WO2015050174A1 - 健康情報処理装置、健康情報表示装置及び方法 - Google Patents
健康情報処理装置、健康情報表示装置及び方法 Download PDFInfo
- Publication number
- WO2015050174A1 WO2015050174A1 PCT/JP2014/076332 JP2014076332W WO2015050174A1 WO 2015050174 A1 WO2015050174 A1 WO 2015050174A1 JP 2014076332 W JP2014076332 W JP 2014076332W WO 2015050174 A1 WO2015050174 A1 WO 2015050174A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- information
- user
- health
- health information
- unit
- Prior art date
Links
Images





























Classifications
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H10/00—ICT specially adapted for the handling or processing of patient-related medical or healthcare data
- G16H10/60—ICT specially adapted for the handling or processing of patient-related medical or healthcare data for patient-specific data, e.g. for electronic patient records
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16H—HEALTHCARE INFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR THE HANDLING OR PROCESSING OF MEDICAL OR HEALTHCARE DATA
- G16H50/00—ICT specially adapted for medical diagnosis, medical simulation or medical data mining; ICT specially adapted for detecting, monitoring or modelling epidemics or pandemics
- G16H50/30—ICT specially adapted for medical diagnosis, medical simulation or medical data mining; ICT specially adapted for detecting, monitoring or modelling epidemics or pandemics for calculating health indices; for individual health risk assessment
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16Z—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS, NOT OTHERWISE PROVIDED FOR
- G16Z99/00—Subject matter not provided for in other main groups of this subclass
Definitions
- Embodiments described herein relate generally to a health information processing apparatus, a health information display apparatus, and a method.
- preemptive medicine is to prevent or delay the onset by predicting onset or making a diagnosis before onset with high accuracy before the onset of the disease, and implementing therapeutic intervention at an appropriate time before onset.
- individualization prevention means prevention of the disease suitable for each individual.
- the present invention has been made in view of the above, and is a health information processing apparatus and a health information display capable of accurately estimating future health risks and performing individual health guidance based on a personal constitution It is an object to provide an apparatus and a method.
- the health information processing apparatus includes an accumulation unit, an analysis unit, and an estimation unit.
- the storage unit stores genome information, which is health information of each user, and biological information and behavior information collected continuously for a plurality of users.
- the analysis unit analyzes the accumulated health information for a plurality of users.
- the estimation unit estimates a future health risk of the predetermined user using the analysis result and the health information of the predetermined user.
- the effect is that it is possible to accurately estimate future health risks and to provide individual health guidance based on the individual's constitution.
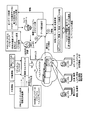
- FIG. 1 is a diagram for explaining a motivational improvement society realized by this embodiment.
- FIG. 2A is a diagram for explaining an example of the present embodiment.
- FIG. 2B is a diagram for explaining the outline of the present embodiment.
- FIG. 3 is a diagram for explaining PHR (Personal Health Record) data in the present embodiment.
- FIG. 4 is a diagram for explaining collection of life log information in the present embodiment.
- FIG. 5 is a diagram for explaining analysis of PHR big data in the present embodiment.
- FIG. 6 is a diagram for explaining a lifestyle type in the present embodiment.
- FIG. 7 is a diagram for explaining a health risk estimation table T in the present embodiment.
- FIG. 8 is a diagram for explaining health risk estimation in the present embodiment.
- FIG. 1 is a diagram for explaining a motivational improvement society realized by this embodiment.
- FIG. 2A is a diagram for explaining an example of the present embodiment.
- FIG. 2B is a diagram for explaining the outline of the present embodiment.
- FIG. 3
- FIG. 9 is a diagram for explaining a spirit forecast portal site in the present embodiment.
- FIG. 10 is a diagram showing a daily human dock processing procedure in the present embodiment.
- FIG. 11 is a diagram showing screen transition of the attending physician portal site in the present embodiment.
- FIG. 12 is a diagram showing screen transition of the user portal site in the present embodiment.
- FIG. 13 is a diagram for explaining a health risk simulation in the present embodiment.
- FIG. 14 is a diagram for explaining a health risk graph displayed to the attending physician and the user in the present embodiment.
- FIG. 15 is a diagram for explaining an example (first example) of a secondary usage service in the present embodiment.
- FIG. 16 is a diagram for explaining an example (first example) of a secondary usage service in the present embodiment.
- FIG. 17 is a diagram for explaining an example (second example) of the secondary usage service in the present embodiment.
- FIG. 18 is a diagram for explaining an example (third example) of the secondary usage service in the present embodiment.
- FIG. 19 is a diagram for explaining an incentive mechanism 1 in the present embodiment.
- FIG. 20 is a diagram for explaining an incentive mechanism 2 in the present embodiment.
- FIG. 21A is a diagram for explaining comparison analysis between users in the present embodiment.
- FIG. 21B is a diagram for explaining comparison analysis between users in the present embodiment.
- FIG. 22 is a diagram for explaining comparison analysis between groups in the present embodiment.
- FIG. 23A is a diagram for explaining a comparative analysis of individuals at a predetermined time in the present embodiment.
- FIG. 23A is a diagram for explaining a comparative analysis of individuals at a predetermined time in the present embodiment.
- FIG. 23B is a diagram for explaining a comparative analysis at a predetermined time of an individual in this embodiment.
- FIG. 24A is a diagram for explaining a comparative analysis of a predetermined period of an individual in this embodiment.
- FIG. 24B is a diagram for explaining a comparative analysis of a predetermined period of an individual in this embodiment.
- FIG. 24C is a diagram for explaining comparative analysis of a predetermined period of an individual in this embodiment.
- FIG. 25 is a functional block diagram of the PHR processing apparatus according to the present embodiment.
- FIG. 26 is a diagram showing a hardware configuration of a PHR processing device (or PHR display device) in the present embodiment.
- a health information processing apparatus for example, a primary use service, a secondary use service, etc.
- a health information display apparatus for example, a health information display apparatus, and a method according to embodiments.
- a plurality of functions for example, a primary use service, a secondary use service, etc.
- Realizing the function is not an essential configuration.
- the health information processing apparatus and the health information display apparatus may be configured to realize a part of a plurality of functions.
- FIG. 1 is a diagram for explaining a motivational society realized by the present embodiment.
- Today it is ideal for everyone to live a healthy life in the family and the community, work and hobbies, but concerns about future illness, dementia, depression, loneliness, concerns about distant families, etc.
- Today's aging society people are threatened and eroded. In such a situation, the motivation for daily life is lowered, not the future image, and it does not become strong.
- “Innovative PHR data” is collected by “Unconscious Sensing” technology in “Daily Ningen Dock”.
- the sensing data includes, for example, heart rate, stress, blood pressure, hormone, blood concentration, sympathetic nerve, drug dose, and the like.
- Sensing data includes, for example, sugar, salt, stomach acid, agricultural chemicals, microorganisms, and environmental substances.
- a PHR processing apparatus 100 is constructed on the healthcare cloud 10. The PHR processing device 100 collects and accumulates life log information in association with each person's biological information and behavior information. Then, as shown in FIG. 1, the PHR processing device 100 stores PHR big data obtained by integrating a large amount of life log information collected in time series and a constitution database based on genome information for a plurality of users on the healthcare cloud 10. Centralized management.
- the PHR processing apparatus 100 analyzes the PHR big data to analyze the risk of developing a future disease based on the genome information, the amount of meal, the amount of exercise, or the response response of the body to the exercise load in an advanced and detailed manner. Eventually, it will be possible to design daily life aiming at an ideal image, such as the risk of disease onset, signs of seizures, personal constitution, diet content optimal for lifestyle, exercise, lifestyle, selection of medicines and supplements, etc.
- the PHR processing apparatus 100 applies, for example, big data mining, integrated genome analysis, simulation, communication visualization and quantification technology, and the like.
- the PHR data collected from each individual in this way is not only used for “primary use” that is fed back to the person by the “daily human dock” mechanism, but also “ It is also used for “next use”. Therefore, in the following, how PHR data is used, the outline of healthcare informatics realized on the healthcare cloud in this embodiment is divided into “primary use” and “secondary use”. I will explain.
- the PHR processing device 100 displays the result of the analysis of the PHR big data on a wearable information terminal worn by the subject, and feeds it back to the subject.
- An example of the feedback is “Notice of future health risks”.
- Target users can use the “Notice of Future Health Risk” service provided on wearable information terminals to understand their future health risks and receive information on how to deal with them.
- the subject can receive encouragement from a doctor or a family (or a virtual family) on the wearable information terminal. For example, in FIG. 1, the subject is receiving guidance from the attending physician (“Reserve salt!”).
- each individual obtains his / her health condition with a wearable information terminal or the like based on information collected casually and accurately, and is obtained by the attending physician, family doctor, or health support staff. Can receive guidance and encouragement. In addition, it is possible to check the mental and physical state management of oneself and family, and the behavior and life.
- the PHR processing apparatus 100 can not only feed back such information to the target person but also feed it back to the medical institution. Based on the analysis result fed back from the PHR processing apparatus 100, the doctor recognizes, for example, a high-risk disease reserve and actively accesses these persons as necessary.
- the sensing data transmitted from the subject is also useful for detecting abnormalities in the subject's body.
- the PHR processing device 100 constantly monitors sensing data transmitted daily for a subject of a high-risk disease-causing reserve army, and immediately feeds back to a medical institution when an abnormality is detected.
- the PHR processing device 100 provides the results of PHR big data analysis to medical institutions, various companies, etc. It can contribute to industry creation. A specific example will be described later.
- FIG. 1 For example, a motivational society will be realized in 5 to 10 years.
- “virtual clone”, “notice of future health risks”, and “family watching service” are listed as technical keywords for realizing a motivated society.
- “virtual clone” and “notice of future health risks” are examples of “primary use”.
- the “family watching service” is an example of “secondary use”.
- the PHR processing apparatus 100 sets a “virtual clone” for each target person and realizes health promotion based on the “virtual clone”.
- the PHR processing apparatus 100 presents each subject with a self-image that reflects a characteristic appearance predicted from a future health state as a “virtual clone” in his / her face and appearance. Intuitively, it is possible to display the future image of X years later, which is influenced by the current life.
- an ideal self-image can be set in the “virtual clone”.
- the “virtual clone” is presented in “Notice of future health risk”.
- the PHR processing apparatus 100 presents “notice of future health risk” to each target person.
- this “Notice of Future Health Risk” a virtual family and the virtual self-image (virtual clone) described above are displayed.
- “Notice of future health risks” reflects the degree of divergence from the ideally designed one and the future of yourself when you continue to live, and provides guidance for the ideal.
- those who see the “Notice of Future Health Risks” are able to receive encouragement, encouragement, and health guidance at all times through dialogue with virtual persons and their families. Can improve the willingness to work toward self-realization.
- a “family watching service” is realized as an example of a secondary usage service.
- a distant family can be watched at any time.
- the ubiquitous life log information is a bond tool for monitoring and communicating so that the elderly who are living alone who are distantly ill can take their meals and drugs properly and understand that they are spending their lives. It can also be used as a reminder when you are not feeling well. As a result, he / she was reluctant and caring about his relatives, and he was unable to be overlooked without noticing the onset of his surroundings. Will also ease. This not only strengthens ties with families and society, but also strengthens itself in a vibrant aging society.
- the achievement degree to the effort target the comparison function with the future image of the competing friends, the public function by their SNS (Social Networking Service), etc.
- SNS Social Networking Service
- functions such as giving local currency points as rewards, for example, it is possible to improve everyone's motivation with the goal of earning points.
- a medical condition is always observed, a sign of a seizure is detected, and a caregiver or rescuer rushes immediately in case of a bad physical condition or emergency, and care for the mind and body. Willing to.
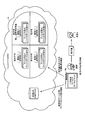
- FIG. 2A is a diagram for explaining an example of the present embodiment.
- the solution system according to the present embodiment includes biological information based on a DNA chip / genome sequence information utilization platform, behavior information that is a real-time life log, and health (self) check by checking the brain and mind. Is implemented, and information is collected in the healthcare cloud 10.
- information on electronic medical records is collected from a hospital or clinic.
- receipt information, work information, health checkup results, etc. in companies and health insurance are collected.
- Cohort data and sequence data are collected from research institutions and universities. Then, the sensing data collected unconsciously from the user A is collected (PHR input in the figure).
- Such a personal health record (PHR) is managed for each user (for example, user A), and a PHR group in which PHRs of many people are aggregated is managed as PHR big data in the healthcare cloud 10.
- PHR big data are managed and managed by a data trust bank (also called a data trust company).
- the data trust bank analyzes the PHR big data (big data analysis), thereby enabling future prediction of each individual and a lifestyle proposal based on the analysis data of the PHR data.
- a family doctor who is a health concierge that provides life support proposes lifestyles based on analysis data of PHR data, and “virtual clones” and “notice of future health risks” based on analysis data. Or provide. That is, it is possible to feed back the individual health guidance such as the energy forecast reflecting the personal constitution and lifestyle, lifestyle change, risk diagnosis, etc. to the data inputted with the PHR data.
- the data trust bank gives the manufacturers and sales / distributors the right to sell and access the PHR data or analysis data to be managed. It becomes possible.
- the PHR data and the analysis data are personal information that requires careful handling, the PHR data and the analysis data are anonymized as necessary as illustrated.
- Examples of various manufacturers and distributors that receive PHR data and analysis data include "security”, “pharmaceuticals”, “food”, and “cosmetics”.
- Various manufacturers, distributors and distributors Can develop high-value-added products and provide services based on healthcare information such as PHR data and analysis data provided.
- product development and services carried out by various manufacturers and distributors / distributors include, for example, drug development, clinical trials (clinical trials) to obtain approval under the Pharmaceutical Affairs Law, movies and programs It covers a very wide range of fields, such as mere marketing that collects biological information that appears in the body from viewers.
- the solution system of the present embodiment is used in such a wide field, and it is possible to cause a chain of innovation in each field.
- the solution system of the present embodiment enables each individual to construct and provide a new sensor for the individual by utilizing the “daily human dock” (for example, based on the user's genome information and lifestyle information). It is also possible to promote the development of a new DNA chip from the analysis data of the PHR data.
- PHR data including genome information is aggregated on the healthcare cloud 10 to form a large-scale genome / cohort database 114a, and the PHR big data accumulated in the large-scale genome / cohort database 114a is collected.
- a mechanism for accurately estimating future health risks for example, the probability of occurrence of each disease
- a system that feeds back individual health guidance that reflects the individual's constitution and lifestyle to this individual (daily human dock) Build up.
- a mechanism for secondary use (use for others and commercial use) of PHR big data aggregated on the healthcare cloud 10 is constructed.
- FIG. 2B is a diagram for explaining an outline of the present embodiment.
- a PHR processing device 100 (also referred to as a “health information processing device”) is constructed on the healthcare cloud 10, and the PHR processing device 100 implements the various mechanisms described above.
- the operation management of the healthcare cloud service including the operation of the PHR processing apparatus 100 is performed by the data trust company 11.
- the data trust company 11 provides various services for providing services to users and medical institutions 13 that receive provision of primary usage services (daily health docks), medical institutions and various companies 15 that receive provision of secondary usage services, etc.
- the procedure is performed online or offline (see dotted line in FIG. 2B).
- the PHR processing apparatus 100 includes a PHR accumulation unit 110 that collects and accumulates PHR data, and a PHR operation management unit 120 that performs operation management of PHR data accumulated in the PHR accumulation unit 110.
- the PHR accumulating unit 110 collects PHR data related to this individual (PHR data 12 in FIG. 2B) from not only individuals but also from research institutions, medical institutions, companies, etc., and aggregates them as individual PHR data.
- PHR data includes life log information continuously collected from individuals, personal genomic information obtained from research institutions, electronic medical record information obtained from medical institutions, and health insurance obtained from companies and health insurance associations. There are union information (receipt information, work information, examination notebook information), mother and child notebook information, school health examination information, and the like. That is, the PHR data is collected not only from individuals but also from various institutions as information related to the health of individuals, and the type is not limited.
- the PHR accumulation unit 110 collects such PHR data on a large scale (for example, on a scale of 150,000 people) and forms a large-scale genome cohort database 114a.
- the large-scale genome cohort database 114a expands the scale of each individual by accumulating new information every day, and also expands the scale by expanding the scope of the collection target person.
- PHR big data when the entire PHR data of the large-scale genome / cohort database 114a is meant, it is referred to as “PHR big data” and distinguished from personal PHR data.
- the PHR data is also called “health information”.
- the PHR operation management unit 120 includes a PHR big data analysis unit 121, a primary usage service providing unit 122 (also referred to as “estimating unit”), and a secondary usage service providing unit 123 (also referred to as “output unit”).
- the PHR big data analysis unit 121 analyzes the PHR big data stored in the large-scale genome cohort database 114a according to a predetermined purpose, and derives the relationship between the genome information, the lifestyle, and the health risk. Then, the PHR big data analysis unit 121 obtains an analysis result indicating some relationship with the combination of the individual constitution and the lifestyle.
- the PHR big data analysis unit 121 performs a cohort analysis on PHR big data, and combines a combination of a genome type and a lifestyle type with a risk of a disease that may develop in the future (referred to as “disease onset risk”). To derive the relevance of Then, the primary use service providing unit 122 applies the relationship derived by the PHR big data analysis unit 121 to the PHR data of each individual, thereby determining the risk of disease onset according to the person's constitution and lifestyle. Then, the primary use service providing unit 122 performs feedback to the person himself / herself by, for example, registering the information on the determined disease onset risk in the portal site 14a of the user.
- the portal site 14a can be browsed by the family and the attending physician in addition to the person himself / herself, and communication between the three parties can be achieved through the portal site 14a. This is the outline of the “daily human dock” in the present embodiment. Details of the “daily human dock” will be described later.
- the PHR big data analysis unit 121 performs a cohort analysis on the PHR big data and derives an analysis result for the secondary use service.
- the secondary usage service providing unit 123 outputs the analysis result derived by the PHR big data analysis unit 121, and various companies (medical institutions, food / supplement sales companies, pharmaceutical companies, medical device manufacturers, distribution companies, To security companies). A specific example of the secondary usage service will be described later.
- the user, the user's family and other related parties, and the user's attending physician are provided by the PHR display device 200 (also referred to as “health information display device”), for example, by the primary use service providing unit 122.
- the PHR display device 200 is a smartphone, a PC (Personal Computer), an Internet TV, a wearable information terminal, or the like.
- the PHR display device 200 includes a display control unit 210 and a display unit 220, and the display control unit 210 displays the future health risk of the user on the display unit 220.
- FIG. 3 is a diagram for explaining PHR data in the present embodiment.
- the PHR data is collected not only from individuals but also from various institutions as information related to the health of individuals, and the type is not limited. Therefore, in the present embodiment, what information is collected as PHR data is considered to be different for each individual.
- the lifestyle type of the person is determined from the personal PHR data. In this embodiment, the lifestyle type is determined by evaluating 10 items (smoking, drinking, sleep, stress, exercise, diet, medicine / supplement, mental state, fatigue, immunity). . Therefore, in this embodiment, it is assumed that PHR data that can evaluate these 10 items is collected from each individual.
- FIG. 3 conceptually shows only genome information and life log information in the PHR data of user A.
- genome information is genetic information of user A.
- a chromosome exists in the nucleus of the cell, and a substance called deoxyribonucleic acid constituting the chromosome is DNA.
- DNA has a double-helical structure with two strands, as well as a series of nucleotides that are the structural unit.
- a gene is a compartment on DNA.
- Nucleotides are those in which deoxyribose sugars are linked by phosphoric acid, and any one of four types of bases binds to deoxyribose sugars. Between the two chains, a base pair of adenine (A) and thymine (T) and a base pair of guanine (G) and cytosine (C) are bound.
- Human genome information is composed of about 3 billion base pairs.
- genome information is the sequence information of about 3 billion base pairs, or the sequence information of about 1 million base pairs that determines the individuality of human beings.
- the PHR accumulating unit 110 may accumulate the base pair sequence information as it is, or accumulate it in the form of a difference from standard genome information (eg, Japanese standard SNP (Single Nucleotide Polymorphism)). Also good. For example, when user A provides his / her blood to a research institution, and the entire base sequence (sequence information) of the genome extracted from user A is specified by the research institution, the sequence information is used as the genome information of user A. Treat as.
- the genome information is not limited to the above-described sequence information, and includes analysis results by various assumed methods such as a DNA chip.
