CN103443266A - 在解脂耶氏酵母中使用啤酒糖酵母suc2基因以利用蔗糖 - Google Patents
在解脂耶氏酵母中使用啤酒糖酵母suc2基因以利用蔗糖 Download PDFInfo
- Publication number
- CN103443266A CN103443266A CN2011800630477A CN201180063047A CN103443266A CN 103443266 A CN103443266 A CN 103443266A CN 2011800630477 A CN2011800630477 A CN 2011800630477A CN 201180063047 A CN201180063047 A CN 201180063047A CN 103443266 A CN103443266 A CN 103443266A
- Authority
- CN
- China
- Prior art keywords
- yarrowia lipolytica
- sequence
- seq
- xpr2
- gene
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 241000235015 Yarrowia lipolytica Species 0.000 title claims abstract description 193
- 229930006000 Sucrose Natural products 0.000 title claims abstract description 98
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 title claims abstract description 98
- 239000005720 sucrose Substances 0.000 title claims abstract description 97
- 240000004808 Saccharomyces cerevisiae Species 0.000 title claims description 48
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 title claims description 47
- 101150014136 SUC2 gene Proteins 0.000 title description 28
- 235000011073 invertase Nutrition 0.000 claims abstract description 164
- 108010051210 beta-Fructofuranosidase Proteins 0.000 claims abstract description 161
- 239000001573 invertase Substances 0.000 claims abstract description 82
- 230000000694 effects Effects 0.000 claims abstract description 64
- 238000000034 method Methods 0.000 claims abstract description 53
- 108090000765 processed proteins & peptides Proteins 0.000 claims abstract description 52
- 102000004196 processed proteins & peptides Human genes 0.000 claims abstract description 35
- 229920001184 polypeptide Polymers 0.000 claims abstract description 34
- 108091033319 polynucleotide Proteins 0.000 claims abstract description 13
- 102000040430 polynucleotide Human genes 0.000 claims abstract description 13
- 239000002157 polynucleotide Substances 0.000 claims abstract description 13
- 229940024606 amino acid Drugs 0.000 claims description 121
- 150000001413 amino acids Chemical class 0.000 claims description 119
- 235000001014 amino acid Nutrition 0.000 claims description 116
- 108010076504 Protein Sorting Signals Proteins 0.000 claims description 95
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 claims description 61
- 229910052799 carbon Inorganic materials 0.000 claims description 61
- 239000012634 fragment Substances 0.000 claims description 59
- 238000006243 chemical reaction Methods 0.000 claims description 55
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 claims description 53
- 239000008103 glucose Substances 0.000 claims description 48
- -1 hydroxy ester Chemical class 0.000 claims description 30
- 229930014626 natural product Natural products 0.000 claims description 25
- 235000020777 polyunsaturated fatty acids Nutrition 0.000 claims description 22
- 235000021466 carotenoid Nutrition 0.000 claims description 14
- 150000001747 carotenoids Chemical class 0.000 claims description 13
- 101710184309 Probable sucrose-6-phosphate hydrolase Proteins 0.000 claims description 12
- 102400000472 Sucrase Human genes 0.000 claims description 12
- 101710112652 Sucrose-6-phosphate hydrolase Proteins 0.000 claims description 12
- LUKBXSAWLPMMSZ-OWOJBTEDSA-N Trans-resveratrol Chemical compound C1=CC(O)=CC=C1\C=C\C1=CC(O)=CC(O)=C1 LUKBXSAWLPMMSZ-OWOJBTEDSA-N 0.000 claims description 9
- 235000018991 trans-resveratrol Nutrition 0.000 claims description 9
- 229930182558 Sterol Natural products 0.000 claims description 8
- 230000002209 hydrophobic effect Effects 0.000 claims description 8
- 150000003432 sterols Chemical class 0.000 claims description 8
- 235000003702 sterols Nutrition 0.000 claims description 8
- 229940088594 vitamin Drugs 0.000 claims description 7
- 229930003231 vitamin Natural products 0.000 claims description 7
- 235000013343 vitamin Nutrition 0.000 claims description 7
- 239000011782 vitamin Substances 0.000 claims description 7
- 150000003722 vitamin derivatives Chemical class 0.000 claims description 7
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 claims description 6
- 229930003935 flavonoid Natural products 0.000 claims description 6
- 235000017173 flavonoids Nutrition 0.000 claims description 6
- 150000002215 flavonoids Chemical class 0.000 claims description 6
- 150000007524 organic acids Chemical class 0.000 claims description 6
- 101710162350 Alkaline extracellular protease Proteins 0.000 claims description 4
- 108050001049 Extracellular proteins Proteins 0.000 claims description 4
- 102000010911 Enzyme Precursors Human genes 0.000 claims description 3
- 108010062466 Enzyme Precursors Proteins 0.000 claims description 3
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 claims description 3
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 claims description 3
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 claims description 3
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 claims description 3
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 claims description 3
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 claims description 3
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 claims description 3
- 229960000310 isoleucine Drugs 0.000 claims description 3
- 229930182817 methionine Natural products 0.000 claims description 3
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 claims description 3
- 108090000623 proteins and genes Proteins 0.000 description 197
- 229960004793 sucrose Drugs 0.000 description 94
- 210000004027 cell Anatomy 0.000 description 93
- 230000001580 bacterial effect Effects 0.000 description 90
- 102000004169 proteins and genes Human genes 0.000 description 67
- 235000018102 proteins Nutrition 0.000 description 66
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 50
- 230000014509 gene expression Effects 0.000 description 50
- 235000020673 eicosapentaenoic acid Nutrition 0.000 description 42
- 150000002632 lipids Chemical class 0.000 description 42
- 239000013612 plasmid Substances 0.000 description 38
- 101100382243 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) YAT1 gene Proteins 0.000 description 34
- 230000012010 growth Effects 0.000 description 34
- 108020004414 DNA Proteins 0.000 description 33
- 239000002773 nucleotide Substances 0.000 description 33
- 125000003729 nucleotide group Chemical group 0.000 description 33
- 239000002253 acid Substances 0.000 description 28
- 101150099000 EXPA1 gene Proteins 0.000 description 25
- 101100119348 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) EXP1 gene Proteins 0.000 description 25
- 101100269618 Streptococcus pneumoniae serotype 4 (strain ATCC BAA-334 / TIGR4) aliA gene Proteins 0.000 description 25
- 108700002148 exportin 1 Proteins 0.000 description 25
- 102100029095 Exportin-1 Human genes 0.000 description 24
- 101100005882 Mus musculus Cel gene Proteins 0.000 description 24
- 101100289046 Mus musculus Lias gene Proteins 0.000 description 24
- 101150091094 lipA gene Proteins 0.000 description 24
- YAFQFNOUYXZVPZ-UHFFFAOYSA-N liproxstatin-1 Chemical compound ClC1=CC=CC(CNC=2C3(CCNCC3)NC3=CC=CC=C3N=2)=C1 YAFQFNOUYXZVPZ-UHFFFAOYSA-N 0.000 description 24
- 108020004705 Codon Proteins 0.000 description 22
- 102000004190 Enzymes Human genes 0.000 description 22
- 108090000790 Enzymes Proteins 0.000 description 22
- 230000028327 secretion Effects 0.000 description 22
- 150000007523 nucleic acids Chemical group 0.000 description 21
- 238000013459 approach Methods 0.000 description 18
- 108010022240 delta-8 fatty acid desaturase Proteins 0.000 description 17
- 239000000194 fatty acid Substances 0.000 description 17
- 239000002243 precursor Substances 0.000 description 17
- 239000000523 sample Substances 0.000 description 17
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 16
- 239000000203 mixture Substances 0.000 description 16
- 108091026890 Coding region Proteins 0.000 description 15
- 244000005700 microbiome Species 0.000 description 15
- 238000004458 analytical method Methods 0.000 description 14
- 235000014113 dietary fatty acids Nutrition 0.000 description 14
- 229930195729 fatty acid Natural products 0.000 description 14
- 150000004665 fatty acids Chemical class 0.000 description 14
- 230000004927 fusion Effects 0.000 description 14
- 238000005336 cracking Methods 0.000 description 13
- 235000019387 fatty acid methyl ester Nutrition 0.000 description 13
- 230000035800 maturation Effects 0.000 description 13
- 230000008569 process Effects 0.000 description 13
- 230000001105 regulatory effect Effects 0.000 description 13
- 241000195619 Euglena gracilis Species 0.000 description 12
- 229930091371 Fructose Natural products 0.000 description 12
- RFSUNEUAIZKAJO-ARQDHWQXSA-N Fructose Chemical compound OC[C@H]1O[C@](O)(CO)[C@@H](O)[C@@H]1O RFSUNEUAIZKAJO-ARQDHWQXSA-N 0.000 description 12
- 239000005715 Fructose Substances 0.000 description 12
- 101100215634 Yarrowia lipolytica (strain CLIB 122 / E 150) XPR2 gene Proteins 0.000 description 12
- 239000002585 base Substances 0.000 description 12
- 230000001276 controlling effect Effects 0.000 description 12
- 239000002609 medium Substances 0.000 description 12
- 238000003752 polymerase chain reaction Methods 0.000 description 12
- 108700012830 rat Lip2 Proteins 0.000 description 12
- 208000016444 Benign adult familial myoclonic epilepsy Diseases 0.000 description 11
- 125000003275 alpha amino acid group Chemical group 0.000 description 11
- 230000008859 change Effects 0.000 description 11
- 230000029087 digestion Effects 0.000 description 11
- 208000016427 familial adult myoclonic epilepsy Diseases 0.000 description 11
- ZGNITFSDLCMLGI-UHFFFAOYSA-N flubendiamide Chemical compound CC1=CC(C(F)(C(F)(F)F)C(F)(F)F)=CC=C1NC(=O)C1=CC=CC(I)=C1C(=O)NC(C)(C)CS(C)(=O)=O ZGNITFSDLCMLGI-UHFFFAOYSA-N 0.000 description 11
- 238000006460 hydrolysis reaction Methods 0.000 description 11
- 238000004519 manufacturing process Methods 0.000 description 11
- 102000039446 nucleic acids Human genes 0.000 description 11
- 108020004707 nucleic acids Proteins 0.000 description 11
- 239000000047 product Substances 0.000 description 11
- SEHFUALWMUWDKS-UHFFFAOYSA-N 5-fluoroorotic acid Chemical compound OC(=O)C=1NC(=O)NC(=O)C=1F SEHFUALWMUWDKS-UHFFFAOYSA-N 0.000 description 10
- 241000235070 Saccharomyces Species 0.000 description 10
- 230000007062 hydrolysis Effects 0.000 description 10
- AZQWKYJCGOJGHM-UHFFFAOYSA-N 1,4-benzoquinone Chemical compound O=C1C=CC(=O)C=C1 AZQWKYJCGOJGHM-UHFFFAOYSA-N 0.000 description 9
- 235000020660 omega-3 fatty acid Nutrition 0.000 description 9
- 239000000126 substance Substances 0.000 description 9
- 238000013519 translation Methods 0.000 description 9
- UPYKUZBSLRQECL-UKMVMLAPSA-N Lycopene Natural products CC(=C/C=C/C=C(C)/C=C/C=C(C)/C=C/C1C(=C)CCCC1(C)C)C=CC=C(/C)C=CC2C(=C)CCCC2(C)C UPYKUZBSLRQECL-UKMVMLAPSA-N 0.000 description 8
- 235000005473 carotenes Nutrition 0.000 description 8
- ACTIUHUUMQJHFO-UPTCCGCDSA-N coenzyme Q10 Chemical class COC1=C(OC)C(=O)C(C\C=C(/C)CC\C=C(/C)CC\C=C(/C)CC\C=C(/C)CC\C=C(/C)CC\C=C(/C)CC\C=C(/C)CC\C=C(/C)CC\C=C(/C)CCC=C(C)C)=C(C)C1=O ACTIUHUUMQJHFO-UPTCCGCDSA-N 0.000 description 8
- 239000013613 expression plasmid Substances 0.000 description 8
- 238000013467 fragmentation Methods 0.000 description 8
- 238000006062 fragmentation reaction Methods 0.000 description 8
- 229910052757 nitrogen Inorganic materials 0.000 description 8
- NCYCYZXNIZJOKI-UHFFFAOYSA-N vitamin A aldehyde Natural products O=CC=C(C)C=CC=C(C)C=CC1=C(C)CCCC1(C)C NCYCYZXNIZJOKI-UHFFFAOYSA-N 0.000 description 8
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 7
- 108700010070 Codon Usage Proteins 0.000 description 7
- 101150023108 XPR2 gene Proteins 0.000 description 7
- 150000001746 carotenes Chemical class 0.000 description 7
- 238000011156 evaluation Methods 0.000 description 7
- 239000007788 liquid Substances 0.000 description 7
- 238000012545 processing Methods 0.000 description 7
- 241000894007 species Species 0.000 description 7
- 210000000130 stem cell Anatomy 0.000 description 7
- 235000000346 sugar Nutrition 0.000 description 7
- 230000009466 transformation Effects 0.000 description 7
- HOBAELRKJCKHQD-UHFFFAOYSA-N (8Z,11Z,14Z)-8,11,14-eicosatrienoic acid Natural products CCCCCC=CCC=CCC=CCCCCCCC(O)=O HOBAELRKJCKHQD-UHFFFAOYSA-N 0.000 description 6
- WQDUMFSSJAZKTM-UHFFFAOYSA-N Sodium methoxide Chemical compound [Na+].[O-]C WQDUMFSSJAZKTM-UHFFFAOYSA-N 0.000 description 6
- KRKNYBCHXYNGOX-UHFFFAOYSA-N citric acid Chemical compound OC(=O)CC(O)(C(O)=O)CC(O)=O KRKNYBCHXYNGOX-UHFFFAOYSA-N 0.000 description 6
- 150000001875 compounds Chemical class 0.000 description 6
- HOBAELRKJCKHQD-QNEBEIHSSA-N dihomo-γ-linolenic acid Chemical compound CCCCC\C=C/C\C=C/C\C=C/CCCCCCC(O)=O HOBAELRKJCKHQD-QNEBEIHSSA-N 0.000 description 6
- 238000005516 engineering process Methods 0.000 description 6
- 239000011663 gamma-carotene Chemical group 0.000 description 6
- 239000001963 growth medium Substances 0.000 description 6
- 108020004999 messenger RNA Proteins 0.000 description 6
- 230000000813 microbial effect Effects 0.000 description 6
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 6
- 241000894006 Bacteria Species 0.000 description 5
- 108010059378 Endopeptidases Proteins 0.000 description 5
- 102000005593 Endopeptidases Human genes 0.000 description 5
- 101800000120 Host translation inhibitor nsp1 Proteins 0.000 description 5
- 101800000517 Leader protein Proteins 0.000 description 5
- 101800000512 Non-structural protein 1 Proteins 0.000 description 5
- 238000000855 fermentation Methods 0.000 description 5
- 230000004151 fermentation Effects 0.000 description 5
- 238000007429 general method Methods 0.000 description 5
- 230000002068 genetic effect Effects 0.000 description 5
- 230000000284 resting effect Effects 0.000 description 5
- 230000003248 secreting effect Effects 0.000 description 5
- 238000012360 testing method Methods 0.000 description 5
- 230000001131 transforming effect Effects 0.000 description 5
- YVLPJIGOMTXXLP-UHFFFAOYSA-N 15-cis-phytoene Chemical compound CC(C)=CCCC(C)=CCCC(C)=CCCC(C)=CC=CC=C(C)CCC=C(C)CCC=C(C)CCC=C(C)C YVLPJIGOMTXXLP-UHFFFAOYSA-N 0.000 description 4
- 102100039239 Amidophosphoribosyltransferase Human genes 0.000 description 4
- 108010039224 Amidophosphoribosyltransferase Proteins 0.000 description 4
- 241000233732 Fusarium verticillioides Species 0.000 description 4
- OYHQOLUKZRVURQ-HZJYTTRNSA-N Linoleic acid Chemical compound CCCCC\C=C/C\C=C/CCCCCCCC(O)=O OYHQOLUKZRVURQ-HZJYTTRNSA-N 0.000 description 4
- 241000907999 Mortierella alpina Species 0.000 description 4
- 108091028043 Nucleic acid sequence Proteins 0.000 description 4
- 108091034117 Oligonucleotide Proteins 0.000 description 4
- 238000012408 PCR amplification Methods 0.000 description 4
- 108091005804 Peptidases Proteins 0.000 description 4
- 102000035195 Peptidases Human genes 0.000 description 4
- 241000223252 Rhodotorula Species 0.000 description 4
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 4
- DTOSIQBPPRVQHS-PDBXOOCHSA-N alpha-linolenic acid Chemical compound CC\C=C/C\C=C/C\C=C/CCCCCCCC(O)=O DTOSIQBPPRVQHS-PDBXOOCHSA-N 0.000 description 4
- 230000003321 amplification Effects 0.000 description 4
- YZXBAPSDXZZRGB-DOFZRALJSA-N arachidonic acid Chemical compound CCCCC\C=C/C\C=C/C\C=C/C\C=C/CCCC(O)=O YZXBAPSDXZZRGB-DOFZRALJSA-N 0.000 description 4
- 230000015572 biosynthetic process Effects 0.000 description 4
- 229940041514 candida albicans extract Drugs 0.000 description 4
- 238000006555 catalytic reaction Methods 0.000 description 4
- 230000004087 circulation Effects 0.000 description 4
- 235000017471 coenzyme Q10 Nutrition 0.000 description 4
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 4
- GVJHHUAWPYXKBD-UHFFFAOYSA-N d-alpha-tocopherol Natural products OC1=C(C)C(C)=C2OC(CCCC(C)CCCC(C)CCCC(C)C)(C)CCC2=C1C GVJHHUAWPYXKBD-UHFFFAOYSA-N 0.000 description 4
- 238000001514 detection method Methods 0.000 description 4
- 239000008121 dextrose Substances 0.000 description 4
- 238000002474 experimental method Methods 0.000 description 4
- 230000008676 import Effects 0.000 description 4
- 230000010354 integration Effects 0.000 description 4
- 230000003834 intracellular effect Effects 0.000 description 4
- 229960004232 linoleic acid Drugs 0.000 description 4
- 239000000463 material Substances 0.000 description 4
- 235000013372 meat Nutrition 0.000 description 4
- VLKZOEOYAKHREP-UHFFFAOYSA-N n-Hexane Chemical class CCCCCC VLKZOEOYAKHREP-UHFFFAOYSA-N 0.000 description 4
- 238000003199 nucleic acid amplification method Methods 0.000 description 4
- 238000005457 optimization Methods 0.000 description 4
- SHUZOJHMOBOZST-UHFFFAOYSA-N phylloquinone Natural products CC(C)CCCCC(C)CCC(C)CCCC(=CCC1=C(C)C(=O)c2ccccc2C1=O)C SHUZOJHMOBOZST-UHFFFAOYSA-N 0.000 description 4
- 230000008488 polyadenylation Effects 0.000 description 4
- 238000011160 research Methods 0.000 description 4
