WO2013058404A1 - Pprモチーフを利用したrna結合性蛋白質の設計方法及びその利用 - Google Patents
Pprモチーフを利用したrna結合性蛋白質の設計方法及びその利用 Download PDFInfo
- Publication number
- WO2013058404A1 WO2013058404A1 PCT/JP2012/077274 JP2012077274W WO2013058404A1 WO 2013058404 A1 WO2013058404 A1 WO 2013058404A1 JP 2012077274 W JP2012077274 W JP 2012077274W WO 2013058404 A1 WO2013058404 A1 WO 2013058404A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- ppr
- rna
- amino acids
- motif
- protein
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images































Classifications
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B15/00—ICT specially adapted for analysing two-dimensional [2D] or three-dimensional [3D] molecular structures, e.g. structural or functional relations or structure alignment
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/415—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from plants
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/82—Vectors or expression systems specially adapted for eukaryotic hosts for plant cells, e.g. plant artificial chromosomes (PACs)
- C12N15/8216—Methods for controlling, regulating or enhancing expression of transgenes in plant cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/82—Vectors or expression systems specially adapted for eukaryotic hosts for plant cells, e.g. plant artificial chromosomes (PACs)
- C12N15/8241—Phenotypically and genetically modified plants via recombinant DNA technology
- C12N15/8261—Phenotypically and genetically modified plants via recombinant DNA technology with agronomic (input) traits, e.g. crop yield
- C12N15/8287—Phenotypically and genetically modified plants via recombinant DNA technology with agronomic (input) traits, e.g. crop yield for fertility modification, e.g. apomixis
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/82—Vectors or expression systems specially adapted for eukaryotic hosts for plant cells, e.g. plant artificial chromosomes (PACs)
- C12N15/8241—Phenotypically and genetically modified plants via recombinant DNA technology
- C12N15/8261—Phenotypically and genetically modified plants via recombinant DNA technology with agronomic (input) traits, e.g. crop yield
- C12N15/8287—Phenotypically and genetically modified plants via recombinant DNA technology with agronomic (input) traits, e.g. crop yield for fertility modification, e.g. apomixis
- C12N15/8289—Male sterility
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/53—Immunoassay; Biospecific binding assay; Materials therefor
- G01N33/5308—Immunoassay; Biospecific binding assay; Materials therefor for analytes not provided for elsewhere, e.g. nucleic acids, uric acid, worms, mites
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
- G16B20/30—Detection of binding sites or motifs
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
- G16B20/50—Mutagenesis
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B30/00—ICT specially adapted for sequence analysis involving nucleotides or amino acids
- G16B30/10—Sequence alignment; Homology search
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B35/00—ICT specially adapted for in silico combinatorial libraries of nucleic acids, proteins or peptides
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16C—COMPUTATIONAL CHEMISTRY; CHEMOINFORMATICS; COMPUTATIONAL MATERIALS SCIENCE
- G16C20/00—Chemoinformatics, i.e. ICT specially adapted for the handling of physicochemical or structural data of chemical particles, elements, compounds or mixtures
- G16C20/60—In silico combinatorial chemistry
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/85—Fusion polypeptide containing an RNA binding domain
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2522/00—Reaction characterised by the use of non-enzymatic proteins
- C12Q2522/10—Nucleic acid binding proteins
- C12Q2522/101—Single or double stranded nucleic acid binding proteins
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16B—BIOINFORMATICS, i.e. INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR GENETIC OR PROTEIN-RELATED DATA PROCESSING IN COMPUTATIONAL MOLECULAR BIOLOGY
- G16B20/00—ICT specially adapted for functional genomics or proteomics, e.g. genotype-phenotype associations
Definitions
- the present invention relates to a protein that can selectively or specifically bind to an intended RNA base or RNA sequence.
- a pentatricopeptide repeat (PPR) motif is used.
- the present invention can be used for identification and design of RNA-binding proteins, identification of target RNAs for PPR proteins, and control of RNA functions.
- the present invention is useful in the medical field, agricultural field, and the like.
- Non-patent Document 1 As proteinaceous factors that act on DNA, research and development using zinc finger proteins (Non-patent Document 1) and TAL effector (Non-patent Documents 2 and 1) as protein engineering materials have been conducted. The development of specifically acting proteinaceous factors is still very limited. This is because, in general, the affinity with the RNA of the amino acid sequence constituting the protein and the rule with the binding RNA sequence are hardly clarified, or the rule is not found. Exceptionally, a pumilio protein consisting of multiple repeats of a puff motif consisting of 38 amino acids has been shown to bind one puf motif to RNA 1 base (Non-patent Document 3).
- Non-patent Document 4 An attempt has been made to use a protein having a novel RNA binding property and a technique for modifying the RNA binding property (Non-patent Document 4).
- puf motifs are highly conserved and are few. Therefore, it is only used to create protein factors that act on limited RNA sequences.
- PPR proteins proteins having a pentatricopeptide repeat (PPR) motif
- the PPR protein is a nuclear code, but it acts exclusively on the regulation, cleavage, translation, splicing, RNA editing, and RNA stability of organelles (chloroplasts and mitochondria) at the RNA level.
- a PPR protein typically has a structure of 35 amino acid motifs with low conservation, that is, about 10 consecutive PPR motifs, and the combination of PPR motifs is responsible for sequence-selective binding to RNA.
- Non-patent Document 6 RNA adapter
- Patent Document 2 The present inventors have proposed a method for modifying an RNA-binding protein using this PPR motif.
- a TALE nuclease architecture for efficient genome editing is biotech. 29, 143-148. Wang, X., McLachlan, J., Zamore, P.D., and Hall, T.M. (2002). Modular recognition of RNA by a human homology domain. Cell 110, 501-512. Cheong, C.G., and Hall, T.M. (2006). Engineering RNA sequence specificity of Pumilio repeats. Proc. Natl. Acad. Sci. USA 103, 13635-13639. Small, I.D., and Peeters, N. (2000). The PPR motif-a TPR-related motif prevalent in plant organellar proteins. Trends Biochem. Sci. 25, 46-47. Woodson, J.D., and Chory, J. (2008). Coordination of gene expression between organellar and nuclear genomes. Nature Rev. Genet. 9, 383-395.
- the properties of the PPR protein as an RNA adapter are expected to be determined by the properties of each PPR motif constituting the PPR protein and the combination of a plurality of PPR motifs.
- the correlation between amino acid composition and function is hardly clear.
- the present inventors have analyzed genetically analyzed PPR proteins, particularly RNA editing (modification of genetic information at the RNA level, particularly from cytosine (hereinafter C) to uracil (hereinafter U).
- PPR protein and its target RNA sequence have been studied. And by using computational science methods, information that governs the binding of specific RNA bases to the three amino acids (amino acids No. 1, 4, and “ii” (-2)) in the PPR motif Clarified that it is included.
- the present inventors indicate that the selectivity (sometimes referred to as specificity) of the binding RNA base of the PPR motif is included in the first helix of the two ⁇ -helix structures constituting the motif 1 In the part that can form a loop structure after the 2nd helix and the 4th amino acid, and the 2nd helix, the 3rd position from the back (C-terminal side) to the 2nd amino acid (“ii”; No.-2) And the present invention was completed.
- the present invention provides the following: [1] A method for designing a protein capable of binding RNA base-selectively or RNA base sequence-specifically; A protein comprising one or more (preferably 2 to 14) PPR motifs consisting of a 30 to 38 amino acid long polypeptide represented by Formula 1
- Helix A is a 12 amino acid long portion capable of forming an ⁇ -helix structure, represented by Formula 2,
- a 1 to A 12 each independently represent an amino acid;
- X is a portion that is absent or consists of 1 to 9 amino acids in length;
- Helix B is a part capable of forming an ⁇ -helix structure consisting of 11 to 13 amino acids in length;
- L is a moiety represented by Formula 3 that is 2 to 7 amino acids long;
- each amino acid is numbered from the C-terminal side as “i” ( ⁇ 1), “ii” ( ⁇ 2), However, L iii to L vii may not exist. )
- a method in which a combination of three amino acids A 1 , A 4 , and L ii , or a combination of two amino acids A 4 , L ii depends on the target RNA base or base sequence.
- a method for identifying a base or base sequence that is a target of an RNA-binding protein comprising one or more (preferably 2 to 14) PPR motifs defined in [1]: Based on any of (3-1) to (3-16) described in 2 or (2-1) to (2-12) described in 3, the identification is based on A 1 of the PPR motif. , A 4 , and L ii , or a combination of the three amino acids, or A 4 , L ii , and a combination of the two amino acids.
- [5] A method for identifying a PPR protein comprising one or more (preferably 2 to 14) PPR motifs defined in [1] capable of binding to a target RNA base or a target RNA having a specific base sequence Because: Based on any of (3-1) to (3-16) described in 2, or any of (2-1) to (2-12) described in 3, depending on the particular bases constituting a target RNA, it is carried out by certified whether the combination of three amino acids of the PPR a 1, a 4 motifs, and L ii, method. [6] A method for controlling the function of RNA, using the protein designed by the method described in [1]. [7] A complex formed by linking a functional region and a protein region designed by the method described in [1].
- a method for modifying cellular genetic material comprising the following steps: Preparing a cell containing RNA having the target sequence; and introducing the complex described in [7] into the cell, the protein region of the complex binds to the RNA having the target sequence; A method for modifying RNA having a target sequence.
- the PPR protein is a protein comprising one or more (preferably 2 to 16) PPR motifs consisting of a 30 to 38 amino acid long polypeptide represented by formula 1 defined in [1].
- the method according to [9]. [11] The method according to [9] or [10], wherein the aminopolymorphism is specified as a polymorphism for each PPR motif.
- the polymorphism of the PPR motif is specified by the combination of the three amino acids A 1 , A 4 , and L ii of the motif of Formula 1 or the combination of the two amino acids A 4 , L ii [9] The method according to any one of [9] to [11].
- the PPR protein gene is an orf687-like gene (ie, a family gene seated at a locus homologous to the “687 gene” encoding Enko B, a gene having 90% or more amino acid sequence identity with Enko B, The method according to any one of claims 9 to 14, wherein the "ORF687 gene” encoding Enko B is a gene having a nucleotide sequence identity of 90% or more.
- the method according to any one of [9] to [15], wherein the protein encoded by various varieties of orf687-like genes is any one of SEQ ID NOs: 576 to 578 and 585 to 591.
- a PPR motif capable of binding to a target RNA base and a protein containing the same can be provided.
- a protein capable of binding to a target RNA having an arbitrary sequence or length can be provided.
- a target RNA of an arbitrary PPR protein can be predicted and identified, and conversely, a PPR protein that binds to an arbitrary RNA can be predicted and identified. Predicting the target RNA sequence reveals its genetic identity and opens up possibilities for use. For example, when fertility is considered as a function of PPR protein in the present invention, an industrially useful PPR protein gene that works as a recovery factor for cytoplasmic male sterility is a function of a homologous gene having various amino acid polymorphisms. Sex can be assayed from differences in its target RNA sequence.
- a complex can be prepared by binding functionality to the PPR motif or PPR protein provided by the present invention.
- a method for delivering the above complex in vivo and allowing it to function, or production of a transformant using a nucleic acid sequence (DNA, RNA) encoding the protein obtained by the present invention can be used for specific modification, control, and addition of functions in various situations in cells, tissues, and individuals).
- FIG. 1 shows the conserved sequence and amino acid number of the PPR motif.
- A ⁇ ⁇ ⁇ ⁇ Amino acids constituting the PPR motif defined in the present invention, and their amino acid numbers are described.
- B The positions on the predicted structure of the three amino acids (Nos. 1, 4 and “ii” (-2)) that control the selectivity of -binding base are shown.
- C The position of the amino acid on the predicted structure. Using the entire amino acid sequence of Arabidopsis CRR4 (SEQ ID NO: 6) and CRR21 (SEQ ID NO: 3) as the query sequence, the predicted structure can be determined using the PHYRE (http://www.sbg.bio.ic.ac.uk/phyre/) program.
- FIG. 2 shows the RNA editing PPR protein analyzed so far and the RNA editing site as a target thereof.
- FIG. 3 shows the PPR motif sequence and amino acid number of Arabidopsis RNA-edited PPR protein.
- Figure 3-2 shows the continuation of Figure 3-1.
- FIG. 4 shows the amino acids in the PPR motif involved in RNA recognition.
- A Identification of amino acids having the ability to designate a binding base in the PPR motif.
- the PPR motif of RNA editing PPR protein was aligned with the upstream sequence of RNA editing site in various positions. Alignment was performed by arranging motifs and bases one-on-one. Alignment P1 made the last PPR motif correspond to the previous base of C being edited. The P2-P6 alignment was obtained by shifting the base sequence by one base to the right. Squares indicate PPR motifs, and diamonds indicate additional motifs (E, E +, DYW) on the C-terminal side.
- RNA base recognition If an amino acid at a specific position in the motif (eg, the amino acid of the green (dark gray in black and white) motif) is responsible for RNA base recognition, low randomness is expected between the corresponding bases in a specific alignment. Yes (bottom right). If not, high randomness is expected (upper right figure).
- C ⁇ Ability to designate the binding RNA base of amino acids 1, 4, and “ii” (-2) in various nucleic acid classifications. (B) Same as.
- nucleic acids are classified into purines or pyrimidines (RY; A & G or U & C) and hydrogen bonding groups (WS; A & U, G & C).
- RY purines or pyrimidines
- WS hydrogen bonding groups
- a & U, G & C hydrogen bonding groups
- E RNA Examples of RNA recognition codes (PPR codes) for several PPR motifs.
- FIG. 5 shows identification (example) of amino acids in a PPR motif involved in RNA recognition.
- Amino acid involved in RNA recognition was searched using a data set of RNA bases corresponding to PPR motifs in each alignment. For example, using the RNA base data corresponding to the PPR motif in the alignment P4, the binding RNA base designation ability of amino acids 4 and 5 was analyzed. In each alignment, data was first sorted by amino acid type, and the number of contained RNA bases was calculated (upper left figure).
- FIG. 6 shows the search for amino acids responsible for the ability to designate RNA bases.
- A The low randomness between the type of amino acid and the frequency of occurrence of bases was calculated for amino acids at all positions in the P1-P6 alignment. Amino acids that showed a significant P value (P ⁇ 0.01) were shown in magenta color (dark gray in black and white display).
- FIG. 7 shows the binding RNA base designation ability by two amino acids. Similar to FIG. 4, the ability to specify the binding RNA base by two different amino acids (1 & 4, 1 & "ii", 4 & "ii” amino acids) was analyzed by low-randomness between the amino acid and the corresponding base.
- FIG. 8 shows the RNA recognition code of the PPR motif extracted from Arabidopsis thaliana.
- FIG. 9 shows the sequence of the red moss RNA-editing PPR protein and the RNA editing site where each protein works.
- the amino acid sequences of Nos. 1, 4, and “ii” (-2) in each PPR motif are shown.
- Magenta and cyan characters (both dark gray in black and white) indicate triPPR extracted from Arabidopsis thaliana or a combination of amino acids homologous to the diPPRP code.
- Additional motifs on the C-terminal side (E, E +, DYW) are also shown.
- the sequence of the RNA editing site where each protein acts is indicated by the position of the alignment P4 shown in FIG. FIG.
- FIG. 10 shows a flowchart of a method for calculating a fitness value between a PPR protein and an RNA editing site RNA sequence.
- a protein PPR model is obtained from Uniprot or PROSITE database, and each amino acid number is assigned according to FIG. Extract amino acids 1, 4 and “ii”.
- the moss PPR protein, PpPPR71 was shown.
- the matching amino acid combination is converted into a triPPR code matrix.
- the motif that could not be converted to the triPPR code is then converted to a diPPR code matrix.
- the RNA editing site 30nt (C edited at the end) is converted into a mathematical matrix.
- the ccmFCeU122SF sequence on which PpPPR71 protein acts is shown.
- the product of the cells corresponding to the protein code matrix and the RNA mathematical formula matrix is obtained, and the fitness value is calculated from the sum.
- the last row of the protein code matrix must be matched to the row corresponding to the 4th previous base of C being edited. This calculation is performed for each of the protein code matrices created from the triPPR code and the diPPR code.
- provisional P values for each RNA sequence are determined for each of the triPPR code and diPPR code.
- the final fitness value (P value) is calculated as the product of the provisional P value of the triPPR and diPPR codes.
- FIG. 11 shows the prediction of the target RNA sequence of the PPR protein using the PPR code.
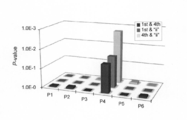
- FIG. 12 shows verification of RNA editing site prediction accuracy using an Arabidopsis RNA editing protein.
- RNA editing site prediction of 13 known PR proteins for all 34 sites of chloroplast RNA editing sites Each diamond indicates the fitness value between the protein and the RNA editing site sequence. The correct RNA editing site is shown in magenta color (solid gray in black and white display).
- B RNA editing site prediction of 11 known PR proteins for all 488 mitochondrial RNA editing sites.
- FIG. 13 shows prediction and experimental verification of the target RNA editing site of Arabidopsis PPR protein AHG11.
- AHG11 motif structure It has a typical RNA-editing PPR protein structure with 12 PPR motifs and additional motifs on the C-terminal side (E, E +, DYW).
- RNA editing site prediction using all RNA editing sites contained in Arabidopsis thaliana chloroplasts and mitochondria. The top 10 editing sites with the highest P values were shown. The presence or absence of RNA editing in wild and mutant strains was experimentally verified and indicated as editing status. The site where editing was detected in both wild and mutant strains was indicated as E, and the site where RNA editing was not found only in the mutant strain was indicated as Un.
- C The results of hail prediction are shown in a graph.
- D Experimental verification of the target RNA editing site of AHG11.
- RNA was extracted from the wild type and ahg11 mutants, cDNA was prepared by reverse transcription, and the nucleotide sequence was analyzed. There are two RNA editing sites (nsd4_362 and _376) in this region. The edited portion is indicated by a black arrow, and the unedited portion is indicated by a white arrow.
- FIG. 14 shows the prediction of target sites from chloroplast genome sequences. Target sites were predicted from the Arabidopsis thaliana chloroplast whole genome sequence (154,478 bp) using 6 PPR proteins.
- FIG. 16 shows an amino acid sequence or a base sequence related to the present invention.
- FIG. 16 shows an amino acid sequence or a base sequence related to the present invention.
- FIG. 16 shows an amino acid sequence or a base sequence related to the present invention.
- FIG. 16 shows an amino acid sequence or a base sequence related to the present invention.
- FIG. 16 shows an amino acid sequence or a base sequence related to the present invention.
- FIG. 16 shows an amino acid sequence or a base sequence related to the present invention.
- FIG. 16 shows an amino acid sequence or a base sequence related to the present invention.
- FIG. 16 shows an amino acid sequence or a base sequence related to the present invention.
- FIG. 16 shows an amino acid sequence or a base sequence related to the present invention.
- FIG. 16 shows an amino acid sequence or a base sequence related to the present invention.
- FIG. 16 shows an amino acid sequence or a base sequence related to the present invention.
- FIG. 17 shows binding analysis of Enko B protein and RNA containing cytoplasmic male sterility (CMS) gene.
- FIG. 18 shows the binding of ORF687-like protein and RNA.
- FIG. 19 shows the binding sequence prediction of the fertility recovery factor acting on the Ogura cytoplasm.
- FIG. 20 shows the secondary structure and structural changes of the candidate binding RNA region of the ORF687-like protein.
- FIG. 21 shows the alignment of the ORF687-like protein.
- FIG. 21 shows the alignment of the ORF687-like protein.
- FIG. 22 shows a list of base-designated amino acids of ORF687-like proteins contained in various rad
- PPR motif means that the E value obtained with PF01535 in Pfam and PS51375 in Prosite is less than a predetermined value when the amino acid sequence is analyzed with a protein domain search program on the web, unless otherwise specified.
- amino acid “ii” (-2) is referred to, 2 amino acids from the second amino acid after the amino acid constituting the PPR motif (C-terminal side) or the first amino acid of the next PPR motif The terminal side, ie, the -2nd amino acid (Fig. 1). If the next PPR motif is not clearly identified, the amino acid two amino acids before the first amino acid of the next helix structure is designated “ii”. Http://pfam.sanger.ac.uk/ for Pfam and http://www.expasy.org/prosite/ for Prosite.
- the conserved amino acid sequence of the PPR motif has low conservation at the amino acid level, but the two ⁇ -helices are well conserved on the secondary structure.
- a typical PPR motif is composed of 35 amino acids, but its length is variable from 30 to 38 amino acids.
- the PPR motif referred to in the present invention consists of a polypeptide having a length of 30 to 38 amino acids represented by Formula 1.
- Helix A is a 12 amino acid long portion capable of forming an ⁇ -helix structure, represented by Formula 2,
- a 1 to A 12 each independently represent an amino acid;
- X is a portion that is absent or consists of 1 to 9 amino acids in length;
- Helix B is a part capable of forming an ⁇ -helix structure consisting of 11 to 13 amino acids in length;
- L is a moiety represented by Formula 3 that is 2 to 7 amino acids long;
- each amino acid is numbered from the C-terminal side as “i” ( ⁇ 1), “ii” ( ⁇ 2), However, L iii to L vii may not exist.
- PPR protein refers to a PPR protein having one or more, preferably two or more PPR motifs, unless otherwise specified.
- protein refers to all substances consisting of polypeptides (chains in which a plurality of amino acids are peptide-bound) unless otherwise specified, and includes those consisting of relatively low molecular weight polypeptides.
- amino acid may refer to a normal amino acid molecule and may refer to an amino acid residue constituting a peptide chain. Which one is pointed out will be apparent to the skilled person from the context.
- ⁇ ⁇ PPR protein is abundant in plants, and in Arabidopsis, 500 proteins and about 5000 motifs can be found. Many terrestrial plants such as rice, poplar, and flax have PPR motifs and PPR proteins with various amino acid sequences. Some PPR proteins are known to be important genes for obtaining F1 seeds for hybrid stress as fertility recovery factors that act in the formation of pollen (male gametes). Similar to recovery from fertility, several PPR proteins have been shown to act on speciation. Most PPR proteins are also known to act on RNA in mitochondria or chloroplasts.
- PPR protein abnormalities identified as LRPPRC are known to cause Leigh ⁇ syndrom French Canadian (LSFC; Lilly syndrome, subacute necrotizing encephalomyelopathy).
- the binding property of the PPR motif to the RNA base when it is referred to as “selective”, the binding activity of any one of the RNA bases to the binding activity of other bases is more than the binding activity unless otherwise specified. It's expensive. This selectivity can be determined by a person skilled in the art by planning and confirming an experiment, and can also be obtained by calculation as disclosed in the examples of the present specification.
- RNA base in the present invention refers to the bases of ribonucleotides constituting RNA, unless otherwise specified, specifically, adenine (A), guanine (G), cytosine (C), or uracil ( U) PPR protein may have selectivity for bases in RNA, but does not bind to nucleic acid monomers.
- the present invention has been found by the present inventors, A 1, A 4, and a combination of three amino acids L ii, and / or A 4, and based on the knowledge of the combination of two amino acids L ii.
- (3-2) a combination of three amino acids of A 1, A 4, and L ii is in turn valine, threonine, when the asparagine, the PPR motif binds strongly to A, then to G, the following It has a selective RNA base binding ability such that it binds to C but not to U.
- (3-3) When the combination of three amino acids A 1 , A 4 , and L ii is valine, asparagine, and asparagine in this order, the PPR motif binds strongly to C, and then to A or U Have a selective RNA base binding ability such that they bind to each other but not to G.
- (3-4) a combination of three amino acids of A 1, A 4, and L ii is in turn, glutamic acid, glycine, in the case of aspartic acid, the PPR motif binds strongly to G, A, U and C It has a selective RNA base binding ability of not binding to.
- (3-5) a combination of three amino acids of A 1, A 4, and L ii is in turn, isoleucine, asparagine, for asparagine, the PPR motifs bind strongly and C, then the U, the following It has a selective RNA base binding ability to bind to A but not to G.
- the above-mentioned analysis is performed by further analyzing computationally the binding between a genetically or molecularly biologically analyzed protein and its potential RNA target sequence.
- the binding between protein and RNA or its selective binding is analyzed using the P value (probability) as an index.
- P value which is a general significance level
- the P value is 0.05 or less (5% contingency), preferably when the P value is 0.01 or less (1% contingency), more preferably more significant than that.
- the probability that the protein and RNA bind is sufficiently high.
- Such determination by the P value can be sufficiently understood by those skilled in the art.
- PPR motif and PPR protein Identification and design: One PPR motif can recognize a specific base of RNA. Based on the present invention, by selecting an appropriate amino acid at a specific position, a selective PPR motif can be selected or designed for each of A, U, G, and C. Furthermore, such a PPR motif can be selected. A protein containing the appropriate sequence can recognize the corresponding specific sequence. Therefore, based on the present invention, it is possible to predict and identify a natural PPR protein that selectively binds to RNA having a specific base sequence, and conversely, predict and identify an RNA that is the target of PPR protein binding. Can be identified. Target prediction / identification is useful in clarifying genetic entities, and is also useful in that it can expand target availability.
- a protein having a PPR motif that can selectively bind to a desired RNA base and a plurality of PPR motifs that can bind to a desired RNA in a sequence-specific manner can be designed.
- the sequence information of the natural PPR motif can be referred to for the portions other than the amino acid at an important position in the PPR motif.
- the natural type may be used as a whole and the design may be performed by substituting only the amino acid at the corresponding position.
- the number of repetitions of the PPR motif can be appropriately determined according to the target sequence, but can be, for example, 2 or more, and can be 2 to 20.
- a 8 of a PPR motif therewith and A 12 of the same PPR motif there is a possibility that cooperate in RNA binding.
- a 8 can be a basic amino acid, preferably lysine, or an acidic amino acid, preferably aspartic acid
- a 12 can be a basic amino acid, a neutral amino acid, or a hydrophobic amino acid.
- the designed motif or protein can be prepared by methods well known to those skilled in the art. That is, the present invention relates to a PPR motif that selectively binds to a specific RNA base focused on a combination of amino acids 1, 4, and “ii”, or a combination of amino acids 4, and “ii”, and an RNA having a specific sequence Provided is a PPR protein that specifically binds to. Above all, when considering the effect on fertility as a function of PPR protein, amino acid No. 4 (A 4 ) and amino acid “ii” are effective regardless of the combination of the above 3 amino acids or 2 amino acids.
- motifs and proteins can be prepared in relatively large amounts by methods well known to those skilled in the art, and such methods encode them from the amino acid sequence of the target motif or protein. Nucleic acid sequences can be determined and cloned to produce transformants that produce the desired motif or protein.
- the PPR motif or PPR protein provided by the present invention can be made into a complex by linking functional regions.
- the functional region refers to a part having a specific biological function in a living body or a cell, such as an enzyme function, a catalytic function, an inhibitory function, an enhancement function, or a part having a function as a label.
- a region includes, for example, a protein, a peptide, a nucleic acid, a physiologically active substance, and a drug.
- An example where the functional region is a protein is ribonuclease (RNase).
- RNase are RNase A (for example, bovine pancreatic ribonuclease A: PDB 2AAS) and RNase H.
- RNase A for example, bovine pancreatic ribonuclease A: PDB 2AAS
- RNase H RNase H
- the complex obtained by the present invention can deliver a functional region in a living body or a cell in an RNA sequence-specific manner to function.
- RNA sequences can be specifically altered or destroyed in vivo or in cells.
- new functions can be added.
- the present invention also provides a method for delivering an RNA sequence-specific functional substance.
- PPR proteins are important in obtaining F1 seeds for hybrid vigor as a fertility recovery factor that works in the formation of pollen (male gametes). According to the present invention, it is expected to develop a technique for identifying a dwarf recovery factor that has not yet been identified, and further utilizing the factor to a high degree. For example, in the case revealed in the Examples of the present application, by detecting an amino acid polymorphism in a specific PPR motif in a PPR protein gene that acts as a fertility recovery factor for cytoplasmic male sterility, Based on the relationship with fertility, it can be determined whether the PPR protein gene of the test sample is a genotype related to fertility or a genotype related to sterility.
- the PPR protein gene that is the target for detecting the polymorphism is a family that sits at a gene locus homologous to the “ORF687 gene” that encodes the ORF687 protein (named Enko B).
- Enko B a gene having 90% or more amino acid sequence identity with Enko B
- ORF687 gene encoding Enko B
- a gene having 90% or more nucleotide sequence identity in the case of a family gene that sits at a gene locus homologous to the “ORF687 gene” that encodes the ENF687 protein of Enzoen (named Enko ⁇ B)
- the PPR motif is a PPR motif composed of a polypeptide having a length of 30 to 38 amino acids represented by the above-described formula 1, and the PPR protein has one or more (preferably 2 to 16) such PPR motifs. It may be characterized by including. In the case of the polymorphism in this PPR motif, it has been clarified in the present invention that each PPR motif is responsible for binding to RNA, or a combination of amino acids 1, 4, “ii”, or 4, “ii “A polymorphism based on the combination of amino acids can be used. As shown by the P value calculated in Fig. 4B or 4D, amino acid No.
- LRPPRC LeighLesyndrom French Canadian
- the present invention can contribute to the treatment of LSFC (prevention, therapy, suppression of progression).
- PPR proteins are also involved in all RNA processing steps, cleavage, RNA editing, translation, splicing, and RNA stabilization found in organelles. According to the present invention, it can be expected that the expression of a desired RNA is modified by modifying the binding base selectivity of the PPR motif.
- the PPR protein used as a material in the present invention functions exclusively for designating the editing site of RNA editing (conversion of genetic information on RNA; in many cases, C ⁇ U) (see references 2 and 3 below).
- This type of PPR protein has an additional motif on the C-terminal side that is suggested to interact with RNA variant enzymes. It can be expected that a PPR protein having such a structure introduces a base polymorphism or treats a disease or condition caused by the base polymorphism.
- some PPR proteins may have an RNA cleaving enzyme on the C-terminal side.
- An RNA sequence-specific RNA cleaving enzyme can be constructed by modifying the binding RNA base selectivity of the N-terminal PPR motif.
- a complex in which a labeling moiety such as GFP is linked can be used to visualize desired RNA in vivo.
- PPR proteins act on DNA.
- One is a transcriptional activator of mitochondrial genes, and the other is a transcriptional activator localized in the nucleus. Therefore, it is possible to design a protein factor that binds to a desired DNA sequence based on the knowledge obtained in the present invention.
- Example 1 Collection of PPR proteins involved in RNA editing and their target sequences Referring to the information shown in Fig. 2, the PPR proteins (SEQ ID NOs: 2 to 24) related to RNA editing in Arabidopsis were analyzed in the Arabidopsis genome.
- RNA editing sites SEQ ID NOs: 48, 50, 53, 55, 57, 59, 60, 61, 62, 63, 64, 65, 68, 69, 70, 71, 73, 74, 76, 78, 80, 122, 206, 228, 232, 252, 284, 316, 338, 339, 358, 430, 433, 455, 552, 563) were collected from the RNA editing database (http://biologia.unical.it/py_script/overview.html).
- the RNA sequence collected 31 bases upstream, including the C (cytosine) residue to be edited.
- Fig. 2 shows all the collected proteins and the RNA editing sites corresponding to each protein.
- the amino acid number defined in the present invention was given to the PPR motif structure in the protein together with the information in the Uniprot database (http://www.uniprot.org/).
- the PPR motif and its amino acid number contained in the PPR proteins of 24 Arabidopsis thaliana (SEQ ID NOs: 2 to 25) used in the experiment are shown in FIG.
- Example 2 Identification of amino acids that confer binding base selectivity From previous studies, PPR proteins involved in RNA editing have motifs with specific conserved amino acid sequences on the C-terminal side (E, E + and DYW motifs, but DYW Is often not present). It has been suggested that the dozen amino acids in the E + motif are necessary for the conversion from C (cytosine) to U (uracil) rather than selective binding to RNA (Reference 3). In addition, past non-patent papers suggest that information necessary for recognition of C to be edited is included in 20 bases upstream and 5 bases downstream.
- a plurality of PPR motifs in the PPR protein recognize “somewhere” in the upstream sequence of C to be edited, and can be expected to be located in the vicinity of C where the E + motif is edited. Furthermore, there is a possibility that an upstream sequence RNA residue to which a specific amino acid in the PPR motif binds is recognized (FIG. 4A).
- RNA-edited PPR proteins and their target RNA sequences described in Example 1. Therefore, first, the last PPR motif in the protein is placed at the first base of C to be edited, and all PPR motifs have a one-to-one correspondence with RNA residues and linear continuity. (Fig. 4A, alignment P1). Next, the RNA sequence was shifted to the right by one base to obtain an alignment of P2 to P6. In this aligned P1-P6 data set, information on the RNA residues corresponding to each PPR motif was collected.
- RNA residues A, U, G or C
- RNA residues For PPR proteins working in RNA editing at 2 or 3 sites, 0.5 or 0.3 points were assigned to the RNA residues that appeared, respectively.
- the type of amino acid and the type of RNA residue that appears can be predicted to be random (high-randomness or high-entropy) (eg, top right of Fig. 4A).
- RNA bases were classified by purine (A and G) or pyrimidine (C and U) (RY), and the same calculation was performed. As a result, a very significant P value (P ⁇ 0.01) with only the fourth amino acid, was obtained (FIG. 4C). This indicates that the RNA base purine / pyrimidine to which the 4th amino acid binds is mainly distinguished.
- the binding base designation ability by the RNA recognition amino acid in the PPR motif shown in FIG. 4C was analyzed in more detail.
- Example 3 Verification of the identified RNA recognition code
- the RNA recognition code of the PPR motif identified using the RNA-edited PPR protein of Arabidopsis thaliana was verified.
- an RNA-edited PPR protein from the moss was used. It has already been clarified that RNA editing at a total of 13 sites (11 sites in mitochondria, 2 sites in chloroplasts; SEQ ID NOs: 32 to 44) is performed in the moss.
- six PPR proteins (PpPPR_56, 71, 77, 78, 79, and 91) have been shown to work in nine RNA edits, respectively.
- the RNA editing site corresponding to the protein is shown in FIG.
- RNA editing site 31-mer sequence with C to be edited as the 3 ′ end
- a sequence around the RNA editing site 31-mer sequence with C to be edited as the 3 ′ end
- This was replaced with a numeric matrix of RNA sequences as shown in FIG.
- the sum of the obtained values was calculated as a matching value (Matching score) between the protein and the RNA sequence. This calculation was performed in the triPPR code, diPPR code, and the respective PPR binding base score matrix (PPR scoring matrix).
- the final P value (applicable value of protein and RNA sequence) was determined as the product of the provisional P value of triPPR code and diPPR code.
- FIG 11 shows the matching values between each moss PPR protein and 13 moss RNA editing sites.
- 6 of the 7 proteins were computationally identified as correct RNA editing sites. That is, this analysis means that three amino acids (No. 1, No. 4, and No. ii) contain all the information related to the binding RNA base designation of the PPR motif.
- a PPR protein that binds to an intended RNA sequence can be searched by referring to the information of three or two combinations of amino acids (triPPR, diPPR code) shown in FIG.
- an artificial protein that binds to the intended RNA sequence can be synthesized by using or linking a PPR motif having the amino acid information.
- Example 4 Identification of target molecules of unanalyzed RNA-edited PPR protein
- Arabidopsis thaliana containing more RNA editing sites than moss 34 chloroplast genomes (SEQ ID NOs: 45 to 78), 488 mitochondrial genomes (SEQ ID NOs: 79-566), see FIG.
- RNA variant sites were predicted for the 24 PPR proteins used for code extraction.
- 10 out of 13 predicted at least one correct RNA editing site with the highest P value.
- the mitochondrial localized PPR protein 8 out of 11 predicted the correct RNA editing site within the top 20 ( Figure 12).
- the target RNA editing site of the unknown function PPR protein was predicted.
- the AHG11 mutant is a mutant that causes abnormalities in the abscisic acid pathway, and the protein encoded by the gene (ahg11, at2g44880) has a typical RNA-edited PPR protein-like motif structure (Figure 13; SEQ ID NO: 1) .
- RNA editing sites were predicted, and RNA editing at 405 mitochondria and 30 chloroplasts including the top 20 was experimentally verified. As a result, it became clear that only the RNA editing of mitochondrial nad4_376, which was predicted with the seventh highest P value, was abnormal in the mutant (FIG. 13).
- RNA sequence was identified from the whole organelle genome sequence, a data set of approximately 3 ⁇ 10 5 RNA sequences.
- the probability matrix of the PPR code shown in FIG. 8 was used.
- the background frequency was applied to motifs with amino acid combinations that do not match the diPPR and triPPR codes.
- the probability matrix of the prepared protein was used for FIMO analysis (http://meme.nbcr.net/meme4_6_1/fimo-intro.html) of the MEME suite together with the Arabidopsis thaliana chloroplast full-base sequence (AP000423).
- RNA binding selectivity can be obtained by combining the amino acids at the positions according to the PPR code by introducing mutations.
- the binding RNA base selection ability of each of triPPR code and diPPR code was evaluated by P value. It can be inferred that a PPR code showing a significant P value (P ⁇ 0.05) has a high ability to select RNA bases.
- Example 5 Prediction of target RNA sequence of radish Rf Next, based on the knowledge obtained in the present invention, the function of a PPR protein acting as a fertility recovery factor for cytoplasmic male sterility was determined (Examples 5 to 5). 9).
- Cytoplasmic Male Sterility is a trait that prevents the male gamete from functioning normally due to mutations in the cytoplasmic genome, particularly the mitochondrial genome. It is known that this trait is often counteracted by a restorer-of-fertility (Rf) gene present in the nucleus, resulting in normal male gametes. It is used for the first-generation hybrid breeding method and is one of the important traits in agriculture. In this CMS-Rf system, it is known that the Rf gene often encodes a PPR protein.
- Rf restorer-of-fertility
- the Ogura type also known as Cosena type
- cytoplasm used for hybrid breeding of Japanese radish and rapeseed is derived from the expression of the orf125 gene in the mitochondrial genome, and the sterility is canceled by the presence of the orf687 gene in the nuclear code. It becomes.
- the orf687 gene product is a PPR protein, and it is thought that by acting on RNA containing orf125, its expression is inactivated, and as a result, sterility is released.
- amino acids (1, 4, ii) that specify the PPR motif from the amino acids of ORF687 protein named Enko B
- a Japanese radish cultivar known to work as a dominant Rf and control the base designation ability (1, 4, ii) was extracted and converted into a PPR code, and then a target RNA sequence was predicted for a transcript containing mitochondrial orf125 (FIG. 19).
- ORF687 protein in parallel, Japanese radish varieties known to work as dominant Rf, orchard's ORF687 protein (named Enko B), also contained in soba and similar to ORF687, but serve as a recessive gene Using ORF687-like proteins (named enko A) and three ORF687-like proteins, which are homologous to horde red ORF687 (named kosena B; a recessive gene) in different radish varieties of Kosena. Its characteristics were analyzed biochemically.
- Enko B is an oligonucleotide primer (Enko_B-F primer and Enko_B-R primer; described in SEQ ID NOs: 567 and 568, respectively)
- Kosena B Is an oligonucleotide primer (kosena_B-F primer and kosena_B-R primer; described in SEQ ID NOs: 569 and 570, respectively)
- Enko A is an oligonucleotide primer (Enko_A-F primer and Enko_A-R primer; described in SEQ ID NOs: 571 and 572, respectively)
- 50 ⁇ l of the reaction solution is amplified by PCR using KOD-FX (TOYOBO) as a DNA extender in 25 cycles of 95 ° C for 30 seconds, 60 ° C for 30 seconds, and 72 ° C for 30 seconds. did.
- the obtained DNA fragment was cloned using the pBAD / Thio-TOPO® vector (Invitrogen) according to the protocol attached to the product.
- the DNA sequence was determined and confirmed to be a sequence homologous to the target DNA sequence (Enko ⁇ B, SEQ ID NO: 573; kosena B, SEQ ID NO: 574; Enko A, SEQ ID NO: 575).
- the cells were mixed with 200 ml of buffer A containing 1 mg / ml lysozyme (50 mM Tris / HCl pH 8.0, 500 mM KCl, 2 mM imidazole, 10 mM MgCl 2 , 0.5% Triton X100, 10
- the cells were disrupted by sonication and freezing and thawing. After centrifugation at 15,000 ⁇ g for 20 minutes, the supernatant was recovered as a crude extract.
- the crude extract was applied to a column packed with a nickel column resin (ProBond A, Invitrogen) equilibrated with buffer A.
- the obtained protein has the amino acid sequence set forth in SEQ ID NO: (Enko B, SEQ ID NO: 576; kosena B, SEQ ID NO: 577; Enko A, SEQ ID NO: 578) and has increased solubility on the N-terminal side.
- This is a fusion protein comprising a thioredkin amino acid sequence and a histidine tag sequence on the C-terminal side.
- 100 ⁇ l of the purified fraction was dialyzed against 500 mL of buffer E (20 mM Tris / hydrochloric acid pH 7.9, 60 mM KCl, 12.5 mM MgCl 2 , 0.1 mM EDTA, 17% glycerol, 2 mM DTT), and used as a purified sample. .
- buffer E (20 mM Tris / hydrochloric acid pH 7.9, 60 mM KCl, 12.5 mM MgCl 2 , 0.1 mM EDTA, 17% glycerol, 2 mM DTT
- RNAa Three types of RNA, RNAa, RNAb, and RNAc, including the mitochondrial DNA sequence of Ogura cytoplasmic radish, were used as substrate RNA.
- RNAa is oligonucleotide primer AF primer and AR primer (SEQ ID NO: 579, 580, respectively)
- RNAb is oligonucleotide primer BF primer and BR primer (SEQ ID NO: 581, 582, respectively)
- RNAC is oligonucleotide primer CF primer and CR primer (SEQ ID NOs: 583 and 584)
- 50 ⁇ l of the reaction solution containing 10 ng of Ogura-type cytoplasmic radish DNA as a template DNA was subjected to KOD in 25 cycles of 95 ° C. for 30 seconds, 60 ° C. for 30 seconds and 72 ° C. for 30 seconds.
- Amplification was performed by PCR using FX (TOYOBO) as a DNA elongation enzyme.
- a T7 promoter sequence for synthesizing the substrate RNA in vitro was added to each forward primer (-F).
- the obtained DNA fragment was developed by agarose gel and then purified by cutting out from the gel.
- NTP mix (10 nmol GTP, CTP, ATP, 0.5 nmol UTP), 4 ⁇ l [ 32 P] ⁇ -UTP (GE Healthcare, 3000 Ci / mmol), T7 RNA polymerase (Takara Bio) using purified DNA fragment as template
- Substrate RNA was synthesized by reacting 20 ⁇ l of the reaction solution containing at 37 ° C. for 60 minutes.
- Substrate RNA was extracted with phenol / chloroform and precipitated with ethanol, and the entire amount was developed by denaturing 6% polyacrylamide gel electrophoresis containing 6 M urea, and exposed to X-ray film for 60 seconds to detect 32 P-labeled RNA.
- RNA was excised from the gel and immersed in 200 ⁇ l of gel eluent (0.3 M sodium acetate, 2.5 mM EDTA, 0.01% SDS) at 4 ° C. for 12 hours to elute the RNA from the gel.
- gel eluent 0.3 M sodium acetate, 2.5 mM EDTA, 0.01% SDS
- 1 ⁇ l of radioactivity was measured, and the total amount of synthesized RNA was calculated.
- RNA was dissolved in ultrapure water to 2500 cpm / ⁇ l (1 fmol / ⁇ l). This preparation method usually yielded about 100 ⁇ l of 2500 cpm / ⁇ l RNA.
- RNA binding activity of the prepared recombinant proteins was analyzed by the gel shift method.
- RNA in the gel was measured with a bioimaging analyzer BAS2000 (Fuji Film).
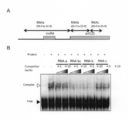
- FIG. 17 shows a binding analysis of Enko B protein and RNA containing cytoplasmic male sterility (CMS) gene.
- FIG. 17A shows a schematic diagram of the vicinity of mitochondria orf125, and also shows the regions of RNA a, RNA bc, RNA b, and RNA c used in the binding experiment.
- FIG. 17B shows the RNA binding of Enko B protein.
- RNA bc 32 P-labeled RNA bc (0.1 ng) with unlabeled RNA a, RNA bc, RNA b, RNA c ( ⁇ 5, ⁇ 10 w / w for RNA bc;
- Gel shift competition experiment was performed by reacting in a 20 ⁇ L reaction solution.
- Complex ( ⁇ ) on the left of the figure indicates a complex of protein and RNA, and Free ( ⁇ ) indicates only RNA.
- protein-RNA binding appears as a difference in mobility of 32 P-labeled RNA. This is because the molecular weight of the 32 P-labeled RNA / protein complex is larger than the molecular weight of the 32 P-labeled RNA alone, so that the mobility in electrophoresis becomes slow.
- a recombinant protein of EnkoB was prepared, and binding to mitochondrial RNA containing orf125 was verified by a competitive gel shift method. RI-labeled RNAb and protein were mixed and then unlabeled RNA was added.
- the candidate sequence of No. 208 shows the most significant P value in the binding sequence prediction shown in FIG. 19, and is located exactly at the 3 ′ end of tRNA methionine.
- RNAa containing No. 208 in in ⁇ vitro binding experiments Fig. 17B Since the sequence and Enko B do not bind, this region was judged not to be related to the fertility / sterility of the Ogura-type cytoplasm.
- RNAb consists of 125b. I tried to narrow down the combined area to 20b by scanning mutation, but I could't narrow it down to a single location (data not yet published). Therefore, there was a possibility that there were multiple binding sites of Enko B in RNAb.
- FIG. 18 shows the binding of ORF687-like protein to RNA.
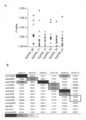
- FIG. 18A shows the result of analyzing the binding of Enko B (Rf), Kosena B (rf), Enko A (rf) and RNAb by the gel shift method with respect to the RNA binding characteristics of the ORF687-like protein.
- FIG. 18B is a graph of the results of (A). From this graph, the dissociation constant (KD) representing the RNA binding ability of each protein was calculated.
- KD dissociation constant
- FIG. 18C the fitness value between Enko B (Rf), Kosena B (rf), Enko A (rf) and a potential binding region was calculated in the same manner as in FIG.
- Kosena B often shows slightly lower RNA binding activity than Enko B (approximately twice as much as KD). However, the level of activity in general RNA binding is often detected with a difference of 10 times or more, and this difference cannot be considered significant.
- FIG. 19 shows a binding sequence prediction of a fertility recovery factor acting on the Ogura-type cytoplasm.
- FIG. 19A shows the binding prediction of Enko B protein using the PPR code
- the lower figure of FIG. 19A shows the structure of RNA containing the CMS gene orf125. See FIG. 17 for RNAa to RNAc regions in FIG. 19A.
- a target RNA sequence predicted from the ORF687 protein sequence (a region of a region (No. 208, 316, 352, 373) showing a significant P value) logo notation, a candidate binding RNA sequence, A logo of target RNA sequence predicted from ORF687-like protein (Kosena B) sequence of rapeseed varieties with recessive rf, Kosena.
- EnkoB and KosenaB were found to differ in designated bases due to amino acid polymorphisms in the second and third PPR motifs (Rf is UA, rf is GC). It was predicted that this difference was directly related to the functional difference between Rf and rf.
- Example 8 RNA structure prediction and analysis
- Rf may bind to the RNAb region, particularly Nos. 316, 352, and 373.
- In vitro analysis also suggested that RNAb may have multiple binding sites. Therefore, secondary structure prediction of RNAb sequence was performed, and attention was paid to the corresponding region.
- FIG. 20 shows the secondary structure and structural change of the candidate binding RNA region of the ORF687-like protein.
- FIG. 20A shows the secondary structure of the region containing No. 306 and the predicted binding site of the ORF687-like protein, and each PPR motif is shown with a corresponding base in a box.
- the second and third PPR motifs which have a significant difference between EnkoB (Rf) and Kosena B (rf), were highlighted.
- FIG. 20B shows the secondary structure of the region containing No. 352 and 373 and the predicted binding site of the ORF687-like protein.
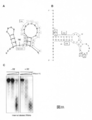
- FIG. 20C the structure of RNAb was changed by Enko B. RNAb and Enko B protein were mixed, and then double-stranded selective RNase (Rnase V1) was added.
- the No. 316 region corresponds to a stem loop structure immediately below the start codon of orf125 (FIG. 20A).
- the 2nd and 3rd PPR motifs which are polymorphic in Enko B and Kosena B, were located in the double strand at the root of the stem loop.
- the corresponding base of the 3rd PPR motif is A in Enko B, whereas it is C in Kosena B (see FIG. 19B).
- a double-stranded structure was also predicted in regions No. 352 and 373, and it was considered that the Rf protein bound to both sides (FIG. 20B). However, in this case, structural destruction (accelerating the formation of a single strand) is predicted due to the Rf bond. Also. The difference in base and structure corresponding to the 2nd and 3rd PPR motifs, which is the difference between Rf and rf, was not considered, and a specific molecular mechanism could not be predicted.
- RNase V1 is an RNase that selectively cleaves only the double-stranded region of RNA.
- substrate RNA was rapidly degraded in the presence of protein, that is, double-stranded RNA formation was promoted in the presence of Rf (Enko B) (FIG. 20C).
- Rf Enko B
- Example 9 Functional determination of fertility recovery ability of ORF687-like gene ORF687-like genes have been isolated from various radish varieties so far, and their functionality as Rf has been estimated by mating experiments. However, the amino acid sequences are very similar, and the functionality as Rf cannot be determined from the overall amino acid conservation.
- sequence analysis of ORF687-like protein was performed. Specifically, sequence analysis as a PPR protein was performed using the protein sequences shown in SEQ ID NOs: 576 to 578 and 585 to 591 as materials. All sequences were used as query sequences, and sequence alignment was obtained by CLUSTALW (http://www.genome.jp/tools/clustalw/).
- amino acids 1, 2, and “ii” ( ⁇ 2) were extracted and used to determine the function of restoring the fertility of the ORF-like protein.
- the PPR code shown in the present invention can speed up the functional judgment of industrially useful PPR proteins that act as a recovery factor.
- this technology applies a new line to a primary hybrid breeding method using the CMS-Rf system, it is possible to determine the presence or absence of its ability to recover fertility from the sequence of the candidate Rf gene.
- the inventors have determined the function of ORF687-like genes in 21 new radish varieties, and have succeeded in determining the dominant / recessive nature of 19 ORF-like genes in the ability to restore fertility (data not yet published). This technology is applicable not only to Ogura-type cytoplasmic radish, but also to various cytoplasms and plant species using PPR protein as Rf.
- Reference 1 Small, ID, and Peeters, N. (2000). The PPR motif-a TPR-related motif prevalent in plant organellar proteins. Trends Biochem. Sci. 25, 46-47.
- Reference 2 Lurin, C., Andres, C., Aubourg, S., Bellaoui, M., Bitton, F., Bruyere, C., Caboche, M., Debast, C., Gualberto, J., Hoffmann , B., et al. (2004) .Genome-wide analysis of Arabidopsis pentatricopeptide repeat proteins reveals their essential role in organelle biogenesis.Plant Cell 16, 2089-2103.
- Reference 3 Okuda, K., Myouga, F., Motohashi, R., Shinozaki, K., and Shikanai, T. (2007). conserveed domain structure of pentatricopeptide repeat proteins involved in chloroplast RNA editing. Proc Natl Acad Sci USA 104, 8178-8183.
- Reference 4 Koizuka N, Imai R, Fujimoto H, Hayakawa T, Kimura Y, et al. (2003) Genetic characterization of a pentatricopeptide repeat protein gene, orf687, that restores fertility in the cytoplasmic male-sterile Kosena radish. Plant J 34: 407-415.