- a DNA chip For example, when user A provides his / her blood to a research institution and analysis is performed using a DNA chip at the research institution, the analysis result is handled as user A's genome information.
- SNP analysis using a DNA chip CNV (Copy Number Variation) analysis, microsatellite analysis, epigenome analysis, gene expression level analysis, etc., for specific diseases (eg, hypertension, hyperlipidemia, obesity, diabetes, etc.)
- CNV Codonuent Analysis
- the life log information is information representing the lifestyle (lifestyle) of the user A.
- biological information and action information are collectively referred to as life log information, and it is considered that accurate life log information can be obtained by associating both as necessary. .
- the acceleration sensor detects the user's posture from the DC component, and identifies the user's action (walking, running, moving by bicycle, moving by car, moving by train, etc.) from the AC component.
- the acceleration sensor obtains the user's momentum from the user's posture and the user's motion.
- the action history is obtained from schedule information input to a wearable information terminal or an information terminal such as a smartphone or a PC.
- the biological information obtained from the biological sensor and the behavior information obtained from the acceleration sensor and other information terminals are associated with each other by time information included in each information, or each information Are related by being recorded in the same record.
- the blood pressure which is biometric information
- this rise is due to stress caused by the meeting. It turns out to be a thing.
- the blood pressure has been lowered after the evening, but when the behavior history associated with this biological information is referred to, it is found that this drop is due to drinking.
- the relationship between blood pressure and exercise is also clarified.
- the biological information and the behavior information are basically handled in association with each other.
- the PHR processing apparatus 100 appropriately selects information necessary for evaluating the lifestyle type and the current health condition as biological information and behavior information to be collected.
- the biological information is various numerical information indicating the current health state, information indicating the amount of components taken into the body, and the presence or absence of a substance.
- the biological information includes blood pressure, heart rate, pulse, body temperature, body component, ion, pH concentration, and the like.
- the biological information includes the amount of components such as sugar and salt, the concentration of gastric acid, the presence of agricultural chemicals, environmental substances, food additives, the intake of alcohol, nicotine, and drug components.
- the behavior information is position information such as exercise amount, sleep amount, schedule information, and GPS (Global Positioning System).
- position information such as exercise amount, sleep amount, schedule information, and GPS (Global Positioning System).
- all or part of the life log information is collected from sensors and various information terminals.
- information obtained from a smartphone exercise system application, schedule application, etc.
- SNS electronic receipt, or the like may be used.
- FIG. 4 is a diagram for explaining the collection of life log information in the present embodiment.
- the wearable information terminal for example, a wristwatch type, a glasses type, a ring type, or the like can be considered.
- This wearable information terminal has a function as a sensor and can collect biological information.
- the wearable information terminal also has a function as a so-called information terminal, and can collect behavior information. Therefore, the wearable information terminal serves as a dock for life log information, and as shown in FIG. 4, the biometric information and behavior information collected individually from the user are associated (paired), and pairing is performed. Later life log information is uploaded to the healthcare cloud 10.
- the wearable information terminal can also receive biological information and behavior information from a sensor or information terminal worn by the user separately from the wearable information terminal. Also in this case, the wearable information terminal associates (pairs) the biological information and behavior information individually collected from the user and uploads the life log information after pairing to the healthcare cloud 10. The pairing may be performed not on the wearable information terminal side but on the healthcare cloud 10 side.
- the wearable information terminal performs personal authentication. That is, the wearable information terminal performs personal authentication as to whether or not the person wearing the terminal is indeed the person.
- the wearable information terminal performs personal authentication by wrist vein authentication.
- the wearable information terminal performs personal authentication by face authentication.
- the wearable information terminal performs personal authentication by retina authentication or iris authentication.
- the wearable information terminal performs personal authentication by finger vein authentication.
- the method of personal authentication is not limited to the method described above.
- this embodiment demonstrated the method of uploading life log information from a wearable information terminal embodiment is not restricted to this.
- life log information may be uploaded from a portable information terminal or a stationary information terminal.
- the large-scale genome cohort database 114a is formed and used as the base data.
- the PHR big data analysis unit 121 performs association with information on the outcome, the outcome, and the life and environment at that time in the lifetime PHR data from birth to death. .
- the PHR big data analysis unit 121 performs a long-term follow-up survey on a specific region cohort in a cohort analysis to be described later, and further performs a comparative analysis with another region cohort to examine differences between regions. .
- Such an analysis can be realized only by targeting the large-scale genome / cohort database 114a, and it is difficult to realize it by a small-scale database, and it is limited to those targeting a specific disease.
- the life log information included in the PHR big data is collected by a sensing technique or the like, so that an accurate and precise analysis can be performed unlike a response by a conventional inquiry.
- the formation of a large-scale genome cohort database 114a enables further acquisition of Japanese low-frequency alleles, construction of comprehensive Japanese original standard SNP databases, standardization of typing arrays, etc. Become.
- the PHR big data analysis unit 121 performs a cohort analysis on the PHR big data accumulated in the large-scale genome / cohort database 114a, and combines the combination of the genome type and the lifestyle type, Deriving an association with risk (ie, risk of developing disease).
- the cohort analysis in the present embodiment refers to a group exposed to a specific factor (a group that applies to a combination of a specific genome type and lifestyle type) and a group that is not exposed (a group that does not correspond to the combination) )
- a group that is not exposed a group that does not correspond to the combination
- the PHR big data analysis unit 121 includes standard data of healthy persons accumulated in the large-scale genome / cohort database 114a, divergence data between healthy persons and unaffected persons, divergence data between healthy persons and affected persons, and life logs. Categorize abnormal signs on information, etc., and clarify the relationship with genome types.
- the method used by the PHR big data analysis unit 121 for analysis is not limited to the above-described cohort analysis, and other methods may be used.
- FIG. 5 is a diagram for explaining the analysis of PHR big data in the present embodiment.
- life log information which is PHR data of each individual
- new PHR data of a new individual is a target for new operation management.
- the scale is expanding every day.
- personal lifetime PHR data is accumulated, so that PHR data of healthy persons, unaffected persons, and affected persons are accumulated when the view is changed. It will be.
- the PHR big data analysis unit 121 performs a cohort analysis on the large-scale genome / cohort database 114a, and estimates a health risk for each combination of genome type and lifestyle type.
- a health risk estimation table T is created.
- the PHR accumulating unit 110 expands the scale of the large-scale genome cohort database 114a by newly accumulating PHR data. Therefore, the PHR big data analysis unit 121 performs a new analysis with the daily expansion of the large-scale genome / cohort database 114a, and obtains a “health risk estimation table T” that is a new analysis result.
- the primary use service providing unit 122 estimates the health risk using the newly obtained analysis result. For this reason, the accuracy of the “health risk estimation table T” is improved day by day, and the accuracy of health risk estimation by the primary use service providing unit 122 is also improved day by day.
- the PHR big data analysis unit 121 includes one base pair of 3 billion base pairs or a combination pattern of a plurality of base pairs, or one million base pairs that represent human personality.
- One of the base pairs or a combination pattern of a plurality of base pairs is set as a genome type.
- FIG. 6 is a diagram for explaining a lifestyle type in the present embodiment.
- the PHR big data analysis unit 121 classifies the 10 items obtained from the life log information into three levels from “level I” to “level III”, and all combinations (for example, 3) is a lifestyle type.
- the lifestyle type in this embodiment is merely an example, and items and levels can be arbitrarily changed. In addition, the way of guiding the lifestyle type itself can be arbitrarily changed.
- the PHR big data analysis unit 121 holds in advance an algorithm for deriving 10 items based on the life log information. For example, the PHR big data analysis unit 121 derives the level of smoking such as the presence / absence of the user's smoking and how much the user has smoked from the “nicotine intake” obtained from the sensor as biometric information. In addition, for example, the PHR big data analysis unit 121 derives the level of alcohol consumption such as whether or not the user has drunk or how much alcohol has been drunk from the “alcohol intake” obtained from the sensor as biometric information.
- the PHR big data analysis unit 121 includes a “heart rate” obtained from a sensor as biometric information, an “alarm setting time” and an “alarm time” obtained from a smartphone as behavior information,
- the sleep level such as the user's sleep time and sleep quality is derived from the life sound obtained from the sensor.
- the PHR big data analysis unit 121 determines how much stress the user has from the “blood pressure” and “heart rate” obtained from the sensor as biometric information, “schedule information” obtained from the smartphone as behavior information, and the like. Derive the level of stress that you feel.
- the PHR big data analysis unit 121 obtains “heart rate” obtained from the sensor as biological information, the posture and action of the user obtained from the sensor as behavior information, and the exercise system application of the smartphone as behavior information. The level of exercise such as how much exercise the user has performed is derived from the obtained “exercise information” or the like.
- the degree of mental tension and relaxation can be derived.
- the PHR big data analysis unit 121 uses the “sugar content”, “salt content”, “stomach acid”, “alcohol intake”, and the like obtained from the sensor as biometric information, and what kind of eating habits the user is sending. Deriving the level of eating habits like Taka. Further, for example, the PHR big data analysis unit 121 derives the level of medicine supplement such as what kind of medicine or supplement the user is taking from the “drug component” obtained from the sensor as biometric information.
- the algorithm described above is merely an example.
- the PHR big data analysis unit 121 obtains the values of the 10 items described above from only one of the biological information and the behavior information in the life log information, or from the combination of both, and uses this value. Based on the level of each item.
- the genome type does not change in principle for the same subject, while the lifestyle type may change over time.
- FIG. 7 is a diagram for explaining the health risk estimation table T in the present embodiment.
- the type and order of diseases having a high onset risk are different if the genome type is different.
- the types and order of diseases with a high risk of onset differ if lifestyle types are different.
- the method of expressing the health risk estimation table T illustrated in FIG. 7 is merely an example, and the types and order of diseases illustrated in FIG. 7 are merely examples for convenience of description.
- the PHR big data analysis unit 121 creates a health risk graph indicating the risk of developing a disease for each combination of genome type and lifestyle type.
- the vertical axis of each health risk graph represents the ratio of lifestyle factors and genomic factors in the risk of developing disease, and the horizontal axis shows diseases. The further to the right of the horizontal axis, the more the disease is affected by lifestyle factors, and the further to the left of the horizontal axis, the more the disease is affected by genomic factors. That is, the health risk graph is a list of diseases that are likely to develop in the future, ordered according to whether they are strongly influenced by genomic factors or lifestyle factors for each combination of genomic type and lifestyle type. .
- the horizontal axis displays the official name of the disease and an ICD (International Classification of Diseases) code based on the international disease classification as the name of the disease.
- ICD International Classification of Diseases
- embodiment is not restricted to this, For example, you may display only the formal name of a disease, or an ICD code.
- alcoholic liver disease (K70) is common in that it is a disease with a strong influence of lifestyle factors, while “goutiness” is a disease with a strong influence of lifestyle factors for Genome type 2 users.
- Arthritis (M1009) is positioned as a disease in which the influence of genomic factors is rather strong for genome type 3 users.
- diabetic nephropathy which is a disease that has a strong influence on lifestyle factors for genome type 3 users, is positioned as a disease on which the influence of genomic factors is rather strong for genome type 2 users. ing.
- the lifestyle type 3 is a user with a high level of drinking
- the lifestyle type 2 is a user with a high level of smoking.
- spinal cerebellar degeneration (G319)”, “gouty arthritis (M1009)”, etc. are positioned as diseases that are strongly influenced by genomic factors. .
- the PHR big data analysis unit 121 refers to the medical history information (for example, obtained from electronic medical record information) of a user having genome type 3 as genomic information, and “ “Disease A, Disease B, Disease C, Disease D” are identified.
- the PHR big data analysis unit 121 refers to the medical history information of a user who has lifestyle type 3 as life log information, and “disease D, disease E, disease” “F, disease G”. Then, the PHR big data analysis unit 121 compares the identified diseases, determines that “disease A, disease B, and disease C” included only in diseases that have a high risk of onset for users of genome type 3 are “effects of genetic factors”.
- the PHR big data analysis unit 121 classifies “disease E, disease F, disease G” included only in diseases having a high risk of onset for lifestyle type 3 users as “diseases that are strongly influenced by lifestyle factors”. To do. Further, the PHR big data analysis unit 121 classifies “disease D” included in both of them into “disease that is strongly influenced by lifestyle factors and genetic factors”.
- the PHR big data analysis unit 121 refers to the medical history information of the user of the combination of the genome type 3 and the lifestyle 3 type, and selects a disease having a high risk of onset for the user of the combination of the genome type 3 and the lifestyle 3 type. Identify.
- the PHR big data analysis unit 121 specifies “disease A, disease C, disease F, disease G” as a disease having a high risk of onset for a user of a combination of genome 3 type and lifestyle 3 type. To do.
- the PHR big data analysis unit 121 calculates “disease A” and “disease C” that are common to “disease A, disease B, and disease C” previously classified as “disease with strong influence of genetic factors”. It is determined that the disease has a strong influence of genetic factors, and is positioned in the left direction on the horizontal axis in the “health risk graph” shown in FIG. In addition, the PHR big data analysis unit 121 calculates “disease F” and “disease G” common to “disease E, disease F, and disease G” previously classified as “diseases with a strong influence of lifestyle factors”. It is determined that the disease has a strong influence of lifestyle factors, and is positioned on the right side of the horizontal axis in the “health risk graph” shown in FIG.
- the PHR big data analysis unit 121 creates the health risk estimation table T shown in FIG. 7 under a certain standard.
- the PHR big data analysis unit 121 has a criterion of “health risk after 10 years (probability of onset of 30%) when a person in a normal state of health continues life of the same lifestyle type for one year”, for example.
- a health risk estimation table T is created.
- the lifestyle type of an actual user varies depending on the length of the period, such as one day, one week, one month, one year, or the like. For example, the amount of drinking increased specially this week because there were many welcome and farewell parties, but the amount of drinking was not so high when considered in one month.
- the primary use service providing unit 122 estimates the health risk of a certain user using the health risk estimation table T
- individual use corresponding to the period of PHR data used for estimation (referred to as an estimation target period) is used. Estimate and make adjustments according to current health conditions.
- the PHR big data analysis unit 121 can appropriately change the above-described criteria. Further, the PHR big data analysis unit 121 can set a plurality of estimated future “time points” among the above-described criteria (for example, one day, one week, one month, one year, five years). Later, 10 years later, 20 years later, etc.). In this case, the PHR big data analysis unit 121 creates a health risk estimation table T corresponding to each criterion. When comparing the health risk estimation tables T at different “time points”, for example, the health risk estimation table T after one month lists the diseases that develop immediately, while the health risk estimation table T after 10 years. May show differences such as listing diseases that develop after a long period of time.
- FIG. 8 is a diagram for explaining health risk estimation in the present embodiment.
- the primary use service providing unit 122 extracts life log information from the PHR data of the user A according to the estimation target period.
- the primary usage service providing unit 122 determines, for example, the life log information D1 of this week, the life log of the current month from the PHR data of the user A according to the estimation target period specified by the operator.
- Information D2 and this year's life log information D3 are extracted.
- the primary use service providing unit 122 obtains values of 10 items (smoking, drinking, sleep, stress, exercise, dietary life, medicine supplement, mental condition, fatigue, immunity) for each estimation target period. Based on this value, the level of each item is derived. Then, for each estimation target period, the primary usage service providing unit 122 converts the lifestyle type that is one of the combination patterns of the levels of each item to the lifestyle type of the user A (the lifestyle type of this week, This month's lifestyle type, this year's lifestyle type). For example, as shown in FIG. 8, the primary usage service providing unit 122 determines the lifestyle type “3” of this week based on this week's life log information D1, and based on this month's life log information D2. The lifestyle type “30 type” of this month is determined, and the lifestyle type “30 type” of this year is determined based on this year's life log information D3.
- the primary use service providing unit 122 refers to the health risk estimation table T using the determined lifestyle type, and identifies the corresponding health risk graph for each estimation target period.
- the lifestyle type 3 health risk graph “alcoholic liver disease (K70)”, “hepatocellular carcinoma (C220)”, and “diabetic nephropathy (E142)”
- the lifestyle type 30 health risk graph “alcoholic liver disease (K70)” and “hepatocellular carcinoma (C220)” are excluded from diseases with a high risk of onset. Only “diabetic nephropathy (E142)” is listed as a disease with a high risk of onset.
- the primary use service providing unit 122 performs adjustment according to the current health state for each health risk graph specified for each estimation target period. For example, the primary use service providing unit 122 changes the content of each health risk graph to the content according to the current health status of each individual user in consideration of the biometric information included in the life log information. For example, when the primary use service providing unit 122 analyzes the biometric information of the user A, it is assumed that the liver function of the user A is in a very good state. Then, the primary use service providing unit 122 displays “alcoholic liver disease (K70)”, “hepatocellular carcinoma (C220)”, “diabetic nephropathy” in the health risk graph of the combination of genome type 3 and lifestyle type 3.
- K70 alcoholic liver disease
- C220 hepatocellular carcinoma
- diabetic nephropathy in the health risk graph of the combination of genome type 3 and lifestyle type 3.
- the primary use service providing unit 122 estimates the health risk
- the individual estimation according to the estimation target period as described above and the adjustment according to the current health state are performed.
- this week”, “this month”, and “this year” are given as the estimation target period, but the embodiment is not limited thereto. It may be a period divided by a fixed unit, such as “for the past one day”, “for the past one week”, “for the past one month”, “for the past one year”, etc., or set appropriately by the user It may be an arbitrary period according to the user's request.
- the PHR big data analysis unit 121 generates a “health risk estimation table T” indicating the ratio of genomic factors and lifestyle factors in the risk of developing disease according to the combination of the genomic type and the lifestyle type. Explained as what to do.
- the PHR big data analysis unit 121 can also generate information indicating a lifestyle that is a factor that further increases the risk of developing a disease for “diseases that are strongly influenced by genomic factors”.
- the PHR big data analysis unit 121 searches a genome type user having an SNP in a certain gene from the genome information. Then, the PHR big data analysis unit 121 identifies a disease having a high risk of onset by referring to the history information of a user of a genome type having an SNP in a certain gene (for example, obtained from electronic medical record information). Subsequently, the PHR big data analysis unit 121 refers to the life log information of a genome type user having an SNP in a certain gene, and identifies a lifestyle that increases the risk of developing the identified disease.
- the health risk graph is created on the assumption of “a person in a standard health state”, but the embodiment is not limited to this.
- diabetes has complications such as renal disorder, retinal disorder, and neuropathy.
- high blood pressure is known to have complications such as stroke, various heart diseases, and kidney damage.
- influenza has complications such as bacterial pneumonia, influenza encephalopathy and myocarditis.
- the risk of developing these complications is increased in the health risk graph of a person suffering from the disease.
- the PHR big data analysis unit 121 classifies persons suffering from complications and performs a cohort analysis, for example, “persons suffering from diabetes”, “ It is possible to create a health risk graph only for affected persons, assuming "persons” and "persons suffering from influenza”. Further, in this case, the primary use service providing unit 122 provides the “daily human dock” service to “a person suffering from diabetes”, “a person suffering from hypertension”, and “a person suffering from influenza”. Can identify a disease with a high risk of onset by referring to a health risk graph dedicated to the affected person.
- the primary usage service providing unit 122 provides the “daily human dock” as the primary usage service by using the health risk estimation table T to provide feedback to the user who provided the PHR data.
- the providing method Various methods are conceivable as the providing method, but one method will be described below with reference to FIG.
- FIG. 9 is a diagram for explaining the spirit forecast portal site in the present embodiment.
- the primary use service providing unit 122 starts up the portal site 14 a for the user A on the healthcare cloud 10 and permits the user A and family members to access the portal site 14 a.
- the primary use service providing unit 122 starts up the portal site 14b for the attending physician on the healthcare cloud 10, and the portal site 14a for the user A is sent to the attending physician via the portal site 14b for the attending physician. Allow access to In this way, by receiving the access of the user A, the family, and the attending physician via the portal site 14a for the user A, feedback to the user A himself and information sharing among the three parties are realized.
- the range that can be browsed through the portal site 14a is different between the attending physician and the user A (and family). That is, the attending physician can view both the user A's PHR data itself and the health risk estimation result based on the PHR data. On the other hand, the user A himself or his / her family cannot browse the user A's PHR data itself.
- the disclosure of genome information to the person should be restricted as appropriate. Note that such a limitation on the viewing range is merely an example, and other limitations may be provided, but it is generally considered that the viewing range of the attending physician is often wider than the viewing range of the person himself / herself.
- the viewing range for the user A himself or her family may be adjusted based on the opinion of the attending physician.
- the primary use service providing unit 122 receives, from the attending physician, designations of items that the user A himself / herself wants to browse and items that should not be browsed among the health risk estimation results. Then, the primary use service providing unit 122 adjusts the viewing range that the user A himself / herself browses according to the designation from the attending physician. For example, the primary usage service providing unit 122 hides some of the diseases that were displayed when displaying the health risk graph for the attending physician when displaying the health risk graph for the user. In the present embodiment, a disease that is strongly influenced by the user's genomic factors may be identified as a disease with a high risk of onset.
- the primary use service providing unit 122 can hide a part of the disease when displaying the health risk graph for the user.
- the primary use service providing unit 122 receives a designation of a disease to be hidden from the attending physician, and reflects the designation when displaying the health risk graph, and hides the designation.
- the present invention is not limited to such intractable diseases.
- the attending physician considers the person's personality not desirable in consideration of the person's personality.
- the primary use service providing unit 122 receives a designation of a disease to be hidden from the attending physician, and reflects the designation in the display of the health risk graph and hides the designation.
- the viewing range is different between the attending doctor and the user A himself / her and the family, and the viewing purpose is also different between the attending physician and the user A himself / her and the family.
- the content 14c for the attending physician and the content 14d for the user A himself / herself and the family are prepared separately. This point will be described in detail when the screen transition is described below.
- the primary use service providing unit 122 displays the health risk estimation result as a “health risk graph”, “virtual clone”, “health status”, “mark that visually represents the health risk”, Presented as one or more of “character information”.
- the primary use service providing unit 122 presents the health risk estimation result by a “virtual clone” associated with the PHR data of the user A himself / herself.
- the “virtual clone” is set in association with each time point from the past to the future, and holds the health state at each time point in the form of a health status scored for each part.
- the primary use service providing unit 122 appropriately extracts diseases that are strongly influenced by lifestyle factors from the health risk graph, performs weighting according to the type of disease, and calculates a score for each part. When a disease at a certain part affects other parts, the primary use service providing unit 122 calculates the score by taking that point into consideration.
- the “virtual clone” holds an image of a facial expression corresponding to the health status. In this way, a sense of distance to the disease can be visualized.
- the past “virtual clone” holds information on the past health status and the health status according to the type of lifestyle, which is found from the past PHR data, and past disease.
- the current “virtual clone” holds information on the current health status and lifestyle type determined from the current PHR data, and on the disease currently being affected.
- the future “virtual clone” holds information on the future health status in which the current lifestyle type is added to the current health state determined from the current PHR data, and information on diseases with a high risk of onset in the future.
- an ideal “virtual clone” for the user A himself / herself is set and presented.
- the user A or the attending physician can grasp the health status of the user A himself from the past to the future by accessing the portal site 14a for the user A and browsing the “virtual clone” of the user A.
- the user A and the attending physician can grasp the patient's medical history and its severity by moving the “virtual clone” time in the past.
- the user A and the attending physician can display the future health risk based on the current lifestyle of the person by moving the time of the “virtual clone” to the future.
- the primary use service providing unit 122 presents the health risk estimation result as a “mark that visually represents the health risk”.
- This mark is, for example, a mark corresponding to the health status, and it is desirable that the mark be easily recognized by the user, such as “devil” if the health status is bad and “angel” if the health status is good.
- the primary use service providing unit 122 presents the health risk estimation result as “character information”.
- the primary use service providing unit 122 appropriately extracts diseases that are strongly influenced by lifestyle factors from the health risk graph, and displays the extracted disease names side by side.
- presenting a self-image that reflects the characteristic appearance predicted from the future health state in one's face and appearance intuitively affects the current life, You may display your future image after X years.
- FIG. 10 is a diagram illustrating a processing procedure of “daily human dock” in the present embodiment. As shown in FIG. 10, it is assumed that the user A has previously registered genome information in the PHR processing apparatus 100 (step S101). In addition, the process of step S101 is a process which should be performed at least once in principle, and the process after step S102 is a process performed repeatedly.
- the user A transmits life log information collected by the sensor and other information terminals to the PHR processing apparatus 100 from the wearable information terminal every day (step S102).
- the PHR accumulation unit 110 of the PHR processing apparatus 100 accumulates the received life log information as PHR data of the user A every day and centrally manages it.
- the primary use service providing unit 122 performs the processing after step S103, for example, at a frequency of once a week.
- the primary use service providing unit 122 determines the lifestyle type of the user A for each health risk estimation target period (step S103). For example, the primary use service providing unit 122 extracts the life log information D1 of this week, the life log information D2 of this month, and the life log information D3 of this year from the PHR data of the user A, and for each estimation target period, the user A Determine the type of lifestyle.
- the primary use service providing unit 122 estimates the health risk for each estimation period of the health risk using the genome type of the user A that has been identified in advance and the lifestyle type determined in step S103.
- the table T is referred to (step S104).
- the primary use service providing unit 122 refers to the health risk estimation table T, and when the genome type of the user A is type 3 and the lifestyle type of this week is type 3, FIG. Identify health risk graphs.
- the primary use service providing unit 122 identifies a health risk graph for each estimation target period.
- the primary usage service providing unit 122 adjusts the health risk graph obtained in step S104 according to the current health state of the user A for each estimation target period (step S105). For example, the primary use service providing unit 122 determines that the risk of developing “hepatocellular carcinoma (C220)” is low when it is determined from the biological information of the user A that the liver function of the user A is extremely good. And remove it from this week's health risk graph.
- C220 hepatocellular carcinoma
- the primary use service providing unit 122 calculates the health status from the present to the future for each estimation target period (step S106), and registers it in the “virtual clone” from the present to the future prepared for each estimation target period. (Step S107). For example, the primary use service providing unit 122 calculates the current health status of the user A based on the current health status calculated in the previous week and the biological information of the current week, and uses this to calculate the current health status of the user A. Register in association with “virtual clone”. Further, the primary use service providing unit 122 calculates the future health status by combining the deduction associated with aging and the deduction associated with the future health risk found in step S105 based on the current health status.
- the primary use service providing unit 122 calculates the health status at a certain time in the future, the health status at an intermediate time between the current time and the current time or a future time after that time is appropriately interpolated. (If there are multiple health risk estimation tables T prepared, use them). For example, the primary use service providing unit 122 calculates the health status at each time point from 1 day, 1 week, 1 month, 1 year, 5 years, 10 years, or 20 years later. In addition, the primary use service providing unit 122 calculates such a health status for each estimation target period.
- the primary use service providing unit 122 updates the health risk ranking list held by the attending doctor of the user A (step S107).
- the primary use service providing unit 122 may be able to obtain a plurality of users who are in charge of the attending physician from, for example, those who have a high risk of developing a disease based on the health status after 10 years when the estimation target period is “this year”.
- a health risk ranking list is created in order. Therefore, the primary use service providing unit 122 updates the health risk ranking list based on the health status of “this year” calculated in step S106.
- the primary use service providing unit 122 reflects the result of the above-described processing on the content for the attending physician and the content for the user A (step S108). For example, the primary use service providing unit 122 reflects the updated health risk ranking in the content for the attending physician. Further, in the content for user A, the primary use service providing unit 122 reflects the lifestyle type for each estimation target period, the health risk graph for each estimation target period, and the health status for each estimation target period.
- the primary use service providing unit 122 notifies registration to the attending physician (step S109).
- the attending physician first browses the health risk ranking on the attending physician's portal site. For example, if user A is ranked higher in the health risk ranking, the attending physician further browses the portal site for user A, records his / her comments, and portal site for user A (Step S110).
- the comment is not limited to the moving image data, and may be a comment using text data.
- the primary use service providing unit 122 notifies the user A himself / herself of registration (step S111), and the user A browses the portal site for the user A (step S112).
- the user A can also reproduce this moving image as the comment of the attending physician.
- the processing procedure shown in FIG. 10 is merely an example.
- the processing procedure that allows the user A himself / herself to browse after waiting for the comment by the attending physician is described, but the embodiment is not limited thereto.
- the primary use service providing unit 122 may notify the registration of the portal site to the three users, the family, and the attending physician at the same time.
- the processing procedure shown in FIG. 10 may be performed without assuming the intervention of the attending physician.
- the setting of the estimation target period, the calculation of the health status, and the like can be arbitrarily changed or omitted depending on the service provision form.
- FIG. 11 is a diagram showing screen transition of the attending physician portal site in the present embodiment
- FIG. 12 is a diagram showing screen transition of the user portal site in the present embodiment. Note that the screen transitions shown in FIGS. 11 and 12 are merely examples, and the order of the screen transitions, the configuration of the screens, and the like can be arbitrarily changed.
- the screen transition exemplified below is displayed on the PHR display device 200 of the attending physician or the PHR display device 200 of the user A himself. This is realized by control by the primary use service providing unit 122 and at the same time by display control by the display control unit 210 on the PHR display device 200 side.
- the attending physician accesses the portal site for the attending physician through the PHR display device 200. Then, as shown in the screen P1 in FIG. 11, it is notified that the health risk ranking list has been updated. Therefore, the attending physician presses the “Enter” button and browses the health risk ranking list.
- the primary use service providing unit 122 displays the health risk ranking on the PHR display device 200 of the attending physician.
- the health risk ranking the name of the user, the health risk score, and the name of the disease with a higher risk of onset are displayed in order of increasing health risk score. For example, it is assumed that the name of the user A is included at the top of the health risk ranking.
- the attending physician selects the name of the user A on the health risk ranking and accesses the portal site for the user A.
- the primary use service providing unit 122 displays the portal site for the user A on the PHR display device 200 of the attending physician.
- the primary use service providing unit 122 displays the current “virtual clone” of the user A.
- tabs for selecting an estimation target period tabs for “this week”, “this month”, and “this year” are set on the screen.
- the attending physician has selected “this week” as the estimation target period.
- a bar is displayed under “virtual clone” as a tool for receiving the time point to be confirmed. For example, the attending physician adjusts the position of this bar to “2023” 10 years later, and presses the “Check health risk graph” button.
- the primary use service providing unit 122 displays the genome type of the user A and the lifestyle type of this week on the attending physician's PHR display device 200, and displays the corresponding health risk graph. indicate.
- the primary usage service providing unit 122 may specifically display the contents of each item of the lifestyle type as necessary. Then, for example, the attending physician presses the “PHR confirmation” button after confirming the health risk graph.
- the primary use service providing unit 122 displays the PHR data of the user A.
- the example which displays life log information in a graph format is shown on screen P5, embodiment is not restricted to this.
- the primary use service providing unit 122 can process and display the PHR data designated by the attending physician into a format desired by the attending physician (for example, a table format). For example, the attending physician presses the “comment” button after confirming the health risk graph and PHR data for each estimation target period.
- the attending physician records a comment video using, for example, the recording function of the PHR display device 200, and uploads the comment video by pressing the “Send” button.
- the attending physician's PHR display device 200 includes a display control unit 210 that displays a user's future health risk estimated based on the user's PHR data on the display unit 220.
- the display control unit 210 displays a health risk ranking list based on comparison among a plurality of users, and when a predetermined user is designated for the health risk ranking list, the future health risk and PHR of the designated user.
- Display data The future health risk is displayed, for example, as a virtual clone, a health risk graph, or other character information.
- the PHR data is displayed in a graph format, a table format, other character information, or the like.
- the display control unit 210 displays the genome type and the lifestyle type as the PHR data of the user.
- illustration is abbreviate
- User A uses the PHR display device 200 to access the portal site for user A. Then, the screen shown in the screen P7 of FIG. 12 is displayed, and the user A presses the “Enter” button to start browsing.
- the primary use service providing unit 122 displays the current “virtual clone” of the user A.
- tabs for selecting an estimation target period (tabs for “this week”, “this month”, and “this year”) are set on the screen.
- the user A has selected “this week” as the estimation target period.
- a bar is displayed under “virtual clone” as a tool for receiving the time point to be confirmed. For example, the user A sets the position of this bar to “2023” 10 years later and presses the “details” button.
- the primary use service providing unit 122 displays the “virtual clone” at the time point designated by the user A and the health status at that point. Further, the primary use service providing unit 122 displays a health risk estimation result “the risk of developing“ alcoholic liver disease ”and“ diabetes ”is increasing in 10 years (2023)”. The primary use service providing unit 122 displays a mark that visually represents the health risk. In the example of the screen P9, a “devil” mark is displayed in order to visually express that the risk of developing a serious disease is increasing. Here, for example, the user presses a “simulation” button.
- FIG. 13 is a diagram for explaining a health risk simulation in the present embodiment.
- the primary usage service providing unit 122 has a GUI (Graphical User Interface) that can select three levels from “level I” to “level III” for 10 items obtained from life log information. ) Is displayed.
- GUI Graphic User Interface
- each level of each item is a button that can be selected by pressing the user.
- the primary usage service providing unit 122 initially displays the current lifestyle type of the user A in a selected state as shown on the left side of FIG. 13, but from the user A as shown on the right side of FIG.
- the user A has lowered the level of the item “drinking” from “level III” to “level II”, and has lowered the level of the item “fatigue” from “level II” to “level I”. . It is also displayed that the lifestyle type has been changed to 30 as a result of selection by user A. Further, the GUI for simulation is not limited to the example of FIG. For example, it may be changed by a pull-down menu or the like.
- the primary use service providing unit 122 specifies a health risk graph corresponding to the simulated lifestyle type, adjusts the health risk graph according to the current health state of the user A, and displays the screen P11. As shown, a simulated health risk graph is displayed.
- the primary use service providing unit 122 changes the display form between displaying the health risk graph for the doctor such as the attending physician and displaying the health risk graph for the user.
- FIG. 14 is a diagram for explaining a health risk graph displayed to the attending physician and the user in the present embodiment.
- the points for changing the display form are mainly the following two points.
- the first point is the display form of the disease name.
- the primary use service providing unit 122 displays the official name of the disease and the ICD code when displaying the health risk graph for the attending physician.
- the primary use service providing unit 122 displays the common name of the disease when displaying the health risk graph for the user.
- the primary use service providing unit 122 displays a disease that has been displayed as “hepatocellular carcinoma (C220)” in the health risk graph for the attending physician, and “liver cancer” in the health risk graph for the user. .
- the primary use service providing unit 122 displays the disease that is displayed as “diabetic nephropathy (E142)” in the health risk graph for the attending physician, and simply “diabetes” in the health risk graph for the user. Is displayed. Note that the primary use service providing unit 122 holds the association between the formal name, the ICD code, and the common name in advance, and refers to this association when displaying the health risk graph, and performs appropriate replacement.
- E142 diabetic nephropathy
- the primary use service providing unit 122 does not display a part of the disease displayed when displaying the health risk graph for the attending physician when displaying the health risk graph for the user.
- a disease that is strongly influenced by the user's genomic factors may be identified as a disease with a high risk of onset.
- diseases that are strongly affected by such genomic factors cannot be avoided even by lifestyle changes. For example, in the case of intractable diseases for which treatment methods cannot be established, notification to the person does not make sense ( (Alternatively, an adverse situation is assumed). Therefore, the primary use service providing unit 122 can hide a part of the disease when displaying the health risk graph for the user.
- the primary use service providing unit 122 displays the disease “spinal cerebellar degeneration (G319)” displayed when displaying the health risk graph for the attending physician as non-display when displaying the health risk graph for the user. Display.
- the primary use service providing unit 122 holds in advance a list of intractable diseases that are strongly influenced by genomic factors, and refers to this list when displaying the health risk graph and appropriately hides the list.
- the primary use service providing unit 122 receives a designation of a disease to be hidden from the attending doctor, and reflects the designation in the display of the health risk graph to hide the designation.
- the primary use service providing unit 122 displays the “virtual clone” after the simulation and the health status.
- the user A can recognize that the health risk and the health status are improved by executing the contents of the simulation by checking the expression of the “virtual clone” after the simulation and the health status.
- the user A can recognize that the onset of “alcoholic liver disease” and “liver cancer” can be avoided by switching to a lifestyle that refrains from drinking a little and takes sufficient rest.
- the primary use service providing unit 122 displays an “angel” mark as a mark that visually represents that the risk of developing a serious illness has decreased. For example, when a comment from the attending physician has been uploaded, the primary use service providing unit 122 displays a “comment from attending physician” button on the screen P12. User A can confirm the comment of the attending physician by pressing the “comment from attending physician” button.
- the PHR display device 200 of the user A himself / herself includes a display control unit 210 that displays the future health risk of the user estimated based on the user's PHR data on the display unit 220.
- the display control unit 210 displays at least one of the target health state of the user A and the guidance information for reaching the target health state together with the future health risk.
- the future health risk is displayed by, for example, “virtual clone”, health status, health risk graph, and other character information.
- the target health state is displayed as an ideal “virtual clone”, an ideal health status, a health risk graph after simulation, and other character information.
- the guidance information is displayed as comments from the attending physician, text information prepared in advance, or the like.
- the display control unit 210 displays a future health risk corresponding to the received time point. Moreover, if the display control part 210 receives the width
- the display control part 210 displays the name of the disease which the user A may develop in the future with a common name as a future health risk. Moreover, when displaying the names of diseases for the user A or the family of the user A, the display control unit 210 hides some of the names of diseases as necessary.
- the primary use service providing unit 122 can present an ideal “virtual clone” to the user A together with the lifestyle to be proposed, and can automatically suggest the lifestyle improvement to the user A.
- the family and the attending physician can monitor the physical and mental health of the user through the “virtual clone”. They can also give appropriate encouragement and guidance towards the ideal. For the user himself / herself, the method and progress for making health can be grasped specifically, and motivation can be further enhanced.
- dialogue and response with the “virtual clone” are not assumed. However, for example, by using simulation technology together, it is possible to realize dialogue and response with the “virtual clone”. Is possible.
- the present embodiment it is possible to accurately present the lifestyle of each individual and the future health risk by continuing the lifestyle using PHR data including genomic information.
- an optimal diet, exercise, lifestyle change, and estimation of medicines and supplements that are effective for individuals can provide a healthier and more ideal environment close to self.
- the achievement check for the ideal self embodies the results of efforts where it is difficult to see the goal, and changes it into motivation and joy.
- this embodiment is also capable of dealing with disaster resilience by remotely grasping and managing the location, survival status, and physical condition when the patient is isolated due to a disaster or the like and the physical condition deteriorates in the evacuation area.
- Health Risk Estimation Table T (Other uses of “Health Risk Estimation Table T”) Further, in the above-described embodiment, as a specific example, the “health risk estimation table T” is referred to by using the user's genome type and lifestyle type, and information on diseases whose lifestyle factors have a strong influence is obtained. An example of feedback as an estimation result has been described. However, the use form of the information obtained from the “health risk estimation table T” is not limited to this.
- the items of life log information collected from the user may be narrowed down to items related to the disease having a high risk of onset, and collected intensively.
- the types and items of sensors used on the user side can be changed in accordance with the user's genome type and lifestyle type.
- the “health risk estimation table T” using the type of the user's genome and the type of lifestyle, information on diseases that are strongly influenced by genomic factors, that is, genetically high risk by the user. It is also possible to estimate the disease.
- the primary use service providing unit 122 may provide a mechanism for quickly supplementing a sign of a disease having a high risk of onset for the user from PHR data transmitted from the user every day.
- the primary use service providing unit 122 provides a threshold value that matches a specific disease, and sequentially checks the PHR data transmitted from the user with the threshold value.
- the PHR processing device 100 is The provision of secondary usage services for PHR data is also assumed.
- the PHR processing apparatus 100 analyzes the large-scale genome cohort database 114a in order to derive a relationship between a combination of a genome type and a lifestyle type and a specific purpose, and an analysis result indicating a certain relationship. And provide it to medical institutions and various companies.
- the PHR big data accumulated in the large-scale genome cohort database 114a is originally PHR data collected from each individual, that is, personal information. For this reason, with regard to the use of PHR data, each individual such as “Allows primary use of PHR data but not secondary use” and “Allows primary use or secondary use of PHR data”. May have different intentions. Therefore, in the present embodiment, the PHR processing device 100 accepts a usage license indicating which usage is permitted in advance with each individual who provides the PHR data, and appends usage permission information to the PHR data. Are managed. The use permission is accepted in the whole PHR data or in units of subdivided items in the PHR data.
- a specific example of the secondary use service will be described on the assumption that this use permission is obtained. The specific examples described below are merely examples, and the secondary usage service is not limited to the following specific examples.
- 15 and 16 are diagrams for explaining an example (first example) of the secondary use service in the present embodiment.
- life log information that is PHR data of each individual is newly accumulated every day, and new individual PHR data is accumulated as a new operation management target.
- the scale is expanding every day.
- the PHR big data analysis unit 121 accepts an input for the purpose of analysis of the efficacy of a specific drug, performs a cohort analysis on the PHR big data accumulated in the large-scale genome cohort database 114a, and determines the type and lifestyle of the genome.
- the relationship between the combination of types and the efficacy of a specific drug is derived.
- the PHR data includes electronic medical record information, and the electronic medical record information includes information on medicines prescribed for the individual and information indicating the subsequent progress.
- the PHR data includes life log information, and the life log information includes information indicating a change in the physical condition of the individual after the medicine is prescribed, and information indicating a life situation of the individual. ing.
- the PHR big data analysis unit 121 performs a cohort analysis on the PHR big data including these pieces of information, thereby deriving the relationship between the combination of the genome type and the lifestyle type, and the drug efficacy and side effects. Then, as shown in FIG. 15, the PHR big data analysis unit 121 classifies the combination of the genome type and the lifestyle type according to the medicinal effect and the presence or absence of side effects.
- the PHR big data analysis unit 121 includes a group exposed to a specific factor (a group that applies to a combination of a specific genome type and a lifestyle type) and a group that is not exposed (a group that does not correspond to the combination). Are followed for a certain period of time, and the efficacy and side effects are compared, and the relationship between the factor (a combination of a specific genome type and lifestyle type) and the efficacy and side effects is derived. Then, the PHR big data analysis unit 121 converts the combination of genome type and lifestyle type into “medicine effect ( ⁇ ), side effect (+)”, “medicine effect ( ⁇ ), side effect ( -) ",” Drug efficacy (+), side effects (+) “and” Drug efficacy (+), side effects (-) ".
- the drug can be prescribed, but side effects need to be considered.
- the drug can be prescribed to those who have a combination of types classified into the group of “medicine efficacy (+), side effect ( ⁇ )”.
- the secondary use service providing unit 123 utilizes the relationship between the combination of the genome type and the lifestyle type, the medicinal effect, and the side effect based on the contract previously made with the medical institution.
- Various methods are conceivable as the providing method. In the following, one method will be described with reference to FIG.
- the secondary usage service providing unit 123 starts up a portal site 14 e for secondary usage services on the healthcare cloud 10, and accesses the portal site 14 e for doctors of medical institutions. Allow. Further, the secondary use service providing unit 123 allows the doctor to access each individual's PHR data and also allows access to the classification result of the combination of the genome type and the lifestyle type. Then, for example, the doctor browses the PHR data of the patient B via the portal site 14e and confirms the combination of the patient B's genome type and lifestyle type. Further, the doctor confirms the classification result via the portal site 14e.
- the doctor collates the patient B's genome type and lifestyle type with the classification result, and should determine whether or not a specific medicine should be prescribed for this patient B, or consider side effects when prescribing. Determine whether or not. Then, the doctor creates a prescription for patient B based on this determination.
- the method of providing the secondary usage service is not limited to the method described above.
- the secondary use service providing unit 123 creates, for example, a real name list including information on an individual's genome type and lifestyle type, and a classification result regarding a specific medicine, and transmits these to a medical institution or the like. Also good.
- the real name list and the classification result may be provided offline.
- FIG. 17 is a diagram for explaining an example (second example) of the secondary usage service in the present embodiment.
- the PHR big data analysis unit 121 accepts an input for an analysis purpose of deriving a relationship with an effect by a component (or a similar component) included in a specific health drink, and is stored in the large-scale genome cohort database 114a. Cohort analysis is performed on the PHR big data, and the association between the combination of genome type and lifestyle type with a specific health drink is derived.
- the PHR data includes life log information, and the life log information includes information indicating the physical condition of the person and information indicating the intake status of foods and supplements.
- the PHR big data analysis unit 121 performs a cohort analysis on the PHR big data including such information, thereby deriving the relationship between the combination of the genome type and the lifestyle type and the specific health drink.
- the PHR big data analysis unit 121 includes a group exposed to a specific factor (a group that applies to a combination of a specific genome type and a lifestyle type) and a group that is not exposed (a group that does not correspond to the combination). By comparing the presence or absence of effects of components (or similar components) contained in a specific health drink to be analyzed for a certain period, factors (combinations of specific genome types and lifestyle types) ) And a specific health drink.
- the PHR big data analysis part 121 is a group which has the effect with respect to the component (or its similar component) contained in a specific health drink by combining the combination of the genome type and the lifestyle type based on the derived relationship. And a group having no effect. Furthermore, the PHR big data analysis unit 121 classifies the groups having effects into two groups in view of eating together with the food / supplement being consumed.
- the secondary use service providing unit 123 determines the relationship between the combination of the genome type and the lifestyle type and the health drink based on the contract made in advance with the food and supplement sales company.
- a secondary use service for use is provided to the food / supplement sales company 15a.
- Various methods are conceivable as the providing method. In the following, one method will be described with reference to FIG.
- the secondary use service providing unit 123 is classified into a group capable of selling or recommending a specific health drink from a group of users who are providers of PHR data. Users who have a combination of different types. Then, the secondary use service providing unit 123 creates a real name list including points to be noted for these users, and transmits the real name list to the food / supplement sales company 15a.
- the real name list may be provided by browsing through the portal site or may be provided offline.
- the food / supplement sales company 15a performs sales promotion activities by direct mail (Direct Mail: DM) using this real name list.
- the food / supplement sales company 15a refers to points to be noted as necessary in sales promotion activities.
- the secondary usage service providing unit 123 tracks PHR data corresponding to a user who can sell a specific health drink or has a combination of types classified into a recommended group for a certain period of time. . Then, the secondary use service providing unit 123 uses the life log information to determine the user who would have purchased this specific health drink, and transmits the purchased user's PHR data to the food / supplement sales company. Note that the purchaser's PHR data may be provided by browsing through a portal site or may be provided offline.
- the food / supplement sales company 15a verifies the effect of the health drink using the PHR data. For example, the food / supplement sales company 15a calculates a quantitative numerical value indicating the effect. Then, the food / supplement sales company 15a is able to sell a specific health drink, or out of the users having combinations of types classified into recommended groups, the calculated numerical value is given to non-purchased users. Provide feedback on the underlying effect.
- the secondary usage service providing unit 123 uses the PHR data to determine a user who would have purchased a specific health drink, and the purchased user's PHR data itself is sent to the food / supplement sales company 15a.
- the example to provide was demonstrated, embodiment is not restricted to this.
- the secondary use service providing unit 123 determines the users who will have purchased a specific health drink, analyzes the PHR data, narrows down the users who have actually obtained the effect, and narrows down the real names of the narrowed down users
- the list may be provided to the food / supplement sales company 15a.
- such narrowing down is effective when the food / supplement sales company 15a desires to conduct sales activities with a target focused on a user who is significantly effective.
- the secondary usage service providing unit 123 narrows down the lifestyle type of the user who has actually obtained the effect, and specifies the lifestyle associated with the effect.
- the secondary use service providing unit 123 can also provide the identified lifestyle information to the food / supplement sales company 15a. In this case, the food / supplement sales company 15a can also make a lifestyle proposal at the time of sales.
- FIG. 18 is a diagram for explaining an example (third example) of the secondary usage service in the present embodiment.
- the secondary use service providing unit 123 accepts a use permission in advance with each user who provides PHR data.
- This usage permission includes, for example, which items in the life log information are permitted to be disclosed (disclosure items) and who is the disclosure partner (disclosure destination).
- the secondary use service providing unit 123 accepts a use permission from the elderly user E on the user E portal site 14f.
- the secondary use for the family watching service is permitted, and the information disclosure partner is the daughter user A or the son user. D.
- the life log information regarding the amount of exercise and the amount of sleep, permitting secondary use to the family watching service, and the information disclosure partner may be the daughter user A or the son user D. It is shown.
- position information of life log information indicates that secondary use for family watching services is not permitted.
- the secondary usage service providing unit 123 notifies the PHR accumulating unit 110 of the usage permission information received for the secondary usage. Then, the PHR accumulating unit 110 appends the usage permission information describing the above-described content to the PHR data transmitted from the user E and stores it.
- the usage permission information may be attached to the entire PHR data, or may be attached to each subdivision item data. Any method can be adopted as long as it is an accompanying method that allows the user license information to be confirmed on the side using the PHR data.
- the secondary use service providing unit 123 provides the security information 15b providing the family watching service by processing the PHR data provided in this way into a form suitable for the family watching service.
- the secondary use service providing unit 123 has a form such as a graph in which each value is plotted in chronological order so that one week's tendency can be easily grasped about blood pressure, heart rate, exercise amount, and sleep amount for one week.
- the processed PHR data is provided to the security company 15b.
- the providing method may be either online or offline.
- the secondary use service providing unit 123 may provide the corresponding PHR data itself to the security company 15b. In this case, the above-described processing is performed by the security company 15b as necessary.
- the security company 15b operates a family watching service.
- the subscriber of the family watching service is the daughter user A of the elderly user E.
- User A in the contract with security company 15b, is that elderly user E is the object of monitoring, and that user D who is the son of user E wants to use this service as well. Decide. Note that the subscriber of the family watching service and the user of the service provided on the PHR processing apparatus 100 side do not necessarily have to match.
- the security company 15b sets up a monitoring portal site 14g for the elderly user E on its own site. Access to the watching portal site 14g is permitted only to the user A and the user D. Then, the user A and the user D can check, for example, the health condition of the mother, the state of exercise, the sleep state, and the like in this week on the watch portal site.
- the secondary usage service providing unit 123 accepts a usage permission regarding a disclosure item and a disclosure destination for the PHR data transmitted from the user. Then, the secondary use service providing unit 123 outputs the user's PHR data or processing information of the PHR data according to the accepted use permission.
- a service can be provided in which the situation of the family can be understood even if they are away. Further, at that time, it is possible to realize a mechanism that can disclose only specified information in the life log information only to a specific partner.
- each life log information is accompanied by usage permission information, and the data is held in such a way that it can be disclosed to a specific partner.
- the first, second, and third examples have been described as secondary use of PHR big data.
- secondary use progresses, not only support services for returning future health risk assessment results to PHR data providers, but also distribution, product sales and service provision, lifestyle design, local currency It is possible to construct a new business model that returns various economic benefits to individuals, local governments, and society, such as a point reduction system that can be used as
- the verification cycle and the evidence are accumulated, and the performance is improved as a system with higher certainty and reliability. Further, since it is composed of various data, its usefulness is also high. By processing these databases and promoting their secondary use in various forms, it has become a basic data based on lifelog big data and genomic information that have been accumulated up to now but have not been able to find sufficient value. It will be possible to give new and innovative value, and it will be possible to create new and innovative industries using them.
- the PHR processing apparatus 100 further constructs an incentive mechanism for continuously transmitting PHR data to each individual.
- Mechanism 1 is cooperation with the secondary usage service.
- the PHR data transmitted by each user is also provided to the secondary usage service when the permission of the user is obtained. Therefore, the PHR processing apparatus 100 is in some form such as a point system (points, mileage, distribution money, etc.) based on the profits obtained by the data trust company 11 in relation to this secondary usage service. Build a mechanism for feedback to each user.
- Mechanism 2 is competition between users. Each user can increase motivation for health by competing with a competitor such as a friend or family. Therefore, the PHR processing device 100 compares, for example, the amount of PHR data and the number of types, biological information such as weight and blood pressure, and behavior information such as the distance and the number of steps walked in a day with each other. , Build a mechanism to compete for wins and losses.
- the competitor may be a virtual friend, lover, family, or the like that is virtually set.
- Mechanism 3 is the energy forecast already described in the above embodiment. That is, each user can receive the future health risk estimated based on the PHR data as an energetic forecast by providing the PHR data to the PHR processing apparatus 100.
- spirit forecasts present future health risks in various ways. For example, if the user can perform estimation according to the estimation target period such as this week, this month, this year, the past one day, the past one week, the past one month, the past one year, or the like, It can also be estimated by selecting an arbitrary time point such as one week later, one month later, one year later, five years later, ten years later, twenty years later, and the like.
- FIG. 19 is a diagram for explaining the incentive mechanism 1 in the present embodiment.
- the primary usage service providing unit 122 includes an incentive processing unit 122 a (also referred to as a “presentation unit”).
- the incentive processing unit 122a evaluates the PHR data of a predetermined user and presents the evaluation result to the predetermined user. For example, the incentive processing unit 122a cooperates with the secondary usage service providing unit 123, and the PHR utilized for the secondary usage is provided from the secondary usage service providing unit 123 with respect to a predetermined user who permits the secondary usage of the PHR data. Utilization information such as the amount of data, the type, the number of types, and the usefulness of the secondary usage service using this PHR data is received. Then, the incentive processing unit 122a calculates points based on the utilization information, and provides information related to the calculated points (for example, the points themselves, the services returned to the user according to the points, the amount of the distribution money, etc.) To present.
- the incentive processing unit 122a presents the public offering information on the portal site 14h of the user A.
- This public offering information includes, for example, an outline of the purpose of secondary use, such as “Please cooperate in the development of pharmaceuticals,” the value of points, and the amount of PHR data required for that purpose (for example, the transmission frequency, the transmission period, and the like) and the type (for example, specific items of biological information and behavior information) are described.
- the user A browses the public offering information and performs an application (use permission) procedure.
- the user A transmits the PHR data to the PHR processing device 100 every day in accordance with the provisions of the PHR data described in the public offering information.
- the PHR data of the user A transmitted and stored in the PHR processing apparatus 100 is eventually provided for the above-mentioned secondary use according to the usage permission.
- the incentive processing unit 122a receives utilization information from the secondary usage service providing unit 123, calculates points based on the utilization information, and presents information regarding the calculated points to the user. For example, as shown in FIG. 19, the incentive processing unit 122 a displays “user A's acquired points OOpts” on the portal site 14 i. Note that the calculation of points does not necessarily have to be performed after secondary use, and may be performed before being provided for secondary use.
- This point system is managed and managed by the data trust company 11, and the data trust company 11 performs a specific return based on the points to the user A.
- the data trust company 11 has earned money related to this secondary usage service, the data trust company 11 is affiliated with a company or a store based on this profit, and the user A We will receive points from companies and products of this partner.
- the point reduction may be in any form such as a service or a free gift.
- the data trust company 11 may remit part of the proceeds to the user A in the form of distribution money.
- the purpose of secondary use services is highly socially significant, such as the development of pharmaceuticals and clinical trials (clinical trials) for obtaining approval under the Pharmaceutical Affairs Law. Some of them are simply part of marketing, such as collecting biometric information that appears on the body from viewers.
- the data trust company 11 can arbitrarily set what purpose is a highly useful purpose and what purpose is a low useful purpose. Can be set to be highly useful and low for marketing purposes. Alternatively, the data trust company 11 may set the usefulness in accordance with the ratio of the profit actually obtained (or the profit expected to be obtained) to the total profit.
- the embodiment is not limited to this.
- the point system by the incentive processing unit 122a may be operated based on the data amount, type, and number of types of PHR data transmitted from the user, separately from the secondary usage service. In this case, for example, for each user's PHR data, the incentive processing unit 122a calculates points based on at least one of the data amount, the type, and the number of types, and presents information about the calculated points to the user. To do.
- the incentive processing unit 122a may calculate points based on some criteria for evaluating the transmission status of PHR data.
- FIG. 20 is a diagram for explaining the incentive mechanism 2 in this embodiment.
- the incentive processing unit 122a evaluates the PHR data of a predetermined user and presents the evaluation result to the predetermined user. For example, as shown in FIG. 20, the incentive processing unit 122a sets a competitive relationship among a plurality of users who are transmitting PHR data, and performs a comparison regarding life log information among the users. Then, the incentive processing unit 122a presents the result to each user who has a competitive relationship.
- the incentive processing unit 122a receives an application from the user A to set the user C as a competitor. Then, the incentive processing unit 122a sets a portal site 14j for performing a competition between the user A and the user C on the healthcare cloud 10, and each of the portal sites of the user A and the user C has a competition site. Link to the portal site 14j. In this way, each of the user A and the user C can browse the two portal sites 14j for competition via their portal sites.
- the incentive processing unit 122a is used for competition between two users at a frequency (for example, once a week, once a month, once a year, etc.) according to a request from the user A and the user C.
- the portal site 14j is updated. For example, it is assumed that the requests from the user A and the user C are once a week.
- the incentive processing unit 122a extracts the information of the competition item designated as the competition target in advance from the PHR data of the user A once a week for the past one week, and similarly, from the PHR data of the user C, Information on competition items designated in advance as competition targets is extracted. And the incentive process part 122a compares the information of the competition item extracted from each PHR data, and determines a win or a loss.
- the incentive processing unit 122a specifies the amount of data and the number of types for each user's PHR data, and from the life log information, the weight information, blood pressure information, and daily average Get the number of steps.
- the user A transmits PHR data for 7 days in one week and transmits 20 items.
- User A succeeds in weight loss of 0.5 kg, blood pressure is normal, and the average number of steps per day is as high as 7,500.
- the user C transmits PHR data for 5 days in one week, and transmits 19 items.
- User C has a weight of 1.0 kg, blood pressure is normal, and the average number of steps per day is as small as 5,000 steps.
- the incentive processing unit 122a evaluates these pieces of information according to a predetermined criterion and determines whether or not the player has won or lost. Then, the incentive processing unit 122a displays the determination result as, for example, a mark visually representing winning or losing, character information, or the like, as shown in FIG. In the example of FIG. 20, the incentive processing unit 122a also gives points to the result of this competition. Note that the competition items and competition standards, the GUI of the competition portal site 14j, the competition feedback method, and the like can be arbitrarily changed. For example, the incentive processing unit 122a may send the competition result to each user's mail address.
- Biometric information includes biomarkers such as proteins, peptides, lipids, and sugar chains.
- biomarkers include, for example, proteins, peptides, lipids, sugar chains and the like contained in body fluids such as serum, urine, tears, saliva, cerebrospinal fluid, pancreatic juice, joint fluid, mammary aspirate, bile, etc. Yes, it reflects the physiological state of the body. Therefore, for example, using a biomarker related to a certain disease leads to early detection of the disease, and early treatment can be performed.
- biomarker information may be collected by, for example, a biosensor, or may be collected by periodic inspection.
- biomarkers include, for example, “total protein”, “GOT (glutamate oxaloacetate transaminase)”, “GPT (glutamate pyruvate transaminase)”, “ALP (alkaline phosphatase)”, which are generally measured by blood tests. , “ ⁇ -GTP ( ⁇ -glutamyl transpeptidase)”, “LDH (lactate dehydrogenase)”, “total bilirubin”, “amylase”, “total cholesterol”, “neutral fat”, “HDL cholesterol” and “hemoglobin” Or the like.
- the biomarkers listed here are merely examples, and biomarkers as biological information are not limited thereto. Currently, biomarkers related to diseases are actively searched using various body fluids, and various biomarkers have been identified. Many biomarkers will be identified in the future. All the biomarkers can be used as the biomarkers in the present embodiment.
- the PHR processing apparatus 100 performs various types of analysis on each piece of biological information and provides the result to the user. For example, the PHR processing apparatus 100 compares the collected data for each type of biological information and derives a comparison result. For example, the PHR processing apparatus 100 analyzes the data of biological information collected every day (for example, blood pressure) by comparing the data of others or comparing the data of individuals. Or Hereinafter, these comparative analyzes will be described.
- the PHR processing apparatus 100 analyzes how the biometric information of a predetermined user is compared with the biometric information of other users.
- the PHR processing apparatus 100 divides a plurality of users into groups, and analyzes how the biometric information of each group is compared with the biometric information of other groups.
- the PHR processing apparatus 100 performs a comparison by grouping a plurality of users based on genome information and attribute information.
- the PHR processing apparatus 100 groups a plurality of users based on the genome information and attribute information. Then, biometric information is compared and analyzed between users in the group. Further, for example, when analyzing how the biometric information of each group is compared with the biometric information of other groups, the PHR processing apparatus 100 groups a plurality of users based on the genome information and attribute information. Divide and analyze biometric information between groups.