- 108091008146 restriction endonucleases Proteins 0.000 description 4
- 239000000243 solution Substances 0.000 description 4
- 235000014347 soups Nutrition 0.000 description 4
- 238000005406 washing Methods 0.000 description 4
- 239000012138 yeast extract Substances 0.000 description 4
- WRIDQFICGBMAFQ-UHFFFAOYSA-N (E)-8-Octadecenoic acid Natural products CCCCCCCCCC=CCCCCCCC(O)=O WRIDQFICGBMAFQ-UHFFFAOYSA-N 0.000 description 3
- LQJBNNIYVWPHFW-UHFFFAOYSA-N 20:1omega9c fatty acid Natural products CCCCCCCCCCC=CCCCCCCCC(O)=O LQJBNNIYVWPHFW-UHFFFAOYSA-N 0.000 description 3
- QSBYPNXLFMSGKH-UHFFFAOYSA-N 9-Heptadecensaeure Natural products CCCCCCCC=CCCCCCCCC(O)=O QSBYPNXLFMSGKH-UHFFFAOYSA-N 0.000 description 3
- 102100034542 Acyl-CoA (8-3)-desaturase Human genes 0.000 description 3
- 239000002028 Biomass Substances 0.000 description 3
- 102000053602 DNA Human genes 0.000 description 3
- 108010073542 Delta-5 Fatty Acid Desaturase Proteins 0.000 description 3
- 241001517212 Euglenaria anabaena Species 0.000 description 3
- 108700007698 Genetic Terminator Regions Proteins 0.000 description 3
- RRHGJUQNOFWUDK-UHFFFAOYSA-N Isoprene Chemical compound CC(=C)C=C RRHGJUQNOFWUDK-UHFFFAOYSA-N 0.000 description 3
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 3
- 239000005642 Oleic acid Substances 0.000 description 3
- ZQPPMHVWECSIRJ-UHFFFAOYSA-N Oleic acid Natural products CCCCCCCCC=CCCCCCCCC(O)=O ZQPPMHVWECSIRJ-UHFFFAOYSA-N 0.000 description 3
- 241001536974 Saccharomyces cerevisiae BY4743 Species 0.000 description 3
- 238000012300 Sequence Analysis Methods 0.000 description 3
- 108091081024 Start codon Proteins 0.000 description 3
- HXWJFEZDFPRLBG-UHFFFAOYSA-N Timnodonic acid Natural products CCCC=CC=CCC=CCC=CCC=CCCCC(O)=O HXWJFEZDFPRLBG-UHFFFAOYSA-N 0.000 description 3
- YXFVVABEGXRONW-UHFFFAOYSA-N Toluene Chemical compound CC1=CC=CC=C1 YXFVVABEGXRONW-UHFFFAOYSA-N 0.000 description 3
- 229930003427 Vitamin E Natural products 0.000 description 3
- 229930003448 Vitamin K Natural products 0.000 description 3
- 238000009825 accumulation Methods 0.000 description 3
- JAZBEHYOTPTENJ-JLNKQSITSA-N all-cis-5,8,11,14,17-icosapentaenoic acid Chemical compound CC\C=C/C\C=C/C\C=C/C\C=C/C\C=C/CCCC(O)=O JAZBEHYOTPTENJ-JLNKQSITSA-N 0.000 description 3
- 125000000539 amino acid group Chemical group 0.000 description 3
- 238000004422 calculation algorithm Methods 0.000 description 3
- 230000008878 coupling Effects 0.000 description 3
- 238000010168 coupling process Methods 0.000 description 3
- 238000005859 coupling reaction Methods 0.000 description 3
- 239000012228 culture supernatant Substances 0.000 description 3
- 230000001419 dependent effect Effects 0.000 description 3
- 230000008034 disappearance Effects 0.000 description 3
- MBMBGCFOFBJSGT-KUBAVDMBSA-N docosahexaenoic acid Natural products CC\C=C/C\C=C/C\C=C/C\C=C/C\C=C/C\C=C/CCC(O)=O MBMBGCFOFBJSGT-KUBAVDMBSA-N 0.000 description 3
- 229960005135 eicosapentaenoic acid Drugs 0.000 description 3
- 235000019197 fats Nutrition 0.000 description 3
- 238000001914 filtration Methods 0.000 description 3
- 235000020664 gamma-linolenic acid Nutrition 0.000 description 3
- VZCCETWTMQHEPK-QNEBEIHSSA-N gamma-linolenic acid Chemical compound CCCCC\C=C/C\C=C/C\C=C/CCCCC(O)=O VZCCETWTMQHEPK-QNEBEIHSSA-N 0.000 description 3
- WIGCFUFOHFEKBI-UHFFFAOYSA-N gamma-tocopherol Natural products CC(C)CCCC(C)CCCC(C)CCCC1CCC2C(C)C(O)C(C)C(C)C2O1 WIGCFUFOHFEKBI-UHFFFAOYSA-N 0.000 description 3
- QXJSBBXBKPUZAA-UHFFFAOYSA-N isooleic acid Natural products CCCCCCCC=CCCCCCCCCC(O)=O QXJSBBXBKPUZAA-UHFFFAOYSA-N 0.000 description 3
- 230000004060 metabolic process Effects 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 210000004898 n-terminal fragment Anatomy 0.000 description 3
- QJGQUHMNIGDVPM-UHFFFAOYSA-N nitrogen group Chemical group [N] QJGQUHMNIGDVPM-UHFFFAOYSA-N 0.000 description 3
- 239000001054 red pigment Substances 0.000 description 3
- 239000000455 rubixanthin Substances 0.000 description 3
- 238000000926 separation method Methods 0.000 description 3
- 239000007974 sodium acetate buffer Substances 0.000 description 3
- 238000003786 synthesis reaction Methods 0.000 description 3
- 238000005809 transesterification reaction Methods 0.000 description 3
- 230000017105 transposition Effects 0.000 description 3
- 235000019165 vitamin E Nutrition 0.000 description 3
- 239000011709 vitamin E Substances 0.000 description 3
- 229940046009 vitamin E Drugs 0.000 description 3
- 235000019168 vitamin K Nutrition 0.000 description 3
- 239000011712 vitamin K Substances 0.000 description 3
- 229940046010 vitamin k Drugs 0.000 description 3
- GVJHHUAWPYXKBD-IEOSBIPESA-N α-tocopherol Chemical compound OC1=C(C)C(C)=C2O[C@@](CCC[C@H](C)CCC[C@H](C)CCCC(C)C)(C)CCC2=C1C GVJHHUAWPYXKBD-IEOSBIPESA-N 0.000 description 3
- XSXIVVZCUAHUJO-AVQMFFATSA-N (11e,14e)-icosa-11,14-dienoic acid Chemical compound CCCCC\C=C\C\C=C\CCCCCCCCCC(O)=O XSXIVVZCUAHUJO-AVQMFFATSA-N 0.000 description 2
- ATCICVFRSJQYDV-UHFFFAOYSA-N (6E,8E,10E,12E,14E,16E,18E,20E,22E,26E)-2,6,10,14,19,23,27,31-octamethyldotriaconta-2,6,8,10,12,14,16,18,20,22,26,30-dodecaene Chemical compound CC(C)=CCCC(C)=CCCC(C)=CC=CC(C)=CC=CC=C(C)C=CC=C(C)C=CC=C(C)CCC=C(C)C ATCICVFRSJQYDV-UHFFFAOYSA-N 0.000 description 2
- YVLPJIGOMTXXLP-UUKUAVTLSA-N 15,15'-cis-Phytoene Natural products C(=C\C=C/C=C(\CC/C=C(\CC/C=C(\CC/C=C(\C)/C)/C)/C)/C)(\CC/C=C(\CC/C=C(\CC/C=C(\C)/C)/C)/C)/C YVLPJIGOMTXXLP-UUKUAVTLSA-N 0.000 description 2
- YVLPJIGOMTXXLP-BAHRDPFUSA-N 15Z-phytoene Natural products CC(=CCCC(=CCCC(=CCCC(=CC=C/C=C(C)/CCC=C(/C)CCC=C(/C)CCC=C(C)C)C)C)C)C YVLPJIGOMTXXLP-BAHRDPFUSA-N 0.000 description 2
- KKAJSJJFBSOMGS-UHFFFAOYSA-N 3,6-diamino-10-methylacridinium chloride Chemical compound [Cl-].C1=C(N)C=C2[N+](C)=C(C=C(N)C=C3)C3=CC2=C1 KKAJSJJFBSOMGS-UHFFFAOYSA-N 0.000 description 2
- PIFPCDRPHCQLSJ-WYIJOVFWSA-N 4,8,12,15,19-Docosapentaenoic acid Chemical compound CC\C=C\CC\C=C\C\C=C\CC\C=C\CC\C=C\CCC(O)=O PIFPCDRPHCQLSJ-WYIJOVFWSA-N 0.000 description 2
- 229920000936 Agarose Polymers 0.000 description 2
- 102000005572 Cathepsin A Human genes 0.000 description 2
- 108010059081 Cathepsin A Proteins 0.000 description 2
- PIFPCDRPHCQLSJ-UHFFFAOYSA-N Clupanodonic acid Natural products CCC=CCCC=CCC=CCCC=CCCC=CCCC(O)=O PIFPCDRPHCQLSJ-UHFFFAOYSA-N 0.000 description 2
- 108091035707 Consensus sequence Proteins 0.000 description 2
- 241001527609 Cryptococcus Species 0.000 description 2
- 244000241257 Cucumis melo Species 0.000 description 2
- 235000015510 Cucumis melo subsp melo Nutrition 0.000 description 2
- 235000021298 Dihomo-γ-linolenic acid Nutrition 0.000 description 2
- 235000021297 Eicosadienoic acid Nutrition 0.000 description 2
- 102100031780 Endonuclease Human genes 0.000 description 2
- 108010042407 Endonucleases Proteins 0.000 description 2
- 241000206602 Eukaryota Species 0.000 description 2
- 101710089384 Extracellular protease Proteins 0.000 description 2
- LLKMUZAISVDKFO-REPGOVCFSA-N Flexixanthin Natural products CC(=C/C=C/C(=C/C=C/C(=C/C=C/C=C(C)/C=C/C=C(C)/C=C/C1=C(C)C(=O)C(O)CC1(C)C)/C)/C)C=CCC(C)(C)O LLKMUZAISVDKFO-REPGOVCFSA-N 0.000 description 2
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 2
- 108090000723 Insulin-Like Growth Factor I Proteins 0.000 description 2
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 2
- 206010027336 Menstruation delayed Diseases 0.000 description 2
- 108091005461 Nucleic proteins Chemical group 0.000 description 2
- 108700026244 Open Reading Frames Proteins 0.000 description 2
- 241000233639 Pythium Species 0.000 description 2
- 241000918585 Pythium aphanidermatum Species 0.000 description 2
- LOUPRKONTZGTKE-WZBLMQSHSA-N Quinine Chemical compound C([C@H]([C@H](C1)C=C)C2)C[N@@]1[C@@H]2[C@H](O)C1=CC=NC2=CC=C(OC)C=C21 LOUPRKONTZGTKE-WZBLMQSHSA-N 0.000 description 2
- 108020004511 Recombinant DNA Proteins 0.000 description 2
- 241000589194 Rhizobium leguminosarum Species 0.000 description 2
- 101001076706 Saccharomyces cerevisiae Invertase 1 Proteins 0.000 description 2
- 101001053411 Saccharomyces cerevisiae Invertase 3 Proteins 0.000 description 2
- 101001053412 Saccharomyces cerevisiae Invertase 4 Proteins 0.000 description 2
- 101001053409 Saccharomyces cerevisiae Invertase 5 Proteins 0.000 description 2
- 101001053400 Saccharomyces cerevisiae Invertase 7 Proteins 0.000 description 2
- 240000000111 Saccharum officinarum Species 0.000 description 2
- 235000007201 Saccharum officinarum Nutrition 0.000 description 2
- 102000013275 Somatomedins Human genes 0.000 description 2
- 235000021355 Stearic acid Nutrition 0.000 description 2
- 108700005078 Synthetic Genes Proteins 0.000 description 2
- 241000223230 Trichosporon Species 0.000 description 2
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 2
- DRTQHJPVMGBUCF-XVFCMESISA-N Uridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-XVFCMESISA-N 0.000 description 2
- 241000235013 Yarrowia Species 0.000 description 2
- JKQXZKUSFCKOGQ-LQFQNGICSA-N Z-zeaxanthin Natural products C([C@H](O)CC=1C)C(C)(C)C=1C=CC(C)=CC=CC(C)=CC=CC=C(C)C=CC=C(C)C=CC1=C(C)C[C@@H](O)CC1(C)C JKQXZKUSFCKOGQ-LQFQNGICSA-N 0.000 description 2
- QOPRSMDTRDMBNK-RNUUUQFGSA-N Zeaxanthin Natural products CC(=C/C=C/C=C(C)/C=C/C=C(C)/C=C/C1=C(C)CCC(O)C1(C)C)C=CC=C(/C)C=CC2=C(C)CC(O)CC2(C)C QOPRSMDTRDMBNK-RNUUUQFGSA-N 0.000 description 2
- FJJCIZWZNKZHII-UHFFFAOYSA-N [4,6-bis(cyanoamino)-1,3,5-triazin-2-yl]cyanamide Chemical compound N#CNC1=NC(NC#N)=NC(NC#N)=N1 FJJCIZWZNKZHII-UHFFFAOYSA-N 0.000 description 2
- ZSLZBFCDCINBPY-ZSJPKINUSA-N acetyl-CoA Chemical compound O[C@@H]1[C@H](OP(O)(O)=O)[C@@H](COP(O)(=O)OP(O)(=O)OCC(C)(C)[C@@H](O)C(=O)NCCC(=O)NCCSC(=O)C)O[C@H]1N1C2=NC=NC(N)=C2N=C1 ZSLZBFCDCINBPY-ZSJPKINUSA-N 0.000 description 2
- OIRDTQYFTABQOQ-KQYNXXCUSA-N adenosine Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OIRDTQYFTABQOQ-KQYNXXCUSA-N 0.000 description 2
- AHANXAKGNAKFSK-PDBXOOCHSA-N all-cis-icosa-11,14,17-trienoic acid Chemical compound CC\C=C/C\C=C/C\C=C/CCCCCCCCCC(O)=O AHANXAKGNAKFSK-PDBXOOCHSA-N 0.000 description 2
- OENHQHLEOONYIE-UKMVMLAPSA-N all-trans beta-carotene Natural products CC=1CCCC(C)(C)C=1/C=C/C(/C)=C/C=C/C(/C)=C/C=C/C=C(C)C=CC=C(C)C=CC1=C(C)CCCC1(C)C OENHQHLEOONYIE-UKMVMLAPSA-N 0.000 description 2
- JKQXZKUSFCKOGQ-LOFNIBRQSA-N all-trans-Zeaxanthin Natural products CC(=C/C=C/C=C(C)/C=C/C=C(C)/C=C/C1=C(C)CC(O)CC1(C)C)C=CC=C(/C)C=CC2=C(C)CC(O)CC2(C)C JKQXZKUSFCKOGQ-LOFNIBRQSA-N 0.000 description 2
- ANVAOWXLWRTKGA-XHGAXZNDSA-N all-trans-alpha-carotene Chemical group CC=1CCCC(C)(C)C=1/C=C/C(/C)=C/C=C/C(/C)=C/C=C/C=C(C)C=CC=C(C)C=CC1C(C)=CCCC1(C)C ANVAOWXLWRTKGA-XHGAXZNDSA-N 0.000 description 2
- NBZANZVJRKXVBH-ITUXNECMSA-N all-trans-alpha-cryptoxanthin Chemical group CC(=C/C=C/C=C(C)/C=C/C=C(C)/C=C/C1=C(C)CC(O)CC1(C)C)C=CC=C(/C)C=CC2C(=CCCC2(C)C)C NBZANZVJRKXVBH-ITUXNECMSA-N 0.000 description 2
- 235000020661 alpha-linolenic acid Nutrition 0.000 description 2
- BFNBIHQBYMNNAN-UHFFFAOYSA-N ammonium sulfate Chemical compound N.N.OS(O)(=O)=O BFNBIHQBYMNNAN-UHFFFAOYSA-N 0.000 description 2
- 229910052921 ammonium sulfate Inorganic materials 0.000 description 2
- 235000011130 ammonium sulphate Nutrition 0.000 description 2
- 230000003698 anagen phase Effects 0.000 description 2
- 235000021342 arachidonic acid Nutrition 0.000 description 2
- 229940114079 arachidonic acid Drugs 0.000 description 2
- 235000013793 astaxanthin Nutrition 0.000 description 2
- 235000013734 beta-carotene Nutrition 0.000 description 2
- 239000011648 beta-carotene Substances 0.000 description 2
- TUPZEYHYWIEDIH-WAIFQNFQSA-N beta-carotene Natural products CC(=C/C=C/C=C(C)/C=C/C=C(C)/C=C/C1=C(C)CCCC1(C)C)C=CC=C(/C)C=CC2=CCCCC2(C)C TUPZEYHYWIEDIH-WAIFQNFQSA-N 0.000 description 2
- 229960002747 betacarotene Drugs 0.000 description 2
- 230000006696 biosynthetic metabolic pathway Effects 0.000 description 2
- FDSDTBUPSURDBL-LOFNIBRQSA-N canthaxanthin Chemical compound CC=1C(=O)CCC(C)(C)C=1/C=C/C(/C)=C/C=C/C(/C)=C/C=C/C=C(C)C=CC=C(C)C=CC1=C(C)C(=O)CCC1(C)C FDSDTBUPSURDBL-LOFNIBRQSA-N 0.000 description 2
- 238000010276 construction Methods 0.000 description 2
- 230000001186 cumulative effect Effects 0.000 description 2
- 230000002950 deficient Effects 0.000 description 2
- 238000006356 dehydrogenation reaction Methods 0.000 description 2
- WGIYGODPCLMGQH-UHFFFAOYSA-N delta-carotene Chemical group CC(C)=CCCC(C)=CC=CC(C)=CC=CC(C)=CC=CC=C(C)C=CC=C(C)C=CC1C(C)=CCCC1(C)C WGIYGODPCLMGQH-UHFFFAOYSA-N 0.000 description 2
- 238000013461 design Methods 0.000 description 2
- 238000000502 dialysis Methods 0.000 description 2
- 235000013681 dietary sucrose Nutrition 0.000 description 2
- 150000002016 disaccharides Chemical class 0.000 description 2
- 238000006073 displacement reaction Methods 0.000 description 2
- 235000006932 echinenone Nutrition 0.000 description 2
- 235000013399 edible fruits Nutrition 0.000 description 2
- IQLUYYHUNSSHIY-HZUMYPAESA-N eicosatetraenoic acid Chemical compound CCCCCCCCCCC\C=C\C=C\C=C\C=C\C(O)=O IQLUYYHUNSSHIY-HZUMYPAESA-N 0.000 description 2
- PRHHYVQTPBEDFE-UHFFFAOYSA-N eicosatrienoic acid Natural products CCCCCC=CCC=CCCCCC=CCCCC(O)=O PRHHYVQTPBEDFE-UHFFFAOYSA-N 0.000 description 2
- 210000002472 endoplasmic reticulum Anatomy 0.000 description 2
- QABFXOMOOYWZLZ-UKMVMLAPSA-N epsilon-carotene Chemical group CC1=CCCC(C)(C)C1/C=C/C(/C)=C/C=C/C(/C)=C/C=C/C=C(C)C=CC=C(C)C=CC1C(C)=CCCC1(C)C QABFXOMOOYWZLZ-UKMVMLAPSA-N 0.000 description 2
- 230000028023 exocytosis Effects 0.000 description 2
- 230000002349 favourable effect Effects 0.000 description 2
- 235000000633 gamma-carotene Nutrition 0.000 description 2
- HRQKOYFGHJYEFS-RZWPOVEWSA-N gamma-carotene Natural products C(=C\C=C\C(=C/C=C/C=C(\C=C\C=C(/C=C/C=1C(C)(C)CCCC=1C)\C)/C)\C)(\C=C\C=C(/CC/C=C(\C)/C)\C)/C HRQKOYFGHJYEFS-RZWPOVEWSA-N 0.000 description 2
- 238000001502 gel electrophoresis Methods 0.000 description 2
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 2
- 229930195733 hydrocarbon Natural products 0.000 description 2
- 230000001939 inductive effect Effects 0.000 description 2
- 229910052500 inorganic mineral Inorganic materials 0.000 description 2
- 229960004488 linolenic acid Drugs 0.000 description 2
- 239000003550 marker Substances 0.000 description 2
- 239000011707 mineral Substances 0.000 description 2
- 238000002156 mixing Methods 0.000 description 2
- 239000003471 mutagenic agent Substances 0.000 description 2
- 235000021290 n-3 DPA Nutrition 0.000 description 2
- 238000006386 neutralization reaction Methods 0.000 description 2
- 230000000050 nutritive effect Effects 0.000 description 2
- OQCDKBAXFALNLD-UHFFFAOYSA-N octadecanoic acid Natural products CCCCCCCC(C)CCCCCCCCC(O)=O OQCDKBAXFALNLD-UHFFFAOYSA-N 0.000 description 2
- ZQPPMHVWECSIRJ-KTKRTIGZSA-N oleic acid Chemical compound CCCCCCCC\C=C/CCCCCCCC(O)=O ZQPPMHVWECSIRJ-KTKRTIGZSA-N 0.000 description 2
- 239000001301 oxygen Substances 0.000 description 2
- 229910052760 oxygen Inorganic materials 0.000 description 2
- 230000037361 pathway Effects 0.000 description 2
- 235000011765 phytoene Nutrition 0.000 description 2
- 238000002360 preparation method Methods 0.000 description 2
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 2
- 238000000746 purification Methods 0.000 description 2
- 230000009467 reduction Effects 0.000 description 2
- 230000002829 reductive effect Effects 0.000 description 2
- 235000009514 rubixanthin Nutrition 0.000 description 2
- ABTRFGSPYXCGMR-SDPRXREBSA-N rubixanthin Natural products O[C@H]1CC(C)(C)C(/C=C/C(=C\C=C\C(=C/C=C/C=C(\C=C\C=C(/C=C/C=C(\CC/C=C(\C)/C)/C)\C)/C)\C)/C)=C(C)C1 ABTRFGSPYXCGMR-SDPRXREBSA-N 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- 238000001228 spectrum Methods 0.000 description 2
- 239000008117 stearic acid Substances 0.000 description 2
- 239000000758 substrate Substances 0.000 description 2
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 2
- KBPHJBAIARWVSC-XQIHNALSSA-N trans-lutein Natural products CC(=C/C=C/C=C(C)/C=C/C=C(C)/C=C/C1=C(C)CC(O)CC1(C)C)C=CC=C(/C)C=CC2C(=CC(O)CC2(C)C)C KBPHJBAIARWVSC-XQIHNALSSA-N 0.000 description 2
- 230000014621 translational initiation Effects 0.000 description 2
- DCXXMTOCNZCJGO-UHFFFAOYSA-N tristearoylglycerol Chemical compound CCCCCCCCCCCCCCCCCC(=O)OCC(OC(=O)CCCCCCCCCCCCCCCCC)COC(=O)CCCCCCCCCCCCCCCCC DCXXMTOCNZCJGO-UHFFFAOYSA-N 0.000 description 2
- 108010087967 type I signal peptidase Proteins 0.000 description 2
- 238000011144 upstream manufacturing Methods 0.000 description 2
- 235000010930 zeaxanthin Nutrition 0.000 description 2
- 239000001775 zeaxanthin Substances 0.000 description 2
- 229940043269 zeaxanthin Drugs 0.000 description 2
- DMASLKHVQRHNES-UPOGUZCLSA-N (3R)-beta,beta-caroten-3-ol Chemical group C([C@H](O)CC=1C)C(C)(C)C=1/C=C/C(/C)=C/C=C/C(/C)=C/C=C/C=C(C)C=CC=C(C)C=CC1=C(C)CCCC1(C)C DMASLKHVQRHNES-UPOGUZCLSA-N 0.000 description 1
- ABTRFGSPYXCGMR-KXQOOQHDSA-N (3R)-beta,psi-caroten-3-ol Chemical compound CC(C)=CCCC(C)=CC=CC(C)=CC=CC(C)=CC=CC=C(C)C=CC=C(C)C=CC1=C(C)C[C@@H](O)CC1(C)C ABTRFGSPYXCGMR-KXQOOQHDSA-N 0.000 description 1
