KR20230157342A - 다중 치환기 실로시빈 유도체 및 사용 방법 - Google Patents
다중 치환기 실로시빈 유도체 및 사용 방법 Download PDFInfo
- Publication number
- KR20230157342A KR20230157342A KR1020237031136A KR20237031136A KR20230157342A KR 20230157342 A KR20230157342 A KR 20230157342A KR 1020237031136 A KR1020237031136 A KR 1020237031136A KR 20237031136 A KR20237031136 A KR 20237031136A KR 20230157342 A KR20230157342 A KR 20230157342A
- Authority
- KR
- South Korea
- Prior art keywords
- group
- nucleic acid
- acid sequence
- seq
- formula
- Prior art date
Links
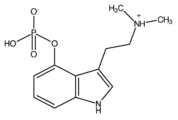
- QKTAAWLCLHMUTJ-UHFFFAOYSA-N psilocybin Chemical class C1C=CC(OP(O)(O)=O)=C2C(CCN(C)C)=CN=C21 QKTAAWLCLHMUTJ-UHFFFAOYSA-N 0.000 title claims abstract description 482
- 238000000034 method Methods 0.000 title claims description 179
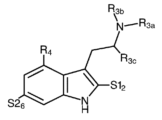
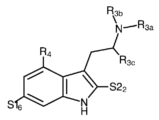
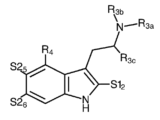
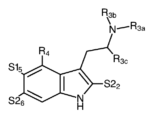
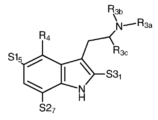
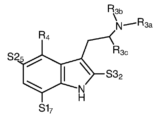
- 150000001875 compounds Chemical class 0.000 claims abstract description 483
- -1 psilocybin derivative compounds Chemical class 0.000 claims abstract description 330
- 239000000376 reactant Substances 0.000 claims abstract description 53
- 239000000203 mixture Substances 0.000 claims abstract description 41
- 238000009472 formulation Methods 0.000 claims abstract description 30
- 239000003237 recreational drug Substances 0.000 claims abstract description 26
- 150000007523 nucleic acids Chemical group 0.000 claims description 629
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 445
- 125000004435 hydrogen atom Chemical group [H]* 0.000 claims description 241
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 claims description 235
- 125000001424 substituent group Chemical group 0.000 claims description 216
- 125000003277 amino group Chemical group 0.000 claims description 215
- UUEVFMOUBSLVJW-UHFFFAOYSA-N oxo-[[1-[2-[2-[2-[4-(oxoazaniumylmethylidene)pyridin-1-yl]ethoxy]ethoxy]ethyl]pyridin-4-ylidene]methyl]azanium;dibromide Chemical compound [Br-].[Br-].C1=CC(=C[NH+]=O)C=CN1CCOCCOCCN1C=CC(=C[NH+]=O)C=C1 UUEVFMOUBSLVJW-UHFFFAOYSA-N 0.000 claims description 214
- QZAYGJVTTNCVMB-UHFFFAOYSA-N serotonin Chemical group C1=C(O)C=C2C(CCN)=CNC2=C1 QZAYGJVTTNCVMB-UHFFFAOYSA-N 0.000 claims description 200
- 125000001844 prenyl group Chemical group [H]C([*])([H])C([H])=C(C([H])([H])[H])C([H])([H])[H] 0.000 claims description 196
- 125000002887 hydroxy group Chemical group [H]O* 0.000 claims description 173
- 125000000449 nitro group Chemical group [O-][N+](*)=O 0.000 claims description 169
- 125000005843 halogen group Chemical group 0.000 claims description 154
- 125000002560 nitrile group Chemical group 0.000 claims description 154
- 229920001184 polypeptide Polymers 0.000 claims description 133
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 133
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 133
- 125000003051 glycosyloxy group Chemical group 0.000 claims description 132
- 150000001732 carboxylic acid derivatives Chemical class 0.000 claims description 117
- 125000000468 ketone group Chemical group 0.000 claims description 117
- 230000000295 complement effect Effects 0.000 claims description 107
- QVDSEJDULKLHCG-UHFFFAOYSA-N Psilocybine Natural products C1=CC(OP(O)(O)=O)=C2C(CCN(C)C)=CNC2=C1 QVDSEJDULKLHCG-UHFFFAOYSA-N 0.000 claims description 95
- 108020003175 receptors Proteins 0.000 claims description 95
- 102000005962 receptors Human genes 0.000 claims description 95
- 102000004190 Enzymes Human genes 0.000 claims description 76
- 108090000790 Enzymes Proteins 0.000 claims description 76
- 239000002243 precursor Substances 0.000 claims description 74
- 229910052731 fluorine Inorganic materials 0.000 claims description 71
- 125000000217 alkyl group Chemical group 0.000 claims description 70
- 125000001153 fluoro group Chemical group F* 0.000 claims description 70
- 230000001851 biosynthetic effect Effects 0.000 claims description 63
- 125000003118 aryl group Chemical group 0.000 claims description 62
- 125000002252 acyl group Chemical group 0.000 claims description 55
- 229910052801 chlorine Inorganic materials 0.000 claims description 55
- 230000004048 modification Effects 0.000 claims description 50
- 238000012986 modification Methods 0.000 claims description 50
- 230000002068 genetic effect Effects 0.000 claims description 48
- 238000006243 chemical reaction Methods 0.000 claims description 47
- 210000004027 cell Anatomy 0.000 claims description 46
- 125000001309 chloro group Chemical group Cl* 0.000 claims description 44
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 40
- 102000039446 nucleic acids Human genes 0.000 claims description 40
- 108020004707 nucleic acids Proteins 0.000 claims description 40
- 108090000121 Aromatic-L-amino-acid decarboxylases Proteins 0.000 claims description 34
- 102000003823 Aromatic-L-amino-acid decarboxylases Human genes 0.000 claims description 34
- 125000000753 cycloalkyl group Chemical group 0.000 claims description 33
- 125000002485 formyl group Chemical class [H]C(*)=O 0.000 claims description 33
- 101710202061 N-acetyltransferase Proteins 0.000 claims description 32
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 claims description 30
- 101710167853 N-methyltransferase Proteins 0.000 claims description 27
- 150000002825 nitriles Chemical class 0.000 claims description 27
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 24
- 125000002777 acetyl group Chemical group [H]C([H])([H])C(*)=O 0.000 claims description 24
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 claims description 24
- UFHFLCQGNIYNRP-UHFFFAOYSA-N Hydrogen Chemical compound [H][H] UFHFLCQGNIYNRP-UHFFFAOYSA-N 0.000 claims description 22
- 239000001257 hydrogen Substances 0.000 claims description 22
- 229910052739 hydrogen Inorganic materials 0.000 claims description 22
- 108010075344 Tryptophan synthase Proteins 0.000 claims description 21
- 229910052736 halogen Inorganic materials 0.000 claims description 21
- 150000002367 halogens Chemical class 0.000 claims description 21
- 125000003368 amide group Chemical group 0.000 claims description 19
- 150000003839 salts Chemical class 0.000 claims description 19
- 239000000546 pharmaceutical excipient Substances 0.000 claims description 17
- 230000001404 mediated effect Effects 0.000 claims description 16
- 125000001160 methoxycarbonyl group Chemical group [H]C([H])([H])OC(*)=O 0.000 claims description 16
- 239000008194 pharmaceutical composition Substances 0.000 claims description 15
- 108010006731 Dimethylallyltranstransferase Proteins 0.000 claims description 14
- 102000005454 Dimethylallyltranstransferase Human genes 0.000 claims description 14
- WKBOTKDWSSQWDR-UHFFFAOYSA-N Bromine atom Chemical group [Br] WKBOTKDWSSQWDR-UHFFFAOYSA-N 0.000 claims description 13
- 239000003085 diluting agent Substances 0.000 claims description 13
- QGZKDVFQNNGYKY-UHFFFAOYSA-N Ammonia Chemical compound N QGZKDVFQNNGYKY-UHFFFAOYSA-N 0.000 claims description 12
- 239000000460 chlorine Substances 0.000 claims description 12
- IJGRMHOSHXDMSA-UHFFFAOYSA-O diazynium Chemical group [NH+]#N IJGRMHOSHXDMSA-UHFFFAOYSA-O 0.000 claims description 12
- 238000004519 manufacturing process Methods 0.000 claims description 11
- 208000020016 psychiatric disease Diseases 0.000 claims description 11
- KZBUYRJDOAKODT-UHFFFAOYSA-N Chlorine Chemical compound ClCl KZBUYRJDOAKODT-UHFFFAOYSA-N 0.000 claims description 10
- 230000000397 acetylating effect Effects 0.000 claims description 10
- 238000000338 in vitro Methods 0.000 claims description 10
- 238000001727 in vivo Methods 0.000 claims description 10
- ZMXDDKWLCZADIW-UHFFFAOYSA-N N,N-Dimethylformamide Chemical compound CN(C)C=O ZMXDDKWLCZADIW-UHFFFAOYSA-N 0.000 claims description 9
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical group OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 claims description 8
- 239000002253 acid Substances 0.000 claims description 8
- 229960002317 succinimide Drugs 0.000 claims description 8
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 claims description 7
- WFDIJRYMOXRFFG-UHFFFAOYSA-N acetic acid anhydride Natural products CC(=O)OC(C)=O WFDIJRYMOXRFFG-UHFFFAOYSA-N 0.000 claims description 7
- 125000003668 acetyloxy group Chemical group [H]C([H])([H])C(=O)O[*] 0.000 claims description 7
- 229910021529 ammonia Inorganic materials 0.000 claims description 6
- 150000002148 esters Chemical class 0.000 claims description 6
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 claims description 6
- 125000003158 alcohol group Chemical group 0.000 claims description 5
- 125000003172 aldehyde group Chemical group 0.000 claims description 5
- 125000002843 carboxylic acid group Chemical group 0.000 claims description 5
- 239000000969 carrier Substances 0.000 claims description 5
- 239000012954 diazonium Substances 0.000 claims description 5
- 150000002340 glycosyl compounds Chemical class 0.000 claims description 5
- JRNVZBWKYDBUCA-UHFFFAOYSA-N N-chlorosuccinimide Chemical group ClN1C(=O)CCC1=O JRNVZBWKYDBUCA-UHFFFAOYSA-N 0.000 claims description 4
- 125000002057 carboxymethyl group Chemical group [H]OC(=O)C([H])([H])[*] 0.000 claims description 4
- 230000000911 decarboxylating effect Effects 0.000 claims description 4
- 229910052698 phosphorus Inorganic materials 0.000 claims description 4
- IOVCWXUNBOPUCH-UHFFFAOYSA-M Nitrite anion Chemical compound [O-]N=O IOVCWXUNBOPUCH-UHFFFAOYSA-M 0.000 claims description 3
- 108020002494 acetyltransferase Proteins 0.000 claims description 3
- 102000005421 acetyltransferase Human genes 0.000 claims description 3
- 238000005917 acylation reaction Methods 0.000 claims description 3
- 150000001989 diazonium salts Chemical class 0.000 claims description 3
- 244000005700 microbiome Species 0.000 claims description 3
- 241000588724 Escherichia coli Species 0.000 claims description 2
- PCLIMKBDDGJMGD-UHFFFAOYSA-N N-bromosuccinimide Chemical group BrN1C(=O)CCC1=O PCLIMKBDDGJMGD-UHFFFAOYSA-N 0.000 claims description 2
- 240000004808 Saccharomyces cerevisiae Species 0.000 claims description 2
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 claims description 2
- 230000001580 bacterial effect Effects 0.000 claims description 2
- 230000003197 catalytic effect Effects 0.000 claims description 2
- 230000014509 gene expression Effects 0.000 claims description 2
- 210000005253 yeast cell Anatomy 0.000 claims description 2
- 125000003275 alpha amino acid group Chemical group 0.000 claims 48
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 claims 3
- 239000011574 phosphorus Substances 0.000 claims 3
- 150000001733 carboxylic acid esters Chemical class 0.000 claims 1
- 150000001299 aldehydes Chemical class 0.000 description 88
- 150000001413 amino acids Chemical group 0.000 description 67
- 238000004949 mass spectrometry Methods 0.000 description 61
- 238000002474 experimental method Methods 0.000 description 52
- 208000035475 disorder Diseases 0.000 description 32
- 229910052799 carbon Inorganic materials 0.000 description 26
- 239000000126 substance Substances 0.000 description 24
- 230000000694 effects Effects 0.000 description 21
- 238000009396 hybridization Methods 0.000 description 19
- 108020004705 Codon Proteins 0.000 description 18
- 150000001721 carbon Chemical group 0.000 description 18
- SIKJAQJRHWYJAI-UHFFFAOYSA-N Indole Chemical compound C1=CC=C2NC=CC2=C1 SIKJAQJRHWYJAI-UHFFFAOYSA-N 0.000 description 17
- 230000008569 process Effects 0.000 description 15
- 125000001041 indolyl group Chemical group 0.000 description 14
- 125000004432 carbon atom Chemical group C* 0.000 description 13
- 125000004430 oxygen atom Chemical group O* 0.000 description 13
- 125000004429 atom Chemical group 0.000 description 12
- 230000027455 binding Effects 0.000 description 12
- 125000003636 chemical group Chemical group 0.000 description 12
- 230000006870 function Effects 0.000 description 12
- 239000003826 tablet Substances 0.000 description 12
- OHCQJHSOBUTRHG-KGGHGJDLSA-N FORSKOLIN Chemical compound O=C([C@@]12O)C[C@](C)(C=C)O[C@]1(C)[C@@H](OC(=O)C)[C@@H](O)[C@@H]1[C@]2(C)[C@@H](O)CCC1(C)C OHCQJHSOBUTRHG-KGGHGJDLSA-N 0.000 description 10
- 125000000539 amino acid group Chemical group 0.000 description 10
- 125000004433 nitrogen atom Chemical group N* 0.000 description 10
- 238000002680 cardiopulmonary resuscitation Methods 0.000 description 9
- PZOUSPYUWWUPPK-UHFFFAOYSA-N indole Natural products CC1=CC=CC2=C1C=CN2 PZOUSPYUWWUPPK-UHFFFAOYSA-N 0.000 description 9
- RKJUIXBNRJVNHR-UHFFFAOYSA-N indolenine Natural products C1=CC=C2CC=NC2=C1 RKJUIXBNRJVNHR-UHFFFAOYSA-N 0.000 description 9
- 238000001228 spectrum Methods 0.000 description 9
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 8
- 239000004615 ingredient Substances 0.000 description 8
- 229910052757 nitrogen Inorganic materials 0.000 description 8
- 238000002360 preparation method Methods 0.000 description 8
- 239000002552 dosage form Substances 0.000 description 7
- 239000003921 oil Substances 0.000 description 7
- 239000000243 solution Substances 0.000 description 7
- 238000006467 substitution reaction Methods 0.000 description 7
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 6
- 238000003556 assay Methods 0.000 description 6
- 150000005829 chemical entities Chemical class 0.000 description 6
- 125000001495 ethyl group Chemical group [H]C([H])([H])C([H])([H])* 0.000 description 6
- DMEGYFMYUHOHGS-UHFFFAOYSA-N heptamethylene Natural products C1CCCCCC1 DMEGYFMYUHOHGS-UHFFFAOYSA-N 0.000 description 6
- 239000007788 liquid Substances 0.000 description 6
- 125000001436 propyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])[H] 0.000 description 6
- 229940076279 serotonin Drugs 0.000 description 6
- 235000001674 Agaricus brunnescens Nutrition 0.000 description 5
- SUZLHDUTVMZSEV-UHFFFAOYSA-N Deoxycoleonol Natural products C12C(=O)CC(C)(C=C)OC2(C)C(OC(=O)C)C(O)C2C1(C)C(O)CCC2(C)C SUZLHDUTVMZSEV-UHFFFAOYSA-N 0.000 description 5
- 208000020401 Depressive disease Diseases 0.000 description 5
- 241001465754 Metazoa Species 0.000 description 5
- 208000021384 Obsessive-Compulsive disease Diseases 0.000 description 5
- KDLHZDBZIXYQEI-UHFFFAOYSA-N Palladium Chemical compound [Pd] KDLHZDBZIXYQEI-UHFFFAOYSA-N 0.000 description 5
- 229940024606 amino acid Drugs 0.000 description 5
- 235000001014 amino acid Nutrition 0.000 description 5
- 230000008901 benefit Effects 0.000 description 5
- 230000015572 biosynthetic process Effects 0.000 description 5
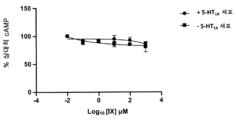
- 238000013262 cAMP assay Methods 0.000 description 5
- OHCQJHSOBUTRHG-UHFFFAOYSA-N colforsin Natural products OC12C(=O)CC(C)(C=C)OC1(C)C(OC(=O)C)C(O)C1C2(C)C(O)CCC1(C)C OHCQJHSOBUTRHG-UHFFFAOYSA-N 0.000 description 5
- 201000010099 disease Diseases 0.000 description 5
- 125000001997 phenyl group Chemical group [H]C1=C([H])C([H])=C(*)C([H])=C1[H] 0.000 description 5
- 239000000843 powder Substances 0.000 description 5
- 239000007787 solid Substances 0.000 description 5
- RGSFGYAAUTVSQA-UHFFFAOYSA-N Cyclopentane Chemical compound C1CCCC1 RGSFGYAAUTVSQA-UHFFFAOYSA-N 0.000 description 4
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 4
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 4
- 208000028017 Psychotic disease Diseases 0.000 description 4
- DBMJMQXJHONAFJ-UHFFFAOYSA-M Sodium laurylsulphate Chemical compound [Na+].CCCCCCCCCCCCOS([O-])(=O)=O DBMJMQXJHONAFJ-UHFFFAOYSA-M 0.000 description 4
- IQFYYKKMVGJFEH-XLPZGREQSA-N Thymidine Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](CO)[C@@H](O)C1 IQFYYKKMVGJFEH-XLPZGREQSA-N 0.000 description 4
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 4
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 4
- 230000004913 activation Effects 0.000 description 4
- 230000009918 complex formation Effects 0.000 description 4
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 4
- 239000007884 disintegrant Substances 0.000 description 4
- 239000003814 drug Substances 0.000 description 4
- 229940079593 drug Drugs 0.000 description 4
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 4
- 150000002430 hydrocarbons Chemical group 0.000 description 4
- HQKMJHAJHXVSDF-UHFFFAOYSA-L magnesium stearate Chemical compound [Mg+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O HQKMJHAJHXVSDF-UHFFFAOYSA-L 0.000 description 4
- BDAGIHXWWSANSR-UHFFFAOYSA-N methanoic acid Natural products OC=O BDAGIHXWWSANSR-UHFFFAOYSA-N 0.000 description 4
- 239000002773 nucleotide Substances 0.000 description 4
- 125000003729 nucleotide group Chemical group 0.000 description 4
- 230000002093 peripheral effect Effects 0.000 description 4
- 102000040430 polynucleotide Human genes 0.000 description 4
- 108091033319 polynucleotide Proteins 0.000 description 4
- 239000002157 polynucleotide Substances 0.000 description 4
- 239000011734 sodium Substances 0.000 description 4
- 229910001415 sodium ion Inorganic materials 0.000 description 4
- 235000019333 sodium laurylsulphate Nutrition 0.000 description 4
- 230000001988 toxicity Effects 0.000 description 4
- 231100000419 toxicity Toxicity 0.000 description 4
- VFTOHJFKIJLYKN-UHFFFAOYSA-N 7-nitro-9h-fluoren-2-ol Chemical group [O-][N+](=O)C1=CC=C2C3=CC=C(O)C=C3CC2=C1 VFTOHJFKIJLYKN-UHFFFAOYSA-N 0.000 description 3
- 208000019901 Anxiety disease Diseases 0.000 description 3
- 208000006096 Attention Deficit Disorder with Hyperactivity Diseases 0.000 description 3
- 206010020751 Hypersensitivity Diseases 0.000 description 3
- 229920000168 Microcrystalline cellulose Polymers 0.000 description 3
- 239000002202 Polyethylene glycol Substances 0.000 description 3
- FKNQFGJONOIPTF-UHFFFAOYSA-N Sodium cation Chemical compound [Na+] FKNQFGJONOIPTF-UHFFFAOYSA-N 0.000 description 3
- 239000011230 binding agent Substances 0.000 description 3
- 239000000872 buffer Substances 0.000 description 3
- 150000001720 carbohydrates Chemical group 0.000 description 3
- 239000006071 cream Substances 0.000 description 3
- 239000010408 film Substances 0.000 description 3
- 235000013305 food Nutrition 0.000 description 3
- 239000000499 gel Substances 0.000 description 3
- 230000003400 hallucinatory effect Effects 0.000 description 3
- 230000005764 inhibitory process Effects 0.000 description 3
- 230000007794 irritation Effects 0.000 description 3
- 150000002576 ketones Chemical class 0.000 description 3
- 230000000670 limiting effect Effects 0.000 description 3
- 239000000314 lubricant Substances 0.000 description 3
- 238000001819 mass spectrum Methods 0.000 description 3
- 235000019813 microcrystalline cellulose Nutrition 0.000 description 3
- 239000008108 microcrystalline cellulose Substances 0.000 description 3
- 229940016286 microcrystalline cellulose Drugs 0.000 description 3
- 239000000178 monomer Substances 0.000 description 3
- 208000022821 personality disease Diseases 0.000 description 3
- 229920001223 polyethylene glycol Polymers 0.000 description 3
- CBIDRCWHNCKSTO-UHFFFAOYSA-N prenyl diphosphate Chemical compound CC(C)=CCO[P@](O)(=O)OP(O)(O)=O CBIDRCWHNCKSTO-UHFFFAOYSA-N 0.000 description 3
- 230000009467 reduction Effects 0.000 description 3
- 201000000980 schizophrenia Diseases 0.000 description 3
- 229930000044 secondary metabolite Natural products 0.000 description 3
- 229910052708 sodium Inorganic materials 0.000 description 3
- 159000000000 sodium salts Chemical class 0.000 description 3
- 239000000725 suspension Substances 0.000 description 3
- 208000024891 symptom Diseases 0.000 description 3
- 230000002194 synthesizing effect Effects 0.000 description 3
- 230000001225 therapeutic effect Effects 0.000 description 3
- 238000005406 washing Methods 0.000 description 3
- 125000004169 (C1-C6) alkyl group Chemical group 0.000 description 2
- OINNEUNVOZHBOX-QIRCYJPOSA-K 2-trans,6-trans,10-trans-geranylgeranyl diphosphate(3-) Chemical compound CC(C)=CCC\C(C)=C\CC\C(C)=C\CC\C(C)=C\COP([O-])(=O)OP([O-])([O-])=O OINNEUNVOZHBOX-QIRCYJPOSA-K 0.000 description 2
- VWFJDQUYCIWHTN-YFVJMOTDSA-N 2-trans,6-trans-farnesyl diphosphate Chemical compound CC(C)=CCC\C(C)=C\CC\C(C)=C\CO[P@](O)(=O)OP(O)(O)=O VWFJDQUYCIWHTN-YFVJMOTDSA-N 0.000 description 2
- OSWFIVFLDKOXQC-UHFFFAOYSA-N 4-(3-methoxyphenyl)aniline Chemical compound COC1=CC=CC(C=2C=CC(N)=CC=2)=C1 OSWFIVFLDKOXQC-UHFFFAOYSA-N 0.000 description 2
- LRFVTYWOQMYALW-UHFFFAOYSA-N 9H-xanthine Chemical compound O=C1NC(=O)NC2=C1NC=N2 LRFVTYWOQMYALW-UHFFFAOYSA-N 0.000 description 2
- IKHGUXGNUITLKF-UHFFFAOYSA-N Acetaldehyde Chemical compound CC=O IKHGUXGNUITLKF-UHFFFAOYSA-N 0.000 description 2
- 229930024421 Adenine Natural products 0.000 description 2
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 2
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 2
- 208000036864 Attention deficit/hyperactivity disease Diseases 0.000 description 2
- 206010003805 Autism Diseases 0.000 description 2
- 208000020706 Autistic disease Diseases 0.000 description 2
- DWRXFEITVBNRMK-UHFFFAOYSA-N Beta-D-1-Arabinofuranosylthymine Natural products O=C1NC(=O)C(C)=CN1C1C(O)C(O)C(CO)O1 DWRXFEITVBNRMK-UHFFFAOYSA-N 0.000 description 2
- 208000020925 Bipolar disease Diseases 0.000 description 2
- PMPVIKIVABFJJI-UHFFFAOYSA-N Cyclobutane Chemical compound C1CCC1 PMPVIKIVABFJJI-UHFFFAOYSA-N 0.000 description 2
- XDTMQSROBMDMFD-UHFFFAOYSA-N Cyclohexane Chemical compound C1CCCCC1 XDTMQSROBMDMFD-UHFFFAOYSA-N 0.000 description 2
- OPFTUNCRGUEPRZ-QLFBSQMISA-N Cyclohexane Natural products CC(=C)[C@@H]1CC[C@@](C)(C=C)[C@H](C(C)=C)C1 OPFTUNCRGUEPRZ-QLFBSQMISA-N 0.000 description 2
- 108020004414 DNA Proteins 0.000 description 2
- 102000053602 DNA Human genes 0.000 description 2
- 208000026331 Disruptive, Impulse Control, and Conduct disease Diseases 0.000 description 2
- 208000030814 Eating disease Diseases 0.000 description 2
- QUSNBJAOOMFDIB-UHFFFAOYSA-N Ethylamine Chemical compound CCN QUSNBJAOOMFDIB-UHFFFAOYSA-N 0.000 description 2
- VWFJDQUYCIWHTN-UHFFFAOYSA-N Farnesyl pyrophosphate Natural products CC(C)=CCCC(C)=CCCC(C)=CCOP(O)(=O)OP(O)(O)=O VWFJDQUYCIWHTN-UHFFFAOYSA-N 0.000 description 2
- 208000019454 Feeding and Eating disease Diseases 0.000 description 2
- 208000011688 Generalised anxiety disease Diseases 0.000 description 2
- GVVPGTZRZFNKDS-YFHOEESVSA-N Geranyl diphosphate Natural products CC(C)=CCC\C(C)=C/COP(O)(=O)OP(O)(O)=O GVVPGTZRZFNKDS-YFHOEESVSA-N 0.000 description 2
- OINNEUNVOZHBOX-XBQSVVNOSA-N Geranylgeranyl diphosphate Natural products [P@](=O)(OP(=O)(O)O)(OC/C=C(\CC/C=C(\CC/C=C(\CC/C=C(\C)/C)/C)/C)/C)O OINNEUNVOZHBOX-XBQSVVNOSA-N 0.000 description 2
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 2
- 208000004547 Hallucinations Diseases 0.000 description 2
- 229920002153 Hydroxypropyl cellulose Polymers 0.000 description 2
- 229930194542 Keto Natural products 0.000 description 2
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 2
- 229920000881 Modified starch Polymers 0.000 description 2
- 206010028980 Neoplasm Diseases 0.000 description 2
- SPCIYGNTAMCTRO-UHFFFAOYSA-N Psilocine Natural products C1=CC(O)=C2C(CCN(C)C)=CNC2=C1 SPCIYGNTAMCTRO-UHFFFAOYSA-N 0.000 description 2
- 241001237914 Psilocybe Species 0.000 description 2
- 208000024791 Schizotypal Personality disease Diseases 0.000 description 2
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 2
- 229920002472 Starch Polymers 0.000 description 2
- QAOWNCQODCNURD-UHFFFAOYSA-N Sulfuric acid Chemical compound OS(O)(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-N 0.000 description 2
- 230000002159 abnormal effect Effects 0.000 description 2
- DPXJVFZANSGRMM-UHFFFAOYSA-N acetic acid;2,3,4,5,6-pentahydroxyhexanal;sodium Chemical compound [Na].CC(O)=O.OCC(O)C(O)C(O)C(O)C=O DPXJVFZANSGRMM-UHFFFAOYSA-N 0.000 description 2
- 229960000643 adenine Drugs 0.000 description 2
- 239000002671 adjuvant Substances 0.000 description 2
- 239000000556 agonist Substances 0.000 description 2
- 150000001408 amides Chemical class 0.000 description 2
- 239000005557 antagonist Substances 0.000 description 2
- 239000003125 aqueous solvent Substances 0.000 description 2
- 208000015802 attention deficit-hyperactivity disease Diseases 0.000 description 2
- IQFYYKKMVGJFEH-UHFFFAOYSA-N beta-L-thymidine Natural products O=C1NC(=O)C(C)=CN1C1OC(CO)C(O)C1 IQFYYKKMVGJFEH-UHFFFAOYSA-N 0.000 description 2
- 230000004071 biological effect Effects 0.000 description 2
- 125000002529 biphenylenyl group Chemical group C1(=CC=CC=2C3=CC=CC=C3C12)* 0.000 description 2
- 125000000484 butyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 2
- 201000011510 cancer Diseases 0.000 description 2
- 239000002775 capsule Substances 0.000 description 2
- 239000001768 carboxy methyl cellulose Substances 0.000 description 2
- 238000004590 computer program Methods 0.000 description 2
- 239000002537 cosmetic Substances 0.000 description 2
- 125000006165 cyclic alkyl group Chemical group 0.000 description 2
- 229950011148 cyclopropane Drugs 0.000 description 2
- 125000001559 cyclopropyl group Chemical group [H]C1([H])C([H])([H])C1([H])* 0.000 description 2
- 229940104302 cytosine Drugs 0.000 description 2
- 230000003247 decreasing effect Effects 0.000 description 2
- 235000014632 disordered eating Nutrition 0.000 description 2
- 239000013583 drug formulation Substances 0.000 description 2
- 125000000031 ethylamino group Chemical group [H]C([H])([H])C([H])([H])N([H])[*] 0.000 description 2
- 239000012847 fine chemical Substances 0.000 description 2
- 239000006260 foam Substances 0.000 description 2
- 235000019253 formic acid Nutrition 0.000 description 2
- 208000029364 generalized anxiety disease Diseases 0.000 description 2
- GVVPGTZRZFNKDS-JXMROGBWSA-N geranyl diphosphate Chemical compound CC(C)=CCC\C(C)=C\CO[P@](O)(=O)OP(O)(O)=O GVVPGTZRZFNKDS-JXMROGBWSA-N 0.000 description 2
- 125000003147 glycosyl group Chemical group 0.000 description 2
- 235000010977 hydroxypropyl cellulose Nutrition 0.000 description 2
- 239000001863 hydroxypropyl cellulose Substances 0.000 description 2
- FDGQSTZJBFJUBT-UHFFFAOYSA-N hypoxanthine Chemical compound O=C1NC=NC2=C1NC=N2 FDGQSTZJBFJUBT-UHFFFAOYSA-N 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 125000003392 indanyl group Chemical group C1(CCC2=CC=CC=C12)* 0.000 description 2
- 125000003454 indenyl group Chemical group C1(C=CC2=CC=CC=C12)* 0.000 description 2
- 239000007924 injection Substances 0.000 description 2
- 238000002347 injection Methods 0.000 description 2
- 230000003993 interaction Effects 0.000 description 2
- OKJPEAGHQZHRQV-UHFFFAOYSA-N iodoform Chemical compound IC(I)I OKJPEAGHQZHRQV-UHFFFAOYSA-N 0.000 description 2
- 239000012669 liquid formulation Substances 0.000 description 2
- 239000007937 lozenge Substances 0.000 description 2
- 235000019359 magnesium stearate Nutrition 0.000 description 2
- 230000003340 mental effect Effects 0.000 description 2
- 230000004630 mental health Effects 0.000 description 2
- 229920000609 methyl cellulose Polymers 0.000 description 2
- 235000010981 methylcellulose Nutrition 0.000 description 2
- 239000001923 methylcellulose Substances 0.000 description 2
- 239000003094 microcapsule Substances 0.000 description 2
- 150000004682 monohydrates Chemical class 0.000 description 2
- 125000001624 naphthyl group Chemical group 0.000 description 2
- 239000002858 neurotransmitter agent Substances 0.000 description 2
- 239000002777 nucleoside Substances 0.000 description 2
- 150000003833 nucleoside derivatives Chemical class 0.000 description 2
- 229910052763 palladium Inorganic materials 0.000 description 2
- 208000019906 panic disease Diseases 0.000 description 2
- 235000019271 petrolatum Nutrition 0.000 description 2
- 230000000144 pharmacologic effect Effects 0.000 description 2
- 125000001792 phenanthrenyl group Chemical group C1(=CC=CC=2C3=CC=CC=C3C=CC12)* 0.000 description 2
- 230000035790 physiological processes and functions Effects 0.000 description 2
- 239000001267 polyvinylpyrrolidone Substances 0.000 description 2
- 229920000036 polyvinylpyrrolidone Polymers 0.000 description 2
- 235000013855 polyvinylpyrrolidone Nutrition 0.000 description 2
- 208000028173 post-traumatic stress disease Diseases 0.000 description 2
- 159000000001 potassium salts Chemical class 0.000 description 2
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 2
- 230000019525 primary metabolic process Effects 0.000 description 2
- 239000000047 product Substances 0.000 description 2
- 230000000069 prophylactic effect Effects 0.000 description 2
- 230000001681 protective effect Effects 0.000 description 2
- 235000018102 proteins Nutrition 0.000 description 2
- 102000004169 proteins and genes Human genes 0.000 description 2
- 108090000623 proteins and genes Proteins 0.000 description 2
- ZBWSBXGHYDWMAK-UHFFFAOYSA-N psilocin Chemical compound C1=CC=C(O)[C]2C(CCN(C)C)=CN=C21 ZBWSBXGHYDWMAK-UHFFFAOYSA-N 0.000 description 2
- 230000000506 psychotropic effect Effects 0.000 description 2
- 229940075993 receptor modulator Drugs 0.000 description 2
- 230000002829 reductive effect Effects 0.000 description 2
- 229920002477 rna polymer Polymers 0.000 description 2
- 230000019491 signal transduction Effects 0.000 description 2
- 230000011664 signaling Effects 0.000 description 2
- LPXPTNMVRIOKMN-UHFFFAOYSA-M sodium nitrite Chemical compound [Na+].[O-]N=O LPXPTNMVRIOKMN-UHFFFAOYSA-M 0.000 description 2
- 239000002904 solvent Substances 0.000 description 2
- 241000894007 species Species 0.000 description 2
- 239000007921 spray Substances 0.000 description 2
- 235000019698 starch Nutrition 0.000 description 2
- 239000008107 starch Substances 0.000 description 2
- 229940032147 starch Drugs 0.000 description 2
- 235000000346 sugar Nutrition 0.000 description 2
- 150000008163 sugars Chemical class 0.000 description 2
- 125000000472 sulfonyl group Chemical group *S(*)(=O)=O 0.000 description 2
- 239000000829 suppository Substances 0.000 description 2
- 239000004094 surface-active agent Substances 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 125000001712 tetrahydronaphthyl group Chemical group C1(CCCC2=CC=CC=C12)* 0.000 description 2
- 229940104230 thymidine Drugs 0.000 description 2
- 238000011200 topical administration Methods 0.000 description 2
- APJYDQYYACXCRM-UHFFFAOYSA-N tryptamine Chemical compound C1=CC=C2C(CCN)=CNC2=C1 APJYDQYYACXCRM-UHFFFAOYSA-N 0.000 description 2
- 229940035893 uracil Drugs 0.000 description 2
- SNICXCGAKADSCV-JTQLQIEISA-N (-)-Nicotine Chemical compound CN1CCC[C@H]1C1=CC=CN=C1 SNICXCGAKADSCV-JTQLQIEISA-N 0.000 description 1
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 1
- LNAZSHAWQACDHT-XIYTZBAFSA-N (2r,3r,4s,5r,6s)-4,5-dimethoxy-2-(methoxymethyl)-3-[(2s,3r,4s,5r,6r)-3,4,5-trimethoxy-6-(methoxymethyl)oxan-2-yl]oxy-6-[(2r,3r,4s,5r,6r)-4,5,6-trimethoxy-2-(methoxymethyl)oxan-3-yl]oxyoxane Chemical compound CO[C@@H]1[C@@H](OC)[C@H](OC)[C@@H](COC)O[C@H]1O[C@H]1[C@H](OC)[C@@H](OC)[C@H](O[C@H]2[C@@H]([C@@H](OC)[C@H](OC)O[C@@H]2COC)OC)O[C@@H]1COC LNAZSHAWQACDHT-XIYTZBAFSA-N 0.000 description 1
- 125000000008 (C1-C10) alkyl group Chemical group 0.000 description 1
- 125000003837 (C1-C20) alkyl group Chemical group 0.000 description 1
- 125000006376 (C3-C10) cycloalkyl group Chemical group 0.000 description 1
- 125000006651 (C3-C20) cycloalkyl group Chemical group 0.000 description 1
- 125000005913 (C3-C6) cycloalkyl group Chemical group 0.000 description 1
- IXPNQXFRVYWDDI-UHFFFAOYSA-N 1-methyl-2,4-dioxo-1,3-diazinane-5-carboximidamide Chemical compound CN1CC(C(N)=N)C(=O)NC1=O IXPNQXFRVYWDDI-UHFFFAOYSA-N 0.000 description 1
- YBYIRNPNPLQARY-UHFFFAOYSA-N 1H-indene Natural products C1=CC=C2CC=CC2=C1 YBYIRNPNPLQARY-UHFFFAOYSA-N 0.000 description 1
- 125000005916 2-methylpentyl group Chemical group 0.000 description 1
- 125000005917 3-methylpentyl group Chemical group 0.000 description 1
- TVEXGJYMHHTVKP-UHFFFAOYSA-N 6-oxabicyclo[3.2.1]oct-3-en-7-one Chemical compound C1C2C(=O)OC1C=CC2 TVEXGJYMHHTVKP-UHFFFAOYSA-N 0.000 description 1
- ZCYVEMRRCGMTRW-UHFFFAOYSA-N 7553-56-2 Chemical compound [I] ZCYVEMRRCGMTRW-UHFFFAOYSA-N 0.000 description 1
- 208000030090 Acute Disease Diseases 0.000 description 1
- 208000008811 Agoraphobia Diseases 0.000 description 1
- 208000000044 Amnesia Diseases 0.000 description 1
- 208000000103 Anorexia Nervosa Diseases 0.000 description 1
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 1
- 208000027448 Attention Deficit and Disruptive Behavior disease Diseases 0.000 description 1
- 241000221198 Basidiomycota Species 0.000 description 1
- 208000030336 Bipolar and Related disease Diseases 0.000 description 1
- 208000021500 Breathing-related sleep disease Diseases 0.000 description 1
- 206010006550 Bulimia nervosa Diseases 0.000 description 1
- 125000000041 C6-C10 aryl group Chemical group 0.000 description 1
- 125000005915 C6-C14 aryl group Chemical group 0.000 description 1
- GAWIXWVDTYZWAW-UHFFFAOYSA-N C[CH]O Chemical group C[CH]O GAWIXWVDTYZWAW-UHFFFAOYSA-N 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- 229920002134 Carboxymethyl cellulose Polymers 0.000 description 1
- PTHCMJGKKRQCBF-UHFFFAOYSA-N Cellulose, microcrystalline Chemical compound OC1C(O)C(OC)OC(CO)C1OC1C(O)C(O)C(OC)C(CO)O1 PTHCMJGKKRQCBF-UHFFFAOYSA-N 0.000 description 1
- ZAMOUSCENKQFHK-UHFFFAOYSA-N Chlorine atom Chemical compound [Cl] ZAMOUSCENKQFHK-UHFFFAOYSA-N 0.000 description 1
- 208000017667 Chronic Disease Diseases 0.000 description 1
- 208000027691 Conduct disease Diseases 0.000 description 1
- 229920002785 Croscarmellose sodium Polymers 0.000 description 1
- LVZWSLJZHVFIQJ-UHFFFAOYSA-N Cyclopropane Chemical compound C1CC1 LVZWSLJZHVFIQJ-UHFFFAOYSA-N 0.000 description 1
- FBPFZTCFMRRESA-FSIIMWSLSA-N D-Glucitol Natural products OC[C@H](O)[C@H](O)[C@@H](O)[C@H](O)CO FBPFZTCFMRRESA-FSIIMWSLSA-N 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- FBPFZTCFMRRESA-JGWLITMVSA-N D-glucitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-JGWLITMVSA-N 0.000 description 1
- AEMOLEFTQBMNLQ-AQKNRBDQSA-N D-glucopyranuronic acid Chemical group OC1O[C@H](C(O)=O)[C@@H](O)[C@H](O)[C@H]1O AEMOLEFTQBMNLQ-AQKNRBDQSA-N 0.000 description 1
- 206010012218 Delirium Diseases 0.000 description 1
- 208000032538 Depersonalisation Diseases 0.000 description 1
- 206010012422 Derealisation Diseases 0.000 description 1
- YZCKVEUIGOORGS-OUBTZVSYSA-N Deuterium Chemical compound [2H] YZCKVEUIGOORGS-OUBTZVSYSA-N 0.000 description 1
- 206010012559 Developmental delay Diseases 0.000 description 1
- 208000007590 Disorders of Excessive Somnolence Diseases 0.000 description 1
- 208000025967 Dissociative Identity disease Diseases 0.000 description 1
- 241000196324 Embryophyta Species 0.000 description 1
- 241001539473 Euphoria Species 0.000 description 1
- 206010015535 Euphoric mood Diseases 0.000 description 1
- 208000026097 Factitious disease Diseases 0.000 description 1
- 208000001836 Firesetting Behavior Diseases 0.000 description 1
- KRHYYFGTRYWZRS-UHFFFAOYSA-M Fluoride anion Chemical compound [F-] KRHYYFGTRYWZRS-UHFFFAOYSA-M 0.000 description 1
- PXGOKWXKJXAPGV-UHFFFAOYSA-N Fluorine Chemical compound FF PXGOKWXKJXAPGV-UHFFFAOYSA-N 0.000 description 1
- 238000005863 Friedel-Crafts acylation reaction Methods 0.000 description 1
- 241000233866 Fungi Species 0.000 description 1
- 108010010803 Gelatin Proteins 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 1
- 208000016619 Histrionic personality disease Diseases 0.000 description 1
- 208000014513 Hoarding disease Diseases 0.000 description 1
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 1
- UGQMRVRMYYASKQ-UHFFFAOYSA-N Hypoxanthine nucleoside Natural products OC1C(O)C(CO)OC1N1C(NC=NC2=O)=C2N=C1 UGQMRVRMYYASKQ-UHFFFAOYSA-N 0.000 description 1
- 206010021403 Illusion Diseases 0.000 description 1
- 201000006347 Intellectual Disability Diseases 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 1
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 1
- ZDXPYRJPNDTMRX-VKHMYHEASA-N L-glutamine Chemical compound OC(=O)[C@@H](N)CCC(N)=O ZDXPYRJPNDTMRX-VKHMYHEASA-N 0.000 description 1
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 1
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 1
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 1
- SHZGCJCMOBCMKK-JFNONXLTSA-N L-rhamnopyranose Chemical group C[C@@H]1OC(O)[C@H](O)[C@H](O)[C@H]1O SHZGCJCMOBCMKK-JFNONXLTSA-N 0.000 description 1
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 1
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 1
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 206010026749 Mania Diseases 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- 208000003863 Marijuana Abuse Diseases 0.000 description 1
- 208000037490 Medically Unexplained Symptoms Diseases 0.000 description 1
- 206010027387 Merycism Diseases 0.000 description 1
- LRHPLDYGYMQRHN-UHFFFAOYSA-N N-Butanol Chemical group CCCCO LRHPLDYGYMQRHN-UHFFFAOYSA-N 0.000 description 1
- WHNWPMSKXPGLAX-UHFFFAOYSA-N N-Vinyl-2-pyrrolidone Chemical compound C=CN1CCCC1=O WHNWPMSKXPGLAX-UHFFFAOYSA-N 0.000 description 1
- 208000027120 Narcissistic personality disease Diseases 0.000 description 1
- 208000027626 Neurocognitive disease Diseases 0.000 description 1
- 208000029726 Neurodevelopmental disease Diseases 0.000 description 1
- 206010057852 Nicotine dependence Diseases 0.000 description 1
- GRYLNZFGIOXLOG-UHFFFAOYSA-N Nitric acid Chemical compound O[N+]([O-])=O GRYLNZFGIOXLOG-UHFFFAOYSA-N 0.000 description 1
- 206010033664 Panic attack Diseases 0.000 description 1
- 206010033864 Paranoia Diseases 0.000 description 1
- 208000027099 Paranoid disease Diseases 0.000 description 1
- 208000006199 Parasomnias Diseases 0.000 description 1
- 239000004264 Petrolatum Substances 0.000 description 1
- 206010034912 Phobia Diseases 0.000 description 1
- 201000009916 Postpartum depression Diseases 0.000 description 1
- NPYPAHLBTDXSSS-UHFFFAOYSA-N Potassium ion Chemical compound [K+] NPYPAHLBTDXSSS-UHFFFAOYSA-N 0.000 description 1
- 208000027030 Premenstrual dysphoric disease Diseases 0.000 description 1
- 102000019337 Prenyltransferases Human genes 0.000 description 1
- 108050006837 Prenyltransferases Proteins 0.000 description 1
- 241000332760 Psilocybe azurescens Species 0.000 description 1
- 241000332761 Psilocybe cyanescens Species 0.000 description 1
- 241001061684 Psilocybe mexicana Species 0.000 description 1
- 208000028665 Reactive Attachment disease Diseases 0.000 description 1
- 208000005793 Restless legs syndrome Diseases 0.000 description 1
- 208000011390 Rumination Syndrome Diseases 0.000 description 1
- 208000000810 Separation Anxiety Diseases 0.000 description 1
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 1
- 208000013738 Sleep Initiation and Maintenance disease Diseases 0.000 description 1
- 206010041250 Social phobia Diseases 0.000 description 1
- 208000027520 Somatoform disease Diseases 0.000 description 1
- 208000013200 Stress disease Diseases 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- QAOWNCQODCNURD-UHFFFAOYSA-L Sulfate Chemical compound [O-]S([O-])(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-L 0.000 description 1
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 1
- 239000004473 Threonine Substances 0.000 description 1
- 208000025569 Tobacco Use disease Diseases 0.000 description 1
- 206010043903 Tobacco abuse Diseases 0.000 description 1
- 208000031674 Traumatic Acute Stress disease Diseases 0.000 description 1
- 208000028552 Treatment-Resistant Depressive disease Diseases 0.000 description 1
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 1
- TVXBFESIOXBWNM-UHFFFAOYSA-N Xylitol Natural products OCCC(O)C(O)C(O)CCO TVXBFESIOXBWNM-UHFFFAOYSA-N 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 239000004480 active ingredient Substances 0.000 description 1
- 239000013543 active substance Substances 0.000 description 1
- 230000001154 acute effect Effects 0.000 description 1
- 208000026345 acute stress disease Diseases 0.000 description 1
- 230000010933 acylation Effects 0.000 description 1
- 238000007792 addition Methods 0.000 description 1
- 208000012826 adjustment disease Diseases 0.000 description 1
- 239000000443 aerosol Substances 0.000 description 1
- 238000012387 aerosolization Methods 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- 208000028505 alcohol-related disease Diseases 0.000 description 1
- 125000003545 alkoxy group Chemical group 0.000 description 1
- 208000030961 allergic reaction Diseases 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 238000005576 amination reaction Methods 0.000 description 1
- 150000001412 amines Chemical class 0.000 description 1
- 238000007098 aminolysis reaction Methods 0.000 description 1
- 230000001195 anabolic effect Effects 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 239000003963 antioxidant agent Substances 0.000 description 1
- 235000006708 antioxidants Nutrition 0.000 description 1
- 208000024823 antisocial personality disease Diseases 0.000 description 1
- 230000036506 anxiety Effects 0.000 description 1
- 239000007864 aqueous solution Substances 0.000 description 1
- 125000000089 arabinosyl group Chemical group C1([C@@H](O)[C@H](O)[C@H](O)CO1)* 0.000 description 1
- 235000009582 asparagine Nutrition 0.000 description 1
- 229960001230 asparagine Drugs 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical group [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 1
- 208000029560 autism spectrum disease Diseases 0.000 description 1
- 208000022804 avoidant personality disease Diseases 0.000 description 1
- 230000003542 behavioural effect Effects 0.000 description 1
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- 235000013361 beverage Nutrition 0.000 description 1
- 208000014679 binge eating disease Diseases 0.000 description 1
- 230000008238 biochemical pathway Effects 0.000 description 1
- 208000022266 body dysmorphic disease Diseases 0.000 description 1
- UORVGPXVDQYIDP-UHFFFAOYSA-N borane Chemical compound B UORVGPXVDQYIDP-UHFFFAOYSA-N 0.000 description 1
- 208000030963 borderline personality disease Diseases 0.000 description 1
- 229910010277 boron hydride Inorganic materials 0.000 description 1
- GDTBXPJZTBHREO-UHFFFAOYSA-N bromine Substances BrBr GDTBXPJZTBHREO-UHFFFAOYSA-N 0.000 description 1
- 229910052794 bromium Inorganic materials 0.000 description 1
- 125000004063 butyryl group Chemical group O=C([*])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- XAAHAAMILDNBPS-UHFFFAOYSA-L calcium hydrogenphosphate dihydrate Chemical compound O.O.[Ca+2].OP([O-])([O-])=O XAAHAAMILDNBPS-UHFFFAOYSA-L 0.000 description 1
- CJZGTCYPCWQAJB-UHFFFAOYSA-L calcium stearate Chemical compound [Ca+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O CJZGTCYPCWQAJB-UHFFFAOYSA-L 0.000 description 1
- 235000013539 calcium stearate Nutrition 0.000 description 1
- 239000008116 calcium stearate Substances 0.000 description 1
- 238000004422 calculation algorithm Methods 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 125000002915 carbonyl group Chemical group [*:2]C([*:1])=O 0.000 description 1
- 235000010948 carboxy methyl cellulose Nutrition 0.000 description 1
- 239000008112 carboxymethyl-cellulose Substances 0.000 description 1
- 229940105329 carboxymethylcellulose Drugs 0.000 description 1
- 230000001925 catabolic effect Effects 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 239000003054 catalyst Substances 0.000 description 1
- 238000003570 cell viability assay Methods 0.000 description 1
- 210000003169 central nervous system Anatomy 0.000 description 1
- 229910052729 chemical element Inorganic materials 0.000 description 1
- 239000003153 chemical reaction reagent Substances 0.000 description 1
- 239000003795 chemical substances by application Substances 0.000 description 1
- 150000003841 chloride salts Chemical class 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 238000004140 cleaning Methods 0.000 description 1
- 239000003086 colorant Substances 0.000 description 1
- 208000030251 communication disease Diseases 0.000 description 1
- 238000009833 condensation Methods 0.000 description 1
- 230000005494 condensation Effects 0.000 description 1
- 235000013409 condiments Nutrition 0.000 description 1
- 238000013270 controlled release Methods 0.000 description 1
- 208000012839 conversion disease Diseases 0.000 description 1
- 229960001681 croscarmellose sodium Drugs 0.000 description 1
- 229960000913 crospovidone Drugs 0.000 description 1
- 235000010947 crosslinked sodium carboxy methyl cellulose Nutrition 0.000 description 1
- 210000004748 cultured cell Anatomy 0.000 description 1
- 125000001995 cyclobutyl group Chemical group [H]C1([H])C([H])([H])C([H])(*)C1([H])[H] 0.000 description 1
- 125000000113 cyclohexyl group Chemical group [H]C1([H])C([H])([H])C([H])([H])C([H])(*)C([H])([H])C1([H])[H] 0.000 description 1
- 125000001511 cyclopentyl group Chemical group [H]C1([H])C([H])([H])C([H])([H])C([H])(*)C1([H])[H] 0.000 description 1
- 230000006735 deficit Effects 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 208000030964 dependent personality disease Diseases 0.000 description 1
- 239000007933 dermal patch Substances 0.000 description 1
- 239000008121 dextrose Substances 0.000 description 1
- 208000035548 disruptive behavior disease Diseases 0.000 description 1
- 206010013461 dissociative amnesia Diseases 0.000 description 1
- 208000018459 dissociative disease Diseases 0.000 description 1
- 230000009429 distress Effects 0.000 description 1
- 230000008482 dysregulation Effects 0.000 description 1
- 208000024732 dysthymic disease Diseases 0.000 description 1
- 239000003571 electronic cigarette Substances 0.000 description 1
- 238000004520 electroporation Methods 0.000 description 1
- 239000003995 emulsifying agent Substances 0.000 description 1
- 230000001804 emulsifying effect Effects 0.000 description 1
- 239000000839 emulsion Substances 0.000 description 1
- 239000003623 enhancer Substances 0.000 description 1
- 230000032050 esterification Effects 0.000 description 1
- 238000005886 esterification reaction Methods 0.000 description 1
- MVPICKVDHDWCJQ-UHFFFAOYSA-N ethyl 3-pyrrolidin-1-ylpropanoate Chemical compound CCOC(=O)CCN1CCCC1 MVPICKVDHDWCJQ-UHFFFAOYSA-N 0.000 description 1
- 150000003947 ethylamines Chemical class 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 239000003889 eye drop Substances 0.000 description 1
- 229940012356 eye drops Drugs 0.000 description 1
- 239000000835 fiber Substances 0.000 description 1
- 239000000945 filler Substances 0.000 description 1
- 239000000796 flavoring agent Substances 0.000 description 1
- 239000011737 fluorine Substances 0.000 description 1
- 235000013355 food flavoring agent Nutrition 0.000 description 1
- 125000002446 fucosyl group Chemical group C1([C@@H](O)[C@H](O)[C@H](O)[C@@H](O1)C)* 0.000 description 1
- 239000003517 fume Substances 0.000 description 1
- 125000003843 furanosyl group Chemical group 0.000 description 1
- 125000002519 galactosyl group Chemical group C1([C@H](O)[C@@H](O)[C@@H](O)[C@H](O1)CO)* 0.000 description 1
- 210000001035 gastrointestinal tract Anatomy 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 229920000159 gelatin Polymers 0.000 description 1
- 239000008273 gelatin Substances 0.000 description 1
- 235000019322 gelatine Nutrition 0.000 description 1
- 235000011852 gelatine desserts Nutrition 0.000 description 1
- 229960001031 glucose Drugs 0.000 description 1
- 125000002791 glucosyl group Chemical group C1([C@H](O)[C@@H](O)[C@H](O)[C@H](O1)CO)* 0.000 description 1
- 235000013922 glutamic acid Nutrition 0.000 description 1
- 239000004220 glutamic acid Substances 0.000 description 1
- ZDXPYRJPNDTMRX-UHFFFAOYSA-N glutamine Natural products OC(=O)C(N)CCC(N)=O ZDXPYRJPNDTMRX-UHFFFAOYSA-N 0.000 description 1
- 150000004676 glycans Polymers 0.000 description 1
- MNQZXJOMYWMBOU-UHFFFAOYSA-N glyceraldehyde Chemical compound OCC(O)C=O MNQZXJOMYWMBOU-UHFFFAOYSA-N 0.000 description 1
- 235000011187 glycerol Nutrition 0.000 description 1
- 239000008187 granular material Substances 0.000 description 1
- 230000012010 growth Effects 0.000 description 1
- 239000001963 growth medium Substances 0.000 description 1
- 150000004820 halides Chemical class 0.000 description 1
- 239000007902 hard capsule Substances 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 125000002017 heptosyl group Chemical group 0.000 description 1
- 150000002402 hexoses Chemical group 0.000 description 1
- 125000000625 hexosyl group Chemical group 0.000 description 1
- 238000004128 high performance liquid chromatography Methods 0.000 description 1
- 239000000017 hydrogel Substances 0.000 description 1
- XMBWDFGMSWQBCA-UHFFFAOYSA-N hydrogen iodide Chemical compound I XMBWDFGMSWQBCA-UHFFFAOYSA-N 0.000 description 1
- 125000002768 hydroxyalkyl group Chemical group 0.000 description 1
- 125000004029 hydroxymethyl group Chemical group [H]OC([H])([H])* 0.000 description 1
- 235000010979 hydroxypropyl methyl cellulose Nutrition 0.000 description 1
- 239000001866 hydroxypropyl methyl cellulose Substances 0.000 description 1
- 229920003088 hydroxypropyl methyl cellulose Polymers 0.000 description 1
- UFVKGYZPFZQRLF-UHFFFAOYSA-N hydroxypropyl methyl cellulose Chemical compound OC1C(O)C(OC)OC(CO)C1OC1C(O)C(O)C(OC2C(C(O)C(OC3C(C(O)C(O)C(CO)O3)O)C(CO)O2)O)C(CO)O1 UFVKGYZPFZQRLF-UHFFFAOYSA-N 0.000 description 1
- 206010020765 hypersomnia Diseases 0.000 description 1
- 150000002466 imines Chemical class 0.000 description 1
- 239000007943 implant Substances 0.000 description 1
- 239000011261 inert gas Substances 0.000 description 1
- 208000015046 intermittent explosive disease Diseases 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 238000000185 intracerebroventricular administration Methods 0.000 description 1
- 238000007917 intracranial administration Methods 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 239000007927 intramuscular injection Substances 0.000 description 1
- 239000007928 intraperitoneal injection Substances 0.000 description 1
- 238000007913 intrathecal administration Methods 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- 229910052740 iodine Inorganic materials 0.000 description 1
- 239000011630 iodine Substances 0.000 description 1
- 125000000959 isobutyl group Chemical group [H]C([H])([H])C([H])(C([H])([H])[H])C([H])([H])* 0.000 description 1
- 125000004491 isohexyl group Chemical group C(CCC(C)C)* 0.000 description 1
- 229960000310 isoleucine Drugs 0.000 description 1
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 1
- 125000001449 isopropyl group Chemical group [H]C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- FPCCSQOGAWCVBH-UHFFFAOYSA-N ketanserin Chemical compound C1=CC(F)=CC=C1C(=O)C1CCN(CCN2C(C3=CC=CC=C3NC2=O)=O)CC1 FPCCSQOGAWCVBH-UHFFFAOYSA-N 0.000 description 1
- 125000001553 ketosyl group Chemical group 0.000 description 1
- 206010023461 kleptomania Diseases 0.000 description 1
- 239000002655 kraft paper Substances 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- 239000003446 ligand Substances 0.000 description 1
- 239000002502 liposome Substances 0.000 description 1
- 239000008297 liquid dosage form Substances 0.000 description 1
- 239000006210 lotion Substances 0.000 description 1
- 208000024714 major depressive disease Diseases 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 229960001855 mannitol Drugs 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 239000002609 medium Substances 0.000 description 1
- HEBKCHPVOIAQTA-UHFFFAOYSA-N meso ribitol Natural products OCC(O)C(O)C(O)CO HEBKCHPVOIAQTA-UHFFFAOYSA-N 0.000 description 1
- 125000000956 methoxy group Chemical group [H]C([H])([H])O* 0.000 description 1
- 239000004530 micro-emulsion Substances 0.000 description 1
- 230000000813 microbial effect Effects 0.000 description 1
- 239000004005 microsphere Substances 0.000 description 1
- 239000002480 mineral oil Substances 0.000 description 1
- 235000010446 mineral oil Nutrition 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 150000002772 monosaccharides Chemical group 0.000 description 1
- 230000036651 mood Effects 0.000 description 1
- 210000004400 mucous membrane Anatomy 0.000 description 1
- 208000027881 multiple personality disease Diseases 0.000 description 1
- 210000003205 muscle Anatomy 0.000 description 1
- 125000004108 n-butyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 125000001280 n-hexyl group Chemical group C(CCCCC)* 0.000 description 1
- 125000000740 n-pentyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 1
- 239000002088 nanocapsule Substances 0.000 description 1
- 201000003631 narcolepsy Diseases 0.000 description 1
- 239000013642 negative control Substances 0.000 description 1
- 238000002610 neuroimaging Methods 0.000 description 1
- 229960002715 nicotine Drugs 0.000 description 1
- SNICXCGAKADSCV-UHFFFAOYSA-N nicotine Natural products CN1CCCC1C1=CC=CN=C1 SNICXCGAKADSCV-UHFFFAOYSA-N 0.000 description 1
- SFDJOSRHYKHMOK-UHFFFAOYSA-N nitramide Chemical group N[N+]([O-])=O SFDJOSRHYKHMOK-UHFFFAOYSA-N 0.000 description 1
- 229910017604 nitric acid Inorganic materials 0.000 description 1
- 125000003835 nucleoside group Chemical group 0.000 description 1
- 208000030459 obsessive-compulsive personality disease Diseases 0.000 description 1
- 239000002674 ointment Substances 0.000 description 1
- 150000002482 oligosaccharides Polymers 0.000 description 1
- 208000024196 oppositional defiant disease Diseases 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 229940100688 oral solution Drugs 0.000 description 1
- 239000003960 organic solvent Substances 0.000 description 1
- 230000001151 other effect Effects 0.000 description 1
- 239000001301 oxygen Substances 0.000 description 1
- 229910052760 oxygen Inorganic materials 0.000 description 1
- 208000024817 paranoid personality disease Diseases 0.000 description 1
- 238000007911 parenteral administration Methods 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 230000035515 penetration Effects 0.000 description 1
- 125000001805 pentosyl group Chemical group 0.000 description 1
- 125000001147 pentyl group Chemical group C(CCCC)* 0.000 description 1
- 239000002304 perfume Substances 0.000 description 1
- 230000002085 persistent effect Effects 0.000 description 1
- 229940066842 petrolatum Drugs 0.000 description 1
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 1
- 125000004437 phosphorous atom Chemical group 0.000 description 1
- 230000000704 physical effect Effects 0.000 description 1
- 230000001766 physiological effect Effects 0.000 description 1
- 230000006461 physiological response Effects 0.000 description 1
- 235000010482 polyoxyethylene sorbitan monooleate Nutrition 0.000 description 1
- 239000000244 polyoxyethylene sorbitan monooleate Substances 0.000 description 1
- 125000001185 polyprenyl group Polymers 0.000 description 1
- 150000004804 polysaccharides Polymers 0.000 description 1
- 229940068968 polysorbate 80 Drugs 0.000 description 1
- 229920000053 polysorbate 80 Polymers 0.000 description 1
- 235000013809 polyvinylpolypyrrolidone Nutrition 0.000 description 1
- 229920000523 polyvinylpolypyrrolidone Polymers 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- 239000011591 potassium Substances 0.000 description 1
- 229910052700 potassium Inorganic materials 0.000 description 1
- XAEFZNCEHLXOMS-UHFFFAOYSA-M potassium benzoate Chemical compound [K+].[O-]C(=O)C1=CC=CC=C1 XAEFZNCEHLXOMS-UHFFFAOYSA-M 0.000 description 1
- 229910001414 potassium ion Inorganic materials 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 230000002265 prevention Effects 0.000 description 1
- BDERNNFJNOPAEC-UHFFFAOYSA-N propan-1-ol Chemical group CCCO BDERNNFJNOPAEC-UHFFFAOYSA-N 0.000 description 1
- 125000001325 propanoyl group Chemical group O=C([*])C([H])([H])C([H])([H])[H] 0.000 description 1
- 238000000159 protein binding assay Methods 0.000 description 1
- 150000003214 pyranose derivatives Chemical class 0.000 description 1
- 201000004645 pyromania Diseases 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000000241 respiratory effect Effects 0.000 description 1
- 230000029058 respiratory gaseous exchange Effects 0.000 description 1
- 208000015212 rumination disease Diseases 0.000 description 1
- 125000002914 sec-butyl group Chemical group [H]C([H])([H])C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 1
- 230000024053 secondary metabolic process Effects 0.000 description 1
- 208000025874 separation anxiety disease Diseases 0.000 description 1
- 208000017520 skin disease Diseases 0.000 description 1
- 208000019116 sleep disease Diseases 0.000 description 1
- 235000010413 sodium alginate Nutrition 0.000 description 1
- 239000000661 sodium alginate Substances 0.000 description 1
- 229940005550 sodium alginate Drugs 0.000 description 1
- 235000019812 sodium carboxymethyl cellulose Nutrition 0.000 description 1
- 229920001027 sodium carboxymethylcellulose Polymers 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 239000001509 sodium citrate Substances 0.000 description 1
- NLJMYIDDQXHKNR-UHFFFAOYSA-K sodium citrate Chemical compound O.O.[Na+].[Na+].[Na+].[O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O NLJMYIDDQXHKNR-UHFFFAOYSA-K 0.000 description 1
- 235000010288 sodium nitrite Nutrition 0.000 description 1
- 239000008109 sodium starch glycolate Substances 0.000 description 1
- 229920003109 sodium starch glycolate Polymers 0.000 description 1
- 229940079832 sodium starch glycolate Drugs 0.000 description 1
- 229940045902 sodium stearyl fumarate Drugs 0.000 description 1
- 239000007901 soft capsule Substances 0.000 description 1
- 239000007909 solid dosage form Substances 0.000 description 1
- 239000006104 solid solution Substances 0.000 description 1
- 239000012453 solvate Substances 0.000 description 1
- 239000000600 sorbitol Substances 0.000 description 1
- 229960002920 sorbitol Drugs 0.000 description 1
- 235000010356 sorbitol Nutrition 0.000 description 1
- 201000001716 specific phobia Diseases 0.000 description 1
- 239000008174 sterile solution Substances 0.000 description 1
- 239000008223 sterile water Substances 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 208000011117 substance-related disease Diseases 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 229960004793 sucrose Drugs 0.000 description 1
- 125000000446 sulfanediyl group Chemical group *S* 0.000 description 1
- 125000001273 sulfonato group Chemical group [O-]S(*)(=O)=O 0.000 description 1
- 150000003467 sulfuric acid derivatives Chemical class 0.000 description 1
- 230000004083 survival effect Effects 0.000 description 1
- 239000000375 suspending agent Substances 0.000 description 1
- 238000013268 sustained release Methods 0.000 description 1
- 239000012730 sustained-release form Substances 0.000 description 1
- 230000009747 swallowing Effects 0.000 description 1
- 239000006188 syrup Substances 0.000 description 1
- 235000020357 syrup Nutrition 0.000 description 1
- 230000009885 systemic effect Effects 0.000 description 1
- 239000007916 tablet composition Substances 0.000 description 1
- 239000006068 taste-masking agent Substances 0.000 description 1
- 235000013616 tea Nutrition 0.000 description 1
- 125000000999 tert-butyl group Chemical group [H]C([H])([H])C(*)(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- 230000009974 thixotropic effect Effects 0.000 description 1
- 125000003944 tolyl group Chemical group 0.000 description 1
- 125000002088 tosyl group Chemical group [H]C1=C([H])C(=C([H])C([H])=C1C([H])([H])[H])S(*)(=O)=O 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 208000002271 trichotillomania Diseases 0.000 description 1
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 1
- 125000003774 valeryl group Chemical group O=C([*])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 239000004474 valine Substances 0.000 description 1
- 239000003981 vehicle Substances 0.000 description 1
- 210000001835 viscera Anatomy 0.000 description 1
- 235000012431 wafers Nutrition 0.000 description 1
- 239000003871 white petrolatum Substances 0.000 description 1
- 229940075420 xanthine Drugs 0.000 description 1
- 239000000811 xylitol Substances 0.000 description 1
- 229960002675 xylitol Drugs 0.000 description 1
- HEBKCHPVOIAQTA-SCDXWVJYSA-N xylitol Chemical compound OC[C@H](O)[C@@H](O)[C@H](O)CO HEBKCHPVOIAQTA-SCDXWVJYSA-N 0.000 description 1
- 235000010447 xylitol Nutrition 0.000 description 1
- 125000000969 xylosyl group Chemical group C1([C@H](O)[C@@H](O)[C@H](O)CO1)* 0.000 description 1
- 125000005023 xylyl group Chemical group 0.000 description 1
- XOOUIPVCVHRTMJ-UHFFFAOYSA-L zinc stearate Chemical compound [Zn+2].CCCCCCCCCCCCCCCCCC([O-])=O.CCCCCCCCCCCCCCCCCC([O-])=O XOOUIPVCVHRTMJ-UHFFFAOYSA-L 0.000 description 1
Images






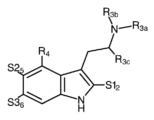
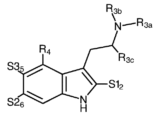
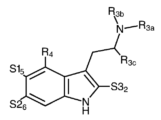

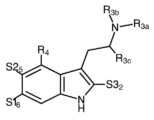








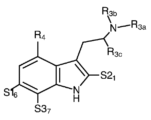

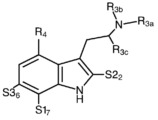
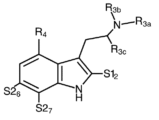




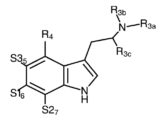


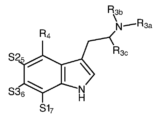


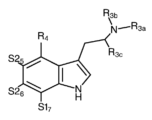
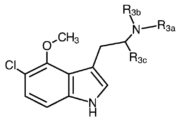
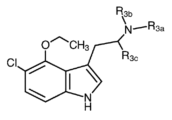









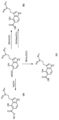

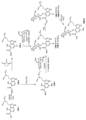
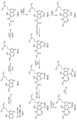
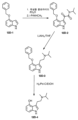















































Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/66—Phosphorus compounds
- A61K31/675—Phosphorus compounds having nitrogen as a ring hetero atom, e.g. pyridoxal phosphate
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07D—HETEROCYCLIC COMPOUNDS
- C07D209/00—Heterocyclic compounds containing five-membered rings, condensed with other rings, with one nitrogen atom as the only ring hetero atom
- C07D209/02—Heterocyclic compounds containing five-membered rings, condensed with other rings, with one nitrogen atom as the only ring hetero atom condensed with one carbocyclic ring
- C07D209/04—Indoles; Hydrogenated indoles
- C07D209/10—Indoles; Hydrogenated indoles with substituted hydrocarbon radicals attached to carbon atoms of the hetero ring
- C07D209/18—Radicals substituted by carbon atoms having three bonds to hetero atoms with at the most one bond to halogen, e.g. ester or nitrile radicals
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/33—Heterocyclic compounds
- A61K31/395—Heterocyclic compounds having nitrogen as a ring hetero atom, e.g. guanethidine or rifamycins
- A61K31/40—Heterocyclic compounds having nitrogen as a ring hetero atom, e.g. guanethidine or rifamycins having five-membered rings with one nitrogen as the only ring hetero atom, e.g. sulpiride, succinimide, tolmetin, buflomedil
- A61K31/403—Heterocyclic compounds having nitrogen as a ring hetero atom, e.g. guanethidine or rifamycins having five-membered rings with one nitrogen as the only ring hetero atom, e.g. sulpiride, succinimide, tolmetin, buflomedil condensed with carbocyclic rings, e.g. carbazole
- A61K31/404—Indoles, e.g. pindolol
- A61K31/4045—Indole-alkylamines; Amides thereof, e.g. serotonin, melatonin
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K31/00—Medicinal preparations containing organic active ingredients
- A61K31/70—Carbohydrates; Sugars; Derivatives thereof
- A61K31/7028—Compounds having saccharide radicals attached to non-saccharide compounds by glycosidic linkages
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/18—Antipsychotics, i.e. neuroleptics; Drugs for mania or schizophrenia
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07D—HETEROCYCLIC COMPOUNDS
- C07D209/00—Heterocyclic compounds containing five-membered rings, condensed with other rings, with one nitrogen atom as the only ring hetero atom
- C07D209/02—Heterocyclic compounds containing five-membered rings, condensed with other rings, with one nitrogen atom as the only ring hetero atom condensed with one carbocyclic ring
- C07D209/04—Indoles; Hydrogenated indoles
- C07D209/10—Indoles; Hydrogenated indoles with substituted hydrocarbon radicals attached to carbon atoms of the hetero ring
- C07D209/14—Radicals substituted by nitrogen atoms, not forming part of a nitro radical
- C07D209/16—Tryptamines
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/10—Transferases (2.)
- C12N9/1025—Acyltransferases (2.3)
- C12N9/1029—Acyltransferases (2.3) transferring groups other than amino-acyl groups (2.3.1)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/10—Transferases (2.)
- C12N9/1085—Transferases (2.) transferring alkyl or aryl groups other than methyl groups (2.5)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/88—Lyases (4.)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P17/00—Preparation of heterocyclic carbon compounds with only O, N, S, Se or Te as ring hetero atoms
- C12P17/10—Nitrogen as only ring hetero atom
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y205/00—Transferases transferring alkyl or aryl groups, other than methyl groups (2.5)
- C12Y205/01—Transferases transferring alkyl or aryl groups, other than methyl groups (2.5) transferring alkyl or aryl groups, other than methyl groups (2.5.1)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y401/00—Carbon-carbon lyases (4.1)
- C12Y401/01—Carboxy-lyases (4.1.1)
- C12Y401/0102—Diaminopimelate decarboxylase (4.1.1.20)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y401/00—Carbon-carbon lyases (4.1)
- C12Y401/01—Carboxy-lyases (4.1.1)
- C12Y401/01028—Aromatic-L-amino-acid decarboxylase (4.1.1.28), i.e. tryptophane-decarboxylase
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y402/00—Carbon-oxygen lyases (4.2)
- C12Y402/01—Hydro-lyases (4.2.1)
- C12Y402/0102—Tryptophan synthase (4.2.1.20)
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Health & Medical Sciences (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Genetics & Genomics (AREA)
- Medicinal Chemistry (AREA)
- Biochemistry (AREA)
- General Engineering & Computer Science (AREA)
- Biomedical Technology (AREA)
- Public Health (AREA)
- Pharmacology & Pharmacy (AREA)
- Veterinary Medicine (AREA)
- Animal Behavior & Ethology (AREA)
- Microbiology (AREA)
- Biotechnology (AREA)
- Molecular Biology (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Epidemiology (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Neurosurgery (AREA)
- Neurology (AREA)
- Psychiatry (AREA)
- Saccharide Compounds (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
Abstract
신규한 다중 치환기 실로시빈 유도체 화합물 및 이를 함유하는 약학적 및 기분전환용 약물 제형이 개시된다. 화합물은 반응물 실로시빈 유도체를 치환기 함유 화합물과 반응시킴에 의해 생성될 수 있다.
Description
관련된 출원
본 출원은 2021년 2월 12일에 출원된 미국 가출원 번호 63/149,001 및 2021년 9월 24일에 출원된 미국 가출원 번호 63/247,881의 이익을 주장하며; 특허 출원 번호 63/149,001 및 63/247,881의 전체 내용은 본 명세서에 참조로 포함된다.
개시내용의 분야
본 명세서에 개시된 조성물 및 방법은 실로시빈으로 알려진 화학적 화합물에 관한 것이다. 더욱이, 본 명세서에 개시된 조성물 및 방법은 특히 다중 치환기를 포함하는 실로시빈의 유도체에 관한 것이다.
다음 단락은 본 개시내용에 대한 배경의 방식으로서 제공된다. 그러나 이는 거기에서 논의된 어떤 것이 선행 기술이거나 해당 기술 분야의 숙련자의 지식의 일부라는 인정은 아니다.
살아있는 유기체의 세포에서 생화학적 경로는 일차 대사의 일부 또는 2차 대사의 일부인 것으로 분류될 수 있다. 세포의 일차 대사의 일부인 경로는 에너지 생산을 위한 이화작용이나 세포에 대한 빌딩 블록 생산을 위한 동화작용에 관여된다. 반면에, 2차 대사산물은 명백한 동화작용이나 이화작용 기능 없이 세포에 의해 생성된다. 2차 대사산물이 치료적 화합물을 포함하여 많은 관점에서 유용할 수 있다는 것이 오랫동안 인식되어 왔다.
예를 들어, 실로시빈은 분류학적으로 균계의 담자균류 부문에 속하는 것으로 분류될 수 있는 특정 버섯에 의해 자연적으로 생성되는 2차 대사산물이다. 실로시빈을 생산할 수 있는 버섯 종은 예를 들어 실로사이베 아주레센스, 실로사이베 세미란시아타, 실로사이베 세르비카, 실로사이베 멕시카나 및 실로사이베 시아네센스와 같은 실로사이베 속에 속하는 종을 포함한다. 실로시빈에 대한 당업계의 관심은 잘 확립되어 있다. 따라서, 예를 들어 실로시빈은 향정신성 화합물이고 따라서 기분전환용 약물로 사용된다. 더욱이, 실로시빈은 정신병 장애에서의 행동 및 신경-영상 연구에서 연구 도구로 사용되고, 말기 암 환자에서의 불안을 치료하는 것(Grob, C. 등, Arch. Gen. Psychiatry, 2011, 68(1) 71-78) 및 치료-내성 우울증의 증상을 완화하는 것(Cathart-Harris, R.L. 등, Lancet Psychiatry, 2016, 3: 619-627)을 포함한, 정신 건강 상태의 치료(Daniel, J. 등, Mental Health Clin/, 2017 ;7(1): 24-28)에서 그 임상적 잠재력에 대해 평가되었다.
실로시빈의 독성은 낮지만, 때때로 함께 또는 개별적으로 "나쁜 여행"으로 지칭되는, 예를 들어 공황 발작, 편집증 및 정신병 상태를 포함하는 부작용은 기분전환용 실로시빈 사용자에 의해 드물게 경험되지 않는다.
따라서 개선된 실로시빈 화합물에 대한 필요성이 당업계에 존재한다.
발명의 요약
다음 문단은 독자에게 보다 상세한 설명을 소개하기 위한 것이지, 본 개시내용의 청구된 대상물을 정의하거나 제한하기 위한 것이 아니다.
일 양태에서, 본 개시내용은 실로시빈 및 이의 유도체 화합물에 관한 것이다.
또 다른 양태에서, 본 개시내용은 실로시빈 유도체 화합물 및 이들 화합물을 제조하고 사용하는 방법에 관한 것이다.
또 다른 양태에서, 본 개시내용은 다중 치환기 실로시빈 유도체 화합물에 관한 것이다.
따라서, 일 양태에서, 본 개시내용은 본 명세서의 교시에 따라 적어도 하나의 실시형태에서, 식 (I)을 갖는 화학적 화합물 또는 이의 염을 제공한다:
(I),
여기서, R2, R4, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 독립적으로 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, O-알킬기, O-아실기 또는 포스페이트기이고, R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, R3c는 수소 원자 또는 카르복실기임.
적어도 하나의 실시형태에서, 양태에서, R2, R4, R5, R6, 또는 R7 중 적어도 3개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 독립적으로 선택된 치환기일 수 있다.
적어도 하나의 실시형태에서, 양태에서, R2, R4, R5, R6, 또는 R7 중 적어도 3개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 3개로부터 독립적으로 선택된 치환기일 수 있다.
적어도 하나의 실시형태에서, 양태에서, R4가 치환기로 치환되지 않는 경우, R4는 수소 원자일 수 있다.
적어도 하나의 실시형태에서, 양태에서, R4 및 R5는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택될 수 있고, R2, R6 및 R7은 수소 원자일 수 있다.
적어도 하나의 실시형태에서, 양태에서, R4 및 R5는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택될 수 있고, R4 및 R5 중 적어도 하나는 프레닐기 또는 할로겐 원자일 수 있고, R2, R6 및 R7은 수소 원자일 수 있다.
적어도 하나의 실시형태에서, 양태에서, R4 및 R6은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택될 수 있고, R2, R4 및 R7은 수소 원자일 수 있다.
적어도 하나의 실시형태에서, 양태에서, R4 및 R6은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택될 수 있고, R4 및 R6 중 적어도 하나는 프레닐기 또는 할로겐 원자일 수 있고, R2, R4 및 R7은 수소 원자일 수 있다.
적어도 하나의 실시형태에서, 양태에서, R4 및 R7은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택될 수 있고, R2, R5 및 R6은 수소 원자일 수 있다.
적어도 하나의 실시형태에서, 양태에서, R4 및 R7은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택될 수 있고, R4 및 R7 중 적어도 하나는 프레닐기 또는 할로겐 원자일 수 있고, R2, R5 및 R6은 수소 원자일 수 있다.
적어도 하나의 실시형태에서, 양태에서, R5 및 R6은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택될 수 있고, R2, R4 및 R7은 수소 원자일 수 있다.
적어도 하나의 실시형태에서, 양태에서, R5 및 R7은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택될 수 있고, R5 및 R6 중 적어도 하나는 프레닐기 또는 할로겐 원자일 수 있고, R2, R4 및 R6은 수소 원자일 수 있다.
적어도 하나의 실시형태에서, 양태에서, R5 및 R7은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택될 수 있고, R2, R4 및 R6은 수소 원자일 수 있다.
적어도 하나의 실시형태에서, 양태에서, R5 및 R7은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택될 수 있고, R5 및 R7 중 적어도 하나는 프레닐기 또는 할로겐 원자일 수 있고, R2, R4 및 R6은 수소 원자일 수 있다.
적어도 하나의 실시형태에서, 양태에서, R6 및 R7은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택될 수 있고, R2, R4 및 R5는 수소 원자일 수 있다.
적어도 하나의 실시형태에서, 양태에서, R6 및 R7은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택될 수 있고, R6 및 R7 중 적어도 하나는 프레닐기 또는 할로겐 원자일 수 있고, R2, R4 및 R5는 수소 원자일 수 있다.
적어도 하나의 실시형태에서, 양태에서, R2는 수소일 수 있고, R4, R5, R6 또는 R7 중 단 2개만이 치환되며, 여기서 제1 치환기는 (i) 할로겐 원자, (ii) 프레닐기, 및 (iii) 니트릴기이고, 제2 치환기는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 선택되고, 여기서 제1 및 제2 치환기는 서로 다른 기에 속한다.
적어도 하나의 실시형태에서, 양태에서, R2는 수소일 수 있고, R4, R5, R6 또는 R7 중 단 2개만이 치환되며, 여기서 제1 치환기는 할로겐 원자이고, 제2 치환기는: (i) 하이드록시기, (ii) 니트로기, (iii) 글리코실옥시기, (iv) 아미노기 또는 N-치환된 아미노기, (v) 카르복실기 또는 카르복실산 유도체, (vi) 알데히드 또는 케톤기, (vii) 프레닐기, 및 (viii) 니트릴기로부터 선택된다.
적어도 하나의 실시형태에서, 양태에서, R2는 수소일 수 있고, R4, R5, R6 또는 R7 중 단 2개만이 치환되며, 여기서 제1 치환기는 프레닐기이고, 제2 치환기는: (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, 및 (viii) 니트릴기로부터 선택된다.
적어도 하나의 실시형태에서, 양태에서, R2는 수소일 수 있고, R4, R5, R6 또는 R7 중 단 2개만이 치환되며, 여기서 제1 치환기는 니트릴 원자이고, 제2 치환기는: (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, 및 (viii) 프레닐기로부터 선택된다.
적어도 하나의 실시형태에서, 양태에서, R2는 수소일 수 있고, R4, R5, R6 또는 R7 중 단 2개만이 치환되며, 여기서 제1 치환기는 (i) 할로겐 원자, (ii) 프레닐기, 및 (iii) 니트릴기로부터 선택되고, 제2 치환기는 (i) 하이드록시기, (ii) 니트로기, (iii) 글리코실옥시기, (iv) 아미노기 또는 N-치환된 아미노기, (v) 카르복실기 또는 카르복실산 유도체, 및 (vi) 알데히드 또는 케톤기로부터 선택된다.
적어도 하나의 실시형태에서, 양태에서, R2는 수소일 수 있고, R4, R5, R6 또는 R7 중 단 2개만이 치환되며, 여기서 제1 치환기는 할로겐 원자이고, 제2 치환기는: (i) 아미노기 또는 N-치환된 아미노기, (ii) 니트릴기, (iii) 니트로기, (iv) 하이드록시기 및 (v) 프레닐기로부터 선택될 수 있는 것으로부터 선택된다.
적어도 하나의 실시형태에서, 양태에서, R2는 수소일 수 있고, R4, R5, R6 또는 R7 중 단 2개만이 치환되며, 여기서 제1 치환기는 프레닐기이고, 제2 치환기는: (i) 카르복실기 또는 카르복실산 유도체, (ii) 할로겐, 및 (iii) 하이드록시기로부터 선택되며, 여기서 R2는 수소 원자일 수 있고, R4, R5, R6 또는 R7 중 2개는 치환기일 수 있다.
적어도 하나의 실시형태에서, 양태에서, R2는 수소일 수 있고, R4, R5, R6 또는 R7 중 2개만이 치환되며, 여기서 제1 치환기는 할로겐 원자이고, 제2 치환기는 프레닐기이다.
적어도 하나의 실시형태에서, 양태에서, R2는 수소일 수 있고, R4, R5, R6 또는 R7 중 2개만이 치환되며, 여기서 제1 치환기는 니트릴기이고, 제2 치환기는 아미노기 또는 N-치환된 아미노기이다.
적어도 하나의 실시형태에서, 양태에서, R5는 카르복실기 또는 아세틸기일 수 있고, R7은 아미노기, 니트릴기, 하이드록시기 또는 할로겐일 수 있다.
적어도 하나의 실시형태에서, 양태에서, R5는 아세트아미딜기일 수 있고, R7은 알데히드기, 카르복실기, 또는 카르복시에스테르일 수 있다.
적어도 하나의 실시형태에서, 양태에서, R5는 아세트아미딜기일 수 있고, R6은 아미노기, 니트로기 또는 할로겐일 수 있고, R7은 알데히드기, 카르복실기 또는 카르복시에스테르일 수 있다.
적어도 하나의 실시형태에서, 양태에서, R5는 카르복시-메틸기 또는 아미드기일 수 있고, R7은 니트로기, 아미노기 또는 할로겐일 수 있다.
적어도 하나의 실시형태에서, 양태에서, R4는 글리코실옥시기일 수 있고, R5는 카르복시-메틸기 또는 아미드기일 수 있고, R7은 니트로기, 및 아미노기 또는 할로겐일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 화학적 화합물(I)은 화학식 (IX), (X), (XI), (XII), (XIII), (XIV), (XV), (XVI), (XVII), (XVIII), (XIX), (XX), (XXI), (XXII), (XXIII), (XXIV), (XXV), (XXVI), (XXVII), (XXVIII), (XXIX), (XXX), (XXXI), (XXXII), (XXXIII), (XXXIV), (XXXV), (XXXVI), (XXXVII), (XXXVIII), (XXXIX), (XL), (XLI), (XLII), (XLIII), (XLIV), (XLV), (XLVI), (XLVII), (XLVIII), (XLIX), (L), (LI), (LII), (LIII), (LIV), (LV) 또는 (LXXVI)를 갖는 화합물로부터 선택될 수 있다:
(IX); (X); (XI); (XII); (XIII); (XIV); (XV); (XVI); (XVII); (XVIII); (XIX); (XX);
(XXI); (XXII); (XXIII); (XXIV); (XXV); (XXVI); (XXVII);(XXVIII);(XXIX);
(XXX); (XXXI); (XXXII);
(XXXIII); (XXXIV); (XXXV); (XXXVI); (XXXVII); (XXXVIII);
(XXXIX); (XL); (XLI);
(XLII); (XLIII); (XLIV); (XLV); (XLVI); (XLVII); (XLVIII); (XLIX); (L); (LI); (LII); (LIII); (LIV); (LV); 및 (LXXVI).
적어도 하나의 실시형태에서, 화학적 화합물(I)은 도 13a, 도 13b 및 도 13c에 도시되고 그 안에서 13A-3, 13A-4, 13A-5, 13A-6, 13A-7, 13A-8, 13A-9, 13A-10, 13B-3, 13B-4, 13B-5, 13B-6, 13B-7, 13B-8, 13B-8, 13C-6, 13C-7, 13C-8, 13C-9, 13C-10, 또는 13C-11로 표시되어 있는 화합물 중 어느 하나일 수 있다.
또 다른 양태에서, 본 개시내용은 실로시빈 유도체 화합물을 포함하는 약학적 및 기분전환용 약물 제형에 관한 것이다. 따라서, 일 양태에서, 본 개시내용은 적어도 하나의 실시형태에서, 유효량의 식 (I)을 갖는 화학적 화합물 또는 이의 염을, 약학적으로 허용가능한 부형제, 희석제 또는 담체와 함께 포함하는 약학적 또는 기분전환용 약물 제형을 제공한다:
(I),
여기서, R2, R4, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 독립적으로 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, O-알킬기, O-아실기 또는 포스페이트기이고, R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, R3c는 수소 원자 또는 카르복실기임.
또 다른 양태에서, 본 개시내용은 정신 장애의 치료 방법에 관한 것이다. 따라서, 본 개시내용은 일 실시형태에서, 정신 장애를 치료하는 방법을 추가로 제공하며, 상기 방법은 식 (I)을 갖는 화학적 화합물 또는 이의 염을 포함하는 약학적 제형을 치료를 필요로 하는 대상체에게 투여하는 것을 포함한다:
(I),
여기서, R2, R4, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 독립적으로 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, O-알킬기, O-아실기 또는 포스페이트기이고, R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, R3c는 수소 원자 또는 카르복실기이고, 여기서 약학적 제형은 대상체에서 정신 장애를 치료하기 위한 유효량으로 투여된다.
적어도 하나의 실시형태에서, 양태에서, 장애는 5-HT2A 수용체 매개된 장애, 또는 5-HT1A 수용체 매개된 장애일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 약 0.001mg 내지 약 5,000mg의 용량이 투여될 수 있다.
또 다른 양태에서, 본 개시내용은 적어도 하나의 실시형태에서, 5-HT2A 수용체 또는 5-HT1A 수용체를 조절하는 방법을 제공하며, 상기 방법은 5-HT2A 수용체 또는 5-HT1A 수용체를 식 (I)을 갖는 화학적 화합물 또는 이의 염과 접촉시키는 것을 포함한다:
(I),
여기서, R2, R4, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 독립적으로 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, O-알킬기, O-아실기 또는 포스페이트기이고, R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, R3c는 수소 원자 또는 카르복실기이다.
적어도 하나의 실시형태에서, 양태에서, 반응 조건은 시험관내 반응 조건일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 반응 조건은 생체내 반응 조건일 수 있다.
또 다른 양태에서, 본 개시내용은 다중 치환기 실로시빈 유도체 화합물을 제조하는 방법에 관한 것이다. 따라서, 일 양태에서, 본 개시내용은 적어도 하나의 실시형태에서, 식 (I)을 갖는 실로시빈 유도체 또는 이의 염을 제조하는 방법을 제공하며:
(I),
여기서, R2, R4, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 독립적으로 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, O-알킬기, O-아실기 또는 포스페이트기이고, R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, R3c는 수소 원자 또는 카르복실기이고, 상기 방법은:
화학식 (II)을 갖는 반응물 실로시빈 유도체:
(II),
를 치환기 함유 화합물과 반응시키는 것을 포함하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자 또는 알코올기이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, 하이드록시기, O-알킬기, O-아실기 또는 포스페이트기이고, R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, R3c는 수소 원자 또는 카르복실기이고,
여기서 치환기 함유 화합물에서 치환기는 화학식 (I)을 갖는 실로시빈 치환기 또는 이의 염을 형성하기에 충분한 반응 조건 하에서 (i) 할로겐 함유 화합물, (ii) 하이드록시기 함유 화합물, (iii) 니트로기 함유 화합물, (iv) 글리코실옥시기 함유 화합물, (v) 아미노기 또는 N-치환된 아미노기 함유 화합물, (vi) 카르복실기 또는 카르복실산 유도체 함유 화합물, (vii) 알데히드 또는 케톤기 함유 화합물, (viii) 프레닐기 함유 화합물, 및 (ix) 니트릴기 함유 화합물로부터 선택된다.
적어도 하나의 실시형태에서, 양태에서, 식 (II)을 갖는 반응물 실로시빈 유도체에서 치환기는 니트로기일 수 있고, 치환기 함유 화합물은 카르복실산 유도체 아세트산 무수물(Ac2O)일 수 있고, 반응물 실로시빈 유도체 및 치환기 함유 화합물은 프리들-크라프트 아실화 반응에서 반응하여 식 (I)을 갖는 제1 실로시빈 유도체를 형성할 수 있으며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 니트로기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 아세틸기이다.
적어도 하나의 실시형태에서, 양태에서, 형성된 제1 실로시빈 유도체는 도 13a에 도시되고 13A-3으로 표지된 화합물일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 식 (I)을 갖는 형성된 제1 실로시빈 유도체는 반응하여 아세틸기를 산화시키고 식 (I)을 갖는 제2 실로시빈 유도체를 형성할 수 있으며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 니트로기일 수 있고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복실기일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 형성된 제2 실로시빈 유도체는 도 13a에 도시되고 13A-4로 표지된 화합물일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 형성된 식 (I)을 갖는 제2 실로시빈 유도체는 반응하여 니트로기를 환원시키고 아미노기, 및 식 (I)을 갖는 제3 실로시빈 유도체를 형성할 수 있으며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아미노기일 수 있고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복실기일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 형성된 제3 실로시빈 유도체는 도 13a에 도시되고 13A-5로 표지된 화합물일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 식 (I)을 갖는 형성된 제3 실로시빈 유도체는 아질산염과 반응하여 디아조늄염에서 아미노기를 전환시키고 식 (I)을 갖는 중간체 실로시빈 유도체를 형성할 수 있으며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 디아조늄기일 수 있고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복실기일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 중간체 형성된 실로시빈 유도체는 도 13a에 도시되고 13A-6으로 표지된 화합물일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 식 (I)을 갖는 중간체 형성된 실로시빈 유도체는 니트릴 함유 화합물과 반응하여 디아조늄기를 전환시키고 식 (I)을 갖는 제4 실로시빈 유도체를 형성할 수 있으며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 니트릴기일 수 있고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복실기일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 형성된 제4 실로시빈 유도체는 도 13a에 도시되고 13A-7로 표지된 화합물일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 식 (I)을 갖는 중간체 형성된 실로시빈 유도체는 물과 반응하여 디아조늄기를 전환시키고 식 (I)을 갖는 제5 실로시빈 유도체를 형성할 수 있으며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 하이드록시기일 수 있고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복실기일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 형성된 제5 실로시빈 유도체는 도 13a에 도시되고 13A-8로 표지된 화합물일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 식 (I)을 갖는 중간체 형성된 실로시빈 유도체는 할로겐 함유 화합물과 반응하여 디아조늄기를 전환시키고 식 (I)을 갖는 제6 실로시빈 유도체를 형성할 수 있으며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 할로겐 원자일 수 있고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복실기일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 형성된 제6 실로시빈 유도체는 도 13a에 도시되고 13A-9 또는 13A-10으로 표지된 화합물일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 식 (II)을 갖는 반응물 실로시빈 유도체에서 치환기는 메톡시카르보닐기일 수 있고, 치환기 함유 화합물은 할로겐 함유 화합물 N-할로-숙신이미드일 수 있고, 반응물 실로시빈 유도체와 치환기 함유 화합물은 반응하여 식 (I)을 갖는 제1 실로시빈 유도체를 형성할 수 있으며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 메톡시 카르보닐기일 수 있고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 할로겐 원자일 수 있다.
적어도 하나의 실시형태에서, 양태에서, N-할로-숙신이미드는 N-클로로-숙신이미드일 수 있고, 형성된 제1 실로시빈 유도체는 도 13b에 도시되고 13B-3으로 표지된 화합물일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 식 (II)을 갖는 반응물 실로시빈 유도체에서 치환기는 메톡시카르보닐기일 수 있고, 치환기 함유 화합물은 니트로 함유 화합물 니트로늄 테트라플루오로보레이트일 수 있고, 반응물 실로시빈 유도체와 치환기 함유 화합물은 반응하여 식 (I)을 갖는 제2 실로시빈 유도체를 형성할 수 있으며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 메톡시 카르보닐기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 니트로기다.
적어도 하나의 실시형태에서, 양태에서, 형성된 제2 실로시빈 유도체는 도 13b에 도시되고 13B-4로 표지된 화합물일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 식 (I)을 갖는 형성된 제1 실로시빈 유도체는 아세틸화된 글리코실 화합물과 반응하여 식 (I)을 갖는 제3 실로시빈 유도체를 형성할 수 있으며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 메톡시 카르보닐기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 글리코실옥시기일 수 있고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 할로겐 원자일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 형성된 제3 실로시빈 유도체는 도 13b에 도시되고 13B-5로 표지된 화합물일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 식 (I)을 갖는 형성된 제2 실로시빈 유도체는 아세틸화된 글리코실 화합물과 반응하여 식 (I)을 갖는 제4 실로시빈 유도체를 형성할 수 있으며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 메톡시카르보닐기일 수 있고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 글리코실옥시기일 수 있고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 니트로기일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 형성된 제4 실로시빈 유도체는 도 13b에 도시되고 13B-6으로 표지된 화합물일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 식 (I)을 갖는 형성된 제3 실로시빈 유도체는 암모니아와 반응하여 아미도기에서의 메톡시카르보닐기를 전환시키고 식 (I)을 갖는 제5 실로시빈 유도체를 형성할 수 있으며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아미도기일 수 있고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 글리코실옥시기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 할로겐 원자일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 형성된 제5 실로시빈 유도체는 도 13b에 도시되고 13B-7로 표지된 화합물일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 식 (I)을 갖는 형성된 제4 실로시빈 유도체는 암모니아와 반응하여 아미도기에서의 메톡시카르보닐기를 전환시키고 식 (I)을 갖는 제6 실로시빈 유도체를 형성할 수 있으며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아미도기일 수 있고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 글리코실옥시기일 수 있고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 니트로기이다.
적어도 하나의 실시형태에서, 양태에서, 형성된 제6 실로시빈 유도체는 도 13b에 도시되고 13B-8로 표지된 화합물일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 식 (I)을 갖는 형성된 제6 실로시빈 유도체는 반응하여 니트로기를 환원시켜 아미노기 및 식 (I)을 갖는 제7 실로시빈 유도체를 형성할 수 있으며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아미도기일 수 있고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 글리코실옥시기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 니트로기일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 형성된 제7 실로시빈 유도체는 도 13b에 도시되고 13B-9로 표지된 화합물일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 식 (II)을 갖는 반응물 실로시빈 유도체에서 치환기는 아세트아미딜기일 수 있고, 치환기 함유 화합물은 할로겐 함유 화합물 N-할로-숙신이미드일 수 있고, 반응물 실로시빈 유도체와 치환기 함유 화합물은 반응하여 식 (I)을 갖는 제1 실로시빈 유도체를 형성할 수 있으며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아세트아미딜기일 수 있고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 할로겐 원자일 수 있다.
적어도 하나의 실시형태에서, 양태에서, N-할로-숙신이미드는 N-브로모-숙신이미드(NBS)일 수 있고, 형성된 제1 실로시빈 유도체는 도 13c에 도시되고 13C-6으로 표지된 화합물일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 식 (II)을 갖는 반응물 실로시빈 유도체에서 치환기는 아세트아미딜기일 수 있고, 치환기 함유 화합물은 디메틸 포름아미드일 수 있고, 반응물 실로시빈 유도체와 치환기 함유 화합물은 반응하여 식 (I)을 갖는 중간체 실로시빈 유도체를 형성할 수 있으며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아세트아미딜기고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 메탄올기일 수 있으며, 여기서 중간체 실로시빈 유도체는 반응하여 메탄올기를 산화시킬 수 있고, 식 (I)을 갖는 제2 실로시빈 유도체를 형성할 수 있으며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아세트아미딜기일 수 있고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복시기일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 중간체 실로시빈 유도체는 도 13c에 도시되고 13C-5로 표지된 화합물일 수 있고, 형성된 제2 실로시빈 유도체는 도 13c에 도시되고 13C-7로 표지된 화합물일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 식 (I)을 갖는 형성된 제2 실로시빈 유도체는 알코올과 반응하여 카르복시기를 에스테르화하여 에스테르 및 식 (I)을 갖는 제3 실로시빈 유도체를 형성할 수 있으며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아세트아미딜기일 수 있고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복실 에스테르일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 형성된 제3 실로시빈 유도체는 도 13c에 도시되고 13C-8로 표지된 화합물일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 식 (I)을 갖는 형성된 제3 실로시빈 유도체는 니트로기 함유 화합물과 반응하여 식 (I)을 갖는 제4 실로시빈 유도체를 형성할 수 있으며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아세트아미딜기일 수 있고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복실 에스테르일 수 있고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 니트로기일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 형성된 제4 실로시빈 유도체는 도 13c에 도시되고 13C-9로 표지된 화합물일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 식 (I)을 갖는 형성된 제4 실로시빈 유도체는 반응하여 니트로기를 환원시켜 아미노기 및 식 (I)을 갖는 제5 실로시빈 유도체를 형성할 수 있으며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아세트아미딜기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복실 에스테르이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 아미노기이다.
적어도 하나의 실시형태에서, 양태에서, 형성된 제5 실로시빈 유도체는 도 13c에 도시되고 13C-10으로 표지된 화합물일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 식 (I)을 갖는 형성된 제5 실로시빈 유도체는 암모니아와 반응하여 아미도기 및 식 (I)을 갖는 제6 실로시빈 유도체를 형성할 수 있으며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아세트아미딜기일 수 있고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복시에스테르이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 아미도기일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 형성된 제6 실로시빈 유도체는 도 13c에 도시되고 13C-11로 표지된 화합물일 수 있다.
또 다른 양태에서, 본 개시내용은 다중 치환기 실로시빈 유도체를 제조하는 추가 방법에 관한 것이다. 따라서, 일 양태에서, 본 개시내용은 적어도 하나의 양태에서, 다중 치환기 실로시빈 유도체를 제조하는 방법을 제공하며, 상기 방법은 식 (LVII)을 갖는 실로시빈 유도체 전구체 화합물:
(LVII)
을 실로시빈 유도체 전구체 화합물의 효소 촉매된 전환을 허용하는 반응 조건 하에서 촉매적 양의 실로시빈 생합성 효소 보체와 접촉시켜, 식 (I)을 갖는 다중 치환기 실로시빈 유도체 화합물을 형성하는 것을 포함하고,
여기서 R2, R4, R5, R6, 또는 R7 중 적어도 하나는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우, R4는 수소 원자, O-알킬기, O-아실기, 또는 포스페이트기이고, 여기서 R3은 수소 원자 또는 -CH2-CHNH2COOH 또는 -CH2-CH2NH2이고,
(I),
여기서, R2, R4, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 독립적으로 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, O-알킬기, O-아실기 또는 포스페이트기이고, R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, R3c는 수소 원자 또는 카르복실기이다.
적어도 하나의 실시형태에서, 양태에서, 반응 조건은 시험관내 반응 조건일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 반응 조건은 생체내 반응 조건일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 유도체 전구체 화합물과 치환기 함유 화합물은 숙주 세포에서 실로시빈 생합성 효소 보체와 접촉될 수 있으며, 여기서 숙주 세포는 작동가능하게 연결된 구성요소로서:
(i) 숙주 세포에서 발현을 조절하는 핵산 서열; 및
(ii) 실로시빈 생합성 효소 보체를 인코딩하는 핵산 서열을 포함하는 키메라 핵산 서열을 포함할 수 있고,
숙주 세포는 성장하여 실로시빈 생합성 효소 보체를 발현하고 다중 치환기 실로시빈 유도체 화합물을 생산할 수 있다.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 다음으로부터 선택된 핵산에 의해 인코딩되는 적어도 하나의 효소를 포함할 수 있다:
(a) 서열번호: 1, 서열번호: 3, 서열번호: 5, 서열번호: 7, 서열번호: 9, 서열번호: 11, 서열번호: 13, 서열번호: 15, 서열번호: 17, 서열번호: 19, 서열번호: 21, 서열번호: 23, 서열번호: 25, 및 서열번호: 48;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 2, 서열번호: 4, 서열번호: 6, 서열번호: 8, 서열번호: 10, 서열번호: 12, 서열번호: 14, 서열번호: 16, 서열번호: 18, 서열번호: 20, 서열번호: 22, 서열번호: 서열번호: 24, 서열번호: 26, 및 서열번호: 49에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 2, 서열번호: 4, 서열번호: 6, 서열번호: 8, 서열번호: 10, 서열번호: 12, 서열번호: 14, 서열번호: 16, 서열번호: 18, 서열번호: 20, 서열번호: 22, 서열번호: 24, 서열번호: 26, 및 서열번호: 49에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 다음으로부터 선택된 핵산에 의해 인코딩되는 트립토판 신타제 서브유닛 B 폴리펩티드를 포함할 수 있다:
(a) 서열번호: 1;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 2에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 2에 제시된 아미노산 서열의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열,
여기서 식 (LVII)을 갖는 실로시빈 유도체 전구체 화합물에서, R2, R4, R5, R6, 또는 R7 중 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 독립적으로 선택된 치환기이고, 여기서 R3은 수소 원자이고, 여기서 R3c가 카르복실기인 식 (I)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물이 형성된다.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 유도체 전구체 화합물은 식 (LVIII)을 갖는 화학적 화합물일 수 있다:
(LVIII),
여기서 R4는 하이드록시기고, R6은 염소 원자이고, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LV)를 가짐:
(LV).
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 R3 -CH2-CHNH2COOH 기를 탈카르복실화시키기 위한 트립토판 데카르복실라제를 추가로 포함할 수 있고, 이에 의해 식 (I)을 갖는 제2 다중 치환기 실로시빈 유도체를 형성할 수 있으며 여기서 R3a 및 R3b는 각각 수소 원자이고, 트립토판 데카르복실라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 3, 서열번호: 5, 및 서열번호: 7;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 4, 서열번호: 6, 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 4, 서열번호: 6 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 유도체 전구체 화합물은 식 (LVIII)을 갖는 화학적 화합물일 수 있다:
(LVIII),
여기서 R4는 불소 원자, 아미노기 또는 하이드록시기이고, R6은 불소 원자, 아미노기, 니트릴 또는 브롬 원자이고, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LIX)을 가지며:
(LIX),
여기서 R4는 불소 원자, 아미노기, 또는 하이드록시기이고, R6은 불소 원자, 아미노기, 니트릴 또는 브롬 원자이고, 제2 다중 치환기 실로시빈 유도체는 식 (XXII), (XXVI), (XXIX), (LII) 또는 (LIV)를 가짐:
(XXII); (XXVI); (XXIX); (LII); 또는 (LIV).
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 화학식 (I)을 갖는 제2 실로시빈 유도체를 아세틸화하기 위한 N-아세틸 트랜스퍼라제를 추가로 포함할 수 있고 이에 의해 화학식 (I)을 갖는 제3 다중 치환기 실로시빈을 형성하며, 여기서 R3a는 수소 원자이고 R3b는 아세틸기이고, N-아세틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 9;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 10에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 10에 제시된 아미노산 서열의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 유도체 전구체 화합물은 식 (LVIII)을 갖는 화학적 화합물일 수 있다:
(LVIII),
여기서 R4는 아세트아미딜기, 불소 원자, 아미노기 또는 하이드록시기이고, R6은 불소 원자, 아미노기, 니트릴 또는 브롬 원자이고, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LIX)을 가지며:
(LIX),
여기서 R4는 아세트아미딜기, 불소 원자, 아미노기 또는 하이드록시기이고, R6은 불소 원자, 아미노기, 니트릴 또는 브롬 원자이고, 여기서 제2 다중 치환기 실로시빈 유도체는 식 (LX)을 가지고:
(LX),
그리고 여기서 제3 다중 치환기 실로시빈 유도체는 식 (IX), (X), (XVIII), (XXI), (XXV) 또는 (XXVIII)을 가짐:
(IX); (X); (XVIII); (XXI); (XXV); 또는 (XXVIII).
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 R3에서 R3 아미노기를 메틸화하고 화학식 (I)을 갖는 제4 다중 치환기 실로시빈 유도체를 형성하기 위한 N-메틸 트랜스퍼라제를 추가로 포함할 수 있으며, 여기서, R3a 및 R3b는 각각 메틸기이거나, R3a는 수소 원자이고 R3b는 메틸기이고, N-메틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 11 및 서열번호: 13;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 유도체 전구체 화합물은 식 (LVIII)을 갖는 화학적 화합물일 수 있다:
(LVIII),
여기서 R4는 아미노기 또는 하이드록시기이고, R6은 염소 원자, 니트릴기 또는 브롬 원자이고, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LIX)을 가지며:
(LIX),
여기서 R4는 아미노기 또는 하이드록시기이고, R6은 염소 원자, 니트릴기 또는 브롬 원자이고, 여기서 제2 다중 치환기 실로시빈 유도체는 식 (LX)를 가지며:
(LX),
그리고 여기서 제4 다중 치환기 실로시빈 유도체는 식 (XXVII), (XL) 또는 (LIII)을 가짐:
(XXVII);(XL); 또는 (LIII).
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 다음으로부터 선택된 핵산에 의해 인코딩되는 프레닐 트랜스퍼라제를 포함할 수 있다:
(a) 서열번호: 15, 서열번호: 17, 서열번호: 19, 및 서열번호: 21;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 16, 서열번호: 18, 서열번호: 20, 및 서열번호: 22에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 16, 서열번호: 18, 서열번호: 20, 및 서열번호: 22에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열,
여기서, 식 (LVII)을 갖는 실로시빈 유도체 전구체 화합물에서, R2, R4, R5, R6, 또는 R7 중 하나는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 선택된 치환기이고, 여기서 R3은 -CH2-CHNH2COOH이고, 그리고 여기서 R2, R4, R5, R6, 또는 R7 중 적어도 하나는 프레닐기이고, R3c는 수소 원자인, 식 (I)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물이 형성됨.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 유도체 전구체 화합물은 식 (LXI)을 갖는 화학적 화합물일 수 있다:
(LXI);
여기서 R4는 하이드록시기고, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (L)을 가짐:
(L).
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 R3 -CH2-CHNH2COOH 기를 탈카르복실화시키기 위한 트립토판 데카르복실라제를 추가로 포함할 수 있고, 이에 의해 식 (I)을 갖는 제2 다중 치환기 실로시빈 유도체를 형성하며 여기서 R3a 및 R3b는 각각 수소 원자이고, 트립토판 데카르복실라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 3, 서열번호: 5, 및 서열번호: 7;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 4, 서열번호: 6, 서열번호: 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 4, 서열번호: 6 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 R3에서 R3 아미노기를 메틸화하고 화학식 (I)을 갖는 제4 다중 치환기 실로시빈 유도체를 형성하기 위한 N-메틸 트랜스퍼라제를 추가로 포함할 수 있으며, 여기서 R3a 및 R3b는 각각 메틸기이거나, R3a는 수소 원자이고 R3b는 메틸기이고, N-메틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 11, 및 서열번호: 13;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 유도체 전구체 화합물은 식 (LXI)을 갖는 화학적 화합물일 수 있다:
(LXI),
여기서 R4는 프로피오닐옥시 또는 아세톡시기고, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LIX)을 가지며:
(LIX),
여기서 R4는 프로피오닐옥시 또는 아세톡시기이고, R6은 프레닐기이고, 그리고 여기서 제2 다중 치환기 실로시빈 유도체는 다음 식을 가지며:
(LX),
여기서 R4는 프로피오닐옥시 또는 아세톡시기이고, R6은 프레닐기이고, 그리고 여기서 제3 다중 치환기 실로시빈 유도체는 식 (XLI) 또는 (XLII)을 가짐:
(XLI); 또는 (XLII).
적어도 하나의 실시형태에서, 양태에서, 실로시빈 유도체 전구체 화합물은 식 (LXII)을 갖는 화학적 화합물일 수 있다:
(LXII),
여기서 R5는 염소 또는 불소 원자이고, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXIII)을 가지며:
(LXIII),
여기서 R5는 염소 또는 불소 원자이고, R6은 프레닐기이고, 그리고 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (XXXVI) 및 (XXXVIII)을 가짐:
(XXXVI); 및 (XXXVIII).
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 화학식 (I)을 갖는 제2 실로시빈 유도체를 아세틸화하고 이에 의해 식 (I)을 갖는 제3 다중 치환기 실로시빈을 형성하기 위해 N-아세틸 트랜스퍼라제를 추가로 포함할 수 있으며, 여기서 R3a는 수소 원자이고 R3b는 아세틸기이고, N-아세틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 9;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 10에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 10에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 유도체 전구체 화합물은 식 (LXI)을 갖는 화학적 화합물일 수 있다:
(LXI),
여기서 R5는 염소 또는 불소 원자이고, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXIII)을 가지며:
(LXIII),
여기서 R5는 염소 또는 불소 원자이고, R6은 프레닐기이고, 그리고 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXIV)을 가지며:
(LXIV),
여기서 R5는 염소 또는 불소 원자이고, R6은 프레닐기이고, 그리고 여기서 제3 다중 치환기 실로시빈 유도체는 식 (XXXV) 또는 (XXXVII)을 가짐:
(XXXV); 또는 (XXXVII).
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 다음으로부터 선택된 핵산에 의해 인코딩되는 트립토판 신타제 서브유닛 B 폴리펩티드를 포함할 수 있다:
(a) 서열번호: 1;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 2에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 2에 제시된 아미노산 서열의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열,
여기서 식 (LVIII)을 갖는 실로시빈 유도체 전구체 화합물에서, R2, R4, R5, R6, 또는 R7 중 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 독립적으로 선택된 치환기이며, 여기서 R3은 수소 원자이고, 그리고 여기서 R3c가 카르복실기인 식 (I)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물이 형성된다.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 유도체 전구체 화합물은 식 (LXV)을 갖는 화학적 화합물일 수 있다:
(LXV),
여기서 R4는 하이드록시기고, R5는 프레닐기이고, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LI)을 가짐:
(LI).
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 R3 -CH2-CHNH2COOH 기를 탈카르복실화시키기 위한 트립토판 데카르복실라제를 추가로 포함할 수 있고, 이에 의해 식 (I)을 갖는 제2 다중 치환기 실로시빈 유도체를 형성하며 여기서 R3a 및 R3b는 각각 수소 원자이고, 트립토판 데카르복실라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 3, 서열번호: 5, 및 서열번호: 7;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 4, 서열번호: 6, 서열번호: 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 4, 서열번호: 6 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 유도체 전구체 화합물은 식 (LXV)을 갖는 화학적 화합물일 수 있다:
(LXV),
여기서 R4는 불소 원자이고 R5는 니트릴기이고, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXIX)을 가지며:
(LXIX),
여기서 R4는 불소 원자이고 여기서 R5는 니트릴기이고, 그리고 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (XIX)을 가짐:
(XIX).
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 화학식 (I)을 갖는 제2 실로시빈 유도체를 아세틸화하기 위한 N-아세틸 트랜스퍼라제를 추가로 포함할 수 있고 이에 의해 화학식 (I)을 갖는 제3 다중 치환기 실로시빈을 형성하며, 여기서 R3a는 수소 원자이고 R3b는 아세틸기이고, N-아세틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 9;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 10에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 10에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 유도체 전구체 화합물은 식 (LXV)을 갖는 화학적 화합물일 수 있다:
(LXV),
여기서 R4는 불소 원자이고 R5는 하이드록시기 또는 니트릴기고, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXIX)을 가지며:
(LXIX),
여기서 R4는 불소 원자이고 여기서 R5는 하이드록시기 또는 니트릴기고, 그리고 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXXII)을 가지며:
(LXXII),
여기서 R4는 불소 원자이고, 여기서 R5는 하이드록시기 또는 니트릴기고, 그리고 여기서 제3 다중 치환기 실로시빈 유도체는 식 (XVII) 또는 (XX)을 가짐:
(XVII); 또는 (XX).
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 다음으로부터 선택된 핵산에 의해 인코딩되는 트립토판 신타제 서브유닛 B 폴리펩티드를 포함할 수 있다:
(a) 서열번호: 1;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 2에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 2에 제시된 아미노산 서열의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열,
여기서 식 (LVIII)을 갖는 실로시빈 유도체 전구체 화합물에서, R2, R4, R5, R6, 또는 R7 중 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 독립적으로 선택된 치환기이고, 여기서 R3은 수소 원자이고, 그리고 여기서 R3c가 카르복실기인 식 (I)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물이 형성된다.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 유도체 전구체 화합물은 식 (LXVI)을 갖는 화학적 화합물일 수 있다:
(LXVI),
여기서 R4는 하이드록시기고, R7은 프레닐기이고, 그리고 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (XLIX)을 가짐:
(XLIX).
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 R3 -CH2-CHNH2COOH 기를 탈카르복실화시키기 위한 트립토판 데카르복실라제를 추가로 포함할 수 있고, 이에 의해 식 (I)을 갖는 제2 다중 치환기 실로시빈 유도체를 형성하며 여기서 R3a 및 R3b는 각각 수소 원자이고, 트립토판 데카르복실라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 3, 서열번호: 5, 및 서열번호: 7;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 4, 서열번호: 6, 서열번호: 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 4, 서열번호: 6 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 유도체 전구체 화합물은 식 (LXVI)을 갖는 화학적 화합물일 수 있다:
(LXVI),
여기서 R4는 불소 원자이고 R7은 니트릴기이고, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXX)을 가지며:
(LXX),
여기서 R4는 불소 원자이고 여기서 R7은 니트릴기이고, 그리고 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (XXIV)을 가짐:
(XXIV).