- the PHR big data analysis unit 121 includes a function as a comparison unit that compares biological information and a function as an analysis unit that analyzes which position is based on the comparison result. Although described as an example, the embodiment is not limited to this, and the PHR processing apparatus 100 may include a comparison unit and an analysis unit.
- the PHR big data analysis unit 121 stores information stored in the PHR storage unit 110. Based on the above, biometric information continuously collected by each user is compared among predetermined biometric information in a group formed by combining genome information and attribute information of each user. And the PHR big data analysis part 121 shows in which position in the said group the value of the biometric information of each user exists based on the comparison result. In addition, when analyzing how the biometric information of each group is compared with the biometric information of other groups, the PHR big data analysis unit 121 is based on the information accumulated in the PHR accumulation unit 110.
- biometric information continuously collected by each user belonging to the group is aggregated and biometric information between the groups is compared.
- the PHR big data analysis part 121 shows where the value of the biometric information of each group exists between groups based on the comparison result.
- the PHR big data analysis unit 121 indicates the position in the distribution of the value of the biological information as the position. That is, the PHR big data analysis unit 121 derives the position of each user value in the distribution of the predetermined biometric information value of each user belonging to the group as the position of each user, and sets the predetermined value of each group as the position of each group. The position of the average value of each group in the distribution of the average value of the biometric information values is derived.
- the attribute information described above includes information on the user's residence area, age, gender, race, and the health insurance association to which the user belongs
- the PHR big data analysis unit 121 includes the genome information of each user as a group. A group is formed by combining the above attribute information.
- the above-described positions include ranks, deviation values, and the like, and the PHR big data analysis unit 121 derives the ranks and deviation values of users in the group or the ranks and deviation values of each group as positions. To do.
- the PHR big data analysis unit 121 classifies a plurality of users into groups G 1 to G 4 according to “genome information: genome type 2” and “attribute information: age”. Then, the PHR big data analysis unit 121 compares, for example, blood pressure for each classified group, and indicates where the blood pressure value of each user is in the group. For example, the PHR big data analysis unit 121 aggregates information on blood pressures (diastolic blood pressure and systolic blood pressure) of all users belonging to the group G 1 of “genome type 2, age: ⁇ 40 years”. Then, as shown in FIG. 21A, histograms are generated for each of the diastolic blood pressure and the systolic blood pressure, and the position of the blood pressure of the user belonging to the group G 1 is derived.
- blood pressures diastolic blood pressure and systolic blood pressure
- the PHR big data analysis unit 121 performs group G 2 of “genome type 2 and age: 40 to 50 years”, and group G 2 of “genome type 2 and age: 50 to 60 years”. 3.
- a blood pressure histogram is generated for each group G 4 of “genome type 2, age: 60 years old” to derive the position of each user's blood pressure for each group.
- the PHR big data analysis unit 121 shows a group formed by “genome information: genome type 2” and “attribute information: age”, but this is merely an example, and the PHR big data analysis unit 121 is configured as other Similarly, in the same type of genome, group multiple users by genome type and age, compare the biometric information for each group, and determine the position of the biometric information value of each user in the group. Show.
- the attribute information is not only age but also gender and residential area.
- the PHR big data analysis unit 121 forms a group of “genome information: genome type 2 and attribute information: male” and a group of “genome information: genome type 2 and attribute information: female”.
- the attribute information used for grouping is not limited to one, and two or more attribute information may be used.
- the PHR processing apparatus 100 forms a group according to “age” of “genome type 2” in “predetermined residential area”.
- the PHR big data analysis unit 121 divides users into groups using “genome information” and “attribute information”, and performs comparative analysis between users for each group. Thereby, the user can grasp
- FIG. 21B a comparative analysis in group G 1 shown in FIG. 21A is taken as an example.
- the measurement value of the blood pressure of the user A belonging to the group G 1 is to derive whether located in which position of the histogram of the group G 1.
- the histogram of the group G 1 may be an aggregate of blood pressure values of each user at one time point, or may be an aggregate of average values in a predetermined period.
- the blood pressure value may be averaged and the average value of each user may be aggregated.
- the blood pressure at the time of waking up is determined based on the heart rate and pulse measured by the biosensor worn by the user, and whether or not the user has woken up is determined. It is.
- the PHR big data analysis unit 121 performs a weekly blood pressure value “systolic blood pressure: 110-125, average value 119” of user A, “diastolic blood pressure: 75-84, average
- the position of the value 81 ”in the histogram in which the average values of the users belonging to the group G 1 are aggregated is derived. That is, the PHR big data analysis unit 121 derives the position of the average value of the systolic blood pressure of the user A in the histogram of the systolic blood pressure, and the average value of the diastolic blood pressure of the user A is the histogram of the diastolic blood pressure. The position of the position is derived.
- the PHR big data analysis unit 121 not only derives the position of the user A in the histogram, but also compares the reference value provided for each group with the measured values of the users belonging to the group.
- the histogram of each group is a collection of biometric information of users having the same genome type and similar attribute information. Therefore, the distribution state of the histogram is considered to reflect the type and attribute information of each genome. Therefore, the average value of the histogram in each group is set as an ideal value (reference value) of the group, and ranking of users and assignment of deviation values are performed based on the degree of deviation from the reference value. For example, the PHR big data analysis unit 121 calculates a difference value between the “average value of 119” of the systolic blood pressure of the user A and the average value (reference value) of the systolic blood pressure of the group G 1 .
- the PHR big data analysis unit 121 calculates a difference value between the “average value: 81” of the diastolic blood pressure of the user A and the average value (reference value) of the diastolic blood pressure of the group G 1 . Then, the PHR big data analysis unit 121 derives the divergence degree based on the difference values respectively calculated for the systolic blood pressure and the diastolic blood pressure. For example, the PHR big data analysis unit 121 derives the sum of absolute values of two difference values as a divergence degree.
- PHR big data analysis unit 121 derives the degree of deviation for all users belonging to the group G 1, ranking and the user A in the group G 1 based on the derived deviation degree, and applying the deviation Do. For example, the PHR big data analysis unit 121 ranks the user so that the degree of deviation from the reference value (average value of the histogram) is smaller and assigns a deviation value. As described above, when the PHR big data analysis unit 121 ranks and assigns a deviation value, the primary use service providing unit 122 provides the result to each user.
- the primary use service providing unit 122 provides blood pressure rank and deviation value information to the mobile terminal that is the PHR display device 200 of the user A.
- the primary use service providing unit As shown in FIG. 21B, 122 shows the result of one point “rank: 232/12543, deviation value: 65” and the average result “rank: 301/12543, deviation value: 62” of user A.
- the display control unit 210 of the portable terminal displays the information provided on the display unit 220 as shown in FIG. 21B. Note that the user A can arbitrarily select a desired date result.
- the PHR big data analysis unit 121 not only assigns ranks and deviation values based on the reference value, but also determines whether the user's measurement value is within the allowable value range. You can also. For example, the PHR big data analysis unit 121 sets the allowable range “ab” for diastolic blood pressure and the allowable range “cd” for systolic blood pressure shown in FIG. It is determined whether or not each is within an allowable range.
- the primary use service providing unit 122 provides the determination result to the user A's mobile terminal.
- the display control unit 210 of the portable terminal displays the determination result on the display unit 220.
- the allowable range set by the PHR big data analysis unit 121 for example, a predetermined value provided by various academic societies, organizations, organizations, or the like can be used.
- the allowable range set by the PHR big data analysis unit 121 may be set based on a histogram.
- the PHR big data analysis unit 121 sets an arbitrary range based on the minimum value and the maximum value of the histogram.
- the PHR big data analysis unit 121 sets a value that reaches 30% of the number of users from the minimum value in ascending order and sets the lower limit value, and counts in descending order from the maximum value. The value reaching 30% is set as the upper limit value.
- the PHR big data analysis unit 121 forms a group in which genome information and attribute information are combined, compares the biometric information in the group, and the biometric information value of each user is within the group. Analyze where it is.
- the above-described blood pressure example is merely an example, and other biological information (for example, heart rate, pulse, body temperature, body component, ion, pH concentration, sugar, salt and other component amounts, gastric acid concentration, A comparative analysis is similarly performed for agrochemicals, environmental substances, presence or absence of food additives, alcohol and nicotine, drug components, biomarkers, and the like.
- FIG. 22 is a diagram for explaining comparison analysis between groups in the present embodiment.
- FIG. 22 shows a case where a plurality of users are divided into groups G 1 to G n by a combination of “attribute information: genome type 2” and “attribute information: residential area” and blood pressure is compared.
- the PHR big data analysis unit 121 calculates average values of blood pressure (diastolic blood pressure, systolic blood pressure) in the groups G 1 to G n , respectively. Then, the PHR big data analysis unit 121 generates a histogram using the average value of diastolic blood pressure and the average value of systolic blood pressure calculated for each group, and the average value of each group is in which position of the histogram. To derive. For example, the PHR big data analysis unit 121 sets the average value of the histogram as a reference value, ranks groups based on the degree of deviation from the reference value, and assigns a deviation value.
- the PHR big data analysis unit 121 calculates a difference value between the average value of the systolic blood pressure of the group G 1 and the average value of the systolic blood pressure of the entire group. Similarly, the PHR big data analysis unit 121 calculates a difference value between the average value of the diastolic blood pressure of the group G 1 and the average value of the diastolic blood pressure of the entire group. Then, the PHR big data analysis unit 121 derives the divergence degree based on the difference values respectively calculated for the systolic blood pressure and the diastolic blood pressure. For example, the PHR big data analysis unit 121 derives the sum of absolute values of two difference values as a divergence degree.
- the PHR big data analysis unit 121 derives the divergence degree for all the groups G 2 to G n , and ranks groups and assigns deviation values based on the derived divergence degree. For example, the PHR big data analysis unit 121 ranks and assigns a deviation value so that a group having a smaller degree of deviation from the reference value (average value of the histogram) is higher. Thus, when the PHR big data analysis unit 121 ranks and assigns a deviation value, the primary usage service providing unit 122 or the secondary usage service providing unit 123 provides the result to a user, a company, an organization, or the like. .
- the secondary use service providing unit 123 provides blood pressure rank information to a terminal such as a company or an organization that desires the result.
- the user who refers to the terminal to which the information is provided can grasp that “area A 5 ” is ranked first and “area A 21 ” is ranked lowest in blood pressure. Thereby, for example, the best measure can be performed for each region.
- the example shown in FIG. 22 is merely an example, and genome information and attribute information are arbitrarily combined to form a group, and arbitrary biometric information is compared. Is shown.
- the average value calculated for each group may be an average value of values at one time point, or may be a value obtained by calculating an average value for a predetermined period for each user and averaging the calculated average values.
- the PHR processing device 100 analyzes how the measurement value of the biological information of a predetermined user changes. For example, the PHR processing apparatus 100 analyzes how the biological information is at a certain point in time, and analyzes how the biological information changes in a predetermined period. Here, the PHR processing apparatus 100 analyzes how the measurement value is relative to the reference value derived based on the genome information.
- the PHR big data analysis unit 121 derives a comparison result between a reference value derived based on genome information and a measurement value collected from a user corresponding to the genome information for predetermined biological information. More specifically, the PHR big data analysis unit 121 compares the result of comparison between the reference value and the measurement value at a predetermined time point, the tendency of the change in the measurement value collected from the user over a predetermined period, and the predetermined value. At least one of the comparison results with the tendency of change in the reference value corresponding to the period width is derived.
- FIG. 23A and FIG. 23B are diagrams for explaining a comparative analysis of individuals at a predetermined point in the present embodiment. For example, as shown in FIG. 23A, when performing a comparative analysis on the blood pressure at the time of rising of the user A of “genome type 2”, the PHR big data analysis unit 121 first sets a reference value based on the type 2 genome.
- a value obtained by aggregating measurement values of users of the same genome type is a value reflecting the genome type, and can be considered as a reference value. Therefore, for example, the PHR big data analysis unit 121 obtains blood pressure data (diastolic blood pressure, systolic blood pressure) of other genome 2 type users from the PHR accumulation unit 110 and generates a histogram. Set an arbitrary range based on the minimum and maximum values. For example, the PHR big data analysis unit 121 sets, as the lower limit, a value that reaches 30% of the number of other users of the genome type 2 and counts in ascending order from the minimum value.
- the PHR big data analysis unit 121 sets the “diastolic blood pressure range (genome type 2)” and “systolic blood pressure range (genome type 2)” shown in FIG. 23A by the method described above.
- the PHR big data analysis part 121 compares the value of the blood pressure of the user A measured at the time of getting up with the set range, as shown in FIG. 23A. That is, the PHR big data analysis unit 121 analyzes whether or not the diastolic blood pressure when the user A gets up is within the diastolic blood pressure range (genome type 2). Similarly, the PHR big data analysis unit 121 analyzes whether the systolic blood pressure when the user A wakes up falls within the systolic blood pressure range (genome type 2). The PHR big data analysis unit 121 performs the above-described analysis on the blood pressure when waking up, which is measured every day. The reference value may be set for each analysis, or may be set every time a certain period elapses.
- the primary use service providing unit 122 provides the result to each user.
- the primary use service providing unit 122 provides the user A's mobile terminal with a comparison result between the daily blood pressure transition and the reference value (range).
- the display control unit 210 of the portable terminal displays the comparison result provided on the display unit 220.
- the display control unit 210 emphasizes the plot indicating the measured value on the day of outage by coloring or blinking, as shown in FIG. 23A. Thereby, the user A can confirm at a glance the measured value deviating from the reference value.
- the mobile terminal communicates with the PHR processing device 100, and the primary use service providing unit 122 performs the action on the previous day of the user A.
- the display control unit 210 displays information on the display unit 220 as shown in FIG. 23A.
- the measurement value to be provided with emphasis to the user is not limited to a value that deviates from the reference value (range), but may be a value that falls within the reference value.
- the display control unit 210 colors or blinks a plot indicating the measurement value of the day when the measurement value of the previous day is out of the reference value and the measurement value of the current day falls within the reference value. Make them emphasize. Thereby, the user A can confirm at a glance the measured value falling within the reference value.
- the mobile terminal communicates with the PHR processing device 100, and the primary use service providing unit 122 performs the action information “exercise” on the previous day of the user A and the action information on the previous week. , Provide action information of a month ago. That is, the display control unit 210 displays information on the display unit 220 as shown in FIG. 23B. Thereby, the user A can estimate the reason why the measured value is within the reference value.
- the PHR big data analysis unit 121 may use an average value of the blood pressure (diastolic blood pressure, systolic blood pressure) at the time of waking up by other users of the genome type 2 as a reference value. In such a case, for example, when the measured value exceeds the reference value (or falls below the reference value), the display control unit 210 highlights and displays the plot indicating the measured value.
- the measurement value at one time point in the day is analyzed has been described.
- the measurement value may be measured a plurality of times a day and analyzed at each time point.
- each measurement value may be analyzed.
- the timing which provides a result to a user can be set arbitrarily.
- the primary use service providing unit 122 may provide the result at the same time when providing the above-mentioned “notice of future health risk” or providing the result to the user every time the analysis is executed. There may be.
- the measurement value when the measurement value is out of the reference value (range), when the measurement value exceeds the reference value, or when the measurement value falls below the reference value, the result is provided to the user. Good. Thereby, for example, when the body temperature changes greatly, a change in body temperature can be immediately notified to the user.
- FIG. 24A to FIG. 24C are diagrams for explaining a comparative analysis of an individual for a predetermined period in the present embodiment.
- FIGS. 24A to FIG. 24C are diagrams for explaining a comparative analysis of an individual for a predetermined period in the present embodiment.
- FIG. 24A to 24C show a case where the tendency of the change in systolic blood pressure of “genome type 2” user A is analyzed.
- FIG. 24A shows a case where the predetermined period is one day
- FIG. 24B shows a case where the predetermined period is one week
- FIG. 24C shows a case where the predetermined period is one year.
- the PHR big data analysis unit 121 acquires measured values of systolic blood pressure collected over time from a plurality of genome type 2 users from the PHR accumulation unit 110, and calculates an average value for each time. Then, the PHR processing apparatus 100 sets the tendency of change of the average value for each time as the tendency of change of the reference value. For example, as shown in FIG. 24A, the PHR big data analysis unit 121 changes the average value of systolic blood pressure collected over time from 0 o'clock to 24 o'clock for a plurality of genome type 2 users. Is set as an ideal pattern. Then, the PHR big data analysis unit 121 derives a comparison result between the tendency of the measurement value change of the user A from 0:00 to 24:00 and the ideal pattern.
- the primary use service providing unit 122 provides the comparison result derived by the PHR big data analysis unit 121 to the mobile terminal of the user A as a graph as illustrated in FIG. 24A.
- the display control unit 210 of the portable terminal displays the provided comparison result on the display unit 220.
- the user A refers to his / her today's measurement values “user A (today)” and “ideal pattern” shown in FIG. 24A, and the systolic blood pressure for today changes to be higher all day than the ideal pattern. You can understand what you were doing and be aware of your blood pressure.
- the PHR processing apparatus 100 can derive not only the trend of today's measurement value but also the trend of the average value obtained by averaging the daily measurement values measured by the user A in the past.
- the primary usage service providing unit 122 displays a graph of “user A (average)” in addition to today's measurement values “user A (today)” and “ideal pattern”.
- the user A can confirm at a glance what kind of situation the today's systolic blood pressure value was compared with a normal value.
- the user A can confirm at a glance what kind of state his / her systolic blood pressure tends to be compared with the ideal pattern. For example, the user A can see not only today's systolic blood pressure but also that the blood pressure has increased normally from the graph shown in FIG. 24A, and can take early measures. .
- the PHR big data analysis unit 121 derives the trend of the systolic blood pressure of the user A for one week and the trend of the systolic blood pressure for one year for the primary use.
- the service providing unit 122 provides each graph to the user A.
- User A can grasp at a glance how his / her systolic blood pressure changes in each period with reference to the graphs shown in FIGS. 24B and 24C.
- the user A tends to become higher in the systolic blood pressure on Friday in one week, but also in the ideal pattern, so that the user A becomes anxious. I can think of it not.
- the user A tends to increase systolic blood pressure in the winter in one year, which is different from the ideal pattern. I can be conscious. Needless to say, the examples shown in FIGS. 23A, 23B, and 24A to 24B are merely examples, and comparative analysis is performed on arbitrary biological information.
- the PHR big data analysis unit 121 derives a comparison result comparing the tendency of changes in biological information with a period of various widths and the tendency of changes in ideal patterns or past measurement values.
- the user can make the state of the body more ideal by referring to the comparison result and living so as to bring the tendency of change in each period closer to the ideal pattern for various biological information.
- the timing which shows the comparison result mentioned above can be set arbitrarily.
- the primary use service providing unit 122 may provide the result at the same time when providing the above-mentioned “notice of future health risk”, or may provide it to the user every time a predetermined period elapses. Also good.
- the PHR big data analysis unit 121 can derive the comparison result between the value derived based on the user attribute information and the measurement value together with the comparison result between the reference value and the measurement value.
- the PHR big data analysis unit 121 includes a range of specified values provided by various academic societies, organizations, organizations, etc. in addition to a range derived from genomic information. May be set.
- the primary use service providing unit 122 provides the user with a comparison result indicating the range derived from the genome information and the range of the specified value.
- the embodiment is not limited thereto, and the analysis result is provided to the attending doctor. Also good. In such a case, the attending physician may send a comment to the user with reference to the analysis result.
- PHR processing apparatus 100 So far, the “daily human dock” service and the “secondary use service” of PHR data provided in this embodiment have been described in detail.
- the basic configuration of the PHR processing apparatus 100 has been described.
- the configuration of the PHR processing apparatus 100 will be described in more detail.
- the PHR accumulation unit 110, the PHR big data analysis unit 121, the primary usage service providing unit 122, and the secondary usage service providing unit 123 described below are all the PHR accumulation unit 110 described in the above-described embodiment, It corresponds to the PHR big data analysis unit 121, the primary usage service providing unit 122, and the secondary usage service providing unit 123, respectively.
- the PHR processing apparatus 100 does not necessarily have to include each unit described below, and the equipment can be omitted as appropriate. Further, the PHR processing apparatus 100 can further include other units.
- FIG. 25 is a functional block diagram of the PHR processing apparatus 100 according to the present embodiment.
- the PHR processing apparatus 100 can be realized by one or more general-purpose computers, and includes a processor, a memory, and an input / output interface. Each unit illustrated in FIG. 25 is appropriately assigned to a processor, a memory, and an input / output interface.