- JKQXZKUSFCKOGQ-JLGXGRJMSA-N (3R,3'R)-beta,beta-carotene-3,3'-diol Chemical compound C([C@H](O)CC=1C)C(C)(C)C=1/C=C/C(/C)=C/C=C/C(/C)=C/C=C/C=C(C)C=CC=C(C)C=CC1=C(C)C[C@@H](O)CC1(C)C JKQXZKUSFCKOGQ-JLGXGRJMSA-N 0.000 description 1
- NBZANZVJRKXVBH-DJPRRHJBSA-N (3R,6'R)-beta,epsilon-caroten-3-ol Chemical compound C([C@H](O)CC=1C)C(C)(C)C=1/C=C/C(/C)=C/C=C/C(/C)=C/C=C/C=C(C)C=CC=C(C)C=C[C@H]1C(C)=CCCC1(C)C NBZANZVJRKXVBH-DJPRRHJBSA-N 0.000 description 1
- GVOIABOMXKDDGU-XRODXAHISA-N (3S,3'S,5R,5'R)-3,3'-dihydroxy-kappa,kappa-carotene-6,6'-dione Chemical group O=C([C@@]1(C)C(C[C@H](O)C1)(C)C)/C=C/C(/C)=C/C=C/C(/C)=C/C=C/C=C(C)C=CC=C(C)C=CC(=O)[C@]1(C)C[C@@H](O)CC1(C)C GVOIABOMXKDDGU-XRODXAHISA-N 0.000 description 1
- GVOIABOMXKDDGU-LOFNIBRQSA-N (3S,3'S,5R,5'R)-3,3'-dihydroxy-kappa,kappa-carotene-6,6'-dione Chemical group CC(=C/C=C/C=C(C)/C=C/C=C(C)/C=C/C(=O)C1(C)CC(O)CC1(C)C)C=CC=C(/C)C=CC(=O)C2(C)CC(O)CC2(C)C GVOIABOMXKDDGU-LOFNIBRQSA-N 0.000 description 1
- SUCKEYMKNGZJHK-ZARIWKGHSA-N (3e,5e,7e,9e,11e,13e,15e,17e)-3-(hydroxymethyl)-18-[(1r,4r)-4-hydroxy-2,6,6-trimethylcyclohex-2-en-1-yl]-1-[(4r)-4-hydroxy-2,6,6-trimethylcyclohexen-1-yl]-7,12,16-trimethyloctadeca-3,5,7,9,11,13,15,17-octaen-2-one Chemical compound C([C@H](O)CC=1C)C(C)(C)C=1CC(=O)C(\CO)=C\C=C\C(\C)=C\C=C\C=C(/C)\C=C\C=C(/C)\C=C\[C@H]1C(C)=C[C@H](O)CC1(C)C SUCKEYMKNGZJHK-ZARIWKGHSA-N 0.000 description 1
- AVKOENOBFIYBSA-WMPRHZDHSA-N (4Z,7Z,10Z,13Z,16Z)-docosa-4,7,10,13,16-pentaenoic acid Chemical compound CCCCC\C=C/C\C=C/C\C=C/C\C=C/C\C=C/CCC(O)=O AVKOENOBFIYBSA-WMPRHZDHSA-N 0.000 description 1
- YUFFSWGQGVEMMI-JLNKQSITSA-N (7Z,10Z,13Z,16Z,19Z)-docosapentaenoic acid Chemical compound CC\C=C/C\C=C/C\C=C/C\C=C/C\C=C/CCCCCC(O)=O YUFFSWGQGVEMMI-JLNKQSITSA-N 0.000 description 1
- KJTLQQUUPVSXIM-ZCFIWIBFSA-M (R)-mevalonate Chemical compound OCC[C@](O)(C)CC([O-])=O KJTLQQUUPVSXIM-ZCFIWIBFSA-M 0.000 description 1
- GJJVAFUKOBZPCB-ZGRPYONQSA-N (r)-3,4-dihydro-2-methyl-2-(4,8,12-trimethyl-3,7,11-tridecatrienyl)-2h-1-benzopyran-6-ol Chemical class OC1=CC=C2OC(CC/C=C(C)/CC/C=C(C)/CCC=C(C)C)(C)CCC2=C1 GJJVAFUKOBZPCB-ZGRPYONQSA-N 0.000 description 1
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 1
- 229940005561 1,4-benzoquinone Drugs 0.000 description 1
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 1
- WFCGYZPOBJZGDF-UHFFFAOYSA-N 2-methylbuta-1,3-diene;phosphono dihydrogen phosphate Chemical compound CC(=C)C=C.OP(O)(=O)OP(O)(O)=O WFCGYZPOBJZGDF-UHFFFAOYSA-N 0.000 description 1
- QXNWZXMBUKUYMD-ITUXNECMSA-N 4-keto-beta-carotene Chemical compound CC=1C(=O)CCC(C)(C)C=1/C=C/C(/C)=C/C=C/C(/C)=C/C=C/C=C(C)C=CC=C(C)C=CC1=C(C)CCCC1(C)C QXNWZXMBUKUYMD-ITUXNECMSA-N 0.000 description 1
- PGYAYSRVSAJXTE-FTLOKQSXSA-N 9'-cis-neoxanthin Chemical compound C(\[C@]12[C@@](O1)(C)C[C@@H](O)CC2(C)C)=C/C(/C)=C\C=C\C(\C)=C\C=C\C=C(/C)\C=C\C=C(/C)C=C=C1C(C)(C)C[C@H](O)C[C@@]1(C)O PGYAYSRVSAJXTE-FTLOKQSXSA-N 0.000 description 1
- 241000238876 Acari Species 0.000 description 1
- QTBSBXVTEAMEQO-UHFFFAOYSA-M Acetate Chemical compound CC([O-])=O QTBSBXVTEAMEQO-UHFFFAOYSA-M 0.000 description 1
- 102100034111 Activin receptor type-1 Human genes 0.000 description 1
- 108700016155 Acyl transferases Proteins 0.000 description 1
- 102100034544 Acyl-CoA 6-desaturase Human genes 0.000 description 1
- ZKHQWZAMYRWXGA-KQYNXXCUSA-N Adenosine triphosphate Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)[C@@H](O)[C@H]1O ZKHQWZAMYRWXGA-KQYNXXCUSA-N 0.000 description 1
- 101100165611 Arabidopsis thaliana VTE3 gene Proteins 0.000 description 1
- CIWBSHSKHKDKBQ-JLAZNSOCSA-N Ascorbic acid Chemical compound OC[C@H](O)[C@H]1OC(=O)C(O)=C1O CIWBSHSKHKDKBQ-JLAZNSOCSA-N 0.000 description 1
- JEBFVOLFMLUKLF-IFPLVEIFSA-N Astaxanthin Natural products CC(=C/C=C/C(=C/C=C/C1=C(C)C(=O)C(O)CC1(C)C)/C)C=CC=C(/C)C=CC=C(/C)C=CC2=C(C)C(=O)C(O)CC2(C)C JEBFVOLFMLUKLF-IFPLVEIFSA-N 0.000 description 1
- 101100189068 Bacillus subtilis (strain 168) proI gene Proteins 0.000 description 1
- 108010023063 Bacto-peptone Proteins 0.000 description 1
- 235000016068 Berberis vulgaris Nutrition 0.000 description 1
- HRQKOYFGHJYEFS-UHFFFAOYSA-N Beta psi-carotene Chemical compound CC(C)=CCCC(C)=CC=CC(C)=CC=CC(C)=CC=CC=C(C)C=CC=C(C)C=CC1=C(C)CCCC1(C)C HRQKOYFGHJYEFS-UHFFFAOYSA-N 0.000 description 1
- 241000335053 Beta vulgaris Species 0.000 description 1
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 1
- 238000009010 Bradford assay Methods 0.000 description 1
- 239000002126 C01EB10 - Adenosine Substances 0.000 description 1
- 101150028535 CRTZ gene Proteins 0.000 description 1
- PKHJWTKRKQNNJE-RJLXQHJHSA-N Caloxanthin Chemical compound CC(C)([C@@H](O)[C@H](O)CC=1C)C=1\C=C\C(\C)=C\C=C\C(\C)=C\C=C\C=C(/C)\C=C\C=C(/C)\C=C\C1=C(C)C[C@@H](O)CC1(C)C PKHJWTKRKQNNJE-RJLXQHJHSA-N 0.000 description 1
- 241000222120 Candida <Saccharomycetales> Species 0.000 description 1
- GVOIABOMXKDDGU-SUKXYCKUSA-N Capsorubin Chemical group O=C(/C=C/C(=C\C=C\C(=C/C=C/C=C(\C=C\C=C(/C=C/C(=O)[C@@]1(C)C(C)(C)C[C@H](O)C1)\C)/C)\C)/C)[C@@]1(C)C(C)(C)C[C@H](O)C1 GVOIABOMXKDDGU-SUKXYCKUSA-N 0.000 description 1
- 239000004215 Carbon black (E152) Substances 0.000 description 1
- 108010078853 Choline-Phosphate Cytidylyltransferase Proteins 0.000 description 1
- 235000001258 Cinchona calisaya Nutrition 0.000 description 1
- ACTIUHUUMQJHFO-UHFFFAOYSA-N Coenzym Q10 Natural products COC1=C(OC)C(=O)C(CC=C(C)CCC=C(C)CCC=C(C)CCC=C(C)CCC=C(C)CCC=C(C)CCC=C(C)CCC=C(C)CCC=C(C)CCC=C(C)C)=C(C)C1=O ACTIUHUUMQJHFO-UHFFFAOYSA-N 0.000 description 1
- 101710095468 Cyclase Proteins 0.000 description 1
- RFSUNEUAIZKAJO-VRPWFDPXSA-N D-Fructose Natural products OC[C@H]1OC(O)(CO)[C@@H](O)[C@@H]1O RFSUNEUAIZKAJO-VRPWFDPXSA-N 0.000 description 1
- KJTLQQUUPVSXIM-UHFFFAOYSA-N DL-mevalonic acid Natural products OCCC(O)(C)CC(O)=O KJTLQQUUPVSXIM-UHFFFAOYSA-N 0.000 description 1
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 1
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 1
- 102100035762 Diacylglycerol O-acyltransferase 2 Human genes 0.000 description 1
- 108010051225 Diacylglycerol cholinephosphotransferase Proteins 0.000 description 1
- HNYJHQMUSVNWPV-DRCJTWAYSA-N Diatoxanthin Chemical compound C([C@H](O)CC=1C)C(C)(C)C=1C#CC(\C)=C\C=C\C(\C)=C\C=C\C=C(/C)\C=C\C=C(/C)\C=C\C1=C(C)C[C@@H](O)CC1(C)C HNYJHQMUSVNWPV-DRCJTWAYSA-N 0.000 description 1
- HNYJHQMUSVNWPV-QWJHPLASSA-N Diatoxanthin Natural products CC(=C/C=C/C=C(C)/C=C/C=C(C)/C#CC1=C(C)CC(O)CC1(C)C)C=CC=C(/C)C=CC2=C(C)CC(O)CC2(C)C HNYJHQMUSVNWPV-QWJHPLASSA-N 0.000 description 1
- 241000196324 Embryophyta Species 0.000 description 1
- 241001245610 Eutreptiella Species 0.000 description 1
- 101150095274 FBA1 gene Proteins 0.000 description 1
- 108010022535 Farnesyl-Diphosphate Farnesyltransferase Proteins 0.000 description 1
- 102100034543 Fatty acid desaturase 3 Human genes 0.000 description 1
- 108010087894 Fatty acid desaturases Proteins 0.000 description 1
- 102000001390 Fructose-Bisphosphate Aldolase Human genes 0.000 description 1
- 108010068561 Fructose-Bisphosphate Aldolase Proteins 0.000 description 1
- 108700039691 Genetic Promoter Regions Proteins 0.000 description 1
- 102100039291 Geranylgeranyl pyrophosphate synthase Human genes 0.000 description 1
- 108010066605 Geranylgeranyl-Diphosphate Geranylgeranyltransferase Proteins 0.000 description 1
- 101000930822 Giardia intestinalis Dipeptidyl-peptidase 4 Proteins 0.000 description 1
- 101150030817 HPT1 gene Proteins 0.000 description 1
- 108700004948 Hawkinsinuria Proteins 0.000 description 1
- 101000799140 Homo sapiens Activin receptor type-1 Proteins 0.000 description 1
- 101000930020 Homo sapiens Diacylglycerol O-acyltransferase 2 Proteins 0.000 description 1
- 101000920629 Homo sapiens Protein 4.1 Proteins 0.000 description 1
- 208000007976 Ketosis Diseases 0.000 description 1
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 1
- 240000008415 Lactuca sativa Species 0.000 description 1
- 235000003228 Lactuca sativa Nutrition 0.000 description 1
- 108010037138 Linoleoyl-CoA Desaturase Proteins 0.000 description 1
- 241001149698 Lipomyces Species 0.000 description 1
- 101150105878 Lman1l gene Proteins 0.000 description 1
- 235000007688 Lycopersicon esculentum Nutrition 0.000 description 1
- VAZQBTJCYODOSV-UHFFFAOYSA-N Me ether-Bacteriopurpurin Natural products COC(C)(C)CC=CC(C)=CC=CC(C)=CC=CC(C)=CC=CC=C(C)C=CC=C(C)C=CC=C(C)C=CCC(C)(C)OC VAZQBTJCYODOSV-UHFFFAOYSA-N 0.000 description 1
- MJVAVZPDRWSRRC-UHFFFAOYSA-N Menadione Chemical compound C1=CC=C2C(=O)C(C)=CC(=O)C2=C1 MJVAVZPDRWSRRC-UHFFFAOYSA-N 0.000 description 1
- ABSPRNADVQNDOU-UHFFFAOYSA-N Menaquinone 1 Natural products C1=CC=C2C(=O)C(CC=C(C)C)=C(C)C(=O)C2=C1 ABSPRNADVQNDOU-UHFFFAOYSA-N 0.000 description 1
- 241001214257 Mene Species 0.000 description 1
- 108010074633 Mixed Function Oxygenases Proteins 0.000 description 1
- 102000008109 Mixed Function Oxygenases Human genes 0.000 description 1
- 101100390535 Mus musculus Fdft1 gene Proteins 0.000 description 1
- 101100284914 Mus musculus Higd1c gene Proteins 0.000 description 1
- 101100261242 Mus musculus Trdmt1 gene Proteins 0.000 description 1
- 206010028980 Neoplasm Diseases 0.000 description 1
- 101100390536 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) erg-6 gene Proteins 0.000 description 1
- ATCICVFRSJQYDV-DDRHJXQASA-N Neurosporene Natural products C(=C\C=C\C(=C/C=C/C=C(\C=C\C=C(/CC/C=C(\CC/C=C(\C)/C)/C)\C)/C)\C)(\C=C\C=C(/CC/C=C(\C)/C)\C)/C ATCICVFRSJQYDV-DDRHJXQASA-N 0.000 description 1
- 241000192656 Nostoc Species 0.000 description 1
- 108020005187 Oligonucleotide Probes Proteins 0.000 description 1
- 101100462124 Oryza sativa subsp. japonica AHP1 gene Proteins 0.000 description 1
- 101100168661 Paracoccus sp. (strain N81106 / MBIC 01143) crtW gene Proteins 0.000 description 1
- 241000199911 Peridinium Species 0.000 description 1
- 241000934740 Peridinium sp. Species 0.000 description 1
- OOUTWVMJGMVRQF-DOYZGLONSA-N Phoenicoxanthin Natural products CC(=C/C=C/C=C(C)/C=C/C=C(C)/C=C/C1=C(C)C(=O)C(O)CC1(C)C)C=CC=C(/C)C=CC2=C(C)C(=O)CCC2(C)C OOUTWVMJGMVRQF-DOYZGLONSA-N 0.000 description 1
- 101710173432 Phytoene synthase Proteins 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- 101710118538 Protease Proteins 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 102100031952 Protein 4.1 Human genes 0.000 description 1
- 108091034057 RNA (poly(A)) Proteins 0.000 description 1
- 101000912235 Rebecca salina Acyl-lipid (7-3)-desaturase Proteins 0.000 description 1
- WEELHWARVOLEJX-IFJHFXLNSA-N Rhodopin glucoside Natural products O(C(CCC/C(=C\C=C\C(=C/C=C/C(=C\C=C\C=C(/C=C/C=C(\C=C\C=C(/CC/C=C(\C)/C)\C)/C)\C)/C)\C)/C)(C)C)[C@H]1[C@H](O)[C@@H](O)[C@H](O)[C@H](CO)O1 WEELHWARVOLEJX-IFJHFXLNSA-N 0.000 description 1
- 101150109921 SQS1 gene Proteins 0.000 description 1
- 101100096529 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) SPS19 gene Proteins 0.000 description 1
- 241000235347 Schizosaccharomyces pombe Species 0.000 description 1
- 101000877236 Siganus canaliculatus Acyl-CoA Delta-4 desaturase Proteins 0.000 description 1
- 241000497386 Silveira Species 0.000 description 1
- HKQXGRCDKWFDBE-CZJSGJJBSA-N Siphonaxanthin Natural products CC(=C/C=C/C=C(C)/C=C/C=C(C)/C(=O)CC1=C(C)CC(O)CC1(C)CO)C=CC=C(/C)C=CC2C(=CC(O)CC2(C)C)C HKQXGRCDKWFDBE-CZJSGJJBSA-N 0.000 description 1
- 240000003768 Solanum lycopersicum Species 0.000 description 1
- 238000002105 Southern blotting Methods 0.000 description 1
- ZSLHSVCDHQRPAB-UHFFFAOYSA-N Spirilloxanthin Natural products COC(C)(C)CC=CC(=CC=CC(=CC=CC(=CC=CC=C(/C)C=CC=C(/C)C=CC=C(/C)CCCC(C)(C)C)C)C)C ZSLHSVCDHQRPAB-UHFFFAOYSA-N 0.000 description 1
- 102000005782 Squalene Monooxygenase Human genes 0.000 description 1
- 108020003891 Squalene monooxygenase Proteins 0.000 description 1
- 102100037997 Squalene synthase Human genes 0.000 description 1
- 101100061456 Streptomyces griseus crtB gene Proteins 0.000 description 1
- 101100114901 Streptomyces griseus crtI gene Proteins 0.000 description 1
- 108020005038 Terminator Codon Proteins 0.000 description 1
- 108700009124 Transcription Initiation Site Proteins 0.000 description 1
- 229920004890 Triton X-100 Polymers 0.000 description 1
- 239000013504 Triton X-100 Substances 0.000 description 1
- LEHOTFFKMJEONL-UHFFFAOYSA-N Uric Acid Chemical compound N1C(=O)NC(=O)C2=C1NC(=O)N2 LEHOTFFKMJEONL-UHFFFAOYSA-N 0.000 description 1
- 101150019890 VTE4 gene Proteins 0.000 description 1
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Chemical compound CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 1
- 108700026986 Yarrowia lipolytica PEX20 Proteins 0.000 description 1
- UYRDHEJRPVSJFM-VSWVFQEASA-N [(1s,3r)-3-hydroxy-4-[(3e,5e,7e,9e,11z)-11-[4-[(e)-2-[(1r,3s,6s)-3-hydroxy-1,5,5-trimethyl-7-oxabicyclo[4.1.0]heptan-6-yl]ethenyl]-5-oxofuran-2-ylidene]-3,10-dimethylundeca-1,3,5,7,9-pentaenylidene]-3,5,5-trimethylcyclohexyl] acetate Chemical compound C[C@@]1(O)C[C@@H](OC(=O)C)CC(C)(C)C1=C=C\C(C)=C\C=C\C=C\C=C(/C)\C=C/1C=C(\C=C\[C@]23[C@@](O2)(C)C[C@@H](O)CC3(C)C)C(=O)O\1 UYRDHEJRPVSJFM-VSWVFQEASA-N 0.000 description 1
- CKUAXEQHGKSLHN-UHFFFAOYSA-N [C].[N] Chemical compound [C].[N] CKUAXEQHGKSLHN-UHFFFAOYSA-N 0.000 description 1
- XJLXINKUBYWONI-DQQFMEOOSA-N [[(2r,3r,4r,5r)-5-(6-aminopurin-9-yl)-3-hydroxy-4-phosphonooxyoxolan-2-yl]methoxy-hydroxyphosphoryl] [(2s,3r,4s,5s)-5-(3-carbamoylpyridin-1-ium-1-yl)-3,4-dihydroxyoxolan-2-yl]methyl phosphate Chemical compound NC(=O)C1=CC=C[N+]([C@@H]2[C@H]([C@@H](O)[C@H](COP([O-])(=O)OP(O)(=O)OC[C@@H]3[C@H]([C@@H](OP(O)(O)=O)[C@@H](O3)N3C4=NC=NC(N)=C4N=C3)O)O2)O)=C1 XJLXINKUBYWONI-DQQFMEOOSA-N 0.000 description 1
- 239000008351 acetate buffer Substances 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 229960005305 adenosine Drugs 0.000 description 1
- 230000002776 aggregation Effects 0.000 description 1
- 238000004220 aggregation Methods 0.000 description 1
- 150000001298 alcohols Chemical class 0.000 description 1
- 101150099105 alien gene Proteins 0.000 description 1
- 150000001335 aliphatic alkanes Chemical class 0.000 description 1
- 125000001931 aliphatic group Chemical group 0.000 description 1
- 239000003513 alkali Substances 0.000 description 1
- IUUXWKRRZDDNQG-UHFFFAOYSA-N all-trans-spheroidene Natural products COC(C)(C)CCCC(C)=CC=CC(C)=CC=CC(C)=CC=CC=C(C)C=CC=C(C)CCC=C(C)CCC=C(C)C IUUXWKRRZDDNQG-UHFFFAOYSA-N 0.000 description 1
- SZCBXWMUOPQSOX-WVJDLNGLSA-N all-trans-violaxanthin Chemical compound C(\[C@]12[C@@](O1)(C)C[C@@H](O)CC2(C)C)=C/C(/C)=C/C=C/C(/C)=C/C=C/C=C(\C)/C=C/C=C(\C)/C=C/[C@]1(C(C[C@H](O)C2)(C)C)[C@]2(C)O1 SZCBXWMUOPQSOX-WVJDLNGLSA-N 0.000 description 1
- BIWLELKAFXRPDE-UHFFFAOYSA-N all-trans-zeta-carotene Chemical group CC(C)=CCCC(C)=CCCC(C)=CC=CC(C)=CC=CC=C(C)C=CC=C(C)CCC=C(C)CCC=C(C)C BIWLELKAFXRPDE-UHFFFAOYSA-N 0.000 description 1
- 229940087168 alpha tocopherol Drugs 0.000 description 1
- NBZANZVJRKXVBH-GYDPHNCVSA-N alpha-Cryptoxanthin Natural products O[C@H]1CC(C)(C)C(/C=C/C(=C\C=C\C(=C/C=C/C=C(\C=C\C=C(/C=C/[C@H]2C(C)=CCCC2(C)C)\C)/C)\C)/C)=C(C)C1 NBZANZVJRKXVBH-GYDPHNCVSA-N 0.000 description 1
- WQZGKKKJIJFFOK-DVKNGEFBSA-N alpha-D-glucose Chemical compound OC[C@H]1O[C@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-DVKNGEFBSA-N 0.000 description 1
- IGABZIVJSNQMPZ-UHFFFAOYSA-N alpha-Zeacarotene Chemical group CC(C)=CCCC(C)=CCCC(C)=CC=CC(C)=CC=CC=C(C)C=CC=C(C)C=CC1C(C)=CCCC1(C)C IGABZIVJSNQMPZ-UHFFFAOYSA-N 0.000 description 1
- 239000011795 alpha-carotene Chemical group 0.000 description 1
- 235000003903 alpha-carotene Nutrition 0.000 description 1
- ANVAOWXLWRTKGA-HLLMEWEMSA-N alpha-carotene Chemical group C(=C\C=C\C=C(/C=C/C=C(\C=C\C=1C(C)(C)CCCC=1C)/C)\C)(\C=C\C=C(/C=C/[C@H]1C(C)=CCCC1(C)C)\C)/C ANVAOWXLWRTKGA-HLLMEWEMSA-N 0.000 description 1
- 235000005861 alpha-cryptoxanthin Nutrition 0.000 description 1
- 239000004411 aluminium Substances 0.000 description 1
- XAGFODPZIPBFFR-UHFFFAOYSA-N aluminium Chemical compound [Al] XAGFODPZIPBFFR-UHFFFAOYSA-N 0.000 description 1
- 229910052782 aluminium Inorganic materials 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 230000000692 anti-sense effect Effects 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- 238000003556 assay Methods 0.000 description 1
- 239000001168 astaxanthin Substances 0.000 description 1
- MQZIGYBFDRPAKN-ZWAPEEGVSA-N astaxanthin Chemical compound C([C@H](O)C(=O)C=1C)C(C)(C)C=1/C=C/C(/C)=C/C=C/C(/C)=C/C=C/C=C(C)C=CC=C(C)C=CC1=C(C)C(=O)[C@@H](O)CC1(C)C MQZIGYBFDRPAKN-ZWAPEEGVSA-N 0.000 description 1
- 229940022405 astaxanthin Drugs 0.000 description 1
- 150000001514 astaxanthins Chemical class 0.000 description 1
- 125000004429 atom Chemical group 0.000 description 1
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 1
- 238000002869 basic local alignment search tool Methods 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- DRTQHJPVMGBUCF-PSQAKQOGSA-N beta-L-uridine Natural products O[C@H]1[C@@H](O)[C@H](CO)O[C@@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-PSQAKQOGSA-N 0.000 description 1
