TW202242108A - 經修飾trem之組合物及其用途 - Google Patents
經修飾trem之組合物及其用途 Download PDFInfo
- Publication number
- TW202242108A TW202242108A TW110148799A TW110148799A TW202242108A TW 202242108 A TW202242108 A TW 202242108A TW 110148799 A TW110148799 A TW 110148799A TW 110148799 A TW110148799 A TW 110148799A TW 202242108 A TW202242108 A TW 202242108A
- Authority
- TW
- Taiwan
- Prior art keywords
- trem
- asgpr
- domain
- binding moiety
- asgpr binding
- Prior art date
Links
- 239000000203 mixture Substances 0.000 title claims abstract description 115
- 102000005427 Asialoglycoprotein Receptor Human genes 0.000 claims abstract description 501
- 108010006523 asialoglycoprotein receptor Proteins 0.000 claims abstract description 501
- 230000027455 binding Effects 0.000 claims abstract description 496
- 238000000034 method Methods 0.000 claims abstract description 33
- 239000012636 effector Substances 0.000 claims abstract description 5
- -1 alkyne radical Chemical class 0.000 claims description 354
- 125000005647 linker group Chemical group 0.000 claims description 147
- 125000003729 nucleotide group Chemical group 0.000 claims description 99
- 239000002773 nucleotide Substances 0.000 claims description 93
- 150000001875 compounds Chemical class 0.000 claims description 92
- 125000000217 alkyl group Chemical group 0.000 claims description 75
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 claims description 73
- 238000012986 modification Methods 0.000 claims description 63
- 229910052739 hydrogen Inorganic materials 0.000 claims description 62
- 239000001257 hydrogen Substances 0.000 claims description 62
- 230000004048 modification Effects 0.000 claims description 61
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 claims description 58
- 229940024606 amino acid Drugs 0.000 claims description 53
- 125000002652 ribonucleotide group Chemical group 0.000 claims description 52
- 150000001413 amino acids Chemical class 0.000 claims description 50
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 claims description 42
- 125000000623 heterocyclic group Chemical group 0.000 claims description 41
- 125000003342 alkenyl group Chemical group 0.000 claims description 39
- 125000000753 cycloalkyl group Chemical group 0.000 claims description 39
- 229940035893 uracil Drugs 0.000 claims description 38
- 125000000304 alkynyl group Chemical group 0.000 claims description 36
- 125000001072 heteroaryl group Chemical group 0.000 claims description 35
- 125000003118 aryl group Chemical group 0.000 claims description 33
- 238000007385 chemical modification Methods 0.000 claims description 31
- 235000000346 sugar Nutrition 0.000 claims description 31
- 229960000643 adenine Drugs 0.000 claims description 30
- 229930024421 Adenine Natural products 0.000 claims description 29
- UFHFLCQGNIYNRP-UHFFFAOYSA-N Hydrogen Chemical compound [H][H] UFHFLCQGNIYNRP-UHFFFAOYSA-N 0.000 claims description 29
- 108091028664 Ribonucleotide Proteins 0.000 claims description 29
- 239000002336 ribonucleotide Substances 0.000 claims description 29
- 150000002431 hydrogen Chemical class 0.000 claims description 28
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 claims description 27
- 125000001188 haloalkyl group Chemical group 0.000 claims description 27
- 125000004404 heteroalkyl group Chemical group 0.000 claims description 25
- 229910052760 oxygen Inorganic materials 0.000 claims description 24
- 229940104302 cytosine Drugs 0.000 claims description 22
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 claims description 22
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 20
- 150000003839 salts Chemical class 0.000 claims description 18
- 125000002947 alkylene group Chemical group 0.000 claims description 15
- 125000004450 alkenylene group Chemical group 0.000 claims description 14
- 125000004419 alkynylene group Chemical group 0.000 claims description 13
- 125000003368 amide group Chemical group 0.000 claims description 13
- 150000001720 carbohydrates Chemical group 0.000 claims description 13
- 235000014633 carbohydrates Nutrition 0.000 claims description 12
- 125000004432 carbon atom Chemical group C* 0.000 claims description 12
- 125000004093 cyano group Chemical group *C#N 0.000 claims description 12
- 229940113082 thymine Drugs 0.000 claims description 11
- 229910052757 nitrogen Inorganic materials 0.000 claims description 10
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 9
- 125000002228 disulfide group Chemical group 0.000 claims description 9
- 125000004185 ester group Chemical group 0.000 claims description 9
- 125000004474 heteroalkylene group Chemical group 0.000 claims description 9
- 239000008194 pharmaceutical composition Substances 0.000 claims description 9
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 claims description 8
- 125000005587 carbonate group Chemical group 0.000 claims description 8
- 125000001033 ether group Chemical group 0.000 claims description 8
- 238000006467 substitution reaction Methods 0.000 claims description 8
- 230000014616 translation Effects 0.000 claims description 8
- 239000002202 Polyethylene glycol Substances 0.000 claims description 7
- 238000009472 formulation Methods 0.000 claims description 7
- 229930182830 galactose Natural products 0.000 claims description 7
- 230000000977 initiatory effect Effects 0.000 claims description 7
- 229920001223 polyethylene glycol Polymers 0.000 claims description 7
- 125000004430 oxygen atom Chemical group O* 0.000 claims description 6
- 201000010099 disease Diseases 0.000 claims description 5
- 125000003827 glycol group Chemical group 0.000 claims description 5
- 125000004435 hydrogen atom Chemical group [H]* 0.000 claims description 5
- 125000000449 nitro group Chemical group [O-][N+](*)=O 0.000 claims description 5
- 208000035475 disorder Diseases 0.000 claims description 4
- 125000001475 halogen functional group Chemical group 0.000 claims description 4
- 239000000546 pharmaceutical excipient Substances 0.000 claims description 4
- 102000003960 Ligases Human genes 0.000 claims description 3
- 108090000364 Ligases Proteins 0.000 claims description 3
- 150000001345 alkine derivatives Chemical class 0.000 claims description 2
- 238000001243 protein synthesis Methods 0.000 claims description 2
- 150000002632 lipids Chemical class 0.000 claims 3
- 239000002105 nanoparticle Substances 0.000 claims 3
- 102000002508 Peptide Elongation Factors Human genes 0.000 claims 1
- 108010068204 Peptide Elongation Factors Proteins 0.000 claims 1
- 150000003291 riboses Chemical class 0.000 claims 1
- 239000012634 fragment Substances 0.000 description 139
- 229910052799 carbon Inorganic materials 0.000 description 124
- 108091028043 Nucleic acid sequence Proteins 0.000 description 85
- 210000004027 cell Anatomy 0.000 description 59
- VNWKTOKETHGBQD-UHFFFAOYSA-N methane Chemical compound C VNWKTOKETHGBQD-UHFFFAOYSA-N 0.000 description 58
- 108010064245 urinary gonadotropin fragment Proteins 0.000 description 54
- 108020004566 Transfer RNA Proteins 0.000 description 52
- 235000001014 amino acid Nutrition 0.000 description 52
- 150000007523 nucleic acids Chemical group 0.000 description 48
- 102000039446 nucleic acids Human genes 0.000 description 46
- 108020004707 nucleic acids Proteins 0.000 description 46
- 125000000548 ribosyl group Chemical group C1([C@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 40
- 108091035707 Consensus sequence Proteins 0.000 description 39
- 125000004429 atom Chemical group 0.000 description 38
- 229920002477 rna polymer Polymers 0.000 description 31
- KXSKAZFMTGADIV-UHFFFAOYSA-N 2-[3-(2-hydroxyethoxy)propoxy]ethanol Chemical compound OCCOCCCOCCO KXSKAZFMTGADIV-UHFFFAOYSA-N 0.000 description 24
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Natural products NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 24
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 23
- 229930185560 Pseudouridine Natural products 0.000 description 23
- PTJWIQPHWPFNBW-UHFFFAOYSA-N Pseudouridine C Natural products OC1C(O)C(CO)OC1C1=CNC(=O)NC1=O PTJWIQPHWPFNBW-UHFFFAOYSA-N 0.000 description 23
- WGDUUQDYDIIBKT-UHFFFAOYSA-N beta-Pseudouridine Natural products OC1OC(CN2C=CC(=O)NC2=O)C(O)C1O WGDUUQDYDIIBKT-UHFFFAOYSA-N 0.000 description 23
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 22
- 108020005098 Anticodon Proteins 0.000 description 20
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 20
- 239000002253 acid Substances 0.000 description 20
- 125000005842 heteroatom Chemical group 0.000 description 20
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 18
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 18
- 238000003776 cleavage reaction Methods 0.000 description 18
- 230000000694 effects Effects 0.000 description 18
- 230000007017 scission Effects 0.000 description 18
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 17
- 238000004519 manufacturing process Methods 0.000 description 17
- 101000629400 Homo sapiens Mesoderm-specific transcript homolog protein Proteins 0.000 description 16
- 101000604197 Homo sapiens Neuronatin Proteins 0.000 description 16
- 101000693243 Homo sapiens Paternally-expressed gene 3 protein Proteins 0.000 description 16
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 16
- 102100026821 Mesoderm-specific transcript homolog protein Human genes 0.000 description 16
- 102100038816 Neuronatin Human genes 0.000 description 16
- 102100025757 Paternally-expressed gene 3 protein Human genes 0.000 description 16
- PTJWIQPHWPFNBW-GBNDHIKLSA-N pseudouridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1C1=CNC(=O)NC1=O PTJWIQPHWPFNBW-GBNDHIKLSA-N 0.000 description 16
- 241000894007 species Species 0.000 description 16
- 241000282414 Homo sapiens Species 0.000 description 15
- 125000005843 halogen group Chemical group 0.000 description 15
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 14
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 14
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 14
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 14
- 230000006870 function Effects 0.000 description 14
- 229910052717 sulfur Inorganic materials 0.000 description 14
- 108020004705 Codon Proteins 0.000 description 13
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 13
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 13
- 108020004485 Nonsense Codon Proteins 0.000 description 13
- 229910019142 PO4 Inorganic materials 0.000 description 13
- 229960002989 glutamic acid Drugs 0.000 description 13
- 235000013922 glutamic acid Nutrition 0.000 description 13
- 239000004220 glutamic acid Substances 0.000 description 13
- 235000021317 phosphate Nutrition 0.000 description 13
- 239000010452 phosphate Substances 0.000 description 13
- 108020004414 DNA Proteins 0.000 description 12
- 108090000623 proteins and genes Proteins 0.000 description 12
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 11
- 239000003795 chemical substances by application Substances 0.000 description 11
- 108020004999 messenger RNA Proteins 0.000 description 11
- 230000003278 mimic effect Effects 0.000 description 11
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 11
- 102000053602 DNA Human genes 0.000 description 10
- 150000002772 monosaccharides Chemical class 0.000 description 10
- 230000004962 physiological condition Effects 0.000 description 10
- 102000004196 processed proteins & peptides Human genes 0.000 description 10
- 235000018102 proteins Nutrition 0.000 description 10
- 102000004169 proteins and genes Human genes 0.000 description 10
- 102000004190 Enzymes Human genes 0.000 description 9
- 108090000790 Enzymes Proteins 0.000 description 9
- 108700026244 Open Reading Frames Proteins 0.000 description 9
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 9
- 210000004369 blood Anatomy 0.000 description 9
- 239000008280 blood Substances 0.000 description 9
- 150000002148 esters Chemical class 0.000 description 9
- 239000002777 nucleoside Substances 0.000 description 9
- 230000003612 virological effect Effects 0.000 description 9
- 239000004475 Arginine Substances 0.000 description 8
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 8
- 239000004471 Glycine Substances 0.000 description 8
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 description 8
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 8
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 8
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 8
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 8
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 8
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 8
- 239000004472 Lysine Substances 0.000 description 8
- 241000124008 Mammalia Species 0.000 description 8
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 description 8
- 229910020008 S(O) Inorganic materials 0.000 description 8
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 8
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 8
- 239000004473 Threonine Substances 0.000 description 8
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 8
- 229960003767 alanine Drugs 0.000 description 8
- 235000004279 alanine Nutrition 0.000 description 8
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 8
- 229960003121 arginine Drugs 0.000 description 8
- 235000009697 arginine Nutrition 0.000 description 8
- 229960001230 asparagine Drugs 0.000 description 8
- 235000009582 asparagine Nutrition 0.000 description 8
- 229960005261 aspartic acid Drugs 0.000 description 8
- 235000003704 aspartic acid Nutrition 0.000 description 8
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 8
- 229960002433 cysteine Drugs 0.000 description 8
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 8
- 235000018417 cysteine Nutrition 0.000 description 8
- 229960002449 glycine Drugs 0.000 description 8
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 8
- 229960002885 histidine Drugs 0.000 description 8
- 238000000338 in vitro Methods 0.000 description 8
- 239000000543 intermediate Substances 0.000 description 8
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 8
- 229960000310 isoleucine Drugs 0.000 description 8
- 229960003136 leucine Drugs 0.000 description 8
- 229960003646 lysine Drugs 0.000 description 8
- 229930182817 methionine Natural products 0.000 description 8
- 229960004452 methionine Drugs 0.000 description 8
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 8
- 229960005190 phenylalanine Drugs 0.000 description 8
- 229920001184 polypeptide Polymers 0.000 description 8
- 230000001124 posttranscriptional effect Effects 0.000 description 8
- 229960002429 proline Drugs 0.000 description 8
- 229960001153 serine Drugs 0.000 description 8
- 210000002966 serum Anatomy 0.000 description 8
- 229960002898 threonine Drugs 0.000 description 8
- 238000012546 transfer Methods 0.000 description 8
- 229960004799 tryptophan Drugs 0.000 description 8
- 229960004441 tyrosine Drugs 0.000 description 8
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 8
- 229940045145 uridine Drugs 0.000 description 8
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical compound N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 7
- 241000700605 Viruses Species 0.000 description 7
- QTBSBXVTEAMEQO-UHFFFAOYSA-N acetic acid Substances CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 7
- XBDQKXXYIPTUBI-UHFFFAOYSA-N dimethylselenoniopropionate Natural products CCC(O)=O XBDQKXXYIPTUBI-UHFFFAOYSA-N 0.000 description 7
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 7
- 125000001570 methylene group Chemical group [H]C([H])([*:1])[*:2] 0.000 description 7
- 238000002360 preparation method Methods 0.000 description 7
- 210000001519 tissue Anatomy 0.000 description 7
- 239000013603 viral vector Substances 0.000 description 7
- LRFVTYWOQMYALW-UHFFFAOYSA-N 9H-xanthine Chemical compound O=C1NC(=O)NC2=C1NC=N2 LRFVTYWOQMYALW-UHFFFAOYSA-N 0.000 description 6
- NYHBQMYGNKIUIF-UUOKFMHZSA-N Guanosine Chemical compound C1=NC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O NYHBQMYGNKIUIF-UUOKFMHZSA-N 0.000 description 6
- 108091093037 Peptide nucleic acid Proteins 0.000 description 6
- DRTQHJPVMGBUCF-XVFCMESISA-N Uridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-XVFCMESISA-N 0.000 description 6
- OIRDTQYFTABQOQ-KQYNXXCUSA-N adenosine group Chemical group [C@@H]1([C@H](O)[C@H](O)[C@@H](CO)O1)N1C=NC=2C(N)=NC=NC12 OIRDTQYFTABQOQ-KQYNXXCUSA-N 0.000 description 6
- 230000004927 fusion Effects 0.000 description 6
- 210000003494 hepatocyte Anatomy 0.000 description 6
- 239000013598 vector Substances 0.000 description 6
- 102000052866 Amino Acyl-tRNA Synthetases Human genes 0.000 description 5
- 108700028939 Amino Acyl-tRNA Synthetases Proteins 0.000 description 5
- 239000002126 C01EB10 - Adenosine Substances 0.000 description 5
- 108090000371 Esterases Proteins 0.000 description 5
- 108091034117 Oligonucleotide Proteins 0.000 description 5
- 230000002378 acidificating effect Effects 0.000 description 5
- 229960005305 adenosine Drugs 0.000 description 5
- 239000000356 contaminant Substances 0.000 description 5
- 229940029575 guanosine Drugs 0.000 description 5
- 210000005260 human cell Anatomy 0.000 description 5
- 125000001041 indolyl group Chemical group 0.000 description 5
- 230000003834 intracellular effect Effects 0.000 description 5
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 5
- 235000019260 propionic acid Nutrition 0.000 description 5
- 238000011160 research Methods 0.000 description 5
- 229960003080 taurine Drugs 0.000 description 5
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 description 5
- OWTQQPNDSWCHOV-UHFFFAOYSA-N 2-[2-[2-[2-[2-[2-[2-[2-[2-[2-[2-[2-[2-[2-(2-hydroxyethoxy)ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethanol Chemical compound OCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCO OWTQQPNDSWCHOV-UHFFFAOYSA-N 0.000 description 4
- NIELXDCPHZJHGM-UHFFFAOYSA-N 2-[2-[2-[2-[2-[2-[2-[2-[2-[2-[2-[2-[2-[2-[2-[2-(2-hydroxyethoxy)ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethoxy]ethanol Chemical compound OCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCO NIELXDCPHZJHGM-UHFFFAOYSA-N 0.000 description 4
- MSWZFWKMSRAUBD-GASJEMHNSA-N 2-amino-2-deoxy-D-galactopyranose Chemical compound N[C@H]1C(O)O[C@H](CO)[C@H](O)[C@@H]1O MSWZFWKMSRAUBD-GASJEMHNSA-N 0.000 description 4
- FZWGECJQACGGTI-UHFFFAOYSA-N 2-amino-7-methyl-1,7-dihydro-6H-purin-6-one Chemical compound NC1=NC(O)=C2N(C)C=NC2=N1 FZWGECJQACGGTI-UHFFFAOYSA-N 0.000 description 4
- KDSNLYIMUZNERS-UHFFFAOYSA-N 2-methylpropanamine Chemical compound CC(C)CN KDSNLYIMUZNERS-UHFFFAOYSA-N 0.000 description 4
- HCGHYQLFMPXSDU-UHFFFAOYSA-N 7-methyladenine Chemical compound C1=NC(N)=C2N(C)C=NC2=N1 HCGHYQLFMPXSDU-UHFFFAOYSA-N 0.000 description 4
- NYHBQMYGNKIUIF-UHFFFAOYSA-N D-guanosine Natural products C1=2NC(N)=NC(=O)C=2N=CN1C1OC(CO)C(O)C1O NYHBQMYGNKIUIF-UHFFFAOYSA-N 0.000 description 4
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 4
- IAJILQKETJEXLJ-UHFFFAOYSA-N Galacturonsaeure Natural products O=CC(O)C(O)C(O)C(O)C(O)=O IAJILQKETJEXLJ-UHFFFAOYSA-N 0.000 description 4
- 101000999322 Homo sapiens Putative insulin-like growth factor 2 antisense gene protein Proteins 0.000 description 4
- 101001073409 Homo sapiens Retrotransposon-derived protein PEG10 Proteins 0.000 description 4
- 241001465754 Metazoa Species 0.000 description 4
- 108091005804 Peptidases Proteins 0.000 description 4
- 102000035195 Peptidases Human genes 0.000 description 4
- 229920000604 Polyethylene Glycol 200 Polymers 0.000 description 4
- 229920002560 Polyethylene Glycol 3000 Polymers 0.000 description 4
- 229920002582 Polyethylene Glycol 600 Polymers 0.000 description 4
- 229920002593 Polyethylene Glycol 800 Polymers 0.000 description 4
- 229920002596 Polyethylene Glycol 900 Polymers 0.000 description 4
- 102100036485 Putative insulin-like growth factor 2 antisense gene protein Human genes 0.000 description 4
- 102100035844 Retrotransposon-derived protein PEG10 Human genes 0.000 description 4
- 229910005965 SO 2 Inorganic materials 0.000 description 4
- 125000002777 acetyl group Chemical group [H]C([H])([H])C(*)=O 0.000 description 4
- 150000001412 amines Chemical class 0.000 description 4
- 125000000852 azido group Chemical group *N=[N+]=[N-] 0.000 description 4
- 125000002619 bicyclic group Chemical group 0.000 description 4
- 230000008859 change Effects 0.000 description 4
- 239000003153 chemical reaction reagent Substances 0.000 description 4
- 125000004122 cyclic group Chemical group 0.000 description 4
- DTPCFIHYWYONMD-UHFFFAOYSA-N decaethylene glycol Chemical compound OCCOCCOCCOCCOCCOCCOCCOCCOCCOCCO DTPCFIHYWYONMD-UHFFFAOYSA-N 0.000 description 4
- MTHSVFCYNBDYFN-UHFFFAOYSA-N diethylene glycol Chemical compound OCCOCCO MTHSVFCYNBDYFN-UHFFFAOYSA-N 0.000 description 4
- XPJRQAIZZQMSCM-UHFFFAOYSA-N heptaethylene glycol Chemical compound OCCOCCOCCOCCOCCOCCOCCO XPJRQAIZZQMSCM-UHFFFAOYSA-N 0.000 description 4
- 238000001727 in vivo Methods 0.000 description 4
- 239000003446 ligand Substances 0.000 description 4
- 239000007788 liquid Substances 0.000 description 4
- 210000004962 mammalian cell Anatomy 0.000 description 4
- RIFHJAODNHLCBH-UHFFFAOYSA-N methanethione Chemical group S=[CH] RIFHJAODNHLCBH-UHFFFAOYSA-N 0.000 description 4
- DUWWHGPELOTTOE-UHFFFAOYSA-N n-(5-chloro-2,4-dimethoxyphenyl)-3-oxobutanamide Chemical compound COC1=CC(OC)=C(NC(=O)CC(C)=O)C=C1Cl DUWWHGPELOTTOE-UHFFFAOYSA-N 0.000 description 4
- 125000003835 nucleoside group Chemical group 0.000 description 4
- GLZWNFNQMJAZGY-UHFFFAOYSA-N octaethylene glycol Chemical compound OCCOCCOCCOCCOCCOCCOCCOCCO GLZWNFNQMJAZGY-UHFFFAOYSA-N 0.000 description 4
- 239000001301 oxygen Substances 0.000 description 4
- 125000004437 phosphorous atom Chemical group 0.000 description 4
- 229910052698 phosphorus Inorganic materials 0.000 description 4
- 229920002523 polyethylene Glycol 1000 Polymers 0.000 description 4
- 229940096913 pseudoisocytidine Drugs 0.000 description 4
- 150000003212 purines Chemical class 0.000 description 4
- 150000003254 radicals Chemical class 0.000 description 4
- 230000009467 reduction Effects 0.000 description 4
- 230000009711 regulatory function Effects 0.000 description 4
- 238000012360 testing method Methods 0.000 description 4
- ILLKMACMBHTSHP-UHFFFAOYSA-N tetradecaethylene glycol Chemical compound OCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCO ILLKMACMBHTSHP-UHFFFAOYSA-N 0.000 description 4
- PSVXZQVXSXSQRO-UHFFFAOYSA-N undecaethylene glycol Chemical compound OCCOCCOCCOCCOCCOCCOCCOCCOCCOCCOCCO PSVXZQVXSXSQRO-UHFFFAOYSA-N 0.000 description 4
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 3
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 3
- OVONXEQGWXGFJD-UHFFFAOYSA-N 4-sulfanylidene-1h-pyrimidin-2-one Chemical compound SC=1C=CNC(=O)N=1 OVONXEQGWXGFJD-UHFFFAOYSA-N 0.000 description 3
- MMUBPEFMCTVKTR-IBNKKVAHSA-N 5-[(2s,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)-2-methyloxolan-2-yl]-1h-pyrimidine-2,4-dione Chemical compound C=1NC(=O)NC(=O)C=1[C@]1(C)O[C@H](CO)[C@@H](O)[C@H]1O MMUBPEFMCTVKTR-IBNKKVAHSA-N 0.000 description 3
- UJBCLAXPPIDQEE-UHFFFAOYSA-N 5-prop-1-ynyl-1h-pyrimidine-2,4-dione Chemical compound CC#CC1=CNC(=O)NC1=O UJBCLAXPPIDQEE-UHFFFAOYSA-N 0.000 description 3
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical group [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 3
- MIKUYHXYGGJMLM-GIMIYPNGSA-N Crotonoside Natural products C1=NC2=C(N)NC(=O)N=C2N1[C@H]1O[C@@H](CO)[C@H](O)[C@@H]1O MIKUYHXYGGJMLM-GIMIYPNGSA-N 0.000 description 3
- HMFHBZSHGGEWLO-SOOFDHNKSA-N D-ribofuranose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-SOOFDHNKSA-N 0.000 description 3
- YCKRFDGAMUMZLT-UHFFFAOYSA-N Fluorine atom Chemical compound [F] YCKRFDGAMUMZLT-UHFFFAOYSA-N 0.000 description 3
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 3
- NSTPXGARCQOSAU-VIFPVBQESA-N N-formyl-L-phenylalanine Chemical compound O=CN[C@H](C(=O)O)CC1=CC=CC=C1 NSTPXGARCQOSAU-VIFPVBQESA-N 0.000 description 3
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 description 3
- RYYWUUFWQRZTIU-UHFFFAOYSA-N Thiophosphoric acid Chemical class OP(O)(S)=O RYYWUUFWQRZTIU-UHFFFAOYSA-N 0.000 description 3
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 3
- XXPIVMBNLKIMFE-UHFFFAOYSA-N [NH4+].[NH4+].[NH4+].[NH4+].[NH4+].[NH4+].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O Chemical compound [NH4+].[NH4+].[NH4+].[NH4+].[NH4+].[NH4+].[O-]P([O-])([O-])=O.[O-]P([O-])([O-])=O XXPIVMBNLKIMFE-UHFFFAOYSA-N 0.000 description 3
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 description 3
- 150000001408 amides Chemical class 0.000 description 3
- 125000003710 aryl alkyl group Chemical group 0.000 description 3
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 3
- DRTQHJPVMGBUCF-PSQAKQOGSA-N beta-L-uridine Natural products O[C@H]1[C@@H](O)[C@H](CO)O[C@@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-PSQAKQOGSA-N 0.000 description 3
- 238000011018 current good manufacturing practice Methods 0.000 description 3
- 229960000684 cytarabine Drugs 0.000 description 3
- 210000001163 endosome Anatomy 0.000 description 3
- 239000002158 endotoxin Substances 0.000 description 3
- 125000001495 ethyl group Chemical group [H]C([H])([H])C([H])([H])* 0.000 description 3
- 238000011156 evaluation Methods 0.000 description 3
- 229910052731 fluorine Inorganic materials 0.000 description 3
- 239000011737 fluorine Substances 0.000 description 3
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 3
- 235000004554 glutamine Nutrition 0.000 description 3
- YACKEPLHDIMKIO-UHFFFAOYSA-N methylphosphonic acid Chemical compound CP(O)(O)=O YACKEPLHDIMKIO-UHFFFAOYSA-N 0.000 description 3
- 150000003833 nucleoside derivatives Chemical class 0.000 description 3
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 3
- 150000004713 phosphodiesters Chemical class 0.000 description 3
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 3
- 235000019833 protease Nutrition 0.000 description 3
- 230000004044 response Effects 0.000 description 3
- 239000000126 substance Substances 0.000 description 3
- 125000000547 substituted alkyl group Chemical group 0.000 description 3
- 239000000758 substrate Substances 0.000 description 3
- 125000000446 sulfanediyl group Chemical group *S* 0.000 description 3
- 230000008685 targeting Effects 0.000 description 3
- 238000010361 transduction Methods 0.000 description 3
- 230000026683 transduction Effects 0.000 description 3
- 238000013519 translation Methods 0.000 description 3
- 241000701161 unidentified adenovirus Species 0.000 description 3
- DRTQHJPVMGBUCF-UHFFFAOYSA-N uracil arabinoside Natural products OC1C(O)C(CO)OC1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-UHFFFAOYSA-N 0.000 description 3
- 229960004295 valine Drugs 0.000 description 3
- 239000004474 valine Substances 0.000 description 3
- 229920001567 vinyl ester resin Polymers 0.000 description 3
- 229940075420 xanthine Drugs 0.000 description 3
- GRYSXUXXBDSYRT-WOUKDFQISA-N (2r,3r,4r,5r)-2-(hydroxymethyl)-4-methoxy-5-[6-(methylamino)purin-9-yl]oxolan-3-ol Chemical compound C1=NC=2C(NC)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1OC GRYSXUXXBDSYRT-WOUKDFQISA-N 0.000 description 2
- 125000006832 (C1-C10) alkylene group Chemical group 0.000 description 2
- MXHRCPNRJAMMIM-BBVRLYRLSA-N 2'-deoxyuridine Chemical compound C1[C@H](O)[C@@H](CO)O[C@@H]1N1C(=O)NC(=O)C=C1 MXHRCPNRJAMMIM-BBVRLYRLSA-N 0.000 description 2
- MSWZFWKMSRAUBD-IVMDWMLBSA-N 2-amino-2-deoxy-D-glucopyranose Chemical compound N[C@H]1C(O)O[C@H](CO)[C@@H](O)[C@@H]1O MSWZFWKMSRAUBD-IVMDWMLBSA-N 0.000 description 2
- MPDKOGQMQLSNOF-GBNDHIKLSA-N 2-amino-5-[(2s,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-1h-pyrimidin-6-one Chemical compound O=C1NC(N)=NC=C1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 MPDKOGQMQLSNOF-GBNDHIKLSA-N 0.000 description 2
- MWBWWFOAEOYUST-UHFFFAOYSA-N 2-aminopurine Chemical compound NC1=NC=C2N=CNC2=N1 MWBWWFOAEOYUST-UHFFFAOYSA-N 0.000 description 2
- RYVNIFSIEDRLSJ-UHFFFAOYSA-N 5-(hydroxymethyl)cytosine Chemical compound NC=1NC(=O)N=CC=1CO RYVNIFSIEDRLSJ-UHFFFAOYSA-N 0.000 description 2
- KBDWGFZSICOZSJ-UHFFFAOYSA-N 5-methyl-2,3-dihydro-1H-pyrimidin-4-one Chemical compound N1CNC=C(C1=O)C KBDWGFZSICOZSJ-UHFFFAOYSA-N 0.000 description 2
- LRSASMSXMSNRBT-UHFFFAOYSA-N 5-methylcytosine Chemical compound CC1=CNC(=O)N=C1N LRSASMSXMSNRBT-UHFFFAOYSA-N 0.000 description 2
- VVZVRYMWEIFUEN-UHFFFAOYSA-N 6-methylpurin-6-amine Chemical compound CC1(N)N=CN=C2N=CN=C12 VVZVRYMWEIFUEN-UHFFFAOYSA-N 0.000 description 2
- YVVMIGRXQRPSIY-UHFFFAOYSA-N 7-deaza-2-aminopurine Chemical compound N1C(N)=NC=C2C=CN=C21 YVVMIGRXQRPSIY-UHFFFAOYSA-N 0.000 description 2
- PEHVGBZKEYRQSX-UHFFFAOYSA-N 7-deaza-adenine Chemical compound NC1=NC=NC2=C1C=CN2 PEHVGBZKEYRQSX-UHFFFAOYSA-N 0.000 description 2
- PFUVOLUPRFCPMN-UHFFFAOYSA-N 7h-purine-6,8-diamine Chemical compound C1=NC(N)=C2NC(N)=NC2=N1 PFUVOLUPRFCPMN-UHFFFAOYSA-N 0.000 description 2
- LPXQRXLUHJKZIE-UHFFFAOYSA-N 8-azaguanine Chemical compound NC1=NC(O)=C2NN=NC2=N1 LPXQRXLUHJKZIE-UHFFFAOYSA-N 0.000 description 2
- MSSXOMSJDRHRMC-UHFFFAOYSA-N 9H-purine-2,6-diamine Chemical compound NC1=NC(N)=C2NC=NC2=N1 MSSXOMSJDRHRMC-UHFFFAOYSA-N 0.000 description 2
- HDZZVAMISRMYHH-UHFFFAOYSA-N 9beta-Ribofuranosyl-7-deazaadenin Natural products C1=CC=2C(N)=NC=NC=2N1C1OC(CO)C(O)C1O HDZZVAMISRMYHH-UHFFFAOYSA-N 0.000 description 2
- 241000272517 Anseriformes Species 0.000 description 2
- 241000272201 Columbiformes Species 0.000 description 2
- SHZGCJCMOBCMKK-UHFFFAOYSA-N D-mannomethylose Natural products CC1OC(O)C(O)C(O)C1O SHZGCJCMOBCMKK-UHFFFAOYSA-N 0.000 description 2
- SRBFZHDQGSBBOR-IOVATXLUSA-N D-xylopyranose Chemical compound O[C@@H]1COC(O)[C@H](O)[C@H]1O SRBFZHDQGSBBOR-IOVATXLUSA-N 0.000 description 2
- 241000702421 Dependoparvovirus Species 0.000 description 2
- RTZKZFJDLAIYFH-UHFFFAOYSA-N Diethyl ether Chemical compound CCOCC RTZKZFJDLAIYFH-UHFFFAOYSA-N 0.000 description 2
- 229930091371 Fructose Natural products 0.000 description 2
- 239000005715 Fructose Substances 0.000 description 2
- 239000012480 LAL reagent Substances 0.000 description 2
- OVRNDRQMDRJTHS-UHFFFAOYSA-N N-acelyl-D-glucosamine Natural products CC(=O)NC1C(O)OC(CO)C(O)C1O OVRNDRQMDRJTHS-UHFFFAOYSA-N 0.000 description 2
- OVRNDRQMDRJTHS-FMDGEEDCSA-N N-acetyl-beta-D-glucosamine Chemical compound CC(=O)N[C@H]1[C@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O OVRNDRQMDRJTHS-FMDGEEDCSA-N 0.000 description 2
- MBLBDJOUHNCFQT-LXGUWJNJSA-N N-acetylglucosamine Natural products CC(=O)N[C@@H](C=O)[C@@H](O)[C@H](O)[C@H](O)CO MBLBDJOUHNCFQT-LXGUWJNJSA-N 0.000 description 2
- 241000286209 Phasianidae Species 0.000 description 2
- 108090000608 Phosphoric Monoester Hydrolases Proteins 0.000 description 2
- 102000004160 Phosphoric Monoester Hydrolases Human genes 0.000 description 2
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 description 2
- DLRVVLDZNNYCBX-UHFFFAOYSA-N Polydextrose Polymers OC1C(O)C(O)C(CO)OC1OCC1C(O)C(O)C(O)C(O)O1 DLRVVLDZNNYCBX-UHFFFAOYSA-N 0.000 description 2
- 241000287530 Psittaciformes Species 0.000 description 2
- CZPWVGJYEJSRLH-UHFFFAOYSA-N Pyrimidine Chemical compound C1=CN=CN=C1 CZPWVGJYEJSRLH-UHFFFAOYSA-N 0.000 description 2
- UCKMPCXJQFINFW-UHFFFAOYSA-N Sulphide Chemical compound [S-2] UCKMPCXJQFINFW-UHFFFAOYSA-N 0.000 description 2
- IQFYYKKMVGJFEH-XLPZGREQSA-N Thymidine Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 IQFYYKKMVGJFEH-XLPZGREQSA-N 0.000 description 2
- 150000007513 acids Chemical class 0.000 description 2
- 150000001336 alkenes Chemical class 0.000 description 2
- 125000002877 alkyl aryl group Chemical group 0.000 description 2
- 125000005600 alkyl phosphonate group Chemical group 0.000 description 2
- SHZGCJCMOBCMKK-DVKNGEFBSA-N alpha-D-quinovopyranose Chemical compound C[C@H]1O[C@H](O)[C@H](O)[C@@H](O)[C@@H]1O SHZGCJCMOBCMKK-DVKNGEFBSA-N 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 2
- PYMYPHUHKUWMLA-UHFFFAOYSA-N arabinose Natural products OCC(O)C(O)C(O)C=O PYMYPHUHKUWMLA-UHFFFAOYSA-N 0.000 description 2
- SRBFZHDQGSBBOR-UHFFFAOYSA-N beta-D-Pyranose-Lyxose Natural products OC1COC(O)C(O)C1O SRBFZHDQGSBBOR-UHFFFAOYSA-N 0.000 description 2
- MSWZFWKMSRAUBD-UHFFFAOYSA-N beta-D-galactosamine Natural products NC1C(O)OC(CO)C(O)C1O MSWZFWKMSRAUBD-UHFFFAOYSA-N 0.000 description 2
- 230000033228 biological regulation Effects 0.000 description 2
- UORVGPXVDQYIDP-UHFFFAOYSA-N borane Chemical compound B UORVGPXVDQYIDP-UHFFFAOYSA-N 0.000 description 2
- 238000004422 calculation algorithm Methods 0.000 description 2
- 238000006243 chemical reaction Methods 0.000 description 2
- 239000003638 chemical reducing agent Substances 0.000 description 2
- 150000001924 cycloalkanes Chemical group 0.000 description 2
- 230000009089 cytolysis Effects 0.000 description 2
- 230000007423 decrease Effects 0.000 description 2
- 230000000593 degrading effect Effects 0.000 description 2
- MXHRCPNRJAMMIM-UHFFFAOYSA-N desoxyuridine Natural products C1C(O)C(CO)OC1N1C(=O)NC(=O)C=C1 MXHRCPNRJAMMIM-UHFFFAOYSA-N 0.000 description 2
- ZPTBLXKRQACLCR-XVFCMESISA-N dihydrouridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)CC1 ZPTBLXKRQACLCR-XVFCMESISA-N 0.000 description 2
- 150000002016 disaccharides Chemical class 0.000 description 2
- VHJLVAABSRFDPM-QWWZWVQMSA-N dithiothreitol Chemical compound SC[C@@H](O)[C@H](O)CS VHJLVAABSRFDPM-QWWZWVQMSA-N 0.000 description 2
- 239000003814 drug Substances 0.000 description 2
- 241001493065 dsRNA viruses Species 0.000 description 2
- 238000001914 filtration Methods 0.000 description 2
- 125000000524 functional group Chemical group 0.000 description 2
- 229960002442 glucosamine Drugs 0.000 description 2
- 150000004676 glycans Chemical class 0.000 description 2
- 238000011194 good manufacturing practice Methods 0.000 description 2
- 125000005155 haloalkylene group Chemical group 0.000 description 2
- FDGQSTZJBFJUBT-UHFFFAOYSA-N hypoxanthine Chemical compound O=C1NC=NC2=C1NC=N2 FDGQSTZJBFJUBT-UHFFFAOYSA-N 0.000 description 2
- 238000007913 intrathecal administration Methods 0.000 description 2
- 238000011068 loading method Methods 0.000 description 2
- 210000003712 lysosome Anatomy 0.000 description 2
- 230000001868 lysosomic effect Effects 0.000 description 2
- 239000003550 marker Substances 0.000 description 2
- 239000002609 medium Substances 0.000 description 2
- WDWDWGRYHDPSDS-UHFFFAOYSA-N methanimine Chemical compound N=C WDWDWGRYHDPSDS-UHFFFAOYSA-N 0.000 description 2
- DJLUSNAYRNFVSM-UHFFFAOYSA-N methyl 2-(2,4-dioxo-1h-pyrimidin-5-yl)acetate Chemical compound COC(=O)CC1=CNC(=O)NC1=O DJLUSNAYRNFVSM-UHFFFAOYSA-N 0.000 description 2
- 229950006780 n-acetylglucosamine Drugs 0.000 description 2
- JRZJOMJEPLMPRA-UHFFFAOYSA-N olefin Natural products CCCCCCCC=C JRZJOMJEPLMPRA-UHFFFAOYSA-N 0.000 description 2
- 229920001542 oligosaccharide Polymers 0.000 description 2
- 150000002482 oligosaccharides Chemical class 0.000 description 2
- 210000000056 organ Anatomy 0.000 description 2
- 239000002245 particle Substances 0.000 description 2
- UEZVMMHDMIWARA-UHFFFAOYSA-M phosphonate Chemical compound [O-]P(=O)=O UEZVMMHDMIWARA-UHFFFAOYSA-M 0.000 description 2
- 239000011574 phosphorus Substances 0.000 description 2
- 229920001282 polysaccharide Polymers 0.000 description 2
- 239000005017 polysaccharide Substances 0.000 description 2
- 230000008569 process Effects 0.000 description 2
- 238000012545 processing Methods 0.000 description 2
- 125000006239 protecting group Chemical group 0.000 description 2
- 230000012846 protein folding Effects 0.000 description 2
- 125000001422 pyrrolinyl group Chemical group 0.000 description 2
- 230000002829 reductive effect Effects 0.000 description 2
- 230000002441 reversible effect Effects 0.000 description 2
- 239000002342 ribonucleoside Substances 0.000 description 2
- 230000019491 signal transduction Effects 0.000 description 2
- 230000011664 signaling Effects 0.000 description 2
- 239000007787 solid Substances 0.000 description 2
- 230000006641 stabilisation Effects 0.000 description 2
- 238000011105 stabilization Methods 0.000 description 2
- 150000003456 sulfonamides Chemical group 0.000 description 2
- BDHFUVZGWQCTTF-UHFFFAOYSA-M sulfonate Chemical compound [O-]S(=O)=O BDHFUVZGWQCTTF-UHFFFAOYSA-M 0.000 description 2
- 125000004434 sulfur atom Chemical group 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 238000010189 synthetic method Methods 0.000 description 2
- 150000004044 tetrasaccharides Chemical class 0.000 description 2
- 150000003568 thioethers Chemical class 0.000 description 2
- 150000003573 thiols Chemical class 0.000 description 2
- VSQQQLOSPVPRAZ-RRKCRQDMSA-N trifluridine Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C(C(F)(F)F)=C1 VSQQQLOSPVPRAZ-RRKCRQDMSA-N 0.000 description 2
- 150000004043 trisaccharides Chemical class 0.000 description 2
- HDZZVAMISRMYHH-KCGFPETGSA-N tubercidin Chemical compound C1=CC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O HDZZVAMISRMYHH-KCGFPETGSA-N 0.000 description 2
- 210000002845 virion Anatomy 0.000 description 2
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Chemical compound O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 2
- 239000008215 water for injection Substances 0.000 description 2
- HDTRYLNUVZCQOY-UHFFFAOYSA-N α-D-glucopyranosyl-α-D-glucopyranoside Natural products OC1C(O)C(O)C(CO)OC1OC1C(O)C(O)C(O)C(CO)O1 HDTRYLNUVZCQOY-UHFFFAOYSA-N 0.000 description 1
- IRBSRWVXPGHGGK-LNYQSQCFSA-N (2R,3R,4S,5R)-2-(2-amino-6-hydroxy-6-methyl-3H-purin-9-yl)-5-(hydroxymethyl)oxolane-3,4-diol Chemical compound CC1(O)NC(N)=NC2=C1N=CN2[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O IRBSRWVXPGHGGK-LNYQSQCFSA-N 0.000 description 1
- VLRCFULRQZKFRM-KQYNXXCUSA-N (2r,3r,4r,5r)-5-(6-aminopurin-9-yl)-2-(hydroxymethyl)-4-sulfanyloxolan-3-ol Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1S VLRCFULRQZKFRM-KQYNXXCUSA-N 0.000 description 1
- JVOJULURLCZUDE-JXOAFFINSA-N (2r,3r,4s,5r)-2-(2-aminopurin-9-yl)-5-(hydroxymethyl)oxolane-3,4-diol Chemical compound C12=NC(N)=NC=C2N=CN1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O JVOJULURLCZUDE-JXOAFFINSA-N 0.000 description 1
- DBZQFUNLCALWDY-PNHWDRBUSA-N (2r,3r,4s,5r)-2-(4-aminoimidazo[4,5-c]pyridin-1-yl)-5-(hydroxymethyl)oxolane-3,4-diol Chemical compound C1=NC=2C(N)=NC=CC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O DBZQFUNLCALWDY-PNHWDRBUSA-N 0.000 description 1
- BSZZPOARGMTJKQ-UUOKFMHZSA-N (2r,3r,4s,5r)-2-(6-amino-2-azidopurin-9-yl)-5-(hydroxymethyl)oxolane-3,4-diol Chemical compound C1=NC=2C(N)=NC(N=[N+]=[N-])=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O BSZZPOARGMTJKQ-UUOKFMHZSA-N 0.000 description 1
- PGHYIISMDPKFKH-UUOKFMHZSA-N (2r,3r,4s,5r)-2-(6-amino-2-bromopurin-9-yl)-5-(hydroxymethyl)oxolane-3,4-diol Chemical compound C1=NC=2C(N)=NC(Br)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O PGHYIISMDPKFKH-UUOKFMHZSA-N 0.000 description 1
- KYJLJOJCMUFWDY-UUOKFMHZSA-N (2r,3r,4s,5r)-2-(6-amino-8-azidopurin-9-yl)-5-(hydroxymethyl)oxolane-3,4-diol Chemical compound [N-]=[N+]=NC1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O KYJLJOJCMUFWDY-UUOKFMHZSA-N 0.000 description 1
- NVUDDRWKCUAERS-PNHWDRBUSA-N (2r,3r,4s,5r)-2-(7-aminoimidazo[4,5-b]pyridin-3-yl)-5-(hydroxymethyl)oxolane-3,4-diol Chemical compound C1=NC=2C(N)=CC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O NVUDDRWKCUAERS-PNHWDRBUSA-N 0.000 description 1
- MQECTKDGEQSNNL-UMCMBGNQSA-N (2r,3r,4s,5r)-2-[6-(14-aminotetradecoxyperoxyperoxyamino)purin-9-yl]-5-(hydroxymethyl)oxolane-3,4-diol Chemical compound C1=NC=2C(NOOOOOCCCCCCCCCCCCCCN)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O MQECTKDGEQSNNL-UMCMBGNQSA-N 0.000 description 1
- XBNDESPXQUOOBQ-LSMLZNGOSA-N (2r,3s)-4-[[(2s)-1-[[2-[[(2s)-1-[[2-[[(2r,3s)-1-[[(2s)-1-[(2s)-2-[[(1s)-1-[(3s,9ar)-1,4-dioxo-3,6,7,8,9,9a-hexahydro-2h-pyrido[1,2-a]pyrazin-3-yl]ethyl]carbamoyl]pyrrolidin-1-yl]-3-methyl-1-oxobutan-2-yl]amino]-3-amino-1-oxobutan-2-yl]amino]-2-oxoethyl]am Chemical compound CCC(C)CCCCC\C=C\CC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)C(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(=O)NCC(=O)N[C@H]([C@H](C)N)C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)[C@H]1C(=O)N2CCCC[C@@H]2C(=O)N1 XBNDESPXQUOOBQ-LSMLZNGOSA-N 0.000 description 1
- BRBOLMMFGHVQNH-MLTZYSBQSA-N (2r,3s,4r,5r)-5-(6-aminopurin-9-yl)-2-azido-2-(hydroxymethyl)oxolane-3,4-diol Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@@](CO)(N=[N+]=[N-])[C@@H](O)[C@H]1O BRBOLMMFGHVQNH-MLTZYSBQSA-N 0.000 description 1
- ZHUBMCMWNICRIP-IWXIMVSXSA-N (2r,3s,4r,5r)-5-(6-aminopurin-9-yl)-2-ethynyl-2-(hydroxymethyl)oxolane-3,4-diol Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@@](CO)(C#C)[C@@H](O)[C@H]1O ZHUBMCMWNICRIP-IWXIMVSXSA-N 0.000 description 1
- KEHFJRVBOUROMM-KBHCAIDQSA-N (2s,3r,4s,5r)-2-(4-amino-5h-pyrrolo[3,2-d]pyrimidin-7-yl)-5-(hydroxymethyl)oxolane-3,4-diol Chemical compound C=1NC=2C(N)=NC=NC=2C=1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O KEHFJRVBOUROMM-KBHCAIDQSA-N 0.000 description 1
- LGQKSQQRKHFMLI-SJYYZXOBSA-N (2s,3r,4s,5r)-2-[(3r,4r,5r,6r)-4,5,6-trihydroxyoxan-3-yl]oxyoxane-3,4,5-triol Chemical compound O[C@@H]1[C@@H](O)[C@H](O)CO[C@H]1O[C@H]1[C@H](O)[C@@H](O)[C@H](O)OC1 LGQKSQQRKHFMLI-SJYYZXOBSA-N 0.000 description 1
- STGXGJRRAJKJRG-JDJSBBGDSA-N (3r,4r,5r)-5-(hydroxymethyl)-3-methoxyoxolane-2,4-diol Chemical compound CO[C@H]1C(O)O[C@H](CO)[C@H]1O STGXGJRRAJKJRG-JDJSBBGDSA-N 0.000 description 1
- 125000000008 (C1-C10) alkyl group Chemical group 0.000 description 1
- 125000005913 (C3-C6) cycloalkyl group Chemical group 0.000 description 1
- 125000006552 (C3-C8) cycloalkyl group Chemical group 0.000 description 1
- FYADHXFMURLYQI-UHFFFAOYSA-N 1,2,4-triazine Chemical class C1=CN=NC=N1 FYADHXFMURLYQI-UHFFFAOYSA-N 0.000 description 1
- 150000000178 1,2,4-triazoles Chemical class 0.000 description 1
- WXUMWLPSZFSIJI-XUTVFYLZSA-N 1-(aminomethyl)-5-[(2S,3R,4S,5R)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]pyrimidine-2,4-dione Chemical compound NCN1C=C([C@H]2[C@H](O)[C@H](O)[C@@H](CO)O2)C(NC1=O)=O WXUMWLPSZFSIJI-XUTVFYLZSA-N 0.000 description 1
- OYTVCAGSWWRUII-DWJKKKFUSA-N 1-Methyl-1-deazapseudouridine Chemical compound CC1C=C(C(=O)NC1=O)[C@H]2[C@@H]([C@@H]([C@H](O2)CO)O)O OYTVCAGSWWRUII-DWJKKKFUSA-N 0.000 description 1
- MIXBUOXRHTZHKR-XUTVFYLZSA-N 1-Methylpseudoisocytidine Chemical compound CN1C=C(C(=O)N=C1N)[C@H]2[C@@H]([C@@H]([C@H](O2)CO)O)O MIXBUOXRHTZHKR-XUTVFYLZSA-N 0.000 description 1
- SVBWNHOBPFJIRU-UHFFFAOYSA-N 1-O-alpha-D-Glucopyranosyl-D-fructose Natural products OC1C(O)C(O)C(CO)OC1OCC1(O)C(O)C(O)C(O)CO1 SVBWNHOBPFJIRU-UHFFFAOYSA-N 0.000 description 1
- YLCCMFLPRRFRJT-VPCXQMTMSA-N 1-[(2R,3R,4S,5R)-3,4-dihydroxy-5-(hydroxymethyl)-2-methyloxolan-2-yl]-4-sulfanylidenepyrimidin-2-one Chemical compound C[C@@]1([C@H](O)[C@H](O)[C@@H](CO)O1)N1C(=O)NC(=S)C=C1 YLCCMFLPRRFRJT-VPCXQMTMSA-N 0.000 description 1
- KPLKOOBPQQYUTM-PNHWDRBUSA-N 1-[(2r,3r,4r,5r)-3-ethynyl-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]pyrimidine-2,4-dione Chemical compound C#C[C@@]1(O)[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=C1 KPLKOOBPQQYUTM-PNHWDRBUSA-N 0.000 description 1
- KPJZKNCZUWDUIF-DNRKLUKYSA-N 1-[(2r,3r,4r,5r)-4-hydroxy-5-(hydroxymethyl)-3-methoxyoxolan-2-yl]-5-prop-1-ynylpyrimidine-2,4-dione Chemical compound CO[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C(C#CC)=C1 KPJZKNCZUWDUIF-DNRKLUKYSA-N 0.000 description 1
- NOLVLJWEGBKCIN-VPCXQMTMSA-N 1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)-2-methyloxolan-2-yl]-2-sulfanylidenepyrimidin-4-one Chemical compound C1=CC(=O)NC(=S)N1[C@]1(C)O[C@H](CO)[C@@H](O)[C@H]1O NOLVLJWEGBKCIN-VPCXQMTMSA-N 0.000 description 1
- RSSRMDMJEZIUJX-XVFCMESISA-N 1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-4-hydrazinylpyrimidin-2-one Chemical compound O=C1N=C(NN)C=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 RSSRMDMJEZIUJX-XVFCMESISA-N 0.000 description 1
- FHPJZSIIXUQGQE-JVZYCSMKSA-N 1-[(2r,3r,4s,5r)-5-azido-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]pyrimidine-2,4-dione Chemical compound O[C@@H]1[C@H](O)[C@](CO)(N=[N+]=[N-])O[C@H]1N1C(=O)NC(=O)C=C1 FHPJZSIIXUQGQE-JVZYCSMKSA-N 0.000 description 1
- WRJWRPFBIXAXCQ-PKIKSRDPSA-N 1-[(2r,3r,4s,5r)-5-ethynyl-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]pyrimidine-2,4-dione Chemical compound O[C@@H]1[C@H](O)[C@](CO)(C#C)O[C@H]1N1C(=O)NC(=O)C=C1 WRJWRPFBIXAXCQ-PKIKSRDPSA-N 0.000 description 1
- QPHRQMAYYMYWFW-FJGDRVTGSA-N 1-[(2r,3s,4r,5r)-3-fluoro-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]pyrimidine-2,4-dione Chemical compound O[C@]1(F)[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=C1 QPHRQMAYYMYWFW-FJGDRVTGSA-N 0.000 description 1
- BNXGRQLXOMSOMV-UHFFFAOYSA-N 1-[4-hydroxy-5-(hydroxymethyl)-3-methoxyoxolan-2-yl]-4-(methylamino)pyrimidin-2-one Chemical compound O=C1N=C(NC)C=CN1C1C(OC)C(O)C(CO)O1 BNXGRQLXOMSOMV-UHFFFAOYSA-N 0.000 description 1
- UDWJDHVNBZRPBP-SYQHCUMBSA-N 1-benzyl-5-[(2s,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]pyrimidine-2,4-dione Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1C(C(NC1=O)=O)=CN1CC1=CC=CC=C1 UDWJDHVNBZRPBP-SYQHCUMBSA-N 0.000 description 1
- GUNOEKASBVILNS-UHFFFAOYSA-N 1-methyl-1-deaza-pseudoisocytidine Chemical compound CC(C=C1C(C2O)OC(CO)C2O)=C(N)NC1=O GUNOEKASBVILNS-UHFFFAOYSA-N 0.000 description 1
- GFYLSDSUCHVORB-IOSLPCCCSA-N 1-methyladenosine Chemical compound C1=NC=2C(=N)N(C)C=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O GFYLSDSUCHVORB-IOSLPCCCSA-N 0.000 description 1
- UTAIYTHAJQNQDW-KQYNXXCUSA-N 1-methylguanosine Chemical compound C1=NC=2C(=O)N(C)C(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O UTAIYTHAJQNQDW-KQYNXXCUSA-N 0.000 description 1
- UVBYMVOUBXYSFV-XUTVFYLZSA-N 1-methylpseudouridine Chemical compound O=C1NC(=O)N(C)C=C1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 UVBYMVOUBXYSFV-XUTVFYLZSA-N 0.000 description 1
- OWEGMIWEEQEYGQ-UHFFFAOYSA-N 100676-05-9 Natural products OC1C(O)C(O)C(CO)OC1OCC1C(O)C(O)C(O)C(OC2C(OC(O)C(O)C2O)CO)O1 OWEGMIWEEQEYGQ-UHFFFAOYSA-N 0.000 description 1
- UHUHBFMZVCOEOV-UHFFFAOYSA-N 1h-imidazo[4,5-c]pyridin-4-amine Chemical compound NC1=NC=CC2=C1N=CN2 UHUHBFMZVCOEOV-UHFFFAOYSA-N 0.000 description 1
- FIRDBEQIJQERSE-QPPQHZFASA-N 2',2'-Difluorodeoxyuridine Chemical compound FC1(F)[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=C1 FIRDBEQIJQERSE-QPPQHZFASA-N 0.000 description 1
- WYDKPTZGVLTYPG-UHFFFAOYSA-N 2,8-diamino-3,7-dihydropurin-6-one Chemical compound N1C(N)=NC(=O)C2=C1N=C(N)N2 WYDKPTZGVLTYPG-UHFFFAOYSA-N 0.000 description 1
- QSHACTSJHMKXTE-UHFFFAOYSA-N 2-(2-aminopropyl)-7h-purin-6-amine Chemical compound CC(N)CC1=NC(N)=C2NC=NC2=N1 QSHACTSJHMKXTE-UHFFFAOYSA-N 0.000 description 1
- PIINGYXNCHTJTF-UHFFFAOYSA-N 2-(2-azaniumylethylamino)acetate Chemical group NCCNCC(O)=O PIINGYXNCHTJTF-UHFFFAOYSA-N 0.000 description 1
- FDZGOVDEFRJXFT-UHFFFAOYSA-N 2-(3-aminopropyl)-7h-purin-6-amine Chemical compound NCCCC1=NC(N)=C2NC=NC2=N1 FDZGOVDEFRJXFT-UHFFFAOYSA-N 0.000 description 1
- YUCFXTKBZFABID-WOUKDFQISA-N 2-(dimethylamino)-9-[(2r,3r,4r,5r)-4-hydroxy-5-(hydroxymethyl)-3-methoxyoxolan-2-yl]-3h-purin-6-one Chemical compound CO[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(NC(=NC2=O)N(C)C)=C2N=C1 YUCFXTKBZFABID-WOUKDFQISA-N 0.000 description 1
- BVLGKOVALHRKNM-XUTVFYLZSA-N 2-Thio-1-methylpseudouridine Chemical compound CN1C=C(C(=O)NC1=S)[C@H]2[C@@H]([C@@H]([C@H](O2)CO)O)O BVLGKOVALHRKNM-XUTVFYLZSA-N 0.000 description 1
- CWXIOHYALLRNSZ-JWMKEVCDSA-N 2-Thiodihydropseudouridine Chemical compound C1C(C(=O)NC(=S)N1)[C@H]2[C@@H]([C@@H]([C@H](O2)CO)O)O CWXIOHYALLRNSZ-JWMKEVCDSA-N 0.000 description 1
- PAYROHWFGZADBR-UHFFFAOYSA-N 2-[[4-amino-5-(5-iodo-4-methoxy-2-propan-2-ylphenoxy)pyrimidin-2-yl]amino]propane-1,3-diol Chemical group C1=C(I)C(OC)=CC(C(C)C)=C1OC1=CN=C(NC(CO)CO)N=C1N PAYROHWFGZADBR-UHFFFAOYSA-N 0.000 description 1
- MSWZFWKMSRAUBD-CBPJZXOFSA-N 2-amino-2-deoxy-D-mannopyranose Chemical compound N[C@@H]1C(O)O[C@H](CO)[C@@H](O)[C@@H]1O MSWZFWKMSRAUBD-CBPJZXOFSA-N 0.000 description 1
- HTOVHZGIBCAAJU-UHFFFAOYSA-N 2-amino-2-propyl-1h-purin-6-one Chemical compound CCCC1(N)NC(=O)C2=NC=NC2=N1 HTOVHZGIBCAAJU-UHFFFAOYSA-N 0.000 description 1
- IZBLFZXCXYDKRW-UHFFFAOYSA-N 2-amino-3,7-dihydropurin-6-one;7h-purine Chemical class C1=NC=C2NC=NC2=N1.N1C(N)=NC(=O)C2=C1N=CN2 IZBLFZXCXYDKRW-UHFFFAOYSA-N 0.000 description 1
- VKRFXNXJOJJPAO-UHFFFAOYSA-N 2-amino-4-(2,4-dioxo-1h-pyrimidin-3-yl)butanoic acid Chemical compound OC(=O)C(N)CCN1C(=O)C=CNC1=O VKRFXNXJOJJPAO-UHFFFAOYSA-N 0.000 description 1
- CTPQMQZKRWLMRA-LYTXVXJPSA-N 2-amino-4-[5-[(2s,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-3-methyl-2,6-dioxopyrimidin-1-yl]butanoic acid Chemical compound O=C1N(CCC(N)C(O)=O)C(=O)N(C)C=C1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 CTPQMQZKRWLMRA-LYTXVXJPSA-N 0.000 description 1
- SOEYIPCQNRSIAV-IOSLPCCCSA-N 2-amino-5-(aminomethyl)-7-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-1h-pyrrolo[2,3-d]pyrimidin-4-one Chemical compound C1=2NC(N)=NC(=O)C=2C(CN)=CN1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O SOEYIPCQNRSIAV-IOSLPCCCSA-N 0.000 description 1
- JRYMOPZHXMVHTA-DAGMQNCNSA-N 2-amino-7-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-1h-pyrrolo[2,3-d]pyrimidin-4-one Chemical compound C1=CC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O JRYMOPZHXMVHTA-DAGMQNCNSA-N 0.000 description 1
- BIRQNXWAXWLATA-IOSLPCCCSA-N 2-amino-7-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-4-oxo-1h-pyrrolo[2,3-d]pyrimidine-5-carbonitrile Chemical compound C1=C(C#N)C=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O BIRQNXWAXWLATA-IOSLPCCCSA-N 0.000 description 1
- RBYIXGAYDLAKCC-GXTPVXIHSA-N 2-amino-7-[(2s,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-1,5-dihydropyrrolo[3,2-d]pyrimidin-4-one Chemical compound C=1NC=2C(=O)NC(N)=NC=2C=1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O RBYIXGAYDLAKCC-GXTPVXIHSA-N 0.000 description 1
- OTDJAMXESTUWLO-UUOKFMHZSA-N 2-amino-9-[(2R,3R,4S,5R)-3,4-dihydroxy-5-(hydroxymethyl)-2-oxolanyl]-3H-purine-6-thione Chemical compound C12=NC(N)=NC(S)=C2N=CN1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OTDJAMXESTUWLO-UUOKFMHZSA-N 0.000 description 1
- FDQMCMRMROYDRV-GSWPYSDESA-N 2-amino-9-[(2r,3r,4r,5r)-3-ethynyl-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-3h-purin-6-one Chemical compound C1=NC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@]1(O)C#C FDQMCMRMROYDRV-GSWPYSDESA-N 0.000 description 1
- HPKQEMIXSLRGJU-UUOKFMHZSA-N 2-amino-9-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-7-methyl-3h-purine-6,8-dione Chemical compound O=C1N(C)C(C(NC(N)=N2)=O)=C2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O HPKQEMIXSLRGJU-UUOKFMHZSA-N 0.000 description 1
- BOCKWHCDQIFZHA-LRXXKQTNSA-N 2-amino-9-[(2r,3r,4s,5r)-5-azido-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-3h-purin-6-one Chemical compound C1=NC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@@](CO)(N=[N+]=[N-])[C@@H](O)[C@H]1O BOCKWHCDQIFZHA-LRXXKQTNSA-N 0.000 description 1
- ZEFNGPRHMTZOFU-BQIHAETKSA-N 2-amino-9-[(2r,3r,4s,5r)-5-ethynyl-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-3h-purin-6-one Chemical compound C1=NC=2C(=O)NC(N)=NC=2N1[C@@H]1O[C@@](CO)(C#C)[C@@H](O)[C@H]1O ZEFNGPRHMTZOFU-BQIHAETKSA-N 0.000 description 1
- RQIYMUKKPIEAMB-TWOGKDBTSA-N 2-amino-9-[(2r,4r,5r)-3,3-difluoro-4-hydroxy-5-(hydroxymethyl)oxolan-2-yl]-3h-purin-6-one Chemical compound C1=2NC(N)=NC(=O)C=2N=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1(F)F RQIYMUKKPIEAMB-TWOGKDBTSA-N 0.000 description 1
- PBFLIOAJBULBHI-JJNLEZRASA-N 2-amino-n-[[9-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]purin-6-yl]carbamoyl]acetamide Chemical compound C1=NC=2C(NC(=O)NC(=O)CN)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O PBFLIOAJBULBHI-JJNLEZRASA-N 0.000 description 1
- ASJSAQIRZKANQN-CRCLSJGQSA-N 2-deoxy-D-ribose Chemical compound OC[C@@H](O)[C@@H](O)CC=O ASJSAQIRZKANQN-CRCLSJGQSA-N 0.000 description 1
- WKMPTBDYDNUJLF-UHFFFAOYSA-N 2-fluoroadenine Chemical compound NC1=NC(F)=NC2=C1N=CN2 WKMPTBDYDNUJLF-UHFFFAOYSA-N 0.000 description 1
- RLZMYTZDQAVNIN-ZOQUXTDFSA-N 2-methoxy-4-thio-uridine Chemical compound COC1=NC(=S)C=CN1[C@H]2[C@@H]([C@@H]([C@H](O2)CO)O)O RLZMYTZDQAVNIN-ZOQUXTDFSA-N 0.000 description 1
- QCPQCJVQJKOKMS-VLSMUFELSA-N 2-methoxy-5-methyl-cytidine Chemical compound CC(C(N)=N1)=CN([C@@H]([C@@H]2O)O[C@H](CO)[C@H]2O)C1OC QCPQCJVQJKOKMS-VLSMUFELSA-N 0.000 description 1
- STISOQJGVFEOFJ-MEVVYUPBSA-N 2-methoxy-cytidine Chemical compound COC(N([C@@H]([C@@H]1O)O[C@H](CO)[C@H]1O)C=C1)N=C1N STISOQJGVFEOFJ-MEVVYUPBSA-N 0.000 description 1
- WBVPJIKOWUQTSD-ZOQUXTDFSA-N 2-methoxyuridine Chemical compound COC1=NC(=O)C=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 WBVPJIKOWUQTSD-ZOQUXTDFSA-N 0.000 description 1
- VWSLLSXLURJCDF-UHFFFAOYSA-N 2-methyl-4,5-dihydro-1h-imidazole Chemical compound CC1=NCCN1 VWSLLSXLURJCDF-UHFFFAOYSA-N 0.000 description 1
- VZQXUWKZDSEQRR-SDBHATRESA-N 2-methylthio-N(6)-(Delta(2)-isopentenyl)adenosine Chemical compound C12=NC(SC)=NC(NCC=C(C)C)=C2N=CN1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O VZQXUWKZDSEQRR-SDBHATRESA-N 0.000 description 1
- JUMHLCXWYQVTLL-KVTDHHQDSA-N 2-thio-5-aza-uridine Chemical compound [C@@H]1([C@H](O)[C@H](O)[C@@H](CO)O1)N1C(=S)NC(=O)N=C1 JUMHLCXWYQVTLL-KVTDHHQDSA-N 0.000 description 1
- VRVXMIJPUBNPGH-XVFCMESISA-N 2-thio-dihydrouridine Chemical compound OC[C@H]1O[C@H]([C@H](O)[C@@H]1O)N1CCC(=O)NC1=S VRVXMIJPUBNPGH-XVFCMESISA-N 0.000 description 1
- YXNIEZJFCGTDKV-JANFQQFMSA-N 3-(3-amino-3-carboxypropyl)uridine Chemical compound O=C1N(CCC(N)C(O)=O)C(=O)C=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 YXNIEZJFCGTDKV-JANFQQFMSA-N 0.000 description 1
- WFOVEDJTASPCIR-UHFFFAOYSA-N 3-[(4-methyl-5-pyridin-4-yl-1,2,4-triazol-3-yl)methylamino]-n-[[2-(trifluoromethyl)phenyl]methyl]benzamide Chemical group N=1N=C(C=2C=CN=CC=2)N(C)C=1CNC(C=1)=CC=CC=1C(=O)NCC1=CC=CC=C1C(F)(F)F WFOVEDJTASPCIR-UHFFFAOYSA-N 0.000 description 1
- VPLZGVOSFFCKFC-UHFFFAOYSA-N 3-methyluracil Chemical compound CN1C(=O)C=CNC1=O VPLZGVOSFFCKFC-UHFFFAOYSA-N 0.000 description 1
- HRBTUPZXFQGNOW-NMFUWQPSSA-N 4-(benzylamino)-1-[(2R,3R,4S,5R)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]pyrimidin-2-one Chemical compound C(C1=CC=CC=C1)NC1=NC(N([C@H]2[C@H](O)[C@H](O)[C@@H](CO)O2)C=C1)=O HRBTUPZXFQGNOW-NMFUWQPSSA-N 0.000 description 1
- ZSIINYPBPQCZKU-BQNZPOLKSA-O 4-Methoxy-1-methylpseudoisocytidine Chemical compound C[N+](CC1[C@H]([C@H]2O)O[C@@H](CO)[C@@H]2O)=C(N)N=C1OC ZSIINYPBPQCZKU-BQNZPOLKSA-O 0.000 description 1
- FGFVODMBKZRMMW-XUTVFYLZSA-N 4-Methoxy-2-thiopseudouridine Chemical compound COC1=C(C=NC(=S)N1)[C@H]2[C@@H]([C@@H]([C@H](O2)CO)O)O FGFVODMBKZRMMW-XUTVFYLZSA-N 0.000 description 1
- HOCJTJWYMOSXMU-XUTVFYLZSA-N 4-Methoxypseudouridine Chemical compound COC1=C(C=NC(=O)N1)[C@H]2[C@@H]([C@@H]([C@H](O2)CO)O)O HOCJTJWYMOSXMU-XUTVFYLZSA-N 0.000 description 1
- LGQKSQQRKHFMLI-UHFFFAOYSA-N 4-O-beta-D-xylopyranosyl-beta-D-xylopyranose Natural products OC1C(O)C(O)COC1OC1C(O)C(O)C(O)OC1 LGQKSQQRKHFMLI-UHFFFAOYSA-N 0.000 description 1
- VTGBLFNEDHVUQA-XUTVFYLZSA-N 4-Thio-1-methyl-pseudouridine Chemical compound S=C1NC(=O)N(C)C=C1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 VTGBLFNEDHVUQA-XUTVFYLZSA-N 0.000 description 1
- DMUQOPXCCOBPID-XUTVFYLZSA-N 4-Thio-1-methylpseudoisocytidine Chemical compound CN1C=C(C(=S)N=C1N)[C@H]2[C@@H]([C@@H]([C@H](O2)CO)O)O DMUQOPXCCOBPID-XUTVFYLZSA-N 0.000 description 1
- MPMKMQHJHDHPBE-RUZDIDTESA-N 4-[[(2r)-1-(1-benzothiophene-3-carbonyl)-2-methylazetidine-2-carbonyl]-[(3-chlorophenyl)methyl]amino]butanoic acid Chemical group O=C([C@@]1(N(CC1)C(=O)C=1C2=CC=CC=C2SC=1)C)N(CCCC(O)=O)CC1=CC=CC(Cl)=C1 MPMKMQHJHDHPBE-RUZDIDTESA-N 0.000 description 1
- RJVOOCIWZSGZPO-JNECXHHRSA-N 4-amino-1-[(2R,3R,4S,5R)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-5-(hydroxymethyl)pyrimidin-2-one 4-amino-1-[(2R,3R,4S,5R)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-5-methylpyrimidin-2-one Chemical compound OCC=1C(=NC(N([C@H]2[C@H](O)[C@H](O)[C@@H](CO)O2)C1)=O)N.CC=1C(=NC(N([C@H]2[C@H](O)[C@H](O)[C@@H](CO)O2)C1)=O)N RJVOOCIWZSGZPO-JNECXHHRSA-N 0.000 description 1
- RDNYOZGTGXUIIY-DNRKLUKYSA-N 4-amino-1-[(2r,3r,4r,5r)-4-hydroxy-5-(hydroxymethyl)-3-methoxyoxolan-2-yl]-5-prop-1-ynylpyrimidin-2-one Chemical compound CO[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)N=C(N)C(C#CC)=C1 RDNYOZGTGXUIIY-DNRKLUKYSA-N 0.000 description 1
- OCMSXKMNYAHJMU-JXOAFFINSA-N 4-amino-1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-2-oxopyrimidine-5-carbaldehyde Chemical compound C1=C(C=O)C(N)=NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 OCMSXKMNYAHJMU-JXOAFFINSA-N 0.000 description 1
- MDWFCNXLWFANLX-JXOAFFINSA-N 4-amino-1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-2-oxopyrimidine-5-carbonitrile Chemical compound C1=C(C#N)C(N)=NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 MDWFCNXLWFANLX-JXOAFFINSA-N 0.000 description 1
- NCZFDEBKMUJQQO-FDDDBJFASA-N 4-amino-1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-5-ethynylpyrimidin-2-one Chemical compound C1=C(C#C)C(N)=NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 NCZFDEBKMUJQQO-FDDDBJFASA-N 0.000 description 1
- OZHIJZYBTCTDQC-JXOAFFINSA-N 4-amino-1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-5-methylpyrimidine-2-thione Chemical compound S=C1N=C(N)C(C)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 OZHIJZYBTCTDQC-JXOAFFINSA-N 0.000 description 1
- JFIWEPHGRUDAJN-DYUFWOLASA-N 4-amino-1-[(2r,3r,4s,5r)-4-ethynyl-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]pyrimidin-2-one Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@H](O)[C@@](O)(C#C)[C@@H](CO)O1 JFIWEPHGRUDAJN-DYUFWOLASA-N 0.000 description 1
- ODLGMSQBFONGNG-JVZYCSMKSA-N 4-amino-1-[(2r,3r,4s,5r)-5-azido-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]pyrimidin-2-one Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@H](O)[C@H](O)[C@](CO)(N=[N+]=[N-])O1 ODLGMSQBFONGNG-JVZYCSMKSA-N 0.000 description 1
- JPVIDVLFVGWECR-PKIKSRDPSA-N 4-amino-1-[(2r,3r,4s,5r)-5-ethynyl-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]pyrimidin-2-one Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@H](O)[C@H](O)[C@](CO)(C#C)O1 JPVIDVLFVGWECR-PKIKSRDPSA-N 0.000 description 1
- PJWBTAIPBFWVHX-FJGDRVTGSA-N 4-amino-1-[(2r,3s,4r,5r)-3-fluoro-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]pyrimidin-2-one Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@](F)(O)[C@H](O)[C@@H](CO)O1 PJWBTAIPBFWVHX-FJGDRVTGSA-N 0.000 description 1
- FBLNVVJQCGUTHY-YPLKXGEDSA-N 4-amino-5-[(e)-2-bromoethenyl]-1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]pyrimidin-2-one Chemical compound C1=C(\C=C\Br)C(N)=NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 FBLNVVJQCGUTHY-YPLKXGEDSA-N 0.000 description 1
- GSDQYSSLIKJJOG-UHFFFAOYSA-N 4-chloro-2-(3-chloroanilino)benzoic acid Chemical group OC(=O)C1=CC=C(Cl)C=C1NC1=CC=CC(Cl)=C1 GSDQYSSLIKJJOG-UHFFFAOYSA-N 0.000 description 1
- GCNTZFIIOFTKIY-UHFFFAOYSA-N 4-hydroxypyridine Chemical compound OC1=CC=NC=C1 GCNTZFIIOFTKIY-UHFFFAOYSA-N 0.000 description 1
- LOICBOXHPCURMU-UHFFFAOYSA-N 4-methoxy-pseudoisocytidine Chemical compound COC1NC(N)=NC=C1C(C1O)OC(CO)C1O LOICBOXHPCURMU-UHFFFAOYSA-N 0.000 description 1
- SJVVKUMXGIKAAI-UHFFFAOYSA-N 4-thio-pseudoisocytidine Chemical compound NC(N1)=NC=C(C(C2O)OC(CO)C2O)C1=S SJVVKUMXGIKAAI-UHFFFAOYSA-N 0.000 description 1
- 125000004032 5'-inosinyl group Chemical group 0.000 description 1
- WPQLFQWYPPALOX-UHFFFAOYSA-N 5-(2-aminopropyl)-1h-pyrimidine-2,4-dione Chemical compound CC(N)CC1=CNC(=O)NC1=O WPQLFQWYPPALOX-UHFFFAOYSA-N 0.000 description 1
- DGCFDETWIXOSIF-UHFFFAOYSA-N 5-[(2,4-dioxo-1H-pyrimidin-5-yl)diazenyl]-1H-pyrimidine-2,4-dione Chemical compound N(=NC=1C(NC(NC=1)=O)=O)C=1C(NC(NC=1)=O)=O DGCFDETWIXOSIF-UHFFFAOYSA-N 0.000 description 1
- DDHOXEOVAJVODV-GBNDHIKLSA-N 5-[(2s,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-2-sulfanylidene-1h-pyrimidin-4-one Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1C1=CNC(=S)NC1=O DDHOXEOVAJVODV-GBNDHIKLSA-N 0.000 description 1
- WSJZETUHYFZTHG-JBBNEOJLSA-N 5-[(2s,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-6-methyl-1h-pyrimidine-2,4-dione Chemical compound N1C(=O)NC(=O)C([C@H]2[C@@H]([C@H](O)[C@@H](CO)O2)O)=C1C WSJZETUHYFZTHG-JBBNEOJLSA-N 0.000 description 1
- GCQYYIHYQMVWLT-YPLKXGEDSA-N 5-[(e)-2-bromoethenyl]-1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]pyrimidine-2,4-dione Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C(\C=C\Br)=C1 GCQYYIHYQMVWLT-YPLKXGEDSA-N 0.000 description 1
- IPRQAJTUSRLECG-UHFFFAOYSA-N 5-[6-(dimethylamino)purin-9-yl]-2-(hydroxymethyl)-4-methoxyoxolan-3-ol Chemical compound COC1C(O)C(CO)OC1N1C2=NC=NC(N(C)C)=C2N=C1 IPRQAJTUSRLECG-UHFFFAOYSA-N 0.000 description 1
- OZQDLJNDRVBCST-SHUUEZRQSA-N 5-amino-2-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-1,2,4-triazin-3-one Chemical compound O=C1N=C(N)C=NN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 OZQDLJNDRVBCST-SHUUEZRQSA-N 0.000 description 1
- OSLBPVOJTCDNEF-DBRKOABJSA-N 5-aza-zebularine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)N=CN=C1 OSLBPVOJTCDNEF-DBRKOABJSA-N 0.000 description 1
- MFEFTTYGMZOIKO-UHFFFAOYSA-N 5-azacytosine Chemical compound NC1=NC=NC(=O)N1 MFEFTTYGMZOIKO-UHFFFAOYSA-N 0.000 description 1
- KELXHQACBIUYSE-UHFFFAOYSA-N 5-methoxy-1h-pyrimidine-2,4-dione Chemical compound COC1=CNC(=O)NC1=O KELXHQACBIUYSE-UHFFFAOYSA-N 0.000 description 1
- ZLAQATDNGLKIEV-UHFFFAOYSA-N 5-methyl-2-sulfanylidene-1h-pyrimidin-4-one Chemical compound CC1=CNC(=S)NC1=O ZLAQATDNGLKIEV-UHFFFAOYSA-N 0.000 description 1
- OZFPSOBLQZPIAV-UHFFFAOYSA-N 5-nitro-1h-indole Chemical compound [O-][N+](=O)C1=CC=C2NC=CC2=C1 OZFPSOBLQZPIAV-UHFFFAOYSA-N 0.000 description 1
- WOFIDIJGQWUTEA-UHFFFAOYSA-N 5-prop-1-ynyl-1H-pyrimidine-2,4-dione 5-(trifluoromethyl)-1H-pyrimidine-2,4-dione Chemical compound FC(C=1C(NC(NC1)=O)=O)(F)F.C(#CC)C=1C(NC(NC1)=O)=O WOFIDIJGQWUTEA-UHFFFAOYSA-N 0.000 description 1
- USVMJSALORZVDV-UHFFFAOYSA-N 6-(gamma,gamma-dimethylallylamino)purine riboside Natural products C1=NC=2C(NCC=C(C)C)=NC=NC=2N1C1OC(CO)C(O)C1O USVMJSALORZVDV-UHFFFAOYSA-N 0.000 description 1
- ZKBQDFAWXLTYKS-UHFFFAOYSA-N 6-Chloro-1H-purine Chemical compound ClC1=NC=NC2=C1NC=N2 ZKBQDFAWXLTYKS-UHFFFAOYSA-N 0.000 description 1
- OZTOEARQSSIFOG-MWKIOEHESA-N 6-Thio-7-deaza-8-azaguanosine Chemical compound Nc1nc(=S)c2cnn([C@@H]3O[C@H](CO)[C@@H](O)[C@H]3O)c2[nH]1 OZTOEARQSSIFOG-MWKIOEHESA-N 0.000 description 1
- KXBCLNRMQPRVTP-UHFFFAOYSA-N 6-amino-1,5-dihydroimidazo[4,5-c]pyridin-4-one Chemical compound O=C1NC(N)=CC2=C1N=CN2 KXBCLNRMQPRVTP-UHFFFAOYSA-N 0.000 description 1
- DCPSTSVLRXOYGS-UHFFFAOYSA-N 6-amino-1h-pyrimidine-2-thione Chemical compound NC1=CC=NC(S)=N1 DCPSTSVLRXOYGS-UHFFFAOYSA-N 0.000 description 1
- QNNARSZPGNJZIX-UHFFFAOYSA-N 6-amino-5-prop-1-ynyl-1h-pyrimidin-2-one Chemical compound CC#CC1=CNC(=O)N=C1N QNNARSZPGNJZIX-UHFFFAOYSA-N 0.000 description 1
- LXHOFEUVCQUXRZ-RRKCRQDMSA-N 6-azathymidine Chemical compound O=C1NC(=O)C(C)=NN1[C@@H]1O[C@H](CO)[C@@H](O)C1 LXHOFEUVCQUXRZ-RRKCRQDMSA-N 0.000 description 1
- SSPYSWLZOPCOLO-UHFFFAOYSA-N 6-azauracil Chemical compound O=C1C=NNC(=O)N1 SSPYSWLZOPCOLO-UHFFFAOYSA-N 0.000 description 1
- WYXSYVWAUAUWLD-SHUUEZRQSA-N 6-azauridine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=N1 WYXSYVWAUAUWLD-SHUUEZRQSA-N 0.000 description 1
- RYYIULNRIVUMTQ-UHFFFAOYSA-N 6-chloroguanine Chemical compound NC1=NC(Cl)=C2N=CNC2=N1 RYYIULNRIVUMTQ-UHFFFAOYSA-N 0.000 description 1
- CKOMXBHMKXXTNW-UHFFFAOYSA-N 6-methyladenine Chemical compound CNC1=NC=NC2=C1N=CN2 CKOMXBHMKXXTNW-UHFFFAOYSA-N 0.000 description 1
- CBNRZZNSRJQZNT-IOSLPCCCSA-O 6-thio-7-deaza-guanosine Chemical compound CC1=C[NH+]([C@@H]([C@@H]2O)O[C@H](CO)[C@H]2O)C(NC(N)=N2)=C1C2=S CBNRZZNSRJQZNT-IOSLPCCCSA-O 0.000 description 1
- RFHIWBUKNJIBSE-KQYNXXCUSA-O 6-thio-7-methyl-guanosine Chemical compound C1=2NC(N)=NC(=S)C=2N(C)C=[N+]1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O RFHIWBUKNJIBSE-KQYNXXCUSA-O 0.000 description 1
- CLGFIVUFZRGQRP-UHFFFAOYSA-N 7,8-dihydro-8-oxoguanine Chemical compound O=C1NC(N)=NC2=C1NC(=O)N2 CLGFIVUFZRGQRP-UHFFFAOYSA-N 0.000 description 1
- MJJUWOIBPREHRU-MWKIOEHESA-N 7-Deaza-8-azaguanosine Chemical compound NC=1NC(C2=C(N=1)N(N=C2)[C@H]1[C@H](O)[C@H](O)[C@H](O1)CO)=O MJJUWOIBPREHRU-MWKIOEHESA-N 0.000 description 1
- ISSMDAFGDCTNDV-UHFFFAOYSA-N 7-deaza-2,6-diaminopurine Chemical compound NC1=NC(N)=C2NC=CC2=N1 ISSMDAFGDCTNDV-UHFFFAOYSA-N 0.000 description 1
- ZTAWTRPFJHKMRU-UHFFFAOYSA-N 7-deaza-8-aza-2,6-diaminopurine Chemical compound NC1=NC(N)=C2NN=CC2=N1 ZTAWTRPFJHKMRU-UHFFFAOYSA-N 0.000 description 1
- SMXRCJBCWRHDJE-UHFFFAOYSA-N 7-deaza-8-aza-2-aminopurine Chemical compound NC1=NC=C2C=NNC2=N1 SMXRCJBCWRHDJE-UHFFFAOYSA-N 0.000 description 1
- LHCPRYRLDOSKHK-UHFFFAOYSA-N 7-deaza-8-aza-adenine Chemical compound NC1=NC=NC2=C1C=NN2 LHCPRYRLDOSKHK-UHFFFAOYSA-N 0.000 description 1
- LOSIULRWFAEMFL-UHFFFAOYSA-N 7-deazaguanine Chemical compound O=C1NC(N)=NC2=C1CC=N2 LOSIULRWFAEMFL-UHFFFAOYSA-N 0.000 description 1
- OGHAROSJZRTIOK-KQYNXXCUSA-O 7-methylguanosine Chemical compound C1=2N=C(N)NC(=O)C=2[N+](C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OGHAROSJZRTIOK-KQYNXXCUSA-O 0.000 description 1
- ASUCSHXLTWZYBA-UMMCILCDSA-N 8-Bromoguanosine Chemical compound C1=2NC(N)=NC(=O)C=2N=C(Br)N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O ASUCSHXLTWZYBA-UMMCILCDSA-N 0.000 description 1
- HCAJQHYUCKICQH-VPENINKCSA-N 8-Oxo-7,8-dihydro-2'-deoxyguanosine Chemical compound C1=2NC(N)=NC(=O)C=2NC(=O)N1[C@H]1C[C@H](O)[C@@H](CO)O1 HCAJQHYUCKICQH-VPENINKCSA-N 0.000 description 1
- HRYKDUPGBWLLHO-UHFFFAOYSA-N 8-azaadenine Chemical compound NC1=NC=NC2=NNN=C12 HRYKDUPGBWLLHO-UHFFFAOYSA-N 0.000 description 1
- 229960005508 8-azaguanine Drugs 0.000 description 1
- RGKBRPAAQSHTED-UHFFFAOYSA-N 8-oxoadenine Chemical compound NC1=NC=NC2=C1NC(=O)N2 RGKBRPAAQSHTED-UHFFFAOYSA-N 0.000 description 1
- FJNCXZZQNBKEJT-UHFFFAOYSA-N 8beta-hydroxymarrubiin Natural products O1C(=O)C2(C)CCCC3(C)C2C1CC(C)(O)C3(O)CCC=1C=COC=1 FJNCXZZQNBKEJT-UHFFFAOYSA-N 0.000 description 1
- IRBAWVGZNJIROV-SFHVURJKSA-N 9-(2-cyclopropylethynyl)-2-[[(2s)-1,4-dioxan-2-yl]methoxy]-6,7-dihydropyrimido[6,1-a]isoquinolin-4-one Chemical group C1=C2C3=CC=C(C#CC4CC4)C=C3CCN2C(=O)N=C1OC[C@@H]1COCCO1 IRBAWVGZNJIROV-SFHVURJKSA-N 0.000 description 1
- KEHFJRVBOUROMM-UHFFFAOYSA-N 9-Deazaadenosine Natural products C=1NC=2C(N)=NC=NC=2C=1C1OC(CO)C(O)C1O KEHFJRVBOUROMM-UHFFFAOYSA-N 0.000 description 1
- OJTAZBNWKTYVFJ-IOSLPCCCSA-N 9-[(2r,3r,4r,5r)-4-hydroxy-5-(hydroxymethyl)-3-methoxyoxolan-2-yl]-2-(methylamino)-3h-purin-6-one Chemical compound C1=2NC(NC)=NC(=O)C=2N=CN1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1OC OJTAZBNWKTYVFJ-IOSLPCCCSA-N 0.000 description 1
- ABXGJJVKZAAEDH-IOSLPCCCSA-N 9-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-2-(dimethylamino)-3h-purine-6-thione Chemical compound C1=NC=2C(=S)NC(N(C)C)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O ABXGJJVKZAAEDH-IOSLPCCCSA-N 0.000 description 1
- ADPMAYFIIFNDMT-KQYNXXCUSA-N 9-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-2-(methylamino)-3h-purine-6-thione Chemical compound C1=NC=2C(=S)NC(NC)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O ADPMAYFIIFNDMT-KQYNXXCUSA-N 0.000 description 1
- WPEKUTPQIYMWJA-AMJCQUEASA-N 9-[(2r,3s,4r,5r)-3-fluoro-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-2-(2-methylpropylamino)-3h-purin-6-one Chemical compound C1=2NC(NCC(C)C)=NC(=O)C=2N=CN1[C@@H]1O[C@H](CO)[C@@H](O)[C@]1(O)F WPEKUTPQIYMWJA-AMJCQUEASA-N 0.000 description 1
- 208000035657 Abasia Diseases 0.000 description 1
- 241000251468 Actinopterygii Species 0.000 description 1
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 1
- 241000710929 Alphavirus Species 0.000 description 1
- 108090000531 Amidohydrolases Proteins 0.000 description 1
- 102000004092 Amidohydrolases Human genes 0.000 description 1
- 241000191985 Anas superciliosa Species 0.000 description 1
- 244000303258 Annona diversifolia Species 0.000 description 1
- 235000002198 Annona diversifolia Nutrition 0.000 description 1
- 102100026292 Asialoglycoprotein receptor 1 Human genes 0.000 description 1
- 101710200897 Asialoglycoprotein receptor 1 Proteins 0.000 description 1
- 102100026293 Asialoglycoprotein receptor 2 Human genes 0.000 description 1
- 101710200901 Asialoglycoprotein receptor 2 Proteins 0.000 description 1
- 241000271566 Aves Species 0.000 description 1
- IYHHRZBKXXKDDY-UHFFFAOYSA-N BI-605906 Chemical group N=1C=2SC(C(N)=O)=C(N)C=2C(C(F)(F)CC)=CC=1N1CCC(S(C)(=O)=O)CC1 IYHHRZBKXXKDDY-UHFFFAOYSA-N 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 239000005711 Benzoic acid Substances 0.000 description 1
- ZOXJGFHDIHLPTG-UHFFFAOYSA-N Boron Chemical group [B] ZOXJGFHDIHLPTG-UHFFFAOYSA-N 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 102000003930 C-Type Lectins Human genes 0.000 description 1
- 108090000342 C-Type Lectins Proteins 0.000 description 1
- QITDXVRAGGJULA-LPWJVIDDSA-N C1(=CC=CC=C1)N1C=C([C@H]2[C@H](O)[C@H](O)[C@@H](CO)O2)C(NC1=O)=O Chemical compound C1(=CC=CC=C1)N1C=C([C@H]2[C@H](O)[C@H](O)[C@@H](CO)O2)C(NC1=O)=O QITDXVRAGGJULA-LPWJVIDDSA-N 0.000 description 1
- QWOJMRHUQHTCJG-UHFFFAOYSA-N CC([CH2-])=O Chemical group CC([CH2-])=O QWOJMRHUQHTCJG-UHFFFAOYSA-N 0.000 description 1
- SSWDEWUZBQUCCX-KKOKHZNYSA-N CCCCCN(C=C([C@@H]([C@@H]1O)O[C@H](CO)[C@H]1O)C(N1)=O)C1=O Chemical compound CCCCCN(C=C([C@@H]([C@@H]1O)O[C@H](CO)[C@H]1O)C(N1)=O)C1=O SSWDEWUZBQUCCX-KKOKHZNYSA-N 0.000 description 1
- UHNRLQRZRNKOKU-UHFFFAOYSA-N CCN(CC1=NC2=C(N1)C1=CC=C(C=C1N=C2N)C1=NNC=C1)C(C)=O Chemical group CCN(CC1=NC2=C(N1)C1=CC=C(C=C1N=C2N)C1=NNC=C1)C(C)=O UHNRLQRZRNKOKU-UHFFFAOYSA-N 0.000 description 1
- IQRCOXVINNRQGK-BGZDPUMWSA-N CS(=O)(=O)CN1C=C([C@H]2[C@H](O)[C@H](O)[C@@H](CO)O2)C(NC1=O)=O Chemical compound CS(=O)(=O)CN1C=C([C@H]2[C@H](O)[C@H](O)[C@@H](CO)O2)C(NC1=O)=O IQRCOXVINNRQGK-BGZDPUMWSA-N 0.000 description 1
- 241000282836 Camelus dromedarius Species 0.000 description 1
- 241000283707 Capra Species 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- 241000282994 Cervidae Species 0.000 description 1
- 229920001661 Chitosan Polymers 0.000 description 1
- 241000711573 Coronaviridae Species 0.000 description 1
- MIKUYHXYGGJMLM-UUOKFMHZSA-N Crotonoside Chemical compound C1=NC2=C(N)NC(=O)N=C2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O MIKUYHXYGGJMLM-UUOKFMHZSA-N 0.000 description 1
- UHDGCWIWMRVCDJ-CCXZUQQUSA-N Cytarabine Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@@H](O)[C@H](O)[C@@H](CO)O1 UHDGCWIWMRVCDJ-CCXZUQQUSA-N 0.000 description 1
- GUBGYTABKSRVRQ-CUHNMECISA-N D-Cellobiose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)OC(O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-CUHNMECISA-N 0.000 description 1
- WQZGKKKJIJFFOK-CBPJZXOFSA-N D-Gulose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@H](O)[C@H]1O WQZGKKKJIJFFOK-CBPJZXOFSA-N 0.000 description 1
- AEMOLEFTQBMNLQ-BZINKQHNSA-N D-Guluronic Acid Chemical compound OC1O[C@H](C(O)=O)[C@H](O)[C@@H](O)[C@H]1O AEMOLEFTQBMNLQ-BZINKQHNSA-N 0.000 description 1
- WQZGKKKJIJFFOK-WHZQZERISA-N D-aldose Chemical compound OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@H]1O WQZGKKKJIJFFOK-WHZQZERISA-N 0.000 description 1
- WQZGKKKJIJFFOK-IVMDWMLBSA-N D-allopyranose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@H](O)[C@@H]1O WQZGKKKJIJFFOK-IVMDWMLBSA-N 0.000 description 1
- LKDRXBCSQODPBY-JDJSBBGDSA-N D-allulose Chemical compound OCC1(O)OC[C@@H](O)[C@@H](O)[C@H]1O LKDRXBCSQODPBY-JDJSBBGDSA-N 0.000 description 1
- FBPFZTCFMRRESA-KAZBKCHUSA-N D-altritol Chemical compound OC[C@@H](O)[C@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KAZBKCHUSA-N 0.000 description 1
- HSNZZMHEPUFJNZ-QMTIVRBISA-N D-keto-manno-heptulose Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)C(=O)CO HSNZZMHEPUFJNZ-QMTIVRBISA-N 0.000 description 1
- HAIWUXASLYEWLM-UHFFFAOYSA-N D-manno-Heptulose Natural products OCC1OC(O)(CO)C(O)C(O)C1O HAIWUXASLYEWLM-UHFFFAOYSA-N 0.000 description 1
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical compound OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 description 1
- AEMOLEFTQBMNLQ-VANFPWTGSA-N D-mannopyranuronic acid Chemical compound OC1O[C@H](C(O)=O)[C@@H](O)[C@H](O)[C@@H]1O AEMOLEFTQBMNLQ-VANFPWTGSA-N 0.000 description 1
- ZAQJHHRNXZUBTE-NQXXGFSBSA-N D-ribulose Chemical compound OC[C@@H](O)[C@@H](O)C(=O)CO ZAQJHHRNXZUBTE-NQXXGFSBSA-N 0.000 description 1
- ZAQJHHRNXZUBTE-UHFFFAOYSA-N D-threo-2-Pentulose Natural products OCC(O)C(O)C(=O)CO ZAQJHHRNXZUBTE-UHFFFAOYSA-N 0.000 description 1
- SQNRKWHRVIAKLP-UHFFFAOYSA-N D-xylobiose Natural products O=CC(O)C(O)C(CO)OC1OCC(O)C(O)C1O SQNRKWHRVIAKLP-UHFFFAOYSA-N 0.000 description 1
- ZAQJHHRNXZUBTE-WUJLRWPWSA-N D-xylulose Chemical compound OC[C@@H](O)[C@H](O)C(=O)CO ZAQJHHRNXZUBTE-WUJLRWPWSA-N 0.000 description 1
- 241000450599 DNA viruses Species 0.000 description 1
- MYMOFIZGZYHOMD-UHFFFAOYSA-N Dioxygen Chemical compound O=O MYMOFIZGZYHOMD-UHFFFAOYSA-N 0.000 description 1
- 108010016626 Dipeptides Proteins 0.000 description 1
- 239000004593 Epoxy Substances 0.000 description 1
- 241000283074 Equus asinus Species 0.000 description 1
- 241000283073 Equus caballus Species 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 102000016359 Fibronectins Human genes 0.000 description 1
- 108010067306 Fibronectins Proteins 0.000 description 1
- RFSUNEUAIZKAJO-ARQDHWQXSA-N Fructose Chemical compound OC[C@H]1O[C@](O)(CO)[C@@H](O)[C@@H]1O RFSUNEUAIZKAJO-ARQDHWQXSA-N 0.000 description 1
- PNNNRSAQSRJVSB-SLPGGIOYSA-N Fucose Natural products C[C@H](O)[C@@H](O)[C@H](O)[C@H](O)C=O PNNNRSAQSRJVSB-SLPGGIOYSA-N 0.000 description 1
- 241000272496 Galliformes Species 0.000 description 1
- 241000287828 Gallus gallus Species 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- 108090000288 Glycoproteins Proteins 0.000 description 1
- 102000003886 Glycoproteins Human genes 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- UGQMRVRMYYASKQ-UHFFFAOYSA-N Hypoxanthine nucleoside Natural products OC1C(O)C(CO)OC1N1C(NC=NC2=O)=C2N=C1 UGQMRVRMYYASKQ-UHFFFAOYSA-N 0.000 description 1
- WPHHQMBITZGDQG-YAYWSOQESA-N IC=1C(NC(N([C@H]2[C@H](O)[C@H](O)[C@@H](CO)O2)C1)=O)=O.BrC=1C(NC(N([C@H]2[C@H](O)[C@H](O)[C@@H](CO)O2)C1)=O)=O Chemical compound IC=1C(NC(N([C@H]2[C@H](O)[C@H](O)[C@@H](CO)O2)C1)=O)=O.BrC=1C(NC(N([C@H]2[C@H](O)[C@H](O)[C@@H](CO)O2)C1)=O)=O WPHHQMBITZGDQG-YAYWSOQESA-N 0.000 description 1
- 229930010555 Inosine Natural products 0.000 description 1
- UGQMRVRMYYASKQ-KQYNXXCUSA-N Inosine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C2=NC=NC(O)=C2N=C1 UGQMRVRMYYASKQ-KQYNXXCUSA-N 0.000 description 1
- AYRXSINWFIIFAE-SCLMCMATSA-N Isomaltose Natural products OC[C@H]1O[C@H](OC[C@@H](O)[C@@H](O)[C@H](O)[C@@H](O)C=O)[C@@H](O)[C@@H](O)[C@@H]1O AYRXSINWFIIFAE-SCLMCMATSA-N 0.000 description 1
- 229930194542 Keto Natural products 0.000 description 1
- 208000007976 Ketosis Diseases 0.000 description 1
- OKPQBUWBBBNTOV-UHFFFAOYSA-N Kojibiose Natural products COC1OC(O)C(OC2OC(OC)C(O)C(O)C2O)C(O)C1O OKPQBUWBBBNTOV-UHFFFAOYSA-N 0.000 description 1
- LKDRXBCSQODPBY-AMVSKUEXSA-N L-(-)-Sorbose Chemical compound OCC1(O)OC[C@H](O)[C@@H](O)[C@@H]1O LKDRXBCSQODPBY-AMVSKUEXSA-N 0.000 description 1
- WQZGKKKJIJFFOK-VSOAQEOCSA-N L-altropyranose Chemical compound OC[C@@H]1OC(O)[C@H](O)[C@@H](O)[C@H]1O WQZGKKKJIJFFOK-VSOAQEOCSA-N 0.000 description 1
- SHZGCJCMOBCMKK-DHVFOXMCSA-N L-fucopyranose Chemical compound C[C@@H]1OC(O)[C@@H](O)[C@H](O)[C@@H]1O SHZGCJCMOBCMKK-DHVFOXMCSA-N 0.000 description 1
- HSNZZMHEPUFJNZ-UHFFFAOYSA-N L-galacto-2-Heptulose Natural products OCC(O)C(O)C(O)C(O)C(=O)CO HSNZZMHEPUFJNZ-UHFFFAOYSA-N 0.000 description 1
- ZFOMKMMPBOQKMC-KXUCPTDWSA-N L-pyrrolysine Chemical compound C[C@@H]1CC=N[C@H]1C(=O)NCCCC[C@H]([NH3+])C([O-])=O ZFOMKMMPBOQKMC-KXUCPTDWSA-N 0.000 description 1
- SHZGCJCMOBCMKK-JFNONXLTSA-N L-rhamnopyranose Chemical compound C[C@@H]1OC(O)[C@H](O)[C@H](O)[C@H]1O SHZGCJCMOBCMKK-JFNONXLTSA-N 0.000 description 1
- PNNNRSAQSRJVSB-UHFFFAOYSA-N L-rhamnose Natural products CC(O)C(O)C(O)C(O)C=O PNNNRSAQSRJVSB-UHFFFAOYSA-N 0.000 description 1
- 102000007330 LDL Lipoproteins Human genes 0.000 description 1
- 108010007622 LDL Lipoproteins Proteins 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- 241000283953 Lagomorpha Species 0.000 description 1
- 241000713666 Lentivirus Species 0.000 description 1
- 241000270322 Lepidosauria Species 0.000 description 1
- GUBGYTABKSRVRQ-PICCSMPSSA-N Maltose Natural products O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@@H](CO)OC(O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-PICCSMPSSA-N 0.000 description 1
- 241000712079 Measles morbillivirus Species 0.000 description 1
- 208000024556 Mendelian disease Diseases 0.000 description 1
- 241000711408 Murine respirovirus Species 0.000 description 1
- IYYIBFCJILKPCO-WOUKDFQISA-O N(2),N(2),N(7)-trimethylguanosine Chemical compound C1=2NC(N(C)C)=NC(=O)C=2N(C)C=[N+]1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O IYYIBFCJILKPCO-WOUKDFQISA-O 0.000 description 1
- RSPURTUNRHNVGF-IOSLPCCCSA-N N(2),N(2)-dimethylguanosine Chemical compound C1=NC=2C(=O)NC(N(C)C)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O RSPURTUNRHNVGF-IOSLPCCCSA-N 0.000 description 1
- ZBYRSRLCXTUFLJ-IOSLPCCCSA-O N(2),N(7)-dimethylguanosine Chemical compound CNC=1NC(C=2[N+](=CN([C@H]3[C@H](O)[C@H](O)[C@@H](CO)O3)C=2N=1)C)=O ZBYRSRLCXTUFLJ-IOSLPCCCSA-O 0.000 description 1
- SLEHROROQDYRAW-KQYNXXCUSA-N N(2)-methylguanosine Chemical compound C1=NC=2C(=O)NC(NC)=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O SLEHROROQDYRAW-KQYNXXCUSA-N 0.000 description 1
- NIDVTARKFBZMOT-PEBGCTIMSA-N N(4)-acetylcytidine Chemical compound O=C1N=C(NC(=O)C)C=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 NIDVTARKFBZMOT-PEBGCTIMSA-N 0.000 description 1
- IJCKBIINTQEGLY-UHFFFAOYSA-N N(4)-acetylcytosine Chemical compound CC(=O)NC1=CC=NC(=O)N1 IJCKBIINTQEGLY-UHFFFAOYSA-N 0.000 description 1
- PJKKQFAEFWCNAQ-UHFFFAOYSA-N N(4)-methylcytosine Chemical compound CNC=1C=CNC(=O)N=1 PJKKQFAEFWCNAQ-UHFFFAOYSA-N 0.000 description 1
- BVIAOQMSVZHOJM-UHFFFAOYSA-N N(6),N(6)-dimethyladenine Chemical compound CN(C)C1=NC=NC2=C1N=CN2 BVIAOQMSVZHOJM-UHFFFAOYSA-N 0.000 description 1
- WVGPGNPCZPYCLK-WOUKDFQISA-N N(6),N(6)-dimethyladenosine Chemical compound C1=NC=2C(N(C)C)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O WVGPGNPCZPYCLK-WOUKDFQISA-N 0.000 description 1
- USVMJSALORZVDV-SDBHATRESA-N N(6)-(Delta(2)-isopentenyl)adenosine Chemical compound C1=NC=2C(NCC=C(C)C)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O USVMJSALORZVDV-SDBHATRESA-N 0.000 description 1
- VQAYFKKCNSOZKM-IOSLPCCCSA-N N(6)-methyladenosine Chemical compound C1=NC=2C(NC)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O VQAYFKKCNSOZKM-IOSLPCCCSA-N 0.000 description 1
- WVGPGNPCZPYCLK-UHFFFAOYSA-N N-Dimethyladenosine Natural products C1=NC=2C(N(C)C)=NC=NC=2N1C1OC(CO)C(O)C1O WVGPGNPCZPYCLK-UHFFFAOYSA-N 0.000 description 1
- SLLVJTURCPWLTP-UHFFFAOYSA-N N-[9-[3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]purin-6-yl]acetamide Chemical compound C1=NC=2C(NC(=O)C)=NC=NC=2N1C1OC(CO)C(O)C1O SLLVJTURCPWLTP-UHFFFAOYSA-N 0.000 description 1
- POFVJRKJJBFPII-UHFFFAOYSA-N N-cyclopentyl-5-[2-[[5-[(4-ethylpiperazin-1-yl)methyl]pyridin-2-yl]amino]-5-fluoropyrimidin-4-yl]-4-methyl-1,3-thiazol-2-amine Chemical group C1(CCCC1)NC=1SC(=C(N=1)C)C1=NC(=NC=C1F)NC1=NC=C(C=C1)CN1CCN(CC1)CC POFVJRKJJBFPII-UHFFFAOYSA-N 0.000 description 1
- LZCNWAXLJWBRJE-ZOQUXTDFSA-N N4-Methylcytidine Chemical compound O=C1N=C(NC)C=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 LZCNWAXLJWBRJE-ZOQUXTDFSA-N 0.000 description 1
- GOSWTRUMMSCNCW-UHFFFAOYSA-N N6-(cis-hydroxyisopentenyl)adenosine Chemical compound C1=NC=2C(NCC=C(CO)C)=NC=NC=2N1C1OC(CO)C(O)C1O GOSWTRUMMSCNCW-UHFFFAOYSA-N 0.000 description 1
- VQAYFKKCNSOZKM-UHFFFAOYSA-N NSC 29409 Natural products C1=NC=2C(NC)=NC=NC=2N1C1OC(CO)C(O)C1O VQAYFKKCNSOZKM-UHFFFAOYSA-N 0.000 description 1
- 206010028980 Neoplasm Diseases 0.000 description 1
- VZQXUWKZDSEQRR-UHFFFAOYSA-N Nucleosid Natural products C12=NC(SC)=NC(NCC=C(C)C)=C2N=CN1C1OC(CO)C(O)C1O VZQXUWKZDSEQRR-UHFFFAOYSA-N 0.000 description 1
- AYRXSINWFIIFAE-UHFFFAOYSA-N O6-alpha-D-Galactopyranosyl-D-galactose Natural products OCC1OC(OCC(O)C(O)C(O)C(O)C=O)C(O)C(O)C1O AYRXSINWFIIFAE-UHFFFAOYSA-N 0.000 description 1
- GFKHSKIYLDMXJJ-JBBNEOJLSA-N OC[C@H]([C@H]([C@H]1O)O)O[C@H]1C(C(N1)=O)=C(CC(F)(F)F)NC1=O Chemical compound OC[C@H]([C@H]([C@H]1O)O)O[C@H]1C(C(N1)=O)=C(CC(F)(F)F)NC1=O GFKHSKIYLDMXJJ-JBBNEOJLSA-N 0.000 description 1
- KRIMDSNQQXJAIF-UHFFFAOYSA-N OP(O)(=O)ON=C=S Chemical class OP(O)(=O)ON=C=S KRIMDSNQQXJAIF-UHFFFAOYSA-N 0.000 description 1
- 108010038807 Oligopeptides Proteins 0.000 description 1
- 102000015636 Oligopeptides Human genes 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 241001494479 Pecora Species 0.000 description 1
- ABLZXFCXXLZCGV-UHFFFAOYSA-N Phosphorous acid Chemical class OP(O)=O ABLZXFCXXLZCGV-UHFFFAOYSA-N 0.000 description 1
- 241000709664 Picornaviridae Species 0.000 description 1
- 229920001100 Polydextrose Polymers 0.000 description 1
- 239000004365 Protease Substances 0.000 description 1
- 102100029812 Protein S100-A12 Human genes 0.000 description 1
- 101710110949 Protein S100-A12 Proteins 0.000 description 1
- 241000125945 Protoparvovirus Species 0.000 description 1
- 230000007022 RNA scission Effects 0.000 description 1
- 241000711798 Rabies lyssavirus Species 0.000 description 1
- 241000712907 Retroviridae Species 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- HAIWUXASLYEWLM-AZEWMMITSA-N Sedoheptulose Natural products OC[C@H]1[C@H](O)[C@H](O)[C@H](O)[C@@](O)(CO)O1 HAIWUXASLYEWLM-AZEWMMITSA-N 0.000 description 1
- XUIMIQQOPSSXEZ-UHFFFAOYSA-N Silicon Chemical compound [Si] XUIMIQQOPSSXEZ-UHFFFAOYSA-N 0.000 description 1
- 241000700584 Simplexvirus Species 0.000 description 1
- 229920002472 Starch Polymers 0.000 description 1
- PJANXHGTPQOBST-VAWYXSNFSA-N Stilbene Natural products C=1C=CC=CC=1/C=C/C1=CC=CC=C1 PJANXHGTPQOBST-VAWYXSNFSA-N 0.000 description 1
- 241000271567 Struthioniformes Species 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 1
- 241000282898 Sus scrofa Species 0.000 description 1
- HDTRYLNUVZCQOY-WSWWMNSNSA-N Trehalose Natural products O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@@H](O)[C@@H](CO)O1 HDTRYLNUVZCQOY-WSWWMNSNSA-N 0.000 description 1
- 235000001484 Trigonella foenum graecum Nutrition 0.000 description 1
- 244000250129 Trigonella foenum graecum Species 0.000 description 1
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 1
- 241000711975 Vesicular stomatitis virus Species 0.000 description 1
- 241001416177 Vicugna pacos Species 0.000 description 1
- OIRDTQYFTABQOQ-UHTZMRCNSA-N Vidarabine Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@@H]1O OIRDTQYFTABQOQ-UHTZMRCNSA-N 0.000 description 1
- YXNIEZJFCGTDKV-UHFFFAOYSA-N X-Nucleosid Natural products O=C1N(CCC(N)C(O)=O)C(=O)C=CN1C1C(O)C(O)C(CO)O1 YXNIEZJFCGTDKV-UHFFFAOYSA-N 0.000 description 1
- 239000004480 active ingredient Substances 0.000 description 1
- IAJILQKETJEXLJ-RSJOWCBRSA-N aldehydo-D-galacturonic acid Chemical compound O=C[C@H](O)[C@@H](O)[C@@H](O)[C@H](O)C(O)=O IAJILQKETJEXLJ-RSJOWCBRSA-N 0.000 description 1
- IAJILQKETJEXLJ-QTBDOELSSA-N aldehydo-D-glucuronic acid Chemical compound O=C[C@H](O)[C@@H](O)[C@H](O)[C@H](O)C(O)=O IAJILQKETJEXLJ-QTBDOELSSA-N 0.000 description 1
- QBYJBZPUGVGKQQ-SJJAEHHWSA-N aldrin Chemical group C1[C@H]2C=C[C@@H]1[C@H]1[C@@](C3(Cl)Cl)(Cl)C(Cl)=C(Cl)[C@@]3(Cl)[C@H]12 QBYJBZPUGVGKQQ-SJJAEHHWSA-N 0.000 description 1
- 125000005024 alkenyl aryl group Chemical group 0.000 description 1
- 125000005217 alkenylheteroaryl group Chemical group 0.000 description 1
- 125000003545 alkoxy group Chemical group 0.000 description 1
- 125000005083 alkoxyalkoxy group Chemical group 0.000 description 1
- 125000004948 alkyl aryl alkyl group Chemical group 0.000 description 1
- 125000005213 alkyl heteroaryl group Chemical group 0.000 description 1
- 125000005025 alkynylaryl group Chemical group 0.000 description 1
- HDTRYLNUVZCQOY-LIZSDCNHSA-N alpha,alpha-trehalose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 HDTRYLNUVZCQOY-LIZSDCNHSA-N 0.000 description 1
- WQZGKKKJIJFFOK-PHYPRBDBSA-N alpha-D-galactose Chemical compound OC[C@H]1O[C@H](O)[C@H](O)[C@@H](O)[C@H]1O WQZGKKKJIJFFOK-PHYPRBDBSA-N 0.000 description 1
- SRBFZHDQGSBBOR-STGXQOJASA-N alpha-D-lyxopyranose Chemical compound O[C@@H]1CO[C@H](O)[C@@H](O)[C@H]1O SRBFZHDQGSBBOR-STGXQOJASA-N 0.000 description 1
- 125000003277 amino group Chemical group 0.000 description 1
- 108010079465 amphomycin Proteins 0.000 description 1
- BBDAGFIXKZCXAH-CCXZUQQUSA-N ancitabine Chemical compound N=C1C=CN2[C@@H]3O[C@H](CO)[C@@H](O)[C@@H]3OC2=N1 BBDAGFIXKZCXAH-CCXZUQQUSA-N 0.000 description 1
- 238000010171 animal model Methods 0.000 description 1
- PYMYPHUHKUWMLA-WDCZJNDASA-N arabinose Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)C=O PYMYPHUHKUWMLA-WDCZJNDASA-N 0.000 description 1
- 125000005018 aryl alkenyl group Chemical group 0.000 description 1
- 125000005015 aryl alkynyl group Chemical group 0.000 description 1
- 238000003556 assay Methods 0.000 description 1
- 230000037429 base substitution Effects 0.000 description 1
- AEMOLEFTQBMNLQ-UHFFFAOYSA-N beta-D-galactopyranuronic acid Natural products OC1OC(C(O)=O)C(O)C(O)C1O AEMOLEFTQBMNLQ-UHFFFAOYSA-N 0.000 description 1
- QLTSDROPCWIKKY-PMCTYKHCSA-N beta-D-glucosaminyl-(1->4)-beta-D-glucosamine Chemical compound O[C@@H]1[C@@H](N)[C@H](O)O[C@H](CO)[C@H]1O[C@H]1[C@H](N)[C@@H](O)[C@H](O)[C@@H](CO)O1 QLTSDROPCWIKKY-PMCTYKHCSA-N 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- GUBGYTABKSRVRQ-QUYVBRFLSA-N beta-maltose Chemical compound OC[C@H]1O[C@H](O[C@H]2[C@H](O)[C@@H](O)[C@H](O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@@H]1O GUBGYTABKSRVRQ-QUYVBRFLSA-N 0.000 description 1
- 239000013060 biological fluid Substances 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 229910000085 borane Inorganic materials 0.000 description 1
- 229910052794 bromium Inorganic materials 0.000 description 1
- 125000000484 butyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 201000011510 cancer Diseases 0.000 description 1
- 229910002091 carbon monoxide Inorganic materials 0.000 description 1
- 150000007942 carboxylates Chemical class 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 238000004113 cell culture Methods 0.000 description 1
- 210000004671 cell-free system Anatomy 0.000 description 1
- 230000033077 cellular process Effects 0.000 description 1
- 230000005754 cellular signaling Effects 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 238000012512 characterization method Methods 0.000 description 1
- 229910052801 chlorine Inorganic materials 0.000 description 1
- 230000001143 conditioned effect Effects 0.000 description 1
- 238000011109 contamination Methods 0.000 description 1
- 125000000392 cycloalkenyl group Chemical group 0.000 description 1
- 125000001995 cyclobutyl group Chemical group [H]C1([H])C([H])([H])C([H])(*)C1([H])[H] 0.000 description 1
- UUGITDASWNOAGG-CCXZUQQUSA-N cyclouridine Chemical compound O=C1C=CN2[C@@H]3O[C@H](CO)[C@@H](O)[C@@H]3OC2=N1 UUGITDASWNOAGG-CCXZUQQUSA-N 0.000 description 1
- 238000000354 decomposition reaction Methods 0.000 description 1
- 230000003247 decreasing effect Effects 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- 150000008266 deoxy sugars Chemical class 0.000 description 1
- 230000000368 destabilizing effect Effects 0.000 description 1
- NAGJZTKCGNOGPW-UHFFFAOYSA-K dioxido-sulfanylidene-sulfido-$l^{5}-phosphane Chemical compound [O-]P([O-])([S-])=S NAGJZTKCGNOGPW-UHFFFAOYSA-K 0.000 description 1
- 239000001177 diphosphate Substances 0.000 description 1
- XPPKVPWEQAFLFU-UHFFFAOYSA-J diphosphate(4-) Chemical compound [O-]P([O-])(=O)OP([O-])([O-])=O XPPKVPWEQAFLFU-UHFFFAOYSA-J 0.000 description 1
- 235000011180 diphosphates Nutrition 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- NAGJZTKCGNOGPW-UHFFFAOYSA-N dithiophosphoric acid Chemical class OP(O)(S)=S NAGJZTKCGNOGPW-UHFFFAOYSA-N 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- CHNUOJQWGUIOLD-NFZZJPOKSA-N epalrestat Chemical compound C=1C=CC=CC=1\C=C(/C)\C=C1/SC(=S)N(CC(O)=O)C1=O CHNUOJQWGUIOLD-NFZZJPOKSA-N 0.000 description 1
- 230000001973 epigenetic effect Effects 0.000 description 1
- 238000004108 freeze drying Methods 0.000 description 1
- 230000005714 functional activity Effects 0.000 description 1
- 125000003843 furanosyl group Chemical group 0.000 description 1
- SDUQYLNIPVEERB-QPPQHZFASA-N gemcitabine Chemical compound O=C1N=C(N)C=CN1[C@H]1C(F)(F)[C@H](O)[C@@H](CO)O1 SDUQYLNIPVEERB-QPPQHZFASA-N 0.000 description 1
- 230000030279 gene silencing Effects 0.000 description 1
- 238000012226 gene silencing method Methods 0.000 description 1
- DLRVVLDZNNYCBX-CQUJWQHSSA-N gentiobiose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@H]1OC[C@@H]1[C@@H](O)[C@H](O)[C@@H](O)C(O)O1 DLRVVLDZNNYCBX-CQUJWQHSSA-N 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 229940097043 glucuronic acid Drugs 0.000 description 1
- 229960002743 glutamine Drugs 0.000 description 1
- MNQZXJOMYWMBOU-UHFFFAOYSA-N glyceraldehyde Chemical compound OCC(O)C=O MNQZXJOMYWMBOU-UHFFFAOYSA-N 0.000 description 1
- 150000002337 glycosamines Chemical class 0.000 description 1
- 150000002386 heptoses Chemical class 0.000 description 1
- 125000004447 heteroarylalkenyl group Chemical group 0.000 description 1
- 125000004446 heteroarylalkyl group Chemical group 0.000 description 1
- 125000005312 heteroarylalkynyl group Chemical group 0.000 description 1
- 125000000592 heterocycloalkyl group Chemical group 0.000 description 1
- 125000004415 heterocyclylalkyl group Chemical group 0.000 description 1
- 150000002402 hexoses Chemical class 0.000 description 1
- 238000009396 hybridization Methods 0.000 description 1
- 125000005597 hydrazone group Chemical group 0.000 description 1
- 125000004356 hydroxy functional group Chemical group O* 0.000 description 1
- 150000002454 idoses Chemical class 0.000 description 1
- IAJILQKETJEXLJ-LECHCGJUSA-N iduronic acid Chemical compound O=C[C@@H](O)[C@H](O)[C@@H](O)[C@H](O)C(O)=O IAJILQKETJEXLJ-LECHCGJUSA-N 0.000 description 1
- 125000005945 imidazopyridyl group Chemical group 0.000 description 1
- 210000002865 immune cell Anatomy 0.000 description 1
- 238000011065 in-situ storage Methods 0.000 description 1
- 230000000415 inactivating effect Effects 0.000 description 1
- 239000005414 inactive ingredient Substances 0.000 description 1
- 230000036512 infertility Effects 0.000 description 1
- 238000002347 injection Methods 0.000 description 1
- 239000007924 injection Substances 0.000 description 1
- 229960003786 inosine Drugs 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- DLRVVLDZNNYCBX-RTPHMHGBSA-N isomaltose Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1OC[C@@H]1[C@@H](O)[C@H](O)[C@@H](O)C(O)O1 DLRVVLDZNNYCBX-RTPHMHGBSA-N 0.000 description 1
- 125000001449 isopropyl group Chemical group [H]C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- VDBNYAPERZTOOF-UHFFFAOYSA-N isoquinolin-1(2H)-one Chemical compound C1=CC=C2C(=O)NC=CC2=C1 VDBNYAPERZTOOF-UHFFFAOYSA-N 0.000 description 1
- BJHIKXHVCXFQLS-PQLUHFTBSA-N keto-D-tagatose Chemical compound OC[C@@H](O)[C@H](O)[C@H](O)C(=O)CO BJHIKXHVCXFQLS-PQLUHFTBSA-N 0.000 description 1
- 125000000468 ketone group Chemical group 0.000 description 1
- 150000002584 ketoses Chemical class 0.000 description 1
- 210000000231 kidney cortex Anatomy 0.000 description 1
- 238000003367 kinetic assay Methods 0.000 description 1
- PZDOWFGHCNHPQD-OQPGPFOOSA-N kojibiose Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](C=O)O[C@H]1O[C@H](CO)[C@@H](O)[C@H](O)[C@H]1O PZDOWFGHCNHPQD-OQPGPFOOSA-N 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- 239000007791 liquid phase Substances 0.000 description 1
- 210000004072 lung Anatomy 0.000 description 1
- 230000002101 lytic effect Effects 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 238000005259 measurement Methods 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- AHIQDGXXLZVOGZ-UGKPPGOTSA-N methyl 3-[1-[(2r,3r,4s,5r)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-2,4-dioxopyrimidin-5-yl]prop-2-enoate Chemical compound O=C1NC(=O)C(C=CC(=O)OC)=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 AHIQDGXXLZVOGZ-UGKPPGOTSA-N 0.000 description 1
- 230000011987 methylation Effects 0.000 description 1
- 238000007069 methylation reaction Methods 0.000 description 1
- IDBOAVAEGRJRIZ-UHFFFAOYSA-N methylidenehydrazine Chemical group NN=C IDBOAVAEGRJRIZ-UHFFFAOYSA-N 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- FZQMZXGTZAPBAK-UHFFFAOYSA-N n-(3-methylbutyl)-7h-purin-6-amine Chemical compound CC(C)CCNC1=NC=NC2=C1NC=N2 FZQMZXGTZAPBAK-UHFFFAOYSA-N 0.000 description 1
- CYDFBLGNJUNSCC-QCNRFFRDSA-N n-[1-[(2r,3r,4r,5r)-4-hydroxy-5-(hydroxymethyl)-3-methoxyoxolan-2-yl]-2-oxopyrimidin-4-yl]acetamide Chemical compound CO[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)N=C(NC(C)=O)C=C1 CYDFBLGNJUNSCC-QCNRFFRDSA-N 0.000 description 1
- DYMRYCZRMAHYKE-UHFFFAOYSA-N n-diazonitramide Chemical compound [O-][N+](=O)N=[N+]=[N-] DYMRYCZRMAHYKE-UHFFFAOYSA-N 0.000 description 1
- 125000001624 naphthyl group Chemical group 0.000 description 1
- 239000013642 negative control Substances 0.000 description 1
- 230000009437 off-target effect Effects 0.000 description 1
- 238000002515 oligonucleotide synthesis Methods 0.000 description 1
- 210000003463 organelle Anatomy 0.000 description 1
- 230000003647 oxidation Effects 0.000 description 1
- 238000007254 oxidation reaction Methods 0.000 description 1
- 230000001590 oxidative effect Effects 0.000 description 1
- 125000000636 p-nitrophenyl group Chemical group [H]C1=C([H])C(=C([H])C([H])=C1*)[N+]([O-])=O 0.000 description 1
- LPNBBFKOUUSUDB-UHFFFAOYSA-N p-toluenecarboxylic acid Natural products CC1=CC=C(C(O)=O)C=C1 LPNBBFKOUUSUDB-UHFFFAOYSA-N 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 150000002972 pentoses Chemical class 0.000 description 1
- 229940124531 pharmaceutical excipient Drugs 0.000 description 1
- 239000000825 pharmaceutical preparation Substances 0.000 description 1
- 229940127557 pharmaceutical product Drugs 0.000 description 1
- 230000003285 pharmacodynamic effect Effects 0.000 description 1
- 239000012071 phase Substances 0.000 description 1
- 125000001997 phenyl group Chemical group [H]C1=C([H])C([H])=C(*)C([H])=C1[H] 0.000 description 1
- XRBCRPZXSCBRTK-UHFFFAOYSA-N phosphonous acid Chemical class OPO XRBCRPZXSCBRTK-UHFFFAOYSA-N 0.000 description 1
- PTMHPRAIXMAOOB-UHFFFAOYSA-L phosphoramidate Chemical compound NP([O-])([O-])=O PTMHPRAIXMAOOB-UHFFFAOYSA-L 0.000 description 1
- 150000008298 phosphoramidates Chemical class 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 210000002706 plastid Anatomy 0.000 description 1
- 239000001259 polydextrose Substances 0.000 description 1
- 229940035035 polydextrose Drugs 0.000 description 1
- 235000013856 polydextrose Nutrition 0.000 description 1
- 229920000642 polymer Polymers 0.000 description 1
- 102000040430 polynucleotide Human genes 0.000 description 1
- 108091033319 polynucleotide Proteins 0.000 description 1
- 239000002157 polynucleotide Substances 0.000 description 1
- 229920001296 polysiloxane Polymers 0.000 description 1
- 244000062645 predators Species 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- ZENDWEPAVHORFD-UHFFFAOYSA-N pyrimidine;urea Chemical compound NC(N)=O.C1=CN=CN=C1 ZENDWEPAVHORFD-UHFFFAOYSA-N 0.000 description 1
- 150000003230 pyrimidines Chemical class 0.000 description 1
- IUVKMZGDUIUOCP-BTNSXGMBSA-N quinbolone Chemical compound O([C@H]1CC[C@H]2[C@H]3[C@@H]([C@]4(C=CC(=O)C=C4CC3)C)CC[C@@]21C)C1=CCCC1 IUVKMZGDUIUOCP-BTNSXGMBSA-N 0.000 description 1
- 102000005962 receptors Human genes 0.000 description 1
- 108020003175 receptors Proteins 0.000 description 1
- 239000002265 redox agent Substances 0.000 description 1
- 125000006853 reporter group Chemical group 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 239000000523 sample Substances 0.000 description 1
- 238000013515 script Methods 0.000 description 1
- HSNZZMHEPUFJNZ-SHUUEZRQSA-N sedoheptulose Chemical compound OC[C@@H](O)[C@@H](O)[C@@H](O)[C@H](O)C(=O)CO HSNZZMHEPUFJNZ-SHUUEZRQSA-N 0.000 description 1
- 229910052710 silicon Inorganic materials 0.000 description 1
- 239000010703 silicon Substances 0.000 description 1
- 125000003808 silyl group Chemical group [H][Si]([H])([H])[*] 0.000 description 1
- KSAVQLQVUXSOCR-UHFFFAOYSA-M sodium lauroyl sarcosinate Chemical group [Na+].CCCCCCCCCCCC(=O)N(C)CC([O-])=O KSAVQLQVUXSOCR-UHFFFAOYSA-M 0.000 description 1
- 239000007790 solid phase Substances 0.000 description 1
- 238000010532 solid phase synthesis reaction Methods 0.000 description 1
- 239000000243 solution Substances 0.000 description 1
- 230000000087 stabilizing effect Effects 0.000 description 1
- 239000008107 starch Substances 0.000 description 1
- 235000019698 starch Nutrition 0.000 description 1
- PJANXHGTPQOBST-UHFFFAOYSA-N stilbene Chemical group C=1C=CC=CC=1C=CC1=CC=CC=C1 PJANXHGTPQOBST-UHFFFAOYSA-N 0.000 description 1
- 235000021286 stilbenes Nutrition 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 125000001424 substituent group Chemical group 0.000 description 1
- 125000005017 substituted alkenyl group Chemical group 0.000 description 1
- 125000003107 substituted aryl group Chemical group 0.000 description 1
- 125000005346 substituted cycloalkyl group Chemical group 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 150000005846 sugar alcohols Chemical class 0.000 description 1
- 150000008163 sugars Chemical class 0.000 description 1
- IIACRCGMVDHOTQ-UHFFFAOYSA-M sulfamate Chemical compound NS([O-])(=O)=O IIACRCGMVDHOTQ-UHFFFAOYSA-M 0.000 description 1
- IIACRCGMVDHOTQ-UHFFFAOYSA-N sulfamic acid Chemical group NS(O)(=O)=O IIACRCGMVDHOTQ-UHFFFAOYSA-N 0.000 description 1
- OKQKDCXVLPGWPO-UHFFFAOYSA-N sulfanylidenephosphane Chemical compound S=P OKQKDCXVLPGWPO-UHFFFAOYSA-N 0.000 description 1
- 239000011593 sulfur Substances 0.000 description 1
- 210000002437 synoviocyte Anatomy 0.000 description 1
- 230000002194 synthesizing effect Effects 0.000 description 1
- 230000009885 systemic effect Effects 0.000 description 1
- 230000002123 temporal effect Effects 0.000 description 1
- 238000011191 terminal modification Methods 0.000 description 1
- 210000001550 testis Anatomy 0.000 description 1
- 150000007970 thio esters Chemical class 0.000 description 1
- DHCDFWKWKRSZHF-UHFFFAOYSA-L thiosulfate(2-) Chemical compound [O-]S([S-])(=O)=O DHCDFWKWKRSZHF-UHFFFAOYSA-L 0.000 description 1
- 229940104230 thymidine Drugs 0.000 description 1
- 230000000699 topical effect Effects 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 230000009261 transgenic effect Effects 0.000 description 1
- NMXLJRHBJVMYPD-IPFGBZKGSA-N trehalulose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@]1(O)CO[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 NMXLJRHBJVMYPD-IPFGBZKGSA-N 0.000 description 1
- 235000001019 trigonella foenum-graecum Nutrition 0.000 description 1
- 239000001226 triphosphate Substances 0.000 description 1
- 235000011178 triphosphate Nutrition 0.000 description 1
- UNXRWKVEANCORM-UHFFFAOYSA-N triphosphoric acid Chemical compound OP(O)(=O)OP(O)(=O)OP(O)(O)=O UNXRWKVEANCORM-UHFFFAOYSA-N 0.000 description 1
- 241001529453 unidentified herpesvirus Species 0.000 description 1
- 241000712461 unidentified influenza virus Species 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- RVCNQQGZJWVLIP-VPCXQMTMSA-N uridin-5-yloxyacetic acid Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C(OCC(O)=O)=C1 RVCNQQGZJWVLIP-VPCXQMTMSA-N 0.000 description 1
- 229940005605 valeric acid Drugs 0.000 description 1
- 239000003981 vehicle Substances 0.000 description 1
- 229960003636 vidarabine Drugs 0.000 description 1
- 229920002554 vinyl polymer Polymers 0.000 description 1
- 230000017613 viral reproduction Effects 0.000 description 1
- RPQZTTQVRYEKCR-WCTZXXKLSA-N zebularine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)N=CC=C1 RPQZTTQVRYEKCR-WCTZXXKLSA-N 0.000 description 1
Images















Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/70—Carbohydrates; Sugars; Derivatives thereof
- A61K31/7088—Compounds having three or more nucleosides or nucleotides
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/111—General methods applicable to biologically active non-coding nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/67—General methods for enhancing the expression
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/35—Nature of the modification
- C12N2310/351—Conjugate
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/50—Physical structure
- C12N2310/53—Physical structure partially self-complementary or closed
- C12N2310/531—Stem-loop; Hairpin
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Biomedical Technology (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Biotechnology (AREA)
- General Engineering & Computer Science (AREA)
- Zoology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Wood Science & Technology (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Microbiology (AREA)
- Plant Pathology (AREA)
- Biophysics (AREA)
- Physics & Mathematics (AREA)
- Public Health (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Medicinal Chemistry (AREA)
- Veterinary Medicine (AREA)
- Epidemiology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
- Peptides Or Proteins (AREA)
- Acyclic And Carbocyclic Compounds In Medicinal Compositions (AREA)
Abstract
本發明大體上係關於包含去唾液酸糖蛋白受體(ASGPR)結合部分的基於tRNA之效應分子(TREM),以及與其相關之組合物及方法。
Description
tRNA為複合RNA分子,其具有多種功能,包括起始及延長蛋白質之能力。
本發明之特徵尤其在於包含去唾液酸糖蛋白受體(ASGPR)結合部分的基於tRNA之效應分子(TREM)實體,以及其組合物及使用方法。ASGPR結合部分可與TREM實體內之核鹼基結合,或在TREM實體之核苷酸間鍵聯內結合,或在TREM實體之末端(例如5'或3'末端)處結合。在一實施例中,TREM實體包含TREM、TREM核心片段或TREM片段。在一實施例中,核鹼基包含腺嘌呤、胸腺嘧啶、胞嘧啶、鳥苷或尿嘧啶,或其變體或經修飾形式。
在一個態樣中,本文所描述之TREM實體(例如TREM)包含式A之序列:[L1]-[ASt域1]-[L2]-[DH域]-[L3]-[ACH域]-[VL域]-[TH域]-[L4]-[ASt域2] (A),其中獨立地,TREM包含ASGPR結合部分。在一實施例中,ASGPR結合部分包含ASGPR碳水化合物及ASGPR連接子。在一實施例中,ASGPR結合部分包含半乳糖(Gal)及/或N-乙醯基半乳胺糖(GalNAc)部分。在一實施例中,ASGPR結合部分包含複數個Gal及/或GalNAc部分(例如2、3、4、5、6、7、8或更多個Gal及/或GalNAc部分)。在一實施例中,ASGPR結合部分包含三觸角GalNAc部分。在一實施例中,TREM進一步包含化學修飾(例如硫代磷酸酯(phosphothiorate)核苷酸間鍵聯,或對TREM內之核糖部分之2'-修飾)。
在一實施例中,ASGPR結合部分存在於TREM中之核苷酸內的核鹼基上。在一實施例中,ASGPR結合部分存在於TREM之5'末端上。在一實施例中,ASGPR結合部分存在於TREM之3'末端上。
在一實施例中,ASGPR結合部分存在於選自L1、ASt域1、L2、DH域、L3、ACH域、VL域、TH域、L4及ASt域2之TREM域中。在一實施例中,ASGPR結合部分存在於L1區中。在一實施例中,ASGPR結合部分存在於AST域1中。在一實施例中,ASGPR結合部分存在於L2區中。在一實施例中,ASGPR結合部分存在於DH域中。在一實施例中,ASGPR結合部分存在於L3區中。在一實施例中,ASGPR結合部分存在於ACH域中。在一實施例中,ASGPR結合部分存在於VL域中。在一實施例中,ASGPR結合部分存在於TH域中。在一實施例中,ASGPR結合部分存在於L4區中。在一實施例中,ASGPR結合部分存在於AST域2中。
在一實施例中,包含ASGPR結合部分之TREM保留支援蛋白質合成、被合成酶裝載、被延長因子結合、將胺基酸引入至肽鏈中、支援延長及/或支援起始之能力。在一實施例中,包含ASGPR結合部分之TREM包含至少X個不含化學修飾之連續核苷酸,其中X大於10。在一實施例中,包含ASGPR結合部分之TREM包含不超過5、10或15個不包含化學修飾的一類核苷酸(例如A、T、C、G或U)。在一實施例中,包含ASGPR結合部分之TREM包含不超過1、2、3、4、5、6、7、8、9、10、12、14、16、18、20、22、24、26、28、30、32、34、36、38、40、42、44、46、48、50、52、54、56、58、60、62、64、66、68、70、72、74、76、78或80個不包含化學修飾的一類核苷酸(例如A、T、C、G或U)。在一實施例中,包含ASGPR結合部分之TREM包含至少X個包含化學修飾之連續核苷酸,其中X大於10。在一實施例中,包含ASGPR結合部分之TREM包含超過5、10或15個包含化學修飾的一類核苷酸(例如A、T、C、G或U)。在一實施例中,包含ASGPR結合部分之TREM包含1、2、3、4、5、6、7、8、9、10、12、14、16、18、20、22、24、26、28、30、32、34、36、38、40、42、44、46、48、50、52、54、56、58、60、62、64、66、68、70、72、74、76、78或80個包含化學修飾的一類核苷酸(例如A、T、C、G或U)。在一實施例中,化學修飾為天然存在之化學修飾或非天然存在之化學修飾(例如硫代磷酸酯核苷酸間鍵聯,或對TREM內之核糖部分之2'-修飾)。在一實施例中,化學修飾包含螢光團。
在另一態樣中,本文所描述的包含ASGPR結合部分之TREM或其組合物可用於調節對應於核酸序列之RNA或由核酸序列編碼之多肽的產生參數(例如表現參數及/或信號傳導參數),該核酸序列包含具有提前終止密碼子(PTC)之內源性開讀框(ORF)。
在另一態樣中,本文所描述的包含ASGPR結合部分之TREM或其組合物可用於調節對應於個體中之內源性開讀框(ORF)之mRNA或由該內源性開讀框編碼之多肽的產生參數的方法中,該ORF包含提前終止密碼子(PTC),該方法包含使該個體與包含ASGPR結合部分之TREM或其組合物以足以調節該mRNA或多肽之產生參數的量及/或時間接觸,其中包含ASGPR結合部分之TREM具有與具有第一序列之密碼子配對的反密碼子,由此調節該個體中之產生參數。在一實施例中,產生參數包含例如如本文所描述之信號傳導參數及/或表現參數。
在另一態樣中,本文所描述的包含ASGPR結合部分之TREM或其組合物可用於治療具有包含提前終止密碼子(PTC)之內源性開讀框(ORF)的個體的方法中,該方法包含:提供包含ASGPR結合部分之TREM或其組合物,其中該包含ASGPR結合部分之TREM包含與該ORF中之該PTC配對的反密碼子;使該個體與該包含ASGPR結合部分之TREM或其組合物以足以治療該個體之量及/或時間接觸,由此治療該個體。在一實施例中,該PTC包含UAA、UGA或UAG。
在另一態樣中,本文所描述的包含ASGPR結合部分之TREM或其組合物可用於治療患有與提前終止密碼子(PTC)相關之疾病或病症的個體的方法中,該方法包含:提供本文所描述的包含ASGPR結合部分之TREM或組合物;使該個體與該包含ASGPR結合部分之TREM或其組合物以足以治療該個體之量及/或時間接觸,由此治療該個體。在一實施例中,該PTC包含UAA、UGA或UAG。在一實施例中,與PTC相關之疾病或病症為本文所描述之疾病或病症,例如癌症或單基因疾病。
前述TREM實體中之任一者之額外特徵(例如TREM、TREM核心片段、TREM片段、TREM組合物、製劑、製備TREM組合物及製劑之方法以及使用TREM組合物及製劑之方法)包括以下所列舉實施例中之一或多者。
熟習此項技術者將認識到或能夠僅使用常規實驗確定本文所描述之本發明特定實施例的許多等效物。此類等效物意欲由以下所列舉實施例涵蓋。
相關申請案之交叉參考
本申請案主張美國臨時申請案第63/130,373號、美國臨時申請案第63/130,374號、美國臨時申請案第63/130,375號、美國臨時申請案第63/130,377號、美國臨時申請案第63/130,381號及美國臨時申請案第63/130,387號之優先權,其中之每一者均申請於2020年12月23日。前述申請案中之每一者之全部內容在此以引用之方式併入。
本發明之特徵在於包含去唾液酸糖蛋白受體(ASGPR)結合部分的基於tRNA之效應分子(TREM)實體(例如TREM、TREM核心片段及TREM片段),以及其組合物及相關使用方法。如本文所揭示,TREM實體(例如TREM)為可介導各種細胞過程之複合分子。可向細胞、組織或個體投與醫藥TREM組合物,例如包含ASGPR結合部分之TREM,以調節此等功能。
定義如本文所使用之術語「受體莖域(AStD)」係指與胺基酸結合的域。在一實施例中,AStD包含ASt域1及ASt域2。舉例而言,ASt域1位於TREM之5'端處或附近,且ASt域2位於TREM之3'端處或附近。AStD包含例如當存在於另外野生型tRNA中時足以在多肽鏈之起始或延長中介導胺基酸(例如其同源胺基酸或非同源胺基酸)之接受及胺基酸(AA)之轉移的RNA序列。通常,AStD包含用於接受莖裝載之3'端腺苷(CCA),該接受莖裝載為合成酶識別之一部分。在一實施例中,AStD與天然存在之AStD (例如表1中之核酸所編碼之AStD)具有至少75%、80%、85%、90%、95%或100%一致性。在一實施例中,TREM可包含AStD (例如表1中之核酸所編碼之AStD)之片段或類似物,該片段在實施例中具有AStD活性且在其他實施例中不具有AStD活性。一般熟習此項技術者可由表1中之核酸所編碼之序列判定本文所提及的域、莖、環或其他序列特徵中之任一者之相關對應序列。舉例而言,一般熟習此項技術者可由表1中之核酸所編碼之tRNA序列判定對應於AStD之序列。在一實施例中,ASGPR結合部分存在於AStD內。在一實施例中,ASGPR結合部分與AStD中之核苷酸內的核鹼基結合。在一實施例中,ASGPR結合部分存在於AStD中之核苷酸間鍵聯內。在一實施例中,ASGPR結合部分存在於AStD內之末端(例如5'或3'末端)上。
在一實施例中,ASt域1包含TREM序列內之位置1至9。在一實施例中,ASGPR結合部分存在於TREM序列內之ASt域1 (例如位置1至9)內。在一實施例中,ASt域2包含TREM序列內之位置65至76。在一實施例中,ASGPR結合部分存在於TREM序列內之ASt域2 (例如位置65至76)內。
在一實施例中,AStD屬於「共通序列」部分中所提供之共通序列的對應序列,或與共通序列相差不超過1、2、5或10個位置。在一實施例中,ASGPR結合部分存在於AStD內,該AStD屬於「共通序列」部分中所提供之共通序列的對應序列,或與共通序列相差不超過1、2、5或10個位置。
在一實施例中,AStD包含式I
ZZZ之殘基R
1-R
2-R
3-R
4-R
5-R
6-R
7(例示性ASt域2)及殘基R
65-R
66-R
67-R
68-R
69-R
70-R
71(例示性ASt域2),其中ZZZ指示二十種胺基酸中之任一者。在一些實施例中,式I
ZZZ係指所有物種。
在一實施例中,AStD包含式II
ZZZ之殘基R
1-R
2-R
3-R
4-R
5-R
6-R
7及殘基R
65-R
66-R
67-R
68-R
69-R
70-R
71,其中ZZZ指示二十種胺基酸中之任一者。在一些實施例中,式II
ZZZ係指哺乳動物。
在一實施例中,AStD包含式III
ZZZ之殘基R
1-R
2-R
3-R
4-R
5-R
6-R
7及殘基R
65-R
66-R
67-R
68-R
69-R
70-R
71,其中ZZZ指示二十種胺基酸中之任一者。在一些實施例中,式III
ZZZ係指人類。
在一實施例中,ZZZ指示以下胺基酸中之任一者:丙胺酸、精胺酸、天冬醯胺、天冬胺酸、半胱胺酸、麩醯胺酸、麩胺酸、甘胺酸、組胺酸、異白胺酸、甲硫胺酸、白胺酸、離胺酸、苯丙胺酸、脯胺酸、絲胺酸、蘇胺酸、色胺酸、酪胺酸或纈胺酸。
如本文所使用之術語「反密碼子髮夾域(ACHD)」係指包含與mRNA中之各別密碼子結合的反密碼子的域,且包含例如當存在於另外野生型tRNA中時足以介導與密碼子之配對(具有或不具有擺動)的序列,例如反密碼子三聯體。在一實施例中,ACHD與天然存在之ACHD (例如表1中之核酸所編碼之ACHD)具有至少75%、80%、85%、90%、95%或100%一致性。在一實施例中,TREM可包含ACHD (例如表1中之核酸所編碼之ACHD)之片段或類似物,該片段在實施例中具有ACHD活性且在其他實施例中不具有ACHD活性。在一實施例中,ASGPR結合部分存在於ACHD內。在一實施例中,ASGPR結合部分與ACHD中之核苷酸內的核鹼基結合。
在一實施例中,ACHD包含TREM序列內之位置27至43。在一實施例中,ASGPR結合部分存在於TREM序列內之ACHD (例如位置27至43)內。
在一實施例中,ACHD屬於「共通序列」部分中所提供之共通序列的對應序列,或與共通序列相差不超過1、2、5或10個位置。在一實施例中,ASGPR結合部分存在於「共通序列」部分中所提供之共通序列的對應序列或與共通序列相差不超過1、2、5或10個位置的序列內。
在一實施例中,ACHD包含式I
ZZZ之殘基-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46,其中ZZZ指示二十種胺基酸中之任一者。在一些實施例中,式I
ZZZ係指所有物種。
在一實施例中,ACHD包含式II
ZZZ之殘基-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46,其中ZZZ指示二十種胺基酸中之任一者。在一些實施例中,式II
ZZZ係指哺乳動物。
在一實施例中,ACHD包含式III
ZZZ之殘基-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46,其中ZZZ指示二十種胺基酸中之任一者。在一些實施例中,式III
ZZZ係指人類。
在一實施例中,ZZZ指示以下胺基酸中之任一者:丙胺酸、精胺酸、天冬醯胺、天冬胺酸、半胱胺酸、麩醯胺酸、麩胺酸、甘胺酸、組胺酸、異白胺酸、甲硫胺酸、白胺酸、離胺酸、苯丙胺酸、脯胺酸、絲胺酸、蘇胺酸、色胺酸、酪胺酸或纈胺酸。
在一實施例中,TREM實體之反密碼子包含三個核苷酸殘基,並且與三個核苷酸密碼子配對。在一實施例中,TREM實體之反密碼子由三個核苷酸殘基組成,並且與由三個核苷酸殘基組成之反密碼子配對。在一實施例中,TREM實體之反密碼子不與具有四個、五個或更大數目個核苷酸殘基之密碼子配對,而是僅與三個密碼子核苷酸殘基配對。
在一實施例中,TREM實體不改變mRNA之讀框。在一實施例中,TREM實體之反密碼子與mRNA之三聯體密碼子配對,且不與相鄰核苷酸配對。
在一實施例中,TREM實體之使用不改變自mRNA轉錄之多肽的長度,例如其不抑制終止密碼子,例如提前終止密碼子。在一實施例中,TREM不改變mRNA之ORF的長度。
如本文所用之術語「去唾液酸糖蛋白受體(ASGPR)結合部分」係指與去唾液酸糖蛋白受體結合之部分。在一實施例中,如本文所描述之ASGPR結合部分係指包含以下之結構:(i) ASGPR碳水化合物及(ii) ASGPR連接子(例如將碳水化合物連接至TREM之連接子)。例示性ASGPR部分包括半乳糖(Gal)、半乳胺糖(GalNH
2)或N-乙醯基半乳胺糖(GalNAc)部分,例如Gal、GalNH
2或GalNAc或其類似物。ASGPR結合部分可包含官能基(例如羥基、羧酸酯基、胺),該等官能基可受化學保護基(例如乙醯基或甲基)保護。在一實施例中,ASGPR結合部分包含三觸角GalNAc部分。在一實施例中,ASGPR結合部分可為本文進一步詳細描述之ASGPR結合部分。
如本文所使用之術語「同源轉接功能TREM」係指利用在本質上與TREM之反密碼子相關的AA (同源AA)介導起始或延長的TREM。
如本文所使用之術語「減少之表現」係指相比參考之減少,例如在改變控制區或添加藥劑引起本發明產物之表現減少的情況下,其係相對於不具有該改變或添加的在其他方面類似的細胞減少。
如本文所使用之術語二氫尿苷髮夾域(DHD)係指包含例如當存在於另外野生型tRNA中時足以介導胺基醯基-tRNA合成酶之識別的RNA序列,例如充當用於TREM之胺基酸裝載的胺基醯基-tRNA合成酶之識別位點的域。在一實施例中,DHD介導TREM三級結構的穩定。在一實施例中,DHD與天然存在之DHD (例如表1中之核酸所編碼之DHD)具有至少75%、80%、85%、90%、95%或100%一致性。在一實施例中,TREM可包含DHD (例如表1中之核酸所編碼之DHD)之片段或類似物,該片段在實施例中具有DHD活性且在其他實施例中不具有DHD活性。在一實施例中,ASGPR結合部分存在於DHD內。在一實施例中,ASGPR結合部分與DHD中之核苷酸內的核鹼基結合。
在一實施例中,DHD包含TREM序列內之位置10至26。在一實施例中,ASGPR結合部分存在於TREM序列內之DHD (例如位置10至26)內。
在一實施例中,DHD屬於「共通序列」部分中所提供之共通序列的對應序列,或與共通序列相差不超過1、2、5或10個位置。在一實施例中,ASGPR結合部分存在於「共通序列」部分中所提供之共通序列的對應序列或與共通序列相差不超過1、2、5或10個位置的序列內。
在一實施例中,DHD包含式I
ZZZ之殘基R
10-R
11-R
12-R
13-R
14R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28,其中ZZZ指示二十種胺基酸中之任一者。在一些實施例中,式I
ZZZ係指所有物種。
在一實施例中,DHD包含式II
ZZZ之殘基R
10-R
11-R
12-R
13-R
14R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28,其中ZZZ指示二十種胺基酸中之任一者。在一些實施例中,式II
ZZZ係指哺乳動物。
在一實施例中,DHD包含式III
ZZZ之殘基R
10-R
11-R
12-R
13-R
14R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28,其中ZZZ指示二十種胺基酸中之任一者。在一些實施例中,式III
ZZZ係指人類。
在一實施例中,ZZZ指示以下胺基酸中之任一者:丙胺酸、精胺酸、天冬醯胺、天冬胺酸、半胱胺酸、麩醯胺酸、麩胺酸、甘胺酸、組胺酸、異白胺酸、甲硫胺酸、白胺酸、離胺酸、苯丙胺酸、脯胺酸、絲胺酸、蘇胺酸、色胺酸、酪胺酸或纈胺酸。
如本文所使用之術語「外源核酸」係指不存在於參考細胞(例如其中引入了外源核酸之細胞)中或與該參考細胞中之最接近序列相差至少一個核苷酸的核酸序列。在一實施例中,外源核酸包含編碼TREM之核酸。
如本文所使用之術語「外源TREM」係指一種TREM,其:
(a)與參考細胞(例如其中引入了外源核酸之細胞)中之最接近序列tRNA相差至少一個核苷酸或一個轉錄後修飾;
(b)已引入至除其中該TREM經轉錄之細胞以外的細胞中;
(c)存在於除其中該TREM天然存在之細胞以外的細胞中;或
(d)具有非野生型之表現圖譜,例如水準或分佈,例如其以比野生型高之水準表現。在一實施例中,表現圖譜可藉由引入至調節表現之核酸中之變化或藉由添加調節RNA分子表現之試劑來介導。在一實施例中,外源TREM包含特性(a)至(d)中之1、2、3或4者。
如本文所使用之術語「GMP級組合物」係指符合當前良好作業規範(cGMP)指南或其他類似要求之組合物。在一實施例中,GMP級組合物可用作醫藥產品。
如本文所使用,術語「增加」及「減少」係指分別引起特定度量之功能、表現或活性的量相對於參考更大或更小的調節。舉例而言,在向細胞、組織或個體投與本文所描述之TREM之後,如本文所描述之度量標記(例如蛋白質轉譯、mRNA穩定性、蛋白質摺疊)之量可相對於投與之前的標記之量或相對於陰性對照劑之效果增加或減少至少5%、10%、15%、20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%或98%、2X、3X、5X、10X或更多。可在投與之後在投與已具有所述效果時(例如治療開始之後至少12小時、24小時、一週、一個月、3個月或6個月)量測度量。
如本文所使用之術語「增加之表現」係指相比參考之增加,例如在改變控制區或添加藥劑引起本發明產物之表現增加的情況下,其係相對於不具有該改變或添加的在其他方面類似的細胞增加。
如本文所使用之術語連接子2區(L2)係指包含「共通序列」部分中所提供之共通序列之殘基R
8至R
9的連接子。
如本文所使用之術語連接子3區(L3)包含「共通序列」部分中所提供之共通序列之殘基R
29的連接子。
如本文所使用之術語連接子4區(L4)係指包含「共通序列」部分中所提供之共通序列之殘基R
72的域。
如本文所使用之關於核苷酸的術語「修飾」係指本發明核苷酸之化學結構之修飾,例如共價修飾。在一實施例中,修飾存在於TREM之核苷酸之核鹼基、核苷酸糖或核苷酸間鍵聯內。修飾可為天然存在或非天然存在的。在一實施例中,修飾為非天然存在的。在一實施例中,修飾為天然存在的。在一實施例中,修飾為合成修飾。在一實施例中,修飾為表5、6、7、8或9中所提供之修飾。
如本文所使用之術語「天然存在之核苷酸」係指不包含非天然存在之修飾的核苷酸。在一實施例中,其包括天然存在之修飾。
如本文所使用之術語「核苷酸」係指包含以下之實體:糖,通常為五聚糖;核鹼基;及磷酸酯連接基團(例如核苷酸間鍵聯)。在一實施例中,核苷酸包含天然存在之核苷酸,例如天然存在於人類細胞中之核苷酸,例如腺嘌呤、胸腺嘧啶、鳥嘌呤、胞嘧啶或尿嘧啶核苷酸。
如本文所使用之術語胸腺嘧啶髮夾域(THD)係指包含例如當存在於另外野生型tRNA中時足以介導核糖體之識別的RNA序列,例如充當核糖體之識別位點以在轉譯期間形成TREM-核糖體複合物的域。在一實施例中,THD與天然存在之THD (例如表1中之核酸所編碼之THD)具有至少75%、80%、85%、90%、95%或100%一致性。在一實施例中,TREM可包含THD (例如表1中之核酸所編碼之THD)之片段或類似物,該片段在實施例中具有THD活性且在其他實施例中不具有THD活性。在一實施例中,ASGPR結合部分存在於THD內。在一實施例中,ASGPR結合部分與THD中之核苷酸內的核鹼基結合。
在一實施例中,THD包含TREM序列內之位置50至64。在一實施例中,ASGPR結合部分存在於TREM序列內之THD (例如位置50至64)內。
在一實施例中,THD屬於「共通序列」部分中所提供之共通序列的對應序列,或與共通序列相差不超過1、2、5或10個位置。
在一實施例中,THD包含式I
ZZZ之殘基-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64,其中ZZZ指示二十種胺基酸中之任一者。在一些實施例中,式I
ZZZ係指所有物種。
在一實施例中,THD包含式II
ZZZ之殘基-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64,其中ZZZ指示二十種胺基酸中之任一者。在一些實施例中,式II
ZZZ係指哺乳動物。
在一實施例中,THD包含式III
ZZZ之殘基-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64,其中ZZZ指示二十種胺基酸中之任一者。在一些實施例中,式III
ZZZ係指人類。
在一實施例中,ZZZ指示以下胺基酸中之任一者:丙胺酸、精胺酸、天冬醯胺、天冬胺酸、半胱胺酸、麩醯胺酸、麩胺酸、甘胺酸、組胺酸、異白胺酸、甲硫胺酸、白胺酸、離胺酸、苯丙胺酸、脯胺酸、絲胺酸、蘇胺酸、色胺酸、酪胺酸或纈胺酸。
如本文所使用之術語「基於tRNA之效應分子」或「TREM」係指包含來自以下(a)至(v)之結構或特性的RNA分子,且其為重組TREM、合成TREM或自異源細胞表現之TREM。本發明中所描述之TREM為合成分子,且例如在無細胞反應中,例如在固態或液相合成反應中製得。TREM在化學上不同,例如在初級序列、修飾類型或位置方面與在細胞中(例如哺乳動物細胞中,例如人類細胞中)製得之內源tRNA分子不同。TREM可具有(a)至(v)之複數個(例如,2、3、4、5、6、7、8、9個)結構及功能。
在一實施例中,TREM為非天然的,如藉由結構或其製造方式所評估。
在一實施例中,TREM包含以下結構或特性中之一或多者:
(a')「共通序列」部分中所提供之共通序列之視情況選用的連接子區,例如連接子1區;
(a)受體莖域(AStD),其通常包含ASt域1及ASt域2;
(a'-1)連接子2區(L2),亦即包含「共通序列」部分中所提供之共通序列之殘基R
8至R
9的連接子,例如連接子2區;
(b) DHD或二氫尿苷髮夾域(DHD);
(b'-1)連接子3區或L3;
(c) ACHD或反密碼子髮夾域;
(d) VLD或可變環域(VLD);
(e) THD或胸腺嘧啶髮夾域(THD);
(e'1)包含「共通序列」部分中所提供之共通序列之殘基R
72的L4連接子;
(f)在生理條件下,其包含莖結構及一個或複數個環結構,例如1、2或3個環。環可包含本文所描述之域,例如選自(a)至(e)之域。環可包含一個或複數個域。在一實施例中,莖或環結構與天然存在之莖或環結構(例如表1中之核酸所編碼之莖或環結構)具有至少75%、80%、85%、90%、95%或100%一致性。在一實施例中,TREM可包含莖或環結構(例如表1中之核酸所編碼之莖或環結構)之片段或類似物,該片段在實施例中具有莖或環結構之活性,且在其他實施例中不具有莖或環結構之活性;
(g)三級結構,例如L形三級結構;
(h)轉接功能,亦即,TREM在多肽鏈之起始或延長中介導胺基酸(例如其同源胺基酸)之接受及AA之轉移;
(i)同源轉接功能,其中TREM介導在本質上與TREM之反密碼子相關之胺基酸(例如同源胺基酸)之接受及併入以起始或延長多肽鏈;
(j)非同源轉接功能,其中TREM在多肽鏈之起始或延長中介導除在本質上與TREM之反密碼子相關之胺基酸以外的胺基酸(例如非同源胺基酸)之接受及併入;
(k)調節功能,例如表觀遺傳功能(例如基因沉默功能或信號傳導路徑調節功能)、細胞命運調節功能、mRNA穩定性調節功能、蛋白質穩定性調節功能、蛋白質轉導調節功能或蛋白質隔室化功能;
(l)允許核糖體結合之結構;
(m)轉錄後修飾,例如天然存在之轉錄後修飾;
(n)抑制tRNA之功能特性,例如tRNA所具有之特性(h)至(k)中之任一者的能力;
(o)調節細胞命運之能力;
(p)調節核糖體佔用之能力;
(q)調節蛋白質轉譯之能力;
(r)調節mRNA穩定性之能力;
(s)調節蛋白質摺疊及結構之能力;
(t)調節蛋白質轉導或隔室化之能力;
(u)調節蛋白質穩定性之能力;或
(v)調節信號傳導路徑,例如細胞信號傳導路徑之能力。
在一實施例中,TREM包含全長tRNA分子或其片段。
在一實施例中,TREM包含以下特性:(a)至(e)。
在一實施例中,TREM包含以下特性:(a)及(c)。
在一實施例中,TREM包含以下特性:(a)、(c)及(h)。
在一實施例中,TREM包含以下特性:(a)、(c)、(h)及(b)。
在一實施例中,TREM包含以下特性:(a)、(c)、(h)及(e)。
在一實施例中,TREM包含以下特性:(a)、(c)、(h)、(b)及(e)。
在一實施例中,TREM包含以下特性:(a)、(c)、(h)、(b)、(e)及(g)。
在一實施例中,TREM包含以下特性:(a)、(c)、(h)及(m)。
在一實施例中,TREM包含以下特性:(a)、(c)、(h)、(m)及(g)。
在一實施例中,TREM包含以下特性:(a)、(c)、(h)、(m)及(b)。
在一實施例中,TREM包含以下特性:(a)、(c)、(h)、(m)及(e)。
在一實施例中,TREM包含以下特性:(a)、(c)、(h)、(m)、(g)、(b)及(e)。
在一實施例中,TREM包含以下特性:(a)、(c)、(h)、(m)、(g)、(b)、(e)及(q)。
在一實施例中,TREM包含:
(i)結合胺基酸之胺基酸連接域(例如AStD,如本文(a)中所描述);及
(ii)結合mRNA中之各別密碼子的反密碼子(例如ACHD,如本文(c)中所描述)。
在一實施例中,TREM包含提供(i)至(ii)之共價鍵聯的可撓性RNA連接子。
在一實施例中,TREM介導蛋白質轉譯。
在一實施例中,TREM包含連接子,例如RNA連接子,例如可撓性RNA連接子,其提供第一結構或域與第二結構或域之間的共價鍵聯。在一實施例中,RNA連接子包含至少1、2、3、4、5、6、7、8、9、10、11、12、13、14或15個核糖核苷酸。TREM可包含一個或複數個連接子,例如在實施例中,包含(a)、(b)、(c)、(d)及(e)之TREM可具有在第一域與第二域之間的第一連接子及在第三域與另一域之間的第二連接子。
在一實施例中,TREM包含式A之序列:[L1]-[ASt域1]-[L2]-[DH域]-[L3]-[ACH域]-[VL域]-[TH域]-[L4]-[ASt域2]。
在一實施例中,TREM包含與表1中列出之DNA序列所編碼之RNA序列至少60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或99%一致或相差不超過1、2、3、4、5、10、15、20、25或30個核糖核苷酸的RNA序列,或其片段或功能片段。在一實施例中,TREM包含表1中列出之DNA序列所編碼之RNA序列,或其片段或功能片段。在一實施例中,TREM包含與表1中列出之DNA序列至少60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或99%一致的DNA序列所編碼之RNA序列,或其片段或功能片段。在一實施例中,TREM包含TREM域,例如本文所描述之域,其包含與表1中列出之DNA序列所編碼之RNA至少60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或99%一致或相差不超過1、2、3、4、5、10或15個核糖核苷酸的RNA序列,或其片段或功能片段。在一實施例中,TREM包含TREM域,例如本文所描述之域,其包含表1中列出之DNA序列所編碼之RNA序列,或其片段或功能片段。在一實施例中,TREM包含TREM域,例如本文所描述之域,其包含與表1中列出之DNA序列至少60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或99%一致的DNA序列所編碼之RNA序列,或其片段或功能片段。
在一實施例中,TREM之長度為76至90個核苷酸。在實施例中,TREM或其片段或功能片段在10至90個核苷酸之間、10至80個核苷酸之間、10至70個核苷酸之間、10至60個核苷酸之間、10至50個核苷酸之間、10至40個核苷酸之間、10至30個核苷酸之間、10至20個核苷酸之間、20至90個核苷酸之間、20至80個核苷酸之間、20至70個核苷酸之間、20至60個核苷酸之間、20至50個核苷酸之間、20至40個核苷酸之間、30至90個核苷酸之間、30至80個核苷酸之間、30至70個核苷酸之間、30至60個核苷酸之間或30至50個核苷酸之間。
在一實施例中,TREM藉由胺基醯基tRNA合成酶用胺基酸胺基醯基化,例如裝載有胺基酸。
在一實施例中,TREM未裝載有胺基酸,例如未裝載之TREM (uTREM)。
在一實施例中,TREM包含少於全長tRNA。在實施例中,TREM可對應於tRNA之天然存在之片段或非天然存在之片段。例示性片段包括:TREM半(例如來自ACHD (例如反密碼子序列)之裂解,例如5'半或3'半);5'片段(例如包含5'端之片段,例如來自DHD或ACHD之裂解);3'片段(例如包含3'端之片段,例如來自THD之裂解);或內部片段(例如來自ACHD、DHD或THD中之一或多者之裂解)。
如本文所使用之術語「TREM核心片段」係指式B之序列之一部分:[L1]
y-[ASt域1]
x-[L2]
y-[DH域]
y-[L3]
y-[ACH域]
x-[VL域]
y-[TH域]
y-[L4]
y-[ASt域2]
x,其中:x=1且y=0或1。
如本文所使用,「TREM片段」係指TREM之一部分,其中該TREM包含式A之序列:[L1]-[ASt域1]-[L2]-[DH域]-[L3]-[ACH域]-[VL域]-[TH域]-[L4]-[ASt域2]。
如本文所使用之術語「非同源轉接功能TREM」係指利用除了在本質上與TREM之反密碼子相關之AA以外的AA (非同源AA)介導起始或延長的TREM。在一實施例中,非同源轉接功能TREM亦稱為誤裝載之TREM (mTREM)。
如本文所使用之術語「非天然存在之序列」係指如下序列:其中腺嘌呤經除腺嘌呤之類似物以外的殘基置換,胞嘧啶經除胞嘧啶之類似物以外的殘基置換,鳥嘌呤經除鳥嘌呤之類似物以外的殘基置換,且尿嘧啶經除尿嘧啶之類似物以外的殘基置換。類似物係指核糖核苷酸A、G、C或U之任何可能衍生物。在一實施例中,具有核糖核苷酸A、G、C或U中之任一者之衍生物的序列為非天然存在之序列。
如本文所使用之術語「醫藥TREM組合物」係指適合於醫藥用途之TREM組合物。通常,醫藥TREM組合物包含醫藥賦形劑。在一實施例中,TREM將為醫藥TREM組合物中之唯一活性成分。在實施例中,醫藥TREM組合物不含、實質上不含或具有少於醫藥學上可接受之量的宿主細胞蛋白質、DNA (例如宿主細胞DNA)、內毒素及細菌。
如本文所使用之關於本發明分子(例如TREM、RNA或tRNA)之術語「轉錄後處理」係指本發明分子之共價修飾。在一實施例中,共價修飾以轉錄後方式出現。在一實施例中,共價修飾以共轉錄方式出現。在一實施例中,修飾在活體內,例如在用於產生TREM之細胞中進行。在一實施例中,離體進行修飾,例如對自產生TREM之細胞分離或獲得的TREM進行修飾。在一實施例中,轉錄後修飾係選自表2中所列出之轉錄後修飾。
如本文所使用之術語「個體」包括任何生物體,諸如人類或其他動物。在實施例中,個體為脊椎動物(例如哺乳動物、鳥類、魚類、爬蟲類或兩棲動物)。在實施例中,個體為哺乳動物,例如人類。在實施例中,方法個體為非人類哺乳動物。在實施例中,個體為非人類哺乳動物,諸如非人類靈長類動物(例如猴、猿)、有蹄類動物(例如牛、水牛、綿羊、山羊、豬、駱駝、駱馬、羊駝、鹿、馬、驢)、食肉動物(例如狗、貓)、嚙齒動物(例如大鼠、小鼠)或兔類動物(例如兔)。在實施例中,個體為鳥類,諸如禽類分類雞形目(例如雞、火雞、雉雞、鵪鶉)、雁形目(例如鴨、鵝)、古頜總目(例如鴕鳥、鴯鶓)、鴿形目(例如鴿子(pigeon)、白鴿(dove))或鸚形目(例如鸚鵡)。個體可為任何年齡組之男性或女性,例如小兒個體(例如嬰兒、兒童、青少年)或成年個體(例如年輕人、中年人或老年人)。非人類個體可為基因轉殖動物。
如本文所使用之術語「合成TREM」係指以與在具有編碼TREM之內源核酸之細胞中合成或藉由該細胞合成不同之方式合成的TREM,例如合成TREM係藉由無細胞固相合成來合成。合成TREM可具有與天然tRNA相同或不同的序列或三級結構。
如本文所使用之術語「重組TREM」係指在藉由人工干預修飾之細胞中表現的TREM,該細胞具有介導TREM之產生的修飾(例如該細胞包含編碼TREM之外源序列)或介導TREM之表現(例如轉錄表現或轉錄後修飾)的修飾。重組TREM可具有與參考tRNA (例如天然tRNA)相同或不同的序列、轉錄後修飾集合或三級結構。
如本文所使用之術語「tRNA」係指呈天然狀態的天然存在之轉移核糖核酸。
如本文所使用之術語「TREM組合物」係指包含複數個TREM、複數個TREM核心片段及/或複數個TREM片段之組合物。TREM組合物可包含一或多種物種之TREM、TREM核心片段或TREM片段。在一實施例中,組合物僅包含單一物種之TREM、TREM核心片段或TREM片段。在一實施例中,TREM組合物包含第一TREM、TREM核心片段或TREM片段物種;及第二TREM、TREM核心片段或TREM片段物種。在一實施例中,TREM組合物包含X個TREM、TREM核心片段或TREM片段物種,其中X=2、3、4、5、6、7、8、9或10。在一實施例中,TREM、TREM核心片段或TREM片段與表1中之核酸所編碼之序列具有至少70%、75%、80%、85%、90%或95%或100%一致性。TREM組合物可包含一或多種物種之TREM、TREM核心片段或TREM片段。在一實施例中,TREM組合物為至少10%、20%、30%、40%、50%、60%、70%、80%、90%、95%或99%乾重之TREM (對於液體組合物,乾重係指在移除實質上全部液體之後,例如在凍乾之後的重量)。在一實施例中,組合物為液體。在一實施例中,組合物為乾燥的,例如凍乾的材料。在一實施例中,組合物為冷凍的組合物。在一實施例中,組合物為無菌的。在一實施例中,組合物包含至少0.5 g、1.0 g、5.0 g、10 g、15 g、25 g、50 g、100 g、200 g、400 g或500 g (例如如藉由乾重所測定)之TREM。
在一實施例中,TREM組合物中至少X%之TREM包含所選位置處之化學修飾,且X為80、90、95、96、97、98、99或99.5。
在一實施例中,TREM組合物中至少X%之TREM包含第一位置處之化學修飾及第二位置處之化學修飾,且X獨立地為80、90、95、96、97、98、99或99.5。在實施例中,第一及第二位置處之修飾相同。在實施例中,第一及第二位置處之修飾不同。在實施例中,第一及第二位置處之核苷酸相同,例如兩者均為腺嘌呤。在實施例中,第一及第二位置處之核苷酸不同,例如一個為腺嘌呤且一個為胸腺嘧啶。
在一實施例中,TREM組合物中至少X%之TREM包含第一位置處之化學修飾且少於Y%之TREM具有第二位置處之化學修飾,其中X為80、90、95、96、97、98、99或99.5且Y為20、20、5、2、1、0.1或0.01。在實施例中,第一及第二位置處之核苷酸相同,例如兩者均為腺嘌呤。在實施例中,第一及第二位置處之核苷酸不同,例如一個為腺嘌呤且一個為胸腺嘧啶。
如本文所使用之術語「可變環域(VLD)」係指包含例如當存在於另外野生型tRNA中時足以介導胺基醯基-tRNA合成酶之識別的RNA序列,例如充當用於TREM之胺基酸裝載的胺基醯基-tRNA合成酶之識別位點的域。在一實施例中,VLD介導TREM三級結構的穩定。在一實施例中,VLD調節(例如增加) TREM例如對其同源胺基酸之特異性,例如VLD調節TREM同源轉接功能。在一實施例中,VLD與天然存在之VLD (例如表1中之核酸所編碼之VLD)具有至少75%、80%、85%、90%、95%或100%一致性。在一實施例中,TREM可包含VLD (例如表1中之核酸所編碼之VLD)之片段或類似物,該片段在實施例中具有VLD活性且在其他實施例中不具有VLD活性。在一實施例中,ASGPR結合部分存在於VLD內。在一實施例中,ASGPR結合部分與VLD中之核苷酸內的核鹼基結合。
在一實施例中,VLD包含TREM序列內之位置44至49。在一實施例中,ASGPR結合部分存在於TREM序列內之VLD (例如位置44至49)內。
在一實施例中,VLD屬於「共通序列」部分中所提供之共通序列的對應序列。
在一實施例中,VLD包含「共通序列」部分中所提供之共通序列之殘基-[R
47]
x,其中x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271)。
TREM實體 本文描述經去唾液酸糖蛋白受體(ASGPR)結合部分修飾之TREM實體(例如TREM、TREM核心片段或TREM片段),以及其組合物及使用方法。TREM實體(例如TREM)係指包含本文所描述之特性中之一或多者的RNA分子。ASGPR結合部分可與TREM實體內之核鹼基結合,或在TREM實體之核苷酸間鍵聯內結合,或在TREM實體之末端(例如5'或3'末端)處結合。TREM實體(例如TREM)可包含例如如表4、5、6或7中所提供之化學修飾。
在一實施例中,TREM實體包括:TREM,其包含式A之序列;TREM核心片段,其包含式B之序列;或TREM片段,其包含TREM之一部分,該TREM包含式A之序列。
在一實施例中,TREM包含式A之序列:[L1]-[ASt域1]-[L2]-[DH域]-[L3]-[ACH域]-[VL域]-[TH域]-[L4]-[ASt域2],其中ASGPR結合部分存在於ASt域1內(例如存在於ASt域1之核鹼基上、末端(例如5'末端)處或核苷酸間鍵聯內)。在一實施例中,ASGPR結合部分存在於ASt域1內之核苷酸的核鹼基上。在一實施例中,ASGPR結合部分存在於ASt域1內之5'末端處或[L1]處。在一實施例中,ASGPR結合部分存在於ASt域1之核苷酸間鍵聯內。在一實施例中,[VL域]為視情況選用的。在一實施例中,[L1]為視情況選用的。
在一實施例中,TREM包含式A之序列:[L1]-[ASt域1]-[L2]-[DH域]-[L3]-[ACH域]-[VL域]-[TH域]-[L4]-[ASt域2],其中ASGPR結合部分存在於ASt域2內(例如存在於ASt域2之核鹼基上、末端(例如3'末端)處或核苷酸間鍵聯內)。在一實施例中,ASGPR結合部分存在於ASt域2內之核苷酸的核鹼基上。在一實施例中,ASGPR結合部分存在於ASt域2內之3'末端處。在一實施例中,ASGPR結合部分存在於ASt域2之核苷酸間鍵聯內。在一實施例中,[VL域]為視情況選用的。在一實施例中,[L1]為視情況選用的。
在一實施例中,TREM包含式A之序列:[L1]-[ASt域1]-[L2]-[DH域]-[L3]-[ACH域] -[VL域]-[TH域]-[L4]-[ASt域2],其中ASGPR結合部分存在於ASt域1及ASt域2中之一者或兩者內(例如存在於ASt域1或ASt域2之核鹼基上、末端(例如5'或3'末端)處或核苷酸間鍵聯內)。在一實施例中,ASGPR結合部分存在於ASt域1或ASt域2內之核苷酸的核鹼基上。在一實施例中,ASGPR結合部分存在於ASt域1內之5'末端或[L1]或ASt域2內之3'末端處。在一實施例中,ASGPR結合部分存在於ASt域1或ASt域2之核苷酸間鍵聯內。在一實施例中,[VL域]為視情況選用的。在一實施例中,[L1]為視情況選用的。
在一實施例中,TREM包含式A之序列:[L1]-[ASt域1]-[L2]-[DH域]-[L3]-[ACH域]-[VL域]-[TH域]-[L4]-[ASt域2],其中ASGPR結合部分存在於DH域內(例如存在於DH域之核鹼基上或核苷酸間鍵聯內)。在一實施例中,ASGPR結合部分存在於DH域內之核苷酸的核鹼基上。在一實施例中,ASGPR結合部分存在於DH域之核苷酸間鍵聯內。在一實施例中,[L1]為視情況選用的。
在一實施例中,TREM包含式A之序列:[L1]-[ASt域1]-[L2]-[DH域]-[L3]-[ACH域]-[VL域]-[TH域]-[L4]-[ASt域2],其中ASGPR結合部分在ACH域內(例如在ACH域之核鹼基上或核苷酸間鍵聯內)。在一實施例中,ASGPR結合部分存在於ACH域內之核苷酸的核鹼基上。在一實施例中,ASGPR結合部分存在於ACH域之核苷酸間鍵聯內。在一實施例中,[VL域]為視情況選用的。在一實施例中,[L1]為視情況選用的。
在一實施例中,TREM包含式A之序列:[L1]-[ASt域1]-[L2]-[DH域]-[L3]-[ACH域]-[VL域]-[TH域]-[L4]-[ASt域2],其中ASGPR結合部分存在於VL域內(例如存在於VL域之核鹼基上或核苷酸間鍵聯內)。在一實施例中,ASGPR結合部分存在於VL域內之核苷酸的核鹼基上。在一實施例中,ASGPR結合部分存在於VL域之核苷酸間鍵聯內。在一實施例中,[L1]為視情況選用的。
在一實施例中,TREM包含式A之序列:[L1]-[ASt域1]-[L2]-[DH域]-[L3]-[ACH域]-[VL域]-[TH域]-[L4]-[ASt域2],其中ASGPR結合部分存在於TH域內(例如存在於TH域之核鹼基上或核苷酸間鍵聯內)。在一實施例中,ASGPR結合部分存在於TH域內之核苷酸的核鹼基上。在一實施例中,ASGPR結合部分存在於TH域之核苷酸間鍵聯內。在一實施例中,[VL域]為視情況選用的。在一實施例中,[L1]為視情況選用的。
在一實施例中,TREM包含式A之序列:[L1]-[ASt域1]-[L2]-[DH域]-[L3]-[ACH域]-[VL域]-[TH域]-[L4]-[ASt域2],其中ASGPR結合部分與選自[ASt域1]、[DH域]、[ACH域]、[TH域]及/或[ASt域2]之一或多個域內的核鹼基結合。在一實施例中,[VL域]為視情況選用的。在一實施例中,[L1]為視情況選用的。
在一實施例中,TREM包含式A之序列:[L1]-[ASt域1]-[L2]-[DH域]-[L3]-[ACH域]-[VL域]-[TH域]-[L4]-[ASt域2],其中ASGPR結合部分與選自[ASt域1]、[DH域]、[ACH域]、[TH域]及/或[ASt域2]之一或多個域內的核苷酸間鍵聯結合。在一實施例中,[VL域]為視情況選用的。在一實施例中,[L1]為視情況選用的。
在一實施例中,TREM核心片段包含式B之序列:[L1]
y-[ASt域1]
x-[L2]
y-[DH域]
y-[L3]
y-[ACH域]
x-[VL域]
y-[TH域]
y-[L4]
y-[ASt域2]
x,其中:x=1且y=0或1,且ASGPR結合部分與ASt域1及ASt域2中之一者或兩者內之核苷酸內的核鹼基結合。在一實施例中,y=0。在一實施例中,y=1。
在一實施例中,TREM核心片段包含式B之序列:[L1]
y-[ASt域1]
x-[L2]
y-[DH域]
y-[L3]
y-[ACH域]
x-[VL域]
y-[TH域]
y-[L4]
y-[ASt域2]
x,其中:x=1且y=0或1,且ASGPR結合部分與DH域內之核苷酸內的核鹼基結合。在一實施例中,y=0。在一實施例中,y=1。
在一實施例中,TREM核心片段包含式B之序列:[L1]
y-[ASt域1]
x-[L2]
y-[DH域]
y-[L3]
y-[ACH域]
x-[VL域]
y-[TH域]
y-[L4]
y-[ASt域2]
x,其中:x=1且y=0或1,且ASGPR結合部分與ACH域內之核苷酸內的核鹼基結合。在一實施例中,y=0。在一實施例中,y=1。
在一實施例中,TREM核心片段包含式B之序列:[L1]
y-[ASt域1]
x-[L2]
y-[DH域]
y-[L3]
y-[ACH域]
x-[VL域]
y-[TH域]
y-[L4]
y-[ASt域2]
x,其中:x=1且y=0或1,且ASGPR結合部分與TH域內之核苷酸內的核鹼基結合。在一實施例中,y=0。在一實施例中,y=1。
在一實施例中,TREM核心片段包含式B之序列:[L1]
y-[ASt域1]
x-[L2]
y-[DH域]
y-[L3]
y-[ACH域]
x-[VL域]
y-[TH域]
y-[L4]
y-[ASt域2]
x,其中:x=1且y=0或1,且ASGPR結合部分與選自[ASt域1]、[DH域]、[ACH域]、[TH域]及/或[ASt域2]之一或多個域內之核鹼基結合。在一實施例中,y=0。在一實施例中,y=1。
在一實施例中,TREM片段包含TREM之一部分,其中TREM包含式A之序列:[L1]-[ASt域1]-[L2]-[DH域]-[L3]-[ACH域] -[VL域]-[TH域]-[L4]-[ASt域2],且其中TREM片段包含:以下中之一者、兩者、三者或全部或任何組合:TREM半(例如來自ACH域(例如反密碼子序列)之裂解,例如5'半或3'半);5'片段(例如包含5'端之片段,例如來自DH域或ACH域之裂解);3'片段(例如包含3'端之片段,例如來自TH域之裂解);或內部片段(例如來自ACH域、DH域或TH域中任一者之裂解)。例示性TREM片段包括:TREM半(例如來自ACHD之裂解,例如5'TREM半或3' TREM半);5'片段(例如包含5'端之片段,例如來自DHD或ACHD之裂解);3'片段(例如包含TREM之3'端之片段,例如來自THD之裂解);或內部片段(例如來自ACHD、DHD或THD中之一或多者之裂解)。
在一實施例中,TREM、TREM核心片段或TREM片段可裝載有胺基酸(例如同源胺基酸);裝載有非同源胺基酸(例如誤裝載之TREM (mTREM));或未裝載有胺基酸(例如未裝載之TREM (uTREM))。在一實施例中,TREM、TREM核心片段或TREM片段可裝載有選自以下之胺基酸:丙胺酸、精胺酸、天冬醯胺、天冬胺酸、半胱胺酸、麩醯胺酸、麩胺酸、甘胺酸、組胺酸、異白胺酸、甲硫胺酸、白胺酸、離胺酸、苯丙胺酸、脯胺酸、絲胺酸、蘇胺酸、色胺酸、酪胺酸或纈胺酸。
在一實施例中,TREM、TREM核心片段或TREM片段為同源TREM。在一實施例中,TREM、TREM核心片段或TREM片段為非同源TREM。在一實施例中,TREM、TREM核心片段或TREM片段識別表2或表3中所提供之密碼子。
表2:密碼子之清單
表3:胺基酸及對應密碼子
| AAA |
| AAC |
| AAG |
| AAU |
| ACA |
| ACC |
| ACG |
| ACU |
| AGA |
| AGC |
| AGG |
| AGU |
| AUA |
| AUC |
| AUG |
| AUU |
| CAA |
| CAC |
| CAG |
| CAU |
| CCA |
| CCC |
| CCG |
| CCU |
| CGA |
| CGC |
| CGG |
| CGU |
| CUA |
| CUC |
| CUG |
| CUU |
| GAA |
| GAC |
| GAG |
| GAU |
| GCA |
| GCC |
| GCG |
| GCU |
| GGA |
| GGC |
| GGG |
| GGU |
| GUA |
| GUC |
| GUG |
| GUU |
| UAA |
| UAC |
| UAG |
| UAU |
| UCA |
| UCC |
| UCG |
| UCU |
| UGA |
| UGC |
| UGG |
| UGU |
| UUA |
| UUC |
| UUG |
| UUU |
| 胺基酸 | mRNA 密碼子 |
| 丙胺酸 | GCU, GCC, GCA, GCG |
| 精胺酸 | CGU, CGC, CGA, CGG, AGA, AGG |
| 天冬醯胺 | AAU, AAC |
| 天冬胺酸 | GAU, GAC |
| 半胱胺酸 | UGU, UGC |
| 麩胺酸 | GAA, GAG |
| 麩醯胺酸 | CAA, CAG |
| 甘胺酸 | GGU, GGC, GGA, GGG |
| 組胺酸 | CAU, CAC |
| 異白胺酸 | AUU, AUC, AUA |
| 白胺酸 | UUA, UUG, CUU, CUC, CUA, CUG |
| 離胺酸 | AAA, AAG |
| 甲硫胺酸 | AUG |
| 苯丙胺酸 | UUU, UUC |
| 脯胺酸 | CCU, CCC, CCA, CCG |
| 絲胺酸 | UCU, UCC, UCA, UCG, AGU, AGC |
| 終止 | UAA, UAG, UGA |
| 蘇胺酸 | ACU, ACC, ACA, ACG |
| 色胺酸 | UGG |
| 酪胺酸 | UAU, UAC |
| 纈胺酸 | GUU, GUC, GUA, GUG |
在一實施例中,TREM包含由表1中所揭示之去氧核糖核酸(DNA)序列(例如,表1中所揭示之SEQ ID NO: 1-451中之任一者)編碼的核糖核酸(RNA)序列。在一實施例中,TREM包含與由表1中提供之DNA序列(例如表1中揭示之SEQ ID NO: 1-451中之任一者)編碼之RNA序列至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致的RNA序列。在一實施例中,TREM包含由與表1中提供之DNA序列(例如表1中揭示之SEQ ID NO: 1-451中之任一者)至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致之DNA序列編碼的RNA序列。
在一實施例中,TREM、TREM核心片段或TREM片段包含由表1中所揭示之DNA序列編碼之RNA序列的至少5、10、15、20、25或30個連續核苷酸,例如由表1中所揭示之SEQ ID NO: 1-451中之任一者編碼之RNA序列的至少5、10、15、20、25或30個連續核苷酸。在一實施例中,TREM、TREM核心片段或TREM片段包含RNA序列之至少5、10、15、20、25或30個連續核苷酸,該RNA序列與由表1中所提供之DNA序列(例如表1中所揭示之SEQ ID NO: 1-451中之任一者)編碼之RNA序列至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致。在一實施例中,TREM、TREM核心片段或TREM片段包含由DNA序列編碼之RNA序列之至少5、10、15、20、25或30個連續核苷酸,該DNA序列與表1中所提供之DNA序列(例如表1中所揭示之SEQ ID NO: 1-451中之任一者)至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致。
在一實施例中,TREM核心片段或TREM片段包含由表1中提供之DNA序列(例如表1中所揭示之SEQ ID NO: 1-451中之任一者)編碼的RNA序列的至少5%、10%、15%、20%、25%、30%、35%、40%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或99%。在一實施例中,TREM核心片段或TREM片段包含與由表1中所提供之DNA序列(例如表1中所揭示之SEQ ID NO: 1-451中之任一者)編碼之RNA序列至少80%、85%、90%、95%、96%、97%、98%或99%一致的RNA序列的至少5%、10%、15%、20%、25%、30%、35%、40%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或99%。在一實施例中,TREM核心片段或TREM片段包含由DNA序列編碼之RNA序列之至少5%、10%、15%、20%、25%、30%、35%、40%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或99%,該DNA序列與表1中所提供之DNA序列(例如表1中所揭示之SEQ ID NO: 1-451中之任一者)至少80%、85%、90%、95%、96%、97%、98%或99%一致。
在一實施例中,TREM核心片段或TREM片段包含由表1中所揭示之DNA序列(例如表1中所揭示之SEQ ID NO: 1-451中之任一者)編碼之RNA序列的至少5個核糖核苷酸(nt)、10 nt、15 nt、20 nt、25 nt、30 nt、35 nt、40 nt、45 nt、50 nt、55 nt或60 nt (但小於全長)。在一實施例中,TREM核心片段或TREM片段包含與由表1中所提供之DNA序列(例如表1中所揭示之SEQ ID NO: 1-451中之任一者)編碼之RNA序列至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致的RNA序列的至少5個核糖核苷酸(nt)、10 nt、15 nt、20 nt、25 nt、30 nt、35 nt、40 nt、45 nt、50 nt、55 nt或60 nt (但小於全長)。在一實施例中,TREM核心片段或TREM片段包含由DNA序列編碼之RNA序列的至少5個核糖核苷酸(nt)、10 nt、15 nt、20 nt、25 nt、30 nt、35 nt、40 nt、45 nt、50 nt、55 nt或60 nt (但小於全長),該DNA序列與表1中所提供之DNA序列(例如表1中所揭示之SEQ ID NO: 1-451中之任一者)至少80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%、99%或100%一致。
在一實施例中,TREM核心片段或TREM片段包含長度在10至90個核糖核苷酸(rnt)之間、10至80 rnt之間、10至70 rnt之間、10至60 rnt之間、10至50 rnt之間、10至40 rnt之間、10至30 rnt之間、10至20 rnt之間、20至90 rnt之間、20至80 rnt之間、20至70 rnt之間、20至60 rnt之間、20至50 rnt之間、20至40 rnt之間、30至90 rnt之間、30至80 rnt之間、30至70 rnt之間、30至60 rnt之間、或30至50 rnt之間的序列。
在任何及所有實施例中,本文所描述之TREM包含式I
ZZZ之共通序列,
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x1-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中(i)
ZZZ指示二十種胺基酸中之任一者;(ii)式I對應於所有物種;(iii) x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271);及(iv) ASGPR結合部分與R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8中之一或多者內的核鹼基結合,或(v) ASGPR結合部分與R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72中之一或多者內的核鹼基結合。
在任何及所有實施例中,本文所描述之TREM包含式II
ZZZ之共通序列,
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x1-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中(i)
ZZZ指示二十種胺基酸中之任一者;(ii)式II對應於哺乳動物;(iii) x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271);及(iv) ASGPR結合部分與R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8中之一或多者內的核鹼基結合,或(v) ASGPR結合部分與R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72中之一或多者內的核鹼基結合。
在任何及所有實施例中,本文所描述之TREM包含式IIII
ZZZ之共通序列,
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x1-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中(i)
ZZZ指示二十種胺基酸中之任一者;(ii)式III對應於人類;(iii) x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271);及(iv) ASGPR結合部分與R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8中之一或多者內的核鹼基結合,或(v) ASGPR結合部分與R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72中之一或多者內的核鹼基結合。
表 1.
| SEQ ID NO | tRNA名稱 | tRNA序列 |
| 1 | Ala_AGC_chr6:28763741-28763812 (-) | GGGGGTATAGCTCAGTGGTAGAGCGCGTGCTTAGCATGCACGAGGTCCTGGGTTCGATCCCCAGTACCTCCA |
| 2 | Ala_AGC_chr6:26687485-26687557 (+) | GGGGAATTAGCTCAAGTGGTAGAGCGCTTGCTTAGCACGCAAGAGGTAGTGGGATCGATGCCCACATTCTCCA |
| 3 | Ala_AGC_chr6:26572092-26572164 (-) | GGGGAATTAGCTCAAATGGTAGAGCGCTCGCTTAGCATGCGAGAGGTAGCGGGATCGATGCCCGCATTCTCCA |
| 4 | Ala_AGC_chr6:26682715-26682787 (+) | GGGGAATTAGCTCAAGTGGTAGAGCGCTTGCTTAGCATGCAAGAGGTAGTGGGATCGATGCCCACATTCTCCA |
| 5 | Ala_AGC_chr6:26705606-26705678 (+) | GGGGAATTAGCTCAAGCGGTAGAGCGCTTGCTTAGCATGCAAGAGGTAGTGGGATCGATGCCCACATTCTCCA |
| 6 | Ala_AGC_chr6:26673590-26673662 (+) | GGGGAATTAGCTCAAGTGGTAGAGCGCTTGCTTAGCATGCAAGAGGTAGTGGGATCAATGCCCACATTCTCCA |
| 7 | Ala_AGC_chr14:89445442-89445514 (+) | GGGGAATTAGCTCAAGTGGTAGAGCGCTCGCTTAGCATGCGAGAGGTAGTGGGATCGATGCCCGCATTCTCCA |
| 8 | Ala_AGC_chr6:58196623-58196695 (-) | GGGGAATTAGCCCAAGTGGTAGAGCGCTTGCTTAGCATGCAAGAGGTAGTGGGATCGATGCCCACATTCTCCA |
| 9 | Ala_AGC_chr6:28806221-28806292 (-) | GGGGGTGTAGCTCAGTGGTAGAGCGCGTGCTTAGCATGCACGAGGCCCCGGGTTCAATCCCCGGCACCTCCA |
| 10 | Ala_AGC_chr6:28574933-28575004 (+) | GGGGGTGTAGCTCAGTGGTAGAGCGCGTGCTTAGCATGTACGAGGTCCCGGGTTCAATCCCCGGCACCTCCA |
| 11 | Ala_AGC_chr6:28626014-28626085 (-) | GGGGATGTAGCTCAGTGGTAGAGCGCATGCTTAGCATGCATGAGGTCCCGGGTTCGATCCCCAGCATCTCCA |
| 12 | Ala_AGC_chr6:28678366-28678437 (+) | GGGGGTGTAGCTCAGTGGTAGAGCGCGTGCTTAGCATGCACGAGGCCCTGGGTTCAATCCCCAGCACCTCCA |
| 13 | Ala_AGC_chr6:28779849-28779920 (-) | GGGGGTATAGCTCAGCGGTAGAGCGCGTGCTTAGCATGCACGAGGTCCTGGGTTCAATCCCCAATACCTCCA |
| 14 | Ala_AGC_chr6:28687481-28687552 (+) | GGGGGTGTAGCTCAGTGGTAGAGCGCGTGCTTAGCATGCACGAGGCCCCGGGTTCAATCCCTGGCACCTCCA |
| 15 | Ala_AGC_chr2:27274082-27274154 (+) | GGGGGATTAGCTCAAATGGTAGAGCGCTCGCTTAGCATGCGAGAGGTAGCGGGATCGATGCCCGCATCCTCCA |
| 16 | Ala_AGC_chr6:26730737-26730809 (+) | GGGGAATTAGCTCAGGCGGTAGAGCGCTCGCTTAGCATGCGAGAGGTAGCGGGATCGACGCCCGCATTCTCCA |
| 17 | Ala_CGC_chr6:26553731-26553802 (+) | GGGGATGTAGCTCAGTGGTAGAGCGCATGCTTCGCATGTATGAGGTCCCGGGTTCGATCCCCGGCATCTCCA |
| 18 | Ala_CGC_chr6:28641613-28641684 (-) | GGGGATGTAGCTCAGTGGTAGAGCGCATGCTTCGCATGTATGAGGCCCCGGGTTCGATCCCCGGCATCTCCA |
| 19 | Ala_CGC_chr2:157257281-157257352 (+) | GGGGATGTAGCTCAGTGGTAGAGCGCGCGCTTCGCATGTGTGAGGTCCCGGGTTCAATCCCCGGCATCTCCA |
| 20 | Ala_CGC_chr6:28697092-28697163 (+) | GGGGGTGTAGCTCAGTGGTAGAGCGCGTGCTTCGCATGTACGAGGCCCCGGGTTCGACCCCCGGCTCCTCCA |
| 21 | Ala_TGC_chr6:28757547-28757618 (-) | GGGGGTGTAGCTCAGTGGTAGAGCGCATGCTTTGCATGTATGAGGTCCCGGGTTCGATCCCCGGCACCTCCA |
| 22 | Ala_TGC_chr6:28611222-28611293 (+) | GGGGATGTAGCTCAGTGGTAGAGCGCATGCTTTGCATGTATGAGGTCCCGGGTTCGATCCCCGGCATCTCCA |
| 23 | Ala_TGC_chr5:180633868-180633939 (+) | GGGGATGTAGCTCAGTGGTAGAGCGCATGCTTTGCATGTATGAGGCCCCGGGTTCGATCCCCGGCATCTCCA |
| 24 | Ala_TGC_chr12:125424512-125424583 (+) | GGGGATGTAGCTCAGTGGTAGAGCGCATGCTTTGCACGTATGAGGCCCCGGGTTCAATCCCCGGCATCTCCA |
| 25 | Ala_TGC_chr6:28785012-28785083 (-) | GGGGGTGTAGCTCAGTGGTAGAGCGCATGCTTTGCATGTATGAGGCCTCGGGTTCGATCCCCGACACCTCCA |
| 26 | Ala_TGC_chr6:28726141-28726212 (-) | GGGGGTGTAGCTCAGTGGTAGAGCACATGCTTTGCATGTGTGAGGCCCCGGGTTCGATCCCCGGCACCTCCA |
| 27 | Ala_TGC_chr6:28770577-28770647 (-) | GGGGGTGTAGCTCAGTGGTAGAGCGCATGCTTTGCATGTATGAGGCCTCGGTTCGATCCCCGACACCTCCA |
| 28 | Arg_ACG_chr6:26328368-26328440 (+) | GGGCCAGTGGCGCAATGGATAACGCGTCTGACTACGGATCAGAAGATTCCAGGTTCGACTCCTGGCTGGCTCG |
| 29 | Arg_ACG_chr3:45730491-45730563 (-) | GGGCCAGTGGCGCAATGGATAACGCGTCTGACTACGGATCAGAAGATTCTAGGTTCGACTCCTGGCTGGCTCG |
| 30 | Arg_CCG_chr6:28710729-28710801 (-) | GGCCGCGTGGCCTAATGGATAAGGCGTCTGATTCCGGATCAGAAGATTGAGGGTTCGAGTCCCTTCGTGGTCG |
| 31 | Arg_CCG_chr17:66016013-66016085 (-) | GACCCAGTGGCCTAATGGATAAGGCATCAGCCTCCGGAGCTGGGGATTGTGGGTTCGAGTCCCATCTGGGTCG |
| 32 | Arg_CCT_chr17:73030001-73030073 (+) | GCCCCAGTGGCCTAATGGATAAGGCACTGGCCTCCTAAGCCAGGGATTGTGGGTTCGAGTCCCACCTGGGGTA |
| 33 | Arg_CCT_chr17:73030526-73030598 (-) | GCCCCAGTGGCCTAATGGATAAGGCACTGGCCTCCTAAGCCAGGGATTGTGGGTTCGAGTCCCACCTGGGGTG |
| 34 | Arg_CCT_chr16:3202901-3202973 (+) | GCCCCGGTGGCCTAATGGATAAGGCATTGGCCTCCTAAGCCAGGGATTGTGGGTTCGAGTCCCACCCGGGGTA |
| 35 | Arg_CCT_chr7:139025446-139025518 (+) | GCCCCAGTGGCCTAATGGATAAGGCATTGGCCTCCTAAGCCAGGGATTGTGGGTTCGAGTCCCATCTGGGGTG |
| 36 | Arg_CCT_chr16:3243918-3243990 (+) | GCCCCAGTGGCCTGATGGATAAGGTACTGGCCTCCTAAGCCAGGGATTGTGGGTTCGAGTTCCACCTGGGGTA |
| 37 | Arg_TCG_chr15:89878304-89878376 (+) | GGCCGCGTGGCCTAATGGATAAGGCGTCTGACTTCGGATCAGAAGATTGCAGGTTCGAGTCCTGCCGCGGTCG |
| 38 | Arg_TCG_chr6:26323046-26323118 (+) | GACCACGTGGCCTAATGGATAAGGCGTCTGACTTCGGATCAGAAGATTGAGGGTTCGAATCCCTCCGTGGTTA |
| 39 | Arg_TCG_chr17:73031208-73031280 (+) | GACCGCGTGGCCTAATGGATAAGGCGTCTGACTTCGGATCAGAAGATTGAGGGTTCGAGTCCCTTCGTGGTCG |
| 40 | Arg_TCG_chr6:26299905-26299977 (+) | GACCACGTGGCCTAATGGATAAGGCGTCTGACTTCGGATCAGAAGATTGAGGGTTCGAATCCCTTCGTGGTTA |
| 41 | Arg_TCG_chr6:28510891-28510963 (-) | GACCACGTGGCCTAATGGATAAGGCGTCTGACTTCGGATCAGAAGATTGAGGGTTCGAATCCCTTCGTGGTTG |
| 42 | Arg_TCG_chr9:112960803-112960875 (+) | GGCCGTGTGGCCTAATGGATAAGGCGTCTGACTTCGGATCAAAAGATTGCAGGTTTGAGTTCTGCCACGGTCG |
| 43 | Arg_TCT_chr1:94313129-94313213 (+) | GGCTCCGTGGCGCAATGGATAGCGCATTGGACTTCTAGAGGCTGAAGGCATTCAAAGGTTCCGGGTTCGAGTCCCGGCGGAGTCG |
| 44 | Arg_TCT_chr17:8024243-8024330 (+) | GGCTCTGTGGCGCAATGGATAGCGCATTGGACTTCTAGTGACGAATAGAGCAATTCAAAGGTTGTGGGTTCGAATCCCACCAGAGTCG |
| 45 | Arg_TCT_chr9:131102355-131102445 (-) | GGCTCTGTGGCGCAATGGATAGCGCATTGGACTTCTAGCTGAGCCTAGTGTGGTCATTCAAAGGTTGTGGGTTCGAGTCCCACCAGAGTCG |
| 46 | Arg_TCT_chr11:59318767-59318852 (+) | GGCTCTGTGGCGCAATGGATAGCGCATTGGACTTCTAGATAGTTAGAGAAATTCAAAGGTTGTGGGTTCGAGTCCCACCAGAGTCG |
| 47 | Arg_TCT_chr1:159111401-159111474 (-) | GTCTCTGTGGCGCAATGGACGAGCGCGCTGGACTTCTAATCCAGAGGTTCCGGGTTCGAGTCCCGGCAGAGATG |
| 48 | Arg_TCT_chr6:27529963-27530049 (+) | GGCTCTGTGGCGCAATGGATAGCGCATTGGACTTCTAGCCTAAATCAAGAGATTCAAAGGTTGCGGGTTCGAGTCCCTCCAGAGTCG |
| 49 | Asn_GTT_chr1:161510031-161510104 (+) | GTCTCTGTGGCGCAATCGGTTAGCGCGTTCGGCTGTTAACCGAAAGGTTGGTGGTTCGATCCCACCCAGGGACG |
| 50 | Asn_GTT_chr1:143879832-143879905 (-) | GTCTCTGTGGCGCAATCGGCTAGCGCGTTTGGCTGTTAACTAAAAGGTTGGCGGTTCGAACCCACCCAGAGGCG |
| 51 | Asn_GTT_chr1:144301611-144301684 (+) | GTCTCTGTGGTGCAATCGGTTAGCGCGTTCCGCTGTTAACCGAAAGCTTGGTGGTTCGAGCCCACCCAGGGATG |
| 52 | Asn_GTT_chr1:149326272-149326345 (-) | GTCTCTGTGGCGCAATCGGCTAGCGCGTTTGGCTGTTAACTAAAAAGTTGGTGGTTCGAACACACCCAGAGGCG |
| 53 | Asn_GTT_chr1:148248115-148248188 (+) | GTCTCTGTGGCGCAATCGGTTAGCGCGTTCGGCTGTTAACCGAAAGGTTGGTGGTTCGAGCCCACCCAGGGACG |
| 54 | Asn_GTT_chr1:148598314-148598387 (-) | GTCTCTGTGGCGCAATCGGTTAGCGCATTCGGCTGTTAACCGAAAGGTTGGTGGTTCGAGCCCACCCAGGGACG |
| 55 | Asn_GTT_chr1:17216172-17216245 (+) | GTCTCTGTGGCGCAATCGGTTAGCGCGTTCGGCTGTTAACCGAAAGATTGGTGGTTCGAGCCCACCCAGGGACG |
| 56 | Asn_GTT_chr1:16847080-16847153 (-) | GTCTCTGTGGCGCAATCGGTTAGCGCGTTCGGCTGTTAACTGAAAGGTTGGTGGTTCGAGCCCACCCAGGGACG |
| 57 | Asn_GTT_chr1:149230570-149230643 (-) | GTCTCTGTGGCGCAATGGGTTAGCGCGTTCGGCTGTTAACCGAAAGGTTGGTGGTTCGAGCCCATCCAGGGACG |
| 58 | Asn_GTT_chr1:148000805-148000878 (+) | GTCTCTGTGGCGTAGTCGGTTAGCGCGTTCGGCTGTTAACCGAAAAGTTGGTGGTTCGAGCCCACCCAGGAACG |
| 59 | Asn_GTT_chr1:149711798-149711871 (-) | GTCTCTGTGGCGCAATCGGCTAGCGCGTTTGGCTGTTAACTAAAAGGTTGGTGGTTCGAACCCACCCAGAGGCG |
| 60 | Asn_GTT_chr1:145979034-145979107 (-) | GTCTCTGTGGCGCAATCGGTTAGCGCGTTCGGCTGTTAACTGAAAGGTTAGTGGTTCGAGCCCACCCGGGGACG |
| 61 | Asp_GTC_chr12:98897281-98897352 (+) | TCCTCGTTAGTATAGTGGTTAGTATCCCCGCCTGTCACGCGGGAGACCGGGGTTCAATTCCCCGACGGGGAG |
| 62 | Asp_GTC_chr1:161410615-161410686 (-) | TCCTCGTTAGTATAGTGGTGAGTATCCCCGCCTGTCACGCGGGAGACCGGGGTTCGATTCCCCGACGGGGAG |
| 63 | Asp_GTC_chr6:27551236-27551307 (-) | TCCTCGTTAGTATAGTGGTGAGTGTCCCCGTCTGTCACGCGGGAGACCGGGGTTCGATTCCCCGACGGGGAG |
| 64 | Cys_GCA_chr7:149007281-149007352 (+) | GGGGGCATAGCTCAGTGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCTGGTTCAAATCCAGGTGCCCCCT |
| 65 | Cys_GCA_chr7:149074601-149074672 (-) | GGGGGTATAGCTCAGGGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCTGGTTCAAATCCAGGTGCCCCCC |
| 66 | Cys_GCA_chr7:149112229-149112300 (-) | GGGGGTATAGCTTAGCGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCCGGTTCAAATCCGGGTGCCCCCT |
| 67 | Cys_GCA_chr7:149344046-149344117 (-) | GGGGGTATAGCTTAGGGGTAGAGCATTTGACTGCAGATCAAAAGGTCCCTGGTTCAAATCCAGGTGCCCCTT |
| 68 | Cys_GCA_chr7:149052766-149052837 (-) | GGGGGTATAGCTCAGGGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCCAGTTCAAATCTGGGTGCCCCCT |
| 69 | Cys_GCA_chr17:37017937-37018008 (-) | GGGGGTATAGCTCAGGGGTAGAGCATTTGACTGCAGATCAAGAAGTCCCCGGTTCAAATCCGGGTGCCCCCT |
| 70 | Cys_GCA_chr7:149281816-149281887 (+) | GGGGGTATAGCTCAGGGGTAGAGCATTTGACTGCAGATCAAGAGGTCTCTGGTTCAAATCCAGGTGCCCCCT |
| 71 | Cys_GCA_chr7:149243631-149243702 (+) | GGGGGTATAGCTCAGGGGTAGAGCACTTGACTGCAGATCAAGAAGTCCTTGGTTCAAATCCAGGTGCCCCCT |
| 72 | Cys_GCA_chr7:149388272-149388343 (-) | GGGGATATAGCTCAGGGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCCGGTTCAAATCCGGGTGCCCCCC |
| 73 | Cys_GCA_chr7:149072850-149072921 (-) | GGGGGTATAGTTCAGGGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCTGGTTCAAATCCAGGTGCCCCCT |
| 74 | Cys_GCA_chr7:149310156-149310227 (-) | GGGGGTATAGCTCAGGGGTAGAGCATTTGACTGCAAATCAAGAGGTCCCTGATTCAAATCCAGGTGCCCCCT |
| 75 | Cys_GCA_chr4:124430005-124430076 (-) | GGGGGTATAGCTCAGTGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCCGGTTCAAATCCGGGTGCCCCCT |
| 76 | Cys_GCA_chr7:149295046-149295117 (+) | GGGCGTATAGCTCAGGGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCCAGTTCAAATCTGGGTGCCCCCT |
| 77 | Cys_GCA_chr7:149361915-149361986 (+) | GGGGGTATAGCTCACAGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCCGGTTCAAATCTGGGTGCCCCCT |
| 78 | Cys_GCA_chr7:149253802-149253871 (+) | GGGCGTATAGCTCAGGGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCCAGTTCAAATCTGGGTGCCCA |
| 79 | Cys_GCA_chr7:149292305-149292376 (-) | GGGGGTATAGCTCACAGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCCGGTTCAAATCCGGTTACTCCCT |
| 80 | Cys_GCA_chr7:149286164-149286235 (-) | GGGGGTATAGCTCAGGGGTAGAGCACTTGACTGCAGATCAAGAGGTCCCTGGTTCAAATCCAGGTGCCCCCT |
| 81 | Cys_GCA_chr17:37025545-37025616 (-) | GGGGGTATAGCTCAGTGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCTGGTTCAAATCCGGGTGCCCCCT |
| 82 | Cys_GCA_chr15:80036997-80037069 (+) | GGGGGTATAGCTCAGTGGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCCGGTTCAAATCCGGGTGCCCCCT |
| 83 | Cys_GCA_chr3:131947944-131948015 (-) | GGGGGTGTAGCTCAGTGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCTGGTTCAAATCCAGGTGCCCCCT |
| 84 | Cys_GCA_chr1:93981834-93981906 (-) | GGGGGTATAGCTCAGGTGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCCGGTTCAAATCCGGGTGCCCCCT |
| 85 | Cys_GCA_chr14:73429679-73429750 (+) | GGGGGTATAGCTCAGGGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCCGGTTCAAATCCGGGTGCCCCCT |
| 86 | Cys_GCA_chr3:131950642-131950713 (-) | GGGGGTATAGCTCAGGGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCTGGTTCAAATCCAGGTGCCCCCT |
| 87 | Gln_CTG_chr6:18836402-18836473 (+) | GGTTCCATGGTGTAATGGTTAGCACTCTGGACTCTGAATCCAGCGATCCGAGTTCAAATCTCGGTGGAACCT |
| 88 | Gln_CTG_chr6:27515531-27515602 (-) | GGTTCCATGGTGTAATGGTTAGCACTCTGGACTCTGAATCCAGCGATCCGAGTTCAAGTCTCGGTGGAACCT |
| 89 | Gln_CTG_chr1:145963304-145963375 (+) | GGTTCCATGGTGTAATGGTGAGCACTCTGGACTCTGAATCCAGCGATCCGAGTTCGAGTCTCGGTGGAACCT |
| 90 | Gln_CTG_chr1:147737382-147737453 (-) | GGTTCCATGGTGTAATGGTAAGCACTCTGGACTCTGAATCCAGCGATCCGAGTTCGAGTCTCGGTGGAACCT |
| 91 | Gln_CTG_chr6:27263212-27263283 (+) | GGTTCCATGGTGTAATGGTTAGCACTCTGGACTCTGAATCCGGTAATCCGAGTTCAAATCTCGGTGGAACCT |
| 92 | Gln_CTG_chr6:27759135-27759206 (-) | GGCCCCATGGTGTAATGGTCAGCACTCTGGACTCTGAATCCAGCGATCCGAGTTCAAATCTCGGTGGGACCC |
| 93 | Gln_CTG_chr1:147800937-147801008 (+) | GGTTCCATGGTGTAATGGTAAGCACTCTGGACTCTGAATCCAGCCATCTGAGTTCGAGTCTCTGTGGAACCT |
| 94 | Gln_TTG_chr17:47269890-47269961 (+) | GGTCCCATGGTGTAATGGTTAGCACTCTGGACTTTGAATCCAGCGATCCGAGTTCAAATCTCGGTGGGACCT |
| 95 | Gln_TTG_chr6:28557156-28557227 (+) | GGTCCCATGGTGTAATGGTTAGCACTCTGGACTTTGAATCCAGCAATCCGAGTTCGAATCTCGGTGGGACCT |
| 96 | Gln_TTG_chr6:26311424-26311495 (-) | GGCCCCATGGTGTAATGGTTAGCACTCTGGACTTTGAATCCAGCGATCCGAGTTCAAATCTCGGTGGGACCT |
| 97 | Gln_TTG_chr6:145503859-145503930 (+) | GGTCCCATGGTGTAATGGTTAGCACTCTGGGCTTTGAATCCAGCAATCCGAGTTCGAATCTTGGTGGGACCT |
| 98 | Glu_CTC_chr1:145399233-145399304 (-) | TCCCTGGTGGTCTAGTGGTTAGGATTCGGCGCTCTCACCGCCGCGGCCCGGGTTCGATTCCCGGTCAGGGAA |
| 99 | Glu_CTC_chr1:249168447-249168518 (+) | TCCCTGGTGGTCTAGTGGTTAGGATTCGGCGCTCTCACCGCCGCGGCCCGGGTTCGATTCCCGGTCAGGAAA |
| 100 | Glu_TTC_chr2:131094701-131094772 (-) | TCCCATATGGTCTAGCGGTTAGGATTCCTGGTTTTCACCCAGGTGGCCCGGGTTCGACTCCCGGTATGGGAA |
| 101 | Glu_TTC_chr13:45492062-45492133 (-) | TCCCACATGGTCTAGCGGTTAGGATTCCTGGTTTTCACCCAGGCGGCCCGGGTTCGACTCCCGGTGTGGGAA |
| 102 | Glu_TTC_chr1:17199078-17199149 (+) | TCCCTGGTGGTCTAGTGGCTAGGATTCGGCGCTTTCACCGCCGCGGCCCGGGTTCGATTCCCGGCCAGGGAA |
| 103 | Glu_TTC_chr1:16861774-16861845 (-) | TCCCTGGTGGTCTAGTGGCTAGGATTCGGCGCTTTCACCGCCGCGGCCCGGGTTCGATTCCCGGTCAGGGAA |
| 104 | Gly_CCC_chr1:16872434-16872504 (-) | GCATTGGTGGTTCAGTGGTAGAATTCTCGCCTCCCACGCGGGAGACCCGGGTTCAATTCCCGGCCAATGCA |
| 105 | Gly_CCC_chr2:70476123-70476193 (-) | GCGCCGCTGGTGTAGTGGTATCATGCAAGATTCCCATTCTTGCGACCCGGGTTCGATTCCCGGGCGGCGCA |
| 106 | Gly_CCC_chr17:19764175-19764245 (+) | GCATTGGTGGTTCAATGGTAGAATTCTCGCCTCCCACGCAGGAGACCCAGGTTCGATTCCTGGCCAATGCA |
| 107 | Gly_GCC_chr1:161413094-161413164 (+) | GCATGGGTGGTTCAGTGGTAGAATTCTCGCCTGCCACGCGGGAGGCCCGGGTTCGATTCCCGGCCCATGCA |
| 108 | Gly_GCC_chr1:161493637-161493707 (-) | GCATTGGTGGTTCAGTGGTAGAATTCTCGCCTGCCACGCGGGAGGCCCGGGTTCGATTCCCGGCCAATGCA |
| 109 | Gly_GCC_chr16:70812114-70812184 (-) | GCATTGGTGGTTCAGTGGTAGAATTCTCGCCTGCCACGCGGGAGGCCCGGGTTTGATTCCCGGCCAGTGCA |
| 110 | Gly_GCC_chr1:161450356-161450426 (+) | GCATAGGTGGTTCAGTGGTAGAATTCTTGCCTGCCACGCAGGAGGCCCAGGTTTGATTCCTGGCCCATGCA |
| 111 | Gly_GCC_chr16:70822597-70822667 (+) | GCATTGGTGGTTCAGTGGTAGAATTCTCGCCTGCCATGCGGGCGGCCGGGCTTCGATTCCTGGCCAATGCA |
| 112 | Gly_TCC_chr19:4724082-4724153 (+) | GCGTTGGTGGTATAGTGGTTAGCATAGCTGCCTTCCAAGCAGTTGACCCGGGTTCGATTCCCGGCCAACGCA |
| 113 | Gly_TCC_chr1:145397864-145397935 (-) | GCGTTGGTGGTATAGTGGTGAGCATAGCTGCCTTCCAAGCAGTTGACCCGGGTTCGATTCCCGGCCAACGCA |
| 114 | Gly_TCC_chr17:8124866-8124937 (+) | GCGTTGGTGGTATAGTGGTAAGCATAGCTGCCTTCCAAGCAGTTGACCCGGGTTCGATTCCCGGCCAACGCA |
| 115 | Gly_TCC_chr1:161409961-161410032 (-) | GCGTTGGTGGTATAGTGGTGAGCATAGTTGCCTTCCAAGCAGTTGACCCGGGCTCGATTCCCGCCCAACGCA |
| 116 | His_GTG_chr1:145396881-145396952 (-) | GCCGTGATCGTATAGTGGTTAGTACTCTGCGTTGTGGCCGCAGCAACCTCGGTTCGAATCCGAGTCACGGCA |
| 117 | His_GTG_chr1:149155828-149155899 (-) | GCCATGATCGTATAGTGGTTAGTACTCTGCGCTGTGGCCGCAGCAACCTCGGTTCGAATCCGAGTCACGGCA |
| 118 | Ile_AAT_chr6:58149254-58149327 (+) | GGCCGGTTAGCTCAGTTGGTTAGAGCGTGGCGCTAATAACGCCAAGGTCGCGGGTTCGATCCCCGTACGGGCCA |
| 119 | Ile_AAT_chr6:27655967-27656040 (+) | GGCCGGTTAGCTCAGTTGGTTAGAGCGTGGTGCTAATAACGCCAAGGTCGCGGGTTCGATCCCCGTACTGGCCA |
| 120 | Ile_AAT_chr6:27242990-27243063 (-) | GGCTGGTTAGCTCAGTTGGTTAGAGCGTGGTGCTAATAACGCCAAGGTCGCGGGTTCGATCCCCGTACTGGCCA |
| 121 | Ile_AAT_chr17:8130309-8130382 (-) | GGCCGGTTAGCTCAGTTGGTTAGAGCGTGGTGCTAATAACGCCAAGGTCGCGGGTTCGAACCCCGTACGGGCCA |
| 122 | Ile_AAT_chr6:26554350-26554423 (+) | GGCCGGTTAGCTCAGTTGGTTAGAGCGTGGTGCTAATAACGCCAAGGTCGCGGGTTCGATCCCCGTACGGGCCA |
| 123 | Ile_AAT_chr6:26745255-26745328 (-) | GGCCGGTTAGCTCAGTTGGTTAGAGCGTGGTGCTAATAACGCTAAGGTCGCGGGTTCGATCCCCGTACTGGCCA |
| 124 | Ile_AAT_chr6:26721221-26721294 (-) | GGCCGGTTAGCTCAGTTGGTCAGAGCGTGGTGCTAATAACGCCAAGGTCGCGGGTTCGATCCCCGTACGGGCCA |
| 125 | Ile_AAT_chr6:27636362-27636435 (+) | GGCCGGTTAGCTCAGTCGGCTAGAGCGTGGTGCTAATAACGCCAAGGTCGCGGGTTCGATCCCCGTACGGGCCA |
| 126 | Ile_AAT_chr6:27241739-27241812 (+) | GGCTGGTTAGTTCAGTTGGTTAGAGCGTGGTGCTAATAACGCCAAGGTCGTGGGTTCGATCCCCATATCGGCCA |
| 127 | Ile_GAT_chrX:3756418-3756491 (-) | GGCCGGTTAGCTCAGTTGGTAAGAGCGTGGTGCTGATAACACCAAGGTCGCGGGCTCGACTCCCGCACCGGCCA |
| 128 | Ile_TAT_chr19:39902808-39902900 (-) | GCTCCAGTGGCGCAATCGGTTAGCGCGCGGTACTTATATGACAGTGCGAGCGGAGCAATGCCGAGGTTGTGAGTTCGATCCTCACCTGGAGCA |
| 129 | Ile_TAT_chr2:43037676-43037768 (+) | GCTCCAGTGGCGCAATCGGTTAGCGCGCGGTACTTATACAGCAGTACATGCAGAGCAATGCCGAGGTTGTGAGTTCGAGCCTCACCTGGAGCA |
| 130 | Ile_TAT_chr6:26988125-26988218 (+) | GCTCCAGTGGCGCAATCGGTTAGCGCGCGGTACTTATATGGCAGTATGTGTGCGAGTGATGCCGAGGTTGTGAGTTCGAGCCTCACCTGGAGCA |
| 131 | Ile_TAT_chr6:27599200-27599293 (+) | GCTCCAGTGGCGCAATCGGTTAGCGCGCGGTACTTATACAACAGTATATGTGCGGGTGATGCCGAGGTTGTGAGTTCGAGCCTCACCTGGAGCA |
| 132 | Ile_TAT_chr6:28505367-28505460 (+) | GCTCCAGTGGCGCAATCGGTTAGCGCGCGGTACTTATAAGACAGTGCACCTGTGAGCAATGCCGAGGTTGTGAGTTCAAGCCTCACCTGGAGCA |
| 133 | Leu_AAG_chr5:180524474-180524555 (-) | GGTAGCGTGGCCGAGCGGTCTAAGGCGCTGGATTAAGGCTCCAGTCTCTTCGGAGGCGTGGGTTCGAATCCCACCGCTGCCA |
| 134 | Leu_AAG_chr5:180614701-180614782 (+) | GGTAGCGTGGCCGAGCGGTCTAAGGCGCTGGATTAAGGCTCCAGTCTCTTCGGGGGCGTGGGTTCGAATCCCACCGCTGCCA |
| 135 | Leu_AAG_chr6:28956779-28956860 (+) | GGTAGCGTGGCCGAGCGGTCTAAGGCGCTGGATTAAGGCTCCAGTCTCTTCGGGGGCGTGGGTTCAAATCCCACCGCTGCCA |
| 136 | Leu_AAG_chr6:28446400-28446481 (-) | GGTAGCGTGGCCGAGTGGTCTAAGACGCTGGATTAAGGCTCCAGTCTCTTCGGGGGCGTGGGTTTGAATCCCACCGCTGCCA |
| 137 | Leu_CAA_chr6:28864000-28864105 (-) | GTCAGGATGGCCGAGTGGTCTAAGGCGCCAGACTCAAGCTAAGCTTCCTCCGCGGTGGGGATTCTGGTCTCCAATGGAGGCGTGGGTTCGAATCCCACTTCTGACA |
| 138 | Leu_CAA_chr6:28908830-28908934 (+) | GTCAGGATGGCCGAGTGGTCTAAGGCGCCAGACTCAAGCTTGGCTTCCTCGTGTTGAGGATTCTGGTCTCCAATGGAGGCGTGGGTTCGAATCCCACTTCTGACA |
| 139 | Leu_CAA_chr6:27573417-27573524 (-) | GTCAGGATGGCCGAGTGGTCTAAGGCGCCAGACTCAAGCTTACTGCTTCCTGTGTTCGGGTCTTCTGGTCTCCGTATGGAGGCGTGGGTTCGAATCCCACTTCTGACA |
| 140 | Leu_CAA_chr6:27570348-27570454 (-) | GTCAGGATGGCCGAGTGGTCTAAGGCGCCAGACTCAAGTTGCTACTTCCCAGGTTTGGGGCTTCTGGTCTCCGCATGGAGGCGTGGGTTCGAATCCCACTTCTGACA |
| 141 | Leu_CAA_chr1:249168054-249168159 (+) | GTCAGGATGGCCGAGTGGTCTAAGGCGCCAGACTCAAGGTAAGCACCTTGCCTGCGGGCTTTCTGGTCTCCGGATGGAGGCGTGGGTTCGAATCCCACTTCTGACA |
| 142 | Leu_CAA_chr11:9296790-9296863 (+) | GCCTCCTTAGTGCAGTAGGTAGCGCATCAGTCTCAAAATCTGAATGGTCCTGAGTTCAAGCCTCAGAGGGGGCA |
| 143 | Leu_CAA_chr1:161581736-161581819 (-) | GTCAGGATGGCCGAGCAGTCTTAAGGCGCTGCGTTCAAATCGCACCCTCCGCTGGAGGCGTGGGTTCGAATCCCACTTTTGACA |
| 144 | Leu_CAG_chr1:161411323-161411405 (+) | GTCAGGATGGCCGAGCGGTCTAAGGCGCTGCGTTCAGGTCGCAGTCTCCCCTGGAGGCGTGGGTTCGAATCCCACTCCTGACA |
| 145 | Leu_CAG_chr16:57333863-57333945 (+) | GTCAGGATGGCCGAGCGGTCTAAGGCGCTGCGTTCAGGTCGCAGTCTCCCCTGGAGGCGTGGGTTCGAATCCCACTTCTGACA |
| 146 | Leu_TAA_chr6:144537684-144537766 (+) | ACCAGGATGGCCGAGTGGTTAAGGCGTTGGACTTAAGATCCAATGGACATATGTCCGCGTGGGTTCGAACCCCACTCCTGGTA |
| 147 | Leu_TAA_chr6:27688898-27688980 (-) | ACCGGGATGGCCGAGTGGTTAAGGCGTTGGACTTAAGATCCAATGGGCTGGTGCCCGCGTGGGTTCGAACCCCACTCTCGGTA |
| 148 | Leu_TAA_chr11:59319228-59319310 (+) | ACCAGAATGGCCGAGTGGTTAAGGCGTTGGACTTAAGATCCAATGGATTCATATCCGCGTGGGTTCGAACCCCACTTCTGGTA |
| 149 | Leu_TAA_chr6:27198334-27198416 (-) | ACCGGGATGGCTGAGTGGTTAAGGCGTTGGACTTAAGATCCAATGGACAGGTGTCCGCGTGGGTTCGAGCCCCACTCCCGGTA |
| 150 | Leu_TAG_chr17:8023632-8023713 (-) | GGTAGCGTGGCCGAGCGGTCTAAGGCGCTGGATTTAGGCTCCAGTCTCTTCGGAGGCGTGGGTTCGAATCCCACCGCTGCCA |
| 151 | Leu_TAG_chr14:21093529-21093610 (+) | GGTAGTGTGGCCGAGCGGTCTAAGGCGCTGGATTTAGGCTCCAGTCTCTTCGGGGGCGTGGGTTCGAATCCCACCACTGCCA |
| 152 | Leu_TAG_chr16:22207032-22207113 (-) | GGTAGCGTGGCCGAGTGGTCTAAGGCGCTGGATTTAGGCTCCAGTCATTTCGATGGCGTGGGTTCGAATCCCACCGCTGCCA |
| 153 | Lys_CTT_chr14:58706613-58706685 (-) | GCCCGGCTAGCTCAGTCGGTAGAGCATGGGACTCTTAATCCCAGGGTCGTGGGTTCGAGCCCCACGTTGGGCG |
| 154 | Lys_CTT_chr19:36066750-36066822 (+) | GCCCAGCTAGCTCAGTCGGTAGAGCATAAGACTCTTAATCTCAGGGTTGTGGATTCGTGCCCCATGCTGGGTG |
| 155 | Lys_CTT_chr19:52425393-52425466 (-) | GCAGCTAGCTCAGTCGGTAGAGCATGAGACTCTTAATCTCAGGGTCATGGGTTCGTGCCCCATGTTGGGTGCCA |
| 156 | Lys_CTT_chr1:145395522-145395594 (-) | GCCCGGCTAGCTCAGTCGGTAGAGCATGAGACTCTTAATCTCAGGGTCGTGGGTTCGAGCCCCACGTTGGGCG |
| 157 | Lys_CTT_chr16:3207406-3207478 (-) | GCCCGGCTAGCTCAGTCGGTAGAGCATGAGACCCTTAATCTCAGGGTCGTGGGTTCGAGCCCCACGTTGGGCG |
| 158 | Lys_CTT_chr16:3241501-3241573 (+) | GCCCGGCTAGCTCAGTCGGTAGAGCATGGGACTCTTAATCTCAGGGTCGTGGGTTCGAGCCCCACGTTGGGCG |
| 159 | Lys_CTT_chr16:3230555-3230627 (-) | GCCCGGCTAGCTCAGTCGATAGAGCATGAGACTCTTAATCTCAGGGTCGTGGGTTCGAGCCGCACGTTGGGCG |
| 160 | Lys_CTT_chr1:55423542-55423614 (-) | GCCCAGCTAGCTCAGTCGGTAGAGCATGAGACTCTTAATCTCAGGGTCATGGGTTTGAGCCCCACGTTTGGTG |
| 161 | Lys_CTT_chr16:3214939-3215011 (+) | GCCTGGCTAGCTCAGTCGGCAAAGCATGAGACTCTTAATCTCAGGGTCGTGGGCTCGAGCTCCATGTTGGGCG |
| 162 | Lys_CTT_chr5:26198539-26198611 (-) | GCCCGACTACCTCAGTCGGTGGAGCATGGGACTCTTCATCCCAGGGTTGTGGGTTCGAGCCCCACATTGGGCA |
| 163 | Lys_TTT_chr16:73512216-73512288 (-) | GCCTGGATAGCTCAGTTGGTAGAGCATCAGACTTTTAATCTGAGGGTCCAGGGTTCAAGTCCCTGTTCAGGCA |
| 164 | Lys_TTT_chr12:27843306-27843378 (+) | ACCCAGATAGCTCAGTCAGTAGAGCATCAGACTTTTAATCTGAGGGTCCAAGGTTCATGTCCCTTTTTGGGTG |
| 165 | Lys_TTT_chr11:122430655-122430727 (+) | GCCTGGATAGCTCAGTTGGTAGAGCATCAGACTTTTAATCTGAGGGTCCAGGGTTCAAGTCCCTGTTCAGGCG |
| 166 | Lys_TTT_chr1:204475655-204475727 (+) | GCCCGGATAGCTCAGTCGGTAGAGCATCAGACTTTTAATCTGAGGGTCCAGGGTTCAAGTCCCTGTTCGGGCG |
| 167 | Lys_TTT_chr6:27559593-27559665 (-) | GCCTGGATAGCTCAGTCGGTAGAGCATCAGACTTTTAATCTGAGGGTCCAGGGTTCAAGTCCCTGTTCAGGCG |
| 168 | Lys_TTT_chr11:59323902-59323974 (+) | GCCCGGATAGCTCAGTCGGTAGAGCATCAGACTTTTAATCTGAGGGTCCGGGGTTCAAGTCCCTGTTCGGGCG |
| 169 | Lys_TTT_chr6:27302769-27302841 (-) | GCCTGGGTAGCTCAGTCGGTAGAGCATCAGACTTTTAATCTGAGGGTCCAGGGTTCAAGTCCCTGTCCAGGCG |
| 170 | Lys_TTT_chr6:28715521-28715593 (+) | GCCTGGATAGCTCAGTTGGTAGAACATCAGACTTTTAATCTGACGGTGCAGGGTTCAAGTCCCTGTTCAGGCG |
| 171 | Met_CAT_chr8:124169470-124169542 (-) | GCCTCGTTAGCGCAGTAGGTAGCGCGTCAGTCTCATAATCTGAAGGTCGTGAGTTCGATCCTCACACGGGGCA |
| 172 | Met_CAT_chr16:71460396-71460468 (+) | GCCCTCTTAGCGCAGTGGGCAGCGCGTCAGTCTCATAATCTGAAGGTCCTGAGTTCGAGCCTCAGAGAGGGCA |
| 173 | Met_CAT_chr6:28912352-28912424 (+) | GCCTCCTTAGCGCAGTAGGCAGCGCGTCAGTCTCATAATCTGAAGGTCCTGAGTTCGAACCTCAGAGGGGGCA |
| 174 | Met_CAT_chr6:26735574-26735646 (-) | GCCCTCTTAGCGCAGCGGGCAGCGCGTCAGTCTCATAATCTGAAGGTCCTGAGTTCGAGCCTCAGAGAGGGCA |
| 175 | Met_CAT_chr6:26701712-26701784 (+) | GCCCTCTTAGCGCAGCTGGCAGCGCGTCAGTCTCATAATCTGAAGGTCCTGAGTTCAAGCCTCAGAGAGGGCA |
| 176 | Met_CAT_chr16:87417628-87417700 (-) | GCCTCGTTAGCGCAGTAGGCAGCGCGTCAGTCTCATAATCTGAAGGTCGTGAGTTCGAGCCTCACACGGGGCA |
| 177 | Met_CAT_chr6:58168492-58168564 (-) | GCCCTCTTAGTGCAGCTGGCAGCGCGTCAGTTTCATAATCTGAAAGTCCTGAGTTCAAGCCTCAGAGAGGGCA |
| 178 | Phe_GAA_chr6:28758499-28758571 (-) | GCCGAAATAGCTCAGTTGGGAGAGCGTTAGACTGAAGATCTAAAGGTCCCTGGTTCGATCCCGGGTTTCGGCA |
| 179 | Phe_GAA_chr11:59333853-59333925 (-) | GCCGAAATAGCTCAGTTGGGAGAGCGTTAGACTGAAGATCTAAAGGTCCCTGGTTCAATCCCGGGTTTCGGCA |
| 180 | Phe_GAA_chr6:28775610-28775682 (-) | GCCGAGATAGCTCAGTTGGGAGAGCGTTAGACTGAAGATCTAAAGGTCCCTGGTTCAATCCCGGGTTTCGGCA |
| 181 | Phe_GAA_chr6:28791093-28791166 (-) | GCCGAAATAGCTCAGTTGGGAGAGCGTTAGACCGAAGATCTTAAAGGTCCCTGGTTCAATCCCGGGTTTCGGCA |
| 182 | Phe_GAA_chr6:28731374-28731447 (-) | GCTGAAATAGCTCAGTTGGGAGAGCGTTAGACTGAAGATCTTAAAGTTCCCTGGTTCAACCCTGGGTTTCAGCC |
| 183 | Pro_AGG_chr16:3241989-3242060 (+) | GGCTCGTTGGTCTAGGGGTATGATTCTCGCTTAGGATGCGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCC |
| 184 | Pro_AGG_chr1:167684725-167684796 (-) | GGCTCGTTGGTCTAGGGGTATGATTCTCGCTTAGGGTGCGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCC |
| 185 | Pro_CGG_chr1:167683962-167684033 (+) | GGCTCGTTGGTCTAGGGGTATGATTCTCGCTTCGGGTGCGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCC |
| 186 | Pro_CGG_chr6:27059521-27059592 (+) | GGCTCGTTGGTCTAGGGGTATGATTCTCGCTTCGGGTGTGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCC |
| 187 | Pro_TGG_chr14:21101165-21101236 (+) | GGCTCGTTGGTCTAGTGGTATGATTCTCGCTTTGGGTGCGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCC |
| 188 | Pro_TGG_chr11:75946869-75946940 (-) | GGCTCGTTGGTCTAGGGGTATGATTCTCGGTTTGGGTCCGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCC |
| 189 | Pro_TGG_chr5:180615854-180615925 (-) | GGCTCGTTGGTCTAGGGGTATGATTCTCGCTTTGGGTGCGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCC |
| 190 | SeC_TCA_chr19:45981859-45981945 (-) | GCCCGGATGATCCTCAGTGGTCTGGGGTGCAGGCTTCAAACCTGTAGCTGTCTAGCGACAGAGTGGTTCAATTCCACCTTTCGGGCG |
| 191 | SeC_TCA_chr22:44546537-44546620 (+) | GCTCGGATGATCCTCAGTGGTCTGGGGTGCAGGCTTCAAACCTGTAGCTGTCTAGTGACAGAGTGGTTCAATTCCACCTTTGTA |
| 192 | Ser_AGA_chr6:27509554-27509635 (-) | GTAGTCGTGGCCGAGTGGTTAAGGCGATGGACTAGAAATCCATTGGGGTTTCCCCGCGCAGGTTCGAATCCTGCCGACTACG |
| 193 | Ser_AGA_chr6:26327817-26327898 (+) | GTAGTCGTGGCCGAGTGGTTAAGGCGATGGACTAGAAATCCATTGGGGTCTCCCCGCGCAGGTTCGAATCCTGCCGACTACG |
| 194 | Ser_AGA_chr6:27499987-27500068 (+) | GTAGTCGTGGCCGAGTGGTTAAGGCGATGGACTAGAAATCCATTGGGGTTTCCCCACGCAGGTTCGAATCCTGCCGACTACG |
| 195 | Ser_AGA_chr6:27521192-27521273 (-) | GTAGTCGTGGCCGAGTGGTTAAGGTGATGGACTAGAAACCCATTGGGGTCTCCCCGCGCAGGTTCGAATCCTGCCGACTACG |
| 196 | Ser_CGA_chr17:8042199-8042280 (-) | GCTGTGATGGCCGAGTGGTTAAGGCGTTGGACTCGAAATCCAATGGGGTCTCCCCGCGCAGGTTCGAATCCTGCTCACAGCG |
| 197 | Ser_CGA_chr6:27177628-27177709 (+) | GCTGTGATGGCCGAGTGGTTAAGGCGTTGGACTCGAAATCCAATGGGGTCTCCCCGCGCAGGTTCAAATCCTGCTCACAGCG |
| 198 | Ser_CGA_chr6:27640229-27640310 (-) | GCTGTGATGGCCGAGTGGTTAAGGTGTTGGACTCGAAATCCAATGGGGGTTCCCCGCGCAGGTTCAAATCCTGCTCACAGCG |
| 199 | Ser_CGA_chr12:56584148-56584229 (+) | GTCACGGTGGCCGAGTGGTTAAGGCGTTGGACTCGAAATCCAATGGGGTTTCCCCGCACAGGTTCGAATCCTGTTCGTGACG |
| 200 | Ser_GCT_chr6:27065085-27065166 (+) | GACGAGGTGGCCGAGTGGTTAAGGCGATGGACTGCTAATCCATTGTGCTCTGCACGCGTGGGTTCGAATCCCACCCTCGTCG |
| 201 | Ser_GCT_chr6:27265775-27265856 (+) | GACGAGGTGGCCGAGTGGTTAAGGCGATGGACTGCTAATCCATTGTGCTCTGCACGCGTGGGTTCGAATCCCACCTTCGTCG |
| 202 | Ser_GCT_chr11:66115591-66115672 (+) | GACGAGGTGGCCGAGTGGTTAAGGCGATGGACTGCTAATCCATTGTGCTTTGCACGCGTGGGTTCGAATCCCATCCTCGTCG |
| 203 | Ser_GCT_chr6:28565117-28565198 (-) | GACGAGGTGGCCGAGTGGTTAAGGCGATGGACTGCTAATCCATTGTGCTCTGCACGCGTGGGTTCGAATCCCATCCTCGTCG |
| 204 | Ser_GCT_chr6:28180815-28180896 (+) | GACGAGGTGGCCGAGTGGTTAAGGCGATGGACTGCTAATCCATTGTGCTCTGCACACGTGGGTTCGAATCCCATCCTCGTCG |
| 205 | Ser_GCT_chr6:26305718-26305801 (-) | GGAGAGGCCTGGCCGAGTGGTTAAGGCGATGGACTGCTAATCCATTGTGCTCTGCACGCGTGGGTTCGAATCCCATCCTCGTCG |
| 206 | Ser_TGA_chr10:69524261-69524342 (+) | GCAGCGATGGCCGAGTGGTTAAGGCGTTGGACTTGAAATCCAATGGGGTCTCCCCGCGCAGGTTCGAACCCTGCTCGCTGCG |
| 207 | Ser_TGA_chr6:27513468-27513549 (+) | GTAGTCGTGGCCGAGTGGTTAAGGCGATGGACTTGAAATCCATTGGGGTTTCCCCGCGCAGGTTCGAATCCTGCCGACTACG |
| 208 | Ser_TGA_chr6:26312824-26312905 (-) | GTAGTCGTGGCCGAGTGGTTAAGGCGATGGACTTGAAATCCATTGGGGTCTCCCCGCGCAGGTTCGAATCCTGCCGACTACG |
| 209 | Ser_TGA_chr6:27473607-27473688 (-) | GTAGTCGTGGCCGAGTGGTTAAGGCGATGGACTTGAAATCCATTGGGGTTTCCCCGCGCAGGTTCGAATCCTGTCGGCTACG |
| 210 | Thr_AGT_chr17:8090478-8090551 (+) | GGCGCCGTGGCTTAGTTGGTTAAAGCGCCTGTCTAGTAAACAGGAGATCCTGGGTTCGAATCCCAGCGGTGCCT |
| 211 | Thr_AGT_chr6:26533145-26533218 (-) | GGCTCCGTGGCTTAGCTGGTTAAAGCGCCTGTCTAGTAAACAGGAGATCCTGGGTTCGAATCCCAGCGGGGCCT |
| 212 | Thr_AGT_chr6:28693795-28693868 (+) | GGCTCCGTAGCTTAGTTGGTTAAAGCGCCTGTCTAGTAAACAGGAGATCCTGGGTTCGACTCCCAGCGGGGCCT |
| 213 | Thr_AGT_chr6:27694473-27694546 (+) | GGCTTCGTGGCTTAGCTGGTTAAAGCGCCTGTCTAGTAAACAGGAGATCCTGGGTTCGAATCCCAGCGAGGCCT |
| 214 | Thr_AGT_chr17:8042770-8042843 (-) | GGCGCCGTGGCTTAGCTGGTTAAAGCGCCTGTCTAGTAAACAGGAGATCCTGGGTTCGAATCCCAGCGGTGCCT |
| 215 | Thr_AGT_chr6:27130050-27130123 (+) | GGCCCTGTGGCTTAGCTGGTCAAAGCGCCTGTCTAGTAAACAGGAGATCCTGGGTTCGAATCCCAGCGGGGCCT |
| 216 | Thr_CGT_chr6:28456770-28456843 (-) | GGCTCTATGGCTTAGTTGGTTAAAGCGCCTGTCTCGTAAACAGGAGATCCTGGGTTCGACTCCCAGTGGGGCCT |
| 217 | Thr_CGT_chr16:14379750-14379821 (+) | GGCGCGGTGGCCAAGTGGTAAGGCGTCGGTCTCGTAAACCGAAGATCACGGGTTCGAACCCCGTCCGTGCCT |
| 218 | Thr_CGT_chr6:28615984-28616057 (-) | GGCTCTGTGGCTTAGTTGGCTAAAGCGCCTGTCTCGTAAACAGGAGATCCTGGGTTCGAATCCCAGCGGGGCCT |
| 219 | Thr_CGT_chr17:29877093-29877164 (+) | GGCGCGGTGGCCAAGTGGTAAGGCGTCGGTCTCGTAAACCGAAGATCGCGGGTTCGAACCCCGTCCGTGCCT |
| 220 | Thr_CGT_chr6:27586135-27586208 (+) | GGCCCTGTAGCTCAGCGGTTGGAGCGCTGGTCTCGTAAACCTAGGGGTCGTGAGTTCAAATCTCACCAGGGCCT |
| 221 | Thr_TGT_chr6:28442329-28442402 (-) | GGCTCTATGGCTTAGTTGGTTAAAGCGCCTGTCTTGTAAACAGGAGATCCTGGGTTCGAATCCCAGTAGAGCCT |
| 222 | Thr_TGT_chr1:222638347-222638419 (+) | GGCTCCATAGCTCAGTGGTTAGAGCACTGGTCTTGTAAACCAGGGGTCGCGAGTTCGATCCTCGCTGGGGCCT |
| 223 | Thr_TGT_chr14:21081949-21082021 (-) | GGCTCCATAGCTCAGGGGTTAGAGCGCTGGTCTTGTAAACCAGGGGTCGCGAGTTCAATTCTCGCTGGGGCCT |
| 224 | Thr_TGT_chr14:21099319-21099391 (-) | GGCTCCATAGCTCAGGGGTTAGAGCACTGGTCTTGTAAACCAGGGGTCGCGAGTTCAAATCTCGCTGGGGCCT |
| 225 | Thr_TGT_chr14:21149849-21149921 (+) | GGCCCTATAGCTCAGGGGTTAGAGCACTGGTCTTGTAAACCAGGGGTCGCGAGTTCAAATCTCGCTGGGGCCT |
| 226 | Thr_TGT_chr5:180618687-180618758 (-) | GGCTCCATAGCTCAGGGGTTAGAGCACTGGTCTTGTAAACCAGGGTCGCGAGTTCAAATCTCGCTGGGGCCT |
| 227 | Trp_CCA_chr17:8124187-8124258 (-) | GGCCTCGTGGCGCAACGGTAGCGCGTCTGACTCCAGATCAGAAGGTTGCGTGTTCAAATCACGTCGGGGTCA |
| 228 | Trp_CCA_chr17:19411494-19411565 (+) | GACCTCGTGGCGCAATGGTAGCGCGTCTGACTCCAGATCAGAAGGTTGCGTGTTCAAGTCACGTCGGGGTCA |
| 229 | Trp_CCA_chr6:26319330-26319401 (-) | GACCTCGTGGCGCAACGGTAGCGCGTCTGACTCCAGATCAGAAGGTTGCGTGTTCAAATCACGTCGGGGTCA |
| 230 | Trp_CCA_chr12:98898030-98898101 (+) | GACCTCGTGGCGCAACGGTAGCGCGTCTGACTCCAGATCAGAAGGCTGCGTGTTCGAATCACGTCGGGGTCA |
| 231 | Trp_CCA_chr7:99067307-99067378 (+) | GACCTCGTGGCGCAACGGCAGCGCGTCTGACTCCAGATCAGAAGGTTGCGTGTTCAAATCACGTCGGGGTCA |
| 232 | Tyr_ATA_chr2:219110549-219110641 (+) | CCTTCAATAGTTCAGCTGGTAGAGCAGAGGACTATAGCTACTTCCTCAGTAGGAGACGTCCTTAGGTTGCTGGTTCGATTCCAGCTTGAAGGA |
| 233 | Tyr_GTA_chr6:26569086-26569176 (+) | CCTTCGATAGCTCAGTTGGTAGAGCGGAGGACTGTAGTTGGCTGTGTCCTTAGACATCCTTAGGTCGCTGGTTCGAATCCGGCTCGAAGGA |
| 234 | Tyr_GTA_chr2:27273650-27273738 (+) | CCTTCGATAGCTCAGTTGGTAGAGCGGAGGACTGTAGTGGATAGGGCGTGGCAATCCTTAGGTCGCTGGTTCGATTCCGGCTCGAAGGA |
| 235 | Tyr_GTA_chr6:26577332-26577420 (+) | CCTTCGATAGCTCAGTTGGTAGAGCGGAGGACTGTAGGCTCATTAAGCAAGGTATCCTTAGGTCGCTGGTTCGAATCCGGCTCGGAGGA |
| 236 | Tyr_GTA_chr14:21125623-21125716 (-) | CCTTCGATAGCTCAGCTGGTAGAGCGGAGGACTGTAGATTGTATAGACATTTGCGGACATCCTTAGGTCGCTGGTTCGATTCCAGCTCGAAGGA |
| 237 | Tyr_GTA_chr8:67025602-67025694 (+) | CCTTCGATAGCTCAGCTGGTAGAGCGGAGGACTGTAGCTACTTCCTCAGCAGGAGACATCCTTAGGTCGCTGGTTCGATTCCGGCTCGAAGGA |
| 238 | Tyr_GTA_chr8:67026223-67026311 (+) | CCTTCGATAGCTCAGCTGGTAGAGCGGAGGACTGTAGGCGCGCGCCCGTGGCCATCCTTAGGTCGCTGGTTCGATTCCGGCTCGAAGGA |
| 239 | Tyr_GTA_chr14:21121258-21121351 (-) | CCTTCGATAGCTCAGCTGGTAGAGCGGAGGACTGTAGCCTGTAGAAACATTTGTGGACATCCTTAGGTCGCTGGTTCGATTCCGGCTCGAAGGA |
| 240 | Tyr_GTA_chr14:21131351-21131444 (-) | CCTTCGATAGCTCAGCTGGTAGAGCGGAGGACTGTAGATTGTACAGACATTTGCGGACATCCTTAGGTCGCTGGTTCGATTCCGGCTCGAAGGA |
| 241 | Tyr_GTA_chr14:21151432-21151520 (+) | CCTTCGATAGCTCAGCTGGTAGAGCGGAGGACTGTAGTACTTAATGTGTGGTCATCCTTAGGTCGCTGGTTCGATTCCGGCTCGAAGGA |
| 242 | Tyr_GTA_chr6:26595102-26595190 (+) | CCTTCGATAGCTCAGCTGGTAGAGCGGAGGACTGTAGGGGTTTGAATGTGGTCATCCTTAGGTCGCTGGTTCGAATCCGGCTCGGAGGA |
| 243 | Tyr_GTA_chr14:21128117-21128210 (-) | CCTTCGATAGCTCAGCTGGTAGAGCGGAGGACTGTAGACTGCGGAAACGTTTGTGGACATCCTTAGGTCGCTGGTTCAATTCCGGCTCGAAGGA |
| 244 | Tyr_GTA_chr6:26575798-26575887 (+) | CTTTCGATAGCTCAGTTGGTAGAGCGGAGGACTGTAGGTTCATTAAACTAAGGCATCCTTAGGTCGCTGGTTCGAATCCGGCTCGAAGGA |
| 245 | Tyr_GTA_chr8:66609532-66609619 (-) | TCTTCAATAGCTCAGCTGGTAGAGCGGAGGACTGTAGGTGCACGCCCGTGGCCATTCTTAGGTGCTGGTTTGATTCCGACTTGGAGAG |
| 246 | Val_AAC_chr3:169490018-169490090 (+) | GTTTCCGTAGTGTAGTGGTTATCACGTTCGCCTAACACGCGAAAGGTCCCCGGTTCGAAACCGGGCGGAAACA |
| 247 | Val_AAC_chr5:180615416-180615488 (-) | GTTTCCGTAGTGTAGTGGTCATCACGTTCGCCTAACACGCGAAAGGTCCCCGGTTCGAAACCGGGCGGAAACA |
| 248 | Val_AAC_chr6:27618707-27618779 (-) | GTTTCCGTAGTGTAGTGGTTATCACGTTCGCCTAACACGCGAAAGGTCCCTGGATCAAAACCAGGCGGAAACA |
| 249 | Val_AAC_chr6:27648885-27648957 (-) | GTTTCCGTAGTGTAGTGGTTATCACGTTCGCCTAACACGCGAAAGGTCCGCGGTTCGAAACCGGGCGGAAACA |
| 250 | Val_AAC_chr6:27203288-27203360 (+) | GTTTCCGTAGTGTAGTGGTTATCACGTTTGCCTAACACGCGAAAGGTCCCCGGTTCGAAACCGGGCAGAAACA |
| 251 | Val_AAC_chr6:28703206-28703277 (-) | GGGGGTGTAGCTCAGTGGTAGAGCGTATGCTTAACATTCATGAGGCTCTGGGTTCGATCCCCAGCACTTCCA |
| 252 | Val_CAC_chr1:161369490-161369562 (-) | GTTTCCGTAGTGTAGTGGTTATCACGTTCGCCTCACACGCGAAAGGTCCCCGGTTCGAAACCGGGCGGAAACA |
| 253 | Val_CAC_chr6:27248049-27248121 (-) | GCTTCTGTAGTGTAGTGGTTATCACGTTCGCCTCACACGCGAAAGGTCCCCGGTTCGAAACCGGGCAGAAGCA |
| 254 | Val_CAC_chr19:4724647-4724719 (-) | GTTTCCGTAGTGTAGCGGTTATCACATTCGCCTCACACGCGAAAGGTCCCCGGTTCGATCCCGGGCGGAAACA |
| 255 | Val_CAC_chr1:149298555-149298627 (-) | GTTTCCGTAGTGTAGTGGTTATCACGTTCGCCTCACACGCGAAAGGTCCCCGGTTCGAAACTGGGCGGAAACA |
| 256 | Val_CAC_chr1:149684088-149684161 (-) | GTTTCCGTAGTGTAGTGGTTATCACGTTCGCCTCACACGCGTAAAGGTCCCCGGTTCGAAACCGGGCGGAAACA |
| 257 | Val_CAC_chr6:27173867-27173939 (-) | GTTTCCGTAGTGGAGTGGTTATCACGTTCGCCTCACACGCGAAAGGTCCCCGGTTTGAAACCAGGCGGAAACA |
| 258 | Val_TAC_chr11:59318102-59318174 (-) | GGTTCCATAGTGTAGTGGTTATCACGTCTGCTTTACACGCAGAAGGTCCTGGGTTCGAGCCCCAGTGGAACCA |
| 259 | Val_TAC_chr11:59318460-59318532 (-) | GGTTCCATAGTGTAGCGGTTATCACGTCTGCTTTACACGCAGAAGGTCCTGGGTTCGAGCCCCAGTGGAACCA |
| 260 | Val_TAC_chr10:5895674-5895746 (-) | GGTTCCATAGTGTAGTGGTTATCACATCTGCTTTACACGCAGAAGGTCCTGGGTTCAAGCCCCAGTGGAACCA |
| 261 | Val_TAC_chr6:27258405-27258477 (+) | GTTTCCGTGGTGTAGTGGTTATCACATTCGCCTTACACGCGAAAGGTCCTCGGGTCGAAACCGAGCGGAAACA |
| 262 | iMet_CAT_chr1:153643726-153643797 (+) | AGCAGAGTGGCGCAGCGGAAGCGTGCTGGGCCCATAACCCAGAGGTCGATGGATCGAAACCATCCTCTGCTA |
| 263 | iMet_CAT_chr6:27745664-27745735 (+) | AGCAGAGTGGCGCAGCGGAAGCGTGCTGGGCCCATAACCCAGAGGTCGATGGATCTAAACCATCCTCTGCTA |
| 264 | Glu_TTC_chr1:16861773-16861845 (-) | TCCCTGGTGGTCTAGTGGCTAGGATTCGGCGCTTTCACCGCCGCGGCCCGGGTTCGATTCCCGGTCAGGGAAT |
| 265 | Gly_CCC_chr1:17004765-17004836 (-) | GCGTTGGTGGTTTAGTGGTAGAATTCTCGCCTCCCATGCGGGAGACCCGGGTTCAATTCCCGGCCACTGCAC |
| 266 | Gly_CCC_chr1:17053779-17053850 (+) | GGCCTTGGTGGTGCAGTGGTAGAATTCTCGCCTCCCACGTGGGAGACCCGGGTTCAATTCCCGGCCAATGCA |
| 267 | Glu_TTC_chr1:17199077-17199149 (+) | GTCCCTGGTGGTCTAGTGGCTAGGATTCGGCGCTTTCACCGCCGCGGCCCGGGTTCGATTCCCGGCCAGGGAA |
| 268 | Asn_GTT_chr1:17216171-17216245 (+) | TGTCTCTGTGGCGCAATCGGTTAGCGCGTTCGGCTGTTAACCGAAAGATTGGTGGTTCGAGCCCACCCAGGGACG |
| 269 | Arg_TCT_chr1:94313128-94313213 (+) | TGGCTCCGTGGCGCAATGGATAGCGCATTGGACTTCTAGAGGCTGAAGGCATTCAAAGGTTCCGGGTTCGAGTCCCGGCGGAGTCG |
| 270 | Lys_CTT_chr1:145395521-145395594 (-) | GCCCGGCTAGCTCAGTCGGTAGAGCATGAGACTCTTAATCTCAGGGTCGTGGGTTCGAGCCCCACGTTGGGCGC |
| 271 | His_GTG_chr1:145396880-145396952 (-) | GCCGTGATCGTATAGTGGTTAGTACTCTGCGTTGTGGCCGCAGCAACCTCGGTTCGAATCCGAGTCACGGCAG |
| 272 | Gly_TCC_chr1:145397863-145397935 (-) | GCGTTGGTGGTATAGTGGTGAGCATAGCTGCCTTCCAAGCAGTTGACCCGGGTTCGATTCCCGGCCAACGCAG |
| 273 | Glu_CTC_chr1:145399232-145399304 (-) | TCCCTGGTGGTCTAGTGGTTAGGATTCGGCGCTCTCACCGCCGCGGCCCGGGTTCGATTCCCGGTCAGGGAAA |
| 274 | Gln_CTG_chr1:145963303-145963375 (+) | AGGTTCCATGGTGTAATGGTGAGCACTCTGGACTCTGAATCCAGCGATCCGAGTTCGAGTCTCGGTGGAACCT |
| 275 | Asn_GTT_chr1:148000804-148000878 (+) | TGTCTCTGTGGCGTAGTCGGTTAGCGCGTTCGGCTGTTAACCGAAAAGTTGGTGGTTCGAGCCCACCCAGGAACG |
| 276 | Asn_GTT_chr1:148248114-148248188 (+) | TGTCTCTGTGGCGCAATCGGTTAGCGCGTTCGGCTGTTAACCGAAAGGTTGGTGGTTCGAGCCCACCCAGGGACG |
| 277 | Asn_GTT_chr1:148598313-148598387 (-) | GTCTCTGTGGCGCAATCGGTTAGCGCATTCGGCTGTTAACCGAAAGGTTGGTGGTTCGAGCCCACCCAGGGACGC |
| 278 | Asn_GTT_chr1:149230569-149230643 (-) | GTCTCTGTGGCGCAATGGGTTAGCGCGTTCGGCTGTTAACCGAAAGGTTGGTGGTTCGAGCCCATCCAGGGACGC |
| 279 | Val_CAC_chr1:149294665-149294736 (-) | GCACTGGTGGTTCAGTGGTAGAATTCTCGCCTCACACGCGGGACACCCGGGTTCAATTCCCGGTCAAGGCAA |
| 280 | Val_CAC_chr1:149298554-149298627 (-) | GTTTCCGTAGTGTAGTGGTTATCACGTTCGCCTCACACGCGAAAGGTCCCCGGTTCGAAACTGGGCGGAAACAG |
| 281 | Gly_CCC_chr1:149680209-149680280 (-) | GCACTGGTGGTTCAGTGGTAGAATTCTCGCCTCCCACGCGGGAGACCCGGGTTTAATTCCCGGTCAAGATAA |
| 282 | Val_CAC_chr1:149684087-149684161 (-) | GTTTCCGTAGTGTAGTGGTTATCACGTTCGCCTCACACGCGTAAAGGTCCCCGGTTCGAAACCGGGCGGAAACAT |
| 283 | Met_CAT_chr1:153643725-153643797 (+) | TAGCAGAGTGGCGCAGCGGAAGCGTGCTGGGCCCATAACCCAGAGGTCGATGGATCGAAACCATCCTCTGCTA |
| 284 | Val_CAC_chr1:161369489-161369562 (-) | GTTTCCGTAGTGTAGTGGTTATCACGTTCGCCTCACACGCGAAAGGTCCCCGGTTCGAAACCGGGCGGAAACAA |
| 285 | Asp_GTC_chr1:161410614-161410686 (-) | TCCTCGTTAGTATAGTGGTGAGTATCCCCGCCTGTCACGCGGGAGACCGGGGTTCGATTCCCCGACGGGGAGG |
| 286 | Gly_GCC_chr1:161413093-161413164 (+) | TGCATGGGTGGTTCAGTGGTAGAATTCTCGCCTGCCACGCGGGAGGCCCGGGTTCGATTCCCGGCCCATGCA |
| 287 | Glu_CTC_chr1:161417017-161417089 (-) | TCCCTGGTGGTCTAGTGGTTAGGATTCGGCGCTCTCACCGCCGCGGCCCGGGTTCGATTCCCGGTCAGGGAAG |
| 288 | Asp_GTC_chr1:161492934-161493006 (+) | ATCCTTGTTACTATAGTGGTGAGTATCTCTGCCTGTCATGCGTGAGAGAGGGGGTCGATTCCCCGACGGGGAG |
| 289 | Gly_GCC_chr1:161493636-161493707 (-) | GCATTGGTGGTTCAGTGGTAGAATTCTCGCCTGCCACGCGGGAGGCCCGGGTTCGATTCCCGGCCAATGCAC |
| 290 | Leu_CAG_chr1:161500131-161500214 (-) | GTCAGGATGGCCGAGCGGTCTAAGGCGCTGCGTTCAGGTCGCAGTCTCCCCTGGAGGCGTGGGTTCGAATCCCACTCCTGACAA |
| 291 | Gly_TCC_chr1:161500902-161500974 (+) | CGCGTTGGTGGTATAGTGGTGAGCATAGCTGCCTTCCAAGCAGTTGACCCGGGTTCGATTCCCGGCCAACGCA |
| 292 | Asn_GTT_chr1:161510030-161510104 (+) | CGTCTCTGTGGCGCAATCGGTTAGCGCGTTCGGCTGTTAACCGAAAGGTTGGTGGTTCGATCCCACCCAGGGACG |
| 293 | Glu_TTC_chr1:161582507-161582579 (+) | CGCGTTGGTGGTGTAGTGGTGAGCACAGCTGCCTTTCAAGCAGTTAACGCGGGTTCGATTCCCGGGTAACGAA |
| 294 | Pro_CGG_chr1:167683961-167684033 (+) | CGGCTCGTTGGTCTAGGGGTATGATTCTCGCTTCGGGTGCGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCC |
| 295 | Pro_AGG_chr1:167684724-167684796 (-) | GGCTCGTTGGTCTAGGGGTATGATTCTCGCTTAGGGTGCGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCCT |
| 296 | Lys_TTT_chr1:204475654-204475727 (+) | CGCCCGGATAGCTCAGTCGGTAGAGCATCAGACTTTTAATCTGAGGGTCCAGGGTTCAAGTCCCTGTTCGGGCG |
| 297 | Lys_TTT_chr1:204476157-204476230 (-) | GCCCGGATAGCTCAGTCGGTAGAGCATCAGACTTTTAATCTGAGGGTCCAGGGTTCAAGTCCCTGTTCGGGCGT |
| 298 | Leu_CAA_chr1:249168053-249168159 (+) | TGTCAGGATGGCCGAGTGGTCTAAGGCGCCAGACTCAAGGTAAGCACCTTGCCTGCGGGCTTTCTGGTCTCCGGATGGAGGCGTGGGTTCGAATCCCACTTCTGACA |
| 299 | Glu_CTC_chr1:249168446-249168518 (+) | TTCCCTGGTGGTCTAGTGGTTAGGATTCGGCGCTCTCACCGCCGCGGCCCGGGTTCGATTCCCGGTCAGGAAA |
| 300 | Tyr_GTA_chr2:27273649-27273738 (+) | GCCTTCGATAGCTCAGTTGGTAGAGCGGAGGACTGTAGTGGATAGGGCGTGGCAATCCTTAGGTCGCTGGTTCGATTCCGGCTCGAAGGA |
| 301 | Ala_AGC_chr2:27274081-27274154 (+) | CGGGGGATTAGCTCAAATGGTAGAGCGCTCGCTTAGCATGCGAGAGGTAGCGGGATCGATGCCCGCATCCTCCA |
| 302 | Ile_TAT_chr2:43037675-43037768 (+) | AGCTCCAGTGGCGCAATCGGTTAGCGCGCGGTACTTATACAGCAGTACATGCAGAGCAATGCCGAGGTTGTGAGTTCGAGCCTCACCTGGAGCA |
| 303 | Gly_CCC_chr2:70476122-70476193 (-) | GCGCCGCTGGTGTAGTGGTATCATGCAAGATTCCCATTCTTGCGACCCGGGTTCGATTCCCGGGCGGCGCAT |
| 304 | Glu_TTC_chr2:131094700-131094772 (-) | TCCCATATGGTCTAGCGGTTAGGATTCCTGGTTTTCACCCAGGTGGCCCGGGTTCGACTCCCGGTATGGGAAC |
| 305 | Ala_CGC_chr2:157257280-157257352 (+) | GGGGGATGTAGCTCAGTGGTAGAGCGCGCGCTTCGCATGTGTGAGGTCCCGGGTTCAATCCCCGGCATCTCCA |
| 306 | Gly_GCC_chr2:157257658-157257729 (-) | GCATTGGTGGTTCAGTGGTAGAATTCTCGCCTGCCACGCGGGAGGCCCGGGTTCGATTCCCGGCCAATGCAA |
| 307 | Arg_ACG_chr3:45730490-45730563 (-) | GGGCCAGTGGCGCAATGGATAACGCGTCTGACTACGGATCAGAAGATTCTAGGTTCGACTCCTGGCTGGCTCGC |
| 308 | Val_AAC_chr3:169490017-169490090 (+) | GGTTTCCGTAGTGTAGTGGTTATCACGTTCGCCTAACACGCGAAAGGTCCCCGGTTCGAAACCGGGCGGAAACA |
| 309 | Val_AAC_chr5:180596609-180596682 (+) | AGTTTCCGTAGTGTAGTGGTTATCACGTTCGCCTAACACGCGAAAGGTCCCCGGTTCGAAACCGGGCGGAAACA |
| 310 | Leu_AAG_chr5:180614700-180614782 (+) | AGGTAGCGTGGCCGAGCGGTCTAAGGCGCTGGATTAAGGCTCCAGTCTCTTCGGGGGCGTGGGTTCGAATCCCACCGCTGCCA |
| 311 | Val_AAC_chr5:180615415-180615488 (-) | GTTTCCGTAGTGTAGTGGTCATCACGTTCGCCTAACACGCGAAAGGTCCCCGGTTCGAAACCGGGCGGAAACAT |
| 312 | Pro_TGG_chr5:180615853-180615925 (-) | GGCTCGTTGGTCTAGGGGTATGATTCTCGCTTTGGGTGCGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCCA |
| 313 | Thr_TGT_chr5:180618686-180618758 (-) | GGCTCCATAGCTCAGGGGTTAGAGCACTGGTCTTGTAAACCAGGGTCGCGAGTTCAAATCTCGCTGGGGCCTG |
| 314 | Ala_TGC_chr5:180633867-180633939 (+) | TGGGGATGTAGCTCAGTGGTAGAGCGCATGCTTTGCATGTATGAGGCCCCGGGTTCGATCCCCGGCATCTCCA |
| 315 | Lys_CTT_chr5:180634754-180634827 (+) | CGCCCGGCTAGCTCAGTCGGTAGAGCATGAGACTCTTAATCTCAGGGTCGTGGGTTCGAGCCCCACGTTGGGCG |
| 316 | Val_AAC_chr5:180645269-180645342 (-) | GTTTCCGTAGTGTAGTGGTTATCACGTTCGCCTAACACGCGAAAGGTCCCCGGTTCGAAACCGGGCGGAAACAA |
| 317 | Lys_CTT_chr5:180648978-180649051 (-) | GCCCGGCTAGCTCAGTCGGTAGAGCATGAGACTCTTAATCTCAGGGTCGTGGGTTCGAGCCCCACGTTGGGCGT |
| 318 | Val_CAC_chr5:180649394-180649467 (-) | GTTTCCGTAGTGTAGTGGTTATCACGTTCGCCTCACACGCGAAAGGTCCCCGGTTCGAAACCGGGCGGAAACAC |
| 319 | Met_CAT_chr6:26286753-26286825 (+) | CAGCAGAGTGGCGCAGCGGAAGCGTGCTGGGCCCATAACCCAGAGGTCGATGGATCGAAACCATCCTCTGCTA |
| 320 | Ser_GCT_chr6:26305717-26305801 (-) | GGAGAGGCCTGGCCGAGTGGTTAAGGCGATGGACTGCTAATCCATTGTGCTCTGCACGCGTGGGTTCGAATCCCATCCTCGTCGC |
| 321 | Gln_TTG_chr6:26311423-26311495 (-) | GGCCCCATGGTGTAATGGTTAGCACTCTGGACTTTGAATCCAGCGATCCGAGTTCAAATCTCGGTGGGACCTG |
| 322 | Gln_TTG_chr6:26311974-26312046 (-) | GGCCCCATGGTGTAATGGTTAGCACTCTGGACTTTGAATCCAGCGATCCGAGTTCAAATCTCGGTGGGACCTA |
| 323 | Ser_TGA_chr6:26312823-26312905 (-) | GTAGTCGTGGCCGAGTGGTTAAGGCGATGGACTTGAAATCCATTGGGGTCTCCCCGCGCAGGTTCGAATCCTGCCGACTACGG |
| 324 | Met_CAT_chr6:26313351-26313423 (-) | AGCAGAGTGGCGCAGCGGAAGCGTGCTGGGCCCATAACCCAGAGGTCGATGGATCGAAACCATCCTCTGCTAT |
| 325 | Arg_TCG_chr6:26323045-26323118 (+) | GGACCACGTGGCCTAATGGATAAGGCGTCTGACTTCGGATCAGAAGATTGAGGGTTCGAATCCCTCCGTGGTTA |
| 326 | Ser_AGA_chr6:26327816-26327898 (+) | TGTAGTCGTGGCCGAGTGGTTAAGGCGATGGACTAGAAATCCATTGGGGTCTCCCCGCGCAGGTTCGAATCCTGCCGACTACG |
| 327 | Met_CAT_chr6:26330528-26330600 (-) | AGCAGAGTGGCGCAGCGGAAGCGTGCTGGGCCCATAACCCAGAGGTCGATGGATCGAAACCATCCTCTGCTAG |
| 328 | Leu_CAG_chr6:26521435-26521518 (+) | CGTCAGGATGGCCGAGCGGTCTAAGGCGCTGCGTTCAGGTCGCAGTCTCCCCTGGAGGCGTGGGTTCGAATCCCACTCCTGACA |
| 329 | Thr_AGT_chr6:26533144-26533218 (-) | GGCTCCGTGGCTTAGCTGGTTAAAGCGCCTGTCTAGTAAACAGGAGATCCTGGGTTCGAATCCCAGCGGGGCCTG |
| 330 | Arg_ACG_chr6:26537725-26537798 (+) | AGGGCCAGTGGCGCAATGGATAACGCGTCTGACTACGGATCAGAAGATTCCAGGTTCGACTCCTGGCTGGCTCG |
| 331 | Val_CAC_chr6:26538281-26538354 (+) | GGTTTCCGTAGTGTAGTGGTTATCACGTTCGCCTCACACGCGAAAGGTCCCCGGTTCGAAACCGGGCGGAAACA |
| 332 | Ala_CGC_chr6:26553730-26553802 (+) | AGGGGATGTAGCTCAGTGGTAGAGCGCATGCTTCGCATGTATGAGGTCCCGGGTTCGATCCCCGGCATCTCCA |
| 333 | Ile_AAT_chr6:26554349-26554423 (+) | TGGCCGGTTAGCTCAGTTGGTTAGAGCGTGGTGCTAATAACGCCAAGGTCGCGGGTTCGATCCCCGTACGGGCCA |
| 334 | Pro_AGG_chr6:26555497-26555569 (+) | CGGCTCGTTGGTCTAGGGGTATGATTCTCGCTTAGGGTGCGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCC |
| 335 | Lys_CTT_chr6:26556773-26556846 (+) | AGCCCGGCTAGCTCAGTCGGTAGAGCATGAGACTCTTAATCTCAGGGTCGTGGGTTCGAGCCCCACGTTGGGCG |
| 336 | Tyr_GTA_chr6:26569085-26569176 (+) | TCCTTCGATAGCTCAGTTGGTAGAGCGGAGGACTGTAGTTGGCTGTGTCCTTAGACATCCTTAGGTCGCTGGTTCGAATCCGGCTCGAAGGA |
| 337 | Ala_AGC_chr6:26572091-26572164 (-) | GGGGAATTAGCTCAAATGGTAGAGCGCTCGCTTAGCATGCGAGAGGTAGCGGGATCGATGCCCGCATTCTCCAG |
| 338 | Met_CAT_chr6:26766443-26766516 (+) | CGCCCTCTTAGCGCAGCGGGCAGCGCGTCAGTCTCATAATCTGAAGGTCCTGAGTTCGAGCCTCAGAGAGGGCA |
| 339 | Ile_TAT_chr6:26988124-26988218 (+) | TGCTCCAGTGGCGCAATCGGTTAGCGCGCGGTACTTATATGGCAGTATGTGTGCGAGTGATGCCGAGGTTGTGAGTTCGAGCCTCACCTGGAGCA |
| 340 | His_GTG_chr6:27125905-27125977 (+) | TGCCGTGATCGTATAGTGGTTAGTACTCTGCGTTGTGGCCGCAGCAACCTCGGTTCGAATCCGAGTCACGGCA |
| 341 | Ile_AAT_chr6:27144993-27145067 (-) | GGCCGGTTAGCTCAGTTGGTTAGAGCGTGGTGCTAATAACGCCAAGGTCGCGGGTTCGATCCCCGTACGGGCCAC |
| 342 | Val_AAC_chr6:27203287-27203360 (+) | AGTTTCCGTAGTGTAGTGGTTATCACGTTTGCCTAACACGCGAAAGGTCCCCGGTTCGAAACCGGGCAGAAACA |
| 343 | Val_CAC_chr6:27248048-27248121 (-) | GCTTCTGTAGTGTAGTGGTTATCACGTTCGCCTCACACGCGAAAGGTCCCCGGTTCGAAACCGGGCAGAAGCAA |
| 344 | Asp_GTC_chr6:27447452-27447524 (+) | TTCCTCGTTAGTATAGTGGTGAGTATCCCCGCCTGTCACGCGGGAGACCGGGGTTCGATTCCCCGACGGGGAG |
| 345 | Ser_TGA_chr6:27473606-27473688 (-) | GTAGTCGTGGCCGAGTGGTTAAGGCGATGGACTTGAAATCCATTGGGGTTTCCCCGCGCAGGTTCGAATCCTGTCGGCTACGG |
| 346 | Gln_CTG_chr6:27487307-27487379 (+) | AGGTTCCATGGTGTAATGGTTAGCACTCTGGACTCTGAATCCAGCGATCCGAGTTCAAATCTCGGTGGAACCT |
| 347 | Asp_GTC_chr6:27551235-27551307 (-) | TCCTCGTTAGTATAGTGGTGAGTGTCCCCGTCTGTCACGCGGGAGACCGGGGTTCGATTCCCCGACGGGGAGA |
| 348 | Val_AAC_chr6:27618706-27618779 (-) | GTTTCCGTAGTGTAGTGGTTATCACGTTCGCCTAACACGCGAAAGGTCCCTGGATCAAAACCAGGCGGAAACAA |
| 349 | Ile_AAT_chr6:27655966-27656040 (+) | CGGCCGGTTAGCTCAGTTGGTTAGAGCGTGGTGCTAATAACGCCAAGGTCGCGGGTTCGATCCCCGTACTGGCCA |
| 350 | Gln_CTG_chr6:27759134-27759206 (-) | GGCCCCATGGTGTAATGGTCAGCACTCTGGACTCTGAATCCAGCGATCCGAGTTCAAATCTCGGTGGGACCCA |
| 351 | Gln_TTG_chr6:27763639-27763711 (-) | GGCCCCATGGTGTAATGGTTAGCACTCTGGACTTTGAATCCAGCGATCCGAGTTCAAATCTCGGTGGGACCTT |
| 352 | Ala_AGC_chr6:28574932-28575004 (+) | TGGGGGTGTAGCTCAGTGGTAGAGCGCGTGCTTAGCATGTACGAGGTCCCGGGTTCAATCCCCGGCACCTCCA |
| 353 | Ala_AGC_chr6:28626013-28626085 (-) | GGGGATGTAGCTCAGTGGTAGAGCGCATGCTTAGCATGCATGAGGTCCCGGGTTCGATCCCCAGCATCTCCAG |
| 354 | Ala_CGC_chr6:28697091-28697163 (+) | AGGGGGTGTAGCTCAGTGGTAGAGCGCGTGCTTCGCATGTACGAGGCCCCGGGTTCGACCCCCGGCTCCTCCA |
| 355 | Ala_AGC_chr6:28806220-28806292 (-) | GGGGGTGTAGCTCAGTGGTAGAGCGCGTGCTTAGCATGCACGAGGCCCCGGGTTCAATCCCCGGCACCTCCAT |
| 356 | Ala_AGC_chr6:28831461-28831533 (-) | GGGGGTGTAGCTCAGTGGTAGAGCGCGTGCTTAGCATGCACGAGGCCCCGGGTTCAATCCCCGGCACCTCCAG |
| 357 | Leu_CAA_chr6:28863999-28864105 (-) | GTCAGGATGGCCGAGTGGTCTAAGGCGCCAGACTCAAGCTAAGCTTCCTCCGCGGTGGGGATTCTGGTCTCCAATGGAGGCGTGGGTTCGAATCCCACTTCTGACAC |
| 358 | Leu_CAA_chr6:28908829-28908934 (+) | TGTCAGGATGGCCGAGTGGTCTAAGGCGCCAGACTCAAGCTTGGCTTCCTCGTGTTGAGGATTCTGGTCTCCAATGGAGGCGTGGGTTCGAATCCCACTTCTGACA |
| 359 | Gln_CTG_chr6:28909377-28909449 (-) | GGTTCCATGGTGTAATGGTTAGCACTCTGGACTCTGAATCCAGCGATCCGAGTTCAAATCTCGGTGGAACCTT |
| 360 | Leu_AAG_chr6:28911398-28911480 (-) | GGTAGCGTGGCCGAGCGGTCTAAGGCGCTGGATTAAGGCTCCAGTCTCTTCGGGGGCGTGGGTTCGAATCCCACCGCTGCCAG |
| 361 | Met_CAT_chr6:28912351-28912424 (+) | TGCCTCCTTAGCGCAGTAGGCAGCGCGTCAGTCTCATAATCTGAAGGTCCTGAGTTCGAACCTCAGAGGGGGCA |
| 362 | Lys_TTT_chr6:28918805-28918878 (+) | AGCCCGGATAGCTCAGTCGGTAGAGCATCAGACTTTTAATCTGAGGGTCCAGGGTTCAAGTCCCTGTTCGGGCG |
| 363 | Met_CAT_chr6:28921041-28921114 (-) | GCCTCCTTAGCGCAGTAGGCAGCGCGTCAGTCTCATAATCTGAAGGTCCTGAGTTCGAACCTCAGAGGGGGCAG |
| 364 | Glu_CTC_chr6:28949975-28950047 (+) | TTCCCTGGTGGTCTAGTGGTTAGGATTCGGCGCTCTCACCGCCGCGGCCCGGGTTCGATTCCCGGTCAGGGAA |
| 365 | Leu_TAA_chr6:144537683-144537766 (+) | CACCAGGATGGCCGAGTGGTTAAGGCGTTGGACTTAAGATCCAATGGACATATGTCCGCGTGGGTTCGAACCCCACTCCTGGTA |
| 366 | Pro_AGG_chr7:128423503-128423575 (+) | TGGCTCGTTGGTCTAGGGGTATGATTCTCGCTTAGGGTGCGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCC |
| 367 | Arg_CCT_chr7:139025445-139025518 (+) | AGCCCCAGTGGCCTAATGGATAAGGCATTGGCCTCCTAAGCCAGGGATTGTGGGTTCGAGTCCCATCTGGGGTG |
| 368 | Cys_GCA_chr7:149388271-149388343 (-) | GGGGATATAGCTCAGGGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCCGGTTCAAATCCGGGTGCCCCCCC |
| 369 | Tyr_GTA_chr8:67025601-67025694 (+) | CCCTTCGATAGCTCAGCTGGTAGAGCGGAGGACTGTAGCTACTTCCTCAGCAGGAGACATCCTTAGGTCGCTGGTTCGATTCCGGCTCGAAGGA |
| 370 | Tyr_GTA_chr8:67026222-67026311 (+) | CCCTTCGATAGCTCAGCTGGTAGAGCGGAGGACTGTAGGCGCGCGCCCGTGGCCATCCTTAGGTCGCTGGTTCGATTCCGGCTCGAAGGA |
| 371 | Ala_AGC_chr8:67026423-67026496 (+) | TGGGGGATTAGCTCAAATGGTAGAGCGCTCGCTTAGCATGCGAGAGGTAGCGGGATCGATGCCCGCATCCTCCA |
| 372 | Ser_AGA_chr8:96281884-96281966 (-) | GTAGTCGTGGCCGAGTGGTTAAGGCGATGGACTAGAAATCCATTGGGGTCTCCCCGCGCAGGTTCGAATCCTGCCGACTACGG |
| 373 | Met_CAT_chr8:124169469-124169542 (-) | GCCTCGTTAGCGCAGTAGGTAGCGCGTCAGTCTCATAATCTGAAGGTCGTGAGTTCGATCCTCACACGGGGCAC |
| 374 | Arg_TCT_chr9:131102354-131102445 (-) | GGCTCTGTGGCGCAATGGATAGCGCATTGGACTTCTAGCTGAGCCTAGTGTGGTCATTCAAAGGTTGTGGGTTCGAGTCCCACCAGAGTCGA |
| 375 | Asn_GTT_chr10:22518437-22518511 (-) | GTCTCTGTGGCGCAATCGGTTAGCGCGTTCGGCTGTTAACCGAAAGGTTGGTGGTTCGAGCCCACCCAGGGACGC |
| 376 | Ser_TGA_chr10:69524260-69524342 (+) | GGCAGCGATGGCCGAGTGGTTAAGGCGTTGGACTTGAAATCCAATGGGGTCTCCCCGCGCAGGTTCGAACCCTGCTCGCTGCG |
| 377 | Val_TAC_chr11:59318101-59318174 (-) | GGTTCCATAGTGTAGTGGTTATCACGTCTGCTTTACACGCAGAAGGTCCTGGGTTCGAGCCCCAGTGGAACCAT |
| 378 | Val_TAC_chr11:59318459-59318532 (-) | GGTTCCATAGTGTAGCGGTTATCACGTCTGCTTTACACGCAGAAGGTCCTGGGTTCGAGCCCCAGTGGAACCAC |
| 379 | Arg_TCT_chr11:59318766-59318852 (+) | TGGCTCTGTGGCGCAATGGATAGCGCATTGGACTTCTAGATAGTTAGAGAAATTCAAAGGTTGTGGGTTCGAGTCCCACCAGAGTCG |
| 380 | Leu_TAA_chr11:59319227-59319310 (+) | TACCAGAATGGCCGAGTGGTTAAGGCGTTGGACTTAAGATCCAATGGATTCATATCCGCGTGGGTTCGAACCCCACTTCTGGTA |
| 381 | Lys_TTT_chr11:59323901-59323974 (+) | GGCCCGGATAGCTCAGTCGGTAGAGCATCAGACTTTTAATCTGAGGGTCCGGGGTTCAAGTCCCTGTTCGGGCG |
| 382 | Phe_GAA_chr11:59324969-59325042 (-) | GCCGAAATAGCTCAGTTGGGAGAGCGTTAGACTGAAGATCTAAAGGTCCCTGGTTCGATCCCGGGTTTCGGCAG |
| 383 | Lys_TTT_chr11:59327807-59327880 (-) | GCCCGGATAGCTCAGTCGGTAGAGCATCAGACTTTTAATCTGAGGGTCCAGGGTTCAAGTCCCTGTTCGGGCGG |
| 384 | Phe_GAA_chr11:59333852-59333925 (-) | GCCGAAATAGCTCAGTTGGGAGAGCGTTAGACTGAAGATCTAAAGGTCCCTGGTTCAATCCCGGGTTTCGGCAG |
| 385 | Ser_GCT_chr11:66115590-66115672 (+) | GGACGAGGTGGCCGAGTGGTTAAGGCGATGGACTGCTAATCCATTGTGCTTTGCACGCGTGGGTTCGAATCCCATCCTCGTCG |
| 386 | Pro_TGG_chr11:75946868-75946940 (-) | GGCTCGTTGGTCTAGGGGTATGATTCTCGGTTTGGGTCCGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCCC |
| 387 | Ser_CGA_chr12:56584147-56584229 (+) | AGTCACGGTGGCCGAGTGGTTAAGGCGTTGGACTCGAAATCCAATGGGGTTTCCCCGCACAGGTTCGAATCCTGTTCGTGACG |
| 388 | Asp_GTC_chr12:98897280-98897352 (+) | CTCCTCGTTAGTATAGTGGTTAGTATCCCCGCCTGTCACGCGGGAGACCGGGGTTCAATTCCCCGACGGGGAG |
| 389 | Trp_CCA_chr12:98898029-98898101 (+) | GGACCTCGTGGCGCAACGGTAGCGCGTCTGACTCCAGATCAGAAGGCTGCGTGTTCGAATCACGTCGGGGTCA |
| 390 | Ala_TGC_chr12:125406300-125406372 (-) | GGGGATGTAGCTCAGTGGTAGAGCGCATGCTTTGCATGTATGAGGCCCCGGGTTCGATCCCCGGCATCTCCAT |
| 391 | Phe_GAA_chr12:125412388-125412461 (-) | GCCGAAATAGCTCAGTTGGGAGAGCGTTAGACTGAAGATCTAAAGGTCCCTGGTTCGATCCCGGGTTTCGGCAC |
| 392 | Ala_TGC_chr12:125424511-125424583 (+) | AGGGGATGTAGCTCAGTGGTAGAGCGCATGCTTTGCACGTATGAGGCCCCGGGTTCAATCCCCGGCATCTCCA |
| 393 | Asn_GTT_chr13:31248100-31248174 (-) | GTCTCTGTGGCGCAATCGGTTAGCGCGTTCGGCTGTTAACCGAAAGGTTGGTGGTTCGAGCCCACCCAGGGACGG |
| 394 | Glu_TTC_chr13:45492061-45492133 (-) | TCCCACATGGTCTAGCGGTTAGGATTCCTGGTTTTCACCCAGGCGGCCCGGGTTCGACTCCCGGTGTGGGAAC |
| 395 | Thr_TGT_chr14:21081948-21082021 (-) | GGCTCCATAGCTCAGGGGTTAGAGCGCTGGTCTTGTAAACCAGGGGTCGCGAGTTCAATTCTCGCTGGGGCCTG |
| 396 | Leu_TAG_chr14:21093528-21093610 (+) | TGGTAGTGTGGCCGAGCGGTCTAAGGCGCTGGATTTAGGCTCCAGTCTCTTCGGGGGCGTGGGTTCGAATCCCACCACTGCCA |
| 397 | Thr_TGT_chr14:21099318-21099391 (-) | GGCTCCATAGCTCAGGGGTTAGAGCACTGGTCTTGTAAACCAGGGGTCGCGAGTTCAAATCTCGCTGGGGCCTC |
| 398 | Pro_TGG_chr14:21101164-21101236 (+) | TGGCTCGTTGGTCTAGTGGTATGATTCTCGCTTTGGGTGCGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCC |
| 399 | Tyr_GTA_chr14:21131350-21131444 (-) | CCTTCGATAGCTCAGCTGGTAGAGCGGAGGACTGTAGATTGTACAGACATTTGCGGACATCCTTAGGTCGCTGGTTCGATTCCGGCTCGAAGGAA |
| 400 | Thr_TGT_chr14:21149848-21149921 (+) | AGGCCCTATAGCTCAGGGGTTAGAGCACTGGTCTTGTAAACCAGGGGTCGCGAGTTCAAATCTCGCTGGGGCCT |
| 401 | Tyr_GTA_chr14:21151431-21151520 (+) | TCCTTCGATAGCTCAGCTGGTAGAGCGGAGGACTGTAGTACTTAATGTGTGGTCATCCTTAGGTCGCTGGTTCGATTCCGGCTCGAAGGA |
| 402 | Pro_TGG_chr14:21152174-21152246 (+) | TGGCTCGTTGGTCTAGGGGTATGATTCTCGCTTTGGGTGCGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCC |
| 403 | Lys_CTT_chr14:58706612-58706685 (-) | GCCCGGCTAGCTCAGTCGGTAGAGCATGGGACTCTTAATCCCAGGGTCGTGGGTTCGAGCCCCACGTTGGGCGC |
| 404 | Ile_AAT_chr14:102783428-102783502 (+) | CGGCCGGTTAGCTCAGTTGGTTAGAGCGTGGTGCTAATAACGCCAAGGTCGCGGGTTCGATCCCCGTACGGGCCA |
| 405 | Glu_TTC_chr15:26327380-26327452 (-) | TCCCACATGGTCTAGCGGTTAGGATTCCTGGTTTTCACCCAGGCGGCCCGGGTTCGACTCCCGGTGTGGGAAT |
| 406 | Ser_GCT_chr15:40886022-40886104 (-) | GACGAGGTGGCCGAGTGGTTAAGGCGATGGACTGCTAATCCATTGTGCTCTGCACGCGTGGGTTCGAATCCCATCCTCGTCGA |
| 407 | His_GTG_chr15:45490803-45490875 (-) | GCCGTGATCGTATAGTGGTTAGTACTCTGCGTTGTGGCCGCAGCAACCTCGGTTCGAATCCGAGTCACGGCAT |
| 408 | His_GTG_chr15:45493348-45493420 (+) | CGCCGTGATCGTATAGTGGTTAGTACTCTGCGTTGTGGCCGCAGCAACCTCGGTTCGAATCCGAGTCACGGCA |
| 409 | Gln_CTG_chr15:66161399-66161471 (-) | GGTTCCATGGTGTAATGGTTAGCACTCTGGACTCTGAATCCAGCGATCCGAGTTCAAATCTCGGTGGAACCTG |
| 410 | Lys_CTT_chr15:79152903-79152976 (+) | TGCCCGGCTAGCTCAGTCGGTAGAGCATGGGACTCTTAATCCCAGGGTCGTGGGTTCGAGCCCCACGTTGGGCG |
| 411 | Arg_TCG_chr15:89878303-89878376 (+) | GGGCCGCGTGGCCTAATGGATAAGGCGTCTGACTTCGGATCAGAAGATTGCAGGTTCGAGTCCTGCCGCGGTCG |
| 412 | Gly_CCC_chr16:686735-686806 (-) | GCGCCGCTGGTGTAGTGGTATCATGCAAGATTCCCATTCTTGCGACCCGGGTTCGATTCCCGGGCGGCGCAC |
| 413 | Arg_CCG_chr16:3200674-3200747 (+) | GGGCCGCGTGGCCTAATGGATAAGGCGTCTGATTCCGGATCAGAAGATTGAGGGTTCGAGTCCCTTCGTGGTCG |
| 414 | Arg_CCT_chr16:3202900-3202973 (+) | CGCCCCGGTGGCCTAATGGATAAGGCATTGGCCTCCTAAGCCAGGGATTGTGGGTTCGAGTCCCACCCGGGGTA |
| 415 | Lys_CTT_chr16:3207405-3207478 (-) | GCCCGGCTAGCTCAGTCGGTAGAGCATGAGACCCTTAATCTCAGGGTCGTGGGTTCGAGCCCCACGTTGGGCGT |
| 416 | Thr_CGT_chr16:14379749-14379821 (+) | AGGCGCGGTGGCCAAGTGGTAAGGCGTCGGTCTCGTAAACCGAAGATCACGGGTTCGAACCCCGTCCGTGCCT |
| 417 | Leu_TAG_chr16:22207031-22207113 (-) | GGTAGCGTGGCCGAGTGGTCTAAGGCGCTGGATTTAGGCTCCAGTCATTTCGATGGCGTGGGTTCGAATCCCACCGCTGCCAC |
| 418 | Leu_AAG_chr16:22308460-22308542 (+) | GGGTAGCGTGGCCGAGCGGTCTAAGGCGCTGGATTAAGGCTCCAGTCTCTTCGGGGGCGTGGGTTCGAATCCCACCGCTGCCA |
| 419 | Leu_CAG_chr16:57333862-57333945 (+) | AGTCAGGATGGCCGAGCGGTCTAAGGCGCTGCGTTCAGGTCGCAGTCTCCCCTGGAGGCGTGGGTTCGAATCCCACTTCTGACA |
| 420 | Leu_CAG_chr16:57334391-57334474 (-) | GTCAGGATGGCCGAGCGGTCTAAGGCGCTGCGTTCAGGTCGCAGTCTCCCCTGGAGGCGTGGGTTCGAATCCCACTTCTGACAG |
| 421 | Met_CAT_chr16:87417627-87417700 (-) | GCCTCGTTAGCGCAGTAGGCAGCGCGTCAGTCTCATAATCTGAAGGTCGTGAGTTCGAGCCTCACACGGGGCAG |
| 422 | Leu_TAG_chr17:8023631-8023713 (-) | GGTAGCGTGGCCGAGCGGTCTAAGGCGCTGGATTTAGGCTCCAGTCTCTTCGGAGGCGTGGGTTCGAATCCCACCGCTGCCAG |
| 423 | Arg_TCT_chr17:8024242-8024330 (+) | TGGCTCTGTGGCGCAATGGATAGCGCATTGGACTTCTAGTGACGAATAGAGCAATTCAAAGGTTGTGGGTTCGAATCCCACCAGAGTCG |
| 424 | Gly_GCC_chr17:8029063-8029134 (+) | CGCATTGGTGGTTCAGTGGTAGAATTCTCGCCTGCCACGCGGGAGGCCCGGGTTCGATTCCCGGCCAATGCA |
| 425 | Ser_CGA_chr17:8042198-8042280 (-) | GCTGTGATGGCCGAGTGGTTAAGGCGTTGGACTCGAAATCCAATGGGGTCTCCCCGCGCAGGTTCGAATCCTGCTCACAGCGT |
| 426 | Thr_AGT_chr17:8042769-8042843 (-) | GGCGCCGTGGCTTAGCTGGTTAAAGCGCCTGTCTAGTAAACAGGAGATCCTGGGTTCGAATCCCAGCGGTGCCTG |
| 427 | Trp_CCA_chr17:8089675-8089747 (+) | CGACCTCGTGGCGCAACGGTAGCGCGTCTGACTCCAGATCAGAAGGTTGCGTGTTCAAATCACGTCGGGGTCA |
| 428 | Ser_GCT_chr17:8090183-8090265 (+) | AGACGAGGTGGCCGAGTGGTTAAGGCGATGGACTGCTAATCCATTGTGCTCTGCACGCGTGGGTTCGAATCCCATCCTCGTCG |
| 429 | Thr_AGT_chr17:8090477-8090551 (+) | CGGCGCCGTGGCTTAGTTGGTTAAAGCGCCTGTCTAGTAAACAGGAGATCCTGGGTTCGAATCCCAGCGGTGCCT |
| 430 | Trp_CCA_chr17:8124186-8124258 (-) | GGCCTCGTGGCGCAACGGTAGCGCGTCTGACTCCAGATCAGAAGGTTGCGTGTTCAAATCACGTCGGGGTCAA |
| 431 | Gly_TCC_chr17:8124865-8124937 (+) | AGCGTTGGTGGTATAGTGGTAAGCATAGCTGCCTTCCAAGCAGTTGACCCGGGTTCGATTCCCGGCCAACGCA |
| 432 | Asp_GTC_chr17:8125555-8125627 (-) | TCCTCGTTAGTATAGTGGTGAGTATCCCCGCCTGTCACGCGGGAGACCGGGGTTCGATTCCCCGACGGGGAGA |
| 433 | Pro_CGG_chr17:8126150-8126222 (-) | GGCTCGTTGGTCTAGGGGTATGATTCTCGCTTCGGGTGCGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCCT |
| 434 | Thr_AGT_chr17:8129552-8129626 (-) | GGCGCCGTGGCTTAGTTGGTTAAAGCGCCTGTCTAGTAAACAGGAGATCCTGGGTTCGAATCCCAGCGGTGCCTT |
| 435 | Ser_AGA_chr17:8129927-8130009 (-) | GTAGTCGTGGCCGAGTGGTTAAGGCGATGGACTAGAAATCCATTGGGGTCTCCCCGCGCAGGTTCGAATCCTGCCGACTACGT |
| 436 | Trp_CCA_chr17:19411493-19411565 (+) | TGACCTCGTGGCGCAATGGTAGCGCGTCTGACTCCAGATCAGAAGGTTGCGTGTTCAAGTCACGTCGGGGTCA |
| 437 | Thr_CGT_chr17:29877092-29877164 (+) | AGGCGCGGTGGCCAAGTGGTAAGGCGTCGGTCTCGTAAACCGAAGATCGCGGGTTCGAACCCCGTCCGTGCCT |
| 438 | Cys_GCA_chr17:37023897-37023969 (+) | AGGGGGTATAGCTCAGTGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCCGGTTCAAATCCGGGTGCCCCCT |
| 439 | Cys_GCA_chr17:37025544-37025616 (-) | GGGGGTATAGCTCAGTGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCTGGTTCAAATCCGGGTGCCCCCTC |
| 440 | Cys_GCA_chr17:37309986-37310058 (-) | GGGGGTATAGCTCAGTGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCCGGTTCAAATCCGGGTGCCCCCTC |
| 441 | Gln_TTG_chr17:47269889-47269961 (+) | AGGTCCCATGGTGTAATGGTTAGCACTCTGGACTTTGAATCCAGCGATCCGAGTTCAAATCTCGGTGGGACCT |
| 442 | Arg_CCG_chr17:66016012-66016085 (-) | GACCCAGTGGCCTAATGGATAAGGCATCAGCCTCCGGAGCTGGGGATTGTGGGTTCGAGTCCCATCTGGGTCGC |
| 443 | Arg_CCT_chr17:73030000-73030073 (+) | AGCCCCAGTGGCCTAATGGATAAGGCACTGGCCTCCTAAGCCAGGGATTGTGGGTTCGAGTCCCACCTGGGGTA |
| 444 | Arg_CCT_chr17:73030525-73030598 (-) | GCCCCAGTGGCCTAATGGATAAGGCACTGGCCTCCTAAGCCAGGGATTGTGGGTTCGAGTCCCACCTGGGGTGT |
| 445 | Arg_TCG_chr17:73031207-73031280 (+) | AGACCGCGTGGCCTAATGGATAAGGCGTCTGACTTCGGATCAGAAGATTGAGGGTTCGAGTCCCTTCGTGGTCG |
| 446 | Asn_GTT_chr19:1383561-1383635 (+) | CGTCTCTGTGGCGCAATCGGTTAGCGCGTTCGGCTGTTAACCGAAAGGTTGGTGGTTCGAGCCCACCCAGGGACG |
| 447 | Gly_TCC_chr19:4724081-4724153 (+) | GGCGTTGGTGGTATAGTGGTTAGCATAGCTGCCTTCCAAGCAGTTGACCCGGGTTCGATTCCCGGCCAACGCA |
| 448 | Val_CAC_chr19:4724646-4724719 (-) | GTTTCCGTAGTGTAGCGGTTATCACATTCGCCTCACACGCGAAAGGTCCCCGGTTCGATCCCGGGCGGAAACAG |
| 449 | Thr_AGT_chr19:33667962-33668036 (+) | TGGCGCCGTGGCTTAGTTGGTTAAAGCGCCTGTCTAGTAAACAGGAGATCCTGGGTTCGAATCCCAGCGGTGCCT |
| 450 | Ile_TAT_chr19:39902807-39902900 (-) | GCTCCAGTGGCGCAATCGGTTAGCGCGCGGTACTTATATGACAGTGCGAGCGGAGCAATGCCGAGGTTGTGAGTTCGATCCTCACCTGGAGCAC |
| 451 | Gly_GCC_chr21:18827106-18827177 (-) | GCATGGGTGGTTCAGTGGTAGAATTCTCGCCTGCCACGCGGGAGGCCCGGGTTCGATTCCCGGCCCATGCAG |
去唾液酸糖蛋白受體結合部分本發明之特徵在於一種包含去唾液酸糖蛋白受體(ASGPR)結合部分之TREM。ASGPR為主要在肝細胞之血竇表面上表現的C型凝集素,且包含主要亞基(48 kDa,ASGPR-1)及次要亞基(40 kDa,ASGPR-2)。ASGPR參與含有N末端半乳糖(Gal)或N末端N-乙醯基半乳胺糖(GalNAc)殘基之糖蛋白(諸如抗體)之結合、內化以及隨後自循環之清除。ASGPR亦顯示參與低密度脂蛋白、纖維結合蛋白及某些免疫細胞之清除,且可由某些病毒用於肝細胞進入(參見例如Yang J.等人(2006)
J Viral Hepat13:158-165及Guy, CS等人(2011)
Nat Rev Immunol8:874-887)。
如本文所描述之ASGPR結合部分可係指包含以下之結構:(i) ASGPR碳水化合物及(ii) ASGPR連接子(例如將碳水化合物連接至TREM之連接子)。如本文所使用之術語「碳水化合物」係指包含以下之化合物:一或多個包含至少3個碳原子(例如以直鏈、分支鏈或環狀結構排列)及氧、氮或硫原子之單醣部分,或包含至少3個碳原子(例如以直鏈、分支鏈或環狀結構排列)及氧、氮或硫原子之單醣部分之片段或變體。各單醣部分或其片段或變體可為丁醣、戊醣、己醣或庚醣。各單醣部分或其片段或變體可以醛醣、酮醣、糖醇之形式且適當時以L或D形式存在。例示性單醣部分可為胺基糖、N-乙醯基胺基糖、亞胺基糖、去氧糖或糖酸。碳水化合物可包含個別單醣部分,或可進一步包含雙醣、寡醣(例如三醣、四醣、五醣、六醣、七醣、八醣)、多醣或其組合。例示性碳水化合物包括核糖、阿拉伯糖(arabinose)、來蘇糖(lyxose)、木糖、去氧核糖、核酮糖、木酮糖、葡萄糖、半乳糖、甘露糖、古洛糖(gulose)、艾杜糖(idose)、塔羅糖(talose)、阿洛糖(allose)、阿卓糖(altrose)、阿洛酮糖(psicose)、果糖、山梨糖、塔格糖(tagatose)、鼠李糖(rhamnose)、pneumose、異鼠李糖(quinovose)、岩藻糖、甘露庚酮糖、景天庚酮糖、半乳胺糖、甘露糖胺、葡萄胺糖、N-乙醯基葡萄胺糖、N-乙醯基半乳胺糖、N-乙醯基甘露胺糖、葡萄糖醛酸、半乳糖醛酸、甘露糖醛酸、古洛糖醛酸、艾杜糖醛酸、塔格糖酮酸、果糖酮酸、半乳胺糖醛酸、甘露胺糖醛酸、葡萄胺糖醛酸、N-乙醯基葡萄胺糖醛酸、N-乙醯基半乳胺糖醛酸、N-乙醯基甘露胺糖醛酸、麥芽糖、乳糖、蔗糖、海藻糖、龍膽二糖、纖維二糖、殼二糖、麴二糖、黑麴黴糖、槐二糖、海藻酮糖、異麥芽糖、木二糖、澱粉、纖維素、殼糖及聚葡萄糖。
碳水化合物可包含一或多個藉由醣苷鍵連接的單醣部分。在一些實施例中,醣苷鍵包含1至>2個醣苷鍵、1至>3個醣苷鍵、1至>4個醣苷鍵或1至>6個醣苷鍵。在一些實施例中,各醣苷鍵可以α或β構形存在。在一實施例中,一或多個單醣部分藉由醣苷鍵直接連接或藉由連接子分離。
在一些實施例中,ASGPR結合部分包含半乳糖(Gal)、半乳胺糖(GalNH
2)或N-乙醯基半乳胺糖(GalNAc)部分,例如Gal、GalNH
2或GalNAc或其類似物。在一實施例中,ASGPR結合部分包含GalNAc部分(例如GalNAc)。在一實施例中,ASGPR結合部分包含複數個GalNAc部分(例如GalNAc),例如至少2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20或更多個GalNAc部分(例如GalNAc)。在一實施例中,ASGPR結合部分包含2與20個之間的GalNAc部分(例如2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20個GalNAc部分)。在一實施例中,ASGPR結合部分包含2與10個之間的GalNAc部分(例如2、3、4、5、6、7、8、9或10個GalNAc部分)。在一實施例中,ASGPR結合部分包含2與5個之間的GalNAc部分(例如2、3、4或5個GalNAc部分)。在一實施例中,ASGPR結合部分包含2個GalNAc部分。在一實施例中,ASGPR結合部分包含3個GalNAc部分。在一實施例中,ASGPR結合部分包含4個GalNAc部分。在一實施例中,ASGPR部分包含5個GalNAc部分。
在一些實施例中,GalNAc部分包含式(I)之結構:
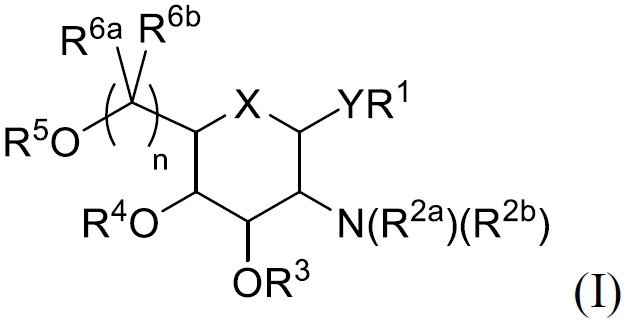 ,或其鹽,其中 X及Y中之每一者獨立地為O、N(R
7)或S;R
1、R
3、R
4及R
5中之每一者獨立地為氫、烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基、雜環基、C(O)-烷基、C(O)-烯基、C(O)-炔基、C(O)-雜烷基、C(O)-鹵烷基、C(O)-芳基、C(O)-雜芳基、C(O)-環烷基或C(O)-雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
8取代;或R
3及R
4與其所連接之氧原子一起形成視情況經一或多個R
8取代之雜環基環;R
2a為氫或烷基;R
2b為-C(O)烷基(例如C(O)CH
3);R
6a及R
6b中之每一者為氫、烷基、烯基、炔基、雜烷基、鹵烷基、鹵基、氰基、硝基、-OR
A、芳基、雜芳基、環烷基或雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
9取代;R
7為氫、烷基或C(O)-烷基;R
8及R
9中之每一者獨立地為氫、鹵基、氰基、烷基、烯基、炔基、雜烷基、鹵烷基、環烷基或雜環基;R
A為氫或烷基、烯基、炔基,且n為0與6之間的整數,其中該式(I)之結構可連接至連接子或TREM之ASt內之核鹼基。
,或其鹽,其中 X及Y中之每一者獨立地為O、N(R
7)或S;R
1、R
3、R
4及R
5中之每一者獨立地為氫、烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基、雜環基、C(O)-烷基、C(O)-烯基、C(O)-炔基、C(O)-雜烷基、C(O)-鹵烷基、C(O)-芳基、C(O)-雜芳基、C(O)-環烷基或C(O)-雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
8取代;或R
3及R
4與其所連接之氧原子一起形成視情況經一或多個R
8取代之雜環基環;R
2a為氫或烷基;R
2b為-C(O)烷基(例如C(O)CH
3);R
6a及R
6b中之每一者為氫、烷基、烯基、炔基、雜烷基、鹵烷基、鹵基、氰基、硝基、-OR
A、芳基、雜芳基、環烷基或雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
9取代;R
7為氫、烷基或C(O)-烷基;R
8及R
9中之每一者獨立地為氫、鹵基、氰基、烷基、烯基、炔基、雜烷基、鹵烷基、環烷基或雜環基;R
A為氫或烷基、烯基、炔基,且n為0與6之間的整數,其中該式(I)之結構可連接至連接子或TREM之ASt內之核鹼基。
在一些實施例中,X為O。在一些實施例中,Y為O。在一些實施例中,R
1、R
3、R
4及R
5中之每一者獨立地為氫或烷基(例如CH
3)。在一些實施例中,R
2a為氫。在一些實施例中,R
2b為C(O)CH
3。在一些實施例中,R
6a及R
6b中之每一者為氫。在一些實施例中,n為0、1、2或3。在一些實施例中,n為1、2或3。在一些實施例中,n為1。在一些實施例中,GalNAc部分在R
2a處連接至連接子或TREM。在一些實施例中,GalNAc部分在R
2b處連接至連接子或TREM。在一些實施例中,GalNAc部分在R
3處連接至連接子或TREM。在一些實施例中,GalNAc部分在R
4處連接至連接子或TREM。在一些實施例中,GalNAc部分在R
5處連接至連接子或TREM。在一些實施例中,GalNAc部分在R
6a或R
6b處連接至連接子或TREM。在一些實施例中,GalNAc部分在複數個位置處,例如在R
1、R
2a、R
2b、R
3、R
4、R
5、R
6a及R
6b中之至少兩者處連接至連接子或TREM。
在一些實施例中,GalNAc部分包含式(I-a)之結構
 ,或其鹽,其中R
2a為氫或烷基;R
2b為-C(O)烷基(例如C(O)CH
3);R
3、R
4及R
5中之每一者獨立地為氫、烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基、雜環基、C(O)-烷基、C(O)-烯基、C(O)-炔基、C(O)-雜烷基、C(O)-鹵烷基、C(O)-芳基、C(O)-雜芳基、C(O)-環烷基或C(O)-雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
8取代;或R
3及R
4與其所連接之氧原子一起形成視情況經一或多個R
8取代之雜環基環;且R
8為氫、鹵基、氰基、烷基、烯基、炔基、雜烷基、鹵烷基、環烷基或雜環基,其中「
,或其鹽,其中R
2a為氫或烷基;R
2b為-C(O)烷基(例如C(O)CH
3);R
3、R
4及R
5中之每一者獨立地為氫、烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基、雜環基、C(O)-烷基、C(O)-烯基、C(O)-炔基、C(O)-雜烷基、C(O)-鹵烷基、C(O)-芳基、C(O)-雜芳基、C(O)-環烷基或C(O)-雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
8取代;或R
3及R
4與其所連接之氧原子一起形成視情況經一或多個R
8取代之雜環基環;且R
8為氫、鹵基、氰基、烷基、烯基、炔基、雜烷基、鹵烷基、環烷基或雜環基,其中「
 」表示呈任何構形之鍵,且「
」表示呈任何構形之鍵,且「
 」表示與TREM (例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端)之連接點。
」表示與TREM (例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端)之連接點。
在一些實施例中,R
3、R
4及R
5中之每一者獨立地為氫或烷基(例如CH
3)。在一些實施例中,R
2a為氫。在一些實施例中,R
2b為C(O)CH
3。
在一些實施例中,GalNAc部分包含式(II)之結構:
 ,或其鹽,其中 X為O、N(R
7)或S;W或Y中之每一者獨立地為O或C(R
10a)(R
10b),其中W及Y中之一者為O;R
1、R
3、R
4及R
5中之每一者獨立地為氫、烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基、雜環基、C(O)-烷基、C(O)-烯基、C(O)-炔基、C(O)-雜烷基、C(O)-鹵烷基、C(O)-芳基、C(O)-雜芳基、C(O)-環烷基或C(O)-雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
8取代;或R
3及R
4與其所連接之氧原子一起形成視情況經一或多個R
8取代之雜環基環;R
2a為氫或烷基;R
2b為-C(O)烷基(例如C(O)CH
3);R
6a及R
6b中之每一者為氫、烷基、烯基、炔基、雜烷基、鹵烷基、鹵基、氰基、硝基、-OR
A、芳基、雜芳基、環烷基或雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
9取代;R
7為氫、烷基或C(O)-烷基;R
8及R
9中之每一者獨立地為氫、鹵基、氰基、烷基、烯基、炔基、雜烷基、鹵烷基、環烷基或雜環基;R
10a及R
10b中之每一者獨立地為氫、雜烷基、鹵烷基或鹵基;且R
A為氫或烷基、烯基、炔基,其中該式(I)之結構可連接至TREM,例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端。
,或其鹽,其中 X為O、N(R
7)或S;W或Y中之每一者獨立地為O或C(R
10a)(R
10b),其中W及Y中之一者為O;R
1、R
3、R
4及R
5中之每一者獨立地為氫、烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基、雜環基、C(O)-烷基、C(O)-烯基、C(O)-炔基、C(O)-雜烷基、C(O)-鹵烷基、C(O)-芳基、C(O)-雜芳基、C(O)-環烷基或C(O)-雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
8取代;或R
3及R
4與其所連接之氧原子一起形成視情況經一或多個R
8取代之雜環基環;R
2a為氫或烷基;R
2b為-C(O)烷基(例如C(O)CH
3);R
6a及R
6b中之每一者為氫、烷基、烯基、炔基、雜烷基、鹵烷基、鹵基、氰基、硝基、-OR
A、芳基、雜芳基、環烷基或雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
9取代;R
7為氫、烷基或C(O)-烷基;R
8及R
9中之每一者獨立地為氫、鹵基、氰基、烷基、烯基、炔基、雜烷基、鹵烷基、環烷基或雜環基;R
10a及R
10b中之每一者獨立地為氫、雜烷基、鹵烷基或鹵基;且R
A為氫或烷基、烯基、炔基,其中該式(I)之結構可連接至TREM,例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端。
在一些實施例中,GalNAc部分包含式(II-a)之結構:
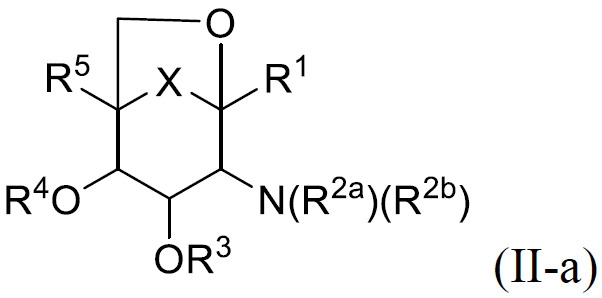 ,或其鹽,其中 X為O、N(R
7)或S;R
1、R
3、R
4及R
5中之每一者獨立地為氫、烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基、雜環基、C(O)-烷基、C(O)-烯基、C(O)-炔基、C(O)-雜烷基、C(O)-鹵烷基、C(O)-芳基、C(O)-雜芳基、C(O)-環烷基或C(O)-雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
8取代;或R
3及R
4與其所連接之氧原子一起形成視情況經一或多個R
8取代之雜環基環;R
2a為氫或烷基;R
2b為-C(O)烷基(例如C(O)CH
3);R
6a及R
6b中之每一者為氫、烷基、烯基、炔基、雜烷基、鹵烷基、鹵基、氰基、硝基、-OR
A、芳基、雜芳基、環烷基或雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
9取代;R
7為氫、烷基或C(O)-烷基;R
8及R
9中之每一者獨立地為氫、鹵基、氰基、烷基、烯基、炔基、雜烷基、鹵烷基、環烷基或雜環基;且R
A為氫或烷基、烯基、炔基,其中該式(I)之結構可連接至TREM,例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端。
,或其鹽,其中 X為O、N(R
7)或S;R
1、R
3、R
4及R
5中之每一者獨立地為氫、烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基、雜環基、C(O)-烷基、C(O)-烯基、C(O)-炔基、C(O)-雜烷基、C(O)-鹵烷基、C(O)-芳基、C(O)-雜芳基、C(O)-環烷基或C(O)-雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
8取代;或R
3及R
4與其所連接之氧原子一起形成視情況經一或多個R
8取代之雜環基環;R
2a為氫或烷基;R
2b為-C(O)烷基(例如C(O)CH
3);R
6a及R
6b中之每一者為氫、烷基、烯基、炔基、雜烷基、鹵烷基、鹵基、氰基、硝基、-OR
A、芳基、雜芳基、環烷基或雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
9取代;R
7為氫、烷基或C(O)-烷基;R
8及R
9中之每一者獨立地為氫、鹵基、氰基、烷基、烯基、炔基、雜烷基、鹵烷基、環烷基或雜環基;且R
A為氫或烷基、烯基、炔基,其中該式(I)之結構可連接至TREM,例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端。
在一些實施例中,GalNAc部分包含式(II-b)之結構:
 ,或其鹽,其中 X為O、N(R
7)或S;R
1、R
3、R
4及R
5中之每一者獨立地為氫、烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基、雜環基、C(O)-烷基、C(O)-烯基、C(O)-炔基、C(O)-雜烷基、C(O)-鹵烷基、C(O)-芳基、C(O)-雜芳基、C(O)-環烷基或C(O)-雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
8取代;或R
3及R
4與其所連接之氧原子一起形成視情況經一或多個R
8取代之雜環基環;R
2a為氫或烷基;R
2b為-C(O)烷基(例如C(O)CH
3);R
6a及R
6b中之每一者為氫、烷基、烯基、炔基、雜烷基、鹵烷基、鹵基、氰基、硝基、-OR
A、芳基、雜芳基、環烷基或雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
9取代;R
7為氫、烷基或C(O)-烷基;R
8及R
9中之每一者獨立地為氫、鹵基、氰基、烷基、烯基、炔基、雜烷基、鹵烷基、環烷基或雜環基;且R
A為氫或烷基、烯基、炔基,其中該式(I)之結構可連接至TREM,例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端。
,或其鹽,其中 X為O、N(R
7)或S;R
1、R
3、R
4及R
5中之每一者獨立地為氫、烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基、雜環基、C(O)-烷基、C(O)-烯基、C(O)-炔基、C(O)-雜烷基、C(O)-鹵烷基、C(O)-芳基、C(O)-雜芳基、C(O)-環烷基或C(O)-雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
8取代;或R
3及R
4與其所連接之氧原子一起形成視情況經一或多個R
8取代之雜環基環;R
2a為氫或烷基;R
2b為-C(O)烷基(例如C(O)CH
3);R
6a及R
6b中之每一者為氫、烷基、烯基、炔基、雜烷基、鹵烷基、鹵基、氰基、硝基、-OR
A、芳基、雜芳基、環烷基或雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
9取代;R
7為氫、烷基或C(O)-烷基;R
8及R
9中之每一者獨立地為氫、鹵基、氰基、烷基、烯基、炔基、雜烷基、鹵烷基、環烷基或雜環基;且R
A為氫或烷基、烯基、炔基,其中該式(I)之結構可連接至TREM,例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端。
在一些實施例中,ASGPR結合部分包含式(III)之結構:
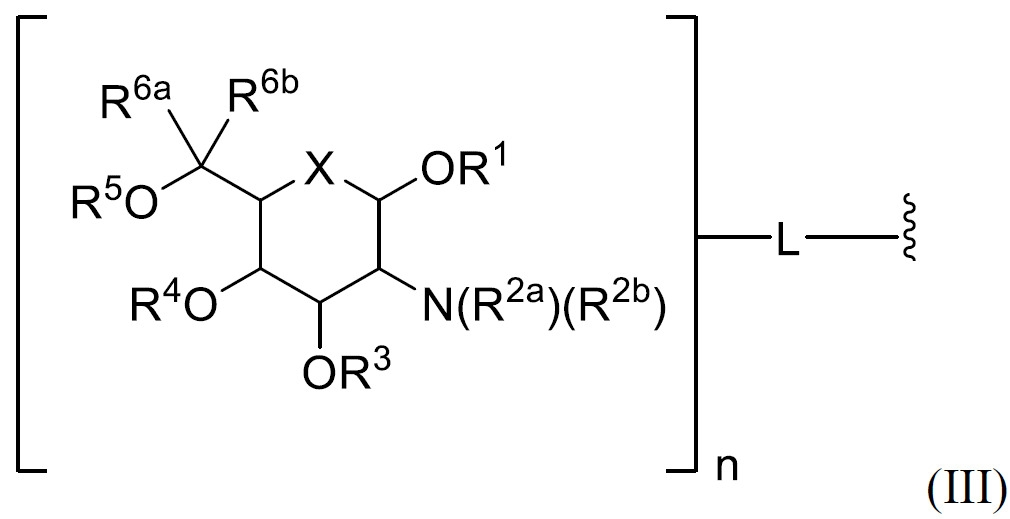 ,或其鹽,其中 R
1、R
2a、R
2b、R
3、R
4、R
5、R
6a及R
6b及其子變數中之每一者如針對式(I)所定義,L為連接子,且n為1與100之間的整數,其中「
」表示與分支點、額外連接子或TREM (例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端)之連接點。
,或其鹽,其中 R
1、R
2a、R
2b、R
3、R
4、R
5、R
6a及R
6b及其子變數中之每一者如針對式(I)所定義,L為連接子,且n為1與100之間的整數,其中「
」表示與分支點、額外連接子或TREM (例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端)之連接點。
在一些實施例中,X為O。在一些實施例中,R
1、R
3、R
4及R
5中之每一者獨立地為氫或烷基(例如CH
3)。在一些實施例中,R
2a為氫。在一些實施例中,R
2b為C(O)CH
3。在一些實施例中,R
6a及R
6b中之每一者為氫。在一些實施例中,n為1與50之間的整數。在一些實施例中,n為1與25之間的整數。在一些實施例中,n為1與10之間的整數。在一些實施例中,n為1與5之間的整數。在一些實施例中,n為1、2、3、4或5。在一些實施例中,n為1。
在一實施例中,L包含伸烷基、伸烯基、伸炔基、伸雜烷基或伸鹵烷基。在一實施例中,L包含酯基、醯胺基、二硫化物基、醚基、碳酸酯基、芳基、雜芳基、環烷基或雜環基。在一實施例中,L為可裂解或不可裂解的。
如本文所使用之術語「連接子」係指例如經由共價鍵連接化合物之兩個或更多個部分的有機部分。連接子可為直鏈或分支鏈的。在一些實施例中,連接子包含雜原子,諸如氮、硫、氧、磷、矽或硼原子。在一些實施例中,連接子包含環狀基團(例如芳基、雜芳基、環烷基或雜環基)。在一些實施例中,連接子包含官能基,諸如醯胺基、酮基、酯基、醚基、硫酯基、硫醚基、硫醇基、羥基、胺基、氰基、硝基、疊氮基、三唑基、吡咯啉基、對硝基苯基、烯基或炔基。連接子內之任何原子可經取代或未經取代。在一些實施例中,連接子包含芳基烷基、芳基烯基、芳基炔基、雜芳基烷基、雜芳基烯基、雜芳基炔基、雜環基烷基、雜環基烯基、雜環基炔基、芳基、雜芳基、雜環基、環烷基、環烯基、烷基芳基烷基、烷基芳基烯基、烷基芳基炔基、烯基芳基烷基、烯基芳基烯基、烯基芳基炔基、炔基芳基烷基、炔基芳基烯基、炔基芳基炔基、烷基雜芳基烷基、烷基雜芳基烯基、烷基雜芳基炔基、烯基雜芳基烷基、烯基雜芳基烯基、烯基雜芳基炔基、炔基雜芳基烷基、炔基雜芳基烯基、炔基雜芳基炔基、烷基雜環基烷基、烷基雜環基烯基、烷基雜環基炔基、烯基雜環基烷基、烯基雜環基烯基、烯基雜環基炔基、炔基雜環基烷基、炔基雜環基烯基、炔基雜環基炔基、烷基芳基、烯基芳基、炔基芳基、烷基雜芳基、烯基雜芳基或炔基雜芳基。在一些實施例中,連接子包含聚乙二醇基團(例如PEG1、PEG2、PEG3、PEG4、PEG5、PEG6、PEG7、PEG8、PEG10、PEG12、PEG14、PEG16、PEG18、PEG20、PEG24、PEG28、PEG32、PEG100、PEG200、PEG250、PEG500、PEG600、PEG700、PEG750、PEG800、PEG900、PEG1000、PEG2000或PEG3000)。在一些實施例中,L包含PEG1、PEG2、PEG3、PEG4、PEG5或PEG6基團。在一些實施例中,L包含複數個PEG1、PEG2、PEG3、PEG4、PEG5或PEG6基團(例如2、3、4或5個PEG1、PEG2、PEG3、PEG4、PEG5或PEG6基團)。在一些實施例中,L包含一個PEG2基團。在一些實施例中,L包含複數個PEG2基團。在一些實施例中,L包含一個PEG3基團。在一些實施例中,L包含複數個PEG3基團。在一些實施例中,L包含一個PEG4基團。在一些實施例中,L包含複數個PEG4基團。
在一些實施例中,連接子包含1與1000個之間的原子(例如1與750個之間的原子、1與500個之間的原子、1與250個之間的原子、1與100個之間的原子、1與75個之間的原子、1與50個之間的原子、1與25個之間的原子及1與10個之間的原子)。在一些實施例中,連接子包含1與100個之間的原子。在一些實施例中,連接子包含1與50個之間的原子。在一些實施例中,連接子包含1與25個之間的原子。
在一些實施例中,連接子為直鏈的,且包含1與1000個之間的原子(例如1與750個之間的原子、1與500個之間的原子、1與250個之間的原子、1與100個之間的原子、1與75個之間的原子、1與50個之間的原子、1與25個之間的原子及1與10個之間的原子)。在一些實施例中,連接子為直鏈的,且包含1與100個之間的原子。在一些實施例中,連接子為直鏈的,且包含1與50個之間的原子。在一些實施例中,連接子為直鏈的,且包含1與25個之間的原子。
在一些實施例中,連接子為分支鏈的,且各分支鏈包含1與1000個之間的原子(例如1與750個之間的原子、1與500個之間的原子、1與250個之間的原子、1與100個之間的原子、1與75個之間的原子、1與50個之間的原子、1與25個之間的原子及1與10個之間的原子)。在一些實施例中,連接子為分支鏈的,且各分支鏈包含1與100個之間的原子。在一些實施例中,連接子為分支鏈的,且各分支鏈包含1與50個之間的原子。在一些實施例中,連接子為分支鏈的,且各分支鏈包含1與25個之間的原子。
在一些實施例中,ASGPR結合部分包含式(III-a)之結構:
 ,或其鹽,其中 R
1、R
2a、R
2b、R
3、R
4、R
5、R
6a及R
6b及其子變數中之每一者如針對式(I)所定義,L
1及L
2中之每一者獨立地為連接子,m及n中之每一者獨立地為1與100之間的整數,且M為連接子,其中「
」表示與分支點、額外連接子或TREM (例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端)之連接點。
,或其鹽,其中 R
1、R
2a、R
2b、R
3、R
4、R
5、R
6a及R
6b及其子變數中之每一者如針對式(I)所定義,L
1及L
2中之每一者獨立地為連接子,m及n中之每一者獨立地為1與100之間的整數,且M為連接子,其中「
」表示與分支點、額外連接子或TREM (例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端)之連接點。
在一些實施例中,X為O (例如A及B中之每一者中之X為O)。在一些實施例中,R
1、R
3、R
4及R
5中之每一者獨立地為氫或烷基(例如CH
3) (例如A及B中之每一者中之R
1、R
3、R
4及R
5獨立地為氫或烷基)。在一些實施例中,R
2a為氫(例如,A及B中之每一者中之R
2a為氫)。在一些實施例中,R
2b為C(O)CH
3(例如,A及B中之每一者中之R
2b為C(O)CH
3)。在一些實施例中,R
6a及R
6b中之每一者為氫(例如,A及B中之每一者中之R
6a及R
6b為氫)。在一些實施例中,m及n中之每一者獨立地為1與50之間的整數。在一些實施例中,m及n中之每一者獨立地為1與25之間的整數。在一些實施例中,m及n中之每一者獨立地為1與10之間的整數。在一些實施例中,m及n中之每一者獨立地為1與5之間的整數。在一些實施例中,m及n中之每一者獨立地為1、2、3、4或5。在一些實施例中,m及n中之每一者獨立地為1。
在一實施例中,L
1及L
2中之每一者獨立地包含伸烷基、伸烯基、伸炔基、伸雜烷基或伸鹵烷基。在一實施例中,L
1及L
2中之每一者獨立地包含酯基、醯胺基、二硫化物基、醚基、碳酸酯基、芳基、雜芳基、環烷基或雜環基。在一實施例中,L
1及L
2中之每一者獨立地為可裂解或不可裂解的。在一些實施例中,L
1及L
2中之每一者獨立地包含聚乙二醇基團(例如PEG1、PEG2、PEG3、PEG4、PEG5、PEG6、PEG7、PEG8、PEG10、PEG12、PEG14、PEG16、PEG18、PEG20、PEG24、PEG28、PEG32、PEG100、PEG200、PEG250、PEG500、PEG600、PEG700、PEG750、PEG800、PEG900、PEG1000、PEG2000或PEG3000)。在一些實施例中,L
1及L
2中之每一者獨立地包含PEG1、PEG2、PEG3、PEG4、PEG5或PEG6基團。在一些實施例中,L
1及L
2中之每一者獨立地包含複數個PEG1、PEG2、PEG3、PEG4、PEG5或PEG6基團(例如2、3、4或5個PEG1、PEG2、PEG3、PEG4、PEG5或PEG6基團)。在一些實施例中,L
1及L
2中之每一者獨立地包含一個PEG2基團。在一些實施例中,L
1及L
2中之每一者獨立地包含複數個PEG2基團。在一些實施例中,L
1及L
2中之每一者獨立地包含一個PEG3基團。在一些實施例中,L
1及L
2中之每一者獨立地包含複數個PEG3基團。在一些實施例中,L
1及L
2中之每一者獨立地包含一個PEG4基團。在一些實施例中,L
1及L
2中之每一者獨立地包含複數個PEG4基團。
在一些實施例中,M包含伸烷基、伸烯基、伸炔基、伸雜烷基或伸鹵烷基。在一實施例中,M包含酯基、醯胺基、二硫化物基、醚基、碳酸酯基、芳基、雜芳基、環烷基或雜環基。在一實施例中,M為可裂解或不可裂解的。
在一些實施例中,ASGPR結合部分包含式(III-b)之結構:
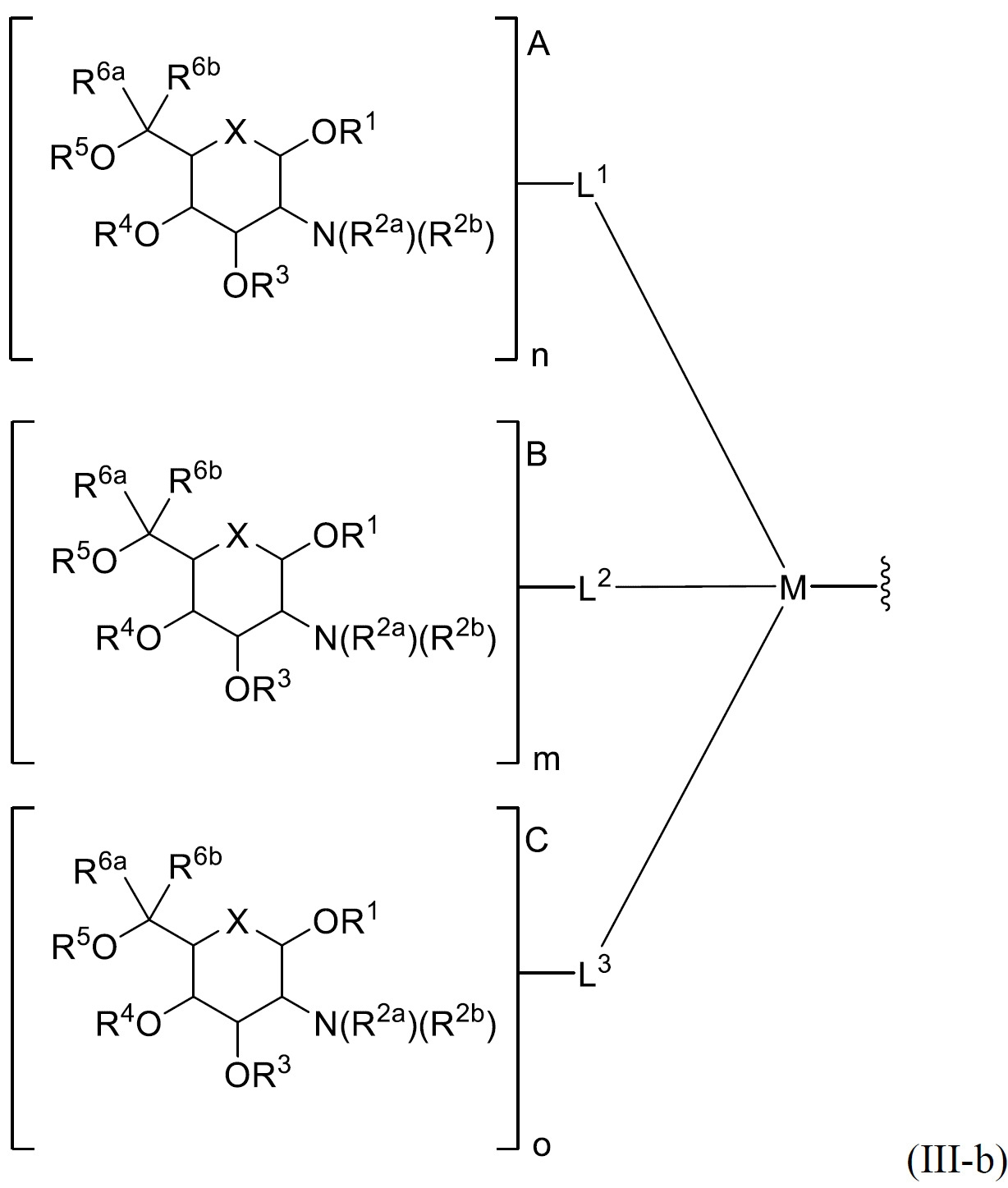 ,或其鹽,其中 R
1、R
2a、R
2b、R
3、R
4、R
5、R
6a及R
6b及其子變數中之每一者如針對式(I)所定義,L
1、L
2及L
3中之每一者獨立地為連接子,m、n及o中之每一者獨立地為1與100之間的整數,且M為連接子,其中「
」表示與分支點、額外連接子或TREM (例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端)之連接點。
,或其鹽,其中 R
1、R
2a、R
2b、R
3、R
4、R
5、R
6a及R
6b及其子變數中之每一者如針對式(I)所定義,L
1、L
2及L
3中之每一者獨立地為連接子,m、n及o中之每一者獨立地為1與100之間的整數,且M為連接子,其中「
」表示與分支點、額外連接子或TREM (例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端)之連接點。
在一些實施例中,X為O (例如,A、B及C中之每一者中之X為O)。在一些實施例中,R
1、R
3、R
4及R
5中之每一者獨立地為氫或烷基(例如CH
3) (例如,A、B及C中之每一者中之R
1、R
3、R
4及R
5獨立地為氫或烷基)。在一些實施例中,R
2a為氫(例如,A、B及C中之每一者中之R
2a為氫)。在一些實施例中,R
2b為C(O)CH
3(例如,A、B及C中之每一者中之R
2b為C(O)CH
3)。在一些實施例中,R
6a及R
6b中之每一者為氫(例如,A、B及C中之每一者中之R
6a及R
6b為氫)。在一些實施例中,m、n及o中之每一者獨立地為1與50之間的整數。在一些實施例中,m、n及o中之每一者獨立地為1與25之間的整數。在一些實施例中,m、n及o中之每一者獨立地為1與10之間的整數。在一些實施例中,m、n及o中之每一者獨立地為1與5之間的整數。在一些實施例中,m、n及o中之每一者獨立地為1、2、3、4或5。在一些實施例中,m、n及o中之每一者獨立地為1。
在一實施例中,L
1、L
2及L
3中之每一者獨立地包含伸烷基、伸烯基、伸炔基、伸雜烷基或伸鹵烷基。在一實施例中,L
1、L
2及L
3中之每一者獨立地包含酯基、醯胺基、二硫化物基、醚基、碳酸酯基、芳基、雜芳基、環烷基或雜環基。在一實施例中,L
1、L
2及L
3中之每一者獨立地為可裂解或不可裂解的。在一實施例中,L
1及L
2中之每一者獨立地為可裂解或不可裂解的。在一些實施例中,L
1、L
2及L
3中之每一者獨立地包含聚乙二醇基團(例如PEG1、PEG2、PEG3、PEG4、PEG5、PEG6、PEG7、PEG8、PEG10、PEG12、PEG14、PEG16、PEG18、PEG20、PEG24、PEG28、PEG32、PEG100、PEG200、PEG250、PEG500、PEG600、PEG700、PEG750、PEG800、PEG900、PEG1000、PEG2000或PEG3000)。在一些實施例中,L
1、L
2及L
3中之每一者獨立地包含PEG1、PEG2、PEG3、PEG4、PEG5或PEG6基團。在一些實施例中,L
1、L
2及L
3中之每一者獨立地包含複數個PEG1、PEG2、PEG3、PEG4、PEG5或PEG6基團(例如2、3、4或5個PEG1、PEG2、PEG3、PEG4、PEG5或PEG6基團)。在一些實施例中,L
1、L
2及L
3中之每一者獨立地包含一個PEG2基團。在一些實施例中,L
1、L
2及L
3中之每一者獨立地包含複數個PEG2基團。在一些實施例中,L
1、L
2及L
3中之每一者獨立地包含一個PEG3基團。在一些實施例中,L
1、L
2及L
3中之每一者獨立地包含複數個PEG3基團。在一些實施例中,L
1、L
2及L
3中之每一者獨立地包含一個PEG4基團。在一些實施例中,L
1、L
2及L
3中之每一者獨立地包含複數個PEG4基團。
在一些實施例中,M包含伸烷基、伸烯基、伸炔基、伸雜烷基或伸鹵烷基。在一實施例中,M包含酯基、醯胺基、二硫化物基、醚基、碳酸酯基、芳基、雜芳基、環烷基或雜環基。在一實施例中,M為可裂解或不可裂解的。
在一些實施例中,ASGPR結合部分包含式(III-c)之結構:
 ,或其鹽,其中 R
2a、R
2b、R
3、R
4、R
5及其子變數中之每一者如針對式(I)所定義,L
1、L
2及L
3中之每一者獨立地為連接子,且M為連接子,其中「
」表示與分支點、額外連接子或TREM (例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端)之連接點。
,或其鹽,其中 R
2a、R
2b、R
3、R
4、R
5及其子變數中之每一者如針對式(I)所定義,L
1、L
2及L
3中之每一者獨立地為連接子,且M為連接子,其中「
」表示與分支點、額外連接子或TREM (例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端)之連接點。
在一些實施例中,R
3、R
4及R
5中之每一者獨立地為氫或烷基(例如CH
3)。在一些實施例中,R
2a為氫。在一些實施例中,R
2b為C(O)CH
3。
在一實施例中,L
1、L
2及L
3中之每一者獨立地包含伸烷基、伸烯基、伸炔基、伸雜烷基或伸鹵烷基。在一實施例中,L
1、L
2及L
3中之每一者獨立地包含酯基、醯胺基、二硫化物基、醚基、碳酸酯基、芳基、雜芳基、環烷基或雜環基。在一實施例中,L
1、L
2及L
3中之每一者獨立地為可裂解或不可裂解的。在一實施例中,L
1及L
2中之每一者獨立地為可裂解或不可裂解的。在一些實施例中,L
1、L
2及L
3中之每一者獨立地包含聚乙二醇基團(例如PEG1、PEG2、PEG3、PEG4、PEG5、PEG6、PEG7、PEG8、PEG10、PEG12、PEG14、PEG16、PEG18、PEG20、PEG24、PEG28、PEG32、PEG100、PEG200、PEG250、PEG500、PEG600、PEG700、PEG750、PEG800、PEG900、PEG1000、PEG2000或PEG3000)。在一些實施例中,L
1、L
2及L
3中之每一者獨立地包含PEG1、PEG2、PEG3、PEG4、PEG5或PEG6基團。在一些實施例中,L
1、L
2及L
3中之每一者獨立地包含複數個PEG1、PEG2、PEG3、PEG4、PEG5或PEG6基團(例如2、3、4或5個PEG1、PEG2、PEG3、PEG4、PEG5或PEG6基團)。在一些實施例中,L
1、L
2及L
3中之每一者獨立地包含一個PEG2基團。在一些實施例中,L
1、L
2及L
3中之每一者獨立地包含複數個PEG2基團。在一些實施例中,L
1、L
2及L
3中之每一者獨立地包含一個PEG3基團。在一些實施例中,L
1、L
2及L
3中之每一者獨立地包含複數個PEG3基團。在一些實施例中,L
1、L
2及L
3中之每一者獨立地包含一個PEG4基團。在一些實施例中,L
1、L
2及L
3中之每一者獨立地包含複數個PEG4基團。
在一些實施例中,M包含伸烷基、伸烯基、伸炔基、伸雜烷基或伸鹵烷基。在一實施例中,M包含酯基、醯胺基、二硫化物基、醚基、碳酸酯基、芳基、雜芳基、環烷基或雜環基。在一實施例中,M為可裂解或不可裂解的。
在一些實施例中,ASGPR結合部分包含選自以下之化合物:





 。
。
在一些實施例中,ASGPR結合部分為化合物(X-i)。在一些實施例中,ASGPR結合部分為化合物(X-ii)。在一些實施例中,ASGPR結合部分為化合物(X-iii)。在一些實施例中,ASGPR結合部分為化合物(X-iv)。在一些實施例中,ASGPR結合部分為化合物(X-v)。在一些實施例中,ASGPR結合部分為化合物(X-vi)。在一些實施例中,ASGPR結合部分為化合物(X-vii)。在一些實施例中,ASGPR結合部分為化合物(X-viii)。在一些實施例中,ASGPR結合部分為化合物(X-ix)。在一些實施例中,ASGPR結合部分為化合物(X-x)。在一些實施例中,ASGPR結合部分為化合物(X-xi)。在一些實施例中,ASGPR結合部分為化合物(X-xii)。在一些實施例中,ASGPR結合部分為化合物(X-xiii)。在一些實施例中,ASGPR結合部分為化合物(X-xiv)。在一些實施例中,ASGPR結合部分為化合物(X-xv)。在一些實施例中,ASGPR結合部分為化合物(X-xvi)。在一些實施例中,ASGPR結合部分為化合物(X-xvii)。在一些實施例中,ASGPR結合部分為化合物(X-xviii)。在一些實施例中,ASGPR結合部分為化合物(X-xix)。在一些實施例中,ASGPR結合部分為化合物(X-xx)。在一些實施例中,ASGPR結合部分為化合物(X-xxi)。在一些實施例中,ASGPR結合部分為化合物(X-xxii)。在一些實施例中,ASGPR結合部分為化合物(X-xxiii)。在一些實施例中,ASGPR結合部分為選自化合物(X-i)、(X-xxii)及(X-xxii)之化合物。
在一些實施例中,ASGPR結合部分包含連接子,該連接子包含環狀部分,諸如吡咯啉環。在一實施例中,ASGPR結合部分包含式(CII)之結構:
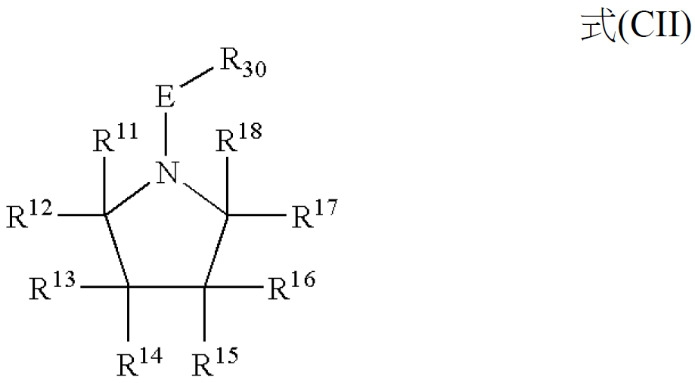 ,或其鹽,其中E不存在或為C(O)、C(O)O、C(O)NH、C(S)、C(S)NH、SO、SO
2或SO
2NH;R
11、R
12、R
13、R
14、R
15、R
16、R
17及R
18在每次出現時各自獨立地為H、-CH
2OR
a或OR
b;R
a及R
b在每次出現時各自獨立地為氫、羥基保護基、視情況經取代之烷基、視情況經取代之芳基、視情況經取代之環烷基、視情況經取代之芳烷基、視情況經取代之烯基、視情況經取代之雜芳基、聚乙二醇(PEG)、磷酸酯、二磷酸酯、三磷酸酯、膦酸酯、硫代膦酸酯、二硫代膦酸酯、硫代磷酸酯(phosphorothioate)、硫代磷酸酯(phosphorothiolate)、二硫代磷酸酯(phosphorodithioate)、二硫代磷酸酯(phosphorothiolothionate)、磷酸二酯、磷酸三酯、活化之磷酸酯基、活化之亞磷酸酯基、胺基亞磷酸酯、固體載體、-P(Z
1)(Z
2)-O-核苷、-P(Z
1)(Z
2)-O-寡核苷酸、-P(Z
1)(O-連接子-R
L)-O-核苷或-P(Z
1)(O-連接子-R
L)-O-寡核苷酸;R
30在每次出現時獨立地為-連接子-R
L或R
31;R
L為氫或配體;R
31為-C(O)CH(N(R
32)
2)(CH
2)
hN(R
32)
2;R
32在每次出現時獨立地為H、-R
L、-連接子-R
L或R
31;Z
1在每次出現時獨立地為O或S;Z
2在每次出現時獨立地為O、S、N(烷基)或視情況經取代之烷基;且h在每次出現時獨立地為1至20。
,或其鹽,其中E不存在或為C(O)、C(O)O、C(O)NH、C(S)、C(S)NH、SO、SO
2或SO
2NH;R
11、R
12、R
13、R
14、R
15、R
16、R
17及R
18在每次出現時各自獨立地為H、-CH
2OR
a或OR
b;R
a及R
b在每次出現時各自獨立地為氫、羥基保護基、視情況經取代之烷基、視情況經取代之芳基、視情況經取代之環烷基、視情況經取代之芳烷基、視情況經取代之烯基、視情況經取代之雜芳基、聚乙二醇(PEG)、磷酸酯、二磷酸酯、三磷酸酯、膦酸酯、硫代膦酸酯、二硫代膦酸酯、硫代磷酸酯(phosphorothioate)、硫代磷酸酯(phosphorothiolate)、二硫代磷酸酯(phosphorodithioate)、二硫代磷酸酯(phosphorothiolothionate)、磷酸二酯、磷酸三酯、活化之磷酸酯基、活化之亞磷酸酯基、胺基亞磷酸酯、固體載體、-P(Z
1)(Z
2)-O-核苷、-P(Z
1)(Z
2)-O-寡核苷酸、-P(Z
1)(O-連接子-R
L)-O-核苷或-P(Z
1)(O-連接子-R
L)-O-寡核苷酸;R
30在每次出現時獨立地為-連接子-R
L或R
31;R
L為氫或配體;R
31為-C(O)CH(N(R
32)
2)(CH
2)
hN(R
32)
2;R
32在每次出現時獨立地為H、-R
L、-連接子-R
L或R
31;Z
1在每次出現時獨立地為O或S;Z
2在每次出現時獨立地為O、S、N(烷基)或視情況經取代之烷基;且h在每次出現時獨立地為1至20。
在一些實施例中,式(CII)化合物係選自:
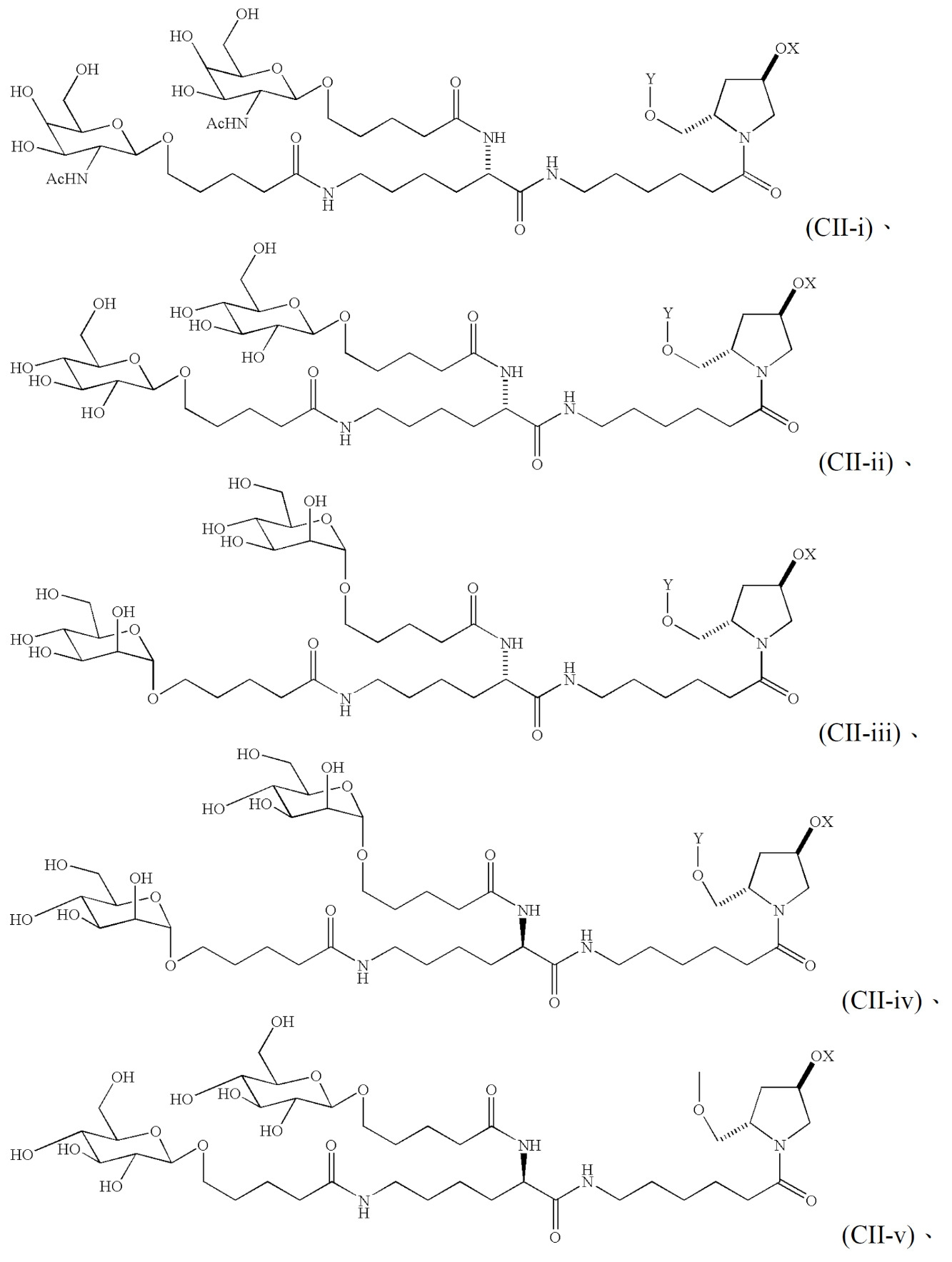
 。
。
在一些實施例中,ASGPR結合部分為美國專利第8,106,022號中所揭示之化合物或子結構,該專利以其全文引用之方式併入本文中。
在一些實施例中,ASGPR結合部分為化合物(CII-i)。在一些實施例中,ASGPR結合部分為化合物(CII-ii)。在一些實施例中,ASGPR結合部分為化合物(CII-iii)。在一些實施例中,ASGPR結合部分為化合物(CII-iv)。在一些實施例中,ASGPR結合部分為化合物(CII-v)。在一些實施例中,ASGPR結合部分為化合物(CII-vi)。
在一些實施例中,ASGPR結合部分為式(C-1)、(C-2)、(C-3)或(C4)之化合物:

 (C-4),
或其醫藥學上可接受之鹽,其中:n為1、2或3;W不存在或為肽;L為-(T-Q-T-Q)
m-,其中各T獨立地不存在或為(C
1-C
10)伸烷基、(C
2-C
10)伸烯基或(C
2-C
10)伸炔基,其中該T之一或多個碳基團可各自獨立地經獨立地選自-O-、-S-及-N(R
4)-之雜原子基團置換,其中該等雜原子基團藉由至少2個碳原子隔開,且其中伸烷基、伸烯基及伸炔基可各自獨立地經一或多個鹵基原子取代;各Q獨立地不存在或為C(O)、C(O)-NR
4、NR
4-C(O)、O-C(O)-NR
4、NR
4-C(O)-O、-CH
2-、雜芳基或選自以下之雜原子基團:O、S、S-S、S(O)、S(O)
2及NR
4,其中至少兩個碳原子使該等雜原子基團O、S、S-S、S(O)、S(O)
2及NR
4與任何其他雜原子基團隔開;各R
4獨立地為-H、-(C
1-C
20)烷基或(C
3-C
8)環烷基,其中烷基或環烷基之由至少兩個碳原子隔開的一至六個-CH
2-基團可經-O-、-S-或-N(R
4)-置換,且烷基之-CH
3-可各自獨立地經選自-N(R
4)
2、-OR
4及-S(R
4)之雜原子基團置換,其中該等雜原子基團由至少2個碳原子隔開;且其中烷基及環烷基可經鹵基原子取代;且m獨立地為0、1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39或40。
(C-4),
或其醫藥學上可接受之鹽,其中:n為1、2或3;W不存在或為肽;L為-(T-Q-T-Q)
m-,其中各T獨立地不存在或為(C
1-C
10)伸烷基、(C
2-C
10)伸烯基或(C
2-C
10)伸炔基,其中該T之一或多個碳基團可各自獨立地經獨立地選自-O-、-S-及-N(R
4)-之雜原子基團置換,其中該等雜原子基團藉由至少2個碳原子隔開,且其中伸烷基、伸烯基及伸炔基可各自獨立地經一或多個鹵基原子取代;各Q獨立地不存在或為C(O)、C(O)-NR
4、NR
4-C(O)、O-C(O)-NR
4、NR
4-C(O)-O、-CH
2-、雜芳基或選自以下之雜原子基團:O、S、S-S、S(O)、S(O)
2及NR
4,其中至少兩個碳原子使該等雜原子基團O、S、S-S、S(O)、S(O)
2及NR
4與任何其他雜原子基團隔開;各R
4獨立地為-H、-(C
1-C
20)烷基或(C
3-C
8)環烷基,其中烷基或環烷基之由至少兩個碳原子隔開的一至六個-CH
2-基團可經-O-、-S-或-N(R
4)-置換,且烷基之-CH
3-可各自獨立地經選自-N(R
4)
2、-OR
4及-S(R
4)之雜原子基團置換,其中該等雜原子基團由至少2個碳原子隔開;且其中烷基及環烷基可經鹵基原子取代;且m獨立地為0、1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39或40。
在一些實施例中,ASGPR結合部分為化合物(C-1)。在一些實施例中,ASGPR結合部分為化合物(C-2)。在一些實施例中,ASGPR結合部分為化合物(C-3)。在一些實施例中,ASGPR結合部分為化合物(C-4)。
在一些實施例中,式(C-1)、(C-2)、(C-3)或(C4)之化合物包含:
 其中n'為1或2,或其醫藥學上可接受之鹽。
其中n'為1或2,或其醫藥學上可接受之鹽。
在一些實施例中,ASGPR結合部分為式(E)之化合物:
 ,
或其醫藥學上可接受之鹽,其中:n為1、2或3;W不存在或為肽; L為-(T-Q-T-Q)
m-,其中各T獨立地不存在或為(C
1-C
10)伸烷基、(C
2-C
10)伸烯基或(C
2-C
10)伸炔基,其中該T之一或多個碳基團可各自獨立地經獨立地選自-O-、-S-及-N(R
4)-之雜原子基團置換,其中該等雜原子基團藉由至少2個碳原子隔開,其中該伸烷基、伸烯基、伸炔基可各自獨立地經一或多個鹵基原子取代;各Q獨立地不存在或為C(O)、C(O)-R
4、R
4-C(O)、O-C(O)-R
4、R
4-C(O)-O、-CH
2-、雜芳基或選自以下之雜原子基團:O、S、S-S、S(O)、S(O)
2及NR
4,其中至少兩個碳原子使該等雜原子基團O、S、S-S、S(O)、S(O)
2及NR
4與任何其他雜原子基團隔開;各R
4獨立地為-H、-(C
1-C
20)烷基、-(C
1-C
20)烯基、-(C
2-C
20)炔基或(C
3-C
6)環烷基,其中烷基或環烷基之由至少兩個碳原子隔開的一至六個-CH
2-基團可經-O-、-S-或-N(R
4)-置換,且烷基之-CH
3可經選自-N(R
4)
2、-OR
4及-S(R
4)之雜原子基團置換,其中該等雜原子基團由至少2個碳原子隔開;且其中烷基、烯基、炔基及環烷基可經鹵基原子取代;各m獨立地為0、1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39或40。
,
或其醫藥學上可接受之鹽,其中:n為1、2或3;W不存在或為肽; L為-(T-Q-T-Q)
m-,其中各T獨立地不存在或為(C
1-C
10)伸烷基、(C
2-C
10)伸烯基或(C
2-C
10)伸炔基,其中該T之一或多個碳基團可各自獨立地經獨立地選自-O-、-S-及-N(R
4)-之雜原子基團置換,其中該等雜原子基團藉由至少2個碳原子隔開,其中該伸烷基、伸烯基、伸炔基可各自獨立地經一或多個鹵基原子取代;各Q獨立地不存在或為C(O)、C(O)-R
4、R
4-C(O)、O-C(O)-R
4、R
4-C(O)-O、-CH
2-、雜芳基或選自以下之雜原子基團:O、S、S-S、S(O)、S(O)
2及NR
4,其中至少兩個碳原子使該等雜原子基團O、S、S-S、S(O)、S(O)
2及NR
4與任何其他雜原子基團隔開;各R
4獨立地為-H、-(C
1-C
20)烷基、-(C
1-C
20)烯基、-(C
2-C
20)炔基或(C
3-C
6)環烷基,其中烷基或環烷基之由至少兩個碳原子隔開的一至六個-CH
2-基團可經-O-、-S-或-N(R
4)-置換,且烷基之-CH
3可經選自-N(R
4)
2、-OR
4及-S(R
4)之雜原子基團置換,其中該等雜原子基團由至少2個碳原子隔開;且其中烷基、烯基、炔基及環烷基可經鹵基原子取代;各m獨立地為0、1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39或40。
在一些實施例中,式(E)化合物係選自:
 (F-2),或其醫藥學上可接受之鹽,且Y如式(E)中所定義。
(F-2),或其醫藥學上可接受之鹽,且Y如式(E)中所定義。
在一些實施例中,n為1。在一些實施例中,n為2。在一些實施例中,n為3。
在式(E)化合物之一些實施例中,化合物為:
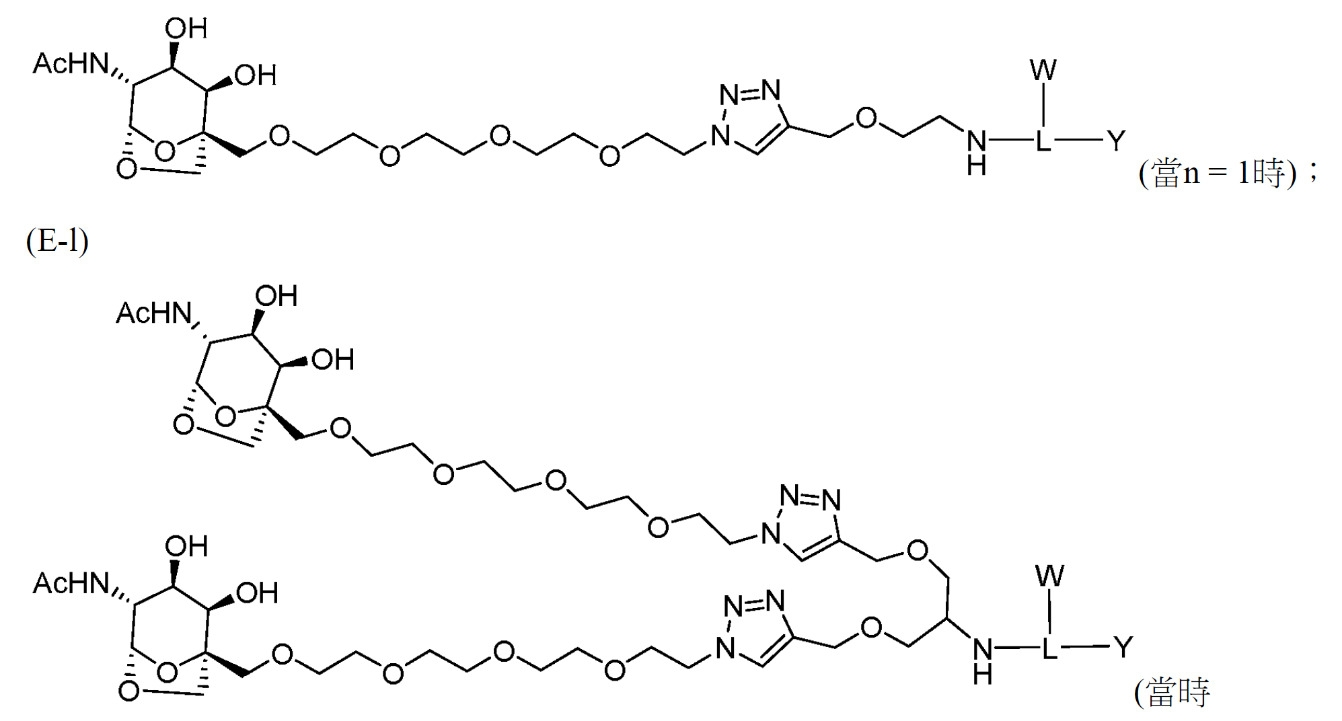
 (E-3),或其醫藥學上可接受之鹽。
(E-3),或其醫藥學上可接受之鹽。
在一些實施例中,ASGPR結合部分為WO2017/083368中所揭示之化合物或子結構,該文獻以其全文引用之方式併入本文中。
在其它實施例中,ASGPR結合部分係選自:

 ,
其中X或Y中之一者為分支點、連接子或TREM (例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端),且X及Y中之另一者為氫。
,
其中X或Y中之一者為分支點、連接子或TREM (例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端),且X及Y中之另一者為氫。
在一實施例中,ASGPR結合部分包含式(XII-a)之結構:
 。在一實施例中,ASGPR結合部分為
Nucleic Acids(2016) 5:e317或WO2015/042447中所揭示之化合物或子結構,該等文獻中之每一者以其全文引用之方式併入本文中。
。在一實施例中,ASGPR結合部分為
Nucleic Acids(2016) 5:e317或WO2015/042447中所揭示之化合物或子結構,該等文獻中之每一者以其全文引用之方式併入本文中。
在一些實施例中,ASGPR結合部分包含式(V-a)之結構:
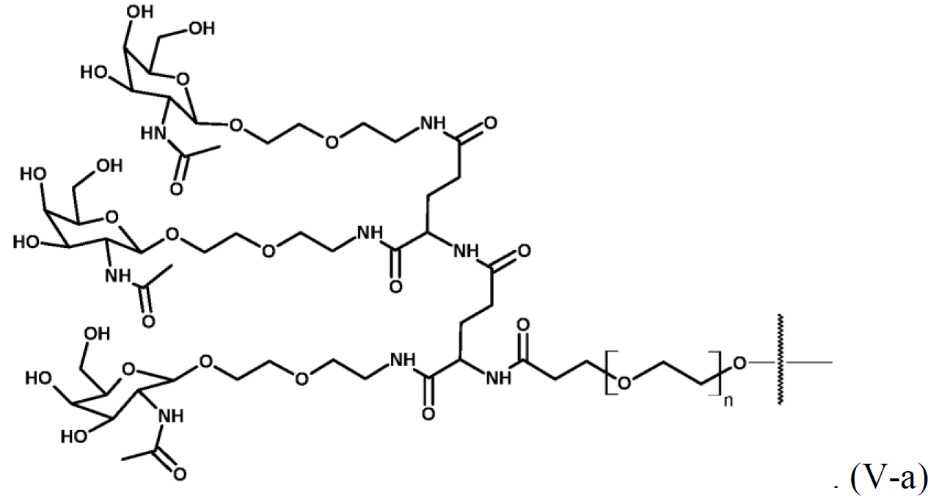 ,其中n為1至20之整數。在一些實施例中,式(V-a)化合物係選自:
,其中n為1至20之整數。在一些實施例中,式(V-a)化合物係選自:
 (V-a-i)、
(V-a-i)、
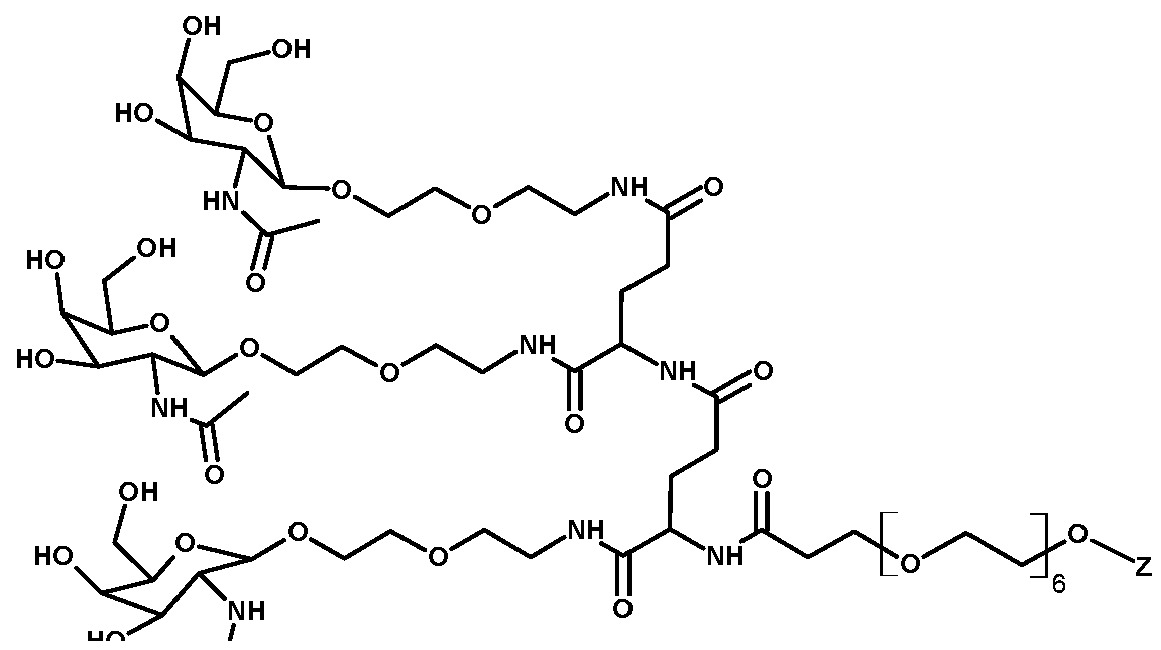 (V-a-ii)及
(V-a-ii)及
 (V-a-iii),其中Z為寡聚化合物,例如連接子或TREM之ASt內之核鹼基。
(V-a-iii),其中Z為寡聚化合物,例如連接子或TREM之ASt內之核鹼基。
在另一實施例中,ASGPR結合部分包含式(V-b)之結構:
 (V-b),其中A為O或S,A'為O、S或NH,且Z為寡聚化合物,例如連接子或TREM (例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端)。
(V-b),其中A為O或S,A'為O、S或NH,且Z為寡聚化合物,例如連接子或TREM (例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端)。
在一些實施例中,ASGPR結合部分包含
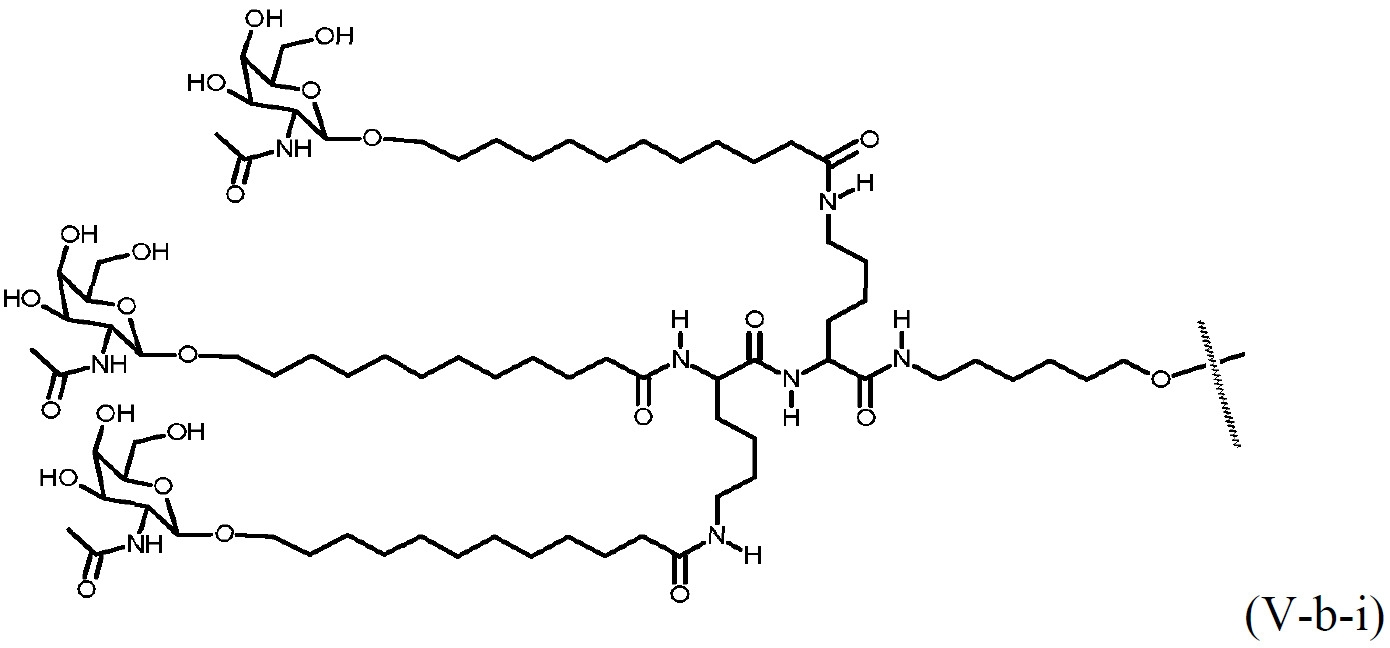 。
。
在一些實施例中,ASGPR結合部分係選自:
 、
、
 及
及
 。
。
在一實施例中,ASGPR結合部分為WO 2017/156012中所揭示之化合物或子結構,該文獻以其全文引用之方式併入本文中。
在一些實施例中,ASGPR結合部分內之羥基例如受乙醯基或縮丙酮化物部分保護。在一些實施例中,ASGPR結合部分內之羥基受乙醯基保護。在一些實施例中,ASGPR結合部分內之羥基受縮丙酮化物基團保護。舉例而言,ASGPR結合部分內之1、2、3、4、5、6、7、8、9、10、11、12或更多個羥基可例如受乙醯基或縮丙酮化物基團保護。在一些實施例中,ASGPR結合部分內之所有羥基皆受保護。
包含ASGPR結合部分之例示性TREM對ASGPR之結合親和力可在0.01 nM至100 mM之間。在一些實施例中,包含ASGPR結合部分之TREM具有小於10 mM,例如7.5 mM、5 mM、2.5 mM、1 mM、0.75 mM、0.5 mM、0.25 mM、0.1 mM、75 nM、50 nM、25 nM、10 nM、5 nM或更小的結合親和力。
包含ASGPR結合部分之例示性TREM可內化至細胞(例如肝細胞)中。在一些實施例中,包含ASGPR結合部分之TREM與不包含ASGPR結合部分之TREM相比具有增加的至細胞中之吸收。舉例而言,包含ASGPR結合部分之TREM內化至細胞中的量可比不包含ASGPR結合部分之TREM內化至細胞中的量高1.1、1.2、1.3、1.4、1.5、1.75、2、3、4、5、6、7、8、9、10、15、20、25、30、35、40、45、50、75、100倍或更多倍。
額外例示性ASGPR部分進一步詳細描述於美國專利第8,828,956號;第9,867,882號;第10,450,568號;第10,808,246號;美國專利公開案第2015/0246133號;第2015/0203843號;及第2012/0095200號;及PCT公開案第WO 2013/166155號、第2012/030683號及第2013/166121號中,該等文獻中之每一者以其全文引用之方式併入本文中。
ASGPR 連接子ASGPR結合部分包含至少一個將碳水化合物連接至TREM之連接子。在一些實施例中,TREM經由如本文所描述之連接子連接至一或多個碳水化合物(例如GalNAc部分,例如式(I)之GalNAc部分)。連接子可為單價或多價的,例如二價、三價、四價或五價的。在一些實施例中,連接子包含選自以下之結構:
式XXXI 式XXXII
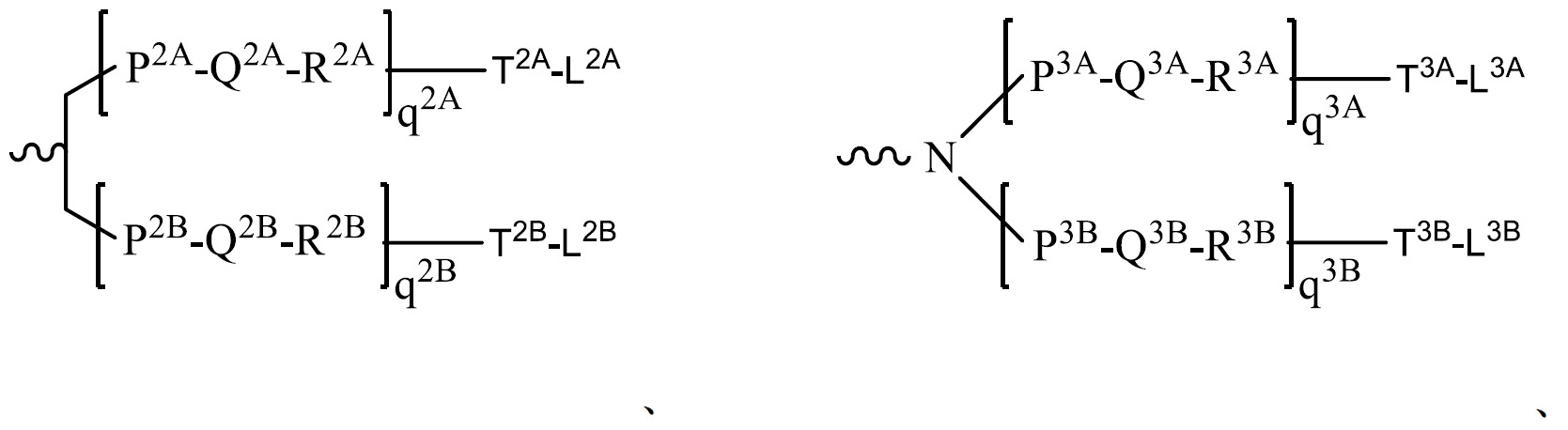
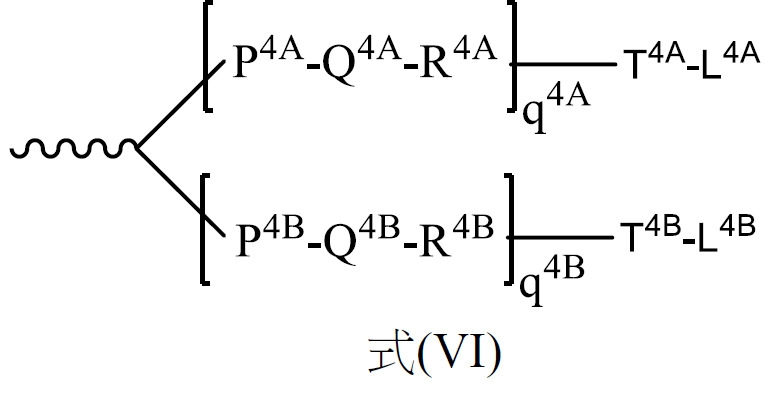 或
或
 ;
式XXXIII 式XXXIV
其中q2A、q2B、q3A、q3B、q4A、q4B、q5A、q5B及q5C在每次出現時獨立地表示0至20,且其中重複單元可相同或不同; P
2A、P
2B、P
3A、P
3B、P
4A、P
4B、P
5A、P
5B、P
5C、T
2A、T
2B、T
3A、T
3B、T
4A、T
4B、T
4A、T
5B、T
5C在每次出現時各自獨立地為不存在、CO、NH、O、S、OC(O)、NHC(O)、CH
2、CH
2NH或CH
2O; Q
2A、Q
2B、Q
3A、Q
3B、Q
4A、Q
4B、Q
5A、Q
5B、Q
5C在每次出現時獨立地為不存在、伸烷基、經取代之伸烷基,其中一或多個亞甲基可間雜有O、S、S(O)、SO
2、N(R
N)、C(R')=C(R'')、C≡C或C(O)中之一或多者或經其封端;R
2A、R
2B、R
3A、R
3B、R
4A、R
4B、R
5A、R
5B、R
5C在每次出現時各自獨立地為不存在、NH、O、S、CH
2、C(O)O、C(O)NH、NHCH(R
a)C(O)、-C(O)-CH(R
a)-NH-、CO、CH=N-O、
;
式XXXIII 式XXXIV
其中q2A、q2B、q3A、q3B、q4A、q4B、q5A、q5B及q5C在每次出現時獨立地表示0至20,且其中重複單元可相同或不同; P
2A、P
2B、P
3A、P
3B、P
4A、P
4B、P
5A、P
5B、P
5C、T
2A、T
2B、T
3A、T
3B、T
4A、T
4B、T
4A、T
5B、T
5C在每次出現時各自獨立地為不存在、CO、NH、O、S、OC(O)、NHC(O)、CH
2、CH
2NH或CH
2O; Q
2A、Q
2B、Q
3A、Q
3B、Q
4A、Q
4B、Q
5A、Q
5B、Q
5C在每次出現時獨立地為不存在、伸烷基、經取代之伸烷基,其中一或多個亞甲基可間雜有O、S、S(O)、SO
2、N(R
N)、C(R')=C(R'')、C≡C或C(O)中之一或多者或經其封端;R
2A、R
2B、R
3A、R
3B、R
4A、R
4B、R
5A、R
5B、R
5C在每次出現時各自獨立地為不存在、NH、O、S、CH
2、C(O)O、C(O)NH、NHCH(R
a)C(O)、-C(O)-CH(R
a)-NH-、CO、CH=N-O、
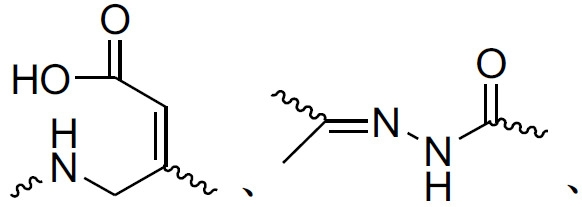
 或雜環基;
L
2A、L
2B、L
3A、L
3B、L
4A、L
4B、L
5A、L
5B及L
5C表示配體;亦即在每次出現時各自獨立地為單醣(諸如GalNAc)、雙醣、三醣、四醣、寡醣或多醣;且R
a為H或胺基酸側鏈。
或雜環基;
L
2A、L
2B、L
3A、L
3B、L
4A、L
4B、L
5A、L
5B及L
5C表示配體;亦即在每次出現時各自獨立地為單醣(諸如GalNAc)、雙醣、三醣、四醣、寡醣或多醣;且R
a為H或胺基酸側鏈。
在一些實施例中,連接子包含:
 ,
其中L
5A、L
5B及L
5C表示單醣,諸如GalNAc衍生物,例如如本文所描述。
,
其中L
5A、L
5B及L
5C表示單醣,諸如GalNAc衍生物,例如如本文所描述。
可裂解連接基團為在細胞外部充分穩定,但進入目標細胞時裂解以釋放連接子固持在一起之兩個部分的連接基團。在一較佳實施例中,可裂解連接基團在目標細胞中或在第一參考條件(其可例如經選擇以模擬或表示細胞內條件)下比在個體血液中或在第二參考條件(其可例如經選擇以模擬或表示血液或血清中存在之條件)下裂解快至少約10倍、20倍、30倍、40倍、50倍、60倍、70倍、80倍、90倍或更多,或快至少約100倍。
可裂解連接基團對裂解因子,例如pH值、氧化還原電位或降解分子之存在敏感。一般而言,裂解劑在細胞內比在血清或血液中更普遍或以更高水準或活性發現。該等降解劑之實例包括:經選擇用於特定受質或不具有受質特異性之氧化還原劑,包括例如可藉由還原來降解氧化還原可裂解連接基團之細胞中存在之氧化或還原酶或諸如硫醇之還原劑;酯酶;可建立酸性環境之胞內體或藥劑,例如產生五或更低之pH的可建立酸性環境之胞內體或藥劑;可藉由充當通用酸、肽酶(其可為受質特異性的)及磷酸酶來水解或降解酸可裂解連接基團的酶。
可裂解鍵聯基團,諸如二硫鍵可對pH值敏感。人類血清之pH值為7.4,而平均細胞內pH值略低,在約7.1至7.3範圍內。胞內體具有更酸性之pH值,在5.5至6.0範圍內,且溶酶體具有甚至更酸性之pH值,為約5.0。一些連接子將具有在較佳pH值下裂解之可裂解連接基團,藉此在細胞內部自配體釋放陽離子脂質或釋放至細胞之所要隔室中。
連接子可包括可由特定酶裂解之可裂解連接基團。併入連接子中之可裂解連接基團之類型可視待靶向細胞而定。舉例而言,靶向肝之配體可經由包括酯基之連接子連接於陽離子脂質。肝細胞富含酯酶,且因此連接子在肝細胞中將比在不富含酯酶之細胞類型中更有效裂解。富含酯酶之其他細胞類型包括肺、腎皮質及睾丸之細胞。當靶向富含肽酶之細胞類型,諸如肝細胞及滑膜細胞時,可使用含有肽鍵之連接子。
一般而言,可藉由測試降解因子(或條件)裂解候選連接基團之能力來評估候選可裂解連接基團之適合性。亦將需要亦測試候選可裂解連接基團在血液中或與其他非目標組織接觸時的抗裂解能力。因此,吾人可確定第一與第二條件之間對裂解的相對易感性,其中第一條件經選擇以指示目標細胞中之裂解,且第二條件經選擇以指示其他組織或生物流體(例如血液或血清)中之裂解。評估可在無細胞系統、細胞、細胞培養物、器官或組織培養物或整個動物中進行。其可適用於在無細胞或培養條件中進行初始評估及藉由在整個動物中進一步評估來確認。在較佳實施例中,適用候選化合物在細胞中(或在經選擇以模擬細胞內條件之活體外條件下)比在血液或血清中(或在經選擇以模擬細胞外條件之活體外條件下)裂解快至少約2倍、4倍、10倍、20倍、30倍、40倍、50倍、60倍、70倍、80倍、90倍或約100倍。
在一個實施例中,可裂解連接基團為在還原或氧化時裂解之氧化還原可裂解連接基團。還原可裂解連接基團之實例為二硫化物連接基團(-S-S-)。為了確定候選可裂解連接基團是否為適合之「還原可裂解連接基團」或例如是否適合與特定TREM部分及特定靶向劑一起使用,可考慮本文所描述之方法。舉例而言,候選物可藉由使用此項技術中已知的試劑,與二硫蘇糖醇(DTT)或其他還原劑一起培育來評估,其模擬將在細胞,例如目標細胞中觀測到的裂解速率。候選物亦可在經選擇以模擬血液或血清條件之條件下進行評估。在一個條件下,候選化合物在血液中裂解至多約10%。在其他實施例中,適用候選化合物在細胞中(或在選擇用於模擬細胞內條件之活體外條件下)比在血液或血清中(或在選擇用於模擬胞外條件之活體外條件下)分解快至少約2倍、4倍、10倍、20倍、30倍、40倍、50倍、60倍、70倍、80倍、90倍或約100倍。候選化合物之裂解速率可使用標準酶動力學分析在經選擇以模擬細胞內介質之條件下測定且與經選擇以模擬細胞外介質之條件比較。
在另一實施例中,可裂解連接子包含基於磷酸酯基之可裂解連接基團。基於磷酸酯之可裂解連接基團藉由降解或水解磷酸酯基之因子裂解。裂解細胞中磷酸酯基之試劑的實例為細胞中之酶,諸如磷酸酶。基於磷酸酯基之連接基團之實例為-O-P(O)(ORk)-O-、-O-P(S)(ORk)-O-、-O-P(S)(SRk)-O-、-S-P(O)(ORk)-O-、-O-P(O)(ORk)-S-、-S-P(O)(ORk)-S-、-O-P(S)(ORk)-S-、-S-P(S)(ORk)-O-、-O-P(O)(Rk)-O-、-O-P(S)(Rk)-O-、-S-P(O)(Rk)-O-、-S-P(S)(Rk)-O-、-S-P(O)(Rk)-S-、-O-P(S)( Rk)-S-。較佳實施例為-O-P(O)(OH)-O-、-O-P(S)(OH)-O-、-O-P(S)(SH)-O-、-S-P(O)(OH)-O-、-O-P(O)(OH)-S-、-S-P(O)(OH)-S-、-O-P(S)(OH)-S-、-S-P(S)(OH)-O-、-O-P(O)(H)-O-、-O-P(S)(H)-O-、-S-P(O)(H)-O、-S-P(S)(H)-O-、-S-P(O)(H)-S-、-O-P(S)(H)-S-。一較佳實施例為-O-P(O)(OH)-O-。此等候選物可使用類似於上文所描述之方法的方法評估。
在另一實施例中,可裂解連接子包含酸可裂解連接基團。酸可裂解連接基團為在酸性條件下裂解之連接基團。在較佳實施例中,酸可裂解連接基團在pH為約6.5或更低(例如,約6.0、5.75、5.5、5.25、5.0或更低)之酸性環境中,或藉由諸如可充當一般酸之酶的試劑來裂解。在細胞中,特定的低pH細胞器,諸如胞內體及溶酶體,可為酸可裂解連接基團提供裂解環境。酸可裂解連接基團之實例包括但不限於腙、酯及胺基酸之酯。酸可裂解基團可具有通式-C=NN-、C(O)O或-OC(O)。一較佳實施例為當附接至酯之氧(烷氧基)的碳為芳基、經取代之烷基或三級烷基,諸如二甲基戊基或三級丁基時。此等候選物可使用類似於上文所描述之方法的方法評估。
在另一實施例中,可裂解連接子包含基於酯之可裂解連接基團。基於酯之可裂解連接基團藉由細胞中之諸如酯酶及醯胺酶的酶裂解。基於酯之可裂解連接基團的實例包括但不限於伸烷基、伸烯基及伸炔基之酯。酯可裂解連接基團具有通式-C(O)O-或-OC(O)-。此等候選物可使用類似於上文所描述之方法的方法評估。
在另一實施例中,可裂解連接子包含基於肽之可裂解連接基團。基於肽之可裂解連接基團係藉由細胞中之酶(諸如肽酶及蛋白酶)裂解。基於肽之可裂解連接基團為胺基酸之間形成以產生寡肽(例如二肽、三肽等)及多肽的肽鍵。基於肽之可裂解基團不包括醯胺基(-C(O)NH-)。醯胺基可在任何伸烷基、伸烯基或伸炔基之間形成。肽鍵為在胺基酸之間形成以產生肽及蛋白質的特殊類型的醯胺鍵。基於肽之裂解基團一般限於胺基酸之間形成以產生肽及蛋白質的肽鍵(亦即醯胺鍵)且不包括整個醯胺官能基。基於肽之可裂解連接基團具有通式-NHCHRAC(O)NHCHRBC(O)- (SEQ ID NO: 13),其中RA及RB為兩個相鄰胺基酸之R基團。此等候選物可使用類似於上文所描述之方法的方法評估。
ASGPR結合部分可結合至TREM之域(ASt域1、DH域、ACH域、VL域、TH域及/或ASt域2)內之任何核苷酸位置。在一實施例中,ASGPR部分結合至TREM內之核鹼基、末端或核苷酸間鍵聯。在一實施例中,ASGPR部分結合至TREM內之核鹼基。在一實施例中,ASGPR結合部分結合至TREM之域(ASt域1、DH域、ACH域、VL域、TH域及/或ASt域2)內之任何腺嘌呤核鹼基。在一實施例中,ASGPR結合部分結合至TREM之域(ASt域1、DH域、ACH域、VL域、TH域及/或ASt域2)內之任何胞嘧啶核鹼基。在一實施例中,其結合至TREM之域(ASt域1、DH域、ACH域、VL域、TH域及/或ASt域2)內之任何鳥苷核鹼基。在一實施例中,其結合至TREM之域(ASt域1、DH域、ACH域、VL域、TH域及/或ASt域2)內之任何尿嘧啶核鹼基。在一實施例中,其結合至TREM之域(ASt域1、DH域、ACH域、VL域、TH域及/或ASt域2)內之任何胸腺嘧啶核鹼基。
在一實施例中,ASGPR結合部分存在於TREM內之TREM位置1處(例如存在於TREM位置1處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置2處(例如存在於TREM位置2處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置3處(例如存在於TREM位置3處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置4處(例如存在於TREM位置4處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置5處(例如存在於TREM位置5處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置6處(例如存在於TREM位置6處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置7處(例如存在於TREM位置7處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置8處(例如存在於TREM位置8處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置9處(例如存在於TREM位置9處之核鹼基內)。
在一實施例中,ASGPR結合部分存在於TREM內之TREM位置10處(例如存在於TREM位置10處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置11處(例如存在於TREM位置11處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置12處(例如存在於TREM位置12處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置13處(例如存在於TREM位置13處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置14處(例如存在於TREM位置14處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置15處(例如存在於TREM位置15處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置16處(例如存在於TREM位置16處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置17處(例如存在於TREM位置17處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置18處(例如存在於TREM位置18處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置19處(例如存在於TREM位置19處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置20處(例如存在於TREM位置20處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置21處(例如存在於TREM位置21處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置22處(例如存在於TREM位置22處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置23處(例如存在於TREM位置23處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置24處(例如存在於TREM位置24處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置25處(例如存在於TREM位置25處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置26處(例如存在於TREM位置26處之核鹼基內)。
在一實施例中,ASGPR結合部分存在於TREM內之TREM位置27處(例如存在於TREM位置27處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置28處(例如存在於TREM位置28處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置29處(例如存在於TREM位置29處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置30處(例如存在於TREM位置30處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置31處(例如存在於TREM位置31處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置32處(例如存在於TREM位置32處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置33處(例如存在於TREM位置33處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置34處(例如存在於TREM位置34處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置35處(例如存在於TREM位置35處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置36處(例如存在於TREM位置36處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置37處(例如存在於TREM位置37處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置38處(例如存在於TREM位置38處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置39處(例如存在於TREM位置39處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置40處(例如存在於TREM位置40處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置41處(例如存在於TREM位置41處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置42處(例如存在於TREM位置42處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置43處(例如存在於TREM位置43處之核鹼基內)。
在一實施例中,ASGPR結合部分存在於TREM內之TREM位置44處(例如存在於TREM位置44處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置45處(例如存在於TREM位置45處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置46處(例如存在於TREM位置46處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置47處(例如存在於TREM位置47處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置48處(例如存在於TREM位置48處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置49處(例如存在於TREM位置49處之核鹼基內)。
在一實施例中,ASGPR結合部分存在於TREM內之TREM位置50處(例如存在於TREM位置50處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置51處(例如存在於TREM位置51處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置52處(例如存在於TREM位置52處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置53處(例如存在於TREM位置53處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置54處(例如存在於TREM位置54處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置55處(例如存在於TREM位置55處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置56處(例如存在於TREM位置56處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置57處(例如存在於TREM位置57處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置58處(例如存在於TREM位置58處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置59處(例如存在於TREM位置59處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置60處(例如存在於TREM位置60處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置61處(例如存在於TREM位置61處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置62處(例如存在於TREM位置62處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置63處(例如存在於TREM位置63處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置64處(例如存在於TREM位置64處之核鹼基內)。
在一實施例中,ASGPR結合部分存在於TREM內之TREM位置65處(例如存在於TREM位置65處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置66處(例如存在於TREM位置66處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置67處(例如存在於TREM位置67處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置68處(例如存在於TREM位置68處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置69處(例如存在於TREM位置69處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置70處(例如存在於TREM位置70處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置71處(例如存在於TREM位置71處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置72處(例如存在於TREM位置72處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置73處(例如存在於TREM位置73處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置74處(例如存在於TREM位置74處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置75處(例如存在於TREM位置75處之核鹼基內)。在一實施例中,ASGPR結合部分存在於TREM內之TREM位置76處(例如存在於TREM位置76處之核鹼基內)。
在一實施例中,ASGPR結合部分結合至TREM位置1處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置2處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置3處之核鹼基(C)。在一實施例中,ASGPR結合部分結合至TREM位置4處之核鹼基(U)。在一實施例中,ASGPR結合部分結合至TREM位置5處之核鹼基(C)。在一實施例中,ASGPR結合部分結合至TREM位置6處之核鹼基(C)。在一實施例中,ASGPR結合部分結合至TREM位置7處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置8處之核鹼基(U)。在一實施例中,ASGPR結合部分結合至TREM位置9處之核鹼基(G)。
在一實施例中,ASGPR結合部分結合至TREM位置10處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置11處之核鹼基(C)。在一實施例中,ASGPR結合部分結合至TREM位置12處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置13處之核鹼基(C)。在一實施例中,ASGPR結合部分結合至TREM位置14處之核鹼基(A)。在一實施例中,ASGPR結合部分結合至TREM位置15處之核鹼基(A)。在一實施例中,ASGPR結合部分結合至TREM位置16處之核鹼基(U)。在一實施例中,ASGPR結合部分結合至TREM位置17處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置18處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置19處之核鹼基(A)。在一實施例中,ASGPR結合部分結合至TREM位置20處之核鹼基(U)。在一實施例中,ASGPR結合部分結合至TREM位置21處之核鹼基(A)。在一實施例中,ASGPR結合部分結合至TREM位置22處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置23處之核鹼基(C)。在一實施例中,ASGPR結合部分結合至TREM位置24處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置25處之核鹼基(C)。在一實施例中,ASGPR結合部分結合至TREM位置26處之核鹼基(A)。
在一實施例中,ASGPR結合部分結合至TREM位置27處之核鹼基(U)。在一實施例中,ASGPR結合部分結合至TREM位置28處之核鹼基(U)。在一實施例中,ASGPR結合部分結合至TREM位置29處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置30處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置31處之核鹼基(A)。在一實施例中,ASGPR結合部分結合至TREM位置32處之核鹼基(C)。在一實施例中,ASGPR結合部分結合至TREM位置33處之核鹼基(U)。在一實施例中,ASGPR結合部分結合至TREM位置34處之核鹼基(U)。在一實施例中,ASGPR結合部分結合至TREM位置35處之核鹼基(C)。在一實施例中,ASGPR結合部分結合至TREM位置36處之核鹼基(A)。在一實施例中,ASGPR結合部分結合至TREM位置37處之核鹼基(A)。在一實施例中,ASGPR結合部分結合至TREM位置38處之核鹼基(A)。在一實施例中,ASGPR結合部分結合至TREM位置39處之核鹼基(U)。在一實施例中,ASGPR結合部分結合至TREM位置40處之核鹼基(U)。在一實施例中,ASGPR結合部分結合至TREM位置41處之核鹼基(C)。在一實施例中,ASGPR結合部分結合至TREM位置42處之核鹼基(A)。在一實施例中,ASGPR結合部分結合至TREM位置43處之核鹼基(A)。
在一實施例中,ASGPR結合部分結合至TREM位置44處之核鹼基(A)。在一實施例中,ASGPR結合部分結合至TREM位置45處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置46處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置47處之核鹼基(U)。在一實施例中,ASGPR結合部分結合至TREM位置48處之核鹼基(U)。在一實施例中,ASGPR結合部分結合至TREM位置49處之核鹼基(C)。
在一實施例中,ASGPR結合部分結合至TREM位置50處之核鹼基(C)。在一實施例中,ASGPR結合部分結合至TREM位置51處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置52處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置53處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置54處之核鹼基(U)。在一實施例中,ASGPR結合部分結合至TREM位置55處之核鹼基(U)。在一實施例中,ASGPR結合部分結合至TREM位置56處之核鹼基(C)。在一實施例中,ASGPR結合部分結合至TREM位置57處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置58處之核鹼基(A)。在一實施例中,ASGPR結合部分結合至TREM位置59處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置60處之核鹼基(U)。在一實施例中,ASGPR結合部分結合至TREM位置61處之核鹼基(C)。在一實施例中,ASGPR結合部分結合至TREM位置62處之核鹼基(C)。在一實施例中,ASGPR結合部分結合至TREM位置63處之核鹼基(C)。在一實施例中,ASGPR結合部分結合至TREM位置64處之核鹼基(G)。
在一實施例中,ASGPR結合部分結合至TREM位置76處之核鹼基(A)。在一實施例中,ASGPR結合部分結合至TREM位置75處之核鹼基(C)。在一實施例中,ASGPR結合部分結合至TREM位置74處之核鹼基(C)。在一實施例中,ASGPR結合部分結合至TREM位置73處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置72處之核鹼基(C)。在一實施例中,ASGPR結合部分結合至TREM位置71處之核鹼基(U)。在一實施例中,ASGPR結合部分結合至TREM位置70處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置69處之核鹼基(A)。在一實施例中,ASGPR結合部分結合至TREM位置68處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置67處之核鹼基(G)。在一實施例中,ASGPR結合部分結合至TREM位置66處之核鹼基(C)。在一實施例中,ASGPR結合部分結合至TREM位置65處之核鹼基(G)。
在一實施例中,包含ASGPR結合部分之TREM包含由表1中所揭示之去氧核糖核酸(DNA)序列(例如,表1中所揭示之SEQ ID NO: 1-451中之任一者)編碼的核糖核酸(RNA)序列。在一實施例中,包含ASGPR結合部分之TREM包含與由表1中所提供之DNA序列(例如,表1中所揭示之SEQ ID NO: 1-451中之任一者)編碼之RNA序列至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致的RNA序列。在一實施例中,包含ASGPR結合部分之TREM包含由與表1中所提供之DNA序列(例如,表1中所揭示之SEQ ID NO: 1-451中之任一者)至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致之DNA序列編碼的RNA序列。
在一實施例中,包含ASGPR結合部分之TREM包含由表1中所揭示之DNA序列編碼之RNA序列的至少5、10、15、20、25或30個連續核苷酸,例如由表1中所揭示之SEQ ID NO: 1-451中之任一者編碼之RNA序列的至少5、10、15、20、25或30個連續核苷酸。在一實施例中,包含ASGPR結合部分之TREM包含與由表1中所提供之DNA序列(例如,表1中所揭示之SEQ ID NO: 1-451中之任一者)編碼之RNA序列至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致的RNA序列的至少5、10、15、20、25或30個連續核苷酸。在一實施例中,包含ASGPR結合部分之TREM包含由與表1中所提供之DNA序列(例如,表1中所揭示之SEQ ID NO: 1-451中之任一者)至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致之DNA序列所編碼的RNA序列的至少5、10、15、20、25或30個連續核苷酸。
在一實施例中,包含ASGPR結合部分之TREM包含由表1中提供之DNA序列(例如表1中所揭示之SEQ ID NO: 1-451中之任一者)編碼的RNA序列的至少5%、10%、15%、20%、25%、30%、35%、40%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或99%。在一實施例中,包含ASGPR結合部分之TREM包含與由表1中所提供之DNA序列(例如表1中所揭示之SEQ ID NO: 1-451中之任一者)編碼之RNA序列至少80%、85%、90%、95%、96%、97%、98%或99%一致的RNA序列的至少5%、10%、15%、20%、25%、30%、35%、40%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或99%。在一實施例中,包含ASGPR結合部分之TREM包含由DNA序列編碼之RNA序列之至少5%、10%、15%、20%、25%、30%、35%、40%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%或99%,該DNA序列與表1中所提供之DNA序列(例如表1中所揭示之SEQ ID NO: 1-451中之任一者)至少80%、85%、90%、95%、96%、97%、98%或99%一致。
在一實施例中,包含ASGPR結合部分之TREM包含由表1中所揭示之DNA序列(例如表1中所揭示之SEQ ID NO: 1-451中之任一者)編碼之RNA序列的至少5個核糖核苷酸(nt)、10 nt、15 nt、20 nt、25 nt、30 nt、35 nt、40 nt、45 nt、50 nt、55 nt或60 nt (但小於全長)。在一實施例中,包含ASGPR結合部分之TREM包含與由表1中所提供之DNA序列(例如表1中所揭示之SEQ ID NO: 1-451中之任一者)編碼之RNA序列至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致的RNA序列的至少5個核糖核苷酸(nt)、10 nt、15 nt、20 nt、25 nt、30 nt、35 nt、40 nt、45 nt、50 nt、55 nt或60 nt (但小於全長)。在一實施例中,包含ASGPR結合部分之TREM包含由與表1中所提供之DNA序列(例如表1中所揭示之SEQ ID NO: 1-451中之任一者)至少80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%、99%或100%一致之DNA序列編碼的RNA序列的至少5個核糖核苷酸(nt)、10 nt、15 nt、20 nt、25 nt、30 nt、35 nt、40 nt、45 nt、50 nt、55 nt或60 nt (但小於全長)。
在一實施例中,包含ASGPR結合部分之TREM包含由表4中所揭示之去氧核糖核酸(DNA)序列(例如,表4中所揭示之SEQ ID NO: 452-561中之任一者)編碼的核糖核酸(RNA)序列。在一實施例中,包含ASGPR結合部分之TREM包含與由表4中所提供之DNA序列(例如,表4中所揭示之SEQ ID NO: 452-561中之任一者)編碼之RNA序列至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致的RNA序列。在一實施例中,包含ASGPR結合部分之TREM包含由與表4中所提供之DNA序列(例如,表4中所揭示之SEQ ID NO: 452-561中之任一者)至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致之DNA序列編碼的RNA序列。
在一實施例中,包含ASGPR結合部分之TREM包含由表4中所提供之DNA序列(例如表4中所揭示之SEQ ID NO: 452-561中之任一者)編碼之RNA序列的至少5個核糖核苷酸(nt)、10 nt、15 nt、20 nt、25 nt、30 nt、35 nt、40 nt、45 nt、50 nt、55 nt或60 nt (但小於全長)。在一實施例中,包含ASGPR結合部分之TREM包含與由表4中所提供之DNA序列(例如表4中所揭示之SEQ ID NO: 452-561中之任一者)編碼之RNA序列至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致的RNA序列的至少5個核糖核苷酸(nt)、10 nt、15 nt、20 nt、25 nt、30 nt、35 nt、40 nt、45 nt、50 nt、55 nt或60 nt (但小於全長)。在一實施例中,包含ASGPR結合部分之TREM包含由與表4中所提供之DNA序列(例如表4中所揭示之SEQ ID NO: 452-561中之任一者)至少80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%、99%或100%一致之DNA序列編碼的RNA序列的至少5個核糖核苷酸(nt)、10 nt、15 nt、20 nt、25 nt、30 nt、35 nt、40 nt、45 nt、50 nt、55 nt或60 nt (但小於全長)。
在一實施例中,包含ASGPR結合部分之TREM為表12中所提供之化合物,例如化合物編號99至131中之任一者。在一實施例中,包含ASGPR結合部分之TREM為化合物99。在一實施例中,包含ASGPR結合部分之TREM為化合物100。在一實施例中,包含ASGPR結合部分之TREM為化合物101。在一實施例中,包含ASGPR結合部分之TREM為化合物102。在一實施例中,包含ASGPR結合部分之TREM為化合物103。在一實施例中,包含ASGPR結合部分之TREM為化合物104。在一實施例中,包含ASGPR結合部分之TREM為化合物105。在一實施例中,包含ASGPR結合部分之TREM為化合物106。在一實施例中,包含ASGPR結合部分之TREM為化合物107。在一實施例中,包含ASGPR結合部分之TREM為化合物108。在一實施例中,包含ASGPR結合部分之TREM為化合物109。在一實施例中,包含ASGPR結合部分之TREM為化合物110。在一實施例中,包含ASGPR結合部分之TREM為化合物111。在一實施例中,包含ASGPR結合部分之TREM為化合物112。在一實施例中,包含ASGPR結合部分之TREM為化合物113。在一實施例中,包含ASGPR結合部分之TREM為化合物114。在一實施例中,包含ASGPR結合部分之TREM為化合物115。在一實施例中,包含ASGPR結合部分之TREM為化合物116。在一實施例中,包含ASGPR結合部分之TREM為化合物117。在一實施例中,包含ASGPR結合部分之TREM為化合物118。在一實施例中,包含ASGPR結合部分之TREM為化合物119。在一實施例中,包含ASGPR結合部分之TREM為化合物120。在一實施例中,包含ASGPR結合部分之TREM為化合物121。在一實施例中,包含ASGPR結合部分之TREM為化合物122。在一實施例中,包含ASGPR結合部分之TREM為化合物123。在一實施例中,包含ASGPR結合部分之TREM為化合物124。在一實施例中,包含ASGPR結合部分之TREM為化合物125。在一實施例中,包含ASGPR結合部分之TREM為化合物126。在一實施例中,包含ASGPR結合部分之TREM為化合物127。在一實施例中,包含ASGPR結合部分之TREM為化合物128。在一實施例中,包含ASGPR結合部分之TREM為化合物129。在一實施例中,包含ASGPR結合部分之TREM為化合物130。在一實施例中,包含ASGPR結合部分之TREM為化合物131。
在一實施例中,包含ASGPR結合部分之TREM包含具有與表12中所提供之TREM (例如表12中所提供之化合物100至131中之任一者)之RNA序列至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致的RNA序列的化合物。在一實施例中,包含ASGPR結合部分之TREM包含表12中所提供之TREM (例如表12中所揭示之化合物100至131中之任一者)的至少5個核糖核苷酸(nt)、10 nt、15 nt、20 nt、25 nt、30 nt、35 nt、40 nt、45 nt、50 nt、55 nt或60 nt (但小於全長)。在一實施例中,包含ASGPR結合部分之TREM包含與表12中所提供之TREM (例如表12中所揭示之化合物100至131中之任一者)至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致的TREM的至少5個核糖核苷酸(nt)、10 nt、15 nt、20 nt、25 nt、30 nt、35 nt、40 nt、45 nt、50 nt、55 nt或60 nt (但小於全長)。
在一實施例中,包含ASGPR結合部分之TREM包含表12中所提供之序列,例如SEQ ID NO: 622-654中之任一者。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 622。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 623。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 624。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 625。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 626。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 627。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 628。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 629。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 630。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 631。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 632。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 633。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 634。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 635。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 636。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 637。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 638。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 639。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 640。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 641。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 642。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 643。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 644。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 645。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 646。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 647。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 648。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 649。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 650。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 651。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 652。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 653。在一實施例中,包含ASGPR結合部分之TREM包含SEQ ID NO. 654。
在一實施例中,包含ASGPR結合部分之TREM包含與表12中所提供之TREM之序列(例如表12中所提供之SEQ ID NO. 622-654中之任一者)至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致的序列。在一實施例中,包含ASGPR結合部分之TREM包含表12中所提供之TREM (例如表12中所揭示之SEQ ID NO. 622-654中之任一者)的至少5個核糖核苷酸(nt)、10 nt、15 nt、20 nt、25 nt、30 nt、35 nt、40 nt、45 nt、50 nt、55 nt或60 nt (但小於全長)。在一實施例中,包含ASGPR結合部分之TREM包含與表12中所提供之TREM (例如表12中所揭示之SEQ ID NO. 622-654中之任一者)至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致的TREM的至少5個核糖核苷酸(nt)、10 nt、15 nt、20 nt、25 nt、30 nt、35 nt、40 nt、45 nt、50 nt、55 nt或60 nt (但小於全長)。
在一實施例中,包含ASGPR結合部分之TREM包含與表12中所提供之TREM (例如表12中所提供之SEQ ID NO. 622-652中之任一者)相差不超過1個核糖核苷酸(nt)、2 nt、3 nt、4 nt、5 nt、6 nt、7 nt、8 nt、9 nt、10 nt、12 nt、14 nt、16 nt、18 nt或20 nt的序列。
在一實施例中,包含ASGPR結合部分之TREM與SEQ ID NO. 622至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致。在一實施例中,包含ASGPR結合部分之TREM與SEQ ID NO. 650至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致。在一實施例中,包含ASGPR結合部分之TREM與SEQ ID NO. 653至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致。
在一實施例中,包含ASGPR結合部分之TREM包含與SEQ ID NO. 622相差至少1個核糖核苷酸(nt)、2 nt、3 nt、4 nt、5 nt、6 nt、7 nt、8 nt、9 nt、10 nt、12 nt、14 nt、16 nt、18 nt、20 nt、25 nt、30 nt、40 nt、45 nt、50 nt、55 nt或更多的序列。在一實施例中,包含ASGPR結合部分之TREM包含與SEQ ID NO. 622相差不超過1個核糖核苷酸(nt)、2 nt、3 nt、4 nt、5 nt、6 nt、7 nt、8 nt、9 nt、10 nt、12 nt、14 nt、16 nt、18 nt或20 nt的序列。在一實施例中,包含ASGPR結合部分之TREM包含與SEQ ID NO. 650相差至少1個核糖核苷酸(nt)、2 nt、3 nt、4 nt、5 nt、6 nt、7 nt、8 nt、9 nt、10 nt、12 nt、14 nt、16 nt、18 nt、20 nt、25 nt、30 nt、40 nt、45 nt、50 nt、55 nt或更多的序列。在一實施例中,包含ASGPR結合部分之TREM包含與SEQ ID NO. 650相差不超過1個核糖核苷酸(nt)、2 nt、3 nt、4 nt、5 nt、6 nt、7 nt、8 nt、9 nt、10 nt、12 nt、14 nt、16 nt、18 nt或20 nt的序列。在一實施例中,包含ASGPR結合部分之TREM包含與SEQ ID NO. 653相差至少1個核糖核苷酸(nt)、2 nt、3 nt、4 nt、5 nt、6 nt、7 nt、8 nt、9 nt、10 nt、12 nt、14 nt、16 nt、18 nt、20 nt、25 nt、30 nt、40 nt、45 nt、50 nt、55 nt或更多的序列。在一實施例中,包含ASGPR結合部分之TREM包含與SEQ ID NO. 653相差不超過1個核糖核苷酸(nt)、2 nt、3 nt、4 nt、5 nt、6 nt、7 nt、8 nt、9 nt、10 nt、12 nt、14 nt、16 nt、18 nt或20 nt的序列。
經化學修飾之TREM 在一些實施例中,TREM實體(例如本文所描述之TREM、TREM核心片段或TREM片段)除ASGPR結合部分以外進一步包含化學修飾,例如表5至9中任一者中所描述之修飾。化學修飾可根據此項技術中已知之方法進行。在一實施例中,化學修飾為細胞(例如人類細胞)不對內源性tRNA進行之修飾。
在一實施例中,化學修飾為細胞(例如人類細胞)可對內源性tRNA進行之修飾,但其中此類修飾處於其不出現在天然tRNA上之位置中。在一實施例中,化學修飾位於天然不具有此類修飾之域、連接子或臂中。在一實施例中,化學修飾位於域、連接子或臂內天然不具有此類修飾之位置處。在一實施例中,化學修飾位於天然不具有此類修飾之核苷酸上。在一實施例中,化學修飾位於域、連接子或臂內天然不具有此類修飾之位置處的核苷酸上。
本發明中之特徵化之核酸中之任一者可藉由此項技術中沿用已久的方法合成及/或修飾,諸如「Current protocols in nucleic acid chemistry」, Beaucage, S.L.等人(編), John Wiley & Sons, Inc., New York, NY, USA中所描述之彼等方法,該文獻在此以引用的方式併入本文中。修飾包括例如末端修飾,例如5'端修飾(磷酸化、結合、反向鍵聯)或3'端修飾(結合、DNA核苷酸、反向鍵聯等);鹼基修飾,例如用穩定化鹼基、去穩定化鹼基或與配偶體之擴充抗體庫鹼基配對之鹼基置換,移除鹼基(無鹼基核苷酸),或結合鹼基;糖修飾(例如在2'位置或4'位置處)或糖之置換;及/或主鏈修飾,包括磷酸二酯鍵聯之修飾或置換。適用於本文所描述之實施例之TREM化合物之特定實例包括(但不限於)含有經修飾之主鏈或非天然核苷間鍵聯的TREM。具有經修飾之主鏈的TREM尤其包括主鏈中不具有磷原子的彼等TREM。出於本說明書之目的,且如此項技術中有時提及,核苷間主鏈中不具有磷原子的經修飾之RNA亦可視為寡核苷。在一些實施例中,經修飾之TREM將在其核苷間主鏈中具有磷原子。
經修飾TREM主鏈包括例如硫代磷酸酯;對掌性硫代磷酸酯;二硫代磷酸酯;磷酸三酯;胺基烷基磷酸三酯;甲基及其他烷基膦酸酯,包括3'-伸烷基膦酸酯及對掌性膦酸酯;亞膦酸酯;胺基磷酸酯,包括3'-胺基胺基磷酸酯及胺基烷基胺基磷酸酯、硫羰基胺基磷酸酯;硫羰基烷基膦酸酯;硫羰基烷基磷酸三酯;及具有正常3'-5'鍵聯之硼烷磷酸酯,此等之2'-5'鍵聯類似物,及具有反轉極性者,其中相鄰核苷單元對以3'-5'至5'-3'或2'-5'至5'-2'鍵聯。亦包括各種鹽、混合鹽及游離酸形式。
揭示上述含磷鍵聯之製備的代表性美國專利包括但不限於美國專利第3,687,808號;第4,469,863號;第4,476,301號;第5,023,243號;第5,177,195號;第5,188,897號;第5,264,423號;第5,276,019號;第5,278,302號;第5,286,717號;第5,321,131號;第5,399,676號;第5,405,939號;第5,453,496號;第5,455,233號;第5,466,677號;第5,476,925號;第5,519,126號;第5,536,821號;第5,541,316號;第5,550,111號;第5,563,253號;第5,571,799號;第5,587,361號;第5,625,050號;第6,028,188號;第6,124,445號;第6,160,109號;第6,169,170號;第6,172,209號;第6,239,265號;第6,277,603號;第6,326,199號;第6,346,614號;第6,444,423號;第6,531,590號;第6,534,639號;第6,608,035號;第6,683,167號;第6,858,715號;第6,867,294號;第6,878,805號;第7,015,315號;第7,041,816號;第7,273,933號;第7,321,029號;及美國專利RE39464,其中之每一者之全部內容在此以引用之方式併入本文中。
其中不包括磷原子之經修飾TREM主鏈具有由短鏈烷基或環烷基核苷間鍵聯、混合雜原子及烷基或環烷基核苷間鍵聯,或一或多個短鏈雜原子或雜環核苷間鍵聯形成之主鏈。此等主鏈包括:具有(N-𠰌啉基)鍵聯(部分地由核苷之糖部分形成)之彼等主鏈;矽氧烷主鏈;硫化物、亞碸及碸主鏈;甲乙醯基(formacetyl)及硫代甲乙醯基主鏈;亞甲基甲乙醯基及硫代甲乙醯基主鏈;含有烯烴之主鏈;胺基磺酸酯主鏈;亞甲基亞胺基及亞甲基肼基主鏈;磺酸酯及磺醯胺主鏈;醯胺主鏈;及具有混合N、O、S及CH
2組成部分之其他主鏈。教示上述寡核苷之製備的代表性美國專利包括但不限於美國專利第5,034,506號;第5,166,315號;第5,185,444號;第5,214,134號;第5,216,141號;第5,235,033號;第5,64,562號;第5,264,564號;第5,405,938號;第5,434,257號;第5,466,677號;第5,470,967號;第5,489,677號;第5,541,307號;第5,561,225號;第5,596,086號;第5,602,240號;第5,608,046號;第5,610,289號;第5,618,704號;第5,623,070號;第5,663,312號;第5,633,360號;第5,677,437號;及第5,677,439號,其中之每一者之全部內容在此以引用之方式併入本文中。
在其他實施例中,涵蓋適用於TREM之合適RNA模擬物,其中核苷酸單元之糖及核苷間鍵聯(亦即主鏈)均由新的基團置換。鹼基單元維持與適當核酸目標化合物雜交。一種此類寡聚化合物,已展示具有極佳雜交特性之RNA模擬物,稱為肽核酸(PNA)。在PNA化合物中,RNA之糖主鏈置換為含有醯胺之主鏈,特定言之胺基乙基甘胺酸主鏈。核鹼基保留且直接或間接結合至主鏈之醯胺部分的氮雜氮原子。教示PNA化合物之製備的代表性美國專利包括但不限於美國專利第5,539,082號;第5,714,331號;及第5,719,262號,其中每一者之全部內容在此以引用之方式併入本文中。適用於本發明之TREM之額外PNA化合物描述於例如Nielsen等人, Science, 1991, 254, 1497-1500中。
本發明中之特徵化之一些實施例包括具有硫代磷酸酯主鏈之TREM及具有雜原子主鏈之寡核苷,且特定言之上述美國專利第5,489,677號之-CH
2-NH-CH
2-、-CH
2-N(CH
3)-O-CH
2- [稱為亞甲基(甲基亞胺基)或MMI主鏈]、-CH
2-O-N(CH
3)-CH
2-、-CH
2-N(CH
3)-N(CH
3)-CH
2-及-N(CH
3)-CH
2-CH
2- [其中天然磷酸二酯主鏈表示為-O-P-O-CH
2-];及上述美國專利第5,602,240號之醯胺主鏈。在一些實施例中,本文中之特徵化之TREM具有上述美國專利第5,034,506號之(N-𠰌啉基)主鏈結構。
本文中之特徵化之TREM可在2'位置處包括以下中之一者:OH;F;O-、S-或N-烷基;O-、S-或N-烯基;O-、S-或N-炔基;或O-烷基-O-烷基,其中烷基、烯基及炔基可為經取代或未經取代之C
1至C
10烷基或C
2至C
10烯基及炔基。例示性適合修飾包括O[(CH
2)
nO]
mCH
3、O(CH
2).
nOCH
3、O(CH
2)
nNH
2、O(CH
2)
nCH
3、O(CH
2)
nONH
2及O(CH
2)
nON[(CH
2)
nCH
3)]
2,其中n及m為1至約10。在其他實施例中,TREM可在2'位置處包括以下中之一者:C
1至C
10低碳數烷基、經取代之低碳數烷基、烷芳基、芳烷基、O-烷芳基或O-芳烷基、SH、SCH
3、OCN、Cl、Br、CN、CF
3、OCF
3、SOCH
3、SO
2CH
3、ONO
2、NO
2、N
3、NH
2、雜環烷基、雜環烷芳基、胺基烷基胺基、聚烷基胺基、經取代之矽基、RNA裂解基團、報導基團、嵌入劑、改良TREM之藥物動力學特性之基團、或改良TREM之藥效學特性之基團及具有類似特性之其他取代基。
在一些實施例中,修飾包括2'-甲氧基乙氧基(2'-O-CH
2CH
2OCH
3,亦稱為2'-O-(2-甲氧基乙基)或2'-MOE) (Martin等人, Helv. Chim. Acta, 1995, 78:486-504),亦即烷氧基-烷氧基。另一例示性修飾為2'-二甲基胺基氧基乙氧基,亦即O(CH
2)
2ON(CH
3)
2基團,亦稱為2'-DMAOE,如下文實例中所描述;及2'-二甲基胺基乙氧基乙氧基(在此項技術中亦稱為2'-O-二甲基胺基乙氧基乙基或2'-DMAEOE),亦即2'-O-CH
2-O-CH
2-N(CH
2)
2。
其他修飾包括2'-甲氧基(2'-OCH
3)、2'-胺基丙氧基(2'-OCH
2CH
2CH
2NH
2)及2'-氟(2'-F)。類似修飾亦可在TREM內之其他位置處進行,特定言之3'末端核苷酸上或2'-5'連接TREM中之糖之3'位置及5'末端核苷酸之5'位置。TREM亦可具有糖模擬物,諸如環丁基部分替代呋喃戊醣基的糖。教示此類經修飾糖結構之製備的代表性美國專利包括但不限於美國專利第4,981,957號;第5,118,800號;第5,319,080號;第5,359,044號;第5,393,878號;第5,446,137號;第5,466,786號;第5,514,785號;第5,519,134號;第5,567,811號;第5,576,427號;第5,591,722號;第5,597,909號;第5,610,300號;第5,627,053號;第5,639,873號;第5,646,265號;第5,658,873號;第5,670,633號;及第5,700,920號,其中之某些與本申請案共同擁有。前述中之每一者之全部內容在此以引用之方式併入本文中。
TREM亦可包括核鹼基(在此項技術中常簡稱為「鹼基」)修飾或取代。如本文所使用,「未經修飾」或「天然」核鹼基包括嘌呤鹼基腺嘌呤(A)及鳥嘌呤(G),及嘧啶鹼基胸腺嘧啶(T)、胞嘧啶(C)及尿嘧啶(U)。經修飾之核鹼基包括其他合成及天然核鹼基,諸如去氧胸腺嘧啶(dT);5-甲基胞嘧啶(5-me-C);5-羥甲基胞嘧啶;黃嘌呤;次黃嘌呤;2-胺基腺嘌呤;腺嘌呤及鳥嘌呤之6-甲基及其他烷基衍生物;腺嘌呤及鳥嘌呤之2-丙基及其他烷基衍生物;2-硫代尿嘧啶、2-硫代胸腺嘧啶及2-硫代胞嘧啶;5-鹵代尿嘧啶及胞嘧啶;5-丙炔基尿嘧啶及胞嘧啶;6-偶氮尿嘧啶、胞嘧啶及胸腺嘧啶;5-尿嘧啶(假尿嘧啶);4-硫代尿嘧啶;8-鹵基、8-胺基、8-硫醇、8-硫代烷基、8-羥基及其他8-經取代之腺嘌呤及鳥嘌呤;5-鹵基(尤其5-溴)、5-三氟甲基及其他5-經取代之尿嘧啶及胞嘧啶;7-甲基鳥嘌呤及7-甲基腺嘌呤;8-氮雜鳥嘌呤及8-氮雜腺嘌呤;7-去氮鳥嘌呤及7-去氮腺嘌呤;以及3-去氮鳥嘌呤及3-去氮腺嘌呤。其他核鹼基包括:美國專利第3,687,808號中所揭示之核鹼基;Modified Nucleosides in Biochemistry, Biotechnology and Medicine, Herdewijn, P.編 Wiley-VCH, 2008中所揭示之核鹼基;The Concise Encyclopedia Of Polymer Science And Engineering, 第858-859頁, Kroschwitz, J. L編, John Wiley & Sons, 1990中所揭示之核鹼基;Englisch等人, Angewandte Chemie, 國際版, 1991, 30, 613所揭示之核鹼基;及Sanghvi, Y S., 第15章, dsRNA Research and Applications, 第289-302頁, Crooke, S. T.及Lebleu, B.編, CRC Press, 1993所揭示之核鹼基。某些此等核鹼基尤其適用於提高本發明特性化之寡聚化合物的結合親和力。此等核鹼基包括5-經取代之嘧啶、6-氮雜嘧啶及N-2、N-6及O-6經取代之嘌呤,包括2-胺基丙基腺嘌呤、5-丙炔基尿嘧啶及5-丙炔基胞嘧啶。已顯示5-甲基胞嘧啶取代可使核酸雙螺旋穩定性提高0.6-1.2℃ (Sanghvi, Y. S., Crooke, S. T.及Lebleu, B.編, dsRNA Research and Applications, CRC Press, Boca Raton, 1993, 第276-278頁)且為例示性鹼基取代,更尤其與2'-O-甲氧基乙基糖修飾組合時。
教示某些上文所提及之經修飾核鹼基以及其他經修飾核鹼基之製備的代表性美國專利包括但不限於上文所提及之美國專利第3,687,808號;第4,845,205號;第5,130,30號;第5,134,066號;第5,175,273號;第5,367,066號;第5,432,272號;第5,457,187號;第5,459,255號;第5,484,908號;第5,502,177號;第5,525,711號;第5,552,540號;第5,587,469號;第5,594,121號;第5,596,091號;第5,614,617號;第5,681,941號;第5,750,692號;第6,015,886號;第6,147,200號;第6,166,197號;第6,222,025號;第6,235,887號;第6,380,368號;第6,528,640號;第6,639,062號;第6,617,438號;第7,045,610號;第7,427,672號;及第7,495,088號,其中之每一者之全部內容在此以引用之方式併入本文中。
TREM亦可經修飾以包括一或多個雙環糖部分。A 「雙環糖」為藉由兩個原子之橋接修飾之呋喃醣基環。「雙環核苷」(「BNA」)為其中糖部分包含連接糖環之兩個碳原子從而形成雙環系統的橋的核苷。在某些實施例中,橋連接糖環之4'-碳與2'-碳。因此,在一些實施例中,本發明之藥劑可包括TREM之RNA,亦可經修飾以包括一或多個鎖核酸(LNA)。鎖核酸為具有經修飾之核糖部分之核苷酸,其中核糖部分包含連接2'及4'碳之額外橋。換言之,LNA為包含雙環糖部分之核苷酸,該雙環糖部分包含4'-CH
2-O-2'橋。此結構將核糖有效地「鎖定」為3'-內結構構形。已顯示將鎖核酸添加至寡核苷酸序列中增加該等寡核苷酸序列在血清中之穩定性,且減少脫靶效應(Elmen, J.等人(2005) Nucleic Acids Research 33(1):439-447;Mook, OR.等人(2007) Mol Cane Ther 6(3):833-843;Grunweller, A.等人(2003) Nucleic Acids Research 31(12):3185-3193)。
在一實施例中,本文所描述之TREM、TREM核心片段或TREM片段包含表5中所提供之化學修飾或其組合。
表 5 :例示性修飾
| 名稱 | |
| 7-去氮-腺苷 | |
| N1-甲基-腺苷 | |
| N6, N6 (二甲基)腺嘌呤 | |
| N6-順-羥基-異戊烯基-腺苷 | |
| 硫代-腺苷 | |
| 2-(胺基)腺嘌呤 | |
| 2-(胺基丙基)腺嘌呤 | |
| 2-(甲基硫基) N6 (異戊烯基)腺嘌呤 | |
| 2-(烷基)腺嘌呤 | |
| 2-(胺基烷基)腺嘌呤 | |
| 2-(胺基丙基)腺嘌呤 | |
| 2-(鹵基)腺嘌呤 | |
| 2-(丙基)腺嘌呤 | |
| 2'-疊氮基-2'-去氧-腺苷 | |
| 2'-去氧-2'-α-胺基腺苷 | |
| 2'-去氧-2'-α-疊氮基腺苷 | |
| 6-(烷基)腺嘌呤 | |
| 6-(甲基)腺嘌呤 | |
| 6-(烷基)腺嘌呤 | |
| 6-(甲基)腺嘌呤 | |
| 7-(去氮)腺嘌呤 | |
| 8-(烯基)腺嘌呤 | |
| 8-(炔基)腺嘌呤 | |
| 8-(胺基)腺嘌呤 | |
| 8-(硫代烷基)腺嘌呤 | |
| 8-(烯基)腺嘌呤 | |
| 8-(烷基)腺嘌呤 | |
| 8-(炔基)腺嘌呤 | |
| 8-(胺基)腺嘌呤 | |
| 8-(鹵基)腺嘌呤 | |
| 8-(羥基)腺嘌呤 | |
| 8-(硫代烷基)腺嘌呤 | |
| 8-(硫醇)腺嘌呤 | |
| 8-疊氮基-腺苷 | |
| 氮雜腺嘌呤 | |
| 去氮腺嘌呤 | |
| N6-(甲基)腺嘌呤 | |
| N6-(異戊基)腺嘌呤 | |
| 7-去氮-8-氮雜-腺苷 | |
| 7-甲基腺嘌呤 | |
| 1-去氮腺苷 | |
| 2'-氟-N6-Bz-去氧腺苷 | |
| 2'-OMe-2-胺基-腺苷 | |
| 2'O-甲基-N6-Bz-去氧腺苷 | |
| 2'-α-乙炔基腺苷 | |
| 2-胺基腺嘌呤 | |
| 2-胺基腺苷 | |
| 2-胺基-腺苷 | |
| 2'-α-三氟甲基腺苷 | |
| 2-疊氮基腺苷 | |
| 2'-β-乙炔基腺苷 | |
| 2-溴腺苷 | |
| 2'-β-三氟甲基腺苷 | |
| 2-氯腺苷 | |
| 2'-去氧-2',2'-二氟腺苷 | |
| 2'-去氧-2'-α-巰基腺苷 | |
| 2'-去氧-2'-α-硫代甲氧基腺苷 | |
| 2'-去氧-2'-β-胺基腺苷 | |
| 2'-去氧-2'-β-疊氮基腺苷 | |
| 2'-去氧-2'-β-溴腺苷 | |
| 2'-去氧-2'-β-氯腺苷 | |
| 2'-去氧-2'-β-氟腺苷 | |
| 2'-去氧-2'-β-碘腺苷 | |
| 2'-去氧-2'-β-巰基腺苷 | |
| 2'-去氧-2'-β-硫代甲氧基腺苷 | |
| 2-氟腺苷 | |
| 2-碘腺苷 | |
| 2-巰基腺苷 | |
| 2-甲氧基-腺嘌呤 | |
| 2-甲基硫基-腺嘌呤 | |
| 2-三氟甲基腺苷 | |
| 3-去氮-3-溴腺苷 | |
| 3-去氮-3-氯腺苷 | |
| 3-去氮-3-氟腺苷 | |
| 3-去氮-3-碘腺苷 | |
| 3-去氮腺苷 | |
| 4'-疊氮基腺苷 | |
| 4'-碳環腺苷 | |
| 4'-乙炔基腺苷 | |
| 5'-高-腺苷 | |
| 8-氮雜-腺苷 | |
| 8-溴-腺苷 | |
| 8-三氟甲基腺苷 | |
| 9-去氮腺苷 | |
| 2-胺基嘌呤 | |
| 7-去氮-2,6-二胺基嘌呤 | |
| 7-去氮-8-氮雜-2,6-二胺基嘌呤 | |
| 7-去氮-8-氮雜-2-胺基嘌呤 | |
| 2,6-二胺基嘌呤 | |
| 7-去氮-8-氮雜-腺嘌呤、7-去氮-2-胺基嘌呤 | |
| 4-甲基胞苷 | |
| 5-氮雜-胞苷 | |
| 假異胞苷 | |
| 吡咯并-胞苷 | |
| α-硫代-胞苷 | |
| 2-(硫基)胞嘧啶 | |
| 2'-胺基-2'-去氧-胞嘧啶 | |
| 2'-疊氮基-2'-去氧-胞嘧啶 | |
| 2'-去氧-2'-α-胺基胞苷 | |
| 2'-去氧-2'-α-疊氮基胞苷 | |
| 3 (去氮) 5 (氮雜)胞嘧啶 | |
| 3 (甲基)胞嘧啶 | |
| 3-(烷基)胞嘧啶 | |
| 3-(去氮) 5 (氮雜)胞嘧啶 | |
| 3-(甲基)胞苷 | |
| 4,2'-O-二甲基胞苷 | |
| 5 (鹵基)胞嘧啶 | |
| 5 (甲基)胞嘧啶 | |
| 5 (丙炔基)胞嘧啶 | |
| 5 (三氟甲基)胞嘧啶 | |
| 5-(烷基)胞嘧啶 | |
| 5-(炔基)胞嘧啶 | |
| 5-(鹵基)胞嘧啶 | |
| 5-(丙炔基)胞嘧啶 | |
| 5-(三氟甲基)胞嘧啶 | |
| 5-溴-胞苷 | |
| 5-碘-胞苷 | |
| 5-丙炔基胞嘧啶 | |
| 6-(偶氮基)胞嘧啶 | |
| 6-氮雜-胞苷 | |
| 氮雜胞嘧啶 | |
| 去氮胞嘧啶 | |
| N4 (乙醯基)胞嘧啶 | |
| 1-甲基-1-去氮-假異胞苷 | |
| 1-甲基-假異胞苷 | |
| 2-甲氧基-5-甲基-胞苷 | |
| 2-甲氧基-胞苷 | |
| 2-硫代-5-甲基-胞苷 | |
| 4-甲氧基-1-甲基-假異胞苷 | |
| 4-甲氧基-假異胞苷 | |
| 4-硫代-l-甲基-1-去氮-假異胞苷 | |
| 4-硫代-1-甲基-假異胞苷 | |
| 4-硫代-假異胞苷 | |
| 5-氮雜-澤布拉恩(zebularine) | |
| 5-甲基-澤布拉恩 | |
| 吡咯并-假異胞苷 | |
| 澤布拉恩 | |
| (E)-5-(2-溴-乙烯基)胞苷 | |
| 2,2'-脫水胞苷 | |
| 2'-氟-N4-Bz-胞苷 | |
| 2'-氟-N4-乙醯基-胞苷 | |
| 2'-O-甲基-N4-乙醯基-胞苷 | |
| 2'-O-甲基-N4-Bz-胞苷 | |
| 2'-a-乙炔基胞苷 | |
| 2'-a-三氟甲基胞苷 | |
| 2'-b-乙炔基胞苷 | |
| 2'-b-三氟甲基胞苷 | |
| 2'-去氧-2',2'-二氟胞苷 | |
| 2'-去氧-2'-α-巰基胞苷 | |
| 2'-去氧-2'-α-硫代甲氧基胞苷 | |
| 2'-去氧-2'-β-胺基胞苷 | |
| 2'-去氧-2'-β-疊氮基胞苷 | |
| 2'-去氧-2'-β-溴胞苷 | |
| 2'-去氧-2'-β-氯胞苷 | |
| 2'-去氧-2'-β-氟胞苷 | |
| 2'-去氧-2'-β-碘胞苷 | |
| 2'-去氧-2'-β-巰基胞苷 | |
| 2'-去氧-2'-β-硫代甲氧基胞苷TP | |
| 2'-O-甲基-5-(1-丙炔基)胞苷 | |
| 3'-乙炔基胞苷 | |
| 4'-疊氮基胞苷 | |
| 4'-碳環胞苷 | |
| 4'-乙炔基胞苷 | |
| 5-(1-丙炔基)阿糖胞苷 | |
| 5-(2-氯-苯基)-2-硫代胞苷 | |
| 5-(4-胺基-苯基)-2-硫代胞苷 | |
| 5-胺基烯丙基-胞嘧啶 | |
| 5-氰基胞苷 | |
| 5-乙炔基阿糖胞苷 | |
| 5-乙炔基胞苷 | |
| 5'-高-胞苷 | |
| 5-甲氧基胞苷 | |
| 5-三氟甲基-胞苷 | |
| N4-胺基-胞苷 | |
| N4-苯甲醯基-胞苷 | |
| 假異胞苷 | |
| 6-硫代-鳥苷 | |
| 7-去氮-鳥苷 | |
| 8-側氧基-鳥苷 | |
| N1-甲基-鳥苷 | |
| α-硫代-鳥苷 | |
| 2-(丙基)鳥嘌呤 | |
| 2-(烷基)鳥嘌呤 | |
| 2'-胺基-2'-去氧-鳥苷 | |
| 2'-疊氮基-2'-去氧-鳥苷 | |
| 2'-去氧-2'-α-胺基鳥苷 | |
| 2'-去氧-2'-α-疊氮基鳥苷 | |
| 6-(甲基)鳥嘌呤 | |
| 6-(烷基)鳥嘌呤 | |
| 6-(甲基)鳥嘌呤 | |
| 6-甲基-鳥苷 | |
| 7-(烷基)鳥嘌呤 | |
| 7-(去氮)鳥嘌呤 | |
| 7-(甲基)鳥嘌呤 | |
| 7-(烷基)鳥嘌呤 | |
| 7-(去氮)鳥嘌呤 | |
| 7-(甲基)鳥嘌呤 | |
| 8-(烷基)鳥嘌呤 | |
| 8-(炔基)鳥嘌呤 | |
| 8-(鹵基)鳥嘌呤 | |
| 8-(硫代烷基)鳥嘌呤 | |
| 8-(烯基)鳥嘌呤 | |
| 8-(烷基)鳥嘌呤 | |
| 8-(炔基)鳥嘌呤 | |
| 8-(胺基)鳥嘌呤 | |
| 8-(鹵基)鳥嘌呤 | |
| 8-(羥基)鳥嘌呤 | |
| 8-(硫代烷基)鳥嘌呤 | |
| 8-(硫醇)鳥嘌呤 | |
| 氮鳥嘌呤 | |
| 去氮鳥嘌呤 | |
| N (甲基)鳥嘌呤 | |
| N-(甲基)鳥嘌呤 | |
| 1-甲基-6-硫代-鳥苷 | |
| 6-甲氧基-鳥苷 | |
| 6-硫代-7-去氮-8-氮雜-鳥苷 | |
| 6-硫代-7-去氮-鳥苷 | |
| 6-硫代-7-甲基-鳥苷 | |
| 7-去氮-8-氮雜-鳥苷 | |
| 7-甲基-8-側氧基-鳥苷 | |
| N2,N2-二甲基-6-硫代-鳥苷 | |
| N2-甲基-6-硫代-鳥苷 | |
| 1-Me-鳥苷 | |
| 2'氟-N2-異丁基-鳥苷 | |
| 2'O-甲基-N2-異丁基-鳥苷 | |
| 2'-α-乙炔基鳥苷 | |
| 2'-α-三氟甲基鳥苷 | |
| 2'-β-乙炔基鳥苷 | |
| 2'-β-三氟甲基鳥苷 | |
| 2'-去氧-2',2'-二氟鳥苷 | |
| 2'-去氧-2'-α-巰基鳥苷 | |
| 2'-去氧-2'-α-硫代甲氧基鳥苷 | |
| 2'-去氧-2'-β-胺基鳥苷 | |
| 2'-去氧-2'-β-疊氮基鳥苷 | |
| 2'-去氧-2'-β-溴鳥苷 | |
| 2'-去氧-2'-β-氯鳥苷 | |
| 2'-去氧-2'-β-氟鳥苷 | |
| 2'-去氧-2'-β-碘鳥苷 | |
| 2'-去氧-2'-β-巰基鳥苷 | |
| 2'-去氧-2'-β-硫代甲氧基鳥苷 | |
| 4'-疊氮基鳥苷 | |
| 4'-碳環鳥苷 | |
| 4'-乙炔基鳥苷 | |
| 5'-高-鳥苷 | |
| 8-溴-鳥苷 | |
| 9-去氮鳥苷 | |
| N2-異丁基-鳥苷 | |
| 7-甲基肌苷 | |
| 烯丙基胺基-胸苷 | |
| 氮雜胸苷 | |
| 去氮胸苷 | |
| 去氧-胸苷 | |
| 5-丙炔基尿嘧啶 | |
| α-硫代-尿苷 | |
| 1-(胺基烷基胺基-羰基乙烯基)- 2(硫基)-假尿嘧啶 | |
| 1-(胺基烷基胺基羰基乙烯基)-2,4-(二硫基)假尿嘧啶 | |
| 1-(胺基烷基胺基羰基乙烯基)-4 (硫基)假尿嘧啶 | |
| 1-(胺基烷基胺基羰基乙烯基)-假尿嘧啶 | |
| 1-(胺基羰基乙烯基)-2(硫基)-假尿嘧啶 | |
| 1-( 胺基羰基乙烯基)-2,4-(二硫基)假尿嘧啶 | |
| 1-(胺基羰基乙烯基)-4 (硫基)假尿嘧啶 | |
| 1-(胺基羰基乙烯基)-假尿嘧啶 | |
| 1-經取代之2-(硫基)-假尿嘧啶 | |
| 1-經取代之2,4-(二硫基)假尿嘧啶 | |
| 1-經取代之4 (硫基)假尿嘧啶 | |
| 1-經取代之假尿嘧啶 | |
| 1-(胺基烷胺基-羰基乙烯基)-2-(硫基)-假尿嘧啶 | |
| 1-甲基-3-(3-胺基-3-羧丙基)假尿苷 | |
| l-甲基-3-(3-胺基-3-羧丙基)假尿苷 | |
| 1-甲基-假UTP | |
| 2 (硫基)假尿嘧啶 | |
| 2'去氧尿苷 | |
| 2'氟尿苷 | |
| 2-(硫基)尿嘧啶 | |
| 2,4-(二硫基)假尿嘧啶 | |
| 2'-甲基, 2'-胺基, 2'疊氮基, 2'氟-鳥苷 | |
| 2'-胺基-2'-去氧-尿苷 | |
| 2'-疊氮基-2'-去氧-尿苷 | |
| 2'-疊氮基-去氧尿苷 | |
| 2'-O-甲基假尿苷 | |
| 2'去氧尿苷 | |
| 2'氟尿苷 | |
| 2'-去氧-2'-α-胺基尿苷TP | |
| 2'-去氧-2'-α-疊氮基尿苷TP | |
| 2-甲基假尿苷 | |
| 3-(3胺基-3-羧丙基)尿嘧啶 | |
| 4-(硫基)假尿嘧啶 | |
| 4-(硫基)假尿嘧啶 | |
| 4-(硫基)尿嘧啶 | |
| 4-硫代尿嘧啶 | |
| 5-(l ,3-二唑-1-烷基)尿嘧啶 | |
| 5-(2-胺基丙基)尿嘧啶 | |
| 5-(胺基烷基)尿嘧啶 | |
| 5-(二甲基胺基烷基)尿嘧啶 | |
| 5-(胍基烷基)尿嘧啶 | |
| 5-(甲氧基羰基甲基)-2-(硫基)尿嘧啶 | |
| 5-(甲氧基羰基-甲基)尿嘧啶 | |
| 5-(甲基)-2-(硫基)尿嘧啶 | |
| 5-(甲基)-2,4-(二硫基)尿嘧啶 | |
| 5 (甲基) 4 (硫基)尿嘧啶 | |
| 5 (甲基胺基甲基)-2 (硫基)尿嘧啶 | |
| 5 (甲基胺基甲基)-2,4 (二硫基)尿嘧啶 | |
| 5 (甲基胺基甲基)-4 (硫基)尿嘧啶 | |
| 5 (丙炔基)尿嘧啶 | |
| 5 (三氟甲基)尿嘧啶 | |
| 5-(2-胺基丙基)尿嘧啶 | |
| 5-(烷基)-2-(硫基)假尿嘧啶 | |
| 5-(烷基)-2,4 (二硫基)假尿嘧啶 | |
| 5-(烷基)-4 (硫基)假尿嘧啶 | |
| 5-(烷基)假尿嘧啶 | |
| 5-(烷基)尿嘧啶 | |
| 5-(炔基)尿嘧啶 | |
| 5-(烯丙基胺基)尿嘧啶 | |
| 5-(氰基烷基)尿嘧啶 | |
| 5-(二烷基胺基烷基)尿嘧啶 | |
| 5-(二甲基胺基烷基)尿嘧啶 | |
| 5-(胍基烷基)尿嘧啶 | |
| 5-(鹵基)尿嘧啶 | |
| 5-(1,3-二唑-l-烷基)尿嘧啶 | |
| 5-(甲氧基)尿嘧啶 | |
| 5-(甲氧基羰基甲基)-2-(硫基)尿嘧啶 | |
| 5-(甲氧基羰基-甲基)尿嘧啶 | |
| 5-(甲基) 2(硫基)尿嘧啶 | |
| 5-(甲基) 2,4 (二硫基)尿嘧啶 | |
| 5-(甲基) 4 (硫基)尿嘧啶 | |
| 5-(甲基)-2-(硫基)假尿嘧啶 | |
| 5-(甲基)-2,4 (二硫基)假尿嘧啶 | |
| 5-(甲基)-4 (硫基)假尿嘧啶 | |
| 5-(甲基)假尿嘧啶 | |
| 5-(甲基胺基甲基)-2 (硫基)尿嘧啶 | |
| 5-(甲基胺基甲基)-2,4(二硫基)尿嘧啶 | |
| 5-(甲基胺基甲基)-4-(硫基)尿嘧啶 | |
| 5-(丙炔基)尿嘧啶 | |
| 5-(三氟甲基)尿嘧啶 | |
| 5-胺基烯丙基-尿苷 | |
| 5-溴-尿苷 | |
| 5-碘-尿苷 | |
| 5-尿嘧啶 | |
| 6 (偶氮基)尿嘧啶 | |
| 6-(偶氮基)尿嘧啶 | |
| 6-氮雜-尿苷 | |
| 烯丙基胺基-尿嘧啶 | |
| 氮雜尿嘧啶 | |
| 去氮尿嘧啶 | |
| N3 (甲基)尿嘧啶 | |
| 假-尿苷-1-2-乙酸 | |
| 假尿嘧啶 | |
| 4-硫代-假尿苷 | |
| 1-羧甲基-假尿苷 | |
| 1-甲基-1-去氮-假尿苷 | |
| 1-丙炔基-尿苷 | |
| 1-牛磺酸甲基-1-甲基-尿苷 | |
| 1-牛磺酸甲基-4-硫代-尿苷 | |
| 1-牛磺酸甲基-假尿苷 | |
| 2-甲氧基-4-硫代-假尿苷 | |
| 2-硫代-l-甲基-1-去氮-假尿苷 | |
| 2-硫代-1-甲基-假尿苷 | |
| 2-硫代-5-氮雜-尿苷 | |
| 2-硫代-二氫假尿苷 | |
| 2-硫代-二氫尿苷 | |
| 2-硫代-假尿苷 | |
| 4-甲氧基-2-硫代-假尿苷 | |
| 4-甲氧基-假尿苷 | |
| 4-硫代-1-甲基-假尿苷 | |
| 4-硫代-假尿苷 | |
| 5-氮雜-尿苷 | |
| 二氫假尿苷 | |
| (±)1-(2-羥丙基)假尿苷 | |
| (2R)-l-(2-羥丙基)假尿苷 | |
| (2S)- l -(2-羥丙基)假尿苷 | |
| (E)-5-(2-溴-乙烯基)阿糖尿苷 | |
| (E)-5-(2-溴-乙烯基)尿苷 | |
| (Z)-5-(2-溴-乙烯基)阿糖尿苷 | |
| (Z)-5-(2-溴-乙烯基)尿苷 | |
| 1-(2,2,2-三氟乙基)-假尿苷 | |
| 1-(2,2,3,3,3-五氟丙基)假尿苷 | |
| 1-(2,2-二乙氧基乙基)假尿苷 | |
| 1-(2,4,6-三甲基苯甲基)假尿苷 | |
| 1-(2,4,6-三甲基-苯甲基)假尿苷 | |
| 1-(2,4,6-三甲基-苯基)假尿苷 | |
| 1-(2-胺基-2-羧乙基)假尿苷 | |
| 1-(2-胺基-乙基)假尿苷 | |
| 1-(2-羥乙基)假尿苷 | |
| 1-(2-甲氧基乙基)假尿苷 | |
| 1-(3,4-雙-三氟甲氧基苯甲基)假尿苷 | |
| 1-(3,4-二甲氧基苯甲基)假尿苷 | |
| 1-(3-胺基-3-羧丙基)假尿苷 | |
| 1-(3-胺基-丙基)假尿苷 | |
| 1-(3-環丙基-丙-2-炔基)假尿苷TP | |
| 1-(4-胺基-4-羧丁基)假尿苷 | |
| 1-(4-胺基-苯甲基)假尿苷 | |
| 1-(4-胺基-丁基)假尿苷 | |
| 1-(4-胺基-苯基)假尿苷 | |
| 1-(4-疊氮基苯甲基)假尿苷 | |
| 1-(4-溴苯甲基)假尿苷 | |
| 1-(4-氯苯甲基)假尿苷 | |
| 1-(4-氟苯甲基)假尿苷 | |
| 1-(4-碘苯甲基)假尿苷 | |
| 1-(4-甲磺醯基苯甲基)假尿苷 | |
| 1-(4-甲氧基苯甲基)假尿苷 | |
| 1-(4-甲氧基-苯甲基)假尿苷 | |
| 1-(4-甲氧基-苯基)假尿苷 | |
| 1-(4-甲基苯甲基)假尿苷 | |
| 1-(4-甲基-苯甲基)假尿苷 | |
| 1-(4-硝基苯甲基)假尿苷 | |
| 1-(4-硝基-苯甲基)假尿苷 | |
| 1(4-硝基-苯基)假尿苷 | |
| 1-(4-硫代甲氧基苯甲基)假尿苷 | |
| 1-(4-三氟甲氧基苯甲基)假尿苷 | |
| 1-(4-三氟甲基苯甲基)假尿苷 | |
| 1-(5-胺基-戊基)假尿苷 | |
| 1-(6-胺基-己基)假尿苷 | |
| 1,6-二甲基-假尿苷 | |
| 1-[3-(2-{2-[2-(2-胺基乙氧基)-乙氧基]-乙氧基}-乙氧基)-丙醯基]假尿苷 | |
| 1-{3-[2-(2-胺基乙氧基)-乙氧基]-丙醯基}假尿苷 | |
| 1-乙醯基假尿苷 | |
| 1-烷基-6-(1-丙炔基)-假尿苷 | |
| 1-烷基-6-(2-丙炔基)-假尿苷 | |
| 1-烷基-6-烯丙基-假尿苷 | |
| 1-烷基-6-乙炔基-假尿苷 | |
| 1-烷基-6-高烯丙基-假尿苷 | |
| 1-烷基-6-乙烯基-假尿苷 | |
| 1-烯丙基假尿苷 | |
| 1-胺基甲基-假尿苷 | |
| 1-苯甲醯基假尿苷 | |
| 1-苯甲氧基甲基假尿苷 | |
| 1-苯甲基-假尿苷 | |
| 1-生物素基-PEG2-假尿苷 | |
| 1-生物素基假尿苷 | |
| 1-丁基-假尿苷 | |
| 1-氰基甲基假尿苷 | |
| 1-環丁基甲基-假尿苷 | |
| 1-環丁基-假尿苷 | |
| 1-環庚基甲基-假尿苷 | |
| 1-環庚基-假尿苷 | |
| 1-環己基甲基-假尿苷 | |
| 1-環己基-假尿苷 | |
| 1-環辛基甲基-假尿苷 | |
| 1-環辛基-假尿苷 | |
| 1-環戊基甲基-假尿苷 | |
| 1-環戊基-假尿苷 | |
| 1-環丙基甲基-假尿苷 | |
| 1-環丙基-假尿苷 | |
| 1-乙基-假尿苷 | |
| 1-己基-假尿苷 | |
| 1-高烯丙基假尿苷 | |
| 1-羥甲基假尿苷 | |
| 1-異丙基-假尿苷 | |
| 1-Me-2-硫代-假尿苷 | |
| 1-Me-4-硫代-假尿苷 | |
| 1-Me-α-硫代-假尿苷 | |
| 1-甲磺醯基甲基假尿苷 | |
| 1-甲氧基甲基假尿苷尿苷 | |
| 1-甲基-6-(2,2,2-三氟乙基)假尿苷 | |
| 1-甲基-6-(4-(N-𠰌啉基))-假尿苷 | |
| 1-甲基-6-(4-硫代(N-𠰌啉基))-假尿苷 | |
| 1-甲基-6-(經取代之苯基)假尿苷 | |
| 1-甲基-6-胺基-假尿苷 | |
| 1-甲基-6-疊氮基-假尿苷 | |
| 1-甲基-6-溴-假尿苷 | |
| 1-甲基-6-丁基-假尿苷 | |
| 1-甲基-6-氯-假尿苷 | |
| 1-甲基-6-氰基-假尿苷 | |
| 1-甲基-6-二甲基胺基-假尿苷 | |
| 1-甲基-6-乙氧基-假尿苷 | |
| 1-甲基-6-羧酸乙酯-假尿苷 | |
| 1-甲基-6-乙基-假尿苷 | |
| 1-甲基-6-氟-假尿苷 | |
| 1-甲基-6-甲醯基-假尿苷 | |
| 1-甲基-6-羥胺基-假尿苷 | |
| 1-甲基-6-羥基-假尿苷 | |
| 1-甲基-6-碘-假尿苷 | |
| 1-甲基-6-異丙基-假尿苷 | |
| 1-甲基-6-甲氧基-假尿苷 | |
| 1-甲基-6-甲基胺基-假尿苷 | |
| 1-甲基-6-苯基-假尿苷 | |
| 1-甲基-6-丙基-假尿苷 | |
| 1-甲基-6-三級丁基-假尿苷 | |
| 1-甲基-6-三氟甲氧基-假尿苷 | |
| 1-甲基-6-三氟甲基-假尿苷 | |
| 1-(N-𠰌啉基)甲基假尿苷 | |
| 1-戊基-假尿苷尿苷 | |
| 1-苯基-假尿苷 | |
| 1-三甲基乙醯基假尿苷 | |
| 1-炔丙基假尿苷 | |
| 1-丙基-假尿苷 | |
| 1-丙炔基-假尿苷 | |
| 1-對甲苯基-假尿苷 | |
| 1-三級丁基-假尿苷 | |
| 1-硫代甲氧基甲基假尿苷 | |
| 1-硫代(N-𠰌啉基)甲基假尿苷 | |
| 1-三氟乙醯基假尿苷 | |
| 1-三氟甲基-假尿苷 | |
| 1-乙烯基假尿苷 | |
| 2,2'-脫水尿苷 | |
| 2'-溴-去氧尿苷 | |
| 2'-F-5-甲基-2'-去氧-尿苷 | |
| 2'-OMe-5-Me-尿苷 | |
| 2'-OMe-假尿苷 | |
| 2'-α-乙炔基尿苷 | |
| 2'-α-三氟甲基尿苷 | |
| 2'-β-乙炔基尿苷 | |
| 2'-β-三氟甲基尿苷 | |
| 2'-去氧-2',2'-二氟尿苷 | |
| 2'-去氧-2'-a-巰基尿苷 | |
| 2'-去氧-2'-α-硫代甲氧基尿苷 | |
| 2'-去氧-2'-β-胺基尿苷 | |
| 2'-去氧-2'-β-疊氮基尿苷 | |
| 2'-去氧-2'-β-溴尿苷 | |
| 2'-去氧-2'-β-氯尿苷 | |
| 2'-去氧-2'-β-氟尿苷 | |
| 2'-去氧-2'-β-碘尿苷 | |
| 2'-去氧-2'-β-巰基尿苷 | |
| 2'-去氧-2'-β-硫代甲氧基尿苷 | |
| 2-甲氧基-4-硫代-尿苷 | |
| 2-甲氧基尿苷 | |
| 2'-O-甲基-5-(1-丙炔基)尿苷 | |
| 3-烷基-假尿苷 | |
| 4'-疊氮基尿苷 | |
| 4'-碳環尿苷 | |
| 4'-乙炔基尿苷 | |
| 5-(1-丙炔基)阿糖尿苷 | |
| 5-(2-呋喃基)尿苷 | |
| 5-氰基尿苷 | |
| 5-二甲基胺基尿苷 | |
| 5'-高-尿苷 | |
| 5-碘-2'-氟-去氧尿苷 | |
| 5-苯基乙炔基尿苷 | |
| 5-三氘代甲基-6-氘代尿苷 | |
| 5-三氟甲基-尿苷 | |
| 5-乙烯基阿糖尿苷 | |
| 6-(2,2,2-三氟乙基)-假尿苷 | |
| 6-(4-(N-𠰌啉基))-假尿苷 | |
| 6-(4-硫代(N-𠰌啉基))-假尿苷 | |
| 6-(經取代之苯基)-假尿苷 | |
| 6-胺基-假尿苷 | |
| 6-疊氮基-假尿苷 | |
| 6-溴-假尿苷 | |
| 6-丁基-假尿苷 | |
| 6-氯-假尿苷 | |
| 6-氰基-假尿苷 | |
| 6-二甲基胺基-假尿苷 | |
| 6-乙氧基-假尿苷 | |
| 6-羧酸乙酯-假尿苷 | |
| 6-乙基-假尿苷 | |
| 6-氟-假尿苷 | |
| 6-甲醯基-假尿苷 | |
| 6-羥胺基-假尿苷 | |
| 6-羥基-假尿苷 | |
| 6-碘-假尿苷 | |
| 6-異丙基-假尿苷 | |
| 6-甲氧基-假尿苷 | |
| 6-甲基胺基-假尿苷 | |
| 6-甲基-假尿苷 | |
| 6-苯基-假尿苷 | |
| 6-苯基-假尿苷 | |
| 6-丙基-假尿苷 | |
| 6-三級丁基-假尿苷 | |
| 6-三氟甲氧基-假尿苷 | |
| 6-三氟甲基-假尿苷 | |
| α-硫代-假尿苷 | |
| 假尿苷1-(4-甲基苯磺酸) TP | |
| 假尿苷1-(4-甲基苯甲酸) TP | |
| 假尿苷1-[3-(2-乙氧基)]丙酸 | |
| 假尿苷1-[3-{2-(2-[2-(2-乙氧基)-乙氧基]-乙氧基)-乙氧基}]丙酸 | |
| 假尿苷1-[3-{2-(2-[2-{2(2-乙氧基)-乙氧基}-乙氧基]-乙氧基)-乙氧基}]丙酸 | |
| 假尿苷1-[3-{2-(2-[2-乙氧基]-乙氧基)-乙氧基}]丙酸 | |
| 假尿苷1-[3-{2-(2-乙氧基)-乙氧基}]丙酸 | |
| 假尿苷1-甲基膦酸 | |
| 假尿苷TP 1-甲基膦酸二乙酯 | |
| 假尿苷-N1-3-丙酸 | |
| 假尿苷-N1-4-丁酸 | |
| 假尿苷-N1-5-戊酸 | |
| 假尿苷-N1-6-己酸 | |
| 假尿苷-N1-7-庚酸 | |
| 假尿苷-N1-甲基-對苯甲酸 | |
| 假尿苷-N1-對苯甲酸 |
在一實施例中,本文所描述之TREM、TREM核心片段或TREM片段包含表6中所提供之修飾或其組合。表6中所提供之修飾天然存在於RNA中,且在本文中在本質上不存在之位置處對合成TREM、TREM核心片段或TREM片段使用。
表 6 : 額外例示性修飾
| 名稱 | |
| 2-甲基硫基-N6-(順-羥基異戊烯基)腺苷 | |
| 2-甲基硫基-N6-甲基腺苷 | |
| 2-甲基硫基-N6-蘇胺醯基胺甲醯基腺苷 | |
| N6-甘胺醯基胺甲醯基腺苷 | |
| N6-異戊烯基腺苷 | |
| N6-甲基腺苷 | |
| N6-蘇胺醯基胺甲醯基腺苷 | |
| 1,2'-O-二甲基腺苷 | |
| 1-甲基腺苷 | |
| 2'-O-甲基腺苷 | |
| 2'-O-核糖苷基腺苷(磷酸酯) | |
| 2-甲基腺苷 | |
| 2-甲基硫基-N6異戊烯基腺苷 | |
| 2-甲基硫基-N6-羥基正纈胺醯基胺甲醯基腺苷 | |
| 2'-O-甲基腺苷 | |
| 2'-O-核糖苷基腺苷(磷酸酯) | |
| 異戊烯基腺苷 | |
| N6-(順-羥基異戊烯基)腺苷 | |
| N6,2'-O-二甲基腺苷 | |
| N6,2'-O-二甲基腺苷 | |
| N6,N6,2'-O-三甲基腺苷 | |
| N6,N6-二甲基腺苷 | |
| N6-乙醯基腺苷 | |
| N6-羥基正纈胺醯基胺甲醯基腺苷 | |
| N6-甲基-N6-蘇胺醯基胺甲醯基腺苷 | |
| 2-甲基腺苷 | |
| 2-甲基硫基-N 6-異戊烯基腺苷 | |
| 2-硫代胞苷 | |
| 3-甲基胞苷 | |
| 5-甲醯基胞苷 | |
| 5-羥甲基胞苷 | |
| 5-甲基胞苷 | |
| N4-乙醯基胞苷 | |
| 2'-O-甲基胞苷 | |
| 2'-O-甲基胞苷 | |
| 5,2'-O-二甲基胞苷 | |
| 5-甲醯基-2'-O-甲基胞苷 | |
| 立西啶(lysidine) | |
| N4,2'-O-二甲基胞苷 | |
| N4-乙醯基-2'-O-甲基胞苷 | |
| N4-甲基胞苷 | |
| N4,N4-二甲基-2'-OMe-胞苷 | |
| 7-甲基鳥苷 | |
| N2,2'-O-二甲基鳥苷 | |
| N2-甲基鳥苷 | |
| 懷俄苷 | |
| 1,2'-O-二甲基鳥苷 | |
| 1-甲基鳥苷 | |
| 2'-O-甲基鳥苷 | |
| 2'-O-核糖苷基鳥苷(磷酸酯) | |
| 2'-O-甲基鳥苷 | |
| 2'-O-核糖苷基鳥苷(磷酸酯) | |
| 7-胺基甲基-7-去氮鳥苷 | |
| 7-氰基-7-去氮鳥苷 | |
| 古嘌苷 | |
| 甲基懷俄苷 | |
| N2,7-二甲基鳥苷 | |
| N2,N2,2'-O-三甲基鳥苷 | |
| N2,N2,7-三甲基鳥苷 | |
| N2,N2-二甲基鳥苷 | |
| N2,7,2'-O-三甲基鳥苷 | |
| 1-甲基肌苷 | |
| 肌苷 | |
| 1,2'-O-二甲基肌苷 | |
| 2'-O-甲基肌苷 | |
| 2'-O-甲基肌苷 | |
| 環氧Q核苷 | |
| 半乳糖苷基-Q核苷 | |
| 甘露糖基-Q核苷 | |
| 2'-O-甲基尿苷 | |
| 2-硫代尿苷 | |
| 3-甲基尿苷 | |
| 5-羧甲基尿苷 | |
| 5-羥基尿苷 | |
| 5-甲基尿苷 | |
| 5-牛磺酸甲基-2-硫代尿苷 | |
| 5-牛磺酸甲基尿苷 | |
| 二氫尿苷 | |
| 假尿苷 | |
| (3-(3-胺基-3-羧丙基)尿苷 | |
| 1-甲基-3-(3-胺基-5-羧丙基)假尿苷 | |
| 1-甲基假尿苷 | |
| 1-甲基-假尿苷 | |
| 2'-O-甲基尿苷 | |
| 2'-O-甲基假尿苷 | |
| 2'-O-甲基尿苷 | |
| 2-硫代-2'-O-甲基尿苷 | |
| 3-(3-胺基-3-羧丙基)尿苷 | |
| 3,2'-O-二甲基尿苷 | |
| 3-甲基-假尿苷 | |
| 4-硫代尿苷 | |
| 5-(羧基羥甲基)尿苷 | |
| 5-(羧基羥甲基)尿苷甲酯 | |
| 5,2'-O-二甲基尿苷 | |
| 5,6-二氫-尿苷 | |
| 5-胺基甲基-2-硫代尿苷 | |
| 5-胺甲醯基甲基-2'-O-甲基尿苷 | |
| 5-胺甲醯基甲基尿苷 | |
| 5-羧基羥甲基尿苷 | |
| 5-羧基羥甲基尿苷甲酯 | |
| 5-羧甲基胺基甲基-2'-O-甲基尿苷 | |
| 5-羧甲基胺基甲基-2-硫代尿苷 | |
| 5-羧甲基胺基甲基-2-硫代尿苷 | |
| 5-羧甲基胺基甲基尿苷 | |
| 5-羧甲基胺基甲基尿苷 | |
| 5-胺甲醯基甲基尿苷 | |
| 5-甲氧基羰基甲基-2'-O-甲基尿苷 | |
| 5-甲氧基羰基甲基-2-硫代尿苷 | |
| 5-甲氧基羰基甲基尿苷 | |
| 5-甲氧基尿苷 | |
| 5-甲基-2-硫代尿苷 | |
| 5-甲基胺基甲基-2-硒基尿苷 | |
| 5-甲基胺基甲基-2-硫代尿苷 | |
| 5-甲基胺基甲基尿苷 | |
| 5-甲基二氫尿苷 | |
| 5-氧乙酸-尿苷 | |
| 5-氧乙酸-甲酯-尿苷 N1-甲基-假尿苷 | |
| 尿苷5-氧乙酸 | |
| 尿苷5-氧乙酸甲酯 | |
| 3-(3-胺基-3-羧丙基)-尿苷 | |
| 5-(異戊烯基胺基甲基)-2-硫代尿苷 | |
| 5-(異戊烯基胺基甲基)-2'-O-甲基尿苷 | |
| 5-(異戊烯基胺基甲基)尿苷 | |
| 懷俄丁苷 | |
| 羥基懷俄丁苷 | |
| 異懷俄苷 | |
| 過氧基懷俄丁苷 | |
| 欠修飾之羥基懷俄丁苷 | |
| 4-去甲基懷俄苷 | |
| 阿卓糖醇 |
在一實施例中,本文所描述之TREM、TREM核心片段或TREM片段包含表7中所提供之化學修飾或其組合。
表 7 : 額外例示性化學修飾
| 名稱 | |
| 2,6-(二胺基)嘌呤 | |
| 1-(氮雜)-2-(硫基)-3-(氮雜)-啡㗁𠯤-1-基 | |
| 1,3-(二氮雜)-2-(側氧基)-啡噻𠯤-1-基 | |
| 1,3-(二氮雜)-2-(側氧基)-啡㗁𠯤-1-基 | |
| 1,3,5-(三氮雜)-2,6-(二氧雜)-萘 | |
| 2 (胺基)嘌呤 | |
| 2,4,5-(三甲基)苯基 | |
| 2'甲基、2'胺基、2'疊氮基、2'氟-胞苷 | |
| 2'甲基、2'胺基、2'疊氮基、2'氟-腺嘌呤 | |
| 2'甲基、2'胺基、2'疊氮基、2'氟-尿苷 | |
| 2'-胺基-2'-去氧核糖 | |
| 2-胺基-6-氯-嘌呤 | |
| 2-氮雜-肌苷基 | |
| 2'-疊氮基-2'-去氧核糖 | |
| 2'氟-2'-去氧核糖 | |
| 經2'-氟修飾之鹼基 | |
| 2'-O-甲基-核糖 | |
| 2-側氧基-7-胺基吡啶并嘧啶-3-基 | |
| 2-側氧基-吡啶并嘧啶-3-基 | |
| 2-吡啶酮 | |
| 3硝基吡咯 | |
| 3-(甲基)-7-(丙炔基)異喹諾酮基 | |
| 3-(甲基)異喹諾酮基 | |
| 4-(氟)-6-(甲基)苯并咪唑 | |
| 4-(甲基)苯并咪唑 | |
| 4-(甲基)吲哚基 | |
| 4,6-(二甲基)吲哚基 | |
| 5硝基吲哚 | |
| 5經取代嘧啶 | |
| 5-(甲基)異喹諾酮基 | |
| 5-硝基吲哚 | |
| 6-(氮雜)嘧啶 | |
| 6-(偶氮基)胸腺嘧啶 | |
| 6-(甲基)-7-(氮雜)吲哚基 | |
| 6-氯-嘌呤 | |
| 6-苯基-吡咯并-嘧啶-2-酮-3-基 | |
| 7-(胺基烷基羥基)-1-(氮雜)-2-(硫基)-3-(氮雜)-啡噻𠯤-1-基 | |
| 7-(胺基烷基羥基)-1-(氮雜)-2-(硫基)-3-(氮雜)-啡㗁𠯤-1-基 | |
| 7-(胺基烷基羥基)-1,3-(二氮雜)-2-(側氧基)-啡㗁𠯤-1-基 | |
| 7-(胺基烷基羥基)-1,3-(二氮雜)-2-(側氧基)-啡噻𠯤-1-基 | |
| 7-(胺基烷基羥基)-1,3-(二氮雜)-2-(側氧基)-啡㗁𠯤-1-基 | |
| 7-(氮雜)吲哚基 | |
| 7-(胍基烷基羥基)-1-(氮雜)-2-(硫基)-3-(氮雜)-啡㗁𠯤-1-基 | |
| 7-(胍基烷基羥基)-1-(氮雜)-2-(硫基)-3-(氮雜)-啡噻𠯤-1-基 | |
| 7-(胍基烷基羥基)-1-(氮雜)-2-(硫基)-3-(氮雜)-啡㗁𠯤-1-基 | |
| 7-(胍基烷基羥基)-1,3-(二氮雜)-2-(側氧基)-啡㗁𠯤-1-基 | |
| 7-(胍基烷基-羥基)-1,3-(二氮雜)-2-(側氧基)-啡噻𠯤-1-基 | |
| 7-(胍基烷基羥基)-1,3-(二氮雜)-2-(側氧基)-啡㗁𠯤-1-基 | |
| 7-(丙炔基)異喹諾酮基 | |
| 7-(丙炔基)異喹諾酮基、丙炔基-7-(氮雜)吲哚基 | |
| 7-去氮-肌苷基 | |
| 7-經取代之1-(氮雜)-2-(硫基)-3-(氮雜)-啡㗁𠯤-1-基 | |
| 7-經取代之1,3-(二氮雜)-2-(側氧基)-啡㗁𠯤-1-基 | |
| 9-(甲基)-咪唑并吡啶基 | |
| 胺基吲哚基 | |
| 蒽基 | |
| 雙-鄰位-(胺基烷基羥基)-6-苯基-吡咯并-嘧啶-2-酮-3-基 | |
| 雙-鄰位經取代之-6-苯基-吡咯并-嘧啶-2-酮-3-基 | |
| 二氟甲苯基 | |
| 次黃嘌呤 | |
| 咪唑并吡啶基 | |
| 肌苷基 | |
| 異喹諾酮基 | |
| 異鳥苷 | |
| N2-經取代之嘌呤 | |
| N6-甲基-2-胺基-嘌呤 | |
| N6-經取代之嘌呤 | |
| N-烷基化衍生物 | |
| 萘基 | |
| 硝基苯并咪唑基 | |
| 硝基咪唑基 | |
| 硝基吲唑基 | |
| 硝基吡唑基 | |
| 水粉蕈素 | |
| O6-經取代之嘌呤 | |
| O-烷基化衍生物 | |
| 鄰位-(胺基烷基羥基)-6-苯基-吡咯并-嘧啶-2-酮-3-基 | |
| 鄰位經取代之-6-苯基-吡咯并-嘧啶-2-酮-3-基 | |
| 側氧基間型黴素(oxoformycin) TP | |
| 對位-(胺基烷基羥基)-6-苯基-吡咯并-嘧啶-2-酮-3-基 | |
| 對位經取代之-6-苯基-吡咯并-嘧啶-2-酮-3-基 | |
| 稠五苯基 | |
| 苯蒽基 | |
| 苯基 | |
| 丙炔基-7-(氮雜)吲哚基 | |
| 芘基 | |
| 吡啶并嘧啶-3-基 | |
| 吡啶并嘧啶-3-基、2-側氧基-7-胺基-吡啶并嘧啶-3-基 | |
| 吡咯并-嘧啶-2-酮-3-基 | |
| 吡咯并嘧啶基 | |
| 吡咯并吡𠯤基 | |
| 芪基 | |
| 經取代之1,2,4-三唑 | |
| 稠四苯基 | |
| 殺結核菌素 | |
| 黃嘌呤 | |
| 黃苷 | |
| 2-硫代-澤布拉恩 | |
| 5-氮雜-2-硫代-澤布拉恩 | |
| 7-去氮-2-胺基-嘌呤 | |
| 吡啶-4-酮核糖核苷 | |
| 2-胺基-核糖苷 | |
| 間型黴素A | |
| 間型黴素B | |
| 吡咯離胺酸 | |
| 2'-OH-阿糖腺苷 | |
| 2'-OH-阿糖胞苷 | |
| 2'-OH-阿糖尿苷 | |
| 2'-OH-阿糖鳥苷 | |
| 5-(2-甲氧羰基乙烯基)尿苷 | |
| N6-(19-胺基-五氧雜十九基)腺苷 |
在一實施例中,本文所描述之TREM、TREM核心片段或TREM片段包含表8中所提供之化學修飾或其組合。
表 8 :例示性主鏈修飾
| 名稱 |
| 3'-伸烷基膦酸酯 |
| 3'-胺基胺基磷酸酯 |
| 含有烯烴之主鏈 |
| 胺基烷基胺基磷酸酯 |
| 胺基烷基磷酸三酯 |
| 硼烷磷酸酯 |
| -CH 2-O-N(CH 3)-CH 2- |
| -CH 2-N(CH 3)-N(CH 3)-CH 2- |
| -CH 2-NH-CH 2- |
| 對掌性膦酸酯 |
| 對掌性硫代磷酸酯 |
| 甲乙醯基及硫代甲乙醯基主鏈 |
| 亞甲基(甲基亞胺基) |
| 亞甲基甲乙醯基及硫代甲乙醯基主鏈 |
| 亞甲基亞胺基及亞甲基肼基主鏈 |
| N-𠰌啉基鍵聯 |
| -N(CH 3)-CH 2-CH 2- |
| 具有雜原子核苷間鍵聯之寡核苷 |
| 亞膦酸酯 |
| 胺基磷酸酯 |
| 二硫代磷酸酯 |
| 硫代磷酸酯核苷間鍵聯 |
| 硫代磷酸酯 |
| 磷酸三酯 |
| PNA |
| 矽氧烷主鏈 |
| 胺基磺酸酯主鏈 |
| 硫化亞碸及碸主鏈 |
| 磺酸酯及磺醯胺主鏈 |
| 硫羰基烷基膦酸酯 |
| 硫羰基烷基磷酸三酯 |
| 硫羰基胺基磷酸酯 |
| 甲基磷酸酯 |
| 膦醯乙酸酯 |
| 硫代磷酸酯 |
| 經約束核酸(CNA) |
| 2'-O-甲基 |
| 2'-O-甲氧基乙基(MOE) |
| 2'氟 |
| 鎖核酸(LNA) |
| ( S)-經約束乙基( cEt) |
| 氟己糖醇核酸(FHNA) |
| 5'-硫代磷酸酯 |
| 磷酸二醯胺𠰌啉寡聚物(PMO) |
| 三環-DNA (tcDNA) |
| ( S) 5'-C-甲基 |
| ( E)-膦酸乙烯酯 |
| 膦酸甲酯 |
| ( S) 5'-C-甲基與磷酸酯 |
| (R) 5'-C-甲基與磷酸酯 |
| DNA |
| (R) 5'-C-甲基 |
| GNA (二醇核酸) |
| 膦酸烷基酯 |
| 硫代磷酸酯 |
| 經約束核酸(CNA) |
| 2'-O-甲基 |
| 2'-O-甲氧基乙基(MOE) |
| 2'氟 |
| 鎖核酸(LNA) |
| ( S)-經約束乙基( cEt) |
| 氟己糖醇核酸(FHNA) |
| 5'-硫代磷酸酯 |
| 磷酸二醯胺𠰌啉寡聚物(PMO) |
| 三環-DNA (tcDNA) |
| ( S) 5'-C-甲基 |
| ( E)-膦酸乙烯酯 |
| 膦酸甲酯 |
| ( S) 5'-C-甲基與磷酸酯 |
| (R) 5'-C-甲基與磷酸酯 |
| DNA |
| (R) 5'-C-甲基 |
| GNA (二醇核酸) |
| 膦酸烷基酯 |
在一實施例中,本文所描述之TREM、TREM核心片段或TREM片段包含表9中所提供之非天然存在之修飾或其組合。
表 9 : 例示性非天然存在之主鏈修飾
| 合成主鏈修飾之名稱 |
| 硫代磷酸酯 |
| 經約束核酸(CNA) |
| 2' O'甲基化 |
| 2'-O-甲氧基乙基核糖(MOE) |
| 2'氟 |
| 鎖核酸(LNA) |
| ( S)-經約束乙基( cEt) |
| 氟己糖醇核酸(FHNA) |
| 5'硫代硫酸酯 |
| 磷酸二醯胺𠰌啉寡聚物(PMO) |
| 三環-DNA (tcDNA) |
| ( S) 5'-C-甲基 |
| ( E)-膦酸乙烯酯 |
| 膦酸甲酯 |
| ( S) 5'-C-甲基與磷酸酯 |
TREM、TREM核心片段及TREM片段融合物 在一實施例中,本文所揭示之TREM、TREM核心片段或TREM片段包含額外部分,例如融合部分。在一實施例中,融合部分可用於純化,用於改變TREM、TREM核心片段或TREM片段之摺疊,或用作靶向部分。在一實施例中,融合部分可包含標籤、連接子,可為可裂解的,或可包括酶之結合位點。在一實施例中,融合部分可安置於TREM之N末端處或TREM、TREM核心片段或TREM片段之C末端處。在一實施例中,融合部分可由編碼TREM、TREM核心片段或TREM片段之相同或不同核酸分子編碼。
TREM共通序列 在一實施例中,本文所揭示之TREM包含本文所提供之共通序列。
在一實施例中,本文所揭示之TREM包含式I
ZZZ之共通序列,其中
ZZZ指示二十種胺基酸中之任一者且式I對應於所有物種。
在一實施例中,本文所揭示之TREM包含式II
ZZZ之共通序列,其中
ZZZ指示二十種胺基酸中之任一者且式II對應於哺乳動物。
在一實施例中,本文所揭示之TREM包含式III
ZZZ之共通序列,其中
ZZZ指示二十種胺基酸中之任一者且式III對應於人類。
在一實施例中,
ZZZ指示二十種胺基酸中之任一者:丙胺酸、精胺酸、天冬醯胺、天冬胺酸、半胱胺酸、麩醯胺酸、麩胺酸、甘胺酸、組胺酸、異白胺酸、甲硫胺酸、白胺酸、離胺酸、苯丙胺酸、脯胺酸、絲胺酸、蘇胺酸、色胺酸、酪胺酸或纈胺酸。
在一實施例中,本文所揭示之TREM包含選自以下之特性:
a)在生理條件下,殘基R
0形成連接子區,例如連接子1區;
b)在生理條件下,殘基R
1-R
2-R
3-R
4-R
5-R
6-R
7及殘基R
65-R
66-R
67-R
68-R
69-R
70-R
71形成莖區,例如AStD莖區;
c)在生理條件下,殘基R
8-R
9形成連接子區,例如連接子2區;
d)在生理條件下,殘基-R
10-R
11-R
12-R
13-R
14R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28形成莖環區,例如D臂區;
e)在生理條件下,殘基-R
29形成連接子區,例如連接子3區;
f)在生理條件下,殘基-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46形成莖環區,例如AC臂區;
g)在生理條件下,殘基-[R
47]
x包含例如如本文所描述之可變區;
h)在生理條件下,殘基-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64形成莖環區,例如T臂區;或
i)在生理條件下,殘基R
72形成連接子區,例如連接子4區。
丙胺酸 TREM 共通序列在一實施例中,本文所揭示之TREM包含式I
ALA之序列(SEQ ID NO: 562),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Ala之共識為:
R
0=不存在;
R
14、R
57=獨立地為A或不存在;
R
26= A、C、G或不存在;
R
5、R
6、R
15、R
16、R
21、R
30、R
31、R
32、R
34、R
37、R
41、R
42、R
43、R
44、R
45、R
48、R
49、R
50、R
58、R
59、R
63、R
64、R
66、R
67=獨立地為N或不存在;
R
11、R
35、R
65=獨立地為A、C、U或不存在;
R
1、R
9、R
20、R
38、R
40、R
51、R
52、R
56=獨立地為A、G或不存在;
R
7、R
22、R
25、R
27、R
29、R
46、R
53、R
72=獨立地為A、G、U或不存在;
R
24、R
69=獨立地為A、U或不存在;
R
70、R
71=獨立地為C或不存在;
R
3、R
4=獨立地為C、G或不存在;
R
12、R
33、R
36、R
62、R
68=獨立地為C、G、U或不存在;
R
13、R
17、R
28、R
39、R
55、R
60、R
61=獨立地為C、U或不存在;
R
10、R
19、R
23=獨立地為G或不存在;
R
2= G、U或不存在;
R
8、R
18、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式II
ALA之序列(SEQ ID NO: 563),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Ala之共識為:
R
0、R
18=不存在;
R
14、R
24、R
57=獨立地為A或不存在;
R
15、R
26、R
64=獨立地為A、C、G或不存在;
R
16、R
31、R
50、R
59=獨立地為N或不存在;
R
11、R
32、R
37、R
41、R
43、R
45、R
49、R
65、R
66=獨立地為A、C、U或不存在;
R
1、R
5、R
9、R
25、R
27、R
38、R
40、R
46、R
51、R
56=獨立地為A、G或不存在;
R
7、R
22、R
29、R
42、R
44、R
53、R
63、R
72=獨立地為A、G、U或不存在;
R
6、R
35、R
69=獨立地為A、U或不存在;
R
55、R
60、R
70、R
71=獨立地為C或不存在;
R
3= C、G或不存在;
R
12、R
36、R
48=獨立地為C、G、U或不存在;
R
13、R
17、R
28、R
30、R
34、R
39、R
58、R
61、R
62、R
67、R
68=獨立地為C、U或不存在;
R
4、R
10、R
19、R
20、R
23、R
52=獨立地為G或不存在;
R
2、R
8、R
33=獨立地為G、U或不存在;
R
21、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式III
ALA之序列(SEQ ID NO: 564),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Ala之共識為:
R
0、R
18=不存在;
R
14、R
24、R
57、R
72=獨立地為A或不存在;
R
15、R
26、R
64=獨立地為A、C、G或不存在;
R
16、R
31、R
50=獨立地為N或不存在;
R
11、R
32、R
37、R
41、R
43、R
45、R
49、R
65、R
66=獨立地為A、C、U或不存在;
R
5、R
9、R
25、R
27、R
38、R
40、R
46、R
51、R
56=獨立地為A、G或不存在;
R
7、R
22、R
29、R
42、R
44、R
53、R
63=獨立地為A、G、U或不存在;
R
6、R
35=獨立地為A、U或不存在;
R
55、R
60、R
61、R
70、R
71=獨立地為C或不存在;
R
12、R
48、R
59=獨立地為C、G、U或不存在;
R
13、R
17、R
28、R
30、R
34、R
39、R
58、R
62、R
67、R
68=獨立地為C、U或不存在;
R
1、R
2、R
3、R
4、R
10、R
19、R
20、R
23、R
52=獨立地為G或不存在;
R
33、R
36=獨立地為G、U或不存在;
R
8、R
21、R
54、R
69=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
精胺酸 TREM 共通序列在一實施例中,本文所揭示之TREM包含式I
ARG之序列(SEQ ID NO: 565),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Arg之共識為:
R
57=A或不存在;
R
9、R
27=獨立地為A、C、G或不存在;
R
1、R
2、R
3、R
4、R
5、R
6、R
7、R
11、R
12、R
16、R
21、R
22、R
23、R
25、R
26、R
29、R
30、R
31、R
32、R
33、R
34、R
37、R
42、R
44、R
45、R
46、R
48、R
49、R
50、R
51、R
58、R
62、R
63、R
64、R
65、R
66、R
67、R
68、R
69、R
70、R
71=獨立地為N或不存在;
R
13、R
17、R
41=獨立地為A、C、U或不存在;
R
19、R
20、R
24、R
40、R
56=獨立地為A、G或不存在;
R
14、R
15、R
72=獨立地為A、G、U或不存在;
R
18= A、U或不存在;
R
38= C或不存在;
R
35、R
43、R
61=獨立地為C、G、U或不存在;
R
28、R
55、R
59、R
60=獨立地為C、U或不存在;
R
0、R
10、R
52=獨立地為G或不存在;
R
8、R
39=獨立地為G、U或不存在;
R
36、R
53、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式II
ARG之序列(SEQ ID NO: 566),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Arg之共識為:
R
18=不存在;
R
24、R
57=獨立地為A或不存在;
R
41= A、C或不存在;
R
3、R
7、R
34、R
50=獨立地為A、C、G或不存在;
R
2、R
5、R
6、R
12、R
26、R
32、R
37、R
44、R
58、R
66、R
67、R
68、R
70=獨立地為N或不存在;
R
49、R
71=獨立地為A、C、U或不存在;
R
1、R
15、R
19、R
25、R
27、R
40、R
45、R
46、R
56、R
72=獨立地為A、G或不存在;
R
14、R
29、R
63=獨立地為A、G、U或不存在;
R
16、R
21=獨立地為A、U或不存在;
R
38、R
61=獨立地為C或不存在;
R
33、R
48=獨立地為C、G或不存在;
R
4、R
9、R
11、R
43、R
62、R
64、R
69=獨立地為C、G、U或不存在;
R
13、R
22、R
28、R
30、R
31、R
35、R
55、R
60、R
65=獨立地為C、U或不存在;
R
0、R
10、R
20、R
23、R
51、R
52=獨立地為G或不存在;
R
8、R
39、R
42=獨立地為G、U或不存在;
R
17、R
36、R
53、R
54、R
59=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式III
ARG之序列(SEQ ID NO: 567),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Arg之共識為:
R
18=不存在;
R
15、R
21、R
24、R
41、R
57=獨立地為A或不存在;
R
34、R
44=獨立地為A、C或不存在;
R
3、R
5、R
58=獨立地為A、C、G或不存在;
R
2、R
6、R
66、R
70=獨立地為N或不存在;
R
37、R
49=獨立地為A、C、U或不存在;
R
1、R
25、R
29、R
40、R
45、R
46、R
50=獨立地為A、G或不存在;
R
14、R
63、R
68=獨立地為A、G、U或不存在;
R
16= A、U或不存在;
R
38、R
61=獨立地為C或不存在;
R
7、R
11、R
12、R
26、R
48=獨立地為C、G或不存在;
R
64、R
67、R
69=獨立地為C、G、U或不存在;
R
4、R
13、R
22、R
28、R
30、R
31、R
35、R
43、R
55、R
60、R
62、R
65、R
71=獨立地為C、U或不存在;
R
0、R
10、R
19、R
20、R
23、R
27、R
33、R
51、R
52、R
56、R
72=獨立地為G或不存在;
R
8、R
9、R
32、R
39、R
42=獨立地為G、U或不存在;
R
17、R
36、R
53、R
54、R
59=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
天冬醯胺 TREM 共通序列在一實施例中,本文所揭示之TREM包含式I
ASN之序列(SEQ ID NO: 568),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Asn之共識為:
R
0、R
18=不存在;
R
41= A或不存在;
R
14、R
48、R
56=獨立地為A、C、G或不存在;
R
2、R
4、R
5、R
6、R
12、R
17、R
26、R
29、R
30、R
31、R
44、R
45、R
46、R
49、R
50、R
58、R
62、R
63、R
65、R
66、R
67、R
68、R
70、R
71=獨立地為N或不存在;
R
11、R
13、R
22、R
42、R
55、R
59=獨立地為A、C、U或不存在;
R
9、R
15、R
24、R
27、R
34、R
37、R
51、R
72=獨立地為A、G或不存在;
R
1、R
7、R
25、R
69=獨立地為A、G、U或不存在;
R
40、R
57=獨立地為A、U或不存在;
R
60= C或不存在;
R
33= C、G或不存在;
R
21、R
32、R
43、R
64=獨立地為C、G、U或不存在;
R
3、R
16、R
28、R
35、R
36、R
61=獨立地為C、U或不存在;
R
10、R
19、R
20、R
52=獨立地為G或不存在;
R
54= G、U或不存在;
R
8、R
23、R
38、R
39、R
53=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式II
ASN之序列(SEQ ID NO: 569),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Asn之共識為:
R
0、R
18=不存在
R
24、R
41、R
46、R
62=獨立地為A或不存在;
R
59= A、C或不存在;
R
14、R
56、R
66=獨立地為A、C、G或不存在;
R
17、R
29=獨立地為N或不存在;
R
11、R
26、R
42、R
55=獨立地為A、C、U或不存在;
R
1、R
9、R
12、R
15、R
25、R
34、R
37、R
48、R
51、R
67、R
68、R
69、R
70、R
72=獨立地為A、G或不存在;
R
44、R
45、R
58=獨立地為A、G、U或不存在;
R
40、R
57=獨立地為A、U或不存在;
R
5、R
28、R
60=獨立地為C或不存在;
R
33、R
65=獨立地為C、G或不存在;
R
21、R
43、R
71=獨立地為C、G、U或不存在;
R
3、R
6、R
13、R
22、R
32、R
35、R
36、R
61、R
63、R
64=獨立地為C、U或不存在;
R
7、R
10、R
19、R
20、R
27、R
49、R
52=獨立地為G或不存在;
R
54= G、U或不存在;
R
2、R
4、R
8、R
16、R
23、R
30、R
31、R
38、R
39、R
50、R
53=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式III
ASN之序列(SEQ ID NO: 570),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Asn之共識為:
R
0、R
18=不存在;
R
24、R
40、R
41、R
46、R
62=獨立地為A或不存在;
R
59= A、C或不存在;
R
14、R
56、R
66=獨立地為A、C、G或不存在;
R
11、R
26、R
42、R
55=獨立地為A、C、U或不存在;
R
1、R
9、R
12、R
15、R
34、R
37、R
48、R
51、R
67、R
68、R
69、R
70=獨立地為A、G或不存在;
R
44、R
45、R
58=獨立地為A、G、U或不存在;
R
57= A、U或不存在;
R
5、R
28、R
60=獨立地為C或不存在;
R
33、R
65=獨立地為C、G或不存在;
R
17、R
21、R
29=獨立地為C、G、U或不存在;
R
3、R
6、R
13、R
22、R
32、R
35、R
36、R
43、R
61、R
63、R
64、R
71=獨立地為C、U或不存在;
R
7、R
10、R
19、R
20、R
25、R
27、R
49、R
52、R
72=獨立地為G或不存在;
R
54= G、U或不存在;
R
2、R
4、R
8、R
16、R
23、R
30、R
31、R
38、R
39、R
50、R
53=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
天冬胺酸 TREM 共通序列在一實施例中,本文所揭示之TREM包含式I
ASP之序列(SEQ ID NO: 571),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Asp之共識為:
R
0=不存在;
R
24、R
71=獨立地為A、C或不存在;
R
33、R
46=獨立地為A、C、G或不存在;
R
2、R
3、R
4、R
5、R
6、R
12、R
16、R
22、R
26、R
29、R
31、R
32、R
44、R
48、R
49、R
58、R
63、R
64、R
66、R
67、R
68、R
69=獨立地為N或不存在;
R
13、R
21、R
34、R
41、R
57、R
65=獨立地為A、C、U或不存在;
R
9、R
10、R
14、R
15、R
20、R
27、R
37、R
40、R
51、R
56、R
72=獨立地為A、G或不存在;
R
7、R
25、R
42=獨立地為A、G、U或不存在;
R
39= C或不存在;
R
50、R
62=獨立地為C、G或不存在;
R
30、R
43、R
45、R
55、R
70=獨立地為C、G、U或不存在;
R
8、R
11、R
17、R
18、R
28、R
35、R
53、R
59、R
60、R
61=獨立地為C、U或不存在;
R
19、R
52=獨立地為G或不存在;
R
1= G、U或不存在;
R
23、R
36、R
38、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式II
ASP之序列(SEQ ID NO: 572),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Asp之共識為:
R
0、R
17、R
18、R
23=獨立地不存在;
R
9、R
40=獨立地為A或不存在;
R
24、R
71=獨立地為A、C或不存在;
R
67、R
68=獨立地為A、C、G或不存在;
R
2、R
6、R
66=獨立地為N或不存在;
R
57、R
63=獨立地為A、C、U或不存在;
R
10、R
14、R
27、R
33、R
37、R
44、R
46、R
51、R
56、R
64、R
72=獨立地為A、G或不存在;
R
7、R
12、R
26、R
65=獨立地為A、U或不存在;
R
39、R
61、R
62=獨立地為C或不存在;
R
3、R
31、R
45、R
70=獨立地為C、G或不存在;
R
4、R
5、R
29、R
43、R
55=獨立地為C、G、U或不存在;
R
8、R
11、R
13、R
30、R
32、R
34、R
35、R
41、R
48、R
53、R
59、R
60=獨立地為C、U或不存在;
R
15、R
19、R
20、R
25、R
42、R
50、R
52=獨立地為G或不存在;
R
1、R
22、R
49、R
58、R
69=獨立地為G、U或不存在;
R
16、R
21、R
28、R
36、R
38、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式III
ASP之序列(SEQ ID NO: 573),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Asp之共識為:
R
0、R
17、R
18、R
23=不存在;
R
9、R
12、R
40、R
65、R
71=獨立地為A或不存在;
R
2、R
24、R
57=獨立地為A、C或不存在;
R
6、R
14、R
27、R
46、R
51、R
56、R
64、R
67、R
68=獨立地為A、G或不存在;
R
3、R
31、R
35、R
39、R
61、R
62=獨立地為C或不存在;
R
66= C、G或不存在;
R
5、R
8、R
29、R
30、R
32、R
34、R
41、R
43、R
48、R
55、R
59、R
60、R
63=獨立地為C、U或不存在;
R
10、R
15、R
19、R
20、R
25、R
33、R
37、R
42、R
44、R
45、R
49、R
50、R
52、R
69、R
70、R
72=獨立地為G或不存在;
R
22、R
58=獨立地為G、U或不存在;
R
1、R
4、R
7、R
11、R
13、R
16、R
21、R
26、R
28、R
36、R
38、R
53、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
半胱胺酸 TREM 共通序列在一實施例中,本文所揭示之TREM包含式I
CYS之序列(SEQ ID NO: 574),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Cys之共識為:
R
0=不存在;
R
14、R
39、R
57=獨立地為A或不存在;
R
41= A、C或不存在;
R
10、R
15、R
27、R
33、R
62=獨立地為A、C、G或不存在;
R
3、R
4、R
5、R
6、R
12、R
13、R
16、R
24、R
26、R
29、R
30、R
31、R
32、R
34、R
42、R
44、R
45、R
46、R
48、R
49、R
58、R
63、R
64、R
66、R
67、R
68、R
69、R
70=獨立地為N或不存在;
R
65= A、C、U或不存在;
R
9、R
25、R
37、R
40、R
52、R
56=獨立地為A、G或不存在;
R
7、R
20、R
51=獨立地為A、G、U或不存在;
R
18、R
38、R
55=獨立地為C或不存在;
R
2= C、G或不存在;
R
21、R
28、R
43、R
50=獨立地為C、G、U或不存在;
R
11、R
22、R
23、R
35、R
36、R
59、R
60、R
61、R
71、R
72=獨立地為C、U或不存在;
R
1、R
19=獨立地為G或不存在;
R
17= G、U或不存在;
R
8、R
53、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式II
CYS之序列(SEQ ID NO: 575),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Cys之共識為:
R
0、R
18、R
23=不存在;
R
14、R
24、R
26、R
29、R
39、R
41、R
45、R
57=獨立地為A或不存在;
R
44= A、C或不存在;
R
27、R
62=獨立地為A、C、G或不存在;
R
16= A、C、G、U或不存在;
R
30、R
70=獨立地為A、C、U或不存在;
R
5、R
7、R
9、R
25、R
34、R
37、R
40、R
46、R
52、R
56、R
58、R
66=獨立地為A、G或不存在;
R
20、R
51=獨立地為A、G、U或不存在;
R
35、R
38、R
43、R
55、R
69=獨立地為C或不存在;
R
2、R
4、R
15=獨立地為C、G或不存在;
R
13= C、G、U或不存在;
R
6、R
11、R
28、R
36、R
48、R
49、R
50、R
60、R
61、R
67、R
68、R
71、R
72=獨立地為C、U或不存在;
R
1、R
3、R
10、R
19、R
33、R
63=獨立地為G或不存在;
R
8、R
17、R
21、R
64=獨立地為G、U或不存在;
R
12、R
22、R
31、R
32、R
42、R
53、R
54、R
65=獨立地為U或不存在;
R
59= U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式III
CYS之序列(SEQ ID NO: 576),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Cys之共識為:
R
0、R
18、R
23=不存在;
R
14、R
24、R
26、R
29、R
34、R
39、R
41、R
45、R
57、R
58=獨立地為A或不存在;
R
44、R
70=獨立地為A、C或不存在;
R
62= A、C、G或不存在;
R
16= N或不存在;
R
5、R
7、R
9、R
20、R
40、R
46、R
51、R
52、R
56、R
66=獨立地為A、G或不存在;
R
28、R
35、R
38、R
43、R
55、R
67、R
69=獨立地為C或不存在;
R
4、R
15=獨立地為C、G或不存在;
R
6、R
11、R
13、R
30、R
48、R
49、R
50、R
60、R
61、R
68、R
71、R
72=獨立地為C、U或不存在;
R
1、R
2、R
3、R
10、R
19、R
25、R
27、R
33、R
37、R
63=獨立地為G或不存在;
R
8、R
21、R
64=獨立地為G、U或不存在;
R
12、R
17、R
22、R
31、R
32、R
36、R
42、R
53、R
54、R
59、R
65=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
麩醯胺酸 TREM 共通序列在一實施例中,本文所揭示之TREM包含式I
GLN之序列(SEQ ID NO: 577),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Gln之共識為:
R
0、R
18=不存在;
R
14、R
24、R
57=獨立地為A或不存在;
R
9、R
26、R
27、R
33、R
56=獨立地為A、C、G或不存在;
R
2、R
4、R
5、R
6、R
12、R
13、R
16、R
21、R
22、R
25、R
29、R
30、R
31、R
32、R
34、R
41、R
42、R
44、R
45、R
46、R
48、R
49、R
50、R
58、R
62、R
63、R
66、R
67、R
68、R
69、R
70=獨立地為N或不存在;
R
17、R
23、R
43、R
65、R
71=獨立地為A、C、U或不存在;
R
15、R
40、R
51、R
52=獨立地為A、G或不存在;
R
1、R
7、R
72=獨立地為A、G、U或不存在;
R
3、R
11、R
37、R
60、R
64=獨立地為C、G、U或不存在;
R
28、R
35、R
55、R
59、R
61=獨立地為C、U或不存在;
R
10、R
19、R
20=獨立地為G或不存在;
R
39= G、U或不存在;
R
8、R
36、R
38、R
53、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式式II
GLN之序列(SEQ ID NO: 578),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Gln之共識為:
R
0、R
18、R
23=不存在;
R
14、R
24、R
57=獨立地為A或不存在;
R
17、R
71=獨立地為A、C或不存在;
R
25、R
26、R
33、R
44、R
46、R
56、R
69=獨立地為A、C、G或不存在;
R
4、R
5、R
12、R
22、R
29、R
30、R
48、R
49、R
63、R
67、R
68=獨立地為N或不存在;
R
31、R
43、R
62、R
65、R
70=獨立地為A、C、U或不存在;
R
15、R
27、R
34、R
40、R
41、R
51、R
52=獨立地為A、G或不存在;
R
2、R
7、R
21、R
45、R
50、R
58、R
66、R
72=獨立地為A、G、U或不存在;
R
3、R
13、R
32、R
37、R
42、R
60、R
64=獨立地為C、G、U或不存在;
R
6、R
11、R
28、R
35、R
55、R
59、R
61=獨立地為C、U或不存在;
R
9、R
10、R
19、R
20=獨立地為G或不存在;
R
1、R
16、R
39=獨立地為G、U或不存在;
R
8、R
36、R
38、R
53、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式III
GLN之序列(SEQ ID NO: 579),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Gln之共識為:
R
0、R
18、R
23=不存在;
R
14、R
24、R
41、R
57=獨立地為A或不存在;
R
17、R
71=獨立地為A、C或不存在;
R
5、R
25、R
26、R
46、R
56、R
69=獨立地為A、C、G或不存在;
R
4、R
22、R
29、R
30、R
48、R
49、R
63、R
68=獨立地為N或不存在;
R
43、R
62、R
65、R
70=獨立地為A、C、U或不存在;
R
15、R
27、R
33、R
34、R
40、R
51、R
52=獨立地為A、G或不存在;
R
2、R
7、R
12、R
45、R
50、R
58、R
66=獨立地為A、G、U或不存在;
R
31= A、U或不存在;
R
32、R
44、R
60=獨立地為C、G或不存在;
R
3、R
13、R
37、R
42、R
64、R
67=獨立地為C、G、U或不存在;
R
6、R
11、R
28、R
35、R
55、R
59、R
61=獨立地為C、U或不存在;
R
9、R
10、R
19、R
20=獨立地為G或不存在;
R
1、R
21、R
39、R
72=獨立地為G、U或不存在;
R
8、R
16、R
36、R
38、R
53、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
麩胺酸 TREM 共通序列在一實施例中,本文所揭示之TREM包含式I
GLU之序列(SEQ ID NO: 580),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Glu之共識為:
R
0=不存在;
R
34、R
43、R
68、R
69=獨立地為A、C、G或不存在;
R
1、R
2、R
5、R
6、R
9、R
12、R
16、R
20、R
21、R
26、R
27、R
29、R
30、R
31、R
32、R
33、R
41、R
44、R
45、R
46、R
48、R
50、R
51、R
58、R
63、R
64、R
65、R
66、R
70、R
71=獨立地為N或不存在;
R
13、R
17、R
23、R
61=獨立地為A、C、U或不存在;
R
10、R
14、R
24、R
40、R
52、R
56=獨立地為A、G或不存在;
R
7、R
15、R
25、R
67、R
72=獨立地為A、G、U或不存在;
R
11、R
57=獨立地為A、U或不存在;
R
39= C、G或不存在;
R
3、R
4、R
22、R
42、R
49、R
55、R
62=獨立地為C、G、U或不存在;
R
18、R
28、R
35、R
37、R
53、R
59、R
60=獨立地為C、U或不存在;
R
19= G或不存在;
R
8、R
36、R
38、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式II
GLU之序列(SEQ ID NO: 581),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Glu之共識為:
R
0、R
18、R
23=不存在;
R
17、R
40=獨立地為A或不存在;
R
26、R
27、R
34、R
43、R
68、R
69、R
71=獨立地為A、C、G或不存在;
R
1、R
2、R
5、R
12、R
21、R
31、R
33、R
41、R
45、R
48、R
51、R
58、R
66、R
70=獨立地為N或不存在;
R
44、R
61=獨立地為A、C、U或不存在;
R
9、R
14、R
24、R
25、R
52、R
56、R
63=獨立地為A、G或不存在;
R
7、R
15、R
46、R
50、R
67、R
72=獨立地為A、G、U或不存在;
R
29、R
57=獨立地為A、U或不存在;
R
60= C或不存在;
R
39= C、G或不存在;
R
3、R
6、R
20、R
30、R
32、R
42、R
55、R
62、R
65=獨立地為C、G、U或不存在;
R
4、R
8、R
16、R
28、R
35、R
37、R
49、R
53、R
59=獨立地為C、U或不存在;
R
10、R
19=獨立地為G或不存在;
R
22、R
64=獨立地為G、U或不存在;
R
11、R
13、R
36、R
38、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式III
GLU之序列(SEQ ID NO: 582),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Glu之共識為:
R
0、R
17、R
18、R
23=不存在;
R
14、R
27、R
40、R
71=獨立地為A或不存在;
R
44= A、C或不存在;
R
43= A、C、G或不存在;
R
1、R
31、R
33、R
45、R
51、R
66=獨立地為N或不存在;
R
21、R
41=獨立地為A、C、U或不存在;
R
7、R
24、R
25、R
50、R
52、R
56、R
63、R
68、R
70=獨立地為A、G或不存在;
R
5、R
46=獨立地為A、G、U或不存在;
R
29、R
57、R
67、R
72=獨立地為A、U或不存在;
R
2、R
39、R
60=獨立地為C或不存在;
R
3、R
12、R
20、R
26、R
34、R
69=獨立地為C、G或不存在;
R
6、R
30、R
42、R
48、R
65=獨立地為C、G、U或不存在;
R
4、R
16、R
28、R
35、R
37、R
49、R
53、R
55、R
58、R
61、R
62=獨立地為C、U或不存在;
R
9、R
10、R
19、R
64=獨立地為G或不存在;
R
15、R
22、R
32=獨立地為G、U或不存在;
R
8、R
11、R
13、R
36、R
38、R
54、R
59=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
甘胺酸 TREM 共通序列在一實施例中,本文所揭示之TREM包含式I
GLY之序列(SEQ ID NO: 583),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Gly之共識為:
R
0=不存在;
R
24= A或不存在;
R
3、R
9、R
40、R
50、R
51=獨立地為A、C、G或不存在;
R
4、R
5、R
6、R
7、R
12、R
16、R
21、R
22、R
26、R
29、R
30、R
31、R
32、R
33、R
34、R
41、R
42、R
43、R
44、R
45、R
46、R
48、R
49、R
58、R
63、R
64、R
65、R
66、R
67、R
68=獨立地為N或不存在;
R
59= A、C、U或不存在;
R
1、R
10、R
14、R
15、R
27、R
56=獨立地為A、G或不存在;
R
20、R
25=獨立地為A、G、U或不存在;
R
57、R
72=獨立地為A、U或不存在;
R
38、R
39、R
60=獨立地為C或不存在;
R
52= C、G或不存在;
R
2、R
19、R
37、R
54、R
55、R
61、R
62、R
69、R
70=獨立地為C、G、U或不存在;
R
11、R
13、R
17、R
28、R
35、R
36、R
71=獨立地為C、U或不存在;
R
8、R
18、R
23、R
53=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式II
GLY之序列(SEQ ID NO: 584),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Gly之共識為:
R
0、R
18、R
23=不存在;
R
24、R
27、R
40、R
72=獨立地為A或不存在;
R
26= A、C或不存在;
R
3、R
7、R
68=獨立地為A、C、G或不存在;
R
5、R
30、R
41、R
42、R
44、R
49、R
67=獨立地為A、C、G、U或不存在;
R
31、R
32、R
34=獨立地為A、C、U或不存在;
R
9、R
10、R
14、R
15、R
33、R
50、R
56=獨立地為A、G或不存在;
R
12、R
16、R
22、R
25、R
29、R
46=獨立地為A、G、U或不存在;
R
57= A、U或不存在;
R
17、R
38、R
39、R
60、R
61、R
71=獨立地為C或不存在;
R
6、R
52、R
64、R
66=獨立地為C、G或不存在;
R
2、R
4、R
37、R
48、R
55、R
65=獨立地為C、G、U或不存在;
R
13、R
35、R
43、R
62、R
69=獨立地為C、U或不存在;
R
1、R
19、R
20、R
51、R
70=獨立地為G或不存在;
R
21、R
45、R
63=獨立地為G、U或不存在;
R
8、R
11、R
28、R
36、R
53、R
54、R
58、R
59=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式III
GLY之序列(SEQ ID NO: 585),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Gly之共識為:
R
0、R
18、R
23=不存在;
R
24、R
27、R
40、R
72=獨立地為A或不存在;
R
26= A、C或不存在;
R
3、R
7、R
49、R
68=獨立地為A、C、G或不存在;
R
5、R
30、R
41、R
44、R
67=獨立地為N或不存在;
R
31、R
32、R
34=獨立地為A、C、U或不存在;
R
9、R
10、R
14、R
15、R
33、R
50、R
56=獨立地為A、G或不存在;
R
12、R
25、R
29、R
42、R
46=獨立地為A、G、U或不存在;
R
16、R
57=獨立地為A、U或不存在;
R
17、R
38、R
39、R
60、R
61、R
71=獨立地為C或不存在;
R
6、R
52、R
64、R
66=獨立地為C、G或不存在;
R
37、R
48、R
65=獨立地為C、G、U或不存在;
R
2、R
4、R
13、R
35、R
43、R
55、R
62、R
69=獨立地為C、U或不存在;
R
1、R
19、R
20、R
51、R
70=獨立地為G或不存在;
R
21、R
22、R
45、R
63=獨立地為G、U或不存在;
R
8、R
11、R
28、R
36、R
53、R
54、R
58、R
59=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
組胺酸 TREM 共通序列在一實施例中,本文所揭示之TREM包含式I
HIS之序列(SEQ ID NO: 586),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於His之共識為:
R
23=不存在;
R
14、R
24、R
57=獨立地為A或不存在;
R
72= A、C或不存在;
R
9、R
27、R
43、R
48、R
69=獨立地為A、C、G或不存在;
R
3、R
4、R
5、R
6、R
12、R
25、R
26、R
29、R
30、R
31、R
34、R
42、R
45、R
46、R
49、R
50、R
58、R
62、R
63、R
66、R
67、R
68=獨立地為N或不存在;
R
13、R
21、R
41、R
44、R
65=獨立地為A、C、U或不存在;
R
40、R
51、R
56、R
70=獨立地為A、G或不存在;
R
7、R
32=獨立地為A、G、U或不存在;
R
55、R
60=獨立地為C或不存在;
R
11、R
16、R
33、R
64=獨立地為C、G、U或不存在;
R
2、R
17、R
22、R
28、R
35、R
53、R
59、R
61、R
71=獨立地為C、U或不存在;
R
1、R
10、R
15、R
19、R
20、R
37、R
39、R
52=獨立地為G或不存在;
R
0= G、U或不存在;
R
8、R
18、R
36、R
38、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式II
HIS之序列(SEQ ID NO: 587),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於His之共識為:
R
0、R
17、R
18、R
23=不存在;
R
7、R
12、R
14、R
24、R
27、R
45、R
57、R
58、R
63、R
67、R
72=獨立地為A或不存在;
R
3= A、C、U或不存在;
R
4、R
43、R
56、R
70=獨立地為A、G或不存在;
R
49= A、U或不存在;
R
2、R
28、R
30、R
41、R
42、R
44、R
48、R
55、R
60、R
66、R
71=獨立地為C或不存在;
R
25= C、G或不存在;
R
9= C、G、U或不存在;
R
8、R
13、R
26、R
33、R
35、R
50、R
53、R
61、R
68=獨立地為C、U或不存在;
R
1、R
6、R
10、R
15、R
19、R
20、R
32、R
34、R
37、R
39、R
40、R
46、R
51、R
52、R
62、R
64、R
69=獨立地為G或不存在;
R
16= G、U或不存在;
R
5、R
11、R
21、R
22、R
29、R
31、R
36、R
38、R
54、R
59、R
65=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式III
HIS之序列(SEQ ID NO: 588),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於His之共識為:
R
0、R
17、R
18、R
23=不存在;
R
7、R
12、R
14、R
24、R
27、R
45、R
57、R
58、R
63、R
67、R
72=獨立地為A或不存在;
R
3= A、C或不存在;
R
4、R
43、R
56、R
70=獨立地為A、G或不存在;
R
49= A、U或不存在;
R
2、R
28、R
30、R
41、R
42、R
44、R
48、R
55、R
60、R
66、R
71=獨立地為C或不存在;
R
8、R
9、R
26、R
33、R
35、R
50、R
61、R
68=獨立地為C、U或不存在;
R
1、R
6、R
10、R
15、R
19、R
20、R
25、R
32、R
34、R
37、R
39、R
40、R
46、R
51、R
52、R
62、R
64、R
69=獨立地為G或不存在;
R
5、R
11、R
13、R
16、R
21、R
22、R
29、R
31、R
36、R
38、R
53、R
54、R
59、R
65=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
異白胺酸 TREM 共通序列在一實施例中,本文所揭示之TREM包含式I
ILE之序列(SEQ ID NO: 589),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Ile之共識為:
R
23=不存在;
R
38、R
41、R
57、R
72=獨立地為A或不存在;
R
1、R
26=獨立地為A、C、G或不存在;
R
0、R
3、R
4、R
6、R
16、R
31、R
32、R
34、R
37、R
42、R
43、R
44、R
45、R
46、R
48、R
49、R
50、R
58、R
59、R
62、R
63、R
64、R
66、R
67、R
68、R
69=獨立地為N或不存在;
R
22、R
61、R
65=獨立地為A、C、U或不存在;
R
9、R
14、R
15、R
24、R
27、R
40=獨立地為A、G或不存在;
R
7、R
25、R
29、R
51、R
56=獨立地為A、G、U或不存在;
R
18、R
54=獨立地為A、U或不存在;
R
60= C或不存在;
R
2、R
52、R
70=獨立地為C、G或不存在;
R
5、R
12、R
21、R
30、R
33、R
71=獨立地為C、G、U或不存在;
R
11、R
13、R
17、R
28、R
35、R
53、R
55=獨立地為C、U或不存在;
R
10、R
19、R
20=獨立地為G或不存在;
R
8、R
36、R
39=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式II
ILE之序列(SEQ ID NO: 590),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Ile之共識為:
R
0、R
18、R
23=不存在;
R
24、R
38、R
40、R
41、R
57、R
72=獨立地為A或不存在;
R
26、R
65=獨立地為A、C或不存在;
R
58、R
59、R
67=獨立地為N或不存在;
R
22= A、C、U或不存在;
R
6、R
9、R
14、R
15、R
29、R
34、R
43、R
46、R
48、R
50、R
51、R
63、R
69=獨立地為A、G或不存在;
R
37、R
56=獨立地為A、G、U或不存在;
R
54= A、U或不存在;
R
28、R
35、R
60、R
62、R
71=獨立地為C或不存在;
R
2、R
52、R
70=獨立地為C、G或不存在;
R
5= C、G、U或不存在;
R
3、R
4、R
11、R
13、R
17、R
21、R
30、R
42、R
44、R
45、R
49、R
53、R
55、R
61、R
64、R
66=獨立地為C、U或不存在;
R
1、R
10、R
19、R
20、R
25、R
27、R
31、R
68=獨立地為G或不存在;
R
7、R
12、R
32=獨立地為G、U或不存在;
R
8、R
16、R
33、R
36、R
39=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式III
ILE之序列(SEQ ID NO: 591),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Ile之共識為:
R
0、R
18、R
23=不存在;
R
14、R
24、R
38、R
40、R
41、R
57、R
72=獨立地為A或不存在;
R
26、R
65=獨立地為A、C或不存在;
R
22、R
59=獨立地為A、C、U或不存在;
R
6、R
9、R
15、R
34、R
43、R
46、R
51、R
56、R
63、R
69=獨立地為A、G或不存在;
R
37= A、G、U或不存在;
R
13、R
28、R
35、R
44、R
55、R
60、R
62、R
71=獨立地為C或不存在;
R
2、R
5、R
70=獨立地為C、G或不存在;
R
58、R
67=獨立地為C、G、U或不存在;
R
3、R
4、R
11、R
17、R
21、R
30、R
42、R
45、R
49、R
53、R
61、R
64、R
66=獨立地為C、U或不存在;
R
1、R
10、R
19、R
20、R
25、R
27、R
29、R
31、R
32、R
48、R
50、R
52、R
68=獨立地為G或不存在;
R
7、R
12=獨立地為G、U或不存在;
R
8、R
16、R
33、R
36、R
39、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
甲硫胺酸 TREM 共通序列在一實施例中,本文所揭示之TREM包含式I
MET之序列(SEQ ID NO: 592),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Met之共識為:
R
0、R
23=不存在;
R
14、R
38、R
40、R
57=獨立地為A或不存在;
R
60= A、C或不存在;
R
33、R
48、R
70=獨立地為A、C、G或不存在;
R
1、R
3、R
4、R
5、R
6、R
11、R
12、R
16、R
17、R
21、R
22、R
26、R
27、R
29、R
30、R
31、R
32、R
42、R
44、R
45、R
46、R
49、R
50、R
58、R
62、R
63、R
66、R
67、R
68、R
69、R
71=獨立地為N或不存在;
R
18、R
35、R
41、R
59、R
65=獨立地為A、C、U或不存在;
R
9、R
15、R
51=獨立地為A、G或不存在;
R
7、R
24、R
25、R
34、R
53、R
56=獨立地為A、G、U或不存在;
R
72= A、U或不存在;
R
37= C或不存在;
R
10、R
55=獨立地為C、G或不存在;
R
2、R
13、R
28、R
43、R
64=獨立地為C、G、U或不存在;
R
36、R
61=獨立地為C、U或不存在;
R
19、R
20、R
52=獨立地為G或不存在;
R
8、R
39、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271)、
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式II
MET之序列(SEQ ID NO: 593),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Met之共識為:
R
0、R
18、R
22、R
23=不存在;
R
14、R
24、R
38、R
40、R
41、R
57、R
72=獨立地為A或不存在;
R
59、R
60、R
62、R
65=獨立地為A、C或不存在;
R
6、R
45、R
67=獨立地為A、C、G或不存在;
R
4= N或不存在;
R
21、R
42=獨立地為A、C、U或不存在;
R
1、R
9、R
27、R
29、R
32、R
46、R
51=獨立地為A、G或不存在;
R
17、R
49、R
53、R
56、R
58=獨立地為A、G、U或不存在;
R
63=A、U或不存在;
R
3、R
13、R
37=獨立地為C或不存在;
R
48、R
55、R
64、R
70=獨立地為C、G或不存在;
R
2、R
5、R
66、R
68=獨立地為C、G、U或不存在;
R
11、R
16、R
26、R
28、R
30、R
31、R
35、R
36、R
43、R
44、R
61、R
71=獨立地為C、U或不存在;
R
10、R
12、R
15、R
19、R
20、R
25、R
33、R
52、R
69=獨立地為G或不存在;
R
7、R
34、R
50=獨立地為G、U或不存在;
R
8、R
39、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式III
MET之序列(SEQ ID NO: 594),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Met之共識為:
R
0、R
18、R
22、R
23=不存在;
R
14、R
24、R
38、R
40、R
41、R
57、R
72=獨立地為A或不存在;
R
59、R
62、R
65=獨立地為A、C或不存在;
R
6、R
67=獨立地為A、C、G或不存在;
R
4、R
21=獨立地為A、C、U或不存在;
R
1、R
9、R
27、R
29、R
32、R
45、R
46、R
51=獨立地為A、G或不存在;
R
17、R
56、R
58=獨立地為A、G、U或不存在;
R
49、R
53、R
63=獨立地為A、U或不存在;
R
3、R
13、R
26、R
37、R
43、R
60=獨立地為C或不存在;
R
2、R
48、R
55、R
64、R
70=獨立地為C、G或不存在;
R
5、R
66=獨立地為C、G、U或不存在;
R
11、R
16、R
28、R
30、R
31、R
35、R
36、R
42、R
44、R
61、R
71=獨立地為C、U或不存在;
R
10、R
12、R
15、R
19、R
20、R
25、R
33、R
52、R
69=獨立地為G或不存在;
R
7、R
34、R
50、R
68=獨立地為G、U或不存在;
R
8、R
39、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
白胺酸 TREM 共通序列在一實施例中,本文所揭示之TREM包含式I
LEU之序列(SEQ ID NO: 595),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Leu之共識為:
R
0=不存在;
R
38、R
57=獨立地為A或不存在;
R
60= A、C或不存在;
R
1、R
13、R
27、R
48、R
51、R
56=獨立地為A、C、G或不存在;
R
2、R
3、R
4、R
5、R
6、R
7、R
9、R
10、R
11、R
12、R
16、R
23、R
26、R
28、R
29、R
30、R
31、R
32、R
33、R
34、R
37、R
41、R
42、R
43、R
44、R
45、R
46、R
49、R
50、R
58、R
62、R
63、R
65、R
66、R
67、R
68、R
69、R
70=獨立地為N或不存在;
R
17、R
18、R
21、R
22、R
25、R
35、R
55=獨立地為A、C、U或不存在;
R
14、R
15、R
39、R
72=獨立地為A、G或不存在;
R
24、R
40=獨立地為A、G、U或不存在;
R
52、R
61、R
64、R
71=獨立地為C、G、U或不存在;
R
36、R
53、R
59=獨立地為C、U或不存在;
R
19= G或不存在;
R
20= G、U或不存在;
R
8、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式II
LEU之序列(SEQ ID NO: 596),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72
其中R為核糖核苷酸殘基且對於Leu之共識為:
R
0=不存在;
R
38、R
57、R
72=獨立地為A或不存在;
R
60= A、C或不存在;
R
4、R
5、R
48、R
50、R
56、R
69=獨立地為A、C、G或不存在;
R
6、R
33、R
41、R
43、R
46、R
49、R
58、R
63、R
66、R
70=獨立地為N或不存在;
R
11、R
12、R
17、R
21、R
22、R
28、R
31、R
37、R
44、R
55=獨立地為A、C、U或不存在;
R
1、R
9、R
14、R
15、R
24、R
27、R
34、R
39=獨立地為A、G或不存在;
R
7、R
29、R
32、R
40、R
45=獨立地為A、G、U或不存在;
R
25= A、U或不存在;
R
13= C、G或不存在;
R
2、R
3、R
16、R
26、R
30、R
52、R
62、R
64、R
65、R
67、R
68=獨立地為C、G、U或不存在;
R
18、R
35、R
42、R
53、R
59、R
61、R
71=獨立地為C、U或不存在;
R
19、R
51=獨立地為G或不存在;
R
10、R
20=獨立地為G、U或不存在;
R
8、R
23、R
36、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式III
LEU之序列(SEQ ID NO: 597),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Leu之共識為:
R
0=不存在;
R
38、R
57、R
72=獨立地為A或不存在;
R
60= A、C或不存在;
R
4、R
5、R
48、R
50、R
56、R
58、R
69=獨立地為A、C、G或不存在;
R
6、R
33、R
43、R
46、R
49、R
63、R
66、R
70=獨立地為N或不存在;
R
11、R
12、R
17、R
21、R
22、R
28、R
31、R
37、R
41、R
44、R
55=獨立地為A、C、U或不存在;
R
1、R
9、R
14、R
15、R
24、R
27、R
34、R
39=獨立地為A、G或不存在;
R
7、R
29、R
32、R
40、R
45=獨立地為A、G、U或不存在;
R
25= A、U或不存在;
R
13= C、G或不存在;
R
2、R
3、R
16、R
30、R
52、R
62、R
64、R
67、R
68=獨立地為C、G、U或不存在;
R
18、R
35、R
42、R
53、R
59、R
61、R
65、R
71=獨立地為C、U或不存在;
R
19、R
51=獨立地為G或不存在;
R
10、R
20、R
26=獨立地為G、U或不存在;
R
8、R
23、R
36、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
離胺酸 TREM 共通序列在一實施例中,本文所揭示之TREM包含式I
LYS之序列(SEQ ID NO: 598),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Lys之共識為:
R
0=不存在;
R
14= A或不存在;
R
40、R
41=獨立地為A、C或不存在;
R
34、R
43、R
51=獨立地為A、C、G或不存在;
R
1、R
2、R
3、R
4、R
5、R
6、R
7、R
11、R
12、R
16、R
21、R
26、R
30、R
31、R
32、R
44、R
45、R
46、R
48、R
49、R
50、R
58、R
62、R
63、R
65、R
66、R
67、R
68、R
69、R
70=獨立地為N或不存在;
R
13、R
17、R
59、R
71=獨立地為A、C、U或不存在;
R
9、R
15、R
19、R
20、R
25、R
27、R
52、R
56=獨立地為A、G或不存在;
R
24、R
29、R
72=獨立地為A、G、U或不存在;
R
18、R
57=獨立地為A、U或不存在;
R
10、R
33=獨立地為C、G或不存在;
R
42、R
61、R
64=獨立地為C、G、U或不存在;
R
28、R
35、R
36、R
37、R
53、R
55、R
60=獨立地為C、U或不存在;
R
8、R
22、R
23、R
38、R
39、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式II
LYS之序列(SEQ ID NO: 599),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Lys之共識為:
R
0、R
18、R
23=不存在;
R
14= A或不存在;
R
40、R
41、R
43=獨立地為A、C或不存在;
R
3、R
7=獨立地為A、C、G或不存在;
R
1、R
6、R
11、R
31、R
45、R
48、R
49、R
63、R
65、R
66、R
68=獨立地為N或不存在;
R
2、R
12、R
13、R
17、R
44、R
67、R
71=獨立地為A、C、U或不存在;
R
9、R
15、R
19、R
20、R
25、R
27、R
34、R
50、R
52、R
56、R
70、R
72=獨立地為A、G或不存在;
R
5、R
24、R
26、R
29、R
32、R
46、R
69=獨立地為A、G、U或不存在;
R
57= A、U或不存在;
R
10、R
61=獨立地為C、G或不存在;
R
4、R
16、R
21、R
30、R
58、R
64=獨立地為C、G、U或不存在;
R
28、R
35、R
36、R
37、R
42、R
53、R
55、R
59、R
60、R
62=獨立地為C、U或不存在;
R
33、R
51=獨立地為G或不存在;
R
8=G、U或不存在;
R
22、R
38、R
39、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式III
LYS之序列(SEQ ID NO: 600),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Lys之共識為:
R
0、R
18、R
23=不存在;
R
9、R
14、R
34、R
41=獨立地為A或不存在;
R
40= A、C或不存在;
R
1、R
3、R
7、R
31=獨立地為A、C、G或不存在;
R
48、R
65、R
68=獨立地為N或不存在;
R
2、R
13、R
17、R
44、R
63、R
66=獨立地為A、C、U或不存在;
R
5、R
15、R
19、R
20、R
25、R
27、R
29、R
50、R
52、R
56、R
70、R
72=獨立地為A、G或不存在;
R
6、R
24、R
32、R
49=獨立地為A、G、U或不存在;
R
12、R
26、R
46、R
57=獨立地為A、U或不存在;
R
11、R
28、R
35、R
43=獨立地為C或不存在;
R
10、R
45、R
61=獨立地為C、G或不存在;
R
4、R
21、R
64=獨立地為C、G、U或不存在;
R
37、R
53、R
55、R
59、R
60、R
62、R
67、R
71=獨立地為C、U或不存在;
R
33、R
51=獨立地為G或不存在;
R
8、R
30、R
58、R
69=獨立地為G、U或不存在;
R
16、R
22、R
36、R
38、R
39、R
42、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
苯丙胺酸 TREM 共通序列在一實施例中,本文所揭示之TREM包含式I
PHE之序列(SEQ ID NO: 601),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Phe之共識為:
R
0、R
23=不存在;
R
9、R
14、R
38、R
39、R
57、R
72=獨立地為A或不存在;
R
71= A、C或不存在;
R
41、R
70=獨立地為A、C、G或不存在;
R
4、R
5、R
6、R
30、R
31、R
32、R
34、R
42、R
44、R
45、R
46、R
48、R
49、R
58、R
62、R
63、R
66、R
67、R
68、R
69=獨立地為N或不存在;
R
16、R
61、R
65=獨立地為A、C、U或不存在;
R
15、R
26、R
27、R
29、R
40、R
56=獨立地為A、G或不存在;
R
7、R
51=獨立地為A、G、U或不存在;
R
22、R
24=獨立地為A、U或不存在;
R
55、R
60=獨立地為C或不存在;
R
2、R
3、R
21、R
33、R
43、R
50、R
64=獨立地為C、G、U或不存在;
R
11、R
12、R
13、R
17、R
28、R
35、R
36、R
59=獨立地為C、U或不存在;
R
10、R
19、R
20、R
25、R
37、R
52=獨立地為G或不存在;
R
1= G、U或不存在;
R
8、R
18、R
53、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式II
PHE之序列(SEQ ID NO: 602),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Phe之共識為:
R
0、R
18、R
23=不存在;
R
14、R
24、R
38、R
39、R
57、R
72=獨立地為A或不存在;
R
46、R
71=獨立地為A、C或不存在;
R
4、R
70=獨立地為A、C、G或不存在;
R
45= A、C、U或不存在;
R
6、R
7、R
15、R
26、R
27、R
32、R
34、R
40、R
41、R
56、R
69=獨立地為A、G或不存在;
R
29= A、G、U或不存在;
R
5、R
9、R
67=獨立地為A、U或不存在;
R
35、R
49、R
55、R
60=獨立地為C或不存在;
R
21、R
43、R
62=獨立地為C、G或不存在;
R
2、R
33、R
68=獨立地為C、G、U或不存在;
R
3、R
11、R
12、R
13、R
28、R
30、R
36、R
42、R
44、R
48、R
58、R
59、R
61、R
66=獨立地為C、U或不存在;
R
10、R
19、R
20、R
25、R
37、R
51、R
52、R
63、R
64=獨立地為G或不存在;
R
1、R
31、R
50=獨立地為G、U或不存在;
R
8、R
16、R
17、R
22、R
53、R
54、R
65=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式III
PHE之序列(SEQ ID NO: 603),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Phe之共識為:
R
0、R
18、R
22、R
23=不存在;
R
5、R
7、R
14、R
24、R
26、R
32、R
34、R
38、R
39、R
41、R
57、R
72=獨立地為A或不存在;
R
46= A、C或不存在;
R
70= A、C、G或不存在;
R
4、R
6、R
15、R
56、R
69=獨立地為A、G或不存在;
R
9、R
45=獨立地為A、U或不存在;
R
2、R
11、R
13、R
35、R
43、R
49、R
55、R
60、R
68、R
71=獨立地為C或不存在;
R
33= C、G或不存在;
R
3、R
28、R
36、R
48、R
58、R
59、R
61=獨立地為C、U或不存在;
R
1、R
10、R
19、R
20、R
21、R
25、R
27、R
29、R
37、R
40、R
51、R
52、R
62、R
63、R
64=獨立地為G或不存在;
R
8、R
12、R
16、R
17、R
30、R
31、R
42、R
44、R
50、R
53、R
54、R
65、R
66、R
67=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
脯胺酸 TREM 共通序列在一實施例中,本文所揭示之TREM包含式I
PRO之序列(SEQ ID NO: 604),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Pro之共識為:
R
0=不存在;
R
14、R
57=獨立地為A或不存在;
R
70、R
72=獨立地為A、C或不存在;
R
9、R
26、R
27=獨立地為A、C、G或不存在;
R
4、R
5、R
6、R
16、R
21、R
29、R
30、R
31、R
32、R
33、R
34、R
37、R
41、R
42、R
43、R
44、R
45、R
46、R
48、R
49、R
50、R
58、R
61、R
62、R
63、R
64、R
66、R
67、R
68=獨立地為N或不存在;
R
35、R
65=獨立地為A、C、U或不存在;
R
24、R
40、R
56=獨立地為A、G或不存在;
R
7、R
25、R
51=獨立地為A、G、U或不存在;
R
55、R
60=獨立地為C或不存在;
R
1、R
3、R
71=獨立地為C、G或不存在;
R
11、R
12、R
20、R
69=獨立地為C、G、U或不存在;
R
13、R
17、R
18、R
22、R
23、R
28、R
59=獨立地為C、U或不存在;
R
10、R
15、R
19、R
38、R
39、R
52=獨立地為G或不存在;
R
2=獨立地為G、U或不存在;
R
8、R
36、R
53、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式II
PRO之序列(SEQ ID NO: 605),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Pro之共識為:
R
0、R
17、R
18、R
22、R
23=不存在
R
14、R
45、R
56、R
57、R
58、R
65、R
68=獨立地為A或不存在;
R
61= A、C、G或不存在;
R
43=N或不存在;
R
37= A、C、U或不存在;
R
24、R
27、R
33、R
40、R
44、R
63=獨立地為A、G或不存在;
R
3、R
12、R
30、R
32、R
48、R
55、R
60、R
70、R
71、R
72=獨立地為C或不存在;
R
5、R
34、R
42、R
66=獨立地為C、G或不存在;
R
20= C、G、U或不存在;
R
35、R
41、R
49、R
62=獨立地為C、U或不存在;
R
1、R
2、R
6、R
9、R
10、R
15、R
19、R
26、R
38、R
39、R
46、R
50、R
51、R
52、R
64、R
67、R
69=獨立地為G或不存在;
R
11、R
16=獨立地為G、U或不存在;
R
4、R
7、R
8、R
13、R
21、R
25、R
28、R
29、R
31、R
36、R
53、R
54、R
59=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式III
PRO之序列(SEQ ID NO: 606),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Pro之共識為:
R
0、R
17、R
18、R
22、R
23=不存在;
R
14、R
45、R
56、R
57、R
58、R
65、R
68=獨立地為A或不存在;
R
37= A、C、U或不存在;
R
24、R
27、R
40=獨立地為A、G或不存在;
R
3、R
5、R
12、R
30、R
32、R
48、R
49、R
55、R
60、R
61、R
62、R
66、R
70、R
71、R
72=獨立地為C或不存在;
R
34、R
42=獨立地為C、G或不存在;
R
43= C、G、U或不存在;
R
41= C、U或不存在;
R
1、R
2、R
6、R
9、R
10、R
15、R
19、R
20、R
26、R
33、R
38、R
39、R
44、R
46、R
50、R
51、R
52、R
63、R
64、R
67、R
69=獨立地為G或不存在;
R
16= G、U或不存在;
R
4、R
7、R
8、R
11、R
13、R
21、R
25、R
28、R
29、R
31、R
35、R
36、R
53、R
54、R
59=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
絲胺酸 TREM 共通序列在一實施例中,本文所揭示之TREM包含式I
SER之序列(SEQ ID NO: 607),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Ser之共識為:
R
0=不存在;
R
14、R
24、R
57=獨立地為A或不存在;
R
41= A、C或不存在;
R
2、R
3、R
4、R
5、R
6、R
7、R
9、R
10、R
11、R
12、R
13、R
16、R
21、R
25、R
26、R
27、R
28、R
30、R
31、R
32、R
33、R
34、R
37、R
42、R
43、R
44、R
45、R
46、R
48、R
49、R
50、R
62、R
63、R
64、R
65、R
66、R
67、R
68、R
69、R
70=獨立地為N或不存在;
R
18= A、C、U或不存在;
R
15、R
40、R
51、R
56=獨立地為A、G或不存在;
R
1、R
29、R
58、R
72=獨立地為A、G、U或不存在;
R
39= A、U或不存在;
R
60= C或不存在;
R
38= C、G或不存在;
R
17、R
22、R
23、R
71=獨立地為C、G、U或不存在;
R
8、R
35、R
36、R
55、R
59、R
61=獨立地為C、U或不存在;
R
19、R
20=獨立地為G或不存在;
R
52= G、U或不存在;
R
53、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式II
SER之序列(SEQ ID NO: 608),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Ser之共識為:
R
0、R
23=不存在;
R
14、R
24、R
41、R
57=獨立地為A或不存在;
R
44= A、C或不存在;
R
25、R
45、R
48=獨立地為A、C、G或不存在;
R
2、R
3、R
4、R
5、R
37、R
50、R
62、R
66、R
67、R
69、R
70=獨立地為N或不存在;
R
12、R
28、R
65=獨立地為A、C、U或不存在;
R
9、R
15、R
29、R
34、R
40、R
56、R
63=獨立地為A、G或不存在;
R
7、R
26、R
30、R
33、R
46、R
58、R
72=獨立地為A、G、U或不存在;
R
39= A、U或不存在;
R
11、R
35、R
60、R
61=獨立地為C或不存在;
R
13、R
38=獨立地為C、G或不存在;
R
6、R
17、R
31、R
43、R
64、R
68=獨立地為C、G、U或不存在;
R
36、R
42、R
49、R
55、R
59、R
71=獨立地為C、U或不存在;
R
10、R
19、R
20、R
27、R
51=獨立地為G或不存在;
R
1、R
16、R
32、R
52=獨立地為G、U或不存在;
R
8、R
18、R
21、R
22、R
53、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式III
SER之序列(SEQ ID NO: 609),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Ser之共識為:
R
0、R
23=不存在;
R
14、R
24、R
41、R
57、R
58=獨立地為A或不存在;
R
44= A、C或不存在;
R
25、R
48=獨立地為A、C、G或不存在;
R
2、R
3、R
5、R
37、R
66、R
67、R
69、R
70=獨立地為N或不存在;
R
12、R
28、R
62=獨立地為A、C、U或不存在;
R
7、R
9、R
15、R
29、R
33、R
34、R
40、R
45、R
56、R
63=獨立地為A、G或不存在;
R
4、R
26、R
46、R
50=獨立地為A、G、U或不存在;
R
30、R
39=獨立地為A、U或不存在;
R
11、R
17、R
35、R
60、R
61=獨立地為C或不存在;
R
13、R
38=獨立地為C、G或不存在;
R
6、R
64=獨立地為C、G、U或不存在;
R
31、R
42、R
43、R
49、R
55、R
59、R
65、R
68、R
71=獨立地為C、U或不存在;
R
10、R
19、R
20、R
27、R
51、R
52=獨立地為G或不存在;
R
1、R
16、R
32、R
72=獨立地為G、U或不存在;
R
8、R
18、R
21、R
22、R
36、R
53、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
蘇胺酸 TREM 共通序列在一實施例中,本文所揭示之TREM包含式I
THR之序列(SEQ ID NO: 610),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Thr之共識為:
R
0、R
23=不存在;
R
14、R
41、R
57=獨立地為A或不存在;
R
56、R
70=獨立地為A、C、G或不存在;
R
4、R
5、R
6、R
7、R
12、R
16、R
26、R
30、R
31、R
32、R
34、R
37、R
42、R
44、R
45、R
46、R
48、R
49、R
50、R
58、R
62、R
63、R
64、R
65、R
66、R
67、R
68、R
72=獨立地為N或不存在;
R
13、R
17、R
21、R
35、R
61=獨立地為A、C、U或不存在;
R
1、R
9、R
24、R
27、R
29、R
69=獨立地為A、G或不存在;
R
15、R
25、R
51=獨立地為A、G、U或不存在;
R
40、R
53=獨立地為A、U或不存在;
R
33、R
43=獨立地為C、G或不存在;
R
2、R
3、R
59=獨立地為C、G、U或不存在;
R
11、R
18、R
22、R
28、R
36、R
54、R
55、R
60、R
71=獨立地為C、U或不存在;
R
10、R
20、R
38、R
52=獨立地為G或不存在;
R
19= G、U或不存在;
R
8、R
39=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式II
THR之序列(SEQ ID NO: 611),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Thr之共識為:
R
0、R
18、R
23=不存在;
R
14、R
41、R
57=獨立地為A或不存在;
R
9、R
42、R
44、R
48、R
56、R
70=獨立地為A、C、G或不存在;
R
4、R
6、R
12、R
26、R
49、R
58、R
63、R
64、R
66、R
68=獨立地為N或不存在;
R
13、R
21、R
31、R
37、R
62=獨立地為A、C、U或不存在;
R
1、R
15、R
24、R
27、R
29、R
46、R
51、R
69=獨立地為A、G或不存在;
R
7、R
25、R
45、R
50、R
67=獨立地為A、G、U或不存在;
R
40、R
53=獨立地為A、U或不存在;
R
35= C或不存在;
R
33、R
43=獨立地為C、G或不存在;
R
2、R
3、R
5、R
16、R
32、R
34、R
59、R
65、R
72=獨立地為C、G、U或不存在;
R
11、R
17、R
22、R
28、R
30、R
36、R
55、R
60、R
61、R
71=獨立地為C、U或不存在;
R
10、R
19、R
20、R
38、R
52=獨立地為G或不存在;
R
8、R
39、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式III
THR之序列(SEQ ID NO: 612),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Thr之共識為:
R
0、R
18、R
23=不存在;
R
14、R
40、R
41、R
57=獨立地為A或不存在;
R
44= A、C或不存在;
R
9、R
42、R
48、R
56=獨立地為A、C、G或不存在;
R
4、R
6、R
12、R
26、R
58、R
64、R
66、R
68=獨立地為N或不存在;
R
13、R
21、R
31、R
37、R
49、R
62=獨立地為A、C、U或不存在;
R
1、R
15、R
24、R
27、R
29、R
46、R
51、R
69=獨立地為A、G或不存在;
R
7、R
25、R
45、R
50、R
63、R
67=獨立地為A、G、U或不存在;
R
53= A、U或不存在;
R
35= C或不存在;
R
2、R
33、R
43、R
70=獨立地為C、G或不存在;
R
5、R
16、R
34、R
59、R
65=獨立地為C、G、U或不存在;
R
3、R
11、R
22、R
28、R
30、R
36、R
55、R
60、R
61、R
71=獨立地為C、U或不存在;
R
10、R
19、R
20、R
38、R
52=獨立地為G或不存在;
R
32= G、U或不存在;
R
8、R
17、R
39、R
54、R
72=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
色胺酸 TREM 共通序列在一實施例中,本文所揭示之TREM包含式I
TRP之序列(SEQ ID NO: 613),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Trp之共識為:
R
0=不存在;
R
24、R
39、R
41、R
57=獨立地為A或不存在;
R
2、R
3、R
26、R
27、R
40、R
48=獨立地為A、C、G或不存在;
R
4、R
5、R
6、R
29、R
30、R
31、R
32、R
34、R
42、R
44、R
45、R
46、R
49、R
51、R
58、R
63、R
66、R
67、R
68=獨立地為N或不存在;
R
13、R
14、R
16、R
18、R
21、R
61、R
65、R
71=獨立地為A、C、U或不存在;
R
1、R
9、R
10、R
15、R
33、R
50、R
56=獨立地為A、G或不存在;
R
7、R
25、R
72=獨立地為A、G、U或不存在;
R
37、R
38、R
55、R
60=獨立地為C或不存在;
R
12、R
35、R
43、R
64、R
69、R
70=獨立地為C、G、U或不存在;
R
11、R
17、R
22、R
28、R
59、R
62=獨立地為C、U或不存在;
R
19、R
20、R
52=獨立地為G或不存在;
R
8、R
23、R
36、R
53、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式II
TRP之序列(SEQ ID NO: 614),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Trp之共識為:
R
0、R
18、R
22、R
23=不存在;
R
14、R
24、R
39、R
41、R
57、R
72=獨立地為A或不存在;
R
3、R
4、R
13、R
61、R
71=獨立地為A、C或不存在;
R
6、R
44=獨立地為A、C、G或不存在;
R
21= A、C、U或不存在;
R
2、R
7、R
15、R
25、R
33、R
34、R
45、R
56、R
63=獨立地為A、G或不存在;
R
58= A、G、U或不存在;
R
46= A、U或不存在;
R
37、R
38、R
55、R
60、R
62=獨立地為C或不存在;
R
12、R
26、R
27、R
35、R
40、R
48、R
67=獨立地為C、G或不存在;
R
32、R
43、R
68=獨立地為C、G、U或不存在;
R
11、R
16、R
28、R
31、R
49、R
59、R
65、R
70=獨立地為C、U或不存在;
R
1、R
9、R
10、R
19、R
20、R
50、R
52、R
69=獨立地為G或不存在;
R
5、R
8、R
29、R
30、R
42、R
51、R
64、R
66=獨立地為G、U或不存在;
R
17、R
36、R
53、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式III
TRP之序列(SEQ ID NO: 615),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Trp之共識為:
R
0、R
18、R
22、R
23=不存在;
R
14、R
24、R
39、R
41、R
57、R
72=獨立地為A或不存在;
R
3、R
4、R
13、R
61、R
71=獨立地為A、C或不存在;
R
6、R
44=獨立地為A、C、G或不存在;
R
21= A、C、U或不存在;
R
2、R
7、R
15、R
25、R
33、R
34、R
45、R
56、R
63=獨立地為A、G或不存在;
R
58= A、G、U或不存在;
R
46= A、U或不存在;
R
37、R
38、R
55、R
60、R
62=獨立地為C或不存在;
R
12、R
26、R
27、R
35、R
40、R
48、R
67=獨立地為C、G或不存在;
R
32、R
43、R
68=獨立地為C、G、U或不存在;
R
11、R
16、R
28、R
31、R
49、R
59、R
65、R
70=獨立地為C、U或不存在;
R
1、R
9、R
10、R
19、R
20、R
50、R
52、R
69=獨立地為G或不存在;
R
5、R
8、R
29、R
30、R
42、R
51、R
64、R
66=獨立地為G、U或不存在;
R
17、R
36、R
53、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
酪胺酸 TREM 共通序列在一實施例中,本文所揭示之TREM包含式I
TYR之序列(SEQ ID NO: 616),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Tyr之共識為:
R
0=不存在;
R
14、R
39、R
57=獨立地為A或不存在;
R
41、R
48、R
51、R
71=獨立地為A、C、G或不存在;
R
3、R
4、R
5、R
6、R
9、R
10、R
12、R
13、R
16、R
25、R
26、R
30、R
31、R
32、R
42、R
44、R
45、R
46、R
49、R
50、R
58、R
62、R
63、R
66、R
67、R
68、R
69、R
70=獨立地為N或不存在;
R
22、R
65=獨立地為A、C、U或不存在;
R
15、R
24、R
27、R
33、R
37、R
40、R
56=獨立地為A、G或不存在;
R
7、R
29、R
34、R
72=獨立地為A、G、U或不存在;
R
23、R
53=獨立地為A、U或不存在;
R
35、R
60=獨立地為C或不存在;
R
20= C、G或不存在;
R
1、R
2、R
28、R
61、R
64=獨立地為C、G、U或不存在;
R
11、R
17、R
21、R
43、R
55=獨立地為C、U或不存在;
R
19、R
52=獨立地為G或不存在;
R
8、R
18、R
36、R
38、R
54、R
59=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式II
TYR之序列(SEQ ID NO: 617),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72
其中R為核糖核苷酸殘基且對於Tyr之共識為:
R
0、R
18、R
23=不存在;
R
7、R
9、R
14、R
24、R
26、R
34、R
39、R
57=獨立地為A或不存在;
R
44、R
69=獨立地為A、C或不存在;
R
71= A、C、G或不存在;
R
68= N或不存在;
R
58= A、C、U或不存在;
R
33、R
37、R
41、R
56、R
62、R
63=獨立地為A、G或不存在;
R
6、R
29、R
72=獨立地為A、G、U或不存在;
R
31、R
45、R
53=獨立地為A、U或不存在;
R
13、R
35、R
49、R
60=獨立地為C或不存在;
R
20、R
48、R
64、R
67、R
70=獨立地為C、G或不存在;
R
1、R
2、R
5、R
16、R
66=獨立地為C、G、U或不存在;
R
11、R
21、R
28、R
43、R
55、R
61=獨立地為C、U或不存在;
R
10、R
15、R
19、R
25、R
27、R
40、R
51、R
52=獨立地為G或不存在;
R
3、R
4、R
30、R
32、R
42、R
46=獨立地為G、U或不存在;
R
8、R
12、R
17、R
22、R
36、R
38、R
50、R
54、R
59、R
65=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式III
TYR之序列(SEQ ID NO: 618),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Tyr之共識為:
R
0、R
18、R
23=不存在;
R
7、R
9、R
14、R
24、R
26、R
34、R
39、R
57、R
72=獨立地為A或不存在;
R
44、R
69=獨立地為A、C或不存在;
R
71= A、C、G或不存在;
R
37、R
41、R
56、R
62、R
63=獨立地為A、G或不存在;
R
6、R
29、R
68=獨立地為A、G、U或不存在;
R
31、R
45、R
58=獨立地為A、U或不存在;
R
13、R
28、R
35、R
49、R
60、R
61=獨立地為C或不存在;
R
5、R
48、R
64、R
67、R
70=獨立地為C、G或不存在;
R
1、R
2=獨立地為C、G、U或不存在;
R
11、R
16、R
21、R
43、R
55、R
66=獨立地為C、U或不存在;
R
10、R
15、R
19、R
20、R
25、R
27、R
33、R
40、R
51、R
52=獨立地為G或不存在;
R
3、R
4、R
30、R
32、R
42、R
46=獨立地為G、U或不存在;
R
8、R
12、R
17、R
22、R
36、R
38、R
50、R
53、R
54、R
59、R
65=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
纈胺酸 TREM 共通序列在一實施例中,本文所揭示之TREM包含式I
VAL之序列(SEQ ID NO: 619),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Val之共識為:
R
0、R
23=不存在;
R
24、R
38、R
57=獨立地為A或不存在;
R
9、R
72=獨立地為A、C、G或不存在;
R
2、R
4、R
5、R
6、R
7、R
12、R
15、R
16、R
21、R
25、R
26、R
29、R
31、R
32、R
33、R
34、R
37、R
41、R
42、R
43、R
44、R
45、R
46、R
48、R
49、R
50、R
58、R
61、R
62、R
63、R
64、R
65、R
66、R
67、R
68、R
69、R
70=獨立地為N或不存在;
R
17、R
35、R
59=獨立地為A、C、U或不存在;
R
10、R
14、R
27、R
40、R
52、R
56=獨立地為A、G或不存在;
R
1、R
3、R
51、R
53=獨立地為A、G、U或不存在;
R
39= C或不存在;
R
13、R
30、R
55=獨立地為C、G、U或不存在;
R
11、R
22、R
28、R
60、R
71=獨立地為C、U或不存在;
R
19= G或不存在;
R
20= G 、U或不存在;
R
8、R
18、R
36、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式II
VAL之序列(SEQ ID NO: 620),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Val之共識為:
R
0、R
18、R
23=不存在;
R
24、R
38、R
57=獨立地為A或不存在;
R
64、R
70、R
72=獨立地為A、C、G或不存在;
R
15、R
16、R
26、R
29、R
31、R
32、R
43、R
44、R
45、R
49、R
50、R
58、R
62、R
65=獨立地為N或不存在;
R
6、R
17、R
34、R
37、R
41、R
59=獨立地為A、C、U或不存在;
R
9、R
10、R
14、R
27、R
40、R
46、R
51、R
52、R
56=獨立地為A、G或不存在;
R
7、R
12、R
25、R
33、R
53、R
63、R
66、R
68=獨立地為A、G、U或不存在;
R
69= A、U或不存在;
R
39= C或不存在;
R
5、R
67=獨立地為C、G或不存在;
R
2、R
4、R
13、R
48、R
55、R
61=獨立地為C、G、U或不存在;
R
11、R
22、R
28、R
30、R
35、R
60、R
71=獨立地為C、U或不存在;
R
19= G或不存在;
R
1、R
3、R
20、R
42=獨立地為G、U或不存在;
R
8、R
21、R
36、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
在一實施例中,本文所揭示之TREM包含式III
VAL之序列(SEQ ID NO: 621),
R
0-R
1-R
2-R
3-R
4-R
5-R
6-R
7-R
8-R
9-R
10-R
11-R
12-R
13-R
14-R
15-R
16-R
17-R
18-R
19-R
20-R
21-R
22-R
23-R
24-R
25-R
26-R
27-R
28-R
29-R
30-R
31-R
32-R
33-R
34-R
35-R
36-R
37-R
38-R
39-R
40-R
41-R
42-R
43-R
44-R
45-R
46-[R
47]
x-R
48-R
49-R
50-R
51-R
52-R
53-R
54-R
55-R
56-R
57-R
58-R
59-R
60-R
61-R
62-R
63-R
64-R
65-R
66-R
67-R
68-R
69-R
70-R
71-R
72其中R為核糖核苷酸殘基且對於Val之共識為:
R
0、R
18、R
23=不存在;
R
24、R
38、R
40、R
57、R
72=獨立地為A或不存在;
R
29、R
64、R
70=獨立地為A、C、G或不存在;
R
49、R
50、R
62=獨立地為N或不存在;
R
16、R
26、R
31、R
32、R
37、R
41、R
43、R
59、R
65=獨立地為A、C、U或不存在;
R
9、R
14、R
27、R
46、R
52、R
56、R
66=獨立地為A、G或不存在;
R
7、R
12、R
25、R
33、R
44、R
45、R
53、R
58、R
63、R
68=獨立地為A、G、U或不存在;
R
69= A、U或不存在;
R
39= C或不存在;
R
5、R
67=獨立地為C、G或不存在;
R
2、R
4、R
13、R
15、R
48、R
55=獨立地為C、G、U或不存在;
R
6、R
11、R
22、R
28、R
30、R
34、R
35、R
60、R
61、R
71=獨立地為C、U或不存在;
R
10、R
19、R
51=獨立地為G或不存在;
R
1、R
3、R
20、R
42=獨立地為G、U或不存在;
R
8、R
17、R
21、R
36、R
54=獨立地為U或不存在;
[R
47]
x= N或不存在;
其中例如x=1-271 (例如x=1-250、x=1-225、x=1-200、x=1-175、x=1-150、x=1-125、x=1-100、x=1-75、x=1-50、x=1-40、x=1-30、x=1-29、x=1-28、x=1-27、x=1-26、x=1-25、x=1-24、x=1-23、x=1-22、x=1-21、x=1-20、x=1-19、x=1-18、x=1-17、x=1-16、x=1-15、x=1-14、x=1-13、x=1-12、x=1-11、x=1-10、x=10-271、x=20-271、x=30-271、x=40-271、x=50-271、x=60-271、x=70-271、x=80-271、x=100-271、x=125-271、x=150-271、x=175-271、x=200-271、x=225-271、x=1、x=2、x=3、x=4、x=5、x=6、x=7、x=8、x=9、x=10、x=11、x=12、x=13、x=14、x=15、x=16、x=17、x=18、x=19、x=20、x=21、x=22、x=23、x=24、x=25、x=26、x=27、x=28、x=29、x=30、x=40、x=50、x=60、x=70、x=80、x=90、x=100、x=110、x=125、x=150、x=175、x=200、x=225、x=250或x=271),
其限制條件為TREM具有以下特性中之一者或兩者:不超過15%之殘基為N;或不超過20個殘基為不存在。
可變區共通序列在一實施例中,本文所揭示之TREM包含位置R
47處之可變區。在一實施例中,可變區之長度為1至271個核糖核苷酸(例如1-250、1-225、1-200、1-175、1-150、1-125、1-100、1-75、1-50、1-40、1-30、1-29、1-28、1-27、1-26、1-25、1-24、1-23、1-22、1-21、1-20、1-19、1-18、1-17、1-16、1-15、1-14、1-13、1-12、1-11、1-10、10-271、20-271、30-271、40-271、50-271、60-271、70-271、80-271、100-271、125-271、150-271、175-271、200-271、225-271、1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、40、50、60、70、80、90、100、110、125、150、175、200、225、250或271個核糖核苷酸)。在一實施例中,可變區包含腺嘌呤、胞嘧啶、鳥嘌呤或尿嘧啶中之任一者、全部或組合。
在一實施例中,可變區包含由表4中所揭示之去氧核糖核酸(DNA)序列(例如,表4中所揭示之SEQ ID NO: 452-561中之任一者)編碼的核糖核酸(RNA)序列。
表4:例示性可變區序列。
| SEQ ID NO | 序列 | |
| 1 | 452 | AAAATATAAATATATTTC |
| 2 | 453 | AAGCT |
| 3 | 454 | AAGTT |
| 4 | 455 | AATTCTTCGGAATGT |
| 5 | 456 | AGA |
| 6 | 457 | AGTCC |
| 7 | 458 | CAACC |
| 8 | 459 | CAATC |
| 9 | 460 | CAGC |
| 10 | 461 | CAGGCGGGTTCTGCCCGCGC |
| 11 | 462 | CATACCTGCAAGGGTATC |
| 12 | 463 | CGACCGCAAGGTTGT |
| 13 | 464 | CGACCTTGCGGTCAT |
| 14 | 465 | CGATGCTAATCACATCGT |
| 15 | 466 | CGATGGTGACATCAT |
| 16 | 467 | CGATGGTTTACATCGT |
| 17 | 468 | CGCCGTAAGGTGT |
| 18 | 469 | CGCCTTAGGTGT |
| 19 | 470 | CGCCTTTCGACGCGT |
| 20 | 471 | CGCTTCACGGCGT |
| 21 | 472 | CGGCAGCAATGCTGT |
| 22 | 473 | CGGCTCCGCCTTC |
| 23 | 474 | CGGGTATCACAGGGTC |
| 24 | 475 | CGGTGCGCAAGCGCTGT |
| 25 | 476 | CGTACGGGTGACCGTACC |
| 26 | 477 | CGTCAAAGACTTC |
| 27 | 478 | CGTCGTAAGACTT |
| 28 | 479 | CGTTGAATAAACGT |
| 29 | 480 | CTGTC |
| 30 | 481 | GGCC |
| 31 | 482 | GGGGATT |
| 32 | 483 | GGTC |
| 33 | 484 | GGTTT |
| 34 | 485 | GTAG |
| 35 | 486 | TAACTAGATACTTTCAGAT |
| 36 | 487 | TACTCGTATGGGTGC |
| 37 | 488 | TACTTTGCGGTGT |
| 38 | 489 | TAGGCGAGTAACATCGTGC |
| 39 | 490 | TAGGCGTGAATAGCGCCTC |
| 40 | 491 | TAGGTCGCGAGAGCGGCGC |
| 41 | 492 | TAGGTCGCGTAAGCGGCGC |
| 42 | 493 | TAGGTGGTTATCCACGC |
| 43 | 494 | TAGTC |
| 44 | 495 | TAGTT |
| 45 | 496 | TATACGTGAAAGCGTATC |
| 46 | 497 | TATAGGGTCAAAAACTCTATC |
| 47 | 498 | TATGCAGAAATACCTGCATC |
| 48 | 499 | TCCCCATACGGGGGC |
| 49 | 500 | TCCCGAAGGGGTTC |
| 50 | 501 | TCTACGTATGTGGGC |
| 51 | 502 | TCTCATAGGAGTTC |
| 52 | 503 | TCTCCTCTGGAGGC |
| 53 | 504 | TCTTAGCAATAAGGT |
| 54 | 505 | TCTTGTAGGAGTTC |
| 55 | 506 | TGAACGTAAGTTCGC |
| 56 | 507 | TGAACTGCGAGGTTCC |
| 57 | 508 | TGAC |
| 58 | 509 | TGACCGAAAGGTCGT |
| 59 | 510 | TGACCGCAAGGTCGT |
| 60 | 511 | TGAGCTCTGCTCTC |
| 61 | 512 | TGAGGCCTCACGGCCTAC |
| 62 | 513 | TGAGGGCAACTTCGT |
| 63 | 514 | TGAGGGTCATACCTCC |
| 64 | 515 | TGAGGGTGCAAATCCTCC |
| 65 | 516 | TGCCGAAAGGCGT |
| 66 | 517 | TGCCGTAAGGCGT |
| 67 | 518 | TGCGGTCTCCGCGC |
| 68 | 519 | TGCTAGAGCAT |
| 69 | 520 | TGCTCGTATAGAGCTC |
| 70 | 521 | TGGACAATTGTCTGC |
| 71 | 522 | TGGACAGATGTCCGT |
| 72 | 523 | TGGACAGGTGTCCGC |
| 73 | 524 | TGGACGGTTGTCCGC |
| 74 | 525 | TGGACTTGTGGTC |
| 75 | 526 | TGGAGATTCTCTCCGC |
| 76 | 527 | TGGCATAGGCCTGC |
| 77 | 528 | TGGCTTATGTCTAC |
| 78 | 529 | TGGGAGTTAATCCCGT |
| 79 | 530 | TGGGATCTTCCCGC |
| 80 | 531 | TGGGCAGAAATGTCTC |
| 81 | 532 | TGGGCGTTCGCCCGC |
| 82 | 533 | TGGGCTTCGCCCGC |
| 83 | 534 | TGGGGGATAACCCCGT |
| 84 | 535 | TGGGGGTTTCCCCGT |
| 85 | 536 | TGGT |
| 86 | 537 | TGGTGGCAACACCGT |
| 87 | 538 | TGGTTTATAGCCGT |
| 88 | 539 | TGTACGGTAATACCGTACC |
| 89 | 540 | TGTCCGCAAGGACGT |
| 90 | 541 | TGTCCTAACGGACGT |
| 91 | 542 | TGTCCTATTAACGGACGT |
| 92 | 543 | TGTCCTTCACGGGCGT |
| 93 | 544 | TGTCTTAGGACGT |
| 94 | 545 | TGTGCGTTAACGCGTACC |
| 95 | 546 | TGTGTCGCAAGGCACC |
| 96 | 547 | TGTTCGTAAGGACTT |
| 97 | 548 | TTCACAGAAATGTGTC |
| 98 | 549 | TTCCCTCGTGGAGT |
| 99 | 550 | TTCCCTCTGGGAGC |
| 100 | 551 | TTCCCTTGTGGATC |
| 101 | 552 | TTCCTTCGGGAGC |
| 102 | 553 | TTCTAGCAATAGAGT |
| 103 | 554 | TTCTCCACTGGGGAGC |
| 104 | 555 | TTCTCGAGAGGGAGC |
| 105 | 556 | TTCTCGTATGAGAGC |
| 106 | 557 | TTTAAGGTTTTCCCTTAAC |
| 107 | 558 | TTTCATTGTGGAGT |
| 108 | 559 | TTTCGAAGGAATCC |
| 109 | 560 | TTTCTTCGGAAGC |
| 110 | 561 | TTTGGGGCAACTCAAC |
對應的核苷酸位置為了確定候選序列中之所選核苷酸位置是否對應於參考序列(例如SEQ ID NO: 622、SEQ ID NO: 623、SEQ ID NO: 624)中之所選位置,進行以下評估中之一或多者。
評估 A :1.將候選序列與表9及10中之共通序列中之每一者比對。選擇具有所比對之最多位置(且具有所比對候選序列之至少60%位置)的共通序列。
該比對如下進行。候選序列及來自表10A至10BB之同功解碼體共通序列係基於用尼德曼-翁施演算法(Needleman-Wunsch algorithm)在用來自表11之匹配評分、錯配罰分-1、空位開放罰分-1及空位延伸罰分-0.5且在末端空位無罰分的情況下運行時所計算之全局成對比對來進行比對。隨後使用與最高總體比對評分之比對,以藉由對比對中匹配位置之數目計數,將其除以候選序列或共通序列中非N鹼基之數目中的較大數目,且將結果乘以100來判定候選序列與共通序列之間的相似性百分比。在(候選序列及單一共通序列之)多個比對因相同評分而相關的情況下,相似性百分比為自相關比對計算之最大相似性百分比。對於候選序列,用表格10A至10B中之其餘同功解碼體共通序列中之每一者重複此過程,且選擇產生最大相似性百分比之比對。若此比對具有等於或大於60%之相似性百分比,則其視為有效比對且用以使候選序列中之位置與共通序列中之位置相關,否則候選序列被視為尚未與同功解碼體共通序列中之任一者比對。若此時存在相關,則在分析中將所有相關共通序列繼續用於步驟2。
2.使用來自步驟1之所選共通序列,判定與候選序列中之所選位置(例如經修飾之位置)比對的共通序列位置編號。隨後,將共通序列中之比對位置之位置編號分配給候選序列中之所選位置,換言之,根據共通序列之編號,對候選序列中之所選位置進行編號。若存在來自步驟一之相關共通序列且其在此步驟2中給出不同位置編號,則將所有此類位置編號繼續用於步驟5。
3.將參考序列與步驟1中所選擇之共通序列比對。比對係如步驟1中所描述進行。
4.根據步驟3中之比對,判定與參考序列中之所選位置(例如經修飾之位置)比對的共通序列位置編號。隨後,將共通序列中之比對位置之位置編號分配給參考序列中之所選位置,換言之,根據共通序列之編號,對參考序列中之所選位置進行編號。若此時存在相關,則在分析中將所有相關共通序列繼續用於步驟5。
5.若針對步驟2中之參考序列判定之位置編號值與針對步驟4中之候選序列判定之位置編號值相同,則該等位置經定義為相對應的。
評估 B :將參考序列(例如本文所描述之TREM序列)與候選序列彼此對比。該比對如下進行。
參考序列及候選序列係基於用尼德曼-翁施演算法在用來自表11之匹配評分、錯配罰分-1、空位開放罰分-1及空位延伸罰分-0.5且在末端空位無罰分的情況下運行時所計算之全局成對比對來進行比對。隨後使用與最高總體比對評分之比對,以藉由對比對中匹配鹼基之數目計數,將其除以候選或參考序列中非N鹼基之數目中的較大數目,且將結果乘以100來判定候選序列與參考序列之間的相似性百分比。在多個比對因相同評分而相關的情況下,相似性百分比為自相關比對計算之最大相似性百分比。若此比對具有等於或大於60%之相似性百分比,則其視為有效比對且用以使候選序列中之位置與參考序列中之位置相關,否則候選序列被視為尚未與參考序列比對。
若參考序列中之所選核苷酸位置(例如經修飾之位置)與候選序列中之所選核苷酸位置(例如經修飾之位置)配對,則該等位置經定義為相對應的。
評估 C :根據全面tRNA編號系統(CtNS)向候選序列分配核苷酸位置編號,該編號系統亦稱為tRNAviz方法(例如,如Lin等人, Nucleic Acids Research, 47:W1, 第W542-W547頁, 2019年7月2日中所描述),其充當tRNA分子之全局編號系統。該比對如下進行。
1.根據tRNAviz方法向候選序列分配核苷酸位置。對於tRNAviz資料庫中不存在之新穎序列,獲得資料庫中之最接近序列之編號。舉例而言,若TREM在任何給定核苷酸位置與資料庫中之序列不同,則使用在該給定核苷酸位置處具有野生型序列之tRNA的編號。
2.根據1中所描述之方法向參考序列分配核苷酸位置。
3.若針對步驟1中之參考序列判定之位置編號值與針對步驟2中之候選序列判定之位置編號值相同,則該等位置經定義為相對應的。
若參考序列及候選序列中之所選位置被認為與評估A、B及C中之至少一者相對應,則該等位置相對應。舉例而言,若兩個位置被認為在評估A下係對應的,但在評估B或評估C下不相對應,則位置經定義為相對應的。類似地,若兩個位置被認為在評估B下係對應的,但在評估A或評估C下不相對應,則位置經定義為相對應的。另外,若兩個位置被認為在評估C下係對應的,但在評估A或評估B下不相對應,則位置經定義為相對應的。
上文給出之編號係為了易於呈現而使用且並不暗示所需序列若進行多於一次評估,則其可以任何次序進行。
表 10A.藉由比對同功解碼體家族之成員針對各同功解碼體以計算方式產生之共通序列
表 10B.藉由比對同功解碼體家族之成員針對各同功解碼體以計算方式產生之共通序列
表 11 :評分值比對
| SEQ ID NO. | 胺基酸 | 反密碼子 | 共通序列 |
| 1200 | Ala | AGC | GGGGAATTAGCTCAAGTGGTAGAGCGCTTGCTTAGCATGCAAGAGGTAGTGGGATCGATGCCCACATTCTCCA |
| 1201 | Ala | CGC | GGGGATGTAGCTCAGTGGTAGAGCGCATGCTTCGCATGTATGAGGTCCCGGGTTCGATCCCCGGCATCTCCA |
| 1202 | Ala | TGC | GGGGGTGTAGCTCAGTGGTAGAGCGCATGCTTTGCATGTATGAGGCCCCGGGTTCGATCCCCGGCACCTCCA |
| 1203 | Arg | ACG | GGGCCAGTGGCGCAATGGATAACGCGTCTGACTACGGATCAGAAGATTCCAGGTTCGACTCCTGGCTGGCTCG |
| 1204 | Arg | CCG | GGCCGCGTGGCCTAATGGATAAGGCGTCTGATTCCGGATCAGAAGATTGAGGGTTCGAGTCCCTTCGTGGTCG |
| 1205 | Arg | CCT | GCCCCAGTGGCCTAATGGATAAGGCACTGGCCTCCTAAGCCAGGGATTGTGGGTTCGAGTCCCACCTGGGGTA |
| 1206 | Arg | TCG | GACCGCGTGGCCTAATGGATAAGGCGTCTGACTTCGGATCAGAAGATTGAGGGTTCGAGTCCCTCCGTGGTCG |
| 1207 | Arg | TCT | GGCTCTGTGGCGCAATGGATNAGCGCATTGGACTTCTAATTCAAAGGTTGCGGGTTCGAGTCCCNCCAGAGTCG |
| 1208 | Asn | GTT | GTCTCTGTGGCGCAATCGGTTAGCGCGTTCGGCTGTTAACCGNAAAGGTTGGTGGTTCGAGCCCACCCAGGGACG |
| 1209 | Asp | GTC | TCCTCGTTAGTATAGTGGTGAGTATCCCCGCCTGTCACGCGGGAGACCGGGGTTCGATTCCCCGACGGGGAG |
| 1210 | Cys | GCA | GGGGGTATAGCTCAGNGGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCCGGTTCAAATCCGGGTGCCCCCT |
| 1211 | Gln | CTG | GGTTCCATGGTGTAATGGTNAGCACTCTGGACTCTGAATCCAGCGATCCGAGTTCAAGTCTCGGTGGAACCT |
| 1212 | Gln | TTG | GGTCCCATGGTGTAATGGTTAGCACTCTGGACTTTGAATCCAGCGATCCGAGTTCAAATCTCGGTGGGACCT |
| 1213 | Glu | CTC | TCCCTGGTGGTCTAGTGGTTAGGATTCGGCGCTCTCACCGCCGCGGCCCGGGTTCGATTCCCGGTCAGGGAA |
| 1214 | Glu | TTC | TCCCTGGTGGTCTAGTGGCTAGGATTCGGCGCTTTCACCGCNGCGGCCCGGGTTCGATTCCCGGTCAGGGAA |
| 1215 | Gly | CCC | GCATTGGTGGTTCAGTGGTAGAATTCTCGCCTCCCACGCNGGAGACCCGGGTTCGATTCCCGGCCAATGCA |
| 1216 | Gly | GCC | GCATTGGTGGTTCAGTGGTAGAATTCTCGCCTGCCACGCGGGAGGCCCGGGTTCGATTCCCGGCCAATGCA |
| 1217 | Gly | TCC | GCGTTGGTGGTATAGTGGTGAGCATAGCTGCCTTCCAAGCAGTTGACCCGGGTTCGATTCCCGGCCAACGCA |
| 1218 | Ile | AAT | GGCCGGTTAGCTCAGTTGGTTAGAGCGTGGTGCTAATAACGCCAAGGTCGCGGGTTCGATCCCCGTACGGGCCA |
| 1219 | Ile | TAT | GCTCCAGTGGCGCAATCGGTTAGCGCGCGGTACTTATAATGCCGAGGTTGTGAGTTCGAGCCTCACCTGGAGCA |
| 1220 | Leu | AAG | GGTAGCGTGGCCGAGCGGTCTAAGGCGCTGGATTAAGGCTCCAGTCTCTTCGGGGGCGTGGGTTCGAATCCCACCGCTGCCA |
| 1221 | Leu | CAA | GTCAGGATGGCCGAGTGGTCNTAAGGCGCCAGACTCAAGTTCTGGTCTCCGNATGGAGGCGTGGGTTCGAATCCCACTTCTGACA |
| 1222 | Leu | CAG | GTCAGGATGGCCGAGCGGTCTAAGGCGCTGCGTTCAGGTCGCAGTCTCCCCTGGAGGCGTGGGTTCGAATCCCACTCCTGACA |
| 1223 | Leu | TAA | ACCAGGATGGCCGAGTGGTTAAGGCGTTGGACTTAAGATCCAATGGACAGATGTCCGCGTGGGTTCGAACCCCACTCCTGGTA |
| 1224 | Leu | TAG | GGTAGCGTGGCCGAGCGGTCTAAGGCGCTGGATTTAGGCTCCAGTCTCTTCGGNGGCGTGGGTTCGAATCCCACCGCTGCCA |
| 1225 | Lys | CTT | GCCCGGCTAGCTCAGTCGGTAGAGCATGAGACTCTTAATCTCAGGGTCGTGGGTTCGAGCCCCACGTTGGGCGNNN |
| 1226 | Lys | TTT | GCCTGGATAGCTCAGTCGGTAGAGCATCAGACTTTTAATCTGAGGGTCCAGGGTTCAAGTCCCTGTTCAGGCG |
| 1227 | Met | CAT | GCCCTCTTAGCGCAGTNGGCAGCGCGTCAGTCTCATAATCTGAAGGTCCTGAGTTCGAGCCTCAGAGAGGGCA |
| 1228 | Phe | GAA | GCCGAAATAGCTCAGTTGGGAGAGCGTTAGACTGAAGATCNTAAAGGTCCCTGGTTCAATCCCGGGTTTCGGCA |
| 1229 | Pro | AGG | GGCTCGTTGGTCTAGGGGTATGATTCTCGCTTAGGATGCGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCC |
| 1230 | Pro | CGG | GGCTCGTTGGTCTAGGGGTATGATTCTCGCTTCGGGTGCGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCC |
| 1231 | Pro | TGG | GGCTCGTTGGTCTAGGGGTATGATTCTCGCTTTGGGTGCGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCC |
| 1232 | Ser | AGA | GTAGTCGTGGCCGAGTGGTTAAGGCGATGGACTAGAAATCCATTGGGGTTTCCCCGCGCAGGTTCGAATCCTGCCGACTACG |
| 1233 | Ser | CGA | GCTGTGATGGCCGAGTGGTTAAGGCGTTGGACTCGAAATCCAATGGGGTCTCCCCGCGCAGGTTCGAATCCTGCTCACAGCG |
| 1234 | Ser | GCT | GACGAGGNNTGGCCGAGTGGTTAAGGCGATGGACTGCTAATCCATTGTGCTCTGCACGCGTGGGTTCGAATCCCATCCTCGTCG |
| 1235 | Ser | TGA | GTAGTCGTGGCCGAGTGGTTAAGGCGATGGACTTGAAATCCATTGGGGTCTCCCCGCGCAGGTTCGAATCCTGCCGGCTACG |
| 1236 | Thr | AGT | GGCTCCGTGGCTTAGCTGGTTAAAGCGCCTGTCTAGTAAACAGGAGATCCTGGGTTCGAATCCCAGCGGGGCCT |
| 1237 | Thr | CGT | GGCNCTGTGGCTNAGTNGGNTAAAGCGCCGGTCTCGTAAACCNGGAGATCNTGGGTTCGAATCCCANCNGGGCCT |
| 1238 | Thr | TGT | GGCTCCATAGCTCAGNGGGTTAGAGCACTGGTCTTGTAAACCAGGGGTCGCGAGTTCAAATCTCGCTGGGGCCT |
| 1239 | Trp | CCA | GACCTCGTGGCGCAACGGTAGCGCGTCTGACTCCAGATCAGAAGGTTGCGTGTTCAAATCACGTCGGGGTCA |
| 1240 | Tyr | GTA | CCTTCGATAGCTCAGCTGGTAGAGCGGAGGACTGTAGATCCTTAGGTCGCTGGTTCGATTCCGGCTCGAAGGA |
| 1241 | Val | AAC | GTTTCCGTAGTGTAGTGGTTATCACGTTCGCCTAACACGCGAAAGGTCCCCGGTTCGAAACCGGGCGGAAACA |
| 1242 | Val | CAC | GTTTCCGTAGTGTAGTGGTTATCACGTTCGCCTCACACGCGAAAGGTCCCCGGTTCGAAACCGGGCGGAAACA |
| 1243 | Val | TAC | GGTTCCATAGTGTAGTGGTTATCACGTCTGCTTTACACGCAGAAGGTCCTGGGTTCGAGCCCCAGTGGAACCA |
| 1244 | iMet | CAT | AGCAGAGTGGCGCAGCGGAAGCGTGCTGGGCCCATAACCCAGAGGTCGATGGATCGAAACCATCCTCTGCTA |
| SEQ ID NO | 胺基酸 | 反密碼子 | 共通序列 |
| 1245 | Ala | AGC | GGGGAATTAGCTCAAGTGGTAGAGCGCTTGCTTAGCATGCAAGAGGTAGTGGGATCGATGCCCACATTCTCCANNN |
| 1246 | Ala | CGC | GGGGATGTAGCTCAGTGGTAGAGCGCATGCTTCGCATGTATGAGGTCCCGGGTTCGATCCCCGGCATCTCCANNN |
| 1247 | Ala | TGC | GGGGGTGTAGCTCAGTGGTAGAGCGCATGCTTTGCATGTATGAGGCCCCGGGTTCGATCCCCGGCACCTCCANNN |
| 1248 | Arg | ACG | GGGCCAGTGGCGCAATGGATAACGCGTCTGACTACGGATCAGAAGATTCCAGGTTCGACTCCTGGCTGGCTCGNNN |
| 1249 | Arg | CCG | GGCCGCGTGGCCTAATGGATAAGGCGTCTGATTCCGGATCAGAAGATTGAGGGTTCGAGTCCCTTCGTGGTCGNNN |
| 1250 | Arg | CCT | GCCCCAGTGGCCTAATGGATAAGGCACTGGCCTCCTAAGCCAGGGATTGTGGGTTCGAGTCCCACCTGGGGTANNN |
| 1251 | Arg | TCG | GACCGCGTGGCCTAATGGATAAGGCGTCTGACTTCGGATCAGAAGATTGAGGGTTCGAGTCCCTCCGTGGTCGNNN |
| 1252 | Arg | TCT | GGCTCTGTGGCGCAATGGATNAGCGCATTGGACTTCTAATTCAAAGGTTGCGGGTTCGAGTCCCNCCAGAGTCGNNN |
| 1253 | Asn | GTT | GTCTCTGTGGCGCAATCGGTTAGCGCGTTCGGCTGTTAACCGNAAAGGTTGGTGGTTCGAGCCCACCCAGGGACGNNN |
| 1254 | Asp | GTC | TCCTCGTTAGTATAGTGGTGAGTATCCCCGCCTGTCACGCGGGAGACCGGGGTTCGATTCCCCGACGGGGAGNNN |
| 1255 | Cys | GCA | GGGGGTATAGCTCAGNGGGTAGAGCATTTGACTGCAGATCAAGAGGTCCCCGGTTCAAATCCGGGTGCCCCCTNNN |
| 1256 | Gln | CTG | GGTTCCATGGTGTAATGGTNAGCACTCTGGACTCTGAATCCAGCGATCCGAGTTCAAGTCTCGGTGGAACCTNNN |
| 1257 | Gln | TTG | GGTCCCATGGTGTAATGGTTAGCACTCTGGACTTTGAATCCAGCGATCCGAGTTCAAATCTCGGTGGGACCTNNN |
| 1258 | Glu | CTC | TCCCTGGTGGTCTAGTGGTTAGGATTCGGCGCTCTCACCGCCGCGGCCCGGGTTCGATTCCCGGTCAGGGAANNN |
| 1259 | Glu | TTC | TCCCTGGTGGTCTAGTGGCTAGGATTCGGCGCTTTCACCGCNGCGGCCCGGGTTCGATTCCCGGTCAGGGAANNN |
| 1260 | Gly | CCC | GCATTGGTGGTTCAGTGGTAGAATTCTCGCCTCCCACGCNGGAGACCCGGGTTCGATTCCCGGCCAATGCANNN |
| 1261 | Gly | GCC | GCATTGGTGGTTCAGTGGTAGAATTCTCGCCTGCCACGCGGGAGGCCCGGGTTCGATTCCCGGCCAATGCANNN |
| 1262 | Gly | TCC | GCGTTGGTGGTATAGTGGTGAGCATAGCTGCCTTCCAAGCAGTTGACCCGGGTTCGATTCCCGGCCAACGCANNN |
| 1263 | Ile | AAT | GGCCGGTTAGCTCAGTTGGTTAGAGCGTGGTGCTAATAACGCCAAGGTCGCGGGTTCGATCCCCGTACGGGCCANNN |
| 1264 | Ile | TAT | GCTCCAGTGGCGCAATCGGTTAGCGCGCGGTACTTATAATGCCGAGGTTGTGAGTTCGAGCCTCACCTGGAGCANNN |
| 1265 | Leu | AAG | GGTAGCGTGGCCGAGCGGTCTAAGGCGCTGGATTAAGGCTCCAGTCTCTTCGGGGGCGTGGGTTCGAATCCCACCGCTGCCANNN |
| 1266 | Leu | CAA | GTCAGGATGGCCGAGTGGTCNTAAGGCGCCAGACTCAAGTTCTGGTCTCCGNATGGAGGCGTGGGTTCGAATCCCACTTCTGACANNN |
| 1267 | Leu | CAG | GTCAGGATGGCCGAGCGGTCTAAGGCGCTGCGTTCAGGTCGCAGTCTCCCCTGGAGGCGTGGGTTCGAATCCCACTCCTGACANNN |
| 1268 | Leu | TAA | ACCAGGATGGCCGAGTGGTTAAGGCGTTGGACTTAAGATCCAATGGACAGATGTCCGCGTGGGTTCGAACCCCACTCCTGGTANNN |
| 1269 | Leu | TAG | GGTAGCGTGGCCGAGCGGTCTAAGGCGCTGGATTTAGGCTCCAGTCTCTTCGGNGGCGTGGGTTCGAATCCCACCGCTGCCANNN |
| 1270 | Lys | CTT | GCCCGGCTAGCTCAGTCGGTAGAGCATGAGACTCTTAATCTCAGGGTCGTGGGTTCGAGCCCCACGTTGGGCGNNNNNN |
| 1271 | Lys | TTT | GCCTGGATAGCTCAGTCGGTAGAGCATCAGACTTTTAATCTGAGGGTCCAGGGTTCAAGTCCCTGTTCAGGCGNNN |
| 1272 | Met | CAT | GCCCTCTTAGCGCAGTNGGCAGCGCGTCAGTCTCATAATCTGAAGGTCCTGAGTTCGAGCCTCAGAGAGGGCANNN |
| 1273 | Phe | GAA | GCCGAAATAGCTCAGTTGGGAGAGCGTTAGACTGAAGATCNTAAAGGTCCCTGGTTCAATCCCGGGTTTCGGCANNN |
| 1274 | Pro | AGG | GGCTCGTTGGTCTAGGGGTATGATTCTCGCTTAGGATGCGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCCNNN |
| 1275 | Pro | CGG | GGCTCGTTGGTCTAGGGGTATGATTCTCGCTTCGGGTGCGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCCNNN |
| 1276 | Pro | TGG | GGCTCGTTGGTCTAGGGGTATGATTCTCGCTTTGGGTGCGAGAGGTCCCGGGTTCAAATCCCGGACGAGCCCNNN |
| 1277 | Ser | AGA | GTAGTCGTGGCCGAGTGGTTAAGGCGATGGACTAGAAATCCATTGGGGTTTCCCCGCGCAGGTTCGAATCCTGCCGACTACGNNN |
| 1278 | Ser | CGA | GCTGTGATGGCCGAGTGGTTAAGGCGTTGGACTCGAAATCCAATGGGGTCTCCCCGCGCAGGTTCGAATCCTGCTCACAGCGNNN |
| 1279 | Ser | GCT | GACGAGGNNTGGCCGAGTGGTTAAGGCGATGGACTGCTAATCCATTGTGCTCTGCACGCGTGGGTTCGAATCCCATCCTCGTCGNNN |
| 1280 | Ser | TGA | GTAGTCGTGGCCGAGTGGTTAAGGCGATGGACTTGAAATCCATTGGGGTCTCCCCGCGCAGGTTCGAATCCTGCCGGCTACGNNN |
| 1281 | Thr | AGT | GGCTCCGTGGCTTAGCTGGTTAAAGCGCCTGTCTAGTAAACAGGAGATCCTGGGTTCGAATCCCAGCGGGGCCTNNN |
| 1282 | Thr | CGT | GGCNCTGTGGCTNAGTNGGNTAAAGCGCCGGTCTCGTAAACCNGGAGATCNTGGGTTCGAATCCCANCNGGGCCTNNN |
| 1283 | Thr | TGT | GGCTCCATAGCTCAGNGGGTTAGAGCACTGGTCTTGTAAACCAGGGGTCGCGAGTTCAAATCTCGCTGGGGCCTNNN |
| 1284 | Trp | CCA | GACCTCGTGGCGCAACGGTAGCGCGTCTGACTCCAGATCAGAAGGTTGCGTGTTCAAATCACGTCGGGGTCANNN |
| 1285 | Tyr | GTA | CCTTCGATAGCTCAGCTGGTAGAGCGGAGGACTGTAGATCCTTAGGTCGCTGGTTCGATTCCGGCTCGAAGGANNN |
| 1286 | Val | AAC | GTTTCCGTAGTGTAGTGGTTATCACGTTCGCCTAACACGCGAAAGGTCCCCGGTTCGAAACCGGGCGGAAACANNN |
| 1287 | Val | CAC | GTTTCCGTAGTGTAGTGGTTATCACGTTCGCCTCACACGCGAAAGGTCCCCGGTTCGAAACCGGGCGGAAACANNN |
| 1288 | Val | TAC | GGTTCCATAGTGTAGTGGTTATCACGTCTGCTTTACACGCAGAAGGTCCTGGGTTCGAGCCCCAGTGGAACCANNN |
| 1289 | iMet | CAT | AGCAGAGTGGCGCAGCGGAAGCGTGCTGGGCCCATAACCCAGAGGTCGATGGATCGAAACCATCCTCTGCTANNN |
| 列 | 候選核苷酸 | 參考核苷酸 | 匹配評分 |
| 1 | A | A | 1 |
| 2 | T | T | 1 |
| 3 | U | T | 1 |
| 4 | C | C | 1 |
| 5 | G | G | 1 |
| 6 | A | N | 0 |
| 7 | T | N | 0 |
| 8 | C | N | 0 |
| 9 | G | N | 0 |
| 10 | N | A | 0 |
| 11 | N | T | 0 |
| 12 | N | C | 0 |
| 13 | N | G | 0 |
| 14 | N | N | 0 |
製備TREM、TREM核心片段及TREM片段之方法 用於合成寡核苷酸之方法為此項技術中已知的且可用於製備本文所揭示之TREM、TREM核心片段或TREM片段。舉例而言,TREM、TREM核心片段或TREM片段可使用固相合成或液相合成來合成。
在一實施例中,根據本文所揭示之合成方法製備之TREM、TREM核心片段或TREM片段與自細胞表現及分離之TREM相比或與天然存在之tRNA相比具有不同修飾圖譜。
用於經由5'-矽基-2'-原酸酯(2'-ACE)化學方法製備合成TREM的例示性方法提供於實例3中。實例3中所提供之方法亦可用於製備合成TREM核心片段或合成TREM片段。額外合成方法揭示於Hartsel SA等人, (2005)
Oligonucleotide Synthesis, 033-050中,其全部內容在此以引用之方式併入。
TREM組合物 在一實施例中,TREM組合物,例如TREM醫藥組合物,包含醫藥學上可接受之賦形劑。例示性賦形劑包括FDA非活性成分資料庫(https://www.accessdata.fda.gov/scripts/cder/iig/index.Cfm)提供之賦形劑。
在一實施例中,TREM組合物,例如TREM醫藥組合物,包含至少1、2、3、4、5、6、7、8、9、10、15、20、30、40、50、60、70、80、90、100或150公克TREM、TREM核心片段或TREM片段。在一實施例中,TREM組合物,例如TREM醫藥組合物,包含至少1、2、3、4、5、6、7、8、9、10、15、20、30、40、50或100毫克TREM、TREM核心片段或TREM片段。
在一實施例中,TREM組合物,例如TREM醫藥組合物,為至少10%、20%、30%、40%、50%、60%、70%、80%、90%、95%或99%乾重之TREM、TREM核心片段或TREM片段。
在一實施例中,TREM組合物包含至少1×10
6個TREM分子、至少1×10
7個TREM分子、至少1×10
8個TREM分子或至少1×10
9個TREM分子。
在一實施例中,TREM組合物包含至少1×10
6個TREM核心片段分子、至少1×10
7個TREM核心片段分子、至少1×10
8個TREM核心片段分子或至少1×10
9個TREM核心片段分子。
在一實施例中,TREM組合物包含至少1×10
6個TREM片段分子、至少1×10
7個TREM片段分子、至少1×10
8個TREM片段分子或至少1×10
9個TREM片段分子。
在一實施例中,藉由本文所揭示之製造方法中之任一者產生的TREM組合物可使用如此項技術中已知之活體外裝載反應裝入胺基酸。
在一實施例中,TREM組合物包含一或多個物種之TREM、TREM核心片段或TREM片段。在一實施例中,TREM組合物包含單一物種之TREM、TREM核心片段或TREM片段。在一實施例中,TREM組合物包含第一TREM、TREM核心片段或TREM片段物種;及第二TREM、TREM核心片段或TREM片段物種。在一實施例中,TREM組合物包含X個TREM、TREM核心片段或TREM片段物種,其中X=2、3、4、5、6、7、8、9或10。
在一實施例中,TREM、TREM核心片段或TREM片段與表1中之核酸所編碼之序列具有至少70%、75%、80%、85%、90%或95%或100%一致性。
在一實施例中,TREM包含本文所提供之共通序列。
TREM組合物可調配為液體組合物、凍乾組合物或冷凍組合物。
在一些實施例中,TREM組合物可經調配以適合於醫藥用途,例如醫藥TREM組合物。在一實施例中,醫藥TREM組合物實質上不含用於分離及/或純化TREM、TREM核心片段或TREM片段之物質及/或試劑。
在一些實施例中,TREM組合物可用注射用水調配。在一些實施例中,用注射用水調配之TREM組合物適合於醫藥用途,例如包含醫藥TREM組合物。
TREM表徵 可評定藉由本文所揭示之方法中之任一者產生的TREM、TREM核心片段或TREM片段或TREM組合物(例如醫藥TREM組合物)的與TREM、TREM核心片段或TREM片段或TREM組合物相關之特徵,諸如TREM、TREM核心片段或TREM片段之純度、無菌性、濃度、結構或功能活性。可藉由提供特徵值,例如藉由評估或測試TREM、TREM核心片段或TREM片段或TREM組合物、或在TREM組合物之產生中之中間物來評估以上提及之特徵中之任一者。亦可將該值與標準或參考值進行比較。響應於評估,TREM組合物可分類為例如準備好釋放、符合人類試驗生產標準、符合ISO標準、符合cGMP標準或符合其他醫藥學標準。回應於評估,TREM組合物可經歷進一步處理,例如其可分成等分試樣,例如分成單劑量或多劑量之量,安置於容器(例如最終用途小瓶)中,包裝、裝運或投入商業中。在實施例中,回應於評估,該等特性中之一或多者可經調節、處理或再處理以最佳化TREM組合物。舉例而言,TREM組合物可經調節、處理或再處理以(i)提高TREM組合物之純度;(ii)降低組合物中之片段之量;(iii)降低組合物中內毒素之量;(iv)提高組合物之活體外轉譯活性;(v)提高組合物之TREM濃度;或(vi)例如藉由降低組合物之pH或藉由過濾來滅活或移除存在於該組合物中之任何病毒污染物。
在一實施例中,TREM、TREM核心片段或TREM片段(例如TREM組合物或TREM組合物產生中之中間物)具有至少30%、40%、50%、60%、70%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99% (亦即按質量計)之純度。
在一實施例中,相對於全長TREM,TREM (例如TREM組合物或TREM組合物產生中之中間物)具有少於0.1%、0.5%、1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、15%、20%、25% TREM片段。
在一實施例中,TREM、TREM核心片段或TREM片段(例如TREM組合物或TREM組合物產生中之中間物)具有低含量內毒素或不存在內毒素,例如如藉由鱟變形細胞溶菌液(Limulus amebocyte lysate;LAL)測試所量測之陰性結果。
在一實施例中,TREM、TREM核心片段或TREM片段(例如TREM組合物或TREM組合物產生中之中間物)具有活體外轉譯活性,例如如藉由實例12至13中所描述之分析所量測。
在一實施例中,TREM、TREM核心片段或TREM片段(例如TREM組合物或TREM組合物產生中之中間物)之TREM濃度為至少0.1 ng/mL、0.5 ng/mL、1 ng/mL、5 ng/mL、10 ng/mL、50 ng/mL、0.1 μg/mL、0.5 μg/mL、1 μg/mL、2 μg/mL、5 μg/mL、10 μg/mL、20 μg/mL、30 μg/mL、40 μg/mL、50 μg/mL、60 μg/mL、70 μg/mL、80 μg/mL、100 μg/mL、200 μg/mL、300 μg/mL、500 μg/mL、1000 μg/mL、5000 μg/mL、10,000 μg/m或100,000 μg/mL。
在一實施例中,TREM、TREM核心片段或TREM片段(例如,TREM組合物或TREM組合物產生中之中間物)為無菌的,例如,如在無菌條件下測試,該組合物或製劑支援少於100種活微生物之生長,該組合物或製劑滿足USP <71>之標準,及/或該組合物或製劑滿足USP <85>之標準。
在一實施例中,TREM、TREM核心片段或TREM片段(例如TREM組合物或TREM組合物產生中之中間物)具有不可偵測含量之病毒污染物,例如無病毒污染物。在一實施例中,滅活或移除存在於組合物中之任何病毒污染物,例如殘餘病毒。在一實施例中,任何病毒污染物(例如殘餘病毒)例如藉由降低組合物之pH而滅活。在一實施例中,例如藉由過濾或本領域中已知之其他方法移除任何病毒污染物,例如殘餘病毒。
TREM投與 本文所描述之任何TREM組合物或醫藥組合物可例如藉由活體外、離體或活體內直接投與至細胞、組織及/或器官來投與至細胞、組織或個體。活體內投與可經由例如局部、全身性及/或非經腸途徑(例如靜脈內、皮下、腹膜內、鞘內、肌肉內、經眼、經鼻、經泌尿生殖器、皮內、經皮、腸內、玻璃體內、腦內、鞘內或硬膜外)投與。
載體及載劑 在一些實施例中,使用載體將本文所描述之TREM、TREM核心片段或TREM片段、或TREM組合物遞送至細胞,例如哺乳動物細胞或人類細胞。載體可為例如質體或病毒。在一些實施例中,遞送為活體內、活體外、離體或原位遞送。在一些實施例中,病毒為腺相關病毒(AAV)、慢病毒、腺病毒。在一些實施例中,該系統或系統組分係利用病毒樣粒子或病毒體遞送至細胞。在一些實施例中,該遞送使用超過一種病毒、病毒樣粒子或病毒體。
載體本文所描述之TREM、TREM組合物或醫藥TREM組合物可包含載劑、可用載劑調配或可以載劑形式遞送。
病毒載體載劑可為病毒載體(例如,包含編碼TREM、TREM核心片段或TREM片段之序列的病毒載體)。病毒載體可投與至細胞或個體(例如人類個體或動物模型)以遞送TREM、TREM核心片段或TREM片段、TREM組合物或醫藥TREM組合物。
病毒載體可經全身性或局部投與(例如注射)。病毒基因體提供可用於將外源性基因有效遞送至哺乳動物細胞中之載體的豐富來源。病毒基因體在此項技術中已知為適用於遞送之載體,因為此類基因體內所含有之聚核苷酸通常藉由通用或專用轉導而併入哺乳動物細胞之核基因體中。此等過程係作為天然病毒複製週期之一部分發生,且不需要添加蛋白質或試劑誘導基因整合。病毒載體之實例包括反轉錄病毒(例如反轉錄病毒科病毒載體)、腺病毒(例如Ad5、Ad26、Ad34、Ad35及Ad48)、小病毒(parvovirus) (例如腺相關病毒)、冠狀病毒、負股RNA病毒(諸如,正黏液病毒(orthomyxovirus) (例如流感病毒)、棒狀病毒(rhabdovirus) (例如狂犬病病毒及水泡性口炎病毒)、副黏液病毒(paramyxovirus) (例如麻疹病毒及仙台病毒))、正股RNA病毒(諸如小核糖核酸病毒(picornavirus)及α病毒(alphavirus)),及雙股DNA病毒(包括腺病毒)、疱疹病毒(例如單純疱疹病毒1型及2型)、艾巴二氏病毒(Epstein-Barr virus)、巨細胞病毒、複製缺陷型疱疹病毒),以及痘病毒(poxvirus) (例如,痘瘡病毒、改良型安卡拉痘苗病毒(modified vaccinia Ankara;MVA)、鳥痘病毒及金絲雀痘病毒)。其他病毒包括例如諾瓦克病毒(Norwalk virus)、披衣病毒(togavirus)、黃病毒(flavivirus)、里奧病毒(reovirus)、乳多泡病毒(papovavirus)、嗜肝DNA病毒(hepadnavirus)、人類乳頭狀瘤病毒、人類泡沫病毒及肝炎病毒。反轉錄病毒之實例包括:鳥類白血病性肉瘤(avian leukosis-sarcoma)病毒、鳥類C型病毒、哺乳動物C型病毒、B型病毒、D型病毒、致癌反轉錄病毒、HTLV-BLV組、慢病毒、α反轉錄病毒、γ反轉錄病毒、泡沫反轉錄病毒(spumavirus) (Coffin, J. M., Retroviridae: The viruses and their replication, Virology (第三版) Lippincott-Raven, Philadelphia, 1996)。其他實例包括鼠類白血病病毒、鼠類肉瘤病毒、小鼠乳房腫瘤病毒、牛白血病病毒、貓白血病病毒、貓肉瘤病毒、鳥類白血病病毒、人類T細胞白血病病毒、狒狒內源性病毒、長臂猿白血病病毒、梅森菲舍猴病毒(Mason Pfizer monkey virus)、猴免疫缺陷病毒、猴肉瘤病毒、勞斯肉瘤病毒(Rous sarcoma virus)及慢病毒。載體之其他實例描述於例如美國專利第5,801,030號中,其教示內容以引用之方式併入本文中。在一些實施例中,該系統或系統組分係利用病毒樣粒子或病毒體遞送至細胞。
基於細胞及囊泡之載劑本文所描述之TREM、TREM核心片段或TREM片段、TREM組合物或醫藥TREM組合物可在囊泡或其他基於膜性載劑中投與至細胞。
在實施例中,本文所描述之TREM、TREM核心片段或TREM片段、或TREM組合物或醫藥TREM組合物係在細胞、囊泡或其他基於膜性載劑中或經由其投與。在一個實施例中,TREM、TREM核心片段、TREM片段或TREM組合物或醫藥TREM組合物可調配於脂質體或其他類似囊泡中。脂質體為由圍繞內部水性隔室之單層或多層脂質雙層及相對不可滲透之外部親脂性磷脂雙層構成的球狀囊泡結構。脂質體可為陰離子型、中性或陽離子型的。脂質體為生物相容性的,無毒性,可遞送親水性與親脂性藥物分子,保護其負荷免被血漿酶降解,且在生物膜及血腦屏障(BBB)中轉運其載荷(關於評述,參見例如Spuch及Navarro, Journal of Drug Delivery, 第2011卷, 文章ID 469679, 第12頁, 2011. 數位物件識別碼:10.1155/2011/469679)。
囊泡可由數種不同類型的脂質製成;然而,磷脂最常用於生成脂質體作為藥物載劑。用於製備多層囊泡脂質之方法係此項技術中已知的(參見例如美國專利第6,693,086號,其關於多層囊泡脂質製備之教示內容以引用的方式併入本文中)。雖然當脂質膜與水溶液混合時,囊泡形成可為自發的,但其亦可藉由使用均質機、音波處理器或擠出設備以震盪形式施加力來加快(關於綜述,參見例如Spuch及Navarro, Journal of Drug Delivery, 第2011卷, 文章ID 469679, 第12頁, 2011. 數位物件識別碼:10.1155/2011/469679)。擠壓脂質可藉由擠壓穿過尺寸減小之過濾器來製備,如Templeton等人, Nature Biotech, 15:647-652, 1997中所描述,其中與擠壓脂質製備有關之教示內容以引用之方式併入本文中。
脂質奈米粒子係為如本文所描述之TREM、TREM核心片段、TREM片段或TREM組合物、或醫藥TREM組合物提供生物相容及生物可降解的遞送系統之載劑的另一實例。奈米結構脂質載劑(NLC)為保留SLN特徵、改善藥物穩定性及負載能力且防止藥物滲漏之經修飾固體脂質奈米粒子(SLN)。聚合物奈米粒子(PNP)為藥物遞送之重要組成部分。此等奈米粒子可有效地將藥物遞送引導至特定目標,且改良藥物穩定性及受控藥物釋放。亦可採用脂質-聚合物奈米粒子(PLN),其為組合脂質體及聚合物之一種新型載劑。此等奈米粒子具有PNP及脂質體之互補優點。PLN由核殼結構構成;聚合物核提供穩定結構,且磷脂殼提供良好生物相容性。因此,兩種組分提高藥物囊封效率,促進表面修飾,且防止水溶性藥物滲漏。關於綜述,參見例如Li等人 2017, Nanomaterials 7, 122; 數位物件識別碼:10.3390/nano7060122。
例示性脂質奈米粒子揭示於國際申請案PCT/US2014/053907中,其全部內容在此以引用之方式併入。舉例而言,PCT/US2014/053907之段落[403至406]或[410至413]中所描述之LNP可用作本文所描述之TREM、TREM核心片段、TREM片段、或TREM組合物或醫藥TREM組合物之載劑。
另外的例示性脂質奈米粒子揭示於美國專利10,562,849中,其全部內容在此以引用之方式併入。舉例而言,如美國專利10,562,849第1欄至第3欄中所描述的式(I)之LNP可用作本文所描述之TREM、TREM核心片段、TREM片段、或TREM組合物或醫藥TREM組合物之載劑。
可用於奈米粒子形成(例如脂質奈米粒子)之脂質包括例如WO2019217941 (其以引用之方式併入)之表4中所描述之彼等脂質,例如含有脂質之奈米粒子可包含WO2019217941之表4中之一或多種脂質。脂質奈米粒子可包括額外要素,諸如聚合物,諸如WO2019217941 (其以引用之方式併入)之表5中所描述之聚合物。
在一些實施例中,結合脂質(若存在)可包括以下中之一或多者:PEG-二醯基甘油(DAG) (諸如l-(單甲氧基-聚乙二醇)-2,3-二肉豆蔻醯基甘油(PEG-DMG))、PEG-二烷氧基丙基(DAA)、PEG-磷脂、PEG-神經醯胺(Cer)、聚乙二醇化磷脂醯乙醇胺(PEG-PE)、PEG丁二酸酯二醯基甘油(PEGS-DAG) (諸如4-0-(2',3'-二(十四醯氧基)丙基-l-0-(w-甲氧基(聚乙氧基)乙基)丁二酸酯(PEG-S-DMG))、PEG二烷氧基丙基胺基甲酸酯、N-(羰基-甲氧基聚乙二醇2000)-1,2-二硬脂醯基-sn-甘油基-3-磷酸乙醇胺鈉鹽及WO2019051289 (其以引用之方式併入)之表2中所描述之彼等以及前述之組合。
在一些實施例中,可併入至脂質奈米粒子中之固醇包括膽固醇或膽固醇衍生物中之一或多者,諸如W02009/127060或US2010/0130588 (其以引用之方式併入)中之彼等。額外例示性固醇包括植物固醇,包括以引用之方式併入本文中的Eygeris等人(2020)中所描述的彼等。
在一些實施例中,脂質粒子包含可離子化脂質、非陽離子脂質、抑制粒子聚集之結合脂質及固醇。此等組分之量可獨立地變化且實現所需特性。舉例而言,在一些實施例中,脂質奈米粒子包含:可離子化脂質,其量為總脂質之約20莫耳%至約90莫耳% (在其它實施例中,其可為20-70% (mol)、30-60% (mol)或40-50% (mol);脂質奈米粒子中存在之總脂質的約50莫耳%至約90莫耳%);非陽離子脂質,其量為總脂質之約5莫耳%至約30莫耳%;結合脂質,其量為總脂質之約0.5莫耳%至約20莫耳%;及固醇,其量為總脂質之約20莫耳%至約50莫耳%。總脂質與核酸之比率可視需要變化。舉例而言,總脂質與核酸之(質量或重量)比率可為約10:1至約30:1。
在一些實施例中,脂質與核酸之比率(質量/質量比率;w/w比率)可在約1:1至約25:1、約10:1至約14:1、約3:1至約15:1、約4:1至約10:1、約5:1至約9:1、或約6:1至約9:1之範圍內。脂質及核酸之量可經調節以提供所需N/P比率,例如3、4、5、6、7、8、9、10或更高之N/P比率。一般而言,脂質奈米粒子調配物之總脂質含量可在約5 mg/ml至約30 mg/ml之範圍內。
可用於(例如與其他脂質組分組合)形成脂質奈米粒子以遞送本文所描述之組合物(例如,本文所描述之核酸(例如RNA))的脂質化合物之一些非限制性實例包括