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Chemical & Material Sciences (AREA)
- Genetics & Genomics (AREA)
- Physics & Mathematics (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biotechnology (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Biophysics (AREA)
- Organic Chemistry (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Theoretical Computer Science (AREA)
- Bioinformatics & Computational Biology (AREA)
- Biomedical Technology (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- General Engineering & Computer Science (AREA)
- Medical Informatics (AREA)
- Evolutionary Biology (AREA)
- Biochemistry (AREA)
- Analytical Chemistry (AREA)
- Microbiology (AREA)
- Cell Biology (AREA)
- Plant Pathology (AREA)
- Medicinal Chemistry (AREA)
- Immunology (AREA)
- Crystallography & Structural Chemistry (AREA)
- Urology & Nephrology (AREA)
- Hematology (AREA)
- Gastroenterology & Hepatology (AREA)
- Botany (AREA)
- Computing Systems (AREA)
- Library & Information Science (AREA)
- Food Science & Technology (AREA)
- Pathology (AREA)
- General Physics & Mathematics (AREA)
- Tropical Medicine & Parasitology (AREA)
Priority Applications (16)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| DK12841435.6T DK2784157T3 (da) | 2011-10-21 | 2012-10-22 | Designfremgangsmåde til et rna-bindende protein under anvendelse af ppr-motiv og anvendelse deraf |
| EP19191694.9A EP3611261A1 (en) | 2011-10-21 | 2012-10-22 | Method for designing rna binding protein uitilizing ppr motif, and use thereof |
| US14/352,697 US9513283B2 (en) | 2011-10-21 | 2012-10-22 | Method for designing RNA binding protein utilizing PPR motif, and use thereof |
| EP12841435.6A EP2784157B1 (en) | 2011-10-21 | 2012-10-22 | Design method for rna-binding protein using ppr motif, and use thereof |
| JP2013539727A JP6164488B2 (ja) | 2011-10-21 | 2012-10-22 | Pprモチーフを利用したrna結合性蛋白質の設計方法及びその利用 |
| ES12841435T ES2751126T3 (es) | 2011-10-21 | 2012-10-22 | Método de diseño para proteína de unión a ARN usando motivo de PPR, y uso del mismo |
| AU2012326971A AU2012326971C1 (en) | 2011-10-21 | 2012-10-22 | Method for designing RNA binding protein utilizing PPR motif, and use thereof |
| US15/335,243 US9984202B2 (en) | 2011-10-21 | 2016-10-26 | Method for designing RNA binding protein utilizing PPR motif, and use thereof |
| AU2017254874A AU2017254874B2 (en) | 2011-10-21 | 2017-10-31 | Method for designing rna binding protein utilizing ppr motif, and use thereof |
| US15/962,127 US10340028B2 (en) | 2011-10-21 | 2018-04-25 | Method for designing RNA binding protein utilizing PPR motif, and use thereof |
| US16/431,429 US10679731B2 (en) | 2011-10-21 | 2019-06-04 | Method for designing RNA binding protein utilizing PPR motif, and use thereof |
| AU2019280013A AU2019280013B2 (en) | 2011-10-21 | 2019-12-11 | Method for designing rna binding protein utilizing ppr motif, and use thereof |
| US16/894,295 US10943671B2 (en) | 2011-10-21 | 2020-06-05 | Method for designing RNA-binding protein utilizing PPR motif, and use thereof |
| US17/195,449 US11742056B2 (en) | 2011-10-21 | 2021-03-08 | Method for designing RNA-binding protein utilizing PPR motif, and use thereof |
| AU2022204654A AU2022204654B2 (en) | 2011-10-21 | 2022-06-29 | Method for designing rna binding protein utilizing ppr motif, and use thereof |
| AU2025204996A AU2025204996A1 (en) | 2011-10-21 | 2025-06-30 | Method for designing rna binding protein utilizing ppr motif, and use thereof |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011-231346 | 2011-10-21 | ||
| JP2011231346 | 2011-10-21 |
Related Child Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US14/352,697 A-371-Of-International US9513283B2 (en) | 2011-10-21 | 2012-10-22 | Method for designing RNA binding protein utilizing PPR motif, and use thereof |
| US15/335,243 Division US9984202B2 (en) | 2011-10-21 | 2016-10-26 | Method for designing RNA binding protein utilizing PPR motif, and use thereof |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2013058404A1 true WO2013058404A1 (ja) | 2013-04-25 |
Family
ID=48141047
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2012/077274 Ceased WO2013058404A1 (ja) | 2011-10-21 | 2012-10-22 | Pprモチーフを利用したrna結合性蛋白質の設計方法及びその利用 |
Country Status (8)
| Country | Link |
|---|---|
| US (7) | US9513283B2 (https=) |
| EP (2) | EP2784157B1 (https=) |
| JP (9) | JP6164488B2 (https=) |
| AU (5) | AU2012326971C1 (https=) |
| DK (1) | DK2784157T3 (https=) |
| ES (1) | ES2751126T3 (https=) |
| PT (1) | PT2784157T (https=) |
| WO (1) | WO2013058404A1 (https=) |
Cited By (25)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2013155555A1 (en) * | 2012-04-16 | 2013-10-24 | The University Of Western Australia | Peptides for the binding of nucleotide targets |
| WO2014175284A1 (ja) * | 2013-04-22 | 2014-10-30 | 国立大学法人九州大学 | Pprモチーフを利用したdna結合性タンパク質およびその利用 |
| WO2015133554A1 (ja) * | 2014-03-05 | 2015-09-11 | 国立大学法人神戸大学 | 標的化したdna配列の核酸塩基を特異的に変換するゲノム配列の改変方法及びそれに用いる分子複合体 |
| WO2017209122A1 (ja) | 2016-06-03 | 2017-12-07 | 国立大学法人九州大学 | 標的mRNAからのタンパク質発現量を向上させるための融合タンパク質 |
| WO2018030488A1 (ja) * | 2016-08-10 | 2018-02-15 | 和光純薬工業株式会社 | Pprモチーフを利用したdna結合性タンパク質およびその利用 |
| JP2018078896A (ja) * | 2011-10-21 | 2018-05-24 | 国立大学法人九州大学 | Pprモチーフを利用したrna結合性蛋白質の設計方法及びその利用 |
| JPWO2017209122A1 (ja) * | 2016-06-03 | 2019-04-04 | 国立大学法人九州大学 | 標的mRNAからのタンパク質発現量を向上させるための融合タンパク質 |
| US10767173B2 (en) | 2015-09-09 | 2020-09-08 | National University Corporation Kobe University | Method for converting genome sequence of gram-positive bacterium by specifically converting nucleic acid base of targeted DNA sequence, and molecular complex used in same |
| US10822617B2 (en) | 2018-06-08 | 2020-11-03 | Locana, Inc. | RNA-targeting fusion protein compositions and methods for use |
| WO2020241876A1 (ja) | 2019-05-29 | 2020-12-03 | エディットフォース株式会社 | 効率的なpprタンパク質の作製方法及びその利用 |
| WO2020241877A1 (ja) | 2019-05-29 | 2020-12-03 | エディットフォース株式会社 | 凝集の少ないpprタンパク質及びその利用 |
| WO2021007529A1 (en) | 2019-07-10 | 2021-01-14 | Locanabio, Inc. | Rna-targeting knockdown and replacement compositions and methods for use |
| WO2021201198A1 (ja) | 2020-03-31 | 2021-10-07 | エディットフォース株式会社 | 標的rnaを編集する方法 |
| US11220693B2 (en) | 2015-11-27 | 2022-01-11 | National University Corporation Kobe University | Method for converting monocot plant genome sequence in which nucleic acid base in targeted DNA sequence is specifically converted, and molecular complex used therein |
| WO2022119974A1 (en) | 2020-12-01 | 2022-06-09 | Locanabio, Inc. | Rna-targeting compositions and methods for treating cag repeat diseases |
| WO2022119979A1 (en) | 2020-12-01 | 2022-06-09 | Locanabio, Inc. | Rna-targeting compositions and methods for treating myotonic dystrophy type 1 |
| JP7125727B1 (ja) | 2021-09-07 | 2022-08-25 | 国立大学法人千葉大学 | 核酸配列改変用組成物および核酸配列の標的部位を改変する方法 |
| US11453891B2 (en) | 2017-05-10 | 2022-09-27 | The Regents Of The University Of California | Directed editing of cellular RNA via nuclear delivery of CRISPR/CAS9 |
| WO2022221278A1 (en) | 2021-04-12 | 2022-10-20 | Locanabio, Inc. | Compositions and methods comprising hybrid promoters |
| WO2022226374A1 (en) | 2021-04-23 | 2022-10-27 | Locanabio, Inc. | Tissue-targeted modified aav capsids and methods of use thereof |
| WO2022226375A1 (en) | 2021-04-23 | 2022-10-27 | Locanabio, Inc. | Tissue-targeted modified aav capsids and methods of use thereof |
| WO2022230924A1 (ja) | 2021-04-30 | 2022-11-03 | 国立大学法人大阪大学 | 筋強直性ジストロフィー1型治療薬 |
| US11667903B2 (en) | 2015-11-23 | 2023-06-06 | The Regents Of The University Of California | Tracking and manipulating cellular RNA via nuclear delivery of CRISPR/CAS9 |
| WO2023154807A2 (en) | 2022-02-09 | 2023-08-17 | Locanabio, Inc. | Compositions and methods for modulating pre-mrna splicing |
| EP4455288A4 (en) * | 2021-12-24 | 2025-12-31 | Gecort Co Ltd | ENZYME, COMPOSITE, RECOMINATING VECTOR, MEDICINE FOR HEREDITARY DISEASE AND POLYNUCLEOTIDE |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108932400B (zh) * | 2017-05-24 | 2021-07-23 | 北京工业大学 | 一种考虑界面信息的有效的蛋白质-rna复合物结构预测方法 |
| CN108959852B (zh) * | 2017-05-24 | 2021-12-24 | 北京工业大学 | 基于氨基酸-核苷酸成对偏好性信息的蛋白质上与rna结合模块的预测方法 |
| US20240296904A1 (en) * | 2021-09-29 | 2024-09-05 | Boe Technology Group Co., Ltd. | Method and apparatus for predicting rna-protein interaction, medium and electronic device |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2002088179A1 (fr) * | 2001-04-25 | 2002-11-07 | Mitsubishi Chemical Corporation | Proteine participant a la restauration de fertilite de la sterilite male cytoplasmique et gene codant ladite proteine |
| JP2002355041A (ja) * | 2001-04-25 | 2002-12-10 | Mitsubishi Chemicals Corp | 細胞質雄性不稔から可稔への回復に関与する遺伝子 |
| WO2009113249A1 (ja) * | 2008-03-12 | 2009-09-17 | 国立大学法人東北大学 | イネcw型雄性不稔細胞質に対する稔性回復遺伝子及び稔性回復方法 |