- 239000011774 beta-cryptoxanthin Chemical group 0.000 description 1
- 235000002360 beta-cryptoxanthin Nutrition 0.000 description 1
- DMASLKHVQRHNES-ITUXNECMSA-N beta-cryptoxanthin Chemical group CC(=C/C=C/C=C(C)/C=C/C=C(C)/C=C/C1=C(C)CC(O)CC1(C)C)C=CC=C(/C)C=CC2=C(C)CCCC2(C)C DMASLKHVQRHNES-ITUXNECMSA-N 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 230000003570 biosynthesizing effect Effects 0.000 description 1
- 229940098773 bovine serum albumin Drugs 0.000 description 1
- 239000000872 buffer Substances 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- PKHJWTKRKQNNJE-DOYZGLONSA-N caloxanthin Natural products CC(=C/C=C/C=C(C)/C=C/C=C(C)/C=C/C1=C(C)CC(O)C(O)C1(C)C)C=CC=C(/C)C=CC2=C(C)CC(O)CC2(C)C PKHJWTKRKQNNJE-DOYZGLONSA-N 0.000 description 1
- 235000012682 canthaxanthin Nutrition 0.000 description 1
- 239000001659 canthaxanthin Substances 0.000 description 1
- 229940008033 canthaxanthin Drugs 0.000 description 1
- 235000009132 capsorubin Nutrition 0.000 description 1
- 239000004202 carbamide Substances 0.000 description 1
- 150000001720 carbohydrates Chemical class 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 125000004432 carbon atom Chemical group C* 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 230000003197 catalytic effect Effects 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 230000010261 cell growth Effects 0.000 description 1
- 210000000170 cell membrane Anatomy 0.000 description 1
- 230000019522 cellular metabolic process Effects 0.000 description 1
- 239000003153 chemical reaction reagent Substances 0.000 description 1
- 230000002759 chromosomal effect Effects 0.000 description 1
- LOUPRKONTZGTKE-UHFFFAOYSA-N cinchonine Natural products C1C(C(C2)C=C)CCN2C1C(O)C1=CC=NC2=CC=C(OC)C=C21 LOUPRKONTZGTKE-UHFFFAOYSA-N 0.000 description 1
- OVSVTCFNLSGAMM-KGBODLQUSA-N cis-phytofluene Natural products CC(=CCCC(=CCCC(=CCCC(=CC=C/C=C(C)/C=C/C=C(C)/CCC=C(/C)CCC=C(C)C)C)C)C)C OVSVTCFNLSGAMM-KGBODLQUSA-N 0.000 description 1
- 238000013373 clone screening Methods 0.000 description 1
- 239000002299 complementary DNA Substances 0.000 description 1
- 238000003169 complementation method Methods 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 238000007796 conventional method Methods 0.000 description 1
- 238000001816 cooling Methods 0.000 description 1
- 101150081158 crtB gene Proteins 0.000 description 1
- 101150000046 crtE gene Proteins 0.000 description 1
- 101150011633 crtI gene Proteins 0.000 description 1
- 101150085103 crtY gene Proteins 0.000 description 1
- 229940104302 cytosine Drugs 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- 238000013016 damping Methods 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 108010011713 delta-15 desaturase Proteins 0.000 description 1
- WGIYGODPCLMGQH-ZNTKZCHQSA-N delta-Carotene Chemical group C(=C\C=C\C(=C/C=C/C=C(\C=C\C=C(/C=C/[C@H]1C(C)=CCCC1(C)C)\C)/C)\C)(\C=C\C=C(/CC/C=C(\C)/C)\C)/C WGIYGODPCLMGQH-ZNTKZCHQSA-N 0.000 description 1
- 235000001581 delta-carotene Nutrition 0.000 description 1
- 239000005547 deoxyribonucleotide Substances 0.000 description 1
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 230000018109 developmental process Effects 0.000 description 1
- 239000012153 distilled water Substances 0.000 description 1
- DVSZKTAMJJTWFG-UHFFFAOYSA-N docosa-2,4,6,8,10,12-hexaenoic acid Chemical compound CCCCCCCCCC=CC=CC=CC=CC=CC=CC(O)=O DVSZKTAMJJTWFG-UHFFFAOYSA-N 0.000 description 1
- 238000001035 drying Methods 0.000 description 1
- 239000012636 effector Substances 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 150000002085 enols Chemical class 0.000 description 1
- 230000007613 environmental effect Effects 0.000 description 1
- 230000002255 enzymatic effect Effects 0.000 description 1
- 125000003700 epoxy group Chemical group 0.000 description 1
- 235000002680 epsilon-carotene Nutrition 0.000 description 1
- QABFXOMOOYWZLZ-UWXQCODUSA-N epsilon-carotene Chemical group CC(=CC=CC=C(C)C=CC=C(C)C=C[C@H]1C(=CCCC1(C)C)C)C=CC=C(C)C=C[C@H]2C(=CCCC2(C)C)C QABFXOMOOYWZLZ-UWXQCODUSA-N 0.000 description 1
- 101150116391 erg9 gene Proteins 0.000 description 1
- 150000002148 esters Chemical class 0.000 description 1
- 239000013604 expression vector Substances 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 239000012530 fluid Substances 0.000 description 1
- 235000013305 food Nutrition 0.000 description 1
- BJHIKXHVCXFQLS-UYFOZJQFSA-N fructose group Chemical group OCC(=O)[C@@H](O)[C@H](O)[C@H](O)CO BJHIKXHVCXFQLS-UYFOZJQFSA-N 0.000 description 1
- SJWWTRQNNRNTPU-ABBNZJFMSA-N fucoxanthin Chemical compound C[C@@]1(O)C[C@@H](OC(=O)C)CC(C)(C)C1=C=C\C(C)=C\C=C\C(\C)=C\C=C\C=C(/C)\C=C\C=C(/C)C(=O)C[C@]1(C(C[C@H](O)C2)(C)C)[C@]2(C)O1 SJWWTRQNNRNTPU-ABBNZJFMSA-N 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 230000002538 fungal effect Effects 0.000 description 1
- VZCCETWTMQHEPK-UHFFFAOYSA-N gamma-Linolensaeure Natural products CCCCCC=CCC=CCC=CCCCCC(O)=O VZCCETWTMQHEPK-UHFFFAOYSA-N 0.000 description 1
- HRQKOYFGHJYEFS-BXOLYSJBSA-N gamma-carotene Chemical group CC(C)=CCC\C(C)=C\C=C\C(\C)=C\C=C\C(\C)=C\C=C\C=C(/C)\C=C\C=C(/C)\C=C\C1=C(C)CCCC1(C)C HRQKOYFGHJYEFS-BXOLYSJBSA-N 0.000 description 1
- 229960002733 gamolenic acid Drugs 0.000 description 1
- 239000007789 gas Substances 0.000 description 1
- 238000010359 gene isolation Methods 0.000 description 1
- 125000002791 glucosyl group Chemical group C1([C@H](O)[C@@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 1
- 229960002989 glutamic acid Drugs 0.000 description 1
- 235000011187 glycerol Nutrition 0.000 description 1
- 210000004517 glycocalyx Anatomy 0.000 description 1
- 230000013595 glycosylation Effects 0.000 description 1
- 238000006206 glycosylation reaction Methods 0.000 description 1
- 238000003306 harvesting Methods 0.000 description 1
- 208000006882 hawkinsinuria Diseases 0.000 description 1
- IPCSVZSSVZVIGE-UHFFFAOYSA-N hexadecanoic acid Chemical compound CCCCCCCCCCCCCCCC(O)=O IPCSVZSSVZVIGE-UHFFFAOYSA-N 0.000 description 1
- 238000009396 hybridization Methods 0.000 description 1
- 150000002430 hydrocarbons Chemical class 0.000 description 1
- 125000001165 hydrophobic group Chemical group 0.000 description 1
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 1
- 238000007901 in situ hybridization Methods 0.000 description 1
- 238000011534 incubation Methods 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 150000002500 ions Chemical class 0.000 description 1
- 150000002576 ketones Chemical class 0.000 description 1
- 238000007834 ligase chain reaction Methods 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 101150077696 lip-1 gene Proteins 0.000 description 1
- XIXADJRWDQXREU-UHFFFAOYSA-M lithium acetate Chemical compound [Li+].CC([O-])=O XIXADJRWDQXREU-UHFFFAOYSA-M 0.000 description 1
- 238000003754 machining Methods 0.000 description 1
- 230000014759 maintenance of location Effects 0.000 description 1
- LTYOQGRJFJAKNA-VFLPNFFSSA-N malonyl-coa Chemical compound O[C@@H]1[C@H](OP(O)(O)=O)[C@@H](COP(O)(=O)OP(O)(=O)OCC(C)(C)C(O)C(=O)NCCC(=O)NCCSC(=O)CC(O)=O)O[C@H]1N1C2=NC=NC(N)=C2N=C1 LTYOQGRJFJAKNA-VFLPNFFSSA-N 0.000 description 1
- 210000004962 mammalian cell Anatomy 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- GRVDJDISBSALJP-UHFFFAOYSA-N methyloxidanyl Chemical group [O]C GRVDJDISBSALJP-UHFFFAOYSA-N 0.000 description 1
- 238000000520 microinjection Methods 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 235000021281 monounsaturated fatty acids Nutrition 0.000 description 1
- 230000035772 mutation Effects 0.000 description 1
- 210000004897 n-terminal region Anatomy 0.000 description 1
- 235000008665 neurosporene Nutrition 0.000 description 1
- 229930027945 nicotinamide-adenine dinucleotide Natural products 0.000 description 1
- 238000007899 nucleic acid hybridization Methods 0.000 description 1
- QIQXTHQIDYTFRH-UHFFFAOYSA-N octadecanoic acid Chemical compound CCCCCCCCCCCCCCCCCC(O)=O QIQXTHQIDYTFRH-UHFFFAOYSA-N 0.000 description 1
- 239000002751 oligonucleotide probe Substances 0.000 description 1
- 210000003463 organelle Anatomy 0.000 description 1
- 239000012044 organic layer Substances 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 210000002220 organoid Anatomy 0.000 description 1
- SECPZKHBENQXJG-FPLPWBNLSA-N palmitoleic acid Chemical compound CCCCCC\C=C/CCCCCCCC(O)=O SECPZKHBENQXJG-FPLPWBNLSA-N 0.000 description 1
- 239000001688 paprika extract Chemical group 0.000 description 1
- 235000012658 paprika extract Nutrition 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 230000007030 peptide scission Effects 0.000 description 1
- UTIQDNPUHSAVDN-UHFFFAOYSA-N peridinin Natural products CC(=O)OC1CC(C)(C)C(=C=CC(=CC=CC=CC=C2/OC(=O)C(=C2)C=CC34OC3(C)CC(O)CC4(C)C)C)C(C)(O)C1 UTIQDNPUHSAVDN-UHFFFAOYSA-N 0.000 description 1
- 210000001322 periplasm Anatomy 0.000 description 1
- MBWXNTAXLNYFJB-NKFFZRIASA-N phylloquinone Chemical compound C1=CC=C2C(=O)C(C/C=C(C)/CCC[C@H](C)CCC[C@H](C)CCCC(C)C)=C(C)C(=O)C2=C1 MBWXNTAXLNYFJB-NKFFZRIASA-N 0.000 description 1
- 235000019175 phylloquinone Nutrition 0.000 description 1
- 239000011772 phylloquinone Substances 0.000 description 1
- 230000004962 physiological condition Effects 0.000 description 1
- 108010001545 phytoene dehydrogenase Proteins 0.000 description 1
- 235000002677 phytofluene Nutrition 0.000 description 1
- OVSVTCFNLSGAMM-UZFNGAIXSA-N phytofluene Chemical compound CC(C)=CCCC(C)=CCCC(C)=CCCC(C)=CC=C\C=C(/C)\C=C\C=C(C)CCC=C(C)CCC=C(C)C OVSVTCFNLSGAMM-UZFNGAIXSA-N 0.000 description 1
- ZYSFBWMZMDHGOJ-SGKBLAECSA-N phytofluene Natural products CC(=CCCC(=CCCC(=CCCC(=CC=C/C=C(C)/CCC=C(/C)C=CC=C(/C)CCC=C(C)C)C)C)C)C ZYSFBWMZMDHGOJ-SGKBLAECSA-N 0.000 description 1
- 229960001898 phytomenadione Drugs 0.000 description 1
- 239000013600 plasmid vector Substances 0.000 description 1
- 230000004481 post-translational protein modification Effects 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 235000019419 proteases Nutrition 0.000 description 1
- 238000002818 protein evolution Methods 0.000 description 1
- 230000020978 protein processing Effects 0.000 description 1
- 229960000948 quinine Drugs 0.000 description 1
- 125000004151 quinonyl group Chemical group 0.000 description 1
- DFNMSBYEEKBETA-FXGCUYOLSA-N rac-3-Hydroxyechinenon Natural products CC(=C/C=C/C=C(C)/C=C/C=C(C)/C=C/C1=C(C)C(=O)C(O)CC1(C)C)C=CC=C(/C)C=CC2=C(C)CCCC2(C)C DFNMSBYEEKBETA-FXGCUYOLSA-N 0.000 description 1
- 239000011541 reaction mixture Substances 0.000 description 1
- 238000003259 recombinant expression Methods 0.000 description 1
- 230000006798 recombination Effects 0.000 description 1
- 238000005215 recombination Methods 0.000 description 1
- NPCOQXAVBJJZBQ-UHFFFAOYSA-N reduced coenzyme Q9 Natural products COC1=C(O)C(C)=C(CC=C(C)CCC=C(C)CCC=C(C)CCC=C(C)CCC=C(C)CCC=C(C)CCC=C(C)CCC=C(C)CCC=C(C)C)C(O)=C1OC NPCOQXAVBJJZBQ-UHFFFAOYSA-N 0.000 description 1
- 230000002940 repellent Effects 0.000 description 1
- 239000005871 repellent Substances 0.000 description 1
- 230000003362 replicative effect Effects 0.000 description 1
- 108010081296 resveratrol synthase Proteins 0.000 description 1
- 230000001177 retroviral effect Effects 0.000 description 1
- CNYVJTJLUKKCGM-RGGGOQHISA-N rhodopin Chemical compound CC(C)=CCC\C(C)=C\C=C\C(\C)=C\C=C\C(\C)=C\C=C\C=C(/C)\C=C\C=C(/C)\C=C\C=C(/C)CCCC(C)(C)O CNYVJTJLUKKCGM-RGGGOQHISA-N 0.000 description 1
- CNYVJTJLUKKCGM-MCBZMHSTSA-N rhodopin Natural products OC(CCC/C(=C\C=C\C(=C/C=C/C(=C\C=C\C=C(/C=C/C=C(\C=C\C=C(/CC/C=C(\C)/C)\C)/C)\C)/C)\C)/C)(C)C CNYVJTJLUKKCGM-MCBZMHSTSA-N 0.000 description 1
- 150000003839 salts Chemical class 0.000 description 1
- 150000004671 saturated fatty acids Chemical class 0.000 description 1
- 238000012216 screening Methods 0.000 description 1
- 238000002864 sequence alignment Methods 0.000 description 1
- 230000009131 signaling function Effects 0.000 description 1
- 230000003584 silencer Effects 0.000 description 1
- 235000021309 simple sugar Nutrition 0.000 description 1
- FJOCMTHZSURUFA-AXYGSFPTSA-N spheroidene Chemical compound COC(C)(C)C\C=C\C(\C)=C\C=C\C(\C)=C\C=C\C(\C)=C\C=C\C=C(/C)\C=C\C=C(/C)CC\C=C(/C)CCC=C(C)C FJOCMTHZSURUFA-AXYGSFPTSA-N 0.000 description 1
- QCZWKLBJYRVKPW-LYWCOASQSA-N spheroidene Natural products COC(C)(C)CC=CC(=CC=CC(=CC=CC(=CC=CC=CC(C)C=C/C=C(C)/CCC=C(/C)CC=C(C)C)C)C)C QCZWKLBJYRVKPW-LYWCOASQSA-N 0.000 description 1
- VAZQBTJCYODOSV-HZUCFJANSA-N spirilloxanthin Chemical compound COC(C)(C)C\C=C\C(\C)=C\C=C\C(\C)=C\C=C\C(\C)=C\C=C\C=C(/C)\C=C\C=C(/C)\C=C\C=C(/C)\C=C\CC(C)(C)OC VAZQBTJCYODOSV-HZUCFJANSA-N 0.000 description 1
- 230000002269 spontaneous effect Effects 0.000 description 1
- 238000010561 standard procedure Methods 0.000 description 1
- 238000003756 stirring Methods 0.000 description 1
- 238000003860 storage Methods 0.000 description 1
- 238000005728 strengthening Methods 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 150000003535 tetraterpenes Chemical class 0.000 description 1
- 235000009657 tetraterpenes Nutrition 0.000 description 1
- 229940113082 thymine Drugs 0.000 description 1
- 210000001519 tissue Anatomy 0.000 description 1
- 229960000984 tocofersolan Drugs 0.000 description 1
- 229930003799 tocopherol Natural products 0.000 description 1
- 239000011732 tocopherol Substances 0.000 description 1
- 235000010384 tocopherol Nutrition 0.000 description 1
- 229960001295 tocopherol Drugs 0.000 description 1
- 229930003802 tocotrienol Natural products 0.000 description 1
- 239000011731 tocotrienol Substances 0.000 description 1
- 229940068778 tocotrienols Drugs 0.000 description 1
- 235000019148 tocotrienols Nutrition 0.000 description 1
- AIBOHNYYKWYQMM-MXBSLTGDSA-N torulene Chemical compound CC(C)=C\C=C\C(\C)=C\C=C\C(\C)=C\C=C\C(\C)=C\C=C\C=C(/C)\C=C\C=C(/C)\C=C\C1=C(C)CCCC1(C)C AIBOHNYYKWYQMM-MXBSLTGDSA-N 0.000 description 1
- ZIUDAKDLOLDEGU-UHFFFAOYSA-N trans-Phytofluen Natural products CC(C)=CCCC(C)CCCC(C)CC=CC(C)=CC=CC=C(C)C=CCC(C)CCCC(C)CCC=C(C)C ZIUDAKDLOLDEGU-UHFFFAOYSA-N 0.000 description 1
- VAZQBTJCYODOSV-SRGNDVFZSA-N trans-Spirilloxanthin Natural products COC(C)(C)CC=C/C(=C/C=C/C(=C/C=C/C(=C/C=C/C=C(C)/C=C/C=C(C)/C=C/C=C(C)/C=CCC(C)(C)OC)/C)/C)/C VAZQBTJCYODOSV-SRGNDVFZSA-N 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 230000032258 transport Effects 0.000 description 1
- UFTFJSFQGQCHQW-UHFFFAOYSA-N triformin Chemical compound O=COCC(OC=O)COC=O UFTFJSFQGQCHQW-UHFFFAOYSA-N 0.000 description 1
- 238000009966 trimming Methods 0.000 description 1
- 150000003648 triterpenes Chemical class 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- 229940035936 ubiquinone Drugs 0.000 description 1
- 235000021122 unsaturated fatty acids Nutrition 0.000 description 1
- 150000004670 unsaturated fatty acids Chemical class 0.000 description 1
- DRTQHJPVMGBUCF-UHFFFAOYSA-N uracil arabinoside Natural products OC1C(O)C(CO)OC1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-UHFFFAOYSA-N 0.000 description 1
- 229940045136 urea Drugs 0.000 description 1
- 229940045145 uridine Drugs 0.000 description 1
- 108700026220 vif Genes Proteins 0.000 description 1
- 235000019245 violaxanthin Nutrition 0.000 description 1
- 239000003643 water by type Substances 0.000 description 1
- 238000005303 weighing Methods 0.000 description 1
- 238000001262 western blot Methods 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
- 235000004835 α-tocopherol Nutrition 0.000 description 1
- 239000002076 α-tocopherol Substances 0.000 description 1
- OENHQHLEOONYIE-JLTXGRSLSA-N β-Carotene Chemical compound CC=1CCCC(C)(C)C=1\C=C\C(\C)=C\C=C\C(\C)=C\C=C\C=C(/C)\C=C\C=C(/C)\C=C\C1=C(C)CCCC1(C)C OENHQHLEOONYIE-JLTXGRSLSA-N 0.000 description 1
Images
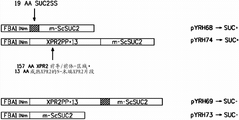






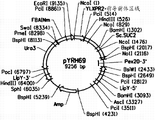




Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N1/00—Microorganisms, e.g. protozoa; Compositions thereof; Processes of propagating, maintaining or preserving microorganisms or compositions thereof; Processes of preparing or isolating a composition containing a microorganism; Culture media therefor
- C12N1/14—Fungi; Culture media therefor
- C12N1/16—Yeasts; Culture media therefor
- C12N1/18—Baker's yeast; Brewer's yeast
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/24—Hydrolases (3) acting on glycosyl compounds (3.2)
- C12N9/2402—Hydrolases (3) acting on glycosyl compounds (3.2) hydrolysing O- and S- glycosyl compounds (3.2.1)
- C12N9/2405—Glucanases
- C12N9/2408—Glucanases acting on alpha -1,4-glucosidic bonds
- C12N9/2431—Beta-fructofuranosidase (3.2.1.26), i.e. invertase
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/62—DNA sequences coding for fusion proteins
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/24—Hydrolases (3) acting on glycosyl compounds (3.2)
- C12N9/2402—Hydrolases (3) acting on glycosyl compounds (3.2) hydrolysing O- and S- glycosyl compounds (3.2.1)
- C12N9/2405—Glucanases
- C12N9/2408—Glucanases acting on alpha -1,4-glucosidic bonds
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/48—Hydrolases (3) acting on peptide bonds (3.4)
- C12N9/50—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25)
- C12N9/58—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from fungi
- C12N9/60—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from fungi from yeast
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P7/00—Preparation of oxygen-containing organic compounds
- C12P7/64—Fats; Fatty oils; Ester-type waxes; Higher fatty acids, i.e. having at least seven carbon atoms in an unbroken chain bound to a carboxyl group; Oxidised oils or fats
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y302/00—Hydrolases acting on glycosyl compounds, i.e. glycosylases (3.2)
- C12Y302/01—Glycosidases, i.e. enzymes hydrolysing O- and S-glycosyl compounds (3.2.1)
- C12Y302/01026—Beta-fructofuranosidase (3.2.1.26), i.e. invertase
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/02—Fusion polypeptide containing a localisation/targetting motif containing a signal sequence
Abstract
本文所公开的是转化的解脂耶氏酵母(Yarrowia lipolytica),其包含编码具有蔗糖转化酶活性的多肽的外源性多核苷酸。还公开了使用所述转化的解脂耶氏酵母的方法。
Description
本专利申请要求2010年12月30日提交的美国临时申请61/428,590的权益,该临时申请全文以引用方式并入本文。
技术领域
本发明属于生物技术领域。更具体地,本发明属于具有使用蔗糖作为碳源的能力的转化的解脂耶氏酵母(Yarrowia lipolytica),其中所述转化的解脂耶氏酵母还可任选地被工程化,以产生所关注的非天然产物,例如多不饱和脂肪酸(“PUFA”)。
背景技术
含油酵母如解脂耶氏酵母具有使用葡萄糖作为它们的唯一碳源的天然能力;然而,这种底物并不总是成本效益最好的碳源。使用蔗糖(单独地或与其它碳源组合地)作为碳源替代葡萄糖,可由于其成本而是有利的。
解脂耶氏酵母不能利用蔗糖作为碳源,因为它没有编码转化酶的基因,转化酶催化蔗糖(二糖)向单糖葡萄糖和果糖的转化。多个在先的研究者已将信号序列融合至编码转化酶的异源性基因(例如,啤酒糖酵母(Saccharomyces cerevisiae)SUC2基因),以将酵母工程化为分泌成熟的转化酶蛋白质至周围的培养基中,然后蔗糖能够在其中被水解。
一种分离自解脂耶氏酵母的人们熟知的信号序列是可诱导的碱性胞外蛋白酶(“AEP”)(EP0220864B1;Davidow等人,J.Bacteriol.,169:4621-4629(1987);Matoba等人,Mol.Cell Biol.,8:4904-4916(1988))。AEP是由解脂耶氏酵母中的XPR2基因编码的。此外,大量被天然地分泌至细胞外。
Nicaud等人(Current Genetics,16:253-260(1989);EP0402226A1)报道了啤酒糖酵母SUC2与解脂耶氏酵母XPR2启动子及其信号序列的嵌合表达,其在解脂耶氏酵母中导致了利用蔗糖的(SUC+)表型。具体地,来自XPR2的23个N-末端氨基酸被融合至截短的SUC2(其中所述截短移除了全长蛋白质的前4个氨基酸)。据报道约10%的转化酶活性在培养物肉汤中被观察到(即,通过胞外分泌),而90%的活性用全细胞被回收(即,转化酶被分泌至周质)。因此,细胞外蔗糖水解的效率是相对低的。
Nicaud等人描述的方法已被其它人在他们开发用蔗糖作为碳源生产柠檬酸的转化的解脂耶氏酵母菌株的努力中使用(Wojtatowicz,M.等人,Pol.J.Food Nutr.Sci.,6/47(4):49-54(1997); A.等人,Appl.Microbiol.Biotechnol.,75:1409-1417(2007);Lazar,Z.等人,Bioresour.Technol.,102:6982-6989(2011))。上文的Foster等人报道,大部分(60-70%)的转化酶活性被发现在细胞表面(即,在全细胞中可检测的细胞绑定的活性,而30-40%的转化酶是在无细胞的培养基中可检测的;来自生物质的最大的转化酶收率是110U/g生物质干重。最近,上文的Lazar等人鉴定了包含两个拷贝的包含解脂耶氏酵母XPR2启动子及其信号序列和啤酒糖酵母SUC2的融合的解脂耶氏酵母菌株,并且证明大部分的转化酶活性与细胞相关(2568至3736U/g是细胞的),而约232至589U/g是细胞外的(即,仅5-20%的活性是细胞外的)。
A.等人,Appl.Microbiol.Biotechnol.,75:1409-1417(2007);Lazar,Z.等人,Bioresour.Technol.,102:6982-6989(2011))。上文的Foster等人报道,大部分(60-70%)的转化酶活性被发现在细胞表面(即,在全细胞中可检测的细胞绑定的活性,而30-40%的转化酶是在无细胞的培养基中可检测的;来自生物质的最大的转化酶收率是110U/g生物质干重。最近,上文的Lazar等人鉴定了包含两个拷贝的包含解脂耶氏酵母XPR2启动子及其信号序列和啤酒糖酵母SUC2的融合的解脂耶氏酵母菌株,并且证明大部分的转化酶活性与细胞相关(2568至3736U/g是细胞的),而约232至589U/g是细胞外的(即,仅5-20%的活性是细胞外的)。
因此,工程化解脂耶氏酵母为具有提高的胞外转化酶活性是合乎期望的,因为其更好地利用蔗糖作为碳源。
发明内容
在一个实施例中,本发明涉及转化的解脂耶氏酵母,其包含编码具有蔗糖转化酶活性的多肽的外源性多核苷酸,其中:
a)所述多肽包含与编码成熟蔗糖转化酶的多肽序列融合的信号序列;并且
b)所述信号序列选自:
(i)Xpr2前导/前体(pre/pro)-区域和N-末端Xpr2片段;和
(ii)蔗糖转化酶信号序列,其中所述蔗糖转化酶信号序列的第二个氨基酸能够是任何疏水性氨基酸;并且
c)基于CLUSTALW比对方法,所述编码成熟蔗糖转化酶的多肽序列与SEQ ID NO:4(“m-ScSUC2”)进行比较时具有至少80%的序列同一性。
优选地,上文所述的蔗糖转化酶信号序列的第二个氨基酸选自:亮氨酸、苯丙氨酸、异亮氨酸、缬氨酸和甲硫氨酸。
在第二个实施例中,所述编码成熟蔗糖转化酶的多肽序列为SEQ IDNO:4(“m-ScSUC2”)中所示的。
在第三个实施例中,所述Xpr2前导/前体-区域和N-末端Xpr2片段来自解脂耶氏酵母,并且所述蔗糖转化酶信号序列来自啤酒糖酵母。优选地,所述Xpr2前导/前体-区域和N-末端Xpr2片段包含:
(i)Xpr2前导/前体-区域,其包含碱性胞外蛋白酶前体的N-末端157个氨基酸;和
(ii)N-末端Xpr2片段,其包含成熟碱性胞外蛋白酶的N-末端13个氨基酸。
优选地,所述Xpr2前导/前体-区域和N-末端Xpr2片段为SEQ ID NO:10[“XPR2PP+13”]中所示的。
在第四个实施例中,所述蔗糖转化酶信号序列为SEQ ID NO:8[“Suc2SS”]中所示的。
在第五个实施例中,所述包含与蔗糖转化酶编码序列融合的信号序列的多肽选自:SEQ ID NO:12[“Suc2SS/m-ScSUC2”]和SEQ ID NO:20[“XPR2PP+13/m-ScSUC2”]。
在第六个实施例中,所述转化的解脂耶氏酵母能够在蔗糖为唯一碳源的条件下生长。
在第七个实施例中,所述转化的解脂耶氏酵母能够产生至少一种所关注的非天然产物。优选地,所述至少一种所关注的非天然产物选自:多不饱和脂肪酸、类胡萝卜素、氨基酸、维生素、甾醇、类黄酮、有机酸、多元醇和羟基酯、醌衍生化合物和白藜芦醇。
在第八个实施例中,任何本发明的转化的解脂耶氏酵母在具有至少蔗糖作为碳源的培养基中生长,其中所述转化的解脂耶氏酵母能够向细胞外分泌至少80%的蔗糖转化酶。
在第九个实施例中,本发明涉及生产至少一种所关注的非天然产物的方法,所述方法包括使本发明的转化的解脂耶氏酵母在具有至少一种碳源的培养基中生长,所述碳源选自:
a)蔗糖;和
b)葡萄糖;
从而产生所述至少一种所关注的非天然产物,以及任选地,回收所述至少一种所关注的非天然产物。
优选地,所述至少一种所关注的非天然产物选自:多不饱和脂肪酸、类胡萝卜素、氨基酸、维生素、甾醇、类黄酮、有机酸、多元醇和羟基酯、醌衍生化合物和白藜芦醇。
在第十个实施例中,所述转化的解脂耶氏酵母能够向细胞外分泌至少80%的蔗糖转化酶。
附图说明和序列描述
图1提供了胞外转化酶表达构建体pYRH68(SEQ ID NO:13)、pYRH74(SEQ ID NO:21)、pYRH69(SEQ ID NO:18)和pYRH73(SEQID NO:15)的图示性总结,以及当这些构建体在解脂耶氏酵母中表达时所得到的表型(即,蔗糖利用的(SUC+)或非蔗糖利用的(SUC-))。
图2A提供了啤酒糖酵母转化酶(“ScSUC2”)的N-末端部分的核苷酸和翻译的氨基酸的序列。更具体地,显示了SEQ ID NO:2的氨基酸1-32;前19个氨基酸对应于本文作为Suc2SS(SEQ ID NO:8)示出的转化酶信号序列,而在空心框中显示的剩余的氨基酸代表成熟的转化酶蛋白质的N-末端,本文中命名为m-ScSUC2(SEQ ID NO:4)。
图2B提供了由XPR2基因编码的解脂耶氏酵母碱性胞外蛋白酶的部分的核苷酸和翻译的氨基酸序列。具体地,显示了碱性胞外蛋白酶前体(SEQ ID NO:6)的氨基酸145-192。其中,虚线框中显示的氨基酸145-157对应于Xpr2前导/前体-区域的C-末端,而氨基酸158-192对应于成熟蛋白质的N-末端Xpr2片段。带下划线的氨基酸对应于本文称为XPR2PP+13(SEQ ID NO:10)的Xpr2前导/前体-区域和N-末端Xpr2片段中存在的N-末端Xpr2片段的13个氨基酸。
图3提供了pZSUC的质粒图谱。
图4提供了下列质粒的质粒图谱:(A)pYRH68和(B)pYRH70。
图5提供了下列质粒的质粒图谱:(A)pYRH73和(B)pYRH69。
图6是pYRH74的质粒图谱。
图7显示了菌株Y4184U+Suc2SS/m-ScSUC2
和Y4184(对照)在葡萄糖和蔗糖培养基上的生长。
图8显示了菌株Z1978U+Suc2SS/m-ScSUC2、Z1978U+2_Suc2SS/m-ScSUC2、Z1978U+XPR2PP+13/m-ScSUC2、Z1978U+m-ScSUC2、Z1978U+XPR2PP+13/Suc2SS/m-ScSUC2和Z1978(对照)在包含下列的培养基上的生长:(A)葡萄糖;和(B)蔗糖。
图9是pZKL3-9DP9N的质粒图谱。
下面的序列遵循37C.F.R.§§1.821-1.825(“对含有核苷酸序列和/或氨基酸序列公开内容的专利申请的要求-序列规则”(“Requirements forPatent Applications Containing Nucleotide Sequences and/or Amino AcidSequence Disclosures-the Sequence Rules”)),并且符合世界知识产权组织(World Intellectual Property Organization)(WIPO)ST.25标准(1998)以及EPO和PCT的序列表要求(规则5.2和49.5(a-bis)以及行政指令(Administrative Instructions)的208节和附录C)。核苷酸的符号和格式以及氨基酸序列数据符合如37C.F.R.§1.822所示的规则。
SEQ ID NO:1至41是表1中鉴定的ORF编码基因、蛋白质(或它们的部分)、引物或质粒。
表1:核酸和蛋白质序列号简述


具体实施方式
本文所引用的所有专利、专利申请和出版物均以引用方式将其全文并入本文。
在本公开中,使用了大量的术语和缩写。给出了如下定义。
“开放阅读框”缩写为“ORF”。
“聚合酶链反应”缩写为“PCR”。
“美国典型培养物保藏中心”缩写为“ATCC”。
“多不饱和脂肪酸”缩写为“PUFA”。
“三酰基甘油”缩写为“TAG”。
“总脂肪酸”缩写为“TFA”。
“脂肪酸甲酯”缩写为“FAME”。
“细胞干重”缩写为“DCW”。
“重量百分比”缩写为“重量%”。
如本文所用,以及在所附的权利要求书中,单数形式“一个”和“所述”包括复数涵义,除非上下文中清楚地另有指明。因此,例如,提及“细胞”包括一个或多个细胞及其本领域技术人员已知的等同物等等。
术语“分泌途径”是指在分泌过程中,细胞转运蛋白质通过其来到细胞外的途径。一般来讲,将被分泌的蛋白质被翻译进粗面内质网[“ER”]中,通过高尔基体转运,然后被整合进囊泡中,囊泡最终在胞吐作用过程中与质膜融合,从而释放所述蛋白质。分泌可组成型地或以受调控的方式发生。
“信号序列”(本领域中也被称为“前导-”序列区域、“信号肽”、“靶向信号”、“转运肽”、或“定位信号”)一般是短肽序列(即,长度为约3-60个氨基酸,位于多肽的N-末端部分),其指导多肽的其余部分在细胞内或向细胞外环境的转运和定位。在真核生物中的平均长度是22.6个氨基酸。信号序列一般包括确定的肽基序,用于通过跨膜(例如,内质网膜)转位将蛋白质靶向它们的功能性位置。转位之后,信号序列随后通常被内源性信号肽酶裂解。包含信号序列的蛋白质被称为“前导蛋白”。
尽管没有共有序列,几乎全部的信号肽具有共同的结构:短的带正电的氨基区域(n-区域);中央疏水性区域(h-区域);和包含被信号肽酶裂解的位点的更为极性的区域(c-区域)(Nielsen等人,ProteinEngineering,10:1-6(1997))。
术语“前体蛋白质”和“蛋白质前体”本文中可互换使用,是指能够通过N-末端“前体-”序列区域的裂解而被修饰的多肽。“前体-”序列区域的去除(通常通过内切蛋白酶)导致“成熟蛋白质”的形成。该“前体-”序列区域可能负责增强多种翻译后修饰、可能是成熟蛋白质的正确折叠所需要的、或者它可能在其翻译后的去除之前起抑制成熟蛋白质的活性的作用。
“前导/前体-蛋白质”具有“前导/前体-”区域,该“前导/前体-”区域附接到当该前导/前体-区域被移除后将成为成熟蛋白质的部分。“前导/前体-蛋白质”既包含“前导-”序列区域(即,N-末端信号序列)又包含“前体-”序列区域(即,并置在所述“前导-”序列区域和当所述前导/前体区域被移除后将成为成熟蛋白质的部分之间)。
术语“转化酶”和“β-呋喃果糖苷酶”是指具有通过水解反应将蔗糖(即,由α-D-葡萄糖分子和β-D-果糖分子通过α-1,4-糖苷键连接形成的二糖)转化为葡萄糖和果糖的能力的蛋白质(EC3.2.1.26)。在啤酒糖酵母中,编码转化酶的基因是Suc2。
术语“胞外转化酶”是指被分泌至微生物细胞在其中生长的培养基中的转化酶。因此,胞外转化酶活性通常在培养基自身中测量。与此相对,“全细胞转化酶”是指没有被分泌至细胞外,而是被分泌至细胞内的周质空间的转化酶。通常,全细胞转化酶活性在完整细胞内被测量。胞外转化酶活性对全细胞活性的相对量(即,百分比)的确定如下:100*培养基中的转化酶活性/[(全细胞中的转化酶活性)+(培养基中的转化酶活性)]。
术语“碱性胞外蛋白酶”或“AEP”是指由解脂耶氏酵母中的XPR2基因编码的蛋白质(EC3.4.21.-)。AEP是由这种酵母分泌的主要的细胞外蛋白质(超过1克每升培养物),99%的该蛋白质存在于无细胞的培养基上清液中。全长蛋白酶的N-末端包含“前导/前体-”区域,其参与成熟蛋白质的加工和分泌。
术语“受关注的非天然产物”指在野生型微生物中非天然产生的任何产物。受关注的非天然产物通常通过重组方法产生,使得合适的异源基因被导入所述宿主微生物以表达异源蛋白质,它是受关注的产物。所关注的优选的非天然产物的非限制性例子包括但不限于:多不饱和脂肪酸、类胡萝卜素、氨基酸、维生素、甾醇、类黄酮、有机酸、多元醇和羟基酯、醌衍生化合物和白藜芦醇。
术语“至少一种编码受关注的非天然产物的异源基因”指来源于与它被导入的宿主微生物不同的起源的基因。异源基因促进宿主微生物中受关注的非天然产物的产生。在一些情况下,可能仅需要单个异源基因以产生所关注的产物,所述产物催化底物直接转化成期望的所关注产物,不需要任何中间步骤或中间途径。作为另外一种选择,可能期望将一系列编码新生物合成途径的基因导入微生物中,使得发生一系列反应以产生期望的所关注的非天然产物。
一般来讲,术语“含油的”指那些倾向于以油形式贮存它们的能源的生物(Weete,Fungal Lipid Biochemistry,第2版,Plenum,1980)。在此过程中,含油微生物的细胞油含量一般符合S形曲线,其中脂质浓度增加,直至在对数生长期晚期或稳定生长期早期时它达到最高浓度,随后在稳定生长期晚期和死亡期期间逐渐下降(Yongrmanitchai和Ward,Appl.Environ.Microbiol.,57:419-25(1991))。就本专利申请的目的而言,术语“含油的”是指能够将它们的干细胞重量[“DCW”]的至少约25%积累为油的那些微生物。
术语“含油酵母”是指能够产生油(即,其中油能够以占它们DCW的超过约25%积累)的被分类为酵母的那些含油微生物。含油酵母的例子包括但不限于如下属:耶氏酵母属(Yarrowia)、假丝酵母属(Candida)、红酵母属(Rhodotorula)、红冬孢酵母属(Rhodosporidium)、隐球酵母属(Cryptococcus)、丝孢酵母属(Trichosporon)和油脂酵母属(Lipomyces)。所述酵母以占其DCW的超过约25%积累油的能力可以是来自重组改造工作或者来自该微生物的天然能力。
术语“碳源”是指微生物将代谢以获得能量的包含碳的营养物质。例如,野生型解脂耶氏酵母能够利用多种碳源,包括葡萄糖、果糖、甘油、乙酸盐、醇类、烷类、脂肪酸、和甘油三酯;然而,它不能够用蔗糖作为唯一的碳源(Barth,G.和C.Gaillardin,FEMS Microbiol.Rev.,19:219-237(1997))。与此相对,本发明的重组解脂耶氏酵母能够利用蔗糖作为唯一的可发酵碳源,或者利用与其它适合的碳源组合的蔗糖。
术语“微生物宿主细胞”和“微生物宿主生物”本文中可互换地使用,并且是指能够接纳外源或异源性基因并且能够表达这些基因的微生物。“重组微生物宿主细胞”是指被重组地工程化改造的微生物宿主细胞(例如,使得微生物宿主细胞被外源性多核苷酸转化)。
如本文所用,“分离的核酸片段”是RNA或DNA的聚合物,它是单链或双链的,任选地包含合成的、非天然的或改变的核苷酸碱基。DNA聚合物形式的分离的核酸片段可由cDNA、基因组DNA或合成DNA的一个或多个片段构成。
氨基酸或核苷酸序列的“基本部分”指这样的部分,该部分包括的多肽的氨基酸序列或基因的核苷酸序列足以推定鉴定所述多肽或基因,所述鉴定或者可由本领域技术人员通过人工评价序列来完成,或者可利用诸如BLAST(Basic Local Alignment Search Tool;Altschul,S.F.等人,J.Mol.Biol.215:403-410(1993))。一般来讲,为了推测鉴定多肽或核酸序列是否与已知的蛋白质或基因同源,需要有10个或更多邻接氨基酸或30个或更多核苷酸的序列。此外,对于核苷酸序列,包含20-30个邻接核苷酸的基因特异性寡核苷酸探针可用于序列依赖性的基因鉴定(如DNA杂交)和基因分离(如细菌菌落或噬菌斑的原位杂交)的方法中。此外,12至15个碱基的短寡核苷酸可在聚合酶链反应(PCR)中用作扩增引物,以便获得包含该引物的特定核酸片段。因此,核苷酸序列的“主要部分”包含的序列足以特异性地鉴定和/或分离包含该序列的核酸片段。
术语“互补”描述了在以反向平行取向对齐时能以Watson-Crick法则进行碱基配对的两条核苷酸碱基序列之间的关系。例如,就DNA而言,腺苷能与胸腺嘧啶碱基配对,胞嘧啶能与鸟嘌呤碱基配对。
“密码子简并性”指允许核苷酸序列在不影响所编码多肽的氨基酸序列的情况下发生变化的遗传密码的性质。技术人员非常了解具体宿主细胞在使用核苷酸密码子来确定给定氨基酸时所表现出的“密码子偏倚性”。因此,当合成基因用以改善在宿主细胞中的表达时,期望对基因进行设计,使得其密码子使用频率接近该宿主细胞优选的密码子使用频率。
“合成基因”可由使用本领域的技术人员已知的方法化学合成的寡核苷酸基本单位组合而成。将这些构件进行连接并退火以形成基因节段,该基因节段随后在酶促作用下装配而构建成完整的基因。因此,基于最优化核苷酸序列以反映宿主细胞的密码子偏好性,可以定制基因用以最优化基因表达。如果密码子使用偏向于宿主偏好的那些密码子,则技术人员会理解成功的基因表达的可能性。优选的密码子的确定可基于对来源于宿主细胞的基因(其中序列信息可获得)的检测。例如,美国专利7,125,672中提供了解脂耶氏酵母的密码子使用谱,该专利以引用方式并入本文。
“基因”指可表达特定蛋白质的核酸片段,并且其可以指单独的编码区或可包括在编码序列之前的调控序列(5'非编码序列)和在编码序列之后的调控序列(3'非编码序列)。“天然基因”指自然状态下与其自身的调控序列一起的基因。“嵌合基因”指为非天然基因的任何基因,包含天然状态下不一起存在的调控序列和编码序列。因此,嵌合基因可包含源自不同来源的调控序列和编码序列,或者源自相同来源、但排列方式与天然存在的排列方式不同的调控序列和编码序列。“内源性基因”指在生物体基因组中处于其天然位置的天然基因。“外来”基因(或外源性基因)指通过基因转移导入至宿主生物内的基因。外来基因可包括插入到非天然生物内的天然基因、导入到天然宿主内的新位置的天然基因,或嵌合基因。“转基因”是已通过转化方法导入基因组内的基因。“经密码子优化的基因”是其密码子使用频率经设计用以模仿宿主细胞优选的密码子使用频率的基因。
“编码序列”指编码特定氨基酸序列的DNA序列。
“合适的调控序列”指位于编码序列的上游(5'非编码序列)、中间或下游(3'非编码序列)的核苷酸序列,其可影响相关编码序列的转录、RNA加工或稳定性或翻译。调控序列可包括启动子、增强子、沉默子、5'非翻译前导序列(例如在转录起始位点和翻译起始密码子之间的序列)、内含子、多腺苷酸化识别序列、RNA加工位点、效应子结合位点和茎-环结构。
“启动子”指能够控制编码序列或功能性RNA表达的DNA序列。一般来讲,编码序列位于启动子序列的3'端。启动子可整个源于天然基因,或者由源于天然存在的不同启动子的不同元件构成,或者甚至包含合成的DNA片段。本领域的技术人员应当理解,不同的启动子可以在不同的组织或细胞类型中,或在不同的发育阶段,或响应不同的环境条件或生理条件而指导基因的表达。引起基因在大部分时间内在大多数细胞类型中表达的启动子通常称为“组成型启动子”。还应当进一步认识到,由于在大多数情况下调控序列的确切边界尚未完全确定,因此不同长度的DNA片段可能具有相同的启动子活性。
术语“3'非编码序列”、“转录终止子”和“终止子”本文中可互换使用,是指位于编码序列3'下游的DNA序列。这包括多腺苷酸化识别序列和编码能影响mRNA加工或基因表达的调控信号的其它序列。多腺苷酸化信号通常表征为影响多腺苷酸片添加到mRNA前体的3'端。3'区可影响相关编码序列的转录、RNA加工或稳定性或翻译。
术语“可操作地连接”指单个核酸片段上的核酸序列的关联,以便其中一个核酸序列的功能受到另一个核酸序列的影响。例如,当启动子能够影响编码序列的表达时,它是可操作地连接至编码序列的。即,编码序列处于启动子的转录控制下。编码序列可以按有义或反义的取向可操作地连接至调控序列。
如本文所用,术语“表达”是指有义(mRNA)或反义RNA的转录和稳定积聚。表达也可指将mRNA翻译成多肽。
“转化”指将核酸分子转移进宿主生物体内。所述核酸分子可以是自主复制的质粒;或者,其可以被整合进宿主生物的基因组。含有转化的核酸片段的宿主生物被称为“转基因”或“重组”或“转化的”生物体或“转化体”。
“稳定转化”是指将核酸片段转移进宿主生物的基因组中(既包括核基因组也包括细胞器基因组),导致基因稳定遗传(即,该核酸片段被“稳定地整合”)。相反“瞬时转化”指将核酸片段转入宿主生物的核中或包含DNA的细胞器中,在无整合或无稳定的遗传特性的情况下引起基因表达。
术语“质粒”和“载体”指通常携带有不属于细胞中心代谢的部分的基因的染色体外元件,并且常常是环状双链DNA片段的形式。这类元件可以是自主复制序列、基因组整合序列、噬菌体或核苷酸序列,并且可能是线性或环状的、单链或双链DNA或RNA(源自任何来源),其中多个核苷酸序列已连接或重组进入独特的结构,该独特结构能够将表达盒引入细胞中。
术语“表达盒”指DNA片段,所述DNA片段包含:所选基因的编码序列和所选基因产物表达所需的位于该编码序列之前(5'非编码序列)和之后(3'非编码序列)的调控序列。因此,表达盒通常由如下序列构成:1)启动子序列;2)编码序列(即,开放阅读框(“ORF”));和3)3'非翻译区(即终止子),在真核生物中其通常含有多腺苷酸化位点。表达盒通常包含于载体中,以有利于克隆和转化。可将不同表达盒转化进包括细菌、酵母、植物和哺乳动物细胞在内的不同生物体中,只要能针对每种宿主使用正确的调控序列。
术语“序列分析软件”指可用于分析核苷酸或氨基酸序列的任何计算机算法或软件程序。“序列分析软件”可商购获得或独立开发。典型的序列分析软件包括但不限于:1)GCG程序包(Wisconsin Package Version9.0,Genetics Computer Group(GCG),Madison,WI);2)BLASTP、BLASTN、BLASTX(Altschul等人,J.Mol.Biol.215:403-410(1990));3)DNASTAR(DNASTAR,Inc.Madison,WI);4)Sequencher(Gene Codes Corporation,Ann Arbor,MI);和5)结合了Smith-Waterman算法的FASTA程序(W.R.Pearson,Comput.MethodsGenome Res.,[Proc.Int.Symp.](1994),Meeting Date1992,111-20,编辑:Suhai,Sandor,Plenum:New York,NY)。在本专利申请的上下文中应当理解,使用序列分析软件进行分析时,分析结果将基于所参考程序的“默认值”,除非另外指明。在此所用的“默认值”将指在首次初始化软件时软件最初加载的任何值或参数集。
在核酸或多肽序列上下文中的“序列同一性”或“同一性”是指两序列中的核酸碱基或氨基酸残基当在指定比较窗口中比对最大匹配时是相同的。因此,“序列同一性百分比”或“同一性百分比”指通过在比较窗口上比较两个最佳对齐的序列而测得的值,其中在与参考序列(其不包含添加或缺失)进行比较时,比较窗口中的多核苷酸或多肽序列的部分可包含添加或缺失(即缺口)以实现两个序列的最佳比对。所述百分比的计算方法是,统计相同的核酸碱基或氨基酸残基在两段序列中同时出现的位点的数量以得到匹配位点数,将此匹配位点数除以比对窗口中的总位点数,再将结果乘以100,从而得到序列一致性百分比。
用于测定“同一性百分比”和“相似性百分比”的方法在被编码于可公开获得的计算机程序中。同一性百分比和相似性百分比能够容易地通过已知方法计算出来,所述方法包括但不限于以下文献中所描述的那些:1)Computational Molecular Biology(Lesk,A.M.编辑)Oxford University:NY(1988);2)Biocomputing:Informatics and Genome Projects(Smith,D.W.编辑)Academic:NY(1993);3)Computer Analysis of SequenceData,Part I(Griffin,A.M.和Griffin,H.G.编辑)Humania:NJ(1994);4)Sequence Analysis in Molecular Biology(von Heinje,G.编辑)Academic(1987);和5)Sequence Analysis Primer(Gribskov,M.和Devereux,J.编辑)Stockton:NY(1991)。
序列比对和同一性百分比或相似性百分比的计算可使用多种设计用于检测同源序列的比对方法确定。
序列的多重比对能够采用包括几种改变形式的算法在内的“Clustal比对方法”进行,包括“Clustal V比对方法”和“ClustalW比对方法”(描述于Higgins和Sharp,CABIOS,5:151-153(1989);Higgins,D.G.等人,Comput.Appl.Biosci.,8:189-191(1992))并存在于MegAlignTM(版本8.0.2)程序(同上)中。用Clustal程序比对序列后,可通过查看程序中的“序列距离”表来获得“同一性百分比”。
本文使用的标准的重组DNA和分子克隆技术是本领域所熟知的并且被描述于下列文献中:Sambrook,J.,Fritsch,E.F.和Maniatis,T.,Molecular Cloning:A Laboratory Manual,第2版,Cold Spring HarborLaboratory:Cold Spring Harbor,NY(1989)(下文称为“Maniatis”);Silhavy,T.J.,Bennan,M.L.和Enquist,L.W.,Experiments with GeneFusions,Cold Spring Harbor Laboratory:Cold Spring Harbor,NY(1984);以及Ausubel,F.M.等人,Current Protocols in MolecularBiology,Greene Publishing Assoc.and Wiley-Interscience出版,Hoboken,NJ(1987)。
解脂耶氏酵母能够被重组地工程化改造以利用蔗糖作为碳源。这涉及工程化该生物以表达编码转化酶的基因,转化酶催化蔗糖向葡萄糖和果糖的转化。然而,由于蔗糖存在于酵母在其中生长的培养基中,蔗糖在被细胞内转化酶水解之前需要被转运进细胞,或者转化酶应在细胞外被表达,其在细胞外能够将培养基中的蔗糖水解为葡萄糖和果糖,葡萄糖和果糖继而能够被转运进细胞。优选地,信号序列被融合至异源性转化酶基因,使得转化酶被向细胞外分泌至周围的培养基中。
啤酒糖酵母发酵蔗糖,因为其表达催化蔗糖向葡萄糖和果糖的转化的功能性的转化酶(EC3.2.1.26;也被称为“β-呋喃果糖苷酶”)。有两种形式的转化酶从啤酒糖酵母中相同的SUC2等位基因表达:由蔗糖抑制调控的分泌的糖基化的形式,和组成型地产生的细胞内的非糖基化的形式。这两种形式之间的差异是由于分泌的、糖基化的转化酶的合成所需要的5’信号序列的存在或不存在。该信号序列已被确定为转化酶蛋白质的前19个氨基酸(Perlman,D.等人,Proc.Natl.Acad.Sci.U.S.A.,79:781-785(1982);Carlson和Botstein,Cell,28(1):145-54(1982);Taussig和Carlson,Nucleic Acids Res.,11:1943-54(1983))。
因此,全长的啤酒糖酵母SUC2[“ScSUC2”]基因(SEQ ID NO:1)长度是1599个核苷酸,编码以糖基化的形式分泌至啤酒糖酵母的周质的532个氨基酸(SEQ ID NO:2)的全长转化酶。与此相对,“成熟的”ScSUC2基因[“m-ScSUC2”]缺少由SEQ ID NO:1的核苷酸1-57编码的19个氨基酸长度的5’信号序列。因此,m-ScSUC2的细胞内非糖基化的形式由如SEQ ID NO:3(其对应于SEQ ID NO:1的核苷酸58-1599)所示的1542bp的核苷酸序列编码,并且其被翻译以产生513个氨基酸(SEQ IDNO:4)的截短的m-ScSUC2蛋白质。
通过细胞的膜分泌的蛋白质通常作为“前导蛋白”在细胞内产生。在这种形式中,蛋白质与附加的“信号”多肽序列融合,所述“信号”多肽序列据推测帮助其分泌和定位,但它最终在分泌过程中被从所分泌的“成熟”蛋白质上裂解。尽管前导蛋白的信号肽共有某些相似性,它们的一级结构是相当不同的。这表明每种蛋白质进化出了特别地适合该种特定蛋白质穿过细胞膜的转位的信号序列。
如上文所讨论的,解脂耶氏酵母天然地将大量的AEP分泌至培养基中。SEQ ID NO:6(长度为454个氨基酸)的全长解脂耶氏酵母AEP由1365bp XPR2基因(SEQ ID NO:5)编码。该蛋白酶的N-末端157个氨基酸残基包含参与成熟蛋白质的加工和分泌的信号序列和前导/前体-区域。
详细的研究显示,合成的AEP带有preproI-proII-proIII N-末端区域,并且发现了四种不同的AEP的前体。氨基酸位点1至13包含分泌信号序列,然后是带有-Xaa-Ala-和-Xaa-Pro-延伸的位点14至33,典型的二肽基氨肽酶识别位点。氨基酸位点54或60被认为是proI和proII区域之间的裂解位点,而位点129或131是proII和proIII区域之间的另一裂解位点。最后,SEQ ID NO:6的氨基酸位点157是proIII和成熟AEP之间的裂解位点(Matoba,S.等人,Mol.Cell Biol.,8(11):4904-4916(1988);亦参见美国专利4,937,189和EP0220864B1)。对应于氨基酸1-157的前导/前体-区域被认为参与蛋白质的折叠、有效的分泌、过早的激活的防止等;没有前导/前体-区域的裂解,AEP蛋白质是无功能的。
Xpr2前导前体-区域已被用于多种异源性蛋白质在解脂耶氏酵母中的分泌;然而,将Xpr2前导前体-区域用于蛋白质的分泌产生了形形色色的结果(Madzak,C.等人,Microbiology,145(1):75-87(1999))。导致不能令人满意的蛋白质表达的原因包括不完全的蛋白质加工(Park,C.S.等人,J.Biol.Chem.,272:6876-6881(1997);Park,C.S.等人,Appl.Biochem.Biotechnol.87:1-15(2000);Swennen,D.等人,Microbiology,148:41-50(2002))和缺少细胞外的表达(Hamsa,P.V.和B.B.Chattoo,Gene,143:165-70(1994);Tharaud,C.等人,Gene,121:111-119(1992))。因此,有人提出前体-序列对于异源性蛋白质的分泌可能不是必须的或者甚至可能是有害的(Madzak,C.等人,J.Biotechnol.,109:63-81(2004);Park等人,J.Biol.Chem.(上文);Tharaud,C.等人,上文)。Tabuchi,M.等人(J.Bacteriol.,179:4179-4189(1997))显示了这一点,在其中羧肽酶Y(CPY)的前导前体-区域对于来自粟酒裂殖酵母的Suc2的分泌是无效的。
表达ScSuc2信号序列(对应于SEQ ID NO:1的核苷酸1-57[即,ScSUC2的氨基酸1-19])在氨基酸位点2是突变的,以引入PciI限制性酶切位点。因此,野生型Leu2残基被突变为另一种疏水性残基Phe2,从而维持信号序列的疏水性,而不影响ScSuc2的分泌过程(Kaiser,C.A.等人,Science,235:312-317(1987))。因此,本发明的一个适合的ScSuc2信号序列(即,“Suc2SS”)如本文的SEQ ID NO:7和8所示。
包括Xpr2前导/前体-区域的构建体被设计为编码SEQ ID NO:10的氨基酸1-170。尽管Xpr2前导/前体-区域在本文中被描述为仅涵盖SEQ IDNO:6的氨基酸1-157,该蛋白酶在前导/前体-区域(即,Xpr2片段的N-末端)之后的附加的13个氨基酸作为“接头”也被包括,以确保Xpr6肽链内切酶能接近Lys156-Arg157裂解位点,因为此前已注意到由于推测的二级结构而导致的融合连接的不准确加工(Park,C.S.等人,J.Biol.Chem.,272:6876-6881(1997))。因此,本发明的一个适合的Xpr2前导/前体-区域和N-末端Xpr2片段(即,“XPR2PP+13”)如本文的SEQ ID NO:9和10所示。
针对转化酶在转化的解脂耶氏酵母中的表达,对总结在下文的表2中并图示在图1中的表达盒进行了评估。更具体地,表达质粒pYRH68包含融合至编码成熟SUC2的基因(即,SEQ ID NO:3;“m-ScSUC2”)的Suc2SS信号序列,表达质粒pYRH70包含融合至SEQ ID NO:3的两个拷贝的Suc2SS信号序列,表达质粒pYRH69包含融合至SEQ ID NO:3的Xpr2前导/前体-区域与N-末端Xpr2片段和Suc2SS信号序列,表达质粒pYRH73仅包含SEQ ID NO:3(而没有作为分泌信号序列的Xpr2前导/前体-区域与N-末端Xpr2片段或Suc2SS信号序列),表达质粒pYRH74包含融合至SEQ ID NO:3的Xpr2前导/前体-区域和N-末端Xpr2片段。“FBAINm启动子区域”(即,来源于由fba1基因[美国专利7,202,356]编码的果糖二磷酸醛缩酶(E.C.4.1.2.13)的‘ATG’翻译起始密码子之前的5’上游非翻译区域)被可操作地连接至上述转化酶基因构建体。
表2:解脂耶氏酵母胞外转化酶表达盒简述

表达上述每一质粒构建体的解脂耶氏酵母转化体在蔗糖在其中是唯一碳源的培养基上生长。只有表达融合至编码成熟SUC2的基因的Suc2SS信号序列(其实际上相当于编码ScSuc2的全长基因[即,SEQ ID NO:2])(即,pYRH68和pYRH70)或融合至编码成熟SUC2的基因的Xpr2前导/前体-区域和N-末端Xpr2片段(即,pYRH74)的那些转化体表达转化酶,即,SUC+表型。因此,这说明这些融合导致了ScSUC2在解脂耶氏酵母中的功能性表达。
在一个方面,本发明涉及转化的解脂耶氏酵母,其包含编码具有蔗糖转化酶活性的多肽的外源性多核苷酸,其中:
(a)所述多肽包含与编码成熟蔗糖转化酶的多肽序列融合的信号序列;并且
(b)所述信号序列选自:
(i)Xpr2前导/前体-区域和N-末端Xpr2片段;和
(ii)蔗糖转化酶信号序列,其中所述蔗糖转化酶信号序列的第二个氨基酸能够是任何疏水性氨基酸;并且
(c)基于CLUSTALW比对方法,所述编码成熟蔗糖转化酶的多肽序列与SEQ ID NO:4(“m-ScSUC2”)进行比较时具有至少80%的序列同一性。
