CN1249079C - 蛋白质的分配方法 - Google Patents
蛋白质的分配方法 Download PDFInfo
- Publication number
- CN1249079C CN1249079C CNB008076022A CN00807602A CN1249079C CN 1249079 C CN1249079 C CN 1249079C CN B008076022 A CNB008076022 A CN B008076022A CN 00807602 A CN00807602 A CN 00807602A CN 1249079 C CN1249079 C CN 1249079C
- Authority
- CN
- China
- Prior art keywords
- fusion rotein
- cell
- hfbi
- atps
- hydrophobin
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 108090000623 proteins and genes Proteins 0.000 title claims abstract description 102
- 102000004169 proteins and genes Human genes 0.000 title claims abstract description 87
- 238000000034 method Methods 0.000 title claims abstract description 55
- 230000008569 process Effects 0.000 title claims abstract description 13
- 238000000638 solvent extraction Methods 0.000 title abstract description 7
- 230000008685 targeting Effects 0.000 claims abstract description 29
- 230000004927 fusion Effects 0.000 claims description 128
- 101710091977 Hydrophobin Proteins 0.000 claims description 50
- 108020004414 DNA Proteins 0.000 claims description 41
- 210000004027 cell Anatomy 0.000 claims description 40
- 238000000926 separation method Methods 0.000 claims description 26
- 239000000284 extract Substances 0.000 claims description 23
- 239000000126 substance Substances 0.000 claims description 17
- 241000223259 Trichoderma Species 0.000 claims description 15
- 150000003839 salts Chemical class 0.000 claims description 15
- 108010059892 Cellulase Proteins 0.000 claims description 11
- 108091005804 Peptidases Proteins 0.000 claims description 11
- 102000035195 Peptidases Human genes 0.000 claims description 11
- 229920000642 polymer Polymers 0.000 claims description 11
- 239000000725 suspension Substances 0.000 claims description 9
- 229940106157 cellulase Drugs 0.000 claims description 8
- 229920002307 Dextran Polymers 0.000 claims description 4
- 229920002472 Starch Polymers 0.000 claims description 4
- 230000013011 mating Effects 0.000 claims description 4
- 239000008107 starch Substances 0.000 claims description 4
- 239000003599 detergent Substances 0.000 claims description 3
- 108010002430 hemicellulase Proteins 0.000 claims description 3
- 229940059442 hemicellulase Drugs 0.000 claims description 3
- 235000019698 starch Nutrition 0.000 claims description 3
- 239000004743 Polypropylene Substances 0.000 claims description 2
- 230000002776 aggregation Effects 0.000 claims description 2
- 238000004220 aggregation Methods 0.000 claims description 2
- 238000012239 gene modification Methods 0.000 claims description 2
- 230000005017 genetic modification Effects 0.000 claims description 2
- 235000013617 genetically modified food Nutrition 0.000 claims description 2
- 229920001155 polypropylene Polymers 0.000 claims description 2
- 230000012743 protein tagging Effects 0.000 claims description 2
- 210000005253 yeast cell Anatomy 0.000 claims description 2
- 101100202428 Neopyropia yezoensis atps gene Proteins 0.000 claims 7
- 230000008521 reorganization Effects 0.000 claims 5
- 108050001049 Extracellular proteins Proteins 0.000 claims 3
- 108020004511 Recombinant DNA Proteins 0.000 claims 1
- 238000010170 biological method Methods 0.000 claims 1
- 230000001413 cellular effect Effects 0.000 claims 1
- 238000012797 qualification Methods 0.000 claims 1
- 238000005204 segregation Methods 0.000 claims 1
- 238000000746 purification Methods 0.000 abstract description 12
- 238000002955 isolation Methods 0.000 abstract 1
- 239000012071 phase Substances 0.000 description 104
- 239000013612 plasmid Substances 0.000 description 72
- 241000499912 Trichoderma reesei Species 0.000 description 55
- 235000018102 proteins Nutrition 0.000 description 53
- 230000001580 bacterial effect Effects 0.000 description 51
- 101001003067 Hypocrea jecorina Hydrophobin-1 Proteins 0.000 description 47
- MSYHGYDAVLDKCE-UHFFFAOYSA-N 2,2,3,3,4,4,4-heptafluoro-1-imidazol-1-ylbutan-1-one Chemical compound FC(F)(F)C(F)(F)C(F)(F)C(=O)N1C=CN=C1 MSYHGYDAVLDKCE-UHFFFAOYSA-N 0.000 description 45
- 230000009182 swimming Effects 0.000 description 38
- 239000000047 product Substances 0.000 description 33
- 239000012634 fragment Substances 0.000 description 29
- 101710098247 Exoglucanase 1 Proteins 0.000 description 27
- 238000005192 partition Methods 0.000 description 27
- 230000014509 gene expression Effects 0.000 description 25
- 230000000694 effects Effects 0.000 description 24
- 238000000605 extraction Methods 0.000 description 24
- 239000000523 sample Substances 0.000 description 24
- 108090000765 processed proteins & peptides Proteins 0.000 description 23
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 22
- 230000033228 biological regulation Effects 0.000 description 20
- 239000000243 solution Substances 0.000 description 20
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 20
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 19
- 238000009826 distribution Methods 0.000 description 19
- 239000006228 supernatant Substances 0.000 description 19
- 102000004190 Enzymes Human genes 0.000 description 18
- 108090000790 Enzymes Proteins 0.000 description 18
- 229920002678 cellulose Polymers 0.000 description 18
- 235000010980 cellulose Nutrition 0.000 description 18
- 229940088598 enzyme Drugs 0.000 description 18
- 108091008146 restriction endonucleases Proteins 0.000 description 18
- 101001003080 Hypocrea jecorina Hydrophobin-2 Proteins 0.000 description 17
- 239000001913 cellulose Substances 0.000 description 16
- ZXEKIIBDNHEJCQ-UHFFFAOYSA-N isobutanol Chemical compound CC(C)CO ZXEKIIBDNHEJCQ-UHFFFAOYSA-N 0.000 description 16
- 235000013339 cereals Nutrition 0.000 description 15
- 238000010790 dilution Methods 0.000 description 15
- 239000012895 dilution Substances 0.000 description 15
- 239000000706 filtrate Substances 0.000 description 15
- 244000144992 flock Species 0.000 description 15
- 241000894006 Bacteria Species 0.000 description 14
- 238000012408 PCR amplification Methods 0.000 description 14
- 230000029087 digestion Effects 0.000 description 14
- 238000002474 experimental method Methods 0.000 description 14
- 239000002609 medium Substances 0.000 description 14
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 13
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 13
- 239000002299 complementary DNA Substances 0.000 description 13
- 238000004519 manufacturing process Methods 0.000 description 13
- 239000000203 mixture Substances 0.000 description 13
- 241000351920 Aspergillus nidulans Species 0.000 description 12
- 108020001507 fusion proteins Proteins 0.000 description 12
- 239000008103 glucose Substances 0.000 description 12
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 12
- DLFVBJFMPXGRIB-UHFFFAOYSA-N Acetamide Chemical compound CC(N)=O DLFVBJFMPXGRIB-UHFFFAOYSA-N 0.000 description 11
- 101100382641 Aspergillus aculeatus cbhB gene Proteins 0.000 description 11
- 229920002684 Sepharose Polymers 0.000 description 11
- 102000004196 processed proteins & peptides Human genes 0.000 description 11
- 108091026890 Coding region Proteins 0.000 description 10
- 108700007698 Genetic Terminator Regions Proteins 0.000 description 10
- 238000005516 engineering process Methods 0.000 description 10
- 239000008101 lactose Substances 0.000 description 10
- ZBJVLWIYKOAYQH-UHFFFAOYSA-N naphthalen-2-yl 2-hydroxybenzoate Chemical compound OC1=CC=CC=C1C(=O)OC1=CC=C(C=CC=C2)C2=C1 ZBJVLWIYKOAYQH-UHFFFAOYSA-N 0.000 description 10
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 9
- 101150083915 cdh1 gene Proteins 0.000 description 9
- 239000012228 culture supernatant Substances 0.000 description 9
- 230000002209 hydrophobic effect Effects 0.000 description 9
- 230000000968 intestinal effect Effects 0.000 description 9
- 239000007788 liquid Substances 0.000 description 9
- 239000000463 material Substances 0.000 description 9
- 239000002245 particle Substances 0.000 description 9
- 239000011780 sodium chloride Substances 0.000 description 9
- 238000012360 testing method Methods 0.000 description 9
- 241000588724 Escherichia coli Species 0.000 description 8
- 241000233866 Fungi Species 0.000 description 8
- 101100232312 Hypocrea jecorina hfb1 gene Proteins 0.000 description 8
- 101100232315 Hypocrea jecorina hfb2 gene Proteins 0.000 description 8
- NVNLLIYOARQCIX-MSHCCFNRSA-N Nisin Chemical compound N1C(=O)[C@@H](CC(C)C)NC(=O)C(=C)NC(=O)[C@@H]([C@H](C)CC)NC(=O)[C@@H](NC(=O)C(=C/C)/NC(=O)[C@H](N)[C@H](C)CC)CSC[C@@H]1C(=O)N[C@@H]1C(=O)N2CCC[C@@H]2C(=O)NCC(=O)N[C@@H](C(=O)N[C@H](CCCCN)C(=O)N[C@@H]2C(NCC(=O)N[C@H](C)C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCSC)C(=O)NCC(=O)N[C@H](CS[C@@H]2C)C(=O)N[C@H](CC(N)=O)C(=O)N[C@H](CCSC)C(=O)N[C@H](CCCCN)C(=O)N[C@@H]2C(N[C@H](C)C(=O)N[C@@H]3C(=O)N[C@@H](C(N[C@H](CC=4NC=NC=4)C(=O)N[C@H](CS[C@@H]3C)C(=O)N[C@H](CO)C(=O)N[C@H]([C@H](C)CC)C(=O)N[C@H](CC=3NC=NC=3)C(=O)N[C@H](C(C)C)C(=O)NC(=C)C(=O)N[C@H](CCCCN)C(O)=O)=O)CS[C@@H]2C)=O)=O)CS[C@@H]1C NVNLLIYOARQCIX-MSHCCFNRSA-N 0.000 description 8
- 108010053775 Nisin Proteins 0.000 description 8
- 108020005038 Terminator Codon Proteins 0.000 description 8
- 150000001413 amino acids Chemical class 0.000 description 8
- 238000004458 analytical method Methods 0.000 description 8
- 238000013016 damping Methods 0.000 description 8
- 239000013604 expression vector Substances 0.000 description 8
- 239000012530 fluid Substances 0.000 description 8
- 238000004128 high performance liquid chromatography Methods 0.000 description 8
- 239000004309 nisin Substances 0.000 description 8
- 235000010297 nisin Nutrition 0.000 description 8
- -1 polyoxyethylene Polymers 0.000 description 8
- 238000005520 cutting process Methods 0.000 description 7
- 101150073906 gpdA gene Proteins 0.000 description 7
- 235000015097 nutrients Nutrition 0.000 description 7
- 238000012216 screening Methods 0.000 description 7
- HSHNITRMYYLLCV-UHFFFAOYSA-N 4-methylumbelliferone Chemical compound C1=C(O)C=CC2=C1OC(=O)C=C2C HSHNITRMYYLLCV-UHFFFAOYSA-N 0.000 description 6
- 101710098246 Exoglucanase 2 Proteins 0.000 description 6
- 229920003171 Poly (ethylene oxide) Polymers 0.000 description 6
- 239000008351 acetate buffer Substances 0.000 description 6
- 235000001014 amino acid Nutrition 0.000 description 6
- 229940024606 amino acid Drugs 0.000 description 6
- 239000008346 aqueous phase Substances 0.000 description 6
- 101150052795 cbh-1 gene Proteins 0.000 description 6
- 239000003795 chemical substances by application Substances 0.000 description 6
- 238000013461 design Methods 0.000 description 6
- 102000037865 fusion proteins Human genes 0.000 description 6
- 239000000499 gel Substances 0.000 description 6
- 101150095733 gpsA gene Proteins 0.000 description 6
- 239000000758 substrate Substances 0.000 description 6
- 239000002028 Biomass Substances 0.000 description 5
- 239000002253 acid Substances 0.000 description 5
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 5
- 238000006243 chemical reaction Methods 0.000 description 5
- 238000004587 chromatography analysis Methods 0.000 description 5
- NKLPQNGYXWVELD-UHFFFAOYSA-M coomassie brilliant blue Chemical compound [Na+].C1=CC(OCC)=CC=C1NC1=CC=C(C(=C2C=CC(C=C2)=[N+](CC)CC=2C=C(C=CC=2)S([O-])(=O)=O)C=2C=CC(=CC=2)N(CC)CC=2C=C(C=CC=2)S([O-])(=O)=O)C=C1 NKLPQNGYXWVELD-UHFFFAOYSA-M 0.000 description 5
- ATDGTVJJHBUTRL-UHFFFAOYSA-N cyanogen bromide Chemical compound BrC#N ATDGTVJJHBUTRL-UHFFFAOYSA-N 0.000 description 5
- 230000005484 gravity Effects 0.000 description 5
- 238000005191 phase separation Methods 0.000 description 5
- 238000012545 processing Methods 0.000 description 5
- 238000011084 recovery Methods 0.000 description 5
- 230000001105 regulatory effect Effects 0.000 description 5
- 235000004400 serine Nutrition 0.000 description 5
- 239000007974 sodium acetate buffer Substances 0.000 description 5
- 238000010186 staining Methods 0.000 description 5
- 238000013518 transcription Methods 0.000 description 5
- 230000035897 transcription Effects 0.000 description 5
- DTQVDTLACAAQTR-UHFFFAOYSA-N trifluoroacetic acid Substances OC(=O)C(F)(F)F DTQVDTLACAAQTR-UHFFFAOYSA-N 0.000 description 5
- KBPLFHHGFOOTCA-UHFFFAOYSA-N 1-Octanol Chemical compound CCCCCCCCO KBPLFHHGFOOTCA-UHFFFAOYSA-N 0.000 description 4
- WCORRBXVISTKQL-WHFBIAKZSA-N Gly-Ser-Ser Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WCORRBXVISTKQL-WHFBIAKZSA-N 0.000 description 4
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 4
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 4
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 4
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 4
- 101100370749 Streptomyces coelicolor (strain ATCC BAA-471 / A3(2) / M145) trpC1 gene Proteins 0.000 description 4
- 239000005862 Whey Substances 0.000 description 4
- 102000007544 Whey Proteins Human genes 0.000 description 4
- 108010046377 Whey Proteins Proteins 0.000 description 4
- 239000013543 active substance Substances 0.000 description 4
- 230000008859 change Effects 0.000 description 4
- 238000001514 detection method Methods 0.000 description 4
- 239000001963 growth medium Substances 0.000 description 4
- 230000007062 hydrolysis Effects 0.000 description 4
- 238000006460 hydrolysis reaction Methods 0.000 description 4
- YQYJSBFKSSDGFO-FWAVGLHBSA-N hygromycin A Chemical compound O[C@H]1[C@H](O)[C@H](C(=O)C)O[C@@H]1Oc1ccc(\C=C(/C)C(=O)N[C@@H]2[C@@H]([C@H]3OCO[C@H]3[C@@H](O)[C@@H]2O)O)cc1O YQYJSBFKSSDGFO-FWAVGLHBSA-N 0.000 description 4
- 239000012535 impurity Substances 0.000 description 4
- 150000002632 lipids Chemical class 0.000 description 4
- 239000012528 membrane Substances 0.000 description 4
- 238000002156 mixing Methods 0.000 description 4
- 238000002161 passivation Methods 0.000 description 4
- 238000011020 pilot scale process Methods 0.000 description 4
- 229910052700 potassium Inorganic materials 0.000 description 4
- 239000001965 potato dextrose agar Substances 0.000 description 4
- 150000003384 small molecules Chemical class 0.000 description 4
- 239000007787 solid Substances 0.000 description 4
- 238000013519 translation Methods 0.000 description 4
- 101150016309 trpC gene Proteins 0.000 description 4
- IDOQDZANRZQBTP-UHFFFAOYSA-N 2-[2-(2,4,4-trimethylpentan-2-yl)phenoxy]ethanol Chemical compound CC(C)(C)CC(C)(C)C1=CC=CC=C1OCCO IDOQDZANRZQBTP-UHFFFAOYSA-N 0.000 description 3
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 3
- 102000002260 Alkaline Phosphatase Human genes 0.000 description 3
- 108020004774 Alkaline Phosphatase Proteins 0.000 description 3
- 241000228212 Aspergillus Species 0.000 description 3
- GUBGYTABKSRVRQ-CUHNMECISA-N D-Cellobiose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)OC(O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-CUHNMECISA-N 0.000 description 3
- 101150094690 GAL1 gene Proteins 0.000 description 3
- 102100028501 Galanin peptides Human genes 0.000 description 3
- 101100121078 Homo sapiens GAL gene Proteins 0.000 description 3
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 3
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 3
- 102000004882 Lipase Human genes 0.000 description 3
- 108090001060 Lipase Proteins 0.000 description 3
- 239000004367 Lipase Substances 0.000 description 3
- 108700026244 Open Reading Frames Proteins 0.000 description 3
- 239000001888 Peptone Substances 0.000 description 3
- 108010080698 Peptones Proteins 0.000 description 3
- 108010076504 Protein Sorting Signals Proteins 0.000 description 3
- 229920004929 Triton X-114 Polymers 0.000 description 3
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 3
- 239000006035 Tryptophane Substances 0.000 description 3
- YTNGABPUXFEOGU-SRVKXCTJSA-N Val-Pro-Arg Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCCN=C(N)N)C(O)=O YTNGABPUXFEOGU-SRVKXCTJSA-N 0.000 description 3
- 101150069003 amdS gene Proteins 0.000 description 3
- 230000003321 amplification Effects 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- 238000004364 calculation method Methods 0.000 description 3
- 210000002421 cell wall Anatomy 0.000 description 3
- 239000003153 chemical reaction reagent Substances 0.000 description 3
- 238000004140 cleaning Methods 0.000 description 3
- 238000010367 cloning Methods 0.000 description 3
- 239000012141 concentrate Substances 0.000 description 3
- 238000010276 construction Methods 0.000 description 3
- 238000005336 cracking Methods 0.000 description 3
- 238000012258 culturing Methods 0.000 description 3
- 238000010828 elution Methods 0.000 description 3
- 238000001704 evaporation Methods 0.000 description 3
- 230000008020 evaporation Effects 0.000 description 3
- 239000000835 fiber Substances 0.000 description 3
- 238000001914 filtration Methods 0.000 description 3
