KR20230031280A - 노화 관련 장애의 치료 방법 - Google Patents
노화 관련 장애의 치료 방법 Download PDFInfo
- Publication number
- KR20230031280A KR20230031280A KR1020237000057A KR20237000057A KR20230031280A KR 20230031280 A KR20230031280 A KR 20230031280A KR 1020237000057 A KR1020237000057 A KR 1020237000057A KR 20237000057 A KR20237000057 A KR 20237000057A KR 20230031280 A KR20230031280 A KR 20230031280A
- Authority
- KR
- South Korea
- Prior art keywords
- target
- soluble
- domain
- binding domain
- tgf
- Prior art date
Links
Images





















































































































































































































































































































































Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
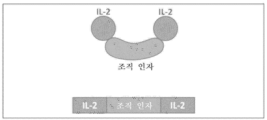
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/177—Receptors; Cell surface antigens; Cell surface determinants
- A61K38/179—Receptors; Cell surface antigens; Cell surface determinants for growth factors; for growth regulators
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/177—Receptors; Cell surface antigens; Cell surface determinants
- A61K38/1793—Receptors; Cell surface antigens; Cell surface determinants for cytokines; for lymphokines; for interferons
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/19—Cytokines; Lymphokines; Interferons
- A61K38/20—Interleukins [IL]
- A61K38/2086—IL-13 to IL-16
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
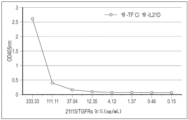
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/36—Blood coagulation or fibrinolysis factors
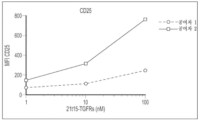
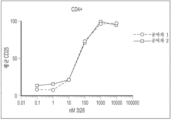
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P29/00—Non-central analgesic, antipyretic or antiinflammatory agents, e.g. antirheumatic agents; Non-steroidal antiinflammatory drugs [NSAID]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P39/00—General protective or antinoxious agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K2300/00—Mixtures or combinations of active ingredients, wherein at least one active ingredient is fully defined in groups A61K31/00 - A61K41/00
Abstract
노쇠 세포의 사멸 또는 수의 감소를 필요로 하는 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포 및 유병(diseased) 세포를 사멸시키거나 수를 감소시키는 방법, 저하를 필요로 하는 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포 및 유병 세포의 축적을 저하시키는 방법이 본원에 제공되며, 대상체에게 TGF-β 수용체의 활성화의 저하를 초래하는 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들) 및/또는 하나 이상의 제제(들)를 투여하는 단계를 포함한다.
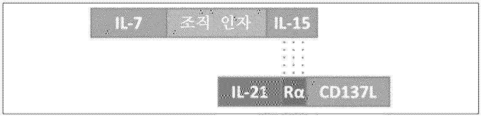
Description
관련 출원의 교차 참조
본 출원은 2020년 6월 1일에 출원된 미국 임시 특허 출원 일련 번호 제63/032,933호, 2020년 6월 1일에 출원된 국제 특허 출원 PCT/US2020/035598호, 및 2020년 11월 25일에 출원된 미국 임시 특허 출원 일련 번호 제63/118,536호에 대해 우선권을 주장하고, 이들은 그 전문이 본원에 인용되어 포함된다.
기술분야
본 개시내용은 면역학 및 세포생물학 분야에 관한 것이다.
노쇠는 표현형 변화, 세포자멸사에 대한 저항성, 및 손상-감지 신호화 경로의 활성화에 의해 동반되는 비가역적인 성장 억제 형태이다. 이의 증식 능력을 소실하여 약 50개 집단 배가(Hayflick 한계라고 칭함) 후 영구적인 정지에 도달하는 배양된 인간 섬유아세포 세포에서 세포 노쇠가 처음에 기재되었다. 노쇠는 산화적 및 유전자독성(genotoxic) 스트레스, DNA 손상, 텔로미어 마모(attrition), 종양원성(oncogenic) 활성화, 미토콘드리아 기능장애, 또는 화학요법제를 포함하여 광범위한 내인성 공격(insult) 및 외인성 공격에 의해 유도될 수 있는 스트레스 반응으로 간주된다.
노쇠 세포는 대사적으로 활성적으로 남아 있고, 이들 세포의 분비 표현형을 통해 조직 항상성, 질환, 및 노화에 영향을 미칠 수 있다. 노쇠는 생리학적 과정으로서 간주되고, 상처 치유, 조직 항상성, 재생, 및 섬유증의 조절을 촉진하는 데 중요하다. 예를 들어, 노쇠 세포의 일시적인 유도는 상처 치유 동안 관찰되고, 상처 해소(resolution)에 기여한다. 노쇠는 또한 종양 억제에서 역할을 한다. 노쇠 세포의 축적은 또한, 나이- 및 노화-관련 질환 및 병태를 유발한다. 노화 표현형은 또한, 만성 염증 반응을 촉발하고 결과적으로 만성 염증 병태를 악화시켜(augment) 종양 성장을 촉진할 수 있다. 노쇠와 노화(aging) 사이의 연관성은 처음에, 노쇠 세포가 노화 조직에서 축적된다는 관찰에 기초하였다. 유전자이식(trasngenic) 모델의 사용은 많은 노화-관련 장애에서 노쇠 세포를 전신적으로 검출할 수 있게 하였다. 노쇠 세포를 선택적으로 제거하기 위한 전략은, 노쇠 세포가 노화-관련 장애에서 인과 관계 역할을 한다는 것을 실증하였다.
세포 노쇠는 초기 성장 억제 후 획득되는 일련의 점진적이고 표현형적으로 다양한 세포 상태이다(문헌[van Deursen, Nature 509(7501):439-446, 2014]) 그러므로, 노쇠 세포는 몇몇 공유된 핵심 특성을 갖는 세포의 불균질한 집단이다(문헌[Dou et al., Nature 550(7676):402-406, 2017]). 따라서, 공통의 노쇠용해(senolytic) 약물 표적을 식별하는 것은 어렵다. 이는 추가로, 전신 투여 시 노쇠 세포를 선택적으로, 안전하게, 그리고 효과적으로 제거하는 노쇠용해제(senolytics)를 개발하는 목표의 달성을 방해한다. 위에 기재된 바와 같이, 면역 세포는 노쇠-세포 생리학적 역할의 이행 후 노쇠 세포를 천연적으로 제거하기 위한 이펙터 세포이다(문헌[Brighton et al., Elife 6, 2017]) 노화 과정 동안 면역계의 약화는 노쇠 세포의 축적을 가능하게 한다(문헌[Karin et al., Nat. Comm. 10(1):5495, 2019]; 문헌[Chambers et al., J. Allergy Clin. Immunol. 145(5):1323-1331, 2020]).
본 발명은 포유류에의 TGF-β 수용체의 활성화의 저하를 초래하는 제제 또는 공통 감마-사슬 계열 사이토카인 수용체 활성화제(예를 들어, 감마-사슬 사이토카인과 이의 동족 수용체(cognate receptor)의 복합체)의 피하 투여가, 생체내에서 노쇠 세포를 효과적으로, 선택적으로, 그리고 안전하게 감소시키는 면역 세포의 역량을 재획득하도록 상기 면역 세포를 촉진하고 활성화시킨다는 발견에 기초한다. 이러한 발견의 관점에서, 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포를 사멸시키거나 이의 수를 감소시키는 방법이 본원에 제공되며, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다. 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 축적을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다. 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 마커의 수준을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다. 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 활성을 감소시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다. 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포로부터 유래된 하나 이상의 노쇠 관련 분비 표현형("SASP": senescence associated secretory phenotype) 인자(들)의 수준 및/또는 활성을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다.
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포를 사멸시키고 이의 수를 감소시키는 방법(및 노쇠 세포의 축적을 저하시키거나 마커를 감소시키는 방법)이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)(예를 들어, 감마-사슬 사이토카인과 이의 동족 수용체의 복합체)를 투여하는 단계를 포함한다. 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 활성을 감소시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함한다. 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포로부터 유래된 하나 이상의 SASP 인자(들)의 수준 및/또는 활성을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함한다.
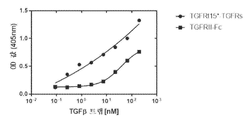
본 발명은 또한, 암을 갖는 포유류에의 NK 세포 활성화제의 투여가 종양 저해를 초래하였고 당뇨병 동물 모델에의 NK 세포 활성화제의 투여가 향상된 피부 및 모발 외양과 질감, 및 저하된 혈당 수준을 실증하였다는 발견에 기초한다. 이러한 발견의 관점에서, 치료를 필요로 하는 대상체에서 노화-관련 질환 또는 병태를 치료하는 방법이 본원에 제공되며, 노화-관련 질환 또는 병태를 갖는 것으로 식별된 대상체에게 치료적 유효량의 하나 이상의 자연 살해(NK) 세포 활성화제(들) 및/또는 치료적 유효수의 활성화된 NK 세포를 투여하는 단계를 포함한다. 노쇠 세포의 사멸 또는 수의 감소를 필요로 하는 대상체에서 노쇠 세포를 사멸시키거나 이의 수를 감소시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 NK 세포 활성화제(들) 및/또는 치료적 유효수의 활성화된 NK 세포를 투여하는 단계를 포함한다. 기간에 걸쳐 향상을 필요로 하는 대상체에서 피부 및/또는 모발의 질감 및/또는 외양을 향상시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 자연 살해(NK) 세포 활성화제(들) 및/또는 치료적 유효수의 활성화된 NK 세포를 투여하는 단계를 포함한다. 기간에 걸쳐 보조를 필요로 하는 대상체에서 비만 치료를 보조하는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 자연 살해(NK) 세포 활성화제(들) 및/또는 치료적 유효수의 활성화된 NK 세포를 투여하는 단계를 포함한다.
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포를 사멸시키거나 이의 수를 감소시키는 방법이 본원에 제공되며, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다.
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 축적을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다.
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 마커의 수준을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다.
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 활성을 감소시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다.
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포로부터 유래된 하나 이상의 SASP 인자(들)의 수준 및/또는 활성을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 대상체는 노화-관련 질환 또는 염증성 질환을 갖는 것으로 이전에 진단되거나 식별되었다. 본원에 기재된 임의의 방법의 일부 구현예에서, 노화-관련 질환은 염증-노화와 관련이 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 노화-관련 질환은 알츠하이머 질환, 동맥류, 낭성 섬유증, 췌장염에서의 섬유증, 녹내장, 고혈압, 염증성 장 질환, 추간판 퇴행, 골관절염, 2형 진성 당뇨병, 지방세포 위축, 지방이영양증, 죽상동맥경화증, 백내장, COPD, 특발성 폐 섬유증, 신장 이식 실패, 간 섬유증, 골질량 손실, 심근 경색, 사르코페니아, 상처 치유, 탈모증, 심근세포 비대, 골관절염, 파킨슨 질환, 연령-연관 폐 조직 탄성 손실, 연령-관련 황반 변성, 악액질, 사구체경화증, 간 경변증, NAFLD, 골다공증, 근위축성 측삭 경화증, 헌팅턴 질환, 척수소뇌 실조증, 다발성 경화증, 신경퇴행, 뇌졸중, 암, 치매, 혈관 질환, 감염 감수성, 만성 염증, 및 신장 기능장애의 군으로부터 선택된다. 본원에 기재된 임의의 방법의 일부 구현예에서, 노화-관련 질환은 하기로 이루어진 군으로부터 선택되는 암이다: 고형 종양, 혈액학적 종양, 육종, 골육종, 교모세포종, 신경모세포종, 흑색종, 횡문근육종, 유잉 육종, 골육종, B-세포 신생물, 다발성 골수종, B-세포 림프종, B-세포 비-호지킨 림프종, 호지킨 림프종, 만성 림프구성 백혈병(CLL), 급성 골수성 백혈병(AML), 만성 골수성 백혈병(CML), 급성 림프구성 백혈병(ALL), 골수이형성 증후군(MDS), 피부 T-세포 림프종, 망막모세포종, 위암, 요로상피세포암종, 폐암, 신세포 암종, 위 및 식도 암, 췌장암, 전립선암, 유방암, 결장직장암, 난소암, 비-소세포 폐 암종, 편평 세포 두경부 암종, 자궁내막암, 자궁경부암, 간암, 및 간세포 암종. 본원에 기재된 임의의 방법의 일부 구현예에서, 염증성 질환은 류마티스 관절염, 염증성 장 질환, 홍반성 루푸스, 루푸스 신염, 당뇨병성 신증, CNS 손상, 알츠하이머 질환, 파킨슨 질환, 근위축성 측삭 경화증, 크론 질환, 다발성 경화증, 길랑-바레 증후군, 건선, 그레이브스 질환, 궤양성 대장염, 비알코올성 지방간염, 기분 장애 및 암 치료-관련 인지 장애의 군으로부터 선택된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 치료-유도 노쇠 세포는 화학요법-유도 노쇠 세포이다. 본원에 기재된 임의의 방법의 일부 구현예에서, TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)의 투여는 대상체의 표적 조직에서 천연-발생 노쇠 세포 및/또는 치료-유도 노쇠 세포의 수 또는 활성의 저하를 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 표적 조직은 지방 조직, 췌장 조직, 간 조직, 신장 조직, 폐 조직, 심장 조직, 혈관 구조, 뼈 조직, 중추신경계(CNS) 조직, 안구 조직, 피부 조직, 근육 조직, 및 2차 림프-기관 조직의 군으로부터 선택된다.
본원에 기재된 임의의 방법의 일부 구현예에서, TGFβ 수용체는 TGF-β 수용체 II(TGFβRII)이다. 본원에 기재된 임의의 방법의 일부 구현예에서, TGFβ 수용체는 TGFβRIII이다.
본원에 기재된 임의의 방법의 일부 구현예에서, TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들) 중 적어도 하나는 가용성 TGF-β 수용체, TGF-β 수용체의 세포외 도메인, TGF-β에 특이적으로 결합하는 항체, TGF-β 수용체에 결합하는 길항제성 항체, 잠복기-관련 펩타이드("LAP": latency-associated peptide)에 결합하는 제제, 또는 TGF-β/LAP 복합체에 결합하는 제제이다. 본원에 기재된 임의의 방법의 일부 구현예에서, TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)는 LAP에의 또는 TGF-β/LAP 복합체에의 결합을 통해 TGF-β 수용체의 활성화를 저하시킨다.
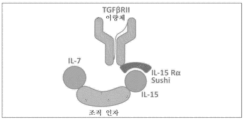
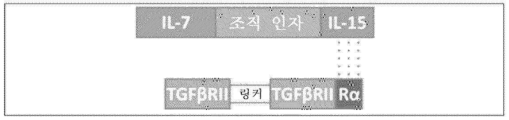
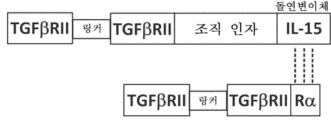
본원에 기재된 임의의 방법의 일부 구현예에서, TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들) 중 적어도 하나는 (a) (i) 제1 표적-결합 도메인; (ii) 가용성 조직 인자 도메인; 및 (iii) 친화도 도메인 쌍의 제1 도메인을 포함하는 제1 키메라 폴리펩타이드; (b) (i) 친화도 도메인 쌍의 제2 도메인; 및 (ii) 제2 표적-결합 도메인을 포함하는 제2 키메라 폴리펩타이드를 포함하는 다중-사슬 키메라 폴리펩타이드이며, 상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 TGF-β 수용체의 리간드에 특이적으로 결합하거나; 상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 TGF-β 수용체에 특이적으로 결합하는 길항제성 항원-결합 도메인이다. 본원에 기재된 임의의 방법의 일부 구현예에서, TGF-β 수용체는 TGFβRII이다. 본원에 기재된 임의의 방법의 일부 구현예에서, TGF-β 수용체는 TGFβRIII이다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인과 가용성 조직 인자 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함한다.
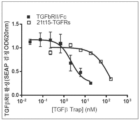
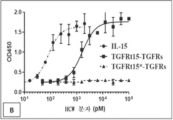
본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함한다.
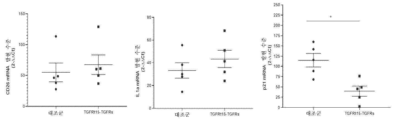
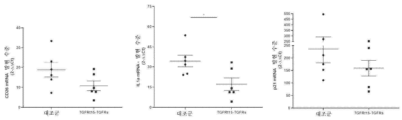
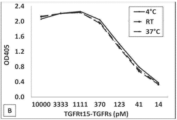
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 항원에 특이적으로 결합한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 상이한 항원에 특이적으로 결합한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 키메라 폴리펩타이드는 하나 이상의 추가 표적-결합 도메인(들)을 추가로 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제2 키메라 폴리펩타이드는 하나 이상의 추가 표적-결합 도메인(들)을 추가로 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 조직 인자 도메인은 가용성 인간 조직 인자 도메인이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 80% 동일한 서열을 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 친화도 도메인 쌍은 인간 IL-15 수용체의 알파 사슬(IL15Rα) 및 가용성 IL-15로부터의 sushi 도메인이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 IL-15는 D8N 또는 D8A 아미노산 치환을 갖는다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 IL-15는 IL-15 활성을 감소시키거나 제거하기 위한 돌연변이를 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 친화도 도메인 쌍은 바르나제(barnase)와 바른스타(barnstar), PKA와 AKAP, 돌연변이화된 RNase I 단편에 기초한 어댑터/도킹 태그 모듈, 및 단백질 신택신(syntaxin), 시냅토태그민(synaptotagmin), 시냅토브레빈(synaptobrevin), 및 SNAP25의 상호작용에 기초한 SNARE 모듈의 군으로부터 선택된다. 본원에 기재된 임의의 방법의 일부 구현예에서, 친화도 도메인 쌍의 제1 도메인 또는 제2 도메인은 공통 감마-사슬 계열 사이토카인 수용체에 특이적으로 결합하는 가용성 공통 감마-사슬 계열 사이토카인 또는 항원-결합 도메인이다.
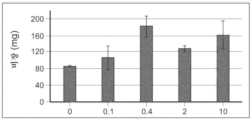
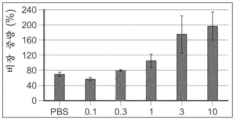
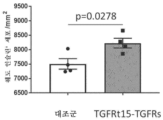
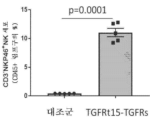
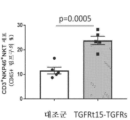
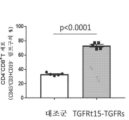
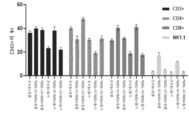
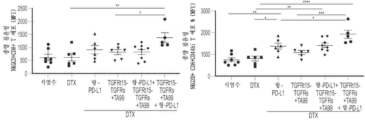
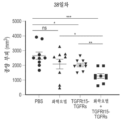
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및/또는 제2 표적-결합 도메인은 가용성 TGF-β 수용체를 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 TGF-β 수용체는 가용성 TGFβRII이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 TGFβRII는 SEQ ID NO: 183과 적어도 80% 동일한 제1 서열, 및 SEQ ID NO: 183과 적어도 80% 동일한 제2 서열을 포함하고, 상기 제1 서열과 제2 서열은 링커에 의해 분리된다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 TGFβRII는 SEQ ID NO: 183과 적어도 90% 동일한 제1 서열, 및 SEQ ID NO: 183과 적어도 90% 동일한 제2 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 TGFβRII는 SEQ ID NO: 183의 제1 서열, 및 SEQ ID NO: 183의 제2 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 링커는 SEQ ID NO: 102의 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 TGFβRII는 SEQ ID NO: 188과 적어도 80% 동일한 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 TGFβRII는 SEQ ID NO: 188과 적어도 90% 동일한 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 TGF-βRII는 SEQ ID NO: 188의 서열을 포함한다.
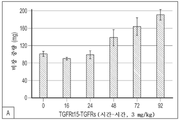
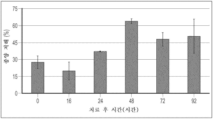
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 80% 동일한 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 90% 동일한 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 키메라 폴리펩타이드는 SEQ ID NO: 236의 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제2 키메라 폴리펩타이드는 SEQ ID NO: 193과 적어도 80% 동일한 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 80% 동일한 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제2 키메라 폴리펩타이드는 SEQ ID NO: 193과 적어도 90% 동일한 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제2 키메라 폴리펩타이드는 SEQ ID NO: 193의 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 키메라 폴리펩타이드는 SEQ ID NO: 236의 서열을 포함한다.
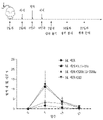
본원에 기재된 임의의 방법의 일부 구현예에서, TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들) 중 적어도 하나는 (i) 제1 표적-결합 도메인; (ii) 가용성 조직 인자 도메인; 및 (iii) 제2 표적-결합 도메인을 포함하는 단일-사슬 키메라 폴리펩타이드이며, 상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 TGF-β 수용체의 리간드에 특이적으로 결합하거나; 상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 TGF-β 수용체에 특이적으로 결합하는 길항제성 항원-결합 도메인이다. 본원에 기재된 임의의 방법의 일부 구현예에서, TGF-β 수용체는 TGF-βRII이다. 본원에 기재된 임의의 방법의 일부 구현예에서, TGF-β 수용체는 TGFβRIII이다.
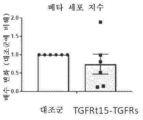
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인과 가용성 조직 인자 도메인은 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 조직 인자 도메인과 제2 표적-결합 도메인은 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 가용성 조직 인자 도메인과 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함한다.
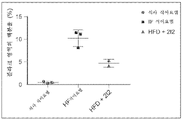
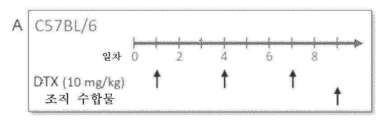
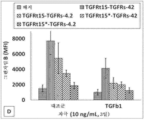
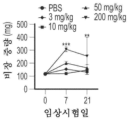
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 항원에 특이적으로 결합한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 상이한 항원에 특이적으로 결합한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 조직 인자 도메인은 가용성 인간 조직 인자 도메인이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 80% 동일한 서열을 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 이의 N-말단 및/또는 C-말단에 하나 이상의 추가 표적-결합 도메인을 추가로 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및/또는 제2 표적-결합 도메인은 가용성 TGF-β 수용체를 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 TGF-β 수용체는 가용성 TGF-βRII이다.
본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 TGF-βRII는 SEQ ID NO: 183과 적어도 80% 동일한 제1 서열, 및 SEQ ID NO: 183과 적어도 80% 동일한 제2 서열을 포함하고, 상기 제1 서열과 제2 서열은 링커에 의해 분리된다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 TGFβRII는 SEQ ID NO: 183과 적어도 90% 동일한 제1 서열, 및 SEQ ID NO: 183과 적어도 90% 동일한 제2 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 TGFβRII는 SEQ ID NO: 183의 제1 서열, 및 SEQ ID NO: 183의 제2 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 링커는 SEQ ID NO: 102의 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 TGFβRII는 SEQ ID NO: 188과 적어도 80% 동일한 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 TGFβRII는 SEQ ID NO: 188과 적어도 90% 동일한 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 TGFβRII는 SEQ ID NO: 188의 서열을 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 대상체에게 2개 이상의 용량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 2개 이상의 용량 중 임의의 2개의 연속 용량은 약 1주 내지 약 1년의 간격을 두고 투여된다. 본원에 기재된 임의의 방법의 일부 구현예에서, 2개 이상의 용량 중 임의의 2개의 연속 용량은 약 1주 내지 약 6개월의 간격을 두고 투여된다. 본원에 기재된 임의의 방법의 일부 구현예에서, 2개 이상의 용량 중 임의의 2개의 연속 용량은 약 1주 내지 약 2개월의 간격을 두고 투여된다. 본원에 기재된 임의의 방법의 일부 구현예에서, 2개 이상의 용량 중 임의의 2개의 연속 용량은 약 1주 내지 약 1개월의 간격을 두고 투여된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 2개 이상의 용량은 피하 투여에 의해 투여된다. 본원에 기재된 임의의 방법의 일부 구현예에서, 2개 이상의 용량은 근육내 투여에 의해 투여된다.
