KR20190118163A - 가족성 고콜레스테롤혈증을 치료하기 위한 유전자 요법 - Google Patents
가족성 고콜레스테롤혈증을 치료하기 위한 유전자 요법 Download PDFInfo
- Publication number
- KR20190118163A KR20190118163A KR1020197024773A KR20197024773A KR20190118163A KR 20190118163 A KR20190118163 A KR 20190118163A KR 1020197024773 A KR1020197024773 A KR 1020197024773A KR 20197024773 A KR20197024773 A KR 20197024773A KR 20190118163 A KR20190118163 A KR 20190118163A
- Authority
- KR
- South Korea
- Prior art keywords
- raav
- leu
- gly
- ser
- asp
- Prior art date
Links
- 206010045261 Type IIa hyperlipidaemia Diseases 0.000 title claims abstract description 104
- 208000000563 Hyperlipoproteinemia Type II Diseases 0.000 title claims abstract description 30
- 102100024640 Low-density lipoprotein receptor Human genes 0.000 title claims abstract description 30
- 201000001386 familial hypercholesterolemia Diseases 0.000 title claims abstract description 30
- 238000001415 gene therapy Methods 0.000 title description 50
- 238000000034 method Methods 0.000 claims abstract description 86
- 241000282414 Homo sapiens Species 0.000 claims abstract description 54
- 230000010076 replication Effects 0.000 claims abstract description 27
- 239000000725 suspension Substances 0.000 claims abstract description 26
- 241000702421 Dependoparvovirus Species 0.000 claims abstract description 22
- 238000001802 infusion Methods 0.000 claims abstract description 21
- 230000002950 deficient Effects 0.000 claims abstract description 18
- 210000003462 vein Anatomy 0.000 claims abstract description 16
- 230000002093 peripheral effect Effects 0.000 claims abstract description 14
- 239000013598 vector Substances 0.000 claims description 237
- 101001051093 Homo sapiens Low-density lipoprotein receptor Proteins 0.000 claims description 188
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 claims description 107
- 238000011282 treatment Methods 0.000 claims description 92
- 208000030673 Homozygous familial hypercholesterolemia Diseases 0.000 claims description 78
- 241000699670 Mus sp. Species 0.000 claims description 74
- 210000000234 capsid Anatomy 0.000 claims description 71
- 210000004185 liver Anatomy 0.000 claims description 62
- 239000002245 particle Substances 0.000 claims description 45
- 230000009467 reduction Effects 0.000 claims description 38
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 claims description 28
- 230000000694 effects Effects 0.000 claims description 26
- 238000010172 mouse model Methods 0.000 claims description 25
- 239000000203 mixture Substances 0.000 claims description 24
- 230000003472 neutralizing effect Effects 0.000 claims description 23
- 238000001990 intravenous administration Methods 0.000 claims description 20
- 241001164825 Adeno-associated virus - 8 Species 0.000 claims description 19
- 230000037396 body weight Effects 0.000 claims description 18
- 230000002829 reductive effect Effects 0.000 claims description 17
- 230000001506 immunosuppresive effect Effects 0.000 claims description 14
- 238000002347 injection Methods 0.000 claims description 14
- 239000007924 injection Substances 0.000 claims description 14
- 239000011780 sodium chloride Substances 0.000 claims description 14
- RVGRUAULSDPKGF-UHFFFAOYSA-N Poloxamer Chemical compound C1CO1.CC1CO1 RVGRUAULSDPKGF-UHFFFAOYSA-N 0.000 claims description 13
- 239000012537 formulation buffer Substances 0.000 claims description 12
- 150000007523 nucleic acids Chemical group 0.000 claims description 12
- 239000002953 phosphate buffered saline Substances 0.000 claims description 12
- 229940122392 PCSK9 inhibitor Drugs 0.000 claims description 11
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 10
- 239000004615 ingredient Substances 0.000 claims description 8
- 229920001993 poloxamer 188 Polymers 0.000 claims description 8
- 229940044519 poloxamer 188 Drugs 0.000 claims description 8
- 238000001356 surgical procedure Methods 0.000 claims description 7
- 239000007864 aqueous solution Substances 0.000 claims description 6
- 229920001983 poloxamer Polymers 0.000 claims description 6
- 229960000502 poloxamer Drugs 0.000 claims description 5
- 230000007812 deficiency Effects 0.000 claims description 4
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 claims description 4
- 239000008194 pharmaceutical composition Substances 0.000 claims 13
- 229910019142 PO4 Inorganic materials 0.000 claims 4
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 claims 4
- 239000010452 phosphate Substances 0.000 claims 4
- 238000003306 harvesting Methods 0.000 abstract description 5
- 102000043555 human LDLR Human genes 0.000 description 166
- 102000002248 Thyroxine-Binding Globulin Human genes 0.000 description 105
- 108010000259 Thyroxine-Binding Globulin Proteins 0.000 description 105
- XUIIKFGFIJCVMT-UHFFFAOYSA-N thyroxine-binding globulin Natural products IC1=CC(CC([NH3+])C([O-])=O)=CC(I)=C1OC1=CC(I)=C(O)C(I)=C1 XUIIKFGFIJCVMT-UHFFFAOYSA-N 0.000 description 105
- 210000004027 cell Anatomy 0.000 description 86
- 108090000623 proteins and genes Proteins 0.000 description 65
- 108010028554 LDL Cholesterol Proteins 0.000 description 62
- 102000000853 LDL receptors Human genes 0.000 description 59
- 108010001831 LDL receptors Proteins 0.000 description 59
- 230000014509 gene expression Effects 0.000 description 55
- 239000013612 plasmid Substances 0.000 description 50
- 241001465754 Metazoa Species 0.000 description 45
- 108700019146 Transgenes Proteins 0.000 description 37
- 241000282326 Felis catus Species 0.000 description 31
- 108010007622 LDL Lipoproteins Proteins 0.000 description 31
- 102000007330 LDL Lipoproteins Human genes 0.000 description 31
- 238000012360 testing method Methods 0.000 description 31
- 108020004414 DNA Proteins 0.000 description 30
- 102000053602 DNA Human genes 0.000 description 30
- 239000000543 intermediate Substances 0.000 description 29
- 238000002560 therapeutic procedure Methods 0.000 description 28
- 201000001320 Atherosclerosis Diseases 0.000 description 24
- 108010047857 aspartylglycine Proteins 0.000 description 22
- 235000012000 cholesterol Nutrition 0.000 description 22
- 230000035772 mutation Effects 0.000 description 22
- 239000000047 product Substances 0.000 description 22
- 108010003415 Aspartate Aminotransferases Proteins 0.000 description 21
- 102000004625 Aspartate Aminotransferases Human genes 0.000 description 21
- 238000003556 assay Methods 0.000 description 21
- 230000007423 decrease Effects 0.000 description 21
- 102100036475 Alanine aminotransferase 1 Human genes 0.000 description 20
- 108010082126 Alanine transaminase Proteins 0.000 description 20
- 239000000872 buffer Substances 0.000 description 20
- 210000002966 serum Anatomy 0.000 description 20
- 238000002648 combination therapy Methods 0.000 description 18
- 238000002360 preparation method Methods 0.000 description 18
- 210000001744 T-lymphocyte Anatomy 0.000 description 17
- 238000005070 sampling Methods 0.000 description 17
- 239000013607 AAV vector Substances 0.000 description 16
- 108010023302 HDL Cholesterol Proteins 0.000 description 16
- 229940079593 drug Drugs 0.000 description 16
- 239000003814 drug Substances 0.000 description 16
- 101150102415 Apob gene Proteins 0.000 description 15
- 150000001413 amino acids Chemical group 0.000 description 15
- 108010038633 aspartylglutamate Proteins 0.000 description 15
- 230000008859 change Effects 0.000 description 15
- 150000002632 lipids Chemical class 0.000 description 15
- 239000000463 material Substances 0.000 description 15
- 230000008569 process Effects 0.000 description 15
- 239000000523 sample Substances 0.000 description 15
- 241000701161 unidentified adenovirus Species 0.000 description 15
- 241000282560 Macaca mulatta Species 0.000 description 14
- 241000699666 Mus <mouse, genus> Species 0.000 description 14
- 238000009472 formulation Methods 0.000 description 14
- 238000004519 manufacturing process Methods 0.000 description 14
- 238000004458 analytical method Methods 0.000 description 13
- 108010050848 glycylleucine Proteins 0.000 description 13
- 230000007170 pathology Effects 0.000 description 13
- 235000018102 proteins Nutrition 0.000 description 13
- 102000004169 proteins and genes Human genes 0.000 description 13
- 238000003753 real-time PCR Methods 0.000 description 13
- 210000000709 aorta Anatomy 0.000 description 12
- 108010078144 glutaminyl-glycine Proteins 0.000 description 12
- 238000013411 master cell bank Methods 0.000 description 12
- 210000001519 tissue Anatomy 0.000 description 12
- 231100000419 toxicity Toxicity 0.000 description 12
- 230000001988 toxicity Effects 0.000 description 12
- 241000702423 Adeno-associated virus - 2 Species 0.000 description 11
- 238000009295 crossflow filtration Methods 0.000 description 11
- 239000003623 enhancer Substances 0.000 description 11
- -1 opioids Proteins 0.000 description 11
- 238000010361 transduction Methods 0.000 description 11
- 230000026683 transduction Effects 0.000 description 11
- 208000002267 Anti-neutrophil cytoplasmic antibody-associated vasculitis Diseases 0.000 description 10
- 241000282693 Cercopithecidae Species 0.000 description 10
- 108091092195 Intron Proteins 0.000 description 10
- 229940127355 PCSK9 Inhibitors Drugs 0.000 description 10
- 230000027455 binding Effects 0.000 description 10
- AIYUHDOJVYHVIT-UHFFFAOYSA-M caesium chloride Chemical compound [Cl-].[Cs+] AIYUHDOJVYHVIT-UHFFFAOYSA-M 0.000 description 10
- 238000011109 contamination Methods 0.000 description 10
- 239000012091 fetal bovine serum Substances 0.000 description 10
- 210000003494 hepatocyte Anatomy 0.000 description 10
- 230000001965 increasing effect Effects 0.000 description 10
- 208000015181 infectious disease Diseases 0.000 description 10
- 230000003902 lesion Effects 0.000 description 10
- 231100000062 no-observed-adverse-effect level Toxicity 0.000 description 10
- 238000004806 packaging method and process Methods 0.000 description 10
- 238000000746 purification Methods 0.000 description 10
- 230000001225 therapeutic effect Effects 0.000 description 10
- 238000004448 titration Methods 0.000 description 10
- 102000005666 Apolipoprotein A-I Human genes 0.000 description 9
- 108010059886 Apolipoprotein A-I Proteins 0.000 description 9
- 229940121710 HMGCoA reductase inhibitor Drugs 0.000 description 9
- 241000880493 Leptailurus serval Species 0.000 description 9
- 241000283973 Oryctolagus cuniculus Species 0.000 description 9
- FTVRVZNYIYWJGB-ACZMJKKPSA-N Ser-Asp-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O FTVRVZNYIYWJGB-ACZMJKKPSA-N 0.000 description 9
- 102000003929 Transaminases Human genes 0.000 description 9
- 108090000340 Transaminases Proteins 0.000 description 9
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 9
- 108010084264 glycyl-glycyl-cysteine Proteins 0.000 description 9
- 239000003018 immunosuppressive agent Substances 0.000 description 9
- 230000008488 polyadenylation Effects 0.000 description 9
- QFJCIRLUMZQUOT-HPLJOQBZSA-N sirolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 QFJCIRLUMZQUOT-HPLJOQBZSA-N 0.000 description 9
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 9
- 231100000041 toxicology testing Toxicity 0.000 description 9
- 230000001052 transient effect Effects 0.000 description 9
- 230000003612 virological effect Effects 0.000 description 9
- 102100040202 Apolipoprotein B-100 Human genes 0.000 description 8
- 101000805768 Banna virus (strain Indonesia/JKT-6423/1980) mRNA (guanine-N(7))-methyltransferase Proteins 0.000 description 8
- BPYKTIZUTYGOLE-IFADSCNNSA-N Bilirubin Chemical compound N1C(=O)C(C)=C(C=C)\C1=C\C1=C(C)C(CCC(O)=O)=C(CC2=C(C(C)=C(\C=C/3C(=C(C=C)C(=O)N\3)C)N2)CCC(O)=O)N1 BPYKTIZUTYGOLE-IFADSCNNSA-N 0.000 description 8
- 101000686790 Chaetoceros protobacilladnavirus 2 Replication-associated protein Proteins 0.000 description 8
- 101000864475 Chlamydia phage 1 Internal scaffolding protein VP3 Proteins 0.000 description 8
- 101000803553 Eumenes pomiformis Venom peptide 3 Proteins 0.000 description 8
- 101000583961 Halorubrum pleomorphic virus 1 Matrix protein Proteins 0.000 description 8
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 8
- 102100032859 Protein AMBP Human genes 0.000 description 8
- 230000005867 T cell response Effects 0.000 description 8
- 241000700605 Viruses Species 0.000 description 8
- 229920000080 bile acid sequestrant Polymers 0.000 description 8
- 210000004369 blood Anatomy 0.000 description 8
- 239000008280 blood Substances 0.000 description 8
- 108010048367 enhanced green fluorescent protein Proteins 0.000 description 8
- 235000009200 high fat diet Nutrition 0.000 description 8
- 230000028993 immune response Effects 0.000 description 8
- 108010057821 leucylproline Proteins 0.000 description 8
- 230000007774 longterm Effects 0.000 description 8
- 231100000682 maximum tolerated dose Toxicity 0.000 description 8
- 238000005259 measurement Methods 0.000 description 8
- 230000000813 microbial effect Effects 0.000 description 8
- 239000013608 rAAV vector Substances 0.000 description 8
- ZAHRKKWIAAJSAO-UHFFFAOYSA-N rapamycin Natural products COCC(O)C(=C/C(C)C(=O)CC(OC(=O)C1CCCCN1C(=O)C(=O)C2(O)OC(CC(OC)C(=CC=CC=CC(C)CC(C)C(=O)C)C)CCC2C)C(C)CC3CCC(O)C(C3)OC)C ZAHRKKWIAAJSAO-UHFFFAOYSA-N 0.000 description 8
- 102000005962 receptors Human genes 0.000 description 8
- 108020003175 receptors Proteins 0.000 description 8
- 229960002930 sirolimus Drugs 0.000 description 8
- 238000001890 transfection Methods 0.000 description 8
- 108700028369 Alleles Proteins 0.000 description 7
- 108091026890 Coding region Proteins 0.000 description 7
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 7
- 108010067770 Endopeptidase K Proteins 0.000 description 7
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 7
- 108700028146 Genetic Enhancer Elements Proteins 0.000 description 7
- 108091005904 Hemoglobin subunit beta Proteins 0.000 description 7
- 101800001691 Inter-alpha-trypsin inhibitor light chain Proteins 0.000 description 7
- HFBCHNRFRYLZNV-GUBZILKMSA-N Leu-Glu-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HFBCHNRFRYLZNV-GUBZILKMSA-N 0.000 description 7
- RGUXWMDNCPMQFB-YUMQZZPRSA-N Leu-Ser-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RGUXWMDNCPMQFB-YUMQZZPRSA-N 0.000 description 7
- XSLXHSYIVPGEER-KZVJFYERSA-N Thr-Ala-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O XSLXHSYIVPGEER-KZVJFYERSA-N 0.000 description 7
- 229940024606 amino acid Drugs 0.000 description 7
- 235000001014 amino acid Nutrition 0.000 description 7
- 239000002256 antimetabolite Substances 0.000 description 7
- 108010016616 cysteinylglycine Proteins 0.000 description 7
- 238000001514 detection method Methods 0.000 description 7
- 238000009826 distribution Methods 0.000 description 7
- 231100000371 dose-limiting toxicity Toxicity 0.000 description 7
- 238000011156 evaluation Methods 0.000 description 7
- 239000000499 gel Substances 0.000 description 7
- 108010018006 histidylserine Proteins 0.000 description 7
- 239000003112 inhibitor Substances 0.000 description 7
- 229930182823 kanamycin A Natural products 0.000 description 7
- 230000001404 mediated effect Effects 0.000 description 7
- 108020004999 messenger RNA Proteins 0.000 description 7
- 230000002441 reversible effect Effects 0.000 description 7
- 241000894007 species Species 0.000 description 7
- 238000005199 ultracentrifugation Methods 0.000 description 7
- RLMISHABBKUNFO-WHFBIAKZSA-N Ala-Ala-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O RLMISHABBKUNFO-WHFBIAKZSA-N 0.000 description 6
- 102000003966 Alpha-1-microglobulin Human genes 0.000 description 6
- 101800001761 Alpha-1-microglobulin Proteins 0.000 description 6
- 101710095342 Apolipoprotein B Proteins 0.000 description 6
- ACEDJCOOPZFUBU-CIUDSAMLSA-N Asp-Cys-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(=O)O)N ACEDJCOOPZFUBU-CIUDSAMLSA-N 0.000 description 6
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 6
- 108090000565 Capsid Proteins Proteins 0.000 description 6
- 102100023321 Ceruloplasmin Human genes 0.000 description 6
- KJJASVYBTKRYSN-FXQIFTODSA-N Cys-Pro-Asp Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CS)N)C(=O)N[C@@H](CC(=O)O)C(=O)O KJJASVYBTKRYSN-FXQIFTODSA-N 0.000 description 6
- 102000004190 Enzymes Human genes 0.000 description 6
- 108090000790 Enzymes Proteins 0.000 description 6
- RQNYYRHRKSVKAB-GUBZILKMSA-N Glu-Cys-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O RQNYYRHRKSVKAB-GUBZILKMSA-N 0.000 description 6
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 6
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 6
- 102000004895 Lipoproteins Human genes 0.000 description 6
- 108090001030 Lipoproteins Proteins 0.000 description 6
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 6
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 6
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 6
- NPGIHFRTRXVWOY-UHFFFAOYSA-N Oil red O Chemical compound Cc1ccc(C)c(c1)N=Nc1cc(C)c(cc1C)N=Nc1c(O)ccc2ccccc12 NPGIHFRTRXVWOY-UHFFFAOYSA-N 0.000 description 6
- 108010034546 Serratia marcescens nuclease Proteins 0.000 description 6
- RRRRCRYTLZVCEN-HJGDQZAQSA-N Thr-Leu-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O RRRRCRYTLZVCEN-HJGDQZAQSA-N 0.000 description 6
- 230000005856 abnormality Effects 0.000 description 6
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 6
- 229960000723 ampicillin Drugs 0.000 description 6
- AVKUERGKIZMTKX-NJBDSQKTSA-N ampicillin Chemical compound C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C(O)=O)(C)C)=CC=CC=C1 AVKUERGKIZMTKX-NJBDSQKTSA-N 0.000 description 6
- 108010008355 arginyl-glutamine Proteins 0.000 description 6
- 108010062796 arginyllysine Proteins 0.000 description 6
- 108010077245 asparaginyl-proline Proteins 0.000 description 6
- 229940096699 bile acid sequestrants Drugs 0.000 description 6
- 238000011072 cell harvest Methods 0.000 description 6
- 238000006243 chemical reaction Methods 0.000 description 6
- 239000002299 complementary DNA Substances 0.000 description 6
- 229940088598 enzyme Drugs 0.000 description 6
- 238000002474 experimental method Methods 0.000 description 6
- 229960000815 ezetimibe Drugs 0.000 description 6
- OLNTVTPDXPETLC-XPWALMASSA-N ezetimibe Chemical compound N1([C@@H]([C@H](C1=O)CC[C@H](O)C=1C=CC(F)=CC=1)C=1C=CC(O)=CC=1)C1=CC=C(F)C=C1 OLNTVTPDXPETLC-XPWALMASSA-N 0.000 description 6
- 238000001914 filtration Methods 0.000 description 6
- 230000006870 function Effects 0.000 description 6
- 229960003444 immunosuppressant agent Drugs 0.000 description 6
- 108010027338 isoleucylcysteine Proteins 0.000 description 6
- 229930027917 kanamycin Natural products 0.000 description 6
- 229960000318 kanamycin Drugs 0.000 description 6
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 6
- 108010034529 leucyl-lysine Proteins 0.000 description 6
- 108010003700 lysyl aspartic acid Proteins 0.000 description 6
- 230000002503 metabolic effect Effects 0.000 description 6
- 210000000056 organ Anatomy 0.000 description 6
- 238000012545 processing Methods 0.000 description 6
- 150000003839 salts Chemical class 0.000 description 6
- 150000003431 steroids Chemical class 0.000 description 6
- 238000012546 transfer Methods 0.000 description 6
- UFTFJSFQGQCHQW-UHFFFAOYSA-N triformin Chemical compound O=COCC(OC=O)COC=O UFTFJSFQGQCHQW-UHFFFAOYSA-N 0.000 description 6
- NMRHDSAOIURTNT-RWMBFGLXSA-N Arg-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N NMRHDSAOIURTNT-RWMBFGLXSA-N 0.000 description 5
- MYLZFUMPZCPJCJ-NHCYSSNCSA-N Asp-Lys-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C(C)C)C(O)=O MYLZFUMPZCPJCJ-NHCYSSNCSA-N 0.000 description 5
- 101710132601 Capsid protein Proteins 0.000 description 5
- 101710197658 Capsid protein VP1 Proteins 0.000 description 5
- FIADUEYFRSCCIK-CIUDSAMLSA-N Cys-Glu-Arg Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FIADUEYFRSCCIK-CIUDSAMLSA-N 0.000 description 5
- IWAXHBCACVWNHT-BQBZGAKWSA-N Gly-Asp-Arg Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IWAXHBCACVWNHT-BQBZGAKWSA-N 0.000 description 5
- 102100021519 Hemoglobin subunit beta Human genes 0.000 description 5
- 241001135569 Human adenovirus 5 Species 0.000 description 5
- KEKTTYCXKGBAAL-VGDYDELISA-N Ile-His-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CO)C(=O)O)N KEKTTYCXKGBAAL-VGDYDELISA-N 0.000 description 5
- 238000008214 LDL Cholesterol Methods 0.000 description 5
- 101150013552 LDLR gene Proteins 0.000 description 5
- DLCAXBGXGOVUCD-PPCPHDFISA-N Lys-Thr-Ile Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O DLCAXBGXGOVUCD-PPCPHDFISA-N 0.000 description 5
- 101100510727 Mus musculus Ldlr gene Proteins 0.000 description 5
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 5
- BQVUABVGYYSDCJ-UHFFFAOYSA-N Nalpha-L-Leucyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)CC(C)C)C(O)=O)=CNC2=C1 BQVUABVGYYSDCJ-UHFFFAOYSA-N 0.000 description 5
- 101100342977 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) leu-1 gene Proteins 0.000 description 5
- 101710163270 Nuclease Proteins 0.000 description 5
- WGAQWMRJUFQXMF-ZPFDUUQYSA-N Pro-Gln-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WGAQWMRJUFQXMF-ZPFDUUQYSA-N 0.000 description 5
- MGDFPGCFVJFITQ-CIUDSAMLSA-N Pro-Glu-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O MGDFPGCFVJFITQ-CIUDSAMLSA-N 0.000 description 5
- 101710118046 RNA-directed RNA polymerase Proteins 0.000 description 5
- QWZIOCFPXMAXET-CIUDSAMLSA-N Ser-Arg-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O QWZIOCFPXMAXET-CIUDSAMLSA-N 0.000 description 5
- DDHFMBDACJYSKW-AQZXSJQPSA-N Trp-Thr-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N)O DDHFMBDACJYSKW-AQZXSJQPSA-N 0.000 description 5
- 108090000631 Trypsin Proteins 0.000 description 5
- 102000004142 Trypsin Human genes 0.000 description 5
- 101710108545 Viral protein 1 Proteins 0.000 description 5
- 239000002168 alkylating agent Substances 0.000 description 5
- 229940100198 alkylating agent Drugs 0.000 description 5
- 238000013459 approach Methods 0.000 description 5
- 230000003143 atherosclerotic effect Effects 0.000 description 5
- 229910002091 carbon monoxide Inorganic materials 0.000 description 5
- 230000001925 catabolic effect Effects 0.000 description 5
- 238000004113 cell culture Methods 0.000 description 5
- 230000010261 cell growth Effects 0.000 description 5
- 239000013592 cell lysate Substances 0.000 description 5
- 238000012512 characterization method Methods 0.000 description 5
- TZRFSLHOCZEXCC-HIVFKXHNSA-N chembl2219536 Chemical compound N1([C@H]2C[C@@H]([C@H](O2)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C(NC(=O)C(C)=C2)=O)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C(N=C(N)C(C)=C2)=O)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C(NC(=O)C(C)=C2)=O)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C3=C(C(NC(N)=N3)=O)N=C2)COP(O)(=O)S[C@@H]2[C@H](O[C@H](C2)N2C3=NC=NC(N)=C3N=C2)COP(O)(=O)S[C@H]2[C@H]([C@@H](O[C@@H]2COP(O)(=O)S[C@H]2[C@H]([C@@H](O[C@@H]2COP(O)(=O)S[C@H]2[C@H]([C@@H](O[C@@H]2COP(O)(=O)S[C@H]2[C@H]([C@@H](O[C@@H]2COP(O)(=O)S[C@H]2[C@H]([C@@H](O[C@@H]2CO)N2C3=C(C(NC(N)=N3)=O)N=C2)OCCOC)N2C(N=C(N)C(C)=C2)=O)OCCOC)N2C(N=C(N)C(C)=C2)=O)OCCOC)N2C(NC(=O)C(C)=C2)=O)OCCOC)N2C(N=C(N)C(C)=C2)=O)OCCOC)SP(O)(=O)OC[C@H]2O[C@H](C[C@@H]2SP(O)(=O)OC[C@H]2O[C@H](C[C@@H]2SP(O)(=O)OC[C@H]2O[C@H](C[C@@H]2SP(O)(=O)OC[C@@H]2[C@H]([C@H]([C@@H](O2)N2C3=C(C(NC(N)=N3)=O)N=C2)OCCOC)SP(O)(=O)OC[C@H]2[C@@H]([C@@H]([C@H](O2)N2C(N=C(N)C(C)=C2)=O)OCCOC)SP(O)(=O)OC[C@H]2[C@@H]([C@@H]([C@H](O2)N2C3=NC=NC(N)=C3N=C2)OCCOC)SP(O)(=O)OC[C@H]2[C@@H]([C@@H]([C@H](O2)N2C(N=C(N)C(C)=C2)=O)OCCOC)SP(O)(=O)OC[C@H]2[C@H](O)[C@@H]([C@H](O2)N2C(N=C(N)C(C)=C2)=O)OCCOC)N2C(N=C(N)C(C)=C2)=O)N2C(NC(=O)C(C)=C2)=O)N2C(NC(=O)C(C)=C2)=O)C=C(C)C(N)=NC1=O TZRFSLHOCZEXCC-HIVFKXHNSA-N 0.000 description 5
- 238000004587 chromatography analysis Methods 0.000 description 5
- 108010060199 cysteinylproline Proteins 0.000 description 5
- 238000011026 diafiltration Methods 0.000 description 5
- 230000029087 digestion Effects 0.000 description 5
- 239000002471 hydroxymethylglutaryl coenzyme A reductase inhibitor Substances 0.000 description 5
- 238000002650 immunosuppressive therapy Methods 0.000 description 5
- 230000007246 mechanism Effects 0.000 description 5
- 229960004778 mipomersen Drugs 0.000 description 5
- 108091060283 mipomersen Proteins 0.000 description 5
- 238000010899 nucleation Methods 0.000 description 5
- 238000011002 quantification Methods 0.000 description 5
- 108010048397 seryl-lysyl-leucine Proteins 0.000 description 5
- 108010026333 seryl-proline Proteins 0.000 description 5
- 150000003626 triacylglycerols Chemical class 0.000 description 5
- 239000012588 trypsin Substances 0.000 description 5
- 108010073969 valyllysine Proteins 0.000 description 5
- SSSROGPPPVTHLX-FXQIFTODSA-N Ala-Arg-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O SSSROGPPPVTHLX-FXQIFTODSA-N 0.000 description 4
- BTYTYHBSJKQBQA-GCJQMDKQSA-N Ala-Asp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](C)N)O BTYTYHBSJKQBQA-GCJQMDKQSA-N 0.000 description 4
- SOBIAADAMRHGKH-CIUDSAMLSA-N Ala-Leu-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SOBIAADAMRHGKH-CIUDSAMLSA-N 0.000 description 4
- 108010008150 Apolipoprotein B-100 Proteins 0.000 description 4
- RCAUJZASOAFTAJ-FXQIFTODSA-N Arg-Asp-Cys Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N)CN=C(N)N RCAUJZASOAFTAJ-FXQIFTODSA-N 0.000 description 4
- JTWOBPNAVBESFW-FXQIFTODSA-N Arg-Cys-Asp Chemical compound C(C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)CN=C(N)N JTWOBPNAVBESFW-FXQIFTODSA-N 0.000 description 4
- UZGFHWIJWPUPOH-IHRRRGAJSA-N Arg-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UZGFHWIJWPUPOH-IHRRRGAJSA-N 0.000 description 4
- LYJXHXGPWDTLKW-HJGDQZAQSA-N Arg-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)O LYJXHXGPWDTLKW-HJGDQZAQSA-N 0.000 description 4
- FTCGGKNCJZOPNB-WHFBIAKZSA-N Asn-Gly-Ser Chemical compound NC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O FTCGGKNCJZOPNB-WHFBIAKZSA-N 0.000 description 4
- JQBCANGGAVVERB-CFMVVWHZSA-N Asn-Ile-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N JQBCANGGAVVERB-CFMVVWHZSA-N 0.000 description 4
- LWXJVHTUEDHDLG-XUXIUFHCSA-N Asn-Leu-Leu-Ser Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O LWXJVHTUEDHDLG-XUXIUFHCSA-N 0.000 description 4
- YDJVIBMKAMQPPP-LAEOZQHASA-N Asp-Glu-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O YDJVIBMKAMQPPP-LAEOZQHASA-N 0.000 description 4
- KESWRFKUZRUTAH-FXQIFTODSA-N Asp-Pro-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O KESWRFKUZRUTAH-FXQIFTODSA-N 0.000 description 4
- CUQDCPXNZPDYFQ-ZLUOBGJFSA-N Asp-Ser-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O CUQDCPXNZPDYFQ-ZLUOBGJFSA-N 0.000 description 4
- 101150044789 Cap gene Proteins 0.000 description 4
- UWXFFVQPAMBETM-ZLUOBGJFSA-N Cys-Asp-Asn Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O UWXFFVQPAMBETM-ZLUOBGJFSA-N 0.000 description 4
- MGAWEOHYNIMOQJ-ACZMJKKPSA-N Cys-Gln-Asp Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CS)N MGAWEOHYNIMOQJ-ACZMJKKPSA-N 0.000 description 4
- PRHGYQOSEHLDRW-VGDYDELISA-N Cys-Ile-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CS)N PRHGYQOSEHLDRW-VGDYDELISA-N 0.000 description 4
- 238000002965 ELISA Methods 0.000 description 4
- WQWMZOIPXWSZNE-WDSKDSINSA-N Gln-Asp-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O WQWMZOIPXWSZNE-WDSKDSINSA-N 0.000 description 4
- CXFUMJQFZVCETK-FXQIFTODSA-N Gln-Cys-Gln Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O CXFUMJQFZVCETK-FXQIFTODSA-N 0.000 description 4
- YJCZUTXLPXBNIO-BHYGNILZSA-N Gln-Trp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CNC3=CC=CC=C32)NC(=O)[C@H](CCC(=O)N)N)C(=O)O YJCZUTXLPXBNIO-BHYGNILZSA-N 0.000 description 4
- QQLBPVKLJBAXBS-FXQIFTODSA-N Glu-Glu-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O QQLBPVKLJBAXBS-FXQIFTODSA-N 0.000 description 4
- DWUKOTKSTDWGAE-BQBZGAKWSA-N Gly-Asn-Arg Chemical compound NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DWUKOTKSTDWGAE-BQBZGAKWSA-N 0.000 description 4
- QCTLGOYODITHPQ-WHFBIAKZSA-N Gly-Cys-Ser Chemical compound [H]NCC(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O QCTLGOYODITHPQ-WHFBIAKZSA-N 0.000 description 4
- BUEFQXUHTUZXHR-LURJTMIESA-N Gly-Gly-Pro zwitterion Chemical compound NCC(=O)NCC(=O)N1CCC[C@H]1C(O)=O BUEFQXUHTUZXHR-LURJTMIESA-N 0.000 description 4
- VLIJYPMATZSOLL-YUMQZZPRSA-N Gly-Lys-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)CN VLIJYPMATZSOLL-YUMQZZPRSA-N 0.000 description 4
- OHUKZZYSJBKFRR-WHFBIAKZSA-N Gly-Ser-Asp Chemical compound [H]NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O OHUKZZYSJBKFRR-WHFBIAKZSA-N 0.000 description 4
- JBCLFWXMTIKCCB-UHFFFAOYSA-N H-Gly-Phe-OH Natural products NCC(=O)NC(C(O)=O)CC1=CC=CC=C1 JBCLFWXMTIKCCB-UHFFFAOYSA-N 0.000 description 4
- 208000035150 Hypercholesterolemia Diseases 0.000 description 4
- BATWGBRIZANGPN-ZPFDUUQYSA-N Ile-Pro-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(=O)N)C(=O)O)N BATWGBRIZANGPN-ZPFDUUQYSA-N 0.000 description 4
- JHNJNTMTZHEDLJ-NAKRPEOUSA-N Ile-Ser-Arg Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O JHNJNTMTZHEDLJ-NAKRPEOUSA-N 0.000 description 4
- UYODHPPSCXBNCS-XUXIUFHCSA-N Ile-Val-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(C)C UYODHPPSCXBNCS-XUXIUFHCSA-N 0.000 description 4
- 108010065920 Insulin Lispro Proteins 0.000 description 4
- CQQGCWPXDHTTNF-GUBZILKMSA-N Leu-Ala-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O CQQGCWPXDHTTNF-GUBZILKMSA-N 0.000 description 4
- YKNBJXOJTURHCU-DCAQKATOSA-N Leu-Asp-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YKNBJXOJTURHCU-DCAQKATOSA-N 0.000 description 4
- MMEDVBWCMGRKKC-GARJFASQSA-N Leu-Asp-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N MMEDVBWCMGRKKC-GARJFASQSA-N 0.000 description 4
- UCBPDSYUVAAHCD-UWVGGRQHSA-N Leu-Pro-Gly Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UCBPDSYUVAAHCD-UWVGGRQHSA-N 0.000 description 4
- 108010033266 Lipoprotein(a) Proteins 0.000 description 4
- 102000057248 Lipoprotein(a) Human genes 0.000 description 4
- SJNZALDHDUYDBU-IHRRRGAJSA-N Lys-Arg-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(O)=O SJNZALDHDUYDBU-IHRRRGAJSA-N 0.000 description 4
- HAUUXTXKJNVIFY-ONGXEEELSA-N Lys-Gly-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O HAUUXTXKJNVIFY-ONGXEEELSA-N 0.000 description 4
- OVAOHZIOUBEQCJ-IHRRRGAJSA-N Lys-Leu-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O OVAOHZIOUBEQCJ-IHRRRGAJSA-N 0.000 description 4
- 241000282553 Macaca Species 0.000 description 4
- MVBZBRKNZVJEKK-DTWKUNHWSA-N Met-Gly-Pro Chemical compound CSCC[C@@H](C(=O)NCC(=O)N1CCC[C@@H]1C(=O)O)N MVBZBRKNZVJEKK-DTWKUNHWSA-N 0.000 description 4
- QAVZUKIPOMBLMC-AVGNSLFASA-N Met-Val-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(C)C QAVZUKIPOMBLMC-AVGNSLFASA-N 0.000 description 4
- 101710081079 Minor spike protein H Proteins 0.000 description 4
- LKRUQZQZMXMKEQ-SFJXLCSZSA-N Phe-Trp-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LKRUQZQZMXMKEQ-SFJXLCSZSA-N 0.000 description 4
- AUQGUYPHJSMAKI-CYDGBPFRSA-N Pro-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H]1CCCN1 AUQGUYPHJSMAKI-CYDGBPFRSA-N 0.000 description 4
- 108010029485 Protein Isoforms Proteins 0.000 description 4
- 102000001708 Protein Isoforms Human genes 0.000 description 4
- WBINSDOPZHQPPM-AVGNSLFASA-N Ser-Glu-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CO)N)O WBINSDOPZHQPPM-AVGNSLFASA-N 0.000 description 4
- RVMNUBQWPVOUKH-HEIBUPTGSA-N Thr-Ser-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RVMNUBQWPVOUKH-HEIBUPTGSA-N 0.000 description 4
- 238000008050 Total Bilirubin Reagent Methods 0.000 description 4
- PXYJUECTGMGIDT-WDSOQIARSA-N Trp-Arg-Leu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(C)C)C(O)=O)=CNC2=C1 PXYJUECTGMGIDT-WDSOQIARSA-N 0.000 description 4
- YRXXUYPYPHRJPB-RXVVDRJESA-N Trp-Gly-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)NCC(=O)N[C@@H](CC3=CNC4=CC=CC=C43)C(=O)O)N YRXXUYPYPHRJPB-RXVVDRJESA-N 0.000 description 4
- STKZKWFOKOCSLW-UMPQAUOISA-N Trp-Thr-Val Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)[C@@H](C)O)=CNC2=C1 STKZKWFOKOCSLW-UMPQAUOISA-N 0.000 description 4
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 4
- 102000000852 Tumor Necrosis Factor-alpha Human genes 0.000 description 4
- IZFVRRYRMQFVGX-NRPADANISA-N Val-Ala-Gln Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N IZFVRRYRMQFVGX-NRPADANISA-N 0.000 description 4
- LNYOXPDEIZJDEI-NHCYSSNCSA-N Val-Asn-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](C(C)C)N LNYOXPDEIZJDEI-NHCYSSNCSA-N 0.000 description 4
- XKVXSCHXGJOQND-ZOBUZTSGSA-N Val-Asp-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N XKVXSCHXGJOQND-ZOBUZTSGSA-N 0.000 description 4
- BWVHQINTNLVWGZ-ZKWXMUAHSA-N Val-Cys-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)O)C(=O)O)N BWVHQINTNLVWGZ-ZKWXMUAHSA-N 0.000 description 4
- UZFNHAXYMICTBU-DZKIICNBSA-N Val-Phe-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N UZFNHAXYMICTBU-DZKIICNBSA-N 0.000 description 4
- YLRAFVVWZRSZQC-DZKIICNBSA-N Val-Phe-Glu Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N YLRAFVVWZRSZQC-DZKIICNBSA-N 0.000 description 4
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 4
- RJURFGZVJUQBHK-UHFFFAOYSA-N actinomycin D Natural products CC1OC(=O)C(C(C)C)N(C)C(=O)CN(C)C(=O)C2CCCN2C(=O)C(C(C)C)NC(=O)C1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)NC4C(=O)NC(C(N5CCCC5C(=O)N(C)CC(=O)N(C)C(C(C)C)C(=O)OC4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-UHFFFAOYSA-N 0.000 description 4
- 108010087924 alanylproline Proteins 0.000 description 4
- 239000003957 anion exchange resin Substances 0.000 description 4
- 238000002617 apheresis Methods 0.000 description 4
- 108010038850 arginyl-isoleucyl-tyrosine Proteins 0.000 description 4
- 238000001574 biopsy Methods 0.000 description 4
- 210000000601 blood cell Anatomy 0.000 description 4
- 238000002512 chemotherapy Methods 0.000 description 4
- 239000000356 contaminant Substances 0.000 description 4
- 230000000875 corresponding effect Effects 0.000 description 4
- DDRJAANPRJIHGJ-UHFFFAOYSA-N creatinine Chemical compound CN1CC(=O)NC1=N DDRJAANPRJIHGJ-UHFFFAOYSA-N 0.000 description 4
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 4
- 231100000673 dose–response relationship Toxicity 0.000 description 4
- 239000000975 dye Substances 0.000 description 4
- 108010006664 gamma-glutamyl-glycyl-glycine Proteins 0.000 description 4
- 230000002068 genetic effect Effects 0.000 description 4
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 4
- 108010049041 glutamylalanine Proteins 0.000 description 4
- 108010026364 glycyl-glycyl-leucine Proteins 0.000 description 4
- 108010050475 glycyl-leucyl-tyrosine Proteins 0.000 description 4
- 108010077515 glycylproline Proteins 0.000 description 4
- 239000001963 growth medium Substances 0.000 description 4
- 108010092114 histidylphenylalanine Proteins 0.000 description 4
- 238000001727 in vivo Methods 0.000 description 4
- 230000002458 infectious effect Effects 0.000 description 4
- 108010077158 leucinyl-arginyl-tryptophan Proteins 0.000 description 4
- 210000000265 leukocyte Anatomy 0.000 description 4
- 108010057952 lysyl-phenylalanyl-lysine Proteins 0.000 description 4
- 238000004949 mass spectrometry Methods 0.000 description 4
- 229960004857 mitomycin Drugs 0.000 description 4
- RTGDFNSFWBGLEC-SYZQJQIISA-N mycophenolate mofetil Chemical compound COC1=C(C)C=2COC(=O)C=2C(O)=C1C\C=C(/C)CCC(=O)OCCN1CCOCC1 RTGDFNSFWBGLEC-SYZQJQIISA-N 0.000 description 4
- 229960004866 mycophenolate mofetil Drugs 0.000 description 4
- 230000037361 pathway Effects 0.000 description 4
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 4
- 230000002688 persistence Effects 0.000 description 4
- 239000013647 rAAV8 vector Substances 0.000 description 4
- 239000011347 resin Substances 0.000 description 4
- 229920005989 resin Polymers 0.000 description 4
- 108010048818 seryl-histidine Proteins 0.000 description 4
- 239000004094 surface-active agent Substances 0.000 description 4
- 239000013603 viral vector Substances 0.000 description 4
- 238000011179 visual inspection Methods 0.000 description 4
- 230000003442 weekly effect Effects 0.000 description 4
- XEXJJJRVTFGWIC-FXQIFTODSA-N Ala-Asn-Arg Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N XEXJJJRVTFGWIC-FXQIFTODSA-N 0.000 description 3
- XAGIMRPOEJSYER-CIUDSAMLSA-N Ala-Cys-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)O)N XAGIMRPOEJSYER-CIUDSAMLSA-N 0.000 description 3
- CNQAFFMNJIQYGX-DRZSPHRISA-N Ala-Phe-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 CNQAFFMNJIQYGX-DRZSPHRISA-N 0.000 description 3
- AUFACLFHBAGZEN-ZLUOBGJFSA-N Ala-Ser-Cys Chemical compound N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O AUFACLFHBAGZEN-ZLUOBGJFSA-N 0.000 description 3
- PEEYDECOOVQKRZ-DLOVCJGASA-N Ala-Ser-Phe Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PEEYDECOOVQKRZ-DLOVCJGASA-N 0.000 description 3
- QKHWNPQNOHEFST-VZFHVOOUSA-N Ala-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](C)N)O QKHWNPQNOHEFST-VZFHVOOUSA-N 0.000 description 3
- VHAQSYHSDKERBS-XPUUQOCRSA-N Ala-Val-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O VHAQSYHSDKERBS-XPUUQOCRSA-N 0.000 description 3
- 102000006991 Apolipoprotein B-100 Human genes 0.000 description 3
- YFWTXMRJJDNTLM-LSJOCFKGSA-N Arg-Ala-His Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N YFWTXMRJJDNTLM-LSJOCFKGSA-N 0.000 description 3
- KJGNDQCYBNBXDA-GUBZILKMSA-N Arg-Arg-Cys Chemical compound C(C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N)CN=C(N)N KJGNDQCYBNBXDA-GUBZILKMSA-N 0.000 description 3
- JSHVMZANPXCDTL-GMOBBJLQSA-N Arg-Asp-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JSHVMZANPXCDTL-GMOBBJLQSA-N 0.000 description 3
- HJAICMSAKODKRF-GUBZILKMSA-N Arg-Cys-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O HJAICMSAKODKRF-GUBZILKMSA-N 0.000 description 3
- XTGGTAWGUFXJSV-NAKRPEOUSA-N Arg-Cys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCCN=C(N)N)N XTGGTAWGUFXJSV-NAKRPEOUSA-N 0.000 description 3
- BGDILZXXDJCKPF-CIUDSAMLSA-N Arg-Gln-Cys Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CS)C(O)=O BGDILZXXDJCKPF-CIUDSAMLSA-N 0.000 description 3
- RKRSYHCNPFGMTA-CIUDSAMLSA-N Arg-Glu-Asn Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O RKRSYHCNPFGMTA-CIUDSAMLSA-N 0.000 description 3
- JAYIQMNQDMOBFY-KKUMJFAQSA-N Arg-Glu-Tyr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JAYIQMNQDMOBFY-KKUMJFAQSA-N 0.000 description 3
- PNIGSVZJNVUVJA-BQBZGAKWSA-N Arg-Gly-Asn Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O PNIGSVZJNVUVJA-BQBZGAKWSA-N 0.000 description 3
- MTYLORHAQXVQOW-AVGNSLFASA-N Arg-Lys-Met Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(O)=O MTYLORHAQXVQOW-AVGNSLFASA-N 0.000 description 3
- JBIRFLWXWDSDTR-CYDGBPFRSA-N Arg-Met-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@H](CCCN=C(N)N)N JBIRFLWXWDSDTR-CYDGBPFRSA-N 0.000 description 3
- OVQJAKFLFTZDNC-GUBZILKMSA-N Arg-Pro-Asp Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O OVQJAKFLFTZDNC-GUBZILKMSA-N 0.000 description 3
- ZPWMEWYQBWSGAO-ZJDVBMNYSA-N Arg-Thr-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZPWMEWYQBWSGAO-ZJDVBMNYSA-N 0.000 description 3
- MEFGKQUUYZOLHM-GMOBBJLQSA-N Asn-Arg-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O MEFGKQUUYZOLHM-GMOBBJLQSA-N 0.000 description 3
- PCKRJVZAQZWNKM-WHFBIAKZSA-N Asn-Asn-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O PCKRJVZAQZWNKM-WHFBIAKZSA-N 0.000 description 3
- UGXVKHRDGLYFKR-CIUDSAMLSA-N Asn-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC(N)=O UGXVKHRDGLYFKR-CIUDSAMLSA-N 0.000 description 3
- ZMWDUIIACVLIHK-GHCJXIJMSA-N Asn-Cys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(=O)N)N ZMWDUIIACVLIHK-GHCJXIJMSA-N 0.000 description 3
- ULRPXVNMIIYDDJ-ACZMJKKPSA-N Asn-Glu-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC(=O)N)N ULRPXVNMIIYDDJ-ACZMJKKPSA-N 0.000 description 3
- COUZKSSMBFADSB-AVGNSLFASA-N Asn-Glu-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC(=O)N)N COUZKSSMBFADSB-AVGNSLFASA-N 0.000 description 3
- PBSQFBAJKPLRJY-BYULHYEWSA-N Asn-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC(=O)N)N PBSQFBAJKPLRJY-BYULHYEWSA-N 0.000 description 3
- OOWSBIOUKIUWLO-RCOVLWMOSA-N Asn-Gly-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O OOWSBIOUKIUWLO-RCOVLWMOSA-N 0.000 description 3
- PTSDPWIHOYMRGR-UGYAYLCHSA-N Asn-Ile-Asn Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O PTSDPWIHOYMRGR-UGYAYLCHSA-N 0.000 description 3
- FHETWELNCBMRMG-HJGDQZAQSA-N Asn-Leu-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O FHETWELNCBMRMG-HJGDQZAQSA-N 0.000 description 3
- FMWHSNJMHUNLAG-FXQIFTODSA-N Asp-Cys-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CCCN=C(N)N FMWHSNJMHUNLAG-FXQIFTODSA-N 0.000 description 3
- RATOMFTUDRYMKX-ACZMJKKPSA-N Asp-Glu-Cys Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(=O)O)N RATOMFTUDRYMKX-ACZMJKKPSA-N 0.000 description 3
- HAFCJCDJGIOYPW-WDSKDSINSA-N Asp-Gly-Gln Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O HAFCJCDJGIOYPW-WDSKDSINSA-N 0.000 description 3
- QCVXMEHGFUMKCO-YUMQZZPRSA-N Asp-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC(O)=O QCVXMEHGFUMKCO-YUMQZZPRSA-N 0.000 description 3
- PZXPWHFYZXTFBI-YUMQZZPRSA-N Asp-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC(O)=O PZXPWHFYZXTFBI-YUMQZZPRSA-N 0.000 description 3
- SNDBKTFJWVEVPO-WHFBIAKZSA-N Asp-Gly-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CO)C(O)=O SNDBKTFJWVEVPO-WHFBIAKZSA-N 0.000 description 3
- NHSDEZURHWEZPN-SXTJYALSSA-N Asp-Ile-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)NC(=O)[C@H](CC(=O)O)N NHSDEZURHWEZPN-SXTJYALSSA-N 0.000 description 3
- RTXQQDVBACBSCW-CFMVVWHZSA-N Asp-Ile-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RTXQQDVBACBSCW-CFMVVWHZSA-N 0.000 description 3
- UMHUHHJMEXNSIV-CIUDSAMLSA-N Asp-Leu-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(O)=O UMHUHHJMEXNSIV-CIUDSAMLSA-N 0.000 description 3
- IOXWDLNHXZOXQP-FXQIFTODSA-N Asp-Met-Ser Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC(=O)O)N IOXWDLNHXZOXQP-FXQIFTODSA-N 0.000 description 3
- DINOVZWPTMGSRF-QXEWZRGKSA-N Asp-Pro-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O DINOVZWPTMGSRF-QXEWZRGKSA-N 0.000 description 3
- MGSVBZIBCCKGCY-ZLUOBGJFSA-N Asp-Ser-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MGSVBZIBCCKGCY-ZLUOBGJFSA-N 0.000 description 3
- IQCJOIHDVFJQFV-LKXGYXEUSA-N Asp-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O IQCJOIHDVFJQFV-LKXGYXEUSA-N 0.000 description 3
- GWWSUMLEWKQHLR-NUMRIWBASA-N Asp-Thr-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)O)N)O GWWSUMLEWKQHLR-NUMRIWBASA-N 0.000 description 3
- LTARLVHGOGBRHN-AAEUAGOBSA-N Asp-Trp-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)NCC(O)=O LTARLVHGOGBRHN-AAEUAGOBSA-N 0.000 description 3
- XWKBWZXGNXTDKY-ZKWXMUAHSA-N Asp-Val-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CC(O)=O XWKBWZXGNXTDKY-ZKWXMUAHSA-N 0.000 description 3
- PLOKOIJSGCISHE-BYULHYEWSA-N Asp-Val-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O PLOKOIJSGCISHE-BYULHYEWSA-N 0.000 description 3
- 239000007989 BIS-Tris Propane buffer Substances 0.000 description 3
- 208000024172 Cardiovascular disease Diseases 0.000 description 3
- 108010004103 Chylomicrons Proteins 0.000 description 3
- RRIJEABIXPKSGP-FXQIFTODSA-N Cys-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CS RRIJEABIXPKSGP-FXQIFTODSA-N 0.000 description 3
- VBPGTULCFGKGTF-ACZMJKKPSA-N Cys-Glu-Asp Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O VBPGTULCFGKGTF-ACZMJKKPSA-N 0.000 description 3
- UXUSHQYYQCZWET-WDSKDSINSA-N Cys-Glu-Gly Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O UXUSHQYYQCZWET-WDSKDSINSA-N 0.000 description 3
- SKSJPIBFNFPTJB-NKWVEPMBSA-N Cys-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CS)N)C(=O)O SKSJPIBFNFPTJB-NKWVEPMBSA-N 0.000 description 3
- VNXXMHTZQGGDSG-CIUDSAMLSA-N Cys-His-Asn Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(O)=O VNXXMHTZQGGDSG-CIUDSAMLSA-N 0.000 description 3
- ANRWXLYGJRSQEQ-CIUDSAMLSA-N Cys-His-Asp Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(O)=O)C(O)=O ANRWXLYGJRSQEQ-CIUDSAMLSA-N 0.000 description 3
- VFGADOJXRLWTBU-JBDRJPRFSA-N Cys-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N VFGADOJXRLWTBU-JBDRJPRFSA-N 0.000 description 3
- MRVSLWQRNWEROS-SVSWQMSJSA-N Cys-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CS)N MRVSLWQRNWEROS-SVSWQMSJSA-N 0.000 description 3
- XZKJEOMFLDVXJG-KATARQTJSA-N Cys-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CS)N)O XZKJEOMFLDVXJG-KATARQTJSA-N 0.000 description 3
- NIXHTNJAGGFBAW-CIUDSAMLSA-N Cys-Lys-Ser Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CS)N NIXHTNJAGGFBAW-CIUDSAMLSA-N 0.000 description 3
- DQGIAOGALAQBGK-BWBBJGPYSA-N Cys-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CS)N)O DQGIAOGALAQBGK-BWBBJGPYSA-N 0.000 description 3
- 108010008532 Deoxyribonuclease I Proteins 0.000 description 3
- 102000007260 Deoxyribonuclease I Human genes 0.000 description 3
- OYTPNWYZORARHL-XHNCKOQMSA-N Gln-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N OYTPNWYZORARHL-XHNCKOQMSA-N 0.000 description 3
- JFSNBQJNDMXMQF-XHNCKOQMSA-N Gln-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)N)N)C(=O)O JFSNBQJNDMXMQF-XHNCKOQMSA-N 0.000 description 3
- OIIIRRTWYLCQNW-ACZMJKKPSA-N Gln-Cys-Asn Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(O)=O OIIIRRTWYLCQNW-ACZMJKKPSA-N 0.000 description 3
- IPHGBVYWRKCGKG-FXQIFTODSA-N Gln-Cys-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O IPHGBVYWRKCGKG-FXQIFTODSA-N 0.000 description 3
- QBLMTCRYYTVUQY-GUBZILKMSA-N Gln-Leu-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O QBLMTCRYYTVUQY-GUBZILKMSA-N 0.000 description 3
- CELXWPDNIGWCJN-WDCWCFNPSA-N Gln-Lys-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CELXWPDNIGWCJN-WDCWCFNPSA-N 0.000 description 3
- QFXNFFZTMFHPST-DZKIICNBSA-N Gln-Phe-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CCC(=O)N)N QFXNFFZTMFHPST-DZKIICNBSA-N 0.000 description 3
- XUMFMAVDHQDATI-DCAQKATOSA-N Gln-Pro-Arg Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O XUMFMAVDHQDATI-DCAQKATOSA-N 0.000 description 3
- LKDIBBOKUAASNP-FXQIFTODSA-N Glu-Ala-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LKDIBBOKUAASNP-FXQIFTODSA-N 0.000 description 3
- XXCDTYBVGMPIOA-FXQIFTODSA-N Glu-Asp-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XXCDTYBVGMPIOA-FXQIFTODSA-N 0.000 description 3
- IESFZVCAVACGPH-PEFMBERDSA-N Glu-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O IESFZVCAVACGPH-PEFMBERDSA-N 0.000 description 3
- OAGVHWYIBZMWLA-YFKPBYRVSA-N Glu-Gly-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)NCC(O)=O OAGVHWYIBZMWLA-YFKPBYRVSA-N 0.000 description 3
- ZWQVYZXPYSYPJD-RYUDHWBXSA-N Glu-Gly-Phe Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ZWQVYZXPYSYPJD-RYUDHWBXSA-N 0.000 description 3
- SJJHXJDSNQJMMW-SRVKXCTJSA-N Glu-Lys-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O SJJHXJDSNQJMMW-SRVKXCTJSA-N 0.000 description 3
- HRBYTAIBKPNZKQ-AVGNSLFASA-N Glu-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCC(O)=O HRBYTAIBKPNZKQ-AVGNSLFASA-N 0.000 description 3
- KJBGAZSLZAQDPV-KKUMJFAQSA-N Glu-Phe-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N KJBGAZSLZAQDPV-KKUMJFAQSA-N 0.000 description 3
- JYXKPJVDCAWMDG-ZPFDUUQYSA-N Glu-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCC(=O)O)N JYXKPJVDCAWMDG-ZPFDUUQYSA-N 0.000 description 3
- DAHLWSFUXOHMIA-FXQIFTODSA-N Glu-Ser-Gln Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O DAHLWSFUXOHMIA-FXQIFTODSA-N 0.000 description 3
- LWYUQLZOIORFFJ-XKBZYTNZSA-N Glu-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O LWYUQLZOIORFFJ-XKBZYTNZSA-N 0.000 description 3
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 3
- WKJKBELXHCTHIJ-WPRPVWTQSA-N Gly-Arg-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N WKJKBELXHCTHIJ-WPRPVWTQSA-N 0.000 description 3
- RPLLQZBOVIVGMX-QWRGUYRKSA-N Gly-Asp-Phe Chemical compound [H]NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O RPLLQZBOVIVGMX-QWRGUYRKSA-N 0.000 description 3
- MQVNVZUEPUIAFA-WDSKDSINSA-N Gly-Cys-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)CN MQVNVZUEPUIAFA-WDSKDSINSA-N 0.000 description 3
- PEZZSFLFXXFUQD-XPUUQOCRSA-N Gly-Cys-Val Chemical compound [H]NCC(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O PEZZSFLFXXFUQD-XPUUQOCRSA-N 0.000 description 3
- XPJBQTCXPJNIFE-ZETCQYMHSA-N Gly-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)CN XPJBQTCXPJNIFE-ZETCQYMHSA-N 0.000 description 3
- AFWYPMDMDYCKMD-KBPBESRZSA-N Gly-Leu-Tyr Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 AFWYPMDMDYCKMD-KBPBESRZSA-N 0.000 description 3
- YHYDTTUSJXGTQK-UWVGGRQHSA-N Gly-Met-Leu Chemical compound CSCC[C@H](NC(=O)CN)C(=O)N[C@@H](CC(C)C)C(O)=O YHYDTTUSJXGTQK-UWVGGRQHSA-N 0.000 description 3
- YYXJFBMCOUSYSF-RYUDHWBXSA-N Gly-Phe-Gln Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O YYXJFBMCOUSYSF-RYUDHWBXSA-N 0.000 description 3
- MXIULRKNFSCJHT-STQMWFEESA-N Gly-Phe-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=CC=C1 MXIULRKNFSCJHT-STQMWFEESA-N 0.000 description 3
- POJJAZJHBGXEGM-YUMQZZPRSA-N Gly-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)CN POJJAZJHBGXEGM-YUMQZZPRSA-N 0.000 description 3
- FKESCSGWBPUTPN-FOHZUACHSA-N Gly-Thr-Asn Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(O)=O FKESCSGWBPUTPN-FOHZUACHSA-N 0.000 description 3
- YDIDLLVFCYSXNY-RCOVLWMOSA-N Gly-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)CN YDIDLLVFCYSXNY-RCOVLWMOSA-N 0.000 description 3
- SBVMXEZQJVUARN-XPUUQOCRSA-N Gly-Val-Ser Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O SBVMXEZQJVUARN-XPUUQOCRSA-N 0.000 description 3
- 108010054147 Hemoglobins Proteins 0.000 description 3
- 102000001554 Hemoglobins Human genes 0.000 description 3
- UPGJWSUYENXOPV-HGNGGELXSA-N His-Gln-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N UPGJWSUYENXOPV-HGNGGELXSA-N 0.000 description 3
- STWGDDDFLUFCCA-GVXVVHGQSA-N His-Glu-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O STWGDDDFLUFCCA-GVXVVHGQSA-N 0.000 description 3
- FYTCLUIYTYFGPT-YUMQZZPRSA-N His-Gly-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)NCC(=O)N[C@@H](CO)C(O)=O FYTCLUIYTYFGPT-YUMQZZPRSA-N 0.000 description 3
- ZHHLTWUOWXHVQJ-YUMQZZPRSA-N His-Ser-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N ZHHLTWUOWXHVQJ-YUMQZZPRSA-N 0.000 description 3
- CUEQQFOGARVNHU-VGDYDELISA-N His-Ser-Ile Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CUEQQFOGARVNHU-VGDYDELISA-N 0.000 description 3
- JUCZDDVZBMPKRT-IXOXFDKPSA-N His-Thr-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N)O JUCZDDVZBMPKRT-IXOXFDKPSA-N 0.000 description 3
- NBWATNYAUVSAEQ-ZEILLAHLSA-N His-Thr-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N)O NBWATNYAUVSAEQ-ZEILLAHLSA-N 0.000 description 3
- WSAILOWUJZEAGC-DCAQKATOSA-N His-Val-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N WSAILOWUJZEAGC-DCAQKATOSA-N 0.000 description 3
- 241000282412 Homo Species 0.000 description 3
- 101001098868 Homo sapiens Proprotein convertase subtilisin/kexin type 9 Proteins 0.000 description 3
- FGBRXCZYVRFNKQ-MXAVVETBSA-N Ile-Phe-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)O)N FGBRXCZYVRFNKQ-MXAVVETBSA-N 0.000 description 3
- XHBYEMIUENPZLY-GMOBBJLQSA-N Ile-Pro-Asn Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O XHBYEMIUENPZLY-GMOBBJLQSA-N 0.000 description 3
- YHFPHRUWZMEOIX-CYDGBPFRSA-N Ile-Val-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(=O)O)N YHFPHRUWZMEOIX-CYDGBPFRSA-N 0.000 description 3
- 102100037850 Interferon gamma Human genes 0.000 description 3
- 108010074328 Interferon-gamma Proteins 0.000 description 3
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 3
- PBCHMHROGNUXMK-DLOVCJGASA-N Leu-Ala-His Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 PBCHMHROGNUXMK-DLOVCJGASA-N 0.000 description 3
- HBJZFCIVFIBNSV-DCAQKATOSA-N Leu-Arg-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC(N)=O)C(O)=O HBJZFCIVFIBNSV-DCAQKATOSA-N 0.000 description 3
- ULXYQAJWJGLCNR-YUMQZZPRSA-N Leu-Asp-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O ULXYQAJWJGLCNR-YUMQZZPRSA-N 0.000 description 3
- MYGQXVYRZMKRDB-SRVKXCTJSA-N Leu-Asp-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN MYGQXVYRZMKRDB-SRVKXCTJSA-N 0.000 description 3
- LAPSXOAUPNOINL-YUMQZZPRSA-N Leu-Gly-Asp Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O LAPSXOAUPNOINL-YUMQZZPRSA-N 0.000 description 3
- POZULHZYLPGXMR-ONGXEEELSA-N Leu-Gly-Val Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O POZULHZYLPGXMR-ONGXEEELSA-N 0.000 description 3
- MJWVXZABPOKJJF-ACRUOGEOSA-N Leu-Phe-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O MJWVXZABPOKJJF-ACRUOGEOSA-N 0.000 description 3
- WMIOEVKKYIMVKI-DCAQKATOSA-N Leu-Pro-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WMIOEVKKYIMVKI-DCAQKATOSA-N 0.000 description 3
- VDIARPPNADFEAV-WEDXCCLWSA-N Leu-Thr-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O VDIARPPNADFEAV-WEDXCCLWSA-N 0.000 description 3
- GZRABTMNWJXFMH-UVOCVTCTSA-N Leu-Thr-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZRABTMNWJXFMH-UVOCVTCTSA-N 0.000 description 3
- CNWDWAMPKVYJJB-NUTKFTJISA-N Leu-Trp-Ala Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)CC(C)C)C(=O)N[C@@H](C)C(O)=O)=CNC2=C1 CNWDWAMPKVYJJB-NUTKFTJISA-N 0.000 description 3
- CRNNMTHBMRFQNG-GUBZILKMSA-N Lys-Glu-Cys Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N CRNNMTHBMRFQNG-GUBZILKMSA-N 0.000 description 3
- IVFUVMSKSFSFBT-NHCYSSNCSA-N Lys-Ile-Gly Chemical compound OC(=O)CNC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCCCN IVFUVMSKSFSFBT-NHCYSSNCSA-N 0.000 description 3
- QOJDBRUCOXQSSK-AJNGGQMLSA-N Lys-Ile-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCCN)C(O)=O QOJDBRUCOXQSSK-AJNGGQMLSA-N 0.000 description 3
- MGKFCQFVPKOWOL-CIUDSAMLSA-N Lys-Ser-Asp Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)O)C(=O)O)N MGKFCQFVPKOWOL-CIUDSAMLSA-N 0.000 description 3
- 241000282567 Macaca fascicularis Species 0.000 description 3
- MVQGZYIOMXAFQG-GUBZILKMSA-N Met-Ala-Arg Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCNC(N)=N MVQGZYIOMXAFQG-GUBZILKMSA-N 0.000 description 3
- AHZNUGRZHMZGFL-GUBZILKMSA-N Met-Arg-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CCCNC(N)=N AHZNUGRZHMZGFL-GUBZILKMSA-N 0.000 description 3
- LBSWWNKMVPAXOI-GUBZILKMSA-N Met-Val-Ser Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O LBSWWNKMVPAXOI-GUBZILKMSA-N 0.000 description 3
- 241001529936 Murinae Species 0.000 description 3
- PESQCPHRXOFIPX-UHFFFAOYSA-N N-L-methionyl-L-tyrosine Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-UHFFFAOYSA-N 0.000 description 3
- 108010079364 N-glycylalanine Proteins 0.000 description 3
- 206010028851 Necrosis Diseases 0.000 description 3
- WMGVYPPIMZPWPN-SRVKXCTJSA-N Phe-Asp-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N WMGVYPPIMZPWPN-SRVKXCTJSA-N 0.000 description 3
- ZFVWWUILVLLVFA-AVGNSLFASA-N Phe-Gln-Cys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N ZFVWWUILVLLVFA-AVGNSLFASA-N 0.000 description 3
- HQCSLJFGZYOXHW-KKUMJFAQSA-N Phe-His-Cys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CS)C(=O)O)N HQCSLJFGZYOXHW-KKUMJFAQSA-N 0.000 description 3
- TXKWKTWYTIAZSV-KKUMJFAQSA-N Phe-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N TXKWKTWYTIAZSV-KKUMJFAQSA-N 0.000 description 3
- YTILBRIUASDGBL-BZSNNMDCSA-N Phe-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 YTILBRIUASDGBL-BZSNNMDCSA-N 0.000 description 3
- CJAHQEZWDZNSJO-KKUMJFAQSA-N Phe-Lys-Cys Chemical compound NCCCC[C@@H](C(=O)N[C@@H](CS)C(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 CJAHQEZWDZNSJO-KKUMJFAQSA-N 0.000 description 3
- UNBFGVQVQGXXCK-KKUMJFAQSA-N Phe-Ser-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O UNBFGVQVQGXXCK-KKUMJFAQSA-N 0.000 description 3
- 229920003171 Poly (ethylene oxide) Polymers 0.000 description 3
- 241000202347 Porcine circovirus Species 0.000 description 3
- NHDVNAKDACFHPX-GUBZILKMSA-N Pro-Arg-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O NHDVNAKDACFHPX-GUBZILKMSA-N 0.000 description 3
- MTHRMUXESFIAMS-DCAQKATOSA-N Pro-Asn-Lys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O MTHRMUXESFIAMS-DCAQKATOSA-N 0.000 description 3
- HQVPQXMCQKXARZ-FXQIFTODSA-N Pro-Cys-Ser Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O HQVPQXMCQKXARZ-FXQIFTODSA-N 0.000 description 3
- LQZZPNDMYNZPFT-KKUMJFAQSA-N Pro-Gln-Phe Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LQZZPNDMYNZPFT-KKUMJFAQSA-N 0.000 description 3
- CLNJSLSHKJECME-BQBZGAKWSA-N Pro-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H]1CCCN1 CLNJSLSHKJECME-BQBZGAKWSA-N 0.000 description 3
- AQSMZTIEJMZQEC-DCAQKATOSA-N Pro-His-Ser Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CO)C(=O)O AQSMZTIEJMZQEC-DCAQKATOSA-N 0.000 description 3
- XYSXOCIWCPFOCG-IHRRRGAJSA-N Pro-Leu-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O XYSXOCIWCPFOCG-IHRRRGAJSA-N 0.000 description 3
- SMFQZMGHCODUPQ-ULQDDVLXSA-N Pro-Lys-Phe Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SMFQZMGHCODUPQ-ULQDDVLXSA-N 0.000 description 3
- PGSWNLRYYONGPE-JYJNAYRXSA-N Pro-Val-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O PGSWNLRYYONGPE-JYJNAYRXSA-N 0.000 description 3
- 102100038955 Proprotein convertase subtilisin/kexin type 9 Human genes 0.000 description 3
- 238000011529 RT qPCR Methods 0.000 description 3
- SRTCFKGBYBZRHA-ACZMJKKPSA-N Ser-Ala-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SRTCFKGBYBZRHA-ACZMJKKPSA-N 0.000 description 3
- VAUMZJHYZQXZBQ-WHFBIAKZSA-N Ser-Asn-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O VAUMZJHYZQXZBQ-WHFBIAKZSA-N 0.000 description 3
- BNFVPSRLHHPQKS-WHFBIAKZSA-N Ser-Asp-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O BNFVPSRLHHPQKS-WHFBIAKZSA-N 0.000 description 3
- SWSRFJZZMNLMLY-ZKWXMUAHSA-N Ser-Asp-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O SWSRFJZZMNLMLY-ZKWXMUAHSA-N 0.000 description 3
- RNFKSBPHLTZHLU-WHFBIAKZSA-N Ser-Cys-Gly Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)NCC(=O)O)N)O RNFKSBPHLTZHLU-WHFBIAKZSA-N 0.000 description 3
- SFTZTYBXIXLRGQ-JBDRJPRFSA-N Ser-Ile-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O SFTZTYBXIXLRGQ-JBDRJPRFSA-N 0.000 description 3
- LQESNKGTTNHZPZ-GHCJXIJMSA-N Ser-Ile-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O LQESNKGTTNHZPZ-GHCJXIJMSA-N 0.000 description 3
- IXZHZUGGKLRHJD-DCAQKATOSA-N Ser-Leu-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IXZHZUGGKLRHJD-DCAQKATOSA-N 0.000 description 3
- XUDRHBPSPAPDJP-SRVKXCTJSA-N Ser-Lys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CO XUDRHBPSPAPDJP-SRVKXCTJSA-N 0.000 description 3
- JCLAFVNDBJMLBC-JBDRJPRFSA-N Ser-Ser-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O JCLAFVNDBJMLBC-JBDRJPRFSA-N 0.000 description 3
- PYTKULIABVRXSC-BWBBJGPYSA-N Ser-Ser-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PYTKULIABVRXSC-BWBBJGPYSA-N 0.000 description 3
- DKGRNFUXVTYRAS-UBHSHLNASA-N Ser-Ser-Trp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O DKGRNFUXVTYRAS-UBHSHLNASA-N 0.000 description 3
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 3
- YEDSOSIKVUMIJE-DCAQKATOSA-N Ser-Val-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O YEDSOSIKVUMIJE-DCAQKATOSA-N 0.000 description 3
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 3
- 108020004682 Single-Stranded DNA Proteins 0.000 description 3
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical compound [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 3
- GZYNMZQXFRWDFH-YTWAJWBKSA-N Thr-Arg-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N)O GZYNMZQXFRWDFH-YTWAJWBKSA-N 0.000 description 3
- IRKWVRSEQFTGGV-VEVYYDQMSA-N Thr-Asn-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IRKWVRSEQFTGGV-VEVYYDQMSA-N 0.000 description 3
- QWMPARMKIDVBLV-VZFHVOOUSA-N Thr-Cys-Ala Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](C)C(O)=O QWMPARMKIDVBLV-VZFHVOOUSA-N 0.000 description 3
- VUVCRYXYUUPGSB-GLLZPBPUSA-N Thr-Gln-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O VUVCRYXYUUPGSB-GLLZPBPUSA-N 0.000 description 3
- CQNFRKAKGDSJFR-NUMRIWBASA-N Thr-Glu-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O CQNFRKAKGDSJFR-NUMRIWBASA-N 0.000 description 3
- PRNGXSILMXSWQQ-OEAJRASXSA-N Thr-Leu-Phe Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O PRNGXSILMXSWQQ-OEAJRASXSA-N 0.000 description 3
- WTMPKZWHRCMMMT-KZVJFYERSA-N Thr-Pro-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WTMPKZWHRCMMMT-KZVJFYERSA-N 0.000 description 3
- MXDOAJQRJBMGMO-FJXKBIBVSA-N Thr-Pro-Gly Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O MXDOAJQRJBMGMO-FJXKBIBVSA-N 0.000 description 3
- AHERARIZBPOMNU-KATARQTJSA-N Thr-Ser-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O AHERARIZBPOMNU-KATARQTJSA-N 0.000 description 3
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 3
- XEEHBQOUZBQVAJ-BPUTZDHNSA-N Trp-Arg-Cys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N XEEHBQOUZBQVAJ-BPUTZDHNSA-N 0.000 description 3
- WEAPHMIKOICYAU-QEJZJMRPSA-N Trp-Cys-Glu Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O WEAPHMIKOICYAU-QEJZJMRPSA-N 0.000 description 3
- YPBYQWFZAAQMGW-XIRDDKMYSA-N Trp-Lys-Asn Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)N)C(=O)O)N YPBYQWFZAAQMGW-XIRDDKMYSA-N 0.000 description 3
- BIBZRFIKOLGWFQ-XIRDDKMYSA-N Trp-Pro-Gln Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CNC3=CC=CC=C32)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O BIBZRFIKOLGWFQ-XIRDDKMYSA-N 0.000 description 3
- RNDWCRUOGGQDKN-UBHSHLNASA-N Trp-Ser-Asp Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O RNDWCRUOGGQDKN-UBHSHLNASA-N 0.000 description 3
- RKISDJMICOREEL-QRTARXTBSA-N Trp-Val-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N RKISDJMICOREEL-QRTARXTBSA-N 0.000 description 3
- MNMYOSZWCKYEDI-JRQIVUDYSA-N Tyr-Asp-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MNMYOSZWCKYEDI-JRQIVUDYSA-N 0.000 description 3
- AVIQBBOOTZENLH-KKUMJFAQSA-N Tyr-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N AVIQBBOOTZENLH-KKUMJFAQSA-N 0.000 description 3
- GZUIDWDVMWZSMI-KKUMJFAQSA-N Tyr-Lys-Cys Chemical compound NCCCC[C@@H](C(=O)N[C@@H](CS)C(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 GZUIDWDVMWZSMI-KKUMJFAQSA-N 0.000 description 3
- VUVVMFSDLYKHPA-PMVMPFDFSA-N Tyr-Lys-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC3=CC=C(C=C3)O)N VUVVMFSDLYKHPA-PMVMPFDFSA-N 0.000 description 3
- MDXLPNRXCFOBTL-BZSNNMDCSA-N Tyr-Ser-Tyr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O MDXLPNRXCFOBTL-BZSNNMDCSA-N 0.000 description 3
- QRCBQDPRKMYTMB-IHPCNDPISA-N Tyr-Trp-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N QRCBQDPRKMYTMB-IHPCNDPISA-N 0.000 description 3
- MQUYPYFPHIPVHJ-MNSWYVGCSA-N Tyr-Trp-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CC3=CC=C(C=C3)O)N)O MQUYPYFPHIPVHJ-MNSWYVGCSA-N 0.000 description 3
- ASQFIHTXXMFENG-XPUUQOCRSA-N Val-Ala-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O ASQFIHTXXMFENG-XPUUQOCRSA-N 0.000 description 3
- AZSHAZJLOZQYAY-FXQIFTODSA-N Val-Ala-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O AZSHAZJLOZQYAY-FXQIFTODSA-N 0.000 description 3
- KXUKIBHIVRYOIP-ZKWXMUAHSA-N Val-Asp-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N KXUKIBHIVRYOIP-ZKWXMUAHSA-N 0.000 description 3
- PFMAFMPJJSHNDW-ZKWXMUAHSA-N Val-Cys-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)N)C(=O)O)N PFMAFMPJJSHNDW-ZKWXMUAHSA-N 0.000 description 3
- VCAWFLIWYNMHQP-UKJIMTQDSA-N Val-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](C(C)C)N VCAWFLIWYNMHQP-UKJIMTQDSA-N 0.000 description 3
- DLMNFMXSNGTSNJ-PYJNHQTQSA-N Val-His-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](C(C)C)N DLMNFMXSNGTSNJ-PYJNHQTQSA-N 0.000 description 3
- OVBMCNDKCWAXMZ-NAKRPEOUSA-N Val-Ile-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](C(C)C)N OVBMCNDKCWAXMZ-NAKRPEOUSA-N 0.000 description 3
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 3
- ZXYPHBKIZLAQTL-QXEWZRGKSA-N Val-Pro-Asp Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N ZXYPHBKIZLAQTL-QXEWZRGKSA-N 0.000 description 3
- LCHZBEUVGAVMKS-RHYQMDGZSA-N Val-Thr-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)[C@@H](C)O)C(O)=O LCHZBEUVGAVMKS-RHYQMDGZSA-N 0.000 description 3
- USXYVSTVPHELAF-RCWTZXSCSA-N Val-Thr-Met Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCSC)C(=O)O)NC(=O)[C@H](C(C)C)N)O USXYVSTVPHELAF-RCWTZXSCSA-N 0.000 description 3
- 108010067390 Viral Proteins Proteins 0.000 description 3
- 230000002159 abnormal effect Effects 0.000 description 3
- 238000009825 accumulation Methods 0.000 description 3
- 238000013103 analytical ultracentrifugation Methods 0.000 description 3
- 238000010171 animal model Methods 0.000 description 3
- 230000000340 anti-metabolite Effects 0.000 description 3
- 229940100197 antimetabolite Drugs 0.000 description 3
- 108010093581 aspartyl-proline Proteins 0.000 description 3
- 238000011888 autopsy Methods 0.000 description 3
- 210000000013 bile duct Anatomy 0.000 description 3
- 230000015572 biosynthetic process Effects 0.000 description 3
- HHKZCCWKTZRCCL-UHFFFAOYSA-N bis-tris propane Chemical compound OCC(CO)(CO)NCCCNC(CO)(CO)CO HHKZCCWKTZRCCL-UHFFFAOYSA-N 0.000 description 3
- 238000011278 co-treatment Methods 0.000 description 3
- 238000012937 correction Methods 0.000 description 3
- 230000003247 decreasing effect Effects 0.000 description 3
- 239000012538 diafiltration buffer Substances 0.000 description 3
- 238000010790 dilution Methods 0.000 description 3
- 239000012895 dilution Substances 0.000 description 3
- 201000010099 disease Diseases 0.000 description 3
- 238000003114 enzyme-linked immunosorbent spot assay Methods 0.000 description 3
- 235000019441 ethanol Nutrition 0.000 description 3
- 235000020937 fasting conditions Nutrition 0.000 description 3
- 210000002950 fibroblast Anatomy 0.000 description 3
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 3
- 238000001476 gene delivery Methods 0.000 description 3
- 239000008103 glucose Substances 0.000 description 3
- 108010042598 glutamyl-aspartyl-glycine Proteins 0.000 description 3
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 3
- 108010010147 glycylglutamine Proteins 0.000 description 3
- 108010087823 glycyltyrosine Proteins 0.000 description 3
- 108010037850 glycylvaline Proteins 0.000 description 3
- 108010025306 histidylleucine Proteins 0.000 description 3
- 108010085325 histidylproline Proteins 0.000 description 3
- 230000004727 humoral immunity Effects 0.000 description 3
- 206010020718 hyperplasia Diseases 0.000 description 3
- 229940125721 immunosuppressive agent Drugs 0.000 description 3
- 239000012535 impurity Substances 0.000 description 3
- 238000000338 in vitro Methods 0.000 description 3
- 238000011835 investigation Methods 0.000 description 3
- 210000005228 liver tissue Anatomy 0.000 description 3
- 108010054155 lysyllysine Proteins 0.000 description 3
- 239000002609 medium Substances 0.000 description 3
- 229960000485 methotrexate Drugs 0.000 description 3
- 239000000178 monomer Substances 0.000 description 3
- 230000000877 morphologic effect Effects 0.000 description 3
- 230000017074 necrotic cell death Effects 0.000 description 3
- 229910052757 nitrogen Inorganic materials 0.000 description 3
- 102000039446 nucleic acids Human genes 0.000 description 3
- 108020004707 nucleic acids Proteins 0.000 description 3
- 230000002572 peristaltic effect Effects 0.000 description 3
- 230000003285 pharmacodynamic effect Effects 0.000 description 3
- 230000000144 pharmacologic effect Effects 0.000 description 3
- 108010083476 phenylalanyltryptophan Proteins 0.000 description 3
- 239000011148 porous material Substances 0.000 description 3
- 108090000765 processed proteins & peptides Proteins 0.000 description 3
- 108010004914 prolylarginine Proteins 0.000 description 3
- 108010053725 prolylvaline Proteins 0.000 description 3
- 230000004044 response Effects 0.000 description 3
- 238000012216 screening Methods 0.000 description 3
- 238000012163 sequencing technique Methods 0.000 description 3
- 239000001488 sodium phosphate Substances 0.000 description 3
- 229910000162 sodium phosphate Inorganic materials 0.000 description 3
- 238000010186 staining Methods 0.000 description 3
- 238000011272 standard treatment Methods 0.000 description 3
- 230000002459 sustained effect Effects 0.000 description 3
- 108010061238 threonyl-glycine Proteins 0.000 description 3
- RYFMWSXOAZQYPI-UHFFFAOYSA-K trisodium phosphate Chemical compound [Na+].[Na+].[Na+].[O-]P([O-])([O-])=O RYFMWSXOAZQYPI-UHFFFAOYSA-K 0.000 description 3
- 108010020532 tyrosyl-proline Proteins 0.000 description 3
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 2
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 2
- MNZHHDPWDWQJCQ-YUMQZZPRSA-N Ala-Leu-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O MNZHHDPWDWQJCQ-YUMQZZPRSA-N 0.000 description 2
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 2
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 2
- 102000007592 Apolipoproteins Human genes 0.000 description 2
- 108010071619 Apolipoproteins Proteins 0.000 description 2
- XEPSCVXTCUUHDT-AVGNSLFASA-N Arg-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CCCN=C(N)N XEPSCVXTCUUHDT-AVGNSLFASA-N 0.000 description 2
- BJNUAWGXPSHQMJ-DCAQKATOSA-N Arg-Gln-Met Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(O)=O BJNUAWGXPSHQMJ-DCAQKATOSA-N 0.000 description 2
- NVCIXQYNWYTLDO-IHRRRGAJSA-N Arg-His-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CCCN=C(N)N)N NVCIXQYNWYTLDO-IHRRRGAJSA-N 0.000 description 2
- LVMUGODRNHFGRA-AVGNSLFASA-N Arg-Leu-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O LVMUGODRNHFGRA-AVGNSLFASA-N 0.000 description 2
- GMFAGHNRXPSSJS-SRVKXCTJSA-N Arg-Leu-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GMFAGHNRXPSSJS-SRVKXCTJSA-N 0.000 description 2
- XIDSGDJNUJRUHE-VEVYYDQMSA-N Asn-Thr-Met Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(O)=O XIDSGDJNUJRUHE-VEVYYDQMSA-N 0.000 description 2
- UGIBTKGQVWFTGX-BIIVOSGPSA-N Asp-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)O)N)C(=O)O UGIBTKGQVWFTGX-BIIVOSGPSA-N 0.000 description 2
- HSWYMWGDMPLTTH-FXQIFTODSA-N Asp-Glu-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O HSWYMWGDMPLTTH-FXQIFTODSA-N 0.000 description 2
- JUWZKMBALYLZCK-WHFBIAKZSA-N Asp-Gly-Asn Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O JUWZKMBALYLZCK-WHFBIAKZSA-N 0.000 description 2
- PGUYEUCYVNZGGV-QWRGUYRKSA-N Asp-Gly-Tyr Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 PGUYEUCYVNZGGV-QWRGUYRKSA-N 0.000 description 2
- 108010006654 Bleomycin Proteins 0.000 description 2
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 2
- CURLTUGMZLYLDI-UHFFFAOYSA-N Carbon dioxide Chemical compound O=C=O CURLTUGMZLYLDI-UHFFFAOYSA-N 0.000 description 2
- PMATZTZNYRCHOR-CGLBZJNRSA-N Cyclosporin A Chemical compound CC[C@@H]1NC(=O)[C@H]([C@H](O)[C@H](C)C\C=C\C)N(C)C(=O)[C@H](C(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)N(C)C(=O)CN(C)C1=O PMATZTZNYRCHOR-CGLBZJNRSA-N 0.000 description 2
- 229930105110 Cyclosporin A Natural products 0.000 description 2
- 108010036949 Cyclosporine Proteins 0.000 description 2
- KSMSFCBQBQPFAD-GUBZILKMSA-N Cys-Pro-Pro Chemical compound SC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 KSMSFCBQBQPFAD-GUBZILKMSA-N 0.000 description 2
- ZGERHCJBLPQPGV-ACZMJKKPSA-N Cys-Ser-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CS)N ZGERHCJBLPQPGV-ACZMJKKPSA-N 0.000 description 2
- 108090000695 Cytokines Proteins 0.000 description 2
- 102000004127 Cytokines Human genes 0.000 description 2
- 108010092160 Dactinomycin Proteins 0.000 description 2
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 2
- KVXVVDFOZNYYKZ-DCAQKATOSA-N Gln-Gln-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O KVXVVDFOZNYYKZ-DCAQKATOSA-N 0.000 description 2
- HVQCEQTUSWWFOS-WDSKDSINSA-N Gln-Gly-Cys Chemical compound C(CC(=O)N)[C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N HVQCEQTUSWWFOS-WDSKDSINSA-N 0.000 description 2
- NLKVNZUFDPWPNL-YUMQZZPRSA-N Glu-Arg-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O NLKVNZUFDPWPNL-YUMQZZPRSA-N 0.000 description 2
- PXHABOCPJVTGEK-BQBZGAKWSA-N Glu-Gln-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O PXHABOCPJVTGEK-BQBZGAKWSA-N 0.000 description 2
- UEGIPZAXNBYCCP-NKWVEPMBSA-N Gly-Cys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CS)NC(=O)CN)C(=O)O UEGIPZAXNBYCCP-NKWVEPMBSA-N 0.000 description 2
- XLFHCWHXKSFVIB-BQBZGAKWSA-N Gly-Gln-Gln Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O XLFHCWHXKSFVIB-BQBZGAKWSA-N 0.000 description 2
- QPDUVFSVVAOUHE-XVKPBYJWSA-N Gly-Gln-Val Chemical compound CC(C)[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)CN)C(O)=O QPDUVFSVVAOUHE-XVKPBYJWSA-N 0.000 description 2
- BIRKKBCSAIHDDF-WDSKDSINSA-N Gly-Glu-Cys Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CS)C(O)=O BIRKKBCSAIHDDF-WDSKDSINSA-N 0.000 description 2
- IDOGEHIWMJMAHT-BYPYZUCNSA-N Gly-Gly-Cys Chemical compound NCC(=O)NCC(=O)N[C@@H](CS)C(O)=O IDOGEHIWMJMAHT-BYPYZUCNSA-N 0.000 description 2
- ORXZVPZCPMKHNR-IUCAKERBSA-N Gly-His-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CNC=N1 ORXZVPZCPMKHNR-IUCAKERBSA-N 0.000 description 2
- YFGONBOFGGWKKY-VHSXEESVSA-N Gly-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)CN)C(=O)O YFGONBOFGGWKKY-VHSXEESVSA-N 0.000 description 2
- NSTUFLGQJCOCDL-UWVGGRQHSA-N Gly-Leu-Arg Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N NSTUFLGQJCOCDL-UWVGGRQHSA-N 0.000 description 2
- VEPBEGNDJYANCF-QWRGUYRKSA-N Gly-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCCN VEPBEGNDJYANCF-QWRGUYRKSA-N 0.000 description 2
- 206010019851 Hepatotoxicity Diseases 0.000 description 2
- 241000238631 Hexapoda Species 0.000 description 2
- ZVKDCQVQTGYBQT-LSJOCFKGSA-N His-Pro-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O ZVKDCQVQTGYBQT-LSJOCFKGSA-N 0.000 description 2
- QCBYAHHNOHBXIH-UWVGGRQHSA-N His-Pro-Gly Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)NCC(O)=O)C1=CN=CN1 QCBYAHHNOHBXIH-UWVGGRQHSA-N 0.000 description 2
- 206010020880 Hypertrophy Diseases 0.000 description 2
- DVRDRICMWUSCBN-UKJIMTQDSA-N Ile-Gln-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N DVRDRICMWUSCBN-UKJIMTQDSA-N 0.000 description 2
- 102000000521 Immunophilins Human genes 0.000 description 2
- 108010016648 Immunophilins Proteins 0.000 description 2
- 102100026720 Interferon beta Human genes 0.000 description 2
- 108090000467 Interferon-beta Proteins 0.000 description 2
- 102000000588 Interleukin-2 Human genes 0.000 description 2
- 108010002350 Interleukin-2 Proteins 0.000 description 2
- 102000003855 L-lactate dehydrogenase Human genes 0.000 description 2
- 108700023483 L-lactate dehydrogenases Proteins 0.000 description 2
- CNNQBZRGQATKNY-DCAQKATOSA-N Leu-Arg-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N CNNQBZRGQATKNY-DCAQKATOSA-N 0.000 description 2
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 2
- JNDYEOUZBLOVOF-AVGNSLFASA-N Leu-Leu-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O JNDYEOUZBLOVOF-AVGNSLFASA-N 0.000 description 2
- YNNPKXBBRZVIRX-IHRRRGAJSA-N Lys-Arg-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O YNNPKXBBRZVIRX-IHRRRGAJSA-N 0.000 description 2
- QKXZCUCBFPEXNK-KKUMJFAQSA-N Lys-Leu-His Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 QKXZCUCBFPEXNK-KKUMJFAQSA-N 0.000 description 2
- PDIDTSZKKFEDMB-UWVGGRQHSA-N Lys-Pro-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O PDIDTSZKKFEDMB-UWVGGRQHSA-N 0.000 description 2
- TVOOGUNBIWAURO-KATARQTJSA-N Lys-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCCCN)N)O TVOOGUNBIWAURO-KATARQTJSA-N 0.000 description 2
- 229930192392 Mitomycin Natural products 0.000 description 2
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 2
- 238000011887 Necropsy Methods 0.000 description 2
- 206010028980 Neoplasm Diseases 0.000 description 2
- PVNIIMVLHYAWGP-UHFFFAOYSA-N Niacin Chemical compound OC(=O)C1=CC=CN=C1 PVNIIMVLHYAWGP-UHFFFAOYSA-N 0.000 description 2
- 239000004677 Nylon Substances 0.000 description 2
- KAGCQPSEVAETCA-JYJNAYRXSA-N Phe-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CC=CC=C1)N KAGCQPSEVAETCA-JYJNAYRXSA-N 0.000 description 2
- 239000004743 Polypropylene Substances 0.000 description 2
- DZZCICYRSZASNF-FXQIFTODSA-N Pro-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 DZZCICYRSZASNF-FXQIFTODSA-N 0.000 description 2
- VXCHGLYSIOOZIS-GUBZILKMSA-N Pro-Ala-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 VXCHGLYSIOOZIS-GUBZILKMSA-N 0.000 description 2
- APKRGYLBSCWJJP-FXQIFTODSA-N Pro-Ala-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O APKRGYLBSCWJJP-FXQIFTODSA-N 0.000 description 2
- FYQSMXKJYTZYRP-DCAQKATOSA-N Pro-Ala-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 FYQSMXKJYTZYRP-DCAQKATOSA-N 0.000 description 2
- OOLOTUZJUBOMAX-GUBZILKMSA-N Pro-Ala-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O OOLOTUZJUBOMAX-GUBZILKMSA-N 0.000 description 2
- LNLNHXIQPGKRJQ-SRVKXCTJSA-N Pro-Arg-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H]1CCCN1 LNLNHXIQPGKRJQ-SRVKXCTJSA-N 0.000 description 2
- SGCZFWSQERRKBD-BQBZGAKWSA-N Pro-Asp-Gly Chemical compound OC(=O)CNC(=O)[C@H](CC(O)=O)NC(=O)[C@@H]1CCCN1 SGCZFWSQERRKBD-BQBZGAKWSA-N 0.000 description 2
- SFECXGVELZFBFJ-VEVYYDQMSA-N Pro-Asp-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SFECXGVELZFBFJ-VEVYYDQMSA-N 0.000 description 2
- SKICPQLTOXGWGO-GARJFASQSA-N Pro-Gln-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)N)C(=O)N2CCC[C@@H]2C(=O)O SKICPQLTOXGWGO-GARJFASQSA-N 0.000 description 2
- WFIVLLFYUZZWOD-RHYQMDGZSA-N Pro-Lys-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WFIVLLFYUZZWOD-RHYQMDGZSA-N 0.000 description 2
- SVXXJYJCRNKDDE-AVGNSLFASA-N Pro-Pro-His Chemical compound C([C@@H](C(=O)O)NC(=O)[C@H]1N(CCC1)C(=O)[C@H]1NCCC1)C1=CN=CN1 SVXXJYJCRNKDDE-AVGNSLFASA-N 0.000 description 2
- BGWKULMLUIUPKY-BQBZGAKWSA-N Pro-Ser-Gly Chemical compound OC(=O)CNC(=O)[C@H](CO)NC(=O)[C@@H]1CCCN1 BGWKULMLUIUPKY-BQBZGAKWSA-N 0.000 description 2
- 108010044159 Proprotein Convertases Proteins 0.000 description 2
- 102000006437 Proprotein Convertases Human genes 0.000 description 2
- OJPHFSOMBZKQKQ-GUBZILKMSA-N Ser-Gln-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CO OJPHFSOMBZKQKQ-GUBZILKMSA-N 0.000 description 2
- NUEHQDHDLDXCRU-GUBZILKMSA-N Ser-Pro-Arg Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O NUEHQDHDLDXCRU-GUBZILKMSA-N 0.000 description 2
- 208000000453 Skin Neoplasms Diseases 0.000 description 2
- 108090000787 Subtilisin Proteins 0.000 description 2
- QJJXYPPXXYFBGM-LFZNUXCKSA-N Tacrolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1\C=C(/C)[C@@H]1[C@H](C)[C@@H](O)CC(=O)[C@H](CC=C)/C=C(C)/C[C@H](C)C[C@H](OC)[C@H]([C@H](C[C@H]2C)OC)O[C@@]2(O)C(=O)C(=O)N2CCCC[C@H]2C(=O)O1 QJJXYPPXXYFBGM-LFZNUXCKSA-N 0.000 description 2
- NKANXQFJJICGDU-QPLCGJKRSA-N Tamoxifen Chemical compound C=1C=CC=CC=1C(/CC)=C(C=1C=CC(OCCN(C)C)=CC=1)/C1=CC=CC=C1 NKANXQFJJICGDU-QPLCGJKRSA-N 0.000 description 2
- MMTOHPRBJKEZHT-BWBBJGPYSA-N Thr-Cys-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O MMTOHPRBJKEZHT-BWBBJGPYSA-N 0.000 description 2
- PRTHQBSMXILLPC-XGEHTFHBSA-N Thr-Ser-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PRTHQBSMXILLPC-XGEHTFHBSA-N 0.000 description 2
- COYHRQWNJDJCNA-NUJDXYNKSA-N Thr-Thr-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O COYHRQWNJDJCNA-NUJDXYNKSA-N 0.000 description 2
- 101150013568 US16 gene Proteins 0.000 description 2
- 108091034131 VA RNA Proteins 0.000 description 2
- SLLKXDSRVAOREO-KZVJFYERSA-N Val-Ala-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C)NC(=O)[C@H](C(C)C)N)O SLLKXDSRVAOREO-KZVJFYERSA-N 0.000 description 2
- LYERIXUFCYVFFX-GVXVVHGQSA-N Val-Leu-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N LYERIXUFCYVFFX-GVXVVHGQSA-N 0.000 description 2
- 206010048215 Xanthomatosis Diseases 0.000 description 2
- 230000035508 accumulation Effects 0.000 description 2
- RJURFGZVJUQBHK-IIXSONLDSA-N actinomycin D Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)N[C@@H]4C(=O)N[C@@H](C(N5CCC[C@H]5C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-IIXSONLDSA-N 0.000 description 2
- 230000004913 activation Effects 0.000 description 2
- 239000004480 active ingredient Substances 0.000 description 2
- 239000013543 active substance Substances 0.000 description 2
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 2
- 102000015395 alpha 1-Antitrypsin Human genes 0.000 description 2
- 108010050122 alpha 1-Antitrypsin Proteins 0.000 description 2
- 229940024142 alpha 1-antitrypsin Drugs 0.000 description 2
- 230000003321 amplification Effects 0.000 description 2
- 229940045799 anthracyclines and related substance Drugs 0.000 description 2
- 239000003242 anti bacterial agent Substances 0.000 description 2
- 229940088710 antibiotic agent Drugs 0.000 description 2
- 229940045719 antineoplastic alkylating agent nitrosoureas Drugs 0.000 description 2
- 229940045985 antineoplastic platinum compound Drugs 0.000 description 2
- 108010013835 arginine glutamate Proteins 0.000 description 2
- 229960002170 azathioprine Drugs 0.000 description 2
- LMEKQMALGUDUQG-UHFFFAOYSA-N azathioprine Chemical compound CN1C=NC([N+]([O-])=O)=C1SC1=NC=NC2=C1NC=N2 LMEKQMALGUDUQG-UHFFFAOYSA-N 0.000 description 2
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 2
- 239000011230 binding agent Substances 0.000 description 2
- 229960001561 bleomycin Drugs 0.000 description 2
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 2
- 108010006025 bovine growth hormone Proteins 0.000 description 2
- 239000003795 chemical substances by application Substances 0.000 description 2
- 229960001265 ciclosporin Drugs 0.000 description 2
- 238000003776 cleavage reaction Methods 0.000 description 2
- 238000011260 co-administration Methods 0.000 description 2
- 238000004590 computer program Methods 0.000 description 2
- 230000001143 conditioned effect Effects 0.000 description 2
- 208000029078 coronary artery disease Diseases 0.000 description 2
- 239000003246 corticosteroid Substances 0.000 description 2
- 229940109239 creatinine Drugs 0.000 description 2
- 229930182912 cyclosporin Natural products 0.000 description 2
- 239000000824 cytostatic agent Substances 0.000 description 2
- 229960000640 dactinomycin Drugs 0.000 description 2
- 238000012217 deletion Methods 0.000 description 2
- 230000037430 deletion Effects 0.000 description 2
- 230000008021 deposition Effects 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 230000018109 developmental process Effects 0.000 description 2
- 235000005911 diet Nutrition 0.000 description 2
- 230000037213 diet Effects 0.000 description 2
- 238000011143 downstream manufacturing Methods 0.000 description 2
- 229940125753 fibrate Drugs 0.000 description 2
- 229960002949 fluorouracil Drugs 0.000 description 2
- 239000003862 glucocorticoid Substances 0.000 description 2
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Chemical compound NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 2
- 230000002440 hepatic effect Effects 0.000 description 2
- 231100000304 hepatotoxicity Toxicity 0.000 description 2
- 230000007686 hepatotoxicity Effects 0.000 description 2
- 108010040030 histidinoalanine Proteins 0.000 description 2
- 230000036039 immunity Effects 0.000 description 2
- 230000002779 inactivation Effects 0.000 description 2
- 230000005764 inhibitory process Effects 0.000 description 2
- 230000000977 initiatory effect Effects 0.000 description 2
- 238000003780 insertion Methods 0.000 description 2
- 230000037431 insertion Effects 0.000 description 2
- 230000003993 interaction Effects 0.000 description 2
- 238000004255 ion exchange chromatography Methods 0.000 description 2
- 150000002500 ions Chemical class 0.000 description 2
- 210000005229 liver cell Anatomy 0.000 description 2
- 238000007449 liver function test Methods 0.000 description 2
- 238000011068 loading method Methods 0.000 description 2
- 229960003566 lomitapide Drugs 0.000 description 2
- MBBCVAKAJPKAKM-UHFFFAOYSA-N lomitapide Chemical compound C12=CC=CC=C2C2=CC=CC=C2C1(C(=O)NCC(F)(F)F)CCCCN(CC1)CCC1NC(=O)C1=CC=CC=C1C1=CC=C(C(F)(F)F)C=C1 MBBCVAKAJPKAKM-UHFFFAOYSA-N 0.000 description 2
- 108010009298 lysylglutamic acid Proteins 0.000 description 2
- 108010064235 lysylglycine Proteins 0.000 description 2
- 239000003120 macrolide antibiotic agent Substances 0.000 description 2
- 229940041033 macrolides Drugs 0.000 description 2
- 210000004962 mammalian cell Anatomy 0.000 description 2
- 238000001819 mass spectrum Methods 0.000 description 2
- 239000012528 membrane Substances 0.000 description 2
- GLVAUDGFNGKCSF-UHFFFAOYSA-N mercaptopurine Chemical compound S=C1NC=NC2=C1NC=N2 GLVAUDGFNGKCSF-UHFFFAOYSA-N 0.000 description 2
- 229960001428 mercaptopurine Drugs 0.000 description 2
- 230000004060 metabolic process Effects 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 238000002887 multiple sequence alignment Methods 0.000 description 2
- 208000010125 myocardial infarction Diseases 0.000 description 2
- 230000007935 neutral effect Effects 0.000 description 2
- 229960003512 nicotinic acid Drugs 0.000 description 2
- 235000001968 nicotinic acid Nutrition 0.000 description 2
- 239000011664 nicotinic acid Substances 0.000 description 2
- 238000003199 nucleic acid amplification method Methods 0.000 description 2
- 229920001778 nylon Polymers 0.000 description 2
- 229940005483 opioid analgesics Drugs 0.000 description 2
- 238000013146 percutaneous coronary intervention Methods 0.000 description 2
- 230000007255 peripheral T cell response Effects 0.000 description 2
- 230000001766 physiological effect Effects 0.000 description 2
- BASFCYQUMIYNBI-UHFFFAOYSA-N platinum Substances [Pt] BASFCYQUMIYNBI-UHFFFAOYSA-N 0.000 description 2
- 150000003058 platinum compounds Chemical class 0.000 description 2
- 229920002401 polyacrylamide Polymers 0.000 description 2
- 229920001155 polypropylene Polymers 0.000 description 2
- 229920001451 polypropylene glycol Polymers 0.000 description 2
- 231100000683 possible toxicity Toxicity 0.000 description 2
- 102000004196 processed proteins & peptides Human genes 0.000 description 2
- 108010077112 prolyl-proline Proteins 0.000 description 2
- 238000004445 quantitative analysis Methods 0.000 description 2
- 230000001105 regulatory effect Effects 0.000 description 2
- 101150066583 rep gene Proteins 0.000 description 2
- 230000007017 scission Effects 0.000 description 2
- 230000028327 secretion Effects 0.000 description 2
- 239000012679 serum free medium Substances 0.000 description 2
- 201000000849 skin cancer Diseases 0.000 description 2
- 239000000243 solution Substances 0.000 description 2
- 210000000952 spleen Anatomy 0.000 description 2
- 238000012289 standard assay Methods 0.000 description 2
- 230000007863 steatosis Effects 0.000 description 2
- 231100000240 steatosis hepatitis Toxicity 0.000 description 2
- 238000003756 stirring Methods 0.000 description 2
- 238000011477 surgical intervention Methods 0.000 description 2
- 230000009885 systemic effect Effects 0.000 description 2
- 229940037128 systemic glucocorticoids Drugs 0.000 description 2
- QJJXYPPXXYFBGM-SHYZHZOCSA-N tacrolimus Natural products CO[C@H]1C[C@H](CC[C@@H]1O)C=C(C)[C@H]2OC(=O)[C@H]3CCCCN3C(=O)C(=O)[C@@]4(O)O[C@@H]([C@H](C[C@H]4C)OC)[C@@H](C[C@H](C)CC(=C[C@@H](CC=C)C(=O)C[C@H](O)[C@H]2C)C)OC QJJXYPPXXYFBGM-SHYZHZOCSA-N 0.000 description 2
- 229960001967 tacrolimus Drugs 0.000 description 2
- 230000008685 targeting Effects 0.000 description 2
- 231100000331 toxic Toxicity 0.000 description 2
- 230000002588 toxic effect Effects 0.000 description 2
- 231100000027 toxicology Toxicity 0.000 description 2
- 238000013519 translation Methods 0.000 description 2
- 238000002054 transplantation Methods 0.000 description 2
- 230000032258 transport Effects 0.000 description 2
- 239000002753 trypsin inhibitor Substances 0.000 description 2
- 108010080629 tryptophan-leucine Proteins 0.000 description 2
- 108010084932 tryptophyl-proline Proteins 0.000 description 2
- 108010045269 tryptophyltryptophan Proteins 0.000 description 2
- 108010051110 tyrosyl-lysine Proteins 0.000 description 2
- 241000701447 unidentified baculovirus Species 0.000 description 2
- IBIDRSSEHFLGSD-UHFFFAOYSA-N valinyl-arginine Natural products CC(C)C(N)C(=O)NC(C(O)=O)CCCN=C(N)N IBIDRSSEHFLGSD-UHFFFAOYSA-N 0.000 description 2
- 210000002845 virion Anatomy 0.000 description 2
- 238000012800 visualization Methods 0.000 description 2
- 239000011534 wash buffer Substances 0.000 description 2
- PKOHVHWNGUHYRE-ZFWWWQNUSA-N (2s)-1-[2-[[(2s)-2-amino-3-(1h-indol-3-yl)propanoyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound O=C([C@H](CC=1C2=CC=CC=C2NC=1)N)NCC(=O)N1CCC[C@H]1C(O)=O PKOHVHWNGUHYRE-ZFWWWQNUSA-N 0.000 description 1
- FFJCNSLCJOQHKM-CLFAGFIQSA-N (z)-1-[(z)-octadec-9-enoxy]octadec-9-ene Chemical compound CCCCCCCC\C=C/CCCCCCCCOCCCCCCCC\C=C/CCCCCCCC FFJCNSLCJOQHKM-CLFAGFIQSA-N 0.000 description 1
- JVKUCNQGESRUCL-UHFFFAOYSA-N 2-Hydroxyethyl 12-hydroxyoctadecanoate Chemical compound CCCCCCC(O)CCCCCCCCCCC(=O)OCCO JVKUCNQGESRUCL-UHFFFAOYSA-N 0.000 description 1
- SCPRYBYMKVYVND-UHFFFAOYSA-N 2-[[2-[[1-(2-amino-4-methylpentanoyl)pyrrolidine-2-carbonyl]amino]-4-methylpentanoyl]amino]-4-methylpentanoic acid Chemical compound CC(C)CC(N)C(=O)N1CCCC1C(=O)NC(CC(C)C)C(=O)NC(CC(C)C)C(O)=O SCPRYBYMKVYVND-UHFFFAOYSA-N 0.000 description 1
- DGZSVBBLLGZHSF-UHFFFAOYSA-N 4,4-diethylpiperidine Chemical compound CCC1(CC)CCNCC1 DGZSVBBLLGZHSF-UHFFFAOYSA-N 0.000 description 1
- 102000012758 APOBEC-1 Deaminase Human genes 0.000 description 1
- 101150012656 APOBEC1 gene Proteins 0.000 description 1
- 241001164823 Adeno-associated virus - 7 Species 0.000 description 1
- 241000958487 Adeno-associated virus 3B Species 0.000 description 1
- ZEXDYVGDZJBRMO-ACZMJKKPSA-N Ala-Asn-Gln Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N ZEXDYVGDZJBRMO-ACZMJKKPSA-N 0.000 description 1
- GORKKVHIBWAQHM-GCJQMDKQSA-N Ala-Asn-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GORKKVHIBWAQHM-GCJQMDKQSA-N 0.000 description 1
- NHCPCLJZRSIDHS-ZLUOBGJFSA-N Ala-Asp-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O NHCPCLJZRSIDHS-ZLUOBGJFSA-N 0.000 description 1
- GSCLWXDNIMNIJE-ZLUOBGJFSA-N Ala-Asp-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O GSCLWXDNIMNIJE-ZLUOBGJFSA-N 0.000 description 1
- PWYFCPCBOYMOGB-LKTVYLICSA-N Ala-Gln-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N PWYFCPCBOYMOGB-LKTVYLICSA-N 0.000 description 1
- IXTPACPAXIOCRG-ACZMJKKPSA-N Ala-Glu-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CS)C(=O)O)N IXTPACPAXIOCRG-ACZMJKKPSA-N 0.000 description 1
- WGDNWOMKBUXFHR-BQBZGAKWSA-N Ala-Gly-Arg Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N WGDNWOMKBUXFHR-BQBZGAKWSA-N 0.000 description 1
- LJFNNUBZSZCZFN-WHFBIAKZSA-N Ala-Gly-Cys Chemical compound N[C@@H](C)C(=O)NCC(=O)N[C@@H](CS)C(=O)O LJFNNUBZSZCZFN-WHFBIAKZSA-N 0.000 description 1
- VGPWRRFOPXVGOH-BYPYZUCNSA-N Ala-Gly-Gly Chemical compound C[C@H](N)C(=O)NCC(=O)NCC(O)=O VGPWRRFOPXVGOH-BYPYZUCNSA-N 0.000 description 1
- MQIGTEQXYCRLGK-BQBZGAKWSA-N Ala-Gly-Pro Chemical compound C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O MQIGTEQXYCRLGK-BQBZGAKWSA-N 0.000 description 1
- OKEWAFFWMHBGPT-XPUUQOCRSA-N Ala-His-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CN=CN1 OKEWAFFWMHBGPT-XPUUQOCRSA-N 0.000 description 1
- 108010076441 Ala-His-His Proteins 0.000 description 1
- CCDFBRZVTDDJNM-GUBZILKMSA-N Ala-Leu-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O CCDFBRZVTDDJNM-GUBZILKMSA-N 0.000 description 1
- UWIQWPWWZUHBAO-ZLIFDBKOSA-N Ala-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)[C@H](C)N)CC(C)C)C(O)=O)=CNC2=C1 UWIQWPWWZUHBAO-ZLIFDBKOSA-N 0.000 description 1
- AJBVYEYZVYPFCF-CIUDSAMLSA-N Ala-Lys-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O AJBVYEYZVYPFCF-CIUDSAMLSA-N 0.000 description 1
- SUHLZMHFRALVSY-YUMQZZPRSA-N Ala-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)NCC(O)=O SUHLZMHFRALVSY-YUMQZZPRSA-N 0.000 description 1
- VCSABYLVNWQYQE-SRVKXCTJSA-N Ala-Lys-Lys Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@@H](CCCCN)C(O)=O VCSABYLVNWQYQE-SRVKXCTJSA-N 0.000 description 1
- VCSABYLVNWQYQE-UHFFFAOYSA-N Ala-Lys-Lys Natural products NCCCCC(NC(=O)C(N)C)C(=O)NC(CCCCN)C(O)=O VCSABYLVNWQYQE-UHFFFAOYSA-N 0.000 description 1
- XUCHENWTTBFODJ-FXQIFTODSA-N Ala-Met-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O XUCHENWTTBFODJ-FXQIFTODSA-N 0.000 description 1
- FQNILRVJOJBFFC-FXQIFTODSA-N Ala-Pro-Asp Chemical compound C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N FQNILRVJOJBFFC-FXQIFTODSA-N 0.000 description 1
- FEGOCLZUJUFCHP-CIUDSAMLSA-N Ala-Pro-Gln Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O FEGOCLZUJUFCHP-CIUDSAMLSA-N 0.000 description 1
- BTRULDJUUVGRNE-DCAQKATOSA-N Ala-Pro-Lys Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O BTRULDJUUVGRNE-DCAQKATOSA-N 0.000 description 1
- XQNRANMFRPCFFW-GCJQMDKQSA-N Ala-Thr-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](C)N)O XQNRANMFRPCFFW-GCJQMDKQSA-N 0.000 description 1
- YCTIYBUTCKNOTI-UWJYBYFXSA-N Ala-Tyr-Asp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N YCTIYBUTCKNOTI-UWJYBYFXSA-N 0.000 description 1
- ZJLORAAXDAJLDC-CQDKDKBSSA-N Ala-Tyr-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O ZJLORAAXDAJLDC-CQDKDKBSSA-N 0.000 description 1
- IYKVSFNGSWTTNZ-GUBZILKMSA-N Ala-Val-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N IYKVSFNGSWTTNZ-GUBZILKMSA-N 0.000 description 1
- 108010088751 Albumins Proteins 0.000 description 1
- 102000009027 Albumins Human genes 0.000 description 1
- 208000022309 Alcoholic Liver disease Diseases 0.000 description 1
- 208000007848 Alcoholism Diseases 0.000 description 1
- ITPDYQOUSLNIHG-UHFFFAOYSA-N Amiodarone hydrochloride Chemical compound [Cl-].CCCCC=1OC2=CC=CC=C2C=1C(=O)C1=CC(I)=C(OCC[NH+](CC)CC)C(I)=C1 ITPDYQOUSLNIHG-UHFFFAOYSA-N 0.000 description 1
- 206010002388 Angina unstable Diseases 0.000 description 1
- 101710081722 Antitrypsin Proteins 0.000 description 1
- 108010027006 Apolipoproteins B Proteins 0.000 description 1
- 102000018616 Apolipoproteins B Human genes 0.000 description 1
- SGYSTDWPNPKJPP-GUBZILKMSA-N Arg-Ala-Arg Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SGYSTDWPNPKJPP-GUBZILKMSA-N 0.000 description 1
- PEFFAAKJGBZBKL-NAKRPEOUSA-N Arg-Ala-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O PEFFAAKJGBZBKL-NAKRPEOUSA-N 0.000 description 1
- IIABBYGHLYWVOS-FXQIFTODSA-N Arg-Asn-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O IIABBYGHLYWVOS-FXQIFTODSA-N 0.000 description 1
- ITVINTQUZMQWJR-QXEWZRGKSA-N Arg-Asn-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(O)=O ITVINTQUZMQWJR-QXEWZRGKSA-N 0.000 description 1
- DXQIQUIQYAGRCC-CIUDSAMLSA-N Arg-Asp-Gln Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)CN=C(N)N DXQIQUIQYAGRCC-CIUDSAMLSA-N 0.000 description 1
- ASQYTJJWAMDISW-BPUTZDHNSA-N Arg-Asp-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N ASQYTJJWAMDISW-BPUTZDHNSA-N 0.000 description 1
- VXXHDZKEQNGXNU-QXEWZRGKSA-N Arg-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N VXXHDZKEQNGXNU-QXEWZRGKSA-N 0.000 description 1
- QIWYWCYNUMJBTC-CIUDSAMLSA-N Arg-Cys-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O QIWYWCYNUMJBTC-CIUDSAMLSA-N 0.000 description 1
- GDVDRMUYICMNFJ-CIUDSAMLSA-N Arg-Cys-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(O)=O GDVDRMUYICMNFJ-CIUDSAMLSA-N 0.000 description 1
- KBBKCNHWCDJPGN-GUBZILKMSA-N Arg-Gln-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KBBKCNHWCDJPGN-GUBZILKMSA-N 0.000 description 1
- JQFJNGVSGOUQDH-XIRDDKMYSA-N Arg-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCN=C(N)N)N)C(O)=O)=CNC2=C1 JQFJNGVSGOUQDH-XIRDDKMYSA-N 0.000 description 1
- PPPXVIBMLFWNSK-BQBZGAKWSA-N Arg-Gly-Cys Chemical compound C(C[C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N)CN=C(N)N PPPXVIBMLFWNSK-BQBZGAKWSA-N 0.000 description 1
- YNSGXDWWPCGGQS-YUMQZZPRSA-N Arg-Gly-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O YNSGXDWWPCGGQS-YUMQZZPRSA-N 0.000 description 1
- OQCWXQJLCDPRHV-UWVGGRQHSA-N Arg-Gly-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O OQCWXQJLCDPRHV-UWVGGRQHSA-N 0.000 description 1
- PHHRSPBBQUFULD-UWVGGRQHSA-N Arg-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCCN=C(N)N)N PHHRSPBBQUFULD-UWVGGRQHSA-N 0.000 description 1
- ZZZWQALDSQQBEW-STQMWFEESA-N Arg-Gly-Tyr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZZZWQALDSQQBEW-STQMWFEESA-N 0.000 description 1
- JEXPNDORFYHJTM-IHRRRGAJSA-N Arg-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCCN=C(N)N JEXPNDORFYHJTM-IHRRRGAJSA-N 0.000 description 1
- BTJVOUQWFXABOI-IHRRRGAJSA-N Arg-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCNC(N)=N BTJVOUQWFXABOI-IHRRRGAJSA-N 0.000 description 1
- GITAWLWBTMJPKH-AVGNSLFASA-N Arg-Met-His Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N GITAWLWBTMJPKH-AVGNSLFASA-N 0.000 description 1
- OISWSORSLQOGFV-AVGNSLFASA-N Arg-Met-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CCCN=C(N)N OISWSORSLQOGFV-AVGNSLFASA-N 0.000 description 1
- INXWADWANGLMPJ-JYJNAYRXSA-N Arg-Phe-Arg Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)CC1=CC=CC=C1 INXWADWANGLMPJ-JYJNAYRXSA-N 0.000 description 1
- FIQKRDXFTANIEJ-ULQDDVLXSA-N Arg-Phe-His Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N FIQKRDXFTANIEJ-ULQDDVLXSA-N 0.000 description 1
- IGFJVXOATGZTHD-UHFFFAOYSA-N Arg-Phe-His Natural products NC(CCNC(=N)N)C(=O)NC(Cc1ccccc1)C(=O)NC(Cc2c[nH]cn2)C(=O)O IGFJVXOATGZTHD-UHFFFAOYSA-N 0.000 description 1
- MNBHKGYCLBUIBC-UFYCRDLUSA-N Arg-Phe-Phe Chemical compound C([C@H](NC(=O)[C@H](CCCNC(N)=N)N)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=CC=C1 MNBHKGYCLBUIBC-UFYCRDLUSA-N 0.000 description 1
- HGKHPCFTRQDHCU-IUCAKERBSA-N Arg-Pro-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O HGKHPCFTRQDHCU-IUCAKERBSA-N 0.000 description 1
- UULLJGQFCDXVTQ-CYDGBPFRSA-N Arg-Pro-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(O)=O UULLJGQFCDXVTQ-CYDGBPFRSA-N 0.000 description 1
- VUGWHBXPMAHEGZ-SRVKXCTJSA-N Arg-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCN=C(N)N VUGWHBXPMAHEGZ-SRVKXCTJSA-N 0.000 description 1
- DNLQVHBBMPZUGJ-BQBZGAKWSA-N Arg-Ser-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O DNLQVHBBMPZUGJ-BQBZGAKWSA-N 0.000 description 1
- ICRHGPYYXMWHIE-LPEHRKFASA-N Arg-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O ICRHGPYYXMWHIE-LPEHRKFASA-N 0.000 description 1
- FBXMCPLCVYUWBO-BPUTZDHNSA-N Arg-Ser-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N FBXMCPLCVYUWBO-BPUTZDHNSA-N 0.000 description 1
- UZSQXCMNUPKLCC-FJXKBIBVSA-N Arg-Thr-Gly Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O UZSQXCMNUPKLCC-FJXKBIBVSA-N 0.000 description 1
- KSHJMDSNSKDJPU-QTKMDUPCSA-N Arg-Thr-His Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 KSHJMDSNSKDJPU-QTKMDUPCSA-N 0.000 description 1
- ZUVMUOOHJYNJPP-XIRDDKMYSA-N Arg-Trp-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZUVMUOOHJYNJPP-XIRDDKMYSA-N 0.000 description 1
- XOZYYXMHMIEJET-XIRDDKMYSA-N Arg-Trp-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCC(O)=O)C(O)=O XOZYYXMHMIEJET-XIRDDKMYSA-N 0.000 description 1
- YHZQOSXDTFRZKU-WDSOQIARSA-N Arg-Trp-Leu Chemical compound C1=CC=C2C(C[C@@H](C(=O)N[C@@H](CC(C)C)C(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N)=CNC2=C1 YHZQOSXDTFRZKU-WDSOQIARSA-N 0.000 description 1
- UVTGNSWSRSCPLP-UHFFFAOYSA-N Arg-Tyr Natural products NC(CCNC(=N)N)C(=O)NC(Cc1ccc(O)cc1)C(=O)O UVTGNSWSRSCPLP-UHFFFAOYSA-N 0.000 description 1
- XEOXPCNONWHHSW-AVGNSLFASA-N Arg-Val-His Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N XEOXPCNONWHHSW-AVGNSLFASA-N 0.000 description 1
- SUMJNGAMIQSNGX-TUAOUCFPSA-N Arg-Val-Pro Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCCNC(N)=N)C(=O)N1CCC[C@@H]1C(O)=O SUMJNGAMIQSNGX-TUAOUCFPSA-N 0.000 description 1
- CPTXATAOUQJQRO-GUBZILKMSA-N Arg-Val-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O CPTXATAOUQJQRO-GUBZILKMSA-N 0.000 description 1
- 208000002109 Argyria Diseases 0.000 description 1
- 206010003210 Arteriosclerosis Diseases 0.000 description 1
- RZVVKNIACROXRM-ZLUOBGJFSA-N Asn-Ala-Asp Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N RZVVKNIACROXRM-ZLUOBGJFSA-N 0.000 description 1
- GXMSVVBIAMWMKO-BQBZGAKWSA-N Asn-Arg-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@H](C(=O)NCC(O)=O)CCCN=C(N)N GXMSVVBIAMWMKO-BQBZGAKWSA-N 0.000 description 1
- LXTGAOAXPSJWOU-DCAQKATOSA-N Asn-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(=O)N)N LXTGAOAXPSJWOU-DCAQKATOSA-N 0.000 description 1
- MFFOYNGMOYFPBD-DCAQKATOSA-N Asn-Arg-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O MFFOYNGMOYFPBD-DCAQKATOSA-N 0.000 description 1
- LJUOLNXOWSWGKF-ACZMJKKPSA-N Asn-Asn-Glu Chemical compound C(CC(=O)O)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N LJUOLNXOWSWGKF-ACZMJKKPSA-N 0.000 description 1
- DAPLJWATMAXPPZ-CIUDSAMLSA-N Asn-Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC(N)=O DAPLJWATMAXPPZ-CIUDSAMLSA-N 0.000 description 1
- NVGWESORMHFISY-SRVKXCTJSA-N Asn-Asn-Phe Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O NVGWESORMHFISY-SRVKXCTJSA-N 0.000 description 1
- JRVABKHPWDRUJF-UBHSHLNASA-N Asn-Asn-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC(=O)N)N JRVABKHPWDRUJF-UBHSHLNASA-N 0.000 description 1
- KLKHFFMNGWULBN-VKHMYHEASA-N Asn-Gly Chemical compound NC(=O)C[C@H](N)C(=O)NCC(O)=O KLKHFFMNGWULBN-VKHMYHEASA-N 0.000 description 1
- RAQMSGVCGSJKCL-FOHZUACHSA-N Asn-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC(N)=O RAQMSGVCGSJKCL-FOHZUACHSA-N 0.000 description 1
- SGAUXNZEFIEAAI-GARJFASQSA-N Asn-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC(=O)N)N)C(=O)O SGAUXNZEFIEAAI-GARJFASQSA-N 0.000 description 1
- PHJPKNUWWHRAOC-PEFMBERDSA-N Asn-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)N)N PHJPKNUWWHRAOC-PEFMBERDSA-N 0.000 description 1
- HXWUJJADFMXNKA-BQBZGAKWSA-N Asn-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](N)CC(N)=O HXWUJJADFMXNKA-BQBZGAKWSA-N 0.000 description 1
- HDHZCEDPLTVHFZ-GUBZILKMSA-N Asn-Leu-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O HDHZCEDPLTVHFZ-GUBZILKMSA-N 0.000 description 1
- WIDVAWAQBRAKTI-YUMQZZPRSA-N Asn-Leu-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O WIDVAWAQBRAKTI-YUMQZZPRSA-N 0.000 description 1
- WXVGISRWSYGEDK-KKUMJFAQSA-N Asn-Lys-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)N)N WXVGISRWSYGEDK-KKUMJFAQSA-N 0.000 description 1
- PPCORQFLAZWUNO-QWRGUYRKSA-N Asn-Phe-Gly Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CC(=O)N)N PPCORQFLAZWUNO-QWRGUYRKSA-N 0.000 description 1
- OOXUBGLNDRGOKT-FXQIFTODSA-N Asn-Ser-Arg Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O OOXUBGLNDRGOKT-FXQIFTODSA-N 0.000 description 1
- REQUGIWGOGSOEZ-ZLUOBGJFSA-N Asn-Ser-Asn Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)C(=O)N REQUGIWGOGSOEZ-ZLUOBGJFSA-N 0.000 description 1
- JWQWPRCDYWNVNM-ACZMJKKPSA-N Asn-Ser-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC(=O)N)N JWQWPRCDYWNVNM-ACZMJKKPSA-N 0.000 description 1
- WUQXMTITJLFXAU-JIOCBJNQSA-N Asn-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)N)N)O WUQXMTITJLFXAU-JIOCBJNQSA-N 0.000 description 1
- KZYSHAMXEBPJBD-JRQIVUDYSA-N Asn-Thr-Tyr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KZYSHAMXEBPJBD-JRQIVUDYSA-N 0.000 description 1
- JPSODRNUDXONAS-XIRDDKMYSA-N Asn-Trp-His Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC3=CN=CN3)C(=O)O)NC(=O)[C@H](CC(=O)N)N JPSODRNUDXONAS-XIRDDKMYSA-N 0.000 description 1
- PQKSVQSMTHPRIB-ZKWXMUAHSA-N Asn-Val-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O PQKSVQSMTHPRIB-ZKWXMUAHSA-N 0.000 description 1
- XEDQMTWEYFBOIK-ACZMJKKPSA-N Asp-Ala-Glu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O XEDQMTWEYFBOIK-ACZMJKKPSA-N 0.000 description 1
- FAEIQWHBRBWUBN-FXQIFTODSA-N Asp-Arg-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC(=O)O)N)CN=C(N)N FAEIQWHBRBWUBN-FXQIFTODSA-N 0.000 description 1
- ILJQISGMGXRZQQ-IHRRRGAJSA-N Asp-Arg-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ILJQISGMGXRZQQ-IHRRRGAJSA-N 0.000 description 1
- QRULNKJGYQQZMW-ZLUOBGJFSA-N Asp-Asn-Asp Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O QRULNKJGYQQZMW-ZLUOBGJFSA-N 0.000 description 1
- UGKZHCBLMLSANF-CIUDSAMLSA-N Asp-Asn-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O UGKZHCBLMLSANF-CIUDSAMLSA-N 0.000 description 1
- NAPNAGZWHQHZLG-ZLUOBGJFSA-N Asp-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CC(=O)O)N NAPNAGZWHQHZLG-ZLUOBGJFSA-N 0.000 description 1
- FTNVLGCFIJEMQT-CIUDSAMLSA-N Asp-Cys-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC(=O)O)N FTNVLGCFIJEMQT-CIUDSAMLSA-N 0.000 description 1
- CSEJMKNZDCJYGJ-XHNCKOQMSA-N Asp-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)O)N)C(=O)O CSEJMKNZDCJYGJ-XHNCKOQMSA-N 0.000 description 1
- UFAQGGZUXVLONR-AVGNSLFASA-N Asp-Gln-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)O)N)O UFAQGGZUXVLONR-AVGNSLFASA-N 0.000 description 1
- VAWNQIGQPUOPQW-ACZMJKKPSA-N Asp-Glu-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O VAWNQIGQPUOPQW-ACZMJKKPSA-N 0.000 description 1
- GHODABZPVZMWCE-FXQIFTODSA-N Asp-Glu-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O GHODABZPVZMWCE-FXQIFTODSA-N 0.000 description 1
- OVPHVTCDVYYTHN-AVGNSLFASA-N Asp-Glu-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 OVPHVTCDVYYTHN-AVGNSLFASA-N 0.000 description 1
- GISFCCXBVJKGEO-QEJZJMRPSA-N Asp-Glu-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O GISFCCXBVJKGEO-QEJZJMRPSA-N 0.000 description 1
- TZOZNVLBTAFJRW-UGYAYLCHSA-N Asp-Ile-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)O)N TZOZNVLBTAFJRW-UGYAYLCHSA-N 0.000 description 1
- QNFRBNZGVVKBNJ-PEFMBERDSA-N Asp-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N QNFRBNZGVVKBNJ-PEFMBERDSA-N 0.000 description 1
- XLILXFRAKOYEJX-GUBZILKMSA-N Asp-Leu-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O XLILXFRAKOYEJX-GUBZILKMSA-N 0.000 description 1
- AYFVRYXNDHBECD-YUMQZZPRSA-N Asp-Leu-Gly Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O AYFVRYXNDHBECD-YUMQZZPRSA-N 0.000 description 1
- AKKUDRZKFZWPBH-SRVKXCTJSA-N Asp-Lys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N AKKUDRZKFZWPBH-SRVKXCTJSA-N 0.000 description 1
- YTXCCDCOHIYQFC-GUBZILKMSA-N Asp-Met-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O YTXCCDCOHIYQFC-GUBZILKMSA-N 0.000 description 1
- GYWQGGUCMDCUJE-DLOVCJGASA-N Asp-Phe-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(O)=O GYWQGGUCMDCUJE-DLOVCJGASA-N 0.000 description 1
- RPUYTJJZXQBWDT-SRVKXCTJSA-N Asp-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC(=O)O)N RPUYTJJZXQBWDT-SRVKXCTJSA-N 0.000 description 1
- QTIZKMMLNUMHHU-DCAQKATOSA-N Asp-Pro-His Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O QTIZKMMLNUMHHU-DCAQKATOSA-N 0.000 description 1
- ITGFVUYOLWBPQW-KKHAAJSZSA-N Asp-Thr-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O ITGFVUYOLWBPQW-KKHAAJSZSA-N 0.000 description 1
- LLRJPYJQNBMOOO-QEJZJMRPSA-N Asp-Trp-Gln Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N LLRJPYJQNBMOOO-QEJZJMRPSA-N 0.000 description 1
- QPDUWAUSSWGJSB-NGZCFLSTSA-N Asp-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N QPDUWAUSSWGJSB-NGZCFLSTSA-N 0.000 description 1
- 206010003827 Autoimmune hepatitis Diseases 0.000 description 1
- 238000012935 Averaging Methods 0.000 description 1
- 208000008439 Biliary Liver Cirrhosis Diseases 0.000 description 1
- 208000033222 Biliary cirrhosis primary Diseases 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 101100284398 Bos taurus BoLA-DQB gene Proteins 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- 235000002566 Capsicum Nutrition 0.000 description 1
- 201000009030 Carcinoma Diseases 0.000 description 1
- 206010008342 Cervix carcinoma Diseases 0.000 description 1
- VEXZGXHMUGYJMC-UHFFFAOYSA-M Chloride anion Chemical compound [Cl-] VEXZGXHMUGYJMC-UHFFFAOYSA-M 0.000 description 1
- 206010008609 Cholangitis sclerosing Diseases 0.000 description 1
- 229940122502 Cholesterol absorption inhibitor Drugs 0.000 description 1
- 208000017667 Chronic Disease Diseases 0.000 description 1
- 206010008909 Chronic Hepatitis Diseases 0.000 description 1
- 108090000317 Chymotrypsin Proteins 0.000 description 1
- 101710094648 Coat protein Proteins 0.000 description 1
- 108020004705 Codon Proteins 0.000 description 1
- 208000035473 Communicable disease Diseases 0.000 description 1
- 108091035707 Consensus sequence Proteins 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- CVOZXIPULQQFNY-ZLUOBGJFSA-N Cys-Ala-Cys Chemical compound C[C@H](NC(=O)[C@@H](N)CS)C(=O)N[C@@H](CS)C(O)=O CVOZXIPULQQFNY-ZLUOBGJFSA-N 0.000 description 1
- CEZSLNCYQUFOSL-BQBZGAKWSA-N Cys-Arg-Gly Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O CEZSLNCYQUFOSL-BQBZGAKWSA-N 0.000 description 1
- QLCPDGRAEJSYQM-LPEHRKFASA-N Cys-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CS)N)C(=O)O QLCPDGRAEJSYQM-LPEHRKFASA-N 0.000 description 1
- DEVDFMRWZASYOF-ZLUOBGJFSA-N Cys-Asn-Asp Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O DEVDFMRWZASYOF-ZLUOBGJFSA-N 0.000 description 1
- SQJSYLDKQBZQTG-FXQIFTODSA-N Cys-Asn-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CS)N SQJSYLDKQBZQTG-FXQIFTODSA-N 0.000 description 1
- CPTUXCUWQIBZIF-ZLUOBGJFSA-N Cys-Asn-Ser Chemical compound SC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O CPTUXCUWQIBZIF-ZLUOBGJFSA-N 0.000 description 1
- FWYBFUDWUUFLDN-FXQIFTODSA-N Cys-Asp-Arg Chemical compound C(C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N)CN=C(N)N FWYBFUDWUUFLDN-FXQIFTODSA-N 0.000 description 1
- VZKXOWRNJDEGLZ-WHFBIAKZSA-N Cys-Asp-Gly Chemical compound SC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O VZKXOWRNJDEGLZ-WHFBIAKZSA-N 0.000 description 1
- YZFCGHIBLBDZDA-ZLUOBGJFSA-N Cys-Asp-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O YZFCGHIBLBDZDA-ZLUOBGJFSA-N 0.000 description 1
- YZKOXEJTLWZOQL-GUBZILKMSA-N Cys-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CS)N YZKOXEJTLWZOQL-GUBZILKMSA-N 0.000 description 1
- PORWNQWEEIOIRH-XHNCKOQMSA-N Cys-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CS)N)C(=O)O PORWNQWEEIOIRH-XHNCKOQMSA-N 0.000 description 1
- UDPSLLFHOLGXBY-FXQIFTODSA-N Cys-Glu-Glu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UDPSLLFHOLGXBY-FXQIFTODSA-N 0.000 description 1
- DZLQXIFVQFTFJY-BYPYZUCNSA-N Cys-Gly-Gly Chemical compound SC[C@H](N)C(=O)NCC(=O)NCC(O)=O DZLQXIFVQFTFJY-BYPYZUCNSA-N 0.000 description 1
- RWAZRMXTVSIVJR-YUMQZZPRSA-N Cys-Gly-His Chemical compound [H]N[C@@H](CS)C(=O)NCC(=O)N[C@@H](CC1=CNC=N1)C(O)=O RWAZRMXTVSIVJR-YUMQZZPRSA-N 0.000 description 1
- XIZWKXATMJODQW-KKUMJFAQSA-N Cys-His-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CS)N XIZWKXATMJODQW-KKUMJFAQSA-N 0.000 description 1
- ODDOYXKAHLKKQY-MMWGEVLESA-N Cys-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CS)N ODDOYXKAHLKKQY-MMWGEVLESA-N 0.000 description 1
- DYBIDOHFRRUMLW-CIUDSAMLSA-N Cys-Leu-Cys Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)CS)C(=O)N[C@@H](CS)C(O)=O DYBIDOHFRRUMLW-CIUDSAMLSA-N 0.000 description 1
- XLLSMEFANRROJE-GUBZILKMSA-N Cys-Leu-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](CS)N XLLSMEFANRROJE-GUBZILKMSA-N 0.000 description 1
- HBHMVBGGHDMPBF-GARJFASQSA-N Cys-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CS)N HBHMVBGGHDMPBF-GARJFASQSA-N 0.000 description 1
- SRIRHERUAMYIOQ-CIUDSAMLSA-N Cys-Leu-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SRIRHERUAMYIOQ-CIUDSAMLSA-N 0.000 description 1
- OZHXXYOHPLLLMI-CIUDSAMLSA-N Cys-Lys-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O OZHXXYOHPLLLMI-CIUDSAMLSA-N 0.000 description 1
- VXLXATVURDNDCG-CIUDSAMLSA-N Cys-Lys-Asp Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CS)N VXLXATVURDNDCG-CIUDSAMLSA-N 0.000 description 1
- SMEYEQDCCBHTEF-FXQIFTODSA-N Cys-Pro-Ala Chemical compound [H]N[C@@H](CS)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O SMEYEQDCCBHTEF-FXQIFTODSA-N 0.000 description 1
- XBELMDARIGXDKY-GUBZILKMSA-N Cys-Pro-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CS)N XBELMDARIGXDKY-GUBZILKMSA-N 0.000 description 1
- CMYVIUWVYHOLRD-ZLUOBGJFSA-N Cys-Ser-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O CMYVIUWVYHOLRD-ZLUOBGJFSA-N 0.000 description 1
- NXQCSPVUPLUTJH-WHFBIAKZSA-N Cys-Ser-Gly Chemical compound SC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O NXQCSPVUPLUTJH-WHFBIAKZSA-N 0.000 description 1
- XWTGTTNUCCEFJI-UBHSHLNASA-N Cys-Ser-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CS)N XWTGTTNUCCEFJI-UBHSHLNASA-N 0.000 description 1
- 230000004543 DNA replication Effects 0.000 description 1
- 230000006820 DNA synthesis Effects 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- 238000001061 Dunnett's test Methods 0.000 description 1
- 208000032928 Dyslipidaemia Diseases 0.000 description 1
- 206010058314 Dysplasia Diseases 0.000 description 1
- 108700039887 Essential Genes Proteins 0.000 description 1
- 108091029865 Exogenous DNA Proteins 0.000 description 1
- 108700024394 Exon Proteins 0.000 description 1
- 201000008808 Fibrosarcoma Diseases 0.000 description 1
- 206010016654 Fibrosis Diseases 0.000 description 1
- 241001200922 Gagata Species 0.000 description 1
- 206010064571 Gene mutation Diseases 0.000 description 1
- 208000009139 Gilbert Disease Diseases 0.000 description 1
- 208000022412 Gilbert syndrome Diseases 0.000 description 1
- HHWQMFIGMMOVFK-WDSKDSINSA-N Gln-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O HHWQMFIGMMOVFK-WDSKDSINSA-N 0.000 description 1
- KVYVOGYEMPEXBT-GUBZILKMSA-N Gln-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O KVYVOGYEMPEXBT-GUBZILKMSA-N 0.000 description 1
- MLZRSFQRBDNJON-GUBZILKMSA-N Gln-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)N)N MLZRSFQRBDNJON-GUBZILKMSA-N 0.000 description 1
- JSYULGSPLTZDHM-NRPADANISA-N Gln-Ala-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O JSYULGSPLTZDHM-NRPADANISA-N 0.000 description 1
- XOKGKOQWADCLFQ-GARJFASQSA-N Gln-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)N)N)C(=O)O XOKGKOQWADCLFQ-GARJFASQSA-N 0.000 description 1
- JESJDAAGXULQOP-CIUDSAMLSA-N Gln-Arg-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)CN=C(N)N JESJDAAGXULQOP-CIUDSAMLSA-N 0.000 description 1
- LJEPDHWNQXPXMM-NHCYSSNCSA-N Gln-Arg-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O LJEPDHWNQXPXMM-NHCYSSNCSA-N 0.000 description 1
- INFBPLSHYFALDE-ACZMJKKPSA-N Gln-Asn-Ala Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O INFBPLSHYFALDE-ACZMJKKPSA-N 0.000 description 1
- SOBBAYVQSNXYPQ-ACZMJKKPSA-N Gln-Asn-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O SOBBAYVQSNXYPQ-ACZMJKKPSA-N 0.000 description 1
- GMGKDVVBSVVKCT-NUMRIWBASA-N Gln-Asn-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GMGKDVVBSVVKCT-NUMRIWBASA-N 0.000 description 1
- ULXXDWZMMSQBDC-ACZMJKKPSA-N Gln-Asp-Asp Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N ULXXDWZMMSQBDC-ACZMJKKPSA-N 0.000 description 1
- RKAQZCDMSUQTSS-FXQIFTODSA-N Gln-Asp-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N RKAQZCDMSUQTSS-FXQIFTODSA-N 0.000 description 1
- IKDOHQHEFPPGJG-FXQIFTODSA-N Gln-Asp-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O IKDOHQHEFPPGJG-FXQIFTODSA-N 0.000 description 1
- IXFVOPOHSRKJNG-LAEOZQHASA-N Gln-Asp-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O IXFVOPOHSRKJNG-LAEOZQHASA-N 0.000 description 1
- MFLMFRZBAJSGHK-ACZMJKKPSA-N Gln-Cys-Ser Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O)N MFLMFRZBAJSGHK-ACZMJKKPSA-N 0.000 description 1
- NKCZYEDZTKOFBG-GUBZILKMSA-N Gln-Gln-Arg Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NKCZYEDZTKOFBG-GUBZILKMSA-N 0.000 description 1
- CITDWMLWXNUQKD-FXQIFTODSA-N Gln-Gln-Asn Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N CITDWMLWXNUQKD-FXQIFTODSA-N 0.000 description 1
- GPISLLFQNHELLK-DCAQKATOSA-N Gln-Gln-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N GPISLLFQNHELLK-DCAQKATOSA-N 0.000 description 1
- MADFVRSKEIEZHZ-DCAQKATOSA-N Gln-Gln-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCC(=O)N)N MADFVRSKEIEZHZ-DCAQKATOSA-N 0.000 description 1
- DRDSQGHKTLSNEA-GLLZPBPUSA-N Gln-Glu-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DRDSQGHKTLSNEA-GLLZPBPUSA-N 0.000 description 1
- NSNUZSPSADIMJQ-WDSKDSINSA-N Gln-Gly-Asp Chemical compound NC(=O)CC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O NSNUZSPSADIMJQ-WDSKDSINSA-N 0.000 description 1
- NROSLUJMIQGFKS-IUCAKERBSA-N Gln-His-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCC(=O)N)N NROSLUJMIQGFKS-IUCAKERBSA-N 0.000 description 1
- ITZWDGBYBPUZRG-KBIXCLLPSA-N Gln-Ile-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O ITZWDGBYBPUZRG-KBIXCLLPSA-N 0.000 description 1
- HHQCBFGKQDMWSP-GUBZILKMSA-N Gln-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)N)N HHQCBFGKQDMWSP-GUBZILKMSA-N 0.000 description 1
- VUVKKXPCKILIBD-AVGNSLFASA-N Gln-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)N)N VUVKKXPCKILIBD-AVGNSLFASA-N 0.000 description 1
- FALJZCPMTGJOHX-SRVKXCTJSA-N Gln-Met-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O FALJZCPMTGJOHX-SRVKXCTJSA-N 0.000 description 1
- DRNMNLKUUKKPIA-HTUGSXCWSA-N Gln-Phe-Thr Chemical compound C[C@@H](O)[C@H](NC(=O)[C@H](Cc1ccccc1)NC(=O)[C@@H](N)CCC(N)=O)C(O)=O DRNMNLKUUKKPIA-HTUGSXCWSA-N 0.000 description 1
- PDXIOFXRBVDSHD-JBACZVJFSA-N Gln-Phe-Trp Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)NC(=O)[C@H](CCC(=O)N)N PDXIOFXRBVDSHD-JBACZVJFSA-N 0.000 description 1
- FNAJNWPDTIXYJN-CIUDSAMLSA-N Gln-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O FNAJNWPDTIXYJN-CIUDSAMLSA-N 0.000 description 1
- HMIXCETWRYDVMO-GUBZILKMSA-N Gln-Pro-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O HMIXCETWRYDVMO-GUBZILKMSA-N 0.000 description 1
- LPIKVBWNNVFHCQ-GUBZILKMSA-N Gln-Ser-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LPIKVBWNNVFHCQ-GUBZILKMSA-N 0.000 description 1
- KPNWAJMEMRCLAL-GUBZILKMSA-N Gln-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N KPNWAJMEMRCLAL-GUBZILKMSA-N 0.000 description 1
- SYZZMPFLOLSMHL-XHNCKOQMSA-N Gln-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCC(=O)N)N)C(=O)O SYZZMPFLOLSMHL-XHNCKOQMSA-N 0.000 description 1
- NHMRJKKAVMENKJ-WDCWCFNPSA-N Gln-Thr-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O NHMRJKKAVMENKJ-WDCWCFNPSA-N 0.000 description 1
- STHSGOZLFLFGSS-SUSMZKCASA-N Gln-Thr-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O STHSGOZLFLFGSS-SUSMZKCASA-N 0.000 description 1
- JKDBRTNMYXYLHO-JYJNAYRXSA-N Gln-Tyr-Leu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)CC1=CC=C(O)C=C1 JKDBRTNMYXYLHO-JYJNAYRXSA-N 0.000 description 1
- ZFBBMCKQSNJZSN-AUTRQRHGSA-N Gln-Val-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZFBBMCKQSNJZSN-AUTRQRHGSA-N 0.000 description 1
- 102000006395 Globulins Human genes 0.000 description 1
- 108010044091 Globulins Proteins 0.000 description 1
- RUFHOVYUYSNDNY-ACZMJKKPSA-N Glu-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(O)=O RUFHOVYUYSNDNY-ACZMJKKPSA-N 0.000 description 1
- RLZBLVSJDFHDBL-KBIXCLLPSA-N Glu-Ala-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O RLZBLVSJDFHDBL-KBIXCLLPSA-N 0.000 description 1
- KKCUFHUTMKQQCF-SRVKXCTJSA-N Glu-Arg-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O KKCUFHUTMKQQCF-SRVKXCTJSA-N 0.000 description 1
- NKSGKPWXSWBRRX-ACZMJKKPSA-N Glu-Asn-Cys Chemical compound C(CC(=O)O)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N NKSGKPWXSWBRRX-ACZMJKKPSA-N 0.000 description 1
- CKRUHITYRFNUKW-WDSKDSINSA-N Glu-Asn-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O CKRUHITYRFNUKW-WDSKDSINSA-N 0.000 description 1
- JPHYJQHPILOKHC-ACZMJKKPSA-N Glu-Asp-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O JPHYJQHPILOKHC-ACZMJKKPSA-N 0.000 description 1
- RTOOAKXIJADOLL-GUBZILKMSA-N Glu-Asp-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N RTOOAKXIJADOLL-GUBZILKMSA-N 0.000 description 1
- SBCYJMOOHUDWDA-NUMRIWBASA-N Glu-Asp-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SBCYJMOOHUDWDA-NUMRIWBASA-N 0.000 description 1
- LSTFYPOGBGFIPP-FXQIFTODSA-N Glu-Cys-Gln Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O LSTFYPOGBGFIPP-FXQIFTODSA-N 0.000 description 1
- ZZIFPJZQHRJERU-WDSKDSINSA-N Glu-Cys-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CS)C(=O)NCC(O)=O ZZIFPJZQHRJERU-WDSKDSINSA-N 0.000 description 1
- BUAKRRKDHSSIKK-IHRRRGAJSA-N Glu-Glu-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 BUAKRRKDHSSIKK-IHRRRGAJSA-N 0.000 description 1
- CUXJIASLBRJOFV-LAEOZQHASA-N Glu-Gly-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O CUXJIASLBRJOFV-LAEOZQHASA-N 0.000 description 1
- LRPXYSGPOBVBEH-IUCAKERBSA-N Glu-Gly-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O LRPXYSGPOBVBEH-IUCAKERBSA-N 0.000 description 1
- OPAINBJQDQTGJY-JGVFFNPUSA-N Glu-Gly-Pro Chemical compound C1C[C@@H](N(C1)C(=O)CNC(=O)[C@H](CCC(=O)O)N)C(=O)O OPAINBJQDQTGJY-JGVFFNPUSA-N 0.000 description 1
- HPJLZFTUUJKWAJ-JHEQGTHGSA-N Glu-Gly-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HPJLZFTUUJKWAJ-JHEQGTHGSA-N 0.000 description 1
- XIKYNVKEUINBGL-IUCAKERBSA-N Glu-His-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)NCC(O)=O XIKYNVKEUINBGL-IUCAKERBSA-N 0.000 description 1
- WVYJNPCWJYBHJG-YVNDNENWSA-N Glu-Ile-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(O)=O WVYJNPCWJYBHJG-YVNDNENWSA-N 0.000 description 1
- XTZDZAXYPDISRR-MNXVOIDGSA-N Glu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCC(=O)O)N XTZDZAXYPDISRR-MNXVOIDGSA-N 0.000 description 1
- INGJLBQKTRJLFO-UKJIMTQDSA-N Glu-Ile-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CCC(O)=O INGJLBQKTRJLFO-UKJIMTQDSA-N 0.000 description 1
- UGSVSNXPJJDJKL-SDDRHHMPSA-N Glu-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N UGSVSNXPJJDJKL-SDDRHHMPSA-N 0.000 description 1
- GJBUAAAIZSRCDC-GVXVVHGQSA-N Glu-Leu-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O GJBUAAAIZSRCDC-GVXVVHGQSA-N 0.000 description 1
- BHXSLRDWXIFKTP-SRVKXCTJSA-N Glu-Met-His Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CCC(=O)O)N BHXSLRDWXIFKTP-SRVKXCTJSA-N 0.000 description 1
- FQFWFZWOHOEVMZ-IHRRRGAJSA-N Glu-Phe-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O FQFWFZWOHOEVMZ-IHRRRGAJSA-N 0.000 description 1
- MXJYXYDREQWUMS-XKBZYTNZSA-N Glu-Thr-Ser Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O MXJYXYDREQWUMS-XKBZYTNZSA-N 0.000 description 1
- HHSKZJZWQFPSKN-AVGNSLFASA-N Glu-Tyr-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O HHSKZJZWQFPSKN-AVGNSLFASA-N 0.000 description 1
- BKMOHWJHXQLFEX-IRIUXVKKSA-N Glu-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](CCC(=O)O)N)O BKMOHWJHXQLFEX-IRIUXVKKSA-N 0.000 description 1
- KIEICAOUSNYOLM-NRPADANISA-N Glu-Val-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O KIEICAOUSNYOLM-NRPADANISA-N 0.000 description 1
- MLILEEIVMRUYBX-NHCYSSNCSA-N Glu-Val-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O MLILEEIVMRUYBX-NHCYSSNCSA-N 0.000 description 1
- HQTDNEZTGZUWSY-XVKPBYJWSA-N Glu-Val-Gly Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCC(O)=O)C(=O)NCC(O)=O HQTDNEZTGZUWSY-XVKPBYJWSA-N 0.000 description 1
- 108010051815 Glutamyl endopeptidase Proteins 0.000 description 1
- RLFSBAPJTYKSLG-WHFBIAKZSA-N Gly-Ala-Asp Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O RLFSBAPJTYKSLG-WHFBIAKZSA-N 0.000 description 1
- VSVZIEVNUYDAFR-YUMQZZPRSA-N Gly-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN VSVZIEVNUYDAFR-YUMQZZPRSA-N 0.000 description 1
- JBRBACJPBZNFMF-YUMQZZPRSA-N Gly-Ala-Lys Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCCN JBRBACJPBZNFMF-YUMQZZPRSA-N 0.000 description 1
- QXPRJQPCFXMCIY-NKWVEPMBSA-N Gly-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)CN QXPRJQPCFXMCIY-NKWVEPMBSA-N 0.000 description 1
- QSDKBRMVXSWAQE-BFHQHQDPSA-N Gly-Ala-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN QSDKBRMVXSWAQE-BFHQHQDPSA-N 0.000 description 1
- OGCIHJPYKVSMTE-YUMQZZPRSA-N Gly-Arg-Glu Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O OGCIHJPYKVSMTE-YUMQZZPRSA-N 0.000 description 1
- RJIVPOXLQFJRTG-LURJTMIESA-N Gly-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N RJIVPOXLQFJRTG-LURJTMIESA-N 0.000 description 1
- JPXNYFOHTHSREU-UWVGGRQHSA-N Gly-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)CN JPXNYFOHTHSREU-UWVGGRQHSA-N 0.000 description 1
- OVSKVOOUFAKODB-UWVGGRQHSA-N Gly-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N OVSKVOOUFAKODB-UWVGGRQHSA-N 0.000 description 1
- GWCRIHNSVMOBEQ-BQBZGAKWSA-N Gly-Arg-Ser Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O GWCRIHNSVMOBEQ-BQBZGAKWSA-N 0.000 description 1
- NZAFOTBEULLEQB-WDSKDSINSA-N Gly-Asn-Glu Chemical compound C(CC(=O)O)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)CN NZAFOTBEULLEQB-WDSKDSINSA-N 0.000 description 1
- XBWMTPAIUQIWKA-BYULHYEWSA-N Gly-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CN XBWMTPAIUQIWKA-BYULHYEWSA-N 0.000 description 1
- TZOVVRJYUDETQG-RCOVLWMOSA-N Gly-Asp-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)CN TZOVVRJYUDETQG-RCOVLWMOSA-N 0.000 description 1
- KTSZUNRRYXPZTK-BQBZGAKWSA-N Gly-Gln-Glu Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O KTSZUNRRYXPZTK-BQBZGAKWSA-N 0.000 description 1
- FIQQRCFQXGLOSZ-WDSKDSINSA-N Gly-Glu-Asp Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O FIQQRCFQXGLOSZ-WDSKDSINSA-N 0.000 description 1
- UFPXDFOYHVEIPI-BYPYZUCNSA-N Gly-Gly-Asp Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC(O)=O UFPXDFOYHVEIPI-BYPYZUCNSA-N 0.000 description 1
- YWAQATDNEKZFFK-BYPYZUCNSA-N Gly-Gly-Ser Chemical compound NCC(=O)NCC(=O)N[C@@H](CO)C(O)=O YWAQATDNEKZFFK-BYPYZUCNSA-N 0.000 description 1
- UQJNXZSSGQIPIQ-FBCQKBJTSA-N Gly-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)CN UQJNXZSSGQIPIQ-FBCQKBJTSA-N 0.000 description 1
- INLIXXRWNUKVCF-JTQLQIEISA-N Gly-Gly-Tyr Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 INLIXXRWNUKVCF-JTQLQIEISA-N 0.000 description 1
- TVDHVLGFJSHPAX-UWVGGRQHSA-N Gly-His-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CN=CN1 TVDHVLGFJSHPAX-UWVGGRQHSA-N 0.000 description 1
- IVSWQHKONQIOHA-YUMQZZPRSA-N Gly-His-Cys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)CN IVSWQHKONQIOHA-YUMQZZPRSA-N 0.000 description 1
- FSPVILZGHUJOHS-QWRGUYRKSA-N Gly-His-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CNC=N1 FSPVILZGHUJOHS-QWRGUYRKSA-N 0.000 description 1
- SWQALSGKVLYKDT-UHFFFAOYSA-N Gly-Ile-Ala Natural products NCC(=O)NC(C(C)CC)C(=O)NC(C)C(O)=O SWQALSGKVLYKDT-UHFFFAOYSA-N 0.000 description 1
- UESJMAMHDLEHGM-NHCYSSNCSA-N Gly-Ile-Leu Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O UESJMAMHDLEHGM-NHCYSSNCSA-N 0.000 description 1
- SCWYHUQOOFRVHP-MBLNEYKQSA-N Gly-Ile-Thr Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SCWYHUQOOFRVHP-MBLNEYKQSA-N 0.000 description 1
- COVXELOAORHTND-LSJOCFKGSA-N Gly-Ile-Val Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C(C)C)C(O)=O COVXELOAORHTND-LSJOCFKGSA-N 0.000 description 1
- IUZGUFAJDBHQQV-YUMQZZPRSA-N Gly-Leu-Asn Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O IUZGUFAJDBHQQV-YUMQZZPRSA-N 0.000 description 1
- YTSVAIMKVLZUDU-YUMQZZPRSA-N Gly-Leu-Asp Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O YTSVAIMKVLZUDU-YUMQZZPRSA-N 0.000 description 1
- LIXWIUAORXJNBH-QWRGUYRKSA-N Gly-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)CN LIXWIUAORXJNBH-QWRGUYRKSA-N 0.000 description 1
- LLZXNUUIBOALNY-QWRGUYRKSA-N Gly-Leu-Lys Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCCN LLZXNUUIBOALNY-QWRGUYRKSA-N 0.000 description 1
- MIIVFRCYJABHTQ-ONGXEEELSA-N Gly-Leu-Val Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O MIIVFRCYJABHTQ-ONGXEEELSA-N 0.000 description 1
- GMTXWRIDLGTVFC-IUCAKERBSA-N Gly-Lys-Glu Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O GMTXWRIDLGTVFC-IUCAKERBSA-N 0.000 description 1
- WDEHMRNSGHVNOH-VHSXEESVSA-N Gly-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)CN)C(=O)O WDEHMRNSGHVNOH-VHSXEESVSA-N 0.000 description 1
- FXLVSYVJDPCIHH-STQMWFEESA-N Gly-Phe-Arg Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FXLVSYVJDPCIHH-STQMWFEESA-N 0.000 description 1
- GGLIDLCEPDHEJO-BQBZGAKWSA-N Gly-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)CN GGLIDLCEPDHEJO-BQBZGAKWSA-N 0.000 description 1
- WDXLKVQATNEAJQ-BQBZGAKWSA-N Gly-Pro-Asp Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O WDXLKVQATNEAJQ-BQBZGAKWSA-N 0.000 description 1
- JJGBXTYGTKWGAT-YUMQZZPRSA-N Gly-Pro-Glu Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O JJGBXTYGTKWGAT-YUMQZZPRSA-N 0.000 description 1
- SSFWXSNOKDZNHY-QXEWZRGKSA-N Gly-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN SSFWXSNOKDZNHY-QXEWZRGKSA-N 0.000 description 1
- YOBGUCWZPXJHTN-BQBZGAKWSA-N Gly-Ser-Arg Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YOBGUCWZPXJHTN-BQBZGAKWSA-N 0.000 description 1
- WNGHUXFWEWTKAO-YUMQZZPRSA-N Gly-Ser-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN WNGHUXFWEWTKAO-YUMQZZPRSA-N 0.000 description 1
- YXTFLTJYLIAZQG-FJXKBIBVSA-N Gly-Thr-Arg Chemical compound NCC(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N YXTFLTJYLIAZQG-FJXKBIBVSA-N 0.000 description 1
- CQMFNTVQVLQRLT-JHEQGTHGSA-N Gly-Thr-Gln Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O CQMFNTVQVLQRLT-JHEQGTHGSA-N 0.000 description 1
- CUVBTVWFVIIDOC-YEPSODPASA-N Gly-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)CN CUVBTVWFVIIDOC-YEPSODPASA-N 0.000 description 1
- NWOSHVVPKDQKKT-RYUDHWBXSA-N Gly-Tyr-Gln Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O NWOSHVVPKDQKKT-RYUDHWBXSA-N 0.000 description 1
- UVTSZKIATYSKIR-RYUDHWBXSA-N Gly-Tyr-Glu Chemical compound [H]NCC(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O UVTSZKIATYSKIR-RYUDHWBXSA-N 0.000 description 1
- PNUFMLXHOLFRLD-KBPBESRZSA-N Gly-Tyr-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CC=C(O)C=C1 PNUFMLXHOLFRLD-KBPBESRZSA-N 0.000 description 1
- DNVDEMWIYLVIQU-RCOVLWMOSA-N Gly-Val-Asp Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O DNVDEMWIYLVIQU-RCOVLWMOSA-N 0.000 description 1
- RYAOJUMWLWUGNW-QMMMGPOBSA-N Gly-Val-Gly Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O RYAOJUMWLWUGNW-QMMMGPOBSA-N 0.000 description 1
- BNMRSWQOHIQTFL-JSGCOSHPSA-N Gly-Val-Phe Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 BNMRSWQOHIQTFL-JSGCOSHPSA-N 0.000 description 1
- IZVICCORZOSGPT-JSGCOSHPSA-N Gly-Val-Tyr Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O IZVICCORZOSGPT-JSGCOSHPSA-N 0.000 description 1
- 108010010234 HDL Lipoproteins Proteins 0.000 description 1
- 102000015779 HDL Lipoproteins Human genes 0.000 description 1
- 102100028972 HLA class I histocompatibility antigen, A alpha chain Human genes 0.000 description 1
- 102100028976 HLA class I histocompatibility antigen, B alpha chain Human genes 0.000 description 1
- 102100028971 HLA class I histocompatibility antigen, C alpha chain Human genes 0.000 description 1
- 108010075704 HLA-A Antigens Proteins 0.000 description 1
- 108010058607 HLA-B Antigens Proteins 0.000 description 1
- 108010052199 HLA-C Antigens Proteins 0.000 description 1
- 206010019280 Heart failures Diseases 0.000 description 1
- 208000018565 Hemochromatosis Diseases 0.000 description 1
- 208000032843 Hemorrhage Diseases 0.000 description 1
- HTTJABKRGRZYRN-UHFFFAOYSA-N Heparin Chemical compound OC1C(NC(=O)C)C(O)OC(COS(O)(=O)=O)C1OC1C(OS(O)(=O)=O)C(O)C(OC2C(C(OS(O)(=O)=O)C(OC3C(C(O)C(O)C(O3)C(O)=O)OS(O)(=O)=O)C(CO)O2)NS(O)(=O)=O)C(C(O)=O)O1 HTTJABKRGRZYRN-UHFFFAOYSA-N 0.000 description 1
- 241000700721 Hepatitis B virus Species 0.000 description 1
- 206010019755 Hepatitis chronic active Diseases 0.000 description 1
- 208000002972 Hepatolenticular Degeneration Diseases 0.000 description 1
- 208000028782 Hereditary disease Diseases 0.000 description 1
- HDXNWVLQSQFJOX-SRVKXCTJSA-N His-Arg-Gln Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N HDXNWVLQSQFJOX-SRVKXCTJSA-N 0.000 description 1
- ZIMTWPHIKZEHSE-UWVGGRQHSA-N His-Arg-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O ZIMTWPHIKZEHSE-UWVGGRQHSA-N 0.000 description 1
- IDNNYVGVSZMQTK-IHRRRGAJSA-N His-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N IDNNYVGVSZMQTK-IHRRRGAJSA-N 0.000 description 1
- MAABHGXCIBEYQR-XVYDVKMFSA-N His-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC1=CN=CN1)N MAABHGXCIBEYQR-XVYDVKMFSA-N 0.000 description 1
- FPNWKONEZAVQJF-GUBZILKMSA-N His-Asn-Gln Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N FPNWKONEZAVQJF-GUBZILKMSA-N 0.000 description 1
- LSQHWKPPOFDHHZ-YUMQZZPRSA-N His-Asp-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)NCC(=O)O)N LSQHWKPPOFDHHZ-YUMQZZPRSA-N 0.000 description 1
- BDHUXUFYNUOUIT-SRVKXCTJSA-N His-Asp-Lys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCCN)C(=O)O)N BDHUXUFYNUOUIT-SRVKXCTJSA-N 0.000 description 1
- VLPMGIJPAWENQB-SRVKXCTJSA-N His-Cys-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O VLPMGIJPAWENQB-SRVKXCTJSA-N 0.000 description 1
- LIEIYPBMQJLASB-SRVKXCTJSA-N His-Gln-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC1=CN=CN1 LIEIYPBMQJLASB-SRVKXCTJSA-N 0.000 description 1
- FDQYIRHBVVUTJF-ZETCQYMHSA-N His-Gly-Gly Chemical compound [O-]C(=O)CNC(=O)CNC(=O)[C@@H]([NH3+])CC1=CN=CN1 FDQYIRHBVVUTJF-ZETCQYMHSA-N 0.000 description 1
- JBSLJUPMTYLLFH-MELADBBJSA-N His-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC3=CN=CN3)N)C(=O)O JBSLJUPMTYLLFH-MELADBBJSA-N 0.000 description 1
- BRZQWIIFIKTJDH-VGDYDELISA-N His-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CN=CN1)N BRZQWIIFIKTJDH-VGDYDELISA-N 0.000 description 1
- UROVZOUMHNXPLZ-AVGNSLFASA-N His-Leu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CN=CN1 UROVZOUMHNXPLZ-AVGNSLFASA-N 0.000 description 1
- AIPUZFXMXAHZKY-QWRGUYRKSA-N His-Leu-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O AIPUZFXMXAHZKY-QWRGUYRKSA-N 0.000 description 1
- BPOHQCZZSFBSON-KKUMJFAQSA-N His-Leu-His Chemical compound CC(C)C[C@H](NC(=O)[C@@H](N)Cc1cnc[nH]1)C(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O BPOHQCZZSFBSON-KKUMJFAQSA-N 0.000 description 1
- VGYOLSOFODKLSP-IHPCNDPISA-N His-Leu-Trp Chemical compound C([C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(O)=O)C1=CN=CN1 VGYOLSOFODKLSP-IHPCNDPISA-N 0.000 description 1
- QEYUCKCWTMIERU-SRVKXCTJSA-N His-Lys-Asp Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(=O)O)C(=O)O)N QEYUCKCWTMIERU-SRVKXCTJSA-N 0.000 description 1
- PBVQWNDMFFCPIZ-ULQDDVLXSA-N His-Pro-Phe Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CN=CN1 PBVQWNDMFFCPIZ-ULQDDVLXSA-N 0.000 description 1
- LNDVNHOSZQPJGI-AVGNSLFASA-N His-Pro-Pro Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(O)=O)C1=CN=CN1 LNDVNHOSZQPJGI-AVGNSLFASA-N 0.000 description 1
- PLCAEMGSYOYIPP-GUBZILKMSA-N His-Ser-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 PLCAEMGSYOYIPP-GUBZILKMSA-N 0.000 description 1
- GIRSNERMXCMDBO-GARJFASQSA-N His-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O GIRSNERMXCMDBO-GARJFASQSA-N 0.000 description 1
- VIJMRAIWYWRXSR-CIUDSAMLSA-N His-Ser-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 VIJMRAIWYWRXSR-CIUDSAMLSA-N 0.000 description 1
- FFYYUUWROYYKFY-IHRRRGAJSA-N His-Val-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O FFYYUUWROYYKFY-IHRRRGAJSA-N 0.000 description 1
- 241001272567 Hominoidea Species 0.000 description 1
- 101500025164 Homo sapiens Alpha-1-microglobulin Proteins 0.000 description 1
- 101000889953 Homo sapiens Apolipoprotein B-100 Proteins 0.000 description 1
- 101000899111 Homo sapiens Hemoglobin subunit beta Proteins 0.000 description 1
- 101500025163 Homo sapiens Inter-alpha-trypsin inhibitor light chain Proteins 0.000 description 1
- 101100181495 Homo sapiens LDLR gene Proteins 0.000 description 1
- 101000923835 Homo sapiens Low density lipoprotein receptor adapter protein 1 Proteins 0.000 description 1
- 101001100327 Homo sapiens RNA-binding protein 45 Proteins 0.000 description 1
- 101000837639 Homo sapiens Thyroxine-binding globulin Proteins 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- 108091006905 Human Serum Albumin Proteins 0.000 description 1
- 102000008100 Human Serum Albumin Human genes 0.000 description 1
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 1
- SHBUUTHKGIVMJT-UHFFFAOYSA-N Hydroxystearate Chemical compound CCCCCCCCCCCCCCCCCC(=O)OO SHBUUTHKGIVMJT-UHFFFAOYSA-N 0.000 description 1
- 206010020772 Hypertension Diseases 0.000 description 1
- 108010046315 IDL Lipoproteins Proteins 0.000 description 1
- QLRMMMQNCWBNPQ-QXEWZRGKSA-N Ile-Arg-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(=O)O)N QLRMMMQNCWBNPQ-QXEWZRGKSA-N 0.000 description 1
- ZZHGKECPZXPXJF-PCBIJLKTSA-N Ile-Asn-Phe Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ZZHGKECPZXPXJF-PCBIJLKTSA-N 0.000 description 1
- UKTUOMWSJPXODT-GUDRVLHUSA-N Ile-Asn-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N UKTUOMWSJPXODT-GUDRVLHUSA-N 0.000 description 1
- HDODQNPMSHDXJT-GHCJXIJMSA-N Ile-Asn-Ser Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O HDODQNPMSHDXJT-GHCJXIJMSA-N 0.000 description 1
- LEHPJMKVGFPSSP-ZQINRCPSSA-N Ile-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)[C@@H](C)CC)C(O)=O)=CNC2=C1 LEHPJMKVGFPSSP-ZQINRCPSSA-N 0.000 description 1
- SVBAHOMTJRFSIC-SXTJYALSSA-N Ile-Ile-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(=O)N)C(=O)O)N SVBAHOMTJRFSIC-SXTJYALSSA-N 0.000 description 1
- YGDWPQCLFJNMOL-MNXVOIDGSA-N Ile-Leu-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N YGDWPQCLFJNMOL-MNXVOIDGSA-N 0.000 description 1
- AKOYRLRUFBZOSP-BJDJZHNGSA-N Ile-Lys-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)O)N AKOYRLRUFBZOSP-BJDJZHNGSA-N 0.000 description 1
- WLRJHVNFGAOYPS-HJPIBITLSA-N Ile-Ser-Tyr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)N WLRJHVNFGAOYPS-HJPIBITLSA-N 0.000 description 1
- NAFIFZNBSPWYOO-RWRJDSDZSA-N Ile-Thr-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N NAFIFZNBSPWYOO-RWRJDSDZSA-N 0.000 description 1
- KBDIBHQICWDGDL-PPCPHDFISA-N Ile-Thr-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N KBDIBHQICWDGDL-PPCPHDFISA-N 0.000 description 1
- NURNJECQNNCRBK-FLBSBUHZSA-N Ile-Thr-Thr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NURNJECQNNCRBK-FLBSBUHZSA-N 0.000 description 1
- ZGKVPOSSTGHJAF-HJPIBITLSA-N Ile-Tyr-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CO)C(=O)O)N ZGKVPOSSTGHJAF-HJPIBITLSA-N 0.000 description 1
- JERJIYYCOGBAIJ-OBAATPRFSA-N Ile-Tyr-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N JERJIYYCOGBAIJ-OBAATPRFSA-N 0.000 description 1
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 1
- 208000029462 Immunodeficiency disease Diseases 0.000 description 1
- 108700005091 Immunoglobulin Genes Proteins 0.000 description 1
- 108010044467 Isoenzymes Proteins 0.000 description 1
- PWWVAXIEGOYWEE-UHFFFAOYSA-N Isophenergan Chemical compound C1=CC=C2N(CC(C)N(C)C)C3=CC=CC=C3SC2=C1 PWWVAXIEGOYWEE-UHFFFAOYSA-N 0.000 description 1
- SHGAZHPCJJPHSC-NUEINMDLSA-N Isotretinoin Chemical compound OC(=O)C=C(C)/C=C/C=C(C)C=CC1=C(C)CCCC1(C)C SHGAZHPCJJPHSC-NUEINMDLSA-N 0.000 description 1
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 1
- RCFDOSNHHZGBOY-UHFFFAOYSA-N L-isoleucyl-L-alanine Natural products CCC(C)C(N)C(=O)NC(C)C(O)=O RCFDOSNHHZGBOY-UHFFFAOYSA-N 0.000 description 1
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 1
- KFKWRHQBZQICHA-STQMWFEESA-N L-leucyl-L-phenylalanine Natural products CC(C)C[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 KFKWRHQBZQICHA-STQMWFEESA-N 0.000 description 1
- LJHGALIOHLRRQN-DCAQKATOSA-N Leu-Ala-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N LJHGALIOHLRRQN-DCAQKATOSA-N 0.000 description 1
- CZCSUZMIRKFFFA-CIUDSAMLSA-N Leu-Ala-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(O)=O CZCSUZMIRKFFFA-CIUDSAMLSA-N 0.000 description 1
- MJOZZTKJZQFKDK-GUBZILKMSA-N Leu-Ala-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(N)=O MJOZZTKJZQFKDK-GUBZILKMSA-N 0.000 description 1
- WNGVUZWBXZKQES-YUMQZZPRSA-N Leu-Ala-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O WNGVUZWBXZKQES-YUMQZZPRSA-N 0.000 description 1
- WSGXUIQTEZDVHJ-GARJFASQSA-N Leu-Ala-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(O)=O WSGXUIQTEZDVHJ-GARJFASQSA-N 0.000 description 1
- GRZSCTXVCDUIPO-SRVKXCTJSA-N Leu-Arg-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O GRZSCTXVCDUIPO-SRVKXCTJSA-N 0.000 description 1
- HASRFYOMVPJRPU-SRVKXCTJSA-N Leu-Arg-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O HASRFYOMVPJRPU-SRVKXCTJSA-N 0.000 description 1
- DUBAVOVZNZKEQQ-AVGNSLFASA-N Leu-Arg-Val Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CCCN=C(N)N DUBAVOVZNZKEQQ-AVGNSLFASA-N 0.000 description 1
- OIARJGNVARWKFP-YUMQZZPRSA-N Leu-Asn-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O OIARJGNVARWKFP-YUMQZZPRSA-N 0.000 description 1
- OGCQGUIWMSBHRZ-CIUDSAMLSA-N Leu-Asn-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O OGCQGUIWMSBHRZ-CIUDSAMLSA-N 0.000 description 1
- ZURHXHNAEJJRNU-CIUDSAMLSA-N Leu-Asp-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O ZURHXHNAEJJRNU-CIUDSAMLSA-N 0.000 description 1
- DLCOFDAHNMMQPP-SRVKXCTJSA-N Leu-Asp-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O DLCOFDAHNMMQPP-SRVKXCTJSA-N 0.000 description 1
- CLVUXCBGKUECIT-HJGDQZAQSA-N Leu-Asp-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CLVUXCBGKUECIT-HJGDQZAQSA-N 0.000 description 1
- GZAUZBUKDXYPEH-CIUDSAMLSA-N Leu-Cys-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CS)C(=O)O)N GZAUZBUKDXYPEH-CIUDSAMLSA-N 0.000 description 1
- PPBKJAQJAUHZKX-SRVKXCTJSA-N Leu-Cys-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CC(C)C PPBKJAQJAUHZKX-SRVKXCTJSA-N 0.000 description 1
- HUEBCHPSXSQUGN-GARJFASQSA-N Leu-Cys-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)N1CCC[C@@H]1C(=O)O)N HUEBCHPSXSQUGN-GARJFASQSA-N 0.000 description 1
- WCTCIIAGNMFYAO-DCAQKATOSA-N Leu-Cys-Val Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(O)=O WCTCIIAGNMFYAO-DCAQKATOSA-N 0.000 description 1
- KAFOIVJDVSZUMD-DCAQKATOSA-N Leu-Gln-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-DCAQKATOSA-N 0.000 description 1
- KAFOIVJDVSZUMD-UHFFFAOYSA-N Leu-Gln-Gln Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)NC(CCC(N)=O)C(O)=O KAFOIVJDVSZUMD-UHFFFAOYSA-N 0.000 description 1
- DPWGZWUMUUJQDT-IUCAKERBSA-N Leu-Gln-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O DPWGZWUMUUJQDT-IUCAKERBSA-N 0.000 description 1
- LOLUPZNNADDTAA-AVGNSLFASA-N Leu-Gln-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O LOLUPZNNADDTAA-AVGNSLFASA-N 0.000 description 1
- FQZPTCNSNPWHLJ-AVGNSLFASA-N Leu-Gln-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O FQZPTCNSNPWHLJ-AVGNSLFASA-N 0.000 description 1
- CIVKXGPFXDIQBV-WDCWCFNPSA-N Leu-Gln-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CIVKXGPFXDIQBV-WDCWCFNPSA-N 0.000 description 1
- HPBCTWSUJOGJSH-MNXVOIDGSA-N Leu-Glu-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HPBCTWSUJOGJSH-MNXVOIDGSA-N 0.000 description 1
- BABSVXFGKFLIGW-UWVGGRQHSA-N Leu-Gly-Arg Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCNC(N)=N BABSVXFGKFLIGW-UWVGGRQHSA-N 0.000 description 1
- FIYMBBHGYNQFOP-IUCAKERBSA-N Leu-Gly-Gln Chemical compound CC(C)C[C@@H](C(=O)NCC(=O)N[C@@H](CCC(=O)N)C(=O)O)N FIYMBBHGYNQFOP-IUCAKERBSA-N 0.000 description 1
- KGCLIYGPQXUNLO-IUCAKERBSA-N Leu-Gly-Glu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O KGCLIYGPQXUNLO-IUCAKERBSA-N 0.000 description 1
- HYIFFZAQXPUEAU-QWRGUYRKSA-N Leu-Gly-Leu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC(C)C HYIFFZAQXPUEAU-QWRGUYRKSA-N 0.000 description 1
- HYMLKESRWLZDBR-WEDXCCLWSA-N Leu-Gly-Thr Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O HYMLKESRWLZDBR-WEDXCCLWSA-N 0.000 description 1
- BKTXKJMNTSMJDQ-AVGNSLFASA-N Leu-His-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N BKTXKJMNTSMJDQ-AVGNSLFASA-N 0.000 description 1
- USLNHQZCDQJBOV-ZPFDUUQYSA-N Leu-Ile-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O USLNHQZCDQJBOV-ZPFDUUQYSA-N 0.000 description 1
- HNDWYLYAYNBWMP-AJNGGQMLSA-N Leu-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(C)C)N HNDWYLYAYNBWMP-AJNGGQMLSA-N 0.000 description 1
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 1
- XVZCXCTYGHPNEM-UHFFFAOYSA-N Leu-Leu-Pro Natural products CC(C)CC(N)C(=O)NC(CC(C)C)C(=O)N1CCCC1C(O)=O XVZCXCTYGHPNEM-UHFFFAOYSA-N 0.000 description 1
- FOBUGKUBUJOWAD-IHPCNDPISA-N Leu-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(C)C)C(O)=O)=CNC2=C1 FOBUGKUBUJOWAD-IHPCNDPISA-N 0.000 description 1
- WXUOJXIGOPMDJM-SRVKXCTJSA-N Leu-Lys-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O WXUOJXIGOPMDJM-SRVKXCTJSA-N 0.000 description 1
- REPBGZHJKYWFMJ-KKUMJFAQSA-N Leu-Lys-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N REPBGZHJKYWFMJ-KKUMJFAQSA-N 0.000 description 1
- FKQPWMZLIIATBA-AJNGGQMLSA-N Leu-Lys-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FKQPWMZLIIATBA-AJNGGQMLSA-N 0.000 description 1
- ARRIJPQRBWRNLT-DCAQKATOSA-N Leu-Met-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ARRIJPQRBWRNLT-DCAQKATOSA-N 0.000 description 1
- GCXGCIYIHXSKAY-ULQDDVLXSA-N Leu-Phe-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O GCXGCIYIHXSKAY-ULQDDVLXSA-N 0.000 description 1
- UHNQRAFSEBGZFZ-YESZJQIVSA-N Leu-Phe-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N UHNQRAFSEBGZFZ-YESZJQIVSA-N 0.000 description 1
- BMVFXOQHDQZAQU-DCAQKATOSA-N Leu-Pro-Asp Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(=O)O)C(=O)O)N BMVFXOQHDQZAQU-DCAQKATOSA-N 0.000 description 1
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 1
- PWPBLZXWFXJFHE-RHYQMDGZSA-N Leu-Pro-Thr Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O PWPBLZXWFXJFHE-RHYQMDGZSA-N 0.000 description 1
- UCXQIIIFOOGYEM-ULQDDVLXSA-N Leu-Pro-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 UCXQIIIFOOGYEM-ULQDDVLXSA-N 0.000 description 1
- JDBQSGMJBMPNFT-AVGNSLFASA-N Leu-Pro-Val Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O JDBQSGMJBMPNFT-AVGNSLFASA-N 0.000 description 1
- IWMJFLJQHIDZQW-KKUMJFAQSA-N Leu-Ser-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 IWMJFLJQHIDZQW-KKUMJFAQSA-N 0.000 description 1
- SBANPBVRHYIMRR-GARJFASQSA-N Leu-Ser-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N SBANPBVRHYIMRR-GARJFASQSA-N 0.000 description 1
- LINKCQUOMUDLKN-KATARQTJSA-N Leu-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N)O LINKCQUOMUDLKN-KATARQTJSA-N 0.000 description 1
- LCNASHSOFMRYFO-WDCWCFNPSA-N Leu-Thr-Gln Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O LCNASHSOFMRYFO-WDCWCFNPSA-N 0.000 description 1
- QWWPYKKLXWOITQ-VOAKCMCISA-N Leu-Thr-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(C)C QWWPYKKLXWOITQ-VOAKCMCISA-N 0.000 description 1
- BTEMNFBEAAOGBR-BZSNNMDCSA-N Leu-Tyr-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCCN)C(=O)O)N BTEMNFBEAAOGBR-BZSNNMDCSA-N 0.000 description 1
- SEOXPEFQEOYURL-PMVMPFDFSA-N Leu-Tyr-Trp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O SEOXPEFQEOYURL-PMVMPFDFSA-N 0.000 description 1
- YIRIDPUGZKHMHT-ACRUOGEOSA-N Leu-Tyr-Tyr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O YIRIDPUGZKHMHT-ACRUOGEOSA-N 0.000 description 1
- VQHUBNVKFFLWRP-ULQDDVLXSA-N Leu-Tyr-Val Chemical compound CC(C)C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C(C)C)C(O)=O)CC1=CC=C(O)C=C1 VQHUBNVKFFLWRP-ULQDDVLXSA-N 0.000 description 1
- TUIOUEWKFFVNLH-DCAQKATOSA-N Leu-Val-Cys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(O)=O TUIOUEWKFFVNLH-DCAQKATOSA-N 0.000 description 1
- XOEDPXDZJHBQIX-ULQDDVLXSA-N Leu-Val-Phe Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XOEDPXDZJHBQIX-ULQDDVLXSA-N 0.000 description 1
- FDBTVENULFNTAL-XQQFMLRXSA-N Leu-Val-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N FDBTVENULFNTAL-XQQFMLRXSA-N 0.000 description 1
- QESXLSQLQHHTIX-RHYQMDGZSA-N Leu-Val-Thr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QESXLSQLQHHTIX-RHYQMDGZSA-N 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 208000017170 Lipid metabolism disease Diseases 0.000 description 1
- 206010067125 Liver injury Diseases 0.000 description 1
- 102100034389 Low density lipoprotein receptor adapter protein 1 Human genes 0.000 description 1
- MPOHDJKRBLVGCT-CIUDSAMLSA-N Lys-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N MPOHDJKRBLVGCT-CIUDSAMLSA-N 0.000 description 1
- NQCJGQHHYZNUDK-DCAQKATOSA-N Lys-Arg-Ser Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CCCN=C(N)N NQCJGQHHYZNUDK-DCAQKATOSA-N 0.000 description 1
- JBRWKVANRYPCAF-XIRDDKMYSA-N Lys-Asn-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCCN)N JBRWKVANRYPCAF-XIRDDKMYSA-N 0.000 description 1
- LMVOVCYVZBBWQB-SRVKXCTJSA-N Lys-Asp-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN LMVOVCYVZBBWQB-SRVKXCTJSA-N 0.000 description 1
- MLLKLNYPZRDIQG-GUBZILKMSA-N Lys-Cys-Gln Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N MLLKLNYPZRDIQG-GUBZILKMSA-N 0.000 description 1
- QQYRCUXKLDGCQN-SRVKXCTJSA-N Lys-Cys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCCCN)N QQYRCUXKLDGCQN-SRVKXCTJSA-N 0.000 description 1
- SFQPJNQDUUYCLA-BJDJZHNGSA-N Lys-Cys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCCCN)N SFQPJNQDUUYCLA-BJDJZHNGSA-N 0.000 description 1
- ULUQBUKAPDUKOC-GVXVVHGQSA-N Lys-Glu-Val Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O ULUQBUKAPDUKOC-GVXVVHGQSA-N 0.000 description 1
- LCMWVZLBCUVDAZ-IUCAKERBSA-N Lys-Gly-Glu Chemical compound [NH3+]CCCC[C@H]([NH3+])C(=O)NCC(=O)N[C@H](C([O-])=O)CCC([O-])=O LCMWVZLBCUVDAZ-IUCAKERBSA-N 0.000 description 1
- XIZQPFCRXLUNMK-BZSNNMDCSA-N Lys-Leu-Phe Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)NC(=O)[C@H](CCCCN)N XIZQPFCRXLUNMK-BZSNNMDCSA-N 0.000 description 1
- YUAXTFMFMOIMAM-QWRGUYRKSA-N Lys-Lys-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O YUAXTFMFMOIMAM-QWRGUYRKSA-N 0.000 description 1
- IPSDPDAOSAEWCN-RHYQMDGZSA-N Lys-Met-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IPSDPDAOSAEWCN-RHYQMDGZSA-N 0.000 description 1
- UDXSLGLHFUBRRM-OEAJRASXSA-N Lys-Phe-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](CCCCN)N)O UDXSLGLHFUBRRM-OEAJRASXSA-N 0.000 description 1
- YTJFXEDRUOQGSP-DCAQKATOSA-N Lys-Pro-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YTJFXEDRUOQGSP-DCAQKATOSA-N 0.000 description 1
- SBQDRNOLGSYHQA-YUMQZZPRSA-N Lys-Ser-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SBQDRNOLGSYHQA-YUMQZZPRSA-N 0.000 description 1
- ZFNYWKHYUMEZDZ-WDSOQIARSA-N Lys-Trp-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@H](CCCCN)N ZFNYWKHYUMEZDZ-WDSOQIARSA-N 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 208000024556 Mendelian disease Diseases 0.000 description 1
- YRAWWKUTNBILNT-FXQIFTODSA-N Met-Ala-Ala Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](C)C(O)=O YRAWWKUTNBILNT-FXQIFTODSA-N 0.000 description 1
- VHGIWFGJIHTASW-FXQIFTODSA-N Met-Ala-Asp Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O VHGIWFGJIHTASW-FXQIFTODSA-N 0.000 description 1
- UZWMJZSOXGOVIN-LURJTMIESA-N Met-Gly-Gly Chemical compound CSCC[C@H](N)C(=O)NCC(=O)NCC(O)=O UZWMJZSOXGOVIN-LURJTMIESA-N 0.000 description 1
- ZEVPMOHYCQFWSE-NAKRPEOUSA-N Met-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCSC)N ZEVPMOHYCQFWSE-NAKRPEOUSA-N 0.000 description 1
- XDGFFEZAZHRZFR-RHYQMDGZSA-N Met-Leu-Thr Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XDGFFEZAZHRZFR-RHYQMDGZSA-N 0.000 description 1
- RDLSEGZJMYGFNS-FXQIFTODSA-N Met-Ser-Asp Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O RDLSEGZJMYGFNS-FXQIFTODSA-N 0.000 description 1
- LHXFNWBNRBWMNV-DCAQKATOSA-N Met-Ser-His Chemical compound CSCC[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N LHXFNWBNRBWMNV-DCAQKATOSA-N 0.000 description 1
- 101100491390 Mus musculus Apob gene Proteins 0.000 description 1
- 241000204031 Mycoplasma Species 0.000 description 1
- 208000031888 Mycoses Diseases 0.000 description 1
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 1
- 108010047562 NGR peptide Proteins 0.000 description 1
- 239000000020 Nitrocellulose Substances 0.000 description 1
- 108020004485 Nonsense Codon Proteins 0.000 description 1
- 108091005461 Nucleic proteins Proteins 0.000 description 1
- 101710087110 ORF6 protein Proteins 0.000 description 1
- 238000010222 PCR analysis Methods 0.000 description 1
- 238000002944 PCR assay Methods 0.000 description 1
- 239000006002 Pepper Substances 0.000 description 1
- 108010033276 Peptide Fragments Proteins 0.000 description 1
- 102000007079 Peptide Fragments Human genes 0.000 description 1
- 208000037581 Persistent Infection Diseases 0.000 description 1
- NEHSHYOUIWBYSA-DCPHZVHLSA-N Phe-Ala-Trp Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC3=CC=CC=C3)N NEHSHYOUIWBYSA-DCPHZVHLSA-N 0.000 description 1
- YMORXCKTSSGYIG-IHRRRGAJSA-N Phe-Arg-Cys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N YMORXCKTSSGYIG-IHRRRGAJSA-N 0.000 description 1
- DJPXNKUDJKGQEE-BZSNNMDCSA-N Phe-Asp-Phe Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O DJPXNKUDJKGQEE-BZSNNMDCSA-N 0.000 description 1
- UNLYPPYNDXHGDG-IHRRRGAJSA-N Phe-Gln-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 UNLYPPYNDXHGDG-IHRRRGAJSA-N 0.000 description 1
- OYQBFWWQSVIHBN-FHWLQOOXSA-N Phe-Glu-Phe Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O OYQBFWWQSVIHBN-FHWLQOOXSA-N 0.000 description 1
- HBGFEEQFVBWYJQ-KBPBESRZSA-N Phe-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC1=CC=CC=C1 HBGFEEQFVBWYJQ-KBPBESRZSA-N 0.000 description 1
- WFHRXJOZEXUKLV-IRXDYDNUSA-N Phe-Gly-Tyr Chemical compound C([C@H](N)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 WFHRXJOZEXUKLV-IRXDYDNUSA-N 0.000 description 1
- RVRRHFPCEOVRKQ-KKUMJFAQSA-N Phe-His-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CC(=O)N)C(=O)O)N RVRRHFPCEOVRKQ-KKUMJFAQSA-N 0.000 description 1
- BEEVXUYVEHXWRQ-YESZJQIVSA-N Phe-His-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CC3=CC=CC=C3)N)C(=O)O BEEVXUYVEHXWRQ-YESZJQIVSA-N 0.000 description 1
- MYQCCQSMKNCNKY-KKUMJFAQSA-N Phe-His-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CO)C(=O)O)N MYQCCQSMKNCNKY-KKUMJFAQSA-N 0.000 description 1
- YVIVIQWMNCWUFS-UFYCRDLUSA-N Phe-Met-Tyr Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N YVIVIQWMNCWUFS-UFYCRDLUSA-N 0.000 description 1
- MGLBSROLWAWCKN-FCLVOEFKSA-N Phe-Phe-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O MGLBSROLWAWCKN-FCLVOEFKSA-N 0.000 description 1
- JLLJTMHNXQTMCK-UBHSHLNASA-N Phe-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC1=CC=CC=C1 JLLJTMHNXQTMCK-UBHSHLNASA-N 0.000 description 1
- NJJBATPLUQHRBM-IHRRRGAJSA-N Phe-Pro-Ser Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)N)C(=O)N[C@@H](CO)C(=O)O NJJBATPLUQHRBM-IHRRRGAJSA-N 0.000 description 1
- AFNJAQVMTIQTCB-DLOVCJGASA-N Phe-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=CC=C1 AFNJAQVMTIQTCB-DLOVCJGASA-N 0.000 description 1
- HBXAOEBRGLCLIW-AVGNSLFASA-N Phe-Ser-Gln Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N HBXAOEBRGLCLIW-AVGNSLFASA-N 0.000 description 1
- RAGOJJCBGXARPO-XVSYOHENSA-N Phe-Thr-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H]([C@H](O)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 RAGOJJCBGXARPO-XVSYOHENSA-N 0.000 description 1
- 241000364051 Pima Species 0.000 description 1
- 235000016761 Piper aduncum Nutrition 0.000 description 1
- 235000017804 Piper guineense Nutrition 0.000 description 1
- 244000203593 Piper nigrum Species 0.000 description 1
- 235000008184 Piper nigrum Nutrition 0.000 description 1
- 239000002202 Polyethylene glycol Substances 0.000 description 1
- 229920001214 Polysorbate 60 Polymers 0.000 description 1
- ZLMJMSJWJFRBEC-UHFFFAOYSA-N Potassium Chemical compound [K] ZLMJMSJWJFRBEC-UHFFFAOYSA-N 0.000 description 1
- 208000012654 Primary biliary cholangitis Diseases 0.000 description 1
- KIZQGKLMXKGDIV-BQBZGAKWSA-N Pro-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 KIZQGKLMXKGDIV-BQBZGAKWSA-N 0.000 description 1
- BNBBNGZZKQUWCD-IUCAKERBSA-N Pro-Arg-Gly Chemical compound NC(N)=NCCC[C@@H](C(=O)NCC(O)=O)NC(=O)[C@@H]1CCCN1 BNBBNGZZKQUWCD-IUCAKERBSA-N 0.000 description 1
- AMBLXEMWFARNNQ-DCAQKATOSA-N Pro-Asn-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@@H]1CCCN1 AMBLXEMWFARNNQ-DCAQKATOSA-N 0.000 description 1
- JARJPEMLQAWNBR-GUBZILKMSA-N Pro-Asp-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O JARJPEMLQAWNBR-GUBZILKMSA-N 0.000 description 1
- NGNNPLJHUFCOMZ-FXQIFTODSA-N Pro-Asp-Cys Chemical compound SC[C@@H](C(O)=O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@@H]1CCCN1 NGNNPLJHUFCOMZ-FXQIFTODSA-N 0.000 description 1
- ZCXQTRXYZOSGJR-FXQIFTODSA-N Pro-Asp-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZCXQTRXYZOSGJR-FXQIFTODSA-N 0.000 description 1
- YKQNVTOIYFQMLW-IHRRRGAJSA-N Pro-Cys-Tyr Chemical compound C([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H]1NCCC1)C1=CC=C(O)C=C1 YKQNVTOIYFQMLW-IHRRRGAJSA-N 0.000 description 1
- LSIWVWRUTKPXDS-DCAQKATOSA-N Pro-Gln-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O LSIWVWRUTKPXDS-DCAQKATOSA-N 0.000 description 1
- HJSCRFZVGXAGNG-SRVKXCTJSA-N Pro-Gln-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H]1CCCN1 HJSCRFZVGXAGNG-SRVKXCTJSA-N 0.000 description 1
- QCARZLHECSFOGG-CIUDSAMLSA-N Pro-Glu-Cys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CS)C(=O)O QCARZLHECSFOGG-CIUDSAMLSA-N 0.000 description 1
- VDGTVWFMRXVQCT-GUBZILKMSA-N Pro-Glu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1 VDGTVWFMRXVQCT-GUBZILKMSA-N 0.000 description 1
- ZTVCLZLGHZXLOT-ULQDDVLXSA-N Pro-Glu-Trp Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O ZTVCLZLGHZXLOT-ULQDDVLXSA-N 0.000 description 1
- ULIWFCCJIOEHMU-BQBZGAKWSA-N Pro-Gly-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 ULIWFCCJIOEHMU-BQBZGAKWSA-N 0.000 description 1
- HAAQQNHQZBOWFO-LURJTMIESA-N Pro-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H]1CCCN1 HAAQQNHQZBOWFO-LURJTMIESA-N 0.000 description 1
- FEPSEIDIPBMIOS-QXEWZRGKSA-N Pro-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H]1CCCN1 FEPSEIDIPBMIOS-QXEWZRGKSA-N 0.000 description 1
- FKLSMYYLJHYPHH-UWVGGRQHSA-N Pro-Gly-Leu Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O FKLSMYYLJHYPHH-UWVGGRQHSA-N 0.000 description 1
- FEVDNIBDCRKMER-IUCAKERBSA-N Pro-Gly-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)CNC(=O)[C@@H]1CCCN1 FEVDNIBDCRKMER-IUCAKERBSA-N 0.000 description 1
- DTQIXTOJHKVEOH-DCAQKATOSA-N Pro-His-Cys Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CS)C(=O)O DTQIXTOJHKVEOH-DCAQKATOSA-N 0.000 description 1
- YTWNSIDWAFSEEI-RWMBFGLXSA-N Pro-His-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CN=CN2)C(=O)N3CCC[C@@H]3C(=O)O YTWNSIDWAFSEEI-RWMBFGLXSA-N 0.000 description 1
- BODDREDDDRZUCF-QTKMDUPCSA-N Pro-His-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@@H]2CCCN2)O BODDREDDDRZUCF-QTKMDUPCSA-N 0.000 description 1
- LXLFEIHKWGHJJB-XUXIUFHCSA-N Pro-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@@H]1CCCN1 LXLFEIHKWGHJJB-XUXIUFHCSA-N 0.000 description 1
- GURGCNUWVSDYTP-SRVKXCTJSA-N Pro-Leu-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O GURGCNUWVSDYTP-SRVKXCTJSA-N 0.000 description 1
- BRJGUPWVFXKBQI-XUXIUFHCSA-N Pro-Leu-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BRJGUPWVFXKBQI-XUXIUFHCSA-N 0.000 description 1
- JUJCUYWRJMFJJF-AVGNSLFASA-N Pro-Lys-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H]1CCCN1 JUJCUYWRJMFJJF-AVGNSLFASA-N 0.000 description 1
- IQAGKQWXVHTPOT-FHWLQOOXSA-N Pro-Lys-Trp Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O IQAGKQWXVHTPOT-FHWLQOOXSA-N 0.000 description 1
- VGVCNKSUVSZEIE-IHRRRGAJSA-N Pro-Phe-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O VGVCNKSUVSZEIE-IHRRRGAJSA-N 0.000 description 1
- RCYUBVHMVUHEBM-RCWTZXSCSA-N Pro-Pro-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O RCYUBVHMVUHEBM-RCWTZXSCSA-N 0.000 description 1
- OWQXAJQZLWHPBH-FXQIFTODSA-N Pro-Ser-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O OWQXAJQZLWHPBH-FXQIFTODSA-N 0.000 description 1
- SNGZLPOXVRTNMB-LPEHRKFASA-N Pro-Ser-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CO)C(=O)N2CCC[C@@H]2C(=O)O SNGZLPOXVRTNMB-LPEHRKFASA-N 0.000 description 1
- GNFHQWNCSSPOBT-ULQDDVLXSA-N Pro-Trp-Gln Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)N[C@@H](CCC(=O)N)C(=O)O GNFHQWNCSSPOBT-ULQDDVLXSA-N 0.000 description 1
- XDKKMRPRRCOELJ-GUBZILKMSA-N Pro-Val-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 XDKKMRPRRCOELJ-GUBZILKMSA-N 0.000 description 1
- IMNVAOPEMFDAQD-NHCYSSNCSA-N Pro-Val-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IMNVAOPEMFDAQD-NHCYSSNCSA-N 0.000 description 1
- ZMLRZBWCXPQADC-TUAOUCFPSA-N Pro-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 ZMLRZBWCXPQADC-TUAOUCFPSA-N 0.000 description 1
- FIODMZKLZFLYQP-GUBZILKMSA-N Pro-Val-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O FIODMZKLZFLYQP-GUBZILKMSA-N 0.000 description 1
- 108010076504 Protein Sorting Signals Proteins 0.000 description 1
- 108010079005 RDV peptide Proteins 0.000 description 1
- 108010003201 RGH 0205 Proteins 0.000 description 1
- 239000012083 RIPA buffer Substances 0.000 description 1
- 102100038823 RNA-binding protein 45 Human genes 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 108700005079 Recessive Genes Proteins 0.000 description 1
- 102000052708 Recessive Genes Human genes 0.000 description 1
- 108020005091 Replication Origin Proteins 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- DWUIECHTAMYEFL-XVYDVKMFSA-N Ser-Ala-His Chemical compound OC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 DWUIECHTAMYEFL-XVYDVKMFSA-N 0.000 description 1
- HBZBPFLJNDXRAY-FXQIFTODSA-N Ser-Ala-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(O)=O HBZBPFLJNDXRAY-FXQIFTODSA-N 0.000 description 1
- WDXYVIIVDIDOSX-DCAQKATOSA-N Ser-Arg-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N WDXYVIIVDIDOSX-DCAQKATOSA-N 0.000 description 1
- QFBNNYNWKYKVJO-DCAQKATOSA-N Ser-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CCCN=C(N)N QFBNNYNWKYKVJO-DCAQKATOSA-N 0.000 description 1
- OYEDZGNMSBZCIM-XGEHTFHBSA-N Ser-Arg-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OYEDZGNMSBZCIM-XGEHTFHBSA-N 0.000 description 1
- OBXVZEAMXFSGPU-FXQIFTODSA-N Ser-Asn-Arg Chemical compound C(C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CO)N)CN=C(N)N OBXVZEAMXFSGPU-FXQIFTODSA-N 0.000 description 1
- ICHZYBVODUVUKN-SRVKXCTJSA-N Ser-Asn-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ICHZYBVODUVUKN-SRVKXCTJSA-N 0.000 description 1
- CNIIKZQXBBQHCX-FXQIFTODSA-N Ser-Asp-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O CNIIKZQXBBQHCX-FXQIFTODSA-N 0.000 description 1
- BGOWRLSWJCVYAQ-CIUDSAMLSA-N Ser-Asp-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O BGOWRLSWJCVYAQ-CIUDSAMLSA-N 0.000 description 1
- DSSOYPJWSWFOLK-CIUDSAMLSA-N Ser-Cys-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(C)C)C(O)=O DSSOYPJWSWFOLK-CIUDSAMLSA-N 0.000 description 1
- RNMRYWZYFHHOEV-CIUDSAMLSA-N Ser-Gln-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O RNMRYWZYFHHOEV-CIUDSAMLSA-N 0.000 description 1
- ULVMNZOKDBHKKI-ACZMJKKPSA-N Ser-Gln-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O ULVMNZOKDBHKKI-ACZMJKKPSA-N 0.000 description 1
- ZOHGLPQGEHSLPD-FXQIFTODSA-N Ser-Gln-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZOHGLPQGEHSLPD-FXQIFTODSA-N 0.000 description 1
- UOLGINIHBRIECN-FXQIFTODSA-N Ser-Glu-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UOLGINIHBRIECN-FXQIFTODSA-N 0.000 description 1
- UFKPDBLKLOBMRH-XHNCKOQMSA-N Ser-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CO)N)C(=O)O UFKPDBLKLOBMRH-XHNCKOQMSA-N 0.000 description 1
- VQBCMLMPEWPUTB-ACZMJKKPSA-N Ser-Glu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VQBCMLMPEWPUTB-ACZMJKKPSA-N 0.000 description 1
- YMTLKLXDFCSCNX-BYPYZUCNSA-N Ser-Gly-Gly Chemical compound OC[C@H](N)C(=O)NCC(=O)NCC(O)=O YMTLKLXDFCSCNX-BYPYZUCNSA-N 0.000 description 1
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 1
- MOQDPPUMFSMYOM-KKUMJFAQSA-N Ser-His-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CN=CN2)NC(=O)[C@H](CO)N MOQDPPUMFSMYOM-KKUMJFAQSA-N 0.000 description 1
- ZUDXUJSYCCNZQJ-DCAQKATOSA-N Ser-His-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](CO)N ZUDXUJSYCCNZQJ-DCAQKATOSA-N 0.000 description 1
- BKZYBLLIBOBOOW-GHCJXIJMSA-N Ser-Ile-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(O)=O)C(O)=O BKZYBLLIBOBOOW-GHCJXIJMSA-N 0.000 description 1
- RIAKPZVSNBBNRE-BJDJZHNGSA-N Ser-Ile-Leu Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O RIAKPZVSNBBNRE-BJDJZHNGSA-N 0.000 description 1
- UIPXCLNLUUAMJU-JBDRJPRFSA-N Ser-Ile-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O UIPXCLNLUUAMJU-JBDRJPRFSA-N 0.000 description 1
- FUMGHWDRRFCKEP-CIUDSAMLSA-N Ser-Leu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O FUMGHWDRRFCKEP-CIUDSAMLSA-N 0.000 description 1
- QYSFWUIXDFJUDW-DCAQKATOSA-N Ser-Leu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYSFWUIXDFJUDW-DCAQKATOSA-N 0.000 description 1
- IUXGJEIKJBYKOO-SRVKXCTJSA-N Ser-Leu-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CO)N IUXGJEIKJBYKOO-SRVKXCTJSA-N 0.000 description 1
- HEUVHBXOVZONPU-BJDJZHNGSA-N Ser-Leu-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O HEUVHBXOVZONPU-BJDJZHNGSA-N 0.000 description 1
- KCGIREHVWRXNDH-GARJFASQSA-N Ser-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N KCGIREHVWRXNDH-GARJFASQSA-N 0.000 description 1
- NNFMANHDYSVNIO-DCAQKATOSA-N Ser-Lys-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NNFMANHDYSVNIO-DCAQKATOSA-N 0.000 description 1
- PTWIYDNFWPXQSD-GARJFASQSA-N Ser-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CO)N)C(=O)O PTWIYDNFWPXQSD-GARJFASQSA-N 0.000 description 1
- FZEUTKVQGMVGHW-AVGNSLFASA-N Ser-Phe-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O FZEUTKVQGMVGHW-AVGNSLFASA-N 0.000 description 1
- XKFJENWJGHMDLI-QWRGUYRKSA-N Ser-Phe-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)NCC(O)=O XKFJENWJGHMDLI-QWRGUYRKSA-N 0.000 description 1
- ZKBKUWQVDWWSRI-BZSNNMDCSA-N Ser-Phe-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZKBKUWQVDWWSRI-BZSNNMDCSA-N 0.000 description 1
- FKYWFUYPVKLJLP-DCAQKATOSA-N Ser-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO FKYWFUYPVKLJLP-DCAQKATOSA-N 0.000 description 1
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 1
- CUXJENOFJXOSOZ-BIIVOSGPSA-N Ser-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CO)N)C(=O)O CUXJENOFJXOSOZ-BIIVOSGPSA-N 0.000 description 1
- OLKICIBQRVSQMA-SRVKXCTJSA-N Ser-Ser-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OLKICIBQRVSQMA-SRVKXCTJSA-N 0.000 description 1
- RXUOAOOZIWABBW-XGEHTFHBSA-N Ser-Thr-Arg Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N RXUOAOOZIWABBW-XGEHTFHBSA-N 0.000 description 1
- SZRNDHWMVSFPSP-XKBZYTNZSA-N Ser-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CO)N)O SZRNDHWMVSFPSP-XKBZYTNZSA-N 0.000 description 1
- PURRNJBBXDDWLX-ZDLURKLDSA-N Ser-Thr-Gly Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CO)N)O PURRNJBBXDDWLX-ZDLURKLDSA-N 0.000 description 1
- ZSDXEKUKQAKZFE-XAVMHZPKSA-N Ser-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N)O ZSDXEKUKQAKZFE-XAVMHZPKSA-N 0.000 description 1
- BDMWLJLPPUCLNV-XGEHTFHBSA-N Ser-Thr-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O BDMWLJLPPUCLNV-XGEHTFHBSA-N 0.000 description 1
- WMZVVNLPHFSUPA-BPUTZDHNSA-N Ser-Trp-Arg Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CO)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)=CNC2=C1 WMZVVNLPHFSUPA-BPUTZDHNSA-N 0.000 description 1
- PIQRHJQWEPWFJG-UWJYBYFXSA-N Ser-Tyr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O PIQRHJQWEPWFJG-UWJYBYFXSA-N 0.000 description 1
- IAOHCSQDQDWRQU-GUBZILKMSA-N Ser-Val-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IAOHCSQDQDWRQU-GUBZILKMSA-N 0.000 description 1
- BEBVVQPDSHHWQL-NRPADANISA-N Ser-Val-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O BEBVVQPDSHHWQL-NRPADANISA-N 0.000 description 1
- 108010022999 Serine Proteases Proteins 0.000 description 1
- 102000012479 Serine Proteases Human genes 0.000 description 1
- 229920001304 Solutol HS 15 Polymers 0.000 description 1
- 241000282898 Sus scrofa Species 0.000 description 1
- 239000004098 Tetracycline Substances 0.000 description 1
- TYVAWPFQYFPSBR-BFHQHQDPSA-N Thr-Ala-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)NCC(O)=O TYVAWPFQYFPSBR-BFHQHQDPSA-N 0.000 description 1
- STGXWWBXWXZOER-MBLNEYKQSA-N Thr-Ala-His Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 STGXWWBXWXZOER-MBLNEYKQSA-N 0.000 description 1
- LVHHEVGYAZGXDE-KDXUFGMBSA-N Thr-Ala-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(=O)O)N)O LVHHEVGYAZGXDE-KDXUFGMBSA-N 0.000 description 1
- QGXCWPNQVCYJEL-NUMRIWBASA-N Thr-Asn-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O QGXCWPNQVCYJEL-NUMRIWBASA-N 0.000 description 1
- ZLNWJMRLHLGKFX-SVSWQMSJSA-N Thr-Cys-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZLNWJMRLHLGKFX-SVSWQMSJSA-N 0.000 description 1
- GCXFWAZRHBRYEM-NUMRIWBASA-N Thr-Gln-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O GCXFWAZRHBRYEM-NUMRIWBASA-N 0.000 description 1
- GUZGCDIZVGODML-NKIYYHGXSA-N Thr-Gln-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N)O GUZGCDIZVGODML-NKIYYHGXSA-N 0.000 description 1
- VGYBYGQXZJDZJU-XQXXSGGOSA-N Thr-Glu-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O VGYBYGQXZJDZJU-XQXXSGGOSA-N 0.000 description 1
- NIEWSKWFURSECR-FOHZUACHSA-N Thr-Gly-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O NIEWSKWFURSECR-FOHZUACHSA-N 0.000 description 1
- DJDSEDOKJTZBAR-ZDLURKLDSA-N Thr-Gly-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O DJDSEDOKJTZBAR-ZDLURKLDSA-N 0.000 description 1
- AMXMBCAXAZUCFA-RHYQMDGZSA-N Thr-Leu-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AMXMBCAXAZUCFA-RHYQMDGZSA-N 0.000 description 1
- ODXKUIGEPAGKKV-KATARQTJSA-N Thr-Leu-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)O)N)O ODXKUIGEPAGKKV-KATARQTJSA-N 0.000 description 1
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 1
- KRDSCBLRHORMRK-JXUBOQSCSA-N Thr-Lys-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O KRDSCBLRHORMRK-JXUBOQSCSA-N 0.000 description 1
- KKPOGALELPLJTL-MEYUZBJRSA-N Thr-Lys-Tyr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 KKPOGALELPLJTL-MEYUZBJRSA-N 0.000 description 1
- KZURUCDWKDEAFZ-XVSYOHENSA-N Thr-Phe-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O KZURUCDWKDEAFZ-XVSYOHENSA-N 0.000 description 1
- NZRUWPIYECBYRK-HTUGSXCWSA-N Thr-Phe-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O NZRUWPIYECBYRK-HTUGSXCWSA-N 0.000 description 1
- IEZVHOULSUULHD-XGEHTFHBSA-N Thr-Ser-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O IEZVHOULSUULHD-XGEHTFHBSA-N 0.000 description 1
- AAZOYLQUEQRUMZ-GSSVUCPTSA-N Thr-Thr-Asn Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(N)=O AAZOYLQUEQRUMZ-GSSVUCPTSA-N 0.000 description 1
- VBMOVTMNHWPZJR-SUSMZKCASA-N Thr-Thr-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O VBMOVTMNHWPZJR-SUSMZKCASA-N 0.000 description 1
- LECUEEHKUFYOOV-ZJDVBMNYSA-N Thr-Thr-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@@H](N)[C@@H](C)O LECUEEHKUFYOOV-ZJDVBMNYSA-N 0.000 description 1
- FBQHKSPOIAFUEI-OWLDWWDNSA-N Thr-Trp-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C)C(O)=O FBQHKSPOIAFUEI-OWLDWWDNSA-N 0.000 description 1
- NLWDSYKZUPRMBJ-IEGACIPQSA-N Thr-Trp-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CC(C)C)C(=O)O)N)O NLWDSYKZUPRMBJ-IEGACIPQSA-N 0.000 description 1
- QNXZCKMXHPULME-ZNSHCXBVSA-N Thr-Val-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N)O QNXZCKMXHPULME-ZNSHCXBVSA-N 0.000 description 1
- 208000032109 Transient ischaemic attack Diseases 0.000 description 1
- GHXXDFDIDHIEIL-WFBYXXMGSA-N Trp-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N GHXXDFDIDHIEIL-WFBYXXMGSA-N 0.000 description 1
- OFNPHOGOJLNVLL-KCTSRDHCSA-N Trp-Ala-His Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N OFNPHOGOJLNVLL-KCTSRDHCSA-N 0.000 description 1
- NMCBVGFGWSIGSB-NUTKFTJISA-N Trp-Ala-Leu Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N NMCBVGFGWSIGSB-NUTKFTJISA-N 0.000 description 1
- HYVLNORXQGKONN-NUTKFTJISA-N Trp-Ala-Lys Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(O)=O)=CNC2=C1 HYVLNORXQGKONN-NUTKFTJISA-N 0.000 description 1
- QNTBGBCOEYNAPV-CWRNSKLLSA-N Trp-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N)C(=O)O QNTBGBCOEYNAPV-CWRNSKLLSA-N 0.000 description 1
- SSNGFWKILJLTQM-QEJZJMRPSA-N Trp-Gln-Asn Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N SSNGFWKILJLTQM-QEJZJMRPSA-N 0.000 description 1
- OGXQLUCMJZSJPW-LYSGOOTNSA-N Trp-Gly-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CC1=CNC2=CC=CC=C21)N)O OGXQLUCMJZSJPW-LYSGOOTNSA-N 0.000 description 1
- WVHUFSCKCBQKJW-HKUYNNGSSA-N Trp-Gly-Tyr Chemical compound C([C@H](NC(=O)CNC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)N)C(O)=O)C1=CC=C(O)C=C1 WVHUFSCKCBQKJW-HKUYNNGSSA-N 0.000 description 1
- YVXIAOOYAKBAAI-SZMVWBNQSA-N Trp-Leu-Gln Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 YVXIAOOYAKBAAI-SZMVWBNQSA-N 0.000 description 1
- VPRHDRKAPYZMHL-SZMVWBNQSA-N Trp-Leu-Glu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O)=CNC2=C1 VPRHDRKAPYZMHL-SZMVWBNQSA-N 0.000 description 1
- WMBFONUKQXGLMU-WDSOQIARSA-N Trp-Leu-Val Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N WMBFONUKQXGLMU-WDSOQIARSA-N 0.000 description 1
- UHXOYRWHIQZAKV-SZMVWBNQSA-N Trp-Pro-Arg Chemical compound O=C([C@H](CC=1C2=CC=CC=C2NC=1)N)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O UHXOYRWHIQZAKV-SZMVWBNQSA-N 0.000 description 1
- KOVPHHXMHLFWPL-BPUTZDHNSA-N Trp-Pro-Asn Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CNC3=CC=CC=C32)N)C(=O)N[C@@H](CC(=O)N)C(=O)O KOVPHHXMHLFWPL-BPUTZDHNSA-N 0.000 description 1
- QYSBJAUCUKHSLU-JYJNAYRXSA-N Tyr-Arg-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O QYSBJAUCUKHSLU-JYJNAYRXSA-N 0.000 description 1
- PZXUIGWOEWWFQM-SRVKXCTJSA-N Tyr-Asn-Asn Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O PZXUIGWOEWWFQM-SRVKXCTJSA-N 0.000 description 1
- CYDVHRFXDMDMGX-KKUMJFAQSA-N Tyr-Asn-His Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N)O CYDVHRFXDMDMGX-KKUMJFAQSA-N 0.000 description 1
- NMKJPMCEKQHRPD-IRXDYDNUSA-N Tyr-Gly-Tyr Chemical compound C([C@H](N)C(=O)NCC(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=C(O)C=C1 NMKJPMCEKQHRPD-IRXDYDNUSA-N 0.000 description 1
- QSFJHIRIHOJRKS-ULQDDVLXSA-N Tyr-Leu-Arg Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QSFJHIRIHOJRKS-ULQDDVLXSA-N 0.000 description 1
- NKUGCYDFQKFVOJ-JYJNAYRXSA-N Tyr-Leu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NKUGCYDFQKFVOJ-JYJNAYRXSA-N 0.000 description 1
- DWAMXBFJNZIHMC-KBPBESRZSA-N Tyr-Leu-Gly Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O DWAMXBFJNZIHMC-KBPBESRZSA-N 0.000 description 1
- DMWNPLOERDAHSY-MEYUZBJRSA-N Tyr-Leu-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O DMWNPLOERDAHSY-MEYUZBJRSA-N 0.000 description 1
- PGEFRHBWGOJPJT-KKUMJFAQSA-N Tyr-Lys-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O PGEFRHBWGOJPJT-KKUMJFAQSA-N 0.000 description 1
- YYLHVUCSTXXKBS-IHRRRGAJSA-N Tyr-Pro-Ser Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O YYLHVUCSTXXKBS-IHRRRGAJSA-N 0.000 description 1
- GQVZBMROTPEPIF-SRVKXCTJSA-N Tyr-Ser-Asp Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O GQVZBMROTPEPIF-SRVKXCTJSA-N 0.000 description 1
- LUMQYLVYUIRHHU-YJRXYDGGSA-N Tyr-Ser-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LUMQYLVYUIRHHU-YJRXYDGGSA-N 0.000 description 1
- 101710095001 Uncharacterized protein in nifU 5'region Proteins 0.000 description 1
- 208000007814 Unstable Angina Diseases 0.000 description 1
- 208000006105 Uterine Cervical Neoplasms Diseases 0.000 description 1
- 108010062497 VLDL Lipoproteins Proteins 0.000 description 1
- CWOSXNKDOACNJN-BZSNNMDCSA-N Val-Arg-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N CWOSXNKDOACNJN-BZSNNMDCSA-N 0.000 description 1
- QPZMOUMNTGTEFR-ZKWXMUAHSA-N Val-Asn-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](C(C)C)N QPZMOUMNTGTEFR-ZKWXMUAHSA-N 0.000 description 1
- UDLYXGYWTVOIKU-QXEWZRGKSA-N Val-Asn-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N UDLYXGYWTVOIKU-QXEWZRGKSA-N 0.000 description 1
- AUMNPAUHKUNHHN-BYULHYEWSA-N Val-Asn-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC(=O)O)C(=O)O)N AUMNPAUHKUNHHN-BYULHYEWSA-N 0.000 description 1
- PVPAOIGJYHVWBT-KKHAAJSZSA-N Val-Asn-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](C(C)C)N)O PVPAOIGJYHVWBT-KKHAAJSZSA-N 0.000 description 1
- NMPXRFYMZDIBRF-ZOBUZTSGSA-N Val-Asn-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)N NMPXRFYMZDIBRF-ZOBUZTSGSA-N 0.000 description 1
- DBOXBUDEAJVKRE-LSJOCFKGSA-N Val-Asn-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N DBOXBUDEAJVKRE-LSJOCFKGSA-N 0.000 description 1
- DDNIHOWRDOXXPF-NGZCFLSTSA-N Val-Asp-Pro Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N DDNIHOWRDOXXPF-NGZCFLSTSA-N 0.000 description 1
- YODDULVCGFQRFZ-ZKWXMUAHSA-N Val-Asp-Ser Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O YODDULVCGFQRFZ-ZKWXMUAHSA-N 0.000 description 1
- SZTTYWIUCGSURQ-AUTRQRHGSA-N Val-Glu-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SZTTYWIUCGSURQ-AUTRQRHGSA-N 0.000 description 1
- URIRWLJVWHYLET-ONGXEEELSA-N Val-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)C(C)C URIRWLJVWHYLET-ONGXEEELSA-N 0.000 description 1
- YTPLVNUZZOBFFC-SCZZXKLOSA-N Val-Gly-Pro Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N1CCC[C@@H]1C(O)=O YTPLVNUZZOBFFC-SCZZXKLOSA-N 0.000 description 1
- LAYSXAOGWHKNED-XPUUQOCRSA-N Val-Gly-Ser Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O LAYSXAOGWHKNED-XPUUQOCRSA-N 0.000 description 1
- KZKMBGXCNLPYKD-YEPSODPASA-N Val-Gly-Thr Chemical compound CC(C)[C@H](N)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O KZKMBGXCNLPYKD-YEPSODPASA-N 0.000 description 1
- SDSCOOZQQGUQFC-GVXVVHGQSA-N Val-His-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N SDSCOOZQQGUQFC-GVXVVHGQSA-N 0.000 description 1
- PTFPUAXGIKTVNN-ONGXEEELSA-N Val-His-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)NCC(=O)O)N PTFPUAXGIKTVNN-ONGXEEELSA-N 0.000 description 1
- KVRLNEILGGVBJX-IHRRRGAJSA-N Val-His-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CN=CN1 KVRLNEILGGVBJX-IHRRRGAJSA-N 0.000 description 1
- KDKLLPMFFGYQJD-CYDGBPFRSA-N Val-Ile-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](C(C)C)N KDKLLPMFFGYQJD-CYDGBPFRSA-N 0.000 description 1
- WNZSAUMKZQXHNC-UKJIMTQDSA-N Val-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N WNZSAUMKZQXHNC-UKJIMTQDSA-N 0.000 description 1
- UMPVMAYCLYMYGA-ONGXEEELSA-N Val-Leu-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O UMPVMAYCLYMYGA-ONGXEEELSA-N 0.000 description 1
- ZHQWPWQNVRCXAX-XQQFMLRXSA-N Val-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C(C)C)N ZHQWPWQNVRCXAX-XQQFMLRXSA-N 0.000 description 1
- RFKJNTRMXGCKFE-FHWLQOOXSA-N Val-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC(C)C)C(O)=O)=CNC2=C1 RFKJNTRMXGCKFE-FHWLQOOXSA-N 0.000 description 1
- ZEBRMWPTJNHXAJ-JYJNAYRXSA-N Val-Phe-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(=O)O)N ZEBRMWPTJNHXAJ-JYJNAYRXSA-N 0.000 description 1
- GIAZPLMMQOERPN-YUMQZZPRSA-N Val-Pro Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(O)=O GIAZPLMMQOERPN-YUMQZZPRSA-N 0.000 description 1
- YTNGABPUXFEOGU-SRVKXCTJSA-N Val-Pro-Arg Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O YTNGABPUXFEOGU-SRVKXCTJSA-N 0.000 description 1
- RYQUMYBMOJYYDK-NHCYSSNCSA-N Val-Pro-Glu Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(=O)O)C(=O)O)N RYQUMYBMOJYYDK-NHCYSSNCSA-N 0.000 description 1
- SJRUJQFQVLMZFW-WPRPVWTQSA-N Val-Pro-Gly Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O SJRUJQFQVLMZFW-WPRPVWTQSA-N 0.000 description 1
- NHXZRXLFOBFMDM-AVGNSLFASA-N Val-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)C(C)C NHXZRXLFOBFMDM-AVGNSLFASA-N 0.000 description 1
- DOFAQXCYFQKSHT-SRVKXCTJSA-N Val-Pro-Pro Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DOFAQXCYFQKSHT-SRVKXCTJSA-N 0.000 description 1
- QSPOLEBZTMESFY-SRVKXCTJSA-N Val-Pro-Val Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O QSPOLEBZTMESFY-SRVKXCTJSA-N 0.000 description 1
- RYHUIHUOYRNNIE-NRPADANISA-N Val-Ser-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N RYHUIHUOYRNNIE-NRPADANISA-N 0.000 description 1
- VHIZXDZMTDVFGX-DCAQKATOSA-N Val-Ser-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N VHIZXDZMTDVFGX-DCAQKATOSA-N 0.000 description 1
- GBIUHAYJGWVNLN-UHFFFAOYSA-N Val-Ser-Pro Natural products CC(C)C(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O GBIUHAYJGWVNLN-UHFFFAOYSA-N 0.000 description 1
- NZYNRRGJJVSSTJ-GUBZILKMSA-N Val-Ser-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O NZYNRRGJJVSSTJ-GUBZILKMSA-N 0.000 description 1
- BZDGLJPROOOUOZ-XGEHTFHBSA-N Val-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](C(C)C)N)O BZDGLJPROOOUOZ-XGEHTFHBSA-N 0.000 description 1
- DOBHJKVVACOQTN-DZKIICNBSA-N Val-Tyr-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CC=C(O)C=C1 DOBHJKVVACOQTN-DZKIICNBSA-N 0.000 description 1
- JXWGBRRVTRAZQA-ULQDDVLXSA-N Val-Tyr-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)[C@H](C(C)C)N JXWGBRRVTRAZQA-ULQDDVLXSA-N 0.000 description 1
- 108020005202 Viral DNA Proteins 0.000 description 1
- 108020000999 Viral RNA Proteins 0.000 description 1
- 208000018839 Wilson disease Diseases 0.000 description 1
- 208000027418 Wounds and injury Diseases 0.000 description 1
- 206010048214 Xanthoma Diseases 0.000 description 1
- PNNCWTXUWKENPE-UHFFFAOYSA-N [N].NC(N)=O Chemical compound [N].NC(N)=O PNNCWTXUWKENPE-UHFFFAOYSA-N 0.000 description 1
- 239000002253 acid Substances 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 208000036981 active tuberculosis Diseases 0.000 description 1
- 230000001154 acute effect Effects 0.000 description 1
- 230000010398 acute inflammatory response Effects 0.000 description 1
- 230000007059 acute toxicity Effects 0.000 description 1
- 231100000403 acute toxicity Toxicity 0.000 description 1
- 108091005764 adaptor proteins Proteins 0.000 description 1
- 102000035181 adaptor proteins Human genes 0.000 description 1
- 238000011374 additional therapy Methods 0.000 description 1
- 230000002776 aggregation Effects 0.000 description 1
- 238000004220 aggregation Methods 0.000 description 1
- 238000011256 aggressive treatment Methods 0.000 description 1
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 1
- 108010044940 alanylglutamine Proteins 0.000 description 1
- 108010047495 alanylglycine Proteins 0.000 description 1
- 108010070944 alanylhistidine Proteins 0.000 description 1
- 206010001584 alcohol abuse Diseases 0.000 description 1
- 208000025746 alcohol use disease Diseases 0.000 description 1
- 102000013529 alpha-Fetoproteins Human genes 0.000 description 1
- 108010026331 alpha-Fetoproteins Proteins 0.000 description 1
- WYTGDNHDOZPMIW-RCBQFDQVSA-N alstonine Natural products C1=CC2=C3C=CC=CC3=NC2=C2N1C[C@H]1[C@H](C)OC=C(C(=O)OC)[C@H]1C2 WYTGDNHDOZPMIW-RCBQFDQVSA-N 0.000 description 1
- 229960005260 amiodarone Drugs 0.000 description 1
- 238000000540 analysis of variance Methods 0.000 description 1
- 230000003872 anastomosis Effects 0.000 description 1
- 238000005349 anion exchange Methods 0.000 description 1
- 238000005571 anion exchange chromatography Methods 0.000 description 1
- 230000001475 anti-trypsic effect Effects 0.000 description 1
- 239000000427 antigen Substances 0.000 description 1
- 108091007433 antigens Proteins 0.000 description 1
- 102000036639 antigens Human genes 0.000 description 1
- 239000003524 antilipemic agent Substances 0.000 description 1
- 108010080488 arginyl-arginyl-leucine Proteins 0.000 description 1
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 1
- 108010043240 arginyl-leucyl-glycine Proteins 0.000 description 1
- 108010068380 arginylarginine Proteins 0.000 description 1
- 108010060035 arginylproline Proteins 0.000 description 1
- 206010003119 arrhythmia Diseases 0.000 description 1
- 208000011775 arteriosclerosis disease Diseases 0.000 description 1
- 108010092854 aspartyllysine Proteins 0.000 description 1
- 229940090047 auto-injector Drugs 0.000 description 1
- 230000001580 bacterial effect Effects 0.000 description 1
- 210000000270 basal cell Anatomy 0.000 description 1
- 230000008901 benefit Effects 0.000 description 1
- 208000027119 bilirubin metabolic disease Diseases 0.000 description 1
- 238000004166 bioassay Methods 0.000 description 1
- 239000000090 biomarker Substances 0.000 description 1
- 238000010241 blood sampling Methods 0.000 description 1
- 210000004556 brain Anatomy 0.000 description 1
- 239000007853 buffer solution Substances 0.000 description 1
- 239000007975 buffered saline Substances 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- 239000001506 calcium phosphate Substances 0.000 description 1
- 229910000389 calcium phosphate Inorganic materials 0.000 description 1
- 235000011010 calcium phosphates Nutrition 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 201000011510 cancer Diseases 0.000 description 1
- 239000002775 capsule Substances 0.000 description 1
- 239000001569 carbon dioxide Substances 0.000 description 1
- 229910002092 carbon dioxide Inorganic materials 0.000 description 1
- 231100000504 carcinogenesis Toxicity 0.000 description 1
- 230000000747 cardiac effect Effects 0.000 description 1
- 210000001715 carotid artery Anatomy 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 239000013553 cell monolayer Substances 0.000 description 1
- 239000006285 cell suspension Substances 0.000 description 1
- 230000003822 cell turnover Effects 0.000 description 1
- 201000010881 cervical cancer Diseases 0.000 description 1
- 239000003638 chemical reducing agent Substances 0.000 description 1
- 238000011210 chromatographic step Methods 0.000 description 1
- 239000012539 chromatography resin Substances 0.000 description 1
- 208000020832 chronic kidney disease Diseases 0.000 description 1
- 208000022831 chronic renal failure syndrome Diseases 0.000 description 1
- 230000007665 chronic toxicity Effects 0.000 description 1
- 231100000160 chronic toxicity Toxicity 0.000 description 1
- 229960002376 chymotrypsin Drugs 0.000 description 1
- 230000007882 cirrhosis Effects 0.000 description 1
- 208000019425 cirrhosis of liver Diseases 0.000 description 1
- 230000007012 clinical effect Effects 0.000 description 1
- 231100000313 clinical toxicology Toxicity 0.000 description 1
- 238000009535 clinical urine test Methods 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 230000015271 coagulation Effects 0.000 description 1
- 238000005345 coagulation Methods 0.000 description 1
- 238000004440 column chromatography Methods 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 229920001577 copolymer Polymers 0.000 description 1
- 210000004351 coronary vessel Anatomy 0.000 description 1
- 230000002596 correlated effect Effects 0.000 description 1
- 229960001334 corticosteroids Drugs 0.000 description 1
- 230000009089 cytolysis Effects 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 230000001086 cytosolic effect Effects 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- 230000009849 deactivation Effects 0.000 description 1
- 230000034994 death Effects 0.000 description 1
- 230000007850 degeneration Effects 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- 238000009795 derivation Methods 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000003795 desorption Methods 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 238000000502 dialysis Methods 0.000 description 1
- 230000035487 diastolic blood pressure Effects 0.000 description 1
- 125000000664 diazo group Chemical group [N-]=[N+]=[*] 0.000 description 1
- 235000014113 dietary fatty acids Nutrition 0.000 description 1
- 238000007847 digital PCR Methods 0.000 description 1
- 239000013024 dilution buffer Substances 0.000 description 1
- 230000003292 diminished effect Effects 0.000 description 1
- 108010054813 diprotin B Proteins 0.000 description 1
- 208000035475 disorder Diseases 0.000 description 1
- 238000011304 droplet digital PCR Methods 0.000 description 1
- 238000002651 drug therapy Methods 0.000 description 1
- 230000002526 effect on cardiovascular system Effects 0.000 description 1
- 230000005670 electromagnetic radiation Effects 0.000 description 1
- 238000001962 electrophoresis Methods 0.000 description 1
- 230000008030 elimination Effects 0.000 description 1
- 238000003379 elimination reaction Methods 0.000 description 1
- 239000012149 elution buffer Substances 0.000 description 1
- 239000002158 endotoxin Substances 0.000 description 1
- 238000003366 endpoint assay Methods 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 210000003743 erythrocyte Anatomy 0.000 description 1
- 210000003527 eukaryotic cell Anatomy 0.000 description 1
- 229960002027 evolocumab Drugs 0.000 description 1
- 210000000744 eyelid Anatomy 0.000 description 1
- 229930195729 fatty acid Natural products 0.000 description 1
- 239000000194 fatty acid Substances 0.000 description 1
- 238000000855 fermentation Methods 0.000 description 1
- 230000004151 fermentation Effects 0.000 description 1
- 238000000799 fluorescence microscopy Methods 0.000 description 1
- 239000007850 fluorescent dye Substances 0.000 description 1
- 239000012634 fragment Substances 0.000 description 1
- 238000002290 gas chromatography-mass spectrometry Methods 0.000 description 1
- 238000012224 gene deletion Methods 0.000 description 1
- 102000018146 globin Human genes 0.000 description 1
- 108060003196 globin Proteins 0.000 description 1
- JYPCXBJRLBHWME-UHFFFAOYSA-N glycyl-L-prolyl-L-arginine Natural products NCC(=O)N1CCCC1C(=O)NC(CCCN=C(N)N)C(O)=O JYPCXBJRLBHWME-UHFFFAOYSA-N 0.000 description 1
- 108010067216 glycyl-glycyl-glycine Proteins 0.000 description 1
- 108010025801 glycyl-prolyl-arginine Proteins 0.000 description 1
- 108010045126 glycyl-tyrosyl-glycine Proteins 0.000 description 1
- 108010059898 glycyl-tyrosyl-lysine Proteins 0.000 description 1
- 108010020688 glycylhistidine Proteins 0.000 description 1
- 108010015792 glycyllysine Proteins 0.000 description 1
- 108010081551 glycylphenylalanine Proteins 0.000 description 1
- 210000002149 gonad Anatomy 0.000 description 1
- 239000011544 gradient gel Substances 0.000 description 1
- 238000005534 hematocrit Methods 0.000 description 1
- 229960002897 heparin Drugs 0.000 description 1
- 229920000669 heparin Polymers 0.000 description 1
- 231100000234 hepatic damage Toxicity 0.000 description 1
- 231100000334 hepatotoxic Toxicity 0.000 description 1
- 230000003082 hepatotoxic effect Effects 0.000 description 1
- 108010036413 histidylglycine Proteins 0.000 description 1
- 239000012510 hollow fiber Substances 0.000 description 1
- 102000048799 human SERPINA7 Human genes 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 229940072106 hydroxystearate Drugs 0.000 description 1
- 208000036796 hyperbilirubinemia Diseases 0.000 description 1
- 210000003090 iliac artery Anatomy 0.000 description 1
- 238000005286 illumination Methods 0.000 description 1
- 238000003384 imaging method Methods 0.000 description 1
- 230000002163 immunogen Effects 0.000 description 1
- 230000001771 impaired effect Effects 0.000 description 1
- 230000008676 import Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000011065 in-situ storage Methods 0.000 description 1
- 238000011534 incubation Methods 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 230000002757 inflammatory effect Effects 0.000 description 1
- 208000014674 injury Diseases 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 201000004332 intermediate coronary syndrome Diseases 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- NBQNWMBBSKPBAY-UHFFFAOYSA-N iodixanol Chemical compound IC=1C(C(=O)NCC(O)CO)=C(I)C(C(=O)NCC(O)CO)=C(I)C=1N(C(=O)C)CC(O)CN(C(C)=O)C1=C(I)C(C(=O)NCC(O)CO)=C(I)C(C(=O)NCC(O)CO)=C1I NBQNWMBBSKPBAY-UHFFFAOYSA-N 0.000 description 1
- 229960004359 iodixanol Drugs 0.000 description 1
- 108010078274 isoleucylvaline Proteins 0.000 description 1
- 229960003350 isoniazid Drugs 0.000 description 1
- QRXWMOHMRWLFEY-UHFFFAOYSA-N isoniazide Chemical compound NNC(=O)C1=CC=NC=C1 QRXWMOHMRWLFEY-UHFFFAOYSA-N 0.000 description 1
- 150000002576 ketones Chemical class 0.000 description 1
- 210000003292 kidney cell Anatomy 0.000 description 1
- 238000009533 lab test Methods 0.000 description 1
- 238000002372 labelling Methods 0.000 description 1
- 108010090333 leucyl-lysyl-proline Proteins 0.000 description 1
- 108010044056 leucyl-phenylalanine Proteins 0.000 description 1
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 1
- 239000003446 ligand Substances 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 108010022197 lipoprotein cholesterol Proteins 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 238000012317 liver biopsy Methods 0.000 description 1
- 201000007270 liver cancer Diseases 0.000 description 1
- 230000008818 liver damage Effects 0.000 description 1
- 208000019423 liver disease Diseases 0.000 description 1
- 208000014018 liver neoplasm Diseases 0.000 description 1
- 239000012160 loading buffer Substances 0.000 description 1
- 239000006166 lysate Substances 0.000 description 1
- 230000003211 malignant effect Effects 0.000 description 1
- 238000007726 management method Methods 0.000 description 1
- 239000012092 media component Substances 0.000 description 1
- 238000013160 medical therapy Methods 0.000 description 1
- 230000037323 metabolic rate Effects 0.000 description 1
- 238000001000 micrograph Methods 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 230000009456 molecular mechanism Effects 0.000 description 1
- 238000009126 molecular therapy Methods 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 210000003098 myoblast Anatomy 0.000 description 1
- 239000013642 negative control Substances 0.000 description 1
- 230000009826 neoplastic cell growth Effects 0.000 description 1
- 239000002547 new drug Substances 0.000 description 1
- 229920001220 nitrocellulos Polymers 0.000 description 1
- 208000008338 non-alcoholic fatty liver disease Diseases 0.000 description 1
- 206010053219 non-alcoholic steatohepatitis Diseases 0.000 description 1
- 230000037434 nonsense mutation Effects 0.000 description 1
- 238000010606 normalization Methods 0.000 description 1
- 238000001543 one-way ANOVA Methods 0.000 description 1
- 210000004789 organ system Anatomy 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 244000052769 pathogen Species 0.000 description 1
- 230000002085 persistent effect Effects 0.000 description 1
- 238000011458 pharmacological treatment Methods 0.000 description 1
- 108010070409 phenylalanyl-glycyl-glycine Proteins 0.000 description 1
- 108010024654 phenylalanyl-prolyl-alanine Proteins 0.000 description 1
- 108010089198 phenylalanyl-prolyl-arginine Proteins 0.000 description 1
- 108010073101 phenylalanylleucine Proteins 0.000 description 1
- 108010051242 phenylalanylserine Proteins 0.000 description 1
- 238000000053 physical method Methods 0.000 description 1
- 229940068196 placebo Drugs 0.000 description 1
- 239000000902 placebo Substances 0.000 description 1
- 230000036470 plasma concentration Effects 0.000 description 1
- 238000013492 plasmid preparation Methods 0.000 description 1
- 239000004033 plastic Substances 0.000 description 1
- 229920003023 plastic Polymers 0.000 description 1
- 229920001223 polyethylene glycol Polymers 0.000 description 1
- 229920001184 polypeptide Polymers 0.000 description 1
- 229920000136 polysorbate Polymers 0.000 description 1
- 210000003240 portal vein Anatomy 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- 230000004481 post-translational protein modification Effects 0.000 description 1
- 229910052700 potassium Inorganic materials 0.000 description 1
- 239000011591 potassium Substances 0.000 description 1
- 230000003389 potentiating effect Effects 0.000 description 1
- 229940096112 prednisol Drugs 0.000 description 1
- 230000002028 premature Effects 0.000 description 1
- 201000000742 primary sclerosing cholangitis Diseases 0.000 description 1
- 229960003912 probucol Drugs 0.000 description 1
- FYPMFJGVHOHGLL-UHFFFAOYSA-N probucol Chemical compound C=1C(C(C)(C)C)=C(O)C(C(C)(C)C)=CC=1SC(C)(C)SC1=CC(C(C)(C)C)=C(O)C(C(C)(C)C)=C1 FYPMFJGVHOHGLL-UHFFFAOYSA-N 0.000 description 1
- 230000002062 proliferating effect Effects 0.000 description 1
- 230000002035 prolonged effect Effects 0.000 description 1
- 108010020755 prolyl-glycyl-glycine Proteins 0.000 description 1
- 108700042769 prolyl-leucyl-glycine Proteins 0.000 description 1
- 108010031719 prolyl-serine Proteins 0.000 description 1
- 108010029020 prolylglycine Proteins 0.000 description 1
- 108010090894 prolylleucine Proteins 0.000 description 1
- 230000000644 propagated effect Effects 0.000 description 1
- 238000010926 purge Methods 0.000 description 1
- 239000000700 radioactive tracer Substances 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000008929 regeneration Effects 0.000 description 1
- 238000011069 regeneration method Methods 0.000 description 1
- 230000003362 replicative effect Effects 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 230000000250 revascularization Effects 0.000 description 1
- 238000003757 reverse transcription PCR Methods 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 208000010157 sclerosing cholangitis Diseases 0.000 description 1
- 238000004062 sedimentation Methods 0.000 description 1
- 230000035945 sensitivity Effects 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 238000002864 sequence alignment Methods 0.000 description 1
- 238000013207 serial dilution Methods 0.000 description 1
- 238000010008 shearing Methods 0.000 description 1
- 229910052708 sodium Inorganic materials 0.000 description 1
- 239000011734 sodium Substances 0.000 description 1
- 238000013112 stability test Methods 0.000 description 1
- 239000012609 strong anion exchange resin Substances 0.000 description 1
- 238000010254 subcutaneous injection Methods 0.000 description 1
- 239000007929 subcutaneous injection Substances 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 239000013589 supplement Substances 0.000 description 1
- 230000004083 survival effect Effects 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 230000035488 systolic blood pressure Effects 0.000 description 1
- 229960001603 tamoxifen Drugs 0.000 description 1
- 210000002435 tendon Anatomy 0.000 description 1
- 229960002180 tetracycline Drugs 0.000 description 1
- 229930101283 tetracycline Natural products 0.000 description 1
- 235000019364 tetracycline Nutrition 0.000 description 1
- 150000003522 tetracyclines Chemical class 0.000 description 1
- 231100000048 toxicity data Toxicity 0.000 description 1
- 230000002110 toxicologic effect Effects 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 230000005026 transcription initiation Effects 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 239000012096 transfection reagent Substances 0.000 description 1
- 230000009261 transgenic effect Effects 0.000 description 1
- 201000010875 transient cerebral ischemia Diseases 0.000 description 1
- 229920000428 triblock copolymer Polymers 0.000 description 1
- QORWJWZARLRLPR-UHFFFAOYSA-H tricalcium bis(phosphate) Chemical compound [Ca+2].[Ca+2].[Ca+2].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O QORWJWZARLRLPR-UHFFFAOYSA-H 0.000 description 1
- PIEPQKCYPFFYMG-UHFFFAOYSA-N tris acetate Chemical compound CC(O)=O.OCC(N)(CO)CO PIEPQKCYPFFYMG-UHFFFAOYSA-N 0.000 description 1
- 230000010415 tropism Effects 0.000 description 1
- 108010029384 tryptophyl-histidine Proteins 0.000 description 1
- 108010015666 tryptophyl-leucyl-glutamic acid Proteins 0.000 description 1
- 108010038745 tryptophylglycine Proteins 0.000 description 1
- 201000008827 tuberculosis Diseases 0.000 description 1
- 210000004881 tumor cell Anatomy 0.000 description 1
- 230000005740 tumor formation Effects 0.000 description 1
- 108010003137 tyrosyltyrosine Proteins 0.000 description 1
- 238000000108 ultra-filtration Methods 0.000 description 1
- 238000001946 ultra-performance liquid chromatography-mass spectrometry Methods 0.000 description 1
- 241001529453 unidentified herpesvirus Species 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
- 210000002700 urine Anatomy 0.000 description 1
- 108010015385 valyl-prolyl-proline Proteins 0.000 description 1
- 239000011800 void material Substances 0.000 description 1
- 238000005406 washing Methods 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
- 150000003952 β-lactams Chemical class 0.000 description 1
Images


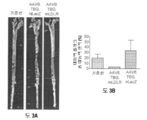



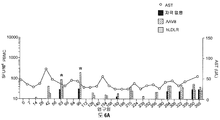




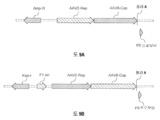



Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
- A61K48/005—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the 'active' part of the composition delivered, i.e. the nucleic acid delivered
- A61K48/0058—Nucleic acids adapted for tissue specific expression, e.g. having tissue specific promoters as part of a contruct
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/06—Antihyperlipidemics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K35/00—Medicinal preparations containing materials or reaction products thereof with undetermined constitution
- A61K35/66—Microorganisms or materials therefrom
- A61K35/76—Viruses; Subviral particles; Bacteriophages
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K35/00—Medicinal preparations containing materials or reaction products thereof with undetermined constitution
- A61K35/66—Microorganisms or materials therefrom
- A61K35/76—Viruses; Subviral particles; Bacteriophages
- A61K35/761—Adenovirus
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/177—Receptors; Cell surface antigens; Cell surface determinants
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K45/00—Medicinal preparations containing active ingredients not provided for in groups A61K31/00 - A61K41/00
- A61K45/06—Mixtures of active ingredients without chemical characterisation, e.g. antiphlogistics and cardiaca
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/02—Inorganic compounds
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/30—Macromolecular organic or inorganic compounds, e.g. inorganic polyphosphates
- A61K47/34—Macromolecular compounds obtained otherwise than by reactions only involving carbon-to-carbon unsaturated bonds, e.g. polyesters, polyamino acids, polysiloxanes, polyphosphazines, copolymers of polyalkylene glycol or poloxamers
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
- A61K48/0075—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy characterised by an aspect of the delivery route, e.g. oral, subcutaneous
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K9/00—Medicinal preparations characterised by special physical form
- A61K9/0012—Galenical forms characterised by the site of application
- A61K9/0019—Injectable compositions; Intramuscular, intravenous, arterial, subcutaneous administration; Compositions to be administered through the skin in an invasive manner
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K9/00—Medicinal preparations characterised by special physical form
- A61K9/10—Dispersions; Emulsions
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/86—Viral vectors
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2217/00—Genetically modified animals
- A01K2217/07—Animals genetically altered by homologous recombination
- A01K2217/075—Animals genetically altered by homologous recombination inducing loss of function, i.e. knock out
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2227/00—Animals characterised by species
- A01K2227/10—Mammal
- A01K2227/105—Murine
-
- A—HUMAN NECESSITIES
- A01—AGRICULTURE; FORESTRY; ANIMAL HUSBANDRY; HUNTING; TRAPPING; FISHING
- A01K—ANIMAL HUSBANDRY; AVICULTURE; APICULTURE; PISCICULTURE; FISHING; REARING OR BREEDING ANIMALS, NOT OTHERWISE PROVIDED FOR; NEW BREEDS OF ANIMALS
- A01K2267/00—Animals characterised by purpose
- A01K2267/03—Animal model, e.g. for test or diseases
- A01K2267/035—Animal model for multifactorial diseases
- A01K2267/0362—Animal model for lipid/glucose metabolism, e.g. obesity, type-2 diabetes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2300/00—Mixtures or combinations of active ingredients, wherein at least one active ingredient is fully defined in groups A61K31/00 - A61K41/00
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2750/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssDNA viruses
- C12N2750/00011—Details
- C12N2750/14011—Parvoviridae
- C12N2750/14111—Dependovirus, e.g. adenoassociated viruses
- C12N2750/14141—Use of virus, viral particle or viral elements as a vector
- C12N2750/14143—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2750/00—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA ssDNA viruses
- C12N2750/00011—Details
- C12N2750/14011—Parvoviridae
- C12N2750/14111—Dependovirus, e.g. adenoassociated viruses
- C12N2750/14151—Methods of production or purification of viral material
- C12N2750/14152—Methods of production or purification of viral material relating to complementing cells and packaging systems for producing virus or viral particles
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2830/00—Vector systems having a special element relevant for transcription
- C12N2830/008—Vector systems having a special element relevant for transcription cell type or tissue specific enhancer/promoter combination
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Organic Chemistry (AREA)
- Pharmacology & Pharmacy (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Epidemiology (AREA)
- Zoology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Molecular Biology (AREA)
- Biotechnology (AREA)
- Biochemistry (AREA)
- Biomedical Technology (AREA)
- Virology (AREA)
- Biophysics (AREA)
- Wood Science & Technology (AREA)
- General Engineering & Computer Science (AREA)
- Microbiology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Immunology (AREA)
- Cell Biology (AREA)
- Gastroenterology & Hepatology (AREA)
- Diabetes (AREA)
- Hematology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Toxicology (AREA)
- Obesity (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Dermatology (AREA)
- Mycology (AREA)
- Inorganic Chemistry (AREA)
Abstract
가족성 고콜레스테롤혈증을 가진 인간 환자에서 성분채집술의 빈도를 감소시키는 데 유용한 처방이 기술된다. 방법은 인간 대상체에게 복제 결핍 재조합 아데노-관련 바이러스 (rAAV)의 현탁액을 말초 정맥을 통한 주입에 의해 투여하는 단계를 포함한다.
Description
1. 서론
본 발명은 가족성 고콜레스테롤혈증 (FH), 특히, 동형접합성 FH (HoFH)를 치료하기 위한 유전자 요법에 관한 것이다.
전자 형태로 제출된 자료의 참조에 의한 통합
출원인은 전자 형태로 별첨하여 제출된 서열 목록 자료를 참조로 포함한다. 이 파일의 제목은 "16-7717C1PCT_ST25.txt"이다.
2. 발명의 배경
가족성 고콜레스테롤혈증 (FH)은 LDL 수용체 (LDLR) 기능에 영향을 주는 유전자의 돌연변이에 의해 유발된, 생명을 위협하는 장애이다 (Goldstein et al. Familial Hypercholesterinemia, in The Metabolic and Molecular Bases of Inherited Disease, C.R. Scriver, et al., Editors. 2001, McGraw-Hill Information Services Company: New York. p. 2863-2913 (2001)). 분자적으로 확인된 FH를 가진 환자들의 >90%가 LDLR을 암호화하는 유전자 (LDLR, MIM 606945)에 돌연변이를 가진 것으로 추정된다. 환자들의 나머지는 3개의 추가의 유전자: 아포리포단백질 (apo) B를 암호화하는 APOB (MIM 107730), 전구단백질 전환효소 서브틸리신/켁신 타입 9 (PCSK9)를 암호화하는 PCSK9 (MIM 607786) 및 LDLR 어댑터 단백질 1을 암호화하는 LDLRAP1 (MIM 695747)에 돌연변이를 가진다. 후자는 열성 유전자와 관련된 유일한 유전자 돌연변이이다. 동형접합은 보통 동일한 유전자의 2개의 대립유전자에서의 돌연변이의 존재에 의해 부여되지만; 이중 이형접합 (2개의 이형접합성 돌연변이, 두 상이한 유전자에서 각각)을 가진 환자들의 사례가 보고된 바 있다. 이형접합성 FH에 대해 500명 중 1명 내지 200명 중 1명의 유병률을 기반으로 (Nordestgaard et al. Eur Heart J, 2013. 34(45): p. 3478-90a (2013), Sjouke et al. Eur Heart J, (2014)), 전세계적으로 7,000명 내지 43,000명이 동형접합성 FH (HoFH)를 가진 것으로 추정된다.
돌연변이 LDLR 대립유전자의 특성 확인은 결실, 삽입, 미스센스 돌연변이 및 넌센스 돌연변이를 포함하여 다양한 돌연변이를 나타냈다 (Goldstein et al. 2001). 1700건 이상의 LDLR 돌연변이가 보고되었다. 이런 유전자형 이질성은 4개의 일반적인 그룹으로 분류되는 수용체들의 생화학적 기능의 가변적인 결과를 유발한다. 부류 1 돌연변이는 검출할 수 없는 단백질과 관련되고 자주 유전자 결실에 의해 유발된다. 부류 2 돌연변이는 단백질의 세포내 처리에서 비정상을 유발한다. 부류 3 돌연변이는 리간드 LDL에 대한 결합에 특이적으로 영향을 미치고, 부류 4 돌연변이는 코팅된 피트(pit)에서 클러스터를 형성하지 않는 수용체 단백질을 암호화한다. 환자 배양된 섬유모세포를 사용하여 평가된 잔류하는 LDLR 활성을 기반으로, 돌연변이들은 또한 수용체 음성으로서 (LDLR의 <2% 잔류 활성) 또는 수용체-결핍으로서 (2 내지 25%의 잔류 활성) 분류된다. 수용체-결핍인 환자들은, 평균적으로, 더 낮은 LDL-C 수준 및 더 적은 악성의 심혈관 과정을 가진다.
손상된 LDL 수용체 기능의 결과로서, HoFH를 가진 환자들에서 미처리된 총 혈장 콜레스테롤 수준은 전형적으로 500 mg/dl보다 크며, 미성숙하고 공격적인 아테롬성 동맥경화증을 초래하여 자주 20세 이전에 심혈관 질환 (CVD) 및 30세 이전에 사망을 초래한다 (Cuchel et al. Eur Heart J, 2014. 35(32): p. 2146-2157 (2014), Goldstein et al. 2001). 그러므로 이 환자들에 대한 공격적 치료의 조기 시작은 필수적이다 (Kolansky et al. 2008). 활용할 수 있는 선택권은 제한된다. 스타틴이 약물학적 처치를 위한 제1선인 것으로 여겨진다. 최대 용량에서도, 대부분의 환자에서 LDL-C 혈장 수준의 단지 10 내지 25%의 감소가 관찰된다 (Marais et al. Atherosclerosis, 2008. 197(1): p. 400-6 (2008); Raal et al. Atherosclerosis, 2000. 150(2): p. 421-8 (2000)). 콜레스테롤 흡수 억제제인 에제티미브(ezetimibe)의 스타틴 요법에의 첨가는 LDL-C 수준의 추가의 10 내지 20%의 감소를 초래할 수 있다 (Gagne et al. Circulation, 2002. 105 (21): p. 2469-2475 (2002)). 담즙산 격리제, 나이아신, 피브레이트(fibrate) 및 프로부콜을 포함하여, 다른 콜레스테롤 저하 약물의 사용은 스타틴-전 시대에 성공적으로 사용되어 왔고 HoFH에서 추가의 LDL-C 감소를 이루는 것으로 여겨질 수 있다; 그러나, 그것들의 사용은 내성 및 약물 이용성에 의해 제한된다. 이 접근법은 CVD 및 전 원인 사망률을 감소시키는 것으로 밝혀졌다 (Raal et al. Circulation, 2011. 124(20): p. 2202-7). 공격적인 다중-약물 요법 접근법의 실행에도 불구하고, HoFH 환자의 LDL-C 수준은 상승된 채로 남아 있고 그것들의 평균 기대 수명은 대략 32년으로 유지된다 (Raal et al. 2011). 여러 비-약물학적 선택권이 또한 수년에 걸쳐 테스트되었다. 수술적 개입, 예컨대 문맥 대 정맥 문합술 (Bilheimer Arteriosclerosis, 1989. 9(1 Suppl): p. I158-I163 (1989); Forman et al. Atherosclerosis, 1982. 41(2-3): p. 349-361 (1982)) 및 회장 우회술 (Deckelbaum et al. N. Engl. J. Med. 1977;296:465-470 1977. 296(9): p. 465-470 (1977))은 단지 부분적이고 일시적인 LDL-C 저하만을 초래하였고 현재 실행할 수 없는 접근법으로 간주된다. 동소성(orthotopic) 간 이식은 HoFH 환자에서 LDL-C 수준을 실질적으로 감소시켰지만 (Ibrahim et al. J Cardiovasc Transl Res, 2012. 5(3): p. 351-8 (2012); Kucukkartallar et al. 2 Pediatr Transplant, 2011. 15(3): p. 281-4 (2011)), 이식-후 수술 합병증 및 사망률의 고위험, 기증체의 부족, 및 면역억제 요법으로의 생명-연장 치료에 대한 요구를 포함하여, 단점 및 위험이 이 접근법의 사용을 제한한다 (Malatack Pediatr Transplant, 2011. 15(2): p. 123-5 (2011); Starzl et al. Lancet, 1984. 1(8391): p. 1382-1383 (1984)). HoFH에서 현재의 치료 기준은 50% 이상 LDL-C를 일시적으로 감소시킬 수 있는 LDL-C의 혈장을 퍼징하는 물리적 방법인 리포단백질 성분채집술(apheresis)을 포함한다 (Thompson Atherosclerosis, 2003. 167(1): p. 1-13 (2003); Vella et al. Mayo Clin Proc, 2001. 76(10): p. 1039-46 (2001)). 치료 세션 후 혈장에서의 LDL-C의 신속한 재-축적 (Eder and Rader Today's Therapeutic Trends, 1996. 14: p. 165-179 (1996))은 매주 또는 격주로 성분채집술을 필요로 한다. 비록 이 과정이 아테롬성 동맥경화증의 개시를 지연시킬 수 있지만 (Thompson et al. Lancet, 1995. 345: p. 811-816; Vella et al. Mayo Clin Proc, 2001. 76(10): p. 1039-46 (2001)), 그것은 힘들고, 값비싸며, 쉽게 이용할 수 없다. 나아가, 비록 그것이 일반적으로는 잘 견뎌지는 과정이더라도, 빈번한 반복 및 정맥내 접근을 필요로 한다는 사실은 많은 HoFH 환자들에게 부담이 될 수 있다.
최근에 3가지의 새로운 약물이 FDA에 의해 HoFH에 대해 특이적인 부가적 요법으로서 승인되었다. 그것들 중 2가지, 로미타피드(lomitapide) 및 미포메르센(mipomersen)이 아포B-함유 리포단백질의 조립 및 분비를 억제하지만, 그것들은 상이한 분자 메커니즘을 통해 그렇게 작용한다 (Cuchel et al. N Engl J Med, 2007. 356(2): p. 148-156 (2007);, Raal et al. Lancet, 2010. 375(9719): p. 998-1006 (2010)). 이 접근법은 로미타피드로 약 50% (Cuchel et al. 2013) 및 미포메르센으로 약 25% (Rall et al. 2010)의 평균에 도달하는 LDL-C의 상당한 감소를 초래한다. 그러나, 그것들의 사용은 내성 및 장기간 부착에 영향을 줄 수 있고 간 지방 축적을 포함하는 부작용의 배열과 관련되며, 그것의 장기간 사용 결과는 아직 완전하게 밝혀지지 않았다.
세 번째는 지질-저하 약물의 새로운 부류, 이형접합성 FH를 가진 환자에서 외관상 선호되는 안전성 프로파일로 LDL-C 수준을 저하시키는 데 효과적인 것으로 밝혀진 전구단백질 전환효소 서브틸리신/켁신 9 (PCSK9)에 대한 단클론성 항체의 부분이다 (Raal et al. Circulation, 2012. 126(20): p. 2408-17 (2012), Raal et al. The Lancet, 2015. 385(9965): p. 341-350 (2015); Stein et al. Circulation, 2013. 128(19): p. 2113-20 (2012)). PCSK9 억제제 에볼로쿠맙(evolocumab) 420 mg으로 12주 동안 4주마다 HoFH의 치료는 위약과 비교하여 LDL-C의 약 30%의 감소를 제공하는 것으로 나타났다 (Raal et al. 2015). 그러나, PCSK9 억제제의 효능은 잔류하는 LDLR 활성에 좌우되고, 잔류하는 LDLR 활성이 없는 환자들에서는 효과가 없다 (Raal et al. 2015, Stein et al. Circulation, 2013. 128(19): p. 2113-20 (2013)). 비록 PCSK9 억제제의 첨가가 FH에 대한 치료 기준이 될 수 있고 HoFH 환자의 하위 세트에서 저급 과콜레스테롤혈증으로의 추가적인 추가 감소를 제공할 수 있지만, PCSK9 억제제는 이 상태의 임상적 관리에 극적으로 영향을 미치지는 않을 것이다.
그러므로, HoFH에 대한 새로운 의학적 요법에 대한 충족되지 못한 의학적 요구가 남아 있다.
3. 발명의 요약
본 발명은 인간 저밀도 리포단백질 수용체 (hLDLR) 유전자를 HoFH로 진단된 환자들 (인간 대상체)의 간 세포에 전달하기 위해 복제 결핍 아데노-관련 바이러스 (AAV)의 사용에 관한 것이다. LDLR 유전자 ("rAAV.hLDLR")의 전달에 사용된 재조합 AAV 벡터 (rAAV)는 간에 대해 향성(tropism)을 가져야 하고 (예컨대 AAV8 캡시드를 가진 rAAV), hLDLR 도입유전자는 간-특이적 발현 제어 요소들에 의해 제어되어야 한다. 그러한 rAAV.hLDLR 벡터는 간에서 치료적 수준의 LDLR 발현을 이루기 위하여 20 내지 30분 기간에 걸쳐 정맥내 (IV) 주입에 의해 투여될 수 있다. 치료적으로 효과적인 용량의 rAAV.hLDLR의 범위는 2.5 x 1012 내지 7.5 x 1012 게놈 복사물 (GC)/환자의 체중 kg이다. 바람직한 구체예에서, rAAV 현탁액은 HoFH의 이중 녹아웃 LDLR-/-Apobec-/- 마우스 모델 (DKO 마우스)에 투여된 5 x 1011 GC/kg의 용량이 DKO 마우스에서 기준선 콜레스테롤 수준을 25% 내지 75% 감소시키도록 효능을 가진다.
치료 목표는 이 질환을 치료하고 현재의 지질-저하 치료에 대한 반응을 개선하기 위한 실현 가능한 접근법으로서 rAAV-기반 간-지향 유전자 요법을 통해 환자의 결함 LDLR을 기능적으로 대체하는 것이다. 발명은 부분적으로, 유효 용량의 안전한 전달을 허용하는 치료 조성물 및 방법의 개발; 및 인간 대상체에서 효과적인 투약에 대한 정제 제조 요건을 충족시키는 개선된 제조 방법을 기반으로 한다.
치료법의 효능은 치료 후에, 예컨대 투약 후에, 환자에서의 인간 LDLR 도입유전자 발현에 대한 대리 바이오마커로서 혈장 LDL-C 수준을 사용하여 평가될 수 있다. 예를 들어, 유전자 요법 치료 후 환자의 혈장 LDL-C의 감소는 기능적 LDLR의 성공적인 변환을 가리킬 것이다. 추가로, 또는 다르게는, 다른 파라미터들이 모니터링될 수 있는데, 한정하는 것은 아니지만, 벡터 투여 전 및 후, 또는 그것들의 조합 후에 총 콜레스테롤 (TC), 비-고밀도 리포단백질 콜레스테롤 (비-HDL-C), HDL-C, 공복 트라이글리세라이드 (TG), 초저밀도 리포단백질 콜레스테롤 (VLDL-C), 리포단백질(a) (Lp(a)), 아포리포단백질 B (apoB), ALC 아포리포단백질 A-I (apoA-I)의 변화를 기준선, 뿐만 아니라 LDL 동역학 연구 (대사 메커니즘 평가)와 비교하여 측정하는 것을 포함한다.
특정 구체예에서, 치료법의 효능은 환자에 의해 요구된 성분채집술의 빈도의 감소에 의해 측정될 수 있다. 특정 구체예에서, AAV8.hLDLR 치료 후에, 환자는 그 또는 그녀에게서 성분채집술에 대한 요구가 25%, 50%, 또는 그 이상으로 감소될 수 있다. 예를 들어, 주마다 AAV8.hLDLR 요법 전에 성분채집술을 받는 환자는 단지 격주의 또는 월 1회의 성분채집술을 필요로 할 수 있고; 다른 구체예에서, 성분채집술은 덜 자주 필요하거나, 또는 필요성이 제거될 수 있다.
특정 구체예에서, 치료법의 효능은 필요한 PCSK9 억제제의 용량의 감소에 의해, 또는 AAV8.hLDLR 치료 후 환자에서 그러한 치료법에 대한 필요성의 제거에 의해 측정될 수 있다. 특정 구체예에서, 치료법의 효능은 필요한 스타틴 또는 담즙산 격리제의 용량의 감소에 의해 측정된다.
특정 구체예에서, 면역억제제 병용 요법이 사용된다. 그러한 면역 억제제 병용 요법은, 예컨대 만약 AAV8에 대해 바람직하지 못하게 높은 중화 항체 수준이 검출된다면 AAV8.hLDLR의 전달 전에 시작될 수 있다. 특정 구체예에서, 병용 요법은 또한 예비적 조치로서 AAV8.hLDLR의 전달 전에 시작될 수 있다. 특정 구체예에서, 면역억제성 병용 요법은, 예컨대 만약 치료 후에 바람직하지 못한 면역 반응이 관찰된다면, AAV8.hLDLR의 전달 후에 시작된다.
그러한 병용 요법에 대한 면역억제제로는, 한정하는 것은 아니지만, 클루코코르티코이드, 스테로이드, 항대사물질, T-세포 억제제, 마크로라이드 (예컨대, 라파마이신 또는 라파로그), 및 알킬화제, 항대사물질, 세포독성 항생물질, 항체, 또는 이뮤노필린(immunophilin)에 작용하는 제제를 포함한 세포정지제(cytostatic agents)를 들 수 있다. 면역 억제제는 니트로겐 머스타드, 니트로소우레아, 백금 화합물, 메토트렉세이트, 아자티오프린, 메르캅토퓨린, 플루오로우라실, 닥티노마이신, 안트라사이클린, 미토마이신 C, 블레오마이신, 미트라마이신, IL-2 수용체- (CD25-) 또는 CD3-지시된 항체, 항-IL-2 항체, 시클로스포린, 타크로리무스, 시로리무스, IFN-β, IFN-γ, 오피오이드, 또는 TNF-α (종양 괴사 인자-알파) 결합제를 들 수 있다. 특정 구체예에서, 면역억제성 요법은 유전자 요법 투여 전 0, 1, 2, 7, 또는 그 이상의 날 전에, 또는 유전자 요법 투여 후 0, 1, 2, 3, 7, 또는 그 이상의 날 후에 시작될 수 있다. 그러한 치료법은 동일한 날에 둘 이상의 약물 (예컨대, 프레드넬리손, 미코페놀레이트 모페틸 (MMF) 및/또는 시로리무스 (즉, 라파마이신))의 공동 투여를 포함할 수 있다. 이들 약물 중 하나 이상이 유전자 요법 투여 후에, 동일한 용량으로 또는 조정된 용량으로 지속될 수 있다. 그러한 치료법은 약 1주 동안 (7일), 약 60일 동안, 또는 필요에 따라 그 이상 지속될 수 있다. 특정 구체예에서, 타크로리무스-유리 처방이 선택된다.
치료에 대한 후보인 환자들은 바람직하게는 LDLR 유전자에 두 개의 돌연변이를 가지고 있는 HoFH로 진단된 성인 (남성 또는 여성 ≥ 18세); 즉, HoFH와 일치하는 임상적 표시의 세팅에서 두 대립 유전자에서 분자적으로 규정된 LDLR 돌연변이를 가진 환자이고, 임상적 표시는 미처리 LDL-C 수준, 예컨대 >300 mg/dl의 LDL-C 수준, 처리된 LDL-C 수준, 예컨대 <300 mg/dl의 LDL-C 수준 및/또는 500 mg/dl보다 큰 총 혈장 콜레스테롤 수준 및 미성숙하고 공격적인 아테롬성 동맥경화증을 포함할 수 있다. 치료에 대한 후보는 스타틴, 에제티미브, 담즙산 격리제, PCSK9 억제제와 같은 지질-저하 약물, 및 LDL 및/또는 혈장 성분채집술로의 치료가 진행 중인 HoFH 환자를 포함한다.
치료 전에, HoFH 환자는 hLDLR 유전자를 전달하기 위해 사용된 AAV 혈청형에 대한 중화 항체 (NAb)에 대해 평가되어야 한다. 그러한 NAb는 변환 효율을 간섭하고 치료 효능을 감소시킬 수 있다. 기준선 혈청 NAb 역가 ≤ 1:10을 가지는 HoFH 환자들이 rAAV.hLDLR 유전자 요법 프로토콜로의 치료에 대한 양호한 후보들이다. 그러나, 다른 기준선 수준을 가진 환자도 선택될 수 있다. 혈청 NAb >1:5의 역가로 HoFH 환자의 치료는 조합 치료법, 예컨대 rAAV.hLDLR 벡터 전달로의 치료 전 및/또는 중에 면역억제제와의 일시적인 병용-치료를 필요로 할 수 있다. 추가로, 또는 다르게는, 환자들은 증가된 간 효소들에 대해 모니터링되고, 일시적인 면역억제제 요법으로 치료될 수 있다 (예컨대 아스파테이트 트란스아미나제 (AST) 또는 알라닌 트란스아미나제 (ALT)의 기준선 수준의 적어도 약 2배가 관찰되는 경우에). 그러한 병용 요법에 대한 면역억제제는, 한정하는 것은 아니지만, 스테로이드, 항대사물질, T-세포 억제제, 및 알킬화제를 포함한다.
발명은 인간 대상체의 AAV8.LDLR 치료에 대한 프로토콜을 기술하는 실시예 (섹션 6, 실시예 1); 질환의 동물 모델에서의 치료의 효능을 증명하는 전-임상 동물 데이터 (섹션 7, 실시예 2); 치료용 AAV.hLDLR 조성물의 제조 및 제제 (섹션 8.1 내지 8.3, 실시예 3); 및 AAV 벡터의 특성확인 방법 (섹션 8.4, 실시예 3)DP 의해 예시된다.
3.1. 정의
본원에서 사용되는 "AA8 캡시드"는 본원에 참조로 포함되고, SEQ ID NO:5로 재생된, GenBank 승인:YP_077180의 암호화된 아미노산 서열을 가지는 AAV8 캡시드를 나타낸다. 이 암호화된 서열로부터의 일부 변화는 본 발명에 포함되는데, 그것은 GenBank 승인:YP_077180; US 특허 7,282,199, 7,790,449; 8,319,480; 8,962,330; US 8,962,332의 참조된 아미노산 서열에 대해 약 99%의 동일성 (즉, 참조된 서열로부터 약 1% 미만의 변화)을 가진 서열을 포함할 수 있다. 다른 구체예에서, AAV8 캡시드는 WO2014/124282에 기술된 AAV8 변종의 VP1 서열 또는 US 2013/0059732 A1 또는 US7588772 B2에 기술된 dj 서열 (본원에 참조로 포함됨)을 가질 수 있다. 캡시드의 제조 방법, 그러므로 암호화 서열, 및 rAAV 바이러스 벡터의 제조 방법이 기술되어 있다. 예컨대 Gao, et al, Proc. Natl. Acad. Sci. U.S.A. 100 (10), 6081-6086 (2003), 미국 2013/0045186A1, 및 WO 2014/124282 참조.
본원에서 사용되는 용어 "NAb 역가"는 표적화된 에피토프 (예컨대 AAV)의 생리적 효과를 중화시키는 중화 항체 (예컨대 항-AAV NAb)가 얼마나 많이 생성되는 지를 측정하는 것을 나타낸다. 항-AAV NAb 역가는 예컨대 Calcedo, R., et al., Worldwide Epidemiology of Neutralizing Antibodies to Adeno-Associated Viruses. Journal of Infectious Diseases, 2009. 199(3): p. 381-390 (본원에 참조로 포함됨)에 기술된 대로 측정될 수 있다.
아미노산 서열의 맥락에서 용어 "퍼센트 (%) 동일성", "서열 동일성", "퍼센트 서열 동일성" 또는 "동일한 퍼센트"는 일치성을 위해 배열될 때 동일한 두 서열의 잔기들을 나타낸다. 퍼센트 동일성은 단백질, 폴리펩타이드, 약 32개의 아미노산, 약 330개의 아미노산 또는 그것들의 펩타이드 단편 또는 상응하는 핵산 서열 암호화 서열의 전체 길이에 걸친 아미노산 서열에 대해 쉽게 측정될 수 있다. 적합한 아미노산 단편은 길이가 적어도 약 8개의 아미노산일 수 있고, 최대 약 700 아미노산일 수 있다. 일반적으로, 두 상이한 서열 사이에서 "동일성", "상동성", 또는 "유사성"을 언급할 때, "동일성", "상동성", 또는 "유사성"은 "배열된" 서열과 관하여 측정된다. "배열된" 서열 또는 "배열"은 참조 서열과 비교하여 빠트린 또는 추가의 염기 또는 아미노산에 대한 교정을 자주 함유하는, 다중 핵산 서열 또는 단백질 (아미노산) 서열을 나타낸다. 배열은 다양한 대중적으로 또는 상업적으로 입수 가능한 다중 서열 배열 프로그램 중 어느 것을 사용하여 수행된다. 서열 배열 프로그램들은 아미노산 서열에 대해 활용 가능한데, 예컨대 "Clustal X", "MAP", "PIMA", "MSA", "BLOCKMAKER", "MEME" 및 "Match-Box" 프로그램들이 있다. 일반적으로, 이 프로그램들 중 어느 것이든지 디폴트 세팅에서 사용되지만, 기술분야의 숙련자들은 필요에 따라 이 세팅들을 변경시킬 수 있다. 다르게는, 기술분야의 숙련자는 적어도 참조된 알고리즘 및 프로그램에 의해 제공되는 것과 같은 동일성 또는 배열의 수준을 제공하는 다른 알고리즘 또는 컴퓨터 프로그램을 활용할 수 있다. 예컨대 J. D. Thomson et al, Nucl. Acids. Res., "A comprehensive comparison of multiple sequence alignments", 27(13):2682-2690 (1999) 참조.
본원에서 사용되는 용어 "작동 가능하게 연결된"은 관심의 유전자 및 관심의 유전자를 제어하기 위해 트랜스로 또는 좀 멀리에서 작용하는 발현 제어 서열과 연속적으로 있는 두 발현 제어 서열을 나타낸다.
"복제-결핍 바이러스" 또는 "바이러스 벡터"는 관심의 유전자를 함유하고 잇는 발현 카세트가 바이러스 캡시드 또는 엔벨로프로 포장되고, 바이러스 캡시드 또는 엔벨로프 내에 또한 포장된 임의의 바이러스 게놈 서열이 복제-결핍성인 합성 또는 인공 바이러스 입자를 나타낸다; 즉 그것들은 자손 비리온을 생성할 수는 없지만 표적 세포를 감염시키는 능력을 보유한다. 한 구체예에서, 바이러스 벡터의 게놈은 복제하는 데 필요한 효소들을 암호화하는 유전자들을 포함하지 않지만 (게놈은 "거트리스(gutless)"가 되도록 - 인공 게놈의 증폭 및 포장에 필요한 신호들이 양옆에 있는 관심의 도입유전자만을 함유하도록 엔지니어링될 수 있음), 이 유전자들은 제조 중에 공급될 수 있다. 그러므로, 복제 및 자손 비리온에 의한 감염이 복제에 필요한 바이러스 효소의 존재시를 제외하면 일어날 수 없기 때문에 유전자 요법에 사용하기에 안전한 것으로 보인다.
하나를 나타내는 용어들은 하나 이상을 나타낸다는 것이 주지되어야 한다. 그 자체로서, 하나를 나타내는 용어, "하나 이상" 및 "적어도 하나"는 본원에서 상호교환적으로 사용된다.
단어 "포함하다(comprise, comprises에 해당함)" 및 "포함하는"은 배타적으로보다는 포괄적으로 해석되어야 한다. 단어 "구성하다", "구성하는", 및 그것의 변용은 포괄적이기보다는 배타적으로 해석되어야 한다. 명세서에서 다양한 구체예들이 "포함하는"이란 말을 사용하여 표시되는 한펴, 다른 상황하에서, 관련된 구체예 또한 "으로 구성되는" 또는 "본질적으로 구성되는"이란 말을 사용하여 해석되고 기술되어야 한다.
본원에서 사용되는, 용어 "약'은 다르게 명시되지 않는 한, 주어진 참조로부터 10%의 가변성을 의미한다.
본 명세서에서 다르게 규정되지 않는 한, 본원에서 사용된 기술적이고 과학적인 용어들은 기술분야에서 숙련자에 의해 및 공개된 텍스트에 대한 참조에 의해 통상적으로 이해되는 것과 같은 의미를 가지며, 기술분야의 숙련자에게 본 출원에서 사용된 많은 용어들에 대한 일반적인 안내를 제공한다.
4. 도면의 간단한 설명
도 1A 내지 1H는 마카크 원숭이 간에서 EGFP 발현 수준에 대한 기존의 AAV8 NAb의 영향을 도시한다. 상이한 유형 및 연령의 마카크 원숭이들을 말초 정맥을 통해 3x1012 GC/kg의 AAV8.TBG.EGFP로 주사하고 7일 후에 희생시키고 간세포 형질도입에 대해 여러 방법으로 분석하였다. 도 1A 내지 1E는 AAV8에 대한 다양한 수준의 기존 중화 항체 (각각 <1:5, 1:5, 1:10 및 1:20)를 가진 동물로부터의 간의 대표적인 섹션을 나타내는 현미경사진들이다. 도 1F는 간세포의 퍼센트 형질도입을 기반으로 한 형질도입 효율의 정량적 형태적 분석을 도시한다. 도 1G는 상대적인 EGFP 강도를 기반으로 한 형질도입 효율의 정량적 형태적 분석을 도시한다. 도 1H는 ELISA에 의한 간 용해물에서의 EGFP 단백질의 정량을 도시한다. 성인 시노몰구스 원숭이 (n = 8, 검은색 원형), 성인 레서스 원숭이 (n = 8, 삼각형), 어린 레서스 원숭이 (n = 5, 사각형).
도 2는 DKO 마우스에서 mLDLR의 장기간 발현을 도시한다. DKO 마우스는 1011 GC/마우스 (5x1012 GC/kg)의 AAV8.TBG.mLDLR (n = 10) 또는 AAV8.TBG.nLacZ (n = 10)로 투약되었다. 혈청의 콜레스테롤 수준이 정기적으로 모니터링되었다. 두 그룹 사이의 통계학적으로 유의미한 차이가 초기에 7일에 나타났고 (p <0.001) 실험의 전체 기간을 통해 유지되었다. 마우스들을 벡터 투여 후 180일째에 희생시켰다.
도 3A 내지 3F는 AAV8.TBG.mLDLR 후에 DKO 마우스에서 아테롬성 동맥경화증의 퇴행을 도시한다. 도 3A는 En 페이스 Sudan IV로 염색한 3 패널 세트이다. 마우스 대동맥을 핀으로 고정하고, 중성 지질을 염색하는 Sudan IV로 염색한다. 벡터 투여 후 60일째 (고지방 식이요법으로 120일째)에 1011 GC/마우스의 AAV8.nLacZ (5x1012 GC/kg) (중간), 1011 GC/마우스의 AAV8.TBG.mLDLR (5x1012 GC/kg) (우측)로 처리된 동물로부터의 대표적인 대동맥, 또는 기준선 (고지방 식이요법으로 60일째)(좌측)이 도시된다. 도 3B는 대동맥의 전체 길이를 따라 오일 레드 O (Oil Red O)로 염색된 대동맥의 형태적 분석 정량된 퍼센트의 결과를 보여주는 막대 그래프이다. 도 3C 내지 3K는 오일 레드 O로 염색된 이 마우스들로부터의 대동맥 기부를 나타낸다. 도 3L은 측정된 기준선 (n = 10), AAV.TBG.nLacZ (n = 9) 및 AAV8.TBG.mLDLR (n = 10)의 총 대동맥 표면의 퍼센트 Sudan IV 염색을 보여주는 막대 그래프이다. 정량을 오일 레드 O 병변에 대해 수행하였다. 아테롬성 동맥경화 병변 면적 데이터에 대해 일원 분산분석을 수행하였다. Dunnett 테스트를 사용함으로써 실험 그룹을 기준선 그룹과 비교하였다. 반복-측정 ANOVA를 사용하여 유전자 전달 후 시간경과에 따른 마우스의 상이한 그룹 중에서 콜레스테롤 수준을 비교하였다. 모든 비교에 대한 통계학적 유의미성을 P,0.05로 배정하였다. 그래프는 평균 SD 값을 나타낸다. *p <0.05, **p <0.01, p <0.001.
p <0.001.
도 4는 테스트 또는 대조군 물품이 주입된 DKO 마우스의 콜레스테롤 수준을 도시한다. DKO 마우스는 7.5x1011 GC/kg, 7.5x1012 GC/kg 또는 6.0x1013 GC/kg의 AAV8.TBG.mLDLR 또는 6.0x1013 GC/kg의 AAV8.TBG.hLDLR 또는 비히클 대조표준 (100 μl PBS)으로 IV 주입되었다. 콜레스테롤 수준은 평균 ± SEM으로서 표시된다. 각 그룹은 동일한 부검 시점으로부터 PBS 대조표준에 비해 혈청 콜레스테롤의 통계학적으로 유의미한 감소를 증명하였다.
도 5A 및 5B는 테스트물 주입된 DKO 마우스에서의 콜레스테롤 수준을 도시한다. 도 5A는 0일, 7일 및 30일째에 측정된 달라지는 용량의 벡터로 처리된 마우스에서의 콜레스테롤 수준 (mg/mL)을 나타낸다. 값은 평균 ± SEM으로서 표시되었다. P<0.05.
도 6A 내지 6C는 벡터 주입된 레서스 원숭이에서의 말초 T 세포 반응을 도시한다. 표시된 데이터는 마카크 원숭이 19498 (도 6A), 090-0287 (도 6B) 및 090-0263 (도 6C)에 대한 T 세포 반응 및 AST 수준의 시간 경과를 나타낸다. 각 연구일에 대해, 106개의 PBMC당 반점-형성 유닛 (SFU)으로서 측정된, 자극 없음, AAV8 및 hLDLR에 대한 T 세포 반응을 각 도면에서 좌측으로부터 우측으로 도표로 나타냈다. 마카크 원숭이 19498 및 090-0287은 및/또는 hLDLR 도입유전자에 대해 양성 말초 T 세포 반응을 나타낸 반면, 090-0263은 그렇지 않았다. *는 유의미하게 바탕값보다 위에 있는 양성 캡시드 반응을 나타낸다.
도 7은 AAV8.TBG.hLDLR 벡터를 개략적으로 도시한다.
도 8A 및 8B는 AAV 시스 플라스미드 구성물을 도시한다. A) 간 특이적 TBG 프로모터 및 AAV2 ITR 요소들이 양옆에 있는 키메라 인트론을 함유한, 부모 시스 클로닝 플라스미드, pENN.AAV.TBG.PI의 선형 표시. B) 인간 LDLR cDNA가 인트론과 폴리 A 신호 사이에서 pENN.AAV.TBG.PI에 클로닝되어 있고 암피실린 내성 유전자가 카나마이신 내성 유전자에 의해 대체된 인간 LDLR 시스 플라스미드, pENN.AAV.TBG.PI.hLDLR.RBG.KanR의 선형 표시.
도 9A 및 9B는 AAV 트랜스 플라스미드를 도시한다. 도 9A는 암피실린 내성 유전자를 가진 AAV8 트랜스 포장 플라스미드, p5E18-VD2/8의 선형 표시이다. 도 9B는 카나마이신 내성 유전자를 가진 AAV8 트랜스 포장 플라스미드, pAAV2/8의 선형 표시이다.
도 10A 및 10B는 아데노바이러스 헬퍼 플라스미드를 도시한다. 도 10A는 부모 플라스미드, pBHG10으로부터, 중간체 pAd△F1 및 pAd△F5를 통해 ad-헬퍼 플라스미드, pAd△F6의 유도를 예시한다. 도 10B는 pAd△F6(Kan)을 생성하기 위해 pAd△F6의 암피실린 내성 유전자가 카나마이신 내성 유전자에 의해 대체된 것을 보여주는 선형 표시이다.
도 11A 및 11B는 AAV8.TBG.hLDLR 벡터 제조 과정을 보여주는 흐름도이다.
도 1A 내지 1H는 마카크 원숭이 간에서 EGFP 발현 수준에 대한 기존의 AAV8 NAb의 영향을 도시한다. 상이한 유형 및 연령의 마카크 원숭이들을 말초 정맥을 통해 3x1012 GC/kg의 AAV8.TBG.EGFP로 주사하고 7일 후에 희생시키고 간세포 형질도입에 대해 여러 방법으로 분석하였다. 도 1A 내지 1E는 AAV8에 대한 다양한 수준의 기존 중화 항체 (각각 <1:5, 1:5, 1:10 및 1:20)를 가진 동물로부터의 간의 대표적인 섹션을 나타내는 현미경사진들이다. 도 1F는 간세포의 퍼센트 형질도입을 기반으로 한 형질도입 효율의 정량적 형태적 분석을 도시한다. 도 1G는 상대적인 EGFP 강도를 기반으로 한 형질도입 효율의 정량적 형태적 분석을 도시한다. 도 1H는 ELISA에 의한 간 용해물에서의 EGFP 단백질의 정량을 도시한다. 성인 시노몰구스 원숭이 (n = 8, 검은색 원형), 성인 레서스 원숭이 (n = 8, 삼각형), 어린 레서스 원숭이 (n = 5, 사각형).
도 2는 DKO 마우스에서 mLDLR의 장기간 발현을 도시한다. DKO 마우스는 1011 GC/마우스 (5x1012 GC/kg)의 AAV8.TBG.mLDLR (n = 10) 또는 AAV8.TBG.nLacZ (n = 10)로 투약되었다. 혈청의 콜레스테롤 수준이 정기적으로 모니터링되었다. 두 그룹 사이의 통계학적으로 유의미한 차이가 초기에 7일에 나타났고 (p <0.001) 실험의 전체 기간을 통해 유지되었다. 마우스들을 벡터 투여 후 180일째에 희생시켰다.
도 3A 내지 3F는 AAV8.TBG.mLDLR 후에 DKO 마우스에서 아테롬성 동맥경화증의 퇴행을 도시한다. 도 3A는 En 페이스 Sudan IV로 염색한 3 패널 세트이다. 마우스 대동맥을 핀으로 고정하고, 중성 지질을 염색하는 Sudan IV로 염색한다. 벡터 투여 후 60일째 (고지방 식이요법으로 120일째)에 1011 GC/마우스의 AAV8.nLacZ (5x1012 GC/kg) (중간), 1011 GC/마우스의 AAV8.TBG.mLDLR (5x1012 GC/kg) (우측)로 처리된 동물로부터의 대표적인 대동맥, 또는 기준선 (고지방 식이요법으로 60일째)(좌측)이 도시된다. 도 3B는 대동맥의 전체 길이를 따라 오일 레드 O (Oil Red O)로 염색된 대동맥의 형태적 분석 정량된 퍼센트의 결과를 보여주는 막대 그래프이다. 도 3C 내지 3K는 오일 레드 O로 염색된 이 마우스들로부터의 대동맥 기부를 나타낸다. 도 3L은 측정된 기준선 (n = 10), AAV.TBG.nLacZ (n = 9) 및 AAV8.TBG.mLDLR (n = 10)의 총 대동맥 표면의 퍼센트 Sudan IV 염색을 보여주는 막대 그래프이다. 정량을 오일 레드 O 병변에 대해 수행하였다. 아테롬성 동맥경화 병변 면적 데이터에 대해 일원 분산분석을 수행하였다. Dunnett 테스트를 사용함으로써 실험 그룹을 기준선 그룹과 비교하였다. 반복-측정 ANOVA를 사용하여 유전자 전달 후 시간경과에 따른 마우스의 상이한 그룹 중에서 콜레스테롤 수준을 비교하였다. 모든 비교에 대한 통계학적 유의미성을 P,0.05로 배정하였다. 그래프는 평균 SD 값을 나타낸다. *p <0.05, **p <0.01,
도 4는 테스트 또는 대조군 물품이 주입된 DKO 마우스의 콜레스테롤 수준을 도시한다. DKO 마우스는 7.5x1011 GC/kg, 7.5x1012 GC/kg 또는 6.0x1013 GC/kg의 AAV8.TBG.mLDLR 또는 6.0x1013 GC/kg의 AAV8.TBG.hLDLR 또는 비히클 대조표준 (100 μl PBS)으로 IV 주입되었다. 콜레스테롤 수준은 평균 ± SEM으로서 표시된다. 각 그룹은 동일한 부검 시점으로부터 PBS 대조표준에 비해 혈청 콜레스테롤의 통계학적으로 유의미한 감소를 증명하였다.
도 5A 및 5B는 테스트물 주입된 DKO 마우스에서의 콜레스테롤 수준을 도시한다. 도 5A는 0일, 7일 및 30일째에 측정된 달라지는 용량의 벡터로 처리된 마우스에서의 콜레스테롤 수준 (mg/mL)을 나타낸다. 값은 평균 ± SEM으로서 표시되었다. P<0.05.
도 6A 내지 6C는 벡터 주입된 레서스 원숭이에서의 말초 T 세포 반응을 도시한다. 표시된 데이터는 마카크 원숭이 19498 (도 6A), 090-0287 (도 6B) 및 090-0263 (도 6C)에 대한 T 세포 반응 및 AST 수준의 시간 경과를 나타낸다. 각 연구일에 대해, 106개의 PBMC당 반점-형성 유닛 (SFU)으로서 측정된, 자극 없음, AAV8 및 hLDLR에 대한 T 세포 반응을 각 도면에서 좌측으로부터 우측으로 도표로 나타냈다. 마카크 원숭이 19498 및 090-0287은 및/또는 hLDLR 도입유전자에 대해 양성 말초 T 세포 반응을 나타낸 반면, 090-0263은 그렇지 않았다. *는 유의미하게 바탕값보다 위에 있는 양성 캡시드 반응을 나타낸다.
도 7은 AAV8.TBG.hLDLR 벡터를 개략적으로 도시한다.
도 8A 및 8B는 AAV 시스 플라스미드 구성물을 도시한다. A) 간 특이적 TBG 프로모터 및 AAV2 ITR 요소들이 양옆에 있는 키메라 인트론을 함유한, 부모 시스 클로닝 플라스미드, pENN.AAV.TBG.PI의 선형 표시. B) 인간 LDLR cDNA가 인트론과 폴리 A 신호 사이에서 pENN.AAV.TBG.PI에 클로닝되어 있고 암피실린 내성 유전자가 카나마이신 내성 유전자에 의해 대체된 인간 LDLR 시스 플라스미드, pENN.AAV.TBG.PI.hLDLR.RBG.KanR의 선형 표시.
도 9A 및 9B는 AAV 트랜스 플라스미드를 도시한다. 도 9A는 암피실린 내성 유전자를 가진 AAV8 트랜스 포장 플라스미드, p5E18-VD2/8의 선형 표시이다. 도 9B는 카나마이신 내성 유전자를 가진 AAV8 트랜스 포장 플라스미드, pAAV2/8의 선형 표시이다.
도 10A 및 10B는 아데노바이러스 헬퍼 플라스미드를 도시한다. 도 10A는 부모 플라스미드, pBHG10으로부터, 중간체 pAd△F1 및 pAd△F5를 통해 ad-헬퍼 플라스미드, pAd△F6의 유도를 예시한다. 도 10B는 pAd△F6(Kan)을 생성하기 위해 pAd△F6의 암피실린 내성 유전자가 카나마이신 내성 유전자에 의해 대체된 것을 보여주는 선형 표시이다.
도 11A 및 11B는 AAV8.TBG.hLDLR 벡터 제조 과정을 보여주는 흐름도이다.
5. 발명의 상세한 설명
복제 결핍 rAAV는 HoFH로 진단된 환자들 (인간 대상체)의 간 세포에 hLDLR 유전자를 전달하기 위해 사용된다. rAAV.hLDLR 벡터는 간에 대한 향성을 가져야 하고 (예컨대 AAV8 캡시드를 가진 rAAV) hLDLR 도입유전자는 간-특이적 발현 제어 요소들에 의해 제어되어야 한다.
그러한 rAAV.hLDLR 벡터는 간에서 치료 수준의 LDLR 발현을 이루기 위하여 약 20 내지 약 30분에 걸친 정맥내 (IV) 주입에 의해 투여될 수 있다. 다른 구체예에서, 더 짧은 (예컨대 10 내지 20분) 또는 더 긴 (예컨대 30분 내지 60분에 걸쳐, 그 중간 시간, 예컨대 약 45분, 또는 더 긴 시간에 걸쳐) 시간이 선택될 수 있다. rAAV.hLDLR의 치료적으로 효과적인 용량은 적어도 약 2.5 x 1012 내지 7.5 x 1012 게놈 복사물 (GC)/환자의 체중 kg의 범위이다. 바람직한 구체예에서, rAAV 현탁액은 HoFH의 이중 녹아웃 LDLR-/-Apobec-/- 마우스 모델 (DKO 마우스)에 투여된 5 x 1011 GC/kg의 용량이 DKO 마우스에서 기준선 콜레스테롤 수준을 25% 내지 75% 감소시키도록 효능을 가진다. 치료 효능은 저밀도 리포단백질 콜레스테롤 (LDL-C) 수준을 도입유전자 발현에 대한 대리물로서 사용하여 평가될 수 있다. 일차 효능 평가는 치료 후 1 내지 3개월째 (예컨대 12주)에 LDL-C 수준을 포함하고, 그런 다음 적어도 약 1년 (약 52주) 동안 효과가 지속된다. 장기간 안전성 및 도입유전자 발현의 지속성은 치료 후에 측정될 수 있다.
특정 구체예에서, 치료법의 효능은 환자에 의해 요구된 성분채집술의 빈도의 감소에 의해 측정될 수 있다. 특정 구체예에서, AAV8.hLDLR 치료 후에, 환자는 그 또는 그녀에게서 성분채집술에 대한 요구가 25%, 50%, 또는 그 이상으로 감소될 수 있다. 예를 들어, 주마다 AAV8.hLDLR 요법 전에 성분채집술을 받는 환자는 단지 격주의 또는 월 1회의 성분채집술을 필요로 할 수 있고; 다른 구체예에서, 성분채집술은 심지어 덜 자주 필요할 수 있거나 필요성이 제거될 수 있다.
특정 구체예에서, 치료법의 효능은 필요한 PCSK9 억제제의 용량의 감소에 의해, 또는 AAV8.hLDLR 치료 후 환자에서 그러한 치료법에 대한 필요성의 제거에 의해 측정될 수 있다. 특정 구체예에서, 치료법의 효능은 필요한 스타틴 또는 담즙산 격리제의 용량의 감소에 의해 측정된다.
치료에 대한 후보인 환자들은 바람직하게는 LDLR 유전자에 두 개의 돌연변이를 가지고 있는 HoFH로 진단된 성인 (남성 또는 여성 ≥ 18세); 즉, HoFH와 일치하는 임상적 표시의 세팅에서 두 대립 유전자에서 분자적으로 규정된 LDLR 돌연변이를 가진 환자이고, 임상적 표시는 미처리 LDL-C 수준, 예컨대 >300 mg/dl의 LDL-C 수준, 처리된 LDL-C 수준, 예컨대 <300 mg/dl의 LDL-C 수준 및/또는 500 mg/dl보다 큰 총 혈장 콜레스테롤 수준 및 미성숙하고 공격적인 아테롬성 동맥경화증을 포함할 수 있다. 치료에 대한 후보는 스타틴, 에제티미브, 담즙산 격리제, PCSK9 억제제와 같은 지질-저하 약물, 및 LDL 및/또는 혈장 성분채집술로의 치료가 진행 중인 HoFH 환자를 포함한다.
치료 전에, HoFH 환자는 hLDLR 유전자를 전달하기 위해 사용된 AAV 혈청형에 대한 중화 항체 (NAb)에 대해 평가되어야 한다. 그러한 NAb는 변환 효율을 간섭하고 치료 효능을 감소시킬 수 있다. 기준선 혈청 NAb 역가 ≤ 1:10을 가지는 HoFH 환자들이 rAAV.hLDLR 유전자 요법 프로토콜로의 치료에 대한 양호한 후보들이다. 혈청 NAb >1:5의 역가로 HoFH 환자의 치료는 조합 치료법, 예컨대 rAAV.hLDLR로의 치료 전/중에 면역억제제와의 일시적인 병용-치료를 필요로 할 수 있다. 추가로, 또는 다르게는, 환자들은 증가된 간 효소들에 대해 모니터링되고, 일시적인 면역억제제 요법으로 치료될 수 있다 (예컨대 아스파테이트 트란스아미나제 (AST) 또는 알라닌 트란스아미나제 (ALT)의 기준선 수준의 적어도 약 2배가 관찰되는 경우에).
특정 구체예에서, 면역억제제 병용 요법이 사용된다. 그러한 면역 억제제 병용 요법은, 예컨대 만약 AAV8에 대해 바람직하지 못하게 높은 중화 항체 수준이 검출된다면 AAV8.hLDLR의 전달 전에 시작될 수 있다. 특정 구체예에서, 병용 요법은 또한 예비적 조치로서 AAV8.hLDLR의 전달 전에 시작될 수 있다. 특정 구체예에서, 면역억제성 병용 요법은, 예컨대 만약 치료 후에 바람직하지 못한 면역 반응이 관찰된다면, AAV8.hLDLR의 전달 후에 시작된다.
그러한 병용 요법에 대한 면역억제제로는, 한정하는 것은 아니지만, 클루코코르티코이드, 스테로이드, 항대사물질, T-세포 억제제, 마크로라이드 (예컨대, 라파마이신 또는 라파로그), 및 알킬화제, 항대사물질, 세포독성 항생물질, 항체, 또는 이뮤노필린에 작용하는 제제를 포함한 세포정지제를 들 수 있다. 면역 억제제는 니트로겐 머스타드, 니트로소우레아, 백금 화합물, 메토트렉세이트, 아자티오프린, 메르캅토퓨린, 플루오로우라실, 닥티노마이신, 안트라사이클린, 미토마이신 C, 블레오마이신, 미트라마이신, IL-2 수용체- (CD25-) 또는 CD3-지시된 항체, 항-IL-2 항체, 시클로스포린, 타크로리무스, 시로리무스, IFN-β, IFN-γ, 오피오이드, 또는 TNF-α (종양 괴사 인자-알파) 결합제를 들 수 있다. 특정 구체예에서, 면역억제성 요법은 유전자 요법 투여 전 0, 1, 2, 7, 또는 그 이상의 날 전에, 또는 유전자 요법 투여 후 0, 1, 2, 3, 7, 또는 그 이상의 날 후에 시작될 수 있다. 그러한 치료법은 동일한 날에 둘 이상의 약물 (예컨대, 프레드넬리손, 미코페놀레이트 모페틸 (MMF) 및/또는 시로리무스 (즉, 라파마이신))의 공동 투여를 포함할 수 있다. 이들 약물 중 하나 이상이 유전자 요법 투여 후에, 동일한 용량으로 또는 조정된 용량으로 지속될 수 있다. 그러한 치료법은 약 1주 동안 (7일), 약 60일 동안, 또는 필요에 따라 그 이상 지속될 수 있다. 특정 구체예에서, 타크로리무스-유리 처방이 선택된다.
5.1. 유전자 요법 벡터
rAAV.hLDLR 벡터는 간에 대한 향성을 가져야 하고 (예컨대 AAV8 캡시드를 가진 rAAV) hLDLR 도입유전자는 간-특이적 발현 제어 요소들에 의해 제어되어야 한다. 벡터는 인간 대상체에 주입하기에 적합한 완충액/담체에 제제화된다. 완충액/담체는 rAAV가 주입 관에 점착되는 것을 방지하지만, 생체내에서 rAAV 결합 활성을 간섭하지 않는 성분을 포함해야 한다.
5.1.1. rAAV.hLDLR 벡터
간 향성을 가진 많은 rAAV 벡터들 중 임의의 것이 사용될 수 있다. rAAV의 캡시드를 위한 공급원으로서 선택될 수 있는 AAV의 예로는, 예컨대 rh10, AAVrh64R1, AAVrh64R2, rh8을 포함한다 [예컨대 미국 공개 특허 출원 번호 2007-0036760-A1; 미국 공개 특허 출원 번호 2009-0197338-A1; EP 1310571 참조]. 또한, WO 2003/042397 (AAV7 및 다른 유인원 AAV), 미국 특허 7790449 및 미국 특허 7282199 (AAV8), WO 2005/033321 및 US 7,906,111 (AAV9), WO 2006/110689 및 WO 2003/042397 (rh10), AAV3B; US 2010/0047174 (AAV-DJ) 참조.
hLDLR 도입유전자는, 한정하는 것은 아니지만, 첨부된 서열 목록에 제공되고, 본원에 참조로 포함된 SEQ ID NO:1, SEQ ID NO:2 및/또는 SEQ ID NO:4에 의해 제공된 서열들 중 하나 이상을 포함한다. SEQ ID NO:1을 참조하면, 이 서열은 약 염기쌍 188 내지 약 염기쌍 250에 위치한 신호 서열 및 약 염기쌍 251 내지 약 염기쌍 2770에 걸쳐 있는 변종 1에 대한 성숙 단백질을 포함한다. SEQ ID NO:1은 또한 엑손들을 확인하는데, 그것들 중 적어도 하나는 hLDLR의 공지된 대체 스플라이스 변종에 없다. 추가로, 또는 선택적으로, 하나 이상의 다른 hLDLR 이소형태를 암호화하는 서열이 선택될 수 있다. 예컨대 이소형태 2, 3, 4, 5 및 6, 그것들의 서열은 http://www.uniprot.org/uniprot/P01130으로부터 활용 가능하다. 예를 들어, 공통 변종은 엑손 4 (SEQ ID NO:1의 bp (255)..(377) 또는 엑손 12 (bp (1546)..(1773))가 없다. 선택적으로, 도입유전자는 이종성 신호 서열을 가진 성숙 단백질에 대한 암호화 서열을 포함할 수 있다. SEQ ID NO:2는 인간 LDLR 및 번역된 단백질 (SEQ ID NO:3)에 대한 cDNA를 제공한다. SEQ ID NO:4는 인간 LDLR에 대한 엔지니어링된 cDNA를 제공한다. 다르게는 또는 추가로, 웹-기반 또는 상업적으로 입수 가능한 컴퓨터 프로그램, 뿐만 아니라 서비스 기반 회사들이 RNA 및/또는 DNA 둘 다를 포함하여, 핵산 암호화 서열에 대한 아미노산 서열을 역번역하기 위해 사용될 수 있다. 예컨대 EMBOSS에 의한 backtranseq, ebi.ac.uk/Tools/st/; Gene Infinity (geneinfinity.org/sms-/sms_backtranslation.html); ExPasy (expasy.org/tools/) 참조.
하기 실시예에서 기술되는 특정 구체예에서, 유전자 요법 벡터는 rAAV8.TBG.hLDLR로 언급되는, 간-특이적 프로모터 (티록신-결합 글로불린, TBG)의 제어하에 hLDLR 도입유전자를 발현하는 AAV8 벡터이다 (도 6 참조). 외부 AAV 벡터 성분은 1:1:18의 비율의 3개의 AAV 바이러스 단백질, VP1, VP2 및 VP3의 60개의 복사물로 구성된 혈청형 8, T=1 20면체 캡시드이다. 캡시드는 단일-가닥의 DNA rAAV 벡터 게놈을 함유한다.
rAAV8.TBG.hLDLR 게놈은 2개의 AAV 역말단 반복부 (ITR)가 양옆에 있는 hLDLR 도입유전자를 함유한다. hLDLR 도입유전자는 인핸서, 프로모터, 인트론, hLDLR 암호화 서열 및 폴리아데닐화 (폴리A) 신호를 포함한다. ITR은 벡터 제조 중에 게놈의 복제 및 포장에 기여하는 유전자 요소이고 rAAV를 생성하기 위해 필요한 유일한 바이러스 cis 요소이다. hLDLR 암호화 서열의 발현은 간세포-특이적 TBG 프로모터로부터 구동된다. 알파 1 마이크로글로불린/비쿠닌(비쿠닌) 인핸서 요소의 2개의 복사물은 프로모터 활성을 자극하기 위하여 TBG 프로모터에 앞선다. 키메라 인트론은 발현을 추가로 향상시키기 위해 존재하고 토끼 베타 글로빈 폴리아데닐화 (폴리A) 신호는 hLDLR mRNA 전사물의 종결을 중재하기 위해 포함된다.
본원에서 기술된 예시적인 플라스미드 및 벡터는 간-특이적 프로모터 티록신 결합 글로불린 (TBG)을 사용한다. 다르게는, 다른 간-특이적 프로모터들이 사용될 수 있다 [예컨대 The Liver Specific 유전자 promoter Database, Cold Spring Harbor, http://rulai.schl.edu/LSPD, Alpha 1 anti-trypsin (A1AT); human albumin Miyatake et al., J. Virol., 71:5124 32 (1997), humAlb; and hepatitis B virus core promoter, Sandig et al., Gene Ther., 3:1002 9 (1996) 참조]. TTR 최소 인핸서/프로모터, 알파-항트립신 프로모터, LSP (845 nt)25 (인트론이 적은 scAAV를 필요로 함). 비록 덜 바람직하긴 하지만, 다른 프로모터, 예컨대 바이러스 프로모터, 구성성 프로모터, 조절 가능한 프로모터 [예컨대 WO 2011/126808 및 WO 2013/04943 참조] 또는 생리적 단서들에 대해 반응하는 프로모터가 사용될 수 있고 본원에 기술된 벡터에 활용될 수 있다.
프로모터에 더불어, 발현 카세트 및/또는 벡터는 다른 적절한 전사 개시, 종결, 인핸서 서열, 효과적인 RNA 처리 신호들, 예컨대 스플라이싱 및 폴리아데닐화 (폴리A) 신호; 세포질 mRNA를 안정화시키는 서열; 번열 효율을 향상시키는 서열 (즉 Kozac 공통 서열); 단백질 안정성을 향상시키는 서열; 및 필요할 때, 암호화된 생성물의 분비를 향상시키는 서열을 함유할 수 있다. 적합한 폴리A 서열의 예는, 예컨대 SV40, 소의 성장 호르몬 (bGH) 및 TK 폴리A를 포함한다. 적합한 인핸서의 예는, 다른 것들 중에서도, 예컨대 알파 페토단백질 인핸서, TTR 최소 프로모터/인핸서, LSP (TH-결합 글로불린 프로모터/알파1-마이크로글로불린/비쿠닌 인핸서)를 포함한다.
이 제어 서열들은 hLDLR 유전자 서열에 "작동 가능하게 연결된"다.
발현 카세트는 바이러스 벡터의 제조에 사용된 플라스미드로 엔지니어링될 수 있다. 발현 카세트를 AAV 바이러스 입자 안으로 포장하기 위해 필요한 최소 서열은 AAV 5' 및 3' ITR로, 그것들은 캡시드와 동일한 AAV 기원을 가지는 것이거나, 상이한 AAV 기원의 것 (AAV 위형(pseudotype))일 수 있다. 한 구체예에서, AAV2로부터의 ITR 서열, 또는 그것 (ITR)의 결실된 버전이 편리를 위해, 그리고 규제 승인을 가속화하기 위해 사용된다. 그러나, 다른 AAV 공급원으로부터의 ITR이 선택될 수 있다. ITR의 공급원이 AAV2로부터 유래하고 AAV 캡시드가 다른 AAV 공급원으로부터 유래되는 경우에, 그 결과의 벡터는 위형으로 명명될 수 있다. 전형적으로, AAV 벡터에 대한 발현 카세트는 AAV 5' ITR, hLDLR 암호화 서열 및 임의의 조절 서열, 및 AAV 3' ITR을 포함한다. 그러나, 이 요소들의 다른 구성형태도 적합할 수 있다. D-서열 및 말단 분해 부위(terminal resolution site, trs)가 결실된, △ITR로 명명된, 5' ITR의 단축 버전이 기술되었다. 다른 구체예에서, 전체-길이 AAV 5' 및 3' ITR이 사용된다.
약어 "sc"는 자체-상보성을 나타낸다. "자체-상보성 AAV"는 재조합 AAV 핵산 서열에 의해 운반된 암호화 영역이 분자내 이중-가닥 DNA 주형을 형성하도록 디자인되어 있는 발현 카세트를 가지는 플라스미드 또는 벡터를 나타낸다. 감염시, 제2 가닥의 세포 매개된 합성을 기다리기보다는, scAAV의 두 상보성 절반은 즉시 복제 및 전사를 위해 준비된 하나의 이중 가닥 DNA (dsDNA) 유닛을 형성하기 위해 회합할 것이다. 예컨대 D M McCarty et al, "Self-complementary recombinant adeno-associated virus (scAAV) vectors promote efficient trabsduction independently of DNA synthesis", Gene Therapy, (August 2001), Vol 8, Number 16, Pages 1248-1254 참조. 자체-상보성 AAV는 예컨대 미국 특허 번호 6,596,535; 7,125,717 및 7,456,683 (이것들은 전문이 참조로 본원에 포함됨)에 기술되어 있다.
5.1.2. rAAV.hLDLR 제제
rAAV.hLDLR 제제는 완충 식염수, 계면활성제, 및 생리적으로 부합하는 염 또는 약 100 mM 염화 나트륨 (NaCl) 내지 약 250 mM 염화 나트륨에 동등한 이온 강도로 조정된 염들의 혼합물, 또는 동등한 이온 농도로 조정된 생리적으로 부합하는 염을 함유하고 있는 수용액 중에 현탁된 유효량의 rAAV.hLDLR 벡터를 함유하고 있는 현탁액이다. 한 구체예에서, 제제는 예컨대 최적화된 qPCR (oqPCR) 또는 예컨대 M. Lock et al, Hu 유전자 Therapy Methods, Hum Gene Ther Methods. 2014 Apr;25(2):115-25. doi: 10.1089/hgtb.2013.131. Epub 2014 Feb 14 (본원에 참조로 포함됨)에 기술되어 있는 것과 같은 디지털 드로플렛 PCR (ddPCR)에 의해 측정되는 바, 약 1.5 x 1011 GC/kg 내지 약 6 x 1013 GC/kg, 또는 약 1 x 1012 내지 약 1.25 x 1013 GC/kg을 함유할 수 있다. 예를 들어, 본원에 제공된 현탁액은 NaCl 및 KCl을 둘 다 함유할 수 있다. pH는 6.5 내지 8, 또는 7 내지 7.5의 범위에 있을 수 있다. 적합한 계면활성제, 또는 계면활성제들의 조합이 폴록사머들, 즉 두 개의 폴리옥시에틸렌 (폴리(산화 에틸렌))의 친수성 사슬이 양옆에 있는 폴리옥시프로필렌 (폴리(산화 프로필렌))의 중심 소수성 사슬로 구성된 비이온성 3블록 코폴리머, SOLUTOL HS 15 (마크로겔-15 하이드록시스테아레이트), LABRASOL (폴리옥시 카프릴릭 글리세라이드), 폴리옥시 10 올레일 에테르, TWEEN (폴리옥시에틸렌 소르비탄 지방산 에스테르), 에탄올 및 폴리에틸렌 글리콜 중에서 선택될 수 있다. 한 구체예에서, 제제는 폴록사머를 함유한다. 이 코폴리머들은 보통 문자 "P" (폴록사머에 대해)와 이어서 3개의 숫자로 명명된다: 처음 두 개의 숫자 x 100은 폴리옥시프로필렌 코어의 대략적인 분자량을 나타내고, 마지막 숫자 x 10은 백분율 폴리옥시에틸렌 함량을 나타낸다. 한 구체예에서 폴록사머 188이 선택된다. 계면활성제는 현탁액의 최대 약 0.0005 % 내지 약 0.001%의 양으로 존재할 수 있다. 한 구체예에서, rAAV. hLDLR 제제는 oqPCR 또는 예컨대 M. Lock et al, Hu Gene Therapy Methods, Hum Gene Ther Methods. 2014 Apr;25(2):115-25. doi: 10.1089/hgtb.2013.131. Epub 2014 Feb 14 (본원에 참조로 포함됨)에 기술되어 있는 것과 같은 디지털 드로플렛 PCR (ddPCR)에 의해 측정되는 바, 적어도 1x1013 게놈 복사물 (GC)/mL 또는 그 이상을 함유하는 현탁액이다. 한 구체예에서, 벡터는 180 mM 염화 나트륨, 10 mM 인산 나트륨, 0.001% 폴록사머 188, pH 7.3을 함유하고 있는 수용액 중에 현탁된다. 제제는 인간 대상체에 사용하기에 적합하고 정맥내로 투여된다. 한 구체예에서, 제제는 20분 (± 5분)에 걸쳐 말초 정맥을 통한 주입에 의해 전달된다. 그러나, 이 시간은 필요에 따라 또는 원하는 대로 조정될 수 있다.
빈(empty) 캡시드가 환자들에게 투여되는 AAV. hLDLR의 용량으로부터 제거되는 것을 보장하기 위하여, 빈 캡시드는 벡터 제조 과정 중에 벡터 입자들로부터, 예컨대 본원에서 단원 8.3.2.5에서 상세하게 논의되는 것과 같은 염화 세슘 구배 초원심분리를 사용하여 분리된다. 한 구체예에서, 포장된 게놈을 함유하고 있는 벡터 입자들은 빈 캡시드로부터, 2016년 12월 9일에 출원된 국제 특허 출원 번호 PCT/US16/65976, 2016년 4월 13일에 출원된 미국 특허 출원 번호 62/322,093 및 2015년 12월 11일에 출원된, "AAV8에 대한 확장형 정제 방법"이란 제목의 미국 특허 출원 번호 62/266,341에 기술된 과정을 사용하여 정제된다. 간단히 설명하면, 게놈-함유 rAAV 벡터 입자들을 rAAV 제조 세포 배양의 정화되고, 농축된 상층액으로부터 선택적으로 포획하고 분리시키는 2-단계 정제 계획이 기술된다. 과정은 rAAV 중간체가 실질적으로 없는 rAAV 벡터 입자를 제공하기 위하여 고염 농도에서 수행된 친화성 포획 방법 및 이어서 높은 pH에서 수행된 음이온 교환 수지 방법을 활용한다.
특정 구체예에서, 방법은 약물학적으로 활성인 게놈 서열을 포함하는 DNA를 함유하는 재조합 AAV8 바이러스 입자를 게놈-결핍(빈) AAV8 캡시드 중간체로부터 분리시킨다. 방법은 (a) 입자와 중간체가 생성된 AAV 생산자 세포 배양으로부터 비-AAV 물질을 제거하기 위해 정제된 재조합 AAV8 바이러스 입자 및 빈 AAV8 캡시드 중간체; 및 20 mM의 Bis-트리스 프로판 (BTP)을 포함하고 약 10.2의 pH인 완충액 A를 포함하는 로딩 현탁액을 형성하는 단계; (b) 강력한 음이온 교환 수지 위에 (a)의 현탁액을 로딩하는 단계로서, 상기 수지는 현탁액 및/또는 용액의 흐름을 위한 입구 및 용기로부터의 용출액의 흐름을 허용하는 출구를 가지는 용기에 있고; (c) 10mM NaCl 및 20mM BTP를 포함하고 약 10.2의 pH를 가지는 완충액 1% B로 로딩된 음이온 교환 수지를 세척하는 단계; (d) 증가하는 염 농도 구배를 로딩되고 세척된 음이온 교환 수지에 적용하는 단계로서, 염 구배 범위는 종점을 포함하여 10 mM 내지 약 190 mM NaCl이거나, 종점과 동등하며; 및 (e) 중간체로부터 정제되는 rAAV 입자를 용출액으로부터 수집하는 단계를 포함한다.
한 구체예에서, 사용된 pH는 10 내지 10.4 (약 10.2)이고, rAAV 입자는 AAV8 중간체로부터 적어도 약 50% 내지 약 90% 정제되거나, 또는 pH는 10.2이고 AAV8 중간체로부터 적어도 약 90% 내지 약 99% 정제된다. 한 구체예에서, 이것은 게놈 복사물에 의해 측정된다. rAAV 입자들 (포장된 게놈)의 스톡 또는 조제물은 스톡 중의 rAAV 입자가 스톡의 rAAV8의 적어도 약 75% 내지 약 100%, 적어도 약 80%, 적어도 약 85%, 적어도 약 90%, 적어도 약 95%, 또는 적어도 99%이고 "빈 캡시드"가 스톡 또는 조제물 중의 rAAV9의 약 1% 미만, 약 5% 미만, 약 10% 미만, 약 15% 미만일 때 AAV 빈 캡시드 (및 다른 중간체)가 "실질적으로 없다".
한 구체예에서, 제제는 1 이하, 바람직하게는 0.75 미만, 더 바람직하게는 0.5, 바람직하게는 0.3 미만의 "빈" 대 "전체"의 비율을 가지는 rAAV 스톡에 의해 특성화된다.
추가의 구체예에서, rAAV 입자의 평균 수율은 적어도 약 70%이다. 이것은 칼럼 위에 로딩된 혼합물에서의 역가 (게놈 복사물) 및 최종 용출액에서의 존재의 양을 측정함으로써 계산될 수 있다. 추가로, 이것들은 q-PCR 분석 및/또는 SDS-PAGE 기법, 예컨대 본원에서 또는 기술분야에서 기술되어 있는 것들을 기반으로 측정될 수 있다.
예를 들어, 빈 및 전체 입자 함량을 계산하기 위하여, 선택된 샘플 (예컨대 GC의 # = 입자의 #인 경우에 요오딕사놀(iodixanol)의 구배-정제된 조제물)에 대한 VP3 밴드 부피가 로딩된 GC 입자들에 대해 도표화된다. 그 결과의 1차 방정식 (y = mx+c)은 테스트 물품 피크의 밴드 부피 중의 입자의 수를 계산하기 위해 사용된다. 그런 다음 로딩된 20 μL당 입자의 수 (pt)에 50을 곱하여 입자 (pt)/mL이 얻어진다. Pt/mL을 GC/mL로 나누어서 입자 대 게놈 복사물의 비율을 얻는다 (pt/GC). Pt/mL-GC/mL은 빈 pt/mL을 제공한다. 빈 pt/mL을 pt/mL로 나누고 곱하기 100을 하면 빈 입자의 백분율이 얻어진다.
일반적으로, 빈 캡시드 및 포장된 게놈을 가진 AAV 벡터 입자에 대한 검정 방법은 기술분야에 알려져 있다. 예컨대 Grimm et al., Gene Therapy (1999) 6:1322-1330; Sommer et al., Molec. Ther. (2003) 7:122-128 참조. 변성된 캡시드를 테스트하기 위하여, 방법은 처리된 AAV 스톡에 대해 3개의 캡시드 단백질을 분리할 수 있는 임의의 겔, 예를 들어 완충액에 3 내지 8%의 트리스-아세테이트를 함유하는 구배 겔로 구성되는, SDS-폴리아크릴아미드 겔 전기영동을 수행하는 단계, 그런 다음 샘플 물질이 분리될 때까지 겔을 작동시키는 단계, 및 겔을 나일론 또는 니트로셀룰로오스 막, 바람직하게는 나일론 위에 블롯팅하는 단계를 포함한다. 그런 다음 항-AAV 캡시드 항체가 변성된 캡시드 단백질, 바람직하게는 항-AAV 캡시드 단클론성 항체, 가장 바람직하게는 B1 항-AAV-2 단클론성 항체에 결합하는 일차 항체로서 사용된다 (Wobus et al.,J. Virol. (2000) 74:9281-9293). 그런 다음 이차 항체, 즉 일차 항체에 결합하고 일차 항체와의 결합을 검출하기 위한 수단을 함유하는 것, 더 바람직하게는 그것에 공유 결합된 검출 분자를 함유하는 항-IgG 항체, 가장 바람직하게는 양고추냉이 과산화효소에 공유적으로 연결된 양 항-마우스 IgG 항체가 사용된다. 결합을 검출하는 방법은 일차 항체와 이차 항체 사이의 결합을 반-정량적으로 측정하기 위해 사용되는데, 바람직하게는 방사성 동위원소 방출, 전자기 복사 또는 비색 변화를 검출할 수 있는 검출 방법, 가장 바람직하게는 화학발광 검출 키트가 사용된다. 예를 들어, SDS-PAGE에 대해, 칼럼 분획으로부터의 샘플이 취해지고 환원제 (예컨대 DTT)를 함유한 SDS-PAGE 로딩 완충액에서 가열되며, 캡시드 단백질이 사전-성형 구배 폴리아크릴아미드 겔 (예컨대, Novex)에서 분해되었다. 은 염색이 SilverXpress (Invitrogen, CA)를 사용하여 제조자의 설명을 따라 수행될 수 있다. 한 구체예에서, 칼럼 분획의 AAV 벡터 게놈 (vg)의 농도는 정량적 실시간 PCR (Q-PCR)에 의해 측정될 수 있다. 샘플은 희석되고 DNase I (또는 다른 적합한 뉴클레아제)로 소화되어 외인성 DNA가 제거된다. 뉴클레아제의 비활성화 후에, 샘플은 추가로 희석되고 프라이머 및 프라이머들 사이의 DNA 서열에 특이적인 TaqManTM 형광 프로브를 사용하여 증폭된다. 규정된 수준의 형광에 도달하기 위해 필요한 사이클의 수 (한계값 사이클, Ct)는 Applied Biosystems Prism 7700 서열 검출 시스템에서 각 샘플에 대해 측정된다. AAV 벡터에 함유된 것과 동일한 서열을 함유하는 플라스미드 DNA가 Q-PCR 반응에서 표준 곡선을 생성하기 위해 사용된다. 샘플로부터 얻어진 사이클 한계값 (Ct)이 플라스미드 표준 곡선의 Ct 값에 대해 표준화함으로써 벡터 게놈 역가를 측정하기 위해 사용된다. 디지털 PCR을 기반으로 한 종점 검정이 또한 사용될 수 있다.
한 측면으로, 광범위한 세린 프로테아제, 예컨대 프로테이나제 K (예컨대 Qiagen으로부터 상업적으로 입수 가능함)를 활용하는 최적화된 q-PCR 방법이 본원에서 제공된다. 더 구체적으로, 최적화된 qPCR 게놈 역가 검정은 표준 검정과 유사하고, 단 DNase I 소화 후에, 샘플은 프로테이나제 K 완충액으로 희석되고 프로테이나제 K와 이어서 열비활성화에 의해 처리된다. 적합하게 샘플은 샘플 크기와 동등한 양의 프로테이나제 K 완충액으로 희석된다. 프로테이나제 K 완충액은 2배 이상으로 농축될 수 있다. 전형적으로, 프로테이나제 K 처리는 약 0.2 mg/mL이지만, 0.1 mg/mL 내지 약 1 mg/mL로 다양할 수 있다. 처리 단계는 일반적으로 약 55℃에서 약 15분 동안 수행되지만, 더 낮은 온도 (예컨대 약 37℃ 내지 약 50℃)에서 더 긴 시간 (예컨대 약 20분 내지 약 30분) 동안, 또는 더 높은 온도 (예컨대 최대 약 60℃)에서 더 짧은 시간 (예컨대 약 5 내지 10분) 동안 수행될 수 있다. 유사하게, 열 비활성화는 일반적으로 약 95℃에서 약 15분이지만, 온도는 낮아질 수 있고 (예컨대 약 70 내지 약 90℃) 시간은 연장될 수 있다 (예컨대 약 20분 내지 약 30분). 그런 다음 샘플은 희석되고 (예컨대 1000배) 표준 검정에서 기술된 것과 같이 TaqMan 분석이 수행될 수 있다.
추가적으로, 또는 다르게는, 드로플렛 디지털 PCR (ddPCR)이 사용될 수 있다. 예를 들어, 단일-가닥 및 자체-상보성 AAV 벡터 게놈 역가를 ddPCR에 의해 측정하는 방법이 기술되어 있다. 예컨대 M. Lock et al, Hu Gene Therapy Methods, Hum Gene Ther Methods. 2014 Apr;25(2):115-25. doi: 10.1089/hgtb.2013.131. Epub 2014 Feb 14 참조.
5.1.3. 제조
rAAV.hLDLR 벡터는 도 11에 나타낸 흐름도에서 나타낸 것과 같이 제조될 수 있다. 간단히 설명하면, 세포 (예컨대 HEK 293 세포)가 적합한 세포 배양 시스템에서 증식되고 벡터 생성을 위해 트랜스펙션된다. 그런 다음 rAAV.hLDLR 벡터는 수득되고, 농축되며 정제되어 벌크 벡터가 준비되고 그것은 다음에 하류 과정에서 채워지고 완성된다.
본원에서 기술된 유전자 요법 벡터의 제조 방법은 기술분야에 잘 알려져 있는 방법들, 예컨대 유전자 요법 벡터의 제조를 위해 사용된 플라스미드 DNA의 생성, 벡터의 생성 및 벡터의 정제를 포함한다. 일부 구체예에서, 유전자 요법 벡터는 AAV 벡터이고 생성된 플라스미드는 AAV 게놈 및 관심의 유전자를 암호화하는 AAV 시스-플라스미드, AAV rep 및 cap 유전자를 함유하는 AAV 트란스-플라스미드, 및 아데노바이러스 헬퍼 플라스미드이다. 벡터 생성 과정은 세포 배양의 개시, 세포의 계대, 세포의 시딩, 플라스미드 DNA로의 세포의 트랜스펙션, 트랜스펙션-후 혈청 유리 배지로의 배지 교환 및 벡터-함유 세포 및 배양 배지의 수득과 같은 방법 단계들을 포함할 수 있다. 수득된 벡터-함유 세포 및 배양 배지는 본원에서 미정제 세포 수득물로서 언급된다.
미정제 세포 수득물은 그런 다음 벡터 수득물의 농축, 벡터 수득물의 투석여과, 벡터 수득물의 뉴클레아제 소화, 마이크로유동화된 중간체의 여과, 크로마토그래피에 의한 정제, 한외여과에 의한 정제, 접선 흐름 여과에 의한 완충액 교환 및 벌크 벡터를 제조하기 위한 제제화 및 여과와 같은 방법 단계들이 수행될 수 있다.
특정 구체예에서, 도 11의 방법과 유사한 방법들이 다른 AAV 프로듀서 세포와 함께 사용될 수 있다. rAAV 벡터의 제조를 위한 수많은 방법이 기술분야에 알려져 있는데, 이를테면 트랜스펙션, 안정한 세포주 생성, 및 아데노바이러스-AAV 하이브리드, 헤르페스바이러스-AAV 하이브리드 및 배큘로바이러스-AAV 하이브리드를 포함하는 감염성 하이브리드 바이러스 제조 시스템이 포함된다. 예컨대 G Ye, et al, Hu Gene Ther Clin Dev, 25:212-217 (Dec 2014); RM Kotin, Hu Mol Genet, 2011, Vol. 20, Rev Issue 1, R2-R6; M. Mietzsch, et al, Hum Gene Therapy, 25:212-222 (Mar 2014); T Virag et al, Hu Gene Therapy, 20:807-817 (August 2009); N. Clement et al, Hum Gene Therapy, 20:796-806 (Aug 2009); DL Thomas et al, Hum Gene Ther, 20:861-870 (Aug 2009) 참조. rAAV 바이러스 입자의 제조를 위한 rAAV 생성 배양은 1) 적합한 숙주 세포, 이를테면, 예를 들어, 인간-유래된 세포주, 예컨대 HeLa, A549 또는 293 세포, 또는 배큘로바이러스 제조 시스템의 경우에 SF-9와 같은 곤충-유래된 세포주; 2) 야생형 또는 돌연변이 아데노바이러스 (예컨대 온도 민감성 아데노바이러스), 헤르페스 바이러스, 배큘로바이러스, 또는 트란스로 또는 시스로 헬퍼 기능을 제공하는 핵산 구성물에 의해 제공된 적합한 헬퍼 바이러스 기능; 3) 기능적 AAV rep 유전자, 기능적 cap 유전자 및 유전자 생성물; 4) AAV ITR 서열이 양 옆에 있는 도입유전자 (예컨대 치료용 도입유전자); 및 5) rAAV 제조를 지지하기 위한 적합한 배지 및 배지 성분들을 모두 필요로 한다.
다양한 적합한 세포 및 세포주들이 AAV의 제조에 사용하기 위해 기술되어 있다. 세포 자체는 임의의 생물학적 유기체, 이를테면 전핵생물 (예컨대 박테리아) 세포, 및 진핵생물 세포, 이를테면 곤충 세포, 효모 세포 및 포유류 세포로부터 선택될 수 있다. 특히 바람직한 숙주 세포는 임의의 포유류 종, 이를테면, 제한 없이, A549, WEHI, 3T3, 10T1/2, BHK, MDCK, COS 1, COS 7, BSC 1, BSC 40, BMT 10, VERO, WI38, HeLa, HEK 293 세포 (기능성 아데노바이러스 E1을 발현함), Saos, C2C12, L 세포, HT1080, HepG2 및 일차 섬유모세포, 간세포 및 인간, 원숭이, 마우스, 래트, 토끼 및 햄스터를 포함하는 포유류로부터 유래된 근모세포 중에서 선택된다. 특정 구체예에서, 세포는 현탁액-적응된 세포이다. 세포를 제공하는 포유류 종의 선택은 본 발명의 제한사항이 아니며; 포유류 세포의 유형, 즉 섬유모세포, 간세포, 종양 세포 등도 제한사항이 아니다.
특정 구체예에서, 유전자 요법 벡터를 제조하기 위해 사용된 방법들은 하기 단원 8, 실시예 3에서 기술된다.
5.2. 환자 집단
치료 후보인 환자들은 바람직하게는 LDLR 유전자에 2개의 돌연변이를 가진 HoFH로 진단된 성인 (남성 또는 여성 ≥ 18세); 즉, HoFH와 일치하는 임상적 표시의 세팅에서 두 대립 유전자에서 분자적으로 규정된 LDLR 돌연변이를 가진 환자들이고, 임상적 표시는 미처리 LDL-C 수준, 예컨대 >300 mg/dl의 LDL-C 수준, 처리된 LDL-C 수준, 예컨대 <300 mg/dl의 LDL-C 수준 및/또는 500 mg/dl보다 큰 총 혈장 콜레스테롤 수준 및 미성숙하고 공격적인 아테롬성 동맥경화증을 포함할 수 있다. 일부 구체예에서, 18세 미만의 환자가 치료될 수 있다. 일부 구체예에서, 치료된 환자는 ≥18세의 남성이다. 일부 구체예에서, 치료된 환자는 ≥18세의 여성이다. 치료에 대한 후보는 스타틴, 에제티미브, 담즙산 격리제, PCSK9 억제제와 같은 지질-저하 약물, 및 LDL 및/또는 혈장 성분채집술로의 치료가 진행 중인 HoFH 환자를 포함한다.
치료 전에, HoFH 환자는 hLDLR 유전자를 전달하기 위해 사요오딘 AAV 혈청형에 대한 NAb에 대해 평가되어야 한다. 그러한 NAb는 변환 효율을 간섭하고 치료 효능을 감소시킬 수 있다. 기준선 혈청 NAb 역가 ≤ 1:10인 HoFH 환자들이 rAAV.hLDLR 유전자 요법 프로토콜로의 치료에 대한 양호한 후보들이다. 그러나, 더 높은 비율을 가진 환자도 특정 상황 하에서 선택될 수 있다. 혈청 NAb >1:5의 역가를 가진 HoFH 환자의 치료는 조합 치료법, 예컨대 면역억제제와의 병용-치료를 필요로 할 수 있지만, 이러한 치료법은 더 낮은 비율을 가진 환자에 대해 선택될 수 있다. 그러한 병용 요법을 위한 면역억제제는, 한정하는 것은 아니지만, 스테로이드, 항대사물질, T-세포 억제제 및 알킬화제를 포함한다. 예를 들어, 그러한 일시적 치료는 7일 동안 매일 1회 감소하는 용량으로, 약 60 mg에서 시작하여 10 mg/일로 감소하는 (제 7 일에는 용량이 없음) 양으로 투약된 스테로이드 (예컨대 프레드니솔)를 포함할 수 있다. 다른 용량 및 약물이 선택될 수 있다.
대상체는 주치의의 재량으로 유전자 요법 치료 전에 및 유전자 요법 치료와 동시에 표준 치료(들) (예컨대 LDL 성분채집술 및/또는 혈장 교환, 및 다른 지질 저하 치료)을 계속하도록 허용될 수 있다. 대안적으로, 의사는 유전자 요법 치료를 투여하기 전에 표준 치료 요법을 중단하고 유전자 요법의 투여 후에 병용 요법으로서 표준 치료를 재개하는 것을 선호할 수 있다. 유전자 요법 처방의 바람직한 종점은 유전자 요법 치료의 투여 후 최대 12주까지 기준순으로부터 저밀도 리포단백질 콜레스테롤 (LDL-C) 감소 및 LDL 아포리포단백질 B (apoB)의 분획 이화 속도 (FCR)의 변화이다. 다른 바람직한 종점은, 예컨대 다음 중 하나 이상의 감소를 포함한다: 총 콜레스테롤 (TC), 비-고밀도 리포단백질 콜레스테롤 (비-HDL-C), 공복 트라이글리세라이드 (TG)의 감소, 및 HDL-C (예컨대 증가된 수준이 바람직함), 초저밀도 리포단백질 콜레스테롤 (VLDL-C), 리포단백질(a) (Lp(a)), 아포리포단백질 B (apoB), 및/또는 아포리포단백질 A-I (apoA-I)의 변화.
한 구체예에서, 환자들은 연구 과정에 걸쳐 단독으로 및/또는 부속 치료의 사용과 조합된 AAV8.hLDLR로의 치료 후에 원하는 LDL-C 한계값 (예컨대 LDL-C <200, <130, 또는 <100 mg/dl)을 이룬다.
특정 구체예에서, 환자는 LDL의 빈도 및/또는 혈장 성분채집술을 포함한, 지질 저하 요법에 대한 감소된 요구를 가질 것이다.
또 다른 구체예에서, 기준선과 비교하여 평가 가능한 황색종(xanthomas)의 수, 크기 또는 정도의 감소가 있을 것이다.
그럼에도 불구하고, 다음 특성들 중 하나 이상을 가지는 환자들은 그들의 주치의의 재량으로 치료로부터 배제될 수 있다:
기준선 혈청 AAV8 NAb 역가 > 1:5, > 1:10. 다른 구체예에서, 주치의는 이런 신체적 특징들(의학적 이력) 중 하나 이상의 존재가 본원에서 제공되는 것과 같은 치료를 방해하지 않아야 하는 것을 결정할 수 있다.
5.3. 투약 및 투여 경로
환자들은 약 20 내지 약 30분에 걸친 말초 정맥을 통한 주입에 의해 투여된 단일 용량의 rAAV.hLDLR을 받는다. 환자에게 투여된 rAAV.hLDLR의 용량은 적어도 2.5 x 1012 GC/kg 또는 7.5 x 1012 GC/kg, 또는 적어도 5 x 1011 GC/kg 내지 약 7.5 x 1012 GC/kg이다 (oqPCR 또는 ddPCR에 의해 측정됨). 그러나, 다른 용량이 선택될 수도 있다. 바람직한 구체예에서, 사용된 rAAV 현탁액은 HoFH의 이중 녹아웃 LDLR-/-Apobec-/- 마우스 모델 (DKO 마우스)에 투여된 5 x 1011 GC/kg의 용량이 DKO 마우스에서 기준선 콜레스테롤 수준을 25% 내지 75%만큼 감소시키는 효능을 가진다.
일부 구체예에서, 환자에게 투여된 rAAV.hLDLR의 용량은 2.5 x 1012 GC/kg 내지 7.5 x 1012 GC/kg의 범위에 있다. 바람직하게, 사용된 rAAV 현탁액은 HoFH의 이중 녹아웃 LDLR-/-Apobec-/- 마우스 모델 (DKO 마우스)에 투여된 5 x 1011 GC/kg의 용량이 DKO 마우스에서 기준선 콜레스테롤 수준을 25% 내지 75%만큼 감소시키는 효능을 가진다. 특정 구체예에서, 환자에게 투여된 rAAV.hLDLR의 용량은 적어도 5 x 1011 GC/kg, 2.5 x 1012 GC/kg, 3.0 x 1012 GC/kg, 3.5 x 1012 GC/kg, 4.0 x 1012 GC/kg, 4.5 x 1012 GC/kg, 5.0 x 1012 GC/kg, 5.5 x 1012 GC/kg, 6.0 x 1012 GC/kg, 6.5 x 1012 GC/kg, 7.0 x 1012 GC/kg, 또는 7.5 x 1012 GC/kg이다.
일부 구체예에서, rAAV.hLDLR은 HoFH의 치료를 위해 하나 이상의 치료법과 조합하여 투여된다. 일부 구체예에서, rAAV.hLDLR은 한정하는 것은 아니지만 에제티미브, 에제디아(ezedia), 담즙산 격리제, LDL 성분채집술, 혈장 성분채집술, 혈장 교환, 로미타피드(lomitapide), 미포메르센(mipomersen) 및/또는 PCSK9 억제제를 포함하여, HoFH를 치료하기 위해 사용된 표준 지질-저하 치료법과 조합하여 투여된다. 일부 구체예에서, rAAV.hLDLR은 나이아신과 조합하여 투여된다. 일부 구체예에서, rAAV.hLDLR은 피브레이트와 조합하여 투여된다.
5.4. 임상 목표의 측정
투여 후 유전자 요법 벡터의 안전성은 벡터 투여 후 최대 약 52주의 다중 시점에서 평가된 부작용의 수, 신체 검사에서 주지된 변화, 및/또는 임상적 실험실 파라미터들에 의해 평가될 수 있다. 비록 생리적 효과가 초기에, 예컨대 약 1일 내지 1주일 내에 관찰될 수 있지만, 꾸준한 상태 수준 발현 수준은 약 12주에 도달된다.
rAAV.hLDLR 투여로 이루어진 LDL-C 감소는 기준선과 비교하여 약 12주째에, 또는 다른 원하는 시점에 LDL-C의 규정된 퍼센트 변화로서 평가될 수 있다.
다른 지질 파라미터들 또한 기준선 값과 비교하여, 약 12주째에, 또는 다른 원하는 시점에서, 특히 총 콜레스테롤 (TC), 비-고밀도 리포단백질 콜레스테롤 (비-HDL-C), HDL-C, 공복 트라이글리세라이드 (TG), 초저밀도 리포단백질 콜레스테롤 (VLDL-C), 리포단백질(a) (Lp(a)), 아포리포단백질 B (apoB), 및 아포리포단백질 A-I (apoA-I)의 퍼센트 변화로 평가될 수 있다. LDL-C에 의해 감소되는 대사 메커니즘은 rAAV.hLDLR 투여 전 및 다시 투여 후 12주 후에 LDL 역학 연구를 수행함으로써 평가될 수 있다. 평가될 일차 파라미터는 LDL apoB의 기능적 대사율(FCR)이다.
본원에서 사용되는 rAAV.hLDLR 벡터는 환자가 이 임상적 종점들 중 적어도 하나를 이루기 위해 충분한 수준의 LDLR을 가질 때 활성 LDLR로 환자의 결핍성 LDLR을 "기능적으로 대체" 또는 "기능적으로 보충"한다. 비-FH 환자에서 정상적인 야생형 임상적 종점 수준의 약 10%의 낮은 내지 100% 미만을 이루는 hLDLR의 발현 수준이 기능적 대체를 제공할 수 있다.
한 구체예에서, 발현은 투약 후 약 8시간 내지 약 24시간의 초기에 관찰될 수 있다. 상기 기술된 원하는 임상 효과중 하나 이상이 투약 후 수일 내지 수주 내에 관찰될 수 있다.
장기간 (최대 260주) 안전성 및 효능은 rAAV.hLDLR 투여 후에 평가될 수 있다.
하기 단락 6.4.1 내지 6.7에서 기술되는 표준 임상 실험실 평가 및 다른 임상 검정들이 부작용, 지질 파라미터의 퍼센트 변화를 평가하는 효능 종점, 약물역학적 평가, 리포단백질 동역학, ApoB-100 농도, 뿐만 아니라 rAAV.hLDLR 벡터에 대한 면역 반응을 모니터링하기 위해 사용될 수 있다.
다음의 실시예는 단지 예시적인 것으로 본 발명을 제한하려는 의도는 아니다.
실시예
6. 실시예 1: 인간 대상체를 치료하기 위한 프로토콜
이 실시예는 저밀도 리포단백질 수용체 (LDLR) 유전자의 돌연변이로 인해 유전자적으로 확인된 동형접합성 가족성 고콜레스테롤혈증 (HoFH)을 가진 환자들에 대한 유전자 요법 치료에 관련된다. 이 실시예에서, 유전자 요법 벡터, AAV8.TBG.hLDLR, hLDLR을 발현하는 복제 결핍 아데노-관련 바이러스 벡터 8 (AAV8)이 HoFH를 가진 환자들에게 투여된다. 치료 효능은 도입유전자 발현에 대한 대리물로서 저밀도 리포단백질 콜레스테롤 (LDL-C) 수준을 사용하여 평가될 수 있다. 일차 효능 평가는 치료 후 약 12주째의 LDL-C 수준과, 그 후 적어도 52주 동안 이어지는 효과의 지속성을 포함한다. 장기간 안전성 및 도입유전자 발현의 지속성은 간 생검 샘플에서 치료 후에 측정될 수 있다.
6.1. 유전자 요법 벡터
유전자 요법 벡터는 간-특이적 프로모터 (티록신-결합 글로불린, TBG)의 제어하에 도입유전자 인간 저밀도 리포단백질 수용체 (hLDLR)를 발현하는 AAV8 벡터이고 이 실시예에서는 AAV8.TBG.hLDLR로 언급된다 (도 7 참조). AAV8.TBG.hLDLR 벡터는 AAV 벡터 활성 성분 및 제제 완충제로 구성된다. 외부 AAV 벡터 성분은 혈청형 8, 1:1:18의 비율의 3개의 AAV 바이러스 단백질, VP1, VP2 및 VP3의 60개의 복사물로 구성되는 T = 1 이십면체 캡시드이다. 캡시드는 단일-가닥 DNA 재조합 AAV (rAAV) 벡터 게놈을 함유한다. 게놈은 2개의 AAV 역 말단 반복부 (ITR)가 양옆에 있는 hLDLR 도입유전자를 함유한다. 인핸서, 프로모터, 인트론, hLDLR 암호화 서열 및 폴리아데닐화 (폴리A) 신호는 hLDLR 도입유전자를 포함한다. ITR은 벡터 제조 중에 게놈의 복제 및 포장에 기여하는 유전사 요소들이며 rAAV를 생성하기 위해 필요한 유일한 바이러스 시스 요소이다. hLDLR 암호화 서열의 발현은 간세포-특이적 TBG 프로모터로부터 구동된다. 알파 1 마이크로글로불린/비쿠닌 인핸서 요소의 2개의 복사물이 TBG 프로모터 앞에 있어서 프로모터활성을 자극한다. 키메라 인트론은 추가로 발현을 향상시키기 위해 존재하고 hLDLR mRNA 전사물의 종결을 중재하기 위해 토끼 베타 글로빈 폴리아데닐화 (폴리A) 신호가 포함된다. 이 벡터를 제조하기 위해 사용된 pAAV.TBG.PI.hLDLRco.RGB의 서열은 SEQ ID NO: 6에 제공된다.
연구용 약제의 제제는 180 mM 염화 나트륨, 10 mM 인산 나트륨, 0.001% 폴록사머 188, pH 7.3을 함유한 수용액 중의 적어도 1x1013 게놈 복사물 (GC)/mL이고 20분 (±5분)에 걸친 말초 정맥을 통한 주입에 의해 투여된다.
6.2. 환자 집단
치료된 환자는 LDLR 유전자에 2개의 돌연변이를 가진 동형접합성 가족성 고콜레스테롤혈증 (HoFH)을 가진 성인이다. 환자는 18세 이상의 남성 또는 여성일 수 있다. 환자들은 미처리 LDL-C 수준, 예컨대 LDL-C 수준 >300 mg/dl, 처리된 LDL-C 수준, 예컨대 LDL-C 수준 <300 mg/dl 및/또는 500 mg/dl보다 큰 총 혈장 콜레스테롤 수준 및 미성숙하고 공격적인 아테롬성 동맥경화증을 포함할 수 있는, HoFH와 일치하는 임상적 표시의 세팅에서 두 대립 유전자에서 분자적으로 규정된 LDLR 돌연변이를 가진다. 치료된 환자는 동시에 지질-저하 약물, 예컨대 스타틴, 에제티미브, 담즙산 격리제, PCSK9 억제제, 및 LDL 성분채집술 및/또는 혈장 성분채집술로의 치료가 동시에 진행될 수 있다.
치료되는 환자들은 기준선 혈청 AAV8 중화 항체 (NAb) 역가 ≤ 1:10을 가질 수 있다. 만약 환자가 기준선 혈청 AAV8 중화 항체 (NAb) 역가 ≤ 1:10을 갖지 않는다면, 환자는 형질도입 기간 중에 면역억제제로 일시적으로 공동-처리될 수 있다. 특정 구체예에서, AAV8 중화 항체 역가를 가진 환자는 더 높거나 (예컨대, ≤ 1:5 내지 ≤ 1:15, 또는 ≤ 1:20) 또는 더 낮을 수 있다 (예컨대, ≤ 1:2 내지 ≤ 1:5). 병용 요법을 위한 면역억제제로는, 한정하는 것은 아니지만 스테로이드, 항대사물, T-세포 억제제 및 알킬화제를 포함한다.
대상체는 그들의 주치의의 재량으로 유전자 요법 치료 전에 및 동시에 그들의 표준 케어 치료(들) (예컨대 LDL 성분채집술 및/또는 혈장 교환, 및 다른 지질 저하 치료)을 계속하도록 허용될 수 있다. 대안으로는, 의사는 유전자 요법 치료를 투여하기 전에 표준 케어 요법을 중단하는 것을 선호하고, 선택적으로 유전자 요법의 투여 후에 병용 요법으로서 표준 케어 치료를 재개시킬 수 있다. 유전자 요법 처방의 바람직한 종점은 유전자 요법 치료의 투여 후 최대 약 12주의, 기준선으로부터 저밀도 리포단백질 콜레스테롤 (LDL-C) 감소 및 LDL 아포리포단백질 B (apoB)의 분획 이화작용 속도 (FCR)의 변화이다.
또 다른 구체예에서, 바람직한 종점은 LDL 성분채집술에 대한 필요성의 감소를 포함하거나 및/또는 혈장 성분채집술이 바람직한 종점이다. 용어 "LDL 성분채집술"은 LDL이 투석과 유사한 과정을 사용하여 혈류로부터 제거되는 방법인 저밀도 리포단백질 (LDL) 성분채집술을 나타내기 위하여 사용된다. LDL 성분채집술은 환자의 혈액으로부터 LDL 콜레스테롤을 제거하는 과정이다. LDL 성분채집술 과정 중에, 혈액 세포는 혈액으로부터 분리된다. 특수 필터가 혈장으로부터 LDL 콜레스테롤을 제거하기 위하여 사용되고, 여과된 혈액은 환자에게 되돌려진다. 단일 LDL 성분채집술 처치는 60 내지 70%의 유해한 LDL 콜레스테롤을 혈액으로부터 제거할 수 있다. 현재 미식품의약국에 의해 승인된 기계는 2개이다. 리포소버(Liposorber)는 덱스트란으로 덮인 필터를 사용하는데, 덱스트란은 LDL에 부착하여 그것을 순환계로부터 제거한다. 다른 기계는 HELP로 불리는 것으로 LDL을 제거하기 위하여 헤파린을 사용한다. 이들 기계 중 어느 것도 HDL (좋은) 콜레스테롤의 양의 유의미한 변화를 유발하지 않는다. 이것들은 현재 관상 동맥 질환의 이력이 있는 2000 ng/mdl 이상의 LDL 콜레스테롤을 가진 환자 및 관상 동맥 질환이 없는 300 mg/dl 이상의 LDL 콜레스테롤 수준을 가진 환자에 대해 승인된다. 예컨대 미국 성분채집술 협회, www. apheresis .com, 및http://c.ymcdn.com/sites/www. apheresis .org/resource/resmgr/-fact_sheets_file/ldl_ apheresis .pdf를 참조한다. 또한, 전세계 성분채집술 협회 [http://world apheresis .org/] 및 미국 지질 협회(USA) [https://www.lipid.org/]를 참조한다. 특정 구체예에서, LDL에 대해 비선택성인 혈장 성분채집술 (혈장성분채집술)은 유전자 요법 치료 전에 사용될 수 있고 그러한 치료에 대한 필요성이 LDL 성분채집술에 대해 본원에 기술된 것과 같이 감소될 수 있다. 본원에서 사용되는 바, 성분채집술의 "감소"는 환자가 성분채집술을 수행하기 위해 필요로 하는 1개월 및/또는 1년 당 횟수의 감소를 나타낸다. 이러한 감소는 rAAV8-hLDLR 요법 전에 사용된 성분채집술의 수준에 비교하여 치료법 후 성분채집술 처치가 10%, 25%, 50%, 75%, 또는 100% (예컨대, 필요성이 제거됨) 줄어들 수 있다. 예를 들어, rAAV8-hLDLR로의 치료 전에 매주 성분채집술을 수행해왔던 선택된 환자는 치료 후 단지 2주마다, 1개월마다, 또는 덜 빈번하게 성분채집술을 필요로 할 수 있다. 또 다른 예에서, rAAV8-hLDLR로의 치료 전에 한 달에 2회 성분채집술을 수행해왔던 선택된 환자는 단지 치료 후 매달, 2개월마다, 분기별로 또는 그것보다 덜 빈번하게 성분채집술을 필요로 할 수 있다.
또 다른 특정 구체예에서, 바람직한 종점은 환자를 치료하기 위해 사용된 PCSK9 억제제의 용량의 감소를 포함하며 환자의 치료가 바람직한 종점이다. 본원에서 사용되는 바, 성분채집술의 "감소"는 환자가 성분채집술을 수행하기 위해 필요로 하는 1개월 및/또는 1년 당 횟수의 감소를 나타낸다. 이러한 감소는 rAAV8-hLDLR 요법 전에 사용된 PCSK9 억제제의 수준에 비교하여 치료법 후 필요한 PCSK9 억제제가 10%, 25%, 50%, 75%, 또는 100% (예컨대, 필요성이 제거됨) 줄어들 수 있다. 예를 들어, HoFH 환자를 rAAV8.hLDLR 치료법 전에 PCSK9 억제제에 대해 한 달에 한 번 주입에 의해 치료하는 것 (예컨대, 300 mg 내지 500 mg 용량을 받음)은 PCSK9 억제제로의 치료를 HeFH 환자와 일치하는 치료 수준으로 감소시키는 능력을 초래할 수 있다. 이것은 환자에서 덜 침범적인 치료법을 수용할 수 있게 하는 것을 초래할 수 있다 (예컨대, 고용량의 주입에 대한 필요성이 제거됨). 예를 들어, 주입에 의해 420 mg을 매달 주입하는 것보다, 환자는 한 달에 한 번 또는 2주마다 (HeFH 용량), 또는 그것보다 덜 빈번하게 주사기 또는 자동주사기로 저용량 (예컨대, 100 내지 140 ng/mL)의 투여에 대해 선택할 수 있다.
6.3. 투약 및 투여 경로
환자들은 말초 정맥을 통한 주입에 의해 투여된 단일 용량의 AAV8.TBG.hLDLR을 받는다. 환자에게 투여된 AAV8.TBG.hLDLR의 용량은 약 2.5x1012 GC/kg 또는 7.5x1012 GC/kg이다. 빈 캡시드가 환자들에게 투여된 AAV8.TBG.hLDLR의 용량으로부터 제거되는 것을 보장하기 위하여, 빈 캡시드는 섹션 8.3.2.5.에서 논의되는 것과 같이, 벡터 정제 과정 중에 염화세슘 구배 초원심분리에 의해 또는 이온 교환 크로마토그래피에 의해 벡터 입자로부터 분리된다.
6.4. 임상 목표의 측정
6.4.1. 수행될 수 있는 표준 임상 실험실 평가:
다음의 임상 프로파일을 치료전 및 후에 테스트할 수 있다:
6.4.2. 관심의 부작용
다음의 임상 검정을 사용하여 독성을 모니터링할 수 있다:
* 빌리루빈 또는 간 효소 (AST, ALT, AlkPhos)에 대한 CTCAE v4.0 등급 3 이상의 실험실 결과.
* 빌리루빈 및 AlkPhos CTCAE v4.0 등급 2 (빌리루빈 >1.5xULN; AlkPhos >2.5xULN).
* AST 또는 ALT에 대해 ≥ 3x ULN (정상의 상한선), 및
* 알칼리성 포스파타제의 상승 없이 > 2x ULN 혈청 총 빌리루빈, 및
* 증가된 총 빌리루빈과 조합된 증가된 트란스아미나제 수준을 설명할 수 있는 다른 근거를 발견할 수 없음.
추가적으로, 추정된 T-세포 매개된 면역 트랜스아미나(transaminitis) (>2x 기준선 및 1xULN)에 대한 코르티코스테로이드 요법을 촉발시킬 수 있는 ALT 또는 AST 상승이 표시되고 기록될 것이다.
6.5. 효능 종점
AAV8.TBG.hLDLR의 투여 후 약 12주째에 지질 파라미터의 퍼센트 변화의 평가를 평가하고 기준선과 비교한다. 이것은 다음을 포함한다:
기준선 LDL-C 값은 실험실 및 생물학적 가변성에 대한 대조군에 AAV8.TBG.hLDLR의 투여 전에 2개의 별도의 경우로 금식 조건하에 얻어진 LDL-C 수준의 평균으로서 계산할 수 있고 믿을만한 효능 평가를 보장해준다.
6.5.1. 약물역학/효능 평가
다음의 효능 실험실 테스트를 금식 조건하에서 평가할 수 있다:
추가적으로, 선택적 LDL apoB 동역학을 치료 전 및 치료 후 12주에 측정할 수 있다. 지질 저하 효능을 벡터 투여 후 약 12, 24 및 52주 째에 기준선으로부터의 퍼센트 변화로서 평가할 수 있다. 기준선 LDL-C 값을 투여 전 2개의 별도의 경우에서 금식 조건하에 얻어진 LDL-C 수준을 평균을 구함으로써 계산한다. 벡터 투여 후 12주째에 LDL-C의 기준선으로부터의 퍼센트 변화는 유전자 전달 효능의 일차 척도이다.
6.6. 리포단백질 동역학
리포단백질 동역학 연구를 LDL-C가 감소되는 대사 메커니즘을 평가하기 위하여 벡터 투여 전 및 투여 후 12주에 다시 수행할 수 있다. 평가할 일차 파라미터는 LDL-apoB의 분획 이화작용 속도 (FCR)이다. apoB의 내인성 표지화는 변성된 류신의 정맥내 주입에 의해 이루어지고, 이어서 48시간 주기에 걸친 혈액 샘플링이 이루어진다.
6.6.1. ApoB-100 분리
VLDL, IDL 및 LDL을 D3-류신 주입 후 유도된 시간에 따른 샘플의 순차적인 초원심분리에 의해 분리한다. Apo B-100을 이 리포단백질들로부터 트리스-글리신 완충 시스템을 사용하는 제조용 소듐 도데실 설페이트-폴리아크릴아미드 겔 전기영동 (SDS PAGE)에 의해 분리한다. 개별 apoB 종 내에서 apoB 농도를 효소-결합 면역흡착 검정 (ELISA)에 의해 측정한다. 총 apoB 농도를 자동 면역혼탁도측정 검정을 사용하여 측정한다.
6.6.2. 동위원소 풍부화 측정
ApoB-100 밴드를 폴리아크릴아미드 겔로부터 잘라낸다. 잘라낸 밴드를 12N HCl에서 100℃에서 24시간 동안 가수분해한다. 아미노산을 N-아이소부틸 에스테르 및 N-헵타플루오로부티르아미드 유도체로 전환시킨 후 가스 크로마토그래피/질량 분석기를 사용하여 분석한다. 동위원소 풍부화 (백분율)를 관찰된 이온 전류 비율로부터 계산한다. 이 포맷의 데이터는 방사성 트레이서 실험에서 특이적 방사능과 유사하다. 각 대상체는 이 과정 중에 apoB-100 대사와 관련하여 정상 상태를 유지하는 것으로 추정된다.
6.7. 약물동역학 및 AAV8 평가에 대한 면역 반응
약물동역학, AAV 벡터에 대한 사전-면역력 및 AAV 벡터에 대한 면역 반응을 평가하기 위하여 다음의 테스트들을 사용할 수 있다:
6.8. 황색종 평가
신체 검사는 임의의 황색종의 확인, 조사 및 설명을 포함한다. 황색종 위치 및 유형, 즉 피부, 눈꺼풀 (눈), 결절 및/또는 힘줄의 기록에 의한 증명이 측정된다. 가능한 경우에는, 계측용 줄자 또는 캘리퍼스를 사용하여 신체 검사 중에 황색종의 크기 (최대 및 최소 크기)를 기록으로 남긴다. 가능하다면, 가장 크고 쉽게 확인할 수 있는 황색종의 디지털 사진을 병변 바로 옆에 테이프 줄자 (밀리미터까지 계측함)를 배치하여 찍는다.
7. 실시예 2: 사전-임상 데이터
HoFH 및 기존의 체액 면역에 대한 동물 모델에서 AAV8.TBG.hLDLR의 효과를 연구하기 위해 비임상 연구를 수행하였다. 다중 단일 용량 약물학 연구를 콜레스테롤의 감소를 측정하는 작은 및 큰 동물 모델에서 수행하였다. 추가적으로, 아테롬성 동맥경화증의 퇴행을 LDLR 및 Apobec1이 둘 다 결핍되고, 일반 식이요법으로도 apoB-100-함유 LDL의 상승으로 인해 심각한 고콜레스테롤혈증을 나타내며 광범위한 아테롬성 동맥경화증을 나타내는 이중 녹아웃 LDLR-/- Apobec1-/- 마우스 모델 (DKO)에서 측정하였다. 이 데이터들을 사용하여 최소 유효 용량을 결정하고 인간 연구에 대한 용량 선택을 적절하게 정당화하였다. 추가로 인간 연구에 대한 적절한 용량을 특성화하고 잠재적인 안전성 신호를 확인하기 위하여, 독물학 연구를 비-인간 영장류 (NHP) 및 HoFH의 마우스 모델에서 수행하였다.
7.1. 기존의 체액 면역: 간으로의 AAV-매개 유전자 전달에 대한 효과
이 연구의 목표는 붉은털 및 시노몰구스 원숭이에서 AAV8 캡시드화된 벡터를 사용하여 간 지시된 유전자 전달에 미치는 기존의 체액 면역의 영향을 평가하는 것이었다. 21마리의 붉은털 및 시노몰구스 원숭이를 AAV8에 대한 기존의 면역력 수준에 대해 사전-선별된 더 큰 동물 집단으로부터 선택하였다. 동물들은 넓은 연령 분포를 보였고 모두 수컷이었다. 이 연구는 낮은 내지 검출할 수 없는 수준의 중화 항체 (NAb)를 가진 한편으로 최대 1:160의 AAV8 NAb 역가를 가진 더 제한된 수의 동물을 포함하는 동물들에 초점이 맞춰졌다. 동물들에 말초 정맥 주입을 통해 간-특이적 티록신 결합 글로불린 (TBG) 프로모터로부터 향상된 녹색 형광 단백질 (EGFP)을 발현하는 3x1012 GC/kg의 AAV8 벡터를 주입하였다. 동물들을 7일 후에 부검하였고 EGFP 발현 및 AAV8 벡터 게놈의 간 표적화에 대해 평가하였다 (도 1). NHP 혈청에서 AAV8에 대한 기존의 NAb를, NHP로부터의 혈청을 벡터 투여 전 및 동시에 마우스에 주입하여 생체내에서 간 지시된 유전자 전달에 미치는 기존의 AAV8 NAb의 영향을 평가하는 시험관내 형질도입 억제 검정을 사용하여, 뿐만 아니라 수동 전달 실험의 맥락에서도 평가하였다 (Wang et al., 2010 Molecular Therapy 18(1):126-134).
AAV8에 대해 검출할 수 없는 내지 낮은 수준의 기존의 NAb를 가진 동물들은 형광 현미경에 의한 EGFP 검출 (도 1) 및 ELISA, 뿐만 아니라 간에서의 벡터 DNA 정량에 의해 증명되는 바, 간에서 고수준의 형질도입을 나타냈다. HoFH의 효능의 관점에서 형질도입의 가장 유용한 척도는 형질도입된 간세포의 퍼센트로, 기존의 NAb가 없을 때에는 17%였다 (4.4% 내지 40%의 범위). 이것은 동일한 용량의 벡터에서 마우스에 관찰된 효율과 매우 밀접하다. 간세포의 형질도입에 유의미하게 영향을 미치는 기존의 NAb의 T 한계 역가는 ≤ 1:5였다 (즉 1:10의 역가 또는 그 이상의 실질적으로 감소된 형질도입). 간 형질도입의 항체-매개된 억제는 간에서 감소된 AAV 게놈과 직접적으로 상관이 있다. 인간 혈청을 AAV8에 대한 기존의 NAb의 증거에 대해 스크리닝하였고 그 결과 약 15%의 성인이 ≤ 1:5를 초과하는 AAV8에 대한 NAb를 가지는 것으로 제시된다. 또한, NAb의 더 높은 수준이 벡터의 생체분포의 변화와 관련되어서, NAb가 간 유전자 전달을 감소시키는 한편 벡터 게놈의 비장으로의 침착이, 비장 형질도입을 증가시키기 않으면서 증가되는 것으로 나타났다.
7.2. HoFH의 마우스 모델에서 혈청 콜레스테롤에 대한 AAV8.TBG.mLDLR의 효과
DKO 마우스 (6 내지 12주령 수컷)를 AAV8.TBG.mLDLR로 IV 주사하였고 대사 보정 및 기존의 아테롬성 동맥경화증 병변의 반전을 추적하였다. 동물들을 또한 총 임상 독성 및 혈청 트란스아미나제의 비정상에 대해 평가하였다. LDLR의 마우스 버전을 DKO 마우스로의 벡터 투여에 활용하였다.
1011 GC/마우스 (5x1012 GC/kg)를 받은 마우스는 고콜레스테롤혈증의 거의 완전한 정상화를 보였고 180일 동안 안정적이었다 (도 2). ALT 수준의 상승 없음 또는 비정상적인 간 생화학을 설치류에서 최고 용량의 벡터 주입 후 최대 6개월 동안 관찰하였다 (Kassim et al., 2010, PLoS One 5(10):e13424).
7.3. 고지방 식이요법의 HoFH의 마우스 모델에서 아테롬성 동맥경화증 병변에 대한 AAV8.TBG.mLDLR의 효과
LDLR의 AAV8-매개된 전달이 총 콜레스테롤의 유의미한 저하를 유도하였으면, mLDLR의 AAV8-매개된 발현을 개념 입증 연구에서 조사하여 아테롬성 동맥경화증 병변에 영향을 미치는지를 측정하였다 (Kassim et al., 2010, PLoS One 5(10):e13424). 수컷 DKO 마우스의 3개 그룹을 고지방 식이요법으로 공급하여 아테롬성 동맥경화증의 진행을 앞당겼다. 2개월 후에, 한 그룹의 마우스들은 단일 IV 주사로 5x1012 GC/kg의 대조군 AAV8.TBG.nLacZ 벡터를 받고 한 그룹은 단일 IV 주사로 5x1012 GC/kg의 AAV8.TBG.mLDLR 벡터를 받은 한편, 제 3 비-개입 그룹은 아테롬성 동맥경화증 병변 정량을 위해 부검하였다. 벡터를 받은 마우스들은 추가로 60일 동안 고지방 식이요법을 유지하였고, 60일째에 부검하였다.
AAV8.TBG.mLDLR 벡터를 받은 동물들은 기준선에서 치료 후 1555 ± 343 mg/dl로부터 7일 후에 266 ± 78 mg/dl로 및 60일 후에 67 ± 13 mg/dl로 총 콜레스테롤의 급격한 저하를 나타냈다. 그에 반해, AAV8.TBG.nLacZ 처리된 마우스의 혈장 콜레스테롤 수준은 기준선에서 1566 ± 276 mg/dl로부터 벡터 후 60일 후에 측정했을 때 1527 ± 67 mg/dl로 실제로 변하지 않은 채로 유지되었다. 모든 동물은 고지방 식이요법으로 2개월 후에 혈청 트란스아미나제의 약간의 증가를 나타냈고, AAV8.TBG.nLacZ 벡터로 처리 후에 상승된 것을 유지하였지만 AAV8.TBG.mLDLR 벡터로의 치료 후에는 정상 수준으로 3배 감소되었다.
기존의 아테롬성 동맥경화증 병변의 진화를 2가지 독립적인 방법에 의해 평가하였다. 첫 번째 방법에서 대동맥을 아치(arch)로부터 장골동맥 분지부까지 개방하고 오일 레드 O로 염색하였다 (도 3A); 형태학적 분석으로 대동맥의 전체 길이를 따라 오일 레드 O로 염색된 대동맥의 퍼센트를 정량하였다 (도 3B). 오일 레드 O는 냉동 섹션 상의 중성 트라이글리세라이드 및 지질의 염색을 위해 사용된 용해성 염료 (지용성 염료) 다이아조 염료이다. 이 염료로의 대동맥의 염색은 지질이 가득한 플라크의 시각화를 허용한다. 도 3에서 나타난 것과 같이, 2개월의 고지방 식이요법은 대동맥의 20%를 차지하는 광범위한 아테롬성 동맥경화증을 초래하였는데, 이것은 벡터의 도입시 기준선 질환을 반영하였고; 이것은 AAV8.TBG.nLacZ 벡터로 치료후에 추가로 2개월에 걸쳐 33%로 증가하였으며, 이것은 아테롬성 동맥경화증의 65%의 추가의 진행을 나타낸다. 그에 반해, AAV8.TBG.mLDLR 벡터로의 치료는 아테롬성 동맥경화증의 퇴행을 2개월에 걸쳐 87%나 유발하였는데, 기준선에서 아테롬성 동맥경화증에 의해 차지된 대동맥의 20%로부터 벡터 투여 후 60일 후에 아테롬성 동맥경화증에 의해 차지된 대동맥은 단지 2.6%였다.
두 번째 방법에서, 총 병변 구역을 대동맥 기부에서 정량하였다 (도 3C 내지 F). 이 분석으로 동일한 전체 동향이 드러났는데, AAV8.TBG.nLacZ 주입된 마우스는 기준선 마우스와 비교하여 2개월에 걸쳐 44% 진행을 보인 한편, AAV8.TBG.mLDLR 주입된 마우스는 기준선 마우스와 비교하여 병변의 64% 퇴행을 증명하였다. 요약하면, AAV8.TBG.mLDLR 주입을 통한 LDLR의 발현이, 대동맥 내의 2개의 상이한 부위에서의 2가지 독립적인 정량 방법에 의해 평가된 바 2개월에 걸쳐 콜레스테롤의 현저한 감소 및 아테롬성 동맥경화증의 실질적인 퇴행을 유발하였다.
7.4. HoFH의 마우스 모델에서 최소 유효량의 평가
HoFH 집단에서 표현형과 유전형 사이의 상관관계의 광범위한 연구는 단지 25 내지 30%의 LDL 및 총 콜레스테롤의 차이가 임상 결과의 실질적 차이로 이어진 것을 증명하였다 (Bertolini et al. 2013, Atherosclerosis 227(2):342-348; Kolansky et al. 2008, Am J Cardiol 102(11):1438-1443; Moorjani et al. 1993, The Lancet 341(8856):1303-1306). 나아가, 30% 미만의 LDL-C 감소와 관련된 지질-저하 치료는 HoFH에 걸린 환자에서 지연된 심혈관 질환 및 연장된 생존율로 이어진다 (Raal et al. 2011, Circulation 124(20):2202-2207). 최근, FDA는 HoFH의 치료에 약물 미포메르센을 승인하였는데 그것의 일차 종점은 기준선으로부터 20 내지 25%의 LDL-C의 감소였다 (Raal et al. 2010, Lancet 375(9719):998-1006).
이런 배경에 반해서, 하기 논의된 유전자 요법 마우스 연구에서 최소 유효 용량 (MED)을 기준선보다 적어도 30% 더 낮은 혈청의 총 콜레스테롤의 통계학적으로 유의미하고 안정한 감소를 유발한 벡터의 최저 용량으로서 규정하였다. MED를 많은 상이한 연구에서 평가하였고 각 실험의 간단한 설명을 하기에서 제공한다.
7.4.1. DKO 마우스에서 AAV8.TBG.mLDLR의 POC 용량-범위 연구
DKO 마우스에서 AAV8.TBG.mLDLR 및 AAV8.TBG.hLDLR의 개념 입증 용량-범위 연구를, 추가의 연구를 위해 적합한 용량을 확인하기 위해 수행하였다. 이 연구들에서, DKO 수컷 마우스를 1.5 내지 500x1011 GC/kg의 상이한 용량의 AAV8.TBG.mLDLR로 IV 주사한 후 혈장 콜레스테롤의 감소를 추적하였다 (Kassim et al., 2010, PLoS One 5(10):e13424). 이 연구 실험에서 사용한 GC 용량 (1.5 내지 500 x 1011)은 정량 PCR (qPCR) 역가를 기반으로 하였다. 최대 30%의 혈장 콜레스테롤의 통계학적으로 유의미한 감소를 1.5x1011 GC/kg의 AAV8.TBG.mLDLR의 용량에서 21일째에 관찰하였고, 더 큰 감소는 더 큰 용량의 벡터에 비례하여 이루어졌다 (Kassim et al., 2010, PLoS One 5(10):e13424). 대사 보정에 이어서 수득한 간 조직의 분석은 벡터 용량에 비례하여 마우스 LDLR 도입유전자 및 단백질의 수준을 나타냈다. 그러므로, 용량-반응 상관관계를 관찰하였다.
7.4.2. DKO 및 LAHB 마우스에서 AAV8.TBG.hLDLR의 용량-범위 연구
DKO 마우스에서 유사한 개념 입증 연구를 마우스 LDLR 유전자보다는 인간 LDL 수용체 (hLDLR) 유전자를 함유한 벡터로 수행하였다. hLDLR 벡터로의 결과는 벡터의 용량이 간에서 도입유전자의 발현 및 벡터 게놈의 침착에 비례하였다는 점에서 mLDLR로 관찰된 결과와 매우 유사하였다 (Kassim et al. 2013, Hum Gene Ther 24(1):19-26). 주요 차이점은 그것의 효능이었다 - 인간 LDLR 벡터는 이 모델에서 덜 강력하였다. 적어도 30%에 가까운 콜레스테롤의 감소가 5x1012 GC/kg 및 5x1011 GC/kg에서 이루어졌지만 (qPCR 역가를 기반으로 한 용량), 통계학적 유의미성은 더 높은 용량에서만 이루어졌다.
관찰된 감소된 GGSMD은 마우스 ApoB에 대한 인간 LDLR의 감소된 친화성에 기여하였다. 이 문제를 우회하기 위하여, 인간 ApoB100을 발현하는, 따라서 인간 연구와 관련된 인간 LDLR과의 인간 apoB100의 상호작용을 더 확실하게 모델로 한 LAHB 마우스 모델을 사용하여 연구를 반복하였다. 두 스트레인 (DKO 대비 LAHB)의 수컷 마우스들은 3가지 벡터 용량 중 하나의 AAV8.TBG.hLDLR (qPCR 역가를 기준으로 0.5x1011 GC/kg, 1.5x1011 GC/kg 및 5.0x1011 GC/kg)을 꼬리 정맥 주사로 받았다. 각 집단으로부터의 동물들을 0일 (벡터 투여 전), 7일째 및 21일째에 출혈시켜서 혈청 콜레스테롤 수준의 평가를 수행하였다. 인간 LDLR은 DKO 마우스에서 mLDLR에 비교하여 LAHB 마우스에서 훨씬 더 효과적이었다: 혈청 콜레스테롤의 30% 감소가 1.5x1011 GC/kg의 용량에서 이루어졌으며, DKO 동물에서 마우스 LDLR 구성물의 이전 연구들로 이루어진 것과 동일한 효능이었다 (Kassim et al. 2013, Hum Gene Ther 24(1):19-26).
7.4.3. HoFH의 마우스 모델에서 AAV8.TBG.mLDLR 및 AAV8.TBG.hLDLR의 비-임상 약물학/독물학 연구
6 내지 22주령의 수컷 및 암컷 DKO 마우스들 (n = 280, 140마리 수컷 및 140마리 암컷)은 3가지 벡터 용량 중 하나의 AAV8.TBG.mLDLR (7.5x1011 GC/kg, 7.5x1012 GC/kg, 6.0x1013 GC/kg) 또는 한 용량의 의도적인 유전자 요법 벡터 AAV8.TBG.hLDLR (6.0x1013 GC/kg)을 꼬리 정맥 주사로 받았다. 동물들은 하기 섹션 8.4.1.에서 기술될 oqPCR 적정법을 사용하여 체중 킬로그램당 게놈 복사물 (GC)을 기준으로 투약받았다. 동물의 추가 집단은 비히클 대조군으로서 PBS를 받았다. 각 집단으로부터의 동물들을 3일, 14일, 90일 및 180일째에 희생시키고, 혈액을 수집하여 혈청 콜레스테롤 수준을 평가하였다 (도 4).
처리된 마우스의 모든 그룹에서 모든 부검 시점에서 콜레스테롤의 신속하고 유의미한 감소가 관찰되었다. 이런 감소는 초기 시점에서는 저용량의 벡터에서 수컷보다 암컷에서 더 적은 것으로 나타났지만, 이런 차이는 시간이 감에 따라 줄어들었고 결국에는 성별간에 검출할만한 차이가 없었다. 각 그룹은 동시 부검 시점에서 PBS 대조군에 비해 적어도 30%의 혈청 콜레스테롤의 통계학적으로 유의미한 감소를 증명하였다. 그러므로, 이 연구를 기반으로 한 MED의 측정은 ≤ 7.5x1011 GC/kg이다.
7.4.4. 동형접합성 가족성 고콜레스테롤혈증의 마우스 모델에서 AAV8.TBG.hLDLR의 효능 연구
12 내지 16주령의 수컷 DKO 마우스 (n=40)를 4가지 용량 중 하나 (1.5x1011 GC/kg, 5.0x1011 GC/kg, 1.5x1012 GC/kg, 5.0x1012 GC/kg)의 AAV8.TBG.hLDLR로 IV 투여하였다 (oqPCR 적정법을 기반으로 한 용량). 동물들을 0일 (벡터 투여 전), 7일 및 30일째에 출혈시켜서 혈청 콜레스테롤을 평가하였다 (도 5). 콜레스테롤의 신속하고 유의미한 감소를, ≥ 5.0x1011 GC/kg으로 처리한 마우스 그룹에서 7일 및 30일째에 관찰하였다. 이 연구를 기반으로 한 MED의 측정은 1.5x1011 GC/kg 내지 5.0x1011 GC/kg이다.
7.5. 레서스 원숭이에서 LDLR+/- 고지방 식이요법에 미치는 AAV8.TBG.rhLDLR의 효과
FH 레서스 원숭이에서 AAV8-LDLR 유전자 전달을 평가하기 위하여 디자인한 연구를 수행하였다. 지방-공급 또는 일반식 공급 형 레서스 원숭이 중 하나에 1013 GC/kg의 AAV8.TBG.rhAFP (대조군 벡터; qPCR 적정법을 기반으로 한 용량)의 투여 후에, 아스파테이트 아미노트란스페라제 (AST) 또는 알라닌 아미노트란스페라젠 (ALT) 값의 상승은 보이지 않았다. 이것은 AAV8 캡시드 자체가 염증성 또는 상해성 간 과정을 촉발시키는 데 기여하지 않는 것을 시사한다.
7.6. HoFH의 마우스 모델에서 AAV8.TBG.hLDLR의 파일럿 생체분포 연구
HoFH에 대한 유전자 요법의 안전성 및 약물역학적 특성을 평가하기 위하여, 파일럿 생체분포 (BD) 연구를 DKO 마우스에서 수행하였다. 이 연구들은 두 가지 경로: 1) 꼬리 정맥에의 IV 주입 또는 2) 간문맥 내 주입 중 하나를 통해 5x1012 GC/kg (qPCR 적정법을 기반으로 한 용량)의 AAV8.TBG.hLDLR 벡터를 전신적으로 투여받은 5마리의 암컷 DKO 마우스에서 벡터 분포 및 지속성을 조사하였다. 두 상이한 시점 (3일 및 28일)에서, 조직의 패널을 수득하였고 총 세포 DNA를 수득한 조직으로부터 추출하였다. 이 파일럿 연구에서, IV 및 간문맥내 경로 둘 다 비슷한 BD 프로파일을 초래하였고, 그것은 환자 및 동물에서 말초 정맥을 통해 유전자 요법 벡터를 주입하는 것에 대한 근거를 지지한다.
7.7. 독물학
HoFH에 대한 유전자 요법의 잠재적 독성을 평가하기 위하여, 약물학/독물학 연구를 DKO 마우스 (HoFH의 마우스 모델), 및 야생형 및 LDLR+/- 레서스 원숭이에서 수행하였다. 연구는 일반식-공급 야생형 및 LDLR+/- 레서스 원숭이에서 독성과 관련된 벡터의 LDLR 도입유전자 발현의 역할의 조사, HoFH의 마우스 모델에서 AAV8.TBG.mLDLR 및 AAV8.TBG.hLDLR의 약물학/독물학 연구, 및 HoFH의 마우스 모델에서 AAV8.TGB.hLDLR의 비-임상 생체분포의 조사를 포함한다. 이 연구들을 하기에서 상세하게 기술한다.
7.8. 일반식-공급 야생형 및 LDLR+/- 레서스 원숭이에서 독성과 관련된 벡터의 LDLR 도입유전자 발현의 역할을 조사하는 비-임상 연구
4마리의 야생형 및 4마리의 LDLR+/- 레서스 원숭이에게 1.25x1013 GC/kg의 AAV8.TBG.hLDLR을 IV로 투여하고 (oqPCR 적정법을 기반으로 한 용량), 비 인간 영장류 (NHP)를 벡터 투여 후 최대 1년 동안 모니터링하였다. 4마리의 동물 (2마리의 야생형 및 2마리의 LDLR+/-)을 벡터 투여 후 28일째에 부검하여 급성 벡터-관련 독성 및 벡터 분포를 평가하였고 4마리의 동물 (2마리의 야생형 및 2마리의 LDLR+/-)을 벡터 투여 후 364/365일째에 부검하여 장기간 벡터-관련 병리 및 벡터 분포를 평가하였다. 야생형 및 LDLR+/- 원숭이의 각 집단은 2마리의 수컷과 2마리의 암컷을 포함하였다.
동물들은 장기간 또는 단기간 임상 후유증 없이 벡터 주입을 잘 견디었다. 생체분포 연구는 시간이 경과함에 따라 감소된, 훨씬 더 적은, 그러나 여전히 검출 가능한 간 외부 분포를 가진 간의 고수준의 안정한 표적화를 증명하였다. 이 데이터들은 효능에 대한 표적 기관인 간 또한 잠재적 독성의 가장 가능성이 있는 공급원임을 시사하였다. 벡터 투여 후 28일과 364/365일째에 수행한 부검에서 수득된 조직의 상세한 리뷰는 간에서 일부의 최소 내지 중간 발견 및 LDLR+/- 원숭이에서 아테롬성 동맥경화증의 약간의 증거를 드러냈다. 간 병리의 성질 및 유사한 병리가 두 마리의 미처리 야생형 동물 중 한 마리에서 관찰되었다는 사실은 병리학자에게 그것들이 테스트물과 관계가 없음을 시사하였다.
한 마리의 동물은 벡터 투여 전에 알라닌 아미노트란스페라제 (ALT)의 지속적인 상승을 나타냈는데, 그것은 벡터가 투여된 후에도 58 내지 169 U/L의 범위의 수준에서 계속되었다. 나머지 동물들은 트란스아미나제가 상승되지 않거나 아스파테이트 아미노트란스페라제 (AST) 및 ALT에서 단지 일시적이고 저수준의 증가만이 있으며, 결코 103 U/L을 초과하지 않는 것을 증명하였다. 가장 일관된 비정상은 벡터 주입 후 나타났는데, 그것들이 테스트물과 관련되었음을 시사한다. 인간 LDLR 또는 AAV8 캡시드에 대한 T 세포의 활성화를 AST/ALT 증가와의 상관관계에 대해 평가하였다. 도 6은 관련된 발견을 증명한 3마리의 선택된 동물에서 AAV 캡시드 ELISPOT 데이터 및 혈청 AST 수준을 나타낸다. 단지 한 마리의 동물만이 상관관계를 보였는데, 103 U/L로의 AST의 증가는 캡시드에 반한 T 세포의 출현에 상응하고 (도 6, 동물 090-0263); 캡시드 T 세포 반응은 지속적인 한편 AST는 정상 범위로 즉시 복귀되었다.
캡시드 및 도입유전자-특이적 T 세포의 존재에 대한 조직-유래 T 세포의 분석은 간 유래 T 세포가 후기 시점에 의해 두 유전형 (야생형 및 LDLR+/-)으로부터의 캡시드에 반응성이 된 것으로 보인 한편 인간 LDLR에 대한 T 세포는 이 후기 시점에서 LDLR+/- 동물에서 검출되었다. 이것은 PBMC가 표적 조직에서 T 세포 구획을 반영하지 못하는 것을 시사한다. 28일 및 364/365일째에 수득한 간 조직을 RT-PCR에 의한 도입유전자의 발현에 대해 분석하였고 T 세포의 임상 병리 또는 출현의 비정상에 의해 영향을 받는 것으로 나타났다.
야생형이나 LDLR+/- 동물이나 어느 것도 일반식 식이요법에서 고콜레스테롤혈증을 나타내지 않았다. 용량-제한 독성 (DLT)을 1.25x1013 GC/kg (oqPCR을 기반으로 함0의 용량에서 관찰하지 못하였는데, 최대 내성 용량 (MTD)이 이 용량과 같거나 이 용량보다 클 것이라는 것을 함축한다. 트란스아미나제의 테스트물 관련 상승을 관찰하였는데, 그것은 낮았고 일시적이었지만 그럼에도 불구하고 존재하였다. 따라서, 무영향관찰용량 (no-observed-adverse-effect-level, NOAEL)은 본원의 실시예 1에서 평가된 단일 고용량보다 적다.
7.9. HoFH의 마우스 모델에서 AAV8.TBG.mLDLR 및 AAV8.TBG.hLDLR의 비-임상 약물학/독물학 연구
이 연구를 DKO 마우스에서, 이 스트레인이 1) 독성과 나란히 개념 입증 효능의 평가, 및 2) LDLR의 결핍 및 관련된 이상지질혈증 및 그것의 후유증, 예컨대 지방증과 관련된 임의의 병리의 세팅에서 벡터-관련 독성의 평가를 허용할 것이기 때문에 수행하였다.
연구를, 실시예 1에서 설명된 것과 같이, HoFH를 가진 인간 대상체에게 투여하기 위한 최고 용량보다 8-배 더 높은, 최고 용량의 AAV8.TBG.hLDLR을 테스트하기 위해 디자인하였다. 쥐과의 LDLR을 발현하는 벡터의 버전을 이 고용량에서, 뿐만 아니라 두 개의 더 낮은 용량에서 테스트하여 독성 파라미터, 뿐만 아니라 콜레스테롤의 감소에 대한 용량의 효과의 형가를 제공하였다. 용량-반응 실험을 인간 LDLR 벡터를 사용하여 인간에서 관찰될 수 있을 독성 및 효능을 더 잘 반영할 쥐과의 LDLR을 발현하는 벡터로 수행하였다.
이 연구에서, 6 내지 22주령의 수컷 및 암컷 DKO 마우스에 AAV8.TBG.mLDLR의용량 (7.5x1011 GC/kg, 7.5x1012 GC/kg 및 6.0x1013 GC/kg) 중 하나 또는 6.0x1013 GC/kg의 벡터 (AAV8.TBG.hLDLR)(oqPCR 적정법을 기반으로 한 용량)를 투여하였다. 동물들을 벡터 투여 후 3일, 14일, 90일, 및 180일째에 부검하였다; 이 시간들을 급성 및 만성 독성뿐 아니라 테스트물의 벡터 발현 프로파일을 포획하기 위해 선택하였다. 도입유전자 발현의 효능을 혈청 콜레스테롤 수준의 측정에 의해 모니터링하였다. 동물들을 포괄적인 임상 병리, 벡터에 대한 면역 반응 (사이토카인, AAV8 캡시드에 대한 NAb, 및 캡시드와 도입유전자 둘 다에 반한 T 세포 반응)에 대해 평가하였고, 부검시 포괄적인 조직병리학적 조사를 위해 조직을 수득하였다.
이 연구로부터의 핵심 독물학 발견은 다음과 같다:
* 트란스아미나제: 비정상은 1 내지 4x ULN 범위의 간 기능 테스트 AST 및 ALT의 상승에 제한되었고 주로 모든 용량의 쥐과의 LDLR 벡터의 90일째에 발견되었다. 고용량의 인간 LDLR 벡터를 투여한 그룹에서는 소수의 수컷 동물에서 <2x ULN의 ALT를 제외하고는 트란스아미나제의 상승은 없었다. 마우스 벡터와 관련된 비정상은 가벼운 정도였고 용량-의존적이지 않았으며, 그러므로 벡터에 관련된 것으로 여겨지지 않았다. 본질적으로 고용량 인간 벡터와 관련된 발견은 없었다. 이 발견들을 기반으로 치료 관련된 독성의 증거는 없었고, 그것은 이 기준을 기반으로 한 무영향관찰용량 (NOAEL)이 6.0x1013 GC/kg인 것을 의미한다.
* PBS가 투여된 동물들은 평가된 모든 기준에 따라 최소 및/또는 가벼운 비정상의 증거를 나타냈다. 치료 관련 병리의 평가에서 본 발명자들은 PBS 주입된 동물에서 발견된 것 이상의 가벼운 것으로 분류한 임의의 발견에 초점을 맞추었다.
* 가벼운 담관 이상증식 및 사인파모양 세포 이상증식을 마우스 및 인간 LDLR 벡터의 고용량의 암컷 마우스에서 관찰하였다. 이것은 고용량에서만 관찰된 벡터 관련 효과를 대표한다.
* 소엽중심성 비대는 단지 수컷에서 고용량이 아닌 벡터에서 가벼운 정도였고, 그것은 벡터와 관련되지 않은 것으로 논란이 된다.
* 최소한의 괴사가 고용량의 인간 LDLR 벡터에서 180일째에 1/7마리 수컷 및 3/7마리 암컷에서 나타났다.
* 고용량의 벡터에서 가벼운 담관 및 사인파모양 이상증식의 발견, 및 고용량의 인간 LDLR 벡터에서 최소한의 괴사의 몇몇 실시예를 기반으로, 이 기준들을 기반으로 한 NOAEL은 7.5x1012 GC/kg과 6.0x1013 GC/kg 사이이다.
한 가지 주지할만한 발견은 독성이 인간 LDLR 벡터로 처리된 것보다 마우스 LDLR 벡터로 처리된 DKO 마우스에서 더 나쁘지 않았다는 것이었고, 그것은 인간 LDLR이 마우스 도입유전자보다 T 세포의 관점에서 더 면역원성이 강한 것인 사례였을 수 있었다. ELISPOT 연구는 인간 도입유전자를 발현하는 고용량의 벡터가 투여된 마우스에서 LDLR-특이적 T 세포의 약간의 활성화를 보였지만, 그것들은 낮았고 독성 데이터를 지지하는 제한된 수의 동물에서만 있었으며, 숙주 반응의 메커니즘이 안전성 관심사에는 기여하지 않은 것으로 여겨지는 것을 시사하였다.
결론적으로, 용량-제한 독성은 없었으며, 그것은 최대로 허용된 용량이 6.0x1013 GC/kg이었던 시험된 최고 용량보다 높았음을 의미한다. 최고 용량에서 간 병리의 가볍고 가역적인 발견을 기반으로, NOAEL은 간에서 가벼운 가역적 병리가 관찰되는 6.0x1013 GC/kg에서 벡터 관련 발견의 명백한 표시가 없는 7.5x1012 GC/kg 사이에서 왔다갔다 한다.
7.10. HoFH의 마우스 모델에서 AAV8.TGB.hLDLR의 비-임상적 생체분포
6 내지 22주령의 수컷 및 암컷 DKO 마우스에 실시예 1 f에서 인간 대상체를 테스트하기 위한 최고 용량인 7.5x1012 GC/kg (oqPCR 적정법에 의해 측정된 용량)의 을 투여하였다. 동물들을 벡터 투여 후 3일, 14일, 90일 및 180일째에 생체분포 평가를 위해 부검하였다. 혈액 외에, 20개의 기관을 수득하였다. 기관의 벡터 게놈의 분포를 수득된 총 게놈 DNA의 정량적, 민감성 PCR 분석에 의해 평가하였다. 각 조직의 한 샘플은 PCR 검정 반응의 타당성을 평가하기 위하여, 벡터 서열의 공지량을 포함하여, 대조군 DNA의 스파이크를 포함하였다.
간의 벡터 GC 수를 다른 기관/조직에서보다 간에서 실질적으로 더 높았고, 그것은 AAV8 캡시드의 높은 간친화성 특성과 일치한다. 예를 들어, 간에서의 벡터 게놈 복사물은 90일째에 임의의 다른 조직에서 발견된 것보다 적어도 100배 더 컸다. 첫 번째 3개의 시점에서 수컷 또는 암컷 마우스들 사이에 유의할만한 차이는 없었다. GC 수는 90일째가 될 때까지 간에서 시간이 경과함에 따라 감소하였고, 그런 다음 안정화되었다. 유사한 감소 경향이 모든 조직에서 관찰되었지만 벡터 복사물 수의 감소는 더 높은 세포 전환율을 가진 조직에서 더 빨랐다. 낮지만 검출 가능한 수준의 벡터 게놈 복사물이 두 성별의 생식샘 및 뇌에 존재하였다.
DKO 마우스에서 AAV8.TBG.hLDLR의 생체분포는 AAV8로 얻어진 공개된 결과와 일치하였다. 간은 IV 주입 후 유전자 전달의 일차 표적이고 간의 게놈 복사물은 시간이 경과함에 따라 유의미하게 감소하지 않는다. 다른 기관들은 벡터 전달에 대해 표적화되지만, 이 비-간 조직들에서의 유전자 전달 수준은 시간이 경과함에 따라 실질적으로 더 낮고 감소한다. 그러므로, 여기서 제시된 데이터는 평가될 일차 기관 시스템이 간인 것을 시사한다.
7.11. 비-임상 안전성 연구로부터의 결론
레서스 원숭이 및 DKO 마우스 연구는 고용량 벡터가 NHP에서 트란스아미나제의 일시적인 상승에 의해, 및 마우스에서 가벼운 담관 및 사인파모양 비대의 일시적인 출현에 의해 저수준, 일시적, 및 무증상의 간 병리 사건과 관련되는 것을 확인해주었다. 벡터로 인한 것으로 여겨지는 다른 독성은 관찰되지 않았다.
원숭이에서 1.25x1013 GC/kg 및 DKO 마우스에서 6x1013 GC/kg과 같이 높은 용량에서 관찰된 DLT는 없었다. NOAEL의 측정은 원숭이에서 트란스아미나제의 상승 및 DKO 마우스에서 조직병리로 반영되는 바와 같이 주로 간 독성에 초점이 맞춰진다. 이것은 원숭이에서 1.25x1013 GC/kg 미만 및 DKO 마우스에서 6x1013 GC/kg 미만, 그러나 7.5x1012 GC/kg보다 큰 NOAEL로 이어진다. 용량은 oqPCR 적정법을 기반으로 하였다.
7.12. 인간 치료를 지지하기 위한 비-임상 데이터의 전체 평가
임상 연구를 위한 용량 선택 및 디자인을 확인해준 약물학 및 독물학 연구로부터 드러난 핵심적인 발견들은 다음과 같다:
이 데이터들을 기반으로, 본 발명자들은 2개의 용량에 도달하였다: 2.5x1012 GC/kg의 단일 용량 또는 7.5x1012 GC/kg의 단일 용량 (oqPCR 적정법을 기반으로 한 용량). 임상에서 테스트하기 위해 제안된 최고 용량은 원숭이 독물학 연구에서 테스트된 최고 용량보다 낮고 DKO 마우스에서 테스트된 최고 용량보다 8-배 더 낮다 - 이것들 중 어느 것도 MTD인 것으로 여겨지지 않았다. MED보다 적어도 5-배 높은 용량이 제안되는데, 그것은 저용량 집단에 참여한 환자들이 잠재적으로 약간의 유익을 가질 수 있을 것임을 시사한다. 더 낮은 용량 또한 DKO 마우스에서의 NOAEL 용량보다 대략 3-배 더 낮고 원숭이에서 테스트된 용량보다 5-배 더 낮다.
8. 실시예 3: AAV8.TBG.hLDLR의 제조
AAV8.TBG.hLDLR 벡터는 AAV 벡터 활성 성분 및 제제 완충제로 구성된다. 외부 AAV 벡터 성분은 혈청형 8, 1:1:18의 비율의 3개의 AAV 바이러스 단백질, VP1, VP2 및 VP3의 60개의 복사물로 구성되는 T = 1 이십면체 캡시드이다. 캡시드는 단일-가닥 DNA 재조합 AAV (rAAV) 벡터 게놈을 함유한다 (도 7). 게놈은 2개의 AAV 역 말단 반복부 (ITR)가 양옆에 있는 인간 저밀도 리포단백질 수용체 (LDLR) 도입유전자를 함유한다. 인핸서, 프로모터, 인트론, 인간 LDLR 암호화 서열 및 폴리아데닐화 (폴리A) 신호는 인간 LDLR 도입유전자를 포함한다. ITR은 벡터 제조 중에 게놈의 복제 및 포장에 기여하는 유전사 요소들이며 rAAV를 생성하기 위해 필요한 유일한 바이러스 시스 요소이다. 인간 LDLR 암호화 서열의 발현은 간세포-특이적 티록신-결합 글로불린 (TBG) 프로모터로부터 구동된다. 알파 1 마이크로글로불린/비쿠닌 인핸서 요소의 2개의 복사물이 TBG 프로모터 앞에 있어서 프로모터활성을 자극한다. 키메라 인트론은 추가로 발현을 향상시키기 위해 존재하고 인간 LDLR mRNA 전사물의 종결을 중재하기 위해 토끼 베타 글로빈 폴리A 신호가 포함된다. 벡터는 제제 완충액 중의 AAV8.TBG.hLDLR 벡터의 현탁액으로서 공급된다. 제제 완충액은 180 mM NaCl, 10 mM 인산 나트륨, 0.001% 폴록사머 188, pH 7.3이다.
벡터 제조 및 벡터의 특성화에 대한 상세를 하기 섹션에서 기술한다.
8.1. AAV8.TBG.hLDLR을 제조하기 위해 사용된 플라스미드
AAV8.TBG.hLDLR의 제조에 사용된 플라스미드는 다음과 같다:
8.1.1. 시스 플라스미드 (벡터 게놈 발현 구성물):
인간 LDLR 발현 카세트를 함유하는 pENN.AAV.TBG.hLDLR.RBG.KanR (도 8). 이 플라스미드는 rAAV 벡터 게놈을 암호화한다. 발현 카세트에 대한 폴리A 신호는 토끼 β 글로빈 유전자로부터 유래한다. 알파 1 마이크로글로불린 /비쿠닌 인핸서 요소의 2개의 복사물이 TBG 프로모터 앞에 있다.
AAV8.TBG.hLDLR의 제조에 사용된 시스 플라스미드를 생성하기 위하여, 인간 LDLR cDNA를 AAV2 ITR-함유 구성물, pENN.AAV.TBG.PI에 클로닝하여 pENN.AAV.TBG.hLDLR.RBG를 생성하였다. pENN.AAV.TBG.PI의 플라스미드 골격은 원래 pKSS-기반 플라스미드인 pZac2.1로부터 유래하였다. pENN.AAV.TBG.hLDLR.RBG의 암피실린 내성 유전자를 절제하여 카나마이신 유전자로 대체하여 pENN.AAV.TBG.hLDLR.RBG.KanR을 생성하였다. 인간 LDLR cDNA의 발현은 키메라 인트론을 가진 TBG 프로모터 (Promega Corporation, Madison, Wisconsin)로부터 구동된다. 발현 카세트에 대한 폴리A 신호는 토끼 β 글로빈 유전자로부터 유래된다. 알파 1 마이크로글로불린 /비쿠닌 인핸서 요소의 2개의 복사물이 TBG 프로모터 앞에 있다.
서열 요소들의 설명
1. 역 말단 반복부 (ITR): AAV ITR (GenBank # NC001401)은 양 단부가 동일하지만, 반대 방향에서 발견되는 서열들이다. AAV2 ITR 서열은 둘 다, AAV 및 아데노바이러스 (ad) 헬퍼 기능이 트란스로 제공될 때, 벡터 DNA 복제 기원 및 벡터 게놈에 대한 포장 신호로서 작용한다. 그 자체로, ITR 서열은 벡터 게놈 복제 및 포장에 필요한 유일한 시스 작용 서열들을 대표한다.
2. 인간 알파 1 마이크로글로불린/비쿠닌 인핸서 (2개의 복사물; 0.1Kb); Genbank # X67082) 이 간 특이적 인핸서 요소는 간-특이성을 빌려주고 TBF 프로모터로부터의 발현을 향상시키는 작용을 한다.
3. 인간 티록신-결합 글로불린 (TBG) 프로모터 (0.46Kb; Genbank # L13470). 이 간세포-특이적 프로모터는 인간 LDLR 암호화 서열의 발현을 구동한다.
4. 인간 LDLR cDNA (2.58Kb; Genbank # NM000527, 완전한 CDS). 인간 LDLR cDNA는 예상된 분자량이 95 kD이고 SDS-PAGE에 의한 외관 분자량이 130 kD인 860개의 아미노산의 저밀도 리포단백질 수용체를 암호화한다.
5. 키메라 인트론 (0.13Kb; Genbank # U47121; Promega Corporation, Madison, Wisconsin). 키메라 인트론은 인간 β-글로빈 유전자의 제 1 인트론으로부터의 5'-도너 부위 및 면역글로불린 유전자 중쇄 가변 영역의 리더와 바디 사이에 위치한 인트론으로부터의 분지 및 3'-수용체 부위로 구성된다. 발현 카세트에서 인트론의 존재는 핵으로부터 세포질로의 mRNA의 수송을 용이하게 해줌으로써, 번역을 위한 mRNA의 꾸준한 수준의 축적을 향상시키는 것으로 밝혀졌다. 이것은 유전자 발현의 증가된 수준을 중재하기 위해 의도된 유전자 벡터의 통상적인 특징이다.
6. 토끼 베타-글로빈 폴리아데닐화 신호: (0.13Kb; GenBank # V00882.1). 토끼 베타-글로빈 폴리아데닐화 신호는 항체 mRNA의 효과적인 폴리아데닐화를 위한 시스 서열을 제공한다. 이 요소는 긴 폴리아데닐 꼬리의 첨가가 이어지는 발생기 전사물의 3' 단부에서의 특이적인 절단 사건인 전사 종결에 대한 신호로서 기능한다.
8.1.2. 트란스 플라스미드 (포장 구성물): pAAV2/8(Kan), AAV2 rep 유전자 및 AAV8 cap 유전자를 함유함 (도 9).
AAV8 트란스 플라스미드 pAAV2/8(Kan)은 AAV2 복제효소 (rep) 유전자 및 비리온 단백질, VP1, VP2 및 VP3을 암호화하는 AAV8 캡시드 (cap) 유전자를 발현한다. AAV8 캡시드 유전자 서열을 원래 레서스 원숭이 (GenBank 승인 AF513852)의 심장 DNA로부터 분리하였다. 키메라 포장 구성물을 생성하기 위하여, AAV2 rep 및 cap 유전자를 함유하는 플라스미드 p5E18을 XbaI 및 XhoI으로 소화시켜서 AAV2 cap 유전자를 제거하였다. AAV2 cap 유전자를 그런 다음 AAV8 cap 유전자의 2.27Kb SpeI/XhoI PCR 단편으로 대체하여 플라스미드 p5E18VD2/8을 생성하였다 (도 9a). 정상적으로 rep 발현을 구동하는 AAV p5 프로모터를 이 구성물에서 rep 유전자의 5' 단부로부터 cap 유전자의 3' 단부로 재위치시킨다. 이 배열은 벡터 수율을 증가시키기 위하여 rep의 발현을 하향-조절하는 작용을 한다. p5E18의 플라스미드 골격은 pBluescript KS로부터 유래한다. 최종 단계로서, 암피실린 내성 유전자를 카나마이신 내성 유전자로 대체하여 pAAV2/8(Kan)을 생성하였다 (도 9B). 전체 pAAV2/8(Kan) trans 플라스미드를 직접 서열분석에 의해 확인하였다.
8.1.3. 아데노바이러스 헬퍼 플라스미드: pAdDF6(Kan)
플라스미드 pAdDF6(Kan)은 15.7Kb의 크기이며 AAV 복제에 중요한 아데노바이러스 게놈, 즉 E2A, E4 및 VA RNA의 영역을 함유한다. pAdDF6(Kan)은 임의의 추가의 아데노바이러스 복제 또는 구조적 유전자를 암호화하지 못하며 복제에 필요한 시스 요소, 예컨대 아데노바이러스 ITR을 함유하지 않고, 그러므로, 감염성 아데노바이러스가 생성될 것으로 예상되지 않는다. 아데노바이러스 E1 필수 유전자 기능은 rAAV 벡터가 제조되는 HEK293 세포에 의해 공급된다. pAdDF6(Kan)은 Ad5 (pBHG10, pBR322 기반 플라스미드)의 E1, E3 결실된 분자 클론으로부터 유래하였다. 결실을 Ad5 DNA에 도입하여 비필수 아데노바이러스 암호화 영역을 제거하고 그 결과의 ad-헬퍼 플라스미드에서 32Kb로부터 12Kb로 아데노바이러스 DNA의 양을 감소시켰다. 마지막으로, 암피실린 내성 유전자를 카나마이신 내성 유전자로 대체하여 pAdDF6(Kan)을 생성하였다 (도 10). DNA 플라스미드 서열분석을 Qiagen Sequencing Services, Germany에 의해 수행하였고, 에 대한 기준 서열과 다음의 아데노바이러스 요소들 사이에서 100% 상동성을 나타냈다: p1707FH-Q: E4 ORF6 3.69-2.81Kb; E2A DNA 결합 단백질 11.8-10.2Kb; VA RNA 영역 12.4-13.4Kb.
상기 기술한 시스, 트란스 및 ad-헬퍼 플라스미들은 각각 카나마이신-내성 카세트를 함유하고, 그러므로 β-락탐 항체는 그것들의 제조에 사용되지 않는다.
8.1.4. 플라스미드 제조
벡터 제조에 사용한 모든 플라스미들은 Puresyn Inc. (Malvern, PA)에 의해 제조되었다. 과정에서 사용된 모든 성장 배지는 동물이 없다. 과정에 사용된 모든 성분은, 발효 플라스크, 용기, 막, 수지, 칼럼, 관, 및 플라스미드와 접촉하게 되는 임의의 성분을 포함하여, 단일 플라스미드에 대해 전용이고 BSE-유리인 것으로 인증된다. 공유되는 성분은 없고 일회용품들이 적절하게 사용된다.
8.2. 세포 뱅크
AAV8.TBG.hLDLR 벡터를 전체적으로 특성화된 마스터 세포 뱅크로부터 유래된 HEK293 작업 세포 뱅크로부터 제조하였다. 두 세포 뱅크의 제조 및 테스트의 상세는 하기에 나타낸다.
8.2.1. HEK293 마스터 세포 뱅크
HEK293 마스터 세포 뱅크 (MCB)는 일차 인간 배아 신장 세포 (HEK) 293의 유도체이다. HEK293 세포주는 전단된 인간 아데노바이러스 타입 5 (Ad5) DNA에 의해 형질전환된 영구적 세포주이다 (Graham et al., 1977, Journal of 유전자ral Virology 36(1):59-72). HEK293 MCB는 미생물 및 바이러스 오염에 대해 광범위하게 테스트되었다. HEK293 MCB는 현재 액체 질소 중에 보관된다. 인간, 유인원, 소 및 돼지 기원의 특이적인 병원체의 존재를 증명하기 위하여 추가의 테스트를 HEK293 MCB에 대해 수행하였다. HEK293 MCB의 인간 기원을 동종효소 분석에 의해 증명하였다.
종양형성 테스트를 누드 (nu/nu) 무흉선 마우스에서 세포 현탁액의 피하 주사 후에 종양 형성을 평가함으로써 또한 HEK293 MCB에서 수행하였다. 이 연구에서, 섬유육종이 10마리의 양성 대조군 마우스 중 10마리에서 주사 부위에서 진단되었고 암종을 10마리의 테스트물 마우스 중 10마리에서 주사 부위에서 진단하였다. 음성 대조군 마우스 중 어느 것에서도 신생물형성은 진단되지 않았다. HEK293 MCB L/N 3006-105679를 또한 돼지의 써코바이러스 (Porcine Circovirus (PCV)) 타입 1 및 2의 존재에 대해 테스트하였다. MCB는 PCV 타입 1 및 2에 대해 음성인 것으로 나타났다.
8.2.2. HEK293 작업 세포 뱅크
HEK293 작업 세포 뱅크 (WCB)를 유럽 약전 논문에 따라 적합성이 증명된 뉴질랜드 근원의 태아 우혈청, FBS (Hyclone PN SH30406.02)를 사용하여 제조하였다. HEK293 WCB를 시드 물질로서 1 바이알 (1 mL)의 MCB를 사용하여 수립하였다. 특성화 테스트를 수행하였고 테스트 결과를 표 4.1에 열거한다.

8.3. 벡터 제조
벡터 제조 과정의일반적 설명을 하기에 제공하며 또한 도 11에서 흐름도에도 반영한다.
8.3.1. 벡터 생성 과정 (상류 과정)
8.3.1.1. T-플라스크 (75cm2)로의 HEK293 WCB 세포 배양의 개시
1 mL에 107 세포를 함유하고 있는 WCB로부터의 1 바이알의 HEK293 세포를 37℃에서 해동하고 10% 태아 우혈청이 첨가된 DMEM (DMEM HG/10% FBS) 고글루코오스를 함유하고 있는 75 cm2 조직 배양 플라스크에서 시딩하였다. 그런 다음 세포를 37℃/5% CO2 인큐베이터에 넣고, 약 70% 집밀도로 성장시키면서 매일 세포 성장을 평가하기 위하여 직접 육안 및 현미경으로 검사하였다. 이 세포들을 계대 1로 지정하고, 벡터 생합성을 위해 세포 시드 트레인을 생성하기 위하여 최대 약 10주 동안 하기 기술하는 것과 같이 계대시킨다. 계대 횟수를 각 계대때에 기록하고 세포를 계대 20 후에 중단한다. 만약 추가의 세포가 벡터 생합성에 필요하다면, 새로운 HEK293 세포 시드 트레인을 HEK293 WCB의 또 다른 바이알로부터 시작한다.
8.3.1.2. 약 2개의 T-플라스크 (225 cm2)로의 세포의 계대
T75 플라스크에서 성장하는 HEK293 세포가 약 70% 집밀도가 될 때, 세포를 플라스크의 표면으로부터 재조합 트립신 (TrypLE)을 사용하여 탈착시키고, DMEM HG/10% FBS를 함유하고 있는 2개의 T225 플라스크에 시딩한다. 세포를 인큐베이터에 놓고 약 70% 집밀도로 성장시킨다. 세포를 육안 검사에 의해 및 현미경을 사용하여 세포 성장, 오염물의 부재 및 일관성에 대해 모니터링한다.
8.3.1.3. 약 10개의 T-플라스크 (225 cm2)로의 세포의 계대
T225 플라스크에서 성장하는 HEK293 세포가 약 70% 집밀도가 될 때, 세포를 재조합 트립신 (TrypLE)을 사용하여 탈착시키고, DMEM HG/10% FBS를 함유하고 있는 10개의 225 cm2 T- 플라스크에 플라스크당 약 3x106 세포의 밀도로 시딩한다. 세포를 37℃/5% CO2 인큐베이터에 넣고 약 70% 집밀도로 성장시킨다. 세포를 직접 육안 검사에 의해 및 현미경을 사용하여 세포 성장, 오염물의 부재, 및 일관성에 대해 모니터링한다. 세포를 세포 시드 트레인을 유지하고 계속되는 벡터 배치의 제조를 지지하기 위한 팽창에 대해 세포를 제공하기 위해 T225 플라스크에서 연속 계대에 의해 유지한다.
8.3.1.4. 약 10개의 롤러 보틀로의 세포의 계대
T225 플라스크에서 성장하는 HEK293 세포가 약 70% 집밀도가 될 때, 세포를 재조합 트립신 (TrypLE)을 사용하여 탈착시키고, 계수한 후 DMEM HG/10% FBS를 함유하고 있는 850cm2 롤러 보틀 (RB)에 시딩한다. 그런 다음 RB를 RB 인큐베이터에 넣고 세포를 약 70% 집밀도로 성장시킨다. RB를 직접 육안 검사에 의해 및 현미경을 사용하여 세포 성장, 오염물의 부재, 및 일관성에 대해 모니터링한다.
8.3.1.5. 약 100개의 롤러 보틀로의 세포의 계대
이전 과정 단계에서 상기에서 기술된 것과 같이 제조된 RB에서 성장하는 HEK293 세포가 약 70% 집밀도가 될 때, 그것들을 재조합 트립신 (TrypLE)을 사용하여 탈착시키고, 계수한 후 DMEM HG/10% FBS를 함유하고 있는 100개의 RB에 시딩한다. 그런 다음 RB를 RB 인큐베이터 (37℃, 5% CO2)에 넣고 약 70% 집밀도로 성장시킨다. 세포를 직접 육안 검사에 의해 및 현미경을 사용하여 세포 성장, 오염물의 부재, 및 일관성에 대해 모니터링한다.
8.3.1.6. 플라스미드 DNA로의 세포의 트랜스펙션
100개의 RB에서 성장하는 HEK293 세포가 약 70% 집밀도가 될 때, 세포를 3개의 플라스미드: AAV 혈청형-특이적 포장 (트란스) 플라스미드, ad-헬퍼 플라스미드, 및 양 옆에 AAV 역 말단 반복부 (ITR)가 있는 인간 LDLR 유전자에 대한 발현 카세트를 함유한 벡터 시스 플라스미드의 각각으로 트랜스펙션한다. 트랜스펙션은 칼슘 포스페이트 방법을 사용하여 수행한다 (플라스미드의 상세에 대해서는 섹션 4.1.1. 참조). RB를 RB 인큐베이터 (37℃, 5% CO2)에 밤새 놓아둔다.
8.3.1.7. 혈청 유리 배지로의 배지 교환
트랜스펙션 후에 100개의 RB를 밤새 인큐베이션한 후에, 트랜스펙션 시약을 함유한 DMEM/10% FBS 배양 배지를 각 RB로부터 흡인에 의해 제거하고 DMEM-HG (FBS 없음)로 대체한다. RB를 RB 인큐베이터로 복귀시켜서 수득할 때까지 37℃, 5% CO2에서 인큐베이션한다.
8.3.1.8. 벡터 수득
RB를 인큐베이터로부터 제거하고 트랜스펙션의 증거 (세포 형태에서 트랜스펙션-유도된 변화, 세포 단층의 탈착)에 대해 및 오염의 임의의 증거에 대해 조사한다. 세포를 각 RB의 교반에 의해 RB 표면으로부터 탈착시킨 후, BioProcess 콘테이너 (BPC)에 연결된 살균된 일회용 깔때기 안으로 부음으로써 수득한다. PBC의 조합한 수득 물질을 '생성물 중간체: 미정제 세포 수득물'로 표지하고 (1) 과정 중의 미생물 오염도 테스트 및 (2) 미생물 오염도, 미코플라스마, 및 우발적인 제제 생성물 방출 테스트를 위해 샘플을 취한다. 미정제 세포 수득물 (CH)로 표지된 생성물 중간체 배치를 추가로 처리할 때까지 2 내지 8℃에서 보관한다.
8.3.2. 벡터 정제 과정 (하류 과정)
통상적인, '플랫폼' 정제 과정을 모든 AAV 혈청형에 대해 사용한 한편 (즉 단계의 동일한 시리즈 및 순서를 통합함), 각 혈청형은 크로마토그래피 수지에 적용된 정화된 세포 용해물을 제조하기 위해 사용된 단계들의 일부 상세 (완충액 조성물 및 pH)에 또한 영향을 미치는 필요조건인, 크로마토그래피 단계를 위한 독특한 조건을 필요로 한다.
8.3.2.1. AAV8 벡터 수득물 농도 및 TFF에 의한 투석여과
미정제 CH를 함유하는 BPC를 인산염-완충 식염수로 평형화된 중공 섬유 (100k MW 컷-오프) TFF 장치의 살균된 저장소의 입구에 연결한다. 미정제 CH를 연동 펌프를 사용하여 TFF 장치에 적용하고 1 내지 2 L로 농축한다. 벡터는 보유되는 (농축됨) 한편 작은 분자량 모이어티 및 완충제는 TFF 필터 기공을 통해 통과하여 버려진다. 그런 다음 수득물을 AAV8 투석여과 완충액을 사용하여 투석여과한다. 투석여과 후에, 농축된 벡터를 5 L BPC에 회수한다. 물질을 '생성물 중간체: 수득 후 TFF'로 표지하고, 과정-내 미생물 오염도 테스트를 위해 샘플을 취한다. 농축된 수득물을 즉시 추가 처리하거나 추가로 처리할 때까지 2 내지 8℃에서 보관한다.
8.3.2.2. 수득물의 미세유동화 및 뉴클레아제 소화
농축되고 투석여과된 수득물에 대해 미세유동화기를 사용하여 개방된 무상 HEK293 세포를 깨트리는 전단을 수행한다. 미세유동화기는 각각의 사용 후 1 N NaOH로 최소 1시간 동안 살균하여, 다음 작동때까지 20% 에틸 알콜올 중에 보관하고, 각각의 사용 전에 WFI로 세정한다. BPC에 함유된 미정제 벡터를 미세유동화기의 살균된 입구부에 부착시키고, 살균된 빈 BPC를 출구부에 부착한다. 미세유동화기에 의해 생성된 기압을 사용하여, 벡터-함유 세포를 미세유동화기 상호작용 챔버 (구불구불한 300 μm 직경의 경로)를 통해 통과시켜서 세포를 용해하고 벡터를 방출시킨다. 미세유동화 과정을 반복하여 세포의 완전한 용해 및 벡터의 고회수율을 보장한다. 미세유동화기를 통한 생성물 중간체의 반복된 통과에 이어서, 유로를 약 500 mL의 AAV8 벤조나제 완충액으로 세정한다. 미세유동화된 벡터를 함유한 5 L의 BPC를 미세유동화기의 출구부로부터 탈착시킨다. 물질을 '생성물 중간체: 최종 미세유동화됨'으로 표지하고, 과정-내 미생물 오염도 테스트를 위해 샘플을 취한다. 미세유동화된 생성물 중간체를 즉시 추가 처리하거나 추가로 처리할 때까지 2 내지 8℃에서 보관한다. 핵산 불순물을 AAV8 입자로부터 100 U/mL Benzonase®의 첨가에 의해 제거한다. BPC의 내용물을 혼합하고 실온에서 적어도 1시간 동안 인큐베이션한다. 뉴클레아제 소화된 생성물 중간체를 추가로 처리한다.
8.3.2.3. 미세유동화된 중간체의 여과
미세유동화되고 소화된 생성물 중간체를 함유한 BPC를 3 μm에서 시작하여 0.45 μm로 작아지는 구배 기공 크기를 가진 카트리지 필터에 연결시킨다. 필터를 AAV 벤조나제 완충액으로 조건화한다. 연동 펌프를 사용하여, 미세유동화된 생성물 중간체를 카트리지 필터를 통해 통과시키고 필터 출구부에 연결된 BPC에 수집한다. 살균된 AAV8 벤조나제 완충액을 필터 카트리지를 통해 펌핑하여 필터를 세정한다. 여과된 생성물 중간체를 다음에 AAV 벤조나제 완충액으로 조건화된 0.2 μm 최종 기공 크기 캡슐 필터에 연결시킨다. 연동 펌프를 사용하여, 여과된 중간체를 카트리지 필터를 통해 통과시키고 필터 출구부에 연결된 BPC에 수집한다. 다량의 살균된 AAV8 벤조나제 완충액을 필터 카트리지를 통해 펌핑하여 필터를 세정한다. 물질을 '생성물 중간체: 후 MF 0.2 μm 여과됨'으로 표지하고, 과정-내 미생물 오염도 테스트를 위해 샘플을 취한다. 물질을 추가로 처리할 때까지 2 내지 8℃에서 밤새 보관한다. 추가의 여과 단계를 정화된 세포 용해물을 크로마토그래피 칼럼에 적용하기 전 크로마토그래피 날에 수행할 수 있다.
8.3.2.4. 음이온-교환 크로마토그래피에 의한 정제
0.2 μm 여과된 생성물 중간체를 희석 완충액 AAV8을 첨가함으로써 NaCl 농도에 대해 조정한다. 벡터를 함유한 세포 용해물을 다음에 음이온 교환 수지를 사용하여 이온 교환 크로마토그래피에 의해 정제한다. GE Healthcare AKTA 파일럿 크로마토그래피 시스템을 대략 1 L의 수지 베드 부피를 함유한 BPG 칼럼으로 피팅한다. 칼럼을 연속적인 흐름 조건을 사용하여 충전하고 수립된 비대칭 명세를 충족시킨다. 시스템을 수립된 과정을 따라 살균하고 다음 작동 때까지 20% 에틸 알코올 중에 보관한다. 사용 직전에, 시스템을 살균된 AAV8 세척 완충액으로 평형화한다. 무균성 기법 및 살균된 물질 및 조성물을 사용하여, 정화된 세포 용해물을 함유한 BPC를 살균된 샘플 입구부에 연결시키고, 하기 열거되는 생물처리 완충액을 함유한 BPC를 AKTA 파일럿상의 살균된 입구부에 연결시킨다. 크로마토그래피 과정 중의 모든 연결부는 무균적으로 수행된다. 정화된 세포 용해물을 칼럼에 적용하고, AAV8 세척 완충액으로 세정한다. 이 조건하에서, 벡터는 칼럼에 결합되고, 불순물은 수지로부터 세정된다. AAV8 입자를 AAV8 용출 완충액을 적용함으로써 칼럼으로부터 용출하고 살균된 플라스틱 보틀 안으로 수집한다. 물질을 '생성물 중간체'로 표지하고 과정-내 미생물 오염도 테스트를 위해 샘플을 취한다. 물질을 즉시 추가 처리한다.
8.3.2.5. CsCl 구배 초원심분리에 의한 정제
상기 기술된 것과 같이 음이온 교환 칼럼 크로마토그래피에 의해 정제된 AAV8 입자는 빈 캡시드 및 다른 생성물 관련 불순물을 함유한다. 빈 캡시드는 벡터 입자로부터 염화세슘 구배 초원심분리에 의해 분리된다. 무균 기법을 사용하여, 염화 세슘을 벡터 '생성물 중간체'에, 1.35 g/mL의 밀도에 상응하는 최종 농도로 부드럽게 혼합하면서 첨가한다. 용액을 0.2 μm 필터를 통해 여과하고, 초원심분리 튜브로 분배한 후, Ti50 로터에서 대략 24시간 동안 15℃에서 초원심분리를 수행한다. 초원심분리 후에, 튜브를 로터로부터 제거하고, 셉티홀(Septihol)로 닦은 후, BSC에 넣었다. 각 튜브를 스탠드에서 클램프로 잠그고 밴드의 시각화를 보조하기 위해 집중적인 조명을 수행하였다. 2개의 주요 밴드가 전형적으로 관찰되는데, 상부 밴드는 빈 캡시드에 상응하고, 하부 밴드는 벡터 입자에 상응한다. 하부 밴드를 각 튜브로부터 살균된 주사기에 부착된 살균된 바늘을 사용하여 회수한다. 각 튜브로부터 회수한 벡터를 조합하고, 과정-내 미생물 오염도, 내독소 및 벡터 역가를 위해 샘플을 취한다. 모아진 물질을 '생성물 중간체: CsCl 구배후'로 표지한 살균된 50 mL 폴리프로필렌 원뿔형 튜브에 넣고, 다음 처리 단계 때까지 -80℃에서 즉시 보관한다.
8.3.2.6. 접선형 흐름 여과에 의한 완충액 교환
테스트 및 모음을 위한 방출 후에, CsCl 밴드 분류 처리 단계를 통해 정제된 벡터의 배치를 조합하고 TFF에 의해 투석여과를 수행하여 벌크 벡터를 제조하였다. 개별 배치로부터 얻어진 샘플의 적정을 기반으로, 모아진 벡터의 부피를 계산된 부피의 살균된 투석여과 완충액을 사용하여 조정한다. 활용할 수 있는 부피에 따라, 모아진, 농도 조정된 벡터의 부분표본에 대해 단일 사용 TFF 장치를 사용하여 TFF를 수행한다. 장치는 사용 전에 살균한 후 투석여과 완충액으로 평형화한다. 일단 투석여과 과정이 완료되면, 벡터를 TFF 장치로부터 살균된 보틀로 회수한다. 물질을 "사전-0.2 μm 여과 벌크"로 표지한다. 물질을 즉시 추가 처리한다.
8.3.2.7. 벌크 벡터를 제조하기위한 제제 및 0.2 μm 여과
개별 TFF 유닛에 의해 제조된 배치를 함께 모아서 500 mL 살균 보틀에서 부드럽게 휘저으면서 혼합한다. 모아진 물질을 다음에 0.22 μm 필터를 통해 통과시켜서 벌크 벡터를 제조한다. 모아진 물질을 벌크 벡터 및 예약된 QC 테스트에 대해 샘플화한 후, 살균된 50 mL 폴리프로필렌 튜브에 부분표본화하여 '벌크 벡터'로 표지한 후, 다음 단계 때까지 -80℃에서 보관한다.
8.4. 벡터의 테스트
혈청형 정체성, 빈 입자 함량 및 도입유전자 생성물 정체성을 포함하여 특성화 검정을 수행한다. 모든 검정의 상세한 설명은 하기에서 나타난다.
8.4.1. 게놈 복사물 (GC) 역가
최적화된 정량적 PCR (oqPCR) 검정을 사용하여 동족 플라스미드 표준과의 비교에 의해 게놈 복사물 역가를 측정한다. oqPCR 검정은 DNase I 및 프로테이나제 K로의 순차적인 소화, 이어서 qPCR 분석을 이용하여 캡시드화된 벡터 게놈 복사물을 측정한다. DNA 검출을 이 동일한 영역에 혼성화하는 형광 태그가 붙은 프로브와 조합하여 RBG 폴리A 영역을 표적화하는 서열 특이적 프라이머를 사용하여 달성한다. 플라스미드 DNA 표준 곡선과의 비교는 임의의 PCR 후 샘플 조작의 필요 없이 역가 측정을 허용한다. 많은 표준, 유효 샘플 및 대조군 (배경 및 DNA 오염에 대한)이 검정에 도입되었다. 이 검정을 민감성, 검출 한계, 정량 범위 및 내부 및 사이의 검정 정확도를 포함하여 검정 파라미터들을 수립하고 규정함으로써 적격성을 판단하였다. 내부 AAV8 참조 로트를 수립하여 적격성확인 연구를 수행하였다.
8.4.2. 효능 검정
생체내 효능 검정을 디자인하여 이중 녹아웃 (DKO) LDLR-/- Apobec-/- HoFH의 마우스 모델의 혈청에서 총 콜레스테롤 수준의 인간 LDLR 벡터-매개된 감소를 검출하였다. 생체내 효능 검정의 개발에 대한 기본은 섹션 4.3.5.11.에서 기술되었다. AAV8.TBG.hLDLR 벡터의 효능을 측정하기 위하여, 6 내지 20주령의 DKO 마우스에 마우스당 5x1011 GC/kg의 PBS에 희석된 벡터를 IV (꼬리 정맥을 통해) 주입한다. 동물들을 안와뒤쪽의 출혈에 의해 출혈시키고 혈청 총 콜레스테롤 수준을 벡터 투여 전 및 후에 (14일 및 30일째에) Antech GLP에 의해 평가한다. 벡터-투여된 동물의 총 콜레스테롤 수준은, 이전 경험을 기반으로 이 용량으로 벡터 투여하고 14일째에 기준선의 25% 내지 75% 감소할 것으로 예상된다. 마우스당 5x1011GC/kg의 용량을 안정성 테스트 전과정에 걸쳐 벡터 효능의 변화의 평가를 허용할 총 콜레스테롤 감소의 예상 범위를 기반으로 하여 임상 검정에 대해 선택하였다.
8.4.3. 벡터 캡시드 정체성: VP3의 AAV 캡시드 질량 분광분석
벡터의 AAV2/8 혈청형의 확인을 질량 분광분석 (MS)에 의해 VP3 캡시드 단백질의 펩타이드의 분석을 기반으로 한 검정에 의해 달성한다. 방법은 SDS-PAGE 겔로부터 절제된 VP3 단백질 밴드의 다중-효소 소화 (트립신, 카이모트립신 및 엔도프로테이나제 Glu-C)와 이어서 캡시드 단백질의 서열에 대한 Q-Exactive Orbitrap 질량 분광계 상에서의 UPLC-MS/MS 상에서의 특성화를 포함한다. 질량 스펙트럼으로부터의 특정 오염 단백질의 확인 및 펩타이드 서열의 유도를 허용하는 탠덤 질량 스펙트럼 (MS) 방법이 개발되었다.
8.4.4. 빈 대 채워진 (empty to full) 입자 비율
분석적 초원심분리에서 측정되는 바 분석적 초원심분리 (AUC) 침강 속도를 사용한 벡터 입자 프로파일은 거대분자 구조 이종성, 형태의 차이 및 회합 또는 응집 상태에 대한 정보를 얻기 위한 우수한 방법이다. 샘플을 세포안으로 로딩하고 12000 RPM에서 Beckman Coulter Proteomelab XL-I 분석용 초원심분리기에서 침강시켰다. 굴절률 스캔을 2분마다 3.3시간 동안 기록하였다. 데이터를 c(s) 모델 (Sedfit 프로그램)에 의해 분석하고 계산한 침강 계수를 표준화된 c(s) 값에 대비하여 도표로 그렸다. 모노머 벡터를 나타내는 주요 피크를 관찰할 수 있어야 한다. 주요 모노머 피크보다 느리게 이동하는 피크의 출현은 빈/잘못 조립된 입자를 가리킨다. 빈 입자 피크의 침강 계수를 빈 AAV8 입자 조제물을 사용하여 수립한다. 주요 모노머 피크 및 선행하는 피크의 직접 정량은 빈 대 채워진 입자 비율의 측정을 허용한다.
8.4.5. 감염 역가
감염 유닛 (IU) 검정을 사용하여 RC32 세포 (HeLa 세포를 발현하는 rep2)에서 벡터의 재생성 흡수 및 복제를 측정한다. 간단히 설명하면, 96 웰 플레이트의 RC32 세포를 벡터의 연속 희석 및 rAAV의 각 희석에서 12개의 복제물로의 Ad5의 균일한 희석에 의하여 공동-감염시킨다. 감염 후 72시간 후에 세포를 용해시키고, 입력을 능가하는 rAAV 벡터 증폭을 검출하기 위하여 qPCR을 수행하였다. 종점 희석 TCID50 계산 (Spearman-Karber)을 수행하여 IU/ml로서 표시된 증식성 역가를 측정한다. "감염력" 값이 세포와 접촉하게 되는 입자들, 수용체 결합, 내부화, 핵으로의 수송 및 게놈 복제에 의존적이기 때문에, 그것들은 검정 기하학 및 사용된 세포주의 적절한 수용체의 존재 및 결합 후 경로에 의해 영향을 받는다. AAV 벡터 수입에 결정적인 수용체 및 결합 후 경로는 보통 불멸화된 세포주에서 유지되고, 그로써 감염력 검정 역가는 존재하는 '감염성' 입자의 수의 절대적인 척도가 아니다. 그러나, 캡시드화된 GC 대 "감염성 유닛"의 비율 (GC/IU 비율로서 기술됨)은 다수의 생성물 일관성의 척도로서 사용될 수 있다. 이런 시험관내 생물검정의 가변성은 아마도 시험관내에서 AAV8 벡터의 낮은 감염력으로 인하여 높다 (30 내지 60%의 CV).
8.4.6 도입유전자 발현 검정
도입유전자 발현을 1x1010 GC (5x1011 GC/kg)의 AAV8.TBG.hLDLR 벡터를 받은 LDLR-/- Apobec-/- 마우스로부터 수득한 간에서 평가한다. 벡터로 앞서 30일 전에 투약된 동물을 안락사시키고, 간을 수득하여 RIPA 완충액에서 균등화하였다. 25 내지 100 ug의 총 간 균등물을 4 내지 12%의 변성 SDS-PAGE 겔에서 전기영동하고 인간 LDLR에 대한 항체를 사용하여 프로빙하여 도입유전자 발현을 측정한다. 벡터를 받지 않았거나 무관한 벡터를 받은 동물을 검정에 대한 대조군으로서 사용한다. 벡터로 처리된 동물들은 번역 후 변형으로 인해 어느 곳에서든지 90 내지 160 kDa로 이동하는 밴드를 나타낼 것으로 예상된다. 상대적인 발현 수준을 밴드의 통합된 강도를 정량함으로써 측정한다.
(서열 목록 자유 텍스트)
다음의 정보를 숫자 식별자 <223> 하에 자유 텍스트를 함유하는 서열에 대해 제공한다.



본 명세서에서 인용된 모든 간행물은 2017년 2월 20일에 출원된 미국 특허 출원 62/461,015, 2016년 12월 6일에 출원된 국제 특허 출원 번호 PCT/US16/65984, 2015년 12월 18일에 출원된 미국 가특허출원 번호 62/269,440 및 2015년 12월 11일에 출원된 미국 가특허출원 번호 62/266,383과 같이, 본원에 그 전문이 참조로 포함된다. 유사하게, 본원에서 언급되고 첨부된 서열 목록에 나타낸 SEQ ID NO는 참조로 포함된다. 발명이 특정 구체예를 참조로 기술된 한편으로, 발명의 사상으로부터 벗어나지 않으면서 변형이 이루어질 수 있는 것이 인지될 것이다. 그러한 변형들은 첨부된 청구범위의 범주 내에 속하는 것으로 의도된다.
SEQUENCE LISTING
<110> The Trustees of the University of Pennsylvania
<120> GENE THERAPY FOR TREATING FAMILIAL HYPERCHOLESTEROLEMIA
<130> UPN-16-7717C1PCT
<150> US 62/461,015
<151> 2017-02-20
<160> 7
<170> PatentIn version 3.5
<210> 1
<211> 5292
<212> DNA
<213> Homo sapiens
<220>
<221> exon
<222> (1)..(254)
<220>
<221> misc_feature
<222> (188)..(2770)
<223> LDLR isoform 1 encoded by full-length CDS, 188-2770; other
variants encoded by alternative splice variants missing an exon;
most common variant missing fourth exon or twelfth exon
<220>
<221> misc_signal
<222> (188)..(250)
<220>
<221> misc_feature
<222> (251)..(2767)
<223> Mature protein of isoform 1
<220>
<221> exon
<222> (255)..(377)
<220>
<221> exon
<222> (378)..(500)
<220>
<221> exon
<222> (501)..(881)
<220>
<221> exon
<222> (882)..(1004)
<220>
<221> exon
<222> (1005)..(1127)
<220>
<221> exon
<222> (1128)..(1247)
<220>
<221> exon
<222> (1248)..(1373)
<220>
<221> exon
<222> (1374)..(1545)
<220>
<221> exon
<222> (1546)..(1773)
<220>
<221> exon
<222> (1774)..(1892)
<220>
<221> exon
<222> (1893)..(2032)
<220>
<221> exon
<222> (2033)..(2174)
<220>
<221> exon
<222> (2175)..(2327)
<220>
<221> exon
<222> (2328)..(2498)
<220>
<221> polyA_signal
<222> (5252)..(5257)
<220>
<221> polyA_site
<222> (5284)..(5284)
<400> 1
ctc ttg cag tga ggt gaa gac att tga aaa tca ccc cac tgc aaa ctc 48
Leu Leu Gln Gly Glu Asp Ile Lys Ser Pro His Cys Lys Leu
1 5 10
ctc ccc ctg cta gaa acc tca cat tga aat gct gta aat gac gtg ggc 96
Leu Pro Leu Leu Glu Thr Ser His Asn Ala Val Asn Asp Val Gly
15 20 25
ccc gag tgc aat cgc ggg aag cca ggg ttt cca gct agg aca cag cag 144
Pro Glu Cys Asn Arg Gly Lys Pro Gly Phe Pro Ala Arg Thr Gln Gln
30 35 40 45
gtc gtg atc cgg gtc ggg aca ctg cct ggc aga ggc tgc gag cat ggg 192
Val Val Ile Arg Val Gly Thr Leu Pro Gly Arg Gly Cys Glu His Gly
50 55 60
gcc ctg ggg ctg gaa att gcg ctg gac cgt cgc ctt gct cct cgc cgc 240
Ala Leu Gly Leu Glu Ile Ala Leu Asp Arg Arg Leu Ala Pro Arg Arg
65 70 75
ggc ggg gac tgc ag t ggg cga cag atg cga aag aaa cga gtt cca gtg 288
Gly Gly Asp Cys Ser Gly Arg Gln Met Arg Lys Lys Arg Val Pro Val
80 85 90
cca aga cgg gaa atg cat ctc cta caa gtg ggt ctg cga tgg cag cgc 336
Pro Arg Arg Glu Met His Leu Leu Gln Val Gly Leu Arg Trp Gln Arg
95 100 105
tga gtg cca gga tgg ctc tga tga gtc cca gga gac gtg ct t gtc tgt 384
Val Pro Gly Trp Leu Val Pro Gly Asp Val Leu Val Cys
110 115 120
cac ctg caa atc cgg gga ctt cag ctg tgg ggg ccg tgt caa ccg ctg 432
His Leu Gln Ile Arg Gly Leu Gln Leu Trp Gly Pro Cys Gln Pro Leu
125 130 135
cat tcc tca gtt ctg gag gtg cga tgg cca agt gga ctg cga caa cgg 480
His Ser Ser Val Leu Glu Val Arg Trp Pro Ser Gly Leu Arg Gln Arg
140 145 150
ctc aga cga gca agg ctg tc c ccc caa gac gtg ctc cca gga cga gtt 528
Leu Arg Arg Ala Arg Leu Ser Pro Gln Asp Val Leu Pro Gly Arg Val
155 160 165 170
tcg ctg cca cga tgg gaa gtg cat ctc tcg gca gtt cgt ctg tga ctc 576
Ser Leu Pro Arg Trp Glu Val His Leu Ser Ala Val Arg Leu Leu
175 180 185
aga ccg gga ctg ctt gga cgg ctc aga cga ggc ctc ctg ccc ggt gct 624
Arg Pro Gly Leu Leu Gly Arg Leu Arg Arg Gly Leu Leu Pro Gly Ala
190 195 200
cac ctg tgg tcc cgc cag ctt cca gtg caa cag ctc cac ctg cat ccc 672
His Leu Trp Ser Arg Gln Leu Pro Val Gln Gln Leu His Leu His Pro
205 210 215
cca gct gtg ggc ctg cga caa cga ccc cga ctg cga aga tgg ctc gga 720
Pro Ala Val Gly Leu Arg Gln Arg Pro Arg Leu Arg Arg Trp Leu Gly
220 225 230
tga gtg gcc gca gcg ctg tag ggg tct tta cgt gtt cca agg gga cag 768
Val Ala Ala Ala Leu Gly Ser Leu Arg Val Pro Arg Gly Gln
235 240 245
tag ccc ctg ctc ggc ctt cga gtt cca ctg cct aag tgg cga gtg cat 816
Pro Leu Leu Gly Leu Arg Val Pro Leu Pro Lys Trp Arg Val His
250 255 260
cca ctc cag ctg gcg ctg tga tgg tgg ccc cga ctg caa gga caa atc 864
Pro Leu Gln Leu Ala Leu Trp Trp Pro Arg Leu Gln Gly Gln Ile
265 270 275
tga cga gga aaa ctg cg c tgt ggc cac ctg tcg ccc tga cga att cca 912
Arg Gly Lys Leu Arg Cys Gly His Leu Ser Pro Arg Ile Pro
280 285 290
gtg ctc tga tgg aaa ctg cat cca tgg cag ccg gca gtg tga ccg gga 960
Val Leu Trp Lys Leu His Pro Trp Gln Pro Ala Val Pro Gly
295 300 305
ata tga ctg caa gga cat gag cga tga agt tgg ctg cgt taa tg t gac 1008
Ile Leu Gln Gly His Glu Arg Ser Trp Leu Arg Cys Asp
310 315
act ctg cga ggg acc caa caa gtt caa gtg tca cag cgg cga atg cat 1056
Thr Leu Arg Gly Thr Gln Gln Val Gln Val Ser Gln Arg Arg Met His
320 325 330
cac cct gga caa agt ctg caa cat ggc tag aga ctg ccg gga ctg gtc 1104
His Pro Gly Gln Ser Leu Gln His Gly Arg Leu Pro Gly Leu Val
335 340 345
aga tga acc cat caa aga gtg cg g gac caa cga atg ctt gga caa caa 1152
Arg Thr His Gln Arg Val Arg Asp Gln Arg Met Leu Gly Gln Gln
350 355 360
cgg cgg ctg ttc cca cgt ctg caa tga cct taa gat cgg cta cga gtg 1200
Arg Arg Leu Phe Pro Arg Leu Gln Pro Asp Arg Leu Arg Val
365 370 375
cct gtg ccc cga cgg ctt cca gct ggt ggc cca gcg aag atg cga ag a 1248
Pro Val Pro Arg Arg Leu Pro Ala Gly Gly Pro Ala Lys Met Arg Arg
380 385 390
tat cga tga gtg tca gga tcc cga cac ctg cag cca gct ctg cgt gaa 1296
Tyr Arg Val Ser Gly Ser Arg His Leu Gln Pro Ala Leu Arg Glu
395 400 405
cct gga ggg tgg cta caa gtg cca gtg tga gga agg ctt cca gct gga 1344
Pro Gly Gly Trp Leu Gln Val Pro Val Gly Arg Leu Pro Ala Gly
410 415 420
ccc cca cac gaa ggc ctg caa ggc tgt gg g ctc cat cgc cta cct ctt 1392
Pro Pro His Glu Gly Leu Gln Gly Cys Gly Leu His Arg Leu Pro Leu
425 430 435 440
ctt cac caa ccg gca cga ggt cag gaa gat gac gct gga ccg gag cga 1440
Leu His Gln Pro Ala Arg Gly Gln Glu Asp Asp Ala Gly Pro Glu Arg
445 450 455
gta cac cag cct cat ccc caa cct gag gaa cgt ggt cgc tct gga cac 1488
Val His Gln Pro His Pro Gln Pro Glu Glu Arg Gly Arg Ser Gly His
460 465 470
gga ggt ggc cag caa tag aat cta ctg gtc tga cct gtc cca gag aat 1536
Gly Gly Gly Gln Gln Asn Leu Leu Val Pro Val Pro Glu Asn
475 480 485
gat ctg cag cac cca gct tga cag agc cca cgg cgt ctc ttc cta tga 1584
Asp Leu Gln His Pro Ala Gln Ser Pro Arg Arg Leu Phe Leu
490 495 500
cac cgt cat cag cag aga cat cca ggc ccc cga cgg gct ggc tgt gga 1632
His Arg His Gln Gln Arg His Pro Gly Pro Arg Arg Ala Gly Cys Gly
505 510 515
ctg gat cca cag caa cat cta ctg gac cga ctc tgt cct ggg cac tgt 1680
Leu Asp Pro Gln Gln His Leu Leu Asp Arg Leu Cys Pro Gly His Cys
520 525 530
ctc tgt tgc gga tac caa ggg cgt gaa gag gaa aac gtt att cag gga 1728
Leu Cys Cys Gly Tyr Gln Gly Arg Glu Glu Glu Asn Val Ile Gln Gly
535 540 545
gaa cgg ctc caa gcc aag ggc cat cgt ggt gga tcc tgt tca tgg ctt 1776
Glu Arg Leu Gln Ala Lys Gly His Arg Gly Gly Ser Cys Ser Trp Leu
550 555 560
cat gta ctg gac tga ctg ggg aac tcc cgc caa gat caa gaa agg ggg 1824
His Val Leu Asp Leu Gly Asn Ser Arg Gln Asp Gln Glu Arg Gly
565 570 575
cct gaa tgg tgt gga cat cta ctc gct ggt gac tga aaa cat tca gtg 1872
Pro Glu Trp Cys Gly His Leu Leu Ala Gly Asp Lys His Ser Val
580 585 590
gcc caa tgg cat cac cct ag a tct cct cag tgg ccg cct cta ctg ggt 1920
Ala Gln Trp His His Pro Arg Ser Pro Gln Trp Pro Pro Leu Leu Gly
595 600 605 610
tga ctc caa act tca ctc cat ctc aag cat cga tgt caa cgg ggg caa 1968
Leu Gln Thr Ser Leu His Leu Lys His Arg Cys Gln Arg Gly Gln
615 620 625
ccg gaa gac cat ctt gga gga tga aaa gag gct ggc cca ccc ctt ctc 2016
Pro Glu Asp His Leu Gly Gly Lys Glu Ala Gly Pro Pro Leu Leu
630 635 640
ctt ggc cgt ctt tga g ga caa agt att ttg gac aga tat cat caa cga 2064
Leu Gly Arg Leu Gly Gln Ser Ile Leu Asp Arg Tyr His Gln Arg
645 650 655
agc cat ttt cag tgc caa ccg cct cac agg ttc cga tgt caa ctt gtt 2112
Ser His Phe Gln Cys Gln Pro Pro His Arg Phe Arg Cys Gln Leu Val
660 665 670
ggc tga aaa cct act gtc ccc aga gga tat ggt tct ctt cca caa cct 2160
Gly Lys Pro Thr Val Pro Arg Gly Tyr Gly Ser Leu Pro Gln Pro
675 680 685
cac cca gcc aag ag g agt gaa ctg gtg tga gag gac cac cct gag caa 2208
His Pro Ala Lys Arg Ser Glu Leu Val Glu Asp His Pro Glu Gln
690 695 700
tgg cgg ctg cca gta tct gtg cct ccc tgc ccc gca gat caa ccc cca 2256
Trp Arg Leu Pro Val Ser Val Pro Pro Cys Pro Ala Asp Gln Pro Pro
705 710 715
ctc gcc caa gtt tac ctg cgc ctg ccc gga cgg cat gct gct ggc cag 2304
Leu Ala Gln Val Tyr Leu Arg Leu Pro Gly Arg His Ala Ala Gly Gln
720 725 730
gga cat gag gag ctg cct cac ag a ggc tga ggc tgc agt ggc cac cca 2352
Gly His Glu Glu Leu Pro His Arg Gly Gly Cys Ser Gly His Pro
735 740 745
gga gac atc cac cgt cag gct aaa ggt cag ctc cac agc cgt aag gac 2400
Gly Asp Ile His Arg Gln Ala Lys Gly Gln Leu His Ser Arg Lys Asp
750 755 760
aca gca cac aac cac ccg acc tgt tcc cga cac ctc ccg gct gcc tgg 2448
Thr Ala His Asn His Pro Thr Cys Ser Arg His Leu Pro Ala Ala Trp
765 770 775 780
ggc cac ccc tgg gct cac cac ggt gga gat agt gac aat gtc tca cca 2496
Gly His Pro Trp Ala His His Gly Gly Asp Ser Asp Asn Val Ser Pro
785 790 795
ag ctctgggcga cgttgctggc agaggaaatg agaagaagcc cagtagcgtg 2548
agggctctgt ccattgtcct ccccatcgtg ctcctcgtct tcctttgcct gggggtcttc 2608
cttctatgga agaactggcg gcttaagaac atcaacagca tcaactttga caaccccgtc 2668
tatcagaaga ccacagagga tgaggtccac atttgccaca accaggacgg ctacagctac 2728
ccctcgagac agatggtcag tctggaggat gacgtggcgt gaacatctgc ctggagtccc 2788
gtccctgccc agaacccttc ctgagacctc gccggccttg ttttattcaa agacagagaa 2848
gaccaaagca ttgcctgcca gagctttgtt ttatatattt attcatctgg gaggcagaac 2908
aggcttcgga cagtgcccat gcaatggctt gggttgggat tttggtttct tcctttcctc 2968
gtgaaggata agagaaacag gcccgggggg accaggatga cacctccatt tctctccagg 3028
aagttttgag tttctctcca ccgtgacaca atcctcaaac atggaagatg aaaggggagg 3088
ggatgtcagg cccagagaag caagtggctt tcaacacaca acagcagatg gcaccaacgg 3148
gaccccctgg ccctgcctca tccaccaatc tctaagccaa acccctaaac tcaggagtca 3208
acgtgtttac ctcttctatg caagccttgc tagacagcca ggttagcctt tgccctgtca 3268
cccccgaatc atgacccacc cagtgtcttt cgaggtgggt ttgtaccttc cttaagccag 3328
gaaagggatt catggcgtcg gaaatgatct ggctgaatcc gtggtggcac cgagaccaaa 3388
ctcattcacc aaatgatgcc acttcccaga ggcagagcct gagtcactgg tcacccttaa 3448
tatttattaa gtgcctgaga cacccggtta ccttggccgt gaggacacgt ggcctgcacc 3508
caggtgtggc tgtcaggaca ccagcctggt gcccatcctc ccgaccccta cccacttcca 3568
ttcccgtggt ctccttgcac tttctcagtt cagagttgta cactgtgtac atttggcatt 3628
tgtgttatta ttttgcactg ttttctgtcg tgtgtgttgg gatgggatcc caggccaggg 3688
aaagcccgtg tcaatgaatg ccggggacag agaggggcag gttgaccggg acttcaaagc 3748
cgtgatcgtg aatatcgaga actgccattg tcgtctttat gtccgcccac ctagtgcttc 3808
cacttctatg caaatgcctc caagccattc acttccccaa tcttgtcgtt gatgggtatg 3868
tgtttaaaac atgcacggtg aggccgggcg cagtggctca cgcctgtaat cccagcactt 3928
tgggaggccg aggcgggtgg atcatgaggt caggagatcg agaccatcct ggctaacacg 3988
tgaaaccccg tctctactaa aaatacaaaa aattagccgg gcgtggtggc gggcacctgt 4048
agtcccagct actcgggagg ctgaggcagg agaatggtgt gaacccggga agcggagctt 4108
gcagtgagcc gagattgcgc cactgcagtc cgcagtctgg cctgggcgac agagcgagac 4168
tccgtctcaa aaaaaaaaaa caaaaaaaaa ccatgcatgg tgcatcagca gcccatggcc 4228
tctggccagg catggcgagg ctgaggtggg aggatggttt gagctcaggc atttgaggct 4288
gtcgtgagct atgattatgc cactgctttc cagcctgggc aacatagtaa gaccccatct 4348
cttaaaaaat gaatttggcc agacacaggt gcctcacgcc tgtaatccca gcactttggg 4408
aggctgagct ggatcacttg agttcaggag ttggagacca ggcctgagca acaaagcgag 4468
atcccatctc tacaaaaacc aaaaagttaa aaatcagctg ggtacggtgg cacgtgcctg 4528
tgatcccagc tacttgggag gctgaggcag gaggatcgcc tgagcccagg aggtggaggt 4588
tgcagtgagc catgatcgag ccactgcact ccagcctggg caacagatga agaccctatt 4648
tcagaaatac aactataaaa aaataaataa atcctccagt ctggatcgtt tgacgggact 4708
tcaggttctt tctgaaatcg ccgtgttact gttgcactga tgtccggaga gacagtgaca 4768
gcctccgtca gactcccgcg tgaagatgtc acaagggatt ggcaattgtc cccagggaca 4828
aaacactgtg tcccccccag tgcagggaac cgtgataagc ctttctggtt tcggagcacg 4888
taaatgcgtc cctgtacaga tagtggggat tttttgttat gtttgcactt tgtatattgg 4948
ttgaaactgt tatcacttat atatatatat atacacacat atatataaaa tctatttatt 5008
tttgcaaacc ctggttgctg tatttgttca gtgactattc tcggggccct gtgtaggggg 5068
ttattgcctc tgaaatgcct cttctttatg tacaaagatt atttgcacga actggactgt 5128
gtgcaacgct ttttgggaga atgatgtccc cgttgtatgt atgagtggct tctgggagat 5188
gggtgtcact ttttaaacca ctgtatagaa ggtttttgta gcctgaatgt cttactgtga 5248
tcaattaaat ttcttaaatg aaccaatttg tctaaaaaaa aaaa 5292
<210> 2
<211> 2583
<212> DNA
<213> Homo sapiens
<220>
<221> CDS
<222> (1)..(2583)
<400> 2
atg ggg ccc tgg ggc tgg aaa ttg cgc tgg acc gtc gcc ttg ctc ctc 48
Met Gly Pro Trp Gly Trp Lys Leu Arg Trp Thr Val Ala Leu Leu Leu
1 5 10 15
gcc gcg gcg ggg act gca gtg ggc gac aga tgt gaa aga aac gag ttc 96
Ala Ala Ala Gly Thr Ala Val Gly Asp Arg Cys Glu Arg Asn Glu Phe
20 25 30
cag tgc caa gac ggg aaa tgc atc tcc tac aag tgg gtc tgc gat ggc 144
Gln Cys Gln Asp Gly Lys Cys Ile Ser Tyr Lys Trp Val Cys Asp Gly
35 40 45
agc gct gag tgc cag gat ggc tct gat gag tcc cag gag acg tgc ttg 192
Ser Ala Glu Cys Gln Asp Gly Ser Asp Glu Ser Gln Glu Thr Cys Leu
50 55 60
tct gtc acc tgc aaa tcc ggg gac ttc agc tgt ggg ggc cgt gtc aac 240
Ser Val Thr Cys Lys Ser Gly Asp Phe Ser Cys Gly Gly Arg Val Asn
65 70 75 80
cgc tgc att cct cag ttc tgg agg tgc gat ggc caa gtg gac tgc gac 288
Arg Cys Ile Pro Gln Phe Trp Arg Cys Asp Gly Gln Val Asp Cys Asp
85 90 95
aac ggc tca gac gag caa ggc tgt ccc ccc aag acg tgc tcc cag gac 336
Asn Gly Ser Asp Glu Gln Gly Cys Pro Pro Lys Thr Cys Ser Gln Asp
100 105 110
gag ttt cgc tgc cac gat ggg aag tgc atc tct cgg cag ttc gtc tgt 384
Glu Phe Arg Cys His Asp Gly Lys Cys Ile Ser Arg Gln Phe Val Cys
115 120 125
gac tca gac cgg gac tgc ttg gac ggc tca gac gag gcc tcc tgc ccg 432
Asp Ser Asp Arg Asp Cys Leu Asp Gly Ser Asp Glu Ala Ser Cys Pro
130 135 140
gtg ctc acc tgt ggt ccc gcc agc ttc cag tgc aac agc tcc acc tgc 480
Val Leu Thr Cys Gly Pro Ala Ser Phe Gln Cys Asn Ser Ser Thr Cys
145 150 155 160
atc ccc cag ctg tgg gcc tgc gac aac gac ccc gac tgc gaa gat ggc 528
Ile Pro Gln Leu Trp Ala Cys Asp Asn Asp Pro Asp Cys Glu Asp Gly
165 170 175
tcg gat gag tgg ccg cag cgc tgt agg ggt ctt tac gtg ttc caa ggg 576
Ser Asp Glu Trp Pro Gln Arg Cys Arg Gly Leu Tyr Val Phe Gln Gly
180 185 190
gac agt agc ccc tgc tcg gcc ttc gag ttc cac tgc cta agt ggc gag 624
Asp Ser Ser Pro Cys Ser Ala Phe Glu Phe His Cys Leu Ser Gly Glu
195 200 205
tgc atc cac tcc agc tgg cgc tgt gat ggt ggc ccc gac tgc aag gac 672
Cys Ile His Ser Ser Trp Arg Cys Asp Gly Gly Pro Asp Cys Lys Asp
210 215 220
aaa tct gac gag gaa aac tgc gct gtg gcc acc tgt cgc cct gac gaa 720
Lys Ser Asp Glu Glu Asn Cys Ala Val Ala Thr Cys Arg Pro Asp Glu
225 230 235 240
ttc cag tgc tct gat gga aac tgc atc cat ggc agc cgg cag tgt gac 768
Phe Gln Cys Ser Asp Gly Asn Cys Ile His Gly Ser Arg Gln Cys Asp
245 250 255
cgg gaa tat gac tgc aag gac atg agc gat gaa gtt ggc tgc gtt aat 816
Arg Glu Tyr Asp Cys Lys Asp Met Ser Asp Glu Val Gly Cys Val Asn
260 265 270
gtg aca ctc tgc gag gga ccc aac aag ttc aag tgt cac agc ggc gaa 864
Val Thr Leu Cys Glu Gly Pro Asn Lys Phe Lys Cys His Ser Gly Glu
275 280 285
tgc atc acc ctg gac aaa gtc tgc aac atg gct aga gac tgc cgg gac 912
Cys Ile Thr Leu Asp Lys Val Cys Asn Met Ala Arg Asp Cys Arg Asp
290 295 300
tgg tca gat gaa ccc atc aaa gag tgc ggg acc aac gaa tgc ttg gac 960
Trp Ser Asp Glu Pro Ile Lys Glu Cys Gly Thr Asn Glu Cys Leu Asp
305 310 315 320
aac aac ggc ggc tgt tcc cac gtc tgc aat gac ctt aag atc ggc tac 1008
Asn Asn Gly Gly Cys Ser His Val Cys Asn Asp Leu Lys Ile Gly Tyr
325 330 335
gag tgc ctg tgc ccc gac ggc ttc cag ctg gtg gcc cag cga aga tgc 1056
Glu Cys Leu Cys Pro Asp Gly Phe Gln Leu Val Ala Gln Arg Arg Cys
340 345 350
gaa gat atc gat gag tgt cag gat ccc gac acc tgc agc cag ctc tgc 1104
Glu Asp Ile Asp Glu Cys Gln Asp Pro Asp Thr Cys Ser Gln Leu Cys
355 360 365
gtg aac ctg gag ggt ggc tac aag tgc cag tgt gag gaa ggc ttc cag 1152
Val Asn Leu Glu Gly Gly Tyr Lys Cys Gln Cys Glu Glu Gly Phe Gln
370 375 380
ctg gac ccc cac acg aag gcc tgc aag gct gtg ggc tcc atc gcc tac 1200
Leu Asp Pro His Thr Lys Ala Cys Lys Ala Val Gly Ser Ile Ala Tyr
385 390 395 400
ctc ttc ttc acc aac cgg cac gag gtc agg aag atg acg ctg gac cgg 1248
Leu Phe Phe Thr Asn Arg His Glu Val Arg Lys Met Thr Leu Asp Arg
405 410 415
agc gag tac acc agc ctc atc ccc aac ctg agg aac gtg gtc gct ctg 1296
Ser Glu Tyr Thr Ser Leu Ile Pro Asn Leu Arg Asn Val Val Ala Leu
420 425 430
gac acg gag gtg gcc agc aat aga atc tac tgg tct gac ctg tcc cag 1344
Asp Thr Glu Val Ala Ser Asn Arg Ile Tyr Trp Ser Asp Leu Ser Gln
435 440 445
aga atg atc tgc agc acc cag ctt gac aga gcc cac ggc gtc tct tcc 1392
Arg Met Ile Cys Ser Thr Gln Leu Asp Arg Ala His Gly Val Ser Ser
450 455 460
tat gac acc gtc atc agc agg gac atc cag gcc ccc gac ggg ctg gct 1440
Tyr Asp Thr Val Ile Ser Arg Asp Ile Gln Ala Pro Asp Gly Leu Ala
465 470 475 480
gtg gac tgg atc cac agc aac atc tac tgg acc gac tct gtc ctg ggc 1488
Val Asp Trp Ile His Ser Asn Ile Tyr Trp Thr Asp Ser Val Leu Gly
485 490 495
act gtc tct gtt gcg gat acc aag ggc gtg aag agg aaa acg tta ttc 1536
Thr Val Ser Val Ala Asp Thr Lys Gly Val Lys Arg Lys Thr Leu Phe
500 505 510
agg gag aac ggc tcc aag cca agg gcc atc gtg gtg gat cct gtt cat 1584
Arg Glu Asn Gly Ser Lys Pro Arg Ala Ile Val Val Asp Pro Val His
515 520 525
ggc ttc atg tac tgg act gac tgg gga act ccc gcc aag atc aag aaa 1632
Gly Phe Met Tyr Trp Thr Asp Trp Gly Thr Pro Ala Lys Ile Lys Lys
530 535 540
ggg ggc ctg aat ggt gtg gac atc tac tcg ctg gtg act gaa aac att 1680
Gly Gly Leu Asn Gly Val Asp Ile Tyr Ser Leu Val Thr Glu Asn Ile
545 550 555 560
cag tgg ccc aat ggc atc acc cta gat ctc ctc agt ggc cgc ctc tac 1728
Gln Trp Pro Asn Gly Ile Thr Leu Asp Leu Leu Ser Gly Arg Leu Tyr
565 570 575
tgg gtt gac tcc aaa ctt cac tcc atc tca agc atc gat gtc aat ggg 1776
Trp Val Asp Ser Lys Leu His Ser Ile Ser Ser Ile Asp Val Asn Gly
580 585 590
ggc aac cgg aag acc atc ttg gag gat gaa aag agg ctg gcc cac ccc 1824
Gly Asn Arg Lys Thr Ile Leu Glu Asp Glu Lys Arg Leu Ala His Pro
595 600 605
ttc tcc ttg gcc gtc ttt gag gac aaa gta ttt tgg aca gat atc atc 1872
Phe Ser Leu Ala Val Phe Glu Asp Lys Val Phe Trp Thr Asp Ile Ile
610 615 620
aac gaa gcc att ttc agt gcc aac cgc ctc aca ggt tcc gat gtc aac 1920
Asn Glu Ala Ile Phe Ser Ala Asn Arg Leu Thr Gly Ser Asp Val Asn
625 630 635 640
ttg ttg gct gaa aac cta ctg tcc cca gag gat atg gtc ctc ttc cac 1968
Leu Leu Ala Glu Asn Leu Leu Ser Pro Glu Asp Met Val Leu Phe His
645 650 655
aac ctc acc cag cca aga gga gtg aac tgg tgt gag agg acc acc ctg 2016
Asn Leu Thr Gln Pro Arg Gly Val Asn Trp Cys Glu Arg Thr Thr Leu
660 665 670
agc aat ggc ggc tgc cag tat ctg tgc ctc cct gcc ccg cag atc aac 2064
Ser Asn Gly Gly Cys Gln Tyr Leu Cys Leu Pro Ala Pro Gln Ile Asn
675 680 685
ccc cac tcg ccc aag ttt acc tgc gcc tgc ccg gac ggc atg ctg ctg 2112
Pro His Ser Pro Lys Phe Thr Cys Ala Cys Pro Asp Gly Met Leu Leu
690 695 700
gcc agg gac atg agg agc tgc ctc aca gag gct gag gct gca gtg gcc 2160
Ala Arg Asp Met Arg Ser Cys Leu Thr Glu Ala Glu Ala Ala Val Ala
705 710 715 720
acc cag gag aca tcc acc gtc agg cta aag gtc agc tcc aca gcc gta 2208
Thr Gln Glu Thr Ser Thr Val Arg Leu Lys Val Ser Ser Thr Ala Val
725 730 735
agg aca cag cac aca acc acc cgg cct gtt ccc gac acc tcc cgg ctg 2256
Arg Thr Gln His Thr Thr Thr Arg Pro Val Pro Asp Thr Ser Arg Leu
740 745 750
cct ggg gcc acc cct ggg ctc acc acg gtg gag ata gtg aca atg tct 2304
Pro Gly Ala Thr Pro Gly Leu Thr Thr Val Glu Ile Val Thr Met Ser
755 760 765
cac caa gct ctg ggc gac gtt gct ggc aga gga aat gag aag aag ccc 2352
His Gln Ala Leu Gly Asp Val Ala Gly Arg Gly Asn Glu Lys Lys Pro
770 775 780
agt agc gtg agg gct ctg tcc att gtc ctc ccc atc gtg ctc ctc gtc 2400
Ser Ser Val Arg Ala Leu Ser Ile Val Leu Pro Ile Val Leu Leu Val
785 790 795 800
ttc ctt tgc ctg ggg gtc ttc ctt cta tgg aag aac tgg cgg ctt aag 2448
Phe Leu Cys Leu Gly Val Phe Leu Leu Trp Lys Asn Trp Arg Leu Lys
805 810 815
aac atc aac agc atc aac ttt gac aac ccc gtc tat cag aag acc aca 2496
Asn Ile Asn Ser Ile Asn Phe Asp Asn Pro Val Tyr Gln Lys Thr Thr
820 825 830
gag gat gag gtc cac att tgc cac aac cag gac ggc tac agc tac ccc 2544
Glu Asp Glu Val His Ile Cys His Asn Gln Asp Gly Tyr Ser Tyr Pro
835 840 845
tcg aga cag atg gtc agt ctg gag gat gac gtg gcg tag 2583
Ser Arg Gln Met Val Ser Leu Glu Asp Asp Val Ala
850 855 860
<210> 3
<211> 860
<212> PRT
<213> Homo sapiens
<400> 3
Met Gly Pro Trp Gly Trp Lys Leu Arg Trp Thr Val Ala Leu Leu Leu
1 5 10 15
Ala Ala Ala Gly Thr Ala Val Gly Asp Arg Cys Glu Arg Asn Glu Phe
20 25 30
Gln Cys Gln Asp Gly Lys Cys Ile Ser Tyr Lys Trp Val Cys Asp Gly
35 40 45
Ser Ala Glu Cys Gln Asp Gly Ser Asp Glu Ser Gln Glu Thr Cys Leu
50 55 60
Ser Val Thr Cys Lys Ser Gly Asp Phe Ser Cys Gly Gly Arg Val Asn
65 70 75 80
Arg Cys Ile Pro Gln Phe Trp Arg Cys Asp Gly Gln Val Asp Cys Asp
85 90 95
Asn Gly Ser Asp Glu Gln Gly Cys Pro Pro Lys Thr Cys Ser Gln Asp
100 105 110
Glu Phe Arg Cys His Asp Gly Lys Cys Ile Ser Arg Gln Phe Val Cys
115 120 125
Asp Ser Asp Arg Asp Cys Leu Asp Gly Ser Asp Glu Ala Ser Cys Pro
130 135 140
Val Leu Thr Cys Gly Pro Ala Ser Phe Gln Cys Asn Ser Ser Thr Cys
145 150 155 160
Ile Pro Gln Leu Trp Ala Cys Asp Asn Asp Pro Asp Cys Glu Asp Gly
165 170 175
Ser Asp Glu Trp Pro Gln Arg Cys Arg Gly Leu Tyr Val Phe Gln Gly
180 185 190
Asp Ser Ser Pro Cys Ser Ala Phe Glu Phe His Cys Leu Ser Gly Glu
195 200 205
Cys Ile His Ser Ser Trp Arg Cys Asp Gly Gly Pro Asp Cys Lys Asp
210 215 220
Lys Ser Asp Glu Glu Asn Cys Ala Val Ala Thr Cys Arg Pro Asp Glu
225 230 235 240
Phe Gln Cys Ser Asp Gly Asn Cys Ile His Gly Ser Arg Gln Cys Asp
245 250 255
Arg Glu Tyr Asp Cys Lys Asp Met Ser Asp Glu Val Gly Cys Val Asn
260 265 270
Val Thr Leu Cys Glu Gly Pro Asn Lys Phe Lys Cys His Ser Gly Glu
275 280 285
Cys Ile Thr Leu Asp Lys Val Cys Asn Met Ala Arg Asp Cys Arg Asp
290 295 300
Trp Ser Asp Glu Pro Ile Lys Glu Cys Gly Thr Asn Glu Cys Leu Asp
305 310 315 320
Asn Asn Gly Gly Cys Ser His Val Cys Asn Asp Leu Lys Ile Gly Tyr
325 330 335
Glu Cys Leu Cys Pro Asp Gly Phe Gln Leu Val Ala Gln Arg Arg Cys
340 345 350
Glu Asp Ile Asp Glu Cys Gln Asp Pro Asp Thr Cys Ser Gln Leu Cys
355 360 365
Val Asn Leu Glu Gly Gly Tyr Lys Cys Gln Cys Glu Glu Gly Phe Gln
370 375 380
Leu Asp Pro His Thr Lys Ala Cys Lys Ala Val Gly Ser Ile Ala Tyr
385 390 395 400
Leu Phe Phe Thr Asn Arg His Glu Val Arg Lys Met Thr Leu Asp Arg
405 410 415
Ser Glu Tyr Thr Ser Leu Ile Pro Asn Leu Arg Asn Val Val Ala Leu
420 425 430
Asp Thr Glu Val Ala Ser Asn Arg Ile Tyr Trp Ser Asp Leu Ser Gln
435 440 445
Arg Met Ile Cys Ser Thr Gln Leu Asp Arg Ala His Gly Val Ser Ser
450 455 460
Tyr Asp Thr Val Ile Ser Arg Asp Ile Gln Ala Pro Asp Gly Leu Ala
465 470 475 480
Val Asp Trp Ile His Ser Asn Ile Tyr Trp Thr Asp Ser Val Leu Gly
485 490 495
Thr Val Ser Val Ala Asp Thr Lys Gly Val Lys Arg Lys Thr Leu Phe
500 505 510
Arg Glu Asn Gly Ser Lys Pro Arg Ala Ile Val Val Asp Pro Val His
515 520 525
Gly Phe Met Tyr Trp Thr Asp Trp Gly Thr Pro Ala Lys Ile Lys Lys
530 535 540
Gly Gly Leu Asn Gly Val Asp Ile Tyr Ser Leu Val Thr Glu Asn Ile
545 550 555 560
Gln Trp Pro Asn Gly Ile Thr Leu Asp Leu Leu Ser Gly Arg Leu Tyr
565 570 575
Trp Val Asp Ser Lys Leu His Ser Ile Ser Ser Ile Asp Val Asn Gly
580 585 590
Gly Asn Arg Lys Thr Ile Leu Glu Asp Glu Lys Arg Leu Ala His Pro
595 600 605
Phe Ser Leu Ala Val Phe Glu Asp Lys Val Phe Trp Thr Asp Ile Ile
610 615 620
Asn Glu Ala Ile Phe Ser Ala Asn Arg Leu Thr Gly Ser Asp Val Asn
625 630 635 640
Leu Leu Ala Glu Asn Leu Leu Ser Pro Glu Asp Met Val Leu Phe His
645 650 655
Asn Leu Thr Gln Pro Arg Gly Val Asn Trp Cys Glu Arg Thr Thr Leu
660 665 670
Ser Asn Gly Gly Cys Gln Tyr Leu Cys Leu Pro Ala Pro Gln Ile Asn
675 680 685
Pro His Ser Pro Lys Phe Thr Cys Ala Cys Pro Asp Gly Met Leu Leu
690 695 700
Ala Arg Asp Met Arg Ser Cys Leu Thr Glu Ala Glu Ala Ala Val Ala
705 710 715 720
Thr Gln Glu Thr Ser Thr Val Arg Leu Lys Val Ser Ser Thr Ala Val
725 730 735
Arg Thr Gln His Thr Thr Thr Arg Pro Val Pro Asp Thr Ser Arg Leu
740 745 750
Pro Gly Ala Thr Pro Gly Leu Thr Thr Val Glu Ile Val Thr Met Ser
755 760 765
His Gln Ala Leu Gly Asp Val Ala Gly Arg Gly Asn Glu Lys Lys Pro
770 775 780
Ser Ser Val Arg Ala Leu Ser Ile Val Leu Pro Ile Val Leu Leu Val
785 790 795 800
Phe Leu Cys Leu Gly Val Phe Leu Leu Trp Lys Asn Trp Arg Leu Lys
805 810 815
Asn Ile Asn Ser Ile Asn Phe Asp Asn Pro Val Tyr Gln Lys Thr Thr
820 825 830
Glu Asp Glu Val His Ile Cys His Asn Gln Asp Gly Tyr Ser Tyr Pro
835 840 845
Ser Arg Gln Met Val Ser Leu Glu Asp Asp Val Ala
850 855 860
<210> 4
<211> 2583
<212> DNA
<213> Artificial Sequence
<220>
<223> Artificial hLDLR
<220>
<221> misc_feature
<222> (1)..(2583)
<223> Artificial hLDLR coding sequence
<400> 4
atgggacctt ggggttggaa actccgctgg acagtggctc tgctcctggc agcagcagga 60
acagccgtgg gagatcgctg cgaaaggaac gagttccagt gccaggacgg caagtgcatc 120
agctacaagt gggtctgcga cggtagcgca gagtgtcagg acggaagcga cgaaagccag 180
gagacttgcc tgagcgtgac ttgcaagtcc ggcgacttct cttgcggagg cagagtgaac 240
cgctgcatcc ctcagttttg gcggtgcgac ggccaggtgg attgcgataa cggaagcgac 300
gagcagggtt gccctcctaa gacttgcagc caggacgaat tccgctgtca cgacggcaag 360
tgcatcagca ggcagttcgt ctgcgacagc gacagggatt gtctggacgg aagcgacgag 420
gcctcttgtc ctgtgctgac ttgtggccca gccagcttcc agtgcaactc cagcacttgc 480
atcccacagc tctgggcttg cgacaacgac ccagattgcg aggacggatc agacgagtgg 540
ccacagcgct gcagaggcct gtacgtgttt cagggcgatt ccagcccttg cagcgctttt 600
gagttccact gcctgagcgg cgagtgcatt cactcttctt ggaggtgcga cggtggccca 660
gattgcaagg acaagagcga cgaggagaat tgcgccgtgg ctacttgcag accagacgaa 720
ttccagtgca gcgacggcaa ttgcatccac ggctctaggc agtgcgacag ggagtacgat 780
tgcaaggaca tgagcgacga agtcggttgc gtgaacgtca ccctctgcga gggtcccaat 840
aagttcaagt gccacagcgg cgagtgcatt accctggaca aggtctgcaa catggccagg 900
gattgccggg attggagcga cgagcctatc aaggagtgcg gcaccaacga gtgcctggat 960
aacaacggcg gctgcagcca cgtgtgcaat gacctgaaga tcggctacga gtgcctctgc 1020
ccagacggat tccagctggt ggctcagaga cgctgcgaag acatcgacga gtgccaggat 1080
cccgacactt gcagccagct gtgcgtgaat ctggagggag gctacaagtg ccagtgcgaa 1140
gagggattcc agctggaccc tcacaccaag gcttgtaaag ccgtgggcag catcgcctac 1200
ctgttcttca ccaacagaca cgaagtgcgg aagatgaccc tggatcggag cgagtacacc 1260
agcctgatcc ctaacctgcg gaacgtggtg gccctggata cagaagtggc cagcaacagg 1320
atctattgga gcgacctgag ccagcggatg atttgcagca cccagctgga cagagcccac 1380
ggagtgtcca gctacgacac cgtgatcagc agagacatcc aggctccaga cggactggca 1440
gtggattgga tccacagcaa catctactgg accgactcag tgctgggaac agtgtccgtg 1500
gccgatacaa agggcgtgaa gcggaagacc ctgttcagag agaacggcag caagcccagg 1560
gctattgtgg tggatcccgt gcacggcttc atgtattgga ccgattgggg cacccccgct 1620
aagatcaaga agggcggcct gaacggcgtg gacatctaca gcctggtgac cgagaacatc 1680
cagtggccca acggaattac cctggacctg ctgagcggca gactgtattg ggtggacagc 1740
aagctgcaca gcatcagcag catcgacgtg aacggcggaa accggaagac catcctggag 1800
gacgagaaga gactggccca ccctttcagc ctggccgtgt tcgaggacaa ggtcttctgg 1860
accgacatca tcaacgaggc catcttcagc gccaacaggc tgacaggaag cgacgtgaac 1920
ctgctggcag agaatctgct gtctcccgag gacatggtgc tgttccacaa cctgacccag 1980
cccagaggcg tcaattggtg cgagagaacc accctgagca acggaggttg ccagtacctg 2040
tgcctgccag cccctcagat taaccctcac agccccaagt tcacttgcgc ttgcccagac 2100
ggcatgctgc tggccagaga tatgcggtct tgtctgacag aagccgaagc cgctgtggct 2160
acacaggaga caagcaccgt gcggctgaag gtgtctagca cagccgtgag aacccagcac 2220
acaaccacca gacccgtgcc agataccagc agactgccag gagctacacc aggactgacc 2280
accgtggaga tcgtgaccat gagccaccag gctctgggag acgtggcagg aagaggaaac 2340
gagaagaagc ctagcagcgt gagagccctg tctatcgtgc tgcccatcgt gctgctggtg 2400
ttcctctgtc tgggcgtgtt cctcctctgg aagaattggc ggctgaagaa catcaacagc 2460
atcaacttcg acaaccccgt gtaccagaag accaccgagg acgaggtgca catttgccac 2520
aaccaggacg gctacagcta ccctagcagg cagatggtgt ccctggaaga cgacgtggct 2580
tga 2583
<210> 5
<211> 738
<212> PRT
<213> Artificial Sequence
<220>
<223> Adeno-associated virus 8 vp1 capsid protein
<400> 5
Met Ala Ala Asp Gly Tyr Leu Pro Asp Trp Leu Glu Asp Asn Leu Ser
1 5 10 15
Glu Gly Ile Arg Glu Trp Trp Ala Leu Lys Pro Gly Ala Pro Lys Pro
20 25 30
Lys Ala Asn Gln Gln Lys Gln Asp Asp Gly Arg Gly Leu Val Leu Pro
35 40 45
Gly Tyr Lys Tyr Leu Gly Pro Phe Asn Gly Leu Asp Lys Gly Glu Pro
50 55 60
Val Asn Ala Ala Asp Ala Ala Ala Leu Glu His Asp Lys Ala Tyr Asp
65 70 75 80
Gln Gln Leu Gln Ala Gly Asp Asn Pro Tyr Leu Arg Tyr Asn His Ala
85 90 95
Asp Ala Glu Phe Gln Glu Arg Leu Gln Glu Asp Thr Ser Phe Gly Gly
100 105 110
Asn Leu Gly Arg Ala Val Phe Gln Ala Lys Lys Arg Val Leu Glu Pro
115 120 125
Leu Gly Leu Val Glu Glu Gly Ala Lys Thr Ala Pro Gly Lys Lys Arg
130 135 140
Pro Val Glu Pro Ser Pro Gln Arg Ser Pro Asp Ser Ser Thr Gly Ile
145 150 155 160
Gly Lys Lys Gly Gln Gln Pro Ala Arg Lys Arg Leu Asn Phe Gly Gln
165 170 175
Thr Gly Asp Ser Glu Ser Val Pro Asp Pro Gln Pro Leu Gly Glu Pro
180 185 190
Pro Ala Ala Pro Ser Gly Val Gly Pro Asn Thr Met Ala Ala Gly Gly
195 200 205
Gly Ala Pro Met Ala Asp Asn Asn Glu Gly Ala Asp Gly Val Gly Ser
210 215 220
Ser Ser Gly Asn Trp His Cys Asp Ser Thr Trp Leu Gly Asp Arg Val
225 230 235 240
Ile Thr Thr Ser Thr Arg Thr Trp Ala Leu Pro Thr Tyr Asn Asn His
245 250 255
Leu Tyr Lys Gln Ile Ser Asn Gly Thr Ser Gly Gly Ala Thr Asn Asp
260 265 270
Asn Thr Tyr Phe Gly Tyr Ser Thr Pro Trp Gly Tyr Phe Asp Phe Asn
275 280 285
Arg Phe His Cys His Phe Ser Pro Arg Asp Trp Gln Arg Leu Ile Asn
290 295 300
Asn Asn Trp Gly Phe Arg Pro Lys Arg Leu Ser Phe Lys Leu Phe Asn
305 310 315 320
Ile Gln Val Lys Glu Val Thr Gln Asn Glu Gly Thr Lys Thr Ile Ala
325 330 335
Asn Asn Leu Thr Ser Thr Ile Gln Val Phe Thr Asp Ser Glu Tyr Gln
340 345 350
Leu Pro Tyr Val Leu Gly Ser Ala His Gln Gly Cys Leu Pro Pro Phe
355 360 365
Pro Ala Asp Val Phe Met Ile Pro Gln Tyr Gly Tyr Leu Thr Leu Asn
370 375 380
Asn Gly Ser Gln Ala Val Gly Arg Ser Ser Phe Tyr Cys Leu Glu Tyr
385 390 395 400
Phe Pro Ser Gln Met Leu Arg Thr Gly Asn Asn Phe Gln Phe Thr Tyr
405 410 415
Thr Phe Glu Asp Val Pro Phe His Ser Ser Tyr Ala His Ser Gln Ser
420 425 430
Leu Asp Arg Leu Met Asn Pro Leu Ile Asp Gln Tyr Leu Tyr Tyr Leu
435 440 445
Ser Arg Thr Gln Thr Thr Gly Gly Thr Ala Asn Thr Gln Thr Leu Gly
450 455 460
Phe Ser Gln Gly Gly Pro Asn Thr Met Ala Asn Gln Ala Lys Asn Trp
465 470 475 480
Leu Pro Gly Pro Cys Tyr Arg Gln Gln Arg Val Ser Thr Thr Thr Gly
485 490 495
Gln Asn Asn Asn Ser Asn Phe Ala Trp Thr Ala Gly Thr Lys Tyr His
500 505 510
Leu Asn Gly Arg Asn Ser Leu Ala Asn Pro Gly Ile Ala Met Ala Thr
515 520 525
His Lys Asp Asp Glu Glu Arg Phe Phe Pro Ser Asn Gly Ile Leu Ile
530 535 540
Phe Gly Lys Gln Asn Ala Ala Arg Asp Asn Ala Asp Tyr Ser Asp Val
545 550 555 560
Met Leu Thr Ser Glu Glu Glu Ile Lys Thr Thr Asn Pro Val Ala Thr
565 570 575
Glu Glu Tyr Gly Ile Val Ala Asp Asn Leu Gln Gln Gln Asn Thr Ala
580 585 590
Pro Gln Ile Gly Thr Val Asn Ser Gln Gly Ala Leu Pro Gly Met Val
595 600 605
Trp Gln Asn Arg Asp Val Tyr Leu Gln Gly Pro Ile Trp Ala Lys Ile
610 615 620
Pro His Thr Asp Gly Asn Phe His Pro Ser Pro Leu Met Gly Gly Phe
625 630 635 640
Gly Leu Lys His Pro Pro Pro Gln Ile Leu Ile Lys Asn Thr Pro Val
645 650 655
Pro Ala Asp Pro Pro Thr Thr Phe Asn Gln Ser Lys Leu Asn Ser Phe
660 665 670
Ile Thr Gln Tyr Ser Thr Gly Gln Val Ser Val Glu Ile Glu Trp Glu
675 680 685
Leu Gln Lys Glu Asn Ser Lys Arg Trp Asn Pro Glu Ile Gln Tyr Thr
690 695 700
Ser Asn Tyr Tyr Lys Ser Thr Ser Val Asp Phe Ala Val Asn Thr Glu
705 710 715 720
Gly Val Tyr Ser Glu Pro Arg Pro Ile Gly Thr Arg Tyr Leu Thr Arg
725 730 735
Asn Leu
<210> 6
<211> 6768
<212> DNA
<213> Artificial Sequence
<220>
<223> pAAV.TBG.PI.hLDLRco.RGB
<220>
<221> repeat_region
<222> (1)..(130)
<223> 5' ITR
<220>
<221> enhancer
<222> (221)..(320)
<223> Alpha mic/bik
<220>
<221> enhancer
<222> (327)..(426)
<223> Alpha mic/bik
<220>
<221> promoter
<222> (442)..(901)
<223> TBG
<220>
<221> TATA_signal
<222> (885)..(888)
<223> TATA
<220>
<221> CDS
<222> (969)..(3551)
<223> codon optimized hLDLR
<220>
<221> polyA_signal
<222> (3603)..(3729)
<223> Rabbit globin poly A
<220>
<221> repeat_region
<222> (3818)..(3947)
<223> 3' ITR
<220>
<221> rep_origin
<222> (4124)..(4579)
<223> f1 ori
<220>
<221> misc_feature
<222> (4710)..(5567)
<223> AP(R)
<220>
<221> rep_origin
<222> (5741)..(6329)
<223> Origin of replication
<400> 6
ctgcgcgctc gctcgctcac tgaggccgcc cgggcaaagc ccgggcgtcg ggcgaccttt 60
ggtcgcccgg cctcagtgag cgagcgagcg cgcagagagg gagtggccaa ctccatcact 120
aggggttcct tgtagttaat gattaacccg ccatgctact tatctaccag ggtaatgggg 180
atcctctaga actatagcta gaattcgccc ttaagctagc aggttaattt ttaaaaagca 240
gtcaaaagtc caagtggccc ttggcagcat ttactctctc tgtttgctct ggttaataat 300
ctcaggagca caaacattcc agatccaggt taatttttaa aaagcagtca aaagtccaag 360
tggcccttgg cagcatttac tctctctgtt tgctctggtt aataatctca ggagcacaaa 420
cattccagat ccggcgcgcc agggctggaa gctacctttg acatcatttc ctctgcgaat 480
gcatgtataa tttctacaga acctattaga aaggatcacc cagcctctgc ttttgtacaa 540
ctttccctta aaaaactgcc aattccactg ctgtttggcc caatagtgag aactttttcc 600
tgctgcctct tggtgctttt gcctatggcc cctattctgc ctgctgaaga cactcttgcc 660
agcatggact taaacccctc cagctctgac aatcctcttt ctcttttgtt ttacatgaag 720
ggtctggcag ccaaagcaat cactcaaagt tcaaacctta tcattttttg ctttgttcct 780
cttggccttg gttttgtaca tcagctttga aaataccatc ccagggttaa tgctggggtt 840
aatttataac taagagtgct ctagttttgc aatacaggac atgctataaa aatggaaaga 900
tgttgctttc tgagagacag ctttattgcg gtagtttatc acagttaaat tgctaacgca 960
gacgttgc atg gga cct tgg ggt tgg aaa ctc cgc tgg aca gtg gct ctg 1010
Met Gly Pro Trp Gly Trp Lys Leu Arg Trp Thr Val Ala Leu
1 5 10
ctc ctg gca gca gca gga aca gcc gtg gga gat cgc tgc gaa agg aac 1058
Leu Leu Ala Ala Ala Gly Thr Ala Val Gly Asp Arg Cys Glu Arg Asn
15 20 25 30
gag ttc cag tgc cag gac ggc aag tgc atc agc tac aag tgg gtc tgc 1106
Glu Phe Gln Cys Gln Asp Gly Lys Cys Ile Ser Tyr Lys Trp Val Cys
35 40 45
gac ggt agc gca gag tgt cag gac gga agc gac gaa agc cag gag act 1154
Asp Gly Ser Ala Glu Cys Gln Asp Gly Ser Asp Glu Ser Gln Glu Thr
50 55 60
tgc ctg agc gtg act tgc aag tcc ggc gac ttc tct tgc gga ggc aga 1202
Cys Leu Ser Val Thr Cys Lys Ser Gly Asp Phe Ser Cys Gly Gly Arg
65 70 75
gtg aac cgc tgc atc cct cag ttt tgg cgg tgc gac ggc cag gtg gat 1250
Val Asn Arg Cys Ile Pro Gln Phe Trp Arg Cys Asp Gly Gln Val Asp
80 85 90
tgc gat aac gga agc gac gag cag ggt tgc cct cct aag act tgc agc 1298
Cys Asp Asn Gly Ser Asp Glu Gln Gly Cys Pro Pro Lys Thr Cys Ser
95 100 105 110
cag gac gaa ttc cgc tgt cac gac ggc aag tgc atc agc agg cag ttc 1346
Gln Asp Glu Phe Arg Cys His Asp Gly Lys Cys Ile Ser Arg Gln Phe
115 120 125
gtc tgc gac agc gac agg gat tgt ctg gac gga agc gac gag gcc tct 1394
Val Cys Asp Ser Asp Arg Asp Cys Leu Asp Gly Ser Asp Glu Ala Ser
130 135 140
tgt cct gtg ctg act tgt ggc cca gcc agc ttc cag tgc aac tcc agc 1442
Cys Pro Val Leu Thr Cys Gly Pro Ala Ser Phe Gln Cys Asn Ser Ser
145 150 155
act tgc atc cca cag ctc tgg gct tgc gac aac gac cca gat tgc gag 1490
Thr Cys Ile Pro Gln Leu Trp Ala Cys Asp Asn Asp Pro Asp Cys Glu
160 165 170
gac gga tca gac gag tgg cca cag cgc tgc aga ggc ctg tac gtg ttt 1538
Asp Gly Ser Asp Glu Trp Pro Gln Arg Cys Arg Gly Leu Tyr Val Phe
175 180 185 190
cag ggc gat tcc agc cct tgc agc gct ttt gag ttc cac tgc ctg agc 1586
Gln Gly Asp Ser Ser Pro Cys Ser Ala Phe Glu Phe His Cys Leu Ser
195 200 205
ggc gag tgc att cac tct tct tgg agg tgc gac ggt ggc cca gat tgc 1634
Gly Glu Cys Ile His Ser Ser Trp Arg Cys Asp Gly Gly Pro Asp Cys
210 215 220
aag gac aag agc gac gag gag aat tgc gcc gtg gct act tgc aga cca 1682
Lys Asp Lys Ser Asp Glu Glu Asn Cys Ala Val Ala Thr Cys Arg Pro
225 230 235
gac gaa ttc cag tgc agc gac ggc aat tgc atc cac ggc tct agg cag 1730
Asp Glu Phe Gln Cys Ser Asp Gly Asn Cys Ile His Gly Ser Arg Gln
240 245 250
tgc gac agg gag tac gat tgc aag gac atg agc gac gaa gtc ggt tgc 1778
Cys Asp Arg Glu Tyr Asp Cys Lys Asp Met Ser Asp Glu Val Gly Cys
255 260 265 270
gtg aac gtc acc ctc tgc gag ggt ccc aat aag ttc aag tgc cac agc 1826
Val Asn Val Thr Leu Cys Glu Gly Pro Asn Lys Phe Lys Cys His Ser
275 280 285
ggc gag tgc att acc ctg gac aag gtc tgc aac atg gcc agg gat tgc 1874
Gly Glu Cys Ile Thr Leu Asp Lys Val Cys Asn Met Ala Arg Asp Cys
290 295 300
cgg gat tgg agc gac gag cct atc aag gag tgc ggc acc aac gag tgc 1922
Arg Asp Trp Ser Asp Glu Pro Ile Lys Glu Cys Gly Thr Asn Glu Cys
305 310 315
ctg gat aac aac ggc ggc tgc agc cac gtg tgc aat gac ctg aag atc 1970
Leu Asp Asn Asn Gly Gly Cys Ser His Val Cys Asn Asp Leu Lys Ile
320 325 330
ggc tac gag tgc ctc tgc cca gac gga ttc cag ctg gtg gct cag aga 2018
Gly Tyr Glu Cys Leu Cys Pro Asp Gly Phe Gln Leu Val Ala Gln Arg
335 340 345 350
cgc tgc gaa gac atc gac gag tgc cag gat ccc gac act tgc agc cag 2066
Arg Cys Glu Asp Ile Asp Glu Cys Gln Asp Pro Asp Thr Cys Ser Gln
355 360 365
ctg tgc gtg aat ctg gag gga ggc tac aag tgc cag tgc gaa gag gga 2114
Leu Cys Val Asn Leu Glu Gly Gly Tyr Lys Cys Gln Cys Glu Glu Gly
370 375 380
ttc cag ctg gac cct cac acc aag gct tgt aaa gcc gtg ggc agc atc 2162
Phe Gln Leu Asp Pro His Thr Lys Ala Cys Lys Ala Val Gly Ser Ile
385 390 395
gcc tac ctg ttc ttc acc aac aga cac gaa gtg cgg aag atg acc ctg 2210
Ala Tyr Leu Phe Phe Thr Asn Arg His Glu Val Arg Lys Met Thr Leu
400 405 410
gat cgg agc gag tac acc agc ctg atc cct aac ctg cgg aac gtg gtg 2258
Asp Arg Ser Glu Tyr Thr Ser Leu Ile Pro Asn Leu Arg Asn Val Val
415 420 425 430
gcc ctg gat aca gaa gtg gcc agc aac agg atc tat tgg agc gac ctg 2306
Ala Leu Asp Thr Glu Val Ala Ser Asn Arg Ile Tyr Trp Ser Asp Leu
435 440 445
agc cag cgg atg att tgc agc acc cag ctg gac aga gcc cac gga gtg 2354
Ser Gln Arg Met Ile Cys Ser Thr Gln Leu Asp Arg Ala His Gly Val
450 455 460
tcc agc tac gac acc gtg atc agc aga gac atc cag gct cca gac gga 2402
Ser Ser Tyr Asp Thr Val Ile Ser Arg Asp Ile Gln Ala Pro Asp Gly
465 470 475
ctg gca gtg gat tgg atc cac agc aac atc tac tgg acc gac tca gtg 2450
Leu Ala Val Asp Trp Ile His Ser Asn Ile Tyr Trp Thr Asp Ser Val
480 485 490
ctg gga aca gtg tcc gtg gcc gat aca aag ggc gtg aag cgg aag acc 2498
Leu Gly Thr Val Ser Val Ala Asp Thr Lys Gly Val Lys Arg Lys Thr
495 500 505 510
ctg ttc aga gag aac ggc agc aag ccc agg gct att gtg gtg gat ccc 2546
Leu Phe Arg Glu Asn Gly Ser Lys Pro Arg Ala Ile Val Val Asp Pro
515 520 525
gtg cac ggc ttc atg tat tgg acc gat tgg ggc acc ccc gct aag atc 2594
Val His Gly Phe Met Tyr Trp Thr Asp Trp Gly Thr Pro Ala Lys Ile
530 535 540
aag aag ggc ggc ctg aac ggc gtg gac atc tac agc ctg gtg acc gag 2642
Lys Lys Gly Gly Leu Asn Gly Val Asp Ile Tyr Ser Leu Val Thr Glu
545 550 555
aac atc cag tgg ccc aac gga att acc ctg gac ctg ctg agc ggc aga 2690
Asn Ile Gln Trp Pro Asn Gly Ile Thr Leu Asp Leu Leu Ser Gly Arg
560 565 570
ctg tat tgg gtg gac agc aag ctg cac agc atc agc agc atc gac gtg 2738
Leu Tyr Trp Val Asp Ser Lys Leu His Ser Ile Ser Ser Ile Asp Val
575 580 585 590
aac ggc gga aac cgg aag acc atc ctg gag gac gag aag aga ctg gcc 2786
Asn Gly Gly Asn Arg Lys Thr Ile Leu Glu Asp Glu Lys Arg Leu Ala
595 600 605
cac cct ttc agc ctg gcc gtg ttc gag gac aag gtc ttc tgg acc gac 2834
His Pro Phe Ser Leu Ala Val Phe Glu Asp Lys Val Phe Trp Thr Asp
610 615 620
atc atc aac gag gcc atc ttc agc gcc aac agg ctg aca gga agc gac 2882
Ile Ile Asn Glu Ala Ile Phe Ser Ala Asn Arg Leu Thr Gly Ser Asp
625 630 635
gtg aac ctg ctg gca gag aat ctg ctg tct ccc gag gac atg gtg ctg 2930
Val Asn Leu Leu Ala Glu Asn Leu Leu Ser Pro Glu Asp Met Val Leu
640 645 650
ttc cac aac ctg acc cag ccc aga ggc gtc aat tgg tgc gag aga acc 2978
Phe His Asn Leu Thr Gln Pro Arg Gly Val Asn Trp Cys Glu Arg Thr
655 660 665 670
acc ctg agc aac gga ggt tgc cag tac ctg tgc ctg cca gcc cct cag 3026
Thr Leu Ser Asn Gly Gly Cys Gln Tyr Leu Cys Leu Pro Ala Pro Gln
675 680 685
att aac cct cac agc ccc aag ttc act tgc gct tgc cca gac ggc atg 3074
Ile Asn Pro His Ser Pro Lys Phe Thr Cys Ala Cys Pro Asp Gly Met
690 695 700
ctg ctg gcc aga gat atg cgg tct tgt ctg aca gaa gcc gaa gcc gct 3122
Leu Leu Ala Arg Asp Met Arg Ser Cys Leu Thr Glu Ala Glu Ala Ala
705 710 715
gtg gct aca cag gag aca agc acc gtg cgg ctg aag gtg tct agc aca 3170
Val Ala Thr Gln Glu Thr Ser Thr Val Arg Leu Lys Val Ser Ser Thr
720 725 730
gcc gtg aga acc cag cac aca acc acc aga ccc gtg cca gat acc agc 3218
Ala Val Arg Thr Gln His Thr Thr Thr Arg Pro Val Pro Asp Thr Ser
735 740 745 750
aga ctg cca gga gct aca cca gga ctg acc acc gtg gag atc gtg acc 3266
Arg Leu Pro Gly Ala Thr Pro Gly Leu Thr Thr Val Glu Ile Val Thr
755 760 765
atg agc cac cag gct ctg gga gac gtg gca gga aga gga aac gag aag 3314
Met Ser His Gln Ala Leu Gly Asp Val Ala Gly Arg Gly Asn Glu Lys
770 775 780
aag cct agc agc gtg aga gcc ctg tct atc gtg ctg ccc atc gtg ctg 3362
Lys Pro Ser Ser Val Arg Ala Leu Ser Ile Val Leu Pro Ile Val Leu
785 790 795
ctg gtg ttc ctc tgt ctg ggc gtg ttc ctc ctc tgg aag aat tgg cgg 3410
Leu Val Phe Leu Cys Leu Gly Val Phe Leu Leu Trp Lys Asn Trp Arg
800 805 810
ctg aag aac atc aac agc atc aac ttc gac aac ccc gtg tac cag aag 3458
Leu Lys Asn Ile Asn Ser Ile Asn Phe Asp Asn Pro Val Tyr Gln Lys
815 820 825 830
acc acc gag gac gag gtg cac att tgc cac aac cag gac ggc tac agc 3506
Thr Thr Glu Asp Glu Val His Ile Cys His Asn Gln Asp Gly Tyr Ser
835 840 845
tac cct agc agg cag atg gtg tcc ctg gaa gac gac gtg gct tga 3551
Tyr Pro Ser Arg Gln Met Val Ser Leu Glu Asp Asp Val Ala
850 855 860
taagtcgacc cgggcggcct cgaggacggg gtgaactacg cctgaggatc cgatcttttt 3611
ccctctgcca aaaattatgg ggacatcatg aagccccttg agcatctgac ttctggctaa 3671
taaaggaaat ttattttcat tgcaatagtg tgttggaatt ttttgtgtct ctcactcgga 3731
agcaattcgt tgatctgaat ttcgaccacc cataataccc attaccctgg tagataagta 3791
gcatggcggg ttaatcatta actacaagga acccctagtg atggagttgg ccactccctc 3851
tctgcgcgct cgctcgctca ctgaggccgg gcgaccaaag gtcgcccgac gcccgggctt 3911
tgcccgggcg gcctcagtga gcgagcgagc gcgcagcctt aattaaccta attcactggc 3971
cgtcgtttta caacgtcgtg actgggaaaa ccctggcgtt acccaactta atcgccttgc 4031
agcacatccc cctttcgcca gctggcgtaa tagcgaagag gcccgcaccg atcgcccttc 4091
ccaacagttg cgcagcctga atggcgaatg ggacgcgccc tgtagcggcg cattaagcgc 4151
ggcgggtgtg gtggttacgc gcagcgtgac cgctacactt gccagcgccc tagcgcccgc 4211
tcctttcgct ttcttccctt cctttctcgc cacgttcgcc ggctttcccc gtcaagctct 4271
aaatcggggg ctccctttag ggttccgatt tagtgcttta cggcacctcg accccaaaaa 4331
acttgattag ggtgatggtt cacgtagtgg gccatcgccc tgatagacgg tttttcgccc 4391
tttgacgttg gagtccacgt tctttaatag tggactcttg ttccaaactg gaacaacact 4451
caaccctatc tcggtctatt cttttgattt ataagggatt ttgccgattt cggcctattg 4511
gttaaaaaat gagctgattt aacaaaaatt taacgcgaat tttaacaaaa tattaacgct 4571
tacaatttag gtggcacttt tcggggaaat gtgcgcggaa cccctatttg tttatttttc 4631
taaatacatt caaatatgta tccgctcatg agacaataac cctgataaat gcttcaataa 4691
tattgaaaaa ggaagagtat gagtattcaa catttccgtg tcgcccttat tccctttttt 4751
gcggcatttt gccttcctgt ttttgctcac ccagaaacgc tggtgaaagt aaaagatgct 4811
gaagatcagt tgggtgcacg agtgggttac atcgaactgg atctcaacag cggtaagatc 4871
cttgagagtt ttcgccccga agaacgtttt ccaatgatga gcacttttaa agttctgcta 4931
tgtggcgcgg tattatcccg tattgacgcc gggcaagagc aactcggtcg ccgcatacac 4991
tattctcaga atgacttggt tgagtactca ccagtcacag aaaagcatct tacggatggc 5051
atgacagtaa gagaattatg cagtgctgcc ataaccatga gtgataacac tgcggccaac 5111
ttacttctga caacgatcgg aggaccgaag gagctaaccg cttttttgca caacatgggg 5171
gatcatgtaa ctcgccttga tcgttgggaa ccggagctga atgaagccat accaaacgac 5231
gagcgtgaca ccacgatgcc tgtagcaatg gcaacaacgt tgcgcaaact attaactggc 5291
gaactactta ctctagcttc ccggcaacaa ttaatagact ggatggaggc ggataaagtt 5351
gcaggaccac ttctgcgctc ggcccttccg gctggctggt ttattgctga taaatctgga 5411
gccggtgagc gtgggtctcg cggtatcatt gcagcactgg ggccagatgg taagccctcc 5471
cgtatcgtag ttatctacac gacggggagt caggcaacta tggatgaacg aaatagacag 5531
atcgctgaga taggtgcctc actgattaag cattggtaac tgtcagacca agtttactca 5591
tatatacttt agattgattt aaaacttcat ttttaattta aaaggatcta ggtgaagatc 5651
ctttttgata atctcatgac caaaatccct taacgtgagt tttcgttcca ctgagcgtca 5711
gaccccgtag aaaagatcaa aggatcttct tgagatcctt tttttctgcg cgtaatctgc 5771
tgcttgcaaa caaaaaaacc accgctacca gcggtggttt gtttgccgga tcaagagcta 5831
ccaactcttt ttccgaaggt aactggcttc agcagagcgc agataccaaa tactgttctt 5891
ctagtgtagc cgtagttagg ccaccacttc aagaactctg tagcaccgcc tacatacctc 5951
gctctgctaa tcctgttacc agtggctgct gccagtggcg ataagtcgtg tcttaccggg 6011
ttggactcaa gacgatagtt accggataag gcgcagcggt cgggctgaac ggggggttcg 6071
tgcacacagc ccagcttgga gcgaacgacc tacaccgaac tgagatacct acagcgtgag 6131
ctatgagaaa gcgccacgct tcccgaaggg agaaaggcgg acaggtatcc ggtaagcggc 6191
agggtcggaa caggagagcg cacgagggag cttccagggg gaaacgcctg gtatctttat 6251
agtcctgtcg ggtttcgcca cctctgactt gagcgtcgat ttttgtgatg ctcgtcaggg 6311
gggcggagcc tatggaaaaa cgccagcaac gcggcctttt tacggttcct ggccttttgc 6371
tggccttttg ctcacatgtt ctttcctgcg ttatcccctg attctgtgga taaccgtatt 6431
accgcctttg agtgagctga taccgctcgc cgcagccgaa cgaccgagcg cagcgagtca 6491
gtgagcgagg aagcggaaga gcgcccaata cgcaaaccgc ctctccccgc gcgttggccg 6551
attcattaat gcagctggca cgacaggttt cccgactgga aagcgggcag tgagcgcaac 6611
gcaattaatg tgagttagct cactcattag gcaccccagg ctttacactt tatgcttccg 6671
gctcgtatgt tgtgtggaat tgtgagcgga taacaatttc acacaggaaa cagctatgac 6731
catgattacg ccagatttaa ttaaggcctt aattagg 6768
<210> 7
<211> 860
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 7
Met Gly Pro Trp Gly Trp Lys Leu Arg Trp Thr Val Ala Leu Leu Leu
1 5 10 15
Ala Ala Ala Gly Thr Ala Val Gly Asp Arg Cys Glu Arg Asn Glu Phe
20 25 30
Gln Cys Gln Asp Gly Lys Cys Ile Ser Tyr Lys Trp Val Cys Asp Gly
35 40 45
Ser Ala Glu Cys Gln Asp Gly Ser Asp Glu Ser Gln Glu Thr Cys Leu
50 55 60
Ser Val Thr Cys Lys Ser Gly Asp Phe Ser Cys Gly Gly Arg Val Asn
65 70 75 80
Arg Cys Ile Pro Gln Phe Trp Arg Cys Asp Gly Gln Val Asp Cys Asp
85 90 95
Asn Gly Ser Asp Glu Gln Gly Cys Pro Pro Lys Thr Cys Ser Gln Asp
100 105 110
Glu Phe Arg Cys His Asp Gly Lys Cys Ile Ser Arg Gln Phe Val Cys
115 120 125
Asp Ser Asp Arg Asp Cys Leu Asp Gly Ser Asp Glu Ala Ser Cys Pro
130 135 140
Val Leu Thr Cys Gly Pro Ala Ser Phe Gln Cys Asn Ser Ser Thr Cys
145 150 155 160
Ile Pro Gln Leu Trp Ala Cys Asp Asn Asp Pro Asp Cys Glu Asp Gly
165 170 175
Ser Asp Glu Trp Pro Gln Arg Cys Arg Gly Leu Tyr Val Phe Gln Gly
180 185 190
Asp Ser Ser Pro Cys Ser Ala Phe Glu Phe His Cys Leu Ser Gly Glu
195 200 205
Cys Ile His Ser Ser Trp Arg Cys Asp Gly Gly Pro Asp Cys Lys Asp
210 215 220
Lys Ser Asp Glu Glu Asn Cys Ala Val Ala Thr Cys Arg Pro Asp Glu
225 230 235 240
Phe Gln Cys Ser Asp Gly Asn Cys Ile His Gly Ser Arg Gln Cys Asp
245 250 255
Arg Glu Tyr Asp Cys Lys Asp Met Ser Asp Glu Val Gly Cys Val Asn
260 265 270
Val Thr Leu Cys Glu Gly Pro Asn Lys Phe Lys Cys His Ser Gly Glu
275 280 285
Cys Ile Thr Leu Asp Lys Val Cys Asn Met Ala Arg Asp Cys Arg Asp
290 295 300
Trp Ser Asp Glu Pro Ile Lys Glu Cys Gly Thr Asn Glu Cys Leu Asp
305 310 315 320
Asn Asn Gly Gly Cys Ser His Val Cys Asn Asp Leu Lys Ile Gly Tyr
325 330 335
Glu Cys Leu Cys Pro Asp Gly Phe Gln Leu Val Ala Gln Arg Arg Cys
340 345 350
Glu Asp Ile Asp Glu Cys Gln Asp Pro Asp Thr Cys Ser Gln Leu Cys
355 360 365
Val Asn Leu Glu Gly Gly Tyr Lys Cys Gln Cys Glu Glu Gly Phe Gln
370 375 380
Leu Asp Pro His Thr Lys Ala Cys Lys Ala Val Gly Ser Ile Ala Tyr
385 390 395 400
Leu Phe Phe Thr Asn Arg His Glu Val Arg Lys Met Thr Leu Asp Arg
405 410 415
Ser Glu Tyr Thr Ser Leu Ile Pro Asn Leu Arg Asn Val Val Ala Leu
420 425 430
Asp Thr Glu Val Ala Ser Asn Arg Ile Tyr Trp Ser Asp Leu Ser Gln
435 440 445
Arg Met Ile Cys Ser Thr Gln Leu Asp Arg Ala His Gly Val Ser Ser
450 455 460
Tyr Asp Thr Val Ile Ser Arg Asp Ile Gln Ala Pro Asp Gly Leu Ala
465 470 475 480
Val Asp Trp Ile His Ser Asn Ile Tyr Trp Thr Asp Ser Val Leu Gly
485 490 495
Thr Val Ser Val Ala Asp Thr Lys Gly Val Lys Arg Lys Thr Leu Phe
500 505 510
Arg Glu Asn Gly Ser Lys Pro Arg Ala Ile Val Val Asp Pro Val His
515 520 525
Gly Phe Met Tyr Trp Thr Asp Trp Gly Thr Pro Ala Lys Ile Lys Lys
530 535 540
Gly Gly Leu Asn Gly Val Asp Ile Tyr Ser Leu Val Thr Glu Asn Ile
545 550 555 560
Gln Trp Pro Asn Gly Ile Thr Leu Asp Leu Leu Ser Gly Arg Leu Tyr
565 570 575
Trp Val Asp Ser Lys Leu His Ser Ile Ser Ser Ile Asp Val Asn Gly
580 585 590
Gly Asn Arg Lys Thr Ile Leu Glu Asp Glu Lys Arg Leu Ala His Pro
595 600 605
Phe Ser Leu Ala Val Phe Glu Asp Lys Val Phe Trp Thr Asp Ile Ile
610 615 620
Asn Glu Ala Ile Phe Ser Ala Asn Arg Leu Thr Gly Ser Asp Val Asn
625 630 635 640
Leu Leu Ala Glu Asn Leu Leu Ser Pro Glu Asp Met Val Leu Phe His
645 650 655
Asn Leu Thr Gln Pro Arg Gly Val Asn Trp Cys Glu Arg Thr Thr Leu
660 665 670
Ser Asn Gly Gly Cys Gln Tyr Leu Cys Leu Pro Ala Pro Gln Ile Asn
675 680 685
Pro His Ser Pro Lys Phe Thr Cys Ala Cys Pro Asp Gly Met Leu Leu
690 695 700
Ala Arg Asp Met Arg Ser Cys Leu Thr Glu Ala Glu Ala Ala Val Ala
705 710 715 720
Thr Gln Glu Thr Ser Thr Val Arg Leu Lys Val Ser Ser Thr Ala Val
725 730 735
Arg Thr Gln His Thr Thr Thr Arg Pro Val Pro Asp Thr Ser Arg Leu
740 745 750
Pro Gly Ala Thr Pro Gly Leu Thr Thr Val Glu Ile Val Thr Met Ser
755 760 765
His Gln Ala Leu Gly Asp Val Ala Gly Arg Gly Asn Glu Lys Lys Pro
770 775 780
Ser Ser Val Arg Ala Leu Ser Ile Val Leu Pro Ile Val Leu Leu Val
785 790 795 800
Phe Leu Cys Leu Gly Val Phe Leu Leu Trp Lys Asn Trp Arg Leu Lys
805 810 815
Asn Ile Asn Ser Ile Asn Phe Asp Asn Pro Val Tyr Gln Lys Thr Thr
820 825 830
Glu Asp Glu Val His Ile Cys His Asn Gln Asp Gly Tyr Ser Tyr Pro
835 840 845
Ser Arg Gln Met Val Ser Leu Glu Asp Asp Val Ala
850 855 860
Claims (38)
- 가족성 고콜레스테롤혈증을 가진 환자에서 성분채집술에 대한 필요성을 감소시키는 방법으로서,
제제 완충액 중의 복제 결핍 재조합 아데노-관련 바이러스 (rAAV)의 현탁액을 포함하는, 인간 대상체에서 말초 정맥 주입에 적합한 제약학적 조성물을 환자에게 투여하는 방법을 포함하며,
(a) rAAV는 AAV ITR을 포함하는 벡터 게놈을 포함하고 핵산 서열은 간 특이적 프로모터에 작동 가능하게 연결된 인간 LDL 수용체 (hLDLR)를 암호화하며, 상기 벡터 게놈은 AAV8 캡시드에서 포장되고;
(b) 제제 완충액은 포스페이트 완충 식염수 및 폴록사머의 수용액을 포함하며; 및
(c) 다음:
(i) rAAV 게놈 복사물 (GC) 역가는 적어도 1 x 1013 GC/ml이고;
(ii) rAAV는 oqPCR 또는 ddPCR에 의해 측정되는 바 빈 캡시드가 적어도 약 95% 없으며;
(iii) 빈:채워진 입자 비율은 0:4 내지 1:4이고; 및
(iv) rAAV 현탁액의 5 x 1011 GC/kg의 용량은 동형접합성 가족성 고콜레스테롤혈증 (HoFH)의 이중 녹아웃 (DKO) LDLR-/-Apobec-/- 마우스 모델에서 기준선 콜레스테롤 수준을 25% 내지 75% 감소시키는 것 중 하나 이상인,
방법. - 제1항에 있어서, 환자는 AAV8 캡시드에 대해 1:10 이하의 중화 항체 역가를 가지는 것을 특징으로 하는 방법.
- 제2항에 있어서, 환자는 면역억제 처방으로 병용 치료되는 것을 특징으로 하는 방법.
- 제3항에 있어서, 환자는 면역억제 처방으로 병용 치료되기 전에 적어도 약 1:5의 중화 항체 역가를 가지는 것을 특징으로 하는 방법.
- 제1항에 있어서, 환자는 AAV8 캡시드에 대해 1:5 이하의 중화 항체 역가를 가지는 것을 특징으로 하는 방법.
- 제1항에 있어서, rAAV는 AAV8.TBG.hLDLR인 것을 특징으로 하는 방법.
- 제1항에 있어서, 제제 완충액은 180mM NaCl, 10mM Na 포스페이트, 0.001% 폴록사머 188, pH 7.3인 것을 특징으로 하는 방법.
- 제1항에 있어서, 조성물은 oqPCR 또는 ddPCR에 의해 측정되는 바 (a) 적어도 약 5 x 1011 게놈 복사물/kg 인간 대상체 체중 또는 (b) 2.5 x 1012 게놈 복사물 (GC)/kg 인간 대상체 체중 내지 7.5 x 1012 게놈 복사물 (GC)/kg 인간 대상체 체중의 용량으로 복제 결핍 재조합 아데노-관련 바이러스 (rAAV)의 현탁액의 말초 정맥을 통한 주입에 의해 인간 대상체에게 투여될 수 있는 것을 특징으로 하는 방법.
- 가족성 고콜레스테롤혈증을 가진 환자에서 성분채집술에 대한 필요성을 감소시키는 데 사용하기에 적합한 제제 완충액 중의 복제 결핍 재조합 아데노-관련 바이러스 (rAAV)의 현탁액을 포함하는, 적합한 제약학적 조성물로서,
(a) rAAV는 AAV ITR을 포함하는 벡터 게놈을 포함하고 핵산 서열은 간 특이적 프로모터에 작동 가능하게 연결된 인간 LDL 수용체 (hLDLR)를 암호화하며, 상기 벡터 게놈은 AAV8 캡시드에서 포장되고;
(b) 제제 완충액은 포스페이트 완충 식염수 및 폴록사머의 수용액을 포함하며; 및
(c) 다음:
(i) rAAV 게놈 복사물 (GC) 역가는 적어도 1 x 1013 GC/ml이고;
(ii) rAAV는 oqPCR 또는 ddPCR에 의해 측정되는 바 빈 캡시드가 적어도 약 95% 없으며;
(iii) 빈:채워진 입자 비율은 0:4 내지 1:4이고; 및
(iv) rAAV 현탁액의 5 x 1011 GC/kg의 용량은 동형접합성 가족성 고콜레스테롤혈증 (HoFH)의 이중 녹아웃 (DKO) LDLR-/-Apobec-/- 마우스 모델에서 기준선 콜레스테롤 수준을 25% 내지 75% 감소시키는 것 중 하나 이상인,
제약학적 조성물. - 가족성 고콜레스테롤혈증을 가진 환자에서 성분채집술에 대한 필요성을 감소시키는 데 사용하기에 적합한 제제 완충액 중의 복제 결핍 재조합 아데노-관련 바이러스 (rAAV)의 현탁액을 포함하는 제약학적 조성물의 용도로서,
(a) rAAV는 AAV ITR을 포함하는 벡터 게놈을 포함하고 핵산 서열은 간 특이적 프로모터에 작동 가능하게 연결된 인간 LDL 수용체 (hLDLR)를 암호화하며, 상기 벡터 게놈은 AAV8 캡시드에서 포장되고;
(b) 제제 완충액은 포스페이트 완충 식염수 및 폴록사머의 수용액을 포함하며; 및
(c) 다음:
(i) rAAV 게놈 복사물 (GC) 역가는 적어도 1 x 1013 GC/ml이고;
(ii) rAAV는 oqPCR 또는 ddPCR에 의해 측정되는 바 빈 캡시드가 적어도 약 95% 없으며;
(iii) 빈:채워진 입자 비율은 0:4 내지 1:4이고; 및
(iv) rAAV 현탁액의 5 x 1011 GC/kg의 용량은 동형접합성 가족성 고콜레스테롤혈증 (HoFH)의 이중 녹아웃 (DKO) LDLR-/-Apobec-/- 마우스 모델에서 기준선 콜레스테롤 수준을 25% 내지 75% 감소시키는 것 중 하나 이상인,
용도. - 제9항 또는 제10항에 있어서, 환자는 AAV8 캡시드에 대해 1:10 이하의 중화 항체 역가를 가지는 것을 특징으로 하는 제약학적 조성물 또는 용도.
- 제9항 내지 제11항 중 어느 한 항에 있어서, 환자는 면역억제 처방으로 병용 치료되는 것을 특징으로 하는 제약학적 조성물 또는 용도.
- 제9항 내지 제12항 중 어느 한 항에 있어서, 환자는 면역억제 처방으로 병용 치료되기 전에 적어도 약 1:5의 중화 항체 역가를 가지는 것을 특징으로 하는 제약학적 조성물 또는 용도.
- 제9항 내지 제12항 중 어느 한 항에 있어서, 환자는 AAV8 캡시드에 대해 1:5 이하의 중화 항체 역가를 가지는 것을 특징으로 하는 제약학적 조성물 또는 용도.
- 제9항 내지 제12항 중 어느 한 항에 있어서, rAAV는 AAV8.TBG.hLDLR인 것을 특징으로 하는 제약학적 조성물 또는 용도.
- 제9항 내지 제15항 중 어느 한 항에 있어서, 제제 완충액은 180mM NaCl, 10mM Na 포스페이트, 0.001% 폴록사머 188, pH 7.3인 것을 특징으로 하는 제약학적 조성물 또는 용도.
- 제9항 내지 제16항 중 어느 한 항에 있어서, 조성물은 oqPCR 또는 ddPCR에 의해 측정되는 바 (a) 적어도 약 5 x 1011 게놈 복사물/kg 인간 대상체 체중 또는 (b) 2.5 x 1012 게놈 복사물 (GC)/kg 인간 대상체 체중 내지 7.5 x 1012 게놈 복사물 (GC)/kg 인간 대상체 체중의 용량으로 복제 결핍 재조합 아데노-관련 바이러스 (rAAV)의 현탁액의 말초 정맥을 통한 주입에 의해 인간 대상체에게 투여될 수 있는 것을 특징으로 하는 제약학적 조성물 또는 용도.
- 제9항 내지 제17항 중 어느 한 항에 있어서, 환자는 동형접합성 FH (HoFH)로 진단된 것을 특징으로 하는 제약학적 조성물 또는 용도.
- 제9항 내지 제17항 중 어느 한 항에 있어서, 환자는 이형접합성 FH (HeFH)로 진단된 것을 특징으로 하는 제약학적 조성물 또는 용도.
- 가족성 고콜레스테롤혈증 (FH)으로 진단된 인간 대상체에서 PCSK9 억제제로의 치료에 대한 필요성을 감소시키는 방법으로서, 인간 대상체에게 oqPCR 또는 ddPCR에 의해 측정되는 바 (a) 적어도 약 5 x 1011 게놈 복사물/kg 인간 대상체 체중 또는 (b) 2.5 x 1012 게놈 복사물 (GC)/kg 인간 대상체 체중 내지 7.5 x 1012 게놈 복사물 (GC)/kg 인간 대상체 체중의 용량으로 복제 결핍 재조합 아데노-관련 바이러스 (rAAV)의 현탁액을 말초 정맥을 통한 주입에 의해 투여하는 단계를 포함하고,
(a) rAAV는 AAV ITR을 포함하는 벡터 게놈을 포함하고 핵산 서열은 간 특이적 프로모터에 작동 가능하게 연결된 야생형 인간 LDL 수용체 (hLDLR)를 암호화하며, 상기 벡터 게놈은 AAV8 캡시드에서 포장되고, 및
(b) rAAV 현탁액은 이중 녹아웃 LDLR-/-Apobec-/- HoFH의 마우스 모델 (DKO 마우스)에 투여된 5 x 1011 GC/Kg의 용량이 DKO 마우스에서 기준선 콜레스테롤 수준을 25% 내지 75% 감소시키는 효능을 가지며; 및
(c) 다음:
(i) rAAV는 oqPCR 또는 ddPCR에 의해 측정되는 바 빈 캡시드가 적어도 약 95% 없으며; 및
(ii) rAAV 빈:채워진 입자 비율은 0:4 내지 1:4인 것 중 하나 이상인,
방법. - 제20항에 있어서, 환자는 AAV8 캡시드에 대해 1:10 이하의 중화 항체 역가를 가지는 것을 특징으로 하는 방법.
- 제20항에 있어서, 환자는 면역억제 처방으로 병용 치료되는 것을 특징으로 하는 방법.
- 제20항에 있어서, 환자는 면역억제 처방으로 병용 치료되기 전에 적어도 약 1:5의 중화 항체 역가를 가지는 것을 특징으로 하는 방법.
- 제20항에 있어서, 환자는 AAV8 캡시드에 대해 1:5 이하의 중화 항체 역가를 가지는 것을 특징으로 하는 방법.
- 제20항에 있어서, rAAV는 AAV8.TBG.hLDLR인 것을 특징으로 하는 방법.
- 제20항에 있어서, 제제 완충액은 180mM NaCl, 10mM Na 포스페이트, 0.001% 폴록사머 188, pH 7.3인 것을 특징으로 하는 방법.
- 제20항에 있어서, 대상체는 동형접합성 FH (HoFH)로 진단된 것을 특징으로 하는 방법.
- 제20항에 있어서, 대상체는 이형접합성 FH (HeFH)로 진단된 것을 특징으로 하는 방법.
- 복제 결핍제의 현탁액을 말초 정맥을 통한 주입에 의해 인간 대상체에게 투여하는 단계를 포함하는, 가족성 고콜레스테롤혈증 (FH)으로 진단된 인간 대상체에서 PCSK9 억제제로의 치료에 대한 필요성을 감소시키는 데 사용하기에 유용한, oqPCR 또는 ddPCR에 의해 측정되는 바 (a) 적어도 약 5 x 1011 게놈 복사물/kg 인간 대상체 체중 또는 (b) 2.5 x 1012 게놈 복사물 (GC)/kg 인간 대상체 체중 내지 7.5 x 1012 게놈 복사물 (GC)/kg 인간 대상체 체중의 용량의 재조합 아데노-관련 바이러스 (rAAV)로서,
(a) rAAV는 AAV ITR을 포함하는 벡터 게놈을 포함하고 핵산 서열은 간 특이적 프로모터에 작동 가능하게 연결된 야생형 인간 LDL 수용체 (hLDLR)를 암호화하며, 상기 벡터 게놈은 AAV8 캡시드에서 포장되고, 및
(b) rAAV 현탁액은 이중 녹아웃 LDLR-/-Apobec-/- HoFH의 마우스 모델 (DKO 마우스)에 투여된 5 x 1011 GC/Kg의 용량이 DKO 마우스에서 기준선 콜레스테롤 수준을 25% 내지 75% 감소시키는 효능을 가지며; 및
(c) 다음:
(i) rAAV는 oqPCR 또는 ddPCR에 의해 측정되는 바 빈 캡시드가 적어도 약 95% 없으며; 및
(ii) rAAV 빈:채워진 입자 비율은 0:4 내지 1:4인 것 중 하나 이상인,
재조합 아데노-관련 바이러스 (rAAV). - 복제 결핍제의 현탁액을 말초 정맥을 통한 주입에 의해 인간 대상체에게 투여하는 단계를 포함하는, 가족성 고콜레스테롤혈증 (FH)으로 진단된 인간 대상체에서 PCSK9 억제제로의 치료에 대한 필요성을 감소시키는 데 사용하기 위한, oqPCR 또는 ddPCR에 의해 측정되는 바 (a) 적어도 약 5 x 1011 게놈 복사물/kg 인간 대상체 체중 또는 (b) 2.5 x 1012 게놈 복사물 (GC)/kg 인간 대상체 체중 내지 7.5 x 1012 게놈 복사물 (GC)/kg 인간 대상체 체중의 용량의 재조합 아데노-관련 바이러스 (rAAV)의 용도로서,
(a) rAAV는 AAV ITR을 포함하는 벡터 게놈을 포함하고 핵산 서열은 간 특이적 프로모터에 작동 가능하게 연결된 야생형 인간 LDL 수용체 (hLDLR)를 암호화하며, 상기 벡터 게놈은 AAV8 캡시드에서 포장되고, 및
(b) rAAV 현탁액은 이중 녹아웃 LDLR-/-Apobec-/- HoFH의 마우스 모델 (DKO 마우스)에 투여된 5 x 1011 GC/Kg의 용량이 DKO 마우스에서 기준선 콜레스테롤 수준을 25% 내지 75% 감소시키는 효능을 가지며; 및
(c) 다음:
(i) rAAV는 oqPCR 또는 ddPCR에 의해 측정되는 바 빈 캡시드가 적어도 약 95% 없으며; 및
(ii) rAAV 빈:채워진 입자 비율은 0:4 내지 1:4인 것 중 하나 이상인,
재조합 아데노-관련 바이러스 (rAAV)의 용도. - 제30항에 있어서, 환자는 AAV8 캡시드에 대해 1:10 이하의 중화 항체 역가를 가지는 것을 특징으로 하는 rAAV 또는 용도.
- 제30항 또는 제31항에 있어서, 환자는 면역억제 처방으로 병용 치료되는 것을 특징으로 하는 rAAV 또는 용도.
- 제30항 내지 제32항 중 어느 한 항에 있어서, 환자는 면역억제 처방으로 병용 치료되기 전에 적어도 약 1:5의 중화 항체 역가를 가지는 것을 특징으로 하는 rAAV 또는 용도.
- 제30항 내지 제32항 중 어느 한 항에 있어서, 환자는 AAV8 캡시드에 대해 1:5 이하의 중화 항체 역가를 가지는 것을 특징으로 하는 rAAV 또는 용도.
- 제30항 내지 제34항 중 어느 한 항에 있어서, rAAV는 AAV8.TBG.hLDLR인 것을 특징으로 하는 rAAV 또는 용도.
- 제30항 내지 제35항 중 어느 한 항에 있어서, 제제 완충액은 180mM NaCl, 10mM Na 포스페이트, 0.001% 폴록사머 188, pH 7.3인 것을 특징으로 하는 rAAV 또는 용도.
- 제30항 내지 제36항 중 어느 한 항에 있어서, 대상체는 동형접합성 FH (HoFH)로 진단된 것을 특징으로 하는 rAAV 또는 용도.
- 제30항 내지 제36항 중 어느 한 항에 있어서, 대상체는 이형접합성 FH (HeFH)로 진단된 것을 특징으로 하는 rAAV 또는 용도.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201762461015P | 2017-02-20 | 2017-02-20 | |
| US62/461,015 | 2017-02-20 | ||
| PCT/US2018/018678 WO2018152485A1 (en) | 2017-02-20 | 2018-02-20 | Gene therapy for treating familial hypercholesterolemia |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20190118163A true KR20190118163A (ko) | 2019-10-17 |
Family
ID=63170484
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020197024773A KR20190118163A (ko) | 2017-02-20 | 2018-02-20 | 가족성 고콜레스테롤혈증을 치료하기 위한 유전자 요법 |
Country Status (8)
| Country | Link |
|---|---|
| US (2) | US11554147B2 (ko) |
| EP (1) | EP3595688A4 (ko) |
| JP (2) | JP2020510648A (ko) |
| KR (1) | KR20190118163A (ko) |
| AU (1) | AU2018220212A1 (ko) |
| CA (1) | CA3051011A1 (ko) |
| IL (1) | IL268276A (ko) |
| WO (1) | WO2018152485A1 (ko) |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6741590B2 (ja) | 2014-04-25 | 2020-08-19 | ザ・トラステイーズ・オブ・ザ・ユニバーシテイ・オブ・ペンシルベニア | コレステロールレベルを低下させるためのldlr変異体および組成物中でのそれらの使用 |
| WO2017100682A1 (en) | 2015-12-11 | 2017-06-15 | The Trustees Of The University Of Pennsylvania | Gene therapy for treating familial hypercholesterolemia |
| EP3595688A4 (en) | 2017-02-20 | 2020-12-30 | The Trustees Of The University Of Pennsylvania | GENE THERAPY TO TREAT FAMILY HYPERCHOLESTERINEMIA |
| WO2021080975A1 (en) * | 2019-10-21 | 2021-04-29 | The Trustees Of The University Of Pennsylvania | Compositions and methods for reducing cholesterol levels |
| AU2022214429A1 (en) | 2021-02-01 | 2023-09-14 | Regenxbio Inc. | Gene therapy for neuronal ceroid lipofuscinoses |
| WO2023081807A1 (en) * | 2021-11-04 | 2023-05-11 | The Trustees of the University of Pennsylvania Penn Center for Innovation | Compositions and methods for reducing pcsk9 levels in a subject |
Family Cites Families (41)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5139941A (en) | 1985-10-31 | 1992-08-18 | University Of Florida Research Foundation, Inc. | AAV transduction vectors |
| US5436146A (en) | 1989-09-07 | 1995-07-25 | The Trustees Of Princeton University | Helper-free stocks of recombinant adeno-associated virus vectors |
| US6268213B1 (en) | 1992-06-03 | 2001-07-31 | Richard Jude Samulski | Adeno-associated virus vector and cis-acting regulatory and promoter elements capable of expressing at least one gene and method of using same for gene therapy |
| US5478745A (en) | 1992-12-04 | 1995-12-26 | University Of Pittsburgh | Recombinant viral vector system |
| US5869305A (en) | 1992-12-04 | 1999-02-09 | The University Of Pittsburgh | Recombinant viral vector system |
| US6204059B1 (en) | 1994-06-30 | 2001-03-20 | University Of Pittsburgh | AAV capsid vehicles for molecular transfer |
| US5741683A (en) | 1995-06-07 | 1998-04-21 | The Research Foundation Of State University Of New York | In vitro packaging of adeno-associated virus DNA |
| US6093570A (en) | 1995-06-07 | 2000-07-25 | The University Of North Carolina At Chapel Hill | Helper virus-free AAV production |
| CA2287478C (en) | 1997-04-14 | 2007-06-19 | Richard J. Samulski | Methods for increasing the efficiency of recombinant aav product |
| WO1999061643A1 (en) | 1998-05-27 | 1999-12-02 | University Of Florida | Method of preparing recombinant adeno-associated virus compositions by using an iodixananol gradient |
| ES2340230T3 (es) | 1998-11-10 | 2010-05-31 | University Of North Carolina At Chapel Hill | Vectores viricos y sus procedimientos de preparacion y administracion. |
| ES2308989T3 (es) | 1999-08-09 | 2008-12-16 | Targeted Genetics Corporation | Aumento de la expresion de una secuencia nucleotidica heterologa a partir de vectores viricos recombinantes que contienen una secuencia que forman pares de bases intracatenarios. |
| US7201898B2 (en) | 2000-06-01 | 2007-04-10 | The University Of North Carolina At Chapel Hill | Methods and compounds for controlled release of recombinant parvovirus vectors |
| NZ578982A (en) | 2001-11-13 | 2011-03-31 | Univ Pennsylvania | A method of detecting and/or identifying adeno-associated virus (AAV) sequences and isolating novel sequences identified thereby |
| ES2975413T3 (es) | 2001-12-17 | 2024-07-05 | Univ Pennsylvania | Secuencias de serotipo 8 de virus adenoasociado (AAV), vectores que las contienen y usos de las mismas |
| US20070015238A1 (en) | 2002-06-05 | 2007-01-18 | Snyder Richard O | Production of pseudotyped recombinant AAV virions |
| ES2648241T3 (es) | 2003-09-30 | 2017-12-29 | The Trustees Of The University Of Pennsylvania | Clados de virus adenoasociados (AAV), secuencias, vectores que contienen el mismo, y usos de los mismos |
| US8999678B2 (en) | 2005-04-07 | 2015-04-07 | The Trustees Of The University Of Pennsylvania | Method of increasing the function of an AAV vector |
| US7456683B2 (en) | 2005-06-09 | 2008-11-25 | Panasonic Corporation | Amplitude error compensating device and quadrature skew error compensating device |
| US7769466B2 (en) | 2006-02-24 | 2010-08-03 | Kenergy, Inc. | Class-E radio frequency amplifier for use with an implantable medical device |
| US7588772B2 (en) | 2006-03-30 | 2009-09-15 | Board Of Trustees Of The Leland Stamford Junior University | AAV capsid library and AAV capsid proteins |
| KR101010352B1 (ko) | 2008-05-30 | 2011-01-25 | 삼성중공업 주식회사 | 전력 제어 장치 및 방법 |
| BRPI1007155A2 (pt) | 2009-01-29 | 2017-05-30 | Univ Of California San Francisco | métodos para tratar um distúrbio neurológico cortical, e para dispensar um agente terapêutico para o córtex em um primata |
| WO2011020118A1 (en) * | 2009-08-14 | 2011-02-17 | Theramind Research, Llc | Methods and compositions for treatment of tuberous sclerosis complex |
| AU2011209743B2 (en) | 2010-01-28 | 2016-03-10 | The Children's Hospital Of Philadelphia | A scalable manufacturing platform for viral vector purification and viral vectors so purified for use in gene therapy |
| US9315825B2 (en) | 2010-03-29 | 2016-04-19 | The Trustees Of The University Of Pennsylvania | Pharmacologically induced transgene ablation system |
| CA2793633A1 (en) | 2010-03-29 | 2011-10-13 | The Trustees Of The University Of Pennsylvania | Pharmacologically induced transgene ablation system |
| JP2014519848A (ja) | 2011-06-20 | 2014-08-21 | ジェネンテック, インコーポレイテッド | Pcsk9結合ポリペプチドと使用方法 |
| WO2013029030A1 (en) | 2011-08-24 | 2013-02-28 | The Board Of Trustees Of The Leland Stanford Junior University | New aav capsid proteins for nucleic acid transfer |
| CA2848201C (en) * | 2011-09-16 | 2020-10-27 | Regeneron Pharmaceuticals, Inc. | Methods for reducing lipoprotein(a) levels by administering an inhibitor of proprotein convertase subtilisin kexin-9 (pcsk9) |
| ES2752191T3 (es) | 2012-02-17 | 2020-04-03 | Childrens Hospital Philadelphia | Composiciones y métodos con vectores de AAV para la transferencia de genes a células, órganos y tejidos |
| US9255250B2 (en) | 2012-12-05 | 2016-02-09 | Sangamo Bioscience, Inc. | Isolated mouse or human cell having an exogenous transgene in an endogenous albumin gene |
| US9567376B2 (en) | 2013-02-08 | 2017-02-14 | The Trustees Of The University Of Pennsylvania | Enhanced AAV-mediated gene transfer for retinal therapies |
| US9873893B2 (en) | 2013-02-15 | 2018-01-23 | The United States Of America As Represented By The Secretary, Dept. Of Health And Human Services | Methods and compositions for treating genetically linked diseases of the eye |
| US9254332B2 (en) | 2013-03-15 | 2016-02-09 | Arecor Limited | Stable aqueous formulations of adenovirus vectors |
| WO2015012924A2 (en) | 2013-04-29 | 2015-01-29 | The Trustees Of The University Of Pennsylvania | Tissue preferential codon modified expression cassettes, vectors containing same, and use thereof |
| SG11201602503TA (en) | 2013-10-03 | 2016-04-28 | Moderna Therapeutics Inc | Polynucleotides encoding low density lipoprotein receptor |
| JP6741590B2 (ja) * | 2014-04-25 | 2020-08-19 | ザ・トラステイーズ・オブ・ザ・ユニバーシテイ・オブ・ペンシルベニア | コレステロールレベルを低下させるためのldlr変異体および組成物中でのそれらの使用 |
| ES2934848T3 (es) | 2015-12-11 | 2023-02-27 | Univ Pennsylvania | Método de purificación escalable para AAV8 |
| WO2017100682A1 (en) * | 2015-12-11 | 2017-06-15 | The Trustees Of The University Of Pennsylvania | Gene therapy for treating familial hypercholesterolemia |
| EP3595688A4 (en) | 2017-02-20 | 2020-12-30 | The Trustees Of The University Of Pennsylvania | GENE THERAPY TO TREAT FAMILY HYPERCHOLESTERINEMIA |
-
2018
- 2018-02-20 EP EP18754347.5A patent/EP3595688A4/en not_active Withdrawn
- 2018-02-20 US US16/486,981 patent/US11554147B2/en active Active
- 2018-02-20 JP JP2019545363A patent/JP2020510648A/ja active Pending
- 2018-02-20 CA CA3051011A patent/CA3051011A1/en active Pending
- 2018-02-20 KR KR1020197024773A patent/KR20190118163A/ko not_active Application Discontinuation
- 2018-02-20 AU AU2018220212A patent/AU2018220212A1/en not_active Abandoned
- 2018-02-20 WO PCT/US2018/018678 patent/WO2018152485A1/en unknown
-
2019
- 2019-07-25 IL IL268276A patent/IL268276A/en unknown
-
2022
- 2022-11-22 US US18/058,126 patent/US20230190837A1/en active Pending
-
2023
- 2023-03-01 JP JP2023030651A patent/JP2023071829A/ja active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| JP2023071829A (ja) | 2023-05-23 |
| AU2018220212A1 (en) | 2019-08-08 |
| EP3595688A1 (en) | 2020-01-22 |
| US11554147B2 (en) | 2023-01-17 |
| JP2020510648A (ja) | 2020-04-09 |
| WO2018152485A1 (en) | 2018-08-23 |
| CA3051011A1 (en) | 2018-08-23 |
| US20230190837A1 (en) | 2023-06-22 |
| EP3595688A4 (en) | 2020-12-30 |
| IL268276A (en) | 2019-09-26 |
| US20200230184A1 (en) | 2020-07-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7361737B2 (ja) | 修飾された第ix因子、並びに、細胞、器官及び組織への遺伝子導入のための組成物、方法及び使用 | |
| KR20190118163A (ko) | 가족성 고콜레스테롤혈증을 치료하기 위한 유전자 요법 | |
| ES2966692T3 (es) | Vectores de virus adenoasociados poliploides y métodos de fabricación y uso de los mismos | |
| KR20180113990A (ko) | 가족성 고콜레스테롤혈증을 치료하기 위한 유전자 요법 | |
| CN113950526A (zh) | 通过靶向体内表观遗传阻遏实现的持久镇痛 | |
| US20210299275A1 (en) | Gene therapy for the treatment of galactosemia | |
| CN112135640A (zh) | 基因疗法的方法 | |
| JP2023154428A (ja) | 合理的なポリプロイド性アデノ随伴ウイルスベクターならびにその製造法および使用法 | |
| CN114846141B (zh) | 一种分离的核酸分子及其应用 | |
| CN115109788A (zh) | Aav介导的人脂蛋白脂酶肝脏异位表达载体及其用途 | |
| JP2023065516A (ja) | 結節性硬化症の遺伝子治療 | |
| KR20210006352A (ko) | Aav-상용성 라미닌-링커 중합 단백질 | |
| KR20210106489A (ko) | 가족성 고콜레스테롤혈증을 치료하기 위한 유전자 요법 | |
| KR20220079857A (ko) | Aav-상용성 라미닌-링커 중합 단백질 | |
| CN108949690B (zh) | 一种制备可实时检测间充质干细胞骨分化的细胞模型的方法 | |
| CN112272565A (zh) | 使用慢病毒基因构建体的递送的体内基因疗法 | |
| US20230346977A1 (en) | Treatment of neuromuscular diseases via gene therapy that expresses klotho protein | |
| CN116768983A (zh) | 一种用于慢性乙型肝炎预防和/或治疗的蛋白、编码基因、重组腺相关病毒及其应用 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| E902 | Notification of reason for refusal | ||
| E601 | Decision to refuse application |