| WO2011072246A2 (en) | 2009-12-10 | 2011-06-16 | Regents Of The University Of Minnesota | Tal effector-mediated dna modification |
| WO2011111829A1 (ja) | 2010-03-11 | 2011-09-15 | 国立大学法人九州大学 | Pprモチーフを利用したrna結合性蛋白質の改変方法 |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4102099B2 (ja) | 2001-04-25 | 2008-06-18 | アンスティテュ ナシオナル ドゥ ラ ルシェルシュ アグロノミック | 細胞質雄性不稔から可稔への回復に関与するタンパク質及びそれをコードする遺伝子 |
| US20040117868A1 (en) | 2002-01-29 | 2004-06-17 | Jun Imamura | Protein participating in restoration from cytoplasmic male sterility to fertility and gene encoding the same |
| US20060041961A1 (en) * | 2004-03-25 | 2006-02-23 | Abad Mark S | Genes and uses for pant improvement |
| DK2784157T3 (da) * | 2011-10-21 | 2019-10-21 | Univ Kyushu Nat Univ Corp | Designfremgangsmåde til et rna-bindende protein under anvendelse af ppr-motiv og anvendelse deraf |
| AU2013248928A1 (en) * | 2012-04-16 | 2014-12-04 | The State Board Of Higher Education On Behalf Of The University Of Oregon | Peptides for the binding of nucleotide targets |
-
2012
- 2012-10-22 DK DK12841435.6T patent/DK2784157T3/da active
- 2012-10-22 ES ES12841435T patent/ES2751126T3/es active Active
- 2012-10-22 WO PCT/JP2012/077274 patent/WO2013058404A1/ja not_active Ceased
- 2012-10-22 JP JP2013539727A patent/JP6164488B2/ja active Active
- 2012-10-22 PT PT128414356T patent/PT2784157T/pt unknown
- 2012-10-22 US US14/352,697 patent/US9513283B2/en active Active
- 2012-10-22 EP EP12841435.6A patent/EP2784157B1/en active Active
- 2012-10-22 EP EP19191694.9A patent/EP3611261A1/en active Pending
- 2012-10-22 AU AU2012326971A patent/AU2012326971C1/en active Active
-
2016
- 2016-10-26 US US15/335,243 patent/US9984202B2/en active Active
-
2017
- 2017-06-07 JP JP2017112765A patent/JP6267388B2/ja active Active
- 2017-06-07 JP JP2017112764A patent/JP6270192B2/ja active Active
- 2017-10-31 AU AU2017254874A patent/AU2017254874B2/en active Active
- 2017-12-21 JP JP2017244765A patent/JP6454398B2/ja active Active
- 2017-12-21 JP JP2017244766A patent/JP6934644B2/ja active Active
-
2018
- 2018-04-25 US US15/962,127 patent/US10340028B2/en active Active
-
2019
- 2019-06-04 US US16/431,429 patent/US10679731B2/en active Active
- 2019-12-11 AU AU2019280013A patent/AU2019280013B2/en active Active
-
2020
- 2020-06-05 US US16/894,295 patent/US10943671B2/en active Active
-
2021
- 2021-03-08 US US17/195,449 patent/US11742056B2/en active Active
- 2021-05-21 JP JP2021086108A patent/JP7157483B2/ja active Active
-
2022
- 2022-06-29 AU AU2022204654A patent/AU2022204654B2/en active Active
- 2022-09-30 JP JP2022158241A patent/JP7381133B2/ja active Active
-
2023
- 2023-07-13 US US18/221,440 patent/US20240047005A1/en active Pending
- 2023-10-26 JP JP2023183886A patent/JP7590019B2/ja active Active
-
2024
- 2024-11-07 JP JP2024194918A patent/JP7789426B2/ja active Active
-
2025
- 2025-06-30 AU AU2025204996A patent/AU2025204996A1/en active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2002088179A1 (fr) * | 2001-04-25 | 2002-11-07 | Mitsubishi Chemical Corporation | Proteine participant a la restauration de fertilite de la sterilite male cytoplasmique et gene codant ladite proteine |
| JP2002355041A (ja) * | 2001-04-25 | 2002-12-10 | Mitsubishi Chemicals Corp | 細胞質雄性不稔から可稔への回復に関与する遺伝子 |
| WO2009113249A1 (ja) * | 2008-03-12 | 2009-09-17 | 国立大学法人東北大学 | イネcw型雄性不稔細胞質に対する稔性回復遺伝子及び稔性回復方法 |
| WO2011072246A2 (en) | 2009-12-10 | 2011-06-16 | Regents Of The University Of Minnesota | Tal effector-mediated dna modification |
| WO2011111829A1 (ja) | 2010-03-11 | 2011-09-15 | 国立大学法人九州大学 | Pprモチーフを利用したrna結合性蛋白質の改変方法 |
Non-Patent Citations (20)
| Title |
|---|
| BARKAN A ET AL.: "A combinatorial amino acid code for RNA recognition by pentatricopeptide repeat proteins", PLOS GENET., vol. 8, no. 8, 16 August 2012 (2012-08-16), pages E1002910, XP003031019 * |
| CHEONG, C.G.; HALL, T.M.: "Engineering RNA sequence specificity of Pumilio repeats", PROC. NATL. ACAD. SCI. USA, vol. 103, 2006, pages 13635 - 13639 |
| DONG S ET AL.: "Specific and modular binding code for cytosine recognition in Pumilio/FBF (PUF) RNA-binding domains", J. BIOL. CHEM., vol. 286, no. 30, 29 July 2011 (2011-07-29), pages 26732 - 26742, XP055064475 * |
| FUJII S ET AL.: "Selection patterns on restorer- like genes reveal a conflict between nuclear and mitochondrial genomes throughout angiosperm evolution", PROC. NATL. ACAD. SCI. USA, vol. 108, no. 4, 25 January 2011 (2011-01-25), pages 1723 - 1728, XP055064474 * |
| GILLMAN JD ET AL.: "The petunia restorer of fertility protein is part of a large mitochondrial complex that interacts with transcripts of the CMS-associated locus", PLANT J., vol. 49, no. 2, 2007, pages 217 - 227, XP055064472 * |
| KEIZO KUNO ET AL.: "Kosena-gata Saiboshitsu Daikon no Nensei Kaifuku Inshi to shite Hataraku PPR Tanpakushitsu no RNA Ketsugono ni Kansuru Kaiseki", DAI 52 KAI PROCEEDINGS OF THE ANNUAL MEETING OF THE JAPANESE SOCIETY OF PLANT PHYSIOLOGISTS, 11 March 2011 (2011-03-11), pages 332, XP008173792 * |
| KOBAYASHI K ET AL.: "Identification and characterization of the RNA binding surface of the pentatricopeptide repeat protein", NUCLEIC ACIDS RES., vol. 40, no. 6, March 2012 (2012-03-01), pages 2712 - 2723, XP055064492 * |
| KOIZUKA N ET AL.: "Genetic characterization of a pentatricopeptide repeat protein gene, orf687, that restores fertility in the cytoplasmic male- sterile Kosena radish", PLANT J., vol. 34, no. 4, 2003, pages 407 - 415, XP003031018 * |
| KOIZUKA N; IMAI R; FUJIMOTO H; HAYAKAWA T; KIMURA Y ET AL.: "Genetic characterization of a pentatricopeptide repeat protein gene, orf687, that restores fertility in the cytoplasmic male-sterile Kosena radish", PLANT J., vol. 34, 2003, pages 407 - 415 |
| LURIN, C.; ANDRES, C.; AUBOURG, S.; BELLAOUI, M.; BITTON, F.; BRUYERE, C.; CABOCHE, M.; DEBAST, C.; GUALBERTO, J.; HOFFMANN, B. ET: "Genome-wide analysis of Arabidopsis pentatricopeptide repeat proteins reveals their essential role in organelle biogenesis", PLANT CELL, vol. 16, 2004, pages 2089 - 2103 |
| MAEDER, M.L.; THIBODEAU-BEGANNY, S.; OSIAK, A.; WRIGHT, D.A.; ANTHONY, R.M.; EICHTINGER, M.; JIANG, T; FOLEY, J.E.; WINFREY, R.J.;: "Rapid ''open-source'' engineering of customized zinc-finger nucleases for highly efficient gene modification", MOL. CELL, vol. 31, 2008, pages 294 - 301 |
| MILLER, J.C.; TAN, S.; QIAO, G; BARLOW, K.A.; WANG, J.; XIA, D.E; MENG, X.; PASCHON, D.E.; LEUNG, E.; HINKLEY, S.J. ET AL.: "A TALE nuclease architecture for efficient genome editing", NATURE BIOTECH., vol. 29, 2011, pages 143 - 148 |
| NAKAMURA T ET AL.: "Mechanistic insight into pentatricopeptide repeat proteins as sequence- specific RNA-binding proteins for organellar RNAs in plants", PLANT CELL PHYSIOL., vol. 53, no. 7, July 2012 (2012-07-01), pages 1171 - 1179, XP055064493 * |
| NAKAMURA T; YAGI Y; KOBAYASHI K.: "Mechanistic insight into pentatricopeptide repeat proteins as sequence-specific RNA-binding proteins for organellar RNAs in plants", PLANT & CELL PHYSIOLOGY, vol. 53, 2012, pages 1171 - 1179 |
| OKUDA, K.; MYOUGA, F.; MOTOHASHI, R.; SHINOZAKI, K.; SHIKANAI, T.: "Conserved domain structure of pentatricopeptide repeat proteins involved in chloroplast RNA editing", PROC. NATL. ACAD. SCI. USA, vol. 104, 2007, pages 8178 - 8183 |
| SMALL, I.D.; PEETERS, N.: "The PPR motif - a TPR-related motif prevalent in plant organellar proteins", TRENDS BIOCHEM. SCI., vol. 25, 2000, pages 46 - 47 |
| SMALL, I.D; PEETERS, N.: "The PPR motif - a TPR-related motif prevalent in plant organellar proteins", TRENDS BIOCHEM. SCI., vol. 25, 2000, pages 46 - 47 |
| WANG, X.; MCLACHLAN, J.; ZAMORE, P.D.; HALL, T.M.: "Modular recognition of RNA by a human pumilio-homology domain", CELL, vol. 110, 2002, pages 501 - 512 |
| WOODSON, J.D.; CHORY, J.: "Coordination of gene expression between organellar and nuclear genomes", NATURE REV. GENET., vol. 9, 2008, pages 383 - 395 |
| YUSUKE YAGI ET AL.: "Pentatricopeptide repeat (PPR) no Hairetsu Tokuiteki RNA Ninshiki Kiko", PROCEEDINGS OF THE 76TH ANNUAL MEETING OF THE BOTANICAL SOCIETY OF JAPAN, 14 September 2012 (2012-09-14), pages 233, XP008173793 * |
Cited By (64)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2018078896A (ja) * | 2011-10-21 | 2018-05-24 | 国立大学法人九州大学 | Pprモチーフを利用したrna結合性蛋白質の設計方法及びその利用 |
| US10679731B2 (en) | 2011-10-21 | 2020-06-09 | Kyushu University, National University Corporation | Method for designing RNA binding protein utilizing PPR motif, and use thereof |
| US10340028B2 (en) | 2011-10-21 | 2019-07-02 | Kyushu University, Nat'l University Corporation | Method for designing RNA binding protein utilizing PPR motif, and use thereof |
| US10943671B2 (en) | 2011-10-21 | 2021-03-09 | Kyushu University, National University Corporation | Method for designing RNA-binding protein utilizing PPR motif, and use thereof |