在一些實施例中,包含式(i)之LNP用於將本文所描述之TREM組合物遞送至肝臟及/或肝細胞。

在一些實施例中,包含式(ii)之LNP用於將本文所描述之TREM組合物遞送至肝臟及/或肝細胞。

在一些實施例中,包含式(iii)之LNP用於將本文所描述之TREM組合物遞送至肝臟及/或肝細胞。

在一些實施例中,包含式(v)之LNP用於將本文所描述之TREM組合物遞送至肝臟及/或肝細胞。

在一些實施例中,包含式(vi)之LNP用於將本文所描述之TREM組合物遞送至肝臟及/或肝細胞。
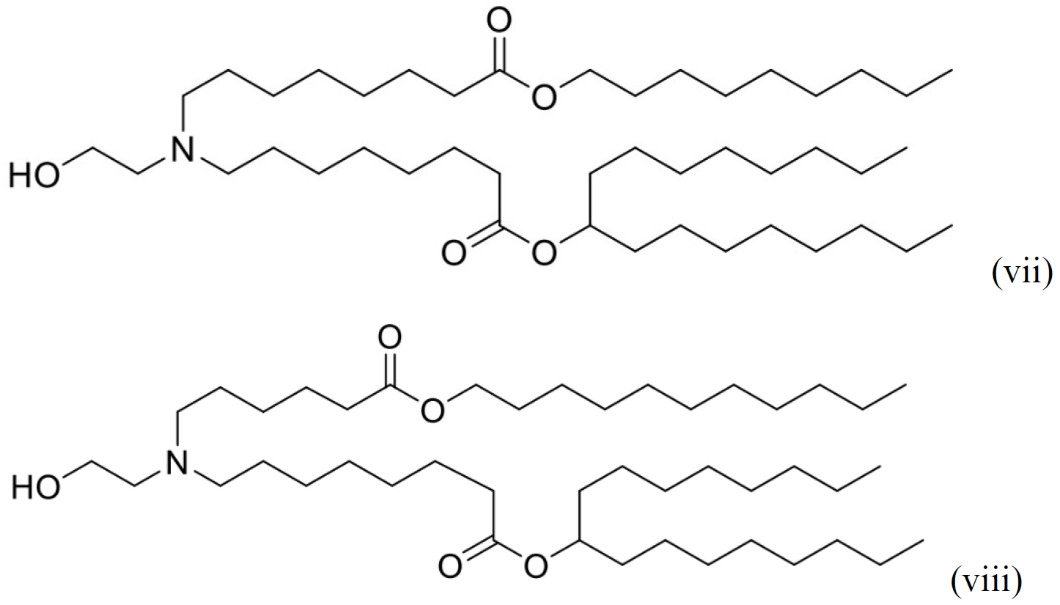
在一些實施例中,包含式(viii)之LNP用於將本文所描述之TREM組合物遞送至肝臟及/或肝細胞。

在一些實施例中,包含式(ix)之LNP用於將本文所描述之TREM組合物遞送至肝臟及/或肝細胞。
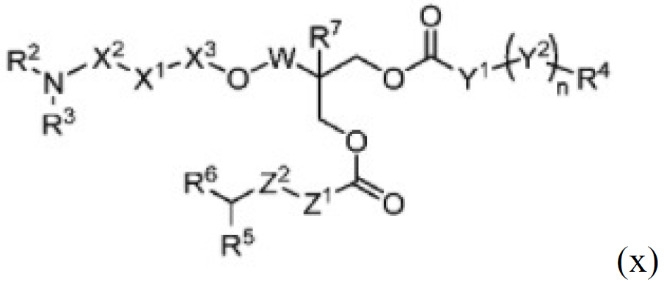 其中X
1為O、NR
1或直接鍵,X
2為C2-5伸烷基,X
3為C(=O)或直接鍵,R
1為H或Me,R
3為C1-3烷基,R
2為C1-3烷基,或R
2與其所連接之氮原子及X
2之1至3個碳原子一起形成4員、5員或6員環,或X
1為NR
1,R
1及R
2與其所連接之氮原子一起形成5員或6員環,或R
2與R
3及其所連接之氮原子一起形成5員、6員或7員環,Y
1為C2-12伸烷基,Y
2係選自
其中X
1為O、NR
1或直接鍵,X
2為C2-5伸烷基,X
3為C(=O)或直接鍵,R
1為H或Me,R
3為C1-3烷基,R
2為C1-3烷基,或R
2與其所連接之氮原子及X
2之1至3個碳原子一起形成4員、5員或6員環,或X
1為NR
1,R
1及R
2與其所連接之氮原子一起形成5員或6員環,或R
2與R
3及其所連接之氮原子一起形成5員、6員或7員環,Y
1為C2-12伸烷基,Y
2係選自

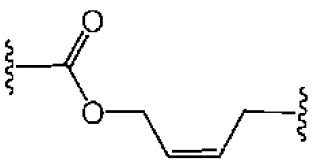
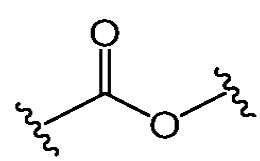 (呈任一定向)、(呈任一定向)、(呈任一定向),
n為0至3,R
4為C1-15烷基,Z
1為C1-6伸烷基或直接鍵,Z
2為
(呈任一定向)、(呈任一定向)、(呈任一定向),
n為0至3,R
4為C1-15烷基,Z
1為C1-6伸烷基或直接鍵,Z
2為
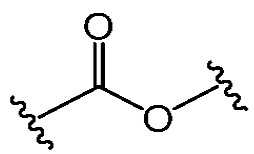 (呈任一定向)或不存在,其限制條件為若Z
1為直接鍵,則Z
2不存在;R
5為C5-9烷基或C6-10烷氧基,R
6為C5-9烷基或C6-10烷氧基,W為亞甲基或直接鍵,且R
7為H或Me或其鹽,其限制條件為若R
3及R
2為C2烷基,X
1為O,X
2為直鏈C3伸烷基,X
3為C(=0),Y
1為直鏈Ce伸烷基,(Y
2)n-R
4為
(呈任一定向)或不存在,其限制條件為若Z
1為直接鍵,則Z
2不存在;R
5為C5-9烷基或C6-10烷氧基,R
6為C5-9烷基或C6-10烷氧基,W為亞甲基或直接鍵,且R
7為H或Me或其鹽,其限制條件為若R
3及R
2為C2烷基,X
1為O,X
2為直鏈C3伸烷基,X
3為C(=0),Y
1為直鏈Ce伸烷基,(Y
2)n-R
4為
 ,R
4為直鏈C5烷基,Z
1為C2伸烷基,Z
2不存在,W為亞甲基,且R
7為H,則R
5及R
6不為Cx烷氧基。
,R
4為直鏈C5烷基,Z
1為C2伸烷基,Z
2不存在,W為亞甲基,且R
7為H,則R
5及R
6不為Cx烷氧基。
在一些實施例中,包含式(xii)之LNP用於將本文所描述之TREM組合物遞送至肝臟及/或肝細胞。

在一些實施例中,包含式(xi)之LNP用於將本文所描述之TREM組合物遞送至肝臟及/或肝細胞。
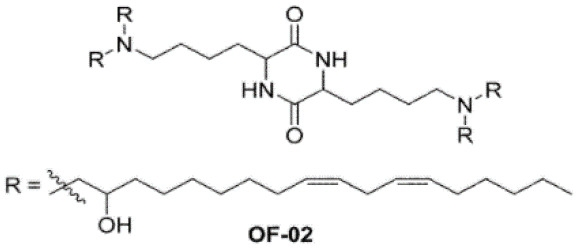 其中R=
其中R=
 (xii)
(xii)

在一些實施例中,LNP包含式(xiii)之化合物及式(xiv)之化合物。

在一些實施例中,包含式(xv)之LNP用於將本文所描述之TREM組合物遞送至肝臟及/或肝細胞。
 (xvi)
(xvi)
在一些實施例中,包含式(xvi)之調配物的LNP用於將本文所描述之TREM組合物遞送至肺內皮細胞。
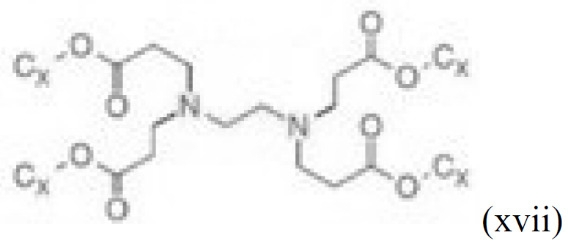
 其中X=
其中X=
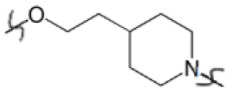 (xviii) (a)
(xviii) (a)
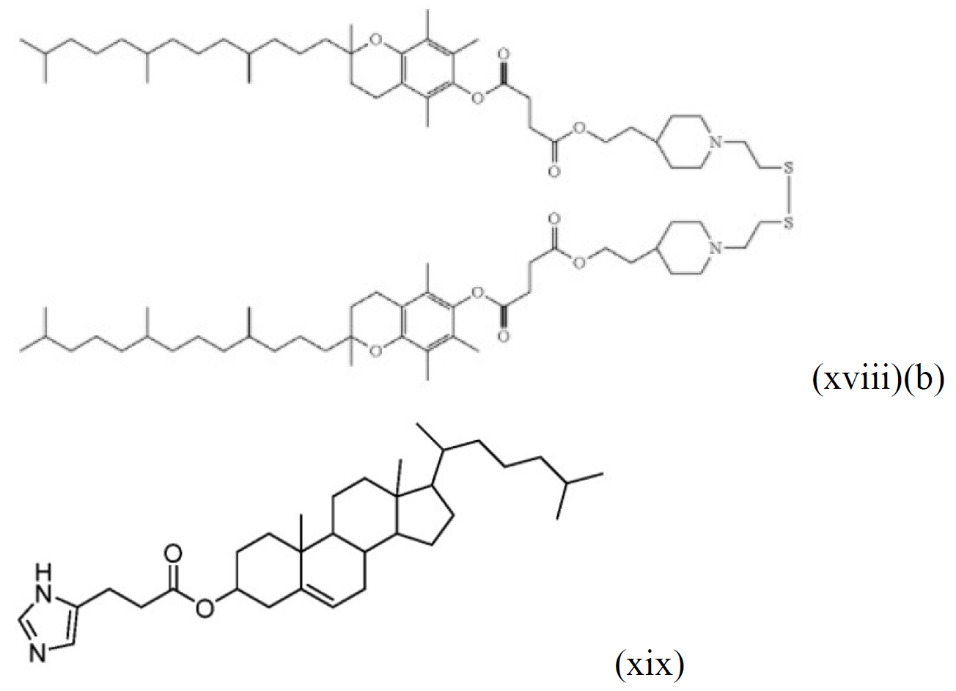
在一些實施例中,用於形式脂質奈米粒子以遞送本文所描述之組合物(例如,本文所描述之TREM)的脂質化合物係藉由以下反應中之一者製備:
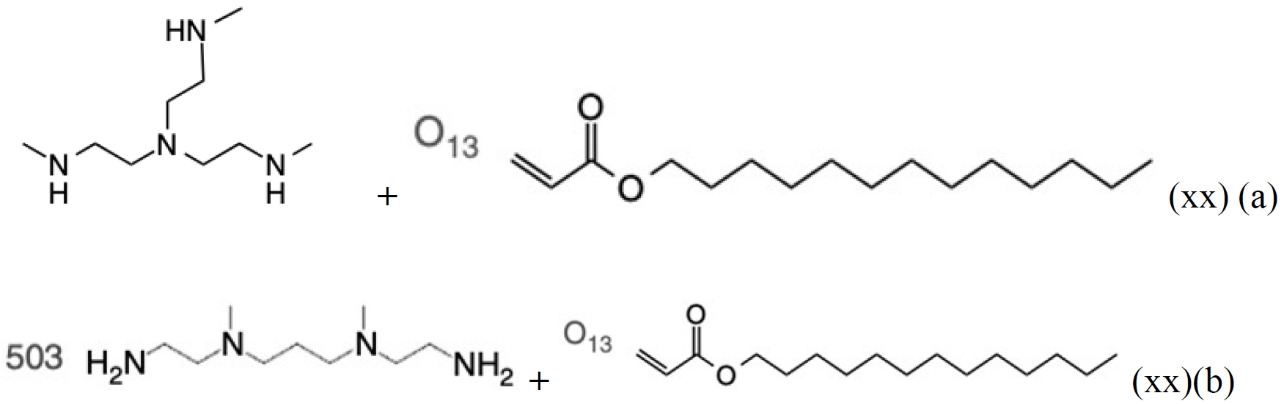
在一些實施例中,本文所描述之組合物(例如,TREM組合物)在包含可離子化脂質之LNP中提供。在一些實施例中,可離子化脂質為8-((2-羥乙基)(6-側氧基-6-(十一烷氧基)己基)胺基)辛酸十七烷-9-基酯(SM-102);例如如US9,867,888 (其以全文引用之方式併入本文中)之實例1中所描述。在一些實施例中,可離子化脂質為十八碳-9,12-二烯酸(9Z,12Z)-3-((4,4-雙(辛氧基)丁醯基)氧基)-2-((((3-(二乙基胺基)丙氧基)羰基)氧基)甲基)丙酯(LP01),例如如WO2015/095340 (其以全文引用之方式併入本文中)之實例13中所合成。在一些實施例中,可離子化脂質為9-((4-二甲基胺基)-丁醯基)氧基)十七烷二酸二((Z)-壬-2-烯-1-基)酯(L319),例如如US2012/0027803 (其以全文引用之方式併入本文中)之實例7、8或9中所合成。在一些實施例中,可離子化脂質為1,1'-((2-(4-(2-((2-(雙(2-羥基十二基)胺基)乙基)(2-羥基十二基)胺基)乙基)哌𠯤-1-基)乙基)氮二基)雙(十二-2-醇) (C12-200),例如如WO2010/053572 (其以全文引用之方式併入本文中)之實例14及16中所合成。在一些實施例中,可離子化脂質為咪唑膽固醇酯(ICE)脂質3-(1H-咪唑-4-基)丙酸(3S,10R,13R,17R)-10,13-二甲基-17-((R)-6-甲基庚-2-基)-2,3,4,7,8,9,10,11,12,13,14,15,16,17-十四氫-lH-環戊[a]菲-3-基酯,例如來自WO2020/106946 (其以全文引用之方式併入本文中)之結構(I)。
在一些實施例中,可離子化脂質可為陽離子脂質、可電離陽離子脂質(例如,取決於pH可以帶正電或中性形式存在之陽離子脂質)或可易於質子化之含胺脂質。在一些實施例中,陽離子脂質為能夠例如在生理條件下帶正電之脂質。例示性陽離子脂質包括攜帶正電荷的一或多個胺基。在一些實施例中,脂質粒子包含陽離子脂質與以下中之一或多者之調配物:中性脂質、可電離含胺脂質、可生物降解的炔烴脂質、類固醇、包括多元不飽和脂質之磷脂、結構性脂質(例如固醇)、PEG、膽固醇及聚合物結合脂質。在一些實施例中,陽離子脂質可為可電離陽離子脂質。如本文所揭示之例示性陽離子脂質可具有超過6.0之有效pKa。在實施例中,脂質奈米粒子可包含具有與第一陽離子脂質不同的有效pKa (例如大於第一有效pKa)的第二陽離子脂質。脂質奈米粒子可包含40莫耳%與60莫耳%之間的陽離子脂質、中性脂質、類固醇、聚合物結合脂質以及囊封在該脂質奈米粒子內或與該脂質奈米粒子締合的治療劑(例如本文所描述之TREM)。在一些實施例中,TREM與陽離子脂質共調配。TREM可吸附至LNP (例如包含陽離子脂質之LNP)的表面。在一些實施例中,TREM可囊封在LNP (例如包含陽離子脂質之LNP)中。在一些實施例中,脂質奈米粒子可包含例如包覆有靶向劑之靶向部分。在實施例中,LNP調配物為可生物降解的。在一些實施例中,包含一或多種本文所描述之脂質(例如式(i)、(ii)、(ii)、(vii)及/或(ix))的脂質奈米粒子囊封至少1%、至少5%、至少10%、至少20%、至少30%、至少40%、至少50%、至少60%、至少70%、至少80%、至少90%、至少92%、至少95%、至少97%、至少98%或100%之TREM。
可用於脂質奈米粒子調配物中的例示性可電離脂質包括但不限於WO2019051289之表1中列出的彼等脂質,該文獻以引用之方式併入本文中。額外例示性脂質包括但不限於以下式中之一或多者:US2016/0311759之X;US20150376115或US2016/0376224之I;US20160151284之I、II或III;US20170210967之I、IA、II或IIA;US20150140070之I-c;US2013/0178541之A;US2013/0303587或US2013/0123338之I;US2015/0141678之I;US2015/0239926之II、III、IV或V;US2017/0119904之I;WO2017/117528之I或II;US2012/0149894之A;US2015/0057373之A;WO2013/116126之A;US2013/0090372之A;US2013/0274523之A;US2013/0274504之A;US2013/0053572之A;W02013/016058之A;W02012/162210之A;US2008/042973之I;US2012/01287670之I、II、III或IV;US2014/0200257之I或II;US2015/0203446之I、II或III;US2015/0005363之I或III;US2014/0308304之I、IA、IB、IC、ID、II、IIA、IIB、IIC、IID或III-XXIV;US2013/0338210;W02009/132131之I、II、III或IV;US2012/01011478之A;US2012/0027796之I或XXXV;US2012/0058144之XIV或XVII;US2013/0323269;US2011/0117125之I;US2011/0256175之I、II或III;US2012/0202871之I、II、III、IV、V、VI、VII、VIII、IX、X、XI、XII;US2011/0076335之I、II、III、IV、V、VI、VII、VIII、X、XII、XIII、XIV、XV或XVI;US2006/008378之I或II;US2013/0123338之I;US2015/0064242之I或X-A-Y-Z;US2013/0022649之XVI、XVII或XVIII;US2013/0116307之I、II或III;US2013/0116307之I、II或III;US2010/0062967之I或II;US2013/0189351之I-X;US2014/0039032之I;US2018/0028664之V;US2016/0317458之I;US2013/0195920之I;US10,221,127之5、6或10;WO2018/081480之III-3;WO2020/081938之I-5或I-8;US9,867,888之18或25;US2019/0136231之A;WO2020/219876之II;US2012/0027803之1;US2019/0240349之OF-02;US10,086,013之23;Miao等人(2020)之cKK-E12/A6;WO2010/053572之C12-200;Dahlman等人(2017)之7C1;Whitehead等人之304-O13或503-O13;US9,708,628之TS-P4C2;WO2020/106946之I;WO2020/106946之I。
在一些實施例中,可離子化脂質為MC3丁酸(6Z,9Z,28Z,31Z)-三十七碳-6,9,28,31-四烯-19-基-4-(二甲基胺基)酯(DLin-MC3-DMA或MC3),例如如WO2019051289A9 (其以全文引用之方式併入本文中)之實例9中所描述。在一些實施例中,可離子化脂質為脂質ATX-002,例如如WO2019051289A9 (其以全文引用之方式併入本文中)之實例10中所描述。在一些實施例中,可離子化脂質為(13Z,16Z)-A,A-二甲基-3-壬基二十二碳-13,16-二烯-1-胺(化合物32),例如如WO2019051289A9 (其以全文引用之方式併入本文中)之實例11中所描述。在一些實施例中,可離子化脂質為化合物6或化合物22,例如如WO2019051289A9 (其以全文引用之方式併入本文中)之實例12中所描述。
例示性非陽離子脂質包括但不限於二硬脂醯基-sn-甘油基-磷酸乙醇胺、二硬脂醯基磷脂醯膽鹼(DSPC)、二油醯基磷脂醯膽鹼(DOPC)、二棕櫚醯基磷脂醯膽鹼(DPPC)、二油醯基磷脂醯甘油(DOPG)、二棕櫚醯基磷脂醯甘油(DPPG)、二油醯基磷脂醯乙醇胺(DOPE)、棕櫚醯基油醯基磷脂醯膽鹼(POPC)、棕櫚醯基油醯基磷脂醯乙醇胺(POPE)、二油醯基磷脂醯乙醇胺4-(N-順丁烯二醯亞胺基甲基)-環己烷-1-甲酸酯(DOPE-mal)、二棕櫚醯基磷脂醯乙醇胺(DPPE)、二肉豆蔻醯基磷酸乙醇胺(DMPE)、二硬脂醯基-磷脂醯基-乙醇胺(DSPE)、單甲基磷脂醯乙醇胺(諸如16-O-單甲基PE)、二甲基磷脂醯乙醇胺(諸如16-O-二甲基PE)、l8-l-反PE、l-十八醯基-2-油醯基-磷脂醯乙醇胺(SOPE)、經氫化之大豆磷脂醯膽鹼(HSPC)、蛋磷脂醯膽鹼(EPC)、二油醯基磷脂醯絲胺酸(DOPS)、鞘磷脂(SM)、二肉豆蔻醯基磷脂醯膽鹼(DMPC)、二肉豆蔻醯基磷脂醯甘油(DMPG)、二硬脂醯基磷脂醯甘油(DSPG)、二芥醯基磷脂醯膽鹼(DEPC)、棕櫚醯基油醯基磷脂醯甘油(POPG)、二反油醯基磷脂醯乙醇胺(DEPE)、卵磷脂、磷脂醯乙醇胺、溶血卵磷脂、溶血磷脂醯乙醇胺、磷脂醯絲胺酸、磷脂醯肌醇、鞘磷脂、蛋鞘磷脂(ESM)、腦磷脂、心磷脂、磷脂酸、腦苷脂、二鯨蠟基磷酸酯、溶血磷脂醯膽鹼、二亞油醯基磷脂醯膽鹼或其混合物。應理解,亦可使用其他二醯基磷脂醯膽鹼及二醯基磷脂醯乙醇胺磷脂。此等脂質中之醯基較佳為衍生自具有C10-C24碳鏈之脂肪酸之醯基,例如月桂醯基、肉豆蔻醯基、棕櫚醯基、硬脂醯基或油醯基。在某些實施例中,額外例示性脂質包括但不限於以引用之方式併入本文中的Kim等人 (2020) dx.doi.org/10.1021/acs.nanolett.0c01386中所描述之彼等脂質。在一些實施例中,此類脂質包括發現改良mRNA (例如DGTS)之肝臟轉染的植物脂質。
適合用於脂質奈米粒子的非陽離子脂質之其他實例包括但不限於非磷脂質,諸如硬脂胺、十二胺、十六胺、棕櫚酸乙醯酯、蓖麻油酸甘油酯、硬脂酸十六基酯、肉豆蔻酸異丙酯、兩性丙烯酸聚合物、月桂基硫酸三乙醇胺、硫酸烷基-芳基酯聚乙氧基化脂肪酸醯胺、溴化二(十八基)二甲基銨、神經醯胺、鞘磷脂及其類似物。其他非陽離子脂質描述於WO2017/099823或美國專利公開案US2018/0028664中,該等文獻之內容以全文引用之方式併入本文中。
在一些實施例中,非陽離子脂質為油酸或US2018/0028664之式I、II或IV之化合物,該文獻以全文引用之方式併入本文中。非陽離子脂質可佔例如脂質奈米粒子中存在的總脂質之0至30% (mol)。在一些實施例中,非陽離子脂質含量為脂質奈米粒子中存在的總脂質之5-20% (mol)或10-15% (mol)。在實施例中,可離子化脂質與中性脂質之莫耳比率在約2:1至約8:1之範圍內(例如約2:1、3:1、4:1、5:1、6:1、7:1或8:1)。
在一些實施例中,脂質奈米粒子不包含任何磷脂。
在一些態樣中,脂質奈米粒子可進一步包含提供膜完整性之組分,諸如固醇。可用於脂質奈米粒子中的一種例示性固醇為膽固醇及其衍生物。膽固醇衍生物之非限制性實例包括極性類似物,諸如5a-膽甾烷醇、53-糞甾醇、膽固醇基-(2'-羥基)-乙基醚、膽固醇基-(4'-羥基)-丁基醚及6-酮膽甾烷醇;非極性類似物,諸如5a-膽甾烷、膽甾烯酮、5a-膽甾烷酮、5p-膽甾烷酮及癸酸膽固醇酯;及其混合物。在一些實施例中,膽固醇衍生物為極性類似物,例如膽固醇基-(4'-羥基)-丁基醚。例示性膽固醇衍生物描述於PCT公開案W02009/127060及美國專利公開案US2010/0130588中,其中之每一者以全文引用之方式併入本文中。
在一些實施例中,提供膜完整性之組分(諸如固醇)可佔脂質奈米粒子中存在的總脂質之0-50% (mol) (例如0-10%、10-20%、20-30%、30-40%或40-50%)。在一些實施例中,此類組分為脂質奈米粒子之總脂質含量的20-50% (mol)、30-40% (mol)。
在一些實施例中,脂質奈米粒子可包含聚乙二醇(PEG)或結合脂質分子。一般而言,此等物質用於抑制脂質奈米粒子之聚集及/或提供空間穩定化。例示性結合脂質包括但不限於PEG-脂質結合物、聚㗁唑啉(POZ)-脂質結合物、聚醯胺-脂質結合物(諸如ATTA-脂質結合物)、陽離子聚合物脂質(CPL)結合物及其混合物。在一些實施例中,結合脂質分子為PEG-脂質結合物,例如(甲氧基聚乙二醇)-結合脂質。
例示性PEG-脂質結合物包括但不限於PEG-二醯基甘油(DAG) (諸如l-(單甲氧基-聚乙二醇)-2,3-二肉豆蔻醯基甘油(PEG-DMG))、PEG-二烷氧基丙基(DAA)、PEG-磷脂、PEG-神經醯胺(Cer)、聚乙二醇化磷脂醯乙醇胺(PEG-PE)、PEG丁二酸酯二醯基甘油(PEGS-DAG) (諸如4-0-(2',3'-二(十四醯氧基)丙基-l-0-(w-甲氧基(聚乙氧基)乙基)丁二酸酯(PEG-S-DMG))、PEG二烷氧基丙基胺基甲酸酯、N-(羰基-甲氧基聚乙二醇2000)-l,2-二硬脂醯基-sn-甘油基-3-磷酸乙醇胺鈉鹽或其混合物。額外例示性PEG-脂質結合物描述於例如US5,885,6l3、US6,287,59l、US2003/0077829、US2003/0077829、US2005/0175682、US2008/0020058、US2011/0117125、US2010/0130588、US2016/0376224、US2017/0119904及US/099823中,其中所有者之內容以全文引用之方式併入本文中。在一些實施例中,PEG-脂質為US2018/0028664之式III、III-a -I、III-a-2、III-b-1、III-b-2或V之化合物,該文獻之內容以全文引用之方式併入本文中。在一些實施例中,PEG-脂質具有US20150376115或US2016/0376224之式II,該兩個文獻之內容以其全文引用之方式併入本文中。在一些實施例中,PEG-DAA結合物可為例如PEG-二月桂基氧基丙基、PEG-二肉豆蔻基氧基丙基、PEG-二棕櫚基氧基丙基或PEG-二硬脂基氧基丙基。PEG-脂質可為以下中之一或多者:PEG-DMG、PEG-二月桂基甘油、PEG-二棕櫚醯基甘油、PEG-二硬脂基甘油、PEG-二月桂基甘油醯胺、PEG-二肉豆蔻基甘油醯胺、PEG-二棕櫚醯基甘油醯胺、PEG-二硬脂基甘油醯胺、PEG-膽固醇(l-[8'-(膽甾-5-烯-3[β]-氧基)甲醯胺基-3',6'-二氧雜辛基]胺甲醯基-[Ω]-甲基-聚(乙二醇)、PEG-DMB (3,4-二-十四氧基苯甲基-[Ω]-甲基-聚(乙二醇)乙醚)及1,2-二肉豆蔻醯基-sn-甘油基-3-磷酸乙醇胺-N-[甲氧基(聚乙二醇)-2000]。在一些實施例中,PEG-脂質包含PEG-DMG、1,2-二肉豆蔻醯基-sn-甘油基-3-磷酸乙醇胺-N-[甲氧基(聚乙二醇)-2000]。在一些實施例中,PEG-脂質包含選自以下之結構:
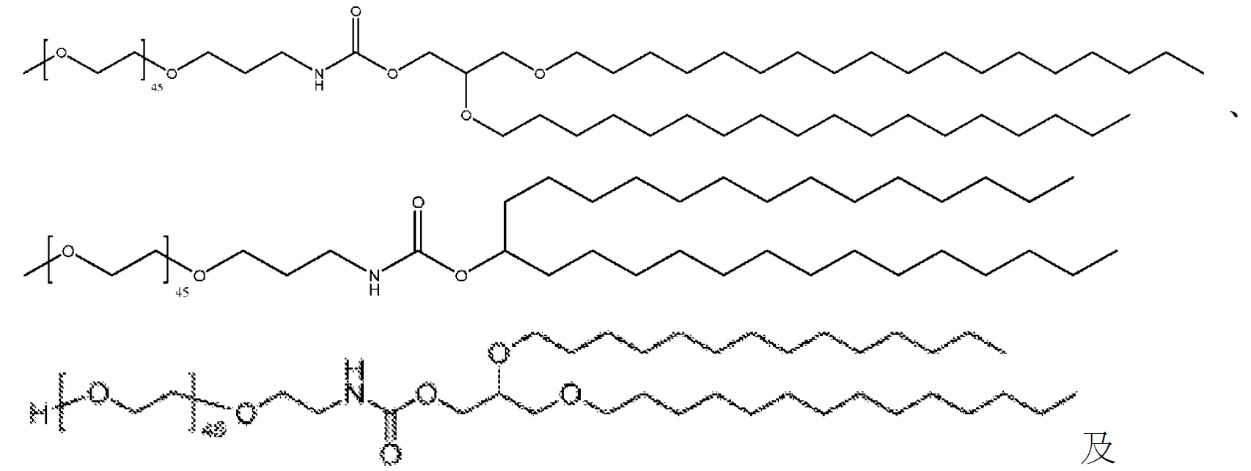
 。
。
在一些實施例中,亦可使用與除PEG外之分子結合的脂質代替PEG-脂質。舉例而言,代替PEG-脂質或除PEG-脂質以外,可使用聚㗁唑啉(POZ)-脂質結合物、聚醯胺-脂質結合物(諸如ATTA-脂質結合物)及陽離子聚合物脂質(GPL)結合物。
例示性結合脂質,亦即PEG-脂質、(POZ)-脂質結合物、ATTA-脂質結合物及陽離子聚合物脂質描述於WO2019051289A9之表2中所列出之PCT及LIS專利申請案中,所有該等申請案之內容以全文引用之方式併入本文中。
在一些實施例中,PEG或結合脂質可佔脂質奈米粒子中存在的總脂質之0-20% (mol)。在一些實施例中,PEG或結合脂質含量為脂質奈米粒子中存在的總脂質之0.5-10%或2-5% (mol)。可離子化脂質、非陽離子脂質、固醇及PEG/結合脂質之莫耳比率可視需要變化。舉例而言,脂質粒子可包含:按組合物之莫耳或總重量計30-70%之可離子化脂質;按組合物之莫耳或總重量計0-60%之膽固醇;按組合物之莫耳或總重量計0-30%之非陽離子脂質;及按組合物之莫耳或總重量計1-10%之結合脂質。較佳地,組合物包含:按組合物之莫耳或總重量計30-40%之可離子化脂質;按組合物之莫耳或總重量計40-50%之膽固醇;及按組合物之莫耳或總重量計10-20%之非陽離子脂質。在一些其他實施例中,組合物為:按組合物之莫耳或總重量計50-75%之可離子化脂質;按組合物之莫耳或總重量計20-40%之膽固醇;及按組合物之莫耳或總重量計5至10%之非陽離子脂質;及按組合物之莫耳或總重量計1-10%之結合脂質。組合物可含有:按組合物之莫耳或總重量計60-70%之可離子化脂質;按組合物之莫耳或總重量計25-35%之膽固醇;及按組合物之莫耳或總重量計5-10%之非陽離子脂質。組合物亦可含有按組合物之莫耳或總重量計至多90%之可離子化脂質及按組合物之莫耳或總重量計2至15%之非陽離子脂質。調配物亦可為例如包含以下之脂質奈米粒子調配物:按組合物之莫耳或總重量計8-30%之可離子化脂質、按組合物之莫耳或總重量計5-30%之非陽離子脂質及按組合物之莫耳或總重量計0-20%之膽固醇;按組合物之莫耳或總重量計4-25%之可離子化脂質、按組合物之莫耳或總重量計4-25%之非陽離子脂質、按組合物之莫耳或總重量計2至25%之膽固醇、按組合物之莫耳或總重量計10至35%之結合脂質及按組合物之莫耳或總重量計5%之膽固醇;或按組合物之莫耳或總重量計2-30%之可離子化脂質、按組合物之莫耳或總重量計2-30%之非陽離子脂質、按組合物之莫耳或總重量計1至15%之膽固醇、按組合物之莫耳或總重量計2至35%之結合脂質及按組合物之莫耳或總重量計1-20%之膽固醇;或甚至按組合物之莫耳或總重量計至多90%之可離子化脂質及按組合物之莫耳或總重量計2-10%之非陽離子脂質;或甚至按組合物之莫耳或總重量計100%之陽離子脂質。在一些實施例中,脂質粒子調配物包含莫耳比率為50:10:38.5:1.5之可離子化脂質、磷脂、膽固醇及PEG化脂質。在一些其他實施例中,脂質粒子調配物包含莫耳比率為60:38.5:1.5之可離子化脂質、膽固醇及PEG化脂質。
在一些實施例中,脂質粒子包含可離子化脂質、非陽離子脂質(例如磷脂)、固醇(例如膽固醇)及PEG化脂質,其中可離子化脂質之脂質莫耳比率在20至70莫耳%範圍內,目標為40-60;非陽離子脂質之莫耳百分比在0至30範圍內,目標為0至15;固醇之莫耳百分比在20至70範圍內,目標為30至50;且PEG化脂質之莫耳百分比在1至6範圍內,目標為2至5。
在一些實施例中,脂質粒子包含莫耳比率為50:10:38.5:1.5之可離子化脂質/非陽離子脂質/固醇/結合脂質。
在一態樣中,本發明提供包含磷脂、卵磷脂、磷脂醯膽鹼及磷脂醯乙醇胺之脂質奈米粒子調配物。
在一些實施例中,亦可包括一或多種額外化合物。彼等化合物可分開投與,或該等額外化合物可包括在本發明之脂質奈米粒子中。換言之,脂質奈米粒子除核酸外亦可含有其他化合物,或至少含有不同於第一核酸之第二核酸。不受限制,其他額外化合物可選自由以下組成之群:小或大有機或無機分子、單醣、雙醣、三醣、寡醣、多醣、肽、蛋白質、肽類似物及其衍生物、肽模擬物、核酸、核酸類似物及衍生物、由生物材料製成之提取物或其任何組合。
在一些實施例中,LNP係藉由添加靶向域而導向特定組織。舉例而言,生物配體可呈現於LNP表面上以增強與呈現同源受體之細胞的相互作用,由此驅動與其中細胞表現受體之組織的關聯及向其中表現受體之組織的負荷遞送。在一些實施例中,生物配體可為驅動遞送至肝臟之配體,例如呈現GalNAc之LNP,其將核酸負荷遞送至呈現去唾液酸糖蛋白受體(ASGPR)之肝細胞。Akinc等人
Mol Ther18(7):1357-1364 (2010)之作品教示三價GalNAc配體與PEG-脂質結合(GalNAc-PEG-DSG)以產生依賴於ASGPR之LNP從而獲得可觀測的LNP負荷效果(參見例如Akinc等人2010之圖6,同前文獻)。例如併有葉酸、轉鐵蛋白或抗體的其他呈現配體之LNP調配物論述於WO2017223135 (以其全文引用之方式併入本文中)以及其中使用之參考文獻中,亦即Kolhatkar等人, Curr Drug Discov Technol. 2011 8:197-206;Musacchio及Torchilin, Front Biosci. 2011 16:1388-1412;Yu等人, Mol Membr Biol. 2010 27:286-298;Patil等人, Crit Rev Ther Drug Carrier Syst. 2008 25:1-61;Benoit等人, Biomacromolecules. 2011 12:2708-2714;Zhao等人, Expert Opin Drug Deliv. 2008 5:309-319;Akinc等人, Mol Ther. 2010 18:1357-1364;Srinivasan等人, Methods Mol Biol. 2012 820:105-116;Ben-Arie等人, Methods Mol Biol. 2012 757:497-507;Peer 2010 J Control Release. 20:63-68;Peer等人, Proc Natl Acad Sci U S A. 2007 104:4095-4100;Kim等人, Methods Mol Biol. 2011 721:339-353;Subramanya等人, Mol Ther. 2010 18:2028-2037;Song等人, Nat Biotechnol. 2005 23:709-717;Peer等人, Science. 2008 319:627-630;及Peer及Lieberman, Gene Ther. 2011 18:1127-1133。
在一些實施例中,藉由向包含傳統組分(諸如可離子化陽離子脂質、兩親媒性磷脂、膽固醇及聚(乙二醇) (PEG)脂質)之調配物中添加選擇性器官靶向(SORT)分子來選擇LNP之組織特異性活性。Cheng等人Nat Nanotechnol 15(4):313-320 (2020)之教示內容表明,添加補充性「SORT」組分取決於SORT分子之百分比及生物物理學特性而精確地改變活體內RNA遞送特徵曲線且介導組織特異性(例如肺、肝臟、脾臟)基因遞送及編輯。
在一些實施例中,LNP包含生物可降解的可離子化脂質。在一些實施例中,LNP包含十八碳-9,12-二烯酸(9Z,12Z)-3-((4,4-雙(辛氧基)丁醯基)氧基)-2-((((3-(二乙基胺基)丙氧基)羰基)氧基)甲基)丙酯(亦稱為(9Z,12Z)-十八碳-9,12-二烯酸3-((4,4-雙(辛氧基)丁醯基)氧基)-2-((((3-(二乙基胺基)丙氧基)羰基)氧基)甲基)丙酯)或另一可離子化脂質。參見例如WO2019/067992、WO/2017/173054、WO2015/095340及WO2014/136086以及其中所提供之參考文獻之脂質。在一些實施例中,在LNP脂質之情形下,術語陽離子及可離子化可互換,例如其中可離子化脂質取決於pH而為陽離子的。
在一些實施例中,LNP調配物之平均LNP直徑可在數十奈米與數百奈米之間,例如藉由動態光散射(DLS)所量測。在一些實施例中,LNP調配物之平均LNP直徑可為約40 nm至約150 nm,諸如約40 nm、45 nm、50 nm、55 nm、60 nm、65 nm、70 nm、75 nm、80 nm、85 nm、90 nm、95 nm、100 nm、105 nm、110 nm、115 nm、120 nm、125 nm、130 nm、135 nm、140 nm、145 nm或150 nm。在一些實施例中,LNP調配物之平均LNP直徑可為約50 nm至約100 nm、約50 nm至約90 nm、約50 nm至約80 nm、約50 nm至約70 nm、約50 nm至約60 nm、約60 nm至約100 nm、約60 nm至約90 nm、約60 nm至約80 nm、約60 nm至約70 nm、約70 nm至約100 nm、約70 nm至約90 nm、約70 nm至約80 nm、約80 nm至約100 nm、約80 nm至約90 nm或約90 nm至約100 nm。在一些實施例中,LNP調配物之平均LNP直徑可為約70 nm至約100 nm。在一特定實施例中,LNP調配物之平均LNP直徑可為約80 nm。在一些實施例中,LNP調配物之平均LNP直徑可為約100 nm。在一些實施例中,LNP調配物之平均LNP直徑在約1 mm至約500 mm、約5 mm至約200 mm、約10 mm至約100 mm、約20 mm至約80 mm、約25 mm至約60 mm、約30 mm至約55 mm、約35 mm至約50 mm或約38 mm至約42 mm之範圍內。
在一些情況下,LNP可為相對均質的。多分散性指數可用於指示LNP之均質性,例如脂質奈米粒子之粒度分佈。小(例如小於0.3)的多分散性指數通常指示窄粒度分佈。LNP之多分散性指數可為約0至約0.25,諸如0.01、0.02、0.03、0.04、0.05、0.06、0.07、0.08、0.09、0.10、0.11、0.12、0.13、0.14、0.15、0.16、0.17、0.18、0.19、0.20、0.21、0.22、0.23、0.24或0.25。在一些實施例中,LNP之多分散性指數可為約0.10至約0.20。
LNP之ζ電勢可用於指示組合物之動電勢。在一些實施例中,ζ電勢可描述LNP之表面電荷。具有相對較低電荷(正或負)之脂質奈米粒子通常為合乎需要的,此係帶更高電荷之物質可能不合需要地與細胞、組織及體內之其他元素相互作用。在一些實施例中,LNP之ζ電勢可為約-10 mV至約+20 mV、約-10 mV至約+15 mV、約-10 mV至約+10 mV、約-10 mV至約+5 mV、約-10 mV至約0 mV、約-10 mV至約-5 mV、約-5 mV至約+20 mV、約-5 mV至約+15 mV、約-5 mV至約+10 mV、約-5 mV至約+5 mV、約-5 mV至約0 mV、約0 mV至約+20 mV、約0 mV至約+15 mV、約0 mV至約+10 mV、約0 mV至約+5 mV、約+5 mV至約+20 mV、約+5 mV至約+15 mV或約+5 mV至約+10 mV。
TREM之囊封效率描述相對於所提供之初始量,在製備之後被LNP囊封或以其他方式與LNP締合的TREM的量。囊封效率理想地較高(例如,接近100%)。囊封效率可例如藉由比較在用一或多種有機溶劑或清潔劑使脂質奈米粒子破裂之前及之後,含有脂質奈米粒子之溶液中TREM的量來量測。陰離子交換樹脂可用於量測溶液中之游離蛋白質或核酸(例如RNA)之量。螢光可用於量測溶液中之游離TREM之量。對於本文所描述之脂質奈米粒子,TREM之囊封效率可為至少50%,例如50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%。在一些實施例中,囊封效率可為至少80%。在一些實施例中,囊封效率可為至少90%。在一些實施例中,囊封效率可為至少95%。
LNP可視情況包含一或多個包衣。在一些實施例中,LNP可調配於具有包衣之膠囊、膜或錠劑中。包括本文所描述之組合物的膠囊、膜或錠劑可具有任何有用的大小、抗張強度、硬度或密度。
LNP之額外例示性脂質、調配物、方法及表徵由WO2020061457教示,該文獻以其全文引用之方式併入本文中。
在一些實施例中,使用脂染胺MessengerMax (Thermo Fisher)或TransIT-mRNA轉染試劑(Mirus Bio)進行活體外或離體細胞脂質體轉染。在某些實施例中,使用GenVoy_ILM可離子化脂質混合物(Precision NanoSystems)調配LNP。在某些實施例中,使用2,2-二亞油基-4-二甲基胺基乙基-[1,3]-二氧雜環戊烷(DLin-KC2-DMA)或二亞油基甲基-4-二甲基胺基丁酸酯(DLin-MC3-DMA或MC3)調配LNP,且其調配物及活體內用途教示於Jayaraman等人Angew Chem Int Ed Engl 51(34):8529-8533 (2012)中,該文獻以其全文引用之方式併入本文中。
經最佳化用於遞送CRISPR-Cas系統(例如Cas9-gRNA RNP、gRNA、Cas9 mRNA之LNP調配物)描述於WO2019067992及WO2019067910中,該兩個文獻以引用之方式併入。
適用於遞送核酸之額外特異性LNP調配物描述於US8158601及US8168775中,該兩個文獻以引用之方式併入,該等調配物包括用於以名稱ONPATTRO出售的帕替斯喃(patisiran)中的調配物。
胞外體亦可用作本文所描述之TREM、TREM核心片段、TREM片段、或TREM組合物或醫藥TREM組合物之藥物遞送媒劑。關於綜述,參見Ha等人2016年7月. Acta Pharmaceutica Sinica B. 第6卷, 第4期, 第287-296頁;https://doi.org/10.1016/j.apsb.2016.02.001。
離體分化之紅血球亦可用作本文所描述之TREM、TREM核心片段、TREM片段、或TREM組合物或醫藥TREM組合物的載劑。參見例如WO2015073587;WO2017123646;WO2017123644;WO2018102740;wO2016183482;WO2015153102;WO2018151829;WO2018009838;Shi等人2014. Proc Natl Acad Sci USA. 111(28): 10131-10136;美國專利9,644,180;Huang等人2017. Nature Communications 8: 423;Shi等人2014. Proc Natl Acad Sci USA. 111(28): 10131-10136。
融質體組合物,例如如WO2018208728中所描述,亦可用作載劑以遞送本文所描述之TREM、TREM核心片段、TREM片段、或TREM組合物或醫藥TREM組合物。
病毒體及病毒樣粒子(VLP)亦可用作載劑以將本文所描述之TREM、TREM核心片段、TREM片段、或TREM組合物或醫藥TREM組合物遞送至所靶向之細胞。
植物奈米囊泡,例如如WO2011097480A1、WO2013070324A1或WO2017004526A1中所描述,亦可用作載劑以遞送本文所描述之TREM、TREM核心片段、TREM片段、或TREM組合物或醫藥TREM組合物。
在無載劑之情況下的遞送本文所描述之TREM、TREM核心片段或TREM片段、TREM組合物或醫藥TREM組合物可在無載劑的情況下例如經由裸遞送TREM、TREM核心片段或TREM片段、TREM組合物或醫藥TREM組合物來投與至細胞。
在一些實施例中,如本文所用之裸遞送係指在無載劑的情況下之遞送。在一些實施例中,在無載劑之情況下的遞送,例如裸遞送,包含利用部分(例如靶向肽)遞送。
在一些實施例中,在無載劑的情況下,例如經由裸遞送將本文所描述之TREM、TREM核心片段或TREM片段、或TREM組合物或醫藥TREM組合物遞送至細胞。在一些實施例中,在無載劑之情況下的遞送,例如裸遞送,包含利用部分(例如靶向肽)遞送。
TREM之用途 包含含有ASGPR結合部分之TREM的組合物(例如,本文所描述之醫藥TREM組合物)可調節細胞、組織或個體之功能。在實施例中,以足以調節(增加或降低)以下參數中之一或多者的量及時間,使本文所描述之包含含有ASGPR結合部分之TREM的組合物(例如醫藥TREM組合物)與細胞或組織接觸或投與至有需要之個體:轉接功能(例如同源或非同源轉接功能),例如起始或延長多肽鏈之速率、效率、穩固性及/或特異性;核糖體結合及/或佔用;調節功能(例如基因沉默或信號傳導);細胞命運;mRNA穩定性;蛋白質穩定性;蛋白質轉導;蛋白質隔室化。相比參考組織、細胞或個體(例如健康、野生型或對照細胞、組織或個體),參數可經調節達例如至少5% (例如至少10%、15%、20%、25%、30%、40%、50%、60%、70%、80%、90%、100%、150%、200%或更多)。
在另一態樣中,本發明提供一種治療具有包含提前終止密碼子(PTC)之內源開讀框(ORF)的個體的方法,其包含:提供本文所揭示之包含TREM、TREM核心片段或TREM片段之TREM組合物,其中該TREM包含與該ORF中之該PTC配對的反密碼子;使該個體與該包含TREM、TREM核心片段或TREM片段之組合物以足以治療該個體之量及/或時間接觸,由此治療該個體。在一實施例中,該PTC包含UAA、UGA或UAG。
在另一態樣中,本發明提供一種治療患有與提前終止密碼子(PTC)相關之疾病或病症的個體的方法,其包含:提供本文所揭示之包含TREM、TREM核心片段或TREM片段之TREM組合物;使該個體與該包含TREM、TREM核心片段或TREM片段之組合物以足以治療該個體之量及/或時間接觸,由此治療該個體。在一實施例中,該PTC包含UAA、UGA或UAG。在一實施例中,與PTC相關之疾病或病症為本文所描述之疾病或病症,例如癌症或單基因疾病。
在本文所揭示之方法中之任一者之一實施例中,具有第一序列之密碼子包含突變(例如點突變,例如無意義突變),從而產生選自UAA、UGA或UAG之提前終止密碼子(PTC)。在一實施例中,具有第一序列之密碼子或PTC包含UAA突變。在一實施例中,具有第一序列之密碼子或PTC包含UGA突變。在一實施例中,具有第一序列之密碼子或PTC包含UAG突變。
在另一態樣中,本發明提供一種製備本文所揭示之TREM、TREM核心片段或TREM片段的方法,其包含將第一核苷酸連接至第二核苷酸以形成TREM。
在一實施例中,TREM、TREM核心片段或TREM片段為非天然存在的(例如合成的)。
在一實施例中,TREM、TREM核心片段或TREM片段藉由無細胞固相合成製備。
在另一態樣中,本發明提供一種調節細胞中之tRNA池的方法,其包含:提供本文所揭示之TREM、TREM核心片段或TREM片段,及使細胞與TREM、TREM核心片段或TREM片段接觸,由此調節細胞中之tRNA池。
在一態樣中,本發明提供一種使細胞、組織或個體與本文所揭示之TREM、TREM核心片段或TREM片段接觸的方法,其包含:使細胞、組織或個體與TREM、TREM核心片段或TREM片段接觸,由此使細胞、組織或個體與TREM、TREM核心片段或TREM片段接觸。
在另一態樣中,本發明提供一種向細胞、組織或個體遞送TREM、TREM核心片段或TREM片段之方法,其包含:提供細胞、組織或個體,及使細胞、組織或個體與本文所揭示之TREM、TREM核心片段或TREM片段接觸。
在一態樣中,本發明提供一種調節細胞中包含內源性開讀框(ORF)之tRNA池的方法,該ORF包含具有第一序列之密碼子,該方法包含:
視情況獲取(i)及(ii)中之一者或兩者之豐度的知識,例如獲取細胞中(i)及(ii)之相對量的知識,其中在該細胞中,(i)為tRNA部分(第一tRNA部分),其具有與ORF中具有第一序列之密碼子配對之反密碼子,且(ii)為同功受體tRNA部分(第二tRNA部分),其具有與除具有第一序列之密碼子以外之密碼子配對的反密碼子;
使該細胞以足以調節該細胞中第一tRNA部分及第二tRNA部分之相對量的量及/或時間與本文所揭示之TREM、TREM核心片段或TREM片段接觸,其中該TREM、TREM核心片段或TREM片段具有與以下配對之反密碼子:具有第一序列之密碼子;或除具有第一序列之密碼子以外的密碼子,
由此調節細胞中之tRNA池。
在另一態樣中,本發明提供一種調節個體中具有ORF之tRNA池的方法,該ORF包含具有第一序列之密碼子,該方法包含:
視情況獲取(i)及(ii)中之一者或兩者之豐度的知識,例如獲取個體中(i)及(ii)之相對量的知識,其中在該個體中,(i)為tRNA部分(第一tRNA部分),其具有與ORF中具有第一序列之密碼子配對之反密碼子,且(ii)為同功受體tRNA部分(第二tRNA部分),其具有與除具有第一序列之密碼子以外之密碼子配對的反密碼子;
使該個體以足以調節該個體中第一tRNA部分及第二tRNA部分之相對量的量及/或時間與本文所揭示之TREM、TREM核心片段或TREM片段接觸,其中該TREM、TREM核心片段或TREM片段具有與以下配對之反密碼子:具有第一序列之密碼子;或除具有第一序列之密碼子以外的密碼子,
由此調節該個體中之tRNA池。
本文中引用之所有參考文獻及公開案均以引用之方式併入本文中。
所列舉的實施例
1. 一種tRNA效應分子(TREM),其包含去唾液酸糖蛋白受體(ASGPR)結合部分,其中該ASGPR結合部分與該TREM之核苷酸內的核鹼基結合,或在該TREM之末端(例如5'或3'末端)處結合,或在TREM之核苷酸間鍵聯內結合。
2. 如實施例1之TREM,其中該ASGPR結合部分與該TREM之核苷酸內的核鹼基結合。
3. 如實施例1至2中任一者之TREM,其中該ASGPR結合部分與該TREM之末端(例如5'或3'末端)結合。
4. 如實施例1至3中任一者之TREM,其中該ASGPR結合部分存在於TREM之核苷酸間鍵聯內。
5. 一種TREM,其包含:
(i)式A之序列,其包含:
[L1]
y-[ASt域1]
x-[L2]
x-[DH域]
x-[L3]
x-[ACH域]
x-[VL域]
y-[TH域]
x-[L4]
x-[ASt域2]
x(A);及
(ii)去唾液酸糖蛋白受體(ASGPR)結合部分(例如GalNAc部分,例如GalNAc);
其中y為0或1且x為1。
6. 如實施例5之TREM,其中該ASGPR結合部分與該ASt域1內之核苷酸內的核鹼基結合。
7. 如實施例1至6中任一者之TREM,其中該ASGPR結合部分與該TREM內之位置1至9中之任一者處的核鹼基結合。
8. 如實施例5之TREM,其中該ASGPR結合部分與該DH域內之核苷酸內的核鹼基結合。
9. 如實施例1至8中任一者之TREM,其中該ASGPR結合部分與該TREM內之位置10至26中之任一者處之核苷酸內的核鹼基結合。
10. 如實施例5之TREM,其中該ASGPR結合部分與該ACH域內之核苷酸內的核鹼基結合。
11. 如實施例1至10中任一者之TREM,其中該ASGPR結合部分與位置27至43中之任一者處之核苷酸內的核鹼基結合。
12. 如實施例5之TREM,其中該ASGPR結合部分與該TH域內之核苷酸內的核鹼基結合。
13. 如實施例1至12中任一者之TREM,其中該ASGPR結合部分與位置50至64中之任一者處之核苷酸內的核鹼基結合。
14. 如實施例5之TREM,其中該ASGPR結合部分與該ASt域2內之核鹼基結合。
15. 如實施例1至14中任一者之TREM,其中該ASGPR結合部分與該TREM內之位置65至76中之任一者處的核鹼基結合。
16. 如實施例1至15中任一者之TREM,其中該ASGPR結合部分(例如GalNAc部分,例如GalNAc)經由共價鍵與該TREM分子之核苷酸之核鹼基部分偶聯(例如偶聯在核鹼基部分中之氮或碳原子處)。
17. 如實施例1至16中任一者之TREM,其中該核鹼基為天然存在之核鹼基或非天然存在之核鹼基。
18. 如實施例1至17中任一者之TREM,其中該核鹼基包含尿嘧啶、腺嘌呤、鳥嘌呤、胞嘧啶、胸腺嘧啶或其變體。
19. 如實施例1至18中任一者之TREM分子,其中該ASGPR結合部分包含GalNAc部分(例如GalNAc或GalNAc類似物)。
20. 如實施例1至19中任一者之TREM分子,其中該ASGPR結合部分包含複數個GalNAc部分。
21. 如實施例1至20中任一者之TREM分子,其中該ASGPR結合部分包含式(I)之結構:
 ,或其鹽,其中:
X及Y中之每一者獨立地為O、N(R
7)或S;
R
1、R
3、R
4及R
5中之每一者獨立地為氫、烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基、雜環基、C(O)-烷基、C(O)-烯基、C(O)-炔基、C(O)-雜烷基、C(O)-鹵烷基、C(O)-芳基、C(O)-雜芳基、C(O)-環烷基或C(O)-雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
8取代;
或R
3及R
4與其所連接之氧原子一起形成視情況經一或多個R
8取代之雜環基環;
R
2a為氫或烷基;R
2b為-C(O)烷基(例如C(O)CH
3);
R
6a及R
6b中之每一者為氫、烷基、烯基、炔基、雜烷基、鹵烷基、鹵基、氰基、硝基、-OR
A、芳基、雜芳基、環烷基或雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
9取代;
R
7為氫、烷基或C(O)-烷基;
R
8及R
9中之每一者獨立地為氫、鹵基、氰基、烷基、烯基、炔基、雜烷基、鹵烷基、環烷基或雜環基;
R
A為氫或烷基、烯基、炔基,且n為0與6之間的整數,其中該式(I)之結構可連接至連接子或TREM。
22. 如實施例21之TREM,其中該GalNAc部分包含複數個式(I)之結構。
23. 如實施例21至22中任一者之TREM,其中該GalNAc部分進一步包含連接子。
24. 如實施例1至23中任一者之TREM,其中該ASGPR結合部分包含式(I-a)之結構:
,或其鹽,其中:
X及Y中之每一者獨立地為O、N(R
7)或S;
R
1、R
3、R
4及R
5中之每一者獨立地為氫、烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基、雜環基、C(O)-烷基、C(O)-烯基、C(O)-炔基、C(O)-雜烷基、C(O)-鹵烷基、C(O)-芳基、C(O)-雜芳基、C(O)-環烷基或C(O)-雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
8取代;
或R
3及R
4與其所連接之氧原子一起形成視情況經一或多個R
8取代之雜環基環;
R
2a為氫或烷基;R
2b為-C(O)烷基(例如C(O)CH
3);
R
6a及R
6b中之每一者為氫、烷基、烯基、炔基、雜烷基、鹵烷基、鹵基、氰基、硝基、-OR
A、芳基、雜芳基、環烷基或雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
9取代;
R
7為氫、烷基或C(O)-烷基;
R
8及R
9中之每一者獨立地為氫、鹵基、氰基、烷基、烯基、炔基、雜烷基、鹵烷基、環烷基或雜環基;
R
A為氫或烷基、烯基、炔基,且n為0與6之間的整數,其中該式(I)之結構可連接至連接子或TREM。
22. 如實施例21之TREM,其中該GalNAc部分包含複數個式(I)之結構。
23. 如實施例21至22中任一者之TREM,其中該GalNAc部分進一步包含連接子。
24. 如實施例1至23中任一者之TREM,其中該ASGPR結合部分包含式(I-a)之結構:
 ,或其鹽,其中:
R
2a為氫或烷基;
R
2b為-C(O)烷基(例如C(O)CH
3);
R
3、R
4及R
5中之每一者獨立地為氫、烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基、雜環基、C(O)-烷基、C(O)-烯基、C(O)-炔基、C(O)-雜烷基、C(O)-鹵烷基、C(O)-芳基、C(O)-雜芳基、C(O)-環烷基或C(O)-雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
8取代;且
R
8為氫、鹵基、氰基、烷基、烯基、炔基、雜烷基、鹵烷基、環烷基或雜環基,
其中「
,或其鹽,其中:
R
2a為氫或烷基;
R
2b為-C(O)烷基(例如C(O)CH
3);
R
3、R
4及R
5中之每一者獨立地為氫、烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基、雜環基、C(O)-烷基、C(O)-烯基、C(O)-炔基、C(O)-雜烷基、C(O)-鹵烷基、C(O)-芳基、C(O)-雜芳基、C(O)-環烷基或C(O)-雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
8取代;且
R
8為氫、鹵基、氰基、烷基、烯基、炔基、雜烷基、鹵烷基、環烷基或雜環基,
其中「
 」表示呈任何構形之鍵,且「
」表示呈任何構形之鍵,且「
 」表示與連接子或TREM之連接點。
25. 如實施例1至24中任一者之TREM,其中該ASGPR結合部分包含式(II)之結構:
」表示與連接子或TREM之連接點。
25. 如實施例1至24中任一者之TREM,其中該ASGPR結合部分包含式(II)之結構:
 ,或其鹽,其中:
X為O、N(R
7)或S;
W或Y中之每一者獨立地為O或C(R
10a)(R
10b),其中W及Y中之一者為O;
R
1、R
3、R
4及R
5中之每一者獨立地為氫、烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基、雜環基、C(O)-烷基、C(O)-烯基、C(O)-炔基、C(O)-雜烷基、C(O)-鹵烷基、C(O)-芳基、C(O)-雜芳基、C(O)-環烷基或C(O)-雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
8取代;
或R
3及R
4與其所連接之氧原子一起形成視情況經一或多個R
8取代之雜環基環;
R
2a為氫或烷基;R
2b為-C(O)烷基(例如C(O)CH
3);
R
6a及R
6b中之每一者為氫、烷基、烯基、炔基、雜烷基、鹵烷基、鹵基、氰基、硝基、-OR
A、芳基、雜芳基、環烷基或雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
9取代;R
7為氫、烷基或C(O)-烷基;
R
8及R
9中之每一者獨立地為氫、鹵基、氰基、烷基、烯基、炔基、雜烷基、鹵烷基、環烷基或雜環基;R
10a及R
10b中之每一者獨立地為氫、雜烷基、鹵烷基或鹵基;且R
A為氫或烷基、烯基、炔基,
其中該式(I)之結構可連接至連接子或TREM。
26. 如實施例1至25中任一者之TREM,其中該ASGPR結合部分包含式(II)之結構:
,或其鹽,其中:
X為O、N(R
7)或S;
W或Y中之每一者獨立地為O或C(R
10a)(R
10b),其中W及Y中之一者為O;
R
1、R
3、R
4及R
5中之每一者獨立地為氫、烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基、雜環基、C(O)-烷基、C(O)-烯基、C(O)-炔基、C(O)-雜烷基、C(O)-鹵烷基、C(O)-芳基、C(O)-雜芳基、C(O)-環烷基或C(O)-雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
8取代;
或R
3及R
4與其所連接之氧原子一起形成視情況經一或多個R
8取代之雜環基環;
R
2a為氫或烷基;R
2b為-C(O)烷基(例如C(O)CH
3);
R
6a及R
6b中之每一者為氫、烷基、烯基、炔基、雜烷基、鹵烷基、鹵基、氰基、硝基、-OR
A、芳基、雜芳基、環烷基或雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
9取代;R
7為氫、烷基或C(O)-烷基;
R
8及R
9中之每一者獨立地為氫、鹵基、氰基、烷基、烯基、炔基、雜烷基、鹵烷基、環烷基或雜環基;R
10a及R
10b中之每一者獨立地為氫、雜烷基、鹵烷基或鹵基;且R
A為氫或烷基、烯基、炔基,
其中該式(I)之結構可連接至連接子或TREM。
26. 如實施例1至25中任一者之TREM,其中該ASGPR結合部分包含式(II)之結構:
 ,或其鹽,其中X為O、N(R
7)或S;
R
1、R
3、R
4及R
5中之每一者獨立地為氫、烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基、雜環基、C(O)-烷基、C(O)-烯基、C(O)-炔基、C(O)-雜烷基、C(O)-鹵烷基、C(O)-芳基、C(O)-雜芳基、C(O)-環烷基或C(O)-雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
8取代;
或R
3及R
4與其所連接之氧原子一起形成視情況經一或多個R
8取代之雜環基環;
R
2a為氫或烷基;R
2b為-C(O)烷基(例如C(O)CH
3);R
6a及R
6b中之每一者為氫、烷基、烯基、炔基、雜烷基、鹵烷基、鹵基、氰基、硝基、-OR
A、芳基、雜芳基、環烷基或雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
9取代;
R
7為氫、烷基或C(O)-烷基;
R
8及R
9中之每一者獨立地為氫、鹵基、氰基、烷基、烯基、炔基、雜烷基、鹵烷基、環烷基或雜環基;且R
A為氫或烷基、烯基、炔基,
其中該式(I)之結構可連接至連接子或TREM。
27. 如實施例1至26中任一者之TREM,其中該ASGPR結合部分包含式(II-b)之結構:
,或其鹽,其中X為O、N(R
7)或S;
R
1、R
3、R
4及R
5中之每一者獨立地為氫、烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基、雜環基、C(O)-烷基、C(O)-烯基、C(O)-炔基、C(O)-雜烷基、C(O)-鹵烷基、C(O)-芳基、C(O)-雜芳基、C(O)-環烷基或C(O)-雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
8取代;
或R
3及R
4與其所連接之氧原子一起形成視情況經一或多個R
8取代之雜環基環;
R
2a為氫或烷基;R
2b為-C(O)烷基(例如C(O)CH
3);R
6a及R
6b中之每一者為氫、烷基、烯基、炔基、雜烷基、鹵烷基、鹵基、氰基、硝基、-OR
A、芳基、雜芳基、環烷基或雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
9取代;
R
7為氫、烷基或C(O)-烷基;
R
8及R
9中之每一者獨立地為氫、鹵基、氰基、烷基、烯基、炔基、雜烷基、鹵烷基、環烷基或雜環基;且R
A為氫或烷基、烯基、炔基,
其中該式(I)之結構可連接至連接子或TREM。
27. 如實施例1至26中任一者之TREM,其中該ASGPR結合部分包含式(II-b)之結構:
 ,或其鹽,其中:
X為O、N(R
7)或S;
R
1、R
3、R
4及R
5中之每一者獨立地為氫、烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基、雜環基、C(O)-烷基、C(O)-烯基、C(O)-炔基、C(O)-雜烷基、C(O)-鹵烷基、C(O)-芳基、C(O)-雜芳基、C(O)-環烷基或C(O)-雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
8取代;
或R
3及R
4與其所連接之氧原子一起形成視情況經一或多個R
8取代之雜環基環;
R
2a為氫或烷基;R
2b為-C(O)烷基(例如C(O)CH
3);
R
6a及R
6b中之每一者為氫、烷基、烯基、炔基、雜烷基、鹵烷基、鹵基、氰基、硝基、-OR
A、芳基、雜芳基、環烷基或雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
9取代;
R
7為氫、烷基或C(O)-烷基;R
8及R
9中之每一者獨立地為氫、鹵基、氰基、烷基、烯基、炔基、雜烷基、鹵烷基、環烷基或雜環基;且
R
A為氫或烷基、烯基、炔基,其中該式(I)之結構可連接至連接子或TREM。
28. 如實施例1至27中任一者之TREM,其中該ASGPR結合部分包含式(III)之結構:
,或其鹽,其中:
X為O、N(R
7)或S;
R
1、R
3、R
4及R
5中之每一者獨立地為氫、烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基、雜環基、C(O)-烷基、C(O)-烯基、C(O)-炔基、C(O)-雜烷基、C(O)-鹵烷基、C(O)-芳基、C(O)-雜芳基、C(O)-環烷基或C(O)-雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
8取代;
或R
3及R
4與其所連接之氧原子一起形成視情況經一或多個R
8取代之雜環基環;
R
2a為氫或烷基;R
2b為-C(O)烷基(例如C(O)CH
3);
R
6a及R
6b中之每一者為氫、烷基、烯基、炔基、雜烷基、鹵烷基、鹵基、氰基、硝基、-OR
A、芳基、雜芳基、環烷基或雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R
9取代;
R
7為氫、烷基或C(O)-烷基;R
8及R
9中之每一者獨立地為氫、鹵基、氰基、烷基、烯基、炔基、雜烷基、鹵烷基、環烷基或雜環基;且
R
A為氫或烷基、烯基、炔基,其中該式(I)之結構可連接至連接子或TREM。
28. 如實施例1至27中任一者之TREM,其中該ASGPR結合部分包含式(III)之結構:
 ,或其鹽,其中R
1、R
2a、R
2b、R
3、R
4、R
5、R
6a及R
6b及其子變數中之每一者如針對式(I)所定義,L為連接子,且n為1與100之間的整數,其中「
,或其鹽,其中R
1、R
2a、R
2b、R
3、R
4、R
5、R
6a及R
6b及其子變數中之每一者如針對式(I)所定義,L為連接子,且n為1與100之間的整數,其中「
 」表示與分支點、額外連接子或TREM之一或多個域內之核苷酸的連接點。
29. 如實施例28之TREM,其中L包含伸烷基、伸烯基、伸炔基、伸雜烷基或伸鹵烷基。
30. 如實施例28至29中任一者之TREM,其中L包含羰基、醯胺、胺或酯部分。
31. 如實施例1至30中任一者之TREM,其中該ASGPR結合部分包含式(III-a)之結構:
」表示與分支點、額外連接子或TREM之一或多個域內之核苷酸的連接點。
29. 如實施例28之TREM,其中L包含伸烷基、伸烯基、伸炔基、伸雜烷基或伸鹵烷基。
30. 如實施例28至29中任一者之TREM,其中L包含羰基、醯胺、胺或酯部分。
31. 如實施例1至30中任一者之TREM,其中該ASGPR結合部分包含式(III-a)之結構:
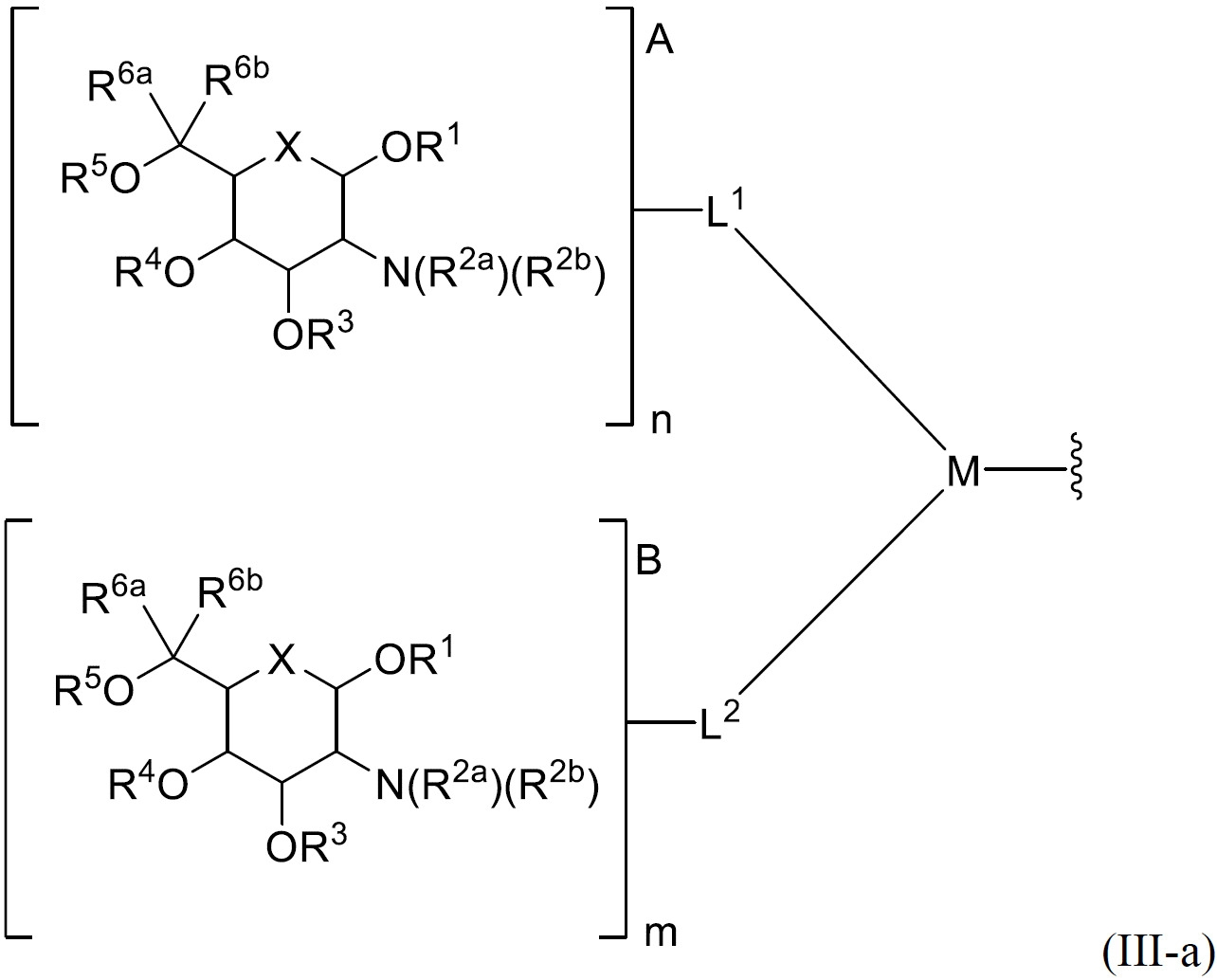 ,或其鹽,其中:
R
1、R
2a、R
2b、R
3、R
4、R
5、R
6a及R
6b及其子變數中之每一者如針對式(I)所定義,L
1及L
2中之每一者獨立地為連接子,m及n中之每一者獨立地為1與100之間的整數,且M為連接子,其中「
」表示與分支點、額外連接子或TREM之一或多個域內之核苷酸的連接點。
32. 如實施例1至31中任一者之TREM,其中該ASGPR結合部分包含式(II-b)之結構:
,或其鹽,其中:
R
1、R
2a、R
2b、R
3、R
4、R
5、R
6a及R
6b及其子變數中之每一者如針對式(I)所定義,L
1及L
2中之每一者獨立地為連接子,m及n中之每一者獨立地為1與100之間的整數,且M為連接子,其中「
」表示與分支點、額外連接子或TREM之一或多個域內之核苷酸的連接點。
32. 如實施例1至31中任一者之TREM,其中該ASGPR結合部分包含式(II-b)之結構:
 ,或其鹽,其中:
R
1、R
2a、R
2b、R
3、R
4、R
5、R
6a及R
6b及其子變數中之每一者如針對式(I)所定義;
L
1、L
2及L
3中之每一者獨立地為連接子;
m、n及o中之每一者獨立地為1與100之間的整數;
且M為分支點,其中「
,或其鹽,其中:
R
1、R
2a、R
2b、R
3、R
4、R
5、R
6a及R
6b及其子變數中之每一者如針對式(I)所定義;
L
1、L
2及L
3中之每一者獨立地為連接子;
m、n及o中之每一者獨立地為1與100之間的整數;
且M為分支點,其中「
 」表示與分支點、額外連接子或TREM之一或多個域內之核苷酸的連接點。
33. 如實施例31至32中任一者之TREM,其中L
1、L
2及視情況L
3中之每一者獨立地包含伸烷基、伸烯基、伸炔基、伸雜烷基或伸鹵烷基。
34. 如實施例31至33中任一者之TREM,其中L
1、L
2及視情況L
3中之每一者獨立地包含羰基、醯胺、胺或酯部分。
35. 如實施例31至34中任一者之TREM,其中M包含伸烷基、伸烯基、伸炔基、伸雜烷基或伸鹵烷基。
36. 如實施例31至35中任一者之TREM,其中M包含羰基、醯胺、胺或酯部分。
37. 如實施例1至36中任一者之TREM,其中該ASGPR結合部分包含式(II-c)之結構:
」表示與分支點、額外連接子或TREM之一或多個域內之核苷酸的連接點。
33. 如實施例31至32中任一者之TREM,其中L
1、L
2及視情況L
3中之每一者獨立地包含伸烷基、伸烯基、伸炔基、伸雜烷基或伸鹵烷基。
34. 如實施例31至33中任一者之TREM,其中L
1、L
2及視情況L
3中之每一者獨立地包含羰基、醯胺、胺或酯部分。
35. 如實施例31至34中任一者之TREM,其中M包含伸烷基、伸烯基、伸炔基、伸雜烷基或伸鹵烷基。
36. 如實施例31至35中任一者之TREM,其中M包含羰基、醯胺、胺或酯部分。
37. 如實施例1至36中任一者之TREM,其中該ASGPR結合部分包含式(II-c)之結構:
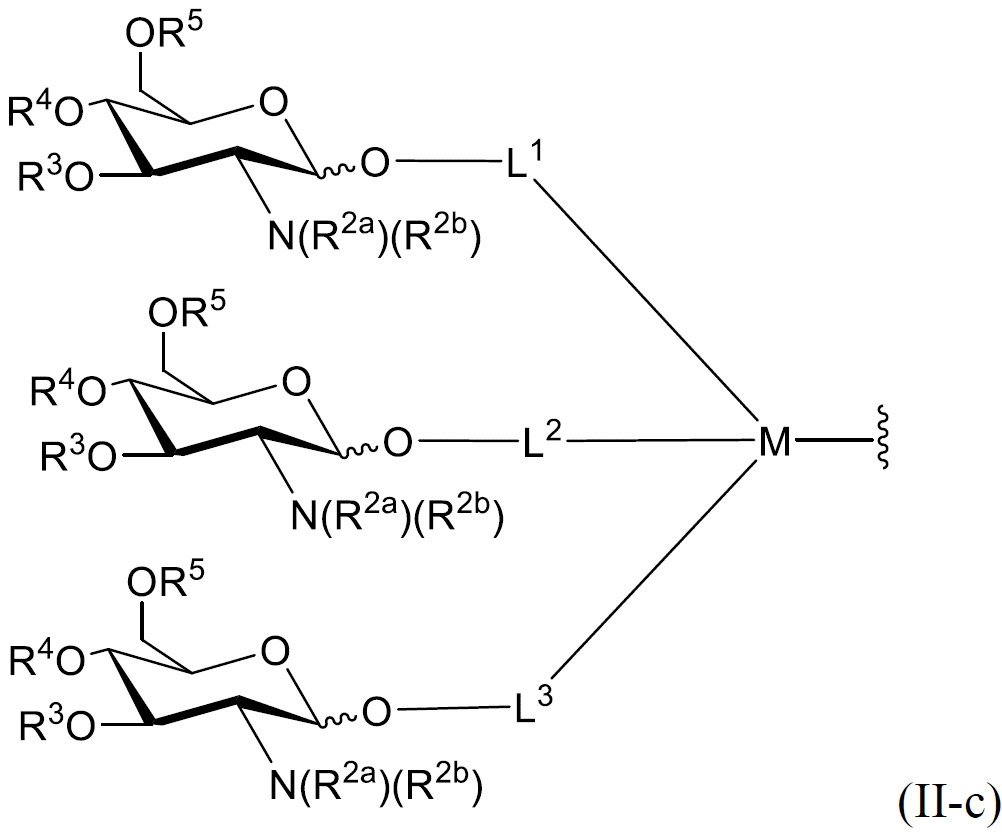 ,或其鹽,其中:
R
2a、R
2b、R
3、R
4、R
5及其子變數中之每一者如針對式(I)所定義;
L
1、L
2及L
3中之每一者獨立地為連接子;且
M為分支點,其中「
,或其鹽,其中:
R
2a、R
2b、R
3、R
4、R
5及其子變數中之每一者如針對式(I)所定義;
L
1、L
2及L
3中之每一者獨立地為連接子;且
M為分支點,其中「
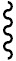 」表示與分支點、額外連接子或TREM之一或多個域內之核苷酸的連接點。
38. 如實施例37之TREM,L
1、L
2及L
3中之每一者獨立地包含伸烷基、伸烯基、伸炔基、伸雜烷基或伸鹵烷基。
39. 如實施例37至38中任一者之TREM,其中L
1、L
2及L
3中之每一者獨立地包含羰基、醯胺、胺或酯部分。
40. 如實施例37至39中任一者之TREM,其中M包含伸烷基、伸烯基、伸炔基、伸雜烷基或伸鹵烷基。
41. 如實施例37至40中任一者之TREM,其中M包含羰基、醯胺、胺或酯部分。
42. 如實施例1至41中任一者之TREM,其中該TREM係選自表12中所提供之TREM,例如化合物99至131中之任一者。
43. 如實施例1至42中任一者之TREM,其中該ASGPR結合部分係選自化合物(X-i)至(X-xxiii)中之任一者及/或其鹽或受保護形式。
44. 如實施例1至43中任一者之TREM,其中該ASGPR結合部分係選自化合物(X-i)、化合物(X-xxii)及化合物(X-xxiii)中之任一者及/或其鹽或受保護形式。
45. 如實施例1至44中任一者之TREM,其中該ASGPR結合部分為化合物(X-i)及/或其鹽或受保護形式。
45. 如實施例1至44中任一者之TREM,其中該ASGPR結合部分為化合物(X-xxii)及/或其鹽或受保護形式。
46. 如實施例1至44中任一者之TREM,其中該ASGPR結合部分為化合物(X-xxiii)及/或其鹽或受保護形式。
47. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與TREM位置1、16、17、19、20、21、46、47或50中之任一者處之核苷酸內的核鹼基結合。
48. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與選自1、2、3、4、5、6、7、8或9之複數個TREM位置處之核苷酸內的核鹼基結合。
49. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與TREM位置10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25或26中之任一者處之核苷酸內的核鹼基結合。
50. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與選自10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25或26之複數個TREM位置處之核苷酸內的核鹼基結合。
51. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與TREM位置27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42或43中之任一者處之核苷酸內的核鹼基結合。
52. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與選自27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42或43之複數個TREM位置處之核苷酸內的核鹼基結合。
53. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與TREM位置50、51、52、53、54、55、56、57、58、59、60、61、62、63或64中之任一者處之核苷酸內的核鹼基結合。
54. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與選自50、51、52、53、54、55、56、57、58、59、60、61、62、63或64之複數個TREM位置處之核苷酸內的核鹼基結合。
55. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與TREM位置65、66、67、68、69、70、71、72、73、74、75或76中之任一者處之核苷酸內的核鹼基結合。
56. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與選自65、66、67、68、69、70、71、72、73、74、75或76之複數個TREM位置處之核苷酸內的核鹼基結合。
57. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與例如包含SEQ ID NO: 1-654中之一者之TREM的TREM位置1、16、17、19、20、21、46、47或50中之任一者處之核苷酸內的核鹼基結合。
58. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與例如包含SEQ ID NO: 1-654中之一者之TREM的TREM位置1、16、17、19、20、21、46、47或50中之任一者處之核苷酸內的核鹼基結合。
59. 如實施例1至58中任一者之TREM,其中該TREM包含選自SEQ ID NO: 1-654中之任一者之序列。
60. 如實施例1至59中任一者之TREM,其中該TREM包含選自表12中所提供之TREM (例如SEQ ID NO: 622-654)中之任一者的序列。
61. 如實施例1至60中任一者之TREM,其中該TREM包含選自SEQ ID NO. 622、SEQ ID NO: 650及SEQ ID NO: 653之序列。
62. 如實施例1至61中任一者之TREM,其中該TREM包含與表12中所提供之TREM之序列(例如表12中所提供之SEQ ID NO. 622-654中之任一者)至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致的序列。
63. 如實施例1至62中任一者之TREM,其中該TREM包含與表12中所提供之TREM之序列(例如表12中所提供之SEQ ID NO. 622-654中之任一者)至少90%、92%、95%、96%、97%、98%或99%一致的序列。
64. 如實施例1至63中任一者之TREM,其中該TREM包含表12中所提供之TREM (例如表12中所揭示之SEQ ID NO. 622-654中之任一者)之至少5個核糖核苷酸(nt)、10 nt、15 nt、20 nt、25 nt、30 nt、35 nt、40 nt、45 nt、50 nt、55 nt、60 nt、65 nt、70 nt或75 nt (但小於全長)。
65. 如實施例1至64中任一者之TREM,其中該TREM包含表12中所提供之TREM (例如表12中所揭示之SEQ ID NO. 622-654中之任一者)之至少60 nt、65 nt、70 nt或75 nt。
66. 如實施例1至65中任一者之TREM,其中該TREM包含與表12中所提供之TREM (例如表12中所揭示之SEQ ID NO. 622-654中之任一者)至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致的TREM之至少5個核糖核苷酸(nt)、10 nt、15 nt、20 nt、25 nt、30 nt、35 nt、40 nt、45 nt、50 nt、55 nt、60 nt、65 nt、70 nt或75 nt (但小於全長)。
67. 如實施例1至66中任一者之TREM,其中該TREM包含與表12中所提供之TREM (例如表12中所揭示之SEQ ID NO. 622-654中之任一者)至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致的TREM之至少60 nt、65 nt、70 nt或75 nt。
68. 如實施例1至67中任一者之TREM,其中該TREM包含與表12中所提供之TREM (例如表12中所提供之SEQ ID NO. 622-652中之任一者)相差不超過1個核糖核苷酸(nt)、2 nt、3 nt、4 nt、5 nt、6 nt、7 nt、8 nt、9 nt、10 nt、12 nt、14 nt、16 nt、18 nt或20 nt的序列。
69. 如實施例1至68中任一者之TREM,其中該TREM係選自SEQ ID NO. 622、SEQ ID NO. 650及SEQ ID NO. 653。
70. 如實施例1至69中任一者之TREM,其中該TREM與SEQ ID NO. 622至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致。
71. 如實施例1至69中任一者之TREM,其中該TREM與SEQ ID NO. 650至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致。
72. 如實施例1至69中任一者之TREM,其中該TREM與SEQ ID NO. 653至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致。
73. 如實施例1至72中任一者之TREM,其中該TREM為表12中所提供之化合物,例如化合物編號99至131中之任一者。
74. 如實施例1至40中任一者之TREM,其中該TREM例如相對於不包含ASGPR結合部分之TREM或天然存在之tRNA保留支援蛋白質合成之能力。
75. 如實施例1至74中任一者之TREM,其中該TREM例如相對於不包含ASGPR結合部分之TREM或天然存在之tRNA保留被合成酶裝載之能力。
76. 如實施例1至75中任一者之TREM,其中該TREM例如相對於不包含ASGPR結合部分之TREM或天然存在之tRNA保留被延長因子結合之能力。
77. 如實施例1至76中任一者之TREM,其中該TREM例如相對於不包含ASGPR結合部分之TREM或天然存在之tRNA保留將胺基酸引入肽鏈中之能力。
78. 如實施例1至77中任一者之TREM,其中該TREM例如相對於不包含ASGPR結合部分之TREM或天然存在之tRNA保留支援延長或支援起始之能力。
79. 如實施例1至78中任一者之TREM,其中該TREM與ASGPR之結合親和力在0.01 nM與100 mM之間。
80. 如實施例1至79中任一者之TREM,其中該TREM包含化學修飾,例如本文所描述之化學修飾,例如表5至表8中任一者中之化學修飾。
81. 一種醫藥組合物,其包含如前述實施例中任一者之TREM。
82. 如實施例81之醫藥組合物,其進一步包含醫藥學上可接受之組分,例如賦形劑。
83. 一種脂質奈米粒子調配物,其包含如實施例1至80中任一者之TREM。
84. 一種脂質奈米粒子調配物,其包含如實施例81至82中任一者之醫藥組合物。
86. 一種向個體或細胞遞送如實施例1至80中任一者之TREM、或如實施例81至82中任一者之醫藥組合物、或如實施例83至84中任一者之脂質奈米粒子的方法。
87. 一種治療患有與PTC相關之疾病或病症之個體的方法,其包含向該個體投與如實施例1至80中任一者之TREM、或如實施例81至82中任一者之醫藥組合物、或如實施例83至84中任一者之脂質奈米粒子,由此治療患有該疾病或病症之該個體。
」表示與分支點、額外連接子或TREM之一或多個域內之核苷酸的連接點。
38. 如實施例37之TREM,L
1、L
2及L
3中之每一者獨立地包含伸烷基、伸烯基、伸炔基、伸雜烷基或伸鹵烷基。
39. 如實施例37至38中任一者之TREM,其中L
1、L
2及L
3中之每一者獨立地包含羰基、醯胺、胺或酯部分。
40. 如實施例37至39中任一者之TREM,其中M包含伸烷基、伸烯基、伸炔基、伸雜烷基或伸鹵烷基。
41. 如實施例37至40中任一者之TREM,其中M包含羰基、醯胺、胺或酯部分。
42. 如實施例1至41中任一者之TREM,其中該TREM係選自表12中所提供之TREM,例如化合物99至131中之任一者。
43. 如實施例1至42中任一者之TREM,其中該ASGPR結合部分係選自化合物(X-i)至(X-xxiii)中之任一者及/或其鹽或受保護形式。
44. 如實施例1至43中任一者之TREM,其中該ASGPR結合部分係選自化合物(X-i)、化合物(X-xxii)及化合物(X-xxiii)中之任一者及/或其鹽或受保護形式。
45. 如實施例1至44中任一者之TREM,其中該ASGPR結合部分為化合物(X-i)及/或其鹽或受保護形式。
45. 如實施例1至44中任一者之TREM,其中該ASGPR結合部分為化合物(X-xxii)及/或其鹽或受保護形式。
46. 如實施例1至44中任一者之TREM,其中該ASGPR結合部分為化合物(X-xxiii)及/或其鹽或受保護形式。
47. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與TREM位置1、16、17、19、20、21、46、47或50中之任一者處之核苷酸內的核鹼基結合。
48. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與選自1、2、3、4、5、6、7、8或9之複數個TREM位置處之核苷酸內的核鹼基結合。
49. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與TREM位置10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25或26中之任一者處之核苷酸內的核鹼基結合。
50. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與選自10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25或26之複數個TREM位置處之核苷酸內的核鹼基結合。
51. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與TREM位置27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42或43中之任一者處之核苷酸內的核鹼基結合。
52. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與選自27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42或43之複數個TREM位置處之核苷酸內的核鹼基結合。
53. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與TREM位置50、51、52、53、54、55、56、57、58、59、60、61、62、63或64中之任一者處之核苷酸內的核鹼基結合。
54. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與選自50、51、52、53、54、55、56、57、58、59、60、61、62、63或64之複數個TREM位置處之核苷酸內的核鹼基結合。
55. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與TREM位置65、66、67、68、69、70、71、72、73、74、75或76中之任一者處之核苷酸內的核鹼基結合。
56. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與選自65、66、67、68、69、70、71、72、73、74、75或76之複數個TREM位置處之核苷酸內的核鹼基結合。
57. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與例如包含SEQ ID NO: 1-654中之一者之TREM的TREM位置1、16、17、19、20、21、46、47或50中之任一者處之核苷酸內的核鹼基結合。
58. 如實施例1至46中任一者之TREM,其中該ASGPR結合部分與例如包含SEQ ID NO: 1-654中之一者之TREM的TREM位置1、16、17、19、20、21、46、47或50中之任一者處之核苷酸內的核鹼基結合。
59. 如實施例1至58中任一者之TREM,其中該TREM包含選自SEQ ID NO: 1-654中之任一者之序列。
60. 如實施例1至59中任一者之TREM,其中該TREM包含選自表12中所提供之TREM (例如SEQ ID NO: 622-654)中之任一者的序列。
61. 如實施例1至60中任一者之TREM,其中該TREM包含選自SEQ ID NO. 622、SEQ ID NO: 650及SEQ ID NO: 653之序列。
62. 如實施例1至61中任一者之TREM,其中該TREM包含與表12中所提供之TREM之序列(例如表12中所提供之SEQ ID NO. 622-654中之任一者)至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致的序列。
63. 如實施例1至62中任一者之TREM,其中該TREM包含與表12中所提供之TREM之序列(例如表12中所提供之SEQ ID NO. 622-654中之任一者)至少90%、92%、95%、96%、97%、98%或99%一致的序列。
64. 如實施例1至63中任一者之TREM,其中該TREM包含表12中所提供之TREM (例如表12中所揭示之SEQ ID NO. 622-654中之任一者)之至少5個核糖核苷酸(nt)、10 nt、15 nt、20 nt、25 nt、30 nt、35 nt、40 nt、45 nt、50 nt、55 nt、60 nt、65 nt、70 nt或75 nt (但小於全長)。
65. 如實施例1至64中任一者之TREM,其中該TREM包含表12中所提供之TREM (例如表12中所揭示之SEQ ID NO. 622-654中之任一者)之至少60 nt、65 nt、70 nt或75 nt。
66. 如實施例1至65中任一者之TREM,其中該TREM包含與表12中所提供之TREM (例如表12中所揭示之SEQ ID NO. 622-654中之任一者)至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致的TREM之至少5個核糖核苷酸(nt)、10 nt、15 nt、20 nt、25 nt、30 nt、35 nt、40 nt、45 nt、50 nt、55 nt、60 nt、65 nt、70 nt或75 nt (但小於全長)。
67. 如實施例1至66中任一者之TREM,其中該TREM包含與表12中所提供之TREM (例如表12中所揭示之SEQ ID NO. 622-654中之任一者)至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致的TREM之至少60 nt、65 nt、70 nt或75 nt。
68. 如實施例1至67中任一者之TREM,其中該TREM包含與表12中所提供之TREM (例如表12中所提供之SEQ ID NO. 622-652中之任一者)相差不超過1個核糖核苷酸(nt)、2 nt、3 nt、4 nt、5 nt、6 nt、7 nt、8 nt、9 nt、10 nt、12 nt、14 nt、16 nt、18 nt或20 nt的序列。
69. 如實施例1至68中任一者之TREM,其中該TREM係選自SEQ ID NO. 622、SEQ ID NO. 650及SEQ ID NO. 653。
70. 如實施例1至69中任一者之TREM,其中該TREM與SEQ ID NO. 622至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致。
71. 如實施例1至69中任一者之TREM,其中該TREM與SEQ ID NO. 650至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致。
72. 如實施例1至69中任一者之TREM,其中該TREM與SEQ ID NO. 653至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致。
73. 如實施例1至72中任一者之TREM,其中該TREM為表12中所提供之化合物,例如化合物編號99至131中之任一者。
74. 如實施例1至40中任一者之TREM,其中該TREM例如相對於不包含ASGPR結合部分之TREM或天然存在之tRNA保留支援蛋白質合成之能力。
75. 如實施例1至74中任一者之TREM,其中該TREM例如相對於不包含ASGPR結合部分之TREM或天然存在之tRNA保留被合成酶裝載之能力。
76. 如實施例1至75中任一者之TREM,其中該TREM例如相對於不包含ASGPR結合部分之TREM或天然存在之tRNA保留被延長因子結合之能力。
77. 如實施例1至76中任一者之TREM,其中該TREM例如相對於不包含ASGPR結合部分之TREM或天然存在之tRNA保留將胺基酸引入肽鏈中之能力。
78. 如實施例1至77中任一者之TREM,其中該TREM例如相對於不包含ASGPR結合部分之TREM或天然存在之tRNA保留支援延長或支援起始之能力。
79. 如實施例1至78中任一者之TREM,其中該TREM與ASGPR之結合親和力在0.01 nM與100 mM之間。
80. 如實施例1至79中任一者之TREM,其中該TREM包含化學修飾,例如本文所描述之化學修飾,例如表5至表8中任一者中之化學修飾。
81. 一種醫藥組合物,其包含如前述實施例中任一者之TREM。
82. 如實施例81之醫藥組合物,其進一步包含醫藥學上可接受之組分,例如賦形劑。
83. 一種脂質奈米粒子調配物,其包含如實施例1至80中任一者之TREM。
84. 一種脂質奈米粒子調配物,其包含如實施例81至82中任一者之醫藥組合物。
86. 一種向個體或細胞遞送如實施例1至80中任一者之TREM、或如實施例81至82中任一者之醫藥組合物、或如實施例83至84中任一者之脂質奈米粒子的方法。
87. 一種治療患有與PTC相關之疾病或病症之個體的方法,其包含向該個體投與如實施例1至80中任一者之TREM、或如實施例81至82中任一者之醫藥組合物、或如實施例83至84中任一者之脂質奈米粒子,由此治療患有該疾病或病症之該個體。
實例
提供以下實例以進一步說明本發明之一些實施例,但不意欲限制本發明之範疇;藉由其示例性之性質,應瞭解,可替代地使用熟習此項技術者已知之其他程序、方法或技術。
實例之目錄
| 實例1 | 所選ASGPR結合部分之製備 |
| 實例2 | 所選核苷酸之製備 |
| 實例3 | 例示性TREM之合成 |
| 實例4 | 具有末端胺基連接子之TREM之合成 |
| 實例5 | 包含ASGPR結合部分之TREM的合成 |
| 實例6 | 作為探針的與生物素結合之TREM分子之合成 |
| 實例7 | 作為探針的與生物素結合之TREM分子之合成 |
| 實例8 | 經由HPLC對GalNAc-TREM之分析 |
| 實例9 | 經由質譜法對GalNAc-TREM之分析 |
| 實例10 | GalNAc-TREM至表現ASGPR之細胞的活體外遞送 |
| 實例11 | GalNAc-TREM至原代人類肝細胞之活體外遞送 |
| 實例12 | 經由以轉染方式投與包含ASGPRG結合部分之TREM對報導蛋白中之提前終止密碼子(PTC)之連讀 |
| 實例13 | 經由在表現ASGPR之細胞中投與包含ASGPR結合部分之TREM對報導蛋白中之提前終止密碼子(PTC)之連讀 |
| 實例14 | 經由投與包含ASGPR結合部分之TREM對α-半乳糖苷酶(GLA) ORF中之提前終止密碼子(PTC)之連讀 |
| 實例15 | 經由投與包含ASGPR結合部分之TREM對α-半乳糖苷酶(GLA) ORF中之提前終止密碼子(PTC)進行連讀以產生功能性GLA蛋白質 |
| 實例16 | 藉由投與GalNAc-TREM對ORF中之錯義突變進行校正 |
| 實例17 | 藉由投與GalNAc-TREM評估含SMC之ORF之蛋白質表現量 |
| 實例18 | 藉由GalNAc-TREM投與調節含SMC之ORF之蛋白質轉譯速率 |
實例 1 : 所選 ASGPR 結合部分之製備 化合物 200 :11-(((2R,3R,4R,5R,6R)-3-乙醯胺基-4,5-二乙醯氧基-6-(乙醯氧基甲基)四氫-2H-哌喃-2-基)氧基)-16,16-雙((3-((3-(5-(((2R,3R,4R,5R,6R)-3-乙醯胺基-4,5-二乙醯氧基-6-(乙醯氧基甲基)四氫-2H-哌喃-2-基)氧基)戊醯胺基)-丙基)胺基)-3-側氧基丙氧基)甲基)-5,11,18-三側氧基-14-氧雜-6,10,17-三氮雜二十九-29-烷酸(化合物100)可根據Nair K.等人(2014)
J. Am. Chem. Soc, 134(49), 16958-16961所提供之程序製備,該文獻以其全文引用之方式併入本文中。

化合物 201:Trebler GalNAc疊氮化物(N-(N-炔丙基十二醯基醯胺基)-參{2-氧雜-6,10-二氮雜-5,11-二側氧基-15-[3,4,6-三-O-乙醯基-2-乙醯胺基-2-去氧-β-D-吡喃葡萄糖基氧基]十五基}甲烷)係商購的(例如,購自Primetich;目錄#0079)。
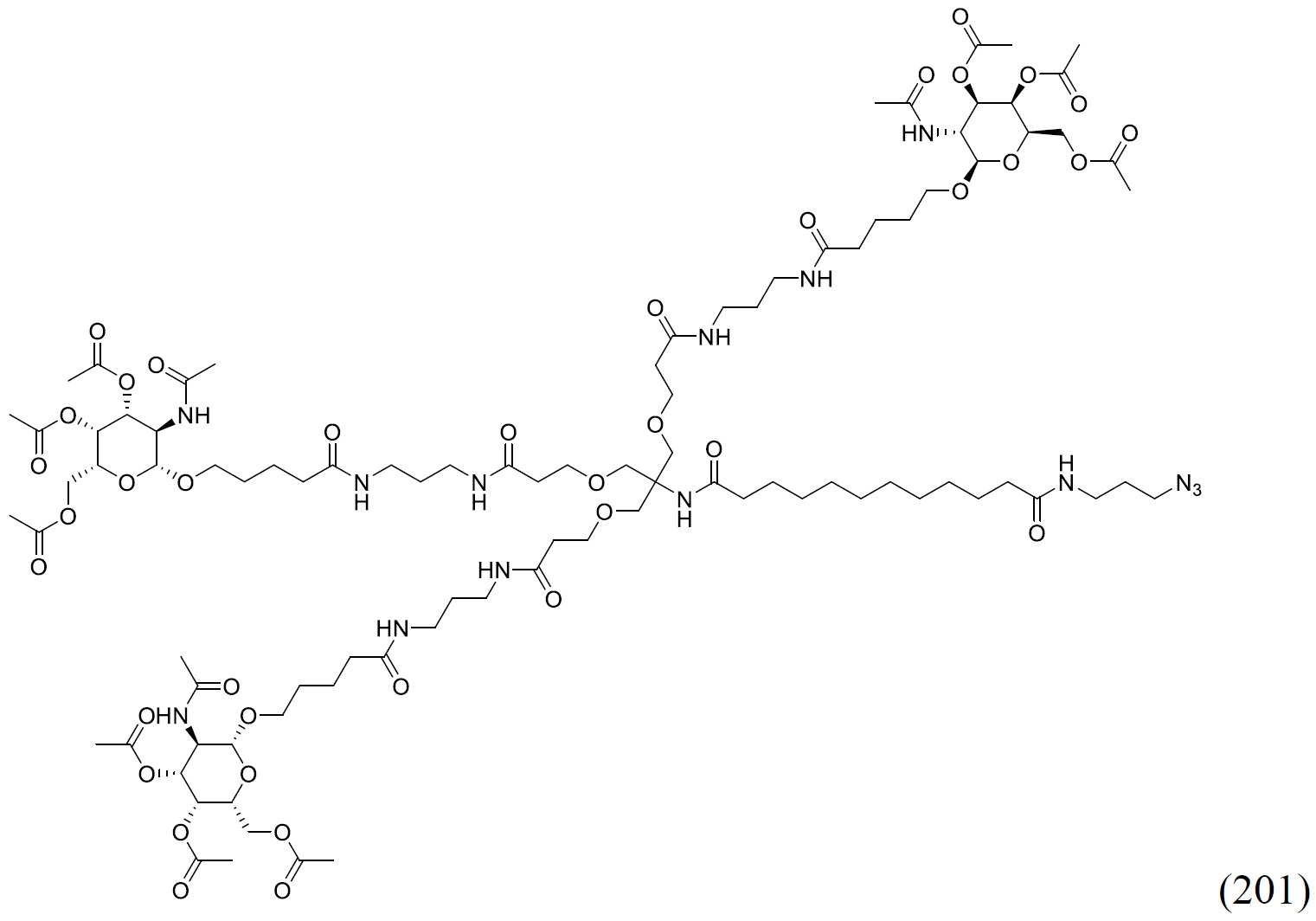
化合物 202 :1-(((2R,3R,4R,5R,6R)-3-乙醯胺基-4,5-二羥基-6-(羥甲基)四氫-2H-哌喃-2-基)氧基)-18,18-雙(17-(((2R,3R,4R,5R,6R)-3-乙醯胺基-4,5-二羥基-6-(羥甲基)四氫-2H-哌喃-2-基)氧基)-5-側氧基-2,9,12,15-四氧雜-6-氮雜十七基)-13,20-二側氧基-3,6,9,16-四氧雜-12,19-二氮雜三十一-31-烷酸

化合物 203:(17S,20S)-1-(((2R,3R,4R,5R,6R)-3-乙醯胺基-4,5-二乙醯氧基-6-(乙醯氧基甲基)四氫-2H-哌喃-2-基)氧基)-20-(1-(((2R,3R,4R,5R,6R)-3-乙醯胺基-4,5-二乙醯氧基-6-(乙醯氧基甲基)四氫-2H-哌喃-2-基)氧基)-11-側氧基-3,6,9-三氧雜-12-氮雜十六-16-基)-17-(2-(2-(2-(2-(((2R,3R,4R,5R,6R)-3-乙醯胺基-4,5-二乙醯氧基-6-(乙醯氧基甲基)四氫-2H-哌喃-2-基)氧基)乙氧基)乙氧基)乙氧基)乙醯胺基)-11,18-二側氧基-3,6,9-三氧雜-12,19-二氮雜二十一-21-烷酸係根據美國專利第9,796,756號中所概述之程序製備,該文獻以其全文引用之方式併入本文中。

實例 2 : 所選核苷酸之製備 胺基核鹼基 1:在諸如AN1之核鹼基處包含胺控點之經修飾核苷酸(C6-U胺基亞磷酸酯(5'-二甲氧基三苯甲基-5-[N-(三氟乙醯胺基己基)-3-丙烯醯亞胺基]-尿苷、2'-O-三異丙基矽基氧基甲基-3'-[(2-氰基乙基)-(N, N-二異丙基)]-胺基亞磷酸酯))可購自Glen Research;目錄# 10-3039。簡言之,胺基修飾劑C6-U胺基亞磷酸酯與以三氟乙酸鹽形式保護之一級胺一起購買,且併入TREM中,得到胺基核鹼基AN1。
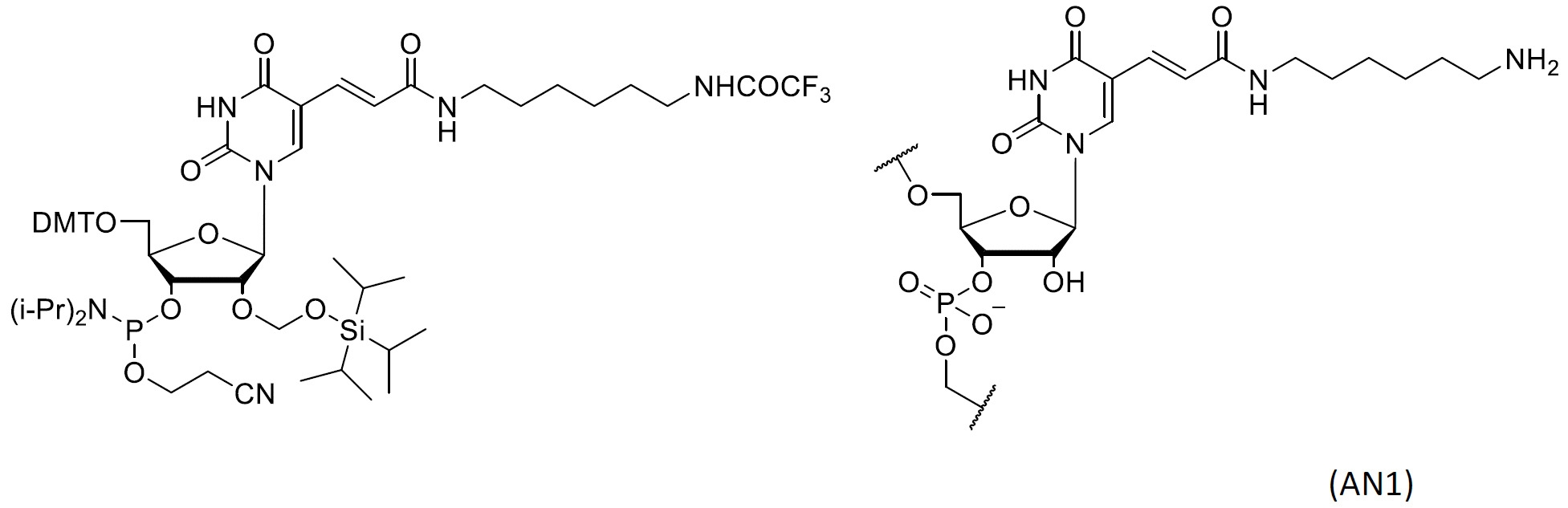
炔烴核鹼基 2:在諸如AN2之核鹼基處包含炔烴控點之經修飾核苷酸(C8-炔烴-dT-CE胺基亞磷酸酯(5'-二甲氧基三苯甲基-5-(八-1,7-二炔基)-2'-去氧尿苷、3'-[(2-氰基乙基)-(N, N-二異丙基)]-胺基亞磷酸酯))可購自Glen Research;目錄# 10-1540。C8-炔烴-dT-CE胺基亞磷酸酯經由標準胺基亞磷酸酯化學方法併入至TREM分子中,得到胺基核鹼基AN2。

實例 3 : 例示性 TREM 之合成實例描述例示性TREM之合成。TREM可根據標準固相合成方法及胺基亞磷酸酯化學方法化學合成且藉由HPLC純化(參見例如Scaringe S.等人(2004)
Curr Protoc Nucleic Acid Chem, 2.10.1-2.10.16;Usman N.等人(1987)
J. Am. Chem. Soc, 109, 7845-7854)。合成中使用的例示性核苷酸胺基亞磷酸酯包括5'-O-二甲氧基三苯甲基-N6-(苯甲醯基)-2'-O-三級丁基二甲基矽基-腺苷-3'-O-(2-氰基乙基-N,N-二異丙基胺基)胺基亞磷酸酯、5'-O-二甲氧基三苯甲基-N4-(乙醯基)-2'-O-三級丁基二甲基矽基-胞苷-3'-O-(2-氰基乙基-N,N-二異丙基胺基)胺基亞磷酸酯、5'-O-二甲氧基三苯甲基-N2-(異丁醯基)-2'-O-三級丁基二甲基矽基-鳥苷-3'-O-(2-氰基乙基-N,N-二異丙基胺基)胺基亞磷酸酯及5'-O-二甲氧基三苯甲基-2'-O-三級丁基二甲基矽基-尿苷-3'-O-(2-氰基乙基-N,N-二異丙基胺基)胺基亞磷酸酯。
大多數TREM以此方式合成,尤其包括:(1)精胺酸非同源TREM (例如TREM-Arg-TGA),其含有ARG-UCU-TREM之序列,但其中反密碼子序列對應於UCA而非UCU (亦即SEQ ID NO: 622);(2)絲胺酸非同源TREM (被稱為TREM-Ser-TAG),其含有SER-GCU-TREM之序列,但其中反密碼子序列對應於CUA而非GCU (亦即SEQ ID NO: 653);及(3)麩醯胺酸非同源TREM (被稱為TREM-Gln-TAA),其含有GLN-CUG-TREM之序列,但其中反密碼子序列對應於UUA而非CUG (亦即SEQ ID NO: 650)。
實例 4 : 具有末端胺基連接子之 TREM 之合成此實例描述在5'末端處具有胺基連接子的TREM分子之合成。在合成器上經由胺基亞磷酸酯化學方法將胺基連接子添加至寡核苷酸之5'端。舉例而言,TFA-胺基C6 CED胺基亞磷酸酯可併入在寡核苷酸之5'端處(化合物205)。可採用類似化學方法將胺基連接子偶聯至3'末端。
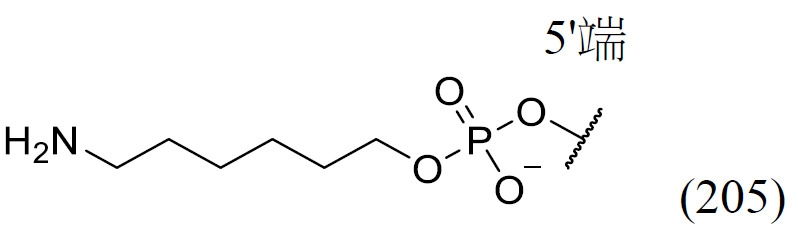
另外,胺基連接子可藉由使用包含胺基己基連接子之胺基亞磷酸酯而併入TREM序列中。在此等情況下,可使用諸如6-(4-單甲氧基三苯甲基胺基)己基-(2-氰基乙基)-(N, N-二異丙基)胺基亞磷酸酯之化合物,其可購自ChemGenes;目錄# CLP-1563。
實例 5 : 包含 ASGPR 結合部分之 TREM 之合成實例描述包含ASGPR結合部分之例示性TREM之合成。可使用將ASGPR結合部分偶聯至TREM的若干種方法,包括採用醯胺形成,且可使用基於三唑之點擊化學方法。
舉例而言,實例1中之羧酸三觸角GalNAc分子(化合物200)經由醯胺鍵形成反應與帶有胺基連接子之寡核苷酸偶聯。簡言之,將化合物200 (2當量)、HATU (1.8當量)及二異丙基乙胺(8當量)於無水乙腈(或無水DMF)中之溶液渦旋2分鐘。向此溶液中添加帶有胺基連接子之TREM (1當量) (諸如實例4中所概述之帶有胺基連接子之TREM)的水溶液。將反應混合物渦旋2分鐘且保持在室溫下60分鐘,此時在真空下移除溶劑,用水稀釋,且藉由逆相管柱層析或離子交換層析來進行純化。在GalNAc部分含有保護基之情況下,藉由適當處理移除此等保護基。舉例而言,當GalNAc部分中之游離羥基經乙醯基保護時,在室溫下進行氫氧化銨處理6小時,接著純化,得到最終GalNAc-TREM結合物(206)。

帶有游離羧酸酯之ASGPR結合部分(諸如化合物200、202及203)亦首先活化成五氟苯基酯(PFP),接著將游離胺偶聯在TREM之3'或5'末端處或在內部偶聯在核鹼基胺(例如核鹼基上之連接子)上。
另外,藉由將帶有游離羧酸酯之某些ASGPR結合部分(諸如化合物200、202及203)轉化為經N-羥基丁二醯亞胺(NHS)活化之化合物而使TREM與各種ASGPR結合部分偶聯。簡言之,將帶有羧酸酯之ASGPR結合部分溶解於二甲基甲醯胺(DMF)中,且添加N-羥基丁二醯亞胺(NHS,1.1當量)及N,N-二異丙基碳化二亞胺(1.1當量)。在室溫下攪拌溶液18小時且不經進一步純化即直接偶聯至TREM。將帶有游離胺基之TREM,諸如具有末端胺基連接子之TREM或帶有經修飾核苷酸(例如AN1或AN2)之TREM,溶解於50 mM碳酸鈉/碳酸氫鹽緩衝液pH 9.6及二甲亞碸(DMSO) 4:6 v/v之混合物中。向此溶液中添加1.2莫耳當量的NHS酯活化之ASGPR結合部分於DMF中之溶液。反應在室溫下進行1小時,其後添加另外1.2莫耳當量的含NHS酯活化之ASGPR結合部分之DMF。1小時之後,用水將反應物稀釋15倍,經由1.2 µm過濾器過濾,且藉由逆相HPLC (Xbridge C18製備型19×50 mm,使用100 mM乙酸三乙胺pH 7/95%乙腈緩衝液系統)純化。接著例如藉由用3M乙酸鈉pH 5.2及80%乙醇處理來移除ASGPR結合部分上之任何保護基。
替代地,帶有炔基之TREM分子與帶有疊氮基之ASGPR結合部分(諸如,Trebler GalNAc疊氮化物(化合物201))結合。該反應經由銅催化之疊氮化物-炔烴環加成(Saneyoshi H.等人 (2017) Bioorg. Med. Chem, 25, 3350-3356;以全文引用之方式併入本文中)進行,且使用標準技術純化,得到含三唑基之部分,諸如下方化合物207。

表12概述根據本文所提供之方案製備的含有ASGPR結合部分之TREM之清單。序列中之各TREM為未結合的(例如對照)或與以下結合:i)本文所描述之ASGPR結合部分(在表格中縮寫為「GalNAc」);ii)螢光團,諸如Cy3;及/或iii)連接子(在表格中縮寫為「5-LC-N」)。各TREM之分子量藉由LC-MS確認,其中發現所測定之分子量在各TREM之分子量計算值的+/- 0.04%內。
表 12:包含ASGPR結合部分之例示性TREM
| 化合物編號 | SEQ ID NO. | 描述詞 | 序列 | MW 計算值 |
| 99 | 622 | Arg-TGA (未結合) | GGCUCCGUGGCGCAAUGGAUAGCGCAUUGGACUUCAAAUUCAAAGGUUCCGGGUUCGAGUCCCGGCGGAGUCGCCA | |
| 100 | 623 | Arg-TGA (1-G-GalNAc - 在5'末端上連接) | [GalNAc]-[TE]-GGGCUCCGUGGCGCAAUGGAUAGCGCAUUGGACUUCAAAUUCAAAGGUUCCGGGUUCGAGUCCCGGCGGAGUCGCCA | 26,355.7 |
| 101 | 624 | Arg-TGA (16-U-GalNAc) | GGCUCCGUGGCGCAAU[GalNAc] GGAUAGCGCAUUGGACUUCAAAUUCAAAGGUUCCGGGUUCGAGUCCCGGCGGAGUCGCCA | 26,343.8 |
| 102 | 625 | Arg-TGA (20-U-GalNAc) | GGCUCCGUGGCGCAAUGGAU[GalNAc]AGCGCAUUGGACUUCAAAUUCAAAGGUUCCGGGUUCGAGUCCCGGCGGAGUCGCCA | 26,343.8 |
| 103 | 626 | Arg-TGA (47-U-GalNAc) | GGCUCCGUGGCGCAAUGGAUAGCGCAUUGGACUUCAAAUUCAAAGGU[GalNAc]UCCGGGUUCGAGUCCCGGCGGAGUCGCCA | 26,343.8 |
| 104 | 627 | Arg-TGA (16-U-GalNAc)及5'-Cy3 | [Cy3]GGCUCCGUGGCGCAAU[GalNAc]GGAUAGCGCAUUGGACUUCAAAUUCAAAGGUUCCGGGUUCGAGUCCCGGCGGAGUCGCCA | 26,851.0 |
| 105 | 628 | Arg-TGA (20-U-GalNAc)及5'-Cy3 | [Cy3]GGCUCCGUGGCGCAAUGGAU[GalNAc]AGCGCAUUGGACUUCAAAUUCAAAGGUUCCGGGUUCGAGUCCCGGCGGAGUCGCCA | 26,851.0 |
| 106 | 629 | Arg-TGA (47-U-GalNAc)及5'-Cy3 | [Cy3]GGCUCCGUGGCGCAAUGGAUAGCGCAUUGGACUUCAAAUUCAAAGGU[GalNAc]UCCGGGUUCGAGUCCCGGCGGAGUCGCCA | 26,851.0 |
| 107 | 630 | Arg-TGA (16-連接子) | GGCUCCGUGGCGCAAU[5-LC-N] GGAUAGCGCAUUGGACUUCAAAUUCAAAGGUUCCGGGUUCGAGUCCCGGCGGAGUCGCCA | 24,676.9 |
| 108 | 631 | Arg-TGA (20-連接子) | GGCUCCGUGGCGCAAUGGAU[5-LC-N]AGCGCAUUGGACUUCAAA UUCAAAGGUUCCGGGUUCGAGUCCCGGCGGAGUCGCCA | 24,676.9 |
| 109 | 632 | Arg-TGA (47-連接子) | GGCUCCGUGGCGCAAUGGAUAGCGCAUUGGACUUCAAAUUCAAAGGU[5-LC-N]UCCGGGUUCGAGUCCC GGCGGAGUCGCCA | 24,676.9 |
| 110 | 633 | Gln-TAA (16-U-GalNAc) | GGUUCCAUGGUGUAAU[GalNAc]GGUAAGCACUCUGGACUUUAAAUCCAGCGAUCCGAGUUCGAGUCUCGGUGGAACCUCCA | 25,890.5 |
| 111 | 634 | Gln-TAA (19-U-GalNAc) | GGUUCCAUGGUGUAAUGGU[GalNAc]AAGCACUCUGGACUUUAAAUCCAGCGAUCCGAGUUCGAGUCUCGGUGGAACCUCCA | 25,890.5 |
| 112 | 635 | Gln-TAA (16-U-GalNAc)及5'-Cy3 | [Cy3]GGUUCCAUGGUGUAAU[GalNAc]GGUAAGCACUCUGGACUUUAAAUCCAGCGAUCCGAGUUCGAGUCUCGGUGGAACCUCCA | 26,397.7 |
| 113 | 636 | Gln-TAA (19-U-GalNAc)及5'-Cy3 | [Cy3]GGUUCCAUGGUGUAAUGGU[GalNAc]AAGCACUCUGGACUUUAAAUCCAGCGAUCCGAGUUCGAGUCUCGGUGGAACCUCCA | 26,397.7 |
| 114 | 637 | Gln-TAA (47-U-GalNAc)及5'-Cy3 | [Cy3]GGUUCCAUGGUGUAAUGGUAAGCACUCUGGACUUUAAAUCCAGCGAU[GalNAc]CCGAGUUCGAGUCUCGGUGGAACCUCCA | 26,397.7 |
| 115 | 638 | Gln-TAA (16-連接子) | GGUUCCAUGGUGUAAU[5-LC-N]GGUAAGCACUCUGGACUUUAAAUCCAGCGAUCCGAGUUCGAGUCUCGGUGGAACCUCCA | 24,223.6 |
| 116 | 639 | Gln-TAA (19-連接子) | GGUUCCAUGGUGUAAUGGU[5-LC-N]AAGCACUCUGGACUUUAAAUCCAGCGAUCCGAGUUCGAGUCUCGGUGGAACCUCCA | 24,223.6 |
| 117 | 640 | Gln-TAA (47-連接子) | GGUUCCAUGGUGUAAUGGUAAGCACUCUGGACUUUAAAUCCAGCGA U[5-LC-N]CCGAGUUCGAGU CUCGGUGGAACCUCCA | 24,223.6 |
| 118 | 641 | Ser-TAG (1-G-GalNAc - 在5'末端上連接) | [GalNAc]-[TE]-GACGAGGUGGCCGAGUGGUUAAGGCGAUGGACUCUAAAUCCAUUGUGCUCUGCACGCGUGGGUUCGAAUCCCAUCCUCGUCGCCA | 29,170.4 |
| 119 | 642 | Ser-TAG (16-U-GalNAc) | GACGAGGUGGCCGAGU[GalNAc]GGUUAAGGCGAUGGACUCUAAAUCCAUUGUGCUCUGCACGCGUGGGUUCGAAUCCCAUCCUCGUCGCCA | 29,158.4 |
| 120 | 643 | Ser-TAG (20-U-GalNAc) | GACGAGGUGGCCGAGUGGUU[GalNAc]AAGGCGAUGGACUCUAAAUCCAUUGUGCUCUGCACGCGUGGGUUCGAAUCCCAUCCUCGUCGCCA | 29,158.4 |
| 121 | 644 | Ser-TAG (46-U-GalNAc) | GACGAGGUGGCCGAGUGGUUAAGGCGAUGGACUCUAAAUCCAUUGU[GalNAc]GCUCUGCACGCGUGGGUUCGAAUCCCAUCCUCGUCGCCA | 29,158.4 |
| 122 | 645 | Ser-TAG (20-U-GalNAc)及5'-Cy3 | [Cy3]GACGAGGUGGCCGAGUGGUU[GalNAc]AAGGCGAUGGACUCUAAAUCCAUUGUGCUCUGCACGCGUGGGUUCGAAUCCCAUCCUCGUCGCCA | 29,665.7 |
| 123 | 646 | Ser-TAG (46-U-GalNAc)及5'-Cy3 | [Cy3]GACGAGGUGGCCGAGUGGUUAAGGCGAUGGACUCUAAAUCCAUUGU[GalNAc]GCUCUGCACGCGUGGGUUCGAAUCCCAUCCUCGUCGCCA | 29,665.7 |
| 124 | 647 | Ser-TAG (16-連接子) | GACGAGGUGGCCGAGU[5-LC-N]GGUUAAGGCGAUGGACUCUAAAUCCAUUGUGCUCUGCACGCGUGGGUUCGAAUCCCAUCCUCGUCGCCA | 27,491.6 |
| 125 | 648 | Ser-TAG (20-連接子) | GACGAGGUGGCCGAGUGGUU[5-LC-N]AAGGCGAUGGACUCUAA AUCCAUUGUGCUCUGCACGCGUGGGUUCGAAUCCCAUCCUCGUCGCCA | 27,491.6 |
| 126 | 649 | Ser-TAG (46-連接子) | GACGAGGUGGCCGAGUGGUUAAGGCGAUGGACUCUAAAUCCAUUGU[5-LC-N]GCUCUGCACGCGUGGGU UCGAAUCCCAUCCUCGUCGCCA | 27,491.6 |
| 127 | 650 | Gln-TAA (未結合) | GGUUCCAUGGUGUAAUGGUAAGCACUCUGGACUUUAAAUCCAGCGAUCCGAGUUCGAGUCUCGGUGGAACCUCCA | |
| 128 | 651 | Gln-TAA-1-G-GalNAc | [GalNAc]-[TE]-GGUUCCAUGGUGUAAUGGUAAGCACUCUGGACUUUAAAUCCAGCGAUCCGAGUUCGAGUCUCGGUGGAACCUCCA | |
| 129 | 652 | Gln-TAA-47-U-GalNAc | GGUUCCAUGGUGUAAUGGUAAGCACUCUGGACUUUAAAUCCAGCGAU[GalNAc]CCGAGUUCGAGUCUCGGUGGAACCUCCA | |
| 130 | 653 | Ser-TAG (未結合) | GACGAGGUGGCCGAGUGGUUAAGGCGAUGGACUCUAAAUCCAUUGUGCUCUGCACGCGUGGGUUCGAAUCCCAUCCUCGUCGCCA | |
| 131 | 654 | Ser-TAG (16-U-GalNAc)及5'-Cy3 | [Cy3]GACGAGGUGGCCGAGU[GalNAc]GGUUAAGGCGAUGGACUCUAAAUCCAUUGUGCUCUGCACGCGUGGGUUCGAAUCCCAUCCUCGUCGCCA |
實例 6 : 作為探針的與生物素結合之 TREM 分子之合成此實例描述與生物素結合之TREM分子之合成。此等分子可例如用作GalNAc-TREM結合物模擬物,且適用於研究沿TREM序列之哪些位置適合用於標記。(+)-生物素N-羥基丁二醯亞胺酯可購自Sigma-Aldrich (目錄# H1759)。可如先前(例如實例4)所描述合成帶有游離胺之TREM分子,然後根據例如Bengstrom M.等人(1990)
Nucleos. Nucleot. Nucl. 9, 123-127中所概述之方法與(+)-生物素N-羥基丁二醯亞胺酯偶聯以形成醯胺鍵。簡言之,可將具有胺基鹼基修飾的TREM分子之溶液與過量的(+)-生物素N-羥基丁二醯亞胺酯混合在一起且在37℃渦旋若干小時。使用LCMS分析來判定反應是否完成。在真空下移除溶劑,且所得殘餘物用水稀釋,接著使用逆相管柱層析進行純化,得到最終化合物(例如化合物208)。
舉例而言,生物素部分在位置20及位置47處安裝於精胺酸非同源TREM分子上,分別稱為TREM-Arg-TGA-生物素-20及TREM-Arg-TGA-Biotin-47。精胺酸非同源TREM分子含有ARG-UCU-TREM主體序列,但其中反密碼子序列對應於UCA而非UCU。

實例 7 : 作為探針的與生物素結合之 TREM 分子之合成此實例描述在5'末端處與生物素結合的TREM分子之合成。(+)-生物素N-羥基丁二醯亞胺酯可購自Sigma-Aldrich (目錄# H1759)。可例如如實例4中所描述製備在5'端處具有胺基連接子的TREM分子。經胺基修飾之TREM然後根據例如Bengstrom M.等人(1990)
Nucleos. Nucleot. Nucl. 9, 123-127中所概述之方法與(+)-生物素N-羥基丁二醯亞胺酯偶聯以形成醯胺鍵。簡言之,可將經胺基修飾之TREM之溶液與過量的(+)-生物素N-羥基丁二醯亞胺酯混合在一起且在37℃渦旋若干小時。使用LCMS分析來判定反應是否完成。在真空下移除溶劑,且所得殘餘物用水稀釋,接著使用逆相管柱層析進行純化,得到最終化合物(例如化合物209)。
舉例而言,生物素部分安裝於精胺酸非同源TREM分子上,被稱作TREM-Arg-TGA-5'-生物素。精胺酸非同源TREM分子含有ARG-UCU-TREM主體序列,但其中反密碼子序列對應於UCA而非UCU。