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 화학식 (I)을 갖는 제2 실로시빈 유도체를 아세틸화하기 위한 N-아세틸 트랜스퍼라제를 추가로 포함할 수 있고 이에 의해 화학식 (I)을 갖는 제3 다중 치환기 실로시빈을 형성하며, 여기서 R3a는 수소 원자이고 R3b는 아세틸기이고, N-아세틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 9;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 10에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 10에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 유도체 전구체 화합물은 식 (LXVI)을 갖는 화학적 화합물일 수 있다:
(LXVI),
여기서 R4는 불소 원자 또는 염소 원자이고 R7은 프레닐기 또는 니트릴기이고, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXX)을 가지며:
(LXX),
여기서 R4는 불소 원자 또는 염소 원자이고 여기서 R7은 프레닐기 또는 니트릴기이고, 그리고 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXXIII)을 가지며:
(LXXIII),
여기서 R4는 불소 원자 또는 염소 원자이고, 여기서 R7은 프레닐기 또는 니트릴기이고, 그리고 여기서 제3 다중 치환기 실로시빈 유도체는 식 (XXIII) 또는 (XX)을 가짐:
(XXIII); 또는 (XXXIV).
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 R3에서 R3 아미노기를 메틸화하고 추가로 화학식 (I)을 갖는 다중 치환기 실로시빈 유도체를 형성하기 위한 N-메틸 트랜스퍼라제를 추가로 포함할 수 있으며, 여기서 R3a 및 R3b는 각각 메틸기이거나, R3a는 수소 원자이고 R3b는 메틸기이고, N-메틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 11, 및 서열번호: 13;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 유도체 전구체 화합물은 식 (LXVI)을 갖는 화학적 화합물일 수 있다:
(LXVI),
여기서 R4는 염소 원자이고 R7은 하이드록시기이고, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXX)을 가지며:
(LXX),
여기서 R4는 하이드록시기고, 여기서 R7은 염소 원자이고, 그리고 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXXIII)을 가지며:
(LXXIII),
여기서 R4는 하이드록시기고, 여기서 R7은 염소 원자이고, 그리고 여기서 제3 다중 치환기 실로시빈 유도체는 식 (XXXIX)을 가짐:
(XXXIX).
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 다음으로부터 선택된 핵산에 의해 인코딩되는 트립토판 신타제 서브유닛 B 폴리펩티드를 포함할 수 있다:
(a) 서열번호: 1;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 2에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 2에 제시된 아미노산 서열의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열,
여기서 식 (LVIII)을 갖는 실로시빈 유도체 전구체 화합물에서, R2, R4, R5, R6, 또는 R7 중 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 독립적으로 선택된 치환기이며, 여기서, R3은 수소 원자이고, 여기서 R3c가 카르복실기인 식 (I)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물이 형성되고, 실로시빈 생합성 효소 보체는 제1 다중 치환기 실로시빈 유도체 화합물의 R3 -CH2-CHNH2COOH 기를 탈카르복실화시키기 위한 트립토판 데카르복실라제를 추가로 포함하고, 이에 의해 식 (I)을 갖는 제2 다중 치환기 실로시빈 유도체를 형성하며 여기서 R3a 및 R3b는 각각 수소 원자이며, 트립토판 데카르복실라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 3, 서열번호: 5, 및 서열번호: 7;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 4, 서열번호: 6, 서열번호: 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 4, 서열번호: 6 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 유도체 전구체 화합물은 식 (LXVII)을 갖는 화학적 화합물일 수 있다:
(LXVII),
여기서 R5는 불소 원자, 염소 원자 또는 니트릴기이고, R6은 불소 원자, 아미노기 또는 프레닐기이고, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXIII)을 가지며:
(LXIII),
여기서 R5는 불소 원자, 염소 원자 또는 니트릴기이고, 여기서 R6은 불소 원자, 아미노기 또는 프레닐기이고, 그리고 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (XI), (XVI), (XXXVI) 또는 (XXXVIII)을 가짐:
(XI); (XVI); (XXXVI); 또는 (XXXVIII).
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 화학식 (I)을 갖는 제2 실로시빈 유도체를 아세틸화하기 위한 N-아세틸 트랜스퍼라제를 추가로 포함할 수 있고 이에 의해 화학식 (I)을 갖는 제3 다중 치환기 실로시빈을 형성하며, 여기서 R3a는 수소 원자이고 R3b는 아세틸기이고, N-아세틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 9;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 10에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 10에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 유도체 전구체 화합물은 식 (LXVII)을 갖는 화학적 화합물일 수 있다:
(LXVII),
여기서 R5는 불소 원자 또는 염소 원자이고 R6은 아미노기, 아세트아미딜기 또는 프레닐기이고, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXIII)을 가지며:
(LXIII),
여기서 R5는 불소 원자 또는 염소 원자이고, 여기서 R6은 아미노기, 아세트아미딜기 또는 프레닐기이고, 그리고 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXXIV)을 가지며:
(LXXIV),
여기서 R5는 불소 원자 또는 염소 원자이고, 여기서 R6은 아미노기, 아세트아미딜기 또는 프레닐기이고, 그리고 여기서 제3 다중 치환기 실로시빈 유도체는 식 (XIV), (XV), (XXXV) 또는 (XXXVII)을 가짐:
(XIV); (XV); (XXXV); 또는 (XXXVII).
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 R3에서 R3 아미노기를 메틸화하고 화학식 (I)을 갖는 제4 다중 치환기 실로시빈 유도체를 형성하기 위한 N-메틸 트랜스퍼라제를 추가로 포함할 수 있으며, 여기서 R3a 및 R3b는 각각 메틸기이거나, 또는 여기서 R3a는 수소 원자이고 R3b는 메틸기이고, N-메틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 11, 및 서열번호: 13;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 유도체 전구체 화합물은 식 (LXVII)을 갖는 화학적 화합물일 수 있다:
(LXVII),
여기서 R5는 염소 원자이고 R6은 프레닐기이고, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXIII)을 가지며:
(LXIII),
여기서 R5는 염소 원자이고, 여기서 R6은 프레닐기이고, 그리고 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXXIV)을 가지며:
(LXXIV),
여기서 R5는 염소 원자이고, R6은 프레닐기이고, 그리고 여기서 제3 다중 치환기 실로시빈 유도체는 식 (XLIV)을 가짐:
(XLIV).
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 다음으로부터 선택된 핵산에 의해 인코딩되는 트립토판 신타제 서브유닛 B 폴리펩티드를 포함할 수 있다:
(a) 서열번호: 1;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 2에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 2에 제시된 아미노산 서열의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열,
여기서 식 (LVIII)을 갖는 실로시빈 유도체 전구체 화합물에서, R2, R4, R5, R6, 또는 R7 중 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 독립적으로 선택된 치환기이며, 여기서 R3은 수소 원자이고, 여기서 R3c가 카르복실기인 식 (I)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물이 형성되고, 실로시빈 생합성 효소 보체는 제1 다중 치환기 실로시빈 유도체 화합물의 R3 -CH2-CHNH2COOH 기를 탈카르복실화시키기 위한 트립토판 데카르복실라제를 추가로 포함하고, 이에 의해 식 (I)을 갖는 제2 다중 치환기 실로시빈 유도체를 형성하며 여기서 R3a 및 R3b는 각각 수소 원자이고, 트립토판 데카르복실라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 3, 서열번호: 5, 및 서열번호: 7;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 4, 서열번호: 6, 서열번호: 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 4, 서열번호: 6 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 유도체 전구체 화합물은 식 (LXVIII)을 갖는 화학적 화합물일 수 있다:
(LXVIII),
여기서 R5는 불소 원자이고, R7은 니트로기 또는 프레닐기이고, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXXI)을 가지며:
(LXXI),
여기서 R5는 불소 원자이고, 여기서 R7은 니트로기 원자 또는 프레닐기이고, 그리고 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (XIII) 또는 (XXXIII)을 가짐:
(XIII); 또는 (XXXIII).
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 화학식 (I)을 갖는 제2 실로시빈 유도체를 아세틸화하기 위한 N-아세틸 트랜스퍼라제를 추가로 포함할 수 있고 이에 의해 화학식 (I)을 갖는 제3 다중 치환기 실로시빈을 형성하며, 여기서 R3a는 수소 원자이고 R3b는 아세틸기이고, N-아세틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 9;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 10에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 10에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
적어도 하나의 실시형태에서, 양태에서, 실로시빈 유도체 전구체 화합물은 식 (LXVIII)을 갖는 화학적 화합물일 수 있다:
(LXVIII),
여기서 R5는 불소 원자이고, R7은 니트로기 또는 프레닐기이고, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXXI)을 가지며:
(LXXI),
여기서 R5는 불소 원자이고, 여기서 R7은 니트로기 원자 또는 프레닐기이고, 그리고 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXXV)을 가지며:
(LXXV),
여기서 R5는 불소 원자이고, 여기서 R7은 니트로기 또는 프레닐기이고, 그리고 여기서 제3 다중 치환기 실로시빈 유도체는 식 (XII) 또는 (XXXII)을 가짐:
(XII); 또는 (XXXII).
적어도 하나의 실시형태에서, 양태에서, 실로시빈 생합성 효소 보체는 다음으로부터 선택된 핵산에 의해 인코딩된 프레닐 트랜스퍼라제를 함유할 수 있다:
(a) 서열번호: 15, 서열번호: 17, 서열번호: 19, 및 서열번호: 21;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 16, 서열번호: 18, 서열번호: 20, 및 서열번호: 22에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 16, 서열번호: 18, 서열번호: 20, 및 서열번호: 22에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열,
여기서 식 (LVIII)을 갖는 실로시빈 유도체 전구체 화합물에서, R2, R4, R5, R6, 또는 R7 중 하나는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 선택된 치환기이며, 여기서 R3은 수소 원자이고, 여기서 R3c가 카르복실 기 또는 수소 원자인 식 (I)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물이 형성된다.
적어도 하나의 실시형태에서, 식 (LXXVII)을 갖는 실로시빈 유도체 전구체 화합물:
(LXXVII),
및 제1 다중 치환기 실로시빈 유도체 화합물은 식 (LXXVI)을 갖는다:
(LXXVI).
적어도 하나의 실시형태에서, 양태에서, 방법은 다중 치환기 실로시빈 유도체 화합물을 숙주 세포 및/또는 숙주 세포 배지로부터 단리하는 것을 포함하는 단계를 추가로 포함할 수 있다.
적어도 하나의 실시형태에서, 양태에서, 숙주 세포는 미생물일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 숙주 세포는 박테리아 세포 또는 효모 세포일 수 있다.
적어도 하나의 실시형태에서, 양태에서, 숙주 세포는 대장균 세포 또는 사카로마이세스 세레비시애 세포일 수 있다.
또 다른 양태에서 본 개시내용은, 적어도 하나의 실시형태에서, 의약품 또는 기분전환용 약물 제형의 제조에서, 식 (I)을 갖는 화학적 화합물 또는 이의 염의 용도를 제공한다:
(I),
여기서, R2, R4, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 독립적으로 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, O-알킬기, O-아실기 또는 포스페이트기이고, 여기서 R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, R3c는 수소 원자 또는 카르복실기임.
적어도 하나의 실시형태에서 제조는 부형제, 희석제 또는 담체와 화학적 화합물을 제형화하는 것을 포함할 수 있다.
또 다른 양태에서 본 개시내용은, 적어도 하나의 실시형태에서, 의약품 또는 기분전환용 약물 제형으로서 희석제, 담체 또는 부형제와 함께, 식 (I)을 갖는 화학적 화합물 또는 이의 염의 용도를 제공한다:
(I),
여기서, R2, R4, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 독립적으로 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, O-알킬기, O-아실기 또는 포스페이트기이고, 여기서 R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, R3c는 수소 원자 또는 카르복실기임.
다른 특징과 장점은 다음 상세한 설명으로부터 명백해질 것이다. 그러나, 상세한 설명은 개시내용의 바람직한 구현을 나타내기는 하지만, 개시내용의 사상 및 범주 내에서 다양한 변경 및 변형이 상세한 설명으로부터 당업자에게 명백할 것이기 때문에, 단지 예시로서만 제공되는 것으로 이해되어야 한다.
개시내용은 첨부된 도면과 관련하여 예로서 기술되는 이하 제공된 단락에 있다. 본 명세서에 제공된 도면은 예시적인 실시형태를 더 잘 이해하고 다양한 실시형태가 어떻게 효과적으로 실행될 수 있는지 더 명확하게 보여주기 위해 제공된다. 도면은 본 개시내용을 제한하려는 의도가 아니다.
도 1은 실로시빈의 화학 구조를 도시한다.
도 2는 실로시빈 및 실로시빈 유도체 화합물, 즉 인돌의 특정 원형 구조를 도시한다. 특정 탄소 및 질소 원자는 인돌 구조 내의 그 위치, 즉 N1, C2, C3 등을 참조하여 본 명세서에서 지칭될 수 있다. 적절한 원자 넘버링이 표시되어 있다.
도 3a, 3b, 3c, 3d, 3e, 3f, 3g, 3h, 3i, 3j, 3k 및 3l은 특정 예의 실로시빈 유도체, 특히 2,5-디-S1,S2-실로시빈 유도체(도 3a), 2,5-디-S2,S1-실로시빈 유도체(도 3b), 2,6-디-S1,S2-실로시빈 유도체(도 3c), 2,6-디-S2,S1-실로시빈 유도체(도 3d), 2,7-디-S1,S2-실로시빈 유도체(도 3e), 2,7-디-S2,S1-실로시빈 유도체(도 3f), 5,6-디-S1,S2-실로시빈 유도체(도 3g), 5,6-디-S2,S1-실로시빈 유도체(도 3h), 5,7-디-S1,S2-실로시빈 유도체(도 3i), 5,7-디-S2,S1-실로시빈 유도체(도 3j), 6,7-디-S1,S2-실로시빈 유도체(도 3k) 및 6,7-디-S2,S1-실로시빈 유도체(도 3l)의 화학 구조를 도시한다. 전술한 S1 및 S2 각각은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택된다. 각각의 도 3a - 3l에서, R3a 및 R3b는 각각 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기일 수 있고, R3c는 수소 원자 또는 카르복실기일 수 있다는 것이 인지된다.
도 4a, 4b, 4c, 4d, 4e 및 4f는 특정한 예의 실로시빈 유도체, 특히 2,5,6-트리-S1,S2,S3-실로시빈 유도체(도 4a), 2,5,6-트리-S1,S3,S2-실로시빈 유도체(도 4b), 2,5,6-트리-S3,S1,S2-실로시빈 유도체(도 4c), 2,5,6-트리-S2,S1,S3-실로시빈 유도체(도 4d), 2,5,6-트리-S3,S2,S1-실로시빈 유도체(도 4e), 및 2,5,6-트리-S2, S3,S1-실로시빈 유도체(도 4f)의 화학 구조를 도시한다. 전술한 S1, S2 및 S3 각각은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 3개로부터 선택된다. 각각의 도 4a - 4f에서, R3a 및 R3b는 각각 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기일 수 있고, R3c는 수소 원자 또는 카르복실기일 수 있다는 것이 인지된다.
도 4g, 4h 및 4i는 특정한 예의 실로시빈 유도체, 특히 2,5,6-트리-S1,S2,S2-실로시빈 유도체(도 4g), 2,5,6-트리-S2,S1,S2-실로시빈 유도체(도 4h), 및 2,5,6-트리-S2,S2,S1-실로시빈 유도체(도 4i)의 화학 구조를 도시한다. 전술한 각각의 S1 및 S2는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택된다. 각각의 도 4g - 4i에서, R3a 및 R3b는 각각 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기일 수 있고, R3c는 수소 원자 또는 카르복실기일 수 있다는 것이 인지된다.
도 5a, 5b, 5c, 5d, 5e 및 5f는 특정 예의 실로시빈 유도체, 특히 2,5,7-트리-S1,S2,S3-실로시빈 유도체(도 5a), 2,5,7-트리-S1,S3,S2-실로시빈 유도체(도 5b), 2,5,7-트리-S3,S1,S2-실로시빈 유도체(도 5c), 2,5,7-트리-S2,S1,S3-실로시빈 유도체(도 5d), 2,5,7-트리-S3,S2,S1-실로시빈 유도체(도 5e), 및 2,5,7-트리-S2, S3,S1-실로시빈 유도체(도 5f)의 화학 구조를 도시한다. 전술한 S1, S2 및 S3 각각은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 3개로부터 선택된다. 각각의 도 5a - 5f에서, R3a 및 R3b는 각각 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기일 수 있고, R3c는 수소 원자 또는 카르복실기일 수 있다는 것이 인지된다.
도 5g, 5h 및 5i는 특정한 예의 실로시빈 유도체, 특히 2,5,7-트리-S1,S2,S2-실로시빈 유도체(도 5g), 2,5,7-트리-S2,S1,S2-실로시빈 유도체(도 5h), 및 2,5,7-트리-S2,S2,S1-실로시빈 유도체(도 5i)의 화학 구조를 도시한다. 전술한 S1 및 S2 각각은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택된다. 각각의 도 5a - 5i에서, R3a 및 R3b는 각각 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기일 수 있고, R3c는 수소 원자 또는 카르복실기일 수 있다는 것이 인지된다.
도 6a, 6b, 6c, 6d, 6e 및 6f는 특정한 예의 실로시빈 유도체, 특히 2,6,7-트리-S1,S2,S3-실로시빈 유도체(도 6a), 2,6,7-트리-S1,S3,S2-실로시빈 유도체(도 6b), 2,6,7-트리-S3,S1,S2-실로시빈 유도체(도 6c), 2,6,7-트리-S2,S1,S3-실로시빈 유도체(도 6d), 2,6,7-트리-S3,S2,S1-실로시빈 유도체(도 6e), 및 2,6,7-트리-S2, S3,S1-실로시빈 유도체(도 6f)의 화학 구조를 도시한다. 전술한 S1, S2 및 S3 각각은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 3개로부터 선택된다. 각각의 도 6a - 6f에서, R3a 및 R3b는 각각 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기일 수 있고, R3c는 수소 원자 또는 카르복실기일 수 있다는 것이 인지된다.
도 6g, 6h 및 6i는 특정한 예의 실로시빈 유도체, 특히 2,6,7-트리-S1,S2,S2-실로시빈 유도체(도 6g), 2,6,7-트리-S2,S1,S2-실로시빈 유도체(도 6h), 및 2,6,7-트리-S2,S2,S1-실로시빈 유도체(도 6i)의 화학 구조를 도시한다. 전술한 S1 및 S2 각각은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택된다. 각각의 도 6g - 6i에서, R3a 및 R3b는 각각 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기일 수 있고, R3c는 수소 원자 또는 카르복실기일 수 있다는 것이 인지된다.
도 7a, 7b, 7c, 7d, 7e 및 7f는 특정한 예의 실로시빈 유도체, 특히 5,6,7-트리-S1,S2,S3-실로시빈 유도체(도 7a), 5,6,7-트리-S1,S3,S2-실로시빈 유도체(도 7b), 5,6,7-트리-S3,S1,S2-실로시빈 유도체(도 7c), 5,6,7-트리-S2,S1,S3-실로시빈 유도체(도 7d), 5,6,7-트리-S3,S2,S1-실로시빈 유도체(도 7e), 및 5,6,7-트리-S2, S3,S1-실로시빈 유도체(도 7f)의 화학 구조를 도시한다. 전술한 S1, S2 및 S3 각각은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 3개로부터 선택된다. 각각의 도 7a - 7f에서, R3a 및 R3b는 각각 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기일 수 있고, R3c는 수소 원자 또는 카르복실기일 수 있다는 것이 인지된다.
도 7g, 7h 및 7i는 특정한 예의 실로시빈 유도체, 특히 5,6,7-트리-S1,S2,S2-실로시빈 유도체(도 7g), 5,6,7-트리-S2,S1,S2-실로시빈 유도체(도 7h), 및 5,6,7-트리-S2,S2,S1-실로시빈 유도체(도 7i)의 화학 구조를 도시한다. 전술한 S1 및 S2 각각은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택된다. 각각의 도 7g - 7i에서, R3a 및 R3b는 각각 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기일 수 있고, R3c는 수소 원자 또는 카르복실기일 수 있다는 것이 인지된다.
도 8a, 8b, 8c, 8d, 8e, 8f 및 8g는 특정한 예의 실로시빈 유도체, 특히 O-알킬화된 실로시빈 유도체, 특히 4-O-메틸-5-클로로-실로시빈 유도체(도 8a), 4-O-에틸-5-클로로-실로시빈 유도체(도 8b), 4-아세톡시-5-클로로-실로시빈 유도체(도 8c), 4-프로피오닐옥시-5-클로로-실로시빈 유도체(도 8d), 4-하이드록시-5-클로로-실로시빈 유도체(도 8e), 4-포스포-5-클로로-실로시빈 유도체(도 8f) 및 5-클로로-실로시빈 유도체(도 8h)의 화학 구조를 도시한다. 각각의 도 8a - 8g에서, R3a 및 R3b는 각각 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기일 수 있고, R3c는 수소 원자 또는 카르복실기일 수 있다는 것이 인지된다.
도 9는 질화된 실로시빈 유도체를 합성하기 위한 예의 화학 반응, 특히 4-O-메틸-실로시빈 유도체가 황산의 존재에서 질산과 반응하여 4-O-메틸-5-니트로-실로시빈 유도체를 형성하는 반응을 도시한다.
도 10은 글리코실화된 실로시빈 유도체를 합성하기 위한 예의 화학 반응, 특히 4-하이드록시-실로시빈 유도체가 글리코실 화합물과 반응하여 4-글리코실-실로시빈 유도체를 형성하는 반응을 도시한다.
도 11a, 11b 및 11c는 후속 N-치환으로 아미노화된 실로시빈 유도체를 합성하기 위한 특정 예의 화학 반응, 특히 4-O-메틸-5-니트로-실로시빈 유도체가 목탄 상의 팔라듐의 촉매작용 하에 수소와 반응하여 4-O-메틸-5-아미노-실로시빈 유도체를 형성하는 반응을 도시한다(도 11a). 5-위치에서 형성된 아미노기는 그 다음 아세트산 무수물로 아실화와 같은 다른 기로 치환될 수 있다. 아미노 기는 또한 알데히드(예컨대 아세트알데히드)와의 축합에 이어서 수소화붕소로 중간체 이민의 환원에 의해 알킬화될 수 있다(도 11b). 도 11c는 촉매의 도움으로 H2O2 및 NH3·H2O로 가능한 방향 아미노화 방법을 도시한다.
도 12a, 12b, 12c 및 12d는 반응물로서 4-하이드록시-실로시빈 유도체를 사용한 4-하이드록시-5-카르복실 실로시빈 유도체(도 12a); 반응물로 아릴할라이드-실로시빈 유도체를 사용한 4-하이드록시-7-카르복실 실로시빈 유도체(도 12b); 시약으로 보호된 실로시빈 유도체를 사용한 카르복실화된 보호된 실로시빈 유도체(도 12c), 및 시약으로 카르복실화된 실로시빈 유도체를 사용한, 카르복실화된 실로시빈 유도체의 나트륨염(a); 에스테르를 형성하는 OH 치환된 카르복실기; (b) 또는 아미드를 형성하는 OH 치환된 카르복실기(c)(도 12d)의 형성을 보여주는 예의 화학 반응을 도시한다.
도 13a, 13b, 13c 및 13d는 실로시빈 유도체를 제조하기 위한 예의 화학 반응을 도시한다. 도 13a는 처음에 합성된 7-질화된 실로시빈 유도체가 C5 및 C7 원자에서 2가지 유형의 기를 함유하는 다른 실로시빈 유도체로의 변환을 도시하며, 특히 C5 원자에서의 기는 케토 기 또는 카르복실산이고, C7 원자에서의 기는 니트로, 아민, 니트릴, 하이드록실, 요오드화물 또는 불화물이다. 도 13b는 처음에 합성된 5-카르복시 실로시빈 유도체를 사용하여 C5 원자 및 C7 원자에서 2가지 유형의 기를 함유하는 다른 O-4-글리코실화된 실로시빈 유도체로의 예의 화학적 변환을 도시하며, 특히 C5 원자에서 기는 에스테르 또는 아미드이고 C7 원자에서의 기는 니트로 또는 아민이다. 도 13c는 C5, C6 및 C7 탄소 원자에서 최대 3개 유형의 기를 함유하는 5,6,7-트리-치환된 실로시빈 유도체를 형성하기 위해 처음에 합성된 5-질화된 실로시빈 유도체의 추가 예의 화학적 변환을 도시한다. C5 탄소 원자에 부착된 기는 니트로, 아미노, 또는 N-아세트아미도기일 수 있는 반면, C6 탄소 원자에 부착된 기는 할라이드, 니트로기 또는 아미노기일 수 있고, C7 탄소 원자에 부착된 기는 포밀, 카르복시 또는 아미드기일 수 있다. 도 13-d는 그 다음 프레닐 트랜스퍼라제를 사용하여 시험관내 또는 생체내에서 프레닐화되어, 예를 들어, 화합물 13-D4의 C6 프레닐화된 유도체를 형성할 수 있는 하이드록시-실로시빈 유도체(화합물 13-D4)의 제조를 도시한다. 도 13a - 13d에서 특정 화합물은 13A-1, 13A-2 등(도 13a). 13B-1, 13B-2 등(도 13b); 13C-1, 13C-2 등(도 13c) 및 13D-1, 13D-2 등(도 13d)으로 표지되어 있다는 것이 인지된다.
도 14a, 14b, 14c, 14d, 14e, 14f 및 14g는 예의 다중 치환기 실로시빈 유도체 화합물, 특히 S14 및 S26 치환기를 보유하는 예의 화합물(도 14a), S14 및 S26 프레닐기를 보유하는 예의 화합물(도 14b), S15 및 S26 프레닐기를 보유하는 예의 화합물(도 14c), S14 및 S25 치환기를 보유하는 예의 화합물(도 14d), S14 및 S27 치환기를 보유하는 예의 화합물(도 14e), S15 및 S26 치환기를 보유하는 예의 화합물(도 14f), 및 S15 및 S27 치환기를 보유하는 예의 화합물(도 14g)을 생합성적으로 제조하기 위한 특정 경로를 도시한다. 각각의 도 14a - 14g에서 예의 화합물에 인접한 로마 숫자는 본 개시내용에서 그렇게 넘버링된 예의 화합물을 지칭한다.
도 15a, 15b, 15c, 15d, 15e, 15f, 15g 및 15h는 본 명세서에 제시된 화학식 (IX)을 갖는 예의 프레닐화된 실로시빈 유도체의 효능을 평가하기 위한 실험적 검정, 특히 화학식 (IX)을 갖는 다중 치환기 실로시빈 유도체에 대한 세포 생존성 검정(도 15a); 5-HT2A 수용체에서 [3H]케탄세린에 대한 포화 결합 검정(도 15b); 양성 대조군(결합)으로서의 실로신에 대한 경쟁 검정(패널 A); 및 음성 대조군(결합 없음)으로서 트립토판에 대한 경쟁 검정(패널 B)(도 15c); "IX"로 지정된, 식 (IX)을 갖는 다중 치환기 실로시빈 유도체 화합물에 대한 경쟁 검정(도 15d, 명확성을 위해 2개의 서로 다른 Y-축, 패널 A 및 패널 B로 플롯됨); +5HT1A 세포 및 -5HT1A 세포에서 일정한(4μM) 포스콜린의 존재에서 그리고 증가하는 농도의 실로신으로 cAMP 검정(도 15e); 일정한(4μM) 포스콜린 및 10μM 세로토닌의 존재에서, 그리고 증가하는 농도의 세로토닌 +5HT1A 세포 및 -5HT1A 세포로 cAMP 검정(도 15f); 일정한(4μM) 포스콜린의 존재에서 cAMP 검정, 및 +5HT1A 세포 및 -5HT1A 세포에서 증가하는 농도의 트립토판으로 cAMP 검정(도 14g); 및 +5HT1A 세포 및 -5HT1A 세포에서 "IX"로 지정된, 식 (IX)을 갖는 다중 치환기 실로시빈 유도체 화합물의 증가하는 농도로, 그리고 일정한(4μM) 포스콜린에서의 cAMP 검정(도 15h)의 수행에서 얻어진 다양한 그래프를 도시한다.
도 16a, 16b 및 16c는 본 명세서에 제시된 화학식 (X)을 갖는 예의 프레닐화된 실로시빈 유도체의 효능을 평가하기 위한 실험적 검정, 특히 화학식 (IX)을 갖는 다중 치환기 실로시빈 유도체에 대한 세포 생존율 분석(도 16a); "IX"로 지정된, 화학식 (IX)을 가진 다중 치환기 실로시빈 유도체 화합물에 대한 경쟁 검정(도 16b); 및 +5HT1A 세포 및 -5HT1A 세포에서 "X"로 지정된, 식 (X)을 갖는 다중 치환기 실로시빈 유도체 화합물의 증가하는 농도로, 그리고 일정한(4μM) 포스콜린에서의 cAMP 검정(도 15h)의 수행에서 얻어진 다양한 그래프를 도시한다.
도 17 및 17b는 질량 분석 데이터의 크로마토그램, 특히 본 명세서에 제시된 화학식 (XII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서의 표현(도 17a); 및 본 명세서에 제시된 화학식 (XII)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 17b)을 도시한다.
도 18a 및 18b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XIV)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 18a); 및 본 명세서에 제시된 화학식 (XII)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 18b)을 도시한다.
도 19a 및 19b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XV)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 19a); 및 본 명세서에 제시된 화학식 (XV)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 19b)을 도시한다
도 20은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XVII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 21a 및 21b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XVIII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 21a); 및 본 명세서에 제시된 화학식 (XVIII)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 21b)을 도시한다.
도 22a 및 22b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXI)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 22a); 및 본 명세서에 제시된 화학식 (XXI)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 22b)을 도시한다.
도 23a 및 23b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXIII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 23a); 및 본 명세서에 제시된 화학식 (XXIII)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 23b)을 도시한다.
도 24는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXV)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 25a 및 25b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXVIII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 25a); 및 본 명세서에 제시된 화학식 (XXVIII)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 25b)을 도시한다.
도 26은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XX)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 27은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XIII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 28은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XVI)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 29는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XIX)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 30은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 31은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXVI)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 32a 및 32b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXIX)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 32a); 및 본 명세서에 제시된 화학식 (XXIX)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 32b)을 도시한다.
도 33은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXVII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 34a 및 34b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXXIV)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 34a); 및 본 명세서에 제시된 화학식 (XXXIV)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 34b)을 도시한다.
도 35a 및 35b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXXII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 35a); 및 본 명세서에 제시된 화학식 (XXXII)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 35b)을 도시한다.
도 36은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXXVI)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 37은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XLIX)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 38은 크로마토그램, 특히 본 명세서에 제시된 화학식 (L)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 39는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XLVII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 40은 크로마토그램, 특히 본 명세서에 제시된 화학식 (LI)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 41은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXXVI)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 42는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXXV)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 43a 및 43b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXXVI)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 43a); 및 본 명세서에 제시된 화학식 (XXXVI)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 43b)을 도시한다.
도 44는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXXVIII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 45는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XL)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 46은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXXIX)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 47은 크로마토그램, 특히 본 명세서에 제시된 화학식 (LII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 48은 크로마토그램, 특히 본 명세서에 제시된 화학식 (LIII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 49는 크로마토그램, 특히 본 명세서에 제시된 화학식 (LIV)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 50은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXX)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 51은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXXI)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 52는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XLI)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 53은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XLII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 54는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XLV)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 55a 및 55b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XLIV)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 55a); 및 본 명세서에 제시된 화학식 (XLIV)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 55b)을 도시한다.
도 56은 크로마토그램, 특히 본 명세서에 제시된 화학식 (LXVVI)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
다음의 상세한 설명과 함께 도면은 개시내용이 실제로 어떻게 구현될 수 있는지를 당업계의 통상인에게 명백하게 한다.
도 1은 실로시빈의 화학 구조를 도시한다.
도 2는 실로시빈 및 실로시빈 유도체 화합물, 즉 인돌의 특정 원형 구조를 도시한다. 특정 탄소 및 질소 원자는 인돌 구조 내의 그 위치, 즉 N1, C2, C3 등을 참조하여 본 명세서에서 지칭될 수 있다. 적절한 원자 넘버링이 표시되어 있다.
도 3a, 3b, 3c, 3d, 3e, 3f, 3g, 3h, 3i, 3j, 3k 및 3l은 특정 예의 실로시빈 유도체, 특히 2,5-디-S1,S2-실로시빈 유도체(도 3a), 2,5-디-S2,S1-실로시빈 유도체(도 3b), 2,6-디-S1,S2-실로시빈 유도체(도 3c), 2,6-디-S2,S1-실로시빈 유도체(도 3d), 2,7-디-S1,S2-실로시빈 유도체(도 3e), 2,7-디-S2,S1-실로시빈 유도체(도 3f), 5,6-디-S1,S2-실로시빈 유도체(도 3g), 5,6-디-S2,S1-실로시빈 유도체(도 3h), 5,7-디-S1,S2-실로시빈 유도체(도 3i), 5,7-디-S2,S1-실로시빈 유도체(도 3j), 6,7-디-S1,S2-실로시빈 유도체(도 3k) 및 6,7-디-S2,S1-실로시빈 유도체(도 3l)의 화학 구조를 도시한다. 전술한 S1 및 S2 각각은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택된다. 각각의 도 3a - 3l에서, R3a 및 R3b는 각각 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기일 수 있고, R3c는 수소 원자 또는 카르복실기일 수 있다는 것이 인지된다.
도 4a, 4b, 4c, 4d, 4e 및 4f는 특정한 예의 실로시빈 유도체, 특히 2,5,6-트리-S1,S2,S3-실로시빈 유도체(도 4a), 2,5,6-트리-S1,S3,S2-실로시빈 유도체(도 4b), 2,5,6-트리-S3,S1,S2-실로시빈 유도체(도 4c), 2,5,6-트리-S2,S1,S3-실로시빈 유도체(도 4d), 2,5,6-트리-S3,S2,S1-실로시빈 유도체(도 4e), 및 2,5,6-트리-S2, S3,S1-실로시빈 유도체(도 4f)의 화학 구조를 도시한다. 전술한 S1, S2 및 S3 각각은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 3개로부터 선택된다. 각각의 도 4a - 4f에서, R3a 및 R3b는 각각 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기일 수 있고, R3c는 수소 원자 또는 카르복실기일 수 있다는 것이 인지된다.
도 4g, 4h 및 4i는 특정한 예의 실로시빈 유도체, 특히 2,5,6-트리-S1,S2,S2-실로시빈 유도체(도 4g), 2,5,6-트리-S2,S1,S2-실로시빈 유도체(도 4h), 및 2,5,6-트리-S2,S2,S1-실로시빈 유도체(도 4i)의 화학 구조를 도시한다. 전술한 각각의 S1 및 S2는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택된다. 각각의 도 4g - 4i에서, R3a 및 R3b는 각각 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기일 수 있고, R3c는 수소 원자 또는 카르복실기일 수 있다는 것이 인지된다.
도 5a, 5b, 5c, 5d, 5e 및 5f는 특정 예의 실로시빈 유도체, 특히 2,5,7-트리-S1,S2,S3-실로시빈 유도체(도 5a), 2,5,7-트리-S1,S3,S2-실로시빈 유도체(도 5b), 2,5,7-트리-S3,S1,S2-실로시빈 유도체(도 5c), 2,5,7-트리-S2,S1,S3-실로시빈 유도체(도 5d), 2,5,7-트리-S3,S2,S1-실로시빈 유도체(도 5e), 및 2,5,7-트리-S2, S3,S1-실로시빈 유도체(도 5f)의 화학 구조를 도시한다. 전술한 S1, S2 및 S3 각각은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 3개로부터 선택된다. 각각의 도 5a - 5f에서, R3a 및 R3b는 각각 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기일 수 있고, R3c는 수소 원자 또는 카르복실기일 수 있다는 것이 인지된다.
도 5g, 5h 및 5i는 특정한 예의 실로시빈 유도체, 특히 2,5,7-트리-S1,S2,S2-실로시빈 유도체(도 5g), 2,5,7-트리-S2,S1,S2-실로시빈 유도체(도 5h), 및 2,5,7-트리-S2,S2,S1-실로시빈 유도체(도 5i)의 화학 구조를 도시한다. 전술한 S1 및 S2 각각은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택된다. 각각의 도 5a - 5i에서, R3a 및 R3b는 각각 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기일 수 있고, R3c는 수소 원자 또는 카르복실기일 수 있다는 것이 인지된다.
도 6a, 6b, 6c, 6d, 6e 및 6f는 특정한 예의 실로시빈 유도체, 특히 2,6,7-트리-S1,S2,S3-실로시빈 유도체(도 6a), 2,6,7-트리-S1,S3,S2-실로시빈 유도체(도 6b), 2,6,7-트리-S3,S1,S2-실로시빈 유도체(도 6c), 2,6,7-트리-S2,S1,S3-실로시빈 유도체(도 6d), 2,6,7-트리-S3,S2,S1-실로시빈 유도체(도 6e), 및 2,6,7-트리-S2, S3,S1-실로시빈 유도체(도 6f)의 화학 구조를 도시한다. 전술한 S1, S2 및 S3 각각은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 3개로부터 선택된다. 각각의 도 6a - 6f에서, R3a 및 R3b는 각각 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기일 수 있고, R3c는 수소 원자 또는 카르복실기일 수 있다는 것이 인지된다.
도 6g, 6h 및 6i는 특정한 예의 실로시빈 유도체, 특히 2,6,7-트리-S1,S2,S2-실로시빈 유도체(도 6g), 2,6,7-트리-S2,S1,S2-실로시빈 유도체(도 6h), 및 2,6,7-트리-S2,S2,S1-실로시빈 유도체(도 6i)의 화학 구조를 도시한다. 전술한 S1 및 S2 각각은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택된다. 각각의 도 6g - 6i에서, R3a 및 R3b는 각각 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기일 수 있고, R3c는 수소 원자 또는 카르복실기일 수 있다는 것이 인지된다.
도 7a, 7b, 7c, 7d, 7e 및 7f는 특정한 예의 실로시빈 유도체, 특히 5,6,7-트리-S1,S2,S3-실로시빈 유도체(도 7a), 5,6,7-트리-S1,S3,S2-실로시빈 유도체(도 7b), 5,6,7-트리-S3,S1,S2-실로시빈 유도체(도 7c), 5,6,7-트리-S2,S1,S3-실로시빈 유도체(도 7d), 5,6,7-트리-S3,S2,S1-실로시빈 유도체(도 7e), 및 5,6,7-트리-S2, S3,S1-실로시빈 유도체(도 7f)의 화학 구조를 도시한다. 전술한 S1, S2 및 S3 각각은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 3개로부터 선택된다. 각각의 도 7a - 7f에서, R3a 및 R3b는 각각 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기일 수 있고, R3c는 수소 원자 또는 카르복실기일 수 있다는 것이 인지된다.
도 7g, 7h 및 7i는 특정한 예의 실로시빈 유도체, 특히 5,6,7-트리-S1,S2,S2-실로시빈 유도체(도 7g), 5,6,7-트리-S2,S1,S2-실로시빈 유도체(도 7h), 및 5,6,7-트리-S2,S2,S1-실로시빈 유도체(도 7i)의 화학 구조를 도시한다. 전술한 S1 및 S2 각각은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택된다. 각각의 도 7g - 7i에서, R3a 및 R3b는 각각 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기일 수 있고, R3c는 수소 원자 또는 카르복실기일 수 있다는 것이 인지된다.
도 8a, 8b, 8c, 8d, 8e, 8f 및 8g는 특정한 예의 실로시빈 유도체, 특히 O-알킬화된 실로시빈 유도체, 특히 4-O-메틸-5-클로로-실로시빈 유도체(도 8a), 4-O-에틸-5-클로로-실로시빈 유도체(도 8b), 4-아세톡시-5-클로로-실로시빈 유도체(도 8c), 4-프로피오닐옥시-5-클로로-실로시빈 유도체(도 8d), 4-하이드록시-5-클로로-실로시빈 유도체(도 8e), 4-포스포-5-클로로-실로시빈 유도체(도 8f) 및 5-클로로-실로시빈 유도체(도 8h)의 화학 구조를 도시한다. 각각의 도 8a - 8g에서, R3a 및 R3b는 각각 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기일 수 있고, R3c는 수소 원자 또는 카르복실기일 수 있다는 것이 인지된다.
도 9는 질화된 실로시빈 유도체를 합성하기 위한 예의 화학 반응, 특히 4-O-메틸-실로시빈 유도체가 황산의 존재에서 질산과 반응하여 4-O-메틸-5-니트로-실로시빈 유도체를 형성하는 반응을 도시한다.
도 10은 글리코실화된 실로시빈 유도체를 합성하기 위한 예의 화학 반응, 특히 4-하이드록시-실로시빈 유도체가 글리코실 화합물과 반응하여 4-글리코실-실로시빈 유도체를 형성하는 반응을 도시한다.
도 11a, 11b 및 11c는 후속 N-치환으로 아미노화된 실로시빈 유도체를 합성하기 위한 특정 예의 화학 반응, 특히 4-O-메틸-5-니트로-실로시빈 유도체가 목탄 상의 팔라듐의 촉매작용 하에 수소와 반응하여 4-O-메틸-5-아미노-실로시빈 유도체를 형성하는 반응을 도시한다(도 11a). 5-위치에서 형성된 아미노기는 그 다음 아세트산 무수물로 아실화와 같은 다른 기로 치환될 수 있다. 아미노 기는 또한 알데히드(예컨대 아세트알데히드)와의 축합에 이어서 수소화붕소로 중간체 이민의 환원에 의해 알킬화될 수 있다(도 11b). 도 11c는 촉매의 도움으로 H2O2 및 NH3·H2O로 가능한 방향 아미노화 방법을 도시한다.
도 12a, 12b, 12c 및 12d는 반응물로서 4-하이드록시-실로시빈 유도체를 사용한 4-하이드록시-5-카르복실 실로시빈 유도체(도 12a); 반응물로 아릴할라이드-실로시빈 유도체를 사용한 4-하이드록시-7-카르복실 실로시빈 유도체(도 12b); 시약으로 보호된 실로시빈 유도체를 사용한 카르복실화된 보호된 실로시빈 유도체(도 12c), 및 시약으로 카르복실화된 실로시빈 유도체를 사용한, 카르복실화된 실로시빈 유도체의 나트륨염(a); 에스테르를 형성하는 OH 치환된 카르복실기; (b) 또는 아미드를 형성하는 OH 치환된 카르복실기(c)(도 12d)의 형성을 보여주는 예의 화학 반응을 도시한다.
도 13a, 13b, 13c 및 13d는 실로시빈 유도체를 제조하기 위한 예의 화학 반응을 도시한다. 도 13a는 처음에 합성된 7-질화된 실로시빈 유도체가 C5 및 C7 원자에서 2가지 유형의 기를 함유하는 다른 실로시빈 유도체로의 변환을 도시하며, 특히 C5 원자에서의 기는 케토 기 또는 카르복실산이고, C7 원자에서의 기는 니트로, 아민, 니트릴, 하이드록실, 요오드화물 또는 불화물이다. 도 13b는 처음에 합성된 5-카르복시 실로시빈 유도체를 사용하여 C5 원자 및 C7 원자에서 2가지 유형의 기를 함유하는 다른 O-4-글리코실화된 실로시빈 유도체로의 예의 화학적 변환을 도시하며, 특히 C5 원자에서 기는 에스테르 또는 아미드이고 C7 원자에서의 기는 니트로 또는 아민이다. 도 13c는 C5, C6 및 C7 탄소 원자에서 최대 3개 유형의 기를 함유하는 5,6,7-트리-치환된 실로시빈 유도체를 형성하기 위해 처음에 합성된 5-질화된 실로시빈 유도체의 추가 예의 화학적 변환을 도시한다. C5 탄소 원자에 부착된 기는 니트로, 아미노, 또는 N-아세트아미도기일 수 있는 반면, C6 탄소 원자에 부착된 기는 할라이드, 니트로기 또는 아미노기일 수 있고, C7 탄소 원자에 부착된 기는 포밀, 카르복시 또는 아미드기일 수 있다. 도 13-d는 그 다음 프레닐 트랜스퍼라제를 사용하여 시험관내 또는 생체내에서 프레닐화되어, 예를 들어, 화합물 13-D4의 C6 프레닐화된 유도체를 형성할 수 있는 하이드록시-실로시빈 유도체(화합물 13-D4)의 제조를 도시한다. 도 13a - 13d에서 특정 화합물은 13A-1, 13A-2 등(도 13a). 13B-1, 13B-2 등(도 13b); 13C-1, 13C-2 등(도 13c) 및 13D-1, 13D-2 등(도 13d)으로 표지되어 있다는 것이 인지된다.
도 14a, 14b, 14c, 14d, 14e, 14f 및 14g는 예의 다중 치환기 실로시빈 유도체 화합물, 특히 S14 및 S26 치환기를 보유하는 예의 화합물(도 14a), S14 및 S26 프레닐기를 보유하는 예의 화합물(도 14b), S15 및 S26 프레닐기를 보유하는 예의 화합물(도 14c), S14 및 S25 치환기를 보유하는 예의 화합물(도 14d), S14 및 S27 치환기를 보유하는 예의 화합물(도 14e), S15 및 S26 치환기를 보유하는 예의 화합물(도 14f), 및 S15 및 S27 치환기를 보유하는 예의 화합물(도 14g)을 생합성적으로 제조하기 위한 특정 경로를 도시한다. 각각의 도 14a - 14g에서 예의 화합물에 인접한 로마 숫자는 본 개시내용에서 그렇게 넘버링된 예의 화합물을 지칭한다.
도 15a, 15b, 15c, 15d, 15e, 15f, 15g 및 15h는 본 명세서에 제시된 화학식 (IX)을 갖는 예의 프레닐화된 실로시빈 유도체의 효능을 평가하기 위한 실험적 검정, 특히 화학식 (IX)을 갖는 다중 치환기 실로시빈 유도체에 대한 세포 생존성 검정(도 15a); 5-HT2A 수용체에서 [3H]케탄세린에 대한 포화 결합 검정(도 15b); 양성 대조군(결합)으로서의 실로신에 대한 경쟁 검정(패널 A); 및 음성 대조군(결합 없음)으로서 트립토판에 대한 경쟁 검정(패널 B)(도 15c); "IX"로 지정된, 식 (IX)을 갖는 다중 치환기 실로시빈 유도체 화합물에 대한 경쟁 검정(도 15d, 명확성을 위해 2개의 서로 다른 Y-축, 패널 A 및 패널 B로 플롯됨); +5HT1A 세포 및 -5HT1A 세포에서 일정한(4μM) 포스콜린의 존재에서 그리고 증가하는 농도의 실로신으로 cAMP 검정(도 15e); 일정한(4μM) 포스콜린 및 10μM 세로토닌의 존재에서, 그리고 증가하는 농도의 세로토닌 +5HT1A 세포 및 -5HT1A 세포로 cAMP 검정(도 15f); 일정한(4μM) 포스콜린의 존재에서 cAMP 검정, 및 +5HT1A 세포 및 -5HT1A 세포에서 증가하는 농도의 트립토판으로 cAMP 검정(도 14g); 및 +5HT1A 세포 및 -5HT1A 세포에서 "IX"로 지정된, 식 (IX)을 갖는 다중 치환기 실로시빈 유도체 화합물의 증가하는 농도로, 그리고 일정한(4μM) 포스콜린에서의 cAMP 검정(도 15h)의 수행에서 얻어진 다양한 그래프를 도시한다.
도 16a, 16b 및 16c는 본 명세서에 제시된 화학식 (X)을 갖는 예의 프레닐화된 실로시빈 유도체의 효능을 평가하기 위한 실험적 검정, 특히 화학식 (IX)을 갖는 다중 치환기 실로시빈 유도체에 대한 세포 생존율 분석(도 16a); "IX"로 지정된, 화학식 (IX)을 가진 다중 치환기 실로시빈 유도체 화합물에 대한 경쟁 검정(도 16b); 및 +5HT1A 세포 및 -5HT1A 세포에서 "X"로 지정된, 식 (X)을 갖는 다중 치환기 실로시빈 유도체 화합물의 증가하는 농도로, 그리고 일정한(4μM) 포스콜린에서의 cAMP 검정(도 15h)의 수행에서 얻어진 다양한 그래프를 도시한다.
도 17 및 17b는 질량 분석 데이터의 크로마토그램, 특히 본 명세서에 제시된 화학식 (XII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서의 표현(도 17a); 및 본 명세서에 제시된 화학식 (XII)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 17b)을 도시한다.
도 18a 및 18b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XIV)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 18a); 및 본 명세서에 제시된 화학식 (XII)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 18b)을 도시한다.
도 19a 및 19b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XV)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 19a); 및 본 명세서에 제시된 화학식 (XV)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 19b)을 도시한다
도 20은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XVII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 21a 및 21b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XVIII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 21a); 및 본 명세서에 제시된 화학식 (XVIII)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 21b)을 도시한다.
도 22a 및 22b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXI)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 22a); 및 본 명세서에 제시된 화학식 (XXI)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 22b)을 도시한다.
도 23a 및 23b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXIII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 23a); 및 본 명세서에 제시된 화학식 (XXIII)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 23b)을 도시한다.
도 24는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXV)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 25a 및 25b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXVIII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 25a); 및 본 명세서에 제시된 화학식 (XXVIII)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 25b)을 도시한다.
도 26은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XX)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 27은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XIII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 28은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XVI)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 29는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XIX)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 30은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 31은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXVI)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 32a 및 32b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXIX)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 32a); 및 본 명세서에 제시된 화학식 (XXIX)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 32b)을 도시한다.
도 33은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXVII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 34a 및 34b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXXIV)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 34a); 및 본 명세서에 제시된 화학식 (XXXIV)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 34b)을 도시한다.
도 35a 및 35b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXXII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 35a); 및 본 명세서에 제시된 화학식 (XXXII)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 35b)을 도시한다.
도 36은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXXVI)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 37은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XLIX)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 38은 크로마토그램, 특히 본 명세서에 제시된 화학식 (L)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 39는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XLVII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 40은 크로마토그램, 특히 본 명세서에 제시된 화학식 (LI)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 41은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXXVI)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 42는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXXV)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 43a 및 43b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXXVI)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 43a); 및 본 명세서에 제시된 화학식 (XXXVI)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 43b)을 도시한다.
도 44는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXXVIII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 45는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XL)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 46은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXXIX)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 47은 크로마토그램, 특히 본 명세서에 제시된 화학식 (LII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 48은 크로마토그램, 특히 본 명세서에 제시된 화학식 (LIII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 49는 크로마토그램, 특히 본 명세서에 제시된 화학식 (LIV)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 50은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXX)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 51은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XXXI)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 52는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XLI)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 53은 크로마토그램, 특히 본 명세서에 제시된 화학식 (XLII)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 54는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XLV)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
도 55a 및 55b는 크로마토그램, 특히 본 명세서에 제시된 화학식 (XLIV)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현(도 55a); 및 본 명세서에 제시된 화학식 (XLIV)을 갖는 다중 치환기 실로시빈 유도체 화합물을 식별하기 위한 실험의 수행에서 얻은 추가 질량 분석 스펙트럼의 형태에서 질량 분석 데이터의 표현(도 55b)을 도시한다.
도 56은 크로마토그램, 특히 본 명세서에 제시된 화학식 (LXVVI)을 갖는 예의 다중 치환기 실로시빈 유도체 화합물을 합성하기 위한 실험의 수행에서 얻은 크로마토그램의 형태에서 추가 질량 분석 데이터의 표현을 도시한다.
다음의 상세한 설명과 함께 도면은 개시내용이 실제로 어떻게 구현될 수 있는지를 당업계의 통상인에게 명백하게 한다.
다양한 구성, 시스템 또는 프로세스가 각각의 청구된 주제의 실시형태의 예를 제공하기 위해 아래에 기술될 것이다. 아래에 기술된 어떠한 실시형태도 임의의 청구된 주제를 제한하지 않고 임의의 청구된 주제는 아래에 기술된 것과 다른 프로세스, 구성 또는 시스템을 커버할 수 있다. 청구된 주제는 아래에 기술된 어느 하나의 구성, 시스템 또는 프로세스의 모든 특징을 갖는 구성, 프로세스 또는 시스템에 제한되지 않고, 아래에 기술된 구성, 시스템 또는 프로세스의 다수 또는 모두에 공통된 특징으로 제한되지 않는다. 아래에 기술된 구성, 시스템 또는 프로세스는 임의의 청구된 주제의 실시형태가 아닌 것이 가능하다. 본 문서에서 청구되지 않은 아래 기술된 구성, 시스템 또는 프로세스에 개시된 임의의 주제는 다른 보호적 장치, 예를 들어 계속되는 특허 출원의 주제일 수 있고, 출원인, 발명자 또는 소유자는 이 문서에서의 그 공개에 의해 임의의 그러한 주제를 포기하거나, 부인하거나 대중에게 헌정할 의도는 없다.
본 명세서 및 청구범위에 사용된 바와 같이, "a", "an" 및 "the"와 같은 단수형은 문맥상 달리 명확하게 나타내지 않는 한 복수형을 포함하고 그 반대도 마찬가지이다. 본 명세서 전반에 걸쳐, 달리 나타내지 않는 한, "포함하다", "포함한다" 및 "포함하는"은 배타적이 아닌 포괄적으로 사용되어, 언급된 정수 또는 정수의 군은 하나 이상의 다른 언급되지 않은 정수 또는 정수의 군을 포함할 수 있다.
다양한 구성, 시스템 또는 프로세스가 각각의 청구된 주제의 실시형태의 예를 제공하기 위해 아래에 기술될 것이다. 아래에 기술된 어떠한 실시형태도 임의의 청구된 주제를 제한하지 않고 임의의 청구된 주제는 아래에 기술된 것과 다른 프로세스, 구성 또는 시스템을 커버할 수 있다. 청구된 주제는 아래에 기술된 어느 하나의 구성, 시스템 또는 프로세스의 모든 특징을 갖는 구성, 프로세스 또는 시스템에 제한되지 않고, 아래에 기술된 구성, 시스템 또는 프로세스의 다수 또는 모두에 공통된 특징으로 제한되지 않는다. 아래에 기술된 구성, 시스템 또는 프로세스는 임의의 청구된 주제의 실시형태가 아닌 것이 가능하다. 본 문서에서 청구되지 않은 아래 기술된 구성, 시스템 또는 프로세스에 개시된 임의의 주제는 다른 보호적 장치, 예를 들어 계속되는 특허 출원의 주제일 수 있고, 출원인, 발명자 또는 소유자는 이 문서에서의 그 공개에 의해 임의의 그러한 주제를 포기하거나, 부인하거나 대중에게 헌정할 의도는 없다.
본 명세서에서 분자량과 같은 물리적 특성 또는 화학식과 같은 화학적 특성에 대해 범위가 사용되는 경우, 범위의 모든 조합 및 하위-조합과 그 안의 특정 실시형태가 포함되는 것으로 의도된다. 조작하는 실시예에서, 또는 다르게 표시된 경우를 제외하고, 본 명세서에 사용된 성분 또는 반응 조건의 양을 나타내는 모든 수치는 모든 경우에 용어 "약"에 의해 변형되는 것으로 이해되어야 한다. 수치 또는 수치 범위를 언급할 때 용어 "약"은 언급된 수치 또는 수치 범위가 실험 변동성 내(또는 통계적 실험 오류 내)에서의 근사치이고 따라서 수치 또는 수치 범위는 문맥상 쉽게 인식할 수 있는 바와 같이 명시된 수치 또는 수치 범위의 1% 내지 15% 사이에서 달라질 수 있음을 의미한다. 더욱이 본 명세서에 기술된 임의의 값의 범위는 범위의 제한 값, 및 주어진 범위 내의 임의의 중간 값 또는 하위-범위를 구체적으로 포함하도록 의도되고, 모든 이러한 중간 값 및 하위-범위는 개별적으로 구체적으로 개시된다(예를 들어, 1 내지 5의 범위는 1, 1.5, 2, 2.75, 3, 3.90, 4 및 5를 포함한다). 유사하게, 본 명세서에 사용된 "실질적으로" 및 "대략적으로"와 같은 정도의 다른 용어는 최종 결과가 유의하게 변경되지 않을 정도로 변형된 용어의 합리적인 정도의 편차를 의미한다. 이들 정도의 용어는 이 편차가 변형되는 용어의 의미를 부정하지 않는 경우 변형된 용어의 편차를 포함하는 것으로 해석되어야 한다.
달리 정의되지 않는 한, 본 명세서에 기술된 제형과 관련하여 사용된 과학적 및 기술적 용어는 당업계의 통상인에 의해 일반적으로 이해되는 의미를 가져야 한다. 본 명세서에서 사용된 용어는 단지 특정한 실시형태를 설명하기 위해 목적이고, 청구범위에 의해서만 정의되는 본 발명의 범주를 제한하려는 의도가 아니다.
모든 간행물, 특허 및 특허 출원은 각각의 개별 간행물, 특허 또는 특허 출원이 그 전체가 참조로 포함되도록 구체적이고 개별적으로 표시된 것과 동일한 정도로 그 전체가 참조로 본 명세서에 포함된다.
용어 및 정의
용어 "실로시빈"은 도 1에 제시된 구조를 갖는 화학적 화합물을 지칭한다.
용어 "인돌 원형 구조"는 도 2에 도시된 화학 구조를 지칭한다. 인돌 원형 구조에서 특정 탄소 원자와 질소 원자는 넘버링되어 있음이 인지된다. 본 명세서에서는 이들 탄소 및 질소 수, 예를 들어, C2, C4, N1 등이 참조될 수 있다. 더욱이, 동일한 넘버링에 따라 인돌 원형 구조에 부착된 화학기, 예를 들어 각각 C4 및 C6 원자에 부착된 R4 및 R6 참조 화학기가 참조될 수 있다. 부가하여, R3A 및 R3B는 이 점에서 원형 인돌 구조의 C3 원자로부터 차례로 연장되는 에틸-아미노기로부터 연장되는 참조 화학기다.
본 명세서에 사용된 용어 "실로시빈 유도체"는 실로시빈으로부터 유도체화될 수 있는 화합물을 지칭하며, 여기서 이러한 화합물은 식 LX(XVIII)을 갖는 인돌 원형 구조 및 C3 에틸아민 또는 에틸아민 유도체기를 포함한다:
(LXXVIII),
여기서 R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, 그리고 여기서 R3c는 수소 원자 또는 카르복실기이다. 실로시빈 유도체는 각각의 C2, C4, C5, C6 및 C7에서 하나 이상의 치환기를 함유하는 화합물을 포함한다. 따라서, 화학식 (LXXVIII)에서, C2, C4, C5, C6 및 C7은 각각, 예를 들어, (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기, (x) O-알킬기, (xi) (xii) O-아실기, (xiii) 포스페이트기, 또는 (xiv) 수소 원자 중 임의의 것일 수 있다.
용어 "다중 치환기 실로시빈 유도체"는 실로시빈 또는 실로시빈 유도체에 2개 이상의 치환기 실체가 결합된 실로시빈 유도체 화합물을 지칭한다. 치환될 수 있는 특정 탄소 원자에 대해 참조될 수 있다. 더욱이, 치환기 실체는 S1, S2, S3 또는 S4로 지칭될 수 있으며, 여기서 S1, S2, S3 및 S4 각각은 서로 다른 치환기 실체를 지칭한다. 예를 들어, 5,7-S1,S2-디-실로시빈 유도체는 탄소 원자 번호 5와 탄소 원자 번호 7(인돌 원형 구조에서 식별됨) 각각이 서로 다른 치환기 실체를 보유하는 실로시빈 유도체를 지칭하거나, 유사하게 2,5,6-트리-S1,S2,S3-실로시빈 유도체는 탄소 원자 번호 2,5,6(인돌 원형 구조에서 식별됨)이 서로 다른 치환기 실체(또는 3개의 치환기 중 적어도 2개는 상이함)를 보유하는 실로시빈 유도체를 지칭한다. 또 다른 예로서, 2,5,6-트리-S1,S2,S2-실로시빈 유도체는 탄소 원자 번호 2,5,6(인돌 원형 구조에서 식별됨) 각각이 치환기 실체를 보유하는 실로시빈 유도체를 지칭하며, 치환기 실체는 탄소 원자 번호 5 및 6이 동일하게 되도록 보유한다. S1, S2, S3 및 S4는 본 명세서에서 S15, S36, S47 등과 같은 수치 첨자를 추가로 포함할 수 있다는 것을 인지한다. 그러한 수치 값이 포함되는 경우, 이들은 원형 인돌 구조의 넘버링된 C 원자를 참조한다. 따라서, 예를 들어, S15는 인돌 고리 구조의 C5 원자로부터 신장하는 치환기 실체이고, S37은 인돌 고리 구조의 C7 원자로부터 신장하는 치환기 실체이고, 등등이다. 용어 다중 치환기 실로시빈 유도체는 화학식 (I)을 갖는 화합물을 추가로 포함한다:
(I),
여기서, R2, R4, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 독립적으로 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, O-알킬기, O-아실기 또는 포스페이트기이고, 여기서 R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, R3c는 수소 원자 또는 카르복실기임. 용어 다중 치환기 실로시빈 유도체는 추가로 또한 식 (IV)을 갖는 화합물을 포함한다:
(IV)
여기서, R2, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 독립적으로 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, 여기서 R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, 여기서 R3c는 수소 원자 또는 카르복실기임. 용어는 나트륨염, 칼륨염 등과 같은 다중 치환기 실로시빈의 염을 추가로 포함한다.
본 명세서에 사용된 용어 "할로겐", "할로겐화된" 및 "할로-"는 불소(F), 염소(Cl), 브롬(Br) 및 요오드(I)로 구성된 화학 원소의 부류를 지칭한다. 따라서 할로겐화된 화합물은 "불소화된", "염소화된", "브롬화된" 또는 "요오드화된" 화합물을 지칭할 수 있다.
본 명세서에 사용된 용어 "포스페이트기" 또는 "포스포기"는 4개의 산소 원자에 공유적으로 결합된(3개의 단일 결합 및 1개의 이중 결합), 인 원자 1개를 함유하는 분자이다. 4개의 산소 원자 중 하나의 산소 원자는 하이드록시기일 수 있고, 비-하이드록실화된 산소 원자 중 하나는 다른 실체에 화학적으로 결합될 수 있다.
본 명세서에 사용된 용어 "하이드록시기" 및 "하이드록시"는 하나의 수소 원자에 결합된 하나의 산소 원자를 함유하고 식 -OH를 갖는 분자를 지칭한다. 그 산소 원자를 통해 하이드록시기는 다른 실체에 화학적으로 결합될 수 있다.
본 명세서에 사용된 용어 "니트로기" 및 "니트로"는 2개의 산소 원자에 결합된 하나의 질소 원자를 함유하고 식 -NO2를 갖는 분자를 지칭한다. 그 질소 원자를 통해 니트로기는 다른 실체에 화학적으로 결합될 수 있다. 더욱이, 니트로기에 부착된 실체는 본 명세서에서 "질화된" 실체로서 지칭될 수 있으며, 예를 들어 질화된 실로시빈 유도체는 니트로기를 보유하는 실로시빈 유도체이다는 것이 인지된다.
본 명세서에 사용된 용어 "아미노기" 및 "아미노"는 수소 원자에 결합된 하나의 질소 원자를 함유하고 식 -NH2를 갖는 분자를 지칭한다. 아미노기는 또한 양성자화되어 식 -NH3 +를 가질 수 있다. 아미노기는 그 질소 원자를 통해 다른 실체와 화학적으로 결합될 수 있다. 더욱이, 아미노기에 부착된 실체는 본 명세서에서 "아미노화된" 실체로서 지칭될 수 있으며, 예를 들어 아미노화된 실로시빈 유도체는 아미노기 또는 N-치환된 아미노기를 보유하는 실로시빈 유도체이다는 것이 인지된다.
본 명세서에 사용된 용어 "N-치환된 아미노기"는 수소 원자 중 적어도 하나가 다른 원자 또는 기, 예컨대, 예를 들어 알킬기, 아실기, 아릴기, 설포닐기 등에 의해 치환된 아미노기를 지칭한다. N-치환된 아미노기는 또한 양성자화될 수 있고, 아미노기는 그 질소 원자를 통해 다른 실체에 화학적으로 결합될 수 있다. 따라서, N-치환된 아미노기는 본 명세서에서 다음과 같이 표현될 수 있다:
또는 .
더욱이 N-치환된 아미노기는 다음을 포함한다:
화학기(IV)(알킬기, 아릴기):
(IV),
여기서 R' 및 R''는 각각 독립적으로 수소 원자, 알킬기 및 아릴기로부터 선택되지만, 그러나 단 R' 및 R'' 중 적어도 하나는 수소 원자가 아님;
화학기(V):
(V),
여기서 R', R" 및 R'''는 각각 독립적으로 수소 원자, 알킬기 및 아릴기로부터 선택되지만, 그러나 단 R', R" 및 R''' 중 적어도 하나는 수소 원자가 아님;
화학기(VI)(아실기):
(VI),
여기서 R' 및 R''는 각각 독립적으로 수소 원자, 알킬기 및 아릴기로부터 선택됨;
화학기(VII)(술포닐기):
(VII),
여기서 R' 및 R''는 각각 독립적으로 수소 원자, 알킬기 및 아릴기로부터 선택됨; 및
화학기(VIII)(술포네이트기):
(Ⅷ),
여기서 R''는 수소 원자, 알킬기, 및 아릴기로부터 선택됨. 화학기 (VI), (VII) 및 (VIII)의 질소 원자는 또한 양성으로 하전되고 H 또는 R'''로 추가로 치환될 수 있다. R', R'' 및 R'''는 본 명세서에서 5a, 6b, 7b 등과 같은 수치 아래 첨자를 추가로 포함할 수 있으며, 예를 들어 각각 R'5a, R''6b 또는 R'''7a로 표현될 수 있다는 것이 인지된다. 이러한 수치 값이 포함된 경우, 이는 원형 인돌 구조의 그렇게 넘버링된 C 원자로부터 차례로 신장하는 아미노기로부터 신장하는 화학적 실체를 나타낸다. 따라서, 예를 들어 R'5a는 인돌 고리 구조의 C5 원자에 부착된 아미노화된 기로부터 신장하는 화학적 실체이고, R'2a는 인돌 고리 구조의 C2 원자에 부착된 아미노화된 기로부터 신장하는 화학적 실체이고, 등등이다. 더욱이, N-치환된 아미노기에 부착된 실체는 본 명세서에서 "아미노화된" 실체로서 지칭될 수 있고, 예를 들어, 아미노화된 실로시빈 유도체는 아미노기 또는 N-치환된 아미노기를 보유하는 실로시빈 유도체이다는 것이 인지된다.
본 명세서에 사용된 용어 "카르복실기", "카르복실" 및 "카르복시"는 산소 원자에 결합된 하나의 탄소 원자 및 하이드록시기를 함유하고 식 -COOH를 갖는 분자를 지칭한다. 카르복실기는 탈양자화된 카르복실기, 즉 식 -COO-를 갖는 카르복실 이온을 포함한다. 그의 탈양자화된 형태에서 카르복실기는 카르복실 염, 예를 들어 나트륨 또는 칼륨 카르복실 염, 또는 유기 카르복실 염을 형성할 수 있으며, 이들 모두는 본 명세서에서 COO-M+로 표현될 수 있다. 카르복실기는 그 탄소 원자를 통해 다른 실체에 화학적으로 결합될 수 있다는 것을 추가로 이해해야 한다. 더욱이, 카르복실기에 부착된 실체는 본 명세서에서 "카르복실화된" 실체로 지칭될 수 있으며, 예를 들어 카르복실화된 실로시빈 유도체는 카르복실기 또는 OH-치환된 카르복실기를 보유하는 실로시빈 유도체이다는 것이 인지된다.
본 명세서에 사용된 용어 "카르복실산 유도체"는 카르복실기의 하이드록시기가 또 다른 원자 또는 기, 예컨대, 예를 들어 -OR" 기 또는 -NR'R''기에 의해 치환된 카르복실기를 지칭한다. 따라서 카르복실산 유도체는 화학 기(III)을 포함한다:
(III),
여기서, R'은 알킬기, 아릴기 및 수소 원자임. 화학 기(III)은 에스테르이다는 것이 인지된다. R'는 본 명세서에서 3c, 6b, 7b 등과 같은 수치 아래첨자를 추가로 포함할 수 있고, 예를 들어 각각 R'3c, R'6b 또는 R'7a로 표현될 수 있다는 것이 인지된다. 그러한 수치 값이 포함된 경우, 이는 원형 인돌 구조의 그렇게 넘버링된 C 원자로부터 차례로 카르복실기로부터 신장하는 화학적 실체를 언급한다. 따라서, 예를 들어, R'5a는 인돌 고리 구조의 C5 원자에 부착된 카르복실화된 기로부터 신장하는 화학적 실체이고, R'2a는 인돌 고리 구조의 C2 원자에 부착된 카르복실화된 기로부터 신장하는 화학적 실체이고, 등등이다. 더욱이, 카르복실산 유도체에 부착된 실체는 본 명세서에서 "카르복실화된" 실체로서 지칭될 수 있으며, 예를 들어, 카르복실화된 실로시빈 유도체는 카르복실기 또는 OH-치환된 카르복실기를 보유하는 실로시빈 유도체이다는 것이 인지된다.
본 명세서에 사용된 용어 "알데히드" 또는 "알데히드기"는 산소 원자에 이중 결합되고 수소 원자에 결합된 하나의 탄소 원자를 함유하고, 추가로 대안적으로 본 명세서에서는 -CHO로 표현될 수 있는 화학식: 을 갖는 분자를 지칭한다. -CHO기는 또한 본 명세서에서 포르밀기로 지칭될 수 있다. 알데히드는 그 탄소 원자를 통해 다른 실체에 화학적으로 결합될 수 있다는 것을 이해해야 한다.
본 명세서에 사용된 용어 "케톤" 또는 "케톤기"는 산소 원자에 이중 결합된 제1 탄소 원자, 및 제2 탄소 원자에 추가로 결합된 제1 탄소 원자인, 2개의 탄소 원자를 함유하고, 화학식: 을 갖는 분자를 지칭하며, 여기서 R은 R에 결합된 탄소 원자가 그의 통상적인 원자가를 달성하도록 함께 취해지는 임의의 실체 또는 복수의 실체이다. 따라서, 예를 들어, R은 3개의 수소 원자를 표현할 수 있거나, R은 2개의 수소 원자와 메틸기를 표현할 수 있다. 케톤은 그 첫 번째 탄소 원자를 통해 알킬렌기 (C1-C6)-알킬렌과 같은 다른 실체에 화학적으로 결합될 수 있다는 것을 이해해야 한다.
본 명세서에 사용된 용어 "니트릴기" 및 "니트릴"은 질소 원자에 결합된 하나의 탄소 원자를 함유하고 화학식 을 갖는 분자를 지칭한다. 니트릴기는 그 탄소 원자를 통해 다른 실체에 화학적으로 결합될 수 있다는 것을 이해해야 한다. 더욱이, 니트릴기에 부착된 실체는 본 명세서에서 "니트릴화된" 실체로서 지칭될 수 있으며, 예를 들어 니트릴화된 실로시빈 유도체는 니트릴기를 보유하는 실로시빈 유도체이다는 것이 주목된다.
본 명세서에 사용된 용어 "글리코실화된" 또는 "글리코실"은 피라노스 또는 푸라노스 형태에서, α 또는 β 배좌에서의 그 아노머 탄소로부터 결합될 수 있거나 결합된 모노-, 디-, 트리-, 올리고-, 또는 폴리-사카라이드기와 같은 사카라이드기를 지칭한다. 산소 원자를 통해 그 아노머 탄소를 통한 다른 실체에 결합되는 경우, 산소 원자를 포함하는 결합된 사카라이드기는 본 명세서에서 "글리코실옥시" 기로 지칭될 수 있다. 예의 모노사카라이드기는 펜토실, 헥소실 또는 헵토실기를 포함하지만 이에 제한되지 않는다. 글리코실옥시기는 또한 다양한 기로 치환될 수 있다. 이러한 치환은 저급 알킬, 저급 알콕시, 아실, 카르복시, 카르복시아미노, 아미노, 아세트아미도, 할로, 티오, 니트로, 케토 및 포스파틸 기를 포함할 수 있으며, 여기서 치환은 사카라이드 상의 하나 이상의 위치에 있을 수 있다. 용어 글리코실에는 글리코실옥시기의 추가 입체이성질체, 광학 이성질체, 아노머 및 에피머가 포함된다. 따라서, 예를 들어 6탄당 기는 알도스 또는 케토스 기일 수 있고, D- 또는 L-배열일 수 있고, α 또는 β 배좌를 취할 수 있으며, 평면-편광에 관하여 우-회전 또는 좌-회전일 수 있다. 예의 글리코실옥시기는 제한 없이, 글루코실기, 글루쿠론산기, 갈락토실기, 푸코실기, 자일로스기, 아라비노스기 및 람노스기를 추가로 포함한다.
본 명세서에 사용된 용어 "프레닐기" 및 "프레닐"은 구조 (LVI)를 갖는 화학기를 지칭하고:
(LVIa),
다음 구조를 갖는 폴리-프레닐 화합물을 추가로 포함한다:
(LVIb),
여기서 n은 2 이상의 값을 갖는 정수, 예를 들어 2, 3, 4, 5 등임. 더욱이, 용어 "프레닐 화합물"은 반응성 프레닐기, 즉 다른 실체에 의해 수용될 수 있는 프레닐기이거나, 실질적으로 이것이거나, 또는 이를 보유하는 화학적 화합물을 지칭한다. 프레닐 화합물은, 예를 들어 게라닐 피로포스페이트(GPP), 디메틸알릴 디포스페이트(DMAPP), 파르네실 피로포스페이트(FPP) 및 게라닐게라닐 피로포스페이트(GGPP)를 포함한다.
본 명세서에 사용된 용어 "알킬기"는 1 내지 "p"개의 탄소 원자를 함유하는 직쇄 및/또는 분지쇄, 포화된 알킬 라디칼("C1-Cp-알킬")을 지칭하고, "p"의 정체에 의존하여, 메틸, 에틸, 프로필, 이소프로필, n-부틸, s-부틸, 이소부틸, t-부틸, 2,2-디메틸부틸, n-펜틸, 2-메틸펜틸, 3-메틸펜틸, 4-메틸펜틸, n-헥실 등을 포함하며, 여기서 변수 p는 알킬 라디칼에서 최대 탄소 원자의 수를 나타내는 정수이다. 알킬기는 제한 없이, 메틸기(-CH3), 에틸기(-C2H5), 프로필기(-C3H7) 및 부틸기(-C4H9)를 포함한, 화학식 -CnH2n+1을 갖는 사슬에 배열된 탄화수소기를 추가로 포함하고 또한 시클로-프로판, 시클로-부탄, 시클로-펜탄, 시클로-헥산 및 시클로-헵탄을 포함한 환형 알킬기를 추가로 포함한다.
용어 "시클로알킬"은 (C3-C20), (C3-C10), 및 (C3-C6) 시클로알킬기를 포함하고 시클로-프로판, 시클로-부탄, 시클로-펜탄, 시클로-헥산 및 시클로-헵탄을 추가로 포함하는 환형 알킬기를 지칭한다.
본 명세서에서 사용된 용어 "O-알킬기"는 화학식 -O-CnH2n+1을 갖는 사슬로 배열된 탄화수소기를 지칭한다. O-알킬기는 제한 없이, O-메틸기(-O-CH3), O-에틸기(-O-C2H5), O-프로필기(-O-C3H7) 및 O-부틸기(-O-C4H9)를 포함한다.
본 명세서에 사용된 용어 "아릴기"는 방향족 고리로 배열된 탄화수소기를 지칭하고, 예를 들어 C6-C14-아릴, C6-C10-아릴일 수 있다. 아릴기는 페닐, 나프틸, 테트라하이드로나프틸, 페난트레닐, 비페닐레닐, 인다닐, 톨릴, 크실릴 또는 인데닐 기 등을 추가로 포함한다.
본 명세서에 사용된 용어 "아실기"는 산소에 이중 결합되고 알킬기에 단일 결합된 탄소 원자를 지칭한다. 탄소 원자는 추가로 다른 실체에 결합될 수 있다. 아실기는 화학식: -C(=O)-CnH2n+1로 기술될 수 있다.
본 명세서에 사용된 용어 "O-아실기"는 탄소 원자가 추가의 산소 원자에 단일 결합된 아실기를 지칭한다. 추가 산소 원자는 다른 실체에 결합될 수 있다. O-아실기는 화학식: -O-C(=O)-CnH2n+1로 기술될 수 있다. 더욱이, 탄소 사슬에 의존하여, 길이 특정 O-아실기는 아세톡시기(n=1), 프로파노일옥시기(n=2), 부티릴옥시기(n=3), 펜타노일옥시기(n=4) 등으로 명명될 수 있다.
본 명세서에 사용된 용어 "알코올기" 또는 "하이드록실알킬"은 화학식 CnHn+1OH를 갖는 사슬로 배열된 탄화수소기를 지칭한다. 탄소 사슬에 의존하여 길이 특정 알코올기는 메탄올기(n=1) 또는 하이드록시메틸, 에탄올기(n=2) 또는 하이드록시에틸, 프로판올기(n=3) 또는 하이드록시프로필, 부탄올기(n=4) 또는 하이드록시부틸 등으로 명명될 수 있다.
본 명세서에 사용된 용어 "5-HT2A 수용체"는 신경전달물질 및 말초 신호 매개체 세로토닌에 대한 수용체 계열의 하위클래스를 지칭한다. 5-HT2A 수용체는 세로토닌의 다수의 중추 및 말초 생리적 기능을 중재할 수 있다. 중추신경계 효과는 환각성 화합물의 환각성 효과의 매개를 포함할 수 있다.
본 명세서에 사용된 용어 "5-HT2A 수용체를 조절하는 것"은 5-HT2A 수용체의 기능을 변경하는 본 명세서에 개시된 화합물의 능력을 지칭한다. 5-HT2A 수용체 조절제는 5-HT2A 수용체의 활성을 활성화할 수 있거나, 5-HT2A 수용체에 노출된 화합물의 농도에 의존하여 5-HT2A 수용체의 활성을 활성화하거나 억제할 수 있거나, 5-HT2A 수용체의 활성을 억제할 수 있다. 이러한 활성화 또는 억제는 신호 전달 경로의 활성화와 같은 특정 이벤트의 발생에 따라 달라질 수 있으며/있거나 특정 세포 유형에서만 나타날 수 있다. 용어 "5-HT2A 수용체를 조절하는 것"은 또한 5-HT2A 수용체와 천연 결합 파트너 사이에 복합체가 형성되어 다량체를 형성할 확률을 증가시키거나 감소시킴에 의해 5-HT2A 수용체의 기능을 변경시키는 것을 지칭한다. 5-HT2A 수용체 조절제는 5-HT2A 수용체와 천연 결합 파트너 사이에 이러한 복합체가 형성될 확률을 증가시킬 수 있으며, 5-HT2A 수용체에 노출된 화합물의 농도에 의존하여 5-HT2A 수용체와 천연 결합 파트너 사이에 복합체가 형성될 확률을 증가시키거나 감소시킬 수 있으며, 그리고 또는 5-HT2A 수용체와 천연 결합 파트너 사이에 복합체가 형성될 확률을 감소시킬 수 있다. 프레닐화된 실로시빈 유도체는 5-HT1A 수용체의 작용제 또는 길항제로서 작용함에 의해 5-HT2A 수용체의 기능을 변경할 수 있고, 본 개시내용에 따른 프레닐화된 실로시빈 유도체는 하나 이상의 다른 분자 실체와 직접 상호작용하거나 이에 결합함에 의해, 또는 이를 통해 간접적으로 상호작용함에 의해 5-HT2A 수용체의 기능을 변경할 수 있다는 것이 추가로 인지된다.
본 명세서에 사용된 용어 "5-HT2A 수용체-매개된 장애"는 비정상적인 5-HT2A 수용체 활성을 특징으로 하는 장애를 지칭한다. 5-HT2A 수용체-매개된 장애는 5-HT2A 수용체를 조절함에 의해 완전히 또는 부분적으로 매개될 수 있다. 특히, 5-HT2A 수용체-매개된 장애는 5-HT2A 수용체의 조절이 기저 장애에 일부 영향을 초래하는 장애, 예를 들어 5-HT2A 수용체 조절제의 투여가 치료되어 지는 대상체 중 적어도 일부에서 어느 정도 개선을 초래하는 장애이다.
본 명세서에 사용된 용어 "5-HT1A 수용체"는 신경전달물질 및 말초 신호 매개체 세로토닌에 대한 수용체 계열의 하위클래스를 지칭한다. 5-HT1A 수용체는 세로토닌의 다수의 중추 및 말초 생리 기능을 중재할 수 있다. 5-HT1A에서의 리간드 활성은 일반적으로 환각과 연관되지 않지만, 많은 환각유발성 화합물이 5-HT1A 수용체를 조절하여 복잡한 생리학적 반응을 부여하는 것으로 알려져 있다(Inserra 등, 2020, Pharmacol Rev 73: 202).
본 명세서에 사용된 용어 "5-HT1A 수용체를 조절하는 것"은 5-HT1A 수용체의 기능을 변경하는 본 명세서에 개시된 화합물의 능력을 지칭한다. 5-HT1A 수용체 조절제는 5-HT1A 수용체의 활성을 활성화할 수 있거나, 5-HT1A 수용체에 노출된 화합물의 농도에 의존하여 5-HT1A 수용체의 활성을 활성화하거나 억제할 수 있거나, 5-HT1A 수용체의 활성을 억제할 수 있다. 이러한 활성화 또는 억제는 신호 전달 경로의 활성화와 같은 특정 이벤트의 발생에 따라 달라질 수 있으며/있거나 특정 세포 유형에서만 나타날 수 있다. 용어 "5-HT1A 수용체를 조절하는 것"은 또한 5-HT1A 수용체와 천연 결합 파트너 사이에 복합체가 형성되어 다량체를 형성할 확률을 증가시키거나 감소시킴에 의해 5-HT1A 수용체의 기능을 변경시키는 것을 지칭한다. 5-HT1A 수용체 조절제는 5-HT1A 수용체와 천연 결합 파트너 사이에 이러한 복합체가 형성될 확률을 증가시킬 수 있으며, 5-HT1A 수용체에 노출된 화합물의 농도에 의존하여 5-HT1A 수용체와 천연 결합 파트너 사이에 복합체가 형성될 확률을 증가시키거나 감소시킬 수 있으며, 그리고 또는 5-HT1A 수용체와 천연 결합 파트너 사이에 복합체가 형성될 확률을 감소시킬 수 있다. 프레닐화된 실로시빈 유도체는 5-HT1A 수용체의 작용제 또는 길항제로서 작용함에 의해 5-HT1A 수용체의 기능을 변경할 수 있고, 본 개시내용에 따른 프레닐화된 실로시빈 유도체는 하나 이상의 다른 분자 실체와 직접 상호작용하거나 이에 결합함에 의해, 또는 이를 통해 간접적으로 상호작용함에 의해 5-HT1A 수용체의 기능을 변경할 수 있다는 것이 추가로 인지된다.
본 명세서에 사용된 용어 "5-HT1A 수용체-매개된 장애"는 비정상적인 5-HT1A 수용체 활성을 특징으로 하는 장애를 지칭한다. 5-HT1A 수용체-매개된 장애는 5-HT1A 수용체를 조절함에 의해 완전히 또는 부분적으로 매개될 수 있다. 특히, 5-HT1A 수용체-매개된 장애는 5-HT1A 수용체의 조절이 기저 장애에 일부 영향을 초래하는 장애, 예를 들어 5-HT1A 수용체 조절제의 투여가 치료되어 지는 대상체 중 적어도 일부에서 어느 정도 개선을 초래하는 장애이다.
본 명세서에서 사용되는 용어 "반응물 실로시빈 유도체 화합물"은 합성 또는 생합성 반응에서 반응하여 이에 의해 또 다른 실로시빈 유도체 화합물을 형성할 수 있는 실로시빈 유도체 화합물을 지칭하고, 일반적으로 반응물을 함유하는 인돌 구조를 포함한다. 용어 "반응물 실로시빈 유도체 화합물"은 용어 "실로시빈 유도체 전구체 화합물"을 포함한다.
본 명세서에서 사용된 용어 "실로시빈 유도체 전구체 화합물"은 다중 치환기 실로시빈 유도체의 합성 또는 생합성에서 전구체 화합물로 작용할 수 있는 화학적 화합물을 지칭하고, 인돌 원형 구조를 포함하는 화합물, 예를 들어, 트립토판 및 트립타민을 포함하고, 식 (LVII)을 갖는 실로시빈 유도체 전구체 화합물을 추가로 포함한다:
(LVII)
여기서 R2, R4, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, O-알킬기, O-아실기 또는 포스페이트기이고, 여기서 R3a는 수소 원자 또는 -CH2-CHNH2COOH 또는 -CH2-CH2NH2임.
본 명세서에 사용된 용어 "실로시빈 생합성 효소 보체"는 단독으로 또는 함께 실로시빈 유도체 전구체 화합물의 화학적 전환을 촉진할 수 있고 다중 치환기 실로시빈 유도체 화합물을 형성하는 하나 이상의 폴리펩티드를 지칭한다. 실로시빈 생합성 효소 보체는, 예를 들어, 트립토판 신타제 B 폴리펩티드, 트립토판 데카르복실라제, N-아세틸 트랜스퍼라제, N-메틸 트랜스퍼라제 및 프레닐 트랜스퍼라제 중 하나 이상을 포함할 수 있다.
본 명세서에 사용된 용어 "트립토판 신타제 B 폴리펩티드"는 (i) 예를 들어, 서열번호: 2를 포함하여, 본 명세서에 제시된 임의의 트립토판 신타제 B 폴리펩티드를 구성하는 아미노산 서열과 실질적으로 동일하거나, 또는 (ii) 적어도 적당히 엄격한 조건 하에서 본 명세서에 제시된 임의의 트립토판 신타제 B 폴리펩티드를 인코딩하는 임의의 핵산 서열에 혼성화할 수 있는 핵산 서열에 의해 인코딩되지만, 동의어 코돈의 사용을 위한 아미노산 잔기의 서열을 포함하는 임의의 및 모든 효소를 지칭한다.
본 명세서에 사용된 용어 "트립토판 데카르복실라제"는 (i) 예를 들어, 서열번호: 4, 서열번호: 6 및 서열번호: 8을 포함하여, 본 명세서에 제시된 임의의 트립토판 데카르복실라제 폴리펩티드를 구성하는 아미노산 서열과 실질적으로 동일하거나, 또는 (ii) 적어도 적당히 엄격한 조건 하에서 본 명세서에 제시된 임의의 트립토판 데카르복실라제를 인코딩하는 임의의 핵산 서열에 혼성화할 수 있는 핵산 서열에 의해 인코딩되지만, 동의어 코돈의 사용을 위한 아미노산 잔기의 서열을 포함하는 임의의 및 모든 효소를 지칭한다.
본 명세서에 사용된 용어 "N-아세틸 트랜스퍼라제"는 (i) 예를 들어, 서열번호: 10을 포함하여, 본 명세서에 제시된 임의의 아세틸 트랜스퍼라제 폴리펩티드를 구성하는 아미노산 서열과 실질적으로 동일하거나, 또는 (ii) 적어도 적당히 엄격한 조건 하에서 본 명세서에 제시된 임의의 아세틸 트랜스퍼라제를 인코딩하는 임의의 핵산 서열에 혼성화할 수 있는 핵산 서열에 의해 인코딩되지만, 동의어 코돈의 사용을 위한 아미노산 잔기의 서열을 포함하는 임의의 및 모든 효소를 지칭한다.
본 명세서에 사용된 용어 "N-메틸 트랜스퍼라제"는 (i) 예를 들어, 서열번호: 12 및 서열번호: 14를 포함하여, 본 명세서에 제시된 임의의 N-메틸 트랜스퍼라제 폴리펩티드를 구성하는 아미노산 서열과 실질적으로 동일하거나, 또는 (ii) 적어도 적당히 엄격한 조건 하에서 본 명세서에 제시된 임의의 N-메틸 트랜스퍼라제를 인코딩하는 임의의 핵산 서열에 혼성화할 수 있는 핵산 서열에 의해 인코딩되지만, 동의어 코돈의 사용을 위한 아미노산 잔기의 서열을 포함하는 임의의 및 모든 효소를 지칭한다.
본 명세서에 사용된 용어 "프레닐 트랜스퍼라제"는 (i) 예를 들어, 서열번호: 16, 서열번호: 18, 서열번호: 20, 및 서열번호: 22를 포함하여, 본 명세서에 제시된 임의의 프레닐 트랜스퍼라제 폴리펩티드를 구성하는 아미노산 서열과 실질적으로 동일하거나, 또는 (ii) 적어도 적당히 엄격한 조건 하에서 본 명세서에 제시된 임의의 프레닐 트랜스퍼라제를 인코딩하는 임의의 핵산 서열에 혼성화할 수 있는 핵산 서열에 의해 인코딩되지만, 동의어 코돈의 사용을 위한 아미노산 잔기의 서열을 포함하는 임의의 및 모든 효소를 지칭한다.
본 명세서에 사용된 용어 "PsiH"는 (i) 예를 들어, 서열번호: 24를 포함하여, 본 명세서에 제시된 임의의 PsiH 폴리펩티드를 구성하는 아미노산 서열과 실질적으로 동일하거나, 또는 (ii) 적어도 적당히 엄격한 조건 하에서 본 명세서에 제시된 임의의 PsiH를 인코딩하는 임의의 핵산 서열에 혼성화할 수 있는 핵산 서열에 의해 인코딩되지만, 동의어 코돈의 사용을 위한 아미노산 잔기의 서열을 포함하는 임의의 및 모든 효소를 지칭한다.
본 명세서에 사용된 용어 "CPR"은 (i) 예를 들어, 서열번호: 26을 포함하여, 본 명세서에 제시된 임의의 CPR 폴리펩티드를 구성하는 아미노산 서열과 실질적으로 동일하거나, 또는 (ii) 적어도 적당히 엄격한 조건 하에서 본 명세서에 제시된 임의의 CPR을 인코딩하는 임의의 핵산 서열에 혼성화할 수 있는 핵산 서열에 의해 인코딩되지만, 동의어 코돈의 사용을 위한 아미노산 잔기의 서열을 포함하는 임의의 및 모든 효소를 지칭한다.
본 명세서에 사용된 용어 "PsiK"는 (i) 예를 들어, 서열번호: 49를 포함하여, 본 명세서에 제시된 임의의 PsiK를 구성하는 아미노산 서열과 실질적으로 동일하거나, 또는 (ii) 적어도 적당히 엄격한 조건 하에서 본 명세서에 제시된 임의의 PsiK를 인코딩하는 임의의 핵산 서열에 혼성화할 수 있는 핵산 서열에 의해 인코딩되지만, 동의어 코돈의 사용을 위한 아미노산 잔기의 서열을 포함하는 임의의 및 모든 효소를 지칭한다.
본 명세서에서 상호교환적으로 사용될 수 있는 용어 "트립토판 신타제 B 폴리펩티드를 인코딩하는 핵산 서열" 및 "트립토판 신타제 B 폴리펩티드를 인코딩하는 핵산 서열"은, 예를 들어, 서열번호: 1을 포함하여, 트립토판 신타제 B 폴리펩티드를 인코딩하는 임의의 및 모든 핵산 서열을 지칭한다. 트립토판 신타제 B 폴리펩티드를 인코딩하는 핵산 서열은 추가로 (i) 본 명세서에 제시된 트립토판 신타제 B 폴리펩티드 서열과 실질적으로 동일한 폴리펩티드를 인코딩하거나; 또는 (ii) 적어도 적당히 엄격한 혼성화 조건 하에서 본 명세서에 제시된 임의의 트립토판 신타제 B 폴리펩티드 핵산 서열에 혼성화하거나 적어도 적당히 엄격한 조건 하에서 이에 혼성화할 수 있지만 동의어 코돈의 사용을 위한 임의의 및 모든 핵산 서열을 포함한다.
본 명세서에서 상호교환적으로 사용될 수 있는 용어 "트립토판 데카르복실라제를 인코딩하는 핵산 서열" 및 "트립토판 데카르복실라제 폴리펩티드를 인코딩하는 핵산 서열"은, 예를 들어, 서열번호: 3, 서열번호: 5 및 서열번호: 7을 포함하여, 트립토판 데카르복실라제 폴리펩티드를 인코딩하는 임의의 및 모든 핵산 서열을 지칭한다. 트립토판 데카르복실라제 폴리펩티드를 인코딩하는 핵산 서열은 추가로 (i) 본 명세서에 제시된 트립토판 데카르복실라제 폴리펩티드 서열과 실질적으로 동일한 폴리펩티드를 인코딩하거나; 또는 (ii) 적어도 적당히 엄격한 혼성화 조건 하에서 본 명세서에 제시된 임의의 트립토판 데카르복실라제 핵산 서열에 혼성화하거나 적어도 적당히 엄격한 조건 하에서 이에 혼성화할 수 있지만 동의어 코돈의 사용을 위한 임의의 및 모든 핵산 서열을 포함한다.
본 명세서에서 상호교환적으로 사용될 수 있는 용어 "N-아세틸 트랜스퍼라제를 인코딩하는 핵산 서열" 및 "N-아세틸 트랜스퍼라제 폴리펩티드를 인코딩하는 핵산 서열"은, 예를 들어, 서열번호: 9를 포함하여, N-아세틸 트랜스퍼라제 폴리펩티드를 인코딩하는 임의의 및 모든 핵산 서열을 지칭한다. N-아세틸 트랜스퍼라제 폴리펩티드를 인코딩하는 핵산 서열은 추가로 (i) 본 명세서에 제시된 N-아세틸 트랜스퍼라제 폴리펩티드 서열과 실질적으로 동일한 폴리펩티드를 인코딩하거나; 또는 (ii) 적어도 적당히 엄격한 혼성화 조건 하에서 본 명세서에 제시된 임의의 N-아세틸 트랜스퍼라제 핵산 서열에 혼성화하거나 적어도 적당히 엄격한 조건 하에서 이에 혼성화할 수 있지만 동의어 코돈의 사용을 위한 임의의 및 모든 핵산 서열을 포함한다.
본 명세서에서 상호교환적으로 사용될 수 있는 용어 "N-메틸 트랜스퍼라제를 인코딩하는 핵산 서열" 및 "N-메틸 트랜스퍼라제 폴리펩티드를 인코딩하는 핵산 서열"은, 예를 들어 서열번호: 11 및 서열번호: 13을 포함하여, N-메틸 트랜스퍼라제 폴리펩티드를 인코딩하는 임의의 및 모든 핵산 서열을 지칭한다. N-메틸 트랜스퍼라제 폴리펩티드를 인코딩하는 핵산 서열은 추가로 (i) 본 명세서에 제시된 N-메틸 트랜스퍼라제 폴리펩티드 서열과 실질적으로 동일한 폴리펩티드를 인코딩하거나; 또는 (ii) 적어도 적당히 엄격한 혼성화 조건 하에서 본 명세서에 제시된 임의의 N-메틸 트랜스퍼라제 핵산 서열에 혼성화하거나 적어도 적당히 엄격한 조건 하에서 이에 혼성화할 수 있지만 동의어 코돈의 사용을 위한 임의의 및 모든 핵산 서열을 포함한다.
본 명세서에서 상호교환적으로 사용될 수 있는 용어 "프레닐 트랜스퍼라제를 인코딩하는 핵산 서열" 및 "프레닐 트랜스퍼라제 폴리펩티드를 인코딩하는 핵산 서열"은, 예를 들어, 서열번호: 15, 서열번호: 17, 서열번호: 19, 및 서열번호: 21을 포함하여, 프레닐 트랜스퍼라제 폴리펩티드를 인코딩하는 임의의 및 모든 핵산 서열을 지칭한다. 프레닐 트랜스퍼라제 폴리펩티드를 인코딩하는 핵산 서열은 추가로 (i) 본 명세서에 제시된 프레닐 트랜스퍼라제 폴리펩티드 서열과 실질적으로 동일한 폴리펩티드를 인코딩하거나; 또는 (ii) 적어도 적당히 엄격한 혼성화 조건 하에서 본 명세서에 제시된 임의의 프레닐 트랜스퍼라제 핵산 서열에 혼성화하거나 적어도 적당히 엄격한 조건 하에서 이에 혼성화할 수 있지만 동의어 코돈의 사용을 위한 임의의 및 모든 핵산 서열을 포함한다.
본 명세서에서 상호교환적으로 사용될 수 있는 용어 "PsiH를 인코딩하는 핵산 서열" 및 "PsiH 폴리펩티드를 인코딩하는 핵산 서열"은, 예를 들어 서열번호: 23을 포함하여, PsiH를 인코딩하는 임의의 및 모든 핵산 서열을 지칭한다. PsiH 폴리펩티드를 인코딩하는 핵산 서열은 추가로 (i) 본 명세서에 제시된 PsiH 폴리펩티드 서열과 실질적으로 동일한 폴리펩티드를 인코딩하거나; 또는 (ii) 적어도 적당히 엄격한 혼성화 조건 하에서 본 명세서에 제시된 임의의 PsiH 핵산 서열에 혼성화하거나 적어도 적당히 엄격한 조건 하에서 이에 혼성화할 수 있지만 동의어 코돈의 사용을 위한 임의의 및 모든 핵산 서열을 포함한다.
본 명세서에서 상호교환적으로 사용될 수 있는 용어 "CPR을 인코딩하는 핵산 서열" 및 "CPR 폴리펩티드를 인코딩하는 핵산 서열"은, 예를 들어 서열번호: 25를 포함하여, CPR을 인코딩하는 임의의 및 모든 핵산 서열을 지칭한다. CPR 폴리펩티드를 인코딩하는 핵산 서열은 추가로 (i) 본 명세서에 제시된 CPR 폴리펩티드 서열과 실질적으로 동일한 폴리펩티드를 인코딩하거나; 또는 (ii) 적어도 적당히 엄격한 혼성화 조건 하에서 본 명세서에 제시된 임의의 CPR 핵산 서열에 혼성화하거나 적어도 적당히 엄격한 조건 하에서 이에 혼성화할 수 있지만 동의어 코돈의 사용을 위한 임의의 및 모든 핵산 서열을 포함한다.
본 명세서에서 상호교환적으로 사용될 수 있는 용어 "PsiK를 인코딩하는 핵산 서열" 및 "PsiK 폴리펩티드를 인코딩하는 핵산 서열"은, 예를 들어 서열번호: 48을 포함하여, PsiK를 인코딩하는 임의의 및 모든 핵산 서열을 지칭한다. PsiK를 인코딩하는 핵산 서열은 추가로 (i) 본 명세서에 제시된 PsiK 폴리펩티드 서열과 실질적으로 동일한 폴리펩티드를 인코딩하거나; 또는 (ii) 적어도 적당히 엄격한 혼성화 조건 하에서 본 명세서에 제시된 임의의 PsiK 핵산 서열에 혼성화하거나 적어도 적당히 엄격한 조건 하에서 이에 혼성화할 수 있지만 동의어 코돈의 사용을 위한 임의의 및 모든 핵산 서열을 포함한다.
본 명세서에 사용된 용어 "핵산" 또는 "핵산 서열"은 자연적으로 발생하는 염기, 당 및 당간(백본) 연결로 구성된 뉴클레오시드 또는 뉴클레오티드 단량체의 서열을 지칭한다. 용어는 또한 비-자연적으로 발생하는 단량체 또는 이의 일부를 포함하는 변형된 또는 치환된 서열을 포함한다. 본 개시내용의 핵산은 데옥시리보핵 핵산(DNA) 또는 리보핵산(RNA)일 수 있고 아데닌, 구아닌, 시토신, 티미딘 및 우라실을 포함하는 자연적으로 발생하는 염기를 포함할 수 있다. 핵산은 또한 변형된 염기를 함유할 수 있다. 이러한 변형된 염기의 예는 아자 및 데아자 아데닌, 구아닌, 시토신, 티미딘 및 우라실, 그리고 크산틴 및 하이포크산틴을 포함한다. 뉴클레오티드 또는 뉴클레오시드 단량체의 서열은 폴리뉴클레오티드 서열, 핵산 서열, 뉴클레오티드 서열, 또는 뉴클레오시드 서열로 지칭될 수 있다.
본 명세서에서 참조 서열번호와 연계하여 사용된 용어 "폴리펩티드"는 (i) 그러한 참조 서열번호를 갖는 폴리펩티드를 구성하는 아미노산 서열과 실질적으로 동일하거나, 또는 (ii) 적어도 적당히 엄격한 조건 하에서 그러한 참조 서열번호를 갖는 폴리펩티드를 인코딩하는 임의의 핵산 서열에 혼성화할 수 있는 핵산 서열에 의해 인코딩되지만, 동의어 코돈의 사용을 위한 아미노산 잔기의 서열을 포함하는 임의의 및 모든 폴리펩티드를 지칭한다. 아미노산 잔기의 서열은 아미노산 서열, 또는 폴리펩티드 서열로 지칭될 수 있다.
본 명세서에서 참조 서열번호와 연계하여 사용된 용어 "폴리펩티드를 인코딩하는 핵산 서열"은 그러한 참조 서열번호를 갖는 폴리펩티드를 인코딩하는 임의의 및 모든 핵산 서열을 지칭한다. 참조 서열번호와 연계하여, 폴리펩티드를 인코딩하는 핵산 서열은 추가로 (i) 그러한 참조 서열번호를 갖는 폴리펩티드와 실질적으로 동일한 폴리펩티드를 인코딩하거나; 또는 (ii) 적어도 적당히 엄격한 혼성화 조건 하에서 그러한 참조 서열번호를 갖는 폴리펩티드를 인코딩하는 임의의 핵산 서열에 혼성화하거나, 적어도 적당히 엄격한 조건 하에서 이에 혼성화할 수 있지만 동의어 코돈의 사용을 위한 임의의 및 모든 핵산 서열을 포함한다.
용어 "실질적으로 동일한"은 2개의 아미노산 서열이 바람직하게는 적어도 70% 동일하고, 보다 바람직하게는 적어도 85% 동일하고, 가장 바람직하게는 적어도 95% 동일하고, 예를 들어 96%, 97%, 98% 또는 99% 동일함을 의미한다. 2개의 아미노산 서열 사이의 동일성의 백분율을 결정하기 위해, 이러한 2개 서열의 아미노산 서열은 예를 들어 Smith and Waterman (Adv. Appl. Math., 1981, 2: 482)에 의해 개정된 Needleman and Wunsch (J. Mol. Biol., 1970, 48: 443)의 정렬 방법을 사용하여 정렬되어, 두 서열 사이에 최고 차수 일치가 얻어지고 두 서열 사이에서 동일한 아미노산의 수가 결정된다. 2개의 아미노산 서열 사이의 동일성 백분율을 계산하는 방법은 일반적으로 당분야에서 인식되고 있고, 예를 들어 Carillo and Lipton (SIAM J. Applied Math., 1988, 48:1073)에 의해 기술된 것과 Computational Molecular Biology, Lesk, e.d. Oxford University Press, New York, 1988, Biocomputing: Informatics and Genomics Projects에 기술된 것을 포함한다. 일반적으로 이러한 계산에는 컴퓨터 프로그램이 이용될 것이다. 이와 관련하여 사용될 수 있는 컴퓨터 프로그램은 GCG (Devereux 등, Nucleic Acids Res., 1984, 12: 387) BLASTP, BLASTN 및 FASTA (Altschul 등, J. Mol. Biol., 1990:215:403)를 포함하지만 이에 제한되지 않는다. 두 폴리펩티드 사이의 동일성 백분율을 결정하기 위한 특히 바람직한 방법은 10의 갭 개방 페널티와 0.1의 갭 확장 페널티를 사용하는 BLOSUM 62 스코어링 매트릭스(Henikoff S & Henikoff, J G, 1992, Proc. Natl. Acad. Sci. USA 89: 10915-10919와 함께 Clustal W 알고리즘(Thompson, J D, Higgines, D G and Gibson T J, 1994, Nucleic Acid Res 22(22): 4673-4680을 포함하여, 두 서열 사이에서 최고 차수 일치가 얻어지며 여기서 두 서열 중 하나의 전체 길이 중 적어도 50%가 정렬에 포함된다.
"적어도 적당히 엄격한 혼성화 조건"이란 용액에서 2개의 상보성인 핵산 분자 사이의 선택적 혼성화를 촉진하는 조건이 선택됨을 의미한다. 혼성화는 핵산 서열 분자의 전부 또는 일부에 대해 발생할 수 있다. 혼성화 부분은 전형적으로 길이가 적어도 15(예를 들어, 20, 25, 30, 40 또는 50) 뉴클레오티드이다. 당업계의 통상인은 핵산 이중체 또는 하이브리드의 안정성이 나트륨 함유 완충액에서 나트륨 이온 농도 및 온도의 함수인 Tm에 의해 결정된다는 것을 인식할 것이다(Tm = 81.5℃ - 16.6 (Log10 [Na+])+0.41(% (G+C)-600/l) 또는 유사한 방정식). 따라서, 하이브리드 안정성을 결정하는 세정 조건의 매개변수는 나트륨 이온 농도와 온도이다. 공지된 핵산 분자와 유사하지만 동일하지는 않은 분자를 식별하기 위해, 1% 불일치는 Tm에서의 약 1℃ 감소를 초래하는 것으로 가정될 수 있으며, 예를 들어 >95% 동일성을 갖는 핵산 분자가 모색되는 경우, 최종 세정 온도는 약 5℃ 정도 감소할 것이다. 이들 고려 사항에 기반하여 당업계의 통상인은 적절한 혼성화 조건을 쉽게 선택할 수 있을 것이다. 바람직한 실시형태에서, 엄격한 혼성화 조건이 선택된다. 예로서, 엄격한 혼성화를 달성하기 위해 다음 조건이 이용될 수 있다: Tm(상기 방정식에 기반함) -5℃에서 5×염화나트륨/구연산나트륨(SSC)/5×덴하르트 용액/1.0% SDS에서의 혼성화, 이어서 60℃에서 0.2×SSC/0.1% SDS의 세정. 적당히 엄격한 혼성화 조건은 42℃에서 3×SSC에서 세정하는 단계를 포함한다. 그러나 대체 완충액, 염, 및 온도를 사용하여 동등한 엄격성이 달성될 수 있다는 것이 이해된다. 혼성화 조건에 관한 추가 지침은 Current Protocols in Molecular Biology, John Wiley & Sons, N.Y., 1989, 6.3.1.-6.3.6 및: Sambrook 등, Molecular Cloning, a Laboratory Manual, Cold Spring Harbor Laboratory Press, 1989, Vol. 3에서 찾을 수 있다.
폴리뉴클레오티드 또는 폴리펩티드와 관련하여 본 명세서에서 사용된 용어 "기능적 변이체"는 언급된 참조 폴리뉴클레오티드 또는 폴리펩티드와 동일한 기능을 수행할 수 있는 폴리뉴클레오티드 또는 폴리펩티드를 지칭한다. 따라서, 예를 들어, 서열번호: 2에 제시된 폴리펩티드의 기능적 변이체는 서열번호: 2에 제시된 폴리펩티드와 동일한 기능을 수행할 수 있는 폴리펩티드를 지칭한다. 기능적 변이체는 언급된 참조 폴리펩티드에 비하여, 변형이 하나 이상의 아미노산의 치환, 결실 또는 첨가를 포함하는 변형된 폴리펩티드를 포함한다. 일부 실시형태에서, 치환은 하나의 아미노산의 유사한 특성을 갖는 아미노산으로의 대체를 초래하는 것이다. 이러한 치환은 제한 없이, (i) 글루탐산 및 아스파르트산; (i) 알라닌, 세린 및 트레오닌; (iii) 이소류신, 류신 및 발린, (iv) 아스파라긴 및 글루타민, 및 (v) 트립토판, 티로신 및 페닐알라닌을 포함한다. 기능적 변이체는 강화된 실로시빈 생합성 생체활성을 유지하거나 나타내는 폴리펩티드를 추가로 포함한다.
본 명세서에서 핵산의 맥락에서 사용된 용어 "키메라"는 자연적으로 연결되지 않은 적어도 2개의 연결된 핵산을 지칭한다. 키메라 핵산은 다양한 천연 기원의 연결된 핵산을 포함한다. 예를 들어, 식물 폴리펩티드를 인코딩하는 핵산에 연결된 미생물 프로모터를 구성하는 핵산은 키메라로 간주된다. 키메라 핵산은 자연적으로 연결되어 있지 않다면 동일한 천연 기원의 핵산을 포함할 수도 있다. 예를 들어, 특정 세포-유형으로부터 얻은 프로모터를 구성하는 핵산은 그 동일한 세포-유형으로부터 얻은 폴리펩티드를 인코딩하는 핵산에 연결될 수 있지만, 일반적으로 프로모터를 구성하는 핵산에는 연결되지 않는다. 키메라 핵산은 또한 임의의 비-자연적으로 발생하는 핵산에 연결된 임의의 자연적으로 발생하는 핵산을 포함하는 핵산을 포함한다.
본 명세서에서 사용된 용어 "약학적 제형"은 그 안에 함유된 향정신성 성분을 포함하는 활성 성분이 효과적인 치료를 제공하도록 하고, 과잉의 독성, 알레르기 반응, 자극 또는 합리적인 위험/이익 비율에 상응하는 기타 부작용을 야기하는 임의의 기타 성분을 함유하지 않는 형태의 제제를 지칭한다. 약학적 제형은 부형제, 담체, 희석제 또는 보조제와 같은 다른 약학적 성분을 함유할 수 있다.
본 명세서에서 사용된 용어 "기분전환용 약물 제형"은 그 안에 함유된 향정신성 성분이 기분전환용 약물로서 투여에 효과적이도록 하고, 과잉의 독성, 알레르기 반응, 자극 또는 합리적인 위험/이익 비율에 상응하는 기타 부작용을 야기하는 임의의 기타 성분을 함유하지 않는 형태의 제제를 지칭한다. 기분전환용 약물 제형은 부형제, 담체, 희석제 또는 보조제와 같은 기타 성분을 함유할 수 있다.
본 명세서에서 사용된 용어 "기분전환용 약물로서 투여에 효과적인"은 투여 시 대상체가 비-의학적 목적으로 향정신성 효과를 자발적으로 유도하도록 하는 형태, 일반적으로 자가-투여의 형태의 제제를 지칭한다. 효과는 의식, 만족, 즐거움, 행복감, 지각 왜곡 또는 환각의 변화된 상태를 포함할 수 있다.
본 명세서에 사용된 용어 "유효량"은 예방적 효과를 포함하고 추가로 향정신성 효과를 포함하여, 원하는 생물학적 또는 치료적 효과를 유도하기에 충분한 활성제, 약학적 제형 또는 기분전환용 약물 제형의 양을 지칭한다. 이러한 효과는 장애, 또는 질환의 징후, 증상 또는 원인 또는 생물학적 시스템의 임의의 기타 원하는 변경과 관련한 효과를 포함할 수 있다. 유효량은 예를 들어 건강 상태, 손상 단계, 장애 단계 또는 질환 단계, 치료되는 대상체의 체중 또는 성별, 투여 시기, 투여 방식, 대상체의 연령, 등에 의존하여 다양할 수 있으며, 이 모두는 당업계의 통상인에 의해 결정될 수 있다.
본 명세서에 사용된 용어 "치료하는" 및 "치료" 등은 바람직한 생리학적, 약리학적 또는 생물학적 효과를 얻는 것을 의미하는 것으로 의도되고, 예방적 및 치료적 치료를 포함한다. 효과는 장애, 또는 장애에 기인할 수 있는 질환, 또는 정신 및 정신과 질환 및 장애를 포함하는 질환의 징후, 증상 또는 원인의 억제, 약화, 개선 또는 역전을 초래할 수 있다. 예방이나 치료의 임상적 증거는 장애, 또는 질환, 대상체, 선택된 치료에 따라 달라질 수 있다.
본 명세서에 사용된 용어 "약학적으로 허용가능한"은 약학적 또는 기분전환용 약물 제형에서의 다른 물질과 상용성이 있고, 과도한 독성, 알레르기 반응, 자극 또는 합리적인 위험/이익 비율에 상응하는 기타 부작용 없이 대상체와 접촉하여 사용하기에 적합한 합리적인 의학적 판단의 범주 내에 있는 부형제, 담체, 희석제 또는 보조제를 포함하는 물질을 지칭한다.
본 명세서에서 상호교환적으로 사용될 수 있는 용어 "실질적으로 순수한" 및 "단리된"은 자연적으로 수반되는 성분으로부터 분리된 화합물, 예를 들어 실로시빈 유도체를 기술한다. 전형적으로, 화합물은 샘플에서 (부피, 습윤 또는 건조 중량, 몰 퍼센트 또는 몰분율에 의해) 전체 물질의 적어도 60%, 더 바람직하게는 적어도 75%, 더 바람직하게는 적어도 90%, 95%, 96%, 97% 또는 98%, 가장 바람직하게는 적어도 99%가 관심있는 화합물일 때 실질적으로 순수하다. 순도는 임의의 적절한 방법, 예를 들어, 크로마토그래피, 겔 전기영동 또는 HPLC 분석에 의해 측정될 수 있다.
효소, 단백질 또는 화학적 화합물과 연관하여 본 명세서에서 사용된 용어 "회수된"은 효소, 단백질 또는 화학적 화합물의 다소 순수한 형태를 지칭한다.
다중 치환기 실로시빈 유도체 화합물을 제조하는 방법과 관련하여 본 명세서에서 사용된 용어 "생체내"는 실로시빈 유도체 전구체 화합물을 다중 치환기 실로시빈 유도체 화합물로 전환시키기 위해, 예를 들어, 성장 배지에서 배양된 세포, 예를 들어, 세포 또는 미생물 내에서 실로시빈 유도체 전구체 화합물을 전환시킬 수 있는 효소와 실로시빈 유도체 전구체 화합물을 접촉시키는 것을 포함하는 방법을 지칭한다. 세포는 일반적으로 예를 들어, 이종으로 발현된 트립토판 신타제 B 폴리펩티드, 트립토판 데카르복실라제, N-아세틸 트랜스퍼라제, N-메틸 트랜스퍼라제 및 프레닐 트랜스퍼라제를 포함하는 실로시빈 생합성 효소 복합체를 발현한다.
다중 치환기 실로시빈 유도체 화합물을 제조하는 방법과 관련하여 본 명세서에서 사용된 용어 "시험관내"는 실로시빈 유도체 전구체 화합물을 다중 치환기 실로시빈 유도체 화합물로 전환시키기 위해, 세포 외부에서, 예를 들어, 마이크로웰 플레이트, 튜브, 플라스크, 비이커, 탱크, 반응기 등에서 실로시빈 유도체 전구체를 전환시킬 수 있는 효소와 실로시빈 유도체 전구체 화합물을 접촉시키는 것을 포함하는 방법을 지칭한다.
일반 구현
본 명세서에서 이전에 언급된 바와 같이, 본 개시내용은 실로시빈 유도체에 관한 것이다. 특히, 본 개시내용은 신규한 다중 치환기 실로시빈 유도체를 제공한다. 일반적으로, 본 명세서에 제공된 조성물은 실로시빈의 기능적 특성에서 벗어나는 기능적 특성을 나타낸다. 따라서, 예를 들어, 다중 치환기 실로시빈 유도체는 실로시빈에서 벗어나는 약리학적 특성을 나타낼 수 있다. 더욱이, 다중 치환기 유도체는 실로시빈 유도체가 실로시빈과 다른 물리-화학적 특성을 나타낼 수 있다. 따라서, 예를 들어 다중 치환기 실로시빈 유도체는 용매, 예를 들어 수성 용매에서 우수한 용해도를 나타낼 수 있다. 이 관점에서 다중 치환기 실로시빈 유도체는 약학적 및 기분전환용 약물 제형의 제형에서 유용하다. 일 실시형태에서, 본 개시내용의 다중 치환기 실로시빈 유도체는 화학적으로 및/또는 생합성적으로 편리하게 생산될 수 있다. 이 방법의 실행은 버섯으로부터 실로시빈의 추출과 다중 치환기 유도체를 얻기 위한 후속 화학 반응의 수행을 피할 수 있다. 더욱이, 버섯의 성장을 피할 수 있고 따라서 기후 및 날씨에 대한 의존도를 제한하고 향정신성 화합물을 함유한 버섯의 재배와 연관된 잠재적인 법적 및 사회적 문제를 제한한다. 방법은 상당량의 다중 치환기 실로시빈 유도체를 효율적으로 생산할 수 있다.
다음에서는 선택된 실시형태가 도면을 참조하여 기술된다.
처음으로 예의 다중 치환기 실로시빈 유도체가 기술될 것이다. 이후 다중 치환기 실로시빈 유도체를 사용하고 제조하는 예의 방법이 기술될 것이다.
따라서, 일 양태에서 본 개시내용은 화학 구조가 도 1에 도시된 실로시빈으로 알려진 화합물의 유도체를 제공한다. 본 명세서에서 제공되는 유도체는 특히 2개 이상의 치환기 실체를 보유하는 실로시빈 유도체를 포함하는 다중 치환기 유도체이다.
따라서, 일 양태에서, 본 개시내용은 본 명세서의 교시에 따라 적어도 하나의 실시형태에서 식 (I)을 갖는 화학적 화합물을 제공한다:
(I),
여기서, R2, R4, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 독립적으로 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, O-알킬기, O-아실기 또는 포스페이트기이고, 여기서 R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, R3c는 수소 원자 또는 카르복실기임.
따라서, 식 (I)을 갖는 화학적 화합물에 관해, 처음으로 본 명세서의 양태에서, R2, R4, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 선택된 치환기 실체이다는 것이 인지된다. 따라서, 본 개시내용의 양태에 따르면, R2, R4, R5, R6, 또는 R7 중 적어도 2개는 치환기 실체이다는 것이 이해되어야 한다. 치환기 실체는 각각 독립적으로 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 선택되고, 그리고 2개(그러나 2개 이하)의 치환기 실체가 선택된 경우 그것은 동일하지 않고, 3개 이상의 치환기 실체가 선택된 경우 선택된 치환기 실체 중 적어도 2개가 동일하지 않다.
본 명세서의 양태에서, 실시형태에서, R2, R4, R5, R6, 또는 R7 중 적어도 3개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 선택된 치환기일 수 있다.
본 명세서의 양태에서, 실시형태에서, R2, R4, R5, R6, 또는 R7 중 적어도 3개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 3개로부터 선택된 치환기일 수 있다.
계속해서 식 (I)을 갖는 화합물을 언급하면, 본 명세서의 추가 양태에서, R4는 포스페이트기 또는 수소 원자일 수 있다.
계속해서 식 (I)을 갖는 화합물을 언급하면, 본 명세서의 추가 양태에서, R3a 및 R3b는 수소 원자, 알킬기, 아실기 또는 아릴기일 수 있다. 따라서, R3a 및 R3b는 각각 수소 원자일 수 있거나, R3a 및 R3b는 각각 메틸기, 에틸기, 프로필기 또는 장쇄 알킬기와 같은 알킬기일 수 있거나, R3a 및 R3b는 각각 아실기거나, R3a 및 R3b는각각 아릴기일 수 있다. 더욱이, R3a 및 R3b 중 하나는 수소 원자일 수 있고, R3a 및 R3b 중 하나는 알킬기일 수 있다. R3a 및 R3b 중 하나는 수소 원자일 수 있고, R3a 및 R3b 중 하나는 아실기일 수 있다. R3a 및 R3b 중 하나는 수소 원자일 수 있고, R3a 및 R3b 중 하나는 아릴기일 수 있다. R3a 및 R3b 중 하나는 알킬기일 수 있고, R3a 및 R3b 중 하나는 아릴기일 수 있다. R3a 및 R3b 중 하나는 알킬기일 수 있고, R3a 및 R3b 중 하나는 아실기일 수 있다. R3a 및 R3b 중 하나는 아실기일 수 있고, R3a 및 R3b 중 하나는 아릴기일 수 있다.
계속해서 식 (I)을 갖는 화합물을 언급하면, 본 명세서의 추가 양태에서, 각각의 비치환된 기 R2, R5, R6 또는 R7은 수소 원자일 수 있다. 더욱이, 본 명세서에서 이전에 언급된 바와 같이, R4는 또한 수소 원자일 수 있다.
본 명세서에 따르면, 양태에서, 2개 또는 3개의 치환기를 포함하는 다중 치환기 실로시빈 유도체가 본 명세서에 개시된다. 이들 각각의 예는 선택된 도면을 참조하여 다음에 논의될 것이다. 특히, 2개의 치환기를 포함하는 다중 치환기 실로시빈 유도체를 포함하는 예를 도 3a-3l을 참조하여 논의되고; 3개의 치환기를 포함하는 다중 치환기 실로시빈의 예를 도 4a-4i, 5a-5i, 6a-6i 및 7a-7i를 참조하여 논의된다. 명확성을 위해, 이들 도면 각각에서, 예를 들어 S15, S25 및 S17과 같은 표기는 각각 5-위치(C5)에 있는 제1 치환기 S1, 5-위치(C5)에 있는 제2 치환기 S2, 및 7-위치(C7)에 있는 제1 치환기 S1을 나타낸다는 것이 인지된다. 유사하게, 특정 도면에서, 예를 들어 S22 및 S26과 같은 동일한 화학적 화합물 내의 표기는 화합물의 2-위치(C2)에 있는 제2 치환기 S2 및 6 위치(C6)에 있는 그 동일한 제2 치환기를 나타낸다(참조: 예를 들어, 도 6i).
따라서, 도 3a-3l에 대해 다음에 참조하면, R2, R5, R6 또는 R7 중 2개가 치환기인, 본 명세서에 따른 다중 치환기 실로시빈 유도체의 예는 다음과 같다: 도 3a에 도시된 2,5-디-S1,S2-실로시빈 유도체, 도 3b에 도시된 2,5-디-S2,S1-실로시빈 유도체, 도 3c에 도시된 2,6-디-S1,S2-실로시빈 유도체, 도 3d에 도시된 2,6-디-S2,S1-실로시빈 유도체, 도 3e에 도시된 2,7-디-S1,S2-실로시빈 유도체, 도 3f에 도시된 2,7-디-S2,S1-실로시빈 유도체, 도 3g에 도시된 5,6-디-S1,S2-실로시빈 유도체, 도 3h에 도시된 5,6-디-S2,S1-실로시빈 유도체, 도 3i에 도시된 5,7-디-S1,S2-실로시빈 유도체, 도 3j에 도시된 5,7-디-S2,S1-실로시빈 유도체, 도 3k에 도시된 6,7-디-S1,S2-실로시빈 유도체 및 도 3l에 도시된 6,7-디-S2,S1-실로시빈 유도체. 전술한 것으로부터 분명한 바와 같이, 각각의 도 3a-3l에서, S1 및 S2는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 두 개 중에서 선택된다.
따라서, 예를 들어, 식 (I)을 갖는 화학적 화합물을 참조하면, 일 예의 실시형태에서, R4, R5, R6, 또는 R7 중 2개는 치환기일 수 있고, 이들 중 하나는 (i) 할로겐 원자, (ii) 프레닐기, 및 (iii) 니트릴기이고, R4, R5, R6, 또는 R7 중 하나는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 선택된 치환기일 수 있으며, 그러나 단 2개의 치환기는 동일하지 않고, R2 및 비치환된 R4, R5, R6, 및 R7은 수소 원자이다. 따라서, 그러한 예의 실시예에서, 도 3a-3l을 참조하면, S1은 (i) 할로겐 원자, (ii) 프레닐기 및 (iii) 니트릴기로부터 선택될 수 있고, S2는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 선택될 수 있거나, 또는 반대로 S2는 (i) 할로겐 원자, (ii) 프레닐기 및 (iii) 니트릴기로부터 선택될 수 있고, S1은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 선택될 수 있다.
따라서, 예를 들어, 식 (I)을 갖는 화학적 화합물을 참조하면, 추가 예의 실시형태에서, R4, R5, R6, 또는 R7 중 2개는 치환기일 수 있으며, 이들 중 하나는 할로겐 원자이고, R4, R5, R6, 또는 R7 중 하나는 (i) 하이드록시기, (ii) 니트로기, (iii) 글리코실옥시기, (iv) 아미노기 또는 N-치환된 아미노기, (v) 카르복실기 또는 카르복실산 유도체, (vi) 알데히드 또는 케톤기, (vii) 프레닐기, (viii) 니트릴기로부터 선택된 치환기일 수 있고, 그리고 R2 및 비치환된 R4, R5, R6, 및 R7은 수소 원자이다. 따라서, 그러한 예의 실시형태에서, 도 3a-3l을 참조하면, S1은 할로겐 원자일 수 있고 S2는 (i) 하이드록시기, (ii) 니트로기, (iii) 글리코실옥시기, (iv) 아미노기 또는 N-치환된 아미노기, (v) 카르복실기 또는 카르복실산 유도체, (vi) 알데히드 또는 케톤기, (vii) 프레닐기, 및 (viii) 니트릴기로부터 선택될 수 있거나, 또는 반대로 S2는 할로겐 원자일 수 있고, S1은 (i) 하이드록시기, (ii) 니트로기, (iii) 글리코실옥시기, (iv) 아미노기 또는 N-치환된 아미노기, (v) 카르복실기 또는 카르복실산 유도체, (vi) 알데히드 또는 케톤기, (vii) 프레닐기, 및 (viii) 니트릴기일 수 있다.
따라서, 예를 들어, 식 (I)을 갖는 화학적 화합물을 참조하면, 추가 예의 실시형태에서, R4, R5, R6, 또는 R7 중 2개는 치환기일 수 있으며, 이들 중 하나는 할로겐 원자이고, R4, R5, R6, 또는 R7 중 하나는 (i) 아미노기, (ii) 니트릴기, (iii) 니트로기, (iv) 하이드록시기 및 (vii) 프레닐기로부터 선택된 치환기일 수 있고, R2 및 비치환된 R4, R5, R6 및 R7은 수소 원자이다. 따라서, 그러한 예의 실시형태에서, 도 3a-3l을 참조하면, S1은 할로겐 원자일 수 있고 S2는 (i) 아미노기, (ii) 니트릴기, (iii) 니트로기, (iv) 하이드록시기 및 (vii) 프레닐기로부터 선택될 수 있거나, 또는, 반대로 S2는 할로겐 원자일 수 있고, S1은 (i) 아미노기, (ii) 니트릴기, (iii) 니트로기, (iv) 하이드록시기, 및 (v) 프레닐기일 수 있다.
따라서, 예를 들어, 식 (I)을 갖는 화학적 화합물을 참조하면, 추가 예의 실시형태에서, R4, R5, R6, 또는 R7 중 2개는 치환기일 수 있으며, 이들 중 하나는 할로겐 원자이고, R4, R5, R6, 또는 R7 중 하나는 프레닐기일 수 있고, R2 및 비치환된 R4, R5, R6 및 R7은 수소 원자이다. 따라서, 그러한 예의 실시형태에서, 도 3a-3l을 참조하면, S1은 할로겐 원자일 수 있고 S2는 프레닐기일 수 있거나, 또는, 반대로 S2는 프레닐기일 수 있고 S1은 할로겐 원자일 수 있다.
따라서, 예를 들어, 식 (I)을 갖는 화학적 화합물을 참조하면, 추가 예의 실시형태에서, R4, R5, R6, 또는 R7 중 2개는 치환기일 수 있으며, 이들 중 하나는 프레닐기이고, R4, R5, R6, 또는 R7 중 하나는 (i) 하이드록시기, (ii) 니트로기, (iii) 글리코실옥시기, (iv) 아미노기 또는 N-치환된 아미노기, (v) 카르복실기 또는 카르복실산 유도체, (vi) 알데히드 또는 케톤기, (vii) 할로겐 원자, 및 (viii) 니트릴기로부터 선택된 치환기일 수 있고, R2 및 비치환된 R4, R5, R6 및 R7은 수소 원자이다. 따라서, 그러한 예의 실시형태에서, 도 3a-3l을 참조하면, S1은 프레닐기일 수 있고, S2는 (i) 하이드록시기, (ii) 니트로기, (iii) 글리코실옥시기, (iv) 아미노기 또는 N-치환된 아미노기, (v) 카르복실기 또는 카르복실산 유도체, (vi) 알데히드 또는 케톤기, (vii) 할로겐 원자 및 (viii) 니트릴기로부터 선택될 수 있거나, 또는, 반대로 S2는 프레닐기일 수 있고, S1은 (i) 하이드록시기, (ii) 니트로기, (iii) 글리코실옥시기, (iv) 아미노기 또는 N-치환된 아미노기, (v) 카르복실기 또는 카르복실산 유도체, (vi) 알데히드 또는 케톤 기, (vii) 할로겐 원자, 및 (viii) 니트릴기일 수 있다.
따라서, 예를 들어, 식 (I)을 갖는 화학적 화합물을 참조하면, 추가 예의 실시형태에서, R4, R5, R6, 또는 R7 중 2개는 치환기일 수 있으며, 이들 중 하나는 프레닐기이고, R4, R5, R6, 또는 R7 중 하나는 (i) 카르복실기 또는 카르복실산 유도체, (ii) 할로겐 원자, 및 (iii) 하이드록시기로부터 선택된 치환기일 수 있고, R2 및 비치환된 R4, R5, R6 및 R7은 수소 원자이다. 따라서, 그러한 예의 실시형태에서, 도 3a-3l을 참조하면, S1은 프레닐기일 수 있고 S2는 (i) 카르복실기 또는 카르복실산 유도체, (ii) 할로겐 원자 및 (iii) 하이드록시기로부터 선택될 수 있거나, 또는, 반대로 S2는 프레닐기일 수 있고, S1은 (i) 카르복실기 또는 카르복실산 유도체, (ii) 할로겐 원자, 및 (iii) 하이드록시기일 수 있다.
따라서, 예를 들어, 식 (I)을 갖는 화학적 화합물을 참조하면, 추가 예의 실시형태에서, R4, R5, R6, 또는 R7 중 2개는 치환기일 수 있으며, 이들 중 하나는 니트릴기이고, R4, R5, R6, 또는 R7 중 하나는 (i) 하이드록시기, (ii) 니트로기, (iii) 글리코실옥시기, (iv) 아미노기 또는 N-치환된 아미노기, (v) 카르복실기 또는 카르복실산 유도체, (vi) 알데히드 또는 케톤기, (vii) 프레닐기, (viii) 할로겐 원자로부터 선택된 치환기일 수 있고, R2 및 비치환된 R4, R5, R6 및 R7은 수소 원자이다. 따라서, 그러한 예의 실시형태에서, 도 3a-3l을 참조하면, S1은 니트릴기일 수 있고 S2는 (i) 하이드록시기, (ii) 니트로기, (iii) 글리코실옥시기, (iv) 아미노기 또는 N-치환된 아미노기, (v) 카르복실기 또는 카르복실산 유도체, (vi) 알데히드 또는 케톤기, (vii) 프레닐기 및 (viii) 할로겐 원자로부터 선택될 수 있거나, 또는, 반대로 S2는 니트릴기일 수 있고, S1은 (i) 하이드록시기, (ii) 니트로기, (iii) 글리코실옥시기, (iv) 아미노기 또는 N-치환된 아미노기, (v) 카르복실기 또는 카르복실산 유도체, (vi) 알데히드 또는 케톤기, (vii) 프레닐기, 및 (viii) 할로겐 원자일 수 있다.
따라서, 예를 들어, 식 (I)을 갖는 화학적 화합물을 참조하면, 추가 예의 실시형태에서, R4, R5, R6, 또는 R7 중 2개는 치환기일 수 있으며, 이들 중 하나는 니트릴기이고, R4, R5, R6, 또는 R7 중 하나는 아미노기 또는 N-치환된 아미노기일 수 있고, R2 및 비치환된 R4, R5, R6 및 R7은 수소 원자이다. 따라서, 예의 실시형태에서, 도 3a-3l을 참조하면, S1은 니트릴기일 수 있고, S2는 아미노기 또는 N-치환된 아미노기일 수 있으며, 반대로, S2는 니트릴기일 수 있고, S1은 아미노기 또는 N-치환된 아미노기일 수 있다.
이제 3개의 치환기를 포함하는 다중 치환기 실로시빈 유도체로 돌아가, 도 4a - 4f, 4g - 4i, 5a - 5f, 5g - 5i, 6a - 6f, 6g - 6i, 7a - 7f, 7g - 7i를 참조하면, 본 명세서에 따른 다중 치환기 실로시빈 유도체의 예가 여기에 도시되어 있으며, 여기서 R2, R5, R6, 또는 R7 중 3개는 치환기이다. 도 4a - 4f, 5a - 5f, 6a - 6f, 및 7a - 7f에 도시된 예에서, 3개의 치환기는 3개의 서로 다른 치환기 S1, S2, S3이다는 것이 인지된다. 도 4g - 4i, 5g - 5i, 6g - 6i, 및 7g - 7i에 도시된 예에서, 3개의 치환기는 3개의 치환기 중 2개가 동일하도록, 즉 S1, S2, S2가 되도록 선택된다. 이와 관련하여 예는 특히 다음과 같다: 도 4a에 도시된 2,5,6-트리-S1,S2,S3-실로시빈 유도체, 도 4b에 도시된 2,5,6-트리-S1,S3,S2-실로시빈 유도체, 도 4c에 도시된 2,5,6-트리-S3,S1,S2-실로시빈 유도체, 도 4d에 도시된 2,5,6-트리-S2,S1,S3-실로시빈 유도체, 도 4e에 도시된 2,5,6-트리-S3,S2,S1-실로시빈 유도체, 및 2,5,6-트리-S2,S3,S1-실로시빈 유도체(도 4f). 전술한 내용으로부터 분명한 바와 같이, 각각의 도 4a - 4f에서, S1, S2 및 S3은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 3개로부터 선택된다.
R2, R5, R6, 또는 R7 중 3개가 치환기인 추가 예가 도 4g, 4h 및 4i에, 특히 도 4g에 도시된 2,5,6-트리-S1,S2,S2-실로시빈 유도체, 도 4h에 도시된 2,5,6-트리-S2,S1,S2-실로시빈 유도체, 및 도 4i에 도시된 2,5,6-트리-S2,S2,S1-실로시빈 유도체로 도시되어 있다. 전술한 것으로부터 분명한 바와 같이, 각각의 도 4g - 4i에서 S1 및 S2는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택된다.
R2, R5, R6, 또는 R7 중 3개가 치환기인 추가 예가 도 5a, 5b, 5c, 5d, 5e 및 5f에, 특히 도 5a에 도시된 2,5,7-트리-S1,S2,S3-실로시빈 유도체), 도 5b에 도시된 2,5,7-트리-S1,S3,S2-실로시빈 유도체, 도 5c에 도시된 2,5,7-트리-S3,S1,S2-실로시빈 유도체, 도 5d에 도시된 2,5,7-트리-S2,S1,S3-실로시빈 유도체, 도 5e에 도시된 2,5,7-트리-S3,S2,S1-실로시빈 유도체, 도 5f에 도시된 2,5,7-트리-S2,S3,S1-실로시빈 유도체로 도시되어 있다. 전술한 것으로부터 분명한 바와 같이 각각의 도 5a - 5i에서 S1, S2 및 S3은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 3개로부터 선택된다.
R2, R5, R6, 또는 R7 중 3개가 치환기인 추가 예가 도 5g, 5h 및 5i에, 특히 도 5g에 도시된 2,5,7-트리-S1,S2,S2-실로시빈 유도체, 도 5h에 도시된 2,5,7-트리-S2,S1,S2-실로시빈 유도체, 및 도 5i에 도시된 2,5,7-트리-S2,S2,S1-실로시빈 유도체로 도시되어 있다. 전술한 것으로부터 분명한 바와 같이 각각의 도 5g - 5i에서, S1 및 S2는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택된다.
R2, R5, R6, 또는 R7 중 3개가 치환기인 추가 예가 도 6a, 6b, 6c, 6d, 6e 및 6f에, 특히 도 6a에 도시된 2,6,7-트리-S1,S2,S3-실로시빈 유도체, 도 6b에 도시된 2,6,7-트리-S1,S3,S2-실로시빈 유도체, 도 6c에 도시된 2,6,7-트리-S3,S1,S2-실로시빈 유도체, 도 6d에 도시된 2,6,7-트리-S2,S1,S3-실로시빈 유도체, 도 6e에 도시된 2,6,7-트리-S3,S2,S1-실로시빈 유도체, 및 2,6,7-트리-S2,S3,S1-실로시빈 유도체(도 6f)로 도시되어 있다. 도 6a - 6i에서, S1, S2 및 S3은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 3개로부터 선택된다는 것이 전술한 것으로부터 분명할 것이다.
R2, R5, R6, 또는 R7 중 3개가 치환기인 추가 예가 도 6g, 6h 및 6i에, 특히 도 6g에 도시된 2,6,7-트리-S1,S2,S2-실로시빈 유도체, 도 6h에 도시된 2,6,7-트리-S2,S1,S2-실로시빈 유도체, 및 도 6i에 도시된 2,6,7-트리-S2,S2,S1-실로시빈 유도체로 도시되어 있다. 도 6a - 6i에서, S1 및 S2는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택된다는 것이 전술한 것으로부터 분명할 것이다.
R2, R5, R6, 또는 R7 중 3개가 치환기인 추가 예가 도 7a, 7b, 7c, 7d, 7e 및 7f에, 특히 도 7a에 도시된 5,6,7-트리-S1,S2,S3-실로시빈 유도체, 도 7b에 도시된 5,6,7-트리-S1,S3,S2-실로시빈 유도체, 도 7c에 도시된 5,6,7-트리-S3,S1,S2-실로시빈 유도체, 도 7d에 도시된 5,6,7-트리-S2,S1,S3-실로시빈 유도체, 도 7e에 도시된 5,6,7-트리-S3,S2,S1-실로시빈 유도체, 및 도 7f에 도시된 5,6,7-트리-S2,S3,S1-실로시빈 유도체로 도시되어 있다. 도 7a - 7f에서, S1, S2 및 S3은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 3개로부터 선택된다는 것이 전술한 것으로부터 분명할 것이다.
R2, R5, R6, 또는 R7 중 3개가 치환기인 추가 예가 도 7g, 7h 및 7i에, 특히 도 7g에 도시된 5,6,7-트리-S1,S2,S2-실로시빈 유도체, 도 7h에 도시된 5,6,7-트리-S2,S1,S2-실로시빈 유도체, 및 도 7i에 도시된 5,6,7-트리-S2,S2,S1-실로시빈 유도체로 도시되어 있다. 각각의 도 7g - 7i에서, S1 및 S2는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택된다는 것이 전술한 것으로부터 분명할 것이다.
더욱이, 도 3a - 3l, 4a - 4i, 5a - 5i, 6a - 6i 및 7a - 7i에 도시된 각각의 예의 실시형태에서, R3a 및 R3b는 수소 원자, 알킬기, 아실기 또는 아릴기일 수 있다는 것이 인지된다. 따라서, R3a 및 R3b는 각각 수소 원자일 수 있거나, R3a 및 R3b는 각각 메틸기, 에틸기, 프로필기 또는 장쇄 알킬기와 같은 알킬기일 수 있거나, R3a 및 R3b는 각각 아실기일 수 있거나, R3a 및 R3b는 각각 아릴기일 수 있다. 더욱이, R3a 및 R3b 중 하나는 수소 원자일 수 있고, R3a 및 R3b 중 하나는 알킬기일 수 있다. R3a 및 R3b 중 하나는 수소 원자일 수 있고, R3a 및 R3b 중 하나는 아실기일 수 있다. R3a 및 R3b 중 하나는 수소 원자일 수 있고, R3a 및 R3b 중 하나는 아릴기일 수 있다. R3a 및 R3b 중 하나는 알킬기일 수 있고, R3a 및 R3b 중 하나는 아릴기일 수 있다. R3a 및 R3b 중 하나는 알킬기일 수 있고, R3a 및 R3b 중 하나는 아실기일 수 있다. R3a 및 R3b 중 하나는 아실기일 수 있고, R3a 및 R3b 중 하나는 아릴기일 수 있다.
본 명세서의 추가적인 양태에서 도 3a - 3l, 4a - 4i, 5a - 5i, 6a - 6i 및 7a - 7i에 도시된 예의 실시형태의 각각에서, R3c는 수소 원자 또는 카르복시기일 수 있다는 것이 인지된다.
본 명세서의 추가적인 양태에서 도 3a - 3l, 4a - 4i, 5a - 5i, 6a - 6i 및 7a - 7i에 도시된 예의 실시형태의 각각에서, R4는 수소 원자, O-알킬기, O-아실기 또는 포스페이트기일 수 있다는 것이 인지된다.
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (IX)을 갖는 화학적 화합물일 수 있다:
(IX).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (X)을 갖는 화학적 화합물일 수 있다:
(X).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XI)을 갖는 화학적 화합물일 수 있다:
(XI).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XII)을 갖는 화학적 화합물일 수 있다:
(XII).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XIII)을 갖는 화학적 화합물일 수 있다:
(XIII).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XIV)을 갖는 화학적 화합물일 수 있다:
(XIV).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (X)을 갖는 화학적 화합물일 수 있다:
(X).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XV)을 갖는 화학적 화합물일 수 있다:
(XV).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XV)을 갖는 화학적 화합물일 수 있다:
(XVI).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XVII)을 갖는 화학적 화합물일 수 있다:
(XVII).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XVIII)을 갖는 화학적 화합물일 수 있다:
(XVIII).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XIX)을 갖는 화학적 화합물일 수 있다:
(XIX).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XX)을 갖는 화학적 화합물일 수 있다:
(XX).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XXI)을 갖는 화학적 화합물일 수 있다:
(XXI).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XXII)을 갖는 화학적 화합물일 수 있다:
(XXII).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XXIII)을 갖는 화학적 화합물일 수 있다:
(XXIII).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (X)을 갖는 화학적 화합물일 수 있다:
(X).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XXIV)을 갖는 화학적 화합물일 수 있다:
(XXIV).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XXV)을 갖는 화학적 화합물일 수 있다:
(XXV).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XVI)을 갖는 화학적 화합물일 수 있다:
(XXVI).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XXVII)을 갖는 화학적 화합물일 수 있다:
(XXVII).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XXVIII)을 갖는 화학적 화합물일 수 있다:
(XXVIII).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XXIX)을 갖는 화학적 화합물일 수 있다:
(XXIX).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XXX)을 갖는 화학적 화합물일 수 있다:
(XXX).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XXXI)을 갖는 화학적 화합물일 수 있다:
(XXXI).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XXXII)을 갖는 화학적 화합물일 수 있다:
(XXXII).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XXXIII)을 갖는 화학적 화합물일 수 있다:
(XXXIII).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XXXIV)을 갖는 화학적 화합물일 수 있다:
(XXXIV).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XXXV)을 갖는 화학적 화합물일 수 있다:
(XXXV).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XXXVI)을 갖는 화학적 화합물일 수 있다:
(XXXVI).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XXXVII)을 갖는 화학적 화합물일 수 있다:
(XXXVII).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XXXVIII)을 갖는 화학적 화합물일 수 있다:
(XXXVIII).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XXXIX)을 갖는 화학적 화합물일 수 있다:
(XXXIX).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XL)을 갖는 화학적 화합물일 수 있다:
(XL).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XLI)을 갖는 화학적 화합물일 수 있다:
(XLI).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XLII)을 갖는 화학적 화합물일 수 있다:
(XLII).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XLIII)을 갖는 화학적 화합물일 수 있다:
(XLIII).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XLIV)을 갖는 화학적 화합물일 수 있다:
(XLIV).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XLV)을 갖는 화학적 화합물일 수 있다:
(XLV).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XLVI)을 갖는 화학적 화합물일 수 있다:
(XLVI).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XLVII)을 갖는 화학적 화합물일 수 있다:
(XLVII).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XLVIII)을 갖는 화학적 화합물일 수 있다:
(XLVIII).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (XLIX)을 갖는 화학적 화합물일 수 있다:
(XLIX).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (L)을 갖는 화학적 화합물일 수 있다:
(L).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (LI)을 갖는 화학적 화합물일 수 있다:
(LI).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (LII)을 갖는 화학적 화합물일 수 있다:
(LII).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (LIII)을 갖는 화학적 화합물일 수 있다:
(LIII).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (LIV)을 갖는 화학적 화합물일 수 있다:
(LIV).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (LV)을 갖는 화학적 화합물일 수 있다:
(LV).
더욱이, 하나의 예의 실시형태에서, 본 개시내용에 따른 다중 치환기 실로시빈 유도체는 식 (LXXVI)을 갖는 화학적 화합물일 수 있다:
(LXXVI).
더욱이, 본 개시내용의 다중 치환기 실로시빈 유도체는 약학적으로 허용가능한 염을 비롯한 이의 염을 포함한다는 것이 인지된다. 따라서, C3 원자로부터 차례로 신장하는 에틸-아미노기의 질소 원자는 양성자화될 수 있고, 양전하는 예를 들어 염화물 또는 황산염 이온에 의해 균형을 이루어 이에 의해 염화물염 또는 황산염을 형성할 수 있다. 더욱이, R4가 포스페이트기인 화합물에서 포스페이트기는 탈양성자화될 수 있고 음전하가 예를 들어 나트륨 이온 또는 칼륨 이온에 의해 균형을 이루어 나트륨염 또는 칼륨염을 형성할 수 있다.
더욱이, R4가 포스페이트기인 경우, 용어 프레닐화된 실로시빈 유도체는 또한 식 (IV)을 갖는 화합물을 포함한다는 것이 인지된다:
(IV)
여기서, R2, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 독립적으로 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, 여기서 R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, 여기서 R3c는 수소 원자 또는 카르복실기임. R3c가 카르복시기인 경우, 식 (Iva)을 갖는 화합물이 추가로 포함된다:
(IVa).
나트륨염, 칼륨염 등과 같은 식 (IV) 및 (IVa)을 갖는 프레닐화화된 실로시빈 유도체의 염이 추가로 포함된다.
따라서, 간단히 요약하자면, 본 개시내용은 다중 치환기 실로시빈 유도체를 제공한다. 개시내용은 특히 식 (I)을 갖는 화학적 화합물을 제공한다:
(I),
여기서, R2, R4, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 독립적으로 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, O-알킬기, O-아실기 또는 포스페이트기이고, 여기서 R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, 그리고 여기서 R3c는 수소 원자 또는 카르복실기임.
또 다른 실시형태에서, R3a 및 R3b는 수소 원자, (C1-C20)-알킬기, (C6-C14)-아릴기, 또는 -C(=O)(C1-C20)-알킬기이다. 또 다른 실시형태에서, R3a 및 R3b는 수소 원자, (C1-C10)-알킬기, (C6-C10)-아릴기, 또는 -C(=O)(C1-C10)-알킬기이다. 또 다른 실시형태에서, R3a 및 R3b는 수소 원자, (C1-C6)-알킬기, 페닐기, 또는 -C(=O)(C1-C6)-알킬기이다. 또 다른 실시형태에서, R3a 및 R3b는 수소 원자, 메틸기, 에틸기, 프로필기, 페닐기, -C(=O)-CH3, -C(=O)-CH2CH3, 또는 -C(=O)-CH2CH2CH3이다.
또 다른 실시형태에서, R3a 및/또는 R3b는 (C1-C20)-시클로-알킬기, 또는 (C1-C10)-시클로-알킬기, (C1-C10)-시클로-알킬기이고, 또는 (C1-C10)-시클로-알킬기이다. 일 실시 형태에서, R3a 및/또는 R3b는 시클로-프로판기, 시클로-부탄기, 시클로-펜탄기, 또는 시클로-헥산기다.
일 실시형태에서, 개시내용의 식의 임의의 정의에서 알킬기(O-알킬 포함)는 C1-C20-알킬이다. 또 다른 실시형태에서, 알킬기는 C1-C10-알킬이다. 또 다른 실시형태에서, 알킬기는 C1-C6-알킬이다. 다른 실시 형태에서, 알킬기는 메틸, 에틸, 프로필, 부틸 또는 펜틸이다.
일 실시형태에서, 개시내용의 화학식의 임의의 정의에서 아실기(O-아실 포함)는 C1-C20-아실(또는 C1-C20-아실-O-)이다. 다른 실시 형태에서, 알킬기는 C1-C10-아실(또는 C1-C10-아실-O-)이다. 다른 실시 형태에서, 알킬기는 C1-C6-아실(또는 C1-C6-아실-O-)이다. 다른 실시 형태에서, 아실기는 O-아실기, 메타노일, 에타노일, 프로파노일, 부타노일 또는 펜타노일이다.
일 실시형태에서, 개시내용의 화학식의 임의의 정의에서 아릴기는 선택적으로 치환된 C6-C14-아릴이다. 또 다른 실시형태에서, 아릴기는 선택적으로 치환된 C6-C10-아릴 또는 페닐이다. 또 다른 실시형태에서, 아릴기는 페닐, 나프틸, 테트라하이드로나프틸, 페난트레닐, 비페닐레닐, 인다닐 또는 인데닐 등이다.
본 개시내용의 다중 치환기 실로시빈 유도체는 약학적 또는 기분전환용 약물 제형을 제조하는데 사용될 수 있다. 따라서 일 실시형태에서, 본 개시내용은 또 다른 양태에서, 다중 치환기 실로시빈 유도체를 포함하는 약학적 및 기분전환용 약물 제형을 추가로 제공한다. 따라서, 일 양태에서, 본 개시내용은 추가 실시형태에서 식 (I)을 갖는 화학적 화합물을 포함하는 약학적 또는 기분전환용 약물 제형을 제공한다:
(I),
여기서, R2, R4, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 독립적으로 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, O-알킬기, O-아실기 또는 포스페이트기이고, 여기서 R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, 그리고 여기서 R3c는 수소 원자 또는 카르복실기임.
약학적 또는 기분전환용 약물 제형은 액체, 정제, 캡슐, 마이크로캡슐, 나노캡슐, 경피 패치, 젤, 폼, 오일, 에어로졸, 나노미립자, 분말, 크림, 에멀젼, 미셀 시스템, 필름, 스프레이, 소란, 주입제, 차, 달인약, 좌제 등으로 제조될 수 있고, 부형제와 함께 니트릴화된 실로시빈 화합물의 약학적으로 허용가능한 염 또는 용매화물을 포함할 수 있다. 본 명세서에서 사용된 용어 "부형제"는 개시내용의 화학적 화합물 이외의 임의의 성분을 의미한다. 당업자가 쉽게 이해할 수 있는 바와 같이, 부형제의 선택은 당업자에게 쉽게 명백한 특정 투여 방식, 본 개시내용의 화학적 화합물의 용해도에 대한 부형제의 효과 및 그의 제조에 대한 방법과 같은 요인에 따라 달라질 수 있다. 이러한 조성물 및 그의 제조에 대한 방법은, 예를 들어 "Remington's Pharmaceutical Sciences", 22nd Edition(Pharmaceutical Press and Philadelphia College of Pharmacy at the University of the Sciences, 2012)에서 찾아볼 수 있다.
본 개시내용의 화합물을 사용할 때 용량은 넓은 한도 내에서 다양할 수 있고, 관례적이고 당업자에게 공지된 바와 같이, 용량은 각각의 개별 사례에서 개별 조건에 맞춰질 수 있다. 용량은, 예를 들어 치료되어 지는 질환의 특성 및 중증도, 환자의 상태, 이용된 화합물, 또는 급성 또는 만성 질환 상태를 치료되거나 예방이 실시되는지 여부, 화합물의 전달 방식, 또는 본 개시내용의 화합물에 부가하여 추가 활성 화합물이 투여되는지 여부에 따라 달라진다. 본 발명의 대표적인 용량은 약 0.001mg 내지 약 5000mg, 약 0.001mg 내지 약 2500mg, 약 0.001mg 내지 약 1000mg, 약 0.001mg 내지 약 500mg, 약 0.001mg 내지 약 250mg, 약 0.001mg 내지 약 100mg, 약 0.001mg 내지 약 50mg, 및 약 0.001mg 내지 약 25mg을 포함하지만 이에 제한되지 않는다. 본 개시내용의 대표적인 용량은 약 0.0001 내지 약 1,000mg, 약 10 내지 약 160mg, 약 10mg, 약 20mg, 약 40mg, 약 80mg 또는 약 160mg을 포함하지만 이에 제한되지 않는다. 특히 상대적으로 많은 양이 필요하다고 간주되는 경우, 예를 들어 2, 3 또는 4회 용량과 같은 다중 용량이 하루 동안 투여될 수 있다. 대상체에 따라 그리고 환자의 의사나 간병인이 적절하다고 판단하는 경우 본 명세서에 기술된 용량으로부터 상향 또는 하향으로 벗어날 필요가 있을 수 있다.
본 개시내용의 다중 치환기 실로시빈 유도체를 포함하는 약학적 및 약물 제형은 경구로 투여될 수 있다. 경구 투여는 화합물이 위장관으로 들어가도록 삼키는 것을 포함할 수 있거나, 화합물이 입에서 직접적으로 혈류로 들어가는 구강 또는 설하 투여가 이용될 수 있다. 경구 투여에 적합한 제형은 고체 및 액체 제형 둘 모두를 포함한다.
고체 제형은 정제, 캡슐(미립자, 액체, 마이크로캡슐 또는 분말 함유), 로젠지(액체-충진된 로젠지 포함), 츄어블, 다중- 및 나노-미립자, 젤, 고용체, 리포솜 제형, 마이크로캡슐화된 제제, 크림, 필름, 소란, 좌약 및 스프레이를 포함한다.
액체 제형은 현탁액, 용액, 시럽 및 엘릭서를 포함한다. 이러한 제형은 연질 또는 경질 캡슐에서 충전제로 이용될 수 있고 전형적으로 담체, 예를 들어 물, 에탄올, 폴리에틸렌 글리콜, 프로필렌 글리콜, 메틸셀룰로오스 또는 적합한 오일, 및 하나 이상의 유화제 및/또는 현탁화제를 포함할 수 있다. 액체 제형은 또한, 예를 들어, 샤세로부터 고체의 재구성에 의해 제조될 수 있다.
결합제는 일반적으로 정제 제형에 응집성 특성을 부여하는데 사용된다. 적합한 결합제는 미세결정질 셀룰로오스, 젤라틴, 당, 폴리에틸렌 글리콜, 천연 및 합성 검, 폴리비닐피롤리돈, 전호화 전분, 하이드록시프로필 셀룰로오스 및 하이드록시프로필 메틸셀룰로오스를 포함한다.
정제는 또한 희석제, 예컨대 락토스(일수화물, 분무-건조된 일수화물, 무수물 등), 만니톨, 자일리톨, 덱스트로스, 수크로스, 소르비톨, 미세결정질 셀룰로오스, 전분 및 이염기성 인산칼슘 이수화물을 함유할 수 있다.
정제는 또한 선택적으로 라우릴황산나트륨 및 폴리소르베이트 80과 같은 표면활성제를 포함할 수 있다. 존재하는 경우, 표면활성제는 정제의 0.2%(w/w) 내지 5%(w/w)를 구성할 수 있다.
정제는 스테아르산마그네슘, 스테아르산칼슘, 스테아르산아연, 스테아릴푸마르산나트륨, 스테아르산마그네슘과 라우릴황산나트륨의 혼합물과 같은 윤활제를 추가로 함유할 수 있다. 윤활제는 일반적으로 정제의 0.25%(w/w) 내지 10%(w/w), 0.5%(w/w) 내지 3%(w/w)를 구성한다.
다중 치환기 실로시빈 유도체에 부가하여, 정제는 붕해제를 함유할 수 있다. 붕해제의 예는 전분 글리콜산 나트륨, 카르복시메틸 셀룰로오스 나트륨, 카르복시메틸 셀룰로오스 칼슘, 크로스카르멜로스 나트륨, 크로스포비돈, 폴리비닐피롤리돈, 메틸 셀룰로오스, 미세결정질 셀룰로오스, 저급 알킬 치환 하이드록시프로필 셀룰로오스, 전분, 전호화 전분 및 알긴산 나트륨을 포함한다. 일반적으로, 붕해제는 복용량 형태의 1%(w/w) 내지 25%(w/w) 또는 5%(w/w) 내지 20%(w/w)를 구성할 것이다.
다른 가능한 보조 성분은 항산화제, 착색제, 향미제, 방부제 및 맛 차폐제를 포함한다.
정제 복용량 형태의 경우, 화합적 화합물의 원하는 유효량에 따라, 본 개시내용의 화학적 화합물은 복용량 형태의 1%(w/w) 내지 80%(w/w), 보다 전형적으로 복용량 형태의 5%(w/w) 내지 60%(w/w)를 구성할 수 있다.
예시적인 정제는 최대 약 80%(w/w)의 화학적 화합물, 약 10%(w/w) 내지 약 90%(w/w) 결합제, 약 0%(w/w) 내지 약 85%(w/w) 희석제, 약 2%(w/w) 내지 약 10%(w/w) 붕해제, 및 약 0.25%(w/w) 내지 약 10%(w/w) 윤활유를 함유한다.
정제의 제형은 "Pharmaceutical Dosage Forms: Tablets", Vol. 1 - Vol. 3, by CRC Press (2008)에 논의되어 있다.
본 개시내용의 다중 치환기 실로시빈 유도체를 포함하는 약학적 및 기분전환용 약물 제형은 또한 혈류, 근육 또는 내부 기관 안으로 직접적으로 투여될 수 있다. 따라서, 약학적 및 기분전환용 약물 제형은 비경구적으로(예를 들어, 피하, 정맥내, 동맥내, 척수강내, 뇌실내, 두개내, 근육내 또는 복강내 주사에 의해) 투여될 수 있다. 비경구 제형은 전형적으로 염, 탄수화물 및 완충제(일 실시형태에서는 pH 3 내지 9)와 같은 부형제를 함유할 수 있는 수성 용액이지만, 일부 적용의 경우 멸균수와 같은 적합한 비히클과 연계하여 사용되어 지는 멸균 비-경구 용액 또는 건조된 형태로서 더 적합하게 제형화될 수 있다.
비경구 투여를 위한 본 개시내용의 다중 치환기 실로시빈 유도체를 포함하는 제형은 즉시 및/또는 변형 방출되도록 제형화될 수 있다. 변형 방출 제형은 지연 방출, 지속 방출, 펄스 방출, 제어 방출, 표적 방출 및 프로그래밍 방출을 포함한다. 따라서, 개시내용의 화학적 화합물은 활성 화합물의 변형 방출을 제공하는 이식된 저장소로서 투여하기 위해 고체, 반-고체 또는 요변성 액체로 제형화될 수 있다. 이러한 제형의 예는 약물-코팅된 스텐트 및 폴리(dl-락틱-코글리콜)산(PGLA) 미세구를 포함한다.
본 개시내용의 약학적 또는 기분전환용 약물 제형은 또한 피부 또는 점막에 국소적으로, 즉 피부로 또는 경피적으로 투여될 수 있다. 이 목적을 위한 예의 약학적 및 기분전환용 약물 제형은 젤, 하이드로겔, 로션, 용액, 크림, 연고, 분진 분말, 화장품, 오일, 점안제, 드레싱, 폼, 필름, 피부 패치, 웨이퍼, 임플란트, 스폰지, 섬유, 붕대 및 마이크로에멀젼을 포함한다. 리포솜도 사용될 수 있다. 예의 담체는 알코올, 물, 광유, 액체 바셀린, 백색 바셀린, 글리세린, 폴리에틸렌 글리콜 및 프로필렌 글리콜을 포함한다. 침투 증강제가 합체될 수 있다(예를 들어, Finnin, B. and Morgan, T.M., 1999 J. Pharm. Sci, 88 (10), 955-958 참조).
국소 투여의 다른 수단은 전기천공법, 이온영동법, 음파영동법, 초음파영동법 및 미세바늘 또는 바늘-없는(예를 들어, Powderject™, Bioject™ 등) 주사에 의한 전달을 포함한다.
흡입 또는 통기용 약학적 및 기분 전환용 약물 제형은 약학적으로 허용가능한 수성 또는 유기 용매, 또는 이의 혼합물 및 분말에 용액 및 현탁액을 포함한다. 액체 또는 고체 약학적 조성물은 적합한 약학적으로 허용가능한 부형제를 함유할 수 있다. 일부 실시형태에서, 약학적 조성물은 국소 또는 전신 효과를 위해 구강 또는 비강 호흡 경로에 의해 투여된다. 약학적으로 허용가능한 용매에서의 약학적 조성물은 불활성 가스의 사용에 의해 분무될 수 있다. 분무화된 용액은 분무 장치에서 직접적으로 흡입될 수 있거나 분무 장치는 안면 마스크 텐트 또는 간헐적 양압 호흡 기계에 부착될 수 있다. 용액, 현탁액 또는 분말 약학적 조성물은 적절한 방식으로 제형을 전달하는 장치로부터 예를 들어 구강으로 또는 비강으로 투여될 수 있다.
본 개시내용의 다중 치환기 실로시빈 유도체 화합물이 기분전환용 약물로서 사용되는 추가 실시형태에서, 화합물은 음식 또는 식품, 음료, 식품 조미료, 개인 케어 제품, 예컨대 화장품, 향수 또는 목욕 오일 또는 오일류(마사지 오일과 같은 국소 투여용, 화상 또는 에어로졸화용 둘 모두)와 같은 조성물에 포함될 수 있다. 본 개시내용의 화학적 화합물은 또한 니코틴 및 향료와 같은 다른 약물을 또한 포함할 수 있는, "전자담배" 제품에 포함될 수 있다.
따라서 다중 치환기 실로시빈 유도체 화합물이 약학적 또는 기분전환용 약물로 사용될 수 있다는 것이 분명해질 것이다. 따라서, 또 다른 양태에서, 본 개시내용은 적어도 하나의 실시형태에서, 식 (I)을 갖는 화학적 화합물의 용도를 제공한다:
(I),
여기서, R2, R4, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 독립적으로 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, O-알킬기, O-아실기 또는 포스페이트기이고, 여기서 R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, 그리고 여기서 R3c는 수소 원자 또는 카르복실기임.
본 개시내용의 화학적 화합물을 포함하는 약학적 제형은 대상체를 치료하고, 특히 대상체에서의 정신 장애를 치료하는데 사용될 수 있다. 따라서, 본 개시내용은 추가 실시형태에서 정신 장애를 치료하는 방법을 포함하며, 상기 방법은 식 (I)을 갖는 화학적 화합물을 포함하는 약학적 제형을 치료를 필요로 하는 대상체에게 투여하는 것을 포함한다:
(I),
여기서, R2, R4, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 독립적으로 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, O-알킬기, O-아실기 또는 포스페이트기이고, 여기서 R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, 그리고 여기서 R3c는 수소 원자 또는 카르복실기임.
치료될 수 있는 정신 장애는 예를 들어 지적 장애, 전반적인 발달 지연, 의사소통 장애, 자폐 스펙트럼 장애 및 주의력-결핍 과잉행동 장애(ADHD)와 같은 신경발달 장애; 조증 및 우울증 에피소드와 같은 양극성 및 관련된 장애; 범불안장애(GAD), 광장공포증, 사회불안장애, 특정 공포증(예를 들어 자연 사건, 의학적, 동물, 상황적), 공황 장애 및 분리 불안 장애와 같은 불안 장애; 급성 스트레스 장애, 적응 장애, 외상후 스트레스 장애(PTSD) 및 반응성 애착 장애와 같은 스트레스 장애; 해리성 기억상실, 해리성 정체감 장애, 및 이인화/현실감상실 장애와 같은 해리성 장애; 신체 증상 장애, 질환 불안 장애, 전환 장애, 및 인위성 장애와 같은 신체형 장애; 신경성 식욕부진, 신경성 폭식증, 반추 장애, 이식장애, 및 폭식 장애와 같은 섭식 장애; 기면증, 불면증 장애, 과다수면, 호흡-관련된 수면 장애, 사건수면 및 하지 불안 증후군과 같은 수면 장애; 도벽, 방화광, 간헐적 폭발 장애, 품행 장애, 및 적대적 반항 장애와 같은 파괴성 장애; 파괴적 기분 조절부전 장애, 주요 우울 장애, 지속성 우울 장애(기분저하), 월경전 불쾌 장애, 물질/약물-유발된 우울증 장애, 산후 우울증, 및 다른 의학적 상태, 예를 들어, 생명을 위협하는 암 상황 내에서의 정신 및 실존적 고통에 의해 야기된 우울 장애와 같은 우울 장애(ACS Pharmacol. Transl. Sci. 4: 553-562; J Psychiatr Res 137: 273-282); 알코올-관련된 장애, 대마초 관련된 장애, 흡입제-사용 관련된 장애, 각성제 사용 장애 및 담배 사용 장애와 같은 물질-관련된 장애; 섬망과 같은 신경인지 장애; 정신 분열증; 강박 장애(OCD), 신체 기형 장애, 축적 장애, 발모병 장애, 피부 벗겨짐 장애, 물질/약물 유발된 강박 장애, 및 다른 의학적 상태와 관련된 강박 장애와 같은 강박 장애; 및 반사회적 인격 장애, 회피성 인격 장애, 경계성 인격 장애, 의존성 인격 장애, 히스테리성 인격 장애, 자기애성 인격 장애, 강박성 인격 장애, 편집성 인격 장애, 정신분열형 인격 장애, 분열형 인격 장애와 같은 인격 장애를 포함한다.
일 양태에서, 본 개시내용의 화합물은 5-HT2A 수용체와 접촉되어 이에 의해 5-HT2A 수용체를 조절하는데 사용될 수 있다. 이러한 접촉시키는 것은 예를 들어 5-HT2A 수용체를 함유하는 샘플, 예를 들어 정제된 5-HT2A 수용체를 함유하는 샘플, 또는 5-HT2A 수용체를 포함하는 세포를 함유하는 샘플에 화합물을 도입함에 의해 시험관내 조건 하에서 본 개시내용의 화합물과 5-HT2A 수용체를 함께 가져오는 것을 포함한다. 시험관내 조건은 본 명세서의 실시예 1에 기술된 조건을 추가로 포함한다. 접촉시키는 것은 생체내 조건 하에서 본 개시내용의 화합물과 5-HT2A 수용체를 함께 가져오는 것을 추가로 포함한다. 이러한 생체내 조건은, 예를 들어, 화합물이 본 명세서에 이전에 기재된 바와 같이 약학적으로 활성인 담체, 희석제 또는 부형제와 함께 제형화되는 경우, 약학적으로 유효량의 본 개시내용의 화합물의 동물 또는 인간 대상체에 대한 투여를 포함하며, 이에 의해 대상체를 치료한다. 5-HT2A 수용체와 접촉하면, 화합물은 5-HT2A 수용체를 활성화하거나 5-HT2A 수용체를 억제할 수 있다.
따라서, 추가 양태에서, 본 명세서에 따라 치료될 수 있는 상태는 임의의 5-HT2A 수용체 매개된 장애일 수 있다. 이러한 장애는 정신분열증, 정신병 장애, 주의력 결핍 과잉행동 장애, 자폐증 및 양극성 장애를 포함하지만 이에 제한되지 않는다.
일 양태에서, 본 개시내용의 화합물은 5-HT1A 수용체와 접촉되어 이에 의해 5-HT1A 수용체를 조절하는데 사용될 수 있다. 이러한 접촉시키는 것은 예를 들어 5-HT1A 수용체를 함유하는 샘플, 예를 들어 정제된 5-HT1A 수용체를 함유하는 샘플, 또는 5-HT1A 수용체를 포함하는 세포를 함유하는 샘플에 화합물을 도입함에 의해 시험관내 조건 하에서 본 개시내용의 화합물과 5-HT1A 수용체를 함께 가져오는 것을 포함한다. 시험관내 조건은 본 명세서의 실시예 1에 기술된 조건을 추가로 포함한다. 접촉시키는 것은 생체내 조건 하에서 본 개시내용의 화합물과 5-HT1A 수용체를 함께 가져오는 것을 추가로 포함한다. 이러한 생체내 조건은, 예를 들어, 화합물이 본 명세서에 이전에 기재된 바와 같이 약학적으로 활성인 담체, 희석제 또는 부형제와 함께 제형화되는 경우, 약학적으로 유효량의 본 개시내용의 화합물의 동물 또는 인간 대상체에 대한 투여를 포함하며, 이에 의해 대상체를 치료한다. 5-HT1A 수용체와 접촉하면, 화합물은 5-HT1A 수용체를 활성화하거나 5-HT2A 수용체를 억제할 수 있다.
따라서, 추가 양태에서, 본 명세서에 따라 치료될 수 있는 질환은 임의의 5-HT1A 수용체 매개된 장애일 수 있다. 이러한 장애는 정신분열증, 정신병 장애, 주의력 결핍 과잉행동 장애, 자폐증 및 양극성 장애를 포함하지만 이에 제한되지 않는다.
일부 실시형태에서, 5-HT1A 수용체 및 5-HT2A 수용체와 접촉된 후, 화합물은 5-HT1A 수용체를 조절, 예를 들어 5-HT1A 수용체를 활성화 또는 억제할 수 있지만, 화합물은 동시에 5-HT2A 수용체를 조절하지 않을 수 있다.
일부 실시형태에서, 5-HT2A 수용체 및 5-HT1A 수용체와 접촉된 후, 화합물은 5-HT2A 수용체를 조절, 예를 들어 5-HT2A 수용체를 활성화 또는 억제할 수 있지만, 화합물은 동시에 5-HT1A 수용체를 조절하지 않을 수 있다.
이제 본 개시내용의 다중 치환기 실로시빈 유도체를 제조하는 방법으로 돌아가면, 본 개시내용의 다중 치환기 실로시빈 유도체는 임의의 유기 화학적 합성 방법, 생합성 방법, 또는 이의 조합을 포함하는 임의의 적합한 방식으로 제조될 수 있다는 것이 처음에 언급된다. 다음으로, 처음에 본 개시내용의 다중 치환기 실로시빈 유도체를 화학적으로 제조하기 위한 예의 방법이 논의될 것이다. 그 후, 다중 치환기 실로시빈 유도체를 제조하기 위한 예의 생합성 방법이 논의될 것이다.
본 개시내용의 다중 치환기 실로시빈 유도체를 제조하는 하나의 적합한 방법은 처음에 반응물 실로시빈 유도체 화합물을 선택 및 획득하거나 제조하고, 치환기 함유 화합물을 선택 및 획득하거나 제조하고, 그 후 반응물 실로시빈 유도체 화합물과 치환기 함유 화합물을 화학적으로 또는 생화학적으로 반응시켜 다중 치환기 실로시빈 유도체 화합물을 얻는 것을 포함한다. 반응물 실로시빈 유도체 화합물이 이미 적어도 하나의 치환기를 보유하지 않는 본 명세서의 실시형태에서, 비치환기 반응물 실로시빈 유도체 화합물(즉, 일반적으로 R2, R5, R6 및 R7이 각각 수소 원자인 인돌 구조 함유 반응물)은 일반적으로 적어도 2개의 치환기 함유 화합물과 순차적으로 반응될 수 있다는 것이 인지된다. 그 예가 도 13a - 13c(2개 이상의 치환기를 보유하는 다중 치환기 실로시빈 유도체를 형성하기 위한 후속 예의 반응을 묘사함)와 연계하여 도 9, 10, 11a - 11c, 및 12a - 12d(단일 치환기를 보유하는 제1 실로시빈 유도체를 형성하기 위한 예의 반응을 묘사함)에 도시되어 있다. 다른 실시형태에서, 반응물 실로시빈 유도체 화합물은 적어도 하나의 치환기를 보유할 수 있고, 적어도 하나의 추가 치환기 함유 화합물(예컨대 도 8a - 8g에 묘사됨)과 반응된다.
따라서, 일 양태에서, 본 개시내용은 적어도 하나의 실시형태에서 식 (I):
(I),
여기서, R2, R4, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 독립적으로 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, O-알킬기, O-아실기 또는 포스페이트기이고, 여기서 R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, 그리고 R3c는 수소 원자 또는 카르복실기임
을 갖는 실로시빈 유도체 또는 이의 염을 제조하는 방법을 제공하며, 상기 방법은:
화학식 (II):
(II),
여기서, R2, R4, R5, R6, 또는 R7 중 하나는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자 또는 알코올기이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, 하이드록시기, O-알킬기, O-아실기 또는 포스페이트기이고, 여기서 R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, 그리고 여기서 R3c는 수소 원자 또는 카르복실기임
을 갖는 반응물 실로시빈 유도체 화합물을, 화학식 (I)을 갖는 실로시빈 치환기 또는 이의 염을 형성하기에 충분한 반응 조건 하에서, 치환기 함유 화합물과 반응시키는 것을 포함하며, 여기서 치환기 함유 화합물에서 치환기는 (i) 할로겐 함유 화합물, (ii) 하이드록시기 함유 화합물, (iii) 니트로기 함유 화합물, (iv) 글리코실옥시기 함유 화합물, (v) 아미노기 또는 N-치환된 아미노기 함유 화합물, (vi) 카르복실기 또는 카르복실산 유도체 함유 화합물, (vii) 알데히드 또는 케톤기 함유 화합물, (viii) 프레닐기 함유 화합물, 및 (ix) 니트릴기 함유 화합물로부터 선택된다.
식 (II)을 갖는 반응물 실로시빈 유도체 화합물은 복수의 화합물을 포괄한다. 일반적으로, 식 (II)을 갖는 반응물 실로시빈 유도체 화합물은 처음에 원하는 다중 치환기 실로시빈 유도체 화합물을 식별하고, 그 안에서의 치환기를 결정하고, 그 후에 식 (II)을 갖는 적절한 반응물 실로시빈 유도체 화합물을 선택함에 의해 선택될 수 있다. 따라서, 예를 들어, S14, S26 다중 치환기 실로시빈 유도체를 제조하는 것이 바람직한 경우, S14 반응물 실로시빈 유도체 화합물이 선택되고 S2 치환기 함유 화합물과 반응되어 원하는 S14, S26 다중 치환기 실로시빈 유도체를 형성할 수 있거나, 또는 S15, S26 다중 치환기 실로시빈 유도체를 제조하는 것이 바람직한 경우, S15 반응물 실로시빈 유도체 화합물이 선택되고 S2 치환기 함유 화합물과 반응되어 S15, S26 다중 치환기 실로시빈 유도체를 형성할 수 있다. 따라서, 더욱이 본 개시내용의 화합물을 제조하기 위한 화학 반응의 수행은 일반적으로 다른 탄소 원자, 즉 C2, C4, C5, C6 및/또는 C7 원자에서의 치환을 포함한다고 말할 수 있다.
따라서, 일례의 실시형태에서, S15가 염소 원자이고, R2, R6 및 R7이 S22, S26 또는 S27인 다중 치환기 실로시빈 유도체를 형성하기 위해, 반응물 실로시빈 유도체는 R4가 O-알킬기이고, R2, R6 및 R7이 수소 원자이고, R5가 염소 원자이고, R3A 및 R3B가 수소 원자, 알킬기, 아실기 또는 아릴기인 화학적 화합물, 예컨대, 예를 들어, 도 8a 및 8b에 도시된 반응물 실로시빈 유도체가 되도록 선택될 수 있다.
하나의 추가 예의 실시형태에서, S15가 염소 원자이고, R2, R6 및 R7이 S22, S26 또는 S27인 다중 치환기 실로시빈 유도체를 형성하기 위해, 반응물 실로시빈 유도체는 R4가 O-아실기이고, R2, R6 및 R7이 수소 원자이고, R5가 염소 원자이고, R3A 및 R3B가 수소 원자, 알킬기, 아실기 또는 아릴기인 화학적 화합물, 예컨대, 예를 들어, 도 8c 및 8d에 도시된 반응물 실로시빈 유도체가 되도록 선택될 수 있다.
하나의 추가 예의 실시형태에서, S15가 염소 원자이고, R2, R6 및 R7이 S22, S26 또는 S27인 다중 치환기 실로시빈 유도체를 형성하기 위해, 반응물 실로시빈 유도체는 R4가 하이드록실기고, R2, R6 및 R7이 수소 원자이고, R5가 염소 원자이고, R3A 및 R3B가 수소 원자, 알킬기, 아실기 또는 아릴기인 화학적 화합물, 예컨대, 예를 들어, 도 8e에 도시된 반응물 실로시빈 유도체가 되도록 선택될 수 있다.
하나의 추가 예의 실시형태에서, S15가 염소 원자이고, R2, R6 및 R7이 S22, S26 또는 S27인 다중 치환기 실로시빈 유도체를 형성하기 위해, 반응물 실로시빈 유도체는 R4가 포스페이트기고, R2, R6 및 R7이 수소 원자이고, R5가 염소 원자이고, R3A 및 R3B가 수소 원자, 알킬기, 아실기 또는 아릴기인 화학적 화합물, 예컨대, 예를 들어, 도 8f에 도시된 반응물 실로시빈 유도체가 되도록 선택될 수 있다.
또 하나의 추가 예의 실시형태에서, S15가 염소 원자이고, R2, R6 및 R7이 S22, S26 또는 S27인 다중 치환기 실로시빈 유도체를 형성하기 위해, 반응물 실로시빈 유도체는 R4가 수소 원자이고, R2, R6 및 R7이 수소 원자이고, R5가 염소 원자이고, R3A 및 R3B가 수소 원자, 알킬기, 아실기 또는 아릴기인 화학적 화합물, 예컨대, 예를 들어, 도 8g에 도시된 반응물 실로시빈 유도체가 되도록 선택될 수 있다.
반응물 실로시빈 유도체 화합물은 다소 화학적으로 순수한 형태로, 예를 들어 적어도 약 95%, 적어도 약 96%, 적어도 97%, 적어도 약 98%, 적어도 약 99%, 또는 적어도 99.9%의 순도를 갖는 실로시빈 유도체 제제의 형태로 제공될 수 있다. 실로시빈 유도체는 화학적으로 합성되거나, 예를 들어 Sigma-Aldrich®(미국 미주리주 세인트 루이스 소재)와 같은 정밀 화학 제조업체로부터 얻을 수 있다.
치환기 함유 화합물은 선택된 반응물 실로시빈 유도체 화합물과 반응할 수 있는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 선택된 치환기를 포함하는 임의의 화합물일 수 있다.
치환기 함유 화합물은, 예를 들어 적어도 약 95%, 적어도 약 96%, 적어도 97%, 적어도 약 98%, 적어도 약 99%, 또는 적어도 99.9%의 순도를 갖는 다소 화학적으로 순수한 형태로 제공될 수 있다. 니트릴 함유 화합물은 합성 또는 정제될 수 있거나, 예를 들어 Sigma-Aldrich®(미국 미주리주 세인트 루이스 소재)와 같은 정밀 화학 제조업체로부터 편리하게 얻을 수 있다.
예로서, 초기 질화된(도 9), 글리코실화된(도 10), 아미노화된(도 11a - 11c) 및 카르복실화된(도 12a - 12d) 실로시빈 유도체를 형성하는 예의 반응이 도 9, 10, 11a - 11c, 12a - 12d, 및 13a - 13c에 도시되어 있다. 각각의 수득된 화합물은 후속적으로 그 다음 예로서 도 13a -13c에 도시된 바와 같이 추가 치환기 함유 화합물과 후속적으로 반응될 수 있다.
따라서, 도 13a을 참조하면, 그 안에서 처음에 합성된 7-질화된 실로시빈 유도체(참조: 화합물 13A-2)에 대한 C5 및 C7 탄소 원자에서 2가지 유형의 기를 함유하는 다른 5,7-디-치환된 실로시빈 유도체로의 예의 화학적 변환이 도시되어 있다. 예를 들어, 화합물 13A-2로 Friedel-Crafts 아실화는 위치선택적으로 C5 탄소에서 아세틸기를 설치하여 화합물 13A-3을 제공할 것이며, 이는 차례로 요오도포름 반응을 통해 상응하는 5-카르복시 유도체(화합물 13A-4)로 추가로 산화될 수 있다. 7-니트로기는 그 다음 포름산을 수소 공급원으로 사용하는 팔라듐-매개된 환원을 통해 상응하는 7-아미노-실로시빈 유도체(화합물 13A-5)로 환원될 수 있다. 7-아미노기는 산성 조건 하에서 아질산나트륨을 시약으로 사용하여 반응성이고 다용도인 7-디아조늄 염(화합물 13A-6)으로 추가로 전환될 수 있다. 반응성 7-디아조늄 염 중간체 화합물 13A-6으로부터, 7-니트릴(화합물 13A-7), 7-하이드록시기(화합물 13A-8), 7-플루오르화물기(화합물 13A-9) 또는 7-요오드화물기(화합물 13A-10)를 추가적으로 함유하는 상응하는 5-카르복시-실로시빈 유도체가 수득될 수 있다.
일례의 실시형태에서, 양태에서, 형성된 제1 실로시빈 유도체는 예를 들어 도 13a에 도시되고 13A-3으로 표지된 화합물과 같은 아세틸기를 보유하는 화합물일 수 있다. 다른 예에서, R2, R4, 또는 R6 또는 R7은 아세틸기를 보유할 수 있다.
따라서, 도 13a 및 식 (I)을 갖는 화학적 화합물을 추가로 참조하면, 형성된 제1 다중 치환기 실로시빈 유도체 화합물이 추가로 반응하여 추가적인 다중 치환기 실로시빈 유도체 화합물을 형성할 수 있다는 것이 명백해질 것이다. 따라서, 예를 들어, 형성된 제1 실로시빈 유도체는 도 13a에 도시되고 13A-3으로 표지된 화합물, 또는 R2, R4, R5, R6, 및 R7의 다른 조합이 니트로기 및 아세틸기를 보유하는 화합물일 수 있다. 이 형성된 제1 실로시빈 유도체는 반응하여 아세틸기를 산화시켜, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 니트로기이고, 그리고 R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 카르복실기인, 식 (I)을 갖는 제2 실로시빈 유도체를 형성할 수 있고, 예를 들어 도 13a에 도시되고 13A-4로 표지된 화합물인, 제2 실로시빈 유도체를 형성할 수 있다.
계속해서 도 13a 및 식 (I)을 갖는 화학적 화합물을 참조하면, 형성된 제2 실로시빈 유도체는 반응하여 니트로기를 환원시키고 아미노기, 및 R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 아미노기고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 카르복실기인, 제3 실로시빈 유도체를 형성할 수 있다. 형성된 제3 실로시빈 유도체는 도 13a에 도시되고 13A-5로 표지된 화합물일 수 있다.
계속해서 도 13a 및 식 (I)을 갖는 화학적 화합물을 참조하면, 형성된 제3 실로시빈 유도체는 아질산염과 반응하여 디아조늄 염에서의 아미노기를 전환시키고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 디아조늄기고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 카르복실기인, 중간체 실로시빈 유도체를 형성할 수 있다. 중간체 형성된 실로시빈 유도체는, 예를 들어 도 13a에 도시되고 13A-6으로 표지된 화합물일 수 있다.
계속해서 도 13a 및 식 (I)을 갖는 화학적 화합물을 참조하면, 중간체 형성된 실로시빈 유도체는 니트릴 함유 화합물과 반응하여 디아조늄기를 전환시키고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 니트릴기이고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 카르복실기인, 제4 실로시빈 유도체, 예를 들어 도 13a에 도시되고 13A-7로 표지된 화합물을 형성할 수 있다.
계속해서 도 13a 및 식 (I)을 갖는 화학적 화합물을 참조하면, 중간체 형성된 실로시빈 유도체는 물과 반응하여 디아조늄기를 전환시키고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 하이드록시기고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 카르복실기인, 제5 실로시빈, 예를 들어 도 13a에 도시되고 13A-8로 표지된 화합물을 형성할 수 있다.
계속해서 도 13a 및 식 (I)을 갖는 화학적 화합물을 참조하면, 중간체 형성된 실로시빈 유도체는 할로겐 함유 화합물과 반응하여 디아조늄기를 전환시키고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 할로겐 원자이고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 카르복실기인, 제6 실로시빈 유도체, 예를 들어 도 13a에 도시되고 13A-9 및 13A-10으로 표지된 화합물을 형성할 수 있다.
다음으로 도 13b를 참조하면, 그 안에서 처음에 합성된 5-카르복시 실로시빈 유도체(화합물: 13B-1 참조)를 사용하여 탄소 원자 C5 및 C7에서 2가지 유형의 기를 함유하는 다른 O-4-글리코실화된 실로시빈 유도체로의 예의 화학적 변환이 도시되어 있다. 따라서, 화합물 13B-1로 시작하여, 5-카르복시 작용기는 Fisher 에스테르화 조건 하에 메탄올에서 선택적으로 에스테르화되어 화합물 13B-2를 제공할 수 있으며, 이는 각각 상응하는 7-클로로(화합물 13B-3) 및 7-니트로(화합물 13B-4) 유도체를 합성하는데 사용될 수 있다. 화합물 13B-3 및 13B-4 둘 모두는 퍼-O-아세틸화된 글리코실 브로마이드로 O-4 위치에서 글리코실화될 수 있고 모든 O-아세테이트를 제거한 후 상응하는 4-O-글리코실화된 유도체 화합물 13A-5 및 13A-6이 수득될 수 있다. 양 화합물의 5-에스테르 작용기는 아미노분해 반응을 통해 5-아미도기로 추가로 전환되어 각각 4-O-글리코실화된 실로시빈 유도체 화합물 13B-7 및 13B-8을 제공할 수 있다. 화합물 13B-8의 7-니트로기는 포름산을 수소 공급원으로 사용하는 팔라듐-매개된 환원을 통해 추가로 환원되어 화합물 13B-9를 제공할 수 있다.
도 13b 및 식 (I)을 갖는 화학적 화합물을 추가로 참조하면, 치환기를 함유하는 반응물 실로시빈 유도체 화합물이 치환기 함유 화합물과 반응하고 초기 다중 치환기 실로시빈 유도체 화합물을 형성하는데 사용될 수 있으며, 이는 차례로 추가적인 다중 치환기 실로시빈 유도체 화합물을 형성하는데 사용될 수 있다는 것이 명백해질 것이다. 따라서, 예를 들어, 반응물 실로시빈 유도체에서의 치환기는 메톡시카르보닐기일 수 있고, 치환기 함유 화합물은 할로겐 함유 화합물 N-할로-숙신이미드일 수 있고, 반응물 실로시빈 유도체와 치환기 함유 화합물은 반응하여 R2, R4, R5, R6, 또는 R7 중 하나는 메톡시 카르보닐기이고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 할로겐 원자인 제1 실로시빈 유도체, 예를 들어, 도 13b에 도시되고 13B-3으로 표지된 화합물을 형성할 수 있다.
계속해서 도 13b 및 식 (I) 및 (II)을 갖는 화학적 화합물을 참조하면, 반응물 실로시빈 유도체는 메톡시카르보닐기를 보유할 수 있고, 치환기 함유 화합물은 니트로 함유 화합물 니트로늄 테트라플루오로보레이트일 수 있고, 반응물 실로시빈 유도체 및 치환기 함유 화합물은 반응하여 R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 메톡시 카르보닐기이고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 니트로기인 제2 실로시빈 유도체를 형성할 수 있고, 형성된 제2 실로시빈 유도체는 도 13b에 도시되고 13B-4로 표지된 화합물일 수 있다.
계속해서 도 13b 및 식 (I)을 갖는 화학적 화합물을 참조하면, 형성된 제1 실로시빈 유도체는 아세틸화된 글리코실 화합물과 반응하고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 메톡시 카르보닐기이고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 글리코실옥시기이고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 할로겐 원자인 제3 실로시빈, 예를 들어, 도 13b에 도시되고 13B-4로 표지된 화합물을 형성할 수 있다.
계속해서 도 13b 및 식 (I)을 갖는 화학적 화합물을 참조하면, 형성된 제2 실로시빈 유도체는 아세틸화된 글리코실 화합물과 반응하고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 메톡시카르보닐기이고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 글리코실옥시기이고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 니트로기인 제4 실로시빈 유도체를 형성할 수 있다. 예를 들어, 형성된 제4 실로시빈 유도체는 도 13b에 도시되고 13B-6으로 표지된 화합물일 수 있다.
계속해서 도 13b 및 식 (I)을 갖는 화학적 화합물을 참조하면, 형성된 제3 실로시빈 유도체는 암모니아와 반응하여 아미도기에서의 메톡시카르보닐기를 전환시키고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 아미도기이고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 글리코실옥시기이고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 할로겐 원자인 제5 실로시빈 유도체, 예를 들어, 도 13b에 도시되고 13B-7로 표지된 화합물을 형성할 수 있다.
계속해서 도 13b 및 식 (I)을 갖는 화학적 화합물을 참조하면, 형성된 제3 실로시빈 유도체는 암모니아와 반응하여 아미도기에서의 메톡시카르보닐기를 전환시키고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 아미도기고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 글리코실옥시기이고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 니트로기인 제6 실로시빈 유도체, 예를 들어, 도 13b에 도시되고 13B-8로 표지된 화합물을 형성할 수 있다.
계속해서 도 13b 및 식 (I)을 갖는 화학적 화합물을 참조하면, 형성된 제6 실로시빈 유도체는 반응하여 니트로기를 환원시켜 아미노기 및, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 아미도기이고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 글리코실옥시기이고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 니트로기인 제7 실로시빈 유도체, 예를 들어, 도 13b에 도시되고 13B-9로 표지된 화합물을 형성할 수 있다.
따라서, 도 13c를 참조하면, 그 안에서 합성된 5-질화된 실로시빈 유도체(참조: 화합물 13C-2)의 최대 3가지 유형의 치환기를 함유하는 5,6,7-트리-치환된 실로시빈 유도체로의 보다 많은 예의 화학적 변환이 도시되어 있다. 예를 들어, 5-니트로기는 수소 공급원으로 포름산의 존재에서 팔라듐-매개된 환원을 통해 5-아미노 유도체(화합물: 13C-3)를 생산하도록 환원될 수 있다. 화학-선택적 N-아세틸화가 메탄올에서 수행되어 상응하는 5-아세트아미노 실로시빈 유도체 화합물 13C-4를 제공할 수 있으며, 이는 그 다음 탄소 원자 C7에서 포르밀화되어 시약으로 DMF-POCl3를 사용하여 7-알데히드 화합물 13C-5를 얻을 수 있다. N-브로모숙신이미드를 사용한 추가 브롬화는 5-아세트아미도-6-브로모-7-포르밀-실로시빈 유도체 화합물 13C-6을 제공할 수 있다. 대안적으로, 화합물 13C-5를 기질로 사용하여, 7-포르밀기는 시약으로 탄산은을 사용한 온화한 조건 하에서 산화되어 7-카르복시 유도체 화합물 13C-7을 제공할 수 있으며, 이는 Fisher 에스테르화 조건을 사용하여 에스테르화되어 화합물 13C-8을 얻을 수 있다. 화합물 13C-8을 니트로소늄 테트라플루오로보레이트와 반응시킴에 의해, 니트로기가 탄소 원자 C6에 위치되어 그의 6-니트로기가 환원되어 화합물 13C-10을 형성할 수 있고 이후에 아미노분해 반응을 거쳐 7-에스테르기를 아미드로 전환시킬 수 있는 5,6,7-삼치환된 실로시빈 유도체 화합물 13C-9를 제공할 수 있다. 이는 신규한 5,6,7-트리-치환 실로시빈 유도체 화합물 13C-11을 제공한다.
도 13c 및 식 (I) 및 (II)을 갖는 화학적 화합물을 추가로 참조하면, 치환기를 함유하는 반응물 실로시빈 유도체 화합물이 치환기 함유 화합물과 반응하고 초기 다중 치환기 실로시빈 유도체 화합물을 형성하는데 사용될 수 있으며, 이는 차례로 추가적인 다중 치환기 실로시빈 유도체 화합물을 형성하는데 사용될 수 있다는 것이 명백해질 것이다. 따라서, 예를 들어, 반응물 실로시빈 유도체에서의 치환기는 아세트아미딜기일 수 있고, 치환기 함유 화합물은 할로겐 함유 화합물 N-할로-숙신이미드(예를 들어, N-브로모-숙신이미드(NBS))일 수 있고, 반응물 실로시빈 유도체와 치환기 함유 화합물은 반응하여 R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 아세트아미딜기고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 할로겐 원자인 제1 실로시빈 유도체, 예를 들어, 도 13c에 도시되고 13C-6으로 표지된 화합물을 형성할 수 있다.
도 13c 및 식 (I) 및 (II)을 갖는 화학적 화합물을 추가로 참조하면, 반응물 실로시빈 유도체 화합물은 아세트아미딜기를 보유할 수 있고, 치환기 함유 화합물은 디메틸 포름아미드일 수 있으며, 반응물 실로시빈 유도체와 치환기 함유 화합물은 반응하여 R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 아세트아미딜기고, R2, R4, R5, R6, 또는 R7 중 적어도 하나 또는 적어도 하나는 메탄올기인 중간체 실로시빈 유도체를 형성할 수 있고, 여기서 중간체 실로시빈 유도체는 반응하여 메탄올기를 산화시키고 R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 아세트아미딜기고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 카르복시인 제2 실로시빈 유도체를 형성한다. 예를 들어, 중간체 실로시빈 유도체는 도 13c에 도시되고 13C-5로 표지된 화합물일 수 있고, 형성된 제2 실로시빈 유도체는 도 13c에 도시되고 13C-7로 표지된 화합물일 수 있다.
도 13c 및 식 (I)을 갖는 화학적 화합물을 추가로 참조하면 식 (I)을 갖는 형성된 제2 실로시빈 유도체는 알코올과 반응하여 카르복시기를 에스테르화하여 에스테르, 및 R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 아세트아미딜기고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 카르복실 에스테르인 제3 실로시빈 유도체, 예를 들어, 도 13c에 도시되고 13C-8로 표지된 화합물을 형성할 수 있다.
도 13c 및 식 (I)을 갖는 화학적 화합물을 추가로 참조하면, 형성된 제3 실로시빈 유도체는 니트로기 함유 화합물과 반응하고 R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 아세트아미딜기고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 카르복실 에스테르이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 니트로기인 제4 실로시빈 유도체, 예를 들어, 도 13c에 도시되고 13C-9로 표지된 화합물을 형성할 수 있다.
도 13c 및 식 (I)을 갖는 화학적 화합물을 추가로 참조하면, 형성된 제4 실로시빈 유도체는 반응하여 니트로기를 환원시켜 아미노기 및, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 아세트아미딜기고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 카르복실 에스테르이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 아미노기인 제5 실로시빈 유도체, 예를 들어, 도 13c에 도시되고 13C-10으로 표지된 화합물을 형성할 수 있다.
도 13c 및 식 (I)을 갖는 화학적 화합물을 추가로 참조하면, 형성된 제4 실로시빈 유도체는 암모니아와 반응하여 아미도기 및, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 아세트아미딜기고, R2, R4, R5, R6, 또는 R7 중 하나 또는 적어도 하나는 카르복시에스테르이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 아미도기인 제6 실로시빈 유도체, 예를 들어, 도 13c에 도시되고 13C-11로 표지된 화합물을 형성할 수 있다.
따라서, 일반적으로 반응물 실로시빈 유도체가 제공되고, 반응물 실로시빈 유도체는 다중 치환기 실로시빈 유도체의 형성을 초래하는 화학 반응에서 반응하도록 이용된다.
도 9, 10, 11a - 11c, 12a - 12d, 및 13a - 13c에 도시된 예의 반응과 같은 반응은 임의의 적합한 반응 용기(예를 들어, 튜브, 병)에서 수행될 수 있다. 사용될 수 있는 적합한 용매는 예를 들어 물, 알코올(예컨대 메탄올, 에탄올, 테트라하이드로푸란(THF), 디클로로메탄, 아세톤, N,N-디메틸포름아미드(DMF), 디메틸술폭시드(DMSO) 또는 용매의 조합이다. 예를 들어, 적절한 온도는, 예를 들어 약 20℃ 내지 약 100℃ 범위일 수 있다. 더욱이, 반응 시간은 다양할 수 있다. 당업자가 쉽게 인식할 수 있듯이, 반응 조건은, 예를 들어, 여러 실로시빈 유도체 반응물 제제를 제조하고 이를 다른 반응 조건, 예를 들어 다른 온도에서, 다른 용매를 사용하여, 다른 촉매 등을 사용하여 다른 반응 용기에서 반응시키고, 수득된 다중 치환기 실로시빈 유도체 반응 생성물을 평가하고, 반응 조건을 조정하고, 원하는 반응 조건을 선택함에 의해 최적화될 수 있다.
다음에 본 개시내용의 다중 치환기 화합물을 제조하기 위한 생합성 방법으로 넘어가면, 이러한 방법은 일반적으로 실로시빈 유도체 전구체 화합물의 전환을 효소적으로 촉매화하고 다중 치환기 실로시빈 유도체 화합물을 형성하기 위한 실로시빈 생합성 효소 보체의 사용을 포함한다. 실로시빈 생합성 효소 보체에 포함된 효소는 도 14a, 14b 및 14c에 도시된 특정 예의 효소 및 예의 화합물을 참조하여 이하에서 논의되는 바와 같이 다양할 수 있다.
따라서, 일 양태에서, 본 개시내용은 다중 치환기 실로시빈 유도체를 제조하는 방법을 추가로 제공하며, 상기 방법은 식 (LVII):
(LVII),
여기서 R2, R4, R5, R6, 또는 R7 중 적어도 하나는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, O-알킬기, O-아실기 또는 포스페이트기이고, R3은 수소 원자 또는 -CH2-CHNH2COOH 또는 -CH2-CH2NH2임,
을 갖는 실로시빈 유도체 전구체 화합물을, 실로시빈 유도체 전구체 화합물의 효소 촉매된 전환을 허용하는 반응 조건 하에서 촉매량의 실로시빈 생합성 효소 보체와 접촉시켜 식 (I)을 갖는 다중 치환기 실로시빈 유도체 화합물을 형성하는 것을 포함한다:
(I),
여기서, R2, R4, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 독립적으로 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, O-알킬기, O-아실기 또는 포스페이트기이고, 여기서 R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, 그리고 여기서 R3c는 수소 원자 또는 카르복실기임.
반응 조건은 시험관내 반응 조건, 생체내 반응 조건, 또는 이의 조합일 수 있다.
시험관내
합성
시험관내 합성은 일반적으로 처음에 전구체 실로시빈 유도체 화합물 및 기타 반응물을 포함하는 시약을 다소 순수한 형태로 제공하는 것을 포함한다. 따라서, 반응물은 실질적으로 순수한 형태에서의 미립자로서 제공될 수 있거나, 물 또는 완충액과 같은 적합한 용매 또는 희석제에 다소 순수한 형태로 용해될 수 있다. 그런 다음 시약은 튜브, 비이커, 플라스크 등과 같은 적합한 반응 용기에서, 또는 더 큰 규모에서는 일반적으로 바람직하게는, 필요에 따라 물, 완충액과 같은 희석제를 더 포함하여 제조될 수 있는, 액체 형태에서의 탱크 또는 반응기에서 조합되고 서로 접촉될 수 있다. 조합된 시약은 일반적으로, 예를 들어, 실험실 크기 자기 교반기(예를 들어, Fisher Scientific®에 의해 제작됨) 또는 휴대용 또는 산업용 믹서와 같은 적합한 교반 또는 혼합 장치를 사용하여 부드럽게 교반함에 의해 혼합되어 혼합물을 형성할 수 있다. 시약의 상대량과 절대량을 원하는 대로 선택될 수 있다. 절대량은 전형적으로, 예를 들어, 실험실 규모(예를 들어, 1L 미만, 100mL 미만, 10mL 미만 또는 1mL 미만 규모), 또는 예를 들어, 상업적 생산 규모(예를 들어, 100L 초과, 1,000L 초과 또는 10,000L 초과 규모)에서와 같이 반응을 수행하려는 규모에 의존할 것이다. 시약의 상대량은 다양할 수 있다. 따라서, 예를 들어, 일 실시형태에서, 전구체 실로시빈 유도체 및 치환기 함유 화합물 각각의 화학량론적 양은 촉매적 양의 효소와 혼합될 수 있다. 원하는 경우, 시약의 비-화학양론적 양, 예를 들어 1:0.95; 1:0.9; 1:0.75; 또는 1:1.05, 1:1.1 또는 1:1.25의 실로시빈 전구체 유도체 대 치환기 함유 화합물의 몰비가 선택될 수 있다.
당업자가 이해하는 바와 같이, 몰량 관점에서, 효소는 촉매제로서 작용하고 전구체 실로시빈 유도체 및 치환기 함유 화합물과는 달리 효소는 반응에서 소모되지 않기 때문에 소량의 효소가 반응을 수행하는데 충분하다. 따라서, 일반적인 관점에서, 촉매적 양은 전구체 실로시빈 유도체 및 치환기 함유 화합물을 전환하고 바람직한 양의 다중 치환기 실로시빈 유도체를 형성하는데 필요한 적어도 최소한의 효소 양으로 생각될 수 있다. 따라서, 예를 들어, 0.1 내지 1,000 효소 단위(예를 들어, 0.1 효소 단위, 1 효소 단위, 10 효소 단위, 50 효소 단위, 100 효소 단위, 250 효소 단위, 500 효소 단위, 또는 1,000 효소 단위)가 반응 혼합물에 포함될 수 있으며, 여기서 당업자에게 공지된 바와 같이, 1 효소 단위는 분당 1μ몰의 기질(즉, 실로시빈 전구체 화합물)을 촉매작용하는 효소의 양이다. 더욱이, 시험관내 반응 조건은 다양할 수 있으며, 예를 들어 약 18℃ 내지 약 37℃의 범위인 온도 및 약 pH 5.0 내지 약 pH 8.5의 범위인 pH를 포함할 수 있다. 더욱이, 촉매작용을 촉진하기 위해 다른 제제, 예를 들어 희석제(예를 들어, 물 또는 완충액), 염 및 pH 변형제가 포함될 수 있다. 시험관내 반응 조건은, 예를 들어, 다른 작동 조건, 예를 들어, 다른 상대적인 양의 시약 등을 포함하는, 다른 양의 효소를 포함하는, 다른 온도, 다른 pH에서 각각 반응되는 복수의 샘플을 준비하고, 형성된 다중 치환기 실로시빈 유도체를 검출함에 의해 조정되고 최적화될 수 있다.
생체내
합성
일 실시형태에서, 실로시빈 유도체 전구체 화합물 및 치환기 함유 화합물은 숙주 세포에서 실로시빈 생합성 효소 보체와 접촉될 수 있으며, 여기서 숙주 세포는 작동가능하게 연결된 성분으로서:
(i) 숙주 세포에서 발현을 조절하는 핵산 서열; 및
(ii) 실로시빈 생합성 효소 보체를 인코딩하는 핵산 서열을 포함하는 키메라 핵산 서열을 포함하고,
숙주 세포는 실로시빈 생합성 효소 보체를 발현하고 다중 치환기 실로시빈 유도체 화합물을 생산하도록 성장된다.
적합한 키메라 핵산 서열은 실로시빈 생합성 효소 보체, 예컨대, 예를 들어, 본 명세서에서 이후 추가로 기술된 바와 같은, 하나 이상의 트립토판 신타제 서브유닛 B 폴리펩티드, 트립토판 데카르복실라제, N-아세틸 트랜스퍼라제, N-메틸 트랜스퍼라제 및 프레닐 트랜스퍼라제를 인코딩하는 서열에 작동가능하게 연결된 숙주 세포에서의 발현을 제어하는 핵산 서열을 포함하는 임의의 핵산 서열을 포함한다.
본 명세서에서 사용될 수 있는 숙주 세포에서 생합성 효소 보체를 인코딩하는 핵산 서열의 발현을 제어할 수 있는 핵산 서열은 숙주 세포에서 폴리펩티드의 발현을 제어할 수 있는 임의의 전사 프로모터를 포함한다. 일반적으로, 본 명세서에 따라 박테리아 숙주를 선택할 때는 박테리아 세포로부터 수득된 프로모터를 사용하는 반면, 진균 숙주 세포를 선택할 때는 진균 프로모터를 사용하고, 식물 세포를 선택할 때는 식물 프로모터를 사용하는 등의 방식으로 된다. 예를 들어, 효모 세포에서의 발현을 위해 사용될 수 있는 특정 예는 Gal10/Gal 1 프로모터와 같은 갈락토스 유도성 프로모터, 또는 대장균 세포에서의 발현을 위한 베타-갈락토시다제 프로모터를 포함한다. 숙주 세포에서 발현을 제어할 수 있는 추가 핵산 요소는 전사 종결자, 인핸서 등을 포함하며, 이들 모두는 본 개시내용의 키메라 핵산 서열에 포함될 수 있다.
키메라 핵산 서열은 숙주 세포에서의 우수한 발현을 보장하는 재조합 발현 벡터 안으로 합체될 수 있으며, 여기서 발현 벡터는 숙주 세포에서의 발현에 적합하다. 용어 "숙주 세포에서의 발현에 적합한"은 재조합 발현 벡터가 세포에서 발현을 달성하는데 필요한 유전적 요소에 연결된 키메라 핵산 서열을 포함한다는 것을 의미한다. 이와 관련하여 발현 벡터에 포함될 수 있는 유전적 요소는 전사 종결 영역, 마커 유전자를 인코딩하는 하나 이상의 핵산 서열, 하나 이상의 복제의 기점 등을 포함한다. 바람직한 실시형태에서, 발현 벡터는, 예를 들어 숙주 세포의 게놈에 벡터 또는 이의 일부의 합체에 필요한 유전적 요소를 추가로 포함한다. 식물 숙주 세포를 사용하는 경우 식물의 핵 게놈 안으로의 합체를 촉진하는 T-DNA 좌우 경계 서열이 사용된다.
본 개시내용에 따르면, 발현 벡터는 마커 유전자를 추가로 함유할 수 있다. 본 개시내용에 따라 사용될 수 있는 마커 유전자는 모든 선택가능하고 스크리닝가능한 마커 유전자를 포함하여 비-형질전환된 세포로부터 형질전환된 세포의 구별을 허용하는 모든 유전자를 포함한다. 마커 유전자는 내성 마커 예컨대, 예를 들어, 카나마이신 또는 암피실린에 대한 항생제 내성 마커, 또는 영양요구성 마커, 예를 들어 leu 마커(Sikorski and Hieter, 1989, Genetics 122(1): 19-27) 또는 ura 마커(Rose and Winston, 1984, Mol. Gen. Genet. 193(3): 557-560일 수 있다. 육안 검사를 통해 형질전환체를 식별하기 위해 이용될 수 있는 스크리닝가능한 마커는 β-글루쿠로니다제(GUS)(미국 특허 번호 5,268,463 및 5,599,670) 및 녹색 형광 단백질(GFP)(Niedz 등, 1995, Plant Cell Rep., 14:403)을 포함한다.
본 문서에 따라 다양한 숙주 세포가 사용될 수 있다. 선택된 숙주 세포는 실로시빈 화합물 또는 이의 유도체를 자연적으로 생성할 수 있거나 세포는 실로시빈 화합물 또는 이의 유도체를 자연적으로 생성하지 못할 수 있다. 숙주 세포는 키메라 핵산 서열의 도입 시 실로시빈 생합성 효소 보체를 이종적으로 발현할 수 있다고 말할 수 있다.
일부 실시형태에서, 숙주 세포는 미생물 세포, 예를 들어 박테리아 세포 또는 효모 세포일 수 있다. 본 명세서에 따라 사용될 수 있는 예의 박테리아 세포는 대장균 세포이다. 본 명세서에 따를 수 있는 예의 효모 세포는 사카로마이세스 세레비시애 세포 또는 야로위아 리피티카 세포이다.
추가 실시형태에서, 숙주 세포는 식물 세포 또는 조류 세포일 수 있다.
본 개시내용의 키메라 핵산 서열을 포함하는 발현 벡터를 포함하는, 핵산 서열을 세포에 도입하고 발현을 달성하기 위해 숙주 세포를 조작하는 다양한 기술 및 방법론이 존재하고 당업자에게 널리 공지되어 있다. 이들 방법은, 예를 들어 양이온 기반 방법, 예를 들어 리튬 이온 또는 칼슘 이온 기반 방법, 전기천공, 바이오리스틱스 및 글라스 비드 기반 방법을 포함한다. 당업자에게 공지된 바와 같이, 선택된 숙주 세포에 의존하여, 숙주 세포에 핵산 물질을 도입하는 방법론은 다양할 수 있고, 더욱이 방법론은, 예를 들어, 상이한 조건을 사용하여 핵산 물질의 흡수를 비교함에 의해 숙주 세포에 의한 핵산 물질의 흡수에 최적화될 수 있다. 자세한 지침은 예를 들어, Sambrook 등, Molecular Cloning, a Laboratory Manual, Cold Spring Harbor Laboratory Press, 2012, Fourth Ed에서 찾아볼 수 있다. 키메라 핵산은 비-자연적으로 발생하는 키메라 핵산 서열이고 숙주 세포에 대해 이종성이라고 말할 수 있다는 것이 인지된다.
편리하게 사용될 수 있는 숙주 세포의 일 예는 대장균이다. 대장균 벡터의 제조는 제한 단리, 결찰, 겔 전기영동, DNA 서열분석, 중합효소 연쇄 반응(PCR) 및 기타 방법론과 같은 일반적으로 알려진 기술을 사용하여 수행될 수 있다. 재조합 발현 벡터를 준비하는데 필요한 필수 단계를 수행하기 위해 광범위한 클로닝 벡터가 이용가능하다. 대장균에서 복제 시스템 기능을 갖는 벡터 중에는 pBR322, pUC 시리즈의 벡터, M13 mp 시리즈의 벡터, pBluescript 등과 같은 벡터가 있다. 대장균에서 사용하기에 적합한 프로모터 서열은, 예를 들어, T7 프로모터, T5 프로모터, 트립토판(trp) 프로모터, 락토스(lac) 프로모터, 트립토판/락토스(tac) 프로모터, 지질단백질(Ipp) 프로모터 및 λ 파지 PL 프로모터를 포함한다. 전형적으로, 클로닝 벡터는 마커, 예를 들어 암피실린 또는 카나마이신 내성 마커와 같은 항생제 내성 마커를 함유하여, 형질전환된 세포를 선택할 수 있게 한다. 핵산 서열은 이들 벡터에 도입될 수 있고, 벡터는 적격인 세포를 제조하거나, 전기천공 또는 당업자에게 잘-알려진 다른 방법론을 사용함에 의해 대장균에 도입될 수 있다. 대장균은 Luria-Broth 배지와 같은 적절한 배지에서 성장되고 수확될 수 있다. 재조합 발현 벡터는 세포를 수확하고 용리할 때 세포로부터 쉽게 회수될 수 있다.
편리하게 사용될 수 있는 또 다른 예의 숙주 세포는 효모 세포이다. 사용될 수 있는 예의 효모 숙주 세포는 칸디다, 클루이베로마이세스, 사카로마이세스, 스키조사카로미세스, 피치아, 한세눌라 및 야로위아 속에 속하는 효모 세포이다. 구체적인 예의 실시형태에서, 효모 세포는 사카로마이세스 세레비시애 세포, 야로위아 리폴리티카 세포, 또는 피키아 파스토리스 세포일 수 있다.
효모 숙주 세포에서 재조합 단백질의 발현을 위한 다수의 벡터가 존재한다. 효모 숙주 세포에 사용될 수 있는 벡터의 예는, 예를 들어, Yip 유형 벡터, Yep 유형 벡터, Yrp 유형 벡터, Ycp 유형 벡터, pGPD-2, pAO815, pGAPZ, pGAPZα, pHIL-D2, pHIL-S1, pPIC3.5K, pPIC9K, pPICZ, pPICZα, pPIC3K, pHWO10, pPUZZLE 및 2μm 플라스미드를 포함한다. 이러한 벡터는 당업계에 공지되어 있으며, 예를 들어 Cregg 등, Mol Biotechnol. (2000) 16(1): 23-52에 기술되어 있다. 효모 숙주 세포에 사용하기에 적합한 프로모터 서열은 또한 공지되어 있으며, 예를 들어 Mattanovich 등, Methods Mol. Biol., 2012, 824:329-58 및 Romanos 등, 1992, Yeast 8: 423-488에 기술되어 있다. 효모 숙주 세포에 사용하기에 적합한 프로모터의 예는 트리오스포스페이트 이소머라제(TPI), 포스포글리세레이트 키나제(PGK), 글리세르알데히드-3-포스페이트 탈수소효소(GAPDH 또는 GAP) 및 이의 변이체, 락타제(LAC) 및 갈락토시다제(GAL) 같은 해당 효소의 프로모터, P. 파스토리스 글루코스-6-포스페이트 이소머라제 프로모터(PPGI), 3-포스포글리세레이트 키나제 프로모터(PPGK), 글리세롤 알데히드 포스페이트 탈수소효소 프로모터(PGAP), 번역 신장 인자 프로모터(PTEF), S. 세레비시애 에놀라제(ENO-1), S. 세레비시애 갈락토키나제(GAL1), S. 세레비시애 알코올 탈수소효소/글리세르알데히드-3-포스페이트 탈수소효소(ADH1, ADH2/GAP), S. 세레비시애 트리오스 포스페이트 이소머라제(TPI), S. 세레비시애 메탈로티오네인(CUP1) ), S. 세레비시애 3-포스포글리세레이트 키나제(PGK) 및 말타제 유전자 프로모터(MAL)를 포함한다. 효모 숙주 세포에 사용하기에 적합한 마커 유전자도 당업계에 공지되어 있다. 따라서, 암피실린 저항성 마커와 같은 항생제 내성 마커는 효모뿐만 아니라, 예를 들어, 류신(LEU2), 트립토판(TRP1 및 TRP2), 우라실(URA3, URA5, URA6), 히스티딘(HIS3) 등과 같은 필수 영양소에 대한 유전적 기능을 제공하는 마커 유전자에 사용될 수 있다. 벡터를 효모 숙주 세포 안으로 도입하는 방법은, 예를 들어 S. Kawai 등, 2010, Bioeng. Bugs 1(6): 395-403에서 찾아볼 수 있다.
추가로, 발현 벡터의 제조 및 대장균 세포, 효모 세포 및 기타 숙주 세포를 포함한 숙주 세포 안으로 이의 도입에 관한 지침은 예를 들어 Sambrook 등, Molecular Cloning, a Laboratory Manual, Cold Spring Harbor Laboratory Press, 2012, Fourth Ed에서 찾아볼 수 있다.
다음으로 도 14a - 14g를 참조하면, 그 안에서 본 개시내용의 다중 치환기 실로시빈 유도체 화합물을 제조하기 위한 예의 생합성 경로가 도시되어 있으며, 예로서 특히 도 14a는 예의 S14, S26 다중 치환기 실로시빈 유도체 화합물이 어떻게 생합성적으로 제조될 수 있는지를 예시한다. 추가 예로서 도 14b는 추가 예의 S14, S26 다중 치환기 실로시빈 유도체 화합물이 어떻게 생합성적으로 제조될 수 있는지를 예시한다. 추가 예로서 도 14c는 추가 예의 S15, S26 다중 치환기 실로시빈 유도체 화합물이 어떻게 생합성적으로 제조될 수 있는지를 예시한다. 예로서 도 14d는 예의 S14, S25 다중 치환기 실로시빈 유도체 화합물이 어떻게 생합성적으로 제조될 수 있는지를 예시한다. 예로서 도 14e는 예의 S14, S27 다중 치환기 실로시빈 유도체 화합물이 어떻게 생합성적으로 제조될 수 있는지를 예시한다. 예로서 도 14f는 예의 S15, S26 다중 치환기 실로시빈 유도체 화합물이 어떻게 생합성적으로 제조될 수 있는지를 예시한다. 또 추가 예로서 도 14g는 예의 S15, S27 다중 치환기 실로시빈 유도체 화합물이 어떻게 생합성적으로 제조될 수 있는지를 예시한다. 도 14a - 14g에 도시된 경로, 효소 및 화합물에 부가하여, 다른 생합성 경로를 사용하여, 탄소 원자 R2, R4, R5, R6, 또는 R7 중 2개 이상이 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 선택된 치환기를 보유하는, 다중 치환기를 포함하며, 예를 들어 도 3a - 3l, 4a - 4i, 5a - 5i, 6a - 6i, 및 7a - 7f에 도시된 다중 치환기 화합물을 추가로 포함하고, 그리고 식 (I)을 갖는 임의의 다중 치환기 실로시빈 유도체 화합물을 추가로 포함하는, 다른 다중 치환기 실로시빈 유도체 화합물을 제조할 수 있음이 이해되어야 한다:
(I),
여기서, R2, R4, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 독립적으로 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, O-알킬기, O-아실기 또는 포스페이트기이고, 여기서 R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, 그리고 여기서 R3c는 수소 원자 또는 카르복실기임.
도 14a - 14g에 도시된 예를 참조하는 것을 포함하여, 본 명세서에 제시된 교시를 따라, 당업자는 본 개시내용의 다중 치환기 실로시빈 유도체 화합물을 생합성적으로 제조하기 위해 적절한 실로시빈 전구체 화합물, 실로시빈 생합성 효소 보체 효소를 선택할 수 있을 것이다.
따라서, 도 14a 및 실로시빈 유도체 전구체 화합물(LVII)을 추가로 참조하면, 실로시빈 생합성 효소 보체는, 예를 들어, 다음으로부터 선택된 핵산에 의해 인코딩되는 트립토판 신타제 서브유닛 B 폴리펩티드를 포함할 수 있다:
(a) 서열번호: 1;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 2에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 2에 제시된 아미노산 서열의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
R2, R4, R5, R6, 또는 R7 중 2개가 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 독립적으로 선택된 치환기이고, 여기서 R3은 수소 원자인 식 (I)을 갖는 제1 실로시빈 유도체 전구체 화합물이 사용될 수 있다. R3c가 카르복실기인 식 (I)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물이 형성될 수 있다. 예를 들어, 실로시빈 유도체 전구체 화합물은 식 (LVIII):
(LVIII),
여기서 R4는 하이드록시기고, 그리고 R6은 염소 원자임,
을 갖는 화학적 화합물일 수 있고, 제1 다중 치환기 실로시빈 유도체 화합물은 식 (LV)을 가지고:
(LV).
트립토판 신타제 서브유닛 B 폴리펩티드에 의해 촉매되는 생체내 또는 시험관내 반응에서 형성될 수 있다.
계속해서 도 14a를 참조하면, 실로시빈 생합성 효소 보체는 제1 다중 치환기 실로시빈 유도체 화합물의 R3 -CH2-CHNH2COOH 기를 탈카르복실화하여 이에 의해 식 (I)을 갖는 제2 다중 치환기 실로시빈 유도체를 형성하는 트립토판 데카르복실라제를 추가로 포함할 수 있으며 여기서 R3a 및 R3b 각각은 수소 원자이고, 트립토판 데카르복실라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 3, 서열번호: 5, 및 서열번호: 7;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 4, 서열번호: 6, 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 4, 서열번호: 6 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
계속해서 도 14a를 참조하면, 예의 실시형태에서, 실로시빈 유도체 전구체 화합물은 식 (LVIII):
(LVIII),
여기서 R4는 불소 원자, 아미노기, 또는 하이드록시기이고, 여기서 R6은 불소 원자, 아미노기, 니트릴 또는 브롬 원자임,
을 갖는 화학적 화합물일 수 있고, 제1 다치환기 실로시빈 유도체 화합물은 식 (LIX)을 갖는다:
(LIX),
여기서 R4는 불소 원자, 아미노기 또는 하이드록시기이고, 여기서 R6은 불소 원자, 아미노기, 니트릴 또는 브롬 원자가 형성될 수 있다. 제1 다중 치환기 실로시빈은 탈카르복실화될 수 있고, 제2 다중 치환기 실로시빈, 예를 들어 식 (XXII), (XXVI), (XXIX), (LII) 또는 (LIV)을 갖는 제2 다중 치환기 실로시빈 유도체가 형성될 수 있다):
(XXII); (XXVI); (XXIX); (LII); 또는 (LIV).
실로시빈 생합성 효소 보체는, 예를 들어, N-아세틸 트랜스퍼라제를 추가로 포함하여 화학식 (I)을 갖는 제2 실로시빈 유도체를 아세틸화하고 이에 의해 화학식 (I)을 갖는 제3 다중 치환기 실로시빈을 형성할 수 있으며, 여기서 R3a는 수소 원자이고 R3b는 아세틸기다. N-아세틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩될 수 있다:
(a) 서열번호: 9;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 10에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 10에 제시된 아미노산 서열의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
따라서, 계속해서 도 14a를 참조하면, 예의 실시형태에서, 실로시빈 유도체 전구체 화합물은 식 (LVIII)을 갖는 화학적 화합물일 수 있다:
(LVIII),
여기서 R4는 아세트아미딜기, 불소 원자, 아미노기 또는 하이드록시기이고, 여기서 R6은 불소 원자, 아미노기, 니트릴 또는 브롬 원자임,
식 (LIX)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물:
(LIX),
여기서 R4는 아세트아미딜기, 불소 원자, 아미노기 또는 하이드록시기이고, 여기서 R6은 불소 원자, 아미노기, 니트릴 또는 브롬 원자임,
이 형성될 수 있다. 그 다음 제1 다중 치환기 실로시빈 유도체는 탈카르복실화될 수 있고, 식 (LX)를 갖는 제2 다중 치환기 실로시빈 유도체:
(LX),
가 형성될 수 있다. 그 후, 제2 다중 치환기 실로시빈 유도체는 아세틸화될 수 있고, 제3 다중 치환기 실로시빈 유도체, 예를 들어 식 (IX), (X), (XVIII), (XXI), (XXV) 또는 (XXVIII)을 갖는 제3 다중 치환기 실로시빈 유도체가 형성될 수 있다:
(IX); (X); (XVIII); (XXI); (XXV); 또는 (XXVIII).
본 명세서에 따른 실로시빈 생합성 효소 보체는, 예를 들어, N-메틸 트랜스퍼라제를 추가로 포함하여 R3에서 R3 아미노기를 메틸화하고 화학식 (I)을 갖는 제4 다중 치환기 실로시빈 유도체를 형성할 수 있으며, 여기서 R3a 및 R3b는 각각 메틸기이거나, R3a는 수소 원자이고 R3b는 메틸기이다. N-메틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩될 수 있다:
(a) 서열번호: 11 및 서열번호: 13;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
계속해서 도 14a을 참조하면, 예의 실시형태에서, 실로시빈 유도체 전구체 화합물은 식 (LVIII)을 갖는 화학적 화합물일 수 있고:
(LVIII),
여기서 R4는 아미노기 또는 하이드록시기이고, R6은 염소 원자, 니트릴기 또는 브롬 원자임, 그리고 식 (LIX)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물:
(LIX),
여기서 R4는 아미노기 또는 하이드록시기이고, R6은 염소 원자, 니트릴기 또는 브롬 원자임,
이 형성될 수 있다. 제1 다중 치환기 실로시빈 유도체 화합물은 탈카르복실화되어 제2 다중 치환기 실로시빈 유도체 화합물을 형성할 수 있으며, 여기서 제2 다중 치환기 실로시빈 유도체는 식 (LX)를 갖는다:
(LX),
제3 다중 치환기 실로시빈 유도체 화합물은 메틸화되어 제4 다중 치환기 실로시빈 유도체, 예를 들어 식 (XXVII), (XL) 또는 (LIII)을 갖는 제4 다중 치환기 실로시빈 유도체 화합물을 형성할 수 있다:
(XXVII); (XL) 또는 (LIII).
본 명세서에 따라, 실로시빈 생합성 효소 보체는 추가의 예의 실시형태에서, 다음으로부터 선택된 핵산에 의해 코딩되는 프레닐 트랜스퍼라제를 포함할 수 있다:
(a) 서열번호: 15, 서열번호: 17, 서열번호: 19, 및 서열번호: 21;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 16, 서열번호: 18, 서열번호: 20, 및 서열번호: 22에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 16, 서열번호: 18, 서열번호: 20, 및 서열번호: 22에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
이와 관련하여 다음에 도 14b를 참조하면, 추가 예의 실시형태에서, 실로시빈 유도체 전구체 화합물은 식 (LXI)을 갖는 화학적 화합물일 수 있고:
(LXI);
여기서 R4는 하이드록시기임, 그리고 제1 다중 치환기 실로시빈 유도체 화합물, 예를 들어 식 (L)을 갖는 제1 형성된 다중 치환기 실로시빈 유도체 화합물이 형성될 수 있다:
(L).
계속해서 도 14b를 참조하면, 실로시빈 생합성 효소 보체는 추가의 예의 실시형태에서, 트립토판 데카르복실라제를 포함하여 R3 -CH2-CHNH2COOH 기를 탈카르복실화하고 이에 의해 식 (I)을 갖는 제2 다중 치환기 실로시빈 유도체를 형성할 수 있으며 여기서 R3a 및 R3b 각각은 수소 원자이다. 트립토판 데카르복실라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩될 수 있다:
(a) 서열번호: 3, 서열번호: 5, 및 서열번호: 7;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 4, 서열번호: 6, 서열번호: 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 4, 서열번호: 6 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
실로시빈 생합성 효소 보체는 추가의 예의 실시형태에서, N-메틸 트랜스퍼라제를 포함하여 R3에서 R3 아미노기를 메틸화하고 식 (I)을 갖는 제4 다중 치환기 실로시빈 유도체를 형성할 수 있으며, 여기서 R3a 및 R3b는 각각 메틸기이거나, 여기서 R3a는 수소 원자이고 R3b는 메틸기이다. 핵산 서열에 의해 인코딩된 N-메틸 트랜스퍼라제는 다음으로부터 선택될 수 있다:
(a) 서열번호: 11, 및 서열번호: 13;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
계속해서 도 14b를 참조하면, 예의 실시형태에서, 실로시빈 유도체 전구체 화합물은 식 (LXI)을 갖는 화학적 화합물일 수 있고:
(LXI),
여기서 R4는 프로피오닐옥시 또는 아세톡시기임, 그리고 식 (LIX)을 갖는 제1 형성된 다중 치환기 실로시빈 유도체 화합물:
(LIX),
여기서 R4는 프로피오닐옥시 또는 아세톡시기이고, R6은 프레닐기임,
이 형성된다. 제1 다중 치환기 실로시빈 유도체 화합물은 탈카르복실화되어 하기 식을 갖는 제2 다중 치환기 실로시빈 유도체를 형성할 수 있다:
(LX)
여기서 R4는 프로피오닐옥시 또는 아세톡시기고, R6은 프레닐기임. 제2 다중 치환기 실로시빈 유도체는 메틸화되어 식 (XLI) 또는 (XLII)을 갖는 제3 다중 치환기 실로시빈 유도체가 될 수 있다:
(XLI); 또는 (XLII).
도 14b를 더 참조하면, S14 실로시빈 유도체 전구체 화합물을 프레닐화하기 위해, 디메틸알릴 피로포스페이트(DMAPP)가 치환기 함유 화합물로 사용될 수 있다는 것이 인지된다. 게라닐 피로포스페이트(GPP), 파르네실 피로포스페이트(FPP) 및 게라닐게라닐 피로포스페이트(GGPP)와 같은 다른 프레닐 함유 화합물이 대안적으로 치환기 함유 화합물로서 사용될 수 있다. 도 14b에 추가로 도시된 바와 같이, DMAPP 자체는 선택적으로 Couillaud 등, 2019, ACS, Omega, 4, 7838 - 7859에 추가로 기술된 바와 같이 산 포스파타제 및 이소펜테닐 포스페이트 키나제를 촉매 효소로 사용하여 디메틸알릴 알코올 DMAOH로부터 생합성적으로(시험관내 또는 생체내) 형성될 수 있다.
다음에 도 14c를 참조하면, 추가 예의 실시형태에서, 실로시빈 유도체 전구체 화합물은 식 (LXII)을 갖는 화학적 화합물일 수 있고:
(LXII),
여기서 R5는 염소 또는 불소 원자임, 그리고 식 (LXIII)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물:
(LXIII),
여기서 R5는 염소 또는 불소 원자이고, R6은 프레닐기임
이 형성될 수 있다. 제1 다중 치환기 실로시빈 유도체는 탈카르복실화되어 식 (XXXVI) 또는 (XXXVIII)을 갖는 제2 다중 치환기 실로시빈 유도체 화합물을 형성할 수 있다:
(XXXVI); 및 (XXXVIII).
하나의 추가 예의 실시형태에서, 실로시빈 생합성 효소 보체는 N-아세틸 트랜스퍼라제를 추가로 포함하여 화학식 (I)을 갖는 제2 실로시빈 유도체를 아세틸화하고 이에 의해 화학식 (I)을 갖는 제3 다중 치환기 실로시빈을 형성할 수 있으며, 여기서 R3a는 수소 원자이고 R3b는 아세틸기이고, N-아세틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 9;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 10에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 10에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
계속해서 도 14c를 참조하면, 실로시빈 유도체 전구체 화합물은 추가 예의 실시형태에서 식 (LXII)을 갖는 화학적 화합물일 수 있고:
(LXI),
여기서 R5는 염소 또는 불소 원자임, 그리고 식 (LXIII)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물:
(LXIII),
여기서 R5는 염소 또는 불소 원자이고, R6은 프레닐기임
이 형성될 수 있다. 제1 다중 치환기 실로시빈 유도체 화합물은 탈카르복실화되어 식 (LXIV)을 갖는 제2 형성된 다중 치환기 실로시빈 유도체 화합물을 형성할 수 있다:
(LXIV),
여기서 R5는 염소 또는 불소 원자이고, R6은 프레닐기임. 제2 다중 치환기 실로시빈 유도체 화합물은 아세틸화되어 식 (XXXV) 또는 (XXXVII)을 갖는 제3 다중 치환기 실로시빈 유도체를 형성할 수 있다:
(XXXV); 또는 (XXXVII).
도 14c를 더 참조하면, 도 14b에 묘사된 생합성 경로와 유사하게, 도 14c에 도시된 S15 실로시빈 유도체 전구체 화합물을 프레닐화하기 위해, 디메틸알릴 피로포스페이트(DMAPP)가 치환기 함유 화합물로 사용될 수 있다.
다음에 도 14d, 및 식 (LVII)을 갖는 실로시빈 유도체 전구체 화합물을 참조하면, 실로시빈 생합성 효소 보체는 예를 들어, 다음으로부터 선택된 핵산에 의해 인코딩된 트립토판 신타제 서브유닛 B 폴리펩티드를 포함할 수 있다:
(a) 서열번호: 1;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 2에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 2에 제시된 아미노산 서열의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
R2, R4, R5, R6, 또는 R7 중 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 독립적으로 선택된 치환기이고, R3은 수소 원자인 식 (I)을 갖는 제1 실로시빈 유도체 전구체 화합물이 사용될 수 있다. R3c가 카르복실기인 식 (I)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물이 형성될 수 있다. 예를 들어, 실로시빈 유도체 전구체 화합물은 식 (LXV)을 갖는 화학적 화합물일 수 있고:
(LXV),
여기서, R4는 하이드록시기고, R5는 프레닐기임, 그리고 식 (LI)을 갖는 제1 형성된 다중 치환기 실로시빈 유도체 화합물:
(LI)
이 형성될 수 있다.
실로시빈 생합성 효소 보체는 트립토판 데카르복실라제를 추가로 포함하여 R3 -CH2-CHNH2COOH 기를 탈카르복실화하고, 이에 의해 식 (I)을 갖는 제2 다중 치환기 실로시빈 유도체를 형성할 수 있으며, 여기서 R3a 및 R3b 각각은 수소 원자이고, 트립토판 데카르복실라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 3, 서열번호: 5, 및 서열번호: 7;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 4, 서열번호: 6, 서열번호: 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 4, 서열번호: 6 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
계속해서 도 14d를 참조하면, 예를 들어, 실로시빈 유도체 전구체 화합물은 식 (LXV)을 갖는 화학적 화합물일 수 있고:
(LXV),
여기서 R4는 불소 원자이고 R5는 니트릴기임, 그리고 식 (LXIX)을 갖는 제1 형성된 다중 치환기 실로시빈 유도체 화합물:
(LXIX),
여기서 R4는 불소 원자이고 R5는 니트릴기임
이 형성될 수 있다. 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 그 다음 제1 다중 치환기 유도체 화합물을 탈카르복실화에 의해 형성될 수 있으며, 제2 다중 치환기 실로시빈 유도체 화합물은 식 (XIX)을 갖는다:
(XIX).
추가 실시형태에서, 실로시빈 생합성 효소 보체는 N-아세틸 트랜스퍼라제를 추가로 포함하여 화학식 (I)을 갖는 제2 실로시빈 유도체를 아세틸화하고 이에 의해 화학식 (I)을 갖는 제3 다중 치환기 실로시빈을 형성할 수 있으며, 여기서 R3a는 수소 원자이고 R3b는 아세틸기며, N-아세틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 9;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 10에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 10에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
계속해서 도 14d를 참조하면, 예를 들어, 실로시빈 유도체 전구체 화합물은 식 (LXV)을 갖는 화학적 화합물일 수 있고:
(LXV),
여기서 R4는 불소 원자이고 R5는 하이드록시기 또는 니트릴기임, 그리고 식 (LXIX)을 갖는 제1 형성된 다중 치환기 실로시빈 유도체 화합물:
(LXIX),
여기서 R4는 불소 원자이고 R5는 하이드록시기 또는 니트릴기임
이 형성될 수 있다. 제1 형성된 다중 치환기 실로시빈 유도체는 탈카르복실화되어 식 (LXXII)을 갖는 제2 다중 치환기 실로시빈 유도체 화합물을 형성할 수 있다:
(LXXII)
여기서 R4는 불소 원자이고, R5는 하이드록시기 또는 니트릴기임.
제2 형성된 다중 치환기 실로시빈 유도체는 그 다음 아세틸화되어 식 (XVII) 또는 (XX)을 갖는 제3 다중 치환기 실로시빈 유도체를 형성할 수 있다:
(XVII); 또는 (XX).
다음에 도 14e를 참조하면, 실로시빈 생합성 효소 보체는 다음으로부터 선택된 핵산에 의해 인코딩되는 트립토판 신타제 서브유닛 B 폴리펩티드를 포함할 수 있다:
(a) 서열번호: 1;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 2에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 2에 제시된 아미노산 서열의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열,
여기서 식 (LVIII)을 갖는 실로시빈 유도체 전구체 화합물에서, R2, R4, R5, R6, 또는 R7 중 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 독립적으로 선택된 치환기이고, 여기서 R3은 수소 원자이고, 그리고 여기서 R3c가 카르복실기인 식 (I)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물이 형성된다. 예를 들어, 실로시빈 유도체 전구체 화합물은 식 (LXVI)을 갖는 화학적 화합물일 수 있고:
(LXVI),
여기서 R4는 하이드록시기고, R7은 프레닐기임, 그리고 식 (XLIX)을 갖는 제1 형성된 다중 치환기 실로시빈 유도체 화합물:
(XLIX),
이 형성될 수 있다.
추가 실시형태에서, 실로시빈 생합성 효소 보체는 트립토판 데카르복실라제를 추가로 포함하여 R3 -CH2-CHNH2COOH 기를 탈카르복실화시키고 이에 의해 식 (I)을 갖는 제2 다중 치환기 실로시빈 유도체를 형성할 수 있으며, 여기서 R3a 및 R3b 각각은 수소 원자이고, 트립토판 데카르복실라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 3, 서열번호: 5, 및 서열번호: 7;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 4, 서열번호: 6, 서열번호: 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 4, 서열번호: 6 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
계속해서 도 14e를 참조하면, 실로시빈 유도체 전구체 화합물은 식 (LXVI)을 갖는 화학적 화합물일 수 있고:
(LXVI),
여기서 R4는 불소 원자이고 R7은 니트릴기임, 그리고 식 (LXX)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물:
(LXX),
여기서 R4는 불소 원자이고 R7은 니트릴기임,
이 형성될 수 있다. 식 (XXIV)을 갖는 제2 형성된 다중 치환기 실로시빈 유도체 화합물:
(XXIV),
이 제1 다중 치환기 실로시빈 유도체 화합물을 탈카르복실화함에 의해 형성될 수 있다.
추가 실시형태에서, 실로시빈 생합성 효소 보체는 N-아세틸 트랜스퍼라제를 추가로 포함하여 화학식 (I)을 갖는 제2 실로시빈 유도체를 아세틸화하고 이에 의해 화학식 (I)을 갖는 제3 다중 치환기 실로시빈을 형성할 수 있으며, 여기서 R3a는 수소 원자이고 R3b는 아세틸기며, N-아세틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 9;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 10에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 10에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
계속해서 도 14e를 참조하면, 실로시빈 유도체 전구체 화합물은 식 (LXVI)을 갖는 화학적 화합물일 수 있고:
(LXVI),
여기서 R4는 불소 원자 또는 염소 원자이고, R7은 프레닐기 또는 니트릴기임, 그리고 식 (LXX)을 갖는 다중 치환기 실로시빈 유도체 화합물:
(LXX),
여기서 R4는 불소 원자 또는 염소 원자이고, R7은 프레닐기 또는 니트릴기임
이 형성될 수 있다. 제1 다중 치환기 실로시빈 유도체 화합물의 탈카르복실화 시, 식 (LXXIII)을 갖는 제2 다중 치환기 실로시빈 유도체 화합물:
(LXXIII),
여기서, R4는 불소 원자 또는 염소 원자이고, R7은 프레닐기 또는 니트릴기임,
이 형성될 수 있다. 아세틸화에 이어서, 식 (XXIII) 또는 (XX)을 갖는 제3 다중 치환기 실로시빈 유도체:
(XXIII); 또는 (XXXIV),
가 형성될 수 있다.
실로시빈 생합성 효소 보체는 N-메틸 트랜스퍼라제를 추가로 포함하여 R3에서 R3 아미노기를 메틸화하고 추가로 화학식 (I)을 갖는 다중 치환기 실로시빈 유도체를 형성할 수 있으며, 여기서 R3a 및 R3b는 각각 메틸기이거나, 또는 R3a는 수소 원자이고 R3b는 메틸기이고, N-메틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 11, 및 서열번호: 13;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
일 실시형태에서, 예를 들어, 실로시빈 유도체 전구체 화합물은 식 (LXVI)을 갖는 화학적 화합물일 수 있고:
(LXVI),
여기서 R4는 염소 원자이고 R7은 하이드록시기임, 그리고 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXX)을 갖는다:
(LXX),
여기서 R4는 하이드록시기고 R7은 염소 원자가 형성될 수 있다. 탈카르복실화에 이어서, 식 (LXXIII)을 갖는 제2 형성된 다중 치환기 실로시빈 유도체 화합물:
(LXXIII),
여기서 R4는 하이드록시기고, R7은 염소 원자임
이 형성될 수 있다 메틸화에 이어서 식 (XXXIX)을 갖는 제3 다중 치환기 실로시빈 유도체:
(XXXIX)
가 형성될 수 있다.
다음에 도 14f를 참조하면, 다른 실시형태에서, 실로시빈 생합성 효소 보체는 다음으로부터 선택된 핵산에 의해 인코딩되는 트립토판 신타제 서브유닛 B 폴리펩티드를 포함할 수 있다:
(a) 서열번호: 1;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 2에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 2에 제시된 아미노산 서열의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열,
여기서 식 (LVIII)을 갖는 실로시빈 유도체 전구체 화합물에서, R2, R4, R5, R6, 또는 R7 중 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 독립적으로 선택된 치환기이고, 여기서 R3은 수소 원자이고, 그리고 R3c가 카르복실기인 식 (I)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물이 형성되고, 실로시빈 생합성 효소 보체는 트립토판 데카르복실라제를 추가로 포함하여 제1 다중 치환기 실로시빈 유도체 화합물의 R3 -CH2-CHNH2COOH 기를 탈카르복실화시키고, 이에 의해 식 (I)을 갖는 제2 다중 치환기 실로시빈 유도체를 형성하며 여기서 R3a 및 R3b 각각은 수소 원자이고, 트립토판 데카르복실라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 3, 서열번호: 5, 및 서열번호: 7;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 4, 서열번호: 6, 서열번호: 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 4, 서열번호: 6 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
계속해서 도 14f를 참조하면, 실로시빈 유도체 전구체 화합물은 식 (LXVII)을 갖는 화학적 화합물일 수 있고:
(LXVII),
여기서 R5는 불소 원자, 염소 원자 또는 니트릴기이고, R6은 불소 원자, 아미노기 또는 프레닐기임, 그리고 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXIII)을 갖는다:
(LXIII),
여기서 R5는 불소 원자, 염소 원자 또는 니트릴기이고, R6은 불소 원자, 아미노기 또는 프레닐기임, 이 형성될 수 있다. 탈카르복실화에 이어서, 식 (XI), (XVI), (XXXVI) 또는 (XXXVIII)을 갖는 제2 형성된 다중 치환기 실로시빈 유도체 화합물:
(XI); (XVI); (XXXVI); 및 (XXXVIII),
이 형성될 수 있다.
실로시빈 생합성 효소 보체는 N-아세틸 트랜스퍼라제를 추가로 포함하여 화학식 (I)을 갖는 제2 실로시빈 유도체를 아세틸화하고 이에 의해 화학식 (I)을 갖는 제3 다중 치환기 실로시빈을 형성할 수 있으며, 여기서 R3a는 수소 원자이고 R3b는 아세틸기이고, N-아세틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 9;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 10에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 10에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
계속해서 도 14f를 참조하면, 일 실시형태에서, 예를 들어, 실로시빈 유도체 전구체 화합물은 식 (LXVII)을 갖는 화학적 화합물일 수 있고:
(LXVII),
여기서 R5는 불소 원자 또는 염소 원자이고 R6은 아미노기, 아세트아미딜기 또는 프레닐기임, 그리고 식 (LXIII)을 갖는 제1 형성된 다중 치환기 실로시빈 유도체 화합물:
(LXIII),
여기서 R5는 불소 원자 또는 염소 원자이고, R6은 아미노기, 아세트아미딜기 또는 프레닐기임
이 형성될 수 있다. 탈카르복실화에 이어서, 식 (LXXIV)을 갖는 제2 다중 치환기 실로시빈 유도체 화합물:
(LXXIV),
여기서 R5는 불소 원자 또는 염소 원자이고, R6은 아미노기, 아세트아미딜기 또는 프레닐기임
이 형성될 수 있다. 아세틸화에 이어서, 식 (XIV), (XV), (XXXV), 또는 (XXXVII)을 갖는 제3 다중 치환기 실로시빈 유도체:
(XIV); (XV); (XXXV); 또는 (XXXVII),
가 형성될 수 있다.
실로시빈 생합성 효소 보체는 N-메틸 트랜스퍼라제를 추가로 포함하여 R3에서 R3 아미노기를 메틸화하고 추가로 화학식 (I)을 갖는 다중 치환기 실로시빈 유도체를 형성할 수 있으며, 여기서 R3a 및 R3b는 각각 메틸기이거나 또는 R3a는 수소 원자이고 R3b는 메틸기이고, N-메틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 11, 및 서열번호: 13;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
계속해서 도 14f를 참조하면, 실로시빈 유도체 전구체 화합물은 식 (LXVII)을 갖는 화학적 화합물일 수 있고:
(LXVII),
여기서 R5는 염소 원자이고 R6은 프레닐기임, 그리고 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXIII)을 갖는다:
(LXIII),
여기서 R5는 염소 원자이고 R6은 프레닐기가 형성될 수 있다. 탈카르복실화에 이어서, 식 (LXXIV)을 갖는 제2 다중 치환기 실로시빈 유도체 화합물:
(LXXIV),
여기서 R5는 염소 원자이고, R6은 프레닐기임
이 형성될 수 있다. 메틸화에 이어서, 식 (XLIV)을 갖는 제3 다중 치환기 실로시빈 유도체:
(XLIV),
가 형성될 수 있다.
다음에 도 14g를 참조하면, 다른 실시형태에서, 실로시빈 생합성 효소 보체는 다음으로부터 선택된 핵산에 의해 인코딩된 트립토판 신타제 서브유닛 B 폴리펩티드를 포함할 수 있다:
(a) 서열번호: 1;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 2에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 2에 제시된 아미노산 서열의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열,
여기서 식 (LVIII)을 갖는 실로시빈 유도체 전구체 화합물에서, R2, R4, R5, R6, 또는 R7 중 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 독립적으로 선택된 치환기이고, 여기서 R3은 수소 원자이고, 그리고 R3c가 카르복실기인 식 (I)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물이 형성되고, 실로시빈 생합성 효소 보체는 트립토판 데카르복실라제를 추가로 포함하여 제1 다중 치환기 실로시빈 유도체 화합물의 R3 -CH2-CHNH2COOH 기를 탈카르복실화시키고 이에 의해 식 (I)을 갖는 제2 다중 치환기 실로시빈 유도체를 형성하며 여기서 R3a 및 R3b 각각은 수소 원자이고, 트립토판 데카르복실라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 3, 서열번호: 5, 및 서열번호: 7;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 4, 서열번호: 6, 서열번호: 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 4, 서열번호: 6 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
계속해서 도 14g를 참조하면, 실로시빈 유도체 전구체 화합물은, 예를 들어, 식 (LXVIII)을 갖는 화학적 화합물일 수 있고:
(LXVIII),
여기서 R5는 불소 원자이고, R7은 니트로기 또는 프레닐기임, 식 (LXXI)을 갖는 제1 형성된 다중 치환기 실로시빈 유도체 화합물:
(LXXI),
여기서 R5는 불소 원자이고, R7은 니트로기 원자 또는 프레닐기임
이 형성될 수 있다. 탈카르복실화에 이어서, 식 (XIII) 또는 (XXXIII)을 갖는 제2 형성된 다중 치환기 실로시빈 유도체 화합물:
(XIII); 또는 (XXXIII)
이 형성될 수 있다.
일 실시형태에서, 실로시빈 생합성 효소 보체는 N-아세틸 트랜스퍼라제를 추가로 포함하여 화학식 (I)을 갖는 제2 실로시빈 유도체를 아세틸화하고 이에 의해 화학식 (I)을 갖는 제3 다중 치환기 실로시빈을 형성할 수 있으며, 여기서 R3a는 수소 원자이고 R3b는 아세틸기이며, N-아세틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩된다:
(a) 서열번호: 9;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 10에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 10에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열.
계속해서 도 14g를 참조하면, 실로시빈 유도체 전구체 화합물은, 예를 들어, 식 (LXVIII)을 갖는 화학적 화합물일 수 있고:
(LXVIII),
여기서 R5는 불소 원자이고, R7은 니트로기 또는 프레닐기임, 식 (LXXI)을 갖는 제1 형성된 다중 치환기 실로시빈 유도체 화합물:
(LXXI),
여기서 R5는 불소 원자이고, R7은 니트로기 원자 또는 프레닐기임
이 형성될 수 있다. 탈카르복실화에 이어서, 식 (LXXV)을 갖는 제2 형성된 다중 치환기 실로시빈 유도체 화합물:
(LXXV),
여기서 R5는 불소 원자이고, R7은 니트로기 또는 프레닐기임
이 형성될 수 있다. 이의 아세틸화에 이어서 식 (XII) 또는 (XXXII)을 갖는 제3 다중 치환기 실로시빈 유도체:
(XII); 또는 (XXXII),
가 형성될 수 있다.
본 명세서에서 이전에 언급된 바와 같이, 일부 실시형태에서, 다중 치환기 실로시빈 유도체는 합성 방법과 생합성 방법의 조합을 이용하여 제조될 수 있다. 따라서, 예를 들어, 도 13d를 참조하면, 화합물 13-D4는 도 13d에 도시된 합성 도식에 따라 (그리고 본 명세서에서 실시예 42에서 추가로 기술된 바와 같이) 합성적으로 제조될 수 있다. 화합물 13-D4는 그 다음 프레닐 트랜스퍼라제를 사용하여 시험관내 또는 생체내에서 프레닐화되어, 예를 들어, 화합물 13-D4의 C6 프레닐화된 유도체를 형성한다.
따라서, 일 실시형태에서, 실로시빈 생합성 효소 보체는 다음으로부터 선택된 핵산에 의해 인코딩된 프레닐 트랜스퍼라제를 함유할 수 있다:
(a) 서열번호: 15, 서열번호: 17, 서열번호: 19, 및 서열번호: 21;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 16, 서열번호: 18, 서열번호: 20, 및 서열번호: 22에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 16, 서열번호: 18, 서열번호: 20, 및 서열번호: 22에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열,
여기서 식 (LVIII)을 갖는 실로시빈 유도체 전구체 화합물에서, R2, R4, R5, R6, 또는 R7 중 하나는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 선택된 치환기이고, R3은 수소 원자이고, 그리고 여기서 R3c가 카르복실기 또는 수소 원자인 식 (I)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물이 형성된다.
일 실시형태에서, 실로시빈 유도체 전구체 화합물은 식 (LXXVII)을 가질 수 있고:
(LXXVII),
그리고 식 (LXXVI)을 갖는 다중 치환기 실로시빈 유도체 화합물:
(LXXVI),
이 형성될 수 있다.
상당히 다양한 상이한 실로시빈 전구체 화합물이 선택될 수 있다는 것이 당업자에게 명백할 것이다. 이와 관련하여 도 14a 및 14g는 지침을 제공하고 당업자가 적절한 실로시빈 유도체 전구체 화합물 및 매칭되는 실로시빈 생합성 효소 보체를 선택할 수 있게 한다.
본 개시내용의 방법에 따라 숙주 세포에 의한 다중 치환기 실로시빈 화합물의 생산 시, 다중 치환기 실로시빈 유도체 화합물은 숙주 세포 현탁액으로부터 추출될 수 있고, 배지 성분 및 세포 파편과 같은 숙주 세포 현탁액 내의 다른 성분으로부터 분리될 수 있다. 분리 기술은 당업자에게 공지되어 있을 것이고, 예를 들어, 용매 추출(예를 들어, 부탄, 클로로포름, 에탄올), 컬럼 크로마토그래피 기반 기술, 고성능 액체 크로마토그래피(HPLC), 예를 들어, 및/또는 역류 분리(CCS) 기반 시스템을 포함한다. 회수된 다중 치환기 실로시빈 유도체 화합물은 다소 순수한 형태로 얻어질 수 있으며, 예를 들어, 적어도 약 60%(w/w), 약 70%(w/w), 약 80%(w/w), 약 90%(w/w), 약 95%(w/w), 약 96%(w/w), 약 97%(w/w), 약 98%(w/w) 또는 약 99%(w/w) 순도의 다중 치환기 유도체 실로시빈 화합물의 제제가 얻어질 수 있다. 따라서, 이 방식으로, 다소 순수한 형태에서의 다중 치환기 실로시빈 유도체가 제조될 수 있다.
이제 전술한 것으로부터 신규한 다중 치환기 실로시빈 유도체뿐만 아니라 다중 치환기 실로시빈 유도체를 제조하는 방법이 본 명세서에 개시된다는 것이 명백해질 것이다. 다중 치환기 실로시빈 화합물은 의약품 또는 기분전환용 약물로 사용하기 위해 제형화될 수 있다.
서열의 요약
서열번호: 1은 PfTrpB-B0A9로 명명된 트립토판 신타제 서브유닛 B 폴리펩티드를 인코딩하는 피로코커스 퓨리오서스 핵산 서열을 제시한다.
서열번호: 2는 PfTrpB-B0A9로 명명된 피로코커스 퓨리오서스 서브유닛 B 트립토판 신타제 서브유닛 B 폴리펩티드의 추론된 아미노산 서열을 제시한다.
서열번호: 3은 BaTDC로 명명된 트립토판 데카르복실라제 폴리펩티드를 인코딩하는 바실러스 아트로페아우스 핵산 서열을 제시한다.
서열번호: 4는 BaTDC로 명명된 바실러스 아트로페아우스 트립토판 데카르복실라제 폴리펩티드의 추론된 아미노산 서열을 제시한다.
서열번호: 5는 ClostSporTDC로 명명된 트립토판 데카르복실라제 폴리펩티드를 인코딩하는 클로스트리디움 스포리디움 핵산 서열을 제시한다.
서열번호: 6은 ClostSporTDC로 명명된 클로스트리디움 스포리디움 트립토판 데카르복실라제 폴리펩티드의 추론된 아미노산 서열을 제시한다.
서열번호: 7은 PsiD 폴리펩티드를 인코딩하는 실로시베 쿠벤시스 핵산 서열을 제시한다.
서열번호: 8은 실로시베 쿠벤시스 PsiD 폴리펩티드의 추론된 아미노산 서열을 제시한다.
서열번호: 9는 PmsF로 명명된 N-아세틸 트랜스퍼라제를 인코딩하는 스트렙토마이세스 그리세오푸스쿠스 핵산 서열을 제시한다.
서열번호: 10은 PmsF로 명명된 스트렙토마이세스 그리세오푸스쿠스 N-아세틸 폴리펩티드의 추론된 아미노산 서열을 제시한다.
서열번호: 11은 EsNMT로 명명된 N-메틸 트랜스퍼라제를 인코딩하는 에페드라 시니카 핵산 서열을 제시한다.
서열번호: 12는 EsNMT로 명명된 에페드라 시니카 N-메틸 트랜스퍼라제 폴리펩티드의 추론된 아미노산 서열을 제시한다.
서열번호: 13은 PsiM 폴리펩티드를 인코딩하는 실로시베 쿠벤시스 핵산 서열을 제시한다.
서열번호: 14는 실로시베 쿠벤시스 PsiM 폴리펩티드의 추론된 아미노산 서열을 제시한다.
서열번호: 15는 7DMATS로 명명된 트립토판 7-프레닐 트랜스퍼라제 폴리펩티드를 인코딩하는 아스퍼길러스 퓨미가투스 핵산 서열을 제시한다.
서열번호: 16은 7DMATS로 명명된 아스퍼길러스 퓨미가투스 트립토판 7-프레닐 트랜스퍼라제 폴리펩티드의 추론된 아미노산 서열을 제시한다.
서열번호: 17은 PriB로 명명된 6-프레닐 트랜스퍼라제 폴리펩티드를 인코딩하는 스트렙토마이세스 sp. RM-5-8 핵산 서열을 제시한다.
서열번호: 18은 PriB로 명명된 스트렙토마이세스 sp. RM-5-8 6-프레닐 트랜스퍼라제 폴리펩티드의 추론된 아미노산 서열을 제시한다.
서열번호: 19는 SCO7467로 명명된 트립토판 5-프레닐 트랜스퍼라제 폴리펩티드를 인코딩하는 스트렙토마이세스 코엘리컬러 핵산 서열을 제시한다.
서열번호: 20은 SCO7467로 명명된 스트렙토마이세스 코엘리컬러 트립토판 5-프레닐 트랜스퍼라제 폴리펩티드의 추론된 아미노산 서열을 제시한다.
서열번호: 21은 FgaPT2로 명명된 트립토판 4-프레닐 트랜스퍼라제 폴리펩티드를 인코딩하는 아스퍼길러스 퓨미가투스 핵산 서열을 제시한다.
서열번호: 22는 FgaPT2로 명명된 아스퍼길러스 퓨미가투스 트립토판 4-프레닐 트랜스퍼라제 폴리펩티드의 추론된 아미노산 서열을 제시한다.
서열번호: 23은 PsiH 폴리펩티드를 인코딩하는 실로시베 쿠벤시스 핵산 서열을 제시한다.
서열번호: 24는 실로시베 쿠벤시스 PsiH 폴리펩티드의 추론된 아미노산 서열을 제시한다.
서열번호: 25는 CPR 폴리펩티드를 인코딩하는 실로시베 쿠벤시스 핵산 서열을 제시한다.
서열번호: 26은 실로시베 쿠벤시스 CPR 폴리펩티드의 추론된 아미노산 서열을 제시한다.
서열번호: 27은 XII-4::TADH1-PsiH-HA-PPGK1-PTDH3-CPR-c-myc-TCYC1로 명명된 합체 카세트로 유용한 인공 핵산을 제시한다.
서열번호: 28은 XII-5::TADH1-PsiK-V5-PPGK1-PTDH3-PsiM-FLAG-TCYC1로 명명된 합체 카세트로 유용한 인공 핵산을 제시한다.
서열번호: 29는 pMM1-PTDH3-ClostSporTDC-His-TCYC1로 명명된 합체 카세트로 유용한 인공 핵산을 제시한다.
서열번호: 30은 PGK1_promoter로 명명된 프로모터로서 유용한 인공 핵산을 제시한다.
서열번호: 31은 TDH3_promoter로 명명된 프로모터로서 유용한 인공 핵산을 제시한다.
서열번호: 32는 CLN1_promoter로 명명된 프로모터로서 유용한 인공 핵산을 제시한다.
서열번호: 33은 UGA1_promoter로 명명된 프로모터로서 유용한 인공 핵산을 제시한다.
서열번호: 34는 pMM1로 명명된 벡터로서 유용한 인공 핵산을 제시한다.
서열번호: 35는 pCDM4로 명명된 벡터로서 유용한 인공 핵산을 제시한다.
서열번호: 36은 pET28a(+)로 명명된 벡터로서 유용한 인공 핵산을 제시한다.
서열번호: 37은 pET23(+)으로 명명된 벡터로서 유용한 인공 핵산을 제시한다.
서열번호: 38은 HA-태그로 명명된 태그로서 유용한 폴리펩티드 서열을 인코딩하는 인공 핵산을 제시한다.
서열번호: 39는 HA-태그로 명명된 태그로서 유용한 인공 폴리펩티드 서열을 제시한다.
서열번호: 40은 c-myc-tag로 명명된 태그로서 유용한 폴리펩티드 서열을 인코딩하는 인공 핵산 서열을 제시한다.
서열번호: 41은 c-myc-tag로 명명된 태그로서 유용한 인공 폴리펩티드 서열을 제시한다.
서열번호: 42는 FLAG-tag로 명명된 태그로서 유용한 폴리펩티드 서열을 인코딩하는 인공 핵산 서열을 제시한다.
서열번호: 43은 FLAG-tag로 명명된 태그로서 유용한 인공 폴리펩티드 서열을 제시한다.
서열번호: 44는 V5-태그로 명명된 태그로서 유용한 폴리펩티드 서열을 인코딩하는 인공 핵산 서열을 제시한다.
서열번호: 45는 V5-태그로 명명된 태그로서 유용한 인공 폴리펩티드 서열을 제시한다.
서열번호: 46은 His-태그로 명명된 태그로서 유용한 폴리펩티드 서열을 인코딩하는 인공 핵산 서열을 제시한다.
서열번호: 47은 His-태그로 명명된 태그로서 유용한 인공 폴리펩티드 서열을 제시한다.
서열번호: 48은 PsiK 폴리펩티드를 인코딩하는 실로시베 쿠벤시스 핵산 서열을 제시한다.
서열번호: 49는 실로시베 쿠벤시스 PsiK 폴리펩티드의 추론된 아미노산 서열을 제시한다.
서열번호: 50은 X-3::TADH1-BaTDC-Flag-PPGK1-PTDH3-CPR-c-myc-TCYC1로 명명된 합체 카세트로서 유용한 인공 핵산을 제시한다.
서열번호: 51은 Xii-2::TADH1-PPGK1-PTDH3-PriB-His-TCYC1로 명명된 합체 카세트로서 유용한 인공 핵산을 제시한다.
서열번호: 52는 X-3::TADH1-ClostSporTDC-Flag-PPGK1-PTDH3-CPR-c-myc-TCYC1로 명명된 합체 카세트로서 유용한 인공 핵산을 제시한다.
서열번호: 53은 Xii-2::TADH1-PPGK1-PTDH3-Af-7DMATS-His-TCYC1로 명명된 합체 카세트로서 유용한 인공 핵산을 제시한다.
서열번호: 54는 pET26b(+)로 명명된 벡터로서 유용한 인공 핵산을 제시한다.
서열
서열번호: 1
ATGTGGTTCGGTGAGTTTGGTGGACAATATGTGCCAGAGACTTTAGTGGGTCCTCTTAAGGAATTGGAAAAGGCATATAAAAGGTTCAAGGACGATGAGGAGTTCAACAGGCAACTAAACTATTATTTGAAGACATGGGCCGGTAGACCAACGCCCTTGTATTATGCTAAGAGGTTAACTGAAAAGATTGGCGGCGCGAAAGTGTATCTGAAAAGAGAAGACCTAGTTCATGGTGGAGCACACAAGACAAATAATGCCATTGGACAAGCACTATTGGCAAAGCTAATGGGTAAAACTAGATTGATAGCTGAGACAGGAGCGGGTCAACATGGGGTCGCGACAGCGATGGCTGGTGCACTACTGGGGATGAAGGTAGATATTTACATGGGTGCTGAGGACGTTGAGCGTCAGAAACTAAATGTCTTCAGGATGAAGCTATTAGGTGCCAATGTTATACCTGTAAATTCTGGCTCAAGAACACTAAAGGACGCCTTCGACGAGGCTCTTAGAGACTGGGTTGCCACTTTCGAGTATACTCATTACTTGATCGGTTCAGTGGTTGGACCACATCCATACCCAACCATCGTTAGGGACTTTCAGAGCGTGATTGGTAGAGAGGCTAAGGCACAGATCTTAGAAGCAGAGGGACAGCTACCTGACGTCATAGTTGCCTGCGTCGGCGGTGGCTCTAACGCAATGGGTATATTCTATCCATTCGTTAATGACAAGAAGGTTAAATTAGTAGGAGTCGAAGCTGGCGGAAAGGGGTTAGAGTCGGGTAAACACTCAGCAAGCTTAAATGCAGGACAGGTAGGGGTGTCCCACGGCATGTTGTCGTATTTCTTGCAAGACGAGGAAGGTCAGATAAAGCCAAGTCATTCAATTGCTCCAGGCCTTGACCACCCCGGTGTTGGTCCAGAGCACGCTTACTTAAAGAAGATTCAAAGGGCCGAGTACGTCGCTGTAACAGACGAAGAGGCATTGAAAGCTTTCCATGAGCTATCCAGAACTGAGGGGATTATACCCGCCCTTGAGTCTGCCCATGCTGTGGCGTACGCCATGAAGTTAGCTAAAGAGATGTCCCGTGACGAAATCATCATTGTAAATCTATCAGGGAGAGGAGACAAGGATTTGGACATTGTATTGAAGGCAAGCGGAAATGTTTGA
서열번호: 2
MWFGEFGGQYVPETLVGPLKELEKAYKRFKDDEEFNRQLNYYLKTWAGRPTPLYYAKRLTEKIGGAKVYLKREDLVHGGAHKTNNAIGQALLAKLMGKTRLIAETGAGQHGVATAMAGALLGMKVDIYMGAEDVERQKLNVFRMKLLGANVIPVNSGSRTLKDAFDEALRDWVATFEYTHYLIGSVVGPHPYPTIVRDFQSVIGREAKAQILEAEGQLPDVIVACVGGGSNAMGIFYPFVNDKKVKLVGVEAGGKGLESGKHSASLNAGQVGVSHGMLSYFLQDEEGQIKPSHSIAPGLDHPGVGPEHAYLKKIQRAEYVAVTDEEALKAFHELSRTEGIIPALESAHAVAYAMKLAKEMSRDEIIIVNLSGRGDKDLDIVLKASGNV
서열번호: 3
ATGATGTCTGAAAATTTGCAATTGTCAGCTGAAGAAATGAGACAATTGGGTTACCAAGCAGTTGATTTGATCATCGATCACATGAACCATTTGAAGTCTAAGCCAGTTTCAGAAACAATCGATTCTGATATCTTGAGAAATAAGTTGACTGAATCTATCCCAGAAAATGGTTCAGATCCAAAGGAATTGTTGCATTTCTTGAACAGAAACGTTTTTAATCAAATTACACATGTTGATCATCCACATTTCTTGGCTTTTGTTCCAGGTCCAAATAATTACGTTGGTGTTGTTGCAGATTTCTTGGCTTCTGGTTTTAATGTTTTTCCAACTGCATGGATTGCTGGTGCAGGTGCTGAACAAATCGAATTGACTACAATTAATTGGTTGAAATCTATGTTGGGTTTTCCAGATTCAGCTGAAGGTTTATTTGTTTCTGGTGGTTCAATGGCAAATTTGACAGCTTTGACTGTTGCAAGACAGGCTAAGTTGAACAACGATATCGAAAATGCTGTTGTTTACTTCTCTGATCAAACACATTTCTCAGTTGATAGAGCATTGAAGGTTTTAGGTTTTAAACATCATCAAATCTGTAGAATCGAAACAGATGAACATTTGAGAATCTCTGTTTCAGCTTTGAAGAAACAAATTAAAGAAGATAGAACTAAGGGTAAAAAGCCATTCTGTGTTATTGCAAATGCTGGTACTACAAATTGTGGTGCTGTTGATTCTTTGAACGAATTAGCAGATTTGTGTAACGATGAAGATGTTTGGTTGCATGCTGATGGTTCTTATGGTGCTCCAGCTATCTTGTCTGAAAAGGGTTCAGCTATGTTGCAAGGTATTCATAGAGCAGATTCTTTGACTTTAGATCCACATAAGTGGTTGTTCCAACCATACGATGTTGGTTGTGTTTTGATCAGAAACTCTCAATATTTGTCAAAGACTTTTAGAATGATGCCAGAATACATCAAGGATTCAGAAACTAACGTTGAAGGTGAAATTAATTTCGGTGAATGTGGTATCGAATTGTCAAGAAGATTCAGAGCTTTGAAGGTTTGGTTGTCTTTTAAAGTTTTCGGTGTTGCTGCTTTTAGACAAGCAATCGATCATGGTATCATGTTAGCAGAACAAGTTGAAGCATTTTTGGGTAAAGCAAAAGATTGGGAAGTTGTTACACCAGCTCAATTGGGTATCGTTACTTTTAGATACATTCCATCTGAATTGGCATCAACAGATACTATTAATGAAATTAATAAGAAATTGGTTAAGGAAATCACACATAGAGGTTTCGCTATGTTATCTACTACAGAATTGAAGGAAAAGGTTGTTATTAGATTGTGTTCAATTAATCCAAGAACTACAACTGAAGAAATGTTGCAAATCATGATGAAGATTAAAGCATTGGCTGAAGAAGTTTCTATTTCATACCCATGTGTTGCTGAATAA
서열번호: 4
MMSENLQLSAEEMRQLGYQAVDLIIDHMNHLKSKPVSETIDSDILRNKLTESIPENGSDPKELLHFLNRNVFNQITHVDHPHFLAFVPGPNNYVGVVADFLASGFNVFPTAWIAGAGAEQIELTTINWLKSMLGFPDSAEGLFVSGGSMANLTALTVARQAKLNNDIENAVVYFSDQTHFSVDRALKVLGFKHHQICRIETDEHLRISVSALKKQIKEDRTKGKKPFCVIANAGTTNCGAVDSLNELADLCNDEDVWLHADGSYGAPAILSEKGSAMLQGIHRADSLTLDPHKWLFQPYDVGCVLIRNSQYLSKTFRMMPEYIKDSETNVEGEINFGECGIELSRRFRALKVWLSFKVFGVAAFRQAIDHGIMLAEQVEAFLGKAKDWEVVTPAQLGIVTFRYIPSELASTDTINEINKKLVKEITHRGFAMLSTTELKEKVVIRLCSINPRTTTEEMLQIMMKIKALAEEVSISYPCVAE
서열번호: 5
ATGAAGTTCTGGAGAAAGTACACACAACAAGAAATGGATGAAAAGATTACTGAATCTTTGGAAAAGACTTTGAACTACGATAACACTAAGACAATCGGTATTCCAGGTACTAAGTTGGATGATACAGTTTTCTATGATGATCATTCTTTCGTTAAGCATTCACCATACTTGAGAACTTTTATTCAAAACCCAAACCATATCGGTTGTCATACTTATGATAAGGCTGATATCTTGTTCGGTGGTACATTCGATATCGAAAGAGAATTAATCCAATTGTTAGCAATCGATGTTTTGAACGGTAACGATGAAGAATTTGATGGTTACGTTACTCAAGGTGGTACAGAAGCTAACATCCAAGCAATGTGGGTTTACAGAAACTACTTCAAGAAAGAAAGAAAGGCTAAGCATGAAGAAATCGCTATCATCACTTCAGCAGATACACATTACTCTGCATACAAAGGTTCAGATTTGTTGAACATCGATATTATTAAGGTTCCAGTTGATTTTTATTCAAGAAAAATTCAAGAAAATACATTGGATTCAATTGTTAAAGAAGCTAAAGAAATTGGTAAAAAGTACTTCATCGTTATCTCTAACATGGGTACTACAATGTTTGGTTCAGTTGATGATCCAGATTTGTACGCTAACATCTTCGATAAGTACAATTTGGAATACAAAATTCATGTTGATGGTGCATTTGGTGGTTTTATATATCCAATTGATAATAAGGAATGTAAAACTGATTTCTCTAATAAGAACGTTTCTTCAATCACATTAGATGGTCATAAGATGTTGCAAGCTCCATACGGTACTGGTATCTTCGTTTCAAGAAAGAATTTGATCCATAACACTTTGACAAAGGAAGCAACTTACATCGAAAATTTGGATGTTACATTGTCTGGTTCAAGATCTGGTTCAAATGCTGTTGCAATTTGGATGGTTTTAGCTTCTTATGGTCCATACGGTTGGATGGAAAAGATTAATAAGTTGAGAAATAGAACTAAATGGTTGTGTAAGCAATTGAACGATATGAGAATTAAATATTACAAAGAAGATTCAATGAATATTGTTACAATTGAAGAACAATATGTTAATAAGGAAATCGCTGAAAAGTACTTTTTAGTTCCAGAAGTTCATAACCCAACTAACAACTGGTACAAGATCGTTGTTATGGAACATGTTGAATTGGATATCTTGAACTCTTTGGTTTACGATTTGAGAAAGTTTAATAAGGAACATTTGAAGGCAATGTAA
서열번호: 6
MKFWRKYTQQEMDEKITESLEKTLNYDNTKTIGIPGTKLDDTVFYDDHSFVKHSPYLRTFIQNPNHIGCHTYDKADILFGGTFDIERELIQLLAIDVLNGNDEEFDGYVTQGGTEANIQAMWVYRNYFKKERKAKHEEIAIITSADTHYSAYKGSDLLNIDIIKVPVDFYSRKIQENTLDSIVKEAKEIGKKYFIVISNMGTTMFGSVDDPDLYANIFDKYNLEYKIHVDGAFGGFIYPIDNKECKTDFSNKNVSSITLDGHKMLQAPYGTGIFVSRKNLIHNTLTKEATYIENLDVTLSGSRSGSNAVAIWMVLASYGPYGWMEKINKLRNRTKWLCKQLNDMRIKYYKEDSMNIVTIEEQYVNKEIAEKYFLVPEVHNPTNNWYKIVVMEHVELDILNSLVYDLRKFNKEHLKAM
서열번호: 7
ATGCAGGTGATACCCGCGTGCAACTCGGCAGCAATAAGATCACTATGTCCTACTCCCGAGTCTTTTAGAAACATGGGATGGCTCTCTGTCAGCGATGCGGTCTACAGCGAGTTCATAGGAGAGTTGGCTACCCGCGCTTCCAATCGAAATTACTCCAACGAGTTCGGCCTCATGCAACCTATCCAGGAATTCAAGGCTTTCATTGAAAGCGACCCGGTGGTGCACCAAGAATTTATTGACATGTTCGAGGGCATTCAGGACTCTCCAAGGAATTATCAGGAACTATGTAATATGTTCAACGATATCTTTCGCAAAGCTCCCGTCTACGGAGACCTTGGCCCTCCCGTTTATATGATTATGGCCAAATTAATGAACACCCGAGCGGGCTTCTCTGCATTCACGAGACAAAGGTTGAACCTTCACTTCAAAAAACTTTTCGATACCTGGGGATTGTTCCTGTCTTCGAAAGATTCTCGAAATGTTCTTGTGGCCGACCAGTTCGACGACAGACATTGCGGCTGGTTGAACGAGCGGGCCTTGTCTGCTATGGTTAAACATTACAATGGACGCGCATTTGATGAAGTCTTCCTCTGCGATAAAAATGCCCCATACTACGGCTTCAACTCTTACGACGACTTCTTTAATCGCAGATTTCGAAACCGAGATATCGACCGACCTGTAGTCGGTGGAGTTAACAACACCACCCTCATTTCTGCTGCTTGCGAATCACTTTCCTACAACGTCTCTTATGACGTCCAGTCTCTCGACACTTTAGTTTTCAAAGGAGAGACTTATTCGCTTAAGCATTTGCTGAATAATGACCCTTTCACCCCACAATTCGAGCATGGGAGTATTCTACAAGGATTCTTGAACGTCACCGCTTACCACCGATGGCACGCACCCGTCAATGGGACAATCGTCAAAATCATCAACGTTCCAGGTACCTACTTTGCGCAAGCCCCGAGCACGATTGGCGACCCTATCCCGGATAACGATTACGACCCACCTCCTTACCTTAAGTCTCTTGTCTACTTCTCTAATATTGCCGCAAGGCAAATTATGTTTATTGAAGCCGACAACAAGGAAATTGGCCTCATTTTCCTTGTGTTCATCGGCATGACCGAAATCTCGACATGTGAAGCCACGGTGTCCGAAGGTCAACACGTCAATCGTGGCGATGACTTGGGAATGTTCCATTTCGGTGGTTCTTCGTTCGCGCTTGGTCTGAGGAAGGATTGCAGGGCAGAGATCGTTGAAAAGTTCACCGAACCCGGAACAGTGATCAGAATCAACGAAGTCGTCGCTGCTCTAAAGGCTTAG
서열번호: 8
MQVIPACNSAAIRSLCPTPESFRNMGWLSVSDAVYSEFIGELATRASNRNYSNEFGLMQPIQEFKAFIESDPVVHQEFIDMFEGIQDSPRNYQELCNMFNDIFRKAPVYGDLGPPVYMIMAKLMNTRAGFSAFTRQRLNLHFKKLFDTWGLFLSSKDSRNVLVADQFDDRHCGWLNERALSAMVKHYNGRAFDEVFLCDKNAPYYGFNSYDDFFNRRFRNRDIDRPVVGGVNNTTLISAACESLSYNVSYDVQSLDTLVFKGETYSLKHLLNNDPFTPQFEHGSILQGFLNVTAYHRWHAPVNGTIVKIINVPGTYFAQAPSTIGDPIPDNDYDPPPYLKSLVYFSNIAARQIMFIEADNKEIGLIFLVFIGMTEISTCEATVSEGQHVNRGDDLGMFHFGGSSFALGLRKDCRAEIVEKFTEPGTVIRINEVVAALKA
서열번호: 9
ATGAACACCTTCAGAACAGCCACTGCCAGAGACATACCTGATGTAGCAGCAACTCTTACGGAAGCCTTCGCAACTGATCCACCCACGCAGTGGGTGTTCCCCGACGGTACTGCCGCCGTCAGCAGGTTCTTTACACATGTTGCAGATAGGGTTCACACGGCCGGTGGTATTGTTGAGCTACTACCAGACAGAGCCGCCATGATTGCATTGCCACCACACGTGAGGCTGCCAGGAGAAGCTGCCGACGGAAGGCAGGCGGAAATTCAGAGAAGGCTGGCAGACAGGCACCCGCTGACACCTCACTACTACCTGCTGTTTTACGGAGTTAGAACGGCACACCAGGGTTCGGGATTGGGCGGAAGAATGCTGGCCAGATTAACTAGCAGAGCTGATAGGGACAGGGTGGGTACATATACTGAGGCATCCACCTGGCGTGGCGCTAGACTGATGCTGAGACATGGATTCCATGCTACAAGGCCACTAAGATTGCCAGATGGACCCAGCATGTTTCCACTTTGGAGAGATCCAATCCATGATCATTCTGAT
서열번호: 10
MNTFRTATARDIPDVAATLTEAFATDPPTQWVFPDGTAAVSRFFTHVADRVHTAGGIVELLPDRAAMIALPPHVRLPGEAADGRQAEIQRRLADRHPLTPHYYLLFYGVRTAHQGSGLGGRMLARLTSRADRDRVGTYTEASTWRGARLMLRHGFHATRPLRLPDGPSMFPLWRDPIHDHSD
서열번호: 11
ATGGGATCCATGGAAGAAGCAAAAATGGCGACCCTGGGCGGTGCGTCCTATGCGATGATTGTGAAAACGATGATGCGCTCTCTGGAAGCAAACCTGATTCCGGATTTTGTGCTGCGTCGCCTGACGCGTATCCTGCTGGCTAGTCGCCTGAAACTGGGTTATAAGCAGACCGCTGAACTGCAACTGGCGGATCTGATGTCATTCGTTGCGTCGCTGAAAACGATGCCGATTGCCCTGTGCACCGAAGAAGCAAAGGGTCAGCATTACGAACTGCCGACCAGCTTTTTCAAACTGGTCCTGGGCAAACATCTGAAGTATAGCTCTGCCTACTTTTCTGAACACACCCGTACGCTGGATGAAGCGGAAGAAGCCATGCTGGCACTGTATTGCGAACGCGCCAAAATTGAAGATGGTCAGAAGATTCTGGACATCGGCTGTGGTTGGGGCAGTTTTTCCCTGTATGTGGCAGAACGTTACCCGAAATGCGAAATTACGGGCCTGTGTAACAGTTCCACCCAAAAAGCCTTCATCGAACAGCAATGCAGCGAACGTCGCCTGTGTAATGTTACCATTTATGCAGATGACATCAGCACCTTTGATACGGAATCTACCTACGACCGCATTATCAGCATCGAAATGTTCGAACACATGAAGAACTACAGTACGCTGCTGAAGAAAATTAGCAAGTGGATGAATCAGGAATGCCTGCTGTTTGTCCATTATTTCTGTCACAAAACCTTTGCGTACCACTTCGAAGATGTGGACGAAGATGACTGGATGGCTCGTTATTTCTTTACCGGCGGCACCATGCCGGCGTCATCGCTGCTGCTGTACTTTCAGGATGACGTCTCAGTGGTTGATCATTGGCTGATTAACGGTAAACACTATGCTCAAACCTCGGAAGAATGGCTGAAGCGTATGGACCACAATCTGAGCTCTATTCTGCCGATCTTTAACGAAACGTATGGCGAAAATGCGGCCAAAAAGTGGCTGGCATACTGGCGCACCTTTTTCATCGCAGTTGCTGAACTGTTCAAATACAACGATGGCGAAGAATGGATGGTGTCCCACTTCCTGTTCAAAAAGAAATAA
서열번호: 12
MGSMEEAKMATLGGASYAMIVKTMMRSLEANLIPDFVLRRLTRILLASRLKLGYKQTAELQLADLMSFVASLKTMPIALCTEEAKGQHYELPTSFFKLVLGKHLKYSSAYFSEHTRTLDEAEEAMLALYCERAKIEDGQKILDIGCGWGSFSLYVAERYPKCEITGLCNSSTQKAFIEQQCSERRLCNVTIYADDISTFDTESTYDRIISIEMFEHMKNYSTLLKKISKWMNQECLLFVHYFCHKTFAYHFEDVDEDDWMARYFFTGGTMPASSLLLYFQDDVSVVDHWLINGKHYAQTSEEWLKRMDHNLSSILPIFNETYGENAAKKWLAYWRTFFIAVAELFKYNDGEEWMVSHFLFKKK
서열번호: 13
ATGCATATCAGAAATCCTTACCGTACACCAATTGACTATCAAGCACTTTCAGAGGCCTTCCCTCCCCTCAAGCCATTTGTGTCTGTCAATGCAGATGGTACCAGTTCTGTTGACCTCACTATCCCAGAAGCCCAGAGGGCGTTCACGGCCGCTCTTCTTCATCGTGACTTCGGGCTCACCATGACCATACCAGAAGACCGTCTGTGCCCAACAGTCCCCAATAGGTTGAACTACGTTCTGTGGATTGAAGATATTTTCAACTACACGAACAAAACCCTCGGCCTGTCGGATGACCGTCCTATTAAAGGCGTTGATATTGGTACAGGAGCCTCCGCAATTTATCCTATGCTTGCCTGTGCTCGGTTCAAGGCATGGTCTATGGTTGGAACAGAGGTCGAGAGGAAGTGCATTGACACGGCCCGCCTCAATGTCGTCGCGAACAATCTCCAAGACCGTCTCTCGATATTAGAGACATCCATTGATGGTCCTATTCTCGTCCCCATTTTCGAGGCGACTGAAGAATACGAATACGAGTTTACTATGTGTAACCCTCCATTCTACGACGGTGCTGCCGATATGCAGACTTCGGATGCTGCCAAAGGATTTGGATTTGGCGTGGGCGCTCCCCATTCTGGAACAGTCATCGAAATGTCGACTGAGGGAGGTGAATCGGCTTTCGTCGCTCAGATGGTCCGTGAGAGCTTGAAGCTTCGAACACGATGCAGATGGTACACGAGTAACTTGGGAAAGCTGAAATCCTTGAAAGAAATAGTGGGGCTGCTGAAAGAACTTGAGATAAGCAACTATGCCATTAACGAATACGTTCAGGGGTCCACACGTCGTTATGCCGTTGCGTGGTCTTTCACTGATATTCAACTGCCTGAGGAGCTTTCTCGTCCCTCTAACCCCGAGCTCAGCTCTCTTTTCTAG
서열번호: 14
MHIRNPYRTPIDYQALSEAFPPLKPFVSVNADGTSSVDLTIPEAQRAFTAALLHRDFGLTMTIPEDRLCPTVPNRLNYVLWIEDIFNYTNKTLGLSDDRPIKGVDIGTGASAIYPMLACARFKAWSMVGTEVERKCIDTARLNVVANNLQDRLSILETSIDGPILVPIFEATEEYEYEFTMCNPPFYDGAADMQTSDAAKGFGFGVGAPHSGTVIEMSTEGGESAFVAQMVRESLKLRTRCRWYTSNLGKLKSLKEIVGLLKELEISNYAINEYVQGSTRRYAVAWSFTDIQLPEELSRPSNPELSSLF
서열번호: 15
ATGTCCATCGGAGCCGAGATCGATTCGCTGGTTCCTGCTCCACCGGGCCTCAACGGCACCGCTGCGGGCTATCCAGCCAAGACGCAGAAGGAGTTAAGCAACGGAGACTTTGACGCGCACGATGGTCTTTCTCTTGCACAACTGACACCGTACGATGTCTTGACGGCTGCACTTCCGCTGCCGGCTCCGGCTTCGAGCACAGGGTTCTGGTGGCGGGAGACGGGCCCTGTTATGAGCAAGCTTTTGGCCAAGGCGAACTACCCTCTTTACACTCATTACAAGTACCTTATGTTATACCATACCCATATTCTCCCATTGTTGGGACCTCGACCGCCGCTCGAGAACTCGACGCACCCGTCGCCGAGTAACGCGCCGTGGAGGTCCTTCCTGACAGACGACTTCACTCCGCTCGAGCCGAGCTGGAACGTGAACGGGAACTCGGAAGCACAGAGCACAATCCGTCTTGGTATTGAACCTATAGGCTTTGAAGCCGGGGCTGCAGCGGACCCATTCAACCAAGCTGCCGTGACGCAGTTCATGCACTCATACGAGGCAACCGAAGTCGGTGCCACGCTGACGCTGTTCGAGCACTTCCGCAACGACATGTTTGTTGGCCCAGAAACGTACGCTGCGTTAAGAGCGAAGATACCAGAAGGCGAGCATACCACACAGAGTTTCCTGGCGTTCGACCTGGACGCGGGTCGTGTCACCACAAAGGCGTACTTTTTCCCGATTCTCATGTCGTTGAAAACTGGACAGAGCACAACAAAGGTGGTCTCTGATTCCATTCTGCATCTAGCGCTGAAGAGTGAGGTGTGGGGTGTGCAGACCATCGCCGCGATGTCGGTCATGGAGGCGTGGATAGGTAGCTACGGTGGCGCGGCAAAGACGGAGATGATCAGCGTCGATTGCGTGAACGAGGCAGACTCTCGGATCAAGATATACGTGCGGATGCCACATACATCCTTGCGGAAGGTAAAAGAGGCGTACTGCTTAGGTGGGCGGTTGACAGACGAGAACACAAAGGAGGGCCTGAAGCTGCTGGACGAGCTGTGGAGGACGGTCTTCGGCATCGACGACGAGGACGCGGAGCTGCCACAGAATAGCCATCGCACCGCAGGCACAATATTCAATTTCGAGCTGAGGCCAGGGAAATGGTTCCCCGAGCCCAAGGTATACCTGCCCGTCCGACACTACTGTGAAAGTGATATGCAGATTGCTAGTCGGCTACAAACGTTCTTTGGAAGGCTCGGATGGCACAACATGGAGAAAGATTATTGCAAGCATCTGGAAGATTTGTTTCCCCATCATCCACTGTCCTCGTCAACGGGCACACACACCTTTCTCTCATTTTCGTATAAGAAGCAGAAGGGGGTCTATATGACCATGTATTATAATCTCCGGGTGTACAGCACCTAA
서열번호: 16
MSIGAEIDSLVPAPPGLNGTAAGYPAKTQKELSNGDFDAHDGLSLAQLTPYDVLTAALPLPAPASSTGFWWRETGPVMSKLLAKANYPLYTHYKYLMLYHTHILPLLGPRPPLENSTHPSPSNAPWRSFLTDDFTPLEPSWNVNGNSEAQSTIRLGIEPIGFEAGAAADPFNQAAVTQFMHSYEATEVGATLTLFEHFRNDMFVGPETYAALRAKIPEGEHTTQSFLAFDLDAGRVTTKAYFFPILMSLKTGQSTTKVVSDSILHLALKSEVWGVQTIAAMSVMEAWIGSYGGAAKTEMISVDCVNEADSRIKIYVRMPHTSLRKVKEAYCLGGRLTDENTKEGLKLLDELWRTVFGIDDEDAELPQNSHRTAGTIFNFELRPGKWFPEPKVYLPVRHYCESDMQIASRLQTFFGRLGWHNMEKDYCKHLEDLFPHHPLSSSTGTHTFLSFSYKKQKGVYMTMYYNLRVYST
서열번호: 17
ATGGGAGGTCCGATGAGCGGTTTCCATTCGGGGGAGGCGCTGCTCGGTGACCTCGCCACCGGTCAGCTGACCAGGCTGTGCGAGGTGGCGGGGCTGACCGAGGCCGACACGGCGGCCTACACGGGGGTGCTGATCGAAAGTCTGGGGACGTCGGCCGGACGGCCGTTGTCCCTGCCACCCCCGTCGCGGACCTTTCTCTCCGACGACCACACCCCCGTGGAGTTCTCCCTGGCCTTCCTGCCGGGACGCGCACCGCACCTGCGGGTCCTGGTGGAACCGGGCTGCTCCAGCGGCGACGACCTGGCGGAAAACGGCCGGGCCGGTCTGCGGGCGGTCCACACCATGGCGGACCGCTGGGGATTCTCCACCGAGCAACTCGACCGGCTGGAGGACCTGTTCTTCCCCTCCTCCCCCGAGGGCCCGCTGGCCCTGTGGTGCGCCCTGGAGCTCCGCTCCGGTGGGGTGCCGGGGGTGAAGGTCTACCTCAACCCCGCGGCGAATGGCGCCGACCGGGCCGCCGAGACGGTACGCGAGGCGCTGGCCAGGCTGGGCCACCTGCAGGCGTTCGACGCGCTGCCCCGGGCGGACGGCTTCCCGTTCCTCGCCCTGGACCTCGGCGACTGGGACGCCCCGCGGGTGAAGATCTACCTCAAACACCTCGGCATGTCCGCCGCCGACGCGGGCTCCCTCCCCCGGATGTCGCCCGCACCGAGCCGGGAGCAGCTGGAGGAGTTCTTCCGCACCGCCGGTGACCTCCCGGCCCCGGGAGACCCGGGGCCCACCGAGGACACCGGCCGGCTCGCCGGGCGCCCCGCCCTCACCTGCCACTCCTTCACGGAGACGGCGACCGGGCGGCCCAGCGGCTACACCCTCCACGTGCCGGTCCGCGACTACGTCCGGCACGACGGCGAGGCACGGGACCGGGCGGTGGCCGTGCTGCGCGAACATGACATGGACAGTGCGGCACTGGACCGGGCGCTGGCCGCCGTGAGCCCCCGCCCGCTGAGTGACGGGGTGGGCCTGATCGCCTATCTGGCACTGGTCCACCAGCGCGGCCGGCCGACACGGGTGACCGTCTACGTCTCCTCCGAGGCGTACGAGGTGCGGCCGCCCCGCGAGACGGTCCCCACCCGCGACCGGGCGCGGGCACGGCTGTGA
서열번호: 18
MGGPMSGFHSGEALLGDLATGQLTRLCEVAGLTEADTAAYTGVLIESLGTSAGRPLSLPPPSRTFLSDDHTPVEFSLAFLPGRAPHLRVLVEPGCSSGDDLAENGRAGLRAVHTMADRWGFSTEQLDRLEDLFFPSSPEGPLALWCALELRSGGVPGVKVYLNPAANGADRAAETVREALARLGHLQAFDALPRADGFPFLALDLGDWDAPRVKIYLKHLGMSAADAGSLPRMSPAPSREQLEEFFRTAGDLPAPGDPGPTEDTGRLAGRPALTCHSFTETATGRPSGYTLHVPVRDYVRHDGEARDRAVAVLREHDMDSAALDRALAAVSPRPLSDGVGLIAYLALVHQRGRPTRVTVYVSSEAYEVRPPRETVPTRDRARARL
서열번호: 19
ATGAGGGCCGCGTCGACGGGCGCGGACCCGCAGGACGCATCCACGCTCGGCTCTTTCACCGGCGGCCAGTTGCGAAGACTCGGCTCGGTCGCCGGTCTGTCCCGCGCCGACGTCGAGACCTACGCACAGGTCCTGACCGACGCATTGGGCCCGGTGGCCCAGCGGCCGCTGAGCCTGGCGCCGCCCACCCGCACCTTCCTGTCGGACGACCACACCCCCGTGGAGTTCTCCCTCTCCTTCCGGCCCGGGGCGGCGCCCGCCATGCGGGTCCTCGTGGAACCGGGCTGCGGTGCGACCAGCCTGGCCGACAACGGCCGTGCCGGTCTTGAGGCGGTCCGCACGATGGCGCGGCGCTGGCACTTCACCACCGACGCCCTCGACGAACTCCTGGACCTGTTCCTGCCGCCCGCTCCGCAGGGCCCCCTCGCCCTGTGGTGCGCCCTGGAACTCAGGCCCGGGGGTGTACCGGGCGTCAAGGTCTATCTGAACCCTGCGGTGGGCGGGGAGGAACGTTCCGCCGCGACGGTGCGCGAGGCCCTGCGCCGGCTCGGGCACCACCAGGCCTTCGACAGCCTCCCCCAGGGCAGTGGATACCCGTTCCTCGCCCTGGACCTCGGGAACTGGACGGAGCCCCGGGCGAAGGTCTACCTGCGCCACGACAACCTCACGGCCGGTCGGGCCGCACGGCTGTCCCGGACGGACTCGGGCCTCGTGCCGACCGCGGTCGAGGGTTTCTTCCGCACCGCCGCGGGTCCCGGCTCCGACGCGGGTGGGCTCGACGGGCGGCCTGCTCAGTCCTGCCACTCCTTCACCGACCCCGGCGCGGAGCGGCCGAGCGGCTTCACCCTGTACATCCCGGTTCGTGACTACGTCCGGCATGACGGGGAGGCCCTGGCGCGGGCGTCCACCGTGCTGCACCACCACGGCATGGACGCCTCCGTGCTCCACCGCGCCCTGGCCGCCCTCACCGAGCGGCGGCCCGAGGACGGGGTGGGCCTGATCGCCTACCTGGCCCTCGCCGGCCAACGGGACCAGCCGCCGCGGGTGACGGCCTACCTCTCCTCGGAGGCCTACACGGTCCGGCCGCCGGTCGTGGAGACCGTCCGCCAACCGCTGTCGGTCGGCTGA
서열번호: 20
MRAASTGADPQDASTLGSFTGGQLRRLGSVAGLSRADVETYAQVLTDALGPVAQRPLSLAPPTRTFLSDDHTPVEFSLSFRPGAAPAMRVLVEPGCGATSLADNGRAGLEAVRTMARRWHFTTDALDELLDLFLPPAPQGPLALWCALELRPGGVPGVKVYLNPAVGGEERSAATVREALRRLGHHQAFDSLPQGSGYPFLALDLGNWTEPRAKVYLRHDNLTAGRAARLSRTDSGLVPTAVEGFFRTAAGPGSDAGGLDGRPAQSCHSFTDPGAERPSGFTLYIPVRDYVRHDGEALARASTVLHHHGMDASVLHRALAALTERRPEDGVGLIAYLALAGQRDQPPRVTAYLSSEAYTVRPPVVETVRQPLSVG
서열번호: 21
ATGAAGGCAGCCAATGCCTCCAGTGCGGAGGCCTATCGAGTTCTTAGTCGCGCCTTTAGATTCGATAATGAAGATCAGAAGCTGTGGTGGCACAGCACTGCCCCGATGTTTGCAAAAATGCTGGAAACTGCCAACTACACCACACCTTGTCAGTATCAATACCTCATCACCTATAAGGAGTGCGTAATTCCCAGTCTCGGATGCTATCCGACCAACAGCGCCCCCCGCTGGTTGAGCATCCTCACTCGATACGGCACTCCGTTCGAATTGAGCCTAAATTGCTCTAATTCAATAGTGAGATACACATTCGAGCCGATCAATCAACATACCGGAACAGATAAAGACCCATTCAATACGCACGCCATCTGGGAGAGCCTGCAGCACCTGCTTCCACTGGAGAAGAGCATTGATCTGGAGTGGTTCCGCCACTTCAAGCACGATCTCACCCTCAACAGTGAAGAATCTGCTTTTCTGGCTCATAATGATCGCCTCGTGGGCGGCACTATCAGGACGCAGAACAAGCTCGCGCTCGATCTGAAGGATGGCCGCTTTGCACTTAAGACGTACATATACCCGGCTCTCAAAGCTGTCGTCACCGGCAAGACAATTCATGAGTTGGTCTTTGGCTCAGTCCGCCGGCTGGCAGTGAGGGAGCCCCGAATCTTGCCCCCACTCAACATGCTGGAGGAATACATCCGATCACGCGGTTCCAAGAGCACTGCCAGTCCCCGCCTAGTGTCCTGTGATCTGACCAGTCCTGCCAAGTCGAGAATCAAGATCTACCTGCTGGAGCAGATGGTTTCACTAGAAGCCATGGAGGACCTGTGGACTCTGGGCGGACGGCGCCGAGACGCTTCCACTTTAGAGGGGCTCTCTCTGGTGCGTGAGCTTTGGGATCTGATCCAACTGTCGCCGGGATTGAAGTCCTATCCGGCGCCGTATCTGCCTCTCGGGGTTATCCCAGACGAGAGGCTGCCGCTTATGGCCAATTTCACCCTGCACCAGAATGACCCGGTCCCAGAGCCGCAAGTATATTTCACAACCTTCGGCATGAACGACATGGCGGTGGCGGATGCCCTGACGACGTTCTTCGAGCGCCGGGGTTGGAGTGAAATGGCCCGCACCTACGAAACTACTTTGAAGTCGTACTACCCCCATGCGGATCATGACAAACTTAACTACCTCCACGCCTACATATCCTTCTCCTACAGGGACCGTACCCCTTATCTGAGTGTCTATCTTCAATCCTTCGAGACAGGGGACTGGGCAGTTGCAAACTTATCCGAATCAAAGGTCAAGTGTCAGGATGCGGCCTGTCAACCCACAGCTTTACCTCCAGATCTGTCAAAGACAGGGGTATATTATTCCGGTCTCCACTGA
서열번호: 22
MKAANASSAEAYRVLSRAFRFDNEDQKLWWHSTAPMFAKMLETANYTTPCQYQYLITYKECVIPSLGCYPTNSAPRWLSILTRYGTPFELSLNCSNSIVRYTFEPINQHTGTDKDPFNTHAIWESLQHLLPLEKSIDLEWFRHFKHDLTLNSEESAFLAHNDRLVGGTIRTQNKLALDLKDGRFALKTYIYPALKAVVTGKTIHELVFGSVRRLAVREPRILPPLNMLEEYIRSRGSKSTASPRLVSCDLTSPAKSRIKIYLLEQMVSLEAMEDLWTLGGRRRDASTLEGLSLVRELWDLIQLSPGLKSYPAPYLPLGVIPDERLPLMANFTLHQNDPVPEPQVYFTTFGMNDMAVADALTTFFERRGWSEMARTYETTLKSYYPHADHDKLNYLHAYISFSYRDRTPYLSVYLQSFETGDWAVANLSESKVKCQDAACQPTALPPDLSKTGVYYSGLH
서열번호: 23
ATGATCGCTGTACTATTCTCCTTCGTCATTGCAGGATGCATATACTACATCGTTTCTCGTAGAGTGAGGCGGTCGCGCTTGCCACCAGGGCCGCCTGGCATTCCTATTCCCTTCATTGGGAACATGTTTGATATGCCTGAAGAATCTCCATGGTTAACATTTCTACAATGGGGACGGGATTACAGTCTGTCTTGCCGCGTTGACTTCTAATATATGAACAGCTAATATATTGTCAGACACCGATATTCTCTACGTGGATGCTGGAGGGACAGAAATGGTTATTCTTAACACGTTGGAGACCATTACCGATCTATTAGAAAAGCGAGGGTCCATTTATTCTGGCCGGTGAGCTGATGTTGAGTTTTTTGCAATTGAATTTGTGGTCACACGTTTCCAGACTTGAGAGTACAATGGTCAACGAACTTATGGGGTGGGAGTTTGACTTAGGGTTCATCACATACGGCGACAGGTGGCGCGAAGAAAGGCGCATGTTCGCCAAGGAGTTCAGTGAGAAGGGCATCAAGCAATTTCGCCATGCTCAAGTGAAAGCTGCCCATCAGCTTGTCCAACAGCTTACCAAAACGCCAGACCGCTGGGCACAACATATTCGCCAGTAAGTACTACTTGAGGAAAATAGCGTACGCTTCGCTGACCGGTCCGTACATCAAAGTCAGATAGCGGCAATGTCACTGGATATTGGTTATGGAATTGATCTTGCAGAAGACGACCCTTGGCTGGAAGCGACCCATTTGGCTAATGAAGGCCTCGCCATAGCATCAGTGCCGGGCAAATTTTGGGTCGATTCGTTCCCTTCTCGTGAGCATCCTTCTTCTATGTAGGAAGGGAAGGAGTCTAACAAGTGTTAGTAAAATACCTTCCTGCTTGGTTCCCAGGTGCTGTCTTCAAGCGCAAAGCGAAGGTCTGGCGAGAAGCCGCCGACCATATGGTTGACATGCCTTATGAAACTATGAGGAAATTAGCAGTTAGTCAAATGCGTTCTCCCCGTATTTTTTCAATACTCTAACTTCAGCTCACAGCCTCAAGGATTGACTCGTCCGTCGTATGCTTCAGCTCGTCTGCAAGCCATGGATCTCAACGGTGACCTTGAGCATCAAGAACACGTAATCAAGAACACAGCCGCAGAGGTTAATGTCGGTAAGTCAAAAGCGTCCGTCGGCAATTCAAAATTCAGGCGCTAAAGTGGGTCTTCTCACCAAGGTGGAGGCGATACTGTAAGGATTTCTCAATCGTTAGAGTATAAGTGTTCTAATGCAGTACATACTCCACCAACCAGACTGTCTCTGCTATGTCTGCGTTCATCTTGGCCATGGTGAAGTACCCTGAGGTCCAGCGAAAGGTTCAAGCGGAGCTTGATGCTCTGACCAATAACGGCCAAATTCCTGACTATGACGAAGAAGATGACTCCTTGCCATACCTCACCGCATGTATCAAGGAGCTTTTCCGGTGGAATCAAATCGCACCCCTCGCTATACCGCACAAATTAATGAAGGACGACGTGTACCGCGGGTATCTGATTCCCAAGAACACTCTAGTCTTCGCAAACACCTGGTGAGGCTGTCCATTCATTCCTAGTACATCCGTTGCCCCACTAATAGCATCTTGATAACAGGGCAGTATTAAACGATCCAGAAGTCTATCCAGATCCCTCTGTGTTCCGCCCAGAAAGATATCTTGGTCCTGACGGGAAGCCTGATAACACTGTACGCGACCCACGTAAAGCGGCATTTGGCTATGGACGACGAAATTGGTAAGTGCGCTTTCAGAACCCCCCCTTCCGTTGACTAGTGCCATGCGCGCATACAATATCGCTATTGATCTGATATAACTTCCCTGCGGCATTTATTTTGGCATTCCTTTAGTCCCGGAATTCATCTAGCGCAGTCGACGGTTTGGATTGCAGGGGCAACCCTCTTATCAGCGTTCAATATCGAGCGACCTGTCGATCAGAATGGGAAGCCCATTGACATACCGGCTGATTTTACTACAGGATTCTTCAGGTAGCTAATTTCCGTCTTTGTGTGCATAATACCCCTAACGACGCACGTTTACCTTTTTGTAAAGACACCCAGTGCCTTTCCAGTGCAGGTTTGTTCCTCGAACAGAGCAAGTCTCACAGTCGGTATCCGGACCCTGA
서열번호: 24
MIAVLFSFVIAGCIYYIVSRRVRRSRLPPGPPGIPIPFIGNMFDMPEESPWLTFLQWGRDYNTDILYVDAGGTEMVILNTLETITDLLEKRGSIYSGRLESTMVNELMGWEFDLGFITYGDRWREERRMFAKEFSEKGIKQFRHAQVKAAHQLVQQLTKTPDRWAQHIRHQIAAMSLDIGYGIDLAEDDPWLEATHLANEGLAIASVPGKFWVDSFPSLKYLPAWFPGAVFKRKAKVWREAADHMVDMPYETMRKLAPQGLTRPSYASARLQAMDLNGDLEHQEHVIKNTAAEVNVGGGDTTVSAMSAFILAMVKYPEVQRKVQAELDALTNNGQIPDYDEEDDSLPYLTACIKELFRWNQIAPLAIPHKLMKDDVYRGYLIPKNTLVFANTWAVLNDPEVYPDPSVFRPERYLGPDGKPDNTVRDPRKAAFGYGRRNCPGIHLAQSTVWIAGATLLSAFNIERPVDQNGKPIDIPADFTTGFFRHPVPFQCRFVPRTEQVSQSVSGP
서열번호: 25
ATGGCTTCTAGTTCTTCCGATGTCTTCGTTTTGGGTCTAGGTGTTGTTTTGGCTGCCTTGTATATCTTCAGAGACCAATTATTCGCTGCTTCTAAGCCAAAGGTGGCTCCAGTTTCCACTACGAAGCCTGCCAACGGTTCCGCTAACCCAAGAGACTTCATCGCCAAGATGAAACAAGGTAAGAAGAGAATCGTAATCTTCTACGGTTCTCAAACTGGTACCGCTGAAGAATATGCTATTCGTTTGGCTAAGGAAGCTAAGCAAAAGTTCGGTCTAGCCTCCTTGGTTTGTGATCCAGAAGAATACGATTTTGAAAAGTTGGACCAATTGCCAGAAGATTCTATTGCTTTCTTCGTCGTTGCTACCTATGGTGAAGGTGAACCTACAGACAACGCTGTCCAATTGTTGCAAAACTTGCAAGATGAAAGCTTCGAATTCTCCTCTGGTGAGAGAAAGTTGTCAGGTTTGAAGTACGTTGTTTTTGGTCTGGGTAACAAGACCTACGAACATTACAACCTCATTGGGAGAACTGTTGACGCTCAATTGGCCAAGATGGGTGCTATCAGAATCGGTGAAAGAGGTGAAGGTGATGATGACAAGTCCATGGAAGAAGACTACTTGGAATGGAAGGATGGTATGTGGGAAGCGTTTGCCACTGCTATGGGTGTTGAAGAAGGTCAAGGTGGTGACTCCGCTGATTTCGTCGTTTCCGAATTGGAATCTCACCCACCAGAAAAGGTTTACCAAGGTGAATTTTCTGCTAGAGCTTTAACCAAAACCAAGGGTATTCACGACGCTAAGAATCCTTTTGCTGCTCCAATTGCGGTTGCTAGAGAATTGTTCCAATCTGTTGTCGATAGAAACTGTGTCCACGTCGAATTCAACATTGAAGGCTCTGGTATCACCTATCAACACGGTGACCACGTTGGTTTGTGGCCATTGAATCCAGATGTTGAAGTCGAACGGTTGTTGTGTGTTTTAGGTTTAGCTGAAAAGAGAGATGCTGTCATCTCCATTGAATCCTTAGACCCGGCTTTGGCTAAGGTTCCATTCCCAGTCCCAACTACTTACGGTGCTGTGTTGAGACACTACATTGACATCTCTGCTGTCGCCGGTAGACAAATCTTGGGTACTTTGTCCAAATTCGCTCCAACCCCAGAAGCTGAAGCTTTCTTGAGAAACTTGAACACTAACAAGGAAGAATACCACAACGTCGTCGCTAACGGTTGTTTGAAATTGGGTGAAATTTTGCAAATCGCTACCGGTAACGACATTACTGTCCCACCAACTACTGCCAACACCACCAAATGGCCAATTCCATTCGACATCATTGTTTCTGCCATCCCAAGATTGCAACCAAGATACTACTCTATCTCTTCTTCCCCAAAAATTCATCCAAACACCATCCACGCTACCGTTGTTGTGCTCAAATACGAAAACGTTCCAACCGAACCAATCCCAAGAAAGTGGGTTTACGGTGTCGGTAGTAACTTCTTGTTGAATTTAAAGTACGCTGTTAACAAGGAACCAGTTCCATACATCACTCAAAATGGCGAACAAAGAGTCGGTGTCCCGGAATACTTGATTGCTGGTCCACGTGGTTCTTACAAGACTGAATCTTTCTACAAGGCTCCAATCCATGTTAGACGTTCTACTTTCCGTTTGCCAACCAACCCAAAGTCTCCAGTCATCATGATTGGTCCAGGTACTGGTGTCGCCCCATTCAGAGGCTTCGTTCAAGAAAGAGTTGCCTTGGCCAGAAGATCCATCGAAAAGAACGGTCCTGACTCTTTGGCTGACTGGGGTCGTATTTCCTTGTTCTACGGTTGTAGAAGATCCGACGAAGACTTCTTGTACAAGGACGAATGGCCACAATACGAAGCTGAGTTGAAGGGTAAGTTCAAGTTGCACTGTGCTTTCTCCAGACAAAACTACAAGCCAGACGGTTCTAAGATTTACGTCCAAGATTTGATCTGGGAAGACAGAGAACACATTGCCGATGCCATCTTAAACGGTAAGGGTTACGTCTACATCTGCGGTGAAGCTAAGTCCATGTCTAAACAAGTTGAAGAAGTTCTAGCCAAGATCTTGGGCGAAGCCAAAGGTGGTTCCGGTCCAGTTGAAGGTGTTGCTGAAGTCAAGTTACTGAAGGAACGGTCCAGATTGATGTTGGATGTCTGGTCTAGG
서열번호: 26
MASSSSDVFVLGLGVVLAALYIFRDQLFAASKPKVAPVSTTKPANGSANPRDFIAKMKQGKKRIVIFYGSQTGTAEEYAIRLAKEAKQKFGLASLVCDPEEYDFEKLDQLPEDSIAFFVVATYGEGEPTDNAVQLLQNLQDESFEFSSGERKLSGLKYVVFGLGNKTYEHYNLIGRTVDAQLAKMGAIRIGERGEGDDDKSMEEDYLEWKDGMWEAFATAMGVEEGQGGDSADFVVSELESHPPEKVYQGEFSARALTKTKGIHDAKNPFAAPIAVARELFQSVVDRNCVHVEFNIEGSGITYQHGDHVGLWPLNPDVEVERLLCVLGLAEKRDAVISIESLDPALAKVPFPVPTTYGAVLRHYIDISAVAGRQILGTLSKFAPTPEAEAFLRNLNTNKEEYHNVVANGCLKLGEILQIATGNDITVPPTTANTTKWPIPFDIIVSAIPRLQPRYYSISSSPKIHPNTIHATVVVLKYENVPTEPIPRKWVYGVGSNFLLNLKYAVNKEPVPYITQNGEQRVGVPEYLIAGPRGSYKTESFYKAPIHVRRSTFRLPTNPKSPVIMIGPGTGVAPFRGFVQERVALARRSIEKNGPDSLADWGRISLFYGCRRSDEDFLYKDEWPQYEAELKGKFKLHCAFSRQNYKPDGSKIYVQDLIWEDREHIADAILNGKGYVYICGEAKSMSKQVEEVLAKILGEAKGGSGPVEGVAEVKLLKERSRLMLDVWS
서열번호: 27
GTATCCGGCTGTTCCTTCATAGCCCTTTCAATGAACGTTGCAGCCCTTTGAAGATTGGCCATTTTGTCAGGACTCGAGCCTGACAGTTGGACCAACGCAACTTTAATTTTTTGTGAAAGAATCTTCGAAGCACTCATACTGGCGATCTTCACGCCCTCCTGCTATTACAAAAGCTGTGTTTTTACAAGAATCAAATTAAGTTAGCAAGATATTATACAACATTATTGATAATTTCAATATCGTGTTCGTACCTGATGACGTATCTGTGCATTGATAAGGCCCGCATGGTTTCAGAAAGCAGAGCGGAACGATTCCAAATTAGTGGCCTTGTGCTTTGCATGTCAATTGTGTTACCTTCAGCTCGTGGATTTGTTTTATCAATACACAGTCTACAGTCAAGAATTTTTTTTATCAAATTTTGCGTTCGAGCGTATAAAATAGCCGCTGTAGCTACTTAAGTTCCTGTTCAGCGATAGTTTTTTTCCATCACACGTACTATGGCAATTAAGTCCTCAGCGAGCTCGCATGGAATGCGTGCGATGAGCGACCTCATGCTATACCTGAGAAAGCAACCTGACCTACAGGAAAGAGTTACTCAAGAATAAGAATTTTCGTTTTAAAACCTAAGAGTCACTTTAAAATTTGTATACACTTATTTTTTTTATAACTTATTTAATAATAAAAATCATAAATCATAAGAAATTCGCTTATTTAGAAGTGTCAACAACGTATCTACCAACGGAATGCGTGCGATTCAGGCGTAGTCTGGAACGTCGTATGGGTATGGACCAGAGACGGATTGAGAAACTTGTTCGGTTCTTGGGACGAATCTACATTGGAATGGAACTGGGTGCCTGAAGAAACCAGTGGTGAAATCAGCTGGGATGTCAATTGGCTTACCGTTTTGGTCAACTGGTCTTTCAATGTTGAAAGCAGACAACAAAGTAGCACCGGCAATCCAAACAGTAGATTGAGCTAGGTGAATACCTGGGCAGTTTCTTCTACCGTAACCGAAAGCAGCCTTTCTTGGGTCTCTAACAGTGTTGTCTGGTTTACCATCAGGACCCAAGTATCTTTCTGGACGGAAAACGGATGGATCTGGATAGACTTCTGGGTCATTCAAAACTGCCCAGGTGTTAGCAAAAACCAATGTGTTCTTTGGAATCAAATAACCTCTGTAAACATCATCCTTCATCAATTTATGAGGGATGGCTAATGGAGCAATTTGGTTCCATCTGAATAATTCCTTGATACAAGCGGTCAAATATGGGAGTGAGTCGTCTTCCTCATCGTAGTCAGGGATTTGACCGTTGTTGGTCAAAGCATCCAATTCAGCTTGAACCTTTCTTTGCACTTCTGGGTATTTAACCATGGCCAATATGAAAGCGGACATAGCAGAGACGGTAGTGTCGCCACCACCAACGTTAACTTCAGCAGCAGTGTTCTTGATAACATGTTCTTGGTGTTCTAAATCACCGTTCAAGTCCATAGCTTGTAATCTAGCAGAAGCGTAAGATGGTCTGGTTAGACCTTGTGGAGCCAACTTTCTCATAGTTTCGTATGGCATGTCAACCATGTGGTCAGCGGCTTCTCTCCAGACCTTGGCCTTACGCTTGAAGACGGCACCTGGGAACCAAGCTGGCAAGTACTTCAAAGATGGGAAGGAGTCAACCCAGAACTTACCTGGAACACTAGCAATGGCCAAACCTTCGTTGGCTAAGTGGGTAGCTTCTAACCATGGGTCATCTTCGGCTAGATCGATACCGTAACCAATGTCCAAAGACATAGCAGCGATTTGATGTCTGATGTGTTGAGCCCACCGGTCCGGAGTCTTGGTCAATTGTTGAACCAATTGGTGAGCAGCCTTGACTTGAGCGTGTCTGAATTGCTTGATACCCTTTTCAGAGAATTCCTTAGCAAACATTCTTCTTTCTTCTCTCCAACGGTCACCGTAAGTGATAAAACCCAGATCAAATTCCCAACCCATCAATTCATTGACCATAGTGGATTCCAATCTACCGGAGTAGATGGAACCACGTTTTTCCAAGAGATCCGTGATAGTTTCCAAGGTGTTTAAAATGACCATTTCGGTACCACCAGCATCTACGTACAAGATATCAGTGTTGTAGTCACGACCCCATTGCAAGAAAGTCAACCATGGAGATTCTTCTGGCATGTCGAACATGTTACCAATAAATGGGATTGGAATTCCTGGTGGACCAGGTGGCAATCTGGATCTACGAACTCTTCTGGAGACGATGTAGTAAATACAACCAGCAATGACGAAAGAGAACAAGACAGCAATCATTGTTTTATATTTGTTGTAAAAAGTAGATAATTACTTCCTTGATGATCTGTAAAAAAGAGAAAAAGAAAGCATCTAAGAACTTGAAAAACTACGAATTAGAAAAGACCAAATATGTATTTCTTGCATTGACCAATTTATGCAAGTTTATATATATGTAAATGTAAGTTTCACGAGGTTCTACTAAACTAAACCACCCCCTTGGTTAGAAGAAAAGAGTGTGTGAGAACAGGCTGTTGTTGTCACACGATTCGGACAATTCTGTTTGAAAGAGAGAGAGTAACAGTACGATCGAACGAACTTTGCTCTGGAGATCACAGTGGGCATCATAGCATGTGGTACTAAACCCTTTCCCGCCATTCCAGAACCTTCGATTGCTTGTTACAAAACCTGTGAGCCGTCGCTAGGACCTTGTTGTGTGACGAAATTGGAAGCTGCAATCAATAGGAAGACAGGAAGTCGAGCGTGTCTGGGTTTTTTCAGTTTTGTTCTTTTTGCAAACAACAGTTTATTCCTGGCATCCACTAAATATAATGGAGCCCGCTTTTTAAGCTGGCATCCAGAAAAAAAAAGAATCCCAGCACCAAAATATTGTTTTCTTCACCAACCATCAGTTCATAGGTCCATTCTCTTAGCGCAACTACAGAGAACAGGGGCACAAACAGGCAAAAAACGGGCACAACCTCAATGGAGTGATGCAACCTGCCTGGAGTAAATGATGACACAAGGCAATTGACCCACGCATGTATCTATCTCATTTTCTTACACCTTCTATTACCTTCTGCTCTCTCTGATTTGGAAAAAGCTGAAAAAAAAGGTTGAAACCAGTTCCCTGAAATTATTCCCCTACTTGACTAATAAGTATATAAAGACGGTAGGTATTGATTGTAATTCTGTAAATCTATTTCTTAAACTTCTTAAATTCTACTTTTATAGTTAGTCTTTTTTTTAGTTTTAAAACACCAAGAACTTAGTTTCGAATAAACACACATAAACAAACAAAATGGCTTCTAGTTCTTCCGATGTCTTCGTTTTGGGTCTAGGTGTTGTTTTGGCTGCCTTGTATATCTTCAGAGACCAATTATTCGCTGCTTCTAAGCCAAAGGTGGCTCCAGTTTCCACTACGAAGCCTGCCAACGGTTCCGCTAACCCAAGAGACTTCATCGCCAAGATGAAACAAGGTAAGAAGAGAATCGTAATCTTCTACGGTTCTCAAACTGGTACCGCTGAAGAATATGCTATTCGTTTGGCTAAGGAAGCTAAGCAAAAGTTCGGTCTAGCCTCCTTGGTTTGTGATCCAGAAGAATACGATTTTGAAAAGTTGGACCAATTGCCAGAAGATTCTATTGCTTTCTTCGTCGTTGCTACCTATGGTGAAGGTGAACCTACAGACAACGCTGTCCAATTGTTGCAAAACTTGCAAGATGAAAGCTTCGAATTCTCCTCTGGTGAGAGAAAGTTGTCAGGTTTGAAGTACGTTGTTTTTGGTCTGGGTAACAAGACCTACGAACATTACAACCTCATTGGGAGAACTGTTGACGCTCAATTGGCCAAGATGGGTGCTATCAGAATCGGTGAAAGAGGTGAAGGTGATGATGACAAGTCCATGGAAGAAGACTACTTGGAATGGAAGGATGGTATGTGGGAAGCGTTTGCCACTGCTATGGGTGTTGAAGAAGGTCAAGGTGGTGACTCCGCTGATTTCGTCGTTTCCGAATTGGAATCTCACCCACCAGAAAAGGTTTACCAAGGTGAATTTTCTGCTAGAGCTTTAACCAAAACCAAGGGTATTCACGACGCTAAGAATCCTTTTGCTGCTCCAATTGCGGTTGCTAGAGAATTGTTCCAATCTGTTGTCGATAGAAACTGTGTCCACGTCGAATTCAACATTGAAGGCTCTGGTATCACCTATCAACACGGTGACCACGTTGGTTTGTGGCCATTGAATCCAGATGTTGAAGTCGAACGGTTGTTGTGTGTTTTAGGTTTAGCTGAAAAGAGAGATGCTGTCATCTCCATTGAATCCTTAGACCCGGCTTTGGCTAAGGTTCCATTCCCAGTCCCAACTACTTACGGTGCTGTGTTGAGACACTACATTGACATCTCTGCTGTCGCCGGTAGACAAATCTTGGGTACTTTGTCCAAATTCGCTCCAACCCCAGAAGCTGAAGCTTTCTTGAGAAACTTGAACACTAACAAGGAAGAATACCACAACGTCGTCGCTAACGGTTGTTTGAAATTGGGTGAAATTTTGCAAATCGCTACCGGTAACGACATTACTGTCCCACCAACTACTGCCAACACCACCAAATGGCCAATTCCATTCGACATCATTGTTTCTGCCATCCCAAGATTGCAACCAAGATACTACTCTATCTCTTCTTCCCCAAAAATTCATCCAAACACCATCCACGCTACCGTTGTTGTGCTCAAATACGAAAACGTTCCAACCGAACCAATCCCAAGAAAGTGGGTTTACGGTGTCGGTAGTAACTTCTTGTTGAATTTAAAGTACGCTGTTAACAAGGAACCAGTTCCATACATCACTCAAAATGGCGAACAAAGAGTCGGTGTCCCGGAATACTTGATTGCTGGTCCACGTGGTTCTTACAAGACTGAATCTTTCTACAAGGCTCCAATCCATGTTAGACGTTCTACTTTCCGTTTGCCAACCAACCCAAAGTCTCCAGTCATCATGATTGGTCCAGGTACTGGTGTCGCCCCATTCAGAGGCTTCGTTCAAGAAAGAGTTGCCTTGGCCAGAAGATCCATCGAAAAGAACGGTCCTGACTCTTTGGCTGACTGGGGTCGTATTTCCTTGTTCTACGGTTGTAGAAGATCCGACGAAGACTTCTTGTACAAGGACGAATGGCCACAATACGAAGCTGAGTTGAAGGGTAAGTTCAAGTTGCACTGTGCTTTCTCCAGACAAAACTACAAGCCAGACGGTTCTAAGATTTACGTCCAAGATTTGATCTGGGAAGACAGAGAACACATTGCCGATGCCATCTTAAACGGTAAGGGTTACGTCTACATCTGCGGTGAAGCTAAGTCCATGTCTAAACAAGTTGAAGAAGTTCTAGCCAAGATCTTGGGCGAAGCCAAAGGTGGTTCCGGTCCAGTTGAAGGTGTTGCTGAAGTCAAGTTACTGAAGGAACGGTCCAGATTGATGTTGGATGTCTGGTCTGAACAAAAGTTAATTTCTGAAGAAGATTTGGAATGAATCGCGTGCATTCATCCGCTCTAACCGAAAAGGAAGGAGTTAGACAACCTGAAGTCTAGGTCCCTATTTATTTTTTTATAGTTATGTTAGTATTAAGAACGTTATTTATATTTCAAATTTTTCTTTTTTTTCTGTACAGACGCGTGTACGCATGTAACATTATACTGAAAACCTTGCTTGAGAAGGTTTTGGGACGCTCGAAGATCGCGTCCCAATTCGCCCTATAGTGAGTCGTATTACGCGCGCTCACTGGCCGTCGTTTTACAACGTCGTGACTGGGAAAACCCTGGCGTTACCCCTGCAGGACTAGTGCTGAGGCATTAATAGTTTACTCAATTCTTGAAGCCAATTTGTACAATTCCCCATTAGAGTCAAATAAAAGGATGCCTCACGGAGGTATGTTACCCGCGCTATTTCACATGGCTCATTGAATTAGAGGTGGAATTTGGTGTACCCTCCCCTCCTCATCTGATGAAGTAGTGATCCGACAATTCTTAAAAGTTGTAGACATTACTTTTACCACCAACTAAGTTGTATTTATATTGCTACCCTTATCCTTTTATATCTAACTAGCGCTCATAAGGTTGGGGCAATACTAAAACTGTGTTCTTATTCAACTCATTAAATACGTGGCAGTACGTACCCTATTAGAAACAATAGGAAACAGCAGAGTCGGAAGAAGCCAAATGCCAGATTTGAAGTCCAAAACCTTGTCAAGCCAATCTTTGGGAGCGGCTATTCCTCCAGAAATTGTGTACCAAATACTTACATACCAGTTTAGGGATTTGTTAAGAAATGACCATCCAGGTACGGCAGAAA
서열번호: 28
CAATCTGGCGGCTTGAGTTCTCAACATGTTTTATTTTTTACTTATATTGCTGGTAGGGTAAAAAAATATAACTCCTAGGAATAGGTTGTCTATATGTTTTTGTCTTGCTTCTATAATTGTAACAAACAAGGAAAGGGAAAATACTGGGTGTAAAAGCCATTGAGTCAAGTTAGGTCATCCCTTTTATACAAAATTTTTCAATTTTTTTTCCAAGATTCTTGTACGATTAATTATTTTTTTTTTGCGTCCTACAGCGTGATGAAAATTTCGCCTGCTGCAAGATGAGCGGGAACGGGCGAAATGTGCACGCGCACAACTTACGAAACGCGGATGAGTCACTGACAGCCACCGCAGAGGTTCTGACTCCTACTGAGCTCTATTGGAGGTGGCAGAACCGGTACCGGAGGAGGCCGCTATAACCGGTTTGAATTTATTGTCACAGTGTCACATCAGCATTAAGTCCTCAGCGAGCTCGCATGGAATGCGTGCGATGAGCGACCTCATGCTATACCTGAGAAAGCAACCTGACCTACAGGAAAGAGTTACTCAAGAATAAGAATTTTCGTTTTAAAACCTAAGAGTCACTTTAAAATTTGTATACACTTATTTTTTTTATAACTTATTTAATAATAAAAATCATAAATCATAAGAAATTCGCTTATTTAGAAGTGTCAACAACGTATCTACCAACGGAATGCGTGCGATTCAGGTGGAGTCCAAACCCAACAAAGGATTTGGAATTGGCTTACCGGCAGTGGAGGATTCCTTTAGCAACGTGGAAGTGATTTCACCGTTGTCGTTGTTACCTCTAGCATCGTGGAAAGCAGCAACACCCTTCTTAACAAAGTTGATTCTTTCTTCTTCAGAACCCCATTGCATGAAGTCAGTCCACATAACAATGTGAGCGGCGATACCAGCGGTAACCTTGGCGTAGTTGATGGAATGCTTGGAAGTACGGGCGTAAGATTGCAAGTAAGCTTGTCTCATGGTTGTACCAACTTGTTCGTCTTGGAATCTGCTAATCAAGTAACAGTCACCCAAGAAGTAACCCAAATCCAATGAAGCTGGACCGTACTTACACAATTCCCAGTCTAAGATGTAGATCTTTTGCAACTTAGATGGGTTACCTTCTTCAAGTTGCAACAAGATGTTCCCAGACCACAAGTCAGCCATGACCAAAGTTTCTTCGGAGTGCATAACATCGTCAACTAGATCCTTGACAACAGTTGGCAACAATGGATCATCGACGCCGTATTTAGCGGCGTTTGGGATAATAGTTTGGTACAATTGGTCAGAGGTGGTTCTACCGACAATGTTACCAGAGAAGAACTTGAATTCTGGGTCGTCTCTTCTTTCTCTACCTATGTTGTGCAATCTGGCGACGAAACCACCAATCTCGGTACCAACCAATCTAGCAATATCGGTAGCCAAAGGTGGCTTAGCAGTAACGTAGTCTAATAAGGTCTTCATTTTACCGACATCTTGCATAATCAAAGCATTGTTTTCCAAGTCATAGTTGAGACCTTCTGGAACAGAGACAATACCATCAACACCACCCAAAACTTCTCTGTTAGCCATCATCAACTTGATAGCTTGGTATTCGTAGACAGAACGTTCAACACCGATTTTGAAATCTTCATCAGTAGACATGTGTGGTTGAGCGTGCTTCAAAATGATAGAAGTGTGACCTTGGTATGGAGCGTTCAATTTAATACGCCAGGTGACGTTAACGAAACCACCGGATAATCTCTTGACACCAGAAGTGTCAACATCTAAAGACAAATGCTTGGTCAAATAGGTGATTAAACCGTCTTCAGTCTTCAAGTCAAAGGCCATTGTTTTATATTTGTTGTAAAAAGTAGATAATTACTTCCTTGATGATCTGTAAAAAAGAGAAAAAGAAAGCATCTAAGAACTTGAAAAACTACGAATTAGAAAAGACCAAATATGTATTTCTTGCATTGACCAATTTATGCAAGTTTATATATATGTAAATGTAAGTTTCACGAGGTTCTACTAAACTAAACCACCCCCTTGGTTAGAAGAAAAGAGTGTGTGAGAACAGGCTGTTGTTGTCACACGATTCGGACAATTCTGTTTGAAAGAGAGAGAGTAACAGTACGATCGAACGAACTTTGCTCTGGAGATCACAGTGGGCATCATAGCATGTGGTACTAAACCCTTTCCCGCCATTCCAGAACCTTCGATTGCTTGTTACAAAACCTGTGAGCCGTCGCTAGGACCTTGTTGTGTGACGAAATTGGAAGCTGCAATCAATAGGAAGACAGGAAGTCGAGCGTGTCTGGGTTTTTTCAGTTTTGTTCTTTTTGCAAACAACAGTTTATTCCTGGCATCCACTAAATATAATGGAGCCCGCTTTTTAAGCTGGCATCCAGAAAAAAAAAGAATCCCAGCACCAAAATATTGTTTTCTTCACCAACCATCAGTTCATAGGTCCATTCTCTTAGCGCAACTACAGAGAACAGGGGCACAAACAGGCAAAAAACGGGCACAACCTCAATGGAGTGATGCAACCTGCCTGGAGTAAATGATGACACAAGGCAATTGACCCACGCATGTATCTATCTCATTTTCTTACACCTTCTATTACCTTCTGCTCTCTCTGATTTGGAAAAAGCTGAAAAAAAAGGTTGAAACCAGTTCCCTGAAATTATTCCCCTACTTGACTAATAAGTATATAAAGACGGTAGGTATTGATTGTAATTCTGTAAATCTATTTCTTAAACTTCTTAAATTCTACTTTTATAGTTAGTCTTTTTTTTAGTTTTAAAACACCAAGAACTTAGTTTCGAATAAACACACATAAACAAACAAAATGCATATCAGAAACCCATATAGAACTCCAATTGACTACCAAGCTTTGTCTGAAGCTTTCCCACCATTGAAGCCATTTGTTTCCGTTAACGCTGATGGTACCTCCTCAGTTGACTTGACCATTCCAGAAGCCCAAAGAGCTTTTACCGCTGCCCTTTTGCACAGAGACTTCGGCTTGACTATGACTATCCCAGAAGATCGTTTGTGTCCAACCGTTCCAAACAGATTGAACTACGTTTTGTGGATTGAAGACATTTTCAACTACACCAACAAGACTTTGGGTTTATCTGACGACCGTCCAATCAAGGGTGTTGATATCGGTACCGGTGCTTCTGCCATTTACCCAATGTTGGCTTGCGCCAGATTCAAGGCTTGGTCCATGGTTGGTACTGAAGTTGAAAGAAAGTGTATCGACACTGCTAGATTAAACGTTGTTGCTAACAACTTGCAAGATCGTCTATCCATCTTGGAAACCTCTATTGACGGTCCAATTTTAGTCCCAATTTTCGAAGCTACCGAAGAATACGAATACGAATTCACCATGTGTAACCCACCTTTCTACGATGGTGCCGCTGACATGCAAACTAGCGATGCTGCAAAGGGTTTTGGTTTCGGTGTCGGTGCTCCACACTCTGGTACAGTCATCGAAATGTCTACTGAAGGTGGTGAATCCGCTTTCGTGGCTCAAATGGTTAGAGAATCTCTTAAGTTGAGAACCAGATGTAGATGGTACACTTCTAACTTAGGTAAGTTGAAATCTTTGAAGGAAATTGTCGGTTTGTTGAAGGAATTAGAAATCTCTAATTACGCCATCAACGAATATGTCCAAGGTTCCACTAGAAGATACGCTGTCGCTTGGAGTTTCACTGATATCCAATTGCCAGAAGAATTGTCCAGACCATCTAATCCTGAATTGTCCTCTTTGTTCGACTACAAGGATGACGATGACAAATGAATCGCGTGCATTCATCCGCTCTAACCGAAAAGGAAGGAGTTAGACAACCTGAAGTCTAGGTCCCTATTTATTTTTTTATAGTTATGTTAGTATTAAGAACGTTATTTATATTTCAAATTTTTCTTTTTTTTCTGTACAGACGCGTGTACGCATGTAACATTATACTGAAAACCTTGCTTGAGAAGGTTTTGGGACGCTCGAAGATCGCGTACCCAATTCGCCCTATAGTGAGTCGTATTACGCGCGCTCACTGGCCGTCGTTTTACAACGTCGTGACTGGGAAAACCCTGGCGTTACCCCTGCAGGACTAGTGCTGAGGCATTAATGCAACTCAGAAGTTTGACAGCAAGCAAGTTCATCATTCGAACTAGCCTTATTGTTTTAGTTCAGTGACAGCGAACTGCCGTACTCGATGCTTTATTTCTCACGGTAGAGCGGAAGAACAGATAGGGGCAGCGTGAGAAGAGTTAGAAAGTAAATTTTTATCACGTCTGAAGTATTCTTATTCATAGGAAATTTTGCAAGGTTTTTTAGCTCAATAACGGGCTAAGTTATATAAGGTGTTCACGCGATTTTCTTGTTATGTATACCTCTTCTCTGAGGAATGGTACTACTGTCCTGATGTAGGCTCCTTAAATTGGTGGGCAAGAATAACTTATCGATATTTTGTATATTGGTCTTGGAGTTCACCACGTAATGCCTGTTTAAGACCATCAGTTAACTCTAGTATTATTTGGTCTTGGCTACTGGCCGTTTGCTATTATTCAAGTCTTTTGTGCCTTCCCGTCGGGTAAGGGAGTTATTTAGGGATACAGAATCTAACGAAAACTAAATCTCAATGATTAACTCTATTTAATCCTTTTTTGAAAGGCAAAAGAGGTCCCTTGTTCACTTACAACGTTCTTAGCCAAATTCGCTTATCACTTACTACTTCACGATATACAGAAGTAAAAACATATAAAAAGATGTCTGTTTGTTTAGCCATCACAAAAGGTATCGCAG
서열번호: 29
TGTTTTATATTTGTTGTAAAAAGTAGATAATTACTTCCTTGATGATCTGTAAAAAAGAGAAAAAGAAAGCATCTAAGAACTTGAAAAACTACGAATTAGAAAAGACCAAATATGTATTTCTTGCATTGACCAATTTATGCAAGTTTATATATATGTAAATGTAAGTTTCACGAGGTTCTACTAAACTAAACCACCCCCTTGGTTAGAAGAAAAGAGTGTGTGAGAACAGGCTGTTGTTGTCACACGATTCGGACAATTCTGTTTGAAAGAGAGAGAGTAACAGTACGATCGAACGAACTTTGCTCTGGAGATCACAGTGGGCATCATAGCATGTGGTACTAAACCCTTTCCCGCCATTCCAGAACCTTCGATTGCTTGTTACAAAACCTGTGAGCCGTCGCTAGGACCTTGTTGTGTGACGAAATTGGAAGCTGCAATCAATAGGAAGACAGGAAGTCGAGCGTGTCTGGGTTTTTTCAGTTTTGTTCTTTTTGCAAACAACAGTTTATTCCTGGCATCCACTAAATATAATGGAGCCCGCTTTTTAAGCTGGCATCCAGAAAAAAAAAGAATCCCAGCACCAAAATATTGTTTTCTTCACCAACCATCAGTTCATAGGTCCATTCTCTTAGCGCAACTACAGAGAACAGGGGCACAAACAGGCAAAAAACGGGCACAACCTCAATGGAGTGATGCAACCTGCCTGGAGTAAATGATGACACAAGGCAATTGACCCACGCATGTATCTATCTCATTTTCTTACACCTTCTATTACCTTCTGCTCTCTCTGATTTGGAAAAAGCTGAAAAAAAAGGTTGAAACCAGTTCCCTGAAATTATTCCCCTACTTGACTAATAAGTATATAAAGACGGTAGGTATTGATTGTAATTCTGTAAATCTATTTCTTAAACTTCTTAAATTCTACTTTTATAGTTAGTCTTTTTTTTAGTTTTAAAACACCAAGAACTTAGTTTCGAATAAACACACATAAACAAACAAAGGATCCATGATGAAGTTCTGGAGAAAGTACACACAACAAGAAATGGATGAAAAGATTACTGAATCTTTGGAAAAGACTTTGAACTACGATAACACTAAGACAATCGGTATTCCAGGTACTAAGTTGGATGATACAGTTTTCTATGATGATCATTCTTTCGTTAAGCATTCACCATACTTGAGAACTTTTATTCAAAACCCAAACCATATCGGTTGTCATACTTATGATAAGGCTGATATCTTGTTCGGTGGTACATTCGATATCGAAAGAGAATTAATCCAATTGTTAGCAATCGATGTTTTGAACGGTAACGATGAAGAATTTGATGGTTACGTTACTCAAGGTGGTACAGAAGCTAACATCCAAGCAATGTGGGTTTACAGAAACTACTTCAAGAAAGAAAGAAAGGCTAAGCATGAAGAAATCGCTATCATCACTTCAGCAGATACACATTACTCTGCATACAAAGGTTCAGATTTGTTGAACATCGATATTATTAAGGTTCCAGTTGATTTTTATTCAAGAAAAATTCAAGAAAATACATTGGATTCAATTGTTAAAGAAGCTAAAGAAATTGGTAAAAAGTACTTCATCGTTATCTCTAACATGGGTACTACAATGTTTGGTTCAGTTGATGATCCAGATTTGTACGCTAACATCTTCGATAAGTACAATTTGGAATACAAAATTCATGTTGATGGTGCATTTGGTGGTTTTATATATCCAATTGATAATAAGGAATGTAAAACTGATTTCTCTAATAAGAACGTTTCTTCAATCACATTAGATGGTCATAAGATGTTGCAAGCTCCATACGGTACTGGTATCTTCGTTTCAAGAAAGAATTTGATCCATAACACTTTGACAAAGGAAGCAACTTACATCGAAAATTTGGATGTTACATTGTCTGGTTCAAGATCTGGTTCAAATGCTGTTGCAATTTGGATGGTTTTAGCTTCTTATGGTCCATACGGTTGGATGGAAAAGATTAATAAGTTGAGAAATAGAACTAAATGGTTGTGTAAGCAATTGAACGATATGAGAATTAAATATTACAAAGAAGATTCAATGAATATTGTTACAATTGAAGAACAATATGTTAATAAGGAAATCGCTGAAAAGTACTTTTTAGTTCCAGAAGTTCATAACCCAACTAACAACTGGTACAAGATCGTTGTTATGGAACATGTTGAATTGGATATCTTGAACTCTTTGGTTTACGATTTGAGAAAGTTTAATAAGGAACATTTGAAGGCAATGCATCATCATCATCATCATTAACCGCGGCTAGCTAAGATCCGCTCTAACCGAAAAGGAAGGAGTTAGACAACCTGAAGTCTAGGTCCCTATTTATTTTTTTATAGTTATGTTAGTATTAAGAACGTTATTTATATTTCAAATTTTTCTTTTTTTTCTGTACAGACGCGTGTACGCATGTAACATTATACTGAAAACCTTGCTTGAGAAGGTTTTGGGACGCTCGAAGATCCAGCTGCATTAATGAATCGGCCAACGCGCGGGGAGAGGCGGTTTGCGTATTGGGCGCTCTTCCGCTTCCTCGCTCACTGACTCGCTGCGCTCGGTCGTTCGGCTGCGGCGAGCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGAACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATCTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTAAATTAAAAATGAAGTTTTAAATCAATCTAAAGTATATATGAGTAAACTTGGTCTGACAGTTACCAATGCTTAATCAGTGAGGCACCTATCTCAGCGATCTGTCTATTTCGTTCATCCATAGTTGCCTGACTCCCCGTCGTGTAGATAACTACGATACGGGAGGGCTTACCATCTGGCCCCAGTGCTGCAATGATACCGCGAGACCCACGCTCACCGGCTCCAGATTTATCAGCAATAAACCAGCCAGCCGGAAGGGCCGAGCGCAGAAGTGGTCCTGCAACTTTATCCGCCTCCATCCAGTCTATTAATTGTTGCCGGGAAGCTAGAGTAAGTAGTTCGCCAGTTAATAGTTTGCGCAACGTTGTTGCCATTGCTACAGGCATCGTGGTGTCACGCTCGTCGTTTGGTATGGCTTCATTCAGCTCCGGTTCCCAACGATCAAGGCGAGTTACATGATCCCCCATGTTGTGCAAAAAAGCGGTTAGCTCCTTCGGTCCTCCGATCGTTGTCAGAAGTAAGTTGGCCGCAGTGTTATCACTCATGGTTATGGCAGCACTGCATAATTCTCTTACTGTCATGCCATCCGTAAGATGCTTTTCTGTGACTGGTGAGTACTCAACCAAGTCATTCTGAGAATAGTGTATGCGGCGACCGAGTTGCTCTTGCCCGGCGTCAATACGGGATAATACCGCGCCACATAGCAGAACTTTAAAAGTGCTCATCATTGGAAAACGTTCTTCGGGGCGAAAACTCTCAAGGATCTTACCGCTGTTGAGATCCAGTTCGATGTAACCCACTCGTGCACCCAACTGATCTTCAGCATCTTTTACTTTCACCAGCGTTTCTGGGTGAGCAAAAACAGGAAGGCAAAATGCCGCAAAAAAGGGAATAAGGGCGACACGGAAATGTTGAATACTCATACTCTTCCTTTTTCAATATTATTGAAGCATTTATCAGGGTTATTGTCTCATGAGCGGATACATATTTGAATGTATTTAGAAAAATAAACAAATAGGGGTTCCGCGCACATTTCCCCGAAAAGTGCCACCTGAACGAAGCATCTGTGCTTCATTTTGTAGAACAAAAATGCAACGCGAGAGCGCTAATTTTTCAAACAAAGAATCTGAGCTGCATTTTTACAGAACAGAAATGCAACGCGAAAGCGCTATTTTACCAACGAAGAATCTGTGCTTCATTTTTGTAAAACAAAAATGCAACGCGAGAGCGCTAATTTTTCAAACAAAGAATCTGAGCTGCATTTTTACAGAACAGAAATGCAACGCGAGAGCGCTATTTTACCAACAAAGAATCTATACTTCTTTTTTGTTCTACAAAAATGCATCCCGAGAGCGCTATTTTTCTAACAAAGCATCTTAGATTACTTTTTTTCTCCTTTGTGCGCTCTATAATGCAGTCTCTTGATAACTTTTTGCACTGTAGGTCCGTTAAGGTTAGAAGAAGGCTACTTTGGTGTCTATTTTCTCTTCCATAAAAAAAGCCTGACTCCACTTCCCGCGTTTACTGATTACTAGCGAAGCTGCGGGTGCATTTTTTCAAGATAAAGGCATCCCCGATTATATTCTATACCGATGTGGATTGCGCATACTTTGTGAACAGAAAGTGATAGCGTTGATGATTCTTCATTGGTCAGAAAATTATGAACGGTTTCTTCTATTTTGTCTCTATATACTACGTATAGGAAATGTTTACATTTTCGTATTGTTTTCGATTCACTCTATGAATAGTTCTTACTACAATTTTTTTGTCTAAAGAGTAATACTAGAGATAAACATAAAAAATGTAGAGGTCGAGTTTAGATGCAAGTTCAAGGAGCGAAAGGTGGATGGGTAGGTTATATAGGGATATAGCACAGAGATATATAGCAAAGAGATACTTTTGAGCAATGTTTGTGGAAGCGGTATTCGCAATATTTTAGTAGCTCGTTACAGTCCGGTGCGTTTTTGGTTTTTTGAAAGTGCGTCTTCAGAGCGCTTTTGGTTTTCAAAAGCGCTCTGAAGTTCCTATACTTTCTAGAGAATAGGAACTTCGGAATAGGAACTTCAAAGCGTTTCCGAAAACGAGCGCTTCCGAAAATGCAACGCGAGCTGCGCACATACAGCTCACTGTTCACGTCGCACCTATATCTGCGTGTTGCCTGTATATATATATACATGAGAAGAACGGCATAGTGCGTGTTTATGCTTAAATGCGTACTTATATGCGTCTATTTATGTAGGATGAAAGGTAGTCTAGTACCTCCTGTGATATTATCCCATTCCATGCGGGGTATCGTATGCTTCCTTCAGCACTACCCTTTAGCTGTTCTATATGCTGCCACTCCTCAATTGGATTAGTCTCATCCTTCAATGCTATCATTTCCTTTGATATTGGATCATACTAAGAAACCATTATTATCATGACATTAACCTATAAAAATAGGCGTATCACGAGGCCCTTTCGTCTCGCGCGTTTCGGTGATGACGGTGAAAACCTCTGACACATGCAGCTCCCGGAGACGGTCACAGCTTGTCTGTAAGCGGATGCCGGGAGCAGACAAGCCCGTCAGGGCGCGTCAGCGGGTGTTGGCGGGTGTCGGGGCTGGCTTAACTATGCGGCATCAGAGCAGATTGTACTGAGAGTGCACCATATTTCACACCGCATAGATCCGTCGAGTTCAAGAGAAAAAAAAAGAAAAAGCAAAAAGAAAAAAGGAAAGCGCGCCTCGTTCAGAATGACACGTATAGAATGATGCATTACCTTGTCATCTTCAGTATCATACTGTTCGTATACATACTTACTGACATTCATAGGTATACATATATACACATGTATATATATCGTATGCTGCAGCTTTAAATAATCGGTGTCACTACATAAGAACACCTTTGGTGGAGGGAACATCGTTGGTACCATTGGGCGAGGTGGCTTCTCTTATGGCAACCGCAAGAGCCTTGAACGCACTCTCACTACGGTGATGATCATTCTTGCCTCGCAGACAATCAACGTGGAGGGTAATTCTGCTAGCCTCTGCAAAGCTTTCAAGAAAATGCGGGATCATCTCGCAAGAGAGATCTCCTACTTTCTCCCTTTGCAAACCAAGTTCGACAACTGCGTACGGCCTGTTCGAAAGATCTACCACCGCTCTGGAAAGTGCCTCATCCAAAGGCGCAAATCCTGATCCAAACCTTTTTACTCCACGCACGGCCCCTAGGGCCTCTTTAAAAGCTTGACCGAGAGCAATCCCGCAGTCTTCAGTGGTGTGATGGTCGTCTATGTGTAAGTCACCAATGCACTCAACGATTAGCGACCAGCCGGAATGCTTGGCCAGAGCATGTATCATATGGTCCAGAAACCCTATACCTGTGTGGACGTTAATCACTTGCGATTGTGTGGCCTGTTCTGCTACTGCTTCTGCCTCTTTTTCTGGGAAGATCGAGTGCTCTATCGCTAGGGGACCACCCTTTAAAGAGATCGCAATCTGAATCTTGGTTTCATTTGTAATACGCTTTACTAGGGCTTTCTGCTCTGTCATCTTTGCCTTCGTTTATCTTGCCTGCTCATTTTTTAGTATATTCTTCGAAGAAATCACATTACTTTATATAATGTATAATTCATTATGTGATAATGCCAATCGCTAAGAAAAAAAAAGAGTCATCCGCTAGGTGGAAAAAAAAAAATGAAAATCATTACCGAGGCATAAAAAAATATAGAGTGTACTAGAGGAGGCCAAGAGTAATAGAAAAAGAAAATTGCGGGAAAGGACTGTGTTATGACTTCCCTGACTAATGCCGTGTTCAAACGATACCTGGCAGTGACTCCTAGCGCTCACCAAGCTCTTAAAACGGGAATTTATGGTGCACTCTCAGTACACGCGCCAGATCTGTTTAGCTTGCCTCGTCCCCGCCGGGTCACCCGGCCAGCGACATGGAGGCCCAGAATACCCTCCTTGACAGTCTTGACGTGCGCAGCTCAGGGGCATGATGTGACTGTCGCCCGTACATTTAGCCCATACATCCCCATGTATAATCATTTGCATCCATACATTTTGATGGCCGCACGGCGCGAAGCAAAAATTACGGCTCCTCGCTGCAGACCTGCGAGCAGGGAAACGCTCCCCTCACAGACGCGTTGAATTGTCCCCACGCCGCGCCCCTGTAGAGAAATATAAAAGGTTAGGATTTGCCACTGAGGTTCTTCTTTCATATACTTCCTTTTAAAATCTTGCTAGGATACAGTTCTCACATCACATCCGAACATAAACAACCATGGGTAAGGAAAAGACTCACGTTTCGAGGCCGCGATTAAATTCCAACATGGATGCTGATTTATATGGGTATAAATGGGCTCGCGATAATGTCGGGCAATCAGGTGCGACAATCTATCGATTGTATGGGAAGCCCGATGCGCCAGAGTTGTTTCTGAAACATGGCAAAGGTAGCGTTGCCAATGATGTTACAGATGAGATGGTCAGACTAAACTGGCTGACGGAATTTATGCCTCTTCCGACCATCAAGCATTTTATCCGTACTCCTGATGATGCATGGTTACTCACCACTGCGATCCCCGGCAAAACAGCATTCCAGGTATTAGAAGAATATCCTGATTCAGGTGAAAATATTGTTGATGCGCTGGCAGTGTTCCTGCGCCGGTTGCATTCGATTCCTGTTTGTAATTGTCCTTTTAACAGCGATCGCGTATTTCGTCTCGCTCAGGCGCAATCACGAATGAATAACGGTTTGGTTGATGCGAGTGATTTTGATGACGAGCGTAATGGCTGGCCTGTTGAACAAGTCTGGAAAGAAATGCATAAGCTTTTGCCATTCTCACCGGATTCAGTCGTCACTCATGGTGATTTCTCACTTGATAACCTTATTTTTGACGAGGGGAAATTAATAGGTTGTATTGATGTTGGACGAGTCGGAATCGCAGACCGATACCAGGATCTTGCCATCCTATGGAACTGCCTCGGTGAGTTTTCTCCTTCATTACAGAAACGGCTTTTTCAAAAATATGGTATTGATAATCCTGATATGAATAAATTGCAGTTTCATTTGATGCTCGATGAGTTTTTCTAATCAGTACTGACAATAAAAAGATTCTTGTTTTCAAGAACTTGTCATTTGTATAGTTTTTTTATATTGTAGTTGTTCTATTTTAATCAAATGTTAGCGTGATTTATATTTTTTTTCGCCTCGACATCATCTGCCCAGATGCGAAGTTAAGTGCGCAGAAAGTAATATCATGCGTCAATCGTATGTGAATGCTGGTCGCTATACTGCTGTCGATTCGATACTAACGCCGCCATCCAGTGTCGAATTCGCCATTCAGGCTGCGCAACTGTTGGGAAGGGCGATCGGTGCGGGCCTCTTCGCTATTACGCCAGCTGAATTGGAGCGACCTCATGCTATACCTGAGAAAGCAACCTGACCTACAGGAAAGAGTTACTCAAGAATAAGAATTTTCGTTTTAAAACCTAAGAGTCACTTTAAAATTTGTATACACTTATTTTTTTTATAACTTATTTAATAATAAAAATCATAAATCATAAGAAATTCGCTTATTTAGAAGTGTCAACAACGTATCTACCAACGATTTGACCCTTTTCCATCTTTTCGTAAATTTCTGGCAAGGTAGACAAGCCGACAACCTTGATTGGAGACTTGACCAAACCTCTGGCGAAGAATTGTTAATTAAGAGCTCAGATCTTTTGCGGCCGC
서열번호: 30
GTTTGCAAAAAGAACAAAACTGAAAAAACCCAGACACGCTCGACTTCCTGTCTTCCTATTGATTGCAGCTTCCAATTTCGTCACACAACAAGGTCCTAGCGACGGCTCACAGGTTTTGTAACAAGCAATCGAAGGTTCTGGAATGGCGGGAAAGGGTTTAGTACCACATGCTATGATGCCCACTGTGATCTCCAGAGCAAAGTTCGTTCGATCGTACTGTTACTCTCTCTCTTTCAAACAGAATTGTCCGAATCGTGTGACAACAACAGCCTGTTCTCACACACTCTTTTCTTCTAACCAAGGGGGTGGTTTAGTTTAGTAGAACCTCGTGAAACTTACATTTACATATATATAAACTTGCATAAATTGGTCAATGCAAGAAATACATATTTGGTCTTTTCTAATTCGTAGTTTTTCAAGTTCTTAGATGCTTTCTTTTTCTCTTTTTTACAGATCATCAAGGAAGTAATTATCTACTTTTTACAACAAATATAAAACA
서열번호: 31
ACAGTTTATTCCTGGCATCCACTAAATATAATGGAGCCCGCTTTTTAAGCTGGCATCCAGAAAAAAAAAGAATCCCAGCACCAAAATATTGTTTTCTTCACCAACCATCAGTTCATAGGTCCATTCTCTTAGCGCAACTACAGAGAACAGGGGCACAAACAGGCAAAAAACGGGCACAACCTCAATGGAGTGATGCAACCTGCCTGGAGTAAATGATGACACAAGGCAATTGACCCACGCATGTATCTATCTCATTTTCTTACACCTTCTATTACCTTCTGCTCTCTCTGATTTGGAAAAAGCTGAAAAAAAAGGTTGAAACCAGTTCCCTGAAATTATTCCCCTACTTGACTAATAAGTATATAAAGACGGTAGGTATTGATTGTAATTCTGTAAATCTATTTCTTAAACTTCTTAAATTCTACTTTTATAGTTAGTCTTTTTTTTAGTTTTAAAACACCAAGAACTTAGTTTCGAATAAACACACATAAACAAACAAA
서열번호: 32
GCTGGATTGAGCTGAATGGTGCCAGGTCGAGGCTGGGAGGGAGACTAACTCGAAAGTGACGAAGACTCGAAAATTAAAAAAAAAGATACTGCAGAAGGCAAGATTGAGAATGGAGTAAAGGCAGCGTGGGTCCCCTGTGGAAACCGCAGTTTTCCTGCGCCAAGTGGTACCGGTGCGAGTGCAGCAATTAATCTCTCGATATTTTCTTAGTATCTCTTTTTATATAAGAATATATTTTGGAATTGGTAATGCTTATCTTCAATAGTTTCTTAGTTGAATGCACACTTAAGAGCAAATTGGCCAAGGAGTTCTTCGTTCGCTTTAATTTATTTCCTGGTTATTGTCAATTTATTCATCCCATCTCCCCAGGATAGAAGAAATTAGTGTAATTTTGCTGACAATACATTTTAACGACGATAACAATAATAGCAATTAAATAAAATAGCACTACCACCACTCCACTGCTCGTTAGCTATTTCTGTAAAATAAATAAAAAGATC
서열번호: 33
ATTCGCGCTATCTCGATTTCTACCTATATAGTTAATCTCTGTACAAAAACAATCTTTCCAACTATCCATTAATCATAGTATATTATCAGCGTCGGCGATTTTACCACGCTTGACAAAAGCCGCGGGCGGGATTCCTGTGGGTAGTGGCACCGGCAGTTAATCTAATCAAAGGCGCTTGAAGGAAGAGATAGATAATAGAACAAAGCAATCGCCGCTTTGGACGGCAAATATGTTTATCCATTGGTGCGGTGATTGGATATGATTTGTCTCCAGTAGTATAAGCAAGCGCCAGATCTGTTTACTGTAAAATTAAGTGAGTAATCTCGCGGGATGTAATGATTTAAGGGAATCTGGTTCAGGTTTTCACATATATTTGTATATAAGGCCATTTGTAATTTCAATAGTTTTAGGATTTTTCCTTCTCCCAAAATACTCACTTACTGTGTTACATTACAGAAAGAACAGACAAGAAACCGTCAATAAGAAATATAACTAAGAACA
서열번호: 34
CAGGTGGCACTTTTCGGGGAAATGTGCGCGGAACCCCTATTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCATGAGACAATAACCCTGATAAATGCTTCAATAATATTGAAAAAGGAAGAGTATGAGTATTCAACATTTCCGTGTCGCCCTTATTCCCTTTTTTGCGGCATTTTGCCTTCCTGTTTTTGCTCACCCAGAAACGCTGGTGAAAGTAAAAGATGCTGAAGATCAGTTGGGTGCACGAGTGGGTTACATCGAACTGGATCTCAACAGCGGTAAGATCCTTGAGAGTTTTCGCCCCGAAGAACGTTTTCCAATGATGAGCACTTTTAAAGTTCTGCTATGTGGCGCGGTATTATCCCGTATTGACGCCGGGCAAGAGCAACTCGGTCGCCGCATACACTATTCTCAGAATGACTTGGTTGAGTACTCACCAGTCACAGAAAAGCATCTTACGGATGGCATGACAGTAAGAGAATTATGCAGTGCTGCCATAACCATGAGTGATAACACTGCGGCCAACTTACTTCTGACAACGATCGGAGGACCGAAGGAGCTAACCGCTTTTTTGCACAACATGGGGGATCATGTAACTCGCCTTGATCGTTGGGAACCGGAGCTGAATGAAGCCATACCAAACGACGAGCGTGACACCACGATGCCTGTAGCAATGGCAACAACGTTGCGCAAACTATTAACTGGCGAACTACTTACTCTAGCTTCCCGGCAACAATTAATAGACTGGATGGAGGCGGATAAAGTTGCAGGACCACTTCTGCGCTCGGCCCTTCCGGCTGGCTGGTTTATTGCTGATAAATCTGGAGCCGGTGAGCGTGGGTCTCGCGGTATCATTGCAGCACTGGGGCCAGATGGTAAGCCCTCCCGTATCGTAGTTATCTACACGACGGGGAGTCAGGCAACTATGGATGAACGAAATAGACAGATCGCTGAGATAGGTGCCTCACTGATTAAGCATTGGTAACTGTCAGACCAAGTTTACTCATATATACTTTAGATTGATTTAAAACTTCATTTTTAATTTAAAAGGATCTAGGTGAAGATCCTTTTTGATAATCTCATGACCAAAATCCCTTAACGTGAGTTTTCGTTCCACTGAGCGTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTGAGATCCTTTTTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAAACCACCGCTACCAGCGGTGGTTTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAAGGTAACTGGCTTCAGCAGAGCGCAGATACCAAATACTGTTCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAAGAACTCTGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACCAGTGGCTGCTGCCAGTGGCGATAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATAGTTACCGGATAAGGCGCAGCGGTCGGGCTGAACGGGGGGTTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTACACCGAACTGAGATACCTACAGCGTGAGCTATGAGAAAGCGCCACGCTTCCCGAAGGGAGAAAGGCGGACAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGAGCGCACGAGGGAGCTTCCAGGGGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCGCCACCTCTGACTTGAGCGTCGATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGCGGCCTTTTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATGTTCTTTCCTGCGTTATCCCCTGATTCTGTGGATAACCGTATTACCGCCTTTGAGTGAGCTGATACCGCTCGCCGCAGCCGAACGACCGAGCGCAGCGAGTCAGTGAGCGAGGAAGCGGAAGAGCGCCCAATACGCAAACCGCCTCTCCCCGCGCGTTGGCCGATTCATTAATGCAGCTGGATCTTCGAGCGTCCCAAAACCTTCTCAAGCAAGGTTTTCAGTATAATGTTACATGCGTACACGCGTCTGTACAGAAAAAAAAGAAAAATTTGAAATATAAATAACGTTCTTAATACTAACATAACTATAAAAAAATAAATAGGGACCTAGACTTCAGGTTGTCTAACTCCTTCCTTTTCGGTTAGAGCGGATCTTAGCTAGCCGCGGTACCAAGCTGGTGGATCCTTTGTTTGTTTATGTGTGTTTATTCGAAACTAAGTTCTTGGTGTTTTAAAACTAAAAAAAAGACTAACTATAAAAGTAGAATTTAAGAAGTTTAAGAAATAGATTTACAGAATTACAATCAATACCTACCGTCTTTATATACTTATTAGTCAAGTAGGGGAATAATTTCAGGGAACTGGTTTCAACCTTTTTTTTCAGCTTTTTCCAAATCAGAGAGAGCAGAAGGTAATAGAAGGTGTAAGAAAATGAGATAGATACATGCGTGGGTCAATTGCCTTGTGTCATCATTTACTCCAGGCAGGTTGCATCACTCCATTGAGGTTGTGCCCGTTTTTTGCCTGTTTGTGCCCCTGTTCTCTGTAGTTGCGCTAAGAGAATGGACCTATGAACTGATGGTTGGTGAAGAAAACAATATTTTGGTGCTGGGATTCTTTTTTTTTCTGGATGCCAGCTTAAAAAGCGGGCTCCATTATATTTAGTGGATGCCAGGAATAAACTGTTGTTTGCAAAAAGAACAAAACTGAAAAAACCCAGACACGCTCGACTTCCTGTCTTCCTATTGATTGCAGCTTCCAATTTCGTCACACAACAAGGTCCTAGCGACGGCTCACAGGTTTTGTAACAAGCAATCGAAGGTTCTGGAATGGCGGGAAAGGGTTTAGTACCACATGCTATGATGCCCACTGTGATCTCCAGAGCAAAGTTCGTTCGATCGTACTGTTACTCTCTCTCTTTCAAACAGAATTGTCCGAATCGTGTGACAACAACAGCCTGTTCTCACACACTCTTTTCTTCTAACCAAGGGGGTGGTTTAGTTTAGTAGAACCTCGTGAAACTTACATTTACATATATATAAACTTGCATAAATTGGTCAATGCAAGAAATACATATTTGGTCTTTTCTAATTCGTAGTTTTTCAAGTTCTTAGATGCTTTCTTTTTCTCTTTTTTACAGATCATCAAGGAAGTAATTATCTACTTTTTACAACAAATATAAAACAGCGGCCGCAAAAGATCTGAGCTCTTAATTAACAATTCTTCGCCAGAGGTTTGGTCAAGTCTCCAATCAAGGTTGTCGGCTTGTCTACCTTGCCAGAAATTTACGAAAAGATGGAAAAGGGTCAAATCGTTGGTAGATACGTTGTTGACACTTCTAAATAAGCGAATTTCTTATGATTTATGATTTTTATTATTAAATAAGTTATAAAAAAAATAAGTGTATACAAATTTTAAAGTGACTCTTAGGTTTTAAAACGAAAATTCTTATTCTTGAGTAACTCTTTCCTGTAGGTCAGGTTGCTTTCTCAGGTATAGCATGAGGTCGCTCCAATTCAGCTGGCGTAATAGCGAAGAGGCCCGCACCGATCGCCCTTCCCAACAGTTGCGCAGCCTGAATGGCGAATTCGACACTGGATGGCGGCGTTAGTATCGAATCGACAGCAGTATAGCGACCAGCATTCACATACGATTGACGCATGATATTACTTTCTGCGCACTTAACTTCGCATCTGGGCAGATGATGTCGAGGCGAAAAAAAATATAAATCACGCTAACATTTGATTAAAATAGAACAACTACAATATAAAAAAACTATACAAATGACAAGTTCTTGAAAACAAGAATCTTTTTATTGTCAGTACTGATTAGAAAAACTCATCGAGCATCAAATGAAACTGCAATTTATTCATATCAGGATTATCAATACCATATTTTTGAAAAAGCCGTTTCTGTAATGAAGGAGAAAACTCACCGAGGCAGTTCCATAGGATGGCAAGATCCTGGTATCGGTCTGCGATTCCGACTCGTCCAACATCAATACAACCTATTAATTTCCCCTCGTCAAAAATAAGGTTATCAAGTGAGAAATCACCATGAGTGACGACTGAATCCGGTGAGAATGGCAAAAGCTTATGCATTTCTTTCCAGACTTGTTCAACAGGCCAGCCATTACGCTCGTCATCAAAATCACTCGCATCAACCAAACCGTTATTCATTCGTGATTGCGCCTGAGCGAGACGAAATACGCGATCGCTGTTAAAAGGACAATTACAAACAGGAATCGAATGCAACCGGCGCAGGAACACTGCCAGCGCATCAACAATATTTTCACCTGAATCAGGATATTCTTCTAATACCTGGAATGCTGTTTTGCCGGGGATCGCAGTGGTGAGTAACCATGCATCATCAGGAGTACGGATAAAATGCTTGATGGTCGGAAGAGGCATAAATTCCGTCAGCCAGTTTAGTCTGACCATCTCATCTGTAACATCATTGGCAACGCTACCTTTGCCATGTTTCAGAAACAACTCTGGCGCATCGGGCTTCCCATACAATCGATAGATTGTCGCACCTGATTGCCCGACATTATCGCGAGCCCATTTATACCCATATAAATCAGCATCCATGTTGGAATTTAATCGCGGCCTCGAAACGTGAGTCTTTTCCTTACCCATGGTTGTTTATGTTCGGATGTGATGTGAGAACTGTATCCTAGCAAGATTTTAAAAGGAAGTATATGAAAGAAGAACCTCAGTGGCAAATCCTAACCTTTTATATTTCTCTACAGGGGCGCGGCGTGGGGACAATTCAACGCGTCTGTGAGGGGAGCGTTTCCCTGCTCGCAGGTCTGCAGCGAGGAGCCGTAATTTTTGCTTCGCGCCGTGCGGCCATCAAAATGTATGGATGCAAATGATTATACATGGGGATGTATGGGCTAAATGTACGGGCGACAGTCACATCATGCCCCTGAGCTGCGCACGTCAAGACTGTCAAGGAGGGTATTCTGGGCCTCCATGTCGCTGGCCGGGTGACCCGGCGGGGACGAGGCAAGCTAAACAGATCTGGCGCGTGTACTGAGAGTGCACCATAAATTCCCGTTTTAAGAGCTTGGTGAGCGCTAGGAGTCACTGCCAGGTATCGTTTGAACACGGCATTAGTCAGGGAAGTCATAACACAGTCCTTTCCCGCAATTTTCTTTTTCTATTACTCTTGGCCTCCTCTAGTACACTCTATATTTTTTTATGCCTCGGTAATGATTTTCATTTTTTTTTTTCCACCTAGCGGATGACTCTTTTTTTTTCTTAGCGATTGGCATTATCACATAATGAATTATACATTATATAAAGTAATGTGATTTCTTCGAAGAATATACTAAAAAATGAGCAGGCAAGATAAACGAAGGCAAAGATGACAGAGCAGAAAGCCCTAGTAAAGCGTATTACAAATGAAACCAAGATTCAGATTGCGATCTCTTTAAAGGGTGGTCCCCTAGCGATAGAGCACTCGATCTTCCCAGAAAAAGAGGCAGAAGCAGTAGCAGAACAGGCCACACAATCGCAAGTGATTAACGTCCACACAGGTATAGGGTTTCTGGACCATATGATACATGCTCTGGCCAAGCATTCCGGCTGGTCGCTAATCGTTGAGTGCATTGGTGACTTACACATAGACGACCATCACACCACTGAAGACTGCGGGATTGCTCTCGGTCAAGCTTTTAAAGAGGCCCTAGGGGCCGTGCGTGGAGTAAAAAGGTTTGGATCAGGATTTGCGCCTTTGGATGAGGCACTTTCCAGAGCGGTGGTAGATCTTTCGAACAGGCCGTACGCAGTTGTCGAACTTGGTTTGCAAAGGGAGAAAGTAGGAGATCTCTCTTGCGAGATGATCCCGCATTTTCTTGAAAGCTTTGCAGAGGCTAGCAGAATTACCCTCCACGTTGATTGTCTGCGAGGCAAGAATGATCATCACCGTAGTGAGAGTGCGTTCAAGGCTCTTGCGGTTGCCATAAGAGAAGCCACCTCGCCCAATGGTACCAACGATGTTCCCTCCACCAAAGGTGTTCTTATGTAGTGACACCGATTATTTAAAGCTGCAGCATACGATATATATACATGTGTATATATGTATACCTATGAATGTCAGTAAGTATGTATACGAACAGTATGATACTGAAGATGACAAGGTAATGCATCATTCTATACGTGTCATTCTGAACGAGGCGCGCTTTCCTTTTTTCTTTTTGCTTTTTCTTTTTTTTTCTCTTGAACTCGACGGATCTATGCGGTGTGAAATATGGTGCACTCTCAGTACAATCTGCTCTGATGCCGCATAGTTAAGCCAGCCCCGACACCCGCCAACACCCGCTGACGCGCCCTGACGGGCTTGTCTGCTCCCGGCATCCGCTTACAGACAAGCTGTGACCGTCTCCGGGAGCTGCATGTGTCAGAGGTTTTCACCGTCATCACCGAAACGCGCGAGACGAAAGGGCCTCGTGATACGCCTATTTTTATAGGTTAATGTCATGATAATAATGGTTTCTTAGTATGATCCAATATCAAAGGAAATGATAGCATTGAAGGATGAGACTAATCCAATTGAGGAGTGGCAGCATATAGAACAGCTAAAGGGTAGTGCTGAAGGAAGCATACGATACCCCGCATGGAATGGGATAATATCACAGGAGGTACTAGACTACCTTTCATCCTACATAAATAGACGCATATAAGTACGCATTTAAGCATAAACACGCACTATGCCGTTCTTCTCATGTATATATATATACAGGCAACACGCAGATATAGGTGCGACGTGAACAGTGAGCTGTATGTGCGCAGCTCGCGTTGCATTTTCGGAAGCGCTCGTTTTCGGAAACGCTTTGAAGTTCCTATTCCGAAGTTCCTATTCTCTAGAAAGTATAGGAACTTCAGAGCGCTTTTGAAAACCAAAAGCGCTCTGAAGACGCACTTTCAAAAAACCAAAAACGCACCGGACTGTAACGAGCTACTAAAATATTGCGAATACCGCTTCCACAAACATTGCTCAAAAGTATCTCTTTGCTATATATCTCTGTGCTATATCCCTATATAACCTACCCATCCACCTTTCGCTCCTTGAACTTGCATCTAAACTCGACCTCTACATTTTTTATGTTTATCTCTAGTATTACTCTTTAGACAAAAAAATTGTAGTAAGAACTATTCATAGAGTGAATCGAAAACAATACGAAAATGTAAACATTTCCTATACGTAGTATATAGAGACAAAATAGAAGAAACCGTTCATAATTTTCTGACCAATGAAGAATCATCAACGCTATCACTTTCTGTTCACAAAGTATGCGCAATCCACATCGGTATAGAATATAATCGGGGATGCCTTTATCTTGAAAAAATGCACCCGCAGCTTCGCTAGTAATCAGTAAACGCGGGAAGTGGAGTCAGGCTTTTTTTATGGAAGAGAAAATAGACACCAAAGTAGCCTTCTTCTAACCTTAACGGACCTACAGTGCAAAAAGTTATCAAGAGACTGCATTATAGAGCGCACAAAGGAGAAAAAAAGTAATCTAAGATGCTTTGTTAGAAAAATAGCGCTCTCGGGATGCATTTTTGTAGAACAAAAAAGAAGTATAGATTCTTTGTTGGTAAAATAGCGCTCTCGCGTTGCATTTCTGTTCTGTAAAAATGCAGCTCAGATTCTTTGTTTGAAAAATTAGCGCTCTCGCGTTGCATTTTTGTTTTACAAAAATGAAGCACAGATTCTTCGTTGGTAAAATAGCGCTTTCGCGTTGCATTTCTGTTCTGTAAAAATGCAGCTCAGATTCTTTGTTTGAAAAATTAGCGCTCTCGCGTTGCATTTTTGTTCTACAAAATGAAGCACAGATGCTTCGTT
서열번호: 35
GCTAACAGCGCGATTTGCTGGTGACCCAATGCGACCAGATGCTCCACGCCCAGTCGCGTACCGTCTTCATGGGAGAAAATAATACTGTTGATGGGTGTCTGGTCAGAGACATCAAGAAATAACGCCGGAACATTAGTGCAGGCAGCTTCCACAGCAATGGCATCCTGGTCATCCAGCGGATAGTTAATGATCAGCCCACTGACGCGTTGCGCGAGAAGATTGTGCACCGCCGCTTTACAGGCTTCGACGCCGCTTCGTTCTACCATCGACACCACCACGCTGGCACCCAGTTGATCGGCGCGAGATTTAATCGCCGCGACAATTTGCGACGGCGCGTGCAGGGCCAGACTGGAGGTGGCAACGCCAATCAGCAACGACTGTTTGCCCGCCAGTTGTTGTGCCACGCGGTTGGGAATGTAATTCAGCTCCGCCATCGCCGCTTCCACTTTTTCCCGCGTTTTCGCAGAAACGTGGCTGGCCTGGTTCACCACGCGGGAAACGGTCTGATAAGAGACACCGGCATACTCTGCGACATCGTATAACGTTACTGGTTTCACATTCACCACCCTGAATTGACTCTCTTCCGGGCGCTATCATGCCATACCGCGAAAGGTTTTGCGCCATTCGATGGTGTCCGGGATCTCGACGCTCTCCCTTATGCGACTCCTGCATTAGGAAGCAGCCCAGTAGTAGGTTGAGGCCGTTGAGCACCGCCGCCGCAAGGAATGGTGCATGCAAGGAGATGGCGCCCAACAGTCCCCCGGCCACGGGGCCTGCCACCATACCCACGCCGAAACAAGCGCTCATGAGCCCGAAGTGGCGAGCCCGATCTTCCCCATCGGTGATGTCGGCGATATAGGCGCCAGCAACCGCACCTGTGGCGCCGGTGATGCCGGCCACGATGCGTCCGGCGTAGCCTAGGATCGAGATCGATCTCGATCCCGCGAAATTAATACGACTCACTATAGGGGAATTGTGAGCGGATAACAATTCCCCTCTAGAAATAATTTTGTTTAACTTTAAGAAGGAGATATACATATGGCAGATCTCAATTGGATATCGGCCGGCCACGCGATCGCTGACGTCGGTACCCTCGAGTCTGGTAAAGAAACCGCTGCTGCGAAATTTGAACGCCAGCACATGGACTCGTCTACTAGTCGCAGCTTAATTAACCTAAACTGCTGCCACCGCTGAGCAATAACTAGCATAACCCCTTGGGGCCTCTAAACGGGTCTTGAGGGGTTTTTTGCTAGCGAAAGGAGGAGTCGACACTGCTTCCGGTAGTCAATAAACCGGTAAACCAGCAATAGACATAAGCGGCTATTTAACGACCCTGCCCTGAACCGACGACCGGGTCATCGTGGCCGGATCTTGCGGCCCCTCGGCTTGAACGAATTGTTAGACATTATTTGCCGACTACCTTGGTGATCTCGCCTTTCACGTAGTGGACAAATTCTTCCAACTGATCTGCGCGCGAGGCCAAGCGATCTTCTTCTTGTCCAAGATAAGCCTGTCTAGCTTCAAGTATGACGGGCTGATACTGGGCCGGCAGGCGCTCCATTGCCCAGTCGGCAGCGACATCCTTCGGCGCGATTTTGCCGGTTACTGCGCTGTACCAAATGCGGGACAACGTAAGCACTACATTTCGCTCATCGCCAGCCCAGTCGGGCGGCGAGTTCCATAGCGTTAAGGTTTCATTTAGCGCCTCAAATAGATCCTGTTCAGGAACCGGATCAAAGAGTTCCTCCGCCGCTGGACCTACCAAGGCAACGCTATGTTCTCTTGCTTTTGTCAGCAAGATAGCCAGATCAATGTCGATCGTGGCTGGCTCGAAGATACCTGCAAGAATGTCATTGCGCTGCCATTCTCCAAATTGCAGTTCGCGCTTAGCTGGATAACGCCACGGAATGATGTCGTCGTGCACAACAATGGTGACTTCTACAGCGCGGAGAATCTCGCTCTCTCCAGGGGAAGCCGAAGTTTCCAAAAGGTCGTTGATCAAAGCTCGCCGCGTTGTTTCATCAAGCCTTACGGTCACCGTAACCAGCAAATCAATATCACTGTGTGGCTTCAGGCCGCCATCCACTGCGGAGCCGTACAAATGTACGGCCAGCAACGTCGGTTCGAGATGGCGCTCGATGACGCCAACTACCTCTGATAGTTGAGTCGATACTTCGGCGATCACCGCTTCCCTCATACTCTTCCTTTTTCAATATTATTGAAGCATTTATCAGGGTTATTGTCTCATGAGCGGATACATATTTGAATGTATTTAGAAAAATAAACAAATAGCCAGCTCACTCGGTCGCTACGCTCCGGGCGTGAGACTGCGGCGGGCGCTGCGGACACATACAAAGTTACCCACAGATTCCGTGGATAAGCAGGGGACTAACATGTGAGGCAAAACAGCAGGGCCGCGCCGGTGGCGTTTTTCCATAGGCTCCGCCCTCCTGCCAGAGTTCACATAAACAGACGCTTTTCCGGTGCATCTGTGGGAGCCGTGAGGCTCAACCATGAATCTGACAGTACGGGCGAAACCCGACAGGACTTAAAGATCCCCACCGTTTCCGGCGGGTCGCTCCCTCTTGCGCTCTCCTGTTCCGACCCTGCCGTTTACCGGATACCTGTTCCGCCTTTCTCCCTTACGGGAAGTGTGGCGCTTTCTCATAGCTCACACACTGGTATCTCGGCTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTAAGCAAGAACTCCCCGTTCAGCCCGACTGCTGCGCCTTATCCGGTAACTGTTCACTTGAGTCCAACCCGGAAAAGCACGGTAAAACGCCACTGGCAGCAGCCATTGGTAACTGGGAGTTCGCAGAGGATTTGTTTAGCTAAACACGCGGTTGCTCTTGAAGTGTGCGCCAAAGTCCGGCTACACTGGAAGGACAGATTTGGTTGCTGTGCTCTGCGAAAGCCAGTTACCACGGTTAAGCAGTTCCCCAACTGACTTAACCTTCGATCAAACCACCTCCCCAGGTGGTTTTTTCGTTTACAGGGCAAAAGATTACGCGCAGAAAAAAAGGATCTCAAGAAGATCCTTTGATCTTTTCTACTGAACCGCTCTAGATTTCAGTGCAATTTATCTCTTCAAATGTAGCACCTGAAGTCAGCCCCATACGATATAAGTTGTAATTCTCATGTTAGTCATGCCCCGCGCCCACCGGAAGGAGCTGACTGGGTTGAAGGCTCTCAAGGGCATCGGTCGAGATCCCGGTGCCTAATGAGTGAGCTAACTTACATTAATTGCGTTGCGCTCACTGCCCGCTTTCCAGTCGGGAAACCTGTCGTGCCAGCTGCATTAATGAATCGGCCAACGCGCGGGGAGAGGCGGTTTGCGTATTGGGCGCCAGGGTGGTTTTTCTTTTCACCAGTGAGACGGGCAACAGCTGATTGCCCTTCACCGCCTGGCCCTGAGAGAGTTGCAGCAAGCGGTCCACGCTGGTTTGCCCCAGCAGGCGAAAATCCTGTTTGATGGTGGTTAACGGCGGGATATAACATGAGCTGTCTTCGGTATCGTCGTATCCCACTACCGAGATGTCCGCACCAACGCGCAGCCCGGACTCGGTAATGGCGCGCATTGCGCCCAGCGCCATCTGATCGTTGGCAACCAGCATCGCAGTGGGAACGATGCCCTCATTCAGCATTTGCATGGTTTGTTGAAAACCGGACATGGCACTCCAGTCGCCTTCCCGTTCCGCTATCGGCTGAATTTGATTGCGAGTGAGATATTTATGCCAGCCAGCCAGACGCAGACGCGCCGAGACAGAACTTAATGGGCCC
서열번호: 36
ATCCGGATATAGTTCCTCCTTTCAGCAAAAAACCCCTCAAGACCCGTTTAGAGGCCCCAAGGGGTTATGCTAGTTATTGCTCAGCGGTGGCAGCAGCCAACTCAGCTTCCTTTCGGGCTTTGTTAGCAGCCGGATCTCAGTGGTGGTGGTGGTGGTGCTCGAGTGCGGCCGCAAGCTTGTCGACGGAGCTCGAATTCGGATCCGCGACCCATTTGCTGTCCACCAGTCATGCTAGCCATATGGCTGCCGCGCGGCACCAGGCCGCTGCTGTGATGATGATGATGATGGCTGCTGCCCATGGTATATCTCCTTCTTAAAGTTAAACAAAATTATTTCTAGAGGGGAATTGTTATCCGCTCACAATTCCCCTATAGTGAGTCGTATTAATTTCGCGGGATCGAGATCTCGATCCTCTACGCCGGACGCATCGTGGCCGGCATCACCGGCGCCACAGGTGCGGTTGCTGGCGCCTATATCGCCGACATCACCGATGGGGAAGATCGGGCTCGCCACTTCGGGCTCATGAGCGCTTGTTTCGGCGTGGGTATGGTGGCAGGCCCCGTGGCCGGGGGACTGTTGGGCGCCATCTCCTTGCATGCACCATTCCTTGCGGCGGCGGTGCTCAACGGCCTCAACCTACTACTGGGCTGCTTCCTAATGCAGGAGTCGCATAAGGGAGAGCGTCGAGATCCCGGACACCATCGAATGGCGCAAAACCTTTCGCGGTATGGCATGATAGCGCCCGGAAGAGAGTCAATTCAGGGTGGTGAATGTGAAACCAGTAACGTTATACGATGTCGCAGAGTATGCCGGTGTCTCTTATCAGACCGTTTCCCGCGTGGTGAACCAGGCCAGCCACGTTTCTGCGAAAACGCGGGAAAAAGTGGAAGCGGCGATGGCGGAGCTGAATTACATTCCCAACCGCGTGGCACAACAACTGGCGGGCAAACAGTCGTTGCTGATTGGCGTTGCCACCTCCAGTCTGGCCCTGCACGCGCCGTCGCAAATTGTCGCGGCGATTAAATCTCGCGCCGATCAACTGGGTGCCAGCGTGGTGGTGTCGATGGTAGAACGAAGCGGCGTCGAAGCCTGTAAAGCGGCGGTGCACAATCTTCTCGCGCAACGCGTCAGTGGGCTGATCATTAACTATCCGCTGGATGACCAGGATGCCATTGCTGTGGAAGCTGCCTGCACTAATGTTCCGGCGTTATTTCTTGATGTCTCTGACCAGACACCCATCAACAGTATTATTTTCTCCCATGAAGACGGTACGCGACTGGGCGTGGAGCATCTGGTCGCATTGGGTCACCAGCAAATCGCGCTGTTAGCGGGCCCATTAAGTTCTGTCTCGGCGCGTCTGCGTCTGGCTGGCTGGCATAAATATCTCACTCGCAATCAAATTCAGCCGATAGCGGAACGGGAAGGCGACTGGAGTGCCATGTCCGGTTTTCAACAAACCATGCAAATGCTGAATGAGGGCATCGTTCCCACTGCGATGCTGGTTGCCAACGATCAGATGGCGCTGGGCGCAATGCGCGCCATTACCGAGTCCGGGCTGCGCGTTGGTGCGGATATCTCGGTAGTGGGATACGACGATACCGAAGACAGCTCATGTTATATCCCGCCGTTAACCACCATCAAACAGGATTTTCGCCTGCTGGGGCAAACCAGCGTGGACCGCTTGCTGCAACTCTCTCAGGGCCAGGCGGTGAAGGGCAATCAGCTGTTGCCCGTCTCACTGGTGAAAAGAAAAACCACCCTGGCGCCCAATACGCAAACCGCCTCTCCCCGCGCGTTGGCCGATTCATTAATGCAGCTGGCACGACAGGTTTCCCGACTGGAAAGCGGGCAGTGAGCGCAACGCAATTAATGTAAGTTAGCTCACTCATTAGGCACCGGGATCTCGACCGATGCCCTTGAGAGCCTTCAACCCAGTCAGCTCCTTCCGGTGGGCGCGGGGCATGACTATCGTCGCCGCACTTATGACTGTCTTCTTTATCATGCAACTCGTAGGACAGGTGCCGGCAGCGCTCTGGGTCATTTTCGGCGAGGACCGCTTTCGCTGGAGCGCGACGATGATCGGCCTGTCGCTTGCGGTATTCGGAATCTTGCACGCCCTCGCTCAAGCCTTCGTCACTGGTCCCGCCACCAAACGTTTCGGCGAGAAGCAGGCCATTATCGCCGGCATGGCGGCCCCACGGGTGCGCATGATCGTGCTCCTGTCGTTGAGGACCCGGCTAGGCTGGCGGGGTTGCCTTACTGGTTAGCAGAATGAATCACCGATACGCGAGCGAACGTGAAGCGACTGCTGCTGCAAAACGTCTGCGACCTGAGCAACAACATGAATGGTCTTCGGTTTCCGTGTTTCGTAAAGTCTGGAAACGCGGAAGTCAGCGCCCTGCACCATTATGTTCCGGATCTGCATCGCAGGATGCTGCTGGCTACCCTGTGGAACACCTACATCTGTATTAACGAAGCGCTGGCATTGACCCTGAGTGATTTTTCTCTGGTCCCGCCGCATCCATACCGCCAGTTGTTTACCCTCACAACGTTCCAGTAACCGGGCATGTTCATCATCAGTAACCCGTATCGTGAGCATCCTCTCTCGTTTCATCGGTATCATTACCCCCATGAACAGAAATCCCCCTTACACGGAGGCATCAGTGACCAAACAGGAAAAAACCGCCCTTAACATGGCCCGCTTTATCAGAAGCCAGACATTAACGCTTCTGGAGAAACTCAACGAGCTGGACGCGGATGAACAGGCAGACATCTGTGAATCGCTTCACGACCACGCTGATGAGCTTTACCGCAGCTGCCTCGCGCGTTTCGGTGATGACGGTGAAAACCTCTGACACATGCAGCTCCCGGAGACGGTCACAGCTTGTCTGTAAGCGGATGCCGGGAGCAGACAAGCCCGTCAGGGCGCGTCAGCGGGTGTTGGCGGGTGTCGGGGCGCAGCCATGACCCAGTCACGTAGCGATAGCGGAGTGTATACTGGCTTAACTATGCGGCATCAGAGCAGATTGTACTGAGAGTGCACCATATATGCGGTGTGAAATACCGCACAGATGCGTAAGGAGAAAATACCGCATCAGGCGCTCTTCCGCTTCCTCGCTCACTGACTCGCTGCGCTCGGTCGTTCGGCTGCGGCGAGCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATCTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAACAATAAAACTGTCTGCTTACATAAACAGTAATACAAGGGGTGTTATGAGCCATATTCAACGGGAAACGTCTTGCTCTAGGCCGCGATTAAATTCCAACATGGATGCTGATTTATATGGGTATAAATGGGCTCGCGATAATGTCGGGCAATCAGGTGCGACAATCTATCGATTGTATGGGAAGCCCGATGCGCCAGAGTTGTTTCTGAAACATGGCAAAGGTAGCGTTGCCAATGATGTTACAGATGAGATGGTCAGACTAAACTGGCTGACGGAATTTATGCCTCTTCCGACCATCAAGCATTTTATCCGTACTCCTGATGATGCATGGTTACTCACCACTGCGATCCCCGGGAAAACAGCATTCCAGGTATTAGAAGAATATCCTGATTCAGGTGAAAATATTGTTGATGCGCTGGCAGTGTTCCTGCGCCGGTTGCATTCGATTCCTGTTTGTAATTGTCCTTTTAACAGCGATCGCGTATTTCGTCTCGCTCAGGCGCAATCACGAATGAATAACGGTTTGGTTGATGCGAGTGATTTTGATGACGAGCGTAATGGCTGGCCTGTTGAACAAGTCTGGAAAGAAATGCATAAACTTTTGCCATTCTCACCGGATTCAGTCGTCACTCATGGTGATTTCTCACTTGATAACCTTATTTTTGACGAGGGGAAATTAATAGGTTGTATTGATGTTGGACGAGTCGGAATCGCAGACCGATACCAGGATCTTGCCATCCTATGGAACTGCCTCGGTGAGTTTTCTCCTTCATTACAGAAACGGCTTTTTCAAAAATATGGTATTGATAATCCTGATATGAATAAATTGCAGTTTCATTTGATGCTCGATGAGTTTTTCTAAGAATTAATTCATGAGCGGATACATATTTGAATGTATTTAGAAAAATAAACAAATAGGGGTTCCGCGCACATTTCCCCGAAAAGTGCCACCTGAAATTGTAAACGTTAATATTTTGTTAAAATTCGCGTTAAATTTTTGTTAAATCAGCTCATTTTTTAACCAATAGGCCGAAATCGGCAAAATCCCTTATAAATCAAAAGAATAGACCGAGATAGGGTTGAGTGTTGTTCCAGTTTGGAACAAGAGTCCACTATTAAAGAACGTGGACTCCAACGTCAAAGGGCGAAAAACCGTCTATCAGGGCGATGGCCCACTACGTGAACCATCACCCTAATCAAGTTTTTTGGGGTCGAGGTGCCGTAAAGCACTAAATCGGAACCCTAAAGGGAGCCCCCGATTTAGAGCTTGACGGGGAAAGCCGGCGAACGTGGCGAGAAAGGAAGGGAAGAAAGCGAAAGGAGCGGGCGCTAGGGCGCTGGCAAGTGTAGCGGTCACGCTGCGCGTAACCACCACACCCGCCGCGCTTAATGCGCCGCTACAGGGCGCGTCCCATTCGCCA
서열번호: 37
ATCCGGATATAGTTCCTCCTTTCAGCAAAAAACCCCTCAAGACCCGTTTAGAGGCCCCAAGGGGTTATGCTAGTTATTGCTCAGCGGTGGCAGCAGCCAACTCAGCTTCCTTTCGGGCTTTGTTAGCAGCCGGATCTCAGTGGTGGTGGTGGTGGTGCTCGAGTGCGGCCGCAAGCTTGTCGACGGAGCTCGAATTCGGATCCTAGAGGGAAACCGTTGTGGTCTCCCTATAGTGAGTCGTATTAATTTCGCGGGATCGAGATCTCGGGCAGCGTTGGGTCCTGGCCACGGGTGCGCATGATCGTGCTCCTGTCGTTGAGGACCCGGCTAGGCTGGCGGGGTTGCCTTACTGGTTAGCAGAATGAATCACCGATACGCGAGCGAACGTGAAGCGACTGCTGCTGCAAAACGTCTGCGACCTGAGCAACAACATGAATGGTCTTCGGTTTCCGTGTTTCGTAAAGTCTGGAAACGCGGAAGTCAGCGCCCTGCACCATTATGTTCCGGATCTGCATCGCAGGATGCTGCTGGCTACCCTGTGGAACACCTACATCTGTATTAACGAAGCGCTGGCATTGACCCTGAGTGATTTTTCTCTGGTCCCGCCGCATCCATACCGCCAGTTGTTTACCCTCACAACGTTCCAGTAACCGGGCATGTTCATCATCAGTAACCCGTATCGTGAGCATCCTCTCTCGTTTCATCGGTATCATTACCCCCATGAACAGAAATCCCCCTTACACGGAGGCATCAGTGACCAAACAGGAAAAAACCGCCCTTAACATGGCCCGCTTTATCAGAAGCCAGACATTAACGCTTCTGGAGAAACTCAACGAGCTGGACGCGGATGAACAGGCAGACATCTGTGAATCGCTTCACGACCACGCTGATGAGCTTTACCGCAGCTGCCTCGCGCGTTTCGGTGATGACGGTGAAAACCTCTGACACATGCAGCTCCCGGAGACGGTCACAGCTTGTCTGTAAGCGGATGCCGGGAGCAGACAAGCCCGTCAGGGCGCGTCAGCGGGTGTTGGCGGGTGTCGGGGCGCAGCCATGACCCAGTCACGTAGCGATAGCGGAGTGTATACTGGCTTAACTATGCGGCATCAGAGCAGATTGTACTGAGAGTGCACCATATATGCGGTGTGAAATACCGCACAGATGCGTAAGGAGAAAATACCGCATCAGGCGCTCTTCCGCTTCCTCGCTCACTGACTCGCTGCGCTCGGTCGTTCGGCTGCGGCGAGCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATCTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTAAATTAAAAATGAAGTTTTAAATCAATCTAAAGTATATATGAGTAAACTTGGTCTGACAGTTACCAATGCTTAATCAGTGAGGCACCTATCTCAGCGATCTGTCTATTTCGTTCATCCATAGTTGCCTGACTCCCCGTCGTGTAGATAACTACGATACGGGAGGGCTTACCATCTGGCCCCAGTGCTGCAATGATACCGCGAGACCCACGCTCACCGGCTCCAGATTTATCAGCAATAAACCAGCCAGCCGGAAGGGCCGAGCGCAGAAGTGGTCCTGCAACTTTATCCGCCTCCATCCAGTCTATTAATTGTTGCCGGGAAGCTAGAGTAAGTAGTTCGCCAGTTAATAGTTTGCGCAACGTTGTTGCCATTGCTGCAGGCATCGTGGTGTCACGCTCGTCGTTTGGTATGGCTTCATTCAGCTCCGGTTCCCAACGATCAAGGCGAGTTACATGATCCCCCATGTTGTGCAAAAAAGCGGTTAGCTCCTTCGGTCCTCCGATCGTTGTCAGAAGTAAGTTGGCCGCAGTGTTATCACTCATGGTTATGGCAGCACTGCATAATTCTCTTACTGTCATGCCATCCGTAAGATGCTTTTCTGTGACTGGTGAGTACTCAACCAAGTCATTCTGAGAATAGTGTATGCGGCGACCGAGTTGCTCTTGCCCGGCGTCAATACGGGATAATACCGCGCCACATAGCAGAACTTTAAAAGTGCTCATCATTGGAAAACGTTCTTCGGGGCGAAAACTCTCAAGGATCTTACCGCTGTTGAGATCCAGTTCGATGTAACCCACTCGTGCACCCAACTGATCTTCAGCATCTTTTACTTTCACCAGCGTTTCTGGGTGAGCAAAAACAGGAAGGCAAAATGCCGCAAAAAAGGGAATAAGGGCGACACGGAAATGTTGAATACTCATACTCTTCCTTTTTCAATATTATTGAAGCATTTATCAGGGTTATTGTCTCATGAGCGGATACATATTTGAATGTATTTAGAAAAATAAACAAATAGGGGTTCCGCGCACATTTCCCCGAAAAGTGCCACCTGAAATTGTAAACGTTAATATTTTGTTAAAATTCGCGTTAAATTTTTGTTAAATCAGCTCATTTTTTAACCAATAGGCCGAAATCGGCAAAATCCCTTATAAATCAAAAGAATAGACCGAGATAGGGTTGAGTGTTGTTCCAGTTTGGAACAAGAGTCCACTATTAAAGAACGTGGACTCCAACGTCAAAGGGCGAAAAACCGTCTATCAGGGCGATGGCCCACTACGTGAACCATCACCCTAATCAAGTTTTTTGGGGTCGAGGTGCCGTAAAGCACTAAATCGGAACCCTAAAGGGAGCCCCCGATTTAGAGCTTGACGGGGAAAGCCGGCGAACGTGGCGAGAAAGGAAGGGAAGAAAGCGAAAGGAGCGGGCGCTAGGGCGCTGGCAAGTGTAGCGGTCACGCTGCGCGTAACCACCACACCCGCCGCGCTTAATGCGCCGCTACAGGGCGCGTCCCATTCGCCA
서열번호: 38
TACCCATACGACGTTCCAGACTACGCC
서열번호: 39
YPYDVPDYA
서열번호: 40
GAACAAAAGTTAATTTCTGAAGAAGATTTGGAA
서열번호: 41
EQKLISEEDL
서열번호: 42
GACTACAAGGATGACGATGACAAA
서열번호: 43
DYKDDDDK
서열번호: 44
GGTAAGCCAATTCCAAATCCTTTGTTGGGTTTGGACTCCACC
서열번호: 45
GKPIPNPLLGLDST
서열번호: 46
CATCATCATCATCATCAT
서열번호: 47
HHHHHH
서열번호: 48
ATGGCGTTCGATCTCAAGACTGAAGACGGCCTCATCACATATCTCACTAAACATCTTTCTTTGGACGTCGACACGAGCGGAGTGAAGCGCCTTAGCGGAGGCTTTGTCAATGTAACCTGGCGCATTAAGCTCAATGCTCCTTATCAAGGTCATACGAGCATCATCCTGAAGCATGCTCAGCCGCACATGTCTACGGATGAGGATTTTAAGATAGGTGTAGAACGTTCGGTTTACGAATACCAGGCTATCAAGCTCATGATGGCCAATCGGGAGGTTCTGGGAGGCGTGGATGGCATAGTTTCTGTGCCAGAAGGCCTGAACTACGACTTAGAGAATAATGCATTGATCATGCAAGATGTCGGGAAGATGAAGACCCTTTTAGATTATGTCACCGCCAAACCGCCACTTGCGACGGATATAGCCCGCCTTGTTGGGACAGAAATTGGGGGGTTCGTTGCCAGACTCCATAACATAGGCCGCGAGAGGCGAGACGATCCTGAGTTCAAATTCTTCTCTGGAAATATTGTCGGAAGGACGACTTCAGACCAGCTGTATCAAACCATCATACCCAACGCAGCGAAATATGGCGTCGATGACCCCTTGCTGCCTACTGTGGTTAAGGACCTTGTGGACGATGTCATGCACAGCGAAGAGACCCTTGTCATGGCGGACCTGTGGAGTGGAAATATTCTTCTCCAGTTGGAGGAGGGAAACCCATCGAAGCTGCAGAAGATATATATCCTGGATTGGGAACTTTGCAAGTACGGCCCAGCGTCGTTGGACCTGGGCTATTTCTTGGGTGACTGCTATTTGATATCCCGCTTTCAAGACGAGCAGGTCGGTACGACGATGCGGCAAGCCTACTTGCAAAGCTATGCGCGTACGAGCAAGCATTCGATCAACTACGCCAAAGTCACTGCAGGTATTGCTGCTCATATTGTGATGTGGACCGACTTTATGCAGTGGGGGAGCGAGGAAGAAAGGATAAATTTTGTGAAAAAGGGGGTAGCTGCCTTTCACGACGCCAGGGGCAACAACGACAATGGGGAAATTACGTCTACCTTACTGAAGGAATCATCCACTGCGTAA
서열번호: 49
MAFDLKTEDGLITYLTKHLSLDVDTSGVKRLSGGFVNVTWRIKLNAPYQGHTSIILKHAQPHMSTDEDFKIGVERSVYEYQAIKLMMANREVLGGVDGIVSVPEGLNYDLENNALIMQDVGKMKTLLDYVTAKPPLATDIARLVGTEIGGFVARLHNIGRERRDDPEFKFFSGNIVGRTTSDQLYQTIIPNAAKYGVDDPLLPTVVKDLVDDVMHSEETLVMADLWSGNILLQLEEGNPSKLQKIYILDWELCKYGPASLDLGYFLGDCYLISRFQDEQVGTTMRQAYLQSYARTSKHSINYAKVTAGIAAHIVMWTDFMQWGSEEERINFVKKGVAAFHDARGNNDNGEITSTLLKESSTA
서열번호: 50
CGAGATCTTTGTGTTCGGTTACCCGGCTCAGATCCTAACTTCTTCTTTTGGTATGTTTATTCGTATAAGTTACTGTTGTCCACAGGCAATACTCTGCAGAAAATTAAAACGGCATTAATGCTAGGACAACCAGAATTGTTACTACTGTATGTGCGATAGTTGATAACTGCAACATTATGCCCGGTATATTCTCAAAAAACCCTATTACTGCATACGAAGAAATCGCAAGAGAAATCTTTCGGTTTGGAAAAGCTCACTGTGAGGTTCCTTGGAGCCAATAGTAATACAGCACAATCCAAGGAAAAATCTGGCCTATATGCAAGGAAGGAGAGATAGTCAAAAGCATTCTTTCCCCTAGAAGTTGGTGCATATATGGCATCGTTAAAACATATTACCCCCAAAATTTCTTCTCTAAACGATGTGCTTGGCCTTTGTTTTGGTTTTTGATGTCGGTCGTTTGAGGCCCCTTGCGGAAAATCGAGATCGCCGAATGGCACGCGAGGGAAGGGAAATAAGGTTTAAAGGCACTGAAACAATAGGCAAGAAGTAGGCGAGAGCCGACATACGAGACTAAATTAAGTCCTCAGCGAGCTCGCATGGAATGCGTGCGATGAGCGACCTCATGCTATACCTGAGAAAGCAACCTGACCTACAGGAAAGAGTTACTCAAGAATAAGAATTTTCGTTTTAAAACCTAAGAGTCACTTTAAAATTTGTATACACTTATTTTTTTTATAACTTATTTAATAATAAAAATCATAAATCATAAGAAATTCGCTTATTTAGAAGTGTCAACAACGTATCTACCAACGGAATGCGTGCGATTCATTTGTCATCGTCATCCTTGTAGTCTTCAGCAACACATGGGTATGAAATAGAAACTTCTTCAGCCAATGCTTTAATCTTCATCATGATTTGCAACATTTCTTCAGTTGTAGTTCTTGGATTAATTGAACACAATCTAATAACAACCTTTTCCTTCAATTCTGTAGTAGATAACATAGCGAAACCTCTATGTGTGATTTCCTTAACCAATTTCTTATTAATTTCATTAATAGTATCTGTTGATGCCAATTCAGATGGAATGTATCTAAAAGTAACGATACCCAATTGAGCTGGTGTAACAACTTCCCAATCTTTTGCTTTACCCAAAAATGCTTCAACTTGTTCTGCTAACATGATACCATGATCGATTGCTTGTCTAAAAGCAGCAACACCGAAAACTTTAAAAGACAACCAAACCTTCAAAGCTCTGAATCTTCTTGACAATTCGATACCACATTCACCGAAATTAATTTCACCTTCAACGTTAGTTTCTGAATCCTTGATGTATTCTGGCATCATTCTAAAAGTCTTTGACAAATATTGAGAGTTTCTGATCAAAACACAACCAACATCGTATGGTTGGAACAACCACTTATGTGGATCTAAAGTCAAAGAATCTGCTCTATGAATACCTTGCAACATAGCTGAACCCTTTTCAGACAAGATAGCTGGAGCACCATAAGAACCATCAGCATGCAACCAAACATCTTCATCGTTACACAAATCTGCTAATTCGTTCAAAGAATCAACAGCACCACAATTTGTAGTACCAGCATTTGCAATAACACAGAATGGCTTTTTACCCTTAGTTCTATCTTCTTTAATTTGTTTCTTCAAAGCTGAAACAGAGATTCTCAAATGTTCATCTGTTTCGATTCTACAGATTTGATGATGTTTAAAACCTAAAACCTTCAATGCTCTATCAACTGAGAAATGTGTTTGATCAGAGAAGTAAACAACAGCATTTTCGATATCGTTGTTCAACTTAGCCTGTCTTGCAACAGTCAAAGCTGTCAAATTTGCCATTGAACCACCAGAAACAAATAAACCTTCAGCTGAATCTGGAAAACCCAACATAGATTTCAACCAATTAATTGTAGTCAATTCGATTTGTTCAGCACCTGCACCAGCAATCCATGCAGTTGGAAAAACATTAAAACCAGAAGCCAAGAAATCTGCAACAACACCAACGTAATTATTTGGACCTGGAACAAAAGCCAAGAAATGTGGATGATCAACATGTGTAATTTGATTAAAAACGTTTCTGTTCAAGAAATGCAACAATTCCTTTGGATCTGAACCATTTTCTGGGATAGATTCAGTCAACTTATTTCTCAAGATATCAGAATCGATTGTTTCTGAAACTGGCTTAGACTTCAAATGGTTCATGTGATCGATGATCAAATCAACTGCTTGGTAACCCAATTGTCTCATTTCTTCAGCTGACAATTGCAAATTTTCAGACATTGTTTTATATTTGTTGTAAAAAGTAGATAATTACTTCCTTGATGATCTGTAAAAAAGAGAAAAAGAAAGCATCTAAGAACTTGAAAAACTACGAATTAGAAAAGACCAAATATGTATTTCTTGCATTGACCAATTTATGCAAGTTTATATATATGTAAATGTAAGTTTCACGAGGTTCTACTAAACTAAACCACCCCCTTGGTTAGAAGAAAAGAGTGTGTGAGAACAGGCTGTTGTTGTCACACGATTCGGACAATTCTGTTTGAAAGAGAGAGAGTAACAGTACGATCGAACGAACTTTGCTCTGGAGATCACAGTGGGCATCATAGCATGTGGTACTAAACCCTTTCCCGCCATTCCAGAACCTTCGATTGCTTGTTACAAAACCTGTGAGCCGTCGCTAGGACCTTGTTGTGTGACGAAATTGGAAGCTGCAATCAATAGGAAGACAGGAAGTCGAGCGTGTCTGGGTTTTTTCAGTTTTGTTCTTTTTGCAAACAACAGTTTATTCCTGGCATCCACTAAATATAATGGAGCCCGCTTTTTAAGCTGGCATCCAGAAAAAAAAAGAATCCCAGCACCAAAATATTGTTTTCTTCACCAACCATCAGTTCATAGGTCCATTCTCTTAGCGCAACTACAGAGAACAGGGGCACAAACAGGCAAAAAACGGGCACAACCTCAATGGAGTGATGCAACCTGCCTGGAGTAAATGATGACACAAGGCAATTGACCCACGCATGTATCTATCTCATTTTCTTACACCTTCTATTACCTTCTGCTCTCTCTGATTTGGAAAAAGCTGAAAAAAAAGGTTGAAACCAGTTCCCTGAAATTATTCCCCTACTTGACTAATAAGTATATAAAGACGGTAGGTATTGATTGTAATTCTGTAAATCTATTTCTTAAACTTCTTAAATTCTACTTTTATAGTTAGTCTTTTTTTTAGTTTTAAAACACCAAGAACTTAGTTTCGAATAAACACACATAAACAAACAAAATGGCTTCTAGTTCTTCCGATGTCTTCGTTTTGGGTCTAGGTGTTGTTTTGGCTGCCTTGTATATCTTCAGAGACCAATTATTCGCTGCTTCTAAGCCAAAGGTGGCTCCAGTTTCCACTACGAAGCCTGCCAACGGTTCCGCTAACCCAAGAGACTTCATCGCCAAGATGAAACAAGGTAAGAAGAGAATCGTAATCTTCTACGGTTCTCAAACTGGTACCGCTGAAGAATATGCTATTCGTTTGGCTAAGGAAGCTAAGCAAAAGTTCGGTCTAGCCTCCTTGGTTTGTGATCCAGAAGAATACGATTTTGAAAAGTTGGACCAATTGCCAGAAGATTCTATTGCTTTCTTCGTCGTTGCTACCTATGGTGAAGGTGAACCTACAGACAACGCTGTCCAATTGTTGCAAAACTTGCAAGATGAAAGCTTCGAATTCTCCTCTGGTGAGAGAAAGTTGTCAGGTTTGAAGTACGTTGTTTTTGGTCTGGGTAACAAGACCTACGAACATTACAACCTCATTGGGAGAACTGTTGACGCTCAATTGGCCAAGATGGGTGCTATCAGAATCGGTGAAAGAGGTGAAGGTGATGATGACAAGTCCATGGAAGAAGACTACTTGGAATGGAAGGATGGTATGTGGGAAGCGTTTGCCACTGCTATGGGTGTTGAAGAAGGTCAAGGTGGTGACTCCGCTGATTTCGTCGTTTCCGAATTGGAATCTCACCCACCAGAAAAGGTTTACCAAGGTGAATTTTCTGCTAGAGCTTTAACCAAAACCAAGGGTATTCACGACGCTAAGAATCCTTTTGCTGCTCCAATTGCGGTTGCTAGAGAATTGTTCCAATCTGTTGTCGATAGAAACTGTGTCCACGTCGAATTCAACATTGAAGGCTCTGGTATCACCTATCAACACGGTGACCACGTTGGTTTGTGGCCATTGAATCCAGATGTTGAAGTCGAACGGTTGTTGTGTGTTTTAGGTTTAGCTGAAAAGAGAGATGCTGTCATCTCCATTGAATCCTTAGACCCGGCTTTGGCTAAGGTTCCATTCCCAGTCCCAACTACTTACGGTGCTGTGTTGAGACACTACATTGACATCTCTGCTGTCGCCGGTAGACAAATCTTGGGTACTTTGTCCAAATTCGCTCCAACCCCAGAAGCTGAAGCTTTCTTGAGAAACTTGAACACTAACAAGGAAGAATACCACAACGTCGTCGCTAACGGTTGTTTGAAATTGGGTGAAATTTTGCAAATCGCTACCGGTAACGACATTACTGTCCCACCAACTACTGCCAACACCACCAAATGGCCAATTCCATTCGACATCATTGTTTCTGCCATCCCAAGATTGCAACCAAGATACTACTCTATCTCTTCTTCCCCAAAAATTCATCCAAACACCATCCACGCTACCGTTGTTGTGCTCAAATACGAAAACGTTCCAACCGAACCAATCCCAAGAAAGTGGGTTTACGGTGTCGGTAGTAACTTCTTGTTGAATTTAAAGTACGCTGTTAACAAGGAACCAGTTCCATACATCACTCAAAATGGCGAACAAAGAGTCGGTGTCCCGGAATACTTGATTGCTGGTCCACGTGGTTCTTACAAGACTGAATCTTTCTACAAGGCTCCAATCCATGTTAGACGTTCTACTTTCCGTTTGCCAACCAACCCAAAGTCTCCAGTCATCATGATTGGTCCAGGTACTGGTGTCGCCCCATTCAGAGGCTTCGTTCAAGAAAGAGTTGCCTTGGCCAGAAGATCCATCGAAAAGAACGGTCCTGACTCTTTGGCTGACTGGGGTCGTATTTCCTTGTTCTACGGTTGTAGAAGATCCGACGAAGACTTCTTGTACAAGGACGAATGGCCACAATACGAAGCTGAGTTGAAGGGTAAGTTCAAGTTGCACTGTGCTTTCTCCAGACAAAACTACAAGCCAGACGGTTCTAAGATTTACGTCCAAGATTTGATCTGGGAAGACAGAGAACACATTGCCGATGCCATCTTAAACGGTAAGGGTTACGTCTACATCTGCGGTGAAGCTAAGTCCATGTCTAAACAAGTTGAAGAAGTTCTAGCCAAGATCTTGGGCGAAGCCAAAGGTGGTTCCGGTCCAGTTGAAGGTGTTGCTGAAGTCAAGTTACTGAAGGAACGGTCCAGATTGATGTTGGATGTCTGGTCTGAACAAAAGTTAATTTCTGAAGAAGATTTGGAATGAATCGCGTGCATTCATCCGCTCTAACCGAAAAGGAAGGAGTTAGACAACCTGAAGTCTAGGTCCCTATTTATTTTTTTATAGTTATGTTAGTATTAAGAACGTTATTTATATTTCAAATTTTTCTTTTTTTTCTGTACAGACGCGTGTACGCATGTAACATTATACTGAAAACCTTGCTTGAGAAGGTTTTGGGACGCTCGAAGATCGCGTCCCAATTCGCCCTATAGTGAGTCGTATTACGCGCGCTCACTGGCCGTCGTTTTACAACGTCGTGACTGGGAAAACCCTGGCGTTACCCCTGCAGGACTAGTGCTGAGGCATTAATACCACTTTTCAATGAAACGGATATTGATATGCTAGTAAAAGGACGAGCTCAAGAGCGAAAATATAAGTAAAGAATTCGAGTGCACTTGTCTCCATGCAGCAAGATTTCATATGAGTCTTTTTTATCTTTTTACTTTTTACATTACACGATATGCACTTTATGAAAATTTAACGAGGTTGGAAGCCGGATAATCAACCAAAATCAGGCACGAAGGCACACTCGTATATGCATGTTGTTGAAACTCTGTTACGCTGAACTAACAATCACACATGTAGAGGTCACCGGGAAAAGTTGCGACCCCATGGAAGGTCGATCTCTTCGTTTGGCTTTGCTTGGCTGGCGGCATTGCGCTTCTTCGCTTATACCCGTCTCTTGACGCTCGAGCTCGTTCATTGAGATACCTTTATTCTTGCACATTTTCTGGCTTTTTTCGCTACTCGGGTACATGTAATCATGCACACAGAAGGTGCTGTAGGGTGAAAGTTCCTTTGTGCTGTCGTTTGTTTTTAATGCCAAACTTTCCGGTGATCAATAACCACCTC
서열번호: 51
CGGCATGCAAACATCTACACAATTAGCAAGGGCAATCCATATTTTGTCTTTTCGCGCCCTGGAAAGGCCTAAGTAATGTCGTAAACGCATTCTATCTGTACTTCAACTCTCCTCTGTGCATTGGTTTGTGCAAATCACATTTTACGATACTGCCAGATATATGCAAAAAGAGAAAACCAAGGGACCAGAACAAAGCAAAATTACGATATTCTTCGAATTCCTTCGTGCTTGACTAAGACAAAGGGATGGACGTAGCGATTTTTAGCGGGCCAAGAACTGGTTCCGAAAAAGCACAGGTACACCGAACCCTCAGCTAAGGAGGGACAGCACCGATGCGGAAGGACAAACTTTCTTTTTGCCTATCACAGTATCTTATCGAGCTAACTATTTTCGACACACATGAAAAAGCAGAAATATTAACGAAAAAGAAAAGAAAGACCATGTCATGTACGGGCAATCAGAATCTGTAACAAGCGCCATTTTTTTTTCTGTATCGGGCCCTCCTTACTGCTCTCCTTCCGTGTAACGCGTTATGAAATTAAGTCCTCAGCGAGCTCGCATGGAATGCGTGCGATGAGCGACCTCATGCTATACCTGAGAAAGCAACCTGACCTACAGGAAAGAGTTACTCAAGAATAAGAATTTTCGTTTTAAAACCTAAGAGTCACTTTAAAATTTGTATACACTTATTTTTTTTATAACTTATTTAATAATAAAAATCATAAATCATAAGAAATTCGCTTATTTAGAAGTGTCAACAACGTATCTACCAACGGAATGCGTGCGATTGTTTTATATTTGTTGTAAAAAGTAGATAATTACTTCCTTGATGATCTGTAAAAAAGAGAAAAAGAAAGCATCTAAGAACTTGAAAAACTACGAATTAGAAAAGACCAAATATGTATTTCTTGCATTGACCAATTTATGCAAGTTTATATATATGTAAATGTAAGTTTCACGAGGTTCTACTAAACTAAACCACCCCCTTGGTTAGAAGAAAAGAGTGTGTGAGAACAGGCTGTTGTTGTCACACGATTCGGACAATTCTGTTTGAAAGAGAGAGAGTAACAGTACGATCGAACGAACTTTGCTCTGGAGATCACAGTGGGCATCATAGCATGTGGTACTAAACCCTTTCCCGCCATTCCAGAACCTTCGATTGCTTGTTACAAAACCTGTGAGCCGTCGCTAGGACCTTGTTGTGTGACGAAATTGGAAGCTGCAATCAATAGGAAGACAGGAAGTCGAGCGTGTCTGGGTTTTTTCAGTTTTGTTCTTTTTGCAAACAACAGTTTATTCCTGGCATCCACTAAATATAATGGAGCCCGCTTTTTAAGCTGGCATCCAGAAAAAAAAAGAATCCCAGCACCAAAATATTGTTTTCTTCACCAACCATCAGTTCATAGGTCCATTCTCTTAGCGCAACTACAGAGAACAGGGGCACAAACAGGCAAAAAACGGGCACAACCTCAATGGAGTGATGCAACCTGCCTGGAGTAAATGATGACACAAGGCAATTGACCCACGCATGTATCTATCTCATTTTCTTACACCTTCTATTACCTTCTGCTCTCTCTGATTTGGAAAAAGCTGAAAAAAAAGGTTGAAACCAGTTCCCTGAAATTATTCCCCTACTTGACTAATAAGTATATAAAGACGGTAGGTATTGATTGTAATTCTGTAAATCTATTTCTTAAACTTCTTAAATTCTACTTTTATAGTTAGTCTTTTTTTTAGTTTTAAAACACCAAGAACTTAGTTTCGAATAAACACACATAAACAAACAAAATGGGAGGTCCGATGAGCGGTTTCCATTCGGGGGAGGCGCTGCTCGGTGACCTCGCCACCGGTCAGCTGACCAGGCTGTGCGAGGTGGCGGGGCTGACCGAGGCCGACACGGCGGCCTACACGGGGGTGCTGATCGAAAGTCTGGGGACGTCGGCCGGACGGCCGTTGTCCCTGCCACCCCCGTCGCGGACCTTTCTCTCCGACGACCACACCCCCGTGGAGTTCTCCCTGGCCTTCCTGCCGGGACGCGCACCGCACCTGCGGGTCCTGGTGGAACCGGGCTGCTCCAGCGGCGACGACCTGGCGGAAAACGGCCGGGCCGGTCTGCGGGCGGTCCACACCATGGCGGACCGCTGGGGATTCTCCACCGAGCAACTCGACCGGCTGGAGGACCTGTTCTTCCCCTCCTCCCCCGAGGGCCCGCTGGCCCTGTGGTGCGCCCTGGAGCTCCGCTCCGGTGGGGTGCCGGGGGTGAAGGTCTACCTCAACCCCGCGGCGAATGGCGCCGACCGGGCCGCCGAGACGGTACGCGAGGCGCTGGCCAGGCTGGGCCACCTGCAGGCGTTCGACGCGCTGCCCCGGGCGGACGGCTTCCCGTTCCTCGCCCTGGACCTCGGCGACTGGGACGCCCCGCGGGTGAAGATCTACCTCAAACACCTCGGCATGTCCGCCGCCGACGCGGGCTCCCTCCCCCGGATGTCGCCCGCACCGAGCCGGGAGCAGCTGGAGGAGTTCTTCCGCACCGCCGGTGACCTCCCGGCCCCGGGAGACCCGGGGCCCACCGAGGACACCGGCCGGCTCGCCGGGCGCCCCGCCCTCACCTGCCACTCCTTCACGGAGACGGCGACCGGGCGGCCCAGCGGCTACACCCTCCACGTGCCGGTCCGCGACTACGTCCGGCACGACGGCGAGGCACGGGACCGGGCGGTGGCCGTGCTGCGCGAACATGACATGGACAGTGCGGCACTGGACCGGGCGCTGGCCGCCGTGAGCCCCCGCCCGCTGAGTGACGGGGTGGGCCTGATCGCCTATCTGGCACTGGTCCACCAGCGCGGCCGGCCGACACGGGTGACCGTCTACGTCTCCTCCGAGGCGTACGAGGTGCGGCCGCCCCGCGAGACGGTCCCCACCCGCGACCGGGCGCGGGCACGGCTGCATCATCATCATCATCATTGAATCGCGTGCATTCATCCGCTCTAACCGAAAAGGAAGGAGTTAGACAACCTGAAGTCTAGGTCCCTATTTATTTTTTTATAGTTATGTTAGTATTAAGAACGTTATTTATATTTCAAATTTTTCTTTTTTTTCTGTACAGACGCGTGTACGCATGTAACATTATACTGAAAACCTTGCTTGAGAAGGTTTTGGGACGCTCGAAGATCGCGTCCCAATTCGCCCTATAGTGAGTCGTATTACGCGCGCTCACTGGCCGTCGTTTTACAACGTCGTGACTGGGAAAACCCTGGCGTTACCCCTGCAGGACTAGTGCTGAGGCATTAATACGACTCTCTCGAAATTTTTCTTAACGCGTCCTTGTACTGCGTCTAACGCTTTTGCCACTTGGATTTCTATTATAGGAAATAGTCTCACTTACTGGGCGACGAATTTTCGCGTTTTGATGAAGCACAGGAAGAATTTCTTTTTTTTTTGGCTTCTTCTGGTTCCGTTTTTTACGCGCACAAATCTAAAAAAAGAAATAATTATAACCTAGTCTCGAAAATTTTCATCGATCCATTCGTTCCTTTTTTTCGATTTTTTCAGATCAAAATTCTTGTTTCTTTCTTTGTCTTAGTTTATATTAAAAGATATTTTGATTTTACTCCTGAACTATTTATTCTTTCTAAGAAGGCCAGAACACTACAGCTGTTTTAACCGACTACGAAGTTCTCCATTCTCGAACACTAGCCTTCATTTACCAAACAGGAACTAGCGTATATCATTAGTCCTTATTCGAAAAGAGATTGGTAGATATTTATTGTAGTTTGTGAGAAGGAGAAAATACTGTCATTGGACTGATAGTTAGAGGACATTAACCTCTCTTACGTTCGCTCA
서열번호: 52
CGAGATCTTTGTGTTCGGTTACCCGGCTCAGATCCTAACTTCTTCTTTTGGTATGTTTATTCGTATAAGTTACTGTTGTCCACAGGCAATACTCTGCAGAAAATTAAAACGGCATTAATGCTAGGACAACCAGAATTGTTACTACTGTATGTGCGATAGTTGATAACTGCAACATTATGCCCGGTATATTCTCAAAAAACCCTATTACTGCATACGAAGAAATCGCAAGAGAAATCTTTCGGTTTGGAAAAGCTCACTGTGAGGTTCCTTGGAGCCAATAGTAATACAGCACAATCCAAGGAAAAATCTGGCCTATATGCAAGGAAGGAGAGATAGTCAAAAGCATTCTTTCCCCTAGAAGTTGGTGCATATATGGCATCGTTAAAACATATTACCCCCAAAATTTCTTCTCTAAACGATGTGCTTGGCCTTTGTTTTGGTTTTTGATGTCGGTCGTTTGAGGCCCCTTGCGGAAAATCGAGATCGCCGAATGGCACGCGAGGGAAGGGAAATAAGGTTTAAAGGCACTGAAACAATAGGCAAGAAGTAGGCGAGAGCCGACATACGAGACTAAATTAAGTCCTCAGCGAGCTCGCATGGAATGCGTGCGATGAGCGACCTCATGCTATACCTGAGAAAGCAACCTGACCTACAGGAAAGAGTTACTCAAGAATAAGAATTTTCGTTTTAAAACCTAAGAGTCACTTTAAAATTTGTATACACTTATTTTTTTTATAACTTATTTAATAATAAAAATCATAAATCATAAGAAATTCGCTTATTTAGAAGTGTCAACAACGTATCTACCAACGGAATGCGTGCGATTCATTTGTCATCGTCATCCTTGTAGTCCATTGCCTTCAAATGTTCCTTATTAAACTTTCTCAAATCGTAAACCAAAGAGTTCAAGATATCCAATTCAACATGTTCCATAACAACGATCTTGTACCAGTTGTTAGTTGGGTTATGAACTTCTGGAACTAAAAAGTACTTTTCAGCGATTTCCTTATTAACATATTGTTCTTCAATTGTAACAATATTCATTGAATCTTCTTTGTAATATTTAATTCTCATATCGTTCAATTGCTTACACAACCATTTAGTTCTATTTCTCAACTTATTAATCTTTTCCATCCAACCGTATGGACCATAAGAAGCTAAAACCATCCAAATTGCAACAGCATTTGAACCAGATCTTGAACCAGACAATGTAACATCCAAATTTTCGATGTAAGTTGCTTCCTTTGTCAAAGTGTTATGGATCAAATTCTTTCTTGAAACGAAGATACCAGTACCGTATGGAGCTTGCAACATCTTATGACCATCTAATGTGATTGAAGAAACGTTCTTATTAGAGAAATCAGTTTTACATTCCTTATTATCAATTGGATATATAAAACCACCAAATGCACCATCAACATGAATTTTGTATTCCAAATTGTACTTATCGAAGATGTTAGCGTACAAATCTGGATCATCAACTGAACCAAACATTGTAGTACCCATGTTAGAGATAACGATGAAGTACTTTTTACCAATTTCTTTAGCTTCTTTAACAATTGAATCCAATGTATTTTCTTGAATTTTTCTTGAATAAAAATCAACTGGAACCTTAATAATATCGATGTTCAACAAATCTGAACCTTTGTATGCAGAGTAATGTGTATCTGCTGAAGTGATGATAGCGATTTCTTCATGCTTAGCCTTTCTTTCTTTCTTGAAGTAGTTTCTGTAAACCCACATTGCTTGGATGTTAGCTTCTGTACCACCTTGAGTAACGTAACCATCAAATTCTTCATCGTTACCGTTCAAAACATCGATTGCTAACAATTGGATTAATTCTCTTTCGATATCGAATGTACCACCGAACAAGATATCAGCCTTATCATAAGTATGACAACCGATATGGTTTGGGTTTTGAATAAAAGTTCTCAAGTATGGTGAATGCTTAACGAAAGAATGATCATCATAGAAAACTGTATCATCCAACTTAGTACCTGGAATACCGATTGTCTTAGTGTTATCGTAGTTCAAAGTCTTTTCCAAAGATTCAGTAATCTTTTCATCCATTTCTTGTTGTGTGTACTTTCTCCAGAACTTCATTGTTTTATATTTGTTGTAAAAAGTAGATAATTACTTCCTTGATGATCTGTAAAAAAGAGAAAAAGAAAGCATCTAAGAACTTGAAAAACTACGAATTAGAAAAGACCAAATATGTATTTCTTGCATTGACCAATTTATGCAAGTTTATATATATGTAAATGTAAGTTTCACGAGGTTCTACTAAACTAAACCACCCCCTTGGTTAGAAGAAAAGAGTGTGTGAGAACAGGCTGTTGTTGTCACACGATTCGGACAATTCTGTTTGAAAGAGAGAGAGTAACAGTACGATCGAACGAACTTTGCTCTGGAGATCACAGTGGGCATCATAGCATGTGGTACTAAACCCTTTCCCGCCATTCCAGAACCTTCGATTGCTTGTTACAAAACCTGTGAGCCGTCGCTAGGACCTTGTTGTGTGACGAAATTGGAAGCTGCAATCAATAGGAAGACAGGAAGTCGAGCGTGTCTGGGTTTTTTCAGTTTTGTTCTTTTTGCAAACAACAGTTTATTCCTGGCATCCACTAAATATAATGGAGCCCGCTTTTTAAGCTGGCATCCAGAAAAAAAAAGAATCCCAGCACCAAAATATTGTTTTCTTCACCAACCATCAGTTCATAGGTCCATTCTCTTAGCGCAACTACAGAGAACAGGGGCACAAACAGGCAAAAAACGGGCACAACCTCAATGGAGTGATGCAACCTGCCTGGAGTAAATGATGACACAAGGCAATTGACCCACGCATGTATCTATCTCATTTTCTTACACCTTCTATTACCTTCTGCTCTCTCTGATTTGGAAAAAGCTGAAAAAAAAGGTTGAAACCAGTTCCCTGAAATTATTCCCCTACTTGACTAATAAGTATATAAAGACGGTAGGTATTGATTGTAATTCTGTAAATCTATTTCTTAAACTTCTTAAATTCTACTTTTATAGTTAGTCTTTTTTTTAGTTTTAAAACACCAAGAACTTAGTTTCGAATAAACACACATAAACAAACAAAATGGCTTCTAGTTCTTCCGATGTCTTCGTTTTGGGTCTAGGTGTTGTTTTGGCTGCCTTGTATATCTTCAGAGACCAATTATTCGCTGCTTCTAAGCCAAAGGTGGCTCCAGTTTCCACTACGAAGCCTGCCAACGGTTCCGCTAACCCAAGAGACTTCATCGCCAAGATGAAACAAGGTAAGAAGAGAATCGTAATCTTCTACGGTTCTCAAACTGGTACCGCTGAAGAATATGCTATTCGTTTGGCTAAGGAAGCTAAGCAAAAGTTCGGTCTAGCCTCCTTGGTTTGTGATCCAGAAGAATACGATTTTGAAAAGTTGGACCAATTGCCAGAAGATTCTATTGCTTTCTTCGTCGTTGCTACCTATGGTGAAGGTGAACCTACAGACAACGCTGTCCAATTGTTGCAAAACTTGCAAGATGAAAGCTTCGAATTCTCCTCTGGTGAGAGAAAGTTGTCAGGTTTGAAGTACGTTGTTTTTGGTCTGGGTAACAAGACCTACGAACATTACAACCTCATTGGGAGAACTGTTGACGCTCAATTGGCCAAGATGGGTGCTATCAGAATCGGTGAAAGAGGTGAAGGTGATGATGACAAGTCCATGGAAGAAGACTACTTGGAATGGAAGGATGGTATGTGGGAAGCGTTTGCCACTGCTATGGGTGTTGAAGAAGGTCAAGGTGGTGACTCCGCTGATTTCGTCGTTTCCGAATTGGAATCTCACCCACCAGAAAAGGTTTACCAAGGTGAATTTTCTGCTAGAGCTTTAACCAAAACCAAGGGTATTCACGACGCTAAGAATCCTTTTGCTGCTCCAATTGCGGTTGCTAGAGAATTGTTCCAATCTGTTGTCGATAGAAACTGTGTCCACGTCGAATTCAACATTGAAGGCTCTGGTATCACCTATCAACACGGTGACCACGTTGGTTTGTGGCCATTGAATCCAGATGTTGAAGTCGAACGGTTGTTGTGTGTTTTAGGTTTAGCTGAAAAGAGAGATGCTGTCATCTCCATTGAATCCTTAGACCCGGCTTTGGCTAAGGTTCCATTCCCAGTCCCAACTACTTACGGTGCTGTGTTGAGACACTACATTGACATCTCTGCTGTCGCCGGTAGACAAATCTTGGGTACTTTGTCCAAATTCGCTCCAACCCCAGAAGCTGAAGCTTTCTTGAGAAACTTGAACACTAACAAGGAAGAATACCACAACGTCGTCGCTAACGGTTGTTTGAAATTGGGTGAAATTTTGCAAATCGCTACCGGTAACGACATTACTGTCCCACCAACTACTGCCAACACCACCAAATGGCCAATTCCATTCGACATCATTGTTTCTGCCATCCCAAGATTGCAACCAAGATACTACTCTATCTCTTCTTCCCCAAAAATTCATCCAAACACCATCCACGCTACCGTTGTTGTGCTCAAATACGAAAACGTTCCAACCGAACCAATCCCAAGAAAGTGGGTTTACGGTGTCGGTAGTAACTTCTTGTTGAATTTAAAGTACGCTGTTAACAAGGAACCAGTTCCATACATCACTCAAAATGGCGAACAAAGAGTCGGTGTCCCGGAATACTTGATTGCTGGTCCACGTGGTTCTTACAAGACTGAATCTTTCTACAAGGCTCCAATCCATGTTAGACGTTCTACTTTCCGTTTGCCAACCAACCCAAAGTCTCCAGTCATCATGATTGGTCCAGGTACTGGTGTCGCCCCATTCAGAGGCTTCGTTCAAGAAAGAGTTGCCTTGGCCAGAAGATCCATCGAAAAGAACGGTCCTGACTCTTTGGCTGACTGGGGTCGTATTTCCTTGTTCTACGGTTGTAGAAGATCCGACGAAGACTTCTTGTACAAGGACGAATGGCCACAATACGAAGCTGAGTTGAAGGGTAAGTTCAAGTTGCACTGTGCTTTCTCCAGACAAAACTACAAGCCAGACGGTTCTAAGATTTACGTCCAAGATTTGATCTGGGAAGACAGAGAACACATTGCCGATGCCATCTTAAACGGTAAGGGTTACGTCTACATCTGCGGTGAAGCTAAGTCCATGTCTAAACAAGTTGAAGAAGTTCTAGCCAAGATCTTGGGCGAAGCCAAAGGTGGTTCCGGTCCAGTTGAAGGTGTTGCTGAAGTCAAGTTACTGAAGGAACGGTCCAGATTGATGTTGGATGTCTGGTCTGAACAAAAGTTAATTTCTGAAGAAGATTTGGAATGAATCGCGTGCATTCATCCGCTCTAACCGAAAAGGAAGGAGTTAGACAACCTGAAGTCTAGGTCCCTATTTATTTTTTTATAGTTATGTTAGTATTAAGAACGTTATTTATATTTCAAATTTTTCTTTTTTTTCTGTACAGACGCGTGTACGCATGTAACATTATACTGAAAACCTTGCTTGAGAAGGTTTTGGGACGCTCGAAGATCGCGTCCCAATTCGCCCTATAGTGAGTCGTATTACGCGCGCTCACTGGCCGTCGTTTTACAACGTCGTGACTGGGAAAACCCTGGCGTTACCCCTGCAGGACTAGTGCTGAGGCATTAATACCACTTTTCAATGAAACGGATATTGATATGCTAGTAAAAGGACGAGCTCAAGAGCGAAAATATAAGTAAAGAATTCGAGTGCACTTGTCTCCATGCAGCAAGATTTCATATGAGTCTTTTTTATCTTTTTACTTTTTACATTACACGATATGCACTTTATGAAAATTTAACGAGGTTGGAAGCCGGATAATCAACCAAAATCAGGCACGAAGGCACACTCGTATATGCATGTTGTTGAAACTCTGTTACGCTGAACTAACAATCACACATGTAGAGGTCACCGGGAAAAGTTGCGACCCCATGGAAGGTCGATCTCTTCGTTTGGCTTTGCTTGGCTGGCGGCATTGCGCTTCTTCGCTTATACCCGTCTCTTGACGCTCGAGCTCGTTCATTGAGATACCTTTATTCTTGCACATTTTCTGGCTTTTTTCGCTACTCGGGTACATGTAATCATGCACACAGAAGGTGCTGTAGGGTGAAAGTTCCTTTGTGCTGTCGTTTGTTTTTAATGCCAAACTTTCCGGTGATCAATAACCACCTC
서열번호: 53
CGGCATGCAAACATCTACACAATTAGCAAGGGCAATCCATATTTTGTCTTTTCGCGCCCTGGAAAGGCCTAAGTAATGTCGTAAACGCATTCTATCTGTACTTCAACTCTCCTCTGTGCATTGGTTTGTGCAAATCACATTTTACGATACTGCCAGATATATGCAAAAAGAGAAAACCAAGGGACCAGAACAAAGCAAAATTACGATATTCTTCGAATTCCTTCGTGCTTGACTAAGACAAAGGGATGGACGTAGCGATTTTTAGCGGGCCAAGAACTGGTTCCGAAAAAGCACAGGTACACCGAACCCTCAGCTAAGGAGGGACAGCACCGATGCGGAAGGACAAACTTTCTTTTTGCCTATCACAGTATCTTATCGAGCTAACTATTTTCGACACACATGAAAAAGCAGAAATATTAACGAAAAAGAAAAGAAAGACCATGTCATGTACGGGCAATCAGAATCTGTAACAAGCGCCATTTTTTTTTCTGTATCGGGCCCTCCTTACTGCTCTCCTTCCGTGTAACGCGTTATGAAATTAAGTCCTCAGCGAGCTCGCATGGAATGCGTGCGATGAGCGACCTCATGCTATACCTGAGAAAGCAACCTGACCTACAGGAAAGAGTTACTCAAGAATAAGAATTTTCGTTTTAAAACCTAAGAGTCACTTTAAAATTTGTATACACTTATTTTTTTTATAACTTATTTAATAATAAAAATCATAAATCATAAGAAATTCGCTTATTTAGAAGTGTCAACAACGTATCTACCAACGGAATGCGTGCGATTGTTTTATATTTGTTGTAAAAAGTAGATAATTACTTCCTTGATGATCTGTAAAAAAGAGAAAAAGAAAGCATCTAAGAACTTGAAAAACTACGAATTAGAAAAGACCAAATATGTATTTCTTGCATTGACCAATTTATGCAAGTTTATATATATGTAAATGTAAGTTTCACGAGGTTCTACTAAACTAAACCACCCCCTTGGTTAGAAGAAAAGAGTGTGTGAGAACAGGCTGTTGTTGTCACACGATTCGGACAATTCTGTTTGAAAGAGAGAGAGTAACAGTACGATCGAACGAACTTTGCTCTGGAGATCACAGTGGGCATCATAGCATGTGGTACTAAACCCTTTCCCGCCATTCCAGAACCTTCGATTGCTTGTTACAAAACCTGTGAGCCGTCGCTAGGACCTTGTTGTGTGACGAAATTGGAAGCTGCAATCAATAGGAAGACAGGAAGTCGAGCGTGTCTGGGTTTTTTCAGTTTTGTTCTTTTTGCAAACAACAGTTTATTCCTGGCATCCACTAAATATAATGGAGCCCGCTTTTTAAGCTGGCATCCAGAAAAAAAAAGAATCCCAGCACCAAAATATTGTTTTCTTCACCAACCATCAGTTCATAGGTCCATTCTCTTAGCGCAACTACAGAGAACAGGGGCACAAACAGGCAAAAAACGGGCACAACCTCAATGGAGTGATGCAACCTGCCTGGAGTAAATGATGACACAAGGCAATTGACCCACGCATGTATCTATCTCATTTTCTTACACCTTCTATTACCTTCTGCTCTCTCTGATTTGGAAAAAGCTGAAAAAAAAGGTTGAAACCAGTTCCCTGAAATTATTCCCCTACTTGACTAATAAGTATATAAAGACGGTAGGTATTGATTGTAATTCTGTAAATCTATTTCTTAAACTTCTTAAATTCTACTTTTATAGTTAGTCTTTTTTTTAGTTTTAAAACACCAAGAACTTAGTTTCGAATAAACACACATAAACAAACAAAATGTCCATCGGTGCTGAAATTGACTCTTTGGTTCCAGCTCCACCAGGTTTGAACGGTACCGCTGCTGGTTACCCAGCCAAGACTCAAAAGGAATTGTCTAACGGCGATTTCGATGCTCACGATGGTCTGTCCTTGGCTCAATTGACTCCATACGATGTTTTAACCGCTGCTTTGCCATTGCCAGCGCCAGCTTCTAGTACTGGTTTCTGGTGGAGAGAAACTGGTCCAGTTATGTCTAAGCTCTTGGCTAAAGCCAACTACCCATTGTACACCCATTACAAGTATTTAATGTTGTACCACACTCACATTTTACCTTTGTTAGGTCCAAGACCACCTTTGGAAAATTCTACCCACCCATCTCCATCAAATGCTCCTTGGAGATCCTTCTTGACCGATGACTTCACCCCATTAGAACCATCTTGGAACGTTAACGGTAACTCCGAAGCACAATCCACTATCAGATTGGGTATTGAACCAATTGGTTTCGAAGCCGGTGCTGCTGCCGACCCATTCAACCAAGCTGCCGTCACCCAATTCATGCACTCCTACGAAGCTACTGAAGTTGGTGCCACTCTAACTTTGTTCGAACACTTCAGAAACGACATGTTCGTCGGTCCAGAGACTTACGCTGCCTTGAGAGCTAAGATTCCTGAAGGTGAGCACACCACTCAATCTTTCTTGGCTTTCGACTTGGACGCCGGTCGTGTCACTACCAAGGCTTACTTCTTCCCAATCTTGATGTCTTTGAAGACCGGTCAATCTACGACCAAAGTTGTTTCCGATTCTATCTTGCACCTAGCTTTGAAGTCTGAAGTTTGGGGTGTCCAAACCATTGCCGCTATGTCGGTCATGGAAGCTTGGATCGGTTCTTACGGTGGTGCTGCTAAGACCGAAATGATCTCCGTTGACTGTGTCAACGAAGCTGACTCCAGAATCAAGATCTACGTTAGAATGCCACACACTAGCTTGAGAAAGGTCAAAGAAGCTTATTGTTTGGGTGGCCGTTTGACTGACGAAAACACCAAGGAAGGTTTGAAATTGTTGGATGAATTGTGGAGAACTGTTTTCGGTATCGATGACGAAGATGCTGAATTACCACAAAACTCTCACAGAACTGCTGGTACTATTTTTAACTTTGAACTAAGACCAGGTAAGTGGTTCCCAGAACCAAAGGTCTACTTGCCAGTCAGACACTACTGTGAATCCGACATGCAAATTGCCTCCAGATTACAAACTTTCTTTGGTCGTTTGGGTTGGCACAACATGGAAAAGGACTACTGCAAGCATTTGGAAGACTTATTCCCTCACCACCCATTGTCCTCCTCTACCGGTACCCACACTTTCTTGTCTTTTTCTTACAAGAAGCAAAAGGGTGTTTACATGACCATGTACTACAACTTGAGAGTTTATTCTACACACCACCATCATCATCATTGAATCGCGTGCATTCATCCGCTCTAACCGAAAAGGAAGGAGTTAGACAACCTGAAGTCTAGGTCCCTATTTATTTTTTTATAGTTATGTTAGTATTAAGAACGTTATTTATATTTCAAATTTTTCTTTTTTTTCTGTACAGACGCGTGTACGCATGTAACATTATACTGAAAACCTTGCTTGAGAAGGTTTTGGGACGCTCGAAGATCGCGTCCCAATTCGCCCTATAGTGAGTCGTATTACGCGCGCTCACTGGCCGTCGTTTTACAACGTCGTGACTGGGAAAACCCTGGCGTTACCCCTGCAGGACTAGTGCTGAGGCATTAATACGACTCTCTCGAAATTTTTCTTAACGCGTCCTTGTACTGCGTCTAACGCTTTTGCCACTTGGATTTCTATTATAGGAAATAGTCTCACTTACTGGGCGACGAATTTTCGCGTTTTGATGAAGCACAGGAAGAATTTCTTTTTTTTTTGGCTTCTTCTGGTTCCGTTTTTTACGCGCACAAATCTAAAAAAAGAAATAATTATAACCTAGTCTCGAAAATTTTCATCGATCCATTCGTTCCTTTTTTTCGATTTTTTCAGATCAAAATTCTTGTTTCTTTCTTTGTCTTAGTTTATATTAAAAGATATTTTGATTTTACTCCTGAACTATTTATTCTTTCTAAGAAGGCCAGAACACTACAGCTGTTTTAACCGACTACGAAGTTCTCCATTCTCGAACACTAGCCTTCATTTACCAAACAGGAACTAGCGTATATCATTAGTCCTTATTCGAAAAGAGATTGGTAGATATTTATTGTAGTTTGTGAGAAGGAGAAAATACTGTCATTGGACTGATAGTTAGAGGACATTAACCTCTCTTACGTTCGCTCA
서열번호: 54
ATCCGGATATAGTTCCTCCTTTCAGCAAAAAACCCCTCAAGACCCGTTTAGAGGCCCCAAGGGGTTATGCTAGTTATTGCTCAGCGGTGGCAGCAGCCAACTCAGCTTCCTTTCGGGCTTTGTTAGCAGCCGGATCTCAGTGGTGGTGGTGGTGGTGCTCGAGTGCGGCCGCAAGCTTGTCGACGGAGCTCGAATTCGGATCCGAATTAATTCCGATATCCATGGCCATCGCCGGCTGGGCAGCGAGGAGCAGCAGACCAGCAGCAGCGGTCGGCAGCAGGTATTTCATATGTATATCTCCTTCTTAAAGTTAAACAAAATTATTTCTAGAGGGGAATTGTTATCCGCTCACAATTCCCCTATAGTGAGTCGTATTAATTTCGCGGGATCGAGATCTCGATCCTCTACGCCGGACGCATCGTGGCCGGCATCACCGGCGCCACAGGTGCGGTTGCTGGCGCCTATATCGCCGACATCACCGATGGGGAAGATCGGGCTCGCCACTTCGGGCTCATGAGCGCTTGTTTCGGCGTGGGTATGGTGGCAGGCCCCGTGGCCGGGGGACTGTTGGGCGCCATCTCCTTGCATGCACCATTCCTTGCGGCGGCGGTGCTCAACGGCCTCAACCTACTACTGGGCTGCTTCCTAATGCAGGAGTCGCATAAGGGAGAGCGTCGAGATCCCGGACACCATCGAATGGCGCAAAACCTTTCGCGGTATGGCATGATAGCGCCCGGAAGAGAGTCAATTCAGGGTGGTGAATGTGAAACCAGTAACGTTATACGATGTCGCAGAGTATGCCGGTGTCTCTTATCAGACCGTTTCCCGCGTGGTGAACCAGGCCAGCCACGTTTCTGCGAAAACGCGGGAAAAAGTGGAAGCGGCGATGGCGGAGCTGAATTACATTCCCAACCGCGTGGCACAACAACTGGCGGGCAAACAGTCGTTGCTGATTGGCGTTGCCACCTCCAGTCTGGCCCTGCACGCGCCGTCGCAAATTGTCGCGGCGATTAAATCTCGCGCCGATCAACTGGGTGCCAGCGTGGTGGTGTCGATGGTAGAACGAAGCGGCGTCGAAGCCTGTAAAGCGGCGGTGCACAATCTTCTCGCGCAACGCGTCAGTGGGCTGATCATTAACTATCCGCTGGATGACCAGGATGCCATTGCTGTGGAAGCTGCCTGCACTAATGTTCCGGCGTTATTTCTTGATGTCTCTGACCAGACACCCATCAACAGTATTATTTTCTCCCATGAAGACGGTACGCGACTGGGCGTGGAGCATCTGGTCGCATTGGGTCACCAGCAAATCGCGCTGTTAGCGGGCCCATTAAGTTCTGTCTCGGCGCGTCTGCGTCTGGCTGGCTGGCATAAATATCTCACTCGCAATCAAATTCAGCCGATAGCGGAACGGGAAGGCGACTGGAGTGCCATGTCCGGTTTTCAACAAACCATGCAAATGCTGAATGAGGGCATCGTTCCCACTGCGATGCTGGTTGCCAACGATCAGATGGCGCTGGGCGCAATGCGCGCCATTACCGAGTCCGGGCTGCGCGTTGGTGCGGATATCTCGGTAGTGGGATACGACGATACCGAAGACAGCTCATGTTATATCCCGCCGTTAACCACCATCAAACAGGATTTTCGCCTGCTGGGGCAAACCAGCGTGGACCGCTTGCTGCAACTCTCTCAGGGCCAGGCGGTGAAGGGCAATCAGCTGTTGCCCGTCTCACTGGTGAAAAGAAAAACCACCCTGGCGCCCAATACGCAAACCGCCTCTCCCCGCGCGTTGGCCGATTCATTAATGCAGCTGGCACGACAGGTTTCCCGACTGGAAAGCGGGCAGTGAGCGCAACGCAATTAATGTAAGTTAGCTCACTCATTAGGCACCGGGATCTCGACCGATGCCCTTGAGAGCCTTCAACCCAGTCAGCTCCTTCCGGTGGGCGCGGGGCATGACTATCGTCGCCGCACTTATGACTGTCTTCTTTATCATGCAACTCGTAGGACAGGTGCCGGCAGCGCTCTGGGTCATTTTCGGCGAGGACCGCTTTCGCTGGAGCGCGACGATGATCGGCCTGTCGCTTGCGGTATTCGGAATCTTGCACGCCCTCGCTCAAGCCTTCGTCACTGGTCCCGCCACCAAACGTTTCGGCGAGAAGCAGGCCATTATCGCCGGCATGGCGGCCCCACGGGTGCGCATGATCGTGCTCCTGTCGTTGAGGACCCGGCTAGGCTGGCGGGGTTGCCTTACTGGTTAGCAGAATGAATCACCGATACGCGAGCGAACGTGAAGCGACTGCTGCTGCAAAACGTCTGCGACCTGAGCAACAACATGAATGGTCTTCGGTTTCCGTGTTTCGTAAAGTCTGGAAACGCGGAAGTCAGCGCCCTGCACCATTATGTTCCGGATCTGCATCGCAGGATGCTGCTGGCTACCCTGTGGAACACCTACATCTGTATTAACGAAGCGCTGGCATTGACCCTGAGTGATTTTTCTCTGGTCCCGCCGCATCCATACCGCCAGTTGTTTACCCTCACAACGTTCCAGTAACCGGGCATGTTCATCATCAGTAACCCGTATCGTGAGCATCCTCTCTCGTTTCATCGGTATCATTACCCCCATGAACAGAAATCCCCCTTACACGGAGGCATCAGTGACCAAACAGGAAAAAACCGCCCTTAACATGGCCCGCTTTATCAGAAGCCAGACATTAACGCTTCTGGAGAAACTCAACGAGCTGGACGCGGATGAACAGGCAGACATCTGTGAATCGCTTCACGACCACGCTGATGAGCTTTACCGCAGCTGCCTCGCGCGTTTCGGTGATGACGGTGAAAACCTCTGACACATGCAGCTCCCGGAGACGGTCACAGCTTGTCTGTAAGCGGATGCCGGGAGCAGACAAGCCCGTCAGGGCGCGTCAGCGGGTGTTGGCGGGTGTCGGGGCGCAGCCATGACCCAGTCACGTAGCGATAGCGGAGTGTATACTGGCTTAACTATGCGGCATCAGAGCAGATTGTACTGAGAGTGCACCATATATGCGGTGTGAAATACCGCACAGATGCGTAAGGAGAAAATACCGCATCAGGCGCTCTTCCGCTTCCTCGCTCACTGACTCGCTGCGCTCGGTCGTTCGGCTGCGGCGAGCGGTATCAGCTCACTCAAAGGCGGTAATACGGTTATCCACAGAATCAGGGGATAACGCAGGAAAGAACATGTGAGCAAAAGGCCAGCAAAAGGCCAGGAACCGTAAAAAGGCCGCGTTGCTGGCGTTTTTCCATAGGCTCCGCCCCCCTGACGAGCATCACAAAAATCGACGCTCAAGTCAGAGGTGGCGAAACCCGACAGGACTATAAAGATACCAGGCGTTTCCCCCTGGAAGCTCCCTCGTGCGCTCTCCTGTTCCGACCCTGCCGCTTACCGGATACCTGTCCGCCTTTCTCCCTTCGGGAAGCGTGGCGCTTTCTCATAGCTCACGCTGTAGGTATCTCAGTTCGGTGTAGGTCGTTCGCTCCAAGCTGGGCTGTGTGCACGAACCCCCCGTTCAGCCCGACCGCTGCGCCTTATCCGGTAACTATCGTCTTGAGTCCAACCCGGTAAGACACGACTTATCGCCACTGGCAGCAGCCACTGGTAACAGGATTAGCAGAGCGAGGTATGTAGGCGGTGCTACAGAGTTCTTGAAGTGGTGGCCTAACTACGGCTACACTAGAAGGACAGTATTTGGTATCTGCGCTCTGCTGAAGCCAGTTACCTTCGGAAAAAGAGTTGGTAGCTCTTGATCCGGCAAACAAACCACCGCTGGTAGCGGTGGTTTTTTTGTTTGCAAGCAGCAGATTACGCGCAGAAAAAAAGGATCTCAAGAAGATCCTTTGATCTTTTCTACGGGGTCTGACGCTCAGTGGAACGAAAACTCACGTTAAGGGATTTTGGTCATGAACAATAAAACTGTCTGCTTACATAAACAGTAATACAAGGGGTGTTATGAGCCATATTCAACGGGAAACGTCTTGCTCTAGGCCGCGATTAAATTCCAACATGGATGCTGATTTATATGGGTATAAATGGGCTCGCGATAATGTCGGGCAATCAGGTGCGACAATCTATCGATTGTATGGGAAGCCCGATGCGCCAGAGTTGTTTCTGAAACATGGCAAAGGTAGCGTTGCCAATGATGTTACAGATGAGATGGTCAGACTAAACTGGCTGACGGAATTTATGCCTCTTCCGACCATCAAGCATTTTATCCGTACTCCTGATGATGCATGGTTACTCACCACTGCGATCCCCGGGAAAACAGCATTCCAGGTATTAGAAGAATATCCTGATTCAGGTGAAAATATTGTTGATGCGCTGGCAGTGTTCCTGCGCCGGTTGCATTCGATTCCTGTTTGTAATTGTCCTTTTAACAGCGATCGCGTATTTCGTCTCGCTCAGGCGCAATCACGAATGAATAACGGTTTGGTTGATGCGAGTGATTTTGATGACGAGCGTAATGGCTGGCCTGTTGAACAAGTCTGGAAAGAAATGCATAAACTTTTGCCATTCTCACCGGATTCAGTCGTCACTCATGGTGATTTCTCACTTGATAACCTTATTTTTGACGAGGGGAAATTAATAGGTTGTATTGATGTTGGACGAGTCGGAATCGCAGACCGATACCAGGATCTTGCCATCCTATGGAACTGCCTCGGTGAGTTTTCTCCTTCATTACAGAAACGGCTTTTTCAAAAATATGGTATTGATAATCCTGATATGAATAAATTGCAGTTTCATTTGATGCTCGATGAGTTTTTCTAAGAATTAATTCATGAGCGGATACATATTTGAATGTATTTAGAAAAATAAACAAATAGGGGTTCCGCGCACATTTCCCCGAAAAGTGCCACCTGAAATTGTAAACGTTAATATTTTGTTAAAATTCGCGTTAAATTTTTGTTAAATCAGCTCATTTTTTAACCAATAGGCCGAAATCGGCAAAATCCCTTATAAATCAAAAGAATAGACCGAGATAGGGTTGAGTGTTGTTCCAGTTTGGAACAAGAGTCCACTATTAAAGAACGTGGACTCCAACGTCAAAGGGCGAAAAACCGTCTATCAGGGCGATGGCCCACTACGTGAACCATCACCCTAATCAAGTTTTTTGGGGTCGAGGTGCCGTAAAGCACTAAATCGGAACCCTAAAGGGAGCCCCCGATTTAGAGCTTGACGGGGAAAGCCGGCGAACGTGGCGAGAAAGGAAGGGAAGAAAGCGAAAGGAGCGGGCGCTAGGGCGCTGGCAAGTGTAGCGGTCACGCTGCGCGTAACCACCACACCCGCCGCGCTTAATGCGCCGCTACAGGGCGCGTCCCATTCGCCA
실시예
실시예 1 - 제1 다중 치환기 실로시빈 유도체의 생합성
대장균 균주 E1을 다음과 같이 작제하였다. 플라스미드 클로닝을 위해, 항생제 마커에 의존하여 Top10 또는 XL1-blue 균주를 사용했다. 표준 LB 배지를 배양을 위해 사용했다. 유전자 발현 및 피딩 실험을 위해, 이용된 모 숙주 균주는 BL21(DE3)이었다. 먼저, pET28a(+)의 NdeI/XhoI 부위(서열번호: 36) 안으로 인-프레임, HIS 태깅된(서열번호: 46) PfTrpB-B0A9 유전자(서열번호: 1)를 삽입함에 의하여 플라스미드 pET28a(+)-PfTrpB-B0A9-HIS를 생성했다. 두 번째 단계로서, 플라스미드 pCDM4(서열번호: 35)로부터, pCDM4의 NdeI/XhoI 부위 안으로 인-프레임, HIS-태깅된(서열번호: 46) BaTDC 유전자(서열번호: 3)를 삽입함에 의하여 플라스미드 pCDM4-BaTDC-HIS를 생성했다. 마지막으로, 플라스미드 pET23a(+)(서열번호: 37)로부터, pET23a(+)의 Nde1/Xho1 부위 안으로 인-프레임, HIS-태깅된(서열번호: 46) PsmF 유전자(서열번호: 9)를 삽입함에 의하여 플라스미드 pET23a(+)-PsmF-HIS를 생성했다. 표적 플라스미드 pET28a(+)-PfTrpB-B0A9-HIS, pCDM4-BaTDC-HIS 및 pET23a(+)-PsmF-HIS를 다음과 같이 BL21(DE3) 세포 안으로 형질전환시켰다: pCDM4-BaTDC-HIS를 먼저 BL21(DE3) 안으로 형질전환시키고, 스트렙토마이신을 사용하여 선택된 형질전환체를 pET28a(+)-PfTrpB-B0A9-HIS와 pET23a(+)-PsmF-HIS로 함께 형질전환시켰다. 최종 대장균 균주(Ec-1)는 스트렙토마이신, 암피실린 및 카나마이신으로 선택되었다. 조작된 대장균의 대규모 배양은 다음과 같이 수행되었다: 종자 배양액을 AMM(Jones 등, 2015, Sci Rep. 5: 11301) 배지에 밤새 접종했다. 그런 다음 밤새 배양액을 Ec-1에 의한 전환을 위해 추가로 0.5%(w/v) 세린, 1M IPTG, 50ug/L 스트렙토마이신, 암피실린 및 카나마이신과 100mg/L 인돌 공급원료(6-플루오로-1H-인돌-4-일아민, www.bldpharm.com)을 함유하는 각각의 AMM 배지 500mL을 함유하는 2개의 플라스크로 분주하였다. 배양액을 24시간 동안 성장시켰다. 그런 다음 배양액을 원심분리(10,000g × 5분)하여 세포 내용물을 제거하고 분비된 유도체를 함유하는 배양 브로쓰를 조합하여 추가 처리 때까지 -80℃에 보관했다. 1.0L의 브로쓰에 10M NaOH 용액을 pH가 ~7에 도달할 때까지 첨가했다. 그 다음 배양액을 에틸 아세테이트(4 x 600ml)로 추출하였다. 유기층을 조합하여 Na2SO4로 건조시키고 이어서 감압 하에 농축하였다. 잔류물을 실리카 겔 상의 플래시 크로마토그래피(디클로로메탄 내 1→2% 메탄올)로 정제하여 연황색 고체로 화합물(7mg)을 얻었다. 정제에 이어서 고해상도 MS(HRMS), 1H NMR 및 선택적 13C NMR을 수행하여 순도를 평가하고 총량을 추정하고 분자 구조를 확인했다. 1H NMR (400 MHz, CD3OD): δ = 1.94 (s, 3H), 3.00 (m, 2H,), 3.38 (m, 2H,), 6.10 (dd, J = 11.7, 2.2 Hz, 1H), 6.38 (dd, J = 9.7, 2.2 Hz, 1H), 6.84 (s, 1H). 13C NMR (100 MHz, CD3OD): δ = 21.0, 29.2, 41.9, 87.1 (d, JC, F = 26.1 Hz), 92,6 (d, JC, F = 27.8 Hz), 111.6, 112.4, 120.7, 138.0 (d, JC, F = 15.0 Hz), 141.7 (d, JC, F = 13.2 Hz), 160.7 (d, JC, F = 232.5 Hz), 172.1. HRMS (ESI) m/z: C12H14FN3O [M+H]+에 대한 계산치 236.1194, 발견치 236.1189. 순도는 95% w/w로 결정되었다. 이들 데이터는 본 명세서에 제시된 예의 화합물 (IX)의 화학 구조에 상응하는 화학 구조를 확인시켜 준다는 것이 인지된다:
(IX)
실로시빈 유도체의 처리 시 세포 생존력의 평가
경쟁적 결합 검정에 적합한 리간드 농도를 확립하기 위해, PrestoBlue 검정을 먼저 수행했다. PrestoBlue 검정은 테트라졸륨 염 형성에 기반하여 세포 대사 활성을 측정하고 일상적인 세포 생존력 검정에 선호되는 방법이다(Terrasso 등, 2017, J Pharmacol Toxicol Methods 83: 72). 이들 검정의 결과는, 부분적으로 최대 1mM 농도의 세포 배양에 대한 임의의 현저한 독성 효과에 대한 사전-스크린으로, 대조군 리간드(예를 들어, 실로시빈, 실로신, DMT)와 신규 유도체 둘 모두를 사용하여 수행되었다. 공지된 세포 독소(트립톤 X-100, Pyrgiotakis G. 등, 2009, Ann. Biomed. Eng. 37: 1464-1473)가 독성의 일반적인 지표로 포함되었다. HepG2 세포주와 같은 간단한 시험관내 시스템 내에서 세포 건강에서의 약물-유발된 변화는 일반적으로 약학적 산업에서 제1-라인 스크리닝 접근법으로 채택된다(Weaver 등, 2017, Expert Opin Drug Metab Toxicol 13:767). HepG2는 약물 대사 및 간독성 연구에 가장 일반적으로 사용되는 인간 간종양이다(Donato 등, 2015, Methods Mol Biol 1250: 77). 본 명세서에서, HepG2 세포는 제조업체의 프로토콜을 사용한 표준 절차를 사용하여 배양되었다(ATCC, HB-8065). 간단히 말하면, 세포를 10% 소 태아 혈청이 보충된 이글스 최소 필수 배지에서 배양하고 5% CO2 존재 하에 37℃에서 성장시켰다. 세포주로 다양한 화합물을 테스트하기 위해, 세포를 투명한 96웰 배양 플레이트에 웰당 20,000개 세포로 접종했다. 24시간 동안 세포가 부착되고 성장하도록 허용한 후, 화합물을 1μM, 10μM, 100μM 및 1mM로 첨가했다. 메탄올을 0.001, 0.01, 0.1 및 1% 농도에서 비히클로 사용하였다. 독성에 대한 양성 대조군으로 사용된 TritonX 농도는 0.0001, 0.001, 0.01 및 0.1%였다. 제조업체의 프로토콜(ThermoFisher Scientific, P50200)에 따라 PrestoBlue 검정으로 세포 생존 가능성을 입수하기 전에 세포를 화합물과 함께 48시간 동안 인큐베이션했다. PrestoBlue 시약을 세포에 첨가하고 판독하기 전에 1시간 동안 인큐베이션했다. SpectraMax iD3 플레이트 판독기에서 600nm에서의 기준을 사용하여 570nm에서 흡광도 판독을 수행했다. 비-처리된 세포는 100% 생존율로 할당되었다. 막대 그래프는 평균 +/- SD, n=3을 보여준다. 유의성은 2-way ANOVA에 이어 Dunnett의 다중 비교 테스트에 의해 결정되었고 ***(P<0.0001), **(P<0.001), *(P<0.005)로 표시된다. 화학식 (IX)을 갖는 유도체에 대해 얻어진 데이터는 도 15a의 x-축에 "IX"로 표시된다.
방사성리간드 수용체 결합 검정.
약물 결합의 평가는 모든 약물-표적 상호작용의 특성화에 대한 필수적인 단계이다(Fang 2012, Exp Opin Drug Discov 7:969). 표적에 대한 약물의 결합 친화도는 전통적으로 그의 생체내 효능의 허용가능한 대용물로 간주된다(N
 ez 등, 2012, Drug Disc Today 17:10). 대체 또는 변조 결합 검정이라고도 불리는 경쟁 검정은 표적 수용체에서 리간드의 활성을 측정하기 위한 일반적인 접근방식이다(Flanagan 2016, Methods Cell Biol 132: 191). 이들 검정에서 작용제 또는 길항제로 작용하는 표준 방사성리간드는 특정 수용체에 속한다. G 단백질-커플링된 수용체 5-HT2A의 경우에, [3H]케탄세린은 5-HT2A 수용체에서 신규한 약물 후보의 경쟁 활성을 평가하기 위한 경쟁 검정에서 일상적으로 사용되는 잘 확립된 길항제이다(Maguire 등, 2012, Methods Mol Biol 897: 31). 따라서, 5-HT2A 수용체에서 신규한 실로시빈 유도체의 활성을 평가하기 위해, [3H]케탄세린을 사용한 경쟁 검정은 다음과 같이 이용되었다. SPA 비드(RPNQ0010), [3H] 케탄세린(NET1233025UC), 5-HT2A를 함유한 멤브레인(ES-313-M400UA) 및 이소플레이트-96 마이크로플레이트(6005040)는 모두 PerkinElmer에서 구입했다. 방사성 결합 검정은 섬광근접접촉법(SPA)을 사용하여 수행되었다. 포화 결합 검정을 위해, 5-HT2A 수용체를 함유한 10ug의 막의 혼합물을 결합 완충액(50mM Tris-HCl pH7.4, 4mM CaCl2, 1mM 아스코르브산, 10mM 파길린 HCl)에서 1시간 동안 튜브 회전기에서 실온에서 1mg의 SPA 비드에 사전-커플링시켰다. 사전-커플링 후, 비드와 막을 증가하는 양의 [3H]케탄세린(0.1525nM에서 5nM)을 갖는 이소플레이트-96 마이크로플레이트에 분취하고 어두운 곳에서 실온에서 2시간 동안 진탕하면서 인큐베이션했다. 인큐베이션 후, 샘플을 MicroBeta 2 마이크로플레이트 카운터(Perkin Elmer) 상에서 판독했다. 비-특이적 결합의 결정은 20mM의 스피페론(S7395-250MG, Sigma)의 존재에서 수행되었다. 케탄세린에 대한 평형 결합 상수(Kd)는 GraphPad PRISM 소프트웨어(버전 9.2.0)의 '원-사이트 포화 결합 분석' 방법을 사용하여 포화 결합 곡선으로부터 결정되었다. 경쟁 결합 검정은 포화 결합 검정에 유사한 고정된(1nM) [3H]케탄세린과 다양한 농도의 트립토판(3nM 내지 1mM), 실로신(30pM 내지 10mM) 또는 표지되지 않은 테스트 화합물(3nM 내지 1mM)을 사용하여 수행되었다. Ki 값은 GraphPad PRISM 소프트웨어의 경쟁적 결합 분석을 사용하여 경쟁 대체 데이터로부터 계산되었다. 트립토판은 5-HT2A 수용체에서 활성을 갖지 않기 때문에 음성 대조군으로 포함되었다. 대조적으로, 실로신은 5-HT2A 수용체에서 확립된 결합 활성을 가지므로 양성 대조군으로 사용되었다(Kim 등, 2020, Cell 182: 1574). 도 15b는 5-HT2A 수용체에서 [3H]케탄세린에 대한 포화 결합 곡선을 도시한다. 패널 A는 5-HT2A 수용체를 함유한 막에 대한 [3H]케탄세린(0.1525nM에서 5nM)의 특정 포화 리간드 결합을 보여주며, 이는 비-특이적 결합 값을 차감한 후 얻어진다(패널 B에 도시됨). 분당 횟수(cpm) 단위의 특이적 결합은 전체 결합에서 비-특이적 결합을 차감함에 의해 계산되었다. 특이적 결합(pmol/mg)은 검정에서 단백질의 mg당 결합된 [3H]케탄세린의 pmol로부터 계산되었다. Kd는 PRISM 소프트웨어(버전 9.2.0)의 원-사이트 결합 모델로 데이터를 피팅함에 의해 계산되었다. 도 15c(패널 A)는 양성 대조군(결합)인 실로신에 대한 경쟁 결합 곡선을 보여준다. (패널 B)는 음성 대조군(결합 없음)으로서 트립토판에 대한 경쟁 결합 곡선을 보여준다. 도 15d는 도면에서 "IX"로 지정된 식 (IX)을 갖는 화합물에 대한 경쟁 결합 곡선을 보여준다. 현저하게는, [3H]케탄세린이 차지하는 5-HT2A 부위에 대한 화합물 (IX)의 경쟁은 단지 ~50% 특이적 결합에 의해 제안된 것처럼 완전한 것으로 보이지 않는다(명확성을 위해 패널 A의 데이터를 재설정된 y-축으로 재플롯팅하는 패널 B를 참조). 케탄세린은 5-HT2A의 다른 부위에 부가하여 작용제(예를 들어, 세로토닌)가 일반적으로 차지하는 두 가지 일차 부위에 결합하는 것으로 알려져 있고(Sleight 등, 1996, Biochem Pharmacol 51:71); 따라서 화합물 (IX)에 의한 불완전한 경쟁은 이 유도체가 케탄세린에 의해 결합된 전체 부위의 특정 하위집합(즉, 분획)에 대해 경쟁한다는 것을 의미한다.
ez 등, 2012, Drug Disc Today 17:10). 대체 또는 변조 결합 검정이라고도 불리는 경쟁 검정은 표적 수용체에서 리간드의 활성을 측정하기 위한 일반적인 접근방식이다(Flanagan 2016, Methods Cell Biol 132: 191). 이들 검정에서 작용제 또는 길항제로 작용하는 표준 방사성리간드는 특정 수용체에 속한다. G 단백질-커플링된 수용체 5-HT2A의 경우에, [3H]케탄세린은 5-HT2A 수용체에서 신규한 약물 후보의 경쟁 활성을 평가하기 위한 경쟁 검정에서 일상적으로 사용되는 잘 확립된 길항제이다(Maguire 등, 2012, Methods Mol Biol 897: 31). 따라서, 5-HT2A 수용체에서 신규한 실로시빈 유도체의 활성을 평가하기 위해, [3H]케탄세린을 사용한 경쟁 검정은 다음과 같이 이용되었다. SPA 비드(RPNQ0010), [3H] 케탄세린(NET1233025UC), 5-HT2A를 함유한 멤브레인(ES-313-M400UA) 및 이소플레이트-96 마이크로플레이트(6005040)는 모두 PerkinElmer에서 구입했다. 방사성 결합 검정은 섬광근접접촉법(SPA)을 사용하여 수행되었다. 포화 결합 검정을 위해, 5-HT2A 수용체를 함유한 10ug의 막의 혼합물을 결합 완충액(50mM Tris-HCl pH7.4, 4mM CaCl2, 1mM 아스코르브산, 10mM 파길린 HCl)에서 1시간 동안 튜브 회전기에서 실온에서 1mg의 SPA 비드에 사전-커플링시켰다. 사전-커플링 후, 비드와 막을 증가하는 양의 [3H]케탄세린(0.1525nM에서 5nM)을 갖는 이소플레이트-96 마이크로플레이트에 분취하고 어두운 곳에서 실온에서 2시간 동안 진탕하면서 인큐베이션했다. 인큐베이션 후, 샘플을 MicroBeta 2 마이크로플레이트 카운터(Perkin Elmer) 상에서 판독했다. 비-특이적 결합의 결정은 20mM의 스피페론(S7395-250MG, Sigma)의 존재에서 수행되었다. 케탄세린에 대한 평형 결합 상수(Kd)는 GraphPad PRISM 소프트웨어(버전 9.2.0)의 '원-사이트 포화 결합 분석' 방법을 사용하여 포화 결합 곡선으로부터 결정되었다. 경쟁 결합 검정은 포화 결합 검정에 유사한 고정된(1nM) [3H]케탄세린과 다양한 농도의 트립토판(3nM 내지 1mM), 실로신(30pM 내지 10mM) 또는 표지되지 않은 테스트 화합물(3nM 내지 1mM)을 사용하여 수행되었다. Ki 값은 GraphPad PRISM 소프트웨어의 경쟁적 결합 분석을 사용하여 경쟁 대체 데이터로부터 계산되었다. 트립토판은 5-HT2A 수용체에서 활성을 갖지 않기 때문에 음성 대조군으로 포함되었다. 대조적으로, 실로신은 5-HT2A 수용체에서 확립된 결합 활성을 가지므로 양성 대조군으로 사용되었다(Kim 등, 2020, Cell 182: 1574). 도 15b는 5-HT2A 수용체에서 [3H]케탄세린에 대한 포화 결합 곡선을 도시한다. 패널 A는 5-HT2A 수용체를 함유한 막에 대한 [3H]케탄세린(0.1525nM에서 5nM)의 특정 포화 리간드 결합을 보여주며, 이는 비-특이적 결합 값을 차감한 후 얻어진다(패널 B에 도시됨). 분당 횟수(cpm) 단위의 특이적 결합은 전체 결합에서 비-특이적 결합을 차감함에 의해 계산되었다. 특이적 결합(pmol/mg)은 검정에서 단백질의 mg당 결합된 [3H]케탄세린의 pmol로부터 계산되었다. Kd는 PRISM 소프트웨어(버전 9.2.0)의 원-사이트 결합 모델로 데이터를 피팅함에 의해 계산되었다. 도 15c(패널 A)는 양성 대조군(결합)인 실로신에 대한 경쟁 결합 곡선을 보여준다. (패널 B)는 음성 대조군(결합 없음)으로서 트립토판에 대한 경쟁 결합 곡선을 보여준다. 도 15d는 도면에서 "IX"로 지정된 식 (IX)을 갖는 화합물에 대한 경쟁 결합 곡선을 보여준다. 현저하게는, [3H]케탄세린이 차지하는 5-HT2A 부위에 대한 화합물 (IX)의 경쟁은 단지 ~50% 특이적 결합에 의해 제안된 것처럼 완전한 것으로 보이지 않는다(명확성을 위해 패널 A의 데이터를 재설정된 y-축으로 재플롯팅하는 패널 B를 참조). 케탄세린은 5-HT2A의 다른 부위에 부가하여 작용제(예를 들어, 세로토닌)가 일반적으로 차지하는 두 가지 일차 부위에 결합하는 것으로 알려져 있고(Sleight 등, 1996, Biochem Pharmacol 51:71); 따라서 화합물 (IX)에 의한 불완전한 경쟁은 이 유도체가 케탄세린에 의해 결합된 전체 부위의 특정 하위집합(즉, 분획)에 대해 경쟁한다는 것을 의미한다.
5-HT
1A
에서의 활성을 평가하기 위해 사용된 세포주 및 대조군 리간드.
CHO-K1/Gα15(GenScript, M00257)(-5-HT1A) 및 CHO-K1/5-HT1A/Gα15(GenScript, M00330)(+5-HT1A) 세포주를 사용했다. 간단히 말하면, CHO-K1/Gα15는 임의로 섞인 Gq 단백질인 Gα15를 구성적으로 발현하는 대조군 세포주이다. 이 대조군 세포주는 5-HT1A 수용체를 인코딩하는 임의의 이식유전자를 결하지만 여전히 포스콜린에 반응한다; 따라서 포스콜린에 대한 cAMP 반응은 5-HT1A 작용제가 존재하는지 여부에 관계없이 동일해야 한다. 반대로, CHO-K1/5-HT1A/Gα15 세포는 CHO-K1 숙주 배경에서 5-HT1A 수용체를 안정적으로 발현한다. 현저하게, Gα15는 대조군과 5-HT1A 세포주 둘 모두에 존재하는 칼슘 흐름 반응을 유도하는 것으로 알려진 임의로 섞인 G 단백질이다. +5-HT1A 세포에서 Gα15는 Gαi/o 대신에 모집될 수 있으며, 이는 이론적으로 cAMP 반응을 약화시킬 수 있다(Rojas and Fiedler 2016, Front Cell Neurosci 10: 272). 따라서, 본 발명자들은 충분한 cAMP 반응이 관찰되었는지를 보장하기 위해 2가지 알려진 5-HT1A 작용제인 실로신(Blair 등, 2000, J Med Chem 43: 4701)과 세로토닌(Rojas and Fiedler 2016, Front Cell Neurosci 10: 272)을 양성 대조군으로 포함했으며, 이에 의해 활성화된 5-HT1A 수용체에 대한 Gαi/o 단백질의 측정가능한 모집을 나타낸다. 대조적으로, 트립토판은 어떤 방식으로든 5-HT1A 수용체를 활성화하거나 조절하는 것으로 알려져 있지 않았고 따라서 음성 대조군으로 사용되었다. 세포는 공급자(GenScript)가 권장하는 대로 다음과 같이 구성된 완전 성장 배지에서 유지되었다: 10% 소 태아 혈청(FBS)(Thermo Scientific #12483020), 200μg/ml 제오신(Thermo Scientific #R25005) 및/또는 100μg/ml 히그로마이신(Thermo Scientific #10687010)을 갖는 Ham's F12 Nutrient mix(HAM's F12, GIBCO #11765-047). 세포는 37℃ 및 5% CO2의 가습된 인큐베이터에서 배양했다. 세포 유지관리는 세포 공급업체에 의해 권장된 바에 따라 수행했다. 간단히 말하면, 세포가 있는 바이알을 액체 질소에서 제거하고 37℃ 수조에서 빠르게 해동했다. 세포가 완전히 해동되기 직전에 바이알의 외부를 70% 에탄올 스프레이에 의해 오염 제거했다. 그런 다음 세포 현탁액을 바이알에서 회수하여 따뜻한(37℃) 완전 성장 배지에 첨가하고 1,000rpm에서 5분간 원심분리했다. 상등액을 버리고, 세포 펠릿을 그 다음 또 다른 10ml의 완전 성장 배지에 재현탁시키고, 10cm 세포 배양 접시(Greiner Bio-One #664160)에 첨가했다. 세포가 약 90% 컨플루언트될 때까지 매 3일마다 배지를 교체했다. ~90% 컨플루언트 세포는 그 다음 유지관리를 위해 10:1로 분할되거나 실험에 사용되었다.
5-HT
1A
수용체 조절의 평가
5-HT1A 활성화가 cAMP 형성을 억제하므로, 5-HT1A 반응을 조절하는 테스트 분자의 능력은 4μM 포스콜린의 적용에 기인하여 생성된 cAMP 수준에서의 변화를 통해 측정되었다. 신규한 분자의 처리에 기인한 세포내 cAMP 수준에서의 변화(임의의 유의한 변화가 발생해야 하는 경우)는 cAMP-Glo 검정 키트(Promega # V1501)를 사용하여 평가되었다. 간단히 말하면, +5-HT1A 세포를 1-6 컬럼에 접종하고 베이스 -5-HT1A 세포를 흰색 벽의 투명 바닥 96-웰 플레이트(Corning, #3903)의 컬럼 7-12에 접종했다. 두 세포 모두는 100μl 완전 성장 배지에 30,000개 세포/웰의 밀도로 접종되고 37℃ 및 5% CO2에서의 가습된 인큐베이터에서 24시간 동안 배양되었다. 실험 당일에 세포의 배지를 혈청/항생제 무함유 배양 배지로 교체하였다. 그런 다음 세포를 유도 배지(4μM 포스콜린, 500mM IBMX(이소부틸-1-메틸크산틴, Sigma-Aldrich, Cat. #17018) 및 100mM(RO 20-1724, Sigma-Aldrich, Cat. #B8279)을 함유하는 혈청/항생제 무함유 배양 배지)에 용해된 테스트 분자로 20분 동안 처리했다. 포스콜린은 cAMP 형성을 유도한 반면 IBMX와 RO 20-1724는 cAMP의 분해를 억제했다. PKA를 용리물에 첨가하고 혼합하고 이어서 PKA의 기질을 첨가했다. PKA는 cAMP에 의해 활성화되었고, PKA 인산화에 기인하여 소비된 ATP의 양은 용리물에서의 cAMP 수준과 직접적으로 상응했다. 감소된 ATP는 루시페린의 옥시루시페린으로의 감소된 전환을 야기하여, 결과적으로 5-HT1A 활성화로 인해 감소된 발광을 부여한다. 요약하면: 이 신호 캐스케이드는 테스트 분자에 의한 5-HT1A 활성화(양성 변조)를 허용하여 cAMP 형성 %가 감소하는 측면에서 측정된다. 반대로, 5-HT1A 수용체가 테스트 분자에 의해 부정적으로 조절될 때 증강된 % cAMP가 예상된다. 마지막으로, (예를 들어, 트립토판으로) 음성 대조군 실험에서 관찰된 것을 넘어 - % cAMP에서의 유의미하지 않은 변화는 테스트 분자가 5-HT1A에 결합하지 않거나 결합이 침묵 반응을 부여한다는 것을 나타낸다. 도 15e는 실로신의 복용량이 증가함에 따라 고정된(4μM) 포스콜린의 존재에서 -5HT1A 배양액과 비교하여 +5HT1A에서 감소된 % cAMP를 보여주며, 이는 실로신의 5-HT1A 활성을 밝힌다. 도 15f는 세로토닌의 복용량이 증가함에 따라 고정된(4μM) 포스콜린의 존재에서 -5HT1A 배양액과 비교하여 +5HT1A에서 감소된 % cAMP를 보여주며, 이는 세로토닌의 5-HT1A 활성을 밝힌다. 도 15g는 트립토판의 복용량이 증가함에 따라 고정된(4μM) 포스콜린의 존재에서 -5HT1A 배양액과 비교하여 +5HT1A에 대한 % cAMP에서 유의미하지 않은 차이를 보여주며, 이는 트립토판에 대한 5-HT1A 활성의 조절이 없음을 밝힌다. 도 15h는 화합물(X)의 복용량이 증가함에 따라 고정된(4μM) 포스콜린의 존재에서 -5HT1A 배양액과 비교하여 +5HT1A에 대한 % cAMP에서 유의미하지 않은 차이를 보여주며, 이는 화합물(X)에 대한 5-HT1A 활성의 조절이 없음을 밝힌다. 화합물(X)는 x-축을 따라 간단히 "X"로 표시된다는 것에 유의한다. 도 15h는 화합물(IX)의 복용량이 증가함에 따라 고정된(4μM) 포스콜린의 존재에서 -5HT1A 배양액과 비교하여 +5HT1A에 대한 % cAMP에서 유의미하지 않은 차이를 보여주며, 이는 화합물(IX)에 대한 5-HT1A 활성의 조절이 없음을 밝힌다. 화합물(IX)은 x-축을 따라 간단히 "IX"로 표시된다는 것에 유의한다. 도 15e - 15h의 경우, cAMP 수준은 리간드 무함유 (0mM) 샘플에서 관찰된 값에 비하여(%) 보고되고; x-축을 따라 값 "0"은 0.0001mM의 리간드 농도를 지칭하고; 오류 막대가 존재하는 경우 3가지 실험(n=3)의 결과를 나타낸다.
실시예 2 - 제2 다중 치환기 실로시빈 유도체의 생합성
대장균 균주 Ec-1이 유도체화된 인돌 공급원료로부터 식 (X)을 갖는 실로시빈 유도체를 생합성하기 위해 사용되었다. Ec-1의 구성은 실시예 1에 기술되어 있다. 조작된 대장균의 대규모 배양 및 물질 저장은 4-플루오로-1H-인돌-6-일아민(Combi-Blocks, www.combi-blocks.com)이 6-플루오로-1H-인돌-4-일아민 대신 사용된 것을 제외하고는 실시예 1에 기술된 바와 같이 수행되었다. 조작된 대장균의 대규모 배양 및 처리는 총 2.0L가 배양된 것을 제외하고는 실시예 1에 기술된 바와 같이 수행되었다. 2리터의 대장균 배양 브로쓰는 에틸 아세테이트(4×1.2L)에 의해 추출되었다. 유기층을 조합하여 Na2SO4로 건조시키고 이어서 감압 하에서 농축하였다. 잔류물을 실리카 겔 상의 플래시 크로마토그래피(디클로로메탄에서 1→3% 메탄올)로 정제하여 화합물을 활색 고체(5mg)로 얻었다. 정제에 이어서 고해상도 MS(HRMS), 1H NMR 및 선택적 13C NMR을 수행하여 순도를 평가하고 총량을 추정하고 분자 구조를 확인했다. 1H NMR (400 MHz, CD3OD): δ = 1.92 (s, 3H), 2.14 (s, 3H), 2.98 (t, J = 7.2, 2H), 3.47 (t, J = 7.2, 2H,), 6.82 (dd, J = 12.9, 1.6 Hz, 1H), 7.00 (s, 1H), 7.56 (d, J = 1.6 Hz, 1H). 13C NMR (100 MHz, CD3OD): δ = 21.1, 22.4, 25.9, 40.5 (d, JC, F = 2.0 Hz), 97.5 (d, JC, F = 24.0 Hz), 98.9 (d, JC,F = 3.4 Hz), 110.5 (d, JC, F = 2.8 Hz), 112.6 (d, JC, F = 20.0 Hz), 122.6, 133.1 (d, JC, F = 10.5 Hz), 139.2 (d, JC, F = 13.6 Hz), 156.2 (d, JC, F = 242.5 Hz), 170.0, 171.8. HRMS (ESI) m/z: C12H16FN3O2 [M+H]+에 대한 계산치 278.1299, 발견치 278.1298. 순도는 95% w/w로 결정되었다. 이들 데이터는 본 명세서에 제시된 예의 화합물 (X)의 화학 구조에 상응하는 화학 구조를 확인시켜 준다는 것이 인지된다:
(X)
실로시빈 유도체의 처리 시 세포 생존력의 평가
세포 생존력은 식 (IX)을 갖는 화합물 대신에 식 (X)을 갖는 화합물이 평가된다 것을 제외하고는 실시예 1에 기재된 바와 같이 평가되었다. 도 16a는 x-축 상에 "X"로 묘사된 식 (X)을 갖는 화합물에 대한 PrestoBlue 검정 결과를 도시한다.
방사성리간드 수용체 결합 검정.
5-HT2A 수용체에서의 활성은 식 (IX)을 갖는 화합물 대신에 식 (X)을 갖는 화합물이 평가되었다는 것을 제외하고 실시예 1에 기술된 바와 같이 평가되었다. 도 16b는 x-축 상에 간단히 "X"로 묘사된 식 (X)을 갖는 화합물에 대한 방사성리간드 경쟁 검정 결과를 보여준다. 실로신의 것과 비교하여 화합물(X)에 대한 상대적으로 높은 Ki 값은 상대적으로 '느슨한' 결합, 또는 5-HT2A 상호작용에 대한 케탄세린과 화합물 (X)에 의한 경미한 경쟁의 정도를 나타낸다. 유사하게 경미한 또는 '느슨한' 결합 프로파일을 나타내는 5-HT2A에 대한 높은 Ki 값(예를 들어, 마이크로몰 범위)이 약물 예컨대 주요 우울 장애, MDMA(Simmler 등, Br. J. Pharmacol. 2013, 168: 458; Setola 등, Molec Pharmacol 2003, 63: 1223)에 대한 중요한 치료법인 셀레길린(Toll 등, NIDA Res. Monogr. 1998, 178: 440) 및 고-프로파일, 잠재적 우울증 치료법(Liechti 등, Curr Top Behav Neurosci 2021, doi: 10.1007/7854_2021_270)인 메스칼린(Rickli 등, Neuropharmacology 2015, 99: 546)에 대해 인지된다.
세포주, 대조군 리간드 및 5-HT
1A
수용체 조절의 평가
세포주 및 대조군 리간드는 실시예 1에 기술된 바와 같았다. 5-HT1A 수용체에서의 활성은 식 (IX)을 갖는 화합물 대신에 식 (X)을 갖는 화합물이 평가되었다는 것을 제외하고 실시예 1에 기술된 바와 같이 평가되었다. 도 16c는 상대적 cAMP %의 단위로 측정된 5-HT1A 검정 결과를 보여주며, 여기서 식 (X)을 갖는 화합물은 x-축 상에 간단히 "X"로 묘사된다. 도 16c는 화합물 (X)의 복용량이 증가함에 따라 고정된(4μM) 포스콜린의 존재에서 -5HT1A 배양액과 비교하여 +5HT1A에 대한 % cAMP에서 유의미하지 않은 차이를 보여주며, 이는 화합물 (X)에 대한 5-HT1A 활성의 조절이 없음을 밝힌다.
실시예 3 - 제3 다중 치환기 실로시빈 유도체의 생합성
대장균 균주 Ec-1이 유도체화된 인돌 공급원료로부터 식 (XII)을 갖는 실로시빈 유도체를 생합성하기 위해 사용되었다. Ec-1의 구성은 실시예 1에 기술되어 있다. 조작된 대장균의 대규모 배양 및 물질 저장은 5-플루오로-7-니트로-1H-인돌(www.bldpharm. com)이 6-플루오로-1H-인돌-4-일아민 대신에 사용되었다는 것을 제외하고 실시예 1에 기술된 바와 같이 수행되었다. 조작된 대장균의 대규모 배양 및 처리는 실시예 1에 기술된 대로 수행되었다. 분석은 액체 크로마토그래피가 Zorbax C18 컬럼(Agilent Technologies)이 장착된 Accela HPLC 시스템(Thermo Fisher Scientific) 대신에 Poroshell 120 SB-C18 컬럼(Agilent Technologies)이 장착된 UltiMate 3000 HPLC(Thermo Fisher Scientific)를 사용하여 수행되었다는 것을 제외하고는 이전에 기술된 방법(Chang 등, 2015, Plant Physiol. 169: 1127-1140)의 변형된 버전의 방법을 이용하여 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 간단히 말하면, 100 마이크로리터의 배양 배지를 건조시키고 100 마이크로리터의 DMSO에 재현탁시켰다. 이 현탁액의 1/10(10 마이크로리터)을 0.5mL/분의 유속으로 주입하고 용매 A(0.1%의 포름산을 갖는 물)와 용매 B(0.1%의 포름산을 갖는 ACN)의 구배는 다음과 같다: 5분에 걸쳐 100%에서 0%(v/v) 용매 A; 1분 동안 0%(v/v)에서 등용매; 0.1분에 걸쳐 0%에서 100%(v/v); 및 1.9분 동안 100%(v/v)에서 등용매. 총 실행 시간은 8분이었다. 가열된 ESI 공급원 및 인터페이스 조건은 다음과 같이 양이온 모드에서 작동되었다: 기화기 온도, 400℃; 공급원 전압, 3kV; 외장 가스, 60au, 보조 가스, 20au; 모세관 온도, 380℃; 모세관 전압, 6V; 튜브 렌즈, 45V. 계측은 100-500m/z 범위에서 m/z의 오비트랩 검출을 사용하여 단일 HR 스캔 이벤트로 수행되었다. 이온 주입 시간은 300ms, 스캔 시간은 1s였다. 외부 및 내부 교정 절차는 <2ppm 오류를 보장하여 원소 식 예측을 용이하게 한다. 화학식 (XII)을 갖는 N-[2-(5-플루오로-7-니트로-1H-인돌-3-일)에틸]아세트아미드의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XII)
이 4.0분에 용출되었다(EIC, 참조: 도 17a). 표준 절차(Men ndez-Perdomo 등, 2021, Mass Spectrom 56: 34683)에 따라 고에너지 충돌(HCD)을 사용한 추가 분석이 전용 LTQ-후 질소 충돌 셀에서 달성되었다. 오비트랩-기반의 HR 단편 검출을 이용하여(정규화된 충돌 에너지, NCE 35), 다음과 같이 식 (XII)을 갖는 표적화된 실로시빈 유도체의 특징적인 후속 진단 이온 종에 원소 식을 할당할 수 있는 기회를 가능하게 한다(도 17b, 표 1)(Servillo L. 등, 2013, J. Agric. Chem. 61: 5156-5162).
ndez-Perdomo 등, 2021, Mass Spectrom 56: 34683)에 따라 고에너지 충돌(HCD)을 사용한 추가 분석이 전용 LTQ-후 질소 충돌 셀에서 달성되었다. 오비트랩-기반의 HR 단편 검출을 이용하여(정규화된 충돌 에너지, NCE 35), 다음과 같이 식 (XII)을 갖는 표적화된 실로시빈 유도체의 특징적인 후속 진단 이온 종에 원소 식을 할당할 수 있는 기회를 가능하게 한다(도 17b, 표 1)(Servillo L. 등, 2013, J. Agric. Chem. 61: 5156-5162).
표 1
실시예 4 - 제4 다중 치환기 실로시빈 유도체의 생합성
대장균 균주 Ec-1이 유도체화된 인돌 공급원료로부터 식 (XIV)을 갖는 실로시빈 유도체를 생합성하기 위해 사용되었다. Ec-1의 구성은 실시예 1에 기술되어 있다. 조작된 대장균의 대규모 배양 및 물질 저장은 5-플루오로-1H-인돌-6-일아민(www.bldpharm. com)이 6-플루오로-1H-인돌-4-일아민 대신에 사용되었다는 것을 제외하고 실시예 1에 기술된 바와 같이 수행되었다. 조작된 대장균의 대규모 배양 및 처리는 실시예 1에 기술된 대로 수행되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XIV)을 갖는 N-[2-(6-아세틸아미노-5-플루오로-1H-인돌-3-일)에틸]아세트아미드의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XIV)
이 3.2분에 용출되었다(EIC, 참조: 도 18a). 표준 절차(Menndez-Perdomo 등, 2021, Mass Spectrom 56: 34683)에 따라 고에너지 충돌(HCD)을 사용한 추가 분석이 전용 LTQ-후 질소 충돌 셀에서 달성되었다. 오비트랩-기반의 HR 단편 검출을 이용하여(정규화된 충돌 에너지, NCE 35), 다음과 같이 식 (XIV)을 갖는 표적화된 실로시빈 유도체의 특징적인 후속 진단 이온 종에 원소 식을 할당할 수 있는 기회를 가능하게 한다(도 18b, 표 2)(Servillo L. 등, 2013, J. Agric. Chem. 61: 5156-5162).
표 2
실시예 5 - 제4 다중 치환기 실로시빈 유도체의 생합성
대장균 균주 Ec-1이 유도체화된 인돌 공급원료로부터 식 (XV)을 갖는 실로시빈 유도체를 생합성하기 위해 사용되었다. Ec-1의 구성은 실시예 1에 기술되어 있다. 조작된 대장균의 대규모 배양 및 물질 저장은 배양이 24시간 대신 14시간 동안 수행되었고, 5-플루오로-1H-인돌-6-일아민(www.bldpharm.com)이 6-플루오로-1H-인돌-4-일아민 대신에 사용되었다는 것을 제외하고 실시예 1에 기술된 바와 같이 수행되었다. 분석은 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XV)을 갖는 N-[2-(6-아세틸아미노-5-플루오로-1H-인돌-3-일)에틸]아세트아미드의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XV)
이 2.5분에 용출되었다(EIC, 참조: 도 19a). 표준 절차(Menndez-Perdomo 등, 2021, Mass Spectrom 56: 34683)에 따라 고에너지 충돌(HCD)을 사용한 추가 분석이 전용 LTQ-후 질소 충돌 셀에서 달성되었다. 오비트랩-기반의 HR 단편 검출을 이용하여(정규화된 충돌 에너지, NCE 35), 다음과 같이 식 (XV)을 갖는 표적화된 실로시빈 유도체의 특징적인 후속 진단 이온 종에 원소 식을 할당할 수 있는 기회를 가능하게 한다(도 19b, 표 3)(Servillo L. 등, 2013, J. Agric. Chem. 61: 5156-5162).
표 3
실시예 6 - 제6 다중 치환기 실로시빈 유도체의 생합성
대장균 균주 Ec-1이 유도체화된 인돌 공급원료로부터 식 (XVII)을 갖는 실로시빈 유도체를 생합성하기 위해 사용되었다. Ec-1의 구성은 실시예 1에 기술되어 있다. 조작된 대장균의 대규모 배양 및 물질 저장은 4-플루오로-1H-인돌-5-카르보니트릴(www.bldpharm. com)이 6-플루오로-1H-인돌-4-일아민 대신에 사용되었다는 것을 제외하고 실시예 1에 기술된 바와 같이 수행되었다. 조작된 대장균의 대규모 배양 및 처리는 실시예 1에 기술된 대로 수행되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XVII)을 갖는 N-[2-(5-시아노-4-플루오로-1H-인돌-3-일)에틸]아세트아미드의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XVII)
이 4.0분에 용출되었다(EIC, 참조: 도 20).
실시예 7 - 제7 다중 치환기 실로시빈 유도체의 생합성
대장균 균주 Ec-1이 유도체화된 인돌 공급원료로부터 식 (XVIII)을 갖는 실로시빈 유도체를 생합성하기 위해 사용되었다. Ec-1의 구성은 실시예 1에 기술되어 있다. 조작된 대장균의 대규모 배양 및 물질 저장은 6-브로모-1H-인돌-4-올(www.bldpharm. com)이 6-플루오로-1H-인돌-4-일아민 대신에 사용되었다는 것을 제외하고 실시예 1에 기술된 바와 같이 수행되었다. 조작된 대장균의 대규모 배양 및 처리는 실시예 1에 기술된 대로 수행되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XVIII)을 갖는 N-[2-(6-브로모-4-하이드록시-1H-인돌-3-일)에틸]아세트아미드의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XVIII)
이 3.8분에 용출되었다(EIC, 참조: 도 21a). 표준 절차(Menndez-Perdomo 등, 2021, Mass Spectrom 56: 34683)에 따라 고에너지 충돌(HCD)을 사용한 추가 분석이 전용 LTQ-후 질소 충돌 셀에서 달성되었다. 오비트랩-기반의 HR 단편 검출을 이용하여(정규화된 충돌 에너지, NCE 35), 다음과 같이 식 (XVIII)을 갖는 표적화된 실로시빈 유도체의 특징적인 후속 진단 이온 종에 원소 식을 할당할 수 있는 기회를 가능하게 한다(도 21b, 표 4)(Servillo L. 등, 2013, J. Agric. Chem. 61: 5156-5162).
표 4
실시예 8 - 제8 다중 치환기 실로시빈 유도체의 생합성
대장균 균주 Ec-1이 유도체화된 인돌 공급원료로부터 식 (XXI)을 갖는 실로시빈 유도체를 생합성하기 위해 사용되었다. Ec-1의 구성은 실시예 1에 기술되어 있다. 조작된 대장균의 대규모 배양 및 물질 저장은 실시예 1에 기술된 바와 같이 수행되었다. 조작된 대장균의 대규모 배양 및 처리는 실시예 1에 기술된 대로 수행되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XXI)을 갖는 N-[2-(4-아세틸아미노-6-플루오로-1H-인돌-3-일)에틸]아세트아미드의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XXI)
이 3.2분에 용출되었다(EIC, 참조: 도 22a). 현저하게, 본 실시예에서는 실시예 1에서 사용된 공급원료와 비교하여 동일한 인돌 공급원료가 제공되었지만, 생성물(XXI)은 생성물(IX)과 동일하지 않다. 실제로 생성물 (XXI)과 (IX) 둘 모두는 6-플루오로-1H-인돌-4-일아민을 Ec-1에 공급함에 의해 달성된다. 그러나, 실시예 1에서는 생성물(IX)만이 정제되었다. 반대로, 본 실시예에서는 생성물(XXI)만이 분석되었다. 표준 절차(Menndez-Perdomo 등, 2021, Mass Spectrom 56: 34683)에 따라 고에너지 충돌(HCD)을 사용한 추가 분석이 전용 LTQ-후 질소 충돌 셀에서 달성되었다. 오비트랩-기반의 HR 단편 검출을 이용하여(정규화된 충돌 에너지, NCE 35), 다음과 같이 식 (XXI)을 갖는 표적화된 실로시빈 유도체의 특징적인 후속 진단 이온 종에 원소 식을 할당할 수 있는 기회를 가능하게 한다(도 22b, 표 5)(Servillo L. 등, 2013, J. Agric. Chem. 61: 5156-5162).
표 5
실시예 9 - 제9 다중 치환기 실로시빈 유도체의 생합성
대장균 균주 Ec-1이 유도체화된 인돌 공급원료로부터 식 (XXIII)을 갖는 실로시빈 유도체를 생합성하기 위해 사용되었다. Ec-1의 구성은 실시예 1에 기술되어 있다. 조작된 대장균의 대규모 배양 및 물질 저장은 4-플루오로-1H-인돌-7-카르보니트릴(www.bldpharm. com)이 6-플루오로-1H-인돌-4-일아민 대신에 사용되었다는 것을 제외하고 실시예 1에 기술된 바와 같이 수행되었다. 조작된 대장균의 대규모 배양 및 처리는 실시예 1에 기술된 대로 수행되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XXIII)을 갖는 N-[2-(7-시아노-4-플루오로-1H-인돌-3-일)에틸]아세트아미드의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XXIII)
이 3.9분에 용출되었다(EIC, 참조: 도 23a). 표준 절차(Menndez-Perdomo 등, 2021, Mass Spectrom 56: 34683)에 따라 고에너지 충돌(HCD)을 사용한 추가 분석이 전용 LTQ-후 질소 충돌 셀에서 달성되었다. 오비트랩-기반의 HR 단편 검출을 이용하여(정규화된 충돌 에너지, NCE 35), 다음과 같이 식 (XXIII)을 갖는 표적화된 실로시빈 유도체의 특징적인 후속 진단 이온 종에 원소 식을 할당할 수 있는 기회를 가능하게 한다(도 23b, 표 6)(Servillo L. 등, 2013, J. Agric. Chem. 61: 5156-5162).
표 6
실시예 10 - 제10 다중 치환기 실로시빈 유도체의 생합성
대장균 균주 Ec-1이 유도체화된 인돌 공급원료로부터 식 (XXV)을 갖는 실로시빈 유도체를 생합성하기 위해 사용되었다. Ec-1의 구성은 실시예 1에 기술되어 있다. 조작된 대장균의 대규모 배양 및 물질 저장은 4-플루오로-1H-인돌-6-일아민이 6-플루오로-1H-인돌-4-일아민 대신에 사용되었다는 것을 제외하고 실시예 1에 기술된 바와 같이 수행되었다. 조작된 대장균의 대규모 배양 및 처리는 실시예 1에 기술된 대로 수행되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XXV)을 갖는 N-[2-(6-아미노-4-플루오로-1H-인돌-3-일)에틸]아세트아미드의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XXV)
이 4.1분에 용출되었다(EIC, 참조: 도 24). 현저하게, 본 실시예에서는 실시예 2에서 사용된 공급원료와 비교하여 동일한 인돌 공급원료가 제공되었지만, 생성물(XXV)은 생성물(X)과 동일하지 않다. 실제로 생성물 (XXV)과 (X) 둘 모두는 4-플루오로-1H-인돌-6-일아민을 Ec-1에 공급함에 의해 달성된다. 그러나, 실시예 2에서는 생성물(X)만이 정제되었다. 반대로, 본 실시예에서는 생성물(XXV)만이 분석되었다.
실시예 11 - 제11 다중 치환기 실로시빈 유도체의 생합성
대장균 균주 Ec-1이 유도체화된 인돌 공급원료로부터 식 (XXVIII)을 갖는 실로시빈 유도체를 생합성하기 위해 사용되었다. Ec-1의 구성은 실시예 1에 기술되어 있다. 조작된 대장균의 대규모 배양 및 물질 저장은 4-아미노-1H-인돌-6-카르보니트릴(www.bldpharm. com)이 6-플루오로-1H-인돌-4-일아민 대신에 사용되었다는 것을 제외하고 실시예 1에 기술된 바와 같이 수행되었다. 조작된 대장균의 대규모 배양 및 처리는 실시예 1에 기술된 대로 수행되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XXVIII)을 갖는 N-[2-(4-아미노-6-시아노-1H-인돌-3-일)에틸]아세트아미드의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XXVIII)
이 3.3분에 용출되었다(EIC, 참조: 도 25a). 표준 절차(Menndez-Perdomo 등, 2021, Mass Spectrom 56: 34683)에 따라 고에너지 충돌(HCD)을 사용한 추가 분석이 전용 LTQ-후 질소 충돌 셀에서 달성되었다. 오비트랩-기반의 HR 단편 검출을 이용하여(정규화된 충돌 에너지, NCE 35), 다음과 같이 식 (XXVIII)을 갖는 표적화된 실로시빈 유도체의 특징적인 후속 진단 이온 종에 원소 식을 할당할 수 있는 기회를 가능하게 한다(도 25b, 표 7)(Servillo L. 등, 2013, J. Agric. Chem. 61: 5156-5162).
표 7
실시예 12 - 제12 다중 치환기 실로시빈 유도체의 생합성
대장균 균주 Ec-1이 유도체화된 인돌 공급원료로부터 식 (XX)을 갖는 실로시빈 유도체를 생합성하기 위해 사용되었다. Ec-1의 구성은 실시예 1에 기술되어 있다. 조작된 대장균의 대규모 배양 및 물질 저장은 4-플루오로-1H-인돌-5-올(www.bldpharm. com)이 6-플루오로-1H-인돌-4-일아민 대신에 사용되었다는 것을 제외하고 실시예 1에 기술된 바와 같이 수행되었다. 조작된 대장균의 대규모 배양 및 처리는 실시예 1에 기술된 대로 수행되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XX)을 갖는 N-[2-(4-플루오로-5-하이드록시-1H-인돌-3-일)에틸]아세트아미드의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XX)
이 3.1분에 용출되었다(EIC, 참조: 도 26).
실시예 13 - 제13 다중 치환기 실로시빈 유도체의 생합성
대장균 균주 Ec-2가 유도체화된 인돌 공급원료로부터 식 (XIII)을 갖는 실로시빈 유도체를 생합성하기 위해 사용되었다. 대장균 균주 Ec-2는 다음과 같이 구축되었다. 플라스미드 클로닝을 위해, 항생제 마커에 의존하여 Top10 또는 XL1-blue 균주가 사용되었다. 표준 LB 배지를 배양을 위해 사용했다. 유전자 발현 및 피딩 실험을 위해 이용된 모 숙주 균주는 BL21(DE3)이었다. 플라스미드 pET28a(+)-PfTrpB-B0A9-HIS 및 pCDM4-BaTDC-HIS를 실시예 1에 기술된 바와 같이 생성했다. 표적 플라스미드 pET28a(+)-PfTrpB-B0A9-HIS 및 pCDM4-BaTDC-HIS를 다음과 같이 BL21(DE3) 세포 안으로 형질전환시켰다: pCDM4-BaTDC-HIS를 먼저 BL21(DE3) 안으로 형질전환시켰다. 스트렙토마이신을 사용하여 선택된 형질전환체를 다음으로 pET28a(+)-PfTrpB-B0A9-HIS로 형질전환시키고 스트렙토마이신과 카나마이신 둘 모두로 선택했다. 조작된 대장균의 대규모 배양 및 물질 저장은 (1) 스트렙토마이신 및 카나마이신만이 선택 목적으로 사용되었고; (2) 5-플루오로-7-니트로-1H-인돌(www.bldpharm.com)이 6-플루오로-1H-인돌-4-일아민 대신에 사용되었다는 것을 제외하고 실시예 1에 기술된 바와 같이 수행되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XIII)을 갖는 2-(5-플루오로-7-니트로-1H-인돌-3-일)에틸아민의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XIII)
이 3.3분에 용출되었다(EIC, 참조: 도 27).
실시예 14 - 제14 다중 치환기 실로시빈 유도체의 생합성
대장균 균주 Ec-2가 유도체화된 인돌 공급원료로부터 식 (XVI)을 갖는 실로시빈 유도체를 생합성하기 위해 사용되었다. Ec-2의 구성은 실시예 13에 기술되어 있다. 조작된 대장균의 대규모 배양 및 물질 저장은 5-플루오로-1H-인돌-6-일아민(www.bldpharm. com)이 5-플루오로-7-니트로-1H-인돌 대신에 사용되었다는 것을 제외하고 실시예 13에 기술된 바와 같이 수행되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XVI)을 갖는 3-(2-아미노에틸)-5-플루오로-1H-인돌-6-아민의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XVI)
이 2.9분에 용출되었다(EIC, 참조: 도 28).
실시예 15 - 제15 다중 치환기 실로시빈 유도체의 생합성
대장균 균주 Ec-2가 유도체화된 인돌 공급원료로부터 식 (XVI)을 갖는 실로시빈 유도체를 생합성하기 위해 사용되었다. Ec-2의 구성은 실시예 13에 기술되어 있다. 조작된 대장균의 대규모 배양 및 물질 저장은 4-플루오로-1H-인돌-5-카르보니트릴(www.bldpharm. com)이 5-플루오로-7-니트로-1H-인돌 대신에 사용되었다는 것을 제외하고 실시예 13에 기술된 바와 같이 수행되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XIX)을 갖는 3-(2-아미노에틸)-4-플루오로-1H-인돌-5-카르보니트릴의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XIX)
이 3.2분에 용출되었다(EIC, 참조: 도 29).
실시예 16 - 제16 다중 치환기 실로시빈 유도체의 생합성
대장균 균주 Ec-2가 유도체화된 인돌 공급원료로부터 식 (XXII)을 갖는 실로시빈 유도체를 생합성하기 위해 사용되었다. Ec-2의 구성은 실시예 13에 기술되어 있다. 조작된 대장균의 대규모 배양 및 물질 저장은 6-플루오로-1H-인돌-4-일아민(www.bldpharm. com)이 5-플루오로-7-니트로-1H-인돌 대신에 사용되었다는 것을 제외하고 실시예 13에 기술된 바와 같이 수행되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XXII)을 갖는 3-(2-아미노에틸)-6-플루오로-1H-인돌-4-아민의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XXII)
이 1.4분에 용출되었다(EIC, 참조: 도 30).
실시예 17 - 제17 다중 치환기 실로시빈 유도체의 생합성
대장균 균주 Ec-2가 유도체화된 인돌 공급원료로부터 식 (XXVI)을 갖는 실로시빈 유도체를 생합성하기 위해 사용되었다. Ec-2의 구성은 실시예 13에 기술되어 있다. 조작된 대장균의 대규모 배양 및 물질 저장은 3-(2-아미노에틸)-4-플루오로-1H-인돌-6-아민(www.bldpharm. com)이 5-플루오로-7-니트로-1H-인돌 대신에 사용되었다는 것을 제외하고 실시예 13에 기술된 바와 같이 수행되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XXVI)을 갖는 3-(2-아미노에틸)-4-플루오로-1H-인돌-6-아민의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XXVI)
이 0.6분에 용출되었다(EIC, 참조: 도 31).
실시예 18 - 제18 다중 치환기 실로시빈 유도체의 생합성
대장균 균주 Ec-2가 유도체화된 인돌 공급원료로부터 식 (XXIX)을 갖는 실로시빈 유도체를 생합성하기 위해 사용되었다. Ec-2의 구성은 실시예 13에 기술되어 있다. 조작된 대장균의 대규모 배양 및 물질 저장은 4-아미노-1H-인돌-6-카르보니트릴(www.bldpharm. com)이 5-플루오로-7-니트로-1H-인돌 대신에 사용되었다는 것을 제외하고 실시예 13에 기술된 바와 같이 수행되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XXIX)을 갖는 4-아미노-3-(2-아미노에틸)-1H-인돌-6-카르보니트릴의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XXIX)
이 2.6분에 용출되었다(EIC, 참조: 도 32a). 표준 절차(Menndez-Perdomo 등, 2021, Mass Spectrom 56: 34683)에 따라 고에너지 충돌(HCD)을 사용한 추가 분석이 전용 LTQ-후 질소 충돌 셀에서 달성되었다. 오비트랩-기반의 HR 단편 검출을 이용하여(정규화된 충돌 에너지, NCE 35), 다음과 같이 식 (XXIX)을 갖는 표적화된 실로시빈 유도체의 특징적인 후속 진단 이온 종에 원소 식을 할당할 수 있는 기회를 가능하게 한다(도 32b, 표 8)(Servillo L. 등, 2013, J. Agric. Chem. 61: 5156-5162).
표 8
실시예 19 - 제19 다중 치환기 실로시빈 유도체의 생합성
대장균 균주 Ec-3이 유도체화된 인돌 공급원료로부터 식 (XXVII)을 갖는 실로시빈 유도체를 생합성하기 위해 사용되었다. 대장균 균주 Ec-2는 다음과 같이 구축되었다. 플라스미드 클로닝을 위해, 항생제 마커에 의존하여 Top10 또는 XL1-blue 균주가 사용되었다. 표준 LB 배지를 배양을 위해 사용했다. 유전자 발현 및 피딩 실험을 위해 이용된 모 숙주 균주는 BL21(DE3)이었다. 먼저, 플라스미드 pET28a(+)-EsNMT-HIS는 pET28a(+)의 NdeI/XhoI 부위(서열번호: 36) 안으로 인-프레임, HIS 태깅된(서열번호: 46) EsNMT 유전자(서열번호: 11)를 삽입함에 의해 생성되었다. 두 번째 단계로서, 플라스미드 pCDM4(서열번호: 35)로부터, 플라스미드 pCDM4-PsiD-HIS는 pCDM4의 NdeI/XhoI 부위 안으로 인-프레임, HIS-태깅된(서열번호: 46) PsiD 유전자(서열번호: 7)를 삽입함에 의해 생성되었다. 이들 표적 플라스미드는 다음과 같이 BL21(DE3) 세포 안으로 순차적으로 형질전환되었다: pCDM4-PsiD-HIS는 먼저 BL21(DE3) 안으로 형질전환되었다. 스트렙토마이신을 사용하여 선택된 형질전환체를 다음으로 pET28a(+)-EsNMT-HIS로 형질전환시키고 스트렙토마이신과 카나마이신 둘 모두로 선택했다. 조작된 대장균의 대규모 배양 및 물질 저장은 (1) 스트렙토마이신 및 카나마이신만이 선택 목적으로 사용되었고; (2) 4-아미노-1H-인돌-6-카르보니트릴(www.bldpharm.com)이 6-플루오로-1H-인돌-4-일아민 대신에 사용되었다는 것을 제외하고 실시예 1에 기술된 바와 같이 수행되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XXVII)을 갖는 4-아미노-3-[2-(메틸아미노)에틸]-1H-인돌-6-카르보니트릴의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XXVII)
이 2.6분에 용출되었다(EIC, 참조: 도 33).
실시예 20 - 제20 다중 치환기 실로시빈 유도체의 생합성
효모(사카로마이세스 세래비지애) 균주 Sc-1이 최종 생성물을 생성하도록 상업적으로 획득되고 유도체화된 인돌, 트립토판 또는 트립타민 공급원료의 생물전환을 가능하게 하는, 모 효모 균주의 유전적 조작을 통해 생성되었다. 모 효모(사카로마이세스 세래비지애) 균주는 유전자형 Matα; ura3-52; trp1-289; leu2-3,112; his3Δ1; MAL2-8C; SUC2를 갖는 CEN.PK였다. 모 균주는 3가지 효소적 단계를 촉매작용하는 7DMATS(서열번호: 16), ClostSporTDC(서열번호: 6) 및 PsmF(서열번호: 10)를 포함하도록 조작되었다. 조작은 또한 CPR(서열번호: 26)을 포함하였지만 이 효소는 생물전환 과정에 사용되지 않았다. 7DMATS, ClostSporTDC 및 CPR은 이전에 기술된 바와 같이 합체 카세트의 염색체 상동성 재조합을 통해 균주에 포함되었다(Dastmalchi 등, 2019, Nat. Chem Biol. 15: 384-390; Chen 등, 2018, Nat. Chem Biol. 14: 738-743). 반대로, PsmF는 단백질 발현 플라스미드 안으로 구축되어 이미 7DMATS, ClostSporTDC 및 CPR을 담지하는 게놈으로 합체된 균주로 형질전환되었다. 7DMATS, ClostSporTDC 및 CPR은 각각 인-프레임, C-말단 HIS(서열번호: 46, 서열번호: 47), FLAG(서열번호: 42, 서열번호: 43), 및 c-MYC(서열번호: 40, 서열번호: 41) 에피토프 태그의 부가로, 각각 서열번호: 15, 서열번호: 5 및 서열번호: 25에 의해 인코딩되었다. 합체 카세트는 구성적 유전자 발현을 가능하게 하는 기술된 바와 같이(Dastmalchi 등, 2019; Chen 등, 2018) S. 세래비지애 게놈 DNA로부터 증폭된 효모 프로모터 서열을 사용하여 구축되었다. 증폭된 프로모터는 PGK1(서열번호: 30), TDH3(서열번호: 31), CLN1(서열번호: 32) 및 UGA1(서열번호: 33)을 포함했다. 2개의 합체 카세트가 조립되었다: 첫 번째, (X-3)::TADH1-ClostSporTDC-Flag-PPGK1-PTDH3-CPR-c-myc-TCYC1(서열번호: 52), 정박된 태깅된 ClostSporTDC 및 CPR. 두 번째(Xii-2)::PTDH3-7DMATS-His-TCYC1(서열번호: 53) 정박된 단지 태깅된 7DMATS. 이들 카세트의 연속적인 게놈 합체는 이전에 기술된 바와 같이 수행되었다(Chen 등, 2018). 이들 두 카세트의 안정적인 합체에 이어서, 균주는 임의로 섞인 N-아세틸트랜스퍼라제인 PsmF(pMM1-pTDH3-PsmF-His-tCYC1)를 인코딩하는 효모 에피솜 벡터로 형질전환에 의해 추가로 조작되었다. pMM1-pTDH3-PsmF-His-tCYC1의 구축을 위해, HIS 에피토프 태그(서열번호: 46)와 인-프레임 융합된 유전자 PsmF(서열번호: 9)를 BamHI/SacII 제한 부위를 사용하여 빈 플라스미드 pMM1(서열번호: 34)에 결찰시켰다. 본 실시예의 경우, 내인성 트립토판 신타제 활성이 충분한 것으로 입증되었으므로 비-천연 또는 조작된 TrpB 유전자의 이종성 발현은 필요하지 않았다. 최종 조작된 균주는 Sc-1로 지칭된다. 유도체 생성물의 대규모 생산을 위해, 다음과 같이 배양을 수행하였다. 종자 배양액을 SD-드롭-아웃 배지에 밤새 접종하였다. 그런 다음 밤새 배양액을 Sc-1에 의한 전환을 위해 2%(w/v) 글루코스, 0.3%(w/v) KH2PO4, 0.05% (w/v) MgSO4.7H2O, 0.5% (w/v) (NH4)2SO4 플러스 500μM 4-클로로-1H-인돌(www.combi-blocks.com)을 함유하는 각각의 SD-드롭-아웃 배지 500mL을 함유하는 2개의 플라스크로 분주하였다. 효모 배양액을 48시간 동안 배양했다. 그런 다음 배양액을 원심분리(10,000g × 5분)하여 세포 내용물을 제거하고 분비된 유도체 생성물를 함유하는 배양 브로쓰를 추가 처리 때까지 -80℃에 보관했다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XXXIV)을 갖는 N-(2-[4-클로로-7-(3-메틸-2-부테닐)-1H-인돌-3-일]에틸)아세트아미드의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XXXIV).
이 5.2분에 용출되었다(EIC, 참조: 도 34a). 표준 절차(Menndez-Perdomo 등, 2021, Mass Spectrom 56: 34683)에 따라 고에너지 충돌(HCD)을 사용한 추가 분석이 전용 LTQ-후 질소 충돌 셀에서 달성되었다. 오비트랩-기반의 HR 단편 검출을 이용하여(정규화된 충돌 에너지, NCE 35), 다음과 같이 식 (XXXIV)을 갖는 표적화된 실로시빈 유도체의 특징적인 후속 진단 이온 종에 원소 식을 할당할 수 있는 기회를 가능하게 한다(도 34b, 표 9)(Servillo L. 등, 2013, J. Agric. Chem. 61: 5156-5162).
표 9
실시예 21 - 제21 다중 치환기 실로시빈 유도체의 생합성
실시예 20에 기술된 동일한 효모 균주(Sc-1) 및 절차를 사용하여, 다음을 제외하고, 화학식 (XXXIII)을 갖는 실로시빈 유도체를 생합성했다: 4-클로로-1H-인돌 대신에, 500μM 5-플루오로-1H-인돌(Combi-Blocks, www.combi-blocks.com)이 생물전환을 위한 공급원료로 공급되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XXXII)을 갖는 2-[5-플루오로-7-(3-메틸-2-부테닐)-1H-인돌-3-일]에틸아민의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XXXII)
이 4.9분에 용출되었다(EIC, 참조: 도 35a). 표준 절차(Menndez-Perdomo 등, 2021, Mass Spectrom 56: 34683)에 따라 고에너지 충돌(HCD)을 사용한 추가 분석이 전용 LTQ-후 질소 충돌 셀에서 달성되었다. 오비트랩-기반의 HR 단편 검출을 이용하여(정규화된 충돌 에너지, NCE 35), 다음과 같이 식 (XXXII)을 갖는 표적화된 실로시빈 유도체의 특징적인 후속 진단 이온 종에 원소 식을 할당할 수 있는 기회를 가능하게 한다(도 35b, 표 10)(Servillo L. 등, 2013, J. Agric. Chem. 61: 5156-5162).
표 10
실시예 22 - 제22 다중 치환기 실로시빈 유도체의 생합성
실시예 20에 기술된 동일한 효모 균주(Sc-1) 및 절차를 사용하여, 다음을 제외하고, 화학식 (XXXIII)을 갖는 실로시빈 유도체를 생합성했다: 4-클로로-1H-인돌 대신에, 500μM 5-플루오로-1H-인돌(Combi-Blocks, www.combi-blocks.com)이 생물전환을 위한 공급원료로 공급되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XXXIII)을 갖는 2-[5-플루오로-7-(3-메틸-2-부테닐)-1H-인돌-3-일]에틸)아세트아미드의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XXXIII)
이 4.2분에 용출되었다(EIC, 참조: 도 36). 현저하게, 본 실시예에서는 실시예 21에서 사용된 공급원료와 비교하여 동일한 인돌 공급원료가 제공되었지만, 생성물(XXXII)은 생성물(XXXIII)과 동일하지 않다. 실제로 생성물 (XXXII)과 (XXXIII) 둘 모두는 5-플루오로-1H-인돌을 Sc-1에 공급함에 의해 달성된다. 그러나, 실시예 21에서는 생성물(XXXII)만이 정제되었다. 반대로, 본 실시예에서는 생성물(XXXIII)만이 분석되었다.
실시예 23 - 제23 다중 치환기 실로시빈 유도체의 생합성
실시예 20에 기술된 동일한 효모 균주(Sc-1) 및 절차를 사용하여, 다음을 제외하고, 화학식 (XLIX)을 갖는 실로시빈 유도체를 생합성했다: 4-클로로-1H-인돌 대신에, 500μM 1H-인돌-4-올(Combi-Blocks, www.combi-blocks.com)이 생물전환을 위한 공급원료로 공급되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XLIX)을 갖는 2-아미노-3-[4-하이드록시-7-(3-메틸-2-부테닐)-1H-인돌-3-일]프로피온산의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XLIX)
이 3.8분에 용출되었다(EIC, 참조: 도 37). 현저하게, 화합물(XLIX)은 Sc-1에 ClostSporTDC 효소의 존재에도 불구하고 카르복실산기를 유지한다. 화합물(XLIX)의 탈카르복실화된 버전은 배양 배지에서 검출가능하지 않았는데, 이는 아마도 수산화된 기질을 수용하는 ClostSporTDC 효소의 본질적인 불능에 기인할 수 있다.
실시예 24 - 제24 다중 치환기 실로시빈 유도체의 생합성
효모(사카로마이세스 세레비시애) 균주 Sc-2가 최종 생성물을 생성하도록 상업적으로 획득되고 유도체화된 인돌, 트립토판 또는 트립타민 공급원료의 생물전환을 가능하게 하는, 모 효모 균주의 플라스미드 형질전환을 통해 생성되었다. 모 효모(사카로마이세스 세래비지애) 균주는 유전자형 Matα; ura3-52; trp1-289; leu2-3,112; his3Δ1; MAL2-8C; SUC2를 갖는 CEN.PK였다. 모 균주는 HIS-태깅된(서열번호: 46, 서열번호: 47), 임의로 섞인 6-프레닐트랜스퍼라제 효소 PriB(서열번호: 18)를 인코딩하는 효모 에피솜 벡터(pMM1-pTDH3-PriB-His-tCYC1)로 형질전환되었다. pMM1-pTDH3-PriB-His-tCYC1의 구축을 위해, HIS 에피토프 태그(서열번호: 46)로 인-프레임 융합된 유전자 PriB(서열번호: 17)를 BamHI/SacII 제한 부위를 사용하여 빈 플라스미드 pMM1(서열번호: 34)에 결찰시켰다. 본 실시예의 경우, 내인성 트립토판 신타제 활성이 충분한 것으로 입증되었으므로 비-천연 또는 조작된 TrpB 유전자의 이종성 발현은 필요하지 않았다. 최종 조작된 균주는 Sc-2로 지칭된다. 유도체 생성물의 대규모 생산을 위해, 배양은 다음을 제외하고 실시예 20에 기술된 바와 같이 수행되었다: 4-클로로-1H-인돌 대신에 500μM 1H-인돌-4-올(Combi-Blocks, www.combi-blocks.com)이 생물전환을 위한 공급원료로 공급되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (L)을 갖는 2-아미노-3-[4-하이드록시-6-(3-메틸-2-부테닐)-1H-인돌-3-일]프로피온산의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(L)
이 3.8분에 용출되었다(EIC, 참조: 도 38).
실시예 25 - 제25 다중 치환기 실로시빈 유도체의 생합성
실시예 24에 기술된 동일한 효모 균주(Sc-2) 및 절차를 사용하여, 다음을 제외하고, 화학식 (XLVIII)을 갖는 실로시빈 유도체를 생합성했다: 1H-인돌-4-올 대신에, 5-브로모-1H-인돌(Combi-Blocks, www.combi-blocks.com)이 생물전환을 위한 공급원료로 공급되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XLVIII)을 갖는 2-아미노-3-[5-브로모-6-(3-메틸-2-부테닐)-1H-인돌-3-일]프로피온산의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XLVIII)
이 4.2분에 용출되었다(EIC, 참조: 도 39).
실시예 26 - 제26 다중 치환기 실로시빈 유도체의 생합성
효모(사카로마이세스 세레비시애) 균주 Sc-3이 최종 생성물을 생성하도록 상업적으로 획득되고 유도체화된 인돌, 트립토판 또는 트립타민 공급원료의 생물전환을 가능하게 하는, 모 효모 균주의 플라스미드 형질전환을 통해 생성되었다. 모 효모(사카로마이세스 세래비지애) 균주는 유전자형 Matα; ura3-52; trp1-289; leu2-3,112; his3Δ1; MAL2-8C; SUC2를 갖는 CEN.PK였다. 모 균주는 5-프레닐트랜스퍼라제 효소 SCO7467(서열번호: 20)을 인코딩하는 효모 에피솜 벡터(pMM1-pTDH3-SCO7467-tCYC1)로 형질전환시켰다. pMM1-pTDH3-SCO7467-tCYC1의 구축을 위해, 유전자 SCO7467(서열번호: 19)을 BamHI/SacII 제한 부위를 사용하여 빈 플라스미드 pMM1(서열번호: 34)에 결찰시켰다. 본 실시예의 경우, 내인성 트립토판 신타제 활성이 충분한 것으로 입증되었으므로 비-천연 또는 조작된 TrpB 유전자의 이종성 발현은 필요하지 않았다. 최종 조작된 균주는 Sc-3으로 지칭되었다. 유도체 생성물의 대규모 생산을 위해, 배양은 다음을 제외하고 실시예 20에 기술된 바와 같이 수행되었다: 4-클로로-1H-인돌 대신에 500μM 1H-인돌-4-올(Combi-Blocks, www.combi-blocks.com)이 생물전환을 위한 공급원료로 공급되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (LI)을 갖는 2-아미노-3-[4-하이드록시-5-(3-메틸-2-부테닐)-1H-인돌-3-일]프로피온산의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(LI)
이 3.8분에 용출되었다(EIC, 참조: 도 40).
실시예 27 - 제27 다중 치환기 실로시빈 유도체의 생합성
효모(사카로마이세스 세래비지애) 균주 Sc-4는 최종 생성물을 생성하도록 상업적으로 획득되고 유도체화된 인돌, 트립토판 또는 트립타민 공급원료의 생물전환을 가능하게 하는, 모 효모 균주의 유전적 조작을 통해 생성되었다. 모 효모(사카로마이세스 세래비지애) 균주는 유전자형 Matα; ura3-52; trp1-289; leu2-3,112; his3Δ1; MAL2-8C; SUC2를 갖는 CEN.PK였다. 모 균주는 3가지 효소적 단계를 촉매작용하는 PriB(서열번호: 18), BaTDC(서열번호: 4) 및 PsmF(서열번호: 10)를 포함하도록 조작되었다. 조작은 또한 CPR(서열번호: 26)을 포함하였지만 이 효소는 생물전환 과정에 사용되지 않았다. PriB, BaTDC 및 CPR은 이전에 기술된 바와 같이 합체 카세트의 염색체 상동성 재조합을 통해 균주에 포함되었다(Dastmalchi 등, 2019, Nat. Chem Biol. 15: 384-390; Chen 등, 2018, Nat. Chem Biol. 14: 738-743). 반대로, PsmF는 단백질 발현 플라스미드 안으로 구축되어 이미 PriB, BaTDC 및 CPR을 담지하는 게놈으로 합체된 균주로 형질전환되었다. PriB, BaTDC 및 CPR은 각각 인-프레임, C-말단 HIS(서열번호: 46, 서열번호: 47), FLAG(서열번호: 42, 서열번호: 43), 및 c-MYC(서열번호: 40, 서열번호: 41) 에피토프 태그의 부가로, 각각 서열번호: 17, 서열번호: 3 및 서열번호: 25에 의해 인코딩되었다. 합체 카세트는 구성적 유전자 발현을 가능하게 하는 기술된 바와 같이(Dastmalchi 등, 2019; Chen 등, 2018) S. 세래비지애 게놈 DNA로부터 증폭된 효모 프로모터 서열을 사용하여 구축되었다. 증폭된 프로모터는 PGK1(서열번호: 30), TDH3(서열번호: 31), CLN1(서열번호: 32) 및 UGA1(서열번호: 33)을 포함했다. 2개의 합체 카세트가 조립되었다: 첫 번째, (X-3)::TADH1-BaTDC-Flag-PPGK1-PTDH3-CPR-c-myc-TCYC1(서열번호: 50), 정박된 태깅된 BaTDC 및 CPR. 두 번째(Xii-2)::PTDH3-PriB-His-TCYC1(서열번호: 51) 정박된 단지 태깅된 PriB. 이들 카세트의 연속적인 게놈 합체는 이전에 기술된 바와 같이 수행되었다(Chen 등, 2018). 이들 두 카세트의 안정적인 합체에 이어서, 균주는 임의로 섞인 N-아세틸트랜스퍼라제인 PsmF(pMM1-pTDH3-PsmF-His-tCYC1)를 인코딩하는 효모 에피솜 벡터로 형질전환에 의해 추가로 조작되었다. pMM1-pTDH3-PsmF-His-tCYC1의 구축을 위해, HIS 에피토프 태그(서열번호: 46)와 인-프레임 융합된 유전자 PsmF(서열번호: 9)를 BamHI/SacII 제한 부위를 사용하여 빈 플라스미드 pMM1(서열번호: 46)에 결찰시켰다. 본 실시예의 경우, 내인성 트립토판 신타제 활성이 충분한 것으로 입증되었으므로 비-천연 또는 조작된 TrpB 유전자의 이종성 발현은 필요하지 않았다. 최종 조작된 균주는 Sc-4로 지칭된다. 유도체 생성물의 대규모 생산을 위해, 배양은 다음을 제외하고 실시예 20에 기술된 바와 같이 수행되었다: 4-클로로-1H-인돌 대신에 500μM 5-클로로-1H-인돌(Combi-Blocks, www.combi-blocks.com)이 생물전환을 위한 공급원료로 공급되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XXXVII)을 갖는 N-(2-[5-클로로-6-(3-메틸-2-부테닐)-1H-인돌-3-일]에틸)아세트아미드의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XXXVII)
이 5.1분에 용출되었다(EIC, 참조: 도 41).
실시예 28 - 제28 다중 치환기 실로시빈 유도체의 생합성
실시예 27에 기술된 동일한 효모 균주(Sc-4) 및 절차를 사용하여, 다음을 제외하고, 화학식 (XXXV)의 실로시빈 유도체를 생합성했다: 5-클로로-1H-인돌 대신, 500μM 5-플루오로-1H-인돌(Combi-Blocks, www.combi-blocks.com)이 생물전환을 위한 공급원료로 공급되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XXXV)을 갖는 N-(2-[5-플루오로-6-(3-메틸-2-부테닐)-1H-인돌-3-일]에틸)아세트아미드의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XXXV)
이 3.8분에 용출되었다(EIC, 참조: 도 42).
실시예 29 - 제29 다중 치환기 실로시빈 유도체의 생합성
효모(사카로마이세스 세레비시애) 균주 Sc-5는 Sc-4를 조립하는 과정에서 중간체로 수득되었다. Sc-5 균주는 Sc-5가 임의로 섞인 N-아세틸트랜스퍼라제인 PsmF(서열번호: 10)를 인코딩하는 추가 에피솜 벡터(pMM1-pTDH3-PsmF-His-tCYC1)를 담지하지 않는다는 점을 제외하면 Sc-4와 본질적으로 동일하다. 따라서, Sc-5는 유도체 형성에 참여하는 염색체 합체 - BaTDC(서열번호: 4)와 PriB(서열번호: 18)를 통해 2가지 효소만 호스팅한다. 세 번째 효소인 CPR(서열번호: 26)은 유사하게 합체되지만 유도체 생산에는 기여하지 않는다. 내인성 트립토판 신타제 활성이 충분하다는 것이 입증되었으므로 비-천연 또는 조작된 TrpB 유전자의 이종성 발현은 필요하지 않았다. 유도체 생성물의 대규모 생산을 위해, 배양은 다음을 제외하고 실시예 20에 기술된 바와 같이 수행되었다: 4-클로로-1H-인돌 대신에 500μM 5-플루오로-1H-인돌(Combi-Blocks, www.combi-blocks.com)이 생물전환을 위한 공급원료로 공급되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XXXVI)을 갖는 2-[5-플루오로-6-(3-메틸-2-부테닐)-1H-인돌-3-일]에틸아민의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XXXVI)
이 4.3분에 용출되었다(EIC, 참조: 도 43). 표준 절차(Menndez-Perdomo 등, 2021, Mass Spectrom 56: 34683)에 따라 고에너지 충돌(HCD)을 사용한 추가 분석이 전용 LTQ-후 질소 충돌 셀에서 달성되었다. 오비트랩-기반의 HR 단편 검출을 이용하여(정규화된 충돌 에너지, NCE 35), 다음과 같이 식 (XXXVI)을 갖는 표적화된 실로시빈 유도체의 특징적인 후속 진단 이온 종에 원소 식을 할당할 수 있는 기회를 가능하게 한다(도 43b, 표 11)(Servillo L. 등, 2013, J. Agric. Chem. 61: 5156-5162).
표 11
실시예 30 - 제30 다중 치환기 실로시빈 유도체의 생합성
실시예 29에 기술된 동일한 효모 균주(Sc-5) 및 절차를 사용하여, 다음을 제외하고, 화학식 (XXXVIII)을 갖는 실로시빈 유도체를 생합성했다: 5-플루오로-1H-인돌 대신, 500μM 5-클로로-1H-인돌(Combi-Blocks, www.combi-blocks.com)이 생물전환을 위한 공급원료로 공급되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XXXVIII)을 갖는 2-[5-클로로-6-(3-메틸-2-부테닐)-1H-인돌-3-일]에틸아민의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XXXVIII)
이 4.4분에 용출되었다(EIC, 참조: 도 44).
실시예 31 - 제31 다중 치환기 실로시빈 유도체의 생합성
효모(사카로마이세스 세래비지애) 균주 Sc-6이 최종 생성물을 생성하도록 상업적으로 획득되고 유도체화된 인돌, 트립토판 또는 트립타민 공급원료의 생물전환을 가능하게 하는, 모 효모 균주의 유전적 조작을 통해 생성되었다. 모 효모(사카로마이세스 세래비지애) 균주는 유전자형 Matα; ura3-52; trp1-289; leu2-3,112; his3Δ1; MAL2-8C; SUC2를 갖는 CEN.PK였다. 모 균주는 여러 효소적 단계를 촉매작용하거나 지지하는 PsiH(서열번호: 24), CPR(서열번호: 26), ClostSporTDC(서열번호: 6) 및 PsiM(서열번호: 14)을 포함하도록 조작되었다. 조작은 또한 PsiK(서열번호: 49)을 포함하였지만 이 효소는 생물전환 과정에 기여할 수 있는 것으로 보이지 않았다. PsiH, CPR, PsiM 및 PsiK는 이전에 기술된 바와 같이 합체 카세트의 염색체 상동성 재조합을 통해 균주에 포함되었다(Dastmalchi 등, 2019, Nat. Chem Biol. 15: 384-390; Chen 등, 2018, Nat. Chem Biol. 14: 738-743). 반대로, ClostSporTDC는 단백질 발현 플라스미드 안으로 구축되어 이미 PsiH, CPR, PsiM 및 PsiK를 담지하는 게놈으로 합체된 균주로 형질전환되었다. PsiH, CPR, ClostSporTDC 및 PsiM은 각각 인-프레임, C-말단 HA(서열번호: 38, 서열번호: 39), c-MYC(서열번호: 40, 서열번호: 41), HIS(서열번호: 46, 서열번호: 47) 및 FLAG(서열번호: 42, 서열번호: 43) 에피토프 태그의 부가로, 각각 서열번호: 23, 서열번호: 25, 서열번호: 5, 및 서열번호: 13에 의해 인코딩되었다. 합체 카세트는 구성적 유전자 발현을 가능하게 하는 기술된 바와 같이(Dastmalchi 등, 2019; Chen 등, 2018) S. 세래비지애 게놈 DNA로부터 증폭된 효모 프로모터 서열을 사용하여 구축되었다. 증폭된 프로모터는 PGK1(서열번호: 30), TDH3(서열번호: 31), CLN1(서열번호: 32) 및 UGA1(서열번호: 33)을 포함했다. 2개의 합체 카세트가 조립되었다: 첫 번째, XII-4::TADH1-PsiH-HA-PPGK1-PTDH3-CPR-c-myc-TCYC1(서열번호: 27), 정박된 태깅된 PsiH 및 CPR. 두 번째, XII-5::TADH1-PsiK-V5-PPGK1-PTDH3-PsiM-FLAG-TCYC1(서열번호: 28), 정박된 태깅된 PsiK 및 PsiM. 이들 카세트의 연속적인 게놈 합체는 이전에 기술된 바와 같이 수행되었다(Chen 등, 2018). 이들 두 카세트의 안정적인 합체에 이어서, 균주는 ClostSporTDC(pMM1-pTDH3-ClostSpor-His-tCYC1)를 인코딩하는 효모 에피솜 벡터로 형질전환에 의해 추가로 조작되었다. pMM1-pTDH3-ClostSpor-His-tCYC1의 구축을 위해, HIS 에피토프 태그(서열번호: 46)와 인-프레임 융합된 유전자 ClostSporTDC(서열번호: 5)를 BamHI/SacII 제한 부위를 사용하여 빈 플라스미드 pMM1(서열번호: 34)에 결찰시켰다. 본 실시예의 경우, 내인성 트립토판 신타제 활성이 충분한 것으로 입증되었으므로 비-천연 또는 조작된 TrpB 유전자의 이종성 발현은 필요하지 않았다. 최종 조작된 균주는 Sc-6으로 지칭된다. Sc-6을 이용하여, 실시예 20에 기술된 동일한 절차를 사용하여, 다음을 제외하고, 화학식 (XL)을 갖는 실로시빈 유도체를 생합성했다: 4-클로로-1H-인돌 대신에, 500μM 6-클로로-1H-인돌(Combi-Blocks, www.combi-blocks.com)이 생물전환을 위한 공급원료로 공급되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XL)을 갖는 6-클로로-3-[2-(디메틸아미노)에틸]-1H-인돌-4-올의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XL)
이 0.38분에 용출되었다(EIC, 참조: 도 45).
실시예 32 - 제32 다중 치환기 실로시빈 유도체의 생합성
실시예 31에 기술된 동일한 효모 균주(Sc-6) 및 절차를 사용하여, 다음을 제외하고, 화학식 (XXXIX)을 갖는 실로시빈 유도체를 생합성했다: 4-클로로-1H-인돌 대신에, 500μM 7-클로로-1H-인돌(Combi-Blocks, www.combi-blocks.com)이 생물전환을 위한 공급원료로 공급되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XXXIX)을 갖는 7-클로로-3-[2-(디메틸아미노)에틸]-1H-인돌-4-올의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XXXIX)
이 3.1분에 용출되었다(EIC, 참조: 도 46).
실시예 33 - 제33 다중 치환기 실로시빈 유도체의 생합성
실시예 31에 기술된 동일한 효모 균주(Sc-6) 및 절차를 사용하여, 다음을 제외하고, 화학식 (LII)을 갖는 실로시빈 유도체를 생합성했다: 4-클로로-1H-인돌 대신에, 500μM 6-플루오로-1H-인돌(Combi-Blocks, www.combi-blocks.com)이 생물전환을 위한 공급원료로 공급되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (LII)을 갖는 3-(2-아미노에틸)-6-플루오로-1H-인돌-4-올의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(LIII)
이 2.3분에 용출되었다(EIC, 참조: 도 47). 현저하게, 생성물(LII)은 메틸트랜스퍼라제 효소 PsiM의 존재에도 불구하고 N,N-디메틸 기능을 갖지 않았으며, 이는 PsiM이 이 생성물(LII)을 기질로 수용할 수 없음을 암시한다.
실시예 34 - 제34 다중 치환기 실로시빈 유도체의 생합성
실시예 31에 기술된 동일한 효모 균주(Sc-6) 및 절차를 사용하여, 다음을 제외하고, 화학식 (LIII)을 갖는 실로시빈 유도체를 생합성했다: 4-클로로-1H-인돌 대신에, 500μM 6-브로모-1H-인돌(Combi-Blocks, www.combi-blocks.com)이 생물전환을 위한 공급원료로 공급되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (LIII)을 갖는 6-브로모-3-[2-(디메틸아미노)에틸]-1H-인돌-4-올의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(LIII)
이 3.2분에 용출되었다(EIC, 참조: 도 48).
실시예 35 - 제35 다중 치환기 실로시빈 유도체의 생합성
실시예 31에 기술된 동일한 효모 균주(Sc-6) 및 절차를 사용하여, 다음을 제외하고, 화학식 (LIV)을 갖는 실로시빈 유도체를 생합성했다: 4-클로로-1H-인돌 대신에, 500μM 6-브로모-1H-인돌(Combi-Blocks, www.combi-blocks.com)이 생물전환을 위한 공급원료로 공급되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (LIV)을 갖는 3-(2-아미노에틸)-6-브로모-1H-인돌-4-올의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(LIV)
이 2.9분에 용출되었다(EIC, 참조: 도 49). 현저하게, 실시예 34에서 사용된 공급원료와 비교하여 본 실시예에서는 동일한 인돌 공급원료가 제공되었지만, 생성물(LIII)은 생성물(LIV)과 동일하지 않았다. 실제로, 생성물 (LIII) 및 (LIV) 둘 모두 6-브로모-1H-인돌을 Sc-6에 공급함에 의해 달성된다. 그러나, 실시예 34에서는 생성물 (LIII)만 분석되었다. 반대로, 본 실시예에서는 생성물 (LIV)만 분석되었다.
실시예 36 - 제36 다중 치환기 실로시빈 유도체의 생합성
실로시빈 유도체의 합성은 FgaPT2 효소 및 시험관내 절차를 사용하여 달성되었다. FgaPT2(서열번호: 21)를 인코딩하는 cDNA를 합성하고 GenScript(www.genscript.com)에서 Nde1 및 Xho1 부위를 사용하여 pET26b(+) 플라스미드(서열번호: 54)로 서브클로닝했다. 최종 플라스미드 pET26b(+)-FgaPT2는 FgaPT2의 인-프레임, C-말단 HIS 태그 융합을 인코딩했다. 정제된 재조합 FgaPT2 효소(서열번호: 22)를 대장균에서 성장시키고 다음과 같이 단리하였다. 플라스미드 pET26b(+)-FgaPT2를 Rosetta(DE3) 적격 대장균 세포 안으로 형질전환시켰다. 형질전환된 Rosetta(DE3) 대장균 세포를 LB 배지에서 30℃에서 밤새 성장시킨 다음 TB(훌륭한 브로쓰) 배지로 옮겨 광학 밀도(OD600)가 0.6-1.5에 도달할 때까지 37℃에서 성장했다. 세포 배양액을 그 다음 재조합 단백질 발현을 개시하도록 0.2mM에서 IPTG의 첨가로 16℃ 인큐베이터로 옮겼다. 20시간 후 세포를 5,000 × g에서 6분 동안 원심분리에 의해 수확하고 세포 펠릿을 단백질 추출 전에 -80℃에 보관했다. FgaPT2 재조합 단백질의 추출 및 정제를 위해 대장균 세포를 50mM 인산나트륨(pH 7.0) 및 300mM NaCl을 함유하는 완충액에 재현탁시킨 다음 5-10분 동안 초음파 처리하여 세포를 파쇄했다. 세포 용리물을 12,000g에서 30분 동안 원심분리하여 가용성 조단백질을 함유한 상등액을 수집했다. 상등액을 코발트 수지(TALON Superflow™, Cytiva)에 적용하여 HIS-태깅된 표적 단백질을 단리했다. 정제된 단백질은 50mM Tris-HCl(pH 7.0), 100mM NaCl 및 10% 글리세롤을 함유하는 완충액에 -80℃에서 저장했다. 트립토판 유도체 2-아미노-3-(5-브로모-1H-인돌-3-일)프로피온산(www.sigmaaldrich.com) 및 DMAPP(www.sigmaaldrich.com)가 반응에서 공동-기질로 사용되었다. 간략하게, 반응은 다음과 같이 설정되었다: 50mM Tris-HCl(pH 8.0), 180μM DMAPP, 0.5mM 트립토판 유도체 및 300μg/mL의 FgaPT2가 함께 첨가되었고 반응은 37℃에서 2시간 동안 진행되었다. 동등한 부피의 MeOH이 첨가되어 반응을 중단시키고 단백질을 침전시켰다. 그런 다음 샘플을 13,000g에서 20분 동안 원심분리하여 원하는 생성물이 함유된 상등액을 제거했다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XXX)을 갖는 2-아미노-3-[5-브로모-4-(3-메틸-2-부테닐)-1H-인돌-3-일]프로피온산의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XXX)
이 4.2분에 용출되었다(EIC, 참조: 도 50).
실시예 37 - 제37 다중 치환기 실로시빈 유도체의 생합성
실로시빈 유도체의 합성은 2-아미노-3-(6-플루오로-1H-인돌-3-일)프로피온산(www.sigmaaldrich.com)이 2-아미노-3-(5-브로모-1H-인돌-3-일)프로피온산 기질 대신 사용되었다는 것을 제외하고 실시예 36에 기술된 FgaPT2 효소 및 시험관내 절차를 사용하여 달성되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XXXI)을 갖는 2-아미노-3-[6-플루오로-4-(3-메틸-2-부테닐)-1H-인돌-3-일]프로피온산의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XXXI)
이 4.0분에 용출되었다(EIC, 참조: 도 51).
실시예 38 - 제38 다중 치환기 실로시빈 유도체의 생합성
실로시빈 유도체의 합성은 PriB 효소 및 시험관내 절차를 사용하여 달성되었다. PriB(서열번호: 17)를 인코딩하는 cDNA를 합성하고 GenScript(www.genscript.com)에서 Nde1 및 Xho1 부위를 사용하여 pET26b(+) 플라스미드(서열번호: 54)로 서브클로닝했다. 최종 플라스미드 pET26b(+)-PriB는 PriB의 인-프레임 C-말단 HIS 태그 융합을 인코딩했다. 정제된 재조합 PriB 효소(서열번호: 18)를 대장균에서 성장시키고 다음과 같이 단리하였다. 플라스미드 pET26b(+)-PriB를 Rosetta(DE3) 적격 대장균 세포 안으로 형질전환시켰다. 형질전환된 Rosetta(DE3) 대장균 세포를 LB 배지에서 30℃에서 밤새 성장시킨 다음 TB(훌륭한 브로쓰) 배지로 옮겨 광학 밀도(OD600)가 0.6-1.5에 도달할 때까지 37℃에서 성장했다. 세포 배양액을 그 다음 재조합 단백질 발현을 개시하도록 0.5mM에서 IPTG의 첨가로 16℃ 인큐베이터로 옮겼다. 20시간 후 세포를 5,000 × g에서 6분 동안 원심분리에 의해 수확하고 세포 펠릿을 단백질 추출 전에 -80℃에 보관했다. PriB 재조합 단백질의 추출 및 정제를 위해 대장균 세포를 50mM 인산나트륨(pH 7.0) 및 300mM NaCl을 함유하는 완충액에 재현탁시킨 다음 5-10분 동안 초음파 처리하여 세포를 파쇄했다. 세포 용리물을 12,000g에서 30분 동안 원심분리하여 가용성 조단백질을 함유한 상등액을 수집했다. 상등액을 코발트 수지(TALON Superflow™, Cytiva)에 적용하여 HIS-태깅된 표적 단백질을 단리했다. 정제된 단백질은 50mM Tris-HCl(pH 7.0), 100mM NaCl 및 10% 글리세롤을 함유하는 완충액에 -80℃에서 저장했다. 공동-기질 3-[2-(디메틸아미노)에틸]-1H-인돌-4-일 프로피오네이트(Indole Shop, www.theindoleshop.com) 및 DMAPP(www.sigmaaldrich.com)이 반응에서 사용되었다. 간략하게, 반응은 다음과 같이 설정되었다: 50mM Tris-HCl(pH 8.0), 180μM DMAPP, 0.5mM 3-[2-(디메틸아미노)에틸]-1H-인돌-4-일 프로피오네이트 및 392μg/mL의 PriB가 함께 첨가되었고 반응은 37℃에서 2시간 동안 진행되었다. 동등한 부피의 MeOH이 첨가되어 반응을 중단시키고 단백질을 침전시켰다. 그런 다음 샘플을 13,000g에서 20분 동안 원심분리하여 원하는 생성물이 함유된 상등액을 제거했다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XLI)을 갖는 3-[2-(디메틸아미노)에틸]-6-(3-메틸-2-부테닐)-1H-인돌-4-일 프로피오네이트의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XLI)
이 4.7분에 용출되었다(EIC, 참조: 도 52).
실시예 39 - 제39 다중 치환기 실로시빈 유도체의 생합성
실로시빈 유도체의 합성은 3-[2-(디메틸아미노)에틸]-1H-인돌-4-일 아세테이트(Indole Shop; www.theindoleshop.com)가 3-[2-(디메틸아미노)에틸]-1H-인돌-4-일 프로피오네이트 기질 대신 사용되었다는 것을 제외하고 실시예 38에 기술된 PriB 효소 및 시험관내 절차를 사용하여 달성되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XLII)을 갖는 3-[2-(디메틸아미노)에틸]-6-(3-메틸-2-부테닐)-1H-인돌-4-일 아세테이트의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XLII)
이 4.4분에 용출되었다(EIC, 참조: 도 53).
실시예 40 - 제40 다중 치환기 실로시빈 유도체의 생합성
실로시빈 유도체의 합성은 3-[2-(디에틸아미노)에틸]-1H-인돌-4-일 아세테이트(Indole Shop; www.theindoleshop.com)가 3-[2-(디메틸아미노)에틸]-1H-인돌-4-일 프로피오네이트 기질 대신 사용되었다는 것을 제외하고 실시예 38에 기술된 PriB 효소 및 시험관내 절차를 사용하여 달성되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XLV)을 갖는 3-[2-(디에틸아미노)에틸]-6-(3-메틸-2-부테닐)-1H-인돌-4-일 아세테이트의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XLV)
이 4.6분에 용출되었다(EIC, 참조: 도 54).
실시예 41 - 제41 다중 치환기 실로시빈 유도체의 합성
실로시빈 유도체의 합성은 N,N-디메틸[2-(5-클로로-1H-인돌-3-일)에틸]아민(Indole Shop; www.theindoleshop.com)이 3-[2-(디메틸아미노)에틸]-1H-인돌-4-일 프로피오네이트 기질 대신 사용되었다는 것을 제외하고 실시예 38에 기술된 PriB 효소 및 시험관내 절차를 사용하여 달성되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (XLIV)을 갖는 N,N-디메틸(2-[5-클로로-6-(3-메틸-2-부테닐)-1H-인돌-3-일]에틸)아민의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(XLIV)
이 4.7분에 용출되었다(EIC, 참조: 도 55a). 표준 절차(Menndez-Perdomo 등, 2021, Mass Spectrom 56: 34683)에 따라 고에너지 충돌(HCD)을 사용한 추가 분석이 전용 LTQ-후 질소 충돌 셀에서 달성되었다. 오비트랩-기반의 HR 단편 검출을 이용하여(정규화된 충돌 에너지, NCE 35), 다음과 같이 식 (XLIV)을 갖는 표적화된 실로시빈 유도체의 특징적인 후속 진단 이온 종에 원소 식을 할당할 수 있는 기회를 가능하게 한다(도 55b, 표 12)(Servillo L. 등, 2013, J. Agric. Chem. 61: 5156-5162).
표 12
실시예 42 - 제42 다중 치환기 실로시빈 유도체의 생합성
실로시빈 유도체의 합성은 (1) 화학적 합성에 이어서 (2) PriB 효소에 의한 시험관내 효소 전환을 사용하여 달성되었다. 화학적 합성은 도 13d에 도시된 합성 절차를 사용하여 수행되었다.
0℃에서 아르곤 살포 하에 무수 디에틸 에테르(10mL) 내 4-벤질옥시인돌 13D-1(1.00mmol, 1.00당량)의 용액에 옥살릴 클로라이드(2.05mmol, 2.05당량)를 30분의 과정에 걸쳐서 점적 부가하고, 0 - 5℃에서 3시간 동안 반응을 계속하였다. 무수 디에틸 에테르(5mL) 내 N-메틸이소프로필아민(5.00mmol, 5.00당량)의 용액을 1시간의 과정에 걸쳐 점적 부가했다. 용액을 진공에서 농축하고, 잔류물을 디클로로메탄(30mL)에 재용해시켰다. 유기 용액을 물(4 × 10mL) 및 염수(1 × 10mL)로 세정한 다음 무수 Na2SO4로 건조하고 감압 하에서 농축하여 화합물 13D-2를 얻었으며, 이를 추가 정제 없이 다음 단계에서 사용했다. 무수 THF(1M, 5.20당량)와 1,4-디옥산(2.0mL)의 혼합물 내 리튬 알루미늄 하이드라이드의 용액을 아르곤 하에서 60℃로 높였다. 무수 THF(2.0mL)와 1,4-디옥산(3.5mL)의 혼합물 내 화합물 13D-2의 용액을 30분에 걸쳐 점적 부가하고, 반응물을 2시간 동안 70℃로 높였다. 반응물을 95℃에서 20시간 동안 추가로 환류시켰다. 0℃로 냉각한 후, 물(0.4mL) - THF(2.0mL)의 혼합물의 점적 부가를 통하여 과량의 리튬 알루미늄 하이드라이드를 켄칭했다. 디에틸 에테르(10mL)를 첨가하고, 반응 혼합물을 실온에서 30분 동안 교반되도록 하였다. 침전물을 진공 여과를 통해 제거하고, 여액을 무수 Na2SO4로 건조하고, 진공 하에 농축하여 화합물 3을 얻었으며 이를 추가 정제 없이 사용했다. 조 화합물 13D-3을 95% EtOH(10mL)에 용해시키고, 활성탄 상 10% 팔라듐(0.110당량)을 첨가하였다. 반응 플라스크를 비우고 그 다음 수소로 다시 충진했다. 실온에서 2시간 동안 교반한 후, 촉매를 여과에 의해 제거하고 용매를 감압 하에서 제거하여 화합물 13D-4를 얻었으며, 이를 물 - 아세토니트릴 + 0.1% 포름산을 용리액으로 사용하여 C18 실리카 겔 상에서 역상 컬럼 크로마토그래피에 의해 정제하였다. 화합물 13D-4는 그 다음 PriB 효소에 의한 생물전환을 위한 기질로 사용되었고, 후자는 실시예 38에 기술된 절차를 사용하여 생성 및 정제된 것이다. PriB에 의한 시험관내 전환은 화합물 13D-4가 3-[2-(디메틸아미노)에틸]-1H-인돌-4-일 프로피오네이트 기질 대신 사용되었다는 것을 제외하고 실시예 38에 기술된 동일한 절차를 사용하여 수행되었다. 분석은 실시예 3에 기술된 대로 고해상도 LC-HESI-LTQ-Orbitrap-XL MS(Thermo Fisher Scientific)를 사용하여 수행되었다. 화학식 (LXXVI)을 갖는 3-( 2-[(이소프로필)-N-메틸아미노]에틸)-6-(3-메틸-2-부테닐)-1H-인돌-4-올의 단일로 양성자화된 형태와 일치하는 정확한 m/z 및 예상된 원소 식을 갖는 단일로 양성자화된 생성물:
(LXXVI)
이 4.2분에 용출되었다(EIC, 참조: 도 56).
SEQUENCE LISTING
<110> MAGICMED INDUSTRIES INC.