- 230000002538 fungal effect Effects 0.000 description 3
- 235000014304 histidine Nutrition 0.000 description 3
- 238000009396 hybridization Methods 0.000 description 3
- 230000001965 increasing effect Effects 0.000 description 3
- 238000011081 inoculation Methods 0.000 description 3
- 230000003993 interaction Effects 0.000 description 3
- 235000015110 jellies Nutrition 0.000 description 3
- 239000008274 jelly Substances 0.000 description 3
- 235000019421 lipase Nutrition 0.000 description 3
- 229930182817 methionine Natural products 0.000 description 3
- 239000000693 micelle Substances 0.000 description 3
- 238000003199 nucleic acid amplification method Methods 0.000 description 3
- 239000002773 nucleotide Substances 0.000 description 3
- 125000003729 nucleotide group Chemical group 0.000 description 3
- 230000002018 overexpression Effects 0.000 description 3
- 235000019319 peptone Nutrition 0.000 description 3
- 229920001184 polypeptide Polymers 0.000 description 3
- 239000002244 precipitate Substances 0.000 description 3
- 238000002360 preparation method Methods 0.000 description 3
- 230000002829 reductive effect Effects 0.000 description 3
- 238000011160 research Methods 0.000 description 3
- 238000010561 standard procedure Methods 0.000 description 3
- GPRLSGONYQIRFK-MNYXATJNSA-N triton Chemical compound [3H+] GPRLSGONYQIRFK-MNYXATJNSA-N 0.000 description 3
- 229960004799 tryptophan Drugs 0.000 description 3
- QRXMUCSWCMTJGU-UHFFFAOYSA-L (5-bromo-4-chloro-1h-indol-3-yl) phosphate Chemical compound C1=C(Br)C(Cl)=C2C(OP([O-])(=O)[O-])=CNC2=C1 QRXMUCSWCMTJGU-UHFFFAOYSA-L 0.000 description 2
- QTBSBXVTEAMEQO-UHFFFAOYSA-M Acetate Chemical compound CC([O-])=O QTBSBXVTEAMEQO-UHFFFAOYSA-M 0.000 description 2
- 102000035101 Aspartic proteases Human genes 0.000 description 2
- 108091005502 Aspartic proteases Proteins 0.000 description 2
- 101100136076 Aspergillus oryzae (strain ATCC 42149 / RIB 40) pel1 gene Proteins 0.000 description 2
- 101710183054 Cryparin Proteins 0.000 description 2
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 2
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 2
- 241000238557 Decapoda Species 0.000 description 2
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 2
- GGLIDLCEPDHEJO-BQBZGAKWSA-N Gly-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)CN GGLIDLCEPDHEJO-BQBZGAKWSA-N 0.000 description 2
- ZZWUYQXMIFTIIY-WEDXCCLWSA-N Gly-Thr-Leu Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O ZZWUYQXMIFTIIY-WEDXCCLWSA-N 0.000 description 2
- 239000004471 Glycine Substances 0.000 description 2
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 2
- 108090001030 Lipoproteins Proteins 0.000 description 2
- 102000004895 Lipoproteins Human genes 0.000 description 2
- AMQJEAYHLZJPGS-UHFFFAOYSA-N N-Pentanol Chemical compound CCCCCO AMQJEAYHLZJPGS-UHFFFAOYSA-N 0.000 description 2
- 241000187654 Nocardia Species 0.000 description 2
- 230000018199 S phase Effects 0.000 description 2
- 241000222481 Schizophyllum commune Species 0.000 description 2
- 101000639942 Schizophyllum commune Fruiting body protein SC3 Proteins 0.000 description 2
- 108091058545 Secretory proteins Proteins 0.000 description 2
- 102000040739 Secretory proteins Human genes 0.000 description 2
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 2
- VMHLLURERBWHNL-UHFFFAOYSA-M Sodium acetate Chemical compound [Na+].CC([O-])=O VMHLLURERBWHNL-UHFFFAOYSA-M 0.000 description 2
- 101150050575 URA3 gene Proteins 0.000 description 2
- 238000001042 affinity chromatography Methods 0.000 description 2
- LFVGISIMTYGQHF-UHFFFAOYSA-N ammonium dihydrogen phosphate Chemical compound [NH4+].OP(O)([O-])=O LFVGISIMTYGQHF-UHFFFAOYSA-N 0.000 description 2
- KLOHDWPABZXLGI-YWUHCJSESA-M ampicillin sodium Chemical compound [Na+].C1([C@@H](N)C(=O)N[C@H]2[C@H]3SC([C@@H](N3C2=O)C([O-])=O)(C)C)=CC=CC=C1 KLOHDWPABZXLGI-YWUHCJSESA-M 0.000 description 2
- 239000007864 aqueous solution Substances 0.000 description 2
- 239000003876 biosurfactant Substances 0.000 description 2
- 230000005587 bubbling Effects 0.000 description 2
- 239000006227 byproduct Substances 0.000 description 2
- 229940041514 candida albicans extract Drugs 0.000 description 2
- 239000003054 catalyst Substances 0.000 description 2
- 101150114858 cbh2 gene Proteins 0.000 description 2
- 239000007795 chemical reaction product Substances 0.000 description 2
- QVFWZNCVPCJQOP-UHFFFAOYSA-N chloralodol Chemical compound CC(O)(C)CC(C)OC(O)C(Cl)(Cl)Cl QVFWZNCVPCJQOP-UHFFFAOYSA-N 0.000 description 2
- 150000001875 compounds Chemical class 0.000 description 2
- 230000001186 cumulative effect Effects 0.000 description 2
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 2
- 238000010612 desalination reaction Methods 0.000 description 2
- 239000003814 drug Substances 0.000 description 2
- 238000000855 fermentation Methods 0.000 description 2
- 230000004151 fermentation Effects 0.000 description 2
- 239000006260 foam Substances 0.000 description 2
- 235000013305 food Nutrition 0.000 description 2
- 238000004108 freeze drying Methods 0.000 description 2
- 230000008014 freezing Effects 0.000 description 2
- 238000007710 freezing Methods 0.000 description 2
- 238000001502 gel electrophoresis Methods 0.000 description 2
- 101150087371 gpd1 gene Proteins 0.000 description 2
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 2
- 101150029559 hph gene Proteins 0.000 description 2
- 230000003301 hydrolyzing effect Effects 0.000 description 2
- 230000005661 hydrophobic surface Effects 0.000 description 2
- 238000009413 insulation Methods 0.000 description 2
- LFEUVBZXUFMACD-UHFFFAOYSA-H lead(2+);trioxido(oxo)-$l^{5}-arsane Chemical compound [Pb+2].[Pb+2].[Pb+2].[O-][As]([O-])([O-])=O.[O-][As]([O-])([O-])=O LFEUVBZXUFMACD-UHFFFAOYSA-H 0.000 description 2
- 239000002523 lectin Substances 0.000 description 2
- 239000007791 liquid phase Substances 0.000 description 2
- 238000000622 liquid--liquid extraction Methods 0.000 description 2
- 230000002101 lytic effect Effects 0.000 description 2
- 239000003550 marker Substances 0.000 description 2
- 230000000813 microbial effect Effects 0.000 description 2
- 244000005700 microbiome Species 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 238000012544 monitoring process Methods 0.000 description 2
- 239000000178 monomer Substances 0.000 description 2
- TVMXDCGIABBOFY-UHFFFAOYSA-N octane Chemical compound CCCCCCCC TVMXDCGIABBOFY-UHFFFAOYSA-N 0.000 description 2
- 239000003960 organic solvent Substances 0.000 description 2
- 101150040383 pel2 gene Proteins 0.000 description 2
- 101150050446 pelB gene Proteins 0.000 description 2
- JTJMJGYZQZDUJJ-UHFFFAOYSA-N phencyclidine Chemical compound C1CCCCN1C1(C=2C=CC=CC=2)CCCCC1 JTJMJGYZQZDUJJ-UHFFFAOYSA-N 0.000 description 2
- XNGIFLGASWRNHJ-UHFFFAOYSA-N phthalic acid Chemical compound OC(=O)C1=CC=CC=C1C(O)=O XNGIFLGASWRNHJ-UHFFFAOYSA-N 0.000 description 2
- 238000001742 protein purification Methods 0.000 description 2
- 238000004445 quantitative analysis Methods 0.000 description 2
- 230000000717 retained effect Effects 0.000 description 2
- 238000003757 reverse transcription PCR Methods 0.000 description 2
- 238000005070 sampling Methods 0.000 description 2
- 239000011734 sodium Substances 0.000 description 2
- 229910052708 sodium Inorganic materials 0.000 description 2
- 239000001632 sodium acetate Substances 0.000 description 2
- 235000017281 sodium acetate Nutrition 0.000 description 2
- 239000002904 solvent Substances 0.000 description 2
- 239000004094 surface-active agent Substances 0.000 description 2
- 125000000430 tryptophan group Chemical group [H]N([H])C(C(=O)O*)C([H])([H])C1=C([H])N([H])C2=C([H])C([H])=C([H])C([H])=C12 0.000 description 2
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 2
- 239000013598 vector Substances 0.000 description 2
- 239000012138 yeast extract Substances 0.000 description 2
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 1
- QAXPOSPGRHYIHE-UHFFFAOYSA-N 2-[2-[2-[2-(2-decoxyethoxy)ethoxy]ethoxy]ethoxy]ethanol Chemical compound CCCCCCCCCCOCCOCCOCCOCCOCCO QAXPOSPGRHYIHE-UHFFFAOYSA-N 0.000 description 1
- PEZMQPADLFXCJJ-ZETCQYMHSA-N 2-[[2-[[(2s)-1-(2-aminoacetyl)pyrrolidine-2-carbonyl]amino]acetyl]amino]acetic acid Chemical compound NCC(=O)N1CCC[C@H]1C(=O)NCC(=O)NCC(O)=O PEZMQPADLFXCJJ-ZETCQYMHSA-N 0.000 description 1
- QMIWYOZFFSLIAK-UHFFFAOYSA-N 3,3,3-trifluoro-2-(trifluoromethyl)prop-1-ene Chemical compound FC(F)(F)C(=C)C(F)(F)F QMIWYOZFFSLIAK-UHFFFAOYSA-N 0.000 description 1
- HVCOBJNICQPDBP-UHFFFAOYSA-N 3-[3-[3,5-dihydroxy-6-methyl-4-(3,4,5-trihydroxy-6-methyloxan-2-yl)oxyoxan-2-yl]oxydecanoyloxy]decanoic acid;hydrate Chemical compound O.OC1C(OC(CC(=O)OC(CCCCCCC)CC(O)=O)CCCCCCC)OC(C)C(O)C1OC1C(O)C(O)C(O)C(C)O1 HVCOBJNICQPDBP-UHFFFAOYSA-N 0.000 description 1
- 101150110188 30 gene Proteins 0.000 description 1
- QFVHZQCOUORWEI-UHFFFAOYSA-N 4-[(4-anilino-5-sulfonaphthalen-1-yl)diazenyl]-5-hydroxynaphthalene-2,7-disulfonic acid Chemical compound C=12C(O)=CC(S(O)(=O)=O)=CC2=CC(S(O)(=O)=O)=CC=1N=NC(C1=CC=CC(=C11)S(O)(=O)=O)=CC=C1NC1=CC=CC=C1 QFVHZQCOUORWEI-UHFFFAOYSA-N 0.000 description 1
- 108091005508 Acid proteases Proteins 0.000 description 1
- MQIGTEQXYCRLGK-BQBZGAKWSA-N Ala-Gly-Pro Chemical compound C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O MQIGTEQXYCRLGK-BQBZGAKWSA-N 0.000 description 1
- 108010088751 Albumins Proteins 0.000 description 1
- 102000009027 Albumins Human genes 0.000 description 1
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 1
- 241000143060 Americamysis bahia Species 0.000 description 1
- WVNFNPGXYADPPO-BQBZGAKWSA-N Arg-Gly-Ser Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O WVNFNPGXYADPPO-BQBZGAKWSA-N 0.000 description 1
- 241000228232 Aspergillus tubingensis Species 0.000 description 1
- 102100032487 Beta-mannosidase Human genes 0.000 description 1
- 101100083069 Candida albicans (strain SC5314 / ATCC MYA-2876) PGA62 gene Proteins 0.000 description 1
- 101100106993 Candida albicans (strain SC5314 / ATCC MYA-2876) YWP1 gene Proteins 0.000 description 1
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 1
- 108010084185 Cellulases Proteins 0.000 description 1
- 102000005575 Cellulases Human genes 0.000 description 1
- 108010008885 Cellulose 1,4-beta-Cellobiosidase Proteins 0.000 description 1
- 101710105223 Cerato-ulmin Proteins 0.000 description 1
- 241000272165 Charadriidae Species 0.000 description 1
- KRKNYBCHXYNGOX-UHFFFAOYSA-K Citrate Chemical compound [O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O KRKNYBCHXYNGOX-UHFFFAOYSA-K 0.000 description 1
- 108020004705 Codon Proteins 0.000 description 1
- SHIBSTMRCDJXLN-UHFFFAOYSA-N Digoxigenin Natural products C1CC(C2C(C3(C)CCC(O)CC3CC2)CC2O)(O)C2(C)C1C1=CC(=O)OC1 SHIBSTMRCDJXLN-UHFFFAOYSA-N 0.000 description 1
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 1
- MYMOFIZGZYHOMD-UHFFFAOYSA-N Dioxygen Chemical compound O=O MYMOFIZGZYHOMD-UHFFFAOYSA-N 0.000 description 1
- 108010001817 Endo-1,4-beta Xylanases Proteins 0.000 description 1
- 101000925662 Enterobacteria phage PRD1 Endolysin Proteins 0.000 description 1
- OTMSDBZUPAUEDD-UHFFFAOYSA-N Ethane Chemical group CC OTMSDBZUPAUEDD-UHFFFAOYSA-N 0.000 description 1
- 101150054379 FLO1 gene Proteins 0.000 description 1
- 108010058643 Fungal Proteins Proteins 0.000 description 1
- 101150082479 GAL gene Proteins 0.000 description 1
- UZWUBBRJWFTHTD-LAEOZQHASA-N Glu-Val-Asn Chemical compound NC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCC(O)=O UZWUBBRJWFTHTD-LAEOZQHASA-N 0.000 description 1
- 102000005720 Glutathione transferase Human genes 0.000 description 1
- 108010070675 Glutathione transferase Proteins 0.000 description 1
- KKBWDNZXYLGJEY-UHFFFAOYSA-N Gly-Arg-Pro Natural products NCC(=O)NC(CCNC(=N)N)C(=O)N1CCCC1C(=O)O KKBWDNZXYLGJEY-UHFFFAOYSA-N 0.000 description 1
- HHRODZSXDXMUHS-LURJTMIESA-N Gly-Met-Gly Chemical compound CSCC[C@H](NC(=O)C[NH3+])C(=O)NCC([O-])=O HHRODZSXDXMUHS-LURJTMIESA-N 0.000 description 1
- BCCRXDTUTZHDEU-VKHMYHEASA-N Gly-Ser Chemical compound NCC(=O)N[C@@H](CO)C(O)=O BCCRXDTUTZHDEU-VKHMYHEASA-N 0.000 description 1
- YDIDLLVFCYSXNY-RCOVLWMOSA-N Gly-Val-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)CN YDIDLLVFCYSXNY-RCOVLWMOSA-N 0.000 description 1
- 229930186217 Glycolipid Natural products 0.000 description 1
- 102000004157 Hydrolases Human genes 0.000 description 1
- 108090000604 Hydrolases Proteins 0.000 description 1
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 1
- 102000014150 Interferons Human genes 0.000 description 1
- 108010050904 Interferons Proteins 0.000 description 1
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical group SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 1
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 1
- 108090001090 Lectins Proteins 0.000 description 1
- 102000004856 Lectins Human genes 0.000 description 1
- 229910009891 LiAc Inorganic materials 0.000 description 1
- 125000000729 N-terminal amino-acid group Chemical group 0.000 description 1
- 101800000135 N-terminal protein Proteins 0.000 description 1
- 239000000020 Nitrocellulose Substances 0.000 description 1
- 108091028043 Nucleic acid sequence Proteins 0.000 description 1
- 230000004989 O-glycosylation Effects 0.000 description 1
- 108091034117 Oligonucleotide Proteins 0.000 description 1
- 241000221671 Ophiostoma ulmi Species 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 101800001452 P1 proteinase Proteins 0.000 description 1
- 241000276498 Pollachius virens Species 0.000 description 1
- ZLMJMSJWJFRBEC-UHFFFAOYSA-N Potassium Chemical compound [K] ZLMJMSJWJFRBEC-UHFFFAOYSA-N 0.000 description 1
- CLNJSLSHKJECME-BQBZGAKWSA-N Pro-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H]1CCCN1 CLNJSLSHKJECME-BQBZGAKWSA-N 0.000 description 1
- DMKWYMWNEKIPFC-IUCAKERBSA-N Pro-Gly-Arg Chemical compound [H]N1CCC[C@H]1C(=O)NCC(=O)N[C@@H](CCCNC(N)=N)C(O)=O DMKWYMWNEKIPFC-IUCAKERBSA-N 0.000 description 1
- KHRLUIPIMIQFGT-AVGNSLFASA-N Pro-Val-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O KHRLUIPIMIQFGT-AVGNSLFASA-N 0.000 description 1
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 1
- 229920001131 Pulp (paper) Polymers 0.000 description 1
- 102000007056 Recombinant Fusion Proteins Human genes 0.000 description 1
- 108010008281 Recombinant Fusion Proteins Proteins 0.000 description 1
- 101100057247 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) ENA5 gene Proteins 0.000 description 1
- 241000222480 Schizophyllum Species 0.000 description 1
- SRSPTFBENMJHMR-WHFBIAKZSA-N Ser-Ser-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SRSPTFBENMJHMR-WHFBIAKZSA-N 0.000 description 1
- SNXUIBACCONSOH-BWBBJGPYSA-N Ser-Thr-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CO)C(O)=O SNXUIBACCONSOH-BWBBJGPYSA-N 0.000 description 1
- LVHHEVGYAZGXDE-KDXUFGMBSA-N Thr-Ala-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(=O)O)N)O LVHHEVGYAZGXDE-KDXUFGMBSA-N 0.000 description 1
- UBDDORVPVLEECX-FJXKBIBVSA-N Thr-Gly-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](CCSC)C(O)=O UBDDORVPVLEECX-FJXKBIBVSA-N 0.000 description 1
- MSIYNSBKKVMGFO-BHNWBGBOSA-N Thr-Gly-Pro Chemical compound C[C@H]([C@@H](C(=O)NCC(=O)N1CCC[C@@H]1C(=O)O)N)O MSIYNSBKKVMGFO-BHNWBGBOSA-N 0.000 description 1
- RVMNUBQWPVOUKH-HEIBUPTGSA-N Thr-Ser-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RVMNUBQWPVOUKH-HEIBUPTGSA-N 0.000 description 1
- 108090000190 Thrombin Proteins 0.000 description 1
- 108010077913 Triamcinolone Acetonide Drug Combination Nystatin Neomycin Sulfate Gramicidin Proteins 0.000 description 1
- 239000013504 Triton X-100 Substances 0.000 description 1
- 229920004890 Triton X-100 Polymers 0.000 description 1
- 108060008682 Tumor Necrosis Factor Proteins 0.000 description 1
- 241000221566 Ustilago Species 0.000 description 1
- GIAZPLMMQOERPN-YUMQZZPRSA-N Val-Pro Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(O)=O GIAZPLMMQOERPN-YUMQZZPRSA-N 0.000 description 1
- YVNQAIFQFWTPLQ-UHFFFAOYSA-O [4-[[4-(4-ethoxyanilino)phenyl]-[4-[ethyl-[(3-sulfophenyl)methyl]amino]-2-methylphenyl]methylidene]-3-methylcyclohexa-2,5-dien-1-ylidene]-ethyl-[(3-sulfophenyl)methyl]azanium Chemical compound C1=CC(OCC)=CC=C1NC1=CC=C(C(=C2C(=CC(C=C2)=[N+](CC)CC=2C=C(C=CC=2)S(O)(=O)=O)C)C=2C(=CC(=CC=2)N(CC)CC=2C=C(C=CC=2)S(O)(=O)=O)C)C=C1 YVNQAIFQFWTPLQ-UHFFFAOYSA-O 0.000 description 1
- 238000010521 absorption reaction Methods 0.000 description 1
- 238000003916 acid precipitation Methods 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 239000004480 active ingredient Substances 0.000 description 1
- 108010005233 alanylglutamic acid Proteins 0.000 description 1
- 108010047495 alanylglycine Proteins 0.000 description 1