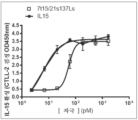
본원에 기재된 임의의 방법의 일부 구현예에서, 2개 이상의 용량은 약 1년 내지 약 60년의 기간에 걸쳐 투여된다. 본원에 기재된 임의의 방법의 일부 구현예에서, 2개 이상의 용량은 약 1년 내지 약 50년의 기간에 걸쳐 투여된다. 본원에 기재된 임의의 방법의 일부 구현예에서, 2개 이상의 용량은 약 1년 내지 약 40년의 기간에 걸쳐 투여된다. 본원에 기재된 임의의 방법의 일부 구현예에서, 2개 이상의 용량은 약 1년 내지 약 30년의 기간에 걸쳐 투여된다. 본원에 기재된 임의의 방법의 일부 구현예에서, 2개 이상의 용량은 약 1년 내지 약 20년의 기간에 걸쳐 투여된다. 본원에 기재된 임의의 방법의 일부 구현예에서, 2개 이상의 용량은 약 1년 내지 약 10년의 기간에 걸쳐 투여된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 용량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)는 대상체가 적어도 30세의 연령에 도달할 때 시작한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 용량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)는 대상체가 적어도 40세의 연령에 도달할 때 시작한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 용량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)는 대상체가 적어도 50세의 연령에 도달할 때 시작한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 용량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)는 대상체가 적어도 60세의 연령에 도달할 때 시작한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 2개 이상의 용량은 각각 kg당 약 0.01 mg의 TGF-β 수용체의 활성화의 저하를 초래하는 각각의 제제 내지 kg당 약 10 mg의 TGF-β 수용체의 활성화의 저하를 초래하는 각각의 제제의 투여량으로 투여된다. 본원에 기재된 임의의 방법의 일부 구현예에서, 2개 이상의 용량은 각각 kg당 약 0.02 mg의 TGF-β 수용체의 활성화의 저하를 초래하는 각각의 제제 내지 kg당 약 5 mg의 TGF-β 수용체의 활성화의 저하를 초래하는 각각의 제제의 투여량으로 투여된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 대상체는 노화-관련 질환 또는 염증성 질환을 갖는 것으로 진단되거나 식별되지 않는다. 본원에 기재된 임의의 방법의 일부 구현예에서, 대상체는 이전에 화학요법제로 치료된 적이 없다. 본원에 기재된 임의의 방법의 일부 구현예에서, 대상체는 이전에 세포 노쇠를 유도하는 치료제로 치료된 적이 없다.
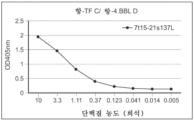
치료를 필요로 하는 대상체에서 노화-관련 질환 또는 병태를 치료하는 방법이 본원에 제공되며, 노화-관련 질환 또는 병태를 갖는 것으로 식별된 대상체에게 치료적 유효량의 하나 이상의 자연 살해(NK) 세포 활성화제(들)를 투여하는 단계를 포함한다.
노쇠 세포의 사멸 또는 수의 감소를 필요로 하는 대상체에서 노쇠 세포를 사멸시키거나 이의 수를 감소시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 NK 세포 활성화제(들)를 투여하는 단계를 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 노쇠 세포는 노쇠 암세포, 노쇠 단핵구, 노쇠 림프구, 노쇠 성상세포, 노쇠 소교세포, 노쇠 뉴런, 노쇠 조직 섬유아세포, 노쇠 피부 섬유아세포, 노쇠 케라틴세포, 또는 다른 분화된 조직-특이적 분열 기능 세포이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 노쇠 암세포는 화학요법-유도 노쇠 세포 또는 방사선-유도 노쇠 세포이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 대상체는 노화-관련 질환 또는 병태를 갖는 것으로 식별되거나 진단되었다.
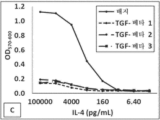
본원에 기재된 임의의 방법의 일부 구현예에서, 노화-관련 질환 또는 병태는 암, 자가면역 질환, 대사 질환, 신경퇴행성 질환, 심혈관 질환, 피부 질환, 조로증 질환, 및 유약 질환(fragility disease)의 군으로부터 선택된다. 본원에 기재된 임의의 방법의 일부 구현예에서, 암은 고형 종양, 혈액학적 종양, 육종, 골육종, 교모세포종, 신경모세포종, 흑색종, 횡문근육종, 유잉 육종, 골육종, B-세포 신생물, 다발성 골수종, B-세포 림프종, B-세포 비-호지킨 림프종, 호지킨 림프종, 만성 림프구성 백혈병(CLL), 급성 골수성 백혈병(AML), 만성 골수성 백혈병(CML), 급성 림프구성 백혈병(ALL), 골수이형성 증후군(MDS), 피부 T-세포 림프종, 망막모세포종, 위암, 요로상피세포암종, 폐암, 신세포 암종, 위 및 식도 암, 췌장암, 전립선암, 유방암, 결장직장암, 난소암, 비-소세포 폐 암종, 편평 세포 두경부 암종, 자궁내막암, 자궁경부암, 간암, 및 간세포 암종의 군으로부터 선택된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 자가면역 질환은 1형 당뇨병이다.
본원에 기재된 임의의 방법의 일부 구현예에서, 대사 질환은 비만, 지방이영양증, 및 2형 진성 당뇨병의 군으로부터 선택된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 신경퇴행성 질환은 알츠하이머 질환, 파킨슨 질환, 및 치매의 군으로부터 선택된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 심혈관 질환은 관상 동맥 질환, 죽상동맥경화증, 및 폐동맥 고혈압의 군으로부터 선택된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 피부 질환은 상처 치유, 탈모증, 주름, 노인성 흑점, 피부 얇아짐, 색소성 건피증, 및 선천성 각화이상증의 군으로부터 선택된다.
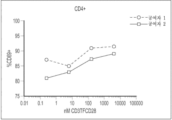
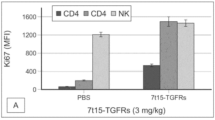
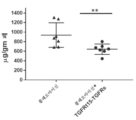
본원에 기재된 임의의 방법의 일부 구현예에서, 조로증 질환은 조로증 및 허친슨-길포트 조로증 증후군(Hutchinson-Gilford Progeria Syndrome)의 군으로부터 선택된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 유약 질환은 유약, 백신화에 대한 민감도, 골다공증, 및 사르코페니아의 군으로부터 선택된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 노화-관련 질환 또는 병태는 골관절염, 지방세포 위축, 특발성 폐 섬유증, 신장 이식 실패, 간 섬유증, 골질량 손실, 사르코페니아, 연령-연관 폐 조직 탄성 손실, 골다공증, 노화-연관 신장 기능장애, 및 화학-유도 신장 기능장애의 군으로부터 선택된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 노화-관련 질환 또는 병태는 2형 당뇨병 또는 죽상동맥경화증이다.
본원에 기재된 임의의 방법의 일부 구현예에서, 투여는 대상체에서 표적 조직 내 노쇠 세포의 수의 저하를 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 표적 조직은 지방 조직, 췌장 조직, 간 조직, 폐 조직, 혈관 구조, 뼈 조직, 중추신경계(CNS) 조직, 안구 조직, 피부 조직, 근육 조직, 및 2차 림프-기관 조직의 군으로부터 선택된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 투여는 활성화된 NK 세포에서 CD25, CD69, mTORC1, SREBP1, IFN-γ, 및 그랜자임 B의 발현 수준의 증가를 초래한다.
치료를 필요로 하는 대상체에서 노화-관련 질환 또는 병태를 치료하는 방법이 또한 본원에 제공되며, 노화-관련 질환 또는 병태를 갖는 것으로 식별된 대상체에게 치료적 유효수의 활성화된 NK 세포를 투여하는 단계를 포함한다.
노쇠 세포의 사멸 또는 수의 감소를 필요로 하는 대상체에서 노쇠 세포를 사멸시키거나 이의 수를 감소시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효수의 활성화된 NK 세포를 투여하는 단계를 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 노쇠 세포는 노쇠 암세포, 노쇠 단핵구, 노쇠 림프구, 노쇠 성상세포, 노쇠 소교세포, 노쇠 뉴런, 노쇠 조직 섬유아세포, 노쇠 피부 섬유아세포, 노쇠 케라틴세포, 또는 다른 분화된 조직-특이적 분열 기능 세포이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 노쇠 암세포는 화학요법-유도 노쇠 세포 또는 방사선-유도 노쇠 세포이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 대상체는 노화-관련 질환 또는 병태를 갖는 것으로 식별되거나 진단되었다.
본원에 기재된 임의의 방법의 일부 구현예에서, 노화-관련 질환 또는 병태는 암, 자가면역 질환, 대사 질환, 신경퇴행성 질환, 심혈관 질환, 피부 질환, 조로증 질환, 및 유약 질환의 군으로부터 선택된다. 본원에 기재된 임의의 방법의 일부 구현예에서, 암은 고형 종양, 혈액학적 종양, 육종, 골육종, 교모세포종, 신경모세포종, 흑색종, 횡문근육종, 유잉 육종, 골육종, B-세포 신생물, 다발성 골수종, B-세포 림프종, B-세포 비-호지킨 림프종, 호지킨 림프종, 만성 림프구성 백혈병(CLL), 급성 골수성 백혈병(AML), 만성 골수성 백혈병(CML), 급성 림프구성 백혈병(ALL), 골수이형성 증후군(MDS), 피부 T-세포 림프종, 망막모세포종, 위암, 요로상피세포암종, 폐암, 신세포 암종, 위 및 식도 암, 췌장암, 전립선암, 유방암, 결장직장암, 난소암, 비-소세포 폐 암종, 편평 세포 두경부 암종, 자궁내막암, 자궁경부암, 간암, 및 간세포 암종의 군으로부터 선택된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 자가면역 질환은 1형 당뇨병이다.
본원에 기재된 임의의 방법의 일부 구현예에서, 대사 질환은 비만, 지방이영양증, 및 2형 진성 당뇨병의 군으로부터 선택된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 신경퇴행성 질환은 알츠하이머 질환, 파킨슨 질환, 및 치매의 군으로부터 선택된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 심혈관 질환은 관상 동맥 질환, 죽상동맥경화증, 및 폐동맥 고혈압의 군으로부터 선택된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 피부 질환은 상처 치유, 탈모증, 주름, 노인성 흑점, 피부 얇아짐, 색소성 건피증, 및 선천성 각화이상증의 군으로부터 선택된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 조로증 질환은 조로증 및 허친슨-길포트 조로증 증후군의 군으로부터 선택된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 유약 질환은 유약, 백신화에 대한 민감도, 골다공증, 및 사르코페니아의 군으로부터 선택된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 노화-관련 질환 또는 병태는 노화-관련 황반 변성, 골관절염, 지방세포 위축, 특발성 폐 섬유증, 신장 이식 실패, 간 섬유증, 골질량 손실, 사르코페니아, 연령-연관 폐 조직 탄성 손실, 골다공증, 노화-연관 신장 기능장애, 및 화학-유도 신장 기능장애의 군으로부터 선택된다.
본원에 기재된 임의의 방법의 일부 구현예는 휴지기(resting) NK 세포를 수득하는 단계; 및 상기 휴지기 NK 세포를 시험관내에서 하나 이상의 NK 세포 활성화제(들)를 포함하는 액체 배양 배지에서 접촉시키는 단계를 추가로 포함하며, 상기 접촉은 후속적으로 대상체에게 투여되는 활성화된 NK 세포의 생성을 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 휴지기 NK 세포는 대상체로부터 수득된 자가(autologous) NK 세포이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 휴지기 NK 세포는 동종이계(allogeneic) 휴지기 NK 세포이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 휴지기 NK 세포는 인공 NK 세포이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 휴지기 NK 세포는 반일치(haploidentical) 휴지기 NK 세포이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 휴지기 NK 세포는 키메라 항원 수용체 또는 재조합 T 세포 수용체를 갖고 있는 유전자-조작된 NK 세포이다. 본원에 기재된 임의의 방법의 일부 구현예는 활성화된 NK 세포가 대상체에게 투여되기 전에 상기 활성화된 NK 세포를 단리하는 단계를 추가로 포함한다. 본원에 기재된 임의의 방법의 일부 구현예는 키메라 항원 수용체 또는 재조합 T 세포 수용체를 인코딩하는 핵산을 휴지기 NK 세포 또는 활성화된 NK 세포 내로 도입한 후 대상체에게 투여하는 단계를 추가로 포함한다.
기간에 걸쳐 향상을 필요로 하는 대상체에서 피부 및/또는 모발의 질감 및/또는 외양을 향상시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 자연 살해(NK) 세포 활성화제(들)를 투여하는 단계를 포함한다.
기간에 걸쳐 향상을 필요로 하는 대상체에서 피부 및/또는 모발의 질감 및/또는 외양을 향상시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효수의 활성화된 NK 세포를 투여하는 단계를 포함한다. 본원에 기재된 임의의 방법의 일부 구현예는 휴지기 NK 세포를 수득하는 단계; 및 상기 휴지기 NK 세포를 시험관내에서 하나 이상의 NK 세포 활성화제(들)를 포함하는 액체 배양 배지에서 접촉시키는 단계를 추가로 포함하며, 상기 접촉은 후속적으로 대상체에게 투여되는 활성화된 NK 세포의 생성을 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 휴지기 NK 세포는 대상체로부터 수득된 자가 NK 세포이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 휴지기 NK 세포는 동종이계 휴지기 NK 세포이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 휴지기 NK 세포는 인공 NK 세포이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 휴지기 NK 세포는 반일치 휴지기 NK 세포이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 휴지기 NK 세포는 키메라 항원 수용체 또는 재조합 T 세포 수용체를 갖고 있는 유전자-조작된 NK 세포이다. 본원에 기재된 임의의 방법의 일부 구현예는 활성화된 NK 세포가 대상체에게 투여되기 전에 상기 활성화된 NK 세포를 단리하는 단계를 추가로 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 기간에 걸쳐 대상체의 피부의 질감 및/또는 외양의 향상을 제공한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 기간에 걸쳐 대상체의 피부에서 주름 형성 속도의 저하를 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 기간에 걸쳐 대상체의 피부의 착색의 향상을 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 기간에 걸쳐 대상체의 피부 상에서 검버섯의 감소를 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 기간에 걸쳐 대상체의 피부의 질감의 향상을 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 기간에 걸쳐 대상체의 모발의 질감 및/또는 외양의 향상을 제공한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 기간에 걸쳐 대상체에서 흰머리 형성 속도의 저하를 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 기간에 걸쳐 대상체에서 흰머리 수의 저하를 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 기간에 걸쳐 대상체에서 모발 손실 속도의 저하를 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 기간에 걸쳐 대상체의 모발의 질감의 향상을 초래한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 기간은 약 1개월 내지 약 10년이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 기간에 걸쳐 대상체의 피부에서 노쇠 피부 섬유아세포 수의 저하를 초래한다.
기간에 걸쳐 보조를 필요로 하는 대상체에서 비만 치료를 보조하는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 자연 살해(NK) 세포 활성화제(들)를 투여하는 단계를 포함한다.
기간에 걸쳐 보조를 필요로 하는 대상체에서 비만 치료를 보조하는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효수의 활성화된 NK 세포를 투여하는 단계를 포함한다. 본원에 기재된 임의의 방법의 일부 구현예는 휴지기 NK 세포를 수득하는 단계; 및 상기 휴지기 NK 세포를 시험관내에서 하나 이상의 NK 세포 활성화제(들)를 포함하는 액체 배양 배지에서 접촉시키는 단계를 추가로 포함하며, 상기 접촉은 후속적으로 대상체에게 투여되는 활성화된 NK 세포의 생성을 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 휴지기 NK 세포는 대상체로부터 수득된 자가 NK 세포이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 휴지기 NK 세포는 동종이계 휴지기 NK 세포이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 휴지기 NK 세포는 인공 NK 세포이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 휴지기 NK 세포는 반일치 휴지기 NK 세포이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 휴지기 NK 세포는 키메라 항원 수용체 또는 재조합 T 세포 수용체를 갖고 있는 유전자-조작된 NK 세포이다. 본원에 기재된 임의의 방법의 일부 구현예는 활성화된 NK 세포가 대상체에게 투여되기 전에 상기 활성화된 NK 세포를 단리하는 단계를 추가로 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 기간에 걸쳐 대상체의 질량의 저하를 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 기간에 걸쳐 대상체의 체질량 지수(BMI)의 저하를 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 기간에 걸쳐 전당뇨병으로부터 2형 당뇨병으로의 진행 속도의 저하를 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 대상체에서 공복 혈청 포도당 수준의 저하를 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 대상체에서 인슐린 감수성의 증가를 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 대상체에서 죽상동맥경화증의 중증도의 저하를 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 기간은 약 2주 내지 약 10년이다.
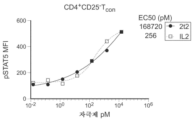
본원에 기재된 임의의 방법의 일부 구현예에서, 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 IL-2에 대한 수용체, IL-7에 대한 수용체, IL-12에 대한 수용체, IL-15에 대한 수용체, IL-18에 대한 수용체, IL-21에 대한 수용체, IL-33, CD16, CD69, CD25, CD59, CD352, NKp80, DNAM-1, 2B4, NKp30, NKp44, NKp46, NKG2D, KIR2DS1, KIR2Ds2/3, KIR2DL4, KIR2DS4, KIR2DS5, 및 KIR3DS1에 대한 수용체 중 하나 이상의 활성화를 초래한다.