<120> MULTI-SUBSTITUENT PSILOCYBIN DERIVATIVES AND METHODS OF USING
<130> 21806-P63978PC00
<150> US 63/149,001
<151> 2021-02-12
<150> US 63/247,881
<151> 2021-09-24
<160> 54
<170> PatentIn version 3.5
<210> 1
<211> 1167
<212> DNA
<213> Pyrococcus furiosus
<400> 1
atgtggttcg gtgagtttgg tggacaatat gtgccagaga ctttagtggg tcctcttaag 60
gaattggaaa aggcatataa aaggttcaag gacgatgagg agttcaacag gcaactaaac 120
tattatttga agacatgggc cggtagacca acgcccttgt attatgctaa gaggttaact 180
gaaaagattg gcggcgcgaa agtgtatctg aaaagagaag acctagttca tggtggagca 240
cacaagacaa ataatgccat tggacaagca ctattggcaa agctaatggg taaaactaga 300
ttgatagctg agacaggagc gggtcaacat ggggtcgcga cagcgatggc tggtgcacta 360
ctggggatga aggtagatat ttacatgggt gctgaggacg ttgagcgtca gaaactaaat 420
gtcttcagga tgaagctatt aggtgccaat gttatacctg taaattctgg ctcaagaaca 480
ctaaaggacg ccttcgacga ggctcttaga gactgggttg ccactttcga gtatactcat 540
tacttgatcg gttcagtggt tggaccacat ccatacccaa ccatcgttag ggactttcag 600
agcgtgattg gtagagaggc taaggcacag atcttagaag cagagggaca gctacctgac 660
gtcatagttg cctgcgtcgg cggtggctct aacgcaatgg gtatattcta tccattcgtt 720
aatgacaaga aggttaaatt agtaggagtc gaagctggcg gaaaggggtt agagtcgggt 780
aaacactcag caagcttaaa tgcaggacag gtaggggtgt cccacggcat gttgtcgtat 840
ttcttgcaag acgaggaagg tcagataaag ccaagtcatt caattgctcc aggccttgac 900
caccccggtg ttggtccaga gcacgcttac ttaaagaaga ttcaaagggc cgagtacgtc 960
gctgtaacag acgaagaggc attgaaagct ttccatgagc tatccagaac tgaggggatt 1020
atacccgccc ttgagtctgc ccatgctgtg gcgtacgcca tgaagttagc taaagagatg 1080
tcccgtgacg aaatcatcat tgtaaatcta tcagggagag gagacaagga tttggacatt 1140
gtattgaagg caagcggaaa tgtttga 1167
<210> 2
<211> 388
<212> PRT
<213> Pyrococcus furiosus
<400> 2
Met Trp Phe Gly Glu Phe Gly Gly Gln Tyr Val Pro Glu Thr Leu Val
1 5 10 15
Gly Pro Leu Lys Glu Leu Glu Lys Ala Tyr Lys Arg Phe Lys Asp Asp
20 25 30
Glu Glu Phe Asn Arg Gln Leu Asn Tyr Tyr Leu Lys Thr Trp Ala Gly
35 40 45
Arg Pro Thr Pro Leu Tyr Tyr Ala Lys Arg Leu Thr Glu Lys Ile Gly
50 55 60
Gly Ala Lys Val Tyr Leu Lys Arg Glu Asp Leu Val His Gly Gly Ala
65 70 75 80
His Lys Thr Asn Asn Ala Ile Gly Gln Ala Leu Leu Ala Lys Leu Met
85 90 95
Gly Lys Thr Arg Leu Ile Ala Glu Thr Gly Ala Gly Gln His Gly Val
100 105 110
Ala Thr Ala Met Ala Gly Ala Leu Leu Gly Met Lys Val Asp Ile Tyr
115 120 125
Met Gly Ala Glu Asp Val Glu Arg Gln Lys Leu Asn Val Phe Arg Met
130 135 140
Lys Leu Leu Gly Ala Asn Val Ile Pro Val Asn Ser Gly Ser Arg Thr
145 150 155 160
Leu Lys Asp Ala Phe Asp Glu Ala Leu Arg Asp Trp Val Ala Thr Phe
165 170 175
Glu Tyr Thr His Tyr Leu Ile Gly Ser Val Val Gly Pro His Pro Tyr
180 185 190
Pro Thr Ile Val Arg Asp Phe Gln Ser Val Ile Gly Arg Glu Ala Lys
195 200 205
Ala Gln Ile Leu Glu Ala Glu Gly Gln Leu Pro Asp Val Ile Val Ala
210 215 220
Cys Val Gly Gly Gly Ser Asn Ala Met Gly Ile Phe Tyr Pro Phe Val
225 230 235 240
Asn Asp Lys Lys Val Lys Leu Val Gly Val Glu Ala Gly Gly Lys Gly
245 250 255
Leu Glu Ser Gly Lys His Ser Ala Ser Leu Asn Ala Gly Gln Val Gly
260 265 270
Val Ser His Gly Met Leu Ser Tyr Phe Leu Gln Asp Glu Glu Gly Gln
275 280 285
Ile Lys Pro Ser His Ser Ile Ala Pro Gly Leu Asp His Pro Gly Val
290 295 300
Gly Pro Glu His Ala Tyr Leu Lys Lys Ile Gln Arg Ala Glu Tyr Val
305 310 315 320
Ala Val Thr Asp Glu Glu Ala Leu Lys Ala Phe His Glu Leu Ser Arg
325 330 335
Thr Glu Gly Ile Ile Pro Ala Leu Glu Ser Ala His Ala Val Ala Tyr
340 345 350
Ala Met Lys Leu Ala Lys Glu Met Ser Arg Asp Glu Ile Ile Ile Val
355 360 365
Asn Leu Ser Gly Arg Gly Asp Lys Asp Leu Asp Ile Val Leu Lys Ala
370 375 380
Ser Gly Asn Val
385
<210> 3
<211> 1446
<212> DNA
<213> Bacillus atrophaeaus
<400> 3
atgatgtctg aaaatttgca attgtcagct gaagaaatga gacaattggg ttaccaagca 60
gttgatttga tcatcgatca catgaaccat ttgaagtcta agccagtttc agaaacaatc 120
gattctgata tcttgagaaa taagttgact gaatctatcc cagaaaatgg ttcagatcca 180
aaggaattgt tgcatttctt gaacagaaac gtttttaatc aaattacaca tgttgatcat 240
ccacatttct tggcttttgt tccaggtcca aataattacg ttggtgttgt tgcagatttc 300
ttggcttctg gttttaatgt ttttccaact gcatggattg ctggtgcagg tgctgaacaa 360
atcgaattga ctacaattaa ttggttgaaa tctatgttgg gttttccaga ttcagctgaa 420
ggtttatttg tttctggtgg ttcaatggca aatttgacag ctttgactgt tgcaagacag 480
gctaagttga acaacgatat cgaaaatgct gttgtttact tctctgatca aacacatttc 540
tcagttgata gagcattgaa ggttttaggt tttaaacatc atcaaatctg tagaatcgaa 600
acagatgaac atttgagaat ctctgtttca gctttgaaga aacaaattaa agaagataga 660
actaagggta aaaagccatt ctgtgttatt gcaaatgctg gtactacaaa ttgtggtgct 720
gttgattctt tgaacgaatt agcagatttg tgtaacgatg aagatgtttg gttgcatgct 780
gatggttctt atggtgctcc agctatcttg tctgaaaagg gttcagctat gttgcaaggt 840
attcatagag cagattcttt gactttagat ccacataagt ggttgttcca accatacgat 900
gttggttgtg ttttgatcag aaactctcaa tatttgtcaa agacttttag aatgatgcca 960
gaatacatca aggattcaga aactaacgtt gaaggtgaaa ttaatttcgg tgaatgtggt 1020
atcgaattgt caagaagatt cagagctttg aaggtttggt tgtcttttaa agttttcggt 1080
gttgctgctt ttagacaagc aatcgatcat ggtatcatgt tagcagaaca agttgaagca 1140
tttttgggta aagcaaaaga ttgggaagtt gttacaccag ctcaattggg tatcgttact 1200
tttagataca ttccatctga attggcatca acagatacta ttaatgaaat taataagaaa 1260
ttggttaagg aaatcacaca tagaggtttc gctatgttat ctactacaga attgaaggaa 1320
aaggttgtta ttagattgtg ttcaattaat ccaagaacta caactgaaga aatgttgcaa 1380
atcatgatga agattaaagc attggctgaa gaagtttcta tttcataccc atgtgttgct 1440
gaataa 1446
<210> 4
<211> 481
<212> PRT
<213> Bacillus atrophaeaus
<400> 4
Met Met Ser Glu Asn Leu Gln Leu Ser Ala Glu Glu Met Arg Gln Leu
1 5 10 15
Gly Tyr Gln Ala Val Asp Leu Ile Ile Asp His Met Asn His Leu Lys
20 25 30
Ser Lys Pro Val Ser Glu Thr Ile Asp Ser Asp Ile Leu Arg Asn Lys
35 40 45
Leu Thr Glu Ser Ile Pro Glu Asn Gly Ser Asp Pro Lys Glu Leu Leu
50 55 60
His Phe Leu Asn Arg Asn Val Phe Asn Gln Ile Thr His Val Asp His
65 70 75 80
Pro His Phe Leu Ala Phe Val Pro Gly Pro Asn Asn Tyr Val Gly Val
85 90 95
Val Ala Asp Phe Leu Ala Ser Gly Phe Asn Val Phe Pro Thr Ala Trp
100 105 110
Ile Ala Gly Ala Gly Ala Glu Gln Ile Glu Leu Thr Thr Ile Asn Trp
115 120 125
Leu Lys Ser Met Leu Gly Phe Pro Asp Ser Ala Glu Gly Leu Phe Val
130 135 140
Ser Gly Gly Ser Met Ala Asn Leu Thr Ala Leu Thr Val Ala Arg Gln
145 150 155 160
Ala Lys Leu Asn Asn Asp Ile Glu Asn Ala Val Val Tyr Phe Ser Asp
165 170 175
Gln Thr His Phe Ser Val Asp Arg Ala Leu Lys Val Leu Gly Phe Lys
180 185 190
His His Gln Ile Cys Arg Ile Glu Thr Asp Glu His Leu Arg Ile Ser
195 200 205
Val Ser Ala Leu Lys Lys Gln Ile Lys Glu Asp Arg Thr Lys Gly Lys
210 215 220
Lys Pro Phe Cys Val Ile Ala Asn Ala Gly Thr Thr Asn Cys Gly Ala
225 230 235 240
Val Asp Ser Leu Asn Glu Leu Ala Asp Leu Cys Asn Asp Glu Asp Val
245 250 255
Trp Leu His Ala Asp Gly Ser Tyr Gly Ala Pro Ala Ile Leu Ser Glu
260 265 270
Lys Gly Ser Ala Met Leu Gln Gly Ile His Arg Ala Asp Ser Leu Thr
275 280 285
Leu Asp Pro His Lys Trp Leu Phe Gln Pro Tyr Asp Val Gly Cys Val
290 295 300
Leu Ile Arg Asn Ser Gln Tyr Leu Ser Lys Thr Phe Arg Met Met Pro
305 310 315 320
Glu Tyr Ile Lys Asp Ser Glu Thr Asn Val Glu Gly Glu Ile Asn Phe
325 330 335
Gly Glu Cys Gly Ile Glu Leu Ser Arg Arg Phe Arg Ala Leu Lys Val
340 345 350
Trp Leu Ser Phe Lys Val Phe Gly Val Ala Ala Phe Arg Gln Ala Ile
355 360 365
Asp His Gly Ile Met Leu Ala Glu Gln Val Glu Ala Phe Leu Gly Lys
370 375 380
Ala Lys Asp Trp Glu Val Val Thr Pro Ala Gln Leu Gly Ile Val Thr
385 390 395 400
Phe Arg Tyr Ile Pro Ser Glu Leu Ala Ser Thr Asp Thr Ile Asn Glu
405 410 415
Ile Asn Lys Lys Leu Val Lys Glu Ile Thr His Arg Gly Phe Ala Met
420 425 430
Leu Ser Thr Thr Glu Leu Lys Glu Lys Val Val Ile Arg Leu Cys Ser
435 440 445
Ile Asn Pro Arg Thr Thr Thr Glu Glu Met Leu Gln Ile Met Met Lys
450 455 460
Ile Lys Ala Leu Ala Glu Glu Val Ser Ile Ser Tyr Pro Cys Val Ala
465 470 475 480
Glu
<210> 5
<211> 1254
<212> DNA
<213> Clostridium sporidium
<400> 5
atgaagttct ggagaaagta cacacaacaa gaaatggatg aaaagattac tgaatctttg 60
gaaaagactt tgaactacga taacactaag acaatcggta ttccaggtac taagttggat 120
gatacagttt tctatgatga tcattctttc gttaagcatt caccatactt gagaactttt 180
attcaaaacc caaaccatat cggttgtcat acttatgata aggctgatat cttgttcggt 240
ggtacattcg atatcgaaag agaattaatc caattgttag caatcgatgt tttgaacggt 300
aacgatgaag aatttgatgg ttacgttact caaggtggta cagaagctaa catccaagca 360
atgtgggttt acagaaacta cttcaagaaa gaaagaaagg ctaagcatga agaaatcgct 420
atcatcactt cagcagatac acattactct gcatacaaag gttcagattt gttgaacatc 480
gatattatta aggttccagt tgatttttat tcaagaaaaa ttcaagaaaa tacattggat 540
tcaattgtta aagaagctaa agaaattggt aaaaagtact tcatcgttat ctctaacatg 600
ggtactacaa tgtttggttc agttgatgat ccagatttgt acgctaacat cttcgataag 660
tacaatttgg aatacaaaat tcatgttgat ggtgcatttg gtggttttat atatccaatt 720
gataataagg aatgtaaaac tgatttctct aataagaacg tttcttcaat cacattagat 780
ggtcataaga tgttgcaagc tccatacggt actggtatct tcgtttcaag aaagaatttg 840
atccataaca ctttgacaaa ggaagcaact tacatcgaaa atttggatgt tacattgtct 900
ggttcaagat ctggttcaaa tgctgttgca atttggatgg ttttagcttc ttatggtcca 960
tacggttgga tggaaaagat taataagttg agaaatagaa ctaaatggtt gtgtaagcaa 1020
ttgaacgata tgagaattaa atattacaaa gaagattcaa tgaatattgt tacaattgaa 1080
gaacaatatg ttaataagga aatcgctgaa aagtactttt tagttccaga agttcataac 1140
ccaactaaca actggtacaa gatcgttgtt atggaacatg ttgaattgga tatcttgaac 1200
tctttggttt acgatttgag aaagtttaat aaggaacatt tgaaggcaat gtaa 1254
<210> 6
<211> 417
<212> PRT
<213> Clostridium sporidium
<400> 6
Met Lys Phe Trp Arg Lys Tyr Thr Gln Gln Glu Met Asp Glu Lys Ile
1 5 10 15
Thr Glu Ser Leu Glu Lys Thr Leu Asn Tyr Asp Asn Thr Lys Thr Ile
20 25 30
Gly Ile Pro Gly Thr Lys Leu Asp Asp Thr Val Phe Tyr Asp Asp His
35 40 45
Ser Phe Val Lys His Ser Pro Tyr Leu Arg Thr Phe Ile Gln Asn Pro
50 55 60
Asn His Ile Gly Cys His Thr Tyr Asp Lys Ala Asp Ile Leu Phe Gly
65 70 75 80
Gly Thr Phe Asp Ile Glu Arg Glu Leu Ile Gln Leu Leu Ala Ile Asp
85 90 95
Val Leu Asn Gly Asn Asp Glu Glu Phe Asp Gly Tyr Val Thr Gln Gly
100 105 110
Gly Thr Glu Ala Asn Ile Gln Ala Met Trp Val Tyr Arg Asn Tyr Phe
115 120 125
Lys Lys Glu Arg Lys Ala Lys His Glu Glu Ile Ala Ile Ile Thr Ser
130 135 140
Ala Asp Thr His Tyr Ser Ala Tyr Lys Gly Ser Asp Leu Leu Asn Ile
145 150 155 160
Asp Ile Ile Lys Val Pro Val Asp Phe Tyr Ser Arg Lys Ile Gln Glu
165 170 175
Asn Thr Leu Asp Ser Ile Val Lys Glu Ala Lys Glu Ile Gly Lys Lys
180 185 190
Tyr Phe Ile Val Ile Ser Asn Met Gly Thr Thr Met Phe Gly Ser Val
195 200 205
Asp Asp Pro Asp Leu Tyr Ala Asn Ile Phe Asp Lys Tyr Asn Leu Glu
210 215 220
Tyr Lys Ile His Val Asp Gly Ala Phe Gly Gly Phe Ile Tyr Pro Ile
225 230 235 240
Asp Asn Lys Glu Cys Lys Thr Asp Phe Ser Asn Lys Asn Val Ser Ser
245 250 255
Ile Thr Leu Asp Gly His Lys Met Leu Gln Ala Pro Tyr Gly Thr Gly
260 265 270
Ile Phe Val Ser Arg Lys Asn Leu Ile His Asn Thr Leu Thr Lys Glu
275 280 285
Ala Thr Tyr Ile Glu Asn Leu Asp Val Thr Leu Ser Gly Ser Arg Ser
290 295 300
Gly Ser Asn Ala Val Ala Ile Trp Met Val Leu Ala Ser Tyr Gly Pro
305 310 315 320
Tyr Gly Trp Met Glu Lys Ile Asn Lys Leu Arg Asn Arg Thr Lys Trp
325 330 335
Leu Cys Lys Gln Leu Asn Asp Met Arg Ile Lys Tyr Tyr Lys Glu Asp
340 345 350
Ser Met Asn Ile Val Thr Ile Glu Glu Gln Tyr Val Asn Lys Glu Ile
355 360 365
Ala Glu Lys Tyr Phe Leu Val Pro Glu Val His Asn Pro Thr Asn Asn
370 375 380
Trp Tyr Lys Ile Val Val Met Glu His Val Glu Leu Asp Ile Leu Asn
385 390 395 400
Ser Leu Val Tyr Asp Leu Arg Lys Phe Asn Lys Glu His Leu Lys Ala
405 410 415
Met
<210> 7
<211> 1320
<212> DNA
<213> Psilocybe cubensis
<400> 7
atgcaggtga tacccgcgtg caactcggca gcaataagat cactatgtcc tactcccgag 60
tcttttagaa acatgggatg gctctctgtc agcgatgcgg tctacagcga gttcatagga 120
gagttggcta cccgcgcttc caatcgaaat tactccaacg agttcggcct catgcaacct 180
atccaggaat tcaaggcttt cattgaaagc gacccggtgg tgcaccaaga atttattgac 240
atgttcgagg gcattcagga ctctccaagg aattatcagg aactatgtaa tatgttcaac 300
gatatctttc gcaaagctcc cgtctacgga gaccttggcc ctcccgttta tatgattatg 360
gccaaattaa tgaacacccg agcgggcttc tctgcattca cgagacaaag gttgaacctt 420
cacttcaaaa aacttttcga tacctgggga ttgttcctgt cttcgaaaga ttctcgaaat 480
gttcttgtgg ccgaccagtt cgacgacaga cattgcggct ggttgaacga gcgggccttg 540
tctgctatgg ttaaacatta caatggacgc gcatttgatg aagtcttcct ctgcgataaa 600
aatgccccat actacggctt caactcttac gacgacttct ttaatcgcag atttcgaaac 660
cgagatatcg accgacctgt agtcggtgga gttaacaaca ccaccctcat ttctgctgct 720
tgcgaatcac tttcctacaa cgtctcttat gacgtccagt ctctcgacac tttagttttc 780
aaaggagaga cttattcgct taagcatttg ctgaataatg accctttcac cccacaattc 840
gagcatggga gtattctaca aggattcttg aacgtcaccg cttaccaccg atggcacgca 900
cccgtcaatg ggacaatcgt caaaatcatc aacgttccag gtacctactt tgcgcaagcc 960
ccgagcacga ttggcgaccc tatcccggat aacgattacg acccacctcc ttaccttaag 1020
tctcttgtct acttctctaa tattgccgca aggcaaatta tgtttattga agccgacaac 1080
aaggaaattg gcctcatttt ccttgtgttc atcggcatga ccgaaatctc gacatgtgaa 1140
gccacggtgt ccgaaggtca acacgtcaat cgtggcgatg acttgggaat gttccatttc 1200
ggtggttctt cgttcgcgct tggtctgagg aaggattgca gggcagagat cgttgaaaag 1260
ttcaccgaac ccggaacagt gatcagaatc aacgaagtcg tcgctgctct aaaggcttag 1320
<210> 8
<211> 439
<212> PRT
<213> Psilocybe cubensis
<400> 8
Met Gln Val Ile Pro Ala Cys Asn Ser Ala Ala Ile Arg Ser Leu Cys
1 5 10 15
Pro Thr Pro Glu Ser Phe Arg Asn Met Gly Trp Leu Ser Val Ser Asp
20 25 30
Ala Val Tyr Ser Glu Phe Ile Gly Glu Leu Ala Thr Arg Ala Ser Asn
35 40 45
Arg Asn Tyr Ser Asn Glu Phe Gly Leu Met Gln Pro Ile Gln Glu Phe
50 55 60
Lys Ala Phe Ile Glu Ser Asp Pro Val Val His Gln Glu Phe Ile Asp
65 70 75 80
Met Phe Glu Gly Ile Gln Asp Ser Pro Arg Asn Tyr Gln Glu Leu Cys
85 90 95
Asn Met Phe Asn Asp Ile Phe Arg Lys Ala Pro Val Tyr Gly Asp Leu
100 105 110
Gly Pro Pro Val Tyr Met Ile Met Ala Lys Leu Met Asn Thr Arg Ala
115 120 125
Gly Phe Ser Ala Phe Thr Arg Gln Arg Leu Asn Leu His Phe Lys Lys
130 135 140
Leu Phe Asp Thr Trp Gly Leu Phe Leu Ser Ser Lys Asp Ser Arg Asn
145 150 155 160
Val Leu Val Ala Asp Gln Phe Asp Asp Arg His Cys Gly Trp Leu Asn
165 170 175
Glu Arg Ala Leu Ser Ala Met Val Lys His Tyr Asn Gly Arg Ala Phe
180 185 190
Asp Glu Val Phe Leu Cys Asp Lys Asn Ala Pro Tyr Tyr Gly Phe Asn
195 200 205
Ser Tyr Asp Asp Phe Phe Asn Arg Arg Phe Arg Asn Arg Asp Ile Asp
210 215 220
Arg Pro Val Val Gly Gly Val Asn Asn Thr Thr Leu Ile Ser Ala Ala
225 230 235 240
Cys Glu Ser Leu Ser Tyr Asn Val Ser Tyr Asp Val Gln Ser Leu Asp
245 250 255
Thr Leu Val Phe Lys Gly Glu Thr Tyr Ser Leu Lys His Leu Leu Asn
260 265 270
Asn Asp Pro Phe Thr Pro Gln Phe Glu His Gly Ser Ile Leu Gln Gly
275 280 285
Phe Leu Asn Val Thr Ala Tyr His Arg Trp His Ala Pro Val Asn Gly
290 295 300
Thr Ile Val Lys Ile Ile Asn Val Pro Gly Thr Tyr Phe Ala Gln Ala
305 310 315 320
Pro Ser Thr Ile Gly Asp Pro Ile Pro Asp Asn Asp Tyr Asp Pro Pro
325 330 335
Pro Tyr Leu Lys Ser Leu Val Tyr Phe Ser Asn Ile Ala Ala Arg Gln
340 345 350
Ile Met Phe Ile Glu Ala Asp Asn Lys Glu Ile Gly Leu Ile Phe Leu
355 360 365
Val Phe Ile Gly Met Thr Glu Ile Ser Thr Cys Glu Ala Thr Val Ser
370 375 380
Glu Gly Gln His Val Asn Arg Gly Asp Asp Leu Gly Met Phe His Phe
385 390 395 400
Gly Gly Ser Ser Phe Ala Leu Gly Leu Arg Lys Asp Cys Arg Ala Glu
405 410 415
Ile Val Glu Lys Phe Thr Glu Pro Gly Thr Val Ile Arg Ile Asn Glu
420 425 430
Val Val Ala Ala Leu Lys Ala
435
<210> 9
<211> 546
<212> DNA
<213> Streptomyces griseofuscus
<400> 9
atgaacacct tcagaacagc cactgccaga gacatacctg atgtagcagc aactcttacg 60
gaagccttcg caactgatcc acccacgcag tgggtgttcc ccgacggtac tgccgccgtc 120
agcaggttct ttacacatgt tgcagatagg gttcacacgg ccggtggtat tgttgagcta 180
ctaccagaca gagccgccat gattgcattg ccaccacacg tgaggctgcc aggagaagct 240
gccgacggaa ggcaggcgga aattcagaga aggctggcag acaggcaccc gctgacacct 300
cactactacc tgctgtttta cggagttaga acggcacacc agggttcggg attgggcgga 360
agaatgctgg ccagattaac tagcagagct gatagggaca gggtgggtac atatactgag 420
gcatccacct ggcgtggcgc tagactgatg ctgagacatg gattccatgc tacaaggcca 480
ctaagattgc cagatggacc cagcatgttt ccactttgga gagatccaat ccatgatcat 540
tctgat 546
<210> 10
<211> 182
<212> PRT
<213> Streptomyces griseofuscus
<400> 10
Met Asn Thr Phe Arg Thr Ala Thr Ala Arg Asp Ile Pro Asp Val Ala
1 5 10 15
Ala Thr Leu Thr Glu Ala Phe Ala Thr Asp Pro Pro Thr Gln Trp Val
20 25 30
Phe Pro Asp Gly Thr Ala Ala Val Ser Arg Phe Phe Thr His Val Ala
35 40 45
Asp Arg Val His Thr Ala Gly Gly Ile Val Glu Leu Leu Pro Asp Arg
50 55 60
Ala Ala Met Ile Ala Leu Pro Pro His Val Arg Leu Pro Gly Glu Ala
65 70 75 80
Ala Asp Gly Arg Gln Ala Glu Ile Gln Arg Arg Leu Ala Asp Arg His
85 90 95
Pro Leu Thr Pro His Tyr Tyr Leu Leu Phe Tyr Gly Val Arg Thr Ala
100 105 110
His Gln Gly Ser Gly Leu Gly Gly Arg Met Leu Ala Arg Leu Thr Ser
115 120 125
Arg Ala Asp Arg Asp Arg Val Gly Thr Tyr Thr Glu Ala Ser Thr Trp
130 135 140
Arg Gly Ala Arg Leu Met Leu Arg His Gly Phe His Ala Thr Arg Pro
145 150 155 160
Leu Arg Leu Pro Asp Gly Pro Ser Met Phe Pro Leu Trp Arg Asp Pro
165 170 175
Ile His Asp His Ser Asp
180
<210> 11
<211> 1092
<212> DNA
<213> Ephedra sinica
<400> 11
atgggatcca tggaagaagc aaaaatggcg accctgggcg gtgcgtccta tgcgatgatt 60
gtgaaaacga tgatgcgctc tctggaagca aacctgattc cggattttgt gctgcgtcgc 120
ctgacgcgta tcctgctggc tagtcgcctg aaactgggtt ataagcagac cgctgaactg 180
caactggcgg atctgatgtc attcgttgcg tcgctgaaaa cgatgccgat tgccctgtgc 240
accgaagaag caaagggtca gcattacgaa ctgccgacca gctttttcaa actggtcctg 300
ggcaaacatc tgaagtatag ctctgcctac ttttctgaac acacccgtac gctggatgaa 360
gcggaagaag ccatgctggc actgtattgc gaacgcgcca aaattgaaga tggtcagaag 420
attctggaca tcggctgtgg ttggggcagt ttttccctgt atgtggcaga acgttacccg 480
aaatgcgaaa ttacgggcct gtgtaacagt tccacccaaa aagccttcat cgaacagcaa 540
tgcagcgaac gtcgcctgtg taatgttacc atttatgcag atgacatcag cacctttgat 600
acggaatcta cctacgaccg cattatcagc atcgaaatgt tcgaacacat gaagaactac 660
agtacgctgc tgaagaaaat tagcaagtgg atgaatcagg aatgcctgct gtttgtccat 720
tatttctgtc acaaaacctt tgcgtaccac ttcgaagatg tggacgaaga tgactggatg 780
gctcgttatt tctttaccgg cggcaccatg ccggcgtcat cgctgctgct gtactttcag 840
gatgacgtct cagtggttga tcattggctg attaacggta aacactatgc tcaaacctcg 900
gaagaatggc tgaagcgtat ggaccacaat ctgagctcta ttctgccgat ctttaacgaa 960
acgtatggcg aaaatgcggc caaaaagtgg ctggcatact ggcgcacctt tttcatcgca 1020
gttgctgaac tgttcaaata caacgatggc gaagaatgga tggtgtccca cttcctgttc 1080
aaaaagaaat aa 1092
<210> 12
<211> 363
<212> PRT
<213> Ephedra sinica
<400> 12
Met Gly Ser Met Glu Glu Ala Lys Met Ala Thr Leu Gly Gly Ala Ser
1 5 10 15
Tyr Ala Met Ile Val Lys Thr Met Met Arg Ser Leu Glu Ala Asn Leu
20 25 30
Ile Pro Asp Phe Val Leu Arg Arg Leu Thr Arg Ile Leu Leu Ala Ser
35 40 45
Arg Leu Lys Leu Gly Tyr Lys Gln Thr Ala Glu Leu Gln Leu Ala Asp
50 55 60
Leu Met Ser Phe Val Ala Ser Leu Lys Thr Met Pro Ile Ala Leu Cys
65 70 75 80
Thr Glu Glu Ala Lys Gly Gln His Tyr Glu Leu Pro Thr Ser Phe Phe
85 90 95
Lys Leu Val Leu Gly Lys His Leu Lys Tyr Ser Ser Ala Tyr Phe Ser
100 105 110
Glu His Thr Arg Thr Leu Asp Glu Ala Glu Glu Ala Met Leu Ala Leu
115 120 125
Tyr Cys Glu Arg Ala Lys Ile Glu Asp Gly Gln Lys Ile Leu Asp Ile
130 135 140
Gly Cys Gly Trp Gly Ser Phe Ser Leu Tyr Val Ala Glu Arg Tyr Pro
145 150 155 160
Lys Cys Glu Ile Thr Gly Leu Cys Asn Ser Ser Thr Gln Lys Ala Phe
165 170 175
Ile Glu Gln Gln Cys Ser Glu Arg Arg Leu Cys Asn Val Thr Ile Tyr
180 185 190
Ala Asp Asp Ile Ser Thr Phe Asp Thr Glu Ser Thr Tyr Asp Arg Ile
195 200 205
Ile Ser Ile Glu Met Phe Glu His Met Lys Asn Tyr Ser Thr Leu Leu
210 215 220
Lys Lys Ile Ser Lys Trp Met Asn Gln Glu Cys Leu Leu Phe Val His
225 230 235 240
Tyr Phe Cys His Lys Thr Phe Ala Tyr His Phe Glu Asp Val Asp Glu
245 250 255
Asp Asp Trp Met Ala Arg Tyr Phe Phe Thr Gly Gly Thr Met Pro Ala
260 265 270
Ser Ser Leu Leu Leu Tyr Phe Gln Asp Asp Val Ser Val Val Asp His
275 280 285
Trp Leu Ile Asn Gly Lys His Tyr Ala Gln Thr Ser Glu Glu Trp Leu
290 295 300
Lys Arg Met Asp His Asn Leu Ser Ser Ile Leu Pro Ile Phe Asn Glu
305 310 315 320
Thr Tyr Gly Glu Asn Ala Ala Lys Lys Trp Leu Ala Tyr Trp Arg Thr
325 330 335
Phe Phe Ile Ala Val Ala Glu Leu Phe Lys Tyr Asn Asp Gly Glu Glu
340 345 350
Trp Met Val Ser His Phe Leu Phe Lys Lys Lys
355 360
<210> 13
<211> 930
<212> DNA
<213> Psilocybe cubensis
<400> 13
atgcatatca gaaatcctta ccgtacacca attgactatc aagcactttc agaggccttc 60
cctcccctca agccatttgt gtctgtcaat gcagatggta ccagttctgt tgacctcact 120
atcccagaag cccagagggc gttcacggcc gctcttcttc atcgtgactt cgggctcacc 180
atgaccatac cagaagaccg tctgtgccca acagtcccca ataggttgaa ctacgttctg 240
tggattgaag atattttcaa ctacacgaac aaaaccctcg gcctgtcgga tgaccgtcct 300
attaaaggcg ttgatattgg tacaggagcc tccgcaattt atcctatgct tgcctgtgct 360
cggttcaagg catggtctat ggttggaaca gaggtcgaga ggaagtgcat tgacacggcc 420
cgcctcaatg tcgtcgcgaa caatctccaa gaccgtctct cgatattaga gacatccatt 480
gatggtccta ttctcgtccc cattttcgag gcgactgaag aatacgaata cgagtttact 540
atgtgtaacc ctccattcta cgacggtgct gccgatatgc agacttcgga tgctgccaaa 600
ggatttggat ttggcgtggg cgctccccat tctggaacag tcatcgaaat gtcgactgag 660
ggaggtgaat cggctttcgt cgctcagatg gtccgtgaga gcttgaagct tcgaacacga 720
tgcagatggt acacgagtaa cttgggaaag ctgaaatcct tgaaagaaat agtggggctg 780
ctgaaagaac ttgagataag caactatgcc attaacgaat acgttcaggg gtccacacgt 840
cgttatgccg ttgcgtggtc tttcactgat attcaactgc ctgaggagct ttctcgtccc 900
tctaaccccg agctcagctc tcttttctag 930
<210> 14
<211> 309
<212> PRT
<213> Psilocybe cubensis
<400> 14
Met His Ile Arg Asn Pro Tyr Arg Thr Pro Ile Asp Tyr Gln Ala Leu
1 5 10 15
Ser Glu Ala Phe Pro Pro Leu Lys Pro Phe Val Ser Val Asn Ala Asp
20 25 30
Gly Thr Ser Ser Val Asp Leu Thr Ile Pro Glu Ala Gln Arg Ala Phe
35 40 45
Thr Ala Ala Leu Leu His Arg Asp Phe Gly Leu Thr Met Thr Ile Pro
50 55 60
Glu Asp Arg Leu Cys Pro Thr Val Pro Asn Arg Leu Asn Tyr Val Leu
65 70 75 80
Trp Ile Glu Asp Ile Phe Asn Tyr Thr Asn Lys Thr Leu Gly Leu Ser
85 90 95
Asp Asp Arg Pro Ile Lys Gly Val Asp Ile Gly Thr Gly Ala Ser Ala
100 105 110
Ile Tyr Pro Met Leu Ala Cys Ala Arg Phe Lys Ala Trp Ser Met Val
115 120 125
Gly Thr Glu Val Glu Arg Lys Cys Ile Asp Thr Ala Arg Leu Asn Val
130 135 140
Val Ala Asn Asn Leu Gln Asp Arg Leu Ser Ile Leu Glu Thr Ser Ile
145 150 155 160
Asp Gly Pro Ile Leu Val Pro Ile Phe Glu Ala Thr Glu Glu Tyr Glu
165 170 175
Tyr Glu Phe Thr Met Cys Asn Pro Pro Phe Tyr Asp Gly Ala Ala Asp
180 185 190
Met Gln Thr Ser Asp Ala Ala Lys Gly Phe Gly Phe Gly Val Gly Ala
195 200 205
Pro His Ser Gly Thr Val Ile Glu Met Ser Thr Glu Gly Gly Glu Ser
210 215 220
Ala Phe Val Ala Gln Met Val Arg Glu Ser Leu Lys Leu Arg Thr Arg
225 230 235 240
Cys Arg Trp Tyr Thr Ser Asn Leu Gly Lys Leu Lys Ser Leu Lys Glu
245 250 255
Ile Val Gly Leu Leu Lys Glu Leu Glu Ile Ser Asn Tyr Ala Ile Asn
260 265 270
Glu Tyr Val Gln Gly Ser Thr Arg Arg Tyr Ala Val Ala Trp Ser Phe
275 280 285
Thr Asp Ile Gln Leu Pro Glu Glu Leu Ser Arg Pro Ser Asn Pro Glu
290 295 300
Leu Ser Ser Leu Phe
305
<210> 15
<211> 1419
<212> DNA
<213> Aspergillus fumigatus
<400> 15
atgtccatcg gagccgagat cgattcgctg gttcctgctc caccgggcct caacggcacc 60
gctgcgggct atccagccaa gacgcagaag gagttaagca acggagactt tgacgcgcac 120
gatggtcttt ctcttgcaca actgacaccg tacgatgtct tgacggctgc acttccgctg 180
ccggctccgg cttcgagcac agggttctgg tggcgggaga cgggccctgt tatgagcaag 240
cttttggcca aggcgaacta ccctctttac actcattaca agtaccttat gttataccat 300
acccatattc tcccattgtt gggacctcga ccgccgctcg agaactcgac gcacccgtcg 360
ccgagtaacg cgccgtggag gtccttcctg acagacgact tcactccgct cgagccgagc 420
tggaacgtga acgggaactc ggaagcacag agcacaatcc gtcttggtat tgaacctata 480
ggctttgaag ccggggctgc agcggaccca ttcaaccaag ctgccgtgac gcagttcatg 540
cactcatacg aggcaaccga agtcggtgcc acgctgacgc tgttcgagca cttccgcaac 600
gacatgtttg ttggcccaga aacgtacgct gcgttaagag cgaagatacc agaaggcgag 660
cataccacac agagtttcct ggcgttcgac ctggacgcgg gtcgtgtcac cacaaaggcg 720
tactttttcc cgattctcat gtcgttgaaa actggacaga gcacaacaaa ggtggtctct 780
gattccattc tgcatctagc gctgaagagt gaggtgtggg gtgtgcagac catcgccgcg 840
atgtcggtca tggaggcgtg gataggtagc tacggtggcg cggcaaagac ggagatgatc 900
agcgtcgatt gcgtgaacga ggcagactct cggatcaaga tatacgtgcg gatgccacat 960
acatccttgc ggaaggtaaa agaggcgtac tgcttaggtg ggcggttgac agacgagaac 1020
acaaaggagg gcctgaagct gctggacgag ctgtggagga cggtcttcgg catcgacgac 1080
gaggacgcgg agctgccaca gaatagccat cgcaccgcag gcacaatatt caatttcgag 1140
ctgaggccag ggaaatggtt ccccgagccc aaggtatacc tgcccgtccg acactactgt 1200
gaaagtgata tgcagattgc tagtcggcta caaacgttct ttggaaggct cggatggcac 1260
aacatggaga aagattattg caagcatctg gaagatttgt ttccccatca tccactgtcc 1320
tcgtcaacgg gcacacacac ctttctctca ttttcgtata agaagcagaa gggggtctat 1380
atgaccatgt attataatct ccgggtgtac agcacctaa 1419
<210> 16
<211> 472
<212> PRT
<213> Aspergillus fumigatus
<400> 16
Met Ser Ile Gly Ala Glu Ile Asp Ser Leu Val Pro Ala Pro Pro Gly
1 5 10 15
Leu Asn Gly Thr Ala Ala Gly Tyr Pro Ala Lys Thr Gln Lys Glu Leu
20 25 30
Ser Asn Gly Asp Phe Asp Ala His Asp Gly Leu Ser Leu Ala Gln Leu
35 40 45
Thr Pro Tyr Asp Val Leu Thr Ala Ala Leu Pro Leu Pro Ala Pro Ala
50 55 60
Ser Ser Thr Gly Phe Trp Trp Arg Glu Thr Gly Pro Val Met Ser Lys
65 70 75 80
Leu Leu Ala Lys Ala Asn Tyr Pro Leu Tyr Thr His Tyr Lys Tyr Leu
85 90 95
Met Leu Tyr His Thr His Ile Leu Pro Leu Leu Gly Pro Arg Pro Pro
100 105 110
Leu Glu Asn Ser Thr His Pro Ser Pro Ser Asn Ala Pro Trp Arg Ser
115 120 125
Phe Leu Thr Asp Asp Phe Thr Pro Leu Glu Pro Ser Trp Asn Val Asn
130 135 140
Gly Asn Ser Glu Ala Gln Ser Thr Ile Arg Leu Gly Ile Glu Pro Ile
145 150 155 160
Gly Phe Glu Ala Gly Ala Ala Ala Asp Pro Phe Asn Gln Ala Ala Val
165 170 175
Thr Gln Phe Met His Ser Tyr Glu Ala Thr Glu Val Gly Ala Thr Leu
180 185 190
Thr Leu Phe Glu His Phe Arg Asn Asp Met Phe Val Gly Pro Glu Thr
195 200 205
Tyr Ala Ala Leu Arg Ala Lys Ile Pro Glu Gly Glu His Thr Thr Gln
210 215 220
Ser Phe Leu Ala Phe Asp Leu Asp Ala Gly Arg Val Thr Thr Lys Ala
225 230 235 240
Tyr Phe Phe Pro Ile Leu Met Ser Leu Lys Thr Gly Gln Ser Thr Thr
245 250 255
Lys Val Val Ser Asp Ser Ile Leu His Leu Ala Leu Lys Ser Glu Val
260 265 270
Trp Gly Val Gln Thr Ile Ala Ala Met Ser Val Met Glu Ala Trp Ile
275 280 285
Gly Ser Tyr Gly Gly Ala Ala Lys Thr Glu Met Ile Ser Val Asp Cys
290 295 300
Val Asn Glu Ala Asp Ser Arg Ile Lys Ile Tyr Val Arg Met Pro His
305 310 315 320
Thr Ser Leu Arg Lys Val Lys Glu Ala Tyr Cys Leu Gly Gly Arg Leu
325 330 335
Thr Asp Glu Asn Thr Lys Glu Gly Leu Lys Leu Leu Asp Glu Leu Trp
340 345 350
Arg Thr Val Phe Gly Ile Asp Asp Glu Asp Ala Glu Leu Pro Gln Asn
355 360 365
Ser His Arg Thr Ala Gly Thr Ile Phe Asn Phe Glu Leu Arg Pro Gly
370 375 380
Lys Trp Phe Pro Glu Pro Lys Val Tyr Leu Pro Val Arg His Tyr Cys
385 390 395 400
Glu Ser Asp Met Gln Ile Ala Ser Arg Leu Gln Thr Phe Phe Gly Arg
405 410 415
Leu Gly Trp His Asn Met Glu Lys Asp Tyr Cys Lys His Leu Glu Asp
420 425 430
Leu Phe Pro His His Pro Leu Ser Ser Ser Thr Gly Thr His Thr Phe
435 440 445
Leu Ser Phe Ser Tyr Lys Lys Gln Lys Gly Val Tyr Met Thr Met Tyr
450 455 460
Tyr Asn Leu Arg Val Tyr Ser Thr
465 470
<210> 17
<211> 1158
<212> DNA
<213> Streptomyces sp. RM-5-8
<400> 17
atgggaggtc cgatgagcgg tttccattcg ggggaggcgc tgctcggtga cctcgccacc 60
ggtcagctga ccaggctgtg cgaggtggcg gggctgaccg aggccgacac ggcggcctac 120
acgggggtgc tgatcgaaag tctggggacg tcggccggac ggccgttgtc cctgccaccc 180
ccgtcgcgga cctttctctc cgacgaccac acccccgtgg agttctccct ggccttcctg 240
ccgggacgcg caccgcacct gcgggtcctg gtggaaccgg gctgctccag cggcgacgac 300
ctggcggaaa acggccgggc cggtctgcgg gcggtccaca ccatggcgga ccgctgggga 360
ttctccaccg agcaactcga ccggctggag gacctgttct tcccctcctc ccccgagggc 420
ccgctggccc tgtggtgcgc cctggagctc cgctccggtg gggtgccggg ggtgaaggtc 480
tacctcaacc ccgcggcgaa tggcgccgac cgggccgccg agacggtacg cgaggcgctg 540
gccaggctgg gccacctgca ggcgttcgac gcgctgcccc gggcggacgg cttcccgttc 600
ctcgccctgg acctcggcga ctgggacgcc ccgcgggtga agatctacct caaacacctc 660
ggcatgtccg ccgccgacgc gggctccctc ccccggatgt cgcccgcacc gagccgggag 720
cagctggagg agttcttccg caccgccggt gacctcccgg ccccgggaga cccggggccc 780
accgaggaca ccggccggct cgccgggcgc cccgccctca cctgccactc cttcacggag 840
acggcgaccg ggcggcccag cggctacacc ctccacgtgc cggtccgcga ctacgtccgg 900
cacgacggcg aggcacggga ccgggcggtg gccgtgctgc gcgaacatga catggacagt 960
gcggcactgg accgggcgct ggccgccgtg agcccccgcc cgctgagtga cggggtgggc 1020
ctgatcgcct atctggcact ggtccaccag cgcggccggc cgacacgggt gaccgtctac 1080
gtctcctccg aggcgtacga ggtgcggccg ccccgcgaga cggtccccac ccgcgaccgg 1140
gcgcgggcac ggctgtga 1158
<210> 18
<211> 385
<212> PRT
<213> Streptomyces sp. RM-5-8
<400> 18
Met Gly Gly Pro Met Ser Gly Phe His Ser Gly Glu Ala Leu Leu Gly
1 5 10 15
Asp Leu Ala Thr Gly Gln Leu Thr Arg Leu Cys Glu Val Ala Gly Leu
20 25 30
Thr Glu Ala Asp Thr Ala Ala Tyr Thr Gly Val Leu Ile Glu Ser Leu
35 40 45
Gly Thr Ser Ala Gly Arg Pro Leu Ser Leu Pro Pro Pro Ser Arg Thr
50 55 60
Phe Leu Ser Asp Asp His Thr Pro Val Glu Phe Ser Leu Ala Phe Leu
65 70 75 80
Pro Gly Arg Ala Pro His Leu Arg Val Leu Val Glu Pro Gly Cys Ser
85 90 95
Ser Gly Asp Asp Leu Ala Glu Asn Gly Arg Ala Gly Leu Arg Ala Val
100 105 110
His Thr Met Ala Asp Arg Trp Gly Phe Ser Thr Glu Gln Leu Asp Arg
115 120 125
Leu Glu Asp Leu Phe Phe Pro Ser Ser Pro Glu Gly Pro Leu Ala Leu
130 135 140
Trp Cys Ala Leu Glu Leu Arg Ser Gly Gly Val Pro Gly Val Lys Val
145 150 155 160
Tyr Leu Asn Pro Ala Ala Asn Gly Ala Asp Arg Ala Ala Glu Thr Val
165 170 175
Arg Glu Ala Leu Ala Arg Leu Gly His Leu Gln Ala Phe Asp Ala Leu
180 185 190
Pro Arg Ala Asp Gly Phe Pro Phe Leu Ala Leu Asp Leu Gly Asp Trp
195 200 205
Asp Ala Pro Arg Val Lys Ile Tyr Leu Lys His Leu Gly Met Ser Ala
210 215 220
Ala Asp Ala Gly Ser Leu Pro Arg Met Ser Pro Ala Pro Ser Arg Glu
225 230 235 240
Gln Leu Glu Glu Phe Phe Arg Thr Ala Gly Asp Leu Pro Ala Pro Gly
245 250 255
Asp Pro Gly Pro Thr Glu Asp Thr Gly Arg Leu Ala Gly Arg Pro Ala
260 265 270
Leu Thr Cys His Ser Phe Thr Glu Thr Ala Thr Gly Arg Pro Ser Gly
275 280 285
Tyr Thr Leu His Val Pro Val Arg Asp Tyr Val Arg His Asp Gly Glu
290 295 300
Ala Arg Asp Arg Ala Val Ala Val Leu Arg Glu His Asp Met Asp Ser
305 310 315 320
Ala Ala Leu Asp Arg Ala Leu Ala Ala Val Ser Pro Arg Pro Leu Ser
325 330 335
Asp Gly Val Gly Leu Ile Ala Tyr Leu Ala Leu Val His Gln Arg Gly
340 345 350
Arg Pro Thr Arg Val Thr Val Tyr Val Ser Ser Glu Ala Tyr Glu Val
355 360 365
Arg Pro Pro Arg Glu Thr Val Pro Thr Arg Asp Arg Ala Arg Ala Arg
370 375 380
Leu
385
<210> 19
<211> 1128
<212> DNA
<213> Streptomyces coelicolor
<400> 19
atgagggccg cgtcgacggg cgcggacccg caggacgcat ccacgctcgg ctctttcacc 60
ggcggccagt tgcgaagact cggctcggtc gccggtctgt cccgcgccga cgtcgagacc 120
tacgcacagg tcctgaccga cgcattgggc ccggtggccc agcggccgct gagcctggcg 180
ccgcccaccc gcaccttcct gtcggacgac cacacccccg tggagttctc cctctccttc 240
cggcccgggg cggcgcccgc catgcgggtc ctcgtggaac cgggctgcgg tgcgaccagc 300
ctggccgaca acggccgtgc cggtcttgag gcggtccgca cgatggcgcg gcgctggcac 360
ttcaccaccg acgccctcga cgaactcctg gacctgttcc tgccgcccgc tccgcagggc 420
cccctcgccc tgtggtgcgc cctggaactc aggcccgggg gtgtaccggg cgtcaaggtc 480
tatctgaacc ctgcggtggg cggggaggaa cgttccgccg cgacggtgcg cgaggccctg 540
cgccggctcg ggcaccacca ggccttcgac agcctccccc agggcagtgg atacccgttc 600
ctcgccctgg acctcgggaa ctggacggag ccccgggcga aggtctacct gcgccacgac 660
aacctcacgg ccggtcgggc cgcacggctg tcccggacgg actcgggcct cgtgccgacc 720
gcggtcgagg gtttcttccg caccgccgcg ggtcccggct ccgacgcggg tgggctcgac 780
gggcggcctg ctcagtcctg ccactccttc accgaccccg gcgcggagcg gccgagcggc 840
ttcaccctgt acatcccggt tcgtgactac gtccggcatg acggggaggc cctggcgcgg 900
gcgtccaccg tgctgcacca ccacggcatg gacgcctccg tgctccaccg cgccctggcc 960
gccctcaccg agcggcggcc cgaggacggg gtgggcctga tcgcctacct ggccctcgcc 1020
ggccaacggg accagccgcc gcgggtgacg gcctacctct cctcggaggc ctacacggtc 1080
cggccgccgg tcgtggagac cgtccgccaa ccgctgtcgg tcggctga 1128
<210> 20
<211> 375
<212> PRT
<213> Streptomyces coelicolor
<400> 20
Met Arg Ala Ala Ser Thr Gly Ala Asp Pro Gln Asp Ala Ser Thr Leu
1 5 10 15
Gly Ser Phe Thr Gly Gly Gln Leu Arg Arg Leu Gly Ser Val Ala Gly
20 25 30
Leu Ser Arg Ala Asp Val Glu Thr Tyr Ala Gln Val Leu Thr Asp Ala
35 40 45
Leu Gly Pro Val Ala Gln Arg Pro Leu Ser Leu Ala Pro Pro Thr Arg
50 55 60
Thr Phe Leu Ser Asp Asp His Thr Pro Val Glu Phe Ser Leu Ser Phe
65 70 75 80
Arg Pro Gly Ala Ala Pro Ala Met Arg Val Leu Val Glu Pro Gly Cys
85 90 95
Gly Ala Thr Ser Leu Ala Asp Asn Gly Arg Ala Gly Leu Glu Ala Val
100 105 110
Arg Thr Met Ala Arg Arg Trp His Phe Thr Thr Asp Ala Leu Asp Glu
115 120 125
Leu Leu Asp Leu Phe Leu Pro Pro Ala Pro Gln Gly Pro Leu Ala Leu
130 135 140
Trp Cys Ala Leu Glu Leu Arg Pro Gly Gly Val Pro Gly Val Lys Val
145 150 155 160
Tyr Leu Asn Pro Ala Val Gly Gly Glu Glu Arg Ser Ala Ala Thr Val
165 170 175
Arg Glu Ala Leu Arg Arg Leu Gly His His Gln Ala Phe Asp Ser Leu
180 185 190
Pro Gln Gly Ser Gly Tyr Pro Phe Leu Ala Leu Asp Leu Gly Asn Trp
195 200 205
Thr Glu Pro Arg Ala Lys Val Tyr Leu Arg His Asp Asn Leu Thr Ala
210 215 220
Gly Arg Ala Ala Arg Leu Ser Arg Thr Asp Ser Gly Leu Val Pro Thr
225 230 235 240
Ala Val Glu Gly Phe Phe Arg Thr Ala Ala Gly Pro Gly Ser Asp Ala
245 250 255
Gly Gly Leu Asp Gly Arg Pro Ala Gln Ser Cys His Ser Phe Thr Asp
260 265 270
Pro Gly Ala Glu Arg Pro Ser Gly Phe Thr Leu Tyr Ile Pro Val Arg
275 280 285
Asp Tyr Val Arg His Asp Gly Glu Ala Leu Ala Arg Ala Ser Thr Val
290 295 300
Leu His His His Gly Met Asp Ala Ser Val Leu His Arg Ala Leu Ala
305 310 315 320
Ala Leu Thr Glu Arg Arg Pro Glu Asp Gly Val Gly Leu Ile Ala Tyr
325 330 335
Leu Ala Leu Ala Gly Gln Arg Asp Gln Pro Pro Arg Val Thr Ala Tyr
340 345 350
Leu Ser Ser Glu Ala Tyr Thr Val Arg Pro Pro Val Val Glu Thr Val
355 360 365
Arg Gln Pro Leu Ser Val Gly
370 375
<210> 21
<211> 1380
<212> DNA
<213> Aspergillus fumigatus
<400> 21
atgaaggcag ccaatgcctc cagtgcggag gcctatcgag ttcttagtcg cgcctttaga 60
ttcgataatg aagatcagaa gctgtggtgg cacagcactg ccccgatgtt tgcaaaaatg 120
ctggaaactg ccaactacac cacaccttgt cagtatcaat acctcatcac ctataaggag 180
tgcgtaattc ccagtctcgg atgctatccg accaacagcg ccccccgctg gttgagcatc 240
ctcactcgat acggcactcc gttcgaattg agcctaaatt gctctaattc aatagtgaga 300
tacacattcg agccgatcaa tcaacatacc ggaacagata aagacccatt caatacgcac 360
gccatctggg agagcctgca gcacctgctt ccactggaga agagcattga tctggagtgg 420
ttccgccact tcaagcacga tctcaccctc aacagtgaag aatctgcttt tctggctcat 480
aatgatcgcc tcgtgggcgg cactatcagg acgcagaaca agctcgcgct cgatctgaag 540
gatggccgct ttgcacttaa gacgtacata tacccggctc tcaaagctgt cgtcaccggc 600
aagacaattc atgagttggt ctttggctca gtccgccggc tggcagtgag ggagccccga 660
atcttgcccc cactcaacat gctggaggaa tacatccgat cacgcggttc caagagcact 720
gccagtcccc gcctagtgtc ctgtgatctg accagtcctg ccaagtcgag aatcaagatc 780
tacctgctgg agcagatggt ttcactagaa gccatggagg acctgtggac tctgggcgga 840
cggcgccgag acgcttccac tttagagggg ctctctctgg tgcgtgagct ttgggatctg 900
atccaactgt cgccgggatt gaagtcctat ccggcgccgt atctgcctct cggggttatc 960
ccagacgaga ggctgccgct tatggccaat ttcaccctgc accagaatga cccggtccca 1020
gagccgcaag tatatttcac aaccttcggc atgaacgaca tggcggtggc ggatgccctg 1080
acgacgttct tcgagcgccg gggttggagt gaaatggccc gcacctacga aactactttg 1140
aagtcgtact acccccatgc ggatcatgac aaacttaact acctccacgc ctacatatcc 1200
ttctcctaca gggaccgtac cccttatctg agtgtctatc ttcaatcctt cgagacaggg 1260
gactgggcag ttgcaaactt atccgaatca aaggtcaagt gtcaggatgc ggcctgtcaa 1320
cccacagctt tacctccaga tctgtcaaag acaggggtat attattccgg tctccactga 1380
<210> 22
<211> 459
<212> PRT
<213> Aspergillus fumigatus
<400> 22
Met Lys Ala Ala Asn Ala Ser Ser Ala Glu Ala Tyr Arg Val Leu Ser
1 5 10 15
Arg Ala Phe Arg Phe Asp Asn Glu Asp Gln Lys Leu Trp Trp His Ser
20 25 30
Thr Ala Pro Met Phe Ala Lys Met Leu Glu Thr Ala Asn Tyr Thr Thr
35 40 45
Pro Cys Gln Tyr Gln Tyr Leu Ile Thr Tyr Lys Glu Cys Val Ile Pro
50 55 60
Ser Leu Gly Cys Tyr Pro Thr Asn Ser Ala Pro Arg Trp Leu Ser Ile
65 70 75 80
Leu Thr Arg Tyr Gly Thr Pro Phe Glu Leu Ser Leu Asn Cys Ser Asn
85 90 95
Ser Ile Val Arg Tyr Thr Phe Glu Pro Ile Asn Gln His Thr Gly Thr
100 105 110
Asp Lys Asp Pro Phe Asn Thr His Ala Ile Trp Glu Ser Leu Gln His
115 120 125
Leu Leu Pro Leu Glu Lys Ser Ile Asp Leu Glu Trp Phe Arg His Phe
130 135 140
Lys His Asp Leu Thr Leu Asn Ser Glu Glu Ser Ala Phe Leu Ala His
145 150 155 160
Asn Asp Arg Leu Val Gly Gly Thr Ile Arg Thr Gln Asn Lys Leu Ala
165 170 175
Leu Asp Leu Lys Asp Gly Arg Phe Ala Leu Lys Thr Tyr Ile Tyr Pro
180 185 190
Ala Leu Lys Ala Val Val Thr Gly Lys Thr Ile His Glu Leu Val Phe
195 200 205
Gly Ser Val Arg Arg Leu Ala Val Arg Glu Pro Arg Ile Leu Pro Pro
210 215 220
Leu Asn Met Leu Glu Glu Tyr Ile Arg Ser Arg Gly Ser Lys Ser Thr
225 230 235 240
Ala Ser Pro Arg Leu Val Ser Cys Asp Leu Thr Ser Pro Ala Lys Ser
245 250 255
Arg Ile Lys Ile Tyr Leu Leu Glu Gln Met Val Ser Leu Glu Ala Met
260 265 270
Glu Asp Leu Trp Thr Leu Gly Gly Arg Arg Arg Asp Ala Ser Thr Leu
275 280 285
Glu Gly Leu Ser Leu Val Arg Glu Leu Trp Asp Leu Ile Gln Leu Ser
290 295 300
Pro Gly Leu Lys Ser Tyr Pro Ala Pro Tyr Leu Pro Leu Gly Val Ile
305 310 315 320
Pro Asp Glu Arg Leu Pro Leu Met Ala Asn Phe Thr Leu His Gln Asn
325 330 335
Asp Pro Val Pro Glu Pro Gln Val Tyr Phe Thr Thr Phe Gly Met Asn
340 345 350
Asp Met Ala Val Ala Asp Ala Leu Thr Thr Phe Phe Glu Arg Arg Gly
355 360 365
Trp Ser Glu Met Ala Arg Thr Tyr Glu Thr Thr Leu Lys Ser Tyr Tyr
370 375 380
Pro His Ala Asp His Asp Lys Leu Asn Tyr Leu His Ala Tyr Ile Ser
385 390 395 400
Phe Ser Tyr Arg Asp Arg Thr Pro Tyr Leu Ser Val Tyr Leu Gln Ser
405 410 415
Phe Glu Thr Gly Asp Trp Ala Val Ala Asn Leu Ser Glu Ser Lys Val
420 425 430
Lys Cys Gln Asp Ala Ala Cys Gln Pro Thr Ala Leu Pro Pro Asp Leu
435 440 445
Ser Lys Thr Gly Val Tyr Tyr Ser Gly Leu His
450 455
<210> 23
<211> 2155
<212> DNA
<213> Psilocybe cubensis
<400> 23
atgatcgctg tactattctc cttcgtcatt gcaggatgca tatactacat cgtttctcgt 60
agagtgaggc ggtcgcgctt gccaccaggg ccgcctggca ttcctattcc cttcattggg 120
aacatgtttg atatgcctga agaatctcca tggttaacat ttctacaatg gggacgggat 180
tacagtctgt cttgccgcgt tgacttctaa tatatgaaca gctaatatat tgtcagacac 240
cgatattctc tacgtggatg ctggagggac agaaatggtt attcttaaca cgttggagac 300
cattaccgat ctattagaaa agcgagggtc catttattct ggccggtgag ctgatgttga 360
gttttttgca attgaatttg tggtcacacg tttccagact tgagagtaca atggtcaacg 420
aacttatggg gtgggagttt gacttagggt tcatcacata cggcgacagg tggcgcgaag 480
aaaggcgcat gttcgccaag gagttcagtg agaagggcat caagcaattt cgccatgctc 540
aagtgaaagc tgcccatcag cttgtccaac agcttaccaa aacgccagac cgctgggcac 600
aacatattcg ccagtaagta ctacttgagg aaaatagcgt acgcttcgct gaccggtccg 660
tacatcaaag tcagatagcg gcaatgtcac tggatattgg ttatggaatt gatcttgcag 720
aagacgaccc ttggctggaa gcgacccatt tggctaatga aggcctcgcc atagcatcag 780
tgccgggcaa attttgggtc gattcgttcc cttctcgtga gcatccttct tctatgtagg 840
aagggaagga gtctaacaag tgttagtaaa ataccttcct gcttggttcc caggtgctgt 900
cttcaagcgc aaagcgaagg tctggcgaga agccgccgac catatggttg acatgcctta 960
tgaaactatg aggaaattag cagttagtca aatgcgttct ccccgtattt tttcaatact 1020
ctaacttcag ctcacagcct caaggattga ctcgtccgtc gtatgcttca gctcgtctgc 1080
aagccatgga tctcaacggt gaccttgagc atcaagaaca cgtaatcaag aacacagccg 1140
cagaggttaa tgtcggtaag tcaaaagcgt ccgtcggcaa ttcaaaattc aggcgctaaa 1200
gtgggtcttc tcaccaaggt ggaggcgata ctgtaaggat ttctcaatcg ttagagtata 1260
agtgttctaa tgcagtacat actccaccaa ccagactgtc tctgctatgt ctgcgttcat 1320
cttggccatg gtgaagtacc ctgaggtcca gcgaaaggtt caagcggagc ttgatgctct 1380
gaccaataac ggccaaattc ctgactatga cgaagaagat gactccttgc catacctcac 1440
cgcatgtatc aaggagcttt tccggtggaa tcaaatcgca cccctcgcta taccgcacaa 1500
attaatgaag gacgacgtgt accgcgggta tctgattccc aagaacactc tagtcttcgc 1560
aaacacctgg tgaggctgtc cattcattcc tagtacatcc gttgccccac taatagcatc 1620
ttgataacag ggcagtatta aacgatccag aagtctatcc agatccctct gtgttccgcc 1680
cagaaagata tcttggtcct gacgggaagc ctgataacac tgtacgcgac ccacgtaaag 1740
cggcatttgg ctatggacga cgaaattggt aagtgcgctt tcagaacccc cccttccgtt 1800
gactagtgcc atgcgcgcat acaatatcgc tattgatctg atataacttc cctgcggcat 1860
ttattttggc attcctttag tcccggaatt catctagcgc agtcgacggt ttggattgca 1920
ggggcaaccc tcttatcagc gttcaatatc gagcgacctg tcgatcagaa tgggaagccc 1980
attgacatac cggctgattt tactacagga ttcttcaggt agctaatttc cgtctttgtg 2040
tgcataatac ccctaacgac gcacgtttac ctttttgtaa agacacccag tgcctttcca 2100
gtgcaggttt gttcctcgaa cagagcaagt ctcacagtcg gtatccggac cctga 2155
<210> 24
<211> 508
<212> PRT
<213> Psilocybe cubensis
<400> 24
Met Ile Ala Val Leu Phe Ser Phe Val Ile Ala Gly Cys Ile Tyr Tyr
1 5 10 15
Ile Val Ser Arg Arg Val Arg Arg Ser Arg Leu Pro Pro Gly Pro Pro
20 25 30
Gly Ile Pro Ile Pro Phe Ile Gly Asn Met Phe Asp Met Pro Glu Glu
35 40 45
Ser Pro Trp Leu Thr Phe Leu Gln Trp Gly Arg Asp Tyr Asn Thr Asp
50 55 60
Ile Leu Tyr Val Asp Ala Gly Gly Thr Glu Met Val Ile Leu Asn Thr
65 70 75 80
Leu Glu Thr Ile Thr Asp Leu Leu Glu Lys Arg Gly Ser Ile Tyr Ser
85 90 95
Gly Arg Leu Glu Ser Thr Met Val Asn Glu Leu Met Gly Trp Glu Phe
100 105 110
Asp Leu Gly Phe Ile Thr Tyr Gly Asp Arg Trp Arg Glu Glu Arg Arg
115 120 125
Met Phe Ala Lys Glu Phe Ser Glu Lys Gly Ile Lys Gln Phe Arg His
130 135 140
Ala Gln Val Lys Ala Ala His Gln Leu Val Gln Gln Leu Thr Lys Thr
145 150 155 160
Pro Asp Arg Trp Ala Gln His Ile Arg His Gln Ile Ala Ala Met Ser
165 170 175
Leu Asp Ile Gly Tyr Gly Ile Asp Leu Ala Glu Asp Asp Pro Trp Leu
180 185 190
Glu Ala Thr His Leu Ala Asn Glu Gly Leu Ala Ile Ala Ser Val Pro
195 200 205
Gly Lys Phe Trp Val Asp Ser Phe Pro Ser Leu Lys Tyr Leu Pro Ala
210 215 220
Trp Phe Pro Gly Ala Val Phe Lys Arg Lys Ala Lys Val Trp Arg Glu
225 230 235 240
Ala Ala Asp His Met Val Asp Met Pro Tyr Glu Thr Met Arg Lys Leu
245 250 255
Ala Pro Gln Gly Leu Thr Arg Pro Ser Tyr Ala Ser Ala Arg Leu Gln
260 265 270
Ala Met Asp Leu Asn Gly Asp Leu Glu His Gln Glu His Val Ile Lys
275 280 285
Asn Thr Ala Ala Glu Val Asn Val Gly Gly Gly Asp Thr Thr Val Ser
290 295 300
Ala Met Ser Ala Phe Ile Leu Ala Met Val Lys Tyr Pro Glu Val Gln
305 310 315 320
Arg Lys Val Gln Ala Glu Leu Asp Ala Leu Thr Asn Asn Gly Gln Ile
325 330 335
Pro Asp Tyr Asp Glu Glu Asp Asp Ser Leu Pro Tyr Leu Thr Ala Cys
340 345 350
Ile Lys Glu Leu Phe Arg Trp Asn Gln Ile Ala Pro Leu Ala Ile Pro
355 360 365
His Lys Leu Met Lys Asp Asp Val Tyr Arg Gly Tyr Leu Ile Pro Lys
370 375 380
Asn Thr Leu Val Phe Ala Asn Thr Trp Ala Val Leu Asn Asp Pro Glu
385 390 395 400
Val Tyr Pro Asp Pro Ser Val Phe Arg Pro Glu Arg Tyr Leu Gly Pro
405 410 415
Asp Gly Lys Pro Asp Asn Thr Val Arg Asp Pro Arg Lys Ala Ala Phe
420 425 430
Gly Tyr Gly Arg Arg Asn Cys Pro Gly Ile His Leu Ala Gln Ser Thr
435 440 445
Val Trp Ile Ala Gly Ala Thr Leu Leu Ser Ala Phe Asn Ile Glu Arg
450 455 460
Pro Val Asp Gln Asn Gly Lys Pro Ile Asp Ile Pro Ala Asp Phe Thr
465 470 475 480
Thr Gly Phe Phe Arg His Pro Val Pro Phe Gln Cys Arg Phe Val Pro
485 490 495
Arg Thr Glu Gln Val Ser Gln Ser Val Ser Gly Pro
500 505
<210> 25
<211> 2187
<212> DNA
<213> Psilocybe cubensis
<400> 25
atggcttcta gttcttccga tgtcttcgtt ttgggtctag gtgttgtttt ggctgccttg 60
tatatcttca gagaccaatt attcgctgct tctaagccaa aggtggctcc agtttccact 120
acgaagcctg ccaacggttc cgctaaccca agagacttca tcgccaagat gaaacaaggt 180
aagaagagaa tcgtaatctt ctacggttct caaactggta ccgctgaaga atatgctatt 240
cgtttggcta aggaagctaa gcaaaagttc ggtctagcct ccttggtttg tgatccagaa 300
gaatacgatt ttgaaaagtt ggaccaattg ccagaagatt ctattgcttt cttcgtcgtt 360
gctacctatg gtgaaggtga acctacagac aacgctgtcc aattgttgca aaacttgcaa 420
gatgaaagct tcgaattctc ctctggtgag agaaagttgt caggtttgaa gtacgttgtt 480
tttggtctgg gtaacaagac ctacgaacat tacaacctca ttgggagaac tgttgacgct 540
caattggcca agatgggtgc tatcagaatc ggtgaaagag gtgaaggtga tgatgacaag 600
tccatggaag aagactactt ggaatggaag gatggtatgt gggaagcgtt tgccactgct 660
atgggtgttg aagaaggtca aggtggtgac tccgctgatt tcgtcgtttc cgaattggaa 720
tctcacccac cagaaaaggt ttaccaaggt gaattttctg ctagagcttt aaccaaaacc 780
aagggtattc acgacgctaa gaatcctttt gctgctccaa ttgcggttgc tagagaattg 840
ttccaatctg ttgtcgatag aaactgtgtc cacgtcgaat tcaacattga aggctctggt 900
atcacctatc aacacggtga ccacgttggt ttgtggccat tgaatccaga tgttgaagtc 960
gaacggttgt tgtgtgtttt aggtttagct gaaaagagag atgctgtcat ctccattgaa 1020
tccttagacc cggctttggc taaggttcca ttcccagtcc caactactta cggtgctgtg 1080
ttgagacact acattgacat ctctgctgtc gccggtagac aaatcttggg tactttgtcc 1140
aaattcgctc caaccccaga agctgaagct ttcttgagaa acttgaacac taacaaggaa 1200
gaataccaca acgtcgtcgc taacggttgt ttgaaattgg gtgaaatttt gcaaatcgct 1260
accggtaacg acattactgt cccaccaact actgccaaca ccaccaaatg gccaattcca 1320
ttcgacatca ttgtttctgc catcccaaga ttgcaaccaa gatactactc tatctcttct 1380
tccccaaaaa ttcatccaaa caccatccac gctaccgttg ttgtgctcaa atacgaaaac 1440
gttccaaccg aaccaatccc aagaaagtgg gtttacggtg tcggtagtaa cttcttgttg 1500
aatttaaagt acgctgttaa caaggaacca gttccataca tcactcaaaa tggcgaacaa 1560
agagtcggtg tcccggaata cttgattgct ggtccacgtg gttcttacaa gactgaatct 1620
ttctacaagg ctccaatcca tgttagacgt tctactttcc gtttgccaac caacccaaag 1680
tctccagtca tcatgattgg tccaggtact ggtgtcgccc cattcagagg cttcgttcaa 1740
gaaagagttg ccttggccag aagatccatc gaaaagaacg gtcctgactc tttggctgac 1800
tggggtcgta tttccttgtt ctacggttgt agaagatccg acgaagactt cttgtacaag 1860
gacgaatggc cacaatacga agctgagttg aagggtaagt tcaagttgca ctgtgctttc 1920
tccagacaaa actacaagcc agacggttct aagatttacg tccaagattt gatctgggaa 1980
gacagagaac acattgccga tgccatctta aacggtaagg gttacgtcta catctgcggt 2040
gaagctaagt ccatgtctaa acaagttgaa gaagttctag ccaagatctt gggcgaagcc 2100
aaaggtggtt ccggtccagt tgaaggtgtt gctgaagtca agttactgaa ggaacggtcc 2160
agattgatgt tggatgtctg gtctagg 2187
<210> 26
<211> 728
<212> PRT
<213> Psilocybe cubensis
<400> 26
Met Ala Ser Ser Ser Ser Asp Val Phe Val Leu Gly Leu Gly Val Val
1 5 10 15
Leu Ala Ala Leu Tyr Ile Phe Arg Asp Gln Leu Phe Ala Ala Ser Lys
20 25 30
Pro Lys Val Ala Pro Val Ser Thr Thr Lys Pro Ala Asn Gly Ser Ala
35 40 45
Asn Pro Arg Asp Phe Ile Ala Lys Met Lys Gln Gly Lys Lys Arg Ile
50 55 60
Val Ile Phe Tyr Gly Ser Gln Thr Gly Thr Ala Glu Glu Tyr Ala Ile
65 70 75 80
Arg Leu Ala Lys Glu Ala Lys Gln Lys Phe Gly Leu Ala Ser Leu Val
85 90 95
Cys Asp Pro Glu Glu Tyr Asp Phe Glu Lys Leu Asp Gln Leu Pro Glu
100 105 110
Asp Ser Ile Ala Phe Phe Val Val Ala Thr Tyr Gly Glu Gly Glu Pro
115 120 125
Thr Asp Asn Ala Val Gln Leu Leu Gln Asn Leu Gln Asp Glu Ser Phe
130 135 140
Glu Phe Ser Ser Gly Glu Arg Lys Leu Ser Gly Leu Lys Tyr Val Val
145 150 155 160
Phe Gly Leu Gly Asn Lys Thr Tyr Glu His Tyr Asn Leu Ile Gly Arg
165 170 175
Thr Val Asp Ala Gln Leu Ala Lys Met Gly Ala Ile Arg Ile Gly Glu
180 185 190
Arg Gly Glu Gly Asp Asp Asp Lys Ser Met Glu Glu Asp Tyr Leu Glu
195 200 205
Trp Lys Asp Gly Met Trp Glu Ala Phe Ala Thr Ala Met Gly Val Glu
210 215 220
Glu Gly Gln Gly Gly Asp Ser Ala Asp Phe Val Val Ser Glu Leu Glu
225 230 235 240
Ser His Pro Pro Glu Lys Val Tyr Gln Gly Glu Phe Ser Ala Arg Ala
245 250 255
Leu Thr Lys Thr Lys Gly Ile His Asp Ala Lys Asn Pro Phe Ala Ala
260 265 270
Pro Ile Ala Val Ala Arg Glu Leu Phe Gln Ser Val Val Asp Arg Asn
275 280 285
Cys Val His Val Glu Phe Asn Ile Glu Gly Ser Gly Ile Thr Tyr Gln
290 295 300
His Gly Asp His Val Gly Leu Trp Pro Leu Asn Pro Asp Val Glu Val
305 310 315 320
Glu Arg Leu Leu Cys Val Leu Gly Leu Ala Glu Lys Arg Asp Ala Val
325 330 335
Ile Ser Ile Glu Ser Leu Asp Pro Ala Leu Ala Lys Val Pro Phe Pro
340 345 350
Val Pro Thr Thr Tyr Gly Ala Val Leu Arg His Tyr Ile Asp Ile Ser
355 360 365
Ala Val Ala Gly Arg Gln Ile Leu Gly Thr Leu Ser Lys Phe Ala Pro
370 375 380
Thr Pro Glu Ala Glu Ala Phe Leu Arg Asn Leu Asn Thr Asn Lys Glu
385 390 395 400
Glu Tyr His Asn Val Val Ala Asn Gly Cys Leu Lys Leu Gly Glu Ile
405 410 415
Leu Gln Ile Ala Thr Gly Asn Asp Ile Thr Val Pro Pro Thr Thr Ala
420 425 430
Asn Thr Thr Lys Trp Pro Ile Pro Phe Asp Ile Ile Val Ser Ala Ile
435 440 445
Pro Arg Leu Gln Pro Arg Tyr Tyr Ser Ile Ser Ser Ser Pro Lys Ile
450 455 460
His Pro Asn Thr Ile His Ala Thr Val Val Val Leu Lys Tyr Glu Asn
465 470 475 480
Val Pro Thr Glu Pro Ile Pro Arg Lys Trp Val Tyr Gly Val Gly Ser
485 490 495
Asn Phe Leu Leu Asn Leu Lys Tyr Ala Val Asn Lys Glu Pro Val Pro
500 505 510
Tyr Ile Thr Gln Asn Gly Glu Gln Arg Val Gly Val Pro Glu Tyr Leu
515 520 525
Ile Ala Gly Pro Arg Gly Ser Tyr Lys Thr Glu Ser Phe Tyr Lys Ala
530 535 540
Pro Ile His Val Arg Arg Ser Thr Phe Arg Leu Pro Thr Asn Pro Lys
545 550 555 560
Ser Pro Val Ile Met Ile Gly Pro Gly Thr Gly Val Ala Pro Phe Arg
565 570 575
Gly Phe Val Gln Glu Arg Val Ala Leu Ala Arg Arg Ser Ile Glu Lys
580 585 590
Asn Gly Pro Asp Ser Leu Ala Asp Trp Gly Arg Ile Ser Leu Phe Tyr
595 600 605
Gly Cys Arg Arg Ser Asp Glu Asp Phe Leu Tyr Lys Asp Glu Trp Pro
610 615 620
Gln Tyr Glu Ala Glu Leu Lys Gly Lys Phe Lys Leu His Cys Ala Phe
625 630 635 640
Ser Arg Gln Asn Tyr Lys Pro Asp Gly Ser Lys Ile Tyr Val Gln Asp
645 650 655
Leu Ile Trp Glu Asp Arg Glu His Ile Ala Asp Ala Ile Leu Asn Gly
660 665 670
Lys Gly Tyr Val Tyr Ile Cys Gly Glu Ala Lys Ser Met Ser Lys Gln
675 680 685
Val Glu Glu Val Leu Ala Lys Ile Leu Gly Glu Ala Lys Gly Gly Ser
690 695 700
Gly Pro Val Glu Gly Val Ala Glu Val Lys Leu Leu Lys Glu Arg Ser
705 710 715 720
Arg Leu Met Leu Asp Val Trp Ser
725
<210> 27
<211> 6347
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 27
gtatccggct gttccttcat agccctttca atgaacgttg cagccctttg aagattggcc 60
attttgtcag gactcgagcc tgacagttgg accaacgcaa ctttaatttt ttgtgaaaga 120
atcttcgaag cactcatact ggcgatcttc acgccctcct gctattacaa aagctgtgtt 180
tttacaagaa tcaaattaag ttagcaagat attatacaac attattgata atttcaatat 240
cgtgttcgta cctgatgacg tatctgtgca ttgataaggc ccgcatggtt tcagaaagca 300
gagcggaacg attccaaatt agtggccttg tgctttgcat gtcaattgtg ttaccttcag 360
ctcgtggatt tgttttatca atacacagtc tacagtcaag aatttttttt atcaaatttt 420
gcgttcgagc gtataaaata gccgctgtag ctacttaagt tcctgttcag cgatagtttt 480
tttccatcac acgtactatg gcaattaagt cctcagcgag ctcgcatgga atgcgtgcga 540
tgagcgacct catgctatac ctgagaaagc aacctgacct acaggaaaga gttactcaag 600
aataagaatt ttcgttttaa aacctaagag tcactttaaa atttgtatac acttattttt 660
tttataactt atttaataat aaaaatcata aatcataaga aattcgctta tttagaagtg 720
tcaacaacgt atctaccaac ggaatgcgtg cgattcaggc gtagtctgga acgtcgtatg 780
ggtatggacc agagacggat tgagaaactt gttcggttct tgggacgaat ctacattgga 840
atggaactgg gtgcctgaag aaaccagtgg tgaaatcagc tgggatgtca attggcttac 900
cgttttggtc aactggtctt tcaatgttga aagcagacaa caaagtagca ccggcaatcc 960
aaacagtaga ttgagctagg tgaatacctg ggcagtttct tctaccgtaa ccgaaagcag 1020
cctttcttgg gtctctaaca gtgttgtctg gtttaccatc aggacccaag tatctttctg 1080
gacggaaaac ggatggatct ggatagactt ctgggtcatt caaaactgcc caggtgttag 1140
caaaaaccaa tgtgttcttt ggaatcaaat aacctctgta aacatcatcc ttcatcaatt 1200
tatgagggat ggctaatgga gcaatttggt tccatctgaa taattccttg atacaagcgg 1260
tcaaatatgg gagtgagtcg tcttcctcat cgtagtcagg gatttgaccg ttgttggtca 1320
aagcatccaa ttcagcttga acctttcttt gcacttctgg gtatttaacc atggccaata 1380
tgaaagcgga catagcagag acggtagtgt cgccaccacc aacgttaact tcagcagcag 1440
tgttcttgat aacatgttct tggtgttcta aatcaccgtt caagtccata gcttgtaatc 1500
tagcagaagc gtaagatggt ctggttagac cttgtggagc caactttctc atagtttcgt 1560
atggcatgtc aaccatgtgg tcagcggctt ctctccagac cttggcctta cgcttgaaga 1620
cggcacctgg gaaccaagct ggcaagtact tcaaagatgg gaaggagtca acccagaact 1680
tacctggaac actagcaatg gccaaacctt cgttggctaa gtgggtagct tctaaccatg 1740
ggtcatcttc ggctagatcg ataccgtaac caatgtccaa agacatagca gcgatttgat 1800
gtctgatgtg ttgagcccac cggtccggag tcttggtcaa ttgttgaacc aattggtgag 1860
cagccttgac ttgagcgtgt ctgaattgct tgataccctt ttcagagaat tccttagcaa 1920
acattcttct ttcttctctc caacggtcac cgtaagtgat aaaacccaga tcaaattccc 1980
aacccatcaa ttcattgacc atagtggatt ccaatctacc ggagtagatg gaaccacgtt 2040
tttccaagag atccgtgata gtttccaagg tgtttaaaat gaccatttcg gtaccaccag 2100
catctacgta caagatatca gtgttgtagt cacgacccca ttgcaagaaa gtcaaccatg 2160
gagattcttc tggcatgtcg aacatgttac caataaatgg gattggaatt cctggtggac 2220
caggtggcaa tctggatcta cgaactcttc tggagacgat gtagtaaata caaccagcaa 2280
tgacgaaaga gaacaagaca gcaatcattg ttttatattt gttgtaaaaa gtagataatt 2340
acttccttga tgatctgtaa aaaagagaaa aagaaagcat ctaagaactt gaaaaactac 2400
gaattagaaa agaccaaata tgtatttctt gcattgacca atttatgcaa gtttatatat 2460
atgtaaatgt aagtttcacg aggttctact aaactaaacc acccccttgg ttagaagaaa 2520
agagtgtgtg agaacaggct gttgttgtca cacgattcgg acaattctgt ttgaaagaga 2580
gagagtaaca gtacgatcga acgaactttg ctctggagat cacagtgggc atcatagcat 2640
gtggtactaa accctttccc gccattccag aaccttcgat tgcttgttac aaaacctgtg 2700
agccgtcgct aggaccttgt tgtgtgacga aattggaagc tgcaatcaat aggaagacag 2760
gaagtcgagc gtgtctgggt tttttcagtt ttgttctttt tgcaaacaac agtttattcc 2820
tggcatccac taaatataat ggagcccgct ttttaagctg gcatccagaa aaaaaaagaa 2880
tcccagcacc aaaatattgt tttcttcacc aaccatcagt tcataggtcc attctcttag 2940
cgcaactaca gagaacaggg gcacaaacag gcaaaaaacg ggcacaacct caatggagtg 3000
atgcaacctg cctggagtaa atgatgacac aaggcaattg acccacgcat gtatctatct 3060
cattttctta caccttctat taccttctgc tctctctgat ttggaaaaag ctgaaaaaaa 3120
aggttgaaac cagttccctg aaattattcc cctacttgac taataagtat ataaagacgg 3180
taggtattga ttgtaattct gtaaatctat ttcttaaact tcttaaattc tacttttata 3240
gttagtcttt tttttagttt taaaacacca agaacttagt ttcgaataaa cacacataaa 3300
caaacaaaat ggcttctagt tcttccgatg tcttcgtttt gggtctaggt gttgttttgg 3360
ctgccttgta tatcttcaga gaccaattat tcgctgcttc taagccaaag gtggctccag 3420
tttccactac gaagcctgcc aacggttccg ctaacccaag agacttcatc gccaagatga 3480
aacaaggtaa gaagagaatc gtaatcttct acggttctca aactggtacc gctgaagaat 3540
atgctattcg tttggctaag gaagctaagc aaaagttcgg tctagcctcc ttggtttgtg 3600
atccagaaga atacgatttt gaaaagttgg accaattgcc agaagattct attgctttct 3660
tcgtcgttgc tacctatggt gaaggtgaac ctacagacaa cgctgtccaa ttgttgcaaa 3720
acttgcaaga tgaaagcttc gaattctcct ctggtgagag aaagttgtca ggtttgaagt 3780
acgttgtttt tggtctgggt aacaagacct acgaacatta caacctcatt gggagaactg 3840
ttgacgctca attggccaag atgggtgcta tcagaatcgg tgaaagaggt gaaggtgatg 3900
atgacaagtc catggaagaa gactacttgg aatggaagga tggtatgtgg gaagcgtttg 3960
ccactgctat gggtgttgaa gaaggtcaag gtggtgactc cgctgatttc gtcgtttccg 4020
aattggaatc tcacccacca gaaaaggttt accaaggtga attttctgct agagctttaa 4080
ccaaaaccaa gggtattcac gacgctaaga atccttttgc tgctccaatt gcggttgcta 4140
gagaattgtt ccaatctgtt gtcgatagaa actgtgtcca cgtcgaattc aacattgaag 4200
gctctggtat cacctatcaa cacggtgacc acgttggttt gtggccattg aatccagatg 4260
ttgaagtcga acggttgttg tgtgttttag gtttagctga aaagagagat gctgtcatct 4320
ccattgaatc cttagacccg gctttggcta aggttccatt cccagtccca actacttacg 4380
gtgctgtgtt gagacactac attgacatct ctgctgtcgc cggtagacaa atcttgggta 4440
ctttgtccaa attcgctcca accccagaag ctgaagcttt cttgagaaac ttgaacacta 4500
acaaggaaga ataccacaac gtcgtcgcta acggttgttt gaaattgggt gaaattttgc 4560
aaatcgctac cggtaacgac attactgtcc caccaactac tgccaacacc accaaatggc 4620
caattccatt cgacatcatt gtttctgcca tcccaagatt gcaaccaaga tactactcta 4680
tctcttcttc cccaaaaatt catccaaaca ccatccacgc taccgttgtt gtgctcaaat 4740
acgaaaacgt tccaaccgaa ccaatcccaa gaaagtgggt ttacggtgtc ggtagtaact 4800
tcttgttgaa tttaaagtac gctgttaaca aggaaccagt tccatacatc actcaaaatg 4860
gcgaacaaag agtcggtgtc ccggaatact tgattgctgg tccacgtggt tcttacaaga 4920
ctgaatcttt ctacaaggct ccaatccatg ttagacgttc tactttccgt ttgccaacca 4980
acccaaagtc tccagtcatc atgattggtc caggtactgg tgtcgcccca ttcagaggct 5040
tcgttcaaga aagagttgcc ttggccagaa gatccatcga aaagaacggt cctgactctt 5100
tggctgactg gggtcgtatt tccttgttct acggttgtag aagatccgac gaagacttct 5160
tgtacaagga cgaatggcca caatacgaag ctgagttgaa gggtaagttc aagttgcact 5220
gtgctttctc cagacaaaac tacaagccag acggttctaa gatttacgtc caagatttga 5280
tctgggaaga cagagaacac attgccgatg ccatcttaaa cggtaagggt tacgtctaca 5340
tctgcggtga agctaagtcc atgtctaaac aagttgaaga agttctagcc aagatcttgg 5400
gcgaagccaa aggtggttcc ggtccagttg aaggtgttgc tgaagtcaag ttactgaagg 5460
aacggtccag attgatgttg gatgtctggt ctgaacaaaa gttaatttct gaagaagatt 5520
tggaatgaat cgcgtgcatt catccgctct aaccgaaaag gaaggagtta gacaacctga 5580
agtctaggtc cctatttatt tttttatagt tatgttagta ttaagaacgt tatttatatt 5640
tcaaattttt cttttttttc tgtacagacg cgtgtacgca tgtaacatta tactgaaaac 5700
cttgcttgag aaggttttgg gacgctcgaa gatcgcgtcc caattcgccc tatagtgagt 5760
cgtattacgc gcgctcactg gccgtcgttt tacaacgtcg tgactgggaa aaccctggcg 5820
ttacccctgc aggactagtg ctgaggcatt aatagtttac tcaattcttg aagccaattt 5880
gtacaattcc ccattagagt caaataaaag gatgcctcac ggaggtatgt tacccgcgct 5940
atttcacatg gctcattgaa ttagaggtgg aatttggtgt accctcccct cctcatctga 6000
tgaagtagtg atccgacaat tcttaaaagt tgtagacatt acttttacca ccaactaagt 6060
tgtatttata ttgctaccct tatcctttta tatctaacta gcgctcataa ggttggggca 6120
atactaaaac tgtgttctta ttcaactcat taaatacgtg gcagtacgta ccctattaga 6180
aacaatagga aacagcagag tcggaagaag ccaaatgcca gatttgaagt ccaaaacctt 6240
gtcaagccaa tctttgggag cggctattcc tccagaaatt gtgtaccaaa tacttacata 6300
ccagtttagg gatttgttaa gaaatgacca tccaggtacg gcagaaa 6347
<210> 28
<211> 4792
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 28
caatctggcg gcttgagttc tcaacatgtt ttatttttta cttatattgc tggtagggta 60
aaaaaatata actcctagga ataggttgtc tatatgtttt tgtcttgctt ctataattgt 120
aacaaacaag gaaagggaaa atactgggtg taaaagccat tgagtcaagt taggtcatcc 180
cttttataca aaatttttca attttttttc caagattctt gtacgattaa ttattttttt 240
tttgcgtcct acagcgtgat gaaaatttcg cctgctgcaa gatgagcggg aacgggcgaa 300
atgtgcacgc gcacaactta cgaaacgcgg atgagtcact gacagccacc gcagaggttc 360
tgactcctac tgagctctat tggaggtggc agaaccggta ccggaggagg ccgctataac 420
cggtttgaat ttattgtcac agtgtcacat cagcattaag tcctcagcga gctcgcatgg 480
aatgcgtgcg atgagcgacc tcatgctata cctgagaaag caacctgacc tacaggaaag 540
agttactcaa gaataagaat tttcgtttta aaacctaaga gtcactttaa aatttgtata 600
cacttatttt ttttataact tatttaataa taaaaatcat aaatcataag aaattcgctt 660
atttagaagt gtcaacaacg tatctaccaa cggaatgcgt gcgattcagg tggagtccaa 720
acccaacaaa ggatttggaa ttggcttacc ggcagtggag gattccttta gcaacgtgga 780
agtgatttca ccgttgtcgt tgttacctct agcatcgtgg aaagcagcaa cacccttctt 840
aacaaagttg attctttctt cttcagaacc ccattgcatg aagtcagtcc acataacaat 900
gtgagcggcg ataccagcgg taaccttggc gtagttgatg gaatgcttgg aagtacgggc 960
gtaagattgc aagtaagctt gtctcatggt tgtaccaact tgttcgtctt ggaatctgct 1020
aatcaagtaa cagtcaccca agaagtaacc caaatccaat gaagctggac cgtacttaca 1080
caattcccag tctaagatgt agatcttttg caacttagat gggttacctt cttcaagttg 1140
caacaagatg ttcccagacc acaagtcagc catgaccaaa gtttcttcgg agtgcataac 1200
atcgtcaact agatccttga caacagttgg caacaatgga tcatcgacgc cgtatttagc 1260
ggcgtttggg ataatagttt ggtacaattg gtcagaggtg gttctaccga caatgttacc 1320
agagaagaac ttgaattctg ggtcgtctct tctttctcta cctatgttgt gcaatctggc 1380
gacgaaacca ccaatctcgg taccaaccaa tctagcaata tcggtagcca aaggtggctt 1440
agcagtaacg tagtctaata aggtcttcat tttaccgaca tcttgcataa tcaaagcatt 1500
gttttccaag tcatagttga gaccttctgg aacagagaca ataccatcaa caccacccaa 1560
aacttctctg ttagccatca tcaacttgat agcttggtat tcgtagacag aacgttcaac 1620
accgattttg aaatcttcat cagtagacat gtgtggttga gcgtgcttca aaatgataga 1680
agtgtgacct tggtatggag cgttcaattt aatacgccag gtgacgttaa cgaaaccacc 1740
ggataatctc ttgacaccag aagtgtcaac atctaaagac aaatgcttgg tcaaataggt 1800
gattaaaccg tcttcagtct tcaagtcaaa ggccattgtt ttatatttgt tgtaaaaagt 1860
agataattac ttccttgatg atctgtaaaa aagagaaaaa gaaagcatct aagaacttga 1920
aaaactacga attagaaaag accaaatatg tatttcttgc attgaccaat ttatgcaagt 1980
ttatatatat gtaaatgtaa gtttcacgag gttctactaa actaaaccac ccccttggtt 2040
agaagaaaag agtgtgtgag aacaggctgt tgttgtcaca cgattcggac aattctgttt 2100
gaaagagaga gagtaacagt acgatcgaac gaactttgct ctggagatca cagtgggcat 2160
catagcatgt ggtactaaac cctttcccgc cattccagaa ccttcgattg cttgttacaa 2220
aacctgtgag ccgtcgctag gaccttgttg tgtgacgaaa ttggaagctg caatcaatag 2280
gaagacagga agtcgagcgt gtctgggttt tttcagtttt gttctttttg caaacaacag 2340
tttattcctg gcatccacta aatataatgg agcccgcttt ttaagctggc atccagaaaa 2400
aaaaagaatc ccagcaccaa aatattgttt tcttcaccaa ccatcagttc ataggtccat 2460
tctcttagcg caactacaga gaacaggggc acaaacaggc aaaaaacggg cacaacctca 2520
atggagtgat gcaacctgcc tggagtaaat gatgacacaa ggcaattgac ccacgcatgt 2580
atctatctca ttttcttaca ccttctatta ccttctgctc tctctgattt ggaaaaagct 2640
gaaaaaaaag gttgaaacca gttccctgaa attattcccc tacttgacta ataagtatat 2700
aaagacggta ggtattgatt gtaattctgt aaatctattt cttaaacttc ttaaattcta 2760
cttttatagt tagtcttttt tttagtttta aaacaccaag aacttagttt cgaataaaca 2820
cacataaaca aacaaaatgc atatcagaaa cccatataga actccaattg actaccaagc 2880
tttgtctgaa gctttcccac cattgaagcc atttgtttcc gttaacgctg atggtacctc 2940
ctcagttgac ttgaccattc cagaagccca aagagctttt accgctgccc ttttgcacag 3000
agacttcggc ttgactatga ctatcccaga agatcgtttg tgtccaaccg ttccaaacag 3060
attgaactac gttttgtgga ttgaagacat tttcaactac accaacaaga ctttgggttt 3120
atctgacgac cgtccaatca agggtgttga tatcggtacc ggtgcttctg ccatttaccc 3180
aatgttggct tgcgccagat tcaaggcttg gtccatggtt ggtactgaag ttgaaagaaa 3240
gtgtatcgac actgctagat taaacgttgt tgctaacaac ttgcaagatc gtctatccat 3300
cttggaaacc tctattgacg gtccaatttt agtcccaatt ttcgaagcta ccgaagaata 3360
cgaatacgaa ttcaccatgt gtaacccacc tttctacgat ggtgccgctg acatgcaaac 3420
tagcgatgct gcaaagggtt ttggtttcgg tgtcggtgct ccacactctg gtacagtcat 3480
cgaaatgtct actgaaggtg gtgaatccgc tttcgtggct caaatggtta gagaatctct 3540
taagttgaga accagatgta gatggtacac ttctaactta ggtaagttga aatctttgaa 3600
ggaaattgtc ggtttgttga aggaattaga aatctctaat tacgccatca acgaatatgt 3660
ccaaggttcc actagaagat acgctgtcgc ttggagtttc actgatatcc aattgccaga 3720
agaattgtcc agaccatcta atcctgaatt gtcctctttg ttcgactaca aggatgacga 3780
tgacaaatga atcgcgtgca ttcatccgct ctaaccgaaa aggaaggagt tagacaacct 3840
gaagtctagg tccctattta tttttttata gttatgttag tattaagaac gttatttata 3900
tttcaaattt ttcttttttt tctgtacaga cgcgtgtacg catgtaacat tatactgaaa 3960
accttgcttg agaaggtttt gggacgctcg aagatcgcgt acccaattcg ccctatagtg 4020
agtcgtatta cgcgcgctca ctggccgtcg ttttacaacg tcgtgactgg gaaaaccctg 4080
gcgttacccc tgcaggacta gtgctgaggc attaatgcaa ctcagaagtt tgacagcaag 4140
caagttcatc attcgaacta gccttattgt tttagttcag tgacagcgaa ctgccgtact 4200
cgatgcttta tttctcacgg tagagcggaa gaacagatag gggcagcgtg agaagagtta 4260
gaaagtaaat ttttatcacg tctgaagtat tcttattcat aggaaatttt gcaaggtttt 4320
ttagctcaat aacgggctaa gttatataag gtgttcacgc gattttcttg ttatgtatac 4380
ctcttctctg aggaatggta ctactgtcct gatgtaggct ccttaaattg gtgggcaaga 4440
ataacttatc gatattttgt atattggtct tggagttcac cacgtaatgc ctgtttaaga 4500
ccatcagtta actctagtat tatttggtct tggctactgg ccgtttgcta ttattcaagt 4560
cttttgtgcc ttcccgtcgg gtaagggagt tatttaggga tacagaatct aacgaaaact 4620
aaatctcaat gattaactct atttaatcct tttttgaaag gcaaaagagg tcccttgttc 4680
acttacaacg ttcttagcca aattcgctta tcacttacta cttcacgata tacagaagta 4740
aaaacatata aaaagatgtc tgtttgttta gccatcacaa aaggtatcgc ag 4792
<210> 29
<211> 9145
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 29
tgttttatat ttgttgtaaa aagtagataa ttacttcctt gatgatctgt aaaaaagaga 60
aaaagaaagc atctaagaac ttgaaaaact acgaattaga aaagaccaaa tatgtatttc 120
ttgcattgac caatttatgc aagtttatat atatgtaaat gtaagtttca cgaggttcta 180
ctaaactaaa ccaccccctt ggttagaaga aaagagtgtg tgagaacagg ctgttgttgt 240
cacacgattc ggacaattct gtttgaaaga gagagagtaa cagtacgatc gaacgaactt 300
tgctctggag atcacagtgg gcatcatagc atgtggtact aaaccctttc ccgccattcc 360
agaaccttcg attgcttgtt acaaaacctg tgagccgtcg ctaggacctt gttgtgtgac 420
gaaattggaa gctgcaatca ataggaagac aggaagtcga gcgtgtctgg gttttttcag 480
ttttgttctt tttgcaaaca acagtttatt cctggcatcc actaaatata atggagcccg 540
ctttttaagc tggcatccag aaaaaaaaag aatcccagca ccaaaatatt gttttcttca 600
ccaaccatca gttcataggt ccattctctt agcgcaacta cagagaacag gggcacaaac 660
aggcaaaaaa cgggcacaac ctcaatggag tgatgcaacc tgcctggagt aaatgatgac 720
acaaggcaat tgacccacgc atgtatctat ctcattttct tacaccttct attaccttct 780
gctctctctg atttggaaaa agctgaaaaa aaaggttgaa accagttccc tgaaattatt 840
cccctacttg actaataagt atataaagac ggtaggtatt gattgtaatt ctgtaaatct 900
atttcttaaa cttcttaaat tctactttta tagttagtct tttttttagt tttaaaacac 960
caagaactta gtttcgaata aacacacata aacaaacaaa ggatccatga tgaagttctg 1020
gagaaagtac acacaacaag aaatggatga aaagattact gaatctttgg aaaagacttt 1080
gaactacgat aacactaaga caatcggtat tccaggtact aagttggatg atacagtttt 1140
ctatgatgat cattctttcg ttaagcattc accatacttg agaactttta ttcaaaaccc 1200
aaaccatatc ggttgtcata cttatgataa ggctgatatc ttgttcggtg gtacattcga 1260
tatcgaaaga gaattaatcc aattgttagc aatcgatgtt ttgaacggta acgatgaaga 1320
atttgatggt tacgttactc aaggtggtac agaagctaac atccaagcaa tgtgggttta 1380
cagaaactac ttcaagaaag aaagaaaggc taagcatgaa gaaatcgcta tcatcacttc 1440
agcagataca cattactctg catacaaagg ttcagatttg ttgaacatcg atattattaa 1500
ggttccagtt gatttttatt caagaaaaat tcaagaaaat acattggatt caattgttaa 1560
agaagctaaa gaaattggta aaaagtactt catcgttatc tctaacatgg gtactacaat 1620
gtttggttca gttgatgatc cagatttgta cgctaacatc ttcgataagt acaatttgga 1680
atacaaaatt catgttgatg gtgcatttgg tggttttata tatccaattg ataataagga 1740
atgtaaaact gatttctcta ataagaacgt ttcttcaatc acattagatg gtcataagat 1800
gttgcaagct ccatacggta ctggtatctt cgtttcaaga aagaatttga tccataacac 1860
tttgacaaag gaagcaactt acatcgaaaa tttggatgtt acattgtctg gttcaagatc 1920
tggttcaaat gctgttgcaa tttggatggt tttagcttct tatggtccat acggttggat 1980
ggaaaagatt aataagttga gaaatagaac taaatggttg tgtaagcaat tgaacgatat 2040
gagaattaaa tattacaaag aagattcaat gaatattgtt acaattgaag aacaatatgt 2100
taataaggaa atcgctgaaa agtacttttt agttccagaa gttcataacc caactaacaa 2160
ctggtacaag atcgttgtta tggaacatgt tgaattggat atcttgaact ctttggttta 2220
cgatttgaga aagtttaata aggaacattt gaaggcaatg catcatcatc atcatcatta 2280
accgcggcta gctaagatcc gctctaaccg aaaaggaagg agttagacaa cctgaagtct 2340
aggtccctat ttattttttt atagttatgt tagtattaag aacgttattt atatttcaaa 2400
tttttctttt ttttctgtac agacgcgtgt acgcatgtaa cattatactg aaaaccttgc 2460
ttgagaaggt tttgggacgc tcgaagatcc agctgcatta atgaatcggc caacgcgcgg 2520
ggagaggcgg tttgcgtatt gggcgctctt ccgcttcctc gctcactgac tcgctgcgct 2580
cggtcgttcg gctgcggcga gcggtatcag ctcactcaaa ggcggtaata cggttatcca 2640
cagaatcagg ggataacgca ggaaagaaca tgtgagcaaa aggccagcaa aaggccagga 2700
accgtaaaaa ggccgcgttg ctggcgtttt tccataggct ccgcccccct gacgagcatc 2760
acaaaaatcg acgctcaagt cagaggtggc gaaacccgac aggactataa agataccagg 2820
cgtttccccc tggaagctcc ctcgtgcgct ctcctgttcc gaccctgccg cttaccggat 2880
acctgtccgc ctttctccct tcgggaagcg tggcgctttc tcatagctca cgctgtaggt 2940
atctcagttc ggtgtaggtc gttcgctcca agctgggctg tgtgcacgaa ccccccgttc 3000
agcccgaccg ctgcgcctta tccggtaact atcgtcttga gtccaacccg gtaagacacg 3060
acttatcgcc actggcagca gccactggta acaggattag cagagcgagg tatgtaggcg 3120
gtgctacaga gttcttgaag tggtggccta actacggcta cactagaaga acagtatttg 3180
gtatctgcgc tctgctgaag ccagttacct tcggaaaaag agttggtagc tcttgatccg 3240
gcaaacaaac caccgctggt agcggtggtt tttttgtttg caagcagcag attacgcgca 3300
gaaaaaaagg atctcaagaa gatcctttga tcttttctac ggggtctgac gctcagtgga 3360
acgaaaactc acgttaaggg attttggtca tgagattatc aaaaaggatc ttcacctaga 3420
tccttttaaa ttaaaaatga agttttaaat caatctaaag tatatatgag taaacttggt 3480
ctgacagtta ccaatgctta atcagtgagg cacctatctc agcgatctgt ctatttcgtt 3540
catccatagt tgcctgactc cccgtcgtgt agataactac gatacgggag ggcttaccat 3600
ctggccccag tgctgcaatg ataccgcgag acccacgctc accggctcca gatttatcag 3660
caataaacca gccagccgga agggccgagc gcagaagtgg tcctgcaact ttatccgcct 3720
ccatccagtc tattaattgt tgccgggaag ctagagtaag tagttcgcca gttaatagtt 3780
tgcgcaacgt tgttgccatt gctacaggca tcgtggtgtc acgctcgtcg tttggtatgg 3840
cttcattcag ctccggttcc caacgatcaa ggcgagttac atgatccccc atgttgtgca 3900
aaaaagcggt tagctccttc ggtcctccga tcgttgtcag aagtaagttg gccgcagtgt 3960
tatcactcat ggttatggca gcactgcata attctcttac tgtcatgcca tccgtaagat 4020
gcttttctgt gactggtgag tactcaacca agtcattctg agaatagtgt atgcggcgac 4080
cgagttgctc ttgcccggcg tcaatacggg ataataccgc gccacatagc agaactttaa 4140
aagtgctcat cattggaaaa cgttcttcgg ggcgaaaact ctcaaggatc ttaccgctgt 4200
tgagatccag ttcgatgtaa cccactcgtg cacccaactg atcttcagca tcttttactt 4260
tcaccagcgt ttctgggtga gcaaaaacag gaaggcaaaa tgccgcaaaa aagggaataa 4320
gggcgacacg gaaatgttga atactcatac tcttcctttt tcaatattat tgaagcattt 4380
atcagggtta ttgtctcatg agcggataca tatttgaatg tatttagaaa aataaacaaa 4440
taggggttcc gcgcacattt ccccgaaaag tgccacctga acgaagcatc tgtgcttcat 4500
tttgtagaac aaaaatgcaa cgcgagagcg ctaatttttc aaacaaagaa tctgagctgc 4560
atttttacag aacagaaatg caacgcgaaa gcgctatttt accaacgaag aatctgtgct 4620
tcatttttgt aaaacaaaaa tgcaacgcga gagcgctaat ttttcaaaca aagaatctga 4680
gctgcatttt tacagaacag aaatgcaacg cgagagcgct attttaccaa caaagaatct 4740
atacttcttt tttgttctac aaaaatgcat cccgagagcg ctatttttct aacaaagcat 4800
cttagattac tttttttctc ctttgtgcgc tctataatgc agtctcttga taactttttg 4860
cactgtaggt ccgttaaggt tagaagaagg ctactttggt gtctattttc tcttccataa 4920
aaaaagcctg actccacttc ccgcgtttac tgattactag cgaagctgcg ggtgcatttt 4980
ttcaagataa aggcatcccc gattatattc tataccgatg tggattgcgc atactttgtg 5040
aacagaaagt gatagcgttg atgattcttc attggtcaga aaattatgaa cggtttcttc 5100
tattttgtct ctatatacta cgtataggaa atgtttacat tttcgtattg ttttcgattc 5160
actctatgaa tagttcttac tacaattttt ttgtctaaag agtaatacta gagataaaca 5220
taaaaaatgt agaggtcgag tttagatgca agttcaagga gcgaaaggtg gatgggtagg 5280
ttatataggg atatagcaca gagatatata gcaaagagat acttttgagc aatgtttgtg 5340
gaagcggtat tcgcaatatt ttagtagctc gttacagtcc ggtgcgtttt tggttttttg 5400
aaagtgcgtc ttcagagcgc ttttggtttt caaaagcgct ctgaagttcc tatactttct 5460
agagaatagg aacttcggaa taggaacttc aaagcgtttc cgaaaacgag cgcttccgaa 5520
aatgcaacgc gagctgcgca catacagctc actgttcacg tcgcacctat atctgcgtgt 5580
tgcctgtata tatatataca tgagaagaac ggcatagtgc gtgtttatgc ttaaatgcgt 5640
acttatatgc gtctatttat gtaggatgaa aggtagtcta gtacctcctg tgatattatc 5700
ccattccatg cggggtatcg tatgcttcct tcagcactac cctttagctg ttctatatgc 5760
tgccactcct caattggatt agtctcatcc ttcaatgcta tcatttcctt tgatattgga 5820
tcatactaag aaaccattat tatcatgaca ttaacctata aaaataggcg tatcacgagg 5880
ccctttcgtc tcgcgcgttt cggtgatgac ggtgaaaacc tctgacacat gcagctcccg 5940
gagacggtca cagcttgtct gtaagcggat gccgggagca gacaagcccg tcagggcgcg 6000
tcagcgggtg ttggcgggtg tcggggctgg cttaactatg cggcatcaga gcagattgta 6060
ctgagagtgc accatatttc acaccgcata gatccgtcga gttcaagaga aaaaaaaaga 6120
aaaagcaaaa agaaaaaagg aaagcgcgcc tcgttcagaa tgacacgtat agaatgatgc 6180
attaccttgt catcttcagt atcatactgt tcgtatacat acttactgac attcataggt 6240
atacatatat acacatgtat atatatcgta tgctgcagct ttaaataatc ggtgtcacta 6300
cataagaaca cctttggtgg agggaacatc gttggtacca ttgggcgagg tggcttctct 6360
tatggcaacc gcaagagcct tgaacgcact ctcactacgg tgatgatcat tcttgcctcg 6420
cagacaatca acgtggaggg taattctgct agcctctgca aagctttcaa gaaaatgcgg 6480
gatcatctcg caagagagat ctcctacttt ctccctttgc aaaccaagtt cgacaactgc 6540
gtacggcctg ttcgaaagat ctaccaccgc tctggaaagt gcctcatcca aaggcgcaaa 6600
tcctgatcca aaccttttta ctccacgcac ggcccctagg gcctctttaa aagcttgacc 6660
gagagcaatc ccgcagtctt cagtggtgtg atggtcgtct atgtgtaagt caccaatgca 6720
ctcaacgatt agcgaccagc cggaatgctt ggccagagca tgtatcatat ggtccagaaa 6780
ccctatacct gtgtggacgt taatcacttg cgattgtgtg gcctgttctg ctactgcttc 6840
tgcctctttt tctgggaaga tcgagtgctc tatcgctagg ggaccaccct ttaaagagat 6900
cgcaatctga atcttggttt catttgtaat acgctttact agggctttct gctctgtcat 6960
ctttgccttc gtttatcttg cctgctcatt ttttagtata ttcttcgaag aaatcacatt 7020
actttatata atgtataatt cattatgtga taatgccaat cgctaagaaa aaaaaagagt 7080
catccgctag gtggaaaaaa aaaaatgaaa atcattaccg aggcataaaa aaatatagag 7140
tgtactagag gaggccaaga gtaatagaaa aagaaaattg cgggaaagga ctgtgttatg 7200
acttccctga ctaatgccgt gttcaaacga tacctggcag tgactcctag cgctcaccaa 7260
gctcttaaaa cgggaattta tggtgcactc tcagtacacg cgccagatct gtttagcttg 7320
cctcgtcccc gccgggtcac ccggccagcg acatggaggc ccagaatacc ctccttgaca 7380
gtcttgacgt gcgcagctca ggggcatgat gtgactgtcg cccgtacatt tagcccatac 7440
atccccatgt ataatcattt gcatccatac attttgatgg ccgcacggcg cgaagcaaaa 7500
attacggctc ctcgctgcag acctgcgagc agggaaacgc tcccctcaca gacgcgttga 7560
attgtcccca cgccgcgccc ctgtagagaa atataaaagg ttaggatttg ccactgaggt 7620
tcttctttca tatacttcct tttaaaatct tgctaggata cagttctcac atcacatccg 7680
aacataaaca accatgggta aggaaaagac tcacgtttcg aggccgcgat taaattccaa 7740
catggatgct gatttatatg ggtataaatg ggctcgcgat aatgtcgggc aatcaggtgc 7800
gacaatctat cgattgtatg ggaagcccga tgcgccagag ttgtttctga aacatggcaa 7860
aggtagcgtt gccaatgatg ttacagatga gatggtcaga ctaaactggc tgacggaatt 7920
tatgcctctt ccgaccatca agcattttat ccgtactcct gatgatgcat ggttactcac 7980
cactgcgatc cccggcaaaa cagcattcca ggtattagaa gaatatcctg attcaggtga 8040
aaatattgtt gatgcgctgg cagtgttcct gcgccggttg cattcgattc ctgtttgtaa 8100
ttgtcctttt aacagcgatc gcgtatttcg tctcgctcag gcgcaatcac gaatgaataa 8160
cggtttggtt gatgcgagtg attttgatga cgagcgtaat ggctggcctg ttgaacaagt 8220
ctggaaagaa atgcataagc ttttgccatt ctcaccggat tcagtcgtca ctcatggtga 8280
tttctcactt gataacctta tttttgacga ggggaaatta ataggttgta ttgatgttgg 8340
acgagtcgga atcgcagacc gataccagga tcttgccatc ctatggaact gcctcggtga 8400
gttttctcct tcattacaga aacggctttt tcaaaaatat ggtattgata atcctgatat 8460
gaataaattg cagtttcatt tgatgctcga tgagtttttc taatcagtac tgacaataaa 8520
aagattcttg ttttcaagaa cttgtcattt gtatagtttt tttatattgt agttgttcta 8580
ttttaatcaa atgttagcgt gatttatatt ttttttcgcc tcgacatcat ctgcccagat 8640
gcgaagttaa gtgcgcagaa agtaatatca tgcgtcaatc gtatgtgaat gctggtcgct 8700
atactgctgt cgattcgata ctaacgccgc catccagtgt cgaattcgcc attcaggctg 8760
cgcaactgtt gggaagggcg atcggtgcgg gcctcttcgc tattacgcca gctgaattgg 8820
agcgacctca tgctatacct gagaaagcaa cctgacctac aggaaagagt tactcaagaa 8880
taagaatttt cgttttaaaa cctaagagtc actttaaaat ttgtatacac ttattttttt 8940
tataacttat ttaataataa aaatcataaa tcataagaaa ttcgcttatt tagaagtgtc 9000
aacaacgtat ctaccaacga tttgaccctt ttccatcttt tcgtaaattt ctggcaaggt 9060
agacaagccg acaaccttga ttggagactt gaccaaacct ctggcgaaga attgttaatt 9120
aagagctcag atcttttgcg gccgc 9145
<210> 30
<211> 499
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 30
gtttgcaaaa agaacaaaac tgaaaaaacc cagacacgct cgacttcctg tcttcctatt 60
gattgcagct tccaatttcg tcacacaaca aggtcctagc gacggctcac aggttttgta 120
acaagcaatc gaaggttctg gaatggcggg aaagggttta gtaccacatg ctatgatgcc 180
cactgtgatc tccagagcaa agttcgttcg atcgtactgt tactctctct ctttcaaaca 240
gaattgtccg aatcgtgtga caacaacagc ctgttctcac acactctttt cttctaacca 300
agggggtggt ttagtttagt agaacctcgt gaaacttaca tttacatata tataaacttg 360
cataaattgg tcaatgcaag aaatacatat ttggtctttt ctaattcgta gtttttcaag 420
ttcttagatg ctttcttttt ctctttttta cagatcatca aggaagtaat tatctacttt 480
ttacaacaaa tataaaaca 499
<210> 31
<211> 500
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 31
acagtttatt cctggcatcc actaaatata atggagcccg ctttttaagc tggcatccag 60
aaaaaaaaag aatcccagca ccaaaatatt gttttcttca ccaaccatca gttcataggt 120
ccattctctt agcgcaacta cagagaacag gggcacaaac aggcaaaaaa cgggcacaac 180
ctcaatggag tgatgcaacc tgcctggagt aaatgatgac acaaggcaat tgacccacgc 240
atgtatctat ctcattttct tacaccttct attaccttct gctctctctg atttggaaaa 300
agctgaaaaa aaaggttgaa accagttccc tgaaattatt cccctacttg actaataagt 360
atataaagac ggtaggtatt gattgtaatt ctgtaaatct atttcttaaa cttcttaaat 420
tctactttta tagttagtct tttttttagt tttaaaacac caagaactta gtttcgaata 480
aacacacata aacaaacaaa 500
<210> 32
<211> 500
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 32
gctggattga gctgaatggt gccaggtcga ggctgggagg gagactaact cgaaagtgac 60
gaagactcga aaattaaaaa aaaagatact gcagaaggca agattgagaa tggagtaaag 120
gcagcgtggg tcccctgtgg aaaccgcagt tttcctgcgc caagtggtac cggtgcgagt 180
gcagcaatta atctctcgat attttcttag tatctctttt tatataagaa tatattttgg 240
aattggtaat gcttatcttc aatagtttct tagttgaatg cacacttaag agcaaattgg 300
ccaaggagtt cttcgttcgc tttaatttat ttcctggtta ttgtcaattt attcatccca 360
tctccccagg atagaagaaa ttagtgtaat tttgctgaca atacatttta acgacgataa 420
caataatagc aattaaataa aatagcacta ccaccactcc actgctcgtt agctatttct 480
gtaaaataaa taaaaagatc 500
<210> 33
<211> 501
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 33
attcgcgcta tctcgatttc tacctatata gttaatctct gtacaaaaac aatctttcca 60
actatccatt aatcatagta tattatcagc gtcggcgatt ttaccacgct tgacaaaagc 120
cgcgggcggg attcctgtgg gtagtggcac cggcagttaa tctaatcaaa ggcgcttgaa 180
ggaagagata gataatagaa caaagcaatc gccgctttgg acggcaaata tgtttatcca 240
ttggtgcggt gattggatat gatttgtctc cagtagtata agcaagcgcc agatctgttt 300
actgtaaaat taagtgagta atctcgcggg atgtaatgat ttaagggaat ctggttcagg 360
ttttcacata tatttgtata taaggccatt tgtaatttca atagttttag gatttttcct 420
tctcccaaaa tactcactta ctgtgttaca ttacagaaag aacagacaag aaaccgtcaa 480
taagaaatat aactaagaac a 501
<210> 34
<211> 7882
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 34
caggtggcac ttttcgggga aatgtgcgcg gaacccctat ttgtttattt ttctaaatac 60
attcaaatat gtatccgctc atgagacaat aaccctgata aatgcttcaa taatattgaa 120
aaaggaagag tatgagtatt caacatttcc gtgtcgccct tattcccttt tttgcggcat 180
tttgccttcc tgtttttgct cacccagaaa cgctggtgaa agtaaaagat gctgaagatc 240
agttgggtgc acgagtgggt tacatcgaac tggatctcaa cagcggtaag atccttgaga 300
gttttcgccc cgaagaacgt tttccaatga tgagcacttt taaagttctg ctatgtggcg 360
cggtattatc ccgtattgac gccgggcaag agcaactcgg tcgccgcata cactattctc 420
agaatgactt ggttgagtac tcaccagtca cagaaaagca tcttacggat ggcatgacag 480
taagagaatt atgcagtgct gccataacca tgagtgataa cactgcggcc aacttacttc 540
tgacaacgat cggaggaccg aaggagctaa ccgctttttt gcacaacatg ggggatcatg 600
taactcgcct tgatcgttgg gaaccggagc tgaatgaagc cataccaaac gacgagcgtg 660
acaccacgat gcctgtagca atggcaacaa cgttgcgcaa actattaact ggcgaactac 720
ttactctagc ttcccggcaa caattaatag actggatgga ggcggataaa gttgcaggac 780
cacttctgcg ctcggccctt ccggctggct ggtttattgc tgataaatct ggagccggtg 840
agcgtgggtc tcgcggtatc attgcagcac tggggccaga tggtaagccc tcccgtatcg 900
tagttatcta cacgacgggg agtcaggcaa ctatggatga acgaaataga cagatcgctg 960
agataggtgc ctcactgatt aagcattggt aactgtcaga ccaagtttac tcatatatac 1020
tttagattga tttaaaactt catttttaat ttaaaaggat ctaggtgaag atcctttttg 1080
ataatctcat gaccaaaatc ccttaacgtg agttttcgtt ccactgagcg tcagaccccg 1140
tagaaaagat caaaggatct tcttgagatc ctttttttct gcgcgtaatc tgctgcttgc 1200
aaacaaaaaa accaccgcta ccagcggtgg tttgtttgcc ggatcaagag ctaccaactc 1260
tttttccgaa ggtaactggc ttcagcagag cgcagatacc aaatactgtt cttctagtgt 1320
agccgtagtt aggccaccac ttcaagaact ctgtagcacc gcctacatac ctcgctctgc 1380
taatcctgtt accagtggct gctgccagtg gcgataagtc gtgtcttacc gggttggact 1440
caagacgata gttaccggat aaggcgcagc ggtcgggctg aacggggggt tcgtgcacac 1500
agcccagctt ggagcgaacg acctacaccg aactgagata cctacagcgt gagctatgag 1560
aaagcgccac gcttcccgaa gggagaaagg cggacaggta tccggtaagc ggcagggtcg 1620
gaacaggaga gcgcacgagg gagcttccag ggggaaacgc ctggtatctt tatagtcctg 1680
tcgggtttcg ccacctctga cttgagcgtc gatttttgtg atgctcgtca ggggggcgga 1740
gcctatggaa aaacgccagc aacgcggcct ttttacggtt cctggccttt tgctggcctt 1800
ttgctcacat gttctttcct gcgttatccc ctgattctgt ggataaccgt attaccgcct 1860
ttgagtgagc tgataccgct cgccgcagcc gaacgaccga gcgcagcgag tcagtgagcg 1920
aggaagcgga agagcgccca atacgcaaac cgcctctccc cgcgcgttgg ccgattcatt 1980
aatgcagctg gatcttcgag cgtcccaaaa ccttctcaag caaggttttc agtataatgt 2040
tacatgcgta cacgcgtctg tacagaaaaa aaagaaaaat ttgaaatata aataacgttc 2100
ttaatactaa cataactata aaaaaataaa tagggaccta gacttcaggt tgtctaactc 2160
cttccttttc ggttagagcg gatcttagct agccgcggta ccaagctggt ggatcctttg 2220
tttgtttatg tgtgtttatt cgaaactaag ttcttggtgt tttaaaacta aaaaaaagac 2280
taactataaa agtagaattt aagaagttta agaaatagat ttacagaatt acaatcaata 2340
cctaccgtct ttatatactt attagtcaag taggggaata atttcaggga actggtttca 2400
accttttttt tcagcttttt ccaaatcaga gagagcagaa ggtaatagaa ggtgtaagaa 2460
aatgagatag atacatgcgt gggtcaattg ccttgtgtca tcatttactc caggcaggtt 2520
gcatcactcc attgaggttg tgcccgtttt ttgcctgttt gtgcccctgt tctctgtagt 2580
tgcgctaaga gaatggacct atgaactgat ggttggtgaa gaaaacaata ttttggtgct 2640
gggattcttt ttttttctgg atgccagctt aaaaagcggg ctccattata tttagtggat 2700
gccaggaata aactgttgtt tgcaaaaaga acaaaactga aaaaacccag acacgctcga 2760
cttcctgtct tcctattgat tgcagcttcc aatttcgtca cacaacaagg tcctagcgac 2820
ggctcacagg ttttgtaaca agcaatcgaa ggttctggaa tggcgggaaa gggtttagta 2880
ccacatgcta tgatgcccac tgtgatctcc agagcaaagt tcgttcgatc gtactgttac 2940
tctctctctt tcaaacagaa ttgtccgaat cgtgtgacaa caacagcctg ttctcacaca 3000
ctcttttctt ctaaccaagg gggtggttta gtttagtaga acctcgtgaa acttacattt 3060
acatatatat aaacttgcat aaattggtca atgcaagaaa tacatatttg gtcttttcta 3120
attcgtagtt tttcaagttc ttagatgctt tctttttctc ttttttacag atcatcaagg 3180
aagtaattat ctacttttta caacaaatat aaaacagcgg ccgcaaaaga tctgagctct 3240
taattaacaa ttcttcgcca gaggtttggt caagtctcca atcaaggttg tcggcttgtc 3300
taccttgcca gaaatttacg aaaagatgga aaagggtcaa atcgttggta gatacgttgt 3360
tgacacttct aaataagcga atttcttatg atttatgatt tttattatta aataagttat 3420
aaaaaaaata agtgtataca aattttaaag tgactcttag gttttaaaac gaaaattctt 3480
attcttgagt aactctttcc tgtaggtcag gttgctttct caggtatagc atgaggtcgc 3540
tccaattcag ctggcgtaat agcgaagagg cccgcaccga tcgcccttcc caacagttgc 3600
gcagcctgaa tggcgaattc gacactggat ggcggcgtta gtatcgaatc gacagcagta 3660
tagcgaccag cattcacata cgattgacgc atgatattac tttctgcgca cttaacttcg 3720
catctgggca gatgatgtcg aggcgaaaaa aaatataaat cacgctaaca tttgattaaa 3780
atagaacaac tacaatataa aaaaactata caaatgacaa gttcttgaaa acaagaatct 3840
ttttattgtc agtactgatt agaaaaactc atcgagcatc aaatgaaact gcaatttatt 3900
catatcagga ttatcaatac catatttttg aaaaagccgt ttctgtaatg aaggagaaaa 3960
ctcaccgagg cagttccata ggatggcaag atcctggtat cggtctgcga ttccgactcg 4020
tccaacatca atacaaccta ttaatttccc ctcgtcaaaa ataaggttat caagtgagaa 4080
atcaccatga gtgacgactg aatccggtga gaatggcaaa agcttatgca tttctttcca 4140
gacttgttca acaggccagc cattacgctc gtcatcaaaa tcactcgcat caaccaaacc 4200
gttattcatt cgtgattgcg cctgagcgag acgaaatacg cgatcgctgt taaaaggaca 4260
attacaaaca ggaatcgaat gcaaccggcg caggaacact gccagcgcat caacaatatt 4320
ttcacctgaa tcaggatatt cttctaatac ctggaatgct gttttgccgg ggatcgcagt 4380
ggtgagtaac catgcatcat caggagtacg gataaaatgc ttgatggtcg gaagaggcat 4440
aaattccgtc agccagttta gtctgaccat ctcatctgta acatcattgg caacgctacc 4500
tttgccatgt ttcagaaaca actctggcgc atcgggcttc ccatacaatc gatagattgt 4560
cgcacctgat tgcccgacat tatcgcgagc ccatttatac ccatataaat cagcatccat 4620
gttggaattt aatcgcggcc tcgaaacgtg agtcttttcc ttacccatgg ttgtttatgt 4680
tcggatgtga tgtgagaact gtatcctagc aagattttaa aaggaagtat atgaaagaag 4740
aacctcagtg gcaaatccta accttttata tttctctaca ggggcgcggc gtggggacaa 4800
ttcaacgcgt ctgtgagggg agcgtttccc tgctcgcagg tctgcagcga ggagccgtaa 4860
tttttgcttc gcgccgtgcg gccatcaaaa tgtatggatg caaatgatta tacatgggga 4920
tgtatgggct aaatgtacgg gcgacagtca catcatgccc ctgagctgcg cacgtcaaga 4980
ctgtcaagga gggtattctg ggcctccatg tcgctggccg ggtgacccgg cggggacgag 5040
gcaagctaaa cagatctggc gcgtgtactg agagtgcacc ataaattccc gttttaagag 5100
cttggtgagc gctaggagtc actgccaggt atcgtttgaa cacggcatta gtcagggaag 5160
tcataacaca gtcctttccc gcaattttct ttttctatta ctcttggcct cctctagtac 5220
actctatatt tttttatgcc tcggtaatga ttttcatttt tttttttcca cctagcggat 5280
gactcttttt ttttcttagc gattggcatt atcacataat gaattataca ttatataaag 5340
taatgtgatt tcttcgaaga atatactaaa aaatgagcag gcaagataaa cgaaggcaaa 5400
gatgacagag cagaaagccc tagtaaagcg tattacaaat gaaaccaaga ttcagattgc 5460
gatctcttta aagggtggtc ccctagcgat agagcactcg atcttcccag aaaaagaggc 5520
agaagcagta gcagaacagg ccacacaatc gcaagtgatt aacgtccaca caggtatagg 5580
gtttctggac catatgatac atgctctggc caagcattcc ggctggtcgc taatcgttga 5640
gtgcattggt gacttacaca tagacgacca tcacaccact gaagactgcg ggattgctct 5700
cggtcaagct tttaaagagg ccctaggggc cgtgcgtgga gtaaaaaggt ttggatcagg 5760
atttgcgcct ttggatgagg cactttccag agcggtggta gatctttcga acaggccgta 5820
cgcagttgtc gaacttggtt tgcaaaggga gaaagtagga gatctctctt gcgagatgat 5880
cccgcatttt cttgaaagct ttgcagaggc tagcagaatt accctccacg ttgattgtct 5940
gcgaggcaag aatgatcatc accgtagtga gagtgcgttc aaggctcttg cggttgccat 6000
aagagaagcc acctcgccca atggtaccaa cgatgttccc tccaccaaag gtgttcttat 6060
gtagtgacac cgattattta aagctgcagc atacgatata tatacatgtg tatatatgta 6120
tacctatgaa tgtcagtaag tatgtatacg aacagtatga tactgaagat gacaaggtaa 6180
tgcatcattc tatacgtgtc attctgaacg aggcgcgctt tccttttttc tttttgcttt 6240
ttcttttttt ttctcttgaa ctcgacggat ctatgcggtg tgaaatatgg tgcactctca 6300
gtacaatctg ctctgatgcc gcatagttaa gccagccccg acacccgcca acacccgctg 6360
acgcgccctg acgggcttgt ctgctcccgg catccgctta cagacaagct gtgaccgtct 6420
ccgggagctg catgtgtcag aggttttcac cgtcatcacc gaaacgcgcg agacgaaagg 6480
gcctcgtgat acgcctattt ttataggtta atgtcatgat aataatggtt tcttagtatg 6540
atccaatatc aaaggaaatg atagcattga aggatgagac taatccaatt gaggagtggc 6600
agcatataga acagctaaag ggtagtgctg aaggaagcat acgatacccc gcatggaatg 6660
ggataatatc acaggaggta ctagactacc tttcatccta cataaataga cgcatataag 6720
tacgcattta agcataaaca cgcactatgc cgttcttctc atgtatatat atatacaggc 6780
aacacgcaga tataggtgcg acgtgaacag tgagctgtat gtgcgcagct cgcgttgcat 6840
tttcggaagc gctcgttttc ggaaacgctt tgaagttcct attccgaagt tcctattctc 6900
tagaaagtat aggaacttca gagcgctttt gaaaaccaaa agcgctctga agacgcactt 6960
tcaaaaaacc aaaaacgcac cggactgtaa cgagctacta aaatattgcg aataccgctt 7020
ccacaaacat tgctcaaaag tatctctttg ctatatatct ctgtgctata tccctatata 7080
acctacccat ccacctttcg ctccttgaac ttgcatctaa actcgacctc tacatttttt 7140
atgtttatct ctagtattac tctttagaca aaaaaattgt agtaagaact attcatagag 7200
tgaatcgaaa acaatacgaa aatgtaaaca tttcctatac gtagtatata gagacaaaat 7260
agaagaaacc gttcataatt ttctgaccaa tgaagaatca tcaacgctat cactttctgt 7320
tcacaaagta tgcgcaatcc acatcggtat agaatataat cggggatgcc tttatcttga 7380
aaaaatgcac ccgcagcttc gctagtaatc agtaaacgcg ggaagtggag tcaggctttt 7440
tttatggaag agaaaataga caccaaagta gccttcttct aaccttaacg gacctacagt 7500
gcaaaaagtt atcaagagac tgcattatag agcgcacaaa ggagaaaaaa agtaatctaa 7560
gatgctttgt tagaaaaata gcgctctcgg gatgcatttt tgtagaacaa aaaagaagta 7620
tagattcttt gttggtaaaa tagcgctctc gcgttgcatt tctgttctgt aaaaatgcag 7680
ctcagattct ttgtttgaaa aattagcgct ctcgcgttgc atttttgttt tacaaaaatg 7740
aagcacagat tcttcgttgg taaaatagcg ctttcgcgtt gcatttctgt tctgtaaaaa 7800
tgcagctcag attctttgtt tgaaaaatta gcgctctcgc gttgcatttt tgttctacaa 7860
aatgaagcac agatgcttcg tt 7882
<210> 35
<211> 3810
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic contruct
<400> 35
gctaacagcg cgatttgctg gtgacccaat gcgaccagat gctccacgcc cagtcgcgta 60
ccgtcttcat gggagaaaat aatactgttg atgggtgtct ggtcagagac atcaagaaat 120
aacgccggaa cattagtgca ggcagcttcc acagcaatgg catcctggtc atccagcgga 180
tagttaatga tcagcccact gacgcgttgc gcgagaagat tgtgcaccgc cgctttacag 240
gcttcgacgc cgcttcgttc taccatcgac accaccacgc tggcacccag ttgatcggcg 300
cgagatttaa tcgccgcgac aatttgcgac ggcgcgtgca gggccagact ggaggtggca 360
acgccaatca gcaacgactg tttgcccgcc agttgttgtg ccacgcggtt gggaatgtaa 420
ttcagctccg ccatcgccgc ttccactttt tcccgcgttt tcgcagaaac gtggctggcc 480
tggttcacca cgcgggaaac ggtctgataa gagacaccgg catactctgc gacatcgtat 540
aacgttactg gtttcacatt caccaccctg aattgactct cttccgggcg ctatcatgcc 600
ataccgcgaa aggttttgcg ccattcgatg gtgtccggga tctcgacgct ctcccttatg 660
cgactcctgc attaggaagc agcccagtag taggttgagg ccgttgagca ccgccgccgc 720
aaggaatggt gcatgcaagg agatggcgcc caacagtccc ccggccacgg ggcctgccac 780
catacccacg ccgaaacaag cgctcatgag cccgaagtgg cgagcccgat cttccccatc 840
ggtgatgtcg gcgatatagg cgccagcaac cgcacctgtg gcgccggtga tgccggccac 900
gatgcgtccg gcgtagccta ggatcgagat cgatctcgat cccgcgaaat taatacgact 960
cactataggg gaattgtgag cggataacaa ttcccctcta gaaataattt tgtttaactt 1020
taagaaggag atatacatat ggcagatctc aattggatat cggccggcca cgcgatcgct 1080
gacgtcggta ccctcgagtc tggtaaagaa accgctgctg cgaaatttga acgccagcac 1140