- 238000005571 anion exchange chromatography Methods 0.000 description 1
- 125000000129 anionic group Chemical group 0.000 description 1
- 238000000137 annealing Methods 0.000 description 1
- 108010069926 arginyl-glycyl-serine Proteins 0.000 description 1
- 235000013405 beer Nutrition 0.000 description 1
- 230000003542 behavioural effect Effects 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- 108010055059 beta-Mannosidase Proteins 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 230000003139 buffering effect Effects 0.000 description 1
- 229910052799 carbon Inorganic materials 0.000 description 1
- 125000002091 cationic group Chemical group 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 238000003776 cleavage reaction Methods 0.000 description 1
- 238000004737 colorimetric analysis Methods 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 238000012790 confirmation Methods 0.000 description 1
- 239000000470 constituent Substances 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 239000000287 crude extract Substances 0.000 description 1
- 238000002425 crystallisation Methods 0.000 description 1
- 230000008025 crystallization Effects 0.000 description 1
- 210000000172 cytosol Anatomy 0.000 description 1
- 230000006378 damage Effects 0.000 description 1
- 238000005202 decontamination Methods 0.000 description 1
- 230000003588 decontaminative effect Effects 0.000 description 1
- 230000007423 decrease Effects 0.000 description 1
- 239000008367 deionised water Substances 0.000 description 1
- 229910021641 deionized water Inorganic materials 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000011033 desalting Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- QONQRTHLHBTMGP-UHFFFAOYSA-N digitoxigenin Natural products CC12CCC(C3(CCC(O)CC3CC3)C)C3C11OC1CC2C1=CC(=O)OC1 QONQRTHLHBTMGP-UHFFFAOYSA-N 0.000 description 1
- SHIBSTMRCDJXLN-KCZCNTNESA-N digoxigenin Chemical compound C1([C@@H]2[C@@]3([C@@](CC2)(O)[C@H]2[C@@H]([C@@]4(C)CC[C@H](O)C[C@H]4CC2)C[C@H]3O)C)=CC(=O)OC1 SHIBSTMRCDJXLN-KCZCNTNESA-N 0.000 description 1
- 239000000539 dimer Substances 0.000 description 1
- 238000011143 downstream manufacturing Methods 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 238000004043 dyeing Methods 0.000 description 1
- 101150066032 egl-1 gene Proteins 0.000 description 1
- 238000001962 electrophoresis Methods 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 108010091371 endoglucanase 1 Proteins 0.000 description 1
- 238000001976 enzyme digestion Methods 0.000 description 1
- 150000002148 esters Chemical class 0.000 description 1
- 238000012869 ethanol precipitation Methods 0.000 description 1
- PSLIMVZEAPALCD-UHFFFAOYSA-N ethanol;ethoxyethane Chemical compound CCO.CCOCC PSLIMVZEAPALCD-UHFFFAOYSA-N 0.000 description 1
- IDGUHHHQCWSQLU-UHFFFAOYSA-N ethanol;hydrate Chemical compound O.CCO IDGUHHHQCWSQLU-UHFFFAOYSA-N 0.000 description 1
- 239000013613 expression plasmid Substances 0.000 description 1
- 239000006052 feed supplement Substances 0.000 description 1
- 230000003311 flocculating effect Effects 0.000 description 1
- 238000005189 flocculation Methods 0.000 description 1
- 230000016615 flocculation Effects 0.000 description 1
- 238000013467 fragmentation Methods 0.000 description 1
- 238000006062 fragmentation reaction Methods 0.000 description 1
- 239000007789 gas Substances 0.000 description 1
- 238000002523 gelfiltration Methods 0.000 description 1
- 230000002068 genetic effect Effects 0.000 description 1
- 238000010353 genetic engineering Methods 0.000 description 1
- 125000005456 glyceride group Chemical group 0.000 description 1
- 125000003147 glycosyl group Chemical group 0.000 description 1
- 230000013595 glycosylation Effects 0.000 description 1
- 238000006206 glycosylation reaction Methods 0.000 description 1
- 108010089804 glycyl-threonine Proteins 0.000 description 1
- 125000001475 halogen functional group Chemical group 0.000 description 1
- 238000010438 heat treatment Methods 0.000 description 1
- LIIALPBMIOVAHH-UHFFFAOYSA-N herniarin Chemical compound C1=CC(=O)OC2=CC(OC)=CC=C21 LIIALPBMIOVAHH-UHFFFAOYSA-N 0.000 description 1
- JHGVLAHJJNKSAW-UHFFFAOYSA-N herniarin Natural products C1CC(=O)OC2=CC(OC)=CC=C21 JHGVLAHJJNKSAW-UHFFFAOYSA-N 0.000 description 1
- 101150102292 hfb1 gene Proteins 0.000 description 1
- 150000002411 histidines Chemical class 0.000 description 1
- 230000036571 hydration Effects 0.000 description 1
- 238000006703 hydration reaction Methods 0.000 description 1
- 239000000413 hydrolysate Substances 0.000 description 1
- 230000005660 hydrophilic surface Effects 0.000 description 1
- 238000004191 hydrophobic interaction chromatography Methods 0.000 description 1
- WGCNASOHLSPBMP-UHFFFAOYSA-N hydroxyacetaldehyde Natural products OCC=O WGCNASOHLSPBMP-UHFFFAOYSA-N 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 230000002779 inactivation Effects 0.000 description 1
- 210000003000 inclusion body Anatomy 0.000 description 1
- 238000011534 incubation Methods 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 239000003262 industrial enzyme Substances 0.000 description 1
- 230000005764 inhibitory process Effects 0.000 description 1
- 239000002054 inoculum Substances 0.000 description 1
- 229910052500 inorganic mineral Inorganic materials 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 230000017730 intein-mediated protein splicing Effects 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 229940079322 interferon Drugs 0.000 description 1
- 230000016507 interphase Effects 0.000 description 1
- 230000003834 intracellular effect Effects 0.000 description 1
- 238000005342 ion exchange Methods 0.000 description 1
- 238000004255 ion exchange chromatography Methods 0.000 description 1
- 150000002500 ions Chemical class 0.000 description 1
- BPHPUYQFMNQIOC-NXRLNHOXSA-N isopropyl beta-D-thiogalactopyranoside Chemical compound CC(C)S[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O BPHPUYQFMNQIOC-NXRLNHOXSA-N 0.000 description 1
- 238000005304 joining Methods 0.000 description 1
- 238000009533 lab test Methods 0.000 description 1
- 238000002386 leaching Methods 0.000 description 1
- 238000013507 mapping Methods 0.000 description 1
- 238000004949 mass spectrometry Methods 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 108010005942 methionylglycine Proteins 0.000 description 1
- ZLQJVGSVJRBUNL-UHFFFAOYSA-N methylumbelliferone Natural products C1=C(O)C=C2OC(=O)C(C)=CC2=C1 ZLQJVGSVJRBUNL-UHFFFAOYSA-N 0.000 description 1
- 239000011707 mineral Substances 0.000 description 1
- 239000011259 mixed solution Substances 0.000 description 1
- 239000002808 molecular sieve Substances 0.000 description 1
- NCXMLFZGDNKEPB-FFPOYIOWSA-N natamycin Chemical compound O[C@H]1[C@@H](N)[C@H](O)[C@@H](C)O[C@H]1O[C@H]1/C=C/C=C/C=C/C=C/C[C@@H](C)OC(=O)/C=C/[C@H]2O[C@@H]2C[C@H](O)C[C@](O)(C[C@H](O)[C@H]2C(O)=O)O[C@H]2C1 NCXMLFZGDNKEPB-FFPOYIOWSA-N 0.000 description 1
- 229960003255 natamycin Drugs 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- JPXMTWWFLBLUCD-UHFFFAOYSA-N nitro blue tetrazolium(2+) Chemical compound COC1=CC(C=2C=C(OC)C(=CC=2)[N+]=2N(N=C(N=2)C=2C=CC=CC=2)C=2C=CC(=CC=2)[N+]([O-])=O)=CC=C1[N+]1=NC(C=2C=CC=CC=2)=NN1C1=CC=C([N+]([O-])=O)C=C1 JPXMTWWFLBLUCD-UHFFFAOYSA-N 0.000 description 1
- 229920001220 nitrocellulos Polymers 0.000 description 1
- 239000002736 nonionic surfactant Substances 0.000 description 1
- 230000001590 oxidative effect Effects 0.000 description 1
- 108091005706 peripheral membrane proteins Proteins 0.000 description 1
- 150000003016 phosphoric acids Chemical class 0.000 description 1
- 125000005498 phthalate group Chemical group 0.000 description 1
- 229920001983 poloxamer Polymers 0.000 description 1
- 239000011591 potassium Substances 0.000 description 1
- 238000001556 precipitation Methods 0.000 description 1
- 230000037452 priming Effects 0.000 description 1
- 108010029020 prolylglycine Proteins 0.000 description 1
- 238000002731 protein assay Methods 0.000 description 1
- 239000012264 purified product Substances 0.000 description 1
- RYVMUASDIZQXAA-UHFFFAOYSA-N pyranoside Natural products O1C2(OCC(C)C(OC3C(C(O)C(O)C(CO)O3)O)C2)C(C)C(C2(CCC3C4(C)CC5O)C)C1CC2C3CC=C4CC5OC(C(C1O)O)OC(CO)C1OC(C1OC2C(C(OC3C(C(O)C(O)C(CO)O3)O)C(O)C(CO)O2)O)OC(CO)C(O)C1OC1OCC(O)C(O)C1O RYVMUASDIZQXAA-UHFFFAOYSA-N 0.000 description 1
- 230000008707 rearrangement Effects 0.000 description 1
- 230000002940 repellent Effects 0.000 description 1
- 239000005871 repellent Substances 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
- 239000012723 sample buffer Substances 0.000 description 1
- 230000007017 scission Effects 0.000 description 1
- 230000003248 secreting effect Effects 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 238000001338 self-assembly Methods 0.000 description 1
- 238000001612 separation test Methods 0.000 description 1
- 238000012163 sequencing technique Methods 0.000 description 1
- 150000003355 serines Chemical class 0.000 description 1
- 238000012807 shake-flask culturing Methods 0.000 description 1
- 238000002791 soaking Methods 0.000 description 1
- URGAHOPLAPQHLN-UHFFFAOYSA-N sodium aluminosilicate Chemical compound [Na+].[Al+3].[O-][Si]([O-])=O.[O-][Si]([O-])=O URGAHOPLAPQHLN-UHFFFAOYSA-N 0.000 description 1
- 239000007790 solid phase Substances 0.000 description 1
- 238000002798 spectrophotometry method Methods 0.000 description 1
- 230000006641 stabilisation Effects 0.000 description 1
- 238000011105 stabilization Methods 0.000 description 1
- 230000003335 steric effect Effects 0.000 description 1
- 239000008399 tap water Substances 0.000 description 1
- 235000020679 tap water Nutrition 0.000 description 1
- BFKJFAAPBSQJPD-UHFFFAOYSA-N tetrafluoroethene Chemical group FC(F)=C(F)F BFKJFAAPBSQJPD-UHFFFAOYSA-N 0.000 description 1
- 229960004072 thrombin Drugs 0.000 description 1
- 238000012549 training Methods 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 230000014621 translational initiation Effects 0.000 description 1
- GFNANZIMVAIWHM-OBYCQNJPSA-N triamcinolone Chemical compound O=C1C=C[C@]2(C)[C@@]3(F)[C@@H](O)C[C@](C)([C@@]([C@H](O)C4)(O)C(=O)CO)[C@@H]4[C@@H]3CCC2=C1 GFNANZIMVAIWHM-OBYCQNJPSA-N 0.000 description 1
- YNJBWRMUSHSURL-UHFFFAOYSA-N trichloroacetic acid Chemical compound OC(=O)C(Cl)(Cl)Cl YNJBWRMUSHSURL-UHFFFAOYSA-N 0.000 description 1
- 238000009941 weaving Methods 0.000 description 1
- 238000005303 weighing Methods 0.000 description 1
- 150000008495 β-glucosides Chemical class 0.000 description 1
Images








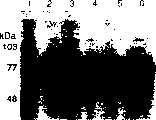




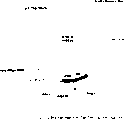



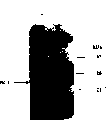


Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K1/00—General methods for the preparation of peptides, i.e. processes for the organic chemical preparation of peptides or proteins of any length
- C07K1/14—Extraction; Separation; Purification
- C07K1/16—Extraction; Separation; Purification by chromatography
- C07K1/20—Partition-, reverse-phase or hydrophobic interaction chromatography
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K7/00—Peptides having 5 to 20 amino acids in a fully defined sequence; Derivatives thereof
- C07K7/04—Linear peptides containing only normal peptide links
- C07K7/06—Linear peptides containing only normal peptide links having 5 to 11 amino acids
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K1/00—General methods for the preparation of peptides, i.e. processes for the organic chemical preparation of peptides or proteins of any length
- C07K1/14—Extraction; Separation; Purification
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/37—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from fungi
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K7/00—Peptides having 5 to 20 amino acids in a fully defined sequence; Derivatives thereof
- C07K7/04—Linear peptides containing only normal peptide links
- C07K7/08—Linear peptides containing only normal peptide links having 12 to 20 amino acids
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/02—Fusion polypeptide containing a localisation/targetting motif containing a signal sequence
Landscapes
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Molecular Biology (AREA)
- Genetics & Genomics (AREA)
- Medicinal Chemistry (AREA)
- Biophysics (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biochemistry (AREA)
- General Health & Medical Sciences (AREA)
- Analytical Chemistry (AREA)
- Mycology (AREA)
- Gastroenterology & Hepatology (AREA)
- Peptides Or Proteins (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Enzymes And Modification Thereof (AREA)
Abstract
本发明是关于在双水相萃取系统(ATPS)中分离和纯化蛋白质。本发明尤其提供了通过把目标蛋白和靶向蛋白融合,在ATPS中对目标蛋白进行分配的方法,其中所述靶向蛋白有把目标蛋白带入其中某一相的能力。
Description
发明领域
本发明是关于在双水相系统(aqueous two-phase system)(ATPS)中分离和纯化蛋白质。本发明尤其提供了通过把目标蛋白和靶向蛋白融合,在ATPS中对目标蛋白进行分配的方法,其中的所述靶向蛋白有把目标蛋白带入其中某一相的能力。
发明背景
在双水相系统(ATPS)中进行液-液萃取,为蛋白质的分离和纯化提供了一项很有效的技术。通过液-液萃取分离大分子和颗粒已众所周知(Albertsson,1996;Walter等,1985;Kula,1990)。主要是应用聚乙二醇(PEG)-盐,PEG-葡聚糖和PEG-淀粉系统。最近发现,具有逆性(reversed)溶解性的两种去污剂适合分离大分子,尤其适合分离蛋白质。
双水相系统(ATPS)的一个优点是其尤其适合不但从培养上清而且从含有细胞和细胞碎片的粗提物中大规模处理微生物蛋白(Kula,1979;Kula,1985)。生物液体及悬浮液的典型特征是,它们为相当小的颗粒,液体与悬浮的固体之间密度差别小,提取物具有高粘度和固体具有高可压缩性(Hustedt等,1985;Bender和Koglin,1986)。这些降低了在蛋白质回收起始阶段传统的固-液分离方法,如离心和过滤的效果。利用双水相系统进行固体去除的步骤能并入液-液分离步骤,因此将澄清与最初的纯化步骤结合起来(Kula,1979;Kula,1985)。
提取过程后,可利用重力下静置以及利用离心来实现相分离(Kula,1985)。ATPS可在小至较小实验室规模,大至较大工业规模的各种规模中应用,因此适于各种蛋白、各种目的和需要。考虑到工业化的生产目的,可利用市售离心机以缩短分离时间。一些学者已经对各种设计的离心机处理大体积双水相系统的可能性进行了研究(Kula,1979;Kula等1981,Kula等1982,Kula 1985)。在以上研究中,学者们应用了聚合物/聚合物或聚合物/盐系统,这些研究结果证明了在离心机中进行双水相系统连续分离的可行性。
建立在非离子表面活性剂基础上的萃取系统已经被描述为标准的聚合物/聚合物或聚合物/盐系统的替代方法。用于相形成的表面活性剂是如聚氧乙烯型非离子去污剂。极性环氧乙烷端基的温度依赖型可逆水化作用是这种双水相系统的基础。发生相分离的温度是浊化点(浊化点萃取)。这种双水相系统尤其适合萃取两亲性生物分子。Bordier(1981)首先证实这种双水相系统可用来从胞液蛋白和外周膜蛋白分离膜结合蛋白。Heusch和Kopp(1988)已经能证实聚乙醇醚/水系统的可混合间隙中形成的层状结构负责选择性萃取疏水物质。
最近,有应用基于表面活性剂的双水相系统成功地从革兰氏阳性微生物玫瑰色诺卡氏菌(Nocardia rhodochrous)混浊培养基中以实验室规模萃取膜结合蛋白(胆固醇氧化酶)的报道(Minuth等,1995)。在均一相中,通过仅添加一种化学化合物,产物可通过溶解作用释放,第二步,通过在升高的温度下萃取分离富含去污剂的相可实现澄清以及最初的纯化。进一步通过基于表面活性剂的萃取,有机溶剂萃取,阴离子交换层析可生产膜结合酶,这产生适于分析性应用的产物(Minuth等,1996)。
在双水相系统中,标靶例如蛋白应该被选择性分配到其中一种相(优选较轻的相)中,而其它物质被分配到另一相(优选较重的相)中。在PEG/盐和PEG/葡聚糖以及其它相似系统中,驱动物质的作用力有几种,如荷电力,疏水力,亲水力,或对空间构象或配基间相互作用的依赖(Albertsson,1986)。有观点认为在基于去污剂的双水相系统中,导致分离的动力主要是疏水作用(Terstappen等,1993)。尽管在ATPS的预测领域开展了大量的工作,但是所设计的模型无一能提示所述相的物理学行为特征,这一领域的预测是几乎不可能的(Johansson等,1998)。
在ATPS中,分配系数被定义为上层相中目的产物的浓度(若是酶则是活性)除以底层相目的蛋白的浓度(酶:活性)。在ATPS系统中,分配系数通常从小于1到小于100(Terstappen等,1992;Terstappen等,1993)。
K=ci,T/ci,B
产量:定义为上层相目的产物的量除以上层相和底部相目的产物的总量。这引出如下公式
如果所需产物在较重的相(如在使用Triton的情况下)产量定义为:
两个共存相的体积比定义为较轻相的体积针对较重相的体积的比。
R=VT/VB
面临纯化成本问题的有用蛋白质有常用作工业用酶的生物催化剂,如细菌和真菌产生的糖基水解酶,蛋白酶和脂酶。这些酶用于如洗衣、纺织、造纸和纸浆、食品和饲料工业。微生物在生长中产生出多种不同酶且其中一部分在某些应用中并不需要,所以需要富集活性成分。这种富集可通过选择合适的生长条件,通过基因工程和/或通过下游加工(例如纯化活性成份)来进行。
蛋白纯化一般通过层析进行。常用的层析方法基于离子交换,疏水相互作用,亲和层析和分子筛。也可应用诸如电泳和结晶等方法。这些方法为领域内熟知,并适用于具有较高市场价值的蛋白质。但在大规模酶生产中,这些方法耗资昂贵不能使终产物维持合理的价格。由于这些酶相似的性质,通常需要几个纯化步骤把它们彼此分离。这常常导致最终产率低,并因此损失大量产物。
木霉属真菌产生的多种细胞外水解酶目前在不同的大规模工业中应用。这些水解酶例如半纤维素酶(例如木聚糖酶和甘露聚糖酶),纤维素酶(例如葡聚糖内切酶和纤维二糖水解酶)和蛋白酶。这些酶的纯化为本领域熟知(Bhikhabhai等,1984;Pere等,1995),但对于大规模工业应用而言,这些纯化方法成本太高。已用替代方法富集这些水解酶,包括利用基因工程去除不必要的基因(Suominen等,1992)。然而,即使经过广泛的基因工程,终产物中仍存在某些小量不必要的活性成分。
ATPS已在T.reesei纤维素酶和葡聚糖内切酶III的纯化中取得了满意的结果,提高了上层相蛋白质的产率(美国专利5,139,943)。在脂酶,木聚糖内切酶和纳他霉素的纯化也对ATPS进行了研究(EP 0 574 050 A1)。然而,并没有提到K和Y值。
如在其它蛋白质纯化方法一样,生物生产的蛋白的相似特性在ATPS中同样有害,例如一种蛋白的选择性分离效果不能达到最佳。为了在纯化中获得选择性,应用了各种亲和层析方法,尤其在进行分析和进行高价值产物的纯化时。这些方法包括免疫亲和层析和为本领域所熟知的各种融合蛋白策略,如将目标蛋白与其它蛋白(例如谷胱甘肽-S-转移酶)、蛋白结构域(例如蛋白A-ZZ结构域)或小分子肽(例如His标记)融合,这些融合对象选择性结合固体载体,因此可回收融合配偶体。融合蛋白适合这样的特殊用途,或可从加入的融合配偶体上切下产物。本领域熟知将融合蛋白从其配偶体上解离的方法,其利用蛋白酶,例如通过X因子,凝血酶或木瓜蛋白酶或通过通常基因工程手段引入蛋白酶切割位点(例如Kex2位点)或自加工结构域(例如Intein,新英格兰实验室)或通过化学切割(例如CNBr)。
ATPS主要在与基于固相分离系统如基于亲和柱的技术相比较时具有优势。利用化学工业领域常用的仪器和设备进行扩大规模的酶提取相对较简单。另外,ATPS可在连续处理过程中使用并且成本相对较高。ATPS可用于一步完成清洗,浓缩和纯化步骤。ATPS可作为第一捕获步骤,但大批量生产时通常不需要进一步纯化。
为了在双相系统中进行选择分离,最近的公开物描述了将12个氨基酸的小分子肽标记与待纯化的蛋白质融合。这些可溶性肽中最成功的例子含有色氨酸。迄今它们主要应用在非常小的分子,如葡萄球菌蛋白A衍生物ZZTO(Berggren等,1999;Hassinen等,1994;Kohler等,1991)。
ATPS的应用目前局限在特定范围内。由于ATPS在蛋白分离、纯化和定位方面的优越性,应该开发高度选择性和强有效的方法。这对于大规模加工(其中ATPS作为纯化、清洗和浓缩的第一捕获步骤或作为唯一步骤通常非常廉价)尤其重要。这种系统应该是通用的,使得该技术足以介导原则上任何的组分向所需相中的分离,而不必考虑其大小或生化性质。
发明简述
在本发明中,我们描述分子和颗粒通过与靶向蛋白融合而实现的选择性分离和分配,这些靶向蛋白可把目标分子和颗粒带到ATPS中的所需相,如果需要可使它们保留在该相中。本发明涉及使ATPS能应用于每种生物技术产品。通过蛋白的遗传标记,通过化学结合,粘连或应用任何其它技术将靶向蛋白添加到所选产物上,可使产物分子转化成更适于在ATPS系统中分离。通过利用ATPS,可将产物或特定成分分配到某一相中,而将其它成分或副产物分配到其它相中。
我们还描述,在ATPS中的有效分离可通过应用靶向蛋白来实现,所述靶向蛋白大于或可大于所需小分子可溶性合成肽标记(12个氨基酸或更小)。这些靶向分子能帮助分离小分子甚至大蛋白和颗粒。不同于小分子肽标记物,靶向分子不必包含色氨酸残基,尽管它们可能包含色氨酸残基。无论是单体形式或形成聚合物时,它们可为疏水型或中度疏水型和/或两亲性。这些蛋白可以是来源于自然界,或为人工设计,或通过本领域已知的突变,基因重排或定向进化的方法获得。通过例如把目标产物与自然或突变的序列文库融合,并筛选融合分子在ATPS中的分离能力,就能筛选出合适的靶向分子。而且,任何能在ATPS中分离的分子都是合适的靶向分子