본원에 기재된 임의의 방법의 일부 구현예에서, IL-2에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 가용성 IL-2 또는 IL-2 수용체에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, IL-7에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 가용성 IL-7 또는 IL-7 수용체에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, IL-12에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 가용성 IL-12 또는 IL-12 수용체에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, IL-15에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 가용성 IL-15 또는 IL-15 수용체에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, IL-21에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 가용성 IL-21 또는 IL-21 수용체에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, IL-33에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 가용성 IL-33 또는 IL-33 수용체에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, CD16에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 CD16에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, CD69에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 CD69에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, CD25 또는 CD59에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 CD25 또는 CD59에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, CD352에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 CD352에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, NKp80에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 NKp80에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, DNAM-1에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 DNAM-1에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, 2B4에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 2B4에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, NKp30에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 NKp30에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, NKp44에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 NKp44에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, NKp46에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 NKp46에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, NKG2D에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 NKG2D에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, KIR2DS1에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR2DS1에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, KIR2DS2/3에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR2DS2/3에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, KIR2DL4에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR2DL4에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, KIR2DS4에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR2DS4에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, KIR2DS5에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR2DS5에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, KIR3DS1에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR3DS1에 특이적으로 결합하는 작용제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 PD-1, TGF-β 수용체, TIGIT, CD1, TIM-3, Siglec-7, IRP60, Tactile, IL1R8, NKG2A/KLRD1, KIR2DL1, KIR2DL2/3, KIR2DL5, KIR3DL1, KIR3DL2, ILT2/LIR-1, 및 LAG-2 중 하나 이상의 활성화의 저하를 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, PD-1의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 PD-1에 특이적으로 결합하는 길항제성 항체, 가용성 PD-1, 가용성 PD-L1, 또는 PD-L1에 특이적으로 결합하는 항체이다. 본원에 기재된 임의의 방법의 일부 구현예에서, TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 가용성 TGF-β 수용체, TGF-β에 특이적으로 결합하는 항체, 또는 TGF-β 수용체에 특이적으로 결합하는 길항제성 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, TIGIT의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 TIGIT에 특이적으로 결합하는 길항제성 항체, 가용성 TIGIT, 또는 TIGIT의 리간드에 특이적으로 결합하는 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, CD1의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 CD1에 특이적으로 결합하는 길항제성 항체, 가용성 CD1, 또는 CD1의 리간드에 특이적으로 결합하는 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, TIM-3의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 TIM-3에 특이적으로 결합하는 길항제성 항체, 가용성 TIM-3, 또는 TIM-3의 리간드에 특이적으로 결합하는 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, Siglec-7의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 Siglec-7에 특이적으로 결합하는 길항제성 항체 또는 Siglec-7의 리간드에 특이적으로 결합하는 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, IRP60의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 IRP60에 특이적으로 결합하는 길항제성 항체 또는 IRP60의 리간드에 특이적으로 결합하는 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, Tactile의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 Tactile에 특이적으로 결합하는 길항제성 항체 또는 Tactile의 리간드에 특이적으로 결합하는 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, IL1R8의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 IL1R8에 특이적으로 결합하는 길항제성 항체 또는 IL1R8의 리간드에 특이적으로 결합하는 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, NKG2A/KLRD1의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 NKG2A/KLRD1에 특이적으로 결합하는 길항제성 항체 또는 NKG2A/KLRD1의 리간드에 특이적으로 결합하는 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, KIR2DL1의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR2DL1에 특이적으로 결합하는 길항제성 항체 또는 KIR2DL1의 리간드에 특이적으로 결합하는 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, KIR2DL2/3의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR2DL2/3에 특이적으로 결합하는 길항제성 항체 또는 KIR2DL2/3의 리간드에 특이적으로 결합하는 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, KIR2DL5의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR2DL5에 특이적으로 결합하는 길항제성 항체 또는 KIR2DL5의 리간드에 특이적으로 결합하는 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, KIR3DL1의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR3DL1에 특이적으로 결합하는 길항제성 항체 또는 KIR3DL1의 리간드에 특이적으로 결합하는 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, KIR3DL2의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR3DL2에 특이적으로 결합하는 길항제성 항체 또는 KIR3DL2의 리간드에 특이적으로 결합하는 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, ILT2/LIR-1의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 ILT2/LIR-1에 특이적으로 결합하는 길항제성 항체 또는 ILT2/LIR-1의 리간드에 특이적으로 결합하는 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, LAG-2의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 LAG-2에 특이적으로 결합하는 길항제성 항체 또는 LAG-2의 리간드에 특이적으로 결합하는 항체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 (i) 제1 표적-결합 도메인; (ii) 가용성 조직 인자 도메인; 및 (iii) 제2 표적-결합 도메인을 포함하는 단일-사슬 키메라 폴리펩타이드이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인과 가용성 조직 인자 도메인은 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 조직 인자 도메인과 제2 표적-결합 도메인은 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 가용성 조직 인자 도메인과 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인과 제2 표적-결합 도메인은 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 제1 표적-결합 도메인과 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제2 표적-결합 도메인과 가용성 조직 인자 도메인은 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 제2 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 항원에 특이적으로 결합한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 상이한 항원에 특이적으로 결합한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 항원-결합 도메인이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 항원-결합 도메인이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 항원-결합 도메인은 scFv 또는 단일 도메인 항체를 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKp30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, 및 CD122에 대한 수용체의 군으로부터 선택되는 표적에 결합한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 단백질이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 인터류킨 또는 사이토카인 단백질은 하기의 군으로부터 선택된다: IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, 및 SCF.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 수용체이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 인터류킨 또는 사이토카인 수용체는 가용성 TGF-β 수용체 II(TGF-βRII), 가용성 TGF-βRIII, TNFα에 대한 가용성 수용체, IL-4에 대한 가용성 수용체, 또는 IL-10에 대한 가용성 수용체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 조직 인자 도메인은 가용성 인간 조직 인자 도메인이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 80% 동일한 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 90% 동일한 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 95% 동일한 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 인간 조직 인자 도메인은 하기 중 하나 이상을 포함하지 않는다: 성숙한 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 라이신; 성숙한 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신; 성숙한 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판; 성숙한 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산; 성숙한 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신; 성숙한 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및 성숙한 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 인간 조직 인자 도메인은 하기 중 임의의 것을 포함하지 않는다: 성숙한 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 라이신; 성숙한 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신; 성숙한 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판; 성숙한 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산; 성숙한 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신; 성숙한 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및 성숙한 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 조직 인자 도메인은 인자 VIIa를 결합할 수 없다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 조직 인자 도메인은 불활성 인자 X를 인자 Xa로 전환시키지 않는다. 본원에 기재된 임의의 방법의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 포유류에서 혈액 응고를 자극시키지 않는다. 본원에 기재된 임의의 방법의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 이의 N-말단 및/또는 C-말단에 하나 이상의 추가 표적-결합 도메인을 추가로 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 이의 N-말단에 하나 이상의 추가 표적-결합 도메인을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 하나 이상의 추가 표적-결합 도메인은 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인에 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 적어도 하나의 추가 표적-결합 도메인과 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 이의 C-말단에 하나 이상의 추가 표적-결합 도메인을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 하나 이상의 추가 표적-결합 도메인 중 하나는 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인에 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 적어도 하나의 추가 표적-결합 도메인과 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 이의 N-말단 및 C-말단에 하나 이상의 추가 표적-결합 도메인을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 하나 이상의 추가 항원-결합 도메인 중 하나는 N-말단에서 상기 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인에 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 N-말단에서 하나 이상의 추가 항원-결합 도메인 중 하나와 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 하나 이상의 추가 항원-결합 도메인 중 하나는 C-말단에서 상기 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인에 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 C-말단에서 하나 이상의 추가 항원-결합 도메인 중 하나와 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 항원에 특이적으로 결합한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 펩타이드에 특이적으로 결합한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 아미노산 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인은 각각 동일한 항원에 특이적으로 결합한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인은 각각 동일한 에피토프에 특이적으로 결합한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인은 각각 동일한 아미노산 서열을 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인은 상이한 항원에 특이적으로 결합한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 표적-결합 도메인 중 하나 이상은 항원-결합 도메인이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인은 각각 항원-결합 도메인이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 항원-결합 도메인은 scFv 또는 단일 도메인 항체를 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 하나 이상의 표적-결합 도메인 중 하나 이상은 CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKp30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, 및 CD122에 대한 수용체의 군으로부터 선택되는 표적에 특이적으로 결합한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인 중 하나 이상은 가용성 인터류킨 또는 사이토카인 단백질이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 인터류킨 또는 사이토카인 단백질은 하기의 군으로부터 선택된다: IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, 및 SCF.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인 중 하나 이상은 가용성 인터류킨 또는 사이토카인 수용체이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 수용체는 가용성 TGF-β 수용체 II(TGF-βRII), 가용성 TGF-βRIII, TNFα에 대한 가용성 수용체, IL-4에 대한 가용성 수용체, 또는 IL-10에 대한 가용성 수용체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 (a) (i) 제1 표적-결합 도메인; (ii) 가용성 조직 인자 도메인; 및 (iii) 친화도 도메인 쌍의 제1 도메인을 포함하는 제1 키메라 폴리펩타이드; 및 (b) (i) 친화도 도메인 쌍의 제2 도메인; 및 (ii) 제2 표적-결합 도메인을 포함하는 제2 키메라 폴리펩타이드를 포함하는 다중-사슬 키메라 폴리펩타이드이며, 이때, 제1 키메라 폴리펩타이드 및 제2 키메라 폴리펩타이드는 친화도 도메인 쌍의 제1 도메인과 제2 도메인의 결합을 통해 회합된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인과 가용성 조직 인자 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 항원에 특이적으로 결합한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 상이한 항원에 특이적으로 결합한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 항원-결합 도메인이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 항원-결합 도메인이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 항원-결합 도메인은 scFv 또는 단일 도메인 항체를 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 하기의 군으로부터 선택되는 표적에 특이적으로 결합한다: CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKp30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, 및 CD122에 대한 수용체.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 단백질이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 인터류킨 또는 사이토카인 단백질은 하기의 군으로부터 선택된다: IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, 및 SCF.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 수용체이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 수용체는 가용성 TGF-β 수용체 II(TGF-βRII), 가용성 TGF-βRIII, TNFα에 대한 가용성 수용체, IL-4에 대한 가용성 수용체, 또는 IL-10에 대한 가용성 수용체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 키메라 폴리펩타이드는 하나 이상의 추가 표적-결합 도메인(들)을 추가로 포함하며, 상기 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나는 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 키메라 폴리펩타이드는 가용성 조직 인자 도메인과 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나 사이에 링커 서열, 및/또는 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나와 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 키메라 폴리펩타이드는 제1 키메라 폴리펩타이드의 N-말단 및/또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 제1 키메라 폴리펩타이드에서 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 키메라 폴리펩타이드는 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인에 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 키메라 폴리펩타이드는 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 제1 표적-결합 도메인 사이에 링커 서열을 추가로 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드의 N-말단 및/또는 C-말단에 배치되고, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한다. 본원에 기재된 임의의 방법의 일부 구현예에서, N-말단에 배치된 하나 이상의 추가 표적-결합 도메인의 적어도 하나의 추가 표적-결합 도메인은 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 키메라 폴리펩타이드는 적어도 하나의 추가 표적-결합 도메인과 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인 사이에 배치된 링커 서열을 추가로 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, C-말단에 배치된 하나 이상의 추가 표적-결합 도메인의 적어도 하나의 추가 표적-결합 도메인은 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 키메라 폴리펩타이드는 적어도 하나의 추가 표적-결합 도메인과 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인 사이에 배치된 링커 서열을 추가로 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 가용성 조직 인자 도메인 및/또는 상기 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 키메라 폴리펩타이드는 (i) 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 가용성 조직 인자 도메인 사이에, 및/또는 (ii) 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 친화도 도메인의 쌍의 제1 도메인 사이에 배치된 링커 서열을 추가로 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제2 키메라 폴리펩타이드는 제2 키메라 폴리펩타이드의 N-말단 및/또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 제2 키메라 폴리펩타이드에서 친화도 도메인의 쌍의 제2 도메인에 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 하나 이상의 제2 표적-결합 도메인 중 적어도 하나의 사이에 링커 서열을 추가로 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 제2 키메라 폴리펩타이드에서 제2 표적-결합 도메인에 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 제2 표적-결합 도메인과 하나 이상의 제2 표적-결합 도메인 중 적어도 하나의 사이에 링커 서열을 추가로 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 항원에 특이적으로 결합한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 펩타이드에 특이적으로 결합한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 아미노산 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인은 각각 동일한 항원에 특이적으로 결합한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인은 각각 동일한 에피토프에 특이적으로 결합한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인은 각각 동일한 아미노산 서열을 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인은 상이한 항원에 특이적으로 결합한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 표적-결합 도메인 중 하나 이상은 항원-결합 도메인이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인은 각각 항원-결합 도메인이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 항원-결합 도메인은 scFv를 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 하나 이상의 표적-결합 도메인 중 하나 이상은 CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKp30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, 및 CD122에 대한 수용체의 군으로부터 선택되는 표적에 특이적으로 결합한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인 중 하나 이상은 가용성 인터류킨 또는 사이토카인 단백질이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 인터류킨 또는 사이토카인 단백질은 하기의 군으로부터 선택된다: IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, 및 SCF.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인 중 하나 이상은 가용성 인터류킨 또는 사이토카인 수용체이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 수용체는 가용성 TGF-β 수용체 II(TGF-βRII), 가용성 TGF-βRIII, TNFα에 대한 가용성 수용체, IL-4에 대한 가용성 수용체, 또는 IL-10에 대한 가용성 수용체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 조직 인자 도메인은 가용성 인간 조직 인자 도메인이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 80% 동일한 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 90% 동일한 서열을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 95% 동일한 서열을 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 인간 조직 인자 도메인은 하기 중 하나 이상을 포함하지 않는다: 성숙한 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 라이신; 성숙한 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신; 성숙한 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판; 성숙한 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산; 성숙한 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신; 성숙한 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및 성숙한 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 인간 조직 인자 도메인은 하기 중 임의의 것을 포함하지 않는다: 성숙한 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 라이신; 성숙한 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신; 성숙한 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판; 성숙한 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산; 성숙한 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신; 성숙한 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및 성숙한 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 조직 인자 도메인은 인자 VIIa에 결합할 수 없다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 조직 인자 도메인은 불활성 인자 X를 인자 Xa로 전환시키지 않는다. 본원에 기재된 임의의 방법의 일부 구현예에서, 다중-사슬 키메라 폴리펩타이드는 포유류에서 혈액 응고를 자극시키지 않는다. 본원에 기재된 임의의 방법의 일부 구현예에서, 친화도 도메인 쌍은 인간 IL-15 수용체의 알파 사슬(IL-15Rα) 및 가용성 IL-15로부터의 sushi 도메인이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 IL-15는 D8N 또는 D8A 아미노산 치환을 갖는다. 본원에 기재된 임의의 방법의 일부 구현예에서, 인간 IL-15Rα는 성숙한 전장 IL-15Rα이다.
본원에 기재된 임의의 방법의 일부 구현예에서, 친화도 도메인 쌍은 바르나제와 바른스타, PKA와 AKAP, 돌연변이화된 RNase I 단편에 기초한 어댑터/도킹 태그 모듈, 및 단백질 신택신, 시냅토태그민, 시냅토브레빈, 및 SNAP25의 상호작용에 기초한 SNARE 모듈의 군으로부터 선택된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 다중-사슬 키메라 폴리펩타이드로서, (a) 각각 (i) 제1 표적-결합 도메인; (ii) Fc 도메인; 및 (iii) 친화도 도메인 쌍의 제1 도메인을 포함하는 제1 및 제2 키메라 폴리펩타이드; 및 (b) 각각 (i) 친화도 도메인 쌍의 제2 도메인; 및 (ii) 제2 표적-결합 도메인을 포함하는 제3 및 제4 키메라 폴리펩타이드를 포함하며, 상기 제1 및 제2 키메라 폴리펩타이드와 제3 및 제4 키메라 폴리펩타이드는 친화도 도메인 쌍의 제1 도메인과 제2 도메인의 결합을 통해 회합되고, 제1 키메라 폴리펩타이드와 제2 키메라 폴리펩타이드는 이들의 Fc 도메인을 통해 회합된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인과 Fc 도메인은 제1 및 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 및 제2 키메라 폴리펩타이드는 상기 제1 및 제2 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 Fc 도메인 사이에 링커 서열을 추가로 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, Fc 도메인과 친화도 도메인 쌍의 제1 도메인은 제1 및 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 및 제2 키메라 폴리펩타이드에서 Fc 도메인과 친화도 도메인 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인은 제3 및 제4 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제3 및 제4 키메라 폴리펩타이드는 상기 제3 및 제4 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 항원에 특이적으로 결합한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 상이한 항원에 특이적으로 결합한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 항원-결합 도메인이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 항원-결합 도메인이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 항원-결합 도메인은 scFv 또는 단일 도메인 항체를 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 하기의 군으로부터 선택되는 표적에 특이적으로 결합한다: CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKp30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, 및 CD122에 대한 수용체.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 단백질이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 인터류킨 또는 사이토카인 단백질은 하기의 군으로부터 선택된다: IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, 및 SCF.
본원에 기재된 임의의 방법의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 수용체이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 수용체는 가용성 TGF-β 수용체 II(TGF-βRII), 가용성 TGF-βRIII, TNFα에 대한 가용성 수용체, IL-4에 대한 가용성 수용체, 또는 IL-10에 대한 가용성 수용체이다.
본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 조직 인자 도메인은 혈액 응고를 자극시키지 않는 가용성 인간 조직 인자 도메인이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 가용성 조직 인자 도메인은 야생형 가용성 인간 조직 인자로부터의 서열을 포함하거나 이로 구성된다.
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포를 사멸시키거나 이의 수를 감소시키는 방법이 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함한다.
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 축적을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함한다.
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 마커의 수준을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함한다.
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 활성을 감소시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함한다.
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포로부터 유래된 하나 이상의 SASP 인자(들)의 수준 및/또는 활성을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함한다.
일부 구현예에서, 대상체는 노화-관련 질환 또는 염증성 질환을 갖는 것으로 이전에 진단되거나 식별되었다. 일부 구현예에서, 노화-관련 질환은 염증-노화와 관련이 있다.
일부 구현예에서, 노화-관련 질환은 하기의 군으로부터 선택된다: 알츠하이머 질환, 동맥류, 낭성 섬유증, 췌장염에서의 섬유증, 녹내장, 고혈압, 특발성 폐 섬유증, 염증성 장 질환, 추간판 퇴행, 골관절염, 2형 진성 당뇨병, 지방세포 위축, 지방이영양증, 죽상동맥경화증, 백내장, COPD, 신장 이식 실패, 간 섬유증, 골질량 손실, 심근 경색, 사르코페니아, 상처 치유, 탈모증, 심근세포 비대, 골관절염, 파킨슨 질환, 연령-연관 폐 조직 탄성 손실, 연령-관련 황반 변성, 악액질, 사구체경화증, 간 경변증, NAFLD, 골다공증, 근위축성 측삭 경화증, 헌팅턴 질환, 척수소뇌 실조증, 다발성 경화증, 신경퇴행, 뇌졸중, 암, 치매, 혈관 질환, 감염 감수성, 만성 염증, 및 신장 기능장애.
일부 구현예에서, 노화-관련 질환은 하기의 군으로부터 선택된다: 고형 종양, 혈액학적 종양, 육종, 골육종, 교모세포종, 신경모세포종, 흑색종, 횡문근육종, 유잉 육종, 골육종, B-세포 신생물, 다발성 골수종, B-세포 림프종, B-세포 비-호지킨 림프종, 호지킨 림프종, 만성 림프구성 백혈병(CLL), 급성 골수성 백혈병(AML), 만성 골수성 백혈병(CML), 급성 림프구성 백혈병(ALL), 골수이형성 증후군(MDS), 피부 T-세포 림프종, 망막모세포종, 위암, 요로상피세포암종, 폐암, 신세포 암종, 위 및 식도 암, 췌장암, 전립선암, 유방암, 결장직장암, 난소암, 비-소세포 폐 암종, 편평 세포 두경부 암종, 자궁내막암, 자궁경부암, 간암, 및 간세포 암종.
일부 구현예에서, 염증성 질환은 하기의 군으로부터 선택된다: 류마티스 관절염, 염증성 장 질환, 홍반성 루푸스, 루푸스 신염, 당뇨병성 신증, CNS 손상, 알츠하이머 질환, 파킨슨 질환, 근위축성 측삭 경화증, 크론 질환, 다발성 경화증, 길랑-바레 증후군, 건선, 그레이브스 질환, 궤양성 대장염, 비알코올성 지방간염, 기분 장애 및 암 치료-관련 인지 장애.
일부 구현예에서, 치료-유도 노쇠 세포는 화학요법-유도 노쇠 세포이다. 일부 구현예에서, 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)의 투여는 대상체의 표적 조직에서 천연-발생 노쇠 세포 및/또는 치료-유도 노쇠 세포의 수의 저하를 초래한다. 일부 구현예에서, 표적 조직은 하기의 군으로부터 선택된다: 지방 조직, 췌장 조직, 간 조직, 신장 조직, 폐 조직, 혈관 구조, 뼈 조직, 중추신경계(CNS) 조직, 안구 조직, 피부 조직, 근육 조직, 및 2차 림프-기관 조직.
일부 구현예에서, 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들) 중 적어도 하나는 공통 감마-사슬 계열 사이토카인 또는 이의 기능성 단편과 상기 공통 감마-사슬 계열 사이토카인 또는 이의 기능성 단편에 특이적으로 결합하는 항체 또는 항체 단편의 복합체이다.
일부 구현예에서, 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들) 중 적어도 하나는 (i) 제1 표적-결합 도메인; (ii) 가용성 조직 인자 도메인; 및 (iii) 제2 표적-결합 도메인을 포함하는 단일-사슬 키메라 폴리펩타이드이며, 상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 공통 감마-사슬 계열 사이토카인, 공통 감마-사슬 계열 사이토카인 수용체에 특이적으로 결합하는 작용제성 항원-결합 도메인, 가용성 공통 감마-사슬 계열 사이토카인 수용체, 또는 공통 감마-사슬 계열 사이토카인에 특이적으로 결합하는 항원-결합 도메인이다.
일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 공통 감마-사슬 계열 사이토카인을 포함한다. 일부 구현예에서, 가용성 공통 감마-사슬 계열 사이토카인은 하기로 이루어진 군으로부터 선택된다: 가용성 IL-2, 가용성 IL-4, 가용성 IL-7, 가용성 IL-9, 가용성 IL-15, 및 가용성 IL-21. 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 공통 감마-사슬 계열 사이토카인 수용체에 특이적으로 결합하는 작용제성 항원-결합 도메인을 포함한다. 일부 구현예에서, 공통 감마-사슬 계열 사이토카인 수용체는 IL-2, IL-4, IL-7, IL-9, IL-15, 및 IL-21 중 하나 이상에 대한 수용체이다. 일부 구현예에서, 작용제성 항원-결합 도메인은 scFv, VHH, 또는 VNAR이다.
일부 구현예에서, 상기 제1 표적-결합 도메인 및 상기 가용성 조직 인자 도메인은 서로 직접적으로 인접해 있다. 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함한다. 일부 구현예에서, 상기 가용성 조직 인자 도메인 및 상기 제2 표적-결합 도메인은 서로 직접적으로 인접해 있다. 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 가용성 조직 인자 도메인과 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함한다. 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 항원에 특이적으로 결합한다. 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합한다. 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 상이한 항원에 특이적으로 결합한다.
일부 구현예에서, 가용성 조직 인자 도메인은 가용성 인간 조직 인자 도메인이다. 일부 구현예에서, 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 80% 동일한 서열을 포함한다. 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 이의 N-말단 및/또는 C-말단에 하나 이상의 추가 표적-결합 도메인을 추가로 포함한다.
일부 구현예에서, 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들) 중 적어도 하나는 (a) (i) 제1 표적-결합 도메인; (ii) 가용성 조직 인자 도메인; 및 (iii) 친화도 도메인 쌍의 제1 도메인을 포함하는 제1 키메라 폴리펩타이드; (b) (i) 친화도 도메인 쌍의 제2 도메인; 및 (ii) 제2 표적-결합 도메인을 포함하는 제2 키메라 폴리펩타이드를 포함하는 다중-사슬 키메라 폴리펩타이드이며, 상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 공통 감마-사슬 계열 사이토카인, 공통 감마-사슬 계열 사이토카인 수용체에 특이적으로 결합하는 작용제성 항원-결합 도메인, 가용성 공통 감마-사슬 계열 사이토카인 수용체, 또는 공통 감마-사슬 계열 사이토카인에 특이적으로 결합하는 항원-결합 도메인이다.
일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 공통 감마-사슬 계열 사이토카인을 포함한다. 일부 구현예에서, 가용성 공통 감마-사슬 계열 사이토카인은 하기의 군으로부터 선택된다: 가용성 IL-2, 가용성 IL-4, 가용성 IL-7, 가용성 IL-9, 가용성 IL-15, 및 가용성 IL-21. 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 공통 감마-사슬 계열 사이토카인 수용체에 특이적으로 결합하는 작용제성 항원-결합 도메인을 포함한다. 일부 구현예에서, 공통 감마-사슬 계열 사이토카인 수용체는 IL-2, IL-4, IL-7, IL-9, IL-15, 및 IL-21 중 하나 이상에 대한 수용체이다. 일부 구현예에서, 작용제성 항원-결합 도메인은 scFv, VHH, 또는 VNAR이다.
일부 구현예에서, 상기 제1 표적-결합 도메인 및 상기 가용성 조직 인자 도메인은 상기 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함한다. 일부 구현예에서, 상기 가용성 조직 인자 도메인 및 상기 친화도 도메인의 쌍의 제1 도메인은 상기 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함한다. 일부 구현예에서, 상기 친화도 도메인의 쌍의 제2 도메인 및 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 상기 친화도 도메인의 쌍의 제2 도메인과 상기 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함한다.
일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 항원에 특이적으로 결합한다. 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 상이한 항원에 특이적으로 결합한다. 일부 구현예에서, 제1 키메라 폴리펩타이드는 하나 이상의 추가 표적-결합 도메인(들)을 추가로 포함한다. 일부 구현예에서, 제2 키메라 폴리펩타이드는 하나 이상의 추가 표적-결합 도메인을 추가로 포함한다.
일부 구현예에서, 가용성 조직 인자 도메인은 가용성 인간 조직 인자 도메인이다. 일부 구현예에서, 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 80% 동일한 서열을 포함한다. 일부 구현예에서, 상기 친화도 도메인의 쌍은 인간 IL-15 수용체의 알파 사슬(IL15Rα) 및 가용성 IL-15로부터의 sushi 도메인이다. 일부 구현예에서, 친화도 도메인 쌍은 하기의 군으로부터 선택된다: 바르나제와 바른스타, PKA와 AKAP, 돌연변이화된 RNase I 단편에 기초한 어댑터/도킹 태그 모듈, 및 단백질 신택신, 시냅토태그민, 시냅토브레빈, 및 SNAP25의 상호작용에 기초한 SNARE 모듈.
일부 구현예에서, 친화도 도메인 쌍의 제1 도메인 또는 제2 도메인은 공통 감마-사슬 계열 사이토카인 수용체에 특이적으로 결합하는 가용성 공통 감마-사슬 계열 사이토카인 또는 항원-결합 도메인이다. 일부 구현예에서, 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들) 중 적어도 하나는 가용성 IL-15 또는 IL-15 작용제이다. 일부 구현예에서, 가용성 IL-15는 SEQ ID NO: 82와 적어도 90% 동일하다. 일부 구현예에서, IL-15 작용제는 IL-15와 가용성 IL-15 수용체(IL-15R)의 전부 또는 일부의 복합체이다. 일부 구현예에서, 가용성 IL-15R의 일부는 IL-15Rα의 일부이다. 일부 구현예에서, 가용성 IL-15Rα의 일부는 IL-15Rα의 sushi 도메인이다. 일부 구현예에서, IL-15 작용제는 Fc 도메인을 추가로 포함한다. 일부 구현예에서, IL-15 작용제는 IL-15와 IL-15Rα로부터의 sushi 도메인을 포함하는 융합 단백질을 포함한다. 일부 구현예에서, 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들) 중 하나는 가용성 IL-2 또는 IL-2 작용제이다. 일부 구현예에서, 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들) 중 하나는 공통 감마-사슬 계열 사이토카인에 특이적으로 결합하는 항체 또는 항원-결합 단편이다.
일부 구현예에서, 방법은 대상체에게 1개, 2개 또는 그 이상의 용량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함한다. 일부 구현예에서, 2개 이상의 용량 중 임의의 2개의 연속 용량은 약 1주 내지 약 1년의 간격을 두고 투여된다. 일부 구현예에서, 2개 이상의 용량 중 임의의 2개의 연속 용량은 약 1주 내지 약 6개월의 간격을 두고 투여된다. 일부 구현예에서, 2개 이상의 용량 중 임의의 2개의 연속 용량은 약 1주 내지 약 2개월의 간격을 두고 투여된다. 일부 구현예에서, 2개 이상의 용량 중 임의의 2개의 연속 용량은 약 1주 내지 약 1개월의 간격을 두고 투여된다.
일부 구현예에서, 1개, 2개 또는 그 이상의 용량은 피하 투여에 의해 투여된다. 일부 구현예에서, 2개 이상의 용량은 근육내 투여에 의해 투여된다. 일부 구현예에서, 2개 이상의 용량은 약 1년 내지 약 60년의 기간에 걸쳐 투여된다. 일부 구현예에서, 2개 이상의 용량은 약 1년 내지 약 50년의 기간에 걸쳐 투여된다. 일부 구현예에서, 2개 이상의 용량은 약 1년 내지 약 40년의 기간에 걸쳐 투여된다. 일부 구현예에서, 2개 이상의 용량은 약 1년 내지 약 30년의 기간에 걸쳐 투여된다. 일부 구현예에서, 2개 이상의 용량은 약 1년 내지 약 20년의 기간에 걸쳐 투여된다. 일부 구현예에서, 2개 이상의 용량은 약 1년 내지 약 10년의 기간에 걸쳐 투여된다.
일부 구현예에서, 2개 이상의 용량은 각각 kg당 약 0.01 mg의 각각의 공통 감마-사슬 계열 사이토카인 수용체 활성화제 내지 kg당 약 10 mg의 각각의 공통 감마-사슬 계열 사이토카인 수용체 활성화제의 투여량으로 투여된다. 일부 구현예에서, 2개 이상의 용량은 각각 kg당 약 0.02 mg의 각각의 공통 감마-사슬 계열 사이토카인 수용체 활성화제 내지 kg당 약 5 mg의 각각의 공통 감마-사슬 계열 사이토카인 수용체 활성화제의 투여량으로 투여된다.
일부 구현예에서, 제1 용량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)는 대상체가 적어도 30세의 연령에 도달할 때 시작한다. 일부 구현예에서, 제1 용량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)는 대상체가 적어도 40세의 연령에 도달할 때 시작한다. 일부 구현예에서, 제1 용량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)는 대상체가 적어도 50세의 연령에 도달할 때 시작한다. 일부 구현예에서, 제1 용량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)는 대상체가 적어도 60세의 연령에 도달할 때 시작한다.
일부 구현예에서, 대상체는 노화-관련 질환 또는 염증성 질환을 갖는 것으로 진단되거나 식별되지 않는다. 일부 구현예에서, 대상체는 이전에 화학요법제로 치료된 적이 없다. 일부 구현예에서, 대상체는 이전에 세포 노쇠를 유도하는 치료제로 치료된 적이 없다. 일부 구현예에서, 방법은 대상체에게 TGF-β 수용체의 활성화의 저하를 초래하는 적어도 하나 이상의 제제(들)를 투여하는 단계를 추가로 포함한다. 일부 구현예에서, TGF-β 수용체의 활성화의 저하를 초래하는 제제는 가용성 TGF-β 수용체, TGF-β 수용체의 세포외 도메인, TGF-β에 특이적으로 결합하는 항체, TGF-β 수용체에 결합하는 길항제성 항체, LAP에 결합하는 제제, 또는 TGF-β/LAP 복합체에 결합하는 제제이다. 일부 구현예에서, TGF-β의 활성화의 저하를 초래하는 하나 이상의 제제(들)는 LAP에의 또는 TGF-β/LAP 복합체에의 결합을 통해 TGF-β 수용체의 활성화를 저하시킨다.
일부 구현예에서, 가용성 인간 조직 인자 도메인은 혈액 응고를 개시하지 않는다. 일부 구현예에서, 방법은 하기의 군으로부터 선택되는 추가 치료제를 투여하는 단계를 추가로 포함한다: 관문 저해제, 화학요법 약물, 및 치료 항체와 같은 제제들의 조합.
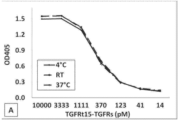
본원에 기재된 임의의 방법의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 37°C에서 적어도 10일 동안 인간 혈청에서 안정하다. 본원에 기재된 임의의 방법의 일부 구현예에서, 다중-사슬 키메라 폴리펩타이드는 37°C에서 적어도 10일 동안 인간 혈청에서 안정하다. 본원에 기재된 임의의 방법의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 유의한 응고(clotting) 활성을 갖지 않는다. 본원에 기재된 임의의 방법의 일부 구현예에서, 다중-사슬 키메라 폴리펩타이드는 유의한 응고 활성을 갖지 않는다.
본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 대상체에서 노화 면역 세포의 회춘(rejuvenation)을 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 노화 면역 세포의 회춘은 대상체에서 유병(diseased) 세포 또는 병원성 감염체의 수의 감소를 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 노화 면역 세포는 노화 NK 세포, 노화 NKT 세포, 노화 T 세포, 노화 B 세포, 노화 단핵구, 노화 대식세포, 노화 호중구, 노화 호염기구, 노화 호산구, 노화 쿠퍼 세포, 및 노화 소교 세포 중 하나 이상을 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 유병 세포는 암세포, 바이러스-감염 세포, 및 세포내-박테리아-감염 세포를 포함한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 감염성 병원체는 바이러스, 박테리아, 진균류, 및 기생충을 포함한다.
본원에 사용된 용어 "키메라"는 2개의 상이한 공급원(예를 들어, 동일하거나 상이한 종으로부터의 예를 들어, 2개의 상이한 천연-발생 단백질)으로부터 원래 유래된 아미노산 서열(예를 들어, 도메인)을 포함하는 폴리펩타이드를 지칭한다. 예를 들어, 키메라 폴리펩타이드는 적어도 2개의 상이한 천연-발생 인간 단백질로부터의 도메인을 포함할 수 있다. 일부 예에서, 키메라 폴리펩타이드는 합성 서열(예를 들어, scFv)인 도메인 및 천연-발생 단백질(예를 들어, 천연-발생 인간 단백질)로부터 유래된 도메인을 포함할 수 있다. 일부 구현예에서, 키메라 폴리펩타이드는 합성 서열인 적어도 2개의 상이한 도메인(예를 들어, 2개의 상이한 scFv)을 포함할 수 있다.
"활성화된 NK 세포"는 예를 들어, 휴지기 NK 세포와 비교하여, CD25, CD69, MTOR-C1, SREBP, IFN-γ, 및 그랜자임(예를 들어, 그랜자임 B) 중 2개 이상(예를 들어, 3개, 4개, 5개, 또는 6개)의 증가된 발현 수준을 실증하는 NK 세포이다. CD25, CD69, MTOR-C1, SREBP, IFN-γ, 및 그랜자임(예를 들어, 그랜자임 B)의 발현 수준을 식별하는 예시적인 방법은 본원에 기재되어 있다.
"휴지기 NK 세포"는 예를 들어, 활성화된 NK 세포와 비교하여, CD25, CD69, MTOR-C1, SREBP, IFN-γ, 및 그랜자임(예를 들어, 그랜자임 B) 중 2개 이상(예를 들어, 3개, 4개, 5개, 또는 6개)의 감소된 발현을 갖는 NK 세포이다.
"NK 세포 활성화제"는 활성화된 NK 세포로 발달하도록 휴지기 NK 세포를 (단독으로 또는 추가 NK 세포 활성화제와 조합하여) 유도하거나 촉진하는 제제이다. NK 세포 활성화제의 비제한적인 예 및 양태는 본원에 기재되어 있다.
"항원-결합 도메인"은 하나 이상의 단백질 도메인(들)(예를 들어, 하나 이상의 상이한 항원(들)에 특이적으로 결합할 수 있는 단일 폴리펩타이드로부터의 아미노산으로부터 형성되거나 2개 이상의 폴리펩타이드(예를 들어, 동일하거나 상이한 폴리펩타이드)로부터의 아미노산으로부터 형성됨)이다. 일부 예에서, 항원-결합 도메인은 천연-발생 항체와 유사한 특이성 및 친화도로 항원 또는 에피토프에 결합할 수 있다. 일부 구현예에서, 항원-결합 도메인은 항체 또는 이의 단편일 수 있다. 일부 구현예에서, 항원-결합 도메인은 대안적인 스캐폴드(alternative scaffold)를 포함할 수 있다. 항원-결합 도메인의 비제한적인 예는 본원에 기재된다. 항원-결합 도메인의 추가 예는 당업계에 알려져 있다.
"가용성 조직 인자 도메인"은 막관통 도메인 및 세포내 도메인이 결여된 야생형 포유류 조직 인자 단백질(예를 들어, 야생형 인간 조직 인자 단백질)의 분절과 적어도 70% 동일성(예를 들어, 적어도 75% 동일성, 적어도 80% 동일성, 적어도 85% 동일성, 적어도 90% 동일성, 적어도 95% 동일성, 적어도 99% 동일성, 또는 100% 동일성)의 분절을 갖는 폴리펩타이드를 지칭한다. 가용성 조직 인자 도메인의 비제한적인 예는 본원에 기재된다.
용어 "가용성 인터류킨 단백질"은 본원에서 성숙한 그리고 분비된 인터류킨 단백질 또는 이의 생물학적 활성 단편을 지칭하는 데 사용된다. 일부 예에서, 가용성 인터류킨 단백질은 야생형의 성숙한 그리고 분비된 포유류 인터류킨 단백질(예를 들어, 야생형 인간 인터류킨 단백질)과 적어도 70% 동일한, 적어도 75% 동일한, 적어도 80% 동일한, 적어도 85% 동일한, 적어도 90% 동일한, 적어도 95% 동일한, 적어도 99% 동일한, 또는 100% 동일하고 이의 생물학적 활성을 보유하는 서열을 포함할 수 있다. 가용성 인터류킨 단백질의 비제한적인 예는 본원에 기재되어 있다.
용어 "가용성 사이토카인 단백질"은 본원에서 성숙한 그리고 분비된 사이토카인 단백질 또는 이의 생물학적 활성 단편을 지칭하는 데 사용된다. 일부 예에서, 가용성 사이토카인 단백질은 야생형의 성숙한 그리고 분비된 포유류 인터류킨 단백질(예를 들어, 야생형 인간 인터류킨 단백질)과 적어도 70% 동일한, 적어도 75% 동일한, 적어도 80% 동일한, 적어도 85% 동일한, 적어도 90% 동일한, 적어도 95% 동일한, 적어도 99% 동일한, 또는 100% 동일하고 이의 생물학적 활성을 보유하는 서열을 포함할 수 있다. 가용성 사이토카인 단백질의 비제한적인 예는 본원에 기재되어 있다.
용어 "가용성 인터류킨 수용체"는 본원에서 가장 넓은 의미로, 하나 이상의 이의 천연 리간드에 (예를 들어, 생리학적 조건 하에, 예를 들어, 실온에서 포스페이트 완충 식염수에서) 결합할 수 있는, 막관통 도메인(및 선택적으로 세포내 도메인)이 결여된 폴리펩타이드를 지칭하는 데 사용된다. 예를 들어, 가용성 인터류킨 수용체는 야생형 인터류킨 수용체의 세포외 도메인과 적어도 70% 동일하고(예를 들어, 적어도 75% 동일한, 적어도 80% 동일한, 적어도 85% 동일한, 적어도 90% 동일한, 적어도 95% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 하나 이상의 이의 천연 리간드에 특이적으로 결합하는 이의 능력을 보유하지만 이의 막관통 도메인이 결여되어 있는(그리고 선택적으로, 이의 세포내 도메인이 추가로 결여되어 있는) 서열을 포함할 수 있다. 가용성 인터류킨 수용체의 비제한적인 예는 본원에 기재되어 있다.
용어 "가용성 사이토카인 수용체"는 본원에서 가장 넓은 의미로, 하나 이상의 이의 천연 리간드에(예를 들어, 생리학적 조건 하에, 예를 들어, 실온에서 포스페이트 완충 식염수에서) 결합할 수 있는, 막관통 도메인(및 선택적으로 세포내 도메인)이 결여된 폴리펩타이드를 지칭하는 데 사용된다. 예를 들어, 가용성 사이토카인 수용체는 야생형 사이토카인 수용체의 세포외 도메인과 적어도 70% 동일하고(예를 들어, 적어도 75% 동일한, 적어도 80% 동일한, 적어도 85% 동일한, 적어도 90% 동일한, 적어도 95% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 하나 이상의 이의 천연 리간드에 특이적으로 결합하는 이의 능력을 보유하지만 이의 막관통 도메인이 결여되어 있는(그리고 선택적으로, 이의 세포내 도메인이 추가로 결여되어 있는) 서열을 포함할 수 있다. 가용성 사이토카인 수용체의 비제한적인 예는 본원에 기재되어 있다.
용어 "항체"는 본원에서 이의 가장 넓은 의미로 사용되고, 항원 또는 에피토프에 특이적으로 결합하는 하나 이상의 항원-결합 도메인을 포함하는 소정의 유형의 면역글로불린 분자를 포함한다. 항체는 예를 들어, 무손상(intact) 항체(예를 들어, 무손상 면역글로불린), 항체 단편, 및 다중-특이적 항체를 특이적으로 포함한다. 항원-결합 도메인의 일례는 VH -VL 이량체에 의해 형성되는 항원-결합 도메인이다. 항체의 추가 예는 본원에 기재되어 있다. 항체의 추가 예는 당업계에 알려져 있다.
"친화도"는 항원-결합 부위와 이의 결합 파트너(예를 들어, 항원 또는 에피토프) 사이의 비-공유 상호작용의 총 합계의 강도를 지칭한다. 다르게 제시되지 않는 한, 본원에 사용된 바와 같이, "친화도"는 내인성 결합 친화도를 지칭하며, 이는 항원-결합 도메인의 구성원과 항원 또는 에피토프 사이의 1:1 상호작용을 반영한다. 분자 X의 파트너 Y에 대한 상기 분자 X의 친화도는 해리 평형 상수(KD)에 의해 표시될 수 있다. 해리 평형 상수에 기여하는 동역학 구성요소는 하기에서 더욱 상세히 기재된다. 친화도는 본원에 기재된 방법을 포함하여 당업계에 알려진 보편적인 방법에 의해 측정될 수 있다. 친화도는 예를 들어, 표면 플라즈몬 공명(SPR) 기술(예를 들어, BIACORE®) 또는 생물층 간섭계(biolayer interferometry)(예를 들어, FORTEBIO®)를 사용하여 결정될 수 있다. 항원-결합 도메인 및 이의 상응하는 항원 또는 에피토프에 대한 친화도를 결정하는 추가 방법은 당업계에 알려져 있다.
본원에 사용된 "단일-사슬 폴리펩타이드"는 단일 단백질 사슬을 지칭한다.
본원에 사용된 "다중-사슬 폴리펩타이드"는 2개 이상(예를 들어, 3, 4, 5, 6, 7, 8, 9, 또는 10개)의 단백질 사슬(예를 들어, 적어도 제1 키메라 폴리펩타이드 및 제2 폴리펩타이드)을 포함하는 폴리펩타이드를 지칭하며, 이때, 2개 이상의 단백질 사슬은 비-공유 결합을 통해 회합되어, 4차 구조를 형성한다.
용어 "친화도 도메인 쌍"은 1 x 10-7 M 미만(예를 들어 1 x 10-8 M 미만, 1 x 10-9 M 미만, 1 x 10-10 M 미만, 또는 1 x 10-11 M 미만)의 KD로 서로 특이적으로 결합하는 2개의 상이한 단백질 도메인(들)이다. 일부 예에서, 친화도 도메인 쌍은 천연-발생 단백질의 쌍일 수 있다. 일부 구현예에서, 친화도 도메인 쌍은 합성 단백질의 쌍일 수 있다. 친화도 도메인 쌍의 비제한적인 예는 본원에 기재되어 있다.
용어 "에피토프"는 항원-결합 도메인에 특이적으로 결합하는 항원의 일부를 의미한다. 에피토프는 예를 들어, 표면-접근 가능한 아미노산 잔기 및/또는 당(sugar) 측쇄로 구성될 수 있고, 특이적인 3-차원 구조 특징, 뿐만 아니라 특이적인 전하 특징을 가질 수 있다. 형태적 에피토프 및 비-형태적 에피토프는, 상기 비-형태적 에피토프가 아니라 형태적 에피토프가 변성 용매의 존재 하에 소실될 수 있다는 점에서 구별된다. 에피토프는 결합에 직접적으로 관여하는 아미노산 잔기, 및 결합에 직접적으로 관여하지 않는 다른 아미노산 잔기를 포함할 수 있다. 항원-결합 도메인이 결합하는 에피토프를 식별하는 방법은 당업계에 알려져 있다.
용어 "치료"는 장애의 적어도 하나의 증상을 호전시키는 것을 의미한다. 일부 예에서, 치료되는 장애는 암이고, 암의 적어도 하나의 증상을 호전시키는 것은 인자의 비정상적인 증식, 유전자 발현, 신호화, 번역, 및/또는 분비를 감소시키는 것을 포함한다. 일반적으로, 치료 방법은 이러한 치료를 필요로 하는 대상체 또는 이러한 치료를 필요로 하는 것으로 결정되었던 대상체에게 장애의 적어도 하나의 증상을 감소시키는 치료적 유효량의 조성물을 투여하는 단계를 포함한다.
다르게 정의되지 않는 한, 본원에서 사용되는 모든 기술적 및 과학적 용어들은 본 발명이 속한 당업계의 숙련자에 의해 보편적으로 이해되는 것과 동일한 의미를 갖는다. 방법 및 물질은 본 발명에 사용하기 위해 본원에 기재되고; 당업계에 알려진 다른 적합한 방법 및 물질 또한 사용될 수 있다. 물질, 방법, 및 실시예는 예시적일 뿐이고, 제한하려는 것이 아니다. 본원에서 언급된 모든 공보, 특허 출원, 특허, 서열, 데이터베이스 엔트리, 및 다른 참고문헌은 그 전체가 참조로서 포함된다. 상충하는 경우, 정의를 포함한 본 명세서가 제어할 것이다.
본 발명의 다른 특질 및 이점은 하기 상세한 설명 및 도면으로부터, 그리고 청구항으로부터 분명해질 것이다.
도 1a 내지 도 1b는 C57BL/6 마우스에서 예시적인 다중-사슬 폴리펩타이드의 면역자극의 결과를 도시한다. 도 1a는 대조군 용액으로 치료된 마우스와 비교하여 증가하는 투여량의 예시적인 다중-사슬 폴리펩타이드로 치료된 마우스의 비장 중량을 도시한다. 도 1b는 대조군 용액으로 치료된 마우스와 비교하여 증가하는 투여량의 예시적인 다중-사슬 폴리펩타이드로 치료된 마우스의 비장에 존재하는 면역 세포 유형의 백분율을 도시한다.
도 2a 내지 도 2b는 C57BL/6 마우스에서 예시적인 다중-사슬 폴리펩타이드의 면역자극의 지속 기간을 도시한다. 도 2a는 3 mg/kg의 예시적인 다중-사슬 폴리펩타이드로 치료된 마우스에서 92시간의 기간에 걸친 비장 중량을 도시한다. 도 2b는 3 mg/kg의 예시적인 다중-사슬 폴리펩타이드로 치료된 마우스에서 92시간의 기간에 걸친 비장에 존재하는 면역 세포 유형의 백분율을 도시한다.
도 3a 내지 도 3b는 예시적인 다중-사슬 폴리펩타이드에 의해 유도되는 면역 세포에서 Ki67 및 그랜자임 B의 발현을 도시한다. 도 3a는 다중-사슬 폴리펩타이드를 이용한 치료-후(post-treatment) 다양한 시점에서 CD4+ T 세포, CD8+ T 세포, 자연 살해(NK) 세포, 및 CD19+ B 세포에서의 Ki67의 발현을 도시한다. 도 3b는 다중-사슬 폴리펩타이드를 이용한 치료-후(post-treatment) 다양한 시점에서 CD4+ T 세포, CD8+ T 세포, 자연 살해(NK) 세포, 및 CD19+ B 세포에서의 그랜자임 B의 발현을 도시한다.
도 4는 치료 후 다양한 시점에서 예시적인 다중-사슬 폴리펩타이드로 치료된 마우스로부터 제조된 비장세포에 의한 종양 저해의 효과를 도시한다.
도 5a 내지 도 5b는 대조군 식이요법을 공급받은 B6.129P2-ApoEtm1Unc/J 마우스(The Jackson Laboratory로부터 구매됨), 고지방 식이요법과 비치료, 및 고지방 식이요법을 공급받고 TGFRt15-TGFRs, 2t2, 또는 21t15-TGFRs로 치료된 마우스의 혈액에서 CD4+ T 세포, CD8+ T 세포, 자연 살해(NK) 세포, 및 CD19+ B 세포의 백분율 및 증식 속도를 도시한다. 도 5a는 각각의 대조군 및 실험군에서 상이한 세포 유형의 백분율을 도시한다. 도 5b는 각각의 대조군 및 실험군에서 상이한 세포 유형의 증식 속도를 도시한다.
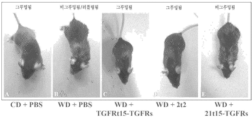
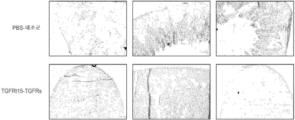
도 6의 A 내지 E는 대조군 또는 고지방 식이요법을 공급받고 비치료되거나 TGFRt15-TGFRs, 2t2, 또는 21t15-TGFRs로 치료된 마우스의 예시적인 신체적 외양을 도시한다.
도 7은 대조군 또는 고지방 식이요법을 공급받고 비치료되거나 TGFRt15-TGFRs, 2t2, 또는 21t15-TGFRs로 치료된 마우스의 공복 체중을 도시한다.
도 8은 대조군 또는 고지방 식이요법을 공급받고 비치료되거나 TGFRt15-TGFRs, 2t2, 또는 21t15-TGFRs로 치료된 마우스의 공복 혈당 수준을 도시한다.
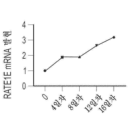
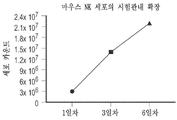
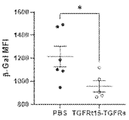
도 9a 내지 도 9f는 화학요법-유도 노쇠 B16F10 세포 및 노쇠 유전자의 발현을 도시한다. 도 9a는 SA β-gal 염색을 사용하여 시각화된 노쇠 B16F10 세포의 화학요법 유도를 도시한다. 도 9b 내지 도 9f는 화학요법-유도 노쇠 B16F10 세포에서 시간 경과에 따른 p21CIP1, IL6, DPP4, RATE1E, 및 ULBP1의 발현을 도시한다.
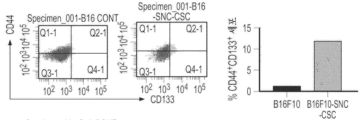
도 10a 내지 도 10f는 화학요법-유도 노쇠 B16F10 세포에 의한 콜로니 형성 및 줄기세포 마커의 발현을 도시한다. 도 10a는 화학요법-유도 노쇠 B16F10 세포에 의한 콜로니 형성을 도시한다. 도 10b 및 도 10c는 대조군 B16F10 세포와 비교하여 화학요법-유도 노쇠 B16F10 세포에 의한 Oct4 mRNA 및 Notch4 mRNA의 발현을 도시한다. 도 10d 내지 도 10f는 CD44, CD24, 및 CD133을 포함한 3개의 줄기세포 마커 중 2개에 대해 이중-양성인 화학요법-유도 노쇠 B16F10 세포의 백분율을 도시한다.
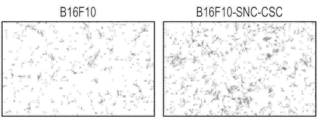
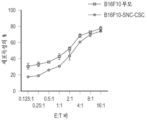
도 11a 내지 도 11c는 화학요법-유도 노쇠 B16F10 세포의 이동 및 침습 특성을 도시한다. 도 11a는 줄기세포 특성(B16F10-SNC-CSC)을 갖는 화학요법-유도 노쇠 세포를 대조군 B16F10 세포와 비교하는 이동 검정의 결과를 도시한다. 도 11b 및 도 11c는 줄기세포 특성(B16F10-SNC-CSC)을 갖는 화학요법-유도 노쇠 세포를 대조군 B16F10 세포와 비교하는 침습 검정의 결과를 도시한다.
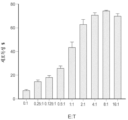
도 12a 및 도 12b는 시험관내 확장된 NK 세포 및 줄기세포 특성(B16F10-SNC-CSC)을 갖는 화학요법-유도 노쇠 세포 또는 대조군 B16F10 세포에 대한 상기 NK 세포의 세포독성을 도시한다. 도 12a는 시험관내 확장된 NK 세포를 수득하는 과정의 예시적인 개략도를 도시한다. 도 12b는 시험관내 확장된 NK 세포 및 줄기세포 특성(B16F10-SNC-CSC)을 갖는 화학요법-유도 노쇠 세포 또는 대조군 B16F10 세포에 대한 확장된 NK 세포의 세포독성을 도시한다.
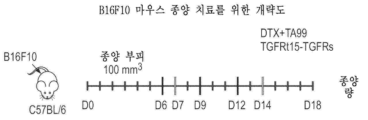
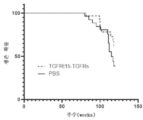
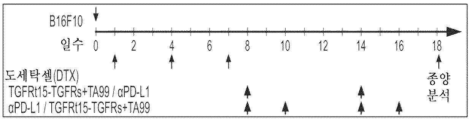
도 13a 내지 도 13c는 마우스 흑색종 모델을 사용한 병용 치료의 결과를 도시한다. 도 13a는 마우스 모델에서 흑색종을 치료하기 위한 예시적인 개략도를 도시한다. 도 13b 및 도 13c는 화학요법 또는 TA99 치료 단독과 비교하여 TGFRt15-TGFRs를 포함한 병용 치료를 이용한 시간 경과에 따른 종양 부피의 변화를 도시한다.
도 14는 대조군 SW1990 세포와 비교하여 인간 췌장 종양 세포주 SW1990에서의 노쇠의 유도 및 노쇠 SW1990 세포에서의 CD44 및 CD24의 발현을 도시한다.
도 15는 화학요법-유도 노쇠 SW1990 세포에 의한 노쇠 마커의 발현을 도시한다.
도 16은 화학요법-유도 노쇠 SW1990 세포 또는 대조군 SW1990 세포에 대한 시험관내 활성화된 인간 NK 세포의 세포독성을 도시한다.
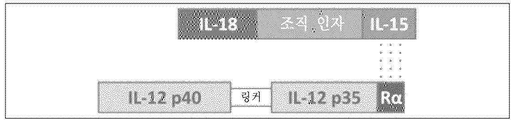
도 17은 예시적인 IL-12/IL-15RαSu DNA 작제물의 도식적 다이어그램을 도시한다.
도 18은 예시적인 IL-18/TF/IL-15 DNA 작제물의 도식적 다이어그램을 도시한다.
도 19는 예시적인 IL-12/IL-15RαSu 작제물과 IL-18/TF/IL-15 DNA 작제물 사이의 상호작용의 도식적 다이어그램을 도시한다.
도 20은 IL-18/TF/IL-15:IL-12/IL-15RαSu 복합체(18t15-12s)를 초래하는 예시적인 IL-12/IL-15RαSu 융합 단백질과 IL-18/TF/IL-15 융합 단백질 사이의 상호작용의 도식적 다이어그램을 도시한다.
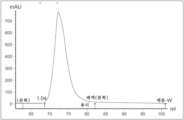
도 21은 항-TF 항체 친화도 컬럼으로부터의 18t15-12s 정제 용리의 크로마토그래프를 도시한다.
도 22는 분석적 크기 배제 컬럼 상에서의 용리 후 항-TF Ab / SEC-정제된 18t15-12s 단백질의 예시적인 크로마토그래프 프로파일을 도시하며, 이는 단백질 응집물로부터 단량체성 다중단백질 18t15-12s 복합체의 분리를 실증한다.
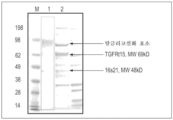
도 23은 이황화 결합 환원 후 18t15-12s 복합체의 4-12% SDS-PAGE의 일례를 도시한다. 레인 1: SeeBlue Plus2 마커; 레인 2: 항-TF Ab-정제 18t15-12s(0.5 μg); 레인 3: 항-TF Ab-정제 18t15-12s(1 μg).
도 24는 탈글리코실화된 및 비-탈글리코실화된 18t15-12s의 SDS PAGE 분석을 도시한다. 레인 1: 항-TF Ab-정제 18t15-12s(0.5 μg), 비-탈글리코실화; 레인 2: 항-TF Ab -정제 18t15-12s(1 μg), 비-탈글리코실화; 레인 3: 18t15-12s(1 μg), 탈글리코실화, 레인 4: Mark12 비염색된 마커.
도 25는 항-인간 조직 인자 항체 포착 및 비오틴화된 항-인간 IL-12 검출 항체(BAF 219)를 포함하는 18t15-12s 복합체에 대한 샌드위치 ELISA를 도시한다.
도 26은 항-인간 조직 인자 항체 포착 및 비오틴화된 항-인간 IL-15 검출 항체(BAM 247)를 포함하는 18t15-12s 복합체에 대한 샌드위치 ELISA를 도시한다.
도 27은 항-인간 조직 인자 항체 포착 및 비오틴화된 항-인간 IL-18 검출 항체(D045-6)를 포함하는 18t15-12s 복합체에 대한 샌드위치 ELISA를 도시한다.
도 28은 항-인간 조직 인자(I43) 포착 항체 및 항-인간 조직 인자 검출 항체를 포함하는 18t15-12s 복합체에 대한 샌드위치 ELISA를 도시한다.
도 29는 18t15-12s 복합체(열린 정사각형) 및 재조합 IL-15(검정색 정사각형)에 의해 매개되는 IL-15-의존적 32Dβ 세포의 증식을 도시한다.
도 30은 18t15-12s 복합체(열린 정사각형) 내에서 IL-18의 생물학적 활성을 도시하며, 이때, 재조합 IL-18(검정색 정사각형) 및 재조합 IL-12(검정색 원형)는 각각 양성 대조군 및 음성 대조군으로서 역할을 한다.
도 31은 18t15-12s 복합체(열린 정사각형) 내에서 IL-12의 생물학적 활성을 도시하며, 이때, 재조합 IL-12(검정색 원형) 및 재조합 IL-18(열린 정사각형)은 각각 양성 대조군 및 음성 대조군으로서 역할을 한다.
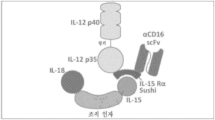
도 32a 및 도 32b는 18t15-12s 복합체에 의해 유도되는 NK 세포 상에서의 CD25의 세포-표면 발현 및 18t15-12s 복합체에 의해 유도되는 NK 세포의 세포-표면 CD69 발현을 도시한다.
도 33은 18t15-12s 복합체에 의해 유도되는 NK 세포의 세포내 IFN-γ 발현의 유세포측정법 그래프를 도시한다.
도 34는 K562 세포에 대한 18t15-12s-유도 인간 NK 세포의 세포독성을 도시한다.
도 35는 예시적인 IL-12/IL-15RαSu/αCD16 DNA 작제물의 도식적 다이어그램을 도시한다.
도 36은 예시적인 IL-18/TF/IL-15 DNA 작제물의 도식적 다이어그램을 도시한다.
도 37은 예시적인 IL-12/IL-15RαSu/αCD16scFv DNA 작제물과 IL-18/TF/IL-15 DNA 작제물 사이의 상호작용의 도식적 다이어그램을 도시한다.
도 38은 예시적인 18t15-12s/αCD16 단백질 복합체의 도식적 다이어그램을 도시한다.
도 39는 항-인간 조직 인자 항체 포착 및 비오틴화된 항-인간 IL-12(BAF 219)(진한 선) 또는 항-인간 조직 인자 검출 항체(연한 선)을 포함하는 18t15-12s16 복합체에 대한 샌드위치 ELISA를 도시한다.
도 40은 예시적인 TGFβRII/IL-15RαSu DNA 작제물의 도식적 다이어그램을 도시한다.
도 41은 예시적인 IL-21/TF/IL-15 작제물의 도식적 다이어그램을 도시한다.
도 42는 예시적인 IL- IL-21/TF/IL-15 작제물과 TGFβRII/IL-15RαSu 작제물 사이의 상호작용의 도식적 다이어그램을 도시한다.
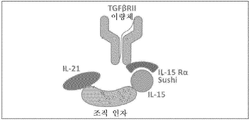
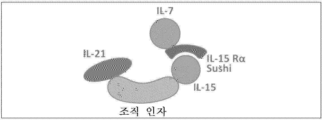
도 43은 IL-21/TF/IL-15/TGFβRII/IL-15RαSu 복합체(21t15-TGFRs)를 초래하는 예시적인 TGFβRII/IL-15RαSu 융합 단백질과 IL-21/TF/IL-15 융합 단백질 사이의 상호작용의 도식적 다이어그램을 도시한다.
도 44는 항-TF 항체 친화도 컬럼으로부터의 21t15-TGFRs 정제 용리의 크로마토그래프를 도시한다.
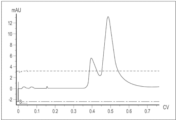
도 45는 주요 단백질 피크 및 고분자량 피크를 나타내는 예시적인 21t15-TGFRs 크기 배제 크로마토그래프를 도시한다.
도 46은 이황화 결합 환원 후 21t15-TGFRs 복합체의 4-12% SDS-PAGE의 일례를 도시한다. 레인 1: Mark12 비염색된 마커(좌측면 상의 숫자는 분자량을 kDa으로 나타냄); 레인 2: 21t15-TGFRs(0.5 μg); 레인 3: 21t15-TGFRs(1 μg); 레인 4: 21t15-TGFRs, 탈글리코실화된(1 μg), 여기서 MW는 53 kDa 및 39.08 kDa의 예상된 크기였다.
도 47은 항-인간 조직 인자 포착 및 비오틴화된 항-인간 IL-21 검출 항체(13-7218-81, BioLegend)를 포함하는 21t15-TGFRs 복합체에 대한 샌드위치 ELISA를 도시한다.
도 48은 항-인간 조직 인자 항체 포착 및 비오틴화된 항-인간 IL-15 검출 항체(BAM 247, R&D Systems)를 포함하는 21t15-TGFRs 복합체에 대한 샌드위치 ELISA를 도시한다.
도 49는 항-인간 조직 인자 항체 포착 및 비오틴화된 항-인간 TGFβRII 검출 항체(BAF241, R&D Systems)를 포함하는 21t15-TGFRs 복합체에 대한 샌드위치 ELISA를 도시한다.
도 50은 항-인간 조직 인자(I43) 포착 항체 및 항-인간 조직 인자 검출 항체를 포함하는 21t15-TGFRs 복합체에 대한 샌드위치 ELISA를 도시한다.
도 51은 IL-15(검정색 정사각형)와 비교하여 21t15-TGFRs 복합체(열린 정사각형)에 의해 매개되는 32Dβ 세포의 IL-15-의존적 증식을 도시한다.
도 52는 21t15-TGFRs 복합체(열린 정사각형) 내에서 TGFβRII 도메인의 생물학적 활성을 도시한다. TGFβRII/Fc(검정색 정사각형)는 양성 대조군으로서 역할을 하였다.
도 53은 21t15-TGFRs 복합체에 의해 유도되는 NK 세포의 세포내-표면 CD25 발현의 유세포측정법 그래프를 도시한다.
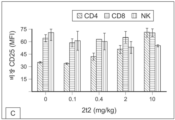
도 54는 21t15-TGFRs 복합체에 의해 유도되는 NK 세포의 세포내-표면 CD69 발현의 유세포측정법 그래프를 도시한다.
도 55는 21t15-TGFRs 복합체에 의해 유도되는 NK 세포의 세포내 IFN-γ 발현의 유세포측정법 그래프를 도시한다.
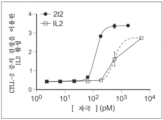
도 56은 K562 세포에 대한 21t15-TGFRs-유도 인간 NK 세포의 세포독성을 도시한다.
도 57은 예시적인 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드의 도식적인 다이어그램이다.
도 58은 항-조직 인자 친화도 컬럼으로부터 예시적인 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드의 용리를 보여주는 크로마토그래프이다.
도 59는 예시적인 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드가 로딩된 Superdex 200 Increase 10/300 GL 겔 여과 컬럼의 용리를 나타내는 크로마토그래프이다.
도 60은 항-조직 인자 친화도 컬럼을 사용하여 정제된 예시적인 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드의 소듐 도데실 설페이트 폴리아크릴아미드 겔(4-12% NuPage Bis-Tris 겔)이다.
도 61은 실시예 1에 기재된 방법을 사용하여 수행된 예시적인 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드의 ELISA 정량화를 나타내는 그래프이다. 정제된 조직 인자는 대조군으로서 사용되었다.
도 62는 2명의 공여자의 혈액으로부터 단리된 CD4+ T-세포에서 CD25 발현을 자극시키는 예시적인 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드의 능력을 나타내는 그래프이다. 실험은 실시예 2에 기재된 바와 같이 수행되었다.
도 63은 2명의 공여자의 혈액으로부터 단리된 CD8+ T-세포에서 CD25 발현을 자극시키는 예시적인 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드의 능력을 나타내는 그래프이다. 실험은 실시예 2에 기재된 바와 같이 수행되었다.
도 64는 2명의 공여자의 혈액으로부터 단리된 CD4+ T-세포에서 CD69 발현을 자극시키는 예시적인 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드의 능력을 나타내는 그래프이다. 실험은 실시예 2에 기재된 바와 같이 수행되었다.
도 65는 예시적인 IL-7/IL-15RαSu DNA 작제물의 도식적 다이어그램을 도시한다.
도 66은 예시적인 IL-21/TF/IL-15 DNA 작제물의 도식적 다이어그램을 도시한다.
도 67은 예시적인 IL-7/IL-15RαSu DNA 작제물과 IL-21/TF/IL-15 DNA 작제물 사이의 상호작용의 도식적 다이어그램을 도시한다.
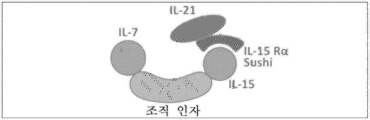
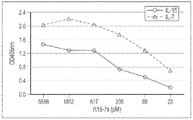
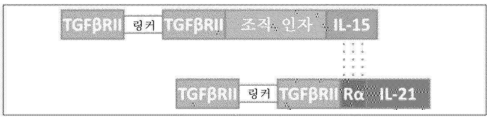
도 68은 IL-21/TF/IL-15:IL-7/IL-15RαSu 복합체(21t15-7s)를 초래하는 예시적인 IL-7/IL-15RαSu 융합 단백질과 IL-21/TF/IL-15 융합 단백질 사이의 상호작용의 도식적 다이어그램을 도시한다.
도 69는 예시적인 IL-21/IL-15RαSu DNA 작제물의 도식적 다이어그램을 도시한다.
도 70은 예시적인 IL-7/TF/IL-15 DNA 작제물의 도식적 다이어그램을 도시한다.
도 71은 예시적인 IL-21/IL-15RαSu DNA 작제물과 IL-7/TF/IL-15 DNA 작제물 사이의 상호작용의 도식적 다이어그램을 도시한다.
도 72는 IL-7/TF/IL-15:IL-21/IL-15RαSU 복합체(7t15-21s)를 초래하는 예시적인 IL-21/IL-15RαSu 융합 단백질과 IL-7/TF/IL-15 융합 단백질 사이의 상호작용의 도식적 다이어그램을 도시한다.
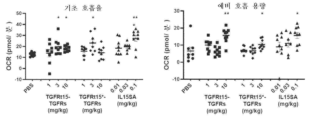
도 73은 2명의 상이한 공여자의 혈액(2 x 106개 세포/mL)으로부터 단리된 인간 NK 세포에 대한 산소 소모율(OCR: oxygen consumption rate)을 pmoles/분으로 도시한다.
도 74는 세포외 산성화율(ECAR: extracellular acidification rate)을
2명의 상이한 공여자의 혈액(2 x 106개 세포/mL)으로부터 단리된 인간 NK 세포에 대해 mpH/분으로 도시한다.
도 75는 7t15-16s21 작제물의 도식을 도시한다.
도 76은 7t15-16s21 작제물의 추가 도식을 도시한다.
도 77a 및 도 77b는 대조군 단백질과 비교하여 인간 CD16b를 발현하는 CHO 세포에의 7t15-16s21의 결합을 도시한다.
도 78a 내지 도 78c는 7t15-16s21을 검출하는 데 있어서 IL-15, IL-21, 및 IL-7에 대한 항체를 사용한 ELISA 실험으로부터의 결과이다.
도 79는 7t15-16s21 또는 재조합 IL-15를 이용한 32Dβ 세포 증식 검정법의 결과를 도시한다.
도 80은 항-TF 항체 수지 상에서 결합 및 용리 후 7t15-16s21 단백질-함유 세포 배양물 상청액의 크로마토그래프 프로파일을 도시한다.
도 81은 7t15-16s21의 분석적 SEC 프로파일을 도시한다.
도 82는 TGFRt15-16s21 작제물의 도식을 도시한다.
도 83은 TGFRt15-16s21 작제물의 추가 도식을 도시한다.
도 84a 및 도 84b는 인간 CD16b를 발현하는 CHO 세포와 TGFRT15-16S21 및 7t15-21s의 결합 친화도를 도시한다. 도 84a는 인간 CD16b를 발현하는 CHO 세포와 TGFRT15-16S21의 결합 친화도를 도시한다. 도 84b는 인간 CD16b를 발현하는 CHO 세포와 7t15-21s의 결합 친화도를 도시한다.
도 85는 TGFRt15-16s21 및 TGFR-Fc에 의한 TGFβ1 저해의 결과를 도시한다.
도 86는 TGFRt15-16s21 또는 재조합 IL-15를 이용한 32Dβ 세포 증식 검정법의 결과를 도시한다.
도 87a 내지 도 87c는 ELISA를 사용하여 TGFRt15-16s21에서 IL-15, IL-21, 및 TGFβRII를 상응하는 항체로 검출하는 결과를 도시한다.
도 88은 항-TF 항체 수지 상에서 결합 및 용리 후 TGFRt15-16s21 단백질-함유 세포 배양물 상청액의 크로마토그래프 프로파일을 도시한다.
도 89는 TGFRt15-16s21의 환원된 SDS-PAGE 분석의 결과를 도시한다.
도 90은 7t15-7s 작제물의 도식을 도시한다.
도 91은 7t15-7s 작제물의 추가 도식을 도시한다.
도 92는 항-TF 항체 수지 상에서 결합 및 용리 후 7t15-7s 단백질-함유 세포 배양물 상청액의 크로마토그래프 프로파일을 도시한다.
도 93은 ELISA를 사용하여 7t15-7s에서 TF, IL-15 및 IL-7의 검출을 도시한다.
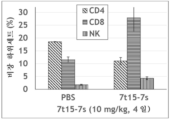
도 94a 및 도 94b는 7t15-7s-치료 마우스 및 대조군-치료 마우스에서 비장 중량 및 면역 세포 유형의 백분율을 도시한다. 도 94a는 PBS 대조군과 비교하여, 7t15-7s로 치료된 마우스에서 비장 중량을 도시한다. 도 94b는 PBS 대조군과 비교하여, 7t15-7s로 치료된 마우스에서 CD4+ T 세포, CD8+ T 세포, 및 NK 세포의 백분율을 도시한다.
도 95는 TGFRt15-TGFRs 작제물의 도식을 도시한다.
도 96은 TGFRt15-TGFRs 작제물의 추가 도식을 도시한다.
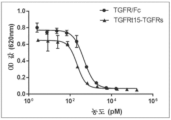
도 97은 TGFRt15-TGFRs 및 TGFR-Fc에 의한 TGFβ1 저해의 결과를 도시한다.
도 98은 TGFRt15-TGFRs 또는 재조합 IL-15를 이용한 32Dβ 세포 증식 검정법의 결과를 도시한다.
도 99a 및 도 99b는 ELISA를 사용하여 TGFRt15-TGFRs에서 IL-15 및 TGFβRII를 상응하는 항체로 검출하는 결과를 도시한다.
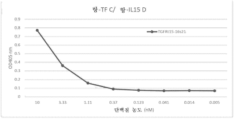
도 100은 항-TF 항체 수지 상에서 결합 및 용리 후 TGFRt15-TGFRs 단백질-함유 세포 배양물 상청액의 크로마토그래프 프로파일을 도시하는 선 그래프이다.
도 101은 TGFRt15-TGFRs의 분석적 SEC 프로파일을 도시한다.
도 102는 환원된 SDS-PAGE에 의해 분석된 바와 같은 탈글리코실화 전과 후의 TGFRt15-TGFRs를 도시한다.
도 103a 및 도 103b는 TGFRt15-TGFRs-치료 마우스 및 대조군-치료 마우스에서 비장 중량 및 면역 세포 유형의 백분율을 도시한다. 도 103a는 PBS 대조군과 비교하여, TGFRt15-TGFRs로 치료된 마우스에서 비장 중량을 도시한다. 도 103b는 PBS 대조군과 비교하여, TGFRt15-TGFRs로 치료된 마우스에서 CD4+ T 세포, CD8+ T 세포, 및 NK 세포의 백분율을 도시한다.
도 104a 및 도 104b는 TGFRt15-TGFRs로 치료된 마우스에서 92시간에 걸친 비장 중량 및 면역자극을 도시한다. 도 104a는 치료 후 16시간, 24시간, 48시간, 72시간, 및 92시간째에 TGFRt15-TGFRs로 치료된 마우스의 비장 중량을 도시한다. 도 104b는 치료 후 16시간, 24시간, 48시간, 72시간, 및 92시간째에 TGFRt15-TGFRs로 치료된 마우스에서 면역 세포의 백분율을 도시한다.
도 105a 및 도 105b는 시간 경과에 따른 TGFRt15-TGFRs로 치료된 마우스에서 Ki67 및 그랜자임 B 발현을 도시한다.
도 106은 C57BL/6 마우스에서 TGFRt15-TGFRs에 의한 비장세포의 세포독성의 증강을 도시한다.
도 107은 췌장암 마우스 모델에서, PBS 치료, 화학치료법 단독, TGFRt15-TGFRs 단독, 또는 화학치료법과 TGFRt15-TGFRs 병용에 반응하는 종양 크기의 변화를 도시한다.
도 108은 TGFRt15-TGFRs로 치료된 마우스에서 단리된 NK 세포의 세포독성을 도시한다.
도 109는 7t15-21s137L(롱 버전) 작제물의 도식을 도시한다.
도 110은 7t15-21s137L(롱 버전) 작제물의 추가 도식을 도시한다.
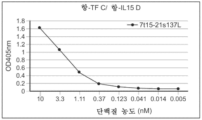
도 111은 항-TF 항체 수지 상에서 결합 및 용리 후 7t15-21s137L(롱 버전) 단백질-함유 세포 배양물 상청액의 크로마토그래프 프로파일을 도시하는 선 그래프이다.
도 112는 7t15-21s137L(롱 버전)의 분석적 SEC 프로파일을 도시한다.
도 113은 CD137L(4.1BBL)에의 7t15-21s137L(쇼트 버전)의 결합을 도시한다.
도 114a 내지 도 114c는 7t15-21s137L(쇼트 버전)에서 ELISA를 이용한 IL-15, IL21, 및 IL7의 검출을 도시한다. 도 114a는 7t15-21s137L(쇼트 버전)에서 ELISA를 이용한 IL-15의 검출을 도시한다. 도 114b는 7t15-21s137L(쇼트 버전)에서 ELISA를 이용한 IL21의 검출을 도시한다. 도 114c는 7t15-21s137L(쇼트 버전)에서 ELISA를 이용한 IL7의 검출을 도시한다.
도 115는 CTLL-2 세포 증식 검정법으로부터의 결과를 도시한다.
도 116은 IL21R-함유 B9 세포 증식을 촉진하는 데 있어서 7t15-1s137L(쇼트 버전)의 활성을 도시한다.
도 117은 7t15-TGFRs 작제물의 도식을 도시한다.
도 118은 7t15-TGFRs 작제물의 추가 도식을 도시한다.
도 119는 7t15-TGFRs 및 TGFR-Fc에 의한 TGFβ1 저해의 결과를 도시한다.
도 120a 내지 도 120c는 ELISA를 이용한 7t15-TGFRs에서의 IL-15, TGFβRII, 및 IL-7의 검출을 도시한다.
도 121은 7t15-TGFRs 또는 재조합 IL-15를 이용한 32Dβ 세포 증식 검정법의 결과를 도시한다.
도 122는 항-TF 항체 수지 상에서 결합 및 용리 후 7t15-TGFRs 단백질-함유 세포 배양물 상청액의 크로마토그래프 프로파일을 도시하는 선 그래프이다.
도 123은 환원된 SDS-PAGE을 사용하여 분석된 바와 같은 탈글리코실화 전과 후의 7t15-TGFRs를 도시한다.
도 124는 7t15-TGFRs 단백질에서 IL-7, IL-15 및 TGFβRII의 ELISA 검출을 도시한다.
도 125a 및 도 125b는 7t15-TGFRs-치료 마우스 및 대조군-치료 마우스에서 비장 중량 및 면역 세포 유형의 백분율을 도시한다. 도 125a는 PBS 대조군과 비교하여, 다양한 투약량에서 7t15-TGFRs로 치료된 마우스에서 비장 중량을 도시한다. 도 125b는 PBS 대조군과 비교하여, 다양한 투약량에서 7t15-TGFRs로 치료된 마우스에서 CD4+ T 세포, CD8+ T 세포, 및 NK 세포의 백분율을 도시한다.
도 126a 및 도 126b는 C57BL/6 마우스에서 7t15-TGFRs에 의한 CD4+ T 세포 및 CD8+ T 세포의 CD44 발현의 상향조절을 도시한다.
도 127a 및 도 127b는 C57BL/6 마우스에서 7t15-TGFRs에 의한 CD8+ T 세포 및 NK 세포의 Ki67 발현 및 그랜자임 B 발현의 상향조절을 도시한다.
도 128은 C57BL/6 마우스에서 7t15-TGFRs에 의한 비장세포의 세포독성의 증강을 도시한다.
도 129는 TGFRt15-21s137L 작제물의 도식을 도시한다.
도 130은 TGFRt15-21s137L 작제물의 추가 도식을 도시한다.
도 131은 항-TF 항체 수지 상에서 결합 및 용리 후 TGFRt15-21s137L 단백질-함유 세포 배양물 상청액의 크로마토그래프 프로파일을 도시하는 선 그래프이다.
도 132는 TGFRt15-TGFRs21 작제물의 도식을 도시한다.
도 133은 TGFRt15-TGFRs21 작제물의 추가 도식을 도시한다.
도 134는 항-TF 항체 수지 상에서 결합 및 용리 후 TGFRt15-TGFRs21 단백질-함유 세포 배양물 상청액의 크로마토그래프 프로파일을 도시하는 선 그래프이다.
도 135는 환원된 SDS-PAGE에 의해 분석된 바와 같은 탈글리코실화 전과 후의 TGFRt15-TGFRs21을 도시한다.
도 136a 및 도 136b는 ELISA를 사용한 TGFRt15-TGFRs21의 구성요소의 검출을 도시한다.
도 137a 및 도 137b는 대조군-치료 마우스 및 TGFRt15-TGFRs21-치료 마우스의 비장에 존재하는 CD4+ T 세포, CD8+ T 세포, 및 자연 살해(NK) 세포의 백분율 및 증식을 도시한다.
도 138은 TGFRt15-TGFRs21로 치료된 마우스에서 비장세포의 그랜자임 B 발현의 상향조절을 도시한다.
도 139는 C57BL/6 마우스에서 TGFRt15-TGFRs21에 의한 비장세포의 세포독성의 증강을 도시한다.
도 140은 TGFRt15-TGFRs16 작제물의 도식을 도시한다.
도 141은 TGFRt15-TGFRs16 작제물의 추가 도식을 도시한다.
도 142는 TGFRt15-TGFRs137L 작제물의 도식을 도시한다.
도 143은 TGFRt15-TGFRs137L 작제물의 추가 도식을 도시한다.
도 144는 예시적인 2t2 단일-사슬 키메라 폴리펩타이드의 도식적인 다이어그램이다.
도 145는 32Dβ 세포 증식 검정법을 사용하여 재조합 IL-2와 비교하여 2t2에서의 IL-2활성을 도시한다.
도 146은 CTLL-2 세포 증식 검정법을 사용하여 재조합 IL-2와 비교하여 2t2에서의 IL-2활성을 도시한다.
도 147은 표준 사료 또는 고지방 식이요법으로 사육되고 PBS 대조군으로 치료되거나(비치료) 2t2로 치료된 ApoE-/- 마우스에서 공복 혈중 포도당 수준을 도시한다.
도 148은 표준 사료 또는 고지방 식이요법으로 사육되고 PBS 대조군으로 치료되거나(비치료) 2t2로 치료된 ApoE-/- 마우스로부터의 혈액 림프구에서 CD4+CD25+FoxP3+ T 조절 세포의 비를 도시한다.
도 149는 항-TF 항체 수지 상에서 결합 및 용리 후 2t2 단백질-함유 세포 배양물 상청액의 크로마토그래프 프로파일을 도시하는 선 그래프이다.
도 150은 2t2의 분석적 SEC 프로파일을 도시한다.
도 151a 및 도 151b는 탈글리코실화 전 및 후에 2t2의 환원된 SDS-PAGE 분석을 도시한다. 도 151a는 탈글리코실화 전에 2t2의 환원된 SDS-PAGE 분석을 도시한다. 도 151b는 탈글리코실화 후에 2t2의 환원된 SDS-PAGE 분석을 도시한다.
도 152a 및 도 152b는 C57BL/6 마우스에서 2t2를 사용한 면역자극의 결과를 도시한다. 도 152a는 2t2로 치료한 후 비장 중량을 도시한다. 도 152b는 2t2 치료 후 면역 세포 유형의 백분율을 도시한다.
도 153은 2t2로 치료된 마우스에서 CD4+ T 세포의 CD25 발현의 상향조절을 도시한다.
도 154는 C57BL/6 마우스에서 2t2의 약물동력학을 도시한다.
도 155a 및 도 155b는 ApoE-/- 마우스에서 고지방-유도 아테롬성 동맥경화증 플라크(plaque)의 형성을 감쇠시키는(attenuate) 데 있어서 2t2의 효과를 도시한다. 도 155a는 표준 사료 또는 고지방 식이요법으로 사육되고 PBS 대조군 또는 2t2로 치료된 ApoE-/- 마우스로부터의 아테롬성 동맥경화증 플라크의 대표도를 도시한다. 도 155b는 각각의 군의 아테롬성 동맥경화증 플라크의 정량적 분석의 결과를 도시한다.
도 156은 대조군-치료 마우스와 비교하여 2t2 치료-마우스에서 공복 포도당 수준을 도시한다.
도 157은 2t2로 치료된 마우스 및 대조군-치료 마우스로부터의 혈액 림프구에서 CD4+CD25+FoxP3+ Tregs의 백분율을 도시한다.
도 158은 예시적인 15t15 단일-사슬 키메라 폴리펩타이드의 도식적인 다이어그램이다.
도 159는 32Dβ 세포 증식 검정법을 사용하여 재조합 IL-15와 비교하여 15t15에서의 IL-15 활성을 도시한다.
도 160은 항-TF 항체 수지 상에서 결합 및 용리 후 15t15 단백질-함유 세포 배양물 상청액의 크로마토그래프 프로파일을 도시하는 선 그래프이다.
도 161a 및 도 161b는 탈글리코실화 전 및 후에 15t15의 환원된 SDS-PAGE 분석을 도시한다. 도 161a는 탈글리코실화 전에 15t15의 환원된 SDS-PAGE 분석을 도시한다. 도 161b는 탈글리코실화 후에 15t15의 환원된 SDS-PAGE 분석을 도시한다.
도 162a 및 도 162b는 18t15-12s, 18t15-12s16, 및 7t15-21s + 항-TF 항체로 자극 후의 NK 세포의 표면 표현형의 변화를 도시하는 한 세트의 히스토그램(도 162a) 및 한 세트의 그래프(도 162b)이다.
도 163은 18t15-12s, 18t15-12s16, 및 7t15-21s로 자극 후, 림프구 집단의 표면 표현형의 변화를 도시하는 한 세트의 그래프이다.
도 164는 18t15-12s로 치료 후 NK 세포에서의 해당작용의 증가를 도시하는 한 세트의 그래프이다.
도 165는 18t15-12s로 자극 후, NK 세포에서 포스포-STAT4 및 포스포-STAT5 수준의 증가를 도시하는 한 세트의 그래프이다.
도 166은 18t15-12s를 이용한 NK 세포의 밤새 자극이 세포 대사를 증강시킴을 도시하는 한 세트의 그래프이다.
도 167a 내지 도 167c는 2t2로 치료 후, C57BL/6 마우스에서 면역자극을 도시하는 한 세트의 그래프이다.
도 168a 및 도 168b는 TGFRt15-TGFRs로 치료 후, C57BL/6 마우스에서 면역자극을 도시하는 한 세트의 그래프이다.
도 169a 내지 도 169c는 서구 식이요법으로 사육되고 TGFRt15-TGFRs 또는 2t2로 치료된 ApoE-/- 마우스에서 Tregs, NK 세포, 및 CD8+ T 세포의 생체내 자극을 도시하는 한 세트의 그래프이다.
도 170a 및 도 170b는 C57BL/6 마우스에서 2t2에 의한 비장세포 증식의 유도를 도시하는 한 세트의 그래프이다.
도 171a 내지 도 171c는 TGFRt15-TGFRs로 치료 후, C57BL/6 마우스에서 면역자극을 도시하는 한 세트의 그래프이다.
도 172a 및 도 172b는 서구 식이요법으로 사육되고 TGFRt15-TGFRs 또는 2t2로 치료된 ApoE-/- 마우스에서 NK 세포 및 CD8+ T 세포의 생체내 증식 유도를 도시하는 한 세트의 그래프이다.
도 173은 7t15-21, TGFRt15-TGFRs 또는 2t2로 치료 후, NSG 마우스에서 7t15-21s 및 항-TF 항체-확장 NK 세포의 지속성을 도시하는 개략도 및 한 세트의 그래프이다.
도 174a 및 도 174b는 NK 세포를 TGFRt15-TGFRs로 처리한 후, NK 세포의 세포독성의 증강을 도시하는 한 세트의 그래프이다.
도 175a 및 도 175b는 NK 세포를 TGFRt15-TGFRs로 처리한 후, NK 세포의 ADCC 활성의 증강을 도시하는 한 세트의 그래프이다.
도 176은 TGFRt15-TGFRs/2t2-활성화된 마우스 NK 세포에 의한 노쇠 B16F10 흑색종 세포의 시험관내 사멸의 그래프이다.
도 177a 내지 도 177h는 흑색종 마우스 모델에서 화학치료법과 병용된 TGFRt15-TGFRs + 항-TRP1 항체(TA99)의 항종양 활성을 도시하는 한 세트의 그래프이다.
도 178a 내지 도 178c는 ApoE-/- 마우스에서 2t2에 의한 서구 식이요법-유도 고혈당의 개선을 도시하는 한 세트의 그래프이다.
도 179는 18t15-12s를 이용하여 자극되고 rhIL-15에서 배양된 후, NK 세포로부터 사이토카인-유도 기억 유사 NK 세포(CIML-NK 세포)로의 분화를 요약하는 세포 표면 염색을 도시하는 한 세트의 그래프이다.
도 180은 CD44 기억 T 세포의 상향조절을 도시한다. 상부 패널은 TGFRt15-TGFRs로 치료 시 CD44 기억 T 세포의 상향조절을 도시한다. 하부 패널은 2t2로 치료 시 CD44 기억 T 세포의 상향조절을 도시한다.
도 181a 및 도 181b는 2t2 또는 IL-2로 치료된 마우스에서 제모 후 모발 재성장의 향상을 도시한다. 도 181a는 PBS-치료, 2t2-치료, 또는 IL-2-치료 마우스에서 제모 후 10일째의 피부 색소침착을 도시한다. 도 181b는 ImageJ 소프트웨어를 사용하여 분석된 바와 같은 PBS-치료, 2t2-치료, 또는 IL-2-치료 마우스에서 색소침착 백분율을 도시한다.
도 182는 PBS-치료, 2t2-치료, 또는 IL-2-치료 마우스에서 제모 후 14일째의 피부 색소침착을 도시한다.
도 183은 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드에 의한 치료 후 인자 X(FX) 활성화의 그래프를 도시한다.
도 184는 프로트롬빈 시간(PT) 시험에서 다양한 농도의 인노빈을 포함하는 완충액에 대한 응고 시간을 도시한다.
도 185는 PT 검정법에서 다중-사슬 키메라 폴리펩타이드에 대한 응고 시간을 도시한다.
도 186은 32DB 세포와 혼합될 때 PT 검정법에서 다중-사슬 키메라 폴리펩타이드의 응고 시간을 도시한다.
도 187은 인간 PBMC와 혼합될 때 PT 검정법에서 다중-사슬 키메라 폴리펩타이드의 응고 시간을 도시한다.
도 188은 CD137(4.1BB)에의 7t15-21s137L(롱 버전) 및 7t15-21s137L(쇼트 버전)의 결합을 도시한다.
도 189a 내지 도 189d는 ELISA를 사용하여 7t15-21s137L(롱 버전)에서 각각의 항체에 의한 IL7, IL21, IL15, 및 4.1BBL의 검출을 도시한다.
도 190은 IL2Rαβγ-함유 CTLL2 세포 증식 검정법에 의해 평가된 바와 같이 7t15-21s137L(롱 버전) 및 7t15-21s137L(쇼트 버전)의 IL-15 활성을 도시한다.
도 191a 내지 도 191c는 2t2 또는 IL2 치료에 반응하여 CD4+CD25hiTreg 세포, CD4+CD25-Tcon 세포, 또는 CD8+ Tcon 세포에서 인간 혈액 림프구 pStat5a 반응을 도시한다. 도 191a는 CD4+CD25hiTreg 세포에서 pSTAT5 반응을 도시한다. 도 C191b는 CD4+CD25-Tcon 세포에서 pSTAT5 반응을 도시한다. 도 191c는 CD8+ Tcon 세포에서 pSTAT5 반응을 도시한다.
도 192a 내지 도 192e는 IL-2 기초 분자(2t2)를 이용한 치료가 마우스 모델에서 제모 후 모낭의 형성을 유도할 수 있음을 도시하는 한 세트의 이미지이다. 도 192a는 대조군 마우스로부터의 이미지이며 - 털이 면도된 후 수행된 제모 단독, 도 192b는 제모에 뒤이어 저용량의 IL-2(1 mg/kg) 투여가 이어진 마우스로부터의 이미지이고, 도 192c 내지 도 192e는 제모에 뒤이어 0.3 mg/kg(도 192c), 1 mg/kg(도 192d), 및 (도 192e) 3 mg/kg에서의 2t2가 이어진 마우스로부터의 이미지를 도시한다. 검정색 화살표는 이후에 피부 내로 연장되고 모발 성장을 용이하게 할 생장기 모낭을 나타낸다.
도 193은 각각의 치료군에 대해 10개 필드당 카운팅된 생장기 모낭의 총 수를 도시한다.
도 194는 7t15-21s+ 항-조직 인자(TF)-항체(IgG1)(50 nM)를 이용한 확장 후 2명의 상이한 공여자로부터의 NK 세포(비노출된 NK 세포에 비해)에서의 DNA 탈메틸화에서 상이한 백분율을 도시하는 그래프이다.
도 195는 TGFRt15-TGFRs를 이용한 단회 용량 치료 후 4일 후의 말초 혈액 분석으로부터의 면역-표현형을 도시하는 한 세트의 그래프이다.
도 196은 TGFRt15-TGFRs를 이용한 단회 용량 치료 후 4일 후의 말초 혈액 분석으로부터의 면역-표현형을 도시하는 한 세트의 그래프이다.
도 197은 TGFRt15-TGFRs를 이용한 제2 투여 후 7일째에 FACS에 의한 β-Gal 염색 분석을 도시하는 그래프이다.
도 198은 TGFRt15-TGFRs를 이용한 제2 투여 후 7일째에 qPCR을 사용하여 결정된 간 조직에서의 노쇠 마커의 수준을 도시하는 한 세트의 그래프이다.
도 199는 TGFRt15-TGFRs를 이용한 제2 투여 후 7일째에 qPCR을 사용하여 결정된 신장 조직에서의 노쇠 마커의 수준을 도시하는 한 세트의 그래프이다.
도 200은 TGFRt15-TGFRs를 이용한 제2 투여 후 7일째에 qPCR을 사용하여 결정된 피부 조직에서의 노쇠 마커의 수준을 도시하는 한 세트의 그래프이다.
도 201은 TGFRt15-TGFRs를 이용한 제2 투여 후 7일째에 qPCR을 사용하여 결정된 폐 조직에서의 노쇠 마커의 수준을 도시하는 한 세트의 그래프이다.
도 202는 TGFRt15-TGFRs를 이용한 제2 치료 후 7일째에 신장 조직 상에서의 β-Gal 염색을 도시하는 한 세트의 조직학적 이미지이다.
도 203a 내지 도 203c는 화학요법이 C57BL/6 마우스에서 p21CIP1p21 노쇠-관련 유전자 발현을 유도함을 도시한다. 도 203a는 실험 치료 계획을 도시하는 예시적인 개략도이다. 도 203b 및 도 203c는 폐(b) 및 간(c) 조직 각각에서 p21CIP1p21의 발현을 도시하는 그래프이다.
도 204는 치료 후 3일차에 IL-15-기초 제제를 이용한 치료 후 면역-표현형 및 세포 증식을 도시하는 한 세트의 그래프이다.
도 205a 내지 도 205c는 TGFRt15-TGFRs 치료가 C57BL/6 마우스에서 노쇠-관련 유전자 발현을 감소시킴을 도시하는 그래프이다. 그래프는 폐에서의 p21CIP1p21과 CD26(a와 b) 및 간(c) 조직에서의 p21CIP1p21의 발현을 도시한다.
도 206은 CD4+, CD8+, 및 Treg 세포 백분율 및 증식을 도시하는 한 세트의 그래프이다.
도 207은 NK, CD19+ 및 단핵구 세포 백분율 및 증식을 도시하는 한 세트의 그래프이다.
도 208a 내지 도 208c는 폐 및 간 조직에서 노쇠 마커 p21CIP1p21 및 CD26의 평가를 도시하는 그래프이다. 도 208a 및 도 208b는 폐 p21CIP1p21(a) 및 폐 CD26(b) 노쇠 마커를 도시한다. 도 208c는 간 p21CIP1p21 노쇠 마커를 도시한다.
도 209는 TGFRt15*-TGFRs 복합체를 초래하는 예시적인 TGFβRII/IL-15RαSu와 TGFβRII/TF/IL-15Mut 단백질 사이의 상호작용의 도식적 다이어그램을 도시한다.
도 210은 예시적인 TGFβRII/IL-15RαSu와 TGFβRII/TF/IL-15Mut 단백질 사이의 상호작용의 도식적 다이어그램을 도시한다.
도 211a는 TGF-β1 및 LAP에의 TGFRt15-TGFRs의 결합 활성을 도시하는 그래프이다.
도 211b는 TGF-β1 및 LAP에의 TGFRII/Fc의 결합 활성을 도시하는 그래프이다.
도 211c는 TGF-β1 및 LAP에의 TGFRt15-TGFRs의 결합 활성을 도시하는 그래프이다.
도 211d는 TGF-β1 및 LAP에의 TGFRt15*-TGFRs의 결합 활성을 도시하는 그래프이다.
도 211e는 CTLL-2에의 TGFRt15-TGFRs, TGFRt15*-TGFRs, 및 7t15-21s의 결합 활성을 도시하는 그래프이다.
도 212a는 TGFRt15-TGFRs 및 TGFRt15*-TGFRs의 TGF- β 1 차단 활성의 그래프이다.
도 212b는 TGFRt15-TGFRs 및 TGFRt15*-TGFRs의 IL-15 생물학적 활성의 그래프이다.
도 212c는 TGF-β1, TGF-β2, 및 TGF-β3이 각각 TGFRt15*-TGFRs의 부재 하에 IL-4-유도 CTLL-2 성장을 유사하게 저해함을 도시하는 그래프이다.
도 212d는 TGFRt15*-TGFRs가 IL-4-유도 CTLL-2 세포 성장의 TGF-β1 및 TGF-β3의 저해를 유의하게 역전시켰음을 도시하는 그래프이다.
도 213a는 4°C, 25°C, 또는 37°C에서의 10-일 인큐베이션 후 TGFRt15-TGFRs의 IL-15 도메인에 대해 어떠한 유의한 손상도 없음을 도시한다.
도 213b는 4°C, 25°C, 또는 37°C에서의 10-일 인큐베이션 후 TGFRt15-TGFRs의 TGFβ-RII 도메인에 대해 어떠한 유의한 손상도 없음을 도시한다.
도 213c는 4°C, 25°C, 또는 37°C에서 10일 동안 인간 혈청에서의 인큐베이션 후 TGFRt15-TGFRs의 TGF-β1 중화 활성을 도시하는 그래프이다.
도 213d는 4°C, 25°C, 또는 37°C에서 10일 동안 인간 혈청에서의 인큐베이션 후 TGFRt15-TGFRs의 IL-15 활성을 도시하는 그래프이다.
도 214a는 도시된 NK 세포 및 작제물을 사용한 검정에서 세포-매개 세포의 세포독성을 도시하는 그래프이다.
도 214b는 도시된 PBMC 및 작제물을 사용한 검정에서 세포-매개 세포의 세포독성을 도시하는 그래프이다.
도 214c는 도시된 NK 세포 및 작제물을 사용한 검정에서 세포내 그랜자임 B 생성을 도시하는 그래프이다.
도 214d는 도시된 PBMC 및 작제물을 사용한 검정에서 세포내 그랜자임 B 생성을 도시하는 그래프이다.
도 214e는 도시된 NK 세포 및 작제물을 사용한 검정에서 인터페론-감마 생성을 도시하는 그래프이다.
도 214f는 도시된 PBMC 및 작제물을 사용한 검정에서 인터페론-감마 생성을 도시하는 그래프이다.
도 215는 암컷 C57BL/6 마우스에서 평가된 TGFRt15-TGFRs의 약물동력학(반감기, t1/2)을 도시하는 그래프이다.
도 216은 C57BL/6 마우스에서 TGFRt15-TGFRs의 독성을 도시하는 그래프이다.
도 217은 C57BL/6 뮤린 흑색종 모델에서 TGFRt15-TGFRs의 항종양 활성을 도시하는 그래프이다.
도 218은 9주령의 C57BL6/j 수컷 마우스에서 TGFRt15-TGFRs의 활성을 도시하며, 마우스는 구강인두 경로를 통해 50 μl의 블레오마이신(2.5 mg/kg, 단회 용량)을 받은 다음, 블레오마이신 치료 후 17일차에 TGFRt15-TGFRs를 피하(3 mg/kg)로 받았다.
도 219는 TGFRt15-TGFRs 또는 TGFRt15*-TGFRs를 이용한 치료 후 4일째에 db/db 마우스에서의 공복 혈장 포도당 수준을 도시한다.
도 220a 내지 도 220c는 TGFRt15-TGFRs 또는 TGFRt15*-TGFRs를 이용한 치료 후 4일째에 db/db 마우스에서의 TGFβ1-3 수준을 도시한다: TGFβ1(도 220a), TGFβ2(도 220b), 및 TGFβ3(도 220c).
도 221a 내지 도 221e는 TGFRt15-TGFRs 또는 TGFRt15*-TGFRs를 이용한 치료 후 4일째에 db/db 마우스에서의 림프구 하위세트를 도시한다: 혈액 NK 세포(도 221a), 혈액 Ki67+ NK 세포(도 221b), 혈액 그랜자임 B+(GzmB+)(도 221c), 혈액 CD8+(도 221d), 및 혈액 CD8+Ki67+ T 세포(도 221e).
도 222a는 TGFRt15*-TGFRs 또는 TGFRt15-TGFRs와 잠복(latent) TGFβ1(SLC)와의 또는 CD39(대조군)와의 상호작용을 도시한다.
도 222b는 TGFRt15*-TGFRs 및 TGFRII-Fc와 잠복 TGFβ1와의 상호작용을 도시한다.
도 223은 PT 검정에서 인노빈의 응고 시간을 도시하는 그래프이다.
도 224는 PT 검정에서 TGFRt15-TGFRs의 응고 시간을 도시하는 그래프이다.
도 225는 신장에서의 노쇠 마커 PAI-1, IL-1α, IL6, 및 IL-1β의 유전자 발현을 도시하고 젊은 vs PBS 또는 TGFRt15-TGFRs 치료된 노화 마우스를 단기간 vs 장기간 추적 관찰로 비교하는 그래프이다.
도 226은 간에서 노쇠 마커 IL-1α 및 IL6의 유전자 발현을 도시하는 그래프이다.
도 227은 신장에서 노쇠 마커 PAI-1의 단백질 발현을 도시한다.
도 228은 IL15SA(양성 대조군) 또는 TGFRt15*-TGFRs + IL15SA가 혈액에서 CD3+CD8+, CD3-NK1.1+, 및 CD3+CD45+ 면역 세포의 백분율의 증가를 매개한 반면, TGFRt15*-TGFRs를 이용한 치료가 이들 세포 집단의 백분율에 거의 효과를 갖지 않거나 전혀 갖지 않았음을 도시하는 그래프이다.
도 229는 IL15SA(양성 대조군) 또는 TGFRt15*-TGFRs + IL15SA가 비장에서 CD3+CD8+, CD3-NK1.1+, 및 CD3+CD45+ 면역 세포의 백분율의 증가를 매개한 반면, TGFRt15*-TGFRs를 이용한 치료가 이들 세포 집단의 백분율에 거의 효과를 갖지 않거나 전혀 갖지 않았음을 도시하는 그래프이다.
도 230a는 시험 물품 치료 후 신장 및 간 조직에서 노쇠 마커 p21의 유전자 발현을 도시한다.
도 230b는 연구 치료 후 신장 및 간 조직에서 노쇠 마커 PAI1의 유전자 발현을 도시한다.
도 230c는 연구 치료 후 신장 및 간 조직에서 노쇠 마커 IL-1α의 유전자 발현을 도시한다.
도 230d는 연구 치료 후 신장 및 간 조직에서 노쇠 마커 IL-6의 유전자 발현을 도시한다.
도 231a는 제시된 제제를 이용한 치료 후 CD4+, CD8+, 및 Treg 세포 백분율 및 증식을 도시한다. 도 231b는 제시된 제제를 이용한 치료 후 NK, CD19+, 및 단핵구 세포 백분율 및 증식을 도시한다.
