CN107108740B - 抗fgfr2/3抗体及其使用方法 - Google Patents
抗fgfr2/3抗体及其使用方法 Download PDFInfo
- Publication number
- CN107108740B CN107108740B CN201580064184.0A CN201580064184A CN107108740B CN 107108740 B CN107108740 B CN 107108740B CN 201580064184 A CN201580064184 A CN 201580064184A CN 107108740 B CN107108740 B CN 107108740B
- Authority
- CN
- China
- Prior art keywords
- antibody
- seq
- fgfr3
- fgfr
- fgfr2
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






































Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2863—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against receptors for growth factors, growth regulators
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P1/00—Drugs for disorders of the alimentary tract or the digestive system
- A61P1/16—Drugs for disorders of the alimentary tract or the digestive system for liver or gallbladder disorders, e.g. hepatoprotective agents, cholagogues, litholytics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P13/00—Drugs for disorders of the urinary system
- A61P13/12—Drugs for disorders of the urinary system of the kidneys
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P15/00—Drugs for genital or sexual disorders; Contraceptives
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P17/00—Drugs for dermatological disorders
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P21/00—Drugs for disorders of the muscular or neuromuscular system
- A61P21/02—Muscle relaxants, e.g. for tetanus or cramps
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/14—Drugs for disorders of the nervous system for treating abnormal movements, e.g. chorea, dyskinesia
- A61P25/16—Anti-Parkinson drugs
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/28—Drugs for disorders of the nervous system for treating neurodegenerative disorders of the central nervous system, e.g. nootropic agents, cognition enhancers, drugs for treating Alzheimer's disease or other forms of dementia
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P27/00—Drugs for disorders of the senses
- A61P27/02—Ophthalmic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/04—Anorexiants; Antiobesity agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/06—Antihyperlipidemics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/08—Drugs for disorders of the metabolism for glucose homeostasis
- A61P3/10—Drugs for disorders of the metabolism for glucose homeostasis for hyperglycaemia, e.g. antidiabetics
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P37/00—Drugs for immunological or allergic disorders
- A61P37/02—Immunomodulators
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P9/00—Drugs for disorders of the cardiovascular system
- A61P9/12—Antihypertensives
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
- C07K16/3015—Breast
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
- C07K16/3023—Lung
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
- C07K16/303—Liver or Pancreas
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/30—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants from tumour cells
- C07K16/3069—Reproductive system, e.g. ovaria, uterus, testes, prostate
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies
- C07K16/40—Immunoglobulins [IGs], e.g. monoclonal or polyclonal antibodies against enzymes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P21/00—Preparation of peptides or proteins
- C12P21/02—Preparation of peptides or proteins having a known sequence of two or more amino acids, e.g. glutathione
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/21—Immunoglobulins specific features characterized by taxonomic origin from primates, e.g. man
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/34—Identification of a linear epitope shorter than 20 amino acid residues or of a conformational epitope defined by amino acid residues
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/73—Inducing cell death, e.g. apoptosis, necrosis or inhibition of cell proliferation
- C07K2317/732—Antibody-dependent cellular cytotoxicity [ADCC]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/70—Immunoglobulins specific features characterized by effect upon binding to a cell or to an antigen
- C07K2317/76—Antagonist effect on antigen, e.g. neutralization or inhibition of binding
Abstract
本发明提供了双重特异性抗FGFR2和FGFR3(FGFR2/3)抗体,及包含这些抗体的组合物和使用这些抗体的方法。
Description
对相关申请的交叉引用
此申请要求2014年11月5日提交的临时美国申请No.62/075,740的优先权,通过述及将其完整收入本文。
序列表
无。
发明领域
一般而言,本发明涉及双重特异性抗FGFR2/3抗体,及其用途。
发明背景
成纤维细胞生长因子(FGF)及其受体(FGFR)在胚胎发育,组织稳态和代谢期间发挥至关重要的作用(Eswarakumar,V.P.,Lax,I.,and Schlessinger,J.2005.Cellularsignaling by fibroblast growth factor receptors.Cytokine Growth Factor Rev16:139-149;L′Hote,C.G.,and Knowles,M.A.2005.Cell responses to FGFR3signalling:growth,differentiation and apoptosis.Exp Cell Res 304:417-431;Dailey,L.,Ambrosetti,D.,Mansukhani,A.,and Basilico,C.2005.Mechanismsunderlying differential responses to FGF signaling.Cytokine Growth Factor Rev16:233-247)。在人中,有22种FGF(FGF1-14,FGF16-23)和4种具有酪氨酸激酶域的FGF受体(FGFR1-4)。FGFR由胞外配体结合区(其具有两个或三个免疫球蛋白样域(IgD1-3)),单次跨膜区,和胞质分裂酪氨酸激酶域组成。FGFR1,2和3每种具有两种主要可变剪接同种型,称作IIIb和IIIc。这些同种型差异在于第二半IgD3中的约50个氨基酸,而且具有独特的组织分布和配体特异性。一般而言,IIIb同种型见于上皮细胞,而IIIc在间充质细胞中表达。一旦与硫酸类肝素蛋白聚糖协同结合FGF,FGFR二聚化并在特定酪氨酸残基处变成磷酸化的。这推动募集至关重要的衔接蛋白,诸如FGFR底物2α(FRS2α),导致多种信号传导级联活化,包括丝裂原活化的蛋白质激酶(MAPK)和PI3K-AKT途径(Eswarakumar,V.P.,Lax,I.,andSchlessinger, J.2005.Cellular signaling by fibroblast growth factorreceptors.Cytokine Growth Factor Rev 16:139-149;Dailey,L.,Ambrosetti,D.,Mansukhani,A.,and Basilico,C.2005.Mechanisms underlying differentialresponses to FGF signaling.Cytokine Growth Factor Rev 16:233-247;Mohammadi,M.,Olsen,S.K.,and Ibrahimi,O.A.2005.Structural basis for fibroblast growthfactor receptor activation.Cytokine Growth Factor Rev 16:107-137)。从而,FGF及其关联受体以背景依赖性方式调节广泛的细胞过程,包括增殖,分化,迁移和存活。
已经将异常活化的FGFR与特定的人恶性联系起来(Eswarakumar,V.P.,Lax,I.,and Schlessinger,J.2005.Cellular signaling by fibroblast growth factorreceptors.Cytokine Growth Factor Rev 16:139-149;Grose,R.,and Dickson,C.2005.Fibroblast growth factor signaling in tumorigenesis.Cytokine GrowthFactor Rev 16:179-186)。特别是,在约15-20%的多发性骨髓瘤患者中发生t(4;14)(p16.3;q32)染色体易位,导致FGFR3过表达且与更短的总体存活有关联(Chang,H.,Stewart,A.K.,Qi,X.Y.,Li,Z.H.,Yi,Q.L.,and Trudel,S.2005.Immunohistochemistryaccurately predicts FGFR3 aberrant expression and t(4;14)in multiplemyeloma.Blood 106:353-355;Chesi,M.,Nardini,E.,Brents,L.A.,Schrock,E.,Ried,T.,Kuehl,W.M.,and Bergsagel,P.L.1997.Frequent translocation t(4;14)(p16.3;q32.3)in multiple myeloma is associated with increased expression and activatingmutations of fibroblast growth factor receptor 3.Nat Genet 16:260-264;Fonseca,R.,Blood,E.,Rue,M.,Harrington,D.,Oken,M.M.,Kyle,R.A.,Dewald,G.W.,VanNess,B.,Van Wier,S.A.,Henderson,K.J.,et al.2003.Clinical and biologicimplications of recurrent genomic aberrations in myeloma.Blood 101:4569-4575;Moreau,P.,Facon,T.,Leleu,X.,Morineau,N.,Huyghe,P.,Harousseau,J.L.,Bataille,R.,and Avet-Loiseau,H.2002.Recurrent 14q32 translocations determine theprognosis of multiple myeloma,especially in patients receiving intensivechemotherapy.Blood 100:1579-1583)。FGFR3还牵涉赋予培养的骨髓瘤细胞系以化学抗性(Pollett,J.B.,Trudel,S.,Stern,D.,Li,Z.H.,and Stewart,A.K.2002.Overexpressionof the myeloma-associated oncogene fibroblast growth factor receptor 3confers dexamethasone resistance.Blood 100:3819-3821),与t(4;14)+患者较差的对常规化疗的临床响应一致(Fonseca,R.,Blood,E.,Rue,M.,Harrington,D.,Oken,M.M.,Kyle,R.A.,Dewald,G.W.,Van Ness,B.,Van Wier,S.A.,Henderson,K.J.,etal.2003.Clinical and biologic implications of recurrent genomic aberrationsin myeloma.Blood 101:4569-4575)。突变活化的FGFR3的过表达足以在造血细胞和成纤维细胞(Bernard-Pierrot,I.,Brams,A.,Dunois-Larde,C.,Caillault,A.,Diez de Medina,S.G.,Cappellen,D.,Graff,G.,Thiery,J.P.,Chopin,D.,Ricol,D.,etal.2006.Oncogenic properties of the mutated forms of fibroblast growth factorreceptor 3b.Carcinogenesis 27:740-747;Agazie,Y.M.,Movilla,N.,Ischenko,I.,andHayman,M.J.2003.The phosphotyrosine phosphatase SHP2is a critical mediator oftransformation induced by the oncogenic fibroblast growth factor receptor3.Oncogene 22:6909-6918;Ronchetti,D.,Greco,A.,Compasso,S.,Colombo,G.,Dell′Era,P.,Otsuki,T.,Lombardi,L.,and Neri,A.2001.Deregulated FGFR3 mutants inmultiple myeloma cell lines with t(4;14):comparative analysis of Y373C,K650Eand the novel G384D mutations.Oncogene 20:3553-3562;Chesi,M.,Brents,L.A.,Ely,S.A.,Bais,C.,Robbiani,D.F.,Mesri,E.A.,Kuehl,W.M.,and Bergsagel,P.L.2001.Activated fibroblast growth factor receptor 3 is an oncogene thatcontributes to tumor progression in multiple myeloma.Blood 97:729-736;Plowright,E.E.,Li,Z.,Bergsagel,P.L.,Chesi,M.,Barber,D.L.,Branch,D.R.,Hawley,R.G.,and Stewart,A.K.2000.Ectopic expression of fibroblast growth factorreceptor 3 promotes myeloma cell proliferation and prevents apoptosis.Blood95:992-998)和鼠骨髓移植模型(Chen,J.,Williams,I.R.,Lee,B.H.,Duclos,N.,Huntly,B.J.,Donoghue,D.J.,and Gilliland,D.G.2005.Constitutively activatedFGFR3mutants signal through PLCgamma-dependent and -independent pathways forhematopoietic transformation.Blood 106:328-337;Li,Z.,Zhu,Y.X.,Plowright,E.E.,Bergsagel,P.L.,Chesi,M.,Patterson,B.,Hawley,T.S.,Hawley,R.G.,and Stewart,A.K.2001.The myeloma-associated oncogene fibroblast growth factor receptor 3is transforming in hematopoietic cells.Blood 97:2413-2419)中诱导致癌转化。因而,已经提出FGFR3作为多发性骨髓瘤中的潜在治疗靶。事实上,数种靶向FGFR,尽管并非对FGFR3选择性的且针对某些其它激酶具有交叉抑制活性的小分子抑制剂已经在培养物中及在小鼠模型中展现针对FGFR3阳性骨髓瘤细胞的细胞毒性(Trudel,S.,Ely,S.,Farooqi,Y.,Affer,M.,Robbiani,D.F.,Chesi,M.,and Bergsagel,P.L.2004.Inhibition offibroblast growth factor receptor 3 induces differentiation and apoptosis int(4;14)myeloma.Blood 103:3521-3528;Trudel,S.,Li,Z.H.,Wei,E.,Wiesmann,M.,Chang,H.,Chen,C.,Reece,D.,Heise,C.,and Stewart,A.K.2005.CHIR-258,a novel,multitargeted tyrosine kinase inhibitor for the potential treatment of t(4;14)multiple myeloma.Blood 105:2941-2948;Chen,J.,Lee,B.H.,Williams,I.R.,Kutok,J.L.,Mitsiades,C.S.,Duclos,N.,Cohen,S.,Adelsperger,J.,Okabe,R.,Coburn,A.,etal.2005.FGFR3 as a therapeutic target of the small molecule inhibitor PKC412in hematopoietic malignancies.Oncogene 24:8259-8267;Paterson,J.L.,Li,Z.,Wen,X.Y.,Masih-Khan,E.,Chang,H.,Pollett,J.B.,Trudel,S.,and Stewart,A.K.2004.Preclinical studies of fibroblast growth factor receptor 3as atherapeutic target in multiple myeloma.Br J Haematol 124:595-603;Grand,E.K.,Chase,A.J.,Heath,C.,Rahemtulla,A.,and Cross,N.C.2004.Targeting FGFR3 inmultiple myeloma:inhibition of t(4;14)-positive cells by SU5402 andPD173074.Leukemia 18:962-966)。
还已经在大比例的膀胱癌中记录了FGFR3过表达(Gomez-Roman,J.J.,Saenz,P.,Molina,M.,Cuevas Gonzalez,J.,Escuredo,K.,Santa Cruz,S.,Junquera,C.,Simon,L.,Martinez,A.,Gutierrez Banos,J.L.,et al.2005.Fibroblast growth factor receptor3 is overexpressed in urinary tract carcinomas and modulates the neoplasticcell growth.Clin Cancer Res 11:459-465;Tomlinson,D.C.,Baldo,O.,Harnden,P.,andKnowles,M.A.2007.FGFR3 protein expression and its relationship to mutationstatus and prognostic variables in bladder cancer.J Pathol 213:91-98)。而且,已经在60-70%的乳头状和16-20%的肌肉侵入性膀胱癌中鉴定出FGFR3中的体细胞活化性突变(Tomlinson,D.C.,Baldo,O.,Harnden,P.,and Knowles,M.A.2007.FGFR3 proteinexpression and its relationship to mutation status and prognostic variablesin bladder cancer.J Pathol 213:91-98;van Rhijn,B.W.,Montironi,R.,Zwarthoff,E.C.,Jobsis,A.C.,and van der Kwast,T.H.2002.Frequent FGFR3mutations inurothelial papilloma.J Pathol 198:245-251)。在细胞培养物实验中,RNA干扰(Bernard-Pierrot,I.,Brams,A.,Dunois-Larde,C.,Caillault,A.,Diez de Medina,S.G.,Cappellen,D.,Graff,G.,Thiery,J.P.,Chopin,D.,Ricol,D.,etal.2006.Oncogenic properties of the mutated forms of fibroblast growth factorreceptor 3b.Carcinogenesis 27:740-747;Tomlinson,D.C.,Hurst,C.D.,and Knowles,M.A.2007.Knockdown by shRNA identifies S249C mutant FGFR3as a potentialtherapeutic target in bladder cancer.Oncogene 26:5889-5899)或FGFR3单链Fv抗体片段抑制膀胱癌细胞增殖(Martinez-Torrecuadrada,J.,Cifuentes,G.,Lopez-Serra,P.,Saenz,P.,Martinez,A.,and Casal,J.I.2005.Targeting the extracellular domain offibroblast growth factor receptor 3 with human single-chain Fv antibodiesinhibits bladder carcinoma cell line proliferation.Clin Cancer Res 11:6280-6290)。一项最近的研究证明FGFR3抗体-毒素缀合物经由FGFR3介导的毒素进入肿瘤的投递而削弱膀胱癌细胞系的异种移植物生长(Martinez-Torrecuadrada,J.L.,Cheung,L.H.,Lopez-Serra,P.,Barderas,R.,Canamero,M.,Ferreiro,S.,Rosenblum,M.G.,and Casal,J.I.2008.Antitumor activity of fibroblast growth factor receptor 3-specificimmunotoxins in a xenograft mouse model of bladder carcinoma is mediated byapoptosis.Mol Cancer Ther 7:862-873)。然而,仍然不清楚FGFR3信号传导是否确实是膀胱肿瘤的体内生长的致癌驱动物。此外,尚未在体内模型的基础上定义在膀胱癌中靶向FGFR3的治疗潜力。涉及FGFR3和抗FGFR3抗体的出版物包括美国专利公开文本No.2005/0147612;Rauchenberger et al,J Biol Chem 278(40):38194-38205(2003);WO2006/048877;Martinez-Torrecuadrada et al,(2008)Mol Cancer Ther 7(4):862-873;WO2007/144893;Trudel et al.(2006)107(10):4039-4046;Martinez-Torrecuadrada etal(2005)Clin Cancer Res 11(17):6280-6290;Gomez-Roman et al(2005)Clin CancerRes 11:459-465;Direnzo,R et al(2007)Proceedings of AACR Annual Meeting,Abstract No.2080;WO2010/002862。美国专利公开文本No.20100291114中公开了FGFR3:抗FGFR3抗体的晶体结构。
虽然能在不破坏成年组织稳态的情况下抑制FGFR2和FGFR3,但是阻断密切相关的调节特定代谢功能的FGFR1和FGFR4意味着极大的安全性风险。本文中重新改造美国专利申请No.20100291114中公开的抗FGFR3抗体以创建以双重特异性结合FGFR3和FGFR2但舍弃FGFR1和FGFR4的功能阻断性抗体。如此,设计并生成了在不阻断FGFR1或FGFR4的情况下阻断FGF结合FGFR2和FGFR3(即FGFR2/3),由此抑制下游信号传导的双重特异性抗体。
清楚的是仍然需要具有最适于开发成治疗剂的临床属性的药剂。
如本文中描述的,经由多轮改造重新设计单特异性结合FGFR3的抗体来结合其它FGFR家族成员,包括募集对FGFR2的结合及去除对FGFR4的结合。使用噬菌体展示文库进行改造的第一步以获取FGFR2结合。每个噬菌体文库制定一个接触CDR的诱变,而且诱变的范围覆盖该CDR中文库容量所容许数目的残基。挑选多个连续位置进行诱变允许CDR主链中的重大自由度。大多数所得的能够啮合FGFR2的克隆包含CDR H2中的所有5处突变。晶体结构证明整个范围的诱变与CDR环的几何学的完全重建有联系。CDR的空间改组的解决方案是众多的,表现为获得了对FGFR2的结合的多种多样H2突变体的鉴定。如此大多样性的解决方案通常没有作为标准亲和力成熟实验的结局看到,由此回收的序列通常含有CDR个体上的稀少位置。因此,获取另外的针对同源抗原的特异性可能需要比亲和力成熟更大的诱变自由度。
第二轮改造是特异性的精炼,去除FGFR4结合。使用抗体CDR环和抗原表面之间的接触残基的详细结构分析来指导噬菌体展示文库的设计。选定的抗体变体显示FGFR4结合的降低及对FGFR2/3的结合的保留。这个特异性精华步骤的序列解决方案与第一轮改造相比更加受限。精炼步骤进一步展现抗体重新改造在密切相关抗原间区分结合特异性的能力。
经由本文中描述的抗体工程改造生成的双重特异性抗体结合两种密切相关的抗原,即FGFR2和FGFR3(抗FGFR2/3抗体)。这些抗FGFR2/3抗体(2B.1.3抗体变体)是规则的IgG分子,即它们使用相同的重和轻链。本发明的某些抗FGFR2/3抗体能分别以二价或单价方式结合两种FGFR2同种型,两种FGFR3同种型或一种FGFR2和一种FGFR3同种型。这与常规双特异性IgG形成对比,后者通常以单价方式使用两个不同的重/轻链对来结合两种不同抗原。所描述的双重特异性抗体与“二合一”抗体共享一些相似性(Grand,E.K.,Chase,A.J.,Heath,C.,Rahemtulla,A.,and Cross,N.C.2004.Targeting FGFR3 in multiplemyeloma:inhibition of t(4;14)-positive cells by SU5402 and PD173074.Leukemia18:962-966)。Bostrom等人随机化了Herceptin的全部3个轻链CDR并选择第二特异性以及亲本特异性。正如预期的,第二特异性来自轻链CDR的主要贡献(Grand,E.K.,Chase,A.J.,Heath,C.,Rahemtulla,A.,and Cross,N.C.2004.Targeting FGFR3 in multiplemyeloma:inhibition oft(4;14)-positive cells by SU5402 and PD173074.Leukemia18:962-966;Gomez-Roman,J.J.,Saenz,P.,Molina,M.,Cuevas Gonzalez,J.,Escuredo,K.,Santa Cruz,S.,Junquera,C.,Simon,L.,Martinez,A.,Gutierrez Banos,J.L.,etal.2005.Fibroblast growth factor receptor 3 is overexpressed in urinary tractcarcinomas and modulates the neoplastic cell growth.Clin Cancer Res 11:459-465)。在一个案例中,尽管EGFR和Her3是同源的,然而抗EGFR/Her3“二合一”抗体的结合表位是不同的(Gomez-Roman,J.J.,Saenz,P.,Molina,M.,Cuevas Gonzalez,J.,Escuredo,K.,Santa Cruz,S.,Junquera,C.,Simon,L.,Martinez,A.,Gutierrez Banos,J.L.,etal.2005.Fibroblast growth factor receptor 3 is overexpressed in urinary tractcarcinomas and modulates the neoplastic cell growth.Clin Cancer Res 11:459-465)。本文中描述的办法与“二合一”抗体的区别在于它重视两种同源抗原之间的序列和结构相似性,而且聚焦于更加受限的诱变集合来在改造期间保留亲本表位。
本文中呈现的抗体工程改造始于一种已有的且广泛表征的抗体,对于癌症疗法具有潜在效用的抗FGFR抗体。自20世纪80年代中期引入第一种治疗性单克隆抗体起,已经在不同疾病领域有许多临床上和商业上成功的抗体药物,包括曲妥珠单抗,cetuximab,adalimumab,贝伐珠单抗,等。这些抗体在抑制它们的分子靶物方面展示杰出的活性。另一方面,像FGFR家族,多种同源蛋白因其各种疾病关联而充当分子靶物。获得靶向功能表位的抗体的传统发现路径,或是动物免疫接种或是其它基于展示的文库选择,并不保证是成功的。或者,如本文中描述的,可以改造抗体以获取针对同源靶物的特异性,由此为抗体发现提供一种备选路径。此外,通过维持功能表位,大概还有生物学功能,这种办法利用先前开发的抗体的有利特性。随着临床抗体全集扩充,可以改造更多的抗体,代替从头开发。潜在应用可包括包含多个作为疾病靶物的成员的蛋白家族,诸如EGFR家族(Tomlinson,D.C.,Baldo,O.,Harnden,P.,and Knowles,M.A.2007.FGFR3 protein expression and itsrelationship to mutation status and prognostic variables in bladder cancer.JPathol 213:91-98),TNFR家族(van Rhijn,B.W.,Montironi,R.,Zwarthoff,E.C.,Jobsis,A.C.,and van der Kwast,T.H.2002.Frequent FGFR3mutations in urothelialpapilloma.J Pathol 198:245-251),TAM家族(Tomlinson,D.C.,Hurst,C.D.,andKnowles,M.A.2007.Knockdown by shRNA identifies S249C mutant FGFR3 as apotential therapeutic target in bladder cancer.Oncogene 26:5889-5899;Martinez-Torrecuadrada,J.,Cifuentes,G.,Lopez-Serra,P.,Saenz,P.,Martinez,A.,and Casal,J.I.2005.Targeting the extracellular domain of fibroblast growthfactor receptor 3 with human single-chain Fv antibodies inhibits bladdercarcinoma cell line proliferation.Clin Cancer Res 11:6280-6290),Ephrin家族(Martinez-Torrecuadrada,J.L.,Cheung,L.H.,Lopez-Serra,P.,Barderas,R.,Canamero,M.,Ferreiro,S.,Rosenblum,M.G.,and Casal,J.I.2008.Antitumor activity offibroblast growth factor receptor 3-specific immunotoxins in a xenograftmouse model of bladder carcinoma is mediated by apoptosis.Mol Cancer Ther 7:862-873)。正如在传统发现过程中,针对同源物的工程化抗体应当视为新的分子,而且仍然需要全面表征它们的生物化学,生物物理和生物学特性以用于任何潜在治疗性应用。
通过述及完整收录本文中所引用的所有参考文献,包括专利申请和出版物。
发明概述
本发明部分基于多种结合FGFR2和FGFR3(“FGFR2/3”)的FGFR结合剂(诸如抗体及其片段)的鉴定。FGFR3代表了一种重要的且有利的治疗靶,而且本发明提供了基于药剂(具体是结合FGFR的药剂)对FGFR3的结合的组合物和方法。具体而言,本发明提供了基于药剂对FGFR2/3的结合(即具有针对FGFR2和FGFR3的双重特异性的药剂的结合)的组合物和方法。如本文中所描述的,本发明的FGFR2/3结合剂提供了重要的治疗剂和诊断剂,供靶向与FGFR3和/或FGFR2信号传导途径的表达和/或活性有关的病理性疾患中使用。因而,本发明提供了与FGFR3和FGFR2结合有关的方法,组合物,试剂盒,和制品。
本发明提供了结合FGFR2和FGFR3的抗体(抗FGFR2/3抗体)。在一个方面,本发明的特征是一种分离的结合FGFR3的抗体。在一些实施方案中,该抗体结合FGFR3IIIb同种型和/或FGFR3IIIc同种型。在一些实施方案中,该抗体结合突变的FGFR3(例如FGFR3IIIb R248C,S249C,G372C,Y375C,K652E中的一种或多种,和/或FGFR3IIIc R248C,S249C,G370C,Y373C,K650E中的一种或多种)。在一些实施方案中,该抗体结合单体FGFR3(例如单体FGFR3IIIb和/或IIIc同种型)。在一些实施方案中,该抗体促进单体FGFR3的形成,诸如通过相对于二聚体FGFR3形式稳定化单体FGFR3形式。在一些实施方案中,该抗体结合FGFR2或其变体。在一些实施方案中,该抗体结合FGFR2和本文中描述的FGFR3变体中任一种或多种。
在一个方面,本发明提供一种分离的抗FGFR2/3抗体,其中该抗体的全长IgG形式以1x 10-7M的Kd或更高亲和力结合人FGFR3。在一个方面,本发明提供一种分离的抗FGFR2/3抗体,其中该抗体的全长IgG形式以1x 10-7M的Kd或更高亲和力结合人FGFR2。如本领域完全确立的,配体对其受体的结合亲和力可以使用多种测定法任一来测定,而且以多种定量数值来表述。因而,在一个实施方案中,结合亲和力表述成Kd值,而且反映了内在结合亲和力(例如具有最小化的亲合效应)。通常且优选的是,结合亲和力是在体外测量的,无论是在无细胞背景下还是在细胞相关背景下。可以使用本领域已知的多种测定法之任一来获得结合亲和力测量,包括本文中所描述的测定法,包括例如Biacore,放射免疫测定法(RIA),和ELISA。在一些实施方案中,该抗体的全长IgG形式以1x 10-8M的Kd或更高亲和力,以1x 10- 9M的Kd或更高亲和力,或以1x 10-10M的Kd或更高亲和力结合人FGFR3。在一些实施方案中,该抗体的全长IgG形式以1x 10-8M的Kd或更高亲和力,以1x 10-9M的Kd或更高亲和力,或以1x 10-10M的Kd或更高亲和力结合人FGFR2。在一些实施方案中,该抗体的全长IgG形式以1x10-8M的Kd或更高亲和力,以1x 10-9M的Kd或更高亲和力,或以1x 10-10M的Kd或更高亲和力结合人FGFR2和FGFR3。
一般而言,本发明的抗FGFR2/3抗体为拮抗性抗体。如此,在一个方面,该抗FGFR2/3抗体抑制FGFR3活性(例如FGFR3-IIIb和/或FGFR3-IIIc活性)。在一些实施方案中,该抗FGFR2/3抗体(通常处于二价形式)不拥有实质性FGFR3激动剂功能。在一些实施方案中,该抗FGFR2/3拮抗性抗体(通常处于二价形式)拥有很少的或无FGFR3激动剂功能。在一个实施方案中,本发明的抗体(通常处于二价形式)不展现具有统计学显著性的超出背景水平的FGFR3激动剂活性水平。
在一个方面,该抗体对FGFR3的结合可抑制该受体与另一个单元的该受体的二聚化,由此该受体的活化受到抑制(至少部分由于缺乏受体二聚化)。抑制可以是直接的或间接的。
在一个方面,本发明提供了抗FGFR2/3抗体不拥有实质性凋亡活性(例如不诱导细胞的凋亡,例如移行细胞癌细胞或多发性骨髓瘤细胞,诸如包含FGFR3易位,诸如t(4;14)易位的多发性骨髓瘤细胞)。在一些实施方案中,该抗FGFR2/3抗体拥有很少的或无凋亡功能。在一些实施方案中,该FGFR2/3抗体不展现具有统计学显著性的超出背景水平的凋亡功能。
在一个方面,本发明提供了不诱导实质性FGFR3下调的抗FGFR2/3抗体。在一些实施方案中,该抗FGFR2/3抗体诱导很少的或无受体下调。在一些实施方案中,该FGFR2/3抗体不诱导具有统计学显著性的超出背景水平的受体下调。
在一个方面,本发明提供了拥有效应器功能的抗FGFR2/3抗体。在一个实施方案中,该效应器功能包含抗体依赖性细胞介导的细胞毒性(ADCC)。在一个实施方案中,本发明的抗FGFR2/3抗体(在一些实施方案中,裸的抗FGFR2/3抗体)能够杀伤细胞,在一些实施方案中,多发性骨髓瘤细胞(例如包含易位,例如t(4;14)易位的多发性骨髓瘤细胞)。在一些实施方案中,本发明的抗FGFR2/3抗体能够杀伤表达约10,000个FGFR3分子每个细胞或更多(诸如约11,000,约12,000,约13,000,约14,000,约15,000,约16,000,约17,000,约18,000或更多个FGFR3分子每个细胞)的细胞。在其它实施方案中,该细胞表达约2000,约3000,约4000,约5000,约6000,约7000,约8000,或更多个FGFR3分子每个细胞。在一些实施方案中,本发明的该抗FGFR2/3抗体能够杀伤表达约10,000个FGFR2分子每个细胞或更多(诸如约11,000,约12,000,约13,000,约14,000,约15,000,约16,000,约17,000,约18,000或更多个FGFR3分子每个细胞)的细胞。在其它实施方案中,该细胞表达约2000,约3000,约4000,约5000,约6000,约7000,约8000,或更多个FGFR2分子每个细胞。
在一个方面,本发明的抗FGFR2/3抗体抑制组成性FGFR3活性。在一些实施方案中,组成性FGFR3活性为配体依赖性FGFR3组成性活性。在一些实施方案中,组成性FGFR3活性为配体不依赖性组成性FGFR3活性。在一个方面,本发明的抗FGFR2/3抗体抑制组成性FGFR2活性。在一个方面,本发明的抗FGFR2/3抗体抑制组成性FGFR2和FGFR3活性。
在一个方面,本发明的抗FGFR2/3抗体抑制包含与FGFR3-IIIbR248C对应的突变的FGFR3。如本文中使用的,术语“包含与FGFR3-IIIbR248C对应的突变”理解为涵盖FGFR3-IIIbR248C和FGFR3-IIIcR248C,以及在与FGFR3-IIIb R248对应的位置处包含R至C突变的另外的FGFR3形式。本领域普通技术人员了解如何比对FGFR3序列以鉴定各自FGFR3序列之间的相应残基,例如比对FGFR3-IIIc序列与FGFR3-IIIb序列以鉴定FGFR3中与FGFR3-IIIb中的R248位置对应的位置。在一些实施方案中,本发明的抗FGFR2/3抗体抑制FGFR3-IIIbR248C和/或FGFR3-IIIcR248C。
在一个方面,本发明的抗FGFR2/3抗体抑制包含与FGFR3-IIIbK652E对应的突变的FGFR3。为了方便起见,术语“包含与FGFR3-IIIbK652E对应的突变”理解为涵盖FGFR3-IIIbK652E和FGFR3-IIIcK650E,以及在与FGFR3-IIIb K652对应的位置处包含K至E突变的另外的FGFR3形式。本领域普通技术人员了解如何比对FGFR3序列以鉴定各自FGFR3序列之间的对应残基,例如比对FGFR3-IIIc序列与FGFR3-IIIb序列以鉴定FGFR3中与FGFR3-IIIb中的K652位置对应的位置。在一些实施方案中,本发明的抗FGFR2/3抗体抑制FGFR3-IIIbK652E和/或FGFR3-IIIcK650E。
在一个方面,本发明的抗FGFR2/3抗体抑制FGFR3包含与FGFR3-IIIbS249C对应的突变。为了方便起见,术语“包含与FGFR3-IIIbS249C对应的突变”理解为涵盖FGFR3-IIIbS249C和FGFR3-IIIcS249C,以及在与FGFR3-IIIb S249对应的位置处包含S至C突变的另外的FGFR3形式。在一些实施方案中,本发明的抗FGFR2/3抗体抑制FGFR3-IIIbS249C和/或FGFR3-IIIcS249C。
在一个方面,本发明的抗FGFR2/3抗体抑制包含与FGFR3-IIIbG372C对应的突变的FGFR3。为了方便起见,术语“包含与FGFR3-IIIbG372C对应的突变”理解为涵盖FGFR3-IIIbG372C和FGFR3-IIIcG370C,以及在与FGFR3-IIIb G372对应的位置处包含G至C突变的另外的FGFR3形式。在一些实施方案中,本发明的抗FGFR2/3抗体抑制FGFR3-IIIbG372C和/或FGFR3-IIIcG370C。
在一个方面,本发明的抗FGFR2/3抗体抑制包含与FGFR3-IIIbY375C对应的突变的FGFR3。为了方便起见,术语“包含与FGFR3-IIIbY375C对应的突变”理解为涵盖FGFR3-IIIbY375C和FGFR3-IIIcY373C,以及在与FGFR3-IIIb S249对应的位置处包含S至C突变的另外的FGFR3形式。在一些实施方案中,本发明的抗FGFR2/3抗体抑制FGFR3-IIIbY375C和/或FGFR3-IIIcY373C。
在一个方面,本发明的抗FGFR2/3抗体抑制(a)FGFR3-IIIbK652E和(b)FGFR3-IIIbR248C,FGFR3-IIIbY375C,FGFR3-IIIbS249C,和FGFR3-IIIbG372C中的一种或多种。
在一个方面,本发明的抗FGFR2/3抗体抑制(a)FGFR3-IIIcK650E和(b)FGFR3-IIIcR248C,FGFR3-IIIcY373C,FGFR3-IIIcS249C,和FGFR3-IIIcG370C中的一种或多种。
在一个方面,本发明的抗FGFR2/3抗体抑制(a)FGFR3-IIIbR248C和(b)FGFR3-IIIbK652E,FGFR3-IIIbY375C,FGFR3-IIIbS249C,和FGFR3-IIIbG372C中的一种或多种。
在一个方面,本发明的抗FGFR2/3抗体抑制(a)FGFR3-IIIcR248C和(b)FGFR3-IIIcK650E,FGFR3-IIIcY373C,FGFR3-IIIcS249C,和FGFR3-IIIcG370C中的一种或多种。
在一个方面,本发明的抗FGFR2/3抗体抑制(a)FGFR3-IIIbG372C和(b)FGFR3-IIIbK652E,FGFR3-IIIbY375C,FGFR3-IIIbS249C,和FGFR3-IIIbR248C中的一种或多种。
在一个方面,本发明的抗FGFR2/3抗体抑制(a)FGFR3-IIIcG370C和(b)FGFR3-IIIcK650E,FGFR3-IIIcY373C,FGFR3-IIIcS249C,和FGFR3-IIIcR248C中的一种或多种。
在一个方面,本发明的抗FGFR2/3抗体抑制FGFR3-IIIbR248C,FGFR3-IIIbK652E,FGFR3-IIIbY375C,FGFR3-IIIbS249C,和FGFR3-IIIbG372C。
在一个方面,本发明的抗FGFR2/3抗体抑制FGFR3-IIIcR248C,FGFR3-IIIcK650E,FGFR3-IIIcY373C,FGFR3-IIIcS249C,和FGFR3-IIIcG370C。
在一个方面,本发明提供了一种分离的抗FGFR2/3抗体,其包含至少一种,两种,三种,四种,或五种选自下述的高变区(HVR)序列:SEQ ID NO 1:RASQDVDTSLA,SEQ ID NO 2:SASFLYS,SEQ ID NO 3:QQSTGHPQT,SEQ ID NO 4:GFPFTSQGIS,SEQ ID NO 5:RTHLGDGSTNYADSVKG,和SEQ ID NO 6:ARTYGIYDTYDKYTEYVMDY。在具体的实施方案中,本发明提供了2B.1.3.10抗FGFR2/3抗体,其包含HVR-L1:RASQDVDTSLA,HVR-L2:SASFLYS,HVR-L3:QQSTGHPQT,HVR-H1:GFPFTSQGIS,HVR-H2:RTHLGDGSTNYADSVKG,和HVR-H3:ARTYGIYDTYDKYTEYVMDY。
在一个方面,本发明提供了一种分离的抗FGFR2/3抗体,其包含至少一种,两种,三种,四种,或五种选自下述的高变区(HVR)序列:SEQ ID NO 7:RASQDVDTSLA,SEQ ID NO 8:SASFLYS,SEQ ID NO 9:QQSTGHPQT,SEQ ID NO 10:GFPFTSTGIS,SEQ ID NO 11:RTHLGDGSTNYADSVKG,和SEQ ID NO 12:ARTYGIYDTYDMYTEYVMDY。在具体的实施方案中,本发明提供了2B.1.3.12抗FGFR2/3抗体,其包含HVR-L1:RASQDVDTSLA,HVR-L2:SASFLYS,HVR-L3:QQSTGHPQT,HVR-H1:GFPFTSTGIS,HVR-H2:RTHLGDGSTNYADSVKG,和HVR-H3:ARTYGIYDTYDMYTEYVMDY。
在某些实施方案中,本文中描述的抗FGFR2/3抗体的HVR-H1在SEQ ID NO:4的位置4-6处包含序列FTS。
在某些实施方案中,本文中描述的抗FGFR2/3抗体的至少一种HVR为变体HVR,其中该变体HVR序列包含SEQ ID NO:1-6中描绘的序列的至少一个残基(至少两个残基,至少三个或更多个残基)的修饰。该修饰期望为替代,插入,或删除。在一些实施方案中,HVR-L1变体包含1-6(1,2,3,4,5,或6)处替代。在一些实施方案中,HVR-L2变体包含1-6(1,2,3,4,5,或6)处替代。在一些实施方案中,HVR-L3变体包含1-6(1,2,3,4,5,或6)处替代。在一些实施方案中,HVR-H1变体包含1-6(1,2,3,4,5,或6)处替代。在一些实施方案中,HVR-H2变体包含1-6(1,2,3,4,5,或6)处替代。在一些实施方案中,HVR-H3变体包含1-6(1,2,3,4,5,或6)处替代。
在某些实施方案中,本文中描述的抗FGFR2/3抗体的HVR-H1为变体HVR-H1,其中该变体HVR-H1在氨基酸P3和/或Q7(SEQ ID NO:4)处包含替代。在具体的实施方案中,该变体HVR-H1包含P3T替代。在具体的实施方案中,该变体HVR-H1包含Q7T或Q7L替代。在具体的实施方案中,该变体HVR-H1包含P3T和Q7L替代。在具体的实施方案中,该变体HVR-H1包含P3T和Q7T替代。在某些实施方案中,该变体HVR-H1包含选自表11中列出的组的序列:TFTST,PFTSL,PFTSQ,和PFTST。
在某些实施方案中,本文中描述的抗FGFR2/3抗体的HVR-H3为变体HVR-H3,其中该变体HVR-H3在氨基酸T9,D11,和/或K12(SEQ ID NO:6)处包含替代。在具体的实施方案中,该变体HVR-H3包含T9I替代。在具体的实施方案中,该变体HVR-H3包含T9L替代。在具体的实施方案中,该变体HVR-H3包含D11V替代。在具体的实施方案中,该变体HVR-H3包含D11G替代。在具体的实施方案中,该变体HVR-H3包含D11E替代。在具体的实施方案中,该变体HVR-H3包含K12D替代。在具体的实施方案中,该变体HVR-H3包含K12N替代。在具体的实施方案中,该变体HVR-H3包含K12G替代。在具体的实施方案中,该变体HVR-H3包含K12E替代。在具体的实施方案中,该变体HVR-H3包含K12M替代。在具体的实施方案中,该变体HVR-H3包含T9L,D11V,和K12D替代。在具体的实施方案中,该变体HVR-H3只包含K12D替代。在具体的实施方案中,该变体HVR-H3包含T9I,D11G,和K12G替代。在具体的实施方案中,该变体HVR-H3只包含K12E替代。在具体的实施方案中,该变体HVR-H3包含T9I和D11E替代。在具体的实施方案中,该变体HVR-H3只包含K12M替代。在某些实施方案中,该变体HVR-H3包含选自表11中列出的组的序列:LYVD,TYDN,IYGG,TYDE,IKEK,TYDK,和TYDM。
在某些实施方案中,本文中描述的抗FGFR2/3抗体的HVR-H1为变体HVR-H1,其中该变体HVR-H1在氨基酸P3和/或Q7(SEQ ID NO:4)处包含替代,而且本文中描述的抗FGFR2/3抗体的HVR-H3为变体HVR-H3,其中该变体HVR-H3在氨基酸T9,D11,和/或K12(SEQ ID NO:6)处包含替代。在某些实施方案中,本发明的抗FGFR2/3抗体的变体HVR-H1和HVR-H3包含选自表11中列出的组的序列:TFTST(HVR-H1)和LYVD(HVR-H3),TFTST(HVR-H1)和TYDN(HVR-H3),TFTST(HVR-H1)和IYGG(HVR-H3),TFTST(HVR-H1)和TYDE(HVR-H3),PFTSL(HVR-H1)和IYEK(HVR-H3),PFTSQ(HVR-H1)和TYDK(HVR-H3),PFTST(HVR-H1)和TYDM(HVR-H3)。
在某些实施方案中,本发明的抗FGFR2/3抗体包含选自由SEQ ID NO:13-44中描述的序列组成的组的HVR-H2序列。在某些实施方案中,本发明的抗FGFR2/3抗体包含选自由SEQ ID NO:45-50中描述的序列组成的组的HVR-H2序列。
在具体的实施方案中,本发明的抗FGFR2/3抗体结合FGFR2-IIIb(SEQ ID NO:51和52),FGFR2-IIIc(SEQ ID NO:53和54),FGFR3-IIIb(SEQ ID NO:55和56),和/或FGFR3-IIIc(SEQ ID NO:57和58)。在某些实施方案中,本发明的抗FGFR2/3抗体结合FGFR2-IIIb,FGFR2-IIIc,FGFR3-IIIb,和FGFR3-IIIc。在具体的实施方案中,本发明的抗FGFR2/3抗体结合选自由FGFR2-IIIb,FGFR2-IIIc,FGFR3-IIIb,和FGFR3-IIIc组成的组的一种FGFR。在具体的实施方案中,本发明的抗FGFR2/3抗体结合选自由FGFR2-IIIb,FGFR2-IIIc,FGFR3-IIIb,和FGFR3-IIIc组成的组的两种FGFR。在具体的实施方案中,本发明的抗FGFR2/3抗体结合选自由FGFR2-IIIb,FGFR2-IIIc,FGFR3-IIIb,和FGFR3-IIIc组成的组的三种FGFR。
本发明的抗体可包含任何合适的可变域框架序列,前提是对FGFR3和FGFR2的结合亲和力得到实质性保留。例如,在有些实施方案中,本发明的抗体包含人亚组III重链框架共有序列。在这些抗体的一个实施方案中,所述框架共有序列包含第71位,第73位和/或第78位处的替代。在这些抗体的有些实施方案中,第71位是A,第73位是T,和/或第78位是A。在一个实施方案中,这些抗体包含huMAb4D5-8( Genentech,Inc.,South SanFrancisco,CA,USA)(在美国专利No.6,407,213&5,821,337,及Lee et al.,J.Mol.Biol.(2004),340(5):1073-1093中也有提及)的重链可变域框架序列。在一个实施方案中,这些抗体进一步包含人κI轻链框架共有序列。在一个具体的实施方案中,这些抗体包含huMAb4D5-8的轻链HVR序列,如美国专利No.6,407,213和5,821,337中所记载的。在一个实施方案中,这些抗体包含huMAb4D5-8(
Genentech,Inc.,South SanFrancisco,CA,USA)(在美国专利No.6,407,213&5,821,337,及Lee et al.,J.Mol.Biol.(2004),340(5):1073-1093中也有提及)的重链可变域框架序列。在一个实施方案中,这些抗体进一步包含人κI轻链框架共有序列。在一个具体的实施方案中,这些抗体包含huMAb4D5-8的轻链HVR序列,如美国专利No.6,407,213和5,821,337中所记载的。在一个实施方案中,这些抗体包含huMAb4D5-8( Genentech,Inc.,South SanFrancisco,CA,USA)(在美国专利No.6,407,213&5,821,337,及Lee et al.,J.Mol.Biol.(2004),340(5):1073-1093中也有提及)的轻链可变域序列。
Genentech,Inc.,South SanFrancisco,CA,USA)(在美国专利No.6,407,213&5,821,337,及Lee et al.,J.Mol.Biol.(2004),340(5):1073-1093中也有提及)的轻链可变域序列。
在一个实施方案中,本发明的抗体的轻链的氨基酸序列包含SEQ ID NO:59。
在一个实施方案中,本发明的抗体的轻链的氨基酸序列包含SEQ ID NO:60。
在一个实施方案中,本发明的抗体的轻链的氨基酸序列包含SEQ ID NO:61。
在一个实施方案中,本发明的抗体的轻链的氨基酸序列包含SEQ ID NO:62。
在一个实施方案中,本发明的抗体的轻链的氨基酸序列包含SEQ ID NO:63。
在一个实施方案中,本发明的抗体的轻链的氨基酸序列包含SEQ ID NO:64。
在一个实施方案中,本发明的抗体的轻链的氨基酸序列包含SEQ ID NO:65。
在一个实施方案中,本发明的抗体的轻链的氨基酸序列包含SEQ ID NO:66。
在一个实施方案中,本发明的抗体的重链的氨基酸序列包含SEQ ID NO:75。
在一个实施方案中,本发明的抗体的重链的氨基酸序列包含SEQ ID NO:76。
在一个实施方案中,本发明的抗体的重链的氨基酸序列包含SEQ ID NO:77。
在一个实施方案中,本发明的抗体的重链的氨基酸序列包含SEQ ID NO:78。
在一个实施方案中,本发明的抗体的重链的氨基酸序列包含SEQ ID NO:79。
在一个实施方案中,本发明的抗体的重链的氨基酸序列包含SEQ ID NO:80。
在一个实施方案中,本发明的抗体的重链的氨基酸序列包含SEQ ID NO:81。
在一个实施方案中,本发明的抗体的重链的氨基酸序列包含SEQ ID NO:82。
在具体的实施方案中,本发明的抗体包含包含SEQ ID NO:59的轻链氨基酸序列和包含SEQ ID NO:75的重链氨基酸序列。在具体的实施方案中,本发明的抗体包含包含SEQID NO:60的轻链氨基酸序列和包含SEQ ID NO:76的重链氨基酸序列。在具体的实施方案中,本发明的抗体包含包含SEQ ID NO:61的轻链氨基酸序列和包含SEQ ID NO:77的重链氨基酸序列。在具体的实施方案中,本发明的抗体包含包含SEQ ID NO:62的轻链氨基酸序列和包含SEQ ID NO:78的重链氨基酸序列。在具体的实施方案中,本发明的抗体包含包含SEQID NO:63的轻链氨基酸序列和包含SEQ ID NO:79的重链氨基酸序列。在具体的实施方案中,本发明的抗体包含包含SEQ ID NO:64的轻链氨基酸序列和包含SEQ ID NO:60的重链氨基酸序列。在具体的实施方案中,本发明的抗体包含包含SEQ ID NO:65的轻链氨基酸序列和包含SEQ ID NO:81的重链氨基酸序列。在具体的实施方案中,本发明的抗体包含包含SEQID NO:66的轻链氨基酸序列和包含SEQ ID NO:82的重链氨基酸序列。
在一个实施方案中,本发明的抗体的轻链的核酸序列包含SEQ ID NO:67。
在一个实施方案中,本发明的抗体的轻链的核酸序列包含SEQ ID NO:68。
在一个实施方案中,本发明的抗体的轻链的核酸序列包含SEQ ID NO:69。
在一个实施方案中,本发明的抗体的轻链的核酸序列包含SEQ ID NO:70。
在一个实施方案中,本发明的抗体的轻链的核酸序列包含SEQ ID NO:71。
在一个实施方案中,本发明的抗体的轻链的核酸序列包含SEQ ID NO:72。
在一个实施方案中,本发明的抗体的轻链的核酸序列包含SEQ ID NO:73。
在一个实施方案中,本发明的抗体的轻链的核酸序列包含SEQ ID NO:74。
在一个实施方案中,本发明的抗体的重链的核酸序列包含SEQ ID NO:83。
在一个实施方案中,本发明的抗体的重链的核酸序列包含SEQ ID NO:84。
在一个实施方案中,本发明的抗体的重链的核酸序列包含SEQ ID NO:85。
在一个实施方案中,本发明的抗体的重链的核酸序列包含SEQ ID NO:86。
在一个实施方案中,本发明的抗体的重链的核酸序列包含SEQ ID NO:87。
在一个实施方案中,本发明的抗体的重链的核酸序列包含SEQ ID NO:88。
在一个实施方案中,本发明的抗体的重链的核酸序列包含SEQ ID NO:89。
在一个实施方案中,本发明的抗体的重链的核酸序列包含SEQ ID NO:90。
在具体的实施方案中,本发明的抗体包含包含SEQ ID NO:67的轻链核酸序列和包含SEQ ID NO:83的重链核酸序列。在具体的实施方案中,本发明的抗体包含包含SEQ IDNO:68的轻链核酸序列和包含SEQ ID NO:84的重链核酸序列。在具体的实施方案中,本发明的抗体包含包含SEQ ID NO:69的轻链核酸序列和包含SEQ ID NO:85的重链核酸序列。在具体的实施方案中,本发明的抗体包含包含SEQ ID NO:70的轻链核酸序列和包含SEQ ID NO:86的重链核酸序列。在具体的实施方案中,本发明的抗体包含包含SEQ ID NO:71的轻链核酸序列和包含SEQ ID NO:87的重链核酸序列。在具体的实施方案中,本发明的抗体包含包含SEQ ID NO:72的轻链核酸序列和包含SEQ ID NO:88的重链核酸序列。在具体的实施方案中,本发明的抗体包含包含SEQ ID NO:73的轻链核酸序列和包含SEQ ID NO:89的重链核酸序列。在具体的实施方案中,本发明的抗体包含包含SEQ ID NO:74的轻链核酸序列和包含SEQ ID NO:90的重链核酸序列。
在某些实施方案中,该抗FGFR2/3抗体包含包含SEQ ID NO:65的轻链氨基酸序列和包含SEQ ID NO:81的重链核酸序列。在具体的实施方案中,该抗FGFR2/3抗体具有下述CDR:
HVR-L1:RASQDVDTSLA(SEQ ID NO:1),
HVR-L2:SASFLYS(SEQ ID NO:2),
HVR-L3:QQSTGHPQT(SEQ ID NO:3),
HVR-H1:GFPFTSQGIS(SEQ ID NO:4),
HVR-H2:RTHLGDGSTNYADSVKG(SEQ ID NO:5),
HVR-H3:ARTYGIYDTYDKYTEYVMDY(SEQ ID NO:6)。
在某些实施方案中,该抗FGFR2/3抗体包含包含SEQ ID NO:66的轻链氨基酸序列和包含SEQ ID NO:82的重链核酸序列。在某些实施方案中,该抗FGFR2/3抗体具有下述CDR:
HVR-L1:RASQDVDTSLA(SEQ ID NO:7)
HVR-L2:SASFLYS(SEQ ID NO:8)
HVR-L3:QQSTGHPQT(SEQ ID NO:9)
HVR-H1:GFPFTSTGIS(SEQ ID NO:10)
HVR-H2:RTHLGDGSTNYADSVKG(SEQ ID NO:11)
HVR-H3:ARTYGIYDTYDMYTEYVMDY(SEQ ID NO:12)
在某些实施方案中,该抗FGFR2/3抗体结合在FGFR2(SEQ ID NO:52和54)氨基酸153-251内的区域:
APYWTNTEKMEKRLHAVPAANTVKFRCPAGGNPMPTMRWLKNGKEFKQEHRIGGYKVRNQHWSLIMESVVPSDKGNYTCVVENEYGSINHTYHLDVVER。
在某些实施方案中该抗FGFR2/3抗体结合在FGFR3(SEQ ID NO:56和58)氨基酸150-248内的区域:
APYWTRPERMDKKLLAVPAANTVRFRCPAAGNPTPSISWLKNGREFRGEHRIGGIKLRHQQWSLVMESVVPSDRGNYTCVVENKFGSIRQTYTLDVLER。
在优选的实施方案中,该抗FGFR2/3抗体结合在FGFR2(SEQ ID NO:52和54)氨基酸153-251内的区域和在FGFR3(SEQ ID NO:56和58)氨基酸150-248内的区域。
在某些实施方案中,该抗FGFR2/3抗体结合在FGFR2(SEQ ID NO:52和54)氨基酸157-181(TNTEKMEKRLHAVPAANTVKFRCPA)内的区域(图9)。在某些实施方案中,该抗FGFR2/3抗体结合在FGFR2(SEQ ID NO:52和54)氨基酸207-220(YKVRNQHWSLIMES)内的区域(图9)。在具体的实施方案中,该抗FGFR2/3抗体结合FGFR2-IIIb中与SEQ ID NO:52对齐的区域。在具体的实施方案中,该抗FGFR2/3抗体结合FGFR2-IIIc中与SEQ ID NO:54对齐的区域。
在某些实施方案中,该抗FGFR2/3抗体结合FGFR2-IIIb(SEQ ID NO:52)氨基酸157-181(TNTEKMEKRLHAVPAANTVKFRCPA)。在某些实施方案中,该抗FGFR2/3抗体结合FGFR2-IIIc(SEQ ID NO:54)氨基酸157-181。在某些实施方案中,该抗FGFR2/3抗体结合FGFR2(SEQID NO:52和54)氨基酸207-220(YKVRNQHWSLIMES)(图9)。在某些实施方案中,该抗FGFR2/3抗体结合FGFR2-IIIb(SEQ ID NO:52)氨基酸207-220。在某些实施方案中,该抗FGFR2/3抗体结合FGFR2-IIIc(SEQ ID NO:54)氨基酸207-220。
在具体的实施方案中,该抗FGFR2/3抗体结合在FGFR2(SEQ ID NO:52和54)氨基酸157-181(TNTEKMEKRLHAVPAANTVKFRCPA)内的区域和在FGFR2-IIIb(SEQ ID NO:52和54)氨基酸207-220(YKVRNQHWSLIMES)内的区域。在具体的实施方案中,该抗FGFR2/3抗体结合FGFR2(SEQ ID NO:52和54)氨基酸157-181(TNTEKMEKRLHAVPAANTVKFRCPA)和FGFR2-IIIb(SEQ ID NO:52和54)氨基酸207-220(YKVRNQHWSLIMES)。
在某些实施方案中,该抗FGFR2/3抗体结合在FGFR3-IIIb(SEQ ID NO:56)氨基酸154-178(TRPERMDKKLLAVPAANTVRFRCPA)内的区域。在某些实施方案中,该抗FGFR2/3抗体结合在FGFR3-IIIc(SEQ ID NO:58)氨基酸154-178(TRPERMDKKLLAVPAANTVRFRCPA)内的区域。在某些实施方案中,该抗FGFR2/3抗体结合在FGFR3-IIIb(SEQ ID NO:56)氨基酸204-217(IKLRHQQWSLVMES)内的区域。在某些实施方案中,该抗FGFR2/3抗体结合在FGFR3-IIIc(SEQID NO:58)氨基酸204-217(IKLRHQQWSLVMES)内的区域。在具体的实施方案中,该抗FGFR2/3抗体结合FGFR3-IIIb中与SEQ ID NO:56对齐的区域。在具体的实施方案中,该抗FGFR2/3抗体结合FGFR3-IIIb中与SEQ ID NO:58对齐的区域。
在具体的实施方案中,该抗FGFR2/3抗体结合FGFR3-IIIb(SEQ ID NO:56)氨基酸154-178(TRPERMDKKLLAVPAANTVRFRCPA)。在具体的实施方案中,该抗FGFR2/3抗体结合FGFR3-IIIc(SEQ ID NO:58)氨基酸154-178(TRPERMDKKLLAVPAANTVRFRCPA)。在具体的实施方案中,该抗FGFR2/3抗体结合FGFR3-IIIb(SEQ ID NO:56)氨基酸204-217(IKLRHQQWSLVMES)。在具体的实施方案中,该抗FGFR2/3抗体结合FGFR3-IIIc(SEQ ID NO:58)氨基酸204-217(IKLRHQQWSLVMES)。
在优选的实施方案中,该抗FGFR2/3抗体结合FGFR2的下述表位:TNTEKMEKRLHAVPAANTVKFRCPA(SEQ ID NO:91)和YKVRNQHWSLIMES(SEQ ID NO:92)。在优选的实施方案中,该抗FGFR2/3抗体结合FGFR3的下述表位:TRPERMDKKLLAVPAANTVRFRCPA(SEQID NO:93)和IKLRHQQWSLVMES(SEQ ID NO:94)。在优选的实施方案中,该抗FGFR2/3抗体结合下述表位:
FGFR2:TNTEKMEKRLHAVPAANTVKFRCPA(SEQ ID NO:91)和YKVRNQHWSLIMES(SEQ IDNO:92),和
FGFR3:TRPERMDKKLLAVPAANTVRFRCPA(SEQ ID NO:93)和IKLRHQQWSLVMES(SEQ IDNO:94)。
在某些实施方案中,该抗FGFR2/3抗体结合SEQ ID NO:91-94。在某些实施方案中,该抗FGFR2/3抗体结合SEQ ID NO:91和92。在某些实施方案中,该抗FGFR2/3抗体结合SEQID NO:91-93。在某些实施方案中,该抗FGFR2/3抗体结合SEQ ID NO:91,93,和94。在某些实施方案中,该抗FGFR2/3抗体结合SEQ ID NO:91和94。在某些实施方案中,该抗FGFR2/3抗体结合SEQ ID NO:92-94。在某些实施方案中,该抗FGFR2/3抗体结合SEQ ID NO:92和93。在某些实施方案中,该抗FGFR2/3抗体结合SEQ ID NO:92和94。在某些实施方案中,该抗FGFR2/3抗体结合SEQ ID NO:93和91。在某些实施方案中,该抗FGFR2/3抗体结合SEQ ID NO:91,92,和94。在某些实施方案中,该抗FGFR2/3抗体结合SEQ ID NO:91-94中提供的任两种或更多种表位的组合。
在某些实施方案中,该抗FGFR2/3抗体结合在FGFR2-IIIb(SEQ ID NO:52)氨基酸153-251内的区域。在某些实施方案中,该抗FGFR2/3抗体结合在FGFR2-IIIc(SEQ ID NO:54)氨基酸153-251内的区域。在优选的实施方案中,该抗FGFR2/3抗体结合在FGFR2-IIIb(SEQ ID NO:52)和FGFR2-IIIc(SEQ ID NO:54)氨基酸153-251内的区域。在某些实施方案中,该抗FGFR2/3抗体结合在FGFR3-IIIb(SEQ ID NO:56)氨基酸150-248内的区域。在某些实施方案中,该抗FGFR2/3抗体结合在FGFR3-IIIb(SEQ ID NO:58)氨基酸150-248内的区域。在优选的实施方案中,该抗FGFR2/3抗体结合在FGFR3-IIIb(SEQ ID NO:56)和FGFR3-IIIc(SEQ ID NO:58)氨基酸150-248内的区域。
在优选的实施方案中,该抗FGFR2/3抗体结合在FGFR2-IIIb(SEQ ID NO:52)和/或FGFR2-IIIc(SEQ ID NO:54)氨基酸153-251内的区域和在FGFR3-IIIb(SEQ ID NO:56)和/或FGFR3-IIIc(SEQ ID NO:58)氨基酸150-248内的区域。
在一些实施方案中,该抗FGFR2/3抗体结合包含一个或多个选自FGFR2(例如SEQID NO:52和54)T157,N158,T159,E160,K161,M162,E163,K164,R165,L166,H167,A168,V169,P170,A171,A172,N173,T174,V175,K176,F177,R178,C179,P180,和A181的氨基酸的表位。在一些实施方案中,该抗FGFR2/3抗体结合包含FGFR2(例如SEQ ID NO:52和54)氨基酸T157,N158,T159,E160,K161,M162,E163,K164,R165,L166,H167,A168,V169,P170,A171,A172,N173,T174,V175,K176,F177,R178,C179,P180,和A181的表位。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR2时与一个或多个FGFR2(例如SEQ ID NO:52和54)氨基酸T157,N158,T159,E160,K161,M162,E163,K164,R165,L166,H167,A168,V169,P170,A171,A172,N173,T174,V175,K176,F177,R178,C179,P180,和A181距离4埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR2时与FGFR2(例如SEQ ID NO:52和54)氨基酸T157,N158,T159,E160,K161,M162,E163,K164,R165,L166,H167,A168,V169,P170,A171,A172,N173,T174,V175,K176,F177,R178,C179,P180,和A181距离4埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR2时与一个或多个FGFR2(例如SEQ ID NO:52和54)氨基酸T157,N158,T159,E160,K161,M162,E163,K164,R165,L166,H167,A168,V169,P170,A171,A172,N173,T174,V175,K176,F177,R178,C179,P180,和A181距离3.5埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR2时与FGFR2(例如SEQ ID NO:52和54)氨基酸T157,N158,T159,E160,K161,M162,E163,K164,R165,L166,H167,A168,V169,P170,A171,A172,N173,T174,V175,K176,F177,R178,C179,P180,和A181距离3.5埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR2时与一个或多个FGFR2(例如SEQ ID NO:52和54)氨基酸T157,N158,T159,E160,K161,M162,E163,K164,R165,L166,H167,A168,V169,P170,A171,A172,N173,T174,V175,K176,F177,R178,C179,P180,和A181距离3.0埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR2时与FGFR2(例如SEQ ID NO:52和54)氨基酸T157,N158,T159,E160,K161,M162,E163,K164,R165,L166,H167,A168,V169,P170,A171,A172,N173,T174,V175,K176,F177,R178,C179,P180,和A181距离3.0埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR2时与一个或多个FGFR2(例如SEQ ID NO:52和54)氨基酸T157,N158,T159,E160,K161,M162,E163,K164,R165,L166,H167,A168,V169,P170,A171,A172,N173,T174,V175,K176,F177,R178,C179,P180,和A181距离4.0,3.75,3.5,3.25,或3.0埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR2时与FGFR2(例如SEQ IDNO:52和54)氨基酸T157,N158,T159,E160,K161,M162,E163,K164,R165,L166,H167,A168,V169,P170,A171,A172,N173,T174,V175,K176,F177,R178,C179,P180,和A181距离4.0,3.75,3.5,3.25,或3.0埃或更少。在一些实施方案中,该一个或多个氨基酸和/或该一个或多个氨基酸残基为约1,2,3,4,5,6,7,8,9,10,11,和/或12个氨基酸和/或氨基酸残基任一。在一些实施方案中,该表位是通过结晶学(例如实施例中描述的结晶学方法)测定的。在优选的实施方案中,该抗FGFR2/3抗体结合人FGFR2(hFGFR2)(例如SEQ ID NO:52和54)。
在一些实施方案中,该抗FGFR2/3抗体结合包含一个或多个选自FGFR2(例如SEQID NO:52和54)Y207,K208,V209,R210,N211,Q212,H213,W214,S215,L216,I217,M218,E219,和S220的氨基酸的表位。在一些实施方案中,该抗FGFR2/3抗体结合包含FGFR2(例如SEQ ID NO:52和54)氨基酸Y207,K208,V209,R210,N211,Q212,H213,W214,S215,L216,I217,M218,E219,和S220的表位。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR2时与一个或多个FGFR2(例如SEQ ID NO:52和54)氨基酸Y207,K208,V209,R210,N211,Q212,H213,W214,S215,L216,I217,M218,E219,和S220距离4埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR2时与FGFR2(例如SEQ ID NO:52和54)氨基酸Y207,K208,V209,R210,N211,Q212,H213,W214,S215,L216,I217,M218,E219,和S220距离4埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR2时与一个或多个FGFR2(例如SEQ ID NO:52和54)氨基酸Y207,K208,V209,R210,N211,Q212,H213,W214,S215,L216,I217,M218,E219,和S220距离3.5埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR2时与FGFR2(例如SEQ ID NO:52和54)氨基酸Y207,K208,V209,R210,N211,Q212,H213,W214,S215,L216,I217,M218,E219,和S220距离3.5埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR2时与一个或多个FGFR2(例如SEQ ID NO:52和54)氨基酸Y207,K208,V209,R210,N211,Q212,H213,W214,S215,L216,I217,M218,E219,和S220距离3.0埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR2时与FGFR2(例如SEQ ID NO:52和54)氨基酸Y207,K208,V209,R210,N211,Q212,H213,W214,S215,L216,I217,M218,E219,和S220距离3.0埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR2时与一个或多个FGFR2(例如SEQID NO:52和54)氨基酸Y207,K208,V209,R210,N211,Q212,H213,W214,S215,L216,I217,M218,E219,和S220距离4.0,3.75,3.5,3.25,或3.0埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR2时与FGFR2(例如SEQ ID NO:52和54)氨基酸Y207,K208,V209,R210,N211,Q212,H213,W214,S215,L216,I217,M218,E219,和S220距离4.0,3.75,3.5,3.25,或3.0埃或更少。在一些实施方案中,该一个或多个氨基酸和/或该一个或多个氨基酸残基为约1,2,3,4,5,6,7,8,9,10,11,和/或12个氨基酸和/或氨基酸残基任一。在一些实施方案中,该表位是通过结晶学(例如实施例中描述的结晶学方法)测定的。在优选的实施方案中,该抗FGFR2/3抗体结合人FGFR2(hFGFR2)(例如SEQ ID NO:52和54)。
在一些实施方案中,该抗FGFR2/3抗体结合包含一个或多个选自FGFR3(例如SEQID NO:56和58)T154,R155,P156,E157,R158,M159,D160,K161,K162,L163,L164,A165,V166,P167,A168,A169,N170,T171,V172,R173,F174,R175,C176,P177,和A178的氨基酸的表位。在一些实施方案中,该抗FGFR2/3抗体结合包含FGFR3(例如SEQ ID NO:56和58)氨基酸T154,R155,P156,E157,R158,M159,D160,K161,K162,L163,L164,A165,V166,P167,A168,A169,N170,T171,V172,R173,F174,R175,C176,P177,和A178的表位。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR3时与一个或多个FGFR3(例如SEQ ID NO:56和58)氨基酸T154,R155,P156,E157,R158,M159,D160,K161,K162,L163,L164,A165,V166,P167,A168,A169,N170,T171,V172,R173,F174,R175,C176,P177,和A178距离4埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR3时与FGFR3(例如SEQ ID NO:56和58)氨基酸T154,R155,P156,E157,R158,M159,D160,K161,K162,L163,L164,A165,V166,P167,A168,A169,N170,T171,V172,R173,F174,R175,C176,P177,和A178距离4埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR3时与一个或多个FGFR3(例如SEQ ID NO:56和58)氨基酸T154,R155,P156,E157,R158,M159,D160,K161,K162,L163,L164,A165,V166,P167,A168,A169,N170,T171,V172,R173,F174,R175,C176,P177,和A178距离3.5埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR3时与FGFR3(例如SEQ ID NO:56和58)氨基酸T154,R155,P156,E157,R158,M159,D160,K161,K162,L163,L164,A165,V166,P167,A168,A169,N170,T171,V172,R173,F174,R175,C176,P177,和A178距离3.5埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR3时与一个或多个FGFR3(例如SEQ ID NO:56和58)氨基酸T154,R155,P156,E157,R158,M159,D160,K161,K162,L163,L164,A165,V166,P167,A168,A169,N170,T171,V172,R173,F174,R175,C176,P177,和A178距离3.0埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR3时与FGFR3(例如SEQ ID NO:56和58)氨基酸T154,R155,P156,E157,R158,M159,D160,K161,K162,L163,L164,A165,V166,P167,A168,A169,N170,T171,V172,R173,F174,R175,C176,P177,和A178距离3.0埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR3时与一个或多个FGFR3(例如SEQ ID NO:56和58)氨基酸T154,R155,P156,E157,R158,M159,D160,K161,K162,L163,L164,A165,V166,P167,A168,A169,N170,T171,V172,R173,F174,R175,C176,P177,和A178距离4.0,3.75,3.5,3.25,或3.0埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR3时与FGFR3(例如SEQ IDNO:56和58)氨基酸T154,R155,P156,E157,R158,M159,D160,K161,K162,L163,L164,A165,V166,P167,A168,A169,N170,T171,V172,R173,F174,R175,C176,P177,和A178距离4.0,3.75,3.5,3.25,或3.0埃或更少。在一些实施方案中,该一个或多个氨基酸和/或该一个或多个氨基酸残基为约1,2,3,4,5,6,7,8,9,10,11,和/或12个氨基酸和/或氨基酸残基任一。在一些实施方案中,该表位是通过结晶学(例如实施例中描述的结晶学方法)测定的。在优选的实施方案中,该抗FGFR2/3抗体结合人FGFR3(hFGFR3)(例如SEQ ID NO:56和58)。
在一些实施方案中,该抗FGFR2/3抗体结合包含一个或多个选自FGFR3(例如SEQID NO:56和58)I204,K205,L206,R207,H208,Q209,Q210,W211,S212,L213,V214,M215,E216,和S217的氨基酸的表位。在一些实施方案中,该抗FGFR2/3抗体结合包含FGFR3(例如SEQ ID NO:56和58)氨基酸I204,K205,L206,R207,H208,Q209,Q210,W211,S212,L213,V214,M215,E216,和S217的表位。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR3时与一个或多个FGFR3(例如SEQ ID NO:56和58)氨基酸I204,K205,L206,R207,H208,Q209,Q210,W211,S212,L213,V214,M215,E216,和S217距离4埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR3时与FGFR3(例如SEQ ID NO:56和58)氨基酸I204,K205,L206,R207,H208,Q209,Q210,W211,S212,L213,V214,M215,E216,和S217距离4埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR3时与一个或多个FGFR3(例如SEQ ID NO:56和58)氨基酸I204,K205,L206,R207,H208,Q209,Q210,W211,S212,L213,V214,M215,E216,和S217距离3.5埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR3时与FGFR3(例如SEQ ID NO:56和58)氨基酸I204,K205,L206,R207,H208,Q209,Q210,W211,S212,L213,V214,M215,E216,和S217距离3.5埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR3时与一个或多个FGFR3(例如SEQ ID NO:56和58)氨基酸I204,K205,L206,R207,H208,Q209,Q210,W211,S212,L213,V214,M215,E216,和S217距离3.0埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR3时与FGFR3(例如SEQ ID NO:56和58)氨基酸I204,K205,L206,R207,H208,Q209,Q210,W211,S212,L213,V214,M215,E216,和S217距离3.0埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR3时与一个或多个FGFR3(例如SEQID NO:56和58)氨基酸I204,K205,L206,R207,H208,Q209,Q210,W211,S212,L213,V214,M215,E216,和S217距离4.0,3.75,3.5,3.25,或3.0埃或更少。在一些实施方案中,该抗FGFR2/3抗体在结合至FGFR3时与FGFR3(例如SEQ ID NO:56和58)氨基酸I204,K205,L206,R207,H208,Q209,Q210,W211,S212,L213,V214,M215,E216,和S217距离4.0,3.75,3.5,3.25,或3.0埃或更少。在一些实施方案中,该一个或多个氨基酸和/或该一个或多个氨基酸残基为约1,2,3,4,5,6,7,8,9,10,11,和/或12个氨基酸和/或氨基酸残基任一。在一些实施方案中,该表位是通过结晶学(例如实施例中描述的结晶学方法)测定的。在优选的实施方案中,该抗FGFR2/3抗体结合人FGFR3(hFGFR3)(例如SEQ ID NO:56和58)。
在具体的实施方案中,该抗FGFR2/3抗体结合FGFR2上选自SEQ ID NO:91和92的一种表位和FGFR3上选自SEQ ID NO:93和94的一种表位。在某些实施方案中,该抗FGFR2/3抗体结合FGFR2上包含SEQ ID NO:91和92的两种表位和FGFR3上选自SEQ ID NO:93和94的一种表位。在某些实施方案中,该抗FGFR2/3抗体结合FGFR2上选自SEQ ID NO:91和92的一种表位和FGFR3上包含SEQ ID NO:93和94的两种表位。在优选的实施方案中,该抗FGFR2/3抗体结合FGFR2上包含SEQ ID NO:91和92的两种表位和FGFR3上包含SEQ ID NO:93和94的两种表位(图9)。
在一个方面,本发明提供了一种抗FGFR2/3抗体,其结合包含下述氨基酸序列,基本上由其组成或由其组成的多肽:TNTEKMEKRLHAVPAANTVKFRCPA(SEQ ID NO:91)和/或YKVRNQHWSLIMES(SEQ ID NO:92)。
在一个方面,本发明提供了一种抗FGFR2/3抗体,其结合包含下述氨基酸序列,基本上由其组成或由其组成的多肽:TRRERMDKKLLAVPAANTVRFRCPA(SEQ ID NO:93)和/或IKLRHQQWSLVMES(SEQ ID NO:94)。
在一个方面,本发明提供了一种抗FGFR2/3抗体,其结合包含下述氨基酸序列,基本上由其组成或由其组成的多肽:TNTEKMEKRLHAVPAANTVKFRCPA(SEQ ID NO:91)或YKVRNQHWSLIMES(SEQ ID NO:92)和TRRERMDKKLLAVPAANTVRFRCPA(SEQ ID NO:93)或IKLRHQQWSLVMES(SEQ ID NO:94)。
在一个实施方案中,本发明的抗FGFR2/3抗体特异性结合与序列TNTEKMEKRLHAVPAANTVKFRCPA(SEQ ID NO:91)和/或YKVRNQHWSLIMES(SEQ ID NO:92)具有至少50%,60%,70%,80%,90%,95%,96%,97%,98%,或99%序列同一性或相似性的氨基酸序列。在一个实施方案中,本发明的抗FGFR2/3抗体特异性结合与序列TRRERMDKKLLAVPAANTVRFRCPA(SEQ ID NO:93)和/或IKLRHQQWSLVMES(SEQ ID NO:94)具有至少50%,60%,70%,80%,90%,95%,96%,97%,98%,或99%序列同一性或相似性的氨基酸序列。
在一个实施方案中,本发明的抗FGFR2/3抗体特异性结合与序列TNTEKMEKRLHAVPAANTVKFRCPA(SEQ ID NO:91)或YKVRNQHWSLIMES(SEQ ID NO:92)具有至少50%,60%,70%,80%,90%,95%,96%,97%,98%,或99%序列同一性或相似性的氨基酸序列和与序列TRRERMDKKLLAVPAANTVRFRCPA(SEQ ID NO:93)或IKLRHQQWSLVMES(SEQ IDNO:94)具有至少50%,60%,70%,80%,90%,95%,96%,97%,98%,或99%序列同一性或相似性的氨基酸序列。
本领域普通技术人员了解如何比对FGFR3序列以鉴定各自FGFR3序列之间的对应残基。类似地,本领域普通技术人员了解如何比对FGFR2序列以鉴定各自FGFR2序列之间的对应残基。
在一个方面,本发明提供了一种抗FGFR2/3抗体,其与上文所述任何抗体竞争对FGFR3和/或FGFR2的结合。在一个方面,本发明提供了一种抗FGFR2/3抗体,其与上文所述任何抗体结合FGFR3和/或FGFR2上相同或相似表位。
如本领域所知道的,及如本文中更详细描述的,描述抗体高变区的氨基酸位置/边界可以有所变化,这取决于本领域中已知的背景和各种定义(如下文所述的)。可变域内的有些位置可以看作杂合高变位置,因为这些位置在一组标准下可认为在高变区内,而在不同的一组标准下被认为在高变区外。在延伸的高变区中也能找到这些位置中的一处或多处(如下文进一步定义的)。
在有些实施方案中,该抗体是单克隆抗体。在其它实施方案中,该抗体是多克隆抗体。在有些实施方案中,该抗体选自下组:嵌合抗体,亲和力成熟抗体,人源化抗体和人抗体。在某些实施方案中,该抗体是抗体片段。在有些实施方案中,该抗体是Fab,Fab′,Fab′-SH,F(ab′)2,或scFv。
在一些实施方案中,该FGFR2/3抗体是包含Fc区的单臂抗体(即重链可变域和轻链可变域形成单一抗原结合臂),其中该Fc区包含第一和第二Fc多肽,其中该第一和第二Fc多肽以复合物存在并形成与包含所述抗原结合臂的Fab分子相比提高所述抗体片段的稳定性的Fc区。参见例如WO2006/015371。
在一个实施方案中,该抗体是嵌合抗体,例如如下的抗体,其包含来自非人供体的抗原结合序列,且该序列被嫁接至异源的非人,人,或人源化序列(例如框架和/或恒定域序列)。在一个实施方案中,该非人供体是小鼠。在另一个实施方案中,抗原结合序列是合成的,例如通过诱变得到的(例如噬菌体展示筛选等)。在一个具体的实施方案中,本发明的嵌合抗体具有鼠V区和人C区。在一个实施方案中,该鼠轻链V区是融合至人卡帕(κ)轻链的。在另一个实施方案中,该鼠重链V区是融合至人IgG1C区的。
本发明的人源化抗体包括那些在框架区(FR)中具有氨基酸替代的及在所嫁接的CDR中具有改变的亲和力成熟变体。CDR或FR中的替代氨基酸不限于那些存在于供体或受体抗体中的。在其它实施方案中,本发明的抗体进一步包含Fc区中的,导致改善的效应器功能(包括增强的CDC和/或ADCC功能和B细胞杀伤)的氨基酸残基改变。本发明的其它抗体包括那些具有增强稳定性的特定改变的那些抗体。在其它实施方案中,本发明的抗体包含Fc区中的,导致降低的效应器功能(例如降低的CDC和/或ADCC功能和/或降低的B细胞杀伤)的氨基酸残基改变。在有些实施方案中,本发明的抗体以降低的对人补体因子C1q和/或天然杀伤(NK)细胞上人Fc受体的结合为特征。在有些实施方案中,本发明的抗体以降低的对人FcγRI,FcγRIIA,和/或FcγRIIIA的结合(诸如结合缺失)为特征。在有些实施方案中,本发明的抗体是属于IgG类的(例如IgG1或IgG4)且包含E233,L234,G236,D265,D270,N297,E318,K320,K322,A327,A330,P331,和/或P329(编号方式依照EU索引)中的至少一处突变。在有些实施方案中,该抗体包含突变L234A/L235A或D265A/N297A。
在该抗体包含Fc区的情况中,可以改变其附着的碳水化合物。例如,美国专利申请No.US 2003/0157108中描述了有缺乏岩藻糖的成熟碳水化合物结构附着于抗体Fc区的抗体。还参见US 2004/0093621。WO 2003/011878和美国专利No.6,602,684中提到了附着于抗体Fc区的碳水化合物中有两分型N-乙酰基葡糖胺(GlcNAc)的抗体。WO 1997/30087中报告了附着于抗体Fc区的寡糖中有至少一个半乳糖残基的抗体。关于有改变的碳水化合物附着于其Fc区的抗体,还参见WO 1998/58964和WO 1999/22764。关于具有修饰的糖基化的抗原结合分子,还参见US 2005/0123546。在一个方面,本发明提供了包含本文中提供的任一抗原结合序列的FGFR3结合多肽,其中该FGFR3结合多肽特异性结合FGFR3,例如人和/或食蟹猴和/或小鼠FGFR3。
本发明的抗体结合(诸如特异性结合)FGFR3(例如FGFR3-IIIb和/或FGFR3-IIIc)和FGFR2(例如FGFR2-IIIb和/或FGFR2-IIIc),而且在一些实施方案中,可调控(例如抑制)FGFR3和/或FGFR2信号传导(诸如FGFR3磷酸化)和/或任何生物学有关FGFR3和/或FGFR3配体生物学途径的破坏和/或任何生物学有关FGFR2和/或FGFR2配体生物学途径的破坏,和/或肿瘤,细胞增殖性病症或癌症的治疗和/或预防;和/或与FGFR3和/或FGFR2表达和/或活性(诸如升高的FGFR3和/或FGFR2表达和/或活性)有关的病症的治疗或预防中的一个或多个方面。在一些实施方案中,该FGFR2/3抗体特异性结合由FGFR3(例如人或小鼠FGFR3)和/或FGFR2(例如人或小鼠FGFR3)组成或本质上由其组成的多肽。在一些实施方案中,该抗体以1x 10-7M的Kd或更高亲和力特异性结合FGFR3。在一些实施方案中,该抗体以1x 10-7M的Kd或更高亲和力特异性结合FGFR2。在一些实施方案中,该抗体以1x 10-7M的Kd或更高亲和力特异性结合FGFR3和FGF2。
在一些实施方案中,该本发明的抗FGFR2/3抗体不是美国专利申请No.2005/0147612中描述的抗FGFR3抗体(例如抗体MSPRO2,MSPRO12,MSPRO59,MSPRO11,MSPRO21,MSPRO24,MSPRO26,MSPRO28,MSPRO29,MSPRO43,MSPRO55),Rauchenberger et al,J BiolChem 278(40):38194-38205(2003)中描述的抗体;PCT申请No.WO2006/048877中描述的抗体(例如抗体PRO-001),Martinez-Torrecuadrada et al,Mol Cancer Ther(2008)7(4):862-873中描述的抗体(例如scFvαFGFR3 3C),Direnzo,R et al(2007)Proceedings ofAACR Annual Meeting,Abstract No.2080中描述的抗体(例如D11),或WO 2010/002862中描述的抗体(例如抗体15D8,27H2,4E7,2G4,20B4)。
在一个方面,本发明提供了组合物,其包含一种或多种本发明的抗体及载剂。在一个实施方案中,所述载剂是药学可接受的。
在另一个方面,本发明提供了核酸,其编码本发明的抗FGFR2/3抗体。
在又一个方面,本发明提供了载体,其包含本发明的核酸。
在另一个方面,本发明提供了组合物,其包含一种或多种本发明的核酸及载剂。在一个实施方案中,所述载剂是药学可接受的。
在一个方面,本发明提供了宿主细胞,其包含本发明的核酸或载体。载体可以是任何类型的,例如重组载体,诸如表达载体。可使用多种宿主细胞中任一种。在一个实施方案中,宿主细胞是原核细胞,例如大肠杆菌。在另一个实施方案中,宿主细胞是真核细胞,例如哺乳动物细胞,诸如中国仓鼠卵巢(CHO)细胞。
在另一个方面,本发明提供了制备本发明抗体的方法。例如,本发明提供了制备抗FGFR2/3抗体(如本文中所定义的,其包括全长抗体及其片段)的方法,所述方法包括在合适的宿主细胞中表达本发明的编码该抗体的重组载体,并回收该抗体。在一些实施方案中,所述方法包括培养包含编码该抗体的核酸的宿主细胞,使得该核酸表达。在一些实施方案中,上述方法进一步包括自宿主细胞培养物回收该抗体。在一些实施方案中,自宿主细胞培养液回收该抗体。在一些实施方案中,该方法进一步包括将回收的抗体与药学可接受载剂,赋形剂,或载剂组合以制备包含人源化抗体的药物配制剂。
在一个方面,本发明提供了一种制品,其包含容器;和装在该容器内的组合物,其中所述组合物包含一种或多种本发明的FGFR2/3抗体。在一个实施方案中,所述组合物包含本发明的核酸。在另一个实施方案中,包含抗体的组合物进一步包含载剂,所述载剂在有些实施方案中是药学可接受的。在一个实施方案中,本发明的制品进一步包含关于对个体施用组合物(例如抗体)的说明书(诸如关于本文中所描述的任何方法的说明书)。
在另一个方面,本发明提供了一种试剂盒,其包含装有组合物的第一容器,所述组合物包含一种或多种本发明的抗FGFR2/3抗体;和装有缓冲液的第二容器。在一个实施方案中,所述缓冲液是药学可接受的。在一个实施方案中,包含抗体的组合物进一步包含载剂,所述载剂在有些实施方案中是药学可接受的。在另一个实施方案中,所述试剂盒进一步包含关于对个体施用组合物(例如抗体)的说明书。
在又一个方面,本发明提供了本发明的抗FGFR2/3抗体,其作为药物使用。
在又一个方面,本发明提供了本发明的抗FGFR2/3抗体,其在治疗或预防病症,诸如与FGFR3活化和/或表达(在一些实施方案中,过表达)有关的病理状况中使用。在又一个方面,本发明提供了本发明的抗FGFR2/3抗体,其在治疗或预防病症,诸如与FGFR2活化和/或表达(在一些实施方案中,过表达)有关的病理状况中使用。
在又一个方面,本发明提供了本发明的抗FGFR2/3抗体,其在治疗或预防病症,诸如与FGFR2和FGFR3活化和/或表达(在一些实施方案中,过表达)有关的病理状况中使用。在一些实施方案中,该病症为癌症,肿瘤,和/或细胞增殖性病症。在一些实施方案中,该癌症,肿瘤,和/或细胞增殖性病症为多发性骨髓瘤或膀胱癌(例如移行细胞癌),乳腺癌或肝癌。
在又一个方面,本发明提供了本发明的抗FGFR2/3抗体,其在治疗或预防病症,诸如骨骼病症中使用。在一些实施方案中,该病症为软骨发育不全(achondroplasia),软骨发育不良(hypochondroplasia),侏儒症(dwarfism),异位发育不良(thantophoricdysplasi)(TD;临床形式TD1和TDII),或颅缝早闭综合征(craniosynostosis syndrome)。
在又一个方面,本发明提供了本发明的抗FGFR2/3抗体,其在降低细胞增殖中使用。
在又一个方面,本发明提供了本发明的抗FGFR2/3抗体,其在杀伤细胞中使用。在一些实施方案中,该细胞为多发性骨髓瘤细胞。在一些实施方案中,该细胞是通过ADCC杀伤的。在一些实施方案中,该抗体为裸的抗体。在一些实施方案中,该细胞过表达FGFR3。在一些实施方案中,该细胞过表达FGFR2。在一些实施方案中,该细胞过表达FGFR2和FGFR3。
在又一个方面,本发明提供了本发明的抗FGFR2/3抗体,其在消减细胞,诸如多发性骨髓瘤细胞中使用。在一些实施方案中,该细胞是通过ADCC杀伤的。在一些实施方案中,该抗体为裸的抗体。在一些实施方案中,该细胞过表达FGFR3。
在又一个方面,本发明提供了本发明的抗FGFR2/3抗体在制备用于病症,诸如与FGFR3,FGFR2,或FGFR2和FGFR3活化和/或表达(在一些实施方案中,过表达)有关的病理状况的治疗性和/或预防性处理的药物中的用途。在一些实施方案中,该病症为癌症,肿瘤,和/或细胞增殖性病症。在一些实施方案中,该癌症,肿瘤,和/或细胞增殖性病症为多发性骨髓瘤或膀胱癌(例如移行细胞癌),乳腺癌或肝癌。在一些实施方案中,该病症为骨骼病症,例如软骨发育不全,软骨发育不良,侏儒症,异位发育不良(TD;临床形式TD1和TDII),或颅缝早闭综合征。
在一个方面,本发明提供了本发明的核酸在制备用于病症,诸如与FGFR3,FGFR2,或FGFR2和FGFR3活化和/或表达(在一些实施方案中,过表达)有关的病理状况的治疗性和/或预防性处理的药物中的用途。在一些实施方案中,该病症为癌症,肿瘤,和/或细胞增殖性病症。在一些实施方案中,该癌症,肿瘤,和/或细胞增殖性病症为多发性骨髓瘤或膀胱癌(例如移行细胞癌),乳腺癌或肝癌。在一些实施方案中,该病症为骨骼病症,例如软骨发育不全,软骨发育不良,侏儒症,异位发育不良(TD;临床形式TD1和TDII),或颅缝早闭综合征。
在另一个方面,本发明提供了本发明的表达载体在制备用于病症,诸如与FGFR3,FGFR2,或FGFR2和FGFR3活化和/或表达(在一些实施方案中,过表达)有关的病理状况的治疗性和/或预防性处理的药物中的用途。在一些实施方案中,该病症为癌症,肿瘤,和/或细胞增殖性病症。在一些实施方案中,该癌症,肿瘤,和/或细胞增殖性病症为多发性骨髓瘤或膀胱癌(例如移行细胞癌),乳腺癌或肝癌。在一些实施方案中,该病症为骨骼病症,例如软骨发育不全,软骨发育不良,侏儒症,异位发育不良(TD;临床形式TD1和TDII),或颅缝早闭综合征。
在还有另一个方面,本发明提供了本发明的宿主细胞在制备用于病症,诸如与FGFR3,FGFR2,或FGFR2和FGFR3活化和/或表达(在一些实施方案中,过表达)有关的病理状况的治疗性和/或预防性处理的药物中的用途。在一些实施方案中,该病症为癌症,肿瘤,和/或细胞增殖性病症。在一些实施方案中,该癌症,肿瘤,和/或细胞增殖性病症为多发性骨髓瘤或膀胱癌(例如移行细胞癌),乳腺癌或肝癌。在一些实施方案中,该病症为骨骼病症,例如软骨发育不全,软骨发育不良,侏儒症,异位发育不良(TD;临床形式TD1和TDII),或颅缝早闭综合征。
在又一个方面,本发明提供了本发明的制品在制备用于病症,诸如与FGFR3,FGFR2,或FGFR2和FGFR3活化和/或表达(在一些实施方案中,过表达)有关的病理状况的治疗性和/或预防性处理的药物中的用途。在一些实施方案中,该病症为癌症,肿瘤,和/或细胞增殖性病症。在一些实施方案中,该癌症,肿瘤,和/或细胞增殖性病症为多发性骨髓瘤或膀胱癌(例如移行细胞癌),乳腺癌或肝癌。在一些实施方案中,该病症为骨骼病症,例如软骨发育不全,软骨发育不良,侏儒症,异位发育不良(TD;临床形式TD1和TDII),或颅缝早闭综合征。
在一个方面,本发明还提供了本发明的试剂盒在制备用于病症,诸如与FGFR3,FGFR2,或FGFR2和FGFR3活化和/或表达(在一些实施方案中,过表达)有关的病理状况的治疗性和/或预防性处理的药物中的用途。在一些实施方案中,该病症为癌症,肿瘤,和/或细胞增殖性病症。在一些实施方案中,该癌症,肿瘤,和/或细胞增殖性病症为多发性骨髓瘤或膀胱癌(例如移行细胞癌),乳腺癌或肝癌。在一些实施方案中,该病症为骨骼病症,例如软骨发育不全,软骨发育不良,侏儒症,异位发育不良(TD;临床形式TD1和TDII),或颅缝早闭综合征。
在又一个方面,本发明提供了本发明的抗FGFR2/3抗体在制备用于抑制细胞增殖的药物中的用途。在又一个方面,本发明提供了本发明的抗FGFR2/3抗体在制备用于细胞杀伤的药物中的用途。在一些实施方案中,该细胞为多发性骨髓瘤细胞。在一些实施方案中,该细胞是通过ADCC杀伤的。在一些实施方案中,该抗体为裸的抗体。在一些实施方案中,该细胞过表达FGFR3。在一些实施方案中,该细胞过表达FGFR2。在一些实施方案中,该细胞过表达FGFR3和FGFR2。
在又一个方面,本发明提供了本发明的抗FGFR2/3抗体在制备用于消减细胞,诸如多发性骨髓瘤细胞的药物中的用途。在一些实施方案中,该细胞是通过ADCC杀伤的。在一些实施方案中,该抗体为裸的抗体。在一些实施方案中,该细胞过表达FGFR3。在一些实施方案中,该细胞过表达FGFR2。在一些实施方案中,该细胞过表达FGFR3和FGFR2。
本发明提供了对于调控与FGFR3的表达和/或信号传导,诸如升高的表达和/或信号传导或不想要的表达和/或信号传导有关的病症有用的方法和组合物。本发明提供了对于调控与FGFR2的表达和/或信号传导,诸如升高的表达和/或信号传导或不想要的表达和/或信号传导有关的病症有用的方法和组合物。本发明提供了对于调控与FGFR3和FGFR2的表达和/或信号传导,诸如升高的表达和/或信号传导或不想要的表达和/或信号传导有关的病症有用的方法和组合物。
本发明的方法可用于影响任何合适病理状态。本文中描述了例示性病症,而且包括选自下组的癌症:非小细胞肺癌,卵巢癌,甲状腺癌,睾丸癌,子宫内膜癌,头颈癌,脑癌(例如成神经细胞瘤或脑膜瘤),皮肤癌(例如黑素瘤,基底细胞癌,或鳞状细胞癌),膀胱癌(例如移行细胞癌),乳腺癌,胃癌,结肠直肠癌(CRC),肝细胞癌,宫颈癌,肺癌,胰腺癌,前列腺癌,和血液学恶性(例如T细胞急性成淋巴细胞性白血病(T-ALL),B细胞急性成淋巴细胞性白血病(B-ALL),急性髓性白血病(AML),B细胞恶性,何杰金(Hodgkin)淋巴瘤,和多发性骨髓瘤)。在一些实施方案中,该病症为侵入性移行细胞癌。在一些实施方案中,该病症为多发性骨髓瘤。另外的例示性病症包括骨骼病症,诸如软骨发育不全,软骨发育不良,侏儒症,异位发育不良(TD;临床形式TD1和TDII),或颅缝早闭综合征。
在某些实施方案中,该癌表达FGFR3,扩增的FGFR3,易位的FGFR3,和/或突变的FGFR3。在某些实施方案中,该癌表达活化的FGFR3。在某些实施方案中,该癌表达易位的FGFR3(例如t(4;14)易位)。在某些实施方案中,该癌表达组成性FGFR3。在一些实施方案中,该组成性FGFR3包含酪氨酸激酶域和/或近膜域和/或配体结合域中的突变。在某些实施方案中,该癌表达配体不依赖性FGFR3。在一些实施方案中,该癌表达配体依赖性FGFR3。
在一些实施方案中,该癌表达包含与FGFR3-IIIbS248C对应的突变的FGFR3。在一些实施方案中,该癌表达FGFR3-IIIbS248C和/或FGFR3-IIIcS248C。
在一些实施方案中,该癌表达包含与FGFR3-IIIbK652E对应的突变的FGFR3。在一些实施方案中,该癌表达FGFR3-IIIbK652E和/或FGFR3-IIIcK650E。
FGFR3包含与FGFR3-IIIbS249C对应的突变。在一些实施方案中,该癌表达FGFR3-IIIbS249C和/或FGFR3-IIIcS249C。
在一个方面,该癌表达包含与FGFR3-IIIbG372C对应的突变的FGFR3。在一些实施方案中,该癌表达FGFR3-IIIbG372C和/或FGFR3-IIIcG370C。
在一个方面,该癌表达包含与FGFR3-IIIbY375C对应的突变的FGFR3。在一些实施方案中,该癌表达FGFR3-IIIbY375C和/或FGFR3-IIIcY373C。
在一些实施方案中,该癌表达(a)FGFR3-IIIbK652E和(b)FGFR3-IIIbR248C,FGFR3-IIIbY375C,FGFR3-IIIbS249C,和FGFR3IIIbG372C中的一种或多种。
在一些实施方案中,该癌表达(a)FGFR3-IIIbR248C和(b)FGFR3-IIIbK652E,FGFR3-IIIbY375C,FGFR3-IIIbS249C,和FGFR3-IIIbG372C中的一种或多种。
在一些实施方案中,该癌表达(a)FGFR3-IIIbG372C和(b)FGFR3-IIIbK652E,FGFR3-IIIbY375C,FGFR3-IIIbS249C,和FGFR3-IIIbR248C中的一种或多种。
在一些实施方案中,该癌表达FGFR3-IIIbR248C,FGFR3-IIIbK652E,FGFR3-IIIbY375C,FGFR3-IIIbS249C,和FGFR3-IIIbG372C。
在某些实施方案中,该癌表达相对于对照样品(例如正常组织的样品)或水平升高水平的磷酸-FGFR3,磷酸-FRS2和/或磷酸-MAPK。
在某些实施方案中,该癌表达FGFR2,扩增的FGFR2,易位的FGFR2,和/或突变的FGFR2。在某些实施方案中,该癌表达活化的FGFR2。在某些实施方案中,该癌表达易位的FGFR2。在某些实施方案中,该癌表达组成性FGFR2。在某些实施方案中,该癌表达配体不依赖性FGFR2。在一些实施方案中,该癌表达配体依赖性FGFR2。
在一些实施方案中,该癌表达包含突变的FGFR2。
在某些实施方案中,该癌表达:1)FGFR3,扩增的FGFR3,易位的FGFR3,和/或突变的FGFR3和2)FGFR2,扩增的FGFR2,易位的FGFR2,和/或突变的FGFR2。在某些实施方案中,该癌表达活化的FGFR3和如上文描述的FGFR2。在某些实施方案中,该癌表达易位的FGFR3(例如t(4;14)易位)和如上文描述的FGFR2。在某些实施方案中,该癌表达组成性FGFR3和如上文描述的FGFR2。在一些实施方案中,该组成性FGFR3包含酪氨酸激酶域和/或近膜域和/或配体结合域中的突变。在某些实施方案中,该癌表达配体不依赖性FGFR3和如上文描述的FGFR2。在一些实施方案中,该癌表达配体依赖性FGFR3和如上文描述的FGFR2。
在一些实施方案中,该癌表达包含与FGFR3-IIIbS248C对应的突变的FGFR3和如上文描述的FGFR2(例如FGFR2,扩增的FGFR2,易位的FGFR2,和/或突变的FGFR2)。在一些实施方案中,该癌表达FGFR3-IIIbS248C和/或FGFR3-IIIcS248C和如上文描述的FGFR2(例如FGFR2,扩增的FGFR2,易位的FGFR2,和/或突变的FGFR2)。
在一些实施方案中,该癌表达包含与FGFR3-IIIbK652E对应的突变的FGFR3和如上文描述的FGFR2(例如FGFR2,扩增的FGFR2,易位的FGFR2,和/或突变的FGFR2)。在一些实施方案中,该癌表达FGFR3-IIIbK652E和/或FGFR3-IIIcK650E和如上文描述的FGFR2(例如FGFR2,扩增的FGFR2,易位的FGFR2,和/或突变的FGFR2)。
在一些实施方案中,该癌表达包含与FGFR3-IIIbS249C对应的突变的FGFR3和如上文描述的FGFR2(例如FGFR2,扩增的FGFR2,易位的FGFR2,和/或突变的FGFR2)。在一些实施方案中,该癌表达FGFR3-IIIbS249C和/或FGFR3-IIIcS249C和如上文描述的FGFR2(例如FGFR2,扩增的FGFR2,易位的FGFR2,和/或突变的FGFR2)。
在一个方面,该癌表达包含与FGFR3-IIIbG372C对应的突变的FGFR3和如上文描述的FGFR2(例如FGFR2,扩增的FGFR2,易位的FGFR2,和/或突变的FGFR2)。在一些实施方案中,该癌表达FGFR3-IIIbG372C和/或FGFR3-IIIcG370C和如上文描述的FGFR2(例如FGFR2,扩增的FGFR2,易位的FGFR2,和/或突变的FGFR2)。
在一个方面,该癌表达包含与FGFR3-IIIbY375C对应的突变的FGFR3和如上文描述的FGFR2(例如FGFR2,扩增的FGFR2,易位的FGFR2,和/或突变的FGFR2)。在一些实施方案中,该癌表达FGFR3-IIIbY375C和/或FGFR3-IIIcY373C和如上文描述的FGFR2(例如FGFR2,扩增的FGFR2,易位的FGFR2,和/或突变的FGFR2)。
在一些实施方案中,该癌表达(a)FGFR3-IIIbK652E和(b)FGFR3-IIIbR248C,FGFR3-IIIbY375C,FGFR3-IIIbS249C,和FGFR3IIIbG372C中的一种或多种和(c)如上文描述的FGFR2(例如FGFR2,扩增的FGFR2,易位的FGFR2,和/或突变的FGFR2)。
在一些实施方案中,该癌表达(a)FGFR3-IIIbR248C和(b)FGFR3-IIIbK652E,FGFR3-IIIbY375C,FGFR3-IIIbS249C,和FGFR3-IIIbG372C中的一种或多种和(c)如上文描述的FGFR2(例如FGFR2,扩增的FGFR2,易位的FGFR2,和/或突变的FGFR2)。
在一些实施方案中,该癌表达(a)FGFR3-IIIbG372C和(b)FGFR3-IIIbK652E,FGFR3-IIIbY375C,FGFR3-IIIbS249C,和FGFR3-IIIbR248C中的一种或多种和(c)如上文描述的FGFR2(例如FGFR2,扩增的FGFR2,易位的FGFR2,和/或突变的FGFR2)。
在一些实施方案中,该癌表达(a)FGFR3-IIIbR248C,FGFR3-IIIbK652E,FGFR3-IIIbY375C,FGFR3-IIIbS249C,和FGFR3-IIIbG372C,和(b)如上文描述的FGFR2(例如FGFR2,扩增的FGFR2,易位的FGFR2,和/或突变的FGFR2)。
在某些实施方案中,该癌表达相对于对照样品(例如正常组织的样品)或水平升高水平的磷酸-FGFR3,磷酸-FRS2和/或磷酸-MAPK和如上文描述的FGFR2(例如FGFR2,扩增的FGFR2,易位的FGFR2,和/或突变的FGFR2)。
在一些实施方案中,该癌表达(例如在细胞表面上)约10,000个FGFR3分子每个细胞或更多(诸如11,000,12,000,13,000,14,000,15,000,16,000,17,000,18,000或更多个FGFR3受体)。在一些实施方案中,该癌表达约13000个FGFR3分子。在其它实施方案中,该癌表达约5000,6000,7000,8000,或更多个FGFR3分子。在一些实施方案中,该癌表达少于约4000,3000,2000,1000,或更少个FGFR3分子。在一些实施方案中,该癌表达少于约1000个FGFR3分子。在一些实施方案中,该癌表达(例如在细胞表面上)约10,000个FGFR2分子每个细胞或更多(诸如11,000,12,000,13,000,14,000,15,000,16,000,17,000,18,000或更多个FGFR2受体)。在一些实施方案中,该癌表达约13000个FGFR2分子。在其它实施方案中,该癌表达约5000,6000,7000,8000,或更多个FGFR2分子。在一些实施方案中,该癌表达少于约4000,3000,2000,1000,或更少个FGFR2分子。在一些实施方案中,该癌表达少于约1000个FGFR2分子。在一些实施方案中,该癌表达(例如在细胞表面上)约10,000个FGFR3和10,000个FGFR2分子每个细胞或更多(诸如11,000,12,000,13,000,14,000,15,000,16,000,17,000,18,000或更多个FGFR3受体和11,000,12,000,13,000,14,000,15,000,16,000,17,000,18,000或更多个FGFR2受体)。在一些实施方案中,该癌表达约13000个FGFR3分子和13000个FGFR2分子。在其它实施方案中,该癌表达约5000,6000,7000,8000,或更多个FGFR3分子和约5000,6000,7000,8000,或更多个FGFR2分子。在一些实施方案中,该癌表达少于约4000,3000,2000,1000,或更少个FGFR3分子和少于约4000,3000,2000,1000,或更少个FGFR2分子。在一些实施方案中,该癌表达少于约1000个FGFR3分子和少于约1000个FGFR2分子。
在一个实施方案中,本发明的方法所靶向的细胞是癌细胞。例如,癌细胞可以是选自下组的癌细胞:乳腺癌细胞,结肠直肠癌细胞,肺癌细胞(例如非小细胞肺癌细胞),甲状腺癌细胞,多发性骨髓瘤细胞,睾丸癌细胞,乳头状癌细胞,结肠癌细胞,胰腺癌细胞,卵巢癌细胞,宫颈癌细胞,中枢神经系统癌细胞,骨源性肉瘤细胞,肾癌细胞,肝细胞癌细胞,膀胱癌细胞(例如移行细胞癌细胞),胃癌细胞,头颈鳞癌细胞,黑素瘤细胞,白血病细胞,多发性骨髓瘤细胞(例如包含t(4:14)FGFR3易位的多发性骨髓瘤细胞)和结肠腺瘤细胞。在一个实施方案中,本发明的方法所靶向的细胞是高度增殖性和/或增生性细胞。在另一个实施方案中,本发明的方法所靶向的细胞是发育异常细胞。在还有另一个实施方案中,本发明的方法所靶向的细胞是转移性细胞。
在一个方面,本发明提供了用于在受试者中抑制细胞增殖的方法,该方法包含对该受试者施用有效量的抗FGFR2/3抗体以降低细胞增殖。
在一个方面,本发明提供了用于在受试者中杀伤细胞的方法,该方法包含对该受试者施用有效量的抗FGFR2/3抗体以杀伤细胞。在一些实施方案中,该细胞是多发性骨髓瘤细胞。在一些实施方案中,该细胞是通过ADCC杀伤的。在一些实施方案中,该抗体是裸的抗体。在一些实施方案中,该细胞过表达FGFR3。在一些实施方案中,该细胞过表达FGFR2。在一些实施方案中,该细胞过表达FGFR3和FGFR2。
在一个方面,本发明提供了用于在受试者中消减细胞(诸如多发性骨髓瘤细胞)的方法,该方法包含对该受试者施用有效量的抗FGFR2/3抗体以杀伤细胞。在一些实施方案中,该细胞是通过ADCC杀伤的。在一些实施方案中,该抗体是裸的抗体。在一些实施方案中,该细胞过表达FGFR2/3。
在一个方面,本发明提供了用于治疗或预防骨骼病症的方法。在一些实施方案中,该病症是软骨发育不全,软骨发育不良,侏儒症,异位发育不良(TD;临床形式TD1和TDII),或颅缝早闭综合征。
本发明的方法可进一步包含另外的治疗步骤。例如,在一个实施方案中,该方法进一步包含将被靶定的细胞和/或组织(例如癌细胞)暴露于辐射处理(radiationtreatment)或化疗剂的步骤。
在一个方面,本发明提供了如下的方法,其包括与有效量的另一种治疗剂组合地施用有效量的抗FGFR2/3抗体,所述另一种治疗剂诸如抗血管发生剂,另一种抗体,化疗剂,细胞毒剂,免疫抑制剂,前体药物,细胞因子,细胞毒性放疗,类固醇,止吐药,癌症疫苗,镇痛药,或生长抑制剂。例如,与抗癌剂或抗血管发生剂组合地使用抗FGFR2/3抗体以治疗各种赘生性或非赘生性疾患。在特定的例子中,该抗FGFR2/3抗体与velcade,revlimid,他莫昔芬(tamoxifen),来曲唑(letrozole),依西美坦(exemestane),阿那曲唑(anastrozole),伊立替康(irinotecan),西妥昔单抗(cetuximab),氟维司群(fulvestrant),长春瑞滨(vinorelbine),贝伐单抗(bevacizumab),长春新碱(vincristine),顺铂(cisplatin),吉西他滨(gemcitabine),甲氨蝶呤(methotrexate),长春碱(vinblastine),卡铂(carboplatin),帕利他赛(paclitaxel),多西他赛(docetaxel),培美曲塞(pemetrexed),5-氟尿嘧啶(5-fluorouracil),多柔比星(doxorubicin),硼替佐米(bortezomib),来那度胺(lenalidomide),地塞米松(dexamethasone),美法仑(melphalin),泼尼松(prednisone),长春新碱(vincristine),和/或沙利度胺(thalidomide)组合使用。
根据要治疗的具体癌症适应证,本发明的组合疗法可以与另外的治疗剂诸如化疗剂或另外的疗法诸如放疗或手术组合。许多已知的化疗剂可以在本发明的组合疗法中使用。优选地,会使用那些作为具体适应证的标准治疗的化疗剂。要组合使用的每种治疗剂的剂量或频率优选与相应药剂在没有其它药剂的情况中使用时的剂量或频率相同,或小于相应药剂在没有其它药剂的情况中使用时的剂量或频率。
在另一个方面,本发明提供了本文中描述的抗FGFR2/3抗体任一,其中该抗FGFR2/3抗体包含可检测标记物。
在另一个方面,本发明提供了本文中描述的抗FGFR2/3抗体任一和FGFR2/3的复合物。在一些实施方案中,该复合物在体内或在体外。在一些实施方案中,该复合物包含癌细胞。在一些实施方案中,该抗FGFR2/3抗体是可检测标记的。
本公开文本还提供了结合β-Klotho(KLB)的抗体和结合KLB和FGFR2和/或FGFR3二者的双特异性抗体(“FGFR2/3+KLB双特异性抗体”),及其使用方法。在具体的实施方案中,该FGFR2/3+KLB双特异性抗体可用于治疗代谢疾病和病症,包括重量减轻和改善葡萄糖和脂质代谢。在某些实施方案中,该FGFR2/3+KLB双特异性抗体可用于在对肝没有显著影响且骨量没有显著损失的情况下治疗代谢病症或疾病。在优选的实施方案中,该FGFR2/3+KLB双特异性抗体用于治疗非酒精性脂肪性肝炎(NASH)。
在某些实施方案中,该双特异性抗体是一种分离的抗体。在某些实施方案中,该双特异性抗体能结合KLB和FGFR2,KLB和FGFR3二者,或KLB,FGFR2,和FGFR3所有三者,其中该抗体结合KLB的C端域。在某些实施方案中,该双特异性抗体结合包括氨基酸序列SSPTRLAVIPWGVRKLLRWVRRNYGDMDIYITAS(SEQ ID NO:103)的KLB片段。
在某些实施方案中,该结合KLB的双特异性抗体还结合在包括氨基酸序列TNTEKMEKRLHAVPAANTVKFRCPA(SEQ ID NO:91)或YKVRNQHWSLIMES(SEQ ID NO:92)的FGFR2片段内的表位。在某些实施方案中,该结合KLB的双特异性抗体还结合在包括氨基酸序列TRPERMDKKLLAVPAANTVRFRCPA(SEQ ID NO:93)和IKLRHQQWSLVMES(SEQ ID NO:94)的FGFR3片段内的表位。在某些实施方案中,该结合KLB的双特异性抗体还结合在包括氨基酸序列TNTEKMEKRLHAVPAANTVKFRCPA(SEQ ID NO:91)或YKVRNQHWSLIMES(SEQ ID NO:92)的FGFR2片段内的表位并结合在包括氨基酸序列TRPERMDKKLLAVPAANTVRFRCPA(SEQ ID NO:93)和IKLRHQQWSLVMES(SEQ ID NO:94)的FGFR3片段内的表位。
在某些实施方案中,该结合KLB的双特异性抗体还结合在与氨基酸序列TNTEKMEKRLHAVPAANTVKFRCPA(SEQ ID NO:91)和/或YKVRNQHWSLIMES(SEQ ID NO:92)具有至少50%,60%,70%,80%,90%,95%,96%,97%,98%,或99%序列同一性或相似性的FGFR2片段内的表位。在某些实施方案中,该结合KLB的双特异性抗体还结合在与氨基酸序列TRPERMDKKLLAVPAANTVRFRCPA(SEQ ID NO:93)和IKLRHQQWSLVMES(SEQ ID NO:94)具有至少50%,60%,70%,80%,90%,95%,96%,97%,98%,或99%序列同一性或相似性的FGFR3片段内的表位。在某些实施方案中,该结合KLB的双特异性抗体还结合在与氨基酸序列TNTEKMEKRLHAVPAANTVKFRCPA(SEQ ID NO:91)和/或YKVRNQHWSLIMES(SEQ ID NO:92)具有至少50%,60%,70%,80%,90%,95%,96%,97%,98%,或99%序列同一性或相似性的FGFR2片段内的表位且还结合在与氨基酸序列TRPERMDKKLLAVPAANTVRFRCPA(SEQ ID NO:93)和IKLRHQQWSLVMES(SEQ ID NO:94)具有至少50%,60%,70%,80%,90%,95%,96%,97%,98%,或99%序列同一性或相似性的FGFR3片段内的表位。
在某些实施方案中,该结合KLB的双特异性抗体还在SEQ ID NO:52或54的157至181的氨基酸序列范围内结合FGFR2。在某些实施方案中,该结合KLB的双特异性抗体还在SEQ ID NO:52或54的207至220的氨基酸序列范围内结合FGFR2。在某些实施方案中,该结合KLB的双特异性抗体还在SEQ ID NO:52或54的157至181和207至220的氨基酸序列范围内结合FGFR2。
在某些实施方案中,该结合KLB和FGFR2/3的双特异性抗体抑制组成性FGFR2和/或FGFR3活性。在某些实施方案中,该组成性FGFR2/3活性为配体依赖性组成性FGFR2/3活性。在某些实施方案中,该组成性FGFR2/3活性为配体不依赖性组成性FGFR2/3活性。在某些实施方案中,该组成性FGFR2/3活性为FGFR2和FGFR3活性。
在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体在体内降低血液葡萄糖水平。在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体并不显著影响骨密度。在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体对肝没有显著影响。在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体以比FGF21诱导显著更低水平在肝中诱导ERK和MEK磷酸化。在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体以10-8M至10-13M的Kd结合KLB。在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体能以10-8M至10-13M的Kd结合FGFR2和/或FGFR3蛋白质。在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体能以10-8M至10-13M的Kd结合FGFR2和/或FGFR3。
在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体结合KLB上存在的表位。例如,而且并非为了限制,本公开文本提供了一种FGFR2/3+KLB双特异性抗体,它能与图11A和11B中所示抗体结合KLB上的相同表位。在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体能与12A11或8C5抗体结合相同表位。在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体能结合在KLB的C端域内的表位。在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体能结合由氨基酸序列SSPTRLAVIPWGVRKLLRWVRRNYGDMDIYITAS(SEQ ID NO:103)组成的KLB片段。
在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体任一的KLB臂是US20150218276(将其完整收入本文)中描述的任何KLB抗体的臂。
在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体任一的FGFR2/3臂是本文中描述的任何FGFR2/3抗体的臂。
在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体包括第一抗体或其抗原结合部分,其包括重链可变区和轻链可变区,其中该重链可变区包括具有与SEQ IDNO:104中所列序列至少95%相同的序列的氨基酸,且该轻链可变区包括具有与SEQ ID NO:105中所列序列至少95%相同的序列的氨基酸。在某些实施方案中,第二抗体或其抗原结合部分包括重链可变区和轻链可变区,其中该重链可变区包括具有与表1第2栏中所列序列至少95%相同的序列的氨基酸,且该轻链可变区包括具有与表1第3栏中所列序列至少95%相同的序列的氨基酸。
表1:例示性FGFR2/3抗体的HC和LC序列
| 抗体 | HC SEQ ID NO: | LC SEQ ID NO: |
| 2B.1.3 | 75 | 59 |
| 2B.1.95 | 76 | 60 |
| 2B.1.73 | 77 | 61 |
| 2B.1.32 | 78 | 62 |
| 2B.1.88 | 79 | 63 |
| 2B.1.1 | 80 | 64 |
| 2B.1.3.10 | 81 | 65 |
| 2B.1.3.12 | 82 | 66 |
在某些实施方案中,本公开文本的抗KLB/抗FGFR1双特异性抗体包括第一抗体或其抗原结合部分,其包括重链区和轻链区,其中该重链区包括具有与SEQ ID NO:106中所列序列至少95%相同的序列的氨基酸,且该轻链区包括具有与SEQ ID NO:107中所列序列至少95%相同的序列的氨基酸。在某些实施方案中,第二抗体或其抗原结合部分包括重链区和轻链区,其中该重链区包括具有与表1第2栏中所列序列至少95%相同的序列的氨基酸,且该轻链区包括具有与表1第3栏中所列序列至少95%相同的序列的氨基酸。
在优选的实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体包括第一抗KLB抗体或其抗原结合部分,其包括重链可变区和轻链可变区,其中该重链可变区包括具有与SEQID NO:104中所列序列至少95%相同的序列的氨基酸,且该轻链可变区包括具有与SEQ IDNO:105中所列序列至少95%相同的序列的氨基酸;和第二抗FGFR2/3抗体或其抗原结合部分,其包括重链可变区和轻链可变区,其中该重链可变区包括具有与SEQ ID NO:66中所列序列至少95%相同的序列的氨基酸,且该轻链可变区包括具有与SEQ ID NO:82中所列序列至少95%相同的序列的氨基酸。
在优选的实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体包括第一抗KLB抗体或其抗原结合部分,其包括重链可变区和轻链可变区,其中该重链可变区包括具有与SEQID NO:106中所列序列至少95%相同的序列的氨基酸,且该轻链可变区包括具有与SEQ IDNO:107中所列序列至少95%相同的序列的氨基酸;和第二抗FGFR2/3抗体或其抗原结合部分,其包括重链可变区和轻链可变区,其中该重链可变区包括具有与SEQ ID NO:82中所列序列至少95%相同的序列的氨基酸,且该轻链可变区包括具有与SEQ ID NO:66中所列序列至少95%相同的序列的氨基酸。
在优选的实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体包括第一抗KLB抗体或其抗原结合部分,其包括重链可变区和轻链可变区,其中该重链可变区包括具有与SEQID NO:106中所列序列至少95%相同的序列的氨基酸,且该轻链可变区包括具有与SEQ IDNO:107中所列序列至少95%相同的序列的氨基酸;和第二抗FGFR2/3抗体或其抗原结合部分,其包括重链和轻链,其中该重链包括具有与SEQ ID NO:282中所列序列至少95%相同的序列的氨基酸,且该轻链包括具有与SEQ ID NO:283中所列序列至少95%相同的序列的氨基酸。
在优选的实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体包括第一抗KLB抗体或其抗原结合部分,其包括重链可变区和轻链可变区,其中该重链可变区包括具有与SEQID NO:106中所列序列至少95%相同的序列的氨基酸,且该轻链可变区包括具有与SEQ IDNO:107中所列序列至少95%相同的序列的氨基酸;和第二抗FGFR2/3抗体或其抗原结合部分,其中轻链上的CDR包含具有与SEQ ID NO:7-9(CDRL1,CDRL2,和CDRL3)至少90%,91%,92%,93%,94%,95%,95%,96%,97%,98%,99%,或100%相同的序列的氨基酸,且其中重链上的CDR包含具有与SEQ ID NO:10-12(CDRH1,CDRH2,和CDRH3)至少90%,91%,92%,93%,94%,95%,95%,96%,97%,98%,99%,或100%相同的序列的氨基酸。
在优选的实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体包括第一抗KLB抗体或其抗原结合部分,其包括重链可变区和轻链可变区,其中该重链可变区包括具有与SEQID NO:106中所列序列至少95%相同的序列的氨基酸,且该轻链可变区包括具有与SEQ IDNO:107中所列序列至少95%相同的序列的氨基酸;和第二抗FGFR2/3抗体或其抗原结合部分,其中轻链上的CDR包含具有与SEQ ID NO:276-278(CDRL1,CDRL2,和CDRL3)至少90%,91%,92%,93%,94%,95%,95%,96%,97%,98%,99%,或100%相同的序列的氨基酸,且其中重链上的CDR包含具有与SEQ ID NO:279-281(CDRH1,CDRH2,和CDRH3)至少90%,91%,92%,93%,94%,95%,95%,96%,97%,98%,99%,或100%相同的序列的氨基酸。
在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体包括第一抗KLB抗体或其抗原结合部分,其包含:(a)包含选自由SEQ ID NO:230-232和236-247组成的组的氨基酸序列的HVR-H3,(b)包含选自由SEQ ID NO:123-137组成的组的氨基酸序列的HVR-L3,和(c)包含选自组由SEQ ID NO:142和248-262成的组的氨基酸序列的HVR-H2。
在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体包括第一抗KLB抗体或其抗原结合部分,其包含:(a)包含选自由SEQ ID NO:230-232和236-247组成的组的氨基酸序列的HVR-H1,(b)包含选自由SEQ ID NO:142和248-262组成的组的氨基酸序列的HVR-H2,和(c)包含选自由SEQ ID NO:263-278组成的组的氨基酸序列的HVR-H3。
在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体包括第一抗KLB抗体或其抗原结合部分,其包含:(a)包含选自由SEQ ID NO:279-293组成的组的氨基酸序列的HVR-L1,(b)包含选自由SEQ ID NO:294-309组成的组的氨基酸序列的HVR-L2,和(c)包含选自由SEQ ID NO:310-324组成的组的氨基酸序列的HVR-L3。
在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体包括第一抗KLB抗体或其抗原结合部分,其包含:(a)包含SEQ ID NO:119的氨基酸序列的HVR-H1,(b)包含SEQID NO:150的氨基酸序列的HVR-H2,(c)包含SEQ ID NO:166的氨基酸序列的HVR-H3,(d)包含SEQ ID NO:181的氨基酸序列的HVR-L1,(e)包含SEQ ID NO:197的氨基酸序列的HVR-L2,和(f)包含SEQ ID NO:212的氨基酸序列的HVR-L3。
在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体包括第一抗KLB抗体或其抗原结合部分,其包含:(a)包含SEQ ID NO:122的氨基酸序列的HVR-H1,(b)包含SEQID NO:153的氨基酸序列的HVR-H2,(c)包含SEQ ID NO:169的氨基酸序列的HVR-H3,(d)包含SEQ ID NO:184的氨基酸序列的HVR-L1,(e)包含SEQ ID NO:200的氨基酸序列的HVR-L2,和(f)包含SEQ ID NO:215的氨基酸序列的HVR-L3。
在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体包括来自抗KLB抗体或其抗原结合部分的一个臂和本文中公开的FGFR2/3抗体的一个臂,该抗KLB抗体或其抗原结合部分选自本文中或US20150218276(将其完整收入本文)中公开的抗KLB抗体任一。在具体的实施方案中,该FGFR2/3+KLB双特异性的臂选自下述组合:
a)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:104(HCVR)和SEQ ID NO:105(LCVR))的一个臂和来自2B.1.3.12抗FGFR2/3抗体(包含SEQ ID NO:82(重链)和SEQ IDNO:66(轻链))的一个臂;
b)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:106(重链)和SEQ ID NO:107(轻链))的一个臂和来自2B.1.3.12抗FGFR2/3抗体(包含SEQ ID NO:82(重链)和SEQ IDNO:66(轻链))的一个臂;
c)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:104(HCVR)和SEQ ID NO:105(LCVR))的一个臂和来自2B.1.3.12抗FGFR2/3抗体(包含SEQ ID NO:7-9(CDRL1,CDRL2,和CDRL3)和SEQ ID NO:10-12(CDRH1,CDRH2,和CDRH3))的一个臂;
d)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:106(重链)和SEQ ID NO:107(轻链))的一个臂和来自2B.1.3.12抗FGFR2/3抗体(包含SEQ ID NO:7-9(CDRL1,CDRL2,和CDRL3)和SEQ ID NO:10-12(CDRH1,CDRH2,和CDRH3))的一个臂;
e)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:104(HCVR)和SEQ ID NO:105(LCVR))的一个臂和来自2B.1.1.6抗FGFR2/3抗体(包含SEQ ID NO:282(重链)和SEQ IDNO:283(轻链))的一个臂;
f)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:106(重链)和SEQ ID NO:107(轻链))的一个臂和来自2B.1.1.6抗FGFR2/3抗体(包含SEQ ID NO:282(重链)和SEQ IDNO:283(轻链))的一个臂;
g)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:104(HCVR)和SEQ ID NO:105(LCVR))的一个臂和来自2B.1.1.6抗FGFR2/3抗体(包含SEQ ID NO:276-278(CDRL1,CDRL2,和CDRL3)和SEQ ID NO:279-281(CDRH1,CDRH2,和CDRH3))的一个臂;和
h)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:106(重链)和SEQ ID NO:107(轻链))的一个臂和来自2B.1.1.6抗FGFR2/3抗体(包含SEQ ID NO:276-278(CDRL1,CDRL2,和CDRL3)和SEQ ID NO:279-281(CDRH1,CDRH2,和CDRH3))的一个臂。
在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体包括第一抗KLB抗体或其抗原结合部分,其包含:(a)包含SEQ ID NO:104的氨基酸序列的重链可变区和(b)包含SEQ ID NO:105的氨基酸序列的轻链可变区。在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体包括第一抗KLB抗体或其抗原结合部分,其包含:(a)包含SEQ ID NO:106的氨基酸序列的重链和(b)包含SEQ ID NO:107的氨基酸序列的轻链。
在另一个方面,本公开文本的FGFR2/3+KLB双特异性抗体包括第一抗KLB抗体或其抗原结合部分,其包含:(a)与SEQ ID NO:104的氨基酸序列具有至少95%序列同一性的重链可变区;(b)与SEQ ID NO:105的氨基酸序列具有至少95%序列同一性的轻链可变区;和(c)(a)中的重链可变区和(b)中的轻链可变区。
在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体是单克隆抗体。在某些实施方案中,该抗体是人,人源化,或嵌合抗体。在某些实施方案中,该抗体具有降低的效应器功能。
在另一个方面,本公开文本提供了一种分离的核酸,其编码本公开文本的FGFR2/3+KLB双特异性抗体。在某些实施方案中,本公开文本提供了一种宿主细胞,其包含编码本公开文本的FGFR2/3+KLB双特异性抗体的核酸。在某些实施方案中,本公开文本提供了一种生成FGFR2/3+KLB双特异性抗体的方法,其包括培养本公开文本的宿主细胞,使得该抗体生成。在某些实施方案中,此方法进一步包括自该宿主细胞回收该FGFR2/3+KLB双特异性抗体。
本公开文本进一步提供了一种药物配制剂,其包含一种或多种本发明的抗体和药学可接受载剂。具体而言,本公开文本提供了一种药物配制剂,其包含本文中描述的FGFR2/3+KLB双特异性抗体。在某些实施方案中,该药物配制剂包含另外的治疗剂。
在另一个方面,本公开文本提供了本发明的FGFR2/3+KLB双特异性抗体,其作为药物使用。在某些实施方案中,该抗KLB/抗FGFR1双特异性抗体在治疗代谢病症,例如多囊卵巢综合征(PCOS),代谢综合征(MetS),肥胖症,非酒精性脂肪性肝炎(NASH),非酒精性脂肪性肝病(NAFLD),高脂血症,高血压,2型糖尿病,非2型糖尿病,1型糖尿病,潜伏性自身免疫性糖尿病(LAD),和年轻人成熟期发作糖尿病(MODY)中使用。在某些实施方案中,FGFR2/3+KLB双特异性抗体在治疗2型糖尿病中使用。在某些实施方案中,FGFR2/3+KLB双特异性抗体在治疗肥胖症中使用。在某些实施方案中,本公开文本提供了FGFR2/3+KLB双特异性抗体,其在治疗巴尔得-别德尔综合征,普拉德-威利综合征,阿耳斯特雷姆综合征,科恩综合征,奥尔布赖特氏遗传性骨营养不良(假甲状旁腺功能减退症),木匠综合征,MOMO综合征,鲁宾斯坦-泰比综合征,脆弱X综合征和伯-福-莱三氏综合征中使用。在某些实施方案中,该FGFR2/3+KLB双特异性抗体在治疗NASH中使用。
在另一个方面,本公开文本提供了本文中公开的FGFR2/3+KLB双特异性抗体在制造用于治疗代谢病症,例如多囊卵巢综合征(PCOS),代谢综合征(MetS),肥胖症,非酒精性脂肪性肝炎(NASH),非酒精性脂肪性肝病(NAFLD),高脂血症,高血压,2型糖尿病,非2型糖尿病,1型糖尿病,潜伏性自身免疫性糖尿病(LAD),和年轻人成熟期发作糖尿病(MODY),和衰老及相关疾病诸如阿尔茨海默氏病,帕金森氏病和ALS的药物中的用途。在某些实施方案中,该代谢病症为2型糖尿病。在某些实施方案中,该代谢病症为NASH。
在另一个方面,本公开文本提供了治疗具有选自由多囊卵巢综合征(PCOS),代谢综合征(MetS),肥胖症,非酒精性脂肪性肝炎(NASH),非酒精性脂肪性肝病(NAFLD),高脂血症,高血压,2型糖尿病,非2型糖尿病,1型糖尿病,潜伏性自身免疫性糖尿病(LAD),和年轻人成熟期发作糖尿病(MODY),和衰老及相关疾病诸如阿尔茨海默氏病,帕金森氏病和ALS组成的组的疾病的个体的方法,该方法包括对该个体施用有效量的一种或多种本公开文本的FGFR2/3+KLB双特异性抗体。在某些实施方案中,该疾病为糖尿病,例如2型糖尿病。在某些实施方案中,该疾病为肥胖症。在某些实施方案中,本公开文本提供了治疗具有选自由巴尔得-别德尔综合征,普拉德-威利综合征,阿耳斯特雷姆综合征,科恩综合征,奥尔布赖特氏遗传性骨营养不良(假甲状旁腺功能减退症),木匠综合征,MOMO综合征,鲁宾斯坦-泰比综合征,脆弱X综合征和伯-福-莱三氏综合征组成的组的疾病和/或病症的个体的方法,该方法包括对该个体施用有效量的一种或多种本公开文本的FGFR2/3+KLB双特异性抗体。在某些实施方案中,该方法进一步包括将另外的治疗剂施用于该个体。在某些实施方案中,使用一种或多种本公开文本的FGFR2/3+KLB双特异性抗体的方法不影响个体中的肝功能。在某些实施方案中,本公开文本提供了用于诱导重量减轻的方法,其包括对个体施用有效量的一种或多种本公开文本的抗体。
在另一个实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体可作为药物使用且包括来自抗KLB抗体或其抗原结合部分的一个臂和本文中公开的FGFR2/3抗体一个臂,该抗KLB抗体或其抗原结合部分选自本文中或US20150218276(将其完整收入本文)中公开的抗KLB抗体任一。在具体的实施方案中,该能作为药物使用的FGFR2/3+KLB双特异性抗体的臂选自下述组合:
a)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:104(HCVR)和SEQ ID NO:105(LCVR))的一个臂和来自2B.1.3.12抗FGFR2/3抗体(包含SEQ ID NO:82(重链)和SEQ IDNO:66(轻链))的一个臂;
b)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:106(重链)和SEQ ID NO:107(轻链))的一个臂和来自2B.1.3.12抗FGFR2/3抗体(包含SEQ ID NO:82(重链)和SEQ IDNO:66(轻链))的一个臂;
c)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:104(HCVR)和SEQ ID NO:105(LCVR))的一个臂和来自2B.1.3.12抗FGFR2/3抗体(包含SEQ ID NO:7-9(CDRL1,CDRL2,和CDRL3)和SEQ ID NO:10-12(CDRH1,CDRH2,和CDRH3))的一个臂;
d)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:106(重链)和SEQ ID NO:107(轻链))的一个臂和来自2B.1.3.12抗FGFR2/3抗体(包含SEQ ID NO:7-9(CDRL1,CDRL2,和CDRL3)和SEQ ID NO:10-12(CDRH1,CDRH2,和CDRH3))的一个臂;
e)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:104(HCVR)和SEQ ID NO:105(LCVR))的一个臂和来自2B.1.1.6抗FGFR2/3抗体(包含SEQ ID NO:282(重链)和SEQ IDNO:283(轻链))的一个臂;
f)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:106(重链)和SEQ ID NO:107(轻链))的一个臂和来自2B.1.1.6抗FGFR2/3抗体(包含SEQ ID NO:282(重链)和SEQ IDNO:283(轻链))的一个臂;
g)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:104(HCVR)和SEQ ID NO:105(LCVR))的一个臂和来自2B.1.1.6抗FGFR2/3抗体(包含SEQ ID NO:276-278(CDRL1,CDRL2,和CDRL3)和SEQ ID NO:279-281(CDRH1,CDRH2,和CDRH3))的一个臂;和
h)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:106(重链)和SEQ ID NO:107(轻链))的一个臂和来自2B.1.1.6抗FGFR2/3抗体(包含SEQ ID NO:276-278(CDRL1,CDRL2,和CDRL3)和SEQ ID NO:279-281(CDRH1,CDRH2,和CDRH3))的一个臂。
在另一个实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体可用于治疗代谢疾病(例如NASH或相关疾病)且包括来自抗KLB抗体或其抗原结合部分的一个臂和本文中公开的FGFR2/3抗体的一个臂,该抗KLB抗体或其抗原结合部分选自本文中或US20150218276(将其完整收入本文)中公开的抗KLB抗体任一。在具体的实施方案中,该可用于治疗代谢疾病(例如NASH或相关疾病)的FGFR2/3+KLB双特异性抗体的臂选自下述组合:
a)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:104(HCVR)和SEQ ID NO:105(LCVR))的一个臂和来自2B.1.3.12抗FGFR2/3抗体(包含SEQ ID NO:82(重链)和SEQ IDNO:66(轻链))的一个臂;
b)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:106(重链)和SEQ ID NO:107(轻链))的一个臂和来自2B.1.3.12抗FGFR2/3抗体(包含SEQ ID NO:82(重链)和SEQ IDNO:66(轻链))的一个臂;
c)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:104(HCVR)和SEQ ID NO:105(LCVR))的一个臂和来自2B.1.3.12抗FGFR2/3抗体(包含SEQ ID NO:7-9(CDRL1,CDRL2,和CDRL3)和SEQ ID NO:10-12(CDRH1,CDRH2,和CDRH3))的一个臂;
d)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:106(重链)和SEQ ID NO:107(轻链))的一个臂和来自2B.1.3.12抗FGFR2/3抗体(包含SEQ ID NO:7-9(CDRL1,CDRL2,和CDRL3)和SEQ ID NO:10-12(CDRH1,CDRH2,和CDRH3))的一个臂;
e)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:104(HCVR)和SEQ ID NO:105(LCVR))的一个臂和来自2B.1.1.6抗FGFR2/3抗体(包含SEQ ID NO:282(重链)和SEQ IDNO:283(轻链))的一个臂;
f)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:106(重链)和SEQ ID NO:107(轻链))的一个臂和来自2B.1.1.6抗FGFR2/3抗体(包含SEQ ID NO:282(重链)和SEQ IDNO:283(轻链))的一个臂;
g)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:104(HCVR)和SEQ ID NO:105(LCVR))的一个臂和来自2B.1.1.6抗FGFR2/3抗体(包含SEQ ID NO:276-278(CDRL1,CDRL2,和CDRL3)和SEQ ID NO:279-281(CDRH1,CDRH2,和CDRH3))的一个臂;和
h)来自8C5.K4.M4L.H3.KNV抗KLB抗体(包含SEQ ID NO:106(重链)和SEQ ID NO:107(轻链))的一个臂和来自2B.1.1.6抗FGFR2/3抗体(包含SEQ ID NO:276-278(CDRL1,CDRL2,和CDRL3)和SEQ ID NO:279-281(CDRH1,CDRH2,和CDRH3))的一个臂。
附图简述
图1显示改造的2B.1抗体对FGF7刺激的MCF-7细胞增殖的抑制效果。误差棒代表SEM。
图2A-2C显示FGFR2D2域和Mab 2B.1.3的Fab片段之间的复合物的晶体结构。图2A显示复合物的总体结构。FGFR2-D2着色为品红色,Fab 2B.1.3的重链绿色而轻链蓝色。图2B显示FGFR2-D2:2B.1.3和FGFR3-D2D3:R3Mab的结构的覆盖图。前一种复合物着色与图2A相同。FGFR3-D2D3着色为黄色,而R3Mab灰色。图2C显示图2B中带框区域的放大呈现,显示两种复合物之间的结构差异。着色方案与图2B相同。
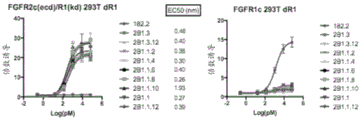
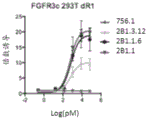
图3A-3D显示R3Mab变体对FGF配体的差异阻断。图3A显示阻断FGF-7结合人FGFR2-IIIb。图3B显示阻断FGF-1结合人FGFR2-IIIc。图3C显示阻断FGF-1结合人FGFR3-IIIb。图3D显示阻断FGF-1结合人FGFR3-IIIc。图3E显示阻断FGF-19结合人FGFR4。
图4A-4C显示2B.1变体在体外抑制FGFR2信号传导且在体内阻抑异种移植物生长。图4A显示胃癌细胞系SNU-16中2B.1变体阻断FGF7刺激的FGFR2信号传导。图4B显示2B.1.3.10和2B.1.3.12对FGFR2依赖性SNU-16异种移植物的生长的影响,与对照抗体比较。图4C显示2B.1.3.10和2B.1.3.12对FGFR3依赖性RT112膀胱癌异种移植物的生长的影响。
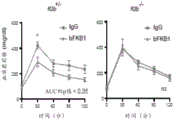
图5显示FGFR3-IIIb上受到R3Mab接触的表面区域(PDB 3GRW)。FGFR3-IIIb的D2和D3域的表面以灰色显示。R3Mab的个别CDR环的接触区域着色。每个CDR的接触面积和它们占总体接触面积的百分比以括弧中的数字标注。
图6显示使用Weblogo 3(Crooks,G.E.,G.Hon,J.M.Chandonia and S.E.Brenner(2004)."WebLogo:a sequence logo generator."Genome Res 14(6):1188-1190)制备的自噬菌体文库为结合FGFR2-IIIb选择的CDR H2的序列标识。
图7显示FGFR2-D2:2B.1.3和FGFR3-D2D3:R3Mab的复合物的总体结构比对。
图8A显示乳腺癌细胞系MFM-223x2.2中2B.1变体阻断FGF7刺激的FGFR2信号传导。图8B显示2B.1.3.10和2B.1.3.12对FGFR2依赖性MFM-223x2.2乳腺癌异种移植物的生长的影响。实验中的小鼠显示雌激素毒性。n=10只每组;误差棒代表SEM。
图9A-9D显示2B.1.3.10(即1.3.10)和2B.1.3.12(即1.3.12)抗FGFR2/3抗体的表位。图9A显示FGFR2-IIIb序列,抗FGFR2/3 1.3.10和1.3.12抗体的表位为下划线和粗体。图9B显示FGFR2-IIIc序列,抗FGFR2/3 1.3.10和1.3.12抗体的表位为下划线和粗体。图9C显示FGFR3-IIIb序列,抗FGFR2/3 1.3.10和1.3.12抗体的表位为下划线和粗体。图9D显示FGFR3-IIIc序列,抗FGFR2/3 1.3.10和1.3.12抗体的表位为下划线和粗体。抗体2B.1.3.10结合FGFR2上由依照SEQ ID NO:52和54的残基编号157-181和207-220的两条β链构成的表位(表位序列还见SEQ ID NO:91和92)。抗体2B.1.3.10还结合FGFR3上由依照SEQ ID NO:56和58的残基编号154-178和204-217的两条β链构成的表位(表位序列还见SEQ ID NO:93和94)。2B.1.3.12与2B.1.3.10结合相同表位。特别是,2B.1.3.12结合FGFR2上由残基编号157-181和207-220的两条β链构成的表位。2B.1.3.12还结合FGFR3上由残基编号154-178和204-217的两条β链构成的表位。
图10显示与抗FGFR2/3抗体1.3,1.95,1.73,1.32,1.88,1.1,1.3.10,和1.3.12对应的核酸和氨基酸SEQ ID NO的图表。
图11A描绘17种抗KLB抗体的轻链可变区序列。CDR L1序列依次为SEQ ID NO:279-293;CDR L2序列依次为SEQ ID NO:294-309;而CDH L3序列依次为SEQ ID NO:123-137。轻链可变区序列依次为SEQ ID NO:111-127。图11B描绘17种抗KLB抗体的重链可变区序列。抗体的CDR H1序列依次(11F1-8C5)为SEQ ID NO:230-232和236-247;CDR H2序列依次为SEQID NO:142和248-262;CDR H3序列依次为SEQ ID NO:263-278。抗体的重链可变区序列依次为SEQ ID NO:216-232。
图12描绘在以0.8μg/ml测量多种抗KLB抗体对表达hKLB的293细胞的结合的FACS图中观察到的中值位移。
图13描绘多种抗KLB抗体对hKLB-ECD-HIS蛋白质的相对结合。
图14A显示小鼠KLB蛋白质的N端氨基酸序列(SEQ ID NO:165),而且显示由KO小鼠中的Klb等位基因编码的相应氨基酸序列(SEQ ID NO:166)。Klb基因中的一处错义突变导致KO等位基因中第二个氨基酸之后的移码,如以红色字母显示的。图14B显示野生型(+/+)和KLB敲除(-/-)小鼠中的附睾白色脂肪组织中的KLB蛋白质表达。图14C显示KLB对于BsAb20影响葡萄糖代谢是重要的。以3mpk接受4次每周注射BsAb20或对照IgG的DIO小鼠中的葡萄糖耐受测试(GTT)。在第23天,最后一次注射后3天,进行GTT。在GTT之前小鼠处于HFD达20周。*p<0.05。
图15A和15B显示SNU-16异种移植物肿瘤中人FGFR2(图15A)和FGFR3(图15B)的检测。裂解肿瘤样品并提交针对人FGFR2和FGFR3蛋白质的Western印迹分析。自当前研究收集的肿瘤显示FGFR3的信号(图15B,5-24道)。另外,自先前SNU-16研究收集的肿瘤(图15B,3道)和体外培养的SNU-16细胞(图B,4道)也显示可检测但更弱的FGFR3表达。
图16A-16C显示表达并测试激动剂活性和FGFR2,FGFR3,和FGFR4结合的7种2B1.1变体。图16A显示详述抗FGFR2/3抗体变体,每种变体的CDRH1-H3的序列,和通过Biacor测定法和ELISA测量的FGFR3亲和力的图表。图16B显示变体对FGFR3的结合亲和力,如通过ELISA测量的。图16C显示变体对FGFR4的结合亲和力,如通过ELISA测量的。
图17A和17B显示抗FGFR2/3抗体变体针对FGFR的活性的比较,使用萤光素酶测定法。图17A显示FGFR3和FGFR4活性。图17B显示FGFR2和FGFR1活性。
图18显示用于选择哪些抗FGFR2/3抗体应当用于FGFGR2/3+KLB双特异性抗体的抗FGFR2/3抗体变体决策矩阵。
图19A-19C显示选定的抗FGFR2/3抗体变体的FGFR活性。图19A显示FGFR3活性。图19B显示FGFR2活性。图19C显示FGFR4活性。
发明详述
成纤维细胞生长因子(FGF)及其酪氨酸激酶受体(FGFR)在调节胚胎发育期间的特定途径,以及成年动物中的多种多样组织的稳态,伤口愈合过程和某些代谢功能中发挥关键作用。在人中,有4种高度同源的FGFR(FGFR1-4)和22种FGF(FGF1-14和FGF16-23)(GoetzR&Mohammadi M(2013)Exploring mechanisms of FGF signalling through the lens ofstructural biology.Nat Rev Mol Cell Biol 14(3):166-180;Turner N&Grose R(2010)Fibroblast growth factor signalling:from development to cancer.Nat RevCancer10(2):116-129;Beenken A&Mohammadi M(2009)The FGF family:biology,pathophysiology and therapy.Nat Rev Drug Discov 8(3):235-253;Wesche J,HaglundK,&Haugsten EM(2011)Fibroblast growth factors and their receptors incancer.Biochem J 437(2):199-213)。FGFR包含胞外区(其具有3个免疫球蛋白域(D1,D2和D3)),单次跨膜区和分裂胞质激酶模块(Goetz R&Mohammadi M(2013)Exploringmechanisms of FGF signalling through the lens of structural biology.Nat RevMol Cell Biol 14(3):166-180;Mohammadi M,Olsen SK,&Ibrahimi OA(2005)Structuralbasis for fibroblast growth factor receptor activation.Cytokine Growth FactorRev 16(2):107-137)。可变剪接产生FGFR 1-3的两种主要变体,称作同种型IIIb和IIIc,它们的区别在于第二半D3及继而配体结合特异性(Chang,H.,Stewart,A.K.,Qi,X.Y.,Li,Z.H.,Yi,Q.L.,and Trudel,S.2005.Immunohistochemistry accurately predicts FGFR3aberrant expression and t(4;14)in multiple myeloma.Blood 106:353-355)。
失调的FGFR 1-4信号传导与数种癌症类型中的发病机理有关(L′Hote,C.G.,andKnowles,M.A.2005.Cell responses to FGFR3signalling:growth,differentiation andapoptosis.Exp Cell Res 304:417-431;Dailey,L.,Ambrosetti,D.,Mansukhani,A.,andBasilico,C.2005.Mechanisms underlying differential responses to FGFsignaling.Cytokine Growth Factor Rev 16:233-247)。基因组FGFR改变(包括基因扩增,染色体易位和活化性突变)能驱动FGF途径的异常活化及促进正常细胞的致瘤转化。在约10%的胃和约4%的三重阴性乳腺癌中发生FGFR2基因扩增(Chesi,M.,Nardini,E.,Brents,L.A.,Schrock,E.,Ried,T.,Kuehl,W.M.,and Bergsagel,P.L.1997.Frequenttranslocation t(4;14)(p16.3;q32.3)in multiple myeloma is associated withincreased expression and activating mutations of fibroblast growth factorreceptor 3.Nat Genet 16:260-264;Fonseca,R.,Blood,E.,Rue,M.,Harrington,D.,Oken,M.M.,Kyle,R.A.,Dewald,G.W.,Van Ness,B.,Van Wier,S.A.,Henderson,K.J.,etal.2003.Clinical and biologic implications of recurrent genomic aberrationsin myeloma.Blood 101:4569-4575;Moreau,P.,Facon,T.,Leleu,X.,Morineau,N.,Huyghe,P.,Harousseau,J.L.,Bataille,R.,and Avet-Loiseau,H.2002.Recurrent 14q32translocations determine the prognosis of multiple myeloma,especially inpatients receiving intensive chemotherapy.Blood 100:1579-1583),而FGFR3扩增与膀胱癌的特定子集有关(Moreau,P.,Facon,T.,Leleu,X.,Morineau,N.,Huyghe,P.,Harousseau,J.L.,Bataille,R.,and Avet-Loiseau,H.2002.Recurrent 14q32translocations determine the prognosis of multiple myeloma,especially inpatients receiving intensive chemotherapy.Blood 100:1579-1583;Pollett,J.B.,Trudel,S.,Stern,D.,Li,Z.H.,and Stewart,A.K.2002.Overexpression of themyeloma-associated oncogene fibroblast growth factor receptor 3 confersdexamethasone resistance.Blood 100:3819-3821)。错义FGFR突变也见于多种类型的癌症(L′Hote,C.G.,and Knowles,M.A.2005.Cell responses to FGFR3 signalling:growth,differentiation and apoptosis.Exp Cell Res 304:417-431;Agazie,Y.M.,Movilla,N.,Ischenko,I.,and Hayman,M.J.2003.The phosphotyrosine phosphataseSHP2 is a critical mediator of transformation induced by the oncogenicfibroblast growth factor receptor 3.Oncogene 22:6909-6918)。具体而言,D2和D3之间的接头区中的氨基酸替代,例如FGFR2中的S252W和FGFR3中的S249C,提升FGF驱动的信号传导和肿瘤细胞增殖并代表体细胞突变的热点(Agazie,Y.M.,Movilla,N.,Ischenko,I.,and Hayman,M.J.2003.The phosphotyrosine phosphatase SHP2 is a criticalmediator of transformation induced by the oncogenic fibroblast growth factorreceptor 3.Oncogene 22:6909-6918;Ronchetti,D.,Greco,A.,Compasso,S.,Colombo,G.,Dell′Era,P.,Otsuki,T.,Lombardi,L.,and Neri,A.2001.Deregulated FGFR3mutants in multiple myeloma cell lines with t(4;14):comparative analysis ofY373C,K650E and the novel G384D mutations.Oncogene 20:3553-3562)。活化性突变也在FGFR的酪氨酸激酶区中发生(Chesi,M.,Brents,L.A.,Ely,S.A.,Bais,C.,Robbiani,D.F.,Mesri,E.A.,Kuehl,W.M.,and Bergsagel,P.L.2001.Activated fibroblast growthfactor receptor 3 is an oncogene that contributes to tumor progression inmultiple myeloma.Blood 97:729-736)。
靶向FGF-FGFR途径是癌症药物开发的一个主要焦点区域。这种努力包括小分子酪氨酸激酶抑制剂(TKI),阻断性抗体,以及配体陷阱(Moreau,P.,Facon,T.,Leleu,X.,Morineau,N.,Huyghe,P.,Harousseau,J.L.,Bataille,R.,and Avet-Loiseau,H.2002.Recurrent 14q32 translocations determine the prognosis of multiplemyeloma,especially in patients receiving intensive chemotherapy.Blood 100:1579-1583)。当前的高效能FGFR TKI对不同FGFR具有有限的选择性(Moreau,P.,Facon,T.,Leleu,X.,Morineau,N.,Huyghe,P.,Harousseau,J.L.,Bataille,R.,and Avet-Loiseau,H.2002.Recurrent 14q32 translocations determine the prognosis of multiplemyeloma,especially in patients receiving intensive chemotherapy.Blood 100:1579-1583),这可能影响它们的治疗窗。例如,经由FGFR1和共同受体Klothoβ的异源复合物的FGF23信号传导的破坏能在患者中导致高磷血症和组织钙化(Plowright,E.E.,Li,Z.,Bergsagel,P.L.,Chesi,M.,Barber,D.L.,Branch,D.R.,Hawley,R.G.,and Stewart,A.K.2000.Ectopic expression of fibroblast growth factor receptor 3 promotesmyeloma cell proliferation and prevents apoptosis.Blood 95:992-998;Chen,J.,Williams,I.R.,Lee,B.H.,Duclos,N.,Huntly,B.J.,Donoghue,D.J.,and Gilliland,D.G.2005.Constitutively activated FGFR3 mutants signal through PLCgamma-dependent and -independent pathways for hematopoietic transformation.Blood106:328-337),而经由FGFR4与Klothoβ的异源复合物的FGF19信号传导的阻断能破坏胆汁酸代谢(Li,Z.,Zhu,Y.X.,Plowright,E.E.,Bergsagel,P.L.,Chesi,M.,Patterson,B.,Hawley,T.S.,Hawley,R.G.,and Stewart,A.K.2001.The myeloma-associated oncogenefibroblast growth factor receptor 3 is transforming in hematopoieticcells.Blood 97:2413-2419)。已经开发了更多选择性抗体来拮抗经由个别FGFR(包括FGFR1(Trudel,S.,Ely,S.,Farooqi,Y.,Affer,M.,Robbiani,D.F.,Chesi,M.,andBergsagel,P.L.2004.Inhibition of fibroblast growth factor receptor 3 inducesdifferentiation and apoptosis in t(4;14)myeloma.Blood 103:3521-3528),FGFR2(Trudel,S.,Li,Z.H.,Wei,E.,Wiesmann,M.,Chang,H.,Chen,C.,Reece,D.,Heise,C.,andStewart,A.K.2005.CHIR-258,a novel,multitargeted tyrosine kinase inhibitor forthe potential treatment of t(4;14)multiple myeloma.Blood 105:2941-2948)和FGFR3(Chen,J.,Lee,B.H.,Williams,I.R.,Kutok,J.L.,Mitsiades,C.S.,Duclos,N.,Cohen,S.,Adelsperger,J.,Okabe,R.,Coburn,A.,et al.2005.FGFR3as a therapeutictarget of the small molecule inhibitor PKC412in hematopoieticmalignancies.Oncogene 24:8259-8267))的配体信号传导。然而,识别超过一种FGFR的抗体至今尚无报告。
先前描述的单特异性抗FGFR3抗体R3Mab有效阻断FGF1和FGF9对野生型FGFR3的IIIb和IIIc同种型二者,以及对FGFR3的某些癌症相关突变体形式的结合(Chen,J.,Lee,B.H.,Williams,I.R.,Kutok,J.L.,Mitsiades,C.S.,Duclos,N.,Cohen,S.,Adelsperger,J.,Okabe,R.,Coburn,A.,et al.2005.FGFR3 as a therapeutic target of the smallmolecule inhibitor PKC412 in hematopoietic malignancies.Oncogene 24:8259-8267;Paterson,J.L.,Li,Z.,Wen,X.Y.,Masih-Khan,E.,Chang,H.,Pollett,J.B.,Trudel,S.,and Stewart,A.K.2004.Preclinical studies of fibroblast growth factorreceptor 3 as a therapeutic target in multiple myeloma.Br J Haematol 124:595-603)。X射线结构分析揭示R3Mab结合FGFR3上的特定表位,它是配体结合所需要的。R3Mab在小鼠中针对人膀胱癌和多发性骨髓瘤肿瘤异种移植物展示有力的抗肿瘤活性。在本研究中,反复使用结构指导的噬菌体展示将R3Mab再改造成携带针对FGFR3和FGFR2而舍弃FGFR1和FGFR4的双重特异性的衍生抗体。此研究的实际目标是拓宽潜在治疗范围,超出亲本分子的治疗范围,同时避免增加安全性风险。再改造的抗体展示在体外对FGF刺激的肿瘤细胞生长的抑制和在体内针对过表达FGFR2或FGFR3的人癌异种移植物的显著功效。
本文中的发明提供了抗FGFR2/3抗体,其对于例如与FGFR2和/或FGFR3的表达和/或活性(诸如升高的表达和/或活性或不想要的表达和/或活性)有关的疾病状态的治疗或预防是有用的。在具体的实施方案中,本文中的发明提供了抗FGFR2/3抗体,其对于例如与FGFR2和FGFR3的表达和/或活性(诸如升高的表达和/或活性或不想要的表达和/或活性)有关的疾病状态的治疗或预防是有用的。在一些实施方案中,本发明的抗体用于治疗肿瘤,癌症,和/或细胞增殖性病症。
在另一个方面,本发明的抗FGFR2/3抗体作为用于FGFR2和/或FGFR3的检测和/或分离,诸如各种组织和细胞类型中FGFR3的检测的试剂找到了效用。在具体的实施方案中,本发明的抗FGFR2/3抗体作为用于FGFR2和FGFR3的检测和/或分离,诸如各种组织和细胞类型中FGFR2和FGFR3的检测的试剂找到了效用。
本发明进一步提供了制备和使用抗FGFR2/3抗体的方法,及编码抗FGFR2/3抗体的多核苷酸。
通用技术
本文中描述或提到的技术和规程一般得到了本领域技术人员的充分理解,而且通常利用常规方法得以采用,诸如例如下列文献中记载的广泛应用的方法:Sambrook etal.,Molecular Cloning:A Laboratory Manual 3rd.edition(2001)Cold Spring HarborLaboratory Press,Cold Spring Harbor,N.Y;CURRENT PROTOCOLS IN MOLECULARBIOLOGY(F.M.Ausubel,et al.eds.,(2003));丛书METHODS IN ENZYMOLOGY(AcademicPress,Inc.):PCR 2:A PRACTICAL APPROACH(M.J.MacPherson,B.D.Hames andG.R.Taylor eds.(1995));Harlow and Lane,eds.(1988)ANTIBODIES,A LABORATORYMANUAL;及ANIMAL CELL CULTURE(R.I.Freshney,ed.(1987))。
定义
“分离的”抗体指已经鉴定且自其天然环境的成分分开和/或回收的抗体。其天然环境的污染性成分指会干扰该抗体的诊断或治疗用途的物质,可包括酶,激素,和其它蛋白质性质或非蛋白质性质的溶质。在优选的实施方案中,将抗体纯化至(1)根据Lowry法的测定,抗体重量超过95%,最优选重量超过99%,(2)足以通过使用转杯式测序仪获得至少15个残基的N-末端或内部氨基酸序列的程度,或(3)根据还原性或非还原性条件下的SDS-PAGE(十二烷基硫酸钠聚丙烯酰胺凝胶电泳)及使用Coomassie蓝或优选的银染色,达到同质。既然抗体天然环境的至少一种成分不会存在,那么分离的抗体包括重组细胞内的原位抗体。然而,分离的抗体通常将通过至少一个纯化步骤来制备。
与参照抗体“竞争结合的抗体”指在竞争测定法中将参照抗体对其抗原的结合阻断50%或更多的抗体,且相反,参照抗体在竞争测定法中将该抗体对其抗原的结合阻断50%或更多。一种例示性的竞争测定法描述于“Antibodies,”Harlow and Lane(ColdSpring Harbor Press,Cold Spring Harbor,NY)。
抗体的“类”指其重链拥有的恒定域或恒定区的类型。抗体有5大类:IgA,IgD,IgE,IgG,和IgM,并且这些中的几种可以进一步分成亚类(同种型),例如,IgG1,IgG2,IgG3,IgG4,IgA1,和IgA2。与不同类免疫球蛋白对应的重链恒定域分别称作α,δ,ε,γ,和μ。
如本文中使用的,术语“细胞毒剂”指抑制或阻止细胞功能和/或引起细胞死亡或破坏的物质。细胞毒剂包括但不限于:放射性同位素(例如At211,I131,I125,Y90,Re186,Re188,Sm153,Bi212,P32,Pb212和Lu的放射性同位素);化学治疗剂或药物(例如甲氨蝶呤(methotrexate),阿霉素(adriamicin),长春花生物碱类(vinca alkaloids)(长春新碱(vincristine),长春碱(vinblastine),依托泊苷(etoposide)),多柔比星(doxorubicin),美法仑(melphalan),丝裂霉素(mitomycin)C,苯丁酸氮芥(chlorambucil),柔红霉素(daunorubicin)或其它嵌入剂);生长抑制剂;酶及其片段,诸如溶核酶;抗生素;毒素,诸如小分子毒素或者细菌,真菌,植物或动物起源的酶活性毒素,包括其片段和/或变体;及下文公开的各种抗肿瘤或抗癌剂。
药剂(例如药物配制剂)的“有效量”指在必需的剂量和时段上有效实现期望的治疗或预防结果的量。例如,而且并非为了限制,“有效量”可以指本文中公开的抗体能够减轻,最小化和/或预防疾病和/或病症的症状,延长存活和/或延长疾病和/或病症复发前的时段的量。
术语“全长抗体”,“完整抗体”,和“全抗体”在本文中可互换使用,指与天然抗体结构具有基本上类似的结构或者具有含有如本文中所限定的Fc区的重链的抗体。
如本文中可互换使用的,术语“宿主细胞”,“宿主细胞系”,和“宿主细胞培养物”指已经导入外源核酸的细胞,包括此类细胞的后代。宿主细胞包括“转化体”和“经转化的细胞”,其包括原代的经转化的细胞及自其衍生的后代而不考虑传代的次数。后代在核酸内容物上可以与亲本细胞不完全相同,而是可以含有突变。本文中包括具有与在初始转化细胞中筛选或选择的相同功能或生物学活性的突变体后代。
如本文中可互换使用的,“个体”或“受试者”是哺乳动物。哺乳动物包括但不限于驯养的动物(例如,牛,绵羊,猫,犬,和马),灵长类(例如,人和非人灵长类诸如猴),家兔,和啮齿类(例如,小鼠和大鼠)。在某些实施方案中,个体或受试者是人。
在用于本文时,术语“单克隆抗体”指从一群基本上同质的抗体获得的抗体,即构成群体的各个抗体是相同的和/或结合相同表位,除了例如含有天然存在的突变或在单克隆抗体制备物的生成期间发生的可能的变体抗体外,此类变体一般以极小量存在。与通常包含针对不同决定簇(表位)的不同抗体的多克隆抗体制备物不同,单克隆抗体制备物的每种单克隆抗体针对抗原上的单一决定簇。如此,修饰语“单克隆”指示抗体自一群基本上同质的抗体获得的特性,而不应解释为要求通过任何特定方法来生成抗体。例如,可以通过多种技术来生成要依照当前公开的主题使用的单克隆抗体,包括但不限于杂交瘤方法,重组DNA方法,噬菌体展示方法,和利用含有所有或部分人免疫球蛋白基因座的转基因动物的方法,本文中描述了用于生成单克隆抗体的此类方法和其它例示性方法。
“裸抗体”指未与异源模块(例如细胞毒性模块)或放射性标记物缀合的抗体。裸抗体可以存在于药物配制剂中。
“天然抗体”指具有不同结构的天然存在的免疫球蛋白分子。例如,天然IgG抗体是约150,000道尔顿的异四聚糖蛋白,由二硫化物键合的两条相同轻链和两条相同重链构成。从N至C端,每条重链具有一个可变区(VH),又称作可变重域或重链可变域,接着是三个恒定域(CH1,CH2,和CH3)。类似地,从N至C端,每条轻链具有一个可变区(VL),又称作可变轻域或轻链可变域,接着是一个恒定轻(CL)域。根据其恒定域氨基酸序列,抗体轻链可归入两种类型中的一种,称作卡帕(κ)和拉姆达(λ)。
如本文中使用的,术语“包装插页”指治疗产品的商业包装中通常包含的用法说明书,其含有关于涉及此类治疗产品应用的适应症,用法,剂量,施用,联合疗法,禁忌症和/或警告的信息。
“分离的”核酸分子指已经鉴定且与核酸的天然来源中通常与之关联的至少一种污染性核酸分子分开的核酸分子。分离的核酸分子不同于在自然界中发现它时的形式或背景。分离的核酸分子因此与存在于天然细胞中时的核酸分子有区别。然而,分离的核酸分子包括通常表达该核酸(例如抗体编码核酸)的细胞中所包含的核酸分子,例如当所述核酸分子在所述细胞中的染色体定位不同于它在天然细胞中的染色体定位时。
“编码抗体的分离的核酸”(包括提到具体抗体,例如抗KLB抗体)指编码抗体重和轻链(或其片段)的一种或多种核酸分子,包括单一载体或不同载体中的此类核酸分子,和存在于宿主细胞中的一个或多个位置的此类核酸分子。
术语“依照Kabat的可变域残基编号方式”或“依照Kabat的氨基酸位置编号方式”及其变体指Kabat等,Sequences of Proteins of Immunological Interest,第5版PublicHealth Service,National Institutes of Health,Bethesda,MD.(1991)中的抗体编辑用于重链可变域或轻链可变域的编号系统。使用此编号系统,实际的线性氨基酸序列可包含较少或另外的氨基酸,对应于可变域FR或CDR的缩短或插入。例如,重链可变域可包含H2残基52后的单一氨基酸插入(依照Kabat为残基52a)及重链FR残基82后的插入残基(例如依照Kabat为残基82a,82b和82c等)。给定抗体的Kabat残基编号方式可通过将抗体序列与“标准”Kabat编号序列比对同源区来确定。
短语“基本上相似”或“基本上相同”在用于本文时表示两个数值(通常一个涉及本发明的抗体而另一个涉及参照/比较抗体)之间足够高的相似程度,以致本领域技术人员将认为在用所述数值(例如Kd值)所测量的生物学特性背景内两个数值之间的差异具有很小的或没有生物学和/或统计学显著性。作为参照/比较抗体该数值的函数,所述两个数值之间的差异优选小于约50%,优选小于约40%,优选小于约30%,优选小于约20%,或优选小于约10%。
“结合亲和力”通常指分子(例如抗体)的单一结合位点与其结合配偶体(例如抗原)之间全部非共价相互作用总和的强度。除非另有说明,在用于本文时,“结合亲和力”指反映结合对的成员(例如抗体与抗原)之间1:1相互作用的内在结合亲和力。分子X对其配偶体Y的亲和力通常可用解离常数(Kd)来表述。希望Kd是1x 10-7,1x 10-8,5x 10-8,1x 10-9,3x10-9,5x 10-9,或甚至1x 10-10或更高亲和力。亲和力可通过本领域知道的常用方法来测量,包括本文中所描述的那些。低亲和力抗体通常缓慢地结合抗原且趋于容易解离,而高亲和力抗体通常更快速地结合抗原且趋于保持更长时间的结合。本领域知道测量结合亲和力的多种方法,其中任一种都可用于本发明的目的。下文描述了具体的示例性实施方案。
在一个实施方案中,依照本发明的“Kd”或“Kd值”是通过如下测定法所述使用Fab型式的感兴趣抗体及其抗原进行的放射性标记抗原结合测定法(RIA)来测量的:通过在存在未标记抗原的滴定系列的条件下,用最小浓度的125I标记抗原平衡Fab,然后用抗Fab抗体包被的平板捕捉结合的抗原来测量Fab对抗原的溶液结合亲和力(Chen等,J Mol Biol293:865-881(1999))。为了确定测定条件,用50mM碳酸钠(pH 9.6)中的5μg/ml捕捉用抗Fab抗体(Cappel Labs)包被微量滴定板(Dynex)过夜,随后用PBS中的2%(w/v)牛血清白蛋白在室温(约23℃)封闭2-5小时。在非吸附平板(Nunc#269620)中,将100pM或26pM[125I]-抗原与连续稀释的感兴趣Fab混合(例如与Presta等,Cancer Res.57:4593-4599(1997)中抗VEGF抗体,Fab-12的评估一致)。然后将感兴趣Fab保温过夜;不过,保温可持续更长时间(例如65个小时)以保证达到平衡。此后,将混合物转移至捕捉板以进行室温保温(例如1小时)。然后除去溶液,并用含0.1% Tween-20的PBS洗板8次。平板干燥后,加入150μl/孔闪烁液(MicroScint-20;Packard),然后在Topcount伽马计数器(Packard)上对平板计数10分钟。选择各Fab给出小于或等于最大结合之20%的浓度用于竞争性结合测定法。依照另一实施方案,Kd或Kd值是通过表面等离振子共振测定法使用BIAcoreTM-2000或BIAcoreTM-3000(BIAcore,Inc.,Piscataway,NJ)在25℃使用固定化抗原CM5芯片在约10个响应单位(RU)测量的。简而言之,依照供应商的说明书用盐酸N-乙基-N’-(3-二甲基氨基丙基)-碳二亚胺(EDC)和N-羟基琥珀酰亚胺(NHS)活化羧甲基化右旋糖苷生物传感器芯片(CM5,BIAcoreInc.)。用10mM乙酸钠pH 4.8将抗原稀释至5μg/ml(约0.2μM),然后以5μl/分钟的流速注入至获得约10个响应单位(RU)的偶联的蛋白质。注入抗原后,注入1M乙醇胺以封闭未反应基团。为了进行动力学测量,在25℃以约25μl/分钟的流速注入在含0.05%Tween 20的PBS(PBST)中两倍连续稀释的Fab(0.78nM至500nM)。在一些实施方案中,对表面等离振子共振测定法使用下述修改:将抗体固定化至CM5生物传感器芯片以实现大约400RU,并为了动力学测量,以约30ul/min的流速注射靶蛋白(例如FGFR3-IIIb或-IIIc)在25℃的PBST缓冲液中的两倍连续稀释液(始于67nM)。使用简单一对一朗格缪尔(Langmuir)结合模型(BIAcoreEvaluation Software 3.2版)通过同时拟合结合和解离传感图计算结合速率(kon)和解离速率(koff)。平衡解离常数(Kd)以比率koff/kon计算。参见例如Chen,Y.等,J Mol Biol 293:865-881(1999)。如果根据上文表面等离振子共振测定法,结合速率超过106M-1S-1,那么结合速率可使用荧光淬灭技术来测定,即根据分光计诸如配备了断流装置的分光光度计(astop-flow equipped spectrophometer)(Aviv Instruments)或8000系列SLM-Aminco分光光度计(ThermoSpectronic)中用搅拌比色杯的测量,在存在浓度渐增的抗原的条件下,测量PBS,pH 7.2中的20nM抗抗原抗体(Fab形式)在25℃的荧光发射强度(激发=295nm;发射=340nm,16nm带通)的升高或降低。
依照本发明的“结合速率”(on-rate,rate of association,association rate)或“kon”也可通过上文所述相同的表面等离振子共振技术使用BIAcoreTM-2000或BIAcoreTM-3000(BIAcore,Inc.,Piscataway,NJ)在25℃使用固定化抗原CM5芯片在约10个响应单位(RU)来测定。简而言之,依照供应商的说明书用盐酸N-乙基-N’-(3-二甲基氨基丙基)-碳二亚胺(EDC)和N-羟基琥珀酰亚胺(NHS)活化羧甲基化右旋糖苷生物传感器芯片(CM5,BIAcore Inc.)。用10mM乙酸钠pH 4.8将抗原稀释至5μg/ml(约0.2μM),然后以5μl/分钟的流速注入至获得约10个响应单位(RU)的偶联蛋白质。注入抗原后,注入1M乙醇胺以封闭未反应基团。为了进行动力学测量,在25℃以约25μl/分钟的流速注入在含0.05%Tween 20的PBS(PBST)中两倍连续稀释的Fab(0.78nM至500nM)。在一些实施方案中,对表面等离振子共振测定法使用下述修改:将抗体固定化至CM5生物传感器芯片以实现大约400RU,并为了动力学测量,以约30ul/min的流速注射靶蛋白(例如FGFR3-IIIb或-IIIc)在25℃的PBST缓冲液中的两倍连续稀释液(始于67nM)。使用简单一对一朗格缪尔(Langmuir)结合模型(BIAcore Evaluation Software 3.2版)通过同时拟合结合和解离传感图计算结合速率(kon)和解离速率(koff)。平衡解离常数(Kd)以比率koff/kon计算。参见例如Chen,Y.等,J MolBiol 293:865-881(1999)。然而,如果根据上文表面等离振子共振测定法,结合速率超过106M-1S-1,那么结合速率优选使用荧光淬灭技术来测定,即根据分光计诸如配备了断流装置的分光光度计(Aviv Instruments)或8000系列SLM-Aminco分光光度计(ThermoSpectronic)中用搅拌比色杯的测量,在存在浓度渐增的抗原的条件下,测量PBS,pH7.2中的20nM抗抗原抗体(Fab形式)在25℃的荧光发射强度(激发=295nm;发射=340nm,16nm带通)的升高或降低。
术语“载体”在用于本文时意指能够运输与其连接的其它核酸的核酸分子。一类载体是“质粒”,指其中可连接另外的DNA区段的环状双链DNA环。另一类载体是噬菌体载体。另一类载体是病毒载体,其中可将另外的DNA区段连接到病毒基因组中。某些载体能够在其所导入的宿主细胞中自主复制(例如具有细菌复制起点的细菌载体和附加型哺乳动物载体)。其它载体(例如非附加型哺乳动物载体)可在导入宿主细胞后整合到宿主细胞的基因组中,由此随着宿主基因组一起复制。此外,某些载体能够指导与其可操作连接的基因表达。此类载体在本文中称为“重组表达载体”(或简称为“重组载体”)。通常,在重组DNA技术中有用的表达载体常常是质粒形式。在本说明书中,“质粒”和“载体”可互换使用,因为质粒是载体的最常用形式。
“多核苷酸”或“核酸”在本文中可互换使用,指任何长度的核苷酸聚合物,包括DNA和RNA。核苷酸可以是脱氧核糖核苷酸,核糖核苷酸,经过修饰的核苷酸或碱基,和/或其类似物,或者是可通过DNA或RNA聚合酶或者通过合成反应掺入聚合物的任何底物。多核苷酸可包含经过修饰的核苷酸,诸如甲基化核苷酸及其类似物。如果有的话,对核苷酸结构的修饰可以在装配聚合物之前或之后进行。核苷酸序列可以由非核苷酸组分中断。多核苷酸可以在合成后进一步修饰,诸如通过与标记物缀合。其它类型的修饰包括例如“帽”,将一个或多个天然存在的核苷酸用类似物替代,核苷酸间修饰诸如例如具有不带电荷连接(例如膦酸甲酯,磷酸三酯,磷酰胺酯(phosphoamidate),氨基甲酸酯等)和具有带电荷连接(例如硫代磷酸酯,二硫代磷酸酯等)的修饰,含有悬垂模块(pendant moiety)诸如例如蛋白质(例如核酸酶,毒素,抗体,信号肽,聚L-赖氨酸等)的修饰,具有嵌入剂(例如吖啶,补骨脂素等)的修饰,含有螯合剂(例如金属,放射性金属,硼,氧化性金属等)的修饰,含有烷化剂的修饰,具有经修饰连接(例如α端基异构核酸(anomeric nucleic acid)等)的修饰,以及未修饰形式的多核苷酸。另外,通常存在于糖类中的任何羟基可以用例如膦酸(phosphonate)基团,磷酸(phosphate)基团替换,用标准保护基团保护,或活化以制备与别的核苷酸的别的连接,或者可缀合至固体或半固体支持物。5′和3′末端OH可磷酸化或者用胺或1-20个碳原子的有机加帽基团模块取代。其它羟基也可衍生成标准保护基团。多核苷酸还可含有本领域普遍知道的核糖或脱氧核糖糖类的类似物形式,包括例如2′-氧-甲基,2′-氧-烯丙基,2′-氟-或2′-叠氮-核糖,碳环糖类似物,α-端基异构糖,差向异构糖诸如阿拉伯糖,木糖或来苏糖,吡喃糖,呋喃糖,景天庚酮糖,无环类似物及脱碱基核苷类似物诸如甲基核糖核苷。可用备选连接基团替换一个或多个磷酸二酯连接。这些备选连接基团包括但不限于以下实施方案,其中磷酸酯用P(O)S(“硫代酸酯”(thioate)),P(S)S(“二硫代酸酯”(dithioate)),(O)NR2(“酰胺酯”(amidate)),P(O)R,P(O)OR′,CO或CH2(“甲缩醛”(formacetal))替代,其中R或R′各自独立为H或者取代的或未取代的烃基(1-20个C),任选含有醚(-O-)连接,芳基,烯基,环烃基,环烯基或芳烃基(araldyl)。并非多核苷酸中的所有连接都必需是相同的。前述描述适用于本文中提及的所有多核苷酸,包括RNA和DNA。
“寡核苷酸”在用于本文时一般指短的多核苷酸,一般是单链,一般是合成的,长度一般但不是必需小于约200个核苷酸。术语“寡核苷酸”与“多核苷酸”并不互相排斥。上文关于多核苷酸的描述同样且完全适用于寡核苷酸。
关于肽或多肽序列的“百分比(%)氨基酸序列同一性”定义为对比序列并在必要时引入缺口以获取最大百分比序列同一性后,且不将任何保守替代视为序列同一性的一部分时,候选序列中与特定肽或多肽序列中的氨基酸残基相同的氨基酸残基的百分率。为测定百分比氨基酸序列同一性目的的比对可以本领域技术范围内的多种方式进行,例如使用公众可得到的计算机软件,诸如BLAST,BLAST-2,ALIGN或Megalign(DNASTAR)软件。本领域技术人员可决定用于测量比对的适宜参数,包括对所比较序列全长获得最大比对所需的任何算法。然而,为了本发明的目的,%氨基酸序列同一性值是使用序列比较计算机程序ALIGN-2获得的,其中下文表中提供了ALIGN-2程序的完整源代码。ALIGN-2序列比较计算机程序由Genentech公司编写,源代码已经连同用户文档一起提交给美国版权局(USCopyright Office,Washington D.C.,20559),并以美国版权注册号TXU510087注册。公众可通过Genentech公司(South San Francisco,California)得到ALIGN-2程序,或者可以自例如WO2007/001851中提供的源代码来汇编。ALIGN2程序应当编译成在UNIX操作系统,优选数码UNIX V4.0D上使用。所有序列比较参数由ALIGN-2程序设定且不变。
在采用ALIGN-2来比较氨基酸序列的情况中,给定氨基酸序列A相对于(to),与(with),或针对(against)给定氨基酸序列B的%氨基酸序列同一性(或者可表述为具有或包含相对于,与,或针对给定氨基酸序列B的某一%氨基酸序列同一性的给定氨基酸序列A)如下计算:
分数X/Y 乘 100
其中X是由序列比对程序ALIGN-2在该程序的A和B比对中评分为相同匹配的氨基酸残基数,且其中Y是B中的氨基酸残基总数。可以领会,若氨基酸序列A的长度与氨基酸序列B的长度不相等,则A相对于B的%氨基酸序列同一性将不等于B相对于A的%氨基酸序列同一性。
在一些实施方案中,两种或更多种氨基酸序列是至少50%,60%,70%,80%,或90%相同的。在一些实施方案中,两种或更多种氨基酸序列是至少95%,97%,98%,99%,或甚至100%相同的。除非另有具体说明,本文中所使用的所有%氨基酸序列同一性值都是依照上一段所述,使用ALIGN-2计算机程序获得的。
如本文中所使用的,除非另有明确的或上下文说明,术语“FGFR3”指任何天然的或变异(无论天然的或合成的)的FGFR3多肽(例如FGFR3-IIIb同等型或FGFR3-IIIc同等型)。术语“天然序列”明确涵盖天然存在的截短形式(例如胞外结构域序列或跨膜亚基序列),天然存在的变体形式(例如可变剪接形式)和天然存在的等位变体。术语“野生型FGFR3”通常指包含天然存在FGFR3蛋白质的氨基酸序列的多肽。术语“野生型FGFR3序列”通常指在天然存在FGFR3中找到的氨基酸序列。
如本文中所使用的,除非另有明确的或上下文说明,术语“FGFR3配体”(可互换称作“FGF”)指任何天然的或变异(无论天然的或合成的)的FGFR3配体(例如FGF1,FGF2,FGF4,FGF8,FGF9,FGF17,FGF18,FGF23)多肽。术语“天然序列”明确涵盖天然存在的截短形式(例如胞外结构域序列或跨膜亚基序列),天然存在的变体形式(例如可变剪接形式)和天然存在的等位变体。术语“野生型FGFR3配体”通常指包含天然存在FGFR3配体蛋白质的氨基酸序列的多肽。术语“野生型FGFR3配体序列”通常指在天然存在FGFR3配体中找到的氨基酸序列。
术语“FGFR3活化”指FGFR3受体的活化或磷酸化。一般而言,FGFR3活化导致信号转导(例如由FGFR3受体的细胞内激酶域引起的,磷酸化FGFR3或底物多肽中的酪氨酸残基)。FGFR3活化可以由FGFR配体结合感兴趣FGFR3受体来介导。FGFR3配体(例如诸如FGF1或FGF9)对FGFR3的结合可活化FGFR3的激酶域并由此导致FGFR3中酪氨酸残基的磷酸化和/或另外的底物多肽中酪氨酸残基的磷酸化。
如本文中所使用的,除非另有明确的或上下文说明,术语“FGFR2”指任何天然的或变异(无论天然的或合成的)的FGFR2多肽(例如FGFR2-IIIb同等型或FGFR2-IIIc同等型)。术语“天然序列”明确涵盖天然存在的截短形式(例如胞外结构域序列或跨膜亚基序列),天然存在的变体形式(例如可变剪接形式)和天然存在的等位变体。术语“野生型FGFR2”通常指包含天然存在FGFR2蛋白质的氨基酸序列的多肽。术语“野生型FGFR2序列”通常指在天然存在FGFR2中找到的氨基酸序列。
如本文中所使用的,除非另有明确的或上下文说明,术语“FGFR2配体”(可互换称作“FGF2”)指任何天然的或变异(无论天然的或合成的)的FGFR2配体。术语“天然序列”明确涵盖天然存在的截短形式(例如胞外结构域序列或跨膜亚基序列),天然存在的变体形式(例如可变剪接形式)和天然存在的等位变体。术语“野生型FGFR2配体”通常指包含天然存在FGFR2配体蛋白质的氨基酸序列的多肽。术语“野生型FGFR2配体序列”通常指在天然存在FGFR2配体中找到的氨基酸序列。
术语“FGFR2活化”指FGFR2受体的活化或磷酸化。FGFR2活化可以由FGFR配体结合感兴趣FGFR2受体来介导。FGFR2配体对FGFR2的结合可活化FGFR2的激酶域并由此导致FGFR2中酪氨酸残基的磷酸化和/或另外的底物多肽中酪氨酸残基的磷酸化。
术语“FGFR2/3抗体”指结合FGFR2和FGFR3的双重特异性抗体。FGFR2/3抗体的非限制性例子包括本文中描述的双重特异性单克隆抗体2B.1.3.10和2B.1.3.12。术语FGFR2/3和“FGFR2和FGFR3”和“FGFR3和FGFR2”在本文中可互换使用。
如本文中所使用的,如例如应用于受体激酶活性,术语“组成性”指受体不依赖配体或其它活化性分子的存在的持续信号传导活性。根据受体的性质,所有活性可以是组成性的,或者受体的活性可以通过其它分子(例如配体)的结合而进一步活化。导致受体活化的细胞事件是本领域普通技术人员公知的。例如,活化可包括寡聚化(例如二聚化,三聚化,等)成高级受体复合物。复合物可包含单一种类的蛋白质,即同聚复合物。或者,复合物可包含至少两种不同蛋白质种类,即异聚复合物。可以通过例如正常或突变体形式的受体在细胞表面上的过表达来引起复合物形成。也可以通过受体中的一处或多处特定突变来引起复合物形成。
如本文中使用的,如例如应用于受体信号传导活性,术语“配体不依赖性的”指不依赖配体的存在的信号传导活性。具有配体依赖性激酶活性的受体不会必然排除配体结合该受体以产生额外的激酶活性活化。
如本文中使用的,如例如应用于受体信号传导活性,术语“配体依赖性的”指依赖配体的存在的信号传导活性。
短语“基因扩增”指在特定细胞或细胞系中形成多拷贝的基因或基因片段的过程。复制区(扩增的DNA的区段)常常称作“扩增子”。通常,所产生的信使RNA(mRNA)的量,即基因表达的水平,也按由所表达特定基因形成的拷贝数的比例增加。
“酪氨酸激酶抑制剂”指一定程度抑制酪氨酸激酶(诸如FGFR2和FGFR3受体)的酪氨酸激酶活性的分子。
“展示出FGFR3表达,扩增,或活化”的癌或生物学样品指在诊断测试中表达(包括过表达)FGFR3,扩增了FGFR3基因,和/或以其它方式表明FGFR3活化或磷酸化的癌或生物学样品。“展示出FGFR2表达,扩增,或活化”的癌或生物学样品指在诊断测试中表达(包括过表达)FGFR2,扩增了FGFR2基因,和/或以其它方式表明FGFR2活化或磷酸化的癌或生物学样品。“展示出FGFR2/3表达,扩增,或活化”或“展示出FGFR2和FGFR3表达,扩增,或活化”的癌或生物学样品指在诊断测试中表达(包括过表达)FGFR2和FGFR3,扩增了FGFR2和FGFR3基因,和/或以其它方式表明FGFR2和FGFR3活化或磷酸化的癌或生物学样品。
如本文中使用的,“Klotho-β”,“KLB”和“β-Klotho”指来自任何脊椎动物来源,包括哺乳动物诸如灵长类(例如人)和啮齿类(例如小鼠和大鼠)的任何天然β-Klotho,除非另有说明。该术语涵盖“全长”,未加工的KLB以及KLB因细胞中的加工所致的任何形式。该术语还涵盖KLB的天然存在变体,例如剪接变体或等位变体。本公开文本的抗体所靶向的人KLB氨基酸序列(排除信号序列)的一个非限制性例子如下:
FSGDGRAIWSKNPNFTPVNESQLFLYDTFPKNFFWGIGTGALQVEGSWKKDGKGPSIWDHFIHTHLKNVSSTNGSSDSYIFLEKDLSALDFIGVSFYQFSISWPRLFPDGIVTVANAKGLQYYSTLLDALVLRNIEPIVTLYHWDLPLALQEKYGGWKNDTIIDIFNDYATYCFQMFGDRVKYWITIHNPYLVAWHGYGTGMHAPGEKGNLAAVYTVGHNLIKAHSKVWHNYNTHFRPHQKGWLSITLGSHWIEPNRSENTMDIFKCQQSMVSVLGWFANPIHGDGDYPEGMRKKLFSVLPIFSEAEKHEMRGTADFFAFSFGPNNFKPLNTMAKMGQNVSLNLREALNWIKLEYNNPRILIAENGWFTDSRVKTEDTTAIYMMKNFLSQVLQAIRLDEIRVFGYTAWSLLDGFEWQDAYTIRRGLFYVDFNSKQKERKPKSSAHYYKQIIRENGFSLKESTPDVQGQFPCDFSWGVTESVLKPESVASSPQFSDPHLYVWNATGNRLLHRVEGVRLKTRPAQCTDFVNIKKQLEMLARMKVTHYRFALDWASVLPTGNLSAVNRQALRYYRCVVSEGLKLGISAMVTLYYPTHAHLGLPEPLLHADGWLNPSTAEAFQAYAGLCFQELGDLVKLWITINEPNRLSDIYNRSGNDTYGAAHNLLVAHALAWRLYDRQFRPSQRGAVSLSLHADWAEPANPYADSHWRAAERFLQFEIAWFAEPLFKTGDYPAAMREYIASKHRRGLSSSALPRLTEAERRLLKGTVDFCALNHFTTRFVMHEQLAGSRYDSDRDIQFLQDITRLSSPTRLAVIPWGVRKLLRWVRRNYGDMDIYITASGIDDQALEDDRLRKYYLGKYLQEVLKAYLIDKVRIKGYYAFKLAEEKSKPRFGFFTSDFKAKSSIQFYNKVISSRGFPFENSSSRCSQTQENTECTVCLFLVQKKPLIFLGCCFFSTLVLLLSIAIFQRQKRRKFWKAKNLQHIPLKKGKRVVS(SEQ ID NO:233)。
在某些实施方案中,KLB蛋白质可包括具有氨基酸序列MKPGCAAGSPGNEWIFFSTDEITTRYRNTMSNGGLQRSVILSALILLRAVTG(SEQ ID NO:234)的N端信号序列。
术语“KLB的C端域”指KLB的羧基端糖苷酶样域。例如,SEQ ID NO:233中显示的例示性KLB蛋白质的C端域包含下述氨基酸序列:
FPCDFSWGVTESVLKPESVASSPQFSDPHLYVWNATGNRLLHRVEGVRLKTRPAQCTDFVNIKKQLEMLARMKVTHYRFALDWASVLPTGNLSAVNRQALRYYRCVVSEGLKLGISAMVTLYYPTHAHLGLPEPLLHADGWLNPSTAEAFQAYAGLCFQELGDLVKLWITINEPNRLSDIYNRSGNDTYGAAHNLLVAHALAWRLYDRQFRPSQRGAVSLSLHADWAEPANPYADSHWRAAERFLQFEIAWFAEPLFKTGDYPAAMREYIASKHRRGLSSSALPRLTEAERRLLKGTVDFCALNHFTTRFVMHEQLAGSRYDSDRDIQFLQDITRLSSPTRLAVIPWGVRKLLRWVRRNYGDMDIYITASGIDDQALEDDRLRKYYLGKYLQEVLKAYLIDKVRIKGYYAFKLAEEKSKPRFGFFTSDFKAKSSIQFYNKVISSRGFPFENSSSR(SEQ ID NO:235)。
术语“抗KLB抗体”和“结合KLB的抗体”指能够以足够亲和力结合KLB,使得该抗体可作为诊断剂和/或治疗剂用于靶向KLB的抗体。在一个实施方案中,如例如通过放射性免疫测定法(RIA)测量的,抗KLB抗体结合无关的,非KLB的蛋白质的程度小于该抗体对KLB的结合的约10%。在某些实施方案中,结合KLB的抗体具有≤1μM,≤100nM,≤10nM,≤1nM,≤0.1nM,≤0.01nM,或≤0.001nM(例如10-8M或更少,例如10-8M到10-13M,例如10-9M到10-13M)的解离常数(Kd)。在某些实施方案中,抗KLB抗体结合在来自不同物种的KLB中保守的KLB表位。在某些实施方案中,抗KLB抗体结合KLB上的在该蛋白的C端部分中的表位。
术语“药物配制剂”指处于如下的形式,使得容许其中含有的活性组分的生物学活性是有效的,且不含对会接受配制剂施用的受试者具有不可接受的毒性的别的成分的制剂。
如本文中使用的,“药学可接受载体”指药物配制剂中与活性组分不同的,且对受试者无毒的组分。药学可接受载体包括但不限于缓冲剂,赋形剂,稳定剂,或防腐剂。
如本文中使用的,“治疗”(及其语法变化形式,诸如“处理”或“处置”)指试图改变所治疗个体的自然进程的临床干预,可以是为了预防或在临床病理学的进程中进行。治疗的期望效果包括但不限于预防疾病的发生或复发,缓解症状,削弱疾病的任何直接或间接病理学后果,预防转移,减缓疾病进展的速率,改善或减轻疾病状态,及免除或改善预后。在某些实施方案中,本公开文本的抗体可用于延迟疾病的发生或减缓疾病的进展。“处理”和“治疗”(treatment)指治疗性处理和预防性措施二者。当它涉及FGFR2/3抗体时,那些需要治疗的包括那些早就患有良性,癌前,或非转移性肿瘤的以及那些要预防癌症发生或复发的。
“展示出FGFR3活化”的癌或生物学样品指在诊断测试中展现出FGFR3活化或磷酸化的癌或生物学样品。此类活化可直接(例如通过ELISA来测量FGFR3磷酸化)或间接测定。“展示出FGFR2活化”的癌或生物学样品指在诊断测试中展现出FGFR2活化或磷酸化的癌或生物学样品。此类活化可直接或间接测定。“展示出FGFR2和FGFR3活化”的癌或生物学样品指在诊断测试中展现出FGFR2和FGFR3活化或磷酸化的癌或生物学样品。此类活化可直接或间接测定。
“展示出组成性FGFR3活化”的癌或生物学样品指在诊断测试中展现出组成性FGFR3活化或磷酸化的癌或生物学样品。此类活化可直接(例如通过ELISA来测量c-FGFR3磷酸化)或间接测定。“展示出组成性FGFR2活化”的癌或生物学样品指在诊断测试中展现出组成性FGFR2活化或磷酸化的癌或生物学样品。此类活化可直接或间接测定。“展示出组成性FGFR2和FGFR3活化”的癌或生物学样品指在诊断测试中展现出组成性FGFR2和FGFR3活化或磷酸化的癌或生物学样品。此类活化可直接或间接测定。
“展示出FGFR3扩增”的癌或生物学样品指在诊断测试中具有扩增的FGFR3基因的癌或生物学样品。“展示出FGFR2扩增”的癌或生物学样品指在诊断测试中具有扩增的FGFR2基因的癌或生物学样品。“展示出FGFR2和FGFR3扩增”的癌或生物学样品指在诊断测试中具有扩增的FGFR2和FGFR3基因的癌或生物学样品。
“展示出FGFR3易位”的癌或生物学样品指在诊断测试中具有易位的FGFR3基因的癌或生物学样品。FGFR3易位的一个例子是t(4;14)易位,它在一些多发性骨髓瘤肿瘤中发生。“展示出FGFR2易位”的癌或生物学样品指在诊断测试中具有易位的FGFR2基因的癌或生物学样品。“展示出FGFR2和FGFR3易位”的癌或生物学样品指在诊断测试中具有易位的FGFR2和FGFR3基因的癌或生物学样品。
“磷酸-ELISA测定法”(phosho-ELISA assay)在本文中指在酶联免疫吸附测定法(ELISA)中评估一种或多种FGFR(例如FGFR2和FGFR3),底物或下游信号分子的磷酸化的测定法,其中使用检测磷酸化的FGFR(例如FGFR2和FGFR3),底物,或下游信号分子的试剂(通常是抗体)。在一些实施方案中,使用检测磷酸化的FGFR2,FGFR3,或pMAPK的抗体。在一个具体的实施方案中,使用检测磷酸化的FGFR2和FGFR3的抗体。该测定法可以对细胞溶胞物,优选来自新鲜的或冷冻的生物学样品的细胞溶胞物进行。
“展示出配体不依赖性FGFR3活化”的癌或生物学样品指在诊断测试中展现出配体不依赖性FGFR3活化或磷酸化的癌或生物学样品。此类活化可直接(例如通过ELISA来测量FGFR3磷酸化)或间接测定。“展示出配体不依赖性FGFR2活化”的癌或生物学样品指在诊断测试中展现出配体不依赖性FGFR2活化或磷酸化的癌或生物学样品。此类活化可直接或间接测定。“展示出配体不依赖性FGFR2/3活化”的癌或生物学样品指在诊断测试中展现出配体不依赖性FGFR2和FGFR3活化或磷酸化的癌或生物学样品。此类活化可直接或间接测定。
“展示出配体依赖性FGFR3活化”的癌或生物学样品指在诊断测试中展现出配体依赖性FGFR3活化或磷酸化的癌或生物学样品。此类活化可直接(例如通过ELISA来测量FGFR3磷酸化)或间接测定。“展示出配体依赖性FGFR2活化”的癌或生物学样品指在诊断测试中展现出配体依赖性FGFR2活化或磷酸化的癌或生物学样品。此类活化可直接或间接测定。“展示出配体依赖性FGFR2/3活化”的癌或生物学样品指在诊断测试中展现出配体依赖性FGFR2/3活化或磷酸化的癌或生物学样品。此类活化可直接或间接测定。
“展示出配体不依赖性FGFR3活化”的癌或生物学样品指在诊断测试中展现出配体不依赖性FGFR3活化或磷酸化的癌或生物学样品。此类活化可直接(例如通过ELISA来测量FGFR3磷酸化)或间接测定。“展示出配体不依赖性FGFR2活化”的癌或生物学样品指在诊断测试中展现出配体不依赖性FGFR2活化或磷酸化的癌或生物学样品。此类活化可直接或间接测定。“展示出配体不依赖性FGFR2/3活化”的癌或生物学样品指在诊断测试中展现出配体不依赖性FGFR2/3活化或磷酸化的癌或生物学样品。此类活化可直接或间接测定。
具有“FGFR3过表达或扩增”的癌细胞指与同一组织类型的非癌性细胞相比,具有显著更高水平的FGFR3蛋白质或基因的癌细胞。此类过表达可以是由基因扩增或者是由转录或翻译提高引起的。可在诊断或预后测定法中通过评估细胞表面上存在的FGFR3蛋白质水平的升高(例如通过免疫组织化学测定法;IHC)来确定FGFR3过表达或扩增。或者/另外,可测量细胞中FGFR3编码核酸的水平,例如通过荧光原位杂交(FISH;参见1998年10月公布的WO 98/45479),Southern印迹,或聚合酶链式反应(PCR)技术,诸如定量实时PCR(qRT-PCR)。除了上述测定法之外,熟练从业人员还可利用各种体内测定法。例如,可将患者身体内的细胞暴露于任选用可检测标记物例如放射性同位素标记的抗体,并且可评估抗体与患者中的细胞的结合,例如通过外部扫描放射性或通过分析取自先前暴露于抗体的患者的活检。
具有“FGFR2过表达或扩增”的癌细胞指与同一组织类型的非癌性细胞相比,具有显著更高水平的FGFR2蛋白质或基因的癌细胞。此类过表达可以是由基因扩增或者是由转录或翻译提高引起的。可在诊断或预后测定法中通过评估细胞表面上存在的FGFR2蛋白质水平的升高(例如通过免疫组织化学测定法;IHC)来确定FGFR2过表达或扩增。或者/另外,可测量细胞中FGFR2编码核酸的水平,例如通过荧光原位杂交(FISH;参见1998年10月公布的WO 98/45479),Southern印迹,或聚合酶链式反应(PCR)技术,诸如定量实时PCR(qRT-PCR)。除了上述测定法之外,熟练从业人员还可利用各种体内测定法。例如,可将患者身体内的细胞暴露于任选用可检测标记物例如放射性同位素标记的抗体,并且可评估抗体与患者中的细胞的结合,例如通过外部扫描放射性或通过分析取自先前暴露于抗体的患者的活检。
具有“FGFR2/3过表达或扩增”的癌细胞指与同一组织类型的非癌性细胞相比,具有显著更高水平的FGFR2和FGFR3蛋白质或基因的癌细胞。此类过表达可以是由基因扩增或者是由转录或翻译提高引起的。可在诊断或预后测定法中通过评估细胞表面上存在的FGFR2和FGFR3蛋白质水平的升高(例如通过免疫组织化学测定法;IHC)来确定FGFR2和FGFR3过表达或扩增。或者/另外,可测量细胞中FGFR2和FGFR3编码核酸的水平,例如通过荧光原位杂交(FISH;参见1998年10月公布的WO 98/45479),Southern印迹,或聚合酶链式反应(PCR)技术,诸如定量实时PCR(qRT-PCR)。除了上述测定法之外,熟练从业人员还可利用各种体内测定法。例如,可将患者身体内的细胞暴露于任选用可检测标记物例如放射性同位素标记的抗体,并且可评估抗体与患者中的细胞的结合,例如通过外部扫描放射性或通过分析取自先前暴露于抗体的患者的活检。
如本文中使用的,术语“突变”指特定蛋白质或核酸(基因,RNA)分别相对于野生型蛋白质或核酸的氨基酸或核酸序列的差异。突变的蛋白质或核酸可以由基因的一个等位基因(杂合的)或两个等位基因(纯合的)表达或者在其中找到,而且它可以是体细胞的或种系的。在本发明中,突变一般是体细胞的。突变包括序列重排,诸如插入,删除,和点突变(包括单核苷酸/氨基酸多态性)。
“抑制”指与参照相比减小或降低活性,功能,和/或量。
当药剂模拟感兴趣多肽(例如FGFR配体,诸如FGF1或FGF9)的至少一项功能性活性时,该药剂拥有“激动性活性或功能”。
如本文中使用的,“激动性抗体”指模拟感兴趣多肽(例如FGFR配体,诸如FGF1或FGF9)的至少一项功能性活性的抗体。
蛋白质“表达”指基因中编码的信息转换成信使RNA(mRNA),然后转换成蛋白质。
在本文中,“表达”感兴趣蛋白质(诸如FGF受体或FGF受体配体)的样品或细胞指其中测定出存在编码该蛋白质的mRNA或蛋白质(包括其片段)的样品或细胞。
“免疫缀合物”(可互换地称作“抗体-药物缀合物”或“ADC”)指抗体缀合至一种或多种细胞毒剂,诸如化疗剂,药物,生长抑制剂,毒素(例如蛋白质毒素,细菌,真菌,植物,或动物起源的酶活性毒素,或其片段),或放射性同位素(即放射缀合物)。
如本文中所使用的,术语“Fc区”一般指包含免疫球蛋白重链C端多肽序列的二聚体复合物,其中C端多肽序列是通过木瓜蛋白酶消化完整抗体可获得的。Fc区可包含天然或变体Fc序列。虽然免疫球蛋白重链的Fc序列的边界可以有所变化,但是人IgG重链Fc序列通常定义为Fc序列自位于大约位置Cys226的氨基酸残基,或自大约位置Pro230,至羧基端的区段。免疫球蛋白的Fc序列一般包含两个恒定域,CH2域和CH3域,且任选包含CH4域。Fc区的C-末端赖氨酸(依照EU编号系统的残基447)可以消除,例如在纯化抗体的过程中或者通过重组改造编码抗体的核酸。因此,依照本发明包含具有Fc区的抗体的组合物可包含具有K447的抗体,消除了所有K447的抗体,或具有与没有K447残基的抗体的混合物。
“Fc多肽”在本文中指构成Fc区的多肽之一。可以自任何合适的免疫球蛋白获得Fc多肽,诸如IgG1,IgG2,IgG3,或IgG4亚型,IgA,IgE,IgD或IgM。在一些实施方案中,Fc多肽包含部分或整个野生型铰链序列(一般位于其N端)。在一些实施方案中,Fc多肽不包含功能性或野生型铰链序列。
“阻断性”抗体或抗体“拮抗剂”指抑制或降低其所结合的抗原的生物学活性的抗体。优选的阻断性抗体或拮抗性抗体完全抑制抗原的生物学活性。
“裸抗体(裸露的抗体)”指未缀合异源分子诸如细胞毒性模块或放射性标记物的抗体。
具有指定抗体的“生物学特征”的抗体指拥有该指定抗体区别于其它结合相同抗原的抗体的一项或多项生物学特征的抗体。
为了筛选结合抗原上感兴趣抗体所结合的表位的抗体,可以实施常规交叉阻断测定法,诸如Antibodies,A Laboratory Manual,Cold Spring Harbor Laboratory,EdHarlow and David Lane(1988)中所记载的。
为了延长包含本发明氨基酸序列的抗体或多肽的半衰期,可如例如美国专利No.5,739,277中所记载的将补救受体结合表位附着于抗体(尤其是抗体片段)。例如,可以将编码补救受体结合表位的核酸分子与编码本发明多肽序列的核酸在同一读码框内相连接,使得由改造后的核酸分子表达的融合蛋白包含补救受体结合表位和本发明的多肽序列。在用于本文时,术语“补救受体结合表位”指IgG分子(例如IgG1,IgG2,IgG3或IgG4)的Fc区中负责延长IgG分子体内血清半衰期的表位(例如Ghetie et al.,Ann.Rev.Immunol.18:739-766(2000),表1)。其Fc区中有替代且血清半衰期延长的抗体还记载于WO00/42072;WO02/060919;Shields et al.,J.Biol.Chem.276:6591-6604(2001);Hinton,J.Biol.Chem.279:6213-6216(2004))。在另一个实施方案中,还可以通过例如附着其它多肽序列来延长血清半衰期。例如,可以将在本发明的方法中有用的抗体或其它多肽附着于血清清蛋白或血清清蛋白中结合FcRn受体或血清清蛋白结合肽的那部分,使得血清清蛋白结合该抗体或多肽,例如此类多肽序列披露于WO01/45746。在一个优选的实施方案中,待附着的血清清蛋白肽包含氨基酸序列DICLPRWGCLW(SEQ ID NO:183)。在另一个实施方案中,Fab的半衰期通过这些方法得到了延长。血清清蛋白结合肽序列还可参见Dennis et al.,J.Biol.Chem.277:35035-35043(2002)。
“片段”指多肽和核酸分子的一部分,其优选含有参比核酸分子或多肽全长的至少10%,20%,30%,40%,50%,60%,70%,80%,90%,95%,或更多。所述片段可含有10,20,30,40,50,60,70,80,90,或100,200,300,400,500,600,或更多个核苷酸,或者10,20,30,40,50,60,70,80,90,100,120,140,160,180,190,200或更多个氨基酸。
如本文中使用的,短语“很少的至无激动剂功能”就本发明的抗体而言表示该抗体不引发生物学上有意义量的激动剂活性,例如在施用于受试者后。正如本领域会理解的,活性的量可以定量或定性测定,只要能进行本发明的抗体和参照对应物之间的比较。可以依照本领域知道的任何测定法或技术测量或检测活性,包括例如本文中描述的。可以平行地或在分开的运行中测定本发明的抗体及其参照对应物的活性的量。在一些实施方案中,本发明的二价抗体不拥有实质性的激动剂功能。
术语“凋亡”和“凋亡活性”以广义使用,指哺乳动物中有序或受控形式的细胞死亡,通常伴随着一种或多种特征性细胞变化,包括细胞质浓缩,质膜微绒毛丧失,细胞核节段化,染色体DNA降解或线粒体功能丧失。此活性可使用本领域已知的多种技术来测定和测量,例如通过细胞生存力测定法,FACS分析或DNA电泳,更具体的是通过膜联蛋白V结合,DNA断裂,细胞收缩,内质网膨胀,细胞碎裂和/或膜囊(称为凋亡小体)形成。
术语“抗体”和“免疫球蛋白”以最广义互换使用,包括单克隆抗体(例如全长或完整单克隆抗体),多克隆抗体,多价抗体,多特异性抗体(例如双特异性抗体,只要它们展现出期望的生物学活性),而且还可以包括某些抗体片段(如本文中更为详细描述的)。抗体可以是人的,人源化的和/或亲和力成熟的。
术语“可变的”指可变域中的某些部分在抗体序列间差异广泛且用于每种特定抗体对其特定抗原的结合和特异性的实情。然而,变异性并非均匀分布于抗体的整个可变域。它集中于轻链和重链可变域中称作互补决定区(CDR)或高变区的三个区段。可变域中更加高度保守的部分称作框架区(FR)。天然重链和轻链的可变域各自包含四个FR,它们大多采取β-折叠片构象,通过形成环状连接且在有些情况中形成β-折叠片结构一部分的三个CDR连接。每条链中的CDR通过FR非常接近地保持在一起,并与另一条链的CDR一起促成抗体的抗原结合位点的形成(参见Kabat等,Sequences of Proteins of ImmunologicalInterest,第5版,National Institute of Health,Bethesda,MD.(1991))。恒定域不直接参与抗体与抗原的结合,但展现出多种效应器功能,诸如抗体依赖性细胞的(细胞)毒性中抗体的参与。
用木瓜蛋白酶消化抗体产生两个相同的抗原结合片段,称为“Fab”片段,各自具有一个抗原结合位点,及剩余的“Fc”片段,其名称反映了它易于结晶的能力。胃蛋白酶处理产生F(ab′)2片段,它具有两个抗原结合位点且仍能够交联抗原。
“Fv”是包含完整抗原识别和结合位点的最小抗体片段。在双链Fv种类中,此区由紧密,非共价结合的一个重链可变域和一个轻链可变域的二聚体组成。在单链Fv种类中,一个重链可变域和一个轻链可变域可以通过柔性肽接头共价相连,使得轻链和重链能在与双链Fv种类类似的“二聚体”结构中相结合。正是在这种构造中,各可变域的三个CDR相互作用而在VH-VL二聚体表面上确定了抗原结合位点。六个CDR共同赋予抗体以抗原结合特异性。然而,即使是单个可变域(或只包含对抗原特异的三个CDR的半个Fv)也具有识别和结合抗原的能力,只是亲和力低于完整结合位点。
Fab片段还包含轻链的恒定域和重链的第一恒定域(CH1)。Fab′片段与Fab片段的不同之处在于重链CH1结构域的羧基末端增加了少数残基,包括来自抗体铰链区的一个或多个半胱氨酸。Fab′-SH是本文中对其中恒定域半胱氨酸残基携带游离硫醇基的Fab′的称谓。F(ab′)2抗体片段最初是作为在Fab′片段之间有铰链半胱氨酸的成对Fab′片段生成的。还知道抗体片段的其它化学偶联。
根据其恒定域的氨基酸序列,来自任何脊椎动物物种的抗体(免疫球蛋白)的“轻链”可归入两种截然不同的型中的一种,称作卡帕(κ)和拉姆达(λ)。
根据其重链恒定域的氨基酸序列,免疫球蛋白可归入不同的类。免疫球蛋白有五大类:IgA,IgD,IgE,IgG和IgM,其中有些可进一步分为亚类(同种型),例如IgG1,IgG2,IgG3,IgG4,IgA1和IgA2。将与不同类的免疫球蛋白对应的重链恒定域分别称作α,δ,ε,γ和μ。不同类的免疫球蛋白的亚基结构和三维构造是众所周知的。“抗体片段”只包含完整抗体的一部分,其中所述部分优选保留该部分存在于完整抗体中时通常与之有关的至少一项,优选大多数或所有功能。抗体片段的例子包括Fab,Fab′,F(ab′)2和Fv片段;双抗体;线性抗体;单链抗体分子;及由抗体片段形成的多特异性抗体。在一个实施方案中,抗体片段包含完整抗体的抗原结合位点,如此保留结合抗原的能力。在另一个实施方案中,抗体片段,例如包含Fc区的抗体片段,保留与Fc区存在于完整抗体中时通常与之有关的至少一项生物学功能,诸如FcRn结合,抗体半衰期调控,ADCC功能和补体结合。在一个实施方案中,抗体片段是体内半衰期与完整抗体基本上相似的单价抗体。例如,这样的抗体片段可包含一个抗原结合臂且其与能够赋予该片段以体内稳定性的Fc序列相连。
术语“高变区”,“HVR”或“HV”在用于本文时指抗体可变域中序列上高度可变和/或形成结构上定义的环的区域。通常,抗体包含六个高变区:三个在VH中(H1,H2,H3),三个在VL中(L1,L2,L3)。本文中使用且涵盖许多高变区的叙述。Kabat互补决定区(CDR)是以序列变异性为基础的,而且是最常用的(Kabat等,Sequences of Proteins of ImmunologicalInterest,第5版,Public Health Service,National Institutes of Health,Bethesda,MD.(1991))。Chothia改为指结构环的位置(Chothia和Lesk,J.Mol.Biol.196:901-917(1987))。AbM高变区代表Kabat CDR与Chothia结构环之间的折衷,而且得到OxfordMolecular的AbM抗体建模软件的使用。“接触(contact)”高变区是以对可获得的复合物晶体结构的分析为基础的。下文记录了这些高变区中每一个的残基。

高变区可包括如下“延伸的高变区”:VL中的24-36或24-34(L1),46-56或50-56(L2)和89-97(L3)及VH中的26-35(H1),50-65或49-65(H2)和93-102,94-102或95-102(H3)。对于这些定义中的每一个,可变区残基是依照Kabat等,见上文编号的。
“框架”或“FR”残基指可变域中除本文中所定义的高变区残基外的那些残基。
非人(例如鼠)抗体的“人源化”形式指最低限度包含衍生自非人免疫球蛋白的序列的嵌合抗体。在极大程度上,人源化抗体指人免疫球蛋白(受体抗体)中的高变区残基用具有期望特异性,亲和力和能力的非人物种(供体抗体)诸如小鼠,大鼠,家兔或非人灵长类的高变区残基替换的免疫球蛋白。在有些情况中,将人免疫球蛋白的框架区(FR)残基用相应的非人残基替换。此外,人源化抗体可包含在受体抗体或供体抗体中没有找到的残基。进行这些修饰是为了进一步改进抗体的性能。一般而言,人源化抗体将包含至少一个,通常两个基本上整个如下可变域,其中所有或基本上所有高变环对应于非人免疫球蛋白的高变环,且所有或基本上所有FR是人免疫球蛋白序列的FR。人源化抗体任选还将包含至少部分免疫球蛋白恒定区(Fc),通常是人免疫球蛋白的恒定区。更多细节参见Jones等,Nature321:522-525(1986);Riechmann等,Nature 332:323-329(1988);Presta,Curr.Op.Struct.Biol.2:593-596(1992)。还可参见以下综述及其引用的参考文献:Vaswani和Hamilton,Ann.Allergy,Asthma&Immunol.1:105-115(1998);Harris,Biochem.Soc.Transactions 23:1035-1038(1995);Hurle和Gross,Curr.Op.Biotech.5:428-433(1994)。
“嵌合”抗体(免疫球蛋白)中重链和/或轻链的一部分与衍生自特定物种或属于特定抗体类别或亚类的抗体中的相应序列相同或同源,而链的剩余部分与衍生自另一物种或属于另一抗体类别或亚类的抗体中的相应序列相同或同源,以及此类抗体的片段,只要它们展现出期望的生物学活性(美国专利No.4,816,567;Morrison等,Proc.Natl.Acad.Sci.USA 81:6851-6855(1984))。本文中所使用的人源化抗体是嵌合抗体的一个子集。
“单链Fv”或“scFv”抗体片段包含抗体的VH和VL结构域,其中这些结构域存在于一条多肽链上。一般而言,scFv多肽在VH与VL结构域之间还包含多肽接头,使得scFv能够形成结合抗原所需的结构。关于scFv的综述参见Pluckthun,在Rosenburg和Moore编的《ThePharmacology of Monoclonal Antibodies》第113卷中,Springer-Verlag,New York,pp.269-315(1994)。
“抗原”指抗体可选择性结合的预定抗原。靶抗原可以是多肽,碳水化合物,核酸,脂质,半抗原或其它天然存在的或合成的化合物。优选地,靶抗原是多肽。
术语“双抗体(diabody)”指具有两个抗原结合位点的小型抗体片段,该片段在同一条多肽链(VH-VL)中包含相连的重链可变域(VH)和轻链可变域(VL)。通过使用过短的接头使得同一条链上的两个结构域之间不能配对,迫使这些结构域与另一条链的互补结构域配对,从而产生两个抗原结合位点。双抗体更完整的记载于例如EP 404,097;WO 93/11161;及Hollinger等,Proc.Natl.Acad.Sci.USA,90:6444-6448(1993)。
“人抗体”指拥有与由人生成的抗体的氨基酸序列对应的氨基酸序列和/或使用本文所公开的用于生成人抗体的任何技术生成的抗体。人抗体的这种定义明确排除包含非人抗原结合残基的人源化抗体。
“亲和力成熟的”抗体指在抗体的一个或多个CDR中具有一处或多处改变,导致该抗体对抗原的亲和力与没有这些改变的亲本抗体相比有所改进的抗体。优选的亲和力成熟的抗体将具有纳摩尔或甚至皮摩尔量级的对靶抗原的亲和力。亲和力成熟的抗体可通过本领域已知规程来生成。Marks等,Bio/Technology 10:779-783(1992)记载了通过VH和VL结构域改组进行的亲和力成熟。以下文献记载了CDR和/或框架残基的随机诱变:Barbas等,PNAS(USA)91:3809-3813(1994);Schier等,Gene 169:147-155(1995);Yelton等,J.Immunol.155:1994-2004(1995);Jackson等,J.Immunol.154(7):3310-9(1995);及Hawkins等,J.Mol.Biol.226:889-896(1992)。
抗体“效应器功能”指那些可归于抗体Fc区(天然序列Fc区或氨基酸序列变体Fc区)且随抗体同种型而变化的生物学活性。抗体效应器功能的例子包括:C1q结合和补体依赖性细胞毒性;Fc受体结合;抗体依赖性细胞介导的细胞毒性(ADCC);吞噬作用;细胞表面受体(例如B细胞受体)下调;和B细胞活化。
“抗体依赖性细胞介导的细胞毒性”或“ADCC”指其中结合到某些细胞毒性细胞(例如天然杀伤(NK)细胞,嗜中性粒细胞和巨噬细胞)上存在的Fc受体(FcR)上的分泌型Ig使得这些细胞毒性效应细胞能够特异性结合携带抗原的靶细胞,随后用细胞毒素杀死靶细胞的细胞毒性形式。该抗体“武装”(arm)细胞毒性细胞,而且是此类杀伤作用绝对要求的。介导ADCC的主要细胞,NK细胞,只表达FcγRIII,而单核细胞表达FcγRI,FcγRII和FcγRIII。Ravetch和Kinet,Annu.Rev.Immunol.9:457-92(1991)第464页表3总结了造血细胞上的FcR表达。为了评估感兴趣分子的ADCC活性,可进行体外ADCC测定法,诸如美国专利No.5,500,362或5,821,337或Presta美国专利No.6,737,056中所记载的。可用于此类测定法的有用的效应细胞包括外周血单个核细胞(PBMC)和天然杀伤(NK)细胞。或者/另外,可在体内评估感兴趣分子的ADCC活性,例如在动物模型中,诸如Clynes等,Proc.Natl.Acad.Sci.USA 95:652-656(1998)中所披露的。
“人效应细胞”指表达一种或多种FcR并行使效应器功能的白细胞。优选的是,该细胞至少表达FcγRIII并行使ADCC效应器功能。介导ADCC的人白细胞的例子包括外周血单个核细胞(PBMC),天然杀伤(NK)细胞,单核细胞,细胞毒性T细胞和嗜中性粒细胞,优选PBMC和NK细胞。效应细胞可以从其天然来源例如血液分离。
“Fc受体”或“FcR”描述结合抗体Fc区的受体。优选的FcR是天然序列人FcR。此外,优选的FcR是结合IgG抗体的FcR(γ受体),包括FcγRI,FcγRII和FcγRIII亚类的受体,包括这些受体的等位变体和可变剪接形式。FcγRII受体包括FcγRIIA(“活化受体”)和FcγRIIB(“抑制受体”),它们具有相似的氨基酸序列,区别主要在其胞质结构域中。活化受体FcγRIIA在其胞质结构域中包含免疫受体基于酪氨酸的活化基序(ITAM)。抑制受体FcγRIIB在其胞质结构域中包含免疫受体基于酪氨酸的抑制基序(ITIM)(参见综述 Annu.Rev.Immunol.15:203-234(1997))。FcR的综述参见Ravetch和Kinet,Annu.Rev.Immunol.9:457-492(1991);Capel等,Immunomethods 4:25-34(1994);de Haas等,J.Lab.Clin.Med.126:330-41(1995)。术语“FcR”在本文中涵盖其它FcR,包括那些未来将会鉴定的。该术语还包括新生儿受体,FcRn,它负责将母体IgG转移给胎儿(Guyer等,J.Immunol.117:587(1976)及Kim等,J.Immunol.24:249(1994))并调节免疫球蛋白的稳态。WO 00/42072(Presta)记载了对FcR的结合提高或降低的抗体变体。在此明确收入该专利出版物的内容作为参考。还可参见Shields等,J.Biol.Chem.9(2):6591-6604(2001)。
Annu.Rev.Immunol.15:203-234(1997))。FcR的综述参见Ravetch和Kinet,Annu.Rev.Immunol.9:457-492(1991);Capel等,Immunomethods 4:25-34(1994);de Haas等,J.Lab.Clin.Med.126:330-41(1995)。术语“FcR”在本文中涵盖其它FcR,包括那些未来将会鉴定的。该术语还包括新生儿受体,FcRn,它负责将母体IgG转移给胎儿(Guyer等,J.Immunol.117:587(1976)及Kim等,J.Immunol.24:249(1994))并调节免疫球蛋白的稳态。WO 00/42072(Presta)记载了对FcR的结合提高或降低的抗体变体。在此明确收入该专利出版物的内容作为参考。还可参见Shields等,J.Biol.Chem.9(2):6591-6604(2001)。
测量对FcRn的结合的方法是已知的(参见例如Ghetie 1997,Hinton 2004)。可测定人FcRn高亲和力结合多肽与人FcRn的体内结合和血清半衰期,例如在表达人FcRn的转基因小鼠或经转染的人细胞系中,或者在施用了Fc变体多肽的灵长类动物中。
“补体依赖性细胞毒性”或“CDC”指存在补体时对靶细胞的溶解。经典补体途径的激活是由补体系统第一组分(C1q)结合其关联抗原所结合的抗体(适宜亚类的)起始的。为了评估补体激活,可进行CDC测定法,例如如Gazzano-Santoro et al.,J.Immunol.Methods202:163(1996)中所记载的。
具有更改的Fc区氨基酸序列及提高或降低的C1q结合能力的多肽变体记载于美国专利No.6,194,551B1和WO 99/51642。在此明确收入那些专利出版物的内容作为参考。还可参见Idusogie等,J.Immunol.164:4178-4184(2000)。
术语“含Fc区多肽”指包含Fc区的多肽,诸如抗体或免疫粘附素。Fc区的C-末端赖氨酸(依照EU编号系统的残基447)可以消除,例如在纯化多肽的过程中或者通过重组改造编码多肽的核酸。因此,依照本发明包含具有Fc区的多肽的组合物可包含具有K447的多肽,消除了所有K447的多肽,或具有与没有K447残基的多肽的混合物。
就本文目的而言,“受体人框架”是包含衍生自人免疫球蛋白框架或人共有框架的VL或VH框架之氨基酸序列的框架。“衍生自”人免疫球蛋白框架或人共有框架的受体人框架可包含与之相同的氨基酸序列,或者可包含预先存在的氨基酸序列变化。当存在预先存在的氨基酸变化时,优选存在不超过5个,优选4个或更少,或者3个或更少预先存在的氨基酸变化。当VH中存在预先存在的氨基酸变化时,优选那些变化只位于71H,73H和78H中的三个,两个,或一个位置;例如,位于那些位置的氨基酸残基可以是71A,73T,和/或78A。在一个实施方案中,VL受体人框架在序列上与VL人免疫球蛋白框架序列或人共有框架序列相同。
“人共有框架”指代表人免疫球蛋白VL或VH框架序列选集中最常见的氨基酸残基的框架。通常,人免疫球蛋白VL或VH序列选集来自可变域序列亚组。通常,序列亚组是如Kabat等的亚组。在一个实施方案中,对于VL,所述亚组是如Kabat等的亚组κI。在一个实施方案中,对于VH,所述亚组是如Kabat等的亚组III。
“VH亚组III共有框架”包含从Kabat等的可变重链亚组III中的氨基酸序列获得的共有序列。在一个实施方案中,VH亚组III共有框架氨基酸序列包含下列各序列的至少一部分或整个:
EVQLVESGGGLVQPGGSLRLSCAAS(SEQ ID NO:95)-H1-WVRQAPGKGLEWV(SEQ ID NO:96)-H2-RFTISRDNSKNTLYLQMNSLRAEDTAVYYC(SEQ ID NO:97)-H3-WGQGTLVTVSS(SEQ ID NO:98)。
“VL亚组I共有框架”包含从Kabat等的可变轻链κ亚组I中的氨基酸序列获得的共有序列。在一个实施方案中,VL亚组I共有框架氨基酸序列包含下列各序列的至少一部分或整个:
DIQMTQSPSSLSASVGDRVTITC(SEQ ID NO:99)-L1-WYQQKPGKAPKLLIY(SEQ ID NO:100)-L2-GVPSRFSGSGSGTDFTLTISSLQPEDFATYYC(SEQ ID NO:101)-L3-FGQGTKVEIK(SEQ IDNO:102)。
在用于本文时,“抗体突变体”或“抗体变体”指抗体的氨基酸序列变体,其中物种依赖性抗体的一个或多个氨基酸残基发生了修饰。此类突变体与物种依赖性抗体必然具有小于100%的序列同一性或相似性。在一个的实施方案中,抗体突变体所具有的氨基酸序列与物种依赖性抗体的重链或轻链可变域的氨基酸序列具有至少75%,更优选至少80%,更优选至少85%,更优选至少90%,最优选至少95%的氨基酸序列同一性或相似性。关于此序列的同一性或相似性在本文中定义为在比对序列并在必要时引入缺口以实现最大百分比序列同一性后,候选序列中与物种依赖性抗体残基相同(即相同残基)或相似(即根据共同侧链特性来自同一组的氨基酸残基,见下文)的氨基酸残基的百分比。N-末端,C-末端,或对可变域(区)之外的抗体序列内部的延伸,删除,或插入都不应视为影响序列同一性或相似性。
“病症”或“疾病”指任何会受益于本发明的物质/分子或方法的治疗的疾患。这包括慢性和急性病症或疾病,包括那些使哺乳动物倾向于所讨论病症的病理状况。本文中待治疗的病症的非限制性例子包括恶性和良性肿瘤;癌瘤,母细胞瘤和肉瘤。
术语“治疗有效量”指在哺乳动物中治疗或预防疾病或病症的治疗剂量。在癌症的情况中,治疗有效量的治疗剂可减少癌细胞的数目;缩小原发性肿瘤的尺寸;抑制(即一定程度的减缓,优选阻止)癌细胞浸润入周围器官;抑制(即一定程度的减缓,优选阻止)肿瘤转移;一定程度的抑制肿瘤生长;和/或一定程度的减轻一种或多种与病症有关的症状。根据药物可阻止现有癌细胞生长和/或杀死现有癌细胞的程度,它可以是细胞抑制性的和/或细胞毒性的。对于癌症疗法,体内功效可以通过例如评估存活持续时间,距疾病进展的时间(TTP),响应率(RR),响应持续时间,和/或生活质量来测量。
术语“癌(症)”和“癌(性)的”指向或描述哺乳动物中典型的以不受调节的细胞生长为特征的生理疾患。此定义中包括良性和恶性癌症。“早期癌症”或“早期肿瘤”指非侵入性的或转移性的,或者归为0期,I期,或II期癌症的癌症。癌症的例子包括但不限于癌,淋巴瘤,母细胞瘤(包括髓母细胞瘤和视网膜母细胞瘤),肉瘤(包括脂肪肉瘤和滑膜细胞肉瘤),神经内分泌肿瘤(包括类癌瘤,胃泌素瘤和胰岛细胞癌),间皮瘤,施旺氏细胞瘤(包括听神经瘤),脑膜瘤,腺癌,黑素瘤,和白血病或淋巴样恶性肿瘤。此类癌症的更具体例子包括鳞状细胞癌(例如上皮鳞状细胞癌),肺癌包括小细胞肺癌(SCLC),非小细胞肺癌(NSCLC),肺的腺癌和肺的鳞癌,腹膜癌,肝细胞癌,胃的癌或胃癌包括胃肠癌,胰腺癌,成胶质细胞瘤,宫颈癌,卵巢癌,肝癌,膀胱癌,肝瘤,乳腺癌(包括转移性乳腺癌),结肠癌,直肠癌,结肠直肠癌,子宫内膜癌或子宫癌,唾液腺癌,肾癌或肾的癌,前列腺癌,外阴癌,甲状腺癌,肝的癌,肛门癌,阴茎癌,睾丸癌,食道癌,胆管肿瘤,及头和颈癌和多发性骨髓瘤。
术语“癌前”指典型地在癌之前或发展成癌的疾患或生长。“癌前”生长会具有以异常细胞周期调节,增殖,或分化为特征的细胞,这些可通过细胞周期调节,细胞增殖,或分化的标志物来测定。
“发育异常”指组织,器官,或细胞的任何异常生长或发育。优选的是,发育异常是高级的或癌前的。
“转移”指癌自其原发部位传播至身体中的其它位置。癌细胞能脱离原发性肿瘤,渗透入淋巴和血管,经由血流而循环和在身体中其它地方的正常组织中的远端病灶(转移)中生长。转移可以是当地的或远端的。转移是一个连续过程,视肿瘤细胞自原发性肿瘤脱落,经由血流而传播,并在远端部位停止而定。在新的部位,该细胞建立血供且能生长至形成危及生命的团块。
肿瘤细胞内的刺激性和抑制性分子途径调节这种行为,而且肿瘤细胞与远端部位中的宿主细胞之间的相互作用也是重要的。
“非转移的”指良性的或保留在原发部位且尚未渗透入淋巴或血管系统或渗透至原发部位以外的组织的癌症。一般而言,非转移性癌症指作为0期,I期,或II期癌症和偶尔的III期癌症的任何癌症。
“原发性肿瘤”或“原发性癌”指初始的癌症,而不是位于受试者身体中另一组织,器官,或位置中的转移病灶。
“良性肿瘤”或“良性癌”指仍然局限于起源部位且没有能力渗透,侵入,或转移至远端部位的肿瘤。
“肿瘤载荷”指身体中癌细胞的数目,肿瘤的尺寸,或癌的量。肿瘤载荷也称作肿瘤负荷。
“肿瘤数目”指肿瘤的数目。
“受试者”指哺乳动物,包括但不限于人或非人哺乳动物,诸如牛,马,犬,绵羊,或猫。优选地,受试者是人。
术语“抗癌疗法”指在治疗癌症中有用的疗法。抗癌治疗剂的例子包括但不限于例如化疗剂,生长抑制剂,细胞毒剂,放射疗法中所使用的药剂,抗血管发生剂,凋亡剂,抗微管蛋白剂,和其它治疗癌症的药剂,抗CD20抗体,血小板衍生生长因子抑制剂(例如GleevecTM(Imatinib Mesylate)),COX-2抑制剂(例如celecoxib),干扰素,细胞因子,结合一种或多种以下靶物的拮抗剂(例如中和性抗体)(ErbB2,ErbB3,ErbB4,PDGFR-β,BlyS,APRIL,BCMA或VEGF受体,TRAIL/Apo2),和其它生物活性和有机化学剂,等。本发明还包括它们的组合。
“化疗剂”指可用于治疗癌症的化学化合物。化疗剂的例子包括可用于治疗癌症的化学化合物。化疗剂的例子包括烷化剂类(alkylating agents),诸如塞替派(thiotepa)和 环磷酰胺(cyclosphosphamide);磺酸烷基酯类(alkyl sulfonates),诸如白消安(busulfan),英丙舒凡(improsulfan)和哌泊舒凡(piposulfan);氮丙啶类(aziridines),诸如苯佐替派(benzodopa),卡波醌(carboquone),美妥替派(meturedopa)和乌瑞替派(uredopa);乙撑亚胺类(ethylenimines)和甲基蜜胺类(methylamelamines),包括六甲蜜胺(altretamine),三乙撑蜜胺(triethylenemelamine),三乙撑磷酰胺(triethylenephosphoramide),三乙撑硫代磷酰胺(triethiylenethiophosphoramide)和三羟甲蜜胺(trimethylolomelamine);番荔枝内酯类(acetogenins)(尤其是布拉他辛(bullatacin)和布拉他辛酮(bullatacinone));喜树碱(camptothecin)(包括合成类似物托泊替康(topotecan));苔藓抑素(bryostatin);callystatin;CC-1065(包括其阿多来新(adozelesin),卡折来新(carzelesin)和比折来新(bizelesin)合成类似物);隐藻素类(cryptophycins)(特别是隐藻素1和隐藻素8);多拉司他汀(dolastatin);duocarmycin(包括合成类似物,KW-2189和CB1-TM1);艾榴塞洛素(eleutherobin);pancratistatin;sarcodictyin;海绵抑素(spongistatin);氮芥类(nitrogen mustards),诸如苯丁酸氮芥(chlorambucil),萘氮芥(chlornaphazine),胆磷酰胺(cholophosphamide),雌莫司汀(estramustine),异环磷酰胺(ifosfamide),双氯乙基甲胺(mechlorethamine),盐酸氧氮芥(mechlorethamine oxide hydrochloride),美法仑(melphalan),新氮芥(novembichin),苯芥胆甾醇(phenesterine),泼尼莫司汀(prednimustine),曲磷胺(trofosfamide),尿嘧啶氮芥(uracil mustard);亚硝脲类(nitrosureas),诸如卡莫司汀(carmustine),氯脲菌素(chlorozotocin),福莫司汀(fotemustine),洛莫司汀(lomustine),尼莫司汀(nimustine)和雷莫司汀(ranimnustine);抗生素类,诸如烯二炔类抗生素(enediyne)(例如加利车霉素(calicheamicin),尤其是加利车霉素γ1I和加利车霉素ωI1(参见例如Agnew(1994)Chem.Intl.Ed.Engl.33:183-186);蒽环类抗生素(dynemicin),包括dynemicin A;二膦酸盐类(bisphosphonates),诸如氯膦酸盐(clodronate);埃斯波霉素(esperamicin);以及新制癌素(neocarzinostatin)发色团和相关色蛋白烯二炔类抗生素发色团),阿克拉霉素(aclacinomysin),放线菌素(actinomycin),氨茴霉素(authramycin),偶氮丝氨酸(azaserine),博来霉素(bleomycin),放线菌素C(cactinomycin),carabicin,洋红霉素(carminomycin),嗜癌霉素(carzinophilin),色霉素(chromomycinis),放线菌素D(dactinomycin),柔红霉素(daunorubicin),地托比星(detorubicin),6-二氮-5-氧-L-正亮氨酸,
环磷酰胺(cyclosphosphamide);磺酸烷基酯类(alkyl sulfonates),诸如白消安(busulfan),英丙舒凡(improsulfan)和哌泊舒凡(piposulfan);氮丙啶类(aziridines),诸如苯佐替派(benzodopa),卡波醌(carboquone),美妥替派(meturedopa)和乌瑞替派(uredopa);乙撑亚胺类(ethylenimines)和甲基蜜胺类(methylamelamines),包括六甲蜜胺(altretamine),三乙撑蜜胺(triethylenemelamine),三乙撑磷酰胺(triethylenephosphoramide),三乙撑硫代磷酰胺(triethiylenethiophosphoramide)和三羟甲蜜胺(trimethylolomelamine);番荔枝内酯类(acetogenins)(尤其是布拉他辛(bullatacin)和布拉他辛酮(bullatacinone));喜树碱(camptothecin)(包括合成类似物托泊替康(topotecan));苔藓抑素(bryostatin);callystatin;CC-1065(包括其阿多来新(adozelesin),卡折来新(carzelesin)和比折来新(bizelesin)合成类似物);隐藻素类(cryptophycins)(特别是隐藻素1和隐藻素8);多拉司他汀(dolastatin);duocarmycin(包括合成类似物,KW-2189和CB1-TM1);艾榴塞洛素(eleutherobin);pancratistatin;sarcodictyin;海绵抑素(spongistatin);氮芥类(nitrogen mustards),诸如苯丁酸氮芥(chlorambucil),萘氮芥(chlornaphazine),胆磷酰胺(cholophosphamide),雌莫司汀(estramustine),异环磷酰胺(ifosfamide),双氯乙基甲胺(mechlorethamine),盐酸氧氮芥(mechlorethamine oxide hydrochloride),美法仑(melphalan),新氮芥(novembichin),苯芥胆甾醇(phenesterine),泼尼莫司汀(prednimustine),曲磷胺(trofosfamide),尿嘧啶氮芥(uracil mustard);亚硝脲类(nitrosureas),诸如卡莫司汀(carmustine),氯脲菌素(chlorozotocin),福莫司汀(fotemustine),洛莫司汀(lomustine),尼莫司汀(nimustine)和雷莫司汀(ranimnustine);抗生素类,诸如烯二炔类抗生素(enediyne)(例如加利车霉素(calicheamicin),尤其是加利车霉素γ1I和加利车霉素ωI1(参见例如Agnew(1994)Chem.Intl.Ed.Engl.33:183-186);蒽环类抗生素(dynemicin),包括dynemicin A;二膦酸盐类(bisphosphonates),诸如氯膦酸盐(clodronate);埃斯波霉素(esperamicin);以及新制癌素(neocarzinostatin)发色团和相关色蛋白烯二炔类抗生素发色团),阿克拉霉素(aclacinomysin),放线菌素(actinomycin),氨茴霉素(authramycin),偶氮丝氨酸(azaserine),博来霉素(bleomycin),放线菌素C(cactinomycin),carabicin,洋红霉素(carminomycin),嗜癌霉素(carzinophilin),色霉素(chromomycinis),放线菌素D(dactinomycin),柔红霉素(daunorubicin),地托比星(detorubicin),6-二氮-5-氧-L-正亮氨酸, 多柔比星(doxorubicin)(包括吗啉代多柔比星,氰基吗啉代多柔比星,2-吡咯代多柔比星和脱氧多柔比星),表柔比星(epirubicin),依索比星(esorubicin),伊达比星(idarubicin),麻西罗霉素(marcellomycin),丝裂霉素类(mitomycins)诸如丝裂霉素C,霉酚酸(mycophenolic acid),诺拉霉素(nogalamycin),橄榄霉素(olivomycin),培洛霉素(peplomycin),泊非霉素(potfiromycin),嘌呤霉素(puromycin),三铁阿霉素(quelamycin),罗多比星(rodorubicin),链黑菌素(streptonigrin),链佐星(streptozocin),杀结核菌素(tubercidin),乌苯美司(ubenimex),净司他丁(zinostatin),佐柔比星(zorubicin);抗代谢物类,诸如甲氨蝶呤(methotrexate)和5-氟尿嘧啶(5-FU);叶酸类似物,诸如二甲叶酸(denopterin),甲氨蝶呤(methotrexate),蝶罗呤(pteropterin),三甲曲沙(trimetrexate);嘌呤类似物,诸如氟达拉滨(fludarabine),6-巯基嘌呤(mercaptopurine),硫咪嘌呤(thiamiprine),硫鸟嘌呤(thioguanine);嘧啶类似物,诸如安西他滨(ancitabine),阿扎胞苷(azacitidine),6-氮尿苷(azauridine),卡莫氟(carmofur),阿糖胞苷(cytarabine),双脱氧尿苷(dideoxyuridine),去氧氟尿苷(doxifluridine),依诺他滨(enocitabine),氟尿苷(floxuridine);雄激素类,诸如卡鲁睾酮(calusterone),丙酸屈他雄酮(dromostanolone propionate),表硫雄醇(epitiostanol),美雄烷(mepitiostane),睾内酯(testolactone);抗肾上腺类,诸如氨鲁米特(aminoglutethimide),米托坦(mitotane),曲洛司坦(trilostane);叶酸补充剂,诸如亚叶酸(frolinic acid);醋葡醛内酯(aceglatone);醛磷酰胺糖苷(aldophosphamideglycoside);氨基乙酰丙酸(aminolevulinic acid);恩尿嘧啶(eniluracil);安吖啶(amsacrine);bestrabucil;比生群(bisantrene);依达曲沙(edatraxate);地磷酰胺(defofamine);地美可辛(demecolcine);地吖醌(diaziquone);elfornithine;依利醋铵(elliptinium acetate);埃坡霉素(epothilone);依托格鲁(etoglucid);硝酸镓;羟脲(hydroxyurea);香菇多糖(lentinan);氯尼达明(lonidainine);美登木素生物碱类(maytansinoids),诸如美登素(maytansine)和安丝菌素(ansamitocin);米托胍腙(mitoguazone);米托蒽醌(mitoxantrone);莫哌达醇(mopidanmol);二胺硝吖啶(nitraerine);喷司他丁(pentostatin);蛋氨氮芥(phenamet);吡柔比星(pirarubicin);洛索蒽醌(losoxantrone);鬼臼酸(podophyllinic acid);2-乙基酰肼(ethylhydrazide);丙卡巴肼(procarbazine);
多柔比星(doxorubicin)(包括吗啉代多柔比星,氰基吗啉代多柔比星,2-吡咯代多柔比星和脱氧多柔比星),表柔比星(epirubicin),依索比星(esorubicin),伊达比星(idarubicin),麻西罗霉素(marcellomycin),丝裂霉素类(mitomycins)诸如丝裂霉素C,霉酚酸(mycophenolic acid),诺拉霉素(nogalamycin),橄榄霉素(olivomycin),培洛霉素(peplomycin),泊非霉素(potfiromycin),嘌呤霉素(puromycin),三铁阿霉素(quelamycin),罗多比星(rodorubicin),链黑菌素(streptonigrin),链佐星(streptozocin),杀结核菌素(tubercidin),乌苯美司(ubenimex),净司他丁(zinostatin),佐柔比星(zorubicin);抗代谢物类,诸如甲氨蝶呤(methotrexate)和5-氟尿嘧啶(5-FU);叶酸类似物,诸如二甲叶酸(denopterin),甲氨蝶呤(methotrexate),蝶罗呤(pteropterin),三甲曲沙(trimetrexate);嘌呤类似物,诸如氟达拉滨(fludarabine),6-巯基嘌呤(mercaptopurine),硫咪嘌呤(thiamiprine),硫鸟嘌呤(thioguanine);嘧啶类似物,诸如安西他滨(ancitabine),阿扎胞苷(azacitidine),6-氮尿苷(azauridine),卡莫氟(carmofur),阿糖胞苷(cytarabine),双脱氧尿苷(dideoxyuridine),去氧氟尿苷(doxifluridine),依诺他滨(enocitabine),氟尿苷(floxuridine);雄激素类,诸如卡鲁睾酮(calusterone),丙酸屈他雄酮(dromostanolone propionate),表硫雄醇(epitiostanol),美雄烷(mepitiostane),睾内酯(testolactone);抗肾上腺类,诸如氨鲁米特(aminoglutethimide),米托坦(mitotane),曲洛司坦(trilostane);叶酸补充剂,诸如亚叶酸(frolinic acid);醋葡醛内酯(aceglatone);醛磷酰胺糖苷(aldophosphamideglycoside);氨基乙酰丙酸(aminolevulinic acid);恩尿嘧啶(eniluracil);安吖啶(amsacrine);bestrabucil;比生群(bisantrene);依达曲沙(edatraxate);地磷酰胺(defofamine);地美可辛(demecolcine);地吖醌(diaziquone);elfornithine;依利醋铵(elliptinium acetate);埃坡霉素(epothilone);依托格鲁(etoglucid);硝酸镓;羟脲(hydroxyurea);香菇多糖(lentinan);氯尼达明(lonidainine);美登木素生物碱类(maytansinoids),诸如美登素(maytansine)和安丝菌素(ansamitocin);米托胍腙(mitoguazone);米托蒽醌(mitoxantrone);莫哌达醇(mopidanmol);二胺硝吖啶(nitraerine);喷司他丁(pentostatin);蛋氨氮芥(phenamet);吡柔比星(pirarubicin);洛索蒽醌(losoxantrone);鬼臼酸(podophyllinic acid);2-乙基酰肼(ethylhydrazide);丙卡巴肼(procarbazine); 多糖复合物(JHS Natural Products,Eugene,OR);雷佐生(razoxane);根霉素(rhizoxin);西佐喃(sizofiran);螺旋锗(spirogermanium);细交链孢菌酮酸(tenuazonic acid);三亚胺醌(triaziquone);2,2′,2”-三氯三乙胺;单端孢菌素类(trichothecenes)(尤其是T-2毒素,疣孢菌素(verracurin)A,杆孢菌素(roridin)A和蛇行菌素(anguidine));乌拉坦(urethan);长春地辛(vindesine);达卡巴嗪(dacarbazine);甘露莫司汀(mannomustine);二溴甘露醇(mitobronitol);二溴卫矛醇(mitolactol);哌泊溴烷(pipobroman);gacytosine;阿糖胞苷(arabinoside)(“Ara-C”);环磷酰胺(cyclophosphamide);塞替派(thiotepa);类紫杉醇类(taxoids),例如
多糖复合物(JHS Natural Products,Eugene,OR);雷佐生(razoxane);根霉素(rhizoxin);西佐喃(sizofiran);螺旋锗(spirogermanium);细交链孢菌酮酸(tenuazonic acid);三亚胺醌(triaziquone);2,2′,2”-三氯三乙胺;单端孢菌素类(trichothecenes)(尤其是T-2毒素,疣孢菌素(verracurin)A,杆孢菌素(roridin)A和蛇行菌素(anguidine));乌拉坦(urethan);长春地辛(vindesine);达卡巴嗪(dacarbazine);甘露莫司汀(mannomustine);二溴甘露醇(mitobronitol);二溴卫矛醇(mitolactol);哌泊溴烷(pipobroman);gacytosine;阿糖胞苷(arabinoside)(“Ara-C”);环磷酰胺(cyclophosphamide);塞替派(thiotepa);类紫杉醇类(taxoids),例如 帕利他塞(paclitaxel)(Bristol-Myers Squibb Oncology,Princeton,N.J.),ABRAXANETM不含克列莫佛(Cremophor),清蛋白改造纳米颗粒剂型帕利他塞(American PharmaceuticalPartners,Schaumberg,Illinois)和
帕利他塞(paclitaxel)(Bristol-Myers Squibb Oncology,Princeton,N.J.),ABRAXANETM不含克列莫佛(Cremophor),清蛋白改造纳米颗粒剂型帕利他塞(American PharmaceuticalPartners,Schaumberg,Illinois)和 多西他塞(doxetaxel)(
多西他塞(doxetaxel)( -Poulenc Rorer,Antony,France);苯丁酸氮芥(chloranbucil);
-Poulenc Rorer,Antony,France);苯丁酸氮芥(chloranbucil); 吉西他滨(gemcitabine);6-硫鸟嘌呤(thioguanine);巯基嘌呤(mercaptopurine);甲氨蝶呤(methotrexate);铂类似物,诸如顺铂(cisplatin)和卡铂(carboplatin);长春碱(vinblastine);铂(platinum);依托泊苷(etoposide)(VP-16);异环磷酰胺(ifosfamide);米托蒽醌(mitoxantrone);长春新碱(vincristine);
吉西他滨(gemcitabine);6-硫鸟嘌呤(thioguanine);巯基嘌呤(mercaptopurine);甲氨蝶呤(methotrexate);铂类似物,诸如顺铂(cisplatin)和卡铂(carboplatin);长春碱(vinblastine);铂(platinum);依托泊苷(etoposide)(VP-16);异环磷酰胺(ifosfamide);米托蒽醌(mitoxantrone);长春新碱(vincristine); 长春瑞滨(vinorelbine);能灭瘤(novantrone);替尼泊苷(teniposide);依达曲沙(edatrexate);道诺霉素(daunomycin);氨基蝶呤(aminopterin);希罗达(xeloda);伊本膦酸盐(ibandronate);伊立替康(irinotecan)(Camptosar,CPT-11)(包括伊立替康及5-FU和亚叶酸的治疗方案);拓扑异构酶抑制剂RFS2000;二氟甲基鸟氨酸(DMFO);类视黄酸类(retinoids),诸如视黄酸(retinoic acid);卡培他滨(capecitabine);考布他汀(combretastatin);VELCADE bortezomib;REVLIMID lenalidomide;亚叶酸(leucovorin)(LV);奥沙利铂(oxaliplatin),包括奥沙利铂治疗方案(FOLFOX);PKC-α,Raf,H-Ras,EGFR(例如Erlotinib(TarcevaTM))和VEGF-A的,降低细胞增殖的抑制剂;及任何上述物质的药剂学可接受的盐,酸或衍生物。
长春瑞滨(vinorelbine);能灭瘤(novantrone);替尼泊苷(teniposide);依达曲沙(edatrexate);道诺霉素(daunomycin);氨基蝶呤(aminopterin);希罗达(xeloda);伊本膦酸盐(ibandronate);伊立替康(irinotecan)(Camptosar,CPT-11)(包括伊立替康及5-FU和亚叶酸的治疗方案);拓扑异构酶抑制剂RFS2000;二氟甲基鸟氨酸(DMFO);类视黄酸类(retinoids),诸如视黄酸(retinoic acid);卡培他滨(capecitabine);考布他汀(combretastatin);VELCADE bortezomib;REVLIMID lenalidomide;亚叶酸(leucovorin)(LV);奥沙利铂(oxaliplatin),包括奥沙利铂治疗方案(FOLFOX);PKC-α,Raf,H-Ras,EGFR(例如Erlotinib(TarcevaTM))和VEGF-A的,降低细胞增殖的抑制剂;及任何上述物质的药剂学可接受的盐,酸或衍生物。
该定义还包括作用于调节或抑制激素对肿瘤作用的抗激素剂诸如抗雌激素类和选择性雌激素受体调控物类(SERM),包括例如他莫昔芬(tamoxifen)(包括 他莫昔芬),雷洛昔芬(raloxifene),屈洛昔芬(droloxifene),4-羟基他莫昔芬,曲沃昔芬(trioxifene),那洛昔芬(keoxifene),LY117018,奥那司酮(onapristone)和
他莫昔芬),雷洛昔芬(raloxifene),屈洛昔芬(droloxifene),4-羟基他莫昔芬,曲沃昔芬(trioxifene),那洛昔芬(keoxifene),LY117018,奥那司酮(onapristone)和 托瑞米芬(toremifene);抑制在肾上腺中调节雌激素生成的芳香酶的芳香酶抑制剂,诸如例如4(5)-咪唑,氨鲁米特(aminoglutethimide),
托瑞米芬(toremifene);抑制在肾上腺中调节雌激素生成的芳香酶的芳香酶抑制剂,诸如例如4(5)-咪唑,氨鲁米特(aminoglutethimide), 醋酸甲地孕酮(megestrol acetate),
醋酸甲地孕酮(megestrol acetate), 依西美坦(exemestane),福美坦(formestanie),法倔唑(fadrozole),
依西美坦(exemestane),福美坦(formestanie),法倔唑(fadrozole), 伏罗唑(vorozole),
伏罗唑(vorozole), 来曲唑(letrozole)和
来曲唑(letrozole)和 阿那曲唑(anastrozole);抗雄激素类,诸如氟他米特(flutamide),尼鲁米特(nilutamide),比卡米特(bicalutamide),亮丙瑞林(leuprolide),和戈舍瑞林(goserelin);以及曲沙他滨(troxacitabine)(1,3-二氧戊环核苷胞嘧啶类似物);反义寡核苷酸,特别是抑制涉及异常(abherant)细胞增殖的信号途经中的基因表达的反义寡核苷酸,诸如例如PKC-α,Raf和H-Ras;核酶,诸如VEGF表达抑制剂(例如
阿那曲唑(anastrozole);抗雄激素类,诸如氟他米特(flutamide),尼鲁米特(nilutamide),比卡米特(bicalutamide),亮丙瑞林(leuprolide),和戈舍瑞林(goserelin);以及曲沙他滨(troxacitabine)(1,3-二氧戊环核苷胞嘧啶类似物);反义寡核苷酸,特别是抑制涉及异常(abherant)细胞增殖的信号途经中的基因表达的反义寡核苷酸,诸如例如PKC-α,Raf和H-Ras;核酶,诸如VEGF表达抑制剂(例如 核酶)和HER2表达抑制剂;疫苗,诸如基因疗法疫苗,例如
核酶)和HER2表达抑制剂;疫苗,诸如基因疗法疫苗,例如 疫苗,
疫苗, 疫苗和
疫苗和 疫苗;
疫苗; rIL-2;
rIL-2; 拓扑异构酶1抑制剂;
拓扑异构酶1抑制剂; rmRH;长春瑞滨(Vinorelbine)和埃斯波霉素(Esperamicins)(见美国专利No.4,675,187);及任何上述物质的药剂学可接受的盐,酸或衍生物。
rmRH;长春瑞滨(Vinorelbine)和埃斯波霉素(Esperamicins)(见美国专利No.4,675,187);及任何上述物质的药剂学可接受的盐,酸或衍生物。
术语“前体药物”在用于本申请时指与母药(parent drug)相比对肿瘤细胞的细胞毒性较小并能够酶促活化或转变为更具活性母药形式的药用活性物质的前体和衍生物形式。参见例如Wilman,“Prodrugs in Cancer Chemotherapy”,Biochemical SocietyTransactions,14,pp.375-382,615th Meeting Belfast(1986)和Stella et al.,“Prodrugs:A Chemical Approach to Targeted Drug Delivery”,Directed DrugDelivery,Borchardt et al.,(ed.),pp.247-267,Humana Press(1985)。本发明的前体药物包括但不限于含磷酸盐/酯前体药物,含硫代磷酸盐/酯前体药物,含硫酸盐/酯前体药物,含肽前体药物,D-氨基酸修饰前体药物,糖基化前体药物,含β-内酰胺前体药物,含任选取代苯氧基乙酰胺的前体药物或含任选取代苯乙酰胺的前体药物,可转化为更具活性而无细胞毒性的药物的5-氟胞嘧啶和其它5-氟尿苷前体药物。可衍生为本发明使用的前体药物形式的细胞毒性药物的例子包括但不限于上文描述的那些化疗剂。
“放射疗法”或“放疗”指使用定向伽马射线或贝塔射线来诱发对细胞的足够损伤,以限制细胞正常发挥功能的能力或全然破坏细胞。应当领会,本领域知道许多方式来确定治疗的剂量和持续时间。典型的治疗作为一次施用来给予,而典型的剂量范围为每天10-200个单位(戈瑞(Gray))。
“生物学样品”(可互换地称作“样品”或“组织或细胞样品”)涵盖自个体获得的且可用于诊断或监测测定法的多种样品类型。该定义涵盖血液和生物学起源的其它液体样品,固体组织样品诸如活检标本或组织培养物或自其衍生的细胞,及其后代。该定义还涵盖在获得它们后已经进行过操作的样品,诸如用试剂处理,增溶,或富集某些成分诸如蛋白质或多核苷酸,或为切片目的而埋藏在半固体或固体基质中。术语“生物学样品”涵盖临床样品,而且还包括培养中的细胞,细胞上清液,细胞溶胞物,血清,血浆,生物学流体,和组织样品。生物学样品的来源可以是实体组织,像来自新鲜的,冷冻的和/或保存的器官或组织样品或活检样品或穿刺样品;血液或任何血液组分;体液,诸如脑脊液,羊水,腹膜液,或间质液;来自妊娠或个体发育中任何时间的细胞。在有些实施方案中,生物学样品是自原发性或转移性肿瘤获得的。生物学样品可含有在自然界中不与该组织天然混和的化合物,诸如防腐剂,抗凝剂,缓冲剂,固定剂,营养物,抗生素,诸如此类。
为本发明目的,组织样品的“切片”指一块或一片组织样品,例如从组织样品上切下来的一薄片组织或细胞。应当了解,可以制作多片组织样品切片并依照本发明进行分析。在有些实施方案中,将组织样品的同一切片用于形态学和分子两个水平的分析或者针对蛋白质和核酸二者进行分析。
术语“标记物”在用于本文时指与试剂诸如核酸探针或抗体直接或间接缀合或融合,以便于检测它所缀合或融合的试剂的化合物或组合物。标记物可以是自身可检测的(例如放射性同位素标记物或荧光标记物),或者在酶标记物的情况中,可催化可检测的底物化合物或组合物的化学改变。
抗FGFR2/3抗体组合物和使用抗FGFR2/3抗体的方法
本发明涵盖组合物(包括药物组合物),其包含抗FGFR2/3抗体;和包含编码抗FGFR2/3抗体的序列的多核苷酸。如本文中所使用的,组合物包含一种或多种结合FGFR2和FGFR3的抗体,和/或一种或多种包含编码一种或多种结合FGFR2和FGFR3的抗体的序列的多核苷酸。这些组合物可进一步包含合适的载体,诸如药学可接受的赋形剂,包括缓冲剂,它们是本领域公知的。
本发明还涵盖分离的抗体和多核苷酸的实施方案。本发明还涵盖基本上纯的抗体和多核苷酸的实施方案。
本发明还涵盖使用抗FGFR2/3抗体(如本文中描述的或如本领域已知的)治疗病症,例如多发性骨髓瘤或过渡阶段癌瘤(例如侵入性过渡阶段癌瘤)的方法。
抗FGFR2/3抗体组合物
本发明的抗FGFR2/3抗体优选是单克隆的。本发明的范围还涵盖本文中所提供的抗FGFR2/3抗体的Fab,Fab′,Fab′-SH和F(ab′)2片段。这些抗体片段可通过传统手段来制备,诸如酶促消化,或者可以通过重组技术来生成。此类抗体片段可以是嵌合的或人源化的。这些片段可用于下文所列的诊断和治疗目的。
单克隆抗体是由一群基本上同质的抗体获得的,即构成群体的各个抗体相同,除了可能以极小量存在的可能的天然存在突变。如此,修饰语“单克隆”指明抗体的特征,即不是不同抗体的混合物。
本发明的抗FGFR2/3单克隆抗体可使用最初由Kohler等,Nature 256:495(1975)记载的杂交瘤方法来制备,或者可以通过重组DNA方法(美国专利No.4,816,567)来制备。
在杂交瘤方法中,免疫小鼠或其它适宜的宿主动物,诸如仓鼠,以引发生成或能够生成如下抗体的淋巴细胞,所述抗体会特异性结合用于免疫的蛋白质。FGFR2/3的抗体可以通过在动物中多次皮下(sc)或腹膜内(ip)注射FGFR2/3和佐剂来生成。FGFR2/3可以使用本领域众所周知的方法来制备,其中有些方法在本文中有进一步描述。例如,人和小鼠FGFR2/3的重组生产在下文中有描述。在一个实施方案中,将动物用融合至免疫球蛋白重链Fc部分的FGFR2/3免疫。在一个优选的实施方案中,将动物用FGFR2/3-IgG1融合蛋白免疫。通常将动物针对FGFR2/3的免疫原性缀合物或衍生物和单磷酰脂质A(MPL)/二棒分枝菌酸海藻糖(trehalose dicrynomycolate,TDM)Ribi Immunochem.Research,Inc.,Hamilton,MT)进行免疫,将溶液皮内注射于多个部位。2周后,对动物进行加强免疫。7-14天后,对动物采血,并对血清测定抗FGFR2/3滴度。对动物进行加强免疫,直到滴度达到平台(plateaus)。
或者,可以在体外免疫淋巴细胞。然后,使用合适的融合剂诸如聚乙二醇将淋巴细胞与骨髓瘤细胞融合,以形成杂交瘤细胞(Goding,Monoclonal Antibodies:Principlesand Practice,pp.59-103,Academic Press,1986)。
将如此制备的杂交瘤细胞在合适的培养基中接种和培养,所述培养基优选含有抑制未融合的亲本骨髓瘤细胞生长或存活的一种或多种物质。例如,若亲本骨髓瘤细胞缺乏酶次黄嘌呤鸟嘌呤磷酸核糖转移酶(HGPRT或HPRT),则用于杂交瘤的培养基典型的将含有次黄嘌呤,氨基喋呤和胸苷(HAT培养基),这些物质阻止HGPRT缺陷细胞生长。
优选的骨髓瘤细胞是那些高效融合,支持所选抗体生成细胞稳定的高水平生成抗体,并对诸如HAT培养基的培养基敏感的。在这些细胞中,优选的骨髓瘤细胞系是鼠骨髓瘤系,诸如那些可从索尔克研究所细胞分配中心(Salk Institute Cell DistributionCenter,San Diego,California,USA)获得的MOPC-21和MPC-11小鼠肿瘤及可从美国典型培养物保藏中心(American Type Culture Collection,Rockville,Maryland,USA)获得的SP-2或X63-Ag8-653细胞所衍生的。人骨髓瘤和小鼠-人异源骨髓瘤细胞系也已描述用于生成人单克隆抗体(Kozbor,J.Immunol.133:3001(1984);Brodeur等,Monoclonal AntibodyProduction Techniques and Applications,pp.51-63,Marcel Dekker,Inc.,New York,1987)。
可对杂交瘤细胞正在其中生长的培养液测定针对FGFR2/3的单克隆抗体的生成。优选的是,通过免疫沉淀或通过体外结合测定法,诸如放射免疫测定法(RIA)或酶联免疫吸附测定法(ELISA),测定由杂交瘤细胞生成的单克隆抗体的结合特异性。
单克隆抗体的结合亲和力可通过例如Munson等,Anal.Biochem.107:220(1980)的Scatchard分析来测定。
在鉴定得到生成具有期望特异性,亲和力和/或活性的抗体的杂交瘤细胞后,该克隆可通过有限稀释规程进行亚克隆并通过标准方法进行培养(Goding,MonoclonalAntibodies:Principles and Practice,pp.59-103,Academic Press,1986)。适于这一目的的培养基包括例如D-MEM或RPMI-1640培养基。另外,杂交瘤细胞可在动物中作为腹水瘤进行体内培养。
可通过常规免疫球蛋白纯化规程,诸如例如蛋白A-Sepharose,羟磷灰石层析,凝胶电泳,透析或亲和层析,将亚克隆分泌的单克隆抗体与培养液,腹水或血清适当分开。
本发明的抗FGFR2/3抗体可以通过使用组合文库筛选具有期望活性的合成抗体克隆来制备。在原理上,通过筛选噬菌体文库来选择合成抗体克隆,所述噬菌体文库含有展示融合至噬菌体外壳蛋白的各种抗体可变区片段(Fv)的噬菌体。通过针对期望抗原的亲和层析淘选此类噬菌体文库。表达能够结合期望抗原的Fv片段的克隆被吸附至抗原,从而与文库中不结合的克隆分开。然后将结合的克隆从抗原上洗脱,而且可以通过额外的抗原吸附/洗脱循环进一步富集。本发明的任何抗FGFR2/3抗体可以如下获得,即设计合适的抗原筛选规程来选择感兴趣的噬菌体克隆,接着使用来自感兴趣的噬菌体克隆的Fv序列和Kabat等,Sequences of Proteins of Immunological Interest,第5版,NIH Publication 91-3242,Bethesda MD(1991),卷1-3中记载的合适的恒定区(Fc)序列构建全长抗FGFR2/3抗体克隆。
抗体的抗原结合域由两个约110个氨基酸的可变(V)区形成,分别来自重链(VL)和轻链(VH),都呈现三个高变环或互补决定区(CDR)。可变域可以功能性的展示在噬菌体上,或是作为单链Fv(scFv)片段(其中VH和VL通过短的,柔性的肽共价相连),或者作为Fab片段(其中它们各自与恒定域融合且非共价相互作用),如Winter等,Ann.Rev.Immunol.,12:433-455(1994)所述。在用于本文时,编码scFv的噬菌体克隆和编码Fab的噬菌体克隆统称为“Fv噬菌体克隆”或“Fv克隆”。
VH和VL基因的全集可以通过聚合酶链式反应(PCR)分开克隆,并在噬菌体文库中随机重组,然后可以搜索抗原结合克隆,如Winter等,Ann.Rev.Immunol.,12:433-455(1994)所述。来自经免疫来源的文库能提供对免疫原有高亲和力的抗体,无需构建杂交瘤。或者,可以克隆未免疫的全集,用于为广泛的非自身的及自身的抗原提供单一人抗体来源,无需任何免疫,如Griffiths等,EMBO J,12:725-734(1993)所述。最后,未免疫的文库还可以以合成方式来构建,即从干细胞克隆未重排的V基因片段,使用包含随机序列的PCR引物来编码高度可变的CDR3区并在体外实现重排,如Hoogenboom和Winter,J.Mol.Biol.,227:381-388(1992)所述。
通过与次要外壳蛋白pIII融合,使用丝状噬菌体来展示抗体片段。抗体片段可以展示为单链Fv片段,其中VH与VL结构域通过柔性多肽间隔物在同一多肽链上相连,例如如Marks等,J.Mol.Biol.,222:581-597(1991)所述,或者展示为Fab片段,其中一条链与pIII融合,而另一条链分泌到细菌宿主细胞周质中,在此装配Fab-外壳蛋白结构,其通过取代一些野生型外壳蛋白而展示在噬菌体表面上,例如如Hoogenboom等,Nucl.Acids Res.,19:4133-4137(1991)所述。
一般而言,从收获自人或动物的免疫细胞获得编码抗体基因片段的核酸。如果希望文库偏向抗FGFR2/3克隆,那么可以给个体免疫FGFR2/3以产生抗体应答,并回收脾细胞和/或循环B细胞或其它外周血淋巴细胞(PBL)用于文库构建。在一个优选的实施方案中,如下得到了偏向抗FGFR2/3克隆的人抗体基因片段文库,即在携带功能性人免疫球蛋白基因阵列(且缺乏功能性内源抗体生成系统)的转基因小鼠中产生抗FGFR2/3抗体应答,使得FGFR2/3免疫产生生成针对FGFR2/3的人抗体的B细胞。生成人抗体的转基因小鼠的产生在下文中有描述。
可以如下获得抗FGFR2/3反应性细胞群的进一步富集,即使用合适的筛选规程来分离表达FGFR2/3特异性膜结合抗体的B细胞,例如通过用FGFR2/3亲和层析或者细胞对荧光染料标记的FGFR2/3的吸附及后续的流动激活细胞分选(FACS)进行的细胞分离。
或者,来自未免疫供体的脾细胞和/或B细胞或其它PBL的使用提供了可能的抗体全集的更佳展现,而且还容许使用FGFR2/3在其中没有抗原性的任何动物(人或非人的)物种构建抗体文库。为了体外掺入抗体基因的文库构建,从个体收获干细胞以提供编码未重排抗体基因区段的核酸。可以从多种动物物种(诸如人,小鼠,大鼠,兔类,luprine,犬,猫,猪,牛,马,和鸟类等)获得感兴趣的免疫细胞。
从感兴趣的细胞回收编码抗体可变基因区段(包括VH和VL区段)的核酸并扩增。就重排的VH和VL基因文库而言,可以如下获得所需DNA,即从淋巴细胞分离基因组DNA或mRNA,接着用与重排的VH和VL基因的5′和3′末端匹配的引物进行聚合酶链式反应(PCR),如Orlandi等,Proc.Natl.Acad.Sci.USA,86:3833-3837(1989)所述,由此构建多样性V基因全集供表达。可以从cDNA和基因组DNA扩增V基因,反向引物位于编码成熟V结构域的外显子的5′末端,正向引物基于J区段内部,如Orlandi等(1989)和Ward等,Nature,341:544-546(1989)所述。然而,为了从cDNA进行扩增,反向引物还可基于前导外显子(leader exon)内,如Jones等,Biotechnol.,9:88-89(1991)所述,正向引物基于恒定区内,如Sastry等,Proc.Natl.Acad.Sci.(USA),86:5728-5732(1989)所述。为了使互补性最大化,引物中可以掺入简并性,如Orlandi等(1989)或Sastry等(1989)所述。优选的是,如下将文库多样性最大化,即使用靶向每个V基因家族的PCR引物来扩增免疫细胞核酸样品中存在的所有可获得的VH和VL排列,例如如Marks等,J.Mol.Biol.,222:581-597(1991)或Orum等,NucleicAcids Res.,21:4491-4498(1993)的方法所述。为了将所扩增的DNA克隆到表达载体中,可以在PCR引物的一端引入罕见的限制性位点作为标签,如Orlandi等(1989)所述,或者用带标签的引物进行进一步的PCR扩增,如Clackson等,Nature,352:624-628(1991)所述。
人工合成的重排的V基因全集可以在体外从V基因区段衍生。大多数人VH基因区段已经克隆和测序(Tomlinson等,J.Mol.Biol.,227:776-798(1992)),并定位(Matsuda等,Nature Genet.,3:88-94(1993));这些克隆的区段(包括H1和H2环的所有主要构型)可用于生成多样性VH基因全集,用到编码序列和长度多样性的H3环的PCR引物,如Hoogenboom和Winter,J.Mol.Biol.,227:381-388(1992)所述。VH全集还可如下生成,所有序列多样性集中于单一长度的长H3环,如Barbas等,Proc.Natl.Acad.Sci.USA,89:4457-4461(1992)所述。人Vκ和Vλ区段已经克隆和测序(Williams和Winter,Eur.J.Immunol.,23:1456-1461(1993)),而且可用于生成合成的轻链全集。基于一系列VH和VL折叠及L3和H3长度的合成的V基因全集会编码具有可观结构多样性的抗体。扩增编码V基因的DNA后,依照Hoogenboom和Winter,J.Mol.Biol.,227:381-388(1992)的方法,可以在体外重排种系V基因区段。
抗体片段全集可以如下构建,即以数种方式将VH与VL基因全集联合在一起。可以在不同载体中创建各个全集,并在体外重组载体,例如如Hogrefe等,Gene,128:119-126(1993)所述,或者在体内通过组合感染来重组载体,例如Waterhouse等,Nucl.Acids Res.,21:2265-2266(1993)中记载的loxP系统。体内重组方法利用Fab片段的双链性质来克服因大肠杆菌转化效率施加的库容量限制。分别克隆未免疫的VH和VL全集,一个克隆入噬菌粒,另一个克隆入噬菌体载体。然后通过用噬菌体感染含噬菌粒的细菌使得每个细胞包含不同的组合来联合两种文库,库容量只受细胞存在数的限制(约1012个克隆)。两种载体都包含体内重组信号,使得VH与VL基因重组到单一复制子上,并共包装成噬菌体病毒粒。这些巨型文库提供了大量的具有优良亲和力(Kd -1为约10-8M)的多样性抗体。
或者,可以将全集依次克隆入同一载体,例如如Barbas等,Proc.Natl.Acad.Sci.USA,88:7978-7982(1991)所述,或者通过PCR装配到一起,然后克隆,如Clackson等,Nature,352:624-628(1991)所述。PCR装配还可用于将VH和VL DNA与编码柔性肽间隔物的DNA连接以形成单链Fv(scFv)全集。在另一种技术中,“细胞内PCR装配”用于通过PCR在淋巴细胞内联合VH与VL基因,然后克隆所连接基因的全集,如Embleton等,Nucl.Acids Res.,20:3831-3837(1992)所述。
未免疫文库(naive library)(天然的或合成的)生成的抗体可具有中等亲和力(Kd -1为约106-107M-1),但还可以如下在体外模拟亲和力成熟,即构建和再次选择次生文库,如Winter等(1994),见上文所述。例如,在Hawkins等,J.Mol.Biol.,226:889-896(1992)的方法或Gram等,Proc.Natl.Acad.Sci USA,89:3576-3580(1992)的方法中,使用易错聚合酶在体外随机引入突变(Leung等,Technique,1:1230-232和236-247(1989))。另外,可以通过随机突变一个或多个CDR来进行亲和力成熟,例如在选定的个别Fv克隆中使用携带跨越感兴趣CDR的随机序列的引物进行PCR并筛选更高亲和力的克隆。WO 96/07754(公布于1996年3月14日)记载了用于在免疫球蛋白轻链的互补决定区中诱导诱变以创建轻链基因文库的方法。另一种高效方法是将通过噬菌体展示选出的VH或VL结构域与得自未免疫供体的天然存在V结构域变体组合,并在数轮链重新改组中筛选更高亲和力,如Marks等,Biotechnol.,10:779-783(1992)所述。此技术容许生成亲和力在10-9M范围的抗体和抗体片段。
FGFR2和FGFR3核酸和氨基酸序列是本领域已知的。可以使用想要的FGFR2和FGFR3区的氨基酸序列来设计编码FGFR2和FGFR3的核酸序列。例如,可以使用R3Mab的氨基酸序列来设计FGFR3。正如本领域公知的,FGFR3有两种主要剪接同种型(isoform),FGFR3 IIIb和FGFR3 IIIc。FGFR3序列是本领域公知的,而且可以包括UniProKB/Swiss-Prot登录号P22607(FGFR3 IIIc)或P22607_2(FGFR3 IIIb)的序列。已经鉴定了FGFR2和FGFR3突变,而且是本领域公知的,包括下述突变(参考UniProKB/Swiss-Prot登录号P22607(FGFR3 IIIc)或P22607_2(FGFR3 IIIb)中显示的序列):

编码FGFR2和/或FGFR3的核酸可以通过本领域已知的多种方法来制备。这些方法包括但不限于通过Engels等,Agnew.Chem.Int.Ed.Engl.,28:716-734(1989)中记载的任何方法,诸如三酯,亚磷酸酯,磷酰胺酯(phosphoramidite)和H-膦酸酯法进行的化学合成。在一个实施方案中,编码FGFR2和/或FGFR3的DNA的设计中使用表达宿主细胞所优选的密码子。或者,编码FGFR2和/或FGFR3的DNA可以从基因组或cDNA文库分离。
构建编码FGFR2和/或FGFR3的DNA分子后,将该DNA分子与表达载体,诸如质粒中的表达控制序列可操作连接,其中所述控制序列受到该载体转化的宿主细胞的识别。一般而言,质粒载体包含复制和控制序列,其衍生自与宿主细胞相容的物种。载体通常携带复制位点,以及编码能够在转化细胞中提供表型选择的蛋白质的序列。适于在原核和真核宿主细胞中表达的载体是本领域已知的,有些在本文中有进一步描述。可以使用真核生物体,诸如酵母或衍生自多细胞生物体诸如哺乳动物的细胞。
任选的是,编码FGFR2和/或FGFR3的DNA与分泌前导序列可操作连接,导致表达产物被宿主细胞分泌到培养基中。分泌前导序列的例子包括stII,ecotin,lamB,疱疹GD,lpp,碱性磷酸酶,转化酶,和α-因子。适用于此处的还有蛋白A的36个氨基酸的前导序列(Abrahmsen等,EMBO J.,4:3901(1985))。
宿主细胞用上文所述本发明的表达或克隆载体转染,优选转化,并在常规营养培养基中培养,培养基可以为了诱导启动子,选择转化子,或扩增编码期望序列的基因而适当修改。
转染指宿主细胞摄取表达载体,无论任何编码序列事实上是否表达。本领域普通技术人员知道许多转染方法,例如CaPO4沉淀和电穿孔。若宿主细胞内存在此载体运转的任何指示,则一般认为转染成功。用于转染的方法是本领域众所周知的,有些在本文中有进一步描述。
转化指将DNA导入生物体,使得DNA可进行复制,或是作为染色体外元件,或是通过染色体整合。根据所用宿主细胞,使用适于所述细胞的标准技术进行转化。用于转化的方法是本领域众所周知的,有些在本文中有进一步描述。
用于生成FGFR2和/或FGFR3的原核宿主细胞可以如Sambrook等,见上文一般所述进行培养。
用于生成FGFR2和/或FGFR3的哺乳动物宿主细胞可以在多种培养基中培养,所述培养基是本领域众所周知的,有些在本文中有描述。
本公开文本提到的宿主细胞涵盖体外培养物中的细胞以及宿主动物体内的细胞。
FGFR2和/或FGFR3的纯化可以使用本领域公认的方法来实现,本文描述了其中一些。
纯化的FGFR2和/或FGFR3可以附着于合适的基质,诸如琼脂糖珠,丙烯酰胺珠,玻璃珠,纤维素,各种丙烯酸共聚物,羟基甲基丙烯酸酯凝胶,聚丙烯酸和聚甲基丙烯酸共聚物,尼龙,中性和离子载体,诸如此类,用于噬菌体展示克隆的亲和层析分离。FGFR2和/或FGFR3蛋白对基质的附着可以通过Methods in Enzymology,卷44(1976)中记载的方法来实现。将蛋白质配体附着于多糖基质,例如琼脂糖,右旋糖苷或纤维素的常用技术涉及用卤化氰活化载体,随后将肽配体的脂肪族伯胺或芳香族伯胺偶联至活化后的基质。
或者,FGFR2和/或FGFR3可用于包被吸附板的孔,在附着至吸附板的宿主细胞上表达,或用于细胞分选,或者缀合至生物素以用链霉亲合素包被的珠捕捉,或者用于本领域已知的用于淘选噬菌体展示库的任何其它方法。
在适于至少部分噬菌体颗粒结合吸附剂的条件下,使噬菌体文库样品接触固定化的FGFR2和/或FGFR3。正常情况下,选择包括pH,离子强度,温度等等的条件来模拟生理条件。对结合至固相的噬菌体进行清洗,然后用酸洗脱,例如如Barbas等,Proc.Natl.Acad.Sci USA,88:7978-7982(1991)所述,或者用碱洗脱,例如如Marks等,J.Mol.Biol.,222:581-597(1991)所述,或者通过FGFR3抗原竞争洗脱,例如在与Clackson等,Nature,352:624-628(1991)的抗原竞争法类似的规程中。噬菌体在单轮选择中可以富集20-1,000倍。此外,富集的噬菌体可以在细菌培养物中进行培养,并进行更多轮选择。
选择的效率取决于许多因素,包括清洗过程中解离的动力学,及单个噬菌体上的多个抗体片段是否能同时结合抗原。具有较快解离动力学(和弱结合亲和力)的抗体可以通过使用短时间的清洗,多价噬菌体展示,及固相中的高抗原包被密度来保留。高密度不仅通过多价相互作用而稳定了噬菌体,而且有利于已解离的噬菌体的再结合。具有较慢解离动力学(和强结合亲和力)的抗体的选择可以通过使用长时间的清洗和单价噬菌体展示(如Bass等,Proteins,8:309-314(1990)和WO 92/09690所述)及低抗原包被密度(如Marks等,Biotechnol.,10:779-783(1992)所述)来促进。
有可能在对FGFR2和/或FGFR3具有不同亲和力的噬菌体抗体之间进行选择,甚至是亲和力略有差异的。然而,选定抗体的随机突变(例如如有些上文所述亲和力成熟技术进行)有可能产生许多突变体,多数结合抗原,少数具有更高的亲和力。通过限制FGFR2和/或FGFR3,罕见的高亲和力噬菌体能竞争胜出。为了保留所有较高亲和力的突变体,可以将噬菌体与过量的生物素化FGFR2和/或FGFR3一起温育,但是生物素化FGFR2和/或FGFR3的摩尔浓度低于FGFR2和/或FGFR3的目标摩尔亲和常数。然后用链霉亲合素包被的顺磁珠捕捉高亲和力的结合噬菌体。此类“平衡捕捉”容许依照结合亲和力来选择抗体,其灵敏性容许从大大过量的低亲和力噬菌体中分离出亲和力只有原值2倍的突变体克隆。还可以操作清洗结合至固相的噬菌体的条件来进行基于解离动力学的区分。
FGFR2/3克隆可以进行活性选择。在一个实施方案中,本发明提供阻断FGFR3受体与它的配体(诸如FGF1和/或FGF9)和FGFR2与它的配体之间的结合的FGFR2/3抗体。对应于此类FGFR2/3抗体的Fv克隆可以如下选择:(1)如上所述自噬菌体文库分离FGFR2/3克隆,并任选通过在合适的细菌宿主中培养所述群体来扩增所分离的噬菌体克隆群体;(2)对想要阻断活性的FGFR2/3和想要不阻断活性的第二蛋白质进行选择;(3)将抗FGFR2/3噬菌体克隆吸附至固定化的FGFR2/3;(4)使用过量的所述第二蛋白质洗脱任何不想要的克隆,它们识别与所述第二蛋白质的结合决定簇交叠或共享的FGFR2/3结合决定簇;并(5)洗脱在步骤(4)后保持吸附的克隆。任选地,具有期望的阻断/不阻断特性的克隆可通过一次或多次重复本文所述选择规程来进一步富集。
本发明的编码杂交瘤衍生单克隆抗体或噬菌体展示Fv克隆的DNA易于使用常规规程分离和测序(例如通过使用设计成自杂交瘤或噬菌体DNA模板特异性扩增感兴趣的重链和轻链编码区的寡核苷酸引物)。一旦分离,可将DNA置于表达载体中,然后将该表达载体转染到原本不生成免疫球蛋白蛋白质的宿主细胞中,诸如大肠杆菌细胞,猿COS细胞,中国仓鼠卵巢(CHO)细胞或骨髓瘤细胞,以在重组宿主细胞中获得期望单克隆抗体的合成。关于编码抗体的DNA在细菌中的重组表达的综述性论文包括Skerra等,Curr.Opinion inImmunol.,5:256(1993)及Pluckthun,Immunol.Rev.,130:151(1992)。
本发明的编码Fv克隆的DNA可以联合编码重链和/或轻链恒定区的已知DNA序列(例如适宜的DNA序列可得自Kabat等,见上文)以形成编码全长或部分重链和/或轻链的克隆。应当领会,任何同种型的恒定区都可用于此目的,包括IgG,IgM,IgA,IgD和IgE恒定区,而且此类恒定区可以得自任何人或动物物种。衍生自一种动物(诸如人)物种的可变域DNA,然后与另一动物物种的恒定区DNA融合以形成“杂合的”全长重链和/或轻链的编码序列的Fv克隆包括在本文所用“嵌合”和“杂合”抗体的定义中。在一个优选的实施方案中,衍生自人可变DNA的Fv克隆与人恒定区DNA融合以形成完全人的,全长或部分重链和/或轻链的编码序列。
还可以修饰本发明的编码衍生自杂交瘤的抗FGFR2/3抗体的DNA,例如通过替代,即用人重链和轻链恒定域的编码序列代替衍生自杂交瘤克隆的同源鼠序列(例如如Morrison等,Proc.Natl.Acad.Sci.USA,81:6851-6855(1984)中的方法)。通过共价接合免疫球蛋白编码序列与非免疫球蛋白多肽的整个或部分编码序列,可以进一步修饰编码杂交瘤或Fv克隆衍生抗体或片段的DNA。可以以该方式制备具有本发明的Fv克隆或杂交瘤克隆衍生抗体的结合特异性的“嵌合”或“杂合”抗体。
双特异性抗体
在一个方面,本发明部分基于结合KLB和FGFR2/3二者的双特异性抗体(“FGFR2/3+KLB双特异性抗体”)的发现。在某些方面,该FGFR2/3+KLB双特异性抗体可用于治疗代谢疾病和病症,此类治疗在对肝没有显著影响且骨量没有显著损失的情况下导致重量减轻和/或改善葡萄糖和脂质代谢。在某些方面,该FGFR2/3+KLB双特异性抗体可用于治疗NASH。
在某些实施方案中,本文中公开的FGFR2/3+KLB双特异性抗体包含本文中公开的抗FGFR2/3抗体任一的第一臂和本文中公开的或US20150218276(将其完整收入本文)中公开的任何抗KLB抗体的第二臂。
在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体对肝,例如肝功能没有显著影响。在某些实施方案中,与FGF21蛋白质对肝中FGFR/KLB受体复合物的调控相比,本公开文本的FGFR2/3+KLB双特异性抗体不调控肝中FGFR/KLB受体复合物的活性。在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体不导致对FGFR4/KLB复合物的抑制和/或不导致肝酶诸如但不限于ALT,AST,ALP和GLDH的升高。在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体在肝中不发挥作为FGFR2c/KLB复合物和/或FGFR3c/KLB复合物的激动剂的功能,那能导致肝中活化的MAPK信号传导和/或改变的Spry4和Dusp6表达。在某些实施方案中,与FGF21蛋白质对MAPK信号传导的活化相比,本公开文本的FGFR2/3+KLB双特异性抗体不导致肝中MAPK信号传导的活化。在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体在肝中不发挥作为FGFR4/KLB复合物的激动剂的功能。
在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体可以是人源化的。在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体包含受体人框架,例如人免疫球蛋白框架或人共有框架。
在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体可以是单克隆抗体,包括嵌合,人源化或人抗体。在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体可以是抗体片段,例如Fv,Fab,Fab’,scFv,双抗体,或F(ab’)2片段。在某些实施方案中,该FGFR2/3+KLB双特异性抗体是全长抗体,例如完整IgG1抗体,或本文中定义的其它抗体类或亚型。在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体可以并入单独的或组合的下文详细描述的任何特征。
本公开文本的FGFR2/3+KLB双特异性抗体例如对于代谢病症的诊断或治疗是有用的。代谢病症的非限制性例子包括多囊卵巢综合征(PCOS),代谢综合征(MetS),肥胖症,非酒精性脂肪性肝炎(NASH),非酒精性脂肪性肝病(NAFLD),高脂血症,高血压,2型糖尿病,非2型糖尿病,1型糖尿病,潜伏性自身免疫性糖尿病(LAD),年轻人成熟期发作糖尿病(MODY),和衰老及相关疾病诸如阿尔茨海默氏病,帕金森氏病和ALS。在优选的方面,该代谢疾病为NASH。
在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体可用于例如代谢病症的诊断或治疗。代谢病症的非限制性例子包括多囊卵巢综合征(PCOS),代谢综合征(MetS),肥胖症,非酒精性脂肪性肝炎(NASH),非酒精性脂肪性肝病(NAFLD),高脂血症,高血压,2型糖尿病,非2型糖尿病,1型糖尿病,潜伏性自身免疫性糖尿病(LAD),年轻人成熟期发作糖尿病(MODY),和衰老及相关疾病诸如阿尔茨海默氏病,帕金森氏病和ALS。在优选的方面,该代谢疾病为NASH。
例示性抗KLB抗体
在一个方面,本公开文本提供了一种分离的结合KLB蛋白质的抗体。在某些实施方案中,本公开文本的抗KLB抗体结合KLB的C端域。在某些实施方案中,本公开文本的抗KLB抗体结合包含氨基酸序列SSPTRLAVIPWGVRKLLRWVRRNYGDMDIYITAS(SEQ ID NO:103)的KLB片段。在某些实施方案中,该抗体与抗KLB抗体,例如本文中描述的8C5结合相同表位。
在某些实施方案中,本公开文本的抗KLB抗体包含至少一种,两种,三种,四种,五种,或六种选自下述的HVR:(a)包含SEQ ID NO:230-232和236-247任一的氨基酸序列的HVR-H1,例如SEQ ID NO:244或247;(b)包含SEQ ID NO:142和248-262任一的氨基酸序列的HVR-H2,例如SEQ ID NO:259或262;(c)包含SEQ ID NO:263-278任一的氨基酸序列的HVR-H3,例如SEQ ID NO:166或169;(d)包含SEQ ID NO:279-293任一的氨基酸序列的HVR-L1,例如SEQ ID NO:171或184;(e)包含SEQ ID NO:294-309任一的氨基酸序列的HVR-L2,例如SEQID NO:197或200;和(f)包含SEQ ID NO:310-324任一的氨基酸序列的HVR-L3,例如SEQ IDNO:212或215。
在某些实施方案中,本公开文本提供了一种抗KLB抗体,其包含至少一种,两种,三种,四种,五种,或六种选自下述的HVR:(a)包含SEQ ID NO:119的HVR-H1;(b)包含SEQ IDNO:150的HVR-H2;(c)包含SEQ ID NO:166的HVR-H3;(d)包含SEQ ID NO:171的HVR-L1;(e)包含SEQ ID NO:197的HVR-L2;和(f)包含SEQ ID NO:212的HVR-L3。在某些实施方案中,本公开文本提供了一种抗KLB抗体,其包含至少一种,两种,三种,四种,五种,或六种选自下述的HVR:(a)包含SEQ ID NO:122的HVR-H1;(b)包含SEQ ID NO 153的HVR-H2;(c)包含SEQ IDNO:169的HVR-H3;(d)包含SEQ ID NO 184的HVR-L1;(e)包含SEQ ID NO:200的HVR-L2;和(f)包含SEQ ID NO:215的HVR-L3。
本公开文本进一步提供了一种抗KLB抗体,其包含与SEQ ID NO:104的氨基酸序列具有至少90%,91%,92%,93%,94%,95%,96%,97%,98%,99%,或100%序列同一性的重链可变域(VH)序列。在某些实施方案中,具有至少90%,91%,92%,93%,94%,95%,96%,97%,98%,或99%同一性的VH序列相对于参照序列含有替代(例如下文公开的保守替代),插入,或删除,但是包含该序列的抗KLB抗体保留结合KLB的能力。在某些实施方案中,在SEQ ID NO:104中替代,插入和/或删除了总共1至10个氨基酸。在某些实施方案中,该替代,插入,或删除发生在HVR以外的区域中(即在FR中)。或者或另外,该抗KLB抗体包含SEQID NO:104中的VH序列,包括下文公开的该序列的翻译后修饰。在某些实施方案中,该VH包含一种,两种或三种选自下述的HVR:(a)包含SEQ ID NO:122的氨基酸序列的HVR-H1,(b)包含SEQ ID NO:153的氨基酸序列的HVR-H2,和(c)包含SEQ ID NO:169的氨基酸序列的HVR-H3。
在另一个方面,本公开文本提供了一种抗KLB抗体,其中该抗体包含与SEQ ID NO:105的氨基酸序列具有至少90%,91%,92%,93%,94%,95%,96%,97%,98%,99%,或100%序列同一性的轻链可变域(VL)。在某些实施方案中,具有至少90%,91%,92%,93%,94%,95%,96%,97%,98%,或99%同一性的VL序列相对于该参照序列含有替代(例如保守替代),插入,或删除,但是包含该序列的抗KLB抗体保留结合KLB的能力。在某些实施方案中,在SEQ ID NO:105中替代,插入和/或删除了总共1至10氨基酸。在某些实施方案中,该替代,插入,或删除发生在HVR以外的区域中(即在FR中)。或者或另外,该抗KLB抗体包含SEQID NO:105中的VL序列,包括该序列的翻译后修饰。在某些实施方案中,该VL包含一种,两种或三种选自下述的HVR:(a)包含SEQ ID NO:184的氨基酸序列的HVR-L1;(b)包含SEQ IDNO:200的氨基酸序列的HVR-L2;和(c)包含SEQ ID NO:215的氨基酸序列的HVR-L3。
本公开文本进一步提供了一种抗KLB抗体,其中该抗体包含上文提供的实施方案任一中的VH和上文提供的实施方案任一中的VL。在某些实施方案中,该抗体包含分别在SEQID NO:104和SEQ ID NO:105中的VH和VL序列,包括那些序列的翻译后修饰。
在某些实施方案中,抗KLB抗体结合由氨基酸序列SSPTRLAVIPWGVRKLLRWVRRNYGDMDIYITAS(SEQ ID NO:103)组成的KLB片段。
双特异性抗FGFR2/3抗体
本公开文本进一步提供了结合KLB和FGFR2/3二者的双特异性抗体(即FGFR2/3+KLB双特异性抗体)。双特异性抗体具有两种不同结合特异性,参见例如美国专利No.5,922,845和5,837,243;Zeilder(1999)J.Immunol.163:1246-1252;Somasundaram(1999)Hum.Antibodies 9:47-54;Keler(1997)Cancer Res.57:4008-4014。例如,而且并非为了限制,当前公开的主题提供了双特异性抗体具有针对KLB上存在的第一表位的一个结合位点(例如抗原结合位点)和针对FGFR2/3上存在的第二表位的第二结合位点。例如,而且并非为了限制,本公开文本提供了一种抗体,其中一个臂结合KLB且包含本文中描述的抗KLB抗体序列任一且第二臂结合FGFR2/3且包含本文中描述的抗FGFR2/3抗体序列任一。在某些实施方案中,本公开文本的FGFR2/3+KLB双特异性抗体具有针对KLB上存在的第一表位的一个结合位点和针对FGFR2/3上存在的第二表位的第二结合位点。
在某些实施方案中,FGFR2/3+KLB双特异性抗体或其抗原结合部分包括重链和轻链区。在某些实施方案中,全长重链包括具有与SEQ ID NO:106中所列序列至少90%,91%,92%,93%,94%,95%,96%,97%,98%,99%,或100%相同的序列的氨基酸。在某些实施方案中,全长轻链包括具有与SEQ ID NO:107中所列序列至少90%,91%,92%,93%,94%,95%,96%,97%,98%,99%,或100%相同的序列的氨基酸。在某些实施方案中,全长重链包括具有SEQ ID NO:106中所列序列的氨基酸。在某些实施方案中,该全长轻链包括具有SEQ ID NO:107中所列序列的氨基酸。
在某些实施方案中,FGFR2/3+KLB双特异性抗体或其抗原结合部分包括重链可变区和轻链可变区。在某些实施方案中,该重链可变区包括具有与SEQ ID NO:104中所列序列至少90%,91%,92%,93%,94%,95%,96%,97%,98%,99%,或100%相同的序列的氨基酸。在某些实施方案中,该轻链可变区包括具有与SEQ ID NO:105中所列序列至少90%,91%,92%,93%,94%,95%,96%,97%,98%,99%,或100%相同的序列的氨基酸。在某些实施方案中,该重链可变区包括具有SEQ ID NO:104中所列序列的氨基酸。在某些实施方案中,该轻链可变区包括具有SEQ ID NO:105中所列序列的氨基酸。
在某些实施方案中,FGFR2/3+KLB双特异性抗体包含至少一种,两种,三种,四种,五种,或六种选自下述的HVR:(a)包含SEQ ID NO:230-232和236-247任一的氨基酸序列的HVR-H1,例如SEQ ID NO:244或247;(b)包含SEQ ID NO:142和248-262任一的氨基酸序列的HVR-H2,例如SEQ ID NO:259或262;(c)包含SEQ ID NO:263-278任一的氨基酸序列的HVR-H3,例如SEQ ID NO:275或278;(d)包含SEQ ID NO:279-293任一的氨基酸序列的HVR-L1,例如SEQ ID NO:280或293;(e)包含SEQ ID NO:294-309任一的氨基酸序列的HVR-L2,例如SEQID NO:306或309;和(f)包含SEQ ID NO:310-324任一的氨基酸序列的HVR-L3,例如SEQ IDNO:321或324。
在某些实施方案中,FGFR2/3+KLB双特异性抗体包含至少一种,两种,三种,四种,五种,或六种选自下述的HVR:(a)包含SEQ ID NO:119的HVR-H1;(b)包含SEQ ID NO:150的HVR-H2;(c)包含SEQ ID NO:166的HVR-H3;(d)包含SEQ ID NO:171的HVR-L1;(e)包含SEQID NO:197的HVR-L2;和(f)包含SEQ ID NO:212的HVR-L3。在某些实施方案中,本公开文本提供了一种抗KLB抗体,其包含至少一种,两种,三种,四种,五种,或六种选自下述的HVR:(a)包含SEQ ID NO:122的HVR-H1;(b)包含SEQ ID NO:153的HVR-H2;(c)包含SEQ ID NO:169的HVR-H3;(d)包含SEQ ID NO:184的HVR-L1;(e)包含SEQ ID NO:200的HVR-L2;和(f)包含SEQ ID NO:215的HVR-L3。
在某些实施方案中,FGFR2/3+KLB双特异性抗体包括包含CDR1,CDR2,和CDR3域的重链可变区,和包含CDR1,CDR2,和CDR3域的轻链可变区。在某些实施方案中,该重链可变区CDR1域包括具有SEQ ID NO:230-232和236-247中所列序列的氨基酸序列。在某些实施方案中,该重链可变区CDR2域包括具有SEQ ID NO:142和248-262中所列序列的氨基酸序列。在某些实施方案中,该重链可变区CDR3域包括具有与SEQ ID NO:263-278至少90%,91%,92%,93%,94%,95%,96%,97%,98%,99%,或100%相同的序列的氨基酸序列。在某些实施方案中,该轻链可变区CDR1域包括具有与SEQ ID NO:279-293至少90%,91%,92%,93%,94%,95%,96%,97%,98%,99%,或100%相同的序列的氨基酸序列。在某些实施方案中,该轻链可变区CDR2域包括具有与SEQ ID NO:294-309至少90%,91%,92%,93%,94%,95%,96%,97%,98%,99%,或100%相同的序列的氨基酸序列。在某些实施方案中,该轻链可变区CDR3域包括具有与SEQ ID NO:310-324至少90%,91%,92%,93%,94%,95%,96%,97%,98%,99%,或100%相同的序列的氨基酸序列。
在某些实施方案中,FGFR2/3+KLB双特异性抗体包括包含CDR1,CDR2,和CDR3域的重链可变区,和包含CDR1,CDR2,和CDR3域的轻链可变区。在某些实施方案中,该重链可变区CDR1域包括具有SEQ ID NO:230-232和236-247中所列序列的氨基酸序列。在某些实施方案中,该重链可变区CDR2域包括具有SEQ ID NO:103和248-262中所列序列的氨基酸序列。在某些实施方案中,该重链可变区CDR3域包括具有SEQ ID NO:263-278中所列序列的氨基酸序列。在某些实施方案中,该轻链可变区CDR1域包括具有SEQ ID NO:279-293中所列序列的氨基酸序列。在某些实施方案中,该轻链可变区CDR2域包括具有SEQ ID NO:294-309中所列序列的氨基酸序列。在某些实施方案中,该轻链可变区CDR3域包括具有SEQ ID NO:310-324中所列序列的氨基酸序列。
在某些实施方案中,FGFR2/3+KLB双特异性抗体包括具有SEQ ID NO:122中所列序列的重链可变区CDR1;具有SEQ ID NO:153中所列序列的重链可变区CDR2;具有SEQ ID NO:169中所列序列的重链可变区CDR3;具有SEQ ID NO:184中所列序列的轻链可变区CDR1;具有SEQ ID NO:200中所列序列的轻链可变区CDR2;和具有SEQ ID NO:215中所列序列的轻链可变区CDR3。
在某些实施方案中,FGFR2/3+KLB双特异性抗体包括第一抗体或其抗原结合部分,且包括第二抗体或其抗原结合部分,其中该第一抗体或其抗原结合部分结合KLB上存在的表位,且该第二抗体或其抗原结合部分结合FGFR2/3上存在的表位。例如,而且并非为了限制,该第一抗体或其抗原结合部分可包括重链可变区和轻链可变区;且该第二抗体或其抗原结合部分可包括重链可变区和轻链可变区。在某些实施方案中,该第一抗体或其抗原结合部分的重链可变区包括具有与SEQ ID NO:104中所列序列至少90%,91%,92%,93%,94%,95%,96%,97%,98%,99%,或100%相同的序列的氨基酸。在某些实施方案中,该第一抗体或其抗原结合部分的轻链可变区包括具有与SEQ ID NO:105中所列序列至少90%,91%,92%,93%,94%,95%,96%,97%,98%,99%,或100%相同的序列的氨基酸。在某些实施方案中,该第二抗体(抗FGFR2/3抗体)或其抗原结合部分的重链包括具有与SEQ IDNO:282中所列序列至少60%,70%,80%,90%,91%,92%,93%,94%,95%,96%,97%,98%,99%,或100%相同的序列的氨基酸。在某些实施方案中,该第二抗体(抗FGFR2/3抗体)或其抗原结合部分的轻链包括具有与SEQ ID NO:283中所列序列至少60%,70%,80%,90%,91%,92%,93%,94%,95%,96%,97%,98%,99%,或100%相同的序列的氨基酸。
在某些实施方案中,本文中提供了与抗KLB抗体结合相同表位的FGFR2/3+KLB双特异性抗体。例如,在某些实施方案中,提供了与包含SEQ ID NO:104的VH序列和SEQ ID NO:105的VL序列的抗KLB抗体结合相同表位的FGFR2/3+KLB双特异性抗体。在某些实施方案中,提供了结合由氨基酸序列SSPTRLAVIPWGVRKLLRWVRRNYGDMDIYITAS(SEQ ID NO:103)组成的KLB片段的FGFR2/3+KLB双特异性抗体。
在某些实施方案中,提供了结合如下KLB片段的FGFR2/3+KLB双特异性抗体,该KLB片段具有与SEQ ID NO:103中所列序列至少90%,91%,92%,93%,94%,95%,96%,97%,98%,99%,或100%相同的氨基酸序列。
在某些实施方案中,本文中提供了与抗KLB抗体结合相同表位的FGFR2/3+KLB双特异性抗体。例如,在某些实施方案中,提供了与包含SEQ ID NO:106的全长重链序列和SEQID NO:107的全长轻链序列的抗KLB抗体结合相同表位的FGFR2/3+KLB双特异性抗体。
在某些实施方案中,本公开文本提供了一种FGFR2/3+KLB双特异性抗体,其与本文中提供的抗FGFR2/3抗体结合相同表位。例如,在某些实施方案中,提供了与包含SEQ IDNO:82的VH序列和SEQ ID NO:66的VL序列的抗FGFR2/3抗体结合相同表位的FGFR2/3+KLB双特异性抗体。在某些实施方案中,提供了结合FGFR2上的包含氨基酸序列TNTEKMEKRLHAVPAANTVKFRCPA(SEQ ID NO:91)和/或YKVRNQHWSLIMES(SEQ ID NO:92)的表位和/或还结合FGFR3上的包含氨基酸序列TRPERMDKKLLAVPAANTVRFRCPA(SEQ ID NO:93)和/或IKLRHQQWSLVMES(SEQ ID NO:94)的表位的FGFR2/3+KLB双特异性抗体。
在某些实施方案中,本公开文本提供了与本文中提供的抗FGFR2/3抗体结合相同表位的FGFR2/3+KLB双特异性抗体。例如,在某些实施方案中,提供了与本文中公开的2B.1.3.12,2B.1.3.10,或该2B.1.1.6抗FGFR2/3抗体结合相同表位的FGFR2/3+KLB双特异性抗体。在某些实施方案中,提供了与抗FGFR2/3抗体2B.1.3.10和2B.1.3.12结合相同表位的FGFR2/3+KLB双特异性抗体(即与2B.1.3.10和2B.1.3.12结合FGFR2上的包含氨基酸序列TNTEKMEKRLHAVPAANTVKFRCPA(SEQ ID NO:91)和/或YKVRNQHWSLIMES(SEQ ID NO:92)的相同表位和/或还结合FGFR3上的包含氨基酸序列TRPERMDKKLLAVPAANTVRFRCPA(SEQ ID NO:93)和/或IKLRHQQWSLVMES(SEQ ID NO:94)的相同表位的FGFR2/3+KLB双特异性抗体)。
在某些实施方案中,本公开文本提供了与本文中提供的2B.1.3.10和2B.1.3.12抗体竞争结合FGFR2/3的FGFR2/3+KLB双特异性抗体。
在某些实施方案中,提供了FGFR2/3+KLB双特异性抗体,其结合具有与SEQ ID NO:103中所列序列至少90%,91%,92%,93%,94%,95%,96%,97%,98%,99%,或100%相同的氨基酸序列的KLB片段,且结合或竞争结合选自TNTEKMEKRLHAVPAANTVKFRCPA(SEQ IDNO:91)和YKVRNQHWSLIMES(SEQ ID NO:92)的FGFR2表位且结合或竞争结合选自TRPERMDKKLLAVPAANTVRFRCPA(SEQ ID NO:93)和IKLRHQQWSLVMES(SEQ ID NO:94)的FGFR3表位。
在某些实施方案中,提供了抗KLB/抗FGFR1双特异性抗体,其结合具有SEQ ID NO:103中所列氨基酸序列的KLB片段且结合或竞争结合SEQ ID NO:91和92中提供的FGFR2表位且结合或竞争结合SEQ ID NO:93和94中提供的FGFR3表位。
抗体片段
本发明涵盖抗体片段。在某些情况中,使用抗体片段,而不是完整抗体有优势。片段的较小尺寸容许快速清除,而且可导致更易于接近实体瘤。
已经开发了用于生成抗体片段的多种技术。传统上,通过蛋白水解消化完整抗体来衍生这些片段(参见例如Morimoto等,Journal of Biochemical and BiophysicalMethods 24:107-117(1992);Brennan等,Science 229:81(1985))。然而,现在可直接由重组宿主细胞生成这些片段。Fab,Fv和scFv抗体片段都可在大肠杆菌中表达及由大肠杆菌分泌,如此容许容易的生成大量的这些片段。可从上文讨论的噬菌体抗体库中分离抗体片段。或者,可直接从大肠杆菌回收Fab′-SH片段并化学偶联以形成F(ab′)2片段(Carter等,Bio/Technology 10:163-167(1992))。依照另一种方法,可直接从重组宿主细胞培养物分离F(ab′)2片段。包含补救受体结合表位残基,具有延长的体内半衰期的Fab和F(ab′)2片段记载于美国专利No.5,869,046。用于生成抗体片段的其它技术对于熟练从业人员将是显而易见的。在其它实施方案中,选择的抗体是单链Fv片段(scFv)(参见例如WO 93/16185;美国专利No.5,571,894;及5,587,458)。Fv和sFv是具有完整结合位点,缺少恒定区的唯一类型;如此,它们适于在体内使用时降低非特异性结合。可构建sFv融合蛋白以生成效应器蛋白质在sFv的氨基或羧基末端的融合物。参见Antibody Engineering,Borrebaeck编,见上文。抗体片段还可以是“线性抗体”,例如如美国专利No.5,641,870中所记载的。此类线性抗体片段可以是单特异性的或双特异性的。
人源化抗体
本发明涵盖人源化抗体。本领域知道用于人源化非人抗体的多种方法。例如,人源化抗体可具有一个或多个从非人来源引入的氨基酸残基。这些非人氨基酸残基常常称为“输入”残基,它们通常取自“输入”可变域。基本上可遵循Winter及其同事的方法进行人源化(Jones等,Nature 321:522-525(1986);Riechmann等,Nature 332:323-327(1988);Verhoeyen等,Science 239:1534-1536(1988)),即用(非人)高变区序列替代人抗体的相应序列。因此,此类“人源化”抗体是嵌合抗体(美国专利No.4,816,567),其中显著少于完整的人可变域用非人物种的相应序列替代。在实践中,人源化抗体通常是如下人抗体,其中有些高变区残基和可能的有些FR残基用啮齿类抗体类似位点的残基替代。
用于制备人源化抗体的人轻链和重链可变域的选择对于降低抗原性是非常重要的。依照所谓的“最适(best-fit)”方法,用啮齿类抗体的可变域序列对已知人可变域序列的整个文库进行筛选。然后选择与啮齿类最接近的人序列作为人源化抗体的人框架(Sims等,J.Immunol.151:2296(1993);Chothia等,J.Mol.Biol.196:901(1987))。另一种方法使用由特定轻链或重链亚组(subgroup)的所有人抗体的共有序列衍生的特定框架。相同框架可用于数种不同的人源化抗体(Carter等,Proc.Natl.Acad.Sci.USA 89:4285(1992);Presta等,J.Immunol.151:2623(1993))。
更为重要的是,抗体在人源化后保留对抗原的高亲和力和其它有利的生物学特性。为了达到此目的,依照一种方法,通过使用亲本序列和人源化序列的三维模型分析亲本序列和各种概念性人源化产物的过程来制备人源化抗体。通常可获得免疫球蛋白三维模型,这是本领域技术人员所熟悉的。还可获得图解和显示所选候选免疫球蛋白序列的可能三维构象结构的计算机程序。通过检查这些显示图像容许分析残基在候选免疫球蛋白序列发挥功能中的可能作用,即分析影响候选免疫球蛋白结合其抗原的能力的残基。这样,可以从受体序列和输入序列中选出FR残基并组合,从而得到期望的抗体特征,诸如对靶抗原的亲和力升高。一般而言,高变区残基直接且最实质性地涉及对抗原结合的影响。
人抗体
本发明的人抗FGFR2/3抗体可以通过如上所述联合选自人衍生噬菌体展示库的Fv克隆可变域序列与已知的人恒定域序列来构建。或者,可以通过杂交瘤方法来生成本发明的人单克隆抗FGFR2/3抗体。用于生成人单克隆抗体的人骨髓瘤和小鼠-人异源骨髓瘤细胞系已有记载,例如Kozbor J.Immunol.,133:3001(1984);Brodeur等,Monoclonal AntibodyProduction Techniques and Applications,pp.51-63(Marcel Dekker,Inc.,New York,1987);及Boerner等,J.Immunol.,147:86(1991)。
现在有可能生成在缺乏内源免疫球蛋白生成的情况下能够在免疫后生成人抗体完整全集的转基因动物(例如小鼠)。例如,已经记载了嵌合和种系突变小鼠中抗体重链连接区(JH)基因的纯合删除导致内源抗体生成的完全抑制。在此类种系突变小鼠中转移大量人种系免疫球蛋白基因会导致在抗原攻击后生成人抗体。参见例如Jakobovits等,Proc.Natl.Acad.Sci.USA 90:2551(1993);Jakobovits等,Nature 362:255-258(1993);Bruggermann等,Year in Immunol.7:33(1993)。
基因改组也可用于自非人(例如啮齿类)抗体衍生人抗体,其中人抗体具有与起始非人抗体相似的亲和力和特异性。依照此方法,它也称为“表位印记”(epitopeimprinting),如上所述通过噬菌体展示技术得到的非人抗体片段的重链或轻链可变区用人V结构域基因全集替换,产生非人链/人链scFv或Fab嵌合物群。用抗原进行的选择导致非人链/人链嵌合scFv或Fab的分离,其中人链恢复了在一级噬菌体展示克隆中消除相应的非人链后遭到破坏的抗原结合位点,即表位决定(印记,imprint)人链配偶体的选择。在重复该过程以替换剩余非人链时,得到人抗体(参见PCT WO 93/06213,公布于1993年4月1日)。与传统的通过CDR移植进行的非人抗体的人源化不同,此技术提供完全人的抗体,它们不含非人起源的FR或CDR残基。
双特异性抗体
双特异性抗体指对至少两种不同抗原具有结合特异性的单克隆抗体,优选人抗体或人源化抗体。在本案中,结合特异性之一针对FGFR3,另一结合特异性针对FGFR2。双特异性抗体还可用于将细胞毒剂定位于表达FGFR3,FGFR2,或FGFR2/3的细胞。可将双特异性抗体制备成全长抗体或抗体片段(例如F(ab′)2双特异性抗体)。
用于构建双特异性抗体的方法是本领域已知的。在传统上,双特异性抗体的重组生产基于两对免疫球蛋白重链-轻链的共表达,其中两种重链具有不同的特异性(Millstein和Cuello,Nature 305:537(1983))。由于免疫球蛋白重链和轻链的随机分配,这些杂交瘤(四源杂交瘤(quadroma))生成10种不同抗体分子的潜在混合物,其中只有一种具有正确的双特异性结构。通常通过亲和层析步骤进行的正确分子的纯化相当麻烦且产物产量低。类似的规程披露于WO 93/08829,公布于1993年5月13日及Traunecker等,EMBOJ.10:3655(1991)。
依照一种不同且更优选的方法,将具有期望结合特异性(抗体-抗原结合位点)的抗体可变域与免疫球蛋白恒定域序列融合。优选的是,与包含至少部分铰链,CH2和CH3区的免疫球蛋白重链恒定域进行融合。优选在至少一种融合物中存在包含轻链结合所必需的位点的第一重链恒定区(CH1)。将编码免疫球蛋白重链融合物和,在需要时,免疫球蛋白轻链的DNA插入分开的表达载体,并共转染到合适的宿主生物体中。在用于构建的三种多肽链比例不等时提供最佳产量的实施方案中,这为调整三种多肽片段的相互比例提供了极大的灵活性。然而,在至少两种多肽链以相等比例表达导致高产量时或在该比例没有特别意义时,有可能将两种或所有三种多肽链的编码序列插入一个表达载体。
在该方法的一个优选实施方案中,双特异性抗体由一个臂上具有第一结合特异性的杂合免疫球蛋白重链,和另一个臂上的杂合免疫球蛋白重链-轻链对(提供第二结合特异性)构成。由于免疫球蛋白轻链仅在半个双特异性分子中的存在提供了便利的分离途径,因此发现这种不对称结构便于将期望的双特异性化合物与不想要的免疫球蛋白链组合分开。该方法披露于WO 94/04690。关于生成双特异性抗体的进一步详情参见例如Suresh等,Methods in Enzymology 121:210(1986)。
依照另一种方法,可改造一对抗体分子间的界面,以将从重组细胞培养物回收的异二聚体的百分比最大化。优选的界面包含至少部分抗体恒定域CH3结构域。在该方法中,将第一抗体分子界面的一个或多个小氨基酸侧链用较大侧链(例如酪氨酸或色氨酸)替换。通过将大氨基酸侧链用较小氨基酸侧链(例如丙氨酸或苏氨酸)替换,在第二抗体分子的界面上产生与大侧链相同或相似大小的补偿性“空腔”。这提供了较之其它不想要的终产物诸如同二聚体提高异二聚体产量的机制。
双特异性抗体包括交联或“异源缀合”抗体。例如,异源缀合物中的一种抗体可与亲合素偶联,另一种抗体与生物素偶联。例如,此类抗体已经建议用于将免疫系统细胞靶向不想要的细胞(美国专利No.4,676,980),及用于治疗HIV感染(WO 91/00360;WO 92/00373;和EP 03089)。可使用任何便利的交联方法来制备异源缀合抗体。合适的交联剂是本领域众所周知的,连同许多交联技术一起披露于美国专利No.4,676,980。
文献中还记载了由抗体片段生成双特异性抗体的技术。例如,可使用化学连接来制备双特异性抗体。Brennan等,Science 229:81(1985)记载了通过蛋白水解切割完整抗体以生成F(ab′)2片段的规程。将这些片段在存在二硫醇络合剂亚砷酸钠的情况下还原,以稳定邻近的二硫醇并防止分子间二硫化物的形成。然后将产生的Fab’片段转变为硫代硝基苯甲酸酯(TNB)衍生物。然后将Fab′-TNB衍生物之一通过巯基乙胺的还原重新恢复成Fab′-硫醇,并与等摩尔量的另一种Fab′-TNB衍生物混合,以形成双特异性抗体。产生的双特异性抗体可用作酶的选择性固定化试剂。
最新的进展便于从大肠杆菌直接回收Fab′-SH片段,这些片段可化学偶联以形成双特异性抗体。Shalaby等,J.Exp.Med.175:217-225(1992)记载了完全人源化的双特异性抗体F(ab′)2分子的生成。由大肠杆菌分开分泌每种Fab′片段,并在体外进行定向化学偶联以形成双特异性抗体。如此形成的双特异性抗体能够结合过表达HER2受体的细胞和正常人T细胞,以及触发人细胞毒性淋巴细胞针对人乳腺肿瘤靶物的溶解活性。
还记载了从重组细胞培养物直接生成和分离双特异性抗体片段的多种技术。例如,已使用亮氨酸拉链生成双特异性抗体。Kostelny等,J.Immunol.148(5):1547-1553(1992)。将来自Fos和Jun蛋白的亮氨酸拉链肽通过基因融合与两种不同抗体的Fab′部分连接。抗体同二聚体在铰链区还原以形成单体,然后重新氧化以形成抗体异二聚体。这种方法也可用于生成抗体同二聚体。Hollinger等,Proc.Natl.Acad.Sci.USA 90:6444-6448(1993)记载的“双抗体”技术提供了构建双特异性抗体片段的替代机制。该片段包含通过接头相连的重链可变域(VH)和轻链可变域(VL),所述接头太短使得同一条链上的两个结构域之间不能配对。因而,迫使一个片段上的VH和VL结构域与另一个片段上的互补VL和VH结构域配对,由此形成两个抗原结合位点。还报道了通过使用单链Fv(sFv)二聚体构建双特异性抗体片段的另一种策略。参见Gruber等,J.Immunol.152:5368(1994)。
涵盖具有超过两个效价的抗体。例如,可制备三特异性抗体。Tutt等,J.Immunol.147:60(1991)。
多价抗体
多价抗体可以比二价抗体更快的受到表达该抗体所结合抗原的细胞的内在化(和/或异化)。本发明的抗体可以是可容易地通过编码抗体多肽链的核酸的重组表达而生成的,具有三个或更多抗原结合位点(例如四价抗体)的多价抗体(IgM类别以外的)。多价抗体可包含二聚化结构域和三个或更多抗原结合位点。优选的二聚化结构域包含(或由其组成)Fc区或铰链区。在这种情况中,抗体会包含Fc区及Fc区氨基末端的三个或更多抗原结合位点。本文中优选的多价抗体包含(或由其组成)三个至约八个,但优选四个抗原结合位点。多价抗体包含至少一条多肽链(且优选两条多肽链),其中所述多肽链包含两个或多个可变域。例如,多肽链可包含VD1-(X1)n-VD2-(X2)n-Fc,其中VD1是第一可变域,VD2是第二可变域,Fc是Fc区的一条多肽链,X1和X2代表氨基酸或多肽,而n是0或1。例如,所述多肽链可包含:VH-CH1-柔性接头-VH-CH1-Fc区链;或VH-CH1-VH-CH1-Fc区链。本文中的多价抗体优选进一步包含至少两条(且优选四条)轻链可变域多肽。本文中的多价抗体可包含例如约两条至约八条轻链可变域多肽。本文涵盖的轻链可变域多肽包含轻链可变域,且任选进一步包含CL域。
抗体变体
在有些实施方案中,涵盖本文所述抗体的氨基酸序列修饰。例如,可能希望改进抗体的结合亲和力和/或其它生物学特性。抗体的氨基酸序列变体是通过将适宜的核苷酸变化引入抗体核酸或通过肽合成而制备的。此类修饰包括例如抗体氨基酸序列内的残基删除和/或插入和/或替代。可进行任何删除,插入和替代组合以获得最终的构建物,倘若最终的构建物具有期望的特征。可在制备序列时将氨基酸改变引入受试抗体氨基酸序列。
可用于鉴定抗体中作为优选诱变位置的某些残基或区域的一种方法称为“丙氨酸扫描诱变”,如Cunningham和Wells,Science 244:1081-1085(1989)中所述。这里,鉴定一个残基或一组靶残基(例如带电荷的残基,诸如精氨酸,天冬氨酸,组氨酸,赖氨酸和谷氨酸)并用中性或带负电荷的氨基酸(最优选丙氨酸或多丙氨酸)替代,以影响氨基酸与抗原的相互作用。然后通过在或对替代位点引入更多或其它变体,推敲那些对替代展示出功能敏感性的氨基酸位置。如此,尽管用于引入氨基酸序列变异的位点是预先决定的,然而突变本身的本质不必预先决定。例如,为了分析指定位点处突变的后果,在靶密码子或区域进行丙氨酸扫描或随机诱变,并对所表达免疫球蛋白筛选期望的活性。
氨基酸序列插入包括氨基和/或羧基末端的融合,长度范围由一个残基至包含上百或更多残基的多肽,以及单个或多个氨基酸残基的序列内插入。末端插入的例子包括具有N末端甲硫氨酰残基的抗体或与细胞毒性多肽融合的抗体。抗体分子的其它插入变体包括将抗体的N或C端与酶(例如用于ADEPT)或延长抗体血清半衰期的多肽融合。
多肽的糖基化典型的或是N-连接的或是O-连接的。N-连接指碳水化合物模块附着于天冬酰胺残基的侧链。三肽序列天冬酰胺-X-丝氨酸和天冬酰胺-X-苏氨酸(其中X是除脯氨酸外的任何氨基酸)是将碳水化合物模块酶促附着于天冬酰胺侧链的识别序列。如此,多肽中这些三肽序列任一的存在产生了潜在的糖基化位点。O-连接的糖基化指将糖类N-乙酰半乳糖胺,半乳糖或木糖之一附着于羟基氨基酸,最常见的是丝氨酸或苏氨酸,但也可使用5-羟脯氨酸或5-羟赖氨酸。
向抗体中添加糖基化位点可通过改变氨基酸序列使其包含一个或多个上述三肽序列而便利地完成(用于N-连接的糖基化位点)。所述改变还可通过向原始抗体的序列中添加或替代一个或多个丝氨酸或苏氨酸残基来进行(用于O-连接的糖基化位点)。
若抗体包含Fc区,则可改变附着其上的碳水化合物。例如,美国专利申请US 2003/0157108(Presta,L.)中记载了有缺乏岩藻糖的成熟碳水化合物结构附着于抗体Fc区的抗体。还可参见US 2004/0093621(Kyowa Hakko Kogyo Co.,Ltd.)。WO 2003/011878(Jean-Mairet等人)和美国专利No.6,602,684(Umana等人)中提到了在附着于抗体Fc区的碳水化合物中有等分N-乙酰葡糖胺(GlcNAc)的抗体。WO 1997/30087(Patel等人)中报告了在附着于抗体Fc区的寡糖中有至少一个半乳糖残基的抗体。关于有更改的碳水化合物附着于其Fc区的抗体还可参见WO 1998/58964(Raju,S.)和WO 1999/22764(Raju,S.)。关于具有改良糖基化的抗原结合分子还可参见US 2005/0123546(Umana等)。
本文中的优选糖基化变体包含Fc区,其中附着于Fc区的碳水化合物结构缺乏岩藻糖。此类变体具有改进的ADCC功能。任选的是,Fc区还包含进一步改进ADCC的一个或多个氨基酸替代,例如Fc区位置298,333和/或334处的替代(Eu残基编号方式)。涉及“脱岩藻糖型”或“岩藻糖缺乏型”抗体的出版物的例子包括:US 2003/0157108;WO 2000/61739;WO 2001/29246;US 2003/0115614;US 2002/0164328;US 2004/0093621;US 2004/0132140;US2004/0110704;US 2004/0110282;US 2004/0109865;WO 2003/085119;WO 2003/084570;WO2005/035586;WO 2005/035778;WO2005/053742;Okazaki等J.Mol.Biol.336:1239-1249(2004);Yamane-Ohnuki等Biotech.Bioeng.87:614(2004)。生成脱岩藻糖化抗体的细胞系的例子包括蛋白质岩藻糖化缺陷的Lec13CHO细胞(Ripka等Arch.Biochem.Biophys.249:533-545(1986);美国专利申请号US 2003/0157108A1,Presta,L;及WO 2004/056312A1,Adams等,尤其是实施例11)和敲除细胞系,诸如α-1,6-岩藻糖转移酶基因,FUT8,敲除的CHO细胞(Yamane-Ohnuki等Biotech.Bioeng.87:614(2004))。
另一类变体是氨基酸替代变体。这些变体在抗体分子中有至少一个氨基酸(至少两个,至少三个,至少四个或更多个)残基用不同残基替代。最有兴趣进行替代诱变的位点包括高变区,但是也涵盖FR改变。下文表中“优选替代”栏显示了保守替代。如果此类替代导致生物学活性变化,那么可导入下文表中称为“例示替代”的更多实质变化,或如下文参照氨基酸分类进一步所述,并筛选产物。
| 原始残基 | 例示替代 | 优选替代 |
| Ala(A) | Val;Leu;Ile | Val |
| Arg(R) | Lys;Gln;Asn | Lys |
| Asn(N) | Gln;His;Asp;Lys;Arg | Gln |
| Asp(D) | Glu;Asn | Glu |
| Cys(C) | Ser;Ala | Ser |
| Gln(Q) | Asn;Glu | Asn |
| Glu(E) | Asp;Gln | Asp |
| Gly(G) | Ala | Ala |
| His(H) | Asn;Gln;Lys;Arg | Arg |
| Ile(I) | Leu;Val;Met;Ala;Phe;正亮氨酸 | Leu |
| Leu(L) | 正亮氨酸;Ile;Val;Met;Ala;Phe | Ile |
| Lys(K) | Arg;Gln;Asn | Arg |
| Met(M) | Leu;Phe;Ile | Leu |
| Phe(F) | Trp;Leu;Val;Ile;Ala;Tyr | Tyr |
| Pro(P) | Ala | Ala |
| Ser(S) | Thr | Thr |
| Thr(T) | Val;Ser | Ser |
| Trp(W) | Tyr;Phe | Tyr |
| Tyr(Y) | Trp;Phe;Thr;Ser | Phe |
| Val(V) | Ile;Leu;Met;Phe;Ala;正亮氨酸 | Leu |
对抗体生物学特性的实质性修饰可通过选择对维持以下方面的效果差异显著的替代来实现:(a)替代区域中多肽主链的结构,例如(折叠)片或螺旋构象,(b)靶位点处分子的电荷或疏水性,或(c)侧链的体积。根据共同的侧链特性,天然存在残基可如下分组:
(1)疏水性的:正亮氨酸,Met,Ala,Val,Leu,Ile;
(2)中性,亲水性的:Cys,Ser,Thr,Asn,Gln;
(3)酸性的:Asp,Glu;
(4)碱性的:His,Lys,Arg;
(5)影响链取向的残基:Gly,Pro;及
(6)芳香族的:Trp,Tyr,Phe。
非保守替代会需要用这些类别之一的成员替换另一个类别的。
一类替代变体涉及替代亲本抗体(例如人源化或人抗体)的一个或多个高变区残基。通常,选择用于进一步开发的所得变体相对于产生它们的亲本抗体会具有改良的生物学特性。用于生成此类替代变体的一种便利方法涉及使用噬菌体展示的亲和力成熟。简而言之,将数个高变区位点(例如6-7个位点)突变,在各个位点产生所有可能的氨基酸替代。将如此生成的抗体展示在丝状噬菌体颗粒上,作为与各个颗粒内包装的M13基因III产物的融合物。然后如本文所公开的对噬菌体展示的变体筛选其生物学活性(例如结合亲和力)。为了鉴定用于修饰的候选高变区位点,可进行丙氨酸扫描诱变以鉴定对抗原结合具有重要贡献的高变区残基。或者/另外,分析抗原-抗体复合物的晶体结构以鉴定抗体和抗原之间的接触点可能是有益的。所述接触残基及邻近残基是依照本文详述的技术进行替代的候选位点。一旦产生这样的变体,如本文所述对该组变体进行筛选,可选择在一种或多种相关测定法中具有优良特性的抗体用于进一步的开发。
编码抗体氨基酸序列变体的核酸分子可通过本领域知道的多种方法来制备。这些方法包括但不限于从天然来源分离(在天然发生氨基酸序列变体的情况中),或者通过对较早制备的变体或非变体型式的抗体进行寡核苷酸介导的(或定点)诱变,PCR诱变和盒式诱变来制备。
可能希望在本发明的免疫球蛋白多肽的Fc区中引入一处或多处氨基酸修饰,由此生成Fc区变体。Fc区变体可包括在一个或多个氨基酸位置(包括铰链半胱氨酸)包含氨基酸修饰(例如替代)的人Fc区序列(例如人IgG1,IgG2,IgG3或IgG4Fc区)。
依照此描述和本领域的教导,涵盖在有些实施方案中,本发明的方法中所使用的抗体与野生型对应抗体相比可在例如Fc区中包含一处或多处改变。与它们的野生型对应物相比,这些抗体仍会基本上保留治疗功效所需要的相同特性。例如,认为可在Fc区中进行将会导致C1q结合和/或补体依赖性细胞毒性(CDC)改变(即或是增强或是削弱)的某些改变,例如WO99/51642中所述。还可参见关注Fc区变体其它例子的Duncan和Winter,Nature 322:738-40(1988);美国专利No.5,648,260;美国专利No.5,624,821;及WO94/29351。WO00/42072(Presta)和WO 2004/056312(Lowman)记载了对FcR的结合提高或降低的抗体变体。在此明确收入这些专利出版物的内容作为参考。还可参见Shields等J.Biol.Chem.9(2):6591-6604(2001)。半衰期延长且对新生儿Fc受体(FcRn)(它负责将母体IgG转移给胎儿)(Guyer等,J.Immunol.117:587(1976)及Kim等,J.Immunol.24:249(1994))的结合改良的抗体记载于US2005/0014934A1(Hinton等)。这些抗体包含具有一处或多处改进Fc区与FcRn结合的替代的Fc区。具有改变的Fc区氨基酸序列且C1q结合能力升高或降低的多肽变体记载于美国专利No.6,194,551B1,WO99/51642。在此明确收入这些专利出版物的内容作为参考。还可参见Idusogie等J.Immunol.164:4178-4184(2000)。
抗体衍生物
可进一步修饰本发明的抗体以包含本领域知道的且易于获得的额外非蛋白质性质模块。优选的是,适于抗体衍生化的模块是水溶性聚合物。水溶性聚合物的非限制性例子包括但不限于聚乙二醇(PEG),乙二醇/丙二醇共聚物,羧甲基纤维素,右旋糖苷,聚乙烯醇,聚乙烯吡咯烷酮,聚-1,3-二氧戊环,聚-1,3,6-三 烷,乙烯/马来酸酐共聚物,聚氨基酸(均聚物或随机共聚物),和右旋糖苷或聚(n-乙烯吡咯烷酮)聚乙二醇,丙二醇均聚物,环氧丙烷/环氧乙烷共聚物,聚氧乙烯化多元醇(例如甘油),聚乙烯醇,及其混合物。由于其在水中的稳定性,聚乙二醇丙醛在生产中可能具有优势。聚合物可以是任何分子量,而且可以是分支的或不分支的。附着到抗体上的聚合物数目可以变化,而且如果附着了一个以上的聚合物,那么它们可以是相同或不同的分子。一般而言,可根据下列考虑来确定用于衍生化的聚合物的数目和/或类型,包括但不限于待改进抗体的具体特性或功能,抗体衍生物是否会用于指定条件下的治疗等。
烷,乙烯/马来酸酐共聚物,聚氨基酸(均聚物或随机共聚物),和右旋糖苷或聚(n-乙烯吡咯烷酮)聚乙二醇,丙二醇均聚物,环氧丙烷/环氧乙烷共聚物,聚氧乙烯化多元醇(例如甘油),聚乙烯醇,及其混合物。由于其在水中的稳定性,聚乙二醇丙醛在生产中可能具有优势。聚合物可以是任何分子量,而且可以是分支的或不分支的。附着到抗体上的聚合物数目可以变化,而且如果附着了一个以上的聚合物,那么它们可以是相同或不同的分子。一般而言,可根据下列考虑来确定用于衍生化的聚合物的数目和/或类型,包括但不限于待改进抗体的具体特性或功能,抗体衍生物是否会用于指定条件下的治疗等。
筛选具有期望特性的抗体
本发明的抗体可以用本领域已知的各种测定法(本文中公开了其中一些)对其物理/化学性质和生物学功能进行表征。在一些实施方案中,抗体表征为如下任一项或多项:减弱或者阻断FGF(诸如FGF1和/或FGF9)结合,减弱或者阻断FGFR3活化,减弱或者阻断FGFR3下游分子信号传导,破坏或阻断FGFR3结合配体(例如FGF1,FGF9),减弱或阻断FGFR3二聚化,促进单体FGFR3形成,结合单体FGFR3,和/或治疗和/或预防肿瘤,细胞增殖性病症或癌症,和/或治疗或预防与FGFR3表达和/或活性(诸如升高的FGFR3表达和/或活性)有关的病症。在一些实施方案中,对抗体筛选升高的FGFR3活化,升高的FGFR3下游分子信号传导,凋亡活性,FGFR3下调,和效应器功能(例如ADCC活性)。在一些实施方案中,抗体表征为如下任一项或多项:减弱或者阻断FGFR2活化,减弱或者阻断FGFR2下游分子信号传导,破坏或阻断FGFR2结合配体,减弱或阻断FGFR2二聚化,促进单体FGFR2形成,结合单体FGFR2,和/或治疗和/或预防肿瘤,细胞增殖性病症或癌症,和/或治疗或预防与FGFR2表达和/或活性(诸如升高的FGFR2表达和/或活性)有关的病症。在一些实施方案中,对抗体筛选升高的FGFR2活化,升高的FGFR2下游分子信号传导,FGFR2下调,和效应器功能(例如ADCC活性)。在一些实施方案中,抗体表征为如下任一项或多项:减弱或者阻断FGFR2和FGFR3活化,减弱或者阻断FGFR2和FGFR3下游分子信号传导,破坏或阻断FGFR2和FGFR3结合配体(例如FGF1,FGF9),减弱或阻断FGFR2和FGFR3二聚化,促进单体FGFR2和FGFR3形成,结合单体FGFR2和单体FGFR3,和/或治疗和/或预防肿瘤,细胞增殖性病症或癌症,和/或治疗或预防与FGFR2和FGFR3表达和/或活性(诸如升高的FGFR2和FGFR3表达和/或活性)有关的病症。在一些实施方案中,对抗体筛选升高的FGFR2和FGFR3活化,升高的FGFR2和FGFR3下游分子信号传导,凋亡活性,FGFR2和FGFR3下调,和效应器功能(例如ADCC活性)。
纯化的抗体还可以通过一系列测定法进行表征,包括但不限于N端测序,氨基酸分析,非变性大小排阻高压液相层析(HPLC),质谱,离子交换层析和木瓜蛋白酶消化。
在本发明的某些实施方案中,对此处制备的抗体分析它们的生物学活性。在一些实施方案中,对本发明的抗体检验它们的抗原结合活性。本领域已知的并且可以在本文中使用的抗原结合测定法包括但不限于利用诸如以下技术的任何直接的或竞争性的结合测定法:Western印迹,放射免疫测定法,ELISA(酶联免疫吸附测定法),“夹心式/三明治式”免疫测定法,免测沉淀测定法,荧光免疫测定法和蛋白A免疫测定法。在下面的实施例部分提供例示性的抗原结合和其它测定法。
如果想要抑制细胞生长的抗FGFR2/3抗体,那么可以在测量细胞生长抑制的体外和/或体内测定法中测试候选抗体。如果想要促进或不促进凋亡的抗FGFR2/3抗体,那么可以在测量凋亡的测定法中测试候选抗体。用于检查癌细胞生长和/或增殖或测定癌细胞凋亡的方法是本领域公知的,而且本文中描述和例示了一些。用于测定细胞生长和/或增殖和/或凋亡的例示性方法包括例如BrdU掺入测定法,MTT,[3H]-胸苷掺入(例如TopCount测定法(PerkinElmer)),细胞存活力测定法(例如CellTiter-Glo(Promega)),DNA片段化测定法,胱天蛋白酶活化测定法,台盼蓝(tryptan blue)排斥,染色质形态测定法,等等。
在一个实施方案中,本发明涵盖具有效应器功能的抗体。在某些实施方案中,测量抗体的Fc活性。可以进行体外和/或体内细胞毒性测定法以证实CDC和/或ADCC活性的降低/消除。例如,可以进行Fc受体(FcR)结合测定法以确保抗体缺失FcγR结合(因此可能缺失ADCC活性),但保留FcRn结合能力。介导ADCC的主要细胞,NK细胞,只表达FcγRIII,而单核细胞表达FcγRI,FcγRII和FcγRIII。在Ravetch和Kinet,Annu.Rev.Immunol 9:457-92(1991)第464页的表3概述了造血细胞上的FcR表达。美国专利No.5,500,362或5,821,337描述了用于评估感兴趣分子的ADCC活性的体外测定法的一个例子。本文中也例示了用于检测ADCC活性的一种测定法。可用于这些测定法的有用效应细胞包括外周血单个核细胞(PBMC)和天然杀伤(NK)细胞。或者/另外,可以在体内评估感兴趣分子的ADCC活性,例如在诸如Clynes等PNAS(USA)95:652-656(1998)中公开的动物模型中。也可以进行C1q结合测定法以证实抗体不能结合C1q从而缺失CDC活性。为了评估补体激活,可以进行CDC测定法,例如Gazzano-Santoro等,J.Immunol.Methods 202:163(1996)所述。也可以利用本领域已知的方法进行FcRn结合和体内清除/半衰期测定,例如实施例部分中描述的那些。
如果想要结合单体FGFR2和/或FGFR3的抗FGFR2/3抗体,那么可以在测量对单体FGFR2和/或FGFR3的结合和对单体FGFR2和/或FGFR3形成的促进的测定法(诸如体外测定法)中测试候选抗体。诸如本领域知道的测定法,而且本文中描述并例示了一些测定法。
如果想要抑制FGFR2和/或FGFR3二聚化的抗FGFR2/3抗体,那么可以在二聚化测定法中测试候选抗体,例如本文中描述的。
在一些实施方案中,测定候选抗体的FGFR2和/或FGFR3激动剂功能。用于评估FGFR2和/或FGFR3抗体的激动剂功能或活性的方法是本领域知道的,而且本文中还描述了一些。
在一些实施方案中,测定FGFR2/3抗体促进FGFR2和/或FGFR3受体下调的能力,例如使用本文中描述和例示的方法。在一个实施方案中,将FGFR2/3抗体与合适的测试细胞,例如膀胱癌细胞系(例如RT112)一起温育,并在合适的时间段后收获细胞裂解物并检查总FGFR2和FGFR3水平。也可以使用FACS分析来检查在与候选FGFR2/3抗体一起温育之后的表面FGFR2和FGFR3受体水平。
载体,宿主细胞,和重组方法
为了重组生产本发明抗体,分离编码它的核酸,并将其插入可复制载体,用于进一步克隆(DNA扩增)或表达。可使用常规规程容易的分离编码抗体的DNA并测序(例如使用能够与编码抗体重链和轻链的基因性特异结合的寡核苷酸探针)。可利用许多载体。载体的选择部分取决于将要使用的宿主细胞。通常,优选的宿主细胞是原核或真核(通常是哺乳动物)起源的。应当领会,任何同种型的恒定区可用于此目的,包括IgG,IgM,IgA,IgD和IgE恒定区,而且此类恒定区可以从任何人或动物物种获得。
a.使用原核宿主细胞生成抗体:
i.载体构建
可使用标准重组技术来获得编码本发明抗体多肽构件的多核苷酸序列。可从抗体生成细胞诸如杂交瘤细胞分离期望的多核苷酸序列并测序。或者,可使用核苷酸合成仪或PCR技术合成多核苷酸。一旦得到,将编码多肽的序列插入能够在原核宿主中复制并表达异源多核苷酸的重组载体。为了本发明,可使用本领域可获得的且知道的许多载体。适宜载体的选择将主要取决于将要插入载体的核酸的大小和将要用载体转化的具体宿主细胞。根据其功能(扩增或表达异源多核苷酸,或二者兼之)及其与它在其中驻留的具体宿主细胞的相容性,每种载体含有多种构件。载体构件通常包括但不限于:复制起点,选择标志基因,启动子,核糖体结合位点(RBS),信号序列,异源核酸插入片段,和转录终止序列。
一般而言,与宿主细胞一起使用的质粒载体包含衍生自与这些宿主相容物种的复制子和控制序列。载体通常携带复制位点,以及能够在转化细胞中提供表型选择的标志序列。例如,通常用衍生自大肠杆菌物种的质粒pBR322转化大肠杆菌。pBR322包含编码氨苄青霉素(Amp)和四环素(Tet)抗性的基因,如此提供轻松鉴定转化细胞的手段。pBR322,其衍生物,或其它微生物质粒或噬菌体还可包含或经修饰而包含可被微生物生物体用于表达内源蛋白质的启动子。Carter等人,美国专利No.5,648,237中详细记载了用于表达特定抗体的pBR322衍生物的例子。
另外,可将包含与宿主微生物相容的复制子和控制序列的噬菌体载体用作这些宿主的转化载体。例如,可使用噬菌体诸如λGEMTM-11来构建可用于转化易感宿主细胞诸如大肠杆菌LE392的重组载体。
本发明的表达载体可包含两种或更多启动子-顺反子对,它们编码每一种多肽构件。启动子是位于顺反子上游(5′)的非翻译调控序列,它调控顺反子的表达。原核启动子通常分成两类,诱导型的和组成性的。诱导型启动子指响应培养条件的变化(例如营养物的存在与否或温度变化)而启动受其控制的顺反子的升高水平转录的启动子。
众所周知受到多种潜在宿主细胞识别的大量启动子。通过限制酶消化切下源DNA中的启动子并将分离的启动子序列插入本发明载体,由此可将选择的启动子与编码轻链或重链的顺反子DNA可操作连接。天然启动子序列和许多异源启动子都可用于指导靶基因的扩增和/或表达。在有些实施方案中,使用异源启动子,因为与天然靶多肽启动子相比,它们通常容许所表达靶基因的更高转录和更高产量。
适用于原核宿主的启动子包括PhoA启动子,β-半乳糖苷酶和乳糖启动子系统,色氨酸(trp)启动子系统,和杂合启动子诸如tac或trc启动子。然而,在细菌中有功能的其它启动子(诸如其它已知的细菌或噬菌体启动子)也是合适的。它们的核苷酸序列已经发表,由此熟练工作人员能够使用提供任何所需限制性位点的接头或衔接头将它们与编码靶轻链和重链的顺反子可操作连接(Siebenlist等,Cell 20:269(1980))。
在本发明的一个方面,重组载体内的每个顺反子都包含指导所表达多肽穿膜转运的分泌信号序列构件。一般而言,信号序列可以是载体的构件,或者它可以是插入载体的靶多肽DNA的一部分。为了本发明而选择的信号序列应当是受到宿主细胞识别并加工(即被信号肽酶切除)的信号序列。对于不识别并加工异源多肽的天然信号序列的原核宿主细胞,将信号序列用选自例如下组的原核信号序列替代:碱性磷酸酶,青霉素酶,Ipp,或热稳定的肠毒素II(STII)前导序列,LamB,PhoE,PelB,OmpA,和MBP。在本发明的一个实施方案中,表达系统的两个顺反子中都使用的信号序列是STII信号序列或其变体。
在另一方面,依照本发明的免疫球蛋白的生成可在宿主细胞的细胞质中发生,因此不需要在每个顺反子内存在分泌信号序列。在那点上,免疫球蛋白轻链和重链在细胞质内表达,折叠和装配而形成功能性免疫球蛋白。某些宿主菌株(例如大肠杆菌trxB-菌株)提供有利于二硫键形成的细胞质条件,从而容许所表达蛋白质亚基的正确折叠和装配。Proba和Pluckthun,Gene 159:203(1995))。
适于表达本发明抗体的原核宿主细胞包括古细菌(Archaebacteria)和真细菌(Eubacteria),诸如革兰氏阴性或革兰氏阳性生物体。有用细菌的例子包括埃希氏菌属(Escherichia)(例如大肠埃希氏菌(E.coli)),芽孢杆菌属(Bacilli)(例如枯草芽孢杆菌(B.subtilis)),肠杆菌属(Enterobacteria),假单胞菌属(Pseudomonas)(例如铜绿假单胞菌(P.aeruginosa))物种,鼠伤寒沙门氏菌(Salmonella typhimurium),粘质沙雷氏菌(Serratia marcescans),克雷伯氏菌属(Klebsiella),变形菌属(Proteus),志贺氏菌属(Shigella),根瘤菌属(Rhizobia),透明颤菌属(Vitreoscilla),或副球菌属(Paracoccus)。在一个实施方案中,使用革兰氏阴性细胞。在一个实施方案中,使用大肠杆菌细胞作为本发明的宿主。大肠杆菌菌株的例子包括菌株W3110(Bachmann,Cellular andMolecular Biology,第2卷,Washington,D.C.,美国微生物学学会,1987,第1190-1219页;ATCC保藏号27,325)及其衍生物,包括具有基因型W3110 ΔfhuA(ΔtonA)ptr3 lac IqlacL8 ΔompTΔ(nmpc-fepE)degP41 kanR的菌株33D3(美国专利No.5,639,635)。其它菌株及其衍生物,诸如大肠杆菌294(ATCC 31,446),大肠杆菌B,大肠杆菌λ1776(ATCC 31,537)和大肠杆菌RV308(ATCC 31,608)也是合适的。这些例子只是例示而非限制。本领域知道用于构建具有指定基因型的任何上述细菌衍生物的方法,参见例如Bass等,Proteins 8:309-314(1990)。通常必需考虑复制子在细菌细胞中的可复制性来选择适宜的细菌。例如,在使用众所周知的质粒诸如pBR322,pBR325,pACYC177或pKN410来提供复制子时,大肠杆菌,沙雷氏菌属,或沙门氏菌属物种可能适于用作宿主。通常,宿主细胞应当分泌最小量的蛋白水解酶,而且可能希望在细胞培养中掺入额外的蛋白酶抑制剂。
ii.抗体生成
用上述表达载体转化宿主细胞,并在为了诱导启动子,选择转化子或扩增编码期望序列的基因而适当改动的常规营养培养基中进行培养。
转化即将DNA导入原核宿主,使得DNA能够进行复制,或是作为染色体外元件或是通过染色体成分。根据所用宿主细胞,使用适于这些细胞的标准技术进行转化。采用氯化钙的钙处理通常用于具有坚固细胞壁屏障的细菌细胞。另一种转化方法采用聚乙二醇/DMSO。使用的还有一种技术是电穿孔。
在本领域知道的且适于培养选定宿主细胞的培养基中培养用于生成本发明多肽的原核细胞。合适培养基的例子包括添加了必需营养补充物的LB培养基(Luria broth)。在有些实施方案中,培养基还含有根据表达载体的构建而选择的选择剂,以选择性容许包含表达载体的原核细胞生长。例如,向用于培养表达氨苄青霉素抗性基因的细胞的培养基中添加氨苄青霉素。
除了碳,氮,和无机磷酸盐来源以外,还可含有适当浓度的任何必需补充物,或是单独加入或是作为与另一种补充物或培养基的混合物,诸如复合氮源。任选的是,培养基可含有一种或多种选自下组的还原剂:谷胱甘肽,半胱氨酸,胱胺,巯基乙酸盐/酯,二硫赤藓糖醇和二硫苏糖醇。
在合适的温度培养原核宿主细胞。例如,对于培养大肠杆菌,优选的温度范围是约20℃至约39℃,更优选约25℃至约37℃,甚至更优选约30℃。主要取决于宿主生物体,培养基的pH可以是范围为约5至约9的任何pH。对于大肠杆菌,pH优选约6.8至约7.4,更优选约7.0。
如果本发明的表达载体中使用诱导型启动子,那么在适于激活启动子的条件下诱导蛋白质表达。在本发明的一个方面,使用PhoA启动子来控制多肽的转录。因而,为了诱导,在磷酸盐限制培养基中培养经过转化的宿主细胞。优选地,磷酸盐限制培养基是C.R.A.P培养基(参见例如Simmons等,J.Immunol.Methods 263:133-147(2002))。根据所采用的载体构建物,可采用多种其它诱导物,正如本领域所知道的。
在一个实施方案中,所表达的本发明多肽分泌到宿主细胞的周质中并从中回收。蛋白质回收通常涉及破坏微生物,通常通过诸如渗透压震扰(osmotic shock),超声处理或裂解等手段。一旦细胞遭到破坏,可通过离心或过滤清除细胞碎片或整个细胞。可以通过例如亲和树脂层析进一步纯化蛋白质。或者,蛋白质可能转运到培养液中并从中分离。可从培养液清除细胞,并将培养物上清液过滤和浓缩,用于进一步纯化所生成蛋白质。可使用普遍知道的方法诸如聚丙烯酰胺凝胶电泳(PAGE)和Western印迹测定法进一步分离和鉴定所表达多肽。
在本发明的一个方面,通过发酵过程大量进行抗体生产。多种大规模补料-分批发酵规程可用于生产重组蛋白。大规模发酵具有至少1000升的容量,优选约1,000至100,000升的容量。这些发酵罐使用搅拌器叶轮来分配氧和养分,尤其是葡萄糖(优选的碳源/能源)。小规模发酵通常指在体积容量不超过约100升的发酵罐中进行的发酵,范围可以是约1升至约100升。
在发酵过程中,通常在将细胞在合适条件下培养至期望密度(例如OD550约180-220,在此阶段细胞处于早期稳定期)后启动蛋白质表达的诱导。根据所采用的载体构建物,可使用多种诱导物,正如本领域知道的和上文描述的。可在诱导前将细胞培养较短的时间。通常将细胞诱导约12-50小时,但是可使用更长或更短的诱导时间。
为了提高本发明多肽的产量和质量,可修改多项发酵条件。例如,为了改善所分泌抗体多肽的正确装配和折叠,可使用过度表达伴侣蛋白诸如Dsb蛋白(DsbA,DsbB,DsbC,DsbD,和/或DsbG)或FkpA(具有伴侣活性的一种肽基脯氨酰-顺式,反式-异构酶)的额外载体来共转化宿主原核细胞。已经证明伴侣蛋白促进在细菌宿主细胞中生成的异源蛋白质的正确折叠和溶解度。Chen等,J.Biol.Chem.274:19601-19605(1999);Georgiou等人,美国专利No.6,083,715;Georgiou等人,美国专利No.6,027,888;Bothmann和Plückthun,J.Biol.Chem.275:17100-17105(2000);Ramm和Plückthun,J.Biol.Chem.275:17106-17113(2000);Arie等,Mol.Microbiol.39:199-210(2001))。
为了将所表达异源蛋白质(尤其是对蛋白水解敏感的异源蛋白质)的蛋白水解降至最低,可将蛋白水解酶缺陷的某些宿主菌株用于本发明。例如,可修饰宿主细胞菌株,在编码已知细菌蛋白酶的基因中进行遗传突变,诸如蛋白酶III,OmpT,DegP,Tsp,蛋白酶I,蛋白酶Mi,蛋白酶V,蛋白酶VI,及其组合。可以获得有些大肠杆菌蛋白酶缺陷菌株,参见例如Joly等,(1998)见上文;Georgiou等人,美国专利No.5,264,365;Georgiou等人,美国专利No.5,508,192;Hara等,Microbial Drug Resistance 2:63-72(1996)。
在一个实施方案中,在本发明的表达系统中使用蛋白水解酶缺陷且经过过度表达一种或多种伴侣蛋白的质粒转化的大肠杆菌菌株作为宿主细胞。
iii.抗体纯化
可采用本领域知道的标准蛋白质纯化方法。下面的规程是合适纯化规程的例示:免疫亲和或离子交换柱上的分级,乙醇沉淀,反相HPLC,硅土或阳离子交换树脂诸如DEAE上的层析,层析聚焦,SDS-PAGE,硫酸铵沉淀,和使用例如Sephadex G-75的凝胶过滤。
在一个方面,将固定化在固相上的蛋白A用于本发明全长抗体产物的免疫亲和纯化。蛋白A是来自金黄色葡萄球菌(Staphylococcus aureas)的41kD细胞壁蛋白质,它以高亲和力结合抗体Fc区。Lindmark等,J.Immunol.Meth.62:1-13(1983))。蛋白A固定化其上的固相优选具有玻璃或石英表面的柱子,更优选可控孔径玻璃柱或硅酸柱。在有些应用中,柱子以诸如甘油等试剂包被,试图防止污染物的非特异性粘附。
作为纯化的第一步,将衍生自如上所述细胞培养物的制备物施加到蛋白A固定化固相上,使得感兴趣抗体特异性结合蛋白A。然后清洗固相以清除与固相非特异性结合的污染物。最后通过洗脱从固相回收感兴趣抗体。
b.使用真核宿主细胞生成抗体:
载体构件通常包括但不限于如下一种或多种:信号序列,复制起点,一种或多种标志基因,增强子元件,启动子,和转录终止序列。
(i)信号序列构件
在真核宿主细胞中使用的载体还可在感兴趣成熟蛋白质或多肽的N端包含信号序列或具有特异性切割位点的其它多肽。优选受到宿主细胞识别并加工(即被信号肽酶切除)的异源信号序列。在哺乳动物细胞表达中,可利用哺乳动物信号序列以及病毒分泌前导,例如单纯疱疹病毒gD信号。
将这些前体区的DNA连接到编码抗体的DNA的读码框中。
(ii)复制起点
通常,哺乳动物表达载体不需要复制起点构件。例如,SV40起点通常可能只因包含早期启动子才使用。
(iii)选择基因构件
表达和克隆载体可包含选择基因,也称为选择标志。典型的选择基因编码如下蛋白质:(a)赋予对抗生素或其它毒素的抗性,例如氨苄青霉素,新霉素,甲氨蝶呤或四环素;(b)补足相应的营养缺陷;或(c)提供不能从复合培养基获得的关键营养物。
选择方案的一个例子利用药物来阻滞宿主细胞的生长。经异源基因成功转化的那些细胞生成赋予药物抗性的蛋白质,如此幸免于选择方案。此类显性选择的例子使用药物新霉素,霉酚酸和潮霉素。
适于哺乳动物细胞的选择标志的另一个例子是能够鉴定有能力摄取抗体核酸的细胞的选择标志,诸如DHFR,胸苷激酶,金属硫蛋白I和II优选灵长类金属硫蛋白基因,腺苷脱氨酶,鸟氨酸脱羧酶等。
例如,首先通过将所有转化子在含有甲氨蝶呤(Mtx,DHFR的一种竞争性拮抗剂)的培养基中进行培养来鉴定经DHFR选择基因转化的细胞。在采用野生型DHFR时,适宜的宿主细胞是DHFR活性缺陷的中国仓鼠卵巢(CHO)细胞系(例如ATCC CRL-9096)。
或者,可通过在含有针对选择标志的选择剂诸如氨基糖苷抗生素例如卡那霉素,新霉素或G418的培养基中培养细胞来选择经编码抗体,野生型DHFR蛋白,和另一种选择标志诸如氨基糖苷3′-磷酸转移酶(APH)的DNA序列转化或共转化的宿主细胞(特别是包含内源DHFR的野生型宿主)。参见美国专利No.4,965,199。
(iv)启动子构件
表达和克隆载体通常包含受到宿主生物体识别的启动子,且与抗体多肽核酸可操作连接。已知真核细胞的启动子序列。事实上,所有真核基因都具有富含AT区,它位于起始转录的位点上游约25至30个碱基处。在许多基因的转录起点上游70至80个碱基处发现的另一种序列是CNCAAT区,其中N可以是任何核苷酸。在大多数真核基因的3′端是AATAAA序列,它可能是向编码序列的3′端添加聚腺苷酸(polyA)尾的信号。所有这些序列合适的插入真核表达载体中。
在哺乳动物宿主细胞中由载体转录抗体多肽受到例如从病毒(诸如多瘤病毒,禽痘病毒,腺病毒(诸如2型腺病毒),牛乳头瘤病毒,禽类肉瘤病毒,巨细胞病毒,逆转录病毒,乙肝病毒,和猿病毒40(SV40))基因组获得的,来自异源哺乳动物启动子(例如肌动蛋白启动子或免疫球蛋白启动子)的,来自热休克启动子的启动子的控制,倘若这些启动子与宿主细胞系统相容的话。
方便地以SV40限制性片段的形式获得SV40病毒的早期和晚期启动子,该片段还包含SV40病毒复制起点。方便地以HindIII E限制性片段的形式获得人巨细胞病毒的立即早期启动子。美国专利No.4,419,446中公开了使用牛乳头瘤病毒作为载体在哺乳动物宿主中表达DNA的系统。美国专利No.4,601,978中记载了该系统的一种修改形式。或者,可使用劳氏肉瘤病毒长末端重复序列作为启动子。
(v)增强子元件构件
常常通过在载体中插入增强子序列来提高高等真核细胞对编码本发明抗体多肽的DNA的转录。现在知道来自哺乳动物基因(珠蛋白,弹性蛋白酶,清蛋白,α-胎蛋白和胰岛素)的许多增强子序列。然而,通常使用来自真核细胞病毒的增强子。例子包括SV40复制起点晚期侧的增强子(bp 100-270),巨细胞病毒早期启动子增强子,多瘤病毒复制起点晚期侧的增强子,和腺病毒增强子。关于激活真核启动子的增强元件还可参见Yaniv,Nature297:17-18(1982)。增强子可剪接到载体中,位于抗体多肽编码序列的5′或3′位置,但是优选位于启动子的5′位点。
(vi)转录终止构件
在真核宿主细胞中使用的表达载体通常还包含终止转录和稳定mRNA所必需的序列。此类序列通常可从真核或病毒DNA或cDNA非翻译区的5′端和偶尔的3′端获得。这些区域包含在编码抗体的mRNA的非翻译区中转录成聚腺苷酸化片段的核苷酸区段。一种有用的转录终止构件是牛生长激素聚腺苷酸化区。参见WO94/11026及其中公开的表达载体。
(vii)宿主细胞的选择和转化
适于克隆或表达本文载体中的DNA的宿主细胞包括本文描述的高等真核细胞,包括脊椎动物宿主细胞。脊椎动物细胞在培养(组织培养)中的繁殖已经成为常规规程。有用哺乳动物宿主细胞系的例子有经SV40转化的猴肾CV1系(COS-7,ATCC CRL 1651),人胚肾系(293细胞或为悬浮培养而亚克隆的293细胞,Graham等,J.Gen.Virol.36:59(1977)),幼仓鼠肾细胞(BHK,ATCC CCL 10),中国仓鼠卵巢细胞/-DHFR(CHO,Urlaub等,Proc.Natl.Acad.Sci.USA 77:4216(1980)),小鼠塞托利(Sertoli)细胞(TM4,Mather,Biol.Reprod.23:243-251(1980)),猴肾细胞(CV1,ATCC CCL 70),非洲绿猴肾细胞(VERO-76,ATCC CRL 1587),人宫颈癌细胞(HELA,ATCC CCL 2),犬肾细胞(MDCK,ATCC CCL 34),牛鼠(buffalo rat)肝细胞(BRL 3A,ATCC CRL 1442),人肺细胞(W138,ATCC CCL 75),人肝细胞(Hep G2,HB 8065),小鼠乳瘤(MMT 060562,ATCC CCL 51),TRI细胞(Mather等,AnnalsN.Y.Acad.Sci.383:44-68(1982)),MRC 5细胞,FS4细胞和人肝肉瘤(hepatoma)系(HepG2)。
为了生成抗体,用上文所述表达或克隆载体转化宿主细胞,并在为了诱导启动子,选择转化子或扩增编码期望序列的基因而适当改动的常规营养培养基中进行培养。
(viii)宿主细胞的培养
可在多种培养基中培养用于生成本发明抗体的宿主细胞。商品化培养基诸如Ham氏F10(Sigma),极限必需培养基(MEM,Sigma),RPMI-1640(Sigma),和Dulbecco氏修改Eagle氏培养基(DMEM,Sigma)适于培养宿主细胞。另外,可使用下列文献中记载的任何培养基作为宿主细胞的培养基:Ham等,Meth.Enz.58:44(1979);Barnes等,Anal.Biochem.102:255(1980);美国专利No.4,767,704;4,657,866;4,927,762;4,560,655;5,122,469;WO 90/03430;WO 87/00195;或美国专利Re.30,985。任何这些培养基可根据需要补充激素和/或其它生长因子(诸如胰岛素,运铁蛋白或表皮生长因子),盐(诸如氯化钠,钙,镁和磷酸盐),缓冲剂(诸如HEPES),核苷酸(诸如腺苷和胸苷),抗生素(诸如GENTAMYCINTM药物),痕量元素(定义为通常以微摩尔范围的终浓度存在的无机化合物),和葡萄糖或等效能源。还可以适宜浓度含有本领域技术人员知道的任何其它必需补充物。培养条件诸如温度,pH等即为表达而选择的宿主细胞先前所用的,这对于普通技术人员是显然的。
(ix)抗体的纯化
在使用重组技术时,可在细胞内生成抗体,或者直接分泌到培养基中。如果在细胞内生成抗体,那么首先通过例如离心或超滤清除微粒碎片,或是宿主细胞或是裂解片段。如果抗体分泌到培养基中,那么通常首先使用商品化蛋白质浓缩滤器(例如Amicon或Millipore Pellicon超滤单元)浓缩来自这些表达系统的上清液。可在任何上述步骤中包括蛋白酶抑制剂诸如PMSF以抑制蛋白水解,而且可包括抗生素以防止外来污染物的生长。
可使用例如羟磷灰石层析,凝胶电泳,透析和亲和层析(优选的纯化技术是亲和层析)来纯化从细胞制备的抗体组合物。蛋白A作为亲和配体的适宜性取决于抗体中存在的任何免疫球蛋白Fc结构域的种类和同种型。蛋白A可用于纯化基于人γ1,γ2,或γ4重链的抗体(Lindmark等,J.Immunol.Meth.62:1-13(1983))。蛋白G推荐用于所有小鼠同种型和人γ3(Guss等,EMBO J.5:1567-1575(1986))。亲和配体所附着的基质最常用的是琼脂糖,但是可使用其它基质。物理稳定的基质诸如可控孔径玻璃或聚(苯乙烯二乙烯)苯容许获得比琼脂糖更快的流速和更短的加工时间。若抗体包含CH3结构域,则可使用Bakerbond ABXTM树脂(J.T.Baker,Phillipsburg,NJ)进行纯化。根据待回收的抗体,也可使用其它蛋白质纯化技术诸如离子交换柱上的分级,乙醇沉淀,反相HPLC,硅土上的层析,肝素SEPHAROSETM上的层析,阴离子或阳离子交换树脂(诸如聚天冬氨酸柱)上的层析,层析聚焦,SDS-PAGE和硫酸铵沉淀。
在任何初步纯化步骤之后,可将含有感兴趣抗体和污染物的混合物进行低pH疏水相互作用层析,使用pH约2.5-4.5的洗脱缓冲液,优选在低盐浓度(例如约0-0.25M盐)进行。
免疫缀合物
本发明还提供了包含缀合有细胞毒剂的本文所述任何抗FGFR2/3抗体的免疫缀合物(可互换的称为“抗体-药物缀合物”或“ADC”),所述细胞毒剂诸如化疗剂,药物,生长抑制剂,毒素(例如细菌,真菌,植物或动物起源的酶活性毒素或其片段)或放射性同位素(即放射缀合物)。
抗体-药物缀合物在癌症治疗中用于局部投递细胞毒剂或细胞抑制剂(即用于杀死或抑制肿瘤细胞的药物)的用途(Syrigos和Epenetos,Anticancer Research 19:605-614(1999);Niculescu-Duvaz和Springer,Adv.Drug Del.Rev.26:151-172(1997);美国专利No.4,975,278)容许将药物模块靶向投递至肿瘤,并在那儿进行细胞内积累,而系统施用这些未经缀合的药物试剂可能在试图消除的肿瘤细胞以外导致不可接受的对正常细胞的毒性水平(Baldwin等,Lancet 603-05(1986年3月15日);Thorpe,“Antibody Carriers OfCytotoxic Agents In Cancer Therapy:A Review”,在《Monoclonal Antibodies′84:Biological And Clinical Applications》中,A.Pinchera等人编,第475-506页,1985)。由此试图获得最大功效及最小毒性。多克隆抗体和单克隆抗体皆有报导可用于这些策略(Rowland等,Cancer Immunol.Immunother.21:183-87(1986))。这些方法中所使用的药物包括道诺霉素(daunomycin),多柔比星(doxorubicin),甲氨蝶呤(methotrexate)和长春地辛(vindesine)(Rowland等,1986,见上文)。抗体-毒素缀合物中所使用的毒素包括细菌毒素诸如白喉毒素,植物毒素诸如蓖麻毒蛋白,小分子毒素诸如格尔德霉素(geldanamycin)(Mandler等,Jour.of the Nat.Cancer Inst.92(19):1573-1581(2000);Mandler等,Bioorganic&Med.Chem.Letters 10:1025-1028(2000);Mandler等,BioconjugateChem.13:786-791(2002)),美登木素生物碱类(EP 1391213;Liu等,Proc.Natl.Acad.Sci.USA 93:8618-8623(1996)),和加利车霉素(Lode等,Cancer Res.58:2928(1998);Hinman等,Cancer Res.53:3336-3342(1993))。毒素可通过包括微管蛋白结合,DNA结合或拓扑异构酶抑制在内的机制发挥其细胞毒性和细胞抑制性的效果。有些细胞毒药物在与大的抗体或蛋白质受体配体缀合时趋于失活或活性降低。

本文(例如上文)描述了可用于生成免疫缀合物的化疗剂。可使用的酶活性毒素及其片段包括白喉毒素A链,白喉毒素的非结合活性片段,外毒素A链(来自铜绿假单胞菌(Pseudomonas aeruginosa)),蓖麻毒蛋白(ricin)A链,相思豆毒蛋白(abrin)A链,蒴莲根毒蛋白(modeccin)A链,α-帚曲霉素(sarcin),油桐(Aleurites fordii)毒蛋白,香石竹(dianthin)毒蛋白,美洲商陆(Phytolaca americana)毒蛋白(PAPI,PAPII和PAP-S),苦瓜(Momordica charantia)抑制物,麻疯树毒蛋白(curcin),巴豆毒蛋白(crotin),肥皂草(Sapaonaria officinalis)抑制物,白树毒蛋白(gelonin),丝林霉素(mitogellin),局限曲菌素(restrictocin),酚霉素(phenomycin),依诺霉素(enomycin)和单端孢菌素(tricothecenes)。参见例如1993年10月28日公布的WO 93/21232。多种放射性核素可用于生成放射缀合抗体。例子包括212Bi,131I,131In,90Y和186Re。抗体和细胞毒剂的缀合物可使用多种双功能蛋白质偶联剂来制备,诸如N-琥珀酰亚氨基-3-(2-吡啶基二硫代)丙酸酯(SPDP),亚氨基硫烷(IT),亚氨酸酯(诸如盐酸己二酰亚氨酸二甲酯),活性酯类(诸如辛二酸二琥珀酰亚氨基酯),醛类(诸如戊二醛),双叠氮化合物(诸如双(对-叠氮苯甲酰基)己二胺),双重氮衍生物(诸如双(对-重氮苯甲酰基)乙二胺),二异氰酸酯(诸如甲苯2,6-二异氰酸酯),和双活性氟化合物(诸如1,5-二氟-2,4-二硝基苯)的双功能衍生物。例如,可如Vitetta等,Science 238:1098(1987)中所述制备蓖麻毒蛋白免疫毒素。碳-14标记的1-异硫氰酸苯甲基-3-甲基二亚乙基三胺五乙酸(MX-DTPA)是用于将放射性核苷酸与抗体缀合的例示性螯合剂。参见WO 94/11026。
本文还涵盖抗体与一种或多种小分子毒素诸如加利车霉素(calicheamicin),美登木素生物碱类(maytansinoids),多拉司他汀类(dolastatins),奥瑞司他汀类(aurostatins),单端孢霉素(trichothecene)和CC1065及这些毒素具有毒素活性的衍生物的缀合物。
i.美登素和美登木素生物碱类
在有些实施方案中,免疫缀合物包含缀合有一个或多个美登木素生物碱分子的本发明抗体(全长或片段)。
美登木素生物碱类是通过抑制微管蛋白多聚化来发挥作用的有丝分裂抑制剂。美登素最初从东非灌木齿叶美登木(Maytenus serrata)分离得到(美国专利No.3,896,111)。随后发现某些微生物也生成美登木素生物碱类,诸如美登醇和C-3美登醇酯(美国专利No.4,151,042)。例如下列美国专利公开了合成美登醇及其衍生物和类似物:4,137,230;4,248,870;4,256,746;4,260,608;4,265,814;4,294,757;4,307,016;4,308,268;4,308,269;4,309,428;4,313,946;4,315,929;4,317,821;4,322,348;4,331,598;4,361,650;4,364,866;4,424,219;4,450,254;4,362,663;及4,371,533。
美登木素生物碱类药物模块在抗体药物缀合物中是有吸引力的药物模块,因为它们:(i)相对易于通过发酵或发酵产物的化学修饰,衍生化来制备;(ii)易于用适于通过非二硫化物接头的缀合抗体的官能团衍生化;(iii)在血浆中稳定;且(iv)有效针对多种肿瘤细胞系。
例如下列专利公开了包含美登木素生物碱类的免疫缀合物及其制备方法和治疗用途:美国专利No.5,208,020;5,416,064;及欧洲专利EP 0 425 235 B1,明确将其公开内容收入本文作为参考。Liu等,Proc.Natl.Acad.Sci.USA 93:8618-8623(1996)记载了包含与针对人结肠直肠癌的单克隆抗体C242连接的称为DM1的美登木素生物碱的免疫缀合物。发现该缀合物具有针对培养的结肠癌细胞的高度细胞毒性,而且在体内肿瘤生长测定法中显示抗肿瘤活性。Chari等,Cancer Research 52:127-131(1992)记载了其中美登木素生物碱经二硫化物接头与结合人结肠癌细胞系上抗原的鼠抗体A7或结合HER-2/neu癌基因的另一种鼠单克隆抗体TA.1缀合的免疫缀合物。在体外在人乳癌细胞系SK-BR-3上测试了TA.1-美登木素生物碱缀合物的细胞毒性,该细胞系每个细胞表达3x105个HER-2表面抗原。药物缀合物达到了与游离美登木素生物碱药物程度相似的细胞毒性,这可通过增加每个抗体分子缀合的美登木素生物碱分子数目来提高。A7-美登木素生物碱缀合物在小鼠中显示低系统性细胞毒性。
抗体-美登木素生物碱缀合物可通过将抗体与美登木素生物碱分子化学连接且不显著削弱抗体或美登木素生物碱分子的生物学活性来制备。参见例如美国专利No.5,208,020,明确将其公开内容收入本文作为参考。每个抗体分子缀合平均3-4个美登木素生物碱分子在增强针对靶细胞的细胞毒性中显示功效,且对抗体的功能或溶解度没有负面影响,尽管预计甚至一个分子的毒素/抗体也将较之裸抗体的使用增强细胞毒性。美登木素生物碱类在本领域是众所周知的,而且可通过已知技术合成或从天然来源分离。例如美国专利No.5,208,020和上文提及的其它专利及非专利发表物中公开了合适的美登木素生物碱类。优选的美登木素生物碱类是美登醇和美登醇分子的芳香环或其它位置经过修饰的美登醇类似物,诸如各种美登醇酯。
本领域知道许多连接基团可用于制备抗体-美登木素生物碱缀合物,包括例如美国专利No.5,208,020或欧洲专利0 425 235 B1;Chari等,Cancer Research 52:127-131(1992);2004年10月8日提交的美国专利申请No.10/960,602中所公开的,明确将其公开内容收入本文作为参考。包含接头构件SMCC的抗体-美登木素生物碱类缀合物可以如2004年10月8日提交的美国专利申请No.10/960,602中所披露的来制备。连接基团包括二硫化物基团,硫醚基团,酸不稳定基团,光不稳定基团,肽酶不稳定基团,或酯酶不稳定基团,正如上文所述专利中所公开的,优选二硫化物和硫醚基团。本文中描述和例示了别的连接基团。
可使用多种双功能蛋白质偶联剂来制备抗体和美登木素生物碱的缀合物,诸如N-琥珀酰亚氨基-3-(2-吡啶基二硫代)丙酸酯(SPDP),琥珀酰亚氨基-4-(N-马来酰亚氨基甲基)环己烷-1-羧酸酯(SMCC),亚氨基硫烷(IT),亚氨酸酯(诸如盐酸己二酰亚氨酸二甲酯),活性酯类(诸如辛二酸二琥珀酰亚氨基酯),醛类(诸如戊二醛),双叠氮化合物(诸如双(对-叠氮苯甲酰基)己二胺),双重氮衍生物(诸如双(对-重氮苯甲酰基)-乙二胺),二异氰酸酯(诸如甲苯2,6-二异氰酸酯),和双活性氟化合物(诸如1,5-二氟-2,4-二硝基苯)的双功能衍生物。特别优选的偶联剂包括N-琥珀酰亚氨基-3-(2-吡啶基二硫代)丙酸酯(SPDP)(Carlsson等,Biochem.J.173:723-737(1978))和N-琥珀酰亚氨基-4-(2-吡啶基硫代)戊酸酯(SPP),由此提供二硫化物连接。
根据连接的类型,可将接头附着于美登木素生物碱分子的多个位置。例如,可使用常规偶联技术通过与羟基的反应来形成酯连接。反应可发生在具有羟基的C-3位置,经羟甲基修饰的C-14位置,经羟基修饰的C-15位置,和具有羟基的C-20位置。在一个优选的实施方案中,在美登醇或美登醇类似物的C-3位置形成连接。
ii.Auristatin和多拉司他汀
在有些实施方案中,免疫缀合物包含与多拉司他汀类(dolastatins)或多拉司他汀肽类似物及衍生物,奥瑞司他汀类缀合的本发明抗体(美国专利No.5,635,483;5,780,588)。多拉司他汀类和奥瑞司他汀类已经显示出干扰微管动力学,GTP水解,及核和细胞分裂(Woyke等(2001)Antimicrob.Agents and Chemother.45(12):3580-3584)且具有抗癌(美国专利No.5,663,149)和抗真菌活性(Pettit et al(1998)Antimicrob.AgentsChemother.42:2961-2965)。多拉司他汀或奥瑞司他汀药物模块可经由肽药物模块的N(氨基)末端或C(羧基)末端附着于抗体(WO 02/088172)。
例示性的奥瑞司他汀实施方案包括N-末端连接的单甲基奥瑞司他汀药物模块DE和DF,披露于“Monomethylvaline Compounds Capable of Conjugation to Ligands”,2004年11月5日提交的美国流水号10/983,340,明确将其公开内容完整收入本文作为参考。
典型的是,基于肽的药物模块可通过在两个或更多氨基酸和/或肽片段之间形成肽键来制备。此类肽键可依照例如肽化学领域众所周知的液相合成法来制备(参见E. 和K.Lübke,The Peptides,卷1,pp 76-136,1965,Academic Press)。奥瑞司他汀/多拉司他汀药物模块可依照以下文献中的方法来制备:美国专利No.US 5,635,483和5,780,588;Pettit等(1989)J.Am.Chem.Soc.111:5463-5465;Pettit等(1998)Anti-CancerDrug Design 13:243-277;Pettit等Synthesis,1996,719-725;Pettit等(1996)J.Chem.Soc.Perkin Trans.1 5:859-863;及Doronina(2003)Nat.Biotechnol.21(7):778-784;“Monomethylvaline Compounds Capable of Conjugation to Ligands”,2004年11月5日提交的美国流水号10/983,340,将其完整收入本文作为参考(披露了例如制备诸如MMAE和MMAF缀合至接头的单甲基缬氨酸化合物的接头和方法)。
和K.Lübke,The Peptides,卷1,pp 76-136,1965,Academic Press)。奥瑞司他汀/多拉司他汀药物模块可依照以下文献中的方法来制备:美国专利No.US 5,635,483和5,780,588;Pettit等(1989)J.Am.Chem.Soc.111:5463-5465;Pettit等(1998)Anti-CancerDrug Design 13:243-277;Pettit等Synthesis,1996,719-725;Pettit等(1996)J.Chem.Soc.Perkin Trans.1 5:859-863;及Doronina(2003)Nat.Biotechnol.21(7):778-784;“Monomethylvaline Compounds Capable of Conjugation to Ligands”,2004年11月5日提交的美国流水号10/983,340,将其完整收入本文作为参考(披露了例如制备诸如MMAE和MMAF缀合至接头的单甲基缬氨酸化合物的接头和方法)。
iii.加利车霉素
在其它实施方案中,免疫缀合物包含缀合有一个或多个加利车霉素分子的本发明抗体。加利车霉素抗生素家族能够在亚皮摩尔浓度生成双链DNA断裂。关于加利车霉素家族缀合物的制备参见美国专利No.5,712,374;5,714,586;5,739,116;5,767,285;5,770,701;5,770,710;5,773,001;和5,877,296(都授予美国Cyanamid公司)。可用的加利车霉素结构类似物包括但不限于γ1 I,α2 I,α3 I,N-乙酰基-γ1 I,PSAG和θI 1(Hinman等,Cancer Research53:3336-3342(1993);Lode等,Cancer Research 58:2925-2928(1998);及上述授予美国Cyanamid公司的美国专利)。可与抗体缀合的另一种抗肿瘤药物是QFA,它是一种抗叶酸药物。加利车霉素和QFA都具有胞内作用位点,且不易穿过质膜。因此,这些试剂经由抗体介导的内在化的细胞摄取大大增强了它们的细胞毒效果。
iv.其它细胞毒剂
可与本发明抗体缀合的其它抗肿瘤剂包括BCNU,链佐星(streptozoicin),长春新碱(vincristine),5-氟尿嘧啶,美国专利No.5,053,394和5,770,710中记载的统称为LL-E33288复合物的试剂家族,及埃斯波霉素类(esperamicins)(美国专利No.5,877,296)。
可用的酶活性毒素及其片段包括白喉毒素A链,白喉毒素的非结合活性片段,外毒素A链(来自铜绿假单胞菌(Pseudomonas aeruginosa)),蓖麻毒蛋白(ricin)A链,相思豆毒蛋白(abrin)A链,蒴莲根毒蛋白(modeccin)A链,α-帚曲霉素(sarcin),油桐(Aleuritesfordii)毒蛋白,香石竹(dianthin)毒蛋白,美洲商陆(Phytolaca americana)毒蛋白(PAPI,PAPII和PAP-S),苦瓜(Momordica charantia)抑制物,麻疯树毒蛋白(curcin),巴豆毒蛋白(crotin),肥皂草(Sapaonaria officinalis)抑制物,白树毒蛋白(gelonin),丝林霉素(mitogellin),局限曲菌素(restrictocin),酚霉素(phenomycin),依诺霉素(enomycin)和单端孢菌素(tricothecenes)。参见例如1993年10月28日公布的WO 93/21232。
本发明还涵盖抗体和具有核酸降解活性的化合物(例如核糖核酸酶或DNA内切核酸酶,诸如脱氧核糖核酸酶;DNA酶)之间形成的免疫缀合物。
为了选择性破坏肿瘤,抗体可包含高度放射性原子。多种放射性同位素可用于生成放射缀合抗体。例子包括At211,I131,I125,Y90,Re186,Re188,Sm153,Bi212,P32,Pb212和Lu的放射性同位素。在将缀合物用于检测时,它可包含放射性原子用于闪烁照相研究,例如tc99m或I123,或是包含自旋标记物用于核磁共振(NMR)成像(也称为磁共振成像,mri),诸如碘-123,碘-131,铟-111,氟-19,碳-13,氮-15,氧-17,钆,锰或铁。
可以已知方式将放射性标记物或其它标记物掺入缀合物。例如,可生物合成肽,或是通过化学氨基酸合成法合成肽,其中使用涉及例如氟-19代替氢的合适氨基酸前体。可以经肽中的半胱氨酸残基来附着标记物,诸如tc99m或I123,Re186,Re188和In111。可以经赖氨酸残基来附着钇-90。IODOGEN法(Fraker等,Biochem.Biophys.Res.Commun.80:49-57(1978))可用于掺入碘-123。《Monoclonal Antibodies in Immunoscintigraphy》(Chatal,CRCPress,1989)详细记载了其它方法。
可使用多种双功能蛋白质偶联剂来制备抗体和细胞毒剂的缀合物,诸如N-琥珀酰亚氨基-3-(2-吡啶基二硫代)丙酸酯(SPDP),琥珀酰亚氨基-4-(N-马来酰亚氨基甲基)环己烷-1-羧酸酯(SMCC),亚氨基硫烷(IT),亚氨酸酯(诸如盐酸己二酰亚氨酸二甲酯),活性酯类(诸如辛二酸二琥珀酰亚氨基酯),醛类(诸如戊二醛),双叠氮化合物(诸如双(对-叠氮苯甲酰基)己二胺),双重氮衍生物(诸如双(对-重氮苯甲酰基)-乙二胺),二异硫氰酸酯(诸如甲苯2,6-二异氰酸酯),和双活性氟化合物(诸如1,5-二氟-2,4-二硝基苯)的双功能衍生物。例如,可如Vitetta等,Science 238:1098(1987)中所述制备蓖麻毒蛋白免疫毒素。碳-14标记的1-异硫氰酸苯甲基-3-甲基二亚乙基三胺五乙酸(MX-DTPA)是用于将放射性核苷酸与抗体缀合的例示性螯合剂。参见WO94/11026。接头可以是便于在细胞中释放细胞毒药物的“可切割接头”。例如,可使用酸不稳定接头,肽酶敏感接头,光不稳定接头,二甲基接头,或含二硫化物接头(Chari等,Cancer Research 52:127-131(1992);美国专利No.5,208,020)。
本发明的化合物明确涵盖但不限于用下列交联剂制备的ADC:商品化(例如购自Pierce Biotechnology Inc.,Rockford,IL,U.S.A.)的BMPS,EMCS,GMBS,HBVS,LC-SMCC,MBS,MPBH,SBAP,SIA,SIAB,SMCC,SMPB,SMPH,sulfo-EMCS,sulfo-GMBS,sulfo-KMUS,sulfo-MBS,sulfo-SIAB,sulfo-SMCC和sulfo-SMPB,和SVSB(琥珀酰亚氨基-(4-乙烯基砜)苯甲酸酯)。见2003-2004年度应用手册和产品目录(Applications Handbook and Catalog)第467-498页。
v.抗体-药物缀合物的制备
在本发明的抗体-药物缀合物(ADC)中,将抗体(Ab)经接头(L)与一个或多个药物模块(D)缀合,例如每个抗体缀合约1个至约20个药物模块。可采用本领域技术人员知道的有机化学反应,条件和试剂通过数种路径来制备通式I的ADC,包括:(1)抗体的亲核基团经共价键与二价接头试剂反应,形成Ab-L,随后与药物模块D反应;和(2)药物模块的亲核基团经共价键与二价接头试剂反应,形成D-L,随后与抗体的亲核基团反应。本文中描述了用于制备ADC的别的方法。
Ab-(L-D)p I
接头可以由一种或多种接头构件构成。例示性的接头构件包括6-马来酰亚氨基己酰基("MC"),马来酰亚氨基丙酰基("MP"),缬氨酸-瓜氨酸("val-cit"),丙氨酸-苯丙氨酸("ala-phe"),对氨基苄氧羰基("PAB"),N-琥珀酰亚氨基4-(2-吡啶基硫代)戊酸酯("SPP"),N-琥珀酰亚氨基4-(N-马来酰亚氨基甲基)环己烷-1羧酸酯("SMCC′),和N-琥珀酰亚氨基(4-碘-乙酰基)氨基苯甲酸酯("SIAB")。本领域知道别的接头构件,本文也描述了一些。还可参见“Monomethylvaline Compounds Capable of Conjugation to Ligands”,2004年11月5日提交的美国流水号10/983,340,将其完整内容收入本文作为参考。
在有些实施方案中,接头可包含氨基酸残基。例示性的氨基酸接头构件包括二肽,三肽,四肽或五肽。例示性的二肽包括:缬氨酸-瓜氨酸(vc或val-cit),丙氨酸-苯丙氨酸(af或ala-phe)。例示性三肽包括:甘氨酸-缬氨酸-瓜氨酸(gly-val-cit)和甘氨酸-甘氨酸-甘氨酸(gly-gly-gly)。构成氨基酸接头构件的氨基酸残基包括那些天然存在的氨基酸,以及次要的氨基酸和非天然存在的氨基酸类似物,诸如瓜氨酸。氨基酸接头构件可以在它们的特定酶(例如肿瘤相关蛋白酶,组织蛋白酶B,C和D,或纤溶酶蛋白酶)的酶促切割的选择性方面进行设计和优化。
抗体的亲核基团包括但不限于:(i)N末端氨基;(ii)侧链氨基,如赖氨酸;(iii)侧链硫醇基,例如半胱氨酸;和(iv)糖基化抗体中糖的羟基或氨基。氨基,硫醇基,和羟基是亲核的,能够与接头模块上的亲电子基团反应而形成共价键,而接头试剂包括:(i)活性酯类,诸如NHS酯,HOBt酯,卤代甲酸酯,和酸性卤化物;(ii)烃基和苯甲基卤化物,诸如卤代乙酰胺;(iii)醛类,酮类,羧基和马来酰亚胺基团。某些抗体具有可还原的链间二硫键,即半胱氨酸桥。可通过还原剂诸如DTT(二硫苏糖醇)处理使抗体具有与接头试剂缀合的反应性。每个半胱氨酸桥理论上会如此形成两个反应性硫醇亲核体。可经由赖氨酸与2-亚氨基硫烷(Traut氏试剂)的反应,导致胺转变为硫醇,从而将额外亲核基团引入抗体。可以通过导入一个,两个,三个,四个,或更多个半胱氨酸残基(例如制备包含一个或多个非天然半胱氨酸氨基酸残基的突变型抗体)而将反应性硫醇基导入抗体。
还可通过修饰抗体来生成本发明的抗体-药物缀合物,即引入可与接头试剂或药物上的亲核取代基反应的亲电子模块。可用例如高碘酸盐氧化剂氧化糖基化抗体的糖,从而形成可与接头试剂或药物模块的胺基团反应的醛或酮基团。所得亚胺Schiff碱基可形成稳定的连接,或者可用例如硼氢化物试剂还原而形成稳定的胺连接。在一个实施方案中,糖基化抗体的碳水化合物部分与半乳糖氧化酶或偏高碘酸钠的反应可在蛋白质中生成羰(醛和酮)基团,它可与药物上的适宜基团反应(Hermanson,Bioconjugate Techniques)。在另一个实施方案中,包含N末端丝氨酸或苏氨酸残基的蛋白质可与偏高碘酸钠反应,导致在第一个氨基酸处生成醛(Geoghegan和Stroh,Bioconjugate Chem.3:138-146(1992);美国专利No.5,362,852)。此类醛可与药物模块或接头亲核体反应。
同样,药物模块上的亲核基团包括但不限于:胺,硫醇,羟基,酰肼,肟,肼,缩氨基硫脲,肼羧酸酯,和芳基酰肼基团,它们能够与接头模块上的亲电子基团反应而形成共价键,而接头试剂包括:(i)活性酯类,诸如NHS酯,HOBt酯,卤代甲酸酯,和酸性卤化物;(ii)烃基和苯甲基卤化物,诸如卤代乙酰胺;(iii)醛类,酮类,羧基,和马来酰亚胺基团。
或者,可通过例如重组技术或肽合成来制备包含抗体和细胞毒剂的融合蛋白。DNA的长度可包含各自编码缀合物两个部分的区域,或是彼此毗邻或是由编码接头肽的区域分开,该接头肽不破坏缀合物的期望特性。
在又一个实施方案中,可将抗体与“受体”(诸如链霉亲合素)缀合从而用于肿瘤预先靶向,其中对个体施用抗体-受体缀合物,接着使用清除剂由循环中清除未结合的缀合物,然后施用与细胞毒剂(例如放射性核苷酸)缀合的“配体”(例如亲合素)。
使用抗FGFR2/3抗体的方法
本发明的特色在于FGFR2/3抗体的使用,作为旨在自这种治疗剂的活性提供有益效应的特定治疗方案的一部分。本发明在治疗各种阶段的,各种类型的癌症中特别有用。
术语癌症涵盖增殖性病症的集合,包括但不限于癌前生长,良性肿瘤,和恶性肿瘤。良性肿瘤仍然局限于起源部位且没有能力渗透,侵入,或转移至远端部位。恶性肿瘤会侵入并损害它们周围的其它组织。它们还能获得脱离起源部位并传播至身体其它部分(转移)(通常经由血流或在淋巴结所处位置经由淋巴系统)的能力。原发性肿瘤以发生它们的组织类型来分类;转移性肿瘤以衍生癌细胞的组织类型来分类。随着时间消逝,恶性肿瘤的细胞变得越来越异常,而且表现出更不像正常细胞。癌细胞外观的这种变化称作肿瘤等级(tumor grade),而且将癌细胞描述为完全分化的(well-differentiated)(低级),中度分化的(moderately-differentiated),不良分化的(poorly-differentiated),或未分化的(undifferentiated)(高级)。完全分化的细胞相当正常,表现为和类似它们起源的正常细胞。未分化的细胞指已经变得如此异常以致于不再可能确定其起源的细胞。
癌症分期系统描述癌症在解剖学上已经传播了多远,而且试图将具有相似预后和处理的患者置于相同分期组中。可实施数项测试来帮助癌症分期,包括活检和某些影像检测诸如胸部x-射线,乳房x射线照片,骨扫描,CT扫描,和MRI扫描。验血和临床评估也用于评估患者的整体健康和检测癌症是否已经传播至某些器官。
为了对癌症分期,美国癌症联合委员会(American Joint Committee on Cancer)首先使用TNM分类系统将癌症(特别是实体瘤)置于字母分类中。给癌症指派字母T(肿瘤大小),N(可触知的结节),和/或M(转移)。T1,T2,T3,和T4描述渐增的原发性病灶尺寸;N0,N1,N2,N3指示渐进发展中的结节累及;而M0和M1反映远端转移的存在与否。
在第二种分期方法中,也称作整体阶段分组(Overall Stage Grouping)或罗马数字分期(Roman Numeral Staging),将癌症分成0期至IV期,掺入了原发性病症的尺寸以及结节传播和远端转移的存在。在这种系统中,将癌症分组成四期,以罗马数字I至IV表示,或者归类为“复发”。对于有些癌症,0期称作“原位”或“Tis”,诸如乳腺癌的原位导管癌或原位小叶癌。高级腺瘤也可归类为0期。一般而言,I期癌症是小的局限性癌症,其通常是可治愈的,而IV期通常代表不能手术治疗的或转移性的癌症。II期和III期癌症通常是局部高级的和/或展现出涉及局部淋巴结。一般而言,较高期数指示更严重的(extensive)疾病,包括更大的肿瘤尺寸和/或癌症传播至邻近原发性肿瘤的附近淋巴结和/或器官。这些阶段有精确定义,但是定义对每一种癌症是不同的,而且是熟练技术人员已知的。
许多癌症登记诸如NCI的“监视流行病学和最终结果程序”(Surveillance,Epidemiology,and End Results Program)(SEER)使用概括分期(summary staging)。这种系统用于所有类型的癌症。它将癌症病历分成五大类:
“原位”指只存在于它开始的细胞层中的早期癌症。
“局限性的”指癌症限于它开始的器官,没有传播的证据。
“区域性的”指癌症已经传播超出起源(原发性)部位至附近的淋巴结或器官和组织。
“远端的”指癌症自原发性部位传播至远端器官或远端淋巴结。
“未知的”用于描述没有足够信息来指明阶段的情况。
另外,癌症在原发性肿瘤被清除后几个月或几年复现是常见的。在所有可见的肿瘤都被根除后复现的癌症称作复发性疾病。在原发性肿瘤的区域中复现的疾病是局部复发的,而作为转移复现的疾病称作远端复发。
肿瘤可以是实体瘤或者是非实体瘤或软组织肿瘤。软组织肿瘤的例子包括白血病(例如慢性髓细胞性白血病(chronic myelogenous leukemia),急性髓细胞性白血病(acute myelogenous leukemia),成人急性成淋巴细胞性白血病(adult acutelymphoblastic leukemia),急性髓细胞性白血病(acute myelogenous leukemia),成熟B细胞急性成淋巴细胞性白血病(mature B-cell acute lymphoblastic leukemia),慢性淋巴细胞性白血病(chronic lymphocytic leukemia),多形核细胞性白血病(polymphocyticleukemia),或毛细胞性白血病(hairy cell leukemia))或淋巴瘤(例如非何杰金氏淋巴瘤,皮肤T细胞淋巴瘤,或何杰金氏病(Hodgkin’s disease))。实体瘤包括血液,骨髓,或淋巴系统以外的身体组织的任何癌症。实体瘤可进一步分成上皮细胞起源的那些和非上皮细胞起源的那些。上皮细胞实体瘤的例子包括胃肠道,结肠,乳腺,前列腺,肺,肾,肝,胰腺,卵巢,头和颈,口腔,胃,十二指肠,小肠,大肠,肛门,胆囊,唇(labium),鼻咽,皮肤,子宫,男性生殖器官,泌尿器官,膀胱,和皮肤的肿瘤。非上皮起源的实体瘤包括肉瘤,脑瘤,和骨瘤。定义部分中描述了肿瘤的其它例子
在一些实施方案中,本文中的患者进行诊断测试,例如在治疗之前和/或期间和/或之后。一般而言,如果进行诊断测试,那么可以从需要治疗的患者获得样品。若受试者患有癌症,则样品可以是肿瘤样品或其它生物学样品,诸如生物学流体,包括但不限于血液,尿液,唾液,腹水或衍生物诸如血清和血浆等等。
本文中的生物学样品可以是固定的样品,例如福尔马林固定,石蜡包埋的(FFPE)样品,或者是冷冻的样品。
用于测定mRNA或蛋白质表达的方法有多种,包括但不限于基因表达概况分析,聚合酶链式反应(PCR)包括定量实时PCR(qRT-PCR),微阵列分析,基因表达系列分析(serialanalysis of gene expression,SAGE),MassARRAY,通过大量平行签名测序(MassiveParallel Signiture Sequencing,MPSS)进行的基因表达分析,蛋白质组学,免疫组化(IHC)等。优选对mRNA定量。所述mRNA分析优选使用聚合酶链式反应(PCR)技术或通过微阵列分析来进行。若采用PCR,则优选的PCR形式是定量实时PCR(qRT-PCR)。在一个实施方案中,如果上文提到的一种或多种基因的表达处于中值或高于中值,例如与相同肿瘤类型的其它样品相比,那么认为是阳性表达。可以在与基因表达的测量基本上同时测定中值表达水平,或者可以事先测定。
多篇已发表的期刊论文(例如Godfrey等,J.Molec.Diagnostics 2:84-91(2000);Specht等,Am.J.Pathol.158:419-29(2001))中给出了使用固定的,石蜡包埋的组织作为RNA来源的代表性基因表达概况分析方案的步骤:包括mRNA分离,纯化,引物延伸和扩增。简单的说,一种代表性方法首先将石蜡包埋的肿瘤组织样品切成约10微米厚的切片。然后提取RNA并除去蛋白质和DNA。分析RNA浓度后,如果需要可以包括RNA修复和/或扩增步骤,并使用基因特异性启动子逆转录RNA,然后PCR。最后分析数据,根据所检验肿瘤样品中鉴定的特征性基因表达模式来确定患者可用的最佳治疗选项。
可以直接地或间接地测定基因或蛋白质表达的检测。
可以(直接地或间接地)测定癌症中的FGFR2和/或FGFR3表达或易位或扩增。多种诊断/预后测定法可用于此目的。在一个实施方案中,可通过IHC来分析FGFR3过表达。可将来自肿瘤活检的石蜡包埋组织切片进行IHC测定法并对照如下FGFR2和/或FGFR3蛋白质染色强度标准:
得分0:未观察到染色或者在少于10%的肿瘤细胞中观察到膜染色。
得分1+:在超过10%的肿瘤细胞中检测到微弱的/刚刚可察觉的膜染色。所述细胞只在其部分膜中有染色。
得分2+:在超过10%的肿瘤细胞中观察到微弱至中等的完全膜染色。
得分3+:在超过10%的肿瘤细胞中观察到中等至强烈的完全膜染色。
在一些实施方案中,那些FGFR2和FGFR3中每一项过表达评估得分为0或1+的肿瘤可表征为FGFR2和FGFR3未过表达,而那些得分为2+或3+的肿瘤可表征为FGFR2和FGFR3中每一项过表达。
在一些实施方案中,FGFR2和FGFR3中每一项过表达的肿瘤可根据对应于每个细胞表达的FGFR2和FGFR3分子中每一项拷贝数的免疫组化得分进行定级,并且可通过生化方法测定:
0=0-90个拷贝/细胞,
1+=至少约100个拷贝/细胞,
2+=至少约1000个拷贝/细胞,
3+=至少约10,000个拷贝/细胞。
或者/另外,可对福尔马林固定,石蜡包埋的肿瘤组织进行FISH测定法以测定肿瘤中FGFR2和/或FGFR3扩增或易位的存在和/或程度(如果有的话)。
可以直接地(例如通过磷酸ELISA测试,或其它检测磷酸化受体的手段)或间接地(例如通过检测活化的下游信号传导途径成分,检测受体二聚体(例如同二聚体,异二聚体),检测基因表达序型等等)测定FGFR2和FGFR3活化。
类似地,可以直接地或间接地(例如通过检测与组成性活性有关的受体突变,检测与组成性活性有关的受体扩增等等)检测组成性FGFR2和FGFR3和/或配体不依赖或配体依赖性FGFR2和FGFR3的存在。
检测核酸突变的方法是本领域公知的。通常而非必需的是,扩增样品中的靶核酸以提供所希望的材料量,来确定是否存在突变。扩增技术是本领域公知的。例如,扩增产物可以涵盖或不涵盖所有编码感兴趣的蛋白质的核酸序列,只要该扩增产物包含怀疑突变所在的特定氨基酸/核酸序列位置。
在一个实施例中,通过将来自样品的核酸与能够与编码突变核酸的核酸特异性杂交的核酸探针接触,并检测所述杂交,由此确定突变的存在。在一个实施方案中,标记探针成可检测的,例如用放射性同位素(3H,32P,33P等),荧光剂(若丹明,荧光素等)或发色剂标记。在有些实施方案中,探针是反义寡聚物,例如PNA,吗啉代-氨基磷酸酯,LNA或2’-烷氧基烷氧基。探针可以有约8个核苷酸至约100个核苷酸,或约10个至约75个,或约15个至约50个,或约20个至约30个。在另一个方面,本发明的核酸探针在试剂盒中提供,用以鉴定样品中的FGFR2和/或FGFR3突变,所述试剂盒包含特异杂交于或临近于编码FGFR2和/或FGFR3的核酸中的突变位点的寡核苷酸。试剂盒可进一步包括说明根据使用试剂盒的杂交测试的结果,用FGFR2和/或FGFR3拮抗剂治疗患包含FGFR2和/或FGFR3突变的肿瘤患者的说明书。
也可通过比较扩增的核酸的电泳迁移率和相应编码野生型FGFR2和/或FGFR3的核酸的电泳迁移率,由此来检测突变。迁移率差异表明扩增的核酸序列中存在突变。可通过任何合适的分子分离技术,例如在聚丙烯酰胺凝胶上,来确定电泳迁移率。
利用酶突变检测(EMD),也可分析核酸来检测突变(Del Tito et al.,ClinicalChemistry 44,731-739,1998)。EMD使用噬菌体解离酶T4内切核酸酶VII,其扫描双链DNA直到它检测并裂解了由碱基对错配造成的结构变形,所述错配由核酸改变诸如点突变,插入和缺失造成。例如通过凝胶电泳,检测到两个由解离酶裂解形成的短片段,表明存在突变。EMD方法的益处是以单个方案直接从扩增反应中鉴定出所检验的点突变,缺失,和插入,不需要纯化样品,缩短了杂交时间,并提高了信噪比。包含比正常至多过量20倍的核酸的混合样品和大小至多4kb的片段可进行测试。可是,EMD扫描不能鉴定在突变阳性样品中发生的特定碱基改变,所以如果需要,通常要额外的测序规程来鉴定特定的突变。如美国专利No.5,869,245所证实的,相似地可用CEL I酶替代解离酶T4内切核酸酶VII。
另一种用于检测突变的简单试剂盒是反向杂交测试条,其与用于检测HFE,TFR2和FPN1基因中造成血色病的多重突变的血色病StripAssayTM(Viennalabs http://www.bamburghmarrsh.com/pdf/4220.pdf)相似。这种测试基于PCR扩增后的序列特异性杂交。对于单突变测试,可使用基于微板的检测系统,而对于多重突变测试,可使用测试条作为“宏阵列”。试剂盒可包括可供样品制备,扩增和突变检测即时使用的试剂。多重扩增方案提供了便利,并允许以非常有限的体积来测试样品。利用直接StripAssay形式,可以在不超过5小时内完成二十个及更多突变的测试,而无需昂贵设备。从样品中分离DNA并体外扩增靶核酸(例如通过PCR),并用生物素标记,一般可在单个(“多重”)扩增反应中进行。然后,扩增产物选择性地与固定在诸如测试条的固体支持物上的寡核苷酸探针(野生型和突变体特异的)杂交,其中探针固定为平行线或条带。利用链霉亲合素-碱性磷酸酶和有色底物,来检测结合的生物素化的扩增子。这样的测试能检测本发明的所有突变或其任意子集。对于特定的突变体探针条带,三种信号传导模式之一是有可能的:(i)仅针对野生型探针的条带,表明是正常的核酸序列,(ii)针对野生型和突变体探针的条带,表明是杂合基因型和(iii)仅针对突变体探针的条带,表明是纯合突变体基因型。因此,在一个方面,本发明提供了检测本发明突变的方法,其包括从样品中分离和/或扩增靶FGFR2和/或FGFR3核酸序列,使得扩增产物包含配体,使扩增产物与包含该配体的可检测结合配偶体的探针接触,而且该探针能够与本发明的突变特异性杂交,然后检测所述探针与所述扩增产物的杂交。在一个实施方案中,配体是生物素,而结合配偶体包括亲合素或链霉亲合素。在一个实施方案中,结合配偶体包括链霉亲合素-碱性磷酸酶,其可用有色底物检测。在一个实施方案中,探针固定于例如测试条上,其中与不同突变互补的探针彼此分开。可选地,扩增的核酸用放射性同位素标记,在该情况中,探针不必包含可检测标记物。
野生型基因的改变涵盖所有形式的突变,诸如插入,倒位,缺失,和/或点突变。在一个实施方案中,突变是体细胞的。体细胞突变是仅发生于某些组织中(例如在肿瘤组织中)且不在种系中遗传的那些。种系突变可以在任何身体组织中找到。
包含靶核酸的样品可通过本领域公知的方法获得,而且它们适于特定类型和位置的肿瘤。组织活检通常用于获得有代表性的肿瘤组织片。可选地,可以已知或认为包含感兴趣的肿瘤细胞的组织/流体的形式间接获取肿瘤细胞。例如,肺癌损伤的样品可通过切除术,支气管镜检,细针抽吸,支气管刷检,或从痰/唾液,胸膜液或血液中获得。可从肿瘤或从其它身体样品诸如尿,痰或血清中检测出突变的基因或基因产物。上述用于检测肿瘤样品中突变的靶基因或基因产物的同样技术可用于其它身体样品。癌细胞从肿瘤上脱落下来,并出现在这些身体样品中。通过筛选这些身体样品,可实现对于诸如癌的疾病的简单早期诊断。另外,通过对这些身体样品测试突变的靶基因或基因产物,可监测治疗的进程。
对组织制备物富集肿瘤细胞的手段是本领域已知的。例如,可以从石蜡或低温保存的切片中分离组织。癌细胞也可通过流式细胞术或激光捕捉显微解剖而与正常细胞分开。这些以及其它从正常细胞中分离肿瘤的技术是本领域公知的。如果肿瘤组织被正常细胞高度污染,那么检测突变可能较为困难,然而最小化污染和/或假阳/阴性结果的技术是已知的,其中一些在下文有描述。例如,也可以对样品评估生物标志物(包括突变)的存在情况,所述标志物已知与感兴趣的肿瘤细胞有关而与相应的正常细胞无关,反之亦然。
可通过用本领域公知的技术来分子克隆靶核酸并测序该核酸,由此来完成靶核酸中点突变的检测。可选地,诸如聚合酶链式反应(PCR)的扩增技术可用于直接从肿瘤组织的基因组DNA制备物中扩增出靶核酸序列。然后确定扩增序列的核酸序列并鉴定其突变。扩增技术是本领域公知的,例如描述于Saiki et al.,Science,239,487,1988;美国专利No.4,683,203和4,683,195中的聚合酶链式反应。
应当注意,设计并选择合适的引物是非常成熟的现有技术。
本领域已知的连接酶链式反应也可用于扩增靶核酸序列。参见例如Wu et al.,Genomics,4,560-569,1989。另外,称为等位基因特异性PCR的技术也可使用。参见例如Ruano和Kidd,Nucleic Acids Research,17,8392,1989。根据该技术,使用的引物在其3’端与特定靶核酸突变杂交。如果不存在特定的突变,那么不会观察到扩增产物。也可以使用耐扩增突变系统(ARMS),其如欧洲专利申请公开第0332435号和Newton et al.,NucleicAcids Research,17,7,1989所公开的。基因的插入和缺失也可通过克隆,测序和扩增来检测。另外,基因或周围标志基因的限制性片段长度多态性(RFLP)探针可用于对等位基因的改变或多态性片段的插入来评分。也可用单链构象多态性(SSCP)分析来检测等位基因的碱基变化变体。参见例如Orita et al.,Proc.Natl.Acad.Sci.USA,86,2766-2770,1989和Genomics,5,874-879,1989。也可用其它用于检测插入和缺失的本领域已知技术。
根据基因野生型表达产物的改变,也可检测野生型基因的改变。这些表达产物包括mRNA以及蛋白质产物。通过扩增和测序mRNA或由mRNA分子克隆制备的cDNA,来检测点突变。利用本领域公知的DNA测序技术,来确定克隆的cDNA的序列。cDNA也可以通过聚合酶链式反应(PCR)来测序。
错配是并不100%互补的杂交核酸双链。缺乏完全的互补性可以是因为缺失,插入,倒位,替代或移码突变造成的。可用错配检测来检测靶核酸中的点突变。尽管这些技术可能不如测序灵敏,然而对大量组织样品来说更容易实施。错配裂解技术的实例是RNA酶保护方法,其在Winter et al.,Proc.Natl.Acad.Sci.USA,82,7575,1985和Meyers et al.,Science,230,1242,1985中有详细描述。例如,本发明的方法可包括使用标记的核糖核酸探针,其与人野生型靶核酸互补。衍生自组织样品的核糖核酸探针和靶核酸在一起退火(杂交),然后用RNA酶A消化,其能够检测双链RNA结构中的一些错配。如果RNA酶A检测到错配,那么它在错配位点裂解。因此,当在电泳凝胶基质上分离退火的RNA制备物时,如果RNA酶A检测到错配并裂解,那么将见到比核糖核酸探针与mRNA或DNA的全长双链RNA小的RNA产物。考虑到它涵盖了怀疑突变了的位置,核糖核酸探针不需要是全长的靶核酸mRNA或基因,但可以是靶核酸的一部分。如果核糖核酸探针仅包含靶核酸mRNA或基因的一个区段,如果希望,那么可能希望使用大量这些探针来筛选整个靶核酸序列的错配。
以相似的方式,可用DNA探针检测错配,例如通过酶或化学裂解进行。参见例如Cotton et al.,Proc.Natl.Acad.Sci.USA,85,4397,1988;和Shenk et al.,Proc.Natl.Acad.Sci.USA,72,989,1975。可选地,通过错配双链体相对于匹配双链体的电泳迁移率变化,可检测错配。参见例如Cariello,Human Genetics,42,726,1988。用核糖核酸探针或DNA探针,可以在杂交前扩增可能包含突变的靶核酸mRNA或DNA。尤其是如果改变是总的重排,诸如缺失和插入,那么利用Southern杂交也可检测靶核酸DNA中的改变。
扩增出的靶核酸DNA序列也可用等位基因特异性探针筛选。这些探针是核酸寡聚物,每一个都包含靶核酸基因中包含已知突变的区域。例如,一个寡聚物的长度可以为约30个核苷酸,对应于部分靶基因序列。通过使用一组这样的等位基因特异性探针,可筛选靶核酸扩增产物,以鉴定靶基因中以前鉴定出的突变的存在。可以例如在尼龙膜上进行扩增的靶核酸序列与等位基因特异性探针的杂交。在严格杂交条件下与特定探针的杂交表明肿瘤组织中存在与等位基因特异性探针中相同的突变。
通过筛选相应野生型蛋白的改变,可检测野生型靶基因的改变。例如,与靶基因产物有免疫反应性的单克隆抗体可用于筛选组织,例如用已知与基因产物(蛋白质)的特定突变位置结合的抗体。例如,所用的抗体可以是结合缺失的外显子的抗体或结合包含靶蛋白缺失部分的构象表位的抗体。缺少关联抗原将表示有突变。突变等位基因产物的特异性抗体也可用于检测突变基因产物。可以从噬菌体展示文库中鉴定抗体。这些免疫学测定法可以以本领域已知的任何便利形式进行。这些包括Western印迹,免疫组织化学测定法和ELISA测定法。任何检测改变的蛋白质的方法都可用于检测野生型靶基因的改变。
利用核酸扩增技术,诸如聚合酶链式反应,引物对可用于确定靶核酸的核苷酸序列。单链DNA引物对可以与靶核酸序列之内或周围的序列退火,从而引发靶序列的扩增。也可使用等位基因特异性引物。该引物仅与特定的突变靶序列退火,因此仅在存在突变的靶序列作为模板的情况下才会扩增出产物。为了便于接下来克隆扩增的序列,引物可具有限制酶位点序列,该序列附加在这些引物的末端。这些酶和位点是本领域公知的。可以用本领域公知的技术来合成引物本身。一般而言,可用寡核苷酸合成仪制造引物,所述仪器可从商业渠道获得。设计特定引物完全在本领域技术范围内。
核酸探针可用于许多目的。它们可用于对基因组DNA的Southern杂交中,并可用于RNA酶保护方法中以检测上文已经讨论过的点突变。探针可用于检测靶核酸扩增产物。利用其它技术,它们也可用于检测野生型基因或mRNA的错配。利用酶(例如S1核酸酶),化学药品(例如羟胺或四氧化锇和哌啶),或错配杂交体相对于完全匹配杂交体的电泳迁移率变化,可检测错配。这些技术是本领域已知的。参见Novack et al.,Proc.Natl.Acad.Sci.USA,83,586,1986。一般而言,探针与激酶结构域外的序列互补。整组核酸探针可用于组成试剂盒来检测靶核酸中的突变。试剂盒容许进行对感兴趣的靶序列的大区域的杂交。探针可彼此交叠或毗邻。
如果用核糖核酸探针来检测mRNA的错配,那么它一般与靶基因的mRNA互补。因此,核糖核酸探针是反义探针,因为它不编码相应的基因产物,因为它与有义链互补。核糖核酸探针一般会用放射性,比色,或荧光材料来标记,这可以通过任何本领域已知方法来实现。如果用核糖核酸探针来检测DNA的错配,它可以是任一极性,即有义的或反义的。相似地,也可用DNA探针来检测错配。
在一些情况中,癌症过表达或不过表达FGFR2和/或FGFR3。可在诊断或预后测定法中通过评估细胞表面上存在的受体蛋白质水平的升高(例如通过免疫组化测定法;IHC)来测定受体过表达。或者/另外,可测量细胞中编码受体的核酸的水平,例如通过荧光原位杂交(FISH;参见1998年10月公布的WO 98/45479),Southern印迹或聚合酶链式反应(PCR)技术,诸如实时定量PCR(RT-PCR)。在上述测定法之外,熟练从业人员还可利用多种体内测定法。例如,可将患者身体内的细胞暴露于任选用可检测标记物例如放射性同位素标记的抗体,并且可评估该抗体对患者身体内细胞的结合,例如通过外部扫描放射性或通过分析取自事先已暴露于所述抗体的患者的活检。
化疗剂
本发明的联合疗法可进一步包含一种或多种化疗剂。组合施用包括使用分开的配制剂或单一药物配制剂的共施用或同时施用和任一次序的序贯施用,其中优选有一段时间所有活性剂同时发挥它们的生物学活性。
如果施用的话,由于药物的组合作用或可归于抗代谢物化疗剂施用的消极副作用,通常以关于它们已知的或任选降低的剂量施用化疗剂。可依照制造商的说明书或根据从业人员凭经验确定的那样使用此类化疗剂的制备和剂量给药日程。
本文中公开了可组合的多种化疗剂。
在一些实施方案中,要组合的化疗剂选自下组:来那度胺(lenalidomide)(REVLIMID),蛋白酶体抑制剂(诸如硼替佐米(bortezomib)(VELCADE)和PS342),bora类紫杉烷(taxoid)(包括多西他塞(docetaxel)和帕利他塞(paclitaxel)),长春药(vinca)(诸如长春瑞滨(vinorelbine)或长春碱(vinblastine)),铂化合物(诸如卡铂(carboplatin)或顺铂(cisplatin)),芳香酶抑制剂(诸如来曲唑(letrozole),阿那曲唑(anastrazole),或依西美坦(exemestane)),抗雌激素(例如氟维司群(fulvestrant)或他莫昔芬(tamoxifen)),依托泊苷(etoposide),塞替哌(thiotepa),环磷酰胺(cyclophosphamide),培美曲塞(pemetrexed),甲氨蝶呤(methotrexate),脂质体多柔比星(liposomaldoxorubicin),PEG化脂质体多柔比星(pegylated liposomal doxorubicin),卡培他滨(capecitabine),吉西他滨(gemcitabine),美法仑(melthalin),多柔比星(doxorubicin),长春新碱(vincristine),COX-2抑制剂(例如塞来考昔(celecoxib)),或类固醇(例如地塞米松(dexamethasone)和泼尼松(prednisone))。在一些实施方案(例如涉及治疗t(4;14)+多发性骨髓瘤的实施方案)中,组合地塞米松和来那度胺,或地塞米松,或硼替佐米,或长春新碱,多柔比星和地塞米松,或沙利度胺和地塞米松,或脂质体多柔比星,长春新碱和地塞米松,或来那度胺和地塞米松,或硼替佐米和地塞米松,或硼替佐米,多柔比星,和地塞米松。在一些实施方案(例如涉及膀胱癌的实施方案)中,组合吉西他滨和顺铂,或紫杉烷(例如帕利他赛,多西他赛),或培美曲塞,或甲氨蝶呤,长春碱,多西他赛和顺铂,或卡铂,或丝裂霉素C组合以5-氟尿嘧啶,或顺铂,或顺铂和5-氟尿嘧啶。
配制,剂量和施用
会以与优良医学实践一致的方式配制,剂量给药和施用本发明中所使用的治疗剂。在此内容中考虑的因素包括所治疗的具体病症,所治疗的具体受试者,患者个体的临床状况,病症的起因,投递药剂的部位,施药的方法,施药的日程安排,要组合的药剂的药物-药物相互作用,和医学从业人员知道的其它因素。
使用本领域已知的标准方法通过将具有期望纯度的活性成分与任选的生理学可接受载体,赋形剂或稳定剂混合来制备治疗用配制剂(Remington’s PharmaceuticalSciences(第20版),A.Gennaro编,2000,Lippincott,Williams&Wilkins,Philadelphia,PA)。可接受的载体包括盐水,或缓冲剂,诸如磷酸盐,柠檬酸盐和其它有机酸;抗氧化剂,包括抗坏血酸;低分子量(少于约10个残基)多肽;蛋白质,诸如血清清蛋白,明胶或免疫球蛋白;亲水性聚合物,诸如聚乙烯吡咯烷酮;氨基酸,诸如甘氨酸,谷氨酰胺,天冬酰胺,精氨酸或赖氨酸;单糖,二糖和其它碳水化合物,包括葡萄糖,甘露糖或糊精;螯合剂,诸如EDTA;糖醇,诸如甘露醇或山梨醇;成盐相反离子,诸如钠;和/或非离子表面活性剂,诸如TWEENTM,PLURONICSTM或PEG。
任选但优选的是,配制剂含有药学可接受盐,优选氯化钠,且优选大约为生理浓度。任选的是,本发明的配制剂可含有药学可接受防腐剂。在一些实施方案中,防腐剂的浓度范围为0.1-2.0%,典型的是v/v。合适的防腐剂包括药学领域已知的那些。苯甲醇,酚,间甲酚,对羟基苯甲酸甲酯,和对羟基苯甲酸丙酯是优选的防腐剂。任选的是,本发明的配制剂可包括药学可接受表面活性剂,其浓度为0.005-0.02%。
本文中的配制剂还可含有超过一种所治疗具体适应症所必需的活性化合物,优选活性互补且彼此没有不利影响的那些。合适的是,此类分子以对于预定目的有效的量组合。
活性成分还可包载于例如通过凝聚技术或通过界面聚合制备的微胶囊中(例如分别是羟甲基纤维素或明胶微胶囊和聚(甲基丙烯酸甲酯)微胶囊),在胶状药物传递系统中(例如脂质体,清蛋白微球体,微乳剂,纳米颗粒和纳米胶囊),或在粗滴乳状液中。此类技术公开于Remington’s Pharmaceutical Sciences,见上文。
可制备持续释放制剂。持续释放制剂的合适例子包括含有本发明抗体的固体疏水性聚合物半透性基质,该基质以定型产品的形式存在,例如薄膜或微胶囊。持续释放基质的例子包括聚酯,水凝胶(例如聚(2-羟乙基-甲基丙烯酸酯)或聚(乙烯醇)),聚交酯(美国专利No.3,773,919),L-谷氨酸和L-谷氨酸γ-乙酯的共聚物,不可降解的乙烯-乙酸乙烯,可降解的乳酸-乙醇酸共聚物诸如LUPRON DEPOTTM(由乳酸-乙醇酸共聚物和醋酸亮丙瑞林构成的可注射微球体)及聚-D-(-)-3-羟基丁酸。虽然诸如乙烯-乙酸乙烯和乳酸-乙醇酸等聚合物能够持续释放分子100天以上,但是某些水凝胶释放蛋白质的时间较短。当胶囊化抗体在体内长时间保持时,它们可能由于暴露于37℃的潮湿环境而变性或聚集,导致生物学活性损失和免疫原性可能改变。可根据相关机制来设计稳定化理性策略。例如,如果发现聚集机制是经由硫醇-二硫化物互换而形成分子间S-S键,那么可通过修饰巯基残基,自酸性溶液冻干,控制湿度,采用适宜添加剂,和开发特定的聚合物基质组合物来实现稳定。
依照已知方法给人类患者施用本发明的治疗剂,诸如静脉内施用(像推注或通过一段时间里的连续输注),通过肌肉内,腹膜内,脑脊髓内,皮下,关节内,滑膜内,鞘内,口服,表面,或吸入路径。回体(ex vivo)策略也可用于治疗性应用。回体策略涉及用编码FGFR2,FGFR3,或FGFR2/3拮抗剂的多核苷酸转染或转导自受试者获得的细胞。然后将经过转染或转导的细胞返回受试者。细胞可以是极其多种类型之任一,包括但不限于造血细胞(例如,骨髓细胞,巨噬细胞,单核细胞,树突细胞,T细胞,或B细胞),成纤维细胞,上皮细胞,内皮细胞,角质形成细胞,或肌肉细胞。
例如,如果FGFR2/3拮抗剂是抗体,那么通过任何合适手段施用抗体,包括胃肠外,皮下,腹膜内,肺内,和鼻内,及(如果想要局部免疫抑制治疗的话)病灶内施用。胃肠外输注包括肌肉内,静脉内,动脉内,腹膜内,或皮下施用。另外,合适的是,通过脉冲输注来施用抗体,特别是使用递减剂量的抗体。优选的是,通过注射给予剂量给药,最优选的是,通过静脉内或皮下注射给予剂量给药,这部分取决于施药是短期的还是长期的。
在另一个例子中,在病症或肿瘤位置允许时,局部施用FGFR2/3拮抗性化合物,例如通过直接注射,而且可以周期性重复注射。也可以在手术切除肿瘤后系统地/全身地将FGFR2/3拮抗剂投递至受试者或直接投递至肿瘤细胞,例如肿瘤或肿瘤床,用以预防或降低局部复发或转移。
组合中的治疗剂的施用通常在规定的时间段里进行(通常是数分钟,数小时,数天或数周,这取决于所选择的组合)。联合疗法旨在涵盖这些治疗剂以序贯方式的施用(也就是说,其中在不同时间施用每一种治疗剂),以及这些治疗剂或治疗剂中至少两种以基本上同时的方式的施用。
可以通过相同路径或不同路径来施用治疗剂。例如,可以通过静脉内注射来施用组合中的抗FGFR2/3抗体,同时可以口服施用所述组合中的化疗剂。或者,例如,可以口服施用这两种治疗剂,或者可以通过静脉内注射来施用这两种治疗剂,这取决于具体的治疗剂。治疗剂的施用次序也随着具体药剂而变化。
根据疾病的类型和严重程度,施用于患者的初始候选剂量是约1μg/kg至100mg/kg每种治疗剂,例如或是通过一次或多次分开施药或是通过连续输注。根据上文所述因素,典型日剂量的范围可以是约1μg/kg至约100mg/kg或更多。对于持续数天或更长的重复施药,根据状况,持续治疗直至根据上文所述方法的测量,癌症得到治疗。然而,其它剂量方案也可能是有用的。
本申请涵盖通过基因疗法来施用FGFR2/3抗体。参见例如1996年3月14日公布的WO96/07321,其关注使用基因疗法来产生胞内抗体。
制品
在本发明的另一个方面,提供了包含可用于治疗,预防和/或诊断上文所述病症的物质的制品。制品包括容器和贴在所述容器上或与其相联的标签或包装插页。合适的容器包括例如瓶子,小管,注射器等。容器可用各种材料制成,诸如玻璃或塑料。容器中装有其自身或在联合其它组合物时有效治疗,预防和/或诊断疾患的组合物,而且可具有无菌存取口(例如容器可以是具有皮下注射针可刺穿的塞子的静脉内溶液袋或小管)。组合物中的至少一种活性剂是本发明的抗体。标签或包装插页指示该组合物用于治疗选择的疾患,诸如癌症。此外,制品可包括(a)其中装有组合物的第一容器,其中所述组合物包含本发明的抗体;和(b)其中装有组合物的第二容器,其中所述组合物包含别的细胞毒剂。本发明此实施方案中的制品还可包括指示第一和第二抗体组合物可用于治疗特定疾患例如癌症的包装插页。或者/另外,制品还可包括第二(或第三)容器,其中装有药学可接受的缓冲剂,诸如注射用抑菌水(BWFI),磷酸盐缓冲盐水,林格氏(Ringer)溶液和右旋糖溶液。它还可包括商业和用户立场上所需的其它物质,包括其它缓冲剂,稀释剂,滤器,针头和注射器。
下面是本发明方法和组合物的实施例。应当理解,根据上文提供的一般描述,可实施各种其它实施方案。
实施例
实施例1。扩宽抗FGFR3抗体的特异性。
实施了实验来扩宽抗FGFR2/3抗体的结合特异性。具体而言,实施了实验来开发用于癌症疗法的具有针对FGFR3和FGFR2的双重特异性,不结合高度相关的受体FGFR1和FGFR4的抗体。出发点为以亚纳摩尔亲和力结合FGFR3IIIb和IIIc同种型的单特异性抗体R3Mab(Qing,J.,X.Du,Y.Chen,P.Chan,H.Li,P.Wu,S.Marsters,S.Stawicki,J.Tien,K.Totpal,S.Ross,S.Stinson,D.Dornan,D.French,Q.R.Wang,J.P.Stephan,Y.Wu,C.Wiesmann andA.Ashkenazi(2009)."Antibody-based targeting of FGFR3 in bladder carcinoma andt(4;14)-positive multiple myeloma in mice."The Journal of clinicalinvestigation 119(5):1216-1229)。R3Mab在体内显示强健的对FGFR3信号传导和肿瘤生长的抑制(Qing,J.,X.Du,Y.Chen,P.Chan,H.Li,P.Wu,S.Marsters,S.Stawicki,J.Tien,K.Totpal,S.Ross,S.Stinson,D.Dornan,D.French,Q.R.Wang,J.P.Stephan,Y.Wu,C.Wiesmann and A.Ashkenazi(2009)."Antibody-based targeting of FGFR3 inbladder carcinoma and t(4;14)-positive multiple myeloma in mice."The Journalof clinical investigation 119(5):1216-1229),而且已经在I期临床试验中进行研究。
抗体重新设计策略受到先前测定的与FGFR3-IIIb复合的R3Mab Fab片段的晶体学结构(PDB 3GRW)的指导(Qing,J.,X.Du,Y.Chen,P.Chan,H.Li,P.Wu,S.Marsters,S.Stawicki,J.Tien,K.Totpal,S.Ross,S.Stinson,D.Dornan,D.French,Q.R.Wang,J.P.Stephan,Y.Wu,C.Wiesmann and A.Ashkenazi(2009)."Antibody-based targetingof FGFR3 in bladder carcinoma and t(4;14)-positive multiple myeloma in mice."The Journal of clinical investigation 119(5):1216-1229)。此结构指示R3Mab与FGFR3-IIIb的D2和D3域二者相互作用。虽然本文中随后发现D2对于R3Mab结合是足够的,但是初始分析基于这种原始结构上的接触。FGFR3-IIIb抗原上的大部分接触表面是由抗体互补决定区(CDR)H3(46%),H1(23%)和L2(22%)贡献的,还有来自CDR H2和框架区(FR)残基的小贡献(Qing,J.,X.Du,Y.Chen,P.Chan,H.Li,P.Wu,S.Marsters,S.Stawicki,J.Tien,K.Totpal,S.Ross,S.Stinson,D.Dornan,D.French,Q.R.Wang,J.P.Stephan,Y.Wu,C.Wiesmann and A.Ashkenazi(2009)."Antibody-based targeting of FGFR3 inbladder carcinoma and t(4;14)-positive multiple myeloma in mice."The Journalof clinical investigation 119(5):1216-1229)(图5)。比较了FGFR3-IIIb和该意图的另外的FGFR2-IIIb抗原之间的相似性。这两种同系物的D2D3区共享68%蛋白质序列同一性,而它们的D2域共享76%同一性(表2)。表2显示相同FGFR的两种同种型(粗体),包括D3中的同种型依赖性区域的D2D3域的完整序列(下划线),和缺乏同种型依赖性区的D2D3域(粗体和下划线)之间的百分比同一性。由于R3Mab结合的FGFR3-IIIb的D3具有与所有其它FGFR结构相比不同的几何学(Qing,J.,X.Du,Y.Chen,P.Chan,H.Li,P.Wu,S.Marsters,S.Stawicki,J.Tien,K.Totpal,S.Ross,S.Stinson,D.Dornan,D.French,Q.R.Wang,J.P.Stephan,Y.Wu,C.Wiesmann and A.Ashkenazi(2009)."Antibody-based targetingof FGFR3 in bladder carcinoma and t(4;14)-positive multiple myeloma in mice."The Journal of clinical investigation 119(5):1216-1229),那么将FGFR2-IIIb和FGFR3-IIIb的结构叠加在它们的D2区上,得到α-碳的计算均方根偏差(RMSD)为 基于这项分析,设计了实验来重新改造R3Mab以同样结合并抑制FGFR2。
基于这项分析,设计了实验来重新改造R3Mab以同样结合并抑制FGFR2。
表2:FGFR蛋白质之间的序列同一性
FGFR的同一性(%)


为了构建噬菌体展示文库,设计了覆盖每个个别重链CDR的大多数残基和所有CDR上的接触残基的选集的突变(表3)。在表3中,N=G,A,T或C;K=G或T。针对对FGFR2-IIIb的结合选择在噬菌体颗粒上作为Fab片段展示的R3Mab变体。我们在这个阶段没有在FGFR3上实施选择,因为我们想要在引入新的FGFR2特异性时保持较低的选择严格性。在第一轮淘选之后,组合来自个别文库噬菌体输出并提交进一步的3轮选择。通过ELISA筛选95个克隆(称作2B.1系列)。在这些中,81个克隆(呈现32种独特序列)结合FGFR2-IIIb。所有结合性克隆显然衍生自H2文库,因为它们含有CDR H2中的而非其它区域的突变(表4)。表4以下划线鉴定与R3Mab中的那些相同的残基。表4以斜体鉴定与R3Mab中那些不同的残基。如表4中使用的,“ND”指检测不到而“NA”指因蛋白质聚集而不可得。所有选定抗体均显示相对于R3Mab实质性改善的对FGFR2-IIIb的结合,KD值的范围为0.3至17nM(表4)。值得注意的是,突变的H2序列含有显著的变异,缺乏明确的共有且在4或5个位置处不同于R3Mab(表4,图6)。如此,有多种可能的解决方案来将FGFR2-IIIb的高亲和力结合赋予R3Mab。
表3:用于募集FGFR2结合特异性的文库设计
CDR H1
| 残基 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 |
| 密码子 | TCT | GGC | TTC | ACC | TTC | ACT | AGT | ACT | GGG |
| 氨基酸 | S | G | F | T | F | T | S | T | G |
| H1文库 | NNK | NNK | NNK | NNK | NNK | NNK | NNK | ||
| H2文库 | |||||||||
| H3文库 | |||||||||
| 组合文库 | NNT | NNK | NNC |
CDR H2
| 残基 | 51 | 52 | 52a | 53 | 54 |
| 密码子 | ATT | TAT | CCT | ACT | AAC |
| 氨基酸 | I | Y | P | T | N |
| H1文库 | |||||
| H2文库 | NNK | NNK | NNK | NNK | NNK |
| H3文库 | |||||
| 组合文库 | NNK |
CDR H3
| 残基 | 96 | 97 | 98 | 99 | 100 | 100a |
| 密码子 | TAC | GGC | ATC | TAC | GAC | CTG |
| 氨基酸 | Y | G | I | Y | D | L |
| H1文库 | ||||||
| H2文库 | ||||||
| H3文库 | NNK | NNK | NNK | NNC | NNK | NNK |
| 组合文库 | NNC | NNK | NNK |
CDR L2
| 残基 | 52 | 53 | 54 |
| 密码子 | TCC | TTC | CTC |
| 氨基酸 | S | F | L |
| H1文库 | |||
| H2文库 | |||
| H3文库 | |||
| 组合文库 | NNC |
表4:与R3Mab中的那些不同的残基


接下来基于它们对FGFR2的亲和力(<3nM)和序列多样性选择了六种变体来测量对FGFR3的结合。所有变体均显示改善的对FGFR3-IIIb的亲和力(表5)。为了进一步评估它们抑制受体依赖性细胞生长的能力,在有或无FGF7(FGFR2-IIIb的一种特异性配体)的情况下测定MCF7乳腺癌细胞的增殖(Goetz,R.and M.Mohammadi(2013)."Exploring mechanismsof FGF signalling through the lens of structural biology."Nat Rev Mol CellBiol 14(3):166-180;Bai,A.,K.Meetze,N.Y.Vo,S.Kollipara,E.K.Mazsa,W.M.Winston,S.Weiler,L.L.Poling,T.Chen,N.S.Ismail,J.Jiang,L.Lerner,J.Gyuris and Z.Weng(2010)."GP369,an FGFR2-IIIb-specific antibody,exhibits potent antitumoractivity against human cancers driven by activated FGFR2 signaling."Cancerresearch 70(19):7630-7639)。与显示较少或无抑制,或甚至展示刺激性效果的其它变体相比,变体2B.1.3展现最大的拮抗活性(图2)。因而,作为功能性抗体结转2B.1.3用于进一步表征。
表5:选定2B.1.3变体对FGFR2-IIIb和FGFR3-IIIb的结合亲和力
| 克隆 | CDR H2 | FGFR2-IIIb K<sub>D</sub>(nM) | FGFR3-IIIb K<sub>D</sub>(nM) |
| R3Mab | IYPTN | ND | 0.24 |
| 2B.1.3 | THLGD | 2.6 | 0.09 |
| 2B.1.95 | LIFFT | 1.8 | 0.19 |
| 2B.1.73 | MIFY<u>N</u> | 1.4 | 0.09 |
| 2B.1.32 | WVGFT | 1.2 | 0.06 |
| 2B.1.88 | <u>I</u>WMFT | 0.64 | 0.05 |
| 2B.1.1 | YWAWD | 0.29 | 0.09 |
*与R3Mab中的那些相同的残基标有下划线。
由于所有FGFR同系物彼此之间均共享接近70%序列同一性(表2),因而评估再改造的变体2B.1.3对其它FGFR的结合。Mab 2B.1.3以与FGFR2-IIIb相似的亲和力结合FGFR2-IIIc(表6)。Mab 2B.1.3还显示比R3Mab高数倍的对FGFR3-IIIb和FGFR3-IIIc的亲和力,尽管所使用的选择策略基于对FGFR2-IIIb的结合。所测试的所有其它选定变体一致展现升高的对FGFR3的亲和力(数据未显示)。此外,Mab 2B.1.3还以32 nM的KD值结合FGFR4,但显示没有对FGFR1的可检测结合(表6)。因此,变体2B.1.3是三特异性的,结合FGFR2,FGFR3和FGFR4,但不结合FGFR1。
表6:R3Mab及其变体对所有FGFR同系物的结合亲和力
KD(nM)


*ND:在500nM检测不到。
实施例2。测定Mab2B.1和FGFR2-IIIb复合物的结构。
具体而言,为了获得关于再改造的变体2B.1.3如何获取针对FGFR2的特异性的直接见解,测定了它与FGFR2复合物的晶体结构(图2A,表7)。首先,通过大肠杆菌中的表达和包涵体的重折叠生成了FGFR2-IIIb D2D3,并通过SDS-PAGE和质谱术判断是完整的。然而,在晶体中,这种蛋白质只含有同种型不依赖性D2域,提示结晶过程期间D2和D3之间的蛋白水解。先前测定的FGFR3-IIIb:R3Mab复合物结构含有FGFR3-IIIb的D2和D3域二者。将FGFR2-D2:Mab 2B.1.3的整个复合物紧密叠加到FGFR3-IIIb:R3Mab结构上(图7),总体α-碳RMSD为 指示再改造保留了与原始抗体R3Mab相同的结合几何学。FGFR3:R3Mab晶体结构提示FGFR3D3和CDR H1环之间的可观相互作用。因此,为了调查D3在结合中的参与,制备了FGFR2和FGFR3的D2域的蛋白质并测量了它们对R3Mab和Mab 2B.1.3的结合亲和力。对两种受体均只观察到非常轻微的单独的D2和D2D3域之间的结合亲和力差异(表8)。如此,D2主要负责R3Mab及其衍生物的结合,而D3发挥微小作用。
指示再改造保留了与原始抗体R3Mab相同的结合几何学。FGFR3:R3Mab晶体结构提示FGFR3D3和CDR H1环之间的可观相互作用。因此,为了调查D3在结合中的参与,制备了FGFR2和FGFR3的D2域的蛋白质并测量了它们对R3Mab和Mab 2B.1.3的结合亲和力。对两种受体均只观察到非常轻微的单独的D2和D2D3域之间的结合亲和力差异(表8)。如此,D2主要负责R3Mab及其衍生物的结合,而D3发挥微小作用。
表7:2B.1.3和FGFR2-D2之间的亲和力的数据收集和细化统计学


*括弧中的数值是分辨率最高的壳的。
表8:FGFR2和FGFR3的单独的D2和D2D3域对R3Mab或Mab 2B.1.3的结合亲和力的比较。
KD(nM)
| FGFR2-D2 | FGFR2-IIIb(D2D3) | FGFR3-D2 | FGFR3-IIIb(D2D3) | |
| R3Mab | ND* | ND* | 0.26 | 0.24 |
| 2B.1.3 | 1.0 | 0.71 | <0.1** | 0.09 |
*ND:在200nM检测不到;**达到Biacore的拟合极限。
Mab 2B.1.3中的CDR H2序列,THLGD,完全不同于R3Mab中的亲本H2序列,IYPTN。正如预期的,两种单抗中CDR H2环的构象实质性不同(图2C)。在将Mab 2B.1.3的可变域比对到R3Mab的可变域上时(图2B),H3环也看来扭曲了几度,导致这两种结构中H3尖端残基Y100b的Cα原子之间 的距离(图2C)。因而,FGFR2 D2域总体的位置相对于FGFR3 D2域的位置位移
的距离(图2C)。因而,FGFR2 D2域总体的位置相对于FGFR3 D2域的位置位移 变体和FGFR抗原之间的界面的比较揭示Mab 2B.1.3中H2和H3 CDR环的此类改组显著改善针对FGFR2表面的挤压。在亲本结构中,R3Mab和FGFR3-D2之间的形状互补性(sc)得分为0.731。如果将FGFR2的D2域比对到FGFR3 D2上并替换FGFR3 D2的话,R3Mab和FGFR2 D2之间的sc下降至0.685。这可以解释R3Mab缺乏对FGFR2的结合(表6)。然而,在新的晶体结构中,2B.1.3和FGFR2-D2之间的sc得分剧烈升高至0.768,与经由再改造R3Mab获取对FGFR2的高亲和力结合一致。
变体和FGFR抗原之间的界面的比较揭示Mab 2B.1.3中H2和H3 CDR环的此类改组显著改善针对FGFR2表面的挤压。在亲本结构中,R3Mab和FGFR3-D2之间的形状互补性(sc)得分为0.731。如果将FGFR2的D2域比对到FGFR3 D2上并替换FGFR3 D2的话,R3Mab和FGFR2 D2之间的sc下降至0.685。这可以解释R3Mab缺乏对FGFR2的结合(表6)。然而,在新的晶体结构中,2B.1.3和FGFR2-D2之间的sc得分剧烈升高至0.768,与经由再改造R3Mab获取对FGFR2的高亲和力结合一致。
由于FGFR之间的显著相似性,2B.1.3与该家族中的多种同系物交叉反应。虽然没有与FGFR2结合一起获取FGFR1结合,但是获取了FGFR4相互作用。考虑到FGFR4抑制具有升高的毒性风险(Pai,R.,D.French,N.Ma,K.Hotzel,E.Plise,L.Salphati,K.D.Setchell,J.Ware,V.Lauriault,L.Schutt,D.Hartley and D.Dambach(2012)."Antibody-mediatedinhibition of fibroblast growth factor 19 results in increased bile acidssynthesis and ileal malabsorption of bile acids in cynomolgus monkeys."Toxicol Sci 126(2):446-456),进行了第二轮再改造来消除FGFR4结合。
实施例3。实施了FGFR3抗体的进一步再改造以去除FGFR4结合。
为了生成结合FGFR2和FGFR3但不结合FGFR4的Mab 2B.1.3衍生物,假设Mab2B.1.3以与它与FGFR2的相互作用类似的模式识别所有FGFR,鉴定了很可能与抗体相互作用但在各种FGFR之间不同的抗原残基(表9)。基于2B.1.3模板构建了三个噬菌体展示文库,随机诱变在接触CDR H1,H3和L2上的选定位置处(表10)。在改造期间,我们试图聚焦于对FGFR2的结合,代替我们在先前的改造中做的那样维持FGFR2和FGFR3二者。因此,在淘选期间用固定化的单独的FGFR2-IIIb进行选择。为了反选择FGFR4结合物,将噬菌体颗粒与过量的可溶性FGFR4-Fc蛋白质一起温育。对于连续多轮选择,将FGFR4-Fc的浓度升高至0.46μM(见方法)。通过ELISA用FGFR2-IIIb和FGFR4测定来自第4轮的个别克隆(n=96),并通过FGFR2与FGFR4结合ELISA值的比值排序。对具有最高FGFR2/FGFR4结合比值的六个克隆测序列,作为IgG表达并表征对FGFR2-IIIb和FGFR4的结合(表11)。所表征的来自H3/L2文库的克隆2B.1.3.2,2B.1.3.4和2B.1.3.6只含有CDR H3中的突变,不含有CDR L2中的突变,而所表征的来自H1/H3文库的克隆2B.1.3.8,2B.1.3.10和2B.1.3.12含有CDR H1和H3二者中的突变。虽然H3中L100a至D100d的4个残基是完全随机化的,但是Y100b保持不变,提示Y100b与FGFR2的相互作用对于结合是至关紧要的。另外,L100a保守突变成Thr或Ile,而V100c大多突变成Asp。含有另外的H1突变T28P的H1/H3突变体展示略微更高的对FGFR2的亲和力。这些抗体以1.4至6.6nM的KD值结合FGFR2,但是在使用高达1μM的浓度进行测量时显示最低限度的对FGFR4的结合,例外是克隆2B.1.3.8仍然保留可检测但较弱的对FGFR4的亲和力(表11)。与R3Mab中的那些相同的残基标有下划线,而与中R3Mab的那些不同的残基为粗体(表11)。2B.1.3变体的序列和亲和力二者的收敛指示最后几轮噬菌体选择已经达到了具有期望功能(即消除FGFR4结合和保留紧密FGFR2结合)的结合物的富集极限。
表9:FGFR2和FGFR4之间与2B.1.3进行潜在接触的位置处的残基变异.

*接触距离的截留为
表10:用于自改造的抗体2B.1.3去除FGFR4结合特异性的文库设计
CDR H1
| 残基 | 28 | 29 | 30 | 31 | 32 |
| 密码子 | ACC | TTC | ACT | AGT | ACT |
| 氨基酸 | T | F | T | S | T |
| 文库H1+H3 | NNK | NNK | |||
| 文库H1+L2 | NNK | NNK | |||
| 文库H3+L2 |
CDR H2
| 残基 | 100a | 100b | 100c | 100d |
| 密码子 | CTG | TAC | GTG | GAC |
| 氨基酸 | L | Y | V | D |
| 文库H1+H3 | NNK | NNK | NNK | NNK |
| 文库H1+L2 | ||||
| 文库H3+L2 | NNK | NNK | NNK | NNK |
CDR H1


N=G,A,T或C;K=G或T
表11:具有最低限度FGFR4结合并维持FGFR2结合的2B.1.3变体
| 克隆 | CDR H1 | CDR H3 | FGFR2-IIIb K<sub>D</sub>(nM) | FGFR4K<sub>D</sub>(nM) |
| 2B.1.3 | <u>TFTST</u> | <u>LYVD</u> | 2.6 | 32 |
| 2B.1.3.2 | <u>TFTST</u> | T<u>Y</u>DN | 6.6 | >1,000 |
| 2B.1.3.4 | <u>TFTST</u> | I<u>Y</u>GG | 5.8 | >1,000 |
| 2B.1.3.6 | <u>TFTST</u> | T<u>Y</u>DE | 5.9 | >1,000 |
| 2B.1.3.8 | P<u>FTS</u>L | I<u>Y</u>EK | 1.4 | ~300 |
| 2B.1.3.10 | P<u>FTS</u>Q | T<u>Y</u>DK | 2.9 | >1,000 |
| 2B.1.3.12 | P<u>FTST</u> | T<u>Y</u>DM | 3.0 | >1,000 |
考虑到对FGFR2和FGFR4的结合的较大差异以及较少的突变是优选的,选择Mab2B.1.3.10和2B.1.3.12用于进一步表征。这两种抗体均显示不结合FGFR1且保留对FGFR3的强结合,亲和力比2B.1.3略微更弱(表6)。因此,在第二步改造之后,2B.1.3衍生物Mab2B.1.3.10和2B.1.3.12与FGFR2和FGFR3交叉反应,但是不识别FGFR4。
我们接下来检查R3Mab变体阻断FGF配体结合特定FGFR的能力。R3Mab阻断FGF配体结合FGFR3-IIIb和-IIIc同种型二者。由于它们对不同FGFR的不同特异性,每种新抗体的阻断谱是不同的(图3)。所有改造的抗体均显示针对FGFR2和FGFR3二者的阻断活性,而R3Mab不抑制FGF7结合FGFR2-IIIb或FGF1结合FGFR2-IIIc。尽管2B.1.3强烈抑制FGF19结合FGFR4,然而由于实质性消除的FGFR4亲和力,2B.1.3.10和2B.1.3.12不阻断后一种相互作用。
实施例4。再改造的Mab变体抑制FGFR2或FGFR3依赖性肿瘤细胞生长。
新改造的变体2B.1.3.10和2B.1.3.12展示针对FGFR2和FGFR3的双重特异性。为了调查它们的生物学活性,我们检查了它们对不同类型的肿瘤细胞中的受体依赖性信号传导和增殖的影响。首先在体外对新变体评估对FGFR2过表达性肿瘤细胞的生长的抑制。SNU-16胃癌和MFM-223x2.2三重阴性乳腺癌细胞系均具有FGFR2扩增,表现为升高的FGFR2基因拷贝数和蛋白质过表达(Kunii,K.,L.Davis,J.Gorenstein,H.Hatch,M.Yashiro,A.DiBacco,C.Elbi and B.Lutterbach(2008)."FGFR2-amplified gastric cancer celllines require FGFR2 and Erbb3 signaling for growth and survival."Cancerresearch 68(7):2340-2348)。在SNU-16细胞中,2B.1.3.10和2B.1.3.12实质性阻抑FGF7诱导的FGFR2磷酸化。另外,这两种2B.1.3变体显著降低下游信号传导分子FRS2α,MAPK,PLCγ1和AKT的磷酸化(图4A)。类似地,这两种变体降低FGF7处理的MFM-223x2.2细胞中FGFR2,FRS2α,MAPK和Her3的磷酸化(图8)。
接下来,调查双重特异性单抗2B.1.3.10和2B.1.3.12在体内抑制FGFR2依赖性或FGFR3依赖性肿瘤异种移植物生长的能力。对于FGFR2特异性处理,对注射人胃癌细胞SNU-16的小鼠给药非特异性IgG对照抗体和双重特异性单抗2B.1.3.10和2B.1.3.12。与对照抗体相比,双重特异性抗体展示约67%和57%的肿瘤生长抑制(图4B)。在另一项实验中,2B.1.3.10和2B.1.3.12还迟滞小鼠中MFM-223x2.2肿瘤异种移植物的生长(图8)。因此,这两种改造的抗体显示抑制FGFR2依赖性肿瘤生长方面的效力。既然它们在改造后保留针对FGFR3的亲本特异性,那么调查对FGFR3依赖性肿瘤生长的抑制。正如预期的,单抗2B.1.3.10和2B.1.3.12均阻抑RT112肿瘤异种移植物的生长(图4C)。总之,改造的抗体能充当有效抑制FGFR2和FGFR3依赖性癌细胞二者生长的双重药剂。然而,改造的变体在RT112模型中的效力与亲本R3Mab相比降低,可能是由于改善的药动学。
RT112细胞系表达FGFR3但不表达FGFR2。正如预期的,单抗2B.1.3.10和2B.1.3.12(在改造后保留针对FGFR3的亲本特异性)二者以及亲本抗体R3Mab阻抑FGFR3过表达性RT112肿瘤异种移植物的生长(图4B)。这些研究中改造的变体2B.1.3.10和2B.1.3.12(肿瘤生长抑制(TGI)值为48%和64%)展示比亲本R3Mab(TGI 82%)更弱的效力,这可以是可能是由于改善的药动学。对于基于FGFR2的功效,我们转向SNU-16细胞系,它表达轻易可检测的FGFR2连同很低的FGFR3水平。对携带SNU-16异种移植物的小鼠给药非特异性IgG对照抗体,亲本R3Mab,或改造的变体2B.1.3.10或2B.1.3.12。改造的变体展示相似的TGI值,分别为63%和61%(图4C)。令人惊讶的是,虽然不结合FGFR2,但是R3Mab也显示44%的可测量TGI。然后收集肿瘤样品并分析FGFR2和FGFR3表达(图15)。FGFR3在体内在SNU-16肿瘤异种移植物中上调,这可以解释在这种模型中观察到的R3Mab的抑制效果。不管怎样,改造的变体显示与R3Mab相比显著更强的活性(p<0.001,第31天)。在另一项实验中,2B.1.3.10和2B.1.3.12还迟滞小鼠中MFM-223x2.2肿瘤异种移植物的生长(图8A和图8B)。总之,改造的抗体能充当有效抑制FGFR2和FGFR3依赖性癌细胞二者生长的双重药剂。
实施例5。通过噬菌体文库选择生成FGFR2结合性R3Mab变体。
先前描述了展示R3Mab Fab片段的噬菌粒(Qing,J.,X.Du,Y.Chen,P.Chan,H.Li,P.Wu,S.Marsters,S.Stawicki,J.Tien,K.Totpal,S.Ross,S.Stinson,D.Dornan,D.French,Q.R.Wang,J.P.Stephan,Y.Wu,C.Wiesmann and A.Ashkenazi(2009)."Antibody-based targeting of FGFR3 in bladder carcinoma and t(4;14)-positivemultiple myeloma in mice."The Journal of clinical investigation 119(5):1216-1229)。引入三个连续终止密码子以替换R3Mab的H1,H2,H3或L2CDR环中每一个的3个残基,充当模板用于构建噬菌体展示文库。然后使用Kunkel等人的方法(Kunkel TA,Bebenek K,&McClary J(1991)Efficient site-directed mutagenesis using uracil-containingDNA.Methods Enzymol 204:125-139)将随机突变引入上述CDR环中的每一个(表3)。然后通过电穿孔(BTX ECM 630)将经过纯化的文库DNA转化入SS320感受态细胞(Clackson T&Lowman HB(2004)Phage display:A practical approach(Oxford University Press))。经过转化的文库细胞在2YT培养基中于37℃生长过夜以容许噬菌体颗粒扩增(Clackson T&Lowman HB(2004)Phage display:A practical approach(Oxford University Press))。为了分选FGFR2结合物,在96孔MaxiSorp板上包被2μg/mL带His标签的FGFR2-IIIb。对于第一轮淘选,分开地将1OD经过纯化的来自每个文库的噬菌体悬浮液与固定化的抗原一起温育。用磷酸盐缓冲盐水加0.05% Tween 20(PBST)简短清洗后,用低pH洗脱结合的噬菌体颗粒。将自个别文库收集的噬菌体合并到一起并在XL1-blue细胞中扩增用于后续轮次的淘选。对于第四轮淘选,清洗步骤延长至三次15分钟清洗,间隔30分钟PBST温育,从而富集紧密结合者。用自第4轮回收的噬菌体颗粒感染XL1-blue细胞并在2YT琼脂上铺板。个别地培养96个随机挑取的菌落用于噬菌体扩增。通过噬菌体ELISA测定上清液以验证FGFR2-IIIb结合。同时,自每个克隆提取噬菌粒DNA并测序。
实施例6。构建文库并选择不结合FGFR4的FGFR2结合者。
基于展示抗体2B.1.3的Fab片段的噬菌粒构建噬菌体展示文库。用于Kunkel诱变的终止模板在CDR H1或H3环任一或二者中包括3个终止密码子。对CDR H1,H3或L2环中的选定位置进行随机诱变(表10)。文库制备规程与上文描述相同。为了选择FGFR4结合降低而FGFR2特异性保留的克隆,在第一轮中,混合1.5OD噬菌体文库与0.5nM FGFR4-Fc蛋白质。将混合物在用2μg/mL FGFR2-IIIb预包被的在MaxiSorp板中于4℃温育过夜。简短清洗结合的噬菌体颗粒,洗脱并扩增用于下一轮选择。在第二轮中,混合1.5OD噬菌体制备物与10nMFGFR4-Fc并于4℃温育过夜。对于第三和第四轮,混合0.5OD噬菌体制备物与460nM FGFR4-Fc蛋白质,并于室温(RT)摇动20分钟,之后与包被的FGFR2-IIIb一起温育。与FGFR2-IIIb一起于室温温育30分钟之后,清洗MaxiSorp板3次,间隔10分钟PBST温育。使用洗脱的噬菌体颗粒感染XL1-blue细胞并在2YT琼脂上铺板。培养随机挑取的克隆用于噬菌体ELISA测定法和DNA测序,如上文描述的。
实施例7。实施噬菌体ELISA结合测定法。
将384孔MaxiSorp板在每个象限中用30μL 1μg/mL E25(对照抗体),FGFR2-IIIb-His,FGFR2-IIIc-His或FGFR4-His于4℃包被过夜。用含2% BSA的PBS于室温封闭1小时之后,将30μL 10倍稀释的噬菌体上清液添加入象限。将板于室温摇动2小时。为了检测结合的噬菌体颗粒,将HRP缀合的抗M13单克隆抗体(GE Healthcare)1:3000稀释并在板中温育15分钟。将TMB过氧化物酶底物添加入每个孔以容许显色。通过添加100μL 1M磷酸来终止反应,之后以450nM的吸光度读板。
实施例8。实施表面等离振子共振(SPR)测定法。
使用Biacore T100(GE Healthcare)测定R3Mab变体对FGFR抗原的结合亲和力。遵循产品说明书将饱和量的抗人Fc单克隆抗体固定化到CM5生物传感器芯片上。在每个流动室中捕捉约500个共振单位的R3Mab衍生抗体分子。以流速30μL/min注射多种浓度的FGFR抗原。在每个结合循环之后,使用3MMgCl2再生流动室。使用T100评估软件实施动力学分析以获得动力学和亲和力常数。
实施例9。蛋白质表达,纯化和结构测定。
通过PCR扩增人FGFR2-IIIb ECD(残基140-369)并亚克隆入pET-21b(+)载体(Novagen)。在大肠杆菌BL21(DE3)pLysS细胞中作为包涵体表达蛋白质。用20mM TrispH7.5,5%甘油,1mM EDTA和2% Triton X-100清洗包涵体,之后在6M盐酸胍,20mM TrispH8,10mM TCEP中溶解。体外折叠后,迅速将包涵体稀释入含有100mM Tris pH 8.0,0.4ML-精氨酸-HCl,2mM EDTA,3.7mM胱胺和6.6mM半胱胺的重折叠缓冲液中至50mg/L。4℃ 72小时后,浓缩折叠混合物并通过5mL肝素HP柱(GE Healthcare)。用MonoS柱和Superdex 200柱进一步纯化样品。如描述的那样表达并纯化2B.1.3 Fab(Qing,J.,X.Du,Y.Chen,P.Chan,H.Li,P.Wu,S.Marsters,S.Stawicki,J.Tien,K.Totpal,S.Ross,S.Stinson,D.Dornan,D.French,Q.R.Wang,J.P.Stephan,Y.Wu,C.Wiesmann and A.Ashkenazi(2009)."Antibody-based targeting of FGFR3 in bladder carcinoma and t(4;14)-positivemultiple myeloma in mice."The Journal of clinical investigation 119(5):1216-1229)。分开地针对10mM Tris pH 7.0,5mM NaCl透析FGFR2和Fab蛋白质,之后以1:1的摩尔比混合到一起。将蛋白质混合物稀释至2mg/mL用于结晶。使用蒸气扩散方法,晶体于20%(w/v)PEG3350,0.1M柠檬酸钠pH 5.5,0.2M硫酸铵生长。由于晶体对防冷冻溶液敏感且一旦转移出母液就破碎,因此最终自静置四个月不触动的盘收获可衍射晶体,其中PEG3350的浓度高得足以提供防冷冻。因而直接自液滴取出晶体并在液氮中骤冻。在劳伦斯·伯克利国家实验室的高级光源中心用 的束波长收集衍射数据。使用HKL2000和Scalepack(Otwinowski Z&Minor W(1997)Processing of X-ray diffraction data collected inoscillation mode.Methods in enzymology 276:307-326)进行数据加工。使用CCP4suite中的程序Phaser(McCoy AJ,et al.(2007)Phaser crystallographic software.JAppl Crystallogr 40(Pt 4):658-674.Winn MD,et al.(2011)Overview of the CCP4suite and current developments.Acta Crystallogr D Biol Crystallogr 67(Pt 4):235-242)以分子置换解答结构。Fab和FGFR2-D2的搜索模型分别为PDB 3GRW和3CU1。在不对称晶胞中找到两种复合物。使用Phenix(Adams PD,et al.(2010)PHENIX:a comprehensivePython-based system for macromolecular structure solution.Acta Crystallogr DBiol Crystallogr 66(Pt 2):213-221)进行刚体和模拟退火细化。用程序Coot(Emsley P,Lohkamp B,Scott WG,&Cowtan K(2010)Features and development of Coot.ActaCrystallogr D Biol Crystallogr 66(Pt 4):486-501)实施手动模型建构。使用Phenix进行位置和原子位移参数的后续细化。以
的束波长收集衍射数据。使用HKL2000和Scalepack(Otwinowski Z&Minor W(1997)Processing of X-ray diffraction data collected inoscillation mode.Methods in enzymology 276:307-326)进行数据加工。使用CCP4suite中的程序Phaser(McCoy AJ,et al.(2007)Phaser crystallographic software.JAppl Crystallogr 40(Pt 4):658-674.Winn MD,et al.(2011)Overview of the CCP4suite and current developments.Acta Crystallogr D Biol Crystallogr 67(Pt 4):235-242)以分子置换解答结构。Fab和FGFR2-D2的搜索模型分别为PDB 3GRW和3CU1。在不对称晶胞中找到两种复合物。使用Phenix(Adams PD,et al.(2010)PHENIX:a comprehensivePython-based system for macromolecular structure solution.Acta Crystallogr DBiol Crystallogr 66(Pt 2):213-221)进行刚体和模拟退火细化。用程序Coot(Emsley P,Lohkamp B,Scott WG,&Cowtan K(2010)Features and development of Coot.ActaCrystallogr D Biol Crystallogr 66(Pt 4):486-501)实施手动模型建构。使用Phenix进行位置和原子位移参数的后续细化。以 的距离截留添加水分子。通过程序MolProbity(Chen VB,et al.(2010)MolProbity:all-atom structure validation formacromolecular crystallography.Acta Crystallogr D Biol Crystallogr 66(Pt 1):12-21)验证最终的模型。没有检测到Ramachandran离群值。
的距离截留添加水分子。通过程序MolProbity(Chen VB,et al.(2010)MolProbity:all-atom structure validation formacromolecular crystallography.Acta Crystallogr D Biol Crystallogr 66(Pt 1):12-21)验证最终的模型。没有检测到Ramachandran离群值。
实施例10。FGF配体阻断ELISA。
将96孔MaxiSorp板用1.5μg/mL抗人Fc抗体(Jackson ImmunoResearch Lab)于4℃包被过夜。用含2% BSA的PBS于室温封闭1小时后,将0.25μg/mL FGFR-Fc融合蛋白于室温温育2小时。清洗板5次,之后添加抗体和FGF配体混合物,是作为49μL 100ng/mL FGF配体,1μL 25mg/mL肝素(Sigma-Aldrich)和50μL抗体稀释液制备的。于室温摇动2小时后,清洗板5次。通过随后于室温与0.5μg/mL生物素化抗FGF抗体(R&D Biosystems)一起温育0.5小时,与1:2,500稀释的链霉亲合素-HRP(Invitrogen)一起温育0.5小时并与TMB底物一起温育直至显色足够来检测结合的配体。
实施例11。细胞系。
SNU16和MFM-223x2.2细胞系是自内部细胞库获得的。细胞系RT112是自ATCC获得的。在补充有10% FBS的RPMI培养基中培养细胞。对所有细胞系测试支原体,交叉污染和遗传指纹(在产生新的储液时)以确保质量及确认世系。细胞系指纹:SNP指纹。每次为了冷冻保存而扩充新的储液时实施SNP基因型。使用Fluidigm多路测定法通过高通量SNP基因型测定验证细胞系同一性。在商业性基因型测定平台上基于次要等位基因频率和存在选择SNP。将SNP概况与来自可得内部和外部数据(在可得时)的SNP调用比较以确定或确认世系。在数据不可得或细胞系世系可疑的情况中,重新购买DNA或细胞系来实施概况分析以确认细胞系世系。SNP。rs11746396,rs16928965,rs2172614,rs10050093,rs10828176,rs16888998,rs16999576,rs1912640,rs2355988,rs3125842,rs10018359,rs10410468,rs10834627,rs11083145,rs11100847,rs11638893,rs12537,rs1956898,rs2069492,rs10740186,rs12486048,rs13032222,rs1635191,rs17174920,rs2590442,rs2714679,rs2928432,rs2999156,rs10461909,rs11180435,rs1784232,rs3783412,rs10885378,rs1726254,rs2391691,rs3739422,rs10108245,rs1425916,rs1325922,rs1709795,rs1934395,rs2280916,rs2563263,rs10755578,rs1529192,rs2927899,rs2848745,rs10977980。短串联重复(STR)概况分析。使用Promega PowerPlex 16系统为每种系测定STR概况。这实施一次并与细胞系的外部STR概况(在可得时)比较以确定细胞系世系。分析的基因座。检测16个基因座(15个STR基因座和用于性别鉴定的Amelogenin),包括D3S1358,TH01,D21S11,D18S51,PentaE,D5S818,D13S317,D7S820,D16S539,CSF1PO,PentaD,AMEL,vWA,D8S1179和TPOX。
实施例12。免疫印迹。
在组织培养板上接种细胞达24小时,用10μg/ml FGFR阻断性抗体或对照抗gD抗体预处理,然后在20μg/ml肝素(Sigma)存在下用25ng/ml FGF-7(R&D Systems)刺激15分钟。将细胞置于冰上,并立即用IP裂解缓冲液(Thermo Scientific)收获蛋白质。使蛋白质裂解物通过注射器,通过离心澄清,然后使用BCA蛋白质测定法(Thermo Scientific)量化。将蛋白质在4-12% Bis-Tris凝胶(Life Technologies)上分开,转移至硝酸纤维素膜,用含5%BSA或奶的TBST封闭30分钟,然后用一抗于4℃印迹过夜。所使用的抗体:磷酸-FGFR(Y653/654),磷酸-FRS2(Y196),磷酸-ERK1/2(T202/Y204),ERK1/2,磷酸-AKT(S473),AKT,磷酸-HER3(Y1289),HER3,磷酸-PLCγ1(Y783),PLCγ1(Cell Signaling);FGFR2,FRS2(SantaCruz Biotechnology);β-肌动蛋白(Sigma)。清洗膜并与适宜的HRP缀合的二抗一起温育1小时,然后清洗并用SuperSignal West Femto化学发光底物(Thermo Scientific)检测。用FluorChem Q(Alpha Innotech)获取发光信号。
实施例13。异种移植物实验。
所有规程得到Genentech科研动物护理和使用委员会批准且符合Genentech科研动物护理和使用委员会设立的方针和原则,而且是在实验动物护理评估和认证协会(AAALAC)认证的动物房中进行的。在细胞接种前1天皮下(s.c.)植入0.36mg雌激素药丸。在6-8周龄雌性NCR裸小鼠(TaconicTM)的乳房脂肪垫#4中接种在含matrigel的HBSS中悬浮的10x106个MFM-223x2.2乳腺癌细胞。将约15-30mm3的SNU-16肿瘤碎片皮下植入6-8周龄雌性Balb/c裸小鼠(Shanghai Laboratory Animal)的右体侧。在6-8周龄雌性C.B-17SCID小鼠(Charles River Lab)中皮下植入在含matrigel的HBSS中悬浮的7x106个RT-112膀胱癌细胞。当均值肿瘤体积达到100-200mm3时(第0天),将小鼠随机化入6只(SNU-16,RT112)或7只(MFM-223 x2.2)的组,并在第1天开始用一周两次腹膜内(i.p.)注射2B1.3.10或2B1.3.12(10,30或50mg/kg)处理。用在PBS中稀释的对照人IgG1抗体(30mg/kg)处理对照组。使用Ultra Cal IV测径器(54 10 111型,Fred V.Fowler Company)以两个维度(长度和宽度)测量肿瘤体积。使用下述公式计算肿瘤体积:肿瘤体积(mm3)=(长度×宽度2)×0.5。使用Adventurer Pro AV812天平(Ohaus)测量动物体重。使用下述公式计算百分比体重变化:体重变化(%)=[(新日子的重量–第0天的重量)/第0天的重量]x 100%。在研究期间对每只动物跟踪百分比体重,为每个组计算百分比体重变化并绘图。
实施例14。FGFR2/3+KLB双特异性抗体的鉴定。
连同本文中描述的抗FGFR2/3抗体的抗肿瘤活性一起,可以生成针对FGFR2/3和KLB的双特异性抗体(“FGFR2/3+KLB双特异性抗体”),其在治疗与FGFR2和/或FGFR3表达有关的增殖性病症和疾病(更具体的说是代谢疾病)中使用。可以通过FGFR2/3+KLB双特异性抗体来治疗的代谢疾病包括但不限于:多囊卵巢综合征(PCOS),代谢综合征(MetS),肥胖症,非酒精性脂肪性肝炎(NASH),非酒精性脂肪性肝病(NAFLD),高脂血症,高血压,2型糖尿病,非2型糖尿病,1型糖尿病,潜伏性自身免疫性糖尿病(LAD),年轻人成熟期发作糖尿病(MODY),2型糖尿病,肥胖症,巴尔得-别德尔综合征,普拉德-威利综合征,阿耳斯特雷姆综合征,科恩综合征,奥尔布赖特氏遗传性骨营养不良(假甲状旁腺功能减退症),木匠综合征,MOMO综合征,鲁宾斯坦-泰比综合征,脆弱X综合征和伯-福-莱三氏综合征。更具体的说,FGFR2/3+KLB双特异性抗体可用于治疗NASH。
最初,实施了实验来比较抗FGFR2/3抗体变体的活性(图17A和17B)。具体而言,在第1天,在96孔板中以0.9x 106的密度接种239T FGFR1删除细胞。在第2天,用包括FGFR,FF萤光素酶,Renill萤光素酶(转染效率对照),和Elk1的构建物转染细胞。在第3天,在无血清培养基中用抗FGFR2/3抗体变体2B1.3,2B1.3.12,2B1.1.2,2B1.1.4,2B1.1.6,2B1.1.8,2B1.1.10,2B1.1,和2B1.1.12刺激细胞。初始浓度为10μg/mL并以1/5实施连续稀释。反应进行7.5小时,并通过自板去除培养基并添加1x被动裂解缓冲液来终止。然后在添加萤光素酶底物之后使用Wallace Envision读板仪分析板并针对Renilla表达标准化。
在实施了但本文中未描述的其它测定法以外部分基于萤光素酶测定法,装配抗FGFR2/3抗体变体决策矩阵(图18)。2B1.3在MCF-7/FGF7测定法中显示出阻断生长并显示FGF19阻断。2B1.3.12阻断肿瘤进展。
基于决策矩阵,进一步检查变体2B1.3.12,2B1.1.6,和2B1.1(图19A-19C),并测试每一个的活性。而且,对2B1.1,2B1.3,和2B1.3.12检测FGFR结合(表12)。在表12中,NB指无结合,而ND指未测定。通过捕捉IgG并使FGFR4-6xHis流过来针对FGFR4测量2B.1.1(表12中以*标示的实验)。稍后,通过捕捉FGFR4-Fc并使抗体Fab片段流过来测定2B.1.3变体的KD(表12)。
表12:R3Mab变体对人FGFR的结合亲和力
| 克隆 | FGFR1-IIIb,IIIc | FGFR2-IIIb | FGFR2-IIIc | FGFR3-IIIb | FGFR3-IIIc | FGFR4 |
| R3Mab | NB | NB | NB | 0.24 | 0.61 | NB |
| 2B.1.1 | NB | 0.29 | 2.8 | ND | ND | 2.8* |
| 2B.1.3 | NB | 2.6 | 2.0 | 0.09 | 0.07 | 32 |
| 2B.1.3.12 | NB | 3.0 | 6.1 | 0.50 | 0.72 | >1,000 |
因此,表达七种2B1.1变体并测试FGFR2,FGFR3,和FGFR4结合的激动活性(图16A-16C)。所有2B1.1变体均使用Biacore测定法显示亚nM至低pM的对FGFR3的亲和力范围。由于FGFR4蛋白质粘性,最好通过Biacore以Fab作为分析物来测定结合亲和力。大多数变体通过ELISA显示对FGFR4的弱结合,2B1.1和2B1.1.4除外。
基于此实施例14中描述的实验,选择变体2B1.3.12和2B1.1.6用于与抗KLB抗体一起装配双特异性。
实施例14:FGFR2/3+KLB双特异性抗体的生成。
可以使用任何双特异性抗体生成方法来生成FGFR2/3+KLB双特异性抗体。在具体的例子中,可以使用节和穴技术来生成本发明的FGFR2/3+KLB双特异性抗体。
可以用编码抗FGFR2/3抗体变体2B1.3.12或2B1.1.6的重和轻链和本文中描述的抗KLB抗体之一的重和轻链的四种表达载体的混合物共转染HEK293细胞(见例如表13和14)。
表13:鼠抗KLB单克隆抗体的CDR H序列


表14:鼠抗KLB单克隆抗体的CDR L序列


可以分别给抗FGFR2/3和抗KLB的重链带上Flag肽和Oct-组氨酸的标签,使得可以通过序贯亲和纯化自条件化培养基纯化异二聚体IgG。然后可以在基于GAL-ELK1的萤光素酶测定法中分析部分纯化的异二聚体IgG以鉴定KLB依赖性激动剂。为了最小化重和轻链的错配,可以与人Fab恒定区一起表达抗FGFR2/3,而且可以与小鼠Fab恒定区一起表达抗KLB。然后最初可以使用来自FGFR2/3抗体变体2B1.3.12或2B1.1.6任一的一个臂和来自本文中描述的KLB抗体任一的一个臂的组合以粗制形式测试带标签的双特异性IgG。具体而言,作为KLB臂的来源的抗KLB抗体可包含:
8C5.K4.M4L.H3.KNV重链可变区
EVQLVESGGGLVQPGGSLRLSCAASDFSLTTYGVHWVRQAPGKGLEWLGVIWSGGSTDYNAAFISRLTISKDNSKNTVYLQMNSLRAEDTAVYYCARDYGSTYVDAIDYWGQGTLVTVSS(SEQ ID NO:104)
8C5.K4.M4L.H3.KNV完整重链
EVQLVESGGGLVQPGGSLRLSCAASDFSLTTYGVHWVRQAPGKGLEWLGVIWSGGSTDYNAAFISRLTISKDNSKNTVYLQMNSLRAEDTAVYYCARDYGSTYVDAIDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYGSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLSCAVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK(SEQ ID NO:106)
8C5.K4.M4L.H3.KNV轻链可变区
DIVLTQSPDSLAVSLGERATINCRASESVESYGNRYMTWYQQKPGQPPKLLIYRAANLQSGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCQQSNEDPWTFGQGTKVEIK(SEQ ID NO:105)
8C5.K4.M4L.H3.KNV完整轻链
DIVLTQSPDSLAVSLGERATINCRASESVESYGNRYMTWYQQKPGQPPKLLIYRAANLQSGVPDRFSGSGSGTDFTLTISSLQAEDVAVYYCQQSNEDPWTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC(SEQ ID NO:107)
而且,可以与人IgG1恒定区(野生型,具有效应器功能)一起及与具有N297G突变以消除效应器功能的人IgG1恒定区一起,或与具有双重[D265G/N297G]突变(DANG)以消除效应器功能的小鼠恒定区一起生成双特异性抗体。
实施例15:双特异性抗体的测试。
可以生成8C5.K4H3.M4L.KNV(见上文实施例14)和不同抗FGFR2/3臂的多种双特异性抗体组合并在有或无KLB的情况中在HEK293细胞中的基于GAL-ELK1的萤光素酶测定法中测试。每种双特异性抗体组合均能在表达重组FGFR2或3和KLB的细胞以剂量依赖性方式诱导萤光素酶活性,但是在没有KLB表达的细胞中不然。此数据能确认FGFR2/3+KLB双特异性保留亲本抗体(例如2B1.3.12或2B1.1.6)的优点。而且,可以关于KLB结合,FGFR2结合,和FGFR3结合测定具有人源化8C5臂(8C5.K4.M4L.H3.KNV)和2B1.3.12或2B1.1.6变体任一的臂的FGFR2/3+KLB双特异性抗体的结合亲和力。
在所描绘的和要求保护的各种实施方案以外,所公开的主题还针对具有本文中公开的和要求保护的特征的其它组合的其它实施方案。照此,本文中呈现的特定特征可以以在所公开的主题的范围内的其它方式彼此组合,使得所公开的主题包括本文中公开的特征的任何合适组合。已经出于例示和描述目的呈现所公开的主题的具体实施方案的前述描述。它并非意图是详尽的或将所公开的主题限制于所公开的那些实施方案。
对本领域技术人员显而易见的是,可以在不背离所公开的主题的精神和范围的情况下在所公开的主题的组合物和方法中进行各种修饰和变化。如此,所公开的主题意图包括在所附权利要求书的范围内的修饰和变化及其等同方案。
本文中应用了多份出版物,专利和专利申请,据此通过援引完整收录它们的内容。
序列
SEQ ID NO:1
2B.1.3.10HVR-L1
RASQDVDTSLA
SEQ ID NO:2
2B.1.3.10HVR-L2
SASFLYS
SEQ ID NO:3
2B.1.3.10HVR-L3
QQSTGHPQT
SEQ ID NO:4
2B.1.3.10HVR-H1
GFPFTSQGIS
SEQ ID NO:5
2B.1.3.10HVR-H2
RTHLGDGSTNYADSVKG
SEQ ID NO:6
2B.1.3.10HVR-H3
ARTYGIYDTYDKYTEYVMDY
SEQ ID NO:7
2B.1.3.12HVR-L1
RASQDVDTSLA
SEQ ID NO:8
2B.1.3.12HVR-L2
SASFLYS
SEQ ID NO:9
2B.1.3.12HVR-L3
QQSTGHPQT
SEQ ID NO:10
2B.1.3.12HVR-H1
GFPFTSTGIS
SEQ ID NO:11
2B.1.3.12 HVR-H2
RTHLGDGSTNYADSVKG
SEQ ID NO:12
2B.1.3.12 HVR-H3
ARTYGIYDTYDMYTEYVMDY
SEQ ID NO:13
2B.1.1 HVR-H2
YWAWD
SEQ ID NO:14
2B.1.88 HVR-H2
IWMFT
SEQ ID NO:15
2B.1.38 HVR-H2
FWAYD
SEQ ID NO:16
2B.1.20 HVR-H2
LDVFW
SEQ ID NO:17
2B.1.32 HVR-H2
WVGFT
SEQ ID NO:18
2B.1.49 HVR-H2
LSFFS
SEQ ID NO:19
2B.1.86 HVR-H2
LSFWT
SEQ ID NO:20
2B.1.9 HVR-H2
YHPYL
SEQ ID NO:21
2B.1.73 HVR-H2
MIFYN
SEQ ID NO:22
2B.1.74 HVR-H2
YHPFR
SEQ ID NO:23
2B.1.14 HVR-H2
LWYFD
SEQ ID NO:24
2B.1.71 HVR-H2
VWMFD
SEQ ID NO:25
2B.1.28 HVR-H2
FWAWS
SEQ ID NO:26
2B.1.95 HVR-H2
LIFFT
SEQ ID NO:27
2B.1.50 HVR-H2
LNFYS
SEQ ID NO:28
2B.1.81 HVR-H2
VNNFY
SEQ ID NO:29
2B.1.25 HVR-H2
WHPWM
SEQ ID NO:30
2B.1.3 HVR-H2
THLGD
SEQ ID NO:31
2B.1.65 HVR-H2
YNAYT
SEQ ID NO:32
2B.1.94 HVR-H2
LVFFS
SEQ ID NO:33
2B.1.78 HVR-H2
LSFYS
SEQ ID NO:34
2B.1.72 HVR-H2
VHPFE
SEQ ID NO:35
2B.1.44 HVR-H2
WWSWG
SEQ ID NO:36
2B.1.52 HVR-H2
FSLGD
SEQ ID NO:37
2B.1.30 HVR-H2
VSFFS
SEQ ID NO:38
2B.1.82 HVR-H2
INFFS
SEQ ID NO:39
2B.1.93 HVR-H2
IDNYW
SEQ ID NO:40
2B.1.55 HVR-H2
VDVFW
SEQ ID NO:41
2B.1.35 HVR-H2
WHPFR
SEQ ID NO:42
2B.1.33 HVR-H2
YHPFH
SEQ ID NO:43
2B.1.80 HVR-H2
YWAFS
SEQ ID NO:44
2B.1.92HVR-H2
WVAFS
SEQ ID NO:45
2B.1.3HVR-H2
THLGD
SEQ ID NO:46
2B.1.95HVR-H2
LIFFT
SEQ ID NO:47
2B.1.73HVR-H2
MIFYN
SEQ ID NO:48
2B.1.32HVR-H2
WVGFT
SEQ ID NO:49
2B.1.88HVR-H2
IWMFT
SEQ ID NO:50
2B.1.1HVR-H2
YWAWD
SEQ ID NO:51
FGFR2-IIIb核酸序列
ATGGTCAGCTGGGGTCGTTTCATCTGCCTGGTCGTGGTCACCATGGCAACCTTGTCCCTGGCCCGGCCCTCCTTCAGTTTAGTTGAGGATACCACATTAGAGCCAGAAGAGCCACCAACCAAATACCAAATCTCTCAACCAGAAGTGTACGTGGCTGCGCCAGGGGAGTCGCTAGAGGTGCGCTGCCTGTTGAAAGATGCCGCCGTGATCAGTTGGACTAAGGATGGGGTGCACTTGGGGCCCAACAATAGGACAGTGCTTATTGGGGAGTACTTGCAGATAAAGGGCGCCACGCCTAGAGACTCCGGCCTCTATGCTTGTACTGCCAGTAGGACTGTAGACAGTGAAACTTGGTACTTCATGGTGAATGTCACAGATGCCATCTCATCCGGAGATGATGAGGATGACACCGATGGTGCGGAAGATTTTGTCAGTGAGAACAGTAACAACAAGAGAGCACCATACTGGACCAACACAGAAAAGATGGAAAAGCGGCTCCATGCTGTGCCTGCGGCCAACACTGTCAAGTTTCGCTGCCCAGCCGGGGGGAACCCAATGCCAACCATGCGGTGGCTGAAAAACGGGAAGGAGTTTAAGCAGGAGCATCGCATTGGAGGCTACAAGGTACGAAACCAGCACTGGAGCCTCATTATGGAAAGTGTGGTCCCATCTGACAAGGGAAATTATACCTGTGTAGTGGAGAATGAATACGGGTCCATCAATCACACGTACCACCTGGATGTTGTGGAGCGATCGCCTCACCGGCCCATCCTCCAAGCCGGACTGCCGGCAAATGCCTCCACAGTGGTCGGAGGAGACGTAGAGTTTGTCTGCAAGGTTTACAGTGATGCCCAGCCCCACATCCAGTGGATCAAGCACGTGGAAAAGAACGGCAGTAAATACGGGCCCGACGGGCTGCCCTACCTCAAGGTTCTCAAGCACTCGGGGATAAATAGTTCCAATGCAGAAGTGCTGGCTCTGTTCAATGTGACCGAGGCGGATGCTGGGGAATATATATGTAAGGTCTCCAATTATATAGGGCAGGCCAACCAGTCTGCCTGGCTCACTGTCCTGCCAAAACAGCAAGCGCCTGGAAGAGAAAAGGAGATTACAGCTTCCCCAGACTACCTGGAGATAGCCATTTACTGCATAGGGGTCTTCTTAATCGCCTGTATGGTGGTAACAGTCATCCTGTGCCGAATGAAGAACACGACCAAGAAGCCAGACTTCAGCAGCCAGCCGGCTGTGCACAAGCTGACCAAACGTATCCCCCTGCGGAGACAGGTAACAGTTTCGGCTGAGTCCAGCTCCTCCATGAACTCCAACACCCCGCTGGTGAGGATAACAACACGCCTCTCTTCAACGGCAGACACCCCCATGCTGGCAGGGGTCTCCGAGTATGAACTTCCAGAGGACCCAAAATGGGAGTTTCCAAGAGATAAGCTGACACTGGGCAAGCCCCTGGGAGAAGGTTGCTTTGGGCAAGTGGTCATGGCGGAAGCAGTGGGAATTGACAAAGACAAGCCCAAGGAGGCGGTCACCGTGGCCGTGAAGATGTTGAAAGATGATGCCACAGAGAAAGACCTTTCTGATCTGGTGTCAGAGATGGAGATGATGAAGATGATTGGGAAACACAAGAATATCATAAATCTTCTTGGAGCCTGCACACAGGATGGGCCTCTCTATGTCATAGTTGAGTATGCCTCTAAAGGCAACCTCCGAGAATACCTCCGAGCCCGGAGGCCACCCGGGATGGAGTACTCCTATGACATTAACCGTGTTCCTGAGGAGCAGATGACCTTCAAGGACTTGGTGTCATGCACCTACCAGCTGGCCAGAGGCATGGAGTACTTGGCTTCCCAAAAATGTATTCATCGAGATTTAGCAGCCAGAAATGTTTTGGTAACAGAAAACAATGTGATGAAAATAGCAGACTTTGGACTCGCCAGAGATATCAACAATATAGACTATTACAAAAAGACCACCAATGGGCGGCTTCCAGTCAAGTGGATGGCTCCAGAAGCCCTGTTTGATAGAGTATACACTCATCAGAGTGATGTCTGGTCCTTCGGGGTGTTAATGTGGGAGATCTTCACTTTAGGGGGCTCGCCCTACCCAGGGATTCCCGTGGAGGAACTTTTTAAGCTGCTGAAGGAAGGACACAGAATGGATAAGCCAGCCAACTGCACCAACGAACTGTACATGATGATGAGGGACTGTTGGCATGCAGTGCCCTCCCAGAGACCAACGTTCAAGCAGTTGGTAGAAGACTTGGATCGAATTCTCACTCTCACAACCAATGAGGAATACTTGGACCTCAGCCAACCTCTCGAACAGTATTCACCTAGTTACCCTGACACAAGAAGTTCTTGTTCTTCAGGAGATGATTCTGTTTTTTCTCCAGACCCCATGCCTTACGAACCATGCCTTCCTCAGTATCCACACATAAACGGCAGTGTTAAAACATGA
SEQ ID NO:52
FGFR2-IIIb氨基酸序列
MVSWGRFICLVVVTMATLSLARPSFSLVEDTTLEPEEPPTKYQISQPEVYVAAPGESLEVRCLLKDAAVISWTKDGVHLGPNNRTVLIGEYLQIKGATPRDSGLYACTASRTVDSETWYFMVNVTDAISSGDDEDDTDGAEDFVSENSNNKRAPYWTNTEKMEKRLHAVPAANTVKFRCPAGGNPMPTMRWLKNGKEFKQEHRIGGYKVRNQHWSLIMESVVPSDKGNYTCVVENEYGSINHTYHLDVVERSPHRPILQAGLPANASTVVGGDVEFVCKVYSDAQPHIQWIKHVEKNGSKYGPDGLPYLKVLKHSGINSSNAEVLALFNVTEADAGEYICKVSNYIGQANQSAWLTVLPKQQAPGREKEITASPDYLEIAIYCIGVFLIACMVVTVILCRMKNTTKKPDFSSQPAVHKLTKRIPLRRQVTVSAESSSSMNSNTPLVRITTRLSSTADTPMLAGVSEYELPEDPKWEFPRDKLTLGKPLGEGCFGQVVMAEAVGIDKDKPKEAVTVAVKMLKDDATEKDLSDLVSEMEMMKMIGKHKNIINLLGACTQDGPLYVIVEYASKGNLREYLRARRPPGMEYSYDINRVPEEQMTFKDLVSCTYQLARGMEYLASQKCIHRDLAARNVLVTENNVMKIADFGLARDINNIDYYKKTTNGRLPVKWMAPEALFDRVYTHQSDVWSFGVLMWEIFTLGGSPYPGIPVEELFKLLKEGHRMDKPANCTNELYMMMRDCWHAVPSQRPTFKQLVEDLDRILTLTTNEEYLDLSQPLEQYSPSYPDTRSSCSSGDDSVFSPDPMPYEPCLPQYPHINGSVKT
SEQ ID NO:53
FGFR2-IIIc核酸序列
ATGGTCAGCTGGGGTCGTTTCATCTGCCTGGTCGTGGTCACCATGGCAACCTTGTCCCTGGCCCGGCCCTCCTTCAGTTTAGTTGAGGATACCACATTAGAGCCAGAAGAGCCACCAACCAAATACCAAATCTCTCAACCAGAAGTGTACGTGGCTGCGCCAGGGGAGTCGCTAGAGGTGCGCTGCCTGTTGAAAGATGCCGCCGTGATCAGTTGGACTAAGGATGGGGTGCACTTGGGGCCCAACAATAGGACAGTGCTTATTGGGGAGTACTTGCAGATAAAGGGCGCCACGCCTAGAGACTCCGGCCTCTATGCTTGTACTGCCAGTAGGACTGTAGACAGTGAAACTTGGTACTTCATGGTGAATGTCACAGATGCCATCTCATCCGGAGATGATGAGGATGACACCGATGGTGCGGAAGATTTTGTCAGTGAGAACAGTAACAACAAGAGAGCACCATACTGGACCAACACAGAAAAGATGGAAAAGCGGCTCCATGCTGTGCCTGCGGCCAACACTGTCAAGTTTCGCTGCCCAGCCGGGGGGAACCCAATGCCAACCATGCGGTGGCTGAAAAACGGGAAGGAGTTTAAGCAGGAGCATCGCATTGGAGGCTACAAGGTACGAAACCAGCACTGGAGCCTCATTATGGAAAGTGTGGTCCCATCTGACAAGGGAAATTATACCTGTGTAGTGGAGAATGAATACGGGTCCATCAATCACACGTACCACCTGGATGTTGTGGAGCGATCGCCTCACCGGCCCATCCTCCAAGCCGGACTGCCGGCAAATGCCTCCACAGTGGTCGGAGGAGACGTAGAGTTTGTCTGCAAGGTTTACAGTGATGCCCAGCCCCACATCCAGTGGATCAAGCACGTGGAAAAGAACGGCAGTAAATACGGGCCCGACGGGCTGCCCTACCTCAAGGTTCTCAAGGCCGCCGGTGTTAACACCACGGACAAAGAGATTGAGGTTCTCTATATTCGGAATGTAACTTTTGAGGACGCTGGGGAATATACGTGCTTGGCGGGTAATTCTATTGGGATATCCTTTCACTCTGCATGGTTGACAGTTCTGCCAGCGCCTGGAAGAGAAAAGGAGATTACAGCTTCCCCAGACTACCTGGAGATAGCCATTTACTGCATAGGGGTCTTCTTAATCGCCTGTATGGTGGTAACAGTCATCCTGTGCCGAATGAAGAACACGACCAAGAAGCCAGACTTCAGCAGCCAGCCGGCTGTGCACAAGCTGACCAAACGTATCCCCCTGCGGAGACAGGTAACAGTTTCGGCTGAGTCCAGCTCCTCCATGAACTCCAACACCCCGCTGGTGAGGATAACAACACGCCTCTCTTCAACGGCAGACACCCCCATGCTGGCAGGGGTCTCCGAGTATGAACTTCCAGAGGACCCAAAATGGGAGTTTCCAAGAGATAAGCTGACACTGGGCAAGCCCCTGGGAGAAGGTTGCTTTGGGCAAGTGGTCATGGCGGAAGCAGTGGGAATTGACAAAGACAAGCCCAAGGAGGCGGTCACCGTGGCCGTGAAGATGTTGAAAGATGATGCCACAGAGAAAGACCTTTCTGATCTGGTGTCAGAGATGGAGATGATGAAGATGATTGGGAAACACAAGAATATCATAAATCTTCTTGGAGCCTGCACACAGGATGGGCCTCTCTATGTCATAGTTGAGTATGCCTCTAAAGGCAACCTCCGAGAATACCTCCGAGCCCGGAGGCCACCCGGGATGGAGTACTCCTATGACATTAACCGTGTTCCTGAGGAGCAGATGACCTTCAAGGACTTGGTGTCATGCACCTACCAGCTGGCCAGAGGCATGGAGTACTTGGCTTCCCAAAAATGTATTCATCGAGATTTAGCAGCCAGAAATGTTTTGGTAACAGAAAACAATGTGATGAAAATAGCAGACTTTGGACTCGCCAGAGATATCAACAATATAGACTATTACAAAAAGACCACCAATGGGCGGCTTCCAGTCAAGTGGATGGCTCCAGAAGCCCTGTTTGATAGAGTATACACTCATCAGAGTGATGTCTGGTCCTTCGGGGTGTTAATGTGGGAGATCTTCACTTTAGGGGGCTCGCCCTACCCAGGGATTCCCGTGGAGGAACTTTTTAAGCTGCTGAAGGAAGGACACAGAATGGATAAGCCAGCCAACTGCACCAACGAACTGTACATGATGATGAGGGACTGTTGGCATGCAGTGCCCTCCCAGAGACCAACGTTCAAGCAGTTGGTAGAAGACTTGGATCGAATTCTCACTCTCACAACCAATGAGGAATACTTGGACCTCAGCCAACCTCTCGAACAGTATTCACCTAGTTACCCTGACACAAGAAGTTCTTGTTCTTCAGGAGATGATTCTGTTTTTTCTCCAGACCCCATGCCTTACGAACCATGCCTTCCTCAGTATCCACACATAAACGGCAGTGTTAAAACATGA
SEQ ID NO:54
FGFR2-IIIc氨基酸序列
MVSWGRFICLVVVTMATLSLARPSFSLVEDTTLEPEEPPTKYQISQPEVYVAAPGESLEVRCLLKDAAVISWTKDGVHLGPNNRTVLIGEYLQIKGATPRDSGLYACTASRTVDSETWYFMVNVTDAISSGDDEDDTDGAEDFVSENSNNKRAPYWTNTEKMEKRLHAVPAANTVKFRCPAGGNPMPTMRWLKNGKEFKQEHRIGGYKVRNQHWSLIMESVVPSDKGNYTCVVENEYGSINHTYHLDVVERSPHRPILQAGLPANASTVVGGDVEFVCKVYSDAQPHIQWIKHVEKNGSKYGPDGLPYLKVLKAAGVNTTDKEIEVLYIRNVTFEDAGEYTCLAGNSIGISFHSAWLTVLPAPGREKEITASPDYLEIAIYCIGVFLIACMVVTVILCRMKNTTKKPDFSSQPAVHKLTKRIPLRRQVTVSAESSSSMNSNTPLVRITTRLSSTADTPMLAGVSEYELPEDPKWEFPRDKLTLGKPLGEGCFGQVVMAEAVGIDKDKPKEAVTVAVKMLKDDATEKDLSDLVSEMEMMKMIGKHKNIINLLGACTQDGPLYVIVEYASKGNLREYLRARRPPGMEYSYDINRVPEEQMTFKDLVSCTYQLARGMEYLASQKCIHRDLAARNVLVTENNVMKIADFGLARDINNIDYYKKTTNGRLPVKWMAPEALFDRVYTHQSDVWSFGVLMWEIFTLGGSPYPGIPVEELFKLLKEGHRMDKPANCTNELYMMMRDCWHAVPSQRPTFKQLVEDLDRILTLTTNEEYLDLSQPLEQYSPSYPDTRSSCSSGDDSVFSPDPMPYEPCLPQYPHINGSVKT
SEQ ID NO:55
FGFR3-IIIb核酸序列
ATGGGCGCCCCTGCCTGCGCCCTCGCGCTCTGCGTGGCCGTGGCCATCGTGGCCGGCGCCTCCTCGGAGTCCTTGGGGACGGAGCAGCGCGTCGTGGGGCGAGCGGCAGAAGTCCCGGGCCCAGAGCCCGGCCAGCAGGAGCAGTTGGTCTTCGGCAGCGGGGATGCTGTGGAGCTGAGCTGTCCCCCGCCCGGGGGTGGTCCCATGGGGCCCACTGTCTGGGTCAAGGATGGCACAGGGCTGGTGCCCTCGGAGCGTGTCCTGGTGGGGCCCCAGCGGCTGCAGGTGCTGAATGCCTCCCACGAGGACTCCGGGGCCTACAGCTGCCGGCAGCGGCTCACGCAGCGCGTACTGTGCCACTTCAGTGTGCGGGTGACAGACGCTCCATCCTCGGGAGATGACGAAGACGGGGAGGACGAGGCTGAGGACACAGGTGTGGACACAGGGGCCCCTTACTGGACACGGCCCGAGCGGATGGACAAGAAGCTGCTGGCCGTGCCGGCCGCCAACACCGTCCGCTTCCGCTGCCCAGCCGCTGGCAACCCCACTCCCTCCATCTCCTGGCTGAAGAACGGCAGGGAGTTCCGCGGCGAGCACCGCATTGGAGGCATCAAGCTGCGGCATCAGCAGTGGAGCCTGGTCATGGAAAGCGTGGTGCCCTCGGACCGCGGCAACTACACCTGCGTCGTGGAGAACAAGTTTGGCAGCATCCGGCAGACGTACACGCTGGACGTGCTGGAGCGCTCCCCGCACCGGCCCATCCTGCAGGCGGGGCTGCCGGCCAACCAGACGGCGGTGCTGGGCAGCGACGTGGAGTTCCACTGCAAGGTGTACAGTGACGCACAGCCCCACATCCAGTGGCTCAAGCACGTGGAGGTGAATGGCAGCAAGGTGGGCCCGGACGGCACACCCTACGTTACCGTGCTCAAGTCCTGGATCAGTGAGAGTGTGGAGGCCGACGTGCGCCTCCGCCTGGCCAATGTGTCGGAGCGGGACGGGGGCGAGTACCTCTGTCGAGCCACCAATTTCATAGGCGTGGCCGAGAAGGCCTTTTGGCTGAGCGTTCACGGGCCCCGAGCAGCCGAGGAGGAGCTGGTGGAGGCTGACGAGGCGGGCAGTGTGTATGCAGGCATCCTCAGCTACGGGGTGGGCTTCTTCCTGTTCATCCTGGTGGTGGCGGCTGTGACGCTCTGCCGCCTGCGCAGCCCCCCCAAGAAAGGCCTGGGCTCCCCCACCGTGCACAAGATCTCCCGCTTCCCGCTCAAGCGACAGGTGTCCCTGGAGTCCAACGCGTCCATGAGCTCCAACACACCACTGGTGCGCATCGCAAGGCTGTCCTCAGGGGAGGGCCCCACGCTGGCCAATGTCTCCGAGCTCGAGCTGCCTGCCGACCCCAAATGGGAGCTGTCTCGGGCCCGGCTGACCCTGGGCAAGCCCCTTGGGGAGGGCTGCTTCGGCCAGGTGGTCATGGCGGAGGCCATCGGCATTGACAAGGACCGGGCCGCCAAGCCTGTCACCGTAGCCGTGAAGATGCTGAAAGACGATGCCACTGACAAGGACCTGTCGGACCTGGTGTCTGAGATGGAGATGATGAAGATGATCGGGAAACACAAAAACATCATCAACCTGCTGGGCGCCTGCACGCAGGGCGGGCCCCTGTACGTGCTGGTGGAGTACGCGGCCAAGGGTAACCTGCGGGAGTTTCTGCGGGCGCGGCGGCCCCCGGGCCTGGACTACTCCTTCGACACCTGCAAGCCGCCCGAGGAGCAGCTCACCTTCAAGGACCTGGTGTCCTGTGCCTACCAGGTGGCCCGGGGCATGGAGTACTTGGCCTCCCAGAAGTGCATCCACAGGGACCTGGCTGCCCGCAATGTGCTGGTGACCGAGGACAACGTGATGAAGATCGCAGACTTCGGGCTGGCCCGGGACGTGCACAACCTCGACTACTACAAGAAGACAACCAACGGCCGGCTGCCCGTGAAGTGGATGGCGCCTGAGGCCTTGTTTGACCGAGTCTACACTCACCAGAGTGACGTCTGGTCCTTTGGGGTCCTGCTCTGGGAGATCTTCACGCTGGGGGGCTCCCCGTACCCCGGCATCCCTGTGGAGGAGCTCTTCAAGCTGCTGAAGGAGGGCCACCGCATGGACAAGCCCGCCAACTGCACACACGACCTGTACATGATCATGCGGGAGTGCTGGCATGCCGCGCCCTCCCAGAGGCCCACCTTCAAGCAGCTGGTGGAGGACCTGGACCGTGTCCTTACCGTGACGTCCACCGACGAGTACCTGGACCTGTCGGCGCCTTTCGAGCAGTACTCCCCGGGTGGCCAGGACACCCCCAGCTCCAGCTCCTCAGGGGACGACTCCGTGTTTGCCCACGACCTGCTGCCCCCGGCCCCACCCAGCAGTGGGGGCTCGCGGACGTGA
SEQ ID NO:56
FGFR3-IIIb氨基酸序列
MGAPACALALCVAVAIVAGASSESLGTEQRVVGRAAEVPGPEPGQQEQLVFGSGDAVELSCPPPGGGPMGPTVWVKDGTGLVPSERVLVGPQRLQVLNASHEDSGAYSCRQRLTQRVLCHFSVRVTDAPSSGDDEDGEDEAEDTGVDTGAPYWTRPERMDKKLLAVPAANTVRFRCPAAGNPTPSISWLKNGREFRGEHRIGGIKLRHQQWSLVMESVVPSDRGNYTCVVENKFGSIRQTYTLDVLERSPHRPILQAGLPANQTAVLGSDVEFHCKVYSDAQPHIQWLKHVEVNGSKVGPDGTPYVTVLKSWISESVEADVRLRLANVSERDGGEYLCRATNFIGVAEKAFWLSVHGPRAAEEELVEADEAGSVYAGILSYGVGFFLFILVVAAVTLCRLRSPPKKGLGSPTVHKISRFPLKRQVSLESNASMSSNTPLVRIARLSSGEGPTLANVSELELPADPKWELSRARLTLGKPLGEGCFGQVVMAEAIGIDKDRAAKPVTVAVKMLKDDATDKDLSDLVSEMEMMKMIGKHKNIINLLGACTQGGPLYVLVEYAAKGNLREFLRARRPPGLDYSFDTCKPPEEQLTFKDLVSCAYQVARGMEYLASQKCIHRDLAARNVLVTEDNVMKIADFGLARDVHNLDYYKKTTNGRLPVKWMAPEALFDRVYTHQSDVWSFGVLLWEIFTLGGSPYPGIPVEELFKLLKEGHRMDKPANCTHDLYMIMRECWHAAPSQRPTFKQLVEDLDRVLTVTSTDEYLDLSAPFEQYSPGGQDTPSSSSSGDDSVFAHDLLPPAPPSSGGSRT
SEQ ID NO:57
FGFR3-IIIc核酸序列
ATGGGCGCCCCTGCCTGCGCCCTCGCGCTCTGCGTGGCCGTGGCCATCGTGGCCGGCGCCTCCTCGGAGTCCTTGGGGACGGAGCAGCGCGTCGTGGGGCGAGCGGCAGAAGTCCCGGGCCCAGAGCCCGGCCAGCAGGAGCAGTTGGTCTTCGGCAGCGGGGATGCTGTGGAGCTGAGCTGTCCCCCGCCCGGGGGTGGTCCCATGGGGCCCACTGTCTGGGTCAAGGATGGCACAGGGCTGGTGCCCTCGGAGCGTGTCCTGGTGGGGCCCCAGCGGCTGCAGGTGCTGAATGCCTCCCACGAGGACTCCGGGGCCTACAGCTGCCGGCAGCGGCTCACGCAGCGCGTACTGTGCCACTTCAGTGTGCGGGTGACAGACGCTCCATCCTCGGGAGATGACGAAGACGGGGAGGACGAGGCTGAGGACACAGGTGTGGACACAGGGGCCCCTTACTGGACACGGCCCGAGCGGATGGACAAGAAGCTGCTGGCCGTGCCGGCCGCCAACACCGTCCGCTTCCGCTGCCCAGCCGCTGGCAACCCCACTCCCTCCATCTCCTGGCTGAAGAACGGCAGGGAGTTCCGCGGCGAGCACCGCATTGGAGGCATCAAGCTGCGGCATCAGCAGTGGAGCCTGGTCATGGAAAGCGTGGTGCCCTCGGACCGCGGCAACTACACCTGCGTCGTGGAGAACAAGTTTGGCAGCATCCGGCAGACGTACACGCTGGACGTGCTGGAGCGCTCCCCGCACCGGCCCATCCTGCAGGCGGGGCTGCCGGCCAACCAGACGGCGGTGCTGGGCAGCGACGTGGAGTTCCACTGCAAGGTGTACAGTGACGCACAGCCCCACATCCAGTGGCTCAAGCACGTGGAGGTGAATGGCAGCAAGGTGGGCCCGGACGGCACACCCTACGTTACCGTGCTCAAGACGGCGGGCGCTAACACCACCGACAAGGAGCTAGAGGTTCTCTCCTTGCACAACGTCACCTTTGAGGACGCCGGGGAGTACACCTGCCTGGCGGGCAATTCTATTGGGTTTTCTCATCACTCTGCGTGGCTGGTGGTGCTGCCAGCCGAGGAGGAGCTGGTGGAGGCTGACGAGGCGGGCAGTGTGTATGCAGGCATCCTCAGCTACGGGGTGGGCTTCTTCCTGTTCATCCTGGTGGTGGCGGCTGTGACGCTCTGCCGCCTGCGCAGCCCCCCCAAGAAAGGCCTGGGCTCCCCCACCGTGCACAAGATCTCCCGCTTCCCGCTCAAGCGACAGGTGTCCCTGGAGTCCAACGCGTCCATGAGCTCCAACACACCACTGGTGCGCATCGCAAGGCTGTCCTCAGGGGAGGGCCCCACGCTGGCCAATGTCTCCGAGCTCGAGCTGCCTGCCGACCCCAAATGGGAGCTGTCTCGGGCCCGGCTGACCCTGGGCAAGCCCCTTGGGGAGGGCTGCTTCGGCCAGGTGGTCATGGCGGAGGCCATCGGCATTGACAAGGACCGGGCCGCCAAGCCTGTCACCGTAGCCGTGAAGATGCTGAAAGACGATGCCACTGACAAGGACCTGTCGGACCTGGTGTCTGAGATGGAGATGATGAAGATGATCGGGAAACACAAAAACATCATCAACCTGCTGGGCGCCTGCACGCAGGGCGGGCCCCTGTACGTGCTGGTGGAGTACGCGGCCAAGGGTAACCTGCGGGAGTTTCTGCGGGCGCGGCGGCCCCCGGGCCTGGACTACTCCTTCGACACCTGCAAGCCGCCCGAGGAGCAGCTCACCTTCAAGGACCTGGTGTCCTGTGCCTACCAGGTGGCCCGGGGCATGGAGTACTTGGCCTCCCAGAAGTGCATCCACAGGGACCTGGCTGCCCGCAATGTGCTGGTGACCGAGGACAACGTGATGAAGATCGCAGACTTCGGGCTGGCCCGGGACGTGCACAACCTCGACTACTACAAGAAGACAACCAACGGCCGGCTGCCCGTGAAGTGGATGGCGCCTGAGGCCTTGTTTGACCGAGTCTACACTCACCAGAGTGACGTCTGGTCCTTTGGGGTCCTGCTCTGGGAGATCTTCACGCTGGGGGGCTCCCCGTACCCCGGCATCCCTGTGGAGGAGCTCTTCAAGCTGCTGAAGGAGGGCCACCGCATGGACAAGCCCGCCAACTGCACACACGACCTGTACATGATCATGCGGGAGTGCTGGCATGCCGCGCCCTCCCAGAGGCCCACCTTCAAGCAGCTGGTGGAGGACCTGGACCGTGTCCTTACCGTGACGTCCACCGACGAGTACCTGGACCTGTCGGCGCCTTTCGAGCAGTACTCCCCGGGTGGCCAGGACACCCCCAGCTCCAGCTCCTCAGGGGACGACTCCGTGTTTGCCCACGACCTGCTGCCCCCGGCCCCACCCAGCAGTGGGGGCTCGCGGACGTGA
SEQ ID NO:58
FGFR3-IIIc氨基酸序列
MGAPACALALCVAVAIVAGASSESLGTEQRVVGRAAEVPGPEPGQQEQLVFGSGDAVELSCPPPGGGPMGPTVWVKDGTGLVPSERVLVGPQRLQVLNASHEDSGAYSCRQRLTQRVLCHFSVRVTDAPSSGDDEDGEDEAEDTGVDTGAPYWTRPERMDKKLLAVPAANTVRFRCPAAGNPTPSISWLKNGREFRGEHRIGGIKLRHQQWSLVMESVVPSDRGNYTCVVENKFGSIRQTYTLDVLERSPHRPILQAGLPANQTAVLGSDVEFHCKVYSDAQPHIQWLKHVEVNGSKVGPDGTPYVTVLKTAGANTTDKELEVLSLHNVTFEDAGEYTCLAGNSIGFSHHSAWLVVLPAEEELVEADEAGSVYAGILSYGVGFFLFILVVAAVTLCRLRSPPKKGLGSPTVHKISRFPLKRQVSLESNASMSSNTPLVRIARLSSGEGPTLANVSELELPADPKWELSRARLTLGKPLGEGCFGQVVMAEAIGIDKDRAAKPVTVAVKMLKDDATDKDLSDLVSEMEMMKMIGKHKNIINLLGACTQGGPLYVLVEYAAKGNLREFLRARRPPGLDYSFDTCKPPEEQLTFKDLVSCAYQVARGMEYLASQKCIHRDLAARNVLVTEDNVMKIADFGLARDVHNLDYYKKTTNGRLPVKWMAPEALFDRVYTHQSDVWSFGVLLWEIFTLGGSPYPGIPVEELFKLLKEGHRMDKPANCTHDLYMIMRECWHAAPSQRPTFKQLVEDLDRVLTVTSTDEYLDLSAPFEQYSPGGQDTPSSSSSGDDSVFAHDLLPPAPPSSGGSRT
SEQ ID NO:59
2B.1.3轻链,氨基酸
DIQMTQSPSSLSASVGDRVTITCRASQDVDTSLAWYKQKPGKAPKLLIYSASFLYSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSTGHPQTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO:60
2B.1.95轻链,氨基酸
DIQMTQSPSSLSASVGDRVTITCRASQDVDTSLAWYKQKPGKAPKLLIYSASFLYSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSTGHPQTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO:61
2B.1.73轻链,氨基酸
DIQMTQSPSSLSASVGDRVTITCRASQDVDTSLAWYKQKPGKAPKLLIYSASFLYSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSTGHPQTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO:62
2B.1.32轻链,氨基酸
DIQMTQSPSSLSASVGDRVTITCRASQDVDTSLAWYKQKPGKAPKLLIYSASFLYSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSTGHPQTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO:63
2B.1.88轻链,氨基酸
DIQMTQSPSSLSASVGDRVTITCRASQDVDTSLAWYKQKPGKAPKLLIYSASFLYSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSTGHPQTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO:64
2B.1.1轻链,氨基酸
DIQMTQSPSSLSASVGDRVTITCRASQDVDTSLAWYKQKPGKAPKLLIYSASFLYSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSTGHPQTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO:65
2B.1.3.10轻链,氨基酸
DIQMTQSPSSLSASVGDRVTITCRASQDVDTSLAWYKQKPGKAPKLLIYSASFLYSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSTGHPQTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO:66
2B.1.3.12轻链,氨基酸
DIQMTQSPSSLSASVGDRVTITCRASQDVDTSLAWYKQKPGKAPKLLIYSASFLYSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSTGHPQTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC
SEQ ID NO:67
2B.1.3轻链,核酸
GATATCCAGATGACCCAGTCCCCGAGCTCCCTGTCCGCCTCTGTGGGCGATAGGGTCACCATCACCTGCCGTGCCAGTCAGGATGTTGATACTTCTCTGGCCTGGTATAAACAGAAACCAGGAAAAGCTCCGAAGCTTCTGATTTACTCGGCATCCTTCCTCTACTCTGGAGTCCCTTCTCGCTTCTCTGGTAGCGGTTCCGGGACGGATTTCACTCTGACCATCAGCAGTCTGCAGCCGGAAGACTTCGCAACTTATTACTGTCAGCAATCTACCGGTCATCCTCAGACGTTCGGACAGGGTACCAAGGTGGAGATCAAACGAACTGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCTTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGT
SEQ ID NO:68
2B.1.95轻链,核酸
GATATCCAGATGACCCAGTCCCCGAGCTCCCTGTCCGCCTCTGTGGGCGATAGGGTCACCATCACCTGCCGTGCCAGTCAGGATGTTGATACTTCTCTGGCCTGGTATAAACAGAAACCAGGAAAAGCTCCGAAGCTTCTGATTTACTCGGCATCCTTCCTCTACTCTGGAGTCCCTTCTCGCTTCTCTGGTAGCGGTTCCGGGACGGATTTCACTCTGACCATCAGCAGTCTGCAGCCGGAAGACTTCGCAACTTATTACTGTCAGCAATCTACCGGTCATCCTCAGACGTTCGGACAGGGTACCAAGGTGGAGATCAAACGAACTGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCTTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGT
SEQ ID NO:69
2B.1.73轻链,核酸
GATATCCAGATGACCCAGTCCCCGAGCTCCCTGTCCGCCTCTGTGGGCGATAGGGTCACCATCACCTGCCGTGCCAGTCAGGATGTTGATACTTCTCTGGCCTGGTATAAACAGAAACCAGGAAAAGCTCCGAAGCTTCTGATTTACTCGGCATCCTTCCTCTACTCTGGAGTCCCTTCTCGCTTCTCTGGTAGCGGTTCCGGGACGGATTTCACTCTGACCATCAGCAGTCTGCAGCCGGAAGACTTCGCAACTTATTACTGTCAGCAATCTACCGGTCATCCTCAGACGTTCGGACAGGGTACCAAGGTGGAGATCAAACGAACTGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCTTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGT
SEQ ID NO:70
2B.1.32轻链,核酸
GATATCCAGATGACCCAGTCCCCGAGCTCCCTGTCCGCCTCTGTGGGCGATAGGGTCACCATCACCTGCCGTGCCAGTCAGGATGTTGATACTTCTCTGGCCTGGTATAAACAGAAACCAGGAAAAGCTCCGAAGCTTCTGATTTACTCGGCATCCTTCCTCTACTCTGGAGTCCCTTCTCGCTTCTCTGGTAGCGGTTCCGGGACGGATTTCACTCTGACCATCAGCAGTCTGCAGCCGGAAGACTTCGCAACTTATTACTGTCAGCAATCTACCGGTCATCCTCAGACGTTCGGACAGGGTACCAAGGTGGAGATCAAACGAACTGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCTTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGT
SEQ ID NO:71
2B.1.88轻链,核酸
GATATCCAGATGACCCAGTCCCCGAGCTCCCTGTCCGCCTCTGTGGGCGATAGGGTCACCATCACCTGCCGTGCCAGTCAGGATGTTGATACTTCTCTGGCCTGGTATAAACAGAAACCAGGAAAAGCTCCGAAGCTTCTGATTTACTCGGCATCCTTCCTCTACTCTGGAGTCCCTTCTCGCTTCTCTGGTAGCGGTTCCGGGACGGATTTCACTCTGACCATCAGCAGTCTGCAGCCGGAAGACTTCGCAACTTATTACTGTCAGCAATCTACCGGTCATCCTCAGACGTTCGGACAGGGTACCAAGGTGGAGATCAAACGAACTGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCTTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGT
SEQ ID NO:72
2B.1.1轻链,核酸
GATATCCAGATGACCCAGTCCCCGAGCTCCCTGTCCGCCTCTGTGGGCGATAGGGTCACCATCACCTGCCGTGCCAGTCAGGATGTTGATACTTCTCTGGCCTGGTATAAACAGAAACCAGGAAAAGCTCCGAAGCTTCTGATTTACTCGGCATCCTTCCTCTACTCTGGAGTCCCTTCTCGCTTCTCTGGTAGCGGTTCCGGGACGGATTTCACTCTGACCATCAGCAGTCTGCAGCCGGAAGACTTCGCAACTTATTACTGTCAGCAATCTACCGGTCATCCTCAGACGTTCGGACAGGGTACCAAGGTGGAGATCAAACGAACTGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCTTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGT
SEQ ID NO:73
2B.1.3.10轻链,核酸
GATATCCAGATGACCCAGTCCCCGAGCTCCCTGTCCGCCTCTGTGGGCGATAGGGTCACCATCACCTGCCGTGCCAGTCAGGATGTTGATACTTCTCTGGCCTGGTATAAACAGAAACCAGGAAAAGCTCCGAAGCTTCTGATTTACTCGGCATCCTTCCTCTACTCTGGAGTCCCTTCTCGCTTCTCTGGTAGCGGTTCCGGGACGGATTTCACTCTGACCATCAGCAGTCTGCAGCCGGAAGACTTCGCAACTTATTACTGTCAGCAATCTACCGGTCATCCTCAGACGTTCGGACAGGGTACCAAGGTGGAGATCAAACGAACTGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCTTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGT
SEQ ID NO:74
2B.1.3.12轻链,核酸
GATATCCAGATGACCCAGTCCCCGAGCTCCCTGTCCGCCTCTGTGGGCGATAGGGTCACCATCACCTGCCGTGCCAGTCAGGATGTTGATACTTCTCTGGCCTGGTATAAACAGAAACCAGGAAAAGCTCCGAAGCTTCTGATTTACTCGGCATCCTTCCTCTACTCTGGAGTCCCTTCTCGCTTCTCTGGTAGCGGTTCCGGGACGGATTTCACTCTGACCATCAGCAGTCTGCAGCCGGAAGACTTCGCAACTTATTACTGTCAGCAATCTACCGGTCATCCTCAGACGTTCGGACAGGGTACCAAGGTGGAGATCAAACGAACTGTGGCTGCACCATCTGTCTTCATCTTCCCGCCATCTGATGAGCAGTTGAAATCTGGAACTGCTTCTGTTGTGTGCCTGCTGAATAACTTCTATCCCAGAGAGGCCAAAGTACAGTGGAAGGTGGATAACGCCCTCCAATCGGGTAACTCCCAGGAGAGTGTCACAGAGCAGGACAGCAAGGACAGCACCTACAGCCTCAGCAGCACCCTGACGCTGAGCAAAGCAGACTACGAGAAACACAAAGTCTACGCCTGCGAAGTCACCCATCAGGGCCTGAGCTCGCCCGTCACAAAGAGCTTCAACAGGGGAGAGTGT
SEQ ID NO:75
2B.1.3重链,氨基酸
EVQLVESGGGLVQPGGSLRLSCAASGFTFTSTGISWVRQAPGKGLEWVGRTHLGDGSTNYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCARTYGIYDLYVDYTEYVMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:76
2B.1.95重链,氨基酸
EVQLVESGGGLVQPGGSLRLSCAASGFTFTSTGISWVRQAPGKGLEWVGRLIFFTGSTNYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCARTYGIYDLYVDYTEYVMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:77
2B.1.73重链,氨基酸
EVQLVESGGGLVQPGGSLRLSCAASGFTFTSTGISWVRQAPGKGLEWVGRMIFYNGSTNYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCARTYGIYDLYVDYTEYVMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:78
2B.1.32重链,氨基酸
EVQLVESGGGLVQPGGSLRLSCAASGFTFTSTGISWVRQAPGKGLEWVGRWVGFTGSTNYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCARTYGIYDLYVDYTEYVMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:79
2B.1.88重链,氨基酸
EVQLVESGGGLVQPGGSLRLSCAASGFTFTSTGISWVRQAPGKGLEWVGRIWMFTGSTNYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCARTYGIYDLYVDYTEYVMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:80
2B.1.1重链,氨基酸
EVQLVESGGGLVQPGGSLRLSCAASGFTFTSTGISWVRQAPGKGLEWVGRYWAWDGSTNYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCARTYGIYDLYVDYTEYVMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:81
2B.1.3.10重链,氨基酸
EVQLVESGGGLVQPGGSLRLSCAASGFPFTSQGISWVRQAPGKGLEWVGRTHLGDGSTNYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCARTYGIYDTYDKYTEYVMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:82
2B.1.3.12重链,氨基酸
EVQLVESGGGLVQPGGSLRLSCAASGFPFTSTGISWVRQAPGKGLEWVGRTHLGDGSTNYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCARTYGIYDTYDMYTEYVMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:83
2B.1.3重链,核酸
GAGGTTCAGCTGGTGGAGTCTGGCGGTGGCCTGGTGCAGCCAGGGGGCTCACTCCGTTTGTCCTGTGCAGCTTCTGGCTTCACCTTCACTAGTACTGGGATTAGCTGGGTGCGTCAGGCCCCGGGTAAGGGCCTGGAATGGGTTGGTAGGACGCATTTGGGTGATGGTTCTACTAACTATGCCGATAGCGTCAAGGGCCGTTTCACTATAAGCGCAGACACATCCAAAAACACAGCCTACCTACAAATGAACAGCTTAAGAGCTGAGGACACTGCCGTCTATTATTGTGCTCGTACCTACGGCATCTACGACCTGTACGTGGACTACACGGAGTACGTTATGGACTACTGGGGTCAAGGAACCCTGGTCACCGTCTCCTCGGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACTGTGCCCTCTAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGGGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAAGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA
SEQ ID NO:84
2B.1.95重链,核酸
GAGGTTCAGCTGGTGGAGTCTGGCGGTGGCCTGGTGCAGCCAGGGGGCTCACTCCGTTTGTCCTGTGCAGCTTCTGGCTTCACCTTCACTAGTACTGGGATTAGCTGGGTGCGTCAGGCCCCGGGTAAGGGCCTGGAATGGGTTGGTAGGTTAATTTTTTTTACAGGTTCTACTAACTATGCCGATAGCGTCAAGGGCCGTTTCACTATAAGCGCAGACACATCCAAAAACACAGCCTACCTACAAATGAACAGCTTAAGAGCTGAGGACACTGCCGTCTATTATTGTGCTCGTACCTACGGCATCTACGACCTGTACGTGGACTACACGGAGTACGTTATGGACTACTGGGTCAAGGAACCCTGGTCACCGTCTCCTCGGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACTGTGCCCTCTAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGGGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAAGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA
SEQ ID NO:85
2B.1.73重链,核酸
GAGGTTCAGCTGGTGGAGTCTGGCGGTGGCCTGGTGCAGCCAGGGGGCTCACTCCGTTTGTCCTGTGCAGCTTCTGGCTTCACCTTCACTAGTACTGGGATTAGCTGGGTGCGTCAGGCCCCGGGTAAGGGCCTGGAATGGGTTGGTAGGATGATTTTTTATAATGGTTCTACTAACTATGCCGATAGCGTCAAGGGCCGTTTCACTATAAGCGCAGACACATCCAAAAACACAGCCTACCTACAAATGAACAGCTTAAGAGCTGAGGACACTGCCGTCTATTATTGTGCTCGTACCTACGGCATCTACGACCTGTACGTGGACTACACGGAGTACGTTATGGACTACTGGGGTCAAGGAACCCTGGTCACCGTCTCCTCGGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACTGTGCCCTCTAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGGGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAAGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA
SEQ ID NO:86
2B.1.32重链,核酸
GAGGTTCAGCTGGTGGAGTCTGGCGGTGGCCTGGTGCAGCCAGGGGGCTCACTCCGTTTGTCCTGTGCAGCTTCTGGCTTCACCTTCACTAGTACTGGGATTAGCTGGGTGCGTCAGGCCCCGGGTAAGGGCCTGGAATGGGTTGGTAGGTGGGTCGGATTTACAGGTTCTACTAACTATGCCGATAGCGTCAAGGGCCGTTTCACTATAAGCGCAGACACATCCAAAAACACAGCCTACCTACAAATGAACAGCTTAAGAGCTGAGGACACTGCCGTCTATTATTGTGCTCGTACCTACGGCATCTACGACCTGTACGTGGACTACACGGAGTACGTTATGGACTACTGGGGTCAAGGAACCCTGGTCACCGTCTCCTCGGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACTGTGCCCTCTAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGGGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAAGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA
SEQ ID NO:87
2B.1.88重链,核酸
GAGGTTCAGCTGGTGGAGTCTGGCGGTGGCCTGGTGCAGCCAGGGGGCTCACTCCGTTTGTCCTGTGCAGCTTCTGGCTTCACCTTCACTAGTACTGGGATTAGCTGGGTGCGTCAGGCCCCGGGTAAGGGCCTGGAATGGGTTGGTAGGATTTGGATGTTTACAGGTTCTACTAACTATGCCGATAGCGTCAAGGGCCGTTTCACTATAAGCGCAGACACATCCAAAAACACAGCCTACCTACAAATGAACAGCTTAAGAGCTGAGGACACTGCCGTCTATTATTGTGCTCGTACCTACGGCATCTACGACCTGTACGTGGACTACACGGAGTACGTTATGGACTACTGGGGTCAAGGAACCCTGGTCACCGTCTCCTCGGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACTGTGCCCTCTAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGGGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAAGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA
SEQ ID NO:88
2B.1.1重链,核酸
GAGGTTCAGCTGGTGGAGTCTGGCGGTGGCCTGGTGCAGCCAGGGGGCTCACTCCGTTTGTCCTGTGCAGCTTCTGGCTTCCCGTTCACTAGTCAGGGGATTAGCTGGGTGCGTCAGGCCCCGGGTAAGGGCCTGGAATGGGTTGGTAGGACGCATTTGGGTGATGGTTCTACTAACTATGCCGATAGCGTCAAGGGCCGTTTCACTATAAGCGCAGACACATCCAAAAACACAGCCTACCTACAAATGAACAGCTTAAGAGCTGAGGACACTGCCGTCTATTATTGTGCTCGTACCTACGGCATCTACGACACGTATGATAAGTACACGGAGTACGTTATGGACTACTGGGGTCAAGGAACCCTGGTCACCGTCTCCTCGGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACTGTGCCCTCTAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGGGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAAGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA
SEQ ID NO:89
2B.1.3.10重链,核酸
GAGGTTCAGCTGGTGGAGTCTGGCGGTGGCCTGGTGCAGCCAGGGGGCTCACTCCGTTTGTCCTGTGCAGCTTCTGGCTTCCCGTTCACTAGTCAGGGGATTAGCTGGGTGCGTCAGGCCCCGGGTAAGGGCCTGGAATGGGTTGGTAGGACGCATTTGGGTGATGGTTCTACTAACTATGCCGATAGCGTCAAGGGCCGTTTCACTATAAGCGCAGACACATCCAAAAACACAGCCTACCTACAAATGAACAGCTTAAGAGCTGAGGACACTGCCGTCTATTATTGTGCTCGTACCTACGGCATCTACGACACGTATGATAAGTACACGGAGTACGTTATGGACTACTGGGGTCAAGGAACCCTGGTCACCGTCTCCTCGGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACTGTGCCCTCTAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGGGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAAGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA
SEQ ID NO:90
2B.1.3.12重链,核酸
GAGGTTCAGCTGGTGGAGTCTGGCGGTGGCCTGGTGCAGCCAGGGGGCTCACTCCGTTTGTCCTGTGCAGCTTCTGGCTTCCCGTTCACTAGTACGGGGATTAGCTGGGTGCGTCAGGCCCCGGGTAAGGGCCTGGAATGGGTTGGTAGGACGCATTTGGGTGATGGTTCTACTAACTATGCCGATAGCGTCAAGGGCCGTTTCACTATAAGCGCAGACACATCCAAAAACACAGCCTACCTACAAATGAACAGCTTAAGAGCTGAGGACACTGCCGTCTATTATTGTGCTCGTACCTACGGCATCTACGACACGTATGATATGTACACGGAGTACGTTATGGACTACTGGGGTCAAGGAACCCTGGTCACCGTCTCCTCGGCCTCCACCAAGGGCCCATCGGTCTTCCCCCTGGCACCCTCCTCCAAGAGCACCTCTGGGGGCACAGCGGCCCTGGGCTGCCTGGTCAAGGACTACTTCCCCGAACCGGTGACGGTGTCGTGGAACTCAGGCGCCCTGACCAGCGGCGTGCACACCTTCCCGGCTGTCCTACAGTCCTCAGGACTCTACTCCCTCAGCAGCGTGGTGACTGTGCCCTCTAGCAGCTTGGGCACCCAGACCTACATCTGCAACGTGAATCACAAGCCCAGCAACACCAAGGTGGACAAGAAAGTTGAGCCCAAATCTTGTGACAAAACTCACACATGCCCACCGTGCCCAGCACCTGAACTCCTGGGGGGACCGTCAGTCTTCCTCTTCCCCCCAAAACCCAAGGACACCCTCATGATCTCCCGGACCCCTGAGGTCACATGCGTGGTGGTGGACGTGAGCCACGAAGACCCTGAGGTCAAGTTCAACTGGTACGTGGACGGCGTGGAGGTGCATAATGCCAAGACAAAGCCGCGGGAGGAGCAGTACAACAGCACGTACCGGGTGGTCAGCGTCCTCACCGTCCTGCACCAGGACTGGCTGAATGGCAAGGAGTACAAGTGCAAGGTCTCCAACAAAGCCCTCCCAGCCCCCATCGAGAAAACCATCTCCAAAGCCAAAGGGCAGCCCCGAGAACCACAGGTGTACACCCTGCCCCCATCCCGGGAAGAGATGACCAAGAACCAGGTCAGCCTGACCTGCCTGGTCAAAGGCTTCTATCCCAGCGACATCGCCGTGGAGTGGGAGAGCAATGGGCAGCCGGAGAACAACTACAAGACCACGCCTCCCGTGCTGGACTCCGACGGCTCCTTCTTCCTCTACAGCAAGCTCACCGTGGACAAGAGCAGGTGGCAGCAGGGGAACGTCTTCTCATGCTCCGTGATGCATGAGGCTCTGCACAACCACTACACGCAGAAGAGCCTCTCCCTGTCTCCGGGTAAA
SEQ ID NO:91
2B.1.3.10FGFR2-IIIb和FGFR2-IIIc表位1
TNTEKMEKRLHAVPAANTVKFRCPA
SEQ ID NO:92
2B.1.3.10FGFR2-IIIb和FGFR2-IIIc表位2
YKVRNQHWSLIMES
SEQ ID NO:93
2B.1.3.10FGFR3-IIIb和FGFR3-IIIc表位1
TRPERMDKKLLAVPAANTVRFRCPA
SEQ ID NO:94
2B.1.3.10FGFR3-IIIb和FGFR3-IIIc表位2
IKLRHQQWSLVMES
SEQ ID NO:95
VH亚组III共有框架
EVQLVESGGGLVQPGGSLRLSCAAS
SEQ ID NO:96
VH亚组III共有框架
WVRQAPGKGLEWV
SEQ ID NO:97
VH亚组III共有框架
RFTISRDNSKNTLYLQMNSLRAEDTAVYYC
SEQ ID NO:98
VH亚组III共有框架
WGQGTLVTVSS
SEQ ID NO:99
VL亚组I共有框架
DIQMTQSPSSLSASVGDRVTITC
SEQ ID NO:100
VL亚组I共有框架
WYQQKPGKAPKLLIY
SEQ ID NO:101
VL亚组I共有框架
GVPSRFSGSGSGTDFTLTISSLQPEDFATYYC
SEQ ID NO:102
VL亚组I共有框架
FGQGTKVEIK
SEQ ID NO:103
Ser Ser Pro Thr Arg Leu Ala Val Ile Pro Trp Gly Val Arg Lys Leu LeuArg Trp Val Arg Arg Asn Tyr Gly Asp Met Asp Ile Tyr Ile Thr Ala Ser
SEQ ID NO:104
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly SerLeu Arg Leu Ser Cys Ala Ala Ser Asp Phe Ser Leu Thr Thr Tyr Gly Val His TrpVal Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Leu Gly Val Ile Trp Ser Gly GlySer Thr Asp Tyr Asn Ala Ala Phe Ile Ser Arg Leu Thr Ile Ser Lys Asp Asn SerLys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val TyrTyr Cys Ala Arg Asp Tyr Gly Ser Thr Tyr Val Asp Ala Ile Asp Tyr Trp Gly GlnGly Thr Leu Val Thr Val Ser Ser
SEQ ID NO:105
Asp Ile Val Leu Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly GluArg Ala Thr Ile Asn Cys Arg Ala Ser Glu Ser Val Glu Ser Tyr Gly Asn Arg TyrMet Thr Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile Tyr Arg AlaAla Asn Leu Gln Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr AspPhe Thr Leu Thr Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys GlnGln Ser Asn Glu Asp Pro Trp Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
SEQ ID NO:106
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly SerLeu Arg Leu Ser Cys Ala Ala Ser Asp Phe Ser Leu Thr Thr Tyr Gly Val His TrpVal Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Leu Gly Val Ile Trp Ser Gly GlySer Thr Asp Tyr Asn Ala Ala Phe Ile Ser Arg Leu Thr Ile Ser Lys Asp Asn SerLys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val TyrTyr Cys Ala Arg Asp Tyr Gly Ser Thr Tyr Val Asp Ala Ile Asp Tyr Trp Gly GlnGly Thr Leu Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro LeuAla Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val LysAsp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser GlyVal His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser ValVal Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn HisLys Pro Ser Asn Thr Lys Val Asp Lys Lys Val Glu Pro Lys Ser Cys Asp Lys ThrHis Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe LeuPhe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr CysVal Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val AspGly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Gly Ser ThrTyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys GluTyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile SerLys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg GluGlu Met Thr Lys Asn Gln Val Ser Leu Ser Cys Ala Val Lys Gly Phe Tyr Pro SerAsp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr ThrPro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Val Ser Lys Leu Thr Val AspLys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala LeuHis Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
SEQ ID NO:107
Asp Ile Val Leu Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly GluArg Ala Thr Ile Asn Cys Arg Ala Ser Glu Ser Val Glu Ser Tyr Gly Asn Arg TyrMet Thr Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile Tyr Arg AlaAla Asn Leu Gln Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr AspPhe Thr Leu Thr Ile Ser Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys GlnGln Ser Asn Glu Asp Pro Trp Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys ArgThr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys SerGly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys ValGln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu Ser Val Thr GluGln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys AlaAsp Tyr Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser SerPro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
SEQ ID NO:108
Ser Tyr Gly Ile Ser
SEQ ID NO:109
Asp Tyr Tyr Met Asn
SEQ ID NO:110
Asn Tyr Gly Val Ser
SEQ ID NO:111
Asp Thr Tyr Met Asn
SEQ ID NO:112
Asp Thr Tyr Ile His
SEQ ID NO:113
Ser Tyr Trp Ile His
SEQ ID NO:114
Asp Thr Phe Thr His
SEQ ID NO:115
Glu Tyr Thr Met Asn
SEQ ID NO:116
Ser Tyr Trp Ile Glu
SEQ ID NO:117
Asp Tyr Glu Met His
SEQ ID NO:118
Asp Thr Tyr Ile His
SEQ ID NO:119
Arg Tyr Trp Met Ser
SEQ ID NO:120
Asn Tyr Gly Met Asn
SEQ ID NO:121
Thr Ser Ala Met Gly Ile Gly
SEQ ID NO:122
Thr Tyr Gly Val His
SEQ ID NO:123
Gln Gln Tyr Ser Lys Leu Pro Trp Thr
SEQ ID NO:124
Phe Gln Gly Thr Gly Tyr Pro Leu Thr
SEQ ID NO:125
His Gln Val Arg Thr Leu Pro Trp Thr
SEQ ID NO:126
Gln Gln Tyr Trp Asn Thr Pro Phe Thr
SEQ ID NO:127
Phe Gln Gly Ser His Val Leu Thr
SEQ ID NO:128
Gln Gln His Tyr Ile Val Pro Tyr Thr
SEQ ID NO:129
Leu Gln Tyr Gly Ser Tyr Pro Trp Thr
SEQ ID NO:130
His Gln Trp Ser Ser Tyr Pro Leu Thr
SEQ ID NO:131
Gln Gln His His Ser Thr Pro Tyr Thr
SEQ ID NO:132
Gln Gln Phe Thr Ile Ser Pro Ser Met Tyr Thr
SEQ ID NO:133
Gln Gln Tyr Asn Ile Ser Pro Tyr Thr
SEQ ID NO:134
Gln Asn Gly His Asn Phe Pro Tyr Thr
SEQ ID NO:135
Gln Gln Tyr Trp Ser Asn Pro Leu Thr
SEQ ID NO:136
Gln Gln Ser Asn Glu Asp Tyr Thr
SEQ ID NO:137
Gln Gln Ser Asn Glu Asp Pro Trp Thr
SEQ ID NO:138
Thr Val Ser Ser Gly Gly Arg Tyr Thr Tyr Tyr Pro Asp Ser Val Lys Gly
SEQ ID NO:139
Trp Ile Asp Pro Glu Asn Asp Asp Thr Ile Tyr Asp Pro Lys Phe Gln Gly
SEQ ID NO:140
Val Ile Trp Gly Asp Gly Ser Ile Asn Tyr His Ser Ala Leu Ile Ser
SEQ ID NO:141
Arg Ile Asp Pro Ser Asn Gly Asn Ala Lys Tyr Asp Pro Lys Phe Gln Gly
SEQ ID NO:142
Arg Ile Asp Pro Ala Asn Gly Asn Thr Lys Tyr Asp Pro Lys Phe Gln Asp
SEQ ID NO:143
Glu Ile Asp Pro Ser Val Ser Asn Ser Asn Tyr Asn Gln Lys Phe Lys Gly
SEQ ID NO:144
Arg Ile Asp Pro Ser Asn Gly Asn Thr Lys Tyr Asp Pro Lys Phe Gln Gly
SEQ ID NO:145
Gly Ile Asn Pro Asn Asn Gly Glu Thr Ser Tyr Asn Gln Lys Phe Lys Gly
SEQ ID NO:146
Glu Ile Phe Pro Gly Gly Gly Ser Thr Ile Tyr Asn Glu Asn Phe Arg Asp
SEQ ID NO:147
Ala Ile Trp Pro Glu Asn Ala Asp Ser Val Tyr Asn Gln Lys Phe Lys Gly
SEQ ID NO:148
Arg Ile Asp Pro Ala Asn Gly Asn Thr Lys Tyr Asp Pro Lys Phe Gln Gly
SEQ ID NO:149
Glu Ile Leu Pro Gly Ser Asp Ser Thr Lys Tyr Val Glu Lys Phe Lys Val
SEQ ID NO:150
Glu Ile Ser Pro Asp Ser Ser Thr Ile Asn Tyr Thr Pro Ser Leu Lys Asp
SEQ ID NO:151
Trp Ile Asp Thr Asp Thr Gly Glu Ala Thr Tyr Thr Asp Asp Phe Lys Gly
SEQ ID NO:152
SEQ ID NO:152
His Ile Trp Trp Asp Asp Asp Lys Arg Tyr Asn Pro Ala Leu Lys Ser
SEQ ID NO:153
Val Ile Trp Ser Gly Gly Ser Thr Asp Tyr Asn Ala Ala Phe Ile Ser
SEQ ID NO:154
Gly Gly Asp Gly Tyr Ala Leu Asp Tyr
SEQ ID NO:155
Phe Thr Thr Val Phe Ala Tyr
SEQ ID NO:156
Thr His Asp Trp Phe Asp Tyr
SEQ ID NO:157
Arg Ala Leu Gly Asn Gly Tyr Ala Leu Gly Tyr
SEQ ID NO:158
Gly Thr Ser Tyr Ser Trp Phe Ala Tyr
SEQ ID NO:159
Leu Gly Val Met Val Tyr Gly Ser Ser Pro Phe Trp Phe Ala Tyr
SEQ ID NO:160
Arg Ala Leu Gly Asn Gly Tyr Ala Met Asp Tyr
SEQ ID NO:161
Lys Thr Thr Asn Tyr
SEQ ID NO:162
Arg Gly Tyr Tyr Asp Ala Ala Trp Phe Asp Tyr
SEQ ID NO:163
Glu Gly Gly Asn Tyr
SEQ ID NO:164
Ser Gly Asn Tyr Gly Ala Met Asp Tyr
SEQ ID NO:165
Gly Gly Tyr His Tyr Pro Gly Trp Leu Val Tyr
SEQ ID NO:166
Pro Ser Pro Ala Leu Asp Tyr
SEQ ID NO:167
Glu Glu Tyr Gly Leu Phe Gly Phe Pro Tyr
SEQ ID NO:168
Ile Asp Gly Ile Tyr Asp Gly Ser Phe Tyr Ala Met Asp Tyr
SEQ ID NO:169
Asp Tyr Gly Ser Thr Tyr Val Asp Ala Ile Asp Tyr
SEQ ID NO:170
Ser Ala Ser Gln Val Ile Ser Asn Tyr Leu Asn
SEQ ID NO:171
Ser Ala Ser Ser Ser Gly Arg Tyr Thr Phe
SEQ ID NO:172
Arg Ala Ser Gln Asp Ile Ser Asn Tyr Phe Asn
SEQ ID NO:173
Lys Ala Ser Asp His Ile Asn Asn Trp Leu Ala
SEQ ID NO:174
Arg Ser Ser Gln Asn Ile Val His Ser Asp Gly Asn Thr Tyr Leu Glu
SEQ ID NO:175
Lys Ala Ser Gln Phe Val Ser Asp Ala Val Ala
SEQ ID NO:176
Arg Ala Ser Gln Glu Ile Ser Gly Tyr Leu Ser
SEQ ID NO:177
Ser Ala Ser Ser Ser Leu Ser Ser Ser Tyr Leu Tyr
SEQ ID NO:178
Lys Ser Ser Gln Ser Leu Leu Asn Ser Gly Asn Gln Lys Asn Ser Leu Ala
SEQ ID NO:179
Arg Ala Ser Ser Ser Val Asn His Met Tyr
SEQ ID NO:180
Lys Ala Ser Gln Asn Val Asp Ser Tyr Val Ala
SEQ ID NO:181
Arg Ala Ser Gln Ser Ile Ser Asp Tyr Val Tyr
SEQ ID NO:182
Lys Ala Ser Glu Asp Ile Tyr Asn Arg Leu Ala
SEQ ID NO:183
Arg Ala Ser Glu Ser Val Asp Ser Tyr Gly Asn Ser Phe Met His
SEQ ID NO:184
Arg Ala Ser Glu Ser Val Glu Ser Tyr Gly Asn Arg Tyr Met Thr
SEQ ID NO:185
Phe Thr Ser Ser Leu Arg Ser
SEQ ID NO:186
Asp Thr Ser Lys Leu Ala Ser
SEQ ID NO:187
Tyr Thr Ser Arg Leu Gln Ser
SEQ ID NO:188
Gly Thr Thr Asn Leu Glu Thr
SEQ ID NO:189
Lys Val Ser Asn Arg Phe Ser
SEQ ID NO:190
Ser Ala Ser Tyr Arg Tyr Thr
SEQ ID NO:191
Gly Ala Ser Asn Leu Glu Thr
SEQ ID NO:192
Ala Ala Ser Thr Leu Asp Ser
SEQ ID NO:193
Gly Ala Ser Asn Leu Ala Ser
SEQ ID NO:194
Leu Ala Ser Thr Arg Glu Ser
SEQ ID NO:195
Tyr Thr Ser Thr Leu Ala Pro
SEQ ID NO:196
Ser Ala Ser Tyr Arg Phe Ser
SEQ ID NO:197
Tyr Ala Ser Gln Ser Ile Ser
SEQ ID NO:198
Ala Ala Thr Ser Leu Glu Thr
SEQ ID NO:199
Arg Ala Ser Asn Leu Glu Ser
SEQ ID NO:200
Arg Ala Ala Asn Leu Gln Ser
SEQ ID NO:201
Gln Gln Tyr Ser Lys Leu Pro Trp Thr
SEQ ID NO:202
Phe Gln Gly Thr Gly Tyr Pro Leu Thr
SEQ ID NO:203
His Gln Val Arg Thr Leu Pro Trp Thr
SEQ ID NO:204
Gln Gln Tyr Trp Asn Thr Pro Phe Thr
SEQ ID NO:205
Phe Gln Gly Ser His Val Leu Thr
SEQ ID NO:206
Gln Gln His Tyr Ile Val Pro Tyr Thr
SEQ ID NO:207
Leu Gln Tyr Gly Ser Tyr Pro Trp Thr
SEQ ID NO:208
His Gln Trp Ser Ser Tyr Pro Leu Thr
SEQ ID NO:209
Gln Gln His His Ser Thr Pro Tyr Thr
SEQ ID NO:210
Gln Gln Phe Thr Ile Ser Pro Ser Met Tyr Thr
SEQ ID NO:211
Gln Gln Tyr Asn Ile Ser Pro Tyr Thr
SEQ ID NO:212
Gln Asn Gly His Asn Phe Pro Tyr Thr
SEQ ID NO:213
Gln Gln Tyr Trp Ser Asn Pro Leu Thr
SEQ ID NO:214
Gln Gln Ser Asn Glu Asp Tyr Thr
SEQ ID NO:215
Gln Gln Ser Asn Glu Asp Pro Trp Thr
SEQ ID NO:216
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Lys Pro Gly Gly SerLeu Lys Leu Ser Cys Ala Pro Ser Gly Phe Thr Phe Ser Ser Tyr Gly Ile Ser TrpVal Arg Gln Thr Pro Glu Lys Arg Leu Glu Trp Val Ala Thr Val Ser Ser Gly GlyArg Tyr Thr Tyr Tyr Pro Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp AsnAla Glu Asn Thr Leu Tyr Leu Gln Met Ser Ser Leu Arg Ser Glu Asp Thr Ala MetTyr Tyr Cys Thr Arg Gly Gly Asp Gly Tyr Ala Leu Asp Tyr Trp Gly Gln Gly ThrSer Val Thr Val Ser Ser
SEQ ID NO:217
Glu Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Val Arg Pro Gly Ala LeuVal Asn Leu Ser Cys Lys Ala Ser Gly Phe Asn Ile Lys Asp Tyr Tyr Met Asn TrpVal Lys Gln Arg Pro Glu Gln Gly Leu Glu Trp Thr Gly Trp Ile Asp Pro Glu AsnAsp Asp Thr Ile Tyr Asp Pro Lys Phe Gln Gly Lys Ala Thr Ile Thr Ala Asp ThrSer Ser Asn Thr Val Tyr Leu Gln Leu Thr Ser Leu Thr Ser Glu Asp Thr Ala ValTyr Tyr Cys Ala Ala Phe Thr Thr Val Phe Ala Tyr Trp Gly His Gln Thr Met ValThr Val Ser Ala
SEQ ID NO:218
Gln Val Gln Val Lys Glu Ser Gly Pro Gly Leu Val Ala Pro Ser Gln SerLeu Ser Ile Thr Cys Thr Val Ser Gly Phe Ser Leu Thr Asn Tyr Gly Val Ser TrpIle Arg Gln Pro Pro Gly Lys Gly Leu Glu Trp Leu Gly Val Ile Trp Gly Asp GlySer Ile Asn Tyr His Ser Ala Leu Ile Ser Arg Leu Thr Ile Thr Lys Asp Asn SerLys Ser Gln Val Phe Leu Lys Leu Asn Ser Leu Glu Ala Asp Asp Thr Ala Thr TyrTyr Cys Ala Lys Thr His Asp Trp Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val ThrVal Ser Ala
SEQ ID NO:219
Glu Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Val Lys Pro Gly Ala SerVal Lys Leu Ser Cys Thr Ala Ala Asp Phe Asn Ile Lys Asp Thr Tyr Met His TrpVal Lys Gln Arg Pro Glu Gln Gly Leu Glu Trp Ile Gly Arg Ile Asp Pro Ser AsnGly Asn Ala Lys Tyr Asp Pro Lys Phe Gln Gly Lys Ala Ser Ile Thr Ala Asp SerSer Ser Asn Thr Ala Tyr Leu His Leu Ser Ser Leu Thr Ser Glu Asp Thr Ala ValTyr Tyr CysAla Ser Arg Ala Leu Gly Asn Gly Tyr Ala Leu Gly Tyr Trp Gly GlnGly Thr Ser Val Thr Val Ser Ser
SEQ ID NO:220
Glu Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Val Lys Pro Gly Ala SerVal Lys Leu Ser Cys Thr Ala Ser Asp Phe Asn Ile Ile Asp Thr Tyr Ile His TrpVal Lys Gln Arg Pro Glu Gln Gly Leu Glu Trp Ile Gly Arg Ile Asp Pro Ala AsnGly Asn Thr Lys Tyr Asp Pro Lys Phe Gln Asp Lys Ala Ala Leu Thr Ser Asp ThrAsp Ser Asn Thr Ala Tyr Leu Leu Phe Asn Ser Leu Thr Ser Glu Asp Thr Ala ValTyr Tyr Cys Ala Arg Gly Thr Ser Tyr Ser Trp Phe Ala Tyr Trp Gly Gln Gly ThrLeu Val Ser Val Ser Ala
SEQ ID NO:221
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Ile Val Lys Pro Gly Ala SerVal Arg Leu Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Ser Tyr Trp Ile His TrpVal Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile Gly Glu Ile Asp Pro Ser ValSer Asn Ser Asn Tyr Asn Gln Lys Phe Lys Gly Lys Ala Thr Leu Thr Ala Asp LysSer Ser Ser Thr Ala Tyr Met Gln Leu Ser Gly Leu Thr Ser Glu Asp Ser Ala ValTyr Phe Cys Val Arg Leu Gly Val Met Val Tyr Gly Ser Ser Pro Phe Trp Phe AlaTyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ala
SEQ ID NO:222
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Ile Val Lys Pro Gly Ala SerVal Arg Leu Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Ser Tyr Trp Ile His TrpVal Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile Gly Glu Ile Asp Pro Ser ValSer Asn Ser Asn Tyr Asn Gln Lys Phe Lys Gly Lys Ala Thr Leu Thr Ala Asp LysSer Ser Ser Thr Ala Tyr Met Gln Leu Ser Gly Leu Thr Ser Glu Asp Ser Ala ValTyr Phe CysVal Arg Leu Gly Val Met Val Tyr Gly Ser Ser Pro Phe Trp Phe AlaTyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ala
SEQ ID NO:223
Glu Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Leu Lys Pro Gly Ala SerVal Arg Leu Ser Cys Thr Ala Ser Gly Phe Asn Ile Gln Asp Thr Phe Thr His TrpVal Arg Gln Arg Pro Glu Gln Gly Leu Glu Trp Ile Gly Arg Ile Asp Pro Ser AsnGly Asn Thr Lys Tyr Asp Pro Lys Phe Gln Gly Lys Ala Lys Ile Leu Ala Asp ThrSer Ser Asn Thr Ala Tyr Leu Gln Leu Ile Gly Leu Thr Ser Glu Asp Thr Ala ValTyr Tyr Cys Ala Ser Arg Ala Leu Gly Asn Gly Tyr Ala Met Asp Tyr Trp Gly GlnGly Thr Ser Val Thr Val Ser Ser
SEQ ID NO:224
Glu Val Pro Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala ThrVal Lys Ile Ser Cys Lys Pro Ser Gly Asp Thr Phe Thr Glu Tyr Thr Met Asn TrpVal Arg Gln Ser His Gly Lys Ser Leu Glu Trp Ile Gly Gly Ile Asn Pro Asn AsnGly Glu Thr Ser Tyr Asn Gln Lys Phe Lys Gly Lys Ala Thr Leu Thr Val Asp LysSer Ser Ser Thr Ala Phe Met Asp Leu Arg Ile Leu Thr Ser Glu Asp Ser Ala ValTyr Phe Cys Ala Arg Lys Thr Thr Asn Tyr Trp Gly Gln Gly Thr Thr Leu Ile ValSer Ser
SEQ ID NO:225
Gln Ile Gln Leu Gln Gln Ser Gly Ala Glu Leu Met Lys Pro Gly Ala SerVal Arg Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Ser Ser Tyr Trp Ile Glu TrpVal Lys Gln Arg Ser Gly His Gly Leu Glu Trp Ile Gly Glu Ile Phe Pro Gly GlyGly Ser Thr Ile Tyr Asn Glu Asn Phe Arg Asp Lys Ala Thr Phe Thr Ala Asp ThrSer Ser Asn Thr Ala Tyr Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala ValTyr Phe Cys Ala Arg Arg Gly Tyr Tyr Asp Ala Ala Trp Phe Asp Tyr Trp Gly GlnGly Thr Leu Val Thr Val Ser Ala
SEQ ID NO:226
Gln Val Gln Leu Lys Gln Ser Gly Ala Glu Leu Val Arg Pro Gly Thr SerVal Thr Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asp Tyr Glu Met His TrpMet Lys Gln Thr Pro Val Tyr Gly Leu Glu Trp Ile Gly Ala Ile Trp Pro Glu AsnAla Asp Ser Val Tyr Asn Gln Lys Phe Lys Gly Lys Val Thr Leu Thr Ala Asp LysSer Ser Ser Thr Ala Tyr Met Asp Leu Arg Ser Leu Thr Ser Glu Asp Ser Ala ValTyr Tyr Cys Thr Arg Glu Gly Gly Asn Tyr Trp Gly Gln Gly Thr Thr Leu Thr ValSer Ser
SEQ ID NO:227
Glu Val Gln Leu Gln Gln Ser Gly Thr Glu Leu Val Arg Pro Gly Ala SerVal Lys Leu Ser Cys Thr Ser Ser Asp Phe Asn Ile Lys Asp Thr Tyr Ile His TrpVal Lys Gln Arg Pro Glu Gln Gly Leu Asp Trp Leu Gly Arg Ile Asp Pro Ala AsnGly Asn Thr Lys Tyr Asp Pro Lys Phe Gln Gly Lys Ala Ala Met Thr Ser Asp ThrSer Ser Asn Thr Ala Tyr Leu Arg Leu Ser Ser Leu Thr Ser Glu Asp Thr Ala ValTyr Tyr Cys Ala Ser Ser Gly Asn Tyr Gly Ala Met Asp Tyr Trp Gly Gln Gly ThrSer Val Thr Val Ser Ser
SEQ ID NO:228
Gln Val Gln Leu Gln Gln Ser Gly Asp Glu Leu Met Lys Pro Gly Ala SerVal Lys Ile Ser Cys Lys Val Thr Gly Asn Thr Phe Ser Ser Tyr Trp Ile Glu TrpVal Lys Gln Arg Pro Gly His Gly Leu Glu Trp Ile Gly Glu Ile Leu Pro Gly SerAsp Ser Thr Lys Tyr Val Glu Lys Phe Lys Val Lys Ala Thr Phe Thr Ala Asp ThrSer Ser Asn Thr Ala Tyr Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala ValTyr Tyr Cys Ala Arg Gly Gly Tyr His Tyr Pro Gly Trp Leu Val Tyr Trp Gly GlnGly Thr Leu Val Thr Val Ser Ala
SEQ ID NO:229
Glu Val Lys Phe Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly SerLeu Arg Leu Ser Cys Ala Val Ser Gly Ile Asp Phe Ser Arg Tyr Trp Met Ser TrpVal Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Ile Gly Glu Ile Ser Pro Asp SerSer Thr Ile Asn Tyr Thr Pro Ser Leu Lys Asp Lys Phe Val Ile Ser Arg Asp AsnAla Lys Asn Thr Leu Tyr Leu Gln Met Ser Lys Val Arg Ser Ala Asp Thr Ala LeuTyr Tyr Cys Ala Arg Pro Ser Pro Ala Leu Asp Tyr Trp Gly Gln Gly Thr Leu ValThr Val Ser Ala
SEQ ID NO:230
Gln Ile Gln Leu Val Gln Ser Gly Pro Glu Leu Lys Lys Pro Gly Glu ThrAla Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ala Phe Ser Asn Tyr Gly Met Asn TrpVal Lys Gln Ala Pro Gly Lys Asp Leu Lys Trp Met Gly Trp Ile Asp Thr Asp ThrGly Glu Ala Thr Tyr Thr Asp Asp Phe Lys Gly Arg Phe Val Phe Ser Leu Glu ThrSer Ala Ser Thr Ala Tyr Leu Gln Ile Asn Asn Leu Lys Asn Glu Asp Met Ala ThrTyr Phe Cys Ala Arg Glu Glu Tyr Gly Leu Phe Gly Phe Pro Tyr Trp Gly His GlyThr Leu Val Thr Val Ser Ala
SEQ ID NO:231
Gln Val Thr Leu Lys Glu Ser Gly Pro Gly Ile Leu Gln Pro Ser Gln ThrLeu Ser Leu Thr Cys Ser Phe Ser Gly Phe Ser Leu Ser Thr Ser Ala Met Gly IleGly Trp Ile Arg Gln Pro Ser Gly Lys Gly Leu Glu Trp Leu Ala His Ile Trp TrpAsp Asp Asp Lys Arg Tyr Asn Pro Ala Leu Lys Ser Arg Leu Thr Ile Ser Lys AspThr Ser Arg Asn Gln Val Phe Leu Lys Ile Ala Ser Val Asp Thr Ala Asp Thr AlaThr Tyr Phe Cys Ala Arg Ile Asp Gly Ile Tyr Asp Gly Ser Phe Tyr Ala Met AspTyr Trp Gly Gln Gly Thr Ser Val Thr Val Ser Ser
SEQ ID NO:232
Gln Val Gln Leu Lys Gln Ser Gly Pro Gly Leu Val Gln Pro Ser Gln SerLeu Ser Val Ala Cys Thr Val Ser Asp Phe Ser Leu Thr Thr Tyr Gly Val His TrpVal Arg Gln Ser Pro Gly Lys Gly Leu Glu Trp Leu Gly Val Ile Trp Ser Gly GlySer Thr Asp Tyr Asn Ala Ala Phe Ile Ser Arg Leu Thr Ile Ser Lys Asp Asn SerLys Ser Gln Val Phe Phe Lys Met Asn Ser Leu Gln Thr Thr Asp Thr Ala Ile TyrTyr Cys Ala Arg Asp Tyr Gly Ser Thr Tyr Val Asp Ala Ile Asp Tyr Trp Gly GlnGly Thr Ser Val Thr Val Ser Ser
SEQ ID NO:233
Phe Ser Gly Asp Gly Arg Ala Ile Trp Ser Lys Asn Pro Asn Phe Thr ProVal Asn Glu Ser Gln Leu Phe Leu Tyr Asp Thr Phe Pro Lys Asn Phe Phe Trp GlyIle Gly Thr Gly Ala Leu Gln Val Glu Gly Ser Trp Lys Lys Asp Gly Lys Gly ProSer Ile Trp Asp His Phe Ile His Thr His Leu Lys Asn Val Ser Ser Thr Asn GlySer Ser Asp Ser Tyr Ile Phe Leu Glu Lys Asp Leu Ser Ala Leu Asp Phe Ile GlyVal Ser Phe Tyr Gln Phe Ser Ile Ser Trp Pro Arg Leu Phe Pro Asp Gly Ile ValThr Val Ala Asn Ala Lys Gly Leu Gln Tyr Tyr Ser Thr Leu Leu Asp Ala Leu ValLeu Arg Asn Ile Glu Pro Ile Val Thr Leu Tyr His Trp Asp Leu Pro Leu Ala LeuGln Glu Lys Tyr Gly Gly Trp Lys Asn Asp Thr Ile Ile Asp Ile Phe Asn Asp TyrAla Thr Tyr Cys Phe Gln Met Phe Gly Asp Arg Val Lys Tyr Trp Ile Thr Ile HisAsn Pro Tyr Leu Val Ala Trp His Gly Tyr Gly Thr Gly Met His Ala Pro Gly GluLys Gly Asn Leu Ala Ala Val Tyr Thr Val Gly His Asn Leu Ile Lys Ala His SerLys Val Trp His Asn Tyr Asn Thr His Phe Arg Pro His Gln Lys Gly Trp Leu SerIle Thr Leu Gly Ser His Trp Ile Glu Pro Asn Arg Ser Glu Asn Thr Met Asp IlePhe Lys Cys Gln Gln Ser Met Val Ser Val Leu Gly Trp Phe Ala Asn Pro Ile HisGly Asp Gly Asp Tyr Pro Glu Gly Met Arg Lys Lys Leu Phe Ser Val Leu Pro IlePhe Ser Glu Ala Glu Lys His Glu Met Arg Gly Thr Ala Asp Phe Phe Ala Phe SerPhe Gly Pro Asn Asn Phe Lys Pro Leu Asn Thr Met Ala Lys Met Gly Gln Asn ValSer Leu Asn Leu Arg Glu Ala Leu Asn Trp Ile Lys Leu Glu Tyr Asn Asn Pro ArgIle Leu Ile Ala Glu Asn Gly Trp Phe Thr Asp Ser Arg Val Lys Thr Glu Asp ThrThr Ala Ile Tyr Met Met Lys Asn Phe Leu Ser Gln Val Leu Gln Ala Ile Arg LeuAsp Glu Ile Arg Val Phe Gly Tyr Thr Ala Trp Ser Leu Leu Asp Gly Phe Glu TrpGln Asp Ala Tyr Thr Ile Arg Arg Gly Leu Phe Tyr Val Asp Phe Asn Ser Lys GlnLys Glu Arg Lys Pro Lys Ser Ser Ala His Tyr Tyr Lys Gln Ile Ile Arg Glu AsnGly Phe Ser Leu Lys Glu Ser Thr Pro Asp Val Gln Gly Gln Phe Pro Cys Asp PheSer Trp Gly Val Thr Glu Ser Val Leu Lys Pro Glu Ser Val Ala Ser Ser Pro GlnPhe Ser Asp Pro His Leu Tyr Val Trp Asn Ala Thr Gly Asn Arg Leu Leu His ArgVal Glu Gly Val Arg Leu Lys Thr Arg Pro Ala Gln Cys Thr Asp Phe Val Asn IleLys Lys Gln Leu Glu Met Leu Ala Arg Met Lys Val Thr His Tyr Arg Phe Ala LeuAsp Trp Ala Ser Val Leu Pro Thr Gly Asn Leu Ser Ala Val Asn Arg Gln Ala LeuArg Tyr Tyr Arg Cys Val Val Ser Glu Gly Leu Lys Leu Gly Ile Ser Ala Met ValThr Leu Tyr Tyr Pro Thr His Ala His Leu Gly Leu Pro Glu Pro Leu Leu His AlaAsp Gly Trp Leu Asn Pro Ser Thr Ala Glu Ala Phe Gln Ala Tyr Ala Gly Leu CysPhe Gln Glu Leu Gly Asp Leu Val Lys Leu Trp Ile Thr Ile Asn Glu Pro Asn ArgLeu Ser Asp Ile Tyr Asn Arg Ser Gly Asn Asp Thr Tyr Gly Ala Ala His Asn LeuLeu Val Ala His Ala Leu Ala Trp Arg Leu Tyr Asp Arg Gln Phe Arg Pro Ser GlnArg Gly Ala Val Ser Leu Ser Leu His Ala Asp Trp Ala Glu Pro Ala Asn Pro TyrAla Asp Ser His Trp Arg Ala Ala Glu Arg Phe Leu Gln Phe Glu Ile Ala Trp PheAla Glu Pro Leu Phe Lys Thr Gly Asp Tyr Pro Ala Ala Met Arg Glu Tyr Ile AlaSer Lys His Arg Arg Gly Leu Ser Ser Ser Ala Leu Pro Arg Leu Thr Glu Ala GluArg Arg Leu Leu Lys Gly Thr Val Asp Phe Cys Ala Leu Asn His Phe Thr Thr ArgPhe Val Met His Glu Gln Leu Ala Gly Ser Arg Tyr Asp Ser Asp Arg Asp Ile GlnPhe Leu Gln Asp Ile Thr Arg Leu Ser Ser Pro Thr Arg Leu Ala Val Ile Pro TrpGly Val Arg Lys Leu Leu Arg Trp Val Arg Arg Asn Tyr Gly Asp Met Asp Ile TyrIle Thr Ala Ser Gly Ile Asp Asp Gln Ala Leu Glu Asp Asp Arg Leu Arg Lys TyrTyr Leu Gly Lys Tyr Leu Gln Glu Val Leu Lys Ala Tyr Leu Ile Asp Lys Val ArgIle Lys Gly Tyr Tyr Ala Phe Lys Leu Ala Glu Glu Lys Ser Lys Pro Arg Phe GlyPhe Phe Thr Ser Asp Phe Lys Ala Lys Ser Ser Ile Gln Phe Tyr Asn Lys Val IleSer Ser Arg Gly Phe Pro Phe Glu Asn Ser Ser Ser Arg Cys Ser Gln Thr Gln GluAsn Thr Glu Cys Thr Val Cys Leu Phe Leu Val Gln Lys Lys Pro Leu Ile Phe LeuGly Cys Cys Phe Phe Ser Thr Leu Val Leu Leu Leu Ser Ile Ala Ile Phe Gln ArgGln Lys Arg Arg Lys Phe Trp Lys Ala Lys Asn Leu Gln His Ile Pro Leu Lys LysGly Lys Arg Val Val Ser
SEQ ID NO:234
Met Lys Pro Gly Cys Ala Ala Gly Ser Pro Gly Asn Glu Trp Ile Phe PheSer Thr Asp Glu Ile Thr Thr Arg Tyr Arg Asn Thr Met Ser Asn Gly Gly Leu GlnArg Ser Val Ile Leu Ser Ala Leu Ile Leu Leu Arg Ala Val Thr Gly
SEQ ID NO:235
Phe Pro Cys Asp Phe Ser Trp Gly Val Thr Glu Ser Val Leu Lys Pro GluSer Val Ala Ser Ser Pro Gln Phe Ser Asp Pro His Leu Tyr Val Trp Asn Ala ThrGly Asn Arg Leu Leu His Arg Val Glu Gly Val Arg Leu Lys Thr Arg Pro Ala GlnCys Thr Asp Phe Val Asn Ile Lys Lys Gln Leu Glu Met Leu Ala Arg Met Lys ValThr His Tyr Arg Phe Ala Leu Asp Trp Ala Ser Val Leu Pro Thr Gly Asn Leu SerAla Val Asn Arg Gln Ala Leu Arg Tyr Tyr Arg Cys Val Val Ser Glu Gly Leu LysLeu Gly Ile Ser Ala Met Val Thr Leu Tyr Tyr Pro Thr His Ala His Leu Gly LeuPro Glu Pro Leu Leu His Ala Asp Gly Trp Leu Asn Pro Ser Thr Ala Glu Ala PheGln Ala Tyr Ala Gly Leu Cys Phe Gln Glu Leu Gly Asp Leu Val Lys Leu Trp IleThr Ile Asn Glu Pro Asn Arg Leu Ser Asp Ile Tyr Asn Arg Ser Gly Asn Asp ThrTyr Gly Ala Ala His Asn Leu Leu Val Ala His Ala Leu Ala Trp Arg Leu Tyr AspArg Gln Phe Arg Pro Ser Gln Arg Gly Ala Val Ser Leu Ser Leu His Ala Asp TrpAla Glu Pro Ala Asn Pro Tyr Ala Asp Ser His Trp Arg Ala Ala Glu Arg Phe LeuGln Phe Glu Ile Ala Trp Phe Ala Glu Pro Leu Phe Lys Thr Gly Asp Tyr Pro AlaAla Met Arg Glu Tyr Ile Ala Ser Lys His Arg Arg Gly Leu Ser Ser Ser Ala LeuPro Arg Leu Thr Glu Ala Glu Arg Arg Leu Leu Lys Gly Thr Val Asp Phe Cys AlaLeu Asn His Phe Thr Thr Arg Phe Val Met His Glu Gln Leu Ala Gly Ser Arg TyrAsp Ser Asp Arg Asp Ile Gln Phe Leu Gln Asp Ile Thr Arg Leu Ser Ser Pro ThrArg Leu Ala Val Ile Pro Trp Gly Val Arg Lys Leu Leu Arg Trp Val Arg Arg AsnTyr Gly Asp Met Asp Ile Tyr Ile Thr Ala Ser Gly Ile Asp Asp Gln Ala Leu GluAsp Asp Arg Leu Arg Lys Tyr Tyr Leu Gly Lys Tyr Leu Gln Glu Val Leu Lys AlaTyr Leu Ile Asp Lys Val Arg Ile Lys Gly Tyr Tyr Ala Phe Lys Leu Ala Glu GluLys Ser Lys Pro Arg Phe Gly Phe Phe Thr Ser Asp Phe Lys Ala Lys Ser Ser IleGln Phe Tyr Asn Lys Val Ile Ser Ser Arg Gly Phe Pro Phe Glu Asn Ser Ser SerArg
SEQ ID NO:236
Asp Ile Gln Met Thr Gln Thr Thr Ser Ser Leu Ser Ala Ser Leu Gly AspArg Val Thr Ile Ile Cys Ser Ala Ser Gln Val Ile Ser Asn Tyr Leu Asn Trp TyrGln Gln Lys Pro Asp Gly Thr Val Lys Leu Leu Ile Tyr Phe Thr Ser Ser Leu ArgSer Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Tyr Ser Leu ThrIle Ser Asn Leu Glu Pro Glu Asp Val Ala Thr Tyr Phe Cys Gln Gln Tyr Ser LysLeu Pro Trp Thr Phe Gly Gly Gly Thr Lys Leu Glu Leu Lys
SEQ ID NO:237
Glu Asn Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro GlyGluLys Val Thr Met Thr Cys Ser Ala Ser Ser Ser Gly Arg Tyr Thr Phe Trp Tyr GlnGln Lys Ser Asn Thr Ala Pro Lys Leu Trp Ile Tyr Asp Thr Ser Lys Leu Ala SerGly Val Pro Gly Arg Phe Ser Gly Ser Gly Ser Gly Asn Ser Tyr Ser Leu Thr IleSer Ser Met Glu Ala Glu Asp Val Ala Thr Tyr Tyr Cys Phe Gln Gly Thr Gly TyrPro Leu Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys
SEQ ID NO:238
Asp Ile Gln Met Thr Gln Thr Pro Ser Ser Leu Ser Ala Ser Leu Gly AspArg Val Thr Ile Asn Cys Arg Ala Ser Gln Asp Ile Ser Asn Tyr Phe Asn Trp TyrGln Gln Lys Pro Asn Gly Thr Ile Lys Leu Leu Ile Tyr Tyr Thr Ser Arg Leu GlnSer Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Tyr Ser Leu ThrIle Ser Asn Leu Glu Gln Glu Asp Lys Ala Thr Tyr Phe Cys His Gln Val Arg ThrLeu Pro Trp Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
SEQ ID NO:239
Asp Ile Gln Met Thr Gln Ser Ser Ser Tyr Leu Ser Val Ser Leu Gly GlySer Val Thr Ile Thr Cys Lys Ala Ser Asp His Ile Asn Asn Trp Leu Ala Trp TyrGln Gln Lys Pro Gly Asn Ala Pro Arg Leu Leu Ile Tyr Gly Thr Thr Asn Leu GluThr Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Arg Asp Tyr Ile Leu SerIle Thr Ser Leu Gln Ser Glu Asp Val Ala Ser Tyr Tyr Cys Gln Gln Tyr Trp AsnThr Pro Phe Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys
SEQ ID NO:240
Ala Val Leu Met Thr Gln Thr Pro Leu Ser Leu Pro Val Ser Leu Gly AspGln Ala Ser Ile Ser Cys Arg Ser Ser Gln Asn Ile Val His Ser Asp Gly Asn ThrTyr Leu Glu Trp Tyr Leu Gln Lys Pro Gly Gln Ser Pro Lys Leu Leu Ile Tyr LysVal Ser Asn Arg Phe Ser Gly Val Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly ArgAsp Phe Thr Leu Lys Ile Ser Arg Val Glu Ala Gly Asp Leu Gly Val Tyr Tyr CysPhe Gln GlySer His Val Leu Thr Phe Gly Ala Gly Thr Arg Leu Glu Leu Lys
SEQ ID NO:241
Asp Ile Val Met Thr Gln Ser Gln Lys Phe Met Ser Thr Ser Val Gly AspArg Val Ser Ile Thr Cys Lys Ala Ser Gln Phe Val Ser Asp Ala Val Ala Trp TyrGln Gln Lys Pro Gly Gln Ser Pro Lys Leu Leu Ile Cys Ser Ala Ser Tyr Arg TyrThr Gly Val Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Phe ThrIle Ser Ser Val Arg Thr Glu Asp Leu Ala Val Tyr Tyr Cys Gln Gln His Tyr IleVal Pro Tyr Thr Phe Gly Gly Gly Thr Thr Leu Glu Ile Glu
SEQ ID NO:242
Asp Ile Val Met Thr Gln Ser Gln Lys Phe Met Ser Thr Ser Val Gly AspArg Val Ser Ile Thr Cys Lys Ala Ser Gln Phe Val Ser Asp Ala Val Ala Trp TyrGln Gln Lys Pro Gly Gln Ser Pro Lys Leu Leu Ile Cys Ser Ala Ser Tyr Arg TyrThr Gly Val Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Phe ThrIle Ser Ser Val Arg Thr Glu Asp Leu Ala Val Tyr Tyr Cys Gln Gln His Tyr IleVal Pro Tyr Thr Phe Gly Gly Gly Thr Thr Leu Glu Ile Glu
SEQ ID NO:243
Asp Ile Gln Met Thr Gln Ser Ser Ser Tyr Leu Ser Val Ser Leu Gly GlyArg Val Thr Ile Thr Cys Lys Ala Ser Asp His Ile Asn Asn Trp Leu Ala Trp TyrGln Gln Lys Pro Gly Asn Ala Pro Arg Leu Leu Ile Ser Gly Ala Ser Asn Leu GluThr Gly Ile Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Lys Asp Tyr Thr Leu ThrIle Thr Ser Leu Gln Thr Glu Asp Val Ala Thr Tyr Tyr Cys Gln Gln Tyr Trp AsnThr Pro Phe Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys
SEQ ID NO:244
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Leu Gly GluArg Val Ser Leu Thr Cys Arg Ala Ser Gln Glu Ile Ser Gly Tyr Leu Ser Trp LeuGln Gln Lys Pro Asp Gly Thr Ile Lys Arg Leu Ile Tyr Ala Ala Ser Thr Leu AspSer Gly Val Pro Arg Arg Phe Ser Gly Ser Arg Ser Gly Ser Asp Tyr Ser Leu ThrIle Ser Ser Leu Glu Ser Glu Asp Phe Ala Asp Tyr Tyr Cys Leu Gln Tyr Gly SerTyr Pro Trp Thr Phe Gly Gly Gly Thr Lys Leu Glu Leu Lys
SEQ ID NO:245
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly GluArg Val Thr Leu Thr Cys Ser Ala Ser Ser Ser Leu Ser Ser Ser Tyr Leu Tyr TrpTyr Gln Gln Lys Pro Gly Ser Ser Pro Lys Leu Trp Ile Tyr Gly Ala Ser Asn LeuAla Ser Gly Val Pro Gly Arg Phe Ser Gly Ser Gly Ser Gly Thr Ser Tyr Ser LeuThr Ile Ser Ser Met Glu Ala Glu Asp Ala Ala Ser Tyr Phe Cys His Gln Trp SerSer Tyr Pro Leu Thr Phe Gly Ser Gly Thr Lys Leu Glu Leu Lys
SEQ ID NO:246
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Pro Met Ser Val Gly GlnLys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Asn Ser Gly Asn Gln LysAsn Ser Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ser Pro Lys Leu Leu Val TyrLeu Ala Ser Thr Arg Glu Ser Gly Val Pro Asp Arg Phe Ile Gly Ser Gly Ser GlyThr Asp Phe Thr Leu Thr Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Asp Tyr PheCys Gln Gln His His Ser Thr Pro Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu LeuLys
SEQ ID NO:247
Glu Ser Val Leu Thr Gln Ser Pro Ala Leu Met Ser Ala Ser Leu Gly GluLys Val Thr Met Thr Cys Arg Ala Ser Ser Ser Val Asn His Met Tyr Trp Tyr GlnGln Lys Ser Asp Ala Ser Pro Lys Leu Trp Ile Tyr Tyr Thr Ser Thr Leu Ala ProGly Val Pro Ala Arg Phe Ser Gly Ser Gly Ser Gly Asn Ser Tyr Ser Leu Thr IleSer Ser Met Glu Gly Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Phe Thr Ile SerPro Ser Met Tyr Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
SEQ ID NO:248
Gly Thr Asp Val Met Asp Tyr
SEQ ID NO:249
Arg Ala Ser Gln Asp Val Ser Thr Ala Val Ala
SEQ ID NO:250
Ser Ala Ser Phe Leu Tyr Ser
SEQ ID NO:251
Gln Gln Ser Tyr Thr Thr Pro Pro Thr
SEQ ID NO:252
Lys Leu His Ala Val Pro Ala Ala Lys Thr Val Lys Phe Lys Cys Pro
SEQ ID NO:253
Phe Lys Pro Asp His Arg Ile Gly Gly Tyr Lys Val Arg Tyr
SEQ ID NO:254
Phe Ser Gly Asp Gly Arg Ala Ile Trp Ser Lys Asn Pro Asn Phe Thr ProVal Asn Glu Ser Gln Leu Phe Leu Tyr Asp Thr Phe Pro Lys Asn Phe Phe Trp GlyIle Gly Thr Gly Ala Leu Gln Val Glu Gly Ser Trp Lys Lys Asp Gly Lys Gly ProSer Ile Trp Asp His Phe Ile His Thr His Leu Lys Asn Val Ser Ser Thr Asn GlySer Ser Asp Ser Tyr Ile Phe Leu Glu Lys Asp Leu Ser Ala Leu Asp Phe Ile GlyVal Ser Phe Tyr Gln Phe Ser Ile Ser Trp Pro Arg Leu Phe Pro Asp Gly Ile ValThr Val Ala Asn Ala Lys Gly Leu Gln Tyr Tyr Ser Thr Leu Leu Asp Ala Leu ValLeu Arg Asn Ile Glu Pro Ile Val Thr Leu Tyr His Trp Asp Leu Pro Leu Ala LeuGln Glu Lys Tyr Gly Gly Trp Lys Asn Asp Thr Ile Ile Asp Ile Phe Asn Asp TyrAla Thr Tyr Cys Phe Gln Met Phe Gly Asp Arg Val Lys Tyr Trp Ile Thr Ile HisAsn Pro Tyr Leu Val Ala Trp His Gly Tyr Gly Thr Gly Met His Ala Pro Gly GluLys Gly Asn Leu Ala Ala Val Tyr Thr Val Gly His Asn Leu Ile Lys Ala His SerLys Val Trp His Asn Tyr Asn Thr His Phe Arg Pro His Gln Lys Gly Trp Leu SerIle Thr Leu Gly Ser His Trp Ile Glu Pro Asn Arg Ser Glu Asn Thr Met Asp IlePhe Lys Cys Gln Gln Ser Met Val Ser Val Leu Gly Trp Phe Ala Asn Pro Ile HisGly Asp Gly Asp Tyr Pro Glu Gly Met Arg Lys Lys Leu Phe Ser Val Leu Pro IlePhe Ser Glu Ala Glu Lys His Glu Met Arg Gly Thr Ala Asp Phe Phe Ala Phe SerPhe Gly Pro Asn Asn Phe Lys Pro Leu Asn Thr Met Ala Lys Met Gly Gln Asn ValSer Leu Asn Leu Arg Glu Ala Leu Asn Trp Ile Lys Leu Glu Tyr Asn Asn Pro ArgIle Leu Ile Ala Glu Asn Gly Trp Phe Thr Asp Ser Arg Val Lys Thr Glu Asp ThrThr Ala Ile Tyr Met Met Lys Asn Phe Leu Ser Gln Val Leu Gln Ala Ile Arg LeuAsp Glu Ile Arg Val Phe Gly Tyr Thr Ala Trp Ser Leu Leu Asp Gly Phe Glu TrpGln Asp Ala Tyr Thr Ile Arg Arg Gly Leu Phe Tyr Val Asp Phe Asn Ser Lys GlnLys Glu Arg Lys Pro Lys Ser Ser Ala His Tyr Tyr Lys Gln Ile Ile Arg Glu AsnGly Phe Ser Leu Lys Glu Ser Thr Pro Asp Val Gln Gly Gln Phe Pro Cys Asp PheSer Trp Gly Val Thr Glu Ser Val Leu Lys Pro Glu Ser Val Ala Ser Ser Pro GlnPhe Ser Asp Pro His Leu Tyr Val Trp Asn Ala Thr Gly Asn Arg Leu Leu His ArgVal Glu Gly Val Arg Leu Lys Thr Arg Pro Ala Gln Cys Thr Asp Phe Val Asn IleLys Lys Gln Leu Glu Met Leu Ala Arg Met Lys Val Thr His Tyr Arg Phe Ala LeuAsp Trp Ala Ser Val Leu Pro Thr Gly Asn Leu Ser Ala Val Asn Arg Gln Ala LeuArg Tyr Tyr Arg Cys Val Val Ser Glu Gly Leu Lys Leu Gly Ile Ser Ala Met ValThr Leu Tyr Tyr Pro Thr His Ala His Leu Gly Leu Pro Glu Pro Leu Leu His AlaAsp Gly Trp Leu Asn Pro Ser Thr Ala Glu Ala Phe Gln Ala Tyr Ala Gly Leu CysPhe Gln Glu Leu Gly Asp Leu Val Lys Leu Trp Ile Thr Ile Asn Glu Pro Asn ArgLeu Ser Asp Ile Tyr Asn Arg Ser Gly Asn Asp Thr Tyr Gly Ala Ala His Asn LeuLeu Val Ala His Ala Leu Ala Trp Arg Leu Tyr Asp Arg Gln Phe Arg Pro Ser GlnArg Gly Ala Val Ser Leu Ser Leu His Ala Asp Trp Ala Glu Pro Ala Asn Pro TyrAla Asp Ser His Trp Arg Ala Ala Glu Arg Phe Leu Gln Phe Glu Ile Ala Trp PheAla Glu Pro Leu Phe Lys Thr Gly Asp Tyr Pro Ala Ala Met Arg Glu Tyr Ile AlaSer Lys His Arg Arg Gly Leu Ser Ser Ser Ala Leu Pro Arg Leu Thr Glu Ala GluArg Arg Leu Leu Lys Gly Thr Val Asp Phe Cys Ala Leu Asn His Phe Thr Thr ArgPhe Val Met His Glu Gln Leu Ala Gly Ser Arg Tyr Asp Ser Asp Arg Asp Ile GlnPhe Leu Gln Asp Ile Thr Arg Leu Ser Ser Pro Thr Arg Leu Ala Val Ile Pro TrpGly Val Arg Lys Leu Leu Arg Trp Val Arg Arg Asn Tyr Gly Asp Met Asp Ile TyrIle Thr Ala Ser Gly Ile Asp Asp Gln Ala Leu Glu Asp Asp Arg Leu Arg Lys TyrTyr Leu Gly Lys Tyr Leu Gln Glu Val Leu Lys Ala Tyr Leu Ile Asp Lys Val ArgIle Lys Gly Tyr Tyr Ala Phe Lys Leu Ala Glu Glu Lys Ser Lys Pro Arg Phe GlyPhe Phe Thr Ser Asp Phe Lys Ala Lys Ser Ser Ile Gln Phe Tyr Asn Lys Val IleSer Ser Arg Gly Phe Pro Phe Glu Asn Ser Ser Ser Arg Cys Ser Gln Thr Gln GluAsn Thr Glu Cys Thr Val Cys Leu Phe Leu Val Gln Lys Lys Pro Leu Ile Phe LeuGly Cys Cys Phe Phe Ser Thr Leu Val Leu Leu Leu Ser Ile Ala Ile Phe Gln ArgGln Lys Arg Arg Lys Phe Trp Lys Ala Lys Asn Leu Gln His Ile Pro Leu Lys LysGly Lys Arg Val Val Ser
SEQ ID NO:255
Met Trp Ser Trp Lys Cys Leu Leu Phe Trp Ala Val Leu Val Thr Ala ThrLeu Cys Thr Ala Arg Pro Ser Pro Thr Leu Pro Glu Gln Ala Gln Pro Trp Gly AlaPro Val Glu Val Glu Ser Phe Leu Val His Pro Gly Asp Leu Leu Gln Leu Arg CysArg Leu Arg Asp Asp Val Gln Ser Ile Asn Trp Leu Arg Asp Gly Val Gln Leu AlaGlu Ser Asn Arg Thr Arg Ile Thr Gly Glu Glu Val Glu Val Gln Asp Ser Val ProAla Asp Ser Gly Leu Tyr Ala Cys Val Thr Ser Ser Pro Ser Gly Ser Asp Thr ThrTyr Phe Ser Val Asn Val Ser Asp Ala Leu Pro Ser Ser Glu Asp Asp Asp Asp AspAsp Asp Ser Ser Ser Glu Glu Lys Glu Thr Asp Asn Thr Lys Pro Asn Pro Val AlaPro Tyr Trp Thr Ser Pro Glu Lys Met Glu Lys Lys Leu His Ala Val Pro Ala AlaLys Thr Val Lys Phe Lys Cys Pro Ser Ser Gly Thr Pro Asn Pro Thr Leu Arg TrpLeu Lys Asn Gly Lys Glu Phe Lys Pro Asp His Arg Ile Gly Gly Tyr Lys Val ArgTyr Ala Thr Trp Ser Ile Ile Met Asp Ser Val Val Pro Ser Asp Lys Gly Asn TyrThr Cys Ile Val Glu Asn Glu Tyr Gly Ser Ile Asn His Thr Tyr Gln Leu Asp ValVal Glu Arg Ser Pro His Arg Pro Ile Leu Gln Ala Gly Leu Pro Ala Asn Lys ThrVal Ala Leu Gly Ser Asn Val Glu Phe Met Cys Lys Val Tyr Ser Asp Pro Gln ProHis Ile Gln Trp Leu Lys His Ile Glu Val Asn Gly Ser Lys Ile Gly Pro Asp AsnLeu Pro Tyr Val Gln Ile Leu Lys Thr Ala Gly Val Asn Thr Thr Asp Lys Glu MetGlu Val Leu His Leu Arg Asn Val Ser Phe Glu Asp Ala Gly Glu Tyr Thr Cys LeuAla Gly Asn Ser Ile Gly Leu Ser His His Ser Ala Trp Leu Thr Val Leu Glu AlaLeu Glu Glu Arg Pro Ala Val Met Thr Ser Pro Leu Tyr Leu Glu Ile Ile Ile TyrCys Thr Gly Ala Phe Leu Ile Ser Cys Met Val Gly Ser Val Ile Val Tyr Lys MetLys Ser Gly Thr Lys Lys Ser Asp Phe His Ser Gln Met Ala Val His Lys Leu AlaLys Ser Ile Pro Leu Arg Arg Gln Val Thr Val Ser Ala Asp Ser Ser Ala Ser MetAsn Ser Gly Val Leu Leu Val Arg Pro Ser Arg Leu Ser Ser Ser Gly Thr Pro MetLeu Ala Gly Val Ser Glu Tyr Glu Leu Pro Glu Asp Pro Arg Trp Glu Leu Pro ArgAsp Arg Leu Val Leu Gly Lys Pro Leu Gly Glu Gly Cys Phe Gly Gln Val Val LeuAla Glu Ala Ile Gly Leu Asp Lys Asp Lys Pro Asn Arg Val Thr Lys Val Ala ValLys Met Leu Lys Ser Asp Ala Thr Glu Lys Asp Leu Ser Asp Leu Ile Ser Glu MetGlu Met Met Lys Met Ile Gly Lys His Lys Asn Ile Ile Asn Leu Leu Gly Ala CysThr Gln Asp Gly Pro Leu Tyr Val Ile Val Glu Tyr Ala Ser Lys Gly Asn Leu ArgGlu Tyr Leu Gln Ala Arg Arg Pro Pro Gly Leu Glu Tyr Cys Tyr Asn Pro Ser HisAsn Pro Glu Glu Gln Leu Ser Ser Lys Asp Leu Val Ser Cys Ala Tyr Gln Val AlaArg Gly Met Glu Tyr Leu Ala Ser Lys Lys Cys Ile His Arg Asp Leu Ala Ala ArgAsn Val Leu Val Thr Glu Asp Asn Val Met Lys Ile Ala Asp Phe Gly Leu Ala ArgAsp Ile His His Ile Asp Tyr Tyr Lys Lys Thr Thr Asn Gly Arg Leu Pro Val LysTrp Met Ala Pro Glu Ala Leu Phe Asp Arg Ile Tyr Thr His Gln Ser Asp Val TrpSer Phe Gly Val Leu Leu Trp Glu Ile Phe Thr Leu Gly Gly Ser Pro Tyr Pro GlyVal Pro Val Glu Glu Leu Phe Lys Leu Leu Lys Glu Gly His Arg Met Asp Lys ProSer Asn Cys Thr Asn Glu Leu Tyr Met Met Met Arg Asp Cys Trp His Ala Val ProSer Gln Arg Pro Thr Phe Lys Gln Leu Val Glu Asp Leu Asp Arg Ile Val Ala LeuThr Ser Asn Gln Glu Tyr Leu Asp Leu Ser Met Pro Leu Asp Gln Tyr Ser Pro SerPhe Pro Asp Thr Arg Ser Ser Thr Cys Ser Ser Gly Glu Asp Ser Val Phe Ser HisGlu Pro Leu Pro Glu Glu Pro Cys Leu Pro Arg His Pro Ala Gln Leu Ala Asn GlyGly Leu Lys Arg Arg
SEQ ID NO:256
Asp Tyr Lys Asp Asp Asp Asp Lys Leu Glu Phe Ser Gly Asp Gly Lys AlaIle Trp Asp Lys Lys Gln Tyr Val Ser Pro Val Asn Pro Gly Gln Leu Phe Leu TyrAsp Thr Phe Pro Lys Asn Phe Ser Trp Gly Val Gly Thr Gly Ala Phe Gln Val GluGly Ser Trp Lys Ala Asp Gly Arg Gly Pro Ser Ile Trp Asp Arg Tyr Val Asp SerHis Leu Arg Gly Val Asn Ser Thr Asp Arg Ser Thr Asp Ser Tyr Val Phe Leu GluLys Asp Leu Leu Ala Leu Asp Phe Leu Gly Val Ser Phe Tyr Gln Phe Ser Ile SerTrp Pro Arg Leu Phe Pro Asn Gly Thr Val Ala Ala Val Asn Ala Lys Gly Leu GlnTyr Tyr Arg Ala Leu Leu Asp Ser Leu Val Leu Arg Asn Ile Glu Pro Ile Val ThrLeu Tyr His Trp Asp Leu Pro Leu Thr Leu Gln Glu Glu Tyr Gly Gly Trp Lys AsnAla Thr Met Ile Asp Leu Phe Asn Asp Tyr Ala Thr Tyr Cys Phe Gln Thr Phe GlyAsp Arg Val Lys Tyr Trp Ile Thr Ile His Asn Pro Tyr Leu Val Ala Trp His GlyPhe Gly Thr Gly Met His Ala Pro Gly Glu Lys Gly Asn Leu Thr Ala Val Tyr ThrVal Gly His Asn Leu Ile Lys Ala His Ser Lys Val Trp His Asn Tyr Asp Lys AsnPhe Arg Pro His Gln Lys Gly Trp Leu Ser Ile Thr Leu Gly Ser His Trp Ile GluPro Asn Arg Thr Glu Asn Met Glu Asp Val Ile Asn Cys Gln His Ser Met Ser SerVal Leu Gly Trp Phe Ala Asn Pro Ile His Gly Asp Gly Asp Tyr Pro Glu Phe MetLys Thr Ser Ser Val Ile Pro Glu Phe Ser Glu Ala Glu Lys Glu Glu Val Arg GlyThr Ala Asp Phe Phe Ala Phe Ser Phe Gly Pro Asn Asn Phe Arg Pro Ser Asn ThrVal Val Lys Met Gly Gln Asn Val Ser Leu Asn Leu Arg Gln Val Leu Asn Trp IleLys Leu Glu Tyr Asp Asn Pro Arg Ile Leu Ile Ser Glu Asn Gly Trp Phe Thr AspSer Tyr Ile Lys Thr Glu Asp Thr Thr Ala Ile Tyr Met Met Lys Asn Phe Leu AsnGln Val Leu Gln Ala Ile Lys Phe Asp Glu Ile Gln Val Phe Gly Tyr Thr Ala TrpThr Leu Leu Asp Gly Phe Glu Trp Gln Asp Ala Tyr Thr Thr Arg Arg Gly Leu PheTyr Val Asp Phe Asn Ser Glu Gln Lys Glu Arg Lys Pro Lys Ser Ser Ala His TyrTyr Lys Gln Ile Ile Gln Asp Asn Gly Phe Pro Leu Gln Glu Ser Thr Pro Asp MetLys Gly Gln Phe Pro Cys Asp Phe Ser Trp Gly Val Thr Glu Ser Val Leu Lys ProGlu Phe Thr Val Ser Ser Pro Gln Phe Thr Asp Pro His Leu Tyr Val Trp Asn ValThr Gly Asn Arg Leu Leu Tyr Arg Val Glu Gly Val Arg Leu Lys Thr Arg Pro SerGln Cys Thr Asp Tyr Val Ser Ile Lys Lys Arg Val Glu Met Leu Ala Lys Met LysVal Thr His Tyr Gln Phe Ala Leu Asp Trp Thr Ser Ile Leu Pro Thr Gly Asn LeuSer Lys Ile Asn Arg Gln Val Leu Arg Tyr Tyr Arg Cys Val Val Ser Glu Gly LeuLys Leu Gly Ile Ser Pro Met Val Thr Leu Tyr His Pro Thr His Ser His Leu GlyLeu Pro Met Pro Leu Leu Ser Ser Gly Gly Trp Leu Asn Thr Asn Thr Ala Lys AlaPhe Gln Asp Tyr Ala Gly Leu Cys Phe Lys Glu Leu Gly Asp Leu Val Lys Leu TrpIle Thr Ile Asn Glu Pro Asn Arg Leu Ser Asp Met Tyr Asn Arg Thr Ser Asn AspThr Tyr Arg Ala Ala His Asn Leu Met Ile Ala His Ala Gln Val Trp His Leu TyrAsp Arg Gln Tyr Arg Pro Val Gln His Gly Ala Val Ser Leu Ser Leu His Ser AspTrp Ala Glu Pro Ala Asn Pro Tyr Val Glu Ser His Trp Lys Ala Ala Glu Arg PheLeu Gln Phe Glu Ile Ala Trp Phe Ala Asp Pro Leu Phe Lys Thr Gly Asp Tyr ProLeu Ala Met Lys Glu Tyr Ile Ala Ser Lys Lys Gln Arg Gly Leu Ser Ser Ser ValLeu Pro Arg Phe Thr Leu Lys Glu Ser Arg Leu Val Lys Gly Thr Ile Asp Phe TyrAla Leu Asn His Phe Thr Thr Arg Phe Val Ile His Lys Gln Leu Asn Thr Asn CysSer Val Ala Asp Arg Asp Val Gln Phe Leu Gln Asp Ile Thr Arg Leu Ser Ser ProSer Arg Leu Ala Val Thr Pro Trp Gly Met Arg Lys Leu Leu Gly Trp Ile Arg ArgAsn Tyr Arg Asp Met Asp Ile Tyr Val Thr Ala Asn Gly Ile Asp Asp Leu Ala LeuGlu Asp Asp Gln Ile Arg Lys Tyr Tyr Leu Glu Lys Tyr Val Gln Glu Ala Leu LysAla Tyr Leu Ile Asp Lys Val Lys Ile Lys Gly Tyr Tyr Ala Phe Lys Leu Thr GluGlu Lys Ser Lys Pro Arg Phe Gly Phe Phe Thr Ser Asp Phe Lys Ala Lys Ser SerVal Gln Phe Tyr Ser Lys Leu Ile Ser Ser Ser Gly Phe Ser Ser Glu Asn Arg SerPro Ala Cys Gly Gln Pro Pro Glu Asp Thr Glu Cys Ala Ile Cys Ser Phe Leu Thr
SEQ ID NO:257
Asp Tyr Lys Asp Asp Asp Asp Lys Leu Asp Phe Pro Gly Asp Gly Arg AlaVal Trp Ser Gln Asn Pro Asn Leu Ser Pro Val Asn Glu Ser Gln Leu Phe Leu TyrAsp Thr Phe Pro Lys Asn Phe Phe Trp Gly Val Gly Thr Gly Ala Phe Gln Val GluGly Ser Trp Lys Lys Asp Gly Lys Gly Leu Ser Val Trp Asp His Phe Ile Ala ThrHis Leu Asn Val Ser Ser Arg Asp Gly Ser Ser Asp Ser Tyr Ile Phe Leu Glu LysAsp Leu Ser Ala Leu Asp Phe Leu Gly Val Ser Phe Tyr Gln Phe Ser Ile Ser TrpPro Arg Leu Phe Pro Asp Gly Thr Val Ala Val Ala Asn Ala Lys Gly Leu Gln TyrTyr Asn Arg Leu Leu Asp Ser Leu Leu Leu Arg Asn Ile Glu Pro Val Val Thr LeuTyr His Trp Asp Leu Pro Trp Ala Leu Gln Glu Lys Tyr Gly Gly Trp Lys Asn GluThr Leu Ile Asp Leu Phe Asn Asp Tyr Ala Thr Tyr Cys Phe Gln Thr Phe Gly AspArg Val Lys Tyr Trp Ile Thr Ile His Asn Pro Tyr Leu Val Ala Trp His Gly TyrGly Thr Gly Leu His Ala Pro Gly Glu Lys Gly Asn Val Ala Ala Val Tyr Thr ValGly His Asn Leu Leu Lys Ala His Ser Lys Val Trp His Asn Tyr Asn Arg Asn PheArg Pro His Gln Lys Gly Trp Leu Ser Ile Thr Leu Gly Ser His Trp Ile Glu ProAsn Arg Ala Glu Ser Ile Val Asp Ile Leu Lys Cys Gln Gln Ser Met Val Ser ValLeu Gly Trp Phe Ala Asn Pro Ile His Gly Asp Gly Asp Tyr Pro Glu Val Met ThrLys Lys Leu Leu Ser Val Leu Pro Ala Phe Ser Glu Ala Glu Lys Asn Glu Val ArgGly Thr Ala Asp Phe Phe Ala Phe Ser Phe Gly Pro Asn Asn Phe Lys Pro Leu AsnThr Met Ala Lys Met Gly Gln Asn Val Ser Leu Asn Leu Arg Gln Val Leu Asn TrpIle Lys Leu Glu Tyr Gly Asn Pro Arg Ile Leu Ile Ala Glu Asn Gly Trp Phe ThrAsp Ser Tyr Val Gln Thr Glu Asp Thr Thr Ala Ile Tyr Met Met Lys Asn Phe LeuAsn Gln Val Leu Gln Ala Ile Arg Leu Asp Gly Val Arg Val Phe Gly Tyr Thr AlaTrp Ser Leu Leu Asp Gly Phe Glu Trp Gln Asp Ala Tyr Asn Thr Arg Arg Gly LeuPhe Tyr Val Asp Phe Asn Ser Glu Gln Arg Glu Arg Arg Pro Lys Ser Ser Ala HisTyr Tyr Lys Gln Val Ile Gly Glu Asn Gly Phe Thr Leu Arg Glu Ala Thr Pro AspLeu Gln Gly Gln Phe Pro Cys Asp Phe Ser Trp Gly Val Thr Glu Ser Val Leu LysPro Glu Ser Val Ala Ser Ser Pro Gln Phe Ser Asp Pro His Leu Tyr Val Trp AsnAla Thr Gly Asn Arg Met Leu His Arg Val Glu Gly Val Arg Leu Lys Thr Arg ProAla Gln Cys Thr Asp Phe Ile Thr Ile Lys Lys Gln Leu Glu Met Leu Ala Arg MetLys Val Thr His Phe Arg Phe Ala Leu Asp Trp Ala Ser Val Leu Pro Thr Gly AsnLeu Ser Glu Val Asn Arg Gln Ala Leu Arg Tyr Tyr Arg Cys Val Val Thr Glu GlyLeu Lys Leu Asn Ile Ser Pro Met Val Thr Leu Tyr Tyr Pro Thr His Ala His LeuGly Leu Pro Ala Pro Leu Leu His Ser Gly Gly Trp Leu Asp Pro Ser Thr Ala LysAla Phe Arg Asp Tyr Ala Gly Leu Cys Phe Arg Glu Leu Gly Asp Leu Val Lys LeuTrp Ile Thr Ile Asn Glu Pro Asn Arg Leu Ser Asp Val Tyr Asn Arg Thr Ser AsnAsp Thr Tyr Gln Ala Ala His Asn Leu Leu Ile Ala His Ala Ile Val Trp His LeuTyr Asp Arg Gln Tyr Arg Pro Ser Gln Arg Gly Ala Leu Ser Leu Ser Leu His SerAsp Trp Ala Glu Pro Ala Asn Pro Tyr Val Ala Ser His Trp Gln Ala Ala Glu ArgPhe Leu Gln Phe Glu Ile Ala Trp Phe Ala Glu Pro Leu Phe Lys Thr Gly Asp TyrPro Val Ala Met Arg Glu Tyr Ile Ala Ser Lys Thr Arg Arg Gly Leu Ser Ser SerVal Leu Pro Arg Phe Ser Asp Ala Glu Arg Arg Leu Val Lys Gly Ala Ala Asp PheTyr Ala Leu Asn His Phe Thr Thr Arg Phe Val Met His Glu Gln Gln Asn Gly SerArg Tyr Asp Ser Asp Arg Asp Val Gln Phe Leu Gln Asp Ile Thr Arg Leu Ala SerPro Ser Arg Leu Ala Val Met Pro Trp Gly Glu Gly Lys Leu Leu Arg Trp Met ArgAsn Asn Tyr Gly Asp Leu Asp Val Tyr Ile Thr Ala Asn Gly Ile Asp Asp Gln AlaLeu Gln Asn Asp Gln Leu Arg Gln Tyr Tyr Leu Glu Lys Tyr Val Gln Glu Ala LeuLys Ala Tyr Leu Ile Asp Lys Ile Lys Ile Lys Gly Tyr Tyr Ala Phe Lys Leu ThrGlu Glu Lys Ser Lys Pro Arg Phe Gly Phe Phe Thr Ser Asp Phe Lys Ala Lys SerSer Ile Gln Phe Tyr Asn Lys Leu Ile Thr Ser Asn Gly Phe Pro Ser Glu Asn GlyGly Pro Arg Cys Asn Gln Thr Gln Gly Asn Pro Glu Cys Thr Val Cys Leu Leu LeuLeu
SEQ ID NO:258
Asp Tyr Lys Asp Asp Asp Asp Lys Leu Glu Phe Ser Gly Asp Gly Arg AlaVal Trp Ser Lys Asn Pro Asn Phe Thr Pro Val Asn Glu Ser Gln Leu Phe Leu TyrAsp Thr Phe Pro Lys Asn Phe Phe Trp Gly Val Gly Thr Gly Ala Leu Gln Val GluGly Ser Trp Lys Lys Asp Gly Lys Gly Pro Ser Ile Trp Asp His Phe Val His ThrHis Leu Lys Asn Val Ser Ser Thr Asn Gly Ser Ser Asp Ser Tyr Ile Phe Leu GluLys Asp Leu Ser Ala Leu Asp Phe Ile Gly Val Ser Phe Tyr Gln Phe Ser Ile SerTrp Pro Arg Leu Phe Pro Asp Gly Ile Val Thr Val Ala Asn Ala Lys Gly Leu GlnTyr Tyr Asn Thr Leu Leu Asp Ser Leu Val Leu Arg Asn
Ile Glu Pro Ile Val Thr Leu Tyr His Trp Asp Leu Pro Leu Ala Leu GlnGlu Lys Tyr Gly Gly Trp Lys Asn Asp Thr Ile Ile Asp Ile Phe Asn Asp Tyr AlaThr Tyr Cys Phe Gln Thr Phe Gly Asp Arg Val Lys Tyr Trp Ile Thr Ile His AsnPro Tyr Leu Val Ala Trp His Gly Tyr Gly Thr Gly Met His Ala Pro Gly Glu LysGly Asn Leu Ala Ala Val Tyr Thr Val Gly His Asn Leu Ile Lys Ala His Ser LysVal Trp His Asn Tyr Asn Thr His Phe Arg Pro His Gln Lys Gly Trp Leu Ser IleThr Leu Gly Ser His Trp Ile Glu Pro Asn Arg Ser Glu Asn Thr Met Asp Ile LeuLys Cys Gln Gln Ser Met Val Ser Val Leu Gly Trp Phe Ala Ser Pro Ile His GlyAsp Gly Asp Tyr Pro Glu Gly Met Lys Lys Lys Leu Leu Ser Ile Leu Pro Leu PheSer Glu Ala Glu Lys Asn Glu Val Arg Gly Thr Ala Asp Phe Phe Ala Phe Ser PheGly Pro Asn Asn Phe Lys Pro Leu Asn Thr Met Ala Lys Met Gly Gln Asn Val SerLeu Asn Leu Arg Glu Ala Leu Asn Trp Ile Lys Leu Glu Tyr Asn Asn Pro Arg IleLeu Ile Ala Glu Asn Gly Trp Phe Thr Asp Ser His Val Lys Thr Glu Asp Thr ThrAla Ile Tyr Met Met Lys Asn Phe Leu Ser Gln Val Leu Gln Ala Ile Arg Leu AspGlu Ile Arg Val Phe Gly Tyr Thr Ala Trp Ser Leu Leu Asp Gly Phe Glu Trp GlnAsp Ala Tyr Thr Ile Arg Arg Gly Leu Phe Tyr Val Asp Phe Asn Ser Lys Gln LysGlu Arg Lys Pro Lys Ser Ser Ala His Tyr Tyr Lys Gln Ile Ile Arg Glu Asn GlyPhe Ser Leu Lys Glu Ala Thr Pro Asp Val Gln Gly Gln Phe Pro Cys Asp Phe SerTrp Gly Val Thr Glu Ser Val Leu Lys Pro Glu Ser Val Ala Ser Ser Pro Gln PheSer Asp Pro Tyr Leu Tyr Val Trp Asn Ala Thr Gly Asn Arg Leu Leu His Arg ValGlu Gly Val Arg Leu Lys Thr Arg Pro Ala Gln Cys Thr Asp Phe Val Asn Ile LysLys Gln Leu Glu Met Leu Ala Arg Met Lys Val Thr His Tyr Arg Phe Ala Leu AspTrp Ala Ser Val Leu Pro Thr Gly Asn Leu Ser Ala Val Asn Arg Gln Ala Leu ArgTyr Tyr Arg Cys Val Val Ser Glu Gly Leu Lys Leu Gly Ile Ser Ala Met Val ThrLeu Tyr Tyr Pro Thr His Ala His Leu Gly Leu Pro Glu Pro Leu Leu His Ala GlyGly Trp Leu Asn Pro Ser Thr Val Glu Ala Phe Gln Ala Tyr Ala Gly Leu Cys PheGln Glu Leu Gly Asp Leu Val Lys Leu Trp Ile Thr Ile Asn Glu Pro Asn Arg LeuSer Asp Ile Tyr Asn Arg Ser Gly Asn Asp Thr Tyr Gly Ala Ala His Asn Leu LeuVal Ala His Ala Leu Ala Trp Arg Leu Tyr Asp Arg Gln Phe Arg Pro Ser Gln ArgGly Ala Val Ser Leu Ser Leu His Ala Asp Trp Ala Glu Pro Ala Asn Pro Tyr AlaAsp Ser His Trp Arg Ala Ala Glu Arg Phe Leu Gln Phe Glu Ile Ala Trp Phe AlaGlu Pro Leu Phe Lys Thr Gly Asp Tyr Pro Ala Ala Met Arg Glu Tyr Ile Ala SerLys His Arg Arg Gly Leu Ser Ser Ser Ala Leu Pro Arg Leu Thr Glu Ala Glu ArgArg Leu Leu Lys Gly Thr Val Asp Phe Cys Ala Leu Asn His Phe Thr Thr Arg PheVal Met His Glu Gln Leu Ala Gly Ser Arg Tyr Asp Ser Asp Arg Asp Ile Gln PheLeu Gln Asp Ile Thr Arg Leu Ser Ser Pro Thr Arg Leu Ala Val Ile Pro Trp GlyVal Arg Lys Leu Leu Arg Trp Val Arg Arg Asn Tyr Gly Asp Met Asp Ile Tyr IleThr Ala Ser Gly Ile Asp Asp Gln Ala Leu Glu Asp Asp Arg Leu Arg Lys Tyr TyrLeu Glu Lys Tyr Leu Gln Glu Val Leu Lys Ala Tyr Leu Ile Asp Lys Val Arg IleLys Gly Tyr Tyr Ala Phe Lys Leu Ala Glu Glu Lys Ser Lys Pro Arg Phe Gly PhePhe Thr Ser Asp Phe Lys Ala Lys Ser Ser Ile Gln Phe Tyr Asn Lys Met Ile SerSer Ser Gly Phe Pro Ser Glu Asn Ser Ser Ser Arg Cys Ser Gln Thr Gln Lys AsnThr Glu Cys Thr Val Cys Leu Phe Leu Ala
SEQ ID NO:259
Asp Tyr Lys Asp Asp Asp Asp Lys Leu Glu Phe Ser Gly Asp Gly Arg AlaVal Trp Ser Lys Asn Pro Asn Phe Thr Pro Val Asn Glu Ser Gln Leu Phe Leu TyrAsp Thr Phe Pro Lys Asn Phe Phe Trp Gly Val Gly Thr Gly Ala Leu Gln Val GluGly Ser Trp Lys Lys Asp Gly Lys Gly Pro Ser Ile Trp Asp His Phe Val His ThrHis Leu Lys Asn Val Ser Ser Thr Asn Gly Ser Ser Asp Ser Tyr Ile Phe Leu GluLys Asp Leu Ser Ala Leu Asp Phe Ile Gly Val Ser Phe Tyr Gln Phe Ser Ile SerTrp Pro Arg Leu Phe Pro Asp Gly Ile Val Thr Val Ala Asn Ala Lys Gly Leu GlnTyr Tyr Asn Ala Leu Leu Asp Ser Leu Val Leu Arg Asn Ile Glu Pro Ile Val ThrLeu Tyr His Trp Asp Leu Pro Leu Ala Leu Gln Glu Lys Tyr Gly Gly Trp Lys AsnAsp Thr Ile Ile Asp Ile Phe Asn Asp Tyr Ala Thr Tyr Cys Phe Gln Thr Phe GlyAsp Arg Val Lys Tyr Trp Ile Thr Ile His Asn Pro Tyr Leu Val Ala Trp His GlyTyr Gly Thr Gly Met His Ala Pro Gly Glu Lys Gly Asn Leu Ala Ala Val Tyr ThrVal Gly His Asn Leu Ile Lys Ala His Ser Lys Val Trp His Asn Tyr Asn Thr HisPhe Arg Pro His Gln Lys Gly Trp Leu Ser Ile Thr Leu Gly Ser His Trp Ile GluPro Asn Arg Ser Glu Asn Thr Met Asp Ile Leu Lys Cys Gln Gln Ser Met Val SerVal Leu Gly Trp Phe Ala Asn Pro Ile His Gly Asp Gly Asp Tyr Pro Glu Gly MetLys Lys Lys Leu Leu Ser Ile Leu Pro Leu Phe Ser Glu Ala Glu Lys Asn Glu ValArg Gly Thr Ala Asp Phe Phe Ala Phe Ser Phe Gly Pro Asn Asn Phe Lys Pro LeuAsn Thr Met Ala Lys Met Gly Gln Asn Val Ser Leu Asn Leu Arg Glu Ala Leu AsnTrp Ile Lys Leu Glu Tyr Asn Asn Pro Gln Ile Leu Ile Ala Glu Asn Gly Trp PheThr Asp Ser His Val Lys Thr Glu Asp Thr Thr Ala Ile Tyr Met Met Lys Asn PheLeu Ser Gln Val Leu Gln Ala Ile Arg Leu Asp Glu Ile Arg Val Phe Gly Tyr ThrAla Trp Ser Leu Leu Asp Gly Phe Glu Trp Gln Asp Ala Tyr Thr Ile Arg Arg GlyLeu Phe Tyr Val Asp Phe Asn Ser Lys Gln Lys Glu Arg Lys Pro Lys Ser Ser AlaHis Tyr Tyr Lys Gln Ile Ile Arg Glu Asn Gly Phe Ser Leu Lys Glu Ala Thr ProAsp Val Gln Gly Gln Phe Pro Cys Asp Phe Ser Trp Gly Val Thr Glu Ser Val LeuLys Pro Glu Ser Val Ala Ser Ser Pro Gln Phe Ser Asp Pro Tyr Leu Tyr Val TrpAsn Ala Thr Gly Asn Arg Leu Leu His Arg Val Glu Gly Val Arg Leu Lys Thr ArgPro Ala Gln Cys Thr Asp Phe Val Asn Ile Lys Lys Gln Leu Glu Met Leu Ala ArgMet Lys Val Thr His Tyr Arg Phe Ala Leu Asp Trp Ala Ser Val Leu Pro Thr GlyAsn Leu Ser Ala Val Asn Arg Gln Ala Leu Arg Tyr Tyr Arg Cys Val Val Ser GluGly Leu Lys Leu Gly Ile Ser Ala Met Val Thr Leu Tyr Tyr Pro Thr His Ala HisLeu Gly Leu Pro Glu Pro Leu Leu His Ala Gly Gly Trp Leu Asn Pro Ser Thr ValGlu Ala Phe Gln Ala Tyr Ala Gly Leu Cys Phe Gln Glu Leu Gly Asp Leu Val LysLeu Trp Ile Thr Ile Asn Glu Pro Asn Arg Leu Ser Asp Ile Tyr Asn Arg Ser GlyAsn Asp Thr Tyr Gly Ala Ala His Asn Leu Leu Val Ala His Ala Leu Ala Trp ArgLeu Tyr Asp Arg Gln Phe Arg Pro Ser Gln Arg Gly Ala Val Ser Leu Ser Leu HisAla Asp Trp Ala Glu Pro Ala Asn Pro Tyr Ala Asp Ser His Trp Arg Ala Ala GluArg Phe Leu Gln Phe Glu Ile Ala Trp Phe Ala Glu Pro Leu Phe Lys Thr Gly AspTyr Pro Ala Ala Met Arg Glu Tyr Ile Ala Ser Lys His Arg Arg Gly Leu Ser SerSer Ala Leu Pro Arg Leu Thr Glu Ala Glu Arg Arg Leu Leu Lys Gly Thr Val AspPhe Cys Ala Leu Asn His Phe Thr Thr Arg Phe Val Met His Glu Gln Leu Ala GlySer Arg Tyr Asp Ser Asp Arg Asp Ile Gln Phe Leu Gln Asp Ile Thr Arg Leu SerSer Pro Thr Arg Leu Ala Val Ile Pro Trp Gly Val Arg Lys Leu Leu Arg Trp ValArg Arg Asn Tyr Gly Asp Met Asp Ile Tyr Ile Thr Ala Ser Gly Ile Asp Asp GlnAla Leu Glu Asp Asp Arg Leu Arg Lys Tyr Tyr Leu Glu Lys Tyr Leu Gln Glu ValLeu Lys Ala Tyr Leu Ile Asp Lys Val Arg Ile Lys Gly Tyr Tyr Ala Phe Lys LeuAla Glu Glu Lys Ser Lys Pro Arg Phe Gly Phe Phe Thr Ser Asp Phe Lys Ala LysSer Ser Ile Gln Phe Tyr Asn Lys Met Ile Ser Ser Ser Gly Phe Pro Ser Glu AsnSer Ser Ser Arg Cys Ser Gln Thr Gln Lys Asn Thr Glu Cys Thr Val Cys Leu PheLeu Val
SEQ ID NO:260
Glu Pro Gly Asp Gly Ala Gln Thr Trp Ala Arg Phe Ser Arg Pro Pro AlaPro Glu Ala Ala Gly Leu Phe Gln Gly Thr Phe Pro Asp Gly Phe Leu Trp Ala ValGly Ser Ala Ala Tyr Gln Thr Glu Gly Gly Trp Gln Gln His Gly Lys Gly Ala SerIle Trp Asp Thr Phe Thr His His Pro Leu Ala Pro Pro Gly Asp Ser Arg Asn AlaSer Leu Pro Leu Gly Ala Pro Ser Pro Leu Gln Pro Ala Thr Gly Asp Val Ala SerAsp Ser Tyr Asn Asn Val Phe Arg Asp Thr Glu Ala Leu Arg Glu Leu Gly Val ThrHis Tyr Arg Phe Ser Ile Ser Trp Ala Arg Val Leu Pro Asn Gly Ser Ala Gly ValPro Asn Arg Glu Gly Leu Arg Tyr Tyr Arg Arg Leu Leu Glu Arg Leu Arg Glu LeuGly Val Gln Pro Val Val Thr Leu Tyr His Trp Asp Leu Pro Gln Arg Leu Gln AspAla Tyr Gly Gly Trp Ala Asn Arg Ala Leu Ala Asp His Phe Arg Asp Tyr Ala GluLeu Cys Phe Arg His Phe Gly Gly Gln Val Lys Tyr Trp Ile Thr Ile Asp Asn ProTyr Val Val Ala Trp His Gly Tyr Ala Thr Gly Arg Leu Ala Pro Gly Ile Arg GlySer Pro Arg Leu Gly Tyr Leu Val Ala His Asn Leu Leu Leu Ala His Ala Lys ValTrp His Leu Tyr Asn Thr Ser Phe Arg Pro Thr Gln Gly Gly Gln Val Ser Ile AlaLeu Ser Ser His Trp Ile Asn Pro Arg Arg Met Thr Asp His Ser Ile Lys Glu CysGln Lys Ser Leu Asp Phe Val Leu Gly Trp Phe Ala Lys Pro Val Phe Ile Asp GlyAsp Tyr Pro Glu Ser Met Lys Asn Asn Leu Ser Ser Ile Leu Pro Asp Phe Thr GluSer Glu Lys Lys Phe Ile Lys Gly Thr Ala Asp Phe Phe Ala Leu Cys Phe Gly ProThr Leu Ser Phe Gln Leu Leu Asp Pro His Met Lys Phe Arg Gln Leu Glu Ser ProAsn Leu Arg Gln Leu Leu Ser Trp Ile Asp Leu Glu Phe Asn His Pro Gln Ile PheIle Val Glu Asn Gly Trp Phe Val Ser Gly Thr Thr Lys Arg Asp Asp Ala Lys TyrMet Tyr Tyr Leu Lys Lys Phe Ile Met Glu Thr Leu Lys Ala Ile Lys Leu Asp GlyVal Asp Val Ile Gly Tyr Thr Ala Trp Ser Leu Met Asp Gly Phe Glu Trp His ArgGly Tyr Ser Ile Arg Arg Gly Leu Phe Tyr Val Asp Phe Leu Ser Gln Asp Lys MetLeu Leu Pro Lys Ser Ser Ala Leu Phe Tyr Gln Lys Leu Ile Glu Lys Asn Gly PhePro Pro Leu Pro Glu Asn Gln Pro Leu Glu Gly Thr Phe Pro Cys Asp Phe Ala TrpGly Val Val Asp Asn Tyr Ile Gln Val Asp Thr Thr Leu Ser Gln Phe Thr Asp LeuAsn Val Tyr Leu Trp Asp Val His His Ser Lys Arg Leu Ile Lys Val Asp Gly ValVal Thr Lys Lys Arg Lys Ser Tyr Cys Val Asp Phe Ala Ala Ile Gln Pro Gln IleAla Leu Leu Gln Glu Met His Val Thr His Phe Arg Phe Ser Leu Asp Trp Ala LeuIle Leu Pro Leu Gly Asn Gln Ser Gln Val Asn His Thr Ile Leu Gln Tyr Tyr ArgCys Met Ala Ser Glu Leu Val Arg Val Asn Ile Thr Pro Val Val Ala Leu Trp GlnPro Met Ala Pro Asn Gln Gly Leu Pro Arg Leu Leu Ala Arg Gln Gly Ala Trp GluAsn Pro Tyr Thr Ala Leu Ala Phe Ala Glu Tyr Ala Arg Leu Cys Phe Gln Glu LeuGly His His Val Lys Leu Trp Ile Thr Met Asn Glu Pro Tyr Thr Arg Asn Met ThrTyr Ser Ala Gly His Asn Leu Leu Lys Ala His Ala Leu Ala Trp His Val Tyr AsnGlu Lys Phe Arg His Ala Gln Asn Gly Lys Ile Ser Ile Ala Leu Gln Ala Asp TrpIle Glu Pro Ala Cys Pro Phe Ser Gln Lys Asp Lys Glu Val Ala Glu Arg Val LeuGlu Phe Asp Ile Gly Trp Leu Ala Glu Pro Ile Phe Gly Ser Gly Asp Tyr Pro TrpVal Met Arg Asp Trp Leu Asn Gln Arg Asn Asn Phe Leu Leu Pro Tyr Phe Thr GluAsp Glu Lys Lys Leu Ile Gln Gly Thr Phe Asp Phe Leu Ala Leu Ser His Tyr ThrThr Ile Leu Val Asp Ser Glu Lys Glu Asp Pro Ile Lys Tyr Asn Asp Tyr Leu GluVal Gln Glu Met Thr Asp Ile Thr Trp Leu Asn Ser Pro Ser Gln Val Ala Val ValPro Trp Gly Leu Arg Lys Val Leu Asn Trp Leu Lys Phe Lys Tyr Gly Asp Leu ProMet Tyr Ile Ile Ser Asn Gly Ile Asp Asp Gly Leu His Ala Glu Asp Asp Gln LeuArg Val Tyr Tyr Met Gln Asn Tyr Ile Asn Glu Ala Leu Lys Ala His Ile Leu AspGly Ile Asn Leu Cys Gly Tyr Phe Ala Tyr Ser Phe Asn Asp Arg Thr Ala Pro ArgPhe Gly Leu Tyr Arg Tyr Ala Ala Asp Gln Phe Glu Pro Lys Ala Ser Met Lys HisTyr Arg Lys Ile Ile Asp Ser Asn Gly Phe Pro Gly Pro Glu Thr Leu Glu Arg PheCys Pro Glu Glu Phe Thr Val Cys Thr Glu Cys Ser Phe Phe His Thr Arg Lys SerLeu Leu Ala Phe Ile Ala Phe Leu Phe Phe Ala Ser Ile Ile Ser Leu Ser Leu IlePhe Tyr Tyr Ser Lys Lys Gly Arg Arg Ser Tyr Lys Leu Glu Asp Tyr Lys Asp AspAsp Asp Lys
SEQ ID NO:261
Ser Thr Tyr Ile Ser
SEQ ID NO:262
Glu Ile Asp Pro Tyr Asp Gly Ala Thr Asp Tyr Ala Asp Ser Val Lys Gly
SEQ ID NO:263
Glu His Phe Asp Ala Trp Val His Tyr Tyr Val Met Asp Tyr
SEQ ID NO:264
Phe Pro Cys Asp Phe Ser Trp Gly Val Thr Glu Ser Val Leu Lys Pro GluSer Val Ala Ser Ser Pro Gln Phe Ser Asp Pro His Leu Tyr Val Trp Asn Ala ThrGly Asn Arg Leu Leu His Arg Val Glu Gly Val Arg Leu Lys Thr Arg Pro Ala GlnCys Thr Asp Phe Val Asn Ile Lys Lys Gln Leu Glu Met Leu Ala Arg Met Lys ValThr His Tyr Arg Phe Ala Leu Asp Trp Ala Ser Val Leu Pro Thr Gly Asn Leu SerAla Val Asn Arg Gln Ala Leu Arg Tyr Tyr Arg Cys Val Val Ser Glu Gly Leu LysLeu Gly Ile Ser Ala Met Val Thr Leu Tyr Tyr Pro Thr His Ala His Leu Gly LeuPro Glu Pro Leu Leu His Ala Asp Gly Trp Leu Asn Pro Ser Thr Ala Glu Ala PheGln Ala Tyr Ala Gly Leu Cys Phe Gln Glu Leu Gly Asp Leu Val Lys Leu Trp IleThr Ile Asn Glu Pro Asn Arg Leu Ser Asp Ile Tyr Asn Arg Ser Gly Asn Asp ThrTyr Gly Ala Ala His Asn Leu Leu Val Ala His Ala Leu Ala Trp Arg Leu Tyr AspArg Gln Phe Arg Pro Ser Gln Arg Gly Ala Val Ser Leu Ser Leu His Ala Asp TrpAla Glu Pro Ala Asn Pro Tyr Ala Asp Ser His Trp Arg Ala Ala Glu Arg Phe LeuGln Phe Glu Ile Ala Trp Phe Ala Glu Pro Leu Phe Lys Thr Gly Asp Tyr Pro AlaAla Met Arg Glu Tyr Ile Ala Ser Lys His Arg Arg Gly Leu Ser Ser Ser Ala LeuPro Arg Leu Thr Glu Ala Glu Arg Arg Leu Leu Lys Gly Thr Val Asp Phe Cys AlaLeu Asn His Phe Thr Thr Arg Phe Val Met His Glu Gln Leu Ala Gly Ser Arg TyrAsp Ser Asp Arg Asp Ile Gln Phe Leu Gln Asp Ile Thr Arg Leu Ser Ser Pro ThrArg Leu Ala Val Ile Pro Trp Gly Val Arg Lys Leu Leu Arg Trp Val Arg Arg AsnTyr Gly Asp Met Asp Ile Tyr Ile Thr Ala Ser Gly Ile Asp Asp Gln Ala Leu GluAsp Asp Arg Leu Arg Lys Tyr Tyr Leu Gly Lys Tyr Leu Gln Glu Val Leu Lys AlaTyr Leu Ile Asp Lys Val Arg Ile Lys Gly Tyr Tyr Ala Phe Lys Leu Ala Glu GluLys Ser Lys Pro Arg Phe Gly Phe Phe Thr Ser Asp Phe Lys Ala Lys Ser Ser IleGln Phe Tyr Asn Lys Val Ile Ser Ser Arg Gly Phe Pro Phe Glu Asn Ser Ser SerArg
SEQ ID NO:265
gttaccggct tctccggaga cgggaaagca atatgg
SEQ ID NO:266
Met Lys Pro Gly Cys Ala Ala Gly Ser Pro Gly Asn Glu Trp Ile Phe PheSer Thr Asp Glu Ile Thr Thr Arg Tyr Arg Asn Thr Met Ser Asn Gly Gly Leu GlnArg Ser Val Ile Leu Ser Ala Leu Ile Leu Leu Arg Ala Val Thr Gly
SEQ ID NO:267
Phe Ser Gly Asp Gly Lys Ala Ile Trp Asp Lys Lys Gln Tyr Val Ser ProVal Asn Pro Ser Gln Leu Phe Leu Tyr Asp Thr Phe Pro Lys Asn Phe Ser Trp GlyVal Gly Thr Gly Ala Phe Gln Val Glu Gly Ser Trp Lys Thr Asp Gly Arg Gly ProSer Ile Trp Asp Arg Tyr Val Tyr Ser His Leu Arg Gly Val Asn Gly Thr Asp ArgSer Thr Asp Ser Tyr Ile Phe Leu Glu Lys Asp Leu Leu Ala Leu Asp Phe Leu GlyVal Ser Phe Tyr Gln Phe Ser Ile Ser Trp Pro Arg Leu Phe Pro Asn Gly Thr ValAla Ala Val Asn Ala Gln Gly Leu Arg Tyr Tyr Arg Ala Leu Leu Asp Ser Leu ValLeu Arg Asn Ile Glu Pro Ile Val Thr Leu Tyr His Trp Asp Leu Pro Leu Thr LeuGln Glu Glu Tyr Gly Gly Trp Lys Asn Ala Thr Met Ile Asp Leu Phe Asn Asp TyrAla Thr Tyr Cys Phe Gln Thr Phe Gly Asp Arg Val Lys Tyr Trp Ile Thr Ile HisAsn Pro Tyr Leu Val Ala Trp His Gly Phe Gly Thr Gly Met His Ala Pro Gly GluLys Gly Asn Leu Thr Ala Val Tyr Thr Val Gly His Asn Leu Ile Lys Ala His SerLys Val Trp His Asn Tyr Asp Lys Asn Phe Arg Pro His Gln Lys Gly Trp Leu SerIle Thr Leu Gly Ser His Trp Ile Glu Pro Asn Arg Thr Asp Asn Met Glu Asp ValIle Asn Cys Gln His Ser Met Ser Ser Val Leu Gly Trp Phe Ala Asn Pro Ile HisGly Asp Gly Asp Tyr Pro Glu Phe Met Lys Thr Gly Ala Met Ile Pro Glu Phe SerGlu Ala Glu Lys Glu Glu Val Arg Gly Thr Ala Asp Phe Phe Ala Phe Ser Phe GlyPro Asn Asn Phe Arg Pro Ser Asn Thr Val Val Lys Met Gly Gln Asn Val Ser LeuAsn Leu Arg Gln Val Leu Asn Trp Ile Lys Leu Glu Tyr Asp Asp Pro Gln Ile LeuIle Ser Glu Asn Gly Trp Phe Thr Asp Ser Tyr Ile Lys Thr Glu Asp Thr Thr AlaIle Tyr Met Met Lys Asn Phe Leu Asn Gln Val Leu Gln Ala Ile Lys Phe Asp GluIle Arg Val Phe Gly Tyr Thr Ala Trp Thr Leu Leu Asp Gly Phe Glu Trp Gln AspAla Tyr Thr Thr Arg Arg Gly Leu Phe Tyr Val Asp Phe Asn Ser Glu Gln Lys GluArg Lys Pro Lys Ser Ser Ala His Tyr Tyr Lys Gln Ile Ile Gln Asp Asn Gly PhePro Leu Lys Glu Ser Thr Pro Asp Met Lys Gly Arg Phe Pro Cys Asp Phe Ser TrpGly Val Thr Glu Ser Val Leu Lys Pro Glu Phe Thr Val Ser Ser Pro Gln Phe ThrAsp Pro His Leu Tyr Val Trp Asn Val Thr Gly Asn Arg Leu Leu Tyr Arg Val GluGly Val Arg Leu Lys Thr Arg Pro Ser Gln Cys Thr Asp Tyr Val Ser Ile Lys LysArg Val Glu Met Leu Ala Lys Met Lys Val Thr His Tyr Gln Phe Ala Leu Asp TrpThr Ser Ile Leu Pro Thr Gly Asn Leu Ser Lys Val Asn Arg Gln Val Leu Arg TyrTyr Arg Cys Val Val Ser Glu Gly Leu Lys Leu Gly Val Phe Pro Met Val Thr LeuTyr His Pro Thr His Ser His Leu Gly Leu Pro Leu Pro Leu Leu Ser Ser Gly GlyTrp Leu Asn Met Asn Thr Ala Lys Ala Phe Gln Asp Tyr Ala Glu Leu Cys Phe ArgGlu Leu Gly Asp Leu Val Lys Leu Trp Ile Thr Ile Asn Glu Pro Asn Arg Leu SerAsp Met Tyr Asn Arg Thr Ser Asn Asp Thr Tyr Arg Ala Ala His Asn Leu Met IleAla His Ala Gln Val Trp His Leu Tyr Asp Arg Gln Tyr Arg Pro Val Gln His GlyAla Val Ser Leu Ser Leu His Cys Asp Trp Ala Glu Pro Ala Asn Pro Phe Val AspSer His Trp Lys Ala Ala Glu Arg Phe Leu Gln Phe Glu Ile Ala Trp Phe Ala AspPro Leu Phe Lys Thr Gly Asp Tyr Pro Ser Val Met Lys Glu Tyr Ile Ala Ser LysAsn Gln Arg Gly Leu Ser Ser Ser Val Leu Pro Arg Phe Thr Ala Lys Glu Ser ArgLeu Val Lys Gly Thr Val Asp Phe Tyr Ala Leu Asn His Phe Thr Thr Arg Phe ValIle His Lys Gln Leu Asn Thr Asn Arg Ser Val Ala Asp Arg Asp Val Gln Phe LeuGln Asp Ile Thr Arg Leu Ser Ser Pro Ser Arg Leu Ala Val Thr Pro Trp Gly ValArg Lys Leu Leu Ala Trp Ile Arg Arg Asn Tyr Arg Asp Arg Asp Ile Tyr Ile ThrAla Asn Gly Ile Asp Asp Leu Ala Leu Glu Asp Asp Gln Ile Arg Lys Tyr Tyr LeuGlu Lys Tyr Val Gln Glu Ala Leu Lys Ala Tyr Leu Ile Asp Lys Val Lys Ile LysGly Tyr Tyr Ala Phe Lys Leu Thr Glu Glu Lys Ser Lys Pro Arg Phe Gly Phe PheThr Ser Asp Phe Arg Ala Lys Ser Ser Val Gln Phe Tyr Ser Lys Leu Ile Ser SerSer Gly Leu Pro Ala Glu Asn Arg Ser Pro Ala Cys Gly Gln Pro Ala Glu Asp ThrAsp Cys Thr Ile Cys Ser Phe Leu Val
SEQ ID NO:268
Met Glu Lys Lys Leu His Ala Val Pro Ala Ala Lys Thr Val Lys Phe LysCys Pro Ser Ser Gly Thr Pro Asn Pro Thr Leu Arg Trp Leu Lys Asn Gly Lys GluPhe Lys Pro Asp His Arg Ile Gly Gly Tyr Lys Val Arg Tyr Ala Thr Trp
SEQ ID NO:269
Ser Ser Pro Thr Arg Leu Ala Val Ile Pro Trp Gly Val Arg Lys Leu LeuArg Trp Val Arg Arg Asn Tyr Gly Asp Met Asp Ile Tyr Ile Thr Ala Ser
SEQ ID NO:270
Ser Ser Pro Thr Arg Leu Ala Val Ile Pro Trp Gly Val Arg Lys Leu LeuArg Trp Val Arg Arg Asn Tyr Gly Asp Met Asp Ile Tyr Ile Thr Ala Ser
SEQ ID NO:271
Ser Ser Pro Ser Arg Leu Ala Val Thr Pro Trp Gly Met Arg Lys Leu LeuGly Trp Ile Arg Arg Asn Tyr Arg Asp Met Asp Ile Tyr Val Thr Ala Asn
SEQ ID NO:272
Ser Ser Pro Ser Arg Leu Ala Val Thr Pro Trp Gly Val Arg Lys Leu LeuAla Trp Ile Arg Arg Asn Tyr Arg Asp Arg Asp Ile Tyr Ile Thr Ala Asn
SEQ ID NO:273
Ala Ser Pro Ser Arg Leu Ala Val Met Pro Trp Gly Glu Gly Lys Leu LeuArg Trp Met Arg Asn Asn Tyr Gly Asp Leu Asp Val Tyr Ile Thr Ala Asn
SEQ ID NO:274
Phe Ser Gly Asp Gly Lys Ala Ile Trp Asp Lys Lys Gln Tyr Val Ser Pro
SEQ ID NO:275
Phe Ser Glu Thr Gly Lys Gln Tyr Gly Ile Lys Asn Ser Thr
SEQ ID NO:276
2B.1.1.6 HVR-L1
RASQDVDTSLA
SEQ ID NO:277
2B.1.1.6 HVR-L2
SASFLYS
SEQ ID NO:278
2B.1.1.6 HVR-L3
QQSTGHPQT
SEQ ID NO:279
2B.1.1.6 HVR-H1
GFTFTSTGIS
SEQ ID NO:280
2B.1.1.6 HVR-H2
RYWAWDGSTNYADSVKG
SEQ ID NO:281
2B.1.1.6 HVR-H3
ARTYGIYDTYDEYTEYVMDY
SEQ ID NO:282
2B.1.1.6 HC
EVQLVESGGGLVQPGGSLRLSCAASGFTFTSTGISWVRQAPGKGLEWVGRYWAWDGSTNYADSVKGRFTISADTSKNTAYLQMNSLRAEDTAVYYCARTYGIYDTYDEYTEYVMDYWGQGTLVTVSSASTKGPSVFPLAPSSKSTSGGTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTQTYICNVNHKPSNTKVDKKVEPKSCDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSREEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO:283
2B.1.1.6 LC
DIQMTQSPSSLSASVGDRVTITCRASQDVDTSLAWYKQKPGKAPKLLIYSASFLYSGVPSRFSGSGSGTDFTLTISSLQPEDFATYYCQQSTGHPQTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC





























































































































































































Claims (22)
1.一种分离的抗体或其抗原结合部分,其结合FGFR2和FGFR3,其中通过表面等离振子共振没有检测到该抗体或其抗原结合部分对FGFR1和FGFR4的结合,且其中该抗体或其抗原结合部分包含: (a) 如GFPFTSQGIS (SEQ ID NO: 4)的氨基酸序列所示的重链可变区CDR1; (b) 如RTHLGDGSTNYADSVKG (SEQ ID NO: 5)的氨基酸序列所示的重链可变区CDR2;(c) 如ARTYGIYDTYDKYTEYVMDY (SEQ ID NO: 6)的氨基酸序列所示的重链可变区CDR3;(d) 如RASQDVDTSLA (SEQ ID NO: 1)的氨基酸序列所示的轻链可变区CDR1; (e) 如SASFLYS (SEQ ID NO: 2)的氨基酸序列所示的轻链可变区CDR2;和 (f) 如QQSTGHPQT(SEQ ID NO: 3)的氨基酸序列所示的轻链可变区CDR3。
2.一种分离的抗体或其抗原结合部分,其结合FGFR2和FGFR3,其中通过表面等离振子共振没有检测到该抗体或其抗原结合部分对FGFR1和FGFR4的结合,且其中该抗体或其抗原结合部分包含:
(a) 如GFPFTSTGIS (SEQ ID NO: 10)的氨基酸序列所示的重链可变区CDR1;
(b) 如RTHLGDGSTNYADSVKG (SEQ ID NO: 11)的氨基酸序列所示的重链可变区CDR2;
(c) 如ARTYGIYDTYDMYTEYVMDY (SEQ ID NO: 12)的氨基酸序列所示的重链可变区CDR3;
(d) 如RASQDVDTSLA (SEQ ID NO: 7)的氨基酸序列所示的轻链可变区CDR1;
(e) 如SASFLYS (SEQ ID NO: 8)的氨基酸序列所示的轻链可变区CDR2;和
(f) 如QQSTGHPQT (SEQ ID NO: 9)的氨基酸序列所示的轻链可变区CDR3。
3.权利要求1的分离的抗体或其抗原结合部分,其包含如SEQ ID NO: 81所示的重链中包含的重链可变区和如SEQ ID NO: 65所示的轻链中包含的轻链可变区。
4.权利要求2的分离的抗体或其抗原结合部分,其包含如SEQ ID NO: 82所示的重链中包含的重链可变区和如SEQ ID NO: 66所示的轻链中包含的轻链可变区。
5.权利要求1-4任一项的分离的抗体或其抗原结合部分,其选自由嵌合抗体,人源化抗体,人抗体,和双特异性抗体组成的组。
6.权利要求1-4任一项的分离的抗体或其抗原结合部分,其为抗体片段。
7.一种多核苷酸,其编码权利要求1-6任一项的抗体或其抗原结合部分。
8.一种载体,其包含权利要求7的多核苷酸。
9.权利要求8的载体,其中该载体为表达载体。
10.一种宿主细胞,其包含权利要求8或9的载体。
11.权利要求10的宿主细胞,其中该宿主细胞是原核的。
12.权利要求10的宿主细胞,其中该宿主细胞是真核的。
13.权利要求10的宿主细胞,其中该宿主细胞是哺乳动物的。
14.一种用于生成抗FGFR2/3抗体的方法,所述方法包含培养包含编码权利要求1-6任一项的抗体或其抗原结合部分的多核苷酸的宿主细胞,使得该多核苷酸表达。
15.权利要求14的方法,所述方法还包含自培养物回收该抗体或其抗原结合部分。
16.权利要求14或15的方法,其中该宿主细胞是原核的。
17.权利要求14或15的方法,其中该宿主细胞是真核的。
18.权利要求14或15的方法,其中该宿主细胞是哺乳动物的。
19.权利要求1-6任一项的抗体或其抗原结合部分在制备供一种用于治疗肿瘤的方法使用的药物中的用途。
20.权利要求1-6任一项的抗体或其抗原结合部分在制备供一种用于治疗癌症的方法使用的药物中的用途。
21.权利要求1-6任一项的抗体或其抗原结合部分在制备供一种用于治疗细胞增殖性病症的方法使用的药物中的用途。
22.一种药物配制剂,其包含权利要求1-6任一项的抗体或其抗原结合部分。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201462075740P | 2014-11-05 | 2014-11-05 | |
| US62/075,740 | 2014-11-05 | ||
| PCT/US2015/059335 WO2016073789A2 (en) | 2014-11-05 | 2015-11-05 | Anti-fgfr2/3 antibodies and methods using same |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN107108740A CN107108740A (zh) | 2017-08-29 |
| CN107108740B true CN107108740B (zh) | 2021-09-17 |
Family
ID=54542605
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201580064184.0A Active CN107108740B (zh) | 2014-11-05 | 2015-11-05 | 抗fgfr2/3抗体及其使用方法 |
Country Status (11)
| Country | Link |
|---|---|
| US (1) | US10208120B2 (zh) |
| EP (1) | EP3215533A2 (zh) |
| JP (1) | JP6877350B2 (zh) |
| KR (1) | KR20170080675A (zh) |
| CN (1) | CN107108740B (zh) |
| BR (1) | BR112017008666A2 (zh) |
| CA (1) | CA2961439A1 (zh) |
| HK (1) | HK1243104A1 (zh) |
| MX (1) | MX2017003478A (zh) |
| RU (1) | RU2017119185A (zh) |
| WO (1) | WO2016073789A2 (zh) |
Families Citing this family (36)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| RU2021107536A (ru) * | 2015-11-23 | 2021-07-02 | Файв Прайм Терапьютикс, Инк. | Ингибиторы fgfr2 отдельно или в комбинации с иммуностимулирующими агентами в лечении рака |
| WO2018045110A1 (en) | 2016-08-30 | 2018-03-08 | Xencor, Inc. | Bispecific immunomodulatory antibodies that bind costimulatory and checkpoint receptors |
| AU2017342559B2 (en) | 2016-10-14 | 2022-03-24 | Xencor, Inc. | Bispecific heterodimeric fusion proteins containing IL-15/IL-15Ralpha Fc-fusion proteins and PD-1 antibody fragments |
| JP2018139530A (ja) | 2017-02-27 | 2018-09-13 | 帝人ファーマ株式会社 | 認知症治療又は予防のためのヒト化抗体及びその製造方法、並びにそれを用いた認知症治療剤又は予防剤 |
| KR102207221B1 (ko) * | 2017-03-06 | 2021-03-24 | 서울대학교산학협력단 | 도펠-타겟팅 분자를 이용한 병리학적 신생혈관 생성을 억제하는 방법 |
| JP2020529832A (ja) | 2017-06-30 | 2020-10-15 | ゼンコア インコーポレイテッド | IL−15/IL−15Rαおよび抗原結合ドメインを含む標的化ヘテロダイマーFc融合タンパク質 |
| WO2019125732A1 (en) | 2017-12-19 | 2019-06-27 | Xencor, Inc. | Engineered il-2 fc fusion proteins |
| CA3097593A1 (en) | 2018-04-18 | 2019-10-24 | Xencor, Inc. | Pd-1 targeted heterodimeric fusion proteins containing il-15/il-15ra fc-fusion proteins and pd-1 antigen binding domains and uses thereof |
| AU2019256529A1 (en) | 2018-04-18 | 2020-11-26 | Xencor, Inc. | TIM-3 targeted heterodimeric fusion proteins containing IL-15/IL-15Ra Fc-fusion proteins and TIM-3 antigen binding domains |
| KR20210003813A (ko) | 2018-04-18 | 2021-01-12 | 젠코어 인코포레이티드 | IL-15/IL-15Rα Fc-융합 단백질 및 LAG-3 항원 결합 도메인을 함유하는 LAG-3 표적화 이종이량체 융합 단백질 |
| IL278090B1 (en) | 2018-04-18 | 2024-03-01 | Xencor Inc | Proteins from heterodimeric il-15/il-15rα ohi-fc and their uses |
| CN109030835B (zh) * | 2018-09-06 | 2021-06-22 | 江苏省人民医院(南京医科大学第一附属医院) | 一种分析Rab8调节Klotho表达在非小细胞肺癌中的作用的方法 |
| JP2022503959A (ja) | 2018-10-03 | 2022-01-12 | ゼンコア インコーポレイテッド | Il-12ヘテロ二量体fc-融合タンパク質 |
| BR112021006783A2 (pt) | 2018-10-12 | 2021-07-13 | Xencor, Inc. | proteína de fusão fc heterodimérica de il-15/r¿ direcionada, composição de ácido nucleico, composição de vetor de expressão, célula hospedeira, e, métodos de produção da proteína de fusão fc heterodimérica de il-15/r¿ direcionada e de tratamento de um câncer. |
| CN111116745B (zh) * | 2018-11-01 | 2022-10-14 | 上海新理念生物医药科技有限公司 | 抗CD79b抗体、其药物偶联物及其应用 |
| WO2020132646A1 (en) | 2018-12-20 | 2020-06-25 | Xencor, Inc. | Targeted heterodimeric fc fusion proteins containing il-15/il-15ra and nkg2d antigen binding domains |
| JP7418756B2 (ja) | 2019-01-23 | 2024-01-22 | ミレニアム ファーマシューティカルズ, インコーポレイテッド | 脱免疫化志賀毒素aサブユニットエフェクターを含むcd38結合性タンパク質 |
| US11414496B2 (en) | 2019-01-23 | 2022-08-16 | Takeda Pharmaceutical Company Limited | Anti-CD38 binding domains |
| US20210171596A1 (en) | 2019-02-21 | 2021-06-10 | Gregory Moore | Untargeted and targeted il-10 fc-fusion proteins |
| US11384146B2 (en) | 2019-04-01 | 2022-07-12 | Curia Ip Holdings, Llc | BTLA-binding antibodies for modulating immune response and treating disease |
| CN110133285B (zh) * | 2019-05-09 | 2022-05-03 | 青岛海兰深生物科技有限公司 | 一种检测抗肝癌天然抗体的检测试剂、试剂盒和方法 |
| CA3141459A1 (en) | 2019-05-17 | 2020-11-26 | Xencor, Inc. | Il-7-fc-fusion proteins |
| US20210102002A1 (en) | 2019-08-06 | 2021-04-08 | Xencor, Inc. | HETERODIMERIC IgG-LIKE BISPECIFIC ANTIBODIES |
| US11851466B2 (en) | 2019-10-03 | 2023-12-26 | Xencor, Inc. | Targeted IL-12 heterodimeric Fc-fusion proteins |
| TW202128757A (zh) | 2019-10-11 | 2021-08-01 | 美商建南德克公司 | 具有改善之特性的 PD-1 標靶 IL-15/IL-15Rα FC 融合蛋白 |
| IL293869A (en) | 2019-12-19 | 2022-08-01 | Ngm Biopharmaceuticals Inc | ilt3 binding factors and methods of their use |
| CN115151567A (zh) | 2019-12-23 | 2022-10-04 | 索特里亚生物治疗药物公司 | 治疗性Fc组合物的化学诱导结合和解离以及T细胞接合器与人血清白蛋白的化学诱导二聚化 |
| AU2020410863A1 (en) * | 2019-12-24 | 2022-06-23 | Dizal (Jiangsu) Pharmaceutical Co., Ltd. | Novel anti-FGFR2b antibodies |
| WO2022076573A1 (en) | 2020-10-06 | 2022-04-14 | Xencor, Inc. | Biomarkers, methods, and compositions for treating autoimmune disease including systemic lupus erythematous (sle) |
| WO2022140701A1 (en) | 2020-12-24 | 2022-06-30 | Xencor, Inc. | Icos targeted heterodimeric fusion proteins containing il-15/il-15ra fc-fusion proteins and icos antigen binding domains |
| WO2022211829A1 (en) | 2021-03-30 | 2022-10-06 | Jazz Pharmaceuticals Ireland Ltd. | Dosing of recombinant l-asparaginase |
| US20230146665A1 (en) | 2021-07-27 | 2023-05-11 | Xencor, Inc. | Il-18-fc fusion proteins |
| CA3225405A1 (en) | 2021-07-28 | 2023-02-02 | Alexander Joachim Paul Ungewickell | Il15/il15r alpha heterodimeric fc-fusion proteins for the treatment of blood cancers |
| WO2023015198A1 (en) | 2021-08-04 | 2023-02-09 | Genentech, Inc. | Il15/il15r alpha heterodimeric fc-fusion proteins for the expansion of nk cells in the treatment of solid tumours |
| WO2023196905A1 (en) | 2022-04-07 | 2023-10-12 | Xencor, Inc. | Lag-3 targeted heterodimeric fusion proteins containing il-15/il-15ra fc-fusion proteins and lag-3 antigen binding domains |
| WO2024015529A2 (en) | 2022-07-14 | 2024-01-18 | Jazz Pharmaceuticals Ireland Ltd. | Combination therapies involving l-asparaginase |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2007144893A2 (en) * | 2006-06-15 | 2007-12-21 | Fibron Ltd. | Antibodies blocking fibroblast growth factor receptor activation and methods of use thereof |
| CA2754163A1 (en) * | 2009-03-25 | 2010-09-30 | Genentech, Inc. | Anti-fgfr3 antibodies and methods using same |
Family Cites Families (124)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3773919A (en) | 1969-10-23 | 1973-11-20 | Du Pont | Polylactide-drug mixtures |
| US3896111A (en) | 1973-02-20 | 1975-07-22 | Research Corp | Ansa macrolides |
| US4151042A (en) | 1977-03-31 | 1979-04-24 | Takeda Chemical Industries, Ltd. | Method for producing maytansinol and its derivatives |
| US4137230A (en) | 1977-11-14 | 1979-01-30 | Takeda Chemical Industries, Ltd. | Method for the production of maytansinoids |
| USRE30985E (en) | 1978-01-01 | 1982-06-29 | Serum-free cell culture media | |
| US4265814A (en) | 1978-03-24 | 1981-05-05 | Takeda Chemical Industries | Matansinol 3-n-hexadecanoate |
| US4307016A (en) | 1978-03-24 | 1981-12-22 | Takeda Chemical Industries, Ltd. | Demethyl maytansinoids |
| JPS5562090A (en) | 1978-10-27 | 1980-05-10 | Takeda Chem Ind Ltd | Novel maytansinoid compound and its preparation |
| US4256746A (en) | 1978-11-14 | 1981-03-17 | Takeda Chemical Industries | Dechloromaytansinoids, their pharmaceutical compositions and method of use |
| JPS55164687A (en) | 1979-06-11 | 1980-12-22 | Takeda Chem Ind Ltd | Novel maytansinoid compound and its preparation |
| JPS5566585A (en) | 1978-11-14 | 1980-05-20 | Takeda Chem Ind Ltd | Novel maytansinoid compound and its preparation |
| JPS55102583A (en) | 1979-01-31 | 1980-08-05 | Takeda Chem Ind Ltd | 20-acyloxy-20-demethylmaytansinoid compound |
| JPS55162791A (en) | 1979-06-05 | 1980-12-18 | Takeda Chem Ind Ltd | Antibiotic c-15003pnd and its preparation |
| JPS55164685A (en) | 1979-06-08 | 1980-12-22 | Takeda Chem Ind Ltd | Novel maytansinoid compound and its preparation |
| JPS55164686A (en) | 1979-06-11 | 1980-12-22 | Takeda Chem Ind Ltd | Novel maytansinoid compound and its preparation |
| US4309428A (en) | 1979-07-30 | 1982-01-05 | Takeda Chemical Industries, Ltd. | Maytansinoids |
| JPS5645483A (en) | 1979-09-19 | 1981-04-25 | Takeda Chem Ind Ltd | C-15003phm and its preparation |
| JPS5645485A (en) | 1979-09-21 | 1981-04-25 | Takeda Chem Ind Ltd | Production of c-15003pnd |
| EP0028683A1 (en) | 1979-09-21 | 1981-05-20 | Takeda Chemical Industries, Ltd. | Antibiotic C-15003 PHO and production thereof |
| WO1982001188A1 (en) | 1980-10-08 | 1982-04-15 | Takeda Chemical Industries Ltd | 4,5-deoxymaytansinoide compounds and process for preparing same |
| US4450254A (en) | 1980-11-03 | 1984-05-22 | Standard Oil Company | Impact improvement of high nitrile resins |
| US4419446A (en) | 1980-12-31 | 1983-12-06 | The United States Of America As Represented By The Department Of Health And Human Services | Recombinant DNA process utilizing a papilloma virus DNA as a vector |
| US4315929A (en) | 1981-01-27 | 1982-02-16 | The United States Of America As Represented By The Secretary Of Agriculture | Method of controlling the European corn borer with trewiasine |
| US4313946A (en) | 1981-01-27 | 1982-02-02 | The United States Of America As Represented By The Secretary Of Agriculture | Chemotherapeutically active maytansinoids from Trewia nudiflora |
| JPS57192389A (en) | 1981-05-20 | 1982-11-26 | Takeda Chem Ind Ltd | Novel maytansinoid |
| US4601978A (en) | 1982-11-24 | 1986-07-22 | The Regents Of The University Of California | Mammalian metallothionein promoter system |
| US4560655A (en) | 1982-12-16 | 1985-12-24 | Immunex Corporation | Serum-free cell culture medium and process for making same |
| US4657866A (en) | 1982-12-21 | 1987-04-14 | Sudhir Kumar | Serum-free, synthetic, completely chemically defined tissue culture media |
| US4816567A (en) | 1983-04-08 | 1989-03-28 | Genentech, Inc. | Recombinant immunoglobin preparations |
| US4675187A (en) | 1983-05-16 | 1987-06-23 | Bristol-Myers Company | BBM-1675, a new antibiotic complex |
| US4767704A (en) | 1983-10-07 | 1988-08-30 | Columbia University In The City Of New York | Protein-free culture medium |
| US4683203A (en) | 1984-04-14 | 1987-07-28 | Redco N.V. | Immobilized enzymes, processes for preparing same, and use thereof |
| US4965199A (en) | 1984-04-20 | 1990-10-23 | Genentech, Inc. | Preparation of functional human factor VIII in mammalian cells using methotrexate based selection |
| US4970198A (en) | 1985-10-17 | 1990-11-13 | American Cyanamid Company | Antitumor antibiotics (LL-E33288 complex) |
| US4683195A (en) | 1986-01-30 | 1987-07-28 | Cetus Corporation | Process for amplifying, detecting, and/or-cloning nucleic acid sequences |
| GB8516415D0 (en) | 1985-06-28 | 1985-07-31 | Celltech Ltd | Culture of animal cells |
| US4676980A (en) | 1985-09-23 | 1987-06-30 | The United States Of America As Represented By The Secretary Of The Department Of Health And Human Services | Target specific cross-linked heteroantibodies |
| US4927762A (en) | 1986-04-01 | 1990-05-22 | Cell Enterprises, Inc. | Cell culture medium with antioxidant |
| IL85035A0 (en) | 1987-01-08 | 1988-06-30 | Int Genetic Eng | Polynucleotide molecule,a chimeric antibody with specificity for human b cell surface antigen,a process for the preparation and methods utilizing the same |
| US5079233A (en) | 1987-01-30 | 1992-01-07 | American Cyanamid Company | N-acyl derivatives of the LL-E33288 antitumor antibiotics, composition and methods for using the same |
| EP0307434B2 (en) | 1987-03-18 | 1998-07-29 | Scotgen Biopharmaceuticals, Inc. | Altered antibodies |
| US4975278A (en) | 1988-02-26 | 1990-12-04 | Bristol-Myers Company | Antibody-enzyme conjugates in combination with prodrugs for the delivery of cytotoxic agents to tumor cells |
| US5053394A (en) | 1988-09-21 | 1991-10-01 | American Cyanamid Company | Targeted forms of methyltrithio antitumor agents |
| US5606040A (en) | 1987-10-30 | 1997-02-25 | American Cyanamid Company | Antitumor and antibacterial substituted disulfide derivatives prepared from compounds possessing a methyl-trithio group |
| US5770701A (en) | 1987-10-30 | 1998-06-23 | American Cyanamid Company | Process for preparing targeted forms of methyltrithio antitumor agents |
| IE61148B1 (en) | 1988-03-10 | 1994-10-05 | Ici Plc | Method of detecting nucleotide sequences |
| DE68925971T2 (de) | 1988-09-23 | 1996-09-05 | Cetus Oncology Corp | Zellenzuchtmedium für erhöhtes zellenwachstum, zur erhöhung der langlebigkeit und expression der produkte |
| US5530101A (en) | 1988-12-28 | 1996-06-25 | Protein Design Labs, Inc. | Humanized immunoglobulins |
| DE3920358A1 (de) | 1989-06-22 | 1991-01-17 | Behringwerke Ag | Bispezifische und oligospezifische, mono- und oligovalente antikoerperkonstrukte, ihre herstellung und verwendung |
| DE69029036T2 (de) | 1989-06-29 | 1997-05-22 | Medarex Inc | Bispezifische reagenzien für die aids-therapie |
| US5208020A (en) | 1989-10-25 | 1993-05-04 | Immunogen Inc. | Cytotoxic agents comprising maytansinoids and their therapeutic use |
| CA2026147C (en) | 1989-10-25 | 2006-02-07 | Ravi J. Chari | Cytotoxic agents comprising maytansinoids and their therapeutic use |
| JPH06500011A (ja) | 1990-06-29 | 1994-01-06 | ラージ スケール バイオロジー コーポレイション | 形質転換された微生物によるメラニンの製造 |
| US5122469A (en) | 1990-10-03 | 1992-06-16 | Genentech, Inc. | Method for culturing Chinese hamster ovary cells to improve production of recombinant proteins |
| US5264365A (en) | 1990-11-09 | 1993-11-23 | Board Of Regents, The University Of Texas System | Protease-deficient bacterial strains for production of proteolytically sensitive polypeptides |
| US5508192A (en) | 1990-11-09 | 1996-04-16 | Board Of Regents, The University Of Texas System | Bacterial host strains for producing proteolytically sensitive polypeptides |
| ES2113940T3 (es) | 1990-12-03 | 1998-05-16 | Genentech Inc | Metodo de enriquecimiento para variantes de proteinas con propiedades de union alteradas. |
| US5571894A (en) | 1991-02-05 | 1996-11-05 | Ciba-Geigy Corporation | Recombinant antibodies specific for a growth factor receptor |
| ES2206447T3 (es) | 1991-06-14 | 2004-05-16 | Genentech, Inc. | Anticuerpo humanizado para heregulina. |
| US7018809B1 (en) | 1991-09-19 | 2006-03-28 | Genentech, Inc. | Expression of functional antibody fragments |
| DK0605522T3 (da) | 1991-09-23 | 2000-01-17 | Medical Res Council | Fremgangsmåde til fremstilling af humaniserede antistoffer |
| US5362852A (en) | 1991-09-27 | 1994-11-08 | Pfizer Inc. | Modified peptide derivatives conjugated at 2-hydroxyethylamine moieties |
| US5587458A (en) | 1991-10-07 | 1996-12-24 | Aronex Pharmaceuticals, Inc. | Anti-erbB-2 antibodies, combinations thereof, and therapeutic and diagnostic uses thereof |
| WO1993008829A1 (en) | 1991-11-04 | 1993-05-13 | The Regents Of The University Of California | Compositions that mediate killing of hiv-infected cells |
| JPH07501451A (ja) | 1991-11-25 | 1995-02-16 | エンゾン・インコーポレイテッド | 多価抗原結合タンパク質 |
| US5667988A (en) | 1992-01-27 | 1997-09-16 | The Scripps Research Institute | Methods for producing antibody libraries using universal or randomized immunoglobulin light chains |
| AU675929B2 (en) | 1992-02-06 | 1997-02-27 | Curis, Inc. | Biosynthetic binding protein for cancer marker |
| ZA932522B (en) | 1992-04-10 | 1993-12-20 | Res Dev Foundation | Immunotoxins directed against c-erbB-2(HER/neu) related surface antigens |
| ATE149570T1 (de) | 1992-08-17 | 1997-03-15 | Genentech Inc | Bispezifische immunoadhesine |
| CA2149329C (en) | 1992-11-13 | 2008-07-15 | Darrell R. Anderson | Therapeutic application of chimeric and radiolabeled antibodies to human b lymphocyte restricted differentiation antigen for treatment of b cell lymphoma |
| US5635483A (en) | 1992-12-03 | 1997-06-03 | Arizona Board Of Regents Acting On Behalf Of Arizona State University | Tumor inhibiting tetrapeptide bearing modified phenethyl amides |
| US5780588A (en) | 1993-01-26 | 1998-07-14 | Arizona Board Of Regents | Elucidation and synthesis of selected pentapeptides |
| JPH08511420A (ja) | 1993-06-16 | 1996-12-03 | セルテック・セラピューテイクス・リミテッド | 抗 体 |
| US5773001A (en) | 1994-06-03 | 1998-06-30 | American Cyanamid Company | Conjugates of methyltrithio antitumor agents and intermediates for their synthesis |
| US5910486A (en) | 1994-09-06 | 1999-06-08 | Uab Research Foundation | Methods for modulating protein function in cells using, intracellular antibody homologues |
| US5639635A (en) | 1994-11-03 | 1997-06-17 | Genentech, Inc. | Process for bacterial production of polypeptides |
| US5663149A (en) | 1994-12-13 | 1997-09-02 | Arizona Board Of Regents Acting On Behalf Of Arizona State University | Human cancer inhibitory pentapeptide heterocyclic and halophenyl amides |
| US5641870A (en) | 1995-04-20 | 1997-06-24 | Genentech, Inc. | Low pH hydrophobic interaction chromatography for antibody purification |
| US5869046A (en) | 1995-04-14 | 1999-02-09 | Genentech, Inc. | Altered polypeptides with increased half-life |
| US5739277A (en) | 1995-04-14 | 1998-04-14 | Genentech Inc. | Altered polypeptides with increased half-life |
| US5712374A (en) | 1995-06-07 | 1998-01-27 | American Cyanamid Company | Method for the preparation of substantiallly monomeric calicheamicin derivative/carrier conjugates |
| US6410690B1 (en) | 1995-06-07 | 2002-06-25 | Medarex, Inc. | Therapeutic compounds comprised of anti-Fc receptor antibodies |
| US5714586A (en) | 1995-06-07 | 1998-02-03 | American Cyanamid Company | Methods for the preparation of monomeric calicheamicin derivative/carrier conjugates |
| GB9603256D0 (en) | 1996-02-16 | 1996-04-17 | Wellcome Found | Antibodies |
| AU2660397A (en) | 1996-04-05 | 1997-10-29 | Board Of Regents, The University Of Texas System | Methods for producing soluble, biologically-active disulfide bond-containing eukaryotic proteins in bacterial cells |
| US5869245A (en) | 1996-06-05 | 1999-02-09 | Fox Chase Cancer Center | Mismatch endonuclease and its use in identifying mutations in targeted polynucleotide strands |
| US5922845A (en) | 1996-07-11 | 1999-07-13 | Medarex, Inc. | Therapeutic multispecific compounds comprised of anti-Fcα receptor antibodies |
| US5994071A (en) | 1997-04-04 | 1999-11-30 | Albany Medical College | Assessment of prostate cancer |
| US6083715A (en) | 1997-06-09 | 2000-07-04 | Board Of Regents, The University Of Texas System | Methods for producing heterologous disulfide bond-containing polypeptides in bacterial cells |
| DE69830315T2 (de) | 1997-06-24 | 2006-02-02 | Genentech Inc., San Francisco | Galactosylierte glykoproteine enthaltende zusammensetzungen und verfahren zur deren herstellung |
| ATE419009T1 (de) | 1997-10-31 | 2009-01-15 | Genentech Inc | Methoden und zusammensetzungen bestehend aus glykoprotein-glykoformen |
| US6194551B1 (en) | 1998-04-02 | 2001-02-27 | Genentech, Inc. | Polypeptide variants |
| ATE375365T1 (de) | 1998-04-02 | 2007-10-15 | Genentech Inc | Antikörper varianten und fragmente davon |
| AU3657899A (en) | 1998-04-20 | 1999-11-08 | James E. Bailey | Glycosylation engineering of antibodies for improving antibody-dependent cellular cytotoxicity |
| US6737056B1 (en) | 1999-01-15 | 2004-05-18 | Genentech, Inc. | Polypeptide variants with altered effector function |
| HUP0104865A3 (en) | 1999-01-15 | 2004-07-28 | Genentech Inc | Polypeptide variants with altered effector function |
| EP2275540B1 (en) | 1999-04-09 | 2016-03-23 | Kyowa Hakko Kirin Co., Ltd. | Method for controlling the activity of immunologically functional molecule |
| EP1229125A4 (en) | 1999-10-19 | 2005-06-01 | Kyowa Hakko Kogyo Kk | PROCESS FOR PRODUCING A POLYPEPTIDE |
| ATE337403T1 (de) | 1999-12-24 | 2006-09-15 | Genentech Inc | Verfahren und verbindungen zur verlängerung der halbwertzeiten bei der ausscheidung von biowirksamen verbindungen |
| US7064191B2 (en) | 2000-10-06 | 2006-06-20 | Kyowa Hakko Kogyo Co., Ltd. | Process for purifying antibody |
| US6946292B2 (en) | 2000-10-06 | 2005-09-20 | Kyowa Hakko Kogyo Co., Ltd. | Cells producing antibody compositions with increased antibody dependent cytotoxic activity |
| EP2341060B1 (en) | 2000-12-12 | 2019-02-20 | MedImmune, LLC | Molecules with extended half-lives, compositions and uses thereof |
| US6884869B2 (en) | 2001-04-30 | 2005-04-26 | Seattle Genetics, Inc. | Pentapeptide compounds and uses related thereto |
| IL159177A0 (en) | 2001-06-20 | 2004-06-01 | Prochon Biotech Ltd | Antibodies that block receptor protein tyrosine kinase activation, methods of screening for and uses thereof |
| NZ592087A (en) | 2001-08-03 | 2012-11-30 | Roche Glycart Ag | Antibody glycosylation variants having increased antibody-dependent cellular cytotoxicity |
| ES2326964T3 (es) | 2001-10-25 | 2009-10-22 | Genentech, Inc. | Composiciones de glicoproteina. |
| US20040093621A1 (en) | 2001-12-25 | 2004-05-13 | Kyowa Hakko Kogyo Co., Ltd | Antibody composition which specifically binds to CD20 |
| AU2003236019A1 (en) | 2002-04-09 | 2003-10-20 | Kyowa Hakko Kirin Co., Ltd. | Drug containing antibody composition appropriate for patient suffering from Fc Gamma RIIIa polymorphism |
| US7691568B2 (en) | 2002-04-09 | 2010-04-06 | Kyowa Hakko Kirin Co., Ltd | Antibody composition-containing medicament |
| CA2481837A1 (en) | 2002-04-09 | 2003-10-16 | Kyowa Hakko Kogyo Co., Ltd. | Production process for antibody composition |
| AU2003236018A1 (en) | 2002-04-09 | 2003-10-20 | Kyowa Hakko Kirin Co., Ltd. | METHOD OF ENHANCING ACTIVITY OF ANTIBODY COMPOSITION OF BINDING TO FcGamma RECEPTOR IIIa |
| ATE503829T1 (de) | 2002-04-09 | 2011-04-15 | Kyowa Hakko Kirin Co Ltd | Zelle mit erniedrigter oder deletierter aktivität eines am gdp-fucosetransport beteiligten proteins |
| US20040110704A1 (en) | 2002-04-09 | 2004-06-10 | Kyowa Hakko Kogyo Co., Ltd. | Cells of which genome is modified |
| US7361740B2 (en) | 2002-10-15 | 2008-04-22 | Pdl Biopharma, Inc. | Alteration of FcRn binding affinities or serum half-lives of antibodies by mutagenesis |
| DE60332957D1 (de) | 2002-12-16 | 2010-07-22 | Genentech Inc | Immunoglobulinvarianten und deren verwendungen |
| US20080241884A1 (en) | 2003-10-08 | 2008-10-02 | Kenya Shitara | Fused Protein Composition |
| AU2004280065A1 (en) | 2003-10-09 | 2005-04-21 | Kyowa Hakko Kirin Co., Ltd. | Process for producing antibody composition by using RNA inhibiting the function of alpha1,6-fucosyltransferase |
| EA036531B1 (ru) | 2003-11-05 | 2020-11-19 | Роше Гликарт Аг | Гуманизированное антитело типа ii к cd20 (варианты), фармацевтическая композиция, содержащая эти варианты антитела, и их применение |
| JPWO2005053742A1 (ja) | 2003-12-04 | 2007-06-28 | 協和醗酵工業株式会社 | 抗体組成物を含有する医薬 |
| SI1773885T1 (sl) | 2004-08-05 | 2010-08-31 | Genentech Inc | Humanizirani anti-CMET antagonisti |
| JP2008519028A (ja) | 2004-11-04 | 2008-06-05 | フィブロン リミテッド | B細胞悪性腫瘍の治療 |
| NZ563370A (en) | 2005-06-20 | 2010-10-29 | Genentech Inc | Compositions and methods for the diagnosis and treatment of tumor |
| EP2313435A4 (en) | 2008-07-01 | 2012-08-08 | Aveo Pharmaceuticals Inc | FIBROBLAST GROWTH FACTOR RECEPTOR 3 (FGFR3) BINDING PROTEINS |
| TWI728373B (zh) | 2013-12-23 | 2021-05-21 | 美商建南德克公司 | 抗體及使用方法 |
-
2015
- 2015-11-05 CA CA2961439A patent/CA2961439A1/en not_active Abandoned
- 2015-11-05 BR BR112017008666-2A patent/BR112017008666A2/pt not_active Application Discontinuation
- 2015-11-05 EP EP15794781.3A patent/EP3215533A2/en not_active Withdrawn
- 2015-11-05 JP JP2017543319A patent/JP6877350B2/ja active Active
- 2015-11-05 RU RU2017119185A patent/RU2017119185A/ru not_active Application Discontinuation
- 2015-11-05 MX MX2017003478A patent/MX2017003478A/es unknown
- 2015-11-05 CN CN201580064184.0A patent/CN107108740B/zh active Active
- 2015-11-05 KR KR1020177015299A patent/KR20170080675A/ko unknown
- 2015-11-05 WO PCT/US2015/059335 patent/WO2016073789A2/en active Application Filing
- 2015-11-05 US US14/934,059 patent/US10208120B2/en active Active
-
2018
- 2018-02-23 HK HK18102604.4A patent/HK1243104A1/zh unknown
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2007144893A2 (en) * | 2006-06-15 | 2007-12-21 | Fibron Ltd. | Antibodies blocking fibroblast growth factor receptor activation and methods of use thereof |
| CA2754163A1 (en) * | 2009-03-25 | 2010-09-30 | Genentech, Inc. | Anti-fgfr3 antibodies and methods using same |
Non-Patent Citations (5)
| Title |
|---|
| "Antibody-based targeting of FGFR3 in bladder carcinoma and t(4;14)-positive multiple myeloma in mice";Jing Qing et al.;《The Journal of Clinical Investigation》;20090531;第119卷(第5期);第1216-1229页 * |
| "FGFR Signaling Promotes the Growth of Triple-Negative and Basal-Like Breast Cancer Cell Lines Both In Vitro and In Vivo";Rachel Sharpe et al.;《Clinical Cancer Research》;20110628;第17卷(第16期);第5275-5286页 * |
| "Mechanisms of FGFR-mediated carcinogenesis";Imran Ahmad et al.;《Biochimica et Biophysica Acta》;20120118;第1823卷;第850-860页 * |
| "The inhibitory anti-FGFR3 antibody, PRO-001, is cytotoxic to t(4;14) multiple myeloma cells";Suzanne Trudel et al.;《BLOOD》;20060515;第107卷(第10期);第4039-4046页 * |
| "成纤维细胞生长因子受体的性质及应用";王晓杰;《吉林大学学报(医学版)》;20100530;第36卷(第3期);第603-606页 * |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2017538442A (ja) | 2017-12-28 |
| US20160244525A1 (en) | 2016-08-25 |
| MX2017003478A (es) | 2018-02-01 |
| US10208120B2 (en) | 2019-02-19 |
| EP3215533A2 (en) | 2017-09-13 |
| JP6877350B2 (ja) | 2021-05-26 |
| WO2016073789A2 (en) | 2016-05-12 |
| RU2017119185A (ru) | 2018-12-05 |
| HK1243104A1 (zh) | 2018-07-06 |
| RU2017119185A3 (zh) | 2019-05-29 |
| KR20170080675A (ko) | 2017-07-10 |
| BR112017008666A2 (pt) | 2018-01-30 |
| WO2016073789A3 (en) | 2016-06-30 |
| CN107108740A (zh) | 2017-08-29 |
| CA2961439A1 (en) | 2016-05-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN107108740B (zh) | 抗fgfr2/3抗体及其使用方法 | |
| US11401333B2 (en) | Anti-FGFR3 antibodies and methods using same | |
| JP2017538442A5 (zh) | ||
| JP2012521759A5 (zh) | ||
| AU2013205318B2 (en) | Anti-FGFR3 antibodies and methods using same |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| REG | Reference to a national code |
Ref country code: HK Ref legal event code: DE Ref document number: 1243104 Country of ref document: HK |
|
| GR01 | Patent grant | ||
| GR01 | Patent grant |