几种利用纯化蛋白分离相应基因的技术可用于找出编码ATPS中适当靶向分子的基因。适当的蛋白或多肽可根据它们的特性来纯化。将细胞,细胞提取物或培养基加入ATPS系统中,并回收已分配进入含疏水相物质的相中的蛋白或肽。也可从,例如培养基泡沫中回收适合的靶向分子,这些泡沫是在微生物培养过程中或因向培养基中鼓泡而形成的。也可从冷冻培养基时产生的聚集物中回收适合作为靶向分子的蛋白和多肽。当靶向分子被纯化以后,应用本领域技术人员熟知的技术分离出相应的基因。这些技术包括:利用针对纯化多肽或肽的抗体筛选基因表达文库,PCR克隆和应用基于N-末端蛋白序列或内部蛋白序列设计的寡核苷酸进行基因组和/或cDNA文库的筛选。
自然界中适合在ATPS中作为靶向蛋白的分子包括疏水蛋白样小分子蛋白。最近从丝状真菌中发现的疏水蛋白是具有有趣的理化特性的分泌蛋白(Wessels,1994;Wsten和Wessels,1997;Kershaw and Talbot,1998)。它们通常是大约70-160个氨基酸的小分子蛋白,在保守模式中含有8个半胱氨酸残基,通常不含色氨酸。但是,带有一个或几个疏水蛋白结构域以及例如多脯氨酸或天冬酰胺/甘氨酸重复序列的多调节蛋白,或含有少于8个半胱氨酸残基的疏水蛋白也被确定(Lora等,1994;Lora等,1995;Arntz andTudzynski,1997)。疏水蛋白可根据它们的亲水性特征分成两类(Wessels,1994)。
目前,虽然已公开了疏水蛋白的30多个基因序列(Wsten和Wessels,1997),但现有蛋白数据主要是有关群交裂褶菌(Schizophyllum communed)疏水蛋白Sc3p(I类),Ophiostoma ulmi的角化-棕腐质(cerato-ulmin)和Cryponectria parasitica的cryparin(II类)。HFB基因经常为天然高表达,但是由于对培养条件的特殊要求和蛋白的生化性质,大量纯化HFB非常困难。例如,Sc3疏水蛋白通过静置培养只能获得每升数毫克的相对中等生产水平(Han Wsten,私人通信)。已公开的纯化方法包括利用有机溶剂从真菌细胞壁进行多步骤萃取,对培养基滤液进行鼓泡或冷冻(Wessels 1994)。还没有成功生产疏水蛋白的报道;角化-棕腐质蛋白水平并不比从其它天然真菌分离物获得的多(Temple等,1997)。
通过振动含有疏水蛋白的溶液,可使蛋白单体形成杆状沉淀。这些结构与在气生结构表面发现的相似。已经证明,纯化的Sc3疏水蛋白可以在亲水和疏水表面自我装配成10nm厚的两亲性分子层(Wsten等,1994a;Wsten等,1994b)。这一层膜与表面牢固相接,不易被诸如热去污剂等破坏。该层中位于亲水表面的疏水侧表现与聚四氟乙烯相似的特性(Wessels,1994)。Sc3聚合物以及角化-棕腐质与cryparin的聚合物,也可形成于气-液或气-空气界面,这样可稳定水中的气泡或油滴。
蛋白质的表面活性通常较低,但疏水蛋白属于表面活性分子,它们的表面活性剂能力至少与传统的生物表面活性剂,例如甘油脂,脂肽/脂蛋白,磷脂,天然脂类和脂肪酸相似(Wsten和Wessels,1997)。实际上,Sc3疏水蛋白是所知的活性最强的生物表面活性剂。它在浓度为50μg/ml时能把水表面张力降低到24mJm2,这是由于在单体自组为两亲性薄膜时构象的变化(Wsten和Wessels,1997)。
各种疏水蛋白样分子的性质是不同的,例如,并不是所有的疏水蛋白都具有形成小杆状结构的能力(例如一些II类分子),或这些分子形成稳定聚合物的能力较弱(Russo等,1992;Carpenter等,1992)。另一组真菌两亲性蛋白为驱避剂(Wsten等,1996(黑粉菌属),综述请参见Kershaw和Talbot,1998)。因此,适合在ATPS中作为靶向蛋白的其它类型蛋白可能仅具有疏水蛋白的部分特性。其它适合的蛋白是疏水性蛋白,例如:脂酶,胆固醇氧化酶,膜蛋白,小分子肽类药物如乳酸链球菌肽,聚合的细胞壁蛋白,脂肽类或以上蛋白的任何一部分或它们的组合物,以及其它分子如糖脂,磷脂,中性脂,与蛋白和肽类组合的脂肪酸。
在本发明中,靶向蛋白,如疏水蛋白样蛋白或其一部分,与要分离的产物分子或成份组合。首先,把形成相的物质和最终可能添加的盐类加入含融合分子或成份,并任选含有杂质的水溶液中。混合所添加的试剂,促进其溶解。一旦溶解,依靠重力沉降或离心作用可形成两相。在分离中靶向蛋白驱使产物进入到例如去污剂富集相中,该相可位于上层或底层。这种方法不但可纯化目标蛋白,而且可把目标产物或组分(如生物催化剂)保存在能进行某种有用的生物技术反应的特定相中。
数种ATPS系统适用实施本发明。这些系统包括含有PEG的系统,基于去污剂的系统和新的热分离聚合物系统。基于去污剂的系统可是非离子型,两性离子型,阳离子型或阴离子型。此系统可基于两亲性多聚去污剂,形成胶束的聚合物。新的聚合物可基于聚乙烯-聚丙烯共聚物,如pluronic block共聚物,玻雷吉(Brij),通过添加聚氧乙烯链到非酯化体产生的脂肪酸的部分酯的聚氧乙烯衍生物和聚氧乙烯衍生物。已知PEG/盐、PEG/葡聚糖和PEG/淀粉(或衍生物如Reppal,hydroxipropyl淀粉)系统,其中PEG与水形成上层相,葡聚糖/淀粉/盐与水形成底层相。所用的盐有磷酸盐,柠檬酸盐,硫酸盐或其它盐类。在本方法中,标靶主要被分配到上层相,而大部分杂质被分离到底部相。一些疏水性杂质也可能被分配到上层相。采用基于去污剂的系统时,只需加入一种形成相的去污剂。另外,也可加入盐类和其它化学试剂。加入上述化学试剂,使该溶液混合。混合后可通过离心或重力沉降进行分离。为了分离进入两相,溶液的温度应超过去污剂的浊化点。如果溶液的温度未达到浊化点,应该加热。如有需要,可在第一步提取之后进行第二步提取,并可对富含产物的相进一步纯化。也可对含有很少量产物和大量副产物的相中的剩余产物再次提取,这样可获得非常好的K值,产量和浓度系数都很高。
本发明的操作方法适合于实验室规模,但是尤其适合于大规模分离。本发明能成功地从大发酵体系中分离蛋白和组份。通过遗传修饰,本发明可用于纯化任何目标蛋白,包括从含有大量蛋白(例如每升数克)的混合物中纯化胞外酶和蛋白质如纤维素酶和半纤维素酶。另外,能从各种培养基分离蛋白,这些培养基包括含有特殊物质如纤维素和陈旧(spent)谷物的工业培养基。本方法可用于从经修饰不产生内源疏水蛋白的菌株培养液纯化产物。可直接对发酵液进行分离,该发酵液中还可含有细胞,甚至是粘性的丝状真菌。用本方法可如实施例9所述获得较高的生物量。实例如真菌Trichoderma reese的胞外内切葡聚糖酶I,其能被例如2类HFBI标记,并可利用非离子聚氧乙烯C12-C18EO5分离。在本例中,去污剂富集相为较轻相,含有绝大部分标记的内切葡聚糖酶,而大多数其它纤维素酶,蛋白酶和其它酶保留在较重的相内。菌丝体也被分离到底部的相内。通过25℃以上的分离温度能完成这种分离。如果加入NaCl或K2SO4这样的盐类,可降低分离温度。
本发明描述了对多种不同生物如细菌,酵母菌和丝状真菌产生的分子的分离。本发明适合纯化位于细胞外或细胞内的产物分子,包括附着在细胞壁上的分子。这不但提供了不同生物是如何分泌融合分子的例子,也提供了所述融合如何能在细胞内产生的例子。
本发明进一步描述含有几个结构域的融合分子是如何构建、成功表达和生产的。本发明描述了靶向分子与小分子蛋白(CBD),中等大小的蛋白(EGI),巨大的高度糖基化蛋白(FloI),以及这些蛋白的不同结构域变体的融合。这些分子能以这种状态进行生物技术应用。或者,可用已知方法将产物从靶向蛋白上切割下来,如利用蛋白酶(如凝血酶,X因子,木瓜蛋白酶),或通过化学切割。另外,切割后使产物与靶向蛋白分离优选用ATPS法,也可用本领域已知的其它分离方法。
一个令人惊讶的特点是,在ATPS中,靶向蛋白也能用来携带大颗粒到目标相中。当颗粒已经含有适于靶向如真菌的孢子/分生孢子的蛋白时便是如此。靶向蛋白也能体外粘附在颗粒或化合物上。如果细胞已分离,可选择使靶向蛋白在重组细胞中表达后暴露在细胞表面,从而利用其介导细胞在ATPS中的分离。在实施例22中演示了这如何进行。其它能把靶向分子引领到细胞表面的分子类型,在例如以下文献中可找到:细菌外膜蛋白和脂蛋白(Stahl and Uhlen,1997),酵母蛋白α-凝集素和絮凝素(flocculin)(Schreuder等,1996;Klis等(1994)WO 94/01567;Frenken(1994)WO 94/18330)
这个系统的另一个优点是,与ATPS结合的本发明提供了不仅从非必需或不必要的蛋白而且从有害蛋白如蛋白酶中分离产物或所需成分的方法,如实施例6所述。因此,本发明尤其适合生产和纯化异源蛋白,例如通常在异源宿主体内以有限量产生的敏感性哺乳动物蛋白。这些异源蛋白包括例如抗体或其片段,干扰素,白细胞介素,氧化酶和其它也可在宿主中产生的任何异源蛋白。可从诸如培养基中在线或半连续分离产物,这样能使蛋白酶和培养基内其它有害成分的影响减至最小。当蛋白在细胞内生成时,本发明还能提供从细胞提取物中分离异源产物,如其生成的内含体的方法。
本发明首次描述了可以不考虑疏水蛋白样分子极其特殊的特性,而大量制备并生产含疏水蛋白样分子的融合蛋白。重要的是,本发明还描述了重组菌株如何产生增加量的疏水蛋白样蛋白。这使得能产生所需靶向蛋白,其在需要时通过体外结合产物或颗粒,而能进一步在ATPS中分离这些分子或颗粒。
重要的是,本发明还描述了在ATPS中如何以较高K值极有效地纯化疏水蛋白样分子。所述分子可以按与上述融合相同的方式分离,例如利用PEG系统或基于去污剂的系统。可从培养基或从细胞中进行分离。这为含疏水蛋白样分子的纯制品的制备带来极大的改进(因为所述含疏水蛋白氧分子的纯制品因其特性而使其纯化非常复杂),并导致不必使用如上所述的已报道的技术。
附图简述
图1图示质粒pMQ 103。
图2图示质粒pMQ 113。
图3图示质粒pMQ 104。
图4图示质粒pMQ 114。
图5图示质粒pMQ 105。
图6图示质粒pMQ 115。
图7图示质粒pMQ 121。
图8利用5%去污剂C12-C18EO5在两相分离中分配EGIcore-HFBI融合蛋白,经10%SDS-PAGE后,凝胶用考马斯亮蓝染色的结果。泳道1,标准分子量;泳道2,纯化的CBHI(4μg):泳道3,纯化的EGI(4μg):泳道4,1/10稀释的VTT-D-98691基于纤维素的培养物滤液;泳道5和6,用5%去污剂分离VTT-D-98691培养物滤液以后分别的1/10稀释的底层相和去污剂相(上层相);泳道7,未稀释的底层相;泳道8,未稀释的VTT-D-98691纤维素培养物滤液。
图9使用不同浓度的去污剂C12-C18EO5在两相分离中分配EGIcore-HFBI融合蛋白,然后进行Western分析的结果。利用抗HFBI抗体检测融合蛋白。泳道1,标准分子量;泳道2,纯化的EGI;泳道3,VTT-D-98691纤维素培养物滤液;泳道4和5,用5%去污剂分离VTT-D-98691培养物滤液以后,分别的去污剂相(上层相)和底层相;泳道6,与泳道3相同但使用2%的去污剂;泳道7,与泳道4相同,但使用2%的去污剂;泳道8,纯化的EGI;泳道9,纯化的CBHI。
图10为用2%去污剂再次萃取上层相时,从内源性CBHI中进一步纯化EGIcore-HFBI融合蛋白,经10%SDS-PAGE后,凝胶经考马斯亮蓝染色的结果。泳道1,标准分子量;泳道2,纯化的CBHI(4μg):泳道3,纯化的EGI(4μg):泳道4,首次萃取后的去污剂相(上层相);泳道5,二次萃取后的去污剂相(上层相)。
图11为EGI-HFBI蛋白用凝血酶处理后经10%SDS-PAGE再经考马斯亮蓝染色的结果。泳道1,标准分子量;泳道2,经3U凝血酶24℃处理72小时的EGI-HFBI(1mg/ml);泳道3,同泳道2,但未加凝血酶;泳道4,经9U凝血酶36℃处理48小时的EGI-HFBI(1mg/ml);泳道5,同泳道4,但未加凝血酶;泳道6,同泳道5,但未在36℃保温;
图12显示质粒pTNS13的图谱。
图13为用5%的去污剂C12-C18EO5在两相分离中分配dCBD-HFBI融合蛋白,然后进行Western分析的结果。利用抗HFBI抗体检测融合蛋白。泳道1,经4倍浓缩的培养物滤液;泳道2,经4倍浓缩的底层相;泳道3,上层相。
图14为质粒pTNS15示图。星号标记为一非功能性限制位点。
图15为质粒pTNS18示图。
图16为质粒pTNS23示图。
图17显示已将表面表达疏水蛋白的细胞分配至去污剂相中:酿酒酵母(S.cerevisiae)VTT-C-99315的上层去污剂相显示混浊,而对照菌株H2155的下层去污剂相显示清晰。
图18为质粒pTNS32示图。
图19为质粒pTH4示图。
图20为质粒pTNS30示图。
图21为质粒pTH1示图。
图22为质粒pTH2示图。
图23为质粒pKS3示图。
图24为SDS凝胶,其显示出HFBI-dCBD在Berol 1532 ATPS系统中的纯化。
图25使用4%的去污剂C12-C18EO5在两相分离中分配HFBI-ENA5ScFv融合蛋白,再进行Western分析的结果。泳道从左边起:(1)标准分子量;(2)VTT-D-00791菌株的上层(富集)相,(3)VTT-D-00791菌株的底层(贫化)相。
图26利用SC3特异性抗体分配SC3疏水蛋白的Western分析结果。泳道1,VTT-D-00791菌株的底层相,泳道2,VTT-D-00792菌株的上层相
图27为监测HFBI在2% Berol 532中的分配的HPLC分析。
图28为监测HFBII在2% Berol 532中的分配的HPLC分析。
本发明用以下实施例进一步阐明,其中描述了本发明融合蛋白的构建,和利用本发明方法进行的目的分子的分配。
实施例
实施例1
构建受木霉属cbhI和gpdI启动子和曲霉属gpdA启动子驱动而表达EGI和EGIcore HFBI融合蛋白的载体
为构建EGI-HFBI融合蛋白,以pTNS9为模板,PCR扩增hfb1(SEQ ID1)编码区(从第23个丝氨酸至终止密码)和其前面的连接肽序列(Val Pro ArgGly Ser Ser Ser Gly Thr Ala Pro Gly Gly),5’引物为:TCG GG
C ACT ACG TGC CAG TAT AGC AAC GAC TAC TAC TCG CAA TGC CTT GTT CCGCGT GGC TCT AGT TCT GGA ACC GCA(SEQ ID 2),3’引物为TCG TACGGA TCC TCA AGC ACC GAC GGC GGT(SEQ ID 3)。在实施例19中对pTNS9进行了详述。5’引物中粗体字母的序列编码EGIC-末端16个残基,斜体序列是凝血酶的酶切位点,下划线的CACTACGTG序列是DraIII酶切位点。3’引物中下划线的GGATCC序列是BamHI酶切位点。经过琼脂糖凝胶纯化的280bp的PCR产物与载体pGEM-T T/A(Promega)连接,构建成pMQ102。
为构建EGIcore-HFBI融合蛋白,以pTNS9为模板,PCR扩增hfb1编码区(如上),5’引物序列为:ACT ACA CGG AG
G AGC TCG ACG ACTTCG AGC AGC CCG AGC TGC ACG CAG AGC AAC GGC AACGGC(SEQ ID 4)。3’引物序列为SEQ ID 3。5’引物中粗体字母的序列编码EGI中410-425位的氨基酸,下划线的GAGCTC序列是SacI酶切位点。经过琼脂糖凝胶纯化的260bp的PCR产物与载体pPCRIIT/A(Invitrogen)连接,构建成pMQ111。
下一步构建在cbhI启动子和终止序列调控下产生EGI-HFBI和EGIcore-HFBI融合蛋白的木霉属表达载体。用作构建体骨架的表达载体是pPLE3 (Nakari等,(1994)WO94/04673),它含有pUC18骨架,并在EcoRI位点处插有cbhI启动子(SEQ ID 5)。cbhI启动子可操作连接至egll全长cDNA(SEQ ID 6)编码序列和cbhI转录终止子(SEQ ID 7)。pMQ102质粒被DraIII和BamHI消化,得到含hfd1和接头序列的280bp片段,将该片段经琼脂糖凝胶纯化,再与DraIII和BamHI消化的质粒pPLE3连接。pMQ111质粒用SacI和BamHI消化,得到含有hfd1的260bp片段,使该片段与经SacI和BamHI消化的pPLE3连接。所得pMQ103质粒(图1)和pMQ113质粒(图2)携有与HFBI经连接肽连接的ECI全长编码序列以及与HFBI经自身接头区连接的EGIcore编码序列,它们分别受控于启动子cbh1和终止子序列。
在木霉属gpdI启动子和终止子序列以及曲霉属gpdA启动子和trpC终止子序列控制下生产EGI-HFBI和EGIcore-HFBI融合蛋白的木霉属表达载体如下构建。用TAA CCG CGG T(SEQ ID 8)和CTA GAC CGC GGT TAAT(SEQ ID 9)作为衔接子退火引物,在pMV4的XbaI和PacI位点之间插入一个SacII位点,得到质粒pMVQ。pMV4质粒含有pNEB193(新英格兰生物实验室)的骨架,并携带1.2kb的木霉属gpdI启动子(SEQID 10)和1.1kb的gpdI终止子(SEQ ID 11),两者分别插入SalI-XbaI和BamHI-AscI位点。用SacII和BarnHI从pMQ103和pMQ113释放EGI-HFBI和EGIcore-HFBI的表达盒,经过琼脂糖凝胶纯化再与经SacII和BamHI消化的pMVQ连接。得到的pMQ104质粒(图3)和pMQ114质粒(图4)分别携带有EGI-HFBI和EGIcore-HFBI表达盒,这些盒受到木霉属gpdI转录调控序列的控制。构建表达质粒pMQ105(图5)和pMQ115(图6),它们分别含有EGI-HFBI和EGIcore-HFBI表达盒,所述盒与曲霉菌的gpdA启动子和trpC终止子可操作地相连。用XbaI和BamHI从质粒pMQ104和pMQ114释放EGI-HFBI和EGIcore-HFBI25表达盒,用T4 DNA聚合酶钝化并与经NcoI消化和T4DNA聚合酶处理的pAN52-1(SEQ ID 12)连接。pAN52-1含有pUC18骨架,并携有构巢曲霉的2.3kb gpdA启动子和0.7kb trpC终止子序列。
实施例2
构建在纤维素酶诱导下于抑制性培养基中过量表达HFBI的载体
为了在启动子cbhI调控下过量表达HFBI蛋白,以pEA10为模板,PCR扩增hfd1的蛋白编码区(Nakari-Setl等,1996)。pEA10含有5.8kb的基因组Sa1I片段,此片段包含hfb1编码序列和侧翼序列。用GTC AA
C CGC GGA CTG CGC ATC ATG AAG TTC TTC GCC ATC(SEQ ID 13)作为PCR的5’端引物,SEQ ID 3作为3’端引物。5’引物中粗体字母的序列是21bp的cbhI启动子,此启动子邻近相应基因的翻译起始点,下划线的CCGCGG是KspI位点。所得430bp片段用KspI和BamHI消化,与用KspI和BamHI消化的pMQ103质粒相连。得到的质粒pMQ121(图7)携带与cbhI转录调控序列可操作地连接的hfb1编码序列。pEA10质粒用来在纤维素酶抑制条件下过量表达HFBI。
实施例3
转化木霉属真菌,纯化能产生EGI-HFBI和EGIcore-HFBI并过量产生HFBI的克隆
基本如(Penttila等,1987)所述,用3-13微克pMQ103,pMQ113,pMQ104,pMQ114,pMQ105,pMQ115,pMQ121和pEA10质粒以及作为选择质粒的1-3微克pToC202,p3SR2或pARO21共转化Trichoderma reesi菌株QM9414(VTT-D-74075)和Rut-C30(VTT-D-86271)。pToC202(pUC19骨架)p3SR2(pBR322骨架)质粒和分别携带构巢曲霉的2.7kb XbaI和5kbEcoRI-SalI基因组片段,这两种质粒含有amdS基因(Hynes等,1983;Tilburn等,1983)。pARO21质粒基本相同于pRLMex30(Mach等1994),并携带与T.reesei的730bp pkiI启动子和1kb cbh2终止子序列可操作相连的大肠杆菌hph基因。所得Amd+和Hyg+转化体分别在含有乙酰胺和潮霉素的平板上划线接种3次(Penttil等,1987)。然后从生长自马铃薯葡萄糖琼脂(Difco)的转化体制备孢子悬液。
在摇瓶或微滴板中的补充了葡萄糖、乳糖或Solka flock纤维素和/或陈旧谷物和/或乳清的混合物的基本培养基上生产融合蛋白EGI-HFBI、EGIcore-HFBI和HFIB,用EGI和HFBI特异性抗体经狭线印迹法或Western分析检测该生产。纯化能产生融合蛋白的克隆的孢子悬浮液,在选择培养板(含有乙酰胺或潮霉素)上进行单孢子培养。为确定最佳生产者,如上述再次分析这些纯化克隆的融合蛋白生产。
所选用于进一步发酵罐培养的T.reesei菌株为VTT-D-98692(pEA10),VTT-D-98492(pMQ121),VTT-D-98693(pMQ103),VTT-D-98691(pMQ113),VTT-D-98681(pMQ105)和VTT-D-98682(pMQ115),这些菌株以QM 9414作为宿主菌株。VTT-D-99702(pMQ113)以Rut-C30作为宿主菌株。
实施例4
培养能产生EGI-HFBI和EGIcore-HFBI蛋白并过量产生HFBI的木霉属菌株
在15升发酵罐中分别培养T.reesei菌株VTT-D-98693(pMQ103)和VTT-D-98691(pMQ113),使得在启动子cbhI的调控下产生EGI-HFBI和EGIcore-HFBI融合体。菌株在含有4% Solka flock纤维素(James RiverCorporation,Berlin,NH)和2%陈旧谷物(Primalco,Koskenkorva,Finland)的基本培养基(Penttila等,1987)中生长5天。也可使Rut-C30菌株VTT-D-99702(pMQ113)在发酵罐(15L)中的4%乳糖培养基中生长,从而产生EGIcore-HFBI。为了诱导在曲霉属gpdA启动子调控下的EGI-HFBI和EGIcore-HFBI融合体的生产,在15升的发酵罐中培养T.reesei菌株VTT-D-98681(pMQ105)和VTT-D-98682(pMQ115)。使菌株在添加2%葡萄糖、0.2%蛋白胨、0.1%酵母浸膏的基本培养基上生长3-5天,期间通过补充葡萄糖使得维持其浓度在1%-3%的范围内。HFBI过量产生菌株VTT-D-98692(pEA10)以类似方式在15升发酵罐中的葡萄糖培养基上培养,于启动子cbh1调控下过量产生HFBI的菌株VTT-D-98492(pMQ121)在15升发酵罐中含4%Solkaflock纤维素和2%陈旧谷物的培养基中培养7天。在含有i)Solka flock纤维素和陈旧谷物或乳清ii)乳糖和iii)葡萄糖的培养基中对转化体的宿主菌株QM 9414(VTT-D-74075)和Rut-C30(VTT-D-86271)以类似于上述的方式进行对照培养。
适当时,也可将某些t.reesei转化菌株和它们的宿主菌株于28℃的摇瓶中培养5-6天,所述摇瓶中含有补充了3%So1ka flock纤维素和1%陈旧谷物,或以葡萄糖补料方式补充了3-4%葡萄糖的木霉属基本培养基(Penttil等,1987)50-150ml。
实施例5
标准的分离试验和分析
若未另行指明,标准ATPS和随后的分析及计算按本实施例所述进行。
通常将全发酵液、上清(离心或过滤所分离的生物量)或纯化蛋白的溶液分配在10ml刻度管中。首先,在管中加入去污剂,然后再加入含蛋白的溶液补足到10ml。管中的去污剂量以重量百分比计。在架空摇床(overheadshaker)上充分混合后,通过在恒温水浴内重力沉降或恒温离心进行分离。通常在30℃进行分离,所用去污剂的标准量是2-5%(w/v)。分离后记录体积比,对较轻相和较重相取样进行分析。
利用SDS-PAGE凝胶定量分析两相分配结果,然后经考马斯亮蓝R-250(Sigma)染色或Western印迹观察融合蛋白。在用Western分析检测EGI-HFBI,EGIcore-HFBI和dCBD-HFBI蛋白时,使用多克隆抗-HFBI抗体以及与抗兔IgG偶联的碱性磷酸酶(Bio-Rad)。联合应用BCIP(5-溴-4-氯-3-吲哚-磷酸)与NBT(氮蓝四唑)(Promega)经比色法检测碱性磷酸酶的活性。
上层相中内源性EGI,CBHI和EGIII杂质应用相应抗体检测。上层相和下层相内的酸性蛋白酶活性用SAP法检测(食品化学药典,496-497页,1981),该方法依据对血红蛋白底物的30分钟酶水解。所有反应在pH4.7,40℃进行。未被水解的底物用14%TCA沉淀,并经过滤清除。所释放的酪氨酸和色氨酸用分光光度法检测。总蛋白浓度应用非干扰性蛋白试验(Non-Interfering Protein AssayTM)(Geno Technology,Inc.)检测。
EGI的活性以4-甲基伞形基(umbelliferyl)-β-D-纤维二糖苷(MUC)(Sigma M 6018)作为底物来检测(Van Tilbergh H.& Caeyssens M.,1985;Van Tilbergh等,1982)。EGI水解β-糖苷健,释放出发荧光的4-甲基伞形酮,可用装有360激发滤片和455nm发射滤片的荧光计检测。CBHI也能水解该底物,添加纤维二糖(C-7252,Sigma)可抑制其水解作用。将适当稀释的含有EGI的液体加入含有50mM乙酸钠缓冲液(pH 5),0.6mM MUC和4.6mM纤维二糖的缓冲液中。把混合物加热到50℃。10分钟后加入2%Na2CO3,pH10终止反应。使用与检测EGI同样的方法检测纯化的CBHI,但不加抑制剂纤维二糖。
分配系数K定义上层相和下层相中各自所测浓度或活性比值。
产量Y按如下公式定义:
其中YT是上层相产量,VB和VT分别是下层相和上层相的体积。可相应描述下层相的产量。
不断检测质量平衡,例如添加的所有蛋白的回收,是否完成以确保避免出现人工高产量(例如由于底层相内蛋白可能的失活)。通常根据总酶活性(EGI野生型加EGI融合型)计算各种数值,这样就低估了融合体的分离值,如在实施例16中证实的。
实施例6
小规模ATPS分离研究和凝胶分析
如实施例4所述,在15升发酵罐中的Solka flock纤维素和陈旧谷物培养基中分别利用T.reesei菌株VTT-D-98693(pMQ103)和VTT-D-98691(pMQ113)生产受cbhI启动子调控的EGI-HFBI和EGIcore-HFBI融合蛋白,如上述在小规模ATPS中分离。
来自两相分离的相利用SDS-PAGE凝胶定量分析,并用考马斯亮蓝染色或Western印迹观察融合蛋白。图8为经考马斯亮蓝染色的SDS-PAGE(10%)。在含非提取的培养滤液的泳道中,可见三条距离很近但明显区别的条带(样本用水作1/10稀释)。最上面的条带是CBHI,中间带是EGIcore-HFBI融合蛋白,下面的是内源EGI。在经ATPS分离的样品中,来自底层相的样品只有两条带(CBHI和EGI),来自顶层相的样品显示一条代表EGIcore-HFBI的带。
用HFBI抗体进行的Western印迹显示,上层相为深色条带,而底层相仅显示弱条带,这说明融合蛋白主要分配在上层去污剂相中。图9显示将纤维素培养基上得到的EGIcore-HFBI融合蛋白分配到上层相。利用相应抗体检测上层相污染的内源性EGI和EGIII,但未检测出信号。
应用CBHI抗体进行Western印迹时,在上层相内发现少量内源性CBHI。在上层相内没有发现EGI,EGIII和蛋白酶。使用2%的去污剂再次分配上层相时,可观察到CBHI被进一步除去,使得相纯化。图10示上层相不再含有CBHI,回收得到了纯净的融合蛋白。
EGIcore-HFBI也可在发酵罐(15L)内的4%乳糖培养基中用Rut-C30菌株VTT-D-99702(pMQ113)来生产。以标准方法在ATPS中分配,得到的结果与从含有纤维素的培养基分配的结果基本相同,这证明,所述纯化可对相关于大规模工业应用的几种培养基来进行。
上层相酸性蛋白酶的活性只有底层相的1/15(下表),证明了酸性蛋白酶留在底层相中。
| A(275nm) | HUT3/ml | |
| 底层相1 | 0.146 | 41.6 |
| 上层相2 | 0.009 | 2.6 |
1用2%去污剂分配VTT-D-98691培养物滤液后1/10稀释的底层相
2用2%去污剂分配VTT-D-98691培养物滤液后1/100稀释的底层相
31HUT=酶浓度,其在反应条件下于1分钟内水解血红蛋白所得水解产物在275nm处的吸收值等于1.10μg酪氨酸/ml 0.006N HCl溶液。
结果显示,可极高效纯化融合蛋白,且所得制品不含真菌产生的其它蛋白质包括蛋白酶。
实施例7
经凝血酶切割后回收ATPS中的天然型EGI
VTT-D-98693菌株产生的EGI-HFBI有一个经设计位于EGI CBD与HFBI间的连接区内的凝血酶切割位点(LVPRGS),该位点使得能在经凝血酶切割后回收天然EGI。EGI-HFBI融合蛋白采用两相分离系统(5%去污剂)从VTT-D-98693菌株在如实施例4所述4%Solka flock纤维素和2%陈旧谷物上生长的培养物滤液(100ml)中纯化。除去底层相后,去污剂相用异丁醇萃取。所得水相(约19ml)分装在eppendorf管中,用真空离心蒸发浓缩器(speed vac)蒸发。所余冻干物用50mM Tris-Cl(pH 8)稀释。为了检测凝血酶的切割效率,将9单位凝血酶(Sigma)与1mg EGI-HFBI融合蛋白在36℃,pH8.0保温24小时以上。利用SDS-PAGE(10%)及考马斯蓝染色检测。
在这样的条件下,保温48小时后仅检查出少量切割(图11),可能是由于接头中O-糖基化所致的空间位阻效应。
实施例8
在ATPS中分配低浓度的EGIcore-HFBI
基于去污剂的双水相系统可成功应用于低浓度(稀释)的EGIcore-HFBI融合蛋白。所述融合蛋白由T.Reesei VTT-D-98691(pMQ113)在15升发酵罐内的Solka flock纤维素和陈旧谷物培养基上受启动子cbhI调控而产生。
上清的起始蛋白浓度是7.0mg/ml。该上清用去离子水分别稀释100倍和1000倍。融合蛋白用2%(w/w)去污剂C12-C18EO5以大于5的分配系数分离。见下表以及用未稀释上清进行的实验。分配系数根据所测的总EGI(野生型和融合蛋白)的活性来计算。
| EGIcore-HFBI的未稀释上清 | 1/100稀释 | 1/1000稀释 | |
| K | 4.1 | 5.3 | 5.6 |
| Y(%) | 38 | 31 | 32 |
实施例9
从含有真菌生物质的培养肉汤中分离EGIcore-HFBI
EGIcore-HFBI由T.reesei菌株VTT-D-98691(pMQ113-2)在实施例4所述Solka flock纤维素和陈旧谷物(250ml摇瓶中50ml)的培养基上产生。培养后立即从全培养液中取部分以3000rpm离心30分钟,倒出上清,向其中加入已离心的菌丝体,从而获得含不同量生物质的人工全培养液。
用5%C12-C18EO5在10克含多达50%湿生物质(生物质的重量除以湿生物质和上清之和)的实验中仍可进行分离,没有任何困难。产量保持在61%-64%,其与仅用上清(无菌丝体)的实验的结果无显著性差异(如下表)。融合蛋白的总回收量甚至更高。这很可能是由于细胞结合型酶被萃取至ATPS中而增加了EGI的总量。分配系数根据所测的总EGI(野生型和融合蛋白)的活性来计算。
| K | Y(%) | |
| 上清 | 5.5 | 62 |
| 上清中25%的湿生物质 | 7.3 | 66 |
| 上清中40%的湿生物质 | 6.4 | 61 |
| 上清中50%的湿生物质 | 7.6 | 64 |
实施例10
在ATPS中分离EGI-HFBI
EGI-HFBI由T.reesei菌株VTT-D-98693(pMQ103)在15升发酵罐中实施例4所述Solka flock纤维素和陈旧谷物培养基上产生,用不同量的C12-C18EO5在10克实验中分配。分配系数显示如下。分配系数根据所测的总EGI(野生型和融合蛋白)的活性来计算,且如在在先实施例中一样,将内源EGI包括在分配系数中。
| 去污剂[%w/w] | 2 | 3 | 5 | 7 |
| K | 1.9 | 1.8 | 1.4 | 1.1 |
实施例11
在50ml样品中分离EGIcore-HFBI
EGIcore-HFBI由T.reesei菌株VTT-D-98691(pMQ113)在15升发酵罐中的如实施例4所述Solka flock纤维素和陈旧谷物培养基上产生使用5%C12-C18EO5在Falcon管的50充实验中分离。得到的分配系数是2.52,产率为51%。分离是在3000rpm 30℃离心30分钟的条件下进行的。所得值是基于所测总EGI(野生型和融合蛋白),包括内源EGI的活性。
实施例12
使用不同去污剂在ATPS中分离EGIcore-HFBI
EGIcore-HFBI由T.reesei菌株VTT-D-98691(pMQ113)在15升发酵罐中的如实施例4所述Solka flock纤维素和陈旧谷物培养基上产生,用2%去污剂在每次的10克实验中进行分配。在本例实验中检测的去污剂是C10 EO5,C12 EO5,C14 EO6(Nikko Chemicals,日本),C12-C18EO5(,,Agrimul NRE 1205“Henkel,德国),C12/14 5EO,C12/14 6EO(Clariant,德国),C9/11 EO5.5(,,Berrol266“Akzo Nobel,德国),Tiiton X-114(Sigma,德国)。分配系数和产率如下所列。所得值是基于所测总EGI(野生型和融合蛋白),包括内源EGI的活性。
| K | Y(融合)% | |
| C10EO5 | 20 | 56 |
| C12EO5 | 15 | 57 |
| C12-C18EO5 | 14 | 66 |
| C12/14 5EO | 12 | 58 |
| C12/14 6EO | 14 | 62 |
| C14EO6 | 11 | 54 |
| C9/11 EO5.5 | 5 | 30 |
| Triton X-114 | 0.16 | 53 |
实施例13
在ATPS中从葡萄糖培养物中分离EGIcore-HFBI
EGIcore-HFBI从如实施例4所述用葡萄糖培养的T.reesei菌株VTT-D-98682(pMQ115)中分离。使用2%的去污剂C12-C18EO5分配上清。以2.4的K值分配融合蛋白。如果与纯化EGI的计算方法相同,那么天然EGI的K值为0.3。
实施例14
使用不同浓度的去污剂分配EGIcore-HFBI
EGIcore-HFBI由T.reesei菌株VTT-D-98691(pMQ113)在15升发酵罐中的如实施例4所述Solka flock纤维素和陈旧谷物培养基上产生,无细胞上清用不同量的去污剂C12-C18 EO5在基于去污剂的ATPS中分配EGIcore-HFBI。下表为分配系数。在图8和图9分别是相应的凝胶电泳和Western抗体印迹结果。所给值是基于所测总EGI的活性。
| 去污剂C12-C18 EO5的量 | K | 产率(%) |
| 1.0% | 6.1 | 9 |
| 2.0% | 4.1 | 38 |
| 3.5% | 3.6 | 50 |
| 5.0% | 2.9 | 55 |
| 7.5% | 1.7 | 53 |
| 10.0% | 1.1 | 58 |
实施例15
再次萃取去污剂相
菌株VTT-D-98691(pMQ113)经摇瓶培养产生含EGIcore-HFBI融合蛋白的上清,对其应用基于去污剂的ATPS系统。在标准条件下使用去污剂C12-C18EO5进行首次萃取,得到的分配系数是16,产率是72%(包括野生型EGI和融合蛋白)。以10mM乙酸钠缓冲液(pH 5)和2%的去污剂再次萃取上层相,得到分配系数是的52,产率是89%。在再次萃取底层相的实验中(2%的去污剂),产率是7.5%,EGI活性的K值是0.8。根据所测总EGI(野生型和融合蛋白)的活性计算出分配系数。由于在样品中有野生型EGI,首次萃取的产率至少是72%,分配系数至少是16。图10为两次提取的SDS-PAGE分析结果。
| 分离步骤 | K | Y(%) |
| 2%的去污剂 | 16 | 72 |
| 再次萃取上层相 | 52 | 89 |
| 再次萃取底层相 | 0.8 | 7.5 |
实施例16
在ATPS中分离纯化的纤维素酶
通过比较EGIcore-HFBI融合蛋白的萃取结果与纯化的野生型EGI和EGIcore的萃取结果,可进一步证实HFBI对分配和终产率的影响。融合蛋白被分配到去污剂相的效果要好100倍以上(如下表所示)。
来自首次萃取的纯化的融合蛋白经再次萃取后分析效果得到改善(见实施例15)可用野生型EGI的分配来解释,所述野生型EGI的分配如下表中用纯化的野生型EGI所证实。野生型EGI能降低首次分配的分配系数(因为EGI活性测的是上层相和底层相的总和),但是再次提取时无野生型EGI可增大EGIcore-HFB融合蛋白的分配系数。纯度还可通过对纯GBHI的分配进行分析而证实,其中所述CBHI是占T.reesei分泌蛋白总量的50%的主要污染蛋白。纯CBHI因此从融合蛋白中被分离,其分配系数为0.5,产率是3.6。
| 分离步骤 | K | Y(%) |
| 再次萃取上层相 | 52 | 89 |
| 萃取纯化的野生型EGI | 0.3 | 2.2 |
| 萃取纯化的EGI-core | 0.3 | 2.3 |
| 萃取纯化的CBHI | 0.5 | 3.6 |
利用K和Y的定义并通过计算质量平衡,能计算出EGI融合蛋白与野生型EGI量之比。据此可推测出“真实”分配系数和产率。“真实”是指在可以仅仅检测EGI融合蛋白的量,而不同时检测野生型EGI的量时可测到的值。
如此计算的基础是再次萃取实验。再次萃取的上层相被认为是纯的。因此,关于VTT-D-98691(pMQ113)如实施例4培养的两种培养物的测量值以及计算的“真实”值见下表。
| 培养容器 | 培养基质 | EGI野生型的K值 | “真实”K值 | EGI野生型的Y(%) | “真实”Y(%) |
| 15升发酵罐 | 乳清滤液 | 4 | 6 | 16 | 54 |
| 250ml摇瓶 | 纤维素 | 16 | 54 | 66 | 90 |
实施例17
在ATPS中纯化HFBI和HFBII
如实施例4所述用葡萄糖作底物培养T.reesei菌株VTT-D-98692(pEA10-103B)可生产HFBI。用2%去污剂C12-C18EO5在标准条件下以大于20的分配系数分离HFBI。