도 232a는 화학요법 및 제시된 제제를 이용한 치료 후 마우스의 폐 조직에서 노쇠 마커 p21의 유전자 발현의 평가를 도시한다.
도 232b는 화학요법 및 제시된 제제를 이용한 치료 후 마우스의 폐 조직에서 노쇠 마커 CD26의 유전자 발현의 평가를 도시한다.
도 232c는 화학요법 및 제시된 제제를 이용한 치료 후 마우스의 간 조직에서 노쇠 마커 p21의 유전자 발현의 평가를 도시한다.
도 233a 내지 도 233b는 TGFRt15-TGFRs 치료가 B16F10 종양 보유 마우스의 말초 혈액에서 면역 세포 증식, 확장 및 활성화를 증강시킴을 도시하는 그래프이다.
도 234는 TGFRt15-TGFRs 치료가 B16F10 종양 보유 마우스의 혈장에서 TGFβ의 수준을 저하시킴을 도시하는 그래프이다.
도 235는 TGFRt15-TGFRs 치료가 B16F10 종양 보유 마우스의 혈장에서 전염증성 사이토카인의 수준을 감소시킴을 도시하는 그래프이다.
도 236은 TGFRt15-TGFRs 치료가 B16F10 종양 보유 마우스의 비장에서 NK 및 CD8 확장을 증강시킴을 도시한다.
도 237a 내지 도 237b는 TGFRt15-TGFRs 치료가 B16F10 종양 보유 마우스에서 비장세포의 해당 활성을 증강시킴을 도시한다.
도 238a 내지 도 238b는 TGFRt15-TGFRs 치료가 B16F10 종양 보유 마우스에서 비장세포의 미토콘드리아 호흡을 증강시킴을 도시한다.
도 239a 내지 도 293b는 TGFRt15-TGFRs 치료가 B16F10 종양 보유 마우스의 종양 내로의 NK 및 CD8 면역 세포 침윤(TIL)을 증강시킴을 도시한다.
도 240은 TGFRt15-TGFRs 치료 후 종양의 조직병리학적 분석을 도시하며, TGFRt15-TGFRs+TA99 항체 치료 후, 종양은 유사분열 및 괴사 활성을 거의 나타내지 않았다. 유사분열 지수는 분열 세포와 상관관계가 있고, 괴사의 존재는 더 공격적인 특질 및 불량한 예후의 측정치이다.
도 241은 B16F10 흑색종 마우스 모델에서 TGFRt15-TGFRs+TA99 항체 및 화학요법과 병용된 항-PD-L1 항체를 도시하는 그래프이다.
도 242는 B16F10 흑색종 마우스 모델에서 TGFRt15-TGFRs의 항종양 효능이 NK 세포 및 CD8 T 세포에 의존적임을 도시하는 그래프이다.
도 243a 내지 도 243b는 화학요법 후 종양 보유 마우스의 간 및 폐 조직에서 노쇠 마커 p21, IL-1α 및 IL6의 유전자 발현을 도시하는 그래프이다.
도 244는 B16F10 GFP 세포의 도세탁셀 처리에 의한 노쇠 마커 p21, IL6, H2AX, 및 NK 세포 리간드, Rae1e 및 ULBP1의 유전자 발현의 유도를 도시하는 그래프이다.
도 245는 종양 보유 마우스에서 치료 후 4일 후에 일일당 종양 침윤 림프구를 도시한다.
도 246a 내지 도 246b는 면역요법 치료를 받은 마우스가 PBS 대조군과 비교하여 4일 및 10일의 치료 후 더 낮은 수의 GFP 양성 노쇠 종양 세포(도 246a), 및 형광 현미경에 의해 평가된 24웰 플레이트에 평판배양된 종양 세포(도 246b)를 보여주었음을 나타내는 종양 세포 상에서의 유세포 분석을 도시한다.
도 247은 시스플라틴으로 신장 손상을 유도하고 TGFRt15-TGFRs로 치료 후 마우스의 신장에서의 TGFβ 수준을 도시한다.
도 248a 내지 도 248c는 C57BL/6 마우스에서 TGFRt15-TGFRs의 반복 용량 피하 투여의 독성학적 효과를 도시한다. 체중 변화는 SD21을 통해 제시된다(도 248a). 비장 중량(도 248b) 및 혈액 세포 카운트 및 차등(differential)(도 248c)은 TGFRt15-TGFRs의 1개 용량 후 SD7 및 2개 용량 후 SD21에서 마우스에 대해 표시된다.
도 249는 PBS, TGFRt15-TGFRs(3 mg/kg) 또는 TGFRt15*-TGFRs(3 mg/kg)를 이용한 생체내 치료 후 마우스에서의 TGF-β 이소형의 혈장 수준을 도시한다.
도 250a 내지 도 250b는 PBS, TGFRt15-TGFRs, TGFRt15*-TGFRs 또는 IL15SA를 이용한 생체내 치료 후 마우스의 비장세포에서 해당 용량의 속도(ECAR)(도 250a) 및 미토콘드리아 호흡 용량(OCR)(도 250b)의 변화를 도시한다.
도 251a 내지 도 251b는 PBS, TGFRt15-TGFRs, 또는 TGFRt15*-TGFRs를 이용한 시험관내 처리 후 마우스 비장세포에서 해당 용량의 속도(ECAR)(도 251a) 및 미토콘드리아 호흡 용량(OCR)(도 251b)의 변화를 도시한다.
도 252a 내지 도 252b는 PBS, TGFRt15-TGFRs, 또는 TGFRt15*-TGFRs를 이용한 시험관내 처리 후 C57BL/6 마우스에서 B16F10 흑색종 종양의 종양 성장 및 생존율의 변화를 도시한다. 종양 부피(도 252a) 및 마우스 생존율(종양 부피 < 4000 mm3에 기초함)(도 252b)이 평가되었다. 마우스는 도 252a에서와 같이 B16F10 흑색종 종양 세포의 주사 전에 면역 세포를 고갈시키기 위해 항-CD8, 항-NK, 또는 항-CD8 및 항-NK Ab로 1주일 동안 복강내 치료되었다. 그 후에, 종양 보유 마우스는 종양 세포 접종 후 1일차 및 4일차에 PBS 또는 20 mg/kg TGFRt15-TGFRs로 치료되었다. 동물의 종양 부피(도 252c) 및 마우스 생존율(도 252d)이 평가되었다. B16F10 종양 보유 마우스는 종양 접종 후 1일차 및 7일차에 PBS 또는 20 mg/kg TGFRt15-TGFRs로 치료되었다(도 252e). 종양 접종 후 11일차에, 종양이 수집되었고, 종양-침윤성 NK1.1+ 세포 및 CD8+ T 세포가 유세포측정법에 의해 정량화되었다.
도 253a 내지 도 253b는 PBS(대조군) 또는 TGFRt15-TGFRs를 받는 db/db 마우스에서 공복 혈장 포도당(도 253a) 및 인슐린(도 253b) 수준에 미치는 치료 효과를 도시한다.
도 254a는 PBS 대조군과 비교하여 TGFRt15-TGFRs를 받는 db/db 마우스의 췌장에서 유전자 발현 수준의 배수 변화를 도시한다.
도 254b 내지 도 254d는 PBS 대조군과 비교하여 TGFRt15-TGFRs를 받는 db/db 마우스에 대해 SASP, 노화 및 베타 세포 지수의 유전자에 대한 췌장 발현 수준의 평균 배수 변화를 각각 도시한다.
도 255a 내지 도 255b는 PBS(대조군)(도 255a) 또는 TGFRt15-TGFRs(도 255b)로 치료된 db/db 마우스로부터의 췌장 조직 절편의 다중스펙트럼 이미지화를 도시한다. 대표적인 췌장도(pancreatic islet)가 제시되며, OPAL-520으로서의 인슐린+ 췌도 베타 세포, OPAL-570(회색-척도 이미지에서 백색 세포로서 표시됨)으로서의 인슐린+p21+ 베타 세포는 PBS 치료군(도 255a)과 비교하여 TGRt15-TGFRs 치료군(도 255b)에서 감소되었다. 도 255c 및 도 255d는 PBS(대조군) 또는 TGFRt15-TGFRs로 치료된 db/db 마우스로부터의 췌장 조직 절편에서 췌도 인슐린+(도 255c) 및 췌도 인슐린+ p21+(도 255d) 세포의 수준을 도시한다.
도 256a 내지 도 256c는 PBS(대조군) 또는 TGFRt15-TGFRs를 받는 db/db 마우스에서 혈액 면역 세포 하위세트의 백분율에 미치는 치료 효과를 도시한다.
도 257은 PBS(비히클)와 비교하여 TGFRt15-TGFRs를 이용한 시노몰구스 원숭이의 피하 치료 후 혈액에서 유도된 Ki67 양성 면역 세포의 백분율을 도시한다.
도 258은 PBS, TGFRt15-TGFRs(3 mg/kg) 또는 TGFRt15*-TGFRs(3 mg/kg)를 이용한 생체내 치료 후 4일째에 젊은(6주령) 및 노화(72주령) 마우스로부터 단리된 비장세포의 해당 기능을 나타내는 세포외 산성화율(ECAR)을 도시한다.
도 259는 PBS, TGFRt15-TGFRs(3 mg/kg) 또는 TGFRt15*-TGFRs(3 mg/kg)를 이용한 생체내 치료 후 4일째에 젊은(6주령) 및 노화(72주령) 마우스로부터 단리된 비장세포의 미토콘드리아 호흡을 나타내는 산소 소모율(OCR)을 도시한다.
도 260은 PBS, TGFRt15-TGFRs(3 mg/kg) 또는 TGFRt15*-TGFRs(3 mg/kg)를 이용한 생체내 치료 후 4일째에 젊은(6주령) 및 노화(72주령) 마우스의 혈액 내 면역 세포 하위세트의 백분율을 도시한다.
도 261은 PBS, TGFRt15-TGFRs 또는 TGFRt15*-TGFRs를 이용한 생체내 치료 후 4일째에 젊은(6주령) 및 노화(72주령) 마우스의 비장 내 면역 세포 하위세트의 백분율을 도시한다.
도 262는 1개 또는 2개 용량의 TGFRt15-TGFRs 치료 후 노화 마우스의 간에서 IL1-α, IL1-β, IL-6, p21 및 PAI-1에 대한 유전자 발현 수준을 도시한다.
도 263은 1개 또는 2개 용량의 TGFRt15-TGFRs 치료 후 노화 마우스의 간 조직의 염증 점수를 도시한다.
도 264는 1개 또는 2개 용량의 TGFRt15-TGFRs 치료 후 노화 마우스의 간에서 IL1-α, IL1-β, IL-6, IL-8, TGF-β, PAI-1, 콜라겐 및 피브로넥틴 단백질의 발현 수준을 도시한다.
도 265는 PBS 또는 TGFRt15-TGFRs를 이용한 생체내 치료 후 4일째에 노화 마우스의 간 조직에서 β-갈락토시다제의 수준을 도시한다.
도 266은 PBS 또는 1개 용량의 TGFRt15-TGFRs(3 mg/kg)를 이용한 피하 치료 후 72주령 C57BL/6 마우스의 생존율 곡선을 도시한다.
도 267은 화학요법 및 TGFRt15-TGFRs + TA99 요법 후 B16F10 종양-보유 마우스의 간에서 SASP 인자의 단백질 수준을 도시한다.
도 268a 내지 도 268b는 화학요법 및 TGFRt15-TGFRs + TA99 요법 후 마우스의 종양에서 TIS B16F10-GFP 세포(도 268a)와 NK 및 CD8+ T 세포(도 268b)의 수준에 미치는 CD8+ T 세포(dpCD8) 및 NK 세포(dpNK) 항체 고갈의 효과를 도시한다.
도 269a 내지 도 269e는 B16F10 종양-보유 마우스에서 면역 관문 저해제와 병용된 TGFRt15-TGFRs + TA99의 항종양 활성 및 작용 기전을 도시한다. 도 269a는 마우스 모델에서 B16F10 흑색종을 치료하기 위한 예시적인 개략도를 도시한다. 도 269b는 PBS 또는 화학요법 치료 단독과 비교하여 도세탁셀 후 TGFRt15-TGFRs+TA99+항-PD-L1 항체를 포함한 병용 치료 후 시간 경과에 걸쳐 그리고 18일차에 종양 부피의 변화를 도시한다. 도 269c 및 도 269d는 18일차에 종양 침윤성 CD28+CD8+ T 세포 및 비장 IFNγ+CD8+ T 세포의 백분율에 미치는 치료 효과를 도시한다. 도 269e는 18일차에 종양 침윤성 CD8+ 및 CD8+CD44hi T 세포의 NKG2D의 수준(MFI)에 미치는 치료 효과를 도시한다.
도 270a 내지 도 270d는 PBS, 겜시타빈 및 nab-파클리탁셀 화학요법, TGFRt15-TGFRs, 또는 TGFRt15-TGFRs+화학요법을 이용한 시험관내 처리 후 C57BL/6 scid 마우스에서 SW1990 인간 췌장 종양의 종양 성장 및 생존율의 변화를 도시한다. 도 270a는 이종이식 마우스 모델에서 SW1990 인간 췌장 종양을 치료하기 위한 예시적인 개략도를 도시한다. 도 270b 및 도 270c는 PBS 또는 화학요법 치료 단독과 비교하여 TGFRt15-TGFRs + 화학요법을 포함한 병용 치료 후 시간 경과에 걸쳐 그리고 38일차 각각에서의 종양 부피의 변화를 도시한다. 도 270d는 SW1990 인간 췌장 종양을 보유하는 마우스의 생존율에 미치는 치료 효과를 도시한다.
도 2a 내지 도 2b는 C57BL/6 마우스에서 예시적인 다중-사슬 폴리펩타이드의 면역자극의 지속 기간을 도시한다. 도 2a는 3 mg/kg의 예시적인 다중-사슬 폴리펩타이드로 치료된 마우스에서 92시간의 기간에 걸친 비장 중량을 도시한다. 도 2b는 3 mg/kg의 예시적인 다중-사슬 폴리펩타이드로 치료된 마우스에서 92시간의 기간에 걸친 비장에 존재하는 면역 세포 유형의 백분율을 도시한다.
도 3a 내지 도 3b는 예시적인 다중-사슬 폴리펩타이드에 의해 유도되는 면역 세포에서 Ki67 및 그랜자임 B의 발현을 도시한다. 도 3a는 다중-사슬 폴리펩타이드를 이용한 치료-후(post-treatment) 다양한 시점에서 CD4+ T 세포, CD8+ T 세포, 자연 살해(NK) 세포, 및 CD19+ B 세포에서의 Ki67의 발현을 도시한다. 도 3b는 다중-사슬 폴리펩타이드를 이용한 치료-후(post-treatment) 다양한 시점에서 CD4+ T 세포, CD8+ T 세포, 자연 살해(NK) 세포, 및 CD19+ B 세포에서의 그랜자임 B의 발현을 도시한다.
도 4는 치료 후 다양한 시점에서 예시적인 다중-사슬 폴리펩타이드로 치료된 마우스로부터 제조된 비장세포에 의한 종양 저해의 효과를 도시한다.
도 5a 내지 도 5b는 대조군 식이요법을 공급받은 B6.129P2-ApoEtm1Unc/J 마우스(The Jackson Laboratory로부터 구매됨), 고지방 식이요법과 비치료, 및 고지방 식이요법을 공급받고 TGFRt15-TGFRs, 2t2, 또는 21t15-TGFRs로 치료된 마우스의 혈액에서 CD4+ T 세포, CD8+ T 세포, 자연 살해(NK) 세포, 및 CD19+ B 세포의 백분율 및 증식 속도를 도시한다. 도 5a는 각각의 대조군 및 실험군에서 상이한 세포 유형의 백분율을 도시한다. 도 5b는 각각의 대조군 및 실험군에서 상이한 세포 유형의 증식 속도를 도시한다.
도 6의 A 내지 E는 대조군 또는 고지방 식이요법을 공급받고 비치료되거나 TGFRt15-TGFRs, 2t2, 또는 21t15-TGFRs로 치료된 마우스의 예시적인 신체적 외양을 도시한다.
도 7은 대조군 또는 고지방 식이요법을 공급받고 비치료되거나 TGFRt15-TGFRs, 2t2, 또는 21t15-TGFRs로 치료된 마우스의 공복 체중을 도시한다.
도 8은 대조군 또는 고지방 식이요법을 공급받고 비치료되거나 TGFRt15-TGFRs, 2t2, 또는 21t15-TGFRs로 치료된 마우스의 공복 혈당 수준을 도시한다.
도 9a 내지 도 9f는 화학요법-유도 노쇠 B16F10 세포 및 노쇠 유전자의 발현을 도시한다. 도 9a는 SA β-gal 염색을 사용하여 시각화된 노쇠 B16F10 세포의 화학요법 유도를 도시한다. 도 9b 내지 도 9f는 화학요법-유도 노쇠 B16F10 세포에서 시간 경과에 따른 p21CIP1, IL6, DPP4, RATE1E, 및 ULBP1의 발현을 도시한다.
도 10a 내지 도 10f는 화학요법-유도 노쇠 B16F10 세포에 의한 콜로니 형성 및 줄기세포 마커의 발현을 도시한다. 도 10a는 화학요법-유도 노쇠 B16F10 세포에 의한 콜로니 형성을 도시한다. 도 10b 및 도 10c는 대조군 B16F10 세포와 비교하여 화학요법-유도 노쇠 B16F10 세포에 의한 Oct4 mRNA 및 Notch4 mRNA의 발현을 도시한다. 도 10d 내지 도 10f는 CD44, CD24, 및 CD133을 포함한 3개의 줄기세포 마커 중 2개에 대해 이중-양성인 화학요법-유도 노쇠 B16F10 세포의 백분율을 도시한다.
도 11a 내지 도 11c는 화학요법-유도 노쇠 B16F10 세포의 이동 및 침습 특성을 도시한다. 도 11a는 줄기세포 특성(B16F10-SNC-CSC)을 갖는 화학요법-유도 노쇠 세포를 대조군 B16F10 세포와 비교하는 이동 검정의 결과를 도시한다. 도 11b 및 도 11c는 줄기세포 특성(B16F10-SNC-CSC)을 갖는 화학요법-유도 노쇠 세포를 대조군 B16F10 세포와 비교하는 침습 검정의 결과를 도시한다.
도 12a 및 도 12b는 시험관내 확장된 NK 세포 및 줄기세포 특성(B16F10-SNC-CSC)을 갖는 화학요법-유도 노쇠 세포 또는 대조군 B16F10 세포에 대한 상기 NK 세포의 세포독성을 도시한다. 도 12a는 시험관내 확장된 NK 세포를 수득하는 과정의 예시적인 개략도를 도시한다. 도 12b는 시험관내 확장된 NK 세포 및 줄기세포 특성(B16F10-SNC-CSC)을 갖는 화학요법-유도 노쇠 세포 또는 대조군 B16F10 세포에 대한 확장된 NK 세포의 세포독성을 도시한다.
도 13a 내지 도 13c는 마우스 흑색종 모델을 사용한 병용 치료의 결과를 도시한다. 도 13a는 마우스 모델에서 흑색종을 치료하기 위한 예시적인 개략도를 도시한다. 도 13b 및 도 13c는 화학요법 또는 TA99 치료 단독과 비교하여 TGFRt15-TGFRs를 포함한 병용 치료를 이용한 시간 경과에 따른 종양 부피의 변화를 도시한다.
도 14는 대조군 SW1990 세포와 비교하여 인간 췌장 종양 세포주 SW1990에서의 노쇠의 유도 및 노쇠 SW1990 세포에서의 CD44 및 CD24의 발현을 도시한다.
도 15는 화학요법-유도 노쇠 SW1990 세포에 의한 노쇠 마커의 발현을 도시한다.
도 16은 화학요법-유도 노쇠 SW1990 세포 또는 대조군 SW1990 세포에 대한 시험관내 활성화된 인간 NK 세포의 세포독성을 도시한다.
도 17은 예시적인 IL-12/IL-15RαSu DNA 작제물의 도식적 다이어그램을 도시한다.
도 18은 예시적인 IL-18/TF/IL-15 DNA 작제물의 도식적 다이어그램을 도시한다.
도 19는 예시적인 IL-12/IL-15RαSu 작제물과 IL-18/TF/IL-15 DNA 작제물 사이의 상호작용의 도식적 다이어그램을 도시한다.
도 20은 IL-18/TF/IL-15:IL-12/IL-15RαSu 복합체(18t15-12s)를 초래하는 예시적인 IL-12/IL-15RαSu 융합 단백질과 IL-18/TF/IL-15 융합 단백질 사이의 상호작용의 도식적 다이어그램을 도시한다.
도 21은 항-TF 항체 친화도 컬럼으로부터의 18t15-12s 정제 용리의 크로마토그래프를 도시한다.
도 22는 분석적 크기 배제 컬럼 상에서의 용리 후 항-TF Ab / SEC-정제된 18t15-12s 단백질의 예시적인 크로마토그래프 프로파일을 도시하며, 이는 단백질 응집물로부터 단량체성 다중단백질 18t15-12s 복합체의 분리를 실증한다.
도 23은 이황화 결합 환원 후 18t15-12s 복합체의 4-12% SDS-PAGE의 일례를 도시한다. 레인 1: SeeBlue Plus2 마커; 레인 2: 항-TF Ab-정제 18t15-12s(0.5 μg); 레인 3: 항-TF Ab-정제 18t15-12s(1 μg).
도 24는 탈글리코실화된 및 비-탈글리코실화된 18t15-12s의 SDS PAGE 분석을 도시한다. 레인 1: 항-TF Ab-정제 18t15-12s(0.5 μg), 비-탈글리코실화; 레인 2: 항-TF Ab -정제 18t15-12s(1 μg), 비-탈글리코실화; 레인 3: 18t15-12s(1 μg), 탈글리코실화, 레인 4: Mark12 비염색된 마커.
도 25는 항-인간 조직 인자 항체 포착 및 비오틴화된 항-인간 IL-12 검출 항체(BAF 219)를 포함하는 18t15-12s 복합체에 대한 샌드위치 ELISA를 도시한다.
도 26은 항-인간 조직 인자 항체 포착 및 비오틴화된 항-인간 IL-15 검출 항체(BAM 247)를 포함하는 18t15-12s 복합체에 대한 샌드위치 ELISA를 도시한다.
도 27은 항-인간 조직 인자 항체 포착 및 비오틴화된 항-인간 IL-18 검출 항체(D045-6)를 포함하는 18t15-12s 복합체에 대한 샌드위치 ELISA를 도시한다.
도 28은 항-인간 조직 인자(I43) 포착 항체 및 항-인간 조직 인자 검출 항체를 포함하는 18t15-12s 복합체에 대한 샌드위치 ELISA를 도시한다.
도 29는 18t15-12s 복합체(열린 정사각형) 및 재조합 IL-15(검정색 정사각형)에 의해 매개되는 IL-15-의존적 32Dβ 세포의 증식을 도시한다.
도 30은 18t15-12s 복합체(열린 정사각형) 내에서 IL-18의 생물학적 활성을 도시하며, 이때, 재조합 IL-18(검정색 정사각형) 및 재조합 IL-12(검정색 원형)는 각각 양성 대조군 및 음성 대조군으로서 역할을 한다.
도 31은 18t15-12s 복합체(열린 정사각형) 내에서 IL-12의 생물학적 활성을 도시하며, 이때, 재조합 IL-12(검정색 원형) 및 재조합 IL-18(열린 정사각형)은 각각 양성 대조군 및 음성 대조군으로서 역할을 한다.
도 32a 및 도 32b는 18t15-12s 복합체에 의해 유도되는 NK 세포 상에서의 CD25의 세포-표면 발현 및 18t15-12s 복합체에 의해 유도되는 NK 세포의 세포-표면 CD69 발현을 도시한다.
도 33은 18t15-12s 복합체에 의해 유도되는 NK 세포의 세포내 IFN-γ 발현의 유세포측정법 그래프를 도시한다.
도 34는 K562 세포에 대한 18t15-12s-유도 인간 NK 세포의 세포독성을 도시한다.
도 35는 예시적인 IL-12/IL-15RαSu/αCD16 DNA 작제물의 도식적 다이어그램을 도시한다.
도 36은 예시적인 IL-18/TF/IL-15 DNA 작제물의 도식적 다이어그램을 도시한다.
