonomic origin containing regions, domains or residues from different species, e.g. chimeric, humanized or veneered
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/34—Identification of a linear epitope shorter than 20 amino acid residues or of a conformational epitope defined by amino acid residues
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/52—Constant or Fc region; Isotype
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/55—Fab or Fab'
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/567—Framework region [FR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/68—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids
- G01N33/6893—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids related to diseases not provided for elsewhere
- G01N33/6896—Neurological disorders, e.g. Alzheimer's disease
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Organic Chemistry (AREA)
- Biomedical Technology (AREA)
- Medicinal Chemistry (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Veterinary Medicine (AREA)
- Neurology (AREA)
- Neurosurgery (AREA)
- Immunology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Molecular Biology (AREA)
- Pharmacology & Pharmacy (AREA)
- Biochemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Urology & Nephrology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Genetics & Genomics (AREA)
- Biophysics (AREA)
- Pathology (AREA)
- Epidemiology (AREA)
- Diabetes (AREA)
- Endocrinology (AREA)
- Gastroenterology & Hepatology (AREA)
- Rheumatology (AREA)
- Toxicology (AREA)
- Microbiology (AREA)
- Hematology (AREA)
- Psychology (AREA)
- Biotechnology (AREA)
- Physics & Mathematics (AREA)
- Analytical Chemistry (AREA)
- General Physics & Mathematics (AREA)
- Cell Biology (AREA)
Abstract
Un anticuerpo que comprende tres CDRs de cadena ligera como lo define Kabat que tienen secuencias de SEQ ID NOs: 25-27 y tres CDRs de cadena pesada como lo define Kabat que tienen secuencias de SEQ ID NOs: 10-12
Description
DESCRIPCIÓN
Anticuerpos que reconocen alfa-sinucleína
Antecedentes
Las sinucleinopatías, también conocidas como enfermedades del cuerpo de Lewy (LBDs), se caracterizan por la degeneración del sistema dopaminérgico, las alteraciones motoras, el deterioro cognitivo y la formación de cuerpos de Lewy (LBs) y/o neuritas de Lewy. (McKeith et al. Neurology (1996) 47:1113-24). Las sinucleinopatías incluyen la enfermedad de Parkinson (incluyendo la enfermedad de Parkinson idiopática), la enfermedad difusa del cuerpo de Lewy (DLBD) también conocida como demencia de los cuerpos de Lewy (DLB), la variante de cuerpo de Lewy de la enfermedad de Alzheimer (LBV), la enfermedad de Alzheimer y Parkinson combinadas, la insuficiencia autonómica pura y múltiples atrofias del sistema (MSA; por ejemplo, atrofia olivopontocerebelosa, degeneración estriatonigral y síndrome de Shy-Drager). Se piensa que varios signos y síntomas no motores son precursores de las sinucleinopatías en la fase prodrómica de las enfermedades (es decir, el período presintomático, subclínico, preclínico o premotor). Dichos signos tempranos incluyen, por ejemplo, el trastorno del comportamiento del sueño REM (RBD), la pérdida de olfato y el estreñimiento (Mahowald et al., Neurology (2010) 75: 488-489). Las enfermedades del cuerpo de Lewy continúan siendo una causa común de trastornos del movimiento y deterioro cognitivo en el envejecimiento de la población (Galasko et al., Arch. Neurol. (1994) 51: 888-95).
La a-sinucleína es parte de una gran familia de proteínas que incluye la p-sinucleína y la Y-sinucleína y la sinoretina. La a-sinucleína se expresa en el estado normal asociado con la sinapsis y se cree que desempeña un papel en la plasticidad neural, el aprendizaje y la memoria. Varios estudios han implicado a la a-sinucleína con un papel central en la patogénesis de la PD. La proteína puede agregarse para formar fibrillas insolubles en afecciones patológicas. Por ejemplo, la sinucleína se acumula en los LBs (Spillantini et al., Nature (1997) 388: 839-40; Takeda et al., J. Pathol. (1998) 152: 367-72; Wakabayashi et al., Neurosci. Lett. (1997) 239: 45-8). Las mutaciones en el gen de la asinucleína se co-segregan con formas familiares raras de parkisonismo (Kruger et al., Nature Gen. (1998) 18: 106-8; Polymeropoulos et al., Science (1997) 276: 2045-7). La sobreexpresión de la a-sinucleína en ratones transgénicos (Masliah et al., Science (2000) 287:1265-9) y Drosofila (Feany et al., Nature (2000) 404: 394-8) imita varios aspectos patológicos de la enfermedad de los cuerpos de Lewy. Además, se ha sugerido que los oligómeros de sinucleína solubles pueden ser neurotóxicos (Conway et al., Proc Natl Acad Sci USA (2000) 97: 571-576; Volles et al., J. Biochem. (2003) 42: 7871-7878). La acumulación de a-sinucleína con alteraciones morfológicas y neurológicas similares en especies y modelos animales tan diversos como humanos, ratones, y moscas sugiere que esta molécula contribuye al desarrollo de la enfermedad de los cuerpos de Lewy.
El documento de Patente US 2009/0208487 se refiere a anticuerpos terapéuticos, designados como 9E4 y 1H7. El anticuerpo 9E4 se une predominantemente a los residuos 122 y 125 de la a-sinucleína. El anticuerpo 1H7 se une predominantemente a los residuos 91-97 de la a-sinucleína. Ambos anticuerpos 9E4 y 1H7 se produjeron por inmunización con a-sinucleína de longitud completa.
El documento de Patente WO 2008/103472 se refiere también a un anticuerpo terapéutico, designado como 9E4. Choi et al (2006) Neuroscience Letters 397: 53-58 se refieren a un anticuerpo, designado como Syn-1, que se produjo por inmunización con a-sinucleína de longitud completa, utilizado en el mapeo de epítopos. Se puede entender que Syn-1 se une a un epítopo que incluye los residuos 121 y 122 de la a-sincucleína debido a su especificidad por la forma humana de la a-sinucleína y estos residuos difieren entre la a-sinucleína humana y la de los roedores. Sin embargo, no se sabe de qué otros residuos contribuyen al epítopo de Syn-1.
Compendio de la invención reivindicada
La invención proporciona un anticuerpo que comprende tres CDRs de cadena ligera según lo definido por Kabat que tiene secuencias de SEQ ID NOs: 25-27 y tres CDRs de cadena pesada según lo definido por Kabat que tiene secuencias SEQ ID NOs: 10-12. Opcionalmente, el anticuerpo es una forma humanizada, quimérica o chapada de un anticuerpo monoclonal 5C1. Opcionalmente, el anticuerpo es un fragmento Fab, o un Fv monocatenario. Opcionalmente, el anticuerpo tiene un isotipo de IgG1 humana. Opcionalmente, el anticuerpo tiene un isotipo del isotipo IgG2 o IgG4 humano.
La invención proporciona un anticuerpo que comprende una región variable de cadena pesada madura que tiene una secuencia de aminoácidos al menos un 90% idéntica a H4 (SEQ ID NO: 17) y una región variable de cadena ligera madura que tiene una secuencia de aminoácidos al menos un 90% idéntica a L3 (SEQ ID NO: 31), en donde el anticuerpo se une específicamente a una alfa-sinucleína humana. En algunos anticuerpos al menos una de las posiciones H11, H27, H30, H48, y H73 está ocupada por L, Y, T, I, y K, respectivamente, y al menos una de las posiciones L12 y L14 está ocupada por S. En algunos anticuerpos las posiciones H11, H27, H30, H48, y H73 están ocupadas por L, Y, T, I, y K, respectivamente y las posiciones L12 y L14 están ocupadas por S. En algunos anticuerpos, al menos una de las posiciones H67, H69, H91, y H94 están ocupadas por A, L, F, y S, respectivamente. En algunos anticuerpos las posiciones H67, h69, y H94 están ocupadas por A, L, y S, respectivamente. En algunos anticuerpos, la posición H94 está ocupada por S. En algunos anticuerpos, al menos una de las posiciones L2, L45, L49, y L87 está ocupada por V, K, N, y F, respectivamente. En algunos anticuerpos,
las posiciones L2, L49, y L87 están ocupadas por V, N, y F, respectivamente. Algunos anticuerpos comprenden una región variable de cadena pesada madura que tiene una secuencia de aminoácidos al menos un 95% idéntica a H4 (SEQ ID NO: 17) y una región variable de cadena ligera madura al menos un 95% idéntica a L3 (SEQ ID NO: 31). Algunos anticuerpos comprenden la región variable de cadena pesada madura que tiene una secuencia de aminoácidos designada como H4 (SEQ ID NO: 17) y la región variable de cadena ligera madura que tiene una secuencia de aminoácidos designada como L3 (SEQ ID NO: 31). Algunos anticuerpos comprenden la región variable de cadena pesada madura que tiene una secuencia de aminoácidos designada como h5 (SEQ ID NO: 18) y una región variable de cadena ligera madura que tiene una secuencia de aminoácidos designada como L3 (SEQ ID NO: 31).
En cualquiera de los anticuerpos anteriores, el anticuerpo puede tener al menos una mutación en la región constante. Opcionalmente, la mutación reduce la fijación o activación del complemento por la región constante. Opcionalmente, el anticuerpo tiene una mutación en una o más de las posiciones 241, 264, 265, 270, 296, 297, 322, 329 y 331 según la numeración de la EU. Opcionalmente, el anticuerpo tiene alanina en las posiciones 318, 320 y 3 En cualquiera de los anticuerpos anteriores, la región variable de cadena pesada madura se puede unir a una región constante de cadena pesada y la región constante de cadena ligera madura se puede unir a una región constante de cadena ligera.
En cualquiera de los anticuerpos anteriores, la región constante de cadena pesada puede ser una forma mutante de la región constante humana natural que tiene una unión reducida a un receptor Fcy con respecto a la región constante humana natural.
En cualquiera de los anticuerpos anteriores, la región constante de cadena pesada puede ser del isotipo IgG1 humano. En algunos anticuerpos el alotipo es G1m3. En algunos anticuerpos, el alotipo es G1m1.
La descripción proporciona también un método para humanizar un anticuerpo, que comprende determinar las secuencias de las regiones variables de las cadenas pesada y ligera de un anticuerpo 5C1 de ratón, sintetizando un ácido nucleico que codifica una cadena pesada humanizada que comprende las CDRs de la cadena pesada del anticuerpo de ratón y un ácido nucleico que codifica una cadena ligera humanizada que comprende las CDRs de la cadena ligera del anticuerpo de ratón, expresando los ácidos nucleicos en una célula huésped para producir un anticuerpo humanizado.
La descripción proporciona también un método para producir una forma humanizada, quimérica o chapada del anticuerpo 5C1, que comprende cultivar las células transformadas con ácidos nucleicos que codifican las cadenas pesada y ligera del anticuerpo, de modo que la célula secrete el anticuerpo; y purificar el anticuerpo a partir del medio de cultivo celular.
La descripción proporciona también un método para producir una línea celular que produce una forma humanizada, quimérica o chapada del anticuerpo 5C1, que comprende introducir un vector que codifica las cadenas pesada y ligera de un anticuerpo y un marcador seleccionable en las células; propagar las células en condiciones para seleccionar las células que tengan un mayor número de copias del vector; aislar las células individuales a partir de las células seleccionadas; y bancar las células clonadas a partir de una célula individual seleccionada en función del rendimiento del anticuerpo. Alguno de dichos métodos comprende además propagar las células bajo condiciones selectivas y detectar las líneas celulares que se expresan de forma natural y secretan al menos 100 mg/L/106 células/24 horas.
La invención proporciona además una composición farmacéutica que comprende un anticuerpo como se definió anteriormente y un vehículo farmacéuticamente aceptable.
La invención proporciona además un anticuerpo como se definió anteriormente para su uso en el tratamiento o la realización de la profilaxis de una enfermedad del cuerpo de Lewy.
La descripción proporciona además un método para reducir la formación de cuerpos de Lewy en un paciente que tiene o está en riesgo de contraer una enfermedad de cuerpos de Lewy, que comprende administrar al paciente una cantidad efectiva de uno cualquiera de los anticuerpos mencionados anteriormente.
La descripción proporciona además un método para tratar un paciente que tiene o está en riesgo de contraer una enfermedad de cuerpos de Lewy, que comprende administrar al paciente un régimen efectivo de uno cualquiera de los anticuerpos mencionados anteriormente. En algunos métodos, la enfermedad es la enfermedad de Parkinson. En algunos métodos, la enfermedad es un trastorno del comportamiento del sueño REM (RBD). En algunos métodos, la enfermedad es la demencia con cuerpos de Lewy (DLB) o atrofia de sistemas múltiples (MSA). En algunos métodos, se inhibe la disminución de la función cognitiva en el paciente. En algunos métodos, se reducen los agregados de alfa-sinucleína neuríticos y/o axonales. En algunos métodos, se reduce la distrofia neurítica en el paciente. En algunos métodos, se conserva la densidad sináptica y/o dendrítica. En algunos métodos, el método conserva la sinaptofisina y/o MAP2 en el paciente.
La descripción proporciona además un método para inhibir la agregación de sinucleína o reducir los cuerpos de Lewy o agregados de sinucleína en un paciente que tiene o está en riesgo de contraer una enfermedad de cuerpos de Lewy, que comprende administrar al paciente una cantidad efectiva de un anticuerpo como se definió mediante uno cualquiera de los anticuerpos mencionados anteriormente. En alguno de dichos métodos, la enfermedad es la enfermedad de Parkinson. En algunos métodos, se inhibe la disminución de la función cognitiva del paciente. En algunos métodos, se reducen los agregados de alfa-sinucleína neuríticos y/o axonales. En algunos métodos, se reduce la distrofia neurítica en el paciente. En algunos métodos, se conserva la densidad sináptica y/o dendrítica. En algunos métodos, el método conserva la sinaptofisina y/o MAP2 en el paciente.
La descripción proporciona además un método para detectar los cuerpos de Lewy en un paciente que tiene o está en riesgo de contraer una enfermedad de cuerpos de Lewy, que comprende administrar al paciente una cantidad efectiva de uno cualquiera de los anticuerpos mencionados anteriormente, en donde el anticuerpo se une a los cuerpos de Lewy; y detectar los cuerpos unidos en el paciente. Opcionalmente, el anticuerpo está marcado.
La invención proporciona además un ácido nucleico aislado, que codifica las cadenas pesadas y/o ligeras de un anticuerpo como se describió anteriormente. La descripción proporciona además un vector o vectores, y células huésped adecuadas para codificar uno cualquiera de los anticuerpos mencionados anteriormente.
Breve descripción de los dibujos
La Figura 1 muestra las secuencias de aminoácidos de la región variable madura de cadena pesada 5C1 de ratón. Las regiones CDR según la definición de Kabat están subrayadas y en negrita.
La Figura 2 muestra las secuencias de aminoácidos de la región variable madura de cadena ligera 5C1 de ratón. Las regiones CDR según la definición de Kabat están subrayadas y en negrita.
La Figura 3 muestra los resultados de la inmunoterapia pasiva con 5C1 en el rendimiento de la memoria en la parte de la sonda del ensayo de laberinto de agua de Morris.
La Figura 4 muestra los resultados de la inmunoterapia pasiva con 5C1 en la velocidad y los errores en el ensayo de haz redondo.
La Figura 5 muestra los resultados de un ensayo ELISA que prueba la afinidad de diferentes anticuerpos 5C1 humanizados.
La Figura 6 muestra los resultados de un experimento de mutagénesis de barrido de alanina utilizado para determinar el epítopo de la a-sinucleína unida por el anticuerpo 9E4. La parte superior de la figura muestra las transferencias de Western de la a-sinucleína de longitud completa (tipo nativo o mutaciones puntuales individuales de los residuos 118-126, como se indica) teñidas con el anticuerpo 9E4 (panel izquierdo) o el anticuerpo de control 1H7 (panel derecho). La parte inferior de la figura muestra el epítopo de la a-sinucleína unida por el anticuerpo 9E4. La Figura 7 muestra los resultados de un experimento de mutagénesis de barrido de alanina utilizado para determinar el epítopo de la a-sinucleína unida por el anticuerpo 5C1. La parte superior de la figura muestra las transferencias de Western de la a-sinucleína de longitud completa (tipo nativo o mutaciones puntuales individuales de los residuos 118-126, como se indica) teñidas con el anticuerpo 5C1 (panel izquierdo) o el anticuerpo de control 1H7 (panel derecho). La parte inferior de la figura muestra el epítopo de la a-sinucleína unida por el anticuerpo 5C1. La Figura 8 muestra los resultados de un experimento de mutagénesis de barrido de alanina utilizado para determinar el epítopo de la a-sinucleína unida por el anticuerpo 5D12. La parte superior de la figura muestra las transferencias de Western de la a-sinucleína de longitud completa (tipo nativo o mutaciones puntuales individuales de los residuos 118-126, como se indica) teñidas con el anticuerpo 5D12 (panel izquierdo) o el anticuerpo de control 1H7 (panel derecho). La parte inferior de la figura muestra el epítopo de la a-sinucleína unida por el anticuerpo 5D12.
La Figura 9 representa un modelo de bola y palos de los aminoácidos de la a-sinucleína próximos a los sitios de unión de los anticuerpos 9E4, 5C1 y 5D12.
Breve descripción de las secuencias
SEQ ID NO: 1 es una a-sincucleína humana de tipo nativo.
SEQ ID NO: 2 es el dominio del componente no-amiloide (NAC) de la a-sinucleína, como describen Jensen et al. (1995).
SEQ ID NO: 3 es el dominio del componente no-amiloide (NAC) de la a-sinucleína, como describen Uéda et al. (1993).
SEQ ID NO: 4 son los residuos 118-129 del aminoácido del inmunógeno peptídico 5C1 de la a-sinucleína humana. VDPDNEAYEGGC
SEQ ID NO: 5 es la secuencia de nucleótidos que codifica la región variable de cadena pesada de 5C1 murino con la secuencia que codifica el péptido señal (subrayado).
ATGGAAAGGCACTGGATCTTTCTCTTCCTGTTATCAGTAACTGGAGGTGTCCACTCCCAGGTCC
AGCTGCAGCAGTCTGGGGCTGAACTGGCAAAACCTGGGACCTCAGTGCAGATGTCCTGCAAGGC
TTCTGGCTACACCTTTACTAATTACTGGATGAACTGGATAAAAGCGAGGCCTGGACAGGGTCTG
GAATGGATTGGGGCTACTAATCCTAACAATGGTTATACTGACTACAATCAGAGGTTCAAGGACA
AGGCCATATTAACTGCAGACAAATCCTCCAATACAGCCTACATGCACCTGAGCAGCCTGACATC
TGAAGACTCTGCAGTCTATTTCTGTGCAAGTGGGGGGCACTTGGCTTACTGGGGCCAGGGGACT
GTGGTCACTGTCTCTGCA SEQ ID NO: 6 es la región variable de cadena pesada de 5C1 murino con el péptido señal (subrayado).
MERHW IFLFLLSVTGGVHSQVQLQQSGAELAKPGTSVQMSCKASGYTFTNYWMHWIKARPGQGL
EWIGATNPNNGYTDYNQRFKDKAILTADKSSNTAYMHLSSLTSEDSAVYFCASGGHLAYWGQGT
VVTVSA SEQ ID NO: 7 es la secuencia de nucleótidos que codifican la región variable de cadena ligera de 5C1 murino con la secuencia que codifica el péptido señal (subrayado).
ATGAAGTTGCCTGTTAGGCTGTTGGTGCTGATGTTCTGGATTCCTGCTTCCAGCAGTGATGTTG
TGATGACCCAAATTCCACTCTACCTGTCTGTCAGTCCTGGAGATCAAGCCTCCATCTCTTGCAG
ATCTAGTCAGAGCCTTTTCCATAGTAAAGGAAACACCTATTTACATTGGTATCTGCAGAAGCCA
GGCCAGTCTCCAAAGCTCCTGATCAACAGGGTTTCCAACCGATTTTCTGGGGTCCCAGACAGGT
TCAGTGGCAGTGGATCAGGGACAGATTTCACACTCAAGATCAGCGGAGTGGAGGCTGAAGATCT
GGGAGTTTATTTCTGTTCTCAAAGTGCACATGTTCCGTGGACGTTCGGTGGAGGCACCAAGCTG
GAAATCAGA SEQ ID NO: 8 es la secuencia de la región variable de cadena ligera de 5C1 murino con el péptido señal (subrayado).
M KLPVR LLVLM FW IPA SSSDVVM TQ IPLYLSVSPG DQ ñSISCRSSQ SLFHSKG NTYLHW YLQ KP GQSPKLLINRVSNRFSGVPDRFSGSGSGTDFTLKISGVEAEDLGVYFCSQSAHVPW TFGGGTKL E IR SEQ ID NO: 9 es la región variable de cadena pesada madura de 5C1 murino con las CDRs subrayadas. Las CDRs subrayadas son las definidas por Kabat, excepto la CDRH1 subrayada que es una composición de las definiciones de Kabat y Chothia.
QVQLQQSGAELftKPGTSVQMSCKASGYTFTMYWMNW IKARPGQGLEW IGATNPNNGYTDYNQRF KDKAILTADKSSNTAYM HLSSLTSEDSAVYFCASG G HLAYWGQGTVVTVSA
SEQ ID NO: 10 es la secuencia de cadena pesada de 5C1 CDR1. NYWMN
SEQ ID NO: 11 es la secuencia de cadena pesada de 5C1 CDR2. ATNPNNGYTDYNQRFKD
SEQ ID NO: 12 es la secuencia de cadena pesada de 5C1 CDR3. GGHLAY
SEQ ID NO: 13 es el FR aceptor de VH humano (Acc#AAY42876.1).
QVQLVQSGAEVKKPGSSVKVSCKASGGTFNNYAINWVRQAPGQGLEWMGGIIPIFGTTTYAQKF
QGRVTITADESTNTAYMELSSLRSEDTAVYYCAREGNLNWLDPWGQGTLVTVSS SEQ ID NO: 14 es la secuencia del 5C1H1 humanizado.
QVQLVQSGAELKKPGSSVKVSCKASGYTFTNYWMNWVRQAPGQGLEWIGATNPNNGYTDYNQRF
KDRATLTADKSTNTAYMELSSLRSEDTAVYYCARGGHLAYWGQGTLVTVSS SEQ ID NO: 15 es la secuencia del 5C1H2 humanizado.
QVQLVQSGAELKKPGSSVKVSCKASGYTFTNYWMNWVRQAPGQGLEWIGATNPNNGYTDYNQRF
KDRVTITADKSTNTAYMELSSLRSEDTAVYYCARGGHLAYWGQGTLVTVSS SEQ ID NO: 16 es la secuencia del 5C1H3 humanizado.
QVQLVQSGAELKKPGSSVKVSCKASGYTFTNYWMNWVRQAPGQGLEWIGATNPNNGYTDYNQRF
KDRATLTADKSTNTAYMELSSERSEDTAVYFCASGGHLAYWGQGTLVTVSS SEQ ID NO: 17 es la secuencia del 5C1H4 humanizado.