atggactcgt ctactagtcg cagcttaatt aacctaaact gctgccaccg ctgagcaata 1200
actagcataa ccccttgggg cctctaaacg ggtcttgagg ggttttttgc tagcgaaagg 1260
aggagtcgac actgcttccg gtagtcaata aaccggtaaa ccagcaatag acataagcgg 1320
ctatttaacg accctgccct gaaccgacga ccgggtcatc gtggccggat cttgcggccc 1380
ctcggcttga acgaattgtt agacattatt tgccgactac cttggtgatc tcgcctttca 1440
cgtagtggac aaattcttcc aactgatctg cgcgcgaggc caagcgatct tcttcttgtc 1500
caagataagc ctgtctagct tcaagtatga cgggctgata ctgggccggc aggcgctcca 1560
ttgcccagtc ggcagcgaca tccttcggcg cgattttgcc ggttactgcg ctgtaccaaa 1620
tgcgggacaa cgtaagcact acatttcgct catcgccagc ccagtcgggc ggcgagttcc 1680
atagcgttaa ggtttcattt agcgcctcaa atagatcctg ttcaggaacc ggatcaaaga 1740
gttcctccgc cgctggacct accaaggcaa cgctatgttc tcttgctttt gtcagcaaga 1800
tagccagatc aatgtcgatc gtggctggct cgaagatacc tgcaagaatg tcattgcgct 1860
gccattctcc aaattgcagt tcgcgcttag ctggataacg ccacggaatg atgtcgtcgt 1920
gcacaacaat ggtgacttct acagcgcgga gaatctcgct ctctccaggg gaagccgaag 1980
tttccaaaag gtcgttgatc aaagctcgcc gcgttgtttc atcaagcctt acggtcaccg 2040
taaccagcaa atcaatatca ctgtgtggct tcaggccgcc atccactgcg gagccgtaca 2100
aatgtacggc cagcaacgtc ggttcgagat ggcgctcgat gacgccaact acctctgata 2160
gttgagtcga tacttcggcg atcaccgctt ccctcatact cttccttttt caatattatt 2220
gaagcattta tcagggttat tgtctcatga gcggatacat atttgaatgt atttagaaaa 2280
ataaacaaat agccagctca ctcggtcgct acgctccggg cgtgagactg cggcgggcgc 2340
tgcggacaca tacaaagtta cccacagatt ccgtggataa gcaggggact aacatgtgag 2400
gcaaaacagc agggccgcgc cggtggcgtt tttccatagg ctccgccctc ctgccagagt 2460
tcacataaac agacgctttt ccggtgcatc tgtgggagcc gtgaggctca accatgaatc 2520
tgacagtacg ggcgaaaccc gacaggactt aaagatcccc accgtttccg gcgggtcgct 2580
ccctcttgcg ctctcctgtt ccgaccctgc cgtttaccgg atacctgttc cgcctttctc 2640
ccttacggga agtgtggcgc tttctcatag ctcacacact ggtatctcgg ctcggtgtag 2700
gtcgttcgct ccaagctggg ctgtaagcaa gaactccccg ttcagcccga ctgctgcgcc 2760
ttatccggta actgttcact tgagtccaac ccggaaaagc acggtaaaac gccactggca 2820
gcagccattg gtaactggga gttcgcagag gatttgttta gctaaacacg cggttgctct 2880
tgaagtgtgc gccaaagtcc ggctacactg gaaggacaga tttggttgct gtgctctgcg 2940
aaagccagtt accacggtta agcagttccc caactgactt aaccttcgat caaaccacct 3000
ccccaggtgg ttttttcgtt tacagggcaa aagattacgc gcagaaaaaa aggatctcaa 3060
gaagatcctt tgatcttttc tactgaaccg ctctagattt cagtgcaatt tatctcttca 3120
aatgtagcac ctgaagtcag ccccatacga tataagttgt aattctcatg ttagtcatgc 3180
cccgcgccca ccggaaggag ctgactgggt tgaaggctct caagggcatc ggtcgagatc 3240
ccggtgccta atgagtgagc taacttacat taattgcgtt gcgctcactg cccgctttcc 3300
agtcgggaaa cctgtcgtgc cagctgcatt aatgaatcgg ccaacgcgcg gggagaggcg 3360
gtttgcgtat tgggcgccag ggtggttttt cttttcacca gtgagacggg caacagctga 3420
ttgcccttca ccgcctggcc ctgagagagt tgcagcaagc ggtccacgct ggtttgcccc 3480
agcaggcgaa aatcctgttt gatggtggtt aacggcggga tataacatga gctgtcttcg 3540
gtatcgtcgt atcccactac cgagatgtcc gcaccaacgc gcagcccgga ctcggtaatg 3600
gcgcgcattg cgcccagcgc catctgatcg ttggcaacca gcatcgcagt gggaacgatg 3660
ccctcattca gcatttgcat ggtttgttga aaaccggaca tggcactcca gtcgccttcc 3720
cgttccgcta tcggctgaat ttgattgcga gtgagatatt tatgccagcc agccagacgc 3780
agacgcgccg agacagaact taatgggccc 3810
<210> 36
<211> 5369
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 36
atccggatat agttcctcct ttcagcaaaa aacccctcaa gacccgttta gaggccccaa 60
ggggttatgc tagttattgc tcagcggtgg cagcagccaa ctcagcttcc tttcgggctt 120
tgttagcagc cggatctcag tggtggtggt ggtggtgctc gagtgcggcc gcaagcttgt 180
cgacggagct cgaattcgga tccgcgaccc atttgctgtc caccagtcat gctagccata 240
tggctgccgc gcggcaccag gccgctgctg tgatgatgat gatgatggct gctgcccatg 300
gtatatctcc ttcttaaagt taaacaaaat tatttctaga ggggaattgt tatccgctca 360
caattcccct atagtgagtc gtattaattt cgcgggatcg agatctcgat cctctacgcc 420
ggacgcatcg tggccggcat caccggcgcc acaggtgcgg ttgctggcgc ctatatcgcc 480
gacatcaccg atggggaaga tcgggctcgc cacttcgggc tcatgagcgc ttgtttcggc 540
gtgggtatgg tggcaggccc cgtggccggg ggactgttgg gcgccatctc cttgcatgca 600
ccattccttg cggcggcggt gctcaacggc ctcaacctac tactgggctg cttcctaatg 660
caggagtcgc ataagggaga gcgtcgagat cccggacacc atcgaatggc gcaaaacctt 720
tcgcggtatg gcatgatagc gcccggaaga gagtcaattc agggtggtga atgtgaaacc 780
agtaacgtta tacgatgtcg cagagtatgc cggtgtctct tatcagaccg tttcccgcgt 840
ggtgaaccag gccagccacg tttctgcgaa aacgcgggaa aaagtggaag cggcgatggc 900
ggagctgaat tacattccca accgcgtggc acaacaactg gcgggcaaac agtcgttgct 960
gattggcgtt gccacctcca gtctggccct gcacgcgccg tcgcaaattg tcgcggcgat 1020
taaatctcgc gccgatcaac tgggtgccag cgtggtggtg tcgatggtag aacgaagcgg 1080
cgtcgaagcc tgtaaagcgg cggtgcacaa tcttctcgcg caacgcgtca gtgggctgat 1140
cattaactat ccgctggatg accaggatgc cattgctgtg gaagctgcct gcactaatgt 1200
tccggcgtta tttcttgatg tctctgacca gacacccatc aacagtatta ttttctccca 1260
tgaagacggt acgcgactgg gcgtggagca tctggtcgca ttgggtcacc agcaaatcgc 1320
gctgttagcg ggcccattaa gttctgtctc ggcgcgtctg cgtctggctg gctggcataa 1380
atatctcact cgcaatcaaa ttcagccgat agcggaacgg gaaggcgact ggagtgccat 1440
gtccggtttt caacaaacca tgcaaatgct gaatgagggc atcgttccca ctgcgatgct 1500
ggttgccaac gatcagatgg cgctgggcgc aatgcgcgcc attaccgagt ccgggctgcg 1560
cgttggtgcg gatatctcgg tagtgggata cgacgatacc gaagacagct catgttatat 1620
cccgccgtta accaccatca aacaggattt tcgcctgctg gggcaaacca gcgtggaccg 1680
cttgctgcaa ctctctcagg gccaggcggt gaagggcaat cagctgttgc ccgtctcact 1740
ggtgaaaaga aaaaccaccc tggcgcccaa tacgcaaacc gcctctcccc gcgcgttggc 1800
cgattcatta atgcagctgg cacgacaggt ttcccgactg gaaagcgggc agtgagcgca 1860
acgcaattaa tgtaagttag ctcactcatt aggcaccggg atctcgaccg atgcccttga 1920
gagccttcaa cccagtcagc tccttccggt gggcgcgggg catgactatc gtcgccgcac 1980
ttatgactgt cttctttatc atgcaactcg taggacaggt gccggcagcg ctctgggtca 2040
ttttcggcga ggaccgcttt cgctggagcg cgacgatgat cggcctgtcg cttgcggtat 2100
tcggaatctt gcacgccctc gctcaagcct tcgtcactgg tcccgccacc aaacgtttcg 2160
gcgagaagca ggccattatc gccggcatgg cggccccacg ggtgcgcatg atcgtgctcc 2220
tgtcgttgag gacccggcta ggctggcggg gttgccttac tggttagcag aatgaatcac 2280
cgatacgcga gcgaacgtga agcgactgct gctgcaaaac gtctgcgacc tgagcaacaa 2340
catgaatggt cttcggtttc cgtgtttcgt aaagtctgga aacgcggaag tcagcgccct 2400
gcaccattat gttccggatc tgcatcgcag gatgctgctg gctaccctgt ggaacaccta 2460
catctgtatt aacgaagcgc tggcattgac cctgagtgat ttttctctgg tcccgccgca 2520
tccataccgc cagttgttta ccctcacaac gttccagtaa ccgggcatgt tcatcatcag 2580
taacccgtat cgtgagcatc ctctctcgtt tcatcggtat cattaccccc atgaacagaa 2640
atccccctta cacggaggca tcagtgacca aacaggaaaa aaccgccctt aacatggccc 2700
gctttatcag aagccagaca ttaacgcttc tggagaaact caacgagctg gacgcggatg 2760
aacaggcaga catctgtgaa tcgcttcacg accacgctga tgagctttac cgcagctgcc 2820
tcgcgcgttt cggtgatgac ggtgaaaacc tctgacacat gcagctcccg gagacggtca 2880
cagcttgtct gtaagcggat gccgggagca gacaagcccg tcagggcgcg tcagcgggtg 2940
ttggcgggtg tcggggcgca gccatgaccc agtcacgtag cgatagcgga gtgtatactg 3000
gcttaactat gcggcatcag agcagattgt actgagagtg caccatatat gcggtgtgaa 3060
ataccgcaca gatgcgtaag gagaaaatac cgcatcaggc gctcttccgc ttcctcgctc 3120
actgactcgc tgcgctcggt cgttcggctg cggcgagcgg tatcagctca ctcaaaggcg 3180
gtaatacggt tatccacaga atcaggggat aacgcaggaa agaacatgtg agcaaaaggc 3240
cagcaaaagg ccaggaaccg taaaaaggcc gcgttgctgg cgtttttcca taggctccgc 3300
ccccctgacg agcatcacaa aaatcgacgc tcaagtcaga ggtggcgaaa cccgacagga 3360
ctataaagat accaggcgtt tccccctgga agctccctcg tgcgctctcc tgttccgacc 3420
ctgccgctta ccggatacct gtccgccttt ctcccttcgg gaagcgtggc gctttctcat 3480
agctcacgct gtaggtatct cagttcggtg taggtcgttc gctccaagct gggctgtgtg 3540
cacgaacccc ccgttcagcc cgaccgctgc gccttatccg gtaactatcg tcttgagtcc 3600
aacccggtaa gacacgactt atcgccactg gcagcagcca ctggtaacag gattagcaga 3660
gcgaggtatg taggcggtgc tacagagttc ttgaagtggt ggcctaacta cggctacact 3720
agaaggacag tatttggtat ctgcgctctg ctgaagccag ttaccttcgg aaaaagagtt 3780
ggtagctctt gatccggcaa acaaaccacc gctggtagcg gtggtttttt tgtttgcaag 3840
cagcagatta cgcgcagaaa aaaaggatct caagaagatc ctttgatctt ttctacgggg 3900
tctgacgctc agtggaacga aaactcacgt taagggattt tggtcatgaa caataaaact 3960
gtctgcttac ataaacagta atacaagggg tgttatgagc catattcaac gggaaacgtc 4020
ttgctctagg ccgcgattaa attccaacat ggatgctgat ttatatgggt ataaatgggc 4080
tcgcgataat gtcgggcaat caggtgcgac aatctatcga ttgtatggga agcccgatgc 4140
gccagagttg tttctgaaac atggcaaagg tagcgttgcc aatgatgtta cagatgagat 4200
ggtcagacta aactggctga cggaatttat gcctcttccg accatcaagc attttatccg 4260
tactcctgat gatgcatggt tactcaccac tgcgatcccc gggaaaacag cattccaggt 4320
attagaagaa tatcctgatt caggtgaaaa tattgttgat gcgctggcag tgttcctgcg 4380
ccggttgcat tcgattcctg tttgtaattg tccttttaac agcgatcgcg tatttcgtct 4440
cgctcaggcg caatcacgaa tgaataacgg tttggttgat gcgagtgatt ttgatgacga 4500
gcgtaatggc tggcctgttg aacaagtctg gaaagaaatg cataaacttt tgccattctc 4560
accggattca gtcgtcactc atggtgattt ctcacttgat aaccttattt ttgacgaggg 4620
gaaattaata ggttgtattg atgttggacg agtcggaatc gcagaccgat accaggatct 4680
tgccatccta tggaactgcc tcggtgagtt ttctccttca ttacagaaac ggctttttca 4740
aaaatatggt attgataatc ctgatatgaa taaattgcag tttcatttga tgctcgatga 4800
gtttttctaa gaattaattc atgagcggat acatatttga atgtatttag aaaaataaac 4860
aaataggggt tccgcgcaca tttccccgaa aagtgccacc tgaaattgta aacgttaata 4920
ttttgttaaa attcgcgtta aatttttgtt aaatcagctc attttttaac caataggccg 4980
aaatcggcaa aatcccttat aaatcaaaag aatagaccga gatagggttg agtgttgttc 5040
cagtttggaa caagagtcca ctattaaaga acgtggactc caacgtcaaa gggcgaaaaa 5100
ccgtctatca gggcgatggc ccactacgtg aaccatcacc ctaatcaagt tttttggggt 5160
cgaggtgccg taaagcacta aatcggaacc ctaaagggag cccccgattt agagcttgac 5220
ggggaaagcc ggcgaacgtg gcgagaaagg aagggaagaa agcgaaagga gcgggcgcta 5280
gggcgctggc aagtgtagcg gtcacgctgc gcgtaaccac cacacccgcc gcgcttaatg 5340
cgccgctaca gggcgcgtcc cattcgcca 5369
<210> 37
<211> 3592
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 37
atccggatat agttcctcct ttcagcaaaa aacccctcaa gacccgttta gaggccccaa 60
ggggttatgc tagttattgc tcagcggtgg cagcagccaa ctcagcttcc tttcgggctt 120
tgttagcagc cggatctcag tggtggtggt ggtggtgctc gagtgcggcc gcaagcttgt 180
cgacggagct cgaattcgga tcctagaggg aaaccgttgt ggtctcccta tagtgagtcg 240
tattaatttc gcgggatcga gatctcgggc agcgttgggt cctggccacg ggtgcgcatg 300
atcgtgctcc tgtcgttgag gacccggcta ggctggcggg gttgccttac tggttagcag 360
aatgaatcac cgatacgcga gcgaacgtga agcgactgct gctgcaaaac gtctgcgacc 420
tgagcaacaa catgaatggt cttcggtttc cgtgtttcgt aaagtctgga aacgcggaag 480
tcagcgccct gcaccattat gttccggatc tgcatcgcag gatgctgctg gctaccctgt 540
ggaacaccta catctgtatt aacgaagcgc tggcattgac cctgagtgat ttttctctgg 600
tcccgccgca tccataccgc cagttgttta ccctcacaac gttccagtaa ccgggcatgt 660
tcatcatcag taacccgtat cgtgagcatc ctctctcgtt tcatcggtat cattaccccc 720
atgaacagaa atccccctta cacggaggca tcagtgacca aacaggaaaa aaccgccctt 780
aacatggccc gctttatcag aagccagaca ttaacgcttc tggagaaact caacgagctg 840
gacgcggatg aacaggcaga catctgtgaa tcgcttcacg accacgctga tgagctttac 900
cgcagctgcc tcgcgcgttt cggtgatgac ggtgaaaacc tctgacacat gcagctcccg 960
gagacggtca cagcttgtct gtaagcggat gccgggagca gacaagcccg tcagggcgcg 1020
tcagcgggtg ttggcgggtg tcggggcgca gccatgaccc agtcacgtag cgatagcgga 1080
gtgtatactg gcttaactat gcggcatcag agcagattgt actgagagtg caccatatat 1140
gcggtgtgaa ataccgcaca gatgcgtaag gagaaaatac cgcatcaggc gctcttccgc 1200
ttcctcgctc actgactcgc tgcgctcggt cgttcggctg cggcgagcgg tatcagctca 1260
ctcaaaggcg gtaatacggt tatccacaga atcaggggat aacgcaggaa agaacatgtg 1320
agcaaaaggc cagcaaaagg ccaggaaccg taaaaaggcc gcgttgctgg cgtttttcca 1380
taggctccgc ccccctgacg agcatcacaa aaatcgacgc tcaagtcaga ggtggcgaaa 1440
cccgacagga ctataaagat accaggcgtt tccccctgga agctccctcg tgcgctctcc 1500
tgttccgacc ctgccgctta ccggatacct gtccgccttt ctcccttcgg gaagcgtggc 1560
gctttctcat agctcacgct gtaggtatct cagttcggtg taggtcgttc gctccaagct 1620
gggctgtgtg cacgaacccc ccgttcagcc cgaccgctgc gccttatccg gtaactatcg 1680
tcttgagtcc aacccggtaa gacacgactt atcgccactg gcagcagcca ctggtaacag 1740
gattagcaga gcgaggtatg taggcggtgc tacagagttc ttgaagtggt ggcctaacta 1800
cggctacact agaaggacag tatttggtat ctgcgctctg ctgaagccag ttaccttcgg 1860
aaaaagagtt ggtagctctt gatccggcaa acaaaccacc gctggtagcg gtggtttttt 1920
tgtttgcaag cagcagatta cgcgcagaaa aaaaggatct caagaagatc ctttgatctt 1980
ttctacgggg tctgacgctc agtggaacga aaactcacgt taagggattt tggtcatgag 2040
attatcaaaa aggatcttca cctagatcct tttaaattaa aaatgaagtt ttaaatcaat 2100
ctaaagtata tatgagtaaa cttggtctga cagttaccaa tgcttaatca gtgaggcacc 2160
tatctcagcg atctgtctat ttcgttcatc catagttgcc tgactccccg tcgtgtagat 2220
aactacgata cgggagggct taccatctgg ccccagtgct gcaatgatac cgcgagaccc 2280
acgctcaccg gctccagatt tatcagcaat aaaccagcca gccggaaggg ccgagcgcag 2340
aagtggtcct gcaactttat ccgcctccat ccagtctatt aattgttgcc gggaagctag 2400
agtaagtagt tcgccagtta atagtttgcg caacgttgtt gccattgctg caggcatcgt 2460
ggtgtcacgc tcgtcgtttg gtatggcttc attcagctcc ggttcccaac gatcaaggcg 2520
agttacatga tcccccatgt tgtgcaaaaa agcggttagc tccttcggtc ctccgatcgt 2580
tgtcagaagt aagttggccg cagtgttatc actcatggtt atggcagcac tgcataattc 2640
tcttactgtc atgccatccg taagatgctt ttctgtgact ggtgagtact caaccaagtc 2700
attctgagaa tagtgtatgc ggcgaccgag ttgctcttgc ccggcgtcaa tacgggataa 2760
taccgcgcca catagcagaa ctttaaaagt gctcatcatt ggaaaacgtt cttcggggcg 2820
aaaactctca aggatcttac cgctgttgag atccagttcg atgtaaccca ctcgtgcacc 2880
caactgatct tcagcatctt ttactttcac cagcgtttct gggtgagcaa aaacaggaag 2940
gcaaaatgcc gcaaaaaagg gaataagggc gacacggaaa tgttgaatac tcatactctt 3000
cctttttcaa tattattgaa gcatttatca gggttattgt ctcatgagcg gatacatatt 3060
tgaatgtatt tagaaaaata aacaaatagg ggttccgcgc acatttcccc gaaaagtgcc 3120
acctgaaatt gtaaacgtta atattttgtt aaaattcgcg ttaaattttt gttaaatcag 3180
ctcatttttt aaccaatagg ccgaaatcgg caaaatccct tataaatcaa aagaatagac 3240
cgagataggg ttgagtgttg ttccagtttg gaacaagagt ccactattaa agaacgtgga 3300
ctccaacgtc aaagggcgaa aaaccgtcta tcagggcgat ggcccactac gtgaaccatc 3360
accctaatca agttttttgg ggtcgaggtg ccgtaaagca ctaaatcgga accctaaagg 3420
gagcccccga tttagagctt gacggggaaa gccggcgaac gtggcgagaa aggaagggaa 3480
gaaagcgaaa ggagcgggcg ctagggcgct ggcaagtgta gcggtcacgc tgcgcgtaac 3540
caccacaccc gccgcgctta atgcgccgct acagggcgcg tcccattcgc ca 3592
<210> 38
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 38
tacccatacg acgttccaga ctacgcc 27
<210> 39
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 39
Tyr Pro Tyr Asp Val Pro Asp Tyr Ala
1 5
<210> 40
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 40
gaacaaaagt taatttctga agaagatttg gaa 33
<210> 41
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 41
Glu Gln Lys Leu Ile Ser Glu Glu Asp Leu
1 5 10
<210> 42
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 42
gactacaagg atgacgatga caaa 24
<210> 43
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 43
Asp Tyr Lys Asp Asp Asp Asp Lys
1 5
<210> 44
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 44
ggtaagccaa ttccaaatcc tttgttgggt ttggactcca cc 42
<210> 45
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 45
Gly Lys Pro Ile Pro Asn Pro Leu Leu Gly Leu Asp Ser Thr
1 5 10
<210> 46
<211> 18
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 46
catcatcatc atcatcat 18
<210> 47
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 47
His His His His His His
1 5
<210> 48
<211> 1089
<212> DNA
<213> Psilocybe cubensis
<400> 48
atggcgttcg atctcaagac tgaagacggc ctcatcacat atctcactaa acatctttct 60
ttggacgtcg acacgagcgg agtgaagcgc cttagcggag gctttgtcaa tgtaacctgg 120
cgcattaagc tcaatgctcc ttatcaaggt catacgagca tcatcctgaa gcatgctcag 180
ccgcacatgt ctacggatga ggattttaag ataggtgtag aacgttcggt ttacgaatac 240
caggctatca agctcatgat ggccaatcgg gaggttctgg gaggcgtgga tggcatagtt 300
tctgtgccag aaggcctgaa ctacgactta gagaataatg cattgatcat gcaagatgtc 360
gggaagatga agaccctttt agattatgtc accgccaaac cgccacttgc gacggatata 420
gcccgccttg ttgggacaga aattgggggg ttcgttgcca gactccataa cataggccgc 480
gagaggcgag acgatcctga gttcaaattc ttctctggaa atattgtcgg aaggacgact 540
tcagaccagc tgtatcaaac catcataccc aacgcagcga aatatggcgt cgatgacccc 600
ttgctgccta ctgtggttaa ggaccttgtg gacgatgtca tgcacagcga agagaccctt 660
gtcatggcgg acctgtggag tggaaatatt cttctccagt tggaggaggg aaacccatcg 720
aagctgcaga agatatatat cctggattgg gaactttgca agtacggccc agcgtcgttg 780
gacctgggct atttcttggg tgactgctat ttgatatccc gctttcaaga cgagcaggtc 840
ggtacgacga tgcggcaagc ctacttgcaa agctatgcgc gtacgagcaa gcattcgatc 900
aactacgcca aagtcactgc aggtattgct gctcatattg tgatgtggac cgactttatg 960
cagtggggga gcgaggaaga aaggataaat tttgtgaaaa agggggtagc tgcctttcac 1020
gacgccaggg gcaacaacga caatggggaa attacgtcta ccttactgaa ggaatcatcc 1080
actgcgtaa 1089
<210> 49
<211> 362
<212> PRT
<213> Psilocybe cubensis
<400> 49
Met Ala Phe Asp Leu Lys Thr Glu Asp Gly Leu Ile Thr Tyr Leu Thr
1 5 10 15
Lys His Leu Ser Leu Asp Val Asp Thr Ser Gly Val Lys Arg Leu Ser
20 25 30
Gly Gly Phe Val Asn Val Thr Trp Arg Ile Lys Leu Asn Ala Pro Tyr
35 40 45
Gln Gly His Thr Ser Ile Ile Leu Lys His Ala Gln Pro His Met Ser
50 55 60
Thr Asp Glu Asp Phe Lys Ile Gly Val Glu Arg Ser Val Tyr Glu Tyr
65 70 75 80
Gln Ala Ile Lys Leu Met Met Ala Asn Arg Glu Val Leu Gly Gly Val
85 90 95
Asp Gly Ile Val Ser Val Pro Glu Gly Leu Asn Tyr Asp Leu Glu Asn
100 105 110
Asn Ala Leu Ile Met Gln Asp Val Gly Lys Met Lys Thr Leu Leu Asp
115 120 125
Tyr Val Thr Ala Lys Pro Pro Leu Ala Thr Asp Ile Ala Arg Leu Val
130 135 140
Gly Thr Glu Ile Gly Gly Phe Val Ala Arg Leu His Asn Ile Gly Arg
145 150 155 160
Glu Arg Arg Asp Asp Pro Glu Phe Lys Phe Phe Ser Gly Asn Ile Val
165 170 175
Gly Arg Thr Thr Ser Asp Gln Leu Tyr Gln Thr Ile Ile Pro Asn Ala
180 185 190
Ala Lys Tyr Gly Val Asp Asp Pro Leu Leu Pro Thr Val Val Lys Asp
195 200 205
Leu Val Asp Asp Val Met His Ser Glu Glu Thr Leu Val Met Ala Asp
210 215 220
Leu Trp Ser Gly Asn Ile Leu Leu Gln Leu Glu Glu Gly Asn Pro Ser
225 230 235 240
Lys Leu Gln Lys Ile Tyr Ile Leu Asp Trp Glu Leu Cys Lys Tyr Gly
245 250 255
Pro Ala Ser Leu Asp Leu Gly Tyr Phe Leu Gly Asp Cys Tyr Leu Ile
260 265 270
Ser Arg Phe Gln Asp Glu Gln Val Gly Thr Thr Met Arg Gln Ala Tyr
275 280 285
Leu Gln Ser Tyr Ala Arg Thr Ser Lys His Ser Ile Asn Tyr Ala Lys
290 295 300
Val Thr Ala Gly Ile Ala Ala His Ile Val Met Trp Thr Asp Phe Met
305 310 315 320
Gln Trp Gly Ser Glu Glu Glu Arg Ile Asn Phe Val Lys Lys Gly Val
325 330 335
Ala Ala Phe His Asp Ala Arg Gly Asn Asn Asp Asn Gly Glu Ile Thr
340 345 350
Ser Thr Leu Leu Lys Glu Ser Ser Thr Ala
355 360
<210> 50
<211> 6379
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 50
cgagatcttt gtgttcggtt acccggctca gatcctaact tcttcttttg gtatgtttat 60
tcgtataagt tactgttgtc cacaggcaat actctgcaga aaattaaaac ggcattaatg 120
ctaggacaac cagaattgtt actactgtat gtgcgatagt tgataactgc aacattatgc 180
ccggtatatt ctcaaaaaac cctattactg catacgaaga aatcgcaaga gaaatctttc 240
ggtttggaaa agctcactgt gaggttcctt ggagccaata gtaatacagc acaatccaag 300
gaaaaatctg gcctatatgc aaggaaggag agatagtcaa aagcattctt tcccctagaa 360
gttggtgcat atatggcatc gttaaaacat attaccccca aaatttcttc tctaaacgat 420
gtgcttggcc tttgttttgg tttttgatgt cggtcgtttg aggccccttg cggaaaatcg 480
agatcgccga atggcacgcg agggaaggga aataaggttt aaaggcactg aaacaatagg 540
caagaagtag gcgagagccg acatacgaga ctaaattaag tcctcagcga gctcgcatgg 600
aatgcgtgcg atgagcgacc tcatgctata cctgagaaag caacctgacc tacaggaaag 660
agttactcaa gaataagaat tttcgtttta aaacctaaga gtcactttaa aatttgtata 720
cacttatttt ttttataact tatttaataa taaaaatcat aaatcataag aaattcgctt 780
atttagaagt gtcaacaacg tatctaccaa cggaatgcgt gcgattcatt tgtcatcgtc 840
atccttgtag tcttcagcaa cacatgggta tgaaatagaa acttcttcag ccaatgcttt 900
aatcttcatc atgatttgca acatttcttc agttgtagtt cttggattaa ttgaacacaa 960
tctaataaca accttttcct tcaattctgt agtagataac atagcgaaac ctctatgtgt 1020
gatttcctta accaatttct tattaatttc attaatagta tctgttgatg ccaattcaga 1080
tggaatgtat ctaaaagtaa cgatacccaa ttgagctggt gtaacaactt cccaatcttt 1140
tgctttaccc aaaaatgctt caacttgttc tgctaacatg ataccatgat cgattgcttg 1200
tctaaaagca gcaacaccga aaactttaaa agacaaccaa accttcaaag ctctgaatct 1260
tcttgacaat tcgataccac attcaccgaa attaatttca ccttcaacgt tagtttctga 1320
atccttgatg tattctggca tcattctaaa agtctttgac aaatattgag agtttctgat 1380
caaaacacaa ccaacatcgt atggttggaa caaccactta tgtggatcta aagtcaaaga 1440
atctgctcta tgaatacctt gcaacatagc tgaacccttt tcagacaaga tagctggagc 1500
accataagaa ccatcagcat gcaaccaaac atcttcatcg ttacacaaat ctgctaattc 1560
gttcaaagaa tcaacagcac cacaatttgt agtaccagca tttgcaataa cacagaatgg 1620
ctttttaccc ttagttctat cttctttaat ttgtttcttc aaagctgaaa cagagattct 1680
caaatgttca tctgtttcga ttctacagat ttgatgatgt ttaaaaccta aaaccttcaa 1740
tgctctatca actgagaaat gtgtttgatc agagaagtaa acaacagcat tttcgatatc 1800
gttgttcaac ttagcctgtc ttgcaacagt caaagctgtc aaatttgcca ttgaaccacc 1860
agaaacaaat aaaccttcag ctgaatctgg aaaacccaac atagatttca accaattaat 1920
tgtagtcaat tcgatttgtt cagcacctgc accagcaatc catgcagttg gaaaaacatt 1980
aaaaccagaa gccaagaaat ctgcaacaac accaacgtaa ttatttggac ctggaacaaa 2040
agccaagaaa tgtggatgat caacatgtgt aatttgatta aaaacgtttc tgttcaagaa 2100
atgcaacaat tcctttggat ctgaaccatt ttctgggata gattcagtca acttatttct 2160
caagatatca gaatcgattg tttctgaaac tggcttagac ttcaaatggt tcatgtgatc 2220
gatgatcaaa tcaactgctt ggtaacccaa ttgtctcatt tcttcagctg acaattgcaa 2280
attttcagac attgttttat atttgttgta aaaagtagat aattacttcc ttgatgatct 2340
gtaaaaaaga gaaaaagaaa gcatctaaga acttgaaaaa ctacgaatta gaaaagacca 2400
aatatgtatt tcttgcattg accaatttat gcaagtttat atatatgtaa atgtaagttt 2460
cacgaggttc tactaaacta aaccaccccc ttggttagaa gaaaagagtg tgtgagaaca 2520
ggctgttgtt gtcacacgat tcggacaatt ctgtttgaaa gagagagagt aacagtacga 2580
tcgaacgaac tttgctctgg agatcacagt gggcatcata gcatgtggta ctaaaccctt 2640
tcccgccatt ccagaacctt cgattgcttg ttacaaaacc tgtgagccgt cgctaggacc 2700
ttgttgtgtg acgaaattgg aagctgcaat caataggaag acaggaagtc gagcgtgtct 2760
gggttttttc agttttgttc tttttgcaaa caacagttta ttcctggcat ccactaaata 2820
taatggagcc cgctttttaa gctggcatcc agaaaaaaaa agaatcccag caccaaaata 2880
ttgttttctt caccaaccat cagttcatag gtccattctc ttagcgcaac tacagagaac 2940
aggggcacaa acaggcaaaa aacgggcaca acctcaatgg agtgatgcaa cctgcctgga 3000
gtaaatgatg acacaaggca attgacccac gcatgtatct atctcatttt cttacacctt 3060
ctattacctt ctgctctctc tgatttggaa aaagctgaaa aaaaaggttg aaaccagttc 3120
cctgaaatta ttcccctact tgactaataa gtatataaag acggtaggta ttgattgtaa 3180
ttctgtaaat ctatttctta aacttcttaa attctacttt tatagttagt ctttttttta 3240
gttttaaaac accaagaact tagtttcgaa taaacacaca taaacaaaca aaatggcttc 3300
tagttcttcc gatgtcttcg ttttgggtct aggtgttgtt ttggctgcct tgtatatctt 3360
cagagaccaa ttattcgctg cttctaagcc aaaggtggct ccagtttcca ctacgaagcc 3420
tgccaacggt tccgctaacc caagagactt catcgccaag atgaaacaag gtaagaagag 3480
aatcgtaatc ttctacggtt ctcaaactgg taccgctgaa gaatatgcta ttcgtttggc 3540
taaggaagct aagcaaaagt tcggtctagc ctccttggtt tgtgatccag aagaatacga 3600
ttttgaaaag ttggaccaat tgccagaaga ttctattgct ttcttcgtcg ttgctaccta 3660
tggtgaaggt gaacctacag acaacgctgt ccaattgttg caaaacttgc aagatgaaag 3720
cttcgaattc tcctctggtg agagaaagtt gtcaggtttg aagtacgttg tttttggtct 3780
gggtaacaag acctacgaac attacaacct cattgggaga actgttgacg ctcaattggc 3840
caagatgggt gctatcagaa tcggtgaaag aggtgaaggt gatgatgaca agtccatgga 3900
agaagactac ttggaatgga aggatggtat gtgggaagcg tttgccactg ctatgggtgt 3960
tgaagaaggt caaggtggtg actccgctga tttcgtcgtt tccgaattgg aatctcaccc 4020
accagaaaag gtttaccaag gtgaattttc tgctagagct ttaaccaaaa ccaagggtat 4080
tcacgacgct aagaatcctt ttgctgctcc aattgcggtt gctagagaat tgttccaatc 4140
tgttgtcgat agaaactgtg tccacgtcga attcaacatt gaaggctctg gtatcaccta 4200
tcaacacggt gaccacgttg gtttgtggcc attgaatcca gatgttgaag tcgaacggtt 4260
gttgtgtgtt ttaggtttag ctgaaaagag agatgctgtc atctccattg aatccttaga 4320
cccggctttg gctaaggttc cattcccagt cccaactact tacggtgctg tgttgagaca 4380
ctacattgac atctctgctg tcgccggtag acaaatcttg ggtactttgt ccaaattcgc 4440
tccaacccca gaagctgaag ctttcttgag aaacttgaac actaacaagg aagaatacca 4500
caacgtcgtc gctaacggtt gtttgaaatt gggtgaaatt ttgcaaatcg ctaccggtaa 4560
cgacattact gtcccaccaa ctactgccaa caccaccaaa tggccaattc cattcgacat 4620
cattgtttct gccatcccaa gattgcaacc aagatactac tctatctctt cttccccaaa 4680
aattcatcca aacaccatcc acgctaccgt tgttgtgctc aaatacgaaa acgttccaac 4740
cgaaccaatc ccaagaaagt gggtttacgg tgtcggtagt aacttcttgt tgaatttaaa 4800
gtacgctgtt aacaaggaac cagttccata catcactcaa aatggcgaac aaagagtcgg 4860
tgtcccggaa tacttgattg ctggtccacg tggttcttac aagactgaat ctttctacaa 4920
ggctccaatc catgttagac gttctacttt ccgtttgcca accaacccaa agtctccagt 4980
catcatgatt ggtccaggta ctggtgtcgc cccattcaga ggcttcgttc aagaaagagt 5040
tgccttggcc agaagatcca tcgaaaagaa cggtcctgac tctttggctg actggggtcg 5100
tatttccttg ttctacggtt gtagaagatc cgacgaagac ttcttgtaca aggacgaatg 5160
gccacaatac gaagctgagt tgaagggtaa gttcaagttg cactgtgctt tctccagaca 5220
aaactacaag ccagacggtt ctaagattta cgtccaagat ttgatctggg aagacagaga 5280
acacattgcc gatgccatct taaacggtaa gggttacgtc tacatctgcg gtgaagctaa 5340
gtccatgtct aaacaagttg aagaagttct agccaagatc ttgggcgaag ccaaaggtgg 5400
ttccggtcca gttgaaggtg ttgctgaagt caagttactg aaggaacggt ccagattgat 5460
gttggatgtc tggtctgaac aaaagttaat ttctgaagaa gatttggaat gaatcgcgtg 5520
cattcatccg ctctaaccga aaaggaagga gttagacaac ctgaagtcta ggtccctatt 5580
tattttttta tagttatgtt agtattaaga acgttattta tatttcaaat ttttcttttt 5640
tttctgtaca gacgcgtgta cgcatgtaac attatactga aaaccttgct tgagaaggtt 5700
ttgggacgct cgaagatcgc gtcccaattc gccctatagt gagtcgtatt acgcgcgctc 5760
actggccgtc gttttacaac gtcgtgactg ggaaaaccct ggcgttaccc ctgcaggact 5820
agtgctgagg cattaatacc acttttcaat gaaacggata ttgatatgct agtaaaagga 5880
cgagctcaag agcgaaaata taagtaaaga attcgagtgc acttgtctcc atgcagcaag 5940
atttcatatg agtctttttt atctttttac tttttacatt acacgatatg cactttatga 6000
aaatttaacg aggttggaag ccggataatc aaccaaaatc aggcacgaag gcacactcgt 6060
atatgcatgt tgttgaaact ctgttacgct gaactaacaa tcacacatgt agaggtcacc 6120
gggaaaagtt gcgaccccat ggaaggtcga tctcttcgtt tggctttgct tggctggcgg 6180
cattgcgctt cttcgcttat acccgtctct tgacgctcga gctcgttcat tgagatacct 6240
ttattcttgc acattttctg gcttttttcg ctactcgggt acatgtaatc atgcacacag 6300
aaggtgctgt agggtgaaag ttcctttgtg ctgtcgtttg tttttaatgc caaactttcc 6360
ggtgatcaat aaccacctc 6379
<210> 51
<211> 3840
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 51
cggcatgcaa acatctacac aattagcaag ggcaatccat attttgtctt ttcgcgccct 60
ggaaaggcct aagtaatgtc gtaaacgcat tctatctgta cttcaactct cctctgtgca 120
ttggtttgtg caaatcacat tttacgatac tgccagatat atgcaaaaag agaaaaccaa 180
gggaccagaa caaagcaaaa ttacgatatt cttcgaattc cttcgtgctt gactaagaca 240
aagggatgga cgtagcgatt tttagcgggc caagaactgg ttccgaaaaa gcacaggtac 300
accgaaccct cagctaagga gggacagcac cgatgcggaa ggacaaactt tctttttgcc 360
tatcacagta tcttatcgag ctaactattt tcgacacaca tgaaaaagca gaaatattaa 420
cgaaaaagaa aagaaagacc atgtcatgta cgggcaatca gaatctgtaa caagcgccat 480
ttttttttct gtatcgggcc ctccttactg ctctccttcc gtgtaacgcg ttatgaaatt 540
aagtcctcag cgagctcgca tggaatgcgt gcgatgagcg acctcatgct atacctgaga 600
aagcaacctg acctacagga aagagttact caagaataag aattttcgtt ttaaaaccta 660
agagtcactt taaaatttgt atacacttat tttttttata acttatttaa taataaaaat 720
cataaatcat aagaaattcg cttatttaga agtgtcaaca acgtatctac caacggaatg 780
cgtgcgattg ttttatattt gttgtaaaaa gtagataatt acttccttga tgatctgtaa 840
aaaagagaaa aagaaagcat ctaagaactt gaaaaactac gaattagaaa agaccaaata 900
tgtatttctt gcattgacca atttatgcaa gtttatatat atgtaaatgt aagtttcacg 960
aggttctact aaactaaacc acccccttgg ttagaagaaa agagtgtgtg agaacaggct 1020
gttgttgtca cacgattcgg acaattctgt ttgaaagaga gagagtaaca gtacgatcga 1080
acgaactttg ctctggagat cacagtgggc atcatagcat gtggtactaa accctttccc 1140
gccattccag aaccttcgat tgcttgttac aaaacctgtg agccgtcgct aggaccttgt 1200
tgtgtgacga aattggaagc tgcaatcaat aggaagacag gaagtcgagc gtgtctgggt 1260
tttttcagtt ttgttctttt tgcaaacaac agtttattcc tggcatccac taaatataat 1320
ggagcccgct ttttaagctg gcatccagaa aaaaaaagaa tcccagcacc aaaatattgt 1380
tttcttcacc aaccatcagt tcataggtcc attctcttag cgcaactaca gagaacaggg 1440
gcacaaacag gcaaaaaacg ggcacaacct caatggagtg atgcaacctg cctggagtaa 1500
atgatgacac aaggcaattg acccacgcat gtatctatct cattttctta caccttctat 1560
taccttctgc tctctctgat ttggaaaaag ctgaaaaaaa aggttgaaac cagttccctg 1620
aaattattcc cctacttgac taataagtat ataaagacgg taggtattga ttgtaattct 1680
gtaaatctat ttcttaaact tcttaaattc tacttttata gttagtcttt tttttagttt 1740
taaaacacca agaacttagt ttcgaataaa cacacataaa caaacaaaat gggaggtccg 1800
atgagcggtt tccattcggg ggaggcgctg ctcggtgacc tcgccaccgg tcagctgacc 1860
aggctgtgcg aggtggcggg gctgaccgag gccgacacgg cggcctacac gggggtgctg 1920
atcgaaagtc tggggacgtc ggccggacgg ccgttgtccc tgccaccccc gtcgcggacc 1980
tttctctccg acgaccacac ccccgtggag ttctccctgg ccttcctgcc gggacgcgca 2040
ccgcacctgc gggtcctggt ggaaccgggc tgctccagcg gcgacgacct ggcggaaaac 2100
ggccgggccg gtctgcgggc ggtccacacc atggcggacc gctggggatt ctccaccgag 2160
caactcgacc ggctggagga cctgttcttc ccctcctccc ccgagggccc gctggccctg 2220
tggtgcgccc tggagctccg ctccggtggg gtgccggggg tgaaggtcta cctcaacccc 2280
gcggcgaatg gcgccgaccg ggccgccgag acggtacgcg aggcgctggc caggctgggc 2340
cacctgcagg cgttcgacgc gctgccccgg gcggacggct tcccgttcct cgccctggac 2400
ctcggcgact gggacgcccc gcgggtgaag atctacctca aacacctcgg catgtccgcc 2460
gccgacgcgg gctccctccc ccggatgtcg cccgcaccga gccgggagca gctggaggag 2520
ttcttccgca ccgccggtga cctcccggcc ccgggagacc cggggcccac cgaggacacc 2580
ggccggctcg ccgggcgccc cgccctcacc tgccactcct tcacggagac ggcgaccggg 2640
cggcccagcg gctacaccct ccacgtgccg gtccgcgact acgtccggca cgacggcgag 2700
gcacgggacc gggcggtggc cgtgctgcgc gaacatgaca tggacagtgc ggcactggac 2760
cgggcgctgg ccgccgtgag cccccgcccg ctgagtgacg gggtgggcct gatcgcctat 2820
ctggcactgg tccaccagcg cggccggccg acacgggtga ccgtctacgt ctcctccgag 2880
gcgtacgagg tgcggccgcc ccgcgagacg gtccccaccc gcgaccgggc gcgggcacgg 2940
ctgcatcatc atcatcatca ttgaatcgcg tgcattcatc cgctctaacc gaaaaggaag 3000
gagttagaca acctgaagtc taggtcccta tttatttttt tatagttatg ttagtattaa 3060
gaacgttatt tatatttcaa atttttcttt tttttctgta cagacgcgtg tacgcatgta 3120
acattatact gaaaaccttg cttgagaagg ttttgggacg ctcgaagatc gcgtcccaat 3180
tcgccctata gtgagtcgta ttacgcgcgc tcactggccg tcgttttaca acgtcgtgac 3240
tgggaaaacc ctggcgttac ccctgcagga ctagtgctga ggcattaata cgactctctc 3300
gaaatttttc ttaacgcgtc cttgtactgc gtctaacgct tttgccactt ggatttctat 3360
tataggaaat agtctcactt actgggcgac gaattttcgc gttttgatga agcacaggaa 3420
gaatttcttt tttttttggc ttcttctggt tccgtttttt acgcgcacaa atctaaaaaa 3480
agaaataatt ataacctagt ctcgaaaatt ttcatcgatc cattcgttcc tttttttcga 3540
ttttttcaga tcaaaattct tgtttctttc tttgtcttag tttatattaa aagatatttt 3600
gattttactc ctgaactatt tattctttct aagaaggcca gaacactaca gctgttttaa 3660
ccgactacga agttctccat tctcgaacac tagccttcat ttaccaaaca ggaactagcg 3720
tatatcatta gtccttattc gaaaagagat tggtagatat ttattgtagt ttgtgagaag 3780
gagaaaatac tgtcattgga ctgatagtta gaggacatta acctctctta cgttcgctca 3840
<210> 52
<211> 6190
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 52
cgagatcttt gtgttcggtt acccggctca gatcctaact tcttcttttg gtatgtttat 60
tcgtataagt tactgttgtc cacaggcaat actctgcaga aaattaaaac ggcattaatg 120
ctaggacaac cagaattgtt actactgtat gtgcgatagt tgataactgc aacattatgc 180
ccggtatatt ctcaaaaaac cctattactg catacgaaga aatcgcaaga gaaatctttc 240
ggtttggaaa agctcactgt gaggttcctt ggagccaata gtaatacagc acaatccaag 300
gaaaaatctg gcctatatgc aaggaaggag agatagtcaa aagcattctt tcccctagaa 360
gttggtgcat atatggcatc gttaaaacat attaccccca aaatttcttc tctaaacgat 420
gtgcttggcc tttgttttgg tttttgatgt cggtcgtttg aggccccttg cggaaaatcg 480
agatcgccga atggcacgcg agggaaggga aataaggttt aaaggcactg aaacaatagg 540
caagaagtag gcgagagccg acatacgaga ctaaattaag tcctcagcga gctcgcatgg 600
aatgcgtgcg atgagcgacc tcatgctata cctgagaaag caacctgacc tacaggaaag 660
agttactcaa gaataagaat tttcgtttta aaacctaaga gtcactttaa aatttgtata 720
cacttatttt ttttataact tatttaataa taaaaatcat aaatcataag aaattcgctt 780
atttagaagt gtcaacaacg tatctaccaa cggaatgcgt gcgattcatt tgtcatcgtc 840
atccttgtag tccattgcct tcaaatgttc cttattaaac tttctcaaat cgtaaaccaa 900
agagttcaag atatccaatt caacatgttc cataacaacg atcttgtacc agttgttagt 960
tgggttatga acttctggaa ctaaaaagta cttttcagcg atttccttat taacatattg 1020
ttcttcaatt gtaacaatat tcattgaatc ttctttgtaa tatttaattc tcatatcgtt 1080
caattgctta cacaaccatt tagttctatt tctcaactta ttaatctttt ccatccaacc 1140
gtatggacca taagaagcta aaaccatcca aattgcaaca gcatttgaac cagatcttga 1200
accagacaat gtaacatcca aattttcgat gtaagttgct tcctttgtca aagtgttatg 1260
gatcaaattc tttcttgaaa cgaagatacc agtaccgtat ggagcttgca acatcttatg 1320
accatctaat gtgattgaag aaacgttctt attagagaaa tcagttttac attccttatt 1380
atcaattgga tatataaaac caccaaatgc accatcaaca tgaattttgt attccaaatt 1440
gtacttatcg aagatgttag cgtacaaatc tggatcatca actgaaccaa acattgtagt 1500
acccatgtta gagataacga tgaagtactt tttaccaatt tctttagctt ctttaacaat 1560
tgaatccaat gtattttctt gaatttttct tgaataaaaa tcaactggaa ccttaataat 1620
atcgatgttc aacaaatctg aacctttgta tgcagagtaa tgtgtatctg ctgaagtgat 1680
gatagcgatt tcttcatgct tagcctttct ttctttcttg aagtagtttc tgtaaaccca 1740
cattgcttgg atgttagctt ctgtaccacc ttgagtaacg taaccatcaa attcttcatc 1800
gttaccgttc aaaacatcga ttgctaacaa ttggattaat tctctttcga tatcgaatgt 1860
accaccgaac aagatatcag ccttatcata agtatgacaa ccgatatggt ttgggttttg 1920
aataaaagtt ctcaagtatg gtgaatgctt aacgaaagaa tgatcatcat agaaaactgt 1980
atcatccaac ttagtacctg gaataccgat tgtcttagtg ttatcgtagt tcaaagtctt 2040
ttccaaagat tcagtaatct tttcatccat ttcttgttgt gtgtactttc tccagaactt 2100
cattgtttta tatttgttgt aaaaagtaga taattacttc cttgatgatc tgtaaaaaag 2160
agaaaaagaa agcatctaag aacttgaaaa actacgaatt agaaaagacc aaatatgtat 2220
ttcttgcatt gaccaattta tgcaagttta tatatatgta aatgtaagtt tcacgaggtt 2280
ctactaaact aaaccacccc cttggttaga agaaaagagt gtgtgagaac aggctgttgt 2340
tgtcacacga ttcggacaat tctgtttgaa agagagagag taacagtacg atcgaacgaa 2400
ctttgctctg gagatcacag tgggcatcat agcatgtggt actaaaccct ttcccgccat 2460
tccagaacct tcgattgctt gttacaaaac ctgtgagccg tcgctaggac cttgttgtgt 2520
gacgaaattg gaagctgcaa tcaataggaa gacaggaagt cgagcgtgtc tgggtttttt 2580
cagttttgtt ctttttgcaa acaacagttt attcctggca tccactaaat ataatggagc 2640
ccgcttttta agctggcatc cagaaaaaaa aagaatccca gcaccaaaat attgttttct 2700
tcaccaacca tcagttcata ggtccattct cttagcgcaa ctacagagaa caggggcaca 2760
aacaggcaaa aaacgggcac aacctcaatg gagtgatgca acctgcctgg agtaaatgat 2820
gacacaaggc aattgaccca cgcatgtatc tatctcattt tcttacacct tctattacct 2880
tctgctctct ctgatttgga aaaagctgaa aaaaaaggtt gaaaccagtt ccctgaaatt 2940
attcccctac ttgactaata agtatataaa gacggtaggt attgattgta attctgtaaa 3000
tctatttctt aaacttctta aattctactt ttatagttag tctttttttt agttttaaaa 3060
caccaagaac ttagtttcga ataaacacac ataaacaaac aaaatggctt ctagttcttc 3120
cgatgtcttc gttttgggtc taggtgttgt tttggctgcc ttgtatatct tcagagacca 3180
attattcgct gcttctaagc caaaggtggc tccagtttcc actacgaagc ctgccaacgg 3240
ttccgctaac ccaagagact tcatcgccaa gatgaaacaa ggtaagaaga gaatcgtaat 3300
cttctacggt tctcaaactg gtaccgctga agaatatgct attcgtttgg ctaaggaagc 3360
taagcaaaag ttcggtctag cctccttggt ttgtgatcca gaagaatacg attttgaaaa 3420
gttggaccaa ttgccagaag attctattgc tttcttcgtc gttgctacct atggtgaagg 3480
tgaacctaca gacaacgctg tccaattgtt gcaaaacttg caagatgaaa gcttcgaatt 3540
ctcctctggt gagagaaagt tgtcaggttt gaagtacgtt gtttttggtc tgggtaacaa 3600
gacctacgaa cattacaacc tcattgggag aactgttgac gctcaattgg ccaagatggg 3660
tgctatcaga atcggtgaaa gaggtgaagg tgatgatgac aagtccatgg aagaagacta 3720
cttggaatgg aaggatggta tgtgggaagc gtttgccact gctatgggtg ttgaagaagg 3780
tcaaggtggt gactccgctg atttcgtcgt ttccgaattg gaatctcacc caccagaaaa 3840
ggtttaccaa ggtgaatttt ctgctagagc tttaaccaaa accaagggta ttcacgacgc 3900
taagaatcct tttgctgctc caattgcggt tgctagagaa ttgttccaat ctgttgtcga 3960
tagaaactgt gtccacgtcg aattcaacat tgaaggctct ggtatcacct atcaacacgg 4020
tgaccacgtt ggtttgtggc cattgaatcc agatgttgaa gtcgaacggt tgttgtgtgt 4080
tttaggttta gctgaaaaga gagatgctgt catctccatt gaatccttag acccggcttt 4140
ggctaaggtt ccattcccag tcccaactac ttacggtgct gtgttgagac actacattga 4200
catctctgct gtcgccggta gacaaatctt gggtactttg tccaaattcg ctccaacccc 4260
agaagctgaa gctttcttga gaaacttgaa cactaacaag gaagaatacc acaacgtcgt 4320
cgctaacggt tgtttgaaat tgggtgaaat tttgcaaatc gctaccggta acgacattac 4380
tgtcccacca actactgcca acaccaccaa atggccaatt ccattcgaca tcattgtttc 4440
tgccatccca agattgcaac caagatacta ctctatctct tcttccccaa aaattcatcc 4500
aaacaccatc cacgctaccg ttgttgtgct caaatacgaa aacgttccaa ccgaaccaat 4560
cccaagaaag tgggtttacg gtgtcggtag taacttcttg ttgaatttaa agtacgctgt 4620
taacaaggaa ccagttccat acatcactca aaatggcgaa caaagagtcg gtgtcccgga 4680
atacttgatt gctggtccac gtggttctta caagactgaa tctttctaca aggctccaat 4740
ccatgttaga cgttctactt tccgtttgcc aaccaaccca aagtctccag tcatcatgat 4800
tggtccaggt actggtgtcg ccccattcag aggcttcgtt caagaaagag ttgccttggc 4860
cagaagatcc atcgaaaaga acggtcctga ctctttggct gactggggtc gtatttcctt 4920
gttctacggt tgtagaagat ccgacgaaga cttcttgtac aaggacgaat ggccacaata 4980
cgaagctgag ttgaagggta agttcaagtt gcactgtgct ttctccagac aaaactacaa 5040
gccagacggt tctaagattt acgtccaaga tttgatctgg gaagacagag aacacattgc 5100
cgatgccatc ttaaacggta agggttacgt ctacatctgc ggtgaagcta agtccatgtc 5160
taaacaagtt gaagaagttc tagccaagat cttgggcgaa gccaaaggtg gttccggtcc 5220
agttgaaggt gttgctgaag tcaagttact gaaggaacgg tccagattga tgttggatgt 5280
ctggtctgaa caaaagttaa tttctgaaga agatttggaa tgaatcgcgt gcattcatcc 5340
gctctaaccg aaaaggaagg agttagacaa cctgaagtct aggtccctat ttattttttt 5400
atagttatgt tagtattaag aacgttattt atatttcaaa tttttctttt ttttctgtac 5460
agacgcgtgt acgcatgtaa cattatactg aaaaccttgc ttgagaaggt tttgggacgc 5520
tcgaagatcg cgtcccaatt cgccctatag tgagtcgtat tacgcgcgct cactggccgt 5580
cgttttacaa cgtcgtgact gggaaaaccc tggcgttacc cctgcaggac tagtgctgag 5640
gcattaatac cacttttcaa tgaaacggat attgatatgc tagtaaaagg acgagctcaa 5700
gagcgaaaat ataagtaaag aattcgagtg cacttgtctc catgcagcaa gatttcatat 5760
gagtcttttt tatcttttta ctttttacat tacacgatat gcactttatg aaaatttaac 5820
gaggttggaa gccggataat caaccaaaat caggcacgaa ggcacactcg tatatgcatg 5880
ttgttgaaac tctgttacgc tgaactaaca atcacacatg tagaggtcac cgggaaaagt 5940
tgcgacccca tggaaggtcg atctcttcgt ttggctttgc ttggctggcg gcattgcgct 6000
tcttcgctta tacccgtctc ttgacgctcg agctcgttca ttgagatacc tttattcttg 6060
cacattttct ggcttttttc gctactcggg tacatgtaat catgcacaca gaaggtgctg 6120
tagggtgaaa gttcctttgt gctgtcgttt gtttttaatg ccaaactttc cggtgatcaa 6180
taaccacctc 6190
<210> 53
<211> 4101
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 53
cggcatgcaa acatctacac aattagcaag ggcaatccat attttgtctt ttcgcgccct 60
ggaaaggcct aagtaatgtc gtaaacgcat tctatctgta cttcaactct cctctgtgca 120
ttggtttgtg caaatcacat tttacgatac tgccagatat atgcaaaaag agaaaaccaa 180
gggaccagaa caaagcaaaa ttacgatatt cttcgaattc cttcgtgctt gactaagaca 240
aagggatgga cgtagcgatt tttagcgggc caagaactgg ttccgaaaaa gcacaggtac 300
accgaaccct cagctaagga gggacagcac cgatgcggaa ggacaaactt tctttttgcc 360
tatcacagta tcttatcgag ctaactattt tcgacacaca tgaaaaagca gaaatattaa 420
cgaaaaagaa aagaaagacc atgtcatgta cgggcaatca gaatctgtaa caagcgccat 480
ttttttttct gtatcgggcc ctccttactg ctctccttcc gtgtaacgcg ttatgaaatt 540
aagtcctcag cgagctcgca tggaatgcgt gcgatgagcg acctcatgct atacctgaga 600
aagcaacctg acctacagga aagagttact caagaataag aattttcgtt ttaaaaccta 660
agagtcactt taaaatttgt atacacttat tttttttata acttatttaa taataaaaat 720
cataaatcat aagaaattcg cttatttaga agtgtcaaca acgtatctac caacggaatg 780
cgtgcgattg ttttatattt gttgtaaaaa gtagataatt acttccttga tgatctgtaa 840
aaaagagaaa aagaaagcat ctaagaactt gaaaaactac gaattagaaa agaccaaata 900
tgtatttctt gcattgacca atttatgcaa gtttatatat atgtaaatgt aagtttcacg 960
aggttctact aaactaaacc acccccttgg ttagaagaaa agagtgtgtg agaacaggct 1020
gttgttgtca cacgattcgg acaattctgt ttgaaagaga gagagtaaca gtacgatcga 1080
acgaactttg ctctggagat cacagtgggc atcatagcat gtggtactaa accctttccc 1140
gccattccag aaccttcgat tgcttgttac aaaacctgtg agccgtcgct aggaccttgt 1200
tgtgtgacga aattggaagc tgcaatcaat aggaagacag gaagtcgagc gtgtctgggt 1260
tttttcagtt ttgttctttt tgcaaacaac agtttattcc tggcatccac taaatataat 1320
ggagcccgct ttttaagctg gcatccagaa aaaaaaagaa tcccagcacc aaaatattgt 1380
tttcttcacc aaccatcagt tcataggtcc attctcttag cgcaactaca gagaacaggg 1440
gcacaaacag gcaaaaaacg ggcacaacct caatggagtg atgcaacctg cctggagtaa 1500
atgatgacac aaggcaattg acccacgcat gtatctatct cattttctta caccttctat 1560
taccttctgc tctctctgat ttggaaaaag ctgaaaaaaa aggttgaaac cagttccctg 1620
aaattattcc cctacttgac taataagtat ataaagacgg taggtattga ttgtaattct 1680
gtaaatctat ttcttaaact tcttaaattc tacttttata gttagtcttt tttttagttt 1740
taaaacacca agaacttagt ttcgaataaa cacacataaa caaacaaaat gtccatcggt 1800
gctgaaattg actctttggt tccagctcca ccaggtttga acggtaccgc tgctggttac 1860
ccagccaaga ctcaaaagga attgtctaac ggcgatttcg atgctcacga tggtctgtcc 1920
ttggctcaat tgactccata cgatgtttta accgctgctt tgccattgcc agcgccagct 1980
tctagtactg gtttctggtg gagagaaact ggtccagtta tgtctaagct cttggctaaa 2040
gccaactacc cattgtacac ccattacaag tatttaatgt tgtaccacac tcacatttta 2100
cctttgttag gtccaagacc acctttggaa aattctaccc acccatctcc atcaaatgct 2160
ccttggagat ccttcttgac cgatgacttc accccattag aaccatcttg gaacgttaac 2220
ggtaactccg aagcacaatc cactatcaga ttgggtattg aaccaattgg tttcgaagcc 2280
ggtgctgctg ccgacccatt caaccaagct gccgtcaccc aattcatgca ctcctacgaa 2340
gctactgaag ttggtgccac tctaactttg ttcgaacact tcagaaacga catgttcgtc 2400
ggtccagaga cttacgctgc cttgagagct aagattcctg aaggtgagca caccactcaa 2460
tctttcttgg ctttcgactt ggacgccggt cgtgtcacta ccaaggctta cttcttccca 2520
atcttgatgt ctttgaagac cggtcaatct acgaccaaag ttgtttccga ttctatcttg 2580
cacctagctt tgaagtctga agtttggggt gtccaaacca ttgccgctat gtcggtcatg 2640
gaagcttgga tcggttctta cggtggtgct gctaagaccg aaatgatctc cgttgactgt 2700
gtcaacgaag ctgactccag aatcaagatc tacgttagaa tgccacacac tagcttgaga 2760
aaggtcaaag aagcttattg tttgggtggc cgtttgactg acgaaaacac caaggaaggt 2820
ttgaaattgt tggatgaatt gtggagaact gttttcggta tcgatgacga agatgctgaa 2880
ttaccacaaa actctcacag aactgctggt actattttta actttgaact aagaccaggt 2940
aagtggttcc cagaaccaaa ggtctacttg ccagtcagac actactgtga atccgacatg 3000
caaattgcct ccagattaca aactttcttt ggtcgtttgg gttggcacaa catggaaaag 3060
gactactgca agcatttgga agacttattc cctcaccacc cattgtcctc ctctaccggt 3120
acccacactt tcttgtcttt ttcttacaag aagcaaaagg gtgtttacat gaccatgtac 3180
tacaacttga gagtttattc tacacaccac catcatcatc attgaatcgc gtgcattcat 3240
ccgctctaac cgaaaaggaa ggagttagac aacctgaagt ctaggtccct atttattttt 3300
ttatagttat gttagtatta agaacgttat ttatatttca aatttttctt ttttttctgt 3360
acagacgcgt gtacgcatgt aacattatac tgaaaacctt gcttgagaag gttttgggac 3420
gctcgaagat cgcgtcccaa ttcgccctat agtgagtcgt attacgcgcg ctcactggcc 3480
gtcgttttac aacgtcgtga ctgggaaaac cctggcgtta cccctgcagg actagtgctg 3540
aggcattaat acgactctct cgaaattttt cttaacgcgt ccttgtactg cgtctaacgc 3600
ttttgccact tggatttcta ttataggaaa tagtctcact tactgggcga cgaattttcg 3660
cgttttgatg aagcacagga agaatttctt ttttttttgg cttcttctgg ttccgttttt 3720
tacgcgcaca aatctaaaaa aagaaataat tataacctag tctcgaaaat tttcatcgat 3780
ccattcgttc ctttttttcg attttttcag atcaaaattc ttgtttcttt ctttgtctta 3840
gtttatatta aaagatattt tgattttact cctgaactat ttattctttc taagaaggcc 3900
agaacactac agctgtttta accgactacg aagttctcca ttctcgaaca ctagccttca 3960
tttaccaaac aggaactagc gtatatcatt agtccttatt cgaaaagaga ttggtagata 4020
tttattgtag tttgtgagaa ggagaaaata ctgtcattgg actgatagtt agaggacatt 4080
aacctctctt acgttcgctc a 4101
<210> 54
<211> 5360
<212> DNA
<213> Artificial Sequence
<220>
<223> Synthetic construct
<400> 54
atccggatat agttcctcct ttcagcaaaa aacccctcaa gacccgttta gaggccccaa 60
ggggttatgc tagttattgc tcagcggtgg cagcagccaa ctcagcttcc tttcgggctt 120
tgttagcagc cggatctcag tggtggtggt ggtggtgctc gagtgcggcc gcaagcttgt 180
cgacggagct cgaattcgga tccgaattaa ttccgatatc catggccatc gccggctggg 240
cagcgaggag cagcagacca gcagcagcgg tcggcagcag gtatttcata tgtatatctc 300
cttcttaaag ttaaacaaaa ttatttctag aggggaattg ttatccgctc acaattcccc 360
tatagtgagt cgtattaatt tcgcgggatc gagatctcga tcctctacgc cggacgcatc 420
gtggccggca tcaccggcgc cacaggtgcg gttgctggcg cctatatcgc cgacatcacc 480
gatggggaag atcgggctcg ccacttcggg ctcatgagcg cttgtttcgg cgtgggtatg 540
gtggcaggcc ccgtggccgg gggactgttg ggcgccatct ccttgcatgc accattcctt 600
gcggcggcgg tgctcaacgg cctcaaccta ctactgggct gcttcctaat gcaggagtcg 660
cataagggag agcgtcgaga tcccggacac catcgaatgg cgcaaaacct ttcgcggtat 720
ggcatgatag cgcccggaag agagtcaatt cagggtggtg aatgtgaaac cagtaacgtt 780
atacgatgtc gcagagtatg ccggtgtctc ttatcagacc gtttcccgcg tggtgaacca 840
ggccagccac gtttctgcga aaacgcggga aaaagtggaa gcggcgatgg cggagctgaa 900
ttacattccc aaccgcgtgg cacaacaact ggcgggcaaa cagtcgttgc tgattggcgt 960
tgccacctcc agtctggccc tgcacgcgcc gtcgcaaatt gtcgcggcga ttaaatctcg 1020
cgccgatcaa ctgggtgcca gcgtggtggt gtcgatggta gaacgaagcg gcgtcgaagc 1080
ctgtaaagcg gcggtgcaca atcttctcgc gcaacgcgtc agtgggctga tcattaacta 1140
tccgctggat gaccaggatg ccattgctgt ggaagctgcc tgcactaatg ttccggcgtt 1200
atttcttgat gtctctgacc agacacccat caacagtatt attttctccc atgaagacgg 1260
tacgcgactg ggcgtggagc atctggtcgc attgggtcac cagcaaatcg cgctgttagc 1320
gggcccatta agttctgtct cggcgcgtct gcgtctggct ggctggcata aatatctcac 1380
tcgcaatcaa attcagccga tagcggaacg ggaaggcgac tggagtgcca tgtccggttt 1440
tcaacaaacc atgcaaatgc tgaatgaggg catcgttccc actgcgatgc tggttgccaa 1500
cgatcagatg gcgctgggcg caatgcgcgc cattaccgag tccgggctgc gcgttggtgc 1560
ggatatctcg gtagtgggat acgacgatac cgaagacagc tcatgttata tcccgccgtt 1620
aaccaccatc aaacaggatt ttcgcctgct ggggcaaacc agcgtggacc gcttgctgca 1680
actctctcag ggccaggcgg tgaagggcaa tcagctgttg cccgtctcac tggtgaaaag 1740
aaaaaccacc ctggcgccca atacgcaaac cgcctctccc cgcgcgttgg ccgattcatt 1800
aatgcagctg gcacgacagg tttcccgact ggaaagcggg cagtgagcgc aacgcaatta 1860
atgtaagtta gctcactcat taggcaccgg gatctcgacc gatgcccttg agagccttca 1920
acccagtcag ctccttccgg tgggcgcggg gcatgactat cgtcgccgca cttatgactg 1980
tcttctttat catgcaactc gtaggacagg tgccggcagc gctctgggtc attttcggcg 2040
aggaccgctt tcgctggagc gcgacgatga tcggcctgtc gcttgcggta ttcggaatct 2100
tgcacgccct cgctcaagcc ttcgtcactg gtcccgccac caaacgtttc ggcgagaagc 2160
aggccattat cgccggcatg gcggccccac gggtgcgcat gatcgtgctc ctgtcgttga 2220
ggacccggct aggctggcgg ggttgcctta ctggttagca gaatgaatca ccgatacgcg 2280
agcgaacgtg aagcgactgc tgctgcaaaa cgtctgcgac ctgagcaaca acatgaatgg 2340
tcttcggttt ccgtgtttcg taaagtctgg aaacgcggaa gtcagcgccc tgcaccatta 2400
tgttccggat ctgcatcgca ggatgctgct ggctaccctg tggaacacct acatctgtat 2460
taacgaagcg ctggcattga ccctgagtga tttttctctg gtcccgccgc atccataccg 2520
ccagttgttt accctcacaa cgttccagta accgggcatg ttcatcatca gtaacccgta 2580
tcgtgagcat cctctctcgt ttcatcggta tcattacccc catgaacaga aatccccctt 2640
acacggaggc atcagtgacc aaacaggaaa aaaccgccct taacatggcc cgctttatca 2700
gaagccagac attaacgctt ctggagaaac tcaacgagct ggacgcggat gaacaggcag 2760
acatctgtga atcgcttcac gaccacgctg atgagcttta ccgcagctgc ctcgcgcgtt 2820
tcggtgatga cggtgaaaac ctctgacaca tgcagctccc ggagacggtc acagcttgtc 2880
tgtaagcgga tgccgggagc agacaagccc gtcagggcgc gtcagcgggt gttggcgggt 2940
gtcggggcgc agccatgacc cagtcacgta gcgatagcgg agtgtatact ggcttaacta 3000
tgcggcatca gagcagattg tactgagagt gcaccatata tgcggtgtga aataccgcac 3060
agatgcgtaa ggagaaaata ccgcatcagg cgctcttccg cttcctcgct cactgactcg 3120
ctgcgctcgg tcgttcggct gcggcgagcg gtatcagctc actcaaaggc ggtaatacgg 3180
ttatccacag aatcagggga taacgcagga aagaacatgt gagcaaaagg ccagcaaaag 3240
gccaggaacc gtaaaaaggc cgcgttgctg gcgtttttcc ataggctccg cccccctgac 3300
gagcatcaca aaaatcgacg ctcaagtcag aggtggcgaa acccgacagg actataaaga 3360
taccaggcgt ttccccctgg aagctccctc gtgcgctctc ctgttccgac cctgccgctt 3420
accggatacc tgtccgcctt tctcccttcg ggaagcgtgg cgctttctca tagctcacgc 3480
tgtaggtatc tcagttcggt gtaggtcgtt cgctccaagc tgggctgtgt gcacgaaccc 3540
cccgttcagc ccgaccgctg cgccttatcc ggtaactatc gtcttgagtc caacccggta 3600
agacacgact tatcgccact ggcagcagcc actggtaaca ggattagcag agcgaggtat 3660
gtaggcggtg ctacagagtt cttgaagtgg tggcctaact acggctacac tagaaggaca 3720
gtatttggta tctgcgctct gctgaagcca gttaccttcg gaaaaagagt tggtagctct 3780
tgatccggca aacaaaccac cgctggtagc ggtggttttt ttgtttgcaa gcagcagatt 3840
acgcgcagaa aaaaaggatc tcaagaagat cctttgatct tttctacggg gtctgacgct 3900
cagtggaacg aaaactcacg ttaagggatt ttggtcatga acaataaaac tgtctgctta 3960
cataaacagt aatacaaggg gtgttatgag ccatattcaa cgggaaacgt cttgctctag 4020
gccgcgatta aattccaaca tggatgctga tttatatggg tataaatggg ctcgcgataa 4080
tgtcgggcaa tcaggtgcga caatctatcg attgtatggg aagcccgatg cgccagagtt 4140
gtttctgaaa catggcaaag gtagcgttgc caatgatgtt acagatgaga tggtcagact 4200
aaactggctg acggaattta tgcctcttcc gaccatcaag cattttatcc gtactcctga 4260
tgatgcatgg ttactcacca ctgcgatccc cgggaaaaca gcattccagg tattagaaga 4320
atatcctgat tcaggtgaaa atattgttga tgcgctggca gtgttcctgc gccggttgca 4380
ttcgattcct gtttgtaatt gtccttttaa cagcgatcgc gtatttcgtc tcgctcaggc 4440
gcaatcacga atgaataacg gtttggttga tgcgagtgat tttgatgacg agcgtaatgg 4500
ctggcctgtt gaacaagtct ggaaagaaat gcataaactt ttgccattct caccggattc 4560
agtcgtcact catggtgatt tctcacttga taaccttatt tttgacgagg ggaaattaat 4620
aggttgtatt gatgttggac gagtcggaat cgcagaccga taccaggatc ttgccatcct 4680
atggaactgc ctcggtgagt tttctccttc attacagaaa cggctttttc aaaaatatgg 4740
tattgataat cctgatatga ataaattgca gtttcatttg atgctcgatg agtttttcta 4800
agaattaatt catgagcgga tacatatttg aatgtattta gaaaaataaa caaatagggg 4860
ttccgcgcac atttccccga aaagtgccac ctgaaattgt aaacgttaat attttgttaa 4920
aattcgcgtt aaatttttgt taaatcagct cattttttaa ccaataggcc gaaatcggca 4980
aaatccctta taaatcaaaa gaatagaccg agatagggtt gagtgttgtt ccagtttgga 5040
acaagagtcc actattaaag aacgtggact ccaacgtcaa agggcgaaaa accgtctatc 5100
agggcgatgg cccactacgt gaaccatcac cctaatcaag ttttttgggg tcgaggtgcc 5160
gtaaagcact aaatcggaac cctaaaggga gcccccgatt tagagcttga cggggaaagc 5220
cggcgaacgt ggcgagaaag gaagggaaga aagcgaaagg agcgggcgct agggcgctgg 5280
caagtgtagc ggtcacgctg cgcgtaacca ccacacccgc cgcgcttaat gcgccgctac 5340
agggcgcgtc ccattcgcca 5360
Claims (134)
- 식 (I)을 갖는 화학적 화합물 또는 이의 염:
(I),
여기서, R2, R4, R5, R6, 또는 R7 중 적어도 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 독립적으로 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, O-알킬기, O-아실기 또는 포스페이트기이고, R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, R3c는 수소 원자 또는 카르복실기임. - 제1항에 있어서, R2, R4, R5, R6, 또는 R7 중 적어도 3개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 2개로부터 선택된 치환기인, 화학적 화합물.
- 제1항에 있어서, R2, R4, R5, R6, 또는 R7 중 적어도 3개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 적어도 3개로부터 선택된 치환기인, 화학적 화합물.
- 제1항에 있어서, R4가 치환기로 치환되지 않은 경우, R4는 수소 원자인, 화학적 화합물.
- 제1항에 있어서, R4 및 R5는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택되고, R2, R6 및 R7은 수소 원자인, 화학적 화합물.
- 제1항에 있어서, R4 및 R5는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택되고, R4 및 R5 중 적어도 하나는 프레닐기 또는 할로겐 원자이고, R2, R6 및 R7은 수소 원자인, 화학적 화합물.
- 제1항에 있어서, R4 및 R6는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택되고, R2, R4 및 R7은 수소 원자인, 화학적 화합물.
- 제1항에 있어서, R4 및 R6은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택되고, R4 및 R6 중 적어도 하나는 프레닐기 또는 할로겐 원자이고, R2, R4 및 R7은 수소 원자인, 화학적 화합물.
- 제1항에 있어서, R4 및 R7은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택되고, R2, R5 및 R6은 수소 원자인, 화학적 화합물.
- 제1항에 있어서, R4 및 R7은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택되고, R4 및 R7 중 적어도 하나는 프레닐기 또는 할로겐 원자이고, R2, R5 및 R6은 수소 원자인, 화학적 화합물.
- 제1항에 있어서, R5 및 R6은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택되고, R2, R4 및 R7은 수소 원자인, 화학적 화합물.
- 제1항에 있어서, R5 및 R7은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택되고, R5 및 R6 중 적어도 하나는 프레닐기 또는 할로겐 원자이고, R2, R4 및 R6은 수소 원자인, 화학적 화합물.
- 제1항에 있어서, R5 및 R7은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택되고, R2, R4 및 R6은 수소 원자인, 화학적 화합물.
- 제1항에 있어서, R5 및 R7은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택되고, R5 및 R7 중 적어도 하나는 프레닐기 또는 할로겐 원자이고, R2, R4 및 R6은 수소 원자인, 화학적 화합물.
- 제1항에 있어서, R6 및 R7은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택되고, R2, R4 및 R5는 수소 원자인, 화학적 화합물.
- 제1항에 있어서, R6 및 R7은 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기 중 2개로부터 선택되고, R6 및 R7 중 적어도 하나는 프레닐기 또는 할로겐 원자이고, R2, R4 및 R5는 수소 원자인, 화학적 화합물.
- 제1항에 있어서, R2는 수소이고, R4, R5, R6 또는 R7 중 단 2개만이 치환되며, 여기서 제1 치환기는 (i) 할로겐 원자, (ii) 프레닐기, 및 (iii) 니트릴기로부터 선택되고, 제2 치환기는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 선택되고, 여기서 제1 및 제2 치환기는 서로 다른 기로부터의 것인, 화학적 화합물.
- 제1항에 있어서, R2는 수소이고, R4, R5, R6 또는 R7 중 단 2개만이 치환되며, 여기서 제1 치환기는 할로겐 원자이고, 제2 치환기는 (i) 하이드록시기, (ii) 니트로기, (iii) 글리코실옥시기, (iv) 아미노기 또는 N-치환된 아미노기, (v) 카르복실기 또는 카르복실산 유도체, (vi) 알데히드 또는 케톤기, (vii) 프레닐기, 및 (viii) 니트릴기로부터 선택된, 화학적 화합물.
- 제1항에 있어서, R2는 수소이고, R4, R5, R6 또는 R7 중 단 2개만이 치환되며, 여기서 제1 치환기는 프레닐기이고, 제2 치환기는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, 및 (viii) 니트릴기로부터 선택된, 화학적 화합물.
- 제1항에 있어서, R2는 수소이고, R4, R5, R6 또는 R7 중 단 2개만이 치환되며, 여기서 제1 치환기는 니트릴기이고, 제2 치환기는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, 및 (viii) 프레닐기로부터 선택된, 화학적 화합물.
- 제1항에 있어서, R2는 수소이고, R4, R5, R6 또는 R7 중 단 2개만이 치환되며, 여기서 제1 치환기는 (i) 할로겐 원자, (ii) 프레닐기, 및 (iii) 니트릴기로부터 선택되고, 제2 치환기는 (i) 하이드록시기, (ii) 니트로기, (iii) 글리코실옥시기, (iv) 아미노기 또는 N-치환된 아미노기, (v) 카르복실기 또는 카르복실산 유도체, 및 (vi) 알데히드 또는 케톤기로부터 선택된, 화학적 화합물.
- 제1항에 있어서, R2는 수소이고, R4, R5, R6 또는 R7 중 단 2개만이 치환되며, 여기서 제1 치환기는 할로겐 원자이고, 제2 치환기는 (i) 아미노기 또는 N-치환된 아미노기, (ii) 니트릴기, (iii) 니트로기, (iv) 하이드록시기 및 (v) 프레닐기로부터 선택된, 화학적 화합물.
- 제1항에 있어서, R2는 수소이고, R4, R5, R6 또는 R7 중 단 2개만이 치환되며, 여기서 제1 치환기는 프레닐기이고, 제2 치환기는 (i) 카르복실기 또는 카르복실산 유도체, (ii) 할로겐, 및 (iii) 하이드록시기로부터 선택된, 화학적 화합물.
- 제1항에 있어서, R2는 수소이고, R4, R5, R6 또는 R7 중 2개만이 치환되며, 여기서 제1 치환기는 할로겐 원자이고, 제2 치환기는 프레닐기인, 화학적 화합물.
- 제1항에 있어서, R2는 수소이고, R4, R5, R6 또는 R7 중 2개만이 치환되며, 여기서 제1 치환기는 니트릴기이고, 제2 치환기는 아미노기 또는 N-치환된 아미노기인, 화학적 화합물.
- 제1항에 있어서, R5는 카르복실기 또는 아세틸기이고, R7은 아미노기, 니트릴기, 하이드록시기 또는 할로겐인, 화학적 화합물.
- 제1항에 있어서, R5는 아세트아미딜기이고, R7은 알데히드기, 카르복실기 또는 카르복시에스테르인, 화학적 화합물.
- 제1항에 있어서, R5는 아세트아미딜기이고, R6은 아미노기, 니트로기 또는 할로겐이고, R7은 알데히드기, 카르복실기 또는 카르복시에스테르인, 화학적 화합물.
- 제1항에 있어서, R5는 카르복시-메틸기 또는 아미드기이고, R7은 니트로기, 및 아미노기 또는 할로겐인, 화학적 화합물.
- 제1항에 있어서, R4는 글리코실옥시기이고, R5는 카르복시-메틸기 또는 아미드기이고, R7은 니트로기, 및 아미노기 또는 할로겐인, 화학적 화합물.
- 제1항에 있어서, 화학적 화합물 (I)은 화학식 (IX), (X), (XI), (XII), (XIII), (XIV), (XV), (XVI), (XVII), (XVIII), (XIX), (XX), (XXI), (XXII), (XXIII), (XXIV), (XXV), (XXVI), (XXVII), (XXVIII), (XXIX), (XXX), (XXXI), (XXXII), (XXXIII), (XXXIV), (XXXV), (XXXVI), (XXXVII), (XXXVIII), (XXXIX), (XL), (XLI), (XLII), (XLIII), (XLIV), (XLV), (XLVI), (XLVII), (XLVIII), (XLIX), (L), (LI), (LII), (LIII), (LIV), 또는 (LV)을 갖는 화합물로부터 선택되는, 화학적 화합물:
(IX); (X); (XI); (XII); (XIII); (XIV); (XV); (XVI); (XVII); (XVIII); (XIX); (XX);
(XXI); (XXII); (XXIII); (XXIV); (XXV); (XXVI); (XXVII);(XXVIII);(XXIX);
(XXX); (XXXI); (XXXII);
(XXXIII); (XXXIV); (XXXV); (XXXVI); (XXXVII); (XXXVIII);
(XXXIX); (XL); (XLI);
(XLII); (XLIII); (XLIV); (XLV); (XLVI); (XLVII); (XLVIII); (XLIX); (L); (LI); (LII); (LIII); (LIV); (LV); 및 (LXXVI). - 제1항에 있어서, 화학적 화합물 (I)이 도 13a, 도 13b 및 도 13c에 도시되고 그 안에서 13A-3, 13A-4, 13A-5, 13A-6, 13A-7, 13A-8, 13A-9, 13A-10, 13B-3, 13B-4, 13B-5, 13B-6, 13B-7, 13B-8, 13B-8, 13C-6, 13C-7, 13C-8, 13C-9, 13C-10, 또는 13C-11로 표지된 화합물 중 어느 하나인, 화학적 화합물.
- 약학적으로 허용가능한 부형제, 희석제 또는 담체와 함께 유효량의 제1항에 따른 화학적 화합물을 포함하는 약학적 또는 기분전환용 약물 제형.
- 정신 장애를 치료하는 방법으로서, 상기 방법은 제1항에 따른 화학적 화합물을 포함하는 약학적 제형을 치료를 필요로 하는 대상체에게 투여하는 것을 포함하며, 여기서 약학적 제형은 상기 대상체에서 정신 장애를 치료하기 위한 유효량으로 투여되는 방법.
- 제34항에 있어서, 장애는 5-HT2A 수용체 매개된 장애, 또는 5-HT1A 수용체 매개된 장애인, 방법.
- 제34항에 있어서, 약 0.001mg 내지 약 5,000mg의 용량이 투여되는, 방법.
- 5-HT2A 수용체 또는 5-HT1A 수용체를 조절하는 방법으로서, 상기 방법은 5-HT2A 수용체 또는 5-HT1A 수용체를 제1항에 따른 화학적 화합물과 접촉시키는 것을 포함하는, 방법.
- 제37항에 있어서, 반응 조건은 시험관내 반응 조건인, 방법.
- 제37항에 있어서, 반응 조건이 생체내 반응 조건인, 방법.
- 제1항에 따른 실로시빈 유도체 화합물을 제조하는 방법으로서, 상기 방법은 화학식 (II)을 갖는 반응물 실로시빈 유도체:
(II),
를 치환기 함유 화합물과 반응시키는 것을 포함하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자 또는 알코올기이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우 R4는 수소 원자, 하이드록시기, O-알킬기, O-아실기 또는 포스페이트기이고, 여기서 R3a 및 R3b는 각각 독립적으로 수소 원자, 알킬기, 시클로알킬기, 아실기 또는 아릴기이고, 그리고 여기서 R3c는 수소 원자 또는 카르복실기이고,
여기서 치환기 함유 화합물에서 치환기는 화학식 (I)을 갖는 실로시빈 치환기 또는 이의 염을 형성하기에 충분한 반응 조건 하에서 (i) 할로겐 함유 화합물, (ii) 하이드록시기 함유 화합물, (iii) 니트로기 함유 화합물, (iv) 글리코실옥시기 함유 화합물, (v) 아미노기 또는 N-치환된 아미노기 함유 화합물, (vi) 카르복실기 또는 카르복실산 유도체 함유 화합물, (vii) 알데히드 또는 케톤기 함유 화합물, (viii) 프레닐기 함유 화합물, 및 (ix) 니트릴기 함유 화합물로부터 선택되는, 방법. - 제40항에 있어서, 식 (II)을 갖는 반응물 실로시빈 유도체에서 치환기는 니트로기이고, 치환기 함유 화합물은 카르복실산 유도체 아세트산 무수물(Ac2O)이고, 반응물 실로시빈 유도체 및 치환기 함유 화합물은 프리들-크라프트 아실화 반응에서 반응하여 식 (I)을 갖는 제1 실로시빈 유도체를 형성하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 니트로기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 아세틸기인, 방법.
- 제41항에 있어서, 형성된 제1 실로시빈 유도체는 도 13a에 도시되고 13A-3으로 표지된 화합물인, 방법.
- 제40항에 있어서, 식 (I)을 갖는 형성된 제1 실로시빈 유도체는 반응하여 아세틸기를 산화시키고 식 (I)을 갖는 제2 실로시빈 유도체를 형성하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 니트로기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복실기인, 방법.
- 제43항에 있어서, 형성된 제2 실로시빈 유도체는 도 13a에 도시되고 13A-4로 표지된 화합물인, 방법.
- 제43항에 있어서, 식 (I)을 갖는 형성된 제2 실로시빈 유도체는 반응하여 니트로기를 환원시키고 아미노기, 및 식 (I)을 갖는 제3 실로시빈 유도체를 형성하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아미노기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복실기인, 방법.
- 제45항에 있어서, 형성된 제3 실로시빈 유도체는 도 13a에 도시되고 13A-5로 표지된 화합물인, 방법.
- 제45항에 있어서, 식 (I)을 갖는 형성된 제3 실로시빈 유도체는 아질산염과 반응하여 디아조늄염에서 아미노기를 전환시키고 식 (I)을 갖는 중간체 실로시빈 유도체를 형성하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 디아조늄기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복실기인, 방법.
- 제47항에 있어서, 중간체 형성된 실로시빈 유도체는 도 13a에 도시되고 13A-6으로 표지된 화합물인, 방법.
- 제47항에 있어서, 식 (I)을 갖는 중간체 형성된 실로시빈 유도체는 니트릴 함유 화합물과 반응하여 디아조늄기를 전환시키고 식 (I)을 갖는 제4 실로시빈 유도체를 형성하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 니트릴기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복실기인, 방법.
- 제49항에 있어서, 형성된 제4 실로시빈 유도체는 도 13a에 도시되고 13A-7로 표지된 화합물인, 방법.
- 제47항에 있어서, 식 (I)을 갖는 중간체 형성된 실로시빈 유도체는 물과 반응하여 디아조늄기를 전환시키고 식 (I)을 갖는 제5 실로시빈 유도체를 형성하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 하이드록시기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복실기인, 방법.
- 제51항에 있어서, 형성된 제5 실로시빈 유도체는 도 13a에 도시되고 13A-8로 표지된 화합물인, 방법.
- 제47항에 있어서, 식 (I)을 갖는 중간체 형성된 실로시빈 유도체는 할로겐 함유 화합물과 반응하여 디아조늄기를 전환시키고 식 (I)을 갖는 제6 실로시빈 유도체를 형성하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 할로겐 원자이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복실기인, 방법.
- 제53항에 있어서, 형성된 제6 실로시빈 유도체는 도 13a에 도시되고 13A-9 또는 13A-10으로 표지된 화합물인, 방법.
- 제40항에 있어서, 식 (II)을 갖는 반응물 실로시빈 유도체에서 치환기는 메톡시카르보닐기이고, 치환기 함유 화합물은 할로겐 함유 화합물 N-할로-숙신이미드이고, 반응물 실로시빈 유도체와 치환기 함유 화합물은 반응하여 식 (I)을 갖는 제1 실로시빈 유도체를 형성하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 메톡시 카르보닐기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 할로겐 원자인, 방법.
- 제55항에 있어서, N-할로-숙신이미드는 N-클로로-숙신이미드이고, 형성된 제1 실로시빈 유도체는 도 13b에 도시되고 13B-3으로 표지된 화합물인, 방법.
- 제40항에 있어서, 식 (II)을 갖는 반응물 실로시빈 유도체에서 치환기는 메톡시카르보닐기이고, 치환기 함유 화합물은 니트로 함유 화합물 니트로늄 테트라플루오로보레이트이고, 반응물 실로시빈 유도체와 치환기 함유 화합물은 반응하여 식 (I)을 갖는 제2 실로시빈 유도체를 형성하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 메톡시 카르보닐기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 니트로기인, 방법.
- 제57항에 있어서, 형성된 제2 실로시빈 유도체는 도 13b에 도시되고 13B-4로 표지된 화합물인, 방법.
- 제40항에 있어서, 식 (I)을 갖는 형성된 제1 실로시빈 유도체는 아세틸화된 글리코실 화합물과 반응하여 식 (I)을 갖는 제3 실로시빈 유도체를 형성하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 메톡시 카르보닐기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 글리코실옥시기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 할로겐 원자인, 방법.
- 제59항에 있어서, 형성된 제3 실로시빈 유도체는 도 13b에 도시되고 13B-5로 표지된 화합물인, 방법.
- 제57항에 있어서, 식 (I)을 갖는 형성된 제2 실로시빈 유도체는 아세틸화된 글리코실 화합물과 반응하여 식 (I)을 갖는 제4 실로시빈 유도체를 형성하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 메톡시카르보닐기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 글리코실옥시기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 니트로기인, 방법.
- 제61항에 있어서, 형성된 제4 실로시빈 유도체는 도 13b에 도시되고 13B-6으로 표지된 화합물인, 방법.
- 제59항에 있어서, 식 (I)을 갖는 형성된 제3 실로시빈 유도체는 암모니아와 반응하여 아미도기에서의 메톡시카르보닐기를 전환시키고 식 (I)을 갖는 제5 실로시빈 유도체를 형성하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아미도기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 글리코실옥시기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 할로겐 원자인, 방법.
- 제63항에 있어서, 형성된 제5 실로시빈 유도체는 도 13b에 도시되고 13B-7로 표지된 화합물인, 방법.
- 제61항에 있어서, 식 (I)을 갖는 형성된 제4 실로시빈 유도체는 암모니아와 반응하여 아미도기에서의 메톡시카르보닐기를 전환시키고 식 (I)을 갖는 제6 실로시빈 유도체를 형성하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아미도기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 글리코실옥시기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 니트로기인, 방법.
- 제65항에 있어서, 형성된 제6 실로시빈 유도체는 도 13b에 도시되고 13B-8로 표지된 화합물인, 방법.
- 제65항에 있어서, 식 (I)을 갖는 형성된 제6 실로시빈 유도체는 반응하여 니트로기를 환원시켜 아미노기 및 식 (I)을 갖는 제7 실로시빈 유도체를 형성하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아미도기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 글리코실옥시기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 니트로기인, 방법.
- 제67항에 있어서, 형성된 제7 실로시빈 유도체는 도 13b에 도시되고 13B-9로 표지된 화합물인, 방법.
- 제40항에 있어서, 식 (II)을 갖는 반응물 실로시빈 유도체에서 치환기는 아세트아미딜기일 수 있고, 치환기 함유 화합물은 할로겐 함유 화합물 N-할로-숙신이미드이고, 반응물 실로시빈 유도체와 치환기 함유 화합물은 반응하여 식 (I)을 갖는 제1 실로시빈 유도체를 형성하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아세트아미딜기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 할로겐 원자인, 방법.
- 제69항에 있어서, N-할로-숙신이미드는 N-브로모-숙신이미드(NBS)이고, 형성된 제1 실로시빈 유도체는 도 13c에 도시되고 13C-6으로 표지된 화합물인, 방법.
- 제69항에 있어서, 식 (II)을 갖는 반응물 실로시빈 유도체에서 치환기는 아세트아미딜기이고, 치환기 함유 화합물은 디메틸 포름아미드이고, 반응물 실로시빈 유도체와 치환기 함유 화합물은 반응하여 식 (I)을 갖는 중간체 실로시빈 유도체를 형성하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아세트아미딜기고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 메탄올기이고, 여기서 중간체 실로시빈 유도체는 추가로 반응하여 메탄올기를 산화시켜 식 (I)을 갖는 제2 실로시빈 유도체를 형성하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아세트아미딜기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복시기인, 방법.
- 제71항에 있어서, 중간체 실로시빈 유도체는 도 13c에 도시되고 13C-5로 표지된 화합물이고, 형성된 제2 실로시빈 유도체는 도 13c에 도시되고 13C-7로 표지된 화합물인, 방법.
- 제71항에 있어서, 식 (I)을 갖는 형성된 제2 실로시빈 유도체는 알코올과 반응하여 카르복시기를 에스테르화하여 에스테르 및 식 (I)을 갖는 제3 실로시빈 유도체를 형성하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아세트아미딜기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복실 에스테르인, 방법.
- 제73항에 있어서, 형성된 제3 실로시빈 유도체는 도 13c에 도시되고 13C-8로 표지된 화합물인, 방법.
- 제73항에 있어서, 식 (I)을 갖는 형성된 제3 실로시빈 유도체는 니트로기 함유 화합물과 반응하여 식 (I)을 갖는 제4 실로시빈 유도체를 형성하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아세트아미딜기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복실 에스테르이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 니트로기인, 방법.
- 제75항에 있어서, 형성된 제4 실로시빈 유도체는 도 13c에 도시되고 13C-9로 표지된 화합물인, 방법.
- 제75항에 있어서, 식 (I)을 갖는 형성된 제4 실로시빈 유도체는 반응하여 니트로기를 환원시켜 아미노기 및 식 (I)을 갖는 제5 실로시빈 유도체를 형성하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아세트아미딜기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복실 에스테르이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 아미노기인, 방법.
- 제77항에 있어서, 형성된 제5 실로시빈 유도체는 도 13c에 도시되고 13C-10으로 표지된 화합물인, 방법.
- 제77항에 있어서, 식 (I)을 갖는 형성된 제5 실로시빈 유도체는 암모니아와 반응하여 아미도기 및 식 (I)을 갖는 제6 실로시빈 유도체를 형성하며, 여기서 R2, R4, R5, R6, 또는 R7 중 하나는 아세트아미딜기이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 카르복시에스테르이고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 아미도기인, 방법.
- 제79항에 있어서, 형성된 제6 실로시빈 유도체는 도 13c에 도시되고 13C-11로 표지된 화합물인, 방법.
- 다중 치환기 실로시빈 유도체를 제조하는 방법으로서, 상기 방법은 식 (LVII)을 갖는 실로시빈 유도체 전구체 화합물:
(LVII)
을 실로시빈 유도체 전구체 화합물의 효소 촉매된 전환을 허용하는 반응 조건 하에서 촉매적 양의 실로시빈 생합성 효소 보체와 접촉시켜 제1항에 따른 다중 치환기 실로시빈 유도체 화합물을 형성하는 것을 포함하고,
여기서 R2, R4, R5, R6, 또는 R7 중 적어도 하나는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 선택된 치환기이고, 여기서 각각의 비치환된 R2, R5, R6, 또는 R7은 수소 원자이고, R4가 임의의 전술한 치환기로 치환되지 않은 경우, R4는 수소 원자, O-알킬기, O-아실기, 또는 포스페이트기이고, 여기서 R3은 수소 원자 또는 -CH2-CHNH2COOH 또는 -CH2-CH2NH2인, 방법 - 제81항에 있어서, 반응 조건은 시험관내 반응 조건인, 방법.
- 제81항에 있어서, 반응 조건은 생체내 반응 조건인, 방법.
- 제81항 또는 제83항에 있어서, 실로시빈 유도체 전구체 화합물 및 치환기 함유 화합물은 숙주 세포에서 실로시빈 생합성 효소 보체와 접촉되며, 여기서 숙주 세포는 작동가능하게 연결된 구성요소로서:
(i) 숙주 세포에서 발현을 조절하는 핵산 서열; 및
(ii) 실로시빈 생합성 효소 보체를 인코딩하는 핵산 서열을 포함하는 키메라 핵산 서열을 포함하고,
상기 숙주 세포는 성장하여 실로시빈 생합성 효소 보체를 발현하고 다중 치환기 실로시빈 유도체 화합물을 생산하는, 방법. - 제84항에 있어서, 실로시빈 생합성 효소 보체는 다음으로부터 선택된 핵산에 의해 인코딩되는 적어도 하나의 효소를 포함하는, 방법:
(f) 서열번호: 1, 서열번호: 3, 서열번호: 5, 서열번호: 7, 서열번호: 9, 서열번호: 11, 서열번호: 13 , 서열번호: 15, 서열번호: 17, 서열번호: 19, 서열번호: 21, 서열번호: 23, 서열번호: 25, 및 서열번호: 48;
(g) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(h) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(i) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(j) 서열번호: 2, 서열번호: 4, 서열번호: 6, 서열번호: 8, 서열번호: 10, 서열번호: 12, 서열번호: 14, 서열번호: 16, 서열번호: 18, 서열번호: 20, 서열번호: 22, 서열번호: 24, 서열번호: 26, 및 서열번호: 49에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 2, 서열번호: 4, 서열번호: 6, 서열번호: 8, 서열번호: 10, 서열번호: 12, 서열번호: 14, 서열번호: 16, 서열번호: 18, 서열번호: 20, 서열번호: 22, 서열번호: 24, 서열번호: 26, 및 서열번호: 49에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열. - 제85항에 있어서, 실로시빈 생합성 효소 보체는
(a) 서열번호: 1;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 2에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 2에 제시된 아미노산 서열의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열
로부터 선택된 핵산에 의해 인코딩되는 트립토판 신타제 서브유닛 B 폴리펩티드를 포함하고,
여기서 식 (LVII)을 갖는 실로시빈 유도체 전구체 화합물에서, R2, R4, R5, R6, 또는 R7 중 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 독립적으로 선택된 치환기이고, 여기서 R3은 수소 원자이고, 여기서 R3c가 카르복실기인 식 (I)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물이 형성되는, 방법. - 제86항에 있어서, 실로시빈 유도체 전구체 화합물은 식 (LVIII)을 갖는 화학적 화합물이고:
(LVIII),
여기서 R4는 하이드록시기이고, R6은 염소 원자이며, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LV)을 갖는, 방법:
(LV). - 제85항에 있어서, 실로시빈 생합성 효소 보체는 R3 -CH2-CHNH2COOH 기를 탈카르복실화시키기 위한 트립토판 데카르복실라제를 추가로 포함하고, 이에 의해 식 (I)을 갖는 제2 다중 치환기 실로시빈 유도체를 형성하며 여기서 R3a 및 R3b는 각각 수소 원자이고, 트립토판 데카르복실라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩되는, 방법:
(a) 서열번호: 3, 서열번호: 5, 및 서열번호: 7;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 4, 서열번호: 6, 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 4, 서열번호: 6 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열. - 제88항에 있어서, 실로시빈 유도체 전구체 화합물은 식 (LVIII)을 갖는 화학적 화합물이고:
(LVIII),
여기서 R4는 불소 원자, 아미노기 또는 하이드록시기이고, R6은 불소 원자, 아미노기, 니트릴 또는 브롬 원자이며, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LIX)을 가지며:
(LIX),
여기서 R4는 불소 원자, 아미노기, 또는 하이드록시기이고, R6은 불소 원자, 아미노기, 니트릴 또는 브롬 원자이며, 제2 다중 치환기 실로시빈 유도체는 식 (XXII), (XXVI), (XXIX), (LII) 또는 (LIV)를 갖는, 방법:
(XXII); (XXVI); (XXIX); (LII); 또는 (LIV). - 제88항에 있어서, 실로시빈 생합성 효소 보체는 화학식 (I)을 갖는 제2 실로시빈 유도체를 아세틸화하기 위한 N-아세틸 트랜스퍼라제를 추가로 포함하고 이에 의해 화학식 (I)을 갖는 제3 다중 치환기 실로시빈을 형성하며, 여기서 R3a는 수소 원자이고 R3b는 아세틸기이고, N-아세틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩되는, 방법:
(a) 서열번호: 9;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 10에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 10에 제시된 아미노산 서열의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열. - 제90항에 있어서, 실로시빈 유도체 전구체 화합물은 식 (LVIII)을 갖는 화학적 화합물이고:
(LVIII),
여기서 R4는 아세트아미딜기, 불소 원자, 아미노기 또는 하이드록시기이고, R6은 불소 원자, 아미노기, 니트릴 또는 브롬 원자이며, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LIX)을 가지고:
(LIX),
여기서 R4는 아세트아미딜기, 불소 원자, 아미노기 또는 하이드록시기이고, R6은 불소 원자, 아미노기, 니트릴 또는 브롬 원자이며, 여기서 제2 다중 치환기 실로시빈 유도체는 식 (LX)을 가지고:
(LX),
여기서 제3 다중 치환기 실로시빈 유도체는 식 (IX), (X), (XVIII), (XXI), (XXV) 또는 (XXVIII)을 갖는, 방법:
(IX); (X); (XVIII); (XXI); (XXV); 또는 (XXVIII). - 제88항에 있어서, 실로시빈 생합성 효소 보체는 R3에서 R3 아미노기를 메틸화하고 화학식 (I)을 갖는 제4 다중 치환기 실로시빈 유도체를 형성하기 위한 N-메틸 트랜스퍼라제를 추가로 포함하며, 여기서, R3a 및 R3b는 각각 메틸기이거나, R3a는 수소 원자이고 R3b는 메틸기이고, N-메틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩되는, 방법:
(a) 서열번호: 11 및 서열번호: 13;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열. - 제92항에 있어서, 실로시빈 유도체 전구체 화합물은 식 (LVIII)을 갖는 화학적 화합물이고:
(LVIII),
여기서 R4는 아미노기 또는 하이드록시기이고, R6은 염소 원자, 니트릴기 또는 브롬 원자이며, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LIX)을 가지고:
(LIX),
여기서 R4는 아미노기 또는 하이드록시기이고, R6은 염소 원자, 니트릴기 또는 브롬 원자이며, 여기서 제2 다중 치환기 실로시빈 유도체는 식 (LX)을 가지고:
(LX),
여기서 제4 다중 치환기 실로시빈 유도체는 식 (XXVII), (XL) 또는 (LIII)을 갖는, 방법:
(XXVII);(XL); 또는 (LIII). - 제88항에 있어서, 실로시빈 생합성 효소 보체는
(a) 서열번호: 15, 서열번호: 17, 서열번호: 19, 및 서열번호: 21;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 16, 서열번호: 18, 서열번호: 20, 및 서열번호: 22에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 16, 서열번호: 18, 서열번호: 20, 및 서열번호: 22에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열
로부터 선택된 핵산에 의해 인코딩되는 프레닐 트랜스퍼라제를 추가로 포함하고,
여기서, 식 (LVII)을 갖는 실로시빈 유도체 전구체 화합물에서, R2, R4, R5, R6, 또는 R7 중 하나는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 선택된 치환기이고, 여기서 R3은 -CH2-CHNH2COOH이고, 여기서 식 (I)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물이 형성되고, R2, R4, R5, R6, 또는 R7 중 적어도 하나는 프레닐기이고, R3c는 수소 원자인, 방법. - 제94항에 있어서, 실로시빈 유도체 전구체 화합물은 식 (LXI)을 갖는 화학적 화합물이고:
(LXI);
여기서 R4는 하이드록시기이며, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (L)을 갖는, 방법:
(L). - 제94항에 있어서, 실로시빈 생합성 효소 보체는 R3 -CH2-CHNH2COOH 기를 탈카르복실화시키기 위한 트립토판 데카르복실라제를 추가로 포함하고, 이에 의해 식 (I)을 갖는 제2 다중 치환기 실로시빈 유도체를 형성하며 여기서 R3a 및 R3b는 각각 수소 원자이고, 트립토판 데카르복실라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩되는, 방법:
(a) 서열번호: 3, 서열번호: 5, 및 서열번호: 7;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 4, 서열번호: 6, 서열번호: 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 4, 서열번호: 6 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열. - 제96항에 있어서, 실로시빈 생합성 효소 보체는 R3에서 R3 아미노기를 메틸화하고 화학식 (I)을 갖는 제4 다중 치환기 실로시빈 유도체를 형성하기 위한 N-메틸 트랜스퍼라제를 추가로 포함하며, 여기서 R3a 및 R3b는 각각 메틸기이거나, R3a는 수소 원자이고 R3b는 메틸기이고, N-메틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩되는, 방법:
(a) 서열번호: 11, 및 서열번호: 13;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열. - 제97항에 있어서, 실로시빈 유도체 전구체 화합물은 식 (LXI)을 갖는 화학적 화합물이고:
(LXI),
여기서 R4는 프로피오닐옥시 또는 아세톡시기이며, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LIX)을 가지고:
(LIX),
여기서 R4는 프로피오닐옥시 또는 아세톡시기이고, R6은 프레닐기이며, 여기서 제2 다중 치환기 실로시빈 유도체는 다음 식을 가지고:
(LX),
여기서 R4는 프로피오닐옥시 또는 아세톡시기이고, R6은 프레닐기이며, 여기서 제3 다중 치환기 실로시빈 유도체는 식 (XLI) 또는 (XLII)을 갖는, 방법:
(XLI); 또는 (XLII). - 제94항에 있어서, 실로시빈 유도체 전구체 화합물은 식 (LXII)을 갖는 화학적 화합물이고:
(LXII),
여기서 R5는 염소 또는 불소 원자이며, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXIII)을 가지고:
(LXIII),
여기서 R5는 염소 또는 불소 원자이고, R6은 프레닐기이며, 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (XXXVI) 및 (XXXVIII)을 갖는, 방법:
(XXXVI); 및 (XXXVIII). - 제96항에 있어서, 실로시빈 생합성 효소 보체는 화학식 (I)을 갖는 제2 실로시빈 유도체를 아세틸화하고 이에 의해 식 (I)을 갖는 제3 다중 치환기 실로시빈을 형성하기 위해 N-아세틸 트랜스퍼라제를 추가로 포함하며, 여기서 R3a는 수소 원자이고 R3b는 아세틸기이고, N-아세틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩되는, 방법:
(a) 서열번호: 9;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 10에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 10에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열. - 제100항에 있어서, 실로시빈 유도체 전구체 화합물은 식 (LXI)을 갖는 화학적 화합물이고:
(LXI),
여기서 R5는 염소 또는 불소 원자이며, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXIII)을 가지고:
(LXIII),
여기서 R5는 염소 또는 불소 원자이고, R6은 프레닐기이며, 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXIV)을 가지고:
(LXIV),
여기서 R5는 염소 또는 불소 원자이고, R6은 프레닐기이며, 여기서 제3 다중 치환기 실로시빈 유도체는 식 (XXXV) 또는 (XXXVII)을 갖는, 방법:
(XXXV); 또는 (XXXVII). - 제85항에 있어서, 실로시빈 생합성 효소 보체는
(a) 서열번호: 1;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 2에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 2에 제시된 아미노산 서열의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열
로부터 선택된 핵산에 의해 인코딩되는 트립토판 신타제 서브유닛 B 폴리펩티드를 포함하고,
여기서 식 (LVIII)을 갖는 실로시빈 유도체 전구체 화합물에서, R2, R4, R5, R6, 또는 R7 중 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 독립적으로 선택된 치환기이며, 여기서 R3은 수소 원자이고, 여기서 식 (I)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물이 형성되고, R3c가 카르복실기인, 방법. - 제85항에 있어서, 실로시빈 유도체 전구체 화합물은 식 (LXV)을 갖는 화학적 화합물이고:
(LXV),
여기서 R4는 하이드록시기고, R5는 프레닐기이며, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LI)을 갖는, 방법:
(LI). - 제102항에 있어서, 실로시빈 생합성 효소 보체는 R3 -CH2-CHNH2COOH 기를 탈카르복실화시키기 위한 트립토판 데카르복실라제를 추가로 포함하고, 이에 의해 식 (I)을 갖는 제2 다중 치환기 실로시빈 유도체를 형성하며 여기서 R3a 및 R3b는 각각 수소 원자이고, 트립토판 데카르복실라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩되는, 방법:
(a) 서열번호: 3, 서열번호: 5, 및 서열번호: 7;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 4, 서열번호: 6, 서열번호: 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 4, 서열번호: 6 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열. - 제104항에 있어서, 실로시빈 유도체 전구체 화합물은 식 (LXV)을 갖는 화학적 화합물이고:
(LXV),
여기서 R4는 불소 원자이고 R5는 니트릴기이며, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXIX)을 가지고:
(LXIX),
여기서 R4는 불소 원자이고 여기서 R5는 니트릴기이며, 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (XIX)을 갖는, 방법:
(XIX). - 제104항에 있어서, 실로시빈 생합성 효소 보체는 화학식 (I)을 갖는 제2 실로시빈 유도체를 아세틸화하기 위한 N-아세틸 트랜스퍼라제를 추가로 포함하고 이에 의해 화학식 (I)을 갖는 제3 다중 치환기 실로시빈을 형성하며, 여기서 R3a는 수소 원자이고 R3b는 아세틸기이고, N-아세틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩되는, 방법:
(a) 서열번호: 9;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 10에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 10에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열. - 제106항에 있어서, 실로시빈 유도체 전구체 화합물은 식 (LXV)을 갖는 화학적 화합물이고:
(LXV),
여기서 R4는 불소 원자이고 R5는 하이드록시기 또는 니트릴기이며, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXIX)을 가지고:
(LXIX),
여기서 R4는 불소 원자이고 여기서 R5는 하이드록시기 또는 니트릴기이며, 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXXII)을 가지고:
(LXXII),
여기서 R4는 불소 원자이고, 여기서 R5는 하이드록시기 또는 니트릴기이며, 여기서 제3 다중 치환기 실로시빈 유도체는 식 (XVII) 또는 (XX)을 갖는, 방법:
(XVII); 또는 (XX). - 제85항에 있어서, 실로시빈 생합성 효소 보체는
(a) 서열번호: 1;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 2에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 2에 제시된 아미노산 서열의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열
로부터 선택된 핵산에 의해 인코딩되는 트립토판 신타제 서브유닛 B 폴리펩티드를 포함하고,
여기서 식 (LVIII)을 갖는 실로시빈 유도체 전구체 화합물에서, R2, R4, R5, R6, 또는 R7 중 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 독립적으로 선택된 치환기이고, 여기서 R3은 수소 원자이고, 그리고 식 (I)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물이 형성되며, 여기서 R3c가 카르복실기인, 방법. - 제108항에 있어서, 실로시빈 유도체 전구체 화합물은 식 (LXVI)을 갖는 화학적 화합물이고:
(LXVI),
여기서 R4는 하이드록시기고, R7은 프레닐기이며, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (XLIX)을 갖는, 방법:
(XLIX). - 제108항에 있어서, 실로시빈 생합성 효소 보체는 R3 -CH2-CHNH2COOH 기를 탈카르복실화시키기 위한 트립토판 데카르복실라제를 추가로 포함하고, 이에 의해 식 (I)을 갖는 제2 다중 치환기 실로시빈 유도체를 형성하며 여기서 R3a 및 R3b는 각각 수소 원자이고, 트립토판 데카르복실라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩되는, 방법:
(a) 서열번호: 3, 서열번호: 5, 및 서열번호: 7;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 4, 서열번호: 6, 서열번호: 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 4, 서열번호: 6 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열. - 제110항에 있어서, 실로시빈 유도체 전구체 화합물은 식 (LXVI)을 갖는 화학적 화합물이고:
(LXVI),
여기서 R4는 불소 원자이고 R7은 니트릴기이며, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXX)을 가지고:
(LXX),
여기서 R4는 불소 원자이고 여기서 R7은 니트릴기이며, 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (XXIV)을 갖는, 방법:
(XXIV). - 제110항에 있어서, 실로시빈 생합성 효소 보체는 화학식 (I)을 갖는 제2 실로시빈 유도체를 아세틸화하기 위한 N-아세틸 트랜스퍼라제를 추가로 포함하고 이에 의해 화학식 (I)을 갖는 제3 다중 치환기 실로시빈을 형성하며, 여기서 R3a는 수소 원자이고 R3b는 아세틸기이고, N-아세틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩되는, 방법:
(a) 서열번호: 9;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 10에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 10에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열. - 제112항에 있어서, 실로시빈 유도체 전구체 화합물은 식 (LXVI)을 갖는 화학적 화합물이고:
(LXVI),
여기서 R4는 불소 원자 또는 염소 원자이고 R7은 프레닐기 또는 니트릴기이며, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXX)을 가지고:
(LXX),
여기서 R4는 불소 원자 또는 염소 원자이고 여기서 R7은 프레닐기 또는 니트릴기이며, 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXXIII)을 가지고:
(LXXIII),
여기서 R4는 불소 원자 또는 염소 원자이고 여기서 R7은 프레닐기 또는 니트릴기이며, 제3 다중 치환기 실로시빈 유도체는 식 (XXIII) 또는 (XX)을 갖는, 방법:
(XXIII); 또는 (XXXIV). - 제110항에 있어서, 실로시빈 생합성 효소 보체는 R3에서 R3 아미노기를 메틸화하고 화학식 (I)을 갖는 제4 다중 치환기 실로시빈 유도체를 형성하기 위한 N-메틸 트랜스퍼라제를 추가로 포함하며, 여기서 R3a 및 R3b는 각각 메틸기이거나, R3a는 수소 원자이고 R3b는 메틸기이고, N-메틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩되는, 방법:
(a) 서열번호: 11, 및 서열번호: 13;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열. - 제114항에 있어서, 실로시빈 유도체 전구체 화합물은 식 (LXVI)을 갖는 화학적 화합물이고:
(LXVI),
여기서 R4는 염소 원자이고 R7은 하이드록시기이며, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXX)을 가지고:
(LXX),
여기서 R4는 하이드록시기고, 여기서 R7은 염소 원자이며, 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXXIII)을 가지고:
(LXXIII),
여기서 R4는 하이드록시기고, 여기서 R7은 염소 원자이며, 여기서 제3 다중 치환기 실로시빈 유도체는 식 (XXXIX)을 갖는, 방법:
(XXXIX). - 제85항에 있어서, 실로시빈 생합성 효소 보체는
(a) 서열번호: 1;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 2에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 2에 제시된 아미노산 서열의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열
로부터 선택된 핵산에 의해 인코딩되는 트립토판 신타제 서브유닛 B 폴리펩티드를 포함하고,
여기서 식 (LVIII)을 갖는 실로시빈 유도체 전구체 화합물에서, R2, R4, R5, R6, 또는 R7 중 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 독립적으로 선택된 치환기이며, 여기서, R3은 수소 원자이고, 여기서 R3c가 카르복실기인 식 (I)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물이 형성되고, 실로시빈 생합성 효소 보체는 제1 다중 치환기 실로시빈 유도체 화합물의 R3 -CH2-CHNH2COOH 기를 탈카르복실화시키기 위한 트립토판 데카르복실라제를 추가로 포함하고, 이에 의해 식 (I)을 갖는 제2 다중 치환기 실로시빈 유도체를 형성하며 여기서 R3a 및 R3b 각각은 수소 원자이며, 트립토판 데카르복실라제는
(a) 서열번호: 3, 서열번호: 5, 및 서열번호: 7;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 4, 서열번호: 6, 서열번호: 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 4, 서열번호: 6 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열
로부터 선택된 핵산 서열에 의해 인코딩되는, 방법. - 제116항에 있어서, 실로시빈 유도체 전구체 화합물은 식 (LXVII)을 갖는 화학적 화합물이고:
(LXVII),
여기서 R5는 불소 원자, 염소 원자 또는 니트릴기이고, R6은 불소 원자, 아미노기 또는 프레닐기이며, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXIII)을 가지고:
(LXIII),
여기서 R5는 불소 원자, 염소 원자 또는 니트릴기이고, 여기서 R6은 불소 원자, 아미노기 또는 프레닐기이며, 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (XI), (XVI), (XXXVI) 또는 (XXXVIII)을 갖는, 방법:
(XI); (XVI); (XXXVI); 및 (XXXVIII). - 제116항에 있어서, 실로시빈 생합성 효소 보체는 화학식 (I)을 갖는 제2 실로시빈 유도체를 아세틸화하기 위한 N-아세틸 트랜스퍼라제를 추가로 포함하고 이에 의해 화학식 (I)을 갖는 제3 다중 치환기 실로시빈을 형성하며, 여기서 R3a는 수소 원자이고 R3b는 아세틸기이고, N-아세틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩되는, 방법:
(a) 서열번호: 9;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 10에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 10에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열. - 제118항에 있어서, 실로시빈 유도체 화합물은 식 (LXVII)을 갖는 화학적 화합물이고:
(LXVII),
여기서 R5는 불소 원자 또는 염소 원자이고 R6은 아미노기, 아세트아미딜기 또는 프레닐기이며, 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXIII)을 가지고:
(LXIII),
여기서 R5는 불소 원자 또는 염소 원자이고, 여기서 R6은 아미노기, 아세트아미딜기 또는 프레닐기이며, 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXXIV)을 가지고:
(LXXIV),
여기서 R5는 불소 원자 또는 염소 원자이고, 여기서 R6은 아미노기, 아세트아미딜기 또는 프레닐기이며, 여기서 제3 다중 치환기 실로시빈 유도체는 식 (XIV), (XV), (XXXV) 또는 (XXXVII)을 갖는, 방법:
(XIV); (XV); (XXXV); 또는 (XXXVII). - 제116항에 있어서, 실로시빈 생합성 효소 보체는 R3에서 R3 아미노기를 메틸화하고 화학식 (I)을 갖는 제4 다중 치환기 실로시빈 유도체를 형성하기 위한 N-메틸 트랜스퍼라제를 추가로 포함하며, 여기서 R3a 및 R3b는 각각 메틸기이거나, 또는 여기서 R3a는 수소 원자이고 R3b는 메틸기이고, N-메틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩되는, 방법:
(a) 서열번호: 11, 및 서열번호: 13;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 12 및 서열번호: 14에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열. - 제120항에 있어서, 실로시빈 유도체 전구체 화합물은 식 (LXVII)을 갖는 화학적 화합물이고:
(LXVII),
여기서 R5는 염소 원자이고 R6은 프레닐기이며, 여기서 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXIII)을 가지고"
(LXIII),
여기서 R5는 염소 원자이고, 여기서 R6은 프레닐기이며, 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXXIV)을 가지고:
(LXXIV),
여기서 R5는 염소 원자이고, R6은 프레닐기이며, 여기서 제3 다중 치환기 실로시빈 유도체는 식 (XLIV)을 갖는, 방법:
(XLIV). - 제85항에 있어서, 실로시빈 생합성 효소 보체는
(a) 서열번호: 1;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 2에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 2에 제시된 아미노산 서열의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열
로부터 선택된 핵산에 의해 인코딩되는 트립토판 신타제 서브유닛 B 폴리펩티드를 포함하고,
여기서 식 (LVIII)을 갖는 실로시빈 유도체 전구체 화합물에서, R2, R4, R5, R6, 또는 R7 중 2개는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 독립적으로 선택된 치환기이며, 여기서 R3은 수소 원자이고, 여기서 R3c가 카르복실기인 식 (I)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물이 형성되고, 실로시빈 생합성 효소 보체는 제1 다중 치환기 실로시빈 유도체 화합물의 R3 -CH2-CHNH2COOH 기를 탈카르복실화시키기 위한 트립토판 데카르복실라제를 추가로 포함하고, 이에 의해 식 (I)을 갖는 제2 다중 치환기 실로시빈 유도체를 형성하며 여기서 R3a 및 R3b 각각은 수소 원자이고, 트립토판 데카르복실라제는
(a) 서열번호: 3, 서열번호: 5, 및 서열번호: 7;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 4, 서열번호: 6, 서열번호: 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 4, 서열번호: 6 및 서열번호: 8에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열
로부터 선택된 핵산 서열에 의해 인코딩되는, 방법. - 제122항에 있어서, 실로시빈 유도체 전구체 화합물은 식 (LXVIII)을 갖는 화학적 화합물이고:
(LXVIII),
여기서 R5는 불소 원자이고, R7은 니트로기 또는 프레닐기이며, 여기서 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXXI)을 가지고:
(LXXI),
여기서 R5는 불소 원자이고, 여기서 R7은 니트로기 원자 또는 프레닐기이며, 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (XIII) 또는 (XXXIII)을 갖는, 방법:
(XIII); 또는 (XXXIII). - 제122항에 있어서, 실로시빈 생합성 효소 보체는 화학식 (I)을 갖는 제2 실로시빈 유도체를 아세틸화하기 위한 N-아세틸 트랜스퍼라제를 추가로 포함하고 이에 의해 화학식 (I)을 갖는 제3 다중 치환기 실로시빈을 형성하며, 여기서 R3a는 수소 원자이고 R3b는 아세틸기고, N-아세틸 트랜스퍼라제는 다음으로부터 선택된 핵산 서열에 의해 인코딩되는, 방법:
(a) 서열번호: 9;
(b) (a)의 핵산 서열과 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열과 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열에 상보성인 핵산 서열;
(e) 서열번호: 10에 제시된 아미노산 서열을 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 10에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열. - 제124항에 있어서, 실로시빈 유도체 전구체 화합물은 식 (LXVIII)을 갖는 화학적 화합물이고:
(LXVIII),
여기서 R5는 불소 원자이고, R7은 니트로기 또는 프레닐기이며, 여기서 제1 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXXI)을 가지고:
(LXXI),
여기서 R5는 불소 원자이고, 여기서 R7은 니트로기 원자 또는 프레닐기이며, 여기서 제2 형성된 다중 치환기 실로시빈 유도체 화합물은 식 (LXXV)을 가지고:
(LXXV),
여기서 R5는 불소 원자이고, 여기서 R7은 니트로기 또는 프레닐기이며, 여기서 제3 다중 치환기 실로시빈 유도체는 식 (XII) 또는 (XXXII)을 갖는, 방법:
(XII); 또는 (XXXII). - 제85항에 있어서, 실로시빈 생합성 효소 보체는
(a) 서열번호: 15, 서열번호: 17, 서열번호: 19, 및 서열번호: 21;
(b) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일한 핵산 서열;
(c) (a)의 핵산 서열 중 어느 하나와 실질적으로 동일하지만 유전자 코드의 변성에 대한 핵산 서열;
(d) (a)의 핵산 서열 중 어느 하나에 상보성인 핵산 서열;
(e) 서열번호: 16, 서열번호: 18, 서열번호: 20, 및 서열번호: 22에 제시된 아미노산 서열 중 어느 하나를 갖는 폴리펩티드를 인코딩하는 핵산 서열;
(f) 서열번호: 16, 서열번호: 18, 서열번호: 20, 및 서열번호: 22에 제시된 아미노산 서열 중 어느 하나의 기능적 변이체를 인코딩하는 핵산 서열; 및
(g) 엄격한 조건 하에서 (a), (b), (c), (d), (e) 또는 (f)에 제시된 핵산 서열 중 어느 하나에 혼성화하는 핵산 서열
로부터 선택된 핵산에 의해 인코딩된 프레닐 트랜스퍼라제를 함유하고,
여기서 식 (LVIII)을 갖는 실로시빈 유도체 전구체 화합물에서, R2, R4, R5, R6, 또는 R7 중 하나는 (i) 할로겐 원자, (ii) 하이드록시기, (iii) 니트로기, (iv) 글리코실옥시기, (v) 아미노기 또는 N-치환된 아미노기, (vi) 카르복실기 또는 카르복실산 유도체, (vii) 알데히드 또는 케톤기, (viii) 프레닐기, 및 (ix) 니트릴기로부터 선택된 치환기이며, 여기서 R3은 수소 원자이고, 여기서 식 (I)을 갖는 제1 다중 치환기 실로시빈 유도체 화합물이 형성되고, 여기서 R3c가 카르복실 기 또는 수소 원자인, 방법. - 제126항에 있어서, 식 (LXXVII)을 갖는 실로시빈 유도체 전구체 화합물:
(LXXVII),
및 제1 다중 치환기 실로시빈 유도체 화합물은 식 (LXXVI)을 갖는, 방법:
(LXXVI). - 제81항 내지 제127항 중 어느 한 항에 있어서, 상기 방법은 숙주 세포 및/또는 숙주 세포 배지로부터 다중 치환기 실로시빈 유도체 화합물을 단리하는 것을 포함하는 단계를 추가로 포함하는, 방법.
- 제81항 내지 제128항 중 어느 한 항에 있어서, 숙주 세포는 미생물인, 방법.
- 제81항 내지 제128항 중 어느 한 항에 있어서, 숙주 세포는 박테리아 세포 또는 효모 세포인, 방법.
- 제81항 내지 제128항 중 어느 한 항에 있어서, 숙주 세포는 대장균 세포 또는 사카로마이세스 세레비시애 세포인, 방법.
- 약학적 또는 기분전환용 약물 제형의 제조에 있어서의 제1항에 따른 화학적 화합물의 용도.
- 제132항에 있어서, 제조는 부형제, 희석제 또는 담체와 화학적 화합물을 제형화하는 것을 포함하는, 화학적 화합물의 용도.
- 약학적 또는 기분전환용 약물 제형으로서 희석제, 담체 또는 부형제와 함께 제1항에 따른 화학적 화합물의 용도.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202163149001P | 2021-02-12 | 2021-02-12 | |
| US63/149,001 | 2021-02-12 | ||
| US202163247881P | 2021-09-24 | 2021-09-24 | |
| US63/247,881 | 2021-09-24 | ||
| PCT/CA2022/050206 WO2022170438A1 (en) | 2021-02-12 | 2022-02-11 | Multi-substituent psilocybin derivatives and methods of using |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20230157342A true KR20230157342A (ko) | 2023-11-16 |
Family
ID=82838865
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237031136A KR20230157342A (ko) | 2021-02-12 | 2022-02-11 | 다중 치환기 실로시빈 유도체 및 사용 방법 |
Country Status (8)
| Country | Link |
|---|---|
| US (2) | US11918594B2 (ko) |
| EP (1) | EP4291549A1 (ko) |
| JP (1) | JP2024506667A (ko) |
| KR (1) | KR20230157342A (ko) |
| AU (1) | AU2022218921A1 (ko) |
| CA (1) | CA3208152A1 (ko) |
| IL (1) | IL305125A (ko) |
| WO (1) | WO2022170438A1 (ko) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2022248635A2 (en) * | 2021-05-27 | 2022-12-01 | Octarine Bio Aps | Methods for producing tryptamine derivatives. |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US3182071A (en) * | 1961-06-27 | 1965-05-04 | Warner Lambert Pharmaceutical | Acylated indole derivatives |
| WO2016134145A2 (en) * | 2015-02-19 | 2016-08-25 | University Of Florida Research Foundation, Inc. | Artificial self-sufficient cytochrome p450s |
| US11591627B2 (en) * | 2018-03-21 | 2023-02-28 | University Of Florida Research Foundation, Incorporated | Modified bacteria for production of nitroaromatics |
| CN114025750A (zh) * | 2019-03-07 | 2022-02-08 | 阿伯门蒂斯有限责任公司 | 包含神经可塑性作用物质的以非迷幻/致幻觉剂量和制剂给药的组合物和使用方法 |
| CA3182156A1 (en) * | 2020-05-08 | 2021-11-11 | Psilera Inc. | Novel compositions of matter and pharmaceutical compositions |
| CN116782896A (zh) * | 2020-09-02 | 2023-09-19 | 恩维瑞克生物科学加拿大公司 | 硝化裸盖菇素衍生物及其用于调节5-ht2a受体和治疗精神障碍的用途 |
| WO2022115944A1 (en) * | 2020-12-01 | 2022-06-09 | Magicmed Industries Inc. | Carboxylated psilocybin derivatives and methods of using |
-
2022
- 2022-02-11 EP EP22752044.2A patent/EP4291549A1/en active Pending
- 2022-02-11 IL IL305125A patent/IL305125A/en unknown
- 2022-02-11 CA CA3208152A patent/CA3208152A1/en active Pending
- 2022-02-11 KR KR1020237031136A patent/KR20230157342A/ko unknown
- 2022-02-11 WO PCT/CA2022/050206 patent/WO2022170438A1/en active Application Filing
- 2022-02-11 JP JP2023548816A patent/JP2024506667A/ja active Pending
- 2022-02-11 AU AU2022218921A patent/AU2022218921A1/en active Pending
- 2022-09-29 US US17/956,139 patent/US11918594B2/en active Active
-
2023
- 2023-12-20 US US18/390,195 patent/US20240122950A1/en active Pending
Also Published As
| Publication number | Publication date |
|---|---|
| AU2022218921A9 (en) | 2024-01-11 |
| JP2024506667A (ja) | 2024-02-14 |
| US20240122950A1 (en) | 2024-04-18 |
| US11918594B2 (en) | 2024-03-05 |
| CA3208152A1 (en) | 2022-08-18 |
| WO2022170438A1 (en) | 2022-08-18 |
| US20230270768A1 (en) | 2023-08-31 |
| AU2022218921A1 (en) | 2023-09-21 |
| IL305125A (en) | 2023-10-01 |
| EP4291549A1 (en) | 2023-12-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| AU2019206054B2 (en) | Production of heterologous polypeptides in microalgae, microalgal extracellular bodies, compositions, and methods of making and uses thereof | |
| KR102092422B1 (ko) | 유전자 조작된 미생물로부터 뮤콘산의 생산 | |
| KR101659101B1 (ko) | 박테리아 [2Fe-2S] 다이하이드록시산 탈수효소의 동정 및 용도 | |
| CN109312360B (zh) | 用于原代细胞的基于转座子的转染系统 | |
| KR20210023833A (ko) | 프로그래밍가능한 염기 편집기 시스템을 이용하여 단일염기다형성을 편집하는 방법 | |
| CN101939434B (zh) | 用于在大豆中提高种子贮藏油脂的生成和改变脂肪酸谱的来自解脂耶氏酵母的dgat基因 | |
| KR20120099509A (ko) | 재조합 숙주 세포에서 육탄당 키나아제의 발현 | |
| KR101447300B1 (ko) | 안트라닐레이트 신타제의 엽록체를 표적으로 하는 발현에 의한 고-트립토판 옥수수의 생산 | |
| CN109563505A (zh) | 用于真核细胞的组装系统 | |
| KR20100118973A (ko) | 이소프렌을 생성하기 위한 조성물 및 방법 | |
| KR20110038087A (ko) | 재생가능 자원으로부터의 이소프렌 중합체 | |
| KR20240005196A (ko) | 유전자 조작된 미생물로부터 개선된 뮤콘산 생산 | |
| KR20210127206A (ko) | 유전성 질환의 치료를 위한 것을 포함하는, 아데노신 데아미나제 염기 편집기를 사용하여 질환-관련 유전자를 편집하는 방법 | |
| DK2623594T3 (da) | Antistof mod human prostaglandin-E2-receptor EP4 | |
| KR20140092759A (ko) | 숙주 세포 및 아이소부탄올의 제조 방법 | |
| KR20110076868A (ko) | 분리 조건 및/또는 안전한 작업 범위 하에서의 c5 탄화수소가 없는 이소프렌의 제조 방법 및 조성물 | |
| KR20140113997A (ko) | 부탄올 생성을 위한 유전자 스위치 | |
| CN101815432A (zh) | 涉及编码核苷二磷酸激酶(ndk)多肽及其同源物的基因的用于修改植物根构造的方法 | |
| KR20120047908A (ko) | 이소프렌 유도체들을 포함하는 연료 조성물들 | |
| KR20110122672A (ko) | 이소프렌 및 공-산물을 제조하는 방법 | |
| CN101627118A (zh) | 由靶向诱变工程化的突变型△8去饱和酶基因及其在制备多不饱和脂肪酸中的用途 | |
| CN110551713A (zh) | 用于修饰梭状芽孢杆菌属细菌的优化的遗传工具 | |
| CN101827938A (zh) | 涉及rt1基因、相关的构建体和方法的具有改变的根构造的植物 | |
| CN113227365A (zh) | 新型乙酰转移酶 | |
| KR20220034212A (ko) | 재조합으로 변형된 아데노 연관 바이러스 헬퍼 벡터 및 재조합으로 변형된 아데노 연관 바이러스의 패키징 효율을 개선하기 위한 그의 용도 |