在优选的实施例中,本发明的转化的解脂耶氏酵母,当在至少具有蔗糖作为碳源的培养基中生长时,将能够向细胞外分泌至少80%的蔗糖转化酶(而细胞内的[或周质的]转化酶活性等于或小于总的转化酶活性的20%)。更具体地,胞外转化酶活性是总的转化酶活性的至少81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%。
如上文所述,如本文的SEQ ID NO:4所示的“成熟”ScSUC2蛋白质[“m-ScSUC2”]缺少由SEQ ID NO:1的核苷酸1-57编码的19个氨基酸长的5’信号序列。优选地,所述编码成熟蔗糖转化酶的多肽序列如SEQ IDNO:4(“m-ScSUC2”)所示。在替代性实施例中,成熟的蔗糖转化酶基于CLUSTALW比对方法与SEQ ID NO:4进行比较时具有至少80%的序列同一性,即,所述多肽与SEQ ID NO:4进行比较时可具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%的同一性。
在一个实施例中,可能期望针对在解脂耶氏酵母中的表达对SEQ IDNO:4进行密码子优化。基于先前对解脂耶氏酵母密码子使用谱的确定,对那些优选的密码子的鉴定以及对‘ATG’起始密码子周围的共有序列的确定(参见美国专利7,238,482)是可能的。
在另一个实施例中,表14(实例8)中的转化酶序列或其部分,可被用于本发明中。作为另外一种选择,任何的这些可被用于利用序列分析软件在相同的或其它的物种中搜寻转化酶同源物。通常,这种计算机软件通过将同源程度赋予多种置换、缺失和其它修饰来匹配相似的序列。使用软件算法,如具有低复杂度滤波器和以下参数的BLASTP比对方法:Expectvalue=10,matrix=Blosum62(Altschul等人,Nucleic Acids Res.,25:3389-3402(1997)),该方法作为用于将表14中的转化酶蛋白质对核酸或蛋白序列数据库进行比较并从而鉴定在优选生物中的相似已知序列的方法是为人们所熟知的。
使用软件算法搜索已知序列数据库尤其适于分离与可公开获得的转化酶序列(如表14中所描述的那些)具有相对低的同一性百分比的同源物。可以预测,分离与可公开获得的转化酶序列具有至少约80%-85%同一性的转化酶同源物将是相对更容易的。此外,那些至少约85%-90%相同的序列将尤其适于分离,那些至少约90%-95%相同的序列将最容易分离。
通过使用转化酶独有的基序已经分离了一些转化酶同源物。基序通过它们在蛋白同源物家族的比对序列中的高度保守性进行鉴定。作为独有的“标记”,它们能决定具有新测定序列的蛋白是否属于以前鉴定过的蛋白家族。这些基序作为用于快速鉴定新的转化酶基因的检测工具是有用的。
本文所述或公开文献中的任何转化酶核酸片段,或任何鉴定的同源物,可用于从相同的或其它的物种中分离编码同源蛋白质的基因。使用序列依赖性规程分离同源基因是本领域熟知的。序列依赖性规程的例子包括但不限于:1)核酸杂交方法;2)DNA和RNA扩增方法,例如核酸扩增技术的多种应用,如聚合酶链反应[“PCR”](美国专利4,683,202);连接酶链反应[“LCR”](Tabor,S.等人,Proc.Natl.Acad.Sci.U.S.A.,82:1074(1985));或链置换扩增[“SDA”](Walker等人,Proc.Natl.Acad.Sci.U.S.A.,89:392(1992));和3)文库构建和互补筛选方法。
本发明的转化的解脂耶氏酵母包含编码具有蔗糖转化酶活性的多肽的外源性多核苷酸,其中所述多肽将包含融合至外源性多核苷酸编码的成熟蔗糖转化酶的信号序列,其中所述信号序列选自:1)Xpr2前导/前体-区域和N-末端Xpr2片段;和2)蔗糖转化酶信号序列,其中所述蔗糖转化酶信号序列的第二个氨基酸能够是任何疏水性氨基酸。
相对于编码Xpr2前导/前体-区域和N-末端Xpr2片段的信号序列,本领域的普通技术人员将能够分析编码碱性胞外蛋白酶(EC3.4.21.-)的适合的XPR2基因,以鉴定相对于编码成熟蛋白质的序列的编码前导/前体-区域的序列。例如,SignalP4.0服务器(生物序列分析中心(Center forBiological Sequence Analysis),系统生物学系(Department of SystemsBiology),丹麦技术大学(Technical University of Denmark),DK-2800Lyngby,Denmark)被用于预测来自不同生物的氨基酸序列中信号肽裂解位点的存在和位置(Nielsen,H.等人,Protein Engineering,10:1-6(1997);Petersen,T.N.等人,Nature Methods,8:785-786(2011))。上述鉴定之后,有可能容易地分离编码全长Xpr2前导/前体-区域的适当的序列,加上附加的成熟的Xpr2蛋白质(即,AEP)的N-末端片段。
上述N-末端Xpr2片段编码成熟蛋白酶的至少约氨基酸1-10以及成熟蛋白酶的至多约氨基酸1-25,以确保Xpr6肽链内切酶能够接近前导/前体-区域与成熟蛋白质之间的裂解位点(尽管就所利用的每一XPR2基因而言,N-末端片段的确切长度将需要以实验方法确定)。
更优选地,成熟蛋白酶的N-末端Xpr2片段将编码成熟蛋白酶的氨基酸1至11、氨基酸1至12、氨基酸1至13、氨基酸1至14、氨基酸1至15、氨基酸1至16、氨基酸1至17、氨基酸1至18、氨基酸1至19、氨基酸1至20、氨基酸1至21、氨基酸1至22、氨基酸1至23或成熟蛋白酶的氨基酸1至24。
来自解脂耶氏酵母的Xpr2前导/前体-区域和N-末端Xpr2片段将包含Xpr2前导/前体-区域的至少157个氨基酸(即,SEQ ID NO:6的氨基酸1-157)和编码成熟蛋白酶的附加的N-末端Xpr2片段(即,SEQ ID NO:6的氨基酸158-167或氨基酸158-168或氨基酸158-169或氨基酸158-170或氨基酸158-171或氨基酸158-172或氨基酸158-173或氨基酸158-174或氨基酸158-175或氨基酸158-176或氨基酸158-177或氨基酸158-178或氨基酸158-179或氨基酸158-180或氨基酸158-181或氨基酸158-182)。
优选的Xpr2前导/前体-区域和N-末端Xpr2片段(即,“XPR2PP+13”,如SEQ ID NO:10所示)包括SEQ ID NO:6的氨基酸1-170,其与Xpr2前导/前体-区域之后的附加的13个氨基酸(即,成熟蛋白酶的氨基酸1至13)相符,以确保Xpr6肽链内切酶接近Lys156-Arg157裂解位点。因此,所述Xpr2前导/前体-区域和N-末端Xpr2片段包含:
(a)Xpr2前导/前体-区域,其包含AEP前体的N-末端157个氨基酸;和
(b)N-末端Xpr2片段,其包含成熟AEP的N-末端13个氨基酸。
能够被转入解脂耶氏酵母的编码具有蔗糖转化酶活性的多肽的一种优选的外源性多核苷酸,包含融合至SEQ ID NO:4的成熟蔗糖转化酶(“m-ScSUC2”)的SEQ ID NO:10的Xpr2前导/前体-区域和N-末端Xpr2片段的信号序列,从而产生XPR2PP+13/m-ScSUC2融合,其具有如SEQ ID NO:19所示的核苷酸序列并且编码SEQ ID NO:20的蛋白质。
所示转化的解脂耶氏酵母包含编码具有蔗糖转化酶活性的多肽的外源性多核苷酸,其中所述多肽包含融合至编码成熟蔗糖转化酶的多肽的信号序列,或者可以使用蔗糖转化酶信号序列,其中所述蔗糖转化酶信号序列的第二个氨基酸能够是任何疏水性氨基酸。
本领域的普通技术人员将能够利用与上文所述相似的方法来鉴定相对于编码成熟转化酶蛋白质的序列的编码转化酶信号序列的序列。鉴定之后,有可能容易地分离转化酶信号序列,以构建具有蔗糖转化酶活性的融合多肽,如本文所述。为清楚起见,蔗糖转化酶信号序列和成熟蔗糖转化酶可分离自单个物种(从而实际上相当于该物种的全长转化酶前导蛋白);或者,蔗糖转化酶信号序列可分离自物种“A”,而成熟蔗糖转化酶可分离自物种“B”。蔗糖转化酶信号序列的第二个氨基酸能够是任何疏水性氨基酸,例如亮氨酸、苯丙氨酸、异亮氨酸、缬氨酸或甲硫氨酸。
研究转化酶信号肽的多个在前的研究已显示,至少20%的基本上随机的氨基酸序列能够至少部分地作为输出信号用于转化酶。输出信号功能与疏水性相关,而不是与信号肽的特定的结构或长度(参见,例如,Kaiser等人,Science,235:312-317(1987);Kaiser和Botstein,Mol.Cell.Biol.,6:2382-2391(1986))。此外,天然的ScSUC2信号序列和成熟ScSUC2之间的连接序列已知对于信号肽的正确裂解是重要的。例如,如果SEQ ID NO:2的残基Ala19被突变为Val,ScSUC2将变成缺陷型的(Schauer等人,J.Cell Biol.,100:1664-1075(1985))。关于SUC2信号序列的修饰的更多信息,参见Ngsee等人(Mol.Cell.Biol.,9:3400-3410(1989))。
在一个实施例中,所述蔗糖转化酶信号序列能够来自糖酵母属(Saccharomyces)的生物。更优选地,蔗糖转化酶信号序列是分离自啤酒糖酵母,例如,如SEQ ID NO:8[“Suc2SS”]所示的蔗糖转化酶信号序列。预期SEQ ID NO:8的第二个氨基酸能够容易地被替代性的疏水性氨基酸取代(即,Phe2能够可供选择地被突变为Leu2、Ile2、Val2或Met2),从而维持信号序列的疏水性而不影响转化酶的分泌过程。更具体地,在本文的转化的解脂耶氏酵母中使用的蔗糖转化酶信号序列与SEQ ID NO:8进行比较时可具有至少51%、52%、53%、54%、55%、56%、57%、58%、59%、60%、61%、62%、63%、64%、65%、66%、67%、68%、69%、70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%的同一性,只要其基本上维持了分泌活性(参见,例如,Kaiser和Botstein,Mol.Cell.Biol.,6:2382-2391(1986))。
用于转入解脂耶氏酵母的编码具有蔗糖转化酶活性的多肽的一种优选的外源性多核苷酸,包含融合至SEQ ID NO:4的成熟蔗糖转化酶(“m-ScSUC2”)的SEQ ID NO:8的Xpr2区域和末端片段的蔗糖转化酶信号序列,从而产生Suc2SS/m-ScSUC2融合,其具有如SEQ ID NO:11所示的核苷酸序列并且编码SEQ ID NO:12的蛋白质。
应当理解,SEQ ID NO:12的Suc2SS/m-ScSUC2融合实际上相当于全长转化酶前导蛋白,例如SEQ ID NO:2中所示的(除了氨基酸2的变异之外),因为Suc2SS信号序列对应于SEQ ID NO:2的氨基酸1-19,而m-ScSUC2对应于氨基酸20-532。因此,例如,具有蔗糖转化酶活性的多肽(基于CLUSTALW比对方法)与SEQ ID NO:2进行比较时具有至少80%的序列同一性,尽管所述多肽与SEQ ID NO:2进行比较时可更优选地具有至少81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、或100%的同一性。
本领域的技术人员知晓描述下列的标准来源的材料:1)用于构建、操纵和分离大分子如DNA分子、质粒等的具体条件和规程;2)重组DNA片段和重组表达构建体的产生;以及3)克隆的筛选和分离。参见Maniatis,Silhavy和Ausubel。
一般来讲,存在于构建体中的序列的具体选择取决于期望的表达产物、宿主细胞的性质以及提出的相对于未转化细胞分离转化细胞的手段。通常,载体含有至少一个表达盒、选择标记和允许自主复制或染色体整合的序列。适合的表达盒通常包含启动子、所选择的基因的编码序列、和终止子(即,嵌合基因)。优选地,两个控制区均来源于来自转化的宿主细胞的基因。
事实上能够指导编码具有蔗糖转化酶活性的多肽的ORF的表达的任何启动子(即,天然的、合成的、或嵌合的)都将是适合的,尽管来自解脂耶氏酵母的转录的和翻译的区域是尤其有用的。表达能以诱导型或组成型完成。诱导型表达可通过诱导可操作地连接至所关注的基因的可调节启动子的活性来完成,而组成型表达可通过利用可操作地连接至所关注的基因的组成型启动子来实现。
终止子能够来源于从中获得启动子的基因的3'区或来源于不同的基因。大量的终止子是已知的,并且在用于与它们所源自的属和物种相同的和不同的属和物种时,在多种宿主中令人满意地起作用。终止子的选择通常更多是为了方便而不是因为任何特殊的性质。优选地,终止子来源于酵母基因。终止子还能够是合成的,本领域的技术人员能够利用可利用的信息来设计和合成终止子。终止子可以是非必需的,但它是高度优选的。
尽管不旨在进行限制,用于重组的解脂耶氏酵母中的优选的启动子和终止子是美国专利公开2009-0093543-A1、美国专利公开2010-0068789-A1、美国专利公开2011-0059496-A1、美国临时专利申请61/469,933(代理人档案号CL4736USPRV,提交于2011年3月31日)、美国临时专利申请61/470,539(代理人档案号CL5380USPRV,提交于2011年4月1日)、美国临时专利申请61/471,736(代理人档案号CL5381USPRV,提交于2011年4月5日)和美国临时专利申请61/472,742(代理人档案号CL5382USPRV,提交于2011年4月7日)中所教导的那些,上述每一公开以引用方式并入本文。更具体地,优选地启动子包括:GPD、GPDIN、GPM、GPM/FBAIN、FBA、FBAIN、FBAINm、GPAT、YAT1、EXP1、DGAT2、EL1、ALK2和SPS19。
许多专门的表达载体已被构建,以获得高的表达率。此类载体是通过调节控制转录、RNA稳定性、翻译、蛋白质稳定性和定位、和从宿主细胞的分泌的某些性质制备的。这些性质包括:相关转录启动子和终止子序列的性质;所克隆基因的拷贝数目(其中可以在单个表达构建体中克隆另外的拷贝和/或将另外的拷贝通过增加质粒拷贝数或通过将克隆基因多次整合进基因组中来引入宿主细胞中);基因是质粒携带的还是整合进了宿主细胞的基因组中;蛋白质在宿主生物内的翻译和正确折叠的效率;所克隆基因的mRNA和蛋白质在宿主细胞内的固有稳定性;以及所克隆基因中的密码子使用,使得其频率与宿主细胞的优选密码子使用频率接近。
适用于在解脂耶氏酵母中表达的DNA盒(例如,包含由启动子、编码具有蔗糖转化酶活性的多肽的ORF和终止子组成的嵌合基因)已被获得之后,其被置于能够在宿主细胞中自主复制的质粒载体中,或者包含所述嵌合基因的DNA片段被直接整合进基因组。表达盒的整合能够在解脂耶氏酵母基因组中随机地发生,或者能够通过使用包含与所述基因组具有足以使重组定向至特定基因座的同源性的区域的构建体来定向。如果构建体靶向内源性基因座,则转录和翻译调控区的全部或某些可由内源性基因座提供。
包含所关注的嵌合的蔗糖转化酶基因的构建体可通过任何标准技术被引入解脂耶氏酵母。这些技术包括转化如醋酸锂转化(Methods inEnzymology,194:186-187(1991))、基因枪轰击(bolistic impact)、电穿孔、显微注射或将所关注的基因导入宿主细胞中的任何其它方法。能够应用于解脂耶氏酵母的更具体的教导包括美国专利4,880,741和美国专利5,071,764以及Chen,D.C.等人(Appl.Microbiol.Biotechnol.,48(2):232-235(1997))。优选地,在解脂耶氏酵母宿主细胞的转化中,线性DNA片段向宿主基因组中的整合是有利的。当期望基因高水平表达时,整合到基因组中的多个位置可以是尤其有用的。优选的基因座包括美国专利公开2009-0093543-A1。
术语“转化的”、“转化体”或“重组体”本文中可互换使用。转化的宿主将具有至少一个拷贝的表达构建体,并且可具有两个或更多个拷贝,这取决于该表达盒是整合到基因组内的、被扩增的、还是存在于具有多拷贝数的染色体外元件上。转化宿主细胞能通过选择导入构建体上包含的标记进行鉴定。作为另外一种选择,分离的标记构建体可用期望的构建体进行共转化,该方法与多种将多个DNA分子导入宿主细胞的转化技术一样。通常,转化的宿主通过它们在选择培养基上生长的能力而被选择,选择培养基可掺入抗生素或缺乏未转化的宿主生长所必需的因子,如营养物质(例如,蔗糖)或生长因子。导入的标记基因可赋予抗生素抗性,或编码必需的生长因子或酶,从而当在转化宿主中表达时允许在选择培养基上生长。转化宿主的选择也能发生在表达标记蛋白能被直接地或间接地检测出来时。更多的选择技术描述于美国专利7,238,482、美国专利7,259,255和WO2006/052870中。
整合的DNA片段在解脂耶氏酵母中的稳定性取决于各个转化体、受体菌株和所用的靶向平台。因此,特定的重组微生物宿主的多个转化体应当被筛选,以获得表现出所期望的表达水平和模式的菌株。DNA印迹的Southern分析(Southern,J.Mol.Biol.,98:503(1975))、mRNA表达的Northern分析(Kroczek,J.Chromatogr.Biomed.Appl.,618(1-2):133-145(1993))、蛋白质表达的Western分析、表型分析或GC分析是适合的筛选方法。
任何解脂耶氏酵母能够根据本发明用编码成熟蔗糖转化酶的适当的多肽序列转化,以产生能够利用蔗糖作为碳源的转化的菌株。能够通过美国典型培养物保藏中心(American Type Culture Collection)获得的易得的解脂耶氏酵母菌株的例子包括,例如8661、8662、9773、15586、16617、16618、18942、18943、18944、18945、20114、20177、20182、20225、20226、20228、20327、20255、20287、20297、20315、20320、20324、20336、20341、20346、20348、20363、20364、20372、20373、20383、20390、20400、20460、20461、20462、20496、20510、20628、20688、20774、20775、20776、20777、20778、20779、20780、20781、20794、20795、20875、20241、20422、20423、32338、32339、32340、32341、34342、32343、32935、34017、34018、34088、34922、38295、42281、44601、46025、46026、46027、46028、46067、46068、46069、46070、46330、46482、46483、46484、46436、60594、62385、64042、74234、76598、76861、76862、76982、90716、90811、90812、90813、90814、90903、90904、90905、96028、201241、201242、201243、201244、201245、201246、201247、201249、或201847。类似地,下列的解脂耶氏酵母菌株能够从加州大学戴维斯分校(University of California Davis(Davis,CA))的Herman J.Phaff酵母培养物保藏中心(Herman J.PhaffYeast Culture Collection)获得:解脂耶氏酵母(Y.lipolytica)49-14、解脂耶氏酵母(Y.lipolytica)49-49、解脂耶氏酵母(Y.lipolytica)50-140、解脂耶氏酵母(Y.lipolytica)50-46、解脂耶氏酵母(Y.lipolytica)50-47、解脂耶氏酵母(Y.lipolytica)51-30、解脂耶氏酵母(Y.lipolytica)60-26、解脂耶氏酵母(Y.lipolytica)70-17、解脂耶氏酵母(Y.lipolytica)70-18、解脂耶氏酵母(Y.lipolytica)70-19、解脂耶氏酵母(Y.lipolytica)70-20、解脂耶氏酵母(Y.lipolytica)74-78、解脂耶氏酵母(Y.lipolytica)74-87、解脂耶氏酵母(Y.lipolytica)74-88、解脂耶氏酵母(Y.lipolytica)74-89、解脂耶氏酵母(Y.lipolytica)76-72、解脂耶氏酵母(Y.lipolytica)76-93、解脂耶氏酵母(Y.lipolytica)77-12T和解脂耶氏酵母(Y.lipolytica)77-17。或者,菌株能够从Dr.Jean-Marc Nicaud的Laboratoire de Microbiologie etGénétique Moléculaire,INRA Centre de Grignon,France获得,包括,例如,解脂耶氏酵母JMY798( K.等人,Appl.Environ.Microbiol.,70(7):3918-24(2004)),解脂耶氏酵母JMY399(Barth,G.和C.Gaillardin.见Nonconventional Yeasts In Biotechnology;Wolf,W.K.编辑;Springer-Verlag:Berlin,Germany,1996;第313-388页)和解脂耶氏酵母JMY154(Wang,H.J.等人,J.Bacteriol.,181(17):5140-8(1999))。
K.等人,Appl.Environ.Microbiol.,70(7):3918-24(2004)),解脂耶氏酵母JMY399(Barth,G.和C.Gaillardin.见Nonconventional Yeasts In Biotechnology;Wolf,W.K.编辑;Springer-Verlag:Berlin,Germany,1996;第313-388页)和解脂耶氏酵母JMY154(Wang,H.J.等人,J.Bacteriol.,181(17):5140-8(1999))。
优选地,解脂耶氏酵母宿主细胞是含油的,即,能够合成并积聚油,其中总的油含量能够占干细胞重量[“DCW”]的大于约25%,更优选占DCW的大于约30%,最优选占DCW的大于约40%。在一个实施例中,被命名为ATCC20362、ATCC8862、ATCC18944、ATCC76982和/或LGAM S(7)1(Papanikolaou S.和Aggelis G.,Bioresour.Technol.,82(1):43-9(2002))的解脂耶氏酵母菌株是尤其适合的。
本发明还涉及包含编码具有蔗糖转化酶活性的多肽的外源性多核苷酸的转化的解脂耶氏酵母(其中所述多肽包含融合至编码成熟蔗糖转化酶的多肽序列的信号序列)并且其中所述转化的解脂耶氏酵母能够产生至少一种所关注的非天然产物。所述至少一种所关注的非天然产物优选当所述转化的解脂耶氏酵母利用蔗糖(或其混合物)作为碳源生长时产生。用异源的基因转化解脂耶氏酵母的顺序并不重要。此类转化也能够是同时的。
适合的所关注的非天然产物的例子包括,例如,多不饱和脂肪酸、类胡萝卜素、氨基酸、维生素、甾醇、类黄酮、有机酸、多元醇和羟基酯、醌衍生化合物和白藜芦醇,尽管这在本文中并不旨在是限制性的。
已经有大量文献证明了与“多不饱和脂肪酸”(或“PUFA”),尤其是ω-3和ω-6PUFA相关的健康有益效果。更具体地,本文中PUFA是指具有至少18个碳原子和2个或更多个双键的脂肪酸。术语“脂肪酸”指不同链长的长链脂族酸(链烷酸),链长为约C12-C22(尽管更长和更短链长的酸均是已知的)。主要的链长介于C16和C22之间。脂肪酸的结构可用简单的记号系统“X:Y”来表示,其中X表示具体脂肪酸中碳(“C”)原子的总数,而Y表示双键的数目。
另外的关于“饱和脂肪酸”对“不饱和脂肪酸”、“单不饱和脂肪酸”对“多不饱和脂肪酸”[“PUFA”]、以及“ω-6脂肪酸”[“n-6”]对“ω-3脂肪酸”[“n-3”]之间的区别的详细信息在美国专利7,238,482中有所提供,该专利以引用方式并入本文。美国专利申请公开2009-0093543-A1,表3,提供了ω-3和ω-6PUFA以及它们的前体的化学名和常用名以及常用缩写的详细摘要。
然而PUFA的一些例子包括但不限于亚油酸[“LA”,18:2ω-6]、γ-亚麻酸[“GLA”,18:3ω-6]、二十碳二烯酸[“EDA”,20:2ω-6]、二高-γ-亚麻酸[“GLA”,20:3ω-6]、花生四烯酸[“ARA”,20:4ω-6]、二十二碳四烯酸[“DTA”,22:4ω-6]、二十二碳五烯酸[“DPAn-6”,22:5ω-6]、α-亚麻酸[“ALA”,18:3ω-3]、十八碳四烯酸[“STA”,18:4ω-3]、二十碳三烯酸[“ETA”,20:3ω-3]、二十碳四烯酸[“ETrA”,20:4ω-3]、二十碳五烯酸[“EPA”,20:5ω-3]、二十二碳五烯酸[“DPAn-3”,22:5ω-3]和二十二碳六烯酸[“DHA”,22:6ω-3]。
许多努力已投入在工程化解脂耶氏酵母菌株用于PUFA生产上。例如,美国专利7,238,482展示了在酵母中生产ω-6和ω-3脂肪酸的可行性。美国专利7,932,077展示了占总脂肪酸28.1%的EPA的重组生产;美国专利7,588,931展示了占总脂肪酸14%的ARA的重组生产;美国专利7,550,286展示了占总脂肪酸5%的DHA的重组生产;以及,美国专利申请公开2009-0093543-A1描述了用于生产EPA的优化的重组菌株,并且展示了占总脂肪酸55.6%的EPA的生产。美国专利申请公开2010-0317072-A1描述了进一步优化的重组解脂耶氏酵母菌株,其产生包含占TFA至多50%的EPA的微生物油,并且具有以TFA的重量百分比测量的EPA对以TFA的重量百分比测量的亚油酸至少3.1的比率。转化的解脂耶氏酵母表达用于生产PUFA的去饱和酶(即,Δ12去饱和酶、Δ6去饱和酶、Δ8去饱和酶、Δ5去饱和酶、Δ17去饱和酶、Δ15去饱和酶、Δ9去饱和酶、Δ4去饱和酶)和延伸酶(即,C14/16延伸酶、C16/18延伸酶、C18/20延伸酶、C20/22延伸酶和Δ9延伸酶)基因的多种组合。然而,在全部这些方法中,PUFA的生产是使用以葡萄糖作为碳源生长的含油酵母展示的。
表3提供了关于上文引用的参考文献中描述的一些具体解脂耶氏酵母菌株的信息,其中所述菌株具有去饱和酶和延伸酶的多种组合,尽管应当认识到,上述具体的菌株和所产生的具体的PUFA(或它们的量)不以任何方式对本发明构成限制。


当以蔗糖作为碳源生长时,类胡萝卜素也被预期作为能够在转化的解脂耶氏酵母中产生的所关注的适合的非天然产物。如本文所用,术语“类胡萝卜素”指一类具有形式上来源于异戊二烯的共轭聚烯碳骨架的烃。这类分子由三萜[“C30diapocarotenoids”]和四萜[“C40类胡萝卜素”]以及它们的氧化衍生物;并且,这些分子通常具有强的光吸收性能,并且长度范围可超过C200。已知其它“类胡萝卜素化合物”的长度为例如C35、C50、C60、C70和C80。术语“类胡萝卜素”可包括胡萝卜素和叶黄素。“胡萝卜素”指烃类胡萝卜素(例如,八氢番茄红素、β-胡萝卜素和番茄红素)。与之相比,术语“叶黄素”指C40类胡萝卜素,其包含羟基-、甲氧基-、氧代-、环氧化物-、羧基-、或醛基官能基团形式的一个或多个氧原子。叶黄素比胡萝卜素的极性更强并且这一特性显著地降低了它们在脂肪和脂质中的溶解度。因此,类胡萝卜素的适合的例子包括:花药黄质、金盏花红素、金盏花黄质、虾青素(即,3,3'-二羟基-β,β-胡萝卜素-4,4'-二酮)、角黄素(即,β,β-胡萝卜素-4,4'-二酮)、辣椒红素、β-隐黄素、α-胡萝卜素、β,ψ-胡萝卜素、δ-胡萝卜素、ε-胡萝卜素、β-胡萝卜素酮基-γ-胡萝卜素、海胆酮、3-羟基海胆酮、3'-羟基海胆酮、γ-胡萝卜素、ψ-胡萝卜素、ζ-胡萝卜素、玉米黄质、金盏花红素、四羟基-β,β'-胡萝卜素-4,4'-二酮、四羟基-β,β'-胡萝卜素-4-酮基、眉藻黄素、红黄质、念珠藻黄素、屈曲黄素、3-羟基-γ-胡萝卜素、3-羟基-4-酮基-γ-胡萝卜素、细菌玉红黄质、细菌玉红黄质醛、4-酮基-γ-胡萝卜素、α-隐黄素、脱氧屈曲黄素、硅藻黄质、7,8-双脱氢虾青素、双脱氢番茄红素、岩藻黄质、岩藻黄醇、异胡萝卜素、β-异胡萝卜素、莴苣黄素、叶黄素、番茄红素、粘细菌酮、新黄质、链孢红素、羟基链孢红索、多甲藻素、八氢番茄红素、六氢番茄红素、紫菌红素乙、紫菌红素乙葡糖苷、4-酮基-玉红黄质、管藻黄质、球形烯、球形烯醇、螺菌黄素、圆酵母素、4-酮基-圆酵母素、3-羟基-4-酮基-圆酵母素、尿酸酯、乙酸尿酸酯、紫黄质、玉米黄质-β-二葡糖苷、以及它们的组合。
野生型解脂耶氏酵母通常不是合成类胡萝卜素的。然而,国际申请公开WO2008/073367和WO2009/126890描述了在重组解脂耶氏酵母中经由导入类胡萝卜素生物合成途径基因产生一组类胡萝卜素,所述基因例如编码香叶基香叶基焦磷酸合酶的crtE、编码八氢番茄红素合酶的crtB、编码八氢番茄红素去饱和酶的crtI、编码番茄红素环化酶的crtY、编码类胡萝卜素羟化酶的crtZ和/或编码类胡萝卜素酮醣的crtW。
当以蔗糖作为碳源生长时,能够在转化的解脂耶氏酵母中产生的其它所关注的非天然产物包括,例如,奎宁衍生的化合物、甾醇和白藜芦醇。术语“至少一种醌衍生的化合物”是指具有氧化还原活性的醌环结构的化合物,并且包括选自下列的化合物:CoQ系列的醌(即,Q6、Q7、Q8、Q9和Q10)、维生素K化合物、维生素E化合物、以及它们的组合。例如,术语辅酶Q10[“CoQ10”]指2,3-二甲氧基-二甲基-6-十异戊二烯-1,4-苯醌,也称为泛醌-10(CAS登记号303-98-0)。CoQ10的苯醌部分从酪氨酸合成,而异戊二烯侧链通过甲羟戊酸途径从乙酰-CoA合成。因此,CoQ化合物如CoQ10的生物合成需要NADPH。“维生素K化合物”包括例如甲基萘醌或叶绿醌,而维生素E化合物包括例如生育酚、生育三烯酚或α-生育酚。术语“白藜芦醇”是指3,4’,5-三羟基二苯乙烯。
美国专利申请公开2009/0142322-A1和WO 2007/120423描述了在解脂耶氏酵母中经由导入异源醌生物合成途径基因产生多种醌衍生的化合物,所述基因例如编码十异戊二烯二磷酸合成酶以产生辅酶Q10的ddsA、编码MenF、MenD、MenC、MenE、MenB、MenA、UbiE、和/或MenG多肽以产生维生素K化合物的基因、以及编码tyrA、pdsl(hppd)、VTEl、HPT1(VTE2)、VTE3、VTE4、和/或GGH多肽以产生维生素E化合物的基因等。国际申请公开WO 2008/130372描述了在解脂耶氏酵母中经由导入编码角鲨烯合酶的ERG9/SQS1和编码角鲨烯环氧酶的ERGl产生甾醇。并且美国专利7,772,444描述了在解脂耶氏酵母中经由导入编码白藜芦醇合酶的基因产生白藜芦醇。
转化的宿主细胞在使嵌合基因(例如,编码转化酶,使得能够生物合成所关注的非天然产物的基因等等)的表达最优化的条件下生长。一般来讲,可被优化的培养基条件包括:碳源的类型和量、氮源的类型和量、碳氮比、不同矿物离子的量、氧水平、生长温度、pH、生物量生产期的时长、油积聚期的时长以及细胞收获的时间和方法。含油酵母通常生长在复合培养基(如酵母提取物-蛋白胨-葡萄糖液体培养基[“YPD”])或缺乏生长所必需的成分并由此强迫选择所需表达盒的确定成分的基本培养基中(如Yeast Nitrogen Base(DIFCO Laboratories,Detroit,MI))。
本发明的发酵培养基包含可发酵的碳源。所述可发酵的碳源能够是,例如,蔗糖、转化蔗糖、葡萄糖、果糖、以及它们的组合。本文中转化蔗糖是指包含大约相等份数的从蔗糖水解而来的果糖和葡萄糖的混合物。转化蔗糖可以是包含25至50%葡萄糖和25至50%果糖的混合物,不过转化蔗糖还可包含蔗糖,蔗糖的量取决于水解的程度。转化蔗糖可通过蔗糖的水解获得,其能够是从多种来源如甘蔗或甜菜获得的。蔗糖向葡萄糖和果糖的水解能够由酸(例如,柠檬酸或抗坏血酸的添加)或由酶(例如,转化酶或β-呋喃果糖苷酶)催化,如本领域中已知的。
在一些实施例中,本文所公开的解脂耶氏酵母生长于在其它糖类的存在下包含蔗糖(“混合糖”)的培养基中。所述混合糖在蔗糖之外还包括至少一种附加的糖。可提供能量源供解脂耶氏酵母细胞代谢的任何糖,或存在于包含蔗糖的混合物中的任何糖均可被包括。然而,与野生型解脂耶氏酵母细胞一样,本文所公开的利用蔗糖的解脂耶氏酵母依然能够用葡萄糖作为唯一碳源。
另外,发酵培养基包含适当的氮源。氮可得自无机(例如(NH4)2SO4)或有机(例如尿素、谷氨酸、或酵母提取物)来源。除了蔗糖和氮源之外,所述发酵培养基还包含适当的矿物、盐、辅因子、缓冲剂、维生素和本领域的技术人员已知适合微生物的生长的其它组分。
本发明中优选的生长培养基是普通的商业制备的培养基,例如YeastNitrogen Base(DIFCO Laboratories,Detroit,MI)。也可以使用其它确定的或合成的生长培养基,微生物学或发酵科学领域的技术人员将知道用于具体微生物生长的合适培养基。适于发酵的pH范围通常介于约pH4.0至pH8.0之间,其中优选将pH5.5至pH7.5作为初始生长条件的范围。发酵可以在有氧或厌氧条件下进行,其中优选微氧条件。
通常,在含油酵母细胞中积聚高水平的PUFA需要包括两个阶段的发酵过程,因为代谢状态应当在生长和脂肪的合成/贮存之间达到“平衡”。因此,最优选的是,两阶段的发酵过程被用于在含油酵母中生产PUFA。这种方法在美国专利7,238,482中有所描述,其也描述了多种合适的发酵工艺设计(即分批式、分批补料式和连续式)和生长过程中的注意事项。
实例
本发明将在下面的实例中得到进一步阐述。应该理解,这些实例尽管说明了本发明的优选实施例,但仅是以例证的方式给出的。根据上面的论述和这些实例,本领域的技术人员能够确定本发明的基本特征,并且在不脱离其实质和范围的情况下,能够对本发明做出各种变化和修改以使其适用于各种用法和条件。
缩写的含义如下:“sec”表示秒,“min”表示分钟,“h”表示小时,“d”表示天,“μL”表示微升,“mL”表示毫升,“L”表示升,“μM”表示微摩尔浓度,“mM”表示毫摩尔浓度,“M”表示摩尔浓度,“mmol”表示毫摩尔,“μmole”表示微摩尔,“g”表示克,“μg”表示微克,“ng”表示纳克,“U”表示单位,“bp”表示碱基对并且“kB”表示千碱基对。
表达盒的命名
表达盒的结构通过简单的记号系统“X::Y::Z”表示,其中X描述启动子片段,Y描述基因片段而Z描述终止子片段,它们均彼此可操作地连接。
解脂耶氏酵母的转化和培养
解脂耶氏酵母菌株ATCC20362购自美国典型培养物保藏中心(Rockville,MD)。解脂耶氏酵母菌株通常是在根据下面所示的配方的数种培养基中于28-30℃生长的。
高葡萄糖培养基[“HGM”](每升):80葡萄糖,2.58g KH2PO4和5.36g K2HPO4,pH7.5(不需要调节)。
高蔗糖培养基[“HSM”](每升):80蔗糖,2.58g KH2PO4和5.36gK2HPO4,pH7.5(不需要调节)。
合成右旋糖培养基[“SD”](每升):6.7g酵母氮源(Yeast Nitrogenbase),含硫酸铵并且不含氨基酸;20g葡萄糖。
合成蔗糖培养基[“SS”](每升):6.7g酵母氮源,含硫酸铵并且不含氨基酸;20g蔗糖。
发酵培养基[“FM”](每升):6.7g/L YNB,不含氨基酸;6g/LKH2PO4;2g/L K2HPO4;1.5g/L MgSO4-七水合物;5g/L酵母提取物;2%碳源(其中所述碳源是葡萄糖或蔗糖)。
解脂耶氏酵母的转化如美国专利申请公开2009-0093543-A1所述进行,其以引用方式并入本文。
解脂耶氏酵母的脂肪酸分析
为了进行脂肪酸[“FA”]分析,将细胞通过离心收集并提取脂质,如Bligh,E.G.&Dyer,W.J.(Can.J.Biochem.Physiol.,37:911-917(1959))所述。通过将脂质提取物与甲醇钠进行酯交换反应而制备脂肪酸甲酯[“FAME”](Roughan,G.和Nishida I.,Arch Biochem Biophys.,276(1):38-46(1990))并随后将其用配有30m×0.25mm(内径)HP-INNOWAX(Hewlett-Packard)柱的Hewlett-Packard6890气相色谱仪(GC)进行分析。炉温以3.5℃/分钟从170℃(保持25分钟)升到185℃。
为了进行直接的碱催化酯交换反应,收获耶氏酵母细胞(0.5mL培养物),在蒸馏水中洗涤一次,并在Speed-Vac中在真空下干燥5-10分钟。将甲醇钠(100μl,1%)和已知量的C15:0三酰基甘油(C15:0TAG;目录号T-145,Nu-Check Prep,Elysian,MN)加入样品,然后涡旋振荡并于50℃摇动样品30分钟。加入3滴1M NaCl和400μl己烷,然后涡旋振荡并旋转样品。移除上层并用GC进行分析。
作为另外一种选择,Lipid Analysis,William W.Christie,2003中描述的修改的碱催化酯交换方法被用于对来自发酵或烧瓶样品的肉汤样品的常规分析。具体地,在室温的水中使肉汤样品迅速解冻,然后称量(0.1mg)至带有0.22μm 离心管过滤器(目录号8161)的涂焦油的2mL微量离心管中。根据先前测定的DCW,使用了样品(75-800μl)。用Eppendorf5430离心机,以14,000rpm离心样品5-7分钟或移除肉汤所需的时间长度。移除过滤器,倒出液体,加入~500μl去离子水至过滤器中洗涤样品。离心除去水后,再次移出过滤器,倒出液体并重新插入过滤器。然后将管子重新插入离心机中,这一次保持盖子打开,离心~3-5分钟进行干燥。然后在管子上方大约1/2处切开过滤器,并插入新的2mL圆底Eppendorf管(目录号2236335-2)。
离心管过滤器(目录号8161)的涂焦油的2mL微量离心管中。根据先前测定的DCW,使用了样品(75-800μl)。用Eppendorf5430离心机,以14,000rpm离心样品5-7分钟或移除肉汤所需的时间长度。移除过滤器,倒出液体,加入~500μl去离子水至过滤器中洗涤样品。离心除去水后,再次移出过滤器,倒出液体并重新插入过滤器。然后将管子重新插入离心机中,这一次保持盖子打开,离心~3-5分钟进行干燥。然后在管子上方大约1/2处切开过滤器,并插入新的2mL圆底Eppendorf管(目录号2236335-2)。
用仅接触切开的过滤器容器边缘而不接触样品或过滤材料的适当的工具将过滤器推至管子的底部。加入已知量的C15:0TAG(同上)甲苯溶液和500μl新鲜制备的1%甲醇钠的甲醇溶液。用适当的工具将样品沉淀块用力捣碎,盖上管子并置于50℃加热块(VWR目录号12621-088)中30分钟。然后使管子冷却至少5分钟。然后,加入400μl己烷和500μl1M NaCl水溶液,涡旋振荡管子2×6秒并离心1分钟。将大约150μl上层(有机层)置于带有插入件的GC小瓶中,并通过GC进行分析。
经由GC分析记录的FAME峰值在与已知脂肪酸进行比较时通过它们的保留时间进行鉴定,并且通过比较FAME与已知量的内部标准品(C15:0TAG)的峰面积进行定量。因此,根据下式计算任何脂肪酸FAME的近似量(μg)[“μg FAME”]:(特定脂肪酸的FAME峰的面积/标准品FAME峰的面积)*(标准品C15:0TAG的μg数),而任何脂肪酸的量(μg)[“μg FA”]根据下式计算:(特定脂肪酸的FAME峰的面积/标准品FAME峰的面积)*(标准品C15:0TAG的μg数)*0.9503,因为1μg的C15:0TAG等于0.9503μg脂肪酸。注意:0.9503的转换因子是大多数脂肪酸测定的近似值,其范围介于0.95和0.96之间。