如实施例4所述用乳清陈旧谷物培养T.reesei菌株VTT-D-74075(QM9414)可生产HFBII。用2%去污剂C12-C18EO5在标准条件下以大于10的分配系数分离HFBII。
疏水蛋白HFBI和HFBII都能较好地分配到ATPS的上层相中。
实施例18
添加了NaCl的基于去污剂的ATPS系统
通过培养T.reesei产生的EGIcore-HFBI在10克实验中用5%C12-C18EO5分离。上清的分配系数为3.5,体积比是0.2。添加1.1%(w/v)NaCl后,分配系数增加到3.5,体积比降低到0.14。
实施例19
构建表达HFBI-dCBD融合蛋白的大肠杆菌菌株,所述HFBI-dCBD含有疏水蛋白I和双纤维素结合(CBD)结构域
以质粒pARO1(Nakari-Setala等,1996)为模板,PCR扩增出280bp的DNA片段,该片段含有修饰的cbh2接头区及其后的hfb1基因从第23位丝氨酸到终止密码子的编码区域。5’引物是5’TCT AGC
AAG CTT GGCTCT AGT TCT GGA ACC GCA CCA GGC GGC AGC AAC GGC AACGGC AAT GTT TGC(SEQ ID 14),3’引物是5’TCG TAC
AAG CTT TCAAGC ACC GAC GGC GGT(SEQ ID 15)。5’和3’引物中粗体标记序列分别编码修饰的CBHI接头(Gly Ser Ser Ser Gly Thr Ala Pro Gly Gly)和转录终止密码子,5’和3’引物中划线部分AAG CTT是HindIII位点。将该PCR片段经琼脂糖凝胶纯化,用HindIII消化,再与经HindIII消化并经SAP(虾(Shrimp)碱性磷酸酶USB)处理的pSP73连接,构建成pTNS9质粒。
为了随后将修饰的CBHII接头-HFBI片段克隆到大肠杆菌表达的载体,用HindIII消化pTNS9,合适的片段经琼脂糖凝胶纯化。将此HindIII片段克隆到经HindIII消化SAP(虾碱性磷酸酶,USB)处理的B599,构建成pTNS13质粒(图12)。大肠杆菌表达载体B599基本与Linder等人(1996)描述的相同,除了在蛋白质编码序列的末端缺少一个终止密码子。载体B599携带融合蛋白的编码序列,该序列包含CBHII CBD(CBHII的41个N-末端残基)和通过CBHI接头区(CBHI接头和CBD是CBHI的最后57个残基)连接的CBHI CBD。B599中融合蛋白的表达和分泌受到tac启动子和pelB信号序列的调控(Takkinen等,1991)。因此,pTNS13表达载体携带由双CBD和HFBI经Gly Ser Ser Ser Gly Thr Ala Pro Gly Gly肽连接在同一读框内的融合蛋白的编码区。这个载体也包含筛选大肠杆菌转化体所用的amp基因。将pTNS13质粒转化至大肠杆菌菌株RV308(su-,ΔlacX74,gal I S II∷OP308,strA),用该菌株生产融合蛋白。
实施例20
在ATPS中分离大肠杆菌中表达的HFBI-dCDB分子
dCDB-HFBI在如上述以pTNS13质粒转化的大肠杆菌菌株RV308生产。将RV308/pTNS13接种物在LB培养基上培养至指数生长期,所述LB培养基含有氨苄青霉素(0.1g/L)和1%葡萄糖。在10升发酵容器中使用Pack等(1993)描述的矿物盐培养基并补充葡萄糖进行发酵。培养期间,温度保持在28℃,pH用NH4OH控制在6.8。通过测量OD600和生物质的干重来监测细胞的生长情况。在稳定生长期后期(OD6600=50-60),用50μM(终浓度)IPTG(异丙基-β-D-硫代乳糖吡喃糖苷)进行诱导以促进融合蛋白的产生。
用培养物滤液和5%去污剂在总体积40ml中对dCDB-HFBI蛋白进行双相分离分析。Western印迹结果显示,以标准方法用5%去污剂进行的双相分配对dCDB-HFBI融合蛋白也有高度特异性。如图13所示,与底层相样品比较,去污剂相的样品显示较强信号。
实施例21
构建在细胞表面表达HFBI-FLO1融合蛋白的酵母菌株
为了构建HFBI-FLO1融合蛋白表达盒,以pARO1(Nakari-Setala等,1996)为模板,PCR扩增hfb1(SEQ ID 1)编码区(从第23位丝氨酸到终止密码子)。5’引物是TCT AGC
TCT AGA AGC AAC GGC AAC GGC AATGTT(SEQ ID 16),3’引物是TGC TAG TCG ACC T
GC TAG CAG CACCGA CGG CGG TCT G(SEQ ID 17)。5’和3’引物中划线部分分别是XbaI和NheI的酶切位点。0.225bp的PCR扩增片段经琼脂糖凝胶纯化,连接到载体pGEM-T(Promega)上,构建成pTNS10。用XbaI和NheI将hfb1片段从pTNS10中切下,连接至已用相同内切酶切割的pTNS15质粒上。除了用BglII位点取代pBR322骨架上的NheI位点,以及在推定的信号序列酶切位点之前的特有AocI位点处,通过接头克隆而引入一个特有的XbaI位点外,pTNS15质粒(图14)与pBR-ADH1-FLO1L质粒(Watari等,1994)基本相同。得到的pTNS18质粒(图15)含有HFBI-FLO1融合蛋白的完整表达盒,其中HFBI取代了推定的酵母絮凝素FLO1(SEQID18)中第26位丝氨酸到第319位丝氨酸的凝集素结构域。
下一步,构建用于生产HFBI-FLO1融合蛋白的酵母表达载体。在构建物中作为骨架的表达载体是pYES2(Invitrogen)(SEQ ID 19),这是一个高拷贝附加型载体,用来诱导重组蛋白在酿酒酵母(S.cerevisiae)中的表达。这一载体携带调节转录的GAL1启动子和CYC1终止子序列,以及2μ复制起始区和用于在宿主菌株中维持并进行筛选的URA3基因。用HindIII消化pTNS18质粒,释放出包含HFBI-FLO1表达盒的3.95kb片段。经琼脂糖凝胶纯化这一片段,连接到经HindIII消化的pYES2上。采用标准的乙醇沉淀法浓缩该连接混合物。该连接混合物应包括未被连接的片段和错误连接的产物,以及载体和插入子彼此正确连接形成的质粒pTNS23(图16),该质粒含有HFBI-FLO1表达盒,此盒与GAL1和CYC1终止子序列可操作相连接。
利用LiAc方法(Gietz等1992年),把上述连接混合物转化到实验用酿酒酵母菌株H452(野生型W303-1A;Thomos和Rothstein,1989)内。挑出能在SC-URA培养板上生长的转化菌落,在选择平板上划线培养。根据Sherman等(1983)的方法,从培养板取下硝酸纤维素复制膜,进行克隆杂交。为了找到包含pTNS23质粒的酵母菌落,用地高辛配基标记的hfd1编码片段与复制膜杂交,然后完全按照生产厂家(Boehringer Mannheim)的操作步骤进行免疫检测。通过分离总DNA而从几个给出阳性杂交信号的酵母菌落回收质粒并用于对大肠杆菌的电穿孔。通过进行限制性作图和测序证实酵母转化体内pTNS23质粒的正确性。选择一个携带pTNS23质粒的转化体进一步进行研究,将其称为VTT-C-99315,它的对照菌株是在H452骨架中携带pYES2质粒的酵母菌株H2155。
实施例22
在ATPS中分离能表达HFB I-Flo1融合蛋白的酵母细胞
在缺乏尿嘧啶的以2%半乳糖作为碳源的合成性完全培养基(SC-URA)(Sherman,1991)上,将酿酒酵母菌株VTT-C-99315(载体pTNS23)和它的对照菌株H2155(载体pYES2)培养至A600约为4。含约6.3×108个细胞的培养液放入ATPS中,使用7%(W/V)C12-18EO5去污剂(来自Henkel的Agrimul NRE)在总体积5ml中进行分配。ATPS按标准方法进行。当通过重力沉淀分离液相后,VTT-C-99315菌株的上层去污剂相明显混浊,而对照菌株的去污剂相则为清澈(图17)。从上层相取样,用0.9%NaCl稀释至10-1-10-5,铺板至YPD平板。30℃培养后,计数酵母菌落,发现YPD平板上VTT-C-99318的菌落数比对照菌株至少多70倍。这充分表明,在含过量细胞的系统中,确实将能在细胞表面表达疏水蛋白的细胞分配到去污剂相中。
实施例23
在含和不含疏水蛋白的纯系统中分配EGIcore-HFBI融合蛋白
游离HFBI和HFBII疏水蛋白对EGIcore-HFBI分配的影响,可通过纯化EGIcore-HFBI的50mM乙酸盐缓冲液(pH5.0)样品在有或没有纯化HFBI和HFBII时,萃取到去污剂相中的效率来研究。萃取后,测定萃取前后对水相中可溶性底物,如甲基伞形酮纤维二糖苷的水解活性的耗损。于30℃用2%C12-18EO5分离0.02g/L EGIcore-HFBI时,如果有0.7g/L的任一种疏水蛋白存在,则萃取效果如下:当没有其它疏水蛋白时,能萃取93%的蛋白;当有HFBII时,能萃取82%;当有HFBI时,能萃取88%。
实施例24
在T.reeseiΔhfb2菌株中生产EGIcore-HFBI融合蛋白以改进融合蛋白在ATPS中的分配
T.reesei菌株QM9414Δhfb2(VTT-D-99726)基本如Penttila等,1987所述用10μg pMQ113质粒(如实施例1所述)和3μg含有编码乙酰胺酶法构巢曲霉amdS基因的选择质粒pTOC202(Hynes等,1983;Tilburn等,1987)转化。pMQ113含有受cdh1启动子和终止子序列调控的可生产EGIcore-HFB
I融合蛋白的表达盒。
将所得Amd+转化体在含乙酰胺的平板(Penttil等,1987)上划线接种两次。然后从马铃薯葡萄糖琼脂(Potato Dextrose agar)(Difco)上生成的转化体制备孢子悬浮液。利用EGI和HFBI特异性抗体对摇瓶或微滴板中补充有Solka flock纤维素的基本培养基上的培养物进行狭线印迹和Western分析来检测融合蛋白EGIcore-HFBI的产生。将能产生融合蛋白的克隆的孢子悬浮液在含乙酰胺的选择平板上纯化为单孢子培养物。为测定最佳生产者,如上述再次分析这些纯化克隆的融合蛋白的产生。
为了在ATPS中使用聚氧乙烯去污剂C12-18EO5开展分配融合蛋白EGIcore-HFB I的实验,在摇瓶中含Solka flock纤维素的培养基上如实施例4所述培养本研究所得最佳生产菌株和作为对照的菌株VTT-D-98691(生产EGIcore-HFBI的QM9414菌株)和VTT-D-74075(QM9414)。
用培养上清如实施例5所述进行标准分配实验。分离以后,记录较轻相与较重相的体积比,从中计算融合蛋白的浓缩系数。另从较轻相和较重相中取样,如实施例5所述进行SDS-PAGE,Western印迹和活性测定。如实施例5所述计算分配系数(K)和产率(K)。
实施例25
构建在T.reesei的cbh I启动子调控下表达EGIcore-HFB II和EGIcore-SC3融合蛋白的载体
为了构建生产EGIcore-HFB II融合蛋白的表达载体,以phfb2(Nakari-Setl等,1997)作为模板,PCR扩增hfd2(SEQ ID 20)编码区(从Ala-16到终止密码子)。5’端引物是CG
G AGG AGC TCG ACG ACT TCG AGCAGC CCG AGC TGC ACG CAG GCT GTC TGC CCT ACC GG(SEQ ID21),3’端引物是TCA TT
G GAT CCGT TAG AAG GTG CCG ATG GC(SEQID 22)。5’端引物中增粗字母区域编码EGI的413-425位氨基酸残基,而划线区GAGCTC是SacI位点。3’端引物的下划线区GGATCC是BamHI位点。扩增的片段用SacI和BamHI消化,并连接到用同样的限制酶切割的pMQ113上。得到的质粒是pTNS32(图18),这个质粒携带在cdh1调节序列(SEQ ID 5和SEQ ID 7)调控下的EGIcore-HFB II融合蛋白的编码序列。
为了构建生产EGIcore-SC3融合蛋白的表达载体,以cSC3/pUC20质粒作为模板,PCR扩增SC3的cDNA(SEQ ID 23),5’端引物是ACT ACACGG AG
G AGC TCG ACG ACT TCG AGC AGC CCG AGC TGC ACGCAG GGT GGC CAC CCG GGC(SEQ ID 24),3’端引物是TCG TAC
GGA TCC TCA GAG GAT GTT GAT GGG(SEQ ID 25)。5’端引物中增粗字母区域编码EGI的413-425位氨基酸残基,下划线的GAGCTC是SacI酶切位点。3’端引物中下划线的GGATCC是BamHI酶切位点。扩增的片段用SacI和BamHI消化,并连接到用同样的限制酶消化的pMQ103(如实施例1)上。得到的质粒是pTH4(图19)。这个质粒携带在cdh1调节序列(SEQ ID 5和SEQID 7)调控下的EGIcore-SC3融合蛋白的编码序列。
cSC3/pUC20质粒携带pUC20载体中翻译起始点到终止密码子的411bpSC3 cDNA序列。在翻译起始点构建了NcoI酶切位点,在翻译终止密码子后面构建了BamHI酶切位点。
实施例26
构建在T.reesei的cbh1启动子调控下表达包含疏水蛋白I和双纤维素结合结构域(CBD)的HFB I-dCBD融合蛋白的载体
为了构建在cdh1启动子调控下生产HFB I-dCBD融合蛋白的表达盒,以pEA10(Nakari-Setala等,Eur.J.Biochem.(1996)235:248-255)为模板,PCR扩增hfd1蛋白编码区。在PCR扩增中,5’端引物是GGA ATT
CCG CGGACT GCG CAT CAT GAA GTT CTT CGC CAT CGC C(SEQ ID 26),3’端引物是TGA ATT C
CA TAT GTT AGG TAC CAC CGG GGC CCA TGC CGGTAG AAG TAG AAG CCC CGG GAG CAC CGA CGG CGG TCT GGCAC(SEQ ID 27)。5’端引物中增粗的字母代表16bp的cdh1启动子,该启动子与相应基因的翻译起始位点相邻,下划线部位CCGCGG是Ksp I位点。3’端引物的下划线部分和增粗字母部分分别是Nde I和Asp718的酶切位点。3’端引物中斜体字母编码含有甲硫氨酸的接头(PGASTSTGMGPGG)。得到的370bp片段用Ksp I和Nde I消化,连接至用同样内切酶消化的pAMH110质粒(Nevalainen,K.M.H.,Penttil,M.E.,Harkki,A.,Teeri,T.T.和Knowles,J.(1991),在分子工业化真菌学(Molecular Industrial Mycolog)一书中,编者Leong,S.A.和Berka,R.,Marcel Dekker.纽约)。得到了pTNS29-2Asp质粒。
为了进一步克隆,去掉pTNS29-2Asp的多接头上的Asp718位点。用SacI和BamHI消化载体,载体的酶切末端用T4 DNA多聚酶钝化,并连接到一起。得到的质粒pTNS29缺少了出现在pTNS29-2Asp的多接头上的SacI、Asp718和SmaI酶切位点。
下一步以pTNS11为模板,PCR扩增双纤维素结合结构域(dCBB)。pTNS11携带融合蛋白的编码序列,该融合蛋白含有经CBHI接头区相连的T.reesei CBHII CBD(CBHII N-末端的41个残基)和CBHI CBD(CBHI接头区和CBD是CBHI的最后57个残基)。该DNA序列来源于大肠杆菌表达载体B599,该载体与Linder等人(生物化学杂志(1996),271:21268-21272)所述基本相同。在PCR扩增中,5’端引物是TGA ATT C
GG TAC CCA GGCTTG CTC AAG CGT C(SEQ ID 28),3’端引物是TGA ATT C
CA TAT GTCACA GGC ACT GAG AGT AGT A(SEQ ID 29)。5’端和3’端的划线部位分别是Asp718和Nde I位点。扩增所得片段用Asp718和NdeI消化,与用Asp718和Nde I消化的质粒pTNS29相连,得到质粒pTNS30。
pTNS30(图20)表达载体因此携带了下述融合蛋白的编码区,该融合蛋白包含经甲硫氨酸连接肽(PGASTSTGMGPGG)连接在同一读码框中的HFBI和双CBD。该融合蛋白的表达受cdh1转录调控序列的调控。所述表达盒可用EcoRI和SphI消化所述质粒而得到。
实施例27
构建在T.reesei的cbh1启动子调控下表达HFBI-单链抗体融合蛋白的载体
构建一表达载体以生产融合蛋白,该融合蛋白在N-末端含有T.reesei的HFBI蛋白,在C-末端包含识别二芳烷基三唑的小分子衍生物的单链抗体(ENA5ScFv)。融合蛋白的生产受cdh1调控序列的调控。为了构建HFBI-ENA5ScFv融合蛋白,用NcoI和XbaI消化pENA5ScFv。包含ena5scfv基因和组氨酸尾(6个组氨酸)的片段经钝化后克隆到pTNS29上,构建成pTH1(图21)。pENA5ScFv载体携带编码区,该区编码ENA5单链抗体中经甘氨酸丝氨酸接头连接的轻链和重链可变区,以及C-末端的6组氨酸标记。单链抗体的转录和分泌分别受到tac启动子和pelB信号序列的调控(Takkinen等,1991)。pTNS29载体携带T.reesei的hfd1编码区,其后接一个接头序列(ProGlyAlaSerThrSerThrGlyMetGlyProGlyGly),它们受cdh1启动子和终止子序列的调控。
为了构建在连接肽中含有凝血酶位点的HFBI-ENA5ScFv融合蛋白,以pENA5ScFv为模板,PCR扩增ena5scfv编码区(从Ala-23到终止密码子)和位于它之前的含凝血酶位点(Gly Thr Leu Val Pro Arg Gly Pro Ala Glu ValAsn Leu Val)的肽接头。5’端引物为GAA TTC
GGT ACC CTC GTC CCTCGC GGT CCC GCC GAA GTG AAC CTG GTG(SEQ ID 30)。3’端引物为TGA ATT C
CA TAT GCT AAC CCC GTT TCA TCT CCA G(SEQ ID 31)。5’端引物中粗体序列编码ENA5ScFv的N-末端前6个残基,序列中斜体部分是凝血酶位点,划线部位GGT ACC是Asp718酶切位点。3’端引物中的粗体序列编码ENA5ScFv的C-末端6个残基,划线的CA TATG是Nde I酶切位点。790bp的PCR片段利用琼脂糖凝胶纯化,并连接到pTNS29,构建成pTH2质粒(图22)。
实施例28
构建在T.reesei中产生群交裂褶菌的I类疏水蛋白SC3的载体以备ATPS
构建能生产群交裂褶菌(Schizophyllum commune)的I类疏水蛋白SC3的T.reesei菌株。为此构建了携带SC3 cDNA的表达载体,所述SC3 cDNA受T.reesei的hfd2启动子和hfd1终止子调控。
以pEA10(Nakari-Setala等,1996)为模板,PCR扩增hfd1终止子(SEQ ID32)。5’端引物为
GAC CTC GAT GCC CGC CCG GGG TCA AG(SEQ ID33),3’端引物为
GTC GAC ATT TCA TTT TAC CCC CCT CG(SEQ ID 34)。5’端和3’端引物中划线序列分别是SacI和SalI位点。PCR片段用SacI和SalI消化,从而使SacI位点通过Klenow钝端化。将该片段克隆到已用SalI和BamHI消化并已将BamHI位点用Klenow钝化的cSC3/pUC20(实施例25所述)载体上。接着,以pTNS8(Nakari-Setala等,1997)为模板,PCR扩增hfb2启动子(SEQ ID 35),5’端引物为
AAG CTT GCA TGC CTG CATCC(SEQ ID 36),3’端引物为
CCA TGG TGA AAG GTG GTG ATG GTTGG(SEQ ID 37)。5’端和3’端引物中的划线序列分别是HindIII和NcoI位点。PCR片段用HindIII和NcoI消化,并克隆在前一步骤所得质粒中SC3cDNA的前面,并用相同限制酶消化。得到质粒pKS2(图23)。
实施例29
构建能产生EGIcore-HFBII、EGIcore-SC3、HFBI-dCBD、HFBI-单链抗体融合蛋白,以及SC3疏水蛋白的T.reesei菌株
基本如Penttil等人,1987所述,用3-13μg质粒pTNS32,pTH1,pTH2,pTH4,pTNS30和pKS2,以及1-3μg选择质粒pToC202或pARO21,共转染T.reesei菌株VTT-D-74075(QM9414),VTT-D-86271(Rut-C30)和VTT-D-99676(Rut-C30Δhfd2)。携带构巢曲霉amdS基因的pToC202(Hynes等,1983;Tilburn等,1983)和携带大肠杆菌hph基因的pARO21如实施例3所述。所得Amd+和Hyg+转化体分别在含乙酰胺和潮霉素的平板上划线接种3次(Penttila等,1987)。然后,从在马铃薯葡萄糖琼脂(Difco)上生长的转化体制备孢子悬浮液。
融合蛋白EGIcore-HFBII、EGIcore-SC3、HFBI-dCBD和HFBI-ENA5ScFv、SC3疏水蛋白的产生,可通过用EGI、SC3、CBD和HFBI特异性抗体,对在摇瓶或微滴板中补充有乳糖或Solka flock纤维素的基本培养基上生长的培养物进行狭线印迹和Western分析来检测。产生融合蛋白的克隆的孢子悬浮液在选择平板(含乙酰胺或潮霉素)上纯化为单孢子菌落。为测定最佳生产菌落,如上述再次分析这些纯化克隆的融合蛋白的产生。。
经筛选可用于进一步培养的T.reesei菌株是X46A(pTNS32,宿主QM9414),VTT-D-00793(pTH4,宿主Rut-C30Δhfb2),VTT-D-99727(pTNS30,宿主Rut-C30Δhfb2),VTT-D-00791(pTH1,宿主Rut-C30)和VTT-D-00792(pKS2,宿主Rut-C30Δhfb2)。这些菌株如实施例4所述培养,培养上清在ATPS中分配。
实施例30
在ATPS后用异丁醇或其它溶剂从去污剂富集相中回收蛋白产物
相分离之后,疏水蛋白或疏水蛋白融合蛋白富集在去污剂相(富集相)中,所述蛋白可通过添加异丁醇或其它溶剂而回收至水相缓冲液中。例如,将在50mM乙酸盐缓冲液中的0.05g/L HFBI用2%Berol 532配制成一系列相同的萃取物。各管加入异丁醇,正戊醇,辛醇或辛烷至终浓度10%。分析回收到水相中的疏水蛋白级分,发现采用异丁醇可回收100%,采用正戊醇为89%,采用辛醇为81%,采用辛烷为70%。级分用如实施例38所述的HPLC分析。
实施例31
在ATPS中分离EGIcore-HFBII融合蛋白
在实施例4所述含3%乳糖培养基的摇瓶中培养T.reesei菌株X46A。在培养上清中加入去污剂C12-18EO5至终浓度5%。系统混合后,静置,用等体积的异丁醇进一步萃取去污剂富集相。在Biogel P-6(Bio-Rad,USA)凝胶过滤基质上更换缓冲液后,在已用15mM乙酸盐平衡的Mono Q柱(Amersham Pharmacia,瑞典)上通过离子交换层析来分析所萃取的蛋白,用线性NaCl梯度洗脱。EGIcore-HFB II融合蛋白向去污相中的分配,可通过分析Mono Q层析柱洗脱峰级分的对4-甲基伞形酮纤维二糖苷的活性,以及其在ATPS中的再萃取来证实。
实施例32
在ATPS中分离EGIcore-SC3融合蛋白
在能生产EGIcore-SC3融合蛋白的T.reesei菌株VTT-D-00793的培养滤液中加入C12-18EO5至终浓度5%,然后进行ATPS分配。静置后,发生相分离,富含融合蛋白的去污剂相再用等体积异丁醇处理,使去污剂进入异丁醇中,而蛋白质留在水相中。所得富含融合蛋白的水相在Biogel P-6(Biorad,USA)上脱盐。融合蛋白向去污剂相中的分配,可通过分析该相中EGIcore融合蛋白配偶体对4-甲基伞形酮纤维二糖苷的酶活性来证实。
实施例33
在ATPS中分离HFBI-dCBD融合蛋白
产生HFBI-dCBD融合蛋白的T.reesei菌株VTT-D-99727在实施例4所述含乳糖的培养基上生长。在500ml培养液上清中加入2%Berol 532至终浓度2%。静置混合液,在分配漏斗(funnel)中发生相分离。上层富集相(10ml)用等体积异丁醇和50mM乙酸盐缓冲液pH5进行萃取。在分离中,融合蛋白选择性富集在缓冲液中,如SDS凝胶电泳所证实(图24)。
实施例34
回收经化学切割的HFBI-dCBD融合配偶体
菌株VTT-D-99727产生的HFBI-dCBD融合蛋白,在HFBI和dCBD之间的连接区域有一个甲硫氨酸(PGASTSTGMGPGG),这一结构使得能用CNBr经化学切割而回收天然HFBI和dCBD。
如实施例33所述纯化HFB I-dCBD融合蛋白。所得水相(~108ml)除含有HFBI-dCBD融合蛋白,仍含有少量CBHI和游离的疏水蛋白(图24)。利用层析法对样品进一步纯化。样品在已用50mM乙酸钠缓冲液pH5.5平衡的Biogel P-6柱上脱盐,再用水按1+3稀释,然后上样至已用10mM乙酸钠缓冲液pH5.5平衡的CM-Sepharose FF柱。CBHI蛋白在流通液中发现,纯化的HFBI-dCBD蛋白可用0.2M NaCl洗脱。
纯化HFBI-dCBD蛋白的样品在真空离心蒸发浓缩器内蒸发至几乎干燥。在干燥样品中加入5倍重量过量的CNBr之0.1M HCl溶液(5mg/ml),进行CNBr裂解。反应在室温(避光)进行24小时。加入10倍体积的水,将样品在真空离心蒸发浓缩器中蒸发至几乎干燥。蒸发后的样品用50mMTris-HCl pH7稀释,裂解通过如实施例37所述的HPLC证实。
用不同浓度的HCl和保温时间使所述处理进一步优化。对CNBr处理的最终样品如实施例33所述进行ATPS分配。HFBI在上层相中发现,dCBD在底层相中发现,从而使两种融合配偶体分离。
实施例35
在ATPS中分离HFB I-单链抗体融合蛋白
VTT-D-00791菌株在含10g/L邻苯二甲酸(phtalate)钾,15g/L KH2PO4,5g/L(NH4)2SO4,3%乳糖和0.2%蛋白胨的培养基上培养7天。30ml培养液用4% C12-18-EO5去污剂如实施例5所述进行ATPS分配。去掉底层相后,用异丁醇萃取去污剂相。去污剂萃取后的水相以及去污剂相经异丁醇萃取后的底层相中的蛋白用三氯乙酸(终浓度10%)沉淀,悬浮于SDS-PAGE样品缓冲液中(考虑经异丁醇萃取的去污剂相的浓度系数),用HFBI特异性抗体进行Western印迹分析。融合蛋白在SDS-PAGE中,在如图25所见的条件下以二聚体(约70kDa)的形式移动。水相样品中仍含有少量融合蛋白。尽管如此,还是可在ATPS系统中分配融合蛋白。
实施例36
在ATPS中分离SC3疏水蛋白
产SC3疏水蛋白的VTT-D-00792菌株在装有含乳糖的培养基的摇瓶中如实施例4所述培养。该真菌所分泌的可溶性蛋白用三氯乙酸沉淀。沉淀的蛋白溶子三氟乙酸,使SC3聚合体解离,然后通入蒸汽使酸蒸发。处理后的蛋白溶于含2.5%去污剂C12-18-EO5的2ml水中。如实施例5所述进行相分离从较轻相和较重相取样,用SC3特异性抗体进行Western印迹分析。根据分析结果,SC3疏水蛋白已分配到去污剂相中(图26)。
实施例37
在ATPS中分离乳链菌肽
1mg纯乳链菌肽(Sigma)(相当于1000 IU)在50mM乙酸钠缓冲液pH5中的溶液,用2%去污剂C12-18EO5在30℃进行ATPS分配,静置液相。去掉底层相,去污剂相用异丁醇萃取,使去污剂进入异丁醇中而乳链菌肽留在水相中。如Qiao等1996所述检测乳链菌肽的生物学活性,从而可评估乳链菌肽富集水相中的分配。比较富集相和乳链菌肽对照在试验板上产生的晕轮,表明乳链菌肽已经以约为5的浓度系数分配到去污剂相中。
实施例38
在ATPS中制备性纯化HFBI和HFBII
为了制备,从0.5L培养上清中萃取HFB I和HFB II,所述培养上清通过在如实施例4所述含有葡萄糖或纤维素的培养基上培养而获得。在培养上清中加入2%(W/W)去污剂,混匀,在分配漏斗中于20℃(如果用C11EO2(Berol 532))或30℃(如果用C12-18EO5(Henkel))静置。收集去污剂相(富集相)并与等体积的异丁醇混合。当使用C11EO2时,还加入等体积的50mM乙酸盐缓冲液。剩余的培养上清为贫化相。纯化结束后,对每步的样品进行HPLC分析(图27和28)。根据HPLC分析结果,HFBI和HFBII已很好地分配到这两种去污剂相中。当使用C11EO2时,HFBI的K值大于1000;HFBII的K值大于78。
收集经异丁醇萃取后的水相,进一步在已用0.1%三氟乙酸水溶液平衡的Vydac 1×20cm半制备C4柱(Vydac,美国)上纯化,用0.1%三氟乙酸的乙腈溶液的线性梯度洗脱。然后将蛋白冻干。用4.6mm×20cm Vydac C4柱进行分析。
实施例39
用纯化的HFBI和HFBII筛选分离条件
HFBI和HFBII从培养上清中经ATPS而纯化,进一步如实施例38所述经制备型HPLC纯化并冻干,将其溶于水至浓度为0.5mg/ml。原液用适于实验的缓冲液稀释。用50mM乙酸缓冲液pH5,50mM甘氨酸pH3和50mMHEPES pH7进行pH筛选,用NaCl或(NH4)2SO4的乙酸盐缓冲液进行离子强度实验。根据疏水蛋白溶液的量称取相应量的表面活性剂,在0、20、30、40℃保温,测定贫化相中的疏水蛋白量。从浓度和体积比的变化计算分配系数,并示于下表中。
用不同的表面活性剂和不同的温度分离疏水蛋白得到的K值
| 温度 | Henkel | Berol 532 | Berol 266 | Triton x114 | |
| HFBI | 0℃ | 0,1 | 368 | NP | NP |
| 20℃ | 0,4 | 1961 | NP | NP | |
| 30℃ | 85 | 2970 | NP | 0,9 | |
| 40℃ | 148 | 682 | 28 | 69 | |
| HFBII | 0℃ | NP | 76 | NP | NP |
| 20℃ | 1,0 | 139 | NP | NP | |
| 30℃ | 67 | 194 | NP | 4,0 | |
| 40℃ | 44 | 102 | 19 | 44 |
NP=无相分离
在40℃下不同盐浓度对K值的影响
| Henkel | Berol 532 | Berol 266 | Triton x114 | ||
| HFBI | 50mM缓冲液 | 244 | 578 | 13 | 39 |
| +1M NaCl | 239 | 33 | 198 | 241 | |
| +1M(NH4)2SO4 | 0,9 | 3,2 | 176 | 612 | |
| HFBII | 50mM缓冲液 | 36 | 80 | 16 | 58 |
| +1M NaCl | 14 | 87 | 61 | 38 | |
| +1M(NH4)2SO4 | 3,1 | 351 | 95 | 35 |
在不同条件下用Berol532分配疏水蛋白的K值
| HFBI 0℃ | HFBI 20℃ | HFBII 0℃ | HFBII 20℃ | |
| 50mM乙酸pH5 | 298 | 614 | 76 | 127 |
| +1M NaCl | 614 | 3781 | 131 | 199 |
| +1M(NH4)2SO4 | 931 | 44 | 203 | 139 |
| pH3 | 614 | 1881 | 73 | 160 |
| pH7 | 361 | 614 | 54 | 126 |
实施例40
根据新推定的T.reesei疏水蛋白在ATPS中的分离对其进行纯化并克隆相应基因
T.reesei菌株VTT-D-99726(QM9414Δhfd2)在如实施例4所述15升发酵容器内的基于乳糖的培养基中培养。然后,取1L培养滤液至ATPS中用5%聚氧乙烯去污剂C12-18E05分配。在30℃发生相分离后,使去污剂相与贫化的水相分离,并通过SDS-PAGE分析。所分析样品中含有约7.5kda的蛋白。另外,还有一些分子量更大的蛋白。在已用50mM乙酸钠-1M(NH4)2SO4缓冲液平衡的Phenyl-Sepharose FF柱上通过疏水相互作用层析法去除这些蛋白。用递减的(NH4)2SO4盐洗脱这些蛋白。收集并浓缩含有约7.5kDa蛋白的级分,进行质谱分析。结果显示纯化的蛋白被降解为三个肽链(2486,2586和2709Da),它们通过二硫键相连。2486 Da肽链的N-末端氨基酸序列是ANAFCPEGLLYTNPLCCDLL,根据半胱氨酸的位置以及与已知疏水蛋白的序列比较,它是一种典型的疏水蛋白。
根据所述氨基酸序列以及2586Da肽链的序列设计简并引物。用于对从获得纯化蛋白的相同培养液中提取的RNA进行RT-PCR(RobusT RT-PCR试剂盒,Finnzymes)。对所得140bp的片段测序。所得序列包含可编码用于设计PCR引物的2486Da肽的部分,证实该PCR产物与纯化的蛋白相对应。
实施例41
在ATPS中试(pilot scale)中纯化EGIcore-HFBI
在1200L中试发酵罐中将能在cdh1启动子调控下生产EGIcore-HFBI融合蛋白的菌株VTT-D-99702培养4天,所述发酵罐内装有含4%乳糖,0.4%蛋白胨和0.1%酵母提取物的基本培养基。培养温度为28℃或在培养期间从27℃到22℃逐步改变。融合蛋白的生产水平为数克/升。培养结束后,菌丝体用鼓式旋转真空滤器以Celite 535硅藻土为助滤剂进行分离。
在分离步骤1中,把1100L上清倒入即时洁净的生物反应器中,将分配温度调整到24.7℃,混入盐和去污剂,使磷酸二氢铵的浓度为0.15M,去污剂C12-18EO5的浓度为4.1%。所述相通过重力沉淀分离,利用底部阀门排掉底部的较重相。同时进行10ml平行实验,以此来研究规模放大分离融合蛋白的效果。10ml和1200L分配的分配系数和浓度系数在检测误差范围内。已分离的去污剂相的再次萃取用首次萃取所得去污剂相通过以自来水代替底层相的一半体积而进行。在30℃把盐浓度调整到0.25M磷酸二氢铵。分离的K和Y值列于下表中。
可选地,在分离步骤2中,将10ml经鼓式过滤的培养液样品置于ATPS中,于25℃用4.1%的C12-18EO5去污剂和1.15M(NH4)H2PO4进行分配。一步分离后的K和Y值列于下表中。
不同中试培养所得上清的萃取实验
| 分离 | 培养温度 | 浓度系数 | K | Y(%) |
| 分离步骤1再次萃取 | 27℃→22℃ | 3.4 | 3.88 | 5970 |
| 分离步骤2 | 29℃ | 2.8 | 8.3 | 81 |
实施例42
在粗硬微团/聚合物系统中分离EGI,EGIcore-RFBI融合蛋白和HFBI疏水蛋白
用纯化的样品进行分离。利用双相分离和实施例38描述的HPLC对HFB I进行纯化。如实施例5所述用两相萃取对EGIcore-HFB I进行纯化,然后用Biogel P-6柱(已用含有150Mm NaCl的20mM乙酸钠pH6缓冲液平衡)进行脱盐处理。纯化的蛋白用不同微团/聚合物系统进行ATPS分配。
下表列出在恒定结线(tie-line)长度下纯化的EGI,HFBI和EGIcore-HFBI的分配系数,反应在三种不同的系统中进行,分别是:31.5℃的TritonX-114/水系统(4.1%wt.),21℃的TritonX-100/Reppal/水系统(8.1%wt./8.2%wt.)和TritonX-114/Reppal/水系统(5.0%wt./4.0%wt.)。括号内是标准差,系统用25mM乙酸钠pH4.0的溶液缓冲。K>1相当于蛋白向微团富集相中的优选分配。
| EG1KEGI | HFBIKHFB | EGIcore-HFBIKEGIHFB | 产率(%)上层相 | |
| Triton X-114Triton X-100/ReppalTriton X-114/Reppal | 0.6(0.1)0.9(0.1)0.7(0.1) | 21.5(1.5)-11.0(1.1) | 8.4(1.0)1.7(0.1)15.4(2.9) | 855691 |
参考文献
Albertsson,P.A.(1986).细胞颗粒和大分子的分配,John Wiley & Sons,New York.
Arntz,C.和Tudzynski,P(1997).麦角菌属生物碱生成培养物中诱导基因的鉴定,当代基因(Curr.Genet.)31:357-360.
Bender,W.和Koglin,B.(1986).Mechanische Trennung von Bioprodukten.Chem.-Ing.-Tech.,58:565-577.
Berggren K.,Veide A.,Nygren P.-A.和Tjerneld F.(1999).用于调控热分离双水相系统的蛋白-肽融合体的基因工程.Biotechnol.Bioeng.62:135-144.
Bhikhabhai,R.,Johansson,G.和Petterson,G.(1984).从Trichodermareesei QM 9414中分离细胞溶解酶.应用生物化学杂志(J.Appl.Biochem)6:336-345.
Bordier C.(1981).膜内在蛋白在Triton X-1 14溶液中的相分离.生物化学杂志(J.Biol.Chem.)25:1604-1607.
Carpenter,C.E.,Mueller,R.J.,Kazmierczak,P.,Zhang,L.,Villalon,D.K.和van Alfen,N.K.(1992).Mol.Plant-Microbe Interact.4:55-61.
Gietz,D.,St.Jean,A.,Woods,R.A.和Schiestl,R.H.(1992).Improvedmethod for high efficiency transformation of intact yeast cells.Nucl.Acid.Res.20:1425.
Hassinen C.,Kohler K.,Veide A.(1994).Journal of Chromatography A,668:121-128.
Heusch,R.和Kopp,F.(1988).非离子型表面活性剂在水溶液中的结构.Progress in Colloid & Polymer Science,77:77-85.
Hustedt,H.,Kroner,K.和Kula,MR.(1985).生物技术中相分配技术的应用.In:Walter,H.,Brooks,D.E.和Fisher,D.(eds.),双水相系统的分配:原理,方法,使用和在生物技术中应用,pp.529-587.
Hynes,M.J.,Corrick,C.M.和King,J.A.(1983).构巢曲霉的含有amdS基因的基因组克隆的分离以及它们在结构分析和调节突变中的应用.分子生化学和细胞化学(Mol.Cell Biol.)3:1430-1439.
Johansson,H.-O.,Karlstrom,G.,Tjerneld,F.和Haynes,A.C.(1998).色谱学杂志B,711:3-17.
Kershaw,M.J.和Talbot,N.J.(1998).疏水蛋白和拒斥剂:在真菌形态生成中具有基础作用的蛋白.Fungal Gen.Biol.23:18-33.
Kula M-R.(1979).借助双水相系统进行酶的萃取和纯化.In:Wingard L;Goldstein,L(eds.),Applied Biochemistry和Bioengineering.New York,Academic Press,pp.71-95.
Kula,M-R.,Kroner,K.H.,Hustedt,H.和SchuKe,H.(1981).萃取酶纯化技术.Ann.N.Y.Acad.Sci.,369:341-354.
Kula,M-R.,Kroner,K.H.和Hustedt,H.(1982).液-液萃取进行酶的纯化.In:Fiechter,A.(ed.),生物化学工程进展,Springer Verlag,Berlin,pp.74-118.
Kula,M-R.(1985).生物聚合物的液-液萃取.In:Humphrey A;CooneyCL(eds.),综合生物技术(Comprehensive Biotechnology),Vol.2.PergamonPress,New York,pp.451-471.
Kula,M-R.(1990).Bioseparation,1:181-189.
Kohler,K.,Ljungquist,C.,Kondo,A.,Veide,A.和Nilsson B.(1991),双水相系统中增强分配系数的工程蛋白.Bio/Technology 9:642-646.
Linder,M.,Salovuori,I.,Ruohonen,L.和Teeri,T.T.(1996).双纤维素接合结构域的特点.生物化学杂志.271:21268-21272.
Lora,J.M.,de la Cruz,J.,Benitez,T.,Llobell,A.和Pintor-Toro,J.A.(1994).Mol.Gen.Genet.242:461-466.
Lora,J.M.,Pintor-Toro,J.A.,Benitez,T.和Romero,L.C.(1995).Mol.Microbiol.18:377-382.
Mach et al.,(1994)当代基因6:567-570.
Minuth,T.,Thommes,J.和Kula,M-R.(1995).利用非离子表面活性剂为基础的双水相系统,从玫瑰色诺卡氏菌(Nocardia rhodochrous)中萃取胆固醇氧化酶.J.Biotechnol.38:151-164.
Minuth,T.,Thommes,J.和Kula,M-R.(1996).利用基于表面活性剂的“浊化点”萃取,有机溶剂萃取和阴离子交换层析法,从玫瑰色诺卡氏菌中纯化膜结合的胆固醇氧化酶.Biotechnol.Appl.Biochem.23:107-116.
Nakari,T.,Onnela,M.-L.,Ilmen,M.,Nevalainen,K.M.H.和Penttila,M.(1994)在有葡萄糖的情况下,真菌启动子的活性,国际申请专利WO94/04673.
Nakari-Setala et al.(1996).Eur.J.Biochem.235:248-255.
Nevalainen,K.M.H.,Penttila,M.E.,Harkki,A.,Teeri,T.T.和Knowles,J.(1991),欧洲生物化学
木霉的分子生物学以及它在表达同源及异源基因方面的应用,In工业真菌分子学.Leong,S.A.和Berka,eds.,R..Marcel Dekker.New York,p.129-148.
Pack,P.,Kujau,M.,Schroeckh,V,Knupfer,U.,Wenderoth,R.,Riesenberg,D.和Pluckthun,A.(1993).利用高密度发酵大肠杆菌生产的,具有与整个抗体相同的抗体抗原亲和性的改进双价微抗体,生物技术(Biotechnology)11:1271-1277.
Penttila,M.,Nevalainen,H.,Ratto,M.,Salminen,E.和Knowles,J.(1987).可分解纤维素的丝状真菌-Trichoderma reesei的通用转化系统,基因(Gene)61:155-164.
Pere,J.,Siika-aho,M.,Buchert,J.和Viikari.L.(1995).纯化的木霉菌纤维素酶对牛皮纸纸浆纤维特性的影响,纸浆与造纸工业技术协会(Tappi)会志78:71-78.
Qiao,M.,Ye,S.,Koponen,O.,Ra,R.,Usabiaga,M.,Immonen,T.,Saris,P.E.J.(1996)乳酸链球菌肽操纵子在乳酸乳球菌N8中的调控作用.应用生物化学杂志.80:626-634.
Russo,P.S.,Blum,F.D.,Ispen,J.D.,Abul-Hajj,Y.J.和Miller,W.G.(1992).Can.J.Bot.60:1414-1422.
Schreuder,M.P.et al.(1996).生物技术趋势(Trends Biotechnol.)14:115-120.
Sherman,F.,Fink,G.R.和Hicks,J.B.(1983).酵母遗传学方法.实验室手册.冷泉港实验室,冷泉港,NY.
Suominen,P.,Mantyla,A.,Saarelainen,R.,Paloheimo,M.,Fagerstrom,R.,Parkkinen,E.和Nevalainen,H.(1992).产生适合应用于纸浆和造纸工业的酶组合的Trichoderma reesei的基因工程p.439-445.(Proc.5th Int.Conf.Biotechn.Pulp Pap.Ind.,Kyoto,Japan,1992).
Stahl,S.和Uhlen,M.(1997).生物技术趋势15:185-192.
Takkinen,K.,Laukkanen,M.-L.,Sizmann,D.,Alfthan,K.,Immonen,T.,Vanne,L.,Kaartinen,M.,Knowles,J.K.C.和Teeri,T.T.(1991).大肠杆菌分泌的含有纤维素接合物结构域的活性单链抗体,蛋白质工程(Protein Eng.)4:837-841.
Temple,B.,Horgen,P.A.,Bernier,L.和Hintz,W.E.(1997).,Dutch Elm病病原体分泌的疏水蛋白,Cerato-ulmin是适合寄生因子,Fungal Gen.Biol.22:39-51.
Terstappen,G.C.,Geerts,A.J.,Kula,M.-R.,1992“基于去污剂的双水相系统在胞外蛋白分离中的应用:纯从石竹假单孢菌脂肪酶P”,Biotechnol.Appl.Biochem.16,228-235.
Terstappen,G.C.,Ramelmeier,R.A.和Kula M.-R.,1993,双水相系统中蛋白质分配,生物技术杂志(J.Biotechnol.)28:263-275.
Thomas,B.J.和Rothstein,R.(1989).在具有转录活性DNA中重组比率的提高,细胞(Cell)56:619-630.
van Tilbeurgh H.和Caeyssens M.(1985).使用低分子量荧光底物进行纤维素酶成分检测和区分,欧洲化学会联合会快报(FEBS letters)187:283-288.
van Tilbeurgh H.,Caeyssens M.和de Bruyne C.K.(1982).4-甲基伞形酮和其它显色糖苷在纤维素水解酶研究中的应用,欧洲化学会联合会快报(FEBS letters)194:152-156.
Tilburn,J.,Scazzocchio,C.,Taylor,G.G.,Zabicky-Zissman,J.H.,Lockington,R.A.和Davies,R.W.(1983).构巢曲霉中通过整合进行的转化,基因(Gene)26:205-221.
Tjerneld,F.,Bemer,S.,Cajarville,A.和Johansson,G.(1986).新的基于可用于酶纯化的羟丙基淀粉的双水相系统,Enz.Microb.Technol.8:417-423.
Veide,A.,Lindback,T.和Enfors,S.(1984).大肠杆菌β-D-半乳糖苷酶在双水相系统中的连续萃取:生物量浓度对分配和质量传递的影响,Enz.Microb.Technol.6:325-330.
Walter,H.,Brooks,D.E.和Fisher,D.(1985).双水相系统的分配,AcademicPress,Inc.,Orlando.
Watari,J.,Nomura,M.,Sahara,H.和Koshino,S.(1994).通过酵母絮凝基因FLO1的染色体整合进行的絮凝酿酒酵母的构建,J.Inst.Brew.100:73-77.
Wessels,J.G.H.(1994).真菌细胞壁形成的发育调节,Annu.Rev.Phytopathol.32;413-437.
Woesten,H.A.B.,Schuren,F.H.J.和Wessels,J.G.H.(1994a).作为构成疏水小棒层的蛋白质膜,真菌疏水蛋白Sc3p在气生菌丝表面的自组装,Eur.J.Cell Biol.63:122-129.
Wosten,H.A.B.,Schuren,F.H.J.和Wessels,J.G.H.(1994b).进入两性蛋白膜的疏水蛋白的相间自组装引起的真菌附着到疏水表面,EMBO J.13:5848-5854.
Wosten,H.A.B.,Bohlmann,R.,Eckerskorn,C.,Lottspeich,F.,Bolker,M.和Kahmann R.(1996)EMBO J.15:4274-4281.
Wosten,H.A.B.和Wessels,J.G.H.(1997).疏水蛋白,从分子结构到在真菌发育中的多种功能,Mycoscience 38:363-374.
序列表
<110>瓦申泰克尼利南塔基马斯凯斯库斯公司(Valtion teknillinen tutkimuskeskus)
<120>蛋白质的分配方法
<130>36834
<140>
<141>
<160>42
<170>Patent In Ver.2.2
<210>1
<211>428
<212>DNA
<213>Trichoderma reesei
<220>
<221>intron
<222>(167)..(236)
<220>
<221>intron
<222>(323)..(386)
<220>
<223>hfb1的编码序列
<400>1
atgaagttct tcgccatcgc cgctctcttt gccgccgctg ccgttgccca gcctctcgag 60
gaccgcagca acggcaacgg caatgtttgc cctcccggcc tcttcagcaa cccccagtgc 120
tgtgccaccc aagtccttgg cctcatcggc cttgactgca aagtccgtaa gttgagccat 180
aacataagaa tcctcttgac ggaaatatgc cttctcactc ctttacccct gaacagcctc 240
ccagaacgtt tacgacggca ccgacttccg caacgtctgc gccaaaaccg gcgcccagcc 300
tctctgctgc gtggcccccg ttgtaagttg atgccccagc tcaagctcca gtctttggca 360
aacccattct gacacccaga ctgcaggccg gccaggctct tctgtgccag accgccgtcg 420
gtgcttga 428
<210>2
<211>78
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 5′引物
<400>2
tcgggcacta cgtgccagta tagcaacgac tactactcgc aatgcct tgt tccgcgtggc 60
tctagttctg gaaccgca 78
<210>3
<211>30
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 3’引物
<400>3
tcgtacggat cctcaagcac cgacggcggt 30
<210>4
<211>63
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 5’引物
<400>4
actacacgga ggagctcgac gacttcgagc agcccgagct gcacgcagag caacggcaac 60
ggc 63
<210>5
<211>2211
<212>DNA
<213>Trichoderma reesei
<220>
<221>promoter
<222>(1)..(2211)
<223>cbh1启动子序列
<400>5
gaattctcac ggtgaatgta ggccttttgt agggtaggaa ttgtcactca agcaccccca 60
acctccatta cgcctccccc atagagttcc caatcagtga gtcatggcac tgttctcaaa 120
tagattgggg agaagttgac ttccgcccag agctgaaggt cgcacaaccg catgatatag 180
ggtcggcaac ggcaaaaaag cacgtggctc accgaaaagc aagatgtttg cgatctaaca 240
tccaggaacc tggatacatc catcatcacg cacgaccact ttgatctgct ggtaaactcg 300
tattcgccct aaaccgaagt gcgtggtaaa tctacacgtg ggcccctttc ggtatactgc 360
gtgtgtcttc tctaggtgca ttctttcctt cctctagtgt tgaattgttt gtgttgggag 420
tccgagctgt aactacctct gaatctctgg agaatggtgg actaacgact accgtgcacc 480
tgcatcatgt atataatagt gatcctgaga aggggggttt ggagcaatgt gggactttga 540
tggtcatcaa acaaagaacg aagacgcctc ttttgcaaag ttttgtttcg gctacggtga 600
agaactggat acttgttgtg tcttctgtgt atttttgtgg caacaagagg ccagagacaa 660
tctattcaaa caccaagctt gctcttttga gctacaagaa cctgtggggt atatatctag 720
agttgtgaag tcggtaatcc cgctgtatag taatacgagt cgcatctaaa tactccgaag 780
ctgctgcgaa cccggagaat cgagatgtgc tggaaagctt ctagcgagcg gctaaattag 840
catgaaaggc tatgagaaat tctggagacg gcttgttgaa tcatggcgtt ccattcttcg 900
acaagcaaag cgttccgtcg cagtagcagg cactcattcc cgaaaaaact cggagattcc 960
taagtagcga tggaaccgga ataatataat aggcaataca ttgagttgcc tcgacggttg 1020
caatgcaggg gtactgagct tggacataac tgttccgtac cccacctctt ctcaaccttt 1080
ggcgtttccc tgattcagcg tacccgtaca agtcgtaatc actattaacc cagactgacc 1140
ggacgtgttt tgcccttcat ttggagaaat aatgtcattg cgatgtgtaa tttgcctgct 1200
tgaccgactg gggctgttcg aagcccgaat gtaggattgt tatccgaact ctgctcgtag 1260
aggcatgttg tgaatctgtg tcgggcagga cacgcctcga aggttcacgg caagggaaac 1320
caccgatagc agtgtctagt agcaacctgt aaagccgcaa tgcagcatca ctggaaaata 1380
caaaccaatg gctaaaagta cataagttaa tgcctaaaga agtcatatac cagcggctaa 1440
taattgtaca atcaagtggc taaacgtacc gtaatttgcc aacgcgttgt ggggttgcag 1500
aagcaacggc aaagcccact tcccacgttt gtttcttcac tcagtccaat ctcagctggt 1560
gatcccccaa ttgggtcgct tgtttgttcc ggtgaagtga aagaagacag aggtaagaat 1620
gtctgactcg gagcgttttg catacaacca agggcagtga tggaagacag tgaaatgttg 1680
acattcaagg agtatttagc cagggatgct tgagtgtatc gtgtaaggag gtttgtctgc 1740
cgatacgacg aatactgtat agtcacttct gatgaagtgg tccatattga aatgtaagtc 1800
ggcactgaac aggcaaaaga ttgagttgaa actgcctaag atctcgggcc ctcgggcttc 1860
ggctttgggt gtacatgttt gtgctccggg caaatgcaaa gtgtggtagg atcgacacac 1920
tgctgccttt accaagcagc tgagggtatg tgataggcaa atgttcaggg gccactgcat 1980
ggtttcgaat agaaagagaa gcttagccaa gaacaatagc cgataaagat agcctcatta 2040
aacgaaatga gctagtaggc aaagtcagcg aatgtgtata tataaaggtt cgaggtccgt 2100
gcctccctca tgctctcccc atctactcat caactcagat cctccaggag acttgtacac 2160
catcttttga ggcacagaaa cccaatagtc aaccgcggac tgcgcatcat g 2211
<210>6
<211>1588
<212>DNA
<213>Trichoderma reesei
<220>
<223>T.reesei egl1 cDNA
<400>6
cccccctatc ttagtccttc ttgttgtccc aaaatggcgc cctcagttac actgccgttg 60
accacggcca tcctggccat tgcccggctc gtcgccgccc agcaaccggg taccagcacc 120
cccgaggtcc atcccaagtt gacaacctac aagtgtacaa agtccggggg gtgcgtggcc 180
caggacacct cggtggtcct tgactggaac taccgctgga tgcacgacgc aaactacaac 240
tcgtgcaccg tcaacggcgg cgtcaacacc acgctctgcc ctgacgaggc gacctgtggc 300
aagaactgct tcatcgaggg cgtcgactac gccgcctcgg gcgtcacgac ctcgggcagc 360
agcctcacca tgaaccagta catgcccagc agctctggcg gctacagcag cgtctctcct 420
cggctgtatc tcctggactc tgacggtgag tacgtgatgc tgaagctcaa cggccaggag 480
ctgagcttcg acgtcgacct ctctgctctg ccgtgtggag agaacggctc gctctacctg 540
tctcagatgg acgagaacgg gggcgccaac cagtataaca cggccggtgc caactacggg 600
agcggctact gcgatgctca gtgccccgtc cagacatgga ggaacggcac cctcaacact 660
agccaccagg gcttctgctg caacgagatg gatatcctgg agggcaactc gagggcgaat 720
gccttgaccc ctcactcttg cacggccacg gcctgcgact ctgccggttg cggcttcaac 780
ccctatggca gcggctacaa aagctactac ggccccggag ataccgttga cacctccaag 840
accttcacca tcatcaccca gttcaacacg gacaacggct cgccctcggg caaccttgtg 900
agcatcaccc gcaagtacca gcaaaacggc gtcgacatcc ccagcgccca gcccggcggc 960
gacaccatct cgtcctgccc gtccgcctca gcctacggcg gcctcgccac catgggcaag 1020
gccctgagca gcggcatggt gctcgtgttc agcatttgga acgacaacag ccagtacatg 1080
aactggctcg acagcggcaa cgccggcccc tgcagcagca ccgagggcaa cccatccaac 1140
atcctggcca acaaccccaa cacgcacgtc gtcttctcca acatccgctg gggagacatt 1200
gggtctacta cgaactcgac tgcgcccccg cccccgcctg cgtccagcac gacgttttcg 1260
actacacgga ggagctcgac gacttcgagc agcccgagct gcacgcagac tcactggggg 1320
cagtgcggtg gcattgggta cagcgggtgc aagacgtgca cgtcgggcac tacgtgccag 1380
tatagcaacg actactactc gcaatgcctt tagagcgttg acttgcctct ggtctgtcca 1440
gacgggggca cgatagaatg cgggcacgca gggagctcgt agacattggg cttaatatat 1500
aagacatgct atgttgtatc tacattagca aatgacaaac aaatgaaaaa gaacttatca 1560
agcaaaaaaa aaaaaaaaaa aaaaaaaa 1588
<210>7
<211>745
<212>DNA
<213>Trichoderma reesei
<220>
<221>terminator
<222>(1)..(745)
<223>T.reesei cbh1终止子
<400>7
ggacctaccc agtctcacta cggccagtgc ggcggtattg gctacagcgg ccccacggtc 60
tgcgccagcg gcacaacttg ccaggtcctg aacccttact actctcagtg cctgtaaagc 120
tccgtgcgaa agcctgacgc accggtagat tcttggtgag cccgtatcat gacggcggcg 180
ggagctacat ggccccgggt gatttatttt ttttgtatct acttctgacc cttttcaaat 240
atacggtcaa ctcatctttc actggagatg cggcctgctt ggtattgcga tgttgtcagc 300
ttggcaaatt gtggctttcg aaaacacaaa acgattcctt agtagccatg cattttaaga 360
taacggaata gaagaaagag gaaattaaaa aaaaaaaaaa aacaaacatc ccgttcataa 420
cccgtagaat cgccgctctt cgtgtatccc agtaccacgt caaaggtatt catgatcgtt 480
caatgttgat attgttccgc cagtatggct ccacccccat ctccgcgaat ctcctcttct 540
cgaacgcggt agtggctgct gccaattggt aatgaccata gggagacaaa cagcataata 600
gcaacagtgg aaattagtgg cgcaat8att gagaacacag tgagaccata gctggcggcc 660
tggaaagcac tgttggagac caacttgtcc gttgcgaggc caacttgcat tgctgtcaag 720
acgatgacaa cgtagccgag gaccc 745
<210>8
<211>10
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:已经退火的引物
<400>8
taaccgcggt 10
<210>9
<211>16
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:已经退火的引物
<400>9
c tagaccgcg gttaat 16
<210>10
<211>1232
<212>DNA
<213>Trichoderma reesei
<220>
<221>promoter
<222>(1)..(1232)
<223>T.reesei gpd1启动子
<400>10
gtcgacacga tatacaggcg cggctgatga taatgatgat cgagcatgac ttgatgctgt 60
atgtgacaat attgactgcg aggaaccatc aggtgtgtat ggatggaatc attctgtaac 120
caccaaggtg catgcatcat aaggattctc ctcagctcac caacaacgaa cgatggccat 180
gttagtgaag gcaccgtgat ggcaagatag aaccactatt gcatctgcgc ttcccacgca 240
cagtacgtca agtaacgtca aagccgccct cccgtaacct cgcccgttgt tgctcccccc 300
gattgcctca atcacatagt acctacctat gcattatggg cggcctcaac ccaccccccc 360
agattgagag ctaccttaca tcaatatggc cagcacctct tcggcgatac atactcgcca 420
ccccagccgg cgcgattgtg tgtactaggt aggctcgtac tataccagca ggagaggtgc 480
tgcttggcaa tcgtgctcag ctgttaggtt gtacttgtat ggtacttgta aggtggtcat 540
gcagttgcta aggtacctag ggagggattc aacgagccct gcttccaatg tccatctgga 600
taggatggcg gctggcgggg ccgaagctgg gaactcgcca acagtcatat gtaatagctc 660
aagttgatga taccgttttg ccagattaga tgcgagaagc agcatgaatg tcgctcatcc 720
gatgccgcat caccgttgtg tcagaaacga ccaagctaag caactaaggt accttaccgt 780
ccactatctc aggtaaccag gtactaccag ctaccctacc tgccgtgcct acctgcttta 840
gtgttaatct ttccacctcc ctcctcaatc ttcttttccc tcctctcctc tttttttttt 900
cttcctcctc ttcttctcca taaccattcc taacaacatc gacattctct cctaatcacc 960
agcctcgcaa atcctcagtt tgtatgtacg tacgtactac aatcatcacc acgatcgtcc 1020
gcccgacgat gcggcttctg ttcgcctgcc cctcctctca ctcgtgccct tgacgagcta 1080
gccccgccag gactctcctg cgtcaccaat ttttttccct atttacccct cctccctctc 1140
tccctctcgt ttcttcctaa caaacaacca ccaccaaaat ctctttggaa gctcacgact 1200
cacgcagctc aattcgcaga tacaaatcta ga 1232
<210>11
<211>1129
<212>DNA
<213>Trichoderma reesei
<220>
<221>terminator
<222>(1)..(1129)
<223>T.reesei gpd1终止子
<400>11
ggatcccgag cattgtctat gaatgcaaac aaaaatagta aataaatagt aattctggcc 60
atgacgaata gagccaatct gctccacttg actatcttgt gactgtatcg tatgtcgaac 120
ccttgactgc ccattcaaac aattgtaaag gaatatagct acaagttatg tctcacgttt 180
gcgtgcgagc ccgtttgtac gttattttga gaaagcgttg ccatcacatg ctcacagtca 240
cttggcttac gatcatgttt gcgatcttcg gtaagaatac acagagtaac gattatctcc 300
atcgcttcta tgattaggta ctcagacaac acatgggaaa caagataacc atcgcatgca 360
aggtcgattc caatcatgat ctggactggg gtattccatc taagccatag taccctcgag 420
agaaggaatg gtaggacctc tcaggcgtcc accatctgtg ctgcaaatcc aagaaacccc 480
ccaaaagcac ctacctatct acctagagta actgcacgag aaaagaaaag gagcagaaga 540
agaatgatct caagaggccg tgaacgcaga aacacactcc tcccaacttt tcaagttttg 600
aacaaaaaaa gaaagatgag gactagaaga tggagtattt ccttcttaga gagctctcgg 660
tgaggtgacc tgtcagggtt taccgcaaac cgtcggtggt tctatccaat taatcaagtc 720
ccgcgcctcg cctcttctct cctgtccttt catagaatcc cgtctccttg ttgcttgatc 780
gaagcggggt tatcgacgcc accaaagatc ttgtcttggt gacttatcaa tcctttggtg 840
atcaaacagc ccccgagtga tcagatccgt aaaagaagaa gaagagtacg atttaaccag 900
accgaggaac aataaagcga gtaaataaca tcaaaataag agtctcgttg aaaattactt 960
gttcctcaat caatcccaac ccccctaaaa gcccttcccc ccatggtata tcccggcagt 1020
aggagagaga tatttccact accgctcacc accaagtgag gcttgccgag agaagaggat 1080
gaatcagaag tgacaacaac gggttgagca catgggatat cggcgcgcc 1129
<210>12
<211>5733
<212>DNA
<213>构巢曲霉(Aspergillus nidulans)
<220>
<223>(1-5733)pAN52-1质粒的序列
<220>
<221>promoter
<222>(1)..(2129)
<223>构巢曲霉(A.nidulans)gpdA启动子
<220>
<221>基因
<222>(2130)..(2304)
<223>构巢曲霉(A.nidulans)gpdA基因
<220>
<221>terminator
<222>(2305)..(3071)
<223>构巢曲霉(A.nidulans)trpC终止子
<220>
<221>misc_feature
<222>(3072)..(5726)
<223>pUC18上从SalI位点到EcoRI位点
<400>12
caattccctt gtatctctac acacaggctc aaatcaataa gaagaacggt tcgtcttttt 60
cgtttatatc ttgcatcgtc ccaaagctat tggcgggata ttctgtttgc agttggctga 120
cttgaagtaa tctctgcaga tctttcgaca ctgaaatacg tcgagcctgc tccgcttgga 180
agcggcgagg agcctcgtcc tgtcacaact accaacatgg agtacgataa gggccagttc 240
cgccagctca ttaagagcca gttcatgggc gttggcatga tggccgtcat gcatctgtac 300
ttcaagtaca ccaacgctct tctgatccag tcgatcatcc gctgaaggcg ctttcgaatc 360
tggttaagat ccacgtcttc gggaagccag cgactggtga cctccagcgt ccctttaagg 420
ctgccaacag ctttctcagc cagggccagc ccaagaccga caaggcctcc ctccagaacg 480
ccgagaagaa ctggaggggt ggtgtcaagg aggagtaagc tccttattga agtcggagga 540
cggagcggtg tcaagaggat attcttcgac tctgtattat agataagatg atgaggaatt 600
ggaggtagca tagcttcatt tggatttgct ttccaggctg agactctagc ttggagcata 660
gagggtcctt tggctttcaa tattctcaag tatctcgagt ttgaacttat tccctgtgaa 720
ccttttattc accaatgagc attggaatga acatgaatct gaggactgca atcgccatga 780
ggttttcgaa atacatccgg atgtcgaagg cttggggcac ctgcgttggt tgaatttaga 840
acgtggcact attgatcatc cgatagctct gcaaagggcg ttgcacaatg caagtcaaac 900
gttgctagca gttccaggtg gaatgttatg atgagcattg tattaaatca ggagatatag 960
catgatctct agttagctca ccacaaaagt cagacggcgt aaccaaaagt cacacaacac 1020
aagctgtaag gatttcggca cggctacgga agacggagaa gccaccttca gtggactcga 1080
gtaccattta attctatttg tgtttgatcg agacctaata cagcccctac aacgaccatc 1140
aaagtcgtat agctaccagt gaggaagtgg actcaaatcg acttcagcaa catctcctgg 1200
ataaacttta agcctaaact atacagaata agataggtgg agagcttata ccgagctccc 1260
aaatctgtcc agatcatggt tgaccggtgc ctggatcttc ctatagaatc atccttattc 1320
gttgacctag ctgattctgg agtgacccag agggtcatga cttgagccta aaatccgccg 1380
cctccaccat ttgtagaaaa atgtgacgaa ctcgtgagct ctgtacagtg accggtgact 1440
ctttctggca tgcggagaga cggacggacg cagagagaag ggctgagtaa taagccactg 1500
gccagacagc tctggcggct ctgaggtgca gtggatgatt attaatccgg gaccggccgc 1560
ccctccgccc cgaagtggaa aggctggtgt gcccctcgtt gaccaagaat ctattgcatc 1620
atcggagaat atggagcttc atcgaatcac cggcagtaag cgaaggagaa tgtgaagcca 1680
ggggtgtata gccgtcggcg aaatagcatg ccattaacct aggtacagaa gtccaattgc 1740
ttccgatctg gtaaaagatt cacgagatag taccttctcc gaagtaggta gagcgagtac 1800
ccggcgcgta agctccctaa ttggcccatc cggcatctgt agggcgtcca aatatcgtgc 1860
ctctcctgct ttgcccggtg tatgaaaccg gaaaggccgc tcaggagctg gccagcggcg 1920
cagaccggga acacaagctg gcagtcgacc catccggtgc tctgcactcg acctgctgag 1980
gtccctcagt ccctggtagg cagctttgcc ccgtctgtcc gcccggtgtg tcggcggggt 2040
tgacaaggtc gttgcgtcag tccaacattt gttgccatat tttcctgctc tccccaccag 2100
ctgctctttt cttttctctt tcttttccca tcttcagtat attcatcttc ccatccaaga 2160
acctttattt cccctaagta agtactttgc tacatccata ctccatcctt cccatccctt 2220
attcctttga acctttcagt tcgagctttc ccacttcatc gcagcttgac taacagctac 2280
cccgcttgag cagacatcac catggatcca cttaacgtta ctgaaatcat caaacagctt 2340
gacgaatctg gatataagat cgttggtgtc gatgtcagct ccggagttga gacaaatggt 2400
gttcaggatc tcgataagat acgttcattt gtccaagcag caaagagtgc cttctagtga 2460
tttaatagct ccatgtcaac aagaataaaa cgcgttttcg ggtttacctc ttccagatac 2520
agctcatctg caatgcatta atgcattgac tgcaacctag taacgccttn caggctccgg 2580
cgaagagaag aatagcttag cagagctatt ttcattttcg ggagacgaga tcaagcagat 2640
caacggtcgt caagagacct acgagactga ggaatccgct cttggctcca cgcgactata 2700
tatttgtctc taattgtact ttgacatgct cctcttcttt actctgatag cttgactatg 2760
aaaattccgt caccagcncc tgggttcgca aagataattg catgtttctt ccttgaactc 2820
tcaagcctac aggacacaca ttcatcgtag gtataaacct cgaaatcant tcctactaag 2880
atggtataca atagtaacca tgcatggttg cctagtgaat gctccgtaac acccaatacg 2940
ccggccgaaa cttttttaca actctcctat gagtcgttta cccagaatgc acaggtacac 3000
ttgtttagag gtaatccttc tttctagaag tcctcgtgta ctgtgtaagc gcccactcca 3060
catctccact cgacctgcag gcatgcaagc ttggcactgg ccgtcgtttt acaacgtcgt 3120
gactgggaaa accctggcgt tacccaactt aatcgccttg cagcacatcc ccctttcgcc 3180
agctggcgta atagcgaaga ggcccgcacc gatcgccctt cccaacagtt gcgcagcctg 3240
aatggcgaat ggcgcctgat gcggtatttt ctccttacgc atctgtgcgg tatttcacac 3300
cgcatatggt gcactctcag tacaatctgc tctgatgccg catagttaag ccagccccga 3360
cacccgccaa cacccgctga cgcgccctga cgggcttgtc tgctcccggc atccgcttac 3420
agacaagctg tgaccgtctc cgggagctgc atgtgtcaga ggttttcacc gtcatcaccg 3480
aaacgcgcga gacgaaaggg cctcgtgata cgcctatttt tataggttaa tgtcatgata 3540
ataatggttt cttagacgtc aggtggcact tttcggggaa atgtgcgcgg aacccctatt 3600
tgtttatttt tctaaataca ttcaaatatg tatccgctca tgagacaata accctgataa 3660
atgcttcaat aatattgaaa aaggaagagt atgagtattc aacatttccg tgtcgccctt 3720
attccctttt ttgcggcatt ttgccttcct gtttttgctc acccagaaac gctggtgaaa 3780
gtaaaagatg ctgaagatca gttgggtgca cgagtgggtt acatcgaact ggatctcaac 3840
agcggtaaga tccttgagag ttttcgcccc gaagaacgtt ttccaatgat gagcactttt 3900
aaagttctgc tatgtggcgc ggtattatcc cgtattgacg ccgggcaaga gcaactcggt 3960
cgccgcatac actattctca gaatgacttg gttgagtact caccagtcac agaaaagcat 4020
cttacggatg gcatgacagt aagagaatta tgcagtgctg ccataaccat gagtgataac 4080
actgcggcca acttacttct gacaacgatc ggaggaccga aggagctaac cgcttttttg 4140
cacaacatgg gggatcatgt aactcgcctt gatcgttggg aaccggagct gaatgaagcc 4200
ataccaaacg acgagcgtga caccacgatg cctgtagcaa tggcaacaac gttgcgcaaa 4260
ctattaactg gcgaactact tactctagct tcccggcaac aattaataga ctggatggag 4320
gcggataaag ttgcaggacc acttctgcgc tcggcccttc cggctggctg gtttattgct 4380
gataaatctg gagccggtga gcgtgggtct cgcggtatca ttgcagcact ggggccagat 4440
ggtaagccct cccgtatcgt agttatctac acgacgggga gtcaggcaac tatggatgaa 4500
cgaaatagac agatcgctga gataggtgcc tcactgatta agcattggta actgtcagac 4560
caagtttact catatatact ttagattgat ttaaaacttc atttttaatt taaaaggatc 4620
taggtgaaga tcctttttga taatctcatg accaaaatcc cttaacgtga gttttcgttc 4680
cactgagcgt cagaccccgt agaaaagatc aaaggatctt cttgagatcc tttttttctg 4740
cgcgtaatct gctgcttgca aacaaaaaaa ccaccgctac cagcggtggt ttgtttgccg 4800
gatcaagagc taccaactct ttttccgaag gtaactggct tcagcagagc gcagatacca 4860
aatactgtcc ttctagtgta gccgtagtta ggccaccact tcaagaactc tgtagcaccg 4920
cctacatacc tcgctctgct aatcctgtta ccagtggctg ctgccagtgg cgataagtcg 4980
tgtcttaccg ggttggactc aagacgatag ttaccggata aggcgcagcg gtcgggctga 5040
acggggggtt cgtgcacaca gcccagcttg gagcgaacga cctacaccga actgagatac 5100
ctacagcgtg agctatgaga aagcgccacg cttcccgaag ggagaaaggc ggacaggtat 5160
ccggtaagcg gcagggtcgg aacaggagag cgcacgaggg agcttccagg gggaaacgcc 5220
tggtatcttt atagtcctgt cgggtttcgc cacctctgac ttgagcgtcg atttttgtga 5280
tgctcgtcag gggggcggag cctatggaaa aacgccagca acgcggcctt tttacggttc 5340
ctggcctttt gctggccttt tgctcacatg ttctttcctg cgttatcccc tgattctgtg 5400
gataaccgta ttaccgcctt tgagtgagct gataccgctc gccgcagccg aacgaccgag 5460
cgcagcgagt cagtgagcga ggaagcggaa gagcgcccaa tacgcaaacc gcctctcccc 5520
gcgcgttggc cgattcatta atgcagctgg cacgacaggt ttcccgactg gaaagcgggc 5580
agtgagcgca acgcaattaa tgtgagttag ctcactcatt aggcacccca ggctttacac 5640
tttatgcttc cggctcgtat gttgtgtgga attgtgagcg gataacaatt tcacacagga 5700
aacagctatg accatgatta cgaattgcgg ccg 5733
<210>13
<211>39
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 5’引物
<400>13
gtcaaccgcg gactgcgcat catgaagttc ttcgccatc 39
<210>14
<211>66
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 5’引物
<400>14
tctagcaagc ttggctctag ttctggaacc gcaccaggcg gcagcaacgg caacggcaat 60
gtttgc 66
<210>15
<211>30
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 3’引物
<400>15
tcgtacaagc tttcaagcac cgacggcggt 30
<210>16
<211>33
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 5’引物
<400>16
tctagctcta gaagcaacgg caacggcaat gtt 33
<210>17
<211>37
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 3’引物
<400>17
tgctagtcga cctgctagca gcaccgacgg cggtctg 37
<210>18
<211>4614
<212>DNA
<213>酿酒酵母(Saccharomyces cerevisiae)
<220>
<223>酿酒酵母(S.cerevisiae)FL01编码序列
<400>18
atgacaatgc ctcatcgcta tatgtttttg gcagtcttta cacttctggc actaactagt 60
gtggcctcag gagccacaga ggcgtgctta ccagcaggcc agaggaaaag tgggatgaat 120
ataaattttt accagtattc attgaaagat tcctccacat attcgaatgc agcatatatg 180
gcttatggat atgcctcaaa aaccaaacta ggttctgtcg gaggacaaac tgatatctcg 240
attgattata atattccctg tgttagttca tcaggcacat ttccttgtcc tcaagaagat 300
tcctatggaa actggggatg caaaggaatg ggtgcttgtt ctaatagtca aggaattgca 360
tactggagta ctgatttatt tggtttctat actaccccaa caaacgtaac cctagaaatg 420
acaggttatt ttttaccacc acagacgggt tcttacacat tcaagtttgc tacagttgac 480
gactctgcaa ttctatcagt aggtggtgca accgcgttca actgttgtgc tcaacagcaa 540
ccgccgatca catcaacgaa ctttaccatt gacggtatca agccatgggg tggaagtttg 600
ccacctaata tcgaaggaac cgtctatatg tacgctggct actattatcc aatgaaggtt 660
gtttactcga acgctgtttc ttggggtaca cttccaatta gtgtgacact tccagatggt 720
accactgtaa gtgatgactt cgaagggtac gtctattcct ttgacgatga cctaagtcaa 780
tctaactgta ctgtccctga cccttcaaat tatgctgtca gtaccactac aactacaacg 840
gaaccatgga ccggtacttt cacttctaca tctactgaaa tgaccaccgt caccggtacc 900
aacggcgttc caactgacga aaccgtcatt gtcatcagaa ctccaacaac tgctagcacc 960
atcataacta caactgagcc atggaacagc acttttacct ctacttctac cgaattgacc 1020
acagtcactg gcaccaatgg tgtacgaact gacgaaacca tcattgtaat cagaacacca 1080
acaacagcca ctactgccat aactacaact gagccatgga acagcacttt tacctctact 1140
tctaccgaat tgaccacagt caccggtacc aatggtttgc caactgatga gaccatcatt 1200
gtcatcagaa caccaacaac agccactact gccatgacta caactcagcc atggaacgac 1260
acttttacct ctacatccac tgaaatgacc accgtcaccg gtaccaacgg tttgccaact 1320
gatgaaacca tcattgtcat cagaacacca acaacagcca ctactgctat gactacaact 1380
cagccatgga acgacacttt tacctctaca tccactgaaa tgaccaccgt caccggtacc 1440
aacggtttgc caactgatga aaccatcatt gtcatcagaa caccaacaac agccactact 1500
gccatgacta caactcagcc atggaacgac acttttacct ctacatccac tgaaatgacc 1560
accgtcaccg gtaccaatgg tttgccaact gatgagacca tcattgtcat cagaacacca 1620
acaacagcca ctactgccat gactacaact cagccatgga acgacacttt tacctctaca 1680
tccactgaaa tgaccaccgt caccggtacc aacggtttgc caactgatga aaccatcatt 1740
gtcatcagaa caccaacaac agccactact gccataacta caactgagcc atggaacagc 1800
acttttacct ctacttctac cgaattgacc acagtcaccg gtaccaatgg tttgccaact 1860
gatgagacca tcattgtcat cagaacacca acaacagcca ctactgccat gactacaact 1920
cagccatgga acgacacttt tacctctaca tccactgaaa tgaccaccgt caccggtacc 1980
aacggtttgc caactgatga aaccatcatt gtcatcagaa caccaacaac agccactact 2040
gccatgacta caactcagcc atggaacgac acttttacct ctacatccac tgaaatgacc 2100
accgtcaccg gtaccaacgg tttgccaact gatgagacca tcattgtcat cagaacacca 2160
acaacagcca ctactgccat gactacaact cagccatgga acgacacttt tacctctaca 2220
tccactgaaa tgaccaccgt caccggtacc aacggcgttc caactgacga aaccgtcatt 2280
gtcatcagaa ctccaactag tgaaggtcta atcagcacca ccactgaacc atggactggt 2340
actttcacct ctacatccac tgagatgacc accgtcaccg gtactaacgg tcaaccaact 2400
gacgaaaccg tgattgttat cagaactcca accagtgaag gtttggttac aaccaccact 2460
gaaccatgga ctggtacttt tacttctaca tctactgaaa tgaccaccat tactggaacc 2520
aacggcgttc caactgacga aaccgtcatt gtcatcagaa ctccaaccag tgaaggtcta 2580
atcagcacca ccactgaacc atggactggt acttttactt ctacatctac tgaaatgacc 2640
accattactg gaaccaatgg tcaaccaact gacgaaaccg ttattgttat cagaactcca 2700
actagtgaag gtctaatcag caccaccact gaaccatgga ctggtacttt cacttctaca 2760
tctactgaaa tgaccaccgt caccggtacc aacggcgttc caactgacga aaccgtcatt 2820
gtcatcagaa ctccaaccag tgaaggtcta atcagcacca ccactgaacc atggactggc 2880
actttcactt cgacttccac tgaggttacc accatcactg gaaccaacgg tcaaccaact 2940
gacgaaactg tgattgttat cagaactcca accagtgaag gtctaatcag caccaccact 3000
gaaccatgga ctggtacttt cacttctaca tctgctgaaa tgaccaccgt caccggtact 3060
aacggtcaac caactgacga aaccgtgatt gttatcagaa ctccaaccag tgaaggtttg 3120
gttacaacca ccactgaacc atggactggt acttttactt cgacttccac tgaaatgtct 3180
actgtcactg gaaccaatgg cttgccaact gatgaaactg tcattgttgt caaaactcca 3240
actactgcca tctcatccag tttgtcatca tcatcttcag gacaaatcac cagctctatc 3300
acgtcttcgc gtccaattat taccccattc tatcctagca atggaacttc tgtgatttct 3360
tcctcagtaa tttcttcctc agtcacttct tctctattca cttcttctcc agtcatttct 3420
tcctcagtca tttcttcttc tacaacaacc tccacttcta tattttctga atcatctaaa 3480
tcatccgtca ttccaaccag tagttccacc tctggttctt ctgagagcga aacgagttca 3540
gctggttctg tctcttcttc ctcttttatc tcttctgaat catcaaaatc tcctacatat 3600
tcttcttcat cattaccact tgttaccagt gcgacaacaa gccaggaaac tgcttcttca 3660
ttaccacctg ctaccactac aaaaacgagc gaacaaacca ctttggttac cgtgacatcc 3720
tgcgagtctc atgtgtgcac tgaatccatc tcccctgcga ttgtttccac agctactgtt 3780
actgttagcg gcgtcacaac agagtatacc acatggtgcc ctatttctac tacagagaca 3840
acaaagcaaa ccaaagggac aacagagcaa accacagaaa caacaaaaca aaccacggta 3900
gttacaattt cttcttgtga atctgacgta tgctctaaga ctgcttctcc agccattgta 3960
tctacaagca ctgctactat taacggcgtt actacagaat acacaacatg gtgtcctatt 4020
tccaccacag aatcgaggca acaaacaacg ctagttactg ttacttcctg cgaatctggt 4080
gtgtgttccg aaactgcttc acctgccatt gtttcgacgg ccacggctac tgtgaatgat 4140
gttgttacgg tctatcctac atggaggcca cagactgcga atgaagagtc tgtcagctct 4200
aaaatgaaca gtgctaccgg tgagacaaca accaatactt tagctgctga aacgactacc 4260
aatactgtag ctgctgagac gattaccaat actggagctg ctgagacgaa aacagtagtc 4320
acctcttcgc tttcaagatc taatcacgct gaaacacaga cggcttccgc gaccgatgtg 4380
attggtcaca gcagtagtgt tgtttctgta tccgaaactg gcaacaccaa gagtctaaca 4440
agttccgggt tgagtactat gtcgcaacag cctcgtagca caccagcaag cagcatggta 4500
ggatatagta cagcttcttt agaaatttca acgtatgctg gcagtgccaa cagcttactg 4560
gccggtagtg gtttaagtgt cttcattgcg tccttattgc tggcaattat ttaa 4614
<210>19
<211>5857
<212>DNA
<213>酿酒酵母(Saccharomyces cerevisiae)和大肠杆菌(E.coli)
<220>
<221>promoter
<222>(1)..(452)
<223>酿酒酵母(S.cerevisiae)GAL1启动子
<220>
<223>(476-495)大肠杆菌(E.coli)T7 promoter/引发位点
<220>
<223>(502-601)大肠杆菌(E.coli)多克隆位点
<220>
<223>(609-857)酿酒酵母(S.cerevisiae)CYC1转录终止子
<220>
<223>(1039-1712)大肠杆菌(E.coli)pMB1上(源自pUC的)起点
<220>
<221>基因
<222>(1857)..(2717)
<223>大肠杆菌(E.coli)氨苄青霉素抗药基因
<220>
<221>基因
<222>(2735)..(3842)
<223>酿酒酵母(S.cerevisiae)URA3基因
<220>
<223>(3846-5317)酿酒酵母(S.cerevisiae)2μ起点
<220>
<223>(5385-5840)大肠杆菌(E.coli)f1起点
<220>
<223>(1-5857)pYES2序列
<400>19
acggattaga agccgccgag cgggtgacag ccctccgaag gaagactctc ctccgtgcgt 60
cctcgtcctc accggtcgcg ttcctgaaac gcagatgtgc ctcgcgccgc actgctccga 120
acaataaaga ttctacaata ctagctttta tggttatgaa gaggaaaaat tggcagtaac 180
ctggccccac aaaccttcaa atgaacgaat caaattaaca accataggat gataatgcga 240
ttagtttttt agccttattt ctggggtaat taatcagcga agcgatgatt tttgatctat 300
taacagatat ataaatgcaa aaactgcatt aaccacttta actaatactt tcaacatttt 360
cggtttgtat tacttcttat tcaaatgtaa taaaagtatc aacaaaaaat tgttaatata 420
cctctatact ttaacgtcaa ggagaaaaaa ccccggatcg gactactagc agctgtaata 480
cgactcacta tagggaatat taagcttggt accgagctcg gatccactag taacggccgc 540
cagtgtgctg gaattctgca gatatccatc acactggcgg ccgctcgagc atgcatctag 600
agggccgcat catgtaatta gttatgtcac gcttacattc acgccctccc cccacatccg 660
ctctaaccga aaaggaagga gttagacaac ctgaagtcta ggtccctatt tattttttta 720
tagttatgtt agtattaaga acgttattta tatttcaaat ttttcttttt tttctgtaca 780
gacgcgtgta cgcatgtaac attatactga aaaccttgct tgagaaggtt ttgggacgct 840
cgaaggcttt aatttgcggc cctgcattaa tgaatcggcc aacgcgcggg gagaggcggt 900
ttgcgtattg ggcgctcttc cgcttcctcg ctcactgact cgctgcgctc ggtcgttcgg 960
ctgcggcgag cggtatcagc tcactcaaag gcggtaatac ggttatccac agaatcaggg 1020
gataacgcag gaaagaacat gtgagcaaaa ggccagcaaa agcccaggaa ccgtaaaaag 1080
gccgcgttgc tggcgttttt ccataggctc cgcccccctg acgagcatca caaaaatcga 1140
cgctcaagtc agaggtggcg aaacccgaca ggactataaa gataccaggc gtttccccct 1200
ggaagctccc tcgtgcgctc tcctgttccg accctgccgc ttaccggata cctgtccgcc 1260
tttctccctt cgggaagcgt ggcgctttct catagctcac gctgtaggta tctcagttcg 1320
gtgtaggtcg ttcgctccaa gctgggctgt gtgcacgaac cccccgttca gcccgaccgc 1380
tgcgccttat ccggtaacta tcgtcttgag tccaacccgg taagacacga cttatcgcca 1440
ctggcagcag ccactggtaa caggattagc agagcgaggt atgtaggcgg tgctacagag 1500
ttcttgaagt ggtggcctaa ctacggctac actagaagga cagtatttgg tatctgcgct 1560
ctgctgaagc cagttacctt cggaaaaaga gttggtagct cttgatccgg caaacaaacc 1620
accgctggta gcggtggttt ttttgtttgc aagcagcaga ttacgcgcag aaaaaaagga 1680
tctcaagaag atcctttgat cttttctacg gggtctgacg ctcagtggaa cgaaaactca 1740
cgttaaggga ttttggtcat gagattatca aaaaggatct tcacctagat ccttttaaat 1800
taaaaatgaa gttttaaatc aatctaaagt atatatgagt aaacttggtc tgacagttac 1860
caatgcttaa tcagtgaggc acctatctca gcgatctgtc tatttcgttc atccatagtt 1920
gcctgactcc ccgtcgtgta gataactacg atacgggagc gcttaccatc tggccccagt 1980
gctgcaatga taccgcgaga cccacgctca ccggctccag atttatcagc aataaaccag 2040
ccagccggaa gggccgagcg cagaagtggt cctgcaactt tatccgcctc cattcagtct 2100
attaattgtt gccgggaagc tagagtaagt agttcgccag ttaatagttt gcgcaacgtt 2160
gttggcattg ctacaggcat cgtggtgtca ctctcgtcgt ttggtatggc ttcattcagc 2220
tccggttccc aacgatcaag gcgagttaca tgatccccca tgttgtgcaa aaaagcggtt 2280
agctccttcg gtcctccgat cgttgtcaga agtaagttgg ccgcagtgtt atcactcatg 2340
gttatggcag cactgcataa ttctcttact gtcatgccat ccgtaagatg cttttctgtg 2400
actggtgagt actcaaccaa gtcattctga gaatagtgta tgcggcgacc gagttgctct 2460
tgcccggcgt caatacggga taatagtgta tcacatagca gaactttaaa agtgctcatc 2520
attggaaaac gttcttcggg gcgaaaactc tcaaggatct taccgctgtt gagatccagt 2580
tcgatgtaac ccactcgtgc acccaactga tcttcagcat cttttacttt caccagcgtt 2640
tctgggtgag caaaaacagg aaggcaaaat gccgcaaaaa agggaataag ggcgacacgg 2700
aaatgttgaa tactcatact cttccttttt caatgggtaa taactgatat aattaaattg 2760
aagctctaat ttgtgagttt agtatacatg catttactta taatacagtt ttttagtttt 2820
gctggccgca tcttctcaaa tatgcttccc agcctgcttt tctgtaacgt tcaccctcta 2880
ccttagcatc ccttcccttt gcaaatagtc ctcttccaac aataataatg tcagatcctg 2940
tagagaccac atcatccacg gttctatact gttgacccaa tgcgtctccc ttgtcatcta 3000
aacccacacc gggtgtcata atcaaccaat cgtaaccttc atctcttcca cccatgtctc 3060
tttgagcaat aaagccgata acaaaatctt tgtcgctctt cgcaatgtca acagtaccct 3120
tagtatattc tccagtagat agggagccct tgcatgacaa ttctgctaac atcaaaaggc 3180
ctctaggttc ctttgttact tcttctgccg cctgcttcaa accgctaaca atacctgggc 3240
ccaccacacc gtgtgcattc gtaatgtctg cccattctgc tattctgtat acacccgcag 3300
agtactgcaa tttgactgta ttaccaatgt cagcaaattt tctgtcttcg aagagtaaaa 3360
aattgtactt ggcggataat gcctttagcg gcttaactgt gccctccatg gaaaaatcag 3420
tcaagatatc cacatgtgtt tttagtaaac aaattttggg acctaatgct tcaactaact 3480
ccagtaattc cttggtggta cgaacatcca atgaagcaca caagtttgtt tgcttttcgt 3540
gcatgatatt aaatagcttg gcagcaacag gactaggatg agtagcagca cgttccttat 3600
atgtagcttt cgacatgatt tatcttcgtt tcctgcaggt ttttgttctg tgcagttggg 3660
ttaagaatac tgggcaattt catgtttctt caacactaca tatgcgtata tataccaatc 3720
taagtctgtg ctccttcctt cgttcttcct tctgttcgga gattaccgaa tcaaaaaaat 3780
ttcaaagaaa ccgaaatcaa aaaaaagaat aaaaaaaaaa tgatgaattg aattgaaaag 3840
ctagcttatc gatgataagc tgtcaaagat gagaattaat tccacggact atagactata 3900
ctagatactc cgtctactgt acgatacact tccgctcagg tccttgtcct ttaacgaggc 3960
cttaccactc ttttgttact ctattgatcc agctcagcaa aggcagtgtg atctaagatt 4020
ctatcttcgc gatgtagtaa aactagctag accgagaaag agactagaaa tgcaaaaggc 4080
acttctacaa tggctgccat cattattatc cgatgtgacg ctgcagcttc tcaatgatat 4140
tcgaatacgc tttgaggaga tacagcctaa tatccgacaa actgttttac agatttacga 4200
tcgtacttgt tacccatcat tgaattttga acatccgaac ctgggagttt tccctgaaac 4260
agatagtata tttgaacctg tataataata tatagtctag cgctttacgg aagacaatgt 4320
atgtatttcg gttcctggag aaactattgc atctattgca taggtaatct tgcacgtcgc 4380
atccccggtt cattttctgc gtttccatct tgcacttcaa tagcatatct ttgttaacga 4440
agcatctgtg cttcattttg tagaacaaaa atgcaacgcg agagcgctaa tttttcaaac 4500
aaagaatctg agctgcattt ttacagaaca gaaatgcaac gcgaaagcgc tattttacca 4560
acgaagaatc tgtgcttcat ttttgtaaaa caaaaatgca acgcgacgag agcgctaatt 4620
tttcaaacaa agaatctgag ctgcattttt acagaacaga aatgcaacgc gagagcgcta 4680
ttttaccaac aaagaatcta tacttctttt ttgttctaca aaaatgcatc ccgagagcgc 4740
tatttttcta acaaagcatc ttagattact ttttttctcc tttgtgcgct ctataatgca 4800
gtctcttgat aactttttgc actgtaggtc cgttaaggtt agaagaaggc tactttggtg 4860
tctattttct cttccataaa aaaagcctga ctccacttcc cgcgtttact gattactagc 4920
gaagctgcgg gtgcattttt tcaagataaa ggcatccccg attatattct ataccgatgt 4980
ggattgcgca tactttgtga acagaaagtg atagcgttga tgattcttca ttggtcagaa 5040
aattatgaac ggtttcttct attttgtctc tatatactac gtataggaaa tgtttacatt 5100
ttcgtattgt tttcgattca ctctatgaat agttcttact acaatttttt tgtctaaaga 5160
gtaatactag agataaacat aaaaaatgta gaggtcgagt ttagatgcaa gttcaaggag 5220
cgaaaggtgg atgggtaggt tatataggga tatagcacag agatatatag caaagagata 5280
cttttgagca atgtttgtgg aagcggtatt cgcaatggga agctccaccc cggttgataa 5340
tcagaaaagc cccaaaaaca ggaagattgt ataagcaaat atttaaattg taaacgttaa 5400
tattttgtta aaattcgcgt taaatttttg ttaaatcagc tcatttttta acgaatagcc 5460
cgaaatcggc aaaatccctt ataaatcaaa agaatagacc gagatagggt tgagtgttgt 5520
tccagtttcc aacaagagtc cactattaaa gaacgtggac tccaacgtca aagggcgaaa 5580
aagggtctat cagggcgatg gcccactacg tgaaccatca ccctaatcaa gttttttggg 5640
gtcgaggtgc cgtaaagcag taaatcggaa gggtaaacgg atgcccccat ttagagcttg 5700
acggggaaag ccggcgaacg tggcgagaaa ggaagggaag aaagcgaaag gagcgggggc 5760
tagggcggtg ggaagtgtag gggtcacgct gggcgtaacc accacacccg ccgcgcttaa 5820
tggggcgcta cagggcgcgt ggggatgatc cactagt 5857
<210>20
<211>403
<212>DNA
<213>Trichoderma reesei
<220>
<223>(1-403)T.reesei的hfb2编码序列
<220>
<221>intron
<222>(131)..(200)
<220>
<221>intron
<222>(287)..(358)
<400>20
atgcagttct tcgccgtcgc cctcttcgcc accagcgccc tggctgctgt ctgccctacc 60
ggcctcttct ccaaccctct gtgctgtgcc accaacgtcc tcgacctcat tggcgttgac 120
tgcaagaccc gtatgttgaa ttccaatctc tgggcatcct gacattggac gatacagttg 180
acttacacga tgctttacag ctaccatcgc cgtcgacact ggcgccatct tccaggctca 240
ctgtgccagc aagggctcca agcctctttg ctgcgttgct cccgtggtaa gtagtgctcg 300
caatggcaaa gaagtaaaaa gacatttggg cctgggatcg ctaactcttg atatcaaggc 360
cgaccaggct ctcctgtgcc agaaggccat cggcaccttc taa 403
<210>21
<211>59
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 5’引物
<400>21
cggaggagct cgacgacttc gagcagcccg agctgcacgc aggctgtctg ccctaccgg 59
<210>22
<211>29
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 3’引物
<400>22
tcattggatc cttagaaggt gccgatggc 29
<210>23
<211>679
<212>DNA
<213>群交裂褶菌(Schizophyllum commune)
<220>
<223>(1-679)SC3编码序列
<220>
<223>(1-92)1st cDNA
<220>
<223>(146-183)2nd cDNA
<220>
<223>(240-317)3rd cDNA
<220>
<223>(374-469)4th cDNA
<220>
<223>(524-586)5th cDNA
<220>
<223>(635-679)6th cDNA
<400>23
atgttcgccc gtctccccgt cgtgttcctc tacgccttcg tcgcgttcgg cgccctcgtc 60
gctgccctcc caggtggcca cccgggcacg acgtacgtcg acctctcacc gtcctctaat 120
gtcttgctga tgaagccccg tatagcacgc cgccggttac gacgacggtg acggtgacca 180
cggtgagtag ctttctcgcc gtcgacgact cgaacgcatt ggctaatttt tgctcatagc 240
cgccctcgac gacgaccatc gccgccggtg gcacgtgtac tacggggtcg ctctcttgct 300
gcaaccaggt tcaatcggta cgtacatcaa agcggcacga ccaggcatct cagctgacgg 360
ccacatcgta caggcgagca gcagccctgt taccgccctc ctcggcctgc tcggcattgt 420
cctcagcgac ctcaacgttc tcgttggcat cagctgctct cccctcactg tgagatcttt 480
ttgttcactg tcccaattac tgcgcactga cagactttgc caggtcatcg gtgtcggagg 540
cagcggctgt tcggcgcaga ccgtctgctg cgaaaacacc caattcgtat gtatactttc 600
catgcgtgtc cctttctccg ctaatcatct gtagaacggg ctgatcaaca tcggttgcac 660
ccccatcaac atcctctga 679
<210>24
<211>63
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 5’引物
<400>24
actacacgga ggagctcgac gacttcgagc agcccgagct gcacgcaggg tggccacccg 60
ggc 63
<210>25
<211>30
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 3’引物
<400>25
tcgtacggat cctcagagga tgttgatggg 30
<210>26
<211>43
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 5’引物
<400>26
ggaattccgc ggactgcgca tcatgaagtt cttcgccatc gcc 43
<210>27
<211>80
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 3’引物
<400>27
tgaattccat atgttaggta ccaccggggc ccatgccggt agaagtagaa gccccgggag 60
caccgacggc ggtctggcac 80
<210>28
<211>31
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 5’引物
<400>28
tgaattcggt acccaggctt gctcaagcgt c 31
<210>29
<211>34
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 3’引物
<400>29
tgaattccat atgtcacagg cactgagagt agta 34
<210>30
<211>48
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 5’引物
<400>30
gaattcggta ccctcgtccc tcgcggtccc gccgaagtga acctggtg 48
<210>31
<211>34
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 3’引物
<400>31
tgaattccat atgctaaccc cgtttcatct ccag 34
<210>32
<211>918
<212>DNA
<213>Trichoderma reesei
<220>
<221>terminator
<222>(1)..(918)
<223>T.reesei hfb1终止子
<400>32
gatgcccgcc cggggtcaag gtgtgcccgt gagaaagccc acaaagtgt t gatgaggacc 60
atttccggta ctgggaaagt tggctccacg tgtttgggca ggtttgggca agttgtgtag 120
atattccatt cgtacgccat tcttattctc caatatttca gtacactttt cttcataaat 180
caaaaagact gctattctct ttgtgacatg ccggaaggga acaattgctc ttggtctctg 240
ttatttgcaa gtaggagtgg gagattcgcc ttagagaaag tagagaagct gtgcttgacc 300
gtggtgtgac tcgacgagga tggactgaga gtgttaggat taggtcgaac gttgaagtgt 360
atacaggatc gtctggcaac ccacggatcc tatgacttga tgcaatggtg aagatgaatg 420
acagtgtaag aggaaaagga aatgtccgcc ttcagctgat atccacgcca atgatacagc 480
gatatacctc caatatctgt gggaacgaga catgacatat ttgtgggaac aacttcaaac 540
agcgagccaa gacctcaata tgcacatcca aagccaaaca t tggcaagac gagagacagt 600
cacattgtcg tcgaaagatg gcatcgtacc caaatcatca gctctcatta tcgcctaaac 660
cacagattgt ttgccgtccc ccaactccaa aacgttacta caaaagacat gggcgaatgc 720
aaagacctga aagcaaaccc tttttgcgac tcaattccct cctttgtcct cggaatgatg 780
atccttcacc aagtaaaaga aaaagaagat tgagataata catgaaaagc acaacggaaa 840
cgaaagaacc aggaaaagaa taaatctatc acgcaccttg tccccacact aaaagcaaca 900
gggggggtaa aatgaaat 918
<210>33
<211>26
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 5’引物
<400>33
gacctcgatg cccgcccggg gtcaag 26
<210>34
<211>26
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 3’引物
<400>34
gtcgacattt cattttaccc ccctcg 26
<210>35
<211>1190
<212>DNA
<213>Trichoderma reesei
<220>
<221>promoter
<222>(1)..(1190)
<223>T.reesei的hfb2启动子
<400>35
ctcgagcagc tgaagcttgc atgcctgcat cctttgtgag cgactgcatc cattttgcac 60
acactgccgt cgacgtctct cttccgacct tggccagctg gacaagcaac acaccaatga 120
cgctttgtat tattagagta tatgcaagtc tcaggactat cgactcaact ctacccaccg 180
aggacgatcg cggcacgata cgccctcgtt ctcattggcc caagcagacc aactgcccct 240
ggagcaagat tcagcccaag ggagatggac ggcagggcac gccaggcccc caccaccaag 300
ccactccctt tggccaaatc agcttgcatg tcaagagaca tcgagctgtg ccttgaaatt 360
actaacaacc agggatggga aacgaagcct gcttttggaa agacaacaat gagagagaga 420
gagagaggga gagagacaat gagtgccaca aacctggtag tgctccgcca atgcgtctga 480
aatgtcacat ccgagtcttg gggcctctgt gagaatgtcc agagtaatac gtgttttgcg 540
aatagtcctc tttcttgagg actggatacc tacgataccc tttttgagtt gatgcggtgc 600
tttcgaagta ttatctggag gatagaagac gtctaggtaa ctacacaaaa ggcctatact 660
ttggggagta gcccaacgaa aggtaactcc tacggcctct tagagccgtc atagatccta 720
cagcctcttg gagccgtcat agatcacatc tgtgtagacc gacattctat gaataatcat 780
ctcatcatgg ccacatacta ctacatacgt gtctctgcct acctgacatg tagcagtggc 840
caagacacca aggccccagc atcaagcctc cctacctatc ccttccattg tacagcggca 900
gagagattgc gatgagccct ctccctacct acagacggct gacaatgtcc gtataccacc 960
agccaacgtg atgaaaacaa ggacatgagg aacagcctgc gagagctgga agatgaagag 1020
ggccagaaaa aaaagtataa agaagacctc gattcccgcc atccaacaat cttttccatc 1080
ctcatcagca cactcatcta caaccatcac cacattcact caactcctct ttctcaactc 1140
tccaaacaca aacattcttt gttgaatacc aaccatcacc acctttcaag 1190
<210>36
<211>20
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 5’引物
<400>36
aagcttgcat gcctgcatcc 20
<210>37
<211>26
<212>DNA
<213>人工序列
<220>
<223>人工序列的描述:PCR 3’引物
<400>37
ccatggtgaa aggtggtgat ggttgg 26
<210>38
<211>13
<212>PRT
<213>Trichoderma reesei
<220>
<223>野生型T.reesei的EGI肽接头
<400>38
Val Pro Arg Gly Ser Ser Ser Gly Thr Ala Pro Gly Gly
1 5 10
<210>39
<211>10
<212>PRT
<213>人工序列
<220>
<223>人工序列的描述:修饰的CBHII接头
<400>39
Gly Ser Ser Ser Gly Thr Ala Pro Gly Gly
1 5 10
<210>40
<211>19
<212>PRT
<213>人工序列
<220>
<223>人工序列的描述:Met/凝血酶接头
<400>40
Pro Gly Arg Pro Val Leu Thr Gly Pro Gly Met Gly Thr Ser Thr Ser
1 5 10 15
Ala Gly Pro
<210>41
<211>13
<212>PRT
<213>人工序列
<220>
<223>人工序列的描述:含Met的接头
<400>41
Pro Gly Ala Ser Thr Ser Thr Gly Met Gly Pro Gly Gly
1 5 10
<210>42
<211>14
<212>PRT
<213>人工序列
<220>
<223>人工序列的描述:含有凝血酶裂解位点的接头
<400>42
Gly Thr Leu Val Pro Arg Gly Pro Ala Gly Val Asn Leu Val
1 5 10
Claims (25)
1.在双水相系统ATPS中分配蛋白或细胞的方法,其包括以下步骤:
a)为了获得融合蛋白或细胞,使目标蛋白或细胞与靶向蛋白组合,其中所述靶向蛋白选自能在ATPS系统中分配并携带所述目标蛋白或细胞至所述相之一中的疏水蛋白及其部分,且
b)使携带靶向蛋白的上述融合蛋白或细胞在ATPS中分离。
2.权利要求1的方法,其中所述疏水蛋白是木霉属疏水蛋白或其一部分。
3.权利要求2的方法,其中所述木霉属疏水蛋白是HFB I、HFB II或SRH I,或它们的一部分。
4.权利要求1的方法,其中所述疏水蛋白或其部分形成集合物。
5.权利要求1的在ATPS中分配细胞的方法,其中在权利要求1的步骤a)中,使目标细胞与靶向蛋白组合包括将所述靶向蛋白带到所述细胞的表面。
6.权利要求5的方法,其中所述细胞是酵母细胞。
7.权利要求5的方法,其中所述细胞是孢子。
8.权利要求5的方法,其中所述靶向蛋白与能将该靶向蛋白带到细胞表面的蛋白融合。
9.权利要求6的方法,其中所述靶向蛋白与能将该靶向蛋白带到细胞表面的蛋白融合。
10.权利要求7的方法,其中所述靶向蛋白与能将该靶向蛋白带到细胞表面的蛋白融合。
11.一种融合蛋白,其含有具有在ATPS中分配和携带所述目标蛋白或细胞进入其中一相的能力的疏水蛋白或其部分,且其与目标蛋白融合。
12.权利要求11的融合蛋白,其中所述目标蛋白是细胞结合型蛋白或其一部分。
13.权利要求11的融合蛋白,其中所述目标蛋白是细胞外蛋白或其一部分。
14.权利要求13的融合蛋白,其中所述细胞外蛋白是木霉属的细胞外蛋白,其选自纤维素酶,半纤维素酶或蛋白酶。
15.权利要求13的融合蛋白,其中所述目标蛋白是抗体蛋白或其一部分。
16.权利要求1的方法,其中所述靶向蛋白与权利要求11-15中任一项所述目标蛋白融合。
17.一种重组生物,其产生权利要求11-15中任一项所述融合蛋白,其中所述生物不是动物或植物。
18.权利要求17的重组生物,其中所述重组生物经过遗传修饰能产生权利要求11-15中任一项所述的融合蛋白。
19.一种重组DNA分子,其含有编码权利要求11-15中任一项所述融合蛋白的DNA分子。
20.利用非人重组生物产生权利要求11-15中任一项所述融合蛋白的方法,其包括以下步骤
a)用能表达所述蛋白的DNA分子转化所述生物,和
b)从所述重组生物的培养物中回收所述蛋白。
21.权利要求1-10及16中任一项的方法,其中所述双水相系统选自PEG/盐,PEG/葡聚糖和PEG/淀粉系统或它们的衍生形式,基于去污剂的双水相系统或热分离聚合物系统。
22.权利要求21的方法,其中所述基于去污剂的ATPS包含一种选自非离子或两性离子去污剂的去污剂。
23.权利要求21的方法,其中所述热分离聚合物系统包含选自聚乙烯-聚丙烯共聚物的聚合物。
24.权利要求1-10及16中任一项的方法,其中所述目标蛋白或细胞分离自含有细胞或细胞提取物的悬浮液。
25.在双水相系统中分离疏水蛋白或其部分的方法,其包括以下步骤
a)使含有所述疏水蛋白或其一部分的溶液与形成该相的化学物质混合,和
b)实施ATPS分离,
其中所述双水相系统如权利要求21-23中任一项所述限定。
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| FI990667 | 1999-03-25 | ||
| FI990667A FI990667A0 (fi) | 1999-03-25 | 1999-03-25 | Menetelmä molekyylien erottamiseksi |
| FI991782 | 1999-08-20 | ||
| FI991782 | 1999-08-20 | ||
| FI19991782 | 1999-08-20 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN1357005A CN1357005A (zh) | 2002-07-03 |
| CN1249079C true CN1249079C (zh) | 2006-04-05 |
Family
ID=26160722
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CNB008076022A Expired - Fee Related CN1249079C (zh) | 1999-03-25 | 2000-03-24 | 蛋白质的分配方法 |
Country Status (14)
| Country | Link |
|---|---|
| US (2) | US7060669B1 (zh) |
| EP (1) | EP1163260B1 (zh) |
| JP (1) | JP4570787B2 (zh) |
| KR (1) | KR100819187B1 (zh) |
| CN (1) | CN1249079C (zh) |
| AT (1) | ATE431834T1 (zh) |
| AU (1) | AU778477B2 (zh) |
| CA (1) | CA2367826A1 (zh) |
| DE (1) | DE60042235D1 (zh) |
| DK (1) | DK1163260T3 (zh) |
| IL (2) | IL145337A0 (zh) |
| NO (1) | NO20014534L (zh) |
| NZ (1) | NZ514891A (zh) |
| WO (1) | WO2000058342A1 (zh) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108348440A (zh) * | 2015-10-26 | 2018-07-31 | 巴斯夫欧洲公司 | 包含hlps的口腔护理产品和方法 |
Families Citing this family (45)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| FI120310B (fi) * | 2001-02-13 | 2009-09-15 | Valtion Teknillinen | Parannettu menetelmä erittyvien proteiinien tuottamiseksi sienissä |
| FI116198B (fi) * | 2001-07-16 | 2005-10-14 | Valtion Teknillinen | Polypeptidien immobilisointimenetelmä |
| ATE390855T1 (de) | 2004-07-27 | 2008-04-15 | Unilever Nv | Belüftete, hydrophobin enthaltende nahrungsmittel |
| US7147912B2 (en) | 2004-08-18 | 2006-12-12 | E. I. Du Pont De Nemours And Company | Amphipathic proteinaceous coating on nanoporous polymer |
| US7241734B2 (en) | 2004-08-18 | 2007-07-10 | E. I. Du Pont De Nemours And Company | Thermophilic hydrophobin proteins and applications for surface modification |
| DE102005005737A1 (de) * | 2005-02-07 | 2006-08-17 | Basf Ag | Neue Hydrophobinfusionsproteine, deren Herstellung und Verwendung |
| EP1848733B1 (de) | 2005-02-07 | 2017-06-21 | Basf Se | Neue hydrophobinfusionsproteine, deren herstellung und verwendung |
| EP1866150B1 (de) | 2005-03-31 | 2016-10-19 | Basf Se | Metallische substrate mit polypeptiden als haftvermittler |
| JP2008534554A (ja) * | 2005-04-01 | 2008-08-28 | ビーエーエスエフ ソシエタス・ヨーロピア | 乳化破壊剤としての蛋白質の使用 |
| EP1868698A1 (de) * | 2005-04-01 | 2007-12-26 | Basf Aktiengesellschaft | Verwendung von proteinen als demulgatoren |
| BRPI0608678A2 (pt) | 2005-04-01 | 2010-11-30 | Basf Ag | uso de uma hidrofobina, processo para perfurar um furo de sondagem para desenvolver depósitos subterráneos, lama de perfuração, e, processo para produzir uma lama de perfuração |
| DE102005027139A1 (de) * | 2005-06-10 | 2006-12-28 | Basf Ag | Neue Cystein-verarmte Hydrophobinfusionsproteine, deren Herstellung und Verwendung |
| DE602006019450D1 (de) | 2005-09-23 | 2011-02-17 | Unilever Nv | Durchlüftete produkte mit verringerter aufrahmung |
| PT1926389E (pt) | 2005-09-23 | 2009-03-23 | Unilever Nv | Produtos gaseificados com ph reduzido |
| DE102005048720A1 (de) | 2005-10-12 | 2007-04-19 | Basf Ag | Verwendung von Proteinen als Antischaum-Komponente in Kraftstoffen |
| ATE394935T1 (de) | 2005-12-21 | 2008-05-15 | Unilever Nv | Gefrorene belüftete süssspeisen |
| CA2632328A1 (en) | 2005-12-22 | 2007-06-28 | Ge Healthcare Bio-Sciences Ab | Preparation of biomolecules |
| PT1978824E (pt) * | 2006-01-31 | 2010-12-21 | Unilever Nv | Composições aeradas compreendendo hidrofobina |
| EP2054687B1 (de) | 2006-08-15 | 2011-10-19 | Basf Se | Verfahren zur herstellung von trockenen freifliessenden hydrophobinzubereitungen |
| JP5245227B2 (ja) * | 2006-08-23 | 2013-07-24 | 三菱瓦斯化学株式会社 | 疎水性化合物の起泡による分離法 |
| CN100453642C (zh) * | 2006-10-10 | 2009-01-21 | 山西职工医学院 | 一种过氧化物酶的提取方法 |
| KR100836171B1 (ko) * | 2007-01-19 | 2008-06-09 | 인하대학교 산학협력단 | 분배 향상 물질이 접합된 생물물질을 이용한 수성이상계추출법에서의 친화성 분리 방법 |
| KR100859791B1 (ko) * | 2007-05-23 | 2008-09-23 | 인하대학교 산학협력단 | 상 형성 물질과 결합된 분자인식 리간드를 이용하여 상형성과 분자특이적 분리를 동시에 수행하는 방법 |
| ES2319844B1 (es) * | 2007-09-12 | 2010-02-16 | Universidad Miguel Hernandez De Elche (70%) | Procedimiento de separacion de proteinas recombinantes en sistemas acuosos de dos fases. |
| WO2009037061A2 (de) * | 2007-09-13 | 2009-03-26 | Basf Se | Verwendung von hydrophobin-polypeptiden als penetrationsverstärker |
| AU2008229927B2 (en) | 2007-10-25 | 2009-08-06 | Unilever Plc | Aerated fat-continuous products |
| DE102008013490A1 (de) * | 2008-03-10 | 2009-09-17 | Bayer Technology Services Gmbh | Verfahren zur Reinigung therapeutischer Proteine |
| US9469869B2 (en) * | 2008-09-05 | 2016-10-18 | The Regents Of The University Of Michigan | Solution microarrays and uses thereof |
| CA2704702C (en) | 2009-06-02 | 2018-06-12 | Unilever Plc | Aerated baked products |
| WO2011116256A2 (en) * | 2010-03-18 | 2011-09-22 | The Regents Of The University Of Michigan | Multiphase microarrays and uses thereof |
| EP2603195A1 (en) | 2010-08-12 | 2013-06-19 | Unilever PLC | Oral care compositions |
| US20120040396A1 (en) * | 2010-08-16 | 2012-02-16 | Amyris, Inc. | Methods for purifying bio-organic compounds |
| MX2013002058A (es) | 2010-08-20 | 2013-04-03 | Unilever Nv | Composicion de tratamiento para cabello. |
| EP2624705B1 (en) | 2010-10-04 | 2015-11-18 | Unilever PLC | Method for producing an edible gas hydrate |
| EA025285B1 (ru) * | 2010-10-20 | 2016-12-30 | Унилевер Н.В. | Пенообразователь, содержащий гидрофобин |
| CN101955509A (zh) * | 2010-11-03 | 2011-01-26 | 温州大学 | 萃取酵母菌中的谷胱甘肽的方法 |
| CA2832975A1 (en) * | 2011-04-15 | 2012-10-18 | Danisco Us Inc. | Methods of purifying hydrophobin |
| FI20115704L (fi) * | 2011-07-01 | 2013-01-02 | Teknologian Tutkimuskeskus Vtt Oy | Vierasproteiinien tuoton parantaminen |
| WO2013018678A1 (ja) * | 2011-07-29 | 2013-02-07 | 東レ株式会社 | ろ過助剤の製造方法 |
| KR101677959B1 (ko) * | 2011-08-10 | 2016-11-21 | 한국과학기술원 | 리파아제 활성이 증대된 양친매성 펩타이드-리파아제 결합체 및 이의 용도 |
| US20130219559A1 (en) | 2012-02-22 | 2013-08-22 | Kimmo Koivu | Method for hydrophobin production in plants and methods to produce hydrophobin multimers in plants and microbes |
| FI127353B (en) * | 2013-07-05 | 2018-04-13 | Teknologian Tutkimuskeskus Vtt Oy | Concentration and purification of hydrophobins and antibodies by a phase separation method |
| FI126194B (en) | 2013-09-13 | 2016-08-15 | Teknologian Tutkimuskeskus Vtt Oy | Ways to form fibrous product |
| US8906972B1 (en) | 2013-12-27 | 2014-12-09 | King Fahd University Of Petroleum And Minerals | Aqueous two phase (ATPSs) of pH-responsive poly(phosphonate-alt-sulfur dioxide) with PEG |
| US12129511B2 (en) | 2022-11-02 | 2024-10-29 | Phase Scientific International, Ltd. | Methods for isolating target analytes from biological samples using ATPS and solid phase media |
Family Cites Families (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5139943A (en) | 1989-06-13 | 1992-08-18 | Genencor International, Inc. | Processes for the recovery of microbially produced chymosin |
| DE4001238A1 (de) * | 1990-01-18 | 1991-07-25 | Basf Ag | Verfahren zur anreicherung bzw. reinigung von biomolekuelen |
| SE9003534D0 (sv) * | 1990-11-06 | 1990-11-06 | Kabigen Ab | A method for isolating and purifying peptides and proteins |
| EP0574050A1 (en) | 1992-05-19 | 1993-12-15 | Gist-Brocades N.V. | Large scale separation and purification of fermentation product |
| KR950702634A (ko) | 1992-07-08 | 1995-07-29 | 이. 아디에 | 융합 단백질을 생성시킴으로써 미생물 세포의 세포벽에 효소를 고정화시키는 방법(Process for Immobilizing Enzymes to the Cell Wall of a Microbial Cell by Producing a Fusion Protein) |
| CA2142602A1 (en) * | 1992-08-19 | 1994-03-03 | Tiina Hannele Nakari | Fungal promoters active in the presence of glucose |
| PT682710E (pt) * | 1993-02-10 | 2004-03-31 | Unilever Nv | Processo de isolamento utilizando proteinas imobilizadas com capacidades de ligacao especificas |
| US5882520A (en) * | 1995-10-26 | 1999-03-16 | The University Of Montana | Use of arabinogalactan in aqueous two phase extractions |
| JP5483301B2 (ja) * | 2005-06-03 | 2014-05-07 | Jx日鉱日石エネルギー株式会社 | 緩衝器用油圧作動油組成物 |
-
2000
- 2000-03-24 AU AU35621/00A patent/AU778477B2/en not_active Ceased
- 2000-03-24 IL IL14533700A patent/IL145337A0/xx unknown
- 2000-03-24 KR KR1020017012216A patent/KR100819187B1/ko not_active IP Right Cessation
- 2000-03-24 WO PCT/FI2000/000249 patent/WO2000058342A1/en not_active Application Discontinuation
- 2000-03-24 CN CNB008076022A patent/CN1249079C/zh not_active Expired - Fee Related
- 2000-03-24 NZ NZ514891A patent/NZ514891A/en not_active IP Right Cessation
- 2000-03-24 DE DE60042235T patent/DE60042235D1/de not_active Expired - Lifetime
- 2000-03-24 US US09/936,823 patent/US7060669B1/en not_active Expired - Fee Related
- 2000-03-24 EP EP00914217A patent/EP1163260B1/en not_active Expired - Lifetime
- 2000-03-24 JP JP2000608042A patent/JP4570787B2/ja not_active Expired - Fee Related
- 2000-03-24 CA CA002367826A patent/CA2367826A1/en not_active Abandoned
- 2000-03-24 DK DK00914217T patent/DK1163260T3/da active
- 2000-03-24 AT AT00914217T patent/ATE431834T1/de not_active IP Right Cessation
-
2001
- 2001-09-09 IL IL145337A patent/IL145337A/en not_active IP Right Cessation
- 2001-09-18 NO NO20014534A patent/NO20014534L/no not_active Application Discontinuation
-
2005
- 2005-10-19 US US11/252,753 patent/US7335492B2/en not_active Expired - Fee Related
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108348440A (zh) * | 2015-10-26 | 2018-07-31 | 巴斯夫欧洲公司 | 包含hlps的口腔护理产品和方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| IL145337A0 (en) | 2002-06-30 |
| EP1163260B1 (en) | 2009-05-20 |
| CA2367826A1 (en) | 2000-10-05 |
| IL145337A (en) | 2009-09-22 |
| JP4570787B2 (ja) | 2010-10-27 |
| KR100819187B1 (ko) | 2008-04-04 |
| KR20010108400A (ko) | 2001-12-07 |
| US7335492B2 (en) | 2008-02-26 |
| US7060669B1 (en) | 2006-06-13 |
| AU3562100A (en) | 2000-10-16 |
| DE60042235D1 (de) | 2009-07-02 |
| JP2002543766A (ja) | 2002-12-24 |
| ATE431834T1 (de) | 2009-06-15 |
| NO20014534D0 (no) | 2001-09-18 |
| WO2000058342A1 (en) | 2000-10-05 |
| CN1357005A (zh) | 2002-07-03 |
| NZ514891A (en) | 2003-10-31 |
| US20060084164A1 (en) | 2006-04-20 |
| EP1163260A1 (en) | 2001-12-19 |
| DK1163260T3 (da) | 2009-08-17 |
| AU778477B2 (en) | 2004-12-09 |
| NO20014534L (no) | 2001-11-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN1249079C (zh) | 蛋白质的分配方法 | |
| AU2018220469B2 (en) | Method and cell line for production of phytocannabinoids and phytocannabinoid analogues in yeast | |
| CN1053013C (zh) | 微生物植酸酶的克隆及表达 | |
| CN1930299A (zh) | 红球菌属的腈水合酶 | |
| CN108949721B (zh) | 表达磷脂酶d的重组菌株及应用 | |
| CN1152942A (zh) | 在酵母中表达的n末端延伸蛋白 | |
| CN1536089A (zh) | 用于在真菌细胞中表达基因的启动子 | |
| CN108431218A (zh) | 高效的不依赖锌离子的磷脂酶c突变体 | |
| CN1274820C (zh) | 一种具有半乳聚糖酶活性的酶 | |
| CN109957520B (zh) | 外源基因表达用毕赤酵母菌株 | |
| CN1212012A (zh) | 具有半乳聚糖酶活性的酶 | |
| KR20110135990A (ko) | Pdh 및 fdh 효소를 발현하는 유전적으로 안정한 플라스미드 | |
| CN1471582A (zh) | 用共有翻译起始区序列制备多肽的方法 | |
| CN1280420C (zh) | 靶物质的制备方法 | |
| CN103261420B (zh) | 用于在真菌细胞中表达基因的启动子 | |
| CN1425069A (zh) | 纯化蛋白质的方法 | |
| CN101875925B (zh) | 一种单双酰脂肪酶、其编码基因及应用 | |
| EP0549062B1 (en) | A eukaryotic expression system | |
| CN1132251A (zh) | 尖孢镰孢的青霉素v酰胺水解酶基因 | |
| CN103773793B (zh) | 一种高效表达人血清白蛋白的方法 | |
| WO2022251056A1 (en) | Transcriptional regulators and polynucleotides encoding the same | |
| CN113699176A (zh) | 高产溶血磷脂酶黑曲霉重组表达菌株的构建及应用 | |
| CN113755509A (zh) | 溶血磷脂酶变体及其构建方法和在黑曲霉菌株中的表达 | |
| CN112522227B (zh) | 高酶活的过氧化氢酶、基因以及高产过氧化氢酶的重组菌株和应用 | |
| CN115052477A (zh) | 在多肽生产中具有提高的生产力的丝状真菌细胞的突变体 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| C06 | Publication | ||
| PB01 | Publication | ||
| C14 | Grant of patent or utility model | ||
| GR01 | Patent grant | ||
| C17 | Cessation of patent right | ||
| CF01 | Termination of patent right due to non-payment of annual fee |
Granted publication date: 20060405 Termination date: 20140324 |