RU2570359C2 - Прием звука посредством выделения геометрической информации из оценок направления его поступления - Google Patents
Прием звука посредством выделения геометрической информации из оценок направления его поступления Download PDFInfo
- Publication number
- RU2570359C2 RU2570359C2 RU2013130233/28A RU2013130233A RU2570359C2 RU 2570359 C2 RU2570359 C2 RU 2570359C2 RU 2013130233/28 A RU2013130233/28 A RU 2013130233/28A RU 2013130233 A RU2013130233 A RU 2013130233A RU 2570359 C2 RU2570359 C2 RU 2570359C2
- Authority
- RU
- Russia
- Prior art keywords
- microphone
- sound
- location
- audio
- virtual
- Prior art date
Links
Images
















Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/16—Vocoder architecture
- G10L19/167—Audio streaming, i.e. formatting and decoding of an encoded audio signal representation into a data stream for transmission or storage purposes
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/04—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using predictive techniques
- G10L19/16—Vocoder architecture
- G10L19/18—Vocoders using multiple modes
- G10L19/20—Vocoders using multiple modes using sound class specific coding, hybrid encoders or object based coding
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R1/00—Details of transducers, loudspeakers or microphones
- H04R1/20—Arrangements for obtaining desired frequency or directional characteristics
- H04R1/32—Arrangements for obtaining desired frequency or directional characteristics for obtaining desired directional characteristic only
- H04R1/326—Arrangements for obtaining desired frequency or directional characteristics for obtaining desired directional characteristic only for microphones
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R3/00—Circuits for transducers, loudspeakers or microphones
- H04R3/005—Circuits for transducers, loudspeakers or microphones for combining the signals of two or more microphones
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS OR SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/008—Multichannel audio signal coding or decoding using interchannel correlation to reduce redundancy, e.g. joint-stereo, intensity-coding or matrixing
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; DEAF-AID SETS; PUBLIC ADDRESS SYSTEMS
- H04R2430/00—Signal processing covered by H04R, not provided for in its groups
- H04R2430/20—Processing of the output signals of the acoustic transducers of an array for obtaining a desired directivity characteristic
- H04R2430/21—Direction finding using differential microphone array [DMA]
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Human Computer Interaction (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- Otolaryngology (AREA)
- Spectroscopy & Molecular Physics (AREA)
- General Health & Medical Sciences (AREA)
- Circuit For Audible Band Transducer (AREA)
- Obtaining Desirable Characteristics In Audible-Bandwidth Transducers (AREA)
- Stereophonic System (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
- Measurement Of Velocity Or Position Using Acoustic Or Ultrasonic Waves (AREA)
Abstract
Изобретение относится к акустике, в частности к средствам обработки звуковых сигналов. Устройство содержит блок оценки местоположения звуковых событий и модуль вычисления информации. Блок оценки местоположения звуковых событий адаптирован для оценки местоположения источника звука на основе информации о первом и втором направлении, информация о которых принимается от первого и второго реальных пространственных микрофонов. Модуль вычисления информации адаптирован для создания выходного аудиосигнала на основе первого записанного входного аудиосигнала, на основе виртуального местоположения виртуального микрофона и на основе местоположения источника звука. Модуль вычисления информации содержит компенсатор распространения, адаптированный для модификации первого входного аудиосигнала на основе первого и второго затухания амплитуды путем регулировки значения амплитуды, значения магнитуды или значения фазы записанного входного аудиосигнала. Также компенсатор адаптирован для компенсации первой временной задержки между поступлением звуковой волны, излучаемой звуковым событием у первого реального пространственного микрофона, и поступлением звуковой волны у виртуального микрофона. Технический результат - повышение качества звучания, уменьшение величины реверберации. 3 н. и 15 з.п. ф-лы, 17 ил.
Description
Область техники, к которой относится изобретение
Настоящее изобретение относится к обработке аудиоданных и, в частности, касается устройств и способа для приема звука посредством выделения геометрической информации из оценок направления его поступления.
Уровень техники
Традиционная запись пространственного звука ставит своей целью зафиксировать звуковое поле с помощью множества микрофонов, так чтобы на стороне воспроизведения слушатель смог воспринимать звуковое изображение, каким оно было в месте записи. В стандартных подходах к записи пространственного звука обычно используются разнесенные всенаправленные микрофоны, например, как в AB-стереофонии, или совмещенные направленные микрофоны, например, как в интенсивной стереофонии, либо более сложные микрофоны, такие как микрофон B-формата, например, как в системе Ambisonics (смотри, например,
[1] R. K. Furness, "Ambisonics - An overview," in AES 8th International Conference, April 1990, pp. 181-189).
Для воспроизведения звука согласно этим непараметрическим подходам необходимые аудиосигналы воспроизведения (например, сигналы, посылаемые на громкоговорители) получают непосредственно из записанных микрофонных сигналов.
В качестве альтернативы могут применяться способы на основе параметрического представления звуковых полей, которые предполагают использование так называемых параметрических пространственных аудиокодеров. Эти способы части предусматривают использование микрофонных матриц для определения одного или нескольких аудиосигналов понижающего микширования вместе с дополнительной пространственной информацией, описывающей пространственный звук. Примерами этого являются прямое аудиокодирование (DirAC) или подход на основе использования так называемых пространственных микрофонов (SAM). Более подробное описание DirAC можно найти в
[2] Pulkki, V., "Directional audio coding in spatial sound reproduction and stereo upmixing," in Proceedings of the AES 28th International Conference, pp. 251-258, Pitea, Sweden, June 30 - July 2, 2006,
[3] V. Pulkki, "Spatial sound reproduction with directional audio coding," J. Audio Eng. Soc, vol. 55, no. 6, pp. 503-516, June 2007.
Более подробное описание использования пространственных микрофонов можно найти в
[4] C. Fallen "Microphone Front-Ends for Spatial Audio Coders", in Proceedings of the AES 125th International Convention, San Francisco, Oct. 2008. [5] M. Kallinger, H. Ochsenfeld, G. Del Galdo, F. Kuch, D. Mahne, R. Schultz-Amling. and O. Thiergart, "A spatial filtering approach for directional audio coding," in Audio Engineering Society Convention 126, Munich, Germany, May 2009.
В способе DirAC информация в пространственном акустическом сигнале содержит направление поступления (DOA) звука и диффузность звукового поля, вычисленные в частотно-временной области. Аудиосигналы для воспроизведения звука могут быть получены на основе их параметрического описания. В некоторых приложениях прием пространственного звука ставит своей целью фиксацию всей звуковой сцены в целом. В других приложениях прием пространственного звука ставит своей целью фиксацию лишь некоторых необходимых компонент. Для записи отдельных источников звука с высоким отношением сигнал-шум и низкой реверберацией часто используют микрофоны ближнего действия, в то время как в дистанционные конфигурации, рассчитанные на большие расстояния, такие как XY-стереофония, обеспечивают механизм для фиксации пространственного представления всей звуковой сцены. Повышенная гибкость с точки зрения направленности может быть достигнута при использовании формирования луча, где для реализации управляемых диаграмм направленности съема звука может быть использована микрофонная матрица. Еще большая гибкость обеспечивается вышеупомянутыми способами, такими как прямое аудиокодирование (DirAC) (смотри [2], [3]), где можно реализовать пространственные фильтры с произвольными диаграммами направленности съема звука, как это описано в
[5] M. Kallinger, H. Ochsenfeld, G. Del Galdo, F. Kuch, D. Mahne, R. Schultz-Amling. and O. Thiergart, "A spatial filtering approach for directional audio coding," in Audio Engineering Society Convention 126, Munich, Germany, May 2009,
а также другие манипуляции для обработки сигналов звуковой сцены (смотри, например,
[6] R. Schultz-Amling, F. Kiich, O. Thiergart, and M. Kallinger, "Acoustical zooming based on a parametric sound field representation," in Audio Engineering Society Convention 128, London UK, May 2010,
[7] J. Herre, C. Falch, D. Mahne, G. Del Galdo, M. Kallinger, and O. Thiergart, "Interactive teleconferencing combining spatial audio object coding and DirAC technology," in Audio Engineering Society Convention 128, London UK, May 2010).
Общим во всех вышеупомянутых концепциях является то, что микрофоны скомпонованы с известными фиксированными геометрическими характеристиками. Интервалы между микрофонами минимальны, насколько это возможно, в случае использования совмещенных микрофонов, в то время как в других способах они обычно составляют несколько сантиметров. Далее любое устройство для записи пространственного звука, способное определять направление поступления звука (например, комбинация направленных микрофонов или микрофонная матрица и т.д.), называется пространственным микрофоном.
Кроме того, общим для всех вышеупомянутых способов является то, что они ограничены представлением звукового поля относительно только одной точки, а именно, места измерения. Таким образом, необходимые микрофоны должны быть размещены в совершенно конкретных, тщательно выбранных местах, например, рядом с источниками звука, или так, чтобы можно было зафиксировать пространственное изображение оптимальным образом.
Однако во многих приложениях это физически невозможно, и, следовательно, выгодно разместить несколько микрофонов подальше от источников звука без потери требуемой способности фиксации звука.
На сегодняшний день существует несколько способов восстановления для оценки звукового поля в точке пространства, отличной от точки, где выполнялось измерение. Одним из таких способов является акустическая голография, описанная в
[8] E. G. Williams, Fourier Acoustics: Sound Radiation and Nearfield Acoustical Holography, Academic Press, 1999.
Акустическая голография позволяет вычислить звуковое поле в любой точке при произвольном объеме при условии, что известны звуковое давление и акустическая скорость частиц на всей поверхности. Следовательно, когда объем велик, потребуется нереально большое количество датчиков. Кроме того, этот способ предполагает, что внутри данного объема отсутствуют источники звука, что делает данный алгоритм неприемлемым для сформулированных потребностей. Соответствующая экстраполяция волнового поля (смотри также [8]) ставит своей целью экстраполяцию известного звукового поля на поверхности объема на внешние области. Однако точность экстраполяции быстро падает с возрастанием расстояния, а также в случае экстраполяций в направлениях, перпендикулярных направлению распространения звука (смотри
[9] A. Kuntz and R. Rabenstein, "Limitations in the extrapolation of wave fields from circular measurements," in 15th European Signal Processing Conference (EUSIPCO 2007), 2007.
[10] A. Walther and C. Faller, "Linear simulation of spaced microphone arrays using b-format recordings," in Audio Engineering Society Convention 128, London UK, May 2010,
где описана модель плоской волны и где экстраполяция поля возможна только в точках, отдаленных от реальных источников звука, например, рядом с точкой измерения.
Главным недостатком традиционных подходов является то, что записанное пространственное изображение всегда связано с используемым пространственным микрофоном. Во многих приложениях нельзя или физически невозможно разместить пространственный микрофон в требуемом месте, например, рядом с источниками звука. В этом случае было бы выгодно разместить множество пространственных микрофонов вдали от звуковой сцены без потери способности требуемой фиксации звука.
В [11] US61/287596: An Apparatus and a Method for Converting a First Parametric Spatial Audio Signal into a Second Parametric Spatial Audio Signal,
предложен способ для виртуального перемещения реального местоположения записи в другое место при воспроизведении через громкоговорители или наушники. Однако этот подход применим лишь к простой звуковой сцене, в которой, как предполагается, все звуковые объекты расположены на одинаковом расстоянии по отношению к реальному пространственному микрофону, используемому для записи. Кроме того, этот способ может дать преимущества только в случае одного пространственного микрофона.
Сущность изобретения
Цель настоящего изобретения состоит в усовершенствовании концепций приема звука посредством извлечения геометрической информации. Цель настоящего изобретения достигается с помощью устройства согласно пункту 1 формулы изобретения, способа согласно пункту 17 формулы изобретения и машиночитаемого носителя согласно пункту 18 изобретения.
Согласно одному варианту обеспечено устройство для создания выходного аудиосигнала для имитации записи, осуществляемой виртуальным микрофоном, находящимся в конфигурируемом виртуальном местоположении в окружающей среде. Устройство содержит блок оценки местоположения звуковых событий и модуль вычисления информации. Блок оценки местоположения звуковых событий приспособлен для оценки местоположения источника звука, указывающего местоположение источника звука в окружающей среде, причем этот блок оценки местоположения звуковых событий приспособлен для оценки местоположения источника звука на основе информации о первом направлении, обеспечиваемой первым реальным пространственным микрофоном, который находится в месте расположения первого реального микрофона в окружающей среде, и основан на информации о втором направлении, обеспечиваемой вторым реальным пространственным микрофоном, который находится в месте расположения второго реального микрофона в упомянутой окружающей среде.
Модуль вычисления информации приспособлен для создания выходного аудиосигнала на основе первого записанного входного аудиосигнала, который записывается первым реальным пространственным микрофоном, на основе местоположения первого реального микрофона, на основе виртуального местоположения виртуального микрофона и на основе местоположения источника звука, где первый реальный пространственный микрофон сконфигурирован для записи первого записанного входного аудиосигнала, или где третий микрофон сконфигурирован для записи первого записанного входного аудиосигнала.
В одном варианте модуль вычисления информации содержит компенсатор распространения, где компенсатор распространения приспособлен для создания первого модифицированного аудиосигнала путем модификации первого записанного входного аудиосигнала на основе первого затухания амплитуды между источником звука и первым реальным пространственным микрофоном и на основе второго затухания амплитуды между источником звука и виртуальным микрофоном, путем регулировки значения амплитуды, значения магнитуды или значения фазы первого записанного входного аудиосигнала, для получения выходного аудиосигнала. В одном варианте первое затухание амплитуды может представлять собой затухание амплитуды звуковой волны, излучаемой источником звука, и второе затухание амплитуды может представлять собой затухание амплитуды звуковой волны, излучаемой источником звука.
Кроме того, компенсатор распространения адаптирован для создания третьего модифицированного аудиосигнала путем модификации третьего записанного входного аудиосигнала, записанного четвертым микрофоном, путем компенсации третьей временной задержки или третьего затухания амплитуды между поступлением звуковой волны, излучаемой звуковым событием, у четвертого микрофона, и поступлением звуковой волны у виртуального микрофона, путем регулировки значения амплитуды, значения магнитуды или значения фазы третьего записанного входного аудиосигнала для получения выходного аудиосигнала.
Согласно другому варианту модуль вычисления информации содержит компенсатор распространения, где компенсатор распространения приспособлен для создания первого модифицированного аудиосигнала путем модификации первого записанного входного аудиосигнала путем компенсации первого затухания между поступлением звуковой волны, излучаемой источником звука, у первого реального пространственного микрофона, и поступлением звуковой волны у виртуального микрофона путем регулировки значения амплитуды, значения магнитуды или значения фазы первого записанного входного аудиосигнала для получения выходного аудиосигнала.
Согласно одному варианту предполагается использовать два или более пространственных микрофона, которые далее называют реальными пространственными микрофонами. Для каждого реального пространственного микрофона можно оценить DOA звука в частотно-временной области. Из информации, собранной реальными пространственными микрофонами, зная их относительное местоположение, можно сформировать выходной сигнал произвольного пространственного микрофона, виртуально размещенного в указанной окружающей среде. Этот пространственный микрофон называют далее виртуальным пространственным микрофоном.
Заметим, что направление поступления (DOA) можно выразить в виде азимутального угла, если речь идет о двумерном пространстве, или в виде пары, состоящей из азимутального угла и угла места, в трехмерном пространстве. В качестве эквивалента можно использовать единичный нормальный вектор, указанный в DOA.
В ряде вариантов обеспечены средства для избирательной пространственной фиксации звука; например, звук, исходящий из конкретного заданного места, может быть зафиксирован, как если бы в этом месте был установлен близлежащий «точечный микрофон». Однако вместо реальной установки этого точечного микрофона можно имитировать его выходной сигнал путем использования двух или более пространственных микрофонов, расположенных в других удаленных местах.
Термин «пространственный микрофон» относится к любому устройству для приема пространственного звука, способному извлекать направление поступления звука (например, комбинация направленных микрофонов, микрофонные матрицы и т.д.).
Термин «непространственный микрофон» относится к любому устройству, которое не приспособлено для извлечения направления поступления звука, например, один всенаправленный или направленный микрофон.
Следует заметить, что термин «реальный пространственный микрофон» относится к пространственному микрофону, определенному выше, который физически существует.
Что касается виртуального пространственного микрофона, то следует заметить, что виртуальный пространственный микрофон может представлять собой микрофон любого требуемого типа или их комбинацию, например, это может быть единичный всенаправленный микрофон, направленный микрофон, пару направленных микрофонов, используемых в обычных стереомикрофонах, но также и микрофонную матрицу.
Настоящее изобретение основано на установленном положении, заключающемся в том, что при использовании двух или более реальных пространственных микрофонов можно оценить местоположение звуковых событий в двухмерном или трехмерном пространстве, что позволяет обеспечить локализацию местоположения. Используя определенные местоположения звуковых событий, можно вычислить звуковой сигнал, который мог бы быть записан виртуальным пространственным микрофоном, произвольно расположенным и ориентированным в пространстве, а также соответствующую дополнительную пространственную информацию, такую как направление поступления из точки обзора виртуального пространственного микрофона.
С этой целью можно предположить, что каждое звуковое событие представляет точечный источник звука, например, изотропный точечный источник звука. Используемый далее термин «реальный источник звука» относится к действительному источнику звука, физически существующему в среде записи, например, собеседники или музыкальные инструменты и т.д. С другой стороны, термины «источник звука» или «звуковое событие» относятся далее к действующему источнику звука, который активен в определенный момент времени или в определенном частотно-временном бине, где источники звука могут представлять, например, реальные источники звука или источники зеркальных изображений. Согласно одному варианту предположим в неявном виде, что звуковую сцену можно смоделировать в виде интенсивности указанных звуковых событий или точечных источников звука. Кроме того, можно предположить, что каждый источник может быть активен только в течение конкретного временного интервала и на частотном слоте в заранее определенном частотно-временном представлении. Расстояние между реальными пространственными микрофонами может быть таким, что результирующее различие между временами распространения будет меньше, чем временное разрешение частотно-временного представления. Последнее предположение гарантирует, что конкретное звуковое событие будет фиксироваться всеми пространственными микрофонами в одном и том же временном слоте. Это означает, что направления DOA, оцененные разными пространственными микрофонами для одного и того же частотно-временного слота, будут действительно соответствовать одному и тому же звуковому событию. Это предположение нетрудно удовлетворить, используя реальные пространственные микрофоны, размещенные в нескольких метрах друг от друга даже в больших помещениях (таких как жилые комнаты или конференц-залы) при временном разрешении, составляющем вплоть до нескольких миллисекунд.
Для локализации источников звука можно использовать микрофонные матрицы. Локализованные источники звука можно по-разному физически интерпретировать в зависимости от их природы. Когда микрофонные матрицы воспринимают звук напрямую, они способны локализовать местоположение действительного источника звука (например, собеседников). Когда микрофонные матрицы принимают отраженные сигналы, они могут локализовать местоположение источника зеркального отражения. Источники зеркального отражения также считаются источниками звука.
Обеспечен параметрический способ, способный оценить звуковой сигнал виртуального микрофона, имеющего произвольное местоположение. В отличие от ранее описанных способов, предложенный способ не ставит своей целью непосредственное восстановление звукового поля, а скорее имеет своей целью обеспечение звука, воспринимаемого подобно звуку, который был бы зафиксирован микрофоном, физически размещенным в этом месте. Это можно обеспечить, используя параметрическую модель звукового поля на основе точечных источников звука, например, изотропных точечных источников звука (IPLS). Необходимую геометрическую информацию, а именно, мгновенное местоположение всех IPLS, можно получить путем выполнения триангуляции направлений поступления, оцененных двумя или более распределенными микрофонными матрицами. Это можно достичь, получив информацию об относительном местоположении и ориентации этих матриц. При этом количество и местоположение действительных источников звука (например, собеседников) заранее знать не обязательно. При заданных параметрических особенностях предложенных концепций, например, касающихся предложенного устройства или способа, виртуальный микрофон может иметь произвольную диаграмму направленности, а также произвольные физические или нефизические свойства, например, в отношении снижения звукового давления с расстоянием. Представленный здесь подход был верифицирован путем исследования точности оценки параметров на основе измерений в реверберирующей среде.
В то время как традиционные способы записи для пространственного аудио ограничены, поскольку полученное пространственное изображение всегда соотнесено с местом, в котором физически размещены микрофоны, варианты настоящего изобретения учитывают, что во многих приложениях микрофоны желательно размещать вне звуковой сцены, причем они еще должны быть способны при этом фиксировать звук с произвольного ракурса. Согласно вариантам изобретения предложены концепции, которые позволяют виртуально разместить виртуальный микрофон в произвольной точке пространства путем вычисления сигнала, воспринимаемого подобно сигналу, который был бы зафиксирован в том случае, если бы микрофон был физически размещен в звуковой сцене. Варианты изобретения позволяют реализовать концепции, которые предполагают использование параметрической модели звукового поля на основе точечных источников звука, например, изотропных точечных источников звука. Необходимую геометрическую информацию можно получить, используя две или более распределенных микрофонных матрицы.
Согласно одному варианту изобретения блок оценки местоположения звуковых событий можно адаптировать для оценки местоположения источника звука на основе первого направления поступления звуковой волны, излучаемой источником звука, в месте расположения первого реального микрофона, в качестве информации о первом направлении, и на основе второго направления поступления звуковой волны в месте расположения второго реального микрофона, в качестве информации о втором направлении.
В других вариантах модуль вычисления информации может содержать модуль вычисления дополнительной пространственной информации для вычисления дополнительной пространственной информации. Модуль вычисления информации может быть адаптирован для оценки направления поступления или интенсивности активизированного звука у виртуального микрофона, в качестве дополнительной пространственной информации на основе вектора местоположения виртуального микрофона и на основе вектора местоположения звукового события.
Согласно еще одному варианту изобретения компенсатор распространения можно адаптировать для создания первого модифицированного аудиосигнала в частотно-временной области путем компенсации первой задержки или затухания амплитуды между поступлением второй волны, излучаемой вторым источником, у первого реального пространственного микрофона, и поступлением звуковой волны у виртуального микрофона путем регулировки значения указанной интенсивности первого записанного входного аудиосигнала, представленного в частотно-временной области.
В одном варианте компенсатор распространения может быть адаптирован для выполнения компенсации распространения путем создания модифицированного значения магнитуды первого модифицированного аудиосигнала с применением формулы:

где d1(k,n) представляет собой расстояние между местоположением первого реального пространственного микрофона и местоположением звукового события, где s(k,n) - расстояние между виртуальным местоположением виртуального микрофона и местоположением источника звука для данного звукового события, где Pref(k,n) - значение магнитуды первого записанного входного аудиосигнала, представляемого в частотно-временной области, и где Pv(k,n) - модифицированное значение магнитуды.
В дополнительном варианте модуль вычисления информации кроме того может содержать объединитель, причем компенсатор распространения кроме того может быть адаптирован для модификации второго записанного входного аудиосигнала, записываемого вторым реальным пространственным микрофоном, посредством компенсации второй задержки или затухания амплитуды между моментом поступления звуковой волны, излучаемой источником звука, на второй реальный пространственный микрофон, и моментом поступления звуковой волны на виртуальный микрофон путем регулировки значения амплитуды, значения магнитуды или значения фазы второго записанного входного аудиосигнала, чтобы получить второй модифицированный аудиосигнал, и где объединитель может быть адаптирован для создания объединенного сигнала путем объединения первого модифицированного аудиосигнала и второго модифицированного аудиосигнала, для получения выходного аудиосигнала.
Согласно еще одному варианту компенсатор распространения кроме того можно адаптировать для модификации одного или нескольких дополнительно записанных входных аудиосигналов, записываемых одним или несколькими дополнительными реальными пространственными микрофонами, посредством компенсации задержек между моментом поступления звуковой волны на виртуальный микрофон и моментом поступления звуковой волны, излучаемой источником звука, на каждый из дополнительных реальных пространственных микрофонов. Каждую задержку или затухание амплитуды можно компенсировать посредством регулировки значения амплитуды, значения магнитуды или значения фазы каждого из дополнительно записанных входных аудиосигналов, чтобы получить множество третьих модифицированных аудиосигналов. Упомянутый объединитель можно адаптировать для создания объединенного сигнала посредством объединения первого модифицированного аудиосигнала и второго модифицированного аудиосигнала и множества третьих модифицированных аудиосигналов для получения выходного аудиосигнала.
В следующем варианте модуль вычисления информации может содержать блок спектрального взвешивания для создания взвешенного аудиосигнала путем модификации первого модифицированного аудиосигнала в зависимости от направления поступления звуковой волны в виртуальном местоположении виртуального микрофона, а также в зависимости от виртуальной ориентации виртуального микрофона для получения выходного аудиосигнала, где первый модифицированный аудиосигнал может быть модифицирован в частотно-временной области.
Кроме того, модуль вычисления информации может содержать блок спектрального взвешивания для создания взвешенного аудиосигнала путем модификации объединенного сигнала в зависимости от направления поступления звуковой волны в виртуальное место нахождения виртуального микрофона, а также в зависимости от виртуальной ориентации виртуального микрофона для получения выходного аудиосигнала, где объединенный сигнал может быть модифицирован в частотно-временной области.
Согласно еще одному варианту блок спектрального взвешивания может быть адаптирован для применения весового коэффициента
α+(1-α)cos(φv(k,n)), или весового коэффициента
0,5+0,5cos(φv (k,n))
для взвешенного аудиосигнала,
где φv(k,n) указывает вектор направления поступления звуковой волны, излучаемой источником звука, в виртуальное место расположения виртуального микрофона.
В одном варианте компенсатор распространения кроме того адаптирован для создания третьего модифицированного аудиосигнала посредством модификации третьего записанного входного аудиосигнала, записываемого всенаправленным микрофоном, путем компенсации третьей задержки или затухания амплитуды между моментом поступления звуковой волны, излучаемой вторым источником звука, на всенаправленный микрофон, и моментом поступления звуковой волны на виртуальный микрофон, путем регулировки значения амплитуды, значения магнитуды или значения фазы третьего записанного входного аудиосигнала, чтобы получить выходной аудиосигнал.
В следующем варианте блок оценки местоположения звуковых событий может быть адаптирован для оценки местоположения источника звука в трехмерной окружающей среде.
Кроме того, согласно еще одному варианту модуль вычисления информации, кроме того, может содержать блок вычисления диффузности, адаптируемый для оценки энергии диффузного звука у виртуального микрофона или энергии прямого звука у виртуального микрофона.
Блок вычисления диффузности согласно следующему варианту может быть адаптирован для оценки энергии  диффузного звука у виртуального микрофона путем применения формулы:
диффузного звука у виртуального микрофона путем применения формулы:

где N - количество реальных пространственных микрофонов из множества реальных пространственных микрофонов, содержащее первый и второй реальный пространственный микрофон, и где  - энергия диффузного звука у i-го реального пространственного микрофона.
- энергия диффузного звука у i-го реального пространственного микрофона.
В следующем варианте блок вычисления диффузности можно адаптировать для оценки энергии прямого звука путем применения формулы:

где «расстояние SMi-IPLS» - расстояние между местоположением i-го реального микрофона и местоположением источника звука, где «расстояние VM-IPLS» - расстояние между виртуальным местоположением и местоположением источника звука и где  - прямая энергия у i-го реального пространственного микрофона.
- прямая энергия у i-го реального пространственного микрофона.
Кроме того, согласно еще одному варианту блок вычисления диффузности может, кроме того, быть адаптирован для оценки диффузности у виртуального микрофона путем оценки энергии диффузного звука у виртуального микрофона и энергии прямого звука у виртуального микрофона с применением формулы:

где  указывает оцениваемую диффузность у виртуального микрофона, где
указывает оцениваемую диффузность у виртуального микрофона, где  указывает оцениваемую энергию диффузного звука и где
указывает оцениваемую энергию диффузного звука и где  указывает оцениваемую энергию прямого звука.
указывает оцениваемую энергию прямого звука.
Краткое описание чертежей
Далее описываются предпочтительные варианты настоящего изобретения со ссылками на чертежи, на которых:
фиг. 1 - устройство для создания выходного сигнала согласно одному варианту настоящего изобретения;
фиг. 2 - входы и выходы устройства и способ создания выходного аудиосигнала согласно настоящему изобретению;
фиг. 3 - базовая структура устройства согласно одному варианту, которая содержит блок оценки местоположения звуковых событий, и модуль вычисления информации;
фиг. 4 - иллюстрация примерного сценария, где реальные пространственные микрофоны изображены в виде однородных линейных матриц из 3 микрофонов каждая;
фиг. 5 - два пространственных микрофона в трехмерном (3D) пространстве для оценки направления поступления звука в 3D пространстве;
фиг. 6 - геометрическая схема, где изотропный точечный источник звука для текущего частотно-временного бина (k,n) расположен у места расположения piPLs(k,n);
фиг. 7 - модуль вычисления информации согласно одному варианту настоящего изобретения;
фиг. 8 - модуль вычисления информации согласно другому варианту настоящего изобретения;
фиг. 9 - два реальных пространственных микрофона, локализованное звуковое событие и местоположение виртуального пространственного микрофона вместе с соответствующими задержками и затуханиями амплитуды;
фиг. 10 - иллюстрация способа получения направления поступления по отношению к виртуальному микрофону согласно одному варианту настоящего изобретения;
фиг. 11 - возможный способ получения DOA звука из точки обзора виртуального микрофона согласно одному варианту настоящего изобретения;
фиг. 12 - блок вычисления информации, дополнительно содержащий блок вычисления диффузности согласно одному варианту настоящего изобретения;
фиг. 13 - блок вычисления диффузности согласно одному варианту настоящего изобретения;
фиг. 14 - пример сценария, в котором невозможна оценка местоположения звуковых событий; и
фиг. 15а-15с - примеры сценариев, где две микрофонные матрицы принимают прямой звук, звук, отраженный стеной, и диффузный звук.
Подробное описание вариантов изобретения
На фиг. 1 показано устройство для создания выходного аудиосигнала с целью имитации записи, выполняющейся виртуальным микрофоном у конфигурируемого виртуального места posVmic его расположения в окружающей среде. Устройство содержит блок 110 оценки местоположения звуковых событий и модуль 120 вычисления информации. Блок 110 оценки местоположения звуковых событий получает информацию di1 о первом направлении от первого реального пространственного микрофона и информацию di2 о втором направлении от второго реального пространственного микрофона. Блок 110 оценки местоположения звуковых событий адаптирован для оценки ssp местоположения звукового события, указывающей местоположение источника звука в окружающей среде, где источник звука излучает звуковую волну, и где блок 110 оценки местоположения звуковых событий адаптирован для оценки ssp местоположения источника звука на основе информации di1 о первом направлении, обеспечиваемой первым реальным пространственным микрофоном, находящимся в месте pos1mic первого реального микрофона в данной окружающей среде, и на основании информации di2 о втором направлении, обеспечиваемой вторым реальным пространственным микрофоном, находящимся в окрестности места расположения второго реального микрофона в данной окружающей среде. Модуль 120 вычисления информации адаптирован для создания выходного аудиосигнала на основе первого записанного входного аудиосигнала is1, записываемого первым реальным пространственным микрофоном, на основе местоположения pos1mic первого реального микрофона и на основе виртуального местоположения posVmic виртуального микрофона. Модуль 120 вычисления информации содержит компенсатор распространения, адаптируемый для создания первого модифицированного аудиосигнала посредством модификации первого записанного входного аудиосигнала is1 посредством компенсации первой задержки или затухания амплитуды между моментом поступления звуковой волны, излучаемой источником звука, у первого реального пространственного микрофона и моментом поступления звуковой волны у виртуального микрофона путем регулировки значения амплитуды, значения магнитуды или значения фазы первого записанного входного аудиосигнала is1, чтобы получить выходной аудиосигнал.
На фиг. 2 показаны входы и выходы устройства и способа согласно одному варианту изобретения. Информация от двух или более реальных пространственных микрофонов 111, 112,… 11N подается в устройство/обрабатывается с использованием упомянутого способа. Эта информация содержит аудиосигналы, зафиксированные реальными пространственными микрофонами, а также информацию о направлении от реальных пространственных микрофонов, например, оценки направления поступления (DOA). Аудиосигналы и информация о направлении, например, оценки управления поступления, могут быть представлены в частотно-временной области. Например, если требуется восстановление в 2D геометрии, и для представления сигналов выбрана область традиционного кратковременного преобразования Фурье (STFT), то DOA можно выразить в виде азимутальных улов, зависящих от k и n, а именно от индексов частоты и времени.
В вариантах настоящего изобретения локализация звукового события в пространстве, а также описание местоположения могут быть выполнены на основе местоположений и ориентаций реальных и виртуальных пространственных микрофонов в общей системе координат. Эта информация может быть представлена входами 121,… 12N и входом 104 на фиг. 2. Вход 104 может дополнительно задать некоторую характеристику виртуального пространственного микрофона, например, его местоположение и диаграмму направленности приема звука, что обсуждается далее. Если виртуальный пространственный микрофон содержит множество виртуальных датчиков, то можно будет учесть их местоположение и соответствующие различные диаграммы направленности приема.
Выходом устройства или соответствующего способа может быть, когда это требуется, один или несколько пространственных сигналов 105, которые были зафиксированы пространственным микрофоном, определенным и размещенным так, как это задано ссылочной позицией 104. Кроме того, устройство (или, скорее, способ) в качестве выхода может предоставить дополнительную пространственную информацию 106, которую можно оценить, используя виртуальный пространственный микрофон.
На фиг. 3 показано устройство согласно одному варианту, которое содержит два основных обрабатывающих блока, блок 201 оценки местоположения звуковых событий и модуль 202 вычисления информации. Блок 201 оценки местоположения звуковых событий может выполнять геометрическое восстановление на основе направлений (DOA), содержащихся во входных сигналах 111,… 11N, и на основе известно местоположения и известной ориентации реальных пространственных микрофонов, где были вычислены направления DOA. Выход блока 205 оценки местоположения звуковых событий содержит оценки местоположения (в 2D или 3D пространстве) источников звука, где звуковые события появляются для каждого частотно-временного бина. Второй обрабатывающий блок 202 является модулем вычисления информации. Согласно варианту изобретения по фиг. 3 второй обрабатывающий блок 202 вычисляет сигнал виртуального микрофона и дополнительную пространственную информацию. Следовательно, это также относится к сигналу виртуального микрофона и блоку 202 вычисления информации. Сигнал виртуального микрофона и блок 202 вычисления дополнительной информации используют местоположения 205 звуковых событий для обработки аудиосигналов, содержащихся в 111,… 11N, для вывода аудиосигнала 105 виртуального микрофона. Если это необходимо, то блок 202 также может вычислить дополнительную пространственную информацию 106, соответствующую виртуальному пространственному микрофону. Изложенные ниже варианты иллюстрируют, как могут функционировать блоки 201 и 202.
Далее подробно описывается операция оценки местоположения, выполняемая блоком оценки местоположения звуковых событий, согласно одному варианту настоящего изобретения.
В зависимости от размерности задачи (2D или 3D) и количества пространственных микрофонов возможно несколько решений задачи оценки местоположения.
Если в 2D пространстве существует два пространственных микрофона (простейший случай из всех возможных), то можно использовать простую триангуляцию. На фиг. 4 показан примерный сценарий, в котором реальные пространственные микрофоны представлены в виде однородных линейных матриц (ULA) из 3 микрофонов каждая. Для частотно-временного бина (k,n) вычисляют направление DOA, выраженное в виде азимутальных углов a1(k,n) и a2(k,n). Это достигается посредством использования блока оценки правильного DOA, такого как ESPRIT (смотри
[13] R. Roy, A. Paulraj, and Т. ailath, "Direction-of-arrival estimation by subspace rotation methods - ESPRIT," in IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Stanford, CA, USA, April 1986),
или (основного) MUSIC (смотри
[14] R. Schmidt, "Multiple emitter location and signal parameter estimation," IEEE Transactions on Antennas and Propagation, vol. 34, no. 3, pp. 276-280, 1986)
для сигналов давления, преобразованных в частотно-временной области.
На фиг. 4 показаны два реальных пространственных микрофона (здесь это две реальных пространственных микрофонных матрицы 410, 420). Два оцененных направления DOA, a1(k,n) и a2(k,n), представлены двумя линиями, где первая линия 430 представляет DOA направление a1(k,n), а вторая линия 440 представляет DOA направление a2(k,n). Применение триангуляции возможно на основе простых геометрических рассуждений при известном местоположении и известной ориентации каждой матрицы.
Триангуляцию применить невозможно, если эти две линии 430, 440 в точности параллельны. Однако в реальных приложениях это крайне маловероятно. Однако не все результаты триангуляции соответствуют физическому или возможному местоположению звукового события в данном рассматриваемом пространстве. Например, полученное в результате оценки местоположение звукового события может оказаться слишком далеким или даже вне предполагаемого пространства, что указывает на несоответствие направлений DOA звуковому событию, которое можно физически интерпретировать с помощью этой используемой модели. Причиной таких результатов может быть шум датчика или слишком сильная реверберация в помещении. Следовательно, согласно одному варианту изобретения указанные нежелательные результаты корректируются так, чтобы модуль 202 вычисления информации смог правильно их трактовать.
На фиг. 5 показан сценарий, где выполняется оценка местоположения звукового события в 3D пространстве. Здесь использованы соответствующие пространственные микрофоны, например, планарная микрофонная матрица или 3D микрофонная матрица. На фиг. 5 показаны первый пространственный микрофон 510, например, первая 3D микрофонная матрица, и второй пространственный микрофон 520, например, вторая 3D микрофонная матрица. Направление DOA в 3D пространстве можно представить, например, в виде азимута и высоты. Для представления направлений DOA можно использовать единичные векторы 530, 540. В соответствии с направлениями DOA построены две линии 550, 560. В 3D пространстве даже при очень надежных оценках две линии 550, 560, построенные согласно указанным направлениям DOA, могут не пересекаться. Однако триангуляцию все же можно выполнить, выбрав, например, среднюю точку минимального отрезка, соединяющего эти две линии.
Аналогичным образом в случае 2D пространства триангуляция может оказаться невыполнимой или может дать физически невозможные результаты для некоторых комбинаций направлений, которые затем также могут быть скорректированы, например, для модуля 202 вычисления информации по фиг. 3.
При наличии более двух пространственных микрофонов возможно несколько решений. Например, объясненную выше триангуляцию можно осуществить для всех пар реальных пространственных микрофонов (если N=3, то 1 с 2, 1 с 3 и 2 с 3). Затем результирующие места расположения можно усреднить (по х и у, а если рассматривается 3D пространство, то и по z). В качестве альтернативы могут быть использованы более сложные концепции. Например, можно применить вероятностные подходы, описанные в
[15] J. Michael Steele, "Optimal Triangulation of Random Samples in the Plane", The Annals of Probability, Vol. 10, No. 3
(Aug., 1982), pp.548-553.
Согласно одному варианту изобретения можно проанализировать звуковое поле в частотно-временной области, полученное, например, посредством кратковременного преобразования Фурье (STFT), где k и n обозначают индекс k частоты и индекс n времени соответственно. Комплексное давление Pv(k,n) в произвольном местоположении pv для определенных кип моделируется в виде одной сферической волны, излучаемой узкополосным изотропным точечным источником, например, с использованием следующей формулы:
где PIPLS(k,n) - сигнал, излучаемый источником IPLS, находящимся в положении pIPLS(k,n). Комплексный коэффициент γ(k, pIPLS(k, n, pv) представляет распространение от pIPLS(k,n) до pv, например, он вводит соответствующие модификации фазы и величины аудиосигнала. Здесь можно предположить, что в каждом частотно-временном бине активен только один IPLS. Тем не менее, в один момент времени также могут быть активными множество узкополосных IPLS, имеющих различное местоположение.
Каждый IPLS моделирует либо прямой звук, либо удаленное отражение в помещении. Местоположение pIPLS(k,n) может идеально соответствовать действительному источнику звука, находящемуся внутри данного помещения, или источнику зеркального отражения, находящемуся вне помещения соответственно. Таким образом, местоположение pIPLS(k,n) также может указывать местоположение источника звука. Следует обратить внимание на то, что термин «реальные источники звука» обозначает действительные источники звука, физически существующие в среде записи, такие как собеседники или музыкальные инструменты. С другой стороны, термины «источники звука», «звуковые события» или «IPLS относятся к эффективным источникам звука, активным в определенные моменты времени или на определенных частотно-временных бинах, где эти источники звука могут, например, представлять реальные источники звука или источники зеркального отражения.
На фиг. 15а-15b показаны микрофонные матрицы, локализующие источники звука. Локализованные источники звука могут быть по-разному физически интерпретированы в зависимости от их природы. Когда микрофонные матрицы воспринимают прямой звук, они способны локализовать местоположение действительного источника звука (например, собеседников). Когда микрофонные матрицы воспринимают отраженные звуки, они могут локализовать местоположение источника зеркального отражения. Источники зеркального отражения также являются источниками звука.
На фиг. 15а показан сценарий, где две микрофонные матрицы 151 и 152 воспринимают прямой звук от действительного источника звука (физически существующего источника звука).
На фиг. 15b показан сценарий, где две микрофонные матрицы 161, 162 принимают отраженный звук, который был отражен стеной. По причине отражения микрофонные матрицы 161, 162 определяют место появления звука как место расположения источника 165 зеркального отражения, которое отличается от местоположения собеседника 163.
Действительный источник 153 звука по фиг. 15а, а также источник 165 зеркального отражения являются оба источниками звука.
На фиг. 15с показан сценарий, где две микрофонные матрицы 171, 172 принимают диффузный звук и не способны локализовать источник звука.
Эта одноволновая модель дает точные результаты только для сред с умеренной реверберацией при условии, что сигналы источника достаточно хорошо удовлетворяют условию отсутствия их частотно-временного перекрытия (WDO-ортогональность). Обычно это действительно для речевых сигналов (смотри, например
[12] S. Rickard and Z. Yilmaz, "On the approximate W-disjoint orthogonality of speech," in Acoustics, Speech and Signal Processing, 2002. ICASSP 2002. IEEE International Conference on, April 2002, vol. 1).
Однако эта модель также обеспечивает хорошую оценку для других сред и поэтому также может найти в них свое применение.
Далее объясняется, как выполняется оценка местоположений pIPLS(k,n) согласно одному варианту изобретения. Местоположение pIPLS(k,n) активного источника IPLS в конкретном частотно-временном бине и, следовательно, оценку звукового события в частотно-временном бине получают с помощью триангуляции на основе направления поступления (DOA) звука, измеренного по меньшей мере в двух разных точках наблюдения.
На фиг. 6 показана геометрическая структура, где источник IPLS текущего частотно-временного слота (k,n) находится в неизвестном положении pIPLS(k,n). Чтобы определить необходимую информацию о DOA, используют два реальных пространственных микрофона, здесь это две микрофонные матрицы, имеющие известную геометрию, местоположение и ориентацию, причем местоположения этих матриц обозначены ссылочными позициями 610 и 620 соответственно. Векторы р1 и р2 указывают на местоположения 610, 620 соответственно. Ориентация матриц определяется единичными векторами с1 и с2. Направление DOA звука определяют в местах 610 и 620 для каждого (k,n), используя алгоритм оценки DOA, например, как это обеспечивается при использовании анализа DirAC (смотри [2], [3]). Таким образом, в качестве выходного результата анализа DirAC могут быть получены единичный вектор  (k,n) первой точки обзора и единичный вектор
(k,n) первой точки обзора и единичный вектор  (k,n) второй точки обзора относительно точки обзора микрофонных матриц (на фиг. 6 они не показаны). Например, при функционировании в 2D пространстве единичный вектор первой точки обзора будет представлен как:
(k,n) второй точки обзора относительно точки обзора микрофонных матриц (на фиг. 6 они не показаны). Например, при функционировании в 2D пространстве единичный вектор первой точки обзора будет представлен как:

Здесь φ1(k,n) представляет азимут DOA, оцененный у первой микрофонной матрицы, показанной на фиг. 6. Соответствующие единичные векторы е1(k,n) и е2(k,n) применительно к глобальной системе координат можно вычислить, применив следующие формулы:

где R - матрицы координатного преобразования, например,

при работе в 2D пространстве и с1=[c1,x c1,y)T. Для выполнения триангуляции d1(k,n) и d2 (k,n) направления можно вычислить как

где d1(k,n)=||d1(k,n)|| и d2(k,n)=||d2(k,n)|| - неизвестные расстояния между IPLS и двумя микрофонными матрицами. Следующее уравнение

может быть решено для d1(k,n). Наконец, местоположение pIPLS(k,n) источника IPLS задается как

В другом варианте уравнение (6) можно решить для d2(k,n), и pIPLS(k,n) вычисляют аналогичным образом, используя d2(k,n).
Уравнение (6) всегда обеспечивает решение при работе в 2D пространстве, если e1(k,n) и e2(k,n) непараллельны. Однако при использовании более двух микрофонных матриц и при работе в 3D пространстве решение получить невозможно, когда векторы d направлений не пересекаются. Согласно одному варианту в этом случае будет вычисляться точка, ближайшая ко всем векторам d направления, и полученный результат можно использовать в качестве местоположения IPLS.
В одном варианте все точки p1, р2, обзора следует расположить таким образом, чтобы звук, излучаемый источником IPLS, попадал в один и тот же временной блок п. Это требование можно простым образом удовлетворить, когда расстояние Л между любыми двумя точками обзора меньше, чем 
где nFFT - длина окна STFT, 0≤R<1 задает перекрытие между последовательными временными кадрами, a fs - частота дискретизации. Например, для 1024-точечного преобразования STFT при частоте 48 кГц с 50% перекрытием (R=0,5) максимальный интервал между матрицами, удовлетворяющий вышеупомянутому требованию, составит Δ=3,65 м.
Далее подробно описывается модуль 202 вычисления информации, например, модуль вычисления сигнала виртуального микрофона и дополнительной информации, согласно одному варианту изобретения.
На фиг. 7 схематически показан модуль 202 вычисления информации согласно одному варианту. Блок вычисления информации содержит компенсатор 500 распространения, объединитель 510 и блок 520 спектрального взвешивания. Модуль 202 вычисления информации получает оценки ssp местоположения источников звука, выполненные блоком оценки местоположения звуковых событий, один или более входных аудиосигналов is, записанных одним или несколькими реальными пространственными микрофонами, местоположение posRealMic одного или нескольких реальных пространственных микрофонов и виртуальное местоположение posVmic виртуального микрофона. Модуль 202 выдает выходной аудиосигнал os, представляющий аудиосигнал виртуального микрофона.
На фиг. 8 показан модуль вычисления информации согласно другому варианту. Модуль вычисления информации по фиг. 8 содержит компенсатор 500 распространения, объединитель 510 и блок 520 спектрального взвешивания. Компенсатор 500 распространения содержит модуль 501 вычисления параметров распространения и модуль 504 компенсации распространения. Объединитель 510 содержит модуль 502 вычисления коэффициентов объединения и модуль 505 объединения. Модуль 520 спектрального взвешивания содержит блок 503 вычисления спектральных весов, модуль 506 применения спектрального взвешивания и модуль 507 вычисления дополнительной информации о спектре.
Для вычисления аудиосигнала виртуального микрофона в модуль 202 вычисления информации, в частности, в модуль 501 вычисления параметров распространения, входящий в состав компенсатора 500 распространения, в модуль 502 вычисления коэффициентов объединения, входящий в состав объединителя 510, и в блок 503 вычисления спектральных весов, входящий в состав блока 520 спектрального взвешивания, подают геометрическую информацию, например, местоположения и ориентацию реальных пространственных микрофонов 121,…, 12N, местоположение, ориентацию и характеристики виртуального пространственного микрофона 104 и оценки местоположения звуковых событий 205. Модуль 501 вычисления параметров распространения, модуль 502 вычисления коэффициентов объединения и блок 503 вычисления спектральных весов вычисляют параметры, используемые при модификации аудиосигналов 111,…, 11N в модуле 504 компенсации распространения, модуле 505 объединения и модуле 506 применения спектрального взвешивания.
В модуле 202 вычисления информации аудиосигналы 111,…, 11N сначала могут быть модифицированы для компенсации эффектов, обусловленных разной длиной траекторий распространения сигнала между местами появления звуковых событий и реальными пространственными микрофонами. Затем эти сигналы могут быть объединены, например, для улучшения отношения сигнал-шум (SNR). Наконец, может быть выполнено спектральное взвешивание результирующего сигнала для учета направленного характера фиксации звука, выполняемой виртуальным микрофоном, а также зависимости усиления от расстояния. Эти три шага боле подробно обсуждаются ниже.
Теперь более подробно объясним, как выполняется компенсация распространения. В верхней части фиг. 9 показаны два реальных пространственных микрофона (первая микрофонная матрица 910 и вторая микрофонная матрица 920), местоположение локализованного звукового события 930 для частотно-временного бина (k,n) и местоположение виртуального пространственного микрофона 940.
В нижней части фиг. 9 показана ось времени. Здесь предполагается, что звуковое событие происходит в момент to, после чего звук распространяется к реальному и виртуальному пространственным микрофонам. Временные задержки поступления, а также амплитуды изменяются с изменением расстояния, так что чем больше длина распространения, тем слабее амплитуда и тем больше время задержки поступления сигнала.
Сигналы у двух реальных матриц можно сравнить только в том случае, если относительная задержка Dt12 между ними мала. В противном случае, один из двух сигналов необходимо временно скорректировать для компенсации относительной задержки Dt12, а возможно и масштабировать для компенсации различных затуханий.
Компенсация задержки между поступлением звука на виртуальный микрофон и поступлением звука на реальные микрофонные матрицы (на один из реальных пространственных микрофонов) изменяет задержку независимо от локализации звукового события, что более чем достаточно для большинства приложений.
Обратимся к фиг. 8, где модуль 501 вычисления параметров распространения адаптирован для вычисления задержек, подлежащих коррекции для каждого реального пространственного микрофона и для каждого звукового события. Если это необходимо, то модуль 501 также вычисляет коэффициенты усиления, необходимые для компенсации разных затуханий амплитуды.
Модуль 504 компенсации распространения сконфигурирован для использования вышеупомянутой информации для модификации соответствующих аудиосигналов. Если сигналы должны быть смещены во времени на небольшую величину (по сравнению с временным окном набора фильтров), то тогда достаточно использовать простое фазовращение. Если задержки большие, то тогда необходимы более сложные варианты. Выходом модуля 504 компенсации распространения являются модифицированные аудиосигналы, представленные в исходной частотно-временной области.
Далее со ссылками на фиг. 6 описывается, как выполняется конкретная оценка компенсации распространения для виртуального микрофона согласно одному варианту изобретения, причем на фиг. 6, в частности, показано местоположение 610 первого реального пространственного микрофона и местоположение 620 второго реального пространственного микрофона.
В разъясняемом в данный момент варианте предполагается, что имеется по меньшей мере первый записанный входной аудиосигнал, например, сигнал давления по меньшей мере у одного из реальных пространственных микрофонов (например, микрофонные матрицы), например, сигнал давления у первого реального пространственного микрофона. Рассматриваемый микрофон считается опорным микрофоном, его местоположение опорным местоположением pref, а сигнал давления опорным сигналом давления Pref(k,n). Однако компенсацию распространения можно выполнить не только по отношению к одному сигналу давления, но также по отношению к сигналам давления от множества (или всех) реальных пространственных микрофонов.
Соотношение между сигналом PIPLS(k,n) давления, излучаемым источником IPLS, и опорным сигналом Pref(k,n) опорного микрофона, расположенного в pref, можно представить формулой (9):

В общем случае комплексный коэффициент γ(k,pa,pb) представляет вращение фазы и затухание амплитуды, внесенные распространением сферической волны из точки ра ее возникновения в точку pb. Однако проведенные на практике испытания показали, что учет только затухания амплитуды в коэффициенте у приводит к приемлемым представлениям сигнала виртуального микрофона со значительно меньшим количеством артефактов по сравнению с учетом также и вращения фазы.
Звуковая энергия, которую можно измерить в конкретной точке пространства, сильно зависит от расстояния r от источника звука (на фиг. 6 от местоположения pIPLS источника звука). Во многих ситуациях эту зависимость можно смоделировать с достаточной точностью, используя хорошо известные физические принципы, например, 1/r затухание звукового давления в дальнем поле точечного источника. Когда расстояние опорного микрофона, например, первого реального микрофона, от источника звука известно, и когда также известно расстояние виртуального микрофона от источника звука, звуковую энергию в месте расположения виртуального микрофона можно оценить исходя из упомянутого сигнала и энергии опорного микрофона, например, первого реального пространственного микрофона. Это означает, что выходной сигнал виртуального микрофона можно получить путем применения правильно определенных коэффициентов усиления к эталонному сигналу давления.
Предположим, что первый реальный пространственный микрофон является опорным микрофоном, и что pref=p1- На фиг. 6 виртуальный микрофон находится в pv. Поскольку геометрия на фиг. 6 известна во всех подробностях, расстояние d1(k,n)=||d1(k,n) || между опорным микрофоном (на фиг. 6 это первый реальный пространственный микрофон) и источником IPLS можно легко определить, также как расстояние s(k,n)=||s(k,n)|| между виртуальным микрофоном и IPLS, а именно

Звуковое давление Pv(k,n) в месте нахождения виртуального микрофона вычисляют, объединив формулы (1) и (9), что приводит к

Как упоминалось выше, в некоторых вариантах коэффициенты γ могут только учитывать затухание амплитуды из-за распространения. Положим, например, что звуковое давление уменьшается с увеличением 1/r, и тогда

Когда указанная модель поддерживается согласно формуле (1), например, когда присутствует только прямой звук, формула (12) позволяет точно восстановить информацию о величине аудиосигнала. Однако в случае чисто диффузных звуковых полей, например, когда предположения, лежащие в основе модели, не удовлетворяются, представленный способ вызывает подавление реверберации сигнала в явном виде при перемещении виртуального микрофона от мест расположения сенсорных матриц. В действительности, как обсуждалось выше, в диффузных звуковых полях следует ожидать, что большинство источников IPLS будут находиться рядом с двумя сенсорными матрицами. Таким образом, при перемещении виртуального микрофона в направлении от этих мест скорее всего увеличится расстояние s=||s|| на фиг. 6. Следовательно, величина опорного давления уменьшается при использовании взвешивания согласно формуле (11). Соответственно, при перемещении виртуального микрофона ближе к действительному источнику звука частотно-временные бины, соответствующие прямому звуку, будут усилены, так что весь аудиосигнал будет восприниматься без диффузии. Путем настройки правила, лежащего в основе формулы (12), можно по желанию обеспечить управление усилением прямого звука и подавлением диффузного звука.
В результате выполнения компенсации для записанного входного аудиосигнала (например, сигнала давления) первого реального пространственного микрофона получают первый модифицированный аудиосигнал. В вариантах изобретения второй модифицированный аудиосигнал можно получить посредством компенсации распространения для записанного второго входного аудиосигнала (второй сигнал давления) второго реального пространственного микрофона.
В других вариантах можно получить дополнительные аудиосигналы путем выполнения компенсации распространения для записанных дополнительных входных аудиосигналов (дополнительные сигналы давления) дополнительных реальных пространственных микрофонов.
Далее более подробно объясняется, как выполняется объединение в блоках 502 и 505 на фиг. 8 согласно одному варианту изобретения. Предположим, что для компенсации различных путей распространения для получения двух или более модифицированных аудиосигналов было модифицировано два или более аудиосигналов из множества различных реальных пространственных микрофонов.
Поскольку аудиосигналы от различных реальных пространственных микрофонов были модифицированы для компенсации различных путей распространения, их можно объединить для повышения качества аудио. Выполнив это, можно, например, увеличить SNR или уменьшить реверберацию.
Возможные решения для объединения содержат:
усреднение с взвешиванием, например, учет SNR или расстояния до виртуального микрофона либо диффузии, которая была оценена реальными пространственными микрофонами. Например, могут быть использованы традиционные решения, такие как объединение при максимальном отношении (MRC) или объединение с равным усилением (EQC); или
линейное объединение некоторых или всех модифицированных аудиосигналов для получения объединенного сигнала. Модифицированные аудиосигналы могут быть взвешены в линейном объединении для получения объединенного сигнала; или
выбор для использования, например, только одного сигнала, например, в зависимости от SNR или расстояния либо диффузности.
Задачей модуля 502, если он применяется, является вычисление параметров для объединения, которое выполняется в модуле 505.
Далее более подробно описывается спектральное взвешивание согласно варианту изобретения. Для этого обратимся к блокам 503 и 506 на фиг. 8. На этом финальном шаге аудиосигнал, являющийся результатом объединения или компенсации распространения входных аудиосигналов, взвешивают в частотно-временной области в соответствии с пространственными характеристиками виртуального пространственного микрофона, заданных входными данными 104, и/или согласно восстановленной геометрии (представленной под ссылочной позицией 205). Для каждого частотно-временного бина геометрическое восстановление позволяет легко получить направление DOA относительно виртуального микрофона, как показано на фиг. 10. Кроме того, также легко вычислить расстояние между виртуальным микрофоном и местоположением звукового события.
Затем с учетом типа требуемого виртуального микрофона вычисляют вес для данного частотно-временного бина.
В случае направленных микрофонов спектральные веса можно вычислить в соответствии с заранее определенной диаграммой направленности приема звука. Например, согласно одному варианту кардиоидный микрофон может иметь диаграмму направленности приема звука, определенную следующей функцией g(тета),
где «тета» - угол между линией визирования виртуального пространственного микрофона и направлением DOA звука из точки обзора виртуального микрофона.
Другой возможностью является использование функций искусственного (нефизического) затухания. В некоторых приложениях может потребоваться подавление звуковых событий далеко от виртуального микрофона с коэффициентом, превышающим коэффициент, характеризующий распространение в ближнем поле. С этой целью некоторые варианты изобретения вводят дополнительную весовую функцию, которая зависит от расстояния между виртуальным микрофоном и звуковым событием. В одном варианте изобретения должны фиксироваться только звуковые события в пределах конкретного расстояния (например, в метрах) от виртуального микрофона.
Что касается направленности виртуального микрофона, то для данного виртуального микрофона можно использовать произвольно выбранные диаграммы направленности. Это позволяет, например, выделить источник из сложной звуковой сцены.
Поскольку направление DOA звука можно вычислить в месте pv расположения виртуального микрофона, а именно

где cv - единичный вектор, описывающий ориентацию виртуального микрофона, можно реализовать произвольную направленность для виртуального микрофона. Например, если предположить, что Pv(k,n) указывает объединенный сигнал или модифицированный аудиосигнал с компенсированным
распространением, то тогда формула:

вычисляет выходной сигнал виртуального микрофона с кардиоидной направленностью. Направленные диаграммы, которые можно создать таким путем, зависят от точности оценки местоположения. В вариантах изобретения один или несколько реальных, непространственных микрофонов, например, всенаправленный микрофон или направленный микрофон, такой как кардиоид, размещены в звуковой сцене вдобавок к реальным пространственным микрофонам для дальнейшего повышения качества звука в виртуальных микрофонных сигналах 105 на фиг. 8. Эти микрофоны не используются для сбора какой-либо геометрической информации, а скорее только для обеспечения более чистого аудиосигнала. Эти микрофоны можно размещать ближе к источникам звука, чем пространственные микрофоны. В этом случае согласно одному варианту изобретения аудиосигналы реальных непространственных микрофонов и данные об их местоположениях подают просто в модуль 504 компенсации распространения по фиг. 8 для обработки вместо аудиосигнала реальных пространственных микрофонов. Затем выполняют компенсацию распространения для одного или нескольких записанных аудиосигналов непространственных микрофонов относительно местоположения одного или нескольких непространственных микрофонов. Таким образом, реализуется вариант изобретения, где используются дополнительные непространственные микрофоны.
В следующем варианте изобретения реализуется вычисление дополнительной пространственной информации от виртуального микрофона. Для вычисления дополнительной пространственной информации 106 от микрофона модуль 202 вычисления информации по фиг. 8 содержит модуль 507 вычисления дополнительной пространственной информации, который адаптирован для приема в качестве входных данных мест 205 расположения источников звука, а также местоположения, ориентации и характеристик 104 виртуального микрофона. В некоторых вариантах в соответствии с дополнительной информацией 106, которую необходимо вычислить, в качестве входного сигнала в модуль 507 вычисления дополнительной пространственной информации также может быть учтен аудиосигнал виртуального микрофона 105.
Выходом модуля 507 вычисления дополнительной пространственной информации является дополнительная информация от виртуального микрофона 106. Этой дополнительной информацией может быть, например, направление DOA или диффузность звука для каждого частотно-временного бина (k,n) от точки обзора виртуального микрофона. Другой возможной дополнительной информацией может быть, например, вектор Iа(k,n) интенсивности активного звука, которую можно измерить в месте расположения виртуального микрофона. Далее описывается, как можно получить эти параметры.
Согласно одному варианту изобретения реализуют оценку DOA для виртуального пространственного микрофона. Модуль 120 вычисления информации адаптирован для оценки, в качестве дополнительной пространственной информации, направления поступления у виртуального микрофона на основе вектора местоположения виртуального микрофона и на основе вектора местоположения звукового события, как показано на фиг. 11.
На фиг. 11 показан возможный способ получения DOA звука из точки обзора виртуального микрофона. Местоположение звукового события, обеспечиваемое блоком 205 на фиг. 8, можно описать для каждого частотно-временного бина (k,n) с помощью вектора r(k,n) местоположения, вектора местоположения звукового события. Аналогичным образом местоположение виртуального микрофона, предоставляемое в виде входа 104 на фиг. 8, можно описать с помощью вектора s(k,n) местоположения, вектора местоположения виртуального микрофона. Кажущееся направление виртуального микрофона можно описать вектором v(k,n). Направление DOA относительно виртуального микрофона задается как a(k,n). Оно представляет угол между v и путем h(k,n) распространения звука. Путь h(k,n) можно вычислить по формуле:

Теперь для каждого (k,n) можно вычислить требуемое направление DOA a(k,n), например, путем определения векторного произведения h(k,n) и v(k,n), а именно
В другом варианте модуль 120 вычисления информации можно адаптировать для оценки интенсивности активного звука у виртуального микрофона в качестве дополнительной
пространственной информации на основе вектора местоположения виртуального микрофона и на основе вектора местоположения звукового события, как показано на фиг. 11.
Исходя из DOA a(k,n), определенного выше, можно получить интенсивность Iа(k,n) активного звука в месте расположения виртуального микрофона. Для этого предполагается, что аудиосигнал 105 виртуального микрофона по фиг. 8 соответствует выходу всенаправленного микрофона, например, предполагается, что виртуальный микрофон является всенаправленным микрофоном. Кроме того, предполагается, что кажущееся направление v на фиг. 11 параллельно оси х системы координат. Поскольку требуемый вектор Ia(k,n) интенсивности активного звука описывает чистый поток энергии через место расположения виртуального микрофона, можно вычислить Ia(k,n), например, по следующей формуле:
где []т обозначает транспонированный вектор, rho - плотность воздуха, a Pv(k,n) - звуковое давление, измеренное виртуальным пространственным микрофоном, например выход 105 блока 506 на фиг. 8.
Если вектор интенсивности активного звука должен вычисляться в общей системе координат, но при этом по месту расположения виртуального микрофона, то можно использовать следующую формулу:
Диффузность звука выражает диффузию звукового поля в данном частотно-временном слоте (смотри, например, [2]). Диффузность выражается значением ψ где 0≤ψ≤1. Диффузность, равная 1, указывает на то, что общая энергия звукового поля является полностью диффузной. Эта информация важна, например, при восстановлении пространственного звука. Традиционно диффузность вычисляют в определенной точке пространства, в которой расположена микрофонная матрица.
Согласно одному варианту диффузность можно вычислить в качестве дополнительного параметра к дополнительной информации, созданной для виртуального микрофона (VM), который по желанию можно разместить в произвольно выбранной точке в звуковой сцене. В этом случае устройство, которое помимо аудиосигнала у виртуального места расположения виртуального микрофона также вычисляет диффузность, можно рассматривать как виртуальный интерфейс DirAC, поскольку можно создать поток DirAC, а именно, аудиосигнал, направление поступления и диффузность для произвольной точки в звуковой сцене. Поток DirAC можно дополнительно обработать, запомнить, передать и воспроизвести на любой произвольно выбранной установке с множеством громкоговорителей. В этом случае слушатель воспринимает звуковую сцену, как будто он находится в месте, определенном виртуальным микрофоном, и ориентирован в направлении, определенном ориентацией виртуального микрофона.
На фиг. 12 показан блок вычисления информации согласно одному варианту изобретения, содержащий блок 801 вычисления диффузности для вычисления диффузности у виртуального микрофона. Блок 202 вычисления информации адаптирован для приема входных данных 111-11N, которые, вдобавок к входам по фиг. 3, также включают в себя диффузность у реальных пространственных микрофонов. Обозначим эти значения как  . Эти дополнительные входные данные подаются в модуль 202 вычисления информации. Выходом 103 блока 801 вычисления диффузности является параметр диффузности, вычисленный в месте расположения виртуального микрофона.
. Эти дополнительные входные данные подаются в модуль 202 вычисления информации. Выходом 103 блока 801 вычисления диффузности является параметр диффузности, вычисленный в месте расположения виртуального микрофона.
Блок 801 вычисления диффузности согласно одному варианту более подробно показан на фиг. 13. Согласно одному варианту оценивается энергия прямого и диффузного звука у каждого из N пространственных микрофонов. Затем, используя информацию о местах расположения источников IPLS и информацию о местах расположения пространственных и виртуальных микрофонов, получают N оценок этих энергий в месте расположения виртуального микрофона. Наконец, эти оценки можно объединить для повышения точности оценки, после чего можно легко вычислить параметр диффузности у виртуального микрофона.
Пусть  и
и  обозначают оценки энергий прямого и диффузного звука для N пространственных микрофонов, вычисленных блоком 810 анализа энергии. Если Pi является комплексным сигналом давления, a ψi диффузность для i-го пространственного микрофона, то тогда значения энергии можно вычислить, например, по формуле:
обозначают оценки энергий прямого и диффузного звука для N пространственных микрофонов, вычисленных блоком 810 анализа энергии. Если Pi является комплексным сигналом давления, a ψi диффузность для i-го пространственного микрофона, то тогда значения энергии можно вычислить, например, по формуле:
Энергия диффузного звука должна быть одинаковой во всех точках; следовательно, оценку энергии  диффузного звука у виртуального микрофона можно вычислить, просто усреднив
диффузного звука у виртуального микрофона можно вычислить, просто усреднив 
 , например, в блоке 820 объединения диффузности, согласно формуле:
, например, в блоке 820 объединения диффузности, согласно формуле:

Более эффективную комбинацию оценок  можно выполнить, если учесть разброс оценок, выполняемых блоками оценки, например, посредством учета SNR.
можно выполнить, если учесть разброс оценок, выполняемых блоками оценки, например, посредством учета SNR.
Энергия прямого звука в результате его распространения зависит от расстояния до источника. Следовательно,  можно модифицировать с учетом распространения звука. Это можно выполнить, например, с помощью блока 830 регулировки распространения прямого звука. Например, если предположить, что энергия прямого звукового поля затухает пропорционально квадрату расстояния, то тогда оценку для прямого звука у вертикального микрофона для i-го пространственного микрофона можно вычислить по формуле:
можно модифицировать с учетом распространения звука. Это можно выполнить, например, с помощью блока 830 регулировки распространения прямого звука. Например, если предположить, что энергия прямого звукового поля затухает пропорционально квадрату расстояния, то тогда оценку для прямого звука у вертикального микрофона для i-го пространственного микрофона можно вычислить по формуле:

По аналогии с блоком 820 объединения диффузности можно объединить оценки энергии прямого звука, полученные у разных пространственных микрофонов, например, с помощью блока 840 объединения прямого звука. Результатом будет  , например, оценка для энергии прямого звука у виртуального микрофона. Диффузность
, например, оценка для энергии прямого звука у виртуального микрофона. Диффузность 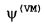 можно вычислить, например, с помощью субвычислителя 850 диффузности, например, по формуле:
можно вычислить, например, с помощью субвычислителя 850 диффузности, например, по формуле:

Как упоминалось выше, в некоторых случаях оценка местоположения звуковых событий, выполняемая блоком оценки местоположения звуковых событий, невозможна, например, в случае ошибочной оценки направления поступления звука. Указанный сценарий показан на фиг. 14. В этих случаях независимо от параметров диффузности, оцененных у разных пространственных микрофонов, и полученных в виде входов 111-11N, диффузность для виртуального микрофона 103 можно установить равной 1 (то есть полная диффузность), так как пространственное когерентное восстановление невозможно.
Вдобавок можно учесть надежность оценок направлений DOA у N пространственных микрофонов. Это можно представить, например, исходя из разброса результатов блока оценки DOA или SNR. Указанная информация может быть также учтена субвычислителем 850 диффузности, так что диффузность 103 виртуального микрофона можно искусственно увеличить в том случае, когда оценки DOA ненадежны. В действительности вследствие вышесказанного оценки 205 местоположения также могут оказаться ненадежными.
Хотя некоторые аспекты изобретения были описаны здесь в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствует шагу способа или отличительному признаку шага способа. Аналогичным образом аспекты, описанные в контексте шага способа, также представляют описание соответствующего блока, элемента или отличительного признака соответствующего устройства.
Предложенный в изобретении составной сигнал можно запомнить на носителе цифровых данных или можно передать через среду передачи, такую как среда беспроводной передачи или среда проводной передачи, например, Интернет.
В зависимости от конкретных требований к реализации варианты данного изобретения можно реализовать аппаратными средствами или программными средствами. Указанная реализация может быть выполнена с использованием носителя цифровых данных, например, гибкого диска, DVD, CD, ROM (ПЗУ), PROM (программируемое ПЗУ), EPROM (стираемое программируемое ПЗУ), EEPROM (электрически стираемое программируемое ПЗУ) или флэш-памяти, содержащий считываемые электронным путем, записанные на нем сигналы управления, которые действуют (или способны к совместному действию) с программируемой компьютерной системой, с тем чтобы реализовать соответствующий способ.
Некоторые варианты согласно настоящему изобретению содержат носитель данных, содержащий считываемые электронным путем управляющие сигналы, которые способны функционировать совместно с программируемой компьютерной системой, с тем чтобы реализовать один из описанных здесь способов.
В общем случае варианты настоящего изобретения можно реализовать в виде компьютерного программного продукта с программным кодом, причем этот программный код предназначен для выполнения одного из способов, когда этот компьютерный программный продукт выполняется на компьютере. Программный код может храниться, например, на считываемом машиной носителе.
Другие варианты содержат компьютерную программу для выполнения описанных здесь способов, которая запомнена на считываемом компьютером носителе.
Другими словами, вариант нового способа представляет собой компьютерную программу, содержащую программный код для выполнения одного из описанных здесь способов, когда эта компьютерная программа выполняется на компьютере.
Таким образом, следующий вариант из числа предложенных новых способов представляет собой носитель данных (или носитель цифровых данных или считываемый компьютером носитель), содержащий записанную на нем компьютерную программу для выполнения одного из описанных здесь способов.
Еще один вариант предложенного здесь оригинального способа представляет собой поток данных или последовательность сигналов, представляющую компьютерную программу для выполнения одного из описанных здесь способов. Этот поток данных или последовательность сигналов может быть сконфигурирована для пересылки через соединение для передачи данных, например через Интернет.
Следующий вариант содержит средство обработки, например компьютер или программируемое логическое устройство, сконфигурированное для или адаптированное к выполнению одного из описанных здесь способов.
Еще один вариант изобретения содержит компьютер с установленной в нем программой для выполнения одного из описанных здесь способов.
В некоторых вариантах для выполнения некоторых или всех функций описанных здесь способов можно использовать программируемое логическое устройство (например, вентильную матрицу, программируемую пользователем). В некоторых вариантах вентильная матрица, программируемая пользователем, может работать совместно с микропроцессором для выполнения одного из описанных здесь способов. В общем случае эти способы предпочтительно выполняются каким-либо аппаратным устройством.
Вышеописанные варианты являются просто иллюстрацией принципов настоящего изобретения. Специалистам в данной области техники очевидны модификации и версии описанных здесь компоновок и деталей изобретения. Таким образом, изобретение ограничивается только объемом представленных пунктов формулы изобретения, а не конкретными деталями, представленными для описания и объяснения предложенных здесь вариантов изобретения.
Список литературы
[1] R. К. Furness, "Ambisonics - An overview," in AES 8 International Conference, April 1990, pp. 181-189.
[2] V. Pulkki, "Directional audio coding in spatial sound reproduction and stereo upmixing," in Proceedings of the AES 28th International Conference, pp. 251-258, Pitea, Sweden, June 30-July 2, 2006.
[3] V. Pulkki, "Spatial sound reproduction with directional audio coding," J. Audio Eng. Soc, vol. 55, no. 6, pp. 503-516, June 2007.
[4] C. Faller: "Microphone Front-Ends for Spatial Audio Coders", in Proceedings of the AES 125th International Convention, San Francisco, Oct. 2008.
[5] M. Kallinger, H. Ochsenfeld, G. Del Galdo, F. Kuch, D. Mahne, R. Schultz-Amling. and 0. Thiergart, "A spatial filtering approach for directional audio coding," in Audio Engineering Society Convention 126, Munich, Germany, May 2009.
[6] R. Schultz-Amling, F. Kuch, O. Thiergart, and M. Kallinger, "Acoustical zooming based on a parametric sound field representation," in Audio Engineering Society Convention 128, London UK, May 2010.
[7] J. Herre, C. Falch, D. Mahne, G. Del Galdo, M. Kallinger, and 0. Thiergart, "Interactive teleconferencing combining spatial audio object coding and DirAC technology," in Audio Engineering Society Convention 128, London UK, May 2010.
[8] E. G. Williams, Fourier Acoustics: Sound Radiation and Nearfield Acoustical Holography, Academic Press, 1999.
[9] A. Kuntz and R. Rabenstein, "Limitations in the extrapolation of wave fields from circular measurements," in 15th European Signal Processing Conference (EUSIPCO 2007), 2007.
[10] A. Walther and C. Faller, "Linear simulation of spaced microphone arrays using b-format recordings," in Audio Engineering Society Convention 128, London UK, May 2010.
[1 1] US 61/287,596: An Apparatus and a Method for Converting a First Parametric Spatial Audio Signal into a Second Parametric Spatial Audio Signal.
[12] S. Rickard and Z. Yilmaz, "On the approximate W-disjoint orthogonality of speech," in Acoustics, Speech and Signal Processing, 2002. ICASSP 2002. IEEE International Conference on, April 2002, vol. 1.
[13] R. Roy, A. Paulraj, and T. Kailath, "Direction-of-arrival estimation by subspace rotation methods - ESPRIT," in IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Stanford, CA, USA, April 1986.
[14] R. Schmidt, "Multiple emitter location and signal parameter estimation," IEEE Transactions on Antennas and Propagation, vol. 34, no. 3, pp. 276-280, 1986.
[15] J. Michael Steele, "Optimal Triangulation of Random Samples in the Plane", The Annals of Probability, Vol. 10, No. 3 (Aug., 1982), pp. 548-553.
[16] F. J. Fahy, Sound Intensity, Essex: Elsevier Science Publishers Ltd., 1989.
[17] R. Schultz-Amling, F. Kuch, M. Kallinger, G. Del Galdo, T. Ahonen and V. Pulkki, "Planar microphone array processing for the analysis and reproduction of spatial audio using directional audio coding," in Audio Engineering Society Convention 124, Amsterdam, The Netherlands, May 2008.
[18] M. Kallinger, F. Kuch, R. Schultz-Amling, G. Del Galdo, T. Ahonen and V. Pulkki, "Enhanced direction estimation using microphone arrays for directional audio coding;" in Hands-Free Speech Communication and Microphone Arrays, 2008. HSCMA 2008, May 2008, pp. 45-48.
Claims (18)
1. Устройство для создания выходного аудиосигнала для имитации записи выходного аудиосигнала виртуальным микрофоном у конфигурируемого виртуального места его расположения в окружающей среде, причем устройство содержит:
блок (110) оценки местоположения звуковых событий для оценки местоположения звукового события, указывающий местоположение звукового события в упомянутой окружающей среде, где звуковое событие активизировано в определенный момент времени или в определенном частотно-временном бине, где звуковое событие представляет собой реальный источник звука или источник зеркального отображения, где блок (110) оценки местоположения звуковых событий сконфигурирован для оценки местоположения звукового события, указывающего местоположение источника зеркального отражения в упомянутой окружающей среде, когда звуковым событием является источник зеркального отражения, и где блок (110) оценки местоположения звуковых событий адаптирован для оценки местоположения звукового события на основе информации о первом направлении, обеспечиваемой первым реальным пространственным микрофоном, который расположен по месту расположения первого реального микрофона в данной окружающей среде, и на основе информации о втором направлении, обеспечиваемой вторым реальным пространственным микрофоном, который расположен по месту расположения второго реального микрофона в данной окружающей среде, где первый реальный пространственный микрофон и второй реальный пространственный микрофон представляют собой физически существующие пространственные микрофоны; и где первый реальный пространственный микрофон и второй реальный пространственный микрофон являются устройствами для приема пространственного звука, способные извлекать информацию о направлении поступления звука, и
модуль (120) вычисления информации для создания выходного аудиосигнала на основе первого записанного входного аудиосигнала, на основе местоположения первого реального микрофона, на основе виртуального местоположения виртуального микрофона и на основе местоположения звукового события;
где первый реальный пространственный микрофон сконфигурирован для записи первого записанного входного аудиосигнала, или где третий микрофон сконфигурирован для записи первого записанного входного аудиосигнала,
где блок (110) оценки местоположения звуковых событий адаптирован для оценки местоположения звукового события на основе первого направления поступления звуковой волны, излучаемой звуковым событием у места расположения первого реального микрофона, в качестве информации о первом направлении и на основе второго направления поступления звуковой волны у места расположения второго реального микрофона в качестве информации о втором направлении, и
где модуль (120) вычисления информации содержит компенсатор (500) распространения,
где компенсатор (500) распространения адаптирован для создания первого модифицированного аудиосигнала путем модификации первого записанного входного аудиосигнала на основе первого затухания амплитуды между звуковым событием и первым реальным пространственным микрофоном и на основе второго затухания амплитуды между звуковым событием и виртуальным микрофоном путем регулировки значения амплитуды, значения магнитуды или значения фазы первого записанного входного аудиосигнала для получения выходного аудиосигнала; или
где компенсатор (500) распространения адаптирован для создания первого модифицированного аудиосигнала путем компенсации первой временной задержки между поступлением звуковой волны, излучаемой звуковым событием у первого реального пространственного микрофона, и поступлением звуковой волны у виртуального микрофона путем регулировки значения амплитуды, значения магнитуды или значения фазы первого записанного входного аудиосигнала для получения выходного аудиосигнала.
блок (110) оценки местоположения звуковых событий для оценки местоположения звукового события, указывающий местоположение звукового события в упомянутой окружающей среде, где звуковое событие активизировано в определенный момент времени или в определенном частотно-временном бине, где звуковое событие представляет собой реальный источник звука или источник зеркального отображения, где блок (110) оценки местоположения звуковых событий сконфигурирован для оценки местоположения звукового события, указывающего местоположение источника зеркального отражения в упомянутой окружающей среде, когда звуковым событием является источник зеркального отражения, и где блок (110) оценки местоположения звуковых событий адаптирован для оценки местоположения звукового события на основе информации о первом направлении, обеспечиваемой первым реальным пространственным микрофоном, который расположен по месту расположения первого реального микрофона в данной окружающей среде, и на основе информации о втором направлении, обеспечиваемой вторым реальным пространственным микрофоном, который расположен по месту расположения второго реального микрофона в данной окружающей среде, где первый реальный пространственный микрофон и второй реальный пространственный микрофон представляют собой физически существующие пространственные микрофоны; и где первый реальный пространственный микрофон и второй реальный пространственный микрофон являются устройствами для приема пространственного звука, способные извлекать информацию о направлении поступления звука, и
модуль (120) вычисления информации для создания выходного аудиосигнала на основе первого записанного входного аудиосигнала, на основе местоположения первого реального микрофона, на основе виртуального местоположения виртуального микрофона и на основе местоположения звукового события;
где первый реальный пространственный микрофон сконфигурирован для записи первого записанного входного аудиосигнала, или где третий микрофон сконфигурирован для записи первого записанного входного аудиосигнала,
где блок (110) оценки местоположения звуковых событий адаптирован для оценки местоположения звукового события на основе первого направления поступления звуковой волны, излучаемой звуковым событием у места расположения первого реального микрофона, в качестве информации о первом направлении и на основе второго направления поступления звуковой волны у места расположения второго реального микрофона в качестве информации о втором направлении, и
где модуль (120) вычисления информации содержит компенсатор (500) распространения,
где компенсатор (500) распространения адаптирован для создания первого модифицированного аудиосигнала путем модификации первого записанного входного аудиосигнала на основе первого затухания амплитуды между звуковым событием и первым реальным пространственным микрофоном и на основе второго затухания амплитуды между звуковым событием и виртуальным микрофоном путем регулировки значения амплитуды, значения магнитуды или значения фазы первого записанного входного аудиосигнала для получения выходного аудиосигнала; или
где компенсатор (500) распространения адаптирован для создания первого модифицированного аудиосигнала путем компенсации первой временной задержки между поступлением звуковой волны, излучаемой звуковым событием у первого реального пространственного микрофона, и поступлением звуковой волны у виртуального микрофона путем регулировки значения амплитуды, значения магнитуды или значения фазы первого записанного входного аудиосигнала для получения выходного аудиосигнала.
2. Устройство по п. 1, в котором модуль (120) вычисления информации содержит модуль (507) вычисления дополнительной пространственной информации для вычисления дополнительной пространственной информации;
в котором модуль (120) вычисления информации адаптирован для оценки направления поступления или интенсивности активного звука у виртуального микрофона в качестве дополнительной пространственной информации на основе вектора местоположения виртуального микрофона и на основе вектора местоположения звукового события.
в котором модуль (120) вычисления информации адаптирован для оценки направления поступления или интенсивности активного звука у виртуального микрофона в качестве дополнительной пространственной информации на основе вектора местоположения виртуального микрофона и на основе вектора местоположения звукового события.
3. Устройство по п. 1, в котором компенсатор (500) распространения адаптирован для создания первого модифицированного аудиосигнала путем модификации первого записанного входного аудиосигнала на основе первого затухания амплитуды между звуковым событием и первым реальным пространственным микрофоном и на основе второго затухания амплитуды между звуковым событием и виртуальным микрофоном путем регулировки значения амплитуды, значения магнитуды или значения фазы первого записанного входного аудиосигнала для получения выходного аудиосигнала,
в котором компенсатор (500) распространения адаптирован для создания первого модифицированного аудиосигнала в частотно-временной области на основе первого затухания амплитуды между звуковым событием и первым реальным пространственным микрофоном и на основе второго затухания амплитуды между звуковым событием и виртуальным микрофоном путем регулировки указанного значения магнитуды первого записанного входного аудиосигнала, представляемого в частотно-временной области.
в котором компенсатор (500) распространения адаптирован для создания первого модифицированного аудиосигнала в частотно-временной области на основе первого затухания амплитуды между звуковым событием и первым реальным пространственным микрофоном и на основе второго затухания амплитуды между звуковым событием и виртуальным микрофоном путем регулировки указанного значения магнитуды первого записанного входного аудиосигнала, представляемого в частотно-временной области.
4. Устройство по п. 1, в котором компенсатор (500) распространения адаптирован для создания первого модифицированного аудиосигнала путем компенсации первой временной задержки между поступлением звуковой волны, излучаемой звуковым событием у первого реального пространственного микрофона, и поступлением звуковой волны у виртуального микрофона путем регулировки значения амплитуды, значения магнитуды или значения фазы первого записанного входного аудиосигнала для получения выходного аудиосигнала,
в котором компенсатор (500) распространения адаптирован для создания первого модифицированного аудиосигнала в частотно-временной области путем компенсации первой временной задержки между поступлением звуковой волны, излучаемой звуковым событием у первого реального пространственного микрофона, и поступлением звуковой волны у виртуального микрофона путем регулировки указанного значения магнитуды первого записанного входного аудиосигнала, представляемого в частотно-временной области.
в котором компенсатор (500) распространения адаптирован для создания первого модифицированного аудиосигнала в частотно-временной области путем компенсации первой временной задержки между поступлением звуковой волны, излучаемой звуковым событием у первого реального пространственного микрофона, и поступлением звуковой волны у виртуального микрофона путем регулировки указанного значения магнитуды первого записанного входного аудиосигнала, представляемого в частотно-временной области.
5. Устройство по п. 1, в котором компенсатор (500) распространения адаптирован для выполнения компенсации распространения путем создания модифицированного значения магнитуды первого модифицированного аудиосигнала с применением формулы:

где d1(k,n) представляет собой расстояние между местоположением первого реального пространственного микрофона и местоположением звукового события, где s(k,n) - расстояние между виртуальным местоположением виртуального микрофона и местоположением звукового события, где Pref(k,n) - значение магнитуды первого записанного входного аудиосигнала, представляемого в частотно-временной области, и где Pv(k,n) - модифицированное значение магнитуды, соответствующее сигналу виртуального микрофона, где k обозначает индекс частоты и где n обозначает индекс времени.
где d1(k,n) представляет собой расстояние между местоположением первого реального пространственного микрофона и местоположением звукового события, где s(k,n) - расстояние между виртуальным местоположением виртуального микрофона и местоположением звукового события, где Pref(k,n) - значение магнитуды первого записанного входного аудиосигнала, представляемого в частотно-временной области, и где Pv(k,n) - модифицированное значение магнитуды, соответствующее сигналу виртуального микрофона, где k обозначает индекс частоты и где n обозначает индекс времени.
6. Устройство по п. 1, в котором модуль (120) вычисления информации, кроме того, содержит объединитель (510), где компенсатор (500) распространения, кроме того, адаптирован для модификации второго записанного входного аудиосигнала, записываемого вторым реальным пространственным микрофоном, путем компенсации второй временной задержки или второго затухания амплитуды между поступлением звуковой волны, излучаемой звуковым событием у второго реального пространственного микрофона, и поступлением звуковой волны у виртуального микрофона, путем регулировки значения амплитуды, значения магнитуды или значения фазы второго записанного входного аудиосигнала для получения второго модифицированного аудиосигнала, и где объединитель (510) адаптирован для создания объединенного сигнала путем объединения первого модифицированного аудиосигнала и второго модифицированного аудиосигнала для получения выходного аудиосигнала.
7. Устройство по п. 6, в котором компенсатор (500) распространения, кроме того, адаптирован для модификации одного или нескольких дополнительных записанных входных аудиосигналов, записываемых одним или несколькими дополнительными реальными пространственными микрофонами путем компенсации временных задержек или затуханий амплитуды между поступлением звуковой волны у виртуального микрофона и поступлением звуковой волны, излучаемой звуковым событием у каждого из дополнительных реальных пространственных микрофонов, где компенсатор (500) распространения адаптирован для компенсации каждой из временных задержек или каждого из затуханий амплитуды путем регулировки значения амплитуды, значения магнитуды или значения фазы каждого из дополнительно записанных входных аудиосигналов для получения множества третьих модифицированных аудиосигналов, и где объединитель (510) адаптирован для создания объединенного сигнала путем объединения первого модифицированного аудиосигнала и второго модифицированного аудиосигнала и множества третьих модифицированных аудиосигналов для получения выходного аудиосигнала.
8. Устройство по п. 1, в котором модуль (120) вычисления информации содержит блок (520) спектрального взвешивания для создания взвешенного аудиосигнала путем модификации первого модифицированного аудиосигнала, зависящего от направления поступления звуковой волны у виртуального местоположения виртуального микрофона и зависящего от единичного вектора, описывающего ориентацию виртуального микрофона, для получения выходного аудиосигнала, где первый модифицированный аудиосигнал модифицируют в частотно-временной области.
9. Устройство по п. 6, в котором модуль (120) вычисления информации содержит блок (520) спектрального взвешивания для создания взвешенного аудиосигнала путем модификации объединенного сигнала, зависящего от направления поступления звуковой волны у виртуального местоположения виртуального микрофона и зависящего от единичного вектора, описывающего ориентацию виртуального микрофона, для получения выходного аудиосигнала, где объединенный сигнал модифицируют в частотно-временной области.
10. Устройство по п. 8, в котором блок (520) спектрального взвешивания адаптирован для применения весового коэффициента α+(1-α)cos(φv(k, n)), или весового коэффициента
0,5+0,5cos (φv(k, n))
для взвешенного аудиосигнала,
где φv(k,n) указывает угол, задающий направления поступления звуковой волны, излучаемой звуковым событием в виртуальном месте расположения виртуального микрофона, где k обозначает индекс частоты и где n обозначает индекс времени.
0,5+0,5cos (φv(k, n))
для взвешенного аудиосигнала,
где φv(k,n) указывает угол, задающий направления поступления звуковой волны, излучаемой звуковым событием в виртуальном месте расположения виртуального микрофона, где k обозначает индекс частоты и где n обозначает индекс времени.
11. Устройство по п. 1, в котором компенсатор (500) распространения, кроме того, адаптирован для создания третьего модифицированного аудиосигнала путем модификации третьего записанного входного аудиосигнала, записанного четвертым микрофоном, путем компенсации третьей временной задержки или третьего затухания амплитуды между поступлением звуковой волны, излучаемой звуковым событием, у четвертого микрофона, и поступлением звуковой волны у виртуального микрофона, путем регулировки значения амплитуды, значения магнитуды или значения фазы третьего записанного входного аудиосигнала для получения выходного аудиосигнала.
12. Устройство по п. 1, в котором блок (110) оценки местоположения звуковых событий адаптирован для оценки местоположения звукового события в трехмерной окружающей среде.
13. Устройство по п. 1, в котором модуль (120) вычисления информации, кроме того, содержит блок (801) вычисления диффузности, адаптируемый для оценки диффузной звуковой энергии у виртуального микрофона или прямой звуковой энергии у виртуального микрофона; в котором блок (801) вычисления диффузности адаптирован для оценки диффузной звуковой энергии у виртуального микрофона на основе диффузных звуковых энергий у первого и второго реального пространственного микрофона.
14. Устройство по п. 13, в котором блок (801) вычисления диффузности адаптирован для оценки диффузной звуковой энергии
 у виртуального микрофона путем применения формулы:
у виртуального микрофона путем применения формулы:

где N - количество реальных пространственных микрофонов из множества реальных пространственных микрофонов, содержащего первый и второй реальный пространственный микрофон, и где - диффузная звуковая энергия у i-го реального пространственного микрофона.
- диффузная звуковая энергия у i-го реального пространственного микрофона.
где N - количество реальных пространственных микрофонов из множества реальных пространственных микрофонов, содержащего первый и второй реальный пространственный микрофон, и где
15. Устройство по п. 13, в котором блок (801) вычисления диффузности адаптирован для оценки прямой звуковой энергии путем применения формулы:

где «расстояние SMi-IPLS» - расстояние между местоположением i-гo реального пространственного микрофона и местоположением звукового события, где «расстояние VM-IPLS» - расстояние между виртуальным местоположением и местоположением звукового события и где - прямая энергия у i-го реального пространственного микрофона.
- прямая энергия у i-го реального пространственного микрофона.
где «расстояние SMi-IPLS» - расстояние между местоположением i-гo реального пространственного микрофона и местоположением звукового события, где «расстояние VM-IPLS» - расстояние между виртуальным местоположением и местоположением звукового события и где
16. Устройство по п. 13, в котором блок (801) вычисления диффузности адаптирован для оценки диффузности у виртуального микрофона путем оценки диффузной звуковой энергии у виртуального микрофона и прямой звуковой энергии у виртуального микрофона и путем применения формулы:

где указывает диффузность у оцениваемого виртуального микрофона, где
указывает диффузность у оцениваемого виртуального микрофона, где  указывает оцениваемую диффузную звуковую энергию и где
указывает оцениваемую диффузную звуковую энергию и где 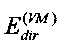 указывает оцениваемую прямую звуковую энергию.
указывает оцениваемую прямую звуковую энергию.
где
17. Способ создания выходного аудиосигнала для имитации записи выходного аудиосигнала виртуальным микрофоном у конфигурируемого виртуального места его расположения в окружающей среде, причем способ содержит:
оценку местоположения звукового события, указывающего местоположение звукового события в упомянутой окружающей среде, где звуковое событие активизировано в определенный момент времени или в определенном частотно-временном бине, где звуковое событие представляет собой реальный источник звука или источник зеркального отображения, где шаг оценки местоположения звукового события содержит оценку местоположения звукового события, указывающего местоположение источника зеркального отражения в упомянутой окружающей среде, когда звуковым событием является источник зеркального отражения, и где шаг оценки местоположения звукового события основан на информации о первом направлении, обеспечиваемой первым реальным пространственным микрофоном, который расположен по месту расположения первого реального микрофона в данной окружающей среде, и на основе информации о втором направлении, обеспечиваемой вторым реальным пространственным микрофоном, который расположен по месту расположения второго реального микрофона в данной окружающей среде, где первый реальный пространственный микрофон и второй реальный пространственный микрофон представляют собой физически существующие пространственные микрофоны; и где первый реальный пространственный микрофон и второй реальный пространственный микрофон являются устройствами для приема пространственного звука, способные извлекать информацию о направлении поступления звука, и
создание выходного аудиосигнала на основе первого записанного входного аудиосигнала, на основе местоположения первого реального микрофона, на основе виртуального местоположения виртуального микрофона и на основе местоположения звукового события;
где первый реальный пространственный микрофон сконфигурирован для записи первого записанного входного аудиосигнала, или где третий микрофон сконфигурирован для записи первого записанного входного аудиосигнала,
где оценку местоположения звукового события выполняют на основе первого направления поступления звуковой волны, излучаемой звуковым событием у места расположения первого реального микрофона в качестве информации о первом направлении, и на основе второго направления поступления звуковой волны у места расположения второго реального микрофона в качестве информации о втором направлении,
где шаг создания выходного аудиосигнала содержит создание первого модифицированного аудиосигнала путем модификации первого записанного входного аудиосигнала на основе первого затухания амплитуды между звуковым событием и первым реальным пространственным микрофоном и на основе второго затухания амплитуды между звуковым событием и виртуальным микрофоном путем регулировки значения амплитуды, значения магнитуды или значения фазы первого записанного входного аудиосигнала для получения выходного аудиосигнала; или где шаг создания выходного аудиосигнала содержит создание первого модифицированного аудиосигнала путем компенсации первой временной задержки между поступлением звуковой волны, излучаемой звуковым событием, у первого реального пространственного микрофона и поступлением звуковой волны у виртуального микрофона путем регулировки значения амплитуды, значения магнитуды или значения фазы первого записанного входного аудиосигнала для получения выходного аудиосигнала.
оценку местоположения звукового события, указывающего местоположение звукового события в упомянутой окружающей среде, где звуковое событие активизировано в определенный момент времени или в определенном частотно-временном бине, где звуковое событие представляет собой реальный источник звука или источник зеркального отображения, где шаг оценки местоположения звукового события содержит оценку местоположения звукового события, указывающего местоположение источника зеркального отражения в упомянутой окружающей среде, когда звуковым событием является источник зеркального отражения, и где шаг оценки местоположения звукового события основан на информации о первом направлении, обеспечиваемой первым реальным пространственным микрофоном, который расположен по месту расположения первого реального микрофона в данной окружающей среде, и на основе информации о втором направлении, обеспечиваемой вторым реальным пространственным микрофоном, который расположен по месту расположения второго реального микрофона в данной окружающей среде, где первый реальный пространственный микрофон и второй реальный пространственный микрофон представляют собой физически существующие пространственные микрофоны; и где первый реальный пространственный микрофон и второй реальный пространственный микрофон являются устройствами для приема пространственного звука, способные извлекать информацию о направлении поступления звука, и
создание выходного аудиосигнала на основе первого записанного входного аудиосигнала, на основе местоположения первого реального микрофона, на основе виртуального местоположения виртуального микрофона и на основе местоположения звукового события;
где первый реальный пространственный микрофон сконфигурирован для записи первого записанного входного аудиосигнала, или где третий микрофон сконфигурирован для записи первого записанного входного аудиосигнала,
где оценку местоположения звукового события выполняют на основе первого направления поступления звуковой волны, излучаемой звуковым событием у места расположения первого реального микрофона в качестве информации о первом направлении, и на основе второго направления поступления звуковой волны у места расположения второго реального микрофона в качестве информации о втором направлении,
где шаг создания выходного аудиосигнала содержит создание первого модифицированного аудиосигнала путем модификации первого записанного входного аудиосигнала на основе первого затухания амплитуды между звуковым событием и первым реальным пространственным микрофоном и на основе второго затухания амплитуды между звуковым событием и виртуальным микрофоном путем регулировки значения амплитуды, значения магнитуды или значения фазы первого записанного входного аудиосигнала для получения выходного аудиосигнала; или где шаг создания выходного аудиосигнала содержит создание первого модифицированного аудиосигнала путем компенсации первой временной задержки между поступлением звуковой волны, излучаемой звуковым событием, у первого реального пространственного микрофона и поступлением звуковой волны у виртуального микрофона путем регулировки значения амплитуды, значения магнитуды или значения фазы первого записанного входного аудиосигнала для получения выходного аудиосигнала.
18. Машиночитаемый носитель данных, содержащий компьютерную программу для реализации способа по п. 17 при ее выполнении на компьютере или процессоре сигналов.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US41962310P | 2010-12-03 | 2010-12-03 | |
| US61/419,623 | 2010-12-03 | ||
| US42009910P | 2010-12-06 | 2010-12-06 | |
| US61/420,099 | 2010-12-06 | ||
| PCT/EP2011/071629 WO2012072798A1 (en) | 2010-12-03 | 2011-12-02 | Sound acquisition via the extraction of geometrical information from direction of arrival estimates |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| RU2013130233A RU2013130233A (ru) | 2015-01-10 |
| RU2570359C2 true RU2570359C2 (ru) | 2015-12-10 |
Family
ID=45406686
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| RU2013130226/08A RU2556390C2 (ru) | 2010-12-03 | 2011-12-02 | Устройство и способ основанного на геометрии кодирования пространственного звука |
| RU2013130233/28A RU2570359C2 (ru) | 2010-12-03 | 2011-12-02 | Прием звука посредством выделения геометрической информации из оценок направления его поступления |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| RU2013130226/08A RU2556390C2 (ru) | 2010-12-03 | 2011-12-02 | Устройство и способ основанного на геометрии кодирования пространственного звука |
Country Status (16)
| Country | Link |
|---|---|
| US (2) | US9396731B2 (ru) |
| EP (2) | EP2647005B1 (ru) |
| JP (2) | JP5878549B2 (ru) |
| KR (2) | KR101619578B1 (ru) |
| CN (2) | CN103460285B (ru) |
| AR (2) | AR084091A1 (ru) |
| AU (2) | AU2011334857B2 (ru) |
| BR (1) | BR112013013681B1 (ru) |
| CA (2) | CA2819502C (ru) |
| ES (2) | ES2525839T3 (ru) |
| HK (1) | HK1190490A1 (ru) |
| MX (2) | MX338525B (ru) |
| PL (1) | PL2647222T3 (ru) |
| RU (2) | RU2556390C2 (ru) |
| TW (2) | TWI530201B (ru) |
| WO (2) | WO2012072798A1 (ru) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11272305B2 (en) | 2016-03-15 | 2022-03-08 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e. V. | Apparatus, method or computer program for generating a sound field description |
Families Citing this family (102)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9558755B1 (en) | 2010-05-20 | 2017-01-31 | Knowles Electronics, Llc | Noise suppression assisted automatic speech recognition |
| EP2600637A1 (en) * | 2011-12-02 | 2013-06-05 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for microphone positioning based on a spatial power density |
| WO2013093565A1 (en) * | 2011-12-22 | 2013-06-27 | Nokia Corporation | Spatial audio processing apparatus |
| CN104054126B (zh) * | 2012-01-19 | 2017-03-29 | 皇家飞利浦有限公司 | 空间音频渲染和编码 |
| EP2893532B1 (en) | 2012-09-03 | 2021-03-24 | Fraunhofer-Gesellschaft zur Förderung der Angewandten Forschung e.V. | Apparatus and method for providing an informed multichannel speech presence probability estimation |
| US9460729B2 (en) * | 2012-09-21 | 2016-10-04 | Dolby Laboratories Licensing Corporation | Layered approach to spatial audio coding |
| US9554203B1 (en) | 2012-09-26 | 2017-01-24 | Foundation for Research and Technolgy—Hellas (FORTH) Institute of Computer Science (ICS) | Sound source characterization apparatuses, methods and systems |
| US10175335B1 (en) | 2012-09-26 | 2019-01-08 | Foundation For Research And Technology-Hellas (Forth) | Direction of arrival (DOA) estimation apparatuses, methods, and systems |
| US9955277B1 (en) | 2012-09-26 | 2018-04-24 | Foundation For Research And Technology-Hellas (F.O.R.T.H.) Institute Of Computer Science (I.C.S.) | Spatial sound characterization apparatuses, methods and systems |
| US20160210957A1 (en) * | 2015-01-16 | 2016-07-21 | Foundation For Research And Technology - Hellas (Forth) | Foreground Signal Suppression Apparatuses, Methods, and Systems |
| US10136239B1 (en) | 2012-09-26 | 2018-11-20 | Foundation For Research And Technology—Hellas (F.O.R.T.H.) | Capturing and reproducing spatial sound apparatuses, methods, and systems |
| US10149048B1 (en) | 2012-09-26 | 2018-12-04 | Foundation for Research and Technology—Hellas (F.O.R.T.H.) Institute of Computer Science (I.C.S.) | Direction of arrival estimation and sound source enhancement in the presence of a reflective surface apparatuses, methods, and systems |
| US9549253B2 (en) * | 2012-09-26 | 2017-01-17 | Foundation for Research and Technology—Hellas (FORTH) Institute of Computer Science (ICS) | Sound source localization and isolation apparatuses, methods and systems |
| US9640194B1 (en) | 2012-10-04 | 2017-05-02 | Knowles Electronics, Llc | Noise suppression for speech processing based on machine-learning mask estimation |
| FR2998438A1 (fr) * | 2012-11-16 | 2014-05-23 | France Telecom | Acquisition de donnees sonores spatialisees |
| EP2747451A1 (en) | 2012-12-21 | 2014-06-25 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Filter and method for informed spatial filtering using multiple instantaneous direction-of-arrivial estimates |
| CN104010265A (zh) | 2013-02-22 | 2014-08-27 | 杜比实验室特许公司 | 音频空间渲染设备及方法 |
| CN104019885A (zh) | 2013-02-28 | 2014-09-03 | 杜比实验室特许公司 | 声场分析系统 |
| WO2014151813A1 (en) | 2013-03-15 | 2014-09-25 | Dolby Laboratories Licensing Corporation | Normalization of soundfield orientations based on auditory scene analysis |
| US10075795B2 (en) | 2013-04-19 | 2018-09-11 | Electronics And Telecommunications Research Institute | Apparatus and method for processing multi-channel audio signal |
| WO2014171791A1 (ko) | 2013-04-19 | 2014-10-23 | 한국전자통신연구원 | 다채널 오디오 신호 처리 장치 및 방법 |
| US9854377B2 (en) | 2013-05-29 | 2017-12-26 | Qualcomm Incorporated | Interpolation for decomposed representations of a sound field |
| CN104240711B (zh) * | 2013-06-18 | 2019-10-11 | 杜比实验室特许公司 | 用于生成自适应音频内容的方法、系统和装置 |
| CN104244164A (zh) | 2013-06-18 | 2014-12-24 | 杜比实验室特许公司 | 生成环绕立体声声场 |
| EP2830050A1 (en) | 2013-07-22 | 2015-01-28 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for enhanced spatial audio object coding |
| EP2830047A1 (en) | 2013-07-22 | 2015-01-28 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for low delay object metadata coding |
| EP2830045A1 (en) | 2013-07-22 | 2015-01-28 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Concept for audio encoding and decoding for audio channels and audio objects |
| EP2830052A1 (en) | 2013-07-22 | 2015-01-28 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Audio decoder, audio encoder, method for providing at least four audio channel signals on the basis of an encoded representation, method for providing an encoded representation on the basis of at least four audio channel signals and computer program using a bandwidth extension |
| US9319819B2 (en) * | 2013-07-25 | 2016-04-19 | Etri | Binaural rendering method and apparatus for decoding multi channel audio |
| US9712939B2 (en) | 2013-07-30 | 2017-07-18 | Dolby Laboratories Licensing Corporation | Panning of audio objects to arbitrary speaker layouts |
| CN104637495B (zh) * | 2013-11-08 | 2019-03-26 | 宏达国际电子股份有限公司 | 电子装置以及音频信号处理方法 |
| CN103618986B (zh) * | 2013-11-19 | 2015-09-30 | 深圳市新一代信息技术研究院有限公司 | 一种3d空间中音源声像体的提取方法及装置 |
| AU2014353473C1 (en) * | 2013-11-22 | 2018-04-05 | Apple Inc. | Handsfree beam pattern configuration |
| CN106465027B (zh) * | 2014-05-13 | 2019-06-04 | 弗劳恩霍夫应用研究促进协会 | 用于边缘衰落幅度平移的装置和方法 |
| US9620137B2 (en) * | 2014-05-16 | 2017-04-11 | Qualcomm Incorporated | Determining between scalar and vector quantization in higher order ambisonic coefficients |
| US10770087B2 (en) | 2014-05-16 | 2020-09-08 | Qualcomm Incorporated | Selecting codebooks for coding vectors decomposed from higher-order ambisonic audio signals |
| WO2016033364A1 (en) * | 2014-08-28 | 2016-03-03 | Audience, Inc. | Multi-sourced noise suppression |
| CN105376691B (zh) | 2014-08-29 | 2019-10-08 | 杜比实验室特许公司 | 感知方向的环绕声播放 |
| CN104168534A (zh) * | 2014-09-01 | 2014-11-26 | 北京塞宾科技有限公司 | 一种全息音频装置及控制方法 |
| US9774974B2 (en) * | 2014-09-24 | 2017-09-26 | Electronics And Telecommunications Research Institute | Audio metadata providing apparatus and method, and multichannel audio data playback apparatus and method to support dynamic format conversion |
| CN104378570A (zh) * | 2014-09-28 | 2015-02-25 | 小米科技有限责任公司 | 录音方法及装置 |
| WO2016056410A1 (ja) * | 2014-10-10 | 2016-04-14 | ソニー株式会社 | 音声処理装置および方法、並びにプログラム |
| CN107533843B (zh) | 2015-01-30 | 2021-06-11 | Dts公司 | 用于捕获、编码、分布和解码沉浸式音频的系统和方法 |
| TWI579835B (zh) * | 2015-03-19 | 2017-04-21 | 絡達科技股份有限公司 | 音效增益方法 |
| EP3079074A1 (fr) * | 2015-04-10 | 2016-10-12 | B<>Com | Procédé de traitement de données pour l'estimation de paramètres de mixage de signaux audio, procédé de mixage, dispositifs, et programmes d'ordinateurs associés |
| US9609436B2 (en) | 2015-05-22 | 2017-03-28 | Microsoft Technology Licensing, Llc | Systems and methods for audio creation and delivery |
| US9530426B1 (en) | 2015-06-24 | 2016-12-27 | Microsoft Technology Licensing, Llc | Filtering sounds for conferencing applications |
| US9601131B2 (en) * | 2015-06-25 | 2017-03-21 | Htc Corporation | Sound processing device and method |
| HK1255002A1 (zh) | 2015-07-02 | 2019-08-02 | 杜比實驗室特許公司 | 根據立體聲記錄確定方位角和俯仰角 |
| US10375472B2 (en) | 2015-07-02 | 2019-08-06 | Dolby Laboratories Licensing Corporation | Determining azimuth and elevation angles from stereo recordings |
| GB2543275A (en) * | 2015-10-12 | 2017-04-19 | Nokia Technologies Oy | Distributed audio capture and mixing |
| TWI577194B (zh) * | 2015-10-22 | 2017-04-01 | 山衛科技股份有限公司 | 環境音源辨識系統及其環境音源辨識之方法 |
| WO2017073324A1 (ja) * | 2015-10-26 | 2017-05-04 | ソニー株式会社 | 信号処理装置、信号処理方法、並びにプログラム |
| US10206040B2 (en) * | 2015-10-30 | 2019-02-12 | Essential Products, Inc. | Microphone array for generating virtual sound field |
| EP3174316B1 (en) * | 2015-11-27 | 2020-02-26 | Nokia Technologies Oy | Intelligent audio rendering |
| US9894434B2 (en) | 2015-12-04 | 2018-02-13 | Sennheiser Electronic Gmbh & Co. Kg | Conference system with a microphone array system and a method of speech acquisition in a conference system |
| US11064291B2 (en) | 2015-12-04 | 2021-07-13 | Sennheiser Electronic Gmbh & Co. Kg | Microphone array system |
| US9956910B2 (en) * | 2016-07-18 | 2018-05-01 | Toyota Motor Engineering & Manufacturing North America, Inc. | Audible notification systems and methods for autonomous vehicles |
| GB2554446A (en) * | 2016-09-28 | 2018-04-04 | Nokia Technologies Oy | Spatial audio signal format generation from a microphone array using adaptive capture |
| US9986357B2 (en) | 2016-09-28 | 2018-05-29 | Nokia Technologies Oy | Fitting background ambiance to sound objects |
| CN109906616B (zh) | 2016-09-29 | 2021-05-21 | 杜比实验室特许公司 | 用于确定一或多个音频源的一或多个音频表示的方法、系统和设备 |
| US9980078B2 (en) | 2016-10-14 | 2018-05-22 | Nokia Technologies Oy | Audio object modification in free-viewpoint rendering |
| US10531220B2 (en) * | 2016-12-05 | 2020-01-07 | Magic Leap, Inc. | Distributed audio capturing techniques for virtual reality (VR), augmented reality (AR), and mixed reality (MR) systems |
| CN106708041B (zh) * | 2016-12-12 | 2020-12-29 | 西安Tcl软件开发有限公司 | 智能音箱、智能音箱定向移动方法及装置 |
| US11096004B2 (en) | 2017-01-23 | 2021-08-17 | Nokia Technologies Oy | Spatial audio rendering point extension |
| US10229667B2 (en) | 2017-02-08 | 2019-03-12 | Logitech Europe S.A. | Multi-directional beamforming device for acquiring and processing audible input |
| US10362393B2 (en) | 2017-02-08 | 2019-07-23 | Logitech Europe, S.A. | Direction detection device for acquiring and processing audible input |
| US10366702B2 (en) | 2017-02-08 | 2019-07-30 | Logitech Europe, S.A. | Direction detection device for acquiring and processing audible input |
| US10366700B2 (en) | 2017-02-08 | 2019-07-30 | Logitech Europe, S.A. | Device for acquiring and processing audible input |
| US10531219B2 (en) | 2017-03-20 | 2020-01-07 | Nokia Technologies Oy | Smooth rendering of overlapping audio-object interactions |
| US10397724B2 (en) | 2017-03-27 | 2019-08-27 | Samsung Electronics Co., Ltd. | Modifying an apparent elevation of a sound source utilizing second-order filter sections |
| US11074036B2 (en) | 2017-05-05 | 2021-07-27 | Nokia Technologies Oy | Metadata-free audio-object interactions |
| US10165386B2 (en) * | 2017-05-16 | 2018-12-25 | Nokia Technologies Oy | VR audio superzoom |
| IT201700055080A1 (it) * | 2017-05-22 | 2018-11-22 | Teko Telecom S R L | Sistema di comunicazione wireless e relativo metodo per il trattamento di dati fronthaul di uplink |
| US10602296B2 (en) | 2017-06-09 | 2020-03-24 | Nokia Technologies Oy | Audio object adjustment for phase compensation in 6 degrees of freedom audio |
| US10334360B2 (en) * | 2017-06-12 | 2019-06-25 | Revolabs, Inc | Method for accurately calculating the direction of arrival of sound at a microphone array |
| GB2563606A (en) | 2017-06-20 | 2018-12-26 | Nokia Technologies Oy | Spatial audio processing |
| GB201710085D0 (en) | 2017-06-23 | 2017-08-09 | Nokia Technologies Oy | Determination of targeted spatial audio parameters and associated spatial audio playback |
| GB201710093D0 (en) * | 2017-06-23 | 2017-08-09 | Nokia Technologies Oy | Audio distance estimation for spatial audio processing |
| CN111108555B (zh) | 2017-07-14 | 2023-12-15 | 弗劳恩霍夫应用研究促进协会 | 使用深度扩展DirAC技术或其他技术生成经增强的声场描述或经修改的声场描述的装置和方法 |
| RU2736418C1 (ru) * | 2017-07-14 | 2020-11-17 | Фраунхофер-Гезелльшафт Цур Фердерунг Дер Ангевандтен Форшунг Е.Ф. | Принцип формирования улучшенного описания звукового поля или модифицированного описания звукового поля с использованием многоточечного описания звукового поля |
| AR112504A1 (es) | 2017-07-14 | 2019-11-06 | Fraunhofer Ges Forschung | Concepto para generar una descripción mejorada de campo de sonido o un campo de sonido modificado utilizando una descripción multi-capa |
| US10264354B1 (en) * | 2017-09-25 | 2019-04-16 | Cirrus Logic, Inc. | Spatial cues from broadside detection |
| US11395087B2 (en) | 2017-09-29 | 2022-07-19 | Nokia Technologies Oy | Level-based audio-object interactions |
| CN111201784B (zh) | 2017-10-17 | 2021-09-07 | 惠普发展公司,有限责任合伙企业 | 通信系统、用于通信的方法和视频会议系统 |
| US10542368B2 (en) | 2018-03-27 | 2020-01-21 | Nokia Technologies Oy | Audio content modification for playback audio |
| TWI690921B (zh) * | 2018-08-24 | 2020-04-11 | 緯創資通股份有限公司 | 收音處理裝置及其收音處理方法 |
| US11017790B2 (en) * | 2018-11-30 | 2021-05-25 | International Business Machines Corporation | Avoiding speech collisions among participants during teleconferences |
| BR112021010964A2 (pt) | 2018-12-07 | 2021-08-31 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Aparelho e método para gerar uma descrição de campo de som |
| EP3928315A4 (en) * | 2019-03-14 | 2022-11-30 | Boomcloud 360, Inc. | SPATIALLY SENSITIVE MULTIBAND COMPRESSION SYSTEM WITH PRIORITY |
| US11968268B2 (en) | 2019-07-30 | 2024-04-23 | Dolby Laboratories Licensing Corporation | Coordination of audio devices |
| KR102154553B1 (ko) * | 2019-09-18 | 2020-09-10 | 한국표준과학연구원 | 지향성이 향상된 마이크로폰 어레이 및 이를 이용한 음장 취득 방법 |
| WO2021060680A1 (en) | 2019-09-24 | 2021-04-01 | Samsung Electronics Co., Ltd. | Methods and systems for recording mixed audio signal and reproducing directional audio |
| TW202123220A (zh) | 2019-10-30 | 2021-06-16 | 美商杜拜研究特許公司 | 使用方向性元資料之多通道音頻編碼及解碼 |
| CN113284504A (zh) | 2020-02-20 | 2021-08-20 | 北京三星通信技术研究有限公司 | 姿态检测方法、装置、电子设备及计算机可读存储介质 |
| US11277689B2 (en) | 2020-02-24 | 2022-03-15 | Logitech Europe S.A. | Apparatus and method for optimizing sound quality of a generated audible signal |
| US11425523B2 (en) * | 2020-04-10 | 2022-08-23 | Facebook Technologies, Llc | Systems and methods for audio adjustment |
| CN112083379B (zh) * | 2020-09-09 | 2023-10-20 | 极米科技股份有限公司 | 基于声源定位的音频播放方法、装置、投影设备及介质 |
| US20240129666A1 (en) * | 2021-01-29 | 2024-04-18 | Nippon Telegraph And Telephone Corporation | Signal processing device, signal processing method, signal processing program, training device, training method, and training program |
| CN116918350A (zh) * | 2021-04-25 | 2023-10-20 | 深圳市韶音科技有限公司 | 声学装置 |
| US20230035531A1 (en) * | 2021-07-27 | 2023-02-02 | Qualcomm Incorporated | Audio event data processing |
| DE202022105574U1 (de) | 2022-10-01 | 2022-10-20 | Veerendra Dakulagi | Ein System zur Klassifizierung mehrerer Signale für die Schätzung der Ankunftsrichtung |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB2414369A (en) * | 2004-05-21 | 2005-11-23 | Hewlett Packard Development Co | Processing audio data |
| RU2315371C2 (ru) * | 2002-12-28 | 2008-01-20 | Самсунг Электроникс Ко., Лтд. | Способ и устройство для смешивания аудиопотока и носитель информации |
| WO2009046223A2 (en) * | 2007-10-03 | 2009-04-09 | Creative Technology Ltd | Spatial audio analysis and synthesis for binaural reproduction and format conversion |
| US20090252356A1 (en) * | 2006-05-17 | 2009-10-08 | Creative Technology Ltd | Spatial audio analysis and synthesis for binaural reproduction and format conversion |
| WO2010028784A1 (en) * | 2008-09-11 | 2010-03-18 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus, method and computer program for providing a set of spatial cues on the basis of a microphone signal and apparatus for providing a two-channel audio signal and a set of spatial cues |
| US20100169103A1 (en) * | 2007-03-21 | 2010-07-01 | Ville Pulkki | Method and apparatus for enhancement of audio reconstruction |
Family Cites Families (65)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH01109996A (ja) * | 1987-10-23 | 1989-04-26 | Sony Corp | マイクロホン装置 |
| JPH04181898A (ja) * | 1990-11-15 | 1992-06-29 | Ricoh Co Ltd | マイクロホン |
| JPH1063470A (ja) * | 1996-06-12 | 1998-03-06 | Nintendo Co Ltd | 画像表示に連動する音響発生装置 |
| US6577738B2 (en) * | 1996-07-17 | 2003-06-10 | American Technology Corporation | Parametric virtual speaker and surround-sound system |
| US6072878A (en) | 1997-09-24 | 2000-06-06 | Sonic Solutions | Multi-channel surround sound mastering and reproduction techniques that preserve spatial harmonics |
| JP3344647B2 (ja) * | 1998-02-18 | 2002-11-11 | 富士通株式会社 | マイクロホンアレイ装置 |
| JP3863323B2 (ja) | 1999-08-03 | 2006-12-27 | 富士通株式会社 | マイクロホンアレイ装置 |
| JP4861593B2 (ja) * | 2000-04-19 | 2012-01-25 | エスエヌケー テック インベストメント エル.エル.シー. | 3次元空間高調波を保存するマルチチャンネルサラウンドサウンドマスタリングおよび再生方法 |
| KR100387238B1 (ko) * | 2000-04-21 | 2003-06-12 | 삼성전자주식회사 | 오디오 변조 기능을 갖는 오디오 재생 장치 및 방법, 그장치를 적용한 리믹싱 장치 및 방법 |
| GB2364121B (en) | 2000-06-30 | 2004-11-24 | Mitel Corp | Method and apparatus for locating a talker |
| JP4304845B2 (ja) * | 2000-08-03 | 2009-07-29 | ソニー株式会社 | 音声信号処理方法及び音声信号処理装置 |
| AU2003269551A1 (en) * | 2002-10-15 | 2004-05-04 | Electronics And Telecommunications Research Institute | Method for generating and consuming 3d audio scene with extended spatiality of sound source |
| KR100626661B1 (ko) * | 2002-10-15 | 2006-09-22 | 한국전자통신연구원 | 공간성이 확장된 음원을 갖는 3차원 음향 장면 처리 방법 |
| KR101014404B1 (ko) * | 2002-11-15 | 2011-02-15 | 소니 주식회사 | 오디오신호의 처리방법 및 처리장치 |
| JP2004193877A (ja) * | 2002-12-10 | 2004-07-08 | Sony Corp | 音像定位信号処理装置および音像定位信号処理方法 |
| KR20040060718A (ko) | 2002-12-28 | 2004-07-06 | 삼성전자주식회사 | 오디오 스트림 믹싱 방법, 그 장치 및 그 정보저장매체 |
| JP3639280B2 (ja) | 2003-02-12 | 2005-04-20 | 任天堂株式会社 | ゲームメッセージ表示方法およびゲームプログラム |
| FI118247B (fi) | 2003-02-26 | 2007-08-31 | Fraunhofer Ges Forschung | Menetelmä luonnollisen tai modifioidun tilavaikutelman aikaansaamiseksi monikanavakuuntelussa |
| JP4133559B2 (ja) | 2003-05-02 | 2008-08-13 | 株式会社コナミデジタルエンタテインメント | 音声再生プログラム、音声再生方法及び音声再生装置 |
| US20060104451A1 (en) * | 2003-08-07 | 2006-05-18 | Tymphany Corporation | Audio reproduction system |
| EP1735779B1 (en) | 2004-04-05 | 2013-06-19 | Koninklijke Philips Electronics N.V. | Encoder apparatus, decoder apparatus, methods thereof and associated audio system |
| KR100586893B1 (ko) | 2004-06-28 | 2006-06-08 | 삼성전자주식회사 | 시변 잡음 환경에서의 화자 위치 추정 시스템 및 방법 |
| WO2006006935A1 (en) | 2004-07-08 | 2006-01-19 | Agency For Science, Technology And Research | Capturing sound from a target region |
| US7617501B2 (en) | 2004-07-09 | 2009-11-10 | Quest Software, Inc. | Apparatus, system, and method for managing policies on a computer having a foreign operating system |
| US7903824B2 (en) * | 2005-01-10 | 2011-03-08 | Agere Systems Inc. | Compact side information for parametric coding of spatial audio |
| DE102005010057A1 (de) | 2005-03-04 | 2006-09-07 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Vorrichtung und Verfahren zum Erzeugen eines codierten Stereo-Signals eines Audiostücks oder Audiodatenstroms |
| EP2030420A4 (en) | 2005-03-28 | 2009-06-03 | Sound Id | PERSONAL AUDIO SYSTEM |
| JP4273343B2 (ja) * | 2005-04-18 | 2009-06-03 | ソニー株式会社 | 再生装置および再生方法 |
| US20070047742A1 (en) | 2005-08-26 | 2007-03-01 | Step Communications Corporation, A Nevada Corporation | Method and system for enhancing regional sensitivity noise discrimination |
| US20090122994A1 (en) * | 2005-10-18 | 2009-05-14 | Pioneer Corporation | Localization control device, localization control method, localization control program, and computer-readable recording medium |
| US8705747B2 (en) | 2005-12-08 | 2014-04-22 | Electronics And Telecommunications Research Institute | Object-based 3-dimensional audio service system using preset audio scenes |
| BRPI0707969B1 (pt) | 2006-02-21 | 2020-01-21 | Koninklijke Philips Electonics N V | codificador de áudio, decodificador de áudio, método de codificação de áudio, receptor para receber um sinal de áudio, transmissor, método para transmitir um fluxo de dados de saída de áudio, e produto de programa de computador |
| GB0604076D0 (en) * | 2006-03-01 | 2006-04-12 | Univ Lancaster | Method and apparatus for signal presentation |
| WO2007099318A1 (en) | 2006-03-01 | 2007-09-07 | The University Of Lancaster | Method and apparatus for signal presentation |
| EP2501128B1 (en) * | 2006-05-19 | 2014-11-12 | Electronics and Telecommunications Research Institute | Object-based 3-dimensional audio service system using preset audio scenes |
| US20080004729A1 (en) * | 2006-06-30 | 2008-01-03 | Nokia Corporation | Direct encoding into a directional audio coding format |
| JP4894386B2 (ja) * | 2006-07-21 | 2012-03-14 | ソニー株式会社 | 音声信号処理装置、音声信号処理方法および音声信号処理プログラム |
| US8229754B1 (en) * | 2006-10-23 | 2012-07-24 | Adobe Systems Incorporated | Selecting features of displayed audio data across time |
| EP2595152A3 (en) * | 2006-12-27 | 2013-11-13 | Electronics and Telecommunications Research Institute | Transkoding apparatus |
| JP4449987B2 (ja) * | 2007-02-15 | 2010-04-14 | ソニー株式会社 | 音声処理装置、音声処理方法およびプログラム |
| JP4221035B2 (ja) * | 2007-03-30 | 2009-02-12 | 株式会社コナミデジタルエンタテインメント | ゲーム音出力装置、音像定位制御方法、および、プログラム |
| JP5520812B2 (ja) | 2007-04-19 | 2014-06-11 | クアルコム,インコーポレイテッド | 音と位置の測定 |
| FR2916078A1 (fr) * | 2007-05-10 | 2008-11-14 | France Telecom | Procede de codage et decodage audio, codeur audio, decodeur audio et programmes d'ordinateur associes |
| US8180062B2 (en) * | 2007-05-30 | 2012-05-15 | Nokia Corporation | Spatial sound zooming |
| US20080298610A1 (en) | 2007-05-30 | 2008-12-04 | Nokia Corporation | Parameter Space Re-Panning for Spatial Audio |
| JP5294603B2 (ja) * | 2007-10-03 | 2013-09-18 | 日本電信電話株式会社 | 音響信号推定装置、音響信号合成装置、音響信号推定合成装置、音響信号推定方法、音響信号合成方法、音響信号推定合成方法、これらの方法を用いたプログラム、及び記録媒体 |
| KR101415026B1 (ko) | 2007-11-19 | 2014-07-04 | 삼성전자주식회사 | 마이크로폰 어레이를 이용한 다채널 사운드 획득 방법 및장치 |
| US20090180631A1 (en) | 2008-01-10 | 2009-07-16 | Sound Id | Personal sound system for display of sound pressure level or other environmental condition |
| JP5686358B2 (ja) * | 2008-03-07 | 2015-03-18 | 学校法人日本大学 | 音源距離計測装置及びそれを用いた音響情報分離装置 |
| KR101461685B1 (ko) * | 2008-03-31 | 2014-11-19 | 한국전자통신연구원 | 다객체 오디오 신호의 부가정보 비트스트림 생성 방법 및 장치 |
| JP2009246827A (ja) * | 2008-03-31 | 2009-10-22 | Nippon Hoso Kyokai <Nhk> | 音源及び仮想音源の位置特定装置、方法及びプログラム |
| US8457328B2 (en) * | 2008-04-22 | 2013-06-04 | Nokia Corporation | Method, apparatus and computer program product for utilizing spatial information for audio signal enhancement in a distributed network environment |
| ES2425814T3 (es) | 2008-08-13 | 2013-10-17 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Aparato para determinar una señal de audio espacial convertida |
| EP2154910A1 (en) * | 2008-08-13 | 2010-02-17 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus for merging spatial audio streams |
| US8023660B2 (en) * | 2008-09-11 | 2011-09-20 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Apparatus, method and computer program for providing a set of spatial cues on the basis of a microphone signal and apparatus for providing a two-channel audio signal and a set of spatial cues |
| WO2010070225A1 (fr) * | 2008-12-15 | 2010-06-24 | France Telecom | Codage perfectionne de signaux audionumeriques multicanaux |
| JP5309953B2 (ja) | 2008-12-17 | 2013-10-09 | ヤマハ株式会社 | 収音装置 |
| EP2205007B1 (en) * | 2008-12-30 | 2019-01-09 | Dolby International AB | Method and apparatus for three-dimensional acoustic field encoding and optimal reconstruction |
| JP5530741B2 (ja) * | 2009-02-13 | 2014-06-25 | 本田技研工業株式会社 | 残響抑圧装置及び残響抑圧方法 |
| JP5197458B2 (ja) * | 2009-03-25 | 2013-05-15 | 株式会社東芝 | 受音信号処理装置、方法およびプログラム |
| JP5314129B2 (ja) * | 2009-03-31 | 2013-10-16 | パナソニック株式会社 | 音響再生装置及び音響再生方法 |
| CN102414743A (zh) * | 2009-04-21 | 2012-04-11 | 皇家飞利浦电子股份有限公司 | 音频信号合成 |
| EP2249334A1 (en) * | 2009-05-08 | 2010-11-10 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Audio format transcoder |
| EP2346028A1 (en) | 2009-12-17 | 2011-07-20 | Fraunhofer-Gesellschaft zur Förderung der Angewandten Forschung e.V. | An apparatus and a method for converting a first parametric spatial audio signal into a second parametric spatial audio signal |
| KR20120059827A (ko) * | 2010-12-01 | 2012-06-11 | 삼성전자주식회사 | 다중 음원 위치추적장치 및 그 위치추적방법 |
-
2011
- 2011-12-02 PL PL11801647T patent/PL2647222T3/pl unknown
- 2011-12-02 AR ARP110104509A patent/AR084091A1/es active IP Right Grant
- 2011-12-02 CN CN201180066795.0A patent/CN103460285B/zh active Active
- 2011-12-02 JP JP2013541377A patent/JP5878549B2/ja active Active
- 2011-12-02 CA CA2819502A patent/CA2819502C/en active Active
- 2011-12-02 TW TW100144576A patent/TWI530201B/zh active
- 2011-12-02 JP JP2013541374A patent/JP5728094B2/ja active Active
- 2011-12-02 KR KR1020137017441A patent/KR101619578B1/ko active IP Right Grant
- 2011-12-02 MX MX2013006150A patent/MX338525B/es active IP Right Grant
- 2011-12-02 EP EP11801648.4A patent/EP2647005B1/en active Active
- 2011-12-02 CA CA2819394A patent/CA2819394C/en active Active
- 2011-12-02 ES ES11801647.6T patent/ES2525839T3/es active Active
- 2011-12-02 WO PCT/EP2011/071629 patent/WO2012072798A1/en active Application Filing
- 2011-12-02 RU RU2013130226/08A patent/RU2556390C2/ru active
- 2011-12-02 AU AU2011334857A patent/AU2011334857B2/en active Active
- 2011-12-02 ES ES11801648.4T patent/ES2643163T3/es active Active
- 2011-12-02 RU RU2013130233/28A patent/RU2570359C2/ru active
- 2011-12-02 WO PCT/EP2011/071644 patent/WO2012072804A1/en active Application Filing
- 2011-12-02 MX MX2013006068A patent/MX2013006068A/es active IP Right Grant
- 2011-12-02 TW TW100144577A patent/TWI489450B/zh active
- 2011-12-02 AU AU2011334851A patent/AU2011334851B2/en active Active
- 2011-12-02 CN CN201180066792.7A patent/CN103583054B/zh active Active
- 2011-12-02 KR KR1020137017057A patent/KR101442446B1/ko active IP Right Grant
- 2011-12-02 BR BR112013013681-2A patent/BR112013013681B1/pt active IP Right Grant
- 2011-12-02 EP EP11801647.6A patent/EP2647222B1/en active Active
- 2011-12-05 AR ARP110104544A patent/AR084160A1/es active IP Right Grant
-
2013
- 2013-05-29 US US13/904,870 patent/US9396731B2/en active Active
- 2013-05-31 US US13/907,510 patent/US10109282B2/en active Active
-
2014
- 2014-04-09 HK HK14103418.2A patent/HK1190490A1/xx unknown
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| RU2315371C2 (ru) * | 2002-12-28 | 2008-01-20 | Самсунг Электроникс Ко., Лтд. | Способ и устройство для смешивания аудиопотока и носитель информации |
| GB2414369A (en) * | 2004-05-21 | 2005-11-23 | Hewlett Packard Development Co | Processing audio data |
| US20090252356A1 (en) * | 2006-05-17 | 2009-10-08 | Creative Technology Ltd | Spatial audio analysis and synthesis for binaural reproduction and format conversion |
| US20100169103A1 (en) * | 2007-03-21 | 2010-07-01 | Ville Pulkki | Method and apparatus for enhancement of audio reconstruction |
| WO2009046223A2 (en) * | 2007-10-03 | 2009-04-09 | Creative Technology Ltd | Spatial audio analysis and synthesis for binaural reproduction and format conversion |
| WO2010028784A1 (en) * | 2008-09-11 | 2010-03-18 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus, method and computer program for providing a set of spatial cues on the basis of a microphone signal and apparatus for providing a two-channel audio signal and a set of spatial cues |
Non-Patent Citations (1)
| Title |
|---|
| Amin Karbasi and Akihiko Sugiyama A NEW DOA ESTIMATION METHOD USING A CIRCULAR MICROPHONE ARRAY // EUSIPCO, 2007. * |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11272305B2 (en) | 2016-03-15 | 2022-03-08 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e. V. | Apparatus, method or computer program for generating a sound field description |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| RU2570359C2 (ru) | Прием звука посредством выделения геометрической информации из оценок направления его поступления | |
| KR101591220B1 (ko) | 공간적 전력 밀도에 기초하여 마이크 위치 결정을 위한 장치 및 방법 | |
| RU2609102C2 (ru) | Устройство и способ для совмещения потоков пространственного аудиокодирования на основе геометрии | |
| Del Galdo et al. | Generating virtual microphone signals using geometrical information gathered by distributed arrays |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| HZ9A | Changing address for correspondence with an applicant |