通过用单个FAME峰面积除以所有FAME峰面积的总数并乘以100,确定了总结以占TFA的重量%表示的每种单独的脂肪酸的量的脂质特征。
通过烧瓶检测法对解脂耶氏酵母中总脂质含量和组成的分析
为了详细分析在解脂耶氏酵母的特定菌株中的总脂质含量和组成,如下进行了烧瓶检测分析。具体而言,一个接种环的新鲜划线的细胞被接种至3mL FM培养基,并于30℃以250rpm培养过夜。测量OD600nm,在125mL烧瓶中,加入一个等分试样的细胞,使得25mL FM培养基中最终的OD600nm为0.3。在30℃振荡培养箱中以250rpm培养2天后,通过离心收集6mL培养物,并在125mL烧瓶中重悬于25mL HGM中。30℃振荡培养箱中以250rpm培养5天后,使用1mL等分试样进行脂肪酸分析(参见上文),并且干燥10mL用于干细胞重量[“DCW”]测定。
就DCW测定而言,通过在Beckman GS-6R离心机的Beckman GH-3.8转子中以4000rpm离心5分钟,收集了10mL培养物。沉淀被重悬于25mL水中,并如上文所述重新收集。将洗涤后的沉淀物重悬在20mL水中并转移到预先称过重的铝盘上。在80℃的真空炉中干燥上述细胞悬浮液过夜。测定细胞的重量。
计算细胞总脂质含量[“TFA%DCW”],并且将其与列表显示以TFA%重量[“%TFA”]表示的每种脂肪酸浓度和以干细胞重量百分比表示的EPA含量[“EPA%DCW”]的数据综合考虑。
实例1
解脂耶氏酵母胞外转化酶表达质粒pZSUC的构建和表达
本实例描述了包含XPR2启动子和信号序列与编码转化酶的啤酒糖酵母SUC2[“m-ScSuc2”]基因的截短变体融合的质粒pZSUC(SEQ ID NO:22),以与Nicaud等人在Current Genetics(16:253-260(1989))中所报道的相似的方式的构建。
更具体地,Nicaud等人报道了当在启动子和解脂耶氏酵母XPR2基因的N-末端氨基酸信号序列的控制下表达啤酒糖酵母SUC2基因时,转化酶向解脂耶氏酵母周质中的分泌。在其中(第257页)表述到,“融合将来自XPR2基因的23个N-末端氨基酸放在转化酶前面,从氨基酸十一开始”(即,全长转化酶的前10个氨基酸因此被截去,而信号序列的氨基酸11-19被包括在将被表达的成熟蛋白质内)。然而,根据Nicaud等人的图1B(第255页),似乎融合构建体反而包括来自XPR2基因的23个N-末端氨基酸作为信号序列,其融合至转化酶,从氨基酸五开始(即,全长转化酶的前4个氨基酸因此被截去,而信号序列的氨基酸5-19被包括在将被表达的成熟蛋白质内)。尽管关于该融合的信息模糊,Nicaud等人报道了其转化酶的表达在转化的解脂耶氏酵母中赋予了利用蔗糖(Suc+)的表型。
以与Nicaud等人(上文)的相似的方式制备了XPR2::SUC2融合构建体(“pZSUC”;图2)。首先,使用耶氏酵母基因组DNA作为模板,并以寡核苷酸YL427和YL428(SEQ ID NO:36和37)作为引物,通过PCR扩增了包含369bp XPR启动子(-369至-1)加上63bp编码区(+1至+63)的432bp DNA片段。在所设计的PCR片段的5'端添加了ClaI位点,在3'端添加了HindIII位点(SEQ ID NO:38)。PCR扩增以50μl总体积进行,它包含:PCR缓冲液(包含10mM KCl、10mM(NH4)2SO4、20mM Tris-HCl(pH8.75)、2mM MgSO4、0.1%Triton X-100)、100μg/mL BSA(最终浓度)、各200μM的脱氧核糖核苷酸三磷酸腺苷、每种引物10pmole、50ng解脂耶氏酵母(ATCC76982)基因组DNA和1μl的Taq DNA聚合酶(Epicentre Technologies)。将热循环仪的条件设定为35个循环的95℃1分钟、56℃30秒、和72℃1分钟,然后在72℃进行10分钟的最终延伸反应。
使用Qiagen PCR纯化试剂盒(Valencia,CA)纯化了PCR产物,然后用ClaI/HindIII消化;通过在1%(w/v)琼脂糖中的凝胶电泳分离了消化的产物,并将ClaI/HindIII片段用于构建pZSUC(下文)。
使用啤酒糖酵母基因组DNA作为模板,并用寡核苷酸YL429和YL430(SEQ ID NO:39和40)作为引物,通过PCR扩增了包含除前10个氨基酸之外的啤酒糖酵母SUC2编码区的1569bp DNA片段。在SUC2编码区的相同的阅读框的5'端添加了HindIII位点,并在SUC2编码区的终止密码子之后添加了BsiWI位点(SEQ ID NO:41)。除了50ng的啤酒糖酵母基因组DNA代替50ng解脂耶氏酵母(ATCC76982)基因组DNA被使用之外,在包含上文所示的组分的50μl总体积中进行了PCR扩增。将热循环仪的条件设定为35个循环的95℃1分钟、56℃30秒、和72℃2分钟,然后在72℃进行10分钟的最终延伸反应。
使用Qiagen PCR纯化试剂盒(Valencia,CA)纯化了PCR产物,然后用HindIII/BsiWI消化;通过在1%(w/v)琼脂糖中的凝胶电泳分离了消化的产物,并将HindIII/BsiWI片段用于构建pZSUC(下文)。
如此,质粒pZSUC2包含下列组分。
表4:质粒pZSUC2的描述

然后,表达质粒pZSUC(SEQ ID NO:22)被转入了解脂耶氏酵母ATCC76982,以测试转化酶的表达。使转化体在合成蔗糖培养基[“SS”]上生长。然而,转化的解脂耶氏酵母菌株不能在蔗糖培养基上生长。
在pZSUC中的XPR2::SUC2融合构建体中,XPR2编码序列(即,前导/前体-区域)的前63bp被用作“信号序列”,并且SUC2基因缺失了前30个核苷酸(即,移除了SUC2信号序列的前10个氨基酸)。在仔细研究了Nicaud等人的描述之后,我们意识到,他们使用了高压蒸汽处理的蔗糖培养基来测试工程化改造的菌株的生长。高压蒸汽处理过程能够使蔗糖水解为果糖和葡萄糖,它们能够被解脂耶氏酵母用作碳源(数据未显示)。
本实例中显示的数据证明,如Nicaud等人所述的表达解脂耶氏酵母XPR2的N-末端21个氨基酸融合至ScSuc2的截短的变体的融合的转化的解脂耶氏酵母菌株,不能使用蔗糖作为碳源。据报道,Suc2信号序列的疏水核心与正确的分泌过程相关联,并且其破坏导致了转化酶在细胞内的积聚(Kaiser和Botstein,Mol.Cell Biol.,6;2382-2391(1986);Perlman等人,Proc.Natl.Acad.Sci.U.S.A.,83:5033-5037(1986))。
实例2
解脂耶氏酵母胞外转化酶表达质粒:pYRH68、pYRH69、pYRH70、
pYRH73和pYRH74的构建
本实例描述了包含XPR2前导前体-区域[“XPR2PP+13”]和/或SUC2信号序列[“Suc2SS”]融合至编码转化酶的“成熟的”啤酒糖酵母SUC2[“m-ScSuc2”]基因的多种不同组合的一系列质粒的构建。每一构建体中的异源性基因侧翼为强的解脂耶氏酵母启动子(FBAINm;参见美国专利7,202,356)和解脂耶氏酵母Pex20终止子序列。
包含SucSS/m-ScSUC2的pYRH68的构建
构建了质粒pYRH68以过表达融合至编码转化酶的“成熟的”ScSUC2基因(“m-ScSUC2”;SEQ ID NO:4)的Suc2信号序列(“SucSS”;SEQ ID NO:8)。然而,本文中作为SucSS/m-ScSUC2描述的该人工融合相当于天然地包含5'信号序列的野生型全长ScSUC2基因。
使用引物Sc.SUC2-5'(SEQ ID NO:23)和Sc.SUC2-3'(SEQ ID NO:24),从啤酒糖酵母BY4743(Open Biosystems,Huntsville,AL)的基因组DNA扩增了编码ScSUC2ORF的1.6kB片段。这些引物被设计为在氨基酸位点2引入PciI限制性酶位点(从而将野生型的Leu2残基改变为Phe2,维持了信号序列的疏水性,而没有影响Suc2的分泌过程[Kaiser等人,Science,235:312-317(1987)])。反应混合物包含1μl的基因组DNA,每种引物各1μl,2μl水,和45μl AccuPrimeTM Pfx SuperMix(Invitrogen;Carlsbad,CA)。扩增如下进行:94℃5分钟进行初始变性,随后在进行35个循环的94℃变性15秒,55℃退火30秒,和68℃延伸2分钟。68℃进行了7分钟的最终延伸循环,然后在4℃终止反应。用PciII/NotI限制性酶消化了ScSUC2ORF,并用于构建质粒pYRH68(图3A;SEQ ID NO:13),其包含下列组分(NcoI和PciI是同裂酶):
表5:质粒pYRH68的描述
包含两个拷贝的SucSS/m-ScSUC2的pYRH70的构建
构建了质粒pYRH70,以表达两个拷贝的SucSS/m-ScSUC2(SEQ IDNO:12),其相当于两个拷贝的天然地包含5'-信号序列的野生型全长ScSUC2基因。用SalI/SwaI切割了质粒pYRH68(SEQ ID NO:13),以插入第二个拷贝的1.6kB PciII/NotI ScSUC2片段。具体地,准备了四元连接,包括:1)pYRH68载体主链;2)PciII/NotI消化的ScSUC2片段;3)从质粒pZKLY-PP2(SEQ ID NO:25;描述于美国专利公开2011-0244512-A1)切下的包含解脂耶氏酵母FBA启动子(美国专利7,202,356)的533bpSalI/NcoI-片段;和,4)包含来自耶氏酵母Lip1基因(GenBank登录号Z50020)的Lip1终止子序列的322bp NotI/SwaI-片段,同样是从pZKLY-PP2(SEQ ID NO:25)切下的。这导致了pYRH70(图3B;SEQ ID NO:14)的合成。
包含m-ScSUC2而不含XPR2PP+13或SUC2SS的pYRH73的构建
构建了质粒pYRH73,以过表达编码转化酶的“成熟的”ScSUC2基因(“m-ScSUC2”;SEQ ID NO:4),其缺少Suc2信号序列(“SucSS”;SEQ ID NO:8)。如此,SucSS的5’-信号序列(对应于SEQ ID NO:2的核苷酸1至57)被从天然地包含5'-信号序列的野生型全长ScSUC2基因截下。使用引物Sc.SUC2-5'(SEQ ID NO:23)和nSc.SUC2-3'(SEQ ID NO:26),从啤酒糖酵母BY4743的基因组DNA扩增了跨越成熟的ScSUC2基因的1.55kB片段。然后用PciII/NotI切割了上述片段,并以与上文所述相同的方式克隆进解脂耶氏酵母载体,以构建质粒pYRH73(图4A;SEQ IDNO:15)。
包含XPR2PP+13/SucSS/m-ScSUC2的pYRH69的构建
构建了质粒pYRH69,以过表达融合至编码转化酶的“成熟”ScSUC2基因(“m-ScSUC2”;SEQ ID NO:4)的融合了SUC2信号序列[“Suc2SS”;SEQ ID NO:8]的XPR2前导前体-区域[“XPR2PP+13”;SEQ ID NO:10]。如前文关于pYRH68所述的,然而,本文中作为SucSS/m-ScSUC2描述的人工融合相当于天然地包含5'信号序列的野生型全长ScSUC2基因。因此,本文中作为XPR2PP+13/SucSS/m-ScSUC2描述的并且如SEQ ID NO:16和17所示的该特定构建体实际上将XPR2PP+13融合至全长的ScSUC2基因。
如上文所讨论的,SEQ ID NO:10的XPR2PP+13区域被设计为编码SEQ ID NO:6的氨基酸1-170,从而在前导前体-区域之后编码了Xpr2的附加的13个氨基酸,以确保Xpr6肽链内切酶能够接近Lys156-Arg157裂解位点。
首先,以与上文中质粒pYRH68的构建中所采用的相同的方式,扩增了编码全长ScSUC2ORF的1.6kB片段,并用PciI/NotI切割。然后,使用引物Yl.XPR2-5'(SEQ ID NO:27)和Yl.XPR2-3'(SEQ ID NO:28),从解脂耶氏酵母ATCC20362的基因组DNA扩增了编码解脂耶氏酵母XPR2基因的N-末端170个氨基酸(即,包括157个氨基酸的前导前体区域加上成熟AEP蛋白质的N-末端13个氨基酸)的片段(即,SEQ ID NO:9加上对应于NcoI和PciI限制性酶的旁侧序列)。消化之后,产生了PciI/NcoI消化的513bp XPR2PP+13片段。
由于PciI和NcoI消化的端是相容的,所述PciI/NcoI消化的513bpXPR2PP+13片段和所述1.6kB PciI/NotI消化的ScSUC2片段被插入PciI/NotI消化的pYRH68主链,以构建pYRH69(图4B;SEQ ID NO:18)。验证了PciI/NcoI消化的513bp XPR2PP+13片段的取向。
用引物Yl.XPR2-5'(SEQ ID NO:27)和Yl.XPR2-3'(SEQ ID NO:28)对pYRH69的测序确认了解脂耶氏酵母ATCC20362的如SEQ ID NO:9所示的XPR2PP+13序列与已公开的XPR2序列(Matoba,S.等人,Mol.Cell Biol.,8:4904-4916(1988))是100%相同的。
包含XPR2PP+13/m-ScSUC2的pYRH74的构建
构建了质粒pYRH74,以过表达融合至编码转化酶的“成熟”ScSUC2基因(“m-ScSUC2”;SEQ ID NO:4)的XPR2前导前体-区域[“XPR2PP+13”;SEQ ID NO:10]。
使用引物Sc.SUC2-5'(SEQ ID NO:23)和nSc.SUC2-3'(SEQ ID NO:24),从啤酒糖酵母BY4743的基因组DNA扩增了跨越成熟的ScSUC2基因的1.55kB片段。
具体地,如上文关于质粒pYRH73和质粒pYRH69所述,分别制备了包含成熟的ScSUC2基因的1.55kB PciI/NotI片段和513bp PciI/NcoIXPR2PP+13片段。这些片段被一起与pYRH68主链连接,以构建质粒pYRH74(图5;SEQ ID NO:21)。
实例3
质粒pYRH68、pYRH69、pYRH70、pYRH73和pYRH74在以蔗糖或
葡萄糖作为唯一碳源生长的解脂耶氏酵母中的转化和表达
用AscI/SphI单独地消化了质粒pYRH68、pYRH69、pYRH70、pYRH73、和pYRH74,用于转入解脂耶氏酵母菌株Y4184U(实例5)和解脂耶氏酵母菌株Z1978U(实例6),这两种菌株均被工程化以产生显著量的EPA%TFA。使转化体在包含蔗糖或葡萄糖作为唯一碳源的多种培养基上生长。
具体地,首先在缺少尿嘧啶的SD培养基平板上选择了转化体(一般方法)。产生了多种Y4184U和Z1978U转化体,如下文表6中所述。
表6:过表达胞外转化酶的解脂耶氏酵母的Y4184U和Z1978转化体
菌株

在SD(即,葡萄糖)和SS(即,蔗糖)培养基中比较了菌株Y4184U+Suc2SS/m-ScSUC2和Y4184(对照)的生长。为了避免蔗糖水解,通过过滤而不是通过高压蒸汽处理对培养基进行了除菌。具体地,细胞以0.03的OD600被接种,并在30℃生长。如图6所示,Y4184U+Suc2SS/m-ScSUC2菌株在蔗糖中生长得非常好,而对照菌株Y4184没能以蔗糖作为唯一碳源生长。当提供了葡萄糖作为唯一碳源时,两种菌株相似地生长。菌株Y4184U+XPR2PP+13/Suc2SS/m-ScSUC2在蔗糖中也没有生长(数据未显示);据推测,两种不同的信号序列可能彼此干扰并妨碍了分泌过程。
然后,在包含蔗糖或者包含葡萄糖作为唯一碳源的FM中比较了菌株Z1978U+Suc2SS/m-ScSUC2、Z1978U+2_Suc2SS/m-ScSUC2、Z1978U+m-ScSUC2、Z1978U+XPR2PP+13/Suc2SS/m-ScSUC2、Z1978+XPR2PP+13/m-ScSUC2和Z1978(对照)的生长。为了避免蔗糖水解,通过过滤而不是通过高压蒸汽处理对培养基进行了除菌。细胞以0.03的OD600被接种,并在30℃生长。在以葡萄糖作为唯一碳源的FM中,全部的菌株差不多地生长(图7A)。在以蔗糖作为唯一碳源的FM中(图7B),菌株Z1978U+Suc2SS/m-ScSUC2、Z1978U+2_Suc2SS/m-ScSUC2和Z1978+XPR2PP+13/m-ScSUC2生长得非常好,但是Z1978U+m-ScSUC2、Z1978U+XPR2PP+13/Suc2SS/m-ScSUC2和Z1978(对照)生长得很少;事实上,残余的生长能够是由于细胞使用酵母提取物作为碳源的能力。
因此,Suc2SS/m-ScSUC2(SEQ ID NO:12)和XPR2PP+13/m-ScSUC2(SEQ ID NO:20)的过表达导致了能够在以蔗糖作为唯一碳源的培养基中生长的转化的解脂耶氏酵母菌株。
实例4
以蔗糖或葡萄糖作为唯一碳源生长的转化的解脂耶氏酵母中的脂质含
量和组成
本实例测试了当在包含蔗糖作为唯一碳源的培养基中生长时,过表达啤酒糖酵母胞外转化酶的Z1978菌株(即,菌株Z1978U+Suc2SS/m-ScSUC2、Z1978U+2_Suc2SS/m-ScSUC2和Z1978+XPR2PP+13/m-ScSUC2)中的脂质含量和组成。在这些菌株中积聚的脂质的水平和组成与以葡萄糖作为唯一碳源生长的对照菌株的是差不多的。
为了评估菌株Z1978U+Suc2SS/m-ScSUC2中蔗糖的利用对总脂质含量和脂肪酸组成的影响,使该菌株的重复的培养物在差不多的含油的条件下在HSM(蔗糖作为唯一碳源)中生长,如“一般方法”中所述。因此,将Z1978U+Suc2SS/m-ScSUC2的两份培养物(分别命名为培养物RHY243和RHY244),与在差不多的含油的条件下在HSM(葡萄糖作为唯一碳源)中生长的对照菌株Z1978的平行双样进行了比较。更具体地,通过首先于30℃在25mL的SD或SS培养基中有氧地培养所述培养物48小时,然后通过离心收集,实现了含油的条件。然后将沉淀物重悬在25mL的HGM或HSM中,并将培养物在250rpm和30℃的振荡培养箱中进一步孵育5天。
上述菌株的干细胞重量[“DCW”]、细胞的总脂质含量[“TFA%DCW”]、以占TFA的重量百分比计的每种脂肪酸的浓度[“%TFA”]和EPA产量(即,以其占干细胞重量的百分比计的EPA含量[“EPA%DCW”])显示在下文的表7中,平均值以灰色高亮显示并标记为“平均值”。脂肪酸的缩写如下:油酸(18:1)、亚油酸(18:2)、和二十碳五烯酸(“EPA”,20:5)。
表7:Z1978(在葡萄糖上生长)和Z1978U+Suc2SS/m-ScSUC2(在蔗
糖上生长)的脂质含量和组成

表7中的结果显示,在蔗糖上生长的菌株Z1978U+Suc2SS/m-ScSUC2的TFA%DCW与在葡萄糖上生长的菌株Z1978的是相似的。然而,当蔗糖是唯一碳源时,观察到了平均EPA%DCW的~10%的降低。
为了确定菌株Z1978U+Suc2SS/m-ScSUC2的菌株表现是否有任何变化,使RHY243(表7)一式两份地生长在作为唯一碳源的葡萄糖或蔗糖中。表8以与表7中所使用的相似的格式总结了DCW、TFA%DCW、以%TFA计的每种脂肪酸的浓度、和EPA%DCW。
表8:在葡萄糖或蔗糖上生长的Z1978U+Suc2SS/m-ScSUC2的脂质含
量和组成


表8中的结果显示,在蔗糖上生长的菌株Z1978U+Suc2SS/m-ScSUC2的TFA%DCW与相同菌株当在葡萄糖上生长时的脂质含量是相似的。然而,当蔗糖是唯一碳源时,观察到了平均EPA%DCW的~10%的降低。
还比较了当在差不多的含油条件下在HSM(以蔗糖作为唯一碳源)中生长时,Z1978U+Suc2SS/m-ScSUC2的两份培养物(即,RHY243和RHY244)、Z1978U+2_Suc2SS/m-ScSUC2的三份培养物(命名为RHY248、RHY249和RHY250)和Z1978+XPR2PP+13/m-ScSUC2的三份培养物(命名为RHY257、RHY258和RHY259)中的总脂质含量和脂肪酸组成,如“一般方法”中所述。将这些菌株与在差不多的含油条件下在HGM(以葡萄糖作为唯一碳源)中生长的对照菌株Z1978的平行双样进行了比较。
表9以与表7中所使用的相似的格式总结了DCW、TFA%DCW、以%TFA计的每种脂肪酸的浓度、和EPA%DCW。
表9:Z1978(在葡萄糖上生长)和Z1978U+Suc2SS/m-ScSUC2、
Z1978U+2_Suc2SS/m-ScSUC2和Z1978U+XPR2PP+13/m-ScSUC2(在蔗糖
上生长)的脂质含量和组成


以上结果显示,以蔗糖作为唯一碳源生长的菌株Z1978U+Suc2SS/m-ScSUC2、Z1978U+2_Suc2SS/m-ScSUC2和Z1978+XPR2PP+13/m-ScSUC2中的TFA%DCW和EPA%DCW与生长在葡萄糖中的对照菌株Z1978的TFA%DCW和EPA%DCW相差小于10%。在这三种SUC2工程化的菌株中,菌株Z1978+XPR2PP+13/m-ScSUC2具有最佳的EPA%DCW表现。全部三种表达SUC2的菌株一致地表现出比对照菌株Z1978高至多14%的最终DCW(g/L)。因此,EPA体积产量在对照菌株Z1978和工程化的利用蔗糖的菌株之间是相似的。
实例5
用于高EPA生产的解脂耶氏酵母菌株Y4184和Y4184U的构建
解脂耶氏酵母菌株Y4184U在上文的实例3中被用作宿主。菌株Y4184U来源于解脂耶氏酵母ATCC20362,能够经由表达Δ9延伸酶/Δ8去饱和酶途径产生相对于总脂质的更高的EPA。该菌株具有Ura-表型,其构建描述于PCT公开WO2008/073367的实例7中,该文献以引用方式并入本文。
菌株Y4184U的开发需要构建菌株Y2224、Y4001、Y4001U、Y4036、Y4036U、Y4069、Y4084、Y4084U1、Y4127(于2007年11月29日以登录号ATCC PTA-8802保藏于美国典型培养物保藏中心(AmericanType Culture Collection))、Y4127U2、Y4158、Y4158U1和Y4184。
相对于野生型解脂耶氏酵母ATCC20362的菌株Y4184(生产占总脂质30.7%的EPA)的最终基因型是未知1-、未知2-、未知4-、未知5-、未知6-、未知7-、YAT1::ME3S::Pex16、EXP1::ME3S::Pex20(2拷贝)、GPAT::EgD9e::Lip2、FBAINm::EgD9eS::Lip2、EXP1::EgD9eS::Lip1、FBA::EgD9eS::Pex20、YAT1::EgD9eS::Lip2、GPD::EgD9eS::Lip2、GPDIN::EgD8M::Lip1、YAT1::EgD8M::Aco、EXP1::EgD8M::Pex16、FBAINm::EgD8M::Pex20、FBAIN::EgD8M::Lip1(2拷贝)、GPM/FBAIN::FmD12S::Oct、EXP1::FmD12S::Aco、YAT1::FmD12::Oct、GPD::FmD12::Pex20、EXP1::EgD5S::Pex20、YAT1::EgD5S::Aco、YAT1::Rd5S::Oct、FBAIN::EgD5::Aco、FBAINm::PaD17::Aco、EXP1::PaD17::Pex16、YAT1::PaD17S::Lip1、YAT1::YlCPT1::Aco、GPD::YlCPT1::Aco。
上文的缩写如下:ME3S是经密码子优化的C16/18延伸酶基因,来源于高山被孢霉(Mortierella alpina)[美国专利7,470,532];EgD9e是小眼虫(Euglena gracilis)Δ9延伸酶基因[美国专利7,645,604];EgD9eS是经密码子优化的Δ9延伸酶基因,来源于小眼虫(Euglena gracilis)[美国专利7,645,604];EgD8M是合成突变Δ8去饱和酶基因[美国专利7,709,239],来源于小眼虫(Euglena gracilis)[美国专利7,256,033];FmD12是串珠镰孢菌(Fusarium moniliforme)Δ12去饱和酶基因[美国专利7,504,259];FmD12S是经密码子优化的Δ12去饱和酶基因,来源于串珠镰孢菌(Fusarium moniliforme)[美国专利7,504,259];EgD5是小眼虫(Euglenagracilis)Δ5去饱和酶[美国专利7,678,560];EgD5S是经密码子优化的Δ5去饱和酶基因,来源于小眼虫(Euglena gracilis)[美国专利7,678,560];RD5S是经密码子优化的Δ5去饱和酶,来源于多甲藻属(Peridinium sp.)CCMP626[美国专利7,695,950];PaD17是瓜果腐霉菌(Pythiumaphanidermatum)Δ17去饱和酶[美国专利7,556,949];PaD17S是经密码子优化的Δ17去饱和酶,来源于瓜果腐霉菌(Pythium aphanidermatum)[美国专利7,556,949];以及,YlCPT1是解脂耶氏酵母二酰基甘油磷酸胆碱转移酶基因[美国专利7,932,077]。
最后,为了破坏菌株Y4184中的Ura3基因,构建体pZKUE3S(PCT公开WO2008/073367,其中的SEQ ID NO:78)被用于将EXP1::ME3S::Pex20嵌合基因整合进菌株Y4184的Ura3基因,以分别产生菌株Y4184U1(占总脂质11.2%的EPA)、Y4184U2(占总脂质10.6%的EPA)和Y4184U4(占总脂质15.5%的EPA)(统称为Y4184U)。
值得注意的是,PCT公开WO2008/073367描述了由于不同的生长条件,Y4184(30.7%)对Y4184U(平均12.4%)中定量的EPA%TFA的差异。
实例6
用于高EPA生产的解脂耶氏酵母菌株Z1978和Z1978U的构建
解脂耶氏酵母菌株Z1978U在上文的实例3中被用作宿主。菌株Z1978U来源于解脂耶氏酵母ATCC20362,能够经由表达Δ9延伸酶/Δ8去饱和酶途径产生相对于总脂质的更高的EPA。该菌株具有Ura-表型,其构建描述于美国专利申请13/218,708(E.I.duPont de Nemours&Co.,Inc.,代理人档案号CL5411USNA,提交于2011年8月26日)的实例2中,该文献以引用方式并入本文。
菌株Z1978U的开发需要构建菌株Y2224、Y4001、Y4001U、Y4036、Y4036U、L135、L135U9、Y8002、Y8006、Y8006U、Y8069、Y8069U、Y8154、Y8154U、Y8269、Y8269U、Y8412(于2009年5月14日以登录号ATCC PTA-10026保藏于美国典型培养物保藏中心(AmericanType Culture Collection))、Y8412U、Y8647、Y8467U、Y9028、Y9028U、Y9502、Y9502U和Z1978。
解脂耶氏酵母菌株Y9502的基因型
菌株Y9502的制备描述于美国专利申请公开2010-0317072-A1中。菌株Y9502来源于解脂耶氏酵母ATCC20362,能够经由表达Δ9延伸酶/Δ8去饱和酶途径产生相对于总脂质约57.0%的EPA。
相对于野生型解脂耶氏酵母ATCC20362的菌株Y9502的最终基因型为Ura+、Pex3-、未知1-、未知2-、未知3-、未知4-、未知5-、未知6-、未知7-、未知8-、未知9-、未知10-、YAT1::ME3S::Pex16、GPD::ME3S::Pex20、YAT1::ME3S::Lip1、FBAINm::EgD9eS::Lip2、EXP1::EgD9eS::Lip1、GPAT::EgD9e::Lip2、YAT1::EgD9eS::Lip2、FBAINm::EgD8M::Pex20、EXP1::EgD8M::Pex16、FBAIN::EgD8M::Lip1、GPD::EaD8S::Pex16(2个拷贝)、YAT1::E389D9eS/EgD8M::Lip1、YAT1::EgD9eS/EgD8M::Aco、FBAINm::EaD9eS/EaD8S::Lip2、GPD::FmD12::Pex20、YAT1::FmD12::Oct、EXP1::FmD12S::Aco、GPDIN::FmD12::Pex16、EXP1::EgD5M::Pex16、FBAIN::EgD5SM::Pex20、GPDIN::EgD5SM::Aco、GPM::EgD5SM::Oct、EXP1::EgD5SM::Lip1、YAT1::EaD5SM::Oct、FBAINm::PaD17::Aco、EXP1::PaD17::Pex16、YAT1::PaD17S::Lip1、YAT1::YlCPT1::Aco、YAT1::MCS::Lip1、FBA::MCS::Lip1、YAT1::MaLPAAT1S::Pex16。
上文使用并且未在实例5中列出的缩写如下:EaD8S是经密码子优化的Δ8去饱和酶基因,来源于Euglena anabaena[美国专利7,790,156];E389D9eS/EgD8M是通过连接来源于小型绿藻属(Eutreptiella sp.)CCMP389(美国专利7,645,604)的经密码子优化的Δ9延伸酶基因(“E389D9eS”)与Δ8去饱和酶“EgD8M”(参见上文)[美国专利申请公开2008-0254191-A1]产生的DGLA合酶;EgD9eS/EgD8M是通过连接Δ9延伸酶“EgD9eS”(同上)与Δ8去饱和酶“EgD8M”(同上)[美国专利申请公开2008-0254191-A1]产生的DGLA合酶;EaD9eS/EgD8M是通过连接来源于E.anabaena的经密码子优化的Δ9延伸酶基因(“EaD9eS”)[美国专利7,794,701]与Δ8去饱和酶“EgD8M”(参见上文)[美国专利申请公开2008-0254191-A1]产生的DGLA合酶;EgD5M和EgD5SM是包含突变HPG基序[美国专利申请公开2010-0075386-A1]的合成突变Δ5去饱和酶基因,来源于小眼虫(Euglena gracilis)[美国专利7,678,560];EaD5SM是包含突变HaGG基序[美国专利申请公开2010-0075386-A1]的合成突变Δ5去饱和酶基因,来源于E.anabaena[美国专利7,943,365];MCS是经密码子优化的丙二酰-CoA合成酶基因,来源于豌豆根瘤菌(Rhizobiumleguminosarum)bv.viciae3841[美国专利申请公开2010-0159558-A1],以及MaLPAAT1S是经密码子优化的溶血磷脂酸酰基转移酶基因,来源于高山被孢霉(Mortierella alpina)[美国专利7,879,591]。
为对菌株Y9502中的总脂质含量和组分进行详细分析进行了烧瓶检测分析,其中细胞在总计7天中进行两阶段生长。基于分析,菌株Y9502产生了3.8g/L DCW、37.1TFA%DCW、21.3EPA%DCW,并且其脂质特征如下,其中每种脂肪酸的浓度以占TFA的重量百分比计[“%TFA”]:16:0(棕榈酸)—2.5,16:1(棕榈油酸)--0.5,18:0(硬脂酸)--2.9,18:1(油酸)--5.0,18:2(LA)—12.7,AlA—0.9,EDA—3.5,DGLA—3.3,ARA--0.8,ETrA--0.7,ETA—2.4,EPA—57.0,其它—7.5。
解脂耶氏酵母菌株Z1978的构建
菌株Z1978从菌株Y9502的开发最早描述于美国临时申请61/377248(对应于美国专利申请13/218,591)和美国临时申请61/428,277(对应于美国专利申请13/218,673)中,上述文献以引用方式并入本文。
具体地,为了破坏菌株Y9502中的Ura3基因,SalI/PacI-消化的构建体pZKUM(参见美国专利申请公开2009-0093543-A1,其中的表15、SEQID NO:133和图8A)被用于按照一般方法将Ura3突变基因整合进菌株Y9502的Ura3基因。使总计27个转化体(从包括8个转化体的第一组、包括8个转化体的第二组、和包括11个转化体的第三组中选择)生长在基本培养基+5-氟乳清酸[“MM+5-FOA”]选择性平板上并于30℃维持2至5天。MM+5-FOA包含(每升):20g葡萄糖、6.7g酵母氮源、75mg尿嘧啶、75mg尿苷,并且基于对一系列从100mg/L至1000mg/L的浓度的FOA活性试验(因为供应商提供的每批料中会发生改变),选用适量的FOA(Zymo Research Corp.,Orange,CA)。
进一步的实验确定了仅第三组转化体拥有真正的Ura-表型。
将所述Ura-细胞从该MM+5-FOA平板刮下并且根据常规方法进行脂肪酸分析。以这种方式,GC分析显示,在第三组的MM+5-FOA平板上生长的pZKUM-转化体1、3、6、7、8、10和11中分别有占TFA28.5%、28.5%、27.4%、28.6%、29.2%、30.3%和29.6%的EPA。这七个菌株分别被命名为菌株Y9502U12、Y9502U14、Y9502U17、Y9502U18、Y9502U19、Y9502U21和Y9502U22(统称为Y9502U)。
然后,构建了构建体pZKL3-9DP9N(图9;SEQ ID NO:29),以将一种Δ9去饱和酶基因、一种磷酸胆碱胞苷酰转移酶基因和一种Δ9延伸酶突变基因整合进菌株Y9502U的耶氏酵母YALI0F32131p基因座(GenBank登录号XM_506121)。因此,pZKL3-9DP9N质粒包含下列组分:
表10:质粒pZKL3-9DP9N(SEQ ID NO:29)的描述

用AscI/SphI消化pZKL3-9DP9N质粒,然后用于转化菌株Y9502U17。将转化的细胞铺在基本培养基[“MM”]平板上并在30°维持3至4天。MM平板包含(每升):20g葡萄糖、1.7g不含氨基酸的酵母氮源、1.0g脯氨酸、和pH6.1(不需要调节)。将单菌落再次划线至MM平板上,随后将其在30℃下接种至液体MM中并以250rpm/min摇动2天。通过离心收集细胞,将其重悬浮于HGM中,然后以250rpm/min摇动5天。对上述细胞进行脂肪酸分析,参见上文。
GC分析显示,所选择的96个用pZKL3-9DP9N产生的Y9502U17菌株中大多数产生占TFA50-56%的EPA。将产生了占TFA约59.0%、56.6%、58.9%、56.5%和57.6%的EPA的五个菌株(即,31、32、35、70和80)分别命名为菌株Z1977、Z1978、Z1979、Z1980和Z1981。
相对于野生型解脂耶氏酵母ATCC20362,这些pZKL3-9DP9N转化的菌株的最终基因型是:Ura+、Pex3-、未知1-、未知2-、未知3-、未知4-、未知5-、未知6-、未知7-、未知8-、未知9-、未知10-、未知11-、YAT1::ME3S::Pex16、GPD::ME3S::Pex20、YAT1::ME3S::Lip1、FBAINm::EgD9eS::Lip2、EXP1::EgD9eS::Lip1、GPAT::EgD9e::Lip2、YAT1::EgD9eS::Lip2、YAT1::EgD9eS-L35G::Pex20、FBAINm::EgD8M::Pex20、EXP1::EgD8M::Pex16、FBAIN::EgD8M::Lip1、GPD::EaD8S::Pex16(2拷贝)、YAT1::E389D9eS/EgD8M::Lip1、YAT1::EgD9eS/EgD8M::Aco、FBAINm::EaD9eS/EaD8S::Lip2、GPDIN::YlD9::Lip1、GPD::FmD12::Pex20、YAT1::FmD12::Oct、EXP1::FmD12S::Aco、GPDIN::FmD12::Pex16、EXP1::EgD5M::Pex16、FBAIN::EgD5SM::Pex20、GPDIN::EgD5SM::Aco、GPM::EgD5SM::Oct、EXP1::EgD5SM::Lip1、YAT1::EaD5SM::Oct、FBAINm::PaD17::Aco、EXP1::PaD17::Pex16、YAT1::PaD17S::Lip1、YAT1::YlCPT1::Aco、YAT1::MCS::Lip1、FBA::MCS::Lip1、YAT1::MaLPAAT1S::Pex16、EXP1::YlPCT::Pex16。
在任何这些通过用pZKL3-9DP9N转化产生的EPA菌株中,YALI0F32131p基因座(GenBank登录号XM_50612)在菌株Z1977、Z1978、Z1979、Z1980和Z1981中的敲除未被确认。
使来自菌株Z1977、Z1978、Z1979、Z1980和Z1981的YPD平板的细胞生长,并就总脂质含量和组成对它们进行了分析。具体地,如“一般方法”中所述进行了烧瓶检测。下文的表11总结了这些菌株中每一种的总脂质含量和组成(即,总DCW、TFA%DCW、以TFA的重量百分比[“%TFA”]计的每种脂肪酸的浓度和EPA%DCW)。脂肪酸是16:0(棕榈酸)、16:1(棕榈油酸)、18:0(硬脂酸)、18:1(油酸)、18:2(亚油酸)、ALA(α-亚麻酸)、EDA(二十碳二烯酸)、DGLA(二高-γ-亚麻酸)、ARA(花生四烯酸)、ETrA(二十碳三烯酸)、ETA(二十碳四烯酸)、EPA(二十碳五烯酸)以及其它的。
随后对菌株Z1978进行部分基因组测序。根据美国专利申请13/218,673所述,该项工作确定所述经工程化改造的菌株实际上仅仅具有四种Δ5去饱和酶基因(即,EXP1::EgD5M::Pex16、FBAIN::EgD5SM::Pex20、EXP1::EgD5SM::Lip1和YAT1::EaD5SM::Oct)而并非整合进耶氏酵母基因组六种Δ5去饱和酶基因(即,嵌合基因EXP1::EgD5M::Pex16、FBAIN::EgD5SM::Pex20、GPDIN::EgD5SM::Aco、GPM::EgD5SM::Oct、EXP1::EgD5SM::Lip1、YAT1::EaD5SM::Oct)。
具体地,为了破坏菌株Z1978中的Ura3基因,构建体pZKUM(参见美国专利申请公开2009-0093543-A1,其中的表15、SEQ ID NO:133和图8A)被用于以与关于菌株Y9502的pZKUM转化所述的(参见上文)相似的方式将Ura3突变基因整合进菌株Z1978的Ura3基因。使总计16个转化体(从第一个包括8个转化体的“B”组和第二个包括8个转化体的“C”组中选择)生长,并鉴定为具有Ura-表型。
GC分析显示,生长在MM+5-FOA平板上的B组pZKUM-转化体菌株1、2、3和4中分别存在占TFA30.8%、31%、30.9%和31.3%的EPA。这4种菌株分别被命名为菌株Z1978BU1、Z1978BU2、Z1978BU3和Z1978BU4。
GC分析显示,生长在MM+5-FOA平板上的C组pZKUM-转化体菌株1、2、5和6中分别存在占TFA34.4%、31.9%、31.2%和31%的EPA。这4种菌株分别被命名为菌株Z1978CU1、Z1978CU2、Z1978CU3和Z1978CU4。
菌株Z1978BU1、Z1978BU2、Z1978BU3、Z1978BU4、Z1978CU1、Z1978CU2、Z1978CU3和Z1978CU4菌株被统称为菌株Z1978U。
实例7
解脂耶氏酵母转化体中分泌的转化酶的定位
用BsiWI/PacI单独地消化了质粒pYRH68(SEQ ID NO:13,包含Suc2SS/m-ScSUC2融合)、pYRH73(SEQ ID NO:15,仅包含m-ScSUC2)、pYRH69(SEQ ID NO:18,包含XPR2PP+13/Suc2SS/m-ScSUC2融合)和/或pYRH74(SEQ ID NO:21,包含XPR2PP+13/m-ScSUC2融合),用于转入解脂耶氏酵母菌株Y2224U(来自野生型耶氏酵母菌株ATCC20362的Ura3基因的自发突变的5-氟乳清酸[“FOA”]抗性突变体)或解脂耶氏酵母菌株Z1978U(实例6)。在转化体全细胞中和从其培养基测定了转化酶活性。
转化酶活性测定
如Silveira等人(Anal.Biochem.,238:26-28(1996))所述(有一些修改)使用全细胞测定了体内转化酶活性。简而言之,通过在4℃离心收集了40mg(干细胞重量)在SD或SS培养基中指数生长的细胞(1.4-1.8的OD600),在冷的乙酸钠缓冲液(50mM,pH5.0)中洗涤三次。于30℃在8mL100mM NaF中搅拌孵育细胞15分钟。添加4mL300mM蔗糖在50mM乙酸钠缓冲液(pH5.0)中的溶液后,在使用Nanosep MF0.2μ(PallLife Sciences;Port Washington,NY)于至多10分钟的不同的时间间隔过滤之后,用葡萄糖分析仪(YSI Life Sciences)测定了转化酶活性。一个单位(U)的酶活性被定义为每分钟产生μmol的葡萄糖,计算了产量以得出每克DCW的转化酶活性单位数。
从1.5mL经过过滤的培养基测量的来自培养基的转化酶活性。为了除去样品中任何残留的糖,在4℃用0.1M乙酸盐缓冲液(pH5.0)透析样品过夜。用100μl的300mM蔗糖在50mM乙酸钠缓冲液(pH5.0)中的溶液孵育经过透析的样品(200μl)至多30分钟。通过添加50μl的1.0MK2HPO4并立即置于95℃加热块中10分钟终止反应。用葡萄糖分析仪(YSI Life Sciences)测量的转化酶活性。通过Coomassie Plus BradfordAssay试剂盒(Thermo Scientific;Rockford,IL),以牛血清白蛋白作为标准品测量了蛋白质浓度。以转化酶活性单位(U)每升培养基计算了活性,并以单位每mg蛋白质计算了比活性。计算了产量以给出转化酶活性单位数每克培养物的DCW。
转化体解脂耶氏酵母Y2224U SUC
+
菌株中的细胞外和全细胞转化酶活
性
使用培养物上清液和全细胞,分别对指数生长的细胞测量了细胞外和全细胞的转化酶活性。进行了来自两个不同的实验的至少四次检测,并报道了平均值,如下文的图12中所示。
表12:来自解脂耶氏酵母菌株Y2224U SUC
+
菌株的培养基和全细胞的
转化酶活性

与生长研究的结果相符,对用pYRH68或pYRH74转化的解脂耶氏酵母菌株,观察了来自培养物上清液和全细胞的转化酶活性。解脂耶氏酵母转化体pRH69和pRH73在蔗糖培养基上没有生长,并且没有来自生长于葡萄糖培养基中的细胞培养物的可检测的细胞外或全细胞转化酶活性。
就转化体Suc2SS/m-ScSuc2对XPR2PP+13/m-ScSuc2而言,转化酶活性是略高的。可能即使有附加的成熟Xpr2的13个氨基酸,仍然有一些二级结构妨碍了分泌信号的加工所需的肽链内切酶的接近。然而,对于两种SUC+菌株而言,超过98%的转化酶活性在培养基中被检测到,并且在培养物上清液中,观察到了比以前报道的更高的按生物质计算的胞外转化酶活性。
转化体解脂耶氏酵母菌株Y1978U SUC
+
菌株中的细胞外和全细胞转化
酶活性
在转化体全细胞中和从其培养基测定了转化酶活性。培养物在含有葡萄糖或蔗糖作为唯一碳源的YP(10g/L Bacto酵母提取物20g/L Bacto蛋白胨)培养基中生长。对于每种SUC2构建体,测试了两种不同的转化体,并报道了平均值,如下文的表13中所示。
表13:来自解脂耶氏酵母Z1978U SUC
+
菌株的培养基和全细胞的转化
酶活性

基于YP的培养基中的蛋白质浓度显著高于基于合成的培养基的那些(表12),降低了转化酶的比活性(U/mg蛋白质)。尽管如此,pRHY68转化体显示了在葡萄糖和蔗糖培养物之间相似的转化酶活性,并且超过90%的转化酶活性在培养基中被检测到。就pYRH74转化体而言,一种转化体在全部条件下显示出比另一种转化体高得多的转化酶活性。因此,平均的转化酶活性具有高的标准误差。即使如此,在以葡萄糖或蔗糖作为唯一碳源的培养基中检测到了超过90%的转化酶活性。
实例8
可公开获得的编码转化酶的基因的鉴定
所述啤酒糖酵母转化酶由SUC2基因编码,本文中列为SEQ ID NO:1。该1599bp的基因编码以糖基化形式分泌至啤酒糖酵母周质的532个氨基酸(SEQ ID NO:2)的全长转化酶。与此相比,缺少19个氨基酸长度的5'信号序列(即,由SEQ ID NO:1的核苷酸1-57编码)的“成熟的”ScSUC2基因[“m-ScSUC2”]如SEQ ID NO:3所示,并且编码SEQ ID NO:4的蛋白质。
使用编码m-ScSUC2(SEQ ID NO:4)的蛋白质序列,进行了美国国家生物技术信息中心[“NCBI”]BLASTP2.2.26+(Basic Local AlignmentSearch Tool;Altschul,S.F.等人,Nucleic Acids Res.,25:3389-3402(1997);Altschul,S.F.等人,FEBS J.,第272卷,第5101-5109页(2005))检索,以鉴定BLAST“nr”数据库(包括所有非冗余GenBankCDS区的翻译序列、蛋白质数据库[“PDB”]中的蛋白质序列数据库、SWISS-PROT蛋白质序列数据库、蛋白质信息资源[“PIR”]中的蛋白质序列数据库和蛋白质研究基金[“PRF”]蛋白质序列数据库,不包括全基因组鸟枪法[“WGS”]计划的环境样品)中的相似序列。
可根据%同一性、%相似性和期望值报告BLASTP比较的结果,所述比较概述了与SEQ ID NO:4具有最高相似性的序列。“%同一性”定义为两种蛋白质之间相同的氨基酸的百分比。“%相似性”定义为两种蛋白质之间相同的或保守的氨基酸的百分比。“期望值”用给定分值估计限定匹配数的匹配的统计显著性,该匹配数是在完全偶然地搜索数据库中这种大小片段时所预期的。
非常多的蛋白质经鉴定与m-ScSUC2(SEQ ID NO:4)具有显著的相似性。表14提供了具有大于或等于“4e-90”的期望值和将该蛋白质特别地鉴定为“转化酶”或“β-呋喃果糖苷酶”的注释的那些命中的部分摘要,不过这不应当被认为是限制了本公开。从下文报道的结果中排除了来自啤酒糖酵母的全部命中。表14中的蛋白质与SEQ ID NO:4具有介于91%至99%之间的查询覆盖度。
表14:一些可公开获得的编码转化酶的基因




































































































Claims (15)
1.转化的解脂耶氏酵母(Yarrowia lipolytica),包含编码具有蔗糖转化酶活性的多肽的外源性多核苷酸,其中:
(a)所述多肽包含与编码成熟蔗糖转化酶的多肽序列融合的信号序列;并且
(b)所述信号序列选自:
(i)Xpr2前导/前体-区域和N-末端Xpr2片段;和
(ii)蔗糖转化酶信号序列,其中所述蔗糖转化酶信号序列的第二个氨基酸能够是任何疏水性氨基酸;并且
(c)基于CLUSTALW比对方法,所述编码成熟蔗糖转化酶的多肽序列在与SEQ ID NO:4进行比较时具有至少80%的序列同一性。
2.根据权利要求1所述的转化的解脂耶氏酵母,其中所述蔗糖转化酶信号序列的第二个氨基酸选自:亮氨酸、苯丙氨酸、异亮氨酸、缬氨酸和甲硫氨酸。
3.根据权利要求1所述的转化的解脂耶氏酵母,其中所述编码成熟蔗糖转化酶的多肽序列为SEQ ID NO:4中所示的。
4.根据权利要求1所述的转化的解脂耶氏酵母,其中所述Xpr2前导/前体-区域和N-末端Xpr2片段来自解脂耶氏酵母,并且所述蔗糖转化酶信号序列来自啤酒糖酵母(Saccharomyces cerevisiae)。
5.根据权利要求4所述的转化的解脂耶氏酵母,其中所述Xpr2前导/前体-区域和N-末端Xpr2片段包括:
(a)Xpr2前导/前体-区域,其包含碱性胞外蛋白酶前体的N-末端157个氨基酸;和
(b)N-末端Xpr2片段,其包含成熟碱性胞外蛋白酶的N-末端13个氨基酸。
6.根据权利要求5所述的转化的解脂耶氏酵母,其中所述Xpr2前导/前体-区域和N-末端Xpr2片段为SEQ ID NO:10中所示的。
7.根据权利要求4所述的转化的解脂耶氏酵母,其中所述蔗糖转化酶信号序列为SEQ ID NO:8中所示的。
8.根据权利要求1所述的转化的解脂耶氏酵母,其中所述包含与蔗糖转化酶编码序列融合的信号序列的多肽选自:SEQ ID NO:12和SEQ IDNO:20。
9.根据权利要求1所述的转化的解脂耶氏酵母,其中所述转化的解脂耶氏酵母能够在蔗糖为唯一碳源的条件下生长。
10.根据权利要求1所述的转化的解脂耶氏酵母,其中所述转化的解脂耶氏酵母能够产生至少一种所关注的非天然产物。
11.根据权利要求10所述的转化的解脂耶氏酵母,其中所述至少一种所关注的非天然产物选自:多不饱和脂肪酸、类胡萝卜素、氨基酸、维生素、甾醇、类黄酮、有机酸、多元醇和羟基酯、醌衍生化合物和白藜芦醇。
12.根据权利要求1或权利要求10所述的转化的解脂耶氏酵母,使所述转化的解脂耶氏酵母在具有至少蔗糖作为碳源的培养基中生长,其中所述转化的解脂耶氏酵母能够向细胞外分泌至少80%的蔗糖转化酶。
13.生产至少一种所关注的非天然产物的方法,包括使权利要求10的转化的解脂耶氏酵母在具有至少一种碳源的培养基中生长,所述碳源选自:
a)蔗糖;和
b)葡萄糖;
从而产生所述至少一种所关注的非天然产物,以及任选地,回收所述至少一种所关注的非天然产物。
14.根据权利要求13所述的方法,其中所述至少一种所关注的非天然产物选自:多不饱和脂肪酸、类胡萝卜素、氨基酸、维生素、甾醇、类黄酮、有机酸、多元醇和羟基酯、醌衍生化合物和白藜芦醇。
15.根据权利要求13所述的方法,其中所述转化的解脂耶氏酵母能够向细胞外分泌至少80%的蔗糖转化酶。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201061428590P | 2010-12-30 | 2010-12-30 | |
| US61/428,590 | 2010-12-30 | ||
| PCT/US2011/060788 WO2012091812A1 (en) | 2010-12-30 | 2011-11-15 | Use of saccharomyces cerevisiae suc2 gene in yarrowia lipolytica for sucrose utilization |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN103443266A true CN103443266A (zh) | 2013-12-11 |
Family
ID=45063228
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN2011800630477A Pending CN103443266A (zh) | 2010-12-30 | 2011-11-15 | 在解脂耶氏酵母中使用啤酒糖酵母suc2基因以利用蔗糖 |
Country Status (10)
| Country | Link |
|---|---|
| US (1) | US8735137B2 (zh) |
| EP (1) | EP2658962A1 (zh) |
| JP (1) | JP2014503216A (zh) |
| KR (1) | KR20140000711A (zh) |
| CN (1) | CN103443266A (zh) |
| AU (1) | AU2011353002A1 (zh) |
| BR (1) | BR112013016769A2 (zh) |
| CA (1) | CA2824584A1 (zh) |
| CL (1) | CL2013001887A1 (zh) |
| WO (1) | WO2012091812A1 (zh) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104178435A (zh) * | 2014-08-21 | 2014-12-03 | 天津科技大学 | 一种适合于高糖面团发酵的高活性干酵母 |
| CN107022499A (zh) * | 2017-05-04 | 2017-08-08 | 北京化工大学 | 调控酿酒酵母社会行为提高生物乙醇发酵速率效率的方法 |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| BR112018010384A2 (pt) | 2015-11-24 | 2018-12-04 | Cargill Inc | levedura geneticamente modificada e processo para fabricar um produto de fermentação |
| CN108070579A (zh) * | 2017-12-21 | 2018-05-25 | 中诺生物科技发展江苏有限公司 | 一种蔗糖转化酶工业化生产方法 |
| CN111996132A (zh) * | 2020-07-21 | 2020-11-27 | 郑州大学 | 一种解脂耶氏酵母表面展示方法 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0329501A1 (fr) * | 1988-01-28 | 1989-08-23 | Institut National De La Recherche Agronomique (Inra) | Séquence ars efficace chez yarrowia lipolytica et procédé pour sa préparation |
| EP0402226A1 (en) * | 1989-06-06 | 1990-12-12 | Institut National De La Recherche Agronomique | Transformation vectors for yeast yarrowia |
| CN1138632A (zh) * | 1985-10-18 | 1996-12-25 | 美国辉瑞有限公司 | 用解脂亚罗威阿酵母转化株表达和分泌异源蛋白质 |
| CN101765661A (zh) * | 2007-06-01 | 2010-06-30 | 索拉兹米公司 | 在微生物中生产油 |
| WO2010147907A1 (en) * | 2009-06-16 | 2010-12-23 | E. I. Du Pont De Nemours And Company | High eicosapentaenoic acid oils from improved optimized strains of yarrowia lipolytica |
Family Cites Families (34)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5071764A (en) | 1983-10-06 | 1991-12-10 | Pfizer Inc. | Process for integrative transformation of yarrowia lipolytica |
| US4880741A (en) | 1983-10-06 | 1989-11-14 | Pfizer Inc. | Process for transformation of Yarrowia lipolytica |
| US4683202A (en) | 1985-03-28 | 1987-07-28 | Cetus Corporation | Process for amplifying nucleic acid sequences |
| US7125672B2 (en) | 2003-05-07 | 2006-10-24 | E. I. Du Pont De Nemours And Company | Codon-optimized genes for the production of polyunsaturated fatty acids in oleaginous yeasts |
| US7238482B2 (en) | 2003-05-07 | 2007-07-03 | E. I. Du Pont De Nemours And Company | Production of polyunsaturated fatty acids in oleaginous yeasts |
| US20110059496A1 (en) | 2003-06-25 | 2011-03-10 | E. I. Du Pont De Nemours And Company | Glyceraldehyde-3-phosphate dehydrogenase and phosphoglycerate mutase promoters for gene expression in oleaginous yeast |
| US7259255B2 (en) | 2003-06-25 | 2007-08-21 | E. I. Du Pont De Nemours And Company | Glyceraldehyde-3-phosphate dehydrogenase and phosphoglycerate mutase promoters for gene expression in oleaginous yeast |
| US7504259B2 (en) | 2003-11-12 | 2009-03-17 | E. I. Du Pont De Nemours And Company | Δ12 desaturases suitable for altering levels of polyunsaturated fatty acids in oleaginous yeast |
| WO2005049805A2 (en) | 2003-11-14 | 2005-06-02 | E.I. Dupont De Nemours And Company | Fructose-bisphosphate aldolase regulatory sequences for gene expression in oleaginous yeast |
| WO2006012326A1 (en) | 2004-06-25 | 2006-02-02 | E.I. Dupont De Nemours And Company | Delta-8 desaturase and its use in making polyunsaturated fatty acids |
| US7879591B2 (en) | 2004-11-04 | 2011-02-01 | E.I. Du Pont De Nemours And Company | High eicosapentaenoic acid producing strains of Yarrowia lipolytica |
| US7588931B2 (en) | 2004-11-04 | 2009-09-15 | E. I. Du Pont De Nemours And Company | High arachidonic acid producing strains of Yarrowia lipolytica |
| US20060094102A1 (en) | 2004-11-04 | 2006-05-04 | Zhixiong Xue | Ammonium transporter promoter for gene expression in oleaginous yeast |
| WO2006125000A2 (en) | 2005-05-19 | 2006-11-23 | E.I. Du Pont De Nemours And Company | Method for the production of resveratrol in a recombinant oleaginous microorganism |
| US7470532B2 (en) | 2005-10-19 | 2008-12-30 | E.I. Du Pont De Nemours And Company | Mortierella alpina C16/18 fatty acid elongase |
| US20070118929A1 (en) | 2005-11-23 | 2007-05-24 | Damude Howard G | Delta-9 elongases and their use in making polyunsaturated fatty acids |
| WO2007120423A2 (en) | 2006-03-20 | 2007-10-25 | Microbia Precision Engineering | Production of quinone derived compounds in oleaginous yeast and fungi |
| US7678560B2 (en) | 2006-05-17 | 2010-03-16 | E.I. Du Pont De Nemours And Company | Δ 5 desaturase and its use in making polyunsaturated fatty acids |
| US7695950B2 (en) | 2006-05-17 | 2010-04-13 | E. I. Du Pont De Nemours And Company | Δ5 desaturase and its use in making polyunsaturated fatty acids |
| WO2008130372A2 (en) | 2006-09-28 | 2008-10-30 | Microbia, Inc. | Production of sterols in oleaginous yeast and fungi |
| EP2087105B1 (en) | 2006-10-30 | 2015-02-25 | E.I. Du Pont De Nemours And Company | Delta 17 desaturase and its use in making polyunsaturated fatty acids |
| US7709239B2 (en) | 2006-12-07 | 2010-05-04 | E.I. Du Pont De Nemours And Company | Mutant Δ8 desaturase genes engineered by targeted mutagenesis and their use in making polyunsaturated fatty acids |
| US8846374B2 (en) | 2006-12-12 | 2014-09-30 | E I Du Pont De Nemours And Company | Carotenoid production in a recombinant oleaginous yeast |
| WO2008124048A2 (en) | 2007-04-03 | 2008-10-16 | E. I. Du Pont De Nemours And Company | Multizymes and their use in making polyunsaturated fatty acids |
| US7790156B2 (en) | 2007-04-10 | 2010-09-07 | E. I. Du Pont De Nemours And Company | Δ-8 desaturases and their use in making polyunsaturated fatty acids |
| US8119860B2 (en) | 2007-04-16 | 2012-02-21 | E. I. Du Pont De Nemours And Company | Delta-9 elongases and their use in making polyunsaturated fatty acids |
| US8957280B2 (en) | 2007-05-03 | 2015-02-17 | E. I. Du Pont De Nemours And Company | Delta-5 desaturases and their use in making polyunsaturated fatty acids |
| JP5711968B2 (ja) | 2007-10-03 | 2015-05-07 | イー・アイ・デュポン・ドウ・ヌムール・アンド・カンパニーE.I.Du Pont De Nemours And Company | 高エイコサペンタエン酸を生成するためのヤロウィア・リポリティカ(YarrowiaLipolytica)の最適化株 |
| US8815567B2 (en) | 2007-11-30 | 2014-08-26 | E I Du Pont De Nemours And Company | Coenzyme Q10 production in a recombinant oleaginous yeast |
| WO2009126890A2 (en) | 2008-04-10 | 2009-10-15 | Microbia, Inc. | Production of carotenoids in oleaginous yeast and fungi |
| CN102197047B (zh) | 2008-09-19 | 2014-07-09 | 纳幕尔杜邦公司 | 突变的δ5去饱和酶及其在制备多不饱和脂肪酸中的用途 |
| BRPI0917722A2 (pt) | 2008-12-18 | 2017-05-30 | Du Pont | organismo transgênico e método para manipular o teor de malonatos em um organismo transgênico |
| US8524485B2 (en) | 2009-06-16 | 2013-09-03 | E I Du Pont De Nemours And Company | Long chain omega-3 and omega-6 polyunsaturated fatty acid biosynthesis by expression of acyl-CoA lysophospholipid acyltransferases |
| WO2011123407A2 (en) | 2010-03-31 | 2011-10-06 | E. I. Du Pont De Nemours And Company | Pentose phosphate pathway upregulation to increase production of non-native products of interest in transgenic microorganisms |
-
2011
- 2011-11-15 AU AU2011353002A patent/AU2011353002A1/en not_active Abandoned
- 2011-11-15 JP JP2013547474A patent/JP2014503216A/ja active Pending
- 2011-11-15 WO PCT/US2011/060788 patent/WO2012091812A1/en active Application Filing
- 2011-11-15 BR BR112013016769A patent/BR112013016769A2/pt not_active IP Right Cessation
- 2011-11-15 EP EP11788953.5A patent/EP2658962A1/en not_active Withdrawn
- 2011-11-15 US US13/296,524 patent/US8735137B2/en not_active Expired - Fee Related
- 2011-11-15 KR KR1020137019892A patent/KR20140000711A/ko not_active Application Discontinuation
- 2011-11-15 CN CN2011800630477A patent/CN103443266A/zh active Pending
- 2011-11-15 CA CA2824584A patent/CA2824584A1/en not_active Abandoned
-
2013
- 2013-06-26 CL CL2013001887A patent/CL2013001887A1/es unknown
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN1138632A (zh) * | 1985-10-18 | 1996-12-25 | 美国辉瑞有限公司 | 用解脂亚罗威阿酵母转化株表达和分泌异源蛋白质 |
| EP0329501A1 (fr) * | 1988-01-28 | 1989-08-23 | Institut National De La Recherche Agronomique (Inra) | Séquence ars efficace chez yarrowia lipolytica et procédé pour sa préparation |
| EP0402226A1 (en) * | 1989-06-06 | 1990-12-12 | Institut National De La Recherche Agronomique | Transformation vectors for yeast yarrowia |
| CN101765661A (zh) * | 2007-06-01 | 2010-06-30 | 索拉兹米公司 | 在微生物中生产油 |
| WO2010147907A1 (en) * | 2009-06-16 | 2010-12-23 | E. I. Du Pont De Nemours And Company | High eicosapentaenoic acid oils from improved optimized strains of yarrowia lipolytica |
Non-Patent Citations (5)
| Title |
|---|
| ANDRÉ FÖRSTER ET AL.: "Citric acid production from sucrose using a recombinant strain of the yeast Yarrowia lipolytica", 《APPL MICROBIOL BIOTECHNOL》 * |
| JEAN-MARE NIEAUD ET AL.: "Expression of invertase activity in Yarrowia lipolytica and its use as a selective marker", 《CURR GENET》 * |
| K. SREEKRISHNA ET AL.: "Invertase gene (SUC2) of Saccharomyces cerevisiae as a dominant marker for transformation of Pichia pastoris", 《GENE》 * |
| SAM MATOBA ET AL: "Intracellular Precursors and Secretion of Alkaline Extracellular Protease of Yarrowia lipolytica", 《MOLECULAR AND CELLULAR BIOLOGY》 * |
| WOJTATOWICZ, MARIA ET AL.: "Kinetics of cell growth and citric acid production by Yarrowia lipolytica Suc+ transformants in sucrose media", 《POLISH JOURNAL OF FOOD & NUTRITION SCIENCES》 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104178435A (zh) * | 2014-08-21 | 2014-12-03 | 天津科技大学 | 一种适合于高糖面团发酵的高活性干酵母 |
| CN107022499A (zh) * | 2017-05-04 | 2017-08-08 | 北京化工大学 | 调控酿酒酵母社会行为提高生物乙醇发酵速率效率的方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20120171719A1 (en) | 2012-07-05 |
| EP2658962A1 (en) | 2013-11-06 |
| CL2013001887A1 (es) | 2014-01-31 |
| KR20140000711A (ko) | 2014-01-03 |
| BR112013016769A2 (pt) | 2016-10-11 |
| WO2012091812A1 (en) | 2012-07-05 |
| CA2824584A1 (en) | 2012-07-05 |
| AU2011353002A1 (en) | 2013-05-30 |
| JP2014503216A (ja) | 2014-02-13 |
| US8735137B2 (en) | 2014-05-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN102197047B (zh) | 突变的δ5去饱和酶及其在制备多不饱和脂肪酸中的用途 | |
| CN102257126B (zh) | 减少发酵过程中的丙二酸副产物 | |
| CN101980595B (zh) | △4去饱和酶及其在制备多不饱和脂肪酸中的用途 | |
| CN1556850B (zh) | 转化破囊壶菌目微生物的产物和方法 | |
| CN101679990B (zh) | △8去饱和酶及其在制备多不饱和脂肪酸中的用途 | |
| CN102216464B (zh) | 操纵snf1蛋白激酶活性用于改变含油生物中的油含量 | |
| CN1878785B (zh) | 适于改变油质酵母中多不饱和脂肪酸水平的△12去饱和酶 | |
| CN101617040B (zh) | △17去饱和酶及其在制备多不饱和脂肪酸中的用途 | |
| CN103189513A (zh) | 上调磷酸戊糖途径以提高转基因微生物中受关注的非天然产物的产量 | |
| Liu et al. | Improved production of arachidonic acid by combined pathway engineering and synthetic enzyme fusion in Yarrowia lipolytica | |
| US7582451B2 (en) | Carotene synthase gene and uses therefor | |
| US20110059496A1 (en) | Glyceraldehyde-3-phosphate dehydrogenase and phosphoglycerate mutase promoters for gene expression in oleaginous yeast | |
| CN102459627B (zh) | 通过酰基-辅酶A溶血磷脂酰基转移酶的表达对长链ω-3和ω-6多不饱和脂肪酸的生物合成的改善 | |
| CN103249834A (zh) | 生产高水平二十碳五烯酸的重组微生物宿主细胞 | |
| CN103443266A (zh) | 在解脂耶氏酵母中使用啤酒糖酵母suc2基因以利用蔗糖 | |
| CN100467593C (zh) | Sqs基因 | |
| CN101018868A (zh) | Schizochytrium脂肪酸合酶(fas)以及与其相关的产品和方法 | |
| CN103502461A (zh) | 在含油酵母中通过提高yap1转录因子活性提高油含量 | |
| CN103080316B (zh) | 突变δ9延伸酶和它们在制备多不饱和脂肪酸中的用途 | |
| Yu et al. | Development and perspective of Rhodotorula toruloides as an efficient cell factory | |
| Rozanov et al. | Diversity and occurrence of methylotrophic yeasts used in genetic engineering | |
| CN104321424A (zh) | 在转基因耶氏酵母属中表达胞浆苹果酸酶以提高脂质产量 | |
| CN103080317B (zh) | 突变型hpgg基序和hdash基序δ‑5去饱和酶以及它们在制备多不饱和脂肪酸中的用途 | |
| CN102171345B (zh) | Δ6去饱和酶及其在制备多不饱和脂肪酸中的用途 | |
| WO2004074490A2 (en) | Method for transforming blakeslea strains |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C02 | Deemed withdrawal of patent application after publication (patent law 2001) | ||
| WD01 | Invention patent application deemed withdrawn after publication |
Application publication date: 20131211 |