KR20170073593A - 키메라 수용체 및 면역 요법에서의 그의 용도 - Google Patents
키메라 수용체 및 면역 요법에서의 그의 용도 Download PDFInfo
- Publication number
- KR20170073593A KR20170073593A KR1020177009209A KR20177009209A KR20170073593A KR 20170073593 A KR20170073593 A KR 20170073593A KR 1020177009209 A KR1020177009209 A KR 1020177009209A KR 20177009209 A KR20177009209 A KR 20177009209A KR 20170073593 A KR20170073593 A KR 20170073593A
- Authority
- KR
- South Korea
- Prior art keywords
- leu
- gly
- ala
- pro
- ser
- Prior art date
Links
- 108700010039 chimeric receptor Proteins 0.000 title claims abstract description 273
- 238000009169 immunotherapy Methods 0.000 title claims abstract description 28
- 210000002865 immune cell Anatomy 0.000 claims abstract description 103
- 230000027455 binding Effects 0.000 claims abstract description 78
- 238000009739 binding Methods 0.000 claims abstract description 77
- 230000011664 signaling Effects 0.000 claims abstract description 71
- 230000010056 antibody-dependent cellular cytotoxicity Effects 0.000 claims abstract description 47
- 150000007523 nucleic acids Chemical class 0.000 claims abstract description 37
- 102000039446 nucleic acids Human genes 0.000 claims abstract description 33
- 108020004707 nucleic acids Proteins 0.000 claims abstract description 33
- 108060003951 Immunoglobulin Proteins 0.000 claims abstract description 20
- 102000018358 immunoglobulin Human genes 0.000 claims abstract description 20
- 230000004913 activation Effects 0.000 claims abstract description 18
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 claims abstract description 5
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 claims abstract description 5
- 210000004027 cell Anatomy 0.000 claims description 408
- 210000001744 T-lymphocyte Anatomy 0.000 claims description 184
- 102000005962 receptors Human genes 0.000 claims description 102
- 108020003175 receptors Proteins 0.000 claims description 102
- 206010028980 Neoplasm Diseases 0.000 claims description 77
- 108090000623 proteins and genes Proteins 0.000 claims description 77
- 229960004641 rituximab Drugs 0.000 claims description 76
- 238000000034 method Methods 0.000 claims description 75
- 230000014509 gene expression Effects 0.000 claims description 70
- 102100029193 Low affinity immunoglobulin gamma Fc region receptor III-A Human genes 0.000 claims description 68
- 102000004169 proteins and genes Human genes 0.000 claims description 61
- 239000013598 vector Substances 0.000 claims description 59
- 230000003013 cytotoxicity Effects 0.000 claims description 55
- 231100000135 cytotoxicity Toxicity 0.000 claims description 55
- 201000011510 cancer Diseases 0.000 claims description 53
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 50
- 108020001756 ligand binding domains Proteins 0.000 claims description 45
- 102000009109 Fc receptors Human genes 0.000 claims description 44
- 108010087819 Fc receptors Proteins 0.000 claims description 44
- 101000851370 Homo sapiens Tumor necrosis factor receptor superfamily member 9 Proteins 0.000 claims description 40
- 102100036856 Tumor necrosis factor receptor superfamily member 9 Human genes 0.000 claims description 40
- 210000000822 natural killer cell Anatomy 0.000 claims description 38
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 36
- 239000008194 pharmaceutical composition Substances 0.000 claims description 35
- 230000001086 cytosolic effect Effects 0.000 claims description 34
- 101000914514 Homo sapiens T-cell-specific surface glycoprotein CD28 Proteins 0.000 claims description 32
- 102100027213 T-cell-specific surface glycoprotein CD28 Human genes 0.000 claims description 32
- 229920001184 polypeptide Polymers 0.000 claims description 30
- 230000019491 signal transduction Effects 0.000 claims description 29
- 230000001225 therapeutic effect Effects 0.000 claims description 29
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 28
- 101100334515 Homo sapiens FCGR3A gene Proteins 0.000 claims description 26
- 239000003814 drug Substances 0.000 claims description 26
- 238000004520 electroporation Methods 0.000 claims description 26
- 238000000338 in vitro Methods 0.000 claims description 24
- -1 ICOS Proteins 0.000 claims description 21
- 108010076504 Protein Sorting Signals Proteins 0.000 claims description 21
- 229940124597 therapeutic agent Drugs 0.000 claims description 21
- 108010002350 Interleukin-2 Proteins 0.000 claims description 20
- 101000917826 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor II-a Proteins 0.000 claims description 19
- 102100029204 Low affinity immunoglobulin gamma Fc region receptor II-a Human genes 0.000 claims description 19
- 102100022153 Tumor necrosis factor receptor superfamily member 4 Human genes 0.000 claims description 19
- 102000017420 CD3 protein, epsilon/gamma/delta subunit Human genes 0.000 claims description 17
- 108050005493 CD3 protein, epsilon/gamma/delta subunit Proteins 0.000 claims description 17
- 101000917824 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor II-b Proteins 0.000 claims description 17
- 229960000575 trastuzumab Drugs 0.000 claims description 17
- 102100026122 High affinity immunoglobulin gamma Fc receptor I Human genes 0.000 claims description 16
- 101000913074 Homo sapiens High affinity immunoglobulin gamma Fc receptor I Proteins 0.000 claims description 16
- 108010052285 Membrane Proteins Proteins 0.000 claims description 16
- 238000010361 transduction Methods 0.000 claims description 16
- 230000026683 transduction Effects 0.000 claims description 16
- 206010029260 Neuroblastoma Diseases 0.000 claims description 15
- 210000002540 macrophage Anatomy 0.000 claims description 15
- 230000001404 mediated effect Effects 0.000 claims description 15
- 108091006020 Fc-tagged proteins Proteins 0.000 claims description 14
- 101710165473 Tumor necrosis factor receptor superfamily member 4 Proteins 0.000 claims description 14
- 210000000440 neutrophil Anatomy 0.000 claims description 14
- 208000010839 B-cell chronic lymphocytic leukemia Diseases 0.000 claims description 13
- 239000012634 fragment Substances 0.000 claims description 13
- 239000000203 mixture Substances 0.000 claims description 13
- 230000001177 retroviral effect Effects 0.000 claims description 13
- 208000005718 Stomach Neoplasms Diseases 0.000 claims description 12
- 239000003937 drug carrier Substances 0.000 claims description 12
- 210000003979 eosinophil Anatomy 0.000 claims description 12
- 206010017758 gastric cancer Diseases 0.000 claims description 12
- 201000011549 stomach cancer Diseases 0.000 claims description 12
- 239000013603 viral vector Substances 0.000 claims description 11
- 108010073816 IgE Receptors Proteins 0.000 claims description 10
- 102000009438 IgE Receptors Human genes 0.000 claims description 10
- 108010073807 IgG Receptors Proteins 0.000 claims description 10
- 102000009490 IgG Receptors Human genes 0.000 claims description 10
- 206010025323 Lymphomas Diseases 0.000 claims description 10
- 208000032839 leukemia Diseases 0.000 claims description 10
- 201000008968 osteosarcoma Diseases 0.000 claims description 10
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 claims description 10
- 206010006187 Breast cancer Diseases 0.000 claims description 9
- 208000026310 Breast neoplasm Diseases 0.000 claims description 9
- 201000009030 Carcinoma Diseases 0.000 claims description 9
- 208000031422 Lymphocytic Chronic B-Cell Leukemia Diseases 0.000 claims description 9
- 102000018697 Membrane Proteins Human genes 0.000 claims description 9
- 208000032852 chronic lymphocytic leukemia Diseases 0.000 claims description 9
- 230000002708 enhancing effect Effects 0.000 claims description 9
- 230000002209 hydrophobic effect Effects 0.000 claims description 9
- 210000003719 b-lymphocyte Anatomy 0.000 claims description 8
- 108010082808 4-1BB Ligand Proteins 0.000 claims description 7
- 102100027207 CD27 antigen Human genes 0.000 claims description 7
- 102100034459 Hepatitis A virus cellular receptor 1 Human genes 0.000 claims description 7
- 101000914511 Homo sapiens CD27 antigen Proteins 0.000 claims description 7
- 101000878602 Homo sapiens Immunoglobulin alpha Fc receptor Proteins 0.000 claims description 7
- 101000716102 Homo sapiens T-cell surface glycoprotein CD4 Proteins 0.000 claims description 7
- 102100038005 Immunoglobulin alpha Fc receptor Human genes 0.000 claims description 7
- 102000003812 Interleukin-15 Human genes 0.000 claims description 7
- 102100036011 T-cell surface glycoprotein CD4 Human genes 0.000 claims description 7
- 102100033177 Vascular endothelial growth factor receptor 2 Human genes 0.000 claims description 7
- 102100031573 Hematopoietic progenitor cell antigen CD34 Human genes 0.000 claims description 6
- 101000777663 Homo sapiens Hematopoietic progenitor cell antigen CD34 Proteins 0.000 claims description 6
- 101000801234 Homo sapiens Tumor necrosis factor receptor superfamily member 18 Proteins 0.000 claims description 6
- 102000016266 T-Cell Antigen Receptors Human genes 0.000 claims description 6
- 102100028785 Tumor necrosis factor receptor superfamily member 14 Human genes 0.000 claims description 6
- 102100033728 Tumor necrosis factor receptor superfamily member 18 Human genes 0.000 claims description 6
- 229960000397 bevacizumab Drugs 0.000 claims description 6
- 239000013604 expression vector Substances 0.000 claims description 6
- 101001068136 Homo sapiens Hepatitis A virus cellular receptor 1 Proteins 0.000 claims description 5
- 101000934346 Homo sapiens T-cell surface antigen CD2 Proteins 0.000 claims description 5
- 101000851007 Homo sapiens Vascular endothelial growth factor receptor 2 Proteins 0.000 claims description 5
- 108010061593 Member 14 Tumor Necrosis Factor Receptors Proteins 0.000 claims description 5
- 108091008874 T cell receptors Proteins 0.000 claims description 5
- 101710120037 Toxin CcdB Proteins 0.000 claims description 5
- 230000003213 activating effect Effects 0.000 claims description 5
- 229960002964 adalimumab Drugs 0.000 claims description 5
- 229960000548 alemtuzumab Drugs 0.000 claims description 5
- 102100022089 Acyl-[acyl-carrier-protein] hydrolase Human genes 0.000 claims description 4
- 101000964894 Bos taurus 14-3-3 protein zeta/delta Proteins 0.000 claims description 4
- 206010009944 Colon cancer Diseases 0.000 claims description 4
- 101000824278 Homo sapiens Acyl-[acyl-carrier-protein] hydrolase Proteins 0.000 claims description 4
- 101000831286 Homo sapiens Protein timeless homolog Proteins 0.000 claims description 4
- 101000752245 Homo sapiens Rho guanine nucleotide exchange factor 5 Proteins 0.000 claims description 4
- 101000611023 Homo sapiens Tumor necrosis factor receptor superfamily member 6 Proteins 0.000 claims description 4
- 206010058467 Lung neoplasm malignant Diseases 0.000 claims description 4
- 206010033128 Ovarian cancer Diseases 0.000 claims description 4
- 206010061535 Ovarian neoplasm Diseases 0.000 claims description 4
- 206010060862 Prostate cancer Diseases 0.000 claims description 4
- 208000000236 Prostatic Neoplasms Diseases 0.000 claims description 4
- 206010039491 Sarcoma Diseases 0.000 claims description 4
- 201000000053 blastoma Diseases 0.000 claims description 4
- 208000029742 colonic neoplasm Diseases 0.000 claims description 4
- 201000008184 embryoma Diseases 0.000 claims description 4
- 229960000578 gemtuzumab Drugs 0.000 claims description 4
- 210000003292 kidney cell Anatomy 0.000 claims description 4
- 201000005202 lung cancer Diseases 0.000 claims description 4
- 208000020816 lung neoplasm Diseases 0.000 claims description 4
- 229960000470 omalizumab Drugs 0.000 claims description 4
- 229960004914 vedolizumab Drugs 0.000 claims description 4
- MJZJYWCQPMNPRM-UHFFFAOYSA-N 6,6-dimethyl-1-[3-(2,4,5-trichlorophenoxy)propoxy]-1,6-dihydro-1,3,5-triazine-2,4-diamine Chemical compound CC1(C)N=C(N)N=C(N)N1OCCCOC1=CC(Cl)=C(Cl)C=C1Cl MJZJYWCQPMNPRM-UHFFFAOYSA-N 0.000 claims description 3
- 108700022150 Designed Ankyrin Repeat Proteins Proteins 0.000 claims description 3
- 108010065805 Interleukin-12 Proteins 0.000 claims description 3
- 102000013462 Interleukin-12 Human genes 0.000 claims description 3
- 206010027406 Mesothelioma Diseases 0.000 claims description 3
- 101100341510 Mus musculus Itgal gene Proteins 0.000 claims description 3
- 206010061902 Pancreatic neoplasm Diseases 0.000 claims description 3
- 208000000453 Skin Neoplasms Diseases 0.000 claims description 3
- 208000024770 Thyroid neoplasm Diseases 0.000 claims description 3
- JAZBEHYOTPTENJ-JLNKQSITSA-N all-cis-5,8,11,14,17-icosapentaenoic acid Chemical compound CC\C=C/C\C=C/C\C=C/C\C=C/C\C=C/CCCC(O)=O JAZBEHYOTPTENJ-JLNKQSITSA-N 0.000 claims description 3
- 238000012258 culturing Methods 0.000 claims description 3
- JAZBEHYOTPTENJ-UHFFFAOYSA-N eicosapentaenoic acid Natural products CCC=CCC=CCC=CCC=CCC=CCCCC(O)=O JAZBEHYOTPTENJ-UHFFFAOYSA-N 0.000 claims description 3
- 229960005135 eicosapentaenoic acid Drugs 0.000 claims description 3
- 235000020673 eicosapentaenoic acid Nutrition 0.000 claims description 3
- 208000005017 glioblastoma Diseases 0.000 claims description 3
- 229960000598 infliximab Drugs 0.000 claims description 3
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 claims description 3
- 229960005027 natalizumab Drugs 0.000 claims description 3
- 239000002773 nucleotide Substances 0.000 claims description 3
- 125000003729 nucleotide group Chemical group 0.000 claims description 3
- 201000002528 pancreatic cancer Diseases 0.000 claims description 3
- 208000008443 pancreatic carcinoma Diseases 0.000 claims description 3
- 201000009410 rhabdomyosarcoma Diseases 0.000 claims description 3
- 201000000849 skin cancer Diseases 0.000 claims description 3
- 201000002510 thyroid cancer Diseases 0.000 claims description 3
- 229960003824 ustekinumab Drugs 0.000 claims description 3
- 208000028564 B-cell non-Hodgkin lymphoma Diseases 0.000 claims description 2
- 208000032612 Glial tumor Diseases 0.000 claims description 2
- 206010018338 Glioma Diseases 0.000 claims description 2
- 108010021625 Immunoglobulin Fragments Proteins 0.000 claims description 2
- 102000008394 Immunoglobulin Fragments Human genes 0.000 claims description 2
- 201000000582 Retinoblastoma Diseases 0.000 claims description 2
- 229960002087 pertuzumab Drugs 0.000 claims description 2
- 239000000344 soap Substances 0.000 claims 2
- 102000002627 4-1BB Ligand Human genes 0.000 claims 1
- 208000004736 B-Cell Leukemia Diseases 0.000 claims 1
- 230000001154 acute effect Effects 0.000 claims 1
- 229960003876 ranibizumab Drugs 0.000 claims 1
- 229960005267 tositumomab Drugs 0.000 claims 1
- 238000002619 cancer immunotherapy Methods 0.000 abstract description 2
- 235000018102 proteins Nutrition 0.000 description 55
- 108020004999 messenger RNA Proteins 0.000 description 48
- 101000917858 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-A Proteins 0.000 description 43
- 108010015792 glycyllysine Proteins 0.000 description 40
- 101000917839 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor III-B Proteins 0.000 description 38
- 239000005090 green fluorescent protein Substances 0.000 description 35
- 108010050848 glycylleucine Proteins 0.000 description 34
- NRQRKMYZONPCTM-CIUDSAMLSA-N Lys-Asp-Ser Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O NRQRKMYZONPCTM-CIUDSAMLSA-N 0.000 description 33
- 102000004144 Green Fluorescent Proteins Human genes 0.000 description 32
- 108010043121 Green Fluorescent Proteins Proteins 0.000 description 32
- 238000002474 experimental method Methods 0.000 description 31
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 31
- 241000699670 Mus sp. Species 0.000 description 30
- QRIYOHQJRDHFKF-UWJYBYFXSA-N Ala-Tyr-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=C(O)C=C1 QRIYOHQJRDHFKF-UWJYBYFXSA-N 0.000 description 25
- 108010087924 alanylproline Proteins 0.000 description 25
- 108010062796 arginyllysine Proteins 0.000 description 24
- IASNWHAGGYTEKX-IUCAKERBSA-N Arg-Arg-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)NCC(O)=O IASNWHAGGYTEKX-IUCAKERBSA-N 0.000 description 23
- 230000000694 effects Effects 0.000 description 22
- 238000000684 flow cytometry Methods 0.000 description 22
- 241000880493 Leptailurus serval Species 0.000 description 20
- 235000001014 amino acid Nutrition 0.000 description 20
- 229940024606 amino acid Drugs 0.000 description 20
- 150000001413 amino acids Chemical class 0.000 description 20
- 239000011230 binding agent Substances 0.000 description 20
- 108010026333 seryl-proline Proteins 0.000 description 19
- 238000011282 treatment Methods 0.000 description 19
- PIDRBUDUWHBYSR-UHFFFAOYSA-N 1-[2-[[2-[(2-amino-4-methylpentanoyl)amino]-4-methylpentanoyl]amino]-4-methylpentanoyl]pyrrolidine-2-carboxylic acid Chemical compound CC(C)CC(N)C(=O)NC(CC(C)C)C(=O)NC(CC(C)C)C(=O)N1CCCC1C(O)=O PIDRBUDUWHBYSR-UHFFFAOYSA-N 0.000 description 18
- HGKHPCFTRQDHCU-IUCAKERBSA-N Arg-Pro-Gly Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O HGKHPCFTRQDHCU-IUCAKERBSA-N 0.000 description 18
- BIAKMWKJMQLZOJ-ZKWXMUAHSA-N His-Ala-Ala Chemical compound C[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)Cc1cnc[nH]1)C(O)=O BIAKMWKJMQLZOJ-ZKWXMUAHSA-N 0.000 description 18
- 102000000588 Interleukin-2 Human genes 0.000 description 18
- SITWEMZOJNKJCH-UHFFFAOYSA-N L-alanine-L-arginine Natural products CC(N)C(=O)NC(C(O)=O)CCCNC(N)=N SITWEMZOJNKJCH-UHFFFAOYSA-N 0.000 description 18
- QEVRUYFHWJJUHZ-DCAQKATOSA-N Met-Ala-Leu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(C)C QEVRUYFHWJJUHZ-DCAQKATOSA-N 0.000 description 18
- 101100342977 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) leu-1 gene Proteins 0.000 description 18
- YDTUEBLEAVANFH-RCWTZXSCSA-N Pro-Val-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 YDTUEBLEAVANFH-RCWTZXSCSA-N 0.000 description 18
- 108010018006 histidylserine Proteins 0.000 description 18
- 108010057821 leucylproline Proteins 0.000 description 18
- 230000035772 mutation Effects 0.000 description 18
- UBKOVSLDWIHYSY-ACZMJKKPSA-N Asn-Glu-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O UBKOVSLDWIHYSY-ACZMJKKPSA-N 0.000 description 17
- HNXWVVHIGTZTBO-LKXGYXEUSA-N Asn-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC(N)=O HNXWVVHIGTZTBO-LKXGYXEUSA-N 0.000 description 17
- KEBJBKIASQVRJS-WDSKDSINSA-N Cys-Gln-Gly Chemical compound C(CC(=O)N)[C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CS)N KEBJBKIASQVRJS-WDSKDSINSA-N 0.000 description 17
- NKLRYVLERDYDBI-FXQIFTODSA-N Glu-Glu-Asp Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NKLRYVLERDYDBI-FXQIFTODSA-N 0.000 description 17
- AAJHGGDRKHYSDH-GUBZILKMSA-N Glu-Pro-Gln Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O AAJHGGDRKHYSDH-GUBZILKMSA-N 0.000 description 17
- HRTRLSRYZZKPCO-BJDJZHNGSA-N Leu-Ile-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HRTRLSRYZZKPCO-BJDJZHNGSA-N 0.000 description 17
- MGDFPGCFVJFITQ-CIUDSAMLSA-N Pro-Glu-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O MGDFPGCFVJFITQ-CIUDSAMLSA-N 0.000 description 17
- CRZRTKAVUUGKEQ-ACZMJKKPSA-N Ser-Gln-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O CRZRTKAVUUGKEQ-ACZMJKKPSA-N 0.000 description 17
- OLKICIBQRVSQMA-SRVKXCTJSA-N Ser-Ser-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OLKICIBQRVSQMA-SRVKXCTJSA-N 0.000 description 17
- MECLEFZMPPOEAC-VOAKCMCISA-N Thr-Leu-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N)O MECLEFZMPPOEAC-VOAKCMCISA-N 0.000 description 17
- VUMCLPHXCBIJJB-PMVMPFDFSA-N Trp-Phe-His Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CC3=CNC4=CC=CC=C43)N VUMCLPHXCBIJJB-PMVMPFDFSA-N 0.000 description 17
- UIDJDMVRDUANDL-BVSLBCMMSA-N Trp-Tyr-Arg Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UIDJDMVRDUANDL-BVSLBCMMSA-N 0.000 description 17
- LYERIXUFCYVFFX-GVXVVHGQSA-N Val-Leu-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N LYERIXUFCYVFFX-GVXVVHGQSA-N 0.000 description 17
- HJSLDXZAZGFPDK-ULQDDVLXSA-N Val-Phe-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)NC(=O)[C@H](C(C)C)N HJSLDXZAZGFPDK-ULQDDVLXSA-N 0.000 description 17
- 108010057083 glutamyl-aspartyl-leucine Proteins 0.000 description 17
- 108010034529 leucyl-lysine Proteins 0.000 description 17
- 108010087846 prolyl-prolyl-glycine Proteins 0.000 description 17
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 16
- IOFVWPYSRSCWHI-JXUBOQSCSA-N Ala-Thr-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C)N IOFVWPYSRSCWHI-JXUBOQSCSA-N 0.000 description 16
- IETUUAHKCHOQHP-KZVJFYERSA-N Ala-Thr-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@H](C)N)[C@@H](C)O)C(O)=O IETUUAHKCHOQHP-KZVJFYERSA-N 0.000 description 16
- REWSWYIDQIELBE-FXQIFTODSA-N Ala-Val-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O REWSWYIDQIELBE-FXQIFTODSA-N 0.000 description 16
- QIWYWCYNUMJBTC-CIUDSAMLSA-N Arg-Cys-Gln Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O QIWYWCYNUMJBTC-CIUDSAMLSA-N 0.000 description 16
- DJIMLSXHXKWADV-CIUDSAMLSA-N Asn-Leu-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(N)=O DJIMLSXHXKWADV-CIUDSAMLSA-N 0.000 description 16
- QXHVOUSPVAWEMX-ZLUOBGJFSA-N Asp-Asp-Ser Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O QXHVOUSPVAWEMX-ZLUOBGJFSA-N 0.000 description 16
- NONWUQAWAANERO-BZSNNMDCSA-N Asp-Phe-Tyr Chemical compound C([C@H](NC(=O)[C@H](CC(O)=O)N)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(O)=O)C1=CC=CC=C1 NONWUQAWAANERO-BZSNNMDCSA-N 0.000 description 16
- DINOVZWPTMGSRF-QXEWZRGKSA-N Asp-Pro-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(O)=O DINOVZWPTMGSRF-QXEWZRGKSA-N 0.000 description 16
- CEZSLNCYQUFOSL-BQBZGAKWSA-N Cys-Arg-Gly Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O CEZSLNCYQUFOSL-BQBZGAKWSA-N 0.000 description 16
- ZPDVKYLJTOFQJV-WDSKDSINSA-N Gln-Asn-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O ZPDVKYLJTOFQJV-WDSKDSINSA-N 0.000 description 16
- QKCZZAZNMMVICF-DCAQKATOSA-N Gln-Leu-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O QKCZZAZNMMVICF-DCAQKATOSA-N 0.000 description 16
- JVSBYEDSSRZQGV-GUBZILKMSA-N Glu-Asp-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O JVSBYEDSSRZQGV-GUBZILKMSA-N 0.000 description 16
- CUYLIWAAAYJKJH-RYUDHWBXSA-N Gly-Glu-Tyr Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 CUYLIWAAAYJKJH-RYUDHWBXSA-N 0.000 description 16
- FKYQEVBRZSFAMJ-QWRGUYRKSA-N Gly-Ser-Tyr Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 FKYQEVBRZSFAMJ-QWRGUYRKSA-N 0.000 description 16
- CTJHHEQNUNIYNN-SRVKXCTJSA-N His-His-Asn Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(O)=O CTJHHEQNUNIYNN-SRVKXCTJSA-N 0.000 description 16
- RPZFUIQVAPZLRH-GHCJXIJMSA-N Ile-Asp-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](C)C(=O)O)N RPZFUIQVAPZLRH-GHCJXIJMSA-N 0.000 description 16
- NLZVTPYXYXMCIP-XUXIUFHCSA-N Ile-Pro-Lys Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(O)=O NLZVTPYXYXMCIP-XUXIUFHCSA-N 0.000 description 16
- HJDZMPFEXINXLO-QPHKQPEJSA-N Ile-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N HJDZMPFEXINXLO-QPHKQPEJSA-N 0.000 description 16
- VQPPIMUZCZCOIL-GUBZILKMSA-N Leu-Gln-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O VQPPIMUZCZCOIL-GUBZILKMSA-N 0.000 description 16
- AAKRWBIIGKPOKQ-ONGXEEELSA-N Leu-Val-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)NCC(O)=O AAKRWBIIGKPOKQ-ONGXEEELSA-N 0.000 description 16
- GQZMPWBZQALKJO-UWVGGRQHSA-N Lys-Gly-Arg Chemical compound [H]N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O GQZMPWBZQALKJO-UWVGGRQHSA-N 0.000 description 16
- LMMBAXJRYSXCOQ-ACRUOGEOSA-N Lys-Tyr-Phe Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](Cc1ccccc1)C(O)=O LMMBAXJRYSXCOQ-ACRUOGEOSA-N 0.000 description 16
- NKDSBBBPGIVWEI-RCWTZXSCSA-N Met-Arg-Thr Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NKDSBBBPGIVWEI-RCWTZXSCSA-N 0.000 description 16
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 16
- NUZHSNLQJDYSRW-BZSNNMDCSA-N Pro-Arg-Trp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O NUZHSNLQJDYSRW-BZSNNMDCSA-N 0.000 description 16
- OFGUOWQVEGTVNU-DCAQKATOSA-N Pro-Lys-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(O)=O OFGUOWQVEGTVNU-DCAQKATOSA-N 0.000 description 16
- LEIKGVHQTKHOLM-IUCAKERBSA-N Pro-Pro-Gly Chemical compound OC(=O)CNC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 LEIKGVHQTKHOLM-IUCAKERBSA-N 0.000 description 16
- HDBOEVPDIDDEPC-CIUDSAMLSA-N Ser-Lys-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O HDBOEVPDIDDEPC-CIUDSAMLSA-N 0.000 description 16
- RRVFEDGUXSYWOW-BZSNNMDCSA-N Ser-Phe-Phe Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O RRVFEDGUXSYWOW-BZSNNMDCSA-N 0.000 description 16
- UHBPFYOQQPFKQR-JHEQGTHGSA-N Thr-Gln-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O UHBPFYOQQPFKQR-JHEQGTHGSA-N 0.000 description 16
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 16
- YOOAQCZYZHGUAZ-KATARQTJSA-N Thr-Leu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O YOOAQCZYZHGUAZ-KATARQTJSA-N 0.000 description 16
- JAWUQFCGNVEDRN-MEYUZBJRSA-N Thr-Tyr-Leu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(C)C)C(=O)O)N)O JAWUQFCGNVEDRN-MEYUZBJRSA-N 0.000 description 16
- CCZXBOFIBYQLEV-IHPCNDPISA-N Trp-Leu-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)Cc1c[nH]c2ccccc12)C(O)=O CCZXBOFIBYQLEV-IHPCNDPISA-N 0.000 description 16
- DLMNFMXSNGTSNJ-PYJNHQTQSA-N Val-His-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CN=CN1)NC(=O)[C@H](C(C)C)N DLMNFMXSNGTSNJ-PYJNHQTQSA-N 0.000 description 16
- MHHAWNPHDLCPLF-ULQDDVLXSA-N Val-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CC=CC=C1 MHHAWNPHDLCPLF-ULQDDVLXSA-N 0.000 description 16
- PZTZYZUTCPZWJH-FXQIFTODSA-N Val-Ser-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PZTZYZUTCPZWJH-FXQIFTODSA-N 0.000 description 16
- 108010013768 glutamyl-aspartyl-proline Proteins 0.000 description 16
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 16
- 108010050475 glycyl-leucyl-tyrosine Proteins 0.000 description 16
- 108010092114 histidylphenylalanine Proteins 0.000 description 16
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 16
- 108010003700 lysyl aspartic acid Proteins 0.000 description 16
- 108010009298 lysylglutamic acid Proteins 0.000 description 16
- 108010017391 lysylvaline Proteins 0.000 description 16
- OANWAFQRNQEDSY-DCAQKATOSA-N Arg-Cys-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCCN=C(N)N)N OANWAFQRNQEDSY-DCAQKATOSA-N 0.000 description 15
- WLVLIYYBPPONRJ-GCJQMDKQSA-N Asn-Thr-Ala Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O WLVLIYYBPPONRJ-GCJQMDKQSA-N 0.000 description 15
- DLISPGXMKZTWQG-IFFSRLJSSA-N Glu-Thr-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O DLISPGXMKZTWQG-IFFSRLJSSA-N 0.000 description 15
- CMNMPCTVCWWYHY-MXAVVETBSA-N Ile-His-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC(C)C)C(=O)O)N CMNMPCTVCWWYHY-MXAVVETBSA-N 0.000 description 15
- IBMVEYRWAWIOTN-UHFFFAOYSA-N L-Leucyl-L-Arginyl-L-Proline Natural products CC(C)CC(N)C(=O)NC(CCCN=C(N)N)C(=O)N1CCCC1C(O)=O IBMVEYRWAWIOTN-UHFFFAOYSA-N 0.000 description 15
- KVOFSTUWVSQMDK-KKUMJFAQSA-N Leu-His-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)CC(C)C)CC1=CN=CN1 KVOFSTUWVSQMDK-KKUMJFAQSA-N 0.000 description 15
- XPVIVVLLLOFBRH-XIRDDKMYSA-N Ser-Trp-Lys Chemical compound NCCCC[C@H](NC(=O)[C@H](Cc1c[nH]c2ccccc12)NC(=O)[C@@H](N)CO)C(O)=O XPVIVVLLLOFBRH-XIRDDKMYSA-N 0.000 description 15
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 15
- VGPWRRFOPXVGOH-BYPYZUCNSA-N Ala-Gly-Gly Chemical compound C[C@H](N)C(=O)NCC(=O)NCC(O)=O VGPWRRFOPXVGOH-BYPYZUCNSA-N 0.000 description 14
- MAZZQZWCCYJQGZ-GUBZILKMSA-N Ala-Pro-Arg Chemical compound [H]N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MAZZQZWCCYJQGZ-GUBZILKMSA-N 0.000 description 14
- FFZJHQODAYHGPO-KZVJFYERSA-N Ala-Pro-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N FFZJHQODAYHGPO-KZVJFYERSA-N 0.000 description 14
- CLOMBHBBUKAUBP-LSJOCFKGSA-N Ala-Val-His Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N CLOMBHBBUKAUBP-LSJOCFKGSA-N 0.000 description 14
- BSYKSCBTTQKOJG-GUBZILKMSA-N Arg-Pro-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O BSYKSCBTTQKOJG-GUBZILKMSA-N 0.000 description 14
- XQDGOJPVMSWZSO-SRVKXCTJSA-N Gln-Pro-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CCC(=O)N)N XQDGOJPVMSWZSO-SRVKXCTJSA-N 0.000 description 14
- 101000914496 Homo sapiens T-cell antigen CD7 Proteins 0.000 description 14
- HDOYNXLPTRQLAD-JBDRJPRFSA-N Ile-Ala-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(=O)O)N HDOYNXLPTRQLAD-JBDRJPRFSA-N 0.000 description 14
- JQSXWJXBASFONF-KKUMJFAQSA-N Leu-Asp-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JQSXWJXBASFONF-KKUMJFAQSA-N 0.000 description 14
- LHALYDBUDCWMDY-CIUDSAMLSA-N Pro-Glu-Ala Chemical compound C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H]1CCCN1)C(O)=O LHALYDBUDCWMDY-CIUDSAMLSA-N 0.000 description 14
- RCYUBVHMVUHEBM-RCWTZXSCSA-N Pro-Pro-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O RCYUBVHMVUHEBM-RCWTZXSCSA-N 0.000 description 14
- QYSFWUIXDFJUDW-DCAQKATOSA-N Ser-Leu-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O QYSFWUIXDFJUDW-DCAQKATOSA-N 0.000 description 14
- 102100027208 T-cell antigen CD7 Human genes 0.000 description 14
- TWLMXDWFVNEFFK-FJXKBIBVSA-N Thr-Arg-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O TWLMXDWFVNEFFK-FJXKBIBVSA-N 0.000 description 14
- ZESGVALRVJIVLZ-VFCFLDTKSA-N Thr-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O ZESGVALRVJIVLZ-VFCFLDTKSA-N 0.000 description 14
- RYSNTWVRSLCAJZ-RYUDHWBXSA-N Tyr-Gln-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 RYSNTWVRSLCAJZ-RYUDHWBXSA-N 0.000 description 14
- MPKPIWFFDWVJGC-IRIUXVKKSA-N Tyr-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O MPKPIWFFDWVJGC-IRIUXVKKSA-N 0.000 description 14
- 239000000427 antigen Substances 0.000 description 14
- 108010029539 arginyl-prolyl-proline Proteins 0.000 description 14
- 108010068380 arginylarginine Proteins 0.000 description 14
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 14
- 230000006870 function Effects 0.000 description 14
- 108010078144 glutaminyl-glycine Proteins 0.000 description 14
- DPNZTBKGAUAZQU-DLOVCJGASA-N Ala-Leu-His Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N DPNZTBKGAUAZQU-DLOVCJGASA-N 0.000 description 13
- IPZQNYYAYVRKKK-FXQIFTODSA-N Ala-Pro-Ala Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O IPZQNYYAYVRKKK-FXQIFTODSA-N 0.000 description 13
- SAHQGRZIQVEJPF-JXUBOQSCSA-N Ala-Thr-Lys Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN SAHQGRZIQVEJPF-JXUBOQSCSA-N 0.000 description 13
- PNQWAUXQDBIJDY-GUBZILKMSA-N Arg-Glu-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PNQWAUXQDBIJDY-GUBZILKMSA-N 0.000 description 13
- QCVXMEHGFUMKCO-YUMQZZPRSA-N Asp-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC(O)=O QCVXMEHGFUMKCO-YUMQZZPRSA-N 0.000 description 13
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 13
- DNPCBMNFQVTHMA-DCAQKATOSA-N Glu-Leu-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O DNPCBMNFQVTHMA-DCAQKATOSA-N 0.000 description 13
- BULIVUZUDBHKKZ-WDSKDSINSA-N Gly-Gln-Asn Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O BULIVUZUDBHKKZ-WDSKDSINSA-N 0.000 description 13
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 13
- PPGBXYKMUMHFBF-KATARQTJSA-N Leu-Ser-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PPGBXYKMUMHFBF-KATARQTJSA-N 0.000 description 13
- LMVOVCYVZBBWQB-SRVKXCTJSA-N Lys-Asp-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN LMVOVCYVZBBWQB-SRVKXCTJSA-N 0.000 description 13
- LCMWVZLBCUVDAZ-IUCAKERBSA-N Lys-Gly-Glu Chemical compound [NH3+]CCCC[C@H]([NH3+])C(=O)NCC(=O)N[C@H](C([O-])=O)CCC([O-])=O LCMWVZLBCUVDAZ-IUCAKERBSA-N 0.000 description 13
- UETQMSASAVBGJY-QWRGUYRKSA-N Lys-Gly-His Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CC1=CNC=N1 UETQMSASAVBGJY-QWRGUYRKSA-N 0.000 description 13
- AFLBTVGQCQLOFJ-AVGNSLFASA-N Lys-Pro-Arg Chemical compound NCCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O AFLBTVGQCQLOFJ-AVGNSLFASA-N 0.000 description 13
- YLLWCSDBVGZLOW-CIUDSAMLSA-N Met-Gln-Ala Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O YLLWCSDBVGZLOW-CIUDSAMLSA-N 0.000 description 13
- UZWMJZSOXGOVIN-LURJTMIESA-N Met-Gly-Gly Chemical compound CSCC[C@H](N)C(=O)NCC(=O)NCC(O)=O UZWMJZSOXGOVIN-LURJTMIESA-N 0.000 description 13
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 13
- WEDZFLRYSIDIRX-IHRRRGAJSA-N Phe-Ser-Arg Chemical compound NC(=N)NCCC[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=CC=C1 WEDZFLRYSIDIRX-IHRRRGAJSA-N 0.000 description 13
- LVVBAKCGXXUHFO-ZLUOBGJFSA-N Ser-Ala-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(O)=O LVVBAKCGXXUHFO-ZLUOBGJFSA-N 0.000 description 13
- UABYBEBXFFNCIR-YDHLFZDLSA-N Tyr-Asp-Val Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O UABYBEBXFFNCIR-YDHLFZDLSA-N 0.000 description 13
- QUILOGWWLXMSAT-IHRRRGAJSA-N Tyr-Gln-Gln Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QUILOGWWLXMSAT-IHRRRGAJSA-N 0.000 description 13
- 108091007433 antigens Proteins 0.000 description 13
- 102000036639 antigens Human genes 0.000 description 13
- 238000002560 therapeutic procedure Methods 0.000 description 13
- 210000004881 tumor cell Anatomy 0.000 description 13
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 12
- WOZDCBHUGJVJPL-AVGNSLFASA-N Arg-Val-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N WOZDCBHUGJVJPL-AVGNSLFASA-N 0.000 description 12
- 102100022005 B-lymphocyte antigen CD20 Human genes 0.000 description 12
- 101000897405 Homo sapiens B-lymphocyte antigen CD20 Proteins 0.000 description 12
- MYGQXVYRZMKRDB-SRVKXCTJSA-N Leu-Asp-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CCCCN MYGQXVYRZMKRDB-SRVKXCTJSA-N 0.000 description 12
- 239000012091 fetal bovine serum Substances 0.000 description 12
- 239000012528 membrane Substances 0.000 description 12
- 238000010186 staining Methods 0.000 description 12
- SSZGOKWBHLOCHK-DCAQKATOSA-N Arg-Lys-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCN=C(N)N SSZGOKWBHLOCHK-DCAQKATOSA-N 0.000 description 11
- 102100025137 Early activation antigen CD69 Human genes 0.000 description 11
- SNLOOPZHAQDMJG-CIUDSAMLSA-N Gln-Glu-Glu Chemical compound NC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O SNLOOPZHAQDMJG-CIUDSAMLSA-N 0.000 description 11
- HSHCEAUPUPJPTE-JYJNAYRXSA-N Gln-Leu-Tyr Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N HSHCEAUPUPJPTE-JYJNAYRXSA-N 0.000 description 11
- AFWYPMDMDYCKMD-KBPBESRZSA-N Gly-Leu-Tyr Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 AFWYPMDMDYCKMD-KBPBESRZSA-N 0.000 description 11
- 101000934374 Homo sapiens Early activation antigen CD69 Proteins 0.000 description 11
- WUHBLPVELFTPQK-KKUMJFAQSA-N Leu-Tyr-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(O)=O WUHBLPVELFTPQK-KKUMJFAQSA-N 0.000 description 11
- 108010077245 asparaginyl-proline Proteins 0.000 description 11
- 239000007924 injection Substances 0.000 description 11
- 238000002347 injection Methods 0.000 description 11
- HQIZDMIGUJOSNI-IUCAKERBSA-N Arg-Gly-Arg Chemical compound N[C@@H](CCCNC(N)=N)C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O HQIZDMIGUJOSNI-IUCAKERBSA-N 0.000 description 10
- JREOBWLIZLXRIS-GUBZILKMSA-N Asn-Glu-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JREOBWLIZLXRIS-GUBZILKMSA-N 0.000 description 10
- XXGQRGQPGFYECI-WDSKDSINSA-N Gly-Cys-Glu Chemical compound NCC(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CCC(O)=O XXGQRGQPGFYECI-WDSKDSINSA-N 0.000 description 10
- LRAUKBMYHHNADU-DKIMLUQUSA-N Ile-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)[C@@H](C)CC)CC1=CC=CC=C1 LRAUKBMYHHNADU-DKIMLUQUSA-N 0.000 description 10
- UCNNZELZXFXXJQ-BZSNNMDCSA-N Leu-Leu-Tyr Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 UCNNZELZXFXXJQ-BZSNNMDCSA-N 0.000 description 10
- ONGCSGVHCSAATF-CIUDSAMLSA-N Met-Ala-Glu Chemical compound CSCC[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O ONGCSGVHCSAATF-CIUDSAMLSA-N 0.000 description 10
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 10
- 125000000539 amino acid group Chemical group 0.000 description 10
- 201000010099 disease Diseases 0.000 description 10
- 239000012636 effector Substances 0.000 description 10
- 238000012360 testing method Methods 0.000 description 10
- MFAMTAVAFBPXDC-LPEHRKFASA-N Arg-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O MFAMTAVAFBPXDC-LPEHRKFASA-N 0.000 description 9
- BIVYLQMZPHDUIH-WHFBIAKZSA-N Asp-Gly-Cys Chemical compound C([C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N)C(=O)O BIVYLQMZPHDUIH-WHFBIAKZSA-N 0.000 description 9
- MQJDLNRXBOELJW-KKUMJFAQSA-N Gln-Pro-Phe Chemical compound N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1ccccc1)C(O)=O MQJDLNRXBOELJW-KKUMJFAQSA-N 0.000 description 9
- RXGLHDWAZQECBI-SRVKXCTJSA-N Leu-Leu-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O RXGLHDWAZQECBI-SRVKXCTJSA-N 0.000 description 9
- SXOFUVGLPHCPRQ-KKUMJFAQSA-N Leu-Tyr-Cys Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CS)C(O)=O SXOFUVGLPHCPRQ-KKUMJFAQSA-N 0.000 description 9
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 9
- 241000699666 Mus <mouse, genus> Species 0.000 description 9
- UPJGUQPLYWTISV-GUBZILKMSA-N Pro-Gln-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O UPJGUQPLYWTISV-GUBZILKMSA-N 0.000 description 9
- 230000006044 T cell activation Effects 0.000 description 9
- APQIVBCUIUDSMB-OSUNSFLBSA-N Val-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](C(C)C)N APQIVBCUIUDSMB-OSUNSFLBSA-N 0.000 description 9
- 239000003242 anti bacterial agent Substances 0.000 description 9
- 229940088710 antibiotic agent Drugs 0.000 description 9
- 210000004369 blood Anatomy 0.000 description 9
- 239000008280 blood Substances 0.000 description 9
- 229940090044 injection Drugs 0.000 description 9
- 230000035755 proliferation Effects 0.000 description 9
- OBVSBEYOMDWLRJ-BFHQHQDPSA-N Ala-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N OBVSBEYOMDWLRJ-BFHQHQDPSA-N 0.000 description 8
- ADSGHMXEAZJJNF-DCAQKATOSA-N Ala-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](C)N ADSGHMXEAZJJNF-DCAQKATOSA-N 0.000 description 8
- WIDVAWAQBRAKTI-YUMQZZPRSA-N Asn-Leu-Gly Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O WIDVAWAQBRAKTI-YUMQZZPRSA-N 0.000 description 8
- IWLZBRTUIVXZJD-OLHMAJIHSA-N Asp-Thr-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(O)=O IWLZBRTUIVXZJD-OLHMAJIHSA-N 0.000 description 8
- BUZMZDDKFCSKOT-CIUDSAMLSA-N Glu-Glu-Glu Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O BUZMZDDKFCSKOT-CIUDSAMLSA-N 0.000 description 8
- ITBHUUMCJJQUSC-LAEOZQHASA-N Glu-Ile-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(O)=O ITBHUUMCJJQUSC-LAEOZQHASA-N 0.000 description 8
- 101100334524 Homo sapiens FCGR3B gene Proteins 0.000 description 8
- 102100029205 Low affinity immunoglobulin gamma Fc region receptor II-b Human genes 0.000 description 8
- 102100029185 Low affinity immunoglobulin gamma Fc region receptor III-B Human genes 0.000 description 8
- 108060001084 Luciferase Proteins 0.000 description 8
- LQGDFDYGDQEMGA-PXDAIIFMSA-N Tyr-Ile-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CC3=CC=C(C=C3)O)N LQGDFDYGDQEMGA-PXDAIIFMSA-N 0.000 description 8
- RJURFGZVJUQBHK-UHFFFAOYSA-N actinomycin D Natural products CC1OC(=O)C(C(C)C)N(C)C(=O)CN(C)C(=O)C2CCCN2C(=O)C(C(C)C)NC(=O)C1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)NC4C(=O)NC(C(N5CCCC5C(=O)N(C)CC(=O)N(C)C(C(C)C)C(=O)OC4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-UHFFFAOYSA-N 0.000 description 8
- 230000000735 allogeneic effect Effects 0.000 description 8
- 230000000259 anti-tumor effect Effects 0.000 description 8
- 108010052670 arginyl-glutamyl-glutamic acid Proteins 0.000 description 8
- 239000003795 chemical substances by application Substances 0.000 description 8
- 238000001727 in vivo Methods 0.000 description 8
- 230000001939 inductive effect Effects 0.000 description 8
- 239000003112 inhibitor Substances 0.000 description 8
- 108010044374 isoleucyl-tyrosine Proteins 0.000 description 8
- 210000001519 tissue Anatomy 0.000 description 8
- 230000003612 virological effect Effects 0.000 description 8
- 238000001262 western blot Methods 0.000 description 8
- BTJVOUQWFXABOI-IHRRRGAJSA-N Arg-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CCCNC(N)=N BTJVOUQWFXABOI-IHRRRGAJSA-N 0.000 description 7
- AHWRSSLYSGLBGD-CIUDSAMLSA-N Asp-Pro-Glu Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O AHWRSSLYSGLBGD-CIUDSAMLSA-N 0.000 description 7
- WDQXKVCQXRNOSI-GHCJXIJMSA-N Cys-Asp-Ile Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WDQXKVCQXRNOSI-GHCJXIJMSA-N 0.000 description 7
- UXIYYUMGFNSGBK-XPUUQOCRSA-N Cys-Gly-Val Chemical compound [H]N[C@@H](CS)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O UXIYYUMGFNSGBK-XPUUQOCRSA-N 0.000 description 7
- 108020004414 DNA Proteins 0.000 description 7
- KCJJFESQRXGTGC-BQBZGAKWSA-N Gln-Glu-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O KCJJFESQRXGTGC-BQBZGAKWSA-N 0.000 description 7
- LWWILHPVAKKLQS-QXEWZRGKSA-N Ile-Gly-Met Chemical compound CC[C@H](C)[C@@H](C(=O)NCC(=O)N[C@@H](CCSC)C(=O)O)N LWWILHPVAKKLQS-QXEWZRGKSA-N 0.000 description 7
- BABSVXFGKFLIGW-UWVGGRQHSA-N Leu-Gly-Arg Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCNC(N)=N BABSVXFGKFLIGW-UWVGGRQHSA-N 0.000 description 7
- 239000005089 Luciferase Substances 0.000 description 7
- GAOJCVKPIGHTGO-UWVGGRQHSA-N Lys-Arg-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O GAOJCVKPIGHTGO-UWVGGRQHSA-N 0.000 description 7
- ZAJNRWKGHWGPDQ-SDDRHHMPSA-N Met-Arg-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N ZAJNRWKGHWGPDQ-SDDRHHMPSA-N 0.000 description 7
- JLMZKEQFMVORMA-SRVKXCTJSA-N Pro-Pro-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 JLMZKEQFMVORMA-SRVKXCTJSA-N 0.000 description 7
- BLPYXIXXCFVIIF-FXQIFTODSA-N Ser-Cys-Arg Chemical compound C(C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CO)N)CN=C(N)N BLPYXIXXCFVIIF-FXQIFTODSA-N 0.000 description 7
- 230000006052 T cell proliferation Effects 0.000 description 7
- QFXVAFIHVWXXBJ-AVGNSLFASA-N Tyr-Ser-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O QFXVAFIHVWXXBJ-AVGNSLFASA-N 0.000 description 7
- 108010079547 glutamylmethionine Proteins 0.000 description 7
- 210000004698 lymphocyte Anatomy 0.000 description 7
- 238000004519 manufacturing process Methods 0.000 description 7
- 238000005259 measurement Methods 0.000 description 7
- 108010000998 wheylin-2 peptide Proteins 0.000 description 7
- VMKCPNBBPGGQBJ-GUBZILKMSA-N Glu-Leu-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N VMKCPNBBPGGQBJ-GUBZILKMSA-N 0.000 description 6
- 101001023379 Homo sapiens Lysosome-associated membrane glycoprotein 1 Proteins 0.000 description 6
- 239000000232 Lipid Bilayer Substances 0.000 description 6
- 102100035133 Lysosome-associated membrane glycoprotein 1 Human genes 0.000 description 6
- 241000124008 Mammalia Species 0.000 description 6
- QARPMYDMYVLFMW-KKUMJFAQSA-N Phe-Pro-Glu Chemical compound C([C@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCC(O)=O)C(O)=O)C1=CC=CC=C1 QARPMYDMYVLFMW-KKUMJFAQSA-N 0.000 description 6
- 102100032101 Tumor necrosis factor ligand superfamily member 9 Human genes 0.000 description 6
- NYTKXWLZSNRILS-IFFSRLJSSA-N Val-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N)O NYTKXWLZSNRILS-IFFSRLJSSA-N 0.000 description 6
- 239000000872 buffer Substances 0.000 description 6
- 230000004663 cell proliferation Effects 0.000 description 6
- 150000001875 compounds Chemical class 0.000 description 6
- 238000004132 cross linking Methods 0.000 description 6
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 6
- 108010006664 gamma-glutamyl-glycyl-glycine Proteins 0.000 description 6
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 6
- 239000008187 granular material Substances 0.000 description 6
- 230000028993 immune response Effects 0.000 description 6
- 238000011534 incubation Methods 0.000 description 6
- 230000004044 response Effects 0.000 description 6
- 230000004936 stimulating effect Effects 0.000 description 6
- 238000013518 transcription Methods 0.000 description 6
- 230000035897 transcription Effects 0.000 description 6
- FUSPCLTUKXQREV-ACZMJKKPSA-N Ala-Glu-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O FUSPCLTUKXQREV-ACZMJKKPSA-N 0.000 description 5
- 208000003950 B-cell lymphoma Diseases 0.000 description 5
- 102100032937 CD40 ligand Human genes 0.000 description 5
- 102000004127 Cytokines Human genes 0.000 description 5
- 108090000695 Cytokines Proteins 0.000 description 5
- 108010092160 Dactinomycin Proteins 0.000 description 5
- 101000679851 Homo sapiens Tumor necrosis factor receptor superfamily member 4 Proteins 0.000 description 5
- NQCJGQHHYZNUDK-DCAQKATOSA-N Lys-Arg-Ser Chemical compound NCCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CO)C(O)=O)CCCN=C(N)N NQCJGQHHYZNUDK-DCAQKATOSA-N 0.000 description 5
- DBOMZJOESVYERT-GUBZILKMSA-N Met-Asn-Met Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCSC)C(=O)O)N DBOMZJOESVYERT-GUBZILKMSA-N 0.000 description 5
- FRKBNXCFJBPJOL-GUBZILKMSA-N Pro-Glu-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O FRKBNXCFJBPJOL-GUBZILKMSA-N 0.000 description 5
- 239000012980 RPMI-1640 medium Substances 0.000 description 5
- MUAFDCVOHYAFNG-RCWTZXSCSA-N Thr-Pro-Arg Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(O)=O MUAFDCVOHYAFNG-RCWTZXSCSA-N 0.000 description 5
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 description 5
- 241000700605 Viruses Species 0.000 description 5
- 238000009175 antibody therapy Methods 0.000 description 5
- 108010047857 aspartylglycine Proteins 0.000 description 5
- 238000007796 conventional method Methods 0.000 description 5
- 231100000433 cytotoxic Toxicity 0.000 description 5
- 230000001472 cytotoxic effect Effects 0.000 description 5
- 230000013595 glycosylation Effects 0.000 description 5
- 238000006206 glycosylation reaction Methods 0.000 description 5
- 238000001802 infusion Methods 0.000 description 5
- 210000005259 peripheral blood Anatomy 0.000 description 5
- 239000011886 peripheral blood Substances 0.000 description 5
- 238000011160 research Methods 0.000 description 5
- 230000000638 stimulation Effects 0.000 description 5
- 230000004083 survival effect Effects 0.000 description 5
- CEHZCZCQHUNAJF-AVGNSLFASA-N (2s)-1-[2-[[(2s)-1-[(2s)-2-amino-5-(diaminomethylideneamino)pentanoyl]pyrrolidine-2-carbonyl]amino]acetyl]pyrrolidine-2-carboxylic acid Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(=O)N1[C@H](C(O)=O)CCC1 CEHZCZCQHUNAJF-AVGNSLFASA-N 0.000 description 4
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 4
- 108010051330 Arg-Pro-Gly-Pro Proteins 0.000 description 4
- VUGWHBXPMAHEGZ-SRVKXCTJSA-N Arg-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCN=C(N)N VUGWHBXPMAHEGZ-SRVKXCTJSA-N 0.000 description 4
- FRBAHXABMQXSJQ-FXQIFTODSA-N Arg-Ser-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O FRBAHXABMQXSJQ-FXQIFTODSA-N 0.000 description 4
- UZFHNLYQWMGUHU-DCAQKATOSA-N Asp-Lys-Arg Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UZFHNLYQWMGUHU-DCAQKATOSA-N 0.000 description 4
- FQHBAQLBIXLWAG-DCAQKATOSA-N Asp-Lys-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)O)N FQHBAQLBIXLWAG-DCAQKATOSA-N 0.000 description 4
- GYWQGGUCMDCUJE-DLOVCJGASA-N Asp-Phe-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C)C(O)=O GYWQGGUCMDCUJE-DLOVCJGASA-N 0.000 description 4
- 108010019670 Chimeric Antigen Receptors Proteins 0.000 description 4
- JTNKVWLMDHIUOG-IHRRRGAJSA-N Cys-Arg-Phe Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O JTNKVWLMDHIUOG-IHRRRGAJSA-N 0.000 description 4
- XABFFGOGKOORCG-CIUDSAMLSA-N Cys-Asp-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O XABFFGOGKOORCG-CIUDSAMLSA-N 0.000 description 4
- 102100026234 Cytokine receptor common subunit gamma Human genes 0.000 description 4
- STHSGOZLFLFGSS-SUSMZKCASA-N Gln-Thr-Thr Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O STHSGOZLFLFGSS-SUSMZKCASA-N 0.000 description 4
- SJPMNHCEWPTRBR-BQBZGAKWSA-N Glu-Glu-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O SJPMNHCEWPTRBR-BQBZGAKWSA-N 0.000 description 4
- WSWAUVHXQREQQG-JYJNAYRXSA-N His-Tyr-Gln Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O WSWAUVHXQREQQG-JYJNAYRXSA-N 0.000 description 4
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 description 4
- 108010017535 Interleukin-15 Receptors Proteins 0.000 description 4
- 102000004556 Interleukin-15 Receptors Human genes 0.000 description 4
- NCTDKZKNBDZDOL-GARJFASQSA-N Lys-Asn-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCCCN)N)C(=O)O NCTDKZKNBDZDOL-GARJFASQSA-N 0.000 description 4
- 108091028043 Nucleic acid sequence Proteins 0.000 description 4
- DLZBBDSPTJBOOD-BPNCWPANSA-N Pro-Tyr-Ala Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C)C(O)=O DLZBBDSPTJBOOD-BPNCWPANSA-N 0.000 description 4
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 description 4
- HEQPKICPPDOSIN-SRVKXCTJSA-N Ser-Asp-Tyr Chemical compound OC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 HEQPKICPPDOSIN-SRVKXCTJSA-N 0.000 description 4
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 4
- 102100025237 T-cell surface antigen CD2 Human genes 0.000 description 4
- NAXBBCLCEOTAIG-RHYQMDGZSA-N Thr-Arg-Lys Chemical compound NC(N)=NCCC[C@H](NC(=O)[C@@H](N)[C@H](O)C)C(=O)N[C@@H](CCCCN)C(O)=O NAXBBCLCEOTAIG-RHYQMDGZSA-N 0.000 description 4
- IIJWXEUNETVJPV-IHRRRGAJSA-N Tyr-Arg-Ser Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CO)C(=O)O)N)O IIJWXEUNETVJPV-IHRRRGAJSA-N 0.000 description 4
- RJURFGZVJUQBHK-IIXSONLDSA-N actinomycin D Chemical compound C[C@H]1OC(=O)[C@H](C(C)C)N(C)C(=O)CN(C)C(=O)[C@@H]2CCCN2C(=O)[C@@H](C(C)C)NC(=O)[C@H]1NC(=O)C1=C(N)C(=O)C(C)=C2OC(C(C)=CC=C3C(=O)N[C@@H]4C(=O)N[C@@H](C(N5CCC[C@H]5C(=O)N(C)CC(=O)N(C)[C@@H](C(C)C)C(=O)O[C@@H]4C)=O)C(C)C)=C3N=C21 RJURFGZVJUQBHK-IIXSONLDSA-N 0.000 description 4
- 239000000556 agonist Substances 0.000 description 4
- 230000001028 anti-proliverative effect Effects 0.000 description 4
- 238000013459 approach Methods 0.000 description 4
- 238000005415 bioluminescence Methods 0.000 description 4
- 230000029918 bioluminescence Effects 0.000 description 4
- 210000001185 bone marrow Anatomy 0.000 description 4
- 210000004899 c-terminal region Anatomy 0.000 description 4
- BQRGNLJZBFXNCZ-UHFFFAOYSA-N calcein am Chemical compound O1C(=O)C2=CC=CC=C2C21C1=CC(CN(CC(=O)OCOC(C)=O)CC(=O)OCOC(C)=O)=C(OC(C)=O)C=C1OC1=C2C=C(CN(CC(=O)OCOC(C)=O)CC(=O)OCOC(=O)C)C(OC(C)=O)=C1 BQRGNLJZBFXNCZ-UHFFFAOYSA-N 0.000 description 4
- 210000000170 cell membrane Anatomy 0.000 description 4
- 238000002659 cell therapy Methods 0.000 description 4
- 229960000640 dactinomycin Drugs 0.000 description 4
- 230000001419 dependent effect Effects 0.000 description 4
- 238000011161 development Methods 0.000 description 4
- 230000018109 developmental process Effects 0.000 description 4
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 4
- 208000035475 disorder Diseases 0.000 description 4
- 230000028023 exocytosis Effects 0.000 description 4
- 238000001415 gene therapy Methods 0.000 description 4
- 230000001024 immunotherapeutic effect Effects 0.000 description 4
- 239000003550 marker Substances 0.000 description 4
- 230000007246 mechanism Effects 0.000 description 4
- 239000002609 medium Substances 0.000 description 4
- 239000002953 phosphate buffered saline Substances 0.000 description 4
- 230000003389 potentiating effect Effects 0.000 description 4
- 238000011084 recovery Methods 0.000 description 4
- 230000001105 regulatory effect Effects 0.000 description 4
- UCSJYZPVAKXKNQ-HZYVHMACSA-N streptomycin Chemical compound CN[C@H]1[C@H](O)[C@@H](O)[C@H](CO)O[C@H]1O[C@@H]1[C@](C=O)(O)[C@H](C)O[C@H]1O[C@@H]1[C@@H](NC(N)=N)[C@H](O)[C@@H](NC(N)=N)[C@H](O)[C@H]1O UCSJYZPVAKXKNQ-HZYVHMACSA-N 0.000 description 4
- 208000024891 symptom Diseases 0.000 description 4
- 241001430294 unidentified retrovirus Species 0.000 description 4
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 description 3
- NHCPCLJZRSIDHS-ZLUOBGJFSA-N Ala-Asp-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O NHCPCLJZRSIDHS-ZLUOBGJFSA-N 0.000 description 3
- PHHRSPBBQUFULD-UWVGGRQHSA-N Arg-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCCN=C(N)N)N PHHRSPBBQUFULD-UWVGGRQHSA-N 0.000 description 3
- JDDYEZGPYBBPBN-JRQIVUDYSA-N Asp-Thr-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O JDDYEZGPYBBPBN-JRQIVUDYSA-N 0.000 description 3
- GIKOVDMXBAFXDF-NHCYSSNCSA-N Asp-Val-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O GIKOVDMXBAFXDF-NHCYSSNCSA-N 0.000 description 3
- 102100024222 B-lymphocyte antigen CD19 Human genes 0.000 description 3
- 101150013553 CD40 gene Proteins 0.000 description 3
- 102100025221 CD70 antigen Human genes 0.000 description 3
- 102000011727 Caspases Human genes 0.000 description 3
- 108010076667 Caspases Proteins 0.000 description 3
- CMSMOCZEIVJLDB-UHFFFAOYSA-N Cyclophosphamide Chemical compound ClCCN(CCCl)P1(=O)NCCCO1 CMSMOCZEIVJLDB-UHFFFAOYSA-N 0.000 description 3
- 241000701022 Cytomegalovirus Species 0.000 description 3
- 102000004190 Enzymes Human genes 0.000 description 3
- 108090000790 Enzymes Proteins 0.000 description 3
- 241000282326 Felis catus Species 0.000 description 3
- KVYVOGYEMPEXBT-GUBZILKMSA-N Gln-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O KVYVOGYEMPEXBT-GUBZILKMSA-N 0.000 description 3
- TWHDOEYLXXQYOZ-FXQIFTODSA-N Gln-Asn-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N TWHDOEYLXXQYOZ-FXQIFTODSA-N 0.000 description 3
- NVEASDQHBRZPSU-BQBZGAKWSA-N Gln-Gln-Gly Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O NVEASDQHBRZPSU-BQBZGAKWSA-N 0.000 description 3
- FGYPOQPQTUNESW-IUCAKERBSA-N Gln-Gly-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)N)N FGYPOQPQTUNESW-IUCAKERBSA-N 0.000 description 3
- BUAKRRKDHSSIKK-IHRRRGAJSA-N Glu-Glu-Tyr Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 BUAKRRKDHSSIKK-IHRRRGAJSA-N 0.000 description 3
- QCTLGOYODITHPQ-WHFBIAKZSA-N Gly-Cys-Ser Chemical compound [H]NCC(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O QCTLGOYODITHPQ-WHFBIAKZSA-N 0.000 description 3
- DHDOADIPGZTAHT-YUMQZZPRSA-N Gly-Glu-Arg Chemical compound NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DHDOADIPGZTAHT-YUMQZZPRSA-N 0.000 description 3
- QITBQGJOXQYMOA-ZETCQYMHSA-N Gly-Gly-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)CNC(=O)CN QITBQGJOXQYMOA-ZETCQYMHSA-N 0.000 description 3
- VAXIVIPMCTYSHI-YUMQZZPRSA-N Gly-His-Asp Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)CN VAXIVIPMCTYSHI-YUMQZZPRSA-N 0.000 description 3
- 101000980825 Homo sapiens B-lymphocyte antigen CD19 Proteins 0.000 description 3
- 101000868215 Homo sapiens CD40 ligand Proteins 0.000 description 3
- 101001055227 Homo sapiens Cytokine receptor common subunit gamma Proteins 0.000 description 3
- 101000917821 Homo sapiens Low affinity immunoglobulin gamma Fc region receptor II-c Proteins 0.000 description 3
- 101000581981 Homo sapiens Neural cell adhesion molecule 1 Proteins 0.000 description 3
- 101000851376 Homo sapiens Tumor necrosis factor receptor superfamily member 8 Proteins 0.000 description 3
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 3
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 3
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 3
- FQZPTCNSNPWHLJ-AVGNSLFASA-N Leu-Gln-Lys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(O)=O FQZPTCNSNPWHLJ-AVGNSLFASA-N 0.000 description 3
- MPSBSKHOWJQHBS-IHRRRGAJSA-N Leu-His-Met Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCSC)C(=O)O)N MPSBSKHOWJQHBS-IHRRRGAJSA-N 0.000 description 3
- 102100029206 Low affinity immunoglobulin gamma Fc region receptor II-c Human genes 0.000 description 3
- 102100027347 Neural cell adhesion molecule 1 Human genes 0.000 description 3
- 239000002033 PVDF binder Substances 0.000 description 3
- LNLNHXIQPGKRJQ-SRVKXCTJSA-N Pro-Arg-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H]1CCCN1 LNLNHXIQPGKRJQ-SRVKXCTJSA-N 0.000 description 3
- QVOGDCQNGLBNCR-FXQIFTODSA-N Ser-Arg-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O QVOGDCQNGLBNCR-FXQIFTODSA-N 0.000 description 3
- XJDMUQCLVSCRSJ-VZFHVOOUSA-N Ser-Thr-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O XJDMUQCLVSCRSJ-VZFHVOOUSA-N 0.000 description 3
- 241000700584 Simplexvirus Species 0.000 description 3
- ZSPQUTWLWGWTPS-HJGDQZAQSA-N Thr-Lys-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O ZSPQUTWLWGWTPS-HJGDQZAQSA-N 0.000 description 3
- 102000006601 Thymidine Kinase Human genes 0.000 description 3
- 108020004440 Thymidine kinase Proteins 0.000 description 3
- 102100036857 Tumor necrosis factor receptor superfamily member 8 Human genes 0.000 description 3
- PEVVXUGSAKEPEN-AVGNSLFASA-N Tyr-Asn-Glu Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O PEVVXUGSAKEPEN-AVGNSLFASA-N 0.000 description 3
- 108091008605 VEGF receptors Proteins 0.000 description 3
- AOILQMZPNLUXCM-AVGNSLFASA-N Val-Val-Lys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN AOILQMZPNLUXCM-AVGNSLFASA-N 0.000 description 3
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 3
- 230000002776 aggregation Effects 0.000 description 3
- 238000004220 aggregation Methods 0.000 description 3
- 238000004458 analytical method Methods 0.000 description 3
- 239000000611 antibody drug conjugate Substances 0.000 description 3
- 229940049595 antibody-drug conjugate Drugs 0.000 description 3
- 230000006907 apoptotic process Effects 0.000 description 3
- 108010060035 arginylproline Proteins 0.000 description 3
- 238000003556 assay Methods 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- OWMVSZAMULFTJU-UHFFFAOYSA-N bis-tris Chemical compound OCCN(CCO)C(CO)(CO)CO OWMVSZAMULFTJU-UHFFFAOYSA-N 0.000 description 3
- 230000020411 cell activation Effects 0.000 description 3
- 238000004113 cell culture Methods 0.000 description 3
- 230000030833 cell death Effects 0.000 description 3
- 230000010261 cell growth Effects 0.000 description 3
- DQLATGHUWYMOKM-UHFFFAOYSA-L cisplatin Chemical compound N[Pt](N)(Cl)Cl DQLATGHUWYMOKM-UHFFFAOYSA-L 0.000 description 3
- 229960004316 cisplatin Drugs 0.000 description 3
- 238000003501 co-culture Methods 0.000 description 3
- 239000002299 complementary DNA Substances 0.000 description 3
- 238000002784 cytotoxicity assay Methods 0.000 description 3
- 231100000263 cytotoxicity test Toxicity 0.000 description 3
- 229960000975 daunorubicin Drugs 0.000 description 3
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 description 3
- 230000034994 death Effects 0.000 description 3
- 238000001514 detection method Methods 0.000 description 3
- 108010009297 diglycyl-histidine Proteins 0.000 description 3
- 229940079593 drug Drugs 0.000 description 3
- 229940088598 enzyme Drugs 0.000 description 3
- VJJPUSNTGOMMGY-MRVIYFEKSA-N etoposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@H](C)OC[C@H]4O3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 VJJPUSNTGOMMGY-MRVIYFEKSA-N 0.000 description 3
- 239000000499 gel Substances 0.000 description 3
- 102000053350 human FCGR3B Human genes 0.000 description 3
- 229940072221 immunoglobulins Drugs 0.000 description 3
- 230000001506 immunosuppresive effect Effects 0.000 description 3
- 230000002401 inhibitory effect Effects 0.000 description 3
- 239000003446 ligand Substances 0.000 description 3
- 239000006166 lysate Substances 0.000 description 3
- 239000000463 material Substances 0.000 description 3
- 230000000394 mitotic effect Effects 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 229910052754 neon Inorganic materials 0.000 description 3
- GKAOGPIIYCISHV-UHFFFAOYSA-N neon atom Chemical compound [Ne] GKAOGPIIYCISHV-UHFFFAOYSA-N 0.000 description 3
- 238000004806 packaging method and process Methods 0.000 description 3
- 239000002245 particle Substances 0.000 description 3
- 230000035515 penetration Effects 0.000 description 3
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 3
- 229920002981 polyvinylidene fluoride Polymers 0.000 description 3
- 238000002360 preparation method Methods 0.000 description 3
- 239000003755 preservative agent Substances 0.000 description 3
- 238000012545 processing Methods 0.000 description 3
- 108010070643 prolylglutamic acid Proteins 0.000 description 3
- 238000012216 screening Methods 0.000 description 3
- 230000028327 secretion Effects 0.000 description 3
- 210000002536 stromal cell Anatomy 0.000 description 3
- 238000006467 substitution reaction Methods 0.000 description 3
- 238000012353 t test Methods 0.000 description 3
- 230000004614 tumor growth Effects 0.000 description 3
- 239000004474 valine Substances 0.000 description 3
- 230000003442 weekly effect Effects 0.000 description 3
- MWWSFMDVAYGXBV-MYPASOLCSA-N (7r,9s)-7-[(2r,4s,5s,6s)-4-amino-5-hydroxy-6-methyloxan-2-yl]oxy-6,9,11-trihydroxy-9-(2-hydroxyacetyl)-4-methoxy-8,10-dihydro-7h-tetracene-5,12-dione;hydrochloride Chemical compound Cl.O([C@@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 MWWSFMDVAYGXBV-MYPASOLCSA-N 0.000 description 2
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 2
- AOJJSUZBOXZQNB-VTZDEGQISA-N 4'-epidoxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-VTZDEGQISA-N 0.000 description 2
- 208000024893 Acute lymphoblastic leukemia Diseases 0.000 description 2
- 208000014697 Acute lymphocytic leukaemia Diseases 0.000 description 2
- WUHJHHGYVVJMQE-BJDJZHNGSA-N Ala-Leu-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O WUHJHHGYVVJMQE-BJDJZHNGSA-N 0.000 description 2
- 108010088751 Albumins Proteins 0.000 description 2
- 102000009027 Albumins Human genes 0.000 description 2
- LXMKTIZAGIBQRX-HRCADAONSA-N Arg-Phe-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=CC=C2)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O LXMKTIZAGIBQRX-HRCADAONSA-N 0.000 description 2
- CIWBSHSKHKDKBQ-JLAZNSOCSA-N Ascorbic acid Chemical compound OC[C@H](O)[C@H]1OC(=O)C(O)=C1O CIWBSHSKHKDKBQ-JLAZNSOCSA-N 0.000 description 2
- XMHFCUKJRCQXGI-CIUDSAMLSA-N Asn-Pro-Gln Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O XMHFCUKJRCQXGI-CIUDSAMLSA-N 0.000 description 2
- PBVLJOIPOGUQQP-CIUDSAMLSA-N Asp-Ala-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O PBVLJOIPOGUQQP-CIUDSAMLSA-N 0.000 description 2
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 2
- 102100029822 B- and T-lymphocyte attenuator Human genes 0.000 description 2
- 102100038080 B-cell receptor CD22 Human genes 0.000 description 2
- 108010077805 Bacterial Proteins Proteins 0.000 description 2
- 108010006654 Bleomycin Proteins 0.000 description 2
- 102100040840 C-type lectin domain family 7 member A Human genes 0.000 description 2
- 108010029697 CD40 Ligand Proteins 0.000 description 2
- 102100036008 CD48 antigen Human genes 0.000 description 2
- 241000283707 Capra Species 0.000 description 2
- DLGOEMSEDOSKAD-UHFFFAOYSA-N Carmustine Chemical compound ClCCNC(=O)N(N=O)CCCl DLGOEMSEDOSKAD-UHFFFAOYSA-N 0.000 description 2
- QYKJOVAXAKTKBR-FXQIFTODSA-N Cys-Asp-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N QYKJOVAXAKTKBR-FXQIFTODSA-N 0.000 description 2
- KABHAOSDMIYXTR-GUBZILKMSA-N Cys-Glu-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CS)N KABHAOSDMIYXTR-GUBZILKMSA-N 0.000 description 2
- 102100039498 Cytotoxic T-lymphocyte protein 4 Human genes 0.000 description 2
- 102100025012 Dipeptidyl peptidase 4 Human genes 0.000 description 2
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 2
- HTIJFSOGRVMCQR-UHFFFAOYSA-N Epirubicin Natural products COc1cccc2C(=O)c3c(O)c4CC(O)(CC(OC5CC(N)C(=O)C(C)O5)c4c(O)c3C(=O)c12)C(=O)CO HTIJFSOGRVMCQR-UHFFFAOYSA-N 0.000 description 2
- 102000018233 Fibroblast Growth Factor Human genes 0.000 description 2
- 108050007372 Fibroblast Growth Factor Proteins 0.000 description 2
- KBKGRMNVKPSQIF-XDTLVQLUSA-N Glu-Ala-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KBKGRMNVKPSQIF-XDTLVQLUSA-N 0.000 description 2
- OAGVHWYIBZMWLA-YFKPBYRVSA-N Glu-Gly-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)NCC(O)=O OAGVHWYIBZMWLA-YFKPBYRVSA-N 0.000 description 2
- LRPXYSGPOBVBEH-IUCAKERBSA-N Glu-Gly-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CC(C)C)C(O)=O LRPXYSGPOBVBEH-IUCAKERBSA-N 0.000 description 2
- KFMBRBPXHVMDFN-UWVGGRQHSA-N Gly-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCNC(N)=N KFMBRBPXHVMDFN-UWVGGRQHSA-N 0.000 description 2
- PDAWDNVHMUKWJR-ZETCQYMHSA-N Gly-Gly-His Chemical compound NCC(=O)NCC(=O)N[C@H](C(O)=O)CC1=CNC=N1 PDAWDNVHMUKWJR-ZETCQYMHSA-N 0.000 description 2
- UHPAZODVFFYEEL-QWRGUYRKSA-N Gly-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)CN UHPAZODVFFYEEL-QWRGUYRKSA-N 0.000 description 2
- GWCJMBNBFYBQCV-XPUUQOCRSA-N Gly-Val-Ala Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O GWCJMBNBFYBQCV-XPUUQOCRSA-N 0.000 description 2
- BAYQNCWLXIDLHX-ONGXEEELSA-N Gly-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)CN BAYQNCWLXIDLHX-ONGXEEELSA-N 0.000 description 2
- 208000009329 Graft vs Host Disease Diseases 0.000 description 2
- HTTJABKRGRZYRN-UHFFFAOYSA-N Heparin Chemical compound OC1C(NC(=O)C)C(O)OC(COS(O)(=O)=O)C1OC1C(OS(O)(=O)=O)C(O)C(OC2C(C(OS(O)(=O)=O)C(OC3C(C(O)C(O)C(O3)C(O)=O)OS(O)(=O)=O)C(CO)O2)NS(O)(=O)=O)C(C(O)=O)O1 HTTJABKRGRZYRN-UHFFFAOYSA-N 0.000 description 2
- RXKFKJVJVHLRIE-XIRDDKMYSA-N His-Ser-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC3=CN=CN3)N RXKFKJVJVHLRIE-XIRDDKMYSA-N 0.000 description 2
- 101000864344 Homo sapiens B- and T-lymphocyte attenuator Proteins 0.000 description 2
- 101000884305 Homo sapiens B-cell receptor CD22 Proteins 0.000 description 2
- 101000934356 Homo sapiens CD70 antigen Proteins 0.000 description 2
- 101000777628 Homo sapiens Leukocyte antigen CD37 Proteins 0.000 description 2
- 101000878605 Homo sapiens Low affinity immunoglobulin epsilon Fc receptor Proteins 0.000 description 2
- 101000633786 Homo sapiens SLAM family member 6 Proteins 0.000 description 2
- 101000633784 Homo sapiens SLAM family member 7 Proteins 0.000 description 2
- 101000633782 Homo sapiens SLAM family member 8 Proteins 0.000 description 2
- 101000633792 Homo sapiens SLAM family member 9 Proteins 0.000 description 2
- 101000914484 Homo sapiens T-lymphocyte activation antigen CD80 Proteins 0.000 description 2
- 101000845170 Homo sapiens Thymic stromal lymphopoietin Proteins 0.000 description 2
- 101000795167 Homo sapiens Tumor necrosis factor receptor superfamily member 13B Proteins 0.000 description 2
- 101000679903 Homo sapiens Tumor necrosis factor receptor superfamily member 25 Proteins 0.000 description 2
- 101000611185 Homo sapiens Tumor necrosis factor receptor superfamily member 5 Proteins 0.000 description 2
- 101000666896 Homo sapiens V-type immunoglobulin domain-containing suppressor of T-cell activation Proteins 0.000 description 2
- 108010038453 Interleukin-2 Receptors Proteins 0.000 description 2
- 102000010789 Interleukin-2 Receptors Human genes 0.000 description 2
- 102000015696 Interleukins Human genes 0.000 description 2
- 108010063738 Interleukins Proteins 0.000 description 2
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 2
- LHSGPCFBGJHPCY-UHFFFAOYSA-N L-leucine-L-tyrosine Natural products CC(C)CC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 LHSGPCFBGJHPCY-UHFFFAOYSA-N 0.000 description 2
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 2
- LJHGALIOHLRRQN-DCAQKATOSA-N Leu-Ala-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N LJHGALIOHLRRQN-DCAQKATOSA-N 0.000 description 2
- CNNQBZRGQATKNY-DCAQKATOSA-N Leu-Arg-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N CNNQBZRGQATKNY-DCAQKATOSA-N 0.000 description 2
- JKGHDYGZRDWHGA-SRVKXCTJSA-N Leu-Asn-Leu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JKGHDYGZRDWHGA-SRVKXCTJSA-N 0.000 description 2
- CCQLQKZTXZBXTN-NHCYSSNCSA-N Leu-Gly-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O CCQLQKZTXZBXTN-NHCYSSNCSA-N 0.000 description 2
- KYIIALJHAOIAHF-KKUMJFAQSA-N Leu-Leu-His Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 KYIIALJHAOIAHF-KKUMJFAQSA-N 0.000 description 2
- 102100031586 Leukocyte antigen CD37 Human genes 0.000 description 2
- 102100038007 Low affinity immunoglobulin epsilon Fc receptor Human genes 0.000 description 2
- 108010064548 Lymphocyte Function-Associated Antigen-1 Proteins 0.000 description 2
- AIRZWUMAHCDDHR-KKUMJFAQSA-N Lys-Leu-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O AIRZWUMAHCDDHR-KKUMJFAQSA-N 0.000 description 2
- 239000004472 Lysine Substances 0.000 description 2
- 229930192392 Mitomycin Natural products 0.000 description 2
- 241001529936 Murinae Species 0.000 description 2
- 101100407308 Mus musculus Pdcd1lg2 gene Proteins 0.000 description 2
- NWIBSHFKIJFRCO-WUDYKRTCSA-N Mytomycin Chemical compound C1N2C(C(C(C)=C(N)C3=O)=O)=C3[C@@H](COC(N)=O)[C@@]2(OC)[C@@H]2[C@H]1N2 NWIBSHFKIJFRCO-WUDYKRTCSA-N 0.000 description 2
- 102100038082 Natural killer cell receptor 2B4 Human genes 0.000 description 2
- MSHZHSPISPJWHW-UHFFFAOYSA-N O-(chloroacetylcarbamoyl)fumagillol Chemical compound O1C(CC=C(C)C)C1(C)C1C(OC)C(OC(=O)NC(=O)CCl)CCC21CO2 MSHZHSPISPJWHW-UHFFFAOYSA-N 0.000 description 2
- 238000012408 PCR amplification Methods 0.000 description 2
- 229930012538 Paclitaxel Natural products 0.000 description 2
- 229930182555 Penicillin Natural products 0.000 description 2
- JGSARLDLIJGVTE-MBNYWOFBSA-N Penicillin G Chemical compound N([C@H]1[C@H]2SC([C@@H](N2C1=O)C(O)=O)(C)C)C(=O)CC1=CC=CC=C1 JGSARLDLIJGVTE-MBNYWOFBSA-N 0.000 description 2
- MJQFZGOIVBDIMZ-WHOFXGATSA-N Phe-Ile-Gly Chemical compound N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)O MJQFZGOIVBDIMZ-WHOFXGATSA-N 0.000 description 2
- IEOHQGFKHXUALJ-JYJNAYRXSA-N Phe-Met-Arg Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O IEOHQGFKHXUALJ-JYJNAYRXSA-N 0.000 description 2
- PBWNICYZGJQKJV-BZSNNMDCSA-N Phe-Phe-Cys Chemical compound N[C@@H](Cc1ccccc1)C(=O)N[C@@H](Cc1ccccc1)C(=O)N[C@@H](CS)C(O)=O PBWNICYZGJQKJV-BZSNNMDCSA-N 0.000 description 2
- 229940122907 Phosphatase inhibitor Drugs 0.000 description 2
- 208000006664 Precursor Cell Lymphoblastic Leukemia-Lymphoma Diseases 0.000 description 2
- AFXCXDQNRXTSBD-FJXKBIBVSA-N Pro-Gly-Thr Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O AFXCXDQNRXTSBD-FJXKBIBVSA-N 0.000 description 2
- DSGSTPRKNYHGCL-JYJNAYRXSA-N Pro-Phe-Met Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCSC)C(O)=O DSGSTPRKNYHGCL-JYJNAYRXSA-N 0.000 description 2
- CHYAYDLYYIJCKY-OSUNSFLBSA-N Pro-Thr-Ile Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CHYAYDLYYIJCKY-OSUNSFLBSA-N 0.000 description 2
- JXVXYRZQIUPYSA-NHCYSSNCSA-N Pro-Val-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O JXVXYRZQIUPYSA-NHCYSSNCSA-N 0.000 description 2
- 108700030875 Programmed Cell Death 1 Ligand 2 Proteins 0.000 description 2
- 102100024213 Programmed cell death 1 ligand 2 Human genes 0.000 description 2
- 229940124158 Protease/peptidase inhibitor Drugs 0.000 description 2
- 238000012341 Quantitative reverse-transcriptase PCR Methods 0.000 description 2
- 102100029197 SLAM family member 6 Human genes 0.000 description 2
- 102100029198 SLAM family member 7 Human genes 0.000 description 2
- 102100029214 SLAM family member 8 Human genes 0.000 description 2
- 102100029196 SLAM family member 9 Human genes 0.000 description 2
- BRGQQXQKPUCUJQ-KBIXCLLPSA-N Ser-Glu-Ile Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BRGQQXQKPUCUJQ-KBIXCLLPSA-N 0.000 description 2
- CRJZZXMAADSBBQ-SRVKXCTJSA-N Ser-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CO CRJZZXMAADSBBQ-SRVKXCTJSA-N 0.000 description 2
- 102100029215 Signaling lymphocytic activation molecule Human genes 0.000 description 2
- 108010003723 Single-Domain Antibodies Proteins 0.000 description 2
- PXIPVTKHYLBLMZ-UHFFFAOYSA-N Sodium azide Chemical compound [Na+].[N-]=[N+]=[N-] PXIPVTKHYLBLMZ-UHFFFAOYSA-N 0.000 description 2
- 102100027222 T-lymphocyte activation antigen CD80 Human genes 0.000 description 2
- 102100033447 T-lymphocyte surface antigen Ly-9 Human genes 0.000 description 2
- 239000006180 TBST buffer Substances 0.000 description 2
- NKANXQFJJICGDU-QPLCGJKRSA-N Tamoxifen Chemical compound C=1C=CC=CC=1C(/CC)=C(C=1C=CC(OCCN(C)C)=CC=1)/C1=CC=CC=C1 NKANXQFJJICGDU-QPLCGJKRSA-N 0.000 description 2
- LMMDEZPNUTZJAY-GCJQMDKQSA-N Thr-Asp-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O LMMDEZPNUTZJAY-GCJQMDKQSA-N 0.000 description 2
- BZTSQFWJNJYZSX-JRQIVUDYSA-N Thr-Tyr-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O BZTSQFWJNJYZSX-JRQIVUDYSA-N 0.000 description 2
- 102100031294 Thymic stromal lymphopoietin Human genes 0.000 description 2
- 102100024587 Tumor necrosis factor ligand superfamily member 15 Human genes 0.000 description 2
- 102100029675 Tumor necrosis factor receptor superfamily member 13B Human genes 0.000 description 2
- 102100033733 Tumor necrosis factor receptor superfamily member 1B Human genes 0.000 description 2
- 102100022203 Tumor necrosis factor receptor superfamily member 25 Human genes 0.000 description 2
- AZZLDIDWPZLCCW-ZEWNOJEFSA-N Tyr-Ile-Phe Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O AZZLDIDWPZLCCW-ZEWNOJEFSA-N 0.000 description 2
- 102100038282 V-type immunoglobulin domain-containing suppressor of T-cell activation Human genes 0.000 description 2
- UMPVMAYCLYMYGA-ONGXEEELSA-N Val-Leu-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O UMPVMAYCLYMYGA-ONGXEEELSA-N 0.000 description 2
- HPANGHISDXDUQY-ULQDDVLXSA-N Val-Lys-Phe Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N HPANGHISDXDUQY-ULQDDVLXSA-N 0.000 description 2
- 102000009484 Vascular Endothelial Growth Factor Receptors Human genes 0.000 description 2
- 102000005789 Vascular Endothelial Growth Factors Human genes 0.000 description 2
- 108010019530 Vascular Endothelial Growth Factors Proteins 0.000 description 2
- JXLYSJRDGCGARV-WWYNWVTFSA-N Vinblastine Natural products O=C(O[C@H]1[C@](O)(C(=O)OC)[C@@H]2N(C)c3c(cc(c(OC)c3)[C@]3(C(=O)OC)c4[nH]c5c(c4CCN4C[C@](O)(CC)C[C@H](C3)C4)cccc5)[C@@]32[C@H]2[C@@]1(CC)C=CCN2CC3)C JXLYSJRDGCGARV-WWYNWVTFSA-N 0.000 description 2
- 239000004480 active ingredient Substances 0.000 description 2
- 239000013543 active substance Substances 0.000 description 2
- 230000001464 adherent effect Effects 0.000 description 2
- 108010024078 alanyl-glycyl-serine Proteins 0.000 description 2
- 108010047495 alanylglycine Proteins 0.000 description 2
- OFHCOWSQAMBJIW-AVJTYSNKSA-N alfacalcidol Chemical compound C1(/[C@@H]2CC[C@@H]([C@]2(CCC1)C)[C@H](C)CCCC(C)C)=C\C=C1\C[C@@H](O)C[C@H](O)C1=C OFHCOWSQAMBJIW-AVJTYSNKSA-N 0.000 description 2
- 229960001220 amsacrine Drugs 0.000 description 2
- XCPGHVQEEXUHNC-UHFFFAOYSA-N amsacrine Chemical compound COC1=CC(NS(C)(=O)=O)=CC=C1NC1=C(C=CC=C2)C2=NC2=CC=CC=C12 XCPGHVQEEXUHNC-UHFFFAOYSA-N 0.000 description 2
- 210000004102 animal cell Anatomy 0.000 description 2
- 229940045799 anthracyclines and related substance Drugs 0.000 description 2
- 239000007864 aqueous solution Substances 0.000 description 2
- 229960001230 asparagine Drugs 0.000 description 2
- 108010068265 aspartyltyrosine Proteins 0.000 description 2
- 230000001363 autoimmune Effects 0.000 description 2
- 239000011324 bead Substances 0.000 description 2
- 230000009286 beneficial effect Effects 0.000 description 2
- 229960001561 bleomycin Drugs 0.000 description 2
- OYVAGSVQBOHSSS-UAPAGMARSA-O bleomycin A2 Chemical compound N([C@H](C(=O)N[C@H](C)[C@@H](O)[C@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)NCCC=1SC=C(N=1)C=1SC=C(N=1)C(=O)NCCC[S+](C)C)[C@@H](O[C@H]1[C@H]([C@@H](O)[C@H](O)[C@H](CO)O1)O[C@@H]1[C@H]([C@@H](OC(N)=O)[C@H](O)[C@@H](CO)O1)O)C=1N=CNC=1)C(=O)C1=NC([C@H](CC(N)=O)NC[C@H](N)C(N)=O)=NC(N)=C1C OYVAGSVQBOHSSS-UAPAGMARSA-O 0.000 description 2
- 230000037396 body weight Effects 0.000 description 2
- 210000000988 bone and bone Anatomy 0.000 description 2
- 210000000481 breast Anatomy 0.000 description 2
- 229960001838 canakinumab Drugs 0.000 description 2
- 230000004611 cancer cell death Effects 0.000 description 2
- 150000001720 carbohydrates Chemical class 0.000 description 2
- 235000014633 carbohydrates Nutrition 0.000 description 2
- 238000005119 centrifugation Methods 0.000 description 2
- 239000003153 chemical reaction reagent Substances 0.000 description 2
- 238000010367 cloning Methods 0.000 description 2
- 238000002648 combination therapy Methods 0.000 description 2
- 230000000295 complement effect Effects 0.000 description 2
- 230000004540 complement-dependent cytotoxicity Effects 0.000 description 2
- 229960004397 cyclophosphamide Drugs 0.000 description 2
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 2
- 229960002806 daclizumab Drugs 0.000 description 2
- 229960001251 denosumab Drugs 0.000 description 2
- 230000004069 differentiation Effects 0.000 description 2
- 239000000539 dimer Substances 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 229960001904 epirubicin Drugs 0.000 description 2
- 229960005420 etoposide Drugs 0.000 description 2
- 229940126864 fibroblast growth factor Drugs 0.000 description 2
- 108020001507 fusion proteins Proteins 0.000 description 2
- 102000037865 fusion proteins Human genes 0.000 description 2
- 208000024908 graft versus host disease Diseases 0.000 description 2
- 239000003102 growth factor Substances 0.000 description 2
- NAQMVNRVTILPCV-UHFFFAOYSA-N hexane-1,6-diamine Chemical compound NCCCCCCN NAQMVNRVTILPCV-UHFFFAOYSA-N 0.000 description 2
- JYGXADMDTFJGBT-VWUMJDOOSA-N hydrocortisone Chemical compound O=C1CC[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 JYGXADMDTFJGBT-VWUMJDOOSA-N 0.000 description 2
- 238000003384 imaging method Methods 0.000 description 2
- 230000002519 immonomodulatory effect Effects 0.000 description 2
- 239000012642 immune effector Substances 0.000 description 2
- 229940121354 immunomodulator Drugs 0.000 description 2
- 238000011503 in vivo imaging Methods 0.000 description 2
- 239000000411 inducer Substances 0.000 description 2
- 230000003993 interaction Effects 0.000 description 2
- 238000001990 intravenous administration Methods 0.000 description 2
- 108010078274 isoleucylvaline Proteins 0.000 description 2
- 230000002147 killing effect Effects 0.000 description 2
- 108010044311 leucyl-glycyl-glycine Proteins 0.000 description 2
- 108010012058 leucyltyrosine Proteins 0.000 description 2
- 230000000670 limiting effect Effects 0.000 description 2
- 230000033001 locomotion Effects 0.000 description 2
- 229960004961 mechlorethamine Drugs 0.000 description 2
- HAWPXGHAZFHHAD-UHFFFAOYSA-N mechlorethamine Chemical compound ClCCN(C)CCCl HAWPXGHAZFHHAD-UHFFFAOYSA-N 0.000 description 2
- 201000001441 melanoma Diseases 0.000 description 2
- 229960001924 melphalan Drugs 0.000 description 2
- SGDBTWWWUNNDEQ-LBPRGKRZSA-N melphalan Chemical compound OC(=O)[C@@H](N)CC1=CC=C(N(CCCl)CCCl)C=C1 SGDBTWWWUNNDEQ-LBPRGKRZSA-N 0.000 description 2
- 229930182817 methionine Natural products 0.000 description 2
- CFCUWKMKBJTWLW-BKHRDMLASA-N mithramycin Chemical compound O([C@@H]1C[C@@H](O[C@H](C)[C@H]1O)OC=1C=C2C=C3C[C@H]([C@@H](C(=O)C3=C(O)C2=C(O)C=1C)O[C@@H]1O[C@H](C)[C@@H](O)[C@H](O[C@@H]2O[C@H](C)[C@H](O)[C@H](O[C@@H]3O[C@H](C)[C@@H](O)[C@@](C)(O)C3)C2)C1)[C@H](OC)C(=O)[C@@H](O)[C@@H](C)O)[C@H]1C[C@@H](O)[C@H](O)[C@@H](C)O1 CFCUWKMKBJTWLW-BKHRDMLASA-N 0.000 description 2
- 229960004857 mitomycin Drugs 0.000 description 2
- 229960001156 mitoxantrone Drugs 0.000 description 2
- KKZJGLLVHKMTCM-UHFFFAOYSA-N mitoxantrone Chemical compound O=C1C2=C(O)C=CC(O)=C2C(=O)C2=C1C(NCCNCCO)=CC=C2NCCNCCO KKZJGLLVHKMTCM-UHFFFAOYSA-N 0.000 description 2
- 238000010369 molecular cloning Methods 0.000 description 2
- 229960001592 paclitaxel Drugs 0.000 description 2
- 230000037361 pathway Effects 0.000 description 2
- 229940049954 penicillin Drugs 0.000 description 2
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 2
- 108010051242 phenylalanylserine Proteins 0.000 description 2
- BASFCYQUMIYNBI-UHFFFAOYSA-N platinum Chemical compound [Pt] BASFCYQUMIYNBI-UHFFFAOYSA-N 0.000 description 2
- 229960003171 plicamycin Drugs 0.000 description 2
- 102000054765 polymorphisms of proteins Human genes 0.000 description 2
- 230000002335 preservative effect Effects 0.000 description 2
- 229960000624 procarbazine Drugs 0.000 description 2
- CPTBDICYNRMXFX-UHFFFAOYSA-N procarbazine Chemical compound CNNCC1=CC=C(C(=O)NC(C)C)C=C1 CPTBDICYNRMXFX-UHFFFAOYSA-N 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 108010004914 prolylarginine Proteins 0.000 description 2
- 230000001737 promoting effect Effects 0.000 description 2
- XJMOSONTPMZWPB-UHFFFAOYSA-M propidium iodide Chemical compound [I-].[I-].C12=CC(N)=CC=C2C2=CC=C(N)C=C2[N+](CCC[N+](C)(CC)CC)=C1C1=CC=CC=C1 XJMOSONTPMZWPB-UHFFFAOYSA-M 0.000 description 2
- ZAHRKKWIAAJSAO-UHFFFAOYSA-N rapamycin Natural products COCC(O)C(=C/C(C)C(=O)CC(OC(=O)C1CCCCN1C(=O)C(=O)C2(O)OC(CC(OC)C(=CC=CC=CC(C)CC(C)C(=O)C)C)CCC2C)C(C)CC3CCC(O)C(C3)OC)C ZAHRKKWIAAJSAO-UHFFFAOYSA-N 0.000 description 2
- 229940044551 receptor antagonist Drugs 0.000 description 2
- 239000002464 receptor antagonist Substances 0.000 description 2
- 238000010188 recombinant method Methods 0.000 description 2
- 230000002829 reductive effect Effects 0.000 description 2
- 108091008146 restriction endonucleases Proteins 0.000 description 2
- 230000035945 sensitivity Effects 0.000 description 2
- 229960002930 sirolimus Drugs 0.000 description 2
- QFJCIRLUMZQUOT-HPLJOQBZSA-N sirolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1C[C@@H](C)[C@H]1OC(=O)[C@@H]2CCCCN2C(=O)C(=O)[C@](O)(O2)[C@H](C)CC[C@H]2C[C@H](OC)/C(C)=C/C=C/C=C/[C@@H](C)C[C@@H](C)C(=O)[C@H](OC)[C@H](O)/C(C)=C/[C@@H](C)C(=O)C1 QFJCIRLUMZQUOT-HPLJOQBZSA-N 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- 210000000130 stem cell Anatomy 0.000 description 2
- 229960005322 streptomycin Drugs 0.000 description 2
- 239000006228 supernatant Substances 0.000 description 2
- RCINICONZNJXQF-MZXODVADSA-N taxol Chemical compound O([C@@H]1[C@@]2(C[C@@H](C(C)=C(C2(C)C)[C@H](C([C@]2(C)[C@@H](O)C[C@H]3OC[C@]3([C@H]21)OC(C)=O)=O)OC(=O)C)OC(=O)[C@H](O)[C@@H](NC(=O)C=1C=CC=CC=1)C=1C=CC=CC=1)O)C(=O)C1=CC=CC=C1 RCINICONZNJXQF-MZXODVADSA-N 0.000 description 2
- NRUKOCRGYNPUPR-QBPJDGROSA-N teniposide Chemical compound COC1=C(O)C(OC)=CC([C@@H]2C3=CC=4OCOC=4C=C3[C@@H](O[C@H]3[C@@H]([C@@H](O)[C@@H]4O[C@@H](OC[C@H]4O3)C=3SC=CC=3)O)[C@@H]3[C@@H]2C(OC3)=O)=C1 NRUKOCRGYNPUPR-QBPJDGROSA-N 0.000 description 2
- 229960001278 teniposide Drugs 0.000 description 2
- WYWHKKSPHMUBEB-UHFFFAOYSA-N tioguanine Chemical compound N1C(N)=NC(=S)C2=C1N=CN2 WYWHKKSPHMUBEB-UHFFFAOYSA-N 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- 230000001052 transient effect Effects 0.000 description 2
- 230000010474 transient expression Effects 0.000 description 2
- 108010073969 valyllysine Proteins 0.000 description 2
- 229960003048 vinblastine Drugs 0.000 description 2
- JXLYSJRDGCGARV-XQKSVPLYSA-N vincaleukoblastine Chemical compound C([C@@H](C[C@]1(C(=O)OC)C=2C(=CC3=C([C@]45[C@H]([C@@]([C@H](OC(C)=O)[C@]6(CC)C=CCN([C@H]56)CC4)(O)C(=O)OC)N3C)C=2)OC)C[C@@](C2)(O)CC)N2CCC2=C1NC1=CC=CC=C21 JXLYSJRDGCGARV-XQKSVPLYSA-N 0.000 description 2
- 229960004528 vincristine Drugs 0.000 description 2
- OGWKCGZFUXNPDA-UHFFFAOYSA-N vincristine Natural products C1C(CC)(O)CC(CC2(C(=O)OC)C=3C(=CC4=C(C56C(C(C(OC(C)=O)C7(CC)C=CCN(C67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)CN1CCC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-UHFFFAOYSA-N 0.000 description 2
- OGWKCGZFUXNPDA-XQKSVPLYSA-N vincristine Chemical compound C([N@]1C[C@@H](C[C@]2(C(=O)OC)C=3C(=CC4=C([C@]56[C@H]([C@@]([C@H](OC(C)=O)[C@]7(CC)C=CCN([C@H]67)CC5)(O)C(=O)OC)N4C=O)C=3)OC)C[C@@](C1)(O)CC)CC1=C2NC2=CC=CC=C12 OGWKCGZFUXNPDA-XQKSVPLYSA-N 0.000 description 2
- 238000005406 washing Methods 0.000 description 2
- OZFAFGSSMRRTDW-UHFFFAOYSA-N (2,4-dichlorophenyl) benzenesulfonate Chemical compound ClC1=CC(Cl)=CC=C1OS(=O)(=O)C1=CC=CC=C1 OZFAFGSSMRRTDW-UHFFFAOYSA-N 0.000 description 1
- VWWKKDNCCLAGRM-GVXVVHGQSA-N (2s)-2-[[2-[[(2s)-2-[[(2s)-2-amino-4-methylpentanoyl]amino]propanoyl]amino]acetyl]amino]-3-methylbutanoic acid Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O VWWKKDNCCLAGRM-GVXVVHGQSA-N 0.000 description 1
- JPSHPWJJSVEEAX-OWPBQMJCSA-N (2s)-2-amino-4-fluoranylpentanedioic acid Chemical compound OC(=O)[C@@H](N)CC([18F])C(O)=O JPSHPWJJSVEEAX-OWPBQMJCSA-N 0.000 description 1
- AUXMWYRZQPIXCC-KNIFDHDWSA-N (2s)-2-amino-4-methylpentanoic acid;(2s)-2-aminopropanoic acid Chemical group C[C@H](N)C(O)=O.CC(C)C[C@H](N)C(O)=O AUXMWYRZQPIXCC-KNIFDHDWSA-N 0.000 description 1
- MZOFCQQQCNRIBI-VMXHOPILSA-N (3s)-4-[[(2s)-1-[[(2s)-1-[[(1s)-1-carboxy-2-hydroxyethyl]amino]-4-methyl-1-oxopentan-2-yl]amino]-5-(diaminomethylideneamino)-1-oxopentan-2-yl]amino]-3-[[2-[[(2s)-2,6-diaminohexanoyl]amino]acetyl]amino]-4-oxobutanoic acid Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CC(O)=O)NC(=O)CNC(=O)[C@@H](N)CCCCN MZOFCQQQCNRIBI-VMXHOPILSA-N 0.000 description 1
- FPVKHBSQESCIEP-UHFFFAOYSA-N (8S)-3-(2-deoxy-beta-D-erythro-pentofuranosyl)-3,6,7,8-tetrahydroimidazo[4,5-d][1,3]diazepin-8-ol Natural products C1C(O)C(CO)OC1N1C(NC=NCC2O)=C2N=C1 FPVKHBSQESCIEP-UHFFFAOYSA-N 0.000 description 1
- FDKXTQMXEQVLRF-ZHACJKMWSA-N (E)-dacarbazine Chemical compound CN(C)\N=N\c1[nH]cnc1C(N)=O FDKXTQMXEQVLRF-ZHACJKMWSA-N 0.000 description 1
- LKJPYSCBVHEWIU-KRWDZBQOSA-N (R)-bicalutamide Chemical compound C([C@@](O)(C)C(=O)NC=1C=C(C(C#N)=CC=1)C(F)(F)F)S(=O)(=O)C1=CC=C(F)C=C1 LKJPYSCBVHEWIU-KRWDZBQOSA-N 0.000 description 1
- 102100025573 1-alkyl-2-acetylglycerophosphocholine esterase Human genes 0.000 description 1
- VSNHCAURESNICA-NJFSPNSNSA-N 1-oxidanylurea Chemical compound N[14C](=O)NO VSNHCAURESNICA-NJFSPNSNSA-N 0.000 description 1
- FUFLCEKSBBHCMO-UHFFFAOYSA-N 11-dehydrocorticosterone Natural products O=C1CCC2(C)C3C(=O)CC(C)(C(CC4)C(=O)CO)C4C3CCC2=C1 FUFLCEKSBBHCMO-UHFFFAOYSA-N 0.000 description 1
- 101800001779 2'-O-methyltransferase Proteins 0.000 description 1
- CTRPRMNBTVRDFH-UHFFFAOYSA-N 2-n-methyl-1,3,5-triazine-2,4,6-triamine Chemical class CNC1=NC(N)=NC(N)=N1 CTRPRMNBTVRDFH-UHFFFAOYSA-N 0.000 description 1
- ZFXQNADNEBRERM-BJDJZHNGSA-N Ala-Ala-Pro-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 ZFXQNADNEBRERM-BJDJZHNGSA-N 0.000 description 1
- WJRXVTCKASUIFF-FXQIFTODSA-N Ala-Cys-Arg Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O WJRXVTCKASUIFF-FXQIFTODSA-N 0.000 description 1
- YEELWQSXYBJVSV-UWJYBYFXSA-N Ala-Cys-Tyr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O YEELWQSXYBJVSV-UWJYBYFXSA-N 0.000 description 1
- NBTGEURICRTMGL-WHFBIAKZSA-N Ala-Gly-Ser Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O NBTGEURICRTMGL-WHFBIAKZSA-N 0.000 description 1
- CBCCCLMNOBLBSC-XVYDVKMFSA-N Ala-His-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CO)C(O)=O CBCCCLMNOBLBSC-XVYDVKMFSA-N 0.000 description 1
- OYJCVIGKMXUVKB-GARJFASQSA-N Ala-Leu-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N OYJCVIGKMXUVKB-GARJFASQSA-N 0.000 description 1
- RGQCNKIDEQJEBT-CQDKDKBSSA-N Ala-Leu-Tyr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 RGQCNKIDEQJEBT-CQDKDKBSSA-N 0.000 description 1
- RUXQNKVQSKOOBS-JURCDPSOSA-N Ala-Phe-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O RUXQNKVQSKOOBS-JURCDPSOSA-N 0.000 description 1
- OLVCTPPSXNRGKV-GUBZILKMSA-N Ala-Pro-Pro Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 OLVCTPPSXNRGKV-GUBZILKMSA-N 0.000 description 1
- YYAVDNKUWLAFCV-ACZMJKKPSA-N Ala-Ser-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O YYAVDNKUWLAFCV-ACZMJKKPSA-N 0.000 description 1
- QOIGKCBMXUCDQU-KDXUFGMBSA-N Ala-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](C)N)O QOIGKCBMXUCDQU-KDXUFGMBSA-N 0.000 description 1
- MTDDMSUUXNQMKK-BPNCWPANSA-N Ala-Tyr-Arg Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N MTDDMSUUXNQMKK-BPNCWPANSA-N 0.000 description 1
- BHFOJPDOQPWJRN-XDTLVQLUSA-N Ala-Tyr-Gln Chemical compound C[C@H](N)C(=O)N[C@@H](Cc1ccc(O)cc1)C(=O)N[C@@H](CCC(N)=O)C(O)=O BHFOJPDOQPWJRN-XDTLVQLUSA-N 0.000 description 1
- 102100026882 Alpha-synuclein Human genes 0.000 description 1
- 241000710929 Alphavirus Species 0.000 description 1
- 102400000068 Angiostatin Human genes 0.000 description 1
- 108010079709 Angiostatins Proteins 0.000 description 1
- 108010049777 Ankyrins Proteins 0.000 description 1
- 102000008102 Ankyrins Human genes 0.000 description 1
- 108020000948 Antisense Oligonucleotides Proteins 0.000 description 1
- 108020005544 Antisense RNA Proteins 0.000 description 1
- UXJCMQFPDWCHKX-DCAQKATOSA-N Arg-Arg-Glu Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O UXJCMQFPDWCHKX-DCAQKATOSA-N 0.000 description 1
- HJVGMOYJDDXLMI-AVGNSLFASA-N Arg-Arg-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@@H](N)CCCNC(N)=N HJVGMOYJDDXLMI-AVGNSLFASA-N 0.000 description 1
- UISQLSIBJKEJSS-GUBZILKMSA-N Arg-Arg-Ser Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CO)C(O)=O UISQLSIBJKEJSS-GUBZILKMSA-N 0.000 description 1
- DXQIQUIQYAGRCC-CIUDSAMLSA-N Arg-Asp-Gln Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)CN=C(N)N DXQIQUIQYAGRCC-CIUDSAMLSA-N 0.000 description 1
- TTXYKSADPSNOIF-IHRRRGAJSA-N Arg-Asp-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O TTXYKSADPSNOIF-IHRRRGAJSA-N 0.000 description 1
- CYXCAHZVPFREJD-LURJTMIESA-N Arg-Gly-Gly Chemical compound NC(=N)NCCC[C@H](N)C(=O)NCC(=O)NCC(O)=O CYXCAHZVPFREJD-LURJTMIESA-N 0.000 description 1
- UZGFHWIJWPUPOH-IHRRRGAJSA-N Arg-Leu-Lys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N UZGFHWIJWPUPOH-IHRRRGAJSA-N 0.000 description 1
- NMRHDSAOIURTNT-RWMBFGLXSA-N Arg-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N NMRHDSAOIURTNT-RWMBFGLXSA-N 0.000 description 1
- FSNVAJOPUDVQAR-AVGNSLFASA-N Arg-Lys-Arg Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FSNVAJOPUDVQAR-AVGNSLFASA-N 0.000 description 1
- AOHKLEBWKMKITA-IHRRRGAJSA-N Arg-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCN=C(N)N)N AOHKLEBWKMKITA-IHRRRGAJSA-N 0.000 description 1
- DNBMCNQKNOKOSD-DCAQKATOSA-N Arg-Pro-Gln Chemical compound NC(N)=NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O DNBMCNQKNOKOSD-DCAQKATOSA-N 0.000 description 1
- XSPKAHFVDKRGRL-DCAQKATOSA-N Arg-Pro-Glu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O XSPKAHFVDKRGRL-DCAQKATOSA-N 0.000 description 1
- YCYXHLZRUSJITQ-SRVKXCTJSA-N Arg-Pro-Pro Chemical compound NC(=N)NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 YCYXHLZRUSJITQ-SRVKXCTJSA-N 0.000 description 1
- KXOPYFNQLVUOAQ-FXQIFTODSA-N Arg-Ser-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O KXOPYFNQLVUOAQ-FXQIFTODSA-N 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- 240000003291 Armoracia rusticana Species 0.000 description 1
- KSBHCUSPLWRVEK-ZLUOBGJFSA-N Asn-Asn-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O KSBHCUSPLWRVEK-ZLUOBGJFSA-N 0.000 description 1
- WPOLSNAQGVHROR-GUBZILKMSA-N Asn-Gln-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC(=O)N)N WPOLSNAQGVHROR-GUBZILKMSA-N 0.000 description 1
- BZWRLDPIWKOVKB-ZPFDUUQYSA-N Asn-Leu-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BZWRLDPIWKOVKB-ZPFDUUQYSA-N 0.000 description 1
- CBHVAFXKOYAHOY-NHCYSSNCSA-N Asn-Val-Leu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O CBHVAFXKOYAHOY-NHCYSSNCSA-N 0.000 description 1
- XPGVTUBABLRGHY-BIIVOSGPSA-N Asp-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N XPGVTUBABLRGHY-BIIVOSGPSA-N 0.000 description 1
- RTXQQDVBACBSCW-CFMVVWHZSA-N Asp-Ile-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O RTXQQDVBACBSCW-CFMVVWHZSA-N 0.000 description 1
- RVMXMLSYBTXCAV-VEVYYDQMSA-N Asp-Pro-Thr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O RVMXMLSYBTXCAV-VEVYYDQMSA-N 0.000 description 1
- 108010024976 Asparaginase Proteins 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- BSYNRYMUTXBXSQ-UHFFFAOYSA-N Aspirin Chemical compound CC(=O)OC1=CC=CC=C1C(O)=O BSYNRYMUTXBXSQ-UHFFFAOYSA-N 0.000 description 1
- 244000075850 Avena orientalis Species 0.000 description 1
- 235000007319 Avena orientalis Nutrition 0.000 description 1
- NOWKCMXCCJGMRR-UHFFFAOYSA-N Aziridine Chemical compound C1CN1 NOWKCMXCCJGMRR-UHFFFAOYSA-N 0.000 description 1
- 239000005552 B01AC04 - Clopidogrel Substances 0.000 description 1
- 239000005528 B01AC05 - Ticlopidine Substances 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 102100024217 CAMPATH-1 antigen Human genes 0.000 description 1
- 108010046080 CD27 Ligand Proteins 0.000 description 1
- 108010017987 CD30 Ligand Proteins 0.000 description 1
- 102000049320 CD36 Human genes 0.000 description 1
- 108010045374 CD36 Antigens Proteins 0.000 description 1
- 108010038940 CD48 Antigen Proteins 0.000 description 1
- 108010065524 CD52 Antigen Proteins 0.000 description 1
- 102100027217 CD82 antigen Human genes 0.000 description 1
- 102100037904 CD9 antigen Human genes 0.000 description 1
- 108010021064 CTLA-4 Antigen Proteins 0.000 description 1
- 229940045513 CTLA4 antagonist Drugs 0.000 description 1
- 101100074325 Caenorhabditis elegans lec-3 gene Proteins 0.000 description 1
- KLWPJMFMVPTNCC-UHFFFAOYSA-N Camptothecin Natural products CCC1(O)C(=O)OCC2=C1C=C3C4Nc5ccccc5C=C4CN3C2=O KLWPJMFMVPTNCC-UHFFFAOYSA-N 0.000 description 1
- 102100026548 Caspase-8 Human genes 0.000 description 1
- 108090000538 Caspase-8 Proteins 0.000 description 1
- 206010057248 Cell death Diseases 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- JWBOIMRXGHLCPP-UHFFFAOYSA-N Chloditan Chemical compound C=1C=CC=C(Cl)C=1C(C(Cl)Cl)C1=CC=C(Cl)C=C1 JWBOIMRXGHLCPP-UHFFFAOYSA-N 0.000 description 1
- KRKNYBCHXYNGOX-UHFFFAOYSA-K Citrate Chemical compound [O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O KRKNYBCHXYNGOX-UHFFFAOYSA-K 0.000 description 1
- PTOAARAWEBMLNO-KVQBGUIXSA-N Cladribine Chemical compound C1=NC=2C(N)=NC(Cl)=NC=2N1[C@H]1C[C@H](O)[C@@H](CO)O1 PTOAARAWEBMLNO-KVQBGUIXSA-N 0.000 description 1
- 102100031162 Collagen alpha-1(XVIII) chain Human genes 0.000 description 1
- 206010010144 Completed suicide Diseases 0.000 description 1
- 206010010356 Congenital anomaly Diseases 0.000 description 1
- MFYSYFVPBJMHGN-UHFFFAOYSA-N Cortisone Natural products O=C1CCC2(C)C3C(=O)CC(C)(C(CC4)(O)C(=O)CO)C4C3CCC2=C1 MFYSYFVPBJMHGN-UHFFFAOYSA-N 0.000 description 1
- MFYSYFVPBJMHGN-ZPOLXVRWSA-N Cortisone Chemical compound O=C1CC[C@]2(C)[C@H]3C(=O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 MFYSYFVPBJMHGN-ZPOLXVRWSA-N 0.000 description 1
- PMATZTZNYRCHOR-CGLBZJNRSA-N Cyclosporin A Chemical compound CC[C@@H]1NC(=O)[C@H]([C@H](O)[C@H](C)C\C=C\C)N(C)C(=O)[C@H](C(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](CC(C)C)N(C)C(=O)[C@@H](C)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)N(C)C(=O)[C@H](C(C)C)NC(=O)[C@H](CC(C)C)N(C)C(=O)CN(C)C1=O PMATZTZNYRCHOR-CGLBZJNRSA-N 0.000 description 1
- 229930105110 Cyclosporin A Natural products 0.000 description 1
- 108010036949 Cyclosporine Proteins 0.000 description 1
- IIGHQOPGMGKDMT-SRVKXCTJSA-N Cys-Asp-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CS)N IIGHQOPGMGKDMT-SRVKXCTJSA-N 0.000 description 1
- BCWIFCLVCRAIQK-ZLUOBGJFSA-N Cys-Ser-Cys Chemical compound C([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CS)N)O BCWIFCLVCRAIQK-ZLUOBGJFSA-N 0.000 description 1
- ZFHXNNXMNLWKJH-HJPIBITLSA-N Cys-Tyr-Ile Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ZFHXNNXMNLWKJH-HJPIBITLSA-N 0.000 description 1
- UHDGCWIWMRVCDJ-CCXZUQQUSA-N Cytarabine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 UHDGCWIWMRVCDJ-CCXZUQQUSA-N 0.000 description 1
- 101710189311 Cytokine receptor common subunit gamma Proteins 0.000 description 1
- 102100027816 Cytotoxic and regulatory T-cell molecule Human genes 0.000 description 1
- 102000053602 DNA Human genes 0.000 description 1
- 239000012623 DNA damaging agent Substances 0.000 description 1
- 241000702421 Dependoparvovirus Species 0.000 description 1
- 206010059866 Drug resistance Diseases 0.000 description 1
- 239000012591 Dulbecco’s Phosphate Buffered Saline Substances 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 238000002965 ELISA Methods 0.000 description 1
- 108010079505 Endostatins Proteins 0.000 description 1
- 102100031984 Ephrin type-B receptor 6 Human genes 0.000 description 1
- 101150094945 FCGR3A gene Proteins 0.000 description 1
- 102100024785 Fibroblast growth factor 2 Human genes 0.000 description 1
- 108090000379 Fibroblast growth factor 2 Proteins 0.000 description 1
- 102000002090 Fibronectin type III Human genes 0.000 description 1
- 108050009401 Fibronectin type III Proteins 0.000 description 1
- GHASVSINZRGABV-UHFFFAOYSA-N Fluorouracil Chemical compound FC1=CNC(=O)NC1=O GHASVSINZRGABV-UHFFFAOYSA-N 0.000 description 1
- 229940123414 Folate antagonist Drugs 0.000 description 1
- 229940032072 GVAX vaccine Drugs 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- 206010071602 Genetic polymorphism Diseases 0.000 description 1
- WUAYFMZULZDSLB-ACZMJKKPSA-N Gln-Ala-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCC(N)=O WUAYFMZULZDSLB-ACZMJKKPSA-N 0.000 description 1
- REJJNXODKSHOKA-ACZMJKKPSA-N Gln-Ala-Asp Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CCC(=O)N)N REJJNXODKSHOKA-ACZMJKKPSA-N 0.000 description 1
- CGVWDTRDPLOMHZ-FXQIFTODSA-N Gln-Glu-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O CGVWDTRDPLOMHZ-FXQIFTODSA-N 0.000 description 1
- CLPQUWHBWXFJOX-BQBZGAKWSA-N Gln-Gly-Gln Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O CLPQUWHBWXFJOX-BQBZGAKWSA-N 0.000 description 1
- TWIAMTNJOMRDAK-GUBZILKMSA-N Gln-Lys-Asp Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(O)=O TWIAMTNJOMRDAK-GUBZILKMSA-N 0.000 description 1
- ILKYYKRAULNYMS-JYJNAYRXSA-N Gln-Lys-Phe Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ILKYYKRAULNYMS-JYJNAYRXSA-N 0.000 description 1
- DCWNCMRZIZSZBL-KKUMJFAQSA-N Gln-Pro-Tyr Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)N)N)C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)O DCWNCMRZIZSZBL-KKUMJFAQSA-N 0.000 description 1
- YRHZWVKUFWCEPW-GLLZPBPUSA-N Gln-Thr-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O YRHZWVKUFWCEPW-GLLZPBPUSA-N 0.000 description 1
- ININBLZFFVOQIO-JHEQGTHGSA-N Gln-Thr-Gly Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)O)NC(=O)[C@H](CCC(=O)N)N)O ININBLZFFVOQIO-JHEQGTHGSA-N 0.000 description 1
- WOMUDRVDJMHTCV-DCAQKATOSA-N Glu-Arg-Arg Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O WOMUDRVDJMHTCV-DCAQKATOSA-N 0.000 description 1
- DSPQRJXOIXHOHK-WDSKDSINSA-N Glu-Asp-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O DSPQRJXOIXHOHK-WDSKDSINSA-N 0.000 description 1
- CKOFNWCLWRYUHK-XHNCKOQMSA-N Glu-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCC(=O)O)N)C(=O)O CKOFNWCLWRYUHK-XHNCKOQMSA-N 0.000 description 1
- PHONAZGUEGIOEM-GLLZPBPUSA-N Glu-Glu-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PHONAZGUEGIOEM-GLLZPBPUSA-N 0.000 description 1
- VSRCAOIHMGCIJK-SRVKXCTJSA-N Glu-Leu-Arg Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O VSRCAOIHMGCIJK-SRVKXCTJSA-N 0.000 description 1
- QMOSCLNJVKSHHU-YUMQZZPRSA-N Glu-Met-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)NCC(O)=O QMOSCLNJVKSHHU-YUMQZZPRSA-N 0.000 description 1
- RFTVTKBHDXCEEX-WDSKDSINSA-N Glu-Ser-Gly Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O RFTVTKBHDXCEEX-WDSKDSINSA-N 0.000 description 1
- RGJKYNUINKGPJN-RWRJDSDZSA-N Glu-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(=O)O)N RGJKYNUINKGPJN-RWRJDSDZSA-N 0.000 description 1
- HHSKZJZWQFPSKN-AVGNSLFASA-N Glu-Tyr-Asp Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(O)=O)C(O)=O HHSKZJZWQFPSKN-AVGNSLFASA-N 0.000 description 1
- 102100041003 Glutamate carboxypeptidase 2 Human genes 0.000 description 1
- PUUYVMYCMIWHFE-BQBZGAKWSA-N Gly-Ala-Arg Chemical compound NCC(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N PUUYVMYCMIWHFE-BQBZGAKWSA-N 0.000 description 1
- VSVZIEVNUYDAFR-YUMQZZPRSA-N Gly-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN VSVZIEVNUYDAFR-YUMQZZPRSA-N 0.000 description 1
- UPOJUWHGMDJUQZ-IUCAKERBSA-N Gly-Arg-Arg Chemical compound NC(=N)NCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UPOJUWHGMDJUQZ-IUCAKERBSA-N 0.000 description 1
- CLODWIOAKCSBAN-BQBZGAKWSA-N Gly-Arg-Asp Chemical compound NC(N)=NCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CC(O)=O)C(O)=O CLODWIOAKCSBAN-BQBZGAKWSA-N 0.000 description 1
- BGVYNAQWHSTTSP-BYULHYEWSA-N Gly-Asn-Ile Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BGVYNAQWHSTTSP-BYULHYEWSA-N 0.000 description 1
- CCQOOWAONKGYKQ-BYPYZUCNSA-N Gly-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)CN CCQOOWAONKGYKQ-BYPYZUCNSA-N 0.000 description 1
- IDOGEHIWMJMAHT-BYPYZUCNSA-N Gly-Gly-Cys Chemical compound NCC(=O)NCC(=O)N[C@@H](CS)C(O)=O IDOGEHIWMJMAHT-BYPYZUCNSA-N 0.000 description 1
- SCWYHUQOOFRVHP-MBLNEYKQSA-N Gly-Ile-Thr Chemical compound NCC(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SCWYHUQOOFRVHP-MBLNEYKQSA-N 0.000 description 1
- YTSVAIMKVLZUDU-YUMQZZPRSA-N Gly-Leu-Asp Chemical compound [H]NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O YTSVAIMKVLZUDU-YUMQZZPRSA-N 0.000 description 1
- NNCSJUBVFBDDLC-YUMQZZPRSA-N Gly-Leu-Ser Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O NNCSJUBVFBDDLC-YUMQZZPRSA-N 0.000 description 1
- PDUHNKAFQXQNLH-ZETCQYMHSA-N Gly-Lys-Gly Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)NCC(O)=O PDUHNKAFQXQNLH-ZETCQYMHSA-N 0.000 description 1
- WDEHMRNSGHVNOH-VHSXEESVSA-N Gly-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)CN)C(=O)O WDEHMRNSGHVNOH-VHSXEESVSA-N 0.000 description 1
- NTBOEZICHOSJEE-YUMQZZPRSA-N Gly-Lys-Ser Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(O)=O NTBOEZICHOSJEE-YUMQZZPRSA-N 0.000 description 1
- ZWRDOVYMQAAISL-UWVGGRQHSA-N Gly-Met-Lys Chemical compound CSCC[C@H](NC(=O)CN)C(=O)N[C@H](C(O)=O)CCCCN ZWRDOVYMQAAISL-UWVGGRQHSA-N 0.000 description 1
- IRJWAYCXIYUHQE-WHFBIAKZSA-N Gly-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)CN IRJWAYCXIYUHQE-WHFBIAKZSA-N 0.000 description 1
- ABPRMMYHROQBLY-NKWVEPMBSA-N Gly-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)CN)C(=O)O ABPRMMYHROQBLY-NKWVEPMBSA-N 0.000 description 1
- OCRQUYDOYKCOQG-IRXDYDNUSA-N Gly-Tyr-Phe Chemical compound C([C@H](NC(=O)CN)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 OCRQUYDOYKCOQG-IRXDYDNUSA-N 0.000 description 1
- GBYYQVBXFVDJPJ-WLTAIBSBSA-N Gly-Tyr-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)NC(=O)CN)O GBYYQVBXFVDJPJ-WLTAIBSBSA-N 0.000 description 1
- 102100035716 Glycophorin-A Human genes 0.000 description 1
- BLCLNMBMMGCOAS-URPVMXJPSA-N Goserelin Chemical compound C([C@@H](C(=O)N[C@H](COC(C)(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1[C@@H](CCC1)C(=O)NNC(N)=O)NC(=O)[C@H](CO)NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H](CC=1NC=NC=1)NC(=O)[C@H]1NC(=O)CC1)C1=CC=C(O)C=C1 BLCLNMBMMGCOAS-URPVMXJPSA-N 0.000 description 1
- 108010069236 Goserelin Proteins 0.000 description 1
- 102100035943 HERV-H LTR-associating protein 2 Human genes 0.000 description 1
- 108010058597 HLA-DR Antigens Proteins 0.000 description 1
- 102000006354 HLA-DR Antigens Human genes 0.000 description 1
- 241000806389 Halegrapha chimaera Species 0.000 description 1
- 208000002250 Hematologic Neoplasms Diseases 0.000 description 1
- 108010007712 Hepatitis A Virus Cellular Receptor 1 Proteins 0.000 description 1
- 101710185991 Hepatitis A virus cellular receptor 1 homolog Proteins 0.000 description 1
- 102100034458 Hepatitis A virus cellular receptor 2 Human genes 0.000 description 1
- 208000009889 Herpes Simplex Diseases 0.000 description 1
- 102100022132 High affinity immunoglobulin epsilon receptor subunit gamma Human genes 0.000 description 1
- 108091010847 High affinity immunoglobulin epsilon receptor subunit gamma Proteins 0.000 description 1
- NOQPTNXSGNPJNS-YUMQZZPRSA-N His-Asn-Gly Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O NOQPTNXSGNPJNS-YUMQZZPRSA-N 0.000 description 1
- LSQHWKPPOFDHHZ-YUMQZZPRSA-N His-Asp-Gly Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)NCC(=O)O)N LSQHWKPPOFDHHZ-YUMQZZPRSA-N 0.000 description 1
- TTYKEFZRLKQTHH-MELADBBJSA-N His-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CC2=CN=CN2)N)C(=O)O TTYKEFZRLKQTHH-MELADBBJSA-N 0.000 description 1
- NKRWVZQTPXPNRZ-SRVKXCTJSA-N His-Met-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCSC)NC(=O)[C@@H](N)CC1=CN=CN1 NKRWVZQTPXPNRZ-SRVKXCTJSA-N 0.000 description 1
- STGQSBKUYSPPIG-CIUDSAMLSA-N His-Ser-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CN=CN1 STGQSBKUYSPPIG-CIUDSAMLSA-N 0.000 description 1
- DGLAHESNTJWGDO-SRVKXCTJSA-N His-Ser-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N DGLAHESNTJWGDO-SRVKXCTJSA-N 0.000 description 1
- FCPSGEVYIVXPPO-QTKMDUPCSA-N His-Thr-Arg Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FCPSGEVYIVXPPO-QTKMDUPCSA-N 0.000 description 1
- 208000017604 Hodgkin disease Diseases 0.000 description 1
- 208000021519 Hodgkin lymphoma Diseases 0.000 description 1
- 208000010747 Hodgkins lymphoma Diseases 0.000 description 1
- 101000834898 Homo sapiens Alpha-synuclein Proteins 0.000 description 1
- 101000749325 Homo sapiens C-type lectin domain family 7 member A Proteins 0.000 description 1
- 101000761938 Homo sapiens CD160 antigen Proteins 0.000 description 1
- 101000716130 Homo sapiens CD48 antigen Proteins 0.000 description 1
- 101000914469 Homo sapiens CD82 antigen Proteins 0.000 description 1
- 101000738354 Homo sapiens CD9 antigen Proteins 0.000 description 1
- 101000889276 Homo sapiens Cytotoxic T-lymphocyte protein 4 Proteins 0.000 description 1
- 101000908391 Homo sapiens Dipeptidyl peptidase 4 Proteins 0.000 description 1
- 101001057612 Homo sapiens Dual specificity protein phosphatase 5 Proteins 0.000 description 1
- 101001064451 Homo sapiens Ephrin type-B receptor 6 Proteins 0.000 description 1
- 101000892862 Homo sapiens Glutamate carboxypeptidase 2 Proteins 0.000 description 1
- 101001074244 Homo sapiens Glycophorin-A Proteins 0.000 description 1
- 101001068133 Homo sapiens Hepatitis A virus cellular receptor 2 Proteins 0.000 description 1
- 101000998120 Homo sapiens Interleukin-3 receptor subunit alpha Proteins 0.000 description 1
- 101000980823 Homo sapiens Leukocyte surface antigen CD53 Proteins 0.000 description 1
- 101001137987 Homo sapiens Lymphocyte activation gene 3 protein Proteins 0.000 description 1
- 101001063392 Homo sapiens Lymphocyte function-associated antigen 3 Proteins 0.000 description 1
- 101000669513 Homo sapiens Metalloproteinase inhibitor 1 Proteins 0.000 description 1
- 101000645296 Homo sapiens Metalloproteinase inhibitor 2 Proteins 0.000 description 1
- 101000946889 Homo sapiens Monocyte differentiation antigen CD14 Proteins 0.000 description 1
- 101001133056 Homo sapiens Mucin-1 Proteins 0.000 description 1
- 101000623901 Homo sapiens Mucin-16 Proteins 0.000 description 1
- 101000934338 Homo sapiens Myeloid cell surface antigen CD33 Proteins 0.000 description 1
- 101001109503 Homo sapiens NKG2-C type II integral membrane protein Proteins 0.000 description 1
- 101000897042 Homo sapiens Nucleotide pyrophosphatase Proteins 0.000 description 1
- 101001098352 Homo sapiens OX-2 membrane glycoprotein Proteins 0.000 description 1
- 101000611936 Homo sapiens Programmed cell death protein 1 Proteins 0.000 description 1
- 101000734646 Homo sapiens Programmed cell death protein 6 Proteins 0.000 description 1
- 101000684208 Homo sapiens Prolyl endopeptidase FAP Proteins 0.000 description 1
- 101000738771 Homo sapiens Receptor-type tyrosine-protein phosphatase C Proteins 0.000 description 1
- 101000633778 Homo sapiens SLAM family member 5 Proteins 0.000 description 1
- 101000652359 Homo sapiens Spermatogenesis-associated protein 2 Proteins 0.000 description 1
- 101000837401 Homo sapiens T-cell leukemia/lymphoma protein 1A Proteins 0.000 description 1
- 101000837398 Homo sapiens T-cell leukemia/lymphoma protein 1B Proteins 0.000 description 1
- 101000946860 Homo sapiens T-cell surface glycoprotein CD3 epsilon chain Proteins 0.000 description 1
- 101000934341 Homo sapiens T-cell surface glycoprotein CD5 Proteins 0.000 description 1
- 101000596234 Homo sapiens T-cell surface protein tactile Proteins 0.000 description 1
- 101000809875 Homo sapiens TYRO protein tyrosine kinase-binding protein Proteins 0.000 description 1
- 101000800116 Homo sapiens Thy-1 membrane glycoprotein Proteins 0.000 description 1
- 101000904724 Homo sapiens Transmembrane glycoprotein NMB Proteins 0.000 description 1
- 101000830596 Homo sapiens Tumor necrosis factor ligand superfamily member 15 Proteins 0.000 description 1
- 101000597779 Homo sapiens Tumor necrosis factor ligand superfamily member 18 Proteins 0.000 description 1
- 101000764263 Homo sapiens Tumor necrosis factor ligand superfamily member 4 Proteins 0.000 description 1
- 101000648507 Homo sapiens Tumor necrosis factor receptor superfamily member 14 Proteins 0.000 description 1
- 101000762805 Homo sapiens Tumor necrosis factor receptor superfamily member 19L Proteins 0.000 description 1
- 101000801232 Homo sapiens Tumor necrosis factor receptor superfamily member 1B Proteins 0.000 description 1
- 108010001336 Horseradish Peroxidase Proteins 0.000 description 1
- 241000714260 Human T-lymphotropic virus 1 Species 0.000 description 1
- 102000017182 Ikaros Transcription Factor Human genes 0.000 description 1
- 108010013958 Ikaros Transcription Factor Proteins 0.000 description 1
- VAXBXNPRXPHGHG-BJDJZHNGSA-N Ile-Ala-Leu Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)O)N VAXBXNPRXPHGHG-BJDJZHNGSA-N 0.000 description 1
- AZEYWPUCOYXFOE-CYDGBPFRSA-N Ile-Arg-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](C(C)C)C(=O)O)N AZEYWPUCOYXFOE-CYDGBPFRSA-N 0.000 description 1
- MVLDERGQICFFLL-ZQINRCPSSA-N Ile-Gln-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)[C@@H](C)CC)C(O)=O)=CNC2=C1 MVLDERGQICFFLL-ZQINRCPSSA-N 0.000 description 1
- QNBYCZTZNOVDMI-HGNGGELXSA-N Ile-His Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@H](C(O)=O)CC1=CN=CN1 QNBYCZTZNOVDMI-HGNGGELXSA-N 0.000 description 1
- IOVUXUSIGXCREV-DKIMLUQUSA-N Ile-Leu-Phe Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 IOVUXUSIGXCREV-DKIMLUQUSA-N 0.000 description 1
- KLJKJVXDHVUMMZ-KKPKCPPISA-N Ile-Phe-Trp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N KLJKJVXDHVUMMZ-KKPKCPPISA-N 0.000 description 1
- ZDNNDIJTUHQCAM-MXAVVETBSA-N Ile-Ser-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N ZDNNDIJTUHQCAM-MXAVVETBSA-N 0.000 description 1
- JTBFQNHKNRZJDS-SYWGBEHUSA-N Ile-Trp-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](C)C(=O)O)N JTBFQNHKNRZJDS-SYWGBEHUSA-N 0.000 description 1
- 229940076838 Immune checkpoint inhibitor Drugs 0.000 description 1
- 102000018071 Immunoglobulin Fc Fragments Human genes 0.000 description 1
- 108010091135 Immunoglobulin Fc Fragments Proteins 0.000 description 1
- 206010062016 Immunosuppression Diseases 0.000 description 1
- 108010065920 Insulin Lispro Proteins 0.000 description 1
- 108010008212 Integrin alpha4beta1 Proteins 0.000 description 1
- 102000006992 Interferon-alpha Human genes 0.000 description 1
- 108010047761 Interferon-alpha Proteins 0.000 description 1
- 108010002352 Interleukin-1 Proteins 0.000 description 1
- 102100033493 Interleukin-3 receptor subunit alpha Human genes 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 1
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 1
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 1
- FBOZXECLQNJBKD-ZDUSSCGKSA-N L-methotrexate Chemical compound C=1N=C2N=C(N)N=C(N)C2=NC=1CN(C)C1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 FBOZXECLQNJBKD-ZDUSSCGKSA-N 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- 102000017578 LAG3 Human genes 0.000 description 1
- 241000254158 Lampyridae Species 0.000 description 1
- 241000713666 Lentivirus Species 0.000 description 1
- WNGVUZWBXZKQES-YUMQZZPRSA-N Leu-Ala-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)NCC(O)=O WNGVUZWBXZKQES-YUMQZZPRSA-N 0.000 description 1
- KWTVLKBOQATPHJ-SRVKXCTJSA-N Leu-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(C)C)N KWTVLKBOQATPHJ-SRVKXCTJSA-N 0.000 description 1
- BPANDPNDMJHFEV-CIUDSAMLSA-N Leu-Asp-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O BPANDPNDMJHFEV-CIUDSAMLSA-N 0.000 description 1
- PVMPDMIKUVNOBD-CIUDSAMLSA-N Leu-Asp-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O PVMPDMIKUVNOBD-CIUDSAMLSA-N 0.000 description 1
- LAGPXKYZCCTSGQ-JYJNAYRXSA-N Leu-Glu-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LAGPXKYZCCTSGQ-JYJNAYRXSA-N 0.000 description 1
- OGUUKPXUTHOIAV-SDDRHHMPSA-N Leu-Glu-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N OGUUKPXUTHOIAV-SDDRHHMPSA-N 0.000 description 1
- DSFYPIUSAMSERP-IHRRRGAJSA-N Leu-Leu-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DSFYPIUSAMSERP-IHRRRGAJSA-N 0.000 description 1
- YOKVEHGYYQEQOP-QWRGUYRKSA-N Leu-Leu-Gly Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O YOKVEHGYYQEQOP-QWRGUYRKSA-N 0.000 description 1
- FAELBUXXFQLUAX-AJNGGQMLSA-N Leu-Leu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(C)C FAELBUXXFQLUAX-AJNGGQMLSA-N 0.000 description 1
- UBZGNBKMIJHOHL-BZSNNMDCSA-N Leu-Leu-Phe Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 UBZGNBKMIJHOHL-BZSNNMDCSA-N 0.000 description 1
- ARRIJPQRBWRNLT-DCAQKATOSA-N Leu-Met-Asn Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(=O)N)C(=O)O)N ARRIJPQRBWRNLT-DCAQKATOSA-N 0.000 description 1
- PTRKPHUGYULXPU-KKUMJFAQSA-N Leu-Phe-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O PTRKPHUGYULXPU-KKUMJFAQSA-N 0.000 description 1
- YRRCOJOXAJNSAX-IHRRRGAJSA-N Leu-Pro-Lys Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCCN)C(=O)O)N YRRCOJOXAJNSAX-IHRRRGAJSA-N 0.000 description 1
- XOWMDXHFSBCAKQ-SRVKXCTJSA-N Leu-Ser-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CC(C)C XOWMDXHFSBCAKQ-SRVKXCTJSA-N 0.000 description 1
- QWWPYKKLXWOITQ-VOAKCMCISA-N Leu-Thr-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(C)C QWWPYKKLXWOITQ-VOAKCMCISA-N 0.000 description 1
- ILDSIMPXNFWKLH-KATARQTJSA-N Leu-Thr-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O ILDSIMPXNFWKLH-KATARQTJSA-N 0.000 description 1
- VHTIZYYHIUHMCA-JYJNAYRXSA-N Leu-Tyr-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O VHTIZYYHIUHMCA-JYJNAYRXSA-N 0.000 description 1
- WFCKERTZVCQXKH-KBPBESRZSA-N Leu-Tyr-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)NCC(O)=O WFCKERTZVCQXKH-KBPBESRZSA-N 0.000 description 1
- ARNIBBOXIAWUOP-MGHWNKPDSA-N Leu-Tyr-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O ARNIBBOXIAWUOP-MGHWNKPDSA-N 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 102100024221 Leukocyte surface antigen CD53 Human genes 0.000 description 1
- 102000003960 Ligases Human genes 0.000 description 1
- 108090000364 Ligases Proteins 0.000 description 1
- 102000019298 Lipocalin Human genes 0.000 description 1
- 108050006654 Lipocalin Proteins 0.000 description 1
- 102100030984 Lymphocyte function-associated antigen 3 Human genes 0.000 description 1
- 102000004083 Lymphotoxin-alpha Human genes 0.000 description 1
- 108090000542 Lymphotoxin-alpha Proteins 0.000 description 1
- MPOHDJKRBLVGCT-CIUDSAMLSA-N Lys-Ala-Asn Chemical compound C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CCCCN)N MPOHDJKRBLVGCT-CIUDSAMLSA-N 0.000 description 1
- IRNSXVOWSXSULE-DCAQKATOSA-N Lys-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN IRNSXVOWSXSULE-DCAQKATOSA-N 0.000 description 1
- CLBGMWIYPYAZPR-AVGNSLFASA-N Lys-Arg-Arg Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O CLBGMWIYPYAZPR-AVGNSLFASA-N 0.000 description 1
- QUCDKEKDPYISNX-HJGDQZAQSA-N Lys-Asn-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QUCDKEKDPYISNX-HJGDQZAQSA-N 0.000 description 1
- KWUKZRFFKPLUPE-HJGDQZAQSA-N Lys-Asp-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWUKZRFFKPLUPE-HJGDQZAQSA-N 0.000 description 1
- MQMIRLVJXQNTRJ-SDDRHHMPSA-N Lys-Gln-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCCN)N)C(=O)O MQMIRLVJXQNTRJ-SDDRHHMPSA-N 0.000 description 1
- OIYWBDBHEGAVST-BZSNNMDCSA-N Lys-His-Tyr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O OIYWBDBHEGAVST-BZSNNMDCSA-N 0.000 description 1
- HVAUKHLDSDDROB-KKUMJFAQSA-N Lys-Lys-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O HVAUKHLDSDDROB-KKUMJFAQSA-N 0.000 description 1
- URGPVYGVWLIRGT-DCAQKATOSA-N Lys-Met-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C)C(O)=O URGPVYGVWLIRGT-DCAQKATOSA-N 0.000 description 1
- LUAJJLPHUXPQLH-KKUMJFAQSA-N Lys-Phe-Ser Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCCCN)N LUAJJLPHUXPQLH-KKUMJFAQSA-N 0.000 description 1
- RIPJMCFGQHGHNP-RHYQMDGZSA-N Lys-Val-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](C(C)C)NC(=O)[C@H](CCCCN)N)O RIPJMCFGQHGHNP-RHYQMDGZSA-N 0.000 description 1
- 108700018351 Major Histocompatibility Complex Proteins 0.000 description 1
- 108090000015 Mesothelin Proteins 0.000 description 1
- 102000003735 Mesothelin Human genes 0.000 description 1
- AXHNAGAYRGCDLG-UWVGGRQHSA-N Met-Lys-Gly Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O AXHNAGAYRGCDLG-UWVGGRQHSA-N 0.000 description 1
- 102100039364 Metalloproteinase inhibitor 1 Human genes 0.000 description 1
- 102100026262 Metalloproteinase inhibitor 2 Human genes 0.000 description 1
- 206010027476 Metastases Diseases 0.000 description 1
- FQISKWAFAHGMGT-SGJOWKDISA-M Methylprednisolone sodium succinate Chemical compound [Na+].C([C@@]12C)=CC(=O)C=C1[C@@H](C)C[C@@H]1[C@@H]2[C@@H](O)C[C@]2(C)[C@@](O)(C(=O)COC(=O)CCC([O-])=O)CC[C@H]21 FQISKWAFAHGMGT-SGJOWKDISA-M 0.000 description 1
- 102000029749 Microtubule Human genes 0.000 description 1
- 108091022875 Microtubule Proteins 0.000 description 1
- 102100035877 Monocyte differentiation antigen CD14 Human genes 0.000 description 1
- 102100034256 Mucin-1 Human genes 0.000 description 1
- 102100023123 Mucin-16 Human genes 0.000 description 1
- 101100328148 Mus musculus Cd300a gene Proteins 0.000 description 1
- 101000597780 Mus musculus Tumor necrosis factor ligand superfamily member 18 Proteins 0.000 description 1
- 102100025243 Myeloid cell surface antigen CD33 Human genes 0.000 description 1
- ZDZOTLJHXYCWBA-VCVYQWHSSA-N N-debenzoyl-N-(tert-butoxycarbonyl)-10-deacetyltaxol Chemical compound O([C@H]1[C@H]2[C@@](C([C@H](O)C3=C(C)[C@@H](OC(=O)[C@H](O)[C@@H](NC(=O)OC(C)(C)C)C=4C=CC=CC=4)C[C@]1(O)C3(C)C)=O)(C)[C@@H](O)C[C@H]1OC[C@]12OC(=O)C)C(=O)C1=CC=CC=C1 ZDZOTLJHXYCWBA-VCVYQWHSSA-N 0.000 description 1
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 1
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 1
- 108091008043 NK cell inhibitory receptors Proteins 0.000 description 1
- 102100022683 NKG2-C type II integral membrane protein Human genes 0.000 description 1
- 102100029527 Natural cytotoxicity triggering receptor 3 ligand 1 Human genes 0.000 description 1
- 101710141230 Natural killer cell receptor 2B4 Proteins 0.000 description 1
- 102000002356 Nectin Human genes 0.000 description 1
- 108060005251 Nectin Proteins 0.000 description 1
- 229930193140 Neomycin Natural products 0.000 description 1
- MWUXSHHQAYIFBG-UHFFFAOYSA-N Nitric oxide Chemical class O=[N] MWUXSHHQAYIFBG-UHFFFAOYSA-N 0.000 description 1
- 102100021969 Nucleotide pyrophosphatase Human genes 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 241000282320 Panthera leo Species 0.000 description 1
- MDHZEOMXGNBSIL-DLOVCJGASA-N Phe-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N MDHZEOMXGNBSIL-DLOVCJGASA-N 0.000 description 1
- UMKYAYXCMYYNHI-AVGNSLFASA-N Phe-Gln-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CC(=O)N)C(=O)O)N UMKYAYXCMYYNHI-AVGNSLFASA-N 0.000 description 1
- KXUZHWXENMYOHC-QEJZJMRPSA-N Phe-Leu-Ala Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O KXUZHWXENMYOHC-QEJZJMRPSA-N 0.000 description 1
- MJAYDXWQQUOURZ-JYJNAYRXSA-N Phe-Lys-Gln Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O MJAYDXWQQUOURZ-JYJNAYRXSA-N 0.000 description 1
- 102000004160 Phosphoric Monoester Hydrolases Human genes 0.000 description 1
- 108090000608 Phosphoric Monoester Hydrolases Proteins 0.000 description 1
- 102000013566 Plasminogen Human genes 0.000 description 1
- 108010051456 Plasminogen Proteins 0.000 description 1
- 102000004211 Platelet factor 4 Human genes 0.000 description 1
- 108090000778 Platelet factor 4 Proteins 0.000 description 1
- 102000015623 Polynucleotide Adenylyltransferase Human genes 0.000 description 1
- 108010024055 Polynucleotide adenylyltransferase Proteins 0.000 description 1
- 239000004743 Polypropylene Substances 0.000 description 1
- 229920001213 Polysorbate 20 Polymers 0.000 description 1
- DZZCICYRSZASNF-FXQIFTODSA-N Pro-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 DZZCICYRSZASNF-FXQIFTODSA-N 0.000 description 1
- KIZQGKLMXKGDIV-BQBZGAKWSA-N Pro-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 KIZQGKLMXKGDIV-BQBZGAKWSA-N 0.000 description 1
- CGBYDGAJHSOGFQ-LPEHRKFASA-N Pro-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 CGBYDGAJHSOGFQ-LPEHRKFASA-N 0.000 description 1
- LCRSGSIRKLXZMZ-BPNCWPANSA-N Pro-Ala-Tyr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O LCRSGSIRKLXZMZ-BPNCWPANSA-N 0.000 description 1
- UTAUEDINXUMHLG-FXQIFTODSA-N Pro-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@@H]1CCCN1 UTAUEDINXUMHLG-FXQIFTODSA-N 0.000 description 1
- PTLOFJZJADCNCD-DCAQKATOSA-N Pro-Glu-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@@H]1CCCN1 PTLOFJZJADCNCD-DCAQKATOSA-N 0.000 description 1
- HAAQQNHQZBOWFO-LURJTMIESA-N Pro-Gly-Gly Chemical compound OC(=O)CNC(=O)CNC(=O)[C@@H]1CCCN1 HAAQQNHQZBOWFO-LURJTMIESA-N 0.000 description 1
- DXTOOBDIIAJZBJ-BQBZGAKWSA-N Pro-Gly-Ser Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CO)C(O)=O DXTOOBDIIAJZBJ-BQBZGAKWSA-N 0.000 description 1
- SUENWIFTSTWUKD-AVGNSLFASA-N Pro-Leu-Val Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O SUENWIFTSTWUKD-AVGNSLFASA-N 0.000 description 1
- FNGOXVQBBCMFKV-CIUDSAMLSA-N Pro-Ser-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O FNGOXVQBBCMFKV-CIUDSAMLSA-N 0.000 description 1
- PKHDJFHFMGQMPS-RCWTZXSCSA-N Pro-Thr-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PKHDJFHFMGQMPS-RCWTZXSCSA-N 0.000 description 1
- GBUNEGKQPSAMNK-QTKMDUPCSA-N Pro-Thr-His Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)NC(=O)[C@@H]2CCCN2)O GBUNEGKQPSAMNK-QTKMDUPCSA-N 0.000 description 1
- RMJZWERKFFNNNS-XGEHTFHBSA-N Pro-Thr-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(O)=O RMJZWERKFFNNNS-XGEHTFHBSA-N 0.000 description 1
- VVEQUISRWJDGMX-VKOGCVSHSA-N Pro-Trp-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)NC(=O)[C@@H]3CCCN3 VVEQUISRWJDGMX-VKOGCVSHSA-N 0.000 description 1
- 101710101148 Probable 6-oxopurine nucleoside phosphorylase Proteins 0.000 description 1
- 102100034785 Programmed cell death protein 6 Human genes 0.000 description 1
- 102000003946 Prolactin Human genes 0.000 description 1
- 108010057464 Prolactin Proteins 0.000 description 1
- 108010029485 Protein Isoforms Proteins 0.000 description 1
- 102000001708 Protein Isoforms Human genes 0.000 description 1
- 102000004022 Protein-Tyrosine Kinases Human genes 0.000 description 1
- 108090000412 Protein-Tyrosine Kinases Proteins 0.000 description 1
- 102000030764 Purine-nucleoside phosphorylase Human genes 0.000 description 1
- 102000018795 RELT Human genes 0.000 description 1
- 108010052562 RELT Proteins 0.000 description 1
- 239000012083 RIPA buffer Substances 0.000 description 1
- 102100037422 Receptor-type tyrosine-protein phosphatase C Human genes 0.000 description 1
- 108020005091 Replication Origin Proteins 0.000 description 1
- 108700008625 Reporter Genes Proteins 0.000 description 1
- 241000714474 Rous sarcoma virus Species 0.000 description 1
- 102000000395 SH3 domains Human genes 0.000 description 1
- 108050008861 SH3 domains Proteins 0.000 description 1
- 102100029216 SLAM family member 5 Human genes 0.000 description 1
- GHPQVUYZQQGEDA-BIIVOSGPSA-N Ser-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N)C(=O)O GHPQVUYZQQGEDA-BIIVOSGPSA-N 0.000 description 1
- MMAPOBOTRUVNKJ-ZLUOBGJFSA-N Ser-Asp-Ser Chemical compound C([C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CO)N)C(=O)O MMAPOBOTRUVNKJ-ZLUOBGJFSA-N 0.000 description 1
- VQBCMLMPEWPUTB-ACZMJKKPSA-N Ser-Glu-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O VQBCMLMPEWPUTB-ACZMJKKPSA-N 0.000 description 1
- BRIZMMZEYSAKJX-QEJZJMRPSA-N Ser-Glu-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CO)N BRIZMMZEYSAKJX-QEJZJMRPSA-N 0.000 description 1
- MUARUIBTKQJKFY-WHFBIAKZSA-N Ser-Gly-Asp Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O MUARUIBTKQJKFY-WHFBIAKZSA-N 0.000 description 1
- MIJWOJAXARLEHA-WDSKDSINSA-N Ser-Gly-Glu Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O MIJWOJAXARLEHA-WDSKDSINSA-N 0.000 description 1
- CICQXRWZNVXFCU-SRVKXCTJSA-N Ser-His-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O CICQXRWZNVXFCU-SRVKXCTJSA-N 0.000 description 1
- MOINZPRHJGTCHZ-MMWGEVLESA-N Ser-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N MOINZPRHJGTCHZ-MMWGEVLESA-N 0.000 description 1
- VMLONWHIORGALA-SRVKXCTJSA-N Ser-Leu-Leu Chemical compound CC(C)C[C@@H](C([O-])=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CO VMLONWHIORGALA-SRVKXCTJSA-N 0.000 description 1
- PTWIYDNFWPXQSD-GARJFASQSA-N Ser-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CO)N)C(=O)O PTWIYDNFWPXQSD-GARJFASQSA-N 0.000 description 1
- JAWGSPUJAXYXJA-IHRRRGAJSA-N Ser-Phe-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@H](CO)N)CC1=CC=CC=C1 JAWGSPUJAXYXJA-IHRRRGAJSA-N 0.000 description 1
- BSXKBOUZDAZXHE-CIUDSAMLSA-N Ser-Pro-Glu Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O BSXKBOUZDAZXHE-CIUDSAMLSA-N 0.000 description 1
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 1
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 1
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 1
- KKKVOZNCLALMPV-XKBZYTNZSA-N Ser-Thr-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O KKKVOZNCLALMPV-XKBZYTNZSA-N 0.000 description 1
- FGBLCMLXHRPVOF-IHRRRGAJSA-N Ser-Tyr-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O FGBLCMLXHRPVOF-IHRRRGAJSA-N 0.000 description 1
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- 108010071390 Serum Albumin Proteins 0.000 description 1
- 102000007562 Serum Albumin Human genes 0.000 description 1
- 108700015968 Slam family Proteins 0.000 description 1
- 241000191967 Staphylococcus aureus Species 0.000 description 1
- 108010023197 Streptokinase Proteins 0.000 description 1
- 238000000692 Student's t-test Methods 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- 108010092262 T-Cell Antigen Receptors Proteins 0.000 description 1
- 208000029052 T-cell acute lymphoblastic leukemia Diseases 0.000 description 1
- 102100039367 T-cell immunoglobulin and mucin domain-containing protein 4 Human genes 0.000 description 1
- 101710174757 T-cell immunoglobulin and mucin domain-containing protein 4 Proteins 0.000 description 1
- 102100028676 T-cell leukemia/lymphoma protein 1A Human genes 0.000 description 1
- 102100028678 T-cell leukemia/lymphoma protein 1B Human genes 0.000 description 1
- 102100035794 T-cell surface glycoprotein CD3 epsilon chain Human genes 0.000 description 1
- 102100025244 T-cell surface glycoprotein CD5 Human genes 0.000 description 1
- 102100035268 T-cell surface protein tactile Human genes 0.000 description 1
- 101710114141 T-lymphocyte surface antigen Ly-9 Proteins 0.000 description 1
- 101710137500 T7 RNA polymerase Proteins 0.000 description 1
- 101150052863 THY1 gene Proteins 0.000 description 1
- 102100038717 TYRO protein tyrosine kinase-binding protein Human genes 0.000 description 1
- QJJXYPPXXYFBGM-LFZNUXCKSA-N Tacrolimus Chemical compound C1C[C@@H](O)[C@H](OC)C[C@@H]1\C=C(/C)[C@@H]1[C@H](C)[C@@H](O)CC(=O)[C@H](CC=C)/C=C(C)/C[C@H](C)C[C@H](OC)[C@H]([C@H](C[C@H]2C)OC)O[C@@]2(O)C(=O)C(=O)N2CCCC[C@H]2C(=O)O1 QJJXYPPXXYFBGM-LFZNUXCKSA-N 0.000 description 1
- 101001051488 Takifugu rubripes Neural cell adhesion molecule L1 Proteins 0.000 description 1
- 229940123237 Taxane Drugs 0.000 description 1
- FOCVUCIESVLUNU-UHFFFAOYSA-N Thiotepa Chemical compound C1CN1P(N1CC1)(=S)N1CC1 FOCVUCIESVLUNU-UHFFFAOYSA-N 0.000 description 1
- BSNZTJXVDOINSR-JXUBOQSCSA-N Thr-Ala-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O BSNZTJXVDOINSR-JXUBOQSCSA-N 0.000 description 1
- CAJFZCICSVBOJK-SHGPDSBTSA-N Thr-Ala-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CAJFZCICSVBOJK-SHGPDSBTSA-N 0.000 description 1
- UTCFSBBXPWKLTG-XKBZYTNZSA-N Thr-Cys-Gln Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N)O UTCFSBBXPWKLTG-XKBZYTNZSA-N 0.000 description 1
- LYGKYFKSZTUXGZ-ZDLURKLDSA-N Thr-Cys-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CS)C(=O)NCC(O)=O LYGKYFKSZTUXGZ-ZDLURKLDSA-N 0.000 description 1
- VUVCRYXYUUPGSB-GLLZPBPUSA-N Thr-Gln-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O VUVCRYXYUUPGSB-GLLZPBPUSA-N 0.000 description 1
- DIPIPFHFLPTCLK-LOKLDPHHSA-N Thr-Gln-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N1CCC[C@@H]1C(=O)O)N)O DIPIPFHFLPTCLK-LOKLDPHHSA-N 0.000 description 1
- LGNBRHZANHMZHK-NUMRIWBASA-N Thr-Glu-Asp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N)O LGNBRHZANHMZHK-NUMRIWBASA-N 0.000 description 1
- BVOVIGCHYNFJBZ-JXUBOQSCSA-N Thr-Leu-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O BVOVIGCHYNFJBZ-JXUBOQSCSA-N 0.000 description 1
- WTMPKZWHRCMMMT-KZVJFYERSA-N Thr-Pro-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WTMPKZWHRCMMMT-KZVJFYERSA-N 0.000 description 1
- JAJOFWABAUKAEJ-QTKMDUPCSA-N Thr-Pro-His Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N)O JAJOFWABAUKAEJ-QTKMDUPCSA-N 0.000 description 1
- VTMGKRABARCZAX-OSUNSFLBSA-N Thr-Pro-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O VTMGKRABARCZAX-OSUNSFLBSA-N 0.000 description 1
- AHERARIZBPOMNU-KATARQTJSA-N Thr-Ser-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O AHERARIZBPOMNU-KATARQTJSA-N 0.000 description 1
- MFMGPEKYBXFIRF-SUSMZKCASA-N Thr-Thr-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MFMGPEKYBXFIRF-SUSMZKCASA-N 0.000 description 1
- BKIOKSLLAAZYTC-KKHAAJSZSA-N Thr-Val-Asn Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O BKIOKSLLAAZYTC-KKHAAJSZSA-N 0.000 description 1
- BKVICMPZWRNWOC-RHYQMDGZSA-N Thr-Val-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)[C@@H](C)O BKVICMPZWRNWOC-RHYQMDGZSA-N 0.000 description 1
- 108090000190 Thrombin Proteins 0.000 description 1
- 102000007614 Thrombospondin 1 Human genes 0.000 description 1
- 108010046722 Thrombospondin 1 Proteins 0.000 description 1
- 102100033523 Thy-1 membrane glycoprotein Human genes 0.000 description 1
- 108090000373 Tissue Plasminogen Activator Proteins 0.000 description 1
- 102000003978 Tissue Plasminogen Activator Human genes 0.000 description 1
- 102000004887 Transforming Growth Factor beta Human genes 0.000 description 1
- 108090001012 Transforming Growth Factor beta Proteins 0.000 description 1
- 108700019146 Transgenes Proteins 0.000 description 1
- 102100023935 Transmembrane glycoprotein NMB Human genes 0.000 description 1
- FYAMXEPQQLNQDM-UHFFFAOYSA-N Tris(1-aziridinyl)phosphine oxide Chemical compound C1CN1P(N1CC1)(=O)N1CC1 FYAMXEPQQLNQDM-UHFFFAOYSA-N 0.000 description 1
- NMOIRIIIUVELLY-WDSOQIARSA-N Trp-Val-Leu Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C(O)=O)C(C)C)=CNC2=C1 NMOIRIIIUVELLY-WDSOQIARSA-N 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 1
- 108010065158 Tumor Necrosis Factor Ligand Superfamily Member 14 Proteins 0.000 description 1
- 102100040247 Tumor necrosis factor Human genes 0.000 description 1
- 102100024586 Tumor necrosis factor ligand superfamily member 14 Human genes 0.000 description 1
- 108090000138 Tumor necrosis factor ligand superfamily member 15 Proteins 0.000 description 1
- 102100035283 Tumor necrosis factor ligand superfamily member 18 Human genes 0.000 description 1
- 102100026890 Tumor necrosis factor ligand superfamily member 4 Human genes 0.000 description 1
- 102100032100 Tumor necrosis factor ligand superfamily member 8 Human genes 0.000 description 1
- 102100026716 Tumor necrosis factor receptor superfamily member 19L Human genes 0.000 description 1
- 101710187830 Tumor necrosis factor receptor superfamily member 1B Proteins 0.000 description 1
- GAYLGYUVTDMLKC-UWJYBYFXSA-N Tyr-Asp-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 GAYLGYUVTDMLKC-UWJYBYFXSA-N 0.000 description 1
- FFCRCJZJARTYCG-KKUMJFAQSA-N Tyr-Cys-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)O)N)O FFCRCJZJARTYCG-KKUMJFAQSA-N 0.000 description 1
- UXUFNBVCPAWACG-SIUGBPQLSA-N Tyr-Gln-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CC1=CC=C(C=C1)O)N UXUFNBVCPAWACG-SIUGBPQLSA-N 0.000 description 1
- OHNXAUCZVWGTLL-KKUMJFAQSA-N Tyr-His-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CS)C(=O)O)N)O OHNXAUCZVWGTLL-KKUMJFAQSA-N 0.000 description 1
- QFHRUCJIRVILCK-YJRXYDGGSA-N Tyr-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N)O QFHRUCJIRVILCK-YJRXYDGGSA-N 0.000 description 1
- 108090000435 Urokinase-type plasminogen activator Proteins 0.000 description 1
- 102000003990 Urokinase-type plasminogen activator Human genes 0.000 description 1
- 102100038929 V-set domain-containing T-cell activation inhibitor 1 Human genes 0.000 description 1
- PAPWZOJOLKZEFR-AVGNSLFASA-N Val-Arg-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(=O)O)N PAPWZOJOLKZEFR-AVGNSLFASA-N 0.000 description 1
- VMRFIKXKOFNMHW-GUBZILKMSA-N Val-Arg-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CO)C(=O)O)N VMRFIKXKOFNMHW-GUBZILKMSA-N 0.000 description 1
- UZDHNIJRRTUKKC-DLOVCJGASA-N Val-Gln-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](C(C)C)C(=O)O)N UZDHNIJRRTUKKC-DLOVCJGASA-N 0.000 description 1
- KVRLNEILGGVBJX-IHRRRGAJSA-N Val-His-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CN=CN1 KVRLNEILGGVBJX-IHRRRGAJSA-N 0.000 description 1
- HGJRMXOWUWVUOA-GVXVVHGQSA-N Val-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N HGJRMXOWUWVUOA-GVXVVHGQSA-N 0.000 description 1
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 1
- WUFHZIRMAZZWRS-OSUNSFLBSA-N Val-Thr-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](C(C)C)N WUFHZIRMAZZWRS-OSUNSFLBSA-N 0.000 description 1
- OFTXTCGQJXTNQS-XGEHTFHBSA-N Val-Thr-Ser Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](C(C)C)N)O OFTXTCGQJXTNQS-XGEHTFHBSA-N 0.000 description 1
- HTONZBWRYUKUKC-RCWTZXSCSA-N Val-Thr-Val Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O HTONZBWRYUKUKC-RCWTZXSCSA-N 0.000 description 1
- AEFJNECXZCODJM-UWVGGRQHSA-N Val-Val-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](C(C)C)C(=O)NCC([O-])=O AEFJNECXZCODJM-UWVGGRQHSA-N 0.000 description 1
- 108010053099 Vascular Endothelial Growth Factor Receptor-2 Proteins 0.000 description 1
- 229940122803 Vinca alkaloid Drugs 0.000 description 1
- 208000008383 Wilms tumor Diseases 0.000 description 1
- 241000021375 Xenogenes Species 0.000 description 1
- 238000009825 accumulation Methods 0.000 description 1
- 229960001138 acetylsalicylic acid Drugs 0.000 description 1
- 229930183665 actinomycin Natural products 0.000 description 1
- 239000012190 activator Substances 0.000 description 1
- 208000009956 adenocarcinoma Diseases 0.000 description 1
- 230000002411 adverse Effects 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- 108010041407 alanylaspartic acid Proteins 0.000 description 1
- 108010005233 alanylglutamic acid Proteins 0.000 description 1
- 125000000217 alkyl group Chemical group 0.000 description 1
- 229940100198 alkylating agent Drugs 0.000 description 1
- 239000002168 alkylating agent Substances 0.000 description 1
- SHGAZHPCJJPHSC-YCNIQYBTSA-N all-trans-retinoic acid Chemical compound OC(=O)\C=C(/C)\C=C\C=C(/C)\C=C\C1=C(C)CCCC1(C)C SHGAZHPCJJPHSC-YCNIQYBTSA-N 0.000 description 1
- 229960000473 altretamine Drugs 0.000 description 1
- 229960003437 aminoglutethimide Drugs 0.000 description 1
- ROBVIMPUHSLWNV-UHFFFAOYSA-N aminoglutethimide Chemical compound C=1C=C(N)C=CC=1C1(CC)CCC(=O)NC1=O ROBVIMPUHSLWNV-UHFFFAOYSA-N 0.000 description 1
- 230000003321 amplification Effects 0.000 description 1
- 229960002932 anastrozole Drugs 0.000 description 1
- YBBLVLTVTVSKRW-UHFFFAOYSA-N anastrozole Chemical compound N#CC(C)(C)C1=CC(C(C)(C#N)C)=CC(CN2N=CN=C2)=C1 YBBLVLTVTVSKRW-UHFFFAOYSA-N 0.000 description 1
- 239000004037 angiogenesis inhibitor Substances 0.000 description 1
- 239000002333 angiotensin II receptor antagonist Substances 0.000 description 1
- 229940125364 angiotensin receptor blocker Drugs 0.000 description 1
- 239000005557 antagonist Substances 0.000 description 1
- 230000001772 anti-angiogenic effect Effects 0.000 description 1
- 230000001093 anti-cancer Effects 0.000 description 1
- 230000000340 anti-metabolite Effects 0.000 description 1
- 239000003146 anticoagulant agent Substances 0.000 description 1
- 229940127219 anticoagulant drug Drugs 0.000 description 1
- 229940100197 antimetabolite Drugs 0.000 description 1
- 239000002256 antimetabolite Substances 0.000 description 1
- 229940045687 antimetabolites folic acid analogs Drugs 0.000 description 1
- 229940045719 antineoplastic alkylating agent nitrosoureas Drugs 0.000 description 1
- 239000003963 antioxidant agent Substances 0.000 description 1
- 235000006708 antioxidants Nutrition 0.000 description 1
- 229940127218 antiplatelet drug Drugs 0.000 description 1
- 239000000074 antisense oligonucleotide Substances 0.000 description 1
- 238000012230 antisense oligonucleotides Methods 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 239000003886 aromatase inhibitor Substances 0.000 description 1
- 229940046844 aromatase inhibitors Drugs 0.000 description 1
- 229960005070 ascorbic acid Drugs 0.000 description 1
- 235000010323 ascorbic acid Nutrition 0.000 description 1
- 239000011668 ascorbic acid Substances 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 108010036999 aspartyl-alanyl-histidyl-lysine Proteins 0.000 description 1
- 108010093581 aspartyl-proline Proteins 0.000 description 1
- FZCSTZYAHCUGEM-UHFFFAOYSA-N aspergillomarasmine B Natural products OC(=O)CNC(C(O)=O)CNC(C(O)=O)CC(O)=O FZCSTZYAHCUGEM-UHFFFAOYSA-N 0.000 description 1
- 230000005784 autoimmunity Effects 0.000 description 1
- VSRXQHXAPYXROS-UHFFFAOYSA-N azanide;cyclobutane-1,1-dicarboxylic acid;platinum(2+) Chemical compound [NH2-].[NH2-].[Pt+2].OC(=O)C1(C(O)=O)CCC1 VSRXQHXAPYXROS-UHFFFAOYSA-N 0.000 description 1
- 229960002170 azathioprine Drugs 0.000 description 1
- LMEKQMALGUDUQG-UHFFFAOYSA-N azathioprine Chemical compound CN1C=NC([N+]([O-])=O)=C1SC1=NC=NC2=C1NC=N2 LMEKQMALGUDUQG-UHFFFAOYSA-N 0.000 description 1
- 230000004888 barrier function Effects 0.000 description 1
- 229960004669 basiliximab Drugs 0.000 description 1
- 229960003270 belimumab Drugs 0.000 description 1
- 229960000997 bicalutamide Drugs 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 239000002981 blocking agent Substances 0.000 description 1
- 229940098773 bovine serum albumin Drugs 0.000 description 1
- 229960000455 brentuximab vedotin Drugs 0.000 description 1
- 230000003139 buffering effect Effects 0.000 description 1
- 239000006227 byproduct Substances 0.000 description 1
- VSJKWCGYPAHWDS-FQEVSTJZSA-N camptothecin Chemical compound C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-FQEVSTJZSA-N 0.000 description 1
- 229940127093 camptothecin Drugs 0.000 description 1
- 229960004562 carboplatin Drugs 0.000 description 1
- 235000012730 carminic acid Nutrition 0.000 description 1
- 229960005243 carmustine Drugs 0.000 description 1
- 230000024245 cell differentiation Effects 0.000 description 1
- 230000022534 cell killing Effects 0.000 description 1
- 239000013592 cell lysate Substances 0.000 description 1
- 230000012292 cell migration Effects 0.000 description 1
- 238000001516 cell proliferation assay Methods 0.000 description 1
- 230000015861 cell surface binding Effects 0.000 description 1
- 210000002421 cell wall Anatomy 0.000 description 1
- 230000007248 cellular mechanism Effects 0.000 description 1
- 230000005754 cellular signaling Effects 0.000 description 1
- 208000019065 cervical carcinoma Diseases 0.000 description 1
- 229960005395 cetuximab Drugs 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 230000000973 chemotherapeutic effect Effects 0.000 description 1
- 238000002512 chemotherapy Methods 0.000 description 1
- 229960004630 chlorambucil Drugs 0.000 description 1
- JCKYGMPEJWAADB-UHFFFAOYSA-N chlorambucil Chemical compound OC(=O)CCCC1=CC=C(N(CCCl)CCCl)C=C1 JCKYGMPEJWAADB-UHFFFAOYSA-N 0.000 description 1
- ZCDOYSPFYFSLEW-UHFFFAOYSA-N chromate(2-) Chemical compound [O-][Cr]([O-])(=O)=O ZCDOYSPFYFSLEW-UHFFFAOYSA-N 0.000 description 1
- 229960001265 ciclosporin Drugs 0.000 description 1
- 108010072917 class-I restricted T cell-associated molecule Proteins 0.000 description 1
- 229960003009 clopidogrel Drugs 0.000 description 1
- GKTWGGQPFAXNFI-HNNXBMFYSA-N clopidogrel Chemical compound C1([C@H](N2CC=3C=CSC=3CC2)C(=O)OC)=CC=CC=C1Cl GKTWGGQPFAXNFI-HNNXBMFYSA-N 0.000 description 1
- 238000005345 coagulation Methods 0.000 description 1
- 230000015271 coagulation Effects 0.000 description 1
- 230000001609 comparable effect Effects 0.000 description 1
- 230000002860 competitive effect Effects 0.000 description 1
- 239000003184 complementary RNA Substances 0.000 description 1
- 238000010276 construction Methods 0.000 description 1
- 150000004696 coordination complex Chemical class 0.000 description 1
- 239000003246 corticosteroid Substances 0.000 description 1
- 229960001334 corticosteroids Drugs 0.000 description 1
- 229960004544 cortisone Drugs 0.000 description 1
- 239000012228 culture supernatant Substances 0.000 description 1
- 229930182912 cyclosporin Natural products 0.000 description 1
- 229960000684 cytarabine Drugs 0.000 description 1
- 230000009089 cytolysis Effects 0.000 description 1
- 230000001461 cytolytic effect Effects 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 229940104302 cytosine Drugs 0.000 description 1
- 210000001151 cytotoxic T lymphocyte Anatomy 0.000 description 1
- 229960003901 dacarbazine Drugs 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 108010025838 dectin 1 Proteins 0.000 description 1
- 230000001934 delay Effects 0.000 description 1
- 238000002716 delivery method Methods 0.000 description 1
- 210000004443 dendritic cell Anatomy 0.000 description 1
- 229960003964 deoxycholic acid Drugs 0.000 description 1
- 229960003957 dexamethasone Drugs 0.000 description 1
- UREBDLICKHMUKA-CXSFZGCWSA-N dexamethasone Chemical compound C1CC2=CC(=O)C=C[C@]2(C)[C@]2(F)[C@@H]1[C@@H]1C[C@@H](C)[C@@](C(=O)CO)(O)[C@@]1(C)C[C@@H]2O UREBDLICKHMUKA-CXSFZGCWSA-N 0.000 description 1
- 238000003745 diagnosis Methods 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- 238000000502 dialysis Methods 0.000 description 1
- 235000013681 dietary sucrose Nutrition 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 229960004497 dinutuximab Drugs 0.000 description 1
- 229960002768 dipyridamole Drugs 0.000 description 1
- IZEKFCXSFNUWAM-UHFFFAOYSA-N dipyridamole Chemical compound C=12N=C(N(CCO)CCO)N=C(N3CCCCC3)C2=NC(N(CCO)CCO)=NC=1N1CCCCC1 IZEKFCXSFNUWAM-UHFFFAOYSA-N 0.000 description 1
- 238000010494 dissociation reaction Methods 0.000 description 1
- 230000005593 dissociations Effects 0.000 description 1
- 238000004090 dissolution Methods 0.000 description 1
- VSJKWCGYPAHWDS-UHFFFAOYSA-N dl-camptothecin Natural products C1=CC=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)C5(O)CC)C4=NC2=C1 VSJKWCGYPAHWDS-UHFFFAOYSA-N 0.000 description 1
- 239000003534 dna topoisomerase inhibitor Substances 0.000 description 1
- 229960003668 docetaxel Drugs 0.000 description 1
- 229960004679 doxorubicin Drugs 0.000 description 1
- 238000005553 drilling Methods 0.000 description 1
- 229960002224 eculizumab Drugs 0.000 description 1
- 229960000284 efalizumab Drugs 0.000 description 1
- 230000002900 effect on cell Effects 0.000 description 1
- 208000023965 endometrium neoplasm Diseases 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- YQGOJNYOYNNSMM-UHFFFAOYSA-N eosin Chemical compound [Na+].OC(=O)C1=CC=CC=C1C1=C2C=C(Br)C(=O)C(Br)=C2OC2=C(Br)C(O)=C(Br)C=C21 YQGOJNYOYNNSMM-UHFFFAOYSA-N 0.000 description 1
- 108010087914 epidermal growth factor receptor VIII Proteins 0.000 description 1
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 description 1
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 description 1
- 230000010502 episomal replication Effects 0.000 description 1
- 229950009760 epratuzumab Drugs 0.000 description 1
- 229940011871 estrogen Drugs 0.000 description 1
- 239000000262 estrogen Substances 0.000 description 1
- AEOCXXJPGCBFJA-UHFFFAOYSA-N ethionamide Chemical compound CCC1=CC(C(N)=S)=CC=N1 AEOCXXJPGCBFJA-UHFFFAOYSA-N 0.000 description 1
- 210000003527 eukaryotic cell Anatomy 0.000 description 1
- 230000017188 evasion or tolerance of host immune response Effects 0.000 description 1
- 230000005713 exacerbation Effects 0.000 description 1
- 239000013613 expression plasmid Substances 0.000 description 1
- 230000002349 favourable effect Effects 0.000 description 1
- 230000020764 fibrinolysis Effects 0.000 description 1
- 238000000799 fluorescence microscopy Methods 0.000 description 1
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 1
- 229960002949 fluorouracil Drugs 0.000 description 1
- IJJVMEJXYNJXOJ-UHFFFAOYSA-N fluquinconazole Chemical compound C=1C=C(Cl)C=C(Cl)C=1N1C(=O)C2=CC(F)=CC=C2N=C1N1C=NC=N1 IJJVMEJXYNJXOJ-UHFFFAOYSA-N 0.000 description 1
- 150000002224 folic acids Chemical class 0.000 description 1
- 230000004927 fusion Effects 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 238000002523 gelfiltration Methods 0.000 description 1
- 229960005277 gemcitabine Drugs 0.000 description 1
- SDUQYLNIPVEERB-QPPQHZFASA-N gemcitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 SDUQYLNIPVEERB-QPPQHZFASA-N 0.000 description 1
- 238000012637 gene transfection Methods 0.000 description 1
- 230000008303 genetic mechanism Effects 0.000 description 1
- 229940045109 genistein Drugs 0.000 description 1
- TZBJGXHYKVUXJN-UHFFFAOYSA-N genistein Natural products C1=CC(O)=CC=C1C1=COC2=CC(O)=CC(O)=C2C1=O TZBJGXHYKVUXJN-UHFFFAOYSA-N 0.000 description 1
- 235000006539 genistein Nutrition 0.000 description 1
- ZCOLJUOHXJRHDI-CMWLGVBASA-N genistein 7-O-beta-D-glucoside Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@H]1OC1=CC(O)=C2C(=O)C(C=3C=CC(O)=CC=3)=COC2=C1 ZCOLJUOHXJRHDI-CMWLGVBASA-N 0.000 description 1
- 108010049041 glutamylalanine Proteins 0.000 description 1
- 125000003630 glycyl group Chemical group [H]N([H])C([H])([H])C(*)=O 0.000 description 1
- 108010000434 glycyl-alanyl-leucine Proteins 0.000 description 1
- 108010084264 glycyl-glycyl-cysteine Proteins 0.000 description 1
- XKUKSGPZAADMRA-UHFFFAOYSA-N glycyl-glycyl-glycine Natural products NCC(=O)NCC(=O)NCC(O)=O XKUKSGPZAADMRA-UHFFFAOYSA-N 0.000 description 1
- 108010078326 glycyl-glycyl-valine Proteins 0.000 description 1
- 108010082286 glycyl-seryl-alanine Proteins 0.000 description 1
- 108010020688 glycylhistidine Proteins 0.000 description 1
- 108010077515 glycylproline Proteins 0.000 description 1
- 229960001743 golimumab Drugs 0.000 description 1
- 229960002913 goserelin Drugs 0.000 description 1
- 230000012010 growth Effects 0.000 description 1
- 229940093915 gynecological organic acid Drugs 0.000 description 1
- 230000009931 harmful effect Effects 0.000 description 1
- 201000010536 head and neck cancer Diseases 0.000 description 1
- 208000014829 head and neck neoplasm Diseases 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 238000011134 hematopoietic stem cell transplantation Methods 0.000 description 1
- 229960002897 heparin Drugs 0.000 description 1
- 229920000669 heparin Polymers 0.000 description 1
- 208000006359 hepatoblastoma Diseases 0.000 description 1
- 229940022353 herceptin Drugs 0.000 description 1
- UUVWYPNAQBNQJQ-UHFFFAOYSA-N hexamethylmelamine Chemical compound CN(C)C1=NC(N(C)C)=NC(N(C)C)=N1 UUVWYPNAQBNQJQ-UHFFFAOYSA-N 0.000 description 1
- 210000003630 histaminocyte Anatomy 0.000 description 1
- 108010025306 histidylleucine Proteins 0.000 description 1
- 229940088597 hormone Drugs 0.000 description 1
- 239000005556 hormone Substances 0.000 description 1
- 239000003668 hormone analog Substances 0.000 description 1
- 102000043381 human DUSP5 Human genes 0.000 description 1
- 210000005260 human cell Anatomy 0.000 description 1
- 229960000890 hydrocortisone Drugs 0.000 description 1
- 229920001600 hydrophobic polymer Polymers 0.000 description 1
- 210000001822 immobilized cell Anatomy 0.000 description 1
- 230000001900 immune effect Effects 0.000 description 1
- 230000008076 immune mechanism Effects 0.000 description 1
- 102000027596 immune receptors Human genes 0.000 description 1
- 108091008915 immune receptors Proteins 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 239000012274 immune-checkpoint protein inhibitor Substances 0.000 description 1
- 229960003444 immunosuppressant agent Drugs 0.000 description 1
- 239000003018 immunosuppressive agent Substances 0.000 description 1
- 230000001771 impaired effect Effects 0.000 description 1
- 231100000405 induce cancer Toxicity 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 238000011081 inoculation Methods 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 210000004692 intercellular junction Anatomy 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 230000031146 intracellular signal transduction Effects 0.000 description 1
- 239000007928 intraperitoneal injection Substances 0.000 description 1
- 229960005386 ipilimumab Drugs 0.000 description 1
- 229960004768 irinotecan Drugs 0.000 description 1
- UWKQSNNFCGGAFS-XIFFEERXSA-N irinotecan Chemical compound C1=C2C(CC)=C3CN(C(C4=C([C@@](C(=O)OC4)(O)CC)C=4)=O)C=4C3=NC2=CC=C1OC(=O)N(CC1)CCC1N1CCCCC1 UWKQSNNFCGGAFS-XIFFEERXSA-N 0.000 description 1
- 238000002955 isolation Methods 0.000 description 1
- 229960000310 isoleucine Drugs 0.000 description 1
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 1
- 229940043355 kinase inhibitor Drugs 0.000 description 1
- 229950000518 labetuzumab Drugs 0.000 description 1
- 231100001231 less toxic Toxicity 0.000 description 1
- 229960003881 letrozole Drugs 0.000 description 1
- HPJKCIUCZWXJDR-UHFFFAOYSA-N letrozole Chemical compound C1=CC(C#N)=CC=C1C(N1N=CN=C1)C1=CC=C(C#N)C=C1 HPJKCIUCZWXJDR-UHFFFAOYSA-N 0.000 description 1
- 108010009932 leucyl-alanyl-glycyl-valine Proteins 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 244000144972 livestock Species 0.000 description 1
- 238000004020 luminiscence type Methods 0.000 description 1
- 210000001165 lymph node Anatomy 0.000 description 1
- 125000003588 lysine group Chemical group [H]N([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 229940124302 mTOR inhibitor Drugs 0.000 description 1
- 230000036210 malignancy Effects 0.000 description 1
- 210000004962 mammalian cell Anatomy 0.000 description 1
- 239000003628 mammalian target of rapamycin inhibitor Substances 0.000 description 1
- GLVAUDGFNGKCSF-UHFFFAOYSA-N mercaptopurine Chemical compound S=C1NC=NC2=C1NC=N2 GLVAUDGFNGKCSF-UHFFFAOYSA-N 0.000 description 1
- 229960001428 mercaptopurine Drugs 0.000 description 1
- 239000003475 metalloproteinase inhibitor Substances 0.000 description 1
- 230000009401 metastasis Effects 0.000 description 1
- 206010061289 metastatic neoplasm Diseases 0.000 description 1
- 229960000485 methotrexate Drugs 0.000 description 1
- 229960004584 methylprednisolone Drugs 0.000 description 1
- HPNSFSBZBAHARI-UHFFFAOYSA-N micophenolic acid Natural products OC1=C(CC=C(C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-UHFFFAOYSA-N 0.000 description 1
- 210000004688 microtubule Anatomy 0.000 description 1
- 235000013336 milk Nutrition 0.000 description 1
- 239000008267 milk Substances 0.000 description 1
- 210000004080 milk Anatomy 0.000 description 1
- 230000004065 mitochondrial dysfunction Effects 0.000 description 1
- 229960000350 mitotane Drugs 0.000 description 1
- 230000037230 mobility Effects 0.000 description 1
- 238000003032 molecular docking Methods 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 210000005087 mononuclear cell Anatomy 0.000 description 1
- 150000002772 monosaccharides Chemical class 0.000 description 1
- 229940014456 mycophenolate Drugs 0.000 description 1
- HPNSFSBZBAHARI-RUDMXATFSA-N mycophenolic acid Chemical compound OC1=C(C\C=C(/C)CCC(O)=O)C(OC)=C(C)C2=C1C(=O)OC2 HPNSFSBZBAHARI-RUDMXATFSA-N 0.000 description 1
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 description 1
- 229930014626 natural product Natural products 0.000 description 1
- 229960004927 neomycin Drugs 0.000 description 1
- 201000008026 nephroblastoma Diseases 0.000 description 1
- 229960002653 nilutamide Drugs 0.000 description 1
- XWXYUMMDTVBTOU-UHFFFAOYSA-N nilutamide Chemical compound O=C1C(C)(C)NC(=O)N1C1=CC=C([N+]([O-])=O)C(C(F)(F)F)=C1 XWXYUMMDTVBTOU-UHFFFAOYSA-N 0.000 description 1
- 239000002840 nitric oxide donor Substances 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- OSTGTTZJOCZWJG-UHFFFAOYSA-N nitrosourea Chemical compound NC(=O)N=NO OSTGTTZJOCZWJG-UHFFFAOYSA-N 0.000 description 1
- 239000002736 nonionic surfactant Substances 0.000 description 1
- 238000003199 nucleic acid amplification method Methods 0.000 description 1
- 238000007899 nucleic acid hybridization Methods 0.000 description 1
- 229960003347 obinutuzumab Drugs 0.000 description 1
- 229960002450 ofatumumab Drugs 0.000 description 1
- 229960002378 oftasceine Drugs 0.000 description 1
- 238000002515 oligonucleotide synthesis Methods 0.000 description 1
- 238000011275 oncology therapy Methods 0.000 description 1
- 238000005457 optimization Methods 0.000 description 1
- 150000007524 organic acids Chemical class 0.000 description 1
- 235000005985 organic acids Nutrition 0.000 description 1
- 229960001756 oxaliplatin Drugs 0.000 description 1
- DWAFYCQODLXJNR-BNTLRKBRSA-L oxaliplatin Chemical compound O1C(=O)C(=O)O[Pt]11N[C@@H]2CCCC[C@H]2N1 DWAFYCQODLXJNR-BNTLRKBRSA-L 0.000 description 1
- 230000000242 pagocytic effect Effects 0.000 description 1
- 229960000402 palivizumab Drugs 0.000 description 1
- 229960001972 panitumumab Drugs 0.000 description 1
- 229960002340 pentostatin Drugs 0.000 description 1
- FPVKHBSQESCIEP-JQCXWYLXSA-N pentostatin Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(N=CNC[C@H]2O)=C2N=C1 FPVKHBSQESCIEP-JQCXWYLXSA-N 0.000 description 1
- 230000002085 persistent effect Effects 0.000 description 1
- 239000000546 pharmaceutical excipient Substances 0.000 description 1
- 108010073101 phenylalanylleucine Proteins 0.000 description 1
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 150000003904 phospholipids Chemical class 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 239000003757 phosphotransferase inhibitor Substances 0.000 description 1
- 239000013612 plasmid Substances 0.000 description 1
- 239000000106 platelet aggregation inhibitor Substances 0.000 description 1
- 238000007747 plating Methods 0.000 description 1
- 229910052697 platinum Inorganic materials 0.000 description 1
- 229920001481 poly(stearyl methacrylate) Polymers 0.000 description 1
- 229920002401 polyacrylamide Polymers 0.000 description 1
- 238000003752 polymerase chain reaction Methods 0.000 description 1
- 108091033319 polynucleotide Proteins 0.000 description 1
- 102000040430 polynucleotide Human genes 0.000 description 1
- 239000002157 polynucleotide Substances 0.000 description 1
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 1
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 1
- 229920001155 polypropylene Polymers 0.000 description 1
- 231100000683 possible toxicity Toxicity 0.000 description 1
- XAEFZNCEHLXOMS-UHFFFAOYSA-M potassium benzoate Chemical compound [K+].[O-]C(=O)C1=CC=CC=C1 XAEFZNCEHLXOMS-UHFFFAOYSA-M 0.000 description 1
- 229960005205 prednisolone Drugs 0.000 description 1
- OIGNJSKKLXVSLS-VWUMJDOOSA-N prednisolone Chemical compound O=C1C=C[C@]2(C)[C@H]3[C@@H](O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 OIGNJSKKLXVSLS-VWUMJDOOSA-N 0.000 description 1
- 229960004618 prednisone Drugs 0.000 description 1
- XOFYZVNMUHMLCC-ZPOLXVRWSA-N prednisone Chemical compound O=C1C=C[C@]2(C)[C@H]3C(=O)C[C@](C)([C@@](CC4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 XOFYZVNMUHMLCC-ZPOLXVRWSA-N 0.000 description 1
- 210000004986 primary T-cell Anatomy 0.000 description 1
- 208000037821 progressive disease Diseases 0.000 description 1
- 229940097325 prolactin Drugs 0.000 description 1
- 230000009696 proliferative response Effects 0.000 description 1
- 108010077112 prolyl-proline Proteins 0.000 description 1
- 108010031719 prolyl-serine Proteins 0.000 description 1
- 230000002685 pulmonary effect Effects 0.000 description 1
- 150000003212 purines Chemical class 0.000 description 1
- 150000003230 pyrimidines Chemical class 0.000 description 1
- 230000005855 radiation Effects 0.000 description 1
- 229960002633 ramucirumab Drugs 0.000 description 1
- 230000009257 reactivity Effects 0.000 description 1
- 230000010076 replication Effects 0.000 description 1
- 230000000284 resting effect Effects 0.000 description 1
- 108010056030 retronectin Proteins 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 229940113912 rituximab injection Drugs 0.000 description 1
- 108091008601 sVEGFR Proteins 0.000 description 1
- 230000003248 secreting effect Effects 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 239000003001 serine protease inhibitor Substances 0.000 description 1
- 108091005475 signaling receptors Proteins 0.000 description 1
- 102000035025 signaling receptors Human genes 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- FHHPUSMSKHSNKW-SMOYURAASA-M sodium deoxycholate Chemical compound [Na+].C([C@H]1CC2)[C@H](O)CC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H]([C@@H](CCC([O-])=O)C)[C@@]2(C)[C@@H](O)C1 FHHPUSMSKHSNKW-SMOYURAASA-M 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 239000000243 solution Substances 0.000 description 1
- 241000894007 species Species 0.000 description 1
- 210000000952 spleen Anatomy 0.000 description 1
- 239000003381 stabilizer Substances 0.000 description 1
- 230000010473 stable expression Effects 0.000 description 1
- 238000011272 standard treatment Methods 0.000 description 1
- 229960005202 streptokinase Drugs 0.000 description 1
- 229960001052 streptozocin Drugs 0.000 description 1
- ZSJLQEPLLKMAKR-GKHCUFPYSA-N streptozocin Chemical compound O=NN(C)C(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O ZSJLQEPLLKMAKR-GKHCUFPYSA-N 0.000 description 1
- 239000007929 subcutaneous injection Substances 0.000 description 1
- 238000010254 subcutaneous injection Methods 0.000 description 1
- 239000000126 substance Substances 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 229960004793 sucrose Drugs 0.000 description 1
- 230000020382 suppression by virus of host antigen processing and presentation of peptide antigen via MHC class I Effects 0.000 description 1
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 description 1
- 238000001356 surgical procedure Methods 0.000 description 1
- 230000002459 sustained effect Effects 0.000 description 1
- 230000002195 synergetic effect Effects 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 235000020357 syrup Nutrition 0.000 description 1
- 239000006188 syrup Substances 0.000 description 1
- 238000007910 systemic administration Methods 0.000 description 1
- 229960001603 tamoxifen Drugs 0.000 description 1
- 230000008685 targeting Effects 0.000 description 1
- KKEYFWRCBNTPAC-UHFFFAOYSA-L terephthalate(2-) Chemical compound [O-]C(=O)C1=CC=C(C([O-])=O)C=C1 KKEYFWRCBNTPAC-UHFFFAOYSA-L 0.000 description 1
- 210000001550 testis Anatomy 0.000 description 1
- ZRKFYGHZFMAOKI-QMGMOQQFSA-N tgfbeta Chemical compound C([C@H](NC(=O)[C@H](C(C)C)NC(=O)CNC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H]([C@@H](C)O)NC(=O)[C@H](CC(C)C)NC(=O)CNC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](NC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCSC)C(C)C)[C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N1[C@@H](CCC1)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O)C1=CC=C(O)C=C1 ZRKFYGHZFMAOKI-QMGMOQQFSA-N 0.000 description 1
- 230000004797 therapeutic response Effects 0.000 description 1
- 229940021747 therapeutic vaccine Drugs 0.000 description 1
- 229960001196 thiotepa Drugs 0.000 description 1
- 108010061238 threonyl-glycine Proteins 0.000 description 1
- 229960004072 thrombin Drugs 0.000 description 1
- 210000001541 thymus gland Anatomy 0.000 description 1
- 229960005001 ticlopidine Drugs 0.000 description 1
- PHWBOXQYWZNQIN-UHFFFAOYSA-N ticlopidine Chemical compound ClC1=CC=CC=C1CN1CC(C=CS2)=C2CC1 PHWBOXQYWZNQIN-UHFFFAOYSA-N 0.000 description 1
- 229960003087 tioguanine Drugs 0.000 description 1
- 239000003104 tissue culture media Substances 0.000 description 1
- 229960000187 tissue plasminogen activator Drugs 0.000 description 1
- 229960003989 tocilizumab Drugs 0.000 description 1
- 229940044693 topoisomerase inhibitor Drugs 0.000 description 1
- 229960000303 topotecan Drugs 0.000 description 1
- UCFGDBYHRUNTLO-QHCPKHFHSA-N topotecan Chemical compound C1=C(O)C(CN(C)C)=C2C=C(CN3C4=CC5=C(C3=O)COC(=O)[C@]5(O)CC)C4=NC2=C1 UCFGDBYHRUNTLO-QHCPKHFHSA-N 0.000 description 1
- 230000002588 toxic effect Effects 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 239000012096 transfection reagent Substances 0.000 description 1
- 230000009261 transgenic effect Effects 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 229960001612 trastuzumab emtansine Drugs 0.000 description 1
- 229960001727 tretinoin Drugs 0.000 description 1
- 125000001493 tyrosinyl group Chemical group [H]OC1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])C([H])(N([H])[H])C(*)=O 0.000 description 1
- 229960005356 urokinase Drugs 0.000 description 1
- 229960005486 vaccine Drugs 0.000 description 1
- GBABOYUKABKIAF-GHYRFKGUSA-N vinorelbine Chemical compound C1N(CC=2C3=CC=CC=C3NC=22)CC(CC)=C[C@H]1C[C@]2(C(=O)OC)C1=CC([C@]23[C@H]([C@]([C@H](OC(C)=O)[C@]4(CC)C=CCN([C@H]34)CC2)(O)C(=O)OC)N2C)=C2C=C1OC GBABOYUKABKIAF-GHYRFKGUSA-N 0.000 description 1
- 229960002066 vinorelbine Drugs 0.000 description 1
Images



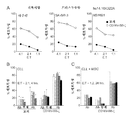


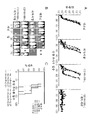

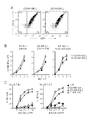




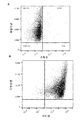

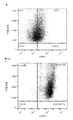

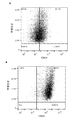


Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K35/00—Medicinal preparations containing materials or reaction products thereof with undetermined constitution
- A61K35/12—Materials from mammals; Compositions comprising non-specified tissues or cells; Compositions comprising non-embryonic stem cells; Genetically modified cells
- A61K35/14—Blood; Artificial blood
- A61K35/17—Lymphocytes; B-cells; T-cells; Natural killer cells; Interferon-activated or cytokine-activated lymphocytes
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/461—Cellular immunotherapy characterised by the cell type used
- A61K39/4611—T-cells, e.g. tumor infiltrating lymphocytes [TIL], lymphokine-activated killer cells [LAK] or regulatory T cells [Treg]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/463—Cellular immunotherapy characterised by recombinant expression
- A61K39/4631—Chimeric Antigen Receptors [CAR]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/464402—Receptors, cell surface antigens or cell surface determinants
- A61K39/464403—Receptors for growth factors
- A61K39/464406—Her-2/neu/ErbB2, Her-3/ErbB3 or Her 4/ ErbB4
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/464402—Receptors, cell surface antigens or cell surface determinants
- A61K39/464411—Immunoglobulin superfamily
- A61K39/464412—CD19 or B4
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/464402—Receptors, cell surface antigens or cell surface determinants
- A61K39/464424—CD20
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/46—Cellular immunotherapy
- A61K39/464—Cellular immunotherapy characterised by the antigen targeted or presented
- A61K39/4643—Vertebrate antigens
- A61K39/4644—Cancer antigens
- A61K39/464469—Tumor associated carbohydrates
- A61K39/464471—Gangliosides, e.g. GM2, GD2 or GD3
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
- A61P35/02—Antineoplastic agents specific for leukemia
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
- A61P37/04—Immunostimulants
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/70517—CD8
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/705—Receptors; Cell surface antigens; Cell surface determinants
- C07K14/70503—Immunoglobulin superfamily
- C07K14/70535—Fc-receptors, e.g. CD16, CD32, CD64 (CD2314/705F)
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
- C07K16/3076—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells against structure-related tumour-associated moieties
- C07K16/3084—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells against structure-related tumour-associated moieties against tumour-associated gangliosides
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/32—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against translation products of oncogenes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C12N15/86—Viral vectors
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0634—Cells from the blood or the immune system
- C12N5/0636—T lymphocytes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K39/46
- A61K2239/31—Indexing codes associated with cellular immunotherapy of group A61K39/46 characterized by the route of administration
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2239/00—Indexing codes associated with cellular immunotherapy of group A61K39/46
- A61K2239/38—Indexing codes associated with cellular immunotherapy of group A61K39/46 characterised by the dose, timing or administration schedule
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
- C07K2317/732—Antibody-dependent cellular cytotoxicity [ADCC]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/02—Fusion polypeptide containing a localisation/targetting motif containing a signal sequence
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/03—Fusion polypeptide containing a localisation/targetting motif containing a transmembrane segment
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/70—Fusion polypeptide containing domain for protein-protein interaction
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2510/00—Genetically modified cells
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2740/00—Reverse transcribing RNA viruses
- C12N2740/00011—Details
- C12N2740/10011—Retroviridae
- C12N2740/10041—Use of virus, viral particle or viral elements as a vector
- C12N2740/10043—Use of virus, viral particle or viral elements as a vector viral genome or elements thereof as genetic vector
Abstract
본원에서는 면역글로불린 분자 (Ig)의 Fc 부위에 대하여 친화성을 가지고, 그에 특이적인 세포외 도메인인 Fc-결합 도메인; 막횡단 도메인; 적어도 하나의 공동 자극 신호전달 도메인; 및 면역수용체 티로신 기반 활성화 모티프 (ITAM)를 포함하는 세포질 신호전달 도메인을 포함하는 키메라 수용체를 개시한다. 상기 키메라 수용체를 코딩하는 핵산 및 키메라 수용체를 발현하는 면역 세포 또한 제공한다. 상기 면역 세포는 항체-의존성 세포-매개 세포독성을 증진시키는 데 및/또는 항체-기반 면역요법, 예컨대, 암 면역요법을 증진시키는 데 사용될 수 있다.
Description
관련 출원에 대한 상호 참조
본 출원은 35 U.S.C. §119하에 2014년 9월 9일 출원된 미국 가출원 번호 62/047,916의 이익을 주장하고, 상기 출원의 전체 내용은 본원에서 참조로 포함된다.
세포 기반 요법, 항체 요법 및 시토카인 요법을 비롯한, 암 면역요법은 정상 조직은 해를 입히지 않고 그대로 두면서, 종양 세포를 공격하는 면역 반응을 유발하는 데 사용된다. 약물 내성의 유전적 기전 및 세포 기전을 회피할 수 있고, 정상 조직은 해를 입히지 않고 그대로 두면서, 종양 세포를 표적화할 수 있는 그의 잠재능에 기인하여, 상기 요법은 다양한 유형의 암을 치료하는 데 있어 유망한 옵션이 된다. T-림프구는 혈액 악성종양에 대한 동종이계 조혈 줄기 세포 이식 (HSCT)의 결과로서 입증되는 바와 같이, 주요한 항-종양 효과를 발휘할 수 있는데, 여기서, T 세포 매개 이식편 대 숙주 질환 (GvHD)은 역으로 질환 재발과 관련이 있으며, 면역억제 중단 또는 공여자 림프구 주입이 재발을 포함할 수 있다 (문헌 [Weiden et al., NEnglJ Med. 1979;300(19):1068-1073]; [Porter et al., NEnglJ Med. 1994;330(2):100-106]; [Kolb et al., Blood. 1995;86(5):2041-2050]; [Slavin et al., Blood. 1996;87(6):2195-2204]; 및 [Appelbaum, Nature. 2001;411(6835):385-389]).
세포 기반 요법은 암 세포 쪽으로 편향된 반응성을 보이는 세포독성 T 세포를 포함할 수 있다 (문헌 [Eshhar et al., Proc . Natl . Acad . Sci . U. S. A.; 1993;90(2):720-724]; [Geiger et al., J Immunol. 1999;162(10):5931-5939]; [Brentjens et al., Nat. Med . 2003;9(3):279-286]; [Cooper et al., Blood. 2003;101(4):1637-1644]; 및 [Imai et al., Leukemia. 2004;18:676-684]). 한 접근법은 하나 이상의 T 세포 활성화 신호전달 도메인에 융합된 항원-결합 도메인을 포함하는 키메라 항원 수용체를 발현하는 것이다. 항원-결합 도메인을 통해 암 항원에 결합하게 되면, T 세포는 활성화되고, 세포독성이 유발된다. 키메라 수용체-발현 자가 T 림프구 주입을 이용하여 수행된 임상 시험에 관한 최근의 결과는 그의 임상적 잠재성에 대한 유력한 증거를 제시하였다 (문헌 [Pule et al., Nat. Med. 2008;14(11):1264-1270]; [Porter et al., N Engl J Med; 2011; 25;365(8):725-733]; [Brentjens et al., Blood. 2011;118(18):4817-4828]; [Till et al., Blood. 2012;119(17):3940-3950]; [Kochenderfer et al., Blood. 2012;119(12):2709-2720]; 및 [Brentjens et al., Sci Transl Med. 2013;5(177):177ra138]).
항체 기반 면역요법, 예컨대, 모노클로날 항체, 항체-융합 단백질, 및 항체 약물 접합체 (ADC)는 다수의 암 유형을 비롯한, 매우 다양한 질환을 치료하는 데 사용된다. 상기 요법은 정상 세포 (예컨대, 암이 아닌 세포)에 대해 상대적으로, 제거하고자 하는 세포 (예컨대, 표적 세포, 예컨대, 암 세포) 상에서 차별적으로 발현되는 세포 표면 분자의 인식에 의존할 수 있다. 항체 기반 면역요법의 암 세포에의 결합은 다양한 기전, 예컨대, 항체 의존성 세포-매개 세포독성 (ADCC), 보체 의존성 세포독성 (CDC), 또는 항체-약물 접합체 (ADC)로부터의 페이로드의 직접적인 세포독성 활성을 통해 암 세포 사멸을 유도할 수 있다.
본 개시내용의 요약
본 개시내용은 면역글로불린 (Ig), 예컨대, IgG 항체의 Fc 부위에 대하여 친화성 및 특이성을 가진 세포외 도메인, 막횡단 도메인, 적어도 하나의 공동 자극 신호전달 도메인, 및 면역수용체 티로신 기반 활성화 모티프 (ITAM)를 포함하는 세포질 신호전달 도메인을 포함하는 키메라 수용체의 디자인을 기초로 한다. 상기 키메라 수용체 구축물을 발현하는 면역 세포는 예컨대, ADCC 활성을 증진시킴으로써 면역 요법, 예컨대, 항체 기반 면역요법의 효능을 증진시킬 것이다.
따라서, 본 개시내용의 한 측면은 (a) 예컨대, IgG의 Fc 부위에 결합하는 것과 같이, 면역글로불린의 Fc 부위에 결합하는 세포외 도메인 (Fc-결합 도메인); (b) 막횡단 도메인; (c) 적어도 하나의 공동 자극 신호전달 도메인; 및 (d) ITAM을 포함하는 세포질 신호전달 도메인을 포함하는 키메라 수용체를 특징으로 한다. 적어도 하나의 공동 자극 신호전달 도메인 또는 ITAM을 포함하는 세포질 신호전달 도메인은 본원에 기술된 바와 같이 키메라 수용체 구축물의 C-말단에 위치할 수 있다. 일부 실시양태에서, ITAM 함유 세포질 신호전달 도메인은 키메라 수용체 구축물의 C-말단에 위치한다. 일부 실시양태에서, (a)는 CD16 (예컨대, CD16A 또는 CD16B)의 세포외 리간드 결합 도메인이고, (d)는 Fc 수용체의 ITAM을 포함하지 않는다. 일부 실시양태에서, (d)는 CD3ζ 또는 FcεR1γ의 세포질 신호전달 도메인이다. 본원에 기술된 키메라 수용체 중 임의의 것은 (a)의 C-말단과 (b)의 N-말단 사이에 위치할 수 있는, (e) 힌지 도메인을 추가로 포함할 수 있다.
일부 실시양태에서, 본원에 기술된 키메라 수용체 구축물의 (a)는 Fc 수용체, 예컨대, Fc-감마 수용체, Fc-알파 수용체, 또는 Fc-엡실론 수용체의 세포외 리간드 결합 도메인이다. 예를 들어, (a)는 CD16 (예컨대, CD16A 또는 CD16B), CD32 (예컨대, CD32A, 또는 CD32B), 또는 CD64 (예컨대, CD64A, CD64B, 또는 CD64C)의 세포외 리간드 결합 도메인이다. 일부 예에서, (a)는 CD16의 세포외 리간드 결합 도메인이 아니다. 다른 실시양태에서, (a)는 CD32 (예컨대, CD32A, 또는 CD32B)의 세포외 리간드 결합 도메인이다.
다른 실시양태에서, (a)는 Ig 분자, 예컨대, IgG 분자의 Fc 부위에 결합할 수 있는, 비-Fc 수용체 자연적으로 발생된 단백질의 것이다. 예를 들어, (a)는 단백질 A 또는 단백질 G 전체 또는 그의 일부일 수 있다. 대안적으로, (a)는 단일 쇄 가변 단편 (scFv), 또는 도메인 항체, 나노바디를 포함하나 이에 제한되지 않는, IgG 분자의 Fc 부위에 결합하는 항체 단편일 수 있다.
추가의 다른 실시양태에서, (a)는 쿠니츠(Kunitz) 도메인 펩티드, 소형 모듈형 면역제약 (SMIP), 에드넥틴, 아비머, 어피바디, DARPin, 또는 안티칼린을 비롯한, IgG 분자의 Fc 부위에 결합할 수 있는 디자인된 (예컨대, 비-자연적으로 발생된) 펩티드이다.
대안적으로, 또는 추가로, (b)인, 키메라 수용체의 막횡단 도메인은 CD8α, CD8β, 4-1BB, CD28, CD34, CD4, FcεRIγ, CD16 (예컨대, CD16A 또는 CD16B), OX40, CD3ζ, CD3ε, CD3γ, CD3δ, TCRα, CD32 (예컨대, CD32A 또는 CD32B), CD64 (예컨대, CD64A, CD64B, 또는 CD64C), VEGFR2, FAS, 및 FGFR2B를 포함하나, 이에 제한되지 않는, 단일 통과 막 단백질의 것일 수 있다. 일부 예에서, 막 단백질은 CD8α가 아니다. 막횡단 도메인은 또한 비-자연적으로 발생된 소수성 단백질 세그먼트일 수 있다.
본원에 기술된 키메라 수용체 구축물 중 임의의 것에서, 본원에 기술된 키메라 수용체의 적어도 하나의 공동 자극 신호전달 도메인은 공동 자극 분자, 예컨대, 4-1BB (CD137로도 또한 공지됨), CD28, CD28LL → GG 변이체, OX40, ICOS, CD27, GITR, HVEM, TIM1, LFA1, 또는 CD2의 것일 수 있다. 일부 예에서, 적어도 하나의 공동 자극 신호전달 도메인은 4-1BB로부터의 것이 아니다. 일부 예에서, 키메라 수용체는 2개의 공동 자극 신호전달 도메인, 예컨대, CD28 및 4-1BB, 또는 CD28LL → GG 변이체 및 4-1BB를 포함한다.
본원에 기술된 키메라 수용체 중 임의의 것에서, 힌지 도메인은 단백질, 예컨대, CD8α, 또는 IgG의 것일 수 있다. 예를 들어, 힌지 도메인은 CD8α의 막횡단 또는 힌지 도메인의 단편일 수 있다. 일부 예에서, 힌지 도메인은 CD8α의 힌지 도메인이 아니다. 일부 예에서, 힌지 도메인은 비-자연적으로 발생된 펩티드, 예컨대, 다양한 길이의, 친수성 잔기로 이루어진 폴리펩티드 (XTEN) 또는 (Gly4Ser)n 폴리펩티드 (여기서, n은 정수 3-12이다)이다.
일부 실시양태에서, 본원에 기술된 키메라 수용체 중 임의의 것은 그의 N-말단에 신호 펩티드, 예컨대, 서열식별번호(SEQ ID NO): 61의 아미노산 서열을 포함할 수 있는, CD8α의 신호 펩티드를 추가로 포함할 수 있다.
본원에 기술된 키메라 수용체의 예는 하기 표 3, 표 4, 및 표 5에 제시된 것과 같은 성분 (a)-(e)를 포함할 수 있다. 일부 예에서, 키메라 수용체는 서열식별번호: 2-30 및 32-56으로부터 선택되는 아미노산 서열, 또는 참조 서열의 신호 펩티드를 제외한, 그의 단편을 포함한다.
구체적인 실시양태에서, 본원에 기술된 키메라 수용체는 F158 FCGR3A (F158 CD16A) 또는 V158 FCGR3A 변이체 (V158 CD16A)의 세포외 리간드 결합 도메인을 포함할 수 있다. 상기 세포외 리간드 결합 도메인은 각각 서열식별번호: 70 및 서열식별번호: 57의 아미노산 서열을 포함할 수 있다.
다른 구체적인 실시양태에서, 본원에 기술된 키메라 수용체는 서열식별번호: 58의 아미노산 서열을 포함할 수 있는, CD8α의 힌지 및 막횡단 도메인을 포함할 수 있다.
대안적으로, 또는 추가로, 본원에 기술된 키메라 수용체는 서열식별번호: 59의 아미노산 서열을 포함할 수 있는, 4-1BB의 공동 자극 신호전달 도메인을 포함할 수 있다.
추가의 다른 구체적인 실시양태에서, 본원에 기술된 키메라 수용체는 서열식별번호: 60의 아미노산 서열을 포함할 수 있는, CD3ζ의 세포질 신호전달 도메인을 포함할 수 있다.
일부 예에서, 본원에 기술된 키메라 수용체는 CD8α의 신호 펩티드, F158 CD16A 또는 V158 CD16A의 세포외 도메인, CD8α의 힌지 및 막횡단 도메인, 4-1BB의 공동 자극 신호전달 도메인, 및 CD3ζ의 세포질 신호전달 도메인을 포함하는 수용체가 아니다. 특정 예에서, 본원에 기술된 키메라 수용체는 서열식별번호: 1 또는 서열식별번호: 31의 아미노산 서열을 포함하지 않는다.
또 다른 측면에서, 본 개시내용은 본원에 기술된 키메라 수용체 중 임의의 것을 코딩하는 뉴클레오티드 서열을 포함하는 핵산 (예컨대, DNA 분자 또는 RNA 분자); 상기 핵산을 포함하는 벡터 (예컨대, 발현 벡터); 및 숙주 세포 (예컨대, 면역 세포, 예컨대, 자연살 세포, 대식세포, 호중구, 호산구, 및 T 세포)를 특징으로 한다. 일부 실시양태에서, 벡터는 바이러스 벡터, 예컨대, 렌티바이러스 벡터 또는 레트로바이러스 벡터이다. 일부 실시양태에서, 벡터는 트랜스포존이거나, 트랜스포존을 함유한다.
일부 실시양태에서, 본원에 기술된 키메라 수용체 중 임의의 것을 발현하는 숙주 세포는 T 림프구 또는 NK 세포이며, 이 둘 모두는 생체외에서 활성화될 수 있고/거나, 확장될 수 있다. 일부 예에서, T 림프구 또는 NK 세포는 암을 앓는 환자 (예컨대, 인간 환자)로부터 단리된 자가 T 림프구 또는 자가 NK 세포이다. 일부 예에서, T 림프구 또는 NK 세포는 동종이계 T 림프구 또는 동종이계 NK 세포이다. T 림프구는 동종이계 T 림프구일 수 있고, 여기서, 내인성 T 세포 수용체의 발현은 억제되거나, 또는 제거될 수 있다. 대안적으로, 또는 추가로, T 림프구는 항-CD3/CD28, IL-2, 및 피토헤모아글루티닌으로 이루어진 군으로부터 선택되는 하나 이상의 작용제의 존재하에서 활성화될 수 있다. NK 세포는 CD137 리간드 단백질, CD137 항체, IL-15 단백질, IL-15 수용체 항체, IL-2 단백질, IL-12 단백질, IL-21 단백질, 및 K562 세포주로 이루어진 군으로부터 선택되는 하나 이상의 작용제의 존재하에서 활성화될 수 있다.
추가의 또 다른 측면에서, 본원에서는 (a) 본원에 기술된 핵산 또는 숙주 세포, 및 (b) 제약상 허용되는 담체를 포함하는 제약 조성물을 기술한다. 일부 예에서, 조성물은 Fc-함유 단백질, 예컨대, 항체 (예컨대, IgG 항체) 또는 Fc-융합 단백질을 추가로 포함할 수 있다. 일부 예에서, 항체는 암 세포에 세포독성이다. 상기 항체는 인간 CD16 (FCGR3A)에 결합하는 인간 또는 인간화 Fc 부위를 포함할 수 있다. 치료학적 항체로는 아달리무맙(Adalimumab), 아도-트라스투주맙 엠탄신(Ado-Trastuzumab emtansine), 알렘투주맙(Alemtuzumab), 바실릭시맙(Basiliximab), 베바시주맙(Bevacizumab), 벨리무맙(Belimumab), 브렌툭시맙(Brentuximab), 카나키누맙(Canakinumab), 세툭시맙(Cetuximab), 다클리주맙(Daclizumab), 데노수맙(Denosumab), 디누툭시맙(Dinutuximab), 에쿨리주맙(Eculizumab), 에팔리주맙(Efalizumab), 에프라투주맙(Epratuzumab), 젬투주맙(Gemtuzumab), 골리무맙(Golimumab), 인플릭시맙(Infliximab), 이필리무맙(Ipilimumab), 라베투주맙(Labetuzumab), 나탈리주맙(Natalizumab), 오비누투주맙(Obinutuzumab), 오파투무맙(Ofatumumab), 오말리주맙(Omalizumab), 팔리비주맙(Palivizumab), 파니투무맙(Panitumumab), 퍼투주맙(Pertuzumab), 라무시루맙(Ramucirumab), 리툭티맙(Ritutimab), 토실리주맙(Tocilizumab), 트라투주맙(Tratuzumab), 우스테키누맙(Ustekinumab), 또는 베돌리주맙(Vedolizumab)을 포함하나, 이에 제한되지 않는다.
본원에서는 또한 (a) 본원에 기술된 핵산 또는 숙주 세포 중 임의의 것을 포함하는 제1 제약 조성물; 및 (b) Fc-함유 단백질, 예컨대, 항체 (예컨대, IgG 항체) 또는 Fc-융합 단백질 (예컨대, 본원에 기술된 것) 및 제약상 허용되는 담체를 포함하는 제2 제약 조성물을 포함하는 키트를 제공한다.
추가로, 본 개시내용은 대상체에서 항체 의존성 세포-매개 세포독성 (ADCC)을 증진시키는 방법을 제공한다. 본 방법은 치료를 필요로 하는 대상체 (예컨대, 인간 암 환자)에게 유효량의, 본원에서 제공하는 키메라 수용체 중 임의의 것을 발현하는 숙주 세포를 투여하는 단계를 포함한다. 일부 실시양태에서, 숙주 세포는 면역 세포, 예컨대, 자연살 세포, 대식세포, 호중구, 호산구, T 세포, 또는 그의 조합이다. 일부 예에서, 숙주 면역 세포는 자가 유래이다. 다른 예에서, 숙주 면역 세포는 동종이계 세포이다. 숙주 면역 세포 중 임의의 것은 생체외에서 활성화되거나, 확장되거나, 또는 그 둘 모두가 이루어질 수 있다.
대상체는 인간 CD16에 결합하는 인간 또는 인간화 Fc 부위를 포함할 수 있는 항암 항체에 의한 치료를 받을 수 있다. 대상체는 암, 예컨대, 암종, 림프종, 육종, 모세포종, 및 백혈병을 앓는 환자일 수 있다. 예를 들어, 환자는 B 세포 기원의 암, 유방암, 위암, 신경모세포종, 골육종, 폐암, 흑색종, 전립선암, 결장암, 신장 세포 암종, 난소암, 횡문근육종, 백혈병, 및 호지킨 림프종을 앓는 환자일 수 있다. B 세포 기원의 암으로는 B 계통 급성 림프모구성 백혈병, B 세포 만성 림프구성 백혈병, 및 B 세포 비호지킨 림프종을 포함하나, 이에 제한되지 않는다.
또 다른 측면에서, 본 개시내용은 항체 기반 면역요법의 효능을 증진시키는 방법에 관한 것이다. 본 방법은 치료학적 항체 (예컨대, 본원에 기술된 치료학적 항체 중 임의의 것)으로 치료받은 적이 있거나, 또는 치료받고 있는 대상체에게 유효량의, 본원에서 제공하는 키메라 수용체 중 임의의 것을 발현하는 숙주 세포를 투여하는 단계를 포함한다. 예시적인 숙주 면역 세포로는 자연살 세포, 대식세포, 호중구, 호산구, T 세포, 또는 그의 조합을 포함하나, 이에 제한되지 않는다. 일부 예에서, 숙주 면역 세포는 자가 유래인 것이다. 다른 예에서, 숙주 면역 세포는 동종이계 세포인 것이다. 숙주 면역 세포 중 임의의 것은 생체외에서 활성화되거나, 확장되거나, 또는 그 둘 모두가 이루어질 수 있다.
일부 예에서, 키메라 수용체를 포함하는 숙주 세포는 Fc-함유 단백질, 예컨대, 본원에 기술된 것과 함께 공동 투여된다. 일부 예에서, 키메라 수용체를 포함하는 숙주 세포는 Fc-함유 단백질 이전 또는 이후에 투여된다. 일부 예에서, 키메라 수용체를 포함하는 숙주 세포가 먼저 투여되고, 이어서, Fc-함유 단백질은 치료학적 반응이 관찰될 때까지 농도를 증가시키기 위해 단계식으로 투여된다.
본원에서 제공하는 방법 중 임의의 것에서, 대상체는 암을 앓는 인간 환자일 수 있고, 치료학적 항체는 암을 치료하기 위한 것이다. 일부 예에서, 암은 림프종, 유방암, 위암, 신경모세포종, 골육종, 폐암, 피부암, 전립선암, 결장암, 신장 세포 암종, 난소암, 횡문근육종, 백혈병, 중피종, 췌장암, 두부경부암, 망막모세포종, 신경교종, 교모세포종, 또는 갑상선암이다.
(a) 본원에 기술된 키메라 수용체 구축물 중 임의의 것을 발현하는 본원에 기술된 바와 같은 면역 세포 및 제약상 허용되는 담체를 포함하는 제약 조성물로서, 필요로 하는 대상체, 예컨대, 인간 암 환자의 ADCC 활성을 증진시키는 데 및/또는 항체 요법의 효능을 증진시키는 데 사용하기 위한 제약 조성물; 및 (b) 의도하는 치료에서 사용하기 위한 의약 제조를 위한 상기 면역 세포의 용도 또한 본 개시내용의 범주 내에 있다. 제약 조성물 중 임의의 것은 Fc-함유 치료제, 예컨대, 항체 또는 Fc-융합 단백질을 추가로 포함할 수 있거나, 또는 그와 함께 공동으로 사용될 수 있다.
추가로, 본 개시내용은 본원에 기술된 바와 같은 키메라 수용체를 발현하는 면역 세포를 제조하는 방법을 제공한다. 본 방법은 (i) 면역 세포 집단을 제공하는 단계; (ii) 면역 세포 내로 벡터 (예컨대, 바이러스 벡터, 예컨대, 렌티바이러스 벡터 또는 레트로바이러스 벡터, 트랜스포존 또는 트랜스포존 서열을 함유하는 벡터) 또는 본원에서 제공하는 키메라 수용체 중 임의의 것을 코딩하는 네이키드 핵산 (예컨대, mRNA)을 도입하는 단계; 및 (iii) 키메라 수용체가 발현될 수 있도록 허용하는 조건하에서 면역 세포를 배양하는 단계를 포함한다. 상기 방법은 (iv) 키메라 수용체를 발현하는 면역 세포를 활성화시키는 단계를 추가로 포함할 수 있다. 면역 세포가 T 세포를 포함하는 경우인 예에서, T 세포는 항-CD3 항체, 항-CD28 항체, IL-2, 및 피토헤모아글루티닌 중 하나 이상의 것의 존재하에서 활성화될 수 있다. T 세포는 내인성 T 세포 수용체의 발현이 억제되거나, 또는 제거될 수 있도록 조작될 수 있다. 면역 세포가 자연살 세포를 포함하는 경우인 예에서, 자연살 세포는 4-1BB 리간드, 항-4-1BB 항체, IL-15, 항-IL-15 수용체 항체, IL-2, IL-12, IL-21 및 K562 세포 중 하나 이상의 것의 존재하에서 활성화될 수 있다.
일부 실시양태에서, 면역 세포 집단은 말초 혈액 단핵 세포 (PBMC)로부터 유래된 것이다. 예시적인 면역 세포로는 자연살 세포, 대식세포, 호중구, 호산구, T 세포, 또는 그의 조합을 포함하나, 이에 제한되지 않는다. 일부 실시양태에서, 면역 세포 (예컨대, PBMC)는 인간 암 환자로부터 유래된 것이다. 일부 실시양태에서, 면역 세포는 인간 공여자로부터 유래된 것이다. 일부 실시양태에서, 면역 세포는 인간 환자 또는 인간 공여자로부터 유래된 줄기 세포 또는 줄기-유사 세포로부터 분화된 것이다. 일부 실시양태에서, 면역 세포는 확립된 세포주, 예컨대, NK-92 세포이다.
본원에서 제공하는 방법 중 임의의 것에서, 벡터는 렌티바이러스 형질도입, 레트로바이러스 형질도입, DNA 전기천공, 또는 RNA 전기천공에 의해 면역 세포 내로 도입될 수 있다. 다른 예에서, 본원에 기술된 키메라 수용체를 코딩하는 RNA 분자는 발현을 위해 면역 세포 내로 도입될 수 있다.
본 개시내용의 하나 이상의 실시양태에 관한 상세한 설명은 하기의 설명에서 기재한다. 본 개시내용의 다른 특징 또는 이점은 수개의 실시양태의 상세한 설명으로부터, 및 첨구된 특허청구범위로부터 자명해질 것이다.
하기 도면은 본 명세서의 일부를 형성하며, 본 개시내용의 특정 측면을 추가로 입증하기 위해 포함되며, 이는 본원에서 제시하는 구체적인 실시양태의 상세한 설명과 함께 조합하여 상기 도면 중 하나 이상의 것을 참조하여 더욱 잘 이해될 수 있다.
도 1은 T 세포에서의 CD16V-BB-ζ 수용체의 발현을 입증하는 다이어그램이다. A: CD16V-BB-ζ 수용체 구축물을 나타낸 개략도. B: 말초 혈액 T 림프구에서의 CD16V-BB-ζ 수용체의 발현을 보여주는 그래프. 유세포 분석 점도표는 GFP 단독 (모의) 또는 GFP 및 CD16V-BB-ζ를 함유하는 벡터가 형질도입된 활성화된 T 림프구에서의 GFP 또는 CD3ζ와 함께 조합된 CD16 (B73.1 항체)의 발현을 도시한 것이다. 각 사분면에는 양성 세포의 비율(%)이 제시되어 있다. C: GFP 단독 또는 CD16V-BB-ζ가 형질도입된 T 림프구로부터의 세포 용해물의 대표적인 웨스턴 블롯을 보여주는 사진이다. 막을 항-CD3ζ 항체로 프로빙하였다.
도 2는 T 세포 서브세트에서의 CD16V-BB-ζ 수용체의 발현을 보여주는 것이다. A: GFP 단독 (모의)을 함유하는 벡터, 및 CD16V-BB-ζ 구축물을 함유하는 벡터로 활성화된 CD3+ T 림프구를 형질도입하였다. 유세포 분석법에 의해 CD4+ 및 CD8+ 세포에서의 CD16의 발현을 시험하였다. 점도표는 하나의 대표적인 실험의 결과를 보여주는 것이다. B: 3명의 공여자로부터의 T 림프구를 이용하여 수득한 결과 (평균 ± SD) 요약 (P = N.S.).
도 3은 CD16V-BB-ζ 수용체의 항체 결합 능력을 입증하는 것이다. A: GFP (모의), 또는 GFP 및 CD16V-BB-ζ를 함유하는 벡터가 형질도입되고, 30분 동안 리툭시맙(Rituximab)과 함께 인큐베이션된 T 림프구; 피코에리트린에 접합된 염소-항 인간 IgG 항체 (GAH IgG) 및 유세포 분석법을 이용하여 세포 표면에 결합된 항체의 양을 시각화하였다. B: CD16V-BB-ζ (V158) 또는 CD16F-BB-ζ (F158)가 형질도입되고, 30분 동안 리툭시맙과 함께 인큐베이션된 저캣(Jurkat) 세포. 플롯은 두 수용체를 발현하는 세포를 이용하여 수득된, GFP의 평균 형광 강도 (MFI), 및 GAH IgG의 MFI 사이의 관계를 비교한 것이다. C: 리툭시맙의 존재하에서 칼세인 AM 오렌지-레드로 표지된, 다우디(Daudi) 세포와 함께 공동 배양된, 모의-형질도입된, 또는 CD16V-BB-ζ가 형질도입된 저캣 세포. 각 점도표의 우측 상부 사분면에는 세포 응집체가 정량화되어 있다. D: 패널 C에 도시된 응집 검정 요약. 막대는 3회에 걸쳐 수행된 실험의 평균 ± SD을 보여주는 것이다. 리툭시맙 ("Ab")의 존재하에서 CD16V-BB-ζ가 형질도입된 저캣 세포에서 측정된 응집이 3개의 다른 배양 조건하에서 측정된 것보다 유의적으로 더 높았다 (t 검정에 의해 P<0.001).
도 4는 트라스투주맙 및 인간 IgG에 결합하는 CD16V-BB-ζ 및 CD16F-BB-ζ 수용체의 상대적인 능력을 보여주는 것이다. CD16V-BB-ζ (V158; 검은색 기호) 또는 CD16F-BB-ζ (F158; 흰색 기호)가 형질도입된 저캣 세포를 30분 동안 트라스투주맙 또는 인간 IgG와 함께 인큐베이션시켰다. 플롯은 수용체 중 어느 하나를 발현하는 세포를 이용하여 수득된, GFP의 평균 형광 강도 (MFI), 및 PE에 접합된 염소-항 인간 (GAH) IgG의 MFI 사이의 관계를 비교한 것이다 (트라스투주맙 및 IgG, 둘 모두에 대하여 P<0.0001).
도 5는 CD16V-BB-ζ 수용체에의 면역글로불린 결합이 T 세포 활성화, 용해성 과립의 엑소사이토시스, 및 세포 증식을 유도한다는 것을 입증하는 것이다. A: GFP (모의), 또는 GFP 및 CD16V-BB-ζ를 함유하는 벡터가 형질도입된 T 림프구를 리툭시맙으로 코팅된 마이크로타이터 플레이트에서 IL-2의 부재하에 48시간 동안 배양하였다; 유세포 분석법에 의해 CD25의 발현을 측정하였다. B: A에 도시된 시험의 결과 요약, 막대는 GFP+ 세포에서의 CD25 발현 (3명의 공여자로부터의 T 세포를 이용하여 수행된 실험의 평균 ± SD)을 보여주는 것이다; CD25 발현은 다른 실험 조건에서보다 리툭시맙 ("Ab")의 존재하에서 CD16V-BB-ζ가 형질도입된 T 림프구에서 유의적으로 더 높았다 (P≤0.003). C: GFP (모의), 또는 GFP 및 CD16V-BB-ζ를 함유하는 벡터가 형질도입된, 4명의 공여자로부터의 T 림프구를 A에서와 같이 (n =3) 또는 다우디 세포 (n =3)와 함께 4시간 동안 배양하였다; CD107a 염색을 유세포 분석법으로 측정하였다. 막대는 6회 수행된 실험의 평균 ± SD를 보여주는 것이다; CD107a 발현은 다른 실험 조건에서보다 리툭시맙 ("Ab")의 존재하에서 CD16V-BB-ζ가 형질도입된 T 림프구에서 유의적으로 더 높았다 (P<0.0001). D: 최대 4주 동안 단독으로, 또는 다우디 세포 존재하에 또는 부재하에 리툭시맙과 함께 배양된 모의- 또는 CD16V-BB-ζ-형질도입된 T 림프구. 기호는 유입 세포수와 비교하였을 때의 세포 회수율(%) (3명의 공여자로부터의 T 세포를 이용하여 수행된 실험의 평균 ± SD)을 나타낸다.
도 6은 시험관내에서의 CD16V-BB-ζ T 림프구에 의해 매개되는 항체 의존성 세포 세포독성을 입증하는 것이다. A: 상응하는 항체의 존재하에서의 모의- 또는 CD16V-BB-ζ-형질도입된 T 림프구에 의해 매개된 암 세포주에 대한 세포독성을 나타내는 대표적인 예. 각 기호는 삼중으로 수행된 배양의 평균 (3개의 비교물 모두에 대한 대응표본 t 검정에 의해 P<0.01)을 나타내는 것이다. 전체 데이터 세트는 도 7에 제시되어 있다. B: 만성 림프구성 백혈병 (CLL) 환자로부터의 1차 세포에 대한, 리툭시맙 ("Ab")의 존재 또는 부재하의, 모의- 또는 CD16V-BB-ζ-형질도입된 T 림프구의 세포독성. (각 환자에 대하여 다른 음영으로 표시된) 각 막대는 2:1 E:T 비율로 3중으로 4시간 동안의 검정법으로 측정된, 평균 (± SD) 세포독성에 상응하는 것이다. CD16V-BB-ζ T 세포 및 항체인 경우의 세포독성이 나머지 다른 3개의 조건 중 임의의 것에서 측정된 것보다 유의적으로 더 높았고 (t 검정에 의해 P<0.0001); 모의-형질도입된 T 세포의 경우, 항체 첨가가 세포독성을 증가시켰다 (P = 0.016); 나머지 다른 모든 비교물: P>0.05. C: 중간엽 기질 세포 (MSC)의 존재하에서 1:2 E:T에서의 24시간 경과 후, 패널 B에서 시험된 같은 CLL 샘플에 대한 세포독성. 각 막대는 2회 수행된 시험의 평균에 상응하는 것이다. CD16V-BB-ζ T 세포 + 항체 경우의 세포독성이 항체 단독 (P = 0.0002) 또는 세포 단독 (P<0.0001)인 경우에서보다 유의적으로 더 높았고 (P<0.0001); 항체 단독인 경우의 세포독성이 세포 단독인 경우에서보다 유의적으로 더 높았다 (P = 0.0045).
도 7은 4시간 동안의 시험관내 세포독성 검정법의 총체적 결과를 보여주는 것이다. 모의- 또는 CD16V-BB-ζ T 림프구를 제시된 세포주, 및 비반응성 인간 면역글로불린 ("Ab 부재") 또는 상응하는 항체 ("Ab")와 함께 공동 배양하였다. 이는 다우디 및 라모스(Ramos)의 경우, 리툭시맙, MCF-7, SKBR-3, 및 MKN-7의 경우, 트라스투주맙, 및 CHLA-255, NB1691, SK-N-SH 및 U-2 OS의 경우, hu14.18K322A였다. T 세포 및/또는 항체 부재하에서 배양된 종양 세포와 비교하였을 때, 세포독성은 2:1 비율로 나타났다 (CHLA-255의 경우, 4:1). 본 결과는 NB1691 및 SK-BR-3의 경우, 3명의 공여자, 및 나머지 세포주의 경우, 1명의 공여자의 T 림프구를 이용하여 수행된 삼중으로 수행된 실험의 평균 (± SD) 세포독성에 상응하는 것이다; 다우디의 결과는 2명의 공여자로부터의 삼중으로 수행된 측정, 및 추가의 4명의 공여자로부터의 T 림프구를 사용하여 수행된 단일 측정의 평균 (± SD) 세포독성이다. T 세포 부재하에서 배양물에 첨가되었을 때, 리툭시맙, 트라스투주맙 또는 hu14.18K322A의 평균 세포독성은 <10%였다.
도 8은 CD16V-BB-ζ T 림프구의 세포독성은 강력하고, 특이적이며, 비결합 IgG에 의해 영향을 받지 않는다는 것을 입증하는 것이다. A: 24시간 동안 비반응성 인간 면역글로불린 ("Ab 부재") 또는 hu14.18K322A 항체 ("Ab")와 함께, 신경모세포종 세포주 NB1691과 공동 배양된 CD16V-BB-ζ T 림프구. 결과는 삼중으로 수행된 실험의 평균 (± SD) 세포독성에 상응하는 것이다. 세포독성은 심지어 1:8 E:T에서도 CD16V-BB-ζ T 세포 단독과 비교하였을 때, CD16V-BB-ζ 세포 + hu14.18K322A 항체의 경우에 유의적으로 더 높게 그대로 유지되었다 (P = 0.0002). B: 리툭시맙, 또는 비반응성 항체 트라스투주맙 또는 hu14.18K322A의 존재하에서의 2:1 E:T에서의 B 세포 림프종 세포주 다우디와 함께 4시간 동안 공동 배양된 모의- 또는 CD16V-BB-ζ-형질도입된 T 림프구. 결과는 삼중으로 수행된 실험의 평균 (± SD) 세포독성에 상응하는 것이다 ("모의" 결과는 각 항체를 이용하여 삼중으로 수행된 실험의 합계이다). 리툭시맙 경우의 세포독성은 다른 모든 실험 조건하의 것보다 유의적으로 더 높았다 (모든 비교물에 대해 P<0.0001). C: 다양한 농도의 면역치료학적 항체 및 상기 항체에 동시에 첨가된) 경쟁 비결합 IgG의 존재하에서 8:1 E:T에서의 CD16V-BB-ζ를 발현하는 T 림프구의 종양 세포주에 대한 세포독성. 기호는 각 항체 농도에 대한 적어도 삼중으로 수행된 실험에 대한 평균 (± SD)에 상응하는 것이다. 각 세포주의 경우, 세포독성은 비결합 IgG의 존재량과 상관없이, 통계학상 다르지 않았다.
도 9는 CD16V-BB-ζ 수용체를 발현하는 T 림프구가 생체내에서 항-종양 활성을 발휘한다는 것을 입증하는 것이다. 루시페라제로 표지된 3 x 105개의 다우디 세포를 i.p.로 NOD-SCID-IL2RG널 마우스에 주사하였다. 4일째를 출발로 하여 4주 동안 주 1회에 걸쳐 i.p.로 리툭시맙 (150 ㎍)을 주사하였다. 4마리 마우스에서는 어떤 따른 처리도 하지 않은 반면, 5마리의 다른 마우스에서는 1차 리툭시맙 주사를 수행한 후, 이어서, 5일째 및 6일째 CD16V-BB-ζ 수용체를 발현하는 T 림프구를 주사하였고 (1 x 107개 i.p.; n = 5); 4마리의 마우스로 이루어진 다른 2개의 군은 각각 리툭시맙 대신 RPMI-1640의 i.p. 주사 후에 CD16V-BB-ζ T 림프구를 받거나, 또는 오직 RPMI-1640 배지만 ("대조군")을 받았다. A: 종양 성장에 관한 생체내 영상화 결과. 각 기호는 한 생체발광 측정치에 상응하는 것이고; 선은 1마리의 마우스에서의 모든 측정치를 연결한 것이다. B: 각 실험 조건에 대한 대표 마우스 (각 군당 2마리씩)가 제시되어 있다. 3일째의 복측 영상을 CD16V-BB-ζ + 리툭시맙 군의 마우스에서의 종양의 존재를 입증하기 위해 증강된 감도로 프로세싱하였다. 생체발광이 5 x 1010 광자/초에 도달하였을 때, 마우스를 안락사시켰다. C: 상이한 처리군의 마우스에 관한 전체 생존 비교.
도 10은 CD16V-BB-ζ 수용체를 발현하는 T 림프구가 생체내에서 항-종양 활성을 발휘한다는 것을 입증하는 것이다. 루시페라제로 표지된 3 x 105개의 NB1691 세포를 i.p.로 NOD-SCID-IL2RG널 마우스에 주사하였다. 5일째를 출발로 하여 4주 동안 주 1회에 걸쳐 i.p.로 Hu14.18K322A 항체 (25 ㎍)를 주사하였다. 4마리 마우스에서는 어떤 따른 처리도 하지 않은 반면, 4마리의 다른 마우스에서는 1차 항체 주사를 수행한 후, 이어서, 6일째 및 7일째 CD16V-BB-ζ 수용체를 발현하는 T 림프구를 주사하였고 (1 x 107개 i.p.; n = 4); 4마리의 마우스로 이루어진 다른 2개의 군은 각각 항체 대신 RPMI-1640의 i.p. 주사 후에 CD16V-BB-ζ T 림프구를 받거나, 또는 오직 RPMI-1640 배지만 ("대조군")을 받았다. A: 종양 성장에 관한 생체내 영상화 결과. 각 기호는 한 생체발광 측정치에 상응하는 것이고; 선은 1마리의 마우스에서의 모든 측정치를 연결한 것이다. B: 각 실험 조건에 대한 모든 마우스의 영상. 생체발광이 1 x 1010 광자/초에 도달하였을 때, 마우스를 안락사시켰다. C: 상이한 처리군의 마우스에 관한 전체 생존 비교.
도 11은 CD16V-BB-ζ 및 CD16F-BB-ζ 수용체를 발현하는 T 림프구 사이의 기능적 차이를 입증하는 것이다. A: 유세포 분석 점도표는 CD16V-BB-ζ 또는 CD16F-BB-ζ가 형질도입된 T 림프구에서의 (B73.1 항체로 검출되는) CD16 및 녹색 형광 단백질 (GFP)의 발현을 보여주는 것이다. 각 사분면에는 양성 세포의 비율(%)이 제시되어 있다. B: CD16V 또는 CD16F 수용체가 형질도입된 T 림프구를 각각 리툭시맙, 트라스투주맙 및 hu14.18K322A의 존재하에서 다우디, SK-BR-3 또는 NB1691 세포와 함께 배양하였다. 모든 항체는 0.1 ㎍/mL로 사용되었다. 기호는 유입 세포수와 비교하였을 때의 세포 회수율(%) (3회에 걸쳐 수행된 실험의 평균 ± SD)을 나타낸다; 1주째 내지 3주째 배양물에 대한 세포 계수는 3개의 배양물 모두에 대한 대응표본 t 검정에 의해 유의적인 차이를 보였다 (다우디, P = 0.0007; SK-BR-3, P = 0.0164; NB1691, P = 0.022). C: 다양한 농도의 리툭시맙의 존재하에서의 다우디 세포에 대한, CD16V-BB-ζ 또는 CD16F-BB-ζ 수용체를 발현하는 T 림프구에 의해 매개되는 항체 의존성 세포 세포독성. 각 기호는 8:1 (좌측) 또는 2:1 (우측) E:T에서의 삼중 배양물의 평균 ± SD를 나타낸다. CD16V-BB-ζ를 발현하는 T 세포의 세포독성이 CD16F-BB-ζ를 발현하는 T 세포의 것보다 유의적으로 더 높았다 (어느 E:T에서든 P<0.001).
도 12는 본 연구에서 사용된 CD16 키메라 수용체를 나타내는 개략도를 보여주는 것이다.
도 13은 상이한 신호전달 도메인을 포함하는 CD16V 수용체의 발현을 보여주는 것이다. 유세포 분석 점도표는 녹색 형광 단백질 (GFP) 단독 (모의) 또는 상이한 CD16V 구축물을 함유하는 벡터가 형질도입된 활성화된 T 림프구에서의 GFP와 함께 조합된 (3G8 항체로 검출되는) CD16의 발현을 보여주는 것이다. 각 사분면에는 양성 세포의 비율(%)이 제시되어 있다.
도 14는 CD16V-BB-ζ는 상이한 신호전달 특성을 가지는 CD16V 수용체보다도 더 높은 T 세포 활성화, 증식 및 세포독성을 유도한다는 것을 입증하는 것이다. A: 다우디 세포 및 리툭시맙 (0.1 ㎍/mL)과 함께한 48시간 동안의 공동 배양 후, 상이한 키메라 수용체를 발현하는 T 림프구에서의 녹색 형광 단백질 (GFP) 평균 형광 강도 (MFI)에 대해 플롯팅된, 유세포 분석법에 의해 CD25 MFI. CD16V-BB-ζ를 포함하는 CD25 발현은 CD16V-ζ, CD16V-FcεRIγ 또는 신호전달 능력이 없는 CD16V ("CD16V-말단절단")에 의해 유발된 것보다 유의적으로 더 높았다 (선형 회귀 분석에 의해 P<0.0001). B: 다양한 CD16V 수용체가 형질도입된 T 림프구를 각각 리툭시맙, 트라스투주맙 및 hu14.18K322A의 존재하에서 다우디, SK-BR-3 또는 NB1691 세포와 함께 배양하였다. 모든 항체는 0.1 ㎍/mL로 사용되었다. 기호는 유입 세포수와 비교하였을 때의 세포 회수율(%) (3회에 걸쳐 수행된 실험의 평균 ± SD)을 나타낸다; 1주째 내지 3주째 배양물에 대한 세포 계수는 3개의 배양물 모두에 대한 대응표본 t 검정에 의해 모든 다른 수용체보다 CD16V-BB-ζ 수용체 경우에 유의적으로 더 높았다 (P<0.0001). C: 각각 리툭시맙, 트라스투주맙 및 hu14.18K322A의 존재하에서의 다우디, SK-BR-3 및 NB1691에 대한 각종 CD16V 수용체를 발현하는 T 림프구 또는 모의-형질도입된 T 세포의 ADCC. 기호는 제시된 E:T에서의 삼중 배양물의 평균 ± SD이다. CD16V-BB-ζ 수용체 경우의 세포독성은 다른 모든 수용체의 것보다 유의적으로 더 높은 반면 (모든 비교물에서 t 검정에 의해 P<0.0001), 모의-형질도입된 림프구, 또는 CD16V-말단절단된 수용체가 형질도입된 림프구의 세포독성은 서로 유의적으로 상이하지는 않았고 (P>0.05); 다우디 (P = 0.006) 및 SK-BR-3 (P = 0.019)에 대한 CD16V-FcεRIγ 경우의 세포독성은 CD3-ζ인 경우의 세포독성보다 유의적으로 더 높았고; 어느 수용체든 그를 발현하는 림프구는 모의-형질도입된 것 또는 CD16V-말단절단으로 형질도입된 것보다 더 높은 세포독성을 가졌다 (모든 비교물에 대해 P<0.01).
도 15는 mRNA 전기천공에 의한 CD16V-BB-ζ 수용체의 발현을 입증하는 것이다. A: CD16V-BB-ζ mRNA로, 또는 mRNA 부재(모의)하에 활성화된 T 림프구를 전기천공하였다; 24시간 경과 후 유세포 분석법에 의해 CD16의 발현을 시험하였다. B: 리툭시맙의 존재하에서 라모스 세포주에 대한 모의 또는 CD16V-BB-ζ 전기천공된 T 세포의 세포독성을 시험하였다. 기호는 세포독성(%)의 평균 ± SD를 나타낸다 (n=3; 모든 E:T 비율에서의 비교물에 대한 P<0.01).
도 16은 키메라 수용체 서열식별번호: 1의 발현이 이루어진 저캣 세포 및 그 발현이 이루어지지 않은 저캣 세포에의 리툭산(Rituxan)의 결합을 보여주는 것이다. 저캣 세포를 mRNA 부재하에 (패널 A) 또는 키메라 수용체 서열식별번호: 1을 코딩하는 mRNA로 (패널 B) 전기천공시키고, 리툭산과 함께 인큐베이션시키고, 결합된 리툭산을 검출하기 위해 PE-표지된 염소-항-인간 항체로 염색하고, 유세포 분석법에 의해 분석하였다. 패널 A 및 B에서, 동일 사분면 게이트를 각 데이터 세트에 적용시켰고, 각 사분면에 세포 비율(%)이 제시되어 있으며, 우측 상단의 사분면은 리툭산 양성 세포를 나타낸다. 패널 C에서는 모의-전기천공된 세포 (채워지지 않은 것) 및 키메라 수용체 서열식별번호: 1을 코딩하는 mRNA로 전기천공된 세포 (회색)에 대한 리툭산 염색의 함수로서 세포 개수가 플롯팅되어 있다.
도 17은 리툭산 및 표적 다우디 세포 존재하에서의 키메라 수용체 서열식별번호: 1의 발현이 이루어진 저캣 세포 및 그 발현이 이루어지지 않은 저캣 세포 상의 CD25 존재를 보여주는 것이다. 저캣 세포를 mRNA 부재하에 (패널 A) 또는 키메라 수용체 서열식별번호: 1을 코딩하는 mRNA로 (패널 17B) 전기천공시킨 후, 이어서, 리툭산 및 표적 다우디 세포와 함께 인큐베이션시켰다. 저캣 세포를 단리시키기 위해 PE-표지된 항-CD7 항체로, 및 CD25 발현을 검출하기 위해 APC-표지된 항-C25 항체로 세포를 염색하고, 유세포 분석법에 의해 분석하였다. 패널 A 및 B에 CD7 양성 세포가 제시되어 있으며, 동일 사분면 게이트를 각 데이터 세트에 적용시켰다. 각 사분면에 세포 비율(%)이 제시되어 있으며, 우측 상단의 사분면은 CD25 양성 세포를 나타낸다. 패널 C는 같은 실험으로부터 얻은 데이터의 히스토그램을 나타내는 것이다. CD7 양성 세포의 개수는 모의-전기천공된 세포 (채워지지 않은 것)에 대한 CD25 염색의 함수로서 플롯팅되어 있고, 키메라 수용체 서열식별번호: 1을 코딩하는 mRNA로 전기천공된 세포 (회색)는 CD25 염색의 함수로서 플롯팅되어 있다.
도 18은 리툭산 및 표적 다우디 세포 존재하에서의 키메라 수용체 서열식별번호: 1의 발현이 이루어진 저캣 세포 및 그 발현이 이루어지지 않은 저캣 세포 상의 CD69 존재를 보여주는 것이다. 저캣 세포를 mRNA 부재하에 (패널 A) 또는 키메라 수용체 서열식별번호: 1을 코딩하는 mRNA로 (패널 B) 전기천공시킨 후, 이어서, 리툭산 및 표적 다우디 세포와 함께 인큐베이션시켰다. 저캣 세포를 단리시키기 위해 PE-표지된 항-CD7 항체로, 및 CD69 발현을 검출하기 위해 APC-표지된 항-C69 항체로 세포를 염색하고, 유세포 분석법에 의해 분석하였다. 패널 A 및 B에 CD7 양성 세포가 제시되어 있으며, 동일 사분면 게이트를 각 데이터 세트에 적용시켰다. 각 사분면에 세포 비율(%)이 제시되어 있으며, 우측 상단의 사분면은 CD69 양성 세포를 나타낸다. 패널 C는 같은 실험으로부터 얻은 데이터의 히스토그램을 나타내는 것이다. CD7 양성 세포의 개수는 모의-전기천공된 세포 (채워지지 않은 것), 및 키메라 수용체 서열식별번호: 1을 코딩하는 mRNA로 전기천공된 세포 (회색)에 대한 CD69 염색의 함수로서 플롯팅되어 있다.
도 19는 키메라 수용체의 대표적인 항-CD3ζ 웨스턴 블롯 분석을 보여주는 것이다. 저캣 세포를 mRNA 부재하에(레인 1), 또는 키메라 수용체 서열식별번호: 1 (레인 2), 서열식별번호: 3 (레인 3), 서열식별번호: 10 (레인 4), 서열식별번호: 11 (레인 5), 서열식별번호: 14 (레인 6), 서열식별번호: 2 (레인 7), 서열식별번호: 4 (레인 8), 서열식별번호: 5 (레인 9), 서열식별번호: 7 (레인 10), 서열식별번호: 8 (레인 11), 서열식별번호: 9 (레인 12), 또는 서열식별번호: 6 (레인 13)을 코딩하는 mRNA로 전기천공시켰다. 세포를 수거하고, 용해시키고, 항-CD3ζ 항체를 이용하여 웨스턴 블롯 분석에 의해 분석하였다. 키메라 수용체 mRNA로 전기천공된 모든 세포로부터의 용해물 중에서 키메라 수용체 단백질을 검출하였다.
도 1은 T 세포에서의 CD16V-BB-ζ 수용체의 발현을 입증하는 다이어그램이다. A: CD16V-BB-ζ 수용체 구축물을 나타낸 개략도. B: 말초 혈액 T 림프구에서의 CD16V-BB-ζ 수용체의 발현을 보여주는 그래프. 유세포 분석 점도표는 GFP 단독 (모의) 또는 GFP 및 CD16V-BB-ζ를 함유하는 벡터가 형질도입된 활성화된 T 림프구에서의 GFP 또는 CD3ζ와 함께 조합된 CD16 (B73.1 항체)의 발현을 도시한 것이다. 각 사분면에는 양성 세포의 비율(%)이 제시되어 있다. C: GFP 단독 또는 CD16V-BB-ζ가 형질도입된 T 림프구로부터의 세포 용해물의 대표적인 웨스턴 블롯을 보여주는 사진이다. 막을 항-CD3ζ 항체로 프로빙하였다.
도 2는 T 세포 서브세트에서의 CD16V-BB-ζ 수용체의 발현을 보여주는 것이다. A: GFP 단독 (모의)을 함유하는 벡터, 및 CD16V-BB-ζ 구축물을 함유하는 벡터로 활성화된 CD3+ T 림프구를 형질도입하였다. 유세포 분석법에 의해 CD4+ 및 CD8+ 세포에서의 CD16의 발현을 시험하였다. 점도표는 하나의 대표적인 실험의 결과를 보여주는 것이다. B: 3명의 공여자로부터의 T 림프구를 이용하여 수득한 결과 (평균 ± SD) 요약 (P = N.S.).
도 3은 CD16V-BB-ζ 수용체의 항체 결합 능력을 입증하는 것이다. A: GFP (모의), 또는 GFP 및 CD16V-BB-ζ를 함유하는 벡터가 형질도입되고, 30분 동안 리툭시맙(Rituximab)과 함께 인큐베이션된 T 림프구; 피코에리트린에 접합된 염소-항 인간 IgG 항체 (GAH IgG) 및 유세포 분석법을 이용하여 세포 표면에 결합된 항체의 양을 시각화하였다. B: CD16V-BB-ζ (V158) 또는 CD16F-BB-ζ (F158)가 형질도입되고, 30분 동안 리툭시맙과 함께 인큐베이션된 저캣(Jurkat) 세포. 플롯은 두 수용체를 발현하는 세포를 이용하여 수득된, GFP의 평균 형광 강도 (MFI), 및 GAH IgG의 MFI 사이의 관계를 비교한 것이다. C: 리툭시맙의 존재하에서 칼세인 AM 오렌지-레드로 표지된, 다우디(Daudi) 세포와 함께 공동 배양된, 모의-형질도입된, 또는 CD16V-BB-ζ가 형질도입된 저캣 세포. 각 점도표의 우측 상부 사분면에는 세포 응집체가 정량화되어 있다. D: 패널 C에 도시된 응집 검정 요약. 막대는 3회에 걸쳐 수행된 실험의 평균 ± SD을 보여주는 것이다. 리툭시맙 ("Ab")의 존재하에서 CD16V-BB-ζ가 형질도입된 저캣 세포에서 측정된 응집이 3개의 다른 배양 조건하에서 측정된 것보다 유의적으로 더 높았다 (t 검정에 의해 P<0.001).
도 4는 트라스투주맙 및 인간 IgG에 결합하는 CD16V-BB-ζ 및 CD16F-BB-ζ 수용체의 상대적인 능력을 보여주는 것이다. CD16V-BB-ζ (V158; 검은색 기호) 또는 CD16F-BB-ζ (F158; 흰색 기호)가 형질도입된 저캣 세포를 30분 동안 트라스투주맙 또는 인간 IgG와 함께 인큐베이션시켰다. 플롯은 수용체 중 어느 하나를 발현하는 세포를 이용하여 수득된, GFP의 평균 형광 강도 (MFI), 및 PE에 접합된 염소-항 인간 (GAH) IgG의 MFI 사이의 관계를 비교한 것이다 (트라스투주맙 및 IgG, 둘 모두에 대하여 P<0.0001).
도 5는 CD16V-BB-ζ 수용체에의 면역글로불린 결합이 T 세포 활성화, 용해성 과립의 엑소사이토시스, 및 세포 증식을 유도한다는 것을 입증하는 것이다. A: GFP (모의), 또는 GFP 및 CD16V-BB-ζ를 함유하는 벡터가 형질도입된 T 림프구를 리툭시맙으로 코팅된 마이크로타이터 플레이트에서 IL-2의 부재하에 48시간 동안 배양하였다; 유세포 분석법에 의해 CD25의 발현을 측정하였다. B: A에 도시된 시험의 결과 요약, 막대는 GFP+ 세포에서의 CD25 발현 (3명의 공여자로부터의 T 세포를 이용하여 수행된 실험의 평균 ± SD)을 보여주는 것이다; CD25 발현은 다른 실험 조건에서보다 리툭시맙 ("Ab")의 존재하에서 CD16V-BB-ζ가 형질도입된 T 림프구에서 유의적으로 더 높았다 (P≤0.003). C: GFP (모의), 또는 GFP 및 CD16V-BB-ζ를 함유하는 벡터가 형질도입된, 4명의 공여자로부터의 T 림프구를 A에서와 같이 (n =3) 또는 다우디 세포 (n =3)와 함께 4시간 동안 배양하였다; CD107a 염색을 유세포 분석법으로 측정하였다. 막대는 6회 수행된 실험의 평균 ± SD를 보여주는 것이다; CD107a 발현은 다른 실험 조건에서보다 리툭시맙 ("Ab")의 존재하에서 CD16V-BB-ζ가 형질도입된 T 림프구에서 유의적으로 더 높았다 (P<0.0001). D: 최대 4주 동안 단독으로, 또는 다우디 세포 존재하에 또는 부재하에 리툭시맙과 함께 배양된 모의- 또는 CD16V-BB-ζ-형질도입된 T 림프구. 기호는 유입 세포수와 비교하였을 때의 세포 회수율(%) (3명의 공여자로부터의 T 세포를 이용하여 수행된 실험의 평균 ± SD)을 나타낸다.
도 6은 시험관내에서의 CD16V-BB-ζ T 림프구에 의해 매개되는 항체 의존성 세포 세포독성을 입증하는 것이다. A: 상응하는 항체의 존재하에서의 모의- 또는 CD16V-BB-ζ-형질도입된 T 림프구에 의해 매개된 암 세포주에 대한 세포독성을 나타내는 대표적인 예. 각 기호는 삼중으로 수행된 배양의 평균 (3개의 비교물 모두에 대한 대응표본 t 검정에 의해 P<0.01)을 나타내는 것이다. 전체 데이터 세트는 도 7에 제시되어 있다. B: 만성 림프구성 백혈병 (CLL) 환자로부터의 1차 세포에 대한, 리툭시맙 ("Ab")의 존재 또는 부재하의, 모의- 또는 CD16V-BB-ζ-형질도입된 T 림프구의 세포독성. (각 환자에 대하여 다른 음영으로 표시된) 각 막대는 2:1 E:T 비율로 3중으로 4시간 동안의 검정법으로 측정된, 평균 (± SD) 세포독성에 상응하는 것이다. CD16V-BB-ζ T 세포 및 항체인 경우의 세포독성이 나머지 다른 3개의 조건 중 임의의 것에서 측정된 것보다 유의적으로 더 높았고 (t 검정에 의해 P<0.0001); 모의-형질도입된 T 세포의 경우, 항체 첨가가 세포독성을 증가시켰다 (P = 0.016); 나머지 다른 모든 비교물: P>0.05. C: 중간엽 기질 세포 (MSC)의 존재하에서 1:2 E:T에서의 24시간 경과 후, 패널 B에서 시험된 같은 CLL 샘플에 대한 세포독성. 각 막대는 2회 수행된 시험의 평균에 상응하는 것이다. CD16V-BB-ζ T 세포 + 항체 경우의 세포독성이 항체 단독 (P = 0.0002) 또는 세포 단독 (P<0.0001)인 경우에서보다 유의적으로 더 높았고 (P<0.0001); 항체 단독인 경우의 세포독성이 세포 단독인 경우에서보다 유의적으로 더 높았다 (P = 0.0045).
도 7은 4시간 동안의 시험관내 세포독성 검정법의 총체적 결과를 보여주는 것이다. 모의- 또는 CD16V-BB-ζ T 림프구를 제시된 세포주, 및 비반응성 인간 면역글로불린 ("Ab 부재") 또는 상응하는 항체 ("Ab")와 함께 공동 배양하였다. 이는 다우디 및 라모스(Ramos)의 경우, 리툭시맙, MCF-7, SKBR-3, 및 MKN-7의 경우, 트라스투주맙, 및 CHLA-255, NB1691, SK-N-SH 및 U-2 OS의 경우, hu14.18K322A였다. T 세포 및/또는 항체 부재하에서 배양된 종양 세포와 비교하였을 때, 세포독성은 2:1 비율로 나타났다 (CHLA-255의 경우, 4:1). 본 결과는 NB1691 및 SK-BR-3의 경우, 3명의 공여자, 및 나머지 세포주의 경우, 1명의 공여자의 T 림프구를 이용하여 수행된 삼중으로 수행된 실험의 평균 (± SD) 세포독성에 상응하는 것이다; 다우디의 결과는 2명의 공여자로부터의 삼중으로 수행된 측정, 및 추가의 4명의 공여자로부터의 T 림프구를 사용하여 수행된 단일 측정의 평균 (± SD) 세포독성이다. T 세포 부재하에서 배양물에 첨가되었을 때, 리툭시맙, 트라스투주맙 또는 hu14.18K322A의 평균 세포독성은 <10%였다.
도 8은 CD16V-BB-ζ T 림프구의 세포독성은 강력하고, 특이적이며, 비결합 IgG에 의해 영향을 받지 않는다는 것을 입증하는 것이다. A: 24시간 동안 비반응성 인간 면역글로불린 ("Ab 부재") 또는 hu14.18K322A 항체 ("Ab")와 함께, 신경모세포종 세포주 NB1691과 공동 배양된 CD16V-BB-ζ T 림프구. 결과는 삼중으로 수행된 실험의 평균 (± SD) 세포독성에 상응하는 것이다. 세포독성은 심지어 1:8 E:T에서도 CD16V-BB-ζ T 세포 단독과 비교하였을 때, CD16V-BB-ζ 세포 + hu14.18K322A 항체의 경우에 유의적으로 더 높게 그대로 유지되었다 (P = 0.0002). B: 리툭시맙, 또는 비반응성 항체 트라스투주맙 또는 hu14.18K322A의 존재하에서의 2:1 E:T에서의 B 세포 림프종 세포주 다우디와 함께 4시간 동안 공동 배양된 모의- 또는 CD16V-BB-ζ-형질도입된 T 림프구. 결과는 삼중으로 수행된 실험의 평균 (± SD) 세포독성에 상응하는 것이다 ("모의" 결과는 각 항체를 이용하여 삼중으로 수행된 실험의 합계이다). 리툭시맙 경우의 세포독성은 다른 모든 실험 조건하의 것보다 유의적으로 더 높았다 (모든 비교물에 대해 P<0.0001). C: 다양한 농도의 면역치료학적 항체 및 상기 항체에 동시에 첨가된) 경쟁 비결합 IgG의 존재하에서 8:1 E:T에서의 CD16V-BB-ζ를 발현하는 T 림프구의 종양 세포주에 대한 세포독성. 기호는 각 항체 농도에 대한 적어도 삼중으로 수행된 실험에 대한 평균 (± SD)에 상응하는 것이다. 각 세포주의 경우, 세포독성은 비결합 IgG의 존재량과 상관없이, 통계학상 다르지 않았다.
도 9는 CD16V-BB-ζ 수용체를 발현하는 T 림프구가 생체내에서 항-종양 활성을 발휘한다는 것을 입증하는 것이다. 루시페라제로 표지된 3 x 105개의 다우디 세포를 i.p.로 NOD-SCID-IL2RG널 마우스에 주사하였다. 4일째를 출발로 하여 4주 동안 주 1회에 걸쳐 i.p.로 리툭시맙 (150 ㎍)을 주사하였다. 4마리 마우스에서는 어떤 따른 처리도 하지 않은 반면, 5마리의 다른 마우스에서는 1차 리툭시맙 주사를 수행한 후, 이어서, 5일째 및 6일째 CD16V-BB-ζ 수용체를 발현하는 T 림프구를 주사하였고 (1 x 107개 i.p.; n = 5); 4마리의 마우스로 이루어진 다른 2개의 군은 각각 리툭시맙 대신 RPMI-1640의 i.p. 주사 후에 CD16V-BB-ζ T 림프구를 받거나, 또는 오직 RPMI-1640 배지만 ("대조군")을 받았다. A: 종양 성장에 관한 생체내 영상화 결과. 각 기호는 한 생체발광 측정치에 상응하는 것이고; 선은 1마리의 마우스에서의 모든 측정치를 연결한 것이다. B: 각 실험 조건에 대한 대표 마우스 (각 군당 2마리씩)가 제시되어 있다. 3일째의 복측 영상을 CD16V-BB-ζ + 리툭시맙 군의 마우스에서의 종양의 존재를 입증하기 위해 증강된 감도로 프로세싱하였다. 생체발광이 5 x 1010 광자/초에 도달하였을 때, 마우스를 안락사시켰다. C: 상이한 처리군의 마우스에 관한 전체 생존 비교.
도 10은 CD16V-BB-ζ 수용체를 발현하는 T 림프구가 생체내에서 항-종양 활성을 발휘한다는 것을 입증하는 것이다. 루시페라제로 표지된 3 x 105개의 NB1691 세포를 i.p.로 NOD-SCID-IL2RG널 마우스에 주사하였다. 5일째를 출발로 하여 4주 동안 주 1회에 걸쳐 i.p.로 Hu14.18K322A 항체 (25 ㎍)를 주사하였다. 4마리 마우스에서는 어떤 따른 처리도 하지 않은 반면, 4마리의 다른 마우스에서는 1차 항체 주사를 수행한 후, 이어서, 6일째 및 7일째 CD16V-BB-ζ 수용체를 발현하는 T 림프구를 주사하였고 (1 x 107개 i.p.; n = 4); 4마리의 마우스로 이루어진 다른 2개의 군은 각각 항체 대신 RPMI-1640의 i.p. 주사 후에 CD16V-BB-ζ T 림프구를 받거나, 또는 오직 RPMI-1640 배지만 ("대조군")을 받았다. A: 종양 성장에 관한 생체내 영상화 결과. 각 기호는 한 생체발광 측정치에 상응하는 것이고; 선은 1마리의 마우스에서의 모든 측정치를 연결한 것이다. B: 각 실험 조건에 대한 모든 마우스의 영상. 생체발광이 1 x 1010 광자/초에 도달하였을 때, 마우스를 안락사시켰다. C: 상이한 처리군의 마우스에 관한 전체 생존 비교.
도 11은 CD16V-BB-ζ 및 CD16F-BB-ζ 수용체를 발현하는 T 림프구 사이의 기능적 차이를 입증하는 것이다. A: 유세포 분석 점도표는 CD16V-BB-ζ 또는 CD16F-BB-ζ가 형질도입된 T 림프구에서의 (B73.1 항체로 검출되는) CD16 및 녹색 형광 단백질 (GFP)의 발현을 보여주는 것이다. 각 사분면에는 양성 세포의 비율(%)이 제시되어 있다. B: CD16V 또는 CD16F 수용체가 형질도입된 T 림프구를 각각 리툭시맙, 트라스투주맙 및 hu14.18K322A의 존재하에서 다우디, SK-BR-3 또는 NB1691 세포와 함께 배양하였다. 모든 항체는 0.1 ㎍/mL로 사용되었다. 기호는 유입 세포수와 비교하였을 때의 세포 회수율(%) (3회에 걸쳐 수행된 실험의 평균 ± SD)을 나타낸다; 1주째 내지 3주째 배양물에 대한 세포 계수는 3개의 배양물 모두에 대한 대응표본 t 검정에 의해 유의적인 차이를 보였다 (다우디, P = 0.0007; SK-BR-3, P = 0.0164; NB1691, P = 0.022). C: 다양한 농도의 리툭시맙의 존재하에서의 다우디 세포에 대한, CD16V-BB-ζ 또는 CD16F-BB-ζ 수용체를 발현하는 T 림프구에 의해 매개되는 항체 의존성 세포 세포독성. 각 기호는 8:1 (좌측) 또는 2:1 (우측) E:T에서의 삼중 배양물의 평균 ± SD를 나타낸다. CD16V-BB-ζ를 발현하는 T 세포의 세포독성이 CD16F-BB-ζ를 발현하는 T 세포의 것보다 유의적으로 더 높았다 (어느 E:T에서든 P<0.001).
도 12는 본 연구에서 사용된 CD16 키메라 수용체를 나타내는 개략도를 보여주는 것이다.
도 13은 상이한 신호전달 도메인을 포함하는 CD16V 수용체의 발현을 보여주는 것이다. 유세포 분석 점도표는 녹색 형광 단백질 (GFP) 단독 (모의) 또는 상이한 CD16V 구축물을 함유하는 벡터가 형질도입된 활성화된 T 림프구에서의 GFP와 함께 조합된 (3G8 항체로 검출되는) CD16의 발현을 보여주는 것이다. 각 사분면에는 양성 세포의 비율(%)이 제시되어 있다.
도 14는 CD16V-BB-ζ는 상이한 신호전달 특성을 가지는 CD16V 수용체보다도 더 높은 T 세포 활성화, 증식 및 세포독성을 유도한다는 것을 입증하는 것이다. A: 다우디 세포 및 리툭시맙 (0.1 ㎍/mL)과 함께한 48시간 동안의 공동 배양 후, 상이한 키메라 수용체를 발현하는 T 림프구에서의 녹색 형광 단백질 (GFP) 평균 형광 강도 (MFI)에 대해 플롯팅된, 유세포 분석법에 의해 CD25 MFI. CD16V-BB-ζ를 포함하는 CD25 발현은 CD16V-ζ, CD16V-FcεRIγ 또는 신호전달 능력이 없는 CD16V ("CD16V-말단절단")에 의해 유발된 것보다 유의적으로 더 높았다 (선형 회귀 분석에 의해 P<0.0001). B: 다양한 CD16V 수용체가 형질도입된 T 림프구를 각각 리툭시맙, 트라스투주맙 및 hu14.18K322A의 존재하에서 다우디, SK-BR-3 또는 NB1691 세포와 함께 배양하였다. 모든 항체는 0.1 ㎍/mL로 사용되었다. 기호는 유입 세포수와 비교하였을 때의 세포 회수율(%) (3회에 걸쳐 수행된 실험의 평균 ± SD)을 나타낸다; 1주째 내지 3주째 배양물에 대한 세포 계수는 3개의 배양물 모두에 대한 대응표본 t 검정에 의해 모든 다른 수용체보다 CD16V-BB-ζ 수용체 경우에 유의적으로 더 높았다 (P<0.0001). C: 각각 리툭시맙, 트라스투주맙 및 hu14.18K322A의 존재하에서의 다우디, SK-BR-3 및 NB1691에 대한 각종 CD16V 수용체를 발현하는 T 림프구 또는 모의-형질도입된 T 세포의 ADCC. 기호는 제시된 E:T에서의 삼중 배양물의 평균 ± SD이다. CD16V-BB-ζ 수용체 경우의 세포독성은 다른 모든 수용체의 것보다 유의적으로 더 높은 반면 (모든 비교물에서 t 검정에 의해 P<0.0001), 모의-형질도입된 림프구, 또는 CD16V-말단절단된 수용체가 형질도입된 림프구의 세포독성은 서로 유의적으로 상이하지는 않았고 (P>0.05); 다우디 (P = 0.006) 및 SK-BR-3 (P = 0.019)에 대한 CD16V-FcεRIγ 경우의 세포독성은 CD3-ζ인 경우의 세포독성보다 유의적으로 더 높았고; 어느 수용체든 그를 발현하는 림프구는 모의-형질도입된 것 또는 CD16V-말단절단으로 형질도입된 것보다 더 높은 세포독성을 가졌다 (모든 비교물에 대해 P<0.01).
도 15는 mRNA 전기천공에 의한 CD16V-BB-ζ 수용체의 발현을 입증하는 것이다. A: CD16V-BB-ζ mRNA로, 또는 mRNA 부재(모의)하에 활성화된 T 림프구를 전기천공하였다; 24시간 경과 후 유세포 분석법에 의해 CD16의 발현을 시험하였다. B: 리툭시맙의 존재하에서 라모스 세포주에 대한 모의 또는 CD16V-BB-ζ 전기천공된 T 세포의 세포독성을 시험하였다. 기호는 세포독성(%)의 평균 ± SD를 나타낸다 (n=3; 모든 E:T 비율에서의 비교물에 대한 P<0.01).
도 16은 키메라 수용체 서열식별번호: 1의 발현이 이루어진 저캣 세포 및 그 발현이 이루어지지 않은 저캣 세포에의 리툭산(Rituxan)의 결합을 보여주는 것이다. 저캣 세포를 mRNA 부재하에 (패널 A) 또는 키메라 수용체 서열식별번호: 1을 코딩하는 mRNA로 (패널 B) 전기천공시키고, 리툭산과 함께 인큐베이션시키고, 결합된 리툭산을 검출하기 위해 PE-표지된 염소-항-인간 항체로 염색하고, 유세포 분석법에 의해 분석하였다. 패널 A 및 B에서, 동일 사분면 게이트를 각 데이터 세트에 적용시켰고, 각 사분면에 세포 비율(%)이 제시되어 있으며, 우측 상단의 사분면은 리툭산 양성 세포를 나타낸다. 패널 C에서는 모의-전기천공된 세포 (채워지지 않은 것) 및 키메라 수용체 서열식별번호: 1을 코딩하는 mRNA로 전기천공된 세포 (회색)에 대한 리툭산 염색의 함수로서 세포 개수가 플롯팅되어 있다.
도 17은 리툭산 및 표적 다우디 세포 존재하에서의 키메라 수용체 서열식별번호: 1의 발현이 이루어진 저캣 세포 및 그 발현이 이루어지지 않은 저캣 세포 상의 CD25 존재를 보여주는 것이다. 저캣 세포를 mRNA 부재하에 (패널 A) 또는 키메라 수용체 서열식별번호: 1을 코딩하는 mRNA로 (패널 17B) 전기천공시킨 후, 이어서, 리툭산 및 표적 다우디 세포와 함께 인큐베이션시켰다. 저캣 세포를 단리시키기 위해 PE-표지된 항-CD7 항체로, 및 CD25 발현을 검출하기 위해 APC-표지된 항-C25 항체로 세포를 염색하고, 유세포 분석법에 의해 분석하였다. 패널 A 및 B에 CD7 양성 세포가 제시되어 있으며, 동일 사분면 게이트를 각 데이터 세트에 적용시켰다. 각 사분면에 세포 비율(%)이 제시되어 있으며, 우측 상단의 사분면은 CD25 양성 세포를 나타낸다. 패널 C는 같은 실험으로부터 얻은 데이터의 히스토그램을 나타내는 것이다. CD7 양성 세포의 개수는 모의-전기천공된 세포 (채워지지 않은 것)에 대한 CD25 염색의 함수로서 플롯팅되어 있고, 키메라 수용체 서열식별번호: 1을 코딩하는 mRNA로 전기천공된 세포 (회색)는 CD25 염색의 함수로서 플롯팅되어 있다.
도 18은 리툭산 및 표적 다우디 세포 존재하에서의 키메라 수용체 서열식별번호: 1의 발현이 이루어진 저캣 세포 및 그 발현이 이루어지지 않은 저캣 세포 상의 CD69 존재를 보여주는 것이다. 저캣 세포를 mRNA 부재하에 (패널 A) 또는 키메라 수용체 서열식별번호: 1을 코딩하는 mRNA로 (패널 B) 전기천공시킨 후, 이어서, 리툭산 및 표적 다우디 세포와 함께 인큐베이션시켰다. 저캣 세포를 단리시키기 위해 PE-표지된 항-CD7 항체로, 및 CD69 발현을 검출하기 위해 APC-표지된 항-C69 항체로 세포를 염색하고, 유세포 분석법에 의해 분석하였다. 패널 A 및 B에 CD7 양성 세포가 제시되어 있으며, 동일 사분면 게이트를 각 데이터 세트에 적용시켰다. 각 사분면에 세포 비율(%)이 제시되어 있으며, 우측 상단의 사분면은 CD69 양성 세포를 나타낸다. 패널 C는 같은 실험으로부터 얻은 데이터의 히스토그램을 나타내는 것이다. CD7 양성 세포의 개수는 모의-전기천공된 세포 (채워지지 않은 것), 및 키메라 수용체 서열식별번호: 1을 코딩하는 mRNA로 전기천공된 세포 (회색)에 대한 CD69 염색의 함수로서 플롯팅되어 있다.
도 19는 키메라 수용체의 대표적인 항-CD3ζ 웨스턴 블롯 분석을 보여주는 것이다. 저캣 세포를 mRNA 부재하에(레인 1), 또는 키메라 수용체 서열식별번호: 1 (레인 2), 서열식별번호: 3 (레인 3), 서열식별번호: 10 (레인 4), 서열식별번호: 11 (레인 5), 서열식별번호: 14 (레인 6), 서열식별번호: 2 (레인 7), 서열식별번호: 4 (레인 8), 서열식별번호: 5 (레인 9), 서열식별번호: 7 (레인 10), 서열식별번호: 8 (레인 11), 서열식별번호: 9 (레인 12), 또는 서열식별번호: 6 (레인 13)을 코딩하는 mRNA로 전기천공시켰다. 세포를 수거하고, 용해시키고, 항-CD3ζ 항체를 이용하여 웨스턴 블롯 분석에 의해 분석하였다. 키메라 수용체 mRNA로 전기천공된 모든 세포로부터의 용해물 중에서 키메라 수용체 단백질을 검출하였다.
항체 기반 면역요법은 다수의 암 유형을 비롯한, 매우 다양한 질환을 치료하는 데 사용된다. 상기 요법은 대개 정상 세포 (예컨대, 암이 아닌 세포)에 대해 상대적으로, 제거하고자 하는 세포 (예컨대, 표적 세포, 예컨대, 암 세포) 상에서 차별적으로 발현되는 세포 표면 분자의 인식에 의존한다 (Weiner et al. Cell (2012) 148(6): 1081-1084). 수개의 항체 기반 면역요법은 시험관내에서 표적 세포 (예컨대, 암 세포)의 항체 의존성 세포-매개 세포독성을 촉진시키는 것으로 밝혀졌으며, 일부의 경우, 이는 일반적으로는 또한 그것이 생체내 작용 기전이라고 간주되고 있다. ADCC는 면역계의 이펙터 세포, 예컨대, 자연살 (NK) 세포, T 세포, 단핵구 세포, 대식세포, 또는 호산구가 특이 항체에 의해 인식된 표적 세포 (예컨대, 암 세포)를 능동적으로 용해시키는 세포-매개 선천성 면역 기전이다.
본원에 기술된 키메라 수용체는 많은 이점을 부여할 것이다. 예를 들어, Fc에 결합하는 세포외 도메인을 통하여 본원에 기술된 키메라 수용체 구축물은 특이 표적 항원 (예컨대, 암 항원)에 직접 결합하기보다는 항체 또는 다른 Fc-함유 분자의 Fc 부위에 결합할 수 있다. 따라서, 본원에 기술된 키메라 수용체 구축물을 발현하는 면역 세포는 항체 또는 또 다른 Fc-함유 분자가 결합하는 임의 유형의 세포의 세포 사멸을 유도할 수 있을 것이다.
본 개시내용은 Fc-함유 분자 (예컨대, 항체 또는 Fc 융합 단백질)에 결합할 수 있는 키메라 수용체, 상기 키메라 수용체를 발현하는 면역 세포, 및 상기 면역 세포를 사용하여 표적 세포 (예컨대, 암 세포)에 대한 ADCC 효과를 증진시키는 방법을 제공한다. 본원에서 사용되는 바, 키메라 수용체란, 숙주 세포의 표면 상에서 발현될 수 있고, Fc 부위를 함유하는 표적 분자에 결합할 수 있는 세포외 도메인, 및 키메라 수용체를 발현하는 면역 세포의 이펙터 기능을 일으키기 위한 하나 이상의 세포질 신호전달 도메인을 포함하는 비-자연적으로 발생된 분자로서, 여기서, 키메라 수용체의 적어도 2개의 도메인은 상이한 분자로부터 유래된 것인 분자를 지칭한다.
Fc-함유 분자, 예컨대, 항체 단백질은 표적, 예컨대, 표적 세포 (예컨대, 암 세포) 상의 세포 표면 분자, 수용체, 또는 탄수화물에 결합할 수 있다. 상기 Fc-함유 분자에 결합할 수 있는 수용체, 예를 들어, 본원에 기술된 키메라 수용체 분자를 발현하는 면역 세포는 표적 세포-결합 항체를 인식하고, 이러한 수용체/항체 결속이 면역 세포를 자극하여 이펙터 기능, 예컨대, 세포독성 과립 방출 또는 세포-사멸-유도 분자의 발현이 수행되고, 이로써, Fc-함유 분자에 의해 인식된 표적 세포의 세포 사멸이 이루어지게 된다.
"약" 또는 "대략"이라는 용어는 관련 기술분야의 통상의 기술자에 의해 측정되는 특정 값이 허용되는 오차 범위 안에 있다는 것을 의미하는 것이며, 상기 오차 범위는 부분적으로는 값이 측정 또는 결정되는 방법, 즉, 측정 시스템의 한계에 의존할 것이다. 예를 들어, "약"이란, 관련 기술분야의 관행에 따라 허용되는 표준 편차 범위 내에 포함되어 있다는 것을 의미한다. 대안적으로, "약"이란, 주어진 값의 최대 ±20%, 바람직하게, 최대 ±10%, 더욱 바람직하게, 최대 ±5%, 및 더욱 바람직하게, 추가로, 최대 ±1% 범위임을 의미할 수 있다. 대안적으로, 특히 생물학적 시스템 또는 프로세스와 관련하여, 상기 용어는 값의 한 자릿수 범위 내에, 바람직하게, 2배 범위 내에 있음을 의미할 수 있다. 특정 값이 본 출원 및 특허청구범위에 기술되는 경우, 달리 언급되지 않는 한, "약"이라는 용어가 내포되며, 이와 관련하여 상기 용어는 특정 값이 허용되는 오차 범위 안에 있다는 것을 의미한다.
본 개시내용이 본원에서 언급된 질환 상태들 중 임의의 것에 관한 것인 한, 본 개시내용과 관련하여, "치료하다," "치료"라는 용어 및 유사 용어는 상기 상태와 연관된 적어도 하나의 증상을 경감, 또는 완화시키거나, 상기 상태의 진행을 저속화 또는 역전시키는 것을 의미한다. 본 개시내용의 의미 범위 안에서, "치료하다"라는 용어는 또한 발병을 정지시키거나, 발병 시점 (즉, 질환의 임상적 소견이 나타나기 전 기간)을 지연시키거나, 또는 질환의 발생 또는 악화 위험을 감소시키는 것을 의미한다. 예를 들어, 암과 관련하여, "치료하다"라는 용어는 환자의 종양 부하량을 제거 또는 감소시키거나, 또는 전이 등을 예방, 지연, 또는 억제시키는 것을 의미할 수 있다.
본원에서 사용되는 바, 용량 또는 양에 적용되는 "치료학상 유효"라는 것은, 본 개시내용의 키메라 수용체를 포함하고, 임의적으로, 종양 특이 세포독성 모노클로날 항체 또는 Fc 부위를 포함하는 또 다른 항-종양 분자 (예컨대, 면역글로불린, 또는 Fc-함유 DNA 또는 RNA의 Fc-부위와 조합된, 종양 표면 수용체에 결합하는 리간드 (예컨대, 시토카인, 면역 세포 수용체)로 구성된 복합 분자)를 추가로 포함하는 화합물 또는 제약 조성물 (예컨대, 면역 세포, 예컨대, T 림프구 및/또는 NK 세포를 포함하는 조성물)이 그를 필요로 하는 대상체에게 투여되었을 때, 원하는 활성을 일으키는 데 충분한 그의 양을 의미한다. 본 개시내용과 관련하여, "치료학상 유효"라는 용어는 본 개시내용의 방법에 의해 치료되는 장애의 소견을 지연시키거나, 그의 진행을 정지시키거나, 그의 적어도 하나의 증상을 경감 또는 완화시키는 데 충분한 화합물 또는 제약 조성물의 양을 의미한다. 활성 성분의 조합이 투여되는 경우, 조합의 유효량은 개별적으로 투여되었다면 효과적인 양이 되는 각 성분의 양을 포함하거나, 또는 포함하지 않을 수 있다.
본 개시내용의 조성물과 관련하여 사용되는 바, "제약상 허용되는"이라는 어구는 분자 엔티티 및 상기 조성물의 다른 성분이 생리학상 허용되고, 포유동물 (예컨대, 인간)에게 투여되었을 때, 전형적으로는 부작용 반응을 일으키지 않는다는 것을 의미한다. 바람직하게, 본원에서 사용되는 바, "제약상 허용되는"이라는 용어는 포유동물에서, 및 더욱 특히, 인간에서의 사용을 위한 것으로 연방 정부 또는 주 정부의 규제 기관에 의해 승인을 받았거나, 또는 미국 약전(U.S. Pharmacopeia) 또는 일반적으로 인정되는 다른 약전에 열거되어 있다는 것을 의미한다.
본원에서 사용되는 바, "대상체"라는 용어는 임의의 포유동물을 의미한다. 바람직한 실시양태에서, 대상체는 인간이다.
본 명세서 및 첨부된 특허청구범위에서 사용되는 바, "하나"("a," "an") 및 "그"라는 단수 형태는 문맥상 달리 명확하게 명시되지 않는 한, 복수 개의 지시 대상도 포함한다.
I.
키메라
수용체
본원에 기술된 키메라 수용체는 면역글로불린의 Fc 부위에 대하여 결합 친화도 및 특이성을 가지는 세포외 도메인 ("Fc 결합제"), 막횡단 도메인, 적어도 하나의 공동 자극 신호전달 도메인, 및 ITAM을 포함하는 세포질 신호전달 도메인을 포함한다. 키메라 수용체는 숙주 세포 상에서 발현되었을 때, 세포외 리간드 결합 도메인은 표적 분자 (예컨대, 항체 또는 Fc-융합 단백질)에의 결합을 위해 세포외에 위치하고, 공동 자극 신호전달 도메인 및 ITAM 함유 세포질 신호전달 도메인은 및/또는 이펙터 신호전달을 일으키기 위해 세포질에 위치하도록 구성된다. 일부 실시양태에서, 본원에 기술된 바와 같은 키메라 수용체 구축물은 N-말단에서 C-말단으로 Fc 결합제, 막횡단 도메인, 적어도 하나의 공동 자극 신호전달 도메인, 및 ITAM 함유 세포질 신호전달 도메인을 포함한다. 다른 실시양태에서, 본원에 기술된 바와 같은 키메라 수용체 구축물은 N-말단에서 C-말단으로 Fc 결합제, 막횡단 도메인, ITAM 함유 세포질 신호전달 도메인, 및 적어도 하나의 공동 자극 신호전달 도메인을 포함한다.
본원에 기술된 키메라 수용체 중 임의의 것은, Fc 결합제의 C-말단 및 막횡단 도메인의 N-말단에 위치할 수 있는 힌지 도메인을 추가로 포함할 수 있다. 대안적으로, 또는 추가로, 본원에 기술된 키메라 수용체 구축물은, 서로 연결되어 있거나, 또는 ITAM 함유 세포질 신호전달 도메인에 의해 분리되어 있을 수 있는, 2개 이상의 공동 자극 신호전달 도메인을 함유할 수 있다. 키메라 수용체 구축물 중의 세포외 Fc 결합제, 막횡단 도메인, 공동 자극 신호전달 도메인(들), 및 ITAM 함유 세포질 신호전달 도메인은 직접적으로, 또는 펩티드 링커를 통해 서로 연결되어 있을 수 있다. 일부 실시양태에서, 본원에 기술된 키메라 수용체 중 임의의 것은 N-말단에 신호 서열을 포함한다.
A.
Fc
결합제
본원에 기술된 키메라 수용체 구축물은 Fc 결합제인, 즉, 적합한 포유동물 (예컨대, 인간, 마우스, 래트, 염소, 양, 또는 원숭이)의 면역글로불린 (예컨대, IgG, IgA, IgM, 또는 IgE)의 Fc 부위에 결합할 수 있는, 세포외 도메인을 포함한다. 적합한 Fc 결합제는 자연적으로 발생된 단백질, 예컨대, 포유동물 Fc 수용체 또는 특정 박테리아 단백질 (예컨대, 단백질 A, 단백질 G)로부터 유래된 것일 수 있다. 추가로, Fc 결합제는 높은 친화성 및 특이성으로 본원에 기술된 Ig 분자 중 임의의 것의 Fc 부위에 특이적으로 결합하도록 조작된 합성 폴리펩티드일 수 있다. 예를 들어, 상기 Fc 결합제는 면역글로불린의 Fc 부위에 특이적으로 결합하는 항체 또는 그의 항원 결합 단편일 수 있다. 예로는 단일 쇄 가변 단편 (scFv), 도메인 항체, 또는 나노바디를 포함하나, 이에 제한되지 않는다. 대안적으로, Fc 결합제는 Fc 부위에 특이적으로 결합하는 합성 펩티드, 예컨대, 쿠니츠 도메인, 소형 모듈형 면역제약 (SMIP), 에드넥틴, 아비머, 어피바디, DARPin, 또는 안티칼린일 수 있고, 이는 Fc에 결합하는 활성에 대해 펩티드 조합 라이브러리를 스크리닝함으로써 확인될 수 있다.
일부 실시양태에서, Fc 결합제는 포유동물 Fc 수용체의 세포외 리간드 결합 도메인이다. 본원에서 사용되는 바, "Fc 수용체"는 다수의 면역 세포 (B 세포, 수지상 세포, 자연살 (NK) 세포, 대식세포, 호중구, 비만 세포, 및 호산구 포함)의 표면 상에서 발현되고, 항체의 Fc 도메인에 대하여 결합 특이성을 보이는 세포 표면 결합 수용체이다. Fc 수용체는 전형적으로 항체의 Fc (단편 결정가능) 부위에 대하여 결합 특이성을 가지는 적어도 2개의 면역글로불린 (Ig)-유사 도메인으로 구성된다. 일부 경우에서, Fc 수용체의 항체의 Fc 부위에의 결합은 항체 의존성 세포-매개 세포독성 (ADCC) 효과를 일으킬 수 있다. 본원에 기술된 바와 같은 키메라 수용체를 구축하는 데 사용되는 Fc 수용체는 자연적으로 발생된 다형성 변이체 (예컨대, CD16 V158 변이체)일 수 있으며, 이는 야생형 대응물과 비교하여 증가 또는 감소된, Fc에 대한 친화성을 가질 수 있다. 대안적으로, Fc 수용체는 Ig 분자의 Fc 부위에의 결합 친화도를 변경시키는 하나 이상의 돌연변이 (예컨대, 최대 10개의 아미노산 잔기 치환)를 보유하는, 야생형 대응물의 기능적 변이체일 수 있다. 일부 경우에서, 돌연변이는 Fc 수용체의 글리코실화 패턴, 및 이로써, Fc에의 결합 친화도를 변경시킬 수 있다.
하기 표에는 Fc 수용체 세포외 도메인 중의 다수의 예시적인 다형성이 열거되어 있다 (예컨대, 문헌 [Kim et al., J. Mol . Evol. 53:1-9, 2001] 참조):
<표 1>
Fc
수용체 중의 예시적인 다형성

Fc 수용체는 그가 결합할 수 있는 항체의 이소형에 기초하여 분류된다. 예를 들어, Fc-감마 수용체 (FcγR)는 일반적으로 IgG 항체, 예컨대, 그의 하나 이상의 서브타입 (즉, IgG1, IgG2, IgG3, IgG4)에 결합하고; Fc-알파 수용체 (FcαR)는 일반적으로 IgA 항체에 결합하고; Fc-엡실론 수용체 (FcεR)는 일반적으로 IgE 항체에 결합한다. 일부 실시양태에서, Fc 수용체는 Fc-감마 수용체, Fc-알파 수용체, 또는 Fc-엡실론 수용체이다. Fc-감마 수용체의 예로는 제한 없이, CD64A, CD64B, CD64C, CD32A, CD32B, CD16A, 및 CD16B를 포함한다. Fc-알파 수용체의 예로는 FcαR1/CD89가 있다. Fc-엡실론 수용체의 예로는 제한 없이, FcεRI 및 FcεRII/CD23을 포함한다. 하기 표에는 본원에 기술된 키메라 수용체를 구축하는 데 사용하기 위한 예시적인 Fc 수용체, 및 상응하는 Fc 도메인에의 그의 결합 활성이 열거되어 있다:
<표 2>
예시적인
Fc
수용체

본원에 기술된 키메라 수용체에서 사용하기 위한 Fc 수용체의 리간드 결합 도메인의 선택은 관련 기술분야의 통상의 기술자에게 자명할 것이다. 예를 들어, 선택은 예컨대, Fc 수용체의 결합이 요구되는 항체의 이소형 및 결합 상호작용의 원하는 친화성과 같은 인자에 의존할 수 있다.
일부 예에서, (a)는 Fc에 대한 친화성을 조절할 수 있는 자연적으로 발생된 다형성을 도입할 수 있는, CD16의 세포외 리간드 결합 도메인이다. 일부 예에서, (a)는 158번 위치에 다형성 (예컨대, 발린 또는 페닐알라닌)을 도입한 CD16의 세포외 리간드 결합 도메인이다. 일부 실시양태에서, (a)는 그의 글리코실화 상태 및 Fc에 대한 그의 친화성을 변경시키는 조건하에서 제조된다.
일부 실시양태에서, (a)는 그를 도입한 키메라 수용체가 IgG 항체의 서브세트에 대해 특이성을 가지도록 만드는 변형을 도입한 CD16의 세포외 리간드 결합 도메인이다. 예를 들어, IgG 서브타입 (예컨대, IgG1)에 대한 친화성을 증가 또는 감소시키는 돌연변이가 도입될 수 있다.
일부 예에서, (a)는 Fc에 대한 친화성을 조절할 수 있는 자연적으로 발생된 다형성을 도입할 수 있는, CD32의 세포외 리간드 결합 도메인이다. 일부 실시양태에서, (a)는 그의 글리코실화 상태 및 Fc에 대한 그의 친화성을 변경시키는 조건하에서 제조된다.
일부 실시양태에서, (a)는 그를 도입한 키메라 수용체가 IgG 항체의 서브세트에 대해 특이성을 가지도록 만드는 변형을 도입한 CD32의 세포외 리간드 결합 도메인이다. 예를 들어, IgG 서브타입 (예컨대, IgG1)에 대한 친화성을 증가 또는 감소시키는 돌연변이가 도입될 수 있다.
일부 예에서, (a)는 Fc에 대한 친화성을 조절할 수 있는 자연적으로 발생된 다형성을 도입할 수 있는, CD64의 세포외 리간드 결합 도메인이다. 일부 실시양태에서, (a)는 그의 글리코실화 상태 및 Fc에 대한 그의 친화성을 변경시키는 조건하에서 제조된다.
일부 실시양태에서, (a)는 그를 도입한 키메라 수용체가 IgG 항체의 서브세트에 대해 특이성을 가지도록 만드는 변형을 도입한 CD64의 세포외 리간드 결합 도메인이다. 예를 들어, IgG 서브타입 (예컨대, IgG1)에 대한 친화성을 증가 또는 감소시키는 돌연변이가 도입될 수 있다.
다른 실시양태에서, Fc 결합제는 IgG 분자의 Fc 부위에 결합할 수 있는 자연적으로 발생된 박테리아 단백질로부터 유래된 것이다. 본원에 기술된 바와 같은 키메라 수용체를 구축하는 데 사용하기 위한 Fc 결합제는 전장의 단백질 또는 그의 기능적 단편일 수 있다. 단백질 A는 원래는 박테리아 스타필로코쿠스 아우레우스(Staphylococcus aureus)의 세포 벽에서 발견되는 42 kDa 표면 단백질이다. 이는 각각이 3-나선형 번들로 폴딩되어 있는 5개의 도메인으로 구성되어 있고, 이는 대부분의 항체의 Fc 영역 뿐만 아니라, 인간 VH3 패밀리 항체의 Fab 영역과의 상호작용을 통해 IgG에 결합할 수 있다. 단백질 G는 포유동물 IgG의 Fab 및 Fc 영역, 둘 모두에 결합하는, C 및 G군 연쇄구균(Streptococcal) 박테리아에서 발현되는, 대략 60 kDa의 단백질이다. 천연 단백질 G는 또한 알부민에 결합하는 반면, 재조합 변이체는 알부민 결합을 제거하도록 조작된 것이다.
키메라 수용체에서 사용하기 위한 Fc 결합제는 조합 생물학 또는 직접 진화 방법을 사용하여 새로 생성할 수 있다. 단백질 스캐폴드 (예컨대, IgG로부터 유래된 scFv, 쿠니츠형 프로테아제 억제제로부터 유래된 쿠니츠 도메인, 안키린 반복부, 단백질 A로부터의 Z 도메인, 리포칼린, 피브로넥틴 III형 도메인, Fyn으로부터의 SH3 도메인 등)로부터 출발하여, 표면 상의 잔기 세트에 대한 아미노산 측쇄는 큰 변이체 스캐폴드 라이브러리 생성을 위해 무작위로 치환될 수 있다. 결합에 대하여 1차 선별한 후, 파지, 리보솜 또는 세포 디스플레이에 의해 증폭시킴으로써 표적 유사 Fc 도메인에 대하여 친화성을 가지는 희귀 변이체를 큰 라이브러리로부터 단리시킬 수 있다. 반복된 회차에 걸쳐 수행되는 선별 및 증폭을 사용하여 표적에 대하여 가장 높은 친화성을 가지는 단백질을 단리시킬 수 있다. Fc-결합 펩티드는 예컨대, 문헌 [DeLano et al., Science, 287:5456 (2000)]; [Jeong et al., Peptides, 31(2):202-206 (2009)]; 및 [Krook et al., J. Immunological Methods, 221(1-2):151-157 (1998)]과 같이, 관련 기술분야에 공지되어 있다. 예시적인 Fc-결합 펩티드는 ETQRCTWHMGELVWCEREHN (서열식별번호: 85), KEASCSYWLGELVWCVAGVE (서열식별번호: 86), 또는 DCAWHLGELVWCT (서열식별번호: 87)의 아미노산 서열을 포함할 수 있다.
본원에 기술된 Fc 결합제 중 임의의 것은 치료학적 항체의 Fc 부위에 대하여 적합한 결합 친화도를 가질 수 있다. 본원에서 사용되는 바, "결합 친화도"란, 겉보기 회합 상수 또는 KA를 지칭한다. KA는 해리 상수인 KD의 역수이다. 본원에 기술된 키메라 수용체의 Fc 수용체 도메인의 세포외 리간드 결합 도메인은 항체의 Fc 부위에 대하여 적어도 10-5, 10-6, 10-7, 10-8, 10-9, 10-10 M 또는 그 미만의 결합 친화도 KD를 가질 수 있다. 일부 실시양태에서, Fc 결합제는, 또 다른 항체, 항체의 이소형, 또는 그의 서브타입에의 Fc 결합제의 결합 친화도와 비교하였을 때, 항체, 항체의 이소형, 또는 그의 서브타입(들)에 대해 높은 결합 친화도를 가진다. 일부 실시양태에서, Fc 수용체의 세포외 리간드 결합 도메인은, 또 다른 항체, 항체의 이소형, 또는 그의 서브타입에의 Fc 수용체의 세포외 리간드 결합 도메인의 결합과 비교하였을 때, 항체, 항체의 이소형, 또는 그의 서브타입(들)에 대해 특이성을 가진다. 고친화도로 결합하는 Fc-감마 수용체로는 CD64A, CD64B, 및 CD64C를 포함한다. 저친화도로 결합하는 Fc-감마 수용체로는 CD32A, CD32B, CD16A, 및 CD16B를 포함한다. 고친화도로 결합하는 Fc-엡실론 수용체는 FcεRI이고, 저친화도로 결합하는 Fc-엡실론 수용체는 FcεRII/CD23이다.
Fc 수용체 또는 Fc 결합제 (예컨대, Fc 수용체의 세포외 리간드 결합 도메인)를 포함하는 키메라 수용체에 대한 결합 친화도 또는 결합 특이성은 평형 투석, 평형 결합, 겔 여과, ELISA, 표면 플라스몬 공명, 또는 분광법을 비롯한, 다양한 방법에 의해 측정될 수 있다.
일부 실시양태에서, Fc 수용체의 세포외 리간드 결합 도메인은 자연적으로 발생된 Fc-감마 수용체, Fc-알파 수용체, 또는 Fc-엡실론 수용체의 세포외 리간드 결합 도메인의 아미노산 서열과 적어도 90% (예컨대, 91, 92, 93, 94, 95, 96, 97, 98, 99%) 동일한 아미노산 서열을 포함한다. 두 아미노산 서열의 "동일성(%)"은 문헌 [Karlin and Altschul Proc. Natl. Acad. Sci. USA 90:5873-77, 1993]에서와 같이 변형된, 문헌 [Karlin and Altschul Proc. Natl. Acad. Sci. USA 87:2264-68, 1990]의 알고리즘을 사용하여 측정될 수 있다. 상기 알고리즘은 문헌 [Altschul, et al. J. Mol. Biol. 215:403-10, 1990]의 NBLAST 및 XBLAST 프로그램 (버전 2.0)으로 도입된다. BLAST 단백질 검색은 XBLAST 프로그램, 스코어=50, 워드길이=3을 사용하여 수행될 수 있고, 이로써, 본 개시내용의 단백질 분자와 상동성이 아미노산 서열을 수득할 수 있다. 두 서열 사이에 갭이 존재할 경우, 문헌 [Altschul et al., Nucleic Acids Res. 25(17):3389-3402, 1997]에 기술된 바와 같이, 갭트 BLAST(Gapped BLAST)가 사용될 수 있다. BLAST 및 갭트 BLAST 프로그램을 사용할 때, 각 프로그램 (예컨대, XBLAST 및 NBLAST)의 디폴트 파라미터가 사용될 수 있다.
Fc 수용체의 세포외 리간드 결합 도메인의 변이체, 예컨대, 본원에 기술된 것 또한 본 개시내용의 범주 내에 포함된다. 일부 실시양태에서, 변이체 세포외 리간드 결합 도메인은 참조 세포외 리간드 결합 도메인의 아미노산 서열과 비교하여 최대 10개의 아미노산 잔기 변이 (예컨대, 1, 2, 3, 4, 또는 5개)를 포함할 수 있다. 일부 실시양태에서, 변이체는 유전자 다형성에 기인한, 자연적으로 발생된 변이체일 수 있다. 다른 실시양태에서, 변이체는 비-자연적으로 발생된 변형된 분자일 수 있다. 예를 들어, 돌연변이는 Fc 수용체의 글리코실화 패턴, 및 이로써, 상응하는 Fc 도메인에의 그의 결합 친화도를 변경시키기 위해 Fc 수용체의 세포외 리간드 결합 도메인 내로 도입될 수 있다.
일부 예에서, Fc 수용체는 본원에 기술된 바와 같은, CD16A, CD16B, CD32A, CD32B, CD32C, CD64A, CD64B, CD64C, 또는 그의 변이체일 수 있다. Fc 수용체의 세포외 리간드 결합 도메인은 본원에 기술된 바와 같은 CD16A, CD16B, CD32A, CD32B, CD32C, CD64A, CD64B, CD64C의 세포외 리간드 결합 도메인의 아미노산 서열과 비교하여 최대 10개의 아미노산 잔기 변이 (예컨대, 1, 2, 3, 4, 5, 또는 8개)를 포함할 수 있다. 하나 이상의 아미노산 변이를 포함하는 상기 Fc 도메인은 변이체로서 지칭될 수 있다. Fc 수용체의 세포외 리간드 결합 도메인의 아미노산 잔기의 돌연변이를 통해, 돌연변이를 포함하지 않는 Fc 수용체 도메인과 비교하였을 때, 항체, 항체의 이소형, 또는 그의 서브타입(들)에 결합하는 Fc 수용체 도메인에 대한 결합 친화도는 증가될 수 있다. 예를 들어, Fc-감마 수용체 CD16A의 잔기 158의 돌연변이를 통해 항체의 Fc 부위에의 Fc 수용체의 결합 친화도는 증가될 수 있다. 일부 실시양태에서, 돌연변이는 Fc-감마 수용체 CD16A의 잔기 158에서의 페닐알라닌에서 발린으로의 치환이며, 이는 CD16A V158 변이체로 지칭된다. 인간 CD16A V158 변이체의 아미노산 서열은 하기에 제공되어 있으며, 여기서, V158 잔기는 굵은/자체로 강조표시되어 있다 (신호 펩티드는 이탤릭체로 표시):

Fc 수용체의 세포외 리간드 결합 도메인 중에서의, 분자, 예컨대, 항체의 Fc 부위에의 결합 친화도를 증진 또는 감소시킬 수 있는 대안적 또는 추가의 돌연변이는 관련 기술분야의 통상의 기술자에게 명백할 것이다. 일부 실시양태에서, Fc 수용체는 CD16A, CD16A V158 변이체, CD16B, CD32A, CD32B, CD32C, CD64A, CD64B, 또는 CD64C이다. 일부 실시양태에서, 본원에 기술된 키메라 수용체 구축물의 세포외 리간드 결합 도메인은 CD16A 또는 CD16A V158 변이체의 세포외 리간드 결합 도메인이다.
B. 막횡단 도메인
본원에 기술된 키메라 수용체의 막횡단 도메인은 관련 기술분야에 공지된 임의 형태의 것일 수 있다. 본원에서 사용되는 바, "막횡단 도메인"이란, 세포 막, 바람직하게, 진핵 세포 막에서 열역학적으로 안정적인 임의의 단백질 구조를 지칭한다. 본원에서 사용되는 키메라 수용체에서의 사용을 위해 상용성인 막횡단 도메인은 자연적으로 발생된 단백질로부터 수득될 수 있다. 대안적으로, 이는 합성 비-자연적으로 발생된 단백질 세그먼트, 예컨대, 세포 막에서 열역학적으로 안정적인 소수성 단백질 세그먼트일 수 있다.
막횡단 도메인은 막횡단 도메인의 3차원 구조에 기초하여 분류된다. 예를 들어, 막횡단 도메인은 하나의 알파 나선, 1 초과의 알파 나선으로 이루어진 복합체, 베타-배럴, 또는 세포의 인지질 이중층에 걸쳐져 있을 수 있는 임의의 다른 안정적인 구조를 형성할 수 있다. 추가로, 막횡단 도메인은 또한 또는 대안적으로 막횡단 도메인이 막을 가로질러 횡단하는 통과 횟수, 및 단백질의 배향을 비롯한, 막횡단 도메인 토폴로지에 기초하여 분류될 수 있다. 예를 들어, 단일 통과 막 단백질은 세포 막을 1회 가로질러 횡단하고, 다회 통과 막 단백질은 세포 막을 적어도 2회 (예컨대, 2, 3, 4, 5, 6, 7회 또는 그 초과) 가로질러 횡단한다.
막 단백질은 세포의 내부 및 외부에 대해 상대적인 그의 말단 및 막-통과 세그먼트(들)의 토폴로지에 의존하여 I형, II형 또는 III형으로 정의될 수 있다. I형 막 단백질은 단일 막 관통 영역을 가지고, 단백질의 N-말단이 세포의 지질 이중층의 세포외 측에 존재하고, 단백질의 C-말단이 세포질 측에 존재하도록 배향되어 있다. II형 막 단백질 또한 단일 막 관통 영역을 가지지만, 단백질의 C-말단이 세포의 지질 이중층의 세포외 측에 존재하고, 단백질의 N-말단이 세포질 측에 존재하도록 배향되어 있다. III형 막 단백질은 다중 막 관통 세그먼트를 가지며, 이는 막횡단 세그먼트의 개수 및 N- 및 C-말단의 위치에 기초하여 추가로 세분될 수 있다.
일부 실시양태에서, 본원에 기술된 키메라 수용체의 막횡단 도메인은 I형 단일 통과 막 단백질로부터 유래된 것이다. 단일 통과 막 단백질로는 CD8α, CD8β, 4-1BB/CD137, CD28, CD34, CD4, FcεRIγ, CD16, OX40/CD134, CD3ζ, CD3ε, CD3γ, CD3δ, TCRα, TCRβ, TCRζ, CD32, CD64, CD64, CD45, CD5, CD9, CD22, CD37, CD80, CD86, CD40, CD40L/CD154, VEGFR2, FAS, 및 FGFR2B를 포함하나, 이에 제한되지 않는다. 일부 실시양태에서, 막횡단 도메인은 하기 CD8α, CD8β, 4-1BB/CD137, CD28, CD34, CD4, FcεRIγ, CD16, OX40/CD134, CD3ζ, CD3ε, CD3γ, CD3δ, TCRα, CD32, CD64, VEGFR2, FAS, 및 FGFR2B로부터 선택되는 막 단백질로부터의 것이다. 일부 예에서, 막횡단 도메인은 CD8α의 것이다. 일부 예에서, 막횡단 도메인은 4-1BB/CD137의 것이다. 다른 예에서, 막횡단 도메인은 CD28 또는 CD34의 것이다. 추가의 다른 예에서, 막횡단 도메인은 인간 CD8α로부터 유래된 것이 아니다. 일부 실시양태에서, 키메라 수용체의 막횡단 도메인은 단일 통과 알파 나선이다.
다회 통과 막 단백질로부터의 막횡단 도메인 또한 본원에 기술된 키메라 수용체에서 사용하기 위한 것으로 상용성일 수 있다. 다회 통과 막 단백질은 복합 (적어도 2, 3, 4, 5, 6, 7개 또는 그 초과의) 알파 나선 또는 베티 시트 구조를 포함할 수 있다. 바람직하게, 다회 통과 막 단백질의 N-말단 및 C-말단은 지질 이중층의 반대측에 존재하고, 예컨대, 단백질의 N-말단은 지질 이중층의 세포질 측에 존재하고, 단백질의 C-말단은 세포외 측에 존재한다. 다회 통과 막 단백질로부터의 하나 또는 다회에 걸친 나선 통과가 본원에 기술된 키메라 수용체를 구축하는 데 사용될 수 있다.
본원에 기술된 키메라 수용체에서 사용하기 위한 막횡단 도메인은 또한 합성, 비-자연적으로 발생된 단백질 세그먼트의 적어도 일부를 포함할 수 있다. 일부 실시양태에서, 막횡단 도메인은 합성, 비-자연적으로 발생된 알파 나선 또는 베타 시트이다. 일부 실시양태에서, 단백질 세그먼트는 적어도 대략 20개의 아미노산, 예컨대, 적어도 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30개, 또는 그 초과의 아미노산이다. 합성 막횡단 도메인의 예는 관련 기술분야에, 예를 들어, 미국 특허 번호 7,052,906 B1에 및 PCT 공개 번호 WO 2000/032776 A2에 공지되어 있으며, 상기 특허과 관련된 개시내용은 본원에서 참조로 포함된다.
일부 실시양태에서, 막횡단 도메인의 아미노산 서열은 시스테인 잔기를 포함하지 않는다. 일부 실시양태에서, 막횡단 도메인의 아미노산 서열은 1개의 시스테인 잔기를 포함한다. 일부 실시양태에서, 막횡단 도메인의 아미노산 서열은 2개의 시스테인 잔기를 포함한다. 일부 실시양태에서, 막횡단 도메인의 아미노산 서열은 2개 초과의 (예컨대, 3, 4, 5개 또는 그 초과의) 시스테인 잔기를 포함한다.
막횡단 도메인은 막횡단 영역, 및 막횡단 도메인의 C-말단 측에 위치하는 세포질 영역을 포함할 수 있다. 막횡단 도메인의 세포질 영역은 3개 이상의 아미노산을 포함할 수 있고, 일부 실시양태에서, 이는 지질 이중층에 막횡단 도메인을 배향시키는 데 도움을 줄 수 있다. 일부 실시양태에서, 하나 이상의 시스테인 잔기는 막횡단 도메인의 막횡단 영역에 존재한다. 일부 실시양태에서, 하나 이상의 시스테인 잔기는 막횡단 도메인의 세포질 영역에 존재한다. 일부 실시양태에서, 막횡단 도메인의 세포질 영역은 양으로 하전된 아미노산을 포함한다. 일부 실시양태에서, 막횡단 도메인의 세포질 영역은 아미노산 아르기닌, 세린, 및 리신을 포함한다.
일부 실시양태에서, 막횡단 도메인의 막횡단 영역은 소수성 아미노산 잔기를 포함한다. 일부 실시양태에서, 막횡단 영역은 주로 소수성 아미노산 잔기, 예컨대, 알라닌, 류신, 이소류신, 메티오닌, 페닐알라닌, 트립토판, 또는 발린을 포함한다. 일부 실시양태에서, 막횡단 영역은 소수성이다. 일부 실시양태에서, 막횡단 영역은 폴리-류신-알라닌 서열을 포함한다.
단백질 또는 단백질 세그먼트의 소수친수성(hydropathy), 또는 소수성 또는 친수성 특징은 관련 기술분야에 공지된 임의의 방법, 예를 들어, 카이트(Kyte) 및 둘리틀(Doolittle) 소수친수성 분석에 의해 평가될 수 있다.
C. 공동 자극 신호전달 도메인
다수의 면역 세포는 세포 증식, 분화 및 생존을 촉진시킬 뿐만 아니라, 세포의 이펙터 기능을 활성화시키기 위해서는, 항원-특이 신호 자극 이외에도, 공동 자극을 필요로 한다. 본원에 기술된 키메라 수용체는 적어도 하나의 공동 자극 신호전달 도메인을 포함한다. 본원에서 사용되는 바, "공동 자극 신호전달 도메인"이라는 용어는 면역 반응, 예컨대, 이펙터 기능을 유도하기 위해 세포 내에서 신호 전달을 매개하는 단백질 중 적어도 일부를 의미한다. 본원에 기술된 키메라 수용체의 공동 자극 신호전달 도메인은 공동 자극 단백질로부터의 세포질 신호전달 도메인일 수 있고, 이는 신호를 전달하고, 면역 세포, 예컨대, T 세포, NK 세포, 대식세포, 호중구, 또는 호산구에 의해 매개되는 반응을 조절한다.
숙주 세포 (예컨대, 면역 세포)에서의 공동 자극 신호전달 도메인의 활성화는 세포가 시토카인의 생산 및 분비, 식세포 특성, 증식, 분화, 생존 및/또는 세포독성을 증가시키거나, 또는 그를 감소시키도록 유도할 수 있다. 임의의 공동 자극 분자의 공동 자극 신호전달 도메인은 본원에 기술된 키메라 수용체에서 사용하기 위한 것으로 상용성일 수 있다. 공동 자극 신호전달 도메인의 유형(들)은 예컨대, 키메라 수용체가 발현되는 면역 세포의 유형 (예컨대, T 세포, NK 세포, 대식세포, 호중구, 또는 호산구) 및 원하는 면역 이펙터 기능 (예컨대, ADCC 효과)과 같은 인자에 기초하여 선택된다. 키메라 수용체에서 사용하기 위한 공동 자극 신호전달 도메인의 예는 공동 자극 단백질의 세포질 신호전달 도메인일 수 있고, 이는 B7/CD28 패밀리의 구성원 (예컨대, B7-1/CD80, B7-2/CD86, B7-H1/PD-L1, B7-H2, B7-H3, B7-H4, B7-H6, B7-H7, BTLA/CD272, CD28, CTLA-4, Gi24/VISTA/B7-H5, ICOS/CD278, PD-1, PD-L2/B7-DC, 및 PDCD6); TNF 슈퍼패밀리의 구성원 (예컨대, 4-1BB/TNFSF9/CD137, 4-1BB 리간드/TNFSF9, BAFF/BLyS/TNFSF13B, BAFF R/TNFRSF13C, CD27/TNFRSF7, CD27 리간드/TNFSF7, CD30/TNFRSF8, CD30 리간드/TNFSF8, CD40/TNFRSF5, CD40/TNFSF5, CD40 리간드/TNFSF5, DR3/TNFRSF25, GITR/TNFRSF18, GITR 리간드/TNFSF18, HVEM/TNFRSF14, LIGHT/TNFSF14, 림포톡신-알파/TNF-베타, OX40/TNFRSF4, OX40 리간드/TNFSF4, RELT/TNFRSF19L, TACI/TNFRSF13B, TL1A/TNFSF15, TNF-알파, 및 TNF RII/TNFRSF1B); SLAM 패밀리의 구성원 (예컨대, 2B4/CD244/SLAMF4, BLAME/SLAMF8, CD2, CD2F-10/SLAMF9, CD48/SLAMF2, CD58/LFA-3, CD84/SLAMF5, CD229/SLAMF3, CRACC/SLAMF7, NTB-A/SLAMF6, 및 SLAM/CD150); 및 임의의 다른 공동 자극 분자, 예컨대, CD2, CD7, CD53, CD82/Kai-1, CD90/Thy1, CD96, CD160, CD200, CD300a/LMIR1, HLA 클래스 I, HLA-DR, 이카로스(Ikaros), 인테그린 알파 4/CD49d, 인테그린 알파 4 베타 1, 인테그린 알파 4 베타 7/LPAM-1, LAG-3, TCL1A, TCL1B, CRTAM, DAP12, 덱틴(Dectin)-1/CLEC7A, DPPIV/CD26, EphB6, TIM-1/KIM-1/HAVCR, TIM-4, TSLP, TSLP R, 림프구 기능 연관 항원-1 (LFA-1), 및 NKG2C를 포함하나, 이에 제한되지 않는다. 일부 실시양태에서, 공동 자극 신호전달 도메인은 4-1BB, CD28, OX40, ICOS, CD27, GITR, HVEM, TIM1, LFA1(CD11a) 또는 CD2, 또는 그의 임의의 변이체의 것이다. 다른 실시양태에서, 공동 자극 신호전달 도메인은 4-1BB로부터 유래된 것이다.
본원에 기술된 공동 자극 신호전달 도메인 중 임의의 것의 변이체 또한 본 개시내용의 범주 내에 포함되며, 이로써, 공동 자극 신호전달 도메인은 면역 세포의 면역 반응을 조절할 수 있다. 일부 실시양태에서, 공동 자극 신호전달 도메인은 야생형 대응물과 비교하였을 때, 최대 10개의 아미노산 잔기 변이 (예컨대, 1, 2, 3, 4, 5 또는 8개)를 포함한다. 하나 이상의 아미노산 변이를 포함하는 상기 공동 자극 신호전달 도메인은 변이체로 지칭될 수 있다.
공동 자극 신호전달 도메인의 아미노산 잔기의 돌연변이는 돌연변이를 포함하지 않는 공동 자극 신호전달 도메인과 비교하였을 때, 신호 전달을 증가시키고, 면역 반응의 자극을 증진시킬 수 있다. 공동 자극 신호전달 도메인의 아미노산 잔기의 돌연변이는 돌연변이를 포함하지 않는 공동 자극 신호전달 도메인과 비교하였을 때, 신호 전달을 감소시키고, 면역 반응의 자극을 감소시킬 수 있다. 예를 들어, 천연 CD28 아미노산 서열의 잔기 186 및 187의 돌연변이는 키메라 수용체의 공동 자극 도메인에 의한 공동 자극 활성, 및 면역 반응 유도를 증가시킬 수 있다. 일부 실시양태에서, 돌연변이는 CD28LL → GG 변이체로 지칭되는, CD28 공동 자극 도메인의 각 186번 및 187번 위치의 리신의 글리신 잔기로의 치환이다. 공동 자극 신호전달 도메인의 공동 자극 활성을 증진시키거나, 또는 감소시킬 수 있는, 상기 도메인에서 이루어질 수 있는 추가의 돌연변이는 관련 기술분야의 통상의 기술자에게 명백할 것이다. 일부 실시양태에서, 공동 자극 신호전달 도메인은 4-1BB, CD28, OX40, 또는 CD28LL → GG 변이체의 것이다. 일부 실시양태에서, 공동 자극 신호전달 도메인은 4-1BB의 것이 아니다.
일부 실시양태에서, 키메라 수용체는 1개 초과의 공동 자극 신호전달 도메인 (예컨대, 2, 3개 또는 그 초과)을 포함할 수 있다. 일부 실시양태에서, 키메라 수용체는 같은 공동 자극 신호전달 도메인을 2개 이상, 예를 들어, CD28의 공동 자극 신호전달 도메인을 2 카피 포함한다. 일부 실시양태에서, 키메라 수용체는 다른 공동 자극 단백질로부터의 2개 이상의 공동 자극 신호전달 도메인, 예컨대, 임의의 2개 이상의 본원에 기술된 공동 자극 단백질을 포함한다. 공동 자극 신호전달 도메인의 유형(들)을 선택하는 것은 인자, 예컨대, 키메라 수용체와 함께 사용하고자 하는 숙주 세포의 유형 (예컨대, 면역 세포, 예컨대, T 세포, NK 세포, 대식세포, 호중구, 또는 호산구) 및 원하는 면역 이펙터 기능에 기초할 수 있다. 일부 실시양태에서, 키메라 수용체는 2개의 공동 자극 신호전달 도메인을 포함한다. 일부 실시양태에서, 2개의 공동 자극 신호전달 도메인은 CD28 및 4-1BB이다. 일부 실시양태에서, 2개의 공동 자극 신호전달 도메인은 CD28LL→GG 변이체 및 4-1BB이다.
D.
면역수용체 티로신 기반 활성화 모티프 (
ITAM
)를 포함하는 세포질 신호전달 도메인
본원에 기술된 키메라 수용체를 구축하는 데 면역수용체 티로신 기반 활성화 모티프 (ITAM)를 포함하는 임의의 세포질 신호전달 도메인이 사용될 수 있다. 본원에서 사용되는 바, "ITAM"은 일반적으로 많은 면역 세포에서 발현되는 신호전달 분자의 테일 부위에 존재하는 보존형 단백질 모티프이다. 모티프는 6-8개의 아미노산에 의해 이격되어 있는 2개의 아미노산 서열 YxxL/I 반복부를 포함할 수 있으며 (여기서, 각 x는 독립적으로 임의의 아미노산이다), 이로써, 보존형 모티프 YxxL/Ix(6-8)YxxL/I를 생성한다. 신호전달 분자 내의 ITAM은 세포 내에서의 신호 전달에 중요하며, 이는 적어도 부분적으로는, 신호전달 분자의 활성화 이후, ITAM 중 티로신 잔기의 인산화에 의해 매개된다. ITAM은 또한 신호전달 경로에 관여하는 다른 단백질에 대한 도킹 부위로서 작용할 수 있다. 일부 예에서, ITAM을 포함하는 세포질 신호전달 도메인은 CD3ζ 또는 FcεR1γ의 것이다. 다른 예에서, ITAM 함유 세포질 신호전달 도메인은 인간 CD3ζ로부터 유래된 것이다. 추가의 다른 예에서, 같은 키메라 수용체 구축물의 세포외 리간드 결합 도메인이 CD16A로부터 유래된 것일 때, ITAM 함유 세포질 신호전달 도메인은 Fc 수용체로부터 유래된 것이 아니다.
한 구체적인 실시양태에서, 상가 또는 시너지 효과를 위해 수개의 신호전달 도메인이 함께 융합될 수 있다. 유용한 추가의 신호전달 도메인의 비제한적인 예로는 TCR 제타 쇄, CD28, OX40/CD134, 4-1BB/CD137, FcεRIy, ICOS/CD278, ILRB/CD122, IL-2RG/CD132, 및 CD40 중 하나 이상의 것의 일부 또는 그들 모두를 포함한다.
E.
힌지
도메인
일부 실시양태에서, 본원에 기술된 키메라 수용체는 세포외 리간드 결합 도메인과 막횡단 도메인 사이에 위치하는 힌지 도메인을 추가로 포함한다. 힌지 도메인은 일반적으로 단백질의 두 도메인 사이에서 발견되며, 단백질의 가요성 및 도메인 중 하나 또는 그 둘 모두의 서로에 대해 상대적인 운동을 허용할 수 있는 아미노산 세그먼트이다. 키메라 수용체의 막횡단 도메인에 대해 상대적인 Fc 수용체의 세포외 리간드 결합 도메인의 상기와 같은 가용성 및 운동을 제공하는 임의의 아미노산 서열이 사용될 수 있다.
힌지 도메인은 약 10-100개의 아미노산, 예컨대, 15-75개의 아미노산, 20-50개의 아미노산, 또는 30-60개의 아미노산을 함유할 수 있다. 일부 실시양태에서, 힌지 도메인의 길이는 10, 11, 12, 13, 14,15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 35, 40, 45, 50, 55, 60, 65, 70, 또는 75개의 아미노산 길이일 수 있다.
일부 실시양태에서, 힌지 도메인은 자연적으로 발생된 단백질의 힌지 도메인이다. 힌지 도메인을 포함하는 것으로 관련 기술분야에 공지된 임의의 단백질의 힌지 도메인은 본원에 기술된 키메라 수용체에서의 사용에 상용성을 띤다. 일부 실시양태에서, 힌지 도메인은 자연적으로 발생된 단백질의 힌지 도메인의 적어도 일부분이며, 키메라 수용체에 가요성을 부여한다. 일부 실시양태에서, 힌지 도메인은 CD8α의 것이다. 일부 실시양태에서, 힌지 도메인은 CD8α의 힌지 도메인의 부위, 예컨대, CD8α의 힌지 도메인의 적어도 15개 (예컨대, 20, 25, 30, 35, 또는 40개)의 연속적인 아미노산을 함유하는 단편이다.
항체, 예컨대, IgG, IgA, IgM, IgE, 또는 IgD 항체의 힌지 도메인 또한 본원에 기술된 키메라 수용체에서의 사용에 상용성을 띤다. 일부 실시양태에서, 힌지 도메인은 항체의 불변 도메인 CH1 및 CH2를 연결하는 힌지 도메인이다. 일부 실시양태에서, 힌지 도메인은 항체의 것이고, 항체의 힌지 도메인 및 항체의 하나 이상의 불변 영역을 포함한다. 일부 실시양태에서, 힌지 도메인은 항체의 힌지 도메인 및 항체의 CH3 불변 영역을 포함한다. 일부 실시양태에서, 힌지 도메인은 항체의 힌지 도메인 및 항체의 CH2 및 CH3 불변 영역을 포함한다. 일부 실시양태에서, 항체는 IgG, IgA, IgM, IgE, 또는 IgD 항체이다. 일부 실시양태에서, 항체는 IgG 항체이다. 일부 실시양태에서, 항체는 IgG1, IgG2, IgG3, 또는 IgG4 항체이다. 일부 실시양태에서, 힌지 영역은 IgG1 항체의 힌지 영역 및 CH2 및 CH3 불변 영역을 포함한다. 일부 실시양태에서, 힌지 영역은 IgG1 항체의 힌지 영역 및 CH3 불변 영역을 포함한다.
비-자연적으로 발생된 펩티드 또한 본원에 기술된 키메라 수용체를 위한 힌지 도메인으로서 사용될 수 있다. 일부 실시양태에서, Fc 수용체의 세포외 리간드 결합 도메인의 C-말단과 막횡단 도메인의 N-말단 사이의 힌지 도메인은 펩티드 링커, 예컨대, (GlyxSer)n 링커 (여기서, x 및 n은 독립적으로 3, 4, 5, 6, 7, 8, 9, 10, 11, 12을 비롯한, 3 내지 12인 정수, 또는 그 초과인 값일 수 있다)이다. 일부 실시양태에서, 힌지 도메인은 (Gly4Ser)n (서열식별번호: 76) (여기서, n은 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60을 비롯한, 3 내지 60인 정수, 또는 그 초과인 값일 수 있다)이다. 일부 실시양태에서, 힌지 도메인은 (Gly4Ser)3 (서열식별번호: 77)이다. 일부 실시양태에서, 힌지 도메인은 (Gly4Ser)6 (서열식별번호: 78)이다. 일부 실시양태에서, 힌지 도메인은 (Gly4Ser)9 (서열식별번호: 79)이다. 일부 실시양태에서, 힌지 도메인은 (Gly4Ser)12 (서열식별번호: 80)이다. 일부 실시양태에서, 힌지 도메인은 (Gly4Ser)15 (서열식별번호: 81)이다. 일부 실시양태에서, 힌지 도메인은 (Gly4Ser)30 (서열식별번호: 82)이다. 일부 실시양태에서, 힌지 도메인은 (Gly4Ser)45 (서열식별번호: 83)이다. 일부 실시양태에서, 힌지 도메인은 (Gly4Ser)60 (서열식별번호: 84)이다.
다른 실시양태에서, 힌지 도메인은 다양한 길이의 친수성 잔기 (예컨대, 10-80개의 아미노산 잔기)로 이루어진 비구조적 폴리펩티드인, 연장된 재조합 폴리펩티드 (XTEN)이다. XTEN 펩티드의 아미노산 서열은 관련 기술분야의 통상의 기술자에게는 명백할 것이며, 이는 예를 들어, 미국 특허 번호 8,673,860 (상기 특허는 본원에서 참조로 포함된다)에서 살펴볼 수 있다. 일부 실시양태에서, 힌지 도메인은 XTEN 펩티드이고, 60개의 아미노산을 포함한다. 일부 실시양태에서, 힌지 도메인은 XTEN 펩티드이고, 30개의 아미노산을 포함한다. 일부 실시양태에서, 힌지 도메인은 XTEN 펩티드이고, 45개의 아미노산을 포함한다. 일부 실시양태에서, 힌지 도메인은 XTEN 펩티드이고, 15개의 아미노산을 포함한다.
F.
신호 펩티드
일부 실시양태에서, 키메라 수용체는 또한 폴리펩티드의 N-말단에 신호 펩티드 (이는 또한 신호 서열로도 공지됨)를 포함한다. 일반적으로, 신호 서열은 폴리펩티드를 세포 중의 원하는 부위로 표적화하는 펩티드 서열이다. 일부 실시양태에서, 신호 서열은 키메라 수용체를 세포의 분비 경로로 표적화하고, 키메라 수용체가 지질 이중층에 통합 및 고정될 수 있게 할 것이다. 본원에 기술된 키메라 수용체에서의 사용에 상용성을 띠는, 자연적으로 발생된 단백질의 신호 서열, 또는 합성, 비-자연적으로 발생된 신호 서열을 비롯한, 신호 서열은 관련 기술분야의 통상의 기술자에게 명백할 것이다. 일부 실시양태에서, 신호 서열은 CD8α로부터의 것이다. 일부 실시양태에서, 신호 서열은 CD28로부터의 것이다. 다른 실시양태에서, 신호 서열은 뮤린 카파 쇄로부터의 것이다. 추가의 다른 실시양태에서, 신호 서열은 CD16으로부터의 것이다.
G.
키메라
수용체의 예
하기 표 3-5는 본원에 기술된 키메라 수용체의 예를 제공한다. 이러한 예시적인 구축물은 N-말단에서부터 C-말단으로 순서대로 신호 서열, Fc 결합제 (예컨대, Fc 수용체의 세포외 도메인), 힌지 도메인, 및 막횡단을 가지며, 공동 자극 도메인 및 세포질 신호전달 도메인의 위치는 바뀔 수 있다.
<표 3>
예시적인 키메라 수용체

<표 4>
예시적인 키메라 수용체

<표 5>
예시적인 키메라 수용체


예시적인 키메라 수용체의 아미노산 서열을 하기에 제공한다 (신호 서열은 이탤릭체로 표시).














일부 실시양태에서, 예컨대, 본원에 개시된 CD16F-BB-ζ 및 CD16V-BB-ζ와 같은, 본원에 기술된 키메라 수용체는 CD16 (CD16F 또는 CD16V, 이는 또한 F158 FCGR3A 및 V158 FCGR3A 변이체로도 공지됨)의 세포외 리간드 결합 도메인, CD8α의 힌지 및 막횡단 도메인, 4-1BB의 공동 자극 신호전달 도메인, 및 CD3ζ의 세포질 신호전달 도메인 중 하나 이상의 것을 포함할 수 있다. 이들 성분의 아미노산 서열 및 예시적인 코딩 뉴클레오티드 서열은 하기 표 6에 제공되어 있다.
<표 6>
예시적인 서열



일부 예에서, 본원에 기술된 키메라 수용체는 상기 열거된 성분들 모두를 포함하지는 않는다. 예를 들어, 본원에 기술된 키메라 수용체는 하기 표 7에 열거된 키메라 수용체 중 어느 것도 아닐 수 있거나, 또는 상기 표 6에 열거된 서열 중 하나 이상의 것을 포함하지 않을 수 있다.
<표 7>
예시적인 키메라 수용체

본원에 개시된 다른 키메라 수용체와 같이, 면역 세포, 예컨대, T 세포 및 NK 세포에서의 이들 예시적인 키메라 수용체의 발현이 상기 세포에 ADCC 능력을 부여할 것이며, 이로써, 표적화된 종양 항원에 상관 없이, 모노클로날 항체 (뿐만 아니라, Fc 부위를 포함하는 다른 항-종양 분자, 예컨대, 면역글로불린 또는 Fc-함유 DNA 또는 RNA의 Fc 부위와 조합된, 종양 표면 수용체에 결합하는 리간드 (예컨대, 시토카인, 면역 세포 수용체)에 의해 구성된 복합 분자)의 항-종양 잠재능을 유의적으로 증강시킬 것이다.
본원에 기술된 다른 키메라 수용체와 같이, 이들 예시적인 키메라 수용체 또한 다중 종양에 대한 항체 요법의 효능을 유의적으로 증강시키는 잠재능을 가진 범용 키메라 수용체이다. 하기 실시예 1에서 논의되는 바와 같이, 레트로바이러스 형질도입에 의해 인간 T 세포에서 발현되었을 때, 본 개시내용의 V158 수용체는 통상의 F158 변이체 (이 또한 본원에서 제공됨)를 함유하는 동일한 키메라 수용체와 비교하였을 때, 예컨대, 항-CD20 항체 리툭시맙과 같은, 인간화 항체를 비롯한 인간 IgG에 대하여 유의적으로 더 높은 친화도를 가진다. 키메라 수용체의 결속이 T 세포 활성화, 용해성 과립 엑소사이토시스 및 증식을 유발한다. CD16V-BB-ζ를 발현하는 T 세포는 낮은 이펙터: 표적 비율에서 리툭시맙의 존재하에 림프종 세포주 및 원발성 만성 림프구성 백혈병 (CLL) 세포를 특이적으로 사멸시키며, 심지어 CLL 배양이 골수 유래 중간엽 세포 상에서 수행된 경우에도 그러한다. 항-HER2 항체 트라스투주맙은 유방암 및 위암 세포에 대하여, 및 항-GD2 항체 hu14.18K322A는 신경모세포종 및 골육종 세포에 대하여 키메라 수용체-매개 항체 의존성 세포 세포독성 (ADCC)을 일으킨다. 실시예 섹션에 추가로 개시되어 있는 바와 같이, 키메라 수용체를 발현하는 T 세포와 리툭시맙은 조합하여 면역결핍 마우스에서 인간 림프종 세포를 퇴치한 반면, T 세포 또는 항체 단독인 경우에는 그러하지 못했다. 상기 기술에 관한 임상적 해석을 가속화하기 위해, 키메라 수용체 mRNA의 전기천공에 기초한 방법을 개발함으로써 바이러스 벡터 사용 없이도 효율적이고, 일시적인 수용체 발현을 이끌었다.
H.
키메라
수용체의 제조 및
키메라
수용체를 포함하는 제약 조성물
본원에 기술된 키메라 수용체 중 임의의 것은 통상의 방법, 예컨대, 재조합 기술에 의해 제조될 수 있다. 본원의 키메라 수용체를 제조하는 방법은 Fc 수용체의 세포외 리간드 결합 도메인, 막횡단 도메인, 적어도 하나의 공동 자극 신호전달 도메인, 및 ITAM을 포함하는 세포질 신호전달 도메인을 비롯한, 키메라 수용체의 각 도메인을 포함하는, 폴리펩티드를 코딩하는 핵산을 생성하는 것을 포함한다. 일부 실시양태에서, 핵산은 또한 Fc 수용체의 세포외 리간드 결합 도메인과 막횡단 도메인 사이의 힌지 도메인을 코딩한다. 키메라 수용체를 코딩하는 핵산은 또한 신호 서열을 코딩할 수 있다. 일부 실시양태에서, 핵산 서열은 서열식별번호: 2-30 및 32-56에 의해 제공되는 예시적인 키메라 수용체 중 어느 하나를 코딩한다.
키메라 수용체의 각 성분의 서열은 통상의 기술, 예컨대, 관련 기술분야에 공지된 다양한 공급원들 중 어느 하나로부터의 PCR 증폭을 통해 수득할 수 있다. 일부 실시양태에서, 키메라 수용체의 성분들 중 하나 이상의 것의 서열은 인간 세포로부터 수득된 것이다. 대안적으로, 키메라 수용체의 하나 이상의 성분의 서열은 합성될 수 있다. 예컨대, PCR 증폭 또는 라이게이션과 같은 방법을 사용하여, 각 성분 (예컨대, 도메인)의 서열은 직접적으로, 또는 (예컨대, 펩티드 링커를 코딩하는 핵선 서열을 사용하여) 간접적으로 간접적으로 연결될 수 있고, 이로써, 키메라 수용체를 코딩하는 핵산 서열을 형성할 수 있다. 대안적으로, 키메라 수용체를 코딩하는 핵산은 합성될 수 있다. 일부 실시양태에서, 핵산은 DNA이다. 다른 실시양태에서, 핵산은 RNA이다.
키메라 수용체 단백질, 상기를 코딩하는 핵산, 및 상기 핵산을 보유하는 발현 벡터 중 임의의 것을 제약상 허용되는 담체와 혼합하여 제약 조성물을 형성할 수 있고, 이 또한 본 개시내용의 범주 내에 포함된다. "허용되는"이란, 담체가 조성물의 활성 성분 (예컨대, 핵산, 벡터, 세포, 또는 치료학적 항체)과 상용성이고, 조성물(들)을 투여받은 대상체에게 부정적인 영향을 미치지 않는다는 것을 의미한다. 본 발명에서 사용하고자 하는 제약 조성물 중 임의의 것은 동결건조된 제제 또는 수용액 형태로 제약상 허용되는 담체, 부형제, 또는 안정제를 포함할 수 있다.
완충제를 비롯한, 제약상 허용되는 담체는 관련 기술분야에 널리 공지되어 있고, 포스페이트, 시트레이트, 및 다른 유기산; 아스코르브산 및 메티오닌을 비롯한, 항산화제; 보존제; 저분자량 폴리펩티드; 단백질, 예컨대, 혈청 알부민, 젤라틴, 또는 면역글로불린; 아미노산; 소수성 중합체; 단당류; 이당류; 및 다른 탄수화물; 금속 복합체; 및/또는 비이온성 계면활성제를 포함할 수 있다. 예컨대 문헌 [Remington: The Science and Practice of Pharmacy 20th Ed. (2000) Lippincott Williams and Wilkins, Ed. K. E. Hoover]을 참조할 수 있다.
본 개시내용의 제약 조성물은 치료하고자 하는 특정 적응증에 필요한 하나 이상의 추가 활성 화합물, 바람직하게, 서로 유해한 영향을 미지치 않는, 상호 보완적인 활성을 가지는 것 또한 함유할 수 있다. 가능한 추가의 활성 화합물에 관한 비제한적인 예로는 예컨대, IL2 뿐만 아니라, 하기 조합 치료에 관한 논의에서 열거되는 다양한 작용제를 포함한다.
II.
키메라
수용체를 발현하는 면역 세포
본원에 기술된 키메라 수용체를 발현하는 숙주 세포는 Fc-함유 치료제, 예컨대, 항체 (예컨대, 치료학적 항체) 또는 Fc-융합 단백질이 결합하는 표적 세포를 인식할 수 있는 특이적인 세포 집단을 제공한다. 상기 숙주 세포 (예컨대, 면역 세포) 상에서 발현된 키메라 수용체 구축물의 세포외 리간드 결합 도메인와 항체 또는 Fc-융합 단백질의 Fc 부위와의 결속으로 활성화 신호가 키메라 수용체 구축물의 공동 자극 신호전달 도메인(들) 및 ITAM 함유 세포질 신호전달 도메인에 전달되고, 이로써, 결국에는 숙주 세포의 세포 증식 및/또는 이펙터 기능, 예컨대, 숙주 세포에 의해 유발되는 ADCC 효과가 활성화된다. 공동 자극 신호전달 도메인(들) 및 ITAM을 포함하는 세포질 신호전달 도메인의 조합을 통해 세포내 다중 신호전달 경로의 활성화가 강력화될 수 있다. 일부 실시양태에서, 숙주 세포는 면역 세포, 예컨대, T 세포, NK 세포, 대식세포, 호중구, 호산구, 또는 그의 임의 조합이다. 일부 실시양태에서, 면역 세포는 T 세포이다. 일부 실시양태에서, 면역 세포는 NK 세포이다. 다른 실시양태에서, 면역 세포는 확립된 세포주, 예를 들어, NK-92 세포일 수 있다.
면역 세포 집단은 임의의 공급원, 예컨대, 말초 혈액 단핵 세포 (PBMC), 골수, 조직, 예컨대, 비장, 림프절, 흉선, 또는 종양 조직으로부터 수득될 수 있다. 원하는 숙주 세포 유형을 수득하는 데 적합한 공급원은 관련 기술분야의 통상의 기술자에게 명백할 것이다. 일부 실시양태에서, 면역 세포 집단은 PBMC로부터 유래된 것이다. 원하는 숙주 세포 유형 (예컨대, 면역 세포, 예컨대, T 세포, NK 세포, 대식세포, 호중구, 호산구, 또는 그의 임의 조합)은 세포를 자극 분자와 함께 공동으로 인큐베이션시킴으로써 수득되는 세포 집단 내에서 확장될 수 있고, 예를 들어, 항-CD3 및 항-CD28 항체는 T 세포의 확장을 위해 사용될 수 있다.
본원에 기술된 키메라 수용체 구축물 중 임의의 것을 발현하는 면역 세포를 구축하기 위해, 키메라 수용체 구축물의 안정적인 또는 일시적인 발현을 위한 발현 벡터를 본원에 기술된 종래 방법을 통해 구축할 수 있고, 면역 숙주 세포 내로 도입할 수 있다. 예를 들어, 키메라 수용체를 코딩하는 핵산을 적합한 프로모터와 작동가능하게 연결되게 적합한 발현 벡터, 예컨대, 바이러스 벡터 내로 클로닝할 수 있다. 적합한 조건하에서 핵산 및 벡터를 제한 효소와 접촉시켜, 서로 쌍을 형성할 수 있고, 리가제로 연결될 수 있는 상보적인 단부를 각 분자 상에 생성할 수 있다. 대안적으로, 키메라 수용체를 코딩하는 핵산의 말단에 합성 핵산 링커를 라이게이션시킬 수 있다. 합성 링커는 벡터 중 특정 제한 부위에 상응하는 핵산 서열을 함유할 수 있다. 발현 벡터/플라스미드/바이러스 벡터 선택은 키메라 수용체의 발현을 위한 숙주 세포의 유형에 의존하지만, 진핵 세포에서의 통합 및 복제에 적합한 것이어야 한다.
본원에 기술된 키메라 수용체의 발현에 다양한 프로모터가 사용될 수 있으며, 이는 제한 없이, 시토메갈로바이러스 (CMV) 중간 초기 프로모터, 바이러스 LTR, 예컨대, 라우스 육종 바이러스 LTR, HIV-LTR, HTLV-1 LTR, 원숭이바이러스 40 (SV40) 초기 프로모터, 헤르페스 단순 tk 바이러스 프로모터를 포함한다. 키메라 수용체 발현을 위한 추가의 프로모터로는 면역 세포에서 구성적으로 활성을 띠는 임의의 프로모터를 포함한다. 대안적으로, 임의의 조절가능한 프로모터가 사용될 수 있고, 이로써, 면역 세포 내에서의 그의 발현은 조절될 수 있다.
추가로, 벡터는 예를 들어, 하기 중 일부 또는 그들 모두를 함유할 수 있다: 선별가능한 마커 유전자, 예컨대, 숙주 세포에서 안정적인 또는 일시적인 형질감염체의 선별을 위한 네오마이신 유전자; 고수준의 전사를 위한 인간 CMV의 중간 초기 유전자로부터의 인핸서/프로모터 서열; mRNA 안정성을 위한 SV40으로부터의 전사 종결 및 RNA 프로세싱 신호; SV40 폴리오마 복제 기점 및 적절한 에피솜 복제를 위한 ColE1; 내부 리보솜 결합 부위 (IRES), 다목적 다중 클로닝 부위; 센스 및 안티센스 RNA의 시험관내 전사를 위한 T7 및 SP6 RNA 프로모터; 유발되었을 때, 벡터를 보유하는 세포의 사멸을 유발하는 "자살 스위치" 또는 "자살 유전자" (예컨대, HSV 티미딘 키나제, 유도성 카스파제, 예컨대, iCasp9), 및 키메라 수용체의 발현을 평가하기 위한 리포터 유전자.
한 구체적인 실시양태에서, 상기 벡터는 또한 자살 유전자를 포함한다. 본원에서 사용되는 바, "자살 유전자"라는 용어는 자살 유전자를 발현하는 세포의 사멸을 유발하는 유전자를 의미한다. 자살 유전자는 작용제, 예컨대, 약물에 대한 감수성을 유전자 발현되는 세포에 부여하고, 세포가 상기 작용제와 접촉하였을 때, 또는 그에 노출되었음을 때, 세포의 사멸을 유발하는 유전자일 수 있다. 자살 유전자는 관련 기술분야에 공지되어 있고 (예를 들어, 문헌 [Suicide Gene Therapy: Methods and Reviews, Springer, Caroline J. (Cancer Research UK Centre for Cancer Therapeutics at the Institute of Cancer Research, Sutton, Surrey, UK), Humana Press, 2004] 참조), 이는 예를 들어, 헤르페스 단순 바이러스 (HSV) 티미딘 키나제 (TK) 유전자, 시토신 다미나제, 퓨린 뉴클레오시드 포스포릴라제, 니트로리덕타제 및 카스파제, 예컨대, 카스파제 8을 포함한다.
적합한 벡터 및 트랜스진을 함유하는 벡터를 제조하는 방법은 관련 기술분야에 널리 공지되어 있고, 이용가능하다. 키메라 수용체의 발현을 위한 벡터의 제조에 관한 예는 예를 들어, US2014/0106449 (상기 문헌은 그 전문이 본원에서 참조로 포함된다)에서 살펴볼 수 있다.
본원에 기술된 키메라 수용체 구축물을 코딩하는 핵산 서열을 포함하는 벡터 중 임의의 것 또한 본 개시내용의 범주 내에 포함된다. 상기 벡터, 또는 그 안에 함유되어 있는 키메라 수용체를 코딩하는 서열은 적합한 방법에 의해 숙주 세포, 예컨대, 숙주 면역 세포 내로 전달될 수 있다. 벡터를 면역 세포로 전달하는 방법은 관련 기술분야에 널리 공지되어 있고, DNA 전기천공, RNA 전기천공, 형질감염 시약, 예컨대, 리포솜, 또는 바이러스 형질도입을 포함할 수 있다.
일부 실시양태에서, 키메라 수용체의 발현을 위한 벡터는 바이러스 형질도입에 의해 숙주 세포로 전달된다. 예시적인 바이러스 전달 방법은 재조합 레트로바이러스 (예컨대, PCT 공개 번호 WO 90/07936; WO 94/03622; WO 93/25698; WO 93/25234; WO 93/11230; WO 93/10218; WO 91/02805; 미국 특허 번호 5,219,740 및 4,777,127; GB 특허 번호 2,200,651; 및 EP 특허 번호 0 345 242 참조), 알파바이러스 기반 벡터, 및 아데노 관련 바이러스 (AAV) 벡터 (예컨대, PCT 공개 번호 WO 94/12649, WO 93/03769; WO 93/19191; WO 94/28938; WO 95/11984 및 WO 95/00655 참조)를 포함하나, 이에 제한되지 않는다. 일부 실시양태에서, 키메라 수용체의 발현을 위한 벡터는 레트로바이러스이다. 일부 실시양태에서, 키메라 수용체의 발현을 위한 벡터는 렌티바이러스이다.
레트로바이러스 형질도입에 관하여 기술하는 참고 문헌의 예로는 미국 특허 번호 5,399,346 (앤더슨(Anderson) 등); [Mann et al., Cell 33:153 (1983)]; 미국 특허 번호 4,650,764 (테민(Temin) 등); 미국 특허 번호 4,980,289 (테민 등); [Markowitz et al., J. Virol. 62:1120 (1988)]; 미국 특허 번호 5,124,263 (테민 등); 국제 특허 공개 번호 WO 95/07358 (1995년 3월 16일, 도허티(Dougherty) 등); 및 [Kuo et al., Blood 82:845 (1993)]을 포함한다. 국제 특허 공개 번호 WO 95/07358에는 일차 B 림프구의 고효율 형질도입이 기술되어 있다. 예를 들어, 사용될 수 있는 mRNA 전기천공 및 레트로바이러스 형질도입에 대한 구체적인 기술에 관해 하기의 실시예 섹션을 참조할 수 있다.
키메라 수용체를 코딩하는 벡터를 바이러스 벡터를 사용하여 숙주 세포로 도입하는 예에서, 면역 세포를 감염시킬 수 있고, 벡터를 보유하는 바이러스 입자는 관련 기술분야에 공지된 임의의 방법에 의해 제조될 수 있고, 이는 예를 들어, PCT 출원 번호 WO 1991/002805A2, WO 1998/009271 A1, 및 미국 특허 6,194,191에서 살펴볼 수 있다. 바이러스 입자를 세포 배양물 상청액으로부터 수거하고, 바이러스 입자를 면역 세포와 접촉시키기 이전에 단리 및/또는 정제할 수 있다.
일부 실시양태에서, 본원에 기술된 키메라 수용체 중 임의의 것을 코딩하는 RNA 분자를 종래 방법 (예컨대, 시험관내 전사)에 의해 제조할 수 있고, 공지된 방법 (예컨대, 문헌 [Rabinovich et al., Human Gene Therapy 17:1027-1035])을 통해 적합한 숙주 세포, 예컨대, 본원에 기술된 것 내로 도입시킬 수 있다. 하기 실시예에서 입증되는 바와 같이, mRNA 전기천공을 통해 T 림프구에서 본 개시내용의 키메라 수용체를 효과적으로 발현시킬 수 있다.
숙주 세포 내로 본원에서 제공하는 키메라 수용체 중 임의의 것을 코딩하는 벡터, 또는 키메라 벡터를 코딩하는 핵산 (예컨대, RNA 분자)을 도입한 후, 키메라 수용체의 발현을 허용하는 조건하에서 세포를 배양한다. 키메라 수용체를 코딩하는 핵산이 조절가능한 프로모터에 의해 조절되는 예에서, 숙주 세포를 조절가능한 프로모터가 활성화되는 조건에서 배양한다. 일부 실시양태에서, 프로모터는 유도가능한 프로모터이고, 면역 세포는 유도 분자의 존재하에서, 또는 유도 분자가 제조되는 조건하에서 배양된다. 키메라 수용체 발현 여부를 측정하는 것은 관련 기술분야의 통상의 기술자에게 명백할 것이며, 임의의 공지된 방법에 의해, 예를 들어, 정량적 역전사 효소 PCR (qRT-PCR)에 의한 키메라 수용체 코딩 mRNA의 검출에 의해, 또는 웨스턴 블롯팅, 형광 현미경법, 및 유세포 분석법을 비롯한 방법에 의한 키메라 수용체 단백질의 검출에 의해 평가될 수 있다. 대안적으로, 키메라 수용체 발현은 면역 세포의 대상체로의 투여 이후에 생체내에서 이루어질 수 있다.
대안적으로, 본원에 개시된 면역 세포 중 임의의 것에서의 키메라 수용체 구축물의 발현은 키메라 수용체 구축물을 코딩하는 RNA 분자 도입에 의해 달성될 수 있다. 상기 RNA 분자는 시험관내 전사에 의해 또는 화학적 합성에 의해 제조될 수 있다. 이어서, RNA 분자를 예컨대, 전기천공에 의해 적합한 숙주 세포, 예컨대, 면역 세포 (예컨대, T 세포, NK 세포, 대식세포, 호중구, 호산구, 또는 그의 임의 조합) 내로 도입할 수 있다. 예를 들어, 문헌 [Rabinovich et al., Human Gene Therapy, 17:1027-1035] 및 WO WO2013/040557에 기술된 방법에 따라, RNA 분자를 합성할 수 있고, 숙주 면역 세포 내로 도입할 수 있다.
본원에 기술된 키메라 수용체 중 임의의 것을 발현하는 숙주 세포를 제조하는 방법은 또한 숙주 세포를 생체외에서 활성화시키는 것을 포함할 수 있다. 숙주 세포를 활성화시킨다는 것은 세포가 이펙터 기능 (예컨대, ADCC)을 수행할 수 있는 활성 상태로 숙주 세포를 자극시킨다는 것을 의미한다. 숙주 세포를 활성화시키는 방법은 키메라 수용체 발현을 위해 사용되는 숙주 세포의 유형에 의존할 것이다. 예를 들어, T 세포는 생체외에서 하나 이상의 분자, 예컨대, 항-CD3 항체, 항-CD28 항체, IL-2, 또는 피토헤모아글루티닌의 존재하에 활성화될 수 있다. 다른 예에서, NK 세포는 생체외에서 한 분자, 예컨대, 4-1BB 리간드, 항-4-1BB 항체, IL-15, 항-IL-15 수용체 항체, IL-2, IL12, IL-21, 및 K562 세포의 존재하에 활성화될 수 있다. 일부 실시양태에서, 본원에 기술된 키메라 수용체 중 임의의 것을 발현하는 숙주 세포는 대상체에게로의 투여 이전에 생체외에서 활성화된다. 숙주 세포 활성화 여부를 측정하는 것은 관련 기술분야의 통상의 기술자에게 명백할 것이며, 세포 활성화와 연관된 하나 이상의 세포 표면 마커의 발현, 시토카인의 발현 또는 분비, 및 세포 형태를 평가하는 것을 포함할 수 있다.
본원에 기술된 키메라 수용체 중 임의의 것을 발현하는 숙주 세포를 제조하는 방법은 생체외에서 숙주 세포를 확장시키는 것을 포함할 수 있다. 숙주 세포를 확장시키는 것은 키메라 수용체를 발현하는 세포의 개수를 증가시키는 임의의 방법, 예를 들어, 숙주 세포가 증식할 수 있도록 허용하거나, 또는 숙주 세포를 자극시켜 증식할 수 있도록 하는 것을 포함할 수 있다. 숙주 세포의 확장을 자극하는 방법은 키메라 수용체의 발현을 위해 사용되는 숙주 세포의 유형에 의존할 것이며, 이는 관련 기술분야의 통상의 기술자에게 명백할 것이다. 일부 실시양태에서, 본원에 기술된 키메라 수용체 중 임의의 것을 발현하는 숙주 세포는 대상체에게 투여하기 이전에 생체외에서 확장된다.
일부 실시양태에서, 키메라 수용체를 발현하는 숙주 세포는 대상체에게 투여하기 이전에 생체외에서 확장되고, 활성화된다. 숙주 세포 활성화 및 확장을 사용하여 바이러스 벡터를 게놈 내로 통합시킬 수 있고, 본원에 기술된 바와 같은 키메라 수용체를 코딩하는 유전자를 발현시킬 수 있다. mRNA 전기천공을 사용할 경우, 비록 전기천공이 활성화된 세포에서 수행될 때에는 더욱 효과적일 수 있지만, 활성화 및/또는 확장이 필요하지 않을 수도 있다. 일부 경우에서, 키메라 수용체는 적합한 숙주 세포 (예컨대, 3-5일 동안)에서 일시적으로 발현된다. 일시적인 발현은, 잠재적인 독성이 있다면, 이로울 수 있으며, 가능한 부작용에 대한 임상 시험의 초기 단계에서 도움이 되어야 한다.
IV.
면역요법에서
키메라
수용체를 발현하는 면역 세포의 적용
본 개시내용의 예시적인 키메라 수용체는 T 림프구에 항체 의존성 세포 세포독성 (ADCC) 능력을 부여하고, NK 세포에서 ADCC를 증진시킨다. 수용체가 종양 세포에 결합된 항체 (또는 Fc 부위를 포함하는 또 다른 항-종양 분자)에 의해 결속되었을 때, 수용체는 T 세포 활성화, 지속적 증식, 및 항체 (또는 Fc 부위를 포함하는 상기 다른 항-종양 분자)에 의해 표적화된 암 세포에 대한 특이적인 세포독성을 유발한다. 하기 실시예 섹션에 개시되어 있는 바와 같이, 본 개시내용의 키메라 수용체를 포함하는 T 림프구는 B 세포 림프종, 유방암 및 위암, 신경모세포종 및 골육종 뿐만 아니라, 원발성 만성 림프구성 백혈병 (CLL)을 비롯한, 매우 다양한 종양 세포 유형에 대해 고도의 세포독성을 보였다. 세포독성은 전반적으로 표적 세포에 결합된 특이 항체의 존재에 의존하였고: 가용성 항체는 세포용해성 과립의 엑소사이토시스를 유도하지 않았고, 비특이적인 세포독성을 유발하지 않았다.
Ig의 Fc 부위에 대한 CD16의 친화성 정도가 ADCC의 중요한 결정 요인이며, 따라서, 항체 면역요법에 대한 임상 반응에 대해 중요한 결정 요인이 된다. Ig에 대한 결합 친화도가 높고, 우수한 ADCC를 매개하는 V158 다형성을 포함하는 CD16기 예로서 선택되었다. 비록 T 세포 증식 및 ADCC 유도에서 F158 수용체가 V158 수용체보다 효능이 더 낮지만, F158 수용체가 V158 수용체보다 생체내 독성이 더 낮을 수 있는 바, 이에 일부 임상적 환경에서는 유용할 수 있다.
본 개시내용의 키메라 수용체는, 하나의 단일 수용체가 다중의 암 세포 유형에 대해 사용될 수 있도록 허용함으로써 T 세포 요법을 촉진시킨다. 이는 또한, 면역회피 기전이 종양에 의해 이용된다면, 궁극적으로 이로울 수 있는 전략법인, 다중 항원의 동시 표적화를 허용한다 (문헌 [Grupp et al., N Engl J Med. 2013]). 항체 투여의 간단한 중단으로 필요할 경우에는 언제나 항체 유도 세포독성은 중단될 수 있다. 본 개시내용의 키메라 수용체를 발현하는 T 세포가 오직 표적 세포에 결합된 항체에 의해서 활성화되기 때문에, 비결합 면역글로불린은 주입된 T 세포에 대하여 어떤 자극도 발휘하지 않아야 한다. 임의의 잠재적인 자가면역 반응성을 제한하기 위해 mRNA 전기천공을 사용하여 키메라 수용체를 일시적으로 발현시킴으로써 임상적 안전성을 추가로 증진시킬 수 있다.
하기 실시예 섹션에 개시된 결과는, 생체외에서 활성화되고 확장되고, 본 개시내용의 키메라 수용체로 유전적으로 변형된 이후에 재주입된, 자가 T 세포의 주입은 ADCC를 유의적으로 증강시켜야 한다는 것을 제안한다. 조합된 CD3ζ/4-1BB 신호전달 또한 T 세포 증식을 유발하기 때문에, 종양 부위에 활성화된 T 세포가 축적되어야 하고, 이는 그의 활성을 추가로 상승시킬 수 있다.
따라서, 한 실시양태에서, 본 개시내용은 암의 항체 기반 면역요법의 효능 증진을 필요로 하는 대상체 내로 치료학상 유효량의 T 림프구 또는 NK 세포를 도입하는 단계를 포함하고, 상기 T 림프구 또는 NK 세포는 본 개시내용의 키메라 수용체를 포함하며, 상기 대상체는 암 세포에 결합할 수 있고, 인간 CD16에 결합할 수 있는 인간환 Fc 부위를 가지는 항체로 치료받고 있는 중인 대상체인, 암의 항체 기반 면역요법의 효능 증진을 필요로 하는 대상체에서 암의 항체 기반 면역요법의 효능을 증진시키는 방법을 제공한다.
A.
면역
요법 효능 증진
본원에 기술된 키메라 수용체 (코딩 핵산 또는 그를 포함하는 벡터)를 발현하는 숙주 세포 (예컨대, 면역 세포)는 대상체에서 ADCC를 증진시키는 데 및/또는 항체 기반 면역요법의 효능을 증진시키는 데 유용하다. 일부 실시양태에서, 대상체는 포유동물, 예컨대, 인간, 원숭이, 마우스, 토끼, 또는 가축 포유동물이다. 일부 실시양태에서, 대상체는 인간이다. 일부 실시양태에서, 대상체는 인간 암 환자이다. 일부 실시양태에서, 대상체는 본원에 기술된 치료학적 항체 중 임의의 것으로 치료받은 적이 있거나, 또는 치료받고 있는 중인 대상체이다.
면역 세포를 제약상 허용되는 담체와 혼합하여 제약 조성물을 형성할 수 있고, 이 또한 본 개시내용의 범주 내에 포함된다.
본원에 기술된 방법을 수행하기 위해, 본원에 기술된 키메라 수용체 구축물 중 임의의 것을 발현하는 면역 세포를 유효량으로 치료를 필요로 하는 대상체 내로 투여할 수 있다. 면역 세포는 대상체에 대해 자가 면역 세포일 수 있고, 즉, 면역 세포는 치료를 필요로 하는 대상체로부터 수득되고, 키메라 수용체 구축물의 발현을 위해 유전적으로 조작되고, 동일한 대상체로 투여된다. 자가 세포를 대상체에게 투여하면, 비-자가 세포를 투여한 경우와 비교하여 숙주 세포의 거부가 감소될 수 있다. 대안적으로, 숙주 세포는 동종이계 세포이고, 즉, 세포는 제1 대상체로부터 수득되고, 키메라 수용체 구축물의 발현을 위해 유전적으로 조작되고, 제1 대상체와는 다르지만, 같은 종인 제2 대상체에게 투여된다. 예를 들어, 동종이계 면역 세포는 인간 공여자로부터 유래될 수 있고, 공여자와 다른 인간 수용자에게 투여될 수 있다.
일부 실시양태에서, 면역 세포는 ADCC 활성을 적어도 20%, 예컨대, 50%, 80%, 100%, 2배, 5배, 10배, 20배, 50배, 100배 또는 그 초과만큼 증진시키는 효과적인 양으로 대상체에게 투여된다.
일부 실시양태에서, 면역 세포는 항체 기반 면역요법의 효능을 증진시키기 위해 치료학적 Fc-함유 치료제 (예컨대, 항체 또는 Fc 융합 분자, 예컨대, Fc 융합 단백질)와 함께 공동으로 사용된다. 항체 기반 면역요법은 면역요법이 대상체에서 유용한 것으로 간주되는 임의의 질환 또는 장애의 증상을 치료, 완화, 또는 감소시키는 데 사용된다. 상기 요법에서, 치료학적 항체는 암 세포에서 차별적으로 발현되는 (즉, 암이 아닌 세포 상에서는 발현되지 않거나, 또는 암이 아닌 세포에서는 더 낮은 수준으로 발현되는) 세포 표면 항원에 결합할 수 있다. 치료학적 항체가 결합하고, 항원 또는 표적 분자를 발현하는 세포가 ADCC의 대상이 되어야 한다는 것을 나타내는 것인 항원 또는 표적 분자의 예로는 제한 없이, CD17/L1-CAM, CD19, CD20, CD22, CD30, CD33, CD37, CD52, CD56, CD70, CD79b, CD138, CEA, DS6, EGFR, EGFRⅴIII, ENPP3, FR, GD2, GPNMB, HER2, IL-13Rα2, 메소텔린(Mesothelin), MUC1, MUC16, 넥틴(Nectin)-4, PSMA, 및 SCL44A4를 포함한다.
항체 기반 면역요법의 효능은 관련 기술분야에 공지된 임의 방법에 의해 평가될 수 있고, 이는 숙련된 전문 의료진에게 명백할 것이다. 예를 들어, 항체 기반 면역요법의 효능은 대상체의 생존 또는 대상체 또는 그의 조직 또는 샘플 중의 종양 또는 암 부하량에 의해 평가될 수 있다. 일부 실시양태에서, 면역 세포는 면역 세포 부재하에서의 효능과 비교하였을 때, 항체 기반 면역요법의 효능을 적어도 20%, 예컨대, 50%, 80%, 100%, 2배, 5배, 10배, 20배, 50배, 100배 또는 그 초과만큼 증진시키는 데 효과적인 양으로 치료를 필요로 하는 대상체에게 투여된다.
본원에 기술된 방법 중 임의의 것에서, 면역 세포, 예컨대, T 림프구 또는 NK 세포는 치료 대상이 되는 대상체로부터 단리된 자가 세포이다. 한 구체적인 실시양태에서, 대상체 내로의 재도입 이전에, 자가 면역 세포 (예컨대, T 림프구 또는 NK 세포)는 생체외에서 활성화되고/거나, 확장된다. 또 다른 실시양태에서, 면역 세포 (예컨대, T 림프구 또는 NK 세포)는 동종이계 세포이다.
한 구체적인 실시양태에서, T 림프구는, 내인성 T 세포 수용체의 발현이 억제되거나, 제거되는 동종이계 T 림프구이다. 한 구체적인 실시양태에서, 대상체 내로의 도입 이전에, 동종이계 T 림프구는 생체외에서 활성화되고/거나, 확장된다. T 림프구는 관련 기술분야에 공지된 임의의 방법에 의해, 예컨대, 항-CD3/CD28, IL-2, 및/또는 피토헤모아글루티닌의 존재하에서 활성화될 수 있다.
NK 세포는 관련 기술분야에 공지된 임의의 방법에 의해, 예컨대, CD137 리간드 단백질, CD137 항체, IL-15 단백질, IL-15 수용체 항체, IL-2 단백질, IL-12 단백질, IL-21 단백질, 및 K562 세포주로 이루어진 군으로부터 선택되는 하나 이상의 작용제의 존재하에서 활성화될 수 있다. 예컨대, NK 세포를 확장시키는 데 유용한 방법에 관한 설명에 대해 미국 특허 번호 7,435,596 및 8,026,097을 참조할 수 있다. 예를 들어, 본 개시내용의 방법에서 사용되는 NK 세포는 주 조직적합 복합체 I 및/또는 II 분자가 없거나, 또는 그를 불충분하게 발현하고, 막 결합 IL-15 및 4-1BB 리간드 (CDI37L)를 발현하도록 유전적으로 변형된 세포에의 노출에 의해 우선적으로 확장될 수 있다. 상기 세포주로는 K562 [ATCC, CCL 243; Lozzio et al., Blood 45(3): 321-334 (1975); Klein et al., Int . J. Cancer 18: 421-431 (1976)], 및 윌름즈 종양 세포주 HFWT (Fehniger et al., Int Rev Immunol 20(3-4):503-534 (2001); Harada H, et al., Exp Hematol 32(7):614-621 (2004)), 자궁 내막 종양 세포주 HHUA, 흑색종 세포주 HMV-II, 간모세포종 세포주 HuH-6, 폐 소세포 암종 세포주 Lu-130 및 Lu-134-A, 신경모세포종 세포주 NB 19 및 N1369, 고환으로부터의 배아 암종 세포주 NEC 14, 자궁경부 암종 세포주 TCO-2, 및 골수-전이된 신경모세포종 세포주 TNB 1 [Harada, et al., Jpn . J. Cancer Res 93: 313-319 (2002)]을 포함하나, 반드시 이에 제한되는 것은 아니다. 바람직하게, 사용되는 세포주, 예컨대, K562 및 HFWT 세포주는 MHC I 및 II 분자, 둘 모두가 없거나, 또는 그를 불충분하게 발현한다. 세포주 대신 고체 지지체가 사용될 수 있다. 상기 지지체는 바람직하게는 그의 표면 상에 NK 세포에 결합할 수 있고, 1차 활성화 이벤트 및/또는 증식성 반응을 유도할 수 있거나, 또는 상기 효과를 가진 분자에 결합할 수 있는 적어도 하나의 분자를 부착시키고 있어야 하며, 이로써, 스캐폴드로서의 작용을 할 수 있다. 지지체는 그의 표면에 CD137 리간드 단백질, CD137 항체, IL-15 단백질 또는 IL-15 수용체 항체를 부착시킬 수 있다. 바람직하게, 지지체는 그의 표면에 결합된 IL-15 수용체 항체 및 CD137 항체를 가질 것이다.
상기 방법의 한 실시양태에서, T 림프구 또는 NK 세포의 대상체로의 도입 (또는 재도입) 후, 이어서, 대상체에게 치료학상 유효량의 IL-2를 투여한다.
본 개시내용의 키메라 수용체는 제한 없이, 키메라 수용체 중 Fc 결합제에 결합하는 Fc 부위를 포함하는 특이 항체가 그에 대하여 존재하거나, 생성될 수 있는 것인, 암종, 림프종, 육종, 모세포종, 및 백혈병을 비롯한, 임의의 암을 치료하는 데 사용될 수 있다. 본 개시내용의 키메라 수용체에 의해 치료될 수 있는 암에 대한 구체적인 비제한적인 예로는 예컨대, B 세포 기원의 암 (예컨대, B 계통 급성 림프모구성 백혈병, B 세포 만성 림프구성 백혈병 및 B 세포 비호지킨 림프종), 유방암, 위암, 신경모세포종, 및 골육종을 포함한다.
본원에 개시된 방법을 수행하기 위해, 유효량의, 키메라 수용체, Fc-함유 치료제 (예컨대, Fc-함유 치료학적 단백질, 예컨대, Fc 융합 단백질 및 치료학적 항체)를 발현하는 면역 세포, 또는 그의 조성물을 치료를 필요로 하는 대상체 (예컨대, 인간 암 환자)에게 적합한 경로를 통해, 예컨대, 정맥내 투여를 통해 투여할 수 있다. 키메라 수용체, Fc-함유 치료제를 발현하는 면역 세포, 또는 그의 조성물 중 임의의 것을 유효량으로 대상체에게 투여할 수 있다. 본원에서 사용되는 바, 유효량이란, 투여시 대상체에게 치료학적 효과를 부여하는 각 작용제 (예컨대, 키메라 수용체, Fc-함유 치료제를 발현하는 숙주 세포, 또는 그의 조성물)의 양을 의미한다. 일정량의, 본원에 기술된 세포 또는 조성물이 치료학적 효과를 달성하였는지 여부를 측정하는 것은 관련 기술분야의 통상의 기술자에게 명백할 것이다. 관련 기술분야의 통상의 기술자가 이해하는 바와 같이, 유효량은 치료되는 특정 병태, 병태의 중증도, 연령, 신체 상태, 크기, 성별 및 체중을 비롯한 개체 환자 파라미터, 치료 지속 기간, (존재할 경우) 공동 요법의 성질, 특정 투여 경로 및 건강요원의 정보 및 전문 지식 내의 유사 인자에 따라 달라진다. 일부 실시양태에서, 유효량은 대상체에서 임의의 질환 또는 장애를 완화시키거나, 경감시키거나, 호전시키거나, 개선시키거나, 증상을 감소시키거나, 또는 그의 진행을 지연시킨다. 일부 실시양태에서, 대상체는 인간이다.
일부 실시양태에서, 대상체는 인간 암 환자이다. 예를 들어, 대상체는 암종, 림프종, 육종, 모세포종, 또는 백혈병을 앓는 인간 환자일 수 있다. 본원에 개시된 세포 및 조성물 투여가 적합할 수 있는 암의 예로는 예를 들어, 림프종, 유방암, 위암, 신경모세포종, 골육종, 폐암, 피부암, 전립선암, 결장암, 신장 세포 암종, 난소암, 횡문근육종, 백혈병, 중피종, 췌장암, 두부경부암, 망막모세포종, 신경교종, 교모세포종, 및 갑상선암을 포함한다.
본 개시내용에 따라, 환자는 체중 1 kg당 약 105 내지 1010개 이상의 세포 (세포/kg)의 범위로, 본 개기내용의 키메라 수용체를 포함하는 면역 세포, 예컨대, T 림프구 또는 NK 세포를 치료학상 유효 용량으로 주입함으로써 치료될 수 있다. 주입은 원하는 반응을 달성할 때까지 환자가 내성을 띨 수 있을 만큼 자주 및 다회에 걸쳐 반복될 수 있다. 적절한 주입 용량 및 스케줄은 환자마다 달라지겠지만,이는 특정 환자에 대한 주치의에 의해 결정될 수 있다. 전형적으로, 대략 106개의 세포/Kg인 초기 용량으로 주입되고, 108개 이상의 세포/Kg으로 단계적으로 증가하게 될 것이다. IL-2는 주입 후, 주입된 세포를 확장시키기 위해 공동 투여될 수 있다. IL-2의 양은 체표면적 1 ㎡당 약 1-5 x 106 국제 단위일 수 있다.
일부 실시양태에서, 본원에 개시된 키메라 수용체 중 임의의 것을 발현하는 면역 세포는, Fc-함유 치료제 (예컨대, Fc-융합 단백질 또는 치료학적 항체)로 치료받은 적이 있거나, 또는 치료받고 있는 중인 대상체에게 투여된다. 본원에 개시된 키메라 수용체 중 어느 하나를 발현하는 면역 세포는 Fc-함유 치료제와 함께 공동 투여될 수 있다. 예를 들어, 면역 세포는 치료학적 항체와 함께 동시에 인간 대상체에게 투여될 수 있다. 대안적으로, 면역 세포는 항체 기반 면역요법 과정 동안 인간 대상체에게 투여될 수 있다. 일부 예에서, 면역 세포 및 치료학적 항체는 적어도 4시간 간격을 두고, 예컨대, 적어도 12시간 간격을 두고, 적어도 1일 간격을 두고, 적어도 3일 간격을 두고, 적어도 1주 간격을 두고, 적어도 2주 간격을 두고, 또는 적어도 1개월 간격을 두고 인간 대상체에게 투여될 수 있다.
치료학적 Fc-함유 치료학적 단백질의 예로는 제한 없이, 아달리무맙, 아도-트라스투주맙 엠탄신, 알렘투주맙, 바실릭시맙, 베바시주맙, 벨리무맙, 브렌툭시맙, 카나키누맙, 세툭시맙, 다클리주맙, 데노수맙, 디누툭시맙, 에쿨리주맙, 에팔리주맙, 에프라투주맙, 젬투주맙, 골리무맙, 인플릭시맙, 이필리무맙, 라베투주맙, 나탈리주맙, 오비누투주맙, 오파투무맙, 오말리주맙, 팔리비주맙, 파니투무맙, 퍼투주맙, 라무시루맙, 리툭티맙, 토실리주맙, 트라투주맙, 우스테키누맙, 및 베돌리주맙을 포함한다.
사용되는 Fc-함유 치료제의 적절한 투여량은 치료하고자 하는 암의 유형, 질환의 중증도 및 진행 과정, 이전 요법, 환자의 임상적 병력 및 항체에 대한 반응, 및 주치의의 재량에 의존할 것이다. 항체는 1회 또는 연속되는 몇회에 걸친 치료로 환자에게 투여될 수 있다. 본 개시내용의 요법의 진행 과정은 종래 기술 및 검정법에 의해 쉽게 모니터링될 수 있다.
Fc-함유 치료제의 투여는, 전신 투여 뿐만 아니라, 질환 부위로의 (예컨대, 원발성 종양으로의) 직접적인 투여를 비롯한, 임의의 적합한 경로에 의해 수행될 수 있다.
B.
조합 치료
본 개시내용에 기술된 조성물 및 방법은 다른 유형의 암 요법, 예컨대, 예컨대, 화학요법, 수술, 방사선 조사, 유전자 요법 등과 함께 사용될 수 있다. 상기 요법은 본 개시내용에 따른 면역요법과 동시에 또는 순차적으로 (임의 순서로) 투여될 수 있다.
추가의 치료제와 함께 공동 투여될 때, 각 작용제에 대해 적합한 치료학상 유효 투여량은 상가 작용 또는 시너지에 기인하여 감량될 수 있다.
본 개시내용의 치료는 다른 면역조절 치료, 예컨대, 예컨대, 치료학적 백신 (제한하는 것은 아니지만, GVAX, DC 기반 백신 등 포함), 체크포인트 억제제 (제한하는 것은 아니지만, CTLA4, PD1, LAG3, TIM3 등을 차단하는 작용제) 또는 활성제 (제한하는 것은 아니지만, 41BB, OX40 등을 증진시키는 작용제)와 함께 조합될 수 있다.
본 개시내용의 면역요법과 함께 조합하는 데 유용한 다른 치료제의 비제한적인 예로는 (i) 항-혈관신생제 (예컨대, TNP-470, 혈소판 인자 4, 트롬보스폰딘-1, 메탈로프로테아제의 조직 억제제 (TIMP1 및 TIMP2), 프로락틴 (16-Kd 단편), 안지오스타틴 (플라스미노겐의 38-Kd 단편), 엔도스타틴, bFGF 가용성 수용체, 형질전환 성장 인자 베타, 인터페론 알파, 가용성 KDR 및 FLT-1 수용체, 태반 프롤리페-관련 단백질 뿐만 아니라, 문헌 [Carmeliet and Jain (2000)]에 열거되어 있는 것; (ii) VEGF 길항제 또는 VEGF 수용체 길항제, 예컨대, 항-VEGF 항체, VEGF 변이체, 가용성 VEGF 수용체 단편, VEGF 또는 VEGFR을 차단할 수 있는 압타머, 중화 항-VEGFR 항체, VEGFR 티로신 키나제의 억제제 및 그의 임의 조합; 및 (iii) 화학요법 화합물, 예컨대, 예컨대, 피리미딘 유사체 (5-플루오로우라실, 플록수리딘, 카페시타빈, 겜시타빈 및 시타라빈), 퓨린 유사체, 폴레이트 길항제 및 관련 억제제 (메르캅토퓨린, 티오구아닌, 펜토스타틴 및 2-클로로데옥시아데노신 (클라드리빈)); 항증식제/유사분열 억제제, 예컨대, 천연 생성물, 예컨대, 빈카 알칼로이드 (빈블라스틴, 빈크리스틴, 및 비노렐빈), 미세관 장애 물질, 예컨대, 탁산 (파클리탁셀, 도세탁셀), 빈크리스틴, 빈블라스틴, 노코다졸, 에포틸론 및 나벨빈, 에피디포도필로톡신 (에토포시드, 테니포시드), DNA 손상제 (악티노마이신, 암사크린, 안트라시클린, 블레오마이신, 부술판, 캄포테신, 카르보플라틴, 클로람부실, 시스플라틴, 시클로포스파미드, 시톡산, 닥티노마이신, 다우노루비신, 독소루비신, 에피루비신, 헥사메틸렌다이아민옥살리플라틴, 이포스파미드, 멜팔란, 메클로레타민, 미토마이신, 미토크산트론, 니트로소우레아, 플리카마이신, 프로카르바진, 탁솔, 탁소테레, 테니포시드, 트리에틸렌티오포스포르아미드 및 에토포시드 (VP16)); 항생제, 예컨대, 닥티노마이신 (악티노마이신 D), 다우노루비신, 독소루비신 (아드리아마이신), 이다루비신, 안트라시클린, 미토크산트론, 블레오마이신, 플리카마이신 (미트라마이신) 및 미토마이신; 효소 (L-아스파라긴을 체계적으로 대사시키고, 그 자신의 아스파라긴을 합성할 수 있는 능력이 없는 세포를 제거하는 L-아스파라기나제); 항혈소판제; 항증식성/유사분열 억제성 알킬화제, 예컨대, 질소 머스타드 (메클로레타민, 시클로포스파미드 및 유사체, 멜팔란, 클로람부실), 에틸렌이민 및 메틸멜라민 (헥사메틸멜라민 및 티오테파), 알킬 술포네이트-부술판, 니트로소우레아 (카르무스틴 (BCNU) 및 유사체, 스트렙토조신), 트라젠-다카르바지닌 (DTIC); 항증식성/유사분열 억제성 항대사물질, 예컨대, 폴산 유사체 (메토트렉세이트); 백금 배위 착물 (시스플라틴, 카르보플라틴), 프로카르바진, 히드록시우레아, 미토탄, 아미노글루테티미드; 호르몬, 호르몬 유사체 (에스트로겐, 타목시펜, 고세렐린, 비칼루타미드, 닐루타미드) 및 아로마타제 억제제 (레트로졸, 아나스트로졸); 항응고제 (헤파린, 합성 헤파린 염, 및 트롬빈의 다른 억제제); 섬유소용해물질 (예컨대, 조직 플라스미노겐 활성제, 스트렙토키나제 및 유로키나제), 아스피린, 디피리다몰, 티클로피딘, 클로피도그렐, 압시시맙; 세포이동 억제제; 분비억제제 (브레벨딘); 면역억제제 (시클로스포린, 타크롤리무스 (FK-506), 시로리무스 (라파마이신), 아자티오프린, 미코페놀레이트 모페틸); 항-혈관신생 화합물 (예컨대, TNP-470, 게니스테인, 베바시주맙) 및 성장 인자 억제제 (예컨대, 섬유모세포 증식 인자 (FGF) 억제제); 안지오텐신 수용체 차단제; 산화질소 공여체; 안티센스 올리고뉴클레오티드; 항체 (트라스투주맙); 세포 주기 억제제 및 분화 유도제 (트레티노인); mTOR 억제제, 토포이소머라제 억제제 (독소루비신 (아드리아마이신), 암사크린, 캄포테신, 다우노루비신, 닥티노마이신, 에니포시드, 에피루비신, 에토포시드, 이다루비신 및 미토크산트론, 토포테칸, 이리노테칸), 코르티코스테로이드제 (코르티손, 덱사메타손, 히드로코르티손, 메틸프레드니솔론, 프레드니손, 및 프레드니솔론); 성장 인자 신호 전달 키나제 억제제; 미토콘드리아 기능이상 유도제 및 카스파제 활성제; 및 크로마틴 장애 물질을 포함한다.
추가의 유용한 작용제에 관한 예에 대해서는 또한 문헌 [Physician's Desk Reference, 59.sup.th edition, (2005), Thomson P D R, Montvale N.J.]; [Gennaro et al., Eds. Remington's The Science and Practice of Pharmacy 20.sup.th edition, (2000), Lippincott Williams and Wilkins, Baltimore Md.]; [Braunwald et al., Eds. Harrison's Principles of Internal Medicine, 15.sup.th edition, (2001), McGraw Hill, NY]; [Berkow et al., Eds. The Merck Manual of Diagnosis and Therapy, (1992), Merck Research Laboratories, Rahway N.J.]를 참조할 수 있다.
V.
치료학적 용도의
키트
본 개시내용은 또한 항체 의존성 세포-매개 세포독성을 증진시키고, 항체 기반 면역요법을 증진시키는 데 키메라 수용체를 사용하기 위한 키트를 제공한다. 상기 키트는 임의의 핵산 또는 숙주 세포 (예컨대, 면역 세포, 예컨대, 본원에 기술된 것), 및 제약상 허용되는 담체를 포함하는 제1 제약 조성물, 및 치료학적 항체 및 제약상 허용되는 담체를 포함하는 제2 제약 조성물을 포함하는 하나 이상의 용기를 포함할 수 있다.
일부 실시양태에서, 키트는 본원에 기술된 방법 중 임의의 것에서 사용을 위한 지침서를 포함할 수 있다. 포함된 지침서는 대상체에서 의도하는 활성, 예컨대, ADCC 활성 증진 및/또는 항체 기반 면역요법의 효능 증진을 달성하기 위해 제1 및 제2 제약 조성물을 대상체에게 투여하는 것에 관한 설명을 포함할 수 있다. 키트는 대상체가 치료를 필요로 하는지 여부를 확인하는 것에 기초하여 치료에 적합한 대상체를 선택하는 것에 관한 설명서를 추가로 포함할 수 있다. 일부 실시양태에서, 지침서는 치료를 필요로 하는 대상체에게 제1 및 제2 제약 조성물을 투여하는 것에 관한 설명서를 포함한다.
본원에 기술된 키메라 수용체 및 제1 및 제2 제약 조성물의 용도에 관한 지침서는 일반적으로 의도하는 치료를 위한 투여량, 투약 스케줄, 및 투여 경로에 관한 정보를 포함한다. 용기는 단위 용량, 벌크 패키지 (예컨대, 다중 투약 패키지) 또는 서브유니트 용량에 대한 것일 수 있다. 본 개시내용의 키트에서 제공되는 지침서는 전형적으로 라벨 또는 패키지 인서트 상의 서면 지침서이다. 라벨 또는 패키지 인서트에는 제약 조성물이 대상체에서 질환 또는 장애를 치료하는 데, 발병을 지연시키는 데, 및/또는 완화시키는 데 사용된다고 명시되어 있다.
본원에서 제공하는 키트는 적합한 패키징 안에 있다. 적합한 패키징은 바이알, 병, 자, 가용성 패키징 등을 포함하나, 이에 제한되지 않는다. 특정 장치, 예컨대, 흡입기, 비강 투여용 장치, 또는 주입 장치와 함께 조합되어 사용하기 위한 패키지 또한 고려된다. 키트는 멸균 접근 포트를 가질 수 있다 (예를 들어, 용기는 피하 주사용 바늘에 의해 관통가능한 마개가 있는 바이알 또는 정맥내 액제 백일 수 있다). 용기는 또한 멸균 접근 포트를 가질 수 있다. 제약 조성물 중의 적어도 하나의 활성제는 본원에 기술된 키메라 수용체이다.
키트는 임의적으로 추가 성분, 예컨대, 완충제 및 해석 정보를 제공할 수 있다. 일반적으로, 키트는 용기, 및 용기 상 또는 그와 결합되어 있는 라벨 또는 패키지 인서트(들)를 포함한다. 일부 실시양태에서, 본 개시내용은 상기 기술된 키트의 내용물을 포함하는 제조 물품을 제공한다.
일반 기술
달리 명시되지 않는 한, 본 개시내용의 실시는, 관련 기술분야에 포함되어 있는 것인, 분자생물학 (재조합 기법 포함), 미생물학, 세포 생물학, 생화학 및 면역학의 종래 기술을 사용할 것이다. 상기 기술은 예컨대, 문헌 [Molecular Cloning: A Laboratory Manual, second edition (Sambrook, et al., 1989) Cold Spring Harbor Press; Oligonucleotide Synthesis (M. J. Gait, ed. 1984)]; [Methods in Molecular Biology, Humana Press; Cell Biology: A Laboratory Notebook (J. E. Cellis, ed., 1989) Academic Press]; [Animal Cell Culture (R. I. Freshney, ed. 1987)]; [Introuction to Cell and Tissue Culture (J. P. Mather and P. E. Roberts, 1998) Plenum Press]; [Cell and Tissue Culture: Laboratory Procedures (A. Doyle, J. B. Griffiths, and D. G. Newell, eds. 1993-8) J. Wiley and Sons; Methods in Enzymology (Academic Press, Inc.)]; [Handbook of Experimental Immunology (D. M. Weir and C. C. Blackwell, eds.): Gene Transfer Vectors for Mammalian Cells (J. M. Miller and M. P. Calos, eds., 1987)]; [Current Protocols in Molecular Biology (F. M. Ausubel, et al. eds. 1987)]; [PCR: The Polymerase Chain Reaction, (Mullis, et al., eds. 1994)]; [Current Protocols in Immunology (J. E. Coligan et al., eds., 1991)]; [Short Protocols in Molecular Biology (Wiley and Sons, 1999)]; [Immunobiology (C. A. Janeway and P. Travers, 1997)]; [Antibodies (P. Finch, 1997)]; [Antibodies: a practice approach (D. Catty., ed., IRL Press, 1988-1989)]; [Monoclonal antibodies: a practical approach (P. Shepherd and C. Dean, eds., Oxford University Press, 2000)]; [Using antibodies: a laboratory manual (E. Harlow and D. Lane (Cold Spring Harbor Laboratory Press, 1999)]; [The Antibodies (M. Zanetti and J. D. Capra, eds. Harwood Academic Publishers, 1995)]; [DNA Cloning: A practical Approach, Volumes I and II (D.N. Glover ed. 1985)]; [Nucleic Acid Hybridization (B.D. Hames & S.J. Higgins eds.(1985≫]; [Transcription and Translation (B.D. Hames & S.J. Higgins, eds. (1984≫]; [Animal Cell Culture (R.I. Freshney, ed. (1986≫]; [Immobilized Cells and Enzymes (lRL Press, (1986≫]; 및 [B. Perbal, A practical Guide To Molecular Cloning (1984); F.M. Ausubel et al. (eds.)]와 같은 문헌에 상세하게 설명되어 있다.
추가의 상세한 설명 없이도, 관련 기술분야의 통상의 기술자는 상기 설명에 기초하여 본 개시내용을 충분히 이용할 수 있을 것으로 판단된다. 그러므로, 하기의 구체적인 실시양태는 어떠한 것이든 어느 방식으로 본 개시내용의 나머지 부분을 제한하는 것이 아니라, 단지 예시적인 것으로 해석되어야 한다. 본원에서 인용된 모든 공개 문헌은 본원에서 언급된 목적 또는 주제를 위한 참조로 포함된다.
실시예
실시예 1. CD16 신호전달 수용체를 발현하는 T 림프구는 항체 의존성 암 세포 사멸을 발휘한다.
물질 및 방법
세포
인간 B 계통 림프종 세포주 다우디 및 라모스, T 세포 급성 림프모구성 백혈병 세포주 저캣, 및 신경모세포종 세포주 CHLA-255, NB1691 및 SK-N-SH는 세인트 주드 칠드런즈 리서치 호스피탈(St. Jude Children's Research Hospital)에서 이용가능하였다. 유방암종 세포주 MCF-7 (ATCC HTB-22) 및 SK-BR-3 (ATCC HTB-30), 및 골육종 세포주 U-2 OS (ATCC HTB-96)는 아메리칸 타입 컬쳐 콜렉션(American Type Culture Collection: ATCC; 미국 메릴랜드주 록빌)으로부터 입수하였고; 위암종 세포주 MKN7은 내셔널 인스티튜트 오브 바이오메디컬 이노베이션(National Institute of Biomedical Innovation: 일본 오사카)으로부터 입수하였다. 다우디, CHLA-255, NB1691, SK-N-SH, SK-BR-3, MCF-7, U-2 OS 및 MKN7에도 또한 반딧불이 루시페라제 유전자를 함유하는 뮤린 줄기 세포 바이러스 (MSCV)-내부 리보솜 진입 부위 (IRES)-녹색 형광 단백질 (GFP) 레트로바이러스 벡터를 형질도입하였다.34 FACS아리아(FACSAria) 세포 분류기 (BD 바이오사이언시스(BD Biosciences: 미국 캘리포니아주 산호세))를 이용하여 그의 GFP 발현에 대해 형질도입된 세포를 선별하였다. 싱가포르 국립대 병원(Singapore's National University Hospital)을 관리하는 영역별 윤리 위원회(Domain Specific Ethics Board)로부터 사전 동의 및 승인을 받은 후, 새로 진단을 받고, 치료받지 않은 B-만성 림프구성 백혈병 (CLL) 환자로부터 말초 혈액 또는 골수 샘플을 수득하였다.
건강한 성인 공여자로부터의 혈소판 기증물의 확인되지 않은 부산물로부터 말초 혈액 샘플을 수득하였다. 어큐-프렙 휴먼 림포사이트 셀 세퍼레에션 메디아(Accu-Prep Human Lymphocytes Cell Separation Media) (어큐레이트 케미컬 & 사이언티픽 코포레이션(Accurate Chemical & Scientific Corp.: 미국 뉴욕주 웨스트버리)) 상에서 원심분리하여 단핵 세포를 농축시키고, 10% 우태아 혈청 (FBS), 항생제, 100 IU 인터루킨 (IL)-2를 포함하는 RPMI-1640 (로슈(Roche: 독일 만하임)) 중에서 항-CD3/CD28 비드 (인비트로겐(Invitrogen: 미국 캘리포니아주 칼즈배드))와 함께 3일 동안 배양하였다. 4일째, CD14, CD16, CD19, CD36, CD56, CD123 및 CD235a 항체 및 자기 비드 (범용 T 세포 단리용 키트 II(Pan T Cell Isolation Kit II; 밀테니 바이오테크(Miltenyi Biotec: 독일 베르기슈 글라트바흐)))의 혼합물을 이용하여 음성 선별에 의해 T 세포를 정제하였다 (순도, >98%). 정제된 T 세포를 상기 배지에서 유지시켰고, 이틀마다 100 IU IL-2를 첨가하였다.
플라스미드, 바이러스 제조 및 유전자 형질도입
pMSCV-IRES-GFP, pEQ-PAM3(-E), 및 pRDF를 세인트 주드 칠드런즈 리서치 호스피탈 벡터 디벨롭먼트 앤드 프로덕션 쉐어드 리소스(Vector Development and Production Shared Resource: 미국 테네시주 멤피스)로부터 입수하였다.10 FCRG3A cDNA는 오리진(Origene: 미국 메릴랜드주 록빌)으로부터 입수하였고, 그의 V158F 변이체는, 프라이머 "F" CTTCTGCAGGGGGCTTGTTGGGAGTAAAAATGTGTC (서열식별번호: 73) 및 "R" GACACATTTTTACTCCCAACAAGCCCCCTGCAGAAG (서열식별번호: 74)를 사용하여 PCR에 의해 부위 지정 돌연변이유발법을 사용하여 생성하였다. CD8α 힌지 및 막횡단 도메인 (서열식별번호: 66), 및 4-1BB (서열식별번호: 67) 및 CD3ζ (서열식별번호: 68)의 세포내 도메인을 코딩하는 폴리뉴클레오티드를 앞서 제조된 항-CD19-41BB-CD3ζ cDNA로부터 서브클로닝하였다 (문헌 [Imai et al., 2004]). PCR에 의해 연장부를 오버랩핑하여 스플라이싱을 사용하여 상기 분자를 어셈블리하였다. 구축물 ("CD16F-BB-ζ" 및 "CD16V-BB-ζ") 및 발현 카세트를 MSCV-IRES-GFP 벡터의 EcoRI 및 MLu1 부위로 서브클로닝하였다.
RD114-위형 레트로바이러스를 생성하기 위해, fuGENE 6 또는 X-tremeGENE 9 (로슈: 미국 인디애나주 인디애나폴리스)를 사용하여 3.5 ㎍의 CD16V-BB-ζ를 코딩하는 cDNA, 3.5 ㎍의 pEQ-PAM3(-E), 및 3 ㎍의 pRDF로 3 x 106개의 293T 세포를 형질감염시켰다 (문헌 [Imai et al., 2004]). 24시간째 10% FBS를 포함하는 RPMI-1640으로 배지를 교체한 후, 48-96시간 경과 후 레트로바이러스를 함유하는 배지를 수거하고, 레트로넥틴 (RetroNectin) (다카라(TakaRa: 일본 오츠))으로 코팅된 폴리프로필린 튜브에 첨가하고, 10 min 동안 1400 g로 원심분리하고 37℃에서 6시간 동안 인큐베이션시켰다. 추가로 원심분리하고, 상청액을 제거한 후, T 세포 (1 x 105개)를 튜브에 첨가하고, 37℃에서 24시간 동안 방치하였다. 이어서, 실험 시점이 형질도입 후 7-21일이 경과할 때까지, FBS, 항생제 및 100 IU/mL IL-2를 포함하는 RPMI-1640 중에서 세포를 유지시켰다.
R-피코에리트린 접합된 항-인간 CD16 (클론 B73.1, BD 바이오사이언시스 파르민겐(BD Biosciences Pharmingen: 미국 캘리포니아주 샌디에고))을 사용하여 유세포 분석법에 의해 CD16의 표면 발현을 분석하였다. 웨스턴 블롯을 위해, 1% 프로테아제 억제제 칵테일 (시그마(Sigma)) 및 1% 포스파타제 억제제 칵테일 2 (시그마)를 함유하는 셀라이틱 M(Cellytic M) 용해 완충제 (시그마: 미국 미주리주 세인트 루이스) 중에서 2 x 107개의 T 세포를 용해시켰다. 원심분리 후, 용해물 상청액을 환원 완충제 (인비트로겐)와 함께, 또는 그의 부재하에서 동량의 LDS 완충제 (인비트로겐: 미국 캘리포니아주 칼즈배드)와 함께 비등시키고, NuPAGE 노벡스 12% 비스-트리스 겔(NuPAGE Novex 12% Bis-Tris Gel) (인비트로겐)에 의해 분리시켰다. 단백질을 폴리비닐리덴 플루오라이드 (PVDF) 막으로 옮기고, 이를 마우스 항-인간 CD3ζ (클론 8D3; BD e바이오사이언스 파르민겐(BD eBioscience Pharmingen))와, 및 염소 항-마우스 IgG 호스래디시 퍼옥시다제-접합된 2차 항체 (셀 시그널링 테크크놀러지(Cell Signaling Technology: 미국 매사추세츠주 댄버스))와 함께 인큐베이션시켰다. 항체 결합은 아머샴 ECL 프라임(Amersham ECL Prime) 검출 시약 (GE 헬쓰케어(GE Healthcare))을 사용하여 밝혀 내었다.
mRNA
전기천공
pVAX1 벡터 (인비트로겐: 미국 캘리포니아주 칼즈배드)를 시험관내 mRNA 전사를 위한 주형으로서 사용하였다. CD16V-BB-ζ cDNA를 pVAX1의 EcoRI 및 XbaI로 서브클로닝하였다. T7 m스크립트 mRNA(T7 mScript mRNA) 제조 시스템 (셀스크립트(CellScript: 미국 위스콘신주 매디슨))을 사용하여 상응하는 mRNA를 시험관내에서 전사시켰다 (문헌 [Shimasaki et al., Cytotherapy. 2012;14(7):830-40]).
전기천공을 위해, 아막사 뉴클레오펙터(Amaxa Nucleofector) (론자(Lonza: 미국 메릴랜드주 워커스빌))를 사용하였다; 밤새도록 200 IU/mL IL-2로 활성화된 1 x 107개의 정제된 T 세포를 셀 라인 뉴클레오펙터 키트 V(Cell Line Nucleofector Kit V) (론자) 중에서 200 ㎍/mL mRNA와 혼합하고, 이를 프로세싱 챔버로 옮기고, 프로그램 X-001을 사용하여 형질감염시켰다. 전기천공 직후, 세포를 프로세싱 챔버로부터 24 웰 플레이트로 옮기고, FBS, 항생제 및 100 IU/mL IL-2를 포함하는 RPMI-1640 (로슈: 독일 만하임) 중에서 배양하였다. 또한, 문헌 [Shimasaki et al., Cytotherapy, 2012, 1-11]을 참조할 수 있다.
항체 결합, 세포 접합 및 세포 증식 검정법
키메라 수용체의 항체 결합 능력을 측정하기 위해, 키메라 수용체 또는 GFP만 함유하는 벡터가 형질도입된 T 림프구 (5 x 105개)를 리툭시맙 (리툭산, 로슈; 0.1-1㎍/mL), 트라스투주맙 (헤르셉틴(Herceptin); 로슈; 0.1-1 ㎍/mL) 및/또는 정제된 인간 IgG (R&D 시스템즈(R&D Systems: 미국 미네소타주 미니애폴리스); 0.1-1 ㎍/mL)와 함께 4℃에서 30분 동안 인큐베이션시켰다. 포스페이트 완충처리된 염수 (PBS)로 2회에 걸쳐 세척한 후, 세포를 염소 항-인간 IgG-PE (써던 바이오테크놀러지 어소시에이츠(Southern Biotechnology Associates: 미국 앨라배마주 버밍엄))와 함께 실온에서 10분 동안 인큐베이션시키고, 어큐리 C6(Accuri C6) 유세포 분석기 (BD 바이오사이언시스)를 사용하여 세포 염색을 측정하였다.
수용체에의 항체 결합이 세포 응집을 촉진시켰는지 여부를 측정하기 위해, CD20 양성 다우디 세포를 셀트레이스(CellTrace) 칼세인 레드-오렌지 AM (인비트로겐)으로 표지하고, 리툭시맙 (0.1 ㎍/mL)과 함께 4℃에서 30분 동안 인큐베이션시켰다. PBS 중에서 2회에 걸쳐 세척한 후, 저캣 세포를 포함하는 세포를 37℃에서 60분 동안 96 둥근 바닥 플레이트 (코스타(Costar: 미국 뉴욕주 코닝))에서 1:1 E:T 비율로 키메라 수용체로 형질도입하거나, 또는 모의-형질도입시켰다. 이종 세포 응집체 (칼세인 AM-GFP 이중 양성)를 형성하는 세포의 비율을 유세포 분석법에 의해 측정하였다.
세포 증식을 측정하기 위해, 키메라 수용체가 형질도입되거나, 또는 모의-형질도입된 1 x 106개의 T 세포를 FBS, 항생제 및 50 IU/mL IL-2를 포함하는 RPMI-1640 중 24 웰 플레이트 (코스타: 미국 뉴욕주 코닝)의 웰에 놓았다. 다우디 세포를 스트렉(Streck) 세포 보존제 (스트렉 라보라토리즈(Streck Laboratories: 미국 네브래스카주 오마하))로 처리하여 증식을 정지시키고, 리툭시맙 (0.1 ㎍/mL)과 함께 4℃에서 30 min 동안 표시하였다. 이를 0, 7, 14 및 21일째 T 세포와 함께 1:1 비율로 웰에 첨가하였다. 배양 후 생존가능한 T 세포의 개수 n을 유세포 분석법에 의해 측정하였다.
CD107
탈과립화
및 세포독성 검정법
CD16 교차 결합이 용해성 과립의 엑소사이토시스를 유발하였는지 여부를 측정하기 위해, 키메라 수용체- 및 모의 형질도입된 T 세포 (1 x 105개)를 리툭시맙으로 코팅된 96 웰 평평한 바닥 플레이트의 각 웰 내에 놓고, 37℃에서 4시간 동안 배양하였다. 다른 실험에서는 T 세포를, 리툭시맙과 미리 인큐베이션된 다우디 세포와 함께 공동 배양하였다. 피코에리트린 (BD 바이오사이언시스)에 접합된 항-인간 CD107a 항체를 배양 시작 시점에 첨가하고, 1시간 후, 골지스톱(GolgiStop) (0.15 ㎕; BD 바이오사이언시스)을 첨가하였다. CD107a 양성 T 세포를 유세포 분석법에 의해 분석하였다.
세포독성을 시험하기 위해, 표적 세포를 10% FBS를 포함하는 RPMI-1640 중에 현탁시키고, 칼세인 AM (인비트로겐)으로 표지하고, 96 웰 둥근 바닥 플레이트 (코스타)에 플레이팅하였다. T 세포를 결과부에 명시되어 있는 바와 같이 다양한 E:T 비율로 첨가하고, 항체 리툭시맙 (리툭산, 로슈), 트라스투주맙 (헤르셉틴, 로슈), 또는 hu14.18K322A (세인트 주드 칠드런즈 GMP(St Jude Children's GMP: 미국 테네시주 멤피스; 1㎍/mL에서)의 제임스 얼레이(James Allay) 박사로부터 입수)와 함께, 또는 그의 부재하에서 표적 세포와 함께 4시간 동안 공동 배양하였다. 배양 종료시, 세포를 수집하고, 같은 부피의 PBS 중에 재현탁시키고, 프로피디움 아이오다이드를 첨가하였다. 어큐리 C6 유세포 분석기를 사용하여 생존가능한 표적 세포 (칼세인 AM-양성, 프로피디움-아이오다이드 음성)의 개수를 계수하였다.34 부착성 세포주의 경우, 루시페라제-표지된 표적 세포를 사용하여 세포독성을 시험하였다. 부착성 세포주 NB1691, CHLA-255, SK-BR-3, MCF-7, U-2 OS 및 MKN7에 대한 세포독성을 측정하기 위해, 그의 루시페라제-표지된 유도체를 사용하였다. 적어도 4시간 동안 플레이팅한 후, 상기 기술된 바와 같이 T 세포를 첨가하였다. 4시간 공동 배양한 후, 프로메가 브라이트-글로(Promega Bright-Glo) 루시페라제 시약 (프로메가: 미국 위스콘신주 매디슨)을 각 웰에 첨가하였고; 5분 후, 플레이트 판독기 바이오테크 FLx800(Biotek FLx800) (바이오테크: 미국 애리조나주 투손)을 사용하여 발광을 측정하고, Gen5 2.0 데이터 애널리시스 소프트웨어(Gen5 2.0 Data Analysis Software)를 사용하여 분석하였다.
이종이식편
실험
루시페라제를 발현하는 다우디 세포를 NOD.Cg-Prkdcscid IL2rgtm1Wjl/SzJ (NOD/scid IL2RG널) 마우스 (잭슨 라보라토리(Jackson Laboratory: 바 하버))에 복강내로 주사하였다 (i.p.; 마우스 1마리당 0.3 x 106개의 세포). 일부 마우스는 5일째 및 6일째 인간 1차 T 세포의 i.p. 주사와 함께 또는 그 주사를 받지 않고, 다우디 접종 후 4일 경과 후에 리툭시맙 (100 ㎍) i.p.을 받았다. T 세포를 3일 동안 항-CD3/CD28 비드로 활성화시키고, CD16V-BB-ζ 수용체를 형질도입하고, 10% FBS를 포함하는 RPMI-1640 중에 재현탁시키고, 마우스 1마리당 1 x 107개의 세포로 주사하였다. 추가의 T 림프구 주사 없이, 4주 동안 매주 리툭시맙 주사를 반복하였다. 모든 마우스는 4주 동안 주당 2회에 걸쳐 1,000-2,000 IU의 IL-2를 i.p. 주사 받았다. 한 마우스 군은 리툭시맙 또는 T 세포 대신 조직 배양 배지를 받았다.
제노겐 IVIS-200(Xenogen IVIS-200) 시스템 (캘리퍼 라이프 사이언시스(Caliper Life Sciences: 미국 매사추세츠주 홉킨턴))을 사용하여 종양 생착 및 성장을 측정하였다. D-루피세핀 포타슘 염 (3 mg/마우스)의 수용액을 i.p. 주사한 후 5분 경과하였을 때, 영상화를 시작하고, 리빙 이미지 3.0(Living Image 3.0) 소프트웨어를 사용하여 루시페라제-발현 세포로부터 방출된 광자를 정량화하였다.
결과
CD16V
-BB-ζ 수용체의 발현
개체 중 약 ¼에서 발현된 FCGR3A (CD16)의 V158 다형성은 고친화성 면역글로불린 Fc 수용체를 코딩하고, 항체 요법에 대한 바람직한 반응과 연관이 있다. FCGR3A 유전자의 V158 변이체를 CD8α의 힌지 및 막횡단 도메인, T 세포 자극 분자 CD3ζ, 및 공동 자극 분자 4-1BB (도 1A)와 조합하였다. CD16V-BB-ζ 구축물 및 GFP를 함유하는 MCSV 레트로바이러스 벡터를 사용하여 12명의 공여자로부터 얻은 말초 혈액 T 림프구에 형질도입하였다: CD3+ 세포에서의 GFP 발현 중앙값은 89.9% (범위, 75.3%-97.1%)였고; 같은 세포에서, 항-CD16 염색에 의해 평가된, 키메라 수용체 표면 발현 중앙값은 83.0% (67.5%-91.8%)였다 (도 1B). 오직 GFP만을 함유하는 벡터가 형질도입된, 같은 공여자로부터 얻은 T 림프구의 GFP 발현 중앙값은 90.3% (67.8%-98.7%)였지만, 오직 1.0% (0.1%-2.7%)만이 CD16을 발현하였다 (도 1B). 수용체 발현은 CD4+ 및 CD8+ T 세포 사이에 유의적인 차이는 없었으며: 77.6% ± 9.2% CD8+ 세포와 비교하였을 때, CD16V-BB-ζ 형질도입 후, 69.8% ± 10.8% CD4+ 세포는 CD16+였다 (도 2).
키메라 수용체의 다른 성분이 발현되었는지 확인하기 위해, CD3ζ 발현 수준을 유세포 분석법에 의해 측정하였다. 도 1B에 제시된 바와 같이, CD16V-BB-ζ-형질도입된 T 림프구는 모의-형질도입된 세포에 의해 발현되는 것보다 훨씬 더 높은 수준으로 CD3ζ를 발현하였고: 평균 형광 강도의 평균 (± SD)은 후자인 경우는 12,547 ± 4,296인 것에 반해, 전자의 것은 45,985 ± 16,365였다 (t 검정에 의해 P = 0.027; n = 3; 도 1B). 항-CD3ζ 항체로 프로빙된 웨스턴 블롯팅에 의해 키메라 단백질의 존재 또한 측정하였다. 도 1C에 제시된 바와 같이, CD16V-BB-ζ-형질도입된 T 림프구는 16 kDa의 내인성 CD3ζ 이외에도, 환원 조건하에서 대략 25 kDa의 키메라 단백질을 발현하였다. 비환원 조건하에서, CD16V-BB-ζ 단백질은 단량체로서 또는 50 kDa의 이량체로서 발현되는 것으로 나타났다.
V158 대 F158 CD16 수용체의 항체 결합 능력
면역글로불린 (Ig)에 결합할 수 있는 CD16V-BB-ζ 키메라 수용체의 능력을 시험하기 위해, 3명의 공여자로부터 얻은 말초 혈액 T 림프구를 형질도입시켰다. 도 3A에 제시된 바와 같이, CD16V-BB-ζ-발현 T 림프구는 리툭시맙과의 인큐베이션 후, 항체로 코팅되었다. 트라스투주맙 및 인간 IgG 경우에도 유사한 결과를 얻었다.
이어서, 고친화성인 FCGR3A (CD16)의 V158 다형성을 함유한, CD16V-BB-ζ 수용체의 Ig-결합 능력을 대신 F158 변이체를 함유한 동일한 수용체 ("CD16F-BB-ζ")의 것과 비교하였다. 저캣 세포에 상기 수용체 중 어느 하나를 도입한 후, 리툭시맙 및 (리툭시맙에 결합하는) 항-인간 Ig PE 항체와 인큐베이션시켰고, PE 형광 강도는 GFP의 것과 관련이 있었다. 도 3B에 제시된 바와 같이, 주어진 GFP의 어느 수준에서든, CD16V-BB-ζ 수용체가 형질도입된 세포는 CD16F-BB-ζ 수용체가 형질도입된 세포의 것보다 더 높은 PE 형광 강도를 가졌고, 이는 전자가 유의적으로 더 높은 항체-결합 친화도를 가졌다는 것을 시사하는 것이다. 트라스투주맙 및 인간 IgG 또한 CD16V-BB-ζ 수용체에 의해서 더 높은 친화도로 결합이 이루어졌다 (도 4).
CD16V-BB-ζ 수용체에의 항체 결합이 이펙터 및 표적 세포의 응집을 촉진시킬 수 있는지 여부를 측정하기 위해, CD16V-BB-ζ (및 GFP)를 발현하는 저캣 세포를 (칼세인 AM 레드-오렌지로 표지된) CD20+ 다우디 세포주와 1:1 비율로 60분 동안 혼합하고, 리툭시맙을 첨가하거나, 또는 첨가하지 않고, GFP-칼세인 이중체 형성을 측정하였다. 3회에 걸쳐 수행된 실험에서, 저캣 세포가 CD16V-BB-ζ 수용체를 발현하고, 리툭시맙이 존재할 경우, 공배양물 중 39.0% ± 1.9%의 이벤트는 이중체였다 (도 3C 및 D). 그에 반해, 리툭시맙 대신 인간 IgG가 존재할 때, 또는 리툭시맙의 존재 여부와 상관 없이, 모의-형질도입된 저캣 세포의 경우에, <5%의 이중체가 존재하였다.
Ig의
CD16V
-BB-ζ에의 결합이 T 세포 활성화,
탈과립화
및 세포 증식을 유도한다.
고정화된 항체에 의한 CD16V-BB-ζ 수용체 가교 결합이 T 림프구에서 활성화 신호를 유도할 수 있는지 여부를 평가하였다. 실제로, CD16V-BB-ζ가 형질도입된 T 림프구는, 리툭시맙으로 코팅된 플레이트 상에서 배양되었을 때, IL-2 수용체 발현 (CD25)을 현저히 증가시킨 반면, 항체 부재하에서, 또는 항체 존재 여부와 상관 없이, 모의-형질도입된 세포에서는 어떤 변화도 관찰되지 않았다 (도 5A 및 B).
IL-2 수용체의 발현 이외에도, CD16V-BB-ζ 수용체 가교 결합은 CD107a 염색에 의해 검출된 바, T 림프구에서 용해성 과립의 엑소사이토시스를 유발하였다. 따라서, 4명의 공여자로부터 얻은 T 림프구를 리툭시맙으로 코팅된 마이크로타이터 플레이트 상에 시딩하였거나 (n = 3) 또는 리툭시맙의 존재하에 다우디 세포와 함께 공동 배양한 (n = 3), 6회에 걸쳐 수행된 실험에서, CD16V-BB-ζ를 발현하는 T 림프구는 CD107a 양성이 되었다 (도 5C).
마지막으로, 수용체 가교 결합이 세포 증식을 유도할 수 있는지 여부를 측정하였다. 도 5D에 제시되어 있는 바와 같이, CD16V-BB-ζ를 발현하는 T 림프구는 리툭시맙 및 다우디 세포 (T 림프구와 1:1 비율)의 존재하에서 확장되었고: 3회에 걸쳐 수행된 실험에서, 7일간의 배양 후 평균 T 세포 회수율은 유입된 세포의 632% (± 97%)였고; 4주간의 배양 후에는 6,877% (± 1,399%)였다. 중요하게는, 심지어 매우 높은 고농도에서도 (1-10 ㎍/mL) 비결합 리툭시맙은 표적 세포 부재하에서 세포 증식에 어떤 유의적인 영향도 미치지 않았고, 리툭시맙의 부재하에서, 또는 항체 및/또는 표적 세포 존재 여부와 상관 없이, 모의-형질도입된 T 세포에서는 어떤 세포 성장도 이루어지지 않았다 (도 5D). 따라서, CD16V-BB-ζ 수용체 가교 결합이 증식을 지속시키는 신호를 유도한다.
CD16V
-BB-ζ를 발현하는 T 림프구가
시험관내
및
생체내
ADCC를
매개한다.
CD16V-BB-ζ 가교 결합이 용해성 과립의 엑소사이토시스를 일으켰다는 관찰 결과는 CD16V-BB-ζ T 림프구가 특이 항체의 존재하에서 표적 세포를 사멸시킬 수 있어야 한다는 것을 암시한다. 실제로, 4시간 동안의 시험관내 세포독성 검정법에서, CD16V-BB-ζ T 림프구는 리툭시맙의 존재하에서 B 세포 림프종 세포주 다우디 및 라모스에 대하여 고도의 세포독성을 보였고: 2:1의 E:T 비율로 4시간 동안의 공동 배양 후, 50% 초과의 표적 세포가 전형적으로 용해되었다 (도 6 및 도 7). 그에 반해, 항체 부재하에서 또는 모의-형질도입된 T 세포의 경우에는 표적 세포 사멸이 낮았다 (도 6 및 도 7). 특히, 본 실험에서 사용된 이펙터 세포는 CD3+ T 림프구로 고도로 강화되었고 (>98%), 어떤 검출불가능한 CD3 CD56+ NK 세포도 함유하지 않았다. CD20+ 1차 CLL 세포로 CD16V-BB-ζ T 림프구의 리툭시맙-매개 세포독성 또한 뚜렷이 나타났고 (n = 5); 도 6B에 제시된 바와 같이, 2:1의 E:T 비율로 4시간 동안의 공동 배양 후, 세포독성은 전형적으로 70%를 초과하였다. 골수 중간엽 기질 세포는 면역억제 효과를 발휘하는 것으로 나타났다. CD16V-BB-ζ T 림프구의 세포독성 능력에 영향을 미치는지 여부를 시험하기 위해, 1:2의 E:T로 24시간 동안 골수 유래 중간엽 기질 세포의 존재하에서 CLL 세포와 함께 공동 배양하였다. 도 6C에 제시된 바와 같이, 중간엽 세포는 ADCC 매개 림프구의 사멸 능력을 감소시키지 않았다.
이어서, 상이한 면역치료학적 항체가 상응하는 항원을 발현하는 세포에 대하여 유사한 세포독성을 일으킬 수 있는지 여부에 관하여 조사하였다. 따라서, HER2 (유방암 세포주 MCF-7 및 SK-BR-3 및 위암 세포주 MKN7) 또는 GD2 (신경모세포종 세포주 CHLA-255, NB1691 및 SK-N-SH, 및 골육종 세포주 U2-OS)를 발현하는 고형 종양 세포에 대한 CD16V-BB-ζ T 림프구의 세포독성을 시험하였다. HER2를 표적화하기 위해 항체 트라스투주맙을 사용하였고, GD2를 표적화하기 위해 hu14.18K322A를 사용하였다. CD16V-BB-ζ T 림프구는 상응하는 항체의 존재하에서 상기 세포에 대해 고도의 세포독성을 보였다 (도 6 및 도 7). NB1691을 사용한 실험에서는 배양 시간을 24시간까지로 연장함으로써 세포독성이 더욱더 낮은 E:T 비율에서도 달성될 수 있는지 여부에 관하여 시험하였다. 도 8에 제시된 바와 같이, hu14.18K322A의 존재하에 1:8 비율에서 세포독성은 50%를 초과하였다. CD16V-BB-ζ-매개 세포 사멸의 특이성을 추가로 시험하기 위해, CD20+ 다우디 세포를 CD16V-BB-ζ T 림프구 및 상이한 특이성을 가지는 항체와 배양하였고: 오직 리툭시맙만이 세포독성을 매개하였고, 트라스투주맙 또는 hu14.18K322A의 존재하에서는 어떤 세포독성 증가도 없었다 (도 8). 마지막으로, 면역치료학적 항체의 존재하에서 CD16V-BB-ζ-매개 세포 사멸이 비결합 단량체 IgG에 의해 억제될 수 있는지 여부에 관하여 측정하였다. 도 8에 제시된 바와 같이, T 세포 세포독성은 심지어 IgG가 세포 결합된 면역치료학적 항체보다 최대 1,000배 더 높은 농도로 존재하는 경우에도 영향을 받지 않았다.
생체내에서 CD16V-BB-ζ T 림프구의 항-종양 능력을 평가하기 위해, 루시페라제-표지된 다우디 세포가 생착된 NOD/scid IL2RG널 마우스를 이용하여 실험을 수행하였다. 리툭시맙과 함께 CD16V-BB-ζ T 림프구를 받은 마우스에 실시간 영상화함으로써 종양 성장을 측정하고, 그의 결과를 리툭시맙 또는 T 림프구 중 어느 하나를 단독으로 받거나, 또는 어떤 처리도 받지 않은 마우스와 비교하였다. 도 9에 제시된 바와 같이, 리툭시맙을 받고, 이어서, CD16V-BB-ζ T 림프구를 받은 마우스를 제외한, 모든 마우스에서 종양 세포 확장이 일어났다. 비처리되거나, 또는 항체 또는 세포 중 하나를 단독으로 받은 12마리의 마우스 중에서는 0마리인 것과 달리, 상기 조합으로 처리된 5마리의 마우스 모두 종양 주사 후 >120일 경과 후에도 여전히 차도가 있었다. 신경모세포종 세포주 NB1691이 생착되고, hu14.18K322A 및 CD16V-BB-ζ T 림프구로 처리된 마우스에서도 또한 강력한 항-종양 활성이 관찰되었다 (도 10).
CD16V
-BB-ζ와 다른 수용체 비교
먼저 CD16V-BB-ζ 또는 CD16F-BB-ζ 수용체를 보유하는 T 세포의 기능을 비교하였다. CD16F-BB-ζ 수용체는 모의-형질도입된 T 세포에서 측정된 것보다 더 높은 T 세포 증식 및 ADCC를 유도하였다. 그럼에도 불구하고, Ig에 대한 그의 더 높은 친화도에 부합하여, CD16V-BB-ζ 수용체는 더 낮은 친화도의 CD16F-BB-ζ 수용체에 의해 유발되는 것보다 유의적으로 더 높은 T 세포 증식 및 ADCC를 유도하였다 (도 11).
이어서, CD16V-BB-ζ를 보유하는 T 세포의 기능을 다른 신호전달 특성을 가지는 다른 수용체를 발현하는 T 세포의 것과 비교하였다. 이는 신호전달 능력이 없는 수용체 ("CD16V-말단절단"), 4-1BB는 없지만, CD3ζ는 포함하는 것 ("CD16V-ζ"), 및 앞서 기술된 것으로서, CD16V을 FcεRIγ의 막횡단 및 세포질 도메인과 조합한 수용체 ("CD16V-FcεRIγ")를 포함하였다 (도 12). 활성화된 T 세포에서의 레트로바이러스 형질도입 후, 모든 수용체가 고도로 발현되었다 (도 13). 도 14에 제시된 바와 같이, CD16V-BB-ζ는 모든 다른 구축물보다 유의적으로 더 높은 활성화, 증식 및 특이적인 세포독성을 유도하였다.
mRNA
전기천공에 의해
CD16V
-BB-ζ 수용체의 발현
상기의 모든 실험에서, CD16V-BB-ζ 발현은 레트로바이러스 형질도입에 의해 실시되었다. 대안적 방법인 mRNA의 전기천공 또한 ADCC 능력을 T 림프구에 부여할 수 있는지 여부를 시험하였다. 2명의 공여자로부터 얻은 활성화된 T 림프구를 전기천공시키고, 높은 발현율을 얻었는데: 전기천공 후 24시간 경과하였을 때, T 림프구의 55% 내지 82%가 CD16+가 되었다 (도 15A). 두번째 공여자에서는 3일째 수용체 발현 또한 시험하였는데, 수용체 발현이 43%일 때, 발현이 72 내지 96시간 동안 지속된, 또 다른 수용체를 이용한 이전 실험의 것과 유사한 결과였다. ADCC는 CD16V-BB-ζ mRNA로 전기천공된 T 림프구에서 활성화되었고: 리툭시맙의 존재하에서, 80% 라모스 세포는 2:1의 E:T 비율에서 4시간 경과 후 사멸한 반면, mRNA 부재하에 전기천공된 세포는 효과가 없었다 (도 15B).
문헌 [Kudo et al., Cancer Res. 2014 Jan 1;74(1):93-103] (상기 문헌의 내용은 본원에서 참조로 포함된다) 또한 참조할 수 있다.
논의
본원에서는 ADCC를 발휘할 수 있는 능력을 T 림프구에 부여하는 키메라 수용체 개발을 기술한다. 종양 세포에 결합한 항체가 CD16V-BB-ζ 수용체에 결속하였을 때, T 세포 활성화가 일어나고, 증식이 지속되며, 항체에 의해 표적화된 암 세포에 대한 특이적인 세포독성이 일어난다. CD16V-BB-ζ T 림프구는 B 세포 림프종, 유방암 및 위암, 신경모세포종 및 골육종 뿐만 아니라, 원발성 CLL 세포를 비롯한, 매우 다양한 종양 세포 유형에 대하여 고도한 세포독성을 보였다. 세포독성은 전반적으로 표적 세포에 결합한 특이적인 항체의 존재에 의존하였고; 비결합 항체는 비특이적인 세포독성을 일으키지 않거나, 또는 세포 결합된 항체의 세포독성에 영향을 미치지 않았다. CD16V-BB-ζ T 세포는 또한 상기 미세환경의 공지된 면역억제 효과와 상관 없이, 중간엽 세포층 상에서 배양되었을 때, CLL 세포를 사멸시켰다. 또한, 리툭시맙 주입된 CD16V-BB-ζ T 림프구는 면역결핍 마우스에서 생착된 B 세포 림프종 세포를 근절시켰고, 신경모세포종 세포가 생착된 마우스에서 항-GD2 항체 존재하에 상당한 항-종양 활성을 보였다. 요약컨대, CD16V-BB-ζ를 발현하는 T 세포는 시험관내 및 생체내에서 강력한 ADCC를 발휘하였다.
Ig의 Fc 부위에 대한 CD16의 친화성은 ADCC의 중요한 결정 요인이며, 따라서, 항체 면역요법에 대한 임상 반응에 영향을 준다. 이러한 이유로, 예를 들어, 글리코조작에 의해, FcγR에 대한 Fc 단편의 친화도를 추가로 증진시키고자 하는 상당한 노력이 진행되고 있다. 본 개시내용의 키메라 수용체를 구축하기 위해, V158 다형성 (서열식별번호: 65)를 포함하는 FCGR3A (CD16) 유전자를 한 예로 선택하였다. 상기 변이체는 Ig에 대하여 더 높은 결합 친화도를 가지는 수용체를 코딩하며, 우수한 ADCC를 매개하는 것으로 밝혀져 있다. 실제로, 더욱 일반적인 F158 변이체를 함유하는 동일한 키메라 수용체와의 측별 비교(side-to-side comparison)에서, CD16V-BB-ζ가 유의적으로 더 높은, 인간 Ig Fc에 결합할 수 있는 능력을 가졌고, 더욱 활발한 증식 및 세포독성을 유도하였으며, 키메라 항원 수용체 기능에서 친화성 역할에 대하여 다룬 최근 연구의 결과를 초래하였다. 현 "제2 세대" 키메라 수용체는 자극 분자를 공동 자극 분자를 조합하여 신호전달을 증강시키고, 활성화 유도된 아폽토시스를 막는다. 그러므로, CD16 V158을 CD3ζ 및 4-1BB (CD137)에 의해 구성된 자극 분자 탠덤과 함께 조합하였다. 실제로, CD16V-BB-ζ 수용체는 CD3ζ 단독의 것을 통해 작용하는 수용체, 또는 FcεRIγ의 것보다 현저히 더 우수한 T 세포 활성화, 증식 및 세포독성을 유도하였다.
종양 세포의 표면 상의 항원을 인식하고, 자극 신호를 전달할 수 있는 수용체를 발현하는 유전적으로 변형된 T 세포의 임상적 잠재능이 임상 시험의 결과에 의해 점점 더 계속해서 입증되고 있다. 무엇보다도 특히, 바이러스 형질도입에 의해 CD19 또는 CD20에 대한 키메라 항원 수용체를 발현하는 자가 T 림프구를 받은 B 세포 악성 종양 환자에서 유의적인 종양 축소 및/또는 완전한 관해가 보고되었다. 상기 전략법을 다른 종양으로 확장하는 것은 또 다른 키메라 항원 수용체 구축물 개발, 및 규제 요건에 따른 대규모 형질도입 조건 최적화를 비롯하, 상당한 노력을 포함한다. 이와 관련하여, 본원에 기술된 CD16V-BB-ζ 수용체는 하나의 단일 수용체가 다중의 암 세포 유형에 대해 사용될 수 있도록 허용함으로써 T 세포 요법 실행을 촉진시켜야 한다. 이는 또한, 단일 특이성을 가지는 키메라 수용체에 의해 표적화되는 마커가 없는 서브클론에 의해 유도되는 백혈병 재발에 관한 최근 보고에 의해 예시된 바와 같이, 면역회피 기전이 종양에 의해 이용된다면, 궁극적으로 이로울 수 있는 전략법인, 다중 항원의 동시 표적화를 허용하여야 한다. 항체 유도 세포독성은, 항체 투여의 간단한 중단에 의해 요구될 경우에는 언제나, 중단되어야 한다. CD16V-BB-ζ를 발현하는 T 세포는 오직 표적 세포에 결합된 항체에 의해서만 활성화되기 때문에, 가용성 면역글로불린은 주입된 T 세포에 대해서는 어떤 자극도 일으키지 않아야 한다. 본원에서 입증된 바와 같이, mRNA 전기천공은 수용체를 매우 효과적으로 발현시킬 수 있다.
항체 요법이 다수의 암 서브유형에 대한 표준 치료법이 되어 왔으며; 그의 임상적 효능은 매개 Fc 수용체의 결속을 통해 ADCC를 일으킬 수 있는 그의 능력에 의해 측정된다. ADCC의 주요 이펙터는 NK 세포이지만, 암 환자에서는 그의 기능이 손상될 수 있다. 예를 들어, HER2를 과다발현하는 위암 세포의 트라스투주맙 매개 ADCC는 조기 질환 환자 또는 건강한 공여자로부터 얻은 샘플을 이용하여 수득한 것과 비교하였을 때, 위암 환자 및 진행성 질환 환자로부터 얻은 말초 혈액 단핵 세포를 이용한 경우에 유의적으로 더 낮았다. 또한, 반응은 NK 세포 억제성 수용체 및 그의 리간드의 유전자형을 비롯한, 다른 인자에 의해 영향을 받을 수도 있다. 본원에서 제시하는 결과는, CD16V-BB-ζ 수용체가 유전적으로 조작된 자가 T 세포의 주입이 ADCC를 유의적으로 증강시켜야 한다는 것을 제안한다. 조합된 CD3ζ/4-1BB 신호전달 또한 T 세포 증식을 유발하는 바, 종양 부위에 활성화된 T 세포가 축적되어야 하며, 이는 그의 활성을 추가로 강화시킬 수 있다. CD16V-BB-ζ 수용체는, 혈액 수집에서부터 CD16V-BB-ζ-발현 세포의 주입까지 단지 몇시간 밖에 소요되지 않는 바, 따라서, 임상적 적용에 매우 적합화된 방법인 mRNA 전기천공에 의해 활성화된 T 림프구에서 뿐만 아니라, 휴지 말초 혈액 단핵구 세포에서도 발현될 수 있다.
실시예 2. 다양한 키메라 수용체의 구축
키메라 수용체 서열식별번호: 1, 서열식별번호: 2, 서열식별번호: 3, 서열식별번호: 4, 서열식별번호: 5, 서열식별번호: 6, 서열식별번호: 7, 서열식별번호: 8, 서열식별번호: 9, 서열식별번호: 10, 서열식별번호: 11, 및 서열식별번호: 14를 코딩하는 핵산 서열을 벡터 pVAX1의 HindIII 및 XbaI 부위로 클로닝하였다. 제한 엔도뉴클레아제 XbaI로 분해하여 DNA 벡터를 선형화하고, T7 RNA 폴리머라제를 사용하여 RNA로 전사시켰다. 이어서, RNA를 셀스크립트(Cellscript)로부터 입수한 스크립트캡 캡핑 엔자임(ScriptCap Capping Enzyme) 및 스크립트캡(ScriptCap) 2'-O-메틸트랜스퍼라제를 이용하여 그의 5'-단부에서 효소적으로 캡핑하여 캡(Cap) 1 구조를 수득하고, 폴리-A 폴리머라제를 사용하여 그의 3'-단부에서 폴리-아데닐화시켰다. 생성된 mRNA를 인비트로겐 네온(Neon) 전기천공 시스템을 사용하여 저캣 세포 내로 전기천공시키고, 10% 우태아 혈청을 포함하는 RPMI-1640 배지 중 37℃에서 6 hr 동안 성장시켰다.
이어서, 배지 중의 전기천공된 세포를 CD20-특이 항체 리툭산 (10 ㎍/mL)과 함께 37℃에서 30 min 동안 인큐베이션시켰다. 세포를 수거하고, 유세포 분석용 완충제 (FC 완충제; Ca2+ 및 Mg2+ 무함유 DPBS, 0.2% 우혈청 알부민, 0.2% NaN3)로 2회에 걸쳐 세척하고, PE-표지된 항-CD16 항체 또는 항-CD32 항체 (서열식별번호: 6의 경우)로 염색하여 키메라 수용체 발현을 검출하거나, 또는 PE-표지된 염소-항-인간 항체로 염색하여 결합된 리툭산을 검출하였다. 염색된 세포는 유세포 분석법에 의해 분석하였다. PE-표지된 항-CD16 또는 항-CD32 항체를 사용하여 모든 구축물로부터의 키메라 수용체 단백질을 검출하였고, 평균 형광 값 범위는 36,000 내지 537,000였다. U구축물 1 (서열식별번호: 1)이 최고 발현 수준을 나타내었다.
도 16 (패널 A 내지 C)은 서열식별번호: 1 mRNA로 전기천공된 세포 및 모의-전기천공된 세포에 결합하는 리툭산에 대한 유세포 분석 데이터를 보여주는 것이다. 모의-전기천공된 세포는 2% 미만인 것과 비교하였을 때, 서열식별번호: 1을 코딩하는 mRNA로 전기천공된 세포 중 95% 초과의 세포가 염소-항-인간 항체로 염색되었으며, 이는 저캣 세포의 표면 상에서 발현된 키메라 수용체가 리툭산에 결합할 수 있었다는 것을 나타낸다 (도 16A 및 16B). PE-표지된 염소-항-인간 항체로 염색하였을 때, 서열식별번호: 1 mRNA-전기천공된 세포의 형광 값의 중앙값은 모의-전기천공된 세포의 형광 값의 중앙값보다 대략 700배 정도 더 높았다 (도 16C, 하기 표 8). 서열식별번호: 2, 서열식별번호: 3, 서열식별번호: 4, 서열식별번호: 5, 서열식별번호: 6, 서열식별번호: 7, 서열식별번호: 8, 서열식별번호: 9, 서열식별번호: 10, 서열식별번호: 11, 및 서열식별번호: 14에 대해서도 유사한 분석을 수행하였다. PE-표지된 염소-항-인간 항체로 염색하였을 때, 상기 구축물에 대한 키메라 수용체 mRNA로 전기천공된 세포의 형광 값의 중앙값은 모의-전기천공된 세포의 형광 값의 중앙값보다 대략 14 내지 680배 정도 더 높았고 (하기 표 8), 이는 저캣 세포의 표면 상에서 발현된 상기 키메라 수용체 단백질 모두가 리툭산에 결합할 수 있었다는 것을 나타낸다.
본 실험은 키메라 수용체 서열식별번호: 1, 서열식별번호: 2, 서열식별번호: 3, 서열식별번호: 4, 서열식별번호: 5, 서열식별번호: 6, 서열식별번호: 7, 서열식별번호: 8, 서열식별번호: 9, 서열식별번호: 10, 서열식별번호: 11, 및 서열식별번호: 14 모두 저캣 세포에서 발현되었고, 이들은 모두 CD20-특이 항체 리툭산에 결합하였다는 것을 시사하였다.
<표 8>
키메라 수용체 구축물에 대한 활성 실험에서의 키메라 수용체의 리툭산에의 결합, 및 CD25 및 CD69 발현에 대한 상대적인 형광 중앙값

실시예 3. 키메라 수용체를 발현하는 세포는 T 세포 활성화 마커를 나타낸다.
상기 실시예 2에 개시된 키메라 수용체를 발현하는 저캣 세포를 세포-표면 활성 마커인 CD25 및 CD69의 존재에 대해 모니터링함으로써 활성에 대해 평가하였다. 본 실험을 위해, 저캣 세포를 인비트로겐 네온 전기천공 시스템을 사용하여 mRNA 없이 (모의) 또는 상기 실시예 2에 기술된 키메라 수용체 구축물을 코딩하는 mRNA로 전기천공시키고, 10% FBS를 포함하는 RPMI-1640 배지 중 37℃에서 8 - 9 hr 동안 성장시켰다. 세포를 수거하고, 10% 우태아 혈청, 50 U/mL 페니실린, 및 50 ㎍/mL 스트렙토마이신을 포함하는 RPMI-1640 배지로 세척하였다. 상기 세포를, 스트렉스(Streck's) 세포 보존제로 고정된, 세포 표면에 CD20을 발현하는 다우디 표적 세포와 1 대 1 비율로, 및 CD20-특이 항체 리툭산 (10 ㎍/mL)과 혼합하였다. 상기 혼합물을 10% 우태아 혈청, 50 U/mL 페니실린, 및 50 ㎍/mL 스트렙토마이신을 포함하는 RPMI-1640 배지 중 37℃에서 18 - 20 hr 동안 인큐베이션시켰다. 세포를 수거하고, 저캣 세포 상에서 각각 PE-표지된 항-CD7 항체로 염색하여 저캣 세포를 검출하고, APC-표지된 항-CD25 항체 또는 APC-표지된 항-CD69 항체로 염색하여 CD25 및 CD69 발현을 검출하였다. 염색된 세포를 유세포 분석법에 의해 평가하였다.
CD7 양성 세포를 CD25 및 CD69, 둘 모두의 발현에 대하여 평가하였다. 모의-전기천공 조건하에서는 3% 미만의 CD7 양성 세포가 APC-표지된 항-CD25 항체로 염색된 것과 비교하였을 때, 서열식별번호: 1을 코딩하는 mRNA가 사용된 조건하에서는 45% 초과의 CD7 양성 세포가 염색되었으며, 이는 상기 실험의 조건하에서 키메라 수용체를 발현하지 않는 세포와 비교하였을 때, 상기 수용체를 발현하는 저캣 세포 상에서 CD25 활성 마커의 발현이 증가되었다는 것을 나타낸다 (도 17A 및 17B). CD7 양성 세포를 APC-표지된 항-CD25 항체를 이용한 염색에 대하여 평가하였을 때, 서열식별번호: 1 mRNA 조건하에서의 형광 값의 중앙값은 모의-전기천공된 세포의 형광 값의 중앙값보다 대략 6.7배 정도 더 높았다 (도 17C, 하기 표 8). 모의-전기천공 조건하에서는 대략 46%의 CD7 양성 세포가 APC-표지된 항-CD69 항체로 염색된 것과 비교하였을 때, 서열식별번호: 1을 코딩하는 mRNA가 사용된 조건하에서는 98% 초과의 CD7 양성 세포가 염색되었으며, 이는 상기 실험의 조건하에서 키메라 수용체를 발현하지 않는 세포와 비교하였을 때, 상기 수용체를 발현하는 저캣 세포 상에서 CD69 활성 마커의 발현이 증가되었다는 것을 나타낸다 (도 18A 및 18B). CD7 양성 세포를 APC-표지된 항-CD69 항체를 이용한 염색에 대하여 평가하였을 때, 서열식별번호: 1 mRNA 조건하에서의 형광 값의 중앙값은 모의-전기천공된 세포의 형광 값의 중앙값보다 대략 69배 정도 더 높았다 (도 18C, 하기 표 8).
서열식별번호: 2, 서열식별번호: 3, 서열식별번호: 4, 서열식별번호: 5, 서열식별번호: 6, 서열식별번호: 7, 서열식별번호: 8, 서열식별번호: 9, 서열식별번호: 10, 서열식별번호: 11, 및 서열식별번호: 14에 대해서도 유사한 분석을 수행하였다. CD7 양성 세포를 APC-표지된 항-CD25 항체를 이용한 염색에 대하여 평가하였을 때, 세포가 상기 구축물에 대한 키메라 수용체를 발현하는 것인 조건에 대한 형광 값의 중앙값은 모의-전기천공된 세포의 형광 값의 중앙값보다 대략 2.3 내지 7.6배 정도 더 높았고 (하기 표 8), 이는 상기 실험의 조건하에서 키메라 수용체를 발현하지 않는 세포와 비교하였을 때, 상기 각각의 수용체를 발현하는 저캣 세포 상에서 CD25 활성 마커의 발현이 증가되었다는 것을 나타낸다 (하기 표 8). CD7 양성 세포를 APC-표지된 항-CD69 항체를 이용한 염색에 대하여 평가하였을 때, 세포가 상기 구축물에 대한 키메라 수용체를 발현하는 것인 조건에 대한 형광 값의 중앙값은 모의-전기천공된 세포의 형광 값의 중앙값보다 대략 10 내지 64배 정도 더 높았고 (하기 표 8), 이는 상기 실험의 조건하에서 키메라 수용체를 발현하지 않는 세포와 비교하였을 때, 상기 각각의 수용체를 발현하는 저캣 세포 상에서 CD69 활성 마커의 발현이 증가되었다는 것을 나타낸다 (하기 표 8).
본 실험은 본 수용체가 CD20-특이 항체인 리툭산 및 CD20을 발현하는 다우디 표적 세포와 상호작용하는 조건하에서 상기 키메라 수용체를 발현하는 저캣 세포가 키메라 수용체를 발현하지 않는 저캣 세포와 비교하였을 때, 활성 마커인 CD25 및 CD69의 증가를 나타낸다는 것을 시사하는 것이다.
실시예 4. 키메라 수용체가 저캣 세포 상에서 발현된다
키메라 수용체를 코딩하는 mRNA로 전기천공된 저캣 세포를 항-CDζ 항체를 이용하는 웨스턴 블롯 분석에 의해 키메라 수용체 발현에 대하여 분석하였다. 본 실험을 위해, 저캣 세포를 인비트로겐 네온 전기천공 시스템을 사용하여 mRNA 없이 (모의) 또는 상기 실시예 2에 개시된 구축물을 코딩하는 mRNA로 전기천공시키고, 10% FBS를 포함하는 RPMI-1640 배지 중 37℃에서 8 - 9 hr 동안 성장시켰다. 세포를 수거하고, 포스파타제 및 프로테아제 억제제의 존재하에서 RIPA 완충제 (50 mM 트리스(Tris)-HCl, 150 mM NaCl, 1 mM EDTA, 1% NP-40, 0.5% 소듐 데옥시콜레이트, pH 7.4)로 용해시켰다. 각 용해물에 대하여, 25 ㎍의 전체 단백질을 4-12% 비스-트리스(Bis-Tris) 폴리아크릴아미드 겔의 한 레인 상에 로딩하였다. 단백질을 PVDF 막으로 옮겨 놓고, 막을 실온에서 1 hr 동안 TBST 완충제 (500 mM 트리스-HCl, 1.5M NaCl, 1% 트윈(Tween)-20, pH 7.4) 중 5% 밀크로 차단하였다. 막을 4℃에서 밤새도록 항-CDζ 항체로 프로빙하고, TBST 완충제로 3회에 걸쳐 세척하고, 호스래디시-퍼옥시다제-결합 염소-항-인간 2차 항체로 프로빙하였다. 호스래디시 퍼옥시다제 화학발광성 기질을 사용하여 단백질 밴드를 시각화하였다.
웨스턴 블롯 실험 결과는 도 19에 제시되어 있다. 항-CDζ 항체는 CDζ 세포내 단백질 서열을 함유하는 키메라 수용체 단백질의 C-말단 영역을 검출한다. 모든 키메라 수용체 구축물에 대하여, 전장의 수용체 단백질에 상응하는 밴드가 검출되었다 (레인 2-13). 키메라 수용체 단백질의 이동성은 단백질의 상이한 분자량과 일관된 방식으로 다르게 나타났다.
본 결과는 상기 키메라 수용체가 상응하는 mRNA를 이용한 전기천공 이후에 저캣 세포에서 모두 발현되었다는 것을 입증한다.
다른 실시양태
본 명세서에 개시된 특징들은 모두 임의 조합으로 조합될 수 있다. 본 명세서에 개시된 각 특징은 동일하거나, 등가이거나, 또는 유사한 목적을 달성하기 위한 대안적 특징에 의해 대체될 수 있다. 따라서, 달리 명확하게 언급되지 않는 한, 개시된 각 특징은 단지 등가적인 또는 유사한 특징을 나타내는 포괄적 시리즈의 예일 뿐이다.
상기 설명으로부터 통상의 기술자는 본 개시내용의 본질적인 특징을 쉽게 확인할 수 있고, 그의 정신 및 범주로부터 벗어남 없이, 본 개시내용을 다양하게 변형 및 수정시킴으로써 다양한 용도 및 조건에 맞게 적합화시킬 수 있다. 따라서, 다른 실시양태 또한 특허청구범위 내에 포함된다.
SEQUENCE LISTING
<110> Unum Therapeutics
<120> CHIMERIC RECEPTORS AND USES THEREOF IN IMMUNE THERAPY
<130> U1199.70000WO00
<140> Not Yet Assigned
<141> Concurrently Herewith
<150> US 62/047,916
<151> 2014-09-09
<160> 87
<170> PatentIn version 3.5
<210> 1
<211> 436
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 1
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu
260 265 270
Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly Arg Lys Lys
275 280 285
Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr
290 295 300
Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly
305 310 315 320
Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
325 330 335
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
340 345 350
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
355 360 365
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
370 375 380
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
385 390 395 400
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
405 410 415
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
420 425 430
Leu Pro Pro Arg
435
<210> 2
<211> 442
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 2
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Ile Ile Ser Phe Phe Leu Ala Leu Thr Ser Thr Ala Leu Leu
260 265 270
Phe Leu Leu Phe Phe Leu Thr Leu Arg Phe Ser Val Val Lys Arg Gly
275 280 285
Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met
290 295 300
Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe
305 310 315 320
Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg
325 330 335
Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn
340 345 350
Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg
355 360 365
Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro
370 375 380
Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala
385 390 395 400
Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His
405 410 415
Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp
420 425 430
Ala Leu His Met Gln Ala Leu Pro Pro Arg
435 440
<210> 3
<211> 442
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 3
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Phe Trp Val Leu Val Val Val Gly Gly Val Leu Ala Cys Tyr
260 265 270
Ser Leu Leu Val Thr Val Ala Phe Ile Ile Phe Trp Val Arg Ser Lys
275 280 285
Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met
290 295 300
Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe
305 310 315 320
Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg
325 330 335
Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn
340 345 350
Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg
355 360 365
Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro
370 375 380
Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala
385 390 395 400
Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His
405 410 415
Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp
420 425 430
Ala Leu His Met Gln Ala Leu Pro Pro Arg
435 440
<210> 4
<211> 436
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 4
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Leu Ile Ala Leu Val Thr Ser Gly Ala Leu Leu Ala Val Leu
260 265 270
Gly Ile Thr Gly Tyr Phe Leu Met Asn Arg Lys Arg Gly Arg Lys Lys
275 280 285
Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr
290 295 300
Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly
305 310 315 320
Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
325 330 335
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
340 345 350
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
355 360 365
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
370 375 380
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
385 390 395 400
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
405 410 415
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
420 425 430
Leu Pro Pro Arg
435
<210> 5
<211> 436
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 5
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Leu Leu Ala Ala Leu Leu Ala Leu Leu Ala Ala Leu Leu Ala
260 265 270
Leu Leu Ala Ala Leu Leu Ala Arg Ser Lys Lys Arg Gly Arg Lys Lys
275 280 285
Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr
290 295 300
Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly
305 310 315 320
Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
325 330 335
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
340 345 350
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
355 360 365
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
370 375 380
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
385 390 395 400
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
405 410 415
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
420 425 430
Leu Pro Pro Arg
435
<210> 6
<211> 428
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 6
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gln Ala Ala Ala Pro Pro Lys Ala Val Leu Lys
20 25 30
Leu Glu Pro Pro Trp Ile Asn Val Leu Gln Glu Asp Ser Val Thr Leu
35 40 45
Thr Cys Gln Gly Ala Arg Ser Pro Glu Ser Asp Ser Ile Gln Trp Phe
50 55 60
His Asn Gly Asn Leu Ile Pro Thr His Thr Gln Pro Ser Tyr Arg Phe
65 70 75 80
Lys Ala Asn Asn Asn Asp Ser Gly Glu Tyr Thr Cys Gln Thr Gly Gln
85 90 95
Thr Ser Leu Ser Asp Pro Val His Leu Thr Val Leu Ser Glu Trp Leu
100 105 110
Val Leu Gln Thr Pro His Leu Glu Phe Gln Glu Gly Glu Thr Ile Met
115 120 125
Leu Arg Cys His Ser Trp Lys Asp Lys Pro Leu Val Lys Val Thr Phe
130 135 140
Phe Gln Asn Gly Lys Ser Gln Lys Phe Ser His Leu Asp Pro Thr Phe
145 150 155 160
Ser Ile Pro Gln Ala Asn His Ser His Ser Gly Asp Tyr His Cys Thr
165 170 175
Gly Asn Ile Gly Tyr Thr Leu Phe Ser Ser Lys Pro Val Thr Ile Thr
180 185 190
Val Gln Val Pro Ser Met Gly Ser Ser Ser Pro Met Gly Thr Thr Thr
195 200 205
Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala Ser Gln Pro
210 215 220
Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly Gly Ala Val
225 230 235 240
His Thr Arg Gly Leu Asp Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro
245 250 255
Leu Ala Gly Thr Cys Gly Val Leu Leu Leu Ser Leu Val Ile Thr Leu
260 265 270
Tyr Cys Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro
275 280 285
Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys
290 295 300
Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val Lys Phe
305 310 315 320
Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu
325 330 335
Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp
340 345 350
Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys
355 360 365
Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala
370 375 380
Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys
385 390 395 400
Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr
405 410 415
Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
420 425
<210> 7
<211> 435
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 7
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu
260 265 270
Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Arg Ser Lys Arg Ser Arg
275 280 285
Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly Pro
290 295 300
Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala Ala
305 310 315 320
Tyr Arg Ser Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr
325 330 335
Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg
340 345 350
Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met
355 360 365
Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu
370 375 380
Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys
385 390 395 400
Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu
405 410 415
Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu
420 425 430
Pro Pro Arg
435
<210> 8
<211> 436
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 8
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu
260 265 270
Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Ala Leu Tyr Leu Leu Arg
275 280 285
Arg Asp Gln Arg Leu Pro Pro Asp Ala His Lys Pro Pro Gly Gly Gly
290 295 300
Ser Phe Arg Thr Pro Ile Gln Glu Glu Gln Ala Asp Ala His Ser Thr
305 310 315 320
Leu Ala Lys Ile Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
325 330 335
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
340 345 350
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
355 360 365
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
370 375 380
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
385 390 395 400
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
405 410 415
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
420 425 430
Leu Pro Pro Arg
435
<210> 9
<211> 477
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 9
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu
260 265 270
Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Arg Ser Lys Arg Ser Arg
275 280 285
Leu Leu His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly Pro
290 295 300
Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala Ala
305 310 315 320
Tyr Arg Ser Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln
325 330 335
Pro Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser
340 345 350
Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val Lys
355 360 365
Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln
370 375 380
Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu
385 390 395 400
Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg
405 410 415
Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met
420 425 430
Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly
435 440 445
Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp
450 455 460
Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
465 470 475
<210> 10
<211> 391
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 10
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys
210 215 220
Gly Val Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly
225 230 235 240
Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val
245 250 255
Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu
260 265 270
Glu Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp
275 280 285
Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn
290 295 300
Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg
305 310 315 320
Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly
325 330 335
Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu
340 345 350
Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu
355 360 365
Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His
370 375 380
Met Gln Ala Leu Pro Pro Arg
385 390
<210> 11
<211> 436
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 11
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Gly Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr
210 215 220
Glu Glu Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr
225 230 235 240
Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Ser Pro Ala Gly Ser
245 250 255
Pro Thr Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu
260 265 270
Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly Arg Lys Lys
275 280 285
Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr
290 295 300
Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly
305 310 315 320
Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
325 330 335
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
340 345 350
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
355 360 365
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
370 375 380
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
385 390 395 400
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
405 410 415
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
420 425 430
Leu Pro Pro Arg
435
<210> 12
<211> 435
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 12
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu
260 265 270
Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Arg Ser Lys Arg Ser Arg
275 280 285
Gly Gly His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly Pro
290 295 300
Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala Ala
305 310 315 320
Tyr Arg Ser Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr
325 330 335
Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg
340 345 350
Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met
355 360 365
Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu
370 375 380
Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys
385 390 395 400
Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu
405 410 415
Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu
420 425 430
Pro Pro Arg
435
<210> 13
<211> 477
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 13
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu
260 265 270
Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Arg Ser Lys Arg Ser Arg
275 280 285
Gly Gly His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly Pro
290 295 300
Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala Ala
305 310 315 320
Tyr Arg Ser Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln
325 330 335
Pro Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser
340 345 350
Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val Lys
355 360 365
Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln
370 375 380
Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu
385 390 395 400
Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg
405 410 415
Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met
420 425 430
Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly
435 440 445
Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp
450 455 460
Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
465 470 475
<210> 14
<211> 437
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 14
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Met Ala Leu Ile Val Leu Gly Gly Val Ala Gly Leu Leu Leu
260 265 270
Phe Ile Gly Leu Gly Ile Phe Phe Cys Val Arg Lys Arg Gly Arg Lys
275 280 285
Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr
290 295 300
Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu
305 310 315 320
Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro
325 330 335
Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly
340 345 350
Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro
355 360 365
Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr
370 375 380
Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly
385 390 395 400
Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln
405 410 415
Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln
420 425 430
Ala Leu Pro Pro Arg
435
<210> 15
<211> 436
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 15
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Met Ala Leu Ile Val Leu Gly Gly Val Ala Gly Leu Leu Leu
260 265 270
Phe Ile Gly Leu Gly Ile Phe Phe Cys Val Arg Arg Ser Lys Arg Ser
275 280 285
Arg Gly Gly His Ser Asp Tyr Met Asn Met Thr Pro Arg Arg Pro Gly
290 295 300
Pro Thr Arg Lys His Tyr Gln Pro Tyr Ala Pro Pro Arg Asp Phe Ala
305 310 315 320
Ala Tyr Arg Ser Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
325 330 335
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
340 345 350
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
355 360 365
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
370 375 380
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
385 390 395 400
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
405 410 415
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
420 425 430
Leu Pro Pro Arg
435
<210> 16
<211> 436
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 16
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Leu Cys Tyr Ile Leu Asp Ala Ile Leu Phe Leu Tyr Gly Ile
260 265 270
Val Leu Thr Leu Leu Tyr Cys Arg Leu Lys Lys Arg Gly Arg Lys Lys
275 280 285
Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr
290 295 300
Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly
305 310 315 320
Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
325 330 335
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
340 345 350
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
355 360 365
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
370 375 380
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
385 390 395 400
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
405 410 415
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
420 425 430
Leu Pro Pro Arg
435
<210> 17
<211> 436
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 17
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Leu Leu Leu Ile Leu Leu Gly Val Leu Ala Gly Val Leu Ala
260 265 270
Thr Leu Ala Ala Leu Leu Ala Arg Ser Lys Lys Arg Gly Arg Lys Lys
275 280 285
Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr
290 295 300
Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly
305 310 315 320
Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
325 330 335
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
340 345 350
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
355 360 365
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
370 375 380
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
385 390 395 400
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
405 410 415
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
420 425 430
Leu Pro Pro Arg
435
<210> 18
<211> 436
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 18
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Ile Thr Leu Gly Leu Leu Val Ala Gly Val Leu Val Leu Leu
260 265 270
Val Ser Leu Gly Val Ala Ile His Leu Cys Lys Arg Gly Arg Lys Lys
275 280 285
Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr
290 295 300
Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly
305 310 315 320
Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
325 330 335
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
340 345 350
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
355 360 365
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
370 375 380
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
385 390 395 400
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
405 410 415
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
420 425 430
Leu Pro Pro Arg
435
<210> 19
<211> 436
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 19
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Val Ser Phe Cys Leu Val Met Val Leu Leu Phe Ala Val Asp
260 265 270
Thr Gly Leu Tyr Phe Ser Val Lys Thr Asn Lys Arg Gly Arg Lys Lys
275 280 285
Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr
290 295 300
Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly
305 310 315 320
Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
325 330 335
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
340 345 350
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
355 360 365
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
370 375 380
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
385 390 395 400
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
405 410 415
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
420 425 430
Leu Pro Pro Arg
435
<210> 20
<211> 436
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 20
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Val Ala Ala Ile Leu Gly Leu Gly Leu Val Leu Gly Leu Leu
260 265 270
Gly Pro Leu Ala Ile Leu Leu Ala Leu Tyr Lys Arg Gly Arg Lys Lys
275 280 285
Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr
290 295 300
Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly
305 310 315 320
Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
325 330 335
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
340 345 350
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
355 360 365
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
370 375 380
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
385 390 395 400
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
405 410 415
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
420 425 430
Leu Pro Pro Arg
435
<210> 21
<211> 436
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 21
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Leu Cys Tyr Leu Leu Asp Gly Ile Leu Phe Ile Tyr Gly Val
260 265 270
Ile Leu Thr Ala Leu Phe Leu Arg Val Lys Lys Arg Gly Arg Lys Lys
275 280 285
Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr
290 295 300
Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly
305 310 315 320
Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
325 330 335
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
340 345 350
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
355 360 365
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
370 375 380
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
385 390 395 400
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
405 410 415
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
420 425 430
Leu Pro Pro Arg
435
<210> 22
<211> 441
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 22
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Val Met Ser Val Ala Thr Ile Val Ile Val Asp Ile Cys Ile
260 265 270
Thr Gly Gly Leu Leu Leu Leu Val Tyr Tyr Trp Ser Lys Asn Arg Lys
275 280 285
Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg
290 295 300
Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro
305 310 315 320
Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser
325 330 335
Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu
340 345 350
Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg
355 360 365
Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln
370 375 380
Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr
385 390 395 400
Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp
405 410 415
Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala
420 425 430
Leu His Met Gln Ala Leu Pro Pro Arg
435 440
<210> 23
<211> 436
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 23
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Gly Phe Leu Phe Ala Glu Ile Val Ser Ile Phe Val Leu Ala
260 265 270
Val Gly Val Tyr Phe Ile Ala Gly Gln Asp Lys Arg Gly Arg Lys Lys
275 280 285
Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr
290 295 300
Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly
305 310 315 320
Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
325 330 335
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
340 345 350
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
355 360 365
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
370 375 380
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
385 390 395 400
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
405 410 415
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
420 425 430
Leu Pro Pro Arg
435
<210> 24
<211> 437
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 24
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Gly Ile Ile Val Thr Asp Val Ile Ala Thr Leu Leu Leu Ala
260 265 270
Leu Gly Val Phe Cys Phe Ala Gly His Glu Thr Lys Arg Gly Arg Lys
275 280 285
Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr
290 295 300
Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu
305 310 315 320
Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro
325 330 335
Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly
340 345 350
Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro
355 360 365
Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr
370 375 380
Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly
385 390 395 400
Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln
405 410 415
Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln
420 425 430
Ala Leu Pro Pro Arg
435
<210> 25
<211> 435
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 25
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val Ala Gly Phe
260 265 270
Asn Leu Leu Met Thr Leu Arg Leu Trp Lys Arg Gly Arg Lys Lys Leu
275 280 285
Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr Gln
290 295 300
Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly
305 310 315 320
Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr
325 330 335
Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg
340 345 350
Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met
355 360 365
Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu
370 375 380
Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys
385 390 395 400
Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu
405 410 415
Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu
420 425 430
Pro Pro Arg
435
<210> 26
<211> 438
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 26
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Ile Ile Val Ala Val Val Ile Ala Thr Ala Val Ala Ala Ile
260 265 270
Val Ala Ala Val Val Ala Leu Ile Tyr Cys Arg Lys Lys Arg Gly Arg
275 280 285
Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln
290 295 300
Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu
305 310 315 320
Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala
325 330 335
Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu
340 345 350
Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp
355 360 365
Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu
370 375 380
Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile
385 390 395 400
Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr
405 410 415
Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met
420 425 430
Gln Ala Leu Pro Pro Arg
435
<210> 27
<211> 436
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 27
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Val Leu Phe Tyr Leu Ala Val Gly Ile Met Phe Leu Val Asn
260 265 270
Thr Val Leu Trp Val Thr Ile Arg Lys Glu Lys Arg Gly Arg Lys Lys
275 280 285
Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr
290 295 300
Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly
305 310 315 320
Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
325 330 335
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
340 345 350
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
355 360 365
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
370 375 380
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
385 390 395 400
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
405 410 415
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
420 425 430
Leu Pro Pro Arg
435
<210> 28
<211> 436
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 28
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Ile Ile Ile Leu Val Gly Thr Ala Val Ile Ala Met Phe Phe
260 265 270
Trp Leu Leu Leu Val Ile Ile Leu Arg Thr Lys Arg Gly Arg Lys Lys
275 280 285
Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr
290 295 300
Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly
305 310 315 320
Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
325 330 335
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
340 345 350
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
355 360 365
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
370 375 380
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
385 390 395 400
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
405 410 415
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
420 425 430
Leu Pro Pro Arg
435
<210> 29
<211> 432
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 29
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Leu Gly Trp Leu Cys Leu Leu Leu Leu Pro Ile Pro Leu Ile
260 265 270
Val Trp Val Lys Arg Lys Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile
275 280 285
Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp
290 295 300
Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu
305 310 315 320
Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly
325 330 335
Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr
340 345 350
Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys
355 360 365
Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys
370 375 380
Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg
385 390 395 400
Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala
405 410 415
Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
420 425 430
<210> 30
<211> 436
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 30
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Ile Ala Ile Tyr Cys Ile Gly Val Phe Leu Ile Ala Cys Met
260 265 270
Val Val Thr Val Ile Leu Cys Arg Met Lys Lys Arg Gly Arg Lys Lys
275 280 285
Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr
290 295 300
Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly
305 310 315 320
Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
325 330 335
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
340 345 350
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
355 360 365
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
370 375 380
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
385 390 395 400
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
405 410 415
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
420 425 430
Leu Pro Pro Arg
435
<210> 31
<211> 436
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 31
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Phe Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu
260 265 270
Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly Arg Lys Lys
275 280 285
Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr
290 295 300
Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly
305 310 315 320
Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
325 330 335
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
340 345 350
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
355 360 365
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
370 375 380
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
385 390 395 400
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
405 410 415
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
420 425 430
Leu Pro Pro Arg
435
<210> 32
<211> 476
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 32
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gln Val Asp Thr Thr Lys Ala Val Ile Thr Leu
20 25 30
Gln Pro Pro Trp Val Ser Val Phe Gln Glu Glu Thr Val Thr Leu His
35 40 45
Cys Glu Val Leu His Leu Pro Gly Ser Ser Ser Thr Gln Trp Phe Leu
50 55 60
Asn Gly Thr Ala Thr Gln Thr Ser Thr Pro Ser Tyr Arg Ile Thr Ser
65 70 75 80
Ala Ser Val Asn Asp Ser Gly Glu Tyr Arg Cys Gln Arg Gly Leu Ser
85 90 95
Gly Arg Ser Asp Pro Ile Gln Leu Glu Ile His Arg Gly Trp Leu Leu
100 105 110
Leu Gln Val Ser Ser Arg Val Phe Thr Glu Gly Glu Pro Leu Ala Leu
115 120 125
Arg Cys His Ala Trp Lys Asp Lys Leu Val Tyr Asn Val Leu Tyr Tyr
130 135 140
Arg Asn Gly Lys Ala Phe Lys Phe Phe His Trp Asn Ser Asn Leu Thr
145 150 155 160
Ile Leu Lys Thr Asn Ile Ser His Asn Gly Thr Tyr His Cys Ser Gly
165 170 175
Met Gly Lys His Arg Tyr Thr Ser Ala Gly Ile Ser Val Thr Val Lys
180 185 190
Glu Leu Phe Pro Ala Pro Val Leu Asn Ala Ser Val Thr Ser Pro Leu
195 200 205
Leu Glu Gly Asn Leu Val Thr Leu Ser Cys Glu Thr Lys Leu Leu Leu
210 215 220
Gln Arg Pro Gly Leu Gln Leu Tyr Phe Ser Phe Tyr Met Gly Ser Lys
225 230 235 240
Thr Leu Arg Gly Arg Asn Thr Ser Ser Glu Tyr Gln Ile Leu Thr Ala
245 250 255
Arg Arg Glu Asp Ser Gly Leu Tyr Trp Cys Glu Ala Ala Thr Glu Asp
260 265 270
Gly Asn Val Leu Lys Arg Ser Pro Glu Leu Glu Leu Gln Val Leu Gly
275 280 285
Leu Gln Leu Pro Thr Pro Val Trp Phe His Ile Tyr Ile Trp Ala Pro
290 295 300
Leu Ala Gly Thr Cys Gly Val Leu Leu Leu Ser Leu Val Ile Thr Leu
305 310 315 320
Tyr Cys Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro
325 330 335
Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys
340 345 350
Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val Lys Phe
355 360 365
Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu
370 375 380
Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp
385 390 395 400
Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys
405 410 415
Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala
420 425 430
Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys
435 440 445
Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr
450 455 460
Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
465 470 475
<210> 33
<211> 623
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 33
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys
210 215 220
Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu
225 230 235 240
Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu
245 250 255
Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys
260 265 270
Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys
275 280 285
Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu
290 295 300
Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys
305 310 315 320
Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys
325 330 335
Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser
340 345 350
Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys
355 360 365
Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln
370 375 380
Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly
385 390 395 400
Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln
405 410 415
Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn
420 425 430
His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys Ile Tyr Ile
435 440 445
Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu Leu Leu Ser Leu Val
450 455 460
Ile Thr Leu Tyr Cys Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe
465 470 475 480
Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly
485 490 495
Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg
500 505 510
Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln
515 520 525
Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp
530 535 540
Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro
545 550 555 560
Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp
565 570 575
Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg
580 585 590
Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr
595 600 605
Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
610 615 620
<210> 34
<211> 510
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 34
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys
210 215 220
Pro Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg
225 230 235 240
Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly
245 250 255
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
260 265 270
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
275 280 285
Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln
290 295 300
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
305 310 315 320
Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys Ile Tyr Ile Trp
325 330 335
Ala Pro Leu Ala Gly Thr Cys Gly Val Leu Leu Leu Ser Leu Val Ile
340 345 350
Thr Leu Tyr Cys Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys
355 360 365
Gln Pro Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys
370 375 380
Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg Val
385 390 395 400
Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn
405 410 415
Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val
420 425 430
Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg
435 440 445
Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys
450 455 460
Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg
465 470 475 480
Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys
485 490 495
Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
500 505 510
<210> 35
<211> 403
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 35
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys
210 215 220
Pro Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu Leu
225 230 235 240
Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly Arg Lys Lys Leu
245 250 255
Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr Gln
260 265 270
Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly
275 280 285
Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr
290 295 300
Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg
305 310 315 320
Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met
325 330 335
Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu
340 345 350
Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys
355 360 365
Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu
370 375 380
Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu
385 390 395 400
Pro Pro Arg
<210> 36
<211> 421
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 36
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Phe
225 230 235 240
Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val
245 250 255
Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly Arg Lys
260 265 270
Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr
275 280 285
Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu
290 295 300
Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro
305 310 315 320
Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly
325 330 335
Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro
340 345 350
Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr
355 360 365
Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly
370 375 380
Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln
385 390 395 400
Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln
405 410 415
Ala Leu Pro Pro Arg
420
<210> 37
<211> 406
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 37
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Phe Ala Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly
225 230 235 240
Val Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly Arg
245 250 255
Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln
260 265 270
Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu
275 280 285
Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala
290 295 300
Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu
305 310 315 320
Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp
325 330 335
Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu
340 345 350
Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile
355 360 365
Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr
370 375 380
Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met
385 390 395 400
Gln Ala Leu Pro Pro Arg
405
<210> 38
<211> 406
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 38
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
210 215 220
Gly Gly Gly Ser Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly
225 230 235 240
Val Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly Arg
245 250 255
Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln
260 265 270
Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu
275 280 285
Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala
290 295 300
Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu
305 310 315 320
Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp
325 330 335
Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu
340 345 350
Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile
355 360 365
Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr
370 375 380
Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met
385 390 395 400
Gln Ala Leu Pro Pro Arg
405
<210> 39
<211> 421
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 39
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
210 215 220
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
225 230 235 240
Gly Gly Ser Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val
245 250 255
Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly Arg Lys
260 265 270
Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr
275 280 285
Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu
290 295 300
Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro
305 310 315 320
Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly
325 330 335
Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro
340 345 350
Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr
355 360 365
Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly
370 375 380
Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln
385 390 395 400
Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln
405 410 415
Ala Leu Pro Pro Arg
420
<210> 40
<211> 436
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 40
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
210 215 220
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
225 230 235 240
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
245 250 255
Gly Ser Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu
260 265 270
Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly Arg Lys Lys
275 280 285
Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr
290 295 300
Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly
305 310 315 320
Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
325 330 335
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
340 345 350
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
355 360 365
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
370 375 380
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
385 390 395 400
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
405 410 415
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
420 425 430
Leu Pro Pro Arg
435
<210> 41
<211> 451
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 41
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
210 215 220
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
225 230 235 240
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
245 250 255
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
260 265 270
Ser Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu Leu
275 280 285
Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly Arg Lys Lys Leu
290 295 300
Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr Gln
305 310 315 320
Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly
325 330 335
Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr
340 345 350
Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg
355 360 365
Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met
370 375 380
Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu
385 390 395 400
Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys
405 410 415
Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu
420 425 430
Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu
435 440 445
Pro Pro Arg
450
<210> 42
<211> 451
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 42
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Gly Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr
210 215 220
Glu Glu Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr
225 230 235 240
Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Ser Pro Ala Gly Ser
245 250 255
Pro Thr Ser Thr Glu Glu Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser
260 265 270
Ala Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu Leu
275 280 285
Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly Arg Lys Lys Leu
290 295 300
Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr Gln
305 310 315 320
Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly
325 330 335
Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr
340 345 350
Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg
355 360 365
Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met
370 375 380
Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu
385 390 395 400
Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys
405 410 415
Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu
420 425 430
Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu
435 440 445
Pro Pro Arg
450
<210> 43
<211> 421
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 43
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Gly Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr
210 215 220
Glu Glu Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr
225 230 235 240
Ser Thr Glu Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val
245 250 255
Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly Arg Lys
260 265 270
Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr
275 280 285
Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu
290 295 300
Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro
305 310 315 320
Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly
325 330 335
Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro
340 345 350
Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr
355 360 365
Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly
370 375 380
Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln
385 390 395 400
Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln
405 410 415
Ala Leu Pro Pro Arg
420
<210> 44
<211> 406
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 44
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Gly Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr
210 215 220
Glu Glu Gly Thr Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly
225 230 235 240
Val Leu Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly Arg
245 250 255
Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln
260 265 270
Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu
275 280 285
Glu Gly Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala
290 295 300
Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu
305 310 315 320
Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp
325 330 335
Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu
340 345 350
Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile
355 360 365
Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr
370 375 380
Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met
385 390 395 400
Gln Ala Leu Pro Pro Arg
405
<210> 45
<211> 433
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 45
Met Leu Arg Leu Leu Leu Ala Leu Asn Leu Phe Pro Ser Ile Gln Val
1 5 10 15
Thr Gly Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val Val Phe Leu
20 25 30
Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val Thr Leu Lys
35 40 45
Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln Trp Phe His
50 55 60
Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe Ile Asp Ala
65 70 75 80
Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr Asn Leu Ser
85 90 95
Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly Trp Leu Leu
100 105 110
Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro Ile His Leu
115 120 125
Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val Thr Tyr Leu
130 135 140
Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser Asp Phe Tyr
145 150 155 160
Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe Cys Arg Gly
165 170 175
Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn Ile Thr Ile
180 185 190
Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe Pro Pro Gly
195 200 205
Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr
210 215 220
Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala
225 230 235 240
Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp Ile
245 250 255
Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu Leu Leu Ser
260 265 270
Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly Arg Lys Lys Leu Leu Tyr
275 280 285
Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu
290 295 300
Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu
305 310 315 320
Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln
325 330 335
Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu
340 345 350
Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly
355 360 365
Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln
370 375 380
Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu
385 390 395 400
Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr
405 410 415
Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro
420 425 430
Arg
<210> 46
<211> 436
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 46
Met Glu Thr Asp Thr Leu Leu Leu Trp Val Leu Leu Leu Trp Val Pro
1 5 10 15
Gly Ser Thr Gly Asp Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu
260 265 270
Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly Arg Lys Lys
275 280 285
Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr
290 295 300
Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly
305 310 315 320
Gly Cys Glu Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
325 330 335
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
340 345 350
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
355 360 365
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
370 375 380
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
385 390 395 400
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
405 410 415
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
420 425 430
Leu Pro Pro Arg
435
<210> 47
<211> 431
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 47
Met Trp Gln Leu Leu Leu Pro Thr Ala Leu Leu Leu Leu Val Ser Ala
1 5 10 15
Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val Val Phe Leu Glu Pro
20 25 30
Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val Thr Leu Lys Cys Gln
35 40 45
Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln Trp Phe His Asn Glu
50 55 60
Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe Ile Asp Ala Ala Thr
65 70 75 80
Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr Asn Leu Ser Thr Leu
85 90 95
Ser Asp Pro Val Gln Leu Glu Val His Ile Gly Trp Leu Leu Leu Gln
100 105 110
Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro Ile His Leu Arg Cys
115 120 125
His Ser Trp Lys Asn Thr Ala Leu His Lys Val Thr Tyr Leu Gln Asn
130 135 140
Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser Asp Phe Tyr Ile Pro
145 150 155 160
Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe Cys Arg Gly Leu Val
165 170 175
Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn Ile Thr Ile Thr Gln
180 185 190
Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe Pro Pro Gly Tyr Gln
195 200 205
Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala
210 215 220
Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly
225 230 235 240
Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp Ile Tyr Ile
245 250 255
Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu Leu Leu Ser Leu Val
260 265 270
Ile Thr Leu Tyr Cys Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe
275 280 285
Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly
290 295 300
Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu Arg
305 310 315 320
Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln
325 330 335
Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp
340 345 350
Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro
355 360 365
Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp
370 375 380
Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg
385 390 395 400
Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr
405 410 415
Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
420 425 430
<210> 48
<211> 432
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 48
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu
260 265 270
Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Cys Trp Leu Thr Lys Lys
275 280 285
Lys Tyr Ser Ser Ser Val His Asp Pro Asn Gly Glu Tyr Met Phe Met
290 295 300
Arg Ala Val Asn Thr Ala Lys Lys Ser Arg Leu Thr Asp Val Thr Leu
305 310 315 320
Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly
325 330 335
Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr
340 345 350
Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys
355 360 365
Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys
370 375 380
Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg
385 390 395 400
Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala
405 410 415
Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
420 425 430
<210> 49
<211> 442
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 49
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu
260 265 270
Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Gln Arg Arg Lys Tyr Arg
275 280 285
Ser Asn Lys Gly Glu Ser Pro Val Glu Pro Ala Glu Pro Cys Arg Tyr
290 295 300
Ser Cys Pro Arg Glu Glu Glu Gly Ser Thr Ile Pro Ile Gln Glu Asp
305 310 315 320
Tyr Arg Lys Pro Glu Pro Ala Cys Ser Pro Arg Val Lys Phe Ser Arg
325 330 335
Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn
340 345 350
Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg
355 360 365
Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro
370 375 380
Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala
385 390 395 400
Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His
405 410 415
Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp
420 425 430
Ala Leu His Met Gln Ala Leu Pro Pro Arg
435 440
<210> 50
<211> 452
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 50
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu
260 265 270
Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Gln Leu Gly Leu His Ile
275 280 285
Trp Gln Leu Arg Ser Gln Cys Met Trp Pro Arg Glu Thr Gln Leu Leu
290 295 300
Leu Glu Val Pro Pro Ser Thr Glu Asp Ala Arg Ser Cys Gln Phe Pro
305 310 315 320
Glu Glu Glu Arg Gly Glu Arg Ser Ala Glu Glu Lys Gly Arg Leu Gly
325 330 335
Asp Leu Trp Val Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala
340 345 350
Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg
355 360 365
Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu
370 375 380
Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
385 390 395 400
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
405 410 415
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
420 425 430
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
435 440 445
Leu Pro Pro Arg
450
<210> 51
<211> 454
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 51
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu
260 265 270
Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Cys Val Lys Arg Arg Lys
275 280 285
Pro Arg Gly Asp Val Val Lys Val Ile Val Ser Val Gln Arg Lys Arg
290 295 300
Gln Glu Ala Glu Gly Glu Ala Thr Val Ile Glu Ala Leu Gln Ala Pro
305 310 315 320
Pro Asp Val Thr Thr Val Ala Val Glu Glu Thr Ile Pro Ser Phe Thr
325 330 335
Gly Arg Ser Pro Asn His Arg Val Lys Phe Ser Arg Ser Ala Asp Ala
340 345 350
Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu
355 360 365
Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp
370 375 380
Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu
385 390 395 400
Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile
405 410 415
Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr
420 425 430
Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met
435 440 445
Gln Ala Leu Pro Pro Arg
450
<210> 52
<211> 442
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 52
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu
260 265 270
Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Lys Tyr Phe Phe Lys
275 280 285
Lys Glu Val Gln Gln Leu Ser Val Ser Phe Ser Ser Leu Gln Ile Lys
290 295 300
Ala Leu Gln Asn Ala Val Glu Lys Glu Val Gln Ala Glu Asp Asn Ile
305 310 315 320
Tyr Ile Glu Asn Ser Leu Tyr Ala Thr Asp Arg Val Lys Phe Ser Arg
325 330 335
Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn
340 345 350
Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg
355 360 365
Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro
370 375 380
Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala
385 390 395 400
Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His
405 410 415
Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp
420 425 430
Ala Leu His Met Gln Ala Leu Pro Pro Arg
435 440
<210> 53
<211> 453
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 53
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu
260 265 270
Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Tyr Lys Val Gly Phe Phe
275 280 285
Lys Arg Asn Leu Lys Glu Lys Met Glu Ala Gly Arg Gly Val Pro Asn
290 295 300
Gly Ile Pro Ala Glu Asp Ser Glu Gln Leu Ala Ser Gly Gln Glu Ala
305 310 315 320
Gly Asp Pro Gly Cys Leu Lys Pro Leu His Glu Lys Asp Ser Glu Ser
325 330 335
Gly Gly Gly Lys Asp Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro
340 345 350
Ala Tyr Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly
355 360 365
Arg Arg Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro
370 375 380
Glu Met Gly Gly Lys Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr
385 390 395 400
Asn Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly
405 410 415
Met Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln
420 425 430
Gly Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln
435 440 445
Ala Leu Pro Pro Arg
450
<210> 54
<211> 510
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 54
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu
260 265 270
Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Lys Lys Gln Arg
275 280 285
Ser Arg Arg Asn Asp Glu Glu Leu Glu Thr Arg Ala His Arg Val Ala
290 295 300
Thr Glu Glu Arg Gly Arg Lys Pro His Gln Ile Pro Ala Ser Thr Pro
305 310 315 320
Gln Asn Pro Ala Thr Ser Gln His Pro Pro Pro Pro Pro Gly His Arg
325 330 335
Ser Gln Ala Pro Ser His Arg Pro Pro Pro Pro Gly His Arg Val Gln
340 345 350
His Gln Pro Gln Lys Arg Pro Pro Ala Pro Ser Gly Thr Gln Val His
355 360 365
Gln Gln Lys Gly Pro Pro Leu Pro Arg Pro Arg Val Gln Pro Lys Pro
370 375 380
Pro His Gly Ala Ala Glu Asn Ser Leu Ser Pro Ser Ser Asn Arg Val
385 390 395 400
Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly Gln Asn
405 410 415
Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr Asp Val
420 425 430
Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys Pro Arg
435 440 445
Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys Asp Lys
450 455 460
Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg Arg Arg
465 470 475 480
Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala Thr Lys
485 490 495
Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
500 505 510
<210> 55
<211> 365
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 55
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Pro Gln Leu Cys Tyr Ile Leu Asp Ala Ile Leu Phe Leu Tyr
260 265 270
Gly Ile Val Leu Thr Leu Leu Tyr Cys Arg Leu Lys Ile Gln Val Arg
275 280 285
Lys Ala Ala Ile Thr Ser Tyr Glu Lys Ser Asp Gly Val Tyr Thr Gly
290 295 300
Leu Ser Thr Arg Asn Gln Glu Thr Tyr Glu Thr Leu Lys His Glu Lys
305 310 315 320
Pro Pro Gln Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln
325 330 335
Pro Phe Met Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser
340 345 350
Cys Arg Phe Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu
355 360 365
<210> 56
<211> 366
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 56
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val
20 25 30
Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val
35 40 45
Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln
50 55 60
Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe
65 70 75 80
Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr
85 90 95
Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu Val His Ile Gly
100 105 110
Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro
115 120 125
Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala Leu His Lys Val
130 135 140
Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser
145 150 155 160
Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe
165 170 175
Cys Arg Gly Leu Val Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn
180 185 190
Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe
195 200 205
Pro Pro Gly Tyr Gln Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro
210 215 220
Ala Pro Thr Ile Ala Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys
225 230 235 240
Arg Pro Ala Ala Gly Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala
245 250 255
Cys Asp Ile Tyr Ile Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu
260 265 270
Leu Leu Ser Leu Val Ile Thr Leu Tyr Cys Lys Arg Gly Arg Lys Lys
275 280 285
Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met Arg Pro Val Gln Thr Thr
290 295 300
Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe Pro Glu Glu Glu Glu Gly
305 310 315 320
Gly Cys Glu Leu Arg Leu Lys Ile Gln Val Arg Lys Ala Ala Ile Thr
325 330 335
Ser Tyr Glu Lys Ser Asp Gly Val Tyr Thr Gly Leu Ser Thr Arg Asn
340 345 350
Gln Glu Thr Tyr Glu Thr Leu Lys His Glu Lys Pro Pro Gln
355 360 365
<210> 57
<211> 192
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 57
Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val Val Phe Leu Glu Pro
1 5 10 15
Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val Thr Leu Lys Cys Gln
20 25 30
Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln Trp Phe His Asn Glu
35 40 45
Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe Ile Asp Ala Ala Thr
50 55 60
Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr Asn Leu Ser Thr Leu
65 70 75 80
Ser Asp Pro Val Gln Leu Glu Val His Ile Gly Trp Leu Leu Leu Gln
85 90 95
Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro Ile His Leu Arg Cys
100 105 110
His Ser Trp Lys Asn Thr Ala Leu His Lys Val Thr Tyr Leu Gln Asn
115 120 125
Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser Asp Phe Tyr Ile Pro
130 135 140
Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe Cys Arg Gly Leu Val
145 150 155 160
Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn Ile Thr Ile Thr Gln
165 170 175
Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe Pro Pro Gly Tyr Gln
180 185 190
<210> 58
<211> 69
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 58
Thr Thr Thr Pro Ala Pro Arg Pro Pro Thr Pro Ala Pro Thr Ile Ala
1 5 10 15
Ser Gln Pro Leu Ser Leu Arg Pro Glu Ala Cys Arg Pro Ala Ala Gly
20 25 30
Gly Ala Val His Thr Arg Gly Leu Asp Phe Ala Cys Asp Ile Tyr Ile
35 40 45
Trp Ala Pro Leu Ala Gly Thr Cys Gly Val Leu Leu Leu Ser Leu Val
50 55 60
Ile Thr Leu Tyr Cys
65
<210> 59
<211> 42
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 59
Lys Arg Gly Arg Lys Lys Leu Leu Tyr Ile Phe Lys Gln Pro Phe Met
1 5 10 15
Arg Pro Val Gln Thr Thr Gln Glu Glu Asp Gly Cys Ser Cys Arg Phe
20 25 30
Pro Glu Glu Glu Glu Gly Gly Cys Glu Leu
35 40
<210> 60
<211> 112
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 60
Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr Gln Gln Gly
1 5 10 15
Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg Glu Glu Tyr
20 25 30
Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met Gly Gly Lys
35 40 45
Pro Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn Glu Leu Gln Lys
50 55 60
Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met Lys Gly Glu Arg
65 70 75 80
Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly Leu Ser Thr Ala
85 90 95
Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala Leu Pro Pro Arg
100 105 110
<210> 61
<211> 21
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 61
Met Ala Leu Pro Val Thr Ala Leu Leu Leu Pro Leu Ala Leu Leu Leu
1 5 10 15
His Ala Ala Arg Pro
20
<210> 62
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 62
cttctgcagg gggcttgttg ggagtaaaaa tgtgtc 36
<210> 63
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 63
gacacatttt tactcccaac aagccccctg cagaag 36
<210> 64
<211> 1311
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 64
atggccttac cagtgaccgc cttgctcctg ccgctggcct tgctgctcca cgccgccagg 60
ccgggcatgc ggactgaaga tctcccaaag gctgtggtgt tcctggagcc tcaatggtac 120
agggtgctcg agaaggacag tgtgactctg aagtgccagg gagcctactc ccctgaggac 180
aattccacac agtggtttca caatgagagc ctcatctcaa gccaggcctc gagctacttc 240
attgacgctg ccacagtcga cgacagtgga gagtacaggt gccagacaaa cctctccacc 300
ctcagtgacc cggtgcagct agaagtccat atcggctggc tgttgctcca ggcccctcgg 360
tgggtgttca aggaggaaga ccctattcac ctgaggtgtc acagctggaa gaacactgct 420
ctgcataagg tcacatattt acagaatggc aaaggcagga agtattttca tcataattct 480
gacttctaca ttccaaaagc cacactcaaa gacagcggct cctacttctg cagggggctt 540
gttgggagta aaaatgtgtc ttcagagact gtgaacatca ccatcactca aggtttggca 600
gtgtcaacca tctcatcatt ctttccacct gggtaccaaa ccacgacgcc agcgccgcga 660
ccaccaacac cggcgcccac catcgcgtcg cagcccctgt ccctgcgccc agaggcgtgc 720
cggccagcgg cggggggcgc agtgcacacg agggggctgg acttcgcctg tgatatctac 780
atctgggcgc ccttggccgg gacttgtggg gtccttctcc tgtcactggt tatcaccctt 840
tactgcaaac ggggcagaaa gaaactcctg tatatattca aacaaccatt tatgagacca 900
gtacaaacta ctcaagagga agatggctgt agctgccgat ttccagaaga agaagaagga 960
ggatgtgaac tgagagtgaa gttcagcagg agcgcagacg cccccgcgta ccagcagggc 1020
cagaaccagc tctataacga gctcaatcta ggacgaagag aggagtacga tgttttggac 1080
aagagacgtg gccgggaccc tgagatgggg ggaaagccga gaaggaagaa ccctcaggaa 1140
ggcctgtaca atgaactgca gaaagataag atggcggagg cctacagtga gattgggatg 1200
aaaggcgagc gccggagggg caaggggcac gatggccttt accagggtct cagtacagcc 1260
accaaggaca cctacgacgc ccttcacatg caggccctgc cccctcgcta a 1311
<210> 65
<211> 576
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 65
ggcatgcgga ctgaagatct cccaaaggct gtggtgttcc tggagcctca atggtacagg 60
gtgctcgaga aggacagtgt gactctgaag tgccagggag cctactcccc tgaggacaat 120
tccacacagt ggtttcacaa tgagagcctc atctcaagcc aggcctcgag ctacttcatt 180
gacgctgcca cagtcgacga cagtggagag tacaggtgcc agacaaacct ctccaccctc 240
agtgacccgg tgcagctaga agtccatatc ggctggctgt tgctccaggc ccctcggtgg 300
gtgttcaagg aggaagaccc tattcacctg aggtgtcaca gctggaagaa cactgctctg 360
cataaggtca catatttaca gaatggcaaa ggcaggaagt attttcatca taattctgac 420
ttctacattc caaaagccac actcaaagac agcggctcct acttctgcag ggggcttgtt 480
gggagtaaaa atgtgtcttc agagactgtg aacatcacca tcactcaagg tttggcagtg 540
tcaaccatct catcattctt tccacctggg taccaa 576
<210> 66
<211> 207
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 66
accacgacgc cagcgccgcg accaccaaca ccggcgccca ccatcgcgtc gcagcccctg 60
tccctgcgcc cagaggcgtg ccggccagcg gcggggggcg cagtgcacac gagggggctg 120
gacttcgcct gtgatatcta catctgggcg cccttggccg ggacttgtgg ggtccttctc 180
ctgtcactgg ttatcaccct ttactgc 207
<210> 67
<211> 126
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 67
aaacggggca gaaagaaact cctgtatata ttcaaacaac catttatgag accagtacaa 60
actactcaag aggaagatgg ctgtagctgc cgatttccag aagaagaaga aggaggatgt 120
gaactg 126
<210> 68
<211> 339
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 68
agagtgaagt tcagcaggag cgcagacgcc cccgcgtacc agcagggcca gaaccagctc 60
tataacgagc tcaatctagg acgaagagag gagtacgatg ttttggacaa gagacgtggc 120
cgggaccctg agatgggggg aaagccgaga aggaagaacc ctcaggaagg cctgtacaat 180
gaactgcaga aagataagat ggcggaggcc tacagtgaga ttgggatgaa aggcgagcgc 240
cggaggggca aggggcacga tggcctttac cagggtctca gtacagccac caaggacacc 300
tacgacgccc ttcacatgca ggccctgccc cctcgctaa 339
<210> 69
<211> 63
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 69
atggccttac cagtgaccgc cttgctcctg ccgctggcct tgctgctcca cgccgccagg 60
ccg 63
<210> 70
<211> 192
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 70
Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val Val Phe Leu Glu Pro
1 5 10 15
Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val Thr Leu Lys Cys Gln
20 25 30
Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln Trp Phe His Asn Glu
35 40 45
Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe Ile Asp Ala Ala Thr
50 55 60
Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr Asn Leu Ser Thr Leu
65 70 75 80
Ser Asp Pro Val Gln Leu Glu Val His Ile Gly Trp Leu Leu Leu Gln
85 90 95
Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro Ile His Leu Arg Cys
100 105 110
His Ser Trp Lys Asn Thr Ala Leu His Lys Val Thr Tyr Leu Gln Asn
115 120 125
Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser Asp Phe Tyr Ile Pro
130 135 140
Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe Cys Arg Gly Leu Phe
145 150 155 160
Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn Ile Thr Ile Thr Gln
165 170 175
Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe Pro Pro Gly Tyr Gln
180 185 190
<210> 71
<211> 1311
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 71
atggccttac cagtgaccgc cttgctcctg ccgctggcct tgctgctcca cgccgccagg 60
ccgggcatgc ggactgaaga tctcccaaag gctgtggtgt tcctggagcc tcaatggtac 120
agggtgctcg agaaggacag tgtgactctg aagtgccagg gagcctactc ccctgaggac 180
aattccacac agtggtttca caatgagagc ctcatctcaa gccaggcctc gagctacttc 240
attgacgctg ccacagtcga cgacagtgga gagtacaggt gccagacaaa cctctccacc 300
ctcagtgacc cggtgcagct agaagtccat atcggctggc tgttgctcca ggcccctcgg 360
tgggtgttca aggaggaaga ccctattcac ctgaggtgtc acagctggaa gaacactgct 420
ctgcataagg tcacatattt acagaatggc aaaggcagga agtattttca tcataattct 480
gacttctaca ttccaaaagc cacactcaaa gacagcggct cctacttctg cagggggctt 540
tttgggagta aaaatgtgtc ttcagagact gtgaacatca ccatcactca aggtttggca 600
gtgtcaacca tctcatcatt ctttccacct gggtaccaaa ccacgacgcc agcgccgcga 660
ccaccaacac cggcgcccac catcgcgtcg cagcccctgt ccctgcgccc agaggcgtgc 720
cggccagcgg cggggggcgc agtgcacacg agggggctgg acttcgcctg tgatatctac 780
atctgggcgc ccttggccgg gacttgtggg gtccttctcc tgtcactggt tatcaccctt 840
tactgcaaac ggggcagaaa gaaactcctg tatatattca aacaaccatt tatgagacca 900
gtacaaacta ctcaagagga agatggctgt agctgccgat ttccagaaga agaagaagga 960
ggatgtgaac tgagagtgaa gttcagcagg agcgcagacg cccccgcgta ccagcagggc 1020
cagaaccagc tctataacga gctcaatcta ggacgaagag aggagtacga tgttttggac 1080
aagagacgtg gccgggaccc tgagatgggg ggaaagccga gaaggaagaa ccctcaggaa 1140
ggcctgtaca atgaactgca gaaagataag atggcggagg cctacagtga gattgggatg 1200
aaaggcgagc gccggagggg caaggggcac gatggccttt accagggtct cagtacagcc 1260
accaaggaca cctacgacgc ccttcacatg caggccctgc cccctcgcta a 1311
<210> 72
<211> 576
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 72
ggcatgcgga ctgaagatct cccaaaggct gtggtgttcc tggagcctca atggtacagg 60
gtgctcgaga aggacagtgt gactctgaag tgccagggag cctactcccc tgaggacaat 120
tccacacagt ggtttcacaa tgagagcctc atctcaagcc aggcctcgag ctacttcatt 180
gacgctgcca cagtcgacga cagtggagag tacaggtgcc agacaaacct ctccaccctc 240
agtgacccgg tgcagctaga agtccatatc ggctggctgt tgctccaggc ccctcggtgg 300
gtgttcaagg aggaagaccc tattcacctg aggtgtcaca gctggaagaa cactgctctg 360
cataaggtca catatttaca gaatggcaaa ggcaggaagt attttcatca taattctgac 420
ttctacattc caaaagccac actcaaagac agcggctcct acttctgcag ggggcttttt 480
gggagtaaaa atgtgtcttc agagactgtg aacatcacca tcactcaagg tttggcagtg 540
tcaaccatct catcattctt tccacctggg taccaa 576
<210> 73
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 73
cttctgcagg gggcttgttg ggagtaaaaa tgtgtc 36
<210> 74
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic Polynucleotide
<400> 74
gacacatttt tactcccaac aagccccctg cagaag 36
<210> 75
<211> 254
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 75
Met Trp Gln Leu Leu Leu Pro Thr Ala Leu Leu Leu Leu Val Ser Ala
1 5 10 15
Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val Val Phe Leu Glu Pro
20 25 30
Gln Trp Tyr Arg Val Leu Glu Lys Asp Ser Val Thr Leu Lys Cys Gln
35 40 45
Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln Trp Phe His Asn Glu
50 55 60
Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe Ile Asp Ala Ala Thr
65 70 75 80
Val Asp Asp Ser Gly Glu Tyr Arg Cys Gln Thr Asn Leu Ser Thr Leu
85 90 95
Ser Asp Pro Val Gln Leu Glu Val His Ile Gly Trp Leu Leu Leu Gln
100 105 110
Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro Ile His Leu Arg Cys
115 120 125
His Ser Trp Lys Asn Thr Ala Leu His Lys Val Thr Tyr Leu Gln Asn
130 135 140
Gly Lys Gly Arg Lys Tyr Phe His His Asn Ser Asp Phe Tyr Ile Pro
145 150 155 160
Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe Cys Arg Gly Leu Val
165 170 175
Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn Ile Thr Ile Thr Gln
180 185 190
Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Phe Pro Pro Gly Tyr Gln
195 200 205
Val Ser Phe Cys Leu Val Met Val Leu Leu Phe Ala Val Asp Thr Gly
210 215 220
Leu Tyr Phe Ser Val Lys Thr Asn Ile Arg Ser Ser Thr Arg Asp Trp
225 230 235 240
Lys Asp His Lys Phe Lys Trp Arg Lys Asp Pro Gln Asp Lys
245 250
<210> 76
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 76
Gly Gly Gly Gly Ser
1 5
<210> 77
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 77
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10 15
<210> 78
<211> 30
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 78
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
20 25 30
<210> 79
<211> 45
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 79
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
35 40 45
<210> 80
<211> 60
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 80
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
35 40 45
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
50 55 60
<210> 81
<211> 75
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 81
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
35 40 45
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
50 55 60
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
65 70 75
<210> 82
<211> 150
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 82
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
35 40 45
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
50 55 60
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
65 70 75 80
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
85 90 95
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
100 105 110
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
130 135 140
Ser Gly Gly Gly Gly Ser
145 150
<210> 83
<211> 225
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 83
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
35 40 45
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
50 55 60
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
65 70 75 80
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
85 90 95
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
100 105 110
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
130 135 140
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
145 150 155 160
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
165 170 175
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
180 185 190
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
195 200 205
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
210 215 220
Ser
225
<210> 84
<211> 300
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 84
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
35 40 45
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
50 55 60
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
65 70 75 80
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
85 90 95
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
100 105 110
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
130 135 140
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
145 150 155 160
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
165 170 175
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
180 185 190
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
195 200 205
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
210 215 220
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
225 230 235 240
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
245 250 255
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
260 265 270
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
275 280 285
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
290 295 300
<210> 85
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 85
Glu Thr Gln Arg Cys Thr Trp His Met Gly Glu Leu Val Trp Cys Glu
1 5 10 15
Arg Glu His Asn
20
<210> 86
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 86
Lys Glu Ala Ser Cys Ser Tyr Trp Leu Gly Glu Leu Val Trp Cys Val
1 5 10 15
Ala Gly Val Glu
20
<210> 87
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Polypeptide
<400> 87
Asp Cys Ala Trp His Leu Gly Glu Leu Val Trp Cys Thr
1 5 10
Claims (72)
- (a) Fc 결합 도메인;
(b) 막횡단 도메인;
(c) 적어도 하나의 공동 자극 신호전달 도메인; 및
(d) 면역수용체 티로신 기반 활성화 모티프 (ITAM)를 포함하는 세포질 신호전달 도메인을 포함하는 키메라 수용체이며; 여기서, (c) 또는 (d)는 키메라 수용체의 C-말단에 위치하고;
여기서,
(i) (a)가 CD16A의 세포외 리간드 결합 도메인인 경우, (d)는 Fc 수용체의 ITAM 도메인을 포함하지 않고,
(ii) 키메라 수용체가 N-말단에서부터 C-말단으로 F158 CD16A 또는 V158 CD16A의 세포외 리간드 결합 도메인, CD8α의 힌지 및 막횡단 도메인, 4-1BB의 공동 자극 신호전달 도메인, 및 CD3ζ의 세포질 신호전달 도메인을 포함하는 수용체는 아닌 것인, 키메라 수용체. - 제1항에 있어서, (d)가 키메라 수용체의 C-말단에 위치하는 것인 키메라 수용체.
- 제1항 또는 제1항에 있어서, (a)의 C-말단과 (b)의 N-말단 사이에 위치하는 (e) 힌지 도메인을 추가로 포함하는 키메라 수용체.
- 제1항 내지 제3항 중 어느 한 항에 있어서, 키메라 수용체의 N-말단에 신호 펩티드를 추가로 포함하는 키메라 수용체.
- 제1항 내지 제4항 중 어느 한 항에 있어서, (a)의 Fc 결합 도메인이
(i) 임의적으로 Fc-감마 수용체, Fc-알파 수용체, 또는 Fc-엡실론 수용체인 Fc-수용체의 세포외 리간드 결합 도메인,
(ii) 면역글로불린의 Fc 부위에 결합하는 항체 단편,
(iii) 면역글로불린의 Fc 부위에 결합하는 자연적으로 발생된 단백질 또는 그의 Fc-결합 단편, 및
(iv) 면역글로불린의 Fc 부위에 결합하는 합성 폴리펩티드
로 이루어진 군으로부터 선택되는 것인 키메라 수용체. - 제5항에 있어서, Fc 결합 도메인이 (i) CD16A, CD32A, 또는 CD64A의 세포외 리간드 결합 도메인인 키메라 수용체.
- 제6항에 있어서, Fc 결합 도메인이 CD32A 또는 CD64A의 세포외 리간드 결합 도메인인 키메라 수용체.
- 제5항에 있어서, Fc 결합 도메인이 (ii) 단일 쇄 가변 단편 (ScFv), 도메인 항체, 또는 나노바디인 키메라 수용체.
- 제5항에 있어서, Fc 결합 도메인이 (iii) 단백질 A 또는 단백질 G인 키메라 수용체.
- 제5항에 있어서, Fc 결합 도메인이 (iv) 쿠니츠(Kunitz) 펩티드, SMIP, 아비머, 어피바디, DARPin, 또는 안티칼린인 키메라 수용체.
- 제1항 내지 제10항 중 어느 한 항에 있어서, (b)의 막횡단 도메인이 단일 통과 막 단백질의 것인 키메라 수용체.
- 제11항에 있어서, 막횡단 도메인이 CD8α, CD8β, 4-1BB, CD28, CD34, CD4, FcεRIγ, CD16A, OX40, CD3ζ, CD3ε, CD3γ, CD3δ, TCRα, CD32, CD64, VEGFR2, FAS, 및 FGFR2B로 이루어진 군으로부터 선택되는 막 단백질의 것인 키메라 수용체.
- 제11항에 있어서, 막횡단 도메인이 CD8β, 4-1BB, CD28, CD34, CD4, FcεRIγ, CD16A, OX40, CD3ζ, CD3ε, CD3γ, CD3δ, TCRα, CD32, CD64, VEGFR2, FAS, 및 FGFR2B로 이루어진 군으로부터 선택되는 막 단백질의 것인 키메라 수용체.
- 제1항 내지 제10항 중 어느 한 항에 있어서, (b)의 막횡단 도메인이 비-자연적으로 발생된 소수성 단백질 세그먼트인 키메라 수용체.
- 제1항 내지 제14항 중 어느 한 항에 있어서, (c)의 적어도 하나의 공동 자극 신호전달 도메인이 4-1BB, CD28, CD28LL → GG 변이체, OX40, ICOS, CD27, GITR, HVEM, TIM1, LFA1, 및 CD2로 이루어진 군으로부터 선택되는 공동 자극 분자의 것인 키메라 수용체.
- 제1항 내지 제14항 중 어느 한 항에 있어서, (c)의 적어도 하나의 공동 자극 신호전달 도메인이 CD28, CD28LL → GG 변이체, OX40, ICOS, CD27, GITR, HVEM, TIM1, LFA1, 및 CD2로 이루어진 군으로부터 선택되는 공동 자극 분자의 것인 키메라 수용체.
- 제1항 내지 제16항 중 어느 한 항에 있어서, 키메라 수용체가 2개의 공동 자극 신호전달 도메인을 포함하는 것인 키메라 수용체.
- 제17항에 있어서, 2개의 공동 자극 도메인이
(i) CD28 및 4-1BB; 또는
(ii) CD28LL → GG 변이체 및 4-1BB인 키메라 수용체. - 제1항 내지 제18항 중 어느 한 항에 있어서, (d)의 세포질 신호전달 도메인이 CD3ζ 또는 FcεR1γ의 세포질 도메인인 키메라 수용체.
- 제3항 내지 제19항 중 어느 한 항에 있어서, (e)의 힌지 도메인이 CD8α 또는 IgG의 것인 키메라 수용체.
- 제3항 내지 제19항 중 어느 한 항에 있어서, 힌지 도메인이 비-자연적으로 발생된 펩티드인 키메라 수용체.
- 제21항에 있어서, 힌지 도메인이 연장된 재조합 폴리펩티드 (XTEN) 또는 (Gly4Ser)n 폴리펩티드이고, 여기서, n은 정수 3-12인 키메라 수용체.
- 제3항에 있어서, 표 3에 제시된 성분 (a)-(e)를 포함하는 키메라 수용체.
- 제23항에 있어서, 서열식별번호(SEQ ID NO): 2-11로부터 선택되는 아미노산 서열을 포함하는 키메라 수용체.
- 제3항에 있어서, 표 4에 제시된 성분 (a)-(e)를 포함하는 키메라 수용체.
- 제25항에 있어서, 서열식별번호: 12-17로부터 선택되는 아미노산 서열을 포함하는 키메라 수용체.
- 제3항에 있어서, 표 5에 제시된 성분 (a)-(e)를 포함하는 키메라 수용체.
- 제27항에 있어서, 서열식별번호: 18-30, 및 32-56으로부터 선택되는 아미노산 서열을 포함하는 키메라 수용체.
- 제1항 내지 제28항 중 어느 한 항의 키메라 수용체를 코딩하는 뉴클레오티드 서열을 포함하는 핵산.
- 제29항에 있어서, RNA 분자인 핵산.
- 제29항의 핵산을 포함하는 벡터.
- 제31항에 있어서, 발현 벡터인 벡터.
- 제32항에 있어서, 바이러스 벡터인 벡터.
- 제33항에 있어서, 바이러스 벡터가 렌티바이러스 벡터 또는 레트로바이러스 벡터인 벡터.
- 제29항 또는 제30항의 핵산, 또는 제31항 내지 제34항 중 어느 한 항의 벡터를 포함하는 숙주 세포.
- 제35항에 있어서, 면역 세포인 숙주 세포.
- 제36항에 있어서, 면역 세포가 자연살 세포, 대식세포, 호중구, 호산구, 또는 T 세포인 숙주 세포.
- 제35항 내지 제37항 중 어느 한 항에 있어서, 숙주 세포가, 내인성 T 세포 수용체의 발현이 억제, 또는 제거되어 있는 T 세포인 숙주 세포.
- (a) 제20항 또는 제30항의 핵산, 제31항 내지 제34항 중 어느 한 항의 벡터, 또는 제35항 내지 제38항 중 어느 한 항의 숙주 세포, 및 (b) 제약상 허용되는 담체를 포함하는 제약 조성물.
- 제39항에 있어서, Fc-함유 치료제를 추가로 포함하는 제약 조성물.
- 제40항에 있어서, Fc-함유 치료제가 Fc 융합 단백질인 제약 조성물.
- 제40항에 있어서, Fc-함유 치료제가 치료학적 항체 또는 Fc 융합 단백질인 제약 조성물.
- 제42항에 있어서, Fc-함유 치료제가 아달리무맙, 아도-트라스투주맙 엠탄신, 알렘투주맙, 바실릭시맙, 베바시주맙, 벨리무맙, 브렌툭시맙, 카나키누맙, 세툭시맙, 다클리주맙, 데노수맙, 디누툭시맙, 에쿨리주맙, 에팔리주맙, 에프라투주맙, 젬투주맙, 골리무맙, 인플릭시맙, 이필리무맙, 라베투주맙, 나탈리주맙, 오비누투주맙, 오파투무맙, 오말리주맙, 팔리비주맙, 파니투무맙, 퍼투주맙, 라무시루맙, 리툭티맙(Ritutimab), 토실리주맙, 트라투주맙, 우스테키누맙, 및 베돌리주맙으로 이루어진 군으로부터 선택되는 치료학적 항체인 제약 조성물.
- (i) 제29항 또는 제30항의 핵산, 제31항 내지 제34항 중 어느 한 항의 벡터, 또는 제35항 내지 제38항 중 어느 한 항의 숙주 세포, 및 (ii) 제약상 허용되는 담체를 포함하는 제1 제약 조성물; 및
Fc-함유 치료제 및 제약상 허용되는 담체를 포함하는 제2 제약 조성물
을 포함하는 키트. - 제44항에 있어서, Fc-함유 치료제가 Fc 융합 단백질인 키트.
- 제44항에 있어서, Fc-함유 치료제가 치료학적 항체인 키트.
- 제46항에 있어서, 치료학적 항체가 아달리무맙, 아도-트라스투주맙 엠탄신, 알렘투주맙, 바실릭시맙, 베바시주맙, 벨리무맙, 브렌툭시맙, 카나키누맙, 세툭시맙, 다클리주맙, 데노수맙, 디누툭시맙, 에쿨리주맙, 에팔리주맙, 에프라투주맙, 젬투주맙, 골리무맙, 인플릭시맙, 이필리무맙, 라베투주맙, 나탈리주맙, 오비누투주맙, 오파투무맙, 오말리주맙, 팔리비주맙, 파니투무맙, 퍼투주맙, 라무시루맙, 리툭티맙, 토실리주맙, 트라투주맙, 우스테키누맙, 및 베돌리주맙으로 이루어진 군으로부터 선택되는 것인 키트.
- 유효량의 제1항 내지 제28항 중 어느 한 항의 키메라 수용체를 발현하는 숙주 면역 세포, 및 제약상 허용되는 담체를 포함하는, 대상체에서 항체-의존성 세포-매개 세포독성 (ADCC)을 증진시키는 데 사용하기 위한, 또는 항체-기반 면역요법의 효능을 증진시키기 위한 제약 조성물.
- 제48항에 있어서, 숙주 면역 세포가 자연살 세포, 대식세포, 호중구, 호산구, T 세포, 또는 그의 조합인 제약 조성물.
- 제48항 또는 제49항에 있어서, 숙주 면역 세포가 자가 유래인 제약 조성물.
- 제48항 또는 제49항에 있어서, 숙주 면역 세포가 동종이계인 제약 조성물.
- 제48항 내지 제51항 중 어느 한 항에 있어서, 숙주 면역 세포가 생체외에서 활성화되거나, 확장되거나, 또는 그 둘 모두가 이루어지는 것인 제약 조성물.
- 제48항 내지 제52항 중 어느 한 항에 있어서, 대상체가 Fc-함유 치료제로 치료받은 적이 있거나, 또는 치료받고 있는 중인 대상체인 제약 조성물.
- 제53항에 있어서, Fc-함유 치료제가 치료학적 항체 또는 Fc 융합 단백질인 제약 조성물.
- 제54항에 있어서, Fc-함유 치료제가 아달리무맙, 아도-트라스투주맙 엠탄신, 알렘투주맙, 바실릭시맙, 베바시주맙, 벨리무맙, 브렌툭시맙, 카나키누맙, 세툭시맙, 세톨리주맙, 다클리주맙, 데노수맙, 디누툭시맙, 에쿨리주맙, 에팔리주맙, 에프라투주맙, 젬투주맙, 골리무맙, 이브리투모맙, 인플릭시맙, 이필리무맙, 라베투주맙, 무로모납, 나탈리주맙, 오비누투주맙, 오파투무맙, 오비누투주맙, 오말리주맙, 팔리비주맙, 파니투무맙, 퍼투주맙, 라무시루맙, 라니비주맙, 리툭티맙, 트로실리주맙(TRocilizumab), 토시투모맙, 트라투주맙, 우스테키누맙, 및 베돌리주맙으로 이루어진 군으로부터 선택되는 치료학적 항체인 제약 조성물.
- 제53항 내지 제55항 중 어느 한 항에 있어서, 대상체가 암을 앓는 인간 환자이고, Fc-함유 치료제가 암 치료용인 제약 조성물.
- 제56항에 있어서, 암이 암종, 림프종, 육종, 모세포종, 및 백혈병으로 이루어진 군으로부터 선택되는 것인 제약 조성물.
- 제57항에 있어서, 암이 B 세포 기원의 암, 유방암, 위암, 신경모세포종, 골육종, 폐암, 피부암, 전립선암, 결장암, 신장 세포 암종, 난소암, 횡문근육종, 백혈병, 중피종, 췌장암, 두부경부암, 망막모세포종, 신경교종, 교모세포종, 및 갑상선암으로 이루어진 군으로부터 선택되는 것인 제약 조성물.
- 제58항에 있어서, B 세포 기원의 암이 B 계통 급성 림프모구성 백혈병, B 세포 만성 림프구성 백혈병, 및 B 세포 비호지킨 림프종으로 이루어진 군으로부터 선택되는 것인 제약 조성물.
- (i) 면역 세포 집단을 제공하는 단계;
(ii) 면역 세포 내로 제1항 내지 제28항 중 어느 한 항의 키메라 수용체를 코딩하는 핵산을 도입하는 단계; 및
(iii) 키메라 수용체가 발현될 수 있도록 허용하는 조건하에서 면역 세포를 배양하는 단계를 포함하는, 키메라 수용체를 발현하는 면역 세포를 제조하는 방법. - 제60항에 있어서, 면역 세포 집단이 말초 혈액 단핵 세포 (PBMC)로부터 유래된 것인 방법.
- 제60항 또는 제61항에 있어서, 면역 세포가 자연살 세포, 대식세포, 호중구, 호산구, T 세포, 또는 그의 조합인 방법.
- 제60항 내지 제62항 중 어느 한 항에 있어서, 면역 세포가 인간 환자로부터 유래된 것인 방법.
- 제63항에 있어서, 인간 환자가 암 환자인 방법.
- 제60항 내지 제64항 중 어느 한 항에 있어서, 핵산이 바이러스 벡터인 방법.
- 제65항에 있어서, 바이러스 벡터가 렌티바이러스 벡터 또는 레트로바이러스 벡터인 방법.
- 제60항 내지 제64항 중 어느 한 항에 있어서, 핵산이 RNA 분자인 방법.
- 제60항 내지 제67항 중 어느 한 항에 있어서, 벡터가 렌티바이러스 형질도입, 레트로바이러스 형질도입, DNA 전기천공, 또는 RNA 전기천공에 의해 면역 세포 내로 도입되는 것인 방법.
- 제60항 내지 제68항 중 어느 한 항에 있어서, (iv) 키메라 수용체를 발현하는 면역 세포를 활성화시키는 단계를 추가로 포함하는 것인 방법.
- 제69항에 있어서, 면역 세포가, 항-CD3 항체, 항-CD28 항체, IL-2, 및 피토헤모아글루티닌 중 하나 이상의 존재하에서 활성화되는 T 세포를 포함하는 것인 방법.
- 제70항에 있어서, 면역 세포가, 내인성 T 세포 수용체가 억제 또는 제거되어 있는 T 세포인 방법.
- 제69항에 있어서, 면역 세포가, 4-1BB 리간드, 항-4-1BB 항체, IL-15, 항-IL-15 수용체 항체, IL-2, IL-12, IL-21 및 K562 세포 중 하나 이상의 존재하에서 활성화되는 자연살 세포를 포함하는 것인 방법.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201462047916P | 2014-09-09 | 2014-09-09 | |
| US62/047,916 | 2014-09-09 | ||
| PCT/US2015/049126 WO2016040441A1 (en) | 2014-09-09 | 2015-09-09 | Chimeric receptors and uses thereof in immune therapy |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20170073593A true KR20170073593A (ko) | 2017-06-28 |
Family
ID=54151414
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020177009209A KR20170073593A (ko) | 2014-09-09 | 2015-09-09 | 키메라 수용체 및 면역 요법에서의 그의 용도 |
Country Status (13)
| Country | Link |
|---|---|
| US (1) | US20180133252A9 (ko) |
| EP (1) | EP3191507A1 (ko) |
| JP (1) | JP2017527310A (ko) |
| KR (1) | KR20170073593A (ko) |
| CN (1) | CN107074969A (ko) |
| AU (1) | AU2015315199B2 (ko) |
| BR (1) | BR112017004675A2 (ko) |
| CA (1) | CA2972714A1 (ko) |
| IL (1) | IL250828A0 (ko) |
| MA (1) | MA40595A (ko) |
| MX (1) | MX2017003062A (ko) |
| SG (2) | SG10201902168PA (ko) |
| WO (1) | WO2016040441A1 (ko) |
Families Citing this family (54)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2014117121A1 (en) | 2013-01-28 | 2014-07-31 | St. Jude Children's Research Hospital, Inc. | A chimeric receptor with nkg2d specificity for use in cell therapy against cancer and infectious disease |
| SG11201602979RA (en) * | 2013-10-17 | 2016-05-30 | Univ Singapore | Chimeric receptor that triggers antibody-dependent cell cytotoxicity against multiple tumors |
| US10144770B2 (en) | 2013-10-17 | 2018-12-04 | National University Of Singapore | Chimeric receptors and uses thereof in immune therapy |
| EP3143134B1 (en) | 2014-05-15 | 2020-10-28 | National University of Singapore | Modified natural killer cells and uses thereof |
| US20170151281A1 (en) | 2015-02-19 | 2017-06-01 | Batu Biologics, Inc. | Chimeric antigen receptor dendritic cell (car-dc) for treatment of cancer |
| EP3466967A1 (en) | 2015-05-18 | 2019-04-10 | TCR2 Therapeutics Inc. | Compositions and methods for tcr reprogramming using fusion proteins |
| EP3430036A4 (en) * | 2016-03-18 | 2019-08-14 | Unum Therapeutics | MODIFIED CHIMERIC RECEPTORS AND CORRESPONDING USES THEREOF IN IMMUNE THERAPY |
| WO2017205254A1 (en) * | 2016-05-23 | 2017-11-30 | Unum Therapeutics | Immune cells expressing antibody-coupled t-cell receptor (actr) for use in inhibiting cancer cells expressing surface immunoglobulin |
| WO2018017649A1 (en) * | 2016-07-19 | 2018-01-25 | Unum Therapeutics Inc. | Use of antibody-coupled t cell receptor (actr) with multiple anti-cancer antibodies in cancer treatment |
| JP7109789B2 (ja) | 2016-08-02 | 2022-08-01 | ティーシーアール2 セラピューティクス インク. | 融合タンパク質を使用したtcrの再プログラム化のための組成物及び方法 |
| DK3445787T3 (da) | 2016-10-07 | 2021-03-01 | Tcr2 Therapeutics Inc | Sammensætninger og fremgangsmåder til omprogrammering af t-cellereceptorer under anvendelse af fusionsproteiner |
| JP7291396B2 (ja) | 2016-11-22 | 2023-06-15 | ティーシーアール2 セラピューティクス インク. | 融合タンパク質を用いたtcrの再プログラミングのための組成物及び方法 |
| WO2018112266A1 (en) * | 2016-12-14 | 2018-06-21 | The Board Of Trustees Of The Leland Stanford Junior University | Il-13 superkine: immune cell targeting constructs and methods of use thereof |
| WO2018132506A1 (en) | 2017-01-10 | 2018-07-19 | The General Hospital Corporation | Chimeric antigen receptors based on alternative signal 1 domains |
| AU2018213407A1 (en) * | 2017-01-30 | 2019-08-08 | Unum Therapeutics Inc. | Improved antibody-coupled T cell receptor constructs and therapeutic uses thereof |
| CN110582298A (zh) * | 2017-02-17 | 2019-12-17 | 优努姆治疗公司 | 抗bcma抗体和抗体偶联t细胞受体(actr)在癌症治疗和b细胞疾病中的联合使用 |
| WO2018170458A1 (en) * | 2017-03-16 | 2018-09-20 | The General Hospital Corporation | Chimeric antigen receptors targeting cd37 |
| MX2019011656A (es) * | 2017-03-27 | 2019-12-02 | Hoffmann La Roche | Formatos mejorados de receptor de union a antigeno. |
| WO2018183385A1 (en) | 2017-03-27 | 2018-10-04 | National University Of Singapore | Truncated nkg2d chimeric receptors and uses thereof in natural killer cell immunotherapy |
| SG11201908337VA (en) | 2017-03-27 | 2019-10-30 | Nat Univ Singapore | Stimulatory cell lines for ex vivo expansion and activation of natural killer cells |
| AU2018241624B2 (en) | 2017-03-27 | 2024-01-25 | F. Hoffmann-La Roche Ag | Improved antigen binding receptors |
| SG11201911617SA (en) | 2017-06-07 | 2020-01-30 | Seattle Genetics Inc | T cells with reduced surface fucosylation and methods of making and using the same |
| KR20200041377A (ko) * | 2017-09-06 | 2020-04-21 | 프레드 헛친슨 켄서 리서치 센터 | Strep-tag 특이적 결합 단백질 및 그 용도 |
| CN111556756A (zh) * | 2017-10-26 | 2020-08-18 | 明尼苏达大学董事会 | 重组免疫细胞、制备方法和使用方法 |
| MX2020004539A (es) * | 2017-11-01 | 2020-08-03 | Allogene Therapeutics Inc | Polipeptidos de caspasa-9 modificados y sus metodos de uso. |
| CN111565730A (zh) * | 2017-11-09 | 2020-08-21 | 桑格摩生物治疗股份有限公司 | 细胞因子诱导型含sh2蛋白(cish)基因的遗传修饰 |
| KR20200080270A (ko) | 2017-11-10 | 2020-07-06 | 더 유나이티드 스테이츠 오브 어메리카, 애즈 리프리젠티드 바이 더 세크러테리, 디파트먼트 오브 헬쓰 앤드 휴먼 서비씨즈 | 종양 항원을 타겟으로 하는 키메릭 항원 수용체 |
| CN111373031A (zh) * | 2017-11-10 | 2020-07-03 | 朱拉生物公司 | 基于主要组织相容性复合物的嵌合受体和其用于治疗自身免疫性疾病的用途 |
| KR20200090927A (ko) * | 2017-12-19 | 2020-07-29 | 아카우오스, 인크. | 내이에 대한 치료적 항체의 aav-매개 전달 |
| CN109970864A (zh) * | 2017-12-28 | 2019-07-05 | 上海细胞治疗研究院 | 一种双向激活共刺激分子受体及其用途 |
| CN111770937A (zh) * | 2017-12-29 | 2020-10-13 | 希望之城 | 中间位使能t细胞 |
| KR102593359B1 (ko) * | 2018-03-19 | 2023-10-24 | 사바 라이프 사이언스 에이비 | Adcc 및 adcp 활성의 향상된 정량화를 위한 시스템 및 제품 |
| WO2020068702A1 (en) * | 2018-09-24 | 2020-04-02 | Fred Hutchinson Cancer Research Center | Chimeric receptor proteins and uses thereof |
| WO2020097193A1 (en) | 2018-11-06 | 2020-05-14 | The Regents Of The University Of California | Chimeric antigen receptors for phagocytosis |
| EP3773918A4 (en) | 2019-03-05 | 2022-01-05 | Nkarta, Inc. | CD19 DIRECTED CHIMERIC ANTIGEN RECEPTORS AND THEIR USES IN IMMUNOTHERAPY |
| KR20220004087A (ko) | 2019-04-19 | 2022-01-11 | 추가이 세이야쿠 가부시키가이샤 | 항체 개변 부위 인식 키메라 수용체 |
| US11026973B2 (en) | 2019-04-30 | 2021-06-08 | Myeloid Therapeutics, Inc. | Engineered phagocytic receptor compositions and methods of use thereof |
| CN110592014A (zh) * | 2019-08-14 | 2019-12-20 | 广东美赛尔细胞生物科技有限公司 | 一种在nk细胞治疗中免辐照体外体内持续去除饲养细胞的方法 |
| JP2022546592A (ja) | 2019-09-03 | 2022-11-04 | マイエロイド・セラピューティクス,インコーポレーテッド | ゲノム組込みのための方法および組成物 |
| CN111944062B (zh) * | 2019-12-09 | 2023-11-07 | 深圳市体内生物医药科技有限公司 | 一种识别Fc片段的嵌合抗原受体及其应用 |
| US10980836B1 (en) | 2019-12-11 | 2021-04-20 | Myeloid Therapeutics, Inc. | Therapeutic cell compositions and methods of manufacturing and use thereof |
| CN111100942B (zh) * | 2019-12-31 | 2023-03-28 | 海南波莲水稻基因科技有限公司 | 与水稻光温敏核雄性不育表型相关的分子标记和应用 |
| EP3875478A1 (en) * | 2020-03-05 | 2021-09-08 | Canvax Biotech, S.L. | Novel non-immunogenic chimeric antigen receptors and uses thereof |
| CN113583139A (zh) * | 2020-07-06 | 2021-11-02 | 上海鑫湾生物科技有限公司 | 一种嵌合受体及其应用 |
| CN116194124A (zh) | 2020-07-31 | 2023-05-30 | 中外制药株式会社 | 包含表达嵌合受体的细胞的药物组合物 |
| CN111876382A (zh) * | 2020-08-14 | 2020-11-03 | 上海星华生物医药科技有限公司 | 一种制备通用型免疫细胞的方法及其应用 |
| WO2022032665A1 (zh) * | 2020-08-14 | 2022-02-17 | 上海星华生物医药科技有限公司 | 一种制备通用型免疫细胞的方法及其应用 |
| AU2021376354A1 (en) | 2020-11-04 | 2023-06-22 | Myeloid Therapeutics, Inc. | Engineered chimeric fusion protein compositions and methods of use thereof |
| WO2022150379A1 (en) * | 2021-01-08 | 2022-07-14 | Regents Of The University Of Minnesota | Nk cell engager molecules and methods of use |
| WO2023049933A1 (en) | 2021-09-27 | 2023-03-30 | Sotio Biotech Inc. | Chimeric receptor polypeptides in combination with trans metabolism molecules that re-direct glucose metabolites out of the glycolysis pathway and therapeutic uses thereof |
| WO2023091909A1 (en) | 2021-11-16 | 2023-05-25 | Sotio Biotech Inc. | Treatment of myxoid/round cell liposarcoma patients |
| CN116715766A (zh) * | 2022-03-30 | 2023-09-08 | 河北森朗生物科技有限公司 | 靶向cd7的纳米抗体及其相关产品和医药用途 |
| WO2024040207A1 (en) | 2022-08-19 | 2024-02-22 | Sotio Biotech Inc. | Genetically engineered natural killer (nk) cells with chimeric receptor polypeptides in combination with trans metabolism molecules and therapeutic uses thereof |
| WO2024040208A1 (en) | 2022-08-19 | 2024-02-22 | Sotio Biotech Inc. | Genetically engineered immune cells with chimeric receptor polypeptides in combination with multiple trans metabolism molecules and therapeutic uses thereof |
Family Cites Families (37)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4650764A (en) | 1983-04-12 | 1987-03-17 | Wisconsin Alumni Research Foundation | Helper cell |
| US4777127A (en) | 1985-09-30 | 1988-10-11 | Labsystems Oy | Human retrovirus-related products and methods of diagnosing and treating conditions associated with said retrovirus |
| GB8702816D0 (en) | 1987-02-07 | 1987-03-11 | Al Sumidaie A M K | Obtaining retrovirus-containing fraction |
| US5219740A (en) | 1987-02-13 | 1993-06-15 | Fred Hutchinson Cancer Research Center | Retroviral gene transfer into diploid fibroblasts for gene therapy |
| US4980289A (en) | 1987-04-27 | 1990-12-25 | Wisconsin Alumni Research Foundation | Promoter deficient retroviral vector |
| AP129A (en) | 1988-06-03 | 1991-04-17 | Smithkline Biologicals S A | Expression of retrovirus gag protein eukaryotic cells |
| US5124263A (en) | 1989-01-12 | 1992-06-23 | Wisconsin Alumni Research Foundation | Recombination resistant retroviral helper cell and products produced thereby |
| EP0454781B1 (en) | 1989-01-23 | 1998-12-16 | Chiron Corporation | Recombinant cells for therapies of infection and hyperproliferative disorders and preparation thereof |
| US5399346A (en) | 1989-06-14 | 1995-03-21 | The United States Of America As Represented By The Department Of Health And Human Services | Gene therapy |
| EP1001032A3 (en) | 1989-08-18 | 2005-02-23 | Chiron Corporation | Recombinant retroviruses delivering vector constructs to target cells |
| US5585362A (en) | 1989-08-22 | 1996-12-17 | The Regents Of The University Of Michigan | Adenovirus vectors for gene therapy |
| CA2115742A1 (en) | 1991-08-20 | 1993-03-04 | Ronald G. Crystal | Adenovirus mediated transfer of genes to the gastrointestinal tract |
| WO1993010218A1 (en) | 1991-11-14 | 1993-05-27 | The United States Government As Represented By The Secretary Of The Department Of Health And Human Services | Vectors including foreign genes and negative selective markers |
| GB9125623D0 (en) | 1991-12-02 | 1992-01-29 | Dynal As | Cell modification |
| FR2688514A1 (fr) | 1992-03-16 | 1993-09-17 | Centre Nat Rech Scient | Adenovirus recombinants defectifs exprimant des cytokines et medicaments antitumoraux les contenant. |
| WO1993025234A1 (en) | 1992-06-08 | 1993-12-23 | The Regents Of The University Of California | Methods and compositions for targeting specific tissue |
| EP0644946A4 (en) | 1992-06-10 | 1997-03-12 | Us Health | VECTOR PARTICLES RESISTANT TO HUMAN SERUM INACTIVATION. |
| GB2269175A (en) | 1992-07-31 | 1994-02-02 | Imperial College | Retroviral vectors |
| JPH08503855A (ja) | 1992-12-03 | 1996-04-30 | ジェンザイム・コーポレイション | 嚢胞性線維症に対する遺伝子治療 |
| DE69434486T2 (de) | 1993-06-24 | 2006-07-06 | Advec Inc. | Adenovirus vektoren für gentherapie |
| US5906928A (en) | 1993-07-30 | 1999-05-25 | University Of Medicine And Dentistry Of New Jersey | Efficient gene transfer into primary murine lymphocytes obviating the need for drug selection |
| ATE314482T1 (de) | 1993-10-25 | 2006-01-15 | Canji Inc | Rekombinante adenoviren-vektor und verfahren zur verwendung |
| WO2000032776A2 (en) | 1998-12-01 | 2000-06-08 | Genentech, Inc. | Secreted amd transmembrane polypeptides and nucleic acids encoding the same |
| US5756910A (en) | 1996-08-28 | 1998-05-26 | Burgett, Inc. | Method and apparatus for actuating solenoids in a player piano |
| ATE348155T1 (de) | 1996-11-20 | 2007-01-15 | Introgen Therapeutics Inc | Ein verbessertes verfahren zur produktion und reinigung von adenoviralen vektoren |
| US7052906B1 (en) | 1999-04-16 | 2006-05-30 | Celltech R & D Limited | Synthetic transmembrane components |
| US20130266551A1 (en) * | 2003-11-05 | 2013-10-10 | St. Jude Children's Research Hospital, Inc. | Chimeric receptors with 4-1bb stimulatory signaling domain |
| US7435596B2 (en) | 2004-11-04 | 2008-10-14 | St. Jude Children's Research Hospital, Inc. | Modified cell line and method for expansion of NK cell |
| DK3006459T3 (da) * | 2008-08-26 | 2021-12-06 | Hope City | Fremgangsmåde og sammensætninger til forbedring af t-cellers antitumoreffektorfunktion |
| LT2393828T (lt) | 2009-02-03 | 2017-01-25 | Amunix Operating Inc. | Prailginti rekombinantiniai polipeptidai ir juos apimančios kompozicijos |
| DE102009013748B4 (de) * | 2009-03-17 | 2012-01-26 | Paul-Ehrlich-Institut | Bestimmung von Interaktionen konstanter Antikörperteile mit Fc-gamma Rezeptoren |
| EP2483301A1 (en) * | 2009-10-01 | 2012-08-08 | The United States Of America, As Represented By The Secretary, Department of Health and Human Services | Anti-vascular endothelial growth factor receptor-2 chimeric antigen receptors and use of same for the treatment of cancer |
| JP5947311B2 (ja) * | 2010-12-09 | 2016-07-06 | ザ トラスティーズ オブ ザ ユニバーシティ オブ ペンシルバニア | 癌を治療するためのキメラ抗原受容体改変t細胞の使用 |
| CN103946952A (zh) | 2011-09-16 | 2014-07-23 | 宾夕法尼亚大学董事会 | 用于治疗癌症的rna改造的t细胞 |
| SG11201602979RA (en) * | 2013-10-17 | 2016-05-30 | Univ Singapore | Chimeric receptor that triggers antibody-dependent cell cytotoxicity against multiple tumors |
| US10144770B2 (en) * | 2013-10-17 | 2018-12-04 | National University Of Singapore | Chimeric receptors and uses thereof in immune therapy |
| US20170151283A1 (en) * | 2014-05-23 | 2017-06-01 | The Trustees Of The University Of Pennsylvania | Compositions and methods for treating antibody resistance |
-
2015
- 2015-09-09 BR BR112017004675A patent/BR112017004675A2/pt not_active IP Right Cessation
- 2015-09-09 EP EP15767396.3A patent/EP3191507A1/en not_active Withdrawn
- 2015-09-09 MX MX2017003062A patent/MX2017003062A/es unknown
- 2015-09-09 WO PCT/US2015/049126 patent/WO2016040441A1/en active Application Filing
- 2015-09-09 CN CN201580048652.5A patent/CN107074969A/zh active Pending
- 2015-09-09 MA MA040595A patent/MA40595A/fr unknown
- 2015-09-09 SG SG10201902168PA patent/SG10201902168PA/en unknown
- 2015-09-09 CA CA2972714A patent/CA2972714A1/en not_active Abandoned
- 2015-09-09 KR KR1020177009209A patent/KR20170073593A/ko unknown
- 2015-09-09 AU AU2015315199A patent/AU2015315199B2/en not_active Ceased
- 2015-09-09 US US15/509,133 patent/US20180133252A9/en not_active Abandoned
- 2015-09-09 SG SG11201701775VA patent/SG11201701775VA/en unknown
- 2015-09-09 JP JP2017533170A patent/JP2017527310A/ja active Pending
-
2017
- 2017-02-27 IL IL250828A patent/IL250828A0/en unknown
Also Published As
| Publication number | Publication date |
|---|---|
| CA2972714A1 (en) | 2016-03-17 |
| SG10201902168PA (en) | 2019-04-29 |
| IL250828A0 (en) | 2017-04-30 |
| US20170281682A1 (en) | 2017-10-05 |
| AU2015315199B2 (en) | 2020-02-27 |
| EP3191507A1 (en) | 2017-07-19 |
| MA40595A (fr) | 2021-05-26 |
| CN107074969A (zh) | 2017-08-18 |
| MX2017003062A (es) | 2017-12-14 |
| BR112017004675A2 (pt) | 2017-12-05 |
| JP2017527310A (ja) | 2017-09-21 |
| SG11201701775VA (en) | 2017-04-27 |
| WO2016040441A1 (en) | 2016-03-17 |
| AU2015315199A1 (en) | 2017-03-16 |
| US20180133252A9 (en) | 2018-05-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10144770B2 (en) | Chimeric receptors and uses thereof in immune therapy | |
| AU2015315199B2 (en) | Chimeric receptors and uses thereof in immune therapy | |
| JP6417413B2 (ja) | 多様な腫瘍に対する抗体依存性細胞毒性を誘発するキメラ受容体 | |
| CN113260368B (zh) | 抗gpc3嵌合抗原受体(car)与反式共刺激分子的组合及其治疗用途 | |
| US20210340219A1 (en) | Chimeric receptor polypeptides in combination with trans metabolism molecules modulating intracellular lactate concentrations and therapeutic uses thereof | |
| KR20210030950A (ko) | 글루코스 이입을 향상시키는 트랜스 대사 분자와 조합된 키메라 수용체 및 이의 치료적 용도 | |
| US20190112349A1 (en) | Modified chimeric receptors and uses thereof in immune therapy | |
| US20190381171A1 (en) | Co-use of anti-bcma antibody and antibody-coupled t cell receptor (actr) in cancer therapy and b cell disorders | |
| US20200181226A1 (en) | Antibody-coupled t cell receptor constructs and therapeutic uses thereof | |
| KR20210045418A (ko) | 크렙스 사이클을 조정하는 트랜스 대사 분자와 조합된 키메라 항원 수용체 폴리펩타이드 및 이의 치료적 용도 | |
| US20210261646A1 (en) | Chimeric receptors in combination with trans metabolism molecules enhancing glucose import and therapeutic uses thereof | |
| WO2020028572A2 (en) | ANTIBODY-COUPLED T CELL RECEPTORS (ACTRs) IN COMBINATION WITH TRANS CO-STIMULATORY MOLECULES AND THERAPEUTIC USES THEREOF | |
| US20190105348A1 (en) | Chimeric receptors and uses thereof in immune therapy | |
| US20190284298A1 (en) | Use of antibody-coupled t cell receptor (actr) with multiple anti-cancer antibodies in cancer treatment | |
| WO2017205254A1 (en) | Immune cells expressing antibody-coupled t-cell receptor (actr) for use in inhibiting cancer cells expressing surface immunoglobulin |