- the PHR processing apparatus 100 includes a PHR accumulation unit 110, a PHR operation management unit 120, and a system control unit 130.
- the system control unit 130 performs overall control of the PHR processing apparatus 100.
- the system control unit 130 accepts the operation of the operator of the data trust company 11, and medical institutions and various companies that receive PHR data management targets, their family members, the account registration of the attending physician, and secondary usage services. Register an account.
- the PHR accumulation unit 110 includes a security function unit 111, a data format conversion / normalization unit 112, an unstructured data processing unit 113, and a PHR data accumulation unit 114.
- the security function unit 111 performs various processes for ensuring the security of the PHR data.
- the PHR data is personal information that requires extremely sensitive handling. Therefore, the security function unit 111 authenticates the connection destination and authorizes access authority as an input / output interface (API: Application Programming Interface) of PHR data. Further, the security function unit 111 anonymizes the PHR data as necessary in order to provide for utilization after performing processing that cannot identify an individual. In addition, the security function unit 111 performs encryption using an appropriately managed encryption key for PHR data that is not anonymized. In addition, when providing the PHR data outside the healthcare cloud 10, the security function unit 111 performs durable data distribution against illegal infringement and the like.
- API Application Programming Interface
- the security function unit 111 is a function for performing appropriate personal authentication for all data access users such as system administrators, researchers who analyze PHR big data, and individual users who register and refer to PHR data. I will provide a.
- the security function unit 111 provides a multi-factor authentication technique capable of ensuring security higher than ID / password authentication.
- the security function unit 111 provides a name identification function for identifying and specifying the owner of data input from various devices and systems.
- the data format conversion / normalization unit 112 flexibly corresponds to the PHR data being transmitted in various data formats by the device, so that the data change / normalization function and the converted normalized data are set in a predetermined format.
- the PHR accumulation unit 110 complements images such as social media, tweets text information, and voices, images, text information, and the like from smartphone applications for analysis related to personal medical / health. Collect information.
- the unstructured data processing unit 113 has an interface function and functions such as speech recognition, natural language analysis, image recognition, and data mining for processing the unstructured data.
- the PHR data storage unit 114 is a large-scale genome cohort database 114a in which PHR big data is stored.
- the PHR operation management unit 120 includes a PHR big data analysis unit 121, a primary usage service providing unit 122, and a secondary usage service providing unit 123.
- the PHR big data analysis unit 121 includes an analysis engine unit 121a, a distributed processing database 121b, and an event processing unit 121c.
- the analysis engine unit 121a performs cohort analysis or the like on the PHR big data stored in the PHR data storage unit 114.
- the analysis by the analysis engine unit 121a may be performed using a distributed processing technique.
- the PHR data storage unit 114 and the distributed processing database 121b cooperate with each other, and the analysis engine unit 121a sets the PHR big data stored in the distributed processing database 121b as a processing target.
- the event processing unit 121c performs event processing in response to the distributed processing by the analysis engine unit 121a.
- the primary usage service providing unit 122 provides the “daily health checkup” service as the primary usage service. Further, the primary use service providing unit 122 includes an incentive processing unit 122a. Incentives are important for individual users to wear sensors and continue to input their own health information and supplementary information for a long time.
- the incentive processing unit 122a provides functions of a point system that can be an incentive, various rankings, game elements, and an advertising model.
- the secondary usage service providing unit 123 provides a secondary usage service.
- FIG. 26 is a diagram illustrating a hardware configuration of the PHR processing device 100 (or the PHR display device 200) in the present embodiment.
- the PHR processing device 100 (or PHR display device 200) includes a central processing unit (CPU) 310, a read only memory (ROM) 320, a random access memory (RAM) 330, a display unit 340, and an input unit 350.
- CPU central processing unit
- ROM read only memory
- RAM random access memory
- the CPU 310, the ROM 320, the RAM 330, the display unit 340, and the input unit 350 are connected via the bus line 301.
- the PHR processing program (or PHR display program) for performing various processes in the above-described embodiment is stored in the ROM 320 and loaded into the RAM 330 via the bus line 301.
- the CPU 310 executes a PHR processing program (or PHR display program) loaded in the RAM 330.
- the CPU 310 reads a PHR processing program (or PHR display program) from the ROM 320 and stores the program in the RAM 330 in accordance with an instruction input from the input unit 350 by the operator. Expand to the area and execute various processes.
- the CPU 310 temporarily stores various data generated in the various processes in a data storage area formed in the RAM 330.
- the PHR processing program (or PHR display program) executed by the PHR processing device 100 is a PHR big data analysis unit 121, a primary usage service providing unit 122, and a secondary usage service providing unit 123 (or , The display control unit 210), and these are loaded on the main storage device, and these are generated on the main storage device.
- the PHR processing device 100 can also build all or part of its functions on a network in the data trust company 11, for example. Further, the PHR processing apparatus 100 does not necessarily have to be constructed at one base. The PHR processing apparatus 100 may be realized by cooperation of functions distributed and arranged at a plurality of bases.
Landscapes
- Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Medical Informatics (AREA)
- Public Health (AREA)
- General Health & Medical Sciences (AREA)
- Primary Health Care (AREA)
- Epidemiology (AREA)
- Biomedical Technology (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Pathology (AREA)
- Medical Treatment And Welfare Office Work (AREA)
- Measuring And Recording Apparatus For Diagnosis (AREA)
- Business, Economics & Management (AREA)
- Tourism & Hospitality (AREA)
- Child & Adolescent Psychology (AREA)
- Economics (AREA)
- Human Resources & Organizations (AREA)
- Marketing (AREA)
- Strategic Management (AREA)
- Physics & Mathematics (AREA)
- General Business, Economics & Management (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
Abstract
Description
以下に説明する実施形態によれば、生きることへのモチベーションが高まる、モチベーション向上社会が実現される。そこで、実施形態の具体的な構成の説明に入る前に、まずは、我々が提案する、モチベーション向上社会の実現について述べる。
本実施形態では、まず、ゲノム情報を含むPHRデータをヘルスケアクラウド10上に集約して大規模ゲノム・コホートデータベース114aを形成し、この大規模ゲノム・コホートデータベース114aに蓄積されたPHRビッグデータを基盤データとすることで、将来の健康リスク(例えば、各疾病の発症確率)を精度良く推定する仕組みを構築する。また、個人のPHRデータを、各方面から継続的に収集して一元管理することで、この個人に対して、本人の体質及びライフスタイルを反映した個別の健康指導をフィードバックする仕組み(日常人間ドック)を構築する。更に、ヘルスケアクラウド10上に集約されたPHRビッグデータの二次利用(他人のための利用や商業的利用)の仕組みを構築する。
次に、図3は、本実施形態におけるPHRデータを説明するための図である。上述したように、PHRデータは、個人の健康に関連する情報として個人のみならず各種機関等から収集されるものであり、その種類に限定はない。したがって、本実施形態では、PHRデータとして何の情報を収集するかという点も個人毎に異なると考える。もっとも、以下に説明するように、本実施形態の「日常人間ドック」では、個人のPHRデータから本人のライフスタイルの型を割り出す。また、このライフスタイルの型は、本実施形態では、10の項目(喫煙、飲酒、睡眠、ストレス、運動、食生活、薬・サプリメント、精神状態、疲れ、免疫)を評価することで割り出される。よって、本実施形態では、この10の項目を評価することが可能なPHRデータが、各個人から収集されることを想定する。なお、図3では、ユーザAのPHRデータのうち、ゲノム情報及びライフログ情報のみを概念的に示す。
続いて、大規模ゲノム・コホートデータベース114aのPHRビッグデータを対象に行われるコホート分析を説明する。ここで、上述したように、本実施形態では、健康状態の評価や健康リスクの推定を精度良く行うために、大規模ゲノム・コホートデータベース114aを形成し、これを基盤データとする。例えば、PHRビッグデータ解析部121は、後述するコホート分析において、生まれてから亡くなるまでの一生涯のPHRデータの中で、疾病発症から転帰、その際の生活や環境に関する情報との紐付けを行う。また、例えば、PHRビッグデータ解析部121は、後述するコホート分析において、特定地域コホートについて長期間の追跡調査を行い、更に他地域コホートとの間で比較解析を行い、地域間の差を検討する。このような解析は、大規模ゲノム・コホートデータベース114aを対象とするからこそ実現可能であり、小規模なものではその実現は困難であり、特定の疾患を対象にしたもの等に限局される。更に、本実施形態において、PHRビッグデータに含まれるライフログ情報は、センシング技術等によって収集されたものであるので、従来の問診による回答とは異なり正確且つ精密な解析が可能となる。なお、大規模ゲノム・コホートデータベース114aが形成されることで、更には、日本人の低頻度アレルの取得、網羅的な日本人のオリジナルの標準SNPデータベースの構築、タイピングアレイの標準化等も可能となる。
さて、本実施形態において、一次利用サービス提供部122は、健康リスク推定テーブルTを用いて、PHRデータを提供したユーザ本人に対するフィードバックを行うことで、「日常人間ドック」を一次利用サービスとして提供する。その提供の手法としては様々な手法が考えられるが、以下では、図9を用いて1つの手法を説明する。
また、上述した実施形態では、具体例として、ユーザのゲノムの型及びライフスタイルの型を用いて「健康リスク推定テーブルT」を参照し、ライフスタイル要因の影響が強い疾病の情報を、健康リスクの推定結果としてフィードバックする例を説明した。しかしながら、「健康リスク推定テーブルT」から得られる情報の利用形態はこれに限られるものではない。
さて、これまで、PHRデータの一次利用サービスの一例として、「日常人間ドック」や、「将来の健康リスクのお知らせ」を説明してきたが、上述したように、本実施形態において、PHR処理装置100は、PHRデータの二次利用サービスの提供も想定している。例えば、PHR処理装置100は、ゲノムの型及びライフスタイルの型の組み合わせとある特定の目的との関連性を導き出すべく大規模ゲノム・コホートデータベース114aを解析し、ある一定の関連性を示す解析結果を得て、これを医療機関や各種企業等に提供する。
さて、これまで、PHRデータの一次利用サービスの一例として、「日常人間ドック」や、「将来の健康リスクのお知らせ」を説明してきた。また、PHRデータの二次利用サービスについても、具体例を挙げて説明してきた。いずれの場合も、一次利用や二次利用に必要なデータ量や種類を満たすPHRデータが、各個人から継続的に送信されることが望ましい。そこで、本実施形態において、PHR処理装置100は、各個人に対してPHRデータを継続的に送信させるためのインセンティブの仕組みも更に構築する。
さて、これまで、ゲノム情報と日々収集されるライフログ情報とを用いてユーザの健康リスクを推定する例などについて説明してきた。しかしながら、ゲノム情報とライフログ情報の利用は上記した例に限られるものではなく、種々の解析に用いられる場合であってもよい。例えば、ライフログ情報において行動情報と関連付けられた生体情報に着目して解析する場合であってもよい。上述したように、各ユーザから日々収集される生体情報は、血圧、心拍数、脈拍、体温、体成分、イオン、pH濃度、糖分、塩分等の成分量、胃酸の濃度、農薬、環境物質、食品添加物の有無、アルコールやニコチン、薬剤成分などが挙げられる。また、生体情報として、タンパク質、ペプチド、脂質、糖鎖などのバイオマーカーなども挙げられる。
これまで、本実施形態において提供される「日常人間ドック」サービスやPHRデータの「二次利用サービス」を詳細に説明してきた。また、PHR処理装置100の基本的な構成を説明してきたが、以下では、PHR処理装置100の構成をより詳細に説明する。なお、以下に説明するPHR蓄積部110、PHRビッグデータ解析部121、一次利用サービス提供部122、二次利用サービス提供部123は、いずれも、上述した実施形態において説明した、PHR蓄積部110、PHRビッグデータ解析部121、一次利用サービス提供部122、二次利用サービス提供部123に、それぞれ対応する。また、PHR処理装置100は、必ずしも以下に説明する各部を備えなければならないものではなく、適宜装備を省略することができる。また、PHR処理装置100は、他の部を更に備えることもできる。
図26は、本実施形態におけるPHR処理装置100(又はPHR表示装置200)のハードウェア構成を示す図である。PHR処理装置100(又はPHR表示装置200)は、CPU(Central Processing Unit)310と、ROM(Read Only Memory)320と、RAM(Random Access Memory)330と、表示部340と、入力部350とを備える。また、PHR処理装置100(又はPHR表示装置200)では、CPU310、ROM320、RAM330、表示部340、及び入力部350が、バスライン301を介して接続されている。
実施形態は、上述した実施形態に限られるものではない。
上述した実施形態では、クラウド上にPHR処理装置100が構築される構成を説明したが、実施形態はこれに限られるものではない。PHR処理装置100は、その機能の全部若しくは一部を、例えば、データ信託会社11内のネットワーク上に構築することもできる。また、PHR処理装置100は、必ずしも1つの拠点に構築されなければならないものではない。複数の拠点に分散配置された機能が連携することで、PHR処理装置100を実現してもよい。
Claims (46)
- 各ユーザの健康情報である、ゲノム情報と、継続的に収集される生体情報及び行動情報とを、複数ユーザ分蓄積する蓄積部と、
蓄積された複数ユーザ分の健康情報を解析する解析部と、
前記解析の結果と所定のユーザの健康情報とを用いて、当該所定のユーザの将来の健康リスクを推定する推定部と
を備えた、健康情報処理装置。 - 前記解析部は、前記複数ユーザ分の健康情報を解析することで、ゲノム情報と、生体情報及び行動情報から導き出されるライフスタイルと、健康リスクとの関連性を導き出す、請求項1に記載の健康情報処理装置。
- 前記解析部は、前記複数ユーザ分の健康情報を解析することで、ゲノム情報から導き出されるゲノムの型、及び、生体情報及び行動情報から導き出されるライフスタイルの型の組み合わせと、将来発症し得る疾病との関連性を導き出す、請求項1又は2に記載の健康情報処理装置。
- 前記解析部は、前記解析の結果として、ゲノムの型及びライフスタイルの型の組み合わせ毎に、ゲノム要因及びライフスタイル要因のいずれの影響を強く受けるかに応じて順序付けされた、前記将来発症し得る疾病のリストを得、
前記推定部は、所定のユーザの健康情報から導き出された当該所定のユーザのゲノムの型及びライフスタイルの型の組み合わせを用いて前記リストを参照することで、当該所定のユーザにて将来発症し得る疾病を推定する、請求項3に記載の健康情報処理装置。 - 前記推定部は、前記所定のユーザの将来の健康リスクを推定する場合に、当該所定のユーザの健康情報から判明する当該所定のユーザの現在の健康状態に応じて、推定の結果を調整する、請求項1又は2に記載の健康情報処理装置。
- 前記蓄積部は、前記健康情報を新たに蓄積することで、複数ユーザ分の健康情報の規模を拡大し、
前記解析部は、前記複数ユーザ分の健康情報の規模の拡大に伴い、新たに解析を行い、新たな解析の結果を得、
前記推定部は、新たに得られた前記解析の結果と所定のユーザの健康情報とを用いて、当該所定のユーザの将来の健康リスクを推定する、請求項1又は2に記載の健康情報処理装置。 - 前記ゲノムの情報は、略30億塩基対の配列情報、略100万塩基対の配列情報、及び、標準ゲノム情報との差分のうち、少なくとも1つを含む、請求項1又は2に記載の健康情報処理装置。
- 前記健康リスクは、各疾病の発症確率である、請求項1又は2に記載の健康情報処理装置。
- 各ユーザの健康情報である、ゲノム情報と、継続的に収集される生体情報及び行動情報とを、複数ユーザ分蓄積する蓄積部と、
蓄積された複数ユーザ分の健康情報を解析する解析部と、
前記蓄積部に蓄積され、前記解析部によって解析された所定のユーザの健康情報を評価し、評価の結果を当該所定のユーザに提示する提示部と
を備えた、健康情報処理装置。 - 前記提示部は、各ユーザから収集される前記健康情報のデータ量、種類、及び種類の数のうち、少なくとも1つに基づいてポイントを算出し、算出したポイントに関する情報を該当のユーザに提示する、請求項9に記載の健康情報処理装置。
- 前記健康情報は、将来の健康リスクの推定と、当該将来の健康リスクの推定とは異なる他の目的の二次利用とに活用されるものであり、
前記提示部は、前記健康情報が活用される二次利用の有用性にも基づいて前記ポイントを算出する、請求項10に記載の健康情報処理装置。 - 前記提示部は、前記健康情報を送信する複数のユーザ間に競争関係を設定し、競争関係が設定されたユーザ間で健康情報に関する比較を行い、比較の結果を各ユーザに提示する、請求項9に記載の健康情報処理装置。
- 表示部と、
ユーザの健康情報である、ゲノム情報と、継続的に収集された生体情報及び行動情報とに基づいて推定された、当該ユーザの将来の健康リスクを前記表示部に表示する表示制御部とを備え、
前記表示制御部は、前記将来の健康リスクとともに、前記ユーザの目標の健康状態及び当該目標の健康状態に到達するための指導情報のうち、少なくとも1つを表示する、健康情報表示装置。 - 前記表示制御部は、操作者から前記推定の時点の指定を受け付けると、受け付けた時点に応じた将来の健康リスクを表示する、請求項13に記載の健康情報表示装置。
- 前記表示制御部は、操作者から、前記推定に用いる前記ユーザの健康情報の期間の幅を受け付けると、受け付けた期間の幅に応じた将来の健康リスクを表示する、請求項13又は14に記載の健康情報表示装置。
- 前記表示制御部は、操作者からライフスタイルの変更指示を受け付けると、受け付けた変更指示に応じてシミュレーションされた将来の健康リスクを、更に表示する、請求項13又は14に記載の健康情報表示装置。
- 前記表示制御部は、前記将来の健康リスクとして、前記ユーザが将来発症し得る疾病の名称を表示する、請求項13又は14に記載の健康情報表示装置。
- 前記表示制御部は、前記ユーザ若しくは前記ユーザの関係者に対して前記疾病の名称を表示する場合には、通称で表示する、請求項17に記載の健康情報表示装置。
- 前記表示制御部は、前記ユーザ若しくは前記ユーザの関係者に対して前記疾病の名称を表示する場合には、一部の疾病の名称を非表示とする、請求項17に記載の健康情報表示装置。
- 表示部と、
ユーザの健康情報である、ゲノム情報と、継続的に収集された生体情報及び行動情報とに基づいて推定された、当該ユーザの将来の健康リスクを前記表示部に表示する表示制御部とを備え、