QVQLVQSGAELKKPGSSVKVSCKASGYTFTNYWMNWVRQAPGQGLEWIGATNPNNGYTDYNQRF
KDRATLTADKSTNTAYMELSSLRSEDTAVYYCASGGHLAYWGQGTLVTVSS SEQ ID NO: 18 es la secuencia del 5C1H5 humanizado.
QVQLVQSGAELKKPGSSVKVSCKASGYTFTNYWMNWVRQAPGQGLEWIGATNPNNGYTDYNQRF KDRVTITADKSTNTAYMELSSLRSEDTAVYYCASGGHLAYW GQGTLVTVSS SEQ ID NO: 19 es la secuencia de ácidos nucleicos que codifican el 5C1H1 humanizado con la secuencia que codifica el péptido señal (subrayado).
ATGGAGTTCGGCCTGTCCTGGCTGTTCCTGGTGGCCATCCTGAAGGGCGTGCAGTGCCAGGTGC
AGCTGGTGCAGTCCGGCGCCGAGCTGAAGAAGCCCGGCTCCTCCGTGAAGGTGTCCTGCAAGGC
CTCCGGCTACACCTTCACCAACTACTGGATGAACTGGGTGCGCCAGGCCCCCGGCCAGGGCCTG
GAGTGGATCGGCGCCACCAACCCCAACAACGGCTACACCGACTACAACCAGCGCTTCAAGGACC
GCGCCACCCTGACCGCCGACAAGTCCACCAACACCGCCTACATGGAGCTGTCCTCCCTGCGCTC
CGAGGACACCGCCGTGTACTACTGCGCCCGCGGCGGCCACCTGGCCTACTGGGGCCAGGGCACC
CTGGTGACCGTGTCCTCC
SEQ ID NO: 20 es la secuencia de ácidos nucleicos que codifica el 5C1H2 humanizado con la secuencia que codifica el péptido señal (subrayado).
R TG ÜR ÜTTCG G C CTÜ TC C TÜ CC TÜT^C CTTJÜTÜÜ CX R TÜ C TÜ A RÜ CC -C Ü^Ü CA Ü TÜ CC A G G TG C
AGCTGGTGCAGTCCGGCGCCGAGCTGAAGAAGCCCGGCTCCTCCGTGAAGGTGTCCTGCAAGGC
CTCCGGCTACACCTTCACCAACTACTGGATGAACTGGGTGCGCCAGGCCCCCGGCCAGGGCCTG
GAGTGGATCGGCGCCACCAACCCCAACAACGGCTACACCGACTACAACCAGCGCTTCAAGGACC
GCGTGACCATCACCGCCGACAAGTCCACCAACACCGCCTACATGGAGCTGTCCTCCCTGCGCTC
CGAGGACACCGCCGTGTACTACTGCGCCCGCGGCGGCCACCTGGCCTACTGGGGCCAGGGCACC
CTGGTGACCGTGTCCTCC SEQ ID NO: 21 es la secuencia de ácidos nucleicos que codifica el 5C1H3 humanizado con la secuencia que codifica el péptido señal (subrayado).
ATGGftGTTCGGCCTGTCCTGGCTGTTCCTGGTGGCCATCCTGAAGGGCGTGCAGTGCCAGGTGC AGCTGGTGCAGTCCGGCGCCGAGCTGAAGAAGCCCGGCTCCTCCGTGAAGGTGTCCTGCAAGGC CTCCGGCTACACCTTCACCAACTACTGGATGAACTGGGTGCGCCAGGCCCCCGGCCAGGGCCTG GAGTGGATCGGCGCCACCAACCCCAACAACGGCTACACCGACTACAACCAGCGCTTCAAGGACC GCGCCACCCTGACCGCCGACAAGTCCACCAACACCGCCTACATGGAGCTGTCCTCCCTGCGCTC CGAGGACACCGCCGTGTACTTCTGCGCCTCCGGCGGCCACCTGGCCTACTGGGGCCAGGGCACC CTGGTGACCGTGTCCTCC SEQ ID NO: 22 es la secuencia de ácidos nucleicos que codifica el 5C1H4 humanizado con la secuencia que codifica el péptido señal (subrayado).
ATGGAGTTCGGCCTGTCCTGGCTGTTCCTGGTGGCCATCCTGAAGGGCGTGCAGTGCCAGGTGC AGCTGGTGCAGTCCGGCGCCGAGCTGAAGAAGCCCGGCTCCTCCGTGAAGGTGTCCTGCAAGGC CTCCGGCTACACCTTCACCAACTACTGGATGAACTGGGTGCGCCAGGCCCCCGGCCAGGGCCTG GAGTGGATCGGCGCCACCAACCCCAACAACGGCTACACCGACTACAACCAGCGCTTCAAGGACC GCGCCACCCTGACCGCCGACAAGTCCACCAACACCGCCTACATGGAGCTGTCCTCCCTGCGCTC CGAGGACACCGCCGTGTACTACTGCGCCTCCGGCGGCCACCTGGCCTACTGGGGCCAGGGCACC CTGGTGACCGTGTCCTCC SEQ ID NO: 23 es la secuencia de ácidos nucleicos que codifica el 5C1H5 humanizado con la secuencia que codifica el péptido señal (subrayado).
ATGGAGTTCGGCCTGTCCTGGCTGTTCCTGGTGGCCATCCTGAAGGGCGTGCAGTGCCAGGTGC AGCTGGTGCAGTCCGGCGCCGAGCTGAAGAAGCCCGGCTCCTCCGTGAAGGTGTCCTGCAAGGC CTCCGGCTACACCTTCACCAACTACTGGATGAACTGGGTGCGCCAGGCCCCCGGCCAGGGCCTG GAGTGGATCGGCGCCACCAACCCCAACAACGGCTACACCGACTACAACCAGCGCTTCAAGGACC GCGTGACCATCACCGCCGACAAGTCCACCAACACCGCCTACATGGAGCTGTCCTCCCTGCGCTC CGAGGACACCGCCGTGTACTACTGCGCCAGCGGCGGCCACCTGGCCTACTGGGGCCAGGGCACC CTGGTGACCGTGTCCTCC
SEQ ID NO: 24 es la secuencia de la región variable de cadena ligera madura de 5C1 murino con las CDRs subrayadas. Las CDRs subrayadas son como las definidas por Kabat.
DVVMTQI P LY L SVSPGDQASI SCRSSQSLFHSKGNTYLHW YLQ KPG Q SPKLLINRVSNRFSGVP DRFSGSGSGT D F T L K I SGVEAED L GVYFCSQSAHVPWTFGGGTKLEIR
SEQ ID NO: 25 es la secuencia de cadena ligera de 5C1 CDR1. RSSQSLFHSKGNTYLH
SEQ ID NO: 26 es la secuencia de cadena ligera de 5C1 CDR2. RVSNRFS
SEQ ID NO: 27 es la secuencia de cadena ligera de 5C1 CDR3. SQSAHVPWT
SEQ ID NO: 28 es el FH Aceptor de VL humano (Acc#CAB51293.1).
D IVM TQSPLSLPVTPG EPASISCRSSQ SLLHSNG YNYLDW YLQ KPG Q SPQ LLIYLG SNRASG VP DRFSGSGSGTDFTLKISRVEAEDVGVYYCM QALQTPPTFGGGTKVEIK SEQ ID NO: 29 es la secuencia del 5C1L1 humanizado.
DVVM TQSPLSLSVSPGEPASISCRSSQSLFHSKGNTYLHW YLQKPGQSPKLLINRVSNRFSGVP DRFSGSGSGTDFTLKISRVEAEDVGVYFCSQSAHVPW TFGGGTKVEIK SEQ ID NO: 30 es la secuencia del 5C1L2 humanizado.
D IVM TQ SPLSLSVS PG EPASISC R SSQ SLFH SKG N TYLH W YLQ KPG Q SPKLLIYR VSN R FSG VP DRFSG SG SG TDFTLKISRVEAEDVG VYFCSQ SAHVPW TFG G G TKVEIK SEQ ID NO: 31 es la secuencia del 5C1L3 humanizado.
DVVMTQSPLSLSVSPGEPASISCRSSQSLFHSKGNTYLHW YLQKPGQSPQLLINRVSNRFSGVP DRFSGSGSGTDFTLKISRVEAEDVGVYFCSQSAHVPW TFGGGTKVEIK SEQ ID NO: 32 es la secuencia del 5C1L4 humanizado.

SEQ ID NO: 33 es la secuencia de ácidos nucleicos que codifican el 5C1L1 humanizado con la secuencia que codifica el péptido señal (subrayado).
ATGGACATGCGCGTGCCCGCCCAGCTGCTGGGCCTGCTGATGCTGTGGGTGTCCGGCTCCTCCG GCGACGTGGTGATGACCCAGTCCCCCCTGTCCCTGTCCGTGTCCCCCGGCGAGCCCGCCTCCAT CTCCTGCCGCTCCTCCCAGTCCCTGTTCCACTCCAAGGGCAACACCTACCTGCACTGGTACCTG CAGAAGCCCGGCCAGTCCCGCAAGCTGCTGATCAACCGCGTGTCCAACCGCTTCTCCGGCGTGC CCGACCGCTTCTCCGGCTCCGGCTCCGGCACCGACTTCACCCTGAAGATCTCCCGCGTGGAGGC CGAGGACGTGGGCGTGTACTTCTGCTCCCAGTCCGCCCACGTGCCCTGGACCTTCGGCGGCGGC ACCAAGGTGGAGATCAAG SEQ ID NO: 34 es la secuencia de ácidos nucleicos que codifica el 5C1L2 humanizado con la secuencia que codifica el péptido señal (subrayado).
ATCGACA'7GCGCC~1GCCCGCCCACCr7CC'T1C-CCCCTGCTCATCCTCT'GGüT'ÜTCCÜCC'7CCrT1CCC GCGACATCGTGATGACCCAGTCCCCCCTGTCCCTGTCCGTGTCCCCCGGCGAGCCCGCCTCCAT CTCCTGCCGCTCCTCCCAGTCCCTGTTCCACTCCAAGGGCAACACCTACCTGCACTGGTACCTG CAGAAGCCCGGCCAGTCCCCCAAGCTGCTGATCTACCGCGTGTCCAACCGCTTCTCCGGCGTGC CCGACCGCTTCTCCGGCTCCGGCTCCGGCACCGACTTCACCCTGAAGATCTCCCGCGTGGAGGC CGAGGACGTGGGCGTGTACTACTGCTCCCAGTCCGCCCACGTGCCCTGGACCTTCGGCGGCGGC ACCAAGGTGGAGATCAAG SEQ ID NO: 35 es la secuencia de ácidos nucleicos que codifica el 5C1L3 humanizado con la secuencia que codifica el péptido señal (subrayado).
AIGGACATGCGCGTGCCCGCCCAGCTGCTGGGCCTGCIGATGCTGTGGGTGTCCGGCTCCTCCG GCGACGTGGTGATGACCCAGTCCCCCCTGTCCCTGTCCGTGTCCCCCGGCGAGCCCGCCTCCAT CTCCTGCCGCTCCTCCCAGTCCCTGTTCCACTCCAAGGGCAACACCTACCTGCACTGGTACCTG CAGAAGCCCGGCCAGTCCCCCCAGCTGCTGATCAACCGCGTGTCCAACCGCTTCTCCGGCGTGC CCGACCGCTTCTCCGGCTCCGGCTCCGGCACCGACTTCACCCTGAAGATCTCCCGCGTGGAGGC CGAGGACGTGGGCGTGTACTTCTGCTCCCAGTCCGCCCACGTGCCCTGGACCTTCGGCGGCGGC ACCAAGGTGGAGATCAAG SEQ ID NO: 36 es la secuencia de ácidos nucleicos que codifica el 5C1L4 con la secuencia que codifica el péptido señal (subrayado).
ATGGACATGCGCGTGCCCGCCCAGCTGCTGGGCCTGCTGATGCTGTGGGTGTCCGGCTCCTCCG GCGACATCGTGATGACCCAGTCCCCCCTGTCCCTGTCCGTGTCCCCCGGCGAGCCCGCCTCCAT CTCCTGCCGCTCCTCCCAGTCCCTGTTCCACTCCAAGGGCAACACCTACCTGCACTGGTACCTG CAGAAGCCCGGCCAGTCCCCCCAGCTGCTGATCTACCGCGTGTCCAACCGCTTCTCCGGCGTGC CCGACCGCTTCTCCGGCTCCGGCTCCGGCACCGACTTCACCCTGAAGATCTCCCGCGTGGAGGC CGAGGACGTGGGCGTGTACTACTGCTCCCAGTCCGCCCACGTGCCCTGGACCTTCGGCGGCGGC ACCAAGGTGGAGATCAAG SEQ ID NO: 37 es la secuencia de ácidos nucleicos que codifica una región constante de IgG1 humano ejemplar. GCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCA CAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTC AGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCC
CTCAGCAGCGTGGTGACCGTGCCCTCCAGCAGCTTGGGCACCCAGACCACATCTGCAACGTGAA
TCACAAGCCCAGCAACACCAAGGTGGACAAGAGAGTTGAGCCCAAATCTTGTGACAAAACTCAC
ACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAA
AACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAG
CCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGTCAAG
ACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGTGTGGTCAGCGTCCTCACCGTCCTGC
ACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCC
CATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACGCTGCCC
CCATCCCGGGAGGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATC
CCAGCGACATCGCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCT
CCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTATAGCAAGCTCACCGTGGACAAGAGCAGGT
GGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCA
GAAGAGCCTCTCCCTGTCCCCGGGTAAATGA
SEQ ID NO: 38 es la secuencia de aminoácidos de una región constante de IgG1 humano ejemplar.
ASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYS
LSSWTVPSSSLGTQTYICNVNHKPSNTKVDKRVEPKSCDKTHTCPPCPAPELLGGPSVFLFPP
KPKDTLMISRTPEVTCWVDVSHEDPEVKFNWYVDGVEVHNVKTKPREEQYNSTYRWSVLTVL
HQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFY
PSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYT
QKSLSLSPGK
SEQ ID NO: 39 es la secuencia de ácidos nucleicos que codifica una región constante de cadena ligera kappa humana ejemplar.
ACTGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTG
CCTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGA
TAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACC
TACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCT
GCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGTTA
G SEQ ID NO: 40 es la secuencia de aminoácidos de una región constante de cadena ligera kappa humana ejemplar.
TVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDST
YSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
Definiciones
La unidad estructural del anticuerpo básico es un tetrámero de subunidades. Cada tetrámero incluye dos pares idénticos de cadenas polipeptídicas, teniendo cada pareja una cadena “ligera” (aproximadamente 25 kDa) y una cadena “pesada” (aproximadamente 50-70 kDa). La parte amino-terminal de cada cadena incluye una región variable de aproximadamente 100 a 110 o más aminoácidos responsables principalmente del reconocimiento de antígenos. Cuando se expresa inicialmente, esta región variable se une típicamente a un péptido señal escindible. La región variable sin el péptido señal se denomina a veces como región variable madura. Así, por ejemplo, una región variable madura de cadena ligera significa una región variable de cadena ligera sin el péptido señal de cadena ligera. La parte carboxi-terminal de cada cadena define una región constante responsable principalmente de
la función efectora. Una región constante puede incluir una cualquiera o la totalidad de una región CH1, región bisagra, región CH2 y región CH3.
Las cadenas ligeras se clasifican como kappa o lambda. Las cadenas pesadas se clasifican como gamma, mu, alfa, delta, o épsilon, y definen el isotipo del anticuerpo como IgG, IgM, IgA, IgD y IgE, respectivamente. Dentro de las cadenas ligera y pesada, las regiones variables y constantes se unen por una región “J” de aproximadamente 12 o más aminoácidos, con la cadena pesada incluyendo también una región “D” de aproximadamente 10 o más aminoácidos (véase en general, Fundamental Immunlology (Paul, W., ed., 2nd ed. Raven Press, N.Y., 1989), Ch. 7) (incorporado por referencia en su totalidad para todos los fines).
Las regiones variables maduras de cada par de cadenas ligeras/pesadas forman el sitio de unión del anticuerpo. Por lo tanto, un anticuerpo intacto tiene dos sitios de unión. A excepción de los anticuerpos bifuncionales o bisespecíficos, los dos sitios de unión son los mismos. Todas las cadenas muestran la misma estructura general de las regiones marco relativamente conservadas (FR) unidas mediante tres regiones hipervariables, también llamadas regiones determinantes de complementariedad o CDR. Las CDRs de las dos cadenas de cada par están alineadas por las regiones marco, permitiendo la unión a un epítopo específico. Desde el extremo N al extremo C, tanto las cadenas ligeras como las pesadas comprenden las regiones FR1, CDR1, FR2, CDR2, FR3, CDR3 y FR4. La asignación de aminoácidos a cada región está de acuerdo con las definiciones de Kabat, Secuencias de Proteínas de Interés Inmunológico (National Institutes of Health, Bethesda, MD, 1987 y 1991), o Chothia & Lesk, J. Mol. Biol.
196: 901-917 (1987); Chothia et al., Nature 342: 878-883 (1989). Kabat también proporciona una convención de numeración ampliamente utilizada (numeración de Kabat) en la que a los residuos correspondientes entre diferentes cadenas pesadas o entre diferentes cadenas ligeras se les asigna el mismo número (por ejemplo, H83 significa la posición 83 por numeración de Kabat en la región variable de cadena pesada madura; asimismo, la posición L36 significa la posición 36 por la numeración de Kabat en la región variable de cadena ligera madura). La numeración de Kabat se utiliza en todo momento para referirse a posiciones en la región variable de un anticuerpo, a menos que se indique explícitamente lo contrario.
El término “anticuerpo” incluye anticuerpos intactos y fragmentos de unión de los mismos. Normalmente, los fragmentos compiten con el anticuerpo intacto del que se derivaron para la unión específica a la diana. Los fragmentos incluyen cadenas pesadas separadas, cadenas ligeras separadas, Fab, Fab', F(ab')2, F(ab')c, Fv, anticuerpos monocatenarios, y anticuerpos de dominio único. Los anticuerpos de dominio (variable) único incluyen regiones VH separadas de sus parejas VL (o viceversa) en anticuerpos convencionales (Ward et al., 1989, Nature 341: 544-546), así como regiones VH (algunas veces conocidas como VHH) de especies como Camelidae o cartilaginous fish (por ejemplo, un tiburón nodriza) en el que las regiones VH no están asociadas con las regiones VL (véase, por ejemplo el documento de Patente WO 9404678). Los anticuerpos de dominio único en los que una cadena está separada de su pareja natural se conocen a veces como Dabs y los anticuerpos de dominio único de Caemelidae o cartilaginous fish se conocen a veces como nanocuerpos. Las regiones constantes o partes de las regiones constantes pueden o no estar presentes en anticuerpos de dominio único. Por ejemplo, la región variable única natural de Camelidae incluye una región variable VHH, y las regiones constantes CH2 y CH3. Los anticuerpos de dominio único, tales como nanocuerpos, se pueden someter a humanización mediante enfoques análogos a los anticuerpos convencionales. Los anticuerpos Dabs se obtienen normalmente de anticuerpos de origen humano. Los fragmentos se pueden producir mediante técnicas de DNA recombinante, o mediante separación enzimática o química de inmunoglobulinas intactas.
El término “anticuerpo” incluye también un anticuerpo bisespecífico y/o un anticuerpo humanizado. Un anticuerpo bisespecífico o bifuncional es un anticuerpo híbrido artificial que tiene dos diferentes pares de cadenas pesadas/ligeras y dos diferentes sitios de unión (véase, por ejemplo, Songsivilai y Lachmann, Clin. Exp. Immunol., 79: 315-321 (1990); Kostelny et al., J. Immunol. 148: 1547-53 (1992)). En algunos anticuerpos bisespecíficos, los dos pares de cadenas pesadas/ligeras diferentes incluyen un par de cadena pesada/cadena ligera de 5C1 humanizado y un par de cadena pesada/cadena ligera específico para un epítopo diferente en una alfa-sinucleína que el unido por 5C1.
En algunos anticuerpos bisespecíficos, una pareja de cadena pesada/cadena ligera es un anticuerpo 5C1 humanizado como se describe más adelante y el par de cadenas ligeras pesadas proviene de un anticuerpo que se une a un receptor expresado en la barrera hematoencefálica, tal como un receptor de insulina, un receptor del factor de crecimiento similar a insulina (IGF), un receptor de leptina o un receptor de lipoproteínas o un receptor de transferrina (Friden et al., PNAS 88: 4771-4775, 1991; Friden et al., Science 259: 373-377, 1993). Dicho anticuerpo bisespecífico se puede transferir a través de la barrera hematoencefálica por medio de la transcitosis mediada por receptores. La captación cerebral del anticuerpo biespecífico puede mejorarse aún más mediante la transformación genética del anticuerpo bisespecífico para reducir su afinidad al receptor de la barrera hematoencefálica. La afinidad reducida por el receptor dio como resultado una distribución más amplia en el cerebro (véase, por ejemplo, Atwal et al., Sci. Trans. Med. 3, 84ra43, 2011; Yu et al., Sci. Trans. Med. 3, 84ra44, 2011).
Ejemplos de anticuerpos bisespecíficos pueden ser también (1) un anticuerpo de dominio variable dual (DVD-Ig), donde cada cadena ligera y cadena pesada contiene dos dominios variables en tándem a través de un enlace peptídico corto (Wu et al., Generation and Characterization of a Dual Variable Domain Immunoglobulin (DVD-IgTM) Molecule, In: Antibody Engineering, Springer Berlin Heidelberg (2010)); (2) un Tandab, que es una unión de dos
diacuerpos monocatenarios que dan como resultado un anticuerpo bisespecífico tetravalente que tiene dos sitios de unión para cada uno de los antígenos diana; (3) un flexocuerpo, que es una combinación de scFvs con un diacuerpo que da como resultado una molécula multivalente; (4) la llamada molécula de “acoplamiento y bloqueo”, basada en el “dominio de dimerización y acoplamiento” en la proteína quinasa A, que, cuando se aplica a los Fabs, puede producir una proteína de unión bisespecífica trivalente que consiste en dos fragmentos Fab idénticos unidos a un fragmento Fab diferente; (5) la llamada molécula Escorpión, que comprende, por ejemplo, dos scFvs unidos a ambos extremos de una región Fc humana. Los ejemplos de plataformas útiles para preparar anticuerpos bisespecíficos incluyen BiTE (Micromet), DART (MacroGenics), Fcab y Mab2 (F-star), IgG1 diseñado por Fc (Xencor) o DuoBody (basado en el intercambio del brazo de Fab, Genmab).
Un “antígeno” es una entidad a la que se une específicamente un anticuerpo.