實例 8 : 經由 HPLC 對 GalNAc-TREM 之分析實例描述經由HPLC對GalNAc-TREM分子之分析。GalNAc-TREM分子可藉由HPLC分析,例如以評估組合物之純度及均質性。使用Waters BEH C18管柱(2.1 mm × 50 mm × 1.7 μm)之Waters Aquity UPLC系統可用於此分析。可藉由將0.5 nmol寡核苷酸溶解於75 μL水中且注射2 μL溶液來準備樣品。所用緩衝液可為:50 mM乙酸二甲基己基銨 + 10% CH
3CN (乙腈)作為緩衝液A,及50 mM乙酸二甲基己基銨 + 75% CH
3CN作為緩衝液B (梯度25-75%緩衝液B經5 min),其中流動速率在60℃下為0.5 mL/min。
實例 9 : 經由質譜法對 GalNAc-TREM 之分析實例描述對GalNAc-TREM分子之質譜分析。可在Thermo Ultimate 3000-LTQ-XL質譜儀上獲取寡核苷酸之ESI-LCMS資料。可藉由將0.5 nmol寡核苷酸溶解於75 μL水中且將10 μL溶液直接注射至Novatia C18 (HTCS-HTC1-4)捕集管柱上來準備樣品。在注射至捕集管柱中之後,可將樣品在LTQ-MS上用85% CH
3CN、50 mM HFIP (六氟-2-丙醇)、10 μM EDTA (乙二胺四乙酸)、0.35% DIPEA (N,N-二異丙基乙胺)直接溶離,且測定質荷比(m/z)。
實例 10. GalNAc-TREM 至表現 ASGPR 之細胞的活體外遞送此實例描述例示性的與GalNAc結合之TREM在自主條件(不存在轉染劑)下至表現ASGPR之U2OS細胞中的活體外遞送。此實例中所描述之方法可用於評估在遞送之後表現ASGR之細胞中GalNAc-TREM之水準。
宿主細胞修飾使用質體轉染及選擇產生經工程改造以穩定表現ASGP受體(ASGPR)之U2OS細胞株。簡言之,細胞用編碼ASGPRI基因之質體及嘌呤黴素選擇卡匣共轉染。次日,用嘌呤黴素選擇細胞。擴增剩餘細胞且測試ASGPR表現。
GalNAc-TREM 在自主條件下之遞送收集經ASGPR工程改造之U2OS細胞且將其在完全生長培養基中稀釋至4×10
4個細胞/毫升,且將100 μL稀釋的細胞懸浮液添加在96孔盤(3904,Corning,USA)中。將盤置放於37℃、5% CO
2之培育箱中,使細胞附著於孔底。20至24小時後,將在5'末端經螢光團(Cy3)修飾之各種GalNAc-TREM在無RNase水中稀釋至10倍濃度(例如,1000 nM),且以1:10稀釋添加至孔中。將盤置放於37℃、5% CO
2培育箱中20至24小時,隨後進行tRNA定量分析以測定GalNAc-TREM之細胞內水準。
使用活體成像之定量 tRNA 遞送tRNA遞送後20至24小時,將盤自培育箱中取出。在抽吸培養基之後,將(Hoechest 33342;Thermofisher,USA)在完全生長培養基中稀釋至1:10,000,且添加至細胞中。將盤在室溫(約25℃)下培育10分鐘,接著用1× DPBS洗滌6次。在最後一次洗滌之後,向盤中添加完全生長培養基(100微升/孔)。隨後在20X放大率下,在具有三個通道(Cy3/DAPI/亮場)之ImageXpress Pico顯微鏡(Molecular Device,USA)下對盤進行成像。Cy3通道之平均強度藉由來自顯微鏡軟體之「細胞評分」功能進行定量。藉由用螢光顯微法觀測Cy3標籤來偵測表現ASGPR1之U2OS細胞對於在沿TREM之三個不同位置處與GalNAc結合之Gln-TAA (化合物112、113及114)的自由吸收(圖1A至圖1F)。陰性對照細胞(圖1G至圖1H)暴露於未結合之Gln-TAA TREM,而陽性對照(圖1I至圖1J)暴露於利用RNAiMAX轉染試劑經GalNAc修飾之Gln-TAA TREM。圖2為顯微結果之平均強度之定量,其表明TREM之自由吸收與經轉染促進的TREM之吸收同樣好。在經Ser-TAG (化合物122及123;圖3A至圖3H及圖4)及Arg-TGA (化合物104、105及106;圖5A至圖5J及圖6)修飾之TREM的情況下獲得類似結果。
實例 11. GalNAc-TREM 至原代人類肝細胞之活體外遞送此實例描述與GalNAc結合之TREM在自主條件(不存在轉染劑)下至原代人類肝細胞中的活體外遞送。此實例中所描述之方法可用於評估在遞送之後肝細胞中GalNAc-TREM之水準。
將一個Liverpool冷凍小瓶(10種供體人類可冷凍接種之肝細胞(X008001-P,BioIVT,USA))小心地解凍,且在以37℃預溫熱之INVITROGRO CP培養基中稀釋。使用細胞計數器測定總細胞計數及活細胞數目。在成功解凍程序的情況下,預期具有>70%存活率。將細胞進一步稀釋至7× 10
5個活細胞/毫升,且將70 μL稀釋的細胞懸浮液接種於經膠原蛋白塗佈之96孔盤(354649,Corning,USA)中。將盤輕輕地前後左右振盪以使細胞均勻分佈。將盤置放於37℃、5% CO
2培育箱中。2小時後,用INVITROGRO CP培養基小心地洗滌盤。將GalNAc-TREM在生長培養基中稀釋至工作濃度(例如100 nM)且添加至孔中。將盤置放於37℃、5% CO
2培育箱中20至24小時,隨後進行tRNA定量分析以測定GalNAc-TREM之細胞內水準。
使用 Cy3 活體成像之定量 tRNA 遞送tRNA遞送後20至24小時,將盤自培育箱中取出。在抽吸培養基之後,將Hoechest 33342 (62249,Thermofisher,USA)在INVITROGRO CP培養基中稀釋至1:10,000,且添加至細胞中。將盤在室溫(約25℃)下培育10分鐘,接著用1× DPBS洗滌6次。在最後一次洗滌之後,向盤中添加INVITROGRO CP培養基(100微升/孔)。隨後在20X放大率下,在具有三個通道(Cy3/DAPI/亮場)之ImageXpress Pico顯微鏡(Molecular Device,USA)下對盤進行成像。Cy3通道之平均強度藉由來自顯微鏡軟體之「細胞評分」功能進行定量。圖7A至圖7J描繪與Cy3結合的經修飾之Gln-TAA TREM之螢光顯微影像。原代人類肝細胞對TREM之自由吸收之效率與同TREM及轉染試劑一起培育之細胞一樣或更佳。圖8為如藉由平均強度所量測的各TREM之吸收的定量。在Ser-TAG TREM (圖9A至圖9H及圖10)及Arg-TGA TREM (圖11A至圖11J及圖12)的情況下獲得類似結果。
實例 12. 經由以轉染方式投與包含 ASGPRG 結合部分之 TREM 對 報導蛋白中之提前終止密碼子 (PTC) 之連讀此實例描述用以測試攜帶ASGPR結合部分之非同源TREM (「GalNAc-TREM」)連讀表現具有PTC之蛋白質的細胞中之PTC的能力的分析。此實例描述三種不同的經GalNAc修飾之TREM (Gln-TAA、Ser-TAG或Arg-TGA),但亦可使用指定其他19種胺基酸中之任一者的TREM。所測試之特異性GalNAc TREM概述於上表12中。
宿主細胞修飾經工程改造以穩定表現含有提前終止密碼子(PTC)之NanoLuc報導構築體的細胞株可根據製造商說明書,使用FlpIn系統產生。
經由轉染將非同源 GalNAc-TREM 遞送至宿主細胞中為確保各TREM之適當摺疊,將GalNAc-TREM在85℃下加熱2分鐘且隨後在4℃下快速冷卻5分鐘。為了將GalNAc-TREM遞送至NanoLuc報導細胞中,根據製造商說明書,使用脂染胺RNAiMAX (ThermoFisher Scientific,USA)對NanoLuc報導細胞進行反向轉染反應。簡言之,將5 μL的2.5 μM GalNAc-TREM溶液稀釋於20 μL RNAiMAX/OptiMEM混合物中。在室溫下輕輕混合30分鐘後,將25 μL GalNAc-TREM/轉染混合物添加至96孔盤中且在添加細胞之前再保持20至30分鐘。收集NanoLuc報導細胞且在完全生長培養基中稀釋至4×10
5個細胞/毫升,且將100 μL稀釋的細胞懸浮液添加至含有GalNAc-TREM之盤中並混合。24小時之後,將100 μL完全生長培養基添加至96孔盤中以用於細胞健康。
轉譯抑制分析為了監測GalNAc-TREM在GalNAc-TREM遞送至細胞中之後48小時連讀報導構築體中之PTC的功效,可根據製造商說明書進行NanoGlo生物發光分析(Promega,USA)。簡言之,更換細胞培養基且使其平衡至室溫。藉由將緩衝液與受質以50:1比率混合來製備NanoGlo試劑。將50 μL混合NanoGlo試劑添加至96孔盤中並在振盪器上以600 rpm混合10分鐘。2分鐘後,將盤以1000 g離心,隨後在室溫下進行5分鐘培育步驟,之後量測樣品生物發光。作為陽性對照,使用表現不具有PTC之NanoLuc報導構築體的宿主細胞。作為陰性對照,使用表現具有PTC之NanoLuc報導構築體的宿主細胞,但無GalNAc-TREM經轉染。以實驗樣品中NanoLuc發光與陽性對照之NanoLuc發光之比率或以實驗樣品中NanoLuc發光與陰性對照之NanoLuc發光之比率來量測GalNAc-TREM的功效。預期若GalNAc-TREM為功能性的,則其可能夠連讀NanoLuc報導體中之終止突變且產生高於陰性對照中量測之發光讀數的發光讀數。若GalNAc-TREM不具功能性,則未拯救終止突變,且偵測到更少或等於陰性對照之發光。各自在不同位置處用GalNAc修飾之Gln-TAA TREM在ASGPR1-U2OS-nLuc-PTC報導細胞中展現出濃度依賴性連讀能力(圖13)。Ser-TAG及Arg-TGA TREM展現出類似的濃度依賴性連讀能力(圖14及圖15)。
評估在TREM序列中包括ASGPR結合部分之影響,且概述於下表13中。各經修飾TREM之資料以相比於模擬物樣品之log2倍數變化形式提供,其中「1」指示小於4.00之log2倍數變化;「2」指示大於或等於4.01之log2倍數變化且小於7.00之log2倍數變化;且「3」指示大於或等於7.01之log2倍數變化。結果顯示ASGPR結合部分及其他修飾在許多位置處耐受,但特定位點對修飾敏感或在經修飾時展現經改良之活性。
表 13:經ASGPR結合部分修飾之例示性TREM之連讀能力
| 化合物編號 | 結果 |
| 100 | 1 |
| 101 | 2 |
| 102 | 2 |
| 103 | 2 |
| 104 | 2 |
| 105 | 2 |
| 106 | 2 |
| 107 | 2 |
| 108 | 2 |
| 109 | 2 |
| 110 | 2 |
| 111 | 2 |
| 112 | 2 |
| 113 | 2 |
| 114 | 3 |
| 115 | 3 |
| 116 | 3 |
| 117 | 3 |
| 118 | 1 |
| 119 | 3 |
| 120 | 1 |
| 121 | 1 |
| 122 | 1 |
| 123 | 1 |
| 124 | 3 |
| 125 | 3 |
| 126 | 3 |
實例 13 : 在表現 ASGPR 之細胞中經由投與包含 ASGPR 結合部分之 TREM 對 報導蛋白中之提前終止密碼子 (PTC) 之 連讀此實例描述用以測試非同源GalNAc-TREM連讀表現具有PTC之報導蛋白的細胞株中之PTC的能力的分析。此實例描述某些TREM序列,但可使用指定20種胺基酸中之任一者的非同源TREM。
宿主細胞修飾經工程改造以穩定表現ASGPR及含有提前終止密碼子(PTC)之NanoLuc報導構築體的細胞株可根據製造商說明書,使用FlpIn系統產生。簡言之,根據製造商說明書,使用Lipofectamine2000用含有具有PTC之Nanoluc報導體的表現載體(諸如pcDNA5/FRT-NanoLuc-TAA及pOG44 Flp-重組酶表現載體)對HEK293T (293T ATCC ® CRL-3216)細胞進行共轉染。在24小時之後,用新鮮培養基更換培養基。次日,將細胞以1:2分離且用100 μg/mL潮黴素進行選擇,持續5天。擴增剩餘細胞且測試報導構築體表現。在該擴增步驟之後,細胞用編碼ASGRI基因之質體及選擇卡匣(諸如嘌呤黴素卡匣)共轉染。次日,用嘌呤黴素選擇細胞。擴增剩餘細胞且測試ASGPR表現。
非同源 GalNAc-TREM 之合成及製備在此實例中,產生精胺酸非同源GalNAc-TREM,使得其含有ARG-UCU-TREM主體之序列但其中反密碼子序列對應於UCA而非UCU,且與GalNAc部分結合。精胺酸非同源GalNAc-TREM可如先前所描述合成且其品質使用如本文所描述之方法控制。為確保適當摺疊,將TREM在85℃下加熱2分鐘且隨後在4℃下快速冷卻5分鐘。
將非同源 GalNAc-TREM 遞送至宿主細胞中如本文所描述,可以自主方式或使用轉染試劑將100 nM精胺酸非同源GalNAc-TREM遞送至哺乳動物細胞。
轉譯抑制分析為了監測精胺酸非同源GalNAc-TREM連讀報導構築體中之PTC的功效,在TREM遞送之後大約24至48小時評估細胞。更換細胞培養基且使細胞平衡至室溫。將與細胞培養基相等體積之ONE-Glo™ EX試劑添加至孔中且在定軌振盪器上以500 rpm混合3分鐘,接著添加與細胞培養基相等體積之NanoDLR™ Stop & Glo,且接著在定軌振盪器上以500 rpm混合3分鐘。在室溫下培育反應物10分鐘且藉由在盤讀取器中讀取發光來偵測NanoLuc活性。作為陽性對照,使用表現不具有PTC之NanoLuc報導構築體的宿主細胞。作為陰性對照,使用表現具有PTC之NanoLuc報導構築體的宿主細胞,但無GalNAc-TREM經轉染。可以實驗樣品中NanoLuc發光與陽性對照之NanoLuc發光之比率來量測GalNAc-TREM的功效。預期若精胺酸非同源TREM為功能性的,則可出現NanoLuc報導體中之終止突變之連讀,且產生高於陰性對照中量測之發光讀數的發光讀數。若精胺酸非同源TREM不具功能性,則終止突變可未經拯救,且偵測到更少或等於陰性對照之發光。
實例 14 : 經由投與包含 ASGPR 結合部分之 TREM 對 α - 半乳糖苷酶 (GLA) ORF 中之 提前終止密碼子 (PTC) 之連讀此實例描述用以測試非同源GalNAc-TREM在肝細胞中連讀α-半乳糖苷酶(GLA)開讀框(ORF)中之PTC (諸如R220X)的能力的分析,該等肝細胞係自再程式化的來源於法布立病(Fabry disease)患者之細胞株分化而來。此實例描述精胺酸非同源GalNAc-TREM,但可使用指定其他19種胺基酸中之任一者的非同源TREM。
來源於患者之細胞在α-半乳糖苷酶(GLA)開讀框(ORF)中具有PTC (諸如R220X)的來源於法布立病患者之纖維母細胞可獲自中心或組織,諸如Coriell Institute (目錄# GM00881及GM02769)。來源於患者之纖維母細胞經再程式化為iPSC,且如先前所示分化成肝細胞(Takahashi, K.及Yamanaka, S. (2006)
Cell 126, 663-676 (2006);Park I.等人 (2008)
Nature 451, 141-146);Jia, B.等人 (2014)
Life Sci. 108, 22-29)。
非同源 GalNAc-TREM 之合成及製備在此實例中,產生精胺酸非同源GalNAc-TREM,使得其含有ARG-UCU-TREM主體之序列但其中反密碼子序列對應於UCA而非UCU,且與GalNAc部分結合。精胺酸非同源GalNAc-TREM如先前所描述合成且其品質使用如實例
8 至 9中所描述之方法控制。為確保適當摺疊,將TREM在85℃下加熱2分鐘且隨後在4℃下快速冷卻5分鐘。
將非同源 GalNAc-TREM 遞送至肝細胞中可以自主方式將100 nM精胺酸非同源GalNAc-TREM遞送至源自來源於法布立病患者之纖維母細胞的iPSC衍生之肝細胞中。
轉譯抑制分析為了監測精胺酸非同源GalNAc-TREM連讀GLA ORF中之PTC的功效,在轉染後24至48小時,更換細胞培養基,且溶解細胞。使用西方墨點法偵測,非同源GalNAc-TREM功效經量測為與未接受TREM之對照肝細胞中發現之GLA表現量相比,給予Arg非同源TREM之再程式化肝細胞中全長蛋白質(在此實例中為GLA酶)之表現量。舉例而言,作為對照,可使用不受疾病影響的個人之細胞(亦即,具有含WT GLA轉錄物之ORF的細胞)。預期若非同源GalNAc-TREM為功能性的,則其可連讀PTC,且將偵測到比尚未投與非同源GalNAc-TREM之再程式化肝細胞中發現之水準更高的全長蛋白質水準。若非同源GalNAc-TREM不具功能性,則將偵測到與尚未投與非同源GalNAc-TREM的來源於患者之纖維母細胞或再程式化肝細胞中所偵測到的水準類似的全長蛋白質水準。
實例 15 : 經由投與包含 ASGPR 結合部分之 TREM 對 α - 半乳糖苷酶 (GLA) ORF 中之 提前終止密碼子 (PTC) 進行 連讀以產生功能性 GLA 蛋白質此實例描述用以測試非同源GalNAc-TREM在肝細胞中連讀α-半乳糖苷酶(GLA)開讀框(ORF)中之PTC (諸如R220X)以產生功能性GLA蛋白質的能力的分析,該等肝細胞係自再程式化的來源於法布立病患者之細胞株分化而來。此實例描述精胺酸非同源GalNAc-TREM,但可使用指定其他19種胺基酸中之任一者的非同源TREM。在α-半乳糖苷酶(GLA)開讀框(ORF)中具有PTC (諸如R220X)的來源於法布立病患者之纖維母細胞可獲自中心或組織,諸如Coriell Institute (目錄# GM00881及GM02769)。細胞可根據實例14中所提供之例示性方案再程式化及分化。
為了監測由於精胺酸非同源GalNAc-TREM介導之PTC連讀而產生的GLA蛋白質之功能性,可根據製造商說明書,使用α半乳糖苷酶活性分析套組(Abcam)進行GLA蛋白質活性分析。替代地,可使用人工受質4-甲基傘形基-α-D-半乳糖苷來測定GLA活性,如先前在Desnick RJ等人,
J Lab Clin Med.1973; 81:157-71中所描述。
實例 16 : 藉由投與 GalNAc-TREM 對 ORF 中之錯義突變進行校正此實例描述投與GalNAc-TREM以校正錯義突變。在此實例中,GalNAc-TREM藉由在蛋白質中併入WT胺基酸(在錯義位置處)將具有錯義突變之報導體轉譯為野生型(WT)蛋白質。
宿主細胞修飾可根據製造商說明書,使用FlpIn系統產生穩定表現含有錯義突變之GFP報導構築體(例如T203I或E222G,其防止在470 nm及390 nm波長下之GFP激發)的細胞株。簡言之,根據製造商說明書,使用脂染胺2000用含有具有錯義突變之GFP報導體的表現載體(諸如pcDNA5/FRT-NanoLuc-TAA及pOG44 Flp-重組酶表現載體)對HEK293T (293T ATCC ® CRL-3216)細胞進行共轉染。在24小時之後,用新鮮培養基更換培養基。次日,將細胞以1:2分離且用100 μg/mL潮黴素進行選擇,持續5天。擴增剩餘細胞且測試報導構築體表現。
將非同源 GalNAc-TREM 轉染至宿主細胞中為了將GalNAc-TREM遞送至哺乳動物細胞中,根據製造商說明書,使用脂染胺2000試劑將100 nM TREM轉染至表現具有錯義突變之ORF的細胞中。在6至18小時之後,移除轉染培養基且用新鮮完全培養基更換。
錯義突變校正分析為了監測GalNAc-TREM校正報導構築體中之錯義突變之功效,在自主遞送GalNAc-TREM之後24至48小時,更換細胞培養基,且量測細胞螢光。未與GalNAc部分結合之TREM用作實驗中之陰性對照,且表現WT GFP之細胞用作分析之陽性對照。若GalNAc-TREM為功能性的,則預期GFP蛋白質在使用螢光計以390 nm激發波長照射時發螢光,如陽性對照中所觀測到。若GalNAc-TREM不具功能性,則GFP蛋白質僅在以470 nm波長激發時發螢光,如陰性對照中所觀測到,指示錯義突變未校正。
實例 17 : 藉由投與 GalNAc-TREM 評估含 SMC 之 ORF 之蛋白質表現量此實例描述投與GalNAc-TREM以改變含SMC之ORF之表現量。
為了建立研究GalNAc-TREM投與對於含SMC之蛋白質之蛋白質表現量的影響(在此實例中,來自編碼脂肪營養蛋白之PNPL3A基因)的系統,將含有PNPL3A rs738408 ORF序列的質體轉染於正常人類肝細胞細胞株THLE-3中,藉由CRISPR/Cas編輯以在PNPLA3之編碼外顯子中含有框移突變,從而基因敲除內源性PNPLA3 (THLE-3_PNPLA3KO細胞)。作為對照,THLE-3_PNPLA3KO細胞之等分試樣經含有野生型PNPL3A ORF序列之質體轉染。
評估含 SMC 之 ORF 之蛋白質水準將GalNAc-TREM遞送至含有rs738408 ORF序列之THLE-3_PNPLA3KO細胞以及遞送至含有野生型PNPL3A ORF序列之THLE-3_PNPLA3KO細胞。在此實例中,GalNAc-TREM含有含AGG反密碼子之脯胺酸同功受體,該AGG反密碼子與CCT密碼子成鹼基對,亦即具有序列GGCUCGUUGGUCUAGGGGUAUGAUUCUCGCUUAGGGUGCG AGAGGUCCCGGGUUCAAAUCCCGGACGAGCCC。時程係在30分鐘至6小時範圍內,使用長達一小時的間隔時間點進行。在各時間點,使細胞胰蛋白酶化,洗滌且溶解。藉由西方墨點法分析細胞溶解物且用針對脂肪營養蛋白之抗體探測墨點。亦探測總蛋白質內參考物(諸如GAPDH、肌動蛋白或微管蛋白)作為內參考物。
可採用此實例中所描述之方法來評估含有rs738408 ORF之細胞中脂肪營養蛋白之表現量。
實例 18 : 藉由 GalNAc-TREM 投與調節含 SMC 之 ORF 之蛋白質轉譯速率此實例描述投與GalNAc-TREM以改變含SMC之ORF之蛋白質轉譯速率。
為監測GalNAc-TREM添加對轉譯延長速率之影響,使用活體外轉譯系統(在此實例中為RRL系統(Promega)),其中報導基因(GFP)隨時間推移之螢光變化為轉譯速率之替代物。
評估含 SMC 之 ORF 之蛋白質轉譯速率首先,可產生使用靶向反密碼子與可變環之間的序列之反義寡核苷酸使內源性tRNA耗乏之哺乳動物溶解物(參見例如Cui等人2018. Nucleic Acids Res. 46(12):6387-6400)。在此實例中,除了0.1至0.5 μg/μL編碼藉由連接子融合至GFP ORF之野生型TERT ORF的mRNA或編碼藉由連接子融合至GFP ORF之rs2736098 TERT的mRNA以外,將包含含有與GCA密碼子成鹼基對之UGC反密碼子(亦即,具有序列GGGGAUGUAGCUCAGUGGUAGAGCGCAUGCUUUGCAUGUAUGAGGUCCCGGGUUCGAUCCCCGGCAUCUCCA)之丙胺酸同功受體的TREM添加至活體外轉譯分析溶解物中。藉由使用λ
ex485/λ
em528,在37℃下的微量盤讀取器上之螢光增加來監測GFP mRNA轉譯之進程,其中資料點歷經1小時之時段每30秒收集一次。繪製隨時間推移之螢光變化量以判定與添加及不添加GalNAc-TREM之rs2736098 ORF相比,野生型ORF之轉譯延長速率。可採用此實例中所描述之方法來評估在GalNAc-TREM存在或不存在下rs2736098 ORF及野生型ORF之轉譯速率。
圖1A至圖1J為描繪表現ASGPR之U2OS細胞的影像,該等細胞經本文所描述的包含ASGPR結合部分之例示性TREM轉染。在此實驗中,藉由螢光顯微法監測及觀測在沿序列之各種位置處具有ASGPR結合部分且與Cy3結合的包含SEQ ID NO. 650主鏈之TREM之吸收。
圖2為圖1A至圖1J之螢光顯微結果的圖形表示。結果描繪為關於給予細胞之寡核苷酸濃度(nM)的平均強度。
圖3A至圖3H為描繪表現ASGPR之U2OS細胞的影像,該等細胞經本文所描述的包含ASGPR結合部分之例示性TREM轉染。在此實驗中,藉由螢光顯微法監測及觀測在沿序列之各種位置處具有ASGPR結合部分且與Cy3結合的包含SEQ ID NO. 650主鏈之TREM之吸收。
圖4為圖3A至圖3H之螢光顯微結果的圖形表示。結果描繪為關於給予細胞之寡核苷酸濃度(nM)的平均強度。
圖5A至圖5J為描繪表現ASGPR之U2OS細胞的影像,該等細胞經本文所描述的包含ASGPR結合部分之例示性TREM轉染。在此實驗中,藉由螢光顯微法監測及觀測在沿序列之各種位置處具有ASGPR結合部分且與Cy3結合的包含SEQ ID NO. 622主鏈之TREM之吸收。
圖6為圖5A至圖5J之螢光顯微結果的圖形表示。結果描繪為關於給予細胞之寡核苷酸濃度(nM)的平均強度。
圖7A至圖7J為描繪原代人類肝細胞對如本文所描述的包含ASGPR結合部分之例示性TREM之吸收的影像。在此實驗中,藉由螢光顯微法監測及觀測在沿序列之各種位置處具有ASGPR結合部分且與Cy3結合的包含SEQ ID NO. 650主鏈之TREM之吸收。
圖8為圖7A至圖7J之螢光顯微結果的圖形表示。結果描繪為關於給予細胞之寡核苷酸濃度(nM)的平均強度。
圖9A至圖9H為描繪原代人類肝細胞對如本文所描述的包含ASGPR結合部分之例示性TREM之吸收的影像。在此實驗中,藉由螢光顯微法監測及觀測在沿序列之各種位置處具有ASGPR結合部分且與Cy3結合的包含SEQ ID NO. 653主鏈之TREM之吸收。
圖10為圖9A至圖9H之螢光顯微結果的圖形表示。結果描繪為關於給予細胞之寡核苷酸濃度(nM)的平均強度。
圖11A至圖11J為描繪原代人類肝細胞對如本文所描述的包含ASGPR結合部分之例示性TREM之吸收的影像。在此實驗中,藉由螢光顯微法監測及觀測在沿序列之各種位置處具有ASGPR結合部分且與Cy3結合的包含SEQ ID NO. 622主鏈之TREM之吸收。
圖12為圖11A至圖11J之螢光顯微結果的圖形表示。結果描繪為關於給予細胞之寡核苷酸濃度(nM)的平均強度。
圖13為描繪表現ASGPR之U2OS細胞對例示性TREM之吸收的結果的曲線圖,該等細胞經nLUC-提前終止密碼子(PTC)報導子轉染。使用RNAiMAX轉染試劑對在沿序列之一位置處包含ASGPR結合部分的包含SEQ ID NO. 650主鏈之例示性TREM進行轉染。結果展示為相對於模擬物(無TREM)樣品之倍數變化。
圖14為描繪表現ASGPR之U2OS細胞對例示性TREM之吸收的結果的曲線圖,該等細胞經nLUC-提前終止密碼子(PTC)報導子轉染。使用RNAiMAX轉染試劑對在沿序列之一位置處包含ASGPR結合部分的包含SEQ ID NO. 653主鏈之例示性TREM進行轉染。結果展示為相對於模擬物(無TREM)樣品之倍數變化。
圖15為描繪表現ASGPR之U2OS細胞對例示性TREM之吸收的結果的曲線圖,該等細胞經nLUC-提前終止密碼子(PTC)報導子轉染。使用RNAiMAX轉染試劑對在沿序列之一位置處包含ASGPR結合部分的包含SEQ ID NO. 622主鏈之例示性TREM進行轉染。結果展示為相對於模擬物(無TREM)樣品之倍數變化。
<![CDATA[<110> 美商旗艦先鋒創新有限責任(VII)公司 (FLAGSHIP PIONEERING, INC.)]]>
<![CDATA[<120> 經修飾TREM之組合物及其用途]]>
<![CDATA[<140> TW 110148799]]>
<![CDATA[<141> 2021-12-24]]>
<![CDATA[<150> 63/130,373]]>
<![CDATA[<151> 2020-12-23]]>
<![CDATA[<150> 63/130,374]]>
<![CDATA[<151> 2020-12-23]]>
<![CDATA[<150> 63/130,375]]>
<![CDATA[<151> 2020-12-23]]>
<![CDATA[<150> 63/130,377]]>
<![CDATA[<151> 2020-12-23]]>
<![CDATA[<150> 63/130,381]]>
<![CDATA[<151> 2020-12-23]]>
<![CDATA[<150> 63/130,387]]>
<![CDATA[<151> 2020-12-23]]>
<![CDATA[<160> 1291 ]]>
<![CDATA[<170> PatentIn 版本 3.5]]>
<![CDATA[<210> 1]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 1]]>
gggggtatag ctcagtggta gagcgcgtgc ttagcatgca cgaggtcctg ggttcgatcc 60
ccagtacctc ca 72
<![CDATA[<210> 2]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 2]]>
ggggaattag ctcaagtggt agagcgcttg cttagcacgc aagaggtagt gggatcgatg 60
cccacattct cca 73
<![CDATA[<210> 3]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 3]]>
ggggaattag ctcaaatggt agagcgctcg cttagcatgc gagaggtagc gggatcgatg 60
cccgcattct cca 73
<![CDATA[<210> 4]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 4]]>
ggggaattag ctcaagtggt agagcgcttg cttagcatgc aagaggtagt gggatcgatg 60
cccacattct cca 73
<![CDATA[<210> 5]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 5]]>
ggggaattag ctcaagcggt agagcgcttg cttagcatgc aagaggtagt gggatcgatg 60
cccacattct cca 73
<![CDATA[<210> 6]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 6]]>
ggggaattag ctcaagtggt agagcgcttg cttagcatgc aagaggtagt gggatcaatg 60
cccacattct cca 73
<![CDATA[<210> 7]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 7]]>
ggggaattag ctcaagtggt agagcgctcg cttagcatgc gagaggtagt gggatcgatg 60
cccgcattct cca 73
<![CDATA[<210> 8]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 8]]>
ggggaattag cccaagtggt agagcgcttg cttagcatgc aagaggtagt gggatcgatg 60
cccacattct cca 73
<![CDATA[<210> 9]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 9]]>
gggggtgtag ctcagtggta gagcgcgtgc ttagcatgca cgaggccccg ggttcaatcc 60
ccggcacctc ca 72
<![CDATA[<210> 10]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 10]]>
gggggtgtag ctcagtggta gagcgcgtgc ttagcatgta cgaggtcccg ggttcaatcc 60
ccggcacctc ca 72
<![CDATA[<210> 11]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 11]]>
ggggatgtag ctcagtggta gagcgcatgc ttagcatgca tgaggtcccg ggttcgatcc 60
ccagcatctc ca 72
<![CDATA[<210> 12]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 12]]>
gggggtgtag ctcagtggta gagcgcgtgc ttagcatgca cgaggccctg ggttcaatcc 60
ccagcacctc ca 72
<![CDATA[<210> 13]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 13]]>
gggggtatag ctcagcggta gagcgcgtgc ttagcatgca cgaggtcctg ggttcaatcc 60
ccaatacctc ca 72
<![CDATA[<210> 14]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 14]]>
gggggtgtag ctcagtggta gagcgcgtgc ttagcatgca cgaggccccg ggttcaatcc 60
ctggcacctc ca 72
<![CDATA[<210> 15]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 15]]>
gggggattag ctcaaatggt agagcgctcg cttagcatgc gagaggtagc gggatcgatg 60
cccgcatcct cca 73
<![CDATA[<210> 16]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 16]]>
ggggaattag ctcaggcggt agagcgctcg cttagcatgc gagaggtagc gggatcgacg 60
cccgcattct cca 73
<![CDATA[<210> 17]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 17]]>
ggggatgtag ctcagtggta gagcgcatgc ttcgcatgta tgaggtcccg ggttcgatcc 60
ccggcatctc ca 72
<![CDATA[<210> 18]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 18]]>
ggggatgtag ctcagtggta gagcgcatgc ttcgcatgta tgaggccccg ggttcgatcc 60
ccggcatctc ca 72
<![CDATA[<210> 19]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 19]]>
ggggatgtag ctcagtggta gagcgcgcgc ttcgcatgtg tgaggtcccg ggttcaatcc 60
ccggcatctc ca 72
<![CDATA[<210> 20]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 20]]>
gggggtgtag ctcagtggta gagcgcgtgc ttcgcatgta cgaggccccg ggttcgaccc 60
ccggctcctc ca 72
<![CDATA[<210> 21]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 21]]>
gggggtgtag ctcagtggta gagcgcatgc tttgcatgta tgaggtcccg ggttcgatcc 60
ccggcacctc ca 72
<![CDATA[<210> 22]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 22]]>
ggggatgtag ctcagtggta gagcgcatgc tttgcatgta tgaggtcccg ggttcgatcc 60
ccggcatctc ca 72
<![CDATA[<210> 23]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 23]]>
ggggatgtag ctcagtggta gagcgcatgc tttgcatgta tgaggccccg ggttcgatcc 60
ccggcatctc ca 72
<![CDATA[<210> 24]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 24]]>
ggggatgtag ctcagtggta gagcgcatgc tttgcacgta tgaggccccg ggttcaatcc 60
ccggcatctc ca 72
<![CDATA[<210> 25]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 25]]>
gggggtgtag ctcagtggta gagcgcatgc tttgcatgta tgaggcctcg ggttcgatcc 60
ccgacacctc ca 72
<![CDATA[<210> 26]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 26]]>
gggggtgtag ctcagtggta gagcacatgc tttgcatgtg tgaggccccg ggttcgatcc 60
ccggcacctc ca 72
<![CDATA[<210> 27]]>
<![CDATA[<211> 71]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 27]]>
gggggtgtag ctcagtggta gagcgcatgc tttgcatgta tgaggcctcg gttcgatccc 60
cgacacctcc a 71
<![CDATA[<210> 28]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 28]]>
gggccagtgg cgcaatggat aacgcgtctg actacggatc agaagattcc aggttcgact 60
cctggctggc tcg 73
<![CDATA[<210> 29]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 29]]>
gggccagtgg cgcaatggat aacgcgtctg actacggatc agaagattct aggttcgact 60
cctggctggc tcg 73
<![CDATA[<210> 30]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 30]]>
ggccgcgtgg cctaatggat aaggcgtctg attccggatc agaagattga gggttcgagt 60
cccttcgtgg tcg 73
<![CDATA[<210> 31]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 31]]>
gacccagtgg cctaatggat aaggcatcag cctccggagc tggggattgt gggttcgagt 60
cccatctggg tcg 73
<![CDATA[<210> 32]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 32]]>
gccccagtgg cctaatggat aaggcactgg cctcctaagc cagggattgt gggttcgagt 60
cccacctggg gta 73
<![CDATA[<210> 33]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 33]]>
gccccagtgg cctaatggat aaggcactgg cctcctaagc cagggattgt gggttcgagt 60
cccacctggg gtg 73
<![CDATA[<210> 34]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 34]]>
gccccggtgg cctaatggat aaggcattgg cctcctaagc cagggattgt gggttcgagt 60
cccacccggg gta 73
<![CDATA[<210> 35]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 35]]>
gccccagtgg cctaatggat aaggcattgg cctcctaagc cagggattgt gggttcgagt 60
cccatctggg gtg 73
<![CDATA[<210> 36]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 36]]>
gccccagtgg cctgatggat aaggtactgg cctcctaagc cagggattgt gggttcgagt 60
tccacctggg gta 73
<![CDATA[<210> 37]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 37]]>
ggccgcgtgg cctaatggat aaggcgtctg acttcggatc agaagattgc aggttcgagt 60
cctgccgcgg tcg 73
<![CDATA[<210> 38]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 38]]>
gaccacgtgg cctaatggat aaggcgtctg acttcggatc agaagattga gggttcgaat 60
ccctccgtgg tta 73
<![CDATA[<210> 39]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 39]]>
gaccgcgtgg cctaatggat aaggcgtctg acttcggatc agaagattga gggttcgagt 60
cccttcgtgg tcg 73
<![CDATA[<210> 40]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 40]]>
gaccacgtgg cctaatggat aaggcgtctg acttcggatc agaagattga gggttcgaat 60
cccttcgtgg tta 73
<![CDATA[<210> 41]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 41]]>
gaccacgtgg cctaatggat aaggcgtctg acttcggatc agaagattga gggttcgaat 60
cccttcgtgg ttg 73
<![CDATA[<210> 42]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 42]]>
ggccgtgtgg cctaatggat aaggcgtctg acttcggatc aaaagattgc aggtttgagt 60
tctgccacgg tcg 73
<![CDATA[<210> 43]]>
<![CDATA[<211> 85]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 43]]>
ggctccgtgg cgcaatggat agcgcattgg acttctagag gctgaaggca ttcaaaggtt 60
ccgggttcga gtcccggcgg agtcg 85
<![CDATA[<210> 44]]>
<![CDATA[<211> 88]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 44]]>
ggctctgtgg cgcaatggat agcgcattgg acttctagtg acgaatagag caattcaaag 60
gttgtgggtt cgaatcccac cagagtcg 88
<![CDATA[<210> 45]]>
<![CDATA[<211> 91]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 45]]>
ggctctgtgg cgcaatggat agcgcattgg acttctagct gagcctagtg tggtcattca 60
aaggttgtgg gttcgagtcc caccagagtc g 91
<![CDATA[<210> 46]]>
<![CDATA[<211> 86]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 46]]>
ggctctgtgg cgcaatggat agcgcattgg acttctagat agttagagaa attcaaaggt 60
tgtgggttcg agtcccacca gagtcg 86
<![CDATA[<210> 47]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 47]]>
gtctctgtgg cgcaatggac gagcgcgctg gacttctaat ccagaggttc cgggttcgag 60
tcccggcaga gatg 74
<![CDATA[<210> 48]]>
<![CDATA[<211> 87]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 48]]>
ggctctgtgg cgcaatggat agcgcattgg acttctagcc taaatcaaga gattcaaagg 60
ttgcgggttc gagtccctcc agagtcg 87
<![CDATA[<210> 49]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 49]]>
gtctctgtgg cgcaatcggt tagcgcgttc ggctgttaac cgaaaggttg gtggttcgat 60
cccacccagg gacg 74
<![CDATA[<210> 50]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 50]]>
gtctctgtgg cgcaatcggc tagcgcgttt ggctgttaac taaaaggttg gcggttcgaa 60
cccacccaga ggcg 74
<![CDATA[<210> 51]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 51]]>
gtctctgtgg tgcaatcggt tagcgcgttc cgctgttaac cgaaagcttg gtggttcgag 60
cccacccagg gatg 74
<![CDATA[<210> 52]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 52]]>
gtctctgtgg cgcaatcggc tagcgcgttt ggctgttaac taaaaagttg gtggttcgaa 60
cacacccaga ggcg 74
<![CDATA[<210> 53]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 53]]>
gtctctgtgg cgcaatcggt tagcgcgttc ggctgttaac cgaaaggttg gtggttcgag 60
cccacccagg gacg 74
<![CDATA[<210> 54]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 54]]>
gtctctgtgg cgcaatcggt tagcgcattc ggctgttaac cgaaaggttg gtggttcgag 60
cccacccagg gacg 74
<![CDATA[<210> 55]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 55]]>
gtctctgtgg cgcaatcggt tagcgcgttc ggctgttaac cgaaagattg gtggttcgag 60
cccacccagg gacg 74
<![CDATA[<210> 56]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 56]]>
gtctctgtgg cgcaatcggt tagcgcgttc ggctgttaac tgaaaggttg gtggttcgag 60
cccacccagg gacg 74
<![CDATA[<210> 57]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 57]]>
gtctctgtgg cgcaatgggt tagcgcgttc ggctgttaac cgaaaggttg gtggttcgag 60
cccatccagg gacg 74
<![CDATA[<210> 58]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 58]]>
gtctctgtgg cgtagtcggt tagcgcgttc ggctgttaac cgaaaagttg gtggttcgag 60
cccacccagg aacg 74
<![CDATA[<210> 59]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 59]]>
gtctctgtgg cgcaatcggc tagcgcgttt ggctgttaac taaaaggttg gtggttcgaa 60
cccacccaga ggcg 74
<![CDATA[<210> 60]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 60]]>
gtctctgtgg cgcaatcggt tagcgcgttc ggctgttaac tgaaaggtta gtggttcgag 60
cccacccggg gacg 74
<![CDATA[<210> 61]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 61]]>
tcctcgttag tatagtggtt agtatccccg cctgtcacgc gggagaccgg ggttcaattc 60
cccgacgggg ag 72
<![CDATA[<210> 62]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 62]]>
tcctcgttag tatagtggtg agtatccccg cctgtcacgc gggagaccgg ggttcgattc 60
cccgacgggg ag 72
<![CDATA[<210> 63]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 63]]>
tcctcgttag tatagtggtg agtgtccccg tctgtcacgc gggagaccgg ggttcgattc 60
cccgacgggg ag 72
<![CDATA[<210> 64]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 64]]>
gggggcatag ctcagtggta gagcatttga ctgcagatca agaggtccct ggttcaaatc 60
caggtgcccc ct 72
<![CDATA[<210> 65]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 65]]>
gggggtatag ctcaggggta gagcatttga ctgcagatca agaggtccct ggttcaaatc 60
caggtgcccc cc 72
<![CDATA[<210> 66]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 66]]>
gggggtatag cttagcggta gagcatttga ctgcagatca agaggtcccc ggttcaaatc 60
cgggtgcccc ct 72
<![CDATA[<210> 67]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 67]]>
gggggtatag cttaggggta gagcatttga ctgcagatca aaaggtccct ggttcaaatc 60
caggtgcccc tt 72
<![CDATA[<210> 68]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 68]]>
gggggtatag ctcaggggta gagcatttga ctgcagatca agaggtcccc agttcaaatc 60
tgggtgcccc ct 72
<![CDATA[<210> 69]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 69]]>
gggggtatag ctcaggggta gagcatttga ctgcagatca agaagtcccc ggttcaaatc 60
cgggtgcccc ct 72
<![CDATA[<210> 70]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 70]]>
gggggtatag ctcaggggta gagcatttga ctgcagatca agaggtctct ggttcaaatc 60
caggtgcccc ct 72
<![CDATA[<210> 71]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 71]]>
gggggtatag ctcaggggta gagcacttga ctgcagatca agaagtcctt ggttcaaatc 60
caggtgcccc ct 72
<![CDATA[<210> 72]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 72]]>
ggggatatag ctcaggggta gagcatttga ctgcagatca agaggtcccc ggttcaaatc 60
cgggtgcccc cc 72
<![CDATA[<210> 73]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 73]]>
gggggtatag ttcaggggta gagcatttga ctgcagatca agaggtccct ggttcaaatc 60
caggtgcccc ct 72
<![CDATA[<210> 74]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 74]]>
gggggtatag ctcaggggta gagcatttga ctgcaaatca agaggtccct gattcaaatc 60
caggtgcccc ct 72
<![CDATA[<210> 75]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 75]]>
gggggtatag ctcagtggta gagcatttga ctgcagatca agaggtcccc ggttcaaatc 60
cgggtgcccc ct 72
<![CDATA[<210> 76]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 76]]>
gggcgtatag ctcaggggta gagcatttga ctgcagatca agaggtcccc agttcaaatc 60
tgggtgcccc ct 72
<![CDATA[<210> 77]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 77]]>
gggggtatag ctcacaggta gagcatttga ctgcagatca agaggtcccc ggttcaaatc 60
tgggtgcccc ct 72
<![CDATA[<210> 78]]>
<![CDATA[<211> 70]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 78]]>
gggcgtatag ctcaggggta gagcatttga ctgcagatca agaggtcccc agttcaaatc 60
tgggtgccca 70
<![CDATA[<210> 79]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 79]]>
gggggtatag ctcacaggta gagcatttga ctgcagatca agaggtcccc ggttcaaatc 60
cggttactcc ct 72
<![CDATA[<210> 80]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 80]]>
gggggtatag ctcaggggta gagcacttga ctgcagatca agaggtccct ggttcaaatc 60
caggtgcccc ct 72
<![CDATA[<210> 81]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 81]]>
gggggtatag ctcagtggta gagcatttga ctgcagatca agaggtccct ggttcaaatc 60
cgggtgcccc ct 72
<![CDATA[<210> 82]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 82]]>
gggggtatag ctcagtgggt agagcatttg actgcagatc aagaggtccc cggttcaaat 60
ccgggtgccc cct 73
<![CDATA[<210> 83]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 83]]>
gggggtgtag ctcagtggta gagcatttga ctgcagatca agaggtccct ggttcaaatc 60
caggtgcccc ct 72
<![CDATA[<210> 84]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 84]]>
gggggtatag ctcaggtggt agagcatttg actgcagatc aagaggtccc cggttcaaat 60
ccgggtgccc cct 73
<![CDATA[<210> 85]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 85]]>
gggggtatag ctcaggggta gagcatttga ctgcagatca agaggtcccc ggttcaaatc 60
cgggtgcccc ct 72
<![CDATA[<210> 86]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 86]]>
gggggtatag ctcaggggta gagcatttga ctgcagatca agaggtccct ggttcaaatc 60
caggtgcccc ct 72
<![CDATA[<210> 87]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 87]]>
ggttccatgg tgtaatggtt agcactctgg actctgaatc cagcgatccg agttcaaatc 60
tcggtggaac ct 72
<![CDATA[<210> 88]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 88]]>
ggttccatgg tgtaatggtt agcactctgg actctgaatc cagcgatccg agttcaagtc 60
tcggtggaac ct 72
<![CDATA[<210> 89]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 89]]>
ggttccatgg tgtaatggtg agcactctgg actctgaatc cagcgatccg agttcgagtc 60
tcggtggaac ct 72
<![CDATA[<210> 90]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 90]]>
ggttccatgg tgtaatggta agcactctgg actctgaatc cagcgatccg agttcgagtc 60
tcggtggaac ct 72
<![CDATA[<210> 91]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 91]]>
ggttccatgg tgtaatggtt agcactctgg actctgaatc cggtaatccg agttcaaatc 60
tcggtggaac ct 72
<![CDATA[<210> 92]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 92]]>
ggccccatgg tgtaatggtc agcactctgg actctgaatc cagcgatccg agttcaaatc 60
tcggtgggac cc 72
<![CDATA[<210> 93]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 93]]>
ggttccatgg tgtaatggta agcactctgg actctgaatc cagccatctg agttcgagtc 60
tctgtggaac ct 72
<![CDATA[<210> 94]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 94]]>
ggtcccatgg tgtaatggtt agcactctgg actttgaatc cagcgatccg agttcaaatc 60
tcggtgggac ct 72
<![CDATA[<210> 95]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 95]]>
ggtcccatgg tgtaatggtt agcactctgg actttgaatc cagcaatccg agttcgaatc 60
tcggtgggac ct 72
<![CDATA[<210> 96]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 96]]>
ggccccatgg tgtaatggtt agcactctgg actttgaatc cagcgatccg agttcaaatc 60
tcggtgggac ct 72
<![CDATA[<210> 97]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 97]]>
ggtcccatgg tgtaatggtt agcactctgg gctttgaatc cagcaatccg agttcgaatc 60
ttggtgggac ct 72
<![CDATA[<210> 98]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 98]]>
tccctggtgg tctagtggtt aggattcggc gctctcaccg ccgcggcccg ggttcgattc 60
ccggtcaggg aa 72
<![CDATA[<210> 99]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 99]]>
tccctggtgg tctagtggtt aggattcggc gctctcaccg ccgcggcccg ggttcgattc 60
ccggtcagga aa 72
<![CDATA[<210> 100]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 100]]>
tcccatatgg tctagcggtt aggattcctg gttttcaccc aggtggcccg ggttcgactc 60
ccggtatggg aa 72
<![CDATA[<210> 101]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 101]]>
tcccacatgg tctagcggtt aggattcctg gttttcaccc aggcggcccg ggttcgactc 60
ccggtgtggg aa 72
<![CDATA[<210> 102]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 102]]>
tccctggtgg tctagtggct aggattcggc gctttcaccg ccgcggcccg ggttcgattc 60
ccggccaggg aa 72
<![CDATA[<210> 103]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 103]]>
tccctggtgg tctagtggct aggattcggc gctttcaccg ccgcggcccg ggttcgattc 60
ccggtcaggg aa 72
<![CDATA[<210> 104]]>
<![CDATA[<211> 71]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 104]]>
gcattggtgg ttcagtggta gaattctcgc ctcccacgcg ggagacccgg gttcaattcc 60
cggccaatgc a 71
<![CDATA[<210> 105]]>
<![CDATA[<211> 71]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 105]]>
gcgccgctgg tgtagtggta tcatgcaaga ttcccattct tgcgacccgg gttcgattcc 60
cgggcggcgc a 71
<![CDATA[<210> 106]]>
<![CDATA[<211> 71]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 106]]>
gcattggtgg ttcaatggta gaattctcgc ctcccacgca ggagacccag gttcgattcc 60
tggccaatgc a 71
<![CDATA[<210> 107]]>
<![CDATA[<211> 71]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 107]]>
gcatgggtgg ttcagtggta gaattctcgc ctgccacgcg ggaggcccgg gttcgattcc 60
cggcccatgc a 71
<![CDATA[<210> 108]]>
<![CDATA[<211> 71]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 108]]>
gcattggtgg ttcagtggta gaattctcgc ctgccacgcg ggaggcccgg gttcgattcc 60
cggccaatgc a 71
<![CDATA[<210> 109]]>
<![CDATA[<211> 71]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 109]]>
gcattggtgg ttcagtggta gaattctcgc ctgccacgcg ggaggcccgg gtttgattcc 60
cggccagtgc a 71
<![CDATA[<210> 110]]>
<![CDATA[<211> 71]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 110]]>
gcataggtgg ttcagtggta gaattcttgc ctgccacgca ggaggcccag gtttgattcc 60
tggcccatgc a 71
<![CDATA[<210> 111]]>
<![CDATA[<211> 71]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 111]]>
gcattggtgg ttcagtggta gaattctcgc ctgccatgcg ggcggccggg cttcgattcc 60
tggccaatgc a 71
<![CDATA[<210> 112]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 112]]>
gcgttggtgg tatagtggtt agcatagctg ccttccaagc agttgacccg ggttcgattc 60
ccggccaacg ca 72
<![CDATA[<210> 113]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 113]]>
gcgttggtgg tatagtggtg agcatagctg ccttccaagc agttgacccg ggttcgattc 60
ccggccaacg ca 72
<![CDATA[<210> 114]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 114]]>
gcgttggtgg tatagtggta agcatagctg ccttccaagc agttgacccg ggttcgattc 60
ccggccaacg ca 72
<![CDATA[<210> 115]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 115]]>
gcgttggtgg tatagtggtg agcatagttg ccttccaagc agttgacccg ggctcgattc 60
ccgcccaacg ca 72
<![CDATA[<210> 116]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 116]]>
gccgtgatcg tatagtggtt agtactctgc gttgtggccg cagcaacctc ggttcgaatc 60
cgagtcacgg ca 72
<![CDATA[<210> 117]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 117]]>
gccatgatcg tatagtggtt agtactctgc gctgtggccg cagcaacctc ggttcgaatc 60
cgagtcacgg ca 72
<![CDATA[<210> 118]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 118]]>
ggccggttag ctcagttggt tagagcgtgg cgctaataac gccaaggtcg cgggttcgat 60
ccccgtacgg gcca 74
<![CDATA[<210> 119]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 119]]>
ggccggttag ctcagttggt tagagcgtgg tgctaataac gccaaggtcg cgggttcgat 60
ccccgtactg gcca 74
<![CDATA[<210> 120]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 120]]>
ggctggttag ctcagttggt tagagcgtgg tgctaataac gccaaggtcg cgggttcgat 60
ccccgtactg gcca 74
<![CDATA[<210> 121]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 121]]>
ggccggttag ctcagttggt tagagcgtgg tgctaataac gccaaggtcg cgggttcgaa 60
ccccgtacgg gcca 74
<![CDATA[<210> 122]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 122]]>
ggccggttag ctcagttggt tagagcgtgg tgctaataac gccaaggtcg cgggttcgat 60
ccccgtacgg gcca 74
<![CDATA[<210> 123]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 123]]>
ggccggttag ctcagttggt tagagcgtgg tgctaataac gctaaggtcg cgggttcgat 60
ccccgtactg gcca 74
<![CDATA[<210> 124]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 124]]>
ggccggttag ctcagttggt cagagcgtgg tgctaataac gccaaggtcg cgggttcgat 60
ccccgtacgg gcca 74
<![CDATA[<210> 125]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 125]]>
ggccggttag ctcagtcggc tagagcgtgg tgctaataac gccaaggtcg cgggttcgat 60
ccccgtacgg gcca 74
<![CDATA[<210> 126]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 126]]>
ggctggttag ttcagttggt tagagcgtgg tgctaataac gccaaggtcg tgggttcgat 60
ccccatatcg gcca 74
<![CDATA[<210> 127]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 127]]>
ggccggttag ctcagttggt aagagcgtgg tgctgataac accaaggtcg cgggctcgac 60
tcccgcaccg gcca 74
<![CDATA[<210> 128]]>
<![CDATA[<211> 93]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 128]]>
gctccagtgg cgcaatcggt tagcgcgcgg tacttatatg acagtgcgag cggagcaatg 60
ccgaggttgt gagttcgatc ctcacctgga gca 93
<![CDATA[<210> 129]]>
<![CDATA[<211> 93]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 129]]>
gctccagtgg cgcaatcggt tagcgcgcgg tacttataca gcagtacatg cagagcaatg 60
ccgaggttgt gagttcgagc ctcacctgga gca 93
<![CDATA[<210> 130]]>
<![CDATA[<211> 94]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 130]]>
gctccagtgg cgcaatcggt tagcgcgcgg tacttatatg gcagtatgtg tgcgagtgat 60
gccgaggttg tgagttcgag cctcacctgg agca 94
<![CDATA[<210> 131]]>
<![CDATA[<211> 94]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 131]]>
gctccagtgg cgcaatcggt tagcgcgcgg tacttataca acagtatatg tgcgggtgat 60
gccgaggttg tgagttcgag cctcacctgg agca 94
<![CDATA[<210> 132]]>
<![CDATA[<211> 94]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 132]]>
gctccagtgg cgcaatcggt tagcgcgcgg tacttataag acagtgcacc tgtgagcaat 60
gccgaggttg tgagttcaag cctcacctgg agca 94
<![CDATA[<210> 133]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 133]]>
ggtagcgtgg ccgagcggtc taaggcgctg gattaaggct ccagtctctt cggaggcgtg 60
ggttcgaatc ccaccgctgc ca 82
<![CDATA[<210> 134]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 134]]>
ggtagcgtgg ccgagcggtc taaggcgctg gattaaggct ccagtctctt cgggggcgtg 60
ggttcgaatc ccaccgctgc ca 82
<![CDATA[<210> 135]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 135]]>
ggtagcgtgg ccgagcggtc taaggcgctg gattaaggct ccagtctctt cgggggcgtg 60
ggttcaaatc ccaccgctgc ca 82
<![CDATA[<210> 136]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 136]]>
ggtagcgtgg ccgagtggtc taagacgctg gattaaggct ccagtctctt cgggggcgtg 60
ggtttgaatc ccaccgctgc ca 82
<![CDATA[<210> 137]]>
<![CDATA[<211> 106]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 137]]>
gtcaggatgg ccgagtggtc taaggcgcca gactcaagct aagcttcctc cgcggtgggg 60
attctggtct ccaatggagg cgtgggttcg aatcccactt ctgaca 106
<![CDATA[<210> 138]]>
<![CDATA[<211> 105]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 138]]>
gtcaggatgg ccgagtggtc taaggcgcca gactcaagct tggcttcctc gtgttgagga 60
ttctggtctc caatggaggc gtgggttcga atcccacttc tgaca 105
<![CDATA[<210> 139]]>
<![CDATA[<211> 108]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 139]]>
gtcaggatgg ccgagtggtc taaggcgcca gactcaagct tactgcttcc tgtgttcggg 60
tcttctggtc tccgtatgga ggcgtgggtt cgaatcccac ttctgaca 108
<![CDATA[<210> 140]]>
<![CDATA[<211> 107]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 140]]>
gtcaggatgg ccgagtggtc taaggcgcca gactcaagtt gctacttccc aggtttgggg 60
cttctggtct ccgcatggag gcgtgggttc gaatcccact tctgaca 107
<![CDATA[<210> 141]]>
<![CDATA[<211> 106]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 141]]>
gtcaggatgg ccgagtggtc taaggcgcca gactcaaggt aagcaccttg cctgcgggct 60
ttctggtctc cggatggagg cgtgggttcg aatcccactt ctgaca 106
<![CDATA[<210> 142]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 142]]>
gcctccttag tgcagtaggt agcgcatcag tctcaaaatc tgaatggtcc tgagttcaag 60
cctcagaggg ggca 74
<![CDATA[<210> 143]]>
<![CDATA[<211> 84]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 143]]>
gtcaggatgg ccgagcagtc ttaaggcgct gcgttcaaat cgcaccctcc gctggaggcg 60
tgggttcgaa tcccactttt gaca 84
<![CDATA[<210> 144]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 144]]>
gtcaggatgg ccgagcggtc taaggcgctg cgttcaggtc gcagtctccc ctggaggcgt 60
gggttcgaat cccactcctg aca 83
<![CDATA[<210> 145]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 145]]>
gtcaggatgg ccgagcggtc taaggcgctg cgttcaggtc gcagtctccc ctggaggcgt 60
gggttcgaat cccacttctg aca 83
<![CDATA[<210> 146]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 146]]>
accaggatgg ccgagtggtt aaggcgttgg acttaagatc caatggacat atgtccgcgt 60
gggttcgaac cccactcctg gta 83
<![CDATA[<210> 147]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 147]]>
accgggatgg ccgagtggtt aaggcgttgg acttaagatc caatgggctg gtgcccgcgt 60
gggttcgaac cccactctcg gta 83
<![CDATA[<210> 148]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 148]]>
accagaatgg ccgagtggtt aaggcgttgg acttaagatc caatggattc atatccgcgt 60
gggttcgaac cccacttctg gta 83
<![CDATA[<210> 149]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 149]]>
accgggatgg ctgagtggtt aaggcgttgg acttaagatc caatggacag gtgtccgcgt 60
gggttcgagc cccactcccg gta 83
<![CDATA[<210> 150]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 150]]>
ggtagcgtgg ccgagcggtc taaggcgctg gatttaggct ccagtctctt cggaggcgtg 60
ggttcgaatc ccaccgctgc ca 82
<![CDATA[<210> 151]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 151]]>
ggtagtgtgg ccgagcggtc taaggcgctg gatttaggct ccagtctctt cgggggcgtg 60
ggttcgaatc ccaccactgc ca 82
<![CDATA[<210> 152]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 152]]>
ggtagcgtgg ccgagtggtc taaggcgctg gatttaggct ccagtcattt cgatggcgtg 60
ggttcgaatc ccaccgctgc ca 82
<![CDATA[<210> 153]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 153]]>
gcccggctag ctcagtcggt agagcatggg actcttaatc ccagggtcgt gggttcgagc 60
cccacgttgg gcg 73
<![CDATA[<210> 154]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 154]]>
gcccagctag ctcagtcggt agagcataag actcttaatc tcagggttgt ggattcgtgc 60
cccatgctgg gtg 73
<![CDATA[<210> 155]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 155]]>
gcagctagct cagtcggtag agcatgagac tcttaatctc agggtcatgg gttcgtgccc 60
catgttgggt gcca 74
<![CDATA[<210> 156]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 156]]>
gcccggctag ctcagtcggt agagcatgag actcttaatc tcagggtcgt gggttcgagc 60
cccacgttgg gcg 73
<![CDATA[<210> 157]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 157]]>
gcccggctag ctcagtcggt agagcatgag acccttaatc tcagggtcgt gggttcgagc 60
cccacgttgg gcg 73
<![CDATA[<210> 158]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 158]]>
gcccggctag ctcagtcggt agagcatggg actcttaatc tcagggtcgt gggttcgagc 60
cccacgttgg gcg 73
<![CDATA[<210> 159]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 159]]>
gcccggctag ctcagtcgat agagcatgag actcttaatc tcagggtcgt gggttcgagc 60
cgcacgttgg gcg 73
<![CDATA[<210> 160]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 160]]>
gcccagctag ctcagtcggt agagcatgag actcttaatc tcagggtcat gggtttgagc 60
cccacgtttg gtg 73
<![CDATA[<210> 161]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 161]]>
gcctggctag ctcagtcggc aaagcatgag actcttaatc tcagggtcgt gggctcgagc 60
tccatgttgg gcg 73
<![CDATA[<210> 162]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 162]]>
gcccgactac ctcagtcggt ggagcatggg actcttcatc ccagggttgt gggttcgagc 60
cccacattgg gca 73
<![CDATA[<210> 163]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 163]]>
gcctggatag ctcagttggt agagcatcag acttttaatc tgagggtcca gggttcaagt 60
ccctgttcag gca 73
<![CDATA[<210> 164]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 164]]>
acccagatag ctcagtcagt agagcatcag acttttaatc tgagggtcca aggttcatgt 60
ccctttttgg gtg 73
<![CDATA[<210> 165]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 165]]>
gcctggatag ctcagttggt agagcatcag acttttaatc tgagggtcca gggttcaagt 60
ccctgttcag gcg 73
<![CDATA[<210> 166]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 166]]>
gcccggatag ctcagtcggt agagcatcag acttttaatc tgagggtcca gggttcaagt 60
ccctgttcgg gcg 73
<![CDATA[<210> 167]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 167]]>
gcctggatag ctcagtcggt agagcatcag acttttaatc tgagggtcca gggttcaagt 60
ccctgttcag gcg 73
<![CDATA[<210> 168]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 168]]>
gcccggatag ctcagtcggt agagcatcag acttttaatc tgagggtccg gggttcaagt 60
ccctgttcgg gcg 73
<![CDATA[<210> 169]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 169]]>
gcctgggtag ctcagtcggt agagcatcag acttttaatc tgagggtcca gggttcaagt 60
ccctgtccag gcg 73
<![CDATA[<210> 170]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 170]]>
gcctggatag ctcagttggt agaacatcag acttttaatc tgacggtgca gggttcaagt 60
ccctgttcag gcg 73
<![CDATA[<210> 171]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 171]]>
gcctcgttag cgcagtaggt agcgcgtcag tctcataatc tgaaggtcgt gagttcgatc 60
ctcacacggg gca 73
<![CDATA[<210> 172]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 172]]>
gccctcttag cgcagtgggc agcgcgtcag tctcataatc tgaaggtcct gagttcgagc 60
ctcagagagg gca 73
<![CDATA[<210> 173]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 173]]>
gcctccttag cgcagtaggc agcgcgtcag tctcataatc tgaaggtcct gagttcgaac 60
ctcagagggg gca 73
<![CDATA[<210> 174]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 174]]>
gccctcttag cgcagcgggc agcgcgtcag tctcataatc tgaaggtcct gagttcgagc 60
ctcagagagg gca 73
<![CDATA[<210> 175]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 175]]>
gccctcttag cgcagctggc agcgcgtcag tctcataatc tgaaggtcct gagttcaagc 60
ctcagagagg gca 73
<![CDATA[<210> 176]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 176]]>
gcctcgttag cgcagtaggc agcgcgtcag tctcataatc tgaaggtcgt gagttcgagc 60
ctcacacggg gca 73
<![CDATA[<210> 177]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 177]]>
gccctcttag tgcagctggc agcgcgtcag tttcataatc tgaaagtcct gagttcaagc 60
ctcagagagg gca 73
<![CDATA[<210> 178]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 178]]>
gccgaaatag ctcagttggg agagcgttag actgaagatc taaaggtccc tggttcgatc 60
ccgggtttcg gca 73
<![CDATA[<210> 179]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 179]]>
gccgaaatag ctcagttggg agagcgttag actgaagatc taaaggtccc tggttcaatc 60
ccgggtttcg gca 73
<![CDATA[<210> 180]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 180]]>
gccgagatag ctcagttggg agagcgttag actgaagatc taaaggtccc tggttcaatc 60
ccgggtttcg gca 73
<![CDATA[<210> 181]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 181]]>
gccgaaatag ctcagttggg agagcgttag accgaagatc ttaaaggtcc ctggttcaat 60
cccgggtttc ggca 74
<![CDATA[<210> 182]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 182]]>
gctgaaatag ctcagttggg agagcgttag actgaagatc ttaaagttcc ctggttcaac 60
cctgggtttc agcc 74
<![CDATA[<210> 183]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 183]]>
ggctcgttgg tctaggggta tgattctcgc ttaggatgcg agaggtcccg ggttcaaatc 60
ccggacgagc cc 72
<![CDATA[<210> 184]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 184]]>
ggctcgttgg tctaggggta tgattctcgc ttagggtgcg agaggtcccg ggttcaaatc 60
ccggacgagc cc 72
<![CDATA[<210> 185]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 185]]>
ggctcgttgg tctaggggta tgattctcgc ttcgggtgcg agaggtcccg ggttcaaatc 60
ccggacgagc cc 72
<![CDATA[<210> 186]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 186]]>
ggctcgttgg tctaggggta tgattctcgc ttcgggtgtg agaggtcccg ggttcaaatc 60
ccggacgagc cc 72
<![CDATA[<210> 187]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 187]]>
ggctcgttgg tctagtggta tgattctcgc tttgggtgcg agaggtcccg ggttcaaatc 60
ccggacgagc cc 72
<![CDATA[<210> 188]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 188]]>
ggctcgttgg tctaggggta tgattctcgg tttgggtccg agaggtcccg ggttcaaatc 60
ccggacgagc cc 72
<![CDATA[<210> 189]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 189]]>
ggctcgttgg tctaggggta tgattctcgc tttgggtgcg agaggtcccg ggttcaaatc 60
ccggacgagc cc 72
<![CDATA[<210> 190]]>
<![CDATA[<211> 87]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 190]]>
gcccggatga tcctcagtgg tctggggtgc aggcttcaaa cctgtagctg tctagcgaca 60
gagtggttca attccacctt tcgggcg 87
<![CDATA[<210> 191]]>
<![CDATA[<211> 84]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 191]]>
gctcggatga tcctcagtgg tctggggtgc aggcttcaaa cctgtagctg tctagtgaca 60
gagtggttca attccacctt tgta 84
<![CDATA[<210> 192]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 192]]>
gtagtcgtgg ccgagtggtt aaggcgatgg actagaaatc cattggggtt tccccgcgca 60
ggttcgaatc ctgccgacta cg 82
<![CDATA[<210> 193]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 193]]>
gtagtcgtgg ccgagtggtt aaggcgatgg actagaaatc cattggggtc tccccgcgca 60
ggttcgaatc ctgccgacta cg 82
<![CDATA[<210> 194]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 194]]>
gtagtcgtgg ccgagtggtt aaggcgatgg actagaaatc cattggggtt tccccacgca 60
ggttcgaatc ctgccgacta cg 82
<![CDATA[<210> 195]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 195]]>
gtagtcgtgg ccgagtggtt aaggtgatgg actagaaacc cattggggtc tccccgcgca 60
ggttcgaatc ctgccgacta cg 82
<![CDATA[<210> 196]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 196]]>
gctgtgatgg ccgagtggtt aaggcgttgg actcgaaatc caatggggtc tccccgcgca 60
ggttcgaatc ctgctcacag cg 82
<![CDATA[<210> 197]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 197]]>
gctgtgatgg ccgagtggtt aaggcgttgg actcgaaatc caatggggtc tccccgcgca 60
ggttcaaatc ctgctcacag cg 82
<![CDATA[<210> 198]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 198]]>
gctgtgatgg ccgagtggtt aaggtgttgg actcgaaatc caatgggggt tccccgcgca 60
ggttcaaatc ctgctcacag cg 82
<![CDATA[<210> 199]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 199]]>
gtcacggtgg ccgagtggtt aaggcgttgg actcgaaatc caatggggtt tccccgcaca 60
ggttcgaatc ctgttcgtga cg 82
<![CDATA[<210> 200]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 200]]>
gacgaggtgg ccgagtggtt aaggcgatgg actgctaatc cattgtgctc tgcacgcgtg 60
ggttcgaatc ccaccctcgt cg 82
<![CDATA[<210> 201]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 201]]>
gacgaggtgg ccgagtggtt aaggcgatgg actgctaatc cattgtgctc tgcacgcgtg 60
ggttcgaatc ccaccttcgt cg 82
<![CDATA[<210> 202]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 202]]>
gacgaggtgg ccgagtggtt aaggcgatgg actgctaatc cattgtgctt tgcacgcgtg 60
ggttcgaatc ccatcctcgt cg 82
<![CDATA[<210> 203]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 203]]>
gacgaggtgg ccgagtggtt aaggcgatgg actgctaatc cattgtgctc tgcacgcgtg 60
ggttcgaatc ccatcctcgt cg 82
<![CDATA[<210> 204]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 204]]>
gacgaggtgg ccgagtggtt aaggcgatgg actgctaatc cattgtgctc tgcacacgtg 60
ggttcgaatc ccatcctcgt cg 82
<![CDATA[<210> 205]]>
<![CDATA[<211> 84]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 205]]>
ggagaggcct ggccgagtgg ttaaggcgat ggactgctaa tccattgtgc tctgcacgcg 60
tgggttcgaa tcccatcctc gtcg 84
<![CDATA[<210> 206]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 206]]>
gcagcgatgg ccgagtggtt aaggcgttgg acttgaaatc caatggggtc tccccgcgca 60
ggttcgaacc ctgctcgctg cg 82
<![CDATA[<210> 207]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 207]]>
gtagtcgtgg ccgagtggtt aaggcgatgg acttgaaatc cattggggtt tccccgcgca 60
ggttcgaatc ctgccgacta cg 82
<![CDATA[<210> 208]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 208]]>
gtagtcgtgg ccgagtggtt aaggcgatgg acttgaaatc cattggggtc tccccgcgca 60
ggttcgaatc ctgccgacta cg 82
<![CDATA[<210> 209]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 209]]>
gtagtcgtgg ccgagtggtt aaggcgatgg acttgaaatc cattggggtt tccccgcgca 60
ggttcgaatc ctgtcggcta cg 82
<![CDATA[<210> 210]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 210]]>
ggcgccgtgg cttagttggt taaagcgcct gtctagtaaa caggagatcc tgggttcgaa 60
tcccagcggt gcct 74
<![CDATA[<210> 211]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 211]]>
ggctccgtgg cttagctggt taaagcgcct gtctagtaaa caggagatcc tgggttcgaa 60
tcccagcggg gcct 74
<![CDATA[<210> 212]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 212]]>
ggctccgtag cttagttggt taaagcgcct gtctagtaaa caggagatcc tgggttcgac 60
tcccagcggg gcct 74
<![CDATA[<210> 213]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 213]]>
ggcttcgtgg cttagctggt taaagcgcct gtctagtaaa caggagatcc tgggttcgaa 60
tcccagcgag gcct 74
<![CDATA[<210> 214]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 214]]>
ggcgccgtgg cttagctggt taaagcgcct gtctagtaaa caggagatcc tgggttcgaa 60
tcccagcggt gcct 74
<![CDATA[<210> 215]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 215]]>
ggccctgtgg cttagctggt caaagcgcct gtctagtaaa caggagatcc tgggttcgaa 60
tcccagcggg gcct 74
<![CDATA[<210> 216]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 216]]>
ggctctatgg cttagttggt taaagcgcct gtctcgtaaa caggagatcc tgggttcgac 60
tcccagtggg gcct 74
<![CDATA[<210> 217]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 217]]>
ggcgcggtgg ccaagtggta aggcgtcggt ctcgtaaacc gaagatcacg ggttcgaacc 60
ccgtccgtgc ct 72
<![CDATA[<210> 218]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 218]]>
ggctctgtgg cttagttggc taaagcgcct gtctcgtaaa caggagatcc tgggttcgaa 60
tcccagcggg gcct 74
<![CDATA[<210> 219]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 219]]>
ggcgcggtgg ccaagtggta aggcgtcggt ctcgtaaacc gaagatcgcg ggttcgaacc 60
ccgtccgtgc ct 72
<![CDATA[<210> 220]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 220]]>
ggccctgtag ctcagcggtt ggagcgctgg tctcgtaaac ctaggggtcg tgagttcaaa 60
tctcaccagg gcct 74
<![CDATA[<210> 221]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 221]]>
ggctctatgg cttagttggt taaagcgcct gtcttgtaaa caggagatcc tgggttcgaa 60
tcccagtaga gcct 74
<![CDATA[<210> 222]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 222]]>
ggctccatag ctcagtggtt agagcactgg tcttgtaaac caggggtcgc gagttcgatc 60
ctcgctgggg cct 73
<![CDATA[<210> 223]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 223]]>
ggctccatag ctcaggggtt agagcgctgg tcttgtaaac caggggtcgc gagttcaatt 60
ctcgctgggg cct 73
<![CDATA[<210> 224]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 224]]>
ggctccatag ctcaggggtt agagcactgg tcttgtaaac caggggtcgc gagttcaaat 60
ctcgctgggg cct 73
<![CDATA[<210> 225]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 225]]>
ggccctatag ctcaggggtt agagcactgg tcttgtaaac caggggtcgc gagttcaaat 60
ctcgctgggg cct 73
<![CDATA[<210> 226]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 226]]>
ggctccatag ctcaggggtt agagcactgg tcttgtaaac cagggtcgcg agttcaaatc 60
tcgctggggc ct 72
<![CDATA[<210> 227]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 227]]>
ggcctcgtgg cgcaacggta gcgcgtctga ctccagatca gaaggttgcg tgttcaaatc 60
acgtcggggt ca 72
<![CDATA[<210> 228]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 228]]>
gacctcgtgg cgcaatggta gcgcgtctga ctccagatca gaaggttgcg tgttcaagtc 60
acgtcggggt ca 72
<![CDATA[<210> 229]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 229]]>
gacctcgtgg cgcaacggta gcgcgtctga ctccagatca gaaggttgcg tgttcaaatc 60
acgtcggggt ca 72
<![CDATA[<210> 230]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 230]]>
gacctcgtgg cgcaacggta gcgcgtctga ctccagatca gaaggctgcg tgttcgaatc 60
acgtcggggt ca 72
<![CDATA[<210> 231]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 231]]>
gacctcgtgg cgcaacggca gcgcgtctga ctccagatca gaaggttgcg tgttcaaatc 60
acgtcggggt ca 72
<![CDATA[<210> 232]]>
<![CDATA[<211> 93]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 232]]>
ccttcaatag ttcagctggt agagcagagg actatagcta cttcctcagt aggagacgtc 60
cttaggttgc tggttcgatt ccagcttgaa gga 93
<![CDATA[<210> 233]]>
<![CDATA[<211> 91]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 233]]>
ccttcgatag ctcagttggt agagcggagg actgtagttg gctgtgtcct tagacatcct 60
taggtcgctg gttcgaatcc ggctcgaagg a 91
<![CDATA[<210> 234]]>
<![CDATA[<211> 89]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 234]]>
ccttcgatag ctcagttggt agagcggagg actgtagtgg atagggcgtg gcaatcctta 60
ggtcgctggt tcgattccgg ctcgaagga 89
<![CDATA[<210> 235]]>
<![CDATA[<211> 89]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 235]]>
ccttcgatag ctcagttggt agagcggagg actgtaggct cattaagcaa ggtatcctta 60
ggtcgctggt tcgaatccgg ctcggagga 89
<![CDATA[<210> 236]]>
<![CDATA[<211> 94]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 236]]>
ccttcgatag ctcagctggt agagcggagg actgtagatt gtatagacat ttgcggacat 60
ccttaggtcg ctggttcgat tccagctcga agga 94
<![CDATA[<210> 237]]>
<![CDATA[<211> 93]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 237]]>
ccttcgatag ctcagctggt agagcggagg actgtagcta cttcctcagc aggagacatc 60
cttaggtcgc tggttcgatt ccggctcgaa gga 93
<![CDATA[<210> 238]]>
<![CDATA[<211> 89]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 238]]>
ccttcgatag ctcagctggt agagcggagg actgtaggcg cgcgcccgtg gccatcctta 60
ggtcgctggt tcgattccgg ctcgaagga 89
<![CDATA[<210> 239]]>
<![CDATA[<211> 94]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 239]]>
ccttcgatag ctcagctggt agagcggagg actgtagcct gtagaaacat ttgtggacat 60
ccttaggtcg ctggttcgat tccggctcga agga 94
<![CDATA[<210> 240]]>
<![CDATA[<211> 94]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 240]]>
ccttcgatag ctcagctggt agagcggagg actgtagatt gtacagacat ttgcggacat 60
ccttaggtcg ctggttcgat tccggctcga agga 94
<![CDATA[<210> 241]]>
<![CDATA[<211> 89]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 241]]>
ccttcgatag ctcagctggt agagcggagg actgtagtac ttaatgtgtg gtcatcctta 60
ggtcgctggt tcgattccgg ctcgaagga 89
<![CDATA[<210> 242]]>
<![CDATA[<211> 89]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 242]]>
ccttcgatag ctcagctggt agagcggagg actgtagggg tttgaatgtg gtcatcctta 60
ggtcgctggt tcgaatccgg ctcggagga 89
<![CDATA[<210> 243]]>
<![CDATA[<211> 94]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 243]]>
ccttcgatag ctcagctggt agagcggagg actgtagact gcggaaacgt ttgtggacat 60
ccttaggtcg ctggttcaat tccggctcga agga 94
<![CDATA[<210> 244]]>
<![CDATA[<211> 90]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 244]]>
ctttcgatag ctcagttggt agagcggagg actgtaggtt cattaaacta aggcatcctt 60
aggtcgctgg ttcgaatccg gctcgaagga 90
<![CDATA[<210> 245]]>
<![CDATA[<211> 88]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 245]]>
tcttcaatag ctcagctggt agagcggagg actgtaggtg cacgcccgtg gccattctta 60
ggtgctggtt tgattccgac ttggagag 88
<![CDATA[<210> 246]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 246]]>
gtttccgtag tgtagtggtt atcacgttcg cctaacacgc gaaaggtccc cggttcgaaa 60
ccgggcggaa aca 73
<![CDATA[<210> 247]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 247]]>
gtttccgtag tgtagtggtc atcacgttcg cctaacacgc gaaaggtccc cggttcgaaa 60
ccgggcggaa aca 73
<![CDATA[<210> 248]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 248]]>
gtttccgtag tgtagtggtt atcacgttcg cctaacacgc gaaaggtccc tggatcaaaa 60
ccaggcggaa aca 73
<![CDATA[<210> 249]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 249]]>
gtttccgtag tgtagtggtt atcacgttcg cctaacacgc gaaaggtccg cggttcgaaa 60
ccgggcggaa aca 73
<![CDATA[<210> 250]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 250]]>
gtttccgtag tgtagtggtt atcacgtttg cctaacacgc gaaaggtccc cggttcgaaa 60
ccgggcagaa aca 73
<![CDATA[<210> 251]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 251]]>
gggggtgtag ctcagtggta gagcgtatgc ttaacattca tgaggctctg ggttcgatcc 60
ccagcacttc ca 72
<![CDATA[<210> 252]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 252]]>
gtttccgtag tgtagtggtt atcacgttcg cctcacacgc gaaaggtccc cggttcgaaa 60
ccgggcggaa aca 73
<![CDATA[<210> 253]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 253]]>
gcttctgtag tgtagtggtt atcacgttcg cctcacacgc gaaaggtccc cggttcgaaa 60
ccgggcagaa gca 73
<![CDATA[<210> 254]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 254]]>
gtttccgtag tgtagcggtt atcacattcg cctcacacgc gaaaggtccc cggttcgatc 60
ccgggcggaa aca 73
<![CDATA[<210> 255]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 255]]>
gtttccgtag tgtagtggtt atcacgttcg cctcacacgc gaaaggtccc cggttcgaaa 60
ctgggcggaa aca 73
<![CDATA[<210> 256]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 256]]>
gtttccgtag tgtagtggtt atcacgttcg cctcacacgc gtaaaggtcc ccggttcgaa 60
accgggcgga aaca 74
<![CDATA[<210> 257]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 257]]>
gtttccgtag tggagtggtt atcacgttcg cctcacacgc gaaaggtccc cggtttgaaa 60
ccaggcggaa aca 73
<![CDATA[<210> 258]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 258]]>
ggttccatag tgtagtggtt atcacgtctg ctttacacgc agaaggtcct gggttcgagc 60
cccagtggaa cca 73
<![CDATA[<210> 259]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 259]]>
ggttccatag tgtagcggtt atcacgtctg ctttacacgc agaaggtcct gggttcgagc 60
cccagtggaa cca 73
<![CDATA[<210> 260]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 260]]>
ggttccatag tgtagtggtt atcacatctg ctttacacgc agaaggtcct gggttcaagc 60
cccagtggaa cca 73
<![CDATA[<210> 261]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 261]]>
gtttccgtgg tgtagtggtt atcacattcg ccttacacgc gaaaggtcct cgggtcgaaa 60
ccgagcggaa aca 73
<![CDATA[<210> 262]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 262]]>
agcagagtgg cgcagcggaa gcgtgctggg cccataaccc agaggtcgat ggatcgaaac 60
catcctctgc ta 72
<![CDATA[<210> 263]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 263]]>
agcagagtgg cgcagcggaa gcgtgctggg cccataaccc agaggtcgat ggatctaaac 60
catcctctgc ta 72
<![CDATA[<210> 264]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 264]]>
tccctggtgg tctagtggct aggattcggc gctttcaccg ccgcggcccg ggttcgattc 60
ccggtcaggg aat 73
<![CDATA[<210> 265]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 265]]>
gcgttggtgg tttagtggta gaattctcgc ctcccatgcg ggagacccgg gttcaattcc 60
cggccactgc ac 72
<![CDATA[<210> 266]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 266]]>
ggccttggtg gtgcagtggt agaattctcg cctcccacgt gggagacccg ggttcaattc 60
ccggccaatg ca 72
<![CDATA[<210> 267]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 267]]>
gtccctggtg gtctagtggc taggattcgg cgctttcacc gccgcggccc gggttcgatt 60
cccggccagg gaa 73
<![CDATA[<210> 268]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 268]]>
tgtctctgtg gcgcaatcgg ttagcgcgtt cggctgttaa ccgaaagatt ggtggttcga 60
gcccacccag ggacg 75
<![CDATA[<210> 269]]>
<![CDATA[<211> 86]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 269]]>
tggctccgtg gcgcaatgga tagcgcattg gacttctaga ggctgaaggc attcaaaggt 60
tccgggttcg agtcccggcg gagtcg 86
<![CDATA[<210> 270]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 270]]>
gcccggctag ctcagtcggt agagcatgag actcttaatc tcagggtcgt gggttcgagc 60
cccacgttgg gcgc 74
<![CDATA[<210> 271]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 271]]>
gccgtgatcg tatagtggtt agtactctgc gttgtggccg cagcaacctc ggttcgaatc 60
cgagtcacgg cag 73
<![CDATA[<210> 272]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 272]]>
gcgttggtgg tatagtggtg agcatagctg ccttccaagc agttgacccg ggttcgattc 60
ccggccaacg cag 73
<![CDATA[<210> 273]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 273]]>
tccctggtgg tctagtggtt aggattcggc gctctcaccg ccgcggcccg ggttcgattc 60
ccggtcaggg aaa 73
<![CDATA[<210> 274]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 274]]>
aggttccatg gtgtaatggt gagcactctg gactctgaat ccagcgatcc gagttcgagt 60
ctcggtggaa cct 73
<![CDATA[<210> 275]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 275]]>
tgtctctgtg gcgtagtcgg ttagcgcgtt cggctgttaa ccgaaaagtt ggtggttcga 60
gcccacccag gaacg 75
<![CDATA[<210> 276]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 276]]>
tgtctctgtg gcgcaatcgg ttagcgcgtt cggctgttaa ccgaaaggtt ggtggttcga 60
gcccacccag ggacg 75
<![CDATA[<210> 277]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 277]]>
gtctctgtgg cgcaatcggt tagcgcattc ggctgttaac cgaaaggttg gtggttcgag 60
cccacccagg gacgc 75
<![CDATA[<210> 278]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 278]]>
gtctctgtgg cgcaatgggt tagcgcgttc ggctgttaac cgaaaggttg gtggttcgag 60
cccatccagg gacgc 75
<![CDATA[<210> 279]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 279]]>
gcactggtgg ttcagtggta gaattctcgc ctcacacgcg ggacacccgg gttcaattcc 60
cggtcaaggc aa 72
<![CDATA[<210> 280]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 280]]>
gtttccgtag tgtagtggtt atcacgttcg cctcacacgc gaaaggtccc cggttcgaaa 60
ctgggcggaa acag 74
<![CDATA[<210> 281]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 281]]>
gcactggtgg ttcagtggta gaattctcgc ctcccacgcg ggagacccgg gtttaattcc 60
cggtcaagat aa 72
<![CDATA[<210> 282]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 282]]>
gtttccgtag tgtagtggtt atcacgttcg cctcacacgc gtaaaggtcc ccggttcgaa 60
accgggcgga aacat 75
<![CDATA[<210> 283]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 283]]>
tagcagagtg gcgcagcgga agcgtgctgg gcccataacc cagaggtcga tggatcgaaa 60
ccatcctctg cta 73
<![CDATA[<210> 284]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 284]]>
gtttccgtag tgtagtggtt atcacgttcg cctcacacgc gaaaggtccc cggttcgaaa 60
ccgggcggaa acaa 74
<![CDATA[<210> 285]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 285]]>
tcctcgttag tatagtggtg agtatccccg cctgtcacgc gggagaccgg ggttcgattc 60
cccgacgggg agg 73
<![CDATA[<210> 286]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 286]]>
tgcatgggtg gttcagtggt agaattctcg cctgccacgc gggaggcccg ggttcgattc 60
ccggcccatg ca 72
<![CDATA[<210> 287]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 287]]>
tccctggtgg tctagtggtt aggattcggc gctctcaccg ccgcggcccg ggttcgattc 60
ccggtcaggg aag 73
<![CDATA[<210> 288]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 288]]>
atccttgtta ctatagtggt gagtatctct gcctgtcatg cgtgagagag ggggtcgatt 60
ccccgacggg gag 73
<![CDATA[<210> 289]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 289]]>
gcattggtgg ttcagtggta gaattctcgc ctgccacgcg ggaggcccgg gttcgattcc 60
cggccaatgc ac 72
<![CDATA[<210> 290]]>
<![CDATA[<211> 84]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 290]]>
gtcaggatgg ccgagcggtc taaggcgctg cgttcaggtc gcagtctccc ctggaggcgt 60
gggttcgaat cccactcctg acaa 84
<![CDATA[<210> 291]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 291]]>
cgcgttggtg gtatagtggt gagcatagct gccttccaag cagttgaccc gggttcgatt 60
cccggccaac gca 73
<![CDATA[<210> 292]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 292]]>
cgtctctgtg gcgcaatcgg ttagcgcgtt cggctgttaa ccgaaaggtt ggtggttcga 60
tcccacccag ggacg 75
<![CDATA[<210> 293]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 293]]>
cgcgttggtg gtgtagtggt gagcacagct gcctttcaag cagttaacgc gggttcgatt 60
cccgggtaac gaa 73
<![CDATA[<210> 294]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 294]]>
cggctcgttg gtctaggggt atgattctcg cttcgggtgc gagaggtccc gggttcaaat 60
cccggacgag ccc 73
<![CDATA[<210> 295]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 295]]>
ggctcgttgg tctaggggta tgattctcgc ttagggtgcg agaggtcccg ggttcaaatc 60
ccggacgagc cct 73
<![CDATA[<210> 296]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 296]]>
cgcccggata gctcagtcgg tagagcatca gacttttaat ctgagggtcc agggttcaag 60
tccctgttcg ggcg 74
<![CDATA[<210> 297]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 297]]>
gcccggatag ctcagtcggt agagcatcag acttttaatc tgagggtcca gggttcaagt 60
ccctgttcgg gcgt 74
<![CDATA[<210> 298]]>
<![CDATA[<211> 107]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 298]]>
tgtcaggatg gccgagtggt ctaaggcgcc agactcaagg taagcacctt gcctgcgggc 60
tttctggtct ccggatggag gcgtgggttc gaatcccact tctgaca 107
<![CDATA[<210> 299]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 299]]>
ttccctggtg gtctagtggt taggattcgg cgctctcacc gccgcggccc gggttcgatt 60
cccggtcagg aaa 73
<![CDATA[<210> 300]]>
<![CDATA[<211> 90]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 300]]>
gccttcgata gctcagttgg tagagcggag gactgtagtg gatagggcgt ggcaatcctt 60
aggtcgctgg ttcgattccg gctcgaagga 90
<![CDATA[<210> 301]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 301]]>
cgggggatta gctcaaatgg tagagcgctc gcttagcatg cgagaggtag cgggatcgat 60
gcccgcatcc tcca 74
<![CDATA[<210> 302]]>
<![CDATA[<211> 94]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 302]]>
agctccagtg gcgcaatcgg ttagcgcgcg gtacttatac agcagtacat gcagagcaat 60
gccgaggttg tgagttcgag cctcacctgg agca 94
<![CDATA[<210> 303]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 303]]>
gcgccgctgg tgtagtggta tcatgcaaga ttcccattct tgcgacccgg gttcgattcc 60
cgggcggcgc at 72
<![CDATA[<210> 304]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 304]]>
tcccatatgg tctagcggtt aggattcctg gttttcaccc aggtggcccg ggttcgactc 60
ccggtatggg aac 73
<![CDATA[<210> 305]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 305]]>
gggggatgta gctcagtggt agagcgcgcg cttcgcatgt gtgaggtccc gggttcaatc 60
cccggcatct cca 73
<![CDATA[<210> 306]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 306]]>
gcattggtgg ttcagtggta gaattctcgc ctgccacgcg ggaggcccgg gttcgattcc 60
cggccaatgc aa 72
<![CDATA[<210> 307]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 307]]>
gggccagtgg cgcaatggat aacgcgtctg actacggatc agaagattct aggttcgact 60
cctggctggc tcgc 74
<![CDATA[<210> 308]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 308]]>
ggtttccgta gtgtagtggt tatcacgttc gcctaacacg cgaaaggtcc ccggttcgaa 60
accgggcgga aaca 74
<![CDATA[<210> 309]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 309]]>
agtttccgta gtgtagtggt tatcacgttc gcctaacacg cgaaaggtcc ccggttcgaa 60
accgggcgga aaca 74
<![CDATA[<210> 310]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 310]]>
aggtagcgtg gccgagcggt ctaaggcgct ggattaaggc tccagtctct tcgggggcgt 60
gggttcgaat cccaccgctg cca 83
<![CDATA[<210> 311]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 311]]>
gtttccgtag tgtagtggtc atcacgttcg cctaacacgc gaaaggtccc cggttcgaaa 60
ccgggcggaa acat 74
<![CDATA[<210> 312]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 312]]>
ggctcgttgg tctaggggta tgattctcgc tttgggtgcg agaggtcccg ggttcaaatc 60
ccggacgagc cca 73
<![CDATA[<210> 313]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 313]]>
ggctccatag ctcaggggtt agagcactgg tcttgtaaac cagggtcgcg agttcaaatc 60
tcgctggggc ctg 73
<![CDATA[<210> 314]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 314]]>
tggggatgta gctcagtggt agagcgcatg ctttgcatgt atgaggcccc gggttcgatc 60
cccggcatct cca 73
<![CDATA[<210> 315]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 315]]>
cgcccggcta gctcagtcgg tagagcatga gactcttaat ctcagggtcg tgggttcgag 60
ccccacgttg ggcg 74
<![CDATA[<210> 316]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 316]]>
gtttccgtag tgtagtggtt atcacgttcg cctaacacgc gaaaggtccc cggttcgaaa 60
ccgggcggaa acaa 74
<![CDATA[<210> 317]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 317]]>
gcccggctag ctcagtcggt agagcatgag actcttaatc tcagggtcgt gggttcgagc 60
cccacgttgg gcgt 74
<![CDATA[<210> 318]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 318]]>
gtttccgtag tgtagtggtt atcacgttcg cctcacacgc gaaaggtccc cggttcgaaa 60
ccgggcggaa acac 74
<![CDATA[<210> 319]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 319]]>
cagcagagtg gcgcagcgga agcgtgctgg gcccataacc cagaggtcga tggatcgaaa 60
ccatcctctg cta 73
<![CDATA[<210> 320]]>
<![CDATA[<211> 85]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 320]]>
ggagaggcct ggccgagtgg ttaaggcgat ggactgctaa tccattgtgc tctgcacgcg 60
tgggttcgaa tcccatcctc gtcgc 85
<![CDATA[<210> 321]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 321]]>
ggccccatgg tgtaatggtt agcactctgg actttgaatc cagcgatccg agttcaaatc 60
tcggtgggac ctg 73
<![CDATA[<210> 322]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 322]]>
ggccccatgg tgtaatggtt agcactctgg actttgaatc cagcgatccg agttcaaatc 60
tcggtgggac cta 73
<![CDATA[<210> 323]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 323]]>
gtagtcgtgg ccgagtggtt aaggcgatgg acttgaaatc cattggggtc tccccgcgca 60
ggttcgaatc ctgccgacta cgg 83
<![CDATA[<210> 324]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 324]]>
agcagagtgg cgcagcggaa gcgtgctggg cccataaccc agaggtcgat ggatcgaaac 60
catcctctgc tat 73
<![CDATA[<210> 325]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 325]]>
ggaccacgtg gcctaatgga taaggcgtct gacttcggat cagaagattg agggttcgaa 60
tccctccgtg gtta 74
<![CDATA[<210> 326]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 326]]>
tgtagtcgtg gccgagtggt taaggcgatg gactagaaat ccattggggt ctccccgcgc 60
aggttcgaat cctgccgact acg 83
<![CDATA[<210> 327]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 327]]>
agcagagtgg cgcagcggaa gcgtgctggg cccataaccc agaggtcgat ggatcgaaac 60
catcctctgc tag 73
<![CDATA[<210> 328]]>
<![CDATA[<211> 84]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 328]]>
cgtcaggatg gccgagcggt ctaaggcgct gcgttcaggt cgcagtctcc cctggaggcg 60
tgggttcgaa tcccactcct gaca 84
<![CDATA[<210> 329]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 329]]>
ggctccgtgg cttagctggt taaagcgcct gtctagtaaa caggagatcc tgggttcgaa 60
tcccagcggg gcctg 75
<![CDATA[<210> 330]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 330]]>
agggccagtg gcgcaatgga taacgcgtct gactacggat cagaagattc caggttcgac 60
tcctggctgg ctcg 74
<![CDATA[<210> 331]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 331]]>
ggtttccgta gtgtagtggt tatcacgttc gcctcacacg cgaaaggtcc ccggttcgaa 60
accgggcgga aaca 74
<![CDATA[<210> 332]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 332]]>
aggggatgta gctcagtggt agagcgcatg cttcgcatgt atgaggtccc gggttcgatc 60
cccggcatct cca 73
<![CDATA[<210> 333]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 333]]>
tggccggtta gctcagttgg ttagagcgtg gtgctaataa cgccaaggtc gcgggttcga 60
tccccgtacg ggcca 75
<![CDATA[<210> 334]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 334]]>
cggctcgttg gtctaggggt atgattctcg cttagggtgc gagaggtccc gggttcaaat 60
cccggacgag ccc 73
<![CDATA[<210> 335]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 335]]>
agcccggcta gctcagtcgg tagagcatga gactcttaat ctcagggtcg tgggttcgag 60
ccccacgttg ggcg 74
<![CDATA[<210> 336]]>
<![CDATA[<211> 92]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 336]]>
tccttcgata gctcagttgg tagagcggag gactgtagtt ggctgtgtcc ttagacatcc 60
ttaggtcgct ggttcgaatc cggctcgaag ga 92
<![CDATA[<210> 337]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 337]]>
ggggaattag ctcaaatggt agagcgctcg cttagcatgc gagaggtagc gggatcgatg 60
cccgcattct ccag 74
<![CDATA[<210> 338]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 338]]>
cgccctctta gcgcagcggg cagcgcgtca gtctcataat ctgaaggtcc tgagttcgag 60
cctcagagag ggca 74
<![CDATA[<210> 339]]>
<![CDATA[<211> 95]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 339]]>
tgctccagtg gcgcaatcgg ttagcgcgcg gtacttatat ggcagtatgt gtgcgagtga 60
tgccgaggtt gtgagttcga gcctcacctg gagca 95
<![CDATA[<210> 340]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 340]]>
tgccgtgatc gtatagtggt tagtactctg cgttgtggcc gcagcaacct cggttcgaat 60
ccgagtcacg gca 73
<![CDATA[<210> 341]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 341]]>
ggccggttag ctcagttggt tagagcgtgg tgctaataac gccaaggtcg cgggttcgat 60
ccccgtacgg gccac 75
<![CDATA[<210> 342]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 342]]>
agtttccgta gtgtagtggt tatcacgttt gcctaacacg cgaaaggtcc ccggttcgaa 60
accgggcaga aaca 74
<![CDATA[<210> 343]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 343]]>
gcttctgtag tgtagtggtt atcacgttcg cctcacacgc gaaaggtccc cggttcgaaa 60
ccgggcagaa gcaa 74
<![CDATA[<210> 344]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 344]]>
ttcctcgtta gtatagtggt gagtatcccc gcctgtcacg cgggagaccg gggttcgatt 60
ccccgacggg gag 73
<![CDATA[<210> 345]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 345]]>
gtagtcgtgg ccgagtggtt aaggcgatgg acttgaaatc cattggggtt tccccgcgca 60
ggttcgaatc ctgtcggcta cgg 83
<![CDATA[<210> 346]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 346]]>
aggttccatg gtgtaatggt tagcactctg gactctgaat ccagcgatcc gagttcaaat 60
ctcggtggaa cct 73
<![CDATA[<210> 347]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 347]]>
tcctcgttag tatagtggtg agtgtccccg tctgtcacgc gggagaccgg ggttcgattc 60
cccgacgggg aga 73
<![CDATA[<210> 348]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 348]]>
gtttccgtag tgtagtggtt atcacgttcg cctaacacgc gaaaggtccc tggatcaaaa 60
ccaggcggaa acaa 74
<![CDATA[<210> 349]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 349]]>
cggccggtta gctcagttgg ttagagcgtg gtgctaataa cgccaaggtc gcgggttcga 60
tccccgtact ggcca 75
<![CDATA[<210> 350]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 350]]>
ggccccatgg tgtaatggtc agcactctgg actctgaatc cagcgatccg agttcaaatc 60
tcggtgggac cca 73
<![CDATA[<210> 351]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 351]]>
ggccccatgg tgtaatggtt agcactctgg actttgaatc cagcgatccg agttcaaatc 60
tcggtgggac ctt 73
<![CDATA[<210> 352]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 352]]>
tgggggtgta gctcagtggt agagcgcgtg cttagcatgt acgaggtccc gggttcaatc 60
cccggcacct cca 73
<![CDATA[<210> 353]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 353]]>
ggggatgtag ctcagtggta gagcgcatgc ttagcatgca tgaggtcccg ggttcgatcc 60
ccagcatctc cag 73
<![CDATA[<210> 354]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 354]]>
agggggtgta gctcagtggt agagcgcgtg cttcgcatgt acgaggcccc gggttcgacc 60
cccggctcct cca 73
<![CDATA[<210> 355]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 355]]>
gggggtgtag ctcagtggta gagcgcgtgc ttagcatgca cgaggccccg ggttcaatcc 60
ccggcacctc cat 73
<![CDATA[<210> 356]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 356]]>
gggggtgtag ctcagtggta gagcgcgtgc ttagcatgca cgaggccccg ggttcaatcc 60
ccggcacctc cag 73
<![CDATA[<210> 357]]>
<![CDATA[<211> 107]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 357]]>
gtcaggatgg ccgagtggtc taaggcgcca gactcaagct aagcttcctc cgcggtgggg 60
attctggtct ccaatggagg cgtgggttcg aatcccactt ctgacac 107
<![CDATA[<210> 358]]>
<![CDATA[<211> 106]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 358]]>
tgtcaggatg gccgagtggt ctaaggcgcc agactcaagc ttggcttcct cgtgttgagg 60
attctggtct ccaatggagg cgtgggttcg aatcccactt ctgaca 106
<![CDATA[<210> 359]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 359]]>
ggttccatgg tgtaatggtt agcactctgg actctgaatc cagcgatccg agttcaaatc 60
tcggtggaac ctt 73
<![CDATA[<210> 360]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 360]]>
ggtagcgtgg ccgagcggtc taaggcgctg gattaaggct ccagtctctt cgggggcgtg 60
ggttcgaatc ccaccgctgc cag 83
<![CDATA[<210> 361]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 361]]>
tgcctcctta gcgcagtagg cagcgcgtca gtctcataat ctgaaggtcc tgagttcgaa 60
cctcagaggg ggca 74
<![CDATA[<210> 362]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 362]]>
agcccggata gctcagtcgg tagagcatca gacttttaat ctgagggtcc agggttcaag 60
tccctgttcg ggcg 74
<![CDATA[<210> 363]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 363]]>
gcctccttag cgcagtaggc agcgcgtcag tctcataatc tgaaggtcct gagttcgaac 60
ctcagagggg gcag 74
<![CDATA[<210> 364]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 364]]>
ttccctggtg gtctagtggt taggattcgg cgctctcacc gccgcggccc gggttcgatt 60
cccggtcagg gaa 73
<![CDATA[<210> 365]]>
<![CDATA[<211> 84]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 365]]>
caccaggatg gccgagtggt taaggcgttg gacttaagat ccaatggaca tatgtccgcg 60
tgggttcgaa ccccactcct ggta 84
<![CDATA[<210> 366]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 366]]>
tggctcgttg gtctaggggt atgattctcg cttagggtgc gagaggtccc gggttcaaat 60
cccggacgag ccc 73
<![CDATA[<210> 367]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 367]]>
agccccagtg gcctaatgga taaggcattg gcctcctaag ccagggattg tgggttcgag 60
tcccatctgg ggtg 74
<![CDATA[<210> 368]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 368]]>
ggggatatag ctcaggggta gagcatttga ctgcagatca agaggtcccc ggttcaaatc 60
cgggtgcccc ccc 73
<![CDATA[<210> 369]]>
<![CDATA[<211> 94]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 369]]>
cccttcgata gctcagctgg tagagcggag gactgtagct acttcctcag caggagacat 60
ccttaggtcg ctggttcgat tccggctcga agga 94
<![CDATA[<210> 370]]>
<![CDATA[<211> 90]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 370]]>
cccttcgata gctcagctgg tagagcggag gactgtaggc gcgcgcccgt ggccatcctt 60
aggtcgctgg ttcgattccg gctcgaagga 90
<![CDATA[<210> 371]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 371]]>
tgggggatta gctcaaatgg tagagcgctc gcttagcatg cgagaggtag cgggatcgat 60
gcccgcatcc tcca 74
<![CDATA[<210> 372]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 372]]>
gtagtcgtgg ccgagtggtt aaggcgatgg actagaaatc cattggggtc tccccgcgca 60
ggttcgaatc ctgccgacta cgg 83
<![CDATA[<210> 373]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 373]]>
gcctcgttag cgcagtaggt agcgcgtcag tctcataatc tgaaggtcgt gagttcgatc 60
ctcacacggg gcac 74
<![CDATA[<210> 374]]>
<![CDATA[<211> 92]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 374]]>
ggctctgtgg cgcaatggat agcgcattgg acttctagct gagcctagtg tggtcattca 60
aaggttgtgg gttcgagtcc caccagagtc ga 92
<![CDATA[<210> 375]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 375]]>
gtctctgtgg cgcaatcggt tagcgcgttc ggctgttaac cgaaaggttg gtggttcgag 60
cccacccagg gacgc 75
<![CDATA[<210> 376]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 376]]>
ggcagcgatg gccgagtggt taaggcgttg gacttgaaat ccaatggggt ctccccgcgc 60
aggttcgaac cctgctcgct gcg 83
<![CDATA[<210> 377]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 377]]>
ggttccatag tgtagtggtt atcacgtctg ctttacacgc agaaggtcct gggttcgagc 60
cccagtggaa ccat 74
<![CDATA[<210> 378]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 378]]>
ggttccatag tgtagcggtt atcacgtctg ctttacacgc agaaggtcct gggttcgagc 60
cccagtggaa ccac 74
<![CDATA[<210> 379]]>
<![CDATA[<211> 87]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 379]]>
tggctctgtg gcgcaatgga tagcgcattg gacttctaga tagttagaga aattcaaagg 60
ttgtgggttc gagtcccacc agagtcg 87
<![CDATA[<210> 380]]>
<![CDATA[<211> 84]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 380]]>
taccagaatg gccgagtggt taaggcgttg gacttaagat ccaatggatt catatccgcg 60
tgggttcgaa ccccacttct ggta 84
<![CDATA[<210> 381]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 381]]>
ggcccggata gctcagtcgg tagagcatca gacttttaat ctgagggtcc ggggttcaag 60
tccctgttcg ggcg 74
<![CDATA[<210> 382]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 382]]>
gccgaaatag ctcagttggg agagcgttag actgaagatc taaaggtccc tggttcgatc 60
ccgggtttcg gcag 74
<![CDATA[<210> 383]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 383]]>
gcccggatag ctcagtcggt agagcatcag acttttaatc tgagggtcca gggttcaagt 60
ccctgttcgg gcgg 74
<![CDATA[<210> 384]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 384]]>
gccgaaatag ctcagttggg agagcgttag actgaagatc taaaggtccc tggttcaatc 60
ccgggtttcg gcag 74
<![CDATA[<210> 385]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 385]]>
ggacgaggtg gccgagtggt taaggcgatg gactgctaat ccattgtgct ttgcacgcgt 60
gggttcgaat cccatcctcg tcg 83
<![CDATA[<210> 386]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 386]]>
ggctcgttgg tctaggggta tgattctcgg tttgggtccg agaggtcccg ggttcaaatc 60
ccggacgagc ccc 73
<![CDATA[<210> 387]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 387]]>
agtcacggtg gccgagtggt taaggcgttg gactcgaaat ccaatggggt ttccccgcac 60
aggttcgaat cctgttcgtg acg 83
<![CDATA[<210> 388]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 388]]>
ctcctcgtta gtatagtggt tagtatcccc gcctgtcacg cgggagaccg gggttcaatt 60
ccccgacggg gag 73
<![CDATA[<210> 389]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 389]]>
ggacctcgtg gcgcaacggt agcgcgtctg actccagatc agaaggctgc gtgttcgaat 60
cacgtcgggg tca 73
<![CDATA[<210> 390]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 390]]>
ggggatgtag ctcagtggta gagcgcatgc tttgcatgta tgaggccccg ggttcgatcc 60
ccggcatctc cat 73
<![CDATA[<210> 391]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 391]]>
gccgaaatag ctcagttggg agagcgttag actgaagatc taaaggtccc tggttcgatc 60
ccgggtttcg gcac 74
<![CDATA[<210> 392]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 392]]>
aggggatgta gctcagtggt agagcgcatg ctttgcacgt atgaggcccc gggttcaatc 60
cccggcatct cca 73
<![CDATA[<210> 393]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 393]]>
gtctctgtgg cgcaatcggt tagcgcgttc ggctgttaac cgaaaggttg gtggttcgag 60
cccacccagg gacgg 75
<![CDATA[<210> 394]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 394]]>
tcccacatgg tctagcggtt aggattcctg gttttcaccc aggcggcccg ggttcgactc 60
ccggtgtggg aac 73
<![CDATA[<210> 395]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 395]]>
ggctccatag ctcaggggtt agagcgctgg tcttgtaaac caggggtcgc gagttcaatt 60
ctcgctgggg cctg 74
<![CDATA[<210> 396]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 396]]>
tggtagtgtg gccgagcggt ctaaggcgct ggatttaggc tccagtctct tcgggggcgt 60
gggttcgaat cccaccactg cca 83
<![CDATA[<210> 397]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 397]]>
ggctccatag ctcaggggtt agagcactgg tcttgtaaac caggggtcgc gagttcaaat 60
ctcgctgggg cctc 74
<![CDATA[<210> 398]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 398]]>
tggctcgttg gtctagtggt atgattctcg ctttgggtgc gagaggtccc gggttcaaat 60
cccggacgag ccc 73
<![CDATA[<210> 399]]>
<![CDATA[<211> 95]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 399]]>
ccttcgatag ctcagctggt agagcggagg actgtagatt gtacagacat ttgcggacat 60
ccttaggtcg ctggttcgat tccggctcga aggaa 95
<![CDATA[<210> 400]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 400]]>
aggccctata gctcaggggt tagagcactg gtcttgtaaa ccaggggtcg cgagttcaaa 60
tctcgctggg gcct 74
<![CDATA[<210> 401]]>
<![CDATA[<211> 90]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 401]]>
tccttcgata gctcagctgg tagagcggag gactgtagta cttaatgtgt ggtcatcctt 60
aggtcgctgg ttcgattccg gctcgaagga 90
<![CDATA[<210> 402]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 402]]>
tggctcgttg gtctaggggt atgattctcg ctttgggtgc gagaggtccc gggttcaaat 60
cccggacgag ccc 73
<![CDATA[<210> 403]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 403]]>
gcccggctag ctcagtcggt agagcatggg actcttaatc ccagggtcgt gggttcgagc 60
cccacgttgg gcgc 74
<![CDATA[<210> 404]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 404]]>
cggccggtta gctcagttgg ttagagcgtg gtgctaataa cgccaaggtc gcgggttcga 60
tccccgtacg ggcca 75
<![CDATA[<210> 405]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 405]]>
tcccacatgg tctagcggtt aggattcctg gttttcaccc aggcggcccg ggttcgactc 60
ccggtgtggg aat 73
<![CDATA[<210> 406]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 406]]>
gacgaggtgg ccgagtggtt aaggcgatgg actgctaatc cattgtgctc tgcacgcgtg 60
ggttcgaatc ccatcctcgt cga 83
<![CDATA[<210> 407]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 407]]>
gccgtgatcg tatagtggtt agtactctgc gttgtggccg cagcaacctc ggttcgaatc 60
cgagtcacgg cat 73
<![CDATA[<210> 408]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 408]]>
cgccgtgatc gtatagtggt tagtactctg cgttgtggcc gcagcaacct cggttcgaat 60
ccgagtcacg gca 73
<![CDATA[<210> 409]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 409]]>
ggttccatgg tgtaatggtt agcactctgg actctgaatc cagcgatccg agttcaaatc 60
tcggtggaac ctg 73
<![CDATA[<210> 410]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 410]]>
tgcccggcta gctcagtcgg tagagcatgg gactcttaat cccagggtcg tgggttcgag 60
ccccacgttg ggcg 74
<![CDATA[<210> 411]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 411]]>
gggccgcgtg gcctaatgga taaggcgtct gacttcggat cagaagattg caggttcgag 60
tcctgccgcg gtcg 74
<![CDATA[<210> 412]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 412]]>
gcgccgctgg tgtagtggta tcatgcaaga ttcccattct tgcgacccgg gttcgattcc 60
cgggcggcgc ac 72
<![CDATA[<210> 413]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 413]]>
gggccgcgtg gcctaatgga taaggcgtct gattccggat cagaagattg agggttcgag 60
tcccttcgtg gtcg 74
<![CDATA[<210> 414]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 414]]>
cgccccggtg gcctaatgga taaggcattg gcctcctaag ccagggattg tgggttcgag 60
tcccacccgg ggta 74
<![CDATA[<210> 415]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 415]]>
gcccggctag ctcagtcggt agagcatgag acccttaatc tcagggtcgt gggttcgagc 60
cccacgttgg gcgt 74
<![CDATA[<210> 416]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 416]]>
aggcgcggtg gccaagtggt aaggcgtcgg tctcgtaaac cgaagatcac gggttcgaac 60
cccgtccgtg cct 73
<![CDATA[<210> 417]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 417]]>
ggtagcgtgg ccgagtggtc taaggcgctg gatttaggct ccagtcattt cgatggcgtg 60
ggttcgaatc ccaccgctgc cac 83
<![CDATA[<210> 418]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 418]]>
gggtagcgtg gccgagcggt ctaaggcgct ggattaaggc tccagtctct tcgggggcgt 60
gggttcgaat cccaccgctg cca 83
<![CDATA[<210> 419]]>
<![CDATA[<211> 84]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 419]]>
agtcaggatg gccgagcggt ctaaggcgct gcgttcaggt cgcagtctcc cctggaggcg 60
tgggttcgaa tcccacttct gaca 84
<![CDATA[<210> 420]]>
<![CDATA[<211> 84]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 420]]>
gtcaggatgg ccgagcggtc taaggcgctg cgttcaggtc gcagtctccc ctggaggcgt 60
gggttcgaat cccacttctg acag 84
<![CDATA[<210> 421]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 421]]>
gcctcgttag cgcagtaggc agcgcgtcag tctcataatc tgaaggtcgt gagttcgagc 60
ctcacacggg gcag 74
<![CDATA[<210> 422]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 422]]>
ggtagcgtgg ccgagcggtc taaggcgctg gatttaggct ccagtctctt cggaggcgtg 60
ggttcgaatc ccaccgctgc cag 83
<![CDATA[<210> 423]]>
<![CDATA[<211> 89]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 423]]>
tggctctgtg gcgcaatgga tagcgcattg gacttctagt gacgaataga gcaattcaaa 60
ggttgtgggt tcgaatccca ccagagtcg 89
<![CDATA[<210> 424]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 424]]>
cgcattggtg gttcagtggt agaattctcg cctgccacgc gggaggcccg ggttcgattc 60
ccggccaatg ca 72
<![CDATA[<210> 425]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 425]]>
gctgtgatgg ccgagtggtt aaggcgttgg actcgaaatc caatggggtc tccccgcgca 60
ggttcgaatc ctgctcacag cgt 83
<![CDATA[<210> 426]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 426]]>
ggcgccgtgg cttagctggt taaagcgcct gtctagtaaa caggagatcc tgggttcgaa 60
tcccagcggt gcctg 75
<![CDATA[<210> 427]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 427]]>
cgacctcgtg gcgcaacggt agcgcgtctg actccagatc agaaggttgc gtgttcaaat 60
cacgtcgggg tca 73
<![CDATA[<210> 428]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 428]]>
agacgaggtg gccgagtggt taaggcgatg gactgctaat ccattgtgct ctgcacgcgt 60
gggttcgaat cccatcctcg tcg 83
<![CDATA[<210> 429]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 429]]>
cggcgccgtg gcttagttgg ttaaagcgcc tgtctagtaa acaggagatc ctgggttcga 60
atcccagcgg tgcct 75
<![CDATA[<210> 430]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 430]]>
ggcctcgtgg cgcaacggta gcgcgtctga ctccagatca gaaggttgcg tgttcaaatc 60
acgtcggggt caa 73
<![CDATA[<210> 431]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 431]]>
agcgttggtg gtatagtggt aagcatagct gccttccaag cagttgaccc gggttcgatt 60
cccggccaac gca 73
<![CDATA[<210> 432]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 432]]>
tcctcgttag tatagtggtg agtatccccg cctgtcacgc gggagaccgg ggttcgattc 60
cccgacgggg aga 73
<![CDATA[<210> 433]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 433]]>
ggctcgttgg tctaggggta tgattctcgc ttcgggtgcg agaggtcccg ggttcaaatc 60
ccggacgagc cct 73
<![CDATA[<210> 434]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 434]]>
ggcgccgtgg cttagttggt taaagcgcct gtctagtaaa caggagatcc tgggttcgaa 60
tcccagcggt gcctt 75
<![CDATA[<210> 435]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 435]]>
gtagtcgtgg ccgagtggtt aaggcgatgg actagaaatc cattggggtc tccccgcgca 60
ggttcgaatc ctgccgacta cgt 83
<![CDATA[<210> 436]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 436]]>
tgacctcgtg gcgcaatggt agcgcgtctg actccagatc agaaggttgc gtgttcaagt 60
cacgtcgggg tca 73
<![CDATA[<210> 437]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 437]]>
aggcgcggtg gccaagtggt aaggcgtcgg tctcgtaaac cgaagatcgc gggttcgaac 60
cccgtccgtg cct 73
<![CDATA[<210> 438]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 438]]>
agggggtata gctcagtggt agagcatttg actgcagatc aagaggtccc cggttcaaat 60
ccgggtgccc cct 73
<![CDATA[<210> 439]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 439]]>
gggggtatag ctcagtggta gagcatttga ctgcagatca agaggtccct ggttcaaatc 60
cgggtgcccc ctc 73
<![CDATA[<210> 440]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 440]]>
gggggtatag ctcagtggta gagcatttga ctgcagatca agaggtcccc ggttcaaatc 60
cgggtgcccc ctc 73
<![CDATA[<210> 441]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 441]]>
aggtcccatg gtgtaatggt tagcactctg gactttgaat ccagcgatcc gagttcaaat 60
ctcggtggga cct 73
<![CDATA[<210> 442]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 442]]>
gacccagtgg cctaatggat aaggcatcag cctccggagc tggggattgt gggttcgagt 60
cccatctggg tcgc 74
<![CDATA[<210> 443]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 443]]>
agccccagtg gcctaatgga taaggcactg gcctcctaag ccagggattg tgggttcgag 60
tcccacctgg ggta 74
<![CDATA[<210> 444]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 444]]>
gccccagtgg cctaatggat aaggcactgg cctcctaagc cagggattgt gggttcgagt 60
cccacctggg gtgt 74
<![CDATA[<210> 445]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 445]]>
agaccgcgtg gcctaatgga taaggcgtct gacttcggat cagaagattg agggttcgag 60
tcccttcgtg gtcg 74
<![CDATA[<210> 446]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 446]]>
cgtctctgtg gcgcaatcgg ttagcgcgtt cggctgttaa ccgaaaggtt ggtggttcga 60
gcccacccag ggacg 75
<![CDATA[<210> 447]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 447]]>
ggcgttggtg gtatagtggt tagcatagct gccttccaag cagttgaccc gggttcgatt 60
cccggccaac gca 73
<![CDATA[<210> 448]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 448]]>
gtttccgtag tgtagcggtt atcacattcg cctcacacgc gaaaggtccc cggttcgatc 60
ccgggcggaa acag 74
<![CDATA[<210> 449]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 449]]>
tggcgccgtg gcttagttgg ttaaagcgcc tgtctagtaa acaggagatc ctgggttcga 60
atcccagcgg tgcct 75
<![CDATA[<210> 450]]>
<![CDATA[<211> 94]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 450]]>
gctccagtgg cgcaatcggt tagcgcgcgg tacttatatg acagtgcgag cggagcaatg 60
ccgaggttgt gagttcgatc ctcacctgga gcac 94
<![CDATA[<210> 451]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 智人]]>
<![CDATA[<400> 451]]>
gcatgggtgg ttcagtggta gaattctcgc ctgccacgcg ggaggcccgg gttcgattcc 60
cggcccatgc ag 72
<![CDATA[<210> 452]]>
<![CDATA[<211> 18]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 452]]>
aaaatataaa tatatttc 18
<![CDATA[<210> 453]]>
<![CDATA[<211> 5]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 453]]>
aagct 5
<![CDATA[<210> 454]]>
<![CDATA[<211> 5]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 454]]>
aagtt 5
<![CDATA[<210> 455]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 455]]>
aattcttcgg aatgt 15
<![CDATA[<210> 456]]>
<![CDATA[<211> 3]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 456]]>
aga 3
<![CDATA[<210> 457]]>
<![CDATA[<211> 5]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 457]]>
agtcc 5
<![CDATA[<210> 458]]>
<![CDATA[<211> 5]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 458]]>
caacc 5
<![CDATA[<210> 459]]>
<![CDATA[<211> 5]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 459]]>
caatc 5
<![CDATA[<210> 460]]>
<![CDATA[<211> 4]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 460]]>
cagc 4
<![CDATA[<210> 461]]>
<![CDATA[<211> 20]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 461]]>
caggcgggtt ctgcccgcgc 20
<![CDATA[<210> 462]]>
<![CDATA[<211> 18]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 462]]>
catacctgca agggtatc 18
<![CDATA[<210> 463]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 463]]>
cgaccgcaag gttgt 15
<![CDATA[<210> 464]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 464]]>
cgaccttgcg gtcat 15
<![CDATA[<210> 465]]>
<![CDATA[<211> 18]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 465]]>
cgatgctaat cacatcgt 18
<![CDATA[<210> 466]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 466]]>
cgatggtgac atcat 15
<![CDATA[<210> 467]]>
<![CDATA[<211> 16]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 467]]>
cgatggttta catcgt 16
<![CDATA[<210> 468]]>
<![CDATA[<211> 13]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 468]]>
cgccgtaagg tgt 13
<![CDATA[<210> 469]]>
<![CDATA[<211> 12]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 469]]>
cgccttaggt gt 12
<![CDATA[<210> 470]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 470]]>
cgcctttcga cgcgt 15
<![CDATA[<210> 471]]>
<![CDATA[<211> 13]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 471]]>
cgcttcacgg cgt 13
<![CDATA[<210> 472]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 472]]>
cggcagcaat gctgt 15
<![CDATA[<210> 473]]>
<![CDATA[<211> 13]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 473]]>
cggctccgcc ttc 13
<![CDATA[<210> 474]]>
<![CDATA[<211> 16]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 474]]>
cgggtatcac agggtc 16
<![CDATA[<210> 475]]>
<![CDATA[<211> 17]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 475]]>
cggtgcgcaa gcgctgt 17
<![CDATA[<210> 476]]>
<![CDATA[<211> 18]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 476]]>
cgtacgggtg accgtacc 18
<![CDATA[<210> 477]]>
<![CDATA[<211> 13]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 477]]>
cgtcaaagac ttc 13
<![CDATA[<210> 478]]>
<![CDATA[<211> 13]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 478]]>
cgtcgtaaga ctt 13
<![CDATA[<210> 479]]>
<![CDATA[<211> 14]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 479]]>
cgttgaataa acgt 14
<![CDATA[<210> 480]]>
<![CDATA[<211> 5]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 480]]>
ctgtc 5
<![CDATA[<210> 481]]>
<![CDATA[<211> 4]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 481]]>
ggcc 4
<![CDATA[<210> 482]]>
<![CDATA[<211> 7]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 482]]>
ggggatt 7
<![CDATA[<210> 483]]>
<![CDATA[<211> 4]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 483]]>
ggtc 4
<![CDATA[<210> 484]]>
<![CDATA[<211> 5]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 484]]>
ggttt 5
<![CDATA[<210> 485]]>
<![CDATA[<211> 4]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 485]]>
gtag 4
<![CDATA[<210> 486]]>
<![CDATA[<211> 19]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 486]]>
taactagata ctttcagat 19
<![CDATA[<210> 487]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 487]]>
tactcgtatg ggtgc 15
<![CDATA[<210> 488]]>
<![CDATA[<211> 13]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 488]]>
tactttgcgg tgt 13
<![CDATA[<210> 489]]>
<![CDATA[<211> 19]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 489]]>
taggcgagta acatcgtgc 19
<![CDATA[<210> 490]]>
<![CDATA[<211> 19]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 490]]>
taggcgtgaa tagcgcctc 19
<![CDATA[<210> 491]]>
<![CDATA[<211> 19]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 491]]>
taggtcgcga gagcggcgc 19
<![CDATA[<210> 492]]>
<![CDATA[<211> 19]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 492]]>
taggtcgcgt aagcggcgc 19
<![CDATA[<210> 493]]>
<![CDATA[<211> 17]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 493]]>
taggtggtta tccacgc 17
<![CDATA[<210> 494]]>
<![CDATA[<211> 5]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 494]]>
tagtc 5
<![CDATA[<210> 495]]>
<![CDATA[<211> 5]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 495]]>
tagtt 5
<![CDATA[<210> 496]]>
<![CDATA[<211> 18]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 496]]>
tatacgtgaa agcgtatc 18
<![CDATA[<210> 497]]>
<![CDATA[<211> 21]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 497]]>
tatagggtca aaaactctat c 21
<![CDATA[<210> 498]]>
<![CDATA[<211> 20]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 498]]>
tatgcagaaa tacctgcatc 20
<![CDATA[<210> 499]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 499]]>
tccccatacg ggggc 15
<![CDATA[<210> 500]]>
<![CDATA[<211> 14]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 500]]>
tcccgaaggg gttc 14
<![CDATA[<210> 501]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 501]]>
tctacgtatg tgggc 15
<![CDATA[<210> 502]]>
<![CDATA[<211> 14]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 502]]>
tctcatagga gttc 14
<![CDATA[<210> 503]]>
<![CDATA[<211> 14]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 503]]>
tctcctctgg aggc 14
<![CDATA[<210> 504]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 504]]>
tcttagcaat aaggt 15
<![CDATA[<210> 505]]>
<![CDATA[<211> 14]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 505]]>
tcttgtagga gttc 14
<![CDATA[<210> 506]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 506]]>
tgaacgtaag ttcgc 15
<![CDATA[<210> 507]]>
<![CDATA[<211> 16]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 507]]>
tgaactgcga ggttcc 16
<![CDATA[<210> 508]]>
<![CDATA[<211> 4]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 508]]>
tgac 4
<![CDATA[<210> 509]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 509]]>
tgaccgaaag gtcgt 15
<![CDATA[<210> 510]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 510]]>
tgaccgcaag gtcgt 15
<![CDATA[<210> 511]]>
<![CDATA[<211> 14]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 511]]>
tgagctctgc tctc 14
<![CDATA[<210> 512]]>
<![CDATA[<211> 18]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 512]]>
tgaggcctca cggcctac 18
<![CDATA[<210> 513]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 513]]>
tgagggcaac ttcgt 15
<![CDATA[<210> 514]]>
<![CDATA[<211> 16]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 514]]>
tgagggtcat acctcc 16
<![CDATA[<210> 515]]>
<![CDATA[<211> 18]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 515]]>
tgagggtgca aatcctcc 18
<![CDATA[<210> 516]]>
<![CDATA[<211> 13]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 516]]>
tgccgaaagg cgt 13
<![CDATA[<210> 517]]>
<![CDATA[<211> 13]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 517]]>
tgccgtaagg cgt 13
<![CDATA[<210> 518]]>
<![CDATA[<211> 14]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 518]]>
tgcggtctcc gcgc 14
<![CDATA[<210> 519]]>
<![CDATA[<211> 11]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 519]]>
tgctagagca t 11
<![CDATA[<210> 520]]>
<![CDATA[<211> 16]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 520]]>
tgctcgtata gagctc 16
<![CDATA[<210> 521]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 521]]>
tggacaattg tctgc 15
<![CDATA[<210> 522]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 522]]>
tggacagatg tccgt 15
<![CDATA[<210> 523]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 523]]>
tggacaggtg tccgc 15
<![CDATA[<210> 524]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 524]]>
tggacggttg tccgc 15
<![CDATA[<210> 525]]>
<![CDATA[<211> 13]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 525]]>
tggacttgtg gtc 13
<![CDATA[<210> 526]]>
<![CDATA[<211> 16]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 526]]>
tggagattct ctccgc 16
<![CDATA[<210> 527]]>
<![CDATA[<211> 14]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 527]]>
tggcataggc ctgc 14
<![CDATA[<210> 528]]>
<![CDATA[<211> 14]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 528]]>
tggcttatgt ctac 14
<![CDATA[<210> 529]]>
<![CDATA[<211> 16]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 529]]>
tgggagttaa tcccgt 16
<![CDATA[<210> 530]]>
<![CDATA[<211> 14]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 530]]>
tgggatcttc ccgc 14
<![CDATA[<210> 531]]>
<![CDATA[<211> 16]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 531]]>
tgggcagaaa tgtctc 16
<![CDATA[<210> 532]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 532]]>
tgggcgttcg cccgc 15
<![CDATA[<210> 533]]>
<![CDATA[<211> 14]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 533]]>
tgggcttcgc ccgc 14
<![CDATA[<210> 534]]>
<![CDATA[<211> 16]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 534]]>
tgggggataa ccccgt 16
<![CDATA[<210> 535]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 535]]>
tgggggtttc cccgt 15
<![CDATA[<210> 536]]>
<![CDATA[<211> 4]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 536]]>
tggt 4
<![CDATA[<210> 537]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 537]]>
tggtggcaac accgt 15
<![CDATA[<210> 538]]>
<![CDATA[<211> 14]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 538]]>
tggtttatag ccgt 14
<![CDATA[<210> 539]]>
<![CDATA[<211> 19]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 539]]>
tgtacggtaa taccgtacc 19
<![CDATA[<210> 540]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 540]]>
tgtccgcaag gacgt 15
<![CDATA[<210> 541]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 541]]>
tgtcctaacg gacgt 15
<![CDATA[<210> 542]]>
<![CDATA[<211> 18]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 542]]>
tgtcctatta acggacgt 18
<![CDATA[<210> 543]]>
<![CDATA[<211> 16]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 543]]>
tgtccttcac gggcgt 16
<![CDATA[<210> 544]]>
<![CDATA[<211> 13]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 544]]>
tgtcttagga cgt 13
<![CDATA[<210> 545]]>
<![CDATA[<211> 18]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 545]]>
tgtgcgttaa cgcgtacc 18
<![CDATA[<210> 546]]>
<![CDATA[<211> 16]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 546]]>
tgtgtcgcaa ggcacc 16
<![CDATA[<210> 547]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 547]]>
tgttcgtaag gactt 15
<![CDATA[<210> 548]]>
<![CDATA[<211> 16]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 548]]>
ttcacagaaa tgtgtc 16
<![CDATA[<210> 549]]>
<![CDATA[<211> 14]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 549]]>
ttccctcgtg gagt 14
<![CDATA[<210> 550]]>
<![CDATA[<211> 14]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 550]]>
ttccctctgg gagc 14
<![CDATA[<210> 551]]>
<![CDATA[<211> 14]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 551]]>
ttcccttgtg gatc 14
<![CDATA[<210> 552]]>
<![CDATA[<211> 13]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 552]]>
ttccttcggg agc 13
<![CDATA[<210> 553]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 553]]>
ttctagcaat agagt 15
<![CDATA[<210> 554]]>
<![CDATA[<211> 16]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 554]]>
ttctccactg gggagc 16
<![CDATA[<210> 555]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 555]]>
ttctcgagag ggagc 15
<![CDATA[<210> 556]]>
<![CDATA[<211> 15]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 556]]>
ttctcgtatg agagc 15
<![CDATA[<210> 557]]>
<![CDATA[<211> 19]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 557]]>
tttaaggttt tcccttaac 19
<![CDATA[<210> 558]]>
<![CDATA[<211> 14]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 558]]>
tttcattgtg gagt 14
<![CDATA[<210> 559]]>
<![CDATA[<211> 14]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 559]]>
tttcgaagga atcc 14
<![CDATA[<210> 560]]>
<![CDATA[<211> 13]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 560]]>
tttcttcgga agc 13
<![CDATA[<210> 561]]>
<![CDATA[<211> 16]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 561]]>
tttggggcaa ctcaac 16
<![CDATA[<210> 562]]>
<![CDATA[<211> 342]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (5)..(6)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (15)..(16)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (21)..(21)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (30)..(32)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (34)..(34)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (37)..(37)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (41)..(45)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (47)..(317)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (47)..(320)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (328)..(329)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (333)..(334)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (336)..(337)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 562]]>
rkssnndurg hbyannyugr ndgwdvdydn nnbnhbnryr nnnnndnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnnnn rrduyranny ybnnhnnbwc cd 342
<![CDATA[<210> 563]]>
<![CDATA[<211> 341]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (16)..(16)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (30)..(30)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (46)..(316)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (46)..(316)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (319)..(319)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (328)..(328)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 563]]>
rksgrwdkrg hbyavnyggu dgarvrydyn hkywbhryrh dhdhrnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnbhnr gducrayncy ydvhhyywcc d 341
<![CDATA[<210> 564]]>
<![CDATA[<211> 341]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (16)..(16)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (30)..(30)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (46)..(316)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (46)..(316)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (319)..(319)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 564]]>
ggggrwdurg hbyavnyggu dgarvrydyn hkywkhryrh dhdhrnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnbhnr gducraybcc ydvhhyyucc a 341
<![CDATA[<210> 565]]>
<![CDATA[<211> 343]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (2)..(8)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (12)..(13)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (17)..(17)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (22)..(24)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (26)..(27)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (30)..(35)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (38)..(38)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (43)..(43)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (45)..(322)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (48)..(318)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (329)..(329)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (333)..(342)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(343)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(343)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 565]]>
gnnnnnnnkv gnnhddnhwr rnnnrnnvyn nnnnnbunck rhnbnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnnnn nnguuyrany ybnnnnnnnn nnd 343
<![CDATA[<210> 566]]>
<![CDATA[<211> 342]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (3)..(3)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (6)..(7)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (13)..(13)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (26)..(26)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (32)..(32)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (37)..(37)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (44)..(44)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (47)..(317)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (47)..(317)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (328)..(328)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (336)..(338)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (340)..(340)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 566]]>
grnvbnnvkb gbnydrwurg wygarnrydy ynsvyunckr mkbnrrnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnshv gguuyranuy cbdbynnnbn hr 342
<![CDATA[<210> 567]]>
<![CDATA[<211> 342]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (3)..(3)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (7)..(7)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (47)..(317)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (47)..(317)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (336)..(336)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (340)..(340)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 567]]>
grnvyvnskk gssydawugg aygarsgyry ykgmyuhckr akymrrnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnshr gguuygavuy cydbynbdbn yg 342
<![CDATA[<210> 568]]>
<![CDATA[<211> 341]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (2)..(2)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (4)..(6)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (12)..(12)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (17)..(17)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (25)..(25)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (28)..(30)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (43)..(316)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (46)..(316)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (318)..(319)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (327)..(327)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (331)..(332)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (334)..(337)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (339)..(340)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 568]]>
dnynnndurg hnhvrynggb hurdnrynnn bsryyruuwa hbnnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnvnnr gukhvwnhcy nnbnnnndnn r 341
<![CDATA[<210> 569]]>
<![CDATA[<211> 341]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (17)..(17)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (28)..(28)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (46)..(316)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (46)..(316)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 569]]>
ruyucygurg hryvrunggb yuarhgcnuu ysryyruuwa hbddannnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnrgur gukhvwdmcy ayysvrrrrb r 341
<![CDATA[<210> 570]]>
<![CDATA[<211> 341]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (46)..(316)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (46)..(316)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 570]]>
ruyucygurg hryvrubggb yuaghgcbuu ysryyruuaa hyddannnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnrgur gukhvwdmcy ayysvrrrry g 341
<![CDATA[<210> 571]]>
<![CDATA[<211> 342]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (2)..(6)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (12)..(12)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (16)..(16)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (22)..(22)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (26)..(26)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (29)..(29)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (31)..(32)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (44)..(44)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (47)..(317)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (47)..(319)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (328)..(328)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (333)..(334)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (336)..(339)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 571]]>
knnnnndyrr ynhrrnyygr hnumdnrynb nnvhyurucr hdbnbvnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnnns rgyubrhnyy ysnnhnnnnb mr 342
<![CDATA[<210> 572]]>
<![CDATA[<211> 339]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (2)..(2)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (6)..(6)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (44)..(314)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (44)..(314)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (333)..(333)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(339)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(339)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 572]]>
knsbbnwyar ywyrgugguk mgwrubysyr yyurucaygb rsrnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnykgrgy ubrhkyycch rwnvvksmr 339
<![CDATA[<210> 573]]>
<![CDATA[<211> 339]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (44)..(314)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (44)..(314)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(339)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(339)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 573]]>
umcuyruyag uaurgugguk mguruyycyg ycugucaygy ggrnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnyggrgu uyrmkyyccy rasrrggag 339
<![CDATA[<210> 574]]>
<![CDATA[<211> 342]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (3)..(6)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (12)..(13)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (16)..(16)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (24)..(24)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (26)..(26)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (29)..(32)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (34)..(34)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (42)..(42)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (44)..(319)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (47)..(317)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (328)..(328)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (333)..(334)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (336)..(340)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 574]]>
gsnnnndurv ynnavnkcgd byynrnvbnn nnvnyyrcar mnbnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnnnb druucranyy yvnnhnnnnn yy 342
<![CDATA[<210> 575]]>
<![CDATA[<211> 340]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (16)..(16)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 575]]>
gsgsryrkrg yubasnkgdk uaravyahuu grcyrcarau cmarnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnyyydr uucraruyyv gkuryychyy 340
<![CDATA[<210> 576]]>
<![CDATA[<211> 340]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (16)..(16)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 576]]>
gggsryrkrg yuyasnugrk uagagcayuu gacugcarau cmarnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnyyyrr uucraauyyv gkurcycmyy 340
<![CDATA[<210> 577]]>
<![CDATA[<211> 341]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (2)..(2)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (4)..(6)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (12)..(13)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (16)..(16)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (20)..(21)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (24)..(24)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (28)..(31)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (33)..(33)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (40)..(41)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (43)..(319)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (46)..(316)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (327)..(327)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (331)..(332)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (335)..(339)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 577]]>
dnbnnnduvg bnnarnhggn nhanvvynnn nvnyubukrn nhnnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnnnr ruuyvanyby nnbhnnnnnh d 341
<![CDATA[<210> 578]]>
<![CDATA[<211> 340]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (4)..(5)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (12)..(12)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (21)..(21)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (27)..(28)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (45)..(317)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (331)..(331)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (335)..(336)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 578]]>
kdbnnydugg ynbarkmggd navvrynnhb vryubukrrb hvdvnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnndrr uuyvadybyh nbhdnnvhmd 340
<![CDATA[<210> 579]]>
<![CDATA[<211> 340]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (4)..(4)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (21)..(21)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (27)..(28)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (45)..(317)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (331)..(331)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (336)..(336)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 579]]>
kdbnvydugg ydbarumggk navvrynnws rryubukrab hsdvnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnndrr uuyvadysyh nbhdbnvhmk 340
<![CDATA[<210> 580]]>
<![CDATA[<211> 342]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (1)..(2)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (5)..(6)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (9)..(9)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (12)..(12)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (16)..(16)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (20)..(21)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (26)..(27)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (29)..(33)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (41)..(41)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (44)..(318)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (47)..(317)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (320)..(321)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (328)..(328)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (333)..(336)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (340)..(341)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 580]]>
nnbbnndunr wnhrdnhygn nbhrdnnynn nnnvyuyusr nbvnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnnbn nryubrwnyy hbnnnndvvn nd 342
<![CDATA[<210> 581]]>
<![CDATA[<211> 340]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (1)..(2)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (5)..(5)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (12)..(12)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (20)..(20)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (29)..(29)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (31)..(31)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (39)..(39)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (43)..(43)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (45)..(316)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (319)..(319)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (326)..(326)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (334)..(334)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (338)..(338)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 581]]>
nnbynbdyrg unurdyagbn krrvvywbnb nvyuyusanb vhndnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnydnr yubrwnychb rkbndvvnvd 340
<![CDATA[<210> 582]]>
<![CDATA[<211> 339]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (1)..(1)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (28)..(28)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (30)..(30)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (42)..(42)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (44)..(314)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (44)..(314)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (318)..(318)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (333)..(333)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(339)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(339)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 582]]>
ncsydbrugg usuakygshk rrsaywbnkn syuyucahbv mndnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnbyrnry uyrwyucyyr gbnwrsraw 339
<![CDATA[<210> 583]]>
<![CDATA[<211> 342]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (4)..(7)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (12)..(12)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (16)..(16)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (21)..(22)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (26)..(26)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (29)..(34)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (41)..(319)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (47)..(317)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (328)..(328)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (333)..(338)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 583]]>
rbvnnnnuvr ynyrrnyubd nnuadnrynn nnnnyybccv nnnnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnnnv vsubbrwnhc bbnnnnnnbb yw 342
<![CDATA[<210> 584]]>
<![CDATA[<211> 340]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (5)..(5)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (28)..(28)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (39)..(40)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (42)..(42)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (317)..(317)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (335)..(335)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 584]]>
gbvbnsvurr udyrrdcggk dadmaudnhh rhyubccann ynkdnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnbnrgs uubrwuuccy ksbsnvygca 340
<![CDATA[<210> 585]]>
<![CDATA[<211> 340]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (5)..(5)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (28)..(28)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (39)..(39)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (42)..(42)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (335)..(335)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 585]]>
gyvynsvurr udyrrwcggk kadmaudnhh rhyubccand ynkdnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnbvrgs uuyrwuuccy ksbsnvygca 340
<![CDATA[<210> 586]]>
<![CDATA[<211> 342]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (4)..(7)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (13)..(13)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (25)..(26)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (29)..(31)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (34)..(34)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (42)..(42)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (45)..(317)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (47)..(317)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (319)..(320)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (328)..(328)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (332)..(333)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (336)..(338)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 586]]>
kgynnnnduv gbnhagbyug ghyannvynn ndbnyugugr hnvhnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnvnn rgyucranyc ynnbhnnnvr ym 342
<![CDATA[<210> 587]]>
<![CDATA[<211> 339]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (44)..(314)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (44)..(314)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(339)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(339)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 587]]>
gchrugaybg uayagkgguu asyacucugy gyuguggccr cagnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnncwyggy ucraaucyga gucaygrca 339
<![CDATA[<210> 588]]>
<![CDATA[<211> 339]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (44)..(314)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (44)..(314)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(339)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(339)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 588]]>
gcmrugayyg uauagugguu agyacucugy gyuguggccr cagnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnncwyggu ucraaucyga gucaygrca 339
<![CDATA[<210> 589]]>
<![CDATA[<211> 342]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (1)..(1)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (4)..(5)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (7)..(7)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (17)..(17)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (31)..(32)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (34)..(34)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (37)..(37)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (42)..(320)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (47)..(317)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (328)..(329)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (332)..(334)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (336)..(339)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 589]]>
nvsnnbndur gybyrrnywg gbhrdvrydb nnbnyunaur annnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnnnn dsywydannc hnnnhnnnns ba 342
<![CDATA[<210> 590]]>
<![CDATA[<211> 340]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (326)..(327)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (335)..(335)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 590]]>
gsyybrkurg ykyrruyggy hagmgcrygk urcudauaay ryyrnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnryrrs ywydanncyc rymyngrsca 340
<![CDATA[<210> 591]]>
<![CDATA[<211> 340]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 591]]>
gsyysrkurg ykcaruyggy hagmgcgygg urcudauaay rcyrnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnngygrg yucrabhcyc rymybgrsca 340
<![CDATA[<210> 592]]>
<![CDATA[<211> 341]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (1)..(1)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (3)..(6)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (11)..(12)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (16)..(17)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (21)..(22)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (25)..(26)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (28)..(31)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (41)..(41)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (43)..(316)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (46)..(316)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (318)..(319)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (327)..(327)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (331)..(332)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (335)..(338)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (340)..(340)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 592]]>
nbnnnndurs nnbarnnhgg nnddnnbnnn nvdhycauah nbnnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnvnnr gdusdanhmy nnbhnnnnvn w 341
<![CDATA[<210> 593]]>
<![CDATA[<211> 339]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (4)..(4)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (44)..(314)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (44)..(314)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(339)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(339)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 593]]>
rbcnbvkurg ygcagydggh agyryryyrg kyycauaahy yvrnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnsdkrgd usdadmmymw smbvbgsya 339
<![CDATA[<210> 594]]>
<![CDATA[<211> 339]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (44)..(314)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (44)..(314)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(339)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(339)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 594]]>
rschbvkurg ygcagydggh agcryryyrg kyycauaayc yrrnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnswkrgw usdadmcymw smbvkgsya 339
<![CDATA[<210> 595]]>
<![CDATA[<211> 342]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (2)..(7)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (9)..(12)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (16)..(16)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (23)..(23)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (26)..(26)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (28)..(34)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (37)..(37)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (41)..(317)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (47)..(317)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (319)..(320)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (328)..(328)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (332)..(333)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (335)..(340)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 595]]>
vnnnnnnunn nnvrrnhhgk hhndhnvnnn nnnnhynard nnnnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnvnn vbyuhvanym bnnbnnnnnn br 342
<![CDATA[<210> 596]]>
<![CDATA[<211> 342]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (6)..(6)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (33)..(33)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (41)..(41)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (43)..(43)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (46)..(317)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (47)..(317)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (319)..(319)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (328)..(328)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (333)..(333)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (336)..(336)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (340)..(340)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 596]]>
rbbvvndurk hhsrrbhygk hhurwbrhdb hdnryuhard nynhdnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnvnv gbyuhvanym ybnbbnbbvn ya 342
<![CDATA[<210> 597]]>
<![CDATA[<211> 342]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (6)..(6)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (33)..(33)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (43)..(43)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (46)..(317)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (47)..(317)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (319)..(319)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (333)..(333)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (336)..(336)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (340)..(340)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 597]]>
rbbvvndurk hhsrrbhygk hhurwkrhdb hdnryuhard hynhdnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnvnv gbyuhvavym ybnbynbbvn ya 342
<![CDATA[<210> 598]]>
<![CDATA[<211> 342]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (1)..(7)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (11)..(12)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (16)..(16)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (21)..(21)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (26)..(26)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (30)..(32)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (44)..(320)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (47)..(317)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (328)..(328)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (332)..(333)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (335)..(340)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 598]]>
nnnnnnnurs nnharnhwrr nuudrnrydn nnsvyyyuum mbvnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnnnn vryuyrwnhy bnnbnnnnnn hd 342
<![CDATA[<210> 599]]>
<![CDATA[<211> 340]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (1)..(1)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (6)..(6)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (11)..(11)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (29)..(29)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (43)..(43)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (45)..(317)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (331)..(331)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (333)..(334)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (336)..(336)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 599]]>
nhvbdnvkrs nhharbhrrb udrdrydbnd gryyyuummy mhndnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnrgr yuyrwbyysy nbnnhndrhr 340
<![CDATA[<210> 600]]>
<![CDATA[<211> 340]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (45)..(316)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (333)..(333)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (336)..(336)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 600]]>
vhvbrdvkas cwharuhrrb udrwrcrkvd gacuyuumau chswnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnndrgr yuyrwkyysy hbnhynkryr 340
<![CDATA[<210> 601]]>
<![CDATA[<211> 341]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (4)..(6)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (29)..(31)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (33)..(33)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (41)..(41)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (43)..(318)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (46)..(316)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (327)..(327)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (331)..(332)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (335)..(338)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 601]]>
kbbnnnduag yyyarhyugg bwwgrryrnn nbnyygaarv nbnnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnnbd guucranych nnbhnnnnvm a 341
<![CDATA[<210> 602]]>
<![CDATA[<211> 340]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 602]]>
kbyvwrruwg yyyaruuggs uagrrydykr brcygaarry syhmnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnyckgg uucrayycys gguywbrvma 340
<![CDATA[<210> 603]]>
<![CDATA[<211> 339]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (44)..(314)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (44)..(314)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(339)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(339)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 603]]>
gcyrarauwg cucaruuggg agagyguuas acygaagauc uwmnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnycuggu ucrayycygg guuucrvca 339
<![CDATA[<210> 604]]>
<![CDATA[<211> 342]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (4)..(6)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (16)..(16)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (21)..(21)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (29)..(34)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (37)..(37)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (41)..(320)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (47)..(317)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (328)..(328)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (331)..(334)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (336)..(338)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 604]]>
sksnnnduvg bbyagnyygb nyyrdvvynn nnnnhunggr nnnnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnnnn dguucranyc nnnnhnnnbm sm 342
<![CDATA[<210> 605]]>
<![CDATA[<211> 338]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (39)..(39)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (43)..(313)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (43)..(313)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(338)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(338)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 605]]>
ggcusguugg kcuagkgbur ugruucucrs yuhggrysnr agnnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnncyggguu caaaucvyrg asgagccc 338
<![CDATA[<210> 606]]>
<![CDATA[<211> 338]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (43)..(313)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (43)..(313)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(338)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(338)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 606]]>
ggcucguugg ucuagkggur ugruucucgs uuhggrysbg agnnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnccggguu caaaucccgg acgagccc 338
<![CDATA[<210> 607]]>
<![CDATA[<211> 342]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (2)..(7)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (9)..(13)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (16)..(16)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (21)..(21)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (25)..(28)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (30)..(34)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (37)..(37)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (42)..(320)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (47)..(317)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (332)..(340)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 607]]>
dnnnnnnynn nnnarnbhgg nbbannnndn nnnnyynswr mnnnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnnnn rkuuyradyc ynnnnnnnnn bd 342
<![CDATA[<210> 608]]>
<![CDATA[<211> 341]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (2)..(5)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (36)..(36)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (46)..(316)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (46)..(316)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (319)..(319)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (331)..(331)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (335)..(336)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (338)..(339)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 608]]>
knnnnbdurg chsarkbugg uuavdghrdb kdrcynswra ybmvdnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnvyng kuuyradycc nrbhnnbnny d 341
<![CDATA[<210> 609]]>
<![CDATA[<211> 341]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (2)..(3)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (5)..(5)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (36)..(36)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (46)..(316)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (46)..(316)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (335)..(336)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (338)..(339)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 609]]>
knndnbrurg chsarkcugg uuavdghrwy krrcunswra yymrdnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnvydg guuyraaycc hrbynnynny k 341
<![CDATA[<210> 610]]>
<![CDATA[<211> 341]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (4)..(7)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (12)..(12)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (16)..(16)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (25)..(25)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (29)..(31)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (33)..(33)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (36)..(36)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (41)..(41)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (43)..(319)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (46)..(316)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (327)..(327)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (331)..(337)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (341)..(341)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 610]]>
rbbnnnnurg ynhadnhykg hyrdnryrnn nsnhynguwa nsnnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnnnd gwyyvanbyh nnnnnnnrvy n 341
<![CDATA[<210> 611]]>
<![CDATA[<211> 340]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (4)..(4)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (6)..(6)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (12)..(12)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (24)..(24)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (317)..(317)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (326)..(326)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (331)..(332)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (334)..(334)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (336)..(336)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 611]]>
rbbnbnduvg ynharbyggh yrdnryryhb sbcyhguwav svdrnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnvndrg wuyvanbyyh nnbndnrvyb 340
<![CDATA[<210> 612]]>
<![CDATA[<211> 340]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (4)..(4)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (6)..(6)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (12)..(12)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (24)..(24)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (326)..(326)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (332)..(332)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (334)..(334)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (336)..(336)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 612]]>
rsynbnduvg ynharbuggh yrdnryryhk sbcyhguaav smdrnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnvhdrg wuyvanbyyh dnbndnrsyu 340
<![CDATA[<210> 613]]>
<![CDATA[<211> 342]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (4)..(6)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (29)..(32)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (34)..(34)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (42)..(42)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (44)..(317)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (47)..(317)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (319)..(319)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (321)..(321)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (328)..(328)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (333)..(333)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (336)..(338)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 613]]>
rvvnnndurr ybhhrhyhgg hyuadvvynn nnrnbuccav anbnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnvnr nguucranyc hynbhnnnbb hd 342
<![CDATA[<210> 614]]>
<![CDATA[<211> 339]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (44)..(314)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (44)..(314)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(339)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(339)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 614]]>
grmmkvrkgg ysmaryuggh arssykkybr rsuccasakb vrwnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnsygkgu ucradycmcr kyksbgyma 339
<![CDATA[<210> 615]]>
<![CDATA[<211> 339]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (44)..(314)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (44)..(314)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(339)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(339)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 615]]>
grmmkvrkgg ysmaryuggh arssykkybr rsuccasakb vrwnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnsygkgu ucradycmcr kyksbgyma 339
<![CDATA[<210> 616]]>
<![CDATA[<211> 342]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (3)..(6)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (9)..(10)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (12)..(13)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (16)..(16)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (25)..(26)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (30)..(32)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (42)..(42)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (44)..(317)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (47)..(317)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (319)..(320)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (328)..(328)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (332)..(333)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (336)..(340)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(342)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 616]]>
bbnnnndunn ynnarnyugs yhwrnnrbdn nnrdcuruar vnynnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnvnn vgwuyranuc bnnbhnnnnn vd 342
<![CDATA[<210> 617]]>
<![CDATA[<211> 340]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (336)..(336)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 617]]>
bbkkbdauag yucagbugsy uagagydkwk racuruagrk ymwknnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnscugg wuyrahucyr rsubsnmsvd 340
<![CDATA[<210> 618]]>
<![CDATA[<211> 340]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 618]]>
bbkksdauag yucagyuggy uagagcdkwk gacuruagrk ymwknnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnscugg uuyrawuccr rsuysdmsva 340
<![CDATA[<210> 619]]>
<![CDATA[<211> 341]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (2)..(2)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (4)..(7)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (12)..(12)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (15)..(16)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (21)..(21)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (24)..(25)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (28)..(28)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (30)..(33)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (36)..(36)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (40)..(319)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (46)..(316)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (327)..(327)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (330)..(339)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(341)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 619]]>
dndnnnnuvr ynbrnnhugk nyannrynbn nnnhunacrn nnnnnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnnnnd rdubranhyn nnnnnnnnny v 341
<![CDATA[<210> 620]]>
<![CDATA[<211> 340]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (15)..(16)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (24)..(24)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (27)..(27)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (29)..(30)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (41)..(43)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (317)..(318)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (326)..(326)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (330)..(330)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (333)..(333)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 620]]>
kbkbshdurr ydbrnnhgku yadnrynynn dhyuhacrhk nnnrnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnbnnrr dubranhybn dvndsdwvyv 340
<![CDATA[<210> 621]]>
<![CDATA[<211> 340]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成聚核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (45)..(315)]]>
<![CDATA[<223> /備註="該區域可能包含1-271個核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (317)..(318)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (330)..(330)]]>
<![CDATA[<223> a, c, u, 或 g]]>
<![CDATA[<220>]]>
<![CDATA[<221> variation]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /replace=" "]]>
<![CDATA[<220>]]>
<![CDATA[<221> misc_feature]]>
<![CDATA[<222> (1)..(340)]]>
<![CDATA[<223> /備註="該序列中的變異體核苷酸與變異體位置之註釋中的核苷酸相比沒有偏好"]]>
<![CDATA[<220> ]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="關於取代及較佳實施例之詳細描述,請參送件之說明書"]]>
<![CDATA[<400> 621]]>
kbkbsydurg ydbrbhugku yadhryvyhh dyyuhacahk hddrnnnnnn nnnnnnnnnn 60
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 120
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 180
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 240
nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnbnngr dubradhyyn dvhrsdwvya 340
<![CDATA[<210> 622]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 622]]>
ggcuccgugg cgcaauggau agcgcauugg acuucaaauu caaagguucc ggguucgagu 60
cccggcggag ucgcca 76
<![CDATA[<210> 623]]>
<![CDATA[<211> 77]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 623]]>
gggcuccgug gcgcaaugga uagcgcauug gacuucaaau ucaaagguuc cggguucgag 60
ucccggcgga gucgcca 77
<![CDATA[<210> 624]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 624]]>
ggcuccgugg cgcaauggau agcgcauugg acuucaaauu caaagguucc ggguucgagu 60
cccggcggag ucgcca 76
<![CDATA[<210> 625]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 625]]>
ggcuccgugg cgcaauggau agcgcauugg acuucaaauu caaagguucc ggguucgagu 60
cccggcggag ucgcca 76
<![CDATA[<210> 626]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 626]]>
ggcuccgugg cgcaauggau agcgcauugg acuucaaauu caaagguucc ggguucgagu 60
cccggcggag ucgcca 76
<![CDATA[<210> 627]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 627]]>
ggcuccgugg cgcaauggau agcgcauugg acuucaaauu caaagguucc ggguucgagu 60
cccggcggag ucgcca 76
<![CDATA[<210> 628]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 628]]>
ggcuccgugg cgcaauggau agcgcauugg acuucaaauu caaagguucc ggguucgagu 60
cccggcggag ucgcca 76
<![CDATA[<210> 629]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 629]]>
ggcuccgugg cgcaauggau agcgcauugg acuucaaauu caaagguucc ggguucgagu 60
cccggcggag ucgcca 76
<![CDATA[<210> 630]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 630]]>
ggcuccgugg cgcaauggau agcgcauugg acuucaaauu caaagguucc ggguucgagu 60
cccggcggag ucgcca 76
<![CDATA[<210> 631]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 631]]>
ggcuccgugg cgcaauggau agcgcauugg acuucaaauu caaagguucc ggguucgagu 60
cccggcggag ucgcca 76
<![CDATA[<210> 632]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 632]]>
ggcuccgugg cgcaauggau agcgcauugg acuucaaauu caaagguucc ggguucgagu 60
cccggcggag ucgcca 76
<![CDATA[<210> 633]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 633]]>
gguuccaugg uguaauggua agcacucugg acuuuaaauc cagcgauccg aguucgaguc 60
ucgguggaac cucca 75
<![CDATA[<210> 634]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 634]]>
gguuccaugg uguaauggua agcacucugg acuuuaaauc cagcgauccg aguucgaguc 60
ucgguggaac cucca 75
<![CDATA[<210> 635]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 635]]>
gguuccaugg uguaauggua agcacucugg acuuuaaauc cagcgauccg aguucgaguc 60
ucgguggaac cucca 75
<![CDATA[<210> 636]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 636]]>
gguuccaugg uguaauggua agcacucugg acuuuaaauc cagcgauccg aguucgaguc 60
ucgguggaac cucca 75
<![CDATA[<210> 637]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 637]]>
gguuccaugg uguaauggua agcacucugg acuuuaaauc cagcgauccg aguucgaguc 60
ucgguggaac cucca 75
<![CDATA[<210> 638]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 638]]>
gguuccaugg uguaauggua agcacucugg acuuuaaauc cagcgauccg aguucgaguc 60
ucgguggaac cucca 75
<![CDATA[<210> 639]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 639]]>
gguuccaugg uguaauggua agcacucugg acuuuaaauc cagcgauccg aguucgaguc 60
ucgguggaac cucca 75
<![CDATA[<210> 640]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 640]]>
gguuccaugg uguaauggua agcacucugg acuuuaaauc cagcgauccg aguucgaguc 60
ucgguggaac cucca 75
<![CDATA[<210> 641]]>
<![CDATA[<211> 85]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 641]]>
gacgaggugg ccgagugguu aaggcgaugg acucuaaauc cauugugcuc ugcacgcgug 60
gguucgaauc ccauccucgu cgcca 85
<![CDATA[<210> 642]]>
<![CDATA[<211> 85]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 642]]>
gacgaggugg ccgagugguu aaggcgaugg acucuaaauc cauugugcuc ugcacgcgug 60
gguucgaauc ccauccucgu cgcca 85
<![CDATA[<210> 643]]>
<![CDATA[<211> 85]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 643]]>
gacgaggugg ccgagugguu aaggcgaugg acucuaaauc cauugugcuc ugcacgcgug 60
gguucgaauc ccauccucgu cgcca 85
<![CDATA[<210> 644]]>
<![CDATA[<211> 85]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 644]]>
gacgaggugg ccgagugguu aaggcgaugg acucuaaauc cauugugcuc ugcacgcgug 60
gguucgaauc ccauccucgu cgcca 85
<![CDATA[<210> 645]]>
<![CDATA[<211> 85]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 645]]>
gacgaggugg ccgagugguu aaggcgaugg acucuaaauc cauugugcuc ugcacgcgug 60
gguucgaauc ccauccucgu cgcca 85
<![CDATA[<210> 646]]>
<![CDATA[<211> 85]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 646]]>
gacgaggugg ccgagugguu aaggcgaugg acucuaaauc cauugugcuc ugcacgcgug 60
gguucgaauc ccauccucgu cgcca 85
<![CDATA[<210> 647]]>
<![CDATA[<211> 85]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 647]]>
gacgaggugg ccgagugguu aaggcgaugg acucuaaauc cauugugcuc ugcacgcgug 60
gguucgaauc ccauccucgu cgcca 85
<![CDATA[<210> 648]]>
<![CDATA[<211> 85]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 648]]>
gacgaggugg ccgagugguu aaggcgaugg acucuaaauc cauugugcuc ugcacgcgug 60
gguucgaauc ccauccucgu cgcca 85
<![CDATA[<210> 649]]>
<![CDATA[<211> 85]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 649]]>
gacgaggugg ccgagugguu aaggcgaugg acucuaaauc cauugugcuc ugcacgcgug 60
gguucgaauc ccauccucgu cgcca 85
<![CDATA[<210> 650]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 650]]>
gguuccaugg uguaauggua agcacucugg acuuuaaauc cagcgauccg aguucgaguc 60
ucgguggaac cucca 75
<![CDATA[<210> 651]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 651]]>
gguuccaugg uguaauggua agcacucugg acuuuaaauc cagcgauccg aguucgaguc 60
ucgguggaac cucca 75
<![CDATA[<210> 652]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 652]]>
gguuccaugg uguaauggua agcacucugg acuuuaaauc cagcgauccg aguucgaguc 60
ucgguggaac cucca 75
<![CDATA[<210> 653]]>
<![CDATA[<211> 85]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 653]]>
gacgaggugg ccgagugguu aaggcgaugg acucuaaauc cauugugcuc ugcacgcgug 60
gguucgaauc ccauccucgu cgcca 85
<![CDATA[<210> 654]]>
<![CDATA[<211> 85]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 654]]>
gacgaggugg ccgagugguu aaggcgaugg acucuaaauc cauugugcuc ugcacgcgug 60
gguucgaauc ccauccucgu cgcca 85
<![CDATA[<210> 655]]>
<![CDATA[<400> 655]]>
000
<![CDATA[<210> 656]]>
<![CDATA[<400> 656]]>
000
<![CDATA[<210> 657]]>
<![CDATA[<400> 657]]>
000
<![CDATA[<210> 658]]>
<![CDATA[<400> 658]]>
000
<![CDATA[<210> 659]]>
<![CDATA[<400> 659]]>
000
<![CDATA[<210> 660]]>
<![CDATA[<400> 660]]>
000
<![CDATA[<210> 661]]>
<![CDATA[<400> 661]]>
000
<![CDATA[<210> 662]]>
<![CDATA[<400> 662]]>
000
<![CDATA[<210> 663]]>
<![CDATA[<400> 663]]>
000
<![CDATA[<210> 664]]>
<![CDATA[<400> 664]]>
000
<![CDATA[<210> 665]]>
<![CDATA[<400> 665]]>
000
<![CDATA[<210> 666]]>
<![CDATA[<400> 666]]>
000
<![CDATA[<210> 667]]>
<![CDATA[<400> 667]]>
000
<![CDATA[<210> 668]]>
<![CDATA[<400> 668]]>
000
<![CDATA[<210> 669]]>
<![CDATA[<400> 669]]>
000
<![CDATA[<210> 670]]>
<![CDATA[<400> 670]]>
000
<![CDATA[<210> 671]]>
<![CDATA[<400> 671]]>
000
<![CDATA[<210> 672]]>
<![CDATA[<400> 672]]>
000
<![CDATA[<210> 673]]>
<![CDATA[<400> 673]]>
000
<![CDATA[<210> 674]]>
<![CDATA[<400> 674]]>
000
<![CDATA[<210> 675]]>
<![CDATA[<400> 675]]>
000
<![CDATA[<210> 676]]>
<![CDATA[<400> 676]]>
000
<![CDATA[<210> 677]]>
<![CDATA[<400> 677]]>
000
<![CDATA[<210> 678]]>
<![CDATA[<400> 678]]>
000
<![CDATA[<210> 679]]>
<![CDATA[<400> 679]]>
000
<![CDATA[<210> 680]]>
<![CDATA[<400> 680]]>
000
<![CDATA[<210> 681]]>
<![CDATA[<400> 681]]>
000
<![CDATA[<210> 682]]>
<![CDATA[<400> 682]]>
000
<![CDATA[<210> 683]]>
<![CDATA[<400> 683]]>
000
<![CDATA[<210> 684]]>
<![CDATA[<400> 684]]>
000
<![CDATA[<210> 685]]>
<![CDATA[<400> 685]]>
000
<![CDATA[<210> 686]]>
<![CDATA[<400> 686]]>
000
<![CDATA[<210> 687]]>
<![CDATA[<400> 687]]>
000
<![CDATA[<210> 688]]>
<![CDATA[<400> 688]]>
000
<![CDATA[<210> 689]]>
<![CDATA[<400> 689]]>
000
<![CDATA[<210> 690]]>
<![CDATA[<400> 690]]>
000
<![CDATA[<210> 691]]>
<![CDATA[<400> 691]]>
000
<![CDATA[<210> 692]]>
<![CDATA[<400> 692]]>
000
<![CDATA[<210> 693]]>
<![CDATA[<400> 693]]>
000
<![CDATA[<210> 694]]>
<![CDATA[<400> 694]]>
000
<![CDATA[<210> 695]]>
<![CDATA[<400> 695]]>
000
<![CDATA[<210> 696]]>
<![CDATA[<400> 696]]>
000
<![CDATA[<210> 697]]>
<![CDATA[<400> 697]]>
000
<![CDATA[<210> 698]]>
<![CDATA[<400> 698]]>
000
<![CDATA[<210> 699]]>
<![CDATA[<400> 699]]>
000
<![CDATA[<210> 700]]>
<![CDATA[<400> 700]]>
000
<![CDATA[<210> 701]]>
<![CDATA[<400> 701]]>
000
<![CDATA[<210> 702]]>
<![CDATA[<400> 702]]>
000
<![CDATA[<210> 703]]>
<![CDATA[<400> 703]]>
000
<![CDATA[<210> 704]]>
<![CDATA[<400> 704]]>
000
<![CDATA[<210> 705]]>
<![CDATA[<400> 705]]>
000
<![CDATA[<210> 706]]>
<![CDATA[<400> 706]]>
000
<![CDATA[<210> 707]]>
<![CDATA[<400> 707]]>
000
<![CDATA[<210> 708]]>
<![CDATA[<400> 708]]>
000
<![CDATA[<210> 709]]>
<![CDATA[<400> 709]]>
000
<![CDATA[<210> 710]]>
<![CDATA[<400> 710]]>
000
<![CDATA[<210> 711]]>
<![CDATA[<400> 711]]>
000
<![CDATA[<210> 712]]>
<![CDATA[<400> 712]]>
000
<![CDATA[<210> 713]]>
<![CDATA[<400> 713]]>
000
<![CDATA[<210> 714]]>
<![CDATA[<400> 714]]>
000
<![CDATA[<210> 715]]>
<![CDATA[<400> 715]]>
000
<![CDATA[<210> 716]]>
<![CDATA[<400> 716]]>
000
<![CDATA[<210> 717]]>
<![CDATA[<400> 717]]>
000
<![CDATA[<210> 718]]>
<![CDATA[<400> 718]]>
000
<![CDATA[<210> 719]]>
<![CDATA[<400> 719]]>
000
<![CDATA[<210> 720]]>
<![CDATA[<400> 720]]>
000
<![CDATA[<210> 721]]>
<![CDATA[<400> 721]]>
000
<![CDATA[<210> 722]]>
<![CDATA[<400> 722]]>
000
<![CDATA[<210> 723]]>
<![CDATA[<400> 723]]>
000
<![CDATA[<210> 724]]>
<![CDATA[<400> 724]]>
000
<![CDATA[<210> 725]]>
<![CDATA[<400> 725]]>
000
<![CDATA[<210> 726]]>
<![CDATA[<400> 726]]>
000
<![CDATA[<210> 727]]>
<![CDATA[<400> 727]]>
000
<![CDATA[<210> 728]]>
<![CDATA[<400> 728]]>
000
<![CDATA[<210> 729]]>
<![CDATA[<400> 729]]>
000
<![CDATA[<210> 730]]>
<![CDATA[<400> 730]]>
000
<![CDATA[<210> 731]]>
<![CDATA[<400> 731]]>
000
<![CDATA[<210> 732]]>
<![CDATA[<400> 732]]>
000
<![CDATA[<210> 733]]>
<![CDATA[<400> 733]]>
000
<![CDATA[<210> 734]]>
<![CDATA[<400> 734]]>
000
<![CDATA[<210> 735]]>
<![CDATA[<400> 735]]>
000
<![CDATA[<210> 736]]>
<![CDATA[<400> 736]]>
000
<![CDATA[<210> 737]]>
<![CDATA[<400> 737]]>
000
<![CDATA[<210> 738]]>
<![CDATA[<400> 738]]>
000
<![CDATA[<210> 739]]>
<![CDATA[<400> 739]]>
000
<![CDATA[<210> 740]]>
<![CDATA[<400> 740]]>
000
<![CDATA[<210> 741]]>
<![CDATA[<400> 741]]>
000
<![CDATA[<210> 742]]>
<![CDATA[<400> 742]]>
000
<![CDATA[<210> 743]]>
<![CDATA[<400> 743]]>
000
<![CDATA[<210> 744]]>
<![CDATA[<400> 744]]>
000
<![CDATA[<210> 745]]>
<![CDATA[<400> 745]]>
000
<![CDATA[<210> 746]]>
<![CDATA[<400> 746]]>
000
<![CDATA[<210> 747]]>
<![CDATA[<400> 747]]>
000
<![CDATA[<210> 748]]>
<![CDATA[<400> 748]]>
000
<![CDATA[<210> 749]]>
<![CDATA[<400> 749]]>
000
<![CDATA[<210> 750]]>
<![CDATA[<400> 750]]>
000
<![CDATA[<210> 751]]>
<![CDATA[<400> 751]]>
000
<![CDATA[<210> 752]]>
<![CDATA[<400> 752]]>
000
<![CDATA[<210> 753]]>
<![CDATA[<400> 753]]>
000
<![CDATA[<210> 754]]>
<![CDATA[<400> 754]]>
000
<![CDATA[<210> 755]]>
<![CDATA[<400> 755]]>
000
<![CDATA[<210> 756]]>
<![CDATA[<400> 756]]>
000
<![CDATA[<210> 757]]>
<![CDATA[<400> 757]]>
000
<![CDATA[<210> 758]]>
<![CDATA[<400> 758]]>
000
<![CDATA[<210> 759]]>
<![CDATA[<400> 759]]>
000
<![CDATA[<210> 760]]>
<![CDATA[<400> 760]]>
000
<![CDATA[<210> 761]]>
<![CDATA[<400> 761]]>
000
<![CDATA[<210> 762]]>
<![CDATA[<400> 762]]>
000
<![CDATA[<210> 763]]>
<![CDATA[<400> 763]]>
000
<![CDATA[<210> 764]]>
<![CDATA[<400> 764]]>
000
<![CDATA[<210> 765]]>
<![CDATA[<400> 765]]>
000
<![CDATA[<210> 766]]>
<![CDATA[<400> 766]]>
000
<![CDATA[<210> 767]]>
<![CDATA[<400> 767]]>
000
<![CDATA[<210> 768]]>
<![CDATA[<400> 768]]>
000
<![CDATA[<210> 769]]>
<![CDATA[<400> 769]]>
000
<![CDATA[<210> 770]]>
<![CDATA[<400> 770]]>
000
<![CDATA[<210> 771]]>
<![CDATA[<400> 771]]>
000
<![CDATA[<210> 772]]>
<![CDATA[<400> 772]]>
000
<![CDATA[<210> 773]]>
<![CDATA[<400> 773]]>
000
<![CDATA[<210> 774]]>
<![CDATA[<400> 774]]>
000
<![CDATA[<210> 775]]>
<![CDATA[<400> 775]]>
000
<![CDATA[<210> 776]]>
<![CDATA[<400> 776]]>
000
<![CDATA[<210> 777]]>
<![CDATA[<400> 777]]>
000
<![CDATA[<210> 778]]>
<![CDATA[<400> 778]]>
000
<![CDATA[<210> 779]]>
<![CDATA[<400> 779]]>
000
<![CDATA[<210> 780]]>
<![CDATA[<400> 780]]>
000
<![CDATA[<210> 781]]>
<![CDATA[<400> 781]]>
000
<![CDATA[<210> 782]]>
<![CDATA[<400> 782]]>
000
<![CDATA[<210> 783]]>
<![CDATA[<400> 783]]>
000
<![CDATA[<210> 784]]>
<![CDATA[<400> 784]]>
000
<![CDATA[<210> 785]]>
<![CDATA[<400> 785]]>
000
<![CDATA[<210> 786]]>
<![CDATA[<400> 786]]>
000
<![CDATA[<210> 787]]>
<![CDATA[<400> 787]]>
000
<![CDATA[<210> 788]]>
<![CDATA[<400> 788]]>
000
<![CDATA[<210> 789]]>
<![CDATA[<400> 789]]>
000
<![CDATA[<210> 790]]>
<![CDATA[<400> 790]]>
000
<![CDATA[<210> 791]]>
<![CDATA[<400> 791]]>
000
<![CDATA[<210> 792]]>
<![CDATA[<400> 792]]>
000
<![CDATA[<210> 793]]>
<![CDATA[<400> 793]]>
000
<![CDATA[<210> 794]]>
<![CDATA[<400> 794]]>
000
<![CDATA[<210> 795]]>
<![CDATA[<400> 795]]>
000
<![CDATA[<210> 796]]>
<![CDATA[<400> 796]]>
000
<![CDATA[<210> 797]]>
<![CDATA[<400> 797]]>
000
<![CDATA[<210> 798]]>
<![CDATA[<400> 798]]>
000
<![CDATA[<210> 799]]>
<![CDATA[<400> 799]]>
000
<![CDATA[<210> 800]]>
<![CDATA[<400> 800]]>
000
<![CDATA[<210> 801]]>
<![CDATA[<400> 801]]>
000
<![CDATA[<210> 802]]>
<![CDATA[<400> 802]]>
000
<![CDATA[<210> 803]]>
<![CDATA[<400> 803]]>
000
<![CDATA[<210> 804]]>
<![CDATA[<400> 804]]>
000
<![CDATA[<210> 805]]>
<![CDATA[<400> 805]]>
000
<![CDATA[<210> 806]]>
<![CDATA[<400> 806]]>
000
<![CDATA[<210> 807]]>
<![CDATA[<400> 807]]>
000
<![CDATA[<210> 808]]>
<![CDATA[<400> 808]]>
000
<![CDATA[<210> 809]]>
<![CDATA[<400> 809]]>
000
<![CDATA[<210> 810]]>
<![CDATA[<400> 810]]>
000
<![CDATA[<210> 811]]>
<![CDATA[<400> 811]]>
000
<![CDATA[<210> 812]]>
<![CDATA[<400> 812]]>
000
<![CDATA[<210> 813]]>
<![CDATA[<400> 813]]>
000
<![CDATA[<210> 814]]>
<![CDATA[<400> 814]]>
000
<![CDATA[<210> 815]]>
<![CDATA[<400> 815]]>
000
<![CDATA[<210> 816]]>
<![CDATA[<400> 816]]>
000
<![CDATA[<210> 817]]>
<![CDATA[<400> 817]]>
000
<![CDATA[<210> 818]]>
<![CDATA[<400> 818]]>
000
<![CDATA[<210> 819]]>
<![CDATA[<400> 819]]>
000
<![CDATA[<210> 820]]>
<![CDATA[<400> 820]]>
000
<![CDATA[<210> 821]]>
<![CDATA[<400> 821]]>
000
<![CDATA[<210> 822]]>
<![CDATA[<400> 822]]>
000
<![CDATA[<210> 823]]>
<![CDATA[<400> 823]]>
000
<![CDATA[<210> 824]]>
<![CDATA[<400> 824]]>
000
<![CDATA[<210> 825]]>
<![CDATA[<400> 825]]>
000
<![CDATA[<210> 826]]>
<![CDATA[<400> 826]]>
000
<![CDATA[<210> 827]]>
<![CDATA[<400> 827]]>
000
<![CDATA[<210> 828]]>
<![CDATA[<400> 828]]>
000
<![CDATA[<210> 829]]>
<![CDATA[<400> 829]]>
000
<![CDATA[<210> 830]]>
<![CDATA[<400> 830]]>
000
<![CDATA[<210> 831]]>
<![CDATA[<400> 831]]>
000
<![CDATA[<210> 832]]>
<![CDATA[<400> 832]]>
000
<![CDATA[<210> 833]]>
<![CDATA[<400> 833]]>
000
<![CDATA[<210> 834]]>
<![CDATA[<400> 834]]>
000
<![CDATA[<210> 835]]>
<![CDATA[<400> 835]]>
000
<![CDATA[<210> 836]]>
<![CDATA[<400> 836]]>
000
<![CDATA[<210> 837]]>
<![CDATA[<400> 837]]>
000
<![CDATA[<210> 838]]>
<![CDATA[<400> 838]]>
000
<![CDATA[<210> 839]]>
<![CDATA[<400> 839]]>
000
<![CDATA[<210> 840]]>
<![CDATA[<400> 840]]>
000
<![CDATA[<210> 841]]>
<![CDATA[<400> 841]]>
000
<![CDATA[<210> 842]]>
<![CDATA[<400> 842]]>
000
<![CDATA[<210> 843]]>
<![CDATA[<400> 843]]>
000
<![CDATA[<210> 844]]>
<![CDATA[<400> 844]]>
000
<![CDATA[<210> 845]]>
<![CDATA[<400> 845]]>
000
<![CDATA[<210> 846]]>
<![CDATA[<400> 846]]>
000
<![CDATA[<210> 847]]>
<![CDATA[<400> 847]]>
000
<![CDATA[<210> 848]]>
<![CDATA[<400> 848]]>
000
<![CDATA[<210> 849]]>
<![CDATA[<400> 849]]>
000
<![CDATA[<210> 850]]>
<![CDATA[<400> 850]]>
000
<![CDATA[<210> 851]]>
<![CDATA[<400> 851]]>
000
<![CDATA[<210> 852]]>
<![CDATA[<400> 852]]>
000
<![CDATA[<210> 853]]>
<![CDATA[<400> 853]]>
000
<![CDATA[<210> 854]]>
<![CDATA[<400> 854]]>
000
<![CDATA[<210> 855]]>
<![CDATA[<400> 855]]>
000
<![CDATA[<210> 856]]>
<![CDATA[<400> 856]]>
000
<![CDATA[<210> 857]]>
<![CDATA[<400> 857]]>
000
<![CDATA[<210> 858]]>
<![CDATA[<400> 858]]>
000
<![CDATA[<210> 859]]>
<![CDATA[<400> 859]]>
000
<![CDATA[<210> 860]]>
<![CDATA[<400> 860]]>
000
<![CDATA[<210> 861]]>
<![CDATA[<400> 861]]>
000
<![CDATA[<210> 862]]>
<![CDATA[<400> 862]]>
000
<![CDATA[<210> 863]]>
<![CDATA[<400> 863]]>
000
<![CDATA[<210> 864]]>
<![CDATA[<400> 864]]>
000
<![CDATA[<210> 865]]>
<![CDATA[<400> 865]]>
000
<![CDATA[<210> 866]]>
<![CDATA[<400> 866]]>
000
<![CDATA[<210> 867]]>
<![CDATA[<400> 867]]>
000
<![CDATA[<210> 868]]>
<![CDATA[<400> 868]]>
000
<![CDATA[<210> 869]]>
<![CDATA[<400> 869]]>
000
<![CDATA[<210> 870]]>
<![CDATA[<400> 870]]>
000
<![CDATA[<210> 871]]>
<![CDATA[<400> 871]]>
000
<![CDATA[<210> 872]]>
<![CDATA[<400> 872]]>
000
<![CDATA[<210> 873]]>
<![CDATA[<400> 873]]>
000
<![CDATA[<210> 874]]>
<![CDATA[<400> 874]]>
000
<![CDATA[<210> 875]]>
<![CDATA[<400> 875]]>
000
<![CDATA[<210> 876]]>
<![CDATA[<400> 876]]>
000
<![CDATA[<210> 877]]>
<![CDATA[<400> 877]]>
000
<![CDATA[<210> 878]]>
<![CDATA[<400> 878]]>
000
<![CDATA[<210> 879]]>
<![CDATA[<400> 879]]>
000
<![CDATA[<210> 880]]>
<![CDATA[<400> 880]]>
000
<![CDATA[<210> 881]]>
<![CDATA[<400> 881]]>
000
<![CDATA[<210> 882]]>
<![CDATA[<400> 882]]>
000
<![CDATA[<210> 883]]>
<![CDATA[<400> 883]]>
000
<![CDATA[<210> 884]]>
<![CDATA[<400> 884]]>
000
<![CDATA[<210> 885]]>
<![CDATA[<400> 885]]>
000
<![CDATA[<210> 886]]>
<![CDATA[<400> 886]]>
000
<![CDATA[<210> 887]]>
<![CDATA[<400> 887]]>
000
<![CDATA[<210> 888]]>
<![CDATA[<400> 888]]>
000
<![CDATA[<210> 889]]>
<![CDATA[<400> 889]]>
000
<![CDATA[<210> 890]]>
<![CDATA[<400> 890]]>
000
<![CDATA[<210> 891]]>
<![CDATA[<400> 891]]>
000
<![CDATA[<210> 892]]>
<![CDATA[<400> 892]]>
000
<![CDATA[<210> 893]]>
<![CDATA[<400> 893]]>
000
<![CDATA[<210> 894]]>
<![CDATA[<400> 894]]>
000
<![CDATA[<210> 895]]>
<![CDATA[<400> 895]]>
000
<![CDATA[<210> 896]]>
<![CDATA[<400> 896]]>
000
<![CDATA[<210> 897]]>
<![CDATA[<400> 897]]>
000
<![CDATA[<210> 898]]>
<![CDATA[<400> 898]]>
000
<![CDATA[<210> 899]]>
<![CDATA[<400> 899]]>
000
<![CDATA[<210> 900]]>
<![CDATA[<400> 900]]>
000
<![CDATA[<210> 901]]>
<![CDATA[<400> 901]]>
000
<![CDATA[<210> 902]]>
<![CDATA[<400> 902]]>
000
<![CDATA[<210> 903]]>
<![CDATA[<400> 903]]>
000
<![CDATA[<210> 904]]>
<![CDATA[<400> 904]]>
000
<![CDATA[<210> 905]]>
<![CDATA[<400> 905]]>
000
<![CDATA[<210> 906]]>
<![CDATA[<400> 906]]>
000
<![CDATA[<210> 907]]>
<![CDATA[<400> 907]]>
000
<![CDATA[<210> 908]]>
<![CDATA[<400> 908]]>
000
<![CDATA[<210> 909]]>
<![CDATA[<400> 909]]>
000
<![CDATA[<210> 910]]>
<![CDATA[<400> 910]]>
000
<![CDATA[<210> 911]]>
<![CDATA[<400> 911]]>
000
<![CDATA[<210> 912]]>
<![CDATA[<400> 912]]>
000
<![CDATA[<210> 913]]>
<![CDATA[<400> 913]]>
000
<![CDATA[<210> 914]]>
<![CDATA[<400> 914]]>
000
<![CDATA[<210> 915]]>
<![CDATA[<400> 915]]>
000
<![CDATA[<210> 916]]>
<![CDATA[<400> 916]]>
000
<![CDATA[<210> 917]]>
<![CDATA[<400> 917]]>
000
<![CDATA[<210> 918]]>
<![CDATA[<400> 918]]>
000
<![CDATA[<210> 919]]>
<![CDATA[<400> 919]]>
000
<![CDATA[<210> 920]]>
<![CDATA[<400> 920]]>
000
<![CDATA[<210> 921]]>
<![CDATA[<400> 921]]>
000
<![CDATA[<210> 922]]>
<![CDATA[<400> 922]]>
000
<![CDATA[<210> 923]]>
<![CDATA[<400> 923]]>
000
<![CDATA[<210> 924]]>
<![CDATA[<400> 924]]>
000
<![CDATA[<210> 925]]>
<![CDATA[<400> 925]]>
000
<![CDATA[<210> 926]]>
<![CDATA[<400> 926]]>
000
<![CDATA[<210> 927]]>
<![CDATA[<400> 927]]>
000
<![CDATA[<210> 928]]>
<![CDATA[<400> 928]]>
000
<![CDATA[<210> 929]]>
<![CDATA[<400> 929]]>
000
<![CDATA[<210> 930]]>
<![CDATA[<400> 930]]>
000
<![CDATA[<210> 931]]>
<![CDATA[<400> 931]]>
000
<![CDATA[<210> 932]]>
<![CDATA[<400> 932]]>
000
<![CDATA[<210> 933]]>
<![CDATA[<400> 933]]>
000
<![CDATA[<210> 934]]>
<![CDATA[<400> 934]]>
000
<![CDATA[<210> 935]]>
<![CDATA[<400> 935]]>
000
<![CDATA[<210> 936]]>
<![CDATA[<400> 936]]>
000
<![CDATA[<210> 937]]>
<![CDATA[<400> 937]]>
000
<![CDATA[<210> 938]]>
<![CDATA[<400> 938]]>
000
<![CDATA[<210> 939]]>
<![CDATA[<400> 939]]>
000
<![CDATA[<210> 940]]>
<![CDATA[<400> 940]]>
000
<![CDATA[<210> 941]]>
<![CDATA[<400> 941]]>
000
<![CDATA[<210> 942]]>
<![CDATA[<400> 942]]>
000
<![CDATA[<210> 943]]>
<![CDATA[<400> 943]]>
000
<![CDATA[<210> 944]]>
<![CDATA[<400> 944]]>
000
<![CDATA[<210> 945]]>
<![CDATA[<400> 945]]>
000
<![CDATA[<210> 946]]>
<![CDATA[<400> 946]]>
000
<![CDATA[<210> 947]]>
<![CDATA[<400> 947]]>
000
<![CDATA[<210> 948]]>
<![CDATA[<400> 948]]>
000
<![CDATA[<210> 949]]>
<![CDATA[<400> 949]]>
000
<![CDATA[<210> 950]]>
<![CDATA[<400> 950]]>
000
<![CDATA[<210> 951]]>
<![CDATA[<400> 951]]>
000
<![CDATA[<210> 952]]>
<![CDATA[<400> 952]]>
000
<![CDATA[<210> 953]]>
<![CDATA[<400> 953]]>
000
<![CDATA[<210> 954]]>
<![CDATA[<400> 954]]>
000
<![CDATA[<210> 955]]>
<![CDATA[<400> 955]]>
000
<![CDATA[<210> 956]]>
<![CDATA[<400> 956]]>
000
<![CDATA[<210> 957]]>
<![CDATA[<400> 957]]>
000
<![CDATA[<210> 958]]>
<![CDATA[<400> 958]]>
000
<![CDATA[<210> 959]]>
<![CDATA[<400> 959]]>
000
<![CDATA[<210> 960]]>
<![CDATA[<400> 960]]>
000
<![CDATA[<210> 961]]>
<![CDATA[<400> 961]]>
000
<![CDATA[<210> 962]]>
<![CDATA[<400> 962]]>
000
<![CDATA[<210> 963]]>
<![CDATA[<400> 963]]>
000
<![CDATA[<210> 964]]>
<![CDATA[<400> 964]]>
000
<![CDATA[<210> 965]]>
<![CDATA[<400> 965]]>
000
<![CDATA[<210> 966]]>
<![CDATA[<400> 966]]>
000
<![CDATA[<210> 967]]>
<![CDATA[<400> 967]]>
000
<![CDATA[<210> 968]]>
<![CDATA[<400> 968]]>
000
<![CDATA[<210> 969]]>
<![CDATA[<400> 969]]>
000
<![CDATA[<210> 970]]>
<![CDATA[<400> 970]]>
000
<![CDATA[<210> 971]]>
<![CDATA[<400> 971]]>
000
<![CDATA[<210> 972]]>
<![CDATA[<400> 972]]>
000
<![CDATA[<210> 973]]>
<![CDATA[<400> 973]]>
000
<![CDATA[<210> 974]]>
<![CDATA[<400> 974]]>
000
<![CDATA[<210> 975]]>
<![CDATA[<400> 975]]>
000
<![CDATA[<210> 976]]>
<![CDATA[<400> 976]]>
000
<![CDATA[<210> 977]]>
<![CDATA[<400> 977]]>
000
<![CDATA[<210> 978]]>
<![CDATA[<400> 978]]>
000
<![CDATA[<210> 979]]>
<![CDATA[<400> 979]]>
000
<![CDATA[<210> 980]]>
<![CDATA[<400> 980]]>
000
<![CDATA[<210> 981]]>
<![CDATA[<400> 981]]>
000
<![CDATA[<210> 982]]>
<![CDATA[<400> 982]]>
000
<![CDATA[<210> 983]]>
<![CDATA[<400> 983]]>
000
<![CDATA[<210> 984]]>
<![CDATA[<400> 984]]>
000
<![CDATA[<210> 985]]>
<![CDATA[<400> 985]]>
000
<![CDATA[<210> 986]]>
<![CDATA[<400> 986]]>
000
<![CDATA[<210> 987]]>
<![CDATA[<400> 987]]>
000
<![CDATA[<210> 988]]>
<![CDATA[<400> 988]]>
000
<![CDATA[<210> 989]]>
<![CDATA[<400> 989]]>
000
<![CDATA[<210> 990]]>
<![CDATA[<400> 990]]>
000
<![CDATA[<210> 991]]>
<![CDATA[<400> 991]]>
000
<![CDATA[<210> 992]]>
<![CDATA[<400> 992]]>
000
<![CDATA[<210> 993]]>
<![CDATA[<400> 993]]>
000
<![CDATA[<210> 994]]>
<![CDATA[<400> 994]]>
000
<![CDATA[<210> 995]]>
<![CDATA[<400> 995]]>
000
<![CDATA[<210> 996]]>
<![CDATA[<400> 996]]>
000
<![CDATA[<210> 997]]>
<![CDATA[<400> 997]]>
000
<![CDATA[<210> 998]]>
<![CDATA[<400> 998]]>
000
<![CDATA[<210> 999]]>
<![CDATA[<400> 999]]>
000
<![CDATA[<210> 1000]]>
<![CDATA[<400> 1000]]>
000
<![CDATA[<210> 1001]]>
<![CDATA[<400> 1001]]>
000
<![CDATA[<210> 1002]]>
<![CDATA[<400> 1002]]>
000
<![CDATA[<210> 1003]]>
<![CDATA[<400> 1003]]>
000
<![CDATA[<210> 1004]]>
<![CDATA[<400> 1004]]>
000
<![CDATA[<210> 1005]]>
<![CDATA[<400> 1005]]>
000
<![CDATA[<210> 1006]]>
<![CDATA[<400> 1006]]>
000
<![CDATA[<210> 1007]]>
<![CDATA[<400> 1007]]>
000
<![CDATA[<210> 1008]]>
<![CDATA[<400> 1008]]>
000
<![CDATA[<210> 1009]]>
<![CDATA[<400> 1009]]>
000
<![CDATA[<210> 1010]]>
<![CDATA[<400> 1010]]>
000
<![CDATA[<210> 1011]]>
<![CDATA[<400> 1011]]>
000
<![CDATA[<210> 1012]]>
<![CDATA[<400> 1012]]>
000
<![CDATA[<210> 1013]]>
<![CDATA[<400> 1013]]>
000
<![CDATA[<210> 1014]]>
<![CDATA[<400> 1014]]>
000
<![CDATA[<210> 1015]]>
<![CDATA[<400> 1015]]>
000
<![CDATA[<210> 1016]]>
<![CDATA[<400> 1016]]>
000
<![CDATA[<210> 1017]]>
<![CDATA[<400> 1017]]>
000
<![CDATA[<210> 1018]]>
<![CDATA[<400> 1018]]>
000
<![CDATA[<210> 1019]]>
<![CDATA[<400> 1019]]>
000
<![CDATA[<210> 1020]]>
<![CDATA[<400> 1020]]>
000
<![CDATA[<210> 1021]]>
<![CDATA[<400> 1021]]>
000
<![CDATA[<210> 1022]]>
<![CDATA[<400> 1022]]>
000
<![CDATA[<210> 1023]]>
<![CDATA[<400> 1023]]>
000
<![CDATA[<210> 1024]]>
<![CDATA[<400> 1024]]>
000
<![CDATA[<210> 1025]]>
<![CDATA[<400> 1025]]>
000
<![CDATA[<210> 1026]]>
<![CDATA[<400> 1026]]>
000
<![CDATA[<210> 1027]]>
<![CDATA[<400> 1027]]>
000
<![CDATA[<210> 1028]]>
<![CDATA[<400> 1028]]>
000
<![CDATA[<210> 1029]]>
<![CDATA[<400> 1029]]>
000
<![CDATA[<210> 1030]]>
<![CDATA[<400> 1030]]>
000
<![CDATA[<210> 1031]]>
<![CDATA[<400> 1031]]>
000
<![CDATA[<210> 1032]]>
<![CDATA[<400> 1032]]>
000
<![CDATA[<210> 1033]]>
<![CDATA[<400> 1033]]>
000
<![CDATA[<210> 1034]]>
<![CDATA[<400> 1034]]>
000
<![CDATA[<210> 1035]]>
<![CDATA[<400> 1035]]>
000
<![CDATA[<210> 1036]]>
<![CDATA[<400> 1036]]>
000
<![CDATA[<210> 1037]]>
<![CDATA[<400> 1037]]>
000
<![CDATA[<210> 1038]]>
<![CDATA[<400> 1038]]>
000
<![CDATA[<210> 1039]]>
<![CDATA[<400> 1039]]>
000
<![CDATA[<210> 1040]]>
<![CDATA[<400> 1040]]>
000
<![CDATA[<210> 1041]]>
<![CDATA[<400> 1041]]>
000
<![CDATA[<210> 1042]]>
<![CDATA[<400> 1042]]>
000
<![CDATA[<210> 1043]]>
<![CDATA[<400> 1043]]>
000
<![CDATA[<210> 1044]]>
<![CDATA[<400> 1044]]>
000
<![CDATA[<210> 1045]]>
<![CDATA[<400> 1045]]>
000
<![CDATA[<210> 1046]]>
<![CDATA[<400> 1046]]>
000
<![CDATA[<210> 1047]]>
<![CDATA[<400> 1047]]>
000
<![CDATA[<210> 1048]]>
<![CDATA[<400> 1048]]>
000
<![CDATA[<210> 1049]]>
<![CDATA[<400> 1049]]>
000
<![CDATA[<210> 1050]]>
<![CDATA[<400> 1050]]>
000
<![CDATA[<210> 1051]]>
<![CDATA[<400> 1051]]>
000
<![CDATA[<210> 1052]]>
<![CDATA[<400> 1052]]>
000
<![CDATA[<210> 1053]]>
<![CDATA[<400> 1053]]>
000
<![CDATA[<210> 1054]]>
<![CDATA[<400> 1054]]>
000
<![CDATA[<210> 1055]]>
<![CDATA[<400> 1055]]>
000
<![CDATA[<210> 1056]]>
<![CDATA[<400> 1056]]>
000
<![CDATA[<210> 1057]]>
<![CDATA[<400> 1057]]>
000
<![CDATA[<210> 1058]]>
<![CDATA[<400> 1058]]>
000
<![CDATA[<210> 1059]]>
<![CDATA[<400> 1059]]>
000
<![CDATA[<210> 1060]]>
<![CDATA[<400> 1060]]>
000
<![CDATA[<210> 1061]]>
<![CDATA[<400> 1061]]>
000
<![CDATA[<210> 1062]]>
<![CDATA[<400> 1062]]>
000
<![CDATA[<210> 1063]]>
<![CDATA[<400> 1063]]>
000
<![CDATA[<210> 1064]]>
<![CDATA[<400> 1064]]>
000
<![CDATA[<210> 1065]]>
<![CDATA[<400> 1065]]>
000
<![CDATA[<210> 1066]]>
<![CDATA[<400> 1066]]>
000
<![CDATA[<210> 1067]]>
<![CDATA[<400> 1067]]>
000
<![CDATA[<210> 1068]]>
<![CDATA[<400> 1068]]>
000
<![CDATA[<210> 1069]]>
<![CDATA[<400> 1069]]>
000
<![CDATA[<210> 1070]]>
<![CDATA[<400> 1070]]>
000
<![CDATA[<210> 1071]]>
<![CDATA[<400> 1071]]>
000
<![CDATA[<210> 1072]]>
<![CDATA[<400> 1072]]>
000
<![CDATA[<210> 1073]]>
<![CDATA[<400> 1073]]>
000
<![CDATA[<210> 1074]]>
<![CDATA[<400> 1074]]>
000
<![CDATA[<210> 1075]]>
<![CDATA[<400> 1075]]>
000
<![CDATA[<210> 1076]]>
<![CDATA[<400> 1076]]>
000
<![CDATA[<210> 1077]]>
<![CDATA[<400> 1077]]>
000
<![CDATA[<210> 1078]]>
<![CDATA[<400> 1078]]>
000
<![CDATA[<210> 1079]]>
<![CDATA[<400> 1079]]>
000
<![CDATA[<210> 1080]]>
<![CDATA[<400> 1080]]>
000
<![CDATA[<210> 1081]]>
<![CDATA[<400> 1081]]>
000
<![CDATA[<210> 1082]]>
<![CDATA[<400> 1082]]>
000
<![CDATA[<210> 1083]]>
<![CDATA[<400> 1083]]>
000
<![CDATA[<210> 1084]]>
<![CDATA[<400> 1084]]>
000
<![CDATA[<210> 1085]]>
<![CDATA[<400> 1085]]>
000
<![CDATA[<210> 1086]]>
<![CDATA[<400> 1086]]>
000
<![CDATA[<210> 1087]]>
<![CDATA[<400> 1087]]>
000
<![CDATA[<210> 1088]]>
<![CDATA[<400> 1088]]>
000
<![CDATA[<210> 1089]]>
<![CDATA[<400> 1089]]>
000
<![CDATA[<210> 1090]]>
<![CDATA[<400> 1090]]>
000
<![CDATA[<210> 1091]]>
<![CDATA[<400> 1091]]>
000
<![CDATA[<210> 1092]]>
<![CDATA[<400> 1092]]>
000
<![CDATA[<210> 1093]]>
<![CDATA[<400> 1093]]>
000
<![CDATA[<210> 1094]]>
<![CDATA[<400> 1094]]>
000
<![CDATA[<210> 1095]]>
<![CDATA[<400> 1095]]>
000
<![CDATA[<210> 1096]]>
<![CDATA[<400> 1096]]>
000
<![CDATA[<210> 1097]]>
<![CDATA[<400> 1097]]>
000
<![CDATA[<210> 1098]]>
<![CDATA[<400> 1098]]>
000
<![CDATA[<210> 1099]]>
<![CDATA[<400> 1099]]>
000
<![CDATA[<210> 1100]]>
<![CDATA[<400> 1100]]>
000
<![CDATA[<210> 1101]]>
<![CDATA[<400> 1101]]>
000
<![CDATA[<210> 1102]]>
<![CDATA[<400> 1102]]>
000
<![CDATA[<210> 1103]]>
<![CDATA[<400> 1103]]>
000
<![CDATA[<210> 1104]]>
<![CDATA[<400> 1104]]>
000
<![CDATA[<210> 1105]]>
<![CDATA[<400> 1105]]>
000
<![CDATA[<210> 1106]]>
<![CDATA[<400> 1106]]>
000
<![CDATA[<210> 1107]]>
<![CDATA[<400> 1107]]>
000
<![CDATA[<210> 1108]]>
<![CDATA[<400> 1108]]>
000
<![CDATA[<210> 1109]]>
<![CDATA[<400> 1109]]>
000
<![CDATA[<210> 1110]]>
<![CDATA[<400> 1110]]>
000
<![CDATA[<210> 1111]]>
<![CDATA[<400> 1111]]>
000
<![CDATA[<210> 1112]]>
<![CDATA[<400> 1112]]>
000
<![CDATA[<210> 1113]]>
<![CDATA[<400> 1113]]>
000
<![CDATA[<210> 1114]]>
<![CDATA[<400> 1114]]>
000
<![CDATA[<210> 1115]]>
<![CDATA[<400> 1115]]>
000
<![CDATA[<210> 1116]]>
<![CDATA[<400> 1116]]>
000
<![CDATA[<210> 1117]]>
<![CDATA[<400> 1117]]>
000
<![CDATA[<210> 1118]]>
<![CDATA[<400> 1118]]>
000
<![CDATA[<210> 1119]]>
<![CDATA[<400> 1119]]>
000
<![CDATA[<210> 1120]]>
<![CDATA[<400> 1120]]>
000
<![CDATA[<210> 1121]]>
<![CDATA[<400> 1121]]>
000
<![CDATA[<210> 1122]]>
<![CDATA[<400> 1122]]>
000
<![CDATA[<210> 1123]]>
<![CDATA[<400> 1123]]>
000
<![CDATA[<210> 1124]]>
<![CDATA[<400> 1124]]>
000
<![CDATA[<210> 1125]]>
<![CDATA[<400> 1125]]>
000
<![CDATA[<210> 1126]]>
<![CDATA[<400> 1126]]>
000
<![CDATA[<210> 1127]]>
<![CDATA[<400> 1127]]>
000
<![CDATA[<210> 1128]]>
<![CDATA[<400> 1128]]>
000
<![CDATA[<210> 1129]]>
<![CDATA[<400> 1129]]>
000
<![CDATA[<210> 1130]]>
<![CDATA[<400> 1130]]>
000
<![CDATA[<210> 1131]]>
<![CDATA[<400> 1131]]>
000
<![CDATA[<210> 1132]]>
<![CDATA[<400> 1132]]>
000
<![CDATA[<210> 1133]]>
<![CDATA[<400> 1133]]>
000
<![CDATA[<210> 1134]]>
<![CDATA[<400> 1134]]>
000
<![CDATA[<210> 1135]]>
<![CDATA[<400> 1135]]>
000
<![CDATA[<210> 1136]]>
<![CDATA[<400> 1136]]>
000
<![CDATA[<210> 1137]]>
<![CDATA[<400> 1137]]>
000
<![CDATA[<210> 1138]]>
<![CDATA[<400> 1138]]>
000
<![CDATA[<210> 1139]]>
<![CDATA[<400> 1139]]>
000
<![CDATA[<210> 1140]]>
<![CDATA[<400> 1140]]>
000
<![CDATA[<210> 1141]]>
<![CDATA[<400> 1141]]>
000
<![CDATA[<210> 1142]]>
<![CDATA[<400> 1142]]>
000
<![CDATA[<210> 1143]]>
<![CDATA[<400> 1143]]>
000
<![CDATA[<210> 1144]]>
<![CDATA[<400> 1144]]>
000
<![CDATA[<210> 1145]]>
<![CDATA[<400> 1145]]>
000
<![CDATA[<210> 1146]]>
<![CDATA[<400> 1146]]>
000
<![CDATA[<210> 1147]]>
<![CDATA[<400> 1147]]>
000
<![CDATA[<210> 1148]]>
<![CDATA[<400> 1148]]>
000
<![CDATA[<210> 1149]]>
<![CDATA[<400> 1149]]>
000
<![CDATA[<210> 1150]]>
<![CDATA[<400> 1150]]>
000
<![CDATA[<210> 1151]]>
<![CDATA[<400> 1151]]>
000
<![CDATA[<210> 1152]]>
<![CDATA[<400> 1152]]>
000
<![CDATA[<210> 1153]]>
<![CDATA[<400> 1153]]>
000
<![CDATA[<210> 1154]]>
<![CDATA[<400> 1154]]>
000
<![CDATA[<210> 1155]]>
<![CDATA[<400> 1155]]>
000
<![CDATA[<210> 1156]]>
<![CDATA[<400> 1156]]>
000
<![CDATA[<210> 1157]]>
<![CDATA[<400> 1157]]>
000
<![CDATA[<210> 1158]]>
<![CDATA[<400> 1158]]>
000
<![CDATA[<210> 1159]]>
<![CDATA[<400> 1159]]>
000
<![CDATA[<210> 1160]]>
<![CDATA[<400> 1160]]>
000
<![CDATA[<210> 1161]]>
<![CDATA[<400> 1161]]>
000
<![CDATA[<210> 1162]]>
<![CDATA[<400> 1162]]>
000
<![CDATA[<210> 1163]]>
<![CDATA[<400> 1163]]>
000
<![CDATA[<210> 1164]]>
<![CDATA[<400> 1164]]>
000
<![CDATA[<210> 1165]]>
<![CDATA[<400> 1165]]>
000
<![CDATA[<210> 1166]]>
<![CDATA[<400> 1166]]>
000
<![CDATA[<210> 1167]]>
<![CDATA[<400> 1167]]>
000
<![CDATA[<210> 1168]]>
<![CDATA[<400> 1168]]>
000
<![CDATA[<210> 1169]]>
<![CDATA[<400> 1169]]>
000
<![CDATA[<210> 1170]]>
<![CDATA[<400> 1170]]>
000
<![CDATA[<210> 1171]]>
<![CDATA[<400> 1171]]>
000
<![CDATA[<210> 1172]]>
<![CDATA[<400> 1172]]>
000
<![CDATA[<210> 1173]]>
<![CDATA[<400> 1173]]>
000
<![CDATA[<210> 1174]]>
<![CDATA[<400> 1174]]>
000
<![CDATA[<210> 1175]]>
<![CDATA[<400> 1175]]>
000
<![CDATA[<210> 1176]]>
<![CDATA[<400> 1176]]>
000
<![CDATA[<210> 1177]]>
<![CDATA[<400> 1177]]>
000
<![CDATA[<210> 1178]]>
<![CDATA[<400> 1178]]>
000
<![CDATA[<210> 1179]]>
<![CDATA[<400> 1179]]>
000
<![CDATA[<210> 1180]]>
<![CDATA[<400> 1180]]>
000
<![CDATA[<210> 1181]]>
<![CDATA[<400> 1181]]>
000
<![CDATA[<210> 1182]]>
<![CDATA[<400> 1182]]>
000
<![CDATA[<210> 1183]]>
<![CDATA[<400> 1183]]>
000
<![CDATA[<210> 1184]]>
<![CDATA[<400> 1184]]>
000
<![CDATA[<210> 1185]]>
<![CDATA[<400> 1185]]>
000
<![CDATA[<210> 1186]]>
<![CDATA[<400> 1186]]>
000
<![CDATA[<210> 1187]]>
<![CDATA[<400> 1187]]>
000
<![CDATA[<210> 1188]]>
<![CDATA[<400> 1188]]>
000
<![CDATA[<210> 1189]]>
<![CDATA[<400> 1189]]>
000
<![CDATA[<210> 1190]]>
<![CDATA[<400> 1190]]>
000
<![CDATA[<210> 1191]]>
<![CDATA[<400> 1191]]>
000
<![CDATA[<210> 1192]]>
<![CDATA[<400> 1192]]>
000
<![CDATA[<210> 1193]]>
<![CDATA[<400> 1193]]>
000
<![CDATA[<210> 1194]]>
<![CDATA[<400> 1194]]>
000
<![CDATA[<210> 1195]]>
<![CDATA[<400> 1195]]>
000
<![CDATA[<210> 1196]]>
<![CDATA[<400> 1196]]>
000
<![CDATA[<210> 1197]]>
<![CDATA[<400> 1197]]>
000
<![CDATA[<210> 1198]]>
<![CDATA[<400> 1198]]>
000
<![CDATA[<210> 1199]]>
<![CDATA[<400> 1199]]>
000
<![CDATA[<210> 1200]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1200]]>
ggggaattag ctcaagtggt agagcgcttg cttagcatgc aagaggtagt gggatcgatg 60
cccacattct cca 73
<![CDATA[<210> 1201]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1201]]>
ggggatgtag ctcagtggta gagcgcatgc ttcgcatgta tgaggtcccg ggttcgatcc 60
ccggcatctc ca 72
<![CDATA[<210> 1202]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1202]]>
gggggtgtag ctcagtggta gagcgcatgc tttgcatgta tgaggccccg ggttcgatcc 60
ccggcacctc ca 72
<![CDATA[<210> 1203]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1203]]>
gggccagtgg cgcaatggat aacgcgtctg actacggatc agaagattcc aggttcgact 60
cctggctggc tcg 73
<![CDATA[<210> 1204]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1204]]>
ggccgcgtgg cctaatggat aaggcgtctg attccggatc agaagattga gggttcgagt 60
cccttcgtgg tcg 73
<![CDATA[<210> 1205]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1205]]>
gccccagtgg cctaatggat aaggcactgg cctcctaagc cagggattgt gggttcgagt 60
cccacctggg gta 73
<![CDATA[<210> 1206]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1206]]>
gaccgcgtgg cctaatggat aaggcgtctg acttcggatc agaagattga gggttcgagt 60
ccctccgtgg tcg 73
<![CDATA[<210> 1207]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (21)..(21)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (65)..(65)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1207]]>
ggctctgtgg cgcaatggat nagcgcattg gacttctaat tcaaaggttg cgggttcgag 60
tcccnccaga gtcg 74
<![CDATA[<210> 1208]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (43)..(43)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1208]]>
gtctctgtgg cgcaatcggt tagcgcgttc ggctgttaac cgnaaaggtt ggtggttcga 60
gcccacccag ggacg 75
<![CDATA[<210> 1209]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1209]]>
tcctcgttag tatagtggtg agtatccccg cctgtcacgc gggagaccgg ggttcgattc 60
cccgacgggg ag 72
<![CDATA[<210> 1210]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (16)..(16)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1210]]>
gggggtatag ctcagngggt agagcatttg actgcagatc aagaggtccc cggttcaaat 60
ccgggtgccc cct 73
<![CDATA[<210> 1211]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (20)..(20)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1211]]>
ggttccatgg tgtaatggtn agcactctgg actctgaatc cagcgatccg agttcaagtc 60
tcggtggaac ct 72
<![CDATA[<210> 1212]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1212]]>
ggtcccatgg tgtaatggtt agcactctgg actttgaatc cagcgatccg agttcaaatc 60
tcggtgggac ct 72
<![CDATA[<210> 1213]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1213]]>
tccctggtgg tctagtggtt aggattcggc gctctcaccg ccgcggcccg ggttcgattc 60
ccggtcaggg aa 72
<![CDATA[<210> 1214]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (42)..(42)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1214]]>
tccctggtgg tctagtggct aggattcggc gctttcaccg cngcggcccg ggttcgattc 60
ccggtcaggg aa 72
<![CDATA[<210> 1215]]>
<![CDATA[<211> 71]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (40)..(40)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1215]]>
gcattggtgg ttcagtggta gaattctcgc ctcccacgcn ggagacccgg gttcgattcc 60
cggccaatgc a 71
<![CDATA[<210> 1216]]>
<![CDATA[<211> 71]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1216]]>
gcattggtgg ttcagtggta gaattctcgc ctgccacgcg ggaggcccgg gttcgattcc 60
cggccaatgc a 71
<![CDATA[<210> 1217]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1217]]>
gcgttggtgg tatagtggtg agcatagctg ccttccaagc agttgacccg ggttcgattc 60
ccggccaacg ca 72
<![CDATA[<210> 1218]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1218]]>
ggccggttag ctcagttggt tagagcgtgg tgctaataac gccaaggtcg cgggttcgat 60
ccccgtacgg gcca 74
<![CDATA[<210> 1219]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1219]]>
gctccagtgg cgcaatcggt tagcgcgcgg tacttataat gccgaggttg tgagttcgag 60
cctcacctgg agca 74
<![CDATA[<210> 1220]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1220]]>
ggtagcgtgg ccgagcggtc taaggcgctg gattaaggct ccagtctctt cgggggcgtg 60
ggttcgaatc ccaccgctgc ca 82
<![CDATA[<210> 1221]]>
<![CDATA[<211> 85]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (21)..(21)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (52)..(52)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1221]]>
gtcaggatgg ccgagtggtc ntaaggcgcc agactcaagt tctggtctcc gnatggaggc 60
gtgggttcga atcccacttc tgaca 85
<![CDATA[<210> 1222]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1222]]>
gtcaggatgg ccgagcggtc taaggcgctg cgttcaggtc gcagtctccc ctggaggcgt 60
gggttcgaat cccactcctg aca 83
<![CDATA[<210> 1223]]>
<![CDATA[<211> 83]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1223]]>
accaggatgg ccgagtggtt aaggcgttgg acttaagatc caatggacag atgtccgcgt 60
gggttcgaac cccactcctg gta 83
<![CDATA[<210> 1224]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (54)..(54)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1224]]>
ggtagcgtgg ccgagcggtc taaggcgctg gatttaggct ccagtctctt cggnggcgtg 60
ggttcgaatc ccaccgctgc ca 82
<![CDATA[<210> 1225]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (74)..(76)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1225]]>
gcccggctag ctcagtcggt agagcatgag actcttaatc tcagggtcgt gggttcgagc 60
cccacgttgg gcgnnn 76
<![CDATA[<210> 1226]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1226]]>
gcctggatag ctcagtcggt agagcatcag acttttaatc tgagggtcca gggttcaagt 60
ccctgttcag gcg 73
<![CDATA[<210> 1227]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (17)..(17)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1227]]>
gccctcttag cgcagtnggc agcgcgtcag tctcataatc tgaaggtcct gagttcgagc 60
ctcagagagg gca 73
<![CDATA[<210> 1228]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (41)..(41)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1228]]>
gccgaaatag ctcagttggg agagcgttag actgaagatc ntaaaggtcc ctggttcaat 60
cccgggtttc ggca 74
<![CDATA[<210> 1229]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1229]]>
ggctcgttgg tctaggggta tgattctcgc ttaggatgcg agaggtcccg ggttcaaatc 60
ccggacgagc cc 72
<![CDATA[<210> 1230]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1230]]>
ggctcgttgg tctaggggta tgattctcgc ttcgggtgcg agaggtcccg ggttcaaatc 60
ccggacgagc cc 72
<![CDATA[<210> 1231]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1231]]>
ggctcgttgg tctaggggta tgattctcgc tttgggtgcg agaggtcccg ggttcaaatc 60
ccggacgagc cc 72
<![CDATA[<210> 1232]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1232]]>
gtagtcgtgg ccgagtggtt aaggcgatgg actagaaatc cattggggtt tccccgcgca 60
ggttcgaatc ctgccgacta cg 82
<![CDATA[<210> 1233]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1233]]>
gctgtgatgg ccgagtggtt aaggcgttgg actcgaaatc caatggggtc tccccgcgca 60
ggttcgaatc ctgctcacag cg 82
<![CDATA[<210> 1234]]>
<![CDATA[<211> 84]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (8)..(9)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1234]]>
gacgaggnnt ggccgagtgg ttaaggcgat ggactgctaa tccattgtgc tctgcacgcg 60
tgggttcgaa tcccatcctc gtcg 84
<![CDATA[<210> 1235]]>
<![CDATA[<211> 82]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1235]]>
gtagtcgtgg ccgagtggtt aaggcgatgg acttgaaatc cattggggtc tccccgcgca 60
ggttcgaatc ctgccggcta cg 82
<![CDATA[<210> 1236]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1236]]>
ggctccgtgg cttagctggt taaagcgcct gtctagtaaa caggagatcc tgggttcgaa 60
tcccagcggg gcct 74
<![CDATA[<210> 1237]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (4)..(4)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (13)..(13)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (17)..(17)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (20)..(20)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (43)..(43)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (51)..(51)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (67)..(67)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (69)..(69)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1237]]>
ggcnctgtgg ctnagtnggn taaagcgccg gtctcgtaaa ccnggagatc ntgggttcga 60
atcccancng ggcct 75
<![CDATA[<210> 1238]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (16)..(16)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1238]]>
ggctccatag ctcagngggt tagagcactg gtcttgtaaa ccaggggtcg cgagttcaaa 60
tctcgctggg gcct 74
<![CDATA[<210> 1239]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1239]]>
gacctcgtgg cgcaacggta gcgcgtctga ctccagatca gaaggttgcg tgttcaaatc 60
acgtcggggt ca 72
<![CDATA[<210> 1240]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1240]]>
ccttcgatag ctcagctggt agagcggagg actgtagatc cttaggtcgc tggttcgatt 60
ccggctcgaa gga 73
<![CDATA[<210> 1241]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1241]]>
gtttccgtag tgtagtggtt atcacgttcg cctaacacgc gaaaggtccc cggttcgaaa 60
ccgggcggaa aca 73
<![CDATA[<210> 1242]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1242]]>
gtttccgtag tgtagtggtt atcacgttcg cctcacacgc gaaaggtccc cggttcgaaa 60
ccgggcggaa aca 73
<![CDATA[<210> 1243]]>
<![CDATA[<211> 73]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1243]]>
ggttccatag tgtagtggtt atcacgtctg ctttacacgc agaaggtcct gggttcgagc 60
cccagtggaa cca 73
<![CDATA[<210> 1244]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1244]]>
agcagagtgg cgcagcggaa gcgtgctggg cccataaccc agaggtcgat ggatcgaaac 60
catcctctgc ta 72
<![CDATA[<210> 1245]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (74)..(76)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1245]]>
ggggaattag ctcaagtggt agagcgcttg cttagcatgc aagaggtagt gggatcgatg 60
cccacattct ccannn 76
<![CDATA[<210> 1246]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (73)..(75)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1246]]>
ggggatgtag ctcagtggta gagcgcatgc ttcgcatgta tgaggtcccg ggttcgatcc 60
ccggcatctc cannn 75
<![CDATA[<210> 1247]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (73)..(75)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1247]]>
gggggtgtag ctcagtggta gagcgcatgc tttgcatgta tgaggccccg ggttcgatcc 60
ccggcacctc cannn 75
<![CDATA[<210> 1248]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (74)..(76)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1248]]>
gggccagtgg cgcaatggat aacgcgtctg actacggatc agaagattcc aggttcgact 60
cctggctggc tcgnnn 76
<![CDATA[<210> 1249]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (74)..(76)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1249]]>
ggccgcgtgg cctaatggat aaggcgtctg attccggatc agaagattga gggttcgagt 60
cccttcgtgg tcgnnn 76
<![CDATA[<210> 1250]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (74)..(76)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1250]]>
gccccagtgg cctaatggat aaggcactgg cctcctaagc cagggattgt gggttcgagt 60
cccacctggg gtannn 76
<![CDATA[<210> 1251]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (74)..(76)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1251]]>
gaccgcgtgg cctaatggat aaggcgtctg acttcggatc agaagattga gggttcgagt 60
ccctccgtgg tcgnnn 76
<![CDATA[<210> 1252]]>
<![CDATA[<211> 77]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (21)..(21)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (65)..(65)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (75)..(77)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1252]]>
ggctctgtgg cgcaatggat nagcgcattg gacttctaat tcaaaggttg cgggttcgag 60
tcccnccaga gtcgnnn 77
<![CDATA[<210> 1253]]>
<![CDATA[<211> 78]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (43)..(43)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (76)..(78)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1253]]>
gtctctgtgg cgcaatcggt tagcgcgttc ggctgttaac cgnaaaggtt ggtggttcga 60
gcccacccag ggacgnnn 78
<![CDATA[<210> 1254]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (73)..(75)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1254]]>
tcctcgttag tatagtggtg agtatccccg cctgtcacgc gggagaccgg ggttcgattc 60
cccgacgggg agnnn 75
<![CDATA[<210> 1255]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (16)..(16)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (74)..(76)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1255]]>
gggggtatag ctcagngggt agagcatttg actgcagatc aagaggtccc cggttcaaat 60
ccgggtgccc cctnnn 76
<![CDATA[<210> 1256]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (20)..(20)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (73)..(75)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1256]]>
ggttccatgg tgtaatggtn agcactctgg actctgaatc cagcgatccg agttcaagtc 60
tcggtggaac ctnnn 75
<![CDATA[<210> 1257]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (73)..(75)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1257]]>
ggtcccatgg tgtaatggtt agcactctgg actttgaatc cagcgatccg agttcaaatc 60
tcggtgggac ctnnn 75
<![CDATA[<210> 1258]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (73)..(75)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1258]]>
tccctggtgg tctagtggtt aggattcggc gctctcaccg ccgcggcccg ggttcgattc 60
ccggtcaggg aannn 75
<![CDATA[<210> 1259]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (42)..(42)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (73)..(75)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1259]]>
tccctggtgg tctagtggct aggattcggc gctttcaccg cngcggcccg ggttcgattc 60
ccggtcaggg aannn 75
<![CDATA[<210> 1260]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (40)..(40)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (72)..(74)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1260]]>
gcattggtgg ttcagtggta gaattctcgc ctcccacgcn ggagacccgg gttcgattcc 60
cggccaatgc annn 74
<![CDATA[<210> 1261]]>
<![CDATA[<211> 74]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (72)..(74)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1261]]>
gcattggtgg ttcagtggta gaattctcgc ctgccacgcg ggaggcccgg gttcgattcc 60
cggccaatgc annn 74
<![CDATA[<210> 1262]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (73)..(75)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1262]]>
gcgttggtgg tatagtggtg agcatagctg ccttccaagc agttgacccg ggttcgattc 60
ccggccaacg cannn 75
<![CDATA[<210> 1263]]>
<![CDATA[<211> 77]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (75)..(77)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1263]]>
ggccggttag ctcagttggt tagagcgtgg tgctaataac gccaaggtcg cgggttcgat 60
ccccgtacgg gccannn 77
<![CDATA[<210> 1264]]>
<![CDATA[<211> 77]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (75)..(77)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1264]]>
gctccagtgg cgcaatcggt tagcgcgcgg tacttataat gccgaggttg tgagttcgag 60
cctcacctgg agcannn 77
<![CDATA[<210> 1265]]>
<![CDATA[<211> 85]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (83)..(85)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1265]]>
ggtagcgtgg ccgagcggtc taaggcgctg gattaaggct ccagtctctt cgggggcgtg 60
ggttcgaatc ccaccgctgc cannn 85
<![CDATA[<210> 1266]]>
<![CDATA[<211> 88]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (21)..(21)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (52)..(52)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (86)..(88)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1266]]>
gtcaggatgg ccgagtggtc ntaaggcgcc agactcaagt tctggtctcc gnatggaggc 60
gtgggttcga atcccacttc tgacannn 88
<![CDATA[<210> 1267]]>
<![CDATA[<211> 86]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (84)..(86)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1267]]>
gtcaggatgg ccgagcggtc taaggcgctg cgttcaggtc gcagtctccc ctggaggcgt 60
gggttcgaat cccactcctg acannn 86
<![CDATA[<210> 1268]]>
<![CDATA[<211> 86]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (84)..(86)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1268]]>
accaggatgg ccgagtggtt aaggcgttgg acttaagatc caatggacag atgtccgcgt 60
gggttcgaac cccactcctg gtannn 86
<![CDATA[<210> 1269]]>
<![CDATA[<211> 85]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (54)..(54)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (83)..(85)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1269]]>
ggtagcgtgg ccgagcggtc taaggcgctg gatttaggct ccagtctctt cggnggcgtg 60
ggttcgaatc ccaccgctgc cannn 85
<![CDATA[<210> 1270]]>
<![CDATA[<211> 79]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (74)..(79)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1270]]>
gcccggctag ctcagtcggt agagcatgag actcttaatc tcagggtcgt gggttcgagc 60
cccacgttgg gcgnnnnnn 79
<![CDATA[<210> 1271]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (74)..(76)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1271]]>
gcctggatag ctcagtcggt agagcatcag acttttaatc tgagggtcca gggttcaagt 60
ccctgttcag gcgnnn 76
<![CDATA[<210> 1272]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (17)..(17)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (74)..(76)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1272]]>
gccctcttag cgcagtnggc agcgcgtcag tctcataatc tgaaggtcct gagttcgagc 60
ctcagagagg gcannn 76
<![CDATA[<210> 1273]]>
<![CDATA[<211> 77]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (41)..(41)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (75)..(77)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1273]]>
gccgaaatag ctcagttggg agagcgttag actgaagatc ntaaaggtcc ctggttcaat 60
cccgggtttc ggcannn 77
<![CDATA[<210> 1274]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (73)..(75)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1274]]>
ggctcgttgg tctaggggta tgattctcgc ttaggatgcg agaggtcccg ggttcaaatc 60
ccggacgagc ccnnn 75
<![CDATA[<210> 1275]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (73)..(75)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1275]]>
ggctcgttgg tctaggggta tgattctcgc ttcgggtgcg agaggtcccg ggttcaaatc 60
ccggacgagc ccnnn 75
<![CDATA[<210> 1276]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (73)..(75)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1276]]>
ggctcgttgg tctaggggta tgattctcgc tttgggtgcg agaggtcccg ggttcaaatc 60
ccggacgagc ccnnn 75
<![CDATA[<210> 1277]]>
<![CDATA[<211> 85]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (83)..(85)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1277]]>
gtagtcgtgg ccgagtggtt aaggcgatgg actagaaatc cattggggtt tccccgcgca 60
ggttcgaatc ctgccgacta cgnnn 85
<![CDATA[<210> 1278]]>
<![CDATA[<211> 85]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (83)..(85)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1278]]>
gctgtgatgg ccgagtggtt aaggcgttgg actcgaaatc caatggggtc tccccgcgca 60
ggttcgaatc ctgctcacag cgnnn 85
<![CDATA[<210> 1279]]>
<![CDATA[<211> 87]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (8)..(9)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (85)..(87)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1279]]>
gacgaggnnt ggccgagtgg ttaaggcgat ggactgctaa tccattgtgc tctgcacgcg 60
tgggttcgaa tcccatcctc gtcgnnn 87
<![CDATA[<210> 1280]]>
<![CDATA[<211> 85]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (83)..(85)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1280]]>
gtagtcgtgg ccgagtggtt aaggcgatgg acttgaaatc cattggggtc tccccgcgca 60
ggttcgaatc ctgccggcta cgnnn 85
<![CDATA[<210> 1281]]>
<![CDATA[<211> 77]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (75)..(77)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1281]]>
ggctccgtgg cttagctggt taaagcgcct gtctagtaaa caggagatcc tgggttcgaa 60
tcccagcggg gcctnnn 77
<![CDATA[<210> 1282]]>
<![CDATA[<211> 78]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (4)..(4)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (13)..(13)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (17)..(17)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (20)..(20)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (43)..(43)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (51)..(51)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (67)..(67)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (69)..(69)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (76)..(78)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1282]]>
ggcnctgtgg ctnagtnggn taaagcgccg gtctcgtaaa ccnggagatc ntgggttcga 60
atcccancng ggcctnnn 78
<![CDATA[<210> 1283]]>
<![CDATA[<211> 77]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (16)..(16)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (75)..(77)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1283]]>
ggctccatag ctcagngggt tagagcactg gtcttgtaaa ccaggggtcg cgagttcaaa 60
tctcgctggg gcctnnn 77
<![CDATA[<210> 1284]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (73)..(75)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1284]]>
gacctcgtgg cgcaacggta gcgcgtctga ctccagatca gaaggttgcg tgttcaaatc 60
acgtcggggt cannn 75
<![CDATA[<210> 1285]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (74)..(76)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1285]]>
ccttcgatag ctcagctggt agagcggagg actgtagatc cttaggtcgc tggttcgatt 60
ccggctcgaa ggannn 76
<![CDATA[<210> 1286]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (74)..(76)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1286]]>
gtttccgtag tgtagtggtt atcacgttcg cctaacacgc gaaaggtccc cggttcgaaa 60
ccgggcggaa acannn 76
<![CDATA[<210> 1287]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (74)..(76)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1287]]>
gtttccgtag tgtagtggtt atcacgttcg cctcacacgc gaaaggtccc cggttcgaaa 60
ccgggcggaa acannn 76
<![CDATA[<210> 1288]]>
<![CDATA[<211> 76]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (74)..(76)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1288]]>
ggttccatag tgtagtggtt atcacgtctg ctttacacgc agaaggtcct gggttcgagc 60
cccagtggaa ccannn 76
<![CDATA[<210> 1289]]>
<![CDATA[<211> 75]]>
<![CDATA[<212> DNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<220>]]>
<![CDATA[<221> modified_base]]>
<![CDATA[<222> (73)..(75)]]>
<![CDATA[<223> a, c, t, g, 未知或其他]]>
<![CDATA[<400> 1289]]>
agcagagtgg cgcagcggaa gcgtgctggg cccataaccc agaggtcgat ggatcgaaac 60
catcctctgc tannn 75
<![CDATA[<210> 1290]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1290]]>
ggcucguugg ucuaggggua ugauucucgc uuagggugcg agaggucccg gguucaaauc 60
ccggacgagc cc 72
<![CDATA[<210> 1291]]>
<![CDATA[<211> 72]]>
<![CDATA[<212> RNA]]>
<![CDATA[<213> 人工序列]]>
<![CDATA[<220>]]>
<![CDATA[<221> 來源]]>
<![CDATA[<223> /備註="人工序列之描述: 合成寡核苷酸"]]>
<![CDATA[<400> 1291]]>
ggggauguag cucaguggua gagcgcaugc uuugcaugua ugaggucccg gguucgaucc 60
ccggcaucuc ca 72













































































































































































































































































































