前記表示制御部は、前記将来の健康リスクとともに、前記ユーザの健康情報を表示する、健康情報表示装置。 - 前記表示制御部は、前記ユーザの健康情報として、ゲノム情報から導き出されるゲノムの型、及び、生体情報及び行動情報から導き出されるライフスタイルの型を表示する、請求項20に記載の健康情報表示装置。
- 前記表示制御部は、前記将来の健康リスクとして、前記ユーザが将来発症し得る疾病の名称を表示する、請求項20又は21に記載の健康情報表示装置。
- 前記表示制御部は、医療従事者に対して前記疾病の名称を表示する場合には、正式名称及びICD(International Classification of Diseases)コードのうち、少なくとも1つで表示する、請求項22に記載の健康情報表示装置。
- 前記表示制御部は、前記ユーザとは異なる他のユーザとの比較に基づいた複数ユーザの健康リスクランキングリストを表示し、当該健康リスクランキングリストに対して所定のユーザが指定された場合に、指定されたユーザの将来の健康リスク及び健康情報を表示することを特徴とする請求項20又は21に記載の健康情報表示装置。
- 各ユーザの健康情報である、ゲノム情報と、継続的に収集される生体情報及び行動情報とを、複数ユーザ分蓄積する蓄積部と、
所定の目的の入力を受け付け、蓄積された複数ユーザ分の健康情報を解析することで、ゲノム情報から導き出されるゲノムの型、及び、生体情報及び行動情報から導き出されるライフスタイルの型の組み合わせと、前記所定の目的との関連性を導き出す解析部と、
前記解析の結果を出力する出力部と
を備えた、健康情報処理装置。 - 前記解析部は、ゲノムの型及びライフスタイルの型の組み合わせを所定の目的との関連性で分類した分類結果を得、
前記出力部は、前記解析の結果として、前記分類結果を出力する、請求項25に記載の健康情報処理装置。 - 前記出力部は、前記分類結果で得られた所定のグループに属するユーザの実名リストを出力する、請求項26に記載の健康情報処理装置。
- 前記出力部は、第1に、前記分類結果で得られた所定のグループに属するユーザの実名リストを出力し、第2に、前記所定のグループに属するユーザのうち一部のユーザの健康情報を出力する、請求項27に記載の健康情報処理装置。
- 各ユーザの健康情報である、ゲノム情報と、継続的に収集される生体情報及び行動情報とを、複数ユーザ分蓄積する蓄積部と、
前記ユーザから、前記健康情報の開示項目、及び、前記健康情報の開示先の利用許諾を受け付け、受け付けた利用許諾の内容に応じて前記健康情報を出力する出力部とを備え、
前記蓄積部は、前記健康情報に前記利用許諾の情報を付帯させて蓄積する、健康情報処理装置。 - 各ユーザの健康情報である、ゲノム情報と、継続的に収集される生体情報とを、複数ユーザ分蓄積する蓄積部と、
前記蓄積部に蓄積された情報に基づいて、所定の生体情報について、前記ゲノム情報と前記各ユーザの属性情報とを組み合わせて形成されるグループの中で、各ユーザの継続的に収集される生体情報を比較する比較部と、
前記比較部で比較した結果に基づき、各ユーザの生体情報の値が当該グループの中のどの位置にあるかを示す解析部と
を備えた、健康情報処理装置。 - 各ユーザの健康情報である、ゲノム情報と、継続的に収集される生体情報とを、複数ユーザ分蓄積する蓄積部と、
前記蓄積部に蓄積された情報に基づいて、前記ゲノム情報と前記各ユーザの属性情報とを組み合わせて形成されるグループごとに、当該グループに属する各ユーザの継続的に収集される生体情報を集約して、グループ間の生体情報を比較する比較部と、
前記比較部で比較した結果に基づき、各グループの生体情報の値がグループ間でどの位置にあるかを示す解析部と
を備えた、健康情報処理装置。 - 前記解析部は、前記位置として、前記生体情報の値の分布においてどの位置にあるかを示す、請求項30又は31に記載の健康情報処理装置。
- 前記解析部は、前記各ユーザの継続的に収集される生体情報を用いて導出した順位及び偏差値のうち少なくとも一方によって、前記生体情報の値がどの位置にあるかを示す、請求項30又は31に記載の健康情報処理装置。
- 前記属性情報は、前記ユーザの居住地域、年齢、性別、人種、所属する健康保険組合の情報を含み、
前記解析部は、前記グループとして、前記各ユーザのゲノム情報と前記属性情報とを組み合わせたグループを形成させる、請求項30又は31に記載の健康情報処理装置。 - 各ユーザの健康情報である、ゲノム情報と、継続的に収集される生体情報とを、複数ユーザ分蓄積する蓄積部と、
所定の生体情報について、前記ゲノム情報に基づいて導出される基準値と、前記ゲノム情報に対応するユーザから収集された計測値との比較結果を導き出す解析部と、
を備えた、健康情報処理装置。 - 前記解析部は、所定の時点における前記基準値と前記計測値との比較結果、及び、所定の期間の幅で前記ユーザから収集された計測値の変化の傾向と前記所定の期間の幅に対応する前記基準値の変化の傾向との比較結果のうち、少なくとも1つを導き出す、請求項35に記載の健康情報処理装置。
- 前記解析部は、前記基準値と前記計測値との比較結果とともに、前記ユーザの属性情報に基づいて導出される値と前記計測値との比較結果を導き出す、請求項35又は36に記載の健康情報処理装置。
- 健康情報処理装置が、
各ユーザの健康情報である、ゲノム情報と、継続的に収集される生体情報及び行動情報とを、各ユーザから収集し、
前記各ユーザの健康情報を、複数ユーザ分蓄積し、
蓄積した複数ユーザ分の健康情報を解析し、
前記解析の結果と所定のユーザの健康情報とを用いて、当該所定のユーザの将来の健康リスクを推定し、
前記将来の健康リスクを、健康情報表示装置に送信する、
健康情報処理方法。 - 健康情報処理装置が、
各ユーザの健康情報である、ゲノム情報と、継続的に収集される生体情報及び行動情報とを、各ユーザから収集し、
前記各ユーザの健康情報を、複数ユーザ分蓄積し、
蓄積した複数ユーザ分の健康情報を解析し、
解析した所定のユーザの健康情報を評価し、
前記評価の結果を当該所定のユーザに提示する、
健康情報処理方法。 - 健康情報表示装置が、
ユーザの健康情報である、ゲノム情報と、継続的に収集された生体情報及び行動情報とに基づいて推定された、当該ユーザの将来の健康リスクを表示部に表示し、
前記将来の健康リスクとともに、前記ユーザの目標の健康状態及び当該目標の健康状態に到達するための指導情報のうち、少なくとも1つを表示する、
健康情報表示方法。 - 健康情報表示装置が、
ユーザの健康情報である、ゲノム情報と、継続的に収集された生体情報及び行動情報とに基づいて推定された、当該ユーザの将来の健康リスクを表示部に表示し、
前記将来の健康リスクとともに、前記ユーザの健康情報を表示する、
健康情報表示方法。 - 健康情報処理装置が、
各ユーザの健康情報である、ゲノム情報と、継続的に収集される生体情報及び行動情報とを、各ユーザから収集し、
前記各ユーザの健康情報を、複数ユーザ分蓄積し、
所定の目的の入力を受け付け、蓄積した複数ユーザ分の健康情報を解析することで、ゲノム情報から導き出されるゲノムの型、及び、生体情報及び行動情報から導き出されるライフスタイルの型の組み合わせと、前記所定の目的との関連性を導き出し、
前記解析の結果を出力する、
健康情報処理方法。 - 健康情報処理装置が、
各ユーザの健康情報である、ゲノム情報と、継続的に収集される生体情報及び行動情報とを、各ユーザから収集し、
前記各ユーザの健康情報を、複数ユーザ分蓄積し、
前記ユーザから、前記健康情報の開示項目、及び、前記健康情報の開示先の利用許諾を受け付け、受け付けた利用許諾の内容に応じて前記健康情報を出力し、
前記健康情報に前記利用許諾の情報を付帯させて蓄積する、
健康情報処理方法。 - 健康情報処理装置が、
ユーザの健康情報である、ゲノム情報と、継続的に収集される生体情報とを、各ユーザから収集し、
前記各ユーザの健康情報を、複数ユーザ分蓄積し、
蓄積した情報に基づいて、所定の生体情報について、前記ゲノム情報と前記各ユーザの属性情報とを組み合わせて形成されるグループの中で、各ユーザの継続的に収集される生体情報を比較し、
比較した結果に基づき、各ユーザの生体情報の値が当該グループの中のどの位置にあるかを示す、
健康情報処理方法。 - 健康情報処理装置が、
各ユーザの健康情報である、ゲノム情報と、継続的に収集される生体情報とを、各ユーザから収集し、
前記各ユーザの健康情報を、複数ユーザ分蓄積し、
蓄積した情報に基づいて、前記ゲノム情報と前記各ユーザの属性情報とを組み合わせて形成されるグループごとに、当該グループに属する各ユーザの継続的に収集される生体情報を集約して、グループ間の生体情報を比較し、
比較した結果に基づき、各グループの生体情報の値がグループ間でどの位置にあるかを示す、
健康情報処理方法。 - 健康情報処理装置が、
各ユーザの健康情報である、ゲノム情報と、継続的に収集される生体情報とを、各ユーザから収集し、
前記各ユーザの健康情報を、複数ユーザ分蓄積し、
所定の生体情報について、前記ゲノム情報に基づいて導出される基準値と、前記ゲノム情報に対応するユーザから収集された計測値との比較結果を導き出す、
健康情報処理方法。
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| SG11201502141RA SG11201502141RA (en) | 2013-10-01 | 2014-10-01 | Health information processing apparatus, health information display apparatus, and method |
| JP2015508354A JP6212784B2 (ja) | 2013-10-01 | 2014-10-01 | 健康情報処理装置及び方法 |
| EP14843220.6A EP3054412A4 (en) | 2013-10-01 | 2014-10-01 | Health information processing device, health information display device, and method |
| CN201480002440.9A CN104704526A (zh) | 2013-10-01 | 2014-10-01 | 健康信息处理装置、健康信息显示装置以及方法 |
| US14/661,785 US20150193588A1 (en) | 2013-10-01 | 2015-03-18 | Health information processing apparatus and method, and health information display apparatus and method |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013-206834 | 2013-10-01 | ||
| JP2013206834 | 2013-10-01 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US14/661,785 Continuation US20150193588A1 (en) | 2013-10-01 | 2015-03-18 | Health information processing apparatus and method, and health information display apparatus and method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2015050174A1 true WO2015050174A1 (ja) | 2015-04-09 |
Family
ID=52778762
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2014/076332 WO2015050174A1 (ja) | 2013-10-01 | 2014-10-01 | 健康情報処理装置、健康情報表示装置及び方法 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US20150193588A1 (ja) |
| EP (1) | EP3054412A4 (ja) |
| JP (3) | JP6212784B2 (ja) |
| CN (1) | CN104704526A (ja) |
| SG (1) | SG11201502141RA (ja) |
| WO (1) | WO2015050174A1 (ja) |
Cited By (33)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017010486A (ja) * | 2015-06-26 | 2017-01-12 | Rizap株式会社 | 情報処理システム、情報処理方法、および、情報処理プログラム |
| JP2017059261A (ja) * | 2013-10-01 | 2017-03-23 | 国立大学法人東北大学 | 健康情報処理装置及び方法 |
| WO2017191847A1 (ja) * | 2016-05-04 | 2017-11-09 | 理香 大熊 | 将来像予測装置 |
| JP2017204199A (ja) * | 2016-05-12 | 2017-11-16 | ヤフー株式会社 | 情報提供装置、情報提供方法および情報提供プログラム |
| JP2018120351A (ja) * | 2017-01-24 | 2018-08-02 | 富士通株式会社 | 情報処理装置、情報処理システム、プログラム及び情報処理方法 |
| JP2018530069A (ja) * | 2015-10-01 | 2018-10-11 | ディーエヌエーナッジ リミテッド | 生体情報を安全に転送するための方法、装置、およびシステム |
| JP2018195217A (ja) * | 2017-05-19 | 2018-12-06 | ヤフー株式会社 | 情報提供装置、情報提供方法および情報提供装置プログラム |
| JP2018195187A (ja) * | 2017-05-19 | 2018-12-06 | ヤフー株式会社 | 情報提供装置、情報提供方法および情報提供装置プログラム |
| JP2018195198A (ja) * | 2017-05-19 | 2018-12-06 | ヤフー株式会社 | 提供装置、提供方法及び提供プログラム |
| JP2019048061A (ja) * | 2018-09-26 | 2019-03-28 | 株式会社メディプリーム | 発病予知ネットワークシステム |
| WO2019087787A1 (ja) * | 2017-10-30 | 2019-05-09 | マクセル株式会社 | 異常データ処理システムおよび異常データ処理方法 |
| JP2019097977A (ja) * | 2017-12-05 | 2019-06-24 | 倉敷紡績株式会社 | 体調管理システム |
| KR20190119838A (ko) * | 2018-04-13 | 2019-10-23 | 유한회사 지에스케이테크놀로지 | 교육용 건강상태 시뮬레이션 장치 |
| JP2020501278A (ja) * | 2016-12-12 | 2020-01-16 | コーニンクレッカ フィリップス エヌ ヴェKoninklijke Philips N.V. | 健康状態の計算解析を容易化するシステム及び方法 |
| WO2020013000A1 (ja) * | 2018-07-13 | 2020-01-16 | オムロンヘルスケア株式会社 | 行動変容支援装置、端末およびサーバ |
| JP2020013230A (ja) * | 2018-07-13 | 2020-01-23 | 木村 裕一 | 構成員健康状態管理システム、構成員健康状態管理方法、及び構成員健康状態管理プログラム |
| US10811140B2 (en) | 2019-03-19 | 2020-10-20 | Dnanudge Limited | Secure set-up of genetic related user account |
| JP2020185382A (ja) * | 2019-05-10 | 2020-11-19 | キヤノンメディカルシステムズ株式会社 | 診断支援装置 |
| US10861594B2 (en) | 2015-10-01 | 2020-12-08 | Dnanudge Limited | Product recommendation system and method |
| US10922397B2 (en) | 2018-07-24 | 2021-02-16 | Dnanudge Limited | Method and device for comparing personal biological data of two users |
| JPWO2021084747A1 (ja) * | 2019-11-01 | 2021-05-06 | ||
| CN112802565A (zh) * | 2019-11-14 | 2021-05-14 | 丰田自动车株式会社 | 记录介质、信息处理装置、信息处理系统以及信息处理方法 |
| JP2021077313A (ja) * | 2019-10-31 | 2021-05-20 | 安博 市村 | 健康状態予測システム、健康状態予測方法、及び、健康状態予測システム用のプログラム |
| JP6887194B1 (ja) * | 2020-09-14 | 2021-06-16 | 株式会社Arblet | 情報処理システム、サーバ、情報処理方法及びプログラム |
| JP2021515631A (ja) * | 2018-03-13 | 2021-06-24 | 株式会社メニコン | 健康データの収集および利用システム |
| JP6949277B1 (ja) * | 2021-01-15 | 2021-10-13 | 三菱電機株式会社 | 未病診断装置、未病診断方法及び学習モデル生成装置 |
| KR102319095B1 (ko) * | 2020-11-26 | 2021-10-28 | 부산대학교병원 | 맞춤형 헬스케어 시스템 |
| JP2022024105A (ja) * | 2020-03-02 | 2022-02-08 | 東芝テック株式会社 | レシートデータ管理装置及びそのプログラム並びにレシートデータ管理方法 |
| JP7075162B1 (ja) * | 2021-08-13 | 2022-05-25 | 株式会社プラニス | 情報処理システム、情報処理方法、コンピュータプログラムおよび情報処理装置 |
| US11403382B2 (en) | 2019-07-24 | 2022-08-02 | Dnanudge Limited | Method and device for comparing personal biological data of two users |
| JP7122048B1 (ja) | 2022-01-31 | 2022-08-19 | 春樹 鳥海 | 未病パラメータ測定システム |
| JP2023033052A (ja) * | 2021-08-27 | 2023-03-09 | 長佳智能股▲分▼有限公司 | 遺伝子診断リスク判定システム |
| WO2024042613A1 (ja) * | 2022-08-23 | 2024-02-29 | 日本電気株式会社 | 端末、端末の制御方法及び記憶媒体 |
Families Citing this family (50)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20130191157A1 (en) * | 2012-01-17 | 2013-07-25 | Optuminsight, Inc. | Unified healthcare intelligence, analytics, and care management |
| US10614502B2 (en) * | 2015-10-16 | 2020-04-07 | International Business Machines Corporation | In-store real-time food item selection recommendations |
| CN105232063B (zh) * | 2015-10-22 | 2017-03-22 | 广东小天才科技有限公司 | 用户心理健康检测方法及智能终端 |
| CN105496136B (zh) * | 2015-12-10 | 2018-03-06 | 嘉兴学院 | 一种智能水杯的信息网络化方法 |
| KR102534850B1 (ko) | 2016-02-03 | 2023-05-18 | 삼성전자주식회사 | 사용자의 건강 상태 모니터링 장치 및 방법과 사용자의 건강 상태 관리 장치 |
| CN105743989A (zh) * | 2016-03-31 | 2016-07-06 | 宇龙计算机通信科技(深圳)有限公司 | 运动信息的推送方法、推送装置和终端 |
| US20200321129A1 (en) * | 2016-05-23 | 2020-10-08 | Nec Solution Innovators, Ltd. | Health condition prediction apparatus, health condition prediction method, and computer-readable recording medium |
| US20180012242A1 (en) * | 2016-07-06 | 2018-01-11 | Samsung Electronics Co., Ltd. | Automatically determining and responding to user satisfaction |
| US11087235B2 (en) * | 2016-08-02 | 2021-08-10 | International Business Machines Corporation | Cohort consensus approach to manufacturing watson Q and A pipeline training cases from historical data |
| JP6974029B2 (ja) * | 2017-05-02 | 2021-12-01 | ポーラ化成工業株式会社 | 画像表示装置、肌状態サポートシステム、画像表示プログラム及び画像表示方法 |
| JP6914743B2 (ja) * | 2017-06-19 | 2021-08-04 | オムロンヘルスケア株式会社 | 健康管理装置、健康管理方法、及び健康管理プログラム |
| JP6587660B2 (ja) * | 2017-08-17 | 2019-10-09 | ヤフー株式会社 | 推定装置、推定方法、及び推定プログラム |
| JP6512648B1 (ja) * | 2017-11-15 | 2019-05-15 | 前田商事株式会社 | ソフトウェア、健康状態判定装置及び健康状態判定方法 |
| JP7131904B2 (ja) * | 2017-12-18 | 2022-09-06 | オムロンヘルスケア株式会社 | 生活習慣管理装置、方法およびプログラム |
| US11855971B2 (en) * | 2018-01-11 | 2023-12-26 | Visa International Service Association | Offline authorization of interactions and controlled tasks |
| JP6342095B1 (ja) * | 2018-01-31 | 2018-06-13 | 豊田通商株式会社 | 健康管理システム、健康管理方法、プログラム、及び記録媒体 |
| JP7016740B2 (ja) * | 2018-03-19 | 2022-02-07 | 日本光電工業株式会社 | 検査支援方法、当該検査支援方法をプロセッサに実行させるプログラム、ならびに当該検査支援方法を実行するための検査装置および支援装置 |
| CN111971756A (zh) * | 2018-03-26 | 2020-11-20 | 日本电气方案创新株式会社 | 健康援助系统、信息提供表格输出设备、方法和程序 |
| JP2021114005A (ja) * | 2018-04-12 | 2021-08-05 | ソニーグループ株式会社 | 情報処理装置および情報処理方法 |
| CN108597577A (zh) * | 2018-04-20 | 2018-09-28 | 深圳市科迈爱康科技有限公司 | 八段锦运动方法、装置及计算机可读存储介质 |
| JP6678201B2 (ja) * | 2018-06-05 | 2020-04-08 | 日清食品ホールディングス株式会社 | 食品情報提供システム、装置、方法及びプログラム |
| JP7135511B2 (ja) * | 2018-07-04 | 2022-09-13 | オムロンヘルスケア株式会社 | 健康管理支援装置、方法、及びプログラム |
| KR102069979B1 (ko) | 2018-08-07 | 2020-01-23 | 주식회사 바디프랜드 | 마사지 장치 기반 사용자 정보 거래 방법 및 시스템 |
| KR102427879B1 (ko) * | 2018-08-07 | 2022-08-01 | 주식회사 바디프랜드 | 마사지 장치 기반 사용자 정보 거래 방법 및 시스템 |
| JP2020027577A (ja) * | 2018-08-17 | 2020-02-20 | 株式会社Pontely | ペット購入支援サービスシステム |
| CN113168918A (zh) * | 2018-11-02 | 2021-07-23 | 国立研究开发法人理化学研究所 | 作成健康定位映射及健康函数的方法、系统及程序、以及它们的使用方法 |
| JP2020078373A (ja) * | 2018-11-12 | 2020-05-28 | 啓太郎 横山 | 情報処理装置及びコンピュータプログラム |
| JP7247432B2 (ja) * | 2018-11-28 | 2023-03-29 | 独立行政法人国立高等専門学校機構 | 疾病・障害コードを用いた被験者の行動支援システム及び行動支援方法 |
| CN109559243A (zh) * | 2018-12-13 | 2019-04-02 | 泰康保险集团股份有限公司 | 保险核保方法、装置、介质及电子设备 |
| CN112955963A (zh) | 2018-12-21 | 2021-06-11 | 爱平世股份有限公司 | 健康风险信息管理装置、健康风险信息管理方法及程序 |
| JP7263095B2 (ja) * | 2019-04-22 | 2023-04-24 | ジェネシスヘルスケア株式会社 | 研究支援システム、研究支援装置、研究支援方法及び研究支援プログラム |
| US20220246259A1 (en) * | 2019-04-26 | 2022-08-04 | Nec Solution Innovators, Ltd. | Lifestyle improvement specific measure presenting device, lifestyle improvement specific measure presenting method, recording medium, and lifestyle improvement specific measure presenting system |
| KR102075152B1 (ko) * | 2019-05-14 | 2020-02-07 | 김형운 | 건강 분석 서비스 제공 장치 및 방법 |
| KR102072815B1 (ko) * | 2019-06-14 | 2020-02-03 | 주식회사 마크로젠 | 마이크로바이옴을 이용한 건강 상태 분류 방법 및 장치 |
| KR102565460B1 (ko) * | 2019-12-16 | 2023-08-09 | 주식회사 바디프랜드 | 마사지 장치 기반 사용자 정보 거래 방법 및 시스템 |
| US20230058760A1 (en) * | 2020-02-03 | 2023-02-23 | Mizkan Holdings Co., Ltd. | Program, information processing method, and information processing device |
| US11157823B2 (en) | 2020-02-04 | 2021-10-26 | Vignet Incorporated | Predicting outcomes of digital therapeutics and other interventions in clinical research |
| US11151462B2 (en) | 2020-02-04 | 2021-10-19 | Vignet Incorporated | Systems and methods for using machine learning to improve processes for achieving readiness |
| JP7339182B2 (ja) * | 2020-02-21 | 2023-09-05 | Kddi株式会社 | 成果報酬判定サーバ、成果報酬判定方法、及びコンピュータプログラム |
| US11328796B1 (en) * | 2020-02-25 | 2022-05-10 | Vignet Incorporated | Techniques for selecting cohorts for decentralized clinical trials for pharmaceutical research |
| US11605038B1 (en) | 2020-05-18 | 2023-03-14 | Vignet Incorporated | Selecting digital health technology to achieve data collection compliance in clinical trials |
| US11461216B1 (en) | 2020-05-18 | 2022-10-04 | Vignet Incorporated | Monitoring and improving data collection using digital health technology |
| WO2022124014A1 (ja) * | 2020-12-07 | 2022-06-16 | ソニーグループ株式会社 | 情報処理装置、データの生成方法、グループ化モデルの生成方法、グループ化モデルの学習方法、情動推定モデルの生成方法及びグループ化用ユーザ情報の生成方法 |
| US11789837B1 (en) | 2021-02-03 | 2023-10-17 | Vignet Incorporated | Adaptive data collection in clinical trials to increase the likelihood of on-time completion of a trial |
| US11316941B1 (en) | 2021-02-03 | 2022-04-26 | Vignet Incorporated | Remotely managing and adapting monitoring programs using machine learning predictions |
| US11296971B1 (en) | 2021-02-03 | 2022-04-05 | Vignet Incorporated | Managing and adapting monitoring programs |
| US11196656B1 (en) | 2021-02-03 | 2021-12-07 | Vignet Incorporated | Improving diversity in cohorts for health research |
| US11521714B1 (en) | 2021-02-03 | 2022-12-06 | Vignet Incorporated | Increasing diversity of participants in health research using adaptive methods |
| US11361846B1 (en) | 2021-02-03 | 2022-06-14 | Vignet Incorporated | Systems and methods for customizing monitoring programs involving remote devices |
| WO2023157606A1 (ja) * | 2022-02-15 | 2023-08-24 | ソニーグループ株式会社 | 情報処理装置、情報処理方法及びプログラム |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2000099605A (ja) * | 1998-09-24 | 2000-04-07 | Fujitsu Ltd | 健診情報分析サーバおよびネットワーク健康情報システム |
| JP2001268548A (ja) * | 2000-03-21 | 2001-09-28 | Sony Corp | 情報処理装置および方法、情報処理システム、並びに記録媒体 |
| JP2001327472A (ja) | 2000-03-14 | 2001-11-27 | Toshiba Corp | 身体装着型生活支援装置および方法 |
| JP2002342492A (ja) * | 2001-05-21 | 2002-11-29 | Hitachi Ltd | 医療情報管理システム、医療情報管理方法、医療情報管理プログラムを記録した記録媒体及び医療情報管理プログラム |
| JP2006320735A (ja) | 2000-03-14 | 2006-11-30 | Toshiba Corp | 身体装着型生活支援装置および方法 |
| JP2007310632A (ja) * | 2006-05-18 | 2007-11-29 | Taito Corp | 分身健康・体型予測システム |
| JP2011134106A (ja) * | 2009-12-24 | 2011-07-07 | Hitachi Ltd | 医療情報収集システム、医療情報収集処理方法及び医療情報収集画面表示制御方法 |
Family Cites Families (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6102856A (en) * | 1997-02-12 | 2000-08-15 | Groff; Clarence P | Wearable vital sign monitoring system |
| JP4785294B2 (ja) * | 2001-08-08 | 2011-10-05 | 勝三 川西 | 健康情報表示装置 |
| JP2006011494A (ja) * | 2004-06-22 | 2006-01-12 | Synergies Jp:Kk | 健康管理支援装置、健康管理支援方法、健康管理支援用プログラム、および、健康管理支援システム |
| JP2012502398A (ja) * | 2008-09-12 | 2012-01-26 | ナビジェニクス インコーポレイティド | 複数の環境的リスク因子及び遺伝的リスク因子を組み込む方法及びシステム |
| JP2010231308A (ja) * | 2009-03-26 | 2010-10-14 | Olympus Corp | 生活習慣病予防装置および生活習慣病予防プログラム |
| US20110224505A1 (en) * | 2010-03-12 | 2011-09-15 | Rajendra Padma Sadhu | User wearable portable communicative device |
| CN103020747A (zh) * | 2011-09-22 | 2013-04-03 | 生命遗传株式会社 | 个人定制健康及美容系统 |
| EP3054412A4 (en) * | 2013-10-01 | 2017-03-01 | Tohoku University | Health information processing device, health information display device, and method |
-
2014
- 2014-10-01 EP EP14843220.6A patent/EP3054412A4/en not_active Withdrawn
- 2014-10-01 SG SG11201502141RA patent/SG11201502141RA/en unknown
- 2014-10-01 CN CN201480002440.9A patent/CN104704526A/zh active Pending
- 2014-10-01 JP JP2015508354A patent/JP6212784B2/ja active Active
- 2014-10-01 WO PCT/JP2014/076332 patent/WO2015050174A1/ja active Application Filing
-
2015
- 2015-03-18 US US14/661,785 patent/US20150193588A1/en not_active Abandoned
-
2016
- 2016-12-26 JP JP2016252035A patent/JP6212787B2/ja active Active
- 2016-12-26 JP JP2016252034A patent/JP6212786B2/ja active Active
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2000099605A (ja) * | 1998-09-24 | 2000-04-07 | Fujitsu Ltd | 健診情報分析サーバおよびネットワーク健康情報システム |
| JP2001327472A (ja) | 2000-03-14 | 2001-11-27 | Toshiba Corp | 身体装着型生活支援装置および方法 |
| JP2006320735A (ja) | 2000-03-14 | 2006-11-30 | Toshiba Corp | 身体装着型生活支援装置および方法 |
| JP2001268548A (ja) * | 2000-03-21 | 2001-09-28 | Sony Corp | 情報処理装置および方法、情報処理システム、並びに記録媒体 |
| JP2002342492A (ja) * | 2001-05-21 | 2002-11-29 | Hitachi Ltd | 医療情報管理システム、医療情報管理方法、医療情報管理プログラムを記録した記録媒体及び医療情報管理プログラム |
| JP2007310632A (ja) * | 2006-05-18 | 2007-11-29 | Taito Corp | 分身健康・体型予測システム |
| JP2011134106A (ja) * | 2009-12-24 | 2011-07-07 | Hitachi Ltd | 医療情報収集システム、医療情報収集処理方法及び医療情報収集画面表示制御方法 |
Non-Patent Citations (2)
| Title |
|---|
| KATSUYUKI OGAWARA: "Big Data o Tsukatte 'Tonyobyo' o Yosoku Dekiru!?", ZUKAI BIG DATA HAYAWAKARI, 29 January 2013 (2013-01-29), pages 104, XP008183027 * |
| See also references of EP3054412A4 |
Cited By (65)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017059261A (ja) * | 2013-10-01 | 2017-03-23 | 国立大学法人東北大学 | 健康情報処理装置及び方法 |
| JP2017010486A (ja) * | 2015-06-26 | 2017-01-12 | Rizap株式会社 | 情報処理システム、情報処理方法、および、情報処理プログラム |
| JP2018530069A (ja) * | 2015-10-01 | 2018-10-11 | ディーエヌエーナッジ リミテッド | 生体情報を安全に転送するための方法、装置、およびシステム |
| US11133095B2 (en) | 2015-10-01 | 2021-09-28 | Dnanudge Limited | Wearable device |
| US10861594B2 (en) | 2015-10-01 | 2020-12-08 | Dnanudge Limited | Product recommendation system and method |
| JPWO2017191847A1 (ja) * | 2016-05-04 | 2019-05-16 | 理香 大熊 | 将来像予測装置 |
| WO2017191847A1 (ja) * | 2016-05-04 | 2017-11-09 | 理香 大熊 | 将来像予測装置 |
| JP2017204199A (ja) * | 2016-05-12 | 2017-11-16 | ヤフー株式会社 | 情報提供装置、情報提供方法および情報提供プログラム |
| JP7010946B2 (ja) | 2016-12-12 | 2022-01-26 | コーニンクレッカ フィリップス エヌ ヴェ | 健康状態の計算解析を容易化するシステム及び方法 |
| JP2020501278A (ja) * | 2016-12-12 | 2020-01-16 | コーニンクレッカ フィリップス エヌ ヴェKoninklijke Philips N.V. | 健康状態の計算解析を容易化するシステム及び方法 |
| JP2018120351A (ja) * | 2017-01-24 | 2018-08-02 | 富士通株式会社 | 情報処理装置、情報処理システム、プログラム及び情報処理方法 |
| WO2018139205A1 (ja) * | 2017-01-24 | 2018-08-02 | 富士通株式会社 | 情報処理装置、情報処理システム、プログラム及び情報処理方法 |
| JP2018195217A (ja) * | 2017-05-19 | 2018-12-06 | ヤフー株式会社 | 情報提供装置、情報提供方法および情報提供装置プログラム |
| JP2018195187A (ja) * | 2017-05-19 | 2018-12-06 | ヤフー株式会社 | 情報提供装置、情報提供方法および情報提供装置プログラム |
| JP2018195198A (ja) * | 2017-05-19 | 2018-12-06 | ヤフー株式会社 | 提供装置、提供方法及び提供プログラム |
| WO2019087787A1 (ja) * | 2017-10-30 | 2019-05-09 | マクセル株式会社 | 異常データ処理システムおよび異常データ処理方法 |
| JP7296495B2 (ja) | 2017-10-30 | 2023-06-22 | マクセル株式会社 | 異常データ処理システムおよび異常データ処理方法 |
| US11607153B2 (en) | 2017-10-30 | 2023-03-21 | Maxell, Ltd. | Abnormal data processing system and abnormal data processing method |
| JP2022059078A (ja) * | 2017-10-30 | 2022-04-12 | マクセル株式会社 | 異常データ処理システムおよび異常データ処理方法 |
| JP7029513B2 (ja) | 2017-10-30 | 2022-03-03 | マクセル株式会社 | 異常データ処理システムおよび異常データ処理方法 |
| JPWO2019087787A1 (ja) * | 2017-10-30 | 2020-10-22 | マクセル株式会社 | 異常データ処理システムおよび異常データ処理方法 |
| JP2021051758A (ja) * | 2017-10-30 | 2021-04-01 | マクセル株式会社 | 異常データ処理システムおよび異常データ処理方法 |
| JP2019097977A (ja) * | 2017-12-05 | 2019-06-24 | 倉敷紡績株式会社 | 体調管理システム |
| JP6993857B2 (ja) | 2017-12-05 | 2022-01-14 | 倉敷紡績株式会社 | 体調管理システム |
| JP7174061B2 (ja) | 2018-03-13 | 2022-11-17 | 株式会社メニコン | 健康モニタリング方法 |
| JP2021515631A (ja) * | 2018-03-13 | 2021-06-24 | 株式会社メニコン | 健康データの収集および利用システム |
| US12064237B2 (en) | 2018-03-13 | 2024-08-20 | Menicon Co., Ltd. | Determination system, computing device, determination method, and program |
| KR102049307B1 (ko) | 2018-04-13 | 2019-11-27 | 유한회사 지에스케이테크놀로지 | 교육용 건강상태 시뮬레이션 장치 |
| KR20190119838A (ko) * | 2018-04-13 | 2019-10-23 | 유한회사 지에스케이테크놀로지 | 교육용 건강상태 시뮬레이션 장치 |
| WO2020013000A1 (ja) * | 2018-07-13 | 2020-01-16 | オムロンヘルスケア株式会社 | 行動変容支援装置、端末およびサーバ |
| JP2020013208A (ja) * | 2018-07-13 | 2020-01-23 | オムロンヘルスケア株式会社 | 行動変容支援装置、端末およびサーバ |
| JP7135521B2 (ja) | 2018-07-13 | 2022-09-13 | オムロンヘルスケア株式会社 | 行動変容支援装置、端末およびサーバ |
| JP7082809B2 (ja) | 2018-07-13 | 2022-06-09 | BioICT株式会社 | 構成員健康状態管理システム、構成員健康状態管理方法、及び構成員健康状態管理プログラム |
| JP2020013230A (ja) * | 2018-07-13 | 2020-01-23 | 木村 裕一 | 構成員健康状態管理システム、構成員健康状態管理方法、及び構成員健康状態管理プログラム |
| US11720659B2 (en) | 2018-07-24 | 2023-08-08 | Dnanudge Limited | Method and device for comparing personal biological data of two users |
| US10922397B2 (en) | 2018-07-24 | 2021-02-16 | Dnanudge Limited | Method and device for comparing personal biological data of two users |
| JP2019048061A (ja) * | 2018-09-26 | 2019-03-28 | 株式会社メディプリーム | 発病予知ネットワークシステム |
| US10811140B2 (en) | 2019-03-19 | 2020-10-20 | Dnanudge Limited | Secure set-up of genetic related user account |
| US11901082B2 (en) | 2019-03-19 | 2024-02-13 | Dnanudge Limited | Secure set-up of genetic related user account |
| JP2020185382A (ja) * | 2019-05-10 | 2020-11-19 | キヤノンメディカルシステムズ株式会社 | 診断支援装置 |
| JP7568423B2 (ja) | 2019-05-10 | 2024-10-16 | キヤノンメディカルシステムズ株式会社 | 診断支援装置 |
| US11403382B2 (en) | 2019-07-24 | 2022-08-02 | Dnanudge Limited | Method and device for comparing personal biological data of two users |
| JP2021077313A (ja) * | 2019-10-31 | 2021-05-20 | 安博 市村 | 健康状態予測システム、健康状態予測方法、及び、健康状態予測システム用のプログラム |
| JP7420145B2 (ja) | 2019-11-01 | 2024-01-23 | 日本電気株式会社 | リスク予測装置、リスク予測方法、及びコンピュータプログラム |
| JPWO2021084747A1 (ja) * | 2019-11-01 | 2021-05-06 | ||
| WO2021084747A1 (ja) * | 2019-11-01 | 2021-05-06 | 日本電気株式会社 | リスク予測装置、リスク予測方法、及びコンピュータプログラム |
| JP7302445B2 (ja) | 2019-11-14 | 2023-07-04 | トヨタ自動車株式会社 | プログラム、情報処理装置、情報処理システム、および情報処理方法 |
| CN112802565A (zh) * | 2019-11-14 | 2021-05-14 | 丰田自动车株式会社 | 记录介质、信息处理装置、信息处理系统以及信息处理方法 |
| US11715567B2 (en) | 2019-11-14 | 2023-08-01 | Toyota Jidosha Kabushiki Kaisha | Storage medium, information processing apparatus, information processing system, and information processing method |
| JP2021081802A (ja) * | 2019-11-14 | 2021-05-27 | トヨタ自動車株式会社 | プログラム、情報処理装置、情報処理システム、および情報処理方法 |
| JP7339315B2 (ja) | 2020-03-02 | 2023-09-05 | 東芝テック株式会社 | レシートデータ管理装置及びそのプログラム、レシートデータ管理方法、レシートデータ管理システム |
| JP2022024105A (ja) * | 2020-03-02 | 2022-02-08 | 東芝テック株式会社 | レシートデータ管理装置及びそのプログラム並びにレシートデータ管理方法 |
| JP7516636B2 (ja) | 2020-03-02 | 2024-07-16 | 東芝テック株式会社 | レシートデータ管理装置及びそのプログラム、レシートデータ管理方法、レシートデータ管理システム |
| JP6887194B1 (ja) * | 2020-09-14 | 2021-06-16 | 株式会社Arblet | 情報処理システム、サーバ、情報処理方法及びプログラム |
| JP2022048069A (ja) * | 2020-09-14 | 2022-03-25 | 株式会社Arblet | 情報処理システム、サーバ、情報処理方法及びプログラム |
| KR102319095B1 (ko) * | 2020-11-26 | 2021-10-28 | 부산대학교병원 | 맞춤형 헬스케어 시스템 |
| JP6949277B1 (ja) * | 2021-01-15 | 2021-10-13 | 三菱電機株式会社 | 未病診断装置、未病診断方法及び学習モデル生成装置 |
| WO2022153469A1 (ja) * | 2021-01-15 | 2022-07-21 | 三菱電機株式会社 | 未病診断装置、未病診断方法及び学習モデル生成装置 |
| WO2023017619A1 (ja) * | 2021-08-13 | 2023-02-16 | 株式会社ビキタン | 情報処理システム、情報処理方法、コンピュータプログラムおよび情報処理装置 |
| JP7075162B1 (ja) * | 2021-08-13 | 2022-05-25 | 株式会社プラニス | 情報処理システム、情報処理方法、コンピュータプログラムおよび情報処理装置 |
| JP7376878B2 (ja) | 2021-08-27 | 2023-11-09 | 長佳智能股▲分▼有限公司 | 遺伝子診断リスク判定システム |
| JP2023033052A (ja) * | 2021-08-27 | 2023-03-09 | 長佳智能股▲分▼有限公司 | 遺伝子診断リスク判定システム |
| JP2023111371A (ja) * | 2022-01-31 | 2023-08-10 | 春樹 鳥海 | 未病パラメータ測定システム |
| JP7122048B1 (ja) | 2022-01-31 | 2022-08-19 | 春樹 鳥海 | 未病パラメータ測定システム |
| WO2024042613A1 (ja) * | 2022-08-23 | 2024-02-29 | 日本電気株式会社 | 端末、端末の制御方法及び記憶媒体 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP6212784B2 (ja) | 2017-10-18 |
| JP6212786B2 (ja) | 2017-10-18 |
| EP3054412A4 (en) | 2017-03-01 |
| JP2017059261A (ja) | 2017-03-23 |
| US20150193588A1 (en) | 2015-07-09 |
| CN104704526A (zh) | 2015-06-10 |
| JP6212787B2 (ja) | 2017-10-18 |
| JPWO2015050174A1 (ja) | 2017-03-09 |
| EP3054412A1 (en) | 2016-08-10 |
| JP2017097895A (ja) | 2017-06-01 |
| SG11201502141RA (en) | 2015-05-28 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6212787B2 (ja) | 健康情報処理装置及び方法 | |
| JP6248326B2 (ja) | 食事型センサ、及びセンシング方法 | |
| AU2021221774B2 (en) | Database management and graphical user interfaces for managing blood glucose levels | |
| JP6360998B2 (ja) | 健康情報処理装置 | |
| US20210319887A1 (en) | Method of treating diabetes informed by social determinants of health | |
| Corsonello et al. | Concealed renal insufficiency and adverse drug reactions in elderly hospitalized patients | |
| Sullivan et al. | Protein-energy undernutrition among elderly hospitalized patients: a prospective study | |
| US11621090B2 (en) | Platform for assessing and treating individuals by sourcing information from groups of resources | |
| US20170262609A1 (en) | Personalized adaptive risk assessment service | |
| Budhiraja et al. | The role of big data in the management of sleep-disordered breathing | |
| Heredia et al. | Coaction between physical activity and fruit and vegetable intake in racially diverse, obese adults | |
| KR20220068594A (ko) | 챗봇 기반의 질의응답 및 생체표지자 데이터를 이용한 맞춤형 영양 관리 시스템 | |
| Leeds et al. | Assessing clinical discharge data preferences among practicing surgeons | |
| Portius | Wish or Truth: Can Digital Interventions Stop the Obesity Crisis? |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| ENP | Entry into the national phase |
Ref document number: 2015508354 Country of ref document: JP Kind code of ref document: A |
|
| REEP | Request for entry into the european phase |
Ref document number: 2014843220 Country of ref document: EP |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2014843220 Country of ref document: EP |
|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 14843220 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |