JP7108575B2 - 難聴のリスクを判定する方法 - Google Patents
難聴のリスクを判定する方法 Download PDFInfo
- Publication number
- JP7108575B2 JP7108575B2 JP2019081861A JP2019081861A JP7108575B2 JP 7108575 B2 JP7108575 B2 JP 7108575B2 JP 2019081861 A JP2019081861 A JP 2019081861A JP 2019081861 A JP2019081861 A JP 2019081861A JP 7108575 B2 JP7108575 B2 JP 7108575B2
- Authority
- JP
- Japan
- Prior art keywords
- snp
- genotype
- disease
- risk
- model
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images











Landscapes
- Investigating Or Analysing Biological Materials (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Description
rs4911495:男性のウエスト-ヒップ比に関するSNP(非特許文献 1)
rs6651806:ストレスに対する反応性に関するSNP(非特許文献 2)
rs6651806:疎外感に関するSNP(非特許文献 3)
rs6651806:ネガティブ思考に関するSNP(非特許文献 4)
rs4246215:血液中のαリノレン酸濃度に関するSNP(非特許文献 5)
rs724577:出生時体重に関するSNP(非特許文献 6)
rs16998073:収縮期血圧に関するSNP(非特許文献 7)
rs16998073:拡張期血圧に関するSNP(非特許文献 8)
rs9809531:匂いの感じやすさ(ブルーチーズ)に関するSNP(非特許文献 9)
rs9326801:アトピー性皮膚炎に関するSNP(非特許文献 10)
rs5955543:腎芽細胞腫(ウィルムス腫瘍)に関するSNP(非特許文献 11)
rs925489:甲状腺機能低下症に関するSNP(非特許文献 12)
rs925489:血液中の甲状腺刺激ホルモン濃度に関するSNP(非特許文献 13)
染色体番号 20
染色体上の位置 33971978
塩基配列 CAGATCTATGCAACACTGAGCACTT[A/C]CAGGGTTAATCTGAACAGAGCTGTT(配列番号1)
染色体番号 X
染色体上の位置 43688964
塩基配列 TTGTGATGACAGATGTTTGAAGTTA[A/C]CAGAATAAAGGAAGTTAATTTGCGA(配列番号2)
染色体番号 11
染色体上の位置 61564299
塩基配列 AAGAGAGAGGGAGATAAAAGGGGGA[T/G]ACAAAAGATGTACAGAAATGATTTC(配列番号3)
染色体番号 4
染色体上の位置 17993410
塩基配列 CCAGCCCTGGACAAAAATTTCAAGC[A/C]TGCCCTCCTTAAAAAAGAAAAAAAT(配列番号4)
染色体番号 4
染色体上の位置 81184341
塩基配列 CCTGGCCTCAGTTTAAACCCAGGGG[T/A]ATGTTGTAAATATTGAGACGGTCTC(配列番号5)
染色体番号 3
染色体上の位置 97869808
塩基配列 TCTGTGCTTGTATGAGTAAGAACCA[T/C]GCAGCCTCTAACTTCCTAAGATGGC(配列番号6)
染色体番号 5
染色体上の位置 109928666
塩基配列 GATGAAACTGTTGCTCACCATACAA[T/G]TATCTAGGTGGCTAGCTCATCTAGG(配列番号7)
染色体番号 X
染色体上の位置 17698397
塩基配列 GGCTGATTATCCCCATGGGAGGAAG[A/G]GGCTGCTGAGGGAAGTGCATGGGCC(配列番号8)
染色体番号 9
染色体上の位置 100546600
塩基配列 CTGGGGAAGCCAAGTGTAGGCACTC[T/C]GGTTAACAGTCCCCGCACAGCTCCG(配列番号9)


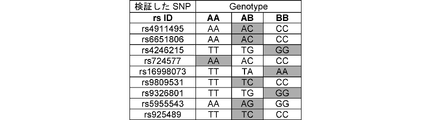
本SNPセットを用いた判定方法の精度について説明する。上記データベースから、テスト用に、利用者の遺伝子型情報と罹患情報とを対応付けたデータセットを作成した。データセットにおける各利用者の本SNPセットの各SNPの遺伝子型を、ホモ接合型(AA,BB)と、ヘテロ接合型(AB)に分類し、分類した各遺伝子型が図2に示す網掛けをした遺伝子型と一致する場合には、xiの値を1と評価し、一致しない場合には0と評価して、x1~xNを特徴量として算出した。
本SNPセットを用いる判定モデルが、各比較SNPセットを用いる比較判定モデルよりも有意に優れたモデルであることを確かめるために、ノンパラメトリック検定の一種であるウィルコクソンの順位和検定を行った。具体的には、本SNPセットを用いる判定モデルのAUCと、各比較SNPセットを用いる比較判定モデルのAUCとに差が無いという帰無仮説を設定し、有意水準を0.01としてウィルコクソンの順位和検定を行った。
Claims (2)
- 難聴に罹患したヒトの遺伝子型データと、難聴に罹患していないヒトの遺伝子型データと、を学習データとして用いて機械学習したモデルを用いて、難聴と正の相関があるrs6651806、及びrs4246215と、難聴と負の相関があるrs5955543、rs9326801、rs16998073、rs9809531、rs925489、rs4911495、及びrs724577を少なくとも含む一塩基多型セットの遺伝子型情報であって、
rs6651806の遺伝子型がAC、rs4246215の遺伝子型がGG、rs5955543の遺伝子型がAG、rs9326801の遺伝子型がGG、rs16998073の遺伝子型がAA、rs9809531の遺伝子型がTC、rs925489の遺伝子型がTC、rs4911495の遺伝子型がAC、及びrs724577の遺伝子型がAAであるか否かに関する遺伝子型情報に基づいて、難聴のリスクを判定する、方法。 - リスクの判定を受ける対象者の体液サンプル、細胞サンプル又は体毛を用いる、請求項1に記載の方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019081861A JP7108575B2 (ja) | 2019-04-23 | 2019-04-23 | 難聴のリスクを判定する方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019081861A JP7108575B2 (ja) | 2019-04-23 | 2019-04-23 | 難聴のリスクを判定する方法 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2020178557A JP2020178557A (ja) | 2020-11-05 |
| JP2020178557A5 JP2020178557A5 (ja) | 2022-03-22 |
| JP7108575B2 true JP7108575B2 (ja) | 2022-07-28 |
Family
ID=73022581
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2019081861A Active JP7108575B2 (ja) | 2019-04-23 | 2019-04-23 | 難聴のリスクを判定する方法 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP7108575B2 (ja) |
-
2019
- 2019-04-23 JP JP2019081861A patent/JP7108575B2/ja active Active
Non-Patent Citations (4)
| Title |
|---|
| Acta Otolaryngol.,2016年,Vol. 136, No. 5,pp.465-469 |
| J. Thorac. Dis.,2016年,Vol. 8, No. 3,pp.430-438 |
| Mitochondrion,2019年,Vol. 46,pp.370-379 |
| Sci. Rep.,2016年,6:19329 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2020178557A (ja) | 2020-11-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7161441B2 (ja) | 慢性副鼻腔炎のリスクを判定する方法 | |
| JP7165098B2 (ja) | 動脈硬化のリスクを判定する方法 | |
| JP7137525B2 (ja) | 接触性皮膚炎のリスクを判定する方法 | |
| JP7140707B2 (ja) | 緑内障のリスクを判定する方法 | |
| JP7161443B2 (ja) | 尿管結石及び/又は腎結石のリスクを判定する方法 | |
| JP7161442B2 (ja) | リウマチのリスクを判定する方法 | |
| JP7165100B2 (ja) | 心房細動及び/又は心室細動のリスクを判定する方法 | |
| JP7108575B2 (ja) | 難聴のリスクを判定する方法 | |
| JP7165099B2 (ja) | 心筋梗塞及び/又は狭心症のリスクを判定する方法 | |
| JP7137520B2 (ja) | 膵炎のリスクを判定する方法 | |
| JP7137523B2 (ja) | じんましんのリスクを判定する方法 | |
| JP7160749B2 (ja) | 先天性股関節脱臼のリスクを判定する方法 | |
| JP7137518B2 (ja) | 甲状腺機能亢進症のリスクを判定する方法 | |
| JP7106490B2 (ja) | 胆石のリスクを判定する方法 | |
| JP7137519B2 (ja) | 結核のリスクを判定する方法 | |
| JP7107883B2 (ja) | てんかんのリスクを判定する方法 | |
| JP7108574B2 (ja) | アレルギー性結膜炎のリスクを判定する方法 | |
| JP7137524B2 (ja) | 変形性膝関節症のリスクを判定する方法 | |
| JP7107885B2 (ja) | 化学物質過敏症のリスクを判定する方法 | |
| JP7106487B2 (ja) | 潰瘍性大腸炎のリスクを判定する方法 | |
| JP7137517B2 (ja) | 鉄欠乏性貧血のリスクを判定する方法 | |
| JP7107884B2 (ja) | 食物アレルギーのリスクを判定する方法 | |
| JP7138077B2 (ja) | 卵巣がん及び/又は子宮がんのリスクを判定する方法 | |
| JP7138074B2 (ja) | B型肝炎及び/又はc型肝炎のリスクを判定する方法 | |
| JP7107882B2 (ja) | 偏頭痛のリスクを判定する方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20200609 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20220117 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20220311 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20220628 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20220715 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7108575 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |