WO2021117841A1 - カブトガニ由来組換えFactorG及びこれを用いたβ-グルカンの測定方法 - Google Patents
カブトガニ由来組換えFactorG及びこれを用いたβ-グルカンの測定方法 Download PDFInfo
- Publication number
- WO2021117841A1 WO2021117841A1 PCT/JP2020/046178 JP2020046178W WO2021117841A1 WO 2021117841 A1 WO2021117841 A1 WO 2021117841A1 JP 2020046178 W JP2020046178 W JP 2020046178W WO 2021117841 A1 WO2021117841 A1 WO 2021117841A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- seq
- subunit
- factor
- amino acid
- nucleic acid
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images





Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/48—Hydrolases (3) acting on peptide bonds (3.4)
- C12N9/50—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25)
- C12N9/64—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/43504—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from invertebrates
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/43504—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from invertebrates
- C07K14/43509—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from invertebrates from crustaceans
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/48—Hydrolases (3) acting on peptide bonds (3.4)
- C12N9/50—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25)
- C12N9/64—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue
- C12N9/6402—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue from non-mammals
- C12N9/6405—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue from non-mammals not being snakes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/48—Hydrolases (3) acting on peptide bonds (3.4)
- C12N9/50—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25)
- C12N9/64—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue
- C12N9/6402—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue from non-mammals
- C12N9/6405—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from animal tissue from non-mammals not being snakes
- C12N9/6408—Serine endopeptidases (3.4.21)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/34—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving hydrolase
- C12Q1/37—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving hydrolase involving peptidase or proteinase
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/20—Fusion polypeptide containing a tag with affinity for a non-protein ligand
- C07K2319/21—Fusion polypeptide containing a tag with affinity for a non-protein ligand containing a His-tag
Definitions
- the present invention includes a heterodimer composed of a novel Factor G ⁇ subunit and Factor G ⁇ subunit derived from horseshoe crab, a method for measuring ⁇ -glucan (hereinafter abbreviated as “BG”) using the heterodimer, and the heterodimer.
- BG ⁇ -glucan
- Deep mycoses in the internal organs, blood system, and lymphatic system are a type of opportunistic infection that affects patients with weakened resistance, such as immunodeficiency, and patients often become extremely serious. ..
- Typical examples of the causative fungi of deep-seated mycosis include Candida and Aspergillus, and BG is commonly present in all cell walls. Therefore, it is useful to detect and measure blood BG.
- the concentration of BG in plasma or serum is used as an index for early diagnosis of deep fungal infection, therapeutic effect and determination of prognosis.
- BG is a polysaccharide whose main chain is a ⁇ (1 ⁇ 3) -bonded glucose repeating structure, and is a substance having a high molecular weight of about several thousand to one million. It may have a (1 ⁇ 6) bond or a (1 ⁇ 4) bond branch.
- Amebocyte Lysate hereinafter abbreviated as "lysate”
- BG has the property of binding to the BG binding domain portion of the FactorG ⁇ subunit.
- BG As a method for measuring BG, for example, the following synthetic substrate method using a synthetic peptide substrate using the reaction pathway mediated by Factor G in the above-mentioned lysate is known.
- Facotr G When BG binds to the BG binding domain portion of the Factor G ⁇ subunit, Facotr G becomes an active Factor G with protease activity.
- the activated Factor G converts the Proclotting enzyme present in the lysate into a Clotting enzyme by its protease activity (Non-Patent Document 1).
- the crotting enzyme releases pNA by amide hydrolysis of the synthetic substrate of a synthetic peptide substrate (eg, Boc-DEL-pNA). Therefore, BG can be quantified by measuring the absorbance of the produced color-developing substance (pNA).
- Non-Patent Document 2 and Patent Document 1 Factor G ⁇ subunit and ⁇ subunit derived from horseshoe crab ( Tachypleus tridentatus ) have already been cloned (Non-Patent Document 2 and Patent Document 1).
- Patent Document 2 Factor G described in Non-Patent Document 2 and Patent Document 1 is used, and the protease activity is measured without adding BG.
- Patent Document 1 The techniques described in Patent Document 1, Patent Document 2, etc. are performed using the gene sequence determined in Non-Patent Document 2, but an insect cell culture medium is used. However, insect cell culture media are known to have BG contamination from yeast extracts. Further, in Patent Document 1, there is no test in which the protease activity is measured without adding BG. Therefore, it is unclear whether Factor G derived from horseshoe crab of the genus Tachypreus produced in Patent Document 1 was BG-specifically activated.
- Non-Patent Document 2 Non-Patent Document 2 and Patent Document 2.
- the recombinant Tachipreus horseshoe crab-derived Factor G produced by the method could not confirm the protease activity even in the presence of BG. That is, it has been difficult to prepare Factor G (precursor) that converts into active Factor G having protease activity in the presence of BG using the DNA sequences described in these documents.
- Patent Document 3 describes that BG was measured with a detection sensitivity on the order of several ng.
- measurement of plasma or serum BG is required to be performed on the order of several pg, so that the detection sensitivity on the order of several ng does not have sufficient performance for use in clinical diagnosis. ..
- the present invention has been made for the purpose of solving the above problems, and has the following configuration.
- the present invention may include the following configurations.
- a vector incorporating a molecule [9] A nucleic acid molecule having a base sequence encoding the same or substantially the same nucleic acid sequence as the amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4, and SEQ ID NO: 6, 8, 10, 12, 14, or.
- a transformant incorporating a molecule [11] A nucleic acid molecule having a base sequence encoding the same or substantially the same nucleic acid sequence as the amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4, and SEQ ID NO: 6, 8, 10, 12, 14, or A transformant incorporating both nucleic acid molecules having a base sequence encoding the same or substantially the same amino acid sequence as the amino acid sequence represented by any one of 16.
- a sample containing BG is treated from the sample by contacting it with a Factor G ⁇ subunit containing the same or substantially the same amino acid sequence as the amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4. How to remove.
- a ⁇ -glucan removal kit comprising a Factor G ⁇ subunit containing the same or substantially the same amino acid sequence as the amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4.
- the heterodimer of the present invention has a BG-dependent protease activity that exerts a protease activity in the presence of BG. Further, if the BG concentration is measured using the heterodimer of the present invention, it is possible to measure BG with higher sensitivity as compared with the conventional BG measurement method. Further, since the heterodimer of the present invention is a recombinant product, there is no lot difference, and there is an effect that it can be manufactured in large quantities at low cost.
- Example 3 is a calibration curve obtained in Example 1 showing the relationship between the lentinan concentration in the sample and the absorbance.
- 3 is a calibration curve showing the relationship between the lentinan concentration in a sample and the absorbance obtained by using the heterodimer of the Factor G ⁇ subunit A and the Factor G ⁇ subunit ⁇ i2 of the present invention in Example 3.
- Example 3 is a calibration curve showing the relationship between the lentinan concentration in a sample and the absorbance obtained by using the heterodimer of Factor G ⁇ subunit B and Facor G ⁇ subunit ⁇ 2 of the present invention in Example 3.
- the heterodimer of Factor G ⁇ subunit A and Facor G ⁇ subunit ⁇ i2 of the present invention obtained in Example 4 the lentinan concentration in the sample was measured, and the result of measuring the BG concentration in the sample was obtained. Shown.
- BG according to the present invention examples include polysaccharides containing BG as a constituent component and having a property of causing an enzymatic reaction of horseshoe crab blood cell extract.
- various bacteria for example, Alcaligenes , Agrobacterium, etc.
- yeasts for example, Saccharomyces , Candida , Cryptococcus , Trichosporon , Rhodotorula, etc.
- molds Aspergillus , Mucor, etc.
- actinomycetes Actinomyces genus, Nocardia genus, etc.
- mushrooms for example, shiitake, Schizophyllum commune, natural polysaccharides obtained from cell walls or the like of Coriolus versicolor, etc.
- curd curd
- Factor G ⁇ subunit of the present invention is a protein containing the same or substantially the same amino acid sequence as the amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4.
- the Factor G ⁇ subunit of the present invention has the property of binding to BG.
- the Factor G ⁇ subunit of the present invention is preferably derived from Limulus polyphemus.
- the amino acid sequence substantially the same as the amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4 is about 80% or more, preferably about 90% or more, the amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4.
- Examples thereof include the amino acid sequence of a protein having a homology of about 95% or more, more preferably about 97% or more, and having a property of binding to BG.
- amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4 examples thereof include an amino acid sequence in which three amino acids, more preferably one or two, and even more preferably one amino acid are substituted, deleted, inserted, or added. Substitutions, deletions, insertions, or additions may occur simultaneously at one or more sites of an amino acid sequence.
- the position and number of substitutions, deletions, insertions, additions, etc. to the amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4 are such that the protein having the amino acid sequence has the properties of the Factor G ⁇ subunit described above. As long as it is optional.
- a preferable specific example of the Factor G ⁇ subunit of the present invention is a Factor G ⁇ subunit protein containing the amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4.
- a Factor G ⁇ subunit protein containing the amino acid sequence represented by SEQ ID NO: 2 is more preferable.
- the Factor G ⁇ subunit of the present invention may have a known tag peptide such as His tag, FLAG tag, Hat tag, SUMO tag, or a so-called spacer linked to its N-terminal or C-terminal. Further, it may have a fragment of a signal peptide having 1 to several amino acids, for example, 1 to 3 amino acids at its N-terminal.
- a protein containing the same or substantially the same amino acid sequence as the amino acid sequence represented by SEQ ID NO: 2 may be abbreviated as "Factor G ⁇ subunit A” or simply “ ⁇ subunit A” below.
- a protein containing the same or substantially the same amino acid sequence as the amino acid sequence represented by SEQ ID NO: 4 may be abbreviated as “Factor G ⁇ subunit B” or simply “ ⁇ subunit B” below.
- Factor G ⁇ subunit When simply described as “Factor G ⁇ subunit”, it means a general term for the Factor G ⁇ subunit of the present invention including both “Factor G ⁇ subunit A” and “Factor G ⁇ subunit B”. Further, when simply described as “amino acid sequence of Factor G ⁇ subunit”, it means a general term for the above-mentioned "amino acid sequence which is the same as or substantially the same as the amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4". ..
- the Factor G ⁇ subunit of the present invention is an amino acid that is the same as or substantially the same as the amino acid sequence represented by any one of SEQ ID NOs: 6, 8, 10, 12, 14, and 16. It is a protein containing a sequence.
- the Factor G ⁇ subunit of the present invention has a domain of serine protease, but has no enzymatic activity, and exhibits protease activity when forming a heterodimer with the Factor G ⁇ subunit of the present invention described above.
- the Factor G ⁇ subunit of the present invention is preferably derived from Limulus polyphemus.
- amino acid sequence that is substantially the same as the amino acid sequence represented by any one of SEQ ID NOs: 6, 8, 10, 12, 14, and 16 is SEQ ID NO: 6, 8, 10, 12, 14, or 16. It has about 80% or more, preferably about 90% or more, more preferably about 95% or more, still more preferably about 97% or more homology with the amino acid sequence represented by any one of the above-mentioned Factor G. Amino acid sequences of proteins having ⁇ -subunit properties can be mentioned.
- amino acid sequence substantially the same as the amino acid sequence represented by any one of SEQ ID NOs: 6, 8, 10, 12, 14, and 16
- the amino acid sequence of SEQ ID NO: 6, 8, 10, 12, 14, Alternatively, in the amino acid sequence represented by any one of 16, 1 to 5, preferably 1 to 3, more preferably 1 to 2, and even more preferably 1 amino acid is substituted, deleted, or inserted.
- the added amino acid sequence can be mentioned.
- Substitutions, deletions, insertions, or additions may occur simultaneously at one or more sites of an amino acid sequence.
- the position and number of subunits, deletions, insertions, additions, etc. to the amino acid sequence represented by any one of SEQ ID NOs: 6, 8, 10, 12, 14, and 16 are determined by the protein having the amino acid sequence. It is optional as long as it has the properties of the Factor G ⁇ subunit.
- Factor G ⁇ subunit of the present invention include a Factor G ⁇ subunit protein containing an amino acid sequence represented by any one of SEQ ID NOs: 6, 8, 10, 12, 14, and 16. ..
- a Factor G ⁇ subunit protein containing an amino acid sequence represented by any one of SEQ ID NOs: 6, 8 or 10 is more preferable.
- a Factor G ⁇ subunit protein containing the amino acid sequence represented by SEQ ID NO: 6 or 8 is more preferable.
- the Factor G ⁇ subunit of the present invention may have a known tag peptide such as His tag, FLAG tag, Hat tag, SUMO tag, or a so-called spacer linked to its N-terminal or C-terminal. Further, it may have a fragment of a signal peptide having 1 to several amino acids, for example, 1 to 3 amino acids at its N-terminal.
- Proteins containing the same or substantially the same amino acid sequence as the amino acid sequence represented by any one of SEQ ID NOs: 6, 8, 10, 12, 14, and 16 of the present invention are named as follows. To do.
- Fractor G ⁇ subunit ⁇ i2 is “ ⁇ subunit ⁇ i2”
- Factor G ⁇ subunit ⁇ i3 is “ ⁇ subunit ⁇ i3”
- Factor G ⁇ subunit ⁇ 2 is “ ⁇ subunit ⁇ 2”
- Factor G ⁇ subunit” " ⁇ 5" may be abbreviated as “ ⁇ subunit ⁇ 5"
- FactorG ⁇ subunit ⁇ C1 may be abbreviated as “ ⁇ subunit ⁇ C1”
- “FactorG ⁇ subunit ⁇ C2” may be abbreviated as " ⁇ subunit ⁇ C2”.
- amino acid sequence of Factor G ⁇ subunit when simply described as "amino acid sequence of Factor G ⁇ subunit", it is the same as or substantially the same as the amino acid sequence represented by any one of the above-mentioned "SEQ ID NOs: 6, 8, 10, 12, 14, and 16". It means a general term for "the same amino acid sequence”.
- heterodimer of the present invention is "a Factor G ⁇ subunit containing the same or substantially the same amino acid sequence as the amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4 and SEQ ID NOs: 6 and 8.
- the heterodimer of the present invention "is a Factor G ⁇ subunit containing the same or substantially the same amino acid sequence as the amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4, and SEQ ID NOs: 6, 8, 10 , 12, 14, or a heterodimer composed of Factor G ⁇ subunits containing the same or substantially the same amino acid sequence as the amino acid sequence represented by any one of 16.
- Vector G ⁇ subunit containing the same or substantially the same amino acid sequence as the amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4", and “SEQ ID NO: 6, 8, 10, 12, 14, or 16". Specific examples of the “Factor G ⁇ subunit” containing the same or substantially the same amino acid sequence as the amino acid sequence represented by any one of the above-mentioned “2. Factor G ⁇ subunit of the present invention” and As described in the section "3. Factor G ⁇ subunit of the present invention”.
- the heterodimer of the present invention has protease activity in the presence of BG.
- Table 1 below shows specific examples of combinations of the Factor G ⁇ subunit and the Factor G ⁇ subunit that constitute the heterodimer of the present invention.
- Preferred combinations of the Factor G ⁇ subunit and the Factor G ⁇ subunit of the heterodimer of the present invention include combinations of combination numbers 1, 2, 3, 4, 5, 6, 8, 9, or 12 in Table 1 above. ..
- the Factor G ⁇ subunit and Factor G ⁇ subunit constituting the heterodimer of the present invention have known tag peptides such as His tag, FLAG tag, Hat tag, and SUMO tag bound to their N-terminal or C-terminal, and so-called spacers. You may be. Further, the Factor G ⁇ subunit and the Factor G ⁇ subunit constituting the heterodimer may have a fragment of a signal peptide having 1 to several amino acids, for example, about 1 to 3 amino acids at the N-terminal thereof.
- Nucleic acid molecule according to the present invention (1) Nucleic acid molecule encoding the Factor G ⁇ subunit of the present invention includes the amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4. Examples thereof include nucleic acid molecules containing a base sequence encoding the same or substantially the same amino acid sequence. Specific examples of "an amino acid sequence that is the same as or substantially the same as the amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4" are as described in the above section "2. Factor G ⁇ subunit of the present invention". is there.
- nucleic acid molecule encoding the Factor G ⁇ subunit of the present invention include the following (i) and (ii).
- nucleic acid molecule containing the same or substantially the same base sequence as the base sequence represented by SEQ ID NO: 1 or SEQ ID NO: 3 The same or substantially the same base sequence as the base sequence represented by SEQ ID NO: 1.
- the nucleic acid molecule containing is encoding the same or substantially the same amino acid sequence as the amino acid sequence represented by SEQ ID NO: 2.
- a nucleic acid molecule containing the same or substantially the same base sequence as the base sequence represented by SEQ ID NO: 3 encodes the same or substantially the same amino acid sequence as the amino acid sequence represented by SEQ ID NO: 4.
- the base sequence of "a nucleic acid molecule containing a base sequence substantially the same as the base sequence represented by SEQ ID NO: 1 or SEQ ID NO: 3" is about 80 with the base sequence represented by SEQ ID NO: 1 or SEQ ID NO: 3. % Or more, preferably about 90% or more, more preferably about 95% or more, still more preferably about 97% or more of the base sequence.
- the base sequence of "a nucleic acid molecule containing a base sequence substantially the same as the base sequence represented by SEQ ID NO: 1 or SEQ ID NO: 3" the base sequence represented by SEQ ID NO: 1 or SEQ ID NO: 3 Examples thereof include base sequences in which 1 to 5, preferably 1 to 3, more preferably 1 to 2, and even more preferably 1 base is substituted, deleted, inserted, or added. Substitutions, deletions, insertions, or additions may occur simultaneously at one or more locations in a single base sequence.
- nucleic acid molecule containing the base sequence represented by SEQ ID NO: 1 or SEQ ID NO: 3 is preferable, and the nucleic acid molecule containing the base sequence represented by SEQ ID NO: 1 is more preferable.
- a nucleic acid molecule containing the same or substantially the same base sequence as the base sequence represented by SEQ ID NO: 1 or SEQ ID NO: 3 may be added with a base sequence encoding a so-called signal peptide. Subsequent signal peptides described in the present specification and the base sequences encoding the same are not particularly limited.
- nucleic acid molecule encoding the "Factor G ⁇ subunit of the present invention to which the base sequence encoding the signal peptide is added" are, for example, the same as or substantially the same as the base sequence represented by SEQ ID NO: 17 or SEQ ID NO: 19. Nucleic acid molecules containing the same base sequence can be mentioned.
- the base sequence of "a nucleic acid molecule containing a base sequence substantially the same as the base sequence represented by SEQ ID NO: 17 or SEQ ID NO: 19" is about 80 with the base sequence represented by SEQ ID NO: 17 or SEQ ID NO: 19. % Or more, preferably about 90% or more, more preferably about 95% or more, still more preferably about 97% or more of the base sequence.
- the base sequence of "a nucleic acid molecule containing a base sequence substantially the same as the base sequence represented by SEQ ID NO: 17 or SEQ ID NO: 19” the base sequence represented by SEQ ID NO: 17 or SEQ ID NO: 19 Examples thereof include base sequences in which 1 to 5, preferably 1 to 3, more preferably 1 to 2, and even more preferably 1 base is substituted, deleted, inserted, or added. Substitutions, deletions, insertions, or additions may occur simultaneously at one or more locations in a single base sequence.
- nucleic acid molecules a nucleic acid molecule containing the base sequence represented by SEQ ID NO: 17 or SEQ ID NO: 19 is preferable, and a nucleic acid molecule containing the base sequence represented by SEQ ID NO: 17 is more preferable.
- nucleic acid molecule containing a base sequence encoding the same or substantially the same nucleic acid sequence as the amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4, and represented by SEQ ID NO: 2 or SEQ ID NO: 4.
- a protein containing the same or substantially the same amino acid sequence as the nucleic acid sequence to be expressed is expressed by a genetic engineering method, it contains a base sequence optimized according to the type of host cell expressing this nucleic acid molecule. Nucleic acid molecule.
- nucleic acid molecules it is a nucleic acid molecule containing a base sequence encoding the amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4, and contains the amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4.
- a nucleic acid molecule containing a base sequence optimized for the type of host cell expressing the nucleic acid molecule is more preferable.
- nucleic acid molecules containing a base sequence encoding the amino acid sequence represented by SEQ ID NO: 2 and a protein containing the amino acid sequence represented by SEQ ID NO: 2 are expressed by a genetic engineering technique, this nucleic acid Nucleic acid molecules containing a base sequence optimized for the type of host cell expressing the molecule are more preferred.
- nucleic acid molecule containing a base sequence encoding the same or substantially the same nucleic acid sequence as the amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4.
- base sequence obtained include nucleic acid molecules containing the same or substantially the same base sequence as the base sequence represented by SEQ ID NO: 33 or SEQ ID NO: 34.
- the base sequence of "a nucleic acid molecule containing a base sequence substantially the same as the base sequence represented by SEQ ID NO: 33 or SEQ ID NO: 34” is about 80 with the base sequence represented by SEQ ID NO: 33 or SEQ ID NO: 34. % Or more, preferably about 90% or more, more preferably about 95% or more, still more preferably about 97% or more of the base sequence.
- the base sequence of "a nucleic acid molecule containing a base sequence substantially the same as the base sequence represented by SEQ ID NO: 33 or SEQ ID NO: 34” the base sequence represented by SEQ ID NO: 33 or SEQ ID NO: 34 Examples thereof include base sequences in which 1 to 5, preferably 1 to 3, more preferably 1 to 2, and even more preferably 1 base is substituted, deleted, inserted, or added. Substitutions, deletions, insertions, or additions may occur simultaneously at one or more locations in a single base sequence.
- nucleic acid molecules a nucleic acid molecule containing the base sequence represented by SEQ ID NO: 33 or SEQ ID NO: 34 is preferable, and a nucleic acid molecule containing the base sequence represented by SEQ ID NO: 33 is particularly preferable.
- a nucleic acid molecule containing the same or substantially the same base sequence as the base sequence represented by SEQ ID NO: 33 or SEQ ID NO: 34 may have a base sequence encoding a so-called signal peptide added.
- Specific examples of such a nucleic acid molecule include a nucleic acid molecule containing the same or substantially the same base sequence as the base sequence represented by SEQ ID NO: 41 or SEQ ID NO: 42.
- the base sequence of "a nucleic acid molecule containing a base sequence substantially the same as the base sequence represented by SEQ ID NO: 41 or SEQ ID NO: 42” is about 80 with the base sequence represented by SEQ ID NO: 41 or SEQ ID NO: 42. % Or more, preferably about 90% or more, more preferably about 95% or more, still more preferably about 97% or more of the base sequence.
- the base sequence of "a nucleic acid molecule containing a base sequence substantially the same as the base sequence represented by SEQ ID NO: 41 or SEQ ID NO: 42” the base sequence represented by SEQ ID NO: 41 or SEQ ID NO: 42 Examples thereof include base sequences in which 1 to 5, preferably 1 to 3, more preferably 1 to 2, and even more preferably 1 base is substituted, deleted, inserted, or added. Substitutions, deletions, insertions, or additions may occur simultaneously at one or more locations in a single base sequence.
- nucleic acid molecules a nucleic acid molecule containing the base sequence represented by SEQ ID NO: 41 or SEQ ID NO: 42 is preferable.
- a nucleic acid molecule containing the nucleotide sequence represented by SEQ ID NO: 41 is more preferable.
- the nucleic acid molecule encoding the Factor G ⁇ subunit of the present invention may be DNA such as cDNA or RNA. Further, the nucleic acid molecule encoding the FactorG ⁇ subunit of the present invention may be single-stranded or double-stranded. In the case of a double strand, for example, it is composed of a base sequence represented by SEQ ID NO: 1, 3, 17, 18, 33, 34, 41, or 42 and a complementary strand thereof.
- nucleic acid molecule encoding the Factor G ⁇ subunit of the present invention has a base sequence encoding a known tag peptide such as His tag, FLAG tag, Hat tag, SUMO tag, or a so-called spacer at its 5'end or 3'end. May be concatenated. Further, a base sequence encoding a signal peptide may be linked to the 5'end.
- a known tag peptide such as His tag, FLAG tag, Hat tag, SUMO tag, or a so-called spacer at its 5'end or 3'end. May be concatenated.
- a base sequence encoding a signal peptide may be linked to the 5'end.
- nucleic acid molecule encoding the Factor G ⁇ subunit of the present invention is represented by any one of SEQ ID NOs: 1, 3, 17, 19, 33, 34, 41, or 42. Examples thereof include nucleic acid molecules containing the nucleotide sequence to be used.
- nucleic acid molecules a nucleic acid molecule containing a base sequence represented by any one of SEQ ID NOs: 1, 17, 33, or 41 is preferable.
- nucleic acid molecules encoding the Factor G ⁇ subunit of the present invention described above may be collectively abbreviated as “nucleic acid molecule ⁇ ” below.
- nucleic acid molecule encoding the Factor G ⁇ subunit of the present invention may be any one of SEQ ID NOs: 6, 8, 10, 12, 14, or 16. Examples thereof include nucleic acid molecules containing a base sequence encoding the same or substantially the same amino acid sequence as the represented amino acid sequence. A specific example of "an amino acid sequence that is the same as or substantially the same as the amino acid sequence represented by any one of SEQ ID NOs: 6, 8, 10, 12, 14, or 16" is described in "3. As explained in the section "FactorG ⁇ subunit".
- nucleic acid molecule encoding the Factor G ⁇ subunit of the present invention include the following (i) and (ii).
- a nucleic acid molecule containing the same or substantially the same base sequence as the base sequence represented by SEQ ID NO: 5 encodes the same or substantially the same amino acid sequence as the amino acid sequence represented by SEQ ID NO: 6. It encodes the amino acid sequence of the FactorG ⁇ subunit ⁇ i2.
- a nucleic acid molecule containing the same or substantially the same base sequence as the base sequence represented by SEQ ID NO: 7 encodes the same or substantially the same amino acid sequence as the amino acid sequence represented by SEQ ID NO: 8. It encodes the amino acid sequence of the FactorG ⁇ subunit ⁇ i3.
- a nucleic acid molecule containing the same or substantially the same base sequence as the base sequence represented by SEQ ID NO: 9 encodes the same or substantially the same amino acid sequence as the amino acid sequence represented by SEQ ID NO: 10. It encodes the amino acid sequence of FactorG ⁇ subunit ⁇ 2.
- a nucleic acid molecule containing the same or substantially the same base sequence as the base sequence represented by SEQ ID NO: 11 is a nucleic acid molecule encoding the same or substantially the same amino acid sequence as the amino acid sequence represented by SEQ ID NO: 12. Is. It encodes the amino acid sequence of FactorG ⁇ subunit ⁇ 5.
- a nucleic acid molecule containing the same or substantially the same base sequence as the base sequence represented by SEQ ID NO: 13 encodes the same or substantially the same amino acid sequence as the amino acid sequence represented by SEQ ID NO: 14. It encodes the amino acid sequence of the FactorG ⁇ subunit ⁇ C1.
- a nucleic acid molecule containing the same or substantially the same base sequence as the base sequence represented by SEQ ID NO: 15 encodes the same or substantially the same amino acid sequence as the amino acid sequence represented by SEQ ID NO: 16. It encodes the amino acid sequence of the FactorG ⁇ subunit ⁇ C2.
- the base sequence of "a nucleic acid molecule containing a base sequence substantially the same as the base sequence represented by any one of SEQ ID NOs: 5, 7, 9, 11, 13, or 15” includes SEQ ID NO: 5. About 80% or more, preferably about 90% or more, more preferably about 95% or more, still more preferably about 97% or more with the base sequence represented by any one of 7, 9, 11, 13, or 15. Examples thereof include base sequences having the same homology.
- the base sequence represented by any one of SEQ ID NOs: 5, 7, 9, 11, 13, or 15 1 to 5, preferably 1 to 3, more preferably 1 to 2, and further.
- a base sequence in which one base is substituted, deleted, inserted, or added is mentioned. Substitutions, deletions, insertions, or additions may occur simultaneously at one or more locations in a single base sequence.
- nucleic acid molecules a nucleic acid molecule containing a base sequence represented by any one of SEQ ID NOs: 5, 7, 9, 11, 13, or 15 is preferable, and any one of SEQ ID NOs: 5, 7, or 9 is preferable.
- a nucleic acid molecule containing the base sequence represented by one is more preferable, and a nucleic acid molecule containing the base sequence represented by SEQ ID NO: 5 or 7 is further preferable.
- a nucleic acid molecule containing the same or substantially the same base sequence as the base sequence represented by any one of SEQ ID NOs: 5, 7, 9, 11, 13, or 15 is a base sequence encoding a so-called signal peptide. May be added.
- the nucleic acid molecule encoding the "Factor G ⁇ subunit of the present invention to which the base sequence encoding the signal peptide is added” any one of SEQ ID NOs: 21, 23, 25, 27, 29, or 31 can be used. Examples thereof include nucleic acid molecules containing the same or substantially the same base sequence as the represented base sequence.
- the base sequence of "a nucleic acid molecule containing a base sequence substantially the same as the base sequence represented by any one of SEQ ID NOs: 21, 23, 25, 27, 29, or 31” includes SEQ ID NO: 21, About 80% or more, preferably about 90% or more, more preferably about 95% or more, still more preferably about 97% or more with the base sequence represented by any one of 23, 25, 27, 29, or 31. Examples thereof include base sequences having the same homology.
- the base sequence of "a nucleic acid molecule containing a base sequence substantially the same as the base sequence represented by any one of SEQ ID NOs: 21, 23, 25, 27, 29, or 31” is a SEQ ID NO: In the base sequence represented by any one of 21, 23, 25, 27, 29, or 31, 1 to 5, preferably 1 to 3, more preferably 1 to 2, and even more preferably 1. Nucleotide sequence in which the base of is substituted, deleted, inserted, or added can be mentioned. Substitutions, deletions, insertions, or additions may occur simultaneously at one or more locations in a single base sequence.
- nucleic acid molecules a nucleic acid molecule containing a base sequence represented by any one of SEQ ID NOs: 21, 23, 25, 27, 29, or 31 is preferable, and any one of SEQ ID NOs: 21, 23, or 25 is preferable.
- a nucleic acid molecule containing the base sequence represented by one is more preferable, and a nucleic acid molecule containing the base sequence represented by SEQ ID NO: 21 or 23 is further preferable.
- a protein containing the same or substantially the same amino acid sequence as the amino acid sequence represented by any one of SEQ ID NOs: 6, 8, 10, 12, 14, or 16 is expressed by a genetic engineering technique.
- a nucleic acid molecule having a base sequence optimized for the type of cell expressing this nucleic acid molecule is expressed by a genetic engineering technique.
- nucleic acid molecules it is a nucleic acid molecule containing a base sequence encoding an amino acid sequence represented by any one of SEQ ID NOs: 6, 8, 10, 12, 14, or 16, and also in SEQ ID NO: 6.
- a protein containing an amino acid sequence represented by any one of 8, 10, 12, 14, or 16 is expressed by a genetic engineering technique, it is optimized according to the type of cell expressing this nucleic acid molecule.
- Nucleic acid molecules having the above-mentioned base sequence are preferable.
- a nucleic acid molecule having a base sequence optimized according to the type of cell expressing the nucleic acid molecule is more preferable.
- nucleic acid molecule containing a base sequence encoding the amino acid sequence represented by SEQ ID NO: 6 or 8 and a protein containing the amino acid sequence represented by SEQ ID NO: 6 or 8 is expressed by a genetic engineering technique.
- a nucleic acid molecule having a base sequence optimized according to the type of cell expressing this nucleic acid molecule is more preferable.
- an insect cell as a host, it contains a base sequence encoding the same or substantially the same amino acid sequence as the amino acid sequence represented by any one of 6, 8, 10, 12, 14, or 16.
- a base sequence optimized for expressing the nucleic acid molecule to be used a nucleic acid containing the same or substantially the same base sequence as the base sequence represented by any one of SEQ ID NOs: 35 to 40 or 69. Nucleic acid is mentioned.
- the base sequence of "a nucleic acid molecule containing a base sequence substantially the same as the base sequence represented by any one of SEQ ID NOs: 35 to 40 or 69" includes any of SEQ ID NOs: 35 to 40 or 69. Examples thereof include a base sequence having a homology of about 80% or more, preferably about 90% or more, more preferably about 95% or more, still more preferably about 97% or more with the base sequence represented by one of them.
- nucleic acid molecule containing a base sequence substantially the same as the base sequence represented by any one of SEQ ID NOs: 35 to 40 or 69 SEQ ID NO: 35 to 40 or 69
- SEQ ID NO: 35 to 40 or 69 In the base sequence represented by any one of the above, 1 to 5, preferably 1 to 3, more preferably 1 to 2, and even more preferably 1 base is substituted, deleted, inserted, or added.
- the base sequence given is mentioned. Substitutions, deletions, insertions, or additions may occur simultaneously at one or more locations in a single base sequence.
- nucleic acid molecules a nucleic acid molecule containing a base sequence represented by any one of SEQ ID NOs: 35 to 40 or 69 is preferable, and any one of SEQ ID NOs: 35, 36, 37, or 69 is represented.
- the nucleic acid molecule containing the base sequence to be used is more preferable, and the nucleic acid molecule containing the base sequence represented by any one of SEQ ID NOs: 35, 36, or 69 is further preferable.
- a nucleic acid molecule containing the same or substantially the same base sequence as the base sequence represented by any one of SEQ ID NOs: 35 to 40 may have a base sequence encoding a so-called signal peptide added.
- Examples of such a nucleic acid molecule include a nucleic acid molecule containing a base sequence substantially the same as the base sequence represented by any one of SEQ ID NOs: 43 to 48.
- a nucleic acid molecule containing a base sequence substantially the same as the base sequence appearing in SEQ ID NO: 68 having a tag sequence with the signal peptide described later can be mentioned.
- the base sequence of "a nucleic acid molecule containing a base sequence substantially the same as the base sequence represented by any one of SEQ ID NOs: 43 to 48 or 68" includes any of SEQ ID NOs: 43 to 48 or 68. Examples thereof include a base sequence having a homology of about 80% or more, preferably about 90% or more, more preferably about 95% or more, still more preferably about 97% or more with the base sequence represented by one of them.
- the base sequence of "a nucleic acid molecule containing a base sequence substantially the same as the base sequence represented by any one of SEQ ID NOs: 43 to 48 or 68" includes SEQ ID NOs: 43 to 48 or 68.
- 1 to 5 preferably 1 to 3, more preferably 1 to 2, and even more preferably 1 base is substituted, deleted, inserted, or added.
- the base sequence given is mentioned. Substitutions, deletions, insertions, or additions may occur simultaneously at one or more locations in a single base sequence.
- nucleic acid molecules a nucleic acid molecule containing a base sequence represented by any one of SEQ ID NOs: 43 to 48 or 68 is preferable, and any one of SEQ ID NOs: 43, 44, 45, or 68 is represented.
- the nucleic acid molecule containing the base sequence to be used is more preferable, and the nucleic acid molecule containing the base sequence represented by SEQ ID NO: 43 or 44 is further preferable.
- the nucleic acid molecule encoding the Factor G ⁇ subunit of the present invention may be DNA such as cDNA or RNA. Further, the nucleic acid molecule encoding the Factor G ⁇ subunit of the present invention may be single-stranded or double-stranded. In the case of a double strand, for example, it is represented by SEQ ID NO: 5, 7, 9, 11, 13, 15, 21, 23, 25, 27, 29, 31, 35-40, 43-48, 68, or 69. It consists of a base sequence and its complementary strand.
- nucleic acid molecule encoding the Factor G ⁇ subunit of the present invention has a base encoding a known tag peptide such as His tag, FLAG tag, Hat tag, SUMO tag, or a so-called spacer at its 5'end or 3'end.
- the sequences may be concatenated.
- a base sequence encoding a signal peptide may be linked to the 5'end.
- nucleic acid molecule encoding the Factor G ⁇ subunit of the present invention are SEQ ID NOs: 5, 7, 9, 11, 13, 15, 21, 23, 25, 27, 29, 31. , 35-40, 43-48, 68, or 69, examples of the nucleic acid molecule containing the nucleotide sequence represented by any one of.
- Nucleic acid molecules containing the base sequence represented by any one of SEQ ID NOs: 5, 7, 9, 21, 23, 25, 35, 36, 37, 43, 44, 45, 68, or 69 are preferable.
- a nucleic acid molecule containing a base sequence represented by any one of SEQ ID NOs: 5, 7, 21, 23, 35, 36, 43, 44, 68, or 69 is more preferable.
- nucleic acid molecules encoding the Factor G ⁇ subunit of the present invention described above may be collectively abbreviated as “nucleic acid molecule ⁇ ” below.
- nucleic acid molecule according to the present invention may be collectively abbreviated as “nucleic acid molecule according to the present invention”.
- the nucleic acid molecule according to the present invention has a base sequence encoding a known tag peptide such as His tag, FLAG tag, Hat tag, SUMO tag or a so-called spacer linked to the 5'end or 3'end. You may be doing it.
- amino acid sequence (SEQ ID NO: 67) in which the signal sequence, Hat tag, SUMO tag, and FactorG ⁇ subunit i2 (amino acid sequence: SEQ ID NO: 6) are arranged in this order from the 5'end side, and encode this amino acid sequence.
- a nucleic acid molecule having a base sequence represented by SEQ ID NO: 68 optimized for insect cells can be mentioned.
- the base sequence encoding Factor G ⁇ subunit i2 is the base sequence represented by SEQ ID NO: 69.
- the nucleic acid molecule according to the present invention may be DNA such as cDNA or RNA.
- Examples of the combination of the nucleic acid molecule ⁇ and the nucleic acid molecule ⁇ that encodes the combination of the Factor G ⁇ subunit and the Factor G ⁇ subunit of the present invention constituting the heterodermer of the present invention include those shown in Table 2 below.
- Preferred combinations of the SEQ ID NOs of (nucleic acid molecule ⁇ -nucleic acid molecule ⁇ ) include combination numbers 1, 2, 3, 4, 5, 6, 8, 9, 12, 13, 14, 15, and 16 in Table 2 above. Combination of 17, 18, 20, 21, 24, 25, 26, 27, 28, 29, 30, 32, 33, 36, 37, 38, 39, 40, 41, 42, 44, 45, 48, or 49 Can be mentioned.
- Method for obtaining heterodimer of the present invention examples include the following three methods. (1) Acquisition method by co-expression (2) Acquisition method by acquiring ⁇ subunit and ⁇ subunit respectively and then binding them (3) Acquisition method by chemical synthesis Among them, considering the yield of heterodimer, etc. , "(1) Acquisition method by co-expression" is preferable.
- the heterodimer of the present invention incorporates the nucleic acid molecule (nucleic acid molecule ⁇ and nucleic acid molecule ⁇ ) according to the present invention into an expression vector such as an appropriate virus or plasmid, and is an appropriate host cell. Is transformed (or transduced) by a conventional method using the recombinant expression vector. The obtained transformant (transductant) is cultured, and the Factor G ⁇ subunit of the present invention and the Factor G ⁇ subunit of the present invention are used. It can be obtained by a well-known method using a gene recombination technique of "co-expressing and secreting the heterodimer of the present invention extracellularly or intracellularly.”
- Examples of the above method include a method using an expression system using eukaryotic cells such as general insect cells, mammalian cells, and yeast, or an expression system using a prokaryote such as Escherichia coli.
- nucleic acid molecule according to the present invention is once incorporated into a transfer vector, and then co-transfected into host insect cells together with baculovirus genomic DNA.
- nucleic acid molecule ⁇ and nucleic acid molecule ⁇ used in this method are as described in the above-mentioned section “5. Nucleic acid molecule according to the present invention”.
- nucleic acid molecule ⁇ used in this method include a nucleic acid molecule containing a base sequence represented by any one of SEQ ID NOs: 1, 3, 17, 19, 33, 34, 41, or 42. Be done. A nucleic acid molecule containing the base sequence represented by any one of SEQ ID NOs: 33, 34, 41, or 42 is more preferable. Nucleic acid molecules containing the nucleotide sequence represented by SEQ ID NO: 41 or 42 are particularly preferable. As the type of nucleic acid molecule, cDNA is more preferable.
- nucleic acid molecule ⁇ used in this method are SEQ ID NOs: 5, 7, 9, 11, 13, 15, 21, 23, 25, 27, 29, 31, 35-40, 43-48, 68, Alternatively, a nucleic acid molecule containing a base sequence represented by any one of 69 can be mentioned.
- a nucleic acid molecule containing the base sequence represented by any one of SEQ ID NOs: 35 to 40, 43 to 48, 68, or 69 is more preferable.
- Nucleic acid molecules containing the base sequence represented by any one of SEQ ID NOs: 43 to 48 or 68 are particularly preferable.
- cDNA is more preferable.
- the method for obtaining the nucleic acid molecule (nucleic acid molecule ⁇ and nucleic acid molecule ⁇ ) according to the present invention is not particularly limited, but is prepared by a chemical synthesis method known per se, or DNA which is usually used for DNA synthesis.
- a nucleic acid molecule according to the present invention can be obtained by a method of synthesizing an oligonucleotide by a usual phosphoamidite method using a synthesizer and purifying it by a conventional method using anion exchange column chromatography.
- NMV Baculovirus-Nuclear Polyhedrosis Virus
- AcNPV Autographa californica nuclear polyhedrosis virus
- Host insect cells include expresSF + TM (manufactured by Protein Science) derived from S. frugiperda , Sf9, Sf21 derived from Spodoptera Frugiperda , High 5 derived from Trichoplusia ni , BTI-TN-5B1-4 (manufactured by Invitrogen). And so on.
- transfer vector examples include vectors for insect cells such as pIEx / Bac-1, pIEx / Bac-3 (Novagen), pVL1392, pVL1393, pBlueBacIII (above, Invitrogen), and pBacPAK9.
- the transfer vector incorporating the nucleic acid molecule according to the present invention can be obtained, for example, by using cDNA as the nucleic acid molecule (nucleic acid molecule ⁇ or / and nucleic acid molecule ⁇ ) according to the present invention and incorporating the cDNA into the transfer vector as described above. Be done.
- the transfer vector may be obtained by a conventional method.
- the cDNA that is the nucleic acid molecule ⁇ or the nucleic acid molecule ⁇ to be incorporated into the transfer vector may be used as it is after being digested with a restriction enzyme or after adding a linker for incorporating the cDNA into the transfer vector, depending on the purpose.
- the desired heterodimer of the present invention may be expressed as a fusion protein with a known marker such as another tag peptide or protein.
- a known marker such as another tag peptide or protein.
- the tag peptides to be fused include FLAG tag, 3XFLAG tag, His tag (His tag, for example, 6 ⁇ His tag) Hat tag, SUMO tag, etc.
- the proteins include ⁇ -galactosidase ( ⁇ -Gal), green fluorescent protein (GFP), Examples include maltose-binding protein (MBP).
- the hetero of the present invention is used. Dimer may be expressed. Specifically, for example, a cDNA having such a sequence may be incorporated into a transfer vector. Then, the heterodimer of the present invention is expressed as a fusion protein with a His tag protein. Therefore, by confirming the expression of this His tag, the expression of the heterodimer of the present invention can be easily confirmed.
- a transfer vector incorporating a nucleic acid molecule and a baculovirus genomic DNA are co-transfected into a host insect cell together.
- ScreenFect TM A plus (Fuji Film sum) is usually used.
- Cotransfection may be performed using a transfection reagent such as Kojunyaku Co., Ltd.
- cotransfection may be performed by a conventional method such as a heat shock method, a calcium phosphate method (Japanese Patent Laid-Open No. 2-227075), or a lipofection method (Proc. Natl. Acad. Sci., USA, 84, 7413, 1987). ..
- the culture supernatant is collected, and recombinant baculovirus is selected and purified by a conventional method such as a limiting dilution method or a plaque method.
- a recombinant baculovirus in which the base sequence of the target nucleic acid molecule ⁇ is incorporated or a recombinant baculovirus (recombinant according to the present invention) in which the base sequence of the nucleic acid molecule ⁇ is incorporated can be obtained. ..
- the recombinant baculovirus (recombinant according to the present invention) obtained above is transfected into a host insect cell by the following method. .. That is, the recombinant baculovirus incorporating the nucleic acid molecule ⁇ and the recombinant baculovirus incorporating the nucleic acid molecule ⁇ are added to the medium of the host cell.
- a host cell which is a transformant according to the present invention obtained by transfection with recombinant baculovirus which is a recombinant according to the present invention can be obtained.
- the transformant according to the present invention can also be obtained by the following method without using baculovirus.
- nucleic acid molecule ⁇ or the nucleic acid molecule ⁇ according to the present invention is incorporated into vector DNA according to, for example, a conventional method. So-called expression vectors are useful.
- the expression vector is one that can replicate, retain or self-proliferate in various host cells of prokaryotic cells and / or eukaryotic cells, and has a function of expressing and producing the polynucleotide of the present invention. There are no particular restrictions. A plasmid vector, a phage vector, etc. are included.
- Such vectors specifically, plasmids used in insect cell expression systems, such as pIZT / V5-His, pIB / V5-His (Termo Fisher Scientific), pIEx and pIEx Bac series (eg pIEx-Bac-1, pIEx-Bac-1, Merck Millipore), Escherichia coli.
- plasmids used in insect cell expression systems such as pIZT / V5-His, pIB / V5-His (Termo Fisher Scientific), pIEx and pIEx Bac series (eg pIEx-Bac-1, pIEx-Bac-1, Merck Millipore), Escherichia coli.
- Derived plasmids such as pUC119 (Takarashuzo), pQE-TRI plasmid (Qiagen), pBluescript II KS + (Stratagene), pBR322 (Takarashuzo), pGEM , PGEX, pUC, pBS, pET, pGEM-3ZpMAL, etc., yeast-derived plasmids such as pB42AD, pESP, pESC, and bacillus-derived plasmids, such as pHT926, pTB51, pHY481.
- yeast-derived plasmids such as pB42AD, pESP, pESC, and bacillus-derived plasmids, such as pHT926, pTB51, pHY481.
- Examples of the plasmid derived from mammalian cells include pCAT3, pcDNA3.1, pCMV, pCAG and the like.
- bacteriophage such as ⁇ phage such as ⁇ ENBL3 (manufactured by Stratagene), ⁇ DASHII (manufactured by Funakoshi), ⁇ gt10, ⁇ gt11 (all manufactured by Toyo Spinning Co., Ltd.) is used as Charmid DNA (Wako Pure Chemical Industries, Ltd.).
- Cosmid vectors such as (manufactured by Wako Pure Chemical Industries, Ltd.) and Lorist6 (manufactured by Wako Pure Chemical Industries, Ltd.) can be mentioned.
- a recombinant expression vector incorporating the nucleic acid molecule according to the present invention can be prepared by incorporating the nucleic acid molecule according to the present invention into the above-mentioned vector or the like by a conventional method.
- a vector include a nucleic acid molecule ⁇ , a nucleic acid molecule ⁇ , or a vector incorporating a nucleic acid molecule ⁇ and a nucleic acid molecule ⁇ .
- the transformant according to the present invention can be prepared by introducing the above-mentioned recombinant expression vector or the like into a host cell.
- a transformant include a nucleic acid molecule ⁇ , a nucleic acid molecule ⁇ , or a transformant incorporating a nucleic acid molecule ⁇ and a nucleic acid molecule ⁇ .
- the transfected host cells (transformers according to the present invention) obtained by the above method are cultured in an appropriate medium according to the host cells. It can be produced by co-expressing the Factor G ⁇ subunit of the present invention and the Factor G ⁇ subunit of the present invention in a culture and separating and purifying the obtained heterodimer of the present invention from the culture.
- the transfected host cells may be cultured by a method known in the art.
- the culture conditions for example, the temperature, the pH of the medium, and the fermentation time may be appropriately set so as to obtain the maximum titer of the heterodimer of the present invention.
- the medium may be, for example, PSFM-J1 medium (manufactured by Fujifilm Wako Pure Chemical Industries, Ltd.), TNM-FH medium, Grace's Insect Medium medium [Proc. Natl. Acad. Sci. USA, (1985)). 82,8404], Sf-100II SFM medium (manufactured by Life Technologies), ExCell400, ExCell405 (all manufactured by JRH Biosciences) and the like. Its pH is preferably 5-8.
- FCS fetal bovine serum
- a medium from which mixed BG has been removed may be used.
- Culturing the transfected host cells is usually carried out at 20 to 40 ° C, preferably 25 to 30 ° C, for about 12 hours to 10 days. If necessary, aeration, stirring, and swirling culture may be performed.
- the heterodimer of the present invention can be obtained from the culture obtained by the above culture as follows.
- the culture of the transformant according to the present invention obtained in the above "3) Culture of host cells” is filtered or centrifuged.
- the cells are removed by a conventional method such as, and a culture filtrate or a culture supernatant is obtained.
- the heterodimer of the present invention is then separated and purified from the culture filtrate or supernatant according to a commonly used method for separating and purifying natural or synthetic proteins.
- the culture of the transformant according to the present invention obtained in 3) above is filtered or centrifuged by a conventional method. After collecting cells or cells and suspending them in an appropriate buffer solution, for example, after destroying the cell wall and / or cell membrane of the cells by a method such as surfactant treatment, ultrasonic treatment, lysozyme treatment, or freeze thawing. , A crude extract containing the heterodimer of the present invention is obtained by a method such as centrifugation or filtration. Then, the heterodimer of the present invention is separated and purified from the crude extract according to a commonly used method for separating and purifying natural or synthetic proteins.
- the expressed protein can be expressed by a known method according to the marker. It can be separated and purified by the method described above.
- Examples of the method for separating and purifying the heterodimer of the present invention include known methods such as salting out and solvent precipitation, dialysis, ultrafiltration, gel filtration chromatography, sodium dodecyl sulfate-polyacrylamide gel electrophoresis, and the like.
- the Factor G ⁇ subunit of the present invention can be obtained by, for example, the following method. You can. Described in "1) Preparation of a recombinant according to the present invention incorporating the nucleic acid molecule according to the present invention” in “6. (1) Acquisition method by co-expression” using the nucleic acid molecule ⁇ according to the present invention.
- a recombinant baculovirus incorporating a nucleic acid molecule ⁇ (which may contain a base sequence encoding a marker such as a signal peptide or His tag sequence) is obtained.
- the recombinant baculovirus is then transfected into host insect cells.
- the transfected host cells are cultured, and the culture solution is subjected to centrifugation or the like to collect the supernatant. Details of the transfection and culture method of insect cells are as described in "6.2) to 3) above.
- the protein is separated and purified by a conventional method to obtain the Factor G ⁇ subunit of the present invention.
- a base sequence encoding a marker such as a His tag sequence is linked to the base sequence of the nucleic acid molecule ⁇ according to the present invention
- the expressed protein is linked to the His tag sequence. Therefore, the protein (Factor G ⁇ subunit) can be purified from the culture supernatant by performing affinity purification by a conventional method using an anti-His-Tag antibody.
- nucleic acid molecule ⁇ used in this method include a nucleic acid molecule containing a base sequence represented by any one of SEQ ID NOs: 1, 3, 17, 19, 33, 34, 41, or 42. Be done. A nucleic acid molecule containing the base sequence represented by any one of SEQ ID NOs: 33, 34, 41, or 42 is more preferable. Nucleic acid molecules containing the nucleotide sequence represented by SEQ ID NO: 41 or 42 are particularly preferable. As the type of nucleic acid molecule, cDNA is more preferable.
- the Factor G ⁇ subunit of the present invention can be acquired by, for example, the following method. Described in "1) Preparation of a recombinant according to the present invention incorporating the nucleic acid molecule according to the present invention” in “6. (1) Acquisition method by co-expression" using the nucleic acid molecule ⁇ according to the present invention. By the method, a recombinant baculovirus incorporating a nucleic acid molecule ⁇ ((which may contain a base sequence encoding a marker such as a signal peptide or His tag sequence)) is obtained.
- the recombinant baculovirus is then transfected into host insect cells.
- the transfected host cells are cultured, and the culture solution is subjected to centrifugation or the like to collect the supernatant. Details of the transfection and culture method of insect cells are as described in "6.2) to 3) above.
- the protein is separated and purified by a conventional method to obtain the Factor G ⁇ subunit of the present invention.
- a base sequence encoding a marker such as a His tag sequence is linked to the base sequence of the nucleic acid molecule ⁇ according to the present invention
- the expressed protein is linked to the His tag sequence. Therefore, the protein (Factor G ⁇ subunit) can be purified from the culture supernatant by obtaining it by a conventional method using an anti-His-Tag antibody and performing affinity purification.
- nucleic acid molecule ⁇ used in this method are SEQ ID NOs: 5, 7, 9, 11, 13, 15, 21, 23, 25, 27, 29, 31, 35-40, 43-48, 68, Alternatively, a nucleic acid molecule containing a base sequence represented by any one of 69 can be mentioned.
- a nucleic acid molecule containing the base sequence represented by any one of SEQ ID NOs: 35 to 40, 43 to 48, 68, or 69 is more preferable.
- Nucleic acid molecules containing the base sequence represented by any one of SEQ ID NOs: 43 to 48 or 68 are particularly preferable.
- cDNA is more preferable.
- the heterodimer of the present invention can be obtained by reacting for several hours to one day and night.
- the solvent for dissolving the Factor G ⁇ and Factor G ⁇ subunits used in the above method has a buffering action in water such as distilled water for injection, for example, pH 5.0 to 10.0, preferably around pH 6.0 to 8.5.
- phosphate buffer, Tris buffer, Good's buffer, glycine buffer, borate buffer, MOPS buffer and the like can be mentioned.
- the buffer concentration in these buffer solutions is usually appropriately selected from the range of 10 to 500 mM, preferably 10 to 300 mM.
- the heterodimer of the present invention can be produced by a general chemical synthesis method according to its amino acid sequence.
- the heterodimer of the present invention can be obtained by a usual chemical synthesis method such as the ruolenylmethyloxycarbonyl method (Fmoc method) and the t-butyloxycarbonyl method (tBoc method). It can also be chemically synthesized using a commercially available peptide synthesizer.
- BG activates the heterodimer of the present invention
- the activated heterodimer activates a proclotting enzyme into a clotting enzyme by its protease activity.
- the crotting enzyme hydrolyzes the synthetic peptide substrate by its enzymatic activity, and the chromogenic group is released from the synthetic peptide substrate to generate color.
- the amount of BG in the sample is calculated by colorimetrically quantifying the generated color development.
- the synthetic peptide substrate used in the method for measuring BG according to the present invention is, for example, a synthetic peptide substrate in which a chromogenic group such as p-nitroaniline (pNA) is bound to the C-terminal, and the enzymatic action of crotting enzyme. Examples thereof include those that are cut by the substrate to produce color.
- the synthetic peptide substrate may be chemically synthesized, but various commercially available ones may be used.
- Boc-Leu-Gly-Arg-pNA Boc-Glu-Gly-Arg-pNA, Ac-Ile-Glu-Gly-Arg-pNA, Boc-Thr-Gly-Arg-pNA, etc.can be mentioned.
- a measuring device for the synthetic substrate method for example, a microplate reader or a spectrophotometer is used.
- BG measuring method is as follows. That is, 10 to 50 ⁇ L of a sample containing BG (containing 0.1 pg to 1 ⁇ g of BG), 20 to 100 ⁇ L of a solution containing the heterodimer of the present invention (containing 0.1 ng to 0.1 mg of the heterodimer of the present invention), and a pro. React with 1 ⁇ M to 10 mM of synthetic peptide substrate such as crotting enzyme and Boc-Thr-Gly-Arg-pNA at 4 to 40 ° C. for 3 to 300 minutes. Then, the absorbance of the reaction solution at, for example, 405 nm (measurement wavelength) and 492 nm (secondary wavelength) is measured. By applying the obtained measured value to a calibration curve showing the relationship between the measured value and the amount of BG obtained by performing the same operation on a BG solution having a known concentration in advance using the same reagent as above, BG in the sample The amount can be calculated.
- Examples of the sample used in the method for measuring BG according to the present invention include clinical specimens such as blood, serum, plasma, urine, lymph, cerebrospinal fluid, pleural effusion, and ascites, pharmaceuticals, medical devices, foods, and the like. Not limited.
- the measurement of BG according to the present invention can be carried out by a method or a measurement system using an automatic analyzer.
- an automatic analyzer There are no particular restrictions on the combination of reagents, etc. when performing measurements using a method or an automatic analyzer, depending on the environment and model of the automatic analyzer to be applied, or taking other factors into consideration.
- the best combination of reagents and the like may be appropriately selected and used.
- the ⁇ -glucan measurement kit of the present invention includes a Factor G ⁇ sub containing the same or substantially the same amino acid sequence as the amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4. Heterogeneous combination of the unit and a Factor G ⁇ subunit containing the same or substantially the same amino acid sequence as the amino acid sequence represented by any one of SEQ ID NOs: 6, 8, 10, 12, 14, or 16. Some include dimers.
- the heterodimer of the present invention in the kit may be a solution dissolved in water or a buffer solution, or a lyophilized product.
- the solvent for dissolving the heterodimer of the present invention is distilled water for injection, for example, pH 5.0 to 10.0, preferably pH 6.5 to 8.5, which has a buffering action near neutrality, such as phosphate buffer, Tris buffer, Good's buffer.
- a buffer solution, a glycine buffer solution, a borate buffer solution, a MOPS buffer solution, or the like is preferable.
- the buffer concentration in these buffer solutions is usually appropriately selected from the range of 10 to 500 mM, preferably 10 to 300 mM.
- the ⁇ -glucan measurement kit of the present invention may contain a procrotting enzyme and / or the above-mentioned synthetic peptide substrate as a constituent reagent. Specific examples are as described above.
- constituent reagents of the ⁇ -glucan measurement kit of the present invention may further contain other suitable reagents usually used in this field, such as buffers and alkaline earth metal salts, and these reagents. May be appropriately selected from those used in so-called biochemical reactions and the like.
- the ⁇ -glucan measurement kit of the present invention may be a kit in which a standard BG for preparing a calibration curve is combined.
- a standard BG a standard product of a commercially available BG manufactured by Fujifilm Wako Pure Chemical Industries, Ltd. or the like may be used, or a product manufactured according to the method described in JP-A-08-075751 may be used. ..
- the reagents in these reagent kits may be freeze-dried products.
- BG can be removed from the sample.
- Specific examples of the Factor G ⁇ subunit of the present invention used in this method are as described in the above section “2.
- Factor G ⁇ subunit of the present invention is more preferred.
- Specific treatment methods include a method of mixing a sample containing BG with an insoluble carrier carrying the Factor G ⁇ subunit of the present invention, and a column packed with a filler carrying the Factor G ⁇ subunit of the present invention. Examples thereof include a method of passing a sample containing BG.
- a column method a method performed according to a general liquid chromatography method can be mentioned.
- the "method of mixing the BG-containing sample and the insoluble carrier carrying the Factor G ⁇ subunit of the present invention" is preferable.
- the sample is mixed with an insoluble carrier carrying the Factor G ⁇ subunit of the invention and preferably shaken.
- the sample is mixed with a solvent in which an insoluble carrier carrying the Factor G ⁇ subunit of the present invention is suspended, preferably with stirring.
- BG can be removed from the sample.
- the usage amount ratio of the insoluble carrier carrying the Factor G ⁇ subunit to the sample should be about 1: 1000 to 1: 3, preferably about 1:10 to 1: 3. Just do it.
- the ratio may be any of a weight ratio (W / W), a capacity ratio (V / V), and a capacity / weight ratio (V / W).
- the time for contacting the sample with the insoluble carrier carrying the Factor G ⁇ subunit may be a time sufficient for the BG in the sample to bind to the Factor G ⁇ subunit, for example, 5 minutes to 1 day, preferably 5 minutes to 1 day. Is 1 to 8 hours.
- an appropriate method such as filtration or decanting may be used.
- Examples of the insoluble carrier for immobilizing the Factor G ⁇ subunit of the present invention used in the above method include cepharose, polystyrene, polypropylene, polyacrylic acid, polymethacrylic acid, polyacrylamide, polyglycidyl methacrylate, polyvinyl chloride, polyethylene, and the like.
- Examples thereof include synthetic polymer compounds such as polychlorocarbonate, silicone resin, and silicone rubber, and inorganic substances such as porous glass, suriglass, ceramics, alumina, silica gel, activated charcoal, and metal oxide. Sepharose and the like are preferable.
- the form of the insoluble carrier those in the form of beads, fine particles, latex particles and the like can be mentioned, but the bead-shaped one is preferable because it is easy to use.
- the particle size is not particularly limited.
- Sepharose beads examples include CNBr-activated Sepharose 4B (manufactured by GE Healthcare).
- the method for immobilizing the Factor G ⁇ subunit on the insoluble carrier may be carried out by contacting the Factor G ⁇ subunit with the insoluble carrier, and is not particularly limited.
- the Factor G ⁇ subunit may be immobilized on the insoluble carrier according to the immobilization method recommended in the instruction manual.
- the method for supporting the FactorG ⁇ subunit on an insoluble carrier specifically includes, for example, the FactorG ⁇ subunit of the present invention in the range of usually 0.1 ⁇ g / mL to 20 mg / mL, preferably 1 ⁇ g / mL to 5 mg / mL. This is done by contacting the solution with a solution containing 0.05 to 2 g of pretreated CNBr-activated Sepharose 4B (manufactured by GE Healthcare) and reacting at an appropriate temperature for a predetermined time, preferably while inversion and mixing. In order to inactivate the unreacted active group, it may be further resuspended in a new solvent and incubated.
- CNBr-activated Sepharose 4B manufactured by GE Healthcare
- the medium for insect cells usually contains yeast extract, it is contaminated with BG. It is also known that normal animal cell media for expression of recombinant proteins, such as FreeStyle TM 293 Expression Medium and FreeStyle TM CHO Expression Medium, are also contaminated with BG. According to the BG removal method according to the present invention, BG can be removed from these media to remove BG contamination. Further, according to the method for removing BG according to the present invention, an inhibitor of BG measurement using Factor G coexisting in the medium can be removed.
- the method for removing BG according to the present invention can not only remove BG contamination of the medium, but can also be applied to the following applications. That is, for example, in an experiment using cultured cells, when the cultured cells have a property of being easily affected by BG, it can be used to eliminate contamination of BG of the reagent used.
- Examples of the BG removal kit of the present invention include a Factor G ⁇ subunit containing the same or substantially the same amino acid sequence as the amino acid sequence represented by SEQ ID NO: 2 or SEQ ID NO: 4, and the above-mentioned removal method. Can be used for.
- Example 1 Acquisition of heterodimer of the present invention-1 ⁇ 1.
- NGS Next Generation Sequencer
- the NGS referred to here is not only the next-generation sequencer device itself, but also the amount of sequencing processing performed by using the next-generation sequencer by executing millions of sequencing reactions in parallel from sample preparation. It also shows the whole system including the increased sequencing method and the subsequent sequence analysis performed on the PC.
- the obtained extract was transferred to a tube, incubated at room temperature for 5 minutes, and then chloroform was added to a concentration of 40% (v / v). It was then stirred for 15 seconds and further incubated at room temperature for 3 minutes. Then, the extract was centrifuged at 12000 xg for 15 minutes at 4 ° C., and then the aqueous phase was transferred to a new tube. Next, 3.5 mL of isopropanol was added and stirred, and then incubated at room temperature for 10 minutes. Next, the extract was centrifuged at 12000 xg for 10 minutes at 4 ° C to obtain a precipitate. The obtained precipitate was washed with 7 mL of 70% ethanol and dried to obtain an RNA precipitate.
- the obtained RNA precipitate was dissolved in 70 ⁇ L sterile water.
- the absorbance of the obtained aqueous RNA solution was measured, and the concentration of the obtained total RNA was measured.
- the concentration of total RNA was 919.8 ng / ⁇ L, and 64 ⁇ g of total RNA was obtained from horseshoe crab blood cells of the genus Limulus.
- the sequence of the DNA sequence portion (including the start codon sequence) encoding the N-terminal side of the DNA sequence (SEQ ID NO: 53, SEQ ID NO: 54) encoding the two types of amino acid sequences obtained in 1-2 above is selected. Based on this, the following primer F1 was designed and synthesized as a Forward primer.
- a band having a size of about 2.2 kbp was cut out, and a PCR fragment was obtained and purified using NucleoSpin TM Gel and PCR Clean-up (manufactured by Takara Bio Inc.).
- the formed colonies were picked up in about 3 mL of LB medium containing 100 ⁇ g / mL ampicillin, inoculated, and cultured with shaking (200 rpm) overnight at 37 ° C. After confirming that the culture broth was suspended, the culture broth was centrifuged at 10000 x g, 1 minute to remove the supernatant, and bacterial cells (equivalent to about 3 mL of the culture broth) were obtained. From the obtained cells, a plasmid was extracted using the QIAprep Spin Miniprep Kit (Qiagen) according to the instructions attached to the kit.
- QIAprep Spin Miniprep Kit Qiagen
- the nucleotide sequence represented by SEQ ID NO: 58 was confirmed.
- the sequences of the stop codon, the poly A signal, and the poly A site were confirmed. From this, it was determined that the nucleotide sequence represented by SEQ ID NO: 58 is the sequence on the 3'end side of the DNA sequence encoding one of the two types of amino acid sequences confirmed in ⁇ 1.> above.
- nucleotide sequence of SEQ ID NO: 58 was contigated with the nucleotide sequence of SEQ ID NO: 53 and the nucleotide sequence of SEQ ID NO: 54, which are the two types of DNA sequences confirmed in ⁇ 1.>.
- the base sequence of SEQ ID NO: 58 overlaps 100% with the base sequence of SEQ ID NO: 54, so that it is possible to construct the full length on a PC. Therefore, the nucleotide sequence of SEQ ID NO: 58 was trimmed and contigated by Vector NTI software (Invitrogen). As a result of the above, a full-length DNA sequence encoding the full-length amino acid sequence of one of the two types of amino acid sequences confirmed in ⁇ 1.> above was confirmed.
- the PCR reaction solution was subjected to agarose gel electrophoresis, and the position of the band was confirmed by a conventional method.
- a band having a size of about 2.2 kbp was cut out, and a PCR fragment was obtained and purified using NucleoSpin TM Gel and PCR Clean-up (manufactured by Takara Bio Inc.). Agarose gel electrophoresis, staining, and band observation were carried out in the same manner as described in the section "21.3'Acquisition of PCR fragments by RACE method" above.
- the following Forward and Reverse primers on the pIEx / Bac-1 vector side were designed.
- the Forward and Reverse primers were mixed with the plasmid obtained above and subjected to Sanger sequencing analysis.
- the obtained sequence data was trimmed and contigated. Trimming and contiging was done by Vector NTI software (Invitrogen). As a result, the base sequence of the full-length DNA encoding the full-length amino acid sequence of the two types of Limulus genus Factor G ⁇ subunits confirmed in ⁇ 1.> above was obtained.
- the acquired base sequence is the base sequence represented by SEQ ID NO: 17 and the base sequence represented by SEQ ID NO: 19.
- Primer F3 5'-AACCAAGTGACCatgaaaaccactctatggacttt-3' (SEQ ID NO: 63)
- Primer R3 5'-GATGGTGGTGCTCGAGTtaaaatactggcacaacttc-3') (SEQ ID NO: 64)
- a cDNA library was prepared by a conventional method using Total RNA derived from blood cell cells of the horseshoe crab of the genus Limulus obtained in 1-1 above and SuperScript TM VILO TM Master Mix (Invitrogen). Using the cDNA library as a template, PCR was performed using primer F3 and primer R3. The composition of the PCR solution is shown in Table 7 below, and the PCR conditions are shown in Table 8 below.
- coli DH5 ⁇ (manufactured by Fujifilm Wako Pure Chemical Industries, Ltd.), incubate on ice for 5 minutes, and heat shock at 42 ° C for 45 seconds. After treatment, it was applied to LB agar medium containing 100 ⁇ g / mL ampicillin. Incubated overnight at 37 ° C to form colonies. The plasmid was obtained from the colony cells by the same method as described in the above section "2-2. Preparation of vector containing 3'side fragment of Factor G ⁇ subunit".
- Table 9 summarizes the following information obtained by the above operations. However, each amino acid sequence and base sequence shown in Table 9 does not include a tag sequence. Each item in Table 9 below has the following meaning.
- -Subunit name FactorG subunit protein name
- -Amino acid sequence number Factor G subunit protein Amino acid sequence sequence number (excluding signal peptide sequence)
- -Nucleotide sequence number SEQ ID NO: of the nucleotide sequence encoding the amino acid sequence of the Factor G subunit protein (excluding the nucleotide sequence encoding the signal peptide sequence)
- -Amino acid sequence number (including signal sequence) SEQ ID NO: of Factor G subunit protein amino acid sequence (including signal peptide sequence)
- -Nucleotide sequence number including signal sequence: SEQ ID NO: of the nucleotide sequence encoding the amino acid sequence of the Factor G subunit protein (including the nucleotide sequence encoding the signal peptide sequence)
- a cDNA having the nucleotide sequence represented by SEQ ID NO: 41, 42, 43, 44, 45, 46, 47, or 48 was synthesized, and the cDNA was used as a pIEx / Bac-1 vector (Novagen). ) was inserted into the NcoI-NotI site to obtain a transfer vector.
- the obtained recombinant baculovirus vector is FactorG ⁇ subunit A, FactorG ⁇ subunit B, FactorG ⁇ subunit ⁇ C1, FactorG ⁇ subunit ⁇ i2, FactorG ⁇ subunit ⁇ i3, FactorG ⁇ subunit ⁇ 2, FactorG ⁇ subunit. It carries a cDNA encoding the amino acid sequence of either ⁇ 5 or FactorG ⁇ subunit ⁇ C2.
- the obtained solution containing the recombinant baculovirus vector was used as a "cotransfection solution".
- Insect cell expresSF + TM manufactured by Protein Science
- serum-free medium PSFM-J1 serum-free medium so as to be 1.5 x 10 6 cells / ml
- 800 ml was prepared in a 2000 ml triangular flask.
- 4 ml of the above-mentioned cotransfection solution was added, and the mixture was cultured with shaking at 130 rpm and 27 ° C. for 3 days.
- the culture broth was centrifuged at 3,000 x g at 4 ° C. for 60 minutes and fractionated into a supernatant and a precipitate. This culture supernatant was collected and used as a Factor G ⁇ subunit B expression culture supernatant.
- FactorG ⁇ subunit B The protein expressed in 5-1 above has a 6 ⁇ His tag sequence linked to the C-terminal side. Therefore, using cOmplete TM His-Tag Purification Resin (Sigma-Aldrich), affinity purification was performed according to the method described in the attached manual, and the Factor G ⁇ subunit B expression culture obtained in 5-1 above was performed. Factor G ⁇ subunit B protein was purified from Qing.
- the serum-free PSFN-J1 medium contained 350 pg / mL or more of BG, but when treated with FactorG ⁇ subunit B, the BG concentration became several pg / mL or less, which was the detection limit. It became a value in the vicinity. From the above, it was found that BG can be removed to the detection limit by treating the medium with FactorG ⁇ subunit B of the present invention.
- LNT inhibitor Lentinan
- LNT is adjusted to 0, 10, 30 pg / mL in the serum-free PSFM-J1 medium or the untreated serum-free PSFM-J1 medium treated with Factor G ⁇ subunit B immobilized beads by the method of 5-4 above.
- the added solution was prepared. Water for injection was used for 0 pg / mL. This prepared solution was designated as "prepared medium to be measured”.
- the LNT used was prepared by dissolving 1 mg "Ajinomoto" for intravenous lentinan in 1 N NaOH.
- reaction solutions having the compositions shown in Table 11 below were prepared and sequentially added to the reaction plates. Then, the reaction was carried out at 37 ° C. for 200 minutes, and after the reaction was completed, 0.04% sodium nitrite (1.0 M hydrochloric acid solution), 0.3% ammonium sulfamate, 0.07% N-1-naphthylethylenediamine dihydrochloride (14% N-1). -Methyl-2-pyrrolidone solution) was sequentially added in an amount of 0.05 mL each for diazo coupling, and the absorbance was measured at 540 nm (control wavelength: 630 nm) using a microplate reader (device name: Spark (manufactured by Tecan)). For the horseshoe crab-derived natural Factor G-containing solution used in Table 11, a fraction fractionated from crude LAL was used according to the method described in Japanese Patent No. 2564632.
- the method of removing BG in the medium using the GactorG ⁇ subunit B of the present invention is a method capable of removing BG by a simpler method than before while maintaining the medium performance. It turned out to be a very good method.
- the culture broth was centrifuged at 3,000 x g at 4 ° C. for 30 minutes and fractionated into a supernatant and a precipitate. This culture supernatant was collected and used as a "recombinant baculovirus solution for expression test".
- the "BG-removed serum-free medium PSFM-J1" used above was obtained by the method of "5. Preparation of BG-removed serum-free PSFM-J1 medium”.
- the "BG-removed serum-free medium PSFM-J1" used above was obtained by the method of "5. Preparation of BG-removed serum-free PSFM-J1 medium”.
- the DNA contained in the baculovirus for expressing the Factor G ⁇ subunit used here is one in which the PA tag sequence and the 6 ⁇ His tag sequence are not linked to the C-terminal side.
- the expression baculovirus having the cDNA encoding the Factor G ⁇ subunit used herein has a cDNA (SEQ ID NO: 41 or SEQ ID NO: 42) encoding the Factor G ⁇ subunit A or B.
- the baculovirus for expression having a cDNA encoding the FactorG ⁇ subunit is a cDNA encoding the FactorG ⁇ subunit ⁇ i2, ⁇ i3, ⁇ 2, ⁇ 5, ⁇ C1, or ⁇ C2 (SEQ ID NOS: 43, 44, 45, 46, 47, or 48).
- Recombinant baculovirus solution for expression test obtained in 6-2 above (recombinant baculovirus solution for Factor G ⁇ subunit A expression test or recombinant baculovirus solution for Factor G ⁇ subunit ⁇ i2 expression test) 90 ⁇ L and 30 ⁇ L of sample buffer (containing 3-mercapto-1,2-propanediol) ( ⁇ 4) (manufactured by Fujifilm Wako Pure Chemical Industries, Ltd.) were mixed and heat-treated for 5 minutes. The heat-treated sample was applied to Super Cep TM Ace, 10-20% gel (manufactured by Fujifilm Wako Pure Chemical Industries, Ltd.), which was set in an easy separator, by 15 ⁇ L.
- the Easy Separator (manufactured by Fujifilm Wako Pure Chemical Industries, Ltd.) was filled with SDS-PAGE buffer, pH8.5 (manufactured by Fujifilm Wako Pure Chemical Industries, Ltd.) and energized at 250 CV for 60 minutes. After electrophoresis, the SDS-PAGE gel was placed on a clear trans TM SP PVDF membrane hydrophilized with methanol, hydrophobic, 0.2 ⁇ m (manufactured by Fujifilm Wako Pure Chemical Industries, Ltd.), and Aqua Blot TM 1 x high efficiency. It was sandwiched from above and below with filter paper soaked in transfer buffer. It was energized for 60 minutes at 1 mA / cm 2 CA.
- Example 2 Glucan-Dependent Protease Activity Confirmation Test of Heterodimer of the Present Invention
- the supernatant containing the co-expression of the Factor G ⁇ subunit and the Factor G ⁇ subunit of the present invention obtained in 6-3 of Example 1 was used as a sample.
- the glucan-dependent protease activity of the obtained co-expressed product was evaluated by the following method.
- reaction solutions having the compositions shown in Table 12 below were prepared and sequentially added to the reaction tubes. Then, the reaction was carried out at 37 ° C. for 200 minutes, and the absorbance at 405 nm (measurement wavelength) and 492 nm (secondary wavelength) was measured using ELx808 (manufactured by BioTek). Table 13 shows the difference in absorbance between the addition of LNT and the absence of addition (blank).
- a cDNA having the nucleotide sequence of Genbank Accession No. AB547712 (SEQ ID NO: 49) encoding the amino acid sequence (BAJ10550.1 (protein_id), SEQ ID NO: 50) of the Factor G ⁇ subunit derived from Limulus polyphemus was prepared.
- the Factor G ⁇ subunit derived from Limulus polyphemus and the Factor G ⁇ subunit of the present invention were co-expressed in the same manner as in Example 1 except that this cDNA was used, and the Factor G ⁇ subunit derived from Limulus polyphemu Tags (AB547712) was used.
- a heterodimer with the Factor G ⁇ subunit of the present invention was obtained. Except for using this heterodimer, a glucan-dependent protease activity confirmation test was conducted in the same manner. The results are also shown in Table 13.
- the LNT used here was prepared by dissolving 1 mg "Ajinomoto" for intravenous lentinan injection in 1N NaOH.
- ⁇ indicates that the blank difference is> 0.1.
- the heterodimer of the Factor G ⁇ subunit of the present invention and the Factor G ⁇ subunit of the present invention can be used for quantitative measurement of BG and diagnosis of mycosis.
- Example 3 Measurement of BG using the heterodimer of the present invention
- the supernatant containing the co-expression of Factor G ⁇ subunit A and Factor G ⁇ subunit ⁇ i2 of the present invention obtained in 6-3 of Example 1, or the present invention.
- the known amount of BG was measured by the following method using a supernatant containing the co-expressor of Factor G ⁇ subunit B and Facer G ⁇ subunit ⁇ 2 of the above as a sample.
- reaction solutions having the compositions shown in Table 15 below were prepared and sequentially added to the reaction tubes.
- 1 mg of lentinan for intravenous injection (manufactured by Ajinomoto Co., Inc.) was added with 1 N NaOH.
- distilled water for injection was used as a blank to which LNT was not added.
- the reaction was carried out at 37 ° C. for 200 minutes, and the absorbance at 405 nm (measurement wavelength) and 492 nm (secondary wavelength) was measured using ELx808 (manufactured by BioTek). The difference in absorbance between LNT-added and non-added (blank) was taken as the absorbance at each LTN concentration.
- a calibration curve was created by plotting the absorbance with respect to the lentinan concentration (converted value, pg / mL, x-axis) in the sample.
- the calibration curve obtained by the measurement using the supernatant containing the co-expressor of Factor G ⁇ subunit A and Factor G ⁇ subunit ⁇ i2 of the present invention is shown in FIG.
- the regression line equation and the correlation coefficient obtained from the measured values by the method of least squares are as follows.
- the calibration curve obtained by the measurement using the supernatant containing the co-expressor of Factor G ⁇ subunit B and Factor G ⁇ subunit ⁇ 2 of the present invention is shown in FIG.
- the regression line equation and the correlation coefficient obtained from the measured values by the method of least squares are as follows.
- Example 4 Acquisition of heterodimer of the present invention-2 (1) Construction of expression vector 1) Construction of FactorG ⁇ subunit A expression vector expression vector The base sequence represented by SEQ ID NO: 41 (including the base sequence and signal sequence optimized for insect cells shown in Table 9) is The included cDNA was inserted into the NcoI-NotI site of the plasmid vector pIEx-Bac-1 vector (Novagen) to construct the FactorG ⁇ subunit A expression vector ( ⁇ (TYPE A) / pIEx-Bac-1).
- Expression vectors ⁇ (TYPE A) / pIEx-Bac-1 and ⁇ i2 / pIEx-Bac-1 (1 ⁇ g each) constructed above, and transfection reagent ScreenFectA plus (manufactured by Fujifilm Wako Pure Chemical Industries, Ltd.) 2 ⁇ L was mixed with 100 ⁇ L of PSFM-J1 medium (manufactured by Wako Pure Chemical Industries, Ltd.), incubated at room temperature for 20 minutes, and then the solution was added to a 6-well plate seeded with expres SF +. Then, the cells were cultured at 27 ° C. for 3 days. After culturing, the culture broth was centrifuged at 12,000 x g at 4 ° C. for 2 minutes and fractionated into a supernatant and a precipitate. The supernatant was frozen and stored.
- Example 3 Glucan-Dependent Protease Activity Confirmation Test Same as in Example 2 except that the obtained supernatant (containing the co-expressed product of Factor G ⁇ subunit A and Factor G ⁇ subunit ⁇ i2 of the present invention) is used as a sample.
- the glucan-dependent protease activity of the obtained co-expressed product was evaluated by the above method.
- the 35 pg / mL LNT solution was added so that the concentration at the time of measurement was 35 pg / mL, 3.5 pg / mL, or 0.35 pg / mL.
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Zoology (AREA)
- Engineering & Computer Science (AREA)
- Wood Science & Technology (AREA)
- Genetics & Genomics (AREA)
- General Health & Medical Sciences (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Molecular Biology (AREA)
- Biochemistry (AREA)
- General Engineering & Computer Science (AREA)
- Biophysics (AREA)
- Medicinal Chemistry (AREA)
- Microbiology (AREA)
- Biomedical Technology (AREA)
- Biotechnology (AREA)
- Immunology (AREA)
- Physics & Mathematics (AREA)
- Analytical Chemistry (AREA)
- Tropical Medicine & Parasitology (AREA)
- Toxicology (AREA)
- Gastroenterology & Hepatology (AREA)
- Insects & Arthropods (AREA)
- Peptides Or Proteins (AREA)
- Enzymes And Modification Thereof (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Abstract
Description
特許文献2では、非特許文献2及び特許文献1に記載のFactor Gを用い、BG無添加でプロテアーゼ活性を測定している。
[1] 配列番号2又は配列番号4で表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列を含有するFactorG αサブユニットと、配列番号6、8、10、12、14、又は16のいずれか一つで表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列を含有するFactorG βサブユニットとの組合せのヘテロダイマー。
[2] 下記から選択される、前記[1]に記載のヘテロダイマー:
(i) 配列番号2で表されるアミノ酸配列を含有するFactorG αサブユニットと、配列番号6で表されるアミノ酸配列を含有するFactorG βサブユニットとの組合せのヘテロダイマー、
(ii) 配列番号2で表されるアミノ酸配列を含有するFactorG αサブユニットと、配列番号8で表されるアミノ酸配列を含有するFactorG βサブユニットとの組合せのヘテロダイマー、
(iii) 配列番号2で表されるアミノ酸配列を含有するFactorG αサブユニットと、配列番号12で表されるアミノ酸配列を含有するFactorG βサブユニットとの組合せのヘテロダイマー、
(iv) 配列番号2で表されるアミノ酸配列を含有するFactorG αサブユニットと、配列番号14で表されるアミノ酸配列を含有するFactorG βサブユニットとの組合せのヘテロダイマー、
(v) 配列番号4で表されるアミノ酸配列を含有するFactorG αサブユニットと、配列番号10で表されるアミノ酸配列を含有するFactorG βサブユニットとの組合せのヘテロダイマー、
(vi) 配列番号4で表されるアミノ酸配列を含有するFactorG αサブユニットと、配列番号16で表されるアミノ酸配列を含有するFactorG βサブユニットのヘテロダイマー。
[3] (i)、(ii)、又は(v)から選択される、前記[2]に記載のヘテロダイマー。
[4] 試料と、配列番号2又は配列番号4で表されるアミノ酸配列を含有するFactorG αサブユニットと、配列番号6、8、10、12、14、又は16のいずれか一つで表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列を含有するFactorG βサブユニットとの組合せのヘテロダイマーを用いた、β-グルカンの測定方法。
[5] 配列番号2又は配列番号4で表されるアミノ酸配列を含有するFactorG αサブユニット。
[6] 配列番号6、8、10、12、14、又は16のいずれか一つで表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列を含有するFactorG βサブユニット。
[7] 配列番号2又は配列番号4で表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列を含有するFactorG αサブユニットと、配列番号6、8、10、12、14、又は16のいずれか一つで表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列を含有するFactorG βサブユニットとの組合せのヘテロダイマーを含む、β―グルカン測定用キット。
[8] 配列番号2、4、6、8、10、12、14、又は16のいずれか一つで表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列をコードする塩基配列を有する核酸分子を組み込んだベクター。
[9] 配列番号2又は配列番号4で表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列をコードする塩基配列を有する核酸分子、及び配列番号6、8、10、12、14、又は16のいずれか一つで表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列をコードする塩基配列を有する核酸分子の両方を組み込んだベクター。
[10] 配列番号2、4、6、8、10、12、14、又は16のいずれか一つで表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列をコードする塩基配列を有する核酸分子を組み込んだ形質転換体。
[11] 配列番号2又は配列番号4で表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列をコードする塩基配列を有する核酸分子、及び配列番号6、8、10、12、14、又は16のいずれか一つで表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列をコードする塩基配列を有する核酸分子の両方を組み込んだ形質転換体。
[12] BGを含有する試料を、配列番号2又は配列番号4で表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列を含有するFactorG αサブユニットと接触させて処理する、試料からBGを除去する方法。
[13] 前記FactorG αサブユニットが不溶性担体に担持されている、前記[13]に記載のBGを除去する方法。
[14] 配列番号2又は配列番号4で表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列を含有するFactorG αサブユニットを含む、β―グルカン除去用キット。
本発明に係るBGとしては、BGをその構成成分として含む多糖類であって、カブトガニ血球抽出物の酵素反応を引き起こす性質のあるものが挙げられる。具体的には、例えば各種細菌類(例えば、Alcaligenes属,Agrobacterium属等)、酵母類(例えば、Saccharomyces属,Candida属,Cryptococcus属,Trichosporon属,Rhodotorula属等)、カビ類(Aspergillus属,Mucor属,Penicillium属,Trichophyton属,Sporothrix属,Phialophora属等)、放線菌類(Actinomyces属,Nocardia属等)、キノコ類(例えば,シイタケ,スエヒロタケ,カワラタケ等)等の細胞壁等から得られる天然の多糖、具体的には例えばカードラン,パキマン,スクレロタン,レンチナン,シゾフィラン,コリオラン等が、或は藻類(例えば、褐藻,ユーグレナ,ケイ藻等)の貯蔵性多糖、具体的には例えばラミナラン、パラミロン等が挙げられる。
本発明のFactorG αサブユニットは、配列番号2又は配列番号4で表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列を含有する蛋白質である。
本発明のFactorG αサブユニットは、BGに結合する性質を有する。
本発明のFactorG αサブユニットの由来としては、Limulus polyphemus由来のものが好ましい。
配列番号4で表されるアミノ酸配列と同一又は実質的に同一のアミノ酸配列を含有する蛋白質を、以下「FactorG αサブユニットB」又は単に「αサブユニットB」と略記する場合がある。
また、単に「FactorG αサブユニットのアミノ酸配列」と記載した場合は、上記した「配列番号2又は配列番号4で表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列」の総称を意味する。
本発明のFactorG βサブユニットは、配列番号6、8、10、12、14、及び16のいずれか一つで表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列を含有する蛋白質である。
本発明のFactorG βサブユニットは、セリンプロテアーゼのドメインを持つが、酵素活性はなく、前記した本発明のFactorG αサブユニットとのヘテロダイマーを形成した場合にプロテアーゼ活性を発揮する。
本発明のFactorG βサブユニットの由来としては、Limulus polyphemus由来のものが好ましい。
・配列番号8で表されるアミノ酸配列と同一又は実質的に同一のアミノ酸配列を含有する本発明のFactorG βサブユニット:FactorG βサブユニットβi3、
・配列番号10で表されるアミノ酸配列と同一又は実質的に同一のアミノ酸配列を含有する本発明のFactorG βサブユニット:FactorG βサブユニットβ2、
・配列番号12で表されるアミノ酸配列と同一又は実質的に同一のアミノ酸配列を含有する本発明のFactorG βサブユニット:FactorG βサブユニットβ5、
・配列番号14で表されるアミノ酸配列と同一又は実質的に同一のアミノ酸配列を含有する本発明のFactorG βサブユニット:FactorG βサブユニットβC1、
・配列番号16で表されるアミノ酸配列と同一又は実質的に同一のアミノ酸配列を含有する本発明のFactorG βサブユニット:FactorG βサブユニットβC2。
本発明のヘテロダイマーは、「配列番号2又は配列番号4で表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列を含有するFactorG αサブユニットと、配列番号6、8、10、12、14、又は16のいずれか一つで表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列を含有するFactorG βサブユニットとの組み合わせのヘテロダイマー」である。

(1)本発明のFactorG αサブユニットをコードする核酸分子
本発明のFactorG αサブユニットをコードする核酸分子としては、配列番号2又は配列番号4で表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列をコードする塩基配列を含有する核酸分子が挙げられる。「配列番号2又は配列番号4で表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列」の具体例は、上記した「2.本発明のFactorG αサブユニット」の項で説明した通りである。
配列番号1で表される塩基配列と同一又は実質的に同一の塩基配列を含有する核酸分子は、配列番号2で表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列をコードする。
配列番号3で表される塩基配列と同一又は実質的に同一の塩基配列を含有する核酸分子は、配列番号4で表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列をコードする。
。
また、本発明のFactorG αサブユニットをコードする核酸分子は一本鎖でも二本鎖であってもよい。二本鎖の場合には、例えば配列番号1、3、17、18、33、34、41、又は42で表される塩基配列とその相補鎖からなるもの等である。
本発明のFactorG βサブユニットをコードする核酸分子としては、配列番号6、8、10、12、14、又は16のいずれか一つで表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列をコードする塩基配列を含有する核酸分子が挙げられる。「配列番号6、8、10、12、14、又は16のいずれか一つで表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列」の具体例は、上記した「3.本発明のFactorG βサブユニット」の項で説明した通りである。
配列番号7で表される塩基配列と同一又は実質的に同一の塩基配列を含有する核酸分子は、配列番号8で表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列をコードする。FactorG βサブユニットβi3のアミノ酸配列をコードする。
配列番号9で表される塩基配列と同一又は実質的に同一の塩基配列を含有する核酸分子は、配列番号10で表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列をコードする。FactorG βサブユニットβ2のアミノ酸配列をコードする。
配列番号11で表される塩基配列と同一又は実質的に同一の塩基配列を含有する核酸分子は、配列番号12で表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列をコードする核酸分子である。FactorG βサブユニットβ5のアミノ酸配列をコードする。
配列番号13で表される塩基配列と同一又は実質的に同一の塩基配列を含有する核酸分子は、配列番号14で表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列をコードする。FactorG βサブユニットβC1のアミノ酸配列をコードする。
配列番号15で表される塩基配列と同一又は実質的に同一の塩基配列を含有する核酸分子は、配列番号16で表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列をコードする。FactorG βサブユニットβC2のアミノ酸配列をコードする。
また、本発明のFactorG βサブユニットをコードする核酸分子は一本鎖でも二本鎖であってもよい。二本鎖の場合には、例えば配列番号5、7、9、11、13、15、21、23、25、27、29、31、35~40、43~48、68、又は69で表される塩基配列とその相補鎖からなるもの等である。
更に、上記「核酸分子α」及び「核酸分子β」をまとめて「本発明に係る核酸分子」と略記する場合がある。
例えば、1、3、5、7、9、11、13、15、17,19、21、23、25、27、29、31のいずれか一つで表される塩基配列にタグをコードする塩基配列を連結した塩基配列を、発現させる細胞の種類に合わせて最適化した核酸分子が挙げられる。
例えば、5'末端側からシグナル配列、Hatタグ、SUMOタグ、FactorG βサブユニットi2(アミノ酸配列:配列番号6)の順に配したアミノ酸配列(配列番号67)を設計し、このアミノ酸配列をコードし、且つ昆虫細胞用に最適化した配列番号68で表される塩基配列を有する核酸分子が挙げられる。配列番号68で表される塩基配列において、FactorG βサブユニットi2をコードする塩基配列は、配列番号69で表される塩基配列である。

本発明のヘテロダイマーの取得方法としては、例えば下記の3通りの方法が挙げられる。
(1)共発現による取得方法
(2)αサブユニットとβサブユニットをそれぞれ取得してから結合させることにより取得する方法
(3)化学合成による取得方法
中でも、ヘテロダイマーの収率等を考慮すると、「(1)共発現による取得方法」が好ましい。
本発明のヘテロダイマーは、「本発明に係る核酸分子(核酸分子α、及び核酸分子β)を、適当なウイルスやプラスミド等の発現ベクターに組み込み、適当な宿主細胞を該組み換え発現ベクターを用いた常法により形質転換(又は形質導入)させる。得られた形質転換体(形質導入体)を培養し、本発明のFactorGαサブユニットと本発明のFactorG βサブユニットを共発現させ、本発明のヘテロダイマーを、細胞外又は細胞内に分泌させる。」という遺伝子組み換え技術を用いた周知の方法で、得ることができる。
バキュロウイルス―昆虫細胞の発現系を利用した本発明に係る組換え体の調製は、通常本発明に係る核酸分子(核酸分子α又は核酸分子β)を一旦トランスファーベクターに組み込んだのち、バキュロウイルスゲノムDNAとともに、宿主となる昆虫細胞にコトランスフェクションすることによりなされる。
本法に用いられる核酸分子α、及び核酸分子βの具体例は、上記した「5.本発明に係る核酸分子」の項に記載した通りである。
上記で得られた組換えバキュロウイルス(本発明に係る組換え体)を、以下の方法で宿主となる昆虫細胞にトランスフェクションさせる。
すなわち、核酸分子αが組み込まれた組換えバキュロウイルスと核酸分子βが組み込まれた組換えバキュロウイルスを、宿主細胞の培地に加える。核酸分子αが組み込まれた組換えバキュロウイルスを、volume of infection (以下、VOIと略記する。)=1/400~1/200、核酸分子βが組み込まれた組換えバキュロウイルスを、VOI=1/200~1/100の割合で加え、FactorG βサブユニットの発現量に対してFactorG αサブユニットの発現量を抑えることが好ましい。この場合、多重感染度(Multiphcity of Infection、以下MOIと略記する)で換算すると、概ねFactorG αサブユニット:FactorG βサブユニット=0.4~0.8:0.9~1.8の比率になる。
本発明のヘテロダイマーは、上記の方法で得られたトランスフェクションされた宿主細胞(本発明に係る形質転換体)を、その宿主細胞に応じた適切な培地中で培養し、培養物中に本発明のFactorG αサブユニットと本発明のFactorG βサブユニットを共発現させ、得られた本発明のヘテロダイマーを該培養物から分離・精製することによって製造することが出来る。
本発明のヘテロダイマーの別の取得方法としては、「本発明のFactorG αサブユニット、及び本発明のFactorG βサブユニットをそれぞれ得る。次いで、得られた本発明のFactorG αサブユニットと本発明のFactorG βサブユニットを結合させる。」方法が挙げられる。
本発明のFactorG αサブユニットは、例えば以下のような方法で取得することが出来る。
本発明に係る核酸分子αを用い、上記「6.(1)共発現による取得方法」の「1)本発明に係る核酸分子を組み込んだ本発明に係る組換え体の調製」に記載された方法で、核酸分子α(シグナルペプチドやHisタグ配列等のマーカーをコードする塩基配列を含んでいてもよい)を組み込んだ組換えバキュロウイルスを得る。
次いで、この組換えバキュロウイルスを宿主となる昆虫細胞にトランスフェクションさせる。トランスフェクションさせた宿主細胞を培養し、培養液を遠心等処理して上清を回収する。昆虫細胞のトランスフェクション及び培養方法の詳細は、上記した「6.2)~3)」に記載した通りである。
本発明のFactorG βサブユニットは、例えば以下のような方法で取得することが出来る。
本発明に係る核酸分子βを用い、上記「6.(1)共発現による取得方法」の「1)本発明に係る核酸分子を組み込んだ本発明に係る組換え体の調製」に記載された方法で、核酸分子β((シグナルペプチドやHisタグ配列等のマーカーをコードする塩基配列を含んでいてもよい))を組み込んだ組換えバキュロウイルスを得る。
次いで、この組換えバキュロウイルスを宿主となる昆虫細胞にトランスフェクションさせる。トランスフェクションさせた宿主細胞を培養し、培養液を遠心等処理して上清を回収する。昆虫細胞のトランスフェクション及び培養方法の詳細は、上記した「6.2)~3)」に記載した通りである。
次いで、精製したFactorG αサブユニットAとFactorG βi2サブユニットを、それぞれBGフリーの10 mM MOPS緩衝液に溶解させた後、それぞれ等モルとなるように混合し、撹拌下に数時間~一昼夜反応させることにより、本発明のヘテロダイマーを得ることが出来る。
上記方法に用いられるFactorG αサブユニット及びFactorG βサブユニットを溶解させる溶媒としては、注射用蒸留水等の水、例えばpH 5.0~10.0、好ましくはpH 6.0~8.5の中性付近に緩衝作用を有する、例えばリン酸緩衝液、トリス緩衝液、グッド緩衝液、グリシン緩衝液、ホウ酸緩衝液、MOPS緩衝液等が挙げられる。また、これらの緩衝液中の緩衝剤濃度としては、通常10~500 mM、好ましくは10~300 mMの範囲から適宜選択される。
また、本発明のヘテロダイマーは、そのアミノ酸配列に従って、一般的な化学合成法により製造することができる。例えば、ルオレニルメチルオキシカルボニル法(Fmoc法)、t-ブチルオキシカルボニル法(tBoc法)等の通常の化学合成法により、本発明のヘテロダイマーを得ることができる。また、市販のペプチド合成機を用いて化学合成することもできる。
本発明のヘテロダイマーを用いてBGを測定する方法としては、いわゆる合成基質法が挙げられる。
すなわち、BGを含有する試料10~50μL(BGを0.1 pg~1 μg含有)を、本発明のヘテロダイマーを含有する溶液20~100μL(本発明のヘテロダイマーを0.1 ng~0.1 mg含有)、プロクロッティングエンザイム、及びBoc-Thr-Gly-Arg-pNA等の合成ペプチド基質 1μM~10 mMと4~40℃で3分~300分間反応させる。その後、反応液の例えば405 nm(測定波長)と492 nm(副波長)における吸光度を測定する。得られた測定値を、予め濃度既知のBG溶液について上記と同じ試薬を用い同様の操作を行って得た、測定値とBG量との関係を示す検量線にあてはめることにより、試料中のBG量を求めることができる。
本発明のβ―グルカン測定用キットとしては、配列番号2又は配列番号4で表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列を含有するFactorG αサブユニットと、配列番号6、8、10、12、14、又は16のいずれか一つで表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列を含有するFactorG βサブユニットとの組合せのヘテロダイマーを含むものが挙げられる。
BGを含有する試料を、本発明のFactorG αサブユニット(αサブユニットA、又はαサブユニットB)と接触させて処理することで、試料からBGを除去することが出来る。
本法に用いられる本発明のFactorG αサブユニットの具体例は、上記「2.本発明のFactorG αサブユニット」の項で説明した通りである。
FactorG αサブユニットBがより好ましい。
BGを含有する試料として細胞や細菌等の培養用培地を用いる場合には、「BGを含有する試料と本発明のFactorG αサブユニットを担持した不溶性担体とを混合する方法」が好ましい。
先ず、試料を本発明のFactorG αサブユニットを担持した不溶性担体と混合し、好ましくは振とうする。又は、試料を、本発明のFactorG αサブユニットを担持した不溶性担体を懸濁させた溶媒と、好ましくは撹拌させながら混合する。その後、試料と本発明のFactorG αサブユニットを担持した不溶性担体を分離すれば、試料からBGを除去することが出来る。
また、市販の不溶性担体を用いる場合には、その取扱説明書で推奨されている固定化方法に従って、FactorG αサブユニットを不溶性担体に固定化させればよい。
また、本発明に係るBGの除去方法によれば、培地中に共存する、FactorGを用いたBGの測定の阻害因子を除去することが出来る。
即ち、例えば培養細胞等を用いた実験に於て、培養細胞がBGの影響を受け易い性質のものであるとき、使用試薬のBGの汚染を排除するために用いることができる。
<1. 次世代シークエンサーを用いたカブトガニ由来FactorG RNAの解析>
以下、「次世代シークエンサー、Next Generation Sequencer」を「NGS」と略記する。
尚、ここで言うNGSは、次世代シークエンサー機器そのものだけではなく、次世代シークエンサーを用いて行われる、サンプル調製から数百万ものシーケンシング反応が並行して実行されることにより配列決定の処理量が増大したシーケンシング手法、その後のPC上で行われる配列解析を含むシステム全般をも示す。
RNA抽出用試薬ISOGEN(富士フイルム和光純薬(株)製)を用い、その製品付属のプロトコルに従って、下記の通りの方法で、Limulus属カブトガニ血球細胞よりtotal RNAを回収した。
上記1-1で得られたLimulus属カブトガニの血球細胞由来Total RNAを用い、TruSeq Stranded mRNA sample Prep kit(イルミナ(株)製)を用いて、Kitに記載の説明書に従って、シーケンスライブラリーを作製した。作製したシーケンスライブラリーを、次世代シーケンサーであるHiSeq 2500を用いた分析に付した。
次いで、上記アッセンブルで得られたアミノ酸配列と、Tachypleus属 FactorG αサブユニットのアミノ酸配列(Accession No.BAA04044.1(Protein ID)、配列番号52、DNA配列:配列番号51)もしくはTachypleus属 FactorG βサブユニットのアミノ酸配列(Accession No. BAA04045.1(Protein ID))との相同検索(blastp)を行った。
取得した配列番号53及び配列番号54のDNA配列は終止コドンを含まないため、Limulus属FactorG αサブユニットの全アミノ酸配列ではなく、そのN末端側の部分配列をコードしていると推定された。
大文字:ベクターへのin-fusion反応時に用いる付加配列
小文字:配列番号53及び配列番号54由来の配列
SMARTerTM RACE 5'/3' Kit (タカラバイオ(株)製)を用い、上記1-1で得られたLimulus属カブトガニの血球細胞由来Total RNAを1st strand cDNAに逆転写し、cDNAライブラリーを作製した。
本kit付属のUPM short primer mix、上記で得られたプライマー F1、及びPrimeSTARTM Max DNA Polymerase (タカラバイオ(株)製)を用いて、PCRを行った。PCR溶液の組成を下記表3に、PCR条件を下記表4に、それぞれ示す。

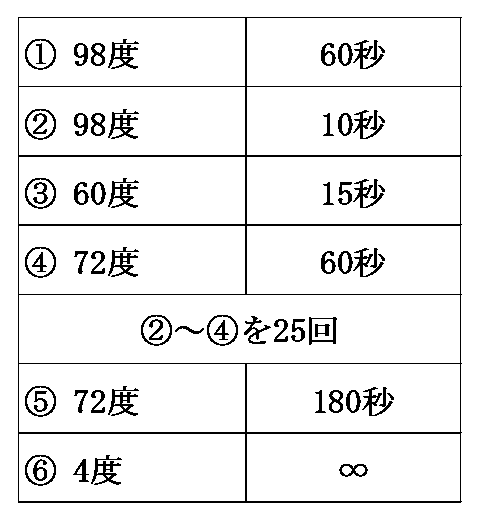
上記2-1で得られたPCRフラグメントとLinearized pRACEベクター(タカラバイオ(株)製)と5×In-Fusion HD Enzyme Premix(タカラバイオ(株)製)とを混合し、50℃で15分反応させ、in-fusion反応溶液を得た。得られたin-fusion反応溶液2.5 μLを、50 μL ECOSTM Competent E. coli DH5 α(富士フイルム和光純薬(株)製)に添加し、氷上で5分インキュベートした。42℃で45秒ヒートショック処理した後、100 μg/mLアンピシリン入りLB寒天培地に塗布した。37℃で一晩インキュベートし、コロニーを形成させた。
上記2-2で得られたプラスミドを、M13-20及びM13-P5(ユニバーサルプライマー、タカラバイオ(株)製)と混合して、サンガーシーケンス解析を行った。
M13-P5 Reverse プライマー:5'-caggaaacagctatgac-3'(配列番号57)
以上の結果、上記<1.>で確認された2種類のアミノ酸配列のうち1種類のFactorG αサブユニットの全長アミノ酸配列をコードしている全長DNA配列が確認された。
そこで、上記<1.>で確認された2種類のDNA配列である配列番号53及び配列番号54の塩基配列をもとに、開始コドンを含むプライマーF2を設計し、配列番号58の3’末端側の塩基配列をもとに終始コドンを含むプライマーR2を設計し、合成した。
大文字:ベクターへのin-fusion反応時に用いる付加配列
小文字:配列番号53及び配列番号54由来の配列
プライマーR2 5'-GGAGCTCCTGCGGCCGCctaaacctttgtaatcttaatc-3' (配列番号60)
大文字:ベクターへのin-fusion反応時に用いる付加配列
小文字:配列番号58由来の配列
上記2-2で得られたプラスミドを鋳型とし、プライマーF2とプライマーR2を用い、KOD DNA polymerase(東洋紡(株)製)を用いてPCRを行った。PCR溶液の組成を表5に、PCR条件を表6にそれぞれ示す。

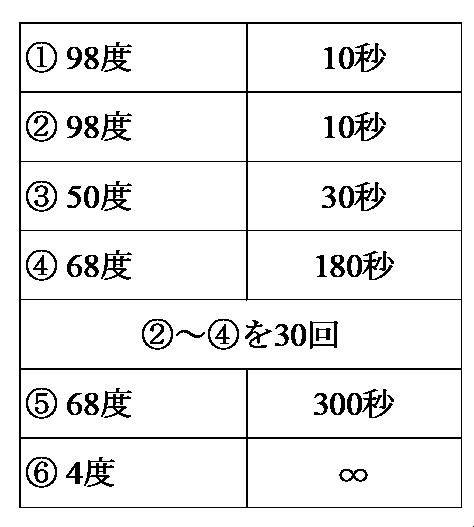
コロニー細胞からのプラスミドの取得は、上記「2-2.FactorG αサブユニットの3’側フラグメント入りベクターの作製」の項に記載の方法と同様の方法で行った。
pIEx/Bac-1ベクター側のReverseプライマー: acgtcgccaactcccattgt (配列番号62)
上記の「1-2.本発明のFactorGサブユニットのアミノ酸配列及び塩基配列等の取得」の工程で、FactorG βサブユニットβi2及びFactorG βサブユニットβi3の全長cDNAの塩基配列、すなわち配列番号21及び配列番号23で表される塩基配列を取得した。確認のため、この塩基配列の5’末端側と3’末端側の塩基配列をもとに、下記のプライマーを設計した。
プライマーR3 5'-GATGGTGGTGCTCGAGTtaaaatactggcacaacttc-3' ) (配列番号64)
上記1-1で得られたLimulus属カブトガニの血球細胞由来のTotal RNAとSuperScriptTM VILOTM Master Mix(Invitrogen社)を用い、常法によりcDNA ライブラリーを作製した。
そのcDNAライブラリーを鋳型として用い、プライマーF3及びプライマーR3を用いて、PCRを行った。PCR溶液の組成を下記表7に、PCR条件を下記表8に、それぞれ示す。


上記3-1で得られたPCRフラグメントと、制限酵素NcoIとXhoIで処理したLinearized pIExTM-4ベクター(Novagen社)と、5×In-Fusion HD Enzyme Premix(タカラバイオ(株))を混合し、50℃で15分反応させ、in-fusion反応溶液を得た。得られたin-fusion反応溶液 2.5 μLを50 μL ECOSTM Competent E. coli DH5 α(富士フイルム和光純薬(株)製)に添加し、氷上で5分インキュベートし、42℃で45秒ヒートショック処理した後、100 μg/mLアンピシリン入りLB寒天培地に塗布した。37℃で一晩インキュベートし、コロニーを形成させた。コロニー細胞からのプラスミドの取得は、上記「2-2.FactorG αサブユニットの3’側フラグメント入りベクターの作製」の項に記載の方法と同様の方法で行った。
上記3-2で得られたシークエンスデータの取得は、pIEx/Bac-1ベクター側のForwardプライマー(配列番号61)及びpIEx/Bac-1ベクター側のReverseプライマー(配列番号62)を用い、上記「2-3. FactorG αサブユニットの3’側フラグメントのサンガーシーケンス解析」に記載の方法と同様の方法で行った。
得られたシーケンスデータを、Vector NTIソフトウェア(Invitrogen社)を用いてトリミングし、コンティグを行った。
その結果、Limulus属FactorG βサブユニットをコードする6種類のDNA配列、すなわち配列番号21、23、25、27、29、及び31で表される塩基配列を取得した。
4-1.トランスファーベクターの構築
前項<2.>及び<3.>で確認された塩基配列である配列番号17、19、21、23、25、27、29、及び31を、それぞれアミノ酸配列へ翻訳した。
尚、下記表9における各項目は、それぞれ以下の意味である。
・サブユニット名:FactorGサブユニット蛋白質の名称、
・アミノ酸配列番号:FactorGサブユニット蛋白質アミノ酸配列の配列番号(シグナルペプチド配列を除く)、
・塩基配列番号:FactorGサブユニット蛋白質のアミノ酸配列をコードする塩基配列の配列番号(シグナルペプチド配列をコードする塩基配列を除く)、
・アミノ酸配列番号(シグナル配列含む):FactorGサブユニット蛋白質アミノ酸配列の配列番号(シグナルペプチド配列を含む)、
・塩基配列番号(シグナル配列含む):FactorGサブユニット蛋白質のアミノ酸配列をコードする塩基配列の配列番号(シグナルペプチド配列をコードする塩基配列を含む)、
・最適化した塩基配列番号:FactorGサブユニット蛋白質を昆虫細胞で発現させるために最適化した塩基配列の配列番号(シグナルペプチド配列をコードする塩基配列を除く)、
・塩基配列番号(シグナル配列含む):FactorGサブユニット蛋白質を昆虫細胞で発現させるために最適化した塩基配列の配列番号(シグナルペプチド配列をコードする塩基配列を含む)。
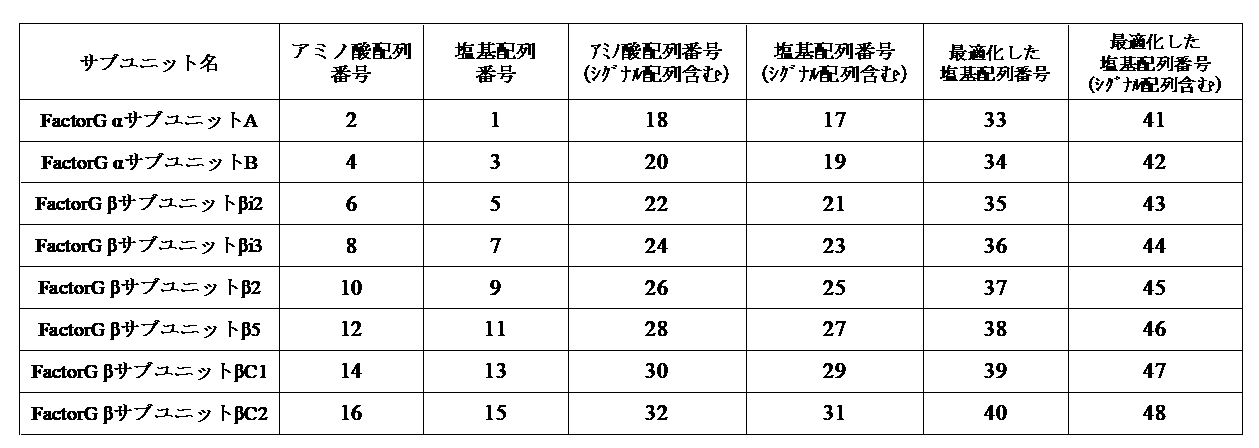
25 cm2フラスコに播いた1.0 x 106 個のSf9細胞(invitorgen社)に、上記4-1で得られたトランスファーベクター各種 2 μg、Linear AcNPV DNA 90 ng及びScreenFectTM A plus(富士フイルム和光純薬(株)製)3 μLを含む無血清PSFM-J1培地(富士フイルム和光純薬(株)製)100 μLを添加した。28℃で7日間静置培養後に培養上清を回収し、組換えバキュロウイルスベクター溶液とした。
得られた組換えバキュロウイルスベクターは、FactorG αサブユニット A、FactorG αサブユニット B、FactorG βサブユニットβC1、FactorG βサブユニットβi2、FactorG βサブユニットβi3、FactorG βサブユニットβ2、FactorG βサブユニットβ5、又はFactorG βサブユニットβC2のいずれか一つのアミノ酸配列をコードするcDNAを保持している。
得られた組換えバキュロウイルスベクターを含有する溶液を「コトランスフェクション溶液」として用いた。
ここで、以下の方法で、本発明のFactorG αサブユニット Bを担持したビーズを用い、昆虫細胞用培地を処理し、培地性能を維持した状態でBGを除去した細胞培養用培地を作製した。
上記4-1及び上記4-2に記載の方法で得られた、PAタグ配列(配列番号65:GVAMPGAEDDVV)及び6×Hisタグ配列をC末端側に連結したFactorG αサブユニットBをコードするcDNA(配列番号66)を有する組換えバキュロウイルスベクター溶液(コトランスフェクション溶液)を用い、以下の操作を行った。
上記5-1で発現した蛋白質は、C末端側に、6×Hisタグ配列が連結している。そこで、cOmpleteTM His-Tag Purification Resin(Sigma-Aldrich社)を使用し、添付のマニュアル記載の方法に準じてアフィニティー精製を行って、上記5-1で得られたFactorG αサブユニットB発現培養上清からFactorG αサブユニットB蛋白質を精製した。
CNBr-activated Sepharose 4B(GE社)1gを1 mM HClで懸濁し、200 mL で洗浄した。洗浄済みCNBr-activated Sepharose 4B 4 ml netを、カップリングバッファー(200 mM NaHCO3, 500 mM NaCl, pH 8.3)に溶解した、上記5-2で得られたFactorG αサブユニットB 16 mgと混合して、4℃、一晩、転倒混和しながらインキュベートした。未反応活性基を不活化するためにビーズを回収し、Tris-HCl buffer, pH 8.0で再懸濁し、2時間、4℃でインキュベーションした。以上の方法で、FactorG αサブユニットB固定化ビーズの懸濁液を得た。
1000 mL 無血清PSFM-J1培地に、上記5-3で得られたFactorG αサブユニットB固定化ビーズの懸濁液0.5 mL netを加え、撹拌振とう機で、室温で4時間撹拌した。その後、0.22μMのPESフィルターに通して、ビーズの除去と滅菌処理を行った。
1)BG除去の確認1-BGの除去
5-4で得られたFactorG αサブユニットB固定化ビーズ処理培地、又は未処理培地を用い、下記表10に記載の組成の反応溶液を調製し、反応用プレートに順次添加した。次いで、37℃で200分反応を行い、反応終了後、0.04%亜硝酸ナトリウム(1.0M塩酸溶液)、0.3%スルファミン酸アンモニウム、0.07%N-1-ナフチルエチレンジアミン二塩酸塩(14% N-1-メチル-2-ピロリドン溶液)を各々0.05mL順次添加してジアゾカップリングし、マイクロプレートリーダー(機器名:Spark(Tecan社製))により540nm(対照波長:630nm)で吸光度を測定した。
尚、ここで用いているカブトガニ由来 天然FactorG含有溶液は、特許第2564632号に記載の方法に従い、粗LALより分画したフラクションを用いた。

図1から明らかな通り、無血清PSFN-J1培地には350 pg/mL以上のBGが含まれていたが、FactorG αサブユニットBで処理すると、BG濃度は数pg/mL以下となり、検出限界付近の値となった。
以上のことから、本発明のFactorG αサブユニットBで培地を処理することにより、BGを検出限界まで除去できることがわかった。
レンチナン(以下LNT)を注射用水で0、5、10、30、60 pg/mLになるように溶解し、「検量線用溶液」とした。すなわち、「検量線用溶液」は培地を含まない。
表11で用いているカブトガニ由来 天然FactorG含有溶液は、特許第2564632号に記載の方法に従い、粗LALより分画したフラクションを用いた。

図2において、--◇--は検量線用溶液を用いて得られた結果を、―▲―は本発明のFactorG αサブユニットBを用いてBG除去処理したPSM-J1培地を用いて得られた結果を、―◆―は未処理のPSM-J1培地を用いて得られた結果を、それぞれ示す。
一方、本発明のFactorG αサブユニットBビーズを用いてBG除去処理を行った無血清PSFM-J1培地を用いて得た検量線(▲、y=0.0065X+0.0048)の傾きは0.065となり、検量線用溶液を用いて得た検量線の傾き(0.007)に近似した値となった。この結果より、本BG除去処理方法によってFactorGを用いたBG測定に影響を及ぼす阻害因子も取り除かれていることが示唆された。
以上のことから、本発明のGactorG αサブユニットBを用いて培地中のBGを除去する方法は、培地性能を維持しながら、従来よりも簡便な方法でBGを除去することが出来る方法として、極めて優れた方法であることがわかった。
6-1. 発現試験用組換えバキュロウイルス溶液の作製
昆虫細胞 expresSF+TM(プロテイン・サイエンス(Protein Science)社製)を、1.5 x 106 cells/mlとなるようにBG除去済み無血清培地PSFM-J1(pH5.5~6.2)で希釈し、125 ml 三角フラスコに50 ml用意した。
これに上記4-2で得られた各コトランスフェクション溶液を0.250 ml加え、130 rpm、27℃で3日間振盪培養した。培養後、培養液を、3,000 x g、4℃で30分間遠心し、上清と沈殿に分画した。この培養上清を回収し、「発現試験用の組換えバキュロウイルス溶液」とした。
尚、上記で用いた「BG除去済み無血清培地PSFM-J1」は、上記「5. BG除去済み無血清PSFM-J1培地の作製」の方法で得た。
上記6-1で作製した発現試験用の組換えバキュロウイルス溶液の力価を組換えFactorG αサブユニットAとβサブユニットβi2を代表とし、以下の方法で測定した。
上記6-1で得られた「FactorG αサブユニットA(PAタグ配列及び6×Hisタグ配列をC末端側に連結していないもの)をコードするcDNA」を有する発現試験用の組換えバキュロウイルスの溶液、又は「FactorG βサブユニットβi2をコードするcDNA」を有する発現試験用の組換えバキュロウイルスの溶液を、それぞれ無血清PSFM-J1培地で105、106、107、108倍に希釈し、これらの溶液をそれぞれ1 mlずつSf9細胞に添加し、室温で1時間穏やかに振盪した。その後、シャーレ上清(ウイルス液)を取り除き、0.5% SeaKemGTG agarose(BMA社製)を含有する無血清PSFM-J1培地4 ml を流し込んで、28℃で7日間静置培養した。7日間後のプレートに0.03%ニュートラルレッド溶液を添加し3時間静置し、染色した。プラーク(透明になっている箇所)数をカウントして、タイター値を算出した。