Claims (65)
- 一種tRNA效應分子(TREM),其包含: (i)式A之序列,其包含: [L1] y-[ASt域1] x-[L2] x-[DH域] x-[L3] x-[ACH域] x-[VL域] y-[TH域] x-[L4] x-[ASt域2] x(A); 其中獨立地,[L1]及[VL域]為視情況選用的; 各y獨立地為0或1;且 各x為0或1;及 (ii)去唾液酸糖蛋白受體(ASGPR)結合部分(例如GalNAc部分,例如GalNAc), 其中該ASGPR結合部分與該TREM之核苷酸內之核鹼基結合,或在該TREM之末端(例如5'或3'末端)處結合,或在TREM之核苷酸間鍵聯內結合。
- 如請求項1之TREM,其中各x為1。
- 如請求項1至2中任一項之TREM,其中該ASGPR部分存在於該L1、ASt域1、L2、DH域、L3、ACH域、VL域、TH域、L4或ASt域內。
- 如請求項1至3中任一項之TREM,其中該ASGPR結合部分存在於L1內。
- 如請求項1至3中任一項之TREM,其中該ASGPR結合部分存在於ASt域1內。
- 如請求項1至3中任一項之TREM,其中該ASGPR結合部分存在於L2內。
- 如請求項1至3中任一項之TREM,其中該ASGPR結合部分存在於DH域內。
- 如請求項1至3中任一項之TREM,其中該ASGPR結合部分存在於L3內。
- 如請求項1至3中任一項之TREM,其中該ASGPR結合部分存在於該ACH域內。
- 如請求項1至3中任一項之TREM,其中該ASGPR結合部分存在於VL域內。
- 如請求項1至3中任一項之TREM,其中該ASGPR結合部分存在於TH域內。
- 如請求項1至3中任一項之TREM,其中該ASGPR結合部分存在於L4內。
- 如請求項1至3中任一項之TREM,其中該ASGPR結合部分存在於ASt域2內。
- 如請求項1至3中任一項之TREM,其中該ASGPR結合部分存在於L1、ASt域1或ASt域2中之一者內。
- 如請求項1至14中任一項之TREM,其中該ASGPR結合部分與該TREM之核苷酸內之核鹼基共價結合,或在該TREM之末端(例如5'或3'末端)處共價結合,或在TREM之核苷酸間鍵聯內共價結合(例如,在核鹼基部分中之氮或碳原子處共價結合)。
- 如請求項1至15中任一項之TREM,其中該ASGPR結合部分(例如GalNAc部分,例如GalNAc)與該TREM之核苷酸內之核鹼基結合。
- 如請求項1至16中任一項之TREM,其中該核鹼基為天然存在之核鹼基或非天然存在之核鹼基。
- 如請求項1至17中任一項之TREM,其中該核鹼基包含尿嘧啶、腺嘌呤、鳥嘌呤、胞嘧啶、胸腺嘧啶或其變體。
- 如請求項1至15中任一項之TREM,其中該ASGPR結合部分(例如GalNAc部分,例如GalNAc)與該TREM內之一個或兩個末端結合。
- 如請求項19之TREM,其中該ASGPR結合部分(例如GalNAc部分,例如GalNAc)與該TREM之5'末端結合。
- 如請求項19之TREM,其中該ASGPR結合部分(例如GalNAc部分,例如GalNAc)與該TREM之3'末端結合。
- 如請求項1至15中任一項之TREM,其中該ASGPR結合部分存在於該TREM之核苷酸間鍵聯內。
- 如請求項1至22中任一項之TREM,其中該TREM包含表12中所提供之TREM (例如SEQ ID NO. 622-654)中任一者之序列。
- 如請求項1至23中任一項之TREM,其中該TREM包含與表12中所提供之TREM之序列(例如表12中所提供之SEQ ID NO. 622-654中之任一者)至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致的序列。
- 如請求項1至24中任一項之TREM,其中該TREM包含與表12中所提供之TREM之序列(例如表12中所提供之SEQ ID NO. 622-654中之任一者)至少90%、92%、95%、96%、97%、98%或99%一致的序列。
- 如請求項1至25中任一項之TREM,其中該TREM包含表12中所提供之TREM (例如表12中所揭示之SEQ ID NO. 622-654中之任一者)之至少5個核糖核苷酸(nt)、10 nt、15 nt、20 nt、25 nt、30 nt、35 nt、40 nt、45 nt、50 nt、55 nt、60 nt、65 nt、70 nt或75 nt (但小於全長)。
- 如請求項1至26中任一項之TREM,其中該TREM包含表12中所提供之TREM (例如表12中所揭示之SEQ ID NO. 622-654中之任一者)之至少60 nt、65 nt、70 nt或75 nt。
- 如請求項1至27中任一項之TREM,其中該TREM包含與表12中所提供之TREM (例如表12中所揭示之SEQ ID NO. 622-654中之任一者)至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致的TREM之至少5個核糖核苷酸(nt)、10 nt、15 nt、20 nt、25 nt、30 nt、35 nt、40 nt、45 nt、50 nt、55 nt、60 nt、65 nt、70 nt或75 nt (但小於全長)。
- 如請求項1至28中任一項之TREM,其中該TREM包含與表12中所提供之TREM (例如表12中所揭示之SEQ ID NO. 622-654中之任一者)至少80%、85%、90%、95%、96%、97%、98%、99%或100%一致的TREM之至少60 nt、65 nt、70 nt或75 nt。
- 如請求項1至29中任一項之TREM,其中該TREM包含與表12中所提供之TREM (例如表12中所提供之SEQ ID NO. 622-652中之任一者)相差不超過1個核糖核苷酸(nt)、2 nt、3 nt、4 nt、5 nt、6 nt、7 nt、8 nt、9 nt、10 nt、12 nt、14 nt、16 nt、18 nt或20 nt的序列。
- 如請求項1至30中任一項之TREM,其中該TREM係選自SEQ ID NO. 622、SEQ ID NO. 650及SEQ ID NO. 653。
- 如請求項1至31中任一項之TREM,其中該TREM與SEQ ID NO. 622至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致。
- 如請求項1至31中任一項之TREM,其中該TREM與SEQ ID NO. 650至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致。
- 如請求項1至31中任一項之TREM,其中該TREM與SEQ ID NO. 653至少60%、65%、70%、75%、80%、82%、85%、87%、88%、90%、92%、95%、96%、97%、98%或99%一致。
- 如請求項1至34中任一項之TREM,其中該ASGPR結合部分包含式(III-b)之結構:,或其鹽,其中: 各X獨立地為O、N(R 7)或S; R 1、R 3、R 4及R 5中之每一者獨立地為氫、烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基、雜環基、C(O)-烷基、C(O)-烯基、C(O)-炔基、C(O)-雜烷基、C(O)-鹵烷基、C(O)-芳基、C(O)-雜芳基、C(O)-環烷基或C(O)-雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R 8取代; 或R 3及R 4與其所連接之氧原子一起形成視情況經一或多個R 8取代之雜環基環; R 2a為氫或烷基; R 2b為-C(O)烷基(例如C(O)CH 3); R 6a及R 6b中之每一者為氫、烷基、烯基、炔基、雜烷基、鹵烷基、鹵基、氰基、硝基、-OR A、芳基、雜芳基、環烷基或雜環基,其中各烷基、烯基、炔基、雜烷基、鹵烷基、芳基、雜芳基、環烷基及雜環基視情況經一或多個R 9取代; R 7為氫、烷基或C(O)-烷基; R 8及R 9中之每一者獨立地為氫、鹵基、氰基、烷基、烯基、炔基、雜烷基、鹵烷基、環烷基或雜環基; R A為氫或烷基、烯基、炔基; L 1、L 2及L 3中之每一者獨立地為連接子; m、n及o中之每一者獨立地為1與100之間的整數; M為連接子, 其中「
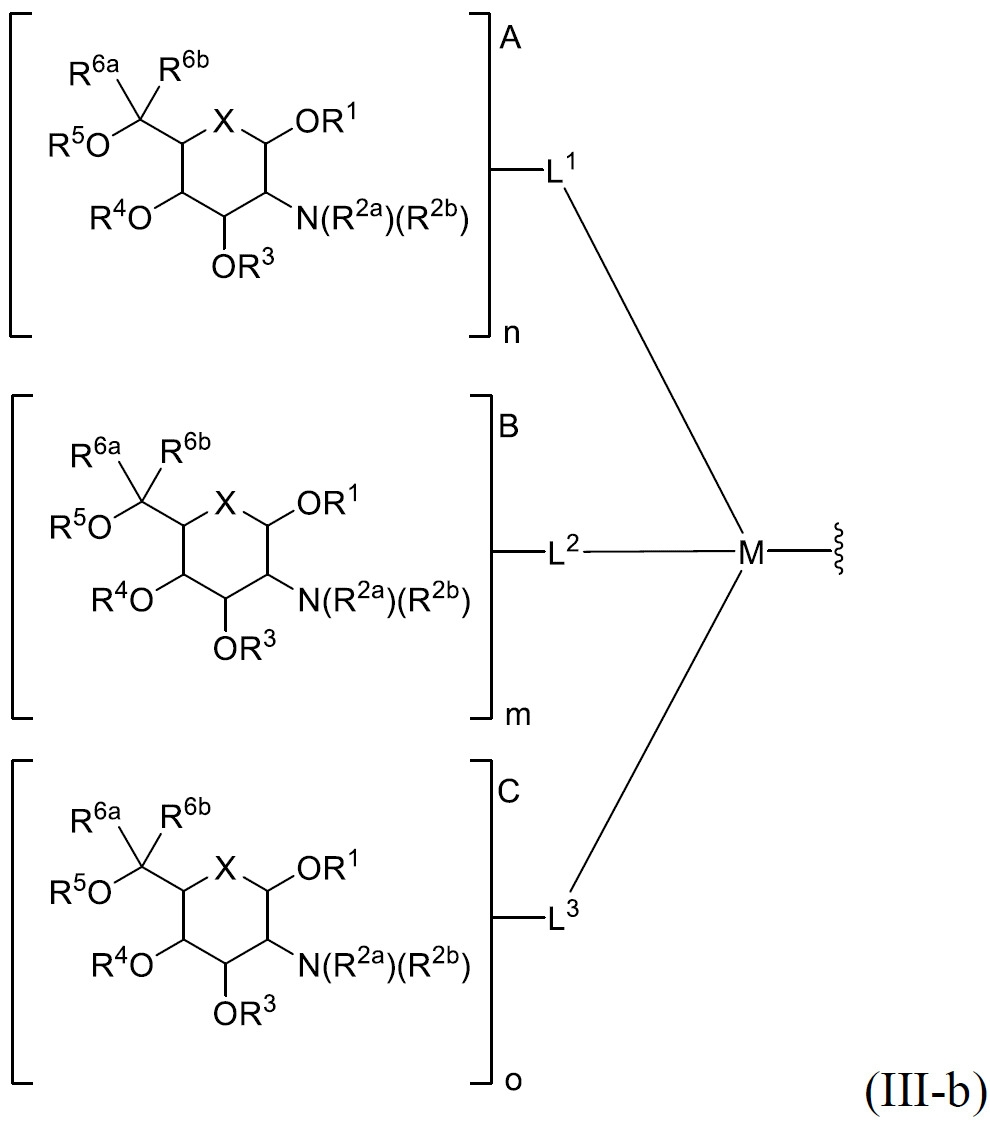 」表示與分支點、額外連接子或TREM (例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端)之連接點。
」表示與分支點、額外連接子或TREM (例如TREM序列內之連接子、核鹼基、核苷酸間鍵聯或末端)之連接點。
- 如請求項35之TREM,其中X為O。
- 如請求項35至36中任一項之TREM,R 1、R 3、R 4及R 5中之每一者獨立地為氫或烷基(例如CH 3)。
- 如請求項35至37中任一項之TREM,R 2a為氫且R 2b為C(O)CH 3。
- 如請求項35至38中任一項之TREM,其中R 6a及R 6b中之每一者為氫。
- 如請求項35至39中任一項之TREM,其中m、n及o中之每一者獨立地為1與10之間的整數。
- 如請求項35至40中任一項之TREM,其中m、n及o中之每一者獨立地為1。
- 如請求項35至41中任一項之TREM,其中L 1、L 2及L 3中之每一者獨立地包含伸烷基、伸烯基、伸炔基、伸雜烷基或伸鹵烷基。
- 如請求項35至42中任一項之TREM,其中L 1、L 2及L 3中之每一者獨立地為可裂解或不可裂解的。
- 如請求項35至43中任一項之TREM,其中L 1、L 2及L 3中之每一者獨立地包含聚乙二醇基團。
- 如請求項35至44中任一項之TREM,其中M包含伸烷基、伸烯基、伸炔基、伸雜烷基或伸鹵烷基。
- 如請求項35至45中任一項之TREM,其中M包含酯基、醯胺基、二硫化物基、醚基、碳酸酯基、芳基、雜芳基、環烷基或雜環基。
- 如請求項35至46中任一項之TREM,其中M為可裂解或不可裂解的。
- 如請求項1至47中任一項之TREM,其中該ASGPR結合部分包含半乳糖(Gal)、半乳胺糖(GalNH 2)或N-乙醯基半乳胺糖(GalNAc)部分。
- 如請求項1至48中任一項之TREM,其中該ASGPR結合部分包含複數個半乳糖(Gal)、半乳胺糖(GalNH 2)或N-乙醯基半乳胺糖(GalNAc)部分。
- 如請求項1至49中任一項之TREM,其中該ASGPR結合部分包含ASGPR碳水化合物及ASGPR連接子。
- 如請求項1至50中任一項之TREM,其中該ASGPR結合部分包含三觸角GalNAc部分。
- 如請求項1至51中任一項之TREM,其中該TREM為表12中所提供之化合物,例如化合物編號99至131中之任一者。
- 如請求項1至52中任一項之TREM,其中該TREM例如相對於不包含ASGPR結合部分之TREM或天然存在之tRNA保留支援蛋白質合成之能力。
- 如請求項1至53中任一項之TREM,其中該TREM例如相對於不包含ASGPR結合部分之TREM或天然存在之tRNA保留被合成酶裝載之能力。
- 如請求項1至54中任一項之TREM,其中該TREM例如相對於不包含ASGPR結合部分之TREM或天然存在之tRNA保留被延長因子結合之能力。
- 如請求項1至55中任一項之TREM,其中該TREM例如相對於不包含ASGPR結合部分之TREM或天然存在之tRNA保留將胺基酸引入肽鏈中之能力。
- 如請求項1至56中任一項之TREM,其中該TREM例如相對於不包含ASGPR結合部分之TREM或天然存在之tRNA保留支援延長或支援起始之能力。
- 如請求項1至57中任一項之TREM,其中該TREM與ASGPR之結合親和力在0.01 nM與100 mM之間。
- 如請求項1至58中任一項之TREM,其中該TREM進一步包含化學修飾(例如天然存在之修飾或非天然存在之化學修飾)。
- 一種醫藥組合物,其包含如請求項1至59中任一項之TREM。
- 如請求項60之醫藥組合物,其進一步包含醫藥學上可接受之組分,例如賦形劑。
- 一種脂質奈米粒子調配物,其包含如請求項1至59中任一項之TREM。
- 一種脂質奈米粒子調配物,其包含如請求項60至61中任一項之醫藥組合物。
- 一種製備如請求項1至59中任一項之TREM的方法。
- 一種用於治療患有與PTC相關之疾病或病症之個體的組合物,其包含向該個體投與本文所描述之包含ASGPR結合部分的TREM (例如,如請求項1至59中任一項之TREM)、或如請求項60至61中任一項之醫藥組合物、或如請求項62至63中任一項之脂質奈米粒子調配物,由此治療患有該疾病或病症之該個體。
Applications Claiming Priority (12)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202063130387P | 2020-12-23 | 2020-12-23 | |
| US202063130375P | 2020-12-23 | 2020-12-23 | |
| US202063130377P | 2020-12-23 | 2020-12-23 | |
| US202063130374P | 2020-12-23 | 2020-12-23 | |
| US202063130373P | 2020-12-23 | 2020-12-23 | |
| US202063130381P | 2020-12-23 | 2020-12-23 | |
| US63/130,377 | 2020-12-23 | ||
| US63/130,374 | 2020-12-23 | ||
| US63/130,387 | 2020-12-23 | ||
| US63/130,381 | 2020-12-23 | ||
| US63/130,373 | 2020-12-23 | ||
| US63/130,375 | 2020-12-23 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| TW202242108A true TW202242108A (zh) | 2022-11-01 |
Family
ID=80445752
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| TW110148799A TW202242108A (zh) | 2020-12-23 | 2021-12-24 | 經修飾trem之組合物及其用途 |
Country Status (10)
| Country | Link |
|---|---|
| EP (1) | EP4267732A1 (zh) |
| JP (1) | JP2024501288A (zh) |
| KR (1) | KR20230135585A (zh) |
| AU (1) | AU2021409740A1 (zh) |
| BR (1) | BR112023012377A2 (zh) |
| CA (1) | CA3206285A1 (zh) |
| IL (1) | IL303886A (zh) |
| MX (1) | MX2023007630A (zh) |
| TW (1) | TW202242108A (zh) |
| WO (1) | WO2022140702A1 (zh) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA3235264A1 (en) * | 2021-10-13 | 2023-04-20 | Flagship Pioneering Innovations Vi, Llc | Trem compositions and methods of use |
| WO2023250112A1 (en) * | 2022-06-22 | 2023-12-28 | Flagship Pioneering Innovations Vi, Llc | Compositions of modified trems and uses thereof |
Family Cites Families (212)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US99823A (en) | 1870-02-15 | Improved indigo soap | ||
| US3687808A (en) | 1969-08-14 | 1972-08-29 | Univ Leland Stanford Junior | Synthetic polynucleotides |
| US4469863A (en) | 1980-11-12 | 1984-09-04 | Ts O Paul O P | Nonionic nucleic acid alkyl and aryl phosphonates and processes for manufacture and use thereof |
| US5023243A (en) | 1981-10-23 | 1991-06-11 | Molecular Biosystems, Inc. | Oligonucleotide therapeutic agent and method of making same |
| US4476301A (en) | 1982-04-29 | 1984-10-09 | Centre National De La Recherche Scientifique | Oligonucleotides, a process for preparing the same and their application as mediators of the action of interferon |
| US5118800A (en) | 1983-12-20 | 1992-06-02 | California Institute Of Technology | Oligonucleotides possessing a primary amino group in the terminal nucleotide |
| US5550111A (en) | 1984-07-11 | 1996-08-27 | Temple University-Of The Commonwealth System Of Higher Education | Dual action 2',5'-oligoadenylate antiviral derivatives and uses thereof |
| FR2567892B1 (fr) | 1984-07-19 | 1989-02-17 | Centre Nat Rech Scient | Nouveaux oligonucleotides, leur procede de preparation et leurs applications comme mediateurs dans le developpement des effets des interferons |
| US5367066A (en) | 1984-10-16 | 1994-11-22 | Chiron Corporation | Oligonucleotides with selectably cleavable and/or abasic sites |
| FR2575751B1 (fr) | 1985-01-08 | 1987-04-03 | Pasteur Institut | Nouveaux nucleosides de derives de l'adenosine, leur preparation et leurs applications biologiques |
| US5235033A (en) | 1985-03-15 | 1993-08-10 | Anti-Gene Development Group | Alpha-morpholino ribonucleoside derivatives and polymers thereof |
| US5166315A (en) | 1989-12-20 | 1992-11-24 | Anti-Gene Development Group | Sequence-specific binding polymers for duplex nucleic acids |
| US5034506A (en) | 1985-03-15 | 1991-07-23 | Anti-Gene Development Group | Uncharged morpholino-based polymers having achiral intersubunit linkages |
| US5405938A (en) | 1989-12-20 | 1995-04-11 | Anti-Gene Development Group | Sequence-specific binding polymers for duplex nucleic acids |
| US5185444A (en) | 1985-03-15 | 1993-02-09 | Anti-Gene Deveopment Group | Uncharged morpolino-based polymers having phosphorous containing chiral intersubunit linkages |
| US5264423A (en) | 1987-03-25 | 1993-11-23 | The United States Of America As Represented By The Department Of Health And Human Services | Inhibitors for replication of retroviruses and for the expression of oncogene products |
| US5276019A (en) | 1987-03-25 | 1994-01-04 | The United States Of America As Represented By The Department Of Health And Human Services | Inhibitors for replication of retroviruses and for the expression of oncogene products |
| DE3851889T2 (de) | 1987-06-24 | 1995-04-13 | Florey Howard Inst | Nukleosid-derivate. |
| US4924624A (en) | 1987-10-22 | 1990-05-15 | Temple University-Of The Commonwealth System Of Higher Education | 2,',5'-phosphorothioate oligoadenylates and plant antiviral uses thereof |
| US5188897A (en) | 1987-10-22 | 1993-02-23 | Temple University Of The Commonwealth System Of Higher Education | Encapsulated 2',5'-phosphorothioate oligoadenylates |
| EP0406309A4 (en) | 1988-03-25 | 1992-08-19 | The University Of Virginia Alumni Patents Foundation | Oligonucleotide n-alkylphosphoramidates |
| US5278302A (en) | 1988-05-26 | 1994-01-11 | University Patents, Inc. | Polynucleotide phosphorodithioates |
| US5216141A (en) | 1988-06-06 | 1993-06-01 | Benner Steven A | Oligonucleotide analogs containing sulfur linkages |
| US5175273A (en) | 1988-07-01 | 1992-12-29 | Genentech, Inc. | Nucleic acid intercalating agents |
| US5134066A (en) | 1989-08-29 | 1992-07-28 | Monsanto Company | Improved probes using nucleosides containing 3-dezauracil analogs |
| US5591722A (en) | 1989-09-15 | 1997-01-07 | Southern Research Institute | 2'-deoxy-4'-thioribonucleosides and their antiviral activity |
| US5399676A (en) | 1989-10-23 | 1995-03-21 | Gilead Sciences | Oligonucleotides with inverted polarity |
| ATE190981T1 (de) | 1989-10-24 | 2000-04-15 | Isis Pharmaceuticals Inc | 2'-modifizierte nukleotide |
| US5264564A (en) | 1989-10-24 | 1993-11-23 | Gilead Sciences | Oligonucleotide analogs with novel linkages |
| US5177198A (en) | 1989-11-30 | 1993-01-05 | University Of N.C. At Chapel Hill | Process for preparing oligoribonucleoside and oligodeoxyribonucleoside boranophosphates |
| US5459255A (en) | 1990-01-11 | 1995-10-17 | Isis Pharmaceuticals, Inc. | N-2 substituted purines |
| US5587361A (en) | 1991-10-15 | 1996-12-24 | Isis Pharmaceuticals, Inc. | Oligonucleotides having phosphorothioate linkages of high chiral purity |
| US5681941A (en) | 1990-01-11 | 1997-10-28 | Isis Pharmaceuticals, Inc. | Substituted purines and oligonucleotide cross-linking |
| US5646265A (en) | 1990-01-11 | 1997-07-08 | Isis Pharmceuticals, Inc. | Process for the preparation of 2'-O-alkyl purine phosphoramidites |
| US5587470A (en) | 1990-01-11 | 1996-12-24 | Isis Pharmaceuticals, Inc. | 3-deazapurines |
| US5670633A (en) | 1990-01-11 | 1997-09-23 | Isis Pharmaceuticals, Inc. | Sugar modified oligonucleotides that detect and modulate gene expression |
| US5852188A (en) | 1990-01-11 | 1998-12-22 | Isis Pharmaceuticals, Inc. | Oligonucleotides having chiral phosphorus linkages |
| US5321131A (en) | 1990-03-08 | 1994-06-14 | Hybridon, Inc. | Site-specific functionalization of oligodeoxynucleotides for non-radioactive labelling |
| US5470967A (en) | 1990-04-10 | 1995-11-28 | The Dupont Merck Pharmaceutical Company | Oligonucleotide analogs with sulfamate linkages |
| GB9009980D0 (en) | 1990-05-03 | 1990-06-27 | Amersham Int Plc | Phosphoramidite derivatives,their preparation and the use thereof in the incorporation of reporter groups on synthetic oligonucleotides |
| EP0455905B1 (en) | 1990-05-11 | 1998-06-17 | Microprobe Corporation | Dipsticks for nucleic acid hybridization assays and methods for covalently immobilizing oligonucleotides |
| JPH0874B2 (ja) | 1990-07-27 | 1996-01-10 | アイシス・ファーマシューティカルス・インコーポレーテッド | 遺伝子発現を検出および変調するヌクレアーゼ耐性、ピリミジン修飾オリゴヌクレオチド |
| US5623070A (en) | 1990-07-27 | 1997-04-22 | Isis Pharmaceuticals, Inc. | Heteroatomic oligonucleoside linkages |
| US5608046A (en) | 1990-07-27 | 1997-03-04 | Isis Pharmaceuticals, Inc. | Conjugated 4'-desmethyl nucleoside analog compounds |
| US5541307A (en) | 1990-07-27 | 1996-07-30 | Isis Pharmaceuticals, Inc. | Backbone modified oligonucleotide analogs and solid phase synthesis thereof |
| US5618704A (en) | 1990-07-27 | 1997-04-08 | Isis Pharmacueticals, Inc. | Backbone-modified oligonucleotide analogs and preparation thereof through radical coupling |
| US5610289A (en) | 1990-07-27 | 1997-03-11 | Isis Pharmaceuticals, Inc. | Backbone modified oligonucleotide analogues |
| US5677437A (en) | 1990-07-27 | 1997-10-14 | Isis Pharmaceuticals, Inc. | Heteroatomic oligonucleoside linkages |
| US5489677A (en) | 1990-07-27 | 1996-02-06 | Isis Pharmaceuticals, Inc. | Oligonucleoside linkages containing adjacent oxygen and nitrogen atoms |
| US5602240A (en) | 1990-07-27 | 1997-02-11 | Ciba Geigy Ag. | Backbone modified oligonucleotide analogs |
| KR100211552B1 (ko) | 1990-08-03 | 1999-08-02 | 디. 꼬쉬 | 유전자 발현 억제용 화합물 및 방법 |
| US5214134A (en) | 1990-09-12 | 1993-05-25 | Sterling Winthrop Inc. | Process of linking nucleosides with a siloxane bridge |
| US5561225A (en) | 1990-09-19 | 1996-10-01 | Southern Research Institute | Polynucleotide analogs containing sulfonate and sulfonamide internucleoside linkages |
| CA2092002A1 (en) | 1990-09-20 | 1992-03-21 | Mark Matteucci | Modified internucleoside linkages |
| US5432272A (en) | 1990-10-09 | 1995-07-11 | Benner; Steven A. | Method for incorporating into a DNA or RNA oligonucleotide using nucleotides bearing heterocyclic bases |
| GB9100304D0 (en) | 1991-01-08 | 1991-02-20 | Ici Plc | Compound |
| US7015315B1 (en) | 1991-12-24 | 2006-03-21 | Isis Pharmaceuticals, Inc. | Gapped oligonucleotides |
| US5719262A (en) | 1993-11-22 | 1998-02-17 | Buchardt, Deceased; Ole | Peptide nucleic acids having amino acid side chains |
| US5714331A (en) | 1991-05-24 | 1998-02-03 | Buchardt, Deceased; Ole | Peptide nucleic acids having enhanced binding affinity, sequence specificity and solubility |
| US5539082A (en) | 1993-04-26 | 1996-07-23 | Nielsen; Peter E. | Peptide nucleic acids |
| US5571799A (en) | 1991-08-12 | 1996-11-05 | Basco, Ltd. | (2'-5') oligoadenylate analogues useful as inhibitors of host-v5.-graft response |
| ES2103918T3 (es) | 1991-10-17 | 1997-10-01 | Ciba Geigy Ag | Nucleosidos biciclicos, oligonucleotidos, procedimiento para su obtencion y productos intermedios. |
| US5594121A (en) | 1991-11-07 | 1997-01-14 | Gilead Sciences, Inc. | Enhanced triple-helix and double-helix formation with oligomers containing modified purines |
| US6235887B1 (en) | 1991-11-26 | 2001-05-22 | Isis Pharmaceuticals, Inc. | Enhanced triple-helix and double-helix formation directed by oligonucleotides containing modified pyrimidines |
| US5484908A (en) | 1991-11-26 | 1996-01-16 | Gilead Sciences, Inc. | Oligonucleotides containing 5-propynyl pyrimidines |
| US5359044A (en) | 1991-12-13 | 1994-10-25 | Isis Pharmaceuticals | Cyclobutyl oligonucleotide surrogates |
| US6277603B1 (en) | 1991-12-24 | 2001-08-21 | Isis Pharmaceuticals, Inc. | PNA-DNA-PNA chimeric macromolecules |
| DK1695979T3 (da) | 1991-12-24 | 2011-10-10 | Isis Pharmaceuticals Inc | Gappede modificerede oligonukleotider |
| FR2687679B1 (fr) | 1992-02-05 | 1994-10-28 | Centre Nat Rech Scient | Oligothionucleotides. |
| DE4203923A1 (de) | 1992-02-11 | 1993-08-12 | Henkel Kgaa | Verfahren zur herstellung von polycarboxylaten auf polysaccharid-basis |
| US5633360A (en) | 1992-04-14 | 1997-05-27 | Gilead Sciences, Inc. | Oligonucleotide analogs capable of passive cell membrane permeation |
| US5434257A (en) | 1992-06-01 | 1995-07-18 | Gilead Sciences, Inc. | Binding compentent oligomers containing unsaturated 3',5' and 2',5' linkages |
| EP0577558A2 (de) | 1992-07-01 | 1994-01-05 | Ciba-Geigy Ag | Carbocyclische Nukleoside mit bicyclischen Ringen, Oligonukleotide daraus, Verfahren zu deren Herstellung, deren Verwendung und Zwischenproduckte |
| US6346614B1 (en) | 1992-07-23 | 2002-02-12 | Hybridon, Inc. | Hybrid oligonucleotide phosphorothioates |
| US5476925A (en) | 1993-02-01 | 1995-12-19 | Northwestern University | Oligodeoxyribonucleotides including 3'-aminonucleoside-phosphoramidate linkages and terminal 3'-amino groups |
| GB9304618D0 (en) | 1993-03-06 | 1993-04-21 | Ciba Geigy Ag | Chemical compounds |
| DK0691968T3 (da) | 1993-03-30 | 1998-02-23 | Sanofi Sa | Acykliske nukleosid-analoge og oligonukleotidsekvenser indeholdende disse |
| JPH08508491A (ja) | 1993-03-31 | 1996-09-10 | スターリング ウインスロップ インコーポレイティド | ホスホジエステル結合をアミド結合に置き換えたオリゴヌクレオチド |
| DE4311944A1 (de) | 1993-04-10 | 1994-10-13 | Degussa | Umhüllte Natriumpercarbonatpartikel, Verfahren zu deren Herstellung und sie enthaltende Wasch-, Reinigungs- und Bleichmittelzusammensetzungen |
| US5955591A (en) | 1993-05-12 | 1999-09-21 | Imbach; Jean-Louis | Phosphotriester oligonucleotides, amidites and method of preparation |
| US6015886A (en) | 1993-05-24 | 2000-01-18 | Chemgenes Corporation | Oligonucleotide phosphate esters |
| US5502177A (en) | 1993-09-17 | 1996-03-26 | Gilead Sciences, Inc. | Pyrimidine derivatives for labeled binding partners |
| KR960705837A (ko) | 1993-11-16 | 1996-11-08 | 라이오넬 엔. 사이몬 | 비포스포네이트 뉴클레오시드간 연결기와 혼합된 비대칭적으로 순수한 포스포네이트 뉴클레오시드간 연결기를 갖는 합성 올리고머(Synthetic Oligomers Having Chirally Pure Phosphonate Internucleosidyl Linkages Mixed with Non-Phosphonate Internucleosidyl Linkages) |
| US5457187A (en) | 1993-12-08 | 1995-10-10 | Board Of Regents University Of Nebraska | Oligonucleotides containing 5-fluorouracil |
| US5446137B1 (en) | 1993-12-09 | 1998-10-06 | Behringwerke Ag | Oligonucleotides containing 4'-substituted nucleotides |
| US5519134A (en) | 1994-01-11 | 1996-05-21 | Isis Pharmaceuticals, Inc. | Pyrrolidine-containing monomers and oligomers |
| US5599922A (en) | 1994-03-18 | 1997-02-04 | Lynx Therapeutics, Inc. | Oligonucleotide N3'-P5' phosphoramidates: hybridization and nuclease resistance properties |
| US5596091A (en) | 1994-03-18 | 1997-01-21 | The Regents Of The University Of California | Antisense oligonucleotides comprising 5-aminoalkyl pyrimidine nucleotides |
| US5627053A (en) | 1994-03-29 | 1997-05-06 | Ribozyme Pharmaceuticals, Inc. | 2'deoxy-2'-alkylnucleotide containing nucleic acid |
| US5625050A (en) | 1994-03-31 | 1997-04-29 | Amgen Inc. | Modified oligonucleotides and intermediates useful in nucleic acid therapeutics |
| US5525711A (en) | 1994-05-18 | 1996-06-11 | The United States Of America As Represented By The Secretary Of The Department Of Health And Human Services | Pteridine nucleotide analogs as fluorescent DNA probes |
| US5597909A (en) | 1994-08-25 | 1997-01-28 | Chiron Corporation | Polynucleotide reagents containing modified deoxyribose moieties, and associated methods of synthesis and use |
| US5885613A (en) | 1994-09-30 | 1999-03-23 | The University Of British Columbia | Bilayer stabilizing components and their use in forming programmable fusogenic liposomes |
| US6608035B1 (en) | 1994-10-25 | 2003-08-19 | Hybridon, Inc. | Method of down-regulating gene expression |
| US6166197A (en) | 1995-03-06 | 2000-12-26 | Isis Pharmaceuticals, Inc. | Oligomeric compounds having pyrimidine nucleotide (S) with 2'and 5 substitutions |
| US6222025B1 (en) | 1995-03-06 | 2001-04-24 | Isis Pharmaceuticals, Inc. | Process for the synthesis of 2′-O-substituted pyrimidines and oligomeric compounds therefrom |
| US5801030A (en) | 1995-09-01 | 1998-09-01 | Genvec, Inc. | Methods and vectors for site-specific recombination |
| US6160109A (en) | 1995-10-20 | 2000-12-12 | Isis Pharmaceuticals, Inc. | Preparation of phosphorothioate and boranophosphate oligomers |
| US6444423B1 (en) | 1996-06-07 | 2002-09-03 | Molecular Dynamics, Inc. | Nucleosides comprising polydentate ligands |
| US6172209B1 (en) | 1997-02-14 | 2001-01-09 | Isis Pharmaceuticals Inc. | Aminooxy-modified oligonucleotides and methods for making same |
| US6639062B2 (en) | 1997-02-14 | 2003-10-28 | Isis Pharmaceuticals, Inc. | Aminooxy-modified nucleosidic compounds and oligomeric compounds prepared therefrom |
| CA2289702C (en) | 1997-05-14 | 2008-02-19 | Inex Pharmaceuticals Corp. | High efficiency encapsulation of charged therapeutic agents in lipid vesicles |
| US6617438B1 (en) | 1997-11-05 | 2003-09-09 | Sirna Therapeutics, Inc. | Oligoribonucleotides with enzymatic activity |
| US6528640B1 (en) | 1997-11-05 | 2003-03-04 | Ribozyme Pharmaceuticals, Incorporated | Synthetic ribonucleic acids with RNAse activity |
| US7273933B1 (en) | 1998-02-26 | 2007-09-25 | Isis Pharmaceuticals, Inc. | Methods for synthesis of oligonucleotides |
| US7045610B2 (en) | 1998-04-03 | 2006-05-16 | Epoch Biosciences, Inc. | Modified oligonucleotides for mismatch discrimination |
| US6531590B1 (en) | 1998-04-24 | 2003-03-11 | Isis Pharmaceuticals, Inc. | Processes for the synthesis of oligonucleotide compounds |
| US6693086B1 (en) | 1998-06-25 | 2004-02-17 | National Jewish Medical And Research Center | Systemic immune activation method using nucleic acid-lipid complexes |
| US6867294B1 (en) | 1998-07-14 | 2005-03-15 | Isis Pharmaceuticals, Inc. | Gapped oligomers having site specific chiral phosphorothioate internucleoside linkages |
| US6465628B1 (en) | 1999-02-04 | 2002-10-15 | Isis Pharmaceuticals, Inc. | Process for the synthesis of oligomeric compounds |
| US6593466B1 (en) | 1999-07-07 | 2003-07-15 | Isis Pharmaceuticals, Inc. | Guanidinium functionalized nucleotides and precursors thereof |
| US6147200A (en) | 1999-08-19 | 2000-11-14 | Isis Pharmaceuticals, Inc. | 2'-O-acetamido modified monomers and oligomers |
| WO2001053307A1 (en) | 2000-01-21 | 2001-07-26 | Geron Corporation | 2'-arabino-fluorooligonucleotide n3'→p5'phosphoramidates: their synthesis and use |
| US20030077829A1 (en) | 2001-04-30 | 2003-04-24 | Protiva Biotherapeutics Inc.. | Lipid-based formulations |
| US6878805B2 (en) | 2002-08-16 | 2005-04-12 | Isis Pharmaceuticals, Inc. | Peptide-conjugated oligomeric compounds |
| DK1661905T3 (da) | 2003-08-28 | 2012-07-23 | Takeshi Imanishi | Hidtil ukendte syntetiske nukleinsyrer af N-O-krydsbindingstype |
| NZ592917A (en) | 2003-09-15 | 2012-12-21 | Protiva Biotherapeutics Inc | Stable polyethyleneglycol (PEG) dialkyloxypropyl (DAA) lipid conjugates |
| JP4380411B2 (ja) | 2004-04-30 | 2009-12-09 | 澁谷工業株式会社 | 滅菌方法 |
| WO2006045116A2 (en) * | 2004-10-20 | 2006-04-27 | The Scripps Research Institute | In vivo site-specific incorporation of n-acetyl-galactosamine amino acids in eubacteria |
| US8852472B2 (en) | 2004-12-27 | 2014-10-07 | Silence Therapeutics Gmbh | Coated lipid complexes and their use |
| US7404969B2 (en) | 2005-02-14 | 2008-07-29 | Sirna Therapeutics, Inc. | Lipid nanoparticle based compositions and methods for the delivery of biologically active molecules |
| JP2009534690A (ja) | 2006-07-10 | 2009-09-24 | メムシック,インコーポレイテッド | 磁場センサーを用いて偏揺れを感知するためのシステム、および、前記システムを用いた携帯用の電子装置 |
| WO2009073809A2 (en) | 2007-12-04 | 2009-06-11 | Alnylam Pharmaceuticals, Inc. | Carbohydrate conjugates as delivery agents for oligonucleotides |
| CA3044134A1 (en) | 2008-01-02 | 2009-07-09 | Arbutus Biopharma Corporation | Improved compositions and methods for the delivery of nucleic acids |
| DK2279254T3 (en) | 2008-04-15 | 2017-09-18 | Protiva Biotherapeutics Inc | PRESENT UNKNOWN LIPID FORMS FOR NUCLEIC ACID ADMINISTRATION |
| WO2009132131A1 (en) | 2008-04-22 | 2009-10-29 | Alnylam Pharmaceuticals, Inc. | Amino lipid based improved lipid formulation |
| JP2011519867A (ja) | 2008-05-01 | 2011-07-14 | ノッド ファーマシューティカルズ, インコーポレイテッド | 治療用リン酸カルシウム粒子、ならびにその作製および使用方法 |
| CA2984026C (en) | 2008-10-09 | 2020-02-11 | Arbutus Biopharma Corporation | Improved amino lipids and methods for the delivery of nucleic acids |
| DK2344639T3 (en) | 2008-10-20 | 2015-07-27 | Alnylam Pharmaceuticals Inc | COMPOSITIONS AND METHODS FOR INHIBITING EXPRESSION OF TRANSTHYRETINE |
| MX353900B (es) | 2008-11-07 | 2018-02-01 | Massachusetts Inst Technology | Lipidoides de aminoalcohol y usos de los mismos. |
| MX359674B (es) | 2008-11-10 | 2018-10-05 | Alnylam Pharmaceuticals Inc | Lipidos y composiciones novedosas para el suministro de terapeuticos. |
| WO2010054384A1 (en) | 2008-11-10 | 2010-05-14 | Alnylam Pharmaceuticals, Inc. | Lipids and compositions for the delivery of therapeutics |
| WO2010141933A1 (en) | 2009-06-05 | 2010-12-09 | Dicerna Pharmaceuticals, Inc. | Specific inhibition of gene expression by nucleic acid containing a dicer substrate |
| KR102205886B1 (ko) | 2009-06-10 | 2021-01-21 | 알닐람 파마슈티칼스 인코포레이티드 | 향상된 지질 조성물 |
| WO2011000106A1 (en) | 2009-07-01 | 2011-01-06 | Protiva Biotherapeutics, Inc. | Improved cationic lipids and methods for the delivery of therapeutic agents |
| EP2449114B9 (en) | 2009-07-01 | 2017-04-19 | Protiva Biotherapeutics Inc. | Novel lipid formulations for delivery of therapeutic agents to solid tumors |
| ES2579936T3 (es) | 2009-08-20 | 2016-08-17 | Sirna Therapeutics, Inc. | Nuevos lípidos catiónicos con diversos grupos de cabeza para el suministro oligonucleotídico |
| US20130022649A1 (en) | 2009-12-01 | 2013-01-24 | Protiva Biotherapeutics, Inc. | Snalp formulations containing antioxidants |
| EP3296398A1 (en) | 2009-12-07 | 2018-03-21 | Arbutus Biopharma Corporation | Compositions for nucleic acid delivery |
| WO2011090965A1 (en) | 2010-01-22 | 2011-07-28 | Merck Sharp & Dohme Corp. | Novel cationic lipids for oligonucleotide delivery |
| WO2011097480A1 (en) | 2010-02-05 | 2011-08-11 | University Of Louisville Research Foundation, Inc. | Exosomal compositions and methods for the treatment of disease |
| US10077232B2 (en) | 2010-05-12 | 2018-09-18 | Arbutus Biopharma Corporation | Cyclic cationic lipids and methods of use |
| EP2569276B1 (en) | 2010-05-12 | 2021-02-24 | Arbutus Biopharma Corporation | Novel cationic lipids and methods of use thereof |
| EP2575764B1 (en) | 2010-06-03 | 2017-04-19 | Alnylam Pharmaceuticals, Inc. | Biodegradable lipids for the delivery of active agents |
| US8748667B2 (en) | 2010-06-04 | 2014-06-10 | Sirna Therapeutics, Inc. | Low molecular weight cationic lipids for oligonucleotide delivery |
| US9006417B2 (en) | 2010-06-30 | 2015-04-14 | Protiva Biotherapeutics, Inc. | Non-liposomal systems for nucleic acid delivery |
| US20130323269A1 (en) | 2010-07-30 | 2013-12-05 | Muthiah Manoharan | Methods and compositions for delivery of active agents |
| ES2727583T3 (es) | 2010-08-31 | 2019-10-17 | Glaxosmithkline Biologicals Sa | Lípidos adecuados para la administración liposómica de ARN que codifica proteínas |
| ES2908978T3 (es) | 2010-08-31 | 2022-05-04 | Sirna Therapeutics Inc | Nuevas entidades químicas simples y métodos para la administración de oligonucleótidos |
| RU2617641C2 (ru) | 2010-09-20 | 2017-04-25 | Сирна Терапьютикс,Инк. | Новые низкомолекулярные катионные липиды для доставки олигонуклеотидов |
| JP2013545723A (ja) | 2010-09-30 | 2013-12-26 | メルク・シャープ・エンド・ドーム・コーポレイション | オリゴヌクレオチドの送達のための低分子量カチオン性脂質 |
| US9029590B2 (en) | 2010-10-21 | 2015-05-12 | Sirna Therapeutics, Inc. | Low molecular weight cationic lipids for oligonucleotide delivery |
| US20120101478A1 (en) | 2010-10-21 | 2012-04-26 | Allergan, Inc. | Dual Cartridge Mixer Syringe |
| US9617461B2 (en) | 2010-12-06 | 2017-04-11 | Schlumberger Technology Corporation | Compositions and methods for well completions |
| EP3192800A1 (en) | 2010-12-17 | 2017-07-19 | Arrowhead Pharmaceuticals, Inc. | Galactose cluster-pharmacokinetic modulator targeting moiety for sirna |
| DK3202760T3 (da) | 2011-01-11 | 2019-11-25 | Alnylam Pharmaceuticals Inc | Pegylerede lipider og deres anvendelse til lægemiddelfremføring |
| WO2012162210A1 (en) | 2011-05-26 | 2012-11-29 | Merck Sharp & Dohme Corp. | Ring constrained cationic lipids for oligonucleotide delivery |
| WO2013016058A1 (en) | 2011-07-22 | 2013-01-31 | Merck Sharp & Dohme Corp. | Novel bis-nitrogen containing cationic lipids for oligonucleotide delivery |
| US9701623B2 (en) | 2011-09-27 | 2017-07-11 | Alnylam Pharmaceuticals, Inc. | Di-aliphatic substituted pegylated lipids |
| CA3119789A1 (en) | 2011-10-27 | 2013-05-02 | Massachusetts Institute Of Technology | Amino acid derivatives functionalized on the n-terminal capable of forming drug encapsulating microspheres |
| US20140308212A1 (en) | 2011-11-07 | 2014-10-16 | University Of Louisville Research Foundation, Inc. | Edible plant-derived microvesicle compositions for diagnosis and treatment of disease |
| JP6093710B2 (ja) | 2011-11-18 | 2017-03-08 | 日油株式会社 | 細胞内動態を改善したカチオン性脂質 |
| DE21212055T1 (de) | 2011-12-07 | 2022-08-04 | Alnylam Pharmaceuticals, Inc. | Biologisch abbaubare lipide zur freisetzung von wirkstoffen |
| WO2013086373A1 (en) | 2011-12-07 | 2013-06-13 | Alnylam Pharmaceuticals, Inc. | Lipids for the delivery of active agents |
| US9463247B2 (en) | 2011-12-07 | 2016-10-11 | Alnylam Pharmaceuticals, Inc. | Branched alkyl and cycloalkyl terminated biodegradable lipids for the delivery of active agents |
| WO2013089151A1 (ja) | 2011-12-12 | 2013-06-20 | 協和発酵キリン株式会社 | カチオン性脂質を含有するドラッグデリバリーシステムのための脂質ナノ粒子 |
| WO2013116126A1 (en) | 2012-02-01 | 2013-08-08 | Merck Sharp & Dohme Corp. | Novel low molecular weight, biodegradable cationic lipids for oligonucleotide delivery |
| KR20220045089A (ko) | 2012-02-24 | 2022-04-12 | 아뷰터스 바이오파마 코포레이션 | 트리알킬 양이온성 지질 및 그의 사용 방법 |
| US9446132B2 (en) | 2012-03-27 | 2016-09-20 | Sima Therapeutics, Inc. | Diether based biodegradable cationic lipids for siRNA delivery |
| AR090906A1 (es) | 2012-05-02 | 2014-12-17 | Merck Sharp & Dohme | Conjugados que contienen tetragalnac y procedimientos para la administracion de oligonucleotidos |
| AR090905A1 (es) | 2012-05-02 | 2014-12-17 | Merck Sharp & Dohme | Conjugados que contienen tetragalnac y peptidos y procedimientos para la administracion de oligonucleotidos, composicion farmaceutica |
| MX2015011955A (es) | 2013-03-08 | 2016-04-07 | Novartis Ag | Lipidos y composiciones de lipidos para el suministro de agentes activos. |
| AU2014287002A1 (en) | 2013-07-11 | 2016-02-11 | Alnylam Pharmaceuticals, Inc. | Oligonucleotide-ligand conjugates and process for their preparation |
| US20160151284A1 (en) | 2013-07-23 | 2016-06-02 | Protiva Biotherapeutics, Inc. | Compositions and methods for delivering messenger rna |
| WO2015042447A1 (en) | 2013-09-20 | 2015-03-26 | Isis Pharmaceuticals, Inc. | Targeted therapeutic nucleosides and their use |
| SG11201602943PA (en) | 2013-10-22 | 2016-05-30 | Shire Human Genetic Therapies | Lipid formulations for delivery of messenger rna |
| BR112016011195A2 (pt) | 2013-11-18 | 2017-09-19 | Rubius Therapeutics Inc | Células eritroides enucleadas e seus métodos de fabricação, composição farmacêutica e seu uso, uso de uma população de células eritroides, biorreator, mistura de células e dispositivo médico |
| US9365610B2 (en) | 2013-11-18 | 2016-06-14 | Arcturus Therapeutics, Inc. | Asymmetric ionizable cationic lipid for RNA delivery |
| KR102095085B1 (ko) | 2013-11-18 | 2020-03-31 | 아크투루스 쎄라퓨틱스, 인크. | Rna 전달을 위한 이온화가능한 양이온성 지질 |
| EP3083556B1 (en) | 2013-12-19 | 2019-12-25 | Novartis AG | Lipids and lipid compositions for the delivery of active agents |
| US10426737B2 (en) | 2013-12-19 | 2019-10-01 | Novartis Ag | Lipids and lipid compositions for the delivery of active agents |
| KR20220150986A (ko) | 2014-04-01 | 2022-11-11 | 루비우스 테라퓨틱스, 아이엔씨. | 면역조절을 위한 방법 및 조성물 |
| JP6594421B2 (ja) | 2014-06-25 | 2019-10-23 | アクイタス セラピューティクス インコーポレイテッド | 核酸の送達のための新規脂質および脂質ナノ粒子製剤 |
| WO2016183482A1 (en) | 2015-05-13 | 2016-11-17 | Rubius Therapeutics, Inc. | Membrane-receiver complex therapeutics |
| JP6800410B2 (ja) | 2015-06-19 | 2020-12-16 | マサチューセッツ インスティテュート オブ テクノロジー | アルケニル置換2,5−ピペラジンジオン、および、対象または細胞に剤を送達するための組成物におけるそれらの使用 |
| WO2017004143A1 (en) | 2015-06-29 | 2017-01-05 | Acuitas Therapeutics Inc. | Lipids and lipid nanoparticle formulations for delivery of nucleic acids |
| AU2016288643A1 (en) | 2015-07-02 | 2018-02-22 | University Of Louisville Research Foundation, Inc. | Edible plant-derived microvesicle compositions for delivery of miRNA and methods for treatment of cancer |
| RS63030B1 (sr) | 2015-09-17 | 2022-04-29 | Modernatx Inc | Jedinjenja i kompozicije za intracelularno isporučivanje terapeutskih sredstava |
| TW201722439A (zh) | 2015-10-09 | 2017-07-01 | 波濤生命科學有限公司 | 寡核苷酸組合物及其方法 |
| WO2017075531A1 (en) | 2015-10-28 | 2017-05-04 | Acuitas Therapeutics, Inc. | Novel lipids and lipid nanoparticle formulations for delivery of nucleic acids |
| US10851367B2 (en) | 2015-11-12 | 2020-12-01 | Pfizer Inc. | Tissue-specific genome engineering using CRISPR-Cas9 |
| MD3386484T2 (ro) | 2015-12-10 | 2022-11-30 | Modernatx Inc | Compoziții și metode de livrare a unor agenți terapeutici |
| EP3397613A1 (en) | 2015-12-30 | 2018-11-07 | Acuitas Therapeutics Inc. | Lipids and lipid nanoparticle formulations for delivery of nucleic acids |
| HRP20220147T1 (hr) | 2016-01-11 | 2022-04-15 | Rubius Therapeutics, Inc. | Pripravci i postupci povezani s multimodalnim terapijskim staničnim sustavima za indikacije raka |
| UY37146A (es) | 2016-03-07 | 2017-09-29 | Arrowhead Pharmaceuticals Inc | Ligandos de direccionamiento para compuestos terapéuticos |
| KR102617874B1 (ko) | 2016-03-30 | 2023-12-22 | 인텔리아 테라퓨틱스, 인크. | Crispr/cas 성분을 위한 지질 나노입자 제제 |
| US10562849B2 (en) | 2016-05-16 | 2020-02-18 | The Board Of Regents Of The University Of Texas System | Cationic sulfonamide amino lipids and amphiphilic zwitterionic amino lipids |
| US20200315967A1 (en) | 2016-06-24 | 2020-10-08 | Modernatx, Inc. | Lipid nanoparticles |
| EP3481943A1 (en) | 2016-07-07 | 2019-05-15 | Rubius Therapeutics, Inc. | Compositions and methods related to therapeutic cell systems expressing exogenous rna |
| EP3532103A1 (en) | 2016-10-26 | 2019-09-04 | Acuitas Therapeutics, Inc. | Lipid nanoparticle formulations |
| US20180153989A1 (en) | 2016-12-02 | 2018-06-07 | Rubius Therapeutics, Inc. | Compositions and methods related to cell systems for penetrating solid tumors |
| US11020435B2 (en) | 2017-02-17 | 2021-06-01 | Rubius Therapeutics, Inc. | Functionalized erythroid cells |
| WO2018208728A1 (en) | 2017-05-08 | 2018-11-15 | Flagship Pioneering, Inc. | Compositions for facilitating membrane fusion and uses thereof |
| JP2020537493A (ja) | 2017-09-08 | 2020-12-24 | ジェネレーション バイオ カンパニー | 非ウイルス性カプシド不含dnaベクターの脂質ナノ粒子製剤 |
| IL311278A (en) | 2017-09-29 | 2024-05-01 | Intellia Therapeutics Inc | Polynucleotides, preparations, and methods for genome editing |
| MX2020007148A (es) | 2017-09-29 | 2020-10-08 | Intellia Therapeutics Inc | Formulaciones. |
| WO2019217941A1 (en) | 2018-05-11 | 2019-11-14 | Beam Therapeutics Inc. | Methods of suppressing pathogenic mutations using programmable base editor systems |
| JP2022501367A (ja) | 2018-09-20 | 2022-01-06 | モデルナティエックス インコーポレイテッドModernaTX, Inc. | 脂質ナノ粒子の調製及びその投与方法 |
| CA3116576A1 (en) | 2018-10-18 | 2020-04-23 | Acuitas Therapeutics, Inc. | Lipids for lipid nanoparticle delivery of active agents |
| AU2019384557A1 (en) | 2018-11-21 | 2021-06-10 | Translate Bio, Inc. | Treatment of cystic fibrosis by delivery of nebulized mRNA encoding CFTR |
| EP3959191A1 (en) | 2019-04-25 | 2022-03-02 | Intellia Therapeutics, Inc. | Ionizable amine lipids and lipid nanoparticles |
| JP2022534988A (ja) * | 2019-05-31 | 2022-08-04 | フラッグシップ パイオニアリング, インコーポレイテッド | tRNAプールを調節するためのTREMの使用 |
-
2021
- 2021-12-23 CA CA3206285A patent/CA3206285A1/en active Pending
- 2021-12-23 IL IL303886A patent/IL303886A/en unknown
- 2021-12-23 KR KR1020237025192A patent/KR20230135585A/ko unknown
- 2021-12-23 BR BR112023012377A patent/BR112023012377A2/pt unknown
- 2021-12-23 MX MX2023007630A patent/MX2023007630A/es unknown
- 2021-12-23 WO PCT/US2021/065159 patent/WO2022140702A1/en active Application Filing
- 2021-12-23 JP JP2023538736A patent/JP2024501288A/ja active Pending
- 2021-12-23 EP EP21854913.7A patent/EP4267732A1/en active Pending
- 2021-12-23 AU AU2021409740A patent/AU2021409740A1/en active Pending
- 2021-12-24 TW TW110148799A patent/TW202242108A/zh unknown
Also Published As
| Publication number | Publication date |
|---|---|
| WO2022140702A1 (en) | 2022-06-30 |
| JP2024501288A (ja) | 2024-01-11 |
| IL303886A (en) | 2023-08-01 |
| EP4267732A1 (en) | 2023-11-01 |
| AU2021409740A1 (en) | 2023-07-06 |
| BR112023012377A2 (pt) | 2023-10-24 |
| CA3206285A1 (en) | 2022-06-30 |
| KR20230135585A (ko) | 2023-09-25 |
| MX2023007630A (es) | 2023-08-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20230330260A1 (en) | Rna formulations | |
| KR20210135494A (ko) | 지질 나노입자의 제조 방법 | |
| CN113271926A (zh) | 脂质纳米颗粒的制备及其施用方法 | |
| JP2019535288A (ja) | オフターゲット効果が低下した修飾rna剤 | |
| KR20190008890A (ko) | 인터류킨-12 (il12)를 코딩하는 폴리뉴클레오티드 및 그의 용도 | |
| KR20180051550A (ko) | 프로그램된 세포사 1 리간드 1 (PD-L1) iRNA 조성물 및 그의 사용 방법 | |
| CN114181942A (zh) | 经修饰的双链rna试剂 | |
| TW202242108A (zh) | 經修飾trem之組合物及其用途 | |
| US20230054178A1 (en) | Trem compositions and uses thereof | |
| US20220290145A1 (en) | Modified RNA Agents with Reduced Off-Target Effect | |
| KR20230011913A (ko) | 표적화된 rna 전달을 위한 조성물 및 방법 | |
| JP2021529173A (ja) | Rig−iアゴニストおよびそれを使用した処置 | |
| KR20160079793A (ko) | Alas1 유전자의 발현을 억제하기 위한 조성물 및 방법 | |
| JP2023527413A (ja) | Trem組成物及びそれに関連する方法 | |
| US20240175020A1 (en) | Compositions of modified trems and uses thereof | |
| CN117083383A (zh) | 经修饰的trem的组合物及其用途 | |
| US20230203509A1 (en) | Trem compositions and methods relating thereto | |
| WO2023250112A1 (en) | Compositions of modified trems and uses thereof | |
| WO2010071587A1 (en) | A complex and method for enhancing nuclear delivery | |
| CA3226651A1 (en) | Compositions and methods for targeted rna delivery | |
| CN118076360A (zh) | 用于靶向rna递送的组合物和方法 | |
| NZ794670A (en) | Modified RNA agents with reduced off-target effect |