| US11742056B2 (en) | 2011-10-21 | 2023-08-29 | Kyushu University, National University Corporation | Method for designing RNA-binding protein utilizing PPR motif, and use thereof |
| WO2013155555A1 (en) * | 2012-04-16 | 2013-10-24 | The University Of Western Australia | Peptides for the binding of nucleotide targets |
| KR102606057B1 (ko) | 2013-04-22 | 2023-11-23 | 고쿠리쓰다이가쿠호진 규슈다이가쿠 | 피피알 단백질을 이용하여 dna 염기 또는 특정 염기서열을 가지는 dna를 동정, 인식 또는 표적화하는 방법 |
| US10189879B2 (en) | 2013-04-22 | 2019-01-29 | Kyushu University, Nat'l University Corporation | DNA-binding protein using PPR motif, and use thereof |
| JP5896547B2 (ja) * | 2013-04-22 | 2016-03-30 | 国立大学法人九州大学 | Pprモチーフを利用したdna結合性タンパク質およびその利用 |
| KR20220076478A (ko) * | 2013-04-22 | 2022-06-08 | 고쿠리쓰다이가쿠호진 규슈다이가쿠 | 피피알 단백질을 이용하여 dna 염기 또는 특정 염기서열을 가지는 dna를 동정, 인식 또는 표적화하는 방법 |
| KR102390485B1 (ko) | 2013-04-22 | 2022-04-22 | 고쿠리쓰다이가쿠호진 규슈다이가쿠 | 피피알 모티프를 가지는 디앤에이 결합 단백질을 포함하는 융합 단백질의 설계방법 |
| KR102893770B1 (ko) | 2013-04-22 | 2025-11-28 | 고쿠리쓰다이가쿠호진 규슈다이가쿠 | 피피알 단백질을 이용하는 dna 결합성 단백질 및 그의 이용 |
| JP2019115347A (ja) * | 2013-04-22 | 2019-07-18 | 国立大学法人九州大学 | Pprモチーフを利用したdna結合性タンパク質およびその利用 |
| KR102326842B1 (ko) | 2013-04-22 | 2021-11-15 | 고쿠리쓰다이가쿠호진 규슈다이가쿠 | 피피알 모티프를 가지는 디앤에이 결합성 단백질을 포함하는 융합 단백질 |
| WO2014175284A1 (ja) * | 2013-04-22 | 2014-10-30 | 国立大学法人九州大学 | Pprモチーフを利用したdna結合性タンパク質およびその利用 |
| KR20210066947A (ko) * | 2013-04-22 | 2021-06-07 | 고쿠리쓰다이가쿠호진 규슈다이가쿠 | 피피알 모티프를 가지는 디앤에이 결합성 단백질을 포함하는 융합 단백질 |
| KR20210037757A (ko) * | 2013-04-22 | 2021-04-06 | 고쿠리쓰다이가쿠호진 규슈다이가쿠 | 피피알 모티프를 가지는 디앤에이 결합 단백질을 포함하는 융합 단백질의 설계방법 |
| US11718846B2 (en) | 2014-03-05 | 2023-08-08 | National University Corporation Kobe University | Genomic sequence modification method for specifically converting nucleic acid bases of targeted DNA sequence, and molecular complex for use in same |
| WO2015133554A1 (ja) * | 2014-03-05 | 2015-09-11 | 国立大学法人神戸大学 | 標的化したdna配列の核酸塩基を特異的に変換するゲノム配列の改変方法及びそれに用いる分子複合体 |
| US10655123B2 (en) | 2014-03-05 | 2020-05-19 | National University Corporation Kobe University | Genomic sequence modification method for specifically converting nucleic acid bases of targeted DNA sequence, and molecular complex for use in same |
| US10767173B2 (en) | 2015-09-09 | 2020-09-08 | National University Corporation Kobe University | Method for converting genome sequence of gram-positive bacterium by specifically converting nucleic acid base of targeted DNA sequence, and molecular complex used in same |
| US11667903B2 (en) | 2015-11-23 | 2023-06-06 | The Regents Of The University Of California | Tracking and manipulating cellular RNA via nuclear delivery of CRISPR/CAS9 |
| US11220693B2 (en) | 2015-11-27 | 2022-01-11 | National University Corporation Kobe University | Method for converting monocot plant genome sequence in which nucleic acid base in targeted DNA sequence is specifically converted, and molecular complex used therein |
| KR20190015374A (ko) | 2016-06-03 | 2019-02-13 | 고쿠리쓰다이가쿠호진 규슈다이가쿠 | 표적 mRNA로부터의 단백질 발현량을 향상시키기 위한 융합 단백질 |
| JPWO2017209122A1 (ja) * | 2016-06-03 | 2019-04-04 | 国立大学法人九州大学 | 標的mRNAからのタンパク質発現量を向上させるための融合タンパク質 |
| WO2017209122A1 (ja) | 2016-06-03 | 2017-12-07 | 国立大学法人九州大学 | 標的mRNAからのタンパク質発現量を向上させるための融合タンパク質 |
| AU2017275184B2 (en) * | 2016-06-03 | 2021-05-06 | Kyushu University, National University Corporation | Fusion protein for improving protein expression from target mRNA |
| US11136361B2 (en) | 2016-06-03 | 2021-10-05 | Kyushu University, National University Corporation | Fusion protein for improving protein expression from target mRNA |
| KR102407776B1 (ko) | 2016-06-03 | 2022-06-10 | 고쿠리쓰다이가쿠호진 규슈다이가쿠 | 표적 mRNA로부터의 단백질 발현량을 향상시키기 위한 융합 단백질 |
| WO2018030488A1 (ja) * | 2016-08-10 | 2018-02-15 | 和光純薬工業株式会社 | Pprモチーフを利用したdna結合性タンパク質およびその利用 |
| JPWO2018030488A1 (ja) * | 2016-08-10 | 2019-06-13 | 富士フイルム和光純薬株式会社 | Pprモチーフを利用したdna結合性タンパク質およびその利用 |
| US12163148B2 (en) | 2017-05-10 | 2024-12-10 | The Regents Of The University Of California | Directed editing of cellular RNA via nuclear delivery of CRISPR/Cas9 |
| US11453891B2 (en) | 2017-05-10 | 2022-09-27 | The Regents Of The University Of California | Directed editing of cellular RNA via nuclear delivery of CRISPR/CAS9 |
| US10822617B2 (en) | 2018-06-08 | 2020-11-03 | Locana, Inc. | RNA-targeting fusion protein compositions and methods for use |
| KR20220023984A (ko) | 2019-05-29 | 2022-03-03 | 에딧포스 인코포레이티드 | 응집이 적은 피피알 단백질 및 그의 이용 |
| KR20220023985A (ko) | 2019-05-29 | 2022-03-03 | 에딧포스 인코포레이티드 | 효율적인 피피알 단백질의 작제방법 및 그의 이용 |
| US12559528B2 (en) | 2019-05-29 | 2026-02-24 | Editforce, Inc. | PPR protein causing less aggregation and use of the same |
| WO2020241876A1 (ja) | 2019-05-29 | 2020-12-03 | エディットフォース株式会社 | 効率的なpprタンパク質の作製方法及びその利用 |
| JP2023145672A (ja) * | 2019-05-29 | 2023-10-11 | エディットフォース株式会社 | 効率的なpprタンパク質の作製方法及びその利用 |
| AU2020283177B2 (en) * | 2019-05-29 | 2025-05-08 | Editforce, Inc. | Efficient method for preparing ppr protein and use of the same |
| JPWO2020241876A1 (https=) * | 2019-05-29 | 2020-12-03 | ||
| WO2020241877A1 (ja) | 2019-05-29 | 2020-12-03 | エディットフォース株式会社 | 凝集の少ないpprタンパク質及びその利用 |
| JP7491515B2 (ja) | 2019-05-29 | 2024-05-28 | エディットフォース株式会社 | 効率的なpprタンパク質の作製方法及びその利用 |
| JP2025107351A (ja) * | 2019-05-29 | 2025-07-17 | エディットフォース株式会社 | 効率的なpprタンパク質の作製方法及びその利用 |
| JP7683865B2 (ja) | 2019-05-29 | 2025-05-27 | エディットフォース株式会社 | 効率的なpprタンパク質の作製方法及びその利用 |
| WO2021007529A1 (en) | 2019-07-10 | 2021-01-14 | Locanabio, Inc. | Rna-targeting knockdown and replacement compositions and methods for use |
| KR20220165747A (ko) | 2020-03-31 | 2022-12-15 | 에딧포스 인코포레이티드 | 표적 rna의 편집방법 |
| WO2021201198A1 (ja) | 2020-03-31 | 2021-10-07 | エディットフォース株式会社 | 標的rnaを編集する方法 |
| WO2022119979A1 (en) | 2020-12-01 | 2022-06-09 | Locanabio, Inc. | Rna-targeting compositions and methods for treating myotonic dystrophy type 1 |
| WO2022119974A1 (en) | 2020-12-01 | 2022-06-09 | Locanabio, Inc. | Rna-targeting compositions and methods for treating cag repeat diseases |
| WO2022221278A1 (en) | 2021-04-12 | 2022-10-20 | Locanabio, Inc. | Compositions and methods comprising hybrid promoters |
| WO2022226375A1 (en) | 2021-04-23 | 2022-10-27 | Locanabio, Inc. | Tissue-targeted modified aav capsids and methods of use thereof |
| WO2022226374A1 (en) | 2021-04-23 | 2022-10-27 | Locanabio, Inc. | Tissue-targeted modified aav capsids and methods of use thereof |
| JPWO2022230924A1 (https=) * | 2021-04-30 | 2022-11-03 | ||
| JP2024069430A (ja) * | 2021-04-30 | 2024-05-21 | エディットフォース株式会社 | 筋強直性ジストロフィー1型治療薬 |
| JP7461687B2 (ja) | 2021-04-30 | 2024-04-04 | エディットフォース株式会社 | 筋強直性ジストロフィー1型治療薬 |
| EP4331619A4 (en) * | 2021-04-30 | 2024-12-25 | Editforce, Inc. | Therapeutic drug for myotonic dystrophy type 1 |
| WO2022230924A1 (ja) | 2021-04-30 | 2022-11-03 | 国立大学法人大阪大学 | 筋強直性ジストロフィー1型治療薬 |
| JP7854207B2 (ja) | 2021-04-30 | 2026-05-01 | エディットフォース株式会社 | 筋強直性ジストロフィー1型治療薬 |
| JP2023038817A (ja) * | 2021-09-07 | 2023-03-17 | 国立大学法人千葉大学 | 核酸配列改変用組成物および核酸配列の標的部位を改変する方法 |
| WO2023038020A1 (ja) * | 2021-09-07 | 2023-03-16 | 国立大学法人千葉大学 | 核酸配列改変用組成物および核酸配列の標的部位を改変する方法 |
| JP7125727B1 (ja) | 2021-09-07 | 2022-08-25 | 国立大学法人千葉大学 | 核酸配列改変用組成物および核酸配列の標的部位を改変する方法 |
| EP4455288A4 (en) * | 2021-12-24 | 2025-12-31 | Gecort Co Ltd | ENZYME, COMPOSITE, RECOMINATING VECTOR, MEDICINE FOR HEREDITARY DISEASE AND POLYNUCLEOTIDE |
| WO2023154807A2 (en) | 2022-02-09 | 2023-08-17 | Locanabio, Inc. | Compositions and methods for modulating pre-mrna splicing |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7381133B2 (ja) | Pprモチーフを利用したrna結合性蛋白質の設計方法及びその利用 | |
| Delannoy et al. | Arabidopsis tRNA adenosine deaminase arginine edits the wobble nucleotide of chloroplast tRNAArg (ACG) and is essential for efficient chloroplast translation | |
| Le Ret et al. | Efficient replication of the plastid genome requires an organellar thymidine kinase | |
| HK40024684A (en) | Method for designing rna binding protein uitilizing ppr motif, and use thereof | |
| JP5194250B2 (ja) | Rna分解酵素活性を有するタンパク質及びその利用 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 12841435 Country of ref document: EP Kind code of ref document: A1 |
|
| DPE1 | Request for preliminary examination filed after expiration of 19th month from priority date (pct application filed from 20040101) | ||
| ENP | Entry into the national phase |
Ref document number: 2013539727 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2012841435 Country of ref document: EP |
|
| ENP | Entry into the national phase |
Ref document number: 2012326971 Country of ref document: AU Date of ref document: 20121022 Kind code of ref document: A |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 14352697 Country of ref document: US |