FactorG αサブユニットAをコードするcDNAを有する組換えバキュロウイルス:2.1×108 pfu/mL
FactorG βサブユニットβi2をコードするcDNAを有する組換えバキュロウイルスi2: 1.4×108 pfu/mL
昆虫細胞 expresSF+TM(プロテイン・サイエンス(Protein Science社製)を、1.5 x 106 cells/mlとなるようにBG除去済み無血清培地PSFM-J1(pH5.5~6.2)で希釈し、125 ml 三角フラスコ12本に50 mlずつ用意した。
上記で用いた「BG除去済み無血清培地PSFM-J1」は、上記「5. BG除去済み無血清PSFM-J1培地の作製」の方法で得た。
尚、ここで使用したFactorG αサブユニット発現用のバキュロウイルスが有するDNAは、PAタグ配列及び6×Hisタグ配列をC末端側に連結していないものである。
また、FactorG βサブユニットをコードするcDNAを有する発現用のバキュロウイルスは、FactorG βサブユニットβi2、βi3、β2、β5、βC1、又はβC2をコードするcDNA(配列番号43、44、45、46、47、又は48)を有する。
上記6-2で得られた発現試験用の組換えバキュロウイルス溶液(FactorG αサブユニットA発現試験用の組換えバキュロウイルス溶液、又はFactorG βサブユニットβi2発現試験用の組換えバキュロウイルス溶液) 90 μLと試料用緩衝液(3-メルカプト-1,2-プロパンジオール含有)(×4)(富士フイルム和光純薬(株)製)30 μLを混合して、5分間熱処理した。熱処理した試料をイージーセパレーターにセットしたスーパーセップTMエース、10-20%ゲル(富士フイルム和光純薬(株)製)に15 μLアプライした。
その結果、rFactorG αサブユニットは約75 kDa、rFacotrG βサブユニットは約40 kDa付近の位置にバンドが確認された。
実施例1の6-3で得られた、本発明のFactorG αサブユニットとFactorG βサブユニットの共発現物が含まれる上清を試料として用い、得られた共発現物のグルカン依存性プロテアーゼ活性の評価を、以下の方法で行った。


表13において、
◎は、 ブランク差>0.1の場合を、
〇は、0.1≧ブランク差>0.01の場合を、
△は、0.01≧ブランク差>0の場合を、
×は、ブランク差= 0の場合を、それぞれ示す。
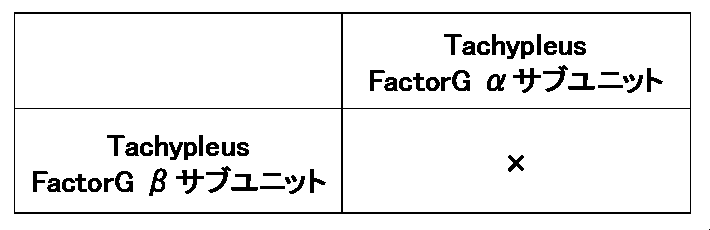
実施例1の6-3で得られた、本発明のFactorG αサブユニットAとFactorG βサブユニットβi2の共発現物が含まれる上清、又は本発明のFactorG αサブユニットBとFacorG βサブユニットβ2の共発現物が含まれる上清を試料として用い、既知のBG量を以下の方法で測定した。
LNT濃度が0.35 pg/mL、3.5 pg/mL、及び35 pg/mLになるように溶解したものをLNT溶液として用いた。また、注射用蒸留水を、LNT無添加のブランクとして用いた。
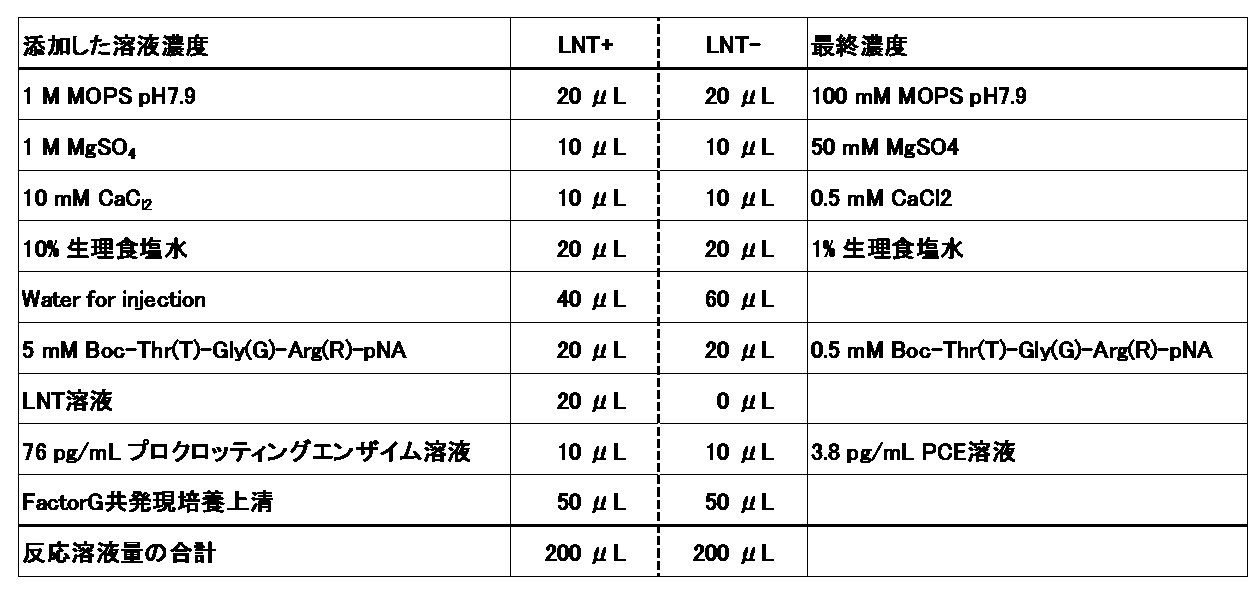
また、測定値から最小2乗法で求めた回帰直線式と相関係数は下記の通りである。
R2=1
また、測定値から最小2乗法で求めた回帰直線式と相関係数は下記の通りである。
R2=0.9938
(1)発現ベクターの構築
1)FactorG αサブユニットA発現ベクター発現ベクターの構築
配列番号41(表9に記載の昆虫細胞用に最適化した塩基配列、シグナル配列含む)で表される塩基配列を有するcDNAをプラスミドベクター pIEx-Bac-1ベクター(Novagen社)のNcoI-NotIサイトへ挿入し、FactorG αサブユニットA発現ベクター(α(TYPE A)/pIEx-Bac-1)を構築した。
5'末端側からシグナル配列、Hatタグ、SUMOタグ、FactorG βサブユニットβi2(アミノ酸配列:配列番号6)の順に配したアミノ酸配列(配列番号67)を設計し、このアミノ酸配列をコードし、且つ昆虫細胞用に最適化した塩基配列(配列番号68)を設計した。この塩基配列のFactorG βサブユニットβi2をコードする塩基配列は、配列番号69で表されるものである。
昆虫細胞 expresSF+(登録商標;プロテイン・サイエンス(Protein Science社製)を、1.0 x 106 cellsとなるようにBG除去済み無血清培地PSFM-J1(pH5.5~6.2)が入った6well plateに播種した。
上記で構築した発現ベクター α(TYPE A)/pIEx-Bac-1及びβi2/ pIEx-Bac-1(それぞれ1μg分)、及びトランスフェクション試薬 ScreenFectA plus(富士フイルム和光純薬(株)製) 2 μLを、PSFM-J1培地(富士フイルム和光純薬(株)製)100μLを混合し、室温で20分インキュベーションした後、溶液をexpresSF+を播種した6well plateに添加した。
その後、27℃で3日間培養した。培養後、培養液を、12,000 x g、4℃で2分間遠心し、上清と沈殿に分画した。上清を凍結させ保存した。
得られた上清(本発明のFactorG αサブユニットAとFactorG βサブユニットβi2の共発現物を含有する)を試料として用いる以外は、実施例2と同様の方法で、得られた共発現物のグルカン依存性プロテアーゼ活性の評価を行った。尚、35pg/mL LNT溶液は、測定時の濃度が35 pg/mL、3.5 pg/mL、又は0.35 pg/mLとなるように加えた。
図5から明らかな通り、本発明のヘテロダイマーを用いてBGの測定を行った場合、試料中のBG濃度が、レンチナン濃度換算値で0.35pg/mLでも十分検出可能であることが確認できた。
Claims (7)
- 配列番号2又は配列番号4で表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列を含有するFactorG αサブユニットと、配列番号6、8、10、12、14、又は16のいずれか一つで表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列を含有するFactorG βサブユニットとの組合せのヘテロダイマー。
- 下記から選択される、請求項1に記載のヘテロダイマー:
(1)配列番号2で表されるアミノ酸配列を含有するFactorG αサブユニットと、配列番号6で表されるアミノ酸配列を含有するFactorG βサブユニットとの組合せのヘテロダイマー、
(2)配列番号2で表されるアミノ酸配列を含有するFactorG αサブユニットと、配列番号8で表されるアミノ酸配列を含有するFactorG βサブユニットとの組合せのヘテロダイマー、
(3)配列番号2で表されるアミノ酸配列を含有するFactorG αサブユニットと、配列番号12で表されるアミノ酸配列を含有するFactorG βサブユニットとの組合せのヘテロダイマー、
(4)配列番号2で表されるアミノ酸配列を含有するFactorG αサブユニットと、配列番号14で表されるアミノ酸配列を含有するFactorG βサブユニットとの組合せのヘテロダイマー、
(5)配列番号4で表されるアミノ酸配列を含有するFactorG αサブユニットと、配列番号10で表されるアミノ酸配列を含有するFactorG βサブユニットとの組合せのヘテロダイマー、
(6)配列番号4で表されるアミノ酸配列を含有するFactorG αサブユニットと、配列番号16で表されるアミノ酸配列を含有するFactorG βサブユニットのヘテロダイマー。 - (1)、(2)、又は(5)から選択される、請求項2に記載のヘテロダイマー。
- 試料と、配列番号2又は配列番号4で表されるアミノ酸配列を含有するFactorG αサブユニットと、配列番号6、8、10、12、14、又は16のいずれか一つで表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列を含有するFactorG βサブユニットとの組合せのヘテロダイマーを用いた、β-グルカンの測定方法。
- 配列番号2又は配列番号4で表されるアミノ酸配列を含有するFactorG αサブユニット。
- 配列番号6、8、10、12、14、又は16のいずれか一つで表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列を含有するFactorG βサブユニット。
- 配列番号2又は配列番号4で表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列を含有するFactorG αサブユニットと、配列番号6、8、10、12、14、又は16のいずれか一つで表されるアミノ酸配列と同一若しくは実質的に同一のアミノ酸配列を含有するFactorG βサブユニットとの組合せのヘテロダイマーを含む、β―グルカン測定用キット。
Priority Applications (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020227019561A KR102785439B1 (ko) | 2019-12-11 | 2020-12-10 | 투구게 유래 재조합 FactorG 및 이것을 이용한 β-글루칸의 측정 방법 |
| EP20898057.3A EP4074827A4 (en) | 2019-12-11 | 2020-12-10 | RECOMBINANT FACTOR G FROM ARROWTAIL CANCER AND METHOD FOR MEASURING SS-GLUCAN THEREFROM |
| CN202080086019.6A CN114846136B (zh) | 2019-12-11 | 2020-12-10 | 源自鲎的重组G因子及使用该重组G因子的β-葡聚糖的测定方法 |
| JP2021564048A JP7358509B2 (ja) | 2019-12-11 | 2020-12-10 | カブトガニ由来組換えFactorG及びこれを用いたβ-グルカンの測定方法 |
| US17/837,735 US12545711B2 (en) | 2019-12-11 | 2022-06-10 | Horseshoe crab-derived recombinant factor G and method of measuring β-glucan using same |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2019-223604 | 2019-12-11 | ||
| JP2019223604 | 2019-12-11 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US17/837,735 Continuation US12545711B2 (en) | 2019-12-11 | 2022-06-10 | Horseshoe crab-derived recombinant factor G and method of measuring β-glucan using same |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2021117841A1 true WO2021117841A1 (ja) | 2021-06-17 |
Family
ID=76329978
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2020/046178 Ceased WO2021117841A1 (ja) | 2019-12-11 | 2020-12-10 | カブトガニ由来組換えFactorG及びこれを用いたβ-グルカンの測定方法 |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US12545711B2 (ja) |
| EP (1) | EP4074827A4 (ja) |
| JP (1) | JP7358509B2 (ja) |
| KR (1) | KR102785439B1 (ja) |
| CN (1) | CN114846136B (ja) |
| WO (1) | WO2021117841A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023013661A1 (ja) | 2021-08-04 | 2023-02-09 | 生化学工業株式会社 | β-グルカン測定用試薬、その製造方法および使用 |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS4832134B1 (ja) | 1968-09-06 | 1973-10-04 | ||
| JPH02227075A (ja) | 1988-09-29 | 1990-09-10 | Kyowa Hakko Kogyo Co Ltd | 新規ポリペプチド |
| JPH0875751A (ja) | 1994-06-30 | 1996-03-22 | Seikagaku Kogyo Co Ltd | エンドトキシン安定化剤、エンドトキシン組成物およびエンドトキシンの測定法 |
| JP2564632B2 (ja) | 1988-11-21 | 1996-12-18 | マルハ株式会社 | β−グルカン類に対する特異性の高いアメボサイト・ライセート及びその製造方法 |
| WO2008004674A1 (en) | 2006-07-07 | 2008-01-10 | Seikagaku Corporation | PRO-CLOTTING ENZYME, AND METHOD FOR DETECTION OF ENDOTOXIN OR (1→3)-β-D-GLUCAN USING THE SAME |
| WO2010107068A1 (ja) * | 2009-03-17 | 2010-09-23 | 和光純薬工業株式会社 | β-グルカンの測定方法及びそれに用いられるβ-グルカン結合性蛋白質 |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7541162B2 (en) * | 2005-03-28 | 2009-06-02 | Seikagaku Corporation | Method for producing factor G derived from horseshoe crab |
| JP5686308B2 (ja) * | 2009-02-20 | 2015-03-18 | 国立大学法人広島大学 | βグルカンの濃度測定方法および濃度測定用キット |
-
2020
- 2020-12-10 JP JP2021564048A patent/JP7358509B2/ja active Active
- 2020-12-10 EP EP20898057.3A patent/EP4074827A4/en active Pending
- 2020-12-10 KR KR1020227019561A patent/KR102785439B1/ko active Active
- 2020-12-10 CN CN202080086019.6A patent/CN114846136B/zh active Active
- 2020-12-10 WO PCT/JP2020/046178 patent/WO2021117841A1/ja not_active Ceased
-
2022
- 2022-06-10 US US17/837,735 patent/US12545711B2/en active Active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS4832134B1 (ja) | 1968-09-06 | 1973-10-04 | ||
| JPH02227075A (ja) | 1988-09-29 | 1990-09-10 | Kyowa Hakko Kogyo Co Ltd | 新規ポリペプチド |
| JP2564632B2 (ja) | 1988-11-21 | 1996-12-18 | マルハ株式会社 | β−グルカン類に対する特異性の高いアメボサイト・ライセート及びその製造方法 |
| JPH0875751A (ja) | 1994-06-30 | 1996-03-22 | Seikagaku Kogyo Co Ltd | エンドトキシン安定化剤、エンドトキシン組成物およびエンドトキシンの測定法 |
| WO2008004674A1 (en) | 2006-07-07 | 2008-01-10 | Seikagaku Corporation | PRO-CLOTTING ENZYME, AND METHOD FOR DETECTION OF ENDOTOXIN OR (1→3)-β-D-GLUCAN USING THE SAME |
| WO2010107068A1 (ja) * | 2009-03-17 | 2010-09-23 | 和光純薬工業株式会社 | β-グルカンの測定方法及びそれに用いられるβ-グルカン結合性蛋白質 |
Non-Patent Citations (7)
| Title |
|---|
| "Genbank", Database accession no. AB547712 |
| DATABASE UniprotKB [online] 8 May 2019 (2019-05-08), "Definition: Subname: Full=Clotting factor G beta subunit", XP055835091, Database accession no. Q27083 * |
| N. SEKI ET AL., J. BIOL. CHEM., vol. 269, no. 2, 1994, pages 1370 - 1374 |
| PROC. NATL. ACAD. SCI. USA, vol. 82, 1985, pages 8404 |
| PROC. NATL. ACAD. SCI., USA, vol. 84, 1987, pages 7413 |
| SEKI, NORIAKI ET AL.: "Horseshoe crab (1,3)-beta -D-glucan-sensitive coagulation factor G", THE JOURNAL OF BIOLOGICAL CHEMISTRY, vol. 269, no. 2, 1994, pages 1370 - 1374, XP002099779 * |
| T. MORITA ET AL., FEBS LETT., vol. 129, 1981, pages 318 - 321 |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023013661A1 (ja) | 2021-08-04 | 2023-02-09 | 生化学工業株式会社 | β-グルカン測定用試薬、その製造方法および使用 |
Also Published As
| Publication number | Publication date |
|---|---|
| US12545711B2 (en) | 2026-02-10 |
| KR20220097504A (ko) | 2022-07-07 |
| JP7358509B2 (ja) | 2023-10-10 |
| JPWO2021117841A1 (ja) | 2021-06-17 |
| US20220306705A1 (en) | 2022-09-29 |
| EP4074827A4 (en) | 2023-11-01 |
| KR102785439B1 (ko) | 2025-03-21 |
| CN114846136B (zh) | 2024-07-12 |
| CN114846136A (zh) | 2022-08-02 |
| EP4074827A1 (en) | 2022-10-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7590530B2 (ja) | エンドトキシン測定剤 | |
| JP2017060486A (ja) | 組換えプロクロッティングエンザイムを用いたエンドトキシンの検出方法 | |
| EP2270145B1 (en) | Novel protein capable of binding to hyaluronic acid, and method for measurement of hyaluronic acid using the same | |
| US7867733B2 (en) | Method for producing factor G derived from horseshoe crab | |
| US12545711B2 (en) | Horseshoe crab-derived recombinant factor G and method of measuring β-glucan using same | |
| JP6141205B2 (ja) | 窒化ケイ素(Si3N4)親和性ペプチド、及びその利用 | |
| KR20230065830A (ko) | DNA 및 RNA 동시 검출을 위한 Cas 복합체 및 이의 용도 | |
| CN116286754B (zh) | 甘露聚糖结合型丝氨酸蛋白酶同系物及其制备方法和应用 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 20898057 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 20227019561 Country of ref document: KR Kind code of ref document: A Ref document number: 2021564048 Country of ref document: JP Kind code of ref document: A |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| ENP | Entry into the national phase |
Ref document number: 2020898057 Country of ref document: EP Effective date: 20220711 |