El término “epítopo” se refiere a un sitio en un antígeno al que se une un anticuerpo. Para los antígenos proteicos, se puede formar un epítopo a partir de aminoácidos contiguos o aminoácidos no contiguos yuxtapuestos por el plegamiento terciario de una o más proteínas. Los epítopos formados a partir de aminoácidos contiguos se retienen típicamente en la exposición a disolventes desnaturalizantes, mientras que los epítopos formados por el plegamiento terciario se pierden típicamente en el tratamiento con disolventes desnaturalizantes. Un epítopo incluye típicamente al menos 2, 3, y más generalmente, al menos 5 u 8-10 aminoácidos en una conformación espacial única. Los métodos para determinar la conformación espacial de los epítopos incluyen, por ejemplo, la cristalografía de rayos X y la resonancia magnética nuclear bidimensional. Véase, por ejemplo, Epitope Mapping Protocols, en Mehtods in Molecular Biology, Vol. 66, Glenn E. Morris, Ed. (1996). Un epítopo puede incluir un residuo C-terminal o un residuo N-terminal. Un epítopo puede incluir también, pero no necesariamente, el grupo amino libre de un polipéptido o el grupo carboxilo libre de un polipéptido. Por lo tanto, un epítopo puede incluir un residuo C-terminal o un residuo N-terminal, pero no incluir necesariamente el grupo carboxilo libre o el grupo amino libre, respectivamente. La especificidad de unión a anticuerpos se define a veces por un rango de aminoácidos. Si se dice que un anticuerpo se une a un epítopo dentro de los aminoácidos 118-126 de la SEQ ID NO: 1, por ejemplo, lo que se quiere decir es que el epítopo está dentro del rango de aminoácidos enumerados incluyendo aquellos que definen los límites externos del rango. No significa necesariamente que cada aminoácido dentro del rango constituya parte del epítopo. Así, por ejemplo, un epítopo dentro de los aminoácidos 118-126, de la SEQ ID NO: 1 puede consistir en los aminoácidos 118-124, 119-125, 120-126, 120-124 o 120-122, entre otros segmentos de SEQ ID NO: 1.
Los anticuerpos que reconocen los mismos epítopos o epítopos superpuestos se pueden identificar en un inmunoensayo simple que muestra la capacidad de un anticuerpo para competir con la unión de otro anticuerpo a un antígeno diana. El epítopo de un anticuerpo puede también definirse por cristalografía de rayos X del anticuerpo unido a su antígeno para identificar los residuos de contacto (el epítopo se define por los residuos que producen el contacto). Alternativamente, dos anticuerpos tienen el mismo epítopo si todas las mutaciones de aminoácidos en el antígeno que reducen o eliminan la unión de un anticuerpo reducen o eliminan la unión al otro. Dos anticuerpos tienen epítopos superpuestos si algunas mutaciones de aminoácidos que reducen o eliminan la unión de un anticuerpo reducen o eliminan la unión del otro.
La competencia entre los anticuerpos se determina mediante un ensayo en el que un anticuerpo sometido al ensayo inhibe la unión específica de un anticuerpo de referencia a un antígeno común. Véase, por ejemplo, Junghans et al., (1990), Cancer Res. 50: 1495. Un anticuerpo de prueba compite con un anticuerpo de referencia si un exceso de un anticuerpo de prueba (por ejemplo, al menos 2x, 5x, 10x, 20x o 100x) inhibe la unión del anticuerpo de referencia en al menos 50%, 75%, 90%, 95%, 98%, o 99% según lo medido en un ensayo de unión competitiva. Los anticuerpos identificados por ensayos de competición (anticuerpos competidores) incluyen anticuerpos que se unen al mismo epítopo que el anticuerpo de referencia y anticuerpos que se unen a un epítopo adyacente suficientemente próximo al epítopo unido por el anticuerpo de referencia para que ocurra un impedimento estérico.
Los anticuerpos de la invención se unen típicamente a sus dianas designadas con una constante de afinidad de al menos 106, 107, 108, 109 o 1010 M-1. Dicha unión es una unión específica en el sentido de que es detectablemente mayor en magnitud y es distinguible de la unión no específica que se produce al menos a una diana no relacionada. La unión específica puede ser el resultado de la formación de enlaces entre grupos funcionales particulares o un ajuste espacial particular (por ejemplo, tipo de cerradura y llave), mientras que la unión no específica suele ser normalmente el resultado de las fuerzas de Van der Waals. Sin embargo, la unión específica no implica necesariamente que un anticuerpo monoclonal se una a una y solo una diana.
Cuando se comparan secuencias de anticuerpos, el porcentaje de identidades de secuencia se determina con secuencias de anticuerpos alineadas al máximo mediante la convención de numeración de Kabat. Después de la alineación, si una región de anticuerpo sujeto (por ejemplo, la región variable madura entera de una cadena pesada o ligera) se compara con la misma región de un anticuerpo de referencia, el porcentaje de identidad de secuencia entre las regiones del anticuerpo sujeto y las regiones del anticuerpo de referencia es el número de posiciones ocupadas por el mismo aminoácido tanto en la región de anticuerpo sujeto como en la región de anticuerpo de referencia dividido por el número total de posiciones alineadas de las dos regiones, sin contar las brechas, multiplicado por 100 para convertirlo a porcentaje.
Para los fines de clasificación de las sustituciones de aminoácidos como conservativas y no conservativas, los aminoácidos se agrupan de la siguiente manera: Grupo I (cadenas laterales hidrofóbicas): met, ala, val, leu, ile; Grupo II (cadenas laterales hidrofílicas neutras): cys, ser, thr; Grupo III (cadenas laterales ácidas): asp, glu; Grupo IV (cadenas laterales básicas): asn, gln, his, lys, arg; Grupo V (residuos que influyen en la orientación de cadena): gly, pro; y Grupo VI (cadenas laterales aromáticas): trp, tyr phe. Las sustituciones conservativas implican sustituciones entre aminoácidos en la misma clase. Las sustituciones no conservativas constituyen el intercambio de un miembro de una de estas clases por un miembro de otra.
Los anticuerpos monoclonales se proporcionan típicamente en forma aislada. Esto significa que el anticuerpo es típicamente al menos el 50% peso/peso puro de proteínas interferentes y otros contaminantes que surgen a partir de su producción o purificación, pero no excluye la posibilidad de que el agente se combine con un exceso de un vehículo(s) farmacéuticamente aceptable u otro vehículo destinado a facilitar su uso. Algunas veces, los anticuerpos monoclonales son al menos 60%, 70%, 80%, 90%, 95%, 96%, 97%, 98%, o 99% peso/peso puro de agregados o fragmentos de dichos anticuerpos monoclonales o de otras proteínas y contaminantes. Alguno de dichos anticuerpos monoclonales puede incluir agregados o fragmentos pero son al menos 99% peso/peso puros de otras proteínas y contaminantes.
Las composiciones o métodos “que comprenden” uno o más elementos enumerados pueden incluir otros elementos no enumerados específicamente. Por ejemplo, una composición que comprende el anticuerpo puede contener el anticuerpo solo o en combinación con otros ingredientes.
La designación de un intervalo de valores incluye todos los números enteros dentro o que definen el intervalo , y todos los subintervalos definidos por números enteros dentro del intervalo.
A menos que se indique lo contrario en el contexto, el término “aproximadamente” abarca los valores dentro del margen de error de la medición (SEM) de un valor establecido.
Significación estadística significa P< 0,05.
Un “paciente” incluye un ser humano u otro sujeto mamífero que recibe tratamiento profiláctico o terapéutico.
Un individuo tiene mayor riesgo de contraer una enfermedad si el sujeto tiene al menos un factor de riesgo conocido (por ejemplo, genético, bioquímico, antecedentes familiares, exposición situacional) que coloca a los individuos con ese factor de riesgo en un riesgo estadísticamente significativo mayor de desarrollar la enfermedad que individuos sin el factor de riesgo.
El término “síntoma” se refiere a una evidencia subjetiva de una enfermedad, tal como la marcha alterada, según lo percibe el paciente. Un “signo” se refiere a la evidencia objetiva de una enfermedad observada por un médico. “Función cognitiva” se refiere a procesos mentales tales como uno cualquiera o todos de atención, memoria, producción y comprensión del lenguaje, resolución de problemas y el interés por el entorno y el cuidado de sí mismo. “Función cognitiva mejorada” o “función cognitiva mejorada” se refiere a la mejora en relación con la línea base, por ejemplo, el diagnóstico o iniciación del tratamiento. “Disminución de la función cognitiva” se refiere a una disminución de la función en relación con dicha línea base.
En sistemas de modelos animales tales como rata o ratón, la función cognitiva puede ser medida por métodos que incluyen utilizar un laberinto en el que los sujetos utilizan la información espacial (por ejemplo, el laberinto de agua de Morris, el laberinto circular de Barnes, el laberinto de brazos radiales elevados, el laberinto en T y otros), el acondicionamiento del miedo, evitación activa, campo abierto iluminado, medidor de actividad oscura, laberinto en cruz elevado, ensayo exploratorio de dos compartimentos o ensayo de natación forzado.
En humanos, la función cognitiva se puede medir por uno o más de varios ensayos estandarizados. Se describieron ejemplos de una prueba o ensayo para la función cognitiva (Ruoppila y Suutama, Scand. J. Soc. Med. Suppl. 53, 44 65, 1997) e incluye ensayos psicométricos estandarizados (por ejemplo, escala de memoria de Wechsler, escala de inteligencia para adultos de Wechsler, Matrices progresivas estándar de Raven, ensayo de capacidades mentales para adultos de Schaie-Thurstone), ensayos neuropsicológicos (por ejemplo, Luria-Nebraska), autoevaluaciones metacognitvas (por ejemplo, cuestionario de metamemoria), ensayos de detección visual-espacial (por ejemplo, Figuras de Poppelreuter, reconocimiento del reloj, dibujo y cancelación del nido de abeja), ensayos de detección cognitiva (por ejemplo, ensayo del estado mini mental de Folstein) y ensayos del tiempo de reacción. Otros ensayos estándar para el rendimiento cognitivo incluyen la subescala cognitiva de la escala de evaluación de la enfermedad de Alzheimer (ADAS-cog); la impresión clínica global de la escala de cambio (CIBIC-escala plus); las actividades de estudio cooperativo de la enfermedad de Alzheimer de la escala de la vida diaria (ADCS-ADL); el examen del mini estado mental (MMSE); el inventario Neuropsiquiátrico (NPI); la escala de la Evaluación de la Demencia clínica (CDR); la batería automatizada de ensayos Neuropsicológicos de Cambridge (CANTAB) o la evaluación clínica de Sandoz-Geriatric (SCAG), ensayo de Stroop, fabricación de senderos, Wechsler Digit Span, y el ensayo cognitivo computarizado CogState. Además, la función cognitiva se puede medir utilizando técnicas de imagen tales como la Tomografía de Emisión de Positrón (PET), imagen de resonancia magnética funcional (fMRI), Tomografía
computarizada de emisión de fotón único (SPECT), o cualquier otra técnica de imagen que permita una medida de la función cerebral.
Descripción detallada de la invención
I. General
La invención proporciona el anticuerpo monoclonal 5C1 y anticuerpos relacionados, como los anticuerpos que se une al mismo epítopo en la a-sinucleína (es decir, un epítopo 118-126 de la a-sincucleína). Los anticuerpos de la invención son útiles, por ejemplo, para tratar trastornos asociados con la acumulación de a-sinucleína, particularmente la acumulación en cuerpos de Lewy. Tales trastornos incluyen enfermedades del cuerpo de Lewy, tales como la enfermedad de Parkinson, la enfermedad del cuerpo de Lewy difuso (DLBD), la variante de cuerpos de Lewy de la enfermedad de Alzheimer (LBV), la enfermedad de Parkinson y Alzheimer combinadas, la insuficiencia autonómica pura y la atrofia de sistemas múltiples (MSA). Los anticuerpos también son útiles para el diagnóstico de enfermedades de cuerpos de Lewy.
II. Moléculas objetivo
La a-sinucleína de tipo nativo natural es un péptido de 140 aminoácidos que tienen la siguiente secuencia de aminoácidos:
MDVFMKGLSKAKEGWAAAEKTKQGVAEAAGKTKEGVLYVGSKTKEGWHGVATVAEKTKEQVT
NVGGAVVTGVTAVAQKTVEGAGSIAAATGFVKKDQLGKNEEGAPQEGILEDMPVDPDNEAYEMP
SEEGYQDYEPEA (SEQ ID NO:l)
(Uéda et al., Proc. Natl. Acad. Sci. USA, 90: 11282-6, 1993; número de acceso al banco de genes: P37840). La proteína tiene tres dominios reconocidos, un dominio de repetición KTKE que cubre los aminoácidos 1-61, un dominio NAC (componente no amiloide) que se extiende desde aproximadamente los aminoácidos 60-95, y un dominio C-terminal ácido que se extiende desde aproximadamente el aminoácido 98 hasta el 140. Jensen et al., (1995) reportaron que el nAc tiene la secuencia de aminoácidos:

(Jensen et al., Biochem. J. 310.1: 91-94; número de acceso al banco de genes S56746). Sin embargo, Uéda et al., (1993) reportaron que el NAC tiene la secuencia de aminoácidos:

(Uéda et al., Proc. Natl. Acad. Sci. USA, 90: 11282-6)
A menos que se vea lo contrario en el contexto, la referencia a a-sicucleína o sus fragmentos incluye las secuencias de aminoácidos de tipo nativo humanas indicadas anteriormente, y las variantes alélicas humanas de las mismas, particularmente aquellas asociadas con la enfermedad del cuerpo de Lewy (por ejemplo, E46K, A30P y A53T, con la primera letra se indica el aminoácido en SEQ ID NO: 1, el número es la posición de codón en SEQ ID NO: 1, y la segunda letra es el aminoácido en la variante alélica). Dichas variantes pueden opcionalmente presentarse individualmente o en cualquier combinación. Las mutaciones inducidas E83Q, A90V, A76T, que mejoran la agregación de alfa sinucleína, pueden también estar presentes individualmente o en combinación unas con otras y/o con las variantes alélicas humanas E46K, A30P y A53t .
III. Enfermedad de los cuerpos de Lewy
Las enfermedades del cuerpo de Lewy (LBD) se caracterizan por la degeneración del sistema dopaminérgico, las alteraciones motoras, el deterioro cognitivo y la formación de cuerpos de Lewy (LBs) (McKeith et al., Neurology (1996) 47:1113-24). Los cuerpos de Lewy son depósitos de proteínas esféricas que se encuentran en las células nerviosas. Su presencia en el cerebro altera la función normal del cerebro interrumpiendo la acción de los mensajeros químicos, incluyendo acetilcolina y dopamina. Las enfermedades del cuerpo de Lewy incluyen la enfermedad de Parkinson (incluida la enfermedad de Parkinson idiopática), la enfermedad difusa del cuerpo de Lewy (DLBD), también conocida como la demencia con cuerpos de Lewy (DLB), la variante del cuerpo de Lewy de la enfermedad de Alzheimer (LBV), la enfermedad de Alzheimer y Parkinson combinada y como atrofia del sistema múltiple (MSA; por ejemplo, atrofia olivopontocerebelosa, degeneración estriatonigral y el síndrome de Shy-Drager). La DLBD comparte los síntomas tanto de la enfermedad de Alzheimer como de Parkinson. La DLBD se diferencia de la enfermedad de Parkinson principalmente en la ubicación de los cuerpos de Lewy. En la DLBD, los cuerpos de Lewy se forman principalmente en la corteza. En la enfermedad de Parkinson, se forman principalmente en la sustancia negra. Otras enfermedades del cuerpo de Lewy incluyen la insuficiencia autonómica pura, disfalgia del
cuerpo de Lewy, LBD incidental, y LBD hereditaria (por ejemplo, mutaciones del gen de la a-sinucleína, PARK3 y PARK4).
IV. Anticuerpos
A. Especificidad de unión y propiedades funcionales
5C1 es un ejemplo de anticuerpo de la invención, cuyas regiones variables maduras de cadena pesada y ligera se designan s Eq ID NO: 9 y SEQ ID NO: 24, respectivamente. La invención también proporciona anticuerpos que compiten con 5C1 para unirse a a-sinucleína, o que se unen al mismo o se superponen al epítopo como 5C1, y tienen propiedades funcionales similares, tales como la reducción de agregados neuronales de a-sinucleína, mejorando la función cognitiva, y/o preservando la densidad sináptica y/o densidad dentrítica.
Otros anticuerpos que tienen dicha especificidad de unión pueden producirse inmunizando ratones con a-sinucleína o un fragmento de la misma (por ejemplo, un fragmento que incluye los residuos de aminoácidos 118-126, o una parte de la misma), y detectando los anticuerpos resultantes para unirse a la a-sinucleína, opcionalmente en competición con 5C1. Se prefiere el uso de un fragmento para generar un anticuerpo que tenga el mismo epítopo que 5C1. Los anticuerpos también pueden detectarse por su efecto en: (1) modelos de roedores transgénicos de asinucleína sometidos a ensayos de comportamiento, como el ensayo del laberinto de agua de Morris (MWM) o el ensayo de haz horizontal, y/o ensayos inmunológicos para la detección de a-sinucleína, agregación de a-sinucleína, sinaptofisina, MAP2 y/o PSD95 en el tejido cerebral; (2) roedores u otros modelos de animales no humanos para una enfermedad caracterizada por la acumulación de a-sinucleína, utilizando ensayos de comportamiento como el ensayo del laberinto de agua de Morris (MWM) o el ensayo de haz horizontal y/o ensayos inmunológicos para la detección de a-sinucleína, agregación de a-sinucleína, sinaptofisina, MAP2, y/o PSD95 en el tejido cerebral; y/o (3) humanos con una afección asociada con la acumulación de a-sinucleína, utilizando los ensayos de comportamiento apropiados. Alternativamente, o además de cualquiera de los enfoques anteriores, los anticuerpos pueden detectarse frente a formas mutagenizadas de a-sinucleína para identificar un anticuerpo que muestre el mismo o similar perfil de unión que 5C1 para una colección de cambios mutacionales. Las mutaciones pueden ser una sustitución sistemática con alanina (o serina si una alanina ya está presente) un residuo a la vez, o intervalos más ampliamente espaciados, a lo largo de la a-sinucleína o a través de una sección de la misma en la que se sabe que reside el epítopo (por ejemplo, residuos 118-126).
Las Figuras 6-8 y el Ejemplo 6 caracterizan el epítopo de 5C1 en comparación con otros dos anticuerpos que se unen dentro de los residuos 118-126, a saber, 9E4 y 5D12. La mutagénesis de alanina prueba el efecto de la mutación de aminoácidos individuales, uno a la vez, en el 118-126 de la alfa-sinucleína. El perfil de los cambios relativos de la afinidad de unión (en otras palabras, contribución a la unión) causados por la mutación de diferentes aminoácidos dentro de los residuos 118-126 caracteriza el epítopo. Para 5C1, la mutagénesis de cualquiera de los residuos 120-122 tiene la mayor reducción de la unión. La mutagénesis del residuo 123 o 124 da como resultado una reducción significativa de la unión, pero no tanto como en una cualquiera de las posiciones 120-122. La mutagénesis del residuo 118, 119, 125 o el residuo 126 da como resultado una pérdida aún menor de la afinidad de unión, esencialmente sin cambios. Para simplificar, los efectos de la mutagénesis pueden subdividirse aproximadamente en tres categorías: reducción esencialmente completa de la unión para los residuos 120-122 (indistinguible del control negativo), esencialmente sin reducción de la unión para los residuos 118, 119, 125 y 126 (indistinguible del control positivo) y reducción intermedia de la afinidad de unión para los residuos 123 y 124. El epítopo de 5C1 se puede caracterizar aproximadamente por tanto como un epítopo lineal que consiste en o consiste esencialmente en los residuos 120-124 de SEQ ID NO: 1, con los residuos 120-122 haciendo la mayor contribución a la unión. Se proporcionan los anticuerpos que tienen el epítopo 5C1 como se caracteriza por una cualquiera de las descripciones en este párrafo. Algunos anticuerpos se caracterizan por un epítopo que consiste esencialmente en los residuos 120-122 y que excluye los residuos 119-120, lo que significa que los residuos 120-122 contribuyen cada vez más a la unión que cualquier otro residuo y los residuos 119 y 120 no hacen una contribución detectable a la unión (por ejemplo, por el método de escaneo de alanina del ejemplo). Los residuos 123 y 124 pueden o no hacer una contribución menor a la unión en dichos anticuerpos.
Para 5D12, el epítopo se caracteriza por la mutagénesis de la alanina de la siguiente manera. La mutagénesis de cualquiera de los residuos 120-122 tiene la mayor reducción de la unión. La mutagénesis del residuo 118, 199, 123 o 124 da como resultado una reducción significativa de la unión, pero no tanto como en cualquiera de las posiciones 120-122. La mutagénesis del residuo 125 o del residuo 126 da como resultado una pérdida aún menor de la afinidad de unión, esencialmente sin cambios. Para simplificar, los efectos de la mutagénesis pueden subdividirse aproximadamente en tres categorías: reducción esencialmente completa de la unión para la mutación de los residuos 120-122 (indistinguible del control negativo), esencialmente sin reducción de la unión de los residuos 125 y 126 (indistinguible del control positivo) y la reducción intermedia de la afinidad de unión para los residuos 118, 119, 123 y 124. El epítopo de 5D12 se puede caracterizar así aproximadamente como un epítopo lineal que consiste en o que consiste esencialmente en los residuos 118-124 de la SEQ ID NO: 1, con los residuos 120-122 haciendo la mayor contribución a la unión. También se proporcionan otros anticuerpos que tienen el epítopo de 5D12 según se caracteriza por cualquiera de las descripciones en este párrafo o en el Ejemplo 6.
Del mismo modo, el epítopo 9E4 se puede caracterizar por una mutación de los residuos 122 y 125 mostrando cada uno una mayor reducción de la unión que cualquiera de los residuos 118-121, 123, 124 o 126. Para simplificar, los efectos de la mutagénesis se pueden dividir aproximadamente en dos categorías: esencialmente reducción completa de la unión para los residuos 122 y 125 y esencialmente ninguna reducción en la unión para los residuos 118-121, 123, 124 y 126. El epítopo 9E4 se puede caracterizar así aproximadamente como un epítopo conformacional en el que los residuos 122 y 125 proporcionan los puntos de contacto (o la mayor contribución a la unión) con 9E4. Se proporcionan otros anticuerpos que tienen el epítopo 9E4 como se caracteriza por cualquiera de las descripciones en este párrafo o en el Ejemplo 6. Opcionalmente, el anticuerpo no es 9E4 u otro anticuerpo que tenga las mismas CDRs que 9E4 ni un anticuerpo que tenga al menos cinco CDRs de Kabat con al menos el 85% de identidad de secuencia con las CDRs correspondientes de 9E4.
Los anticuerpos que tienen la especificidad de unión de un anticuerpo murino seleccionado (por ejemplo, 5C1) también se pueden producir utilizando una variante del método de presentación de fagos. Véase Winter, documento de Patente WO 92/20791. Este método es particularmente adecuado para producir anticuerpos humanos. En este método, la región variable de cadena pesada o de cadena ligera del anticuerpo murino seleccionado se utiliza como material de partida. Si, por ejemplo, se selecciona una región variable de cadena ligera como material de partida, se construye una biblioteca de fagos en la que los miembros muestran la misma región variable de cadena ligera (es decir, el material de partida murino) y una región variable de cadena pesada diferente. Las regiones variables de cadena pesada se pueden obtener, por ejemplo, de una biblioteca de regiones variables de cadena pesada humana reorganizadas. Se selecciona un fago que muestra una fuerte unión específica para la a-sinucleína (por ejemplo, al menos 108 M-1, y preferiblemente al menos 109 M'1). La región variable de cadena pesada de este fago sirve como material de partida para construir una biblioteca de fagos adicional. En esta biblioteca, cada fago muestra la misma región variable de cadena pesada (es decir, la región identificada a partir de la primera biblioteca de visualización) y una región variable de cadena ligera diferente. Las regiones variables de cadena ligera se pueden obtener, por ejemplo, de una biblioteca de regiones de cadena ligera variable humana reorganizadas. De nuevo, se seleccionan los fagos que muestran una fuerte unión específica para la a-sinucleína. Los anticuerpos resultantes normalmente tienen la misma o similar especificidad de epítopo que el material de partida murino.
Otros anticuerpos se pueden obtener por mutagénesis del cDNA que codifica las cadenas pesadas y ligeras de un anticuerpo ejemplar, tal como 5C1. En consecuencia, los anticuerpos monoclonales que son al menos 70%, 80%, 90%, 95%, 96%, 97%, 98% o 99% idénticos a 5C1 en la secuencia de aminoácidos de las regiones variables de cadena pesada y/o ligera maduras y mantiene sus propiedades funcionales, y/o que difieren del anticuerpo respectivo en un pequeño número de sustituciones de aminoácidos funcionalmente inconsecuentes (por ejemplo, sustituciones conservativas), eliminaciones, o inserciones también se incluyen en la invención.
La invención también incluye anticuerpos monoclonales que tienen algunas o todas (por ejemplo, 3, 4, 5, y preferiblemente 6) CDRs en su totalidad o sustancialmente de 5C1. Dichos anticuerpos pueden incluir una región variable de cadena pesada que tiene al menos dos, y generalmente las tres, CDRs en su totalidad o sustancialmente de la región variable de cadena pesada de 5C1 y/o región variable de cadena ligera que tienen al menos dos, y generalmente las tres, CDRs en su totalidad o sustancialmente de la región variable de cadena ligera de 5C1. Anticuerpos preferidos incluyen tanto cadenas pesadas como ligeras. Una CDR es sustancialmente de una CDR de 5C1 correspondiente cuando no contiene más de 4, 3, 2 o 1 sustituciones, inserciones o eliminaciones, excepto que CDRH2 (cuando está definido por Kabat) no puede tener más de 6, 5, 4, 3, 2 o 1 sustituciones, inserciones o eliminaciones. Tales anticuerpos tienen preferiblemente al menos 70%, 80%, 90%, 95%, 96%, 97% 98% o 99% de identidad con 5C1 en la secuencia de aminoácidos de las regiones variables de cadena pesada y/o ligera maduras y mantienen sus propiedades funcionales, y/o difieren de 5C1 por un pequeño número de sustituciones de aminoácidos funcionalmente inconsecuentes (por ejemplo, sustituciones conservativas), eliminaciones, o inserciones.
Los anticuerpos preferidos muestran una actividad funcional similar a 5C1, por ejemplo, reduciendo los agregados de a-sinucleína neuríticos y/o axonales, reduciendo la distrofia neurítica, mejorando la función cognitiva, invirtiendo, tratando o inhibiendo el deterioro cognitivo, y/o preservando o aumentando la densidad sináptica y/o densidad dentrítica.
B. Anticuerpos quiméricos y recubiertos
La invención proporciona además formas quiméricas y recubiertas de anticuerpos no humanos, particularmente 5C1.
Un anticuerpo quimérico es un anticuerpo en el que las regiones variables maduras de cadenas ligeras y pesadas de un anticuerpo no humano (por ejemplo, un ratón) se combinan con regiones constantes de cadena ligera y pesada humanas. Típicamente, las regiones constantes de cadena ligera y pesada son de origen humano, pero las regiones constantes pueden originarse a partir de diferentes especies no humanas diferentes según sea necesario (por ejemplo, para facilitar el ensayo del anticuerpo no humano en un modelo animal apropiado). Dichos anticuerpos conservan sustancial o totalmente la especificidad de unión del anticuerpo de ratón, y pueden ser aproximadamente dos tercios de la secuencia humana contribuida por las regiones constantes humanas.
Un anticuerpo recubierto es un tipo de anticuerpo humanizado que retiene algunas y generalmente todas la CDRs y algunos de los residuos de marco de la región variable no humana de un anticuerpo no humano, pero reemplaza otros residuos del marco de región variable que pueden contribuir a los epítopos de las células B o T, por ejemplo, residuos expuestos (Padlan, Mol. Immunol. 28: 489, 1991) con residuos de las posiciones correspondientes de una secuencia de anticuerpo humano. El resultado es un anticuerpo en el que las CDRs son en su totalidad o sustancialmente de un anticuerpo no humano y los marcos de región variable del anticuerpo no humano se hacen más parecidos a los humanos por las sustituciones.
C. Anticuerpos humanizados
Los anticuerpos humanizados 5C1 se unen específicamente a la a-sinucleína humana. La afinidad de algunos anticuerpos humanizados (es decir, Ka) puede estar, por ejemplo, dentro de un factor de cinco o dos de la del anticuerpo 5C1 murino. Algunos anticuerpos humanizados tienen una afinidad que es la misma, dentro del error experimental, que la del 5C1 murino. Algunos anticuerpos humanizados tienen una afinidad mayor que la del 5C1 murino. Los anticuerpos humanizados preferidos se unen al mismo epítopo y/o compiten con el 5C1 murino para unirse a la a-sinucleína humana.
Un anticuerpo humanizado es un anticuerpo genéticamente modificado en el que las CDRs de un anticuerpo “donador” no humano (por ejemplo, 5C1 murino) se injerta en secuencias de anticuerpos “aceptores” humanos (véase, por ejemplo, Queen, documentos de Patente US 5,530,101 y 5,585,089; Winter, documento de Patente US 5,225,539, Carter, documento de Patente US 6,407,213, Adair, documentos de Patente US 5,859,205 y 6,881,557, Foote, documento de Patente US 6,881,557). Las secuencias de anticuerpos aceptores pueden ser, por ejemplo, una secuencia de anticuerpo humano maduro, una composición de tales secuencias, una secuencia de consenso de secuencias de anticuerpos humanos, o una secuencia de región de línea germinal. Por lo tanto, un anticuerpo humanizado 5C1 es un anticuerpo que tiene algunas o todas las CDRs en su totalidad o sustancialmente de 5C1 murino y la secuencia de marco de región variable y regiones constantes, si están presentes, en su totalidad o sustancialmente de secuencias de anticuerpos humanos. Similarmente una cadena pesada humanizada tiene al menos dos y generalmente las tres CDRs en su totalidad o sustancialmente de una cadena pesada de un anticuerpo donador, y una secuencia de marco de región variable de cadena pesada y una región constante de cadena pesada, si está presente, sustancialmente de secuencias marco de región variable de cadena pesada y secuencias de región constante. Similarmente una cadena ligera humanizada tiene al menos dos y generalmente la tres CDRs en su totalidad o sustancialmente de una cadena ligera de anticuerpo donador, y una secuencia marco de región variable de cadena ligera y una región constante de cadena ligera, si está presente, sustancialmente de secuencias marco de región variable de cadena ligera y secuencias de región constante. Aparte de nanocuerpos y dAbs, un anticuerpo humanizado comprende una cadena pesada humanizada y una cadena ligera humanizada. Preferiblemente al menos el 85%, 90%, 95% o 100% de los residuos correspondientes (según lo define Kabat) son idénticos entre las respectivas CDRs. Las secuencias marco de región variable de una cadena de anticuerpo o la región constante de una cadena de anticuerpo son sustancialmente de una secuencia marco de región variable humana o región constante humana, respectivamente, cuando al menos el 85%, 90%, 95%, 96%, 97%, 98%, 99%, o 100% de los residuos correspondientes definidos por Kabat son idénticos.
Aunque los anticuerpos humanizados incorporan a menudo las seis CDRs (preferiblemente según lo define Kabat) de un anticuerpo de ratón, también se pueden hacer con menos de todas las CDRs (al menos 3, 4 o 5) CDRs de un anticuerpo de ratón (por ejemplo, Pascalis et al., J. immunol. 169: 3076, 2002; Vajdos et al., Journal of Molecular Biology, 320: 415-428, 2002; Iwahashi et al., Mol. Immunol. 36:1079-1091, 1999; Tamura et al., Journal of immunology, 164: 1432-1441, 2000).
En algunos anticuerpos, solo se necesita una parte de las CDRs, concretamente el subconjunto de residuos de CDR necesarios para la unión, denominados residuos determinantes de la especificidad (SDRs) (Kashmiri et al., Methods (2005) 36(1): 25-34), necesarios para retener la unión en un anticuerpo humanizado. Los residuos de CDR que no entran en contacto con el antígeno y que no están en los SDR pueden identificarse en base a estudios previos (por ejemplo uno o más o todos los residuos H60-H65 en CDR H2 a veces no son necesarios), de regiones de CDRs de Kabat que se encuentran fuera de los bucles hipervariables de Chothia (Chothia, J. Mol. Biol. 196: 901, 1987), mediante modelado molecular y/o empíricamente, o como se describe en Gonzales et al., Mol. Immunol. 41: 863, 2004. En dichos anticuerpos humanizados, en las posiciones en las que uno o más residuos de CDR donadores están ausentes o en las que se omite una CDR donante, el aminoácido que ocupa la posición puede ser un aminoácido que ocupa la posición correspondiente (mediante la numeración de Kabat) en la secuencia del anticuerpo aceptor. El número de dichas sustituciones de aceptores para aminoácidos donadores en las CDRs para incluir refleja un equilibrio de consideraciones competitivas. Dichas sustituciones son potencialmente ventajosas para disminuir el número de aminoácidos de ratón en un anticuerpo humanizado y, en consecuencia, disminuir la inmunogenicidad potencial. Sin embargo, las sustituciones también pueden causar cambios de afinidad, y preferiblemente se evitan reducciones significativas en la afinidad. Las posiciones para la sustitución dentro de las CDRs y los aminoácidos para sustituir también se pueden seleccionar empíricamente.
Las secuencias de anticuerpos aceptores humanos se pueden seleccionar opcionalmente de entre las muchas secuencias de anticuerpos humanos conocidas para proporcionar un alto grado de identidad de secuencia (por
ejemplo, 65%-85% de identidad) entre los marcos de región variable de la secuencia aceptora humana y los correspondientes marcos de región variable de una cadena de anticuerpo donador.
Ciertos aminoácidos de los residuos del marco de región variable humana pueden seleccionarse para la sustitución en base a su posible influencia en la conformación de CDR y/o la unión al antígeno. La investigación de dichas posibles influencias se realiza mediante modelado, examen de las características de los aminoácidos en localizaciones particulares, o la observación empírica de los efectos de la sustitución o mutagénesis de aminoácidos particulares.
Por ejemplo, cuando un aminoácido difiere entre un residuo de marco de región variable murina y un residuo de marco de región variable humano seleccionado, el aminoácido de marco humano se puede sustituir por el aminoácido de marco equivalente del anticuerpo de ratón cuando se espera razonablemente que el aminoácido: (1) se una de forma no covalente al antígeno directamente,
(2) es adyacente a una región CDR,
(3) de lo contrario, interactúa con una región CDR (por ejemplo, está dentro de aproximadamente 6 A de una región CDR), (por ejemplo, se identifica modelando la cadena ligera o pesada en la estructura resuelta de una cadena de inmunoglobulina conocida homóloga); y
(4) un residuo que participa en la interfaz VL-VH.
Los residuos del marco de las clases (1) - (3) como se define en Queen, documento de Patente US 5,530,101 se refieren a veces alternativamente como residuos canónicos y vernier. Los residuos del marco que ayudan a definir la conformación de un bucle de CDR se denominan algunas veces como residuos canónicos (Chothia y Lesk, J. Mol. Biol. 196, 901-917 (1987), Thornton & Martin J. Mol. Biol., 263, 800-815, 1996). Los residuos del marco que soportan las conformaciones del bucle de unión al antígeno y desempeñan un papel en al ajuste fino del ajuste de un anticuerpo al antígeno se denominan a veces residuos de vernier (Foote & Winter, 1992, J. Mol. Biol. 224, 487-499). Otros residuos del marco que son candidatos para la sustitución son los residuos que crean un sitio de glicosilación potencial. Aún otros candidatos para la sustitución son aminoácidos del marco humano aceptor que son inusuales para una inmunoglobulina humana en esa posición. Estos aminoácidos pueden sustituirse con aminoácidos de la posición equivalente del anticuerpo donador del ratón o de las posiciones equivalentes de las inmunoglobulinas humanas más típicas.
La invención proporciona formas humanizadas del anticuerpo 5C1 de ratón. El anticuerpo de ratón comprende regiones variables de cadena pesada y ligera maduras que tienen secuencias de aminoácidos que comprenden SEQ ID NO: 9 y SEQ ID NO: 24, respectivamente. La invención proporciona cinco ejemplos de regiones variables de cadena pesada madura humanizada: H1, SEQ ID NO: 14; H2, SEQ ID NO: 15; H3, SEQ ID NO: 16; H4, SEQ ID NO: 17; y H5, SEQ ID NO: 18. La invención proporciona además cuatro ejemplos de regiones variables de cadena ligera madura humanizada: L1, SEQ ID NO: 29; L2, SEQ ID NO: 30; L3 SEQ ID NO: 31; y L4, SEQ ID NO: 32. Los anticuerpos incluye cualquier permutación de estas regiones variables de cadena pesada y ligera madura que se proporcionen, es decir, H1L2, H1L3, H1L4, H2L1, H2L2, H2L3, H2L4, H3L1, H3L2, H3L3, H3L4, H4L1, H4L2, H4L3, H4L4, H5L1, H5L2, H5L3, o H5L4. La variante H4L3, que incluye ocho retromutaciones de cadena pesada y cinco retromutaciones de cadena ligera, tiene una afinidad a la a-sinucleína (medida en un instrumento Biacore) que está dentro de un factor de dos de las afinidades de los anticuerpos 5C1 murinos y quiméricos. Véase la Tabla 3, a continuación. Según lo medido por ELISA, la variante H4L3 tiene una afinidad por la a-sinucleína que es sustancialmente la misma que la de un anticuerpo quimérico 5C1 (dentro del error experimental) y superior al del anticuerpo 5C1 murino. Véase la Figura 5. Además, la variante H5L3, que incluye seis retromutaciones de cadena pesada y cinco retromutaciones de cadena ligera, proporciona una afinidad a la a-sinucleína humana (medida en un instrumento Biacore) que está dentro de un factor de cuatro las afinidades de los anticuerpos 5C1 murinos y quiméricos. Véase Tabla 3, a continuación. La variante H3L4, que incluye nueve retromutaciones de cadena pesada y dos retromutaciones de cadena ligera, también proporciona una afinidad a la a-sinucleína humana (medida por ELISA) que es sustancialmente la misma del anticuerpo 5C1 quimérico, dentro del error experimental, y las variantes H3L3 y H3L1, que incluye cada una nueve retromutaciones de cadena pesada y cinco y seis retromutaciones de cadena ligera, respectivamente, proporcionan afinidades a la a-sinucleína que son superiores al anticuerpo 5C1 murino (medido por ELISA).
La invención proporciona variantes del anticuerpo 5C1 humanizado H4L3 en las que la región variable de cadena pesada madura humanizada muestra al menos un 90%, 95%, 96%, 97%, 98%, o 99% de identidad con H4 (SEQ ID NO: 17) y la región variable de cadena ligera madura humanizada muestra al menos un 90%, 95%, 96%. 97%, 98%, o 99% de identidad de secuencia con L3 (SEQ ID NO: 31). En alguno de dichos anticuerpos, se retiene al menos una, dos, tres, cuatro, cinco, seis, siete, ocho, nueve, diez, once, doce, o las trece de las retromutaciones en H4L3. La invención también proporciona variantes del anticuerpo 5C1 humanizado H5L3 en las que la región variable de cadena pesada madura humanizada muestra al menos 90%, 95%, 96%, 97%, 98%, o 99% de identidad con H5 (SEQ ID NO: 18) y la región variable de cadena ligera madura humanizada muestra al menos 90%, 95%, 96%, 97%, 98%, o 99% de identidad de secuencia con L3 (SEQ ID NO: 31). En alguno de dichos anticuerpos, se retiene al
menos una, dos, tres, cuatro, cinco, seis, siete, ocho, nueve, diez, o la once de las retromutaciones en H5L3. La invención también proporciona variantes del anticuerpo 5C1 humanizado H3L4 en las que la región variable de cadena pesada madura humanizada muestra al menos 90%, 95%, 96%, 97%, 98%, o 99% de identidad con H3 (SEQ ID NO: 16) y la región variable de cadena ligera madura humanizada muestra al menos 90%, 95%, 96%, 97%, 98%, o 99% de identidad de secuencia con L4 (SEQ ID NO: 32). En alguno de dichos anticuerpos, se retienen al menos una, dos, tres, cuatro, cinco, seis, siete, ocho, nueve, diez, o la once retromutaciones en H3L4. En algunos anticuerpos, al menos una de las posiciones H11, H27, H30, H48, y H73 en la región Vh está ocupada por L, Y, T, I, y K, respectivamente. En algunos anticuerpos, las posiciones H11, H27, H30, H48, y H73 en la región Vh están ocupadas por L, Y, T, I, y K, respectivamente. En algunos anticuerpos, al menos una de las posiciones H67, H69, H91, y H94 en la región Vh está ocupada por A, L, F, y S, respectivamente. En algunos anticuerpos, las posiciones H67, H69, y H94 en la región Vh está ocupada por A, L, y S, respectivamente, como en la versión H4. En algunos anticuerpos, la posición H94 está ocupada por S, como en la versión H5. En algunos anticuerpos, las posiciones H67, H69, H91 y H94 en la región Vh están ocupadas por A, L, F, y S, respectivamente, como en la versión H3. En algunos anticuerpos, al menos una de las posiciones L12 y L14 en la región Vk está ocupada por S. En algunos anticuerpos, las posiciones L12 y L14 en la región Vk están ambas ocupadas por S, como en las versiones L3 y L4. En algunos anticuerpos, al menos una de las posiciones L2, L45, L49, y L87 en la región Vk está ocupada por V, K, N, y F, respectivamente. En algunos anticuerpos, al menos una de las posiciones L2, L45, L49, y L87 en la región Vk está ocupada por V, K, N, y F, respectivamente. En algunos anticuerpos, las posiciones L2, L49, y L87 en la región Vk están ocupadas por V, N, y F, respectivamente, como en la versión L3. En algunos anticuerpos, las posiciones L2, L45, L49, y L87 en la región Vk están ocupadas por V, K, N, y F, respectivamente, como en la versión L1. Las regiones CDR de dichos anticuerpos humanizados pueden ser idénticas o sustancialmente idénticas a las regiones CDR de H4L3 o H5L3, que son los mismas que las del anticuerpo donador de ratón. Las regiones CDR pueden definirse mediante cualquier definición convencional (por ejemplo, Chothia) pero son preferiblemente como las define Kabat. Una posibilidad de variación adicional en variantes de 5C1 humanizado son las retromutaciones adicionales en los marcos de región variable. Muchos de los residuos de los marcos que no están en contacto con las CDR en el mAb humanizado pueden acomodar sustituciones de aminoácidos de las posiciones correspondientes del mAb de ratón donador u otros anticuerpos de ratón o humanos, e incluso muchos residuos potenciales de contacto con CDR son también susceptibles de sustitución o incluso los aminoácidos dentro de las CDRs se pueden alterar, por ejemplo, con los residuos encontrados en la posición correspondiente de la secuencia aceptora humana utilizada para suministrar los marcos de región variable. Además, se puede utilizar secuencias aceptoras humanas alternativas, por ejemplo, para la cadena pesada y/o ligera. Si se utilizan diferentes secuencias aceptoras, es posible que una o más de las retromutaciones recomendadas anteriormente no puedan realizarse debido a que los residuos del donador y aceptor correspondientes ya no son los mismos sin la retromutación. Por ejemplo, cuando se utiliza una secuencia aceptora de cadena pesada en la que la posición H11 ya está ocupada por L, H48 ya está ocupada por I y/o H73 ya está ocupada por K, no es necesaria la retromutación correspondiente. De manera similar, cuando se utiliza una secuencia aceptora de cadena ligera en la que la posición L12 y/o L14 está ocupada por S, no es necesaria la correspondiente retromutación.
La invención también incluye anticuerpos humanizados en los que las regiones variables de cadena ligera y pesada maduras muestran al menos 90%, 95%, 96%, 97%, 98%, o 99% de identidad de secuencia con las regiones variables de cadena ligera y pesada maduras de los H1L1, H1L2, H1L3, H1L4, H2L1, H2L2, H2L3, H2L4, H3L1, H3L2, H3L3, H4L1, H4L2, H4L4, H5L1, H5L2, o H5L4 de 5C1 humanizados. Las regiones CDR de dichos anticuerpos humanizados pueden ser idénticas o sustancialmente idénticas a aquellas del anticuerpo donador de ratón. Las regiones CDR se pueden definir mediante cualquier definición convencional (por ejemplo, Chothia) pero son preferiblemente como las define Kabat.
D. Selección de la región constante
Las regiones variables de cadena pesada y ligera de anticuerpos quiméricos, humanizados (incluyendo recubiertos), o humanos se pueden unir a al menos una parte de una región constante suficiente para interactuar con el receptor Fc. La región constante es típicamente humana, pero se puede seleccionar una región constante no humana si es necesario.
La elección de la región constante depende, en parte, de si se desea el complemento dependiente del anticuerpo y/o la toxicidad mediada por células. Por ejemplo, los isotipos humanos IgG1 e IgG3 tienen citotoxicidad mediada por el complemento mientras que los isotipos IgG2 e IgG4 tienen una citotoxicidad pobre o nula mediada por el complemento. Una región constante IgG1 humana adecuada para la inclusión en los anticuerpos de la invención puede tener la secuencia de SEQ ID NO: 38. Las regiones constantes de cadena ligera pueden ser lambda o kappa. Una región constante de cadena ligera kappa humana adecuada para la inclusión en los anticuerpos de la invención puede tener la secuencia SEQ ID NO: 40. Los anticuerpos se pueden expresar como tetrámeros que contienen dos cadenas ligeras y dos cadenas pesada, como cadenas pesadas separadas, como cadenas ligeras separadas, como Fab, Fab', F(ab')2, o fragmentos Fv, o como anticuerpos monocatenarios en los que las regiones variables de cadena pesada y ligera se unen a través de un espaciador.
Las regiones constantes humanas muestran una variación alotípica y una variación isoalotípica entre individuos diferentes. Es decir, las regiones constantes pueden diferir en diferentes individuos en una o más posiciones polimórficas. Los isoalotipos difieren de los alotipos en que los sueros que reconocen un isoalotipo se unen a una
región no polimórfica de uno o más isotipos diferentes. La referencia a una región constante humana incluye una región constante con cualquier alotipo natural o cualquier permutación de los residuos que ocupan las posiciones polimórficas en los alotipos naturales o hasta 3, 5 o 10 sustituciones para reducir o aumentar la función efectora como se describe a continuación.
Uno o varios aminoácidos en el extremo amino o carboxi de cadena ligera y/o pesada, tal como la lisisn C-terminal de cadena pesada, pueden faltar o derivatizarse en parte o en la totalidad de las moléculas. Las sustituciones se pueden hacer en las regiones constantes para disminuir o aumentar la función efectora tal como la citotoxicidad mediada por el complemento o ADCC (véase, por ejemplo, Winter et al., documento de Patente US No. 5,624,821; Tso et al., documento de Patente Us No. 5,834,597; y Lazar et al., Proc. Natl. Acad. Sci. USA 103: 4005, 2006), o prolongar la vida media en humanos (véase, por ejemplo, Hinton et al., J. Biol. Chem. 279: 6213, 2004). Ejemplos de sustituciones incluyen una Gln en la posición 250 y/o una Leu en la posición 428 (la numeración EU se utiliza en este párrafo para la región constante) para aumentar la vida media de un anticuerpo. La sustitución de cualquiera o todas las posiciones 234, 235, 236 y/o 237 reduce la afinidad por los receptores Fcy, particularmente el receptor FcyRI (véase, por ejemplo, el documento de Patente US 6,624,821). Se puede utilizar una sustitución de alanina en las posiciones 234, 235 y 237 de la IgG1 humano para reducir las funciones efectoras. Opcionalmente, las posiciones 234, 236 y/o 237 en la IgG2 humana se sustituyen con alanina y la posición 235 con glutamina (véase, por ejemplo, el documento de Patente 5,624,821). En algunos aspectos, se utiliza una mutación en una o más de las posiciones 241, 264, 265, 270, 296, 297, 322, 329, y 331 por la numeración de la UE de la igG1 humana. En algunos aspectos, se utiliza una mutación en una o más de 318, 320, y 322 por la numeración de UE de la IgG1 humana. En algunos aspectos, el isotipo es IgG2 o IgG4 humano.
E. Anticuerpos humanos
Los anticuerpos humanos contra la a-sinucleína se proporcionan mediante una variedad de técnicas que se describen a continuación. Algunos anticuerpos humanos se seleccionan mediante experimentos de unión competitiva, o de lo contrario, para que tengan la misma o superpuesta especificidad de epítopo que el 5C1. Los anticuerpos humanos se pueden también detectar para determinar la especificidad de un epítopo particular utilizando solo un fragmento de a-sinucleína (por ejemplo, residuos de aminoácidos 118-126) como inmunógeno, y/o detectar anticuerpos frente a una colección de mutantes de deleción de a-sinucleína. Otra técnica para producir anticuerpos humanos es la metodología trioma (Oestberg et al., Hybridoma 2: 361-367 (1983); Oestberg, documento de Patente U.S. Pat. No. 4,634,664; y Engleman et al., documento de Patente U.S. Pat. No. 4,634,666). Otra técnica implica ratones transgénicos inmunizantes que expresan genes de inmunoglobulina humanos, tales como el XenoMouse®, AlivaMab Mouse o Veloceimmune Mouse (véase, por ejemplo, Lonberg et al., documento de Patente WO93/1222, documentos de Patente U.S. Pat. No. 5,877,397, U.S. Pat. No. 5,874,299, U.S. Pat. No. 5,814,318, U.S. Pat. No. 5,789,650, U.S. Pat. No. 5,770,429, U.S. Pat. No. 5,661,016, U.S. Pat. No. 5,633,425, U.S. Pat. No.
5,625,126, U.S. Pat. No. 5,569,825, U.S. Pat. No. 5,545,806, Nature 148, 1547-1553 (1994), Nature Biotechnology 14, 826 (1996), Kucherlapati, y documento de Patente WO 91/10741). Otra técnica es la presentación de fagos (véase, por ejemplo, Dower et al., documento de Patente WO 91/17271 y McCafferty et al., documentos de Patente WO 92/01047, U.S. Pat. No. 5,877,218, U.S. Pat. No. 5,871,907, U.S. Pat. No. 5,858,657, U.S. Pat. No. 5,837,242, U.S. Pat. No. 5,733,743 y U.S. Pat. No. 5,565,332). En estos métodos, se producen bibliotecas de fagos en las que los miembros muestran diferentes anticuerpos en sus superficies externas. Los anticuerpos se muestran normalmente como fragmentos Fv o Fab. Los anticuerpos que muestran fagos con una especificidad deseada se seleccionan mediante el enriquecimiento por afinidad a un péptido de a-sinucleína o un fragmento del mismo. Otra técnica es secuenciar el DNA de células B humanas según los procedimientos generales descritos en Reddy et al., Nat Biotechnol. 2010 Sept 28(9): 965-9 (Epub 2010 Aug 29), y los documentos de Patente US 20110053803, 20100099103, 20100291066, 20100035763, y 20100151471. Brevemente, las células B se pueden obtener de un humano sospechoso de tener anticuerpos anti-a-sinucleína, por ejemplo, un humano inmunizado con a-sinucleína, fragmentos de la misma, polipéptidos más largos que contienen a-sinucleína o fragmentos de la misma, o anticuerpos anti-idiotípicos. El mRNA de los anticuerpos de las células B se retrotranscriben después en cDNA y se secuencian utilizando, por ejemplo, la tecnología de secuenciación 454. Después de obtener las secuencias de las cadenas de cada anticuerpo, las cadenas se pueden emparejar juntas (por ejemplo, utilizando bioinformática), clonar, expresar, y secretar para las propiedades deseadas.
F. Expresión de anticuerpos recombinantes
Se conocen varios métodos para producir anticuerpos quiméricos y humanizados utilizando líneas celulares que expresan anticuerpos (por ejemplo, hibridoma). Por ejemplo, las regiones variables de la inmunoglobulina de los anticuerpos se pueden clonar y secuenciar utilizando métodos bien conocidos. En un método, la región variable VH de cadena pesada se clona mediante RT-PCR utilizando mRNA preparado a partir de células de hibridoma. Se emplean cebadores consensuados para el péptido líder de la región VH que abarca el codón de iniciación de la traducción como el cebador 5' y un cebador 3' específico de las regiones constantes g2b. Ejemplos de cebadores se describen en la solicitud de Patente U.S. 2005/0009150 de Schenk et al. (en adelante, “Schenk”). Las secuencias de múltiples clones derivados independientemente pueden compararse para garantizar que no se introduzcan cambios durante la amplificación. La secuencia de la región VH se puede determinar también o confirmar mediante la secuenciación de un fragmento VH obtenido mediante la tecnología RACE RT-PCR de 5' y el cebador específico 3' de g2b.
La región variable VL de cadena ligera se puede clonar de manera análoga a la región VH. En un enfoque, un conjunto de cebadores consensuados diseñado para la amplificación de las regiones VL se diseña para hibridar con la región VL que abarca el codón de inicio de la traducción, y un cebador 3' específico para la región Ck posterior a la región de unión V-J. En un segundo enfoque, la metodología RACE RT-PCR de 5' se emplea para clonar un cDNA que codifica VL. Ejemplos de cebadores se describen en Schenk, supra. Las secuencias clonadas se combinan después con secuencias que codifican regiones constantes humanas (u otras especies no humanas). Ejemplos de secuencias que codifican regiones constantes humanas incluyen SEQ ID NO: 37, que codifica una región constante IgG1 humana, y SEQ ID NO: 39, que codifica una región constante de cadena ligera kappa humana.
En un enfoque, las regiones variables de cadena pesada y ligera se rediseñan genéticamente para codificar las secuencias donadoras de empalme posteriores a las uniones VDJ o VJ, y se clonan en el vector de expresión de mamíferos, tal como pCMV-hYl para la cadena pesada, y pCMV-Mcl para la cadena ligera. Estos vectores codifican las regiones constantes y1 y Ck humanas como fragmentos exónicos posteriores al casete de región variable insertado. Tras la verificación de la secuencia, los vectores de expresión de cadena pesada y cadena ligera se pueden co-transfectar en células CHO para producir anticuerpos quiméricos. Se recogen medios condicionados 48 horas después de la transfección y se analizan mediante el análisis de transferencia de Western para la producción de anticuerpos o por ELISA para la unión del antígeno. Los anticuerpos quiméricos se humanizan como se describió anteriormente.
Los anticuerpos quiméricos, recubiertos, humanizados y humanos se producen típicamente mediante expresión recombinante. Los constructos de ácidos nucleicos recombinantes incluyen típicamente una secuencia de control de expresión unida operativamente a las secuencias codificantes de las cadenas de anticuerpos, que incluyen elemento(s) de control de expresión asociados de manera natural o heterólogos, tal como un promotor. Una vez que el vector se ha incorporado en un huésped apropiado, el huésped se mantiene en condiciones adecuadas para un alto nivel de expresión de las secuencias de nucleótidos, y se recogen y purifican los anticuerpos de la reacción cruzada.
Estos vectores de expresión se replican típicamente en los organismos huéspedes como episomas o como parte integral del DNA cromosómico del huésped. Comúnmente, los vectores de expresión contienen marcadores de selección, por ejemplo, resistencia a la ampicilina o resistencia a la higromicina, para permitir la detección de aquellas células transformadas con las secuenciad de DNA deseadas.
E. coli es un huésped procariota útil para la clonación de secuencias de DNA que codifican los polipéptidos descritos en la presente memoria. Los microbios, tales como la levadura son también útiles para la expresión. Saccharomyces es un huésped de levadura, con vectores adecuados que tienen secuencias de control de expresión, un origen de replicación, secuencias de terminación y similares según se desee. Promotores típicos incluyen 3-fosfoglicerato quinasa y otras enzimas glicolíticas. Promotores de levadura inducibles incluyen, entre otros, promotores de alcohol deshidrogenasa, isocitocromo C, y enzimas responsables para la utilización de maltosa y galactosa.
Las células de mamíferos son células huésped para la expresión de segmentos de nucleótidos que codifican inmunoglobulinas o fragmentos de las mismas. Véase Winnacker, From Genes to Clones, (VCH Publishers, NY, 1987). Se han desarrollado varias líneas celulares de huéspedes adecuadas capaces de secretar proteínas heterólogas intactas, e incluyen líneas de células CHO, varias líneas de células COS, células HeLa, células L, células de riñón embrionario humano y líneas celulares de mieloma. Las células pueden ser no humanas. Los vectores de expresión para estas células pueden incluir secuencias de control de expresión, tal como un origen de replicación, un promotor, un potenciador (Queen et al., Immunol. Rev. 89: 49 (1986)), y sitios de información de procesamiento necesarios, tales como sitios de unión de ribosomas, sitios de empalme de RNA, sitios de poliadenilación, y secuencias de terminación transcripcional. Las secuencias de control de expresión pueden incluir promotores derivados de genes endógenos, citomegalovirus, SV40, adenovirus, papilomavirus bovino, y similares. Véase Co et al., J. Immunol. 148: 1149 (1992).
Alternativamente, las secuencias que codifican anticuerpos se pueden incorporar en los transgenes para la introducción en el genoma de un animal transgénico y su posterior expresión en la leche del animal transgénico (véase, por ejemplo, los documentos de Patente U.S. Pat. No. 5,741,957, U.S. Pat. No. 5,304,489, U.S. Pat. No.
5,849,992). Transgenes adecuados incluyen secuencias codificantes para cadenas ligeras y/o pesadas en enlaces operables con un promotor o potenciador de un gen específico de la glándula mamaria, tal como caseína o la betalactoglobulina.
Los vectores que contienen los segmentos de DNA de interés se pueden transferir en la célula huésped mediante métodos que dependen del tipo de huésped celular. Por ejemplo, la transfección con cloruro de calcio se utiliza comúnmente para células procarióticas, mientras que el tratamiento con fosfato de calcio, electroporación, lipofección, la biolística o la transfección basada en virus se pueden utilizar para otros huéspedes celulares. Otros métodos utilizados para transformar las células mamíferas incluyen el uso de polibreno, fusión de protoplastos, liposomas, electroporación y microinyección. Para la producción de animales transgénicos, los transgenes se pueden microinyectar en ovocitos fertilizados, o pueden incorporarse en el genoma de las células madre embrionarias, y los núcleos de dichas células se transfieren a ovocitos enucleados.
Habiendo introducido el vector(s) que codifica las cadenas pesadas y ligeras de anticuerpos en un cultivo celular, se pueden detectar los grupos de células para determinar la productividad de crecimiento y la calidad del producto en medios libres de suero. Los grupos de células de mayor producción pueden someterse después a la clonación de una sola célula basada en FACS para generar líneas monoclonales. Se pueden utilizar productividades específicas de más de 50 pg o 100 pg por célula por día, que corresponden a títulos de producto de más de 7,5 g/L de cultivo. Los anticuerpos producidos por clones de células individuales también se pueden probar para determinar la turbidez, las propiedades de filtración, PAGE, IEF, exploración UV, HP-SEC, mapeo de carbohidratos-oligosacáridos, espectrometría de masas y ensayos de unión, tales como ELISA o Biacore. Un clon seleccionado puede después depositarse en múltiples viales y almacenarse congelados para su uso posterior.
Una vez expresados, los anticuerpos se pueden purificar según procedimientos estándar de la técnica, incluyendo captura de proteína A, purificación por HPLC, cromatografía en columna, electroforesis en gel y similares (véase, en general, Scopes, Protein Purification (Springer-Verlag, NY, 1982)).
Se puede emplear la metodología para la producción comercial de anticuerpos, incluyendo la optimización de codón, selección de promotores, elementos de transcripción, y terminadores, clonación de células individuales libres de suero, bancos de células, uso de marcadores de selección para la amplificación del número de copias, terminadores de CHO, clonación de células individuales libres de suero, mejora de los títulos de proteínas (véase, por ejemplo, los documentos de Patente US 5,786,464, US 6,114,148, US 6,063,598, US 7,569,339, WO2004/050884, WO2008/012142, WO2008/012142, WO2005/019442, WO2008/107388, y WO2009/027471, y el documento de Patente US 5,888,809).
G. Ensayos de detección de anticuerpos
Los anticuerpos se pueden someter a varias detecciones que incluyen ensayos de unión, detecciones funcionales, detecciones en modelos animales de enfermedades asociadas los depósitos de a-sinucleína, y ensayos clínicos. Los ensayos de unión analizan la unión específica y, opcionalmente, la afinidad y la especificidad del epítopo a la asinucleína (o un fragmento de la misma, como los residuos de aminoácidos 118-126). Dichas detecciones se realizan a veces en competencia con un anticuerpo ejemplar como el 5C1. Opcionalmente, el anticuerpo o la diana de a-sinucleína se inmovilizan en dicho ensayo. Los ensayos funcionales se pueden realizar en modelos celulares que incluyen células que expresan de forman natural la a-sinucleína o se transfectan con DNA que codifica la asinucleína o un fragmento de la misma. Las células adecuadas incluyen células neuronales. Las células pueden detectarse para niveles reducidos de a-sinucleína (por ejemplo, mediante transferencia de Western o inmunoprecipitación de extractos celulares o sobrenadantes), niveles reducidos de a-sinucleína agregada (por ejemplo, mediante inmunohistoquímica y/o métodos confocales) y/o toxicidad reducida atribuible a la a-sinucleína. Las detecciones de modelos animales prueban la capacidad del anticuerpo para tratar los signos o síntomas terapéuticos o profilácticos en un modelo animal que simula una enfermedad humana asociada con los depósitos de a-sinucleína, como una enfermedad del cuerpo de Lewy. Los signos o síntomas adecuados que pueden monitorizarse incluyen el equilibrio motor, la coordinación, y los déficits cognitivos. El grado de deterioro se puede determinar por comparación con un control apropiado, como el equilibrio motor, la coordinación o la deficiencia cognitiva en animales de control que han recibido un anticuerpo de control (por ejemplo, un anticuerpo de control del isotipo coincidente), un placebo, o ningún tratamiento en todos. Los modelos transgénicos u otros modelos animales de las enfermedades del cuerpo de Lewy pueden expresar un transgén de a-sinucleína humana. Para facilitar los ensayos en modelos animales, se pueden utilizar anticuerpos que tienen una región constante apropiada para el modelo animal. Se puede concluir que una versión humanizada de un anticuerpo será efectiva si el correspondiente anticuerpo de ratón o anticuerpo quimérico es efectivo en un modelo animal apropiado y el anticuerpo humanizado tiene una afinidad de unión similar (por ejemplo, por un factor de 1,5, 2, o 3, dentro del error experimental).
Los ensayos clínicos prueban la seguridad y la eficacia en un ser humano que tiene una enfermedad asociada con los depósitos de a-sinucleína.
H. Ácidos nucleicos
La invención proporciona además los ácidos nucleicos que codifican cualquiera de las cadenas pesada o ligera descritas anteriormente. Típicamente, los ácidos nucleicos codifican también un péptido señal unido a las cadenas pesadas y ligeras maduras. Ejemplos adecuados de péptidos señal incluyen los residuos de aminoácidos 1-19 de SEQ ID NO: 6 (codificado por los nucleótidos 1-57 de SEQ ID NO: 5) y los residuos de aminoácidos 1-19 de SEQ ID NO: 8 (codificado por los nucleótidos 1-57 de SEQ ID NO: 7). Las secuencias codificantes en los ácidos nucleicos pueden estar en una unión operable con secuencias reguladoras para asegurar la expresión de las secuencias codificantes, tales como un promotor, potenciador, sitio de unión al ribosoma, señal de terminación de la transcripción y similares. Los ácidos nucleicos que codifican cadenas pesadas y ligeras pueden aparecer en forma aislada o pueden clonarse en uno o más vectores. Los ácidos nucleicos se pueden sintetizar, por ejemplo, mediante síntesis en estado sólido o PCR de oligonucleótidos superpuestos. Los ácidos nucleicos que codifican cadenas pesadas y ligeras pueden unirse como un ácido nucleico contiguo, por ejemplo, dentro de un vector de expresión, o pueden estar separado, por ejemplo, cada uno clonado en su propio vector de expresión.
V. Aplicaciones terapéuticas
La invención proporciona varios métodos para tratar o efectuar profilaxis de la enfermedad del cuerpo de Lewy en pacientes que padecen o están en riesgo de contraer dicha enfermedad. Los pacientes susceptibles de tratamiento incluyen individuos con riesgo de enfermedad de una LBD pero que no presentan síntomas, así como pacientes que presentan síntomas o signos de advertencia tempranos de sinucleinopatías, por ejemplo, desaceleración del e Eg , manifestaciones neuropsiquiátricas (depresión, demencia, alucinaciones, ansiedad, apatía, anhedonia), cambios autonómicos (hipotensión ortostática, trastornos de la vejiga, estreñimiento, incontinencia fecal, sialorrea, disfagia, disfunción sexual, cambios en el flujo sanguíneo cerebral), cambios sensoriales ( olfato, dolor, sensaciones anormales de la discriminación del color), trastornos del sueño (trastorno de la conducta del sueño REM (RBD), síndrome de las piernas inquietas/movimientos periódicos de las extremidades, hipersomnia, insomnio) y otros signos y síntomas diversos (fatiga, diplopía, visión borrosa, seborrea, pérdida/ganancia de peso). Por lo tanto, los presentes métodos se pueden administrar profilácticamente a individuos que tienen un riesgo genético conocido de una LBD. Tales individuos incluyen aquellos que tienen parientes que han experimentado esta enfermedad y aquellos cuyo riesgo está determinado por el análisis de marcadores genéticos o bioquímicos. Los marcadores genéticos del riesgo hacia la PD incluyen mutaciones en los genes de a-sinucleína o Parkin, UCHLI, y CYP2D6; particularmente las mutaciones en las posiciones 30 y 53 del gen de la a-sinucleína. Los individuos que padecen actualmente la enfermedad de Parkinson pueden ser reconocidos por sus manifestaciones clínicas, incluyendo temblor en reposo, rigidez muscular, bradicinesia e inestabilidad postural.
En pacientes asintomáticos, el tratamiento puede empezar a cualquier edad (por ejemplo, 10, 20, 30). Normalmente, sin embargo, no es necesario comenzar el tratamiento hasta que el paciente alcance los 40, 50, 60 o 70. El tratamiento implica generalmente múltiples dosis durante un periodo de tiempo. El tratamiento puede controlarse analizando el anticuerpo, o las respuestas de las células T o B activadas a un agente terapéutico (por ejemplo, una forma truncada del péptido de la a-sinucleína) a lo largo del tiempo. Si la respuesta disminuye, se indica una dosis de refuerzo.
La invención proporciona métodos para tratar o efectuar profilaxis de la enfermedad de cuerpos de Lewy en un paciente por la administración de las composiciones de anticuerpos en condiciones que generan una respuesta terapéutica beneficiosa en el paciente (por ejemplo, la reducción de agregados de alfa-sinucleína neuríticos o axonales, reducción de la distrofia neurítica, mejora de la función cognitiva, y/o reversión, tratamiento o inhibición del deterioro cognitivo) en el paciente. En algunos métodos, las áreas de distrofia neurítica en el neuropilo del neocórtex y/o ganglios basales se pueden reducir en un 10%, 20%, 30%, 40% o más en comparación con un control.
El deterioro cognitivo, la disminución progresiva de la función cognitiva, los cambios en la morfología del cerebro y los cambios en la función cerebrovascular se observan con frecuencia en pacientes que padecen o que están en riesgo de contraer la enfermedad de cuerpos de Lewy. La invención proporciona métodos para inhibir el deterioro de la función cognitiva en tales pacientes.
La invención también proporciona métodos para preservar o aumentar la densidad sináptica y/o la densidad dentrítica. Un índice de cambios en la densidad sináptica o dentrítica se puede medir mediante marcadores de formación de sinapsis (sinaptofisina) y/o dendritas (MAP2). En algunos métodos, la densidad sináptica o dendrítica se puede restaurar al nivel de densidad sináptica o dentrítica en un sujeto sano. En algunos métodos, el nivel de densidad sináptica o dentrítica en un paciente puede elevarse en un 5%, 10%, 15%, 20%, 25%, 30% o más en comparación con un control.
VI. Composiciones farmacéuticas y métodos de tratamiento
En aplicaciones profilácticas, un anticuerpo o una composición farmacéutica del mismo se administra a un paciente susceptible a, o en riesgo de una enfermedad en un régimen (dosis, frecuencia y vía de administración) eficaz para reducir el riesgo, disminuir la gravedad, o retrasar la aparición de al menos un signo o síntoma de la enfermedad. En algunas aplicaciones profilácticas, el régimen es eficaz para inhibir o retrasar la acumulación de alfa-sinucleína y fragmentos truncados en el cerebro, y/o inhibir o retrasar sus efectos tóxicos y/o inhibir y/o retrasar el desarrollo de déficits de comportamiento. En aplicaciones terapéuticas, se administra un anticuerpo a un paciente sospechoso de, o que ya padece una enfermedad del cuerpo de Lewy en un régimen (dosis, frecuencia y vía de administración) eficaz para mejorar o al menos inhibir el deterioro adicional de al menos un signo o síntoma de la enfermedad. En algunas aplicaciones terapéuticas, el régimen es eficaz para reducir o al menos inhibir el aumento adicional de los niveles de alfa-sinucleína y fragmentos truncados, toxicidades asociadas y/o déficits de comportamiento.
Un régimen se considera terapéuticamente o profilácticamente eficaz si un paciente tratado individualmente logra un resultado más favorable que el resultado promedio en una población de control de pacientes comparables no tratados por los métodos de la invención, o si se demuestra un resultado más favorable en pacientes tratados frente a pacientes de control en un ensayo clínico controlado (por ejemplo, un ensayo de fase II, de fase II/III o de fase III) a un nivel de p < 0,05 o 0,01 o incluso de 0,001.
Las dosis efectivas varían dependiendo de muchos factores diferentes, incluyendo los medios de administración, el sitio diana, el estado fisiológico del paciente incluyendo el tipo de enfermedad del cuerpo de Lewy, si el paciente es
portador de ApoE, si el paciente es humano o un animal, otros medicamentos administrados y si el tratamiento es profiláctico o terapéutico.
Un ejemplo de intervalo de dosificación para anticuerpos es de aproximadamente 0,01 a 5 mg/kg, y más normalmente de 0,1 a 3 mg/kg o 0,15-2 mg/kg o 0,15-1,5 mg/kg, de peso corporal del paciente. El anticuerpo puede administrarse como dosis diarias, o en días alternativos, semanalmente, quincenalmente, mensualmente, trimestralmente, o según cualquier otro programa determinado mediante un análisis empírico. Un ejemplo de tratamiento implica la administración en dosis múltiples durante un periodo prolongado, por ejemplo, de al menos seis meses. Ejemplos de regímenes de tratamiento adicionales implican la administración una vez cada dos semanas o una vez al mes o una vez cada 3 a 6 meses.
Los anticuerpos se pueden administrar por vía periférica (es decir, una en el que un anticuerpo administrado o introducido atraviesa la barrera hematoencefálica para alcanzar un sitio deseado en el cerebro. Las vías de administración incluyen administración tópica, intravenosa, oral, subcutánea, intraarterial, intracraneal, intratecal, intraperitoneal, intranasal o intramuscular. Algunas de las vías para la administración de anticuerpos son intravenosa y subcutánea. Este tipo de inyección se realiza más generalmente en los músculos de los brazos o las piernas. En algunos métodos, los anticuerpos se inyectan directamente en un tejido particular donde se acumulan depósitos, por ejemplo, inyección intracraneal.
Composiciones farmacéuticas para la administración parenteral pueden ser estériles y sustancialmente isotónicas y fabricada bajo condiciones GMP. Las composiciones farmacéuticas pueden proporcionarse en forma de dosis unitarias (es decir, la dosis para una administración única). Las composiciones farmacéuticas se pueden formular utilizando uno o más vehículos, diluyentes, excipientes o auxiliares fisiológicamente aceptables. La formulación depende de la vía de administración elegida. Para inyección, los anticuerpos se pueden formular en soluciones acuosas, preferiblemente en tampones compatibles fisiológicamente tales como la solución de Hank, solución de Ringer, o solución salina fisiológica o tampón acetato (para reducir las molestias en el lugar de la inyección). La solución puede contener agentes de formulación tales como agentes de suspensión, estabilización y/o dispersión. Alternativamente los anticuerpos pueden estar en forma liofilizada para su constitución con un vehículo adecuado, por ejemplo, agua estéril libre de pirógenos, antes de su uso.
Los presentes regímenes se pueden administrar en combinación con otros agentes eficaces en el tratamiento o profilaxis de la enfermedad que se está tratando. Por ejemplo, en el caso de la enfermedad de Parkinson, la inmunoterapia frente a la alfa-sincucleína, documento de Patente WO/2008/103472, Levodopa, agonistas de la dopamina, inhibidores de la COMT, los inhibidores de la MAO-B, la amantadina, o agentes anticolinérgicos se pueden utilizar en combinación con los regímenes presentes.
VII. Otras aplicaciones
Los anticuerpos descritos anteriormente se pueden utilizar para detectar a-sinucleína en el contexto del diagnóstico clínico o tratamiento o investigación. Los anticuerpos se pueden vender también como reactivos de investigación para investigación de laboratorio en la detección de células que contienen a-sinucleína y su respuesta a diversos estímulos. En dichos usos, los anticuerpos monoclonales se pueden marcar con moléculas fluorescentes, moléculas marcadas por spin, enzimas o radioisotipos, y se pueden proporcionar en la forma de un equipo de reactivos con todos los reactivos necesarios para realizar el ensayo para la a-sinucleína. Los anticuerpos se pueden utilizar también para purificar a-sinucleína, por ejemplo, por cromatografía de afinidad.
Los anticuerpos se pueden utilizar para detectar LBs en un paciente. Dichos métodos son útiles para diagnosticar o confirmar el diagnóstico de EP, u otra enfermedad asociada con la presencia de LBs en el cerebro o su susceptibilidad. Por ejemplo, los métodos se pueden utilizar en un paciente que se presenta con síntomas de demencia. Si el paciente tiene LBs, entonces es probable que el paciente sufra una enfermedad de cuerpo de Lewy, tal como la enfermedad de Parkinson. Los métodos se pueden utilizar también en pacientes asintomáticos. La presencia de cuerpos de Lewy u otros depósitos anormales de a-sinucleína indica susceptibilidad a una futura enfermedad sintomática. Los métodos también son útiles para monitorizar la progresión de la enfermedad y/o la respuesta al tratamiento en pacientes a los que se les ha diagnosticado previamente una enfermedad de cuerpo de Lewy.
Los métodos pueden realizarse administrando un anticuerpo y luego detectando el anticuerpo después de que se haya unido. Si se desea, la respuesta de eliminación se puede evitar utilizando un fragmento de anticuerpo que carezca de una región constante de longitud completa, como un Fab. En algunos métodos, el mismo anticuerpo puede servir como reactivo de diagnóstico y tratamiento.
Para el diagnóstico (por ejemplo, imágenes in vivo), los anticuerpos se pueden administrar mediante inyección intravenosa en el cuerpo del paciente, o directamente en el cerebro mediante la inyección intracraneal o perforando un agujero a través del cráneo. La dosis de reactivo debe estar dentro de los mismos rangos que para los métodos de tratamiento. Típicamente, el anticuerpo está marcado, aunque en algunos métodos, el anticuerpo no está marcado y se usa un agente de marcaje secundario para unirse al anticuerpo. La elección de la etiqueta depende de los medios de detección. Por ejemplo, una etiqueta fluorescente es adecuada para la detección óptica. El uso de
etiquetas paramagnéticas es adecuado para la detección tomográfica sin intervención quirúrgica. Las etiquetas radiactivas también se pueden detectar utilizando PET o SPECT.
El diagnóstico se realiza comparando el número, tamaño y/o intensidad de los loci etiquetados con los valores de la línea base correspondientes. Los valores de la línea base pueden representar los niveles medios en una población de individuos no enfermos. Los valores de la línea base también pueden representar niveles previos determinados en el mismo paciente. Por ejemplo, los valores de la línea base se pueden determinar en un paciente antes de comenzar el tratamiento, y los valores medidos posteriormente se comparan con los valores de la línea base. Una disminución en los valores en relación con la línea base muestra una respuesta positiva al tratamiento.
Los anticuerpos se pueden utilizar para generar anticuerpos anti-idiotipo, (véase, por ejemplo, Greenspan & Bona, FASEB J. 7(5): 437-444, 1989; y Nissinoff, J. Immunol. 147:2429-2438, 1991). Dichos anticuerpos anti-idiotipos se pueden utilizar en farmacocinéticas, farmacodinámicas, estudios de biodistribución así como en estudios clínicos de anticuerpos humanos-anti-humanos (HAHA) en individuos tratados con los anticuerpos. Por ejemplo, los anticuerpos anti-idiotípicos se unen específicamente a la región variable de los anticuerpos 5C1 humanizados y, por lo tanto, pueden utilizarse para detectar anticuerpos 5C1 humanizados en estudios farmacocinéticos y ayudan a cuantificar las respuestas de anticuerpos humano-anti-humano (HAHA) en individuos tratados.
VIII. Equipo de reactivos
También se proporcionan equipos de reactivos que incluyen un anticuerpo específico de a-sinucleína e instrucciones de uso. Dichos equipos de reactivos se pueden utilizar, por ejemplo, para realizar los métodos de diagnóstico descritos anteriormente. Un equipo de reactivos también puede incluir una etiqueta. Los equipos de reactivos también suelen contener etiquetas que proporcionan instrucciones para el uso de los equipos de reactivos. El etiquetado también puede incluir un gráfico u otro régimen de correspondencia que correlaciona los niveles del marcador medido con los niveles de anticuerpos frente a la a-sinucleína. El término etiquetado se refiere generalmente a cualquier material escrito o grabado que se adjunte o acompañe de otro modo a un equipo de reactivos en cualquier momento durante su fabricación, transporte, venta o uso. Por ejemplo, el término etiquetado abarca folletos publicitarios y folletos, materiales de embalaje, instrucciones, casetes de audio o video, discos de computadora, así como la escritura impresa directamente en los equipos de reactivos.
También se proporcionan equipos de reactivos de diagnóstico para realizar imágenes in vivo. Tales equipos de reactivos contienen típicamente un anticuerpo que se une a un epítopo de a-sinucleína como se describe en la presente memoria. El anticuerpo se puede marcar o se incluye un reactivo de marcaje secundario en el equipo de reactivos. El equipo de reactivos puede incluir instrucciones para realizar un ensayo de imágenes in vivo.
Todas las solicitudes de Patente, el sitio web, otras publicaciones, los números de acceso y similares citados anteriormente o a continuación, se incorporan por referencia en su totalidad para todos los fines en la misma medida que si cada artículo individual se indicará específica e individualmente como tal. Si diferentes versiones de una secuencia están asociadas con un número de acceso en diferentes momentos, se entiende la versión asociada con el número de acceso en la fecha de presentación efectiva de esta solicitud. La fecha de presentación efectiva significa la fecha de presentación real anterior a la fecha de presentación de una solicitud de prioridad, refiriéndose al número de acceso, si corresponde. Del mismo modo, si se publican diferentes versiones de una publicación, sitio web o similares en diferentes momentos, la versión más reciente publicada en la fecha de presentación efectiva de la solicitud se entiende a menos que se indique lo contrario. Cualquier característica, etapa, elemento, realización, o aspecto de la invención se puede utilizar en combinación con cualquier otra a menos que se indique específicamente lo contrario. Aunque la presente invención se ha descrito con cierto detalle a modo de ilustración y los ejemplos con fines de claridad y comprensión, será evidente que ciertos cambios y modificaciones pueden ponerse en práctica dentro del alcance de las reivindicaciones adjuntas.
Ejemplos
Ejemplo 1: Aislamiento del 5C1 murino
El anticuerpo 5C1 murino se generó en un ratón inyectado con un conjugado peptídico que contenía el inmunógeno peptídico VDPDNEAYEGGC (SEQ ID NO: 14) acoplado a un anticuerpo antiratón de oveja. El péptido, que incluye los residuos 118-126 de la a-sinucleína unida a un péptido GGC C-terminal, se acopló a un anticuerpo antiratón de oveja a través de un enlazador de maleimida unido al residuo de cisteína C-terminal.
Ejemplo 2: Inmunización pasiva con anticuerpos de a-sinucleína
Para probar el efecto de los anticuerpos de a-sinucleína en un modelo animal para la enfermedad del cuerpo de Lewy, se utilizaron varios anticuerpos de a-sinucleína para inmunizar ratones pasivamente. Se utilizaron ratones hembra de 3-4 meses de edad, knockout de a-sinucleína y transgénicos de a-sinucleína (línea 61) (n = 14/grupo). Los anticuerpos que se probaron incluyeron:
9E4 (IgG1, epítopo: aminoácidos 118-126 de a-sinucleína);
5C1 (IgG1, inmunogen: aminoácidos 118-126 de a-sinucleína, cys-enlazador);
5D12 (IgG2, inmunogen: aminoácidos 118-126 de a-sinucleína, n-enlazador);
1H7 (IgG1, epítopo: aminoácidos 91-99 de a-sinucleína); y
27-1 (IgG1 anticuerpo de control).
Los ratones recibieron una dosis de anticuerpo de 10 mg/kg durante un período de 5 meses, para un total de 21 inyecciones. Además, los animales se inyectaron con lentivirus (LV) que expresaba a-sinucleína humana (wt) mediante introducción unilateral de a-sinucleína humana (wt) en el hipocampo.
Los anticuerpos leídos incluyeron anticuerpos de a-sinucleína de Chemicon (epítopo: a-sinucleína de longitud completa), Millipore (epítopo: a-sinucleína de longitud completa), y ELADW 105 (epítopo: aminoácidos 121-124 de asinucleína, preferiblemente con a-sinucleína truncada en el residuo 122-124).
Puntos finales: los títulos de anticuerpos se controlaron antes de la finalización del experimento. El comportamiento se evaluó mediante el ensayo del laberinto de agua de Morris (MWM) y las pruebas de haz redondo horizontal. La prueba de haz redondo evalúa el equilibrio motor, la coordinación y la marcha utilizando dos haces de diámetro variable. El haz A (haz de entrenamiento) tiene un diámetro mayor y, por lo tanto, es más fácil de atravesar. El haz D (haz de prueba) es más pequeño en diámetro y, por lo tanto, más difícil de atravesar. El rendimiento del laberinto de agua se llevó a cabo en la semana 10 y justo antes de la terminación. Al finalizar el experimento, los ratones se sacrificaron y se obtuvieron mediciones neuropatológicas para la agregación de a-sinucleína, sinptofisina y MAP2. Además, se obtuvieron mediciones de bioquímica para la a-sinucleína, PSD95, y sinaptofisina. El etiquetado confocal y multimarcado seleccionado se llevó a cabo utilizando marcadores sinápticos, neuronales y gliales.
Resultados: Los resultados mostraron que todos los anticuerpos, excepto 5D12, produjeron una reducción significativa en la acumulación de a-sinucleína y la preservación de las densidades sinápticas y dendríticas, así como resultados positivos en el rendimiento de MWM. El anticuerpo 9E4 fue efectivo en estudios in vitro e in vivo, así como en ensayos de comportamiento. En particular, los resultados indican que los anticuerpos de a-sinucleína pueden reducir los agregados de a-sinucleína neuríticos/axonales.
Resultados de comportamiento: Los anticuerpos 5C1 y 9E4 mejoraron el rendimiento del laberinto de agua en ratones transgénicos de a-sinucleína, al igual que el 1H7, aunque en menor medida. Véase la Figura 3. En contraste, el anticuerpo 5D12 no mejoró el rendimiento del laberinto de agua en ratones transgénicos de asinucleína. Con respecto al ensayo del haz redondo horizontal, los anticuerpos 9E4 y 1H7 mejoraron el rendimiento medido tanto por la velocidad como por el número de errores, mientras que los anticuerpos 5D12 y 5C1 no lo hicieron. Véase la Figura 4. Los datos de la Figura 4 se presentan como el número de deslizamientos/10 cm (es decir, “errores”) y la relación de la distancia recorrida dividida por el tiempo que se tarda en recorrer la distancia (es decir, “velocidad”, medida en unidades de 10 cm/s).
Resultados de neuropatología: Los anticuerpos 5C1, 9E4 y 1H7 redujeron la distrofia neurítica positiva de ELADW-105, mientras que el anticuerpo 5D12 no lo hizo. En ratones transgénicos de a-sinucleína, el anticuerpo 9E4 redujo el área de neuropil en un 43% en el neocórtex y en un 40% en los ganglios basales, en comparación con los ratones de control (es decir, ratones que recibieron el anticuerpo de control 27-1 IgG1). El anticuerpo 9E4 también conservó la tinción para sinaptofisina y MAP2 en el neocórtex y en los ganglios basales.
Ejemplo 3: Secuenciación de los dominios variables de 5C1
El mRNA se extrajo y purificó a partir de una célula de hibridoma 5C1 utilizando un equipo de reactivos QIAGEN® OLIGOTEX® mRNA. El mRNA purificado se transcribió a continuación en cDNA utilizando un cebador anti-sentido oligo dT y el equipo de reactivos INVITROGEN® SUPERSCRIPT® II. Las secuencias de ácidos nucleicos que codifican las regiones variables de cadena pesada y cadena ligera de 5C1 se amplificaron a partir de cDNA mediante PCR, utilizando cebadores de sentido VH y VL degenerados y un cebador anti-sentido específico del gen (CH/CL). Los productos de PCR, que se diseñaron para incluir la secuencia del péptido señal, el dominio variable, y el dominio constante (hasta el cebador anti-sentido), se purificaron en gel, se clonaron en un vector romo o un vector TA, y se secuenciaron después. Las secuencias se dedujeron del análisis de al menos 3 clones independientes que tienen un marco de lectura abierto que comienza con una metionina y se extiende a través de la región variable hasta la región constante.
El ácido nucleico que codifica la región variable de cadena pesada de 5C1 tiene la secuencia de SEQ ID NO: 5. La secuencia de proteínas correspondiente (Fig. 1), que incluye un péptido señal en las posiciones 1-19 (subrayada) es la siguiente:
MERHWIFLFLLSVTGGVHSQVQLQQSGAELAKPGTSVQMSCKASGYTFTNYWMN
WIKARPGQGLEWIGATNPNNGYTDYNQRFKDKAILTADKSSNTAYMHLSSLTSE
DSAVYFCASGGHLAYWGQGTWTVSA (SEQ ID NO: 6)
El ácido nucleico que codifica la región variable de cadena ligera de 5C1 tiene la secuencia de SEQ ID NO: 7. La secuencia de proteínas correspondiente (Fig. 2), que incluye un péptido señal en las posiciones 1-19 (subrayada) es la siguiente:
MKLPVRLLVLMFWIPASSSDVVMTQIPLYLSVSPGDQASISCRSSQSLFHSKGN
TYLHWYLQKPGQSPKLLINRVSNRFSGVPDRFSGSGSGTDFTLKISGVEAEDLG
VYFCSQSAHVPWTFGGGTKLEIR (SEQ TD N O :8)
La secuencia de aminoácidos para la región variable de cadena pesada de 5C1 maduro (SEQ ID NO: 9) se muestra en la Tabla 1 (a continuación), y la secuencia de aminoácidos correspondiente para la región variable de cadena ligera de 5C1 maduro (SEQ ID NO: 24) se muestra en la Tabla 2 (a continuación). La numeración de Kabat se utiliza en todo.
Ejemplo 4: Humanización de 5C1 murino
El análisis de las CDRs de la región Vh de 3H6 revela una CDR-H1 de 5 residuos (SEQ ID NO: 10), una CDR-H2 de 17 residuos (SEQ ID NO: 11), y una CDR-H3 de 6 residuos (SEQ ID NO: 12). Análisis similares de las CDRs de la región Vk de 3H6 revela una c Dr-L1 de 16 residuos (SEQ ID NO: 25), una CDR-L2 de 7 residuos (SEQ ID NO: 26), y una CDR-L3 de 9 residuos (SEQ ID NO: 27).
El análisis de los residuos en la interfaz entre las regiones Vk y Vh de 5C1 revela que la mayoría de los residuos son los que se encuentran comúnmente.
Una búsqueda en la base de datos de secuencias de proteínas no redundantes del NCBI permitió la selección de marcos humanos adecuados en los que injertar las CDRs murinas de 5C1. Para Vk, se eligió una cadena ligera kappa humana con el código de acceso NCBI CAB51293.1 (GI: 5578786; SEQ ID NO: 28). Para Vh, se eligió la cadena pesada de Ig humana AAY42876.1 (GI: 66096557; SEQ ID NO: 13).
Ejemplos de diseños Vh y Vk humanizados, con retromutaciones basadas en los marcos humanos seleccionados, se muestran en la Tabla 1 y Tabla 2, respectivamente.
Ejemplos de diseños de Vh humanizada
Se diseñaron cinco diferentes versiones de la región Vh de 5C1, H1, H2, H3, H4 y H5. En la selección de retromutaciones, los residuos H11, H27, H30, H48, H67, H69, H73, H91 y H94 se centraron en última instancia. En cada uno de los diseños de la región Vh humanizada, los residuos H11, H27, H30, H48 y H73 fueron retromutados a L, Y, T, I y K, respectivamente, porque los residuos formaban parte de CDR-H1 según la definición de Chothia (H27 y H30) o los residuos correspondientes en la secuencia de marco humana eran residuos de baja frecuencia (V en la posición H11, M en la posición H48, y E en la posición H73). Para la versión H1 (SEQ ID NO: 14), los residuos adicionales H67 y H69 fueron retromutados (a A y L, respectivamente) para preservar el empaquetamiento de CDR. En la versión h2 (SEQ ID NO: 15), no se introdujeron retromutaciones adicionales (es decir, se eliminaron las retromutaciones en las posiciones H67 y H69 en la versión H1). En la versión H3 (SEQ ID NO: 16), los residuos adicionales H67, H69, H91 y H94 fueron retromutados (a A, L, F, y S, respectivamente). Las retromutaciones H67, H69, y H94 fueron para preservar el empaquetamiento de CDR, mientras que H91, un residuo de interfaz Vh/Vk, se retromutó para probar su impacto en la interfaz. En la versión H4 (SEQ ID NO: 17), los residuos adicionales H67, H69 y H94 se retromutaron (a A, L y S, respectivamente). Por lo tanto, la versión H4 difiere de H3 en que se elimina la mutación en H91. En la versión H5 (SEQ ID NO: 18), el residuo adiciona1H94 se retromutó también (a S), para preservar el empaquetamiento de CDR.
Tabla 1: Regiones Vh de 5C1 humanizadas


_
; ! ! ¡
: ! í í : : : i i : ; : ;


_
'
:
:
•

Ejemplos de secuencias de ácidos nucleicos que codifican H1, H2, H3, H4 y H5 de 5C1 humanizado se proporcionan en SEQ ID NOs: 19, 20, 21, 22, y 23, respectivamente.
Ejemplos de diseños de Vk humanizados
Se diseñaron cuatro diferentes versiones humanizadas L1, L2, L3 y L4 de la región Vk de 5C1. En la selección de retromutaciones, los residuos L2, L12, L14, L45, L49, y L87 se centraron en última instancia. En cada uno de los diseños de la región Vk humanizada, los residuos L12 y L14 fueron retromutados a S debido a que los residuos correspondientes en la secuencia de marco humano (P y T, respectivamente) son residuos de baja frecuencia. Para la versión L1 (SEQ ID NO: 29), los residuos adicionales L2, L45, L49, y L87 fueron retromutados (a V, K, N, y F, respectivamente. L2 es un residuo canónico/que interactúa con CDR; L45 sufre un cambio de polaridad/carga de las secuencias de marco murino a humano (K a Q), y por lo tanto podría impactar el plegamiento; L49 es un residuo de Vernier; y L87 es un residuo de interfaz Vh/Vk. En la versión L2 (SEQ ID NO: 30), el residuo adicional L45 se retromutó a K. Por lo tanto, en relación con L1, se eliminaron las retromutaciones en los residuos L2, L49, y L87. En la versión L3 (SEQ ID NO: 31), los residuos adicionales L2, L49, y L87 se retromutaron (a V, N, y F, respectivamente). Por lo tanto, en relación con L1, se eliminó la retromutación en el residuo L45. En la versión L4 (SEQ ID NO: 32), no se retromutaron los residuos adicionales (es decir, solo se retromutaron los residuos L12 y L14).
Tabla 2: Regiones Vk de 5C1 humanizado

Kabat Lineal FR o (SEQID (SEQID NO: (SEQID (SEQID (SEQID (SEQID #
 DR
DR


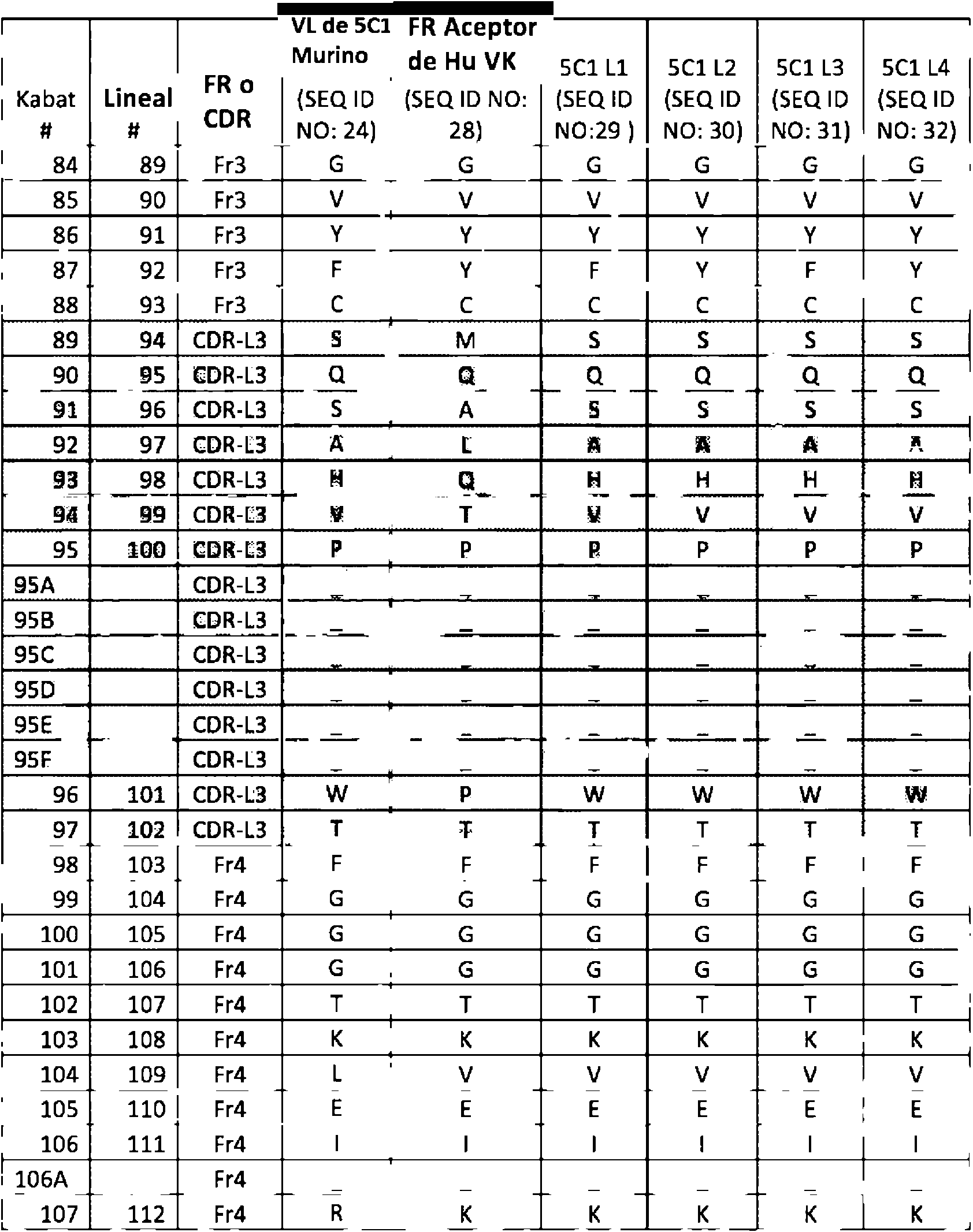
Ejemplos de secuencias de ácidos nucleicos que codifican L1, L2, L3, y L4 de 5C1 humanizado se proporcionan en SEQ ID NOs: 33, 34, 35, y 36, respectivamente.
Ejemplo 5: Afinidad de anticuerpos 5C1 humanizados para alfa-sinucleína
La afinidad de varias combinaciones de proteínas de cadena pesada humanizada y cadena ligera humanizada de 5C1 para a-sinucleína se analizó mediante ELISA. Como se muestra en la Figura 5, la versión H1L1 del anticuerpo 5C1 humanizado no mostró afinidad por la a-sinucleína en las condiciones del ensayo. En contraste, el anticuerpo 5C1 quimérico tuvo una afinidad mayor para la a-sinucleína que el anticuerpo 5C1 murino. Las versiones humanizadas H3L4, H4L3, y H L3 quimérico se comportaron de manera comparable, y casi tan bien como el anticuerpo 5C1 quimérico. Además, las versiones humanizadas H3L3 y H3L1 se realizaron de manera comparable, aunque con una afinidad ligeramente más baja que H3L4, H4L3 Y H L3 quimérico.
Varias versiones de anticuerpos 5C1 humanizados se analizaron también por Biacore, para determinar con mayor precisión las afinidades de unión. Se preparó un chip CM5 de IgG anti-humana de Biacore siguiendo el protocolo
suministrado por GE Healthcare. Cada versión de anticuerpo 5C1 humanizado se capturó independientemente a un nivel donde Rmax no excedería de 50, utilizando la ecuación:
Rmax = (RU del anticuerpo capturado) * (MW de la sinucleína) / (MW del anticuerpo capturado) * 2
El factor de 2 en el denominador es para el número de sitios de unión en el anticuerpo. La alfa-sinucleína se hizo fluir sobre el corte a una concentración que varió de ~ 10x por encima de la KD esperada a ~ 10x por debajo de la KD esperada. Los datos se recopilaron y se restó la doble referencia para tener en cuenta la deriva y una pequeña cantidad de unión no específica. Los datos se analizaron utilizando el software de evaluación BIAcore utilizando un modelo 1:1 y un ajuste global.
Los resultados del análisis de Biacore se resumen en la Tabla 3 (a continuación). Los datos indican que la mayor parte de la pérdida de afinidad por la alfa-sinucleína se debe a un aumento de la tasa de desconexión en algunas versiones de anticuerpos. Sobre la base de los datos de afinidad, H4L3 se identificó como un anticuerpo preferido. Tabla 3: Afinidades determinadas por Biacore de variantes de anticuerpos 5C1
Variante # Ratón de marco AAs K
d
K
o n
K
o ff
de 5C1
HC LC
m5C1 82 80 68.7 7.5x104/s 5.1x103/s nM
Ch5C1 82 80 86.0 6.1x104/s 5.3x103/s nM
65, incl. 9 retromutaciones (V11L, G27Y,
h5C1_H3L4 N30T, M48I, V67A, I69L, E73K, Y91F, 69, incl. 2 retromutaciones 1237.0
(P12S, T14S) n R94S) M 4.4x104/s 54.5x103/s
72, incl. 5 retromutaciones
h5C1_H4L3 (I2V, P12S, T14S, Y49N, 119.8 4.4x104/s 5.1x103/s nM
64, incl. 8 retromutaciones (V11L, G27Y, Y87F)
N30T, M48I, V67A, I69L, E73K, R94S)
h5C1_H4L4 69, incl. 2 retromutaciones 600.9
(P12S, T14S) nM 5.3x104/s 32.4x103/s
72, incl. 5 retromutaciones
h5C1_H5L3 (I2V, P12S, T14S, Y49N, 283.1 3.9x104/s 11.1x103/s 62, incl. 6 retromutaciones (V11L, G27Y, Y87F) nM
N30T, M48I, E73K, R94S)
h5C1_H5L4 6
(P
9
1
,
2
in
S
c
,
l.
T
2
14
r
S
et
) romutaciones 1062.0
nM 3.7x104/s 40.3x103/s
Ejemplo 6: Mutagénesis de barrido de alanina
Los epítopos unidos por los anticuerpos 5C1, 9E4 y 5D12 se han mapeado aproximadamente para que estén dentro de los residuos 118-126 de la alfa-sinucléina debido a los anticuerpos que se unen a los péptidos superpuestos. Este ejemplo describe un mapeo más preciso, mediante la mutagénesis de barrido de alanina, de cada residuo entre las posiciones 118 y 126 de la alfa sinucleína. La alanina se utiliza debido a su grupo funcional metilo, no voluminoso, químicamente inerte, que sin embargo imita las preferencias de estructura secundaria que poseen muchos de los otros aminoácidos. Las partes superiores de las Figs. 6, 7 y 8 muestran los resultados de las transferencias de Western teñidas con los anticuerpos 9E4, 5C1 y 5D12, respectivamente. Las transferencias incluyen alfa-sinucleína de longitud completa y mutantes puntuales de la alfa-sinucleína producidos por mutagénesis de barrido de alanina de los residuos 118-126 y se tiñeron con 0,5 pg/ml de anticuerpo. Las mutaciones en las posiciones 122 y 125 anulan esencialmente la unión de 9E4, mientras que las mutaciones en otras posiciones tienen poco o ningún efecto. Por lo tanto, 9E4 se pone en contacto predominantemente con los residuos 122 y 125. Las mutaciones en las posiciones 120-122 eliminan esencialmente la unión de 5C1, y las mutaciones en las posiciones 123 y 124 reducen sustancialmente pero no eliminan la unión. Por lo tanto, 5C1 se pone en contacto
predominantemente con los residuos 120-122 y, en menor medida, con los restos 123-124. Las mutaciones en las posiciones 120-122 eliminaron esencialmente la unión de 5D12, y las mutaciones en las posiciones 118, 119, 123 y 124 redujeron sustancialmente pero no eliminaron la unión. Por lo tanto, 5D12 se une predominantemente a las posiciones 120-122 y, en menor medida, a las posiciones 118, 119, 123 y 124. En cada una de las Figs. 6-8, el anticuerpo 1H7 se utiliza como control. 1H7 se une a los residuos 91-98 de la alfa-sinucleína, y por lo tanto se espera que se una a la alfa-sinucleína independientemente de la presencia de mutaciones en los residuos 118-126. Las diferentes especificidades de unión de 9E4 en comparación con 5C1 y 5D12 pueden reflejar en parte sus respectivos métodos de producción. El 9E4 se preparó mediante inmunización con alfa-sinucleína de longitud completa dando como resultado un anticuerpo que se une a un epítopo conformacional. 5C1 y 5D12 se prepararon mediante inmunización con un péptido de 10 aminoácidos dando como resultado un epítopo lineal.
La Fig. 9 es un modelo de bola y palo de los aminoácidos en la alfa-sinucleína próximos a los sitios de unión de los anticuerpos 9E4, 5C1 y 5D12. Los dos residuos discontinuos del epítopo enlazado por 9E4, los residuos 122 y 125, forman un bolsillo en la conformación de la proteína de alfa-sinucleína de longitud completa.
Claims (14)
1. Un anticuerpo que comprende tres CDRs de cadena ligera como lo define Kabat que tienen secuencias de SEQ ID NOs: 25-27 y tres CDRs de cadena pesada como lo define Kabat que tienen secuencias de SEQ ID NOs: 10-12.
2. El anticuerpo de la reivindicación 1 que es 5C1 o una forma quimérica, recubierta, o humanizada del mismo, en donde 5C1 es un anticuerpo de ratón caracterizado por una región variable de cadena pesada que tiene una secuencia de aminoácidos que comprende SEQ ID NO: 9 y una región variable de cadena ligera que tiene una secuencia de aminoácidos que comprende SEQ ID NO: 24.
3. El anticuerpo de la reivindicación 1 que comprende una región variable de cadena pesada madura que tiene una secuencia de aminoácidos al menos 90% idéntica a SEQ ID NO: 17 (H4) y una región variable de cadena ligera madura que tiene una secuencia de aminoácidos al menos 90% idéntica a SEQ ID NO: 31 (L3), en donde el anticuerpo se une específicamente a alfa-sinucleína humana.
4. El anticuerpo de la reivindicación 3, siempre que las posiciones 11, 27, 30, 48 y 73 de la región variable de cadena pesada madura estén ocupadas por L, Y, T, I y K, respectivamente, y las posiciones 12 y 14 de la región variable de cadena ligera madura estén ocupadas por S.
5. El anticuerpo de la reivindicación 4, siempre que las posiciones 67, 69 y 94 de la región variable de cadena pesada madura estén ocupadas por A, L, y S, respectivamente.
6. El anticuerpo de la reivindicación 5, siempre que las posiciones 2, 49 y 87 de la región variable de cadena ligera madura estén ocupadas por V, N, y F, respectivamente.
7. El anticuerpo de una cualquiera de las reivindicaciones 1 a 6, que comprende una región variable de cadena pesada madura que tiene una secuencia de aminoácidos al menos 95% idéntica a SEQ ID NO: 17 (H4) y una región variable de cadena ligera madura al menos 95% idéntica a SEQ ID NO: 31 (L3).
8. El anticuerpo de una cualquiera de las reivindicaciones 1 a 7, en donde la región variable de cadena pesada madura se une a la región constante de cadena pesada y la región variable de cadena ligera madura se une a la región constante de cadena ligera, opcionalmente una región constante de cadena pesada que tiene la secuencia de SEQ ID NO: 38 siempre que falte la lisina C-terminal, y/o una región constante de cadena ligera que tiene la secuencia de SEQ ID NO: 40.
9. El anticuerpo de la reivindicación 3 o 8, en donde la región variable de cadena pesada madura tiene una secuencia de aminoácidos designada como SEQ ID NO: 17 (H4) y la región variable de cadena ligera madura tiene una secuencia de aminoácidos designada como SEQ ID NO: 31 (L3).
10. El anticuerpo de la reivindicación 3 o 8, en donde la región variable de cadena pesada madura tiene una secuencia de aminoácidos designada como SEQ ID NO: 18 (H5) y la región variable de cadena ligera madura tiene una secuencia de aminoácidos designada como SEQ ID NO: 31 (L3).
11. El anticuerpo de una cualquiera de las reivindicaciones anteriores, en donde el anticuerpo es un fragmento Fab.
12. Una composición farmacéutica que comprende un anticuerpo como se define en una cualquiera de las reivindicaciones 1 a 11 y un vehículo farmacéuticamente aceptable.
13. Un ácido nucleico que codifica las cadenas pesadas y ligeras de un anticuerpo como se describe en una cualquiera de las reivindicaciones 1 a 11.
14. El anticuerpo como se define en una cualquiera de las reivindicaciones 1 a 11 para su uso en el tratamiento o la realización de profilaxis de una enfermedad de cuerpo de Lewy.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201261711204P | 2012-10-08 | 2012-10-08 | |
| US201261719281P | 2012-10-26 | 2012-10-26 | |
| US201361840432P | 2013-06-27 | 2013-06-27 | |
| US201361872366P | 2013-08-30 | 2013-08-30 | |
| PCT/US2013/063945 WO2014058924A2 (en) | 2012-10-08 | 2013-10-08 | Antibodies recognizing alpha-synuclein |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2701406T3 true ES2701406T3 (es) | 2019-02-22 |
Family
ID=50478052
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES13845625T Active ES2701406T3 (es) | 2012-10-08 | 2013-10-08 | Anticuerpos que reconocen alfa-sinucleína |
Country Status (20)
| Country | Link |
|---|---|
| US (6) | US9605056B2 (es) |
| EP (2) | EP3498296A1 (es) |
| JP (1) | JP6511396B2 (es) |
| KR (1) | KR102163001B1 (es) |
| CN (2) | CN109180812A (es) |
| AU (2) | AU2013329381B2 (es) |
| BR (1) | BR112015007882A2 (es) |
| CA (1) | CA2886254A1 (es) |
| EA (1) | EA034312B1 (es) |
| ES (1) | ES2701406T3 (es) |
| IL (1) | IL238192B (es) |
| MX (1) | MX365099B (es) |
| MY (1) | MY169086A (es) |
| NZ (1) | NZ706337A (es) |
| PH (1) | PH12015500767B1 (es) |
| SA (1) | SA515360253B1 (es) |
| SG (1) | SG11201502662QA (es) |
| UA (1) | UA118441C2 (es) |
| WO (1) | WO2014058924A2 (es) |
| ZA (1) | ZA201502213B (es) |
Families Citing this family (50)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9034337B2 (en) | 2003-10-31 | 2015-05-19 | Prothena Biosciences Limited | Treatment and delay of outset of synucleinopathic and amyloidogenic disease |
| ES2546863T3 (es) | 2007-02-23 | 2015-09-29 | Prothena Biosciences Limited | Prevención y tratamiento de enfermedad sinucleinopática y amiloidogénica |
| ES2937409T3 (es) | 2011-10-28 | 2023-03-28 | Prothena Biosciences Ltd | Anticuerpos humanizados que reconocen la alfa-sinucleína |
| CN104619724B (zh) | 2012-01-27 | 2018-05-04 | 普罗典娜生物科学有限公司 | 识别α-突触核蛋白的人源化抗体 |
| UA118441C2 (uk) | 2012-10-08 | 2019-01-25 | Протена Біосаєнсиз Лімітед | Антитіло, що розпізнає альфа-синуклеїн |
| US10513555B2 (en) | 2013-07-04 | 2019-12-24 | Prothena Biosciences Limited | Antibody formulations and methods |
| EP3129051A1 (en) * | 2014-04-08 | 2017-02-15 | Prothena Biosciences Limited | Blood-brain barrier shuttles containing antibodies recognizing alpha-synuclein |
| WO2016061389A2 (en) | 2014-10-16 | 2016-04-21 | Genentech, Inc. | Anti-alpha-synuclein antibodies and methods of use |
| US10464999B2 (en) | 2015-01-28 | 2019-11-05 | Prothena Biosciences Limited | Anti-transthyretin antibodies |
| TWI769570B (zh) * | 2015-01-28 | 2022-07-01 | 愛爾蘭商普羅佘納生物科技有限公司 | 抗甲狀腺素運送蛋白抗體 |
| US10633433B2 (en) | 2015-01-28 | 2020-04-28 | Prothena Biosciences Limited | Anti-transthyretin antibodies |
| US9879080B2 (en) | 2015-01-28 | 2018-01-30 | Prothena Biosciences Limited | Anti-transthyretin antibodies |
| GB201512203D0 (en) | 2015-07-13 | 2015-08-19 | Lundbeck & Co As H | Agents,uses and methods |
| PE20250392A1 (es) | 2016-06-02 | 2025-02-11 | Medimmune Ltd | Anticuerpos a la alfa-sinucleina y usos de los mismos |
| US10889635B2 (en) | 2016-11-15 | 2021-01-12 | H. Lundbeck A/S | Agents, uses and methods for the treatment of synucleinopathy |
| US11237176B2 (en) * | 2016-12-02 | 2022-02-01 | Prothena Biosciences Limited | Infrared assay detecting secondary structure profiles of alpha-synuclein |
| BR112018016717A2 (pt) * | 2016-12-16 | 2018-12-26 | H Lundbeck As | agentes, usos e métodos |
| US10364286B2 (en) | 2016-12-22 | 2019-07-30 | H. Lundbeck A/S | Monoclonal anti-alpha-synuclein antibodies for preventing tau aggregation |
| US12049493B2 (en) | 2017-01-06 | 2024-07-30 | Abl Bio Inc. | Anti-alpha-synuclein antibodies and uses thereof |
| BR112019016374A2 (pt) * | 2017-02-17 | 2020-04-07 | Bristol-Myers Squibb Company | anticorpos para alfa-sinucleína e usos dos mesmos |
| JOP20190227A1 (ar) * | 2017-03-31 | 2019-09-30 | Biogen Int Neuroscience Gmbh | تركيبات وطرق لعلاج اعتلالات السينوكلين |
| IL270361B2 (en) | 2017-05-01 | 2025-04-01 | Univ Pennsylvania | Monoclonal antibodies against alpha-synuclein fibrils |
| KR102784294B1 (ko) * | 2017-05-02 | 2025-03-19 | 프로테나 바이오사이언시즈 리미티드 | 타우 인식 항체 |
| WO2019040617A1 (en) | 2017-08-23 | 2019-02-28 | The Trustees Of The University Of Pennsylvania | MONOCLONAL ANTIBODIES AGAINST PATHOLOGICAL ALPHA-SYNUCLEIN AND METHODS USING SAME |
| CN111757730A (zh) | 2017-10-06 | 2020-10-09 | 普罗塞纳生物科学有限公司 | 检测甲状腺素运载蛋白的方法 |
| BR112020006434A2 (pt) | 2017-10-06 | 2020-11-03 | Prothena Biosciences Limited | anticorpos anti-transtirretina |
| SG11202004187UA (en) | 2017-11-29 | 2020-06-29 | Prothena Biosciences Ltd | Lyophilized formulation of a monoclonal antibody against transthyretin |
| KR102263812B1 (ko) * | 2017-12-14 | 2021-06-14 | 에이비엘바이오 주식회사 | a-syn/IGF1R에 대한 이중 특이 항체 및 그 용도 |
| GB201720975D0 (en) * | 2017-12-15 | 2018-01-31 | Ucb Biopharma Sprl | Anti-alpha synuclein antibodies |
| GB201720970D0 (en) | 2017-12-15 | 2018-01-31 | Ucb Biopharma Sprl | Antibodies |
| WO2020003203A1 (en) * | 2018-06-27 | 2020-01-02 | Mor Research Applications | Antibodies for the treatment of synucleinopathies and neuroinflammation |
| KR20210081356A (ko) * | 2018-10-19 | 2021-07-01 | 얀센 백신스 앤드 프리벤션 비.브이. | 항-시누클레인 항체 |
| TWI734279B (zh) | 2018-12-14 | 2021-07-21 | 美商美國禮來大藥廠 | 抗α-突觸核蛋白抗體及其用途 |
| CN110172098B (zh) * | 2019-05-27 | 2023-03-10 | 长春工业大学 | 抗α-突触核蛋白的单克隆抗体及其应用 |
| JP7500085B2 (ja) * | 2019-07-02 | 2024-06-17 | シャンハイテック ユニバーシティ | レプチン受容体に対する抗体 |
| WO2021055881A1 (en) * | 2019-09-20 | 2021-03-25 | Denali Therapeutics Inc. | Anti-alpha-synuclein antibodies and methods of use thereof |
| WO2021214277A1 (en) | 2020-04-24 | 2021-10-28 | F. Hoffmann-La Roche Ag | Enzyme and pathway modulation with sulfhydryl compounds and their derivatives |
| AU2021276401A1 (en) | 2020-05-19 | 2022-12-15 | Othair Prothena Limited | Multi-epitope vaccine for the treatment of Alzheimer's disease |
| TWI745993B (zh) | 2020-06-04 | 2021-11-11 | 國立高雄大學 | α-突觸核蛋白感測薄膜及其製造方法與用途 |
| WO2022060236A1 (en) * | 2020-09-17 | 2022-03-24 | Qatar Foundation For Education, Science And Community Development | ANTIBODY COMPOSITIONS TARGETING NON-PHOSPHORYLATED α-SYNUCLEIN AGGREGATES |
| CN116438191A (zh) * | 2020-09-18 | 2023-07-14 | 欧萨尔普罗席纳有限公司 | 治疗阿尔茨海默病之多表位疫苗 |
| US12248291B2 (en) | 2021-06-09 | 2025-03-11 | Tyco Fire & Security Gmbh | Central energy system with expert subplant models |
| US12105487B2 (en) | 2021-12-06 | 2024-10-01 | Tyco Fire & Security Gmbh | Control system for building equipment with optimization search reduction based on equipment models and parameters |
| CN113912714B (zh) * | 2021-12-15 | 2022-02-22 | 北京凯祥弘康生物科技有限公司 | 特异性结合α-突触核蛋白的抗体及其应用 |
| US12292723B2 (en) | 2022-01-21 | 2025-05-06 | Tyco Fire & Security Gmbh | Generating set of curtailment actions predicted to achieve net consumption target for a subperiod |
| US12099350B2 (en) | 2022-03-04 | 2024-09-24 | Tyco Fire & Security Gmbh | Central plant with automatic subplant models |
| CN115032400A (zh) * | 2022-03-28 | 2022-09-09 | 首都医科大学附属北京天坛医院 | α-突触核蛋白在辅助诊断神经退行性疾病中的用途 |
| US12282306B2 (en) | 2022-04-29 | 2025-04-22 | Tyco Fire & Security Gmbh | Control system for building equipment with dynamic capacity constraints |
| TW202440629A (zh) | 2022-12-29 | 2024-10-16 | 瑞典商阿斯特捷利康公司 | 用於治療α共核蛋白病(SYNUCLEINOPATHIES)之組合物及方法 |
| KR20240176098A (ko) * | 2023-06-14 | 2024-12-24 | 경상국립대학교산학협력단 | 알파 시누클레인 에피토프를 유효성분으로 포함하는 파킨슨병의 예방 또는 치료용 조성물 |
Family Cites Families (102)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CH652145A5 (de) | 1982-01-22 | 1985-10-31 | Sandoz Ag | Verfahren zur in vitro-herstellung von hybridomen welche humane monoklonale antikoerper erzeugen. |
| US4634666A (en) | 1984-01-06 | 1987-01-06 | The Board Of Trustees Of The Leland Stanford Junior University | Human-murine hybridoma fusion partner |
| US5225539A (en) | 1986-03-27 | 1993-07-06 | Medical Research Council | Recombinant altered antibodies and methods of making altered antibodies |
| EP0832981A1 (en) | 1987-02-17 | 1998-04-01 | Pharming B.V. | DNA sequences to target proteins to the mammary gland for efficient secretion |
| AU600575B2 (en) | 1987-03-18 | 1990-08-16 | Sb2, Inc. | Altered antibodies |
| US5530101A (en) | 1988-12-28 | 1996-06-25 | Protein Design Labs, Inc. | Humanized immunoglobulins |
| US5633076A (en) | 1989-12-01 | 1997-05-27 | Pharming Bv | Method of producing a transgenic bovine or transgenic bovine embryo |
| US5859205A (en) | 1989-12-21 | 1999-01-12 | Celltech Limited | Humanised antibodies |
| EP1690935A3 (en) | 1990-01-12 | 2008-07-30 | Abgenix, Inc. | Generation of xenogeneic antibodies |
| IE64738B1 (en) | 1990-03-20 | 1995-09-06 | Akzo Nv | Stabilized gonadotropin containing preparations |
| US5427908A (en) | 1990-05-01 | 1995-06-27 | Affymax Technologies N.V. | Recombinant library screening methods |
| GB9015198D0 (en) | 1990-07-10 | 1990-08-29 | Brien Caroline J O | Binding substance |
| DK0585287T3 (da) | 1990-07-10 | 2000-04-17 | Cambridge Antibody Tech | Fremgangsmåde til fremstilling af specifikke bindingsparelementer |
| US5770429A (en) | 1990-08-29 | 1998-06-23 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| US5814318A (en) | 1990-08-29 | 1998-09-29 | Genpharm International Inc. | Transgenic non-human animals for producing heterologous antibodies |
| US5874299A (en) | 1990-08-29 | 1999-02-23 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| DE69133476T2 (de) | 1990-08-29 | 2006-01-05 | GenPharm International, Inc., Palo Alto | Transgene Mäuse fähig zur Produktion heterologer Antikörper |
| US5661016A (en) | 1990-08-29 | 1997-08-26 | Genpharm International Inc. | Transgenic non-human animals capable of producing heterologous antibodies of various isotypes |
| US5625126A (en) | 1990-08-29 | 1997-04-29 | Genpharm International, Inc. | Transgenic non-human animals for producing heterologous antibodies |
| US5545806A (en) | 1990-08-29 | 1996-08-13 | Genpharm International, Inc. | Ransgenic non-human animals for producing heterologous antibodies |
| US5877397A (en) | 1990-08-29 | 1999-03-02 | Genpharm International Inc. | Transgenic non-human animals capable of producing heterologous antibodies of various isotypes |
| US5789650A (en) | 1990-08-29 | 1998-08-04 | Genpharm International, Inc. | Transgenic non-human animals for producing heterologous antibodies |
| US5633425A (en) | 1990-08-29 | 1997-05-27 | Genpharm International, Inc. | Transgenic non-human animals capable of producing heterologous antibodies |
| DE69230142T2 (de) | 1991-05-15 | 2000-03-09 | Cambridge Antibody Technology Ltd. | Verfahren zur herstellung von spezifischen bindungspaargliedern |
| US5858657A (en) | 1992-05-15 | 1999-01-12 | Medical Research Council | Methods for producing members of specific binding pairs |
| DE69233254T2 (de) | 1991-06-14 | 2004-09-16 | Genentech, Inc., South San Francisco | Humanisierter Heregulin Antikörper |
| US5565332A (en) | 1991-09-23 | 1996-10-15 | Medical Research Council | Production of chimeric antibodies - a combinatorial approach |
| JPH07503132A (ja) | 1991-12-17 | 1995-04-06 | ジェンファーム インターナショナル,インコーポレイティド | 異種抗体を産生することができるトランスジェニック非ヒト動物 |
| US5733743A (en) | 1992-03-24 | 1998-03-31 | Cambridge Antibody Technology Limited | Methods for producing members of specific binding pairs |
| ES2322324T3 (es) | 1992-08-21 | 2009-06-19 | Vrije Universiteit Brussel | Inmumoglobulinas desprovistas de cadenas ligeras. |
| DE69329974T2 (de) | 1992-12-04 | 2001-07-19 | Medical Research Council, London | Multivalente und multispezifische bindungsproteine, deren herstellung und verwendung |
| US5827690A (en) | 1993-12-20 | 1998-10-27 | Genzyme Transgenics Corporatiion | Transgenic production of antibodies in milk |
| US5877218A (en) | 1994-01-10 | 1999-03-02 | Teva Pharmaceutical Industries, Ltd. | Compositions containing and methods of using 1-aminoindan and derivatives thereof and process for preparing optically active 1-aminoindan derivatives |
| US5786464C1 (en) | 1994-09-19 | 2012-04-24 | Gen Hospital Corp | Overexpression of mammalian and viral proteins |
| DE69620877T2 (de) | 1995-02-06 | 2002-12-12 | Genetics Institute, Inc. | Arzneimittelformulierungen für il-12 |
| DE19539493A1 (de) | 1995-10-24 | 1997-04-30 | Thomae Gmbh Dr K | Starker homologer Promotor aus Hamster |
| US5834597A (en) | 1996-05-20 | 1998-11-10 | Protein Design Labs, Inc. | Mutated nonactivating IgG2 domains and anti CD3 antibodies incorporating the same |
| US6114148C1 (en) | 1996-09-20 | 2012-05-01 | Gen Hospital Corp | High level expression of proteins |
| US5888809A (en) | 1997-05-01 | 1999-03-30 | Icos Corporation | Hamster EF-1α transcriptional regulatory DNA |
| CN1316055A (zh) * | 1998-07-03 | 2001-10-03 | 基因创新有限公司 | 神经变性的鉴别诊断 |
| WO2000046750A1 (en) | 1999-02-05 | 2000-08-10 | Samsung Electronics Co., Ltd. | Image texture retrieving method and apparatus thereof |
| TWI255272B (en) | 2000-12-06 | 2006-05-21 | Guriq Basi | Humanized antibodies that recognize beta amyloid peptide |
| MXPA05000511A (es) | 2001-07-12 | 2005-09-30 | Jefferson Foote | Anticuepros super humanizados. |
| CA2485342A1 (en) | 2002-05-13 | 2004-05-13 | Alexion Pharmaceuticals, Inc. | Humanized antibodies against the venezuelan equine encephalitis virus |
| TW200509968A (en) | 2002-11-01 | 2005-03-16 | Elan Pharm Inc | Prevention and treatment of synucleinopathic disease |
| US8506959B2 (en) | 2002-11-01 | 2013-08-13 | Neotope Biosciences Limited | Prevention and treatment of synucleinopathic and amyloidogenic disease |
| US9034337B2 (en) * | 2003-10-31 | 2015-05-19 | Prothena Biosciences Limited | Treatment and delay of outset of synucleinopathic and amyloidogenic disease |
| US20080014194A1 (en) * | 2003-10-31 | 2008-01-17 | Elan Pharmaceuticals, Inc. | Prevention and Treatment of Synucleinopathic and Amyloidogenic Disease |
| JP4344325B2 (ja) | 2002-11-29 | 2009-10-14 | ベーリンガー インゲルハイム ファルマ ゲゼルシャフト ミット ベシュレンクテル ハフツング ウント コンパニー コマンディトゲゼルシャフト | 新規なネオマイシンホスホトランスフェラーゼ遺伝子及び高生産組換え細胞の選抜方法 |
| HRP20050934B1 (hr) | 2003-04-04 | 2014-09-26 | Genentech, Inc. | Formulacije s visokom koncentracijom antitijela i proteina |
| US7358331B2 (en) | 2003-05-19 | 2008-04-15 | Elan Pharmaceuticals, Inc. | Truncated fragments of alpha-synuclein in Lewy body disease |
| DE10338531A1 (de) | 2003-08-19 | 2005-04-07 | Boehringer Ingelheim Pharma Gmbh & Co. Kg | Verfahren zur Reklonierung von Produktionszellen |
| WO2005047860A2 (en) * | 2003-11-08 | 2005-05-26 | Elan Pharmaceuticals, Inc. | Antibodies to alpha-synuclein |
| AU2004297616B2 (en) | 2003-12-04 | 2008-12-18 | Xencor, Inc. | Methods of generating variant proteins with increased host string content and compositions thereof |
| JO3000B1 (ar) | 2004-10-20 | 2016-09-05 | Genentech Inc | مركبات أجسام مضادة . |
| JP4620739B2 (ja) | 2004-11-10 | 2011-01-26 | ベーリンガー インゲルハイム ファルマ ゲゼルシャフト ミット ベシュレンクテル ハフツング ウント コンパニー コマンディトゲゼルシャフト | Cho細胞に対する細胞保存戦略を最適化するためのフローサイトメトリ分析の使用 |
| CA2657953A1 (en) | 2005-07-19 | 2007-01-25 | University Of Rochester | Alpha-synuclein antibodies and methods related thereto |
| WO2007021255A1 (en) * | 2005-08-09 | 2007-02-22 | Elan Pharmaceuticals, Inc. | Antibodies to alpha-synuclein |
| US8148085B2 (en) | 2006-05-15 | 2012-04-03 | Sea Lane Biotechnologies, Llc | Donor specific antibody libraries |
| MX2009000476A (es) | 2006-07-14 | 2009-01-28 | Ac Immune Sa | Anticuerpo humanizado contra beta amiloide. |
| US20080124760A1 (en) | 2006-07-26 | 2008-05-29 | Barbara Enenkel | Regulatory Nucleic Acid Elements |
| CN101663320A (zh) | 2007-02-23 | 2010-03-03 | 先灵公司 | 工程改造的抗IL-23p19抗体 |
| CA2678963C (en) | 2007-02-23 | 2018-05-01 | Elan Pharmaceuticals, Inc. | Prevention and treatment of synucleinopathic and amyloidogenic disease |
| US8147833B2 (en) | 2007-02-23 | 2012-04-03 | Neotope Biosciences Limited | Prevention and treatment of synucleinopathic and amyloidogenic disease |
| AR065573A1 (es) | 2007-03-02 | 2009-06-17 | Boehringer Ingelheim Int | Metodo de produccion de proteinas heterologas por expresion de una proteina con dominio de trasnferencia de lipido relacionada con proteina reguladora de la esteroidogenesis aguda start. |
| US8071097B2 (en) | 2007-03-22 | 2011-12-06 | Genentech, Inc. | Apoptotic anti-IgE antibodies |
| CA2681743A1 (en) | 2007-03-22 | 2008-09-25 | Imclone Llc | Stable antibody formulations |
| EP2031064A1 (de) | 2007-08-29 | 2009-03-04 | Boehringer Ingelheim Pharma GmbH & Co. KG | Verfahren zur Steigerung von Proteintitern |
| RU2476238C2 (ru) | 2007-12-21 | 2013-02-27 | Ф. Хоффманн-Ля Рош Аг | Препарат антитела |
| HUE025560T2 (en) * | 2007-12-28 | 2016-03-29 | Prothena Biosciences Ltd | Treatment and prophylaxis of amyloidosis |
| WO2009123748A1 (en) | 2008-04-05 | 2009-10-08 | Single Cell Technology, Inc. | Method of obtaining antibodies of interest and nucleotides encoding same |
| PT2282758T (pt) | 2008-04-29 | 2019-02-12 | Bioarctic Ab | Anticorpos e vacinas para uso em métodos terapêuticos e diagnósticos para perturbações relacionadas com a alfa-sinucleína |
| WO2009141239A1 (en) | 2008-05-20 | 2009-11-26 | F. Hoffmann-La Roche Ag | A pharmaceutical formulation comprising an antibody against ox40l, uses thereof |
| US20120276019A1 (en) | 2008-07-25 | 2012-11-01 | Diamedica Inc. | Tissue kallikrein for the treatment of parkinson's disease |
| DE102008048129A1 (de) | 2008-09-20 | 2010-04-22 | Lfk-Lenkflugkörpersysteme Gmbh | Flugkörper mit zumindest einem Bremsfallschirm sowie Befestigungsvorrichtung zur Befestigung eines Bremsfallschirms an einem Flugkörper |
| CA2736430A1 (en) | 2008-09-30 | 2010-04-08 | Abbott Laboratories | Improved antibody libraries |
| GB2467704B (en) | 2008-11-07 | 2011-08-24 | Mlc Dx Inc | A method for determining a profile of recombined DNA sequences in T-cells and/or B-cells |
| JP5810413B2 (ja) | 2008-12-19 | 2015-11-11 | バイオジェン インターナショナル ニューロサイエンス ゲーエムベーハー | ヒト抗アルファシヌクレイン自己抗体 |
| CN102686237B (zh) | 2009-07-28 | 2018-10-19 | 夏尔人类遗传性治疗公司 | 用于治疗戈谢病的组合物 |
| US20110053803A1 (en) | 2009-08-26 | 2011-03-03 | Xin Ge | Methods for creating antibody libraries |
| AR078161A1 (es) | 2009-09-11 | 2011-10-19 | Hoffmann La Roche | Formulaciones farmaceuticas muy concentradas de un anticuerpo anti cd20. uso de la formulacion. metodo de tratamiento. |
| US20130116413A1 (en) | 2009-12-29 | 2013-05-09 | Dr. Reddy's Laboratories, Inc. | Purification of proteins |
| EP2366714A1 (en) | 2010-03-03 | 2011-09-21 | Dr. Rentschler Holding GmbH & Co. KG | Naturally occuring autoantibodies against alpha-synuclein that inhibit the aggregation and cytotoxicity of alpha-synuclein |
| TW201134488A (en) | 2010-03-11 | 2011-10-16 | Ucb Pharma Sa | PD-1 antibodies |
| WO2011127324A2 (en) | 2010-04-08 | 2011-10-13 | JN Biosciences, LLC | Antibodies to cd122 |
| AU2011265054B2 (en) | 2010-06-08 | 2016-09-15 | Genentech, Inc. | Cysteine engineered antibodies and conjugates |
| EP2581113B1 (en) | 2010-06-11 | 2018-05-09 | Kyowa Hakko Kirin Co., Ltd. | Anti-tim-3 antibody |
| SI2593128T1 (en) | 2010-07-15 | 2018-08-31 | Adheron Therapeutics, Inc. | Humanized antibodies targeting the EC1 Kaderina-11 domain and associated compositions and procedures |
| NZ608943A (en) | 2010-10-11 | 2015-04-24 | Abbvie Bahamas Ltd | Processes for purification of proteins |
| EP2673635A4 (en) * | 2011-02-07 | 2015-08-12 | Neotope Biosciences Ltd | IMMUNOTHERAPY THROUGH APOE |
| WO2012160536A1 (en) | 2011-05-26 | 2012-11-29 | Dr Reddy's Laboratories Limited | Antibody purification |
| JP6061922B2 (ja) | 2011-06-22 | 2017-01-18 | ザ ジェネラル ホスピタル コーポレイション | プロテイノパチーの処置方法 |
| EP2726098A1 (en) | 2011-06-30 | 2014-05-07 | F.Hoffmann-La Roche Ag | Anti-c-met antibody formulations |
| ES2937409T3 (es) | 2011-10-28 | 2023-03-28 | Prothena Biosciences Ltd | Anticuerpos humanizados que reconocen la alfa-sinucleína |
| PL3091029T3 (pl) | 2011-10-31 | 2023-04-11 | F. Hoffmann-La Roche Ag | Formulacje przeciwciała anty-IL13 |
| CN104619724B (zh) | 2012-01-27 | 2018-05-04 | 普罗典娜生物科学有限公司 | 识别α-突触核蛋白的人源化抗体 |
| TR201909156T4 (tr) | 2012-08-29 | 2019-07-22 | Hoffmann La Roche | Kan beyin bariyeri mekiği. |
| US8925815B2 (en) | 2012-09-05 | 2015-01-06 | Symbol Technologies, Inc. | Checkout system for and method of preventing a customer-operated accessory reader facing a bagging area from imaging targets on products passed through a clerk-operated workstation to the bagging area |
| UA118441C2 (uk) | 2012-10-08 | 2019-01-25 | Протена Біосаєнсиз Лімітед | Антитіло, що розпізнає альфа-синуклеїн |
| US10513555B2 (en) | 2013-07-04 | 2019-12-24 | Prothena Biosciences Limited | Antibody formulations and methods |
| EP3129051A1 (en) | 2014-04-08 | 2017-02-15 | Prothena Biosciences Limited | Blood-brain barrier shuttles containing antibodies recognizing alpha-synuclein |
| US10084674B2 (en) | 2015-09-09 | 2018-09-25 | International Business Machines Corporation | Virtual desktop operation and data continuity preservation |
-
2013
- 2013-08-10 UA UAA201504527A patent/UA118441C2/uk unknown
- 2013-10-08 CA CA2886254A patent/CA2886254A1/en not_active Abandoned
- 2013-10-08 EA EA201590627A patent/EA034312B1/ru unknown
- 2013-10-08 KR KR1020157010222A patent/KR102163001B1/ko not_active Expired - Fee Related
- 2013-10-08 WO PCT/US2013/063945 patent/WO2014058924A2/en active Application Filing
- 2013-10-08 EP EP18206357.8A patent/EP3498296A1/en not_active Withdrawn
- 2013-10-08 MY MYPI2015701093A patent/MY169086A/en unknown
- 2013-10-08 AU AU2013329381A patent/AU2013329381B2/en not_active Ceased
- 2013-10-08 ES ES13845625T patent/ES2701406T3/es active Active
- 2013-10-08 SG SG11201502662QA patent/SG11201502662QA/en unknown
- 2013-10-08 US US14/049,169 patent/US9605056B2/en not_active Expired - Fee Related
- 2013-10-08 US US14/434,089 patent/US20150259404A1/en not_active Abandoned
- 2013-10-08 EP EP13845625.6A patent/EP2903648B1/en active Active
- 2013-10-08 NZ NZ706337A patent/NZ706337A/en not_active IP Right Cessation
- 2013-10-08 BR BR112015007882A patent/BR112015007882A2/pt not_active Application Discontinuation
- 2013-10-08 CN CN201811198984.3A patent/CN109180812A/zh active Pending
- 2013-10-08 MX MX2015003852A patent/MX365099B/es active IP Right Grant
- 2013-10-08 CN CN201380052445.8A patent/CN104822389B/zh not_active Expired - Fee Related
- 2013-10-08 JP JP2015535895A patent/JP6511396B2/ja not_active Expired - Fee Related
-
2015
- 2015-03-31 ZA ZA2015/02213A patent/ZA201502213B/en unknown
- 2015-04-07 PH PH12015500767A patent/PH12015500767B1/en unknown
- 2015-04-08 SA SA515360253A patent/SA515360253B1/ar unknown
- 2015-04-12 IL IL238192A patent/IL238192B/en active IP Right Grant
-
2017
- 2017-02-10 US US15/429,962 patent/US10081674B2/en not_active Expired - Fee Related
-
2018
- 2018-08-21 US US16/107,949 patent/US10301382B2/en not_active Expired - Fee Related
- 2018-11-29 AU AU2018271353A patent/AU2018271353A1/en not_active Abandoned
-
2019
- 2019-04-16 US US16/385,968 patent/US10669331B2/en not_active Expired - Fee Related
-
2020
- 2020-04-23 US US16/856,855 patent/US10875910B2/en not_active Expired - Fee Related
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10875910B2 (en) | Antibodies recognizing alpha-synuclein | |
| JP6807893B2 (ja) | α−シヌクレインを認識するヒト化抗体 | |
| JP6744856B2 (ja) | α−シヌクレインを認識する抗体を含む血液脳関門シャトル | |
| AU2016202622B2 (en) | Humanized antibodies that recognize alpha-synuclein | |
| HK40003309A (en) | ANTIBODIES THAT RECOGNIZE α-SYNUCLEIN | |
| HK1212361B (en) | Antibodies recognizing alpha-synuclein |