도 37은 예시적인 IL-12/IL-15RαSu/αCD16scFv DNA 작제물과 IL-18/TF/IL-15 DNA 작제물 사이의 상호작용의 도식적 다이어그램을 도시한다.
도 38은 예시적인 18t15-12s/αCD16 단백질 복합체의 도식적 다이어그램을 도시한다.
도 39는 항-인간 조직 인자 항체 포착 및 비오틴화된 항-인간 IL-12(BAF 219)(진한 선) 또는 항-인간 조직 인자 검출 항체(연한 선)을 포함하는 18t15-12s16 복합체에 대한 샌드위치 ELISA를 도시한다.
도 40은 예시적인 TGFβRII/IL-15RαSu DNA 작제물의 도식적 다이어그램을 도시한다.
도 41은 예시적인 IL-21/TF/IL-15 작제물의 도식적 다이어그램을 도시한다.
도 42는 예시적인 IL- IL-21/TF/IL-15 작제물과 TGFβRII/IL-15RαSu 작제물 사이의 상호작용의 도식적 다이어그램을 도시한다.
도 43은 IL-21/TF/IL-15/TGFβRII/IL-15RαSu 복합체(21t15-TGFRs)를 초래하는 예시적인 TGFβRII/IL-15RαSu 융합 단백질과 IL-21/TF/IL-15 융합 단백질 사이의 상호작용의 도식적 다이어그램을 도시한다.
도 44는 항-TF 항체 친화도 컬럼으로부터의 21t15-TGFRs 정제 용리의 크로마토그래프를 도시한다.
도 45는 주요 단백질 피크 및 고분자량 피크를 나타내는 예시적인 21t15-TGFRs 크기 배제 크로마토그래프를 도시한다.
도 46은 이황화 결합 환원 후 21t15-TGFRs 복합체의 4-12% SDS-PAGE의 일례를 도시한다. 레인 1: Mark12 비염색된 마커(좌측면 상의 숫자는 분자량을 kDa으로 나타냄); 레인 2: 21t15-TGFRs(0.5 μg); 레인 3: 21t15-TGFRs(1 μg); 레인 4: 21t15-TGFRs, 탈글리코실화된(1 μg), 여기서 MW는 53 kDa 및 39.08 kDa의 예상된 크기였다.
도 47은 항-인간 조직 인자 포착 및 비오틴화된 항-인간 IL-21 검출 항체(13-7218-81, BioLegend)를 포함하는 21t15-TGFRs 복합체에 대한 샌드위치 ELISA를 도시한다.
도 48은 항-인간 조직 인자 항체 포착 및 비오틴화된 항-인간 IL-15 검출 항체(BAM 247, R&D Systems)를 포함하는 21t15-TGFRs 복합체에 대한 샌드위치 ELISA를 도시한다.
도 49는 항-인간 조직 인자 항체 포착 및 비오틴화된 항-인간 TGFβRII 검출 항체(BAF241, R&D Systems)를 포함하는 21t15-TGFRs 복합체에 대한 샌드위치 ELISA를 도시한다.
도 50은 항-인간 조직 인자(I43) 포착 항체 및 항-인간 조직 인자 검출 항체를 포함하는 21t15-TGFRs 복합체에 대한 샌드위치 ELISA를 도시한다.
도 51은 IL-15(검정색 정사각형)와 비교하여 21t15-TGFRs 복합체(열린 정사각형)에 의해 매개되는 32Dβ 세포의 IL-15-의존적 증식을 도시한다.
도 52는 21t15-TGFRs 복합체(열린 정사각형) 내에서 TGFβRII 도메인의 생물학적 활성을 도시한다. TGFβRII/Fc(검정색 정사각형)는 양성 대조군으로서 역할을 하였다.
도 53은 21t15-TGFRs 복합체에 의해 유도되는 NK 세포의 세포내-표면 CD25 발현의 유세포측정법 그래프를 도시한다.
도 54는 21t15-TGFRs 복합체에 의해 유도되는 NK 세포의 세포내-표면 CD69 발현의 유세포측정법 그래프를 도시한다.
도 55는 21t15-TGFRs 복합체에 의해 유도되는 NK 세포의 세포내 IFN-γ 발현의 유세포측정법 그래프를 도시한다.
도 56은 K562 세포에 대한 21t15-TGFRs-유도 인간 NK 세포의 세포독성을 도시한다.
도 57은 예시적인 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드의 도식적인 다이어그램이다.
도 58은 항-조직 인자 친화도 컬럼으로부터 예시적인 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드의 용리를 보여주는 크로마토그래프이다.
도 59는 예시적인 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드가 로딩된 Superdex 200 Increase 10/300 GL 겔 여과 컬럼의 용리를 나타내는 크로마토그래프이다.
도 60은 항-조직 인자 친화도 컬럼을 사용하여 정제된 예시적인 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드의 소듐 도데실 설페이트 폴리아크릴아미드 겔(4-12% NuPage Bis-Tris 겔)이다.
도 61은 실시예 1에 기재된 방법을 사용하여 수행된 예시적인 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드의 ELISA 정량화를 나타내는 그래프이다. 정제된 조직 인자는 대조군으로서 사용되었다.
도 62는 2명의 공여자의 혈액으로부터 단리된 CD4+ T-세포에서 CD25 발현을 자극시키는 예시적인 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드의 능력을 나타내는 그래프이다. 실험은 실시예 2에 기재된 바와 같이 수행되었다.
도 63은 2명의 공여자의 혈액으로부터 단리된 CD8+ T-세포에서 CD25 발현을 자극시키는 예시적인 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드의 능력을 나타내는 그래프이다. 실험은 실시예 2에 기재된 바와 같이 수행되었다.
도 64는 2명의 공여자의 혈액으로부터 단리된 CD4+ T-세포에서 CD69 발현을 자극시키는 예시적인 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드의 능력을 나타내는 그래프이다. 실험은 실시예 2에 기재된 바와 같이 수행되었다.
도 65는 예시적인 IL-7/IL-15RαSu DNA 작제물의 도식적 다이어그램을 도시한다.
도 66은 예시적인 IL-21/TF/IL-15 DNA 작제물의 도식적 다이어그램을 도시한다.
도 67은 예시적인 IL-7/IL-15RαSu DNA 작제물과 IL-21/TF/IL-15 DNA 작제물 사이의 상호작용의 도식적 다이어그램을 도시한다.
도 68은 IL-21/TF/IL-15:IL-7/IL-15RαSu 복합체(21t15-7s)를 초래하는 예시적인 IL-7/IL-15RαSu 융합 단백질과 IL-21/TF/IL-15 융합 단백질 사이의 상호작용의 도식적 다이어그램을 도시한다.
도 69는 예시적인 IL-21/IL-15RαSu DNA 작제물의 도식적 다이어그램을 도시한다.
도 70은 예시적인 IL-7/TF/IL-15 DNA 작제물의 도식적 다이어그램을 도시한다.
도 71은 예시적인 IL-21/IL-15RαSu DNA 작제물과 IL-7/TF/IL-15 DNA 작제물 사이의 상호작용의 도식적 다이어그램을 도시한다.
도 72는 IL-7/TF/IL-15:IL-21/IL-15RαSU 복합체(7t15-21s)를 초래하는 예시적인 IL-21/IL-15RαSu 융합 단백질과 IL-7/TF/IL-15 융합 단백질 사이의 상호작용의 도식적 다이어그램을 도시한다.
도 73은 2명의 상이한 공여자의 혈액(2 x 106개 세포/mL)으로부터 단리된 인간 NK 세포에 대한 산소 소모율(OCR: oxygen consumption rate)을 pmoles/분으로 도시한다.
도 74는 세포외 산성화율(ECAR: extracellular acidification rate)을
2명의 상이한 공여자의 혈액(2 x 106개 세포/mL)으로부터 단리된 인간 NK 세포에 대해 mpH/분으로 도시한다.
도 75는 7t15-16s21 작제물의 도식을 도시한다.
도 76은 7t15-16s21 작제물의 추가 도식을 도시한다.
도 77a 및 도 77b는 대조군 단백질과 비교하여 인간 CD16b를 발현하는 CHO 세포에의 7t15-16s21의 결합을 도시한다.
도 78a 내지 도 78c는 7t15-16s21을 검출하는 데 있어서 IL-15, IL-21, 및 IL-7에 대한 항체를 사용한 ELISA 실험으로부터의 결과이다.
도 79는 7t15-16s21 또는 재조합 IL-15를 이용한 32Dβ 세포 증식 검정법의 결과를 도시한다.
도 80은 항-TF 항체 수지 상에서 결합 및 용리 후 7t15-16s21 단백질-함유 세포 배양물 상청액의 크로마토그래프 프로파일을 도시한다.
도 81은 7t15-16s21의 분석적 SEC 프로파일을 도시한다.
도 82는 TGFRt15-16s21 작제물의 도식을 도시한다.
도 83은 TGFRt15-16s21 작제물의 추가 도식을 도시한다.
도 84a 및 도 84b는 인간 CD16b를 발현하는 CHO 세포와 TGFRT15-16S21 및 7t15-21s의 결합 친화도를 도시한다. 도 84a는 인간 CD16b를 발현하는 CHO 세포와 TGFRT15-16S21의 결합 친화도를 도시한다. 도 84b는 인간 CD16b를 발현하는 CHO 세포와 7t15-21s의 결합 친화도를 도시한다.
도 85는 TGFRt15-16s21 및 TGFR-Fc에 의한 TGFβ1 저해의 결과를 도시한다.
도 86는 TGFRt15-16s21 또는 재조합 IL-15를 이용한 32Dβ 세포 증식 검정법의 결과를 도시한다.
도 87a 내지 도 87c는 ELISA를 사용하여 TGFRt15-16s21에서 IL-15, IL-21, 및 TGFβRII를 상응하는 항체로 검출하는 결과를 도시한다.
도 88은 항-TF 항체 수지 상에서 결합 및 용리 후 TGFRt15-16s21 단백질-함유 세포 배양물 상청액의 크로마토그래프 프로파일을 도시한다.
도 89는 TGFRt15-16s21의 환원된 SDS-PAGE 분석의 결과를 도시한다.
도 90은 7t15-7s 작제물의 도식을 도시한다.
도 91은 7t15-7s 작제물의 추가 도식을 도시한다.
도 92는 항-TF 항체 수지 상에서 결합 및 용리 후 7t15-7s 단백질-함유 세포 배양물 상청액의 크로마토그래프 프로파일을 도시한다.
도 93은 ELISA를 사용하여 7t15-7s에서 TF, IL-15 및 IL-7의 검출을 도시한다.
도 94a 및 도 94b는 7t15-7s-치료 마우스 및 대조군-치료 마우스에서 비장 중량 및 면역 세포 유형의 백분율을 도시한다. 도 94a는 PBS 대조군과 비교하여, 7t15-7s로 치료된 마우스에서 비장 중량을 도시한다. 도 94b는 PBS 대조군과 비교하여, 7t15-7s로 치료된 마우스에서 CD4+ T 세포, CD8+ T 세포, 및 NK 세포의 백분율을 도시한다.
도 95는 TGFRt15-TGFRs 작제물의 도식을 도시한다.
도 96은 TGFRt15-TGFRs 작제물의 추가 도식을 도시한다.
도 97은 TGFRt15-TGFRs 및 TGFR-Fc에 의한 TGFβ1 저해의 결과를 도시한다.
도 98은 TGFRt15-TGFRs 또는 재조합 IL-15를 이용한 32Dβ 세포 증식 검정법의 결과를 도시한다.
도 99a 및 도 99b는 ELISA를 사용하여 TGFRt15-TGFRs에서 IL-15 및 TGFβRII를 상응하는 항체로 검출하는 결과를 도시한다.
도 100은 항-TF 항체 수지 상에서 결합 및 용리 후 TGFRt15-TGFRs 단백질-함유 세포 배양물 상청액의 크로마토그래프 프로파일을 도시하는 선 그래프이다.
도 101은 TGFRt15-TGFRs의 분석적 SEC 프로파일을 도시한다.
도 102는 환원된 SDS-PAGE에 의해 분석된 바와 같은 탈글리코실화 전과 후의 TGFRt15-TGFRs를 도시한다.
도 103a 및 도 103b는 TGFRt15-TGFRs-치료 마우스 및 대조군-치료 마우스에서 비장 중량 및 면역 세포 유형의 백분율을 도시한다. 도 103a는 PBS 대조군과 비교하여, TGFRt15-TGFRs로 치료된 마우스에서 비장 중량을 도시한다. 도 103b는 PBS 대조군과 비교하여, TGFRt15-TGFRs로 치료된 마우스에서 CD4+ T 세포, CD8+ T 세포, 및 NK 세포의 백분율을 도시한다.
도 104a 및 도 104b는 TGFRt15-TGFRs로 치료된 마우스에서 92시간에 걸친 비장 중량 및 면역자극을 도시한다. 도 104a는 치료 후 16시간, 24시간, 48시간, 72시간, 및 92시간째에 TGFRt15-TGFRs로 치료된 마우스의 비장 중량을 도시한다. 도 104b는 치료 후 16시간, 24시간, 48시간, 72시간, 및 92시간째에 TGFRt15-TGFRs로 치료된 마우스에서 면역 세포의 백분율을 도시한다.
도 105a 및 도 105b는 시간 경과에 따른 TGFRt15-TGFRs로 치료된 마우스에서 Ki67 및 그랜자임 B 발현을 도시한다.
도 106은 C57BL/6 마우스에서 TGFRt15-TGFRs에 의한 비장세포의 세포독성의 증강을 도시한다.
도 107은 췌장암 마우스 모델에서, PBS 치료, 화학치료법 단독, TGFRt15-TGFRs 단독, 또는 화학치료법과 TGFRt15-TGFRs 병용에 반응하는 종양 크기의 변화를 도시한다.
도 108은 TGFRt15-TGFRs로 치료된 마우스에서 단리된 NK 세포의 세포독성을 도시한다.
도 109는 7t15-21s137L(롱 버전) 작제물의 도식을 도시한다.
도 110은 7t15-21s137L(롱 버전) 작제물의 추가 도식을 도시한다.
도 111은 항-TF 항체 수지 상에서 결합 및 용리 후 7t15-21s137L(롱 버전) 단백질-함유 세포 배양물 상청액의 크로마토그래프 프로파일을 도시하는 선 그래프이다.
도 112는 7t15-21s137L(롱 버전)의 분석적 SEC 프로파일을 도시한다.
도 113은 CD137L(4.1BBL)에의 7t15-21s137L(쇼트 버전)의 결합을 도시한다.
도 114a 내지 도 114c는 7t15-21s137L(쇼트 버전)에서 ELISA를 이용한 IL-15, IL21, 및 IL7의 검출을 도시한다. 도 114a는 7t15-21s137L(쇼트 버전)에서 ELISA를 이용한 IL-15의 검출을 도시한다. 도 114b는 7t15-21s137L(쇼트 버전)에서 ELISA를 이용한 IL21의 검출을 도시한다. 도 114c는 7t15-21s137L(쇼트 버전)에서 ELISA를 이용한 IL7의 검출을 도시한다.
도 115는 CTLL-2 세포 증식 검정법으로부터의 결과를 도시한다.
도 116은 IL21R-함유 B9 세포 증식을 촉진하는 데 있어서 7t15-1s137L(쇼트 버전)의 활성을 도시한다.
도 117은 7t15-TGFRs 작제물의 도식을 도시한다.
도 118은 7t15-TGFRs 작제물의 추가 도식을 도시한다.
도 119는 7t15-TGFRs 및 TGFR-Fc에 의한 TGFβ1 저해의 결과를 도시한다.
도 120a 내지 도 120c는 ELISA를 이용한 7t15-TGFRs에서의 IL-15, TGFβRII, 및 IL-7의 검출을 도시한다.
도 121은 7t15-TGFRs 또는 재조합 IL-15를 이용한 32Dβ 세포 증식 검정법의 결과를 도시한다.
도 122는 항-TF 항체 수지 상에서 결합 및 용리 후 7t15-TGFRs 단백질-함유 세포 배양물 상청액의 크로마토그래프 프로파일을 도시하는 선 그래프이다.
도 123은 환원된 SDS-PAGE을 사용하여 분석된 바와 같은 탈글리코실화 전과 후의 7t15-TGFRs를 도시한다.
도 124는 7t15-TGFRs 단백질에서 IL-7, IL-15 및 TGFβRII의 ELISA 검출을 도시한다.
도 125a 및 도 125b는 7t15-TGFRs-치료 마우스 및 대조군-치료 마우스에서 비장 중량 및 면역 세포 유형의 백분율을 도시한다. 도 125a는 PBS 대조군과 비교하여, 다양한 투약량에서 7t15-TGFRs로 치료된 마우스에서 비장 중량을 도시한다. 도 125b는 PBS 대조군과 비교하여, 다양한 투약량에서 7t15-TGFRs로 치료된 마우스에서 CD4+ T 세포, CD8+ T 세포, 및 NK 세포의 백분율을 도시한다.
도 126a 및 도 126b는 C57BL/6 마우스에서 7t15-TGFRs에 의한 CD4+ T 세포 및 CD8+ T 세포의 CD44 발현의 상향조절을 도시한다.
도 127a 및 도 127b는 C57BL/6 마우스에서 7t15-TGFRs에 의한 CD8+ T 세포 및 NK 세포의 Ki67 발현 및 그랜자임 B 발현의 상향조절을 도시한다.
도 128은 C57BL/6 마우스에서 7t15-TGFRs에 의한 비장세포의 세포독성의 증강을 도시한다.
도 129는 TGFRt15-21s137L 작제물의 도식을 도시한다.
도 130은 TGFRt15-21s137L 작제물의 추가 도식을 도시한다.
도 131은 항-TF 항체 수지 상에서 결합 및 용리 후 TGFRt15-21s137L 단백질-함유 세포 배양물 상청액의 크로마토그래프 프로파일을 도시하는 선 그래프이다.
도 132는 TGFRt15-TGFRs21 작제물의 도식을 도시한다.
도 133은 TGFRt15-TGFRs21 작제물의 추가 도식을 도시한다.
도 134는 항-TF 항체 수지 상에서 결합 및 용리 후 TGFRt15-TGFRs21 단백질-함유 세포 배양물 상청액의 크로마토그래프 프로파일을 도시하는 선 그래프이다.
도 135는 환원된 SDS-PAGE에 의해 분석된 바와 같은 탈글리코실화 전과 후의 TGFRt15-TGFRs21을 도시한다.
도 136a 및 도 136b는 ELISA를 사용한 TGFRt15-TGFRs21의 구성요소의 검출을 도시한다.
도 137a 및 도 137b는 대조군-치료 마우스 및 TGFRt15-TGFRs21-치료 마우스의 비장에 존재하는 CD4+ T 세포, CD8+ T 세포, 및 자연 살해(NK) 세포의 백분율 및 증식을 도시한다.
도 138은 TGFRt15-TGFRs21로 치료된 마우스에서 비장세포의 그랜자임 B 발현의 상향조절을 도시한다.
도 139는 C57BL/6 마우스에서 TGFRt15-TGFRs21에 의한 비장세포의 세포독성의 증강을 도시한다.
도 140은 TGFRt15-TGFRs16 작제물의 도식을 도시한다.
도 141은 TGFRt15-TGFRs16 작제물의 추가 도식을 도시한다.
도 142는 TGFRt15-TGFRs137L 작제물의 도식을 도시한다.
도 143은 TGFRt15-TGFRs137L 작제물의 추가 도식을 도시한다.
도 144는 예시적인 2t2 단일-사슬 키메라 폴리펩타이드의 도식적인 다이어그램이다.
도 145는 32Dβ 세포 증식 검정법을 사용하여 재조합 IL-2와 비교하여 2t2에서의 IL-2활성을 도시한다.
도 146은 CTLL-2 세포 증식 검정법을 사용하여 재조합 IL-2와 비교하여 2t2에서의 IL-2활성을 도시한다.
도 147은 표준 사료 또는 고지방 식이요법으로 사육되고 PBS 대조군으로 치료되거나(비치료) 2t2로 치료된 ApoE-/- 마우스에서 공복 혈중 포도당 수준을 도시한다.
도 148은 표준 사료 또는 고지방 식이요법으로 사육되고 PBS 대조군으로 치료되거나(비치료) 2t2로 치료된 ApoE-/- 마우스로부터의 혈액 림프구에서 CD4+CD25+FoxP3+ T 조절 세포의 비를 도시한다.
도 149는 항-TF 항체 수지 상에서 결합 및 용리 후 2t2 단백질-함유 세포 배양물 상청액의 크로마토그래프 프로파일을 도시하는 선 그래프이다.
도 150은 2t2의 분석적 SEC 프로파일을 도시한다.
도 151a 및 도 151b는 탈글리코실화 전 및 후에 2t2의 환원된 SDS-PAGE 분석을 도시한다. 도 151a는 탈글리코실화 전에 2t2의 환원된 SDS-PAGE 분석을 도시한다. 도 151b는 탈글리코실화 후에 2t2의 환원된 SDS-PAGE 분석을 도시한다.
도 152a 및 도 152b는 C57BL/6 마우스에서 2t2를 사용한 면역자극의 결과를 도시한다. 도 152a는 2t2로 치료한 후 비장 중량을 도시한다. 도 152b는 2t2 치료 후 면역 세포 유형의 백분율을 도시한다.
도 153은 2t2로 치료된 마우스에서 CD4+ T 세포의 CD25 발현의 상향조절을 도시한다.
도 154는 C57BL/6 마우스에서 2t2의 약물동력학을 도시한다.
도 155a 및 도 155b는 ApoE-/- 마우스에서 고지방-유도 아테롬성 동맥경화증 플라크(plaque)의 형성을 감쇠시키는(attenuate) 데 있어서 2t2의 효과를 도시한다. 도 155a는 표준 사료 또는 고지방 식이요법으로 사육되고 PBS 대조군 또는 2t2로 치료된 ApoE-/- 마우스로부터의 아테롬성 동맥경화증 플라크의 대표도를 도시한다. 도 155b는 각각의 군의 아테롬성 동맥경화증 플라크의 정량적 분석의 결과를 도시한다.
도 156은 대조군-치료 마우스와 비교하여 2t2 치료-마우스에서 공복 포도당 수준을 도시한다.
도 157은 2t2로 치료된 마우스 및 대조군-치료 마우스로부터의 혈액 림프구에서 CD4+CD25+FoxP3+ Tregs의 백분율을 도시한다.
도 158은 예시적인 15t15 단일-사슬 키메라 폴리펩타이드의 도식적인 다이어그램이다.
도 159는 32Dβ 세포 증식 검정법을 사용하여 재조합 IL-15와 비교하여 15t15에서의 IL-15 활성을 도시한다.
도 160은 항-TF 항체 수지 상에서 결합 및 용리 후 15t15 단백질-함유 세포 배양물 상청액의 크로마토그래프 프로파일을 도시하는 선 그래프이다.
도 161a 및 도 161b는 탈글리코실화 전 및 후에 15t15의 환원된 SDS-PAGE 분석을 도시한다. 도 161a는 탈글리코실화 전에 15t15의 환원된 SDS-PAGE 분석을 도시한다. 도 161b는 탈글리코실화 후에 15t15의 환원된 SDS-PAGE 분석을 도시한다.
도 162a 및 도 162b는 18t15-12s, 18t15-12s16, 및 7t15-21s + 항-TF 항체로 자극 후의 NK 세포의 표면 표현형의 변화를 도시하는 한 세트의 히스토그램(도 162a) 및 한 세트의 그래프(도 162b)이다.
도 163은 18t15-12s, 18t15-12s16, 및 7t15-21s로 자극 후, 림프구 집단의 표면 표현형의 변화를 도시하는 한 세트의 그래프이다.
도 164는 18t15-12s로 치료 후 NK 세포에서의 해당작용의 증가를 도시하는 한 세트의 그래프이다.
도 165는 18t15-12s로 자극 후, NK 세포에서 포스포-STAT4 및 포스포-STAT5 수준의 증가를 도시하는 한 세트의 그래프이다.
도 166은 18t15-12s를 이용한 NK 세포의 밤새 자극이 세포 대사를 증강시킴을 도시하는 한 세트의 그래프이다.
도 167a 내지 도 167c는 2t2로 치료 후, C57BL/6 마우스에서 면역자극을 도시하는 한 세트의 그래프이다.
도 168a 및 도 168b는 TGFRt15-TGFRs로 치료 후, C57BL/6 마우스에서 면역자극을 도시하는 한 세트의 그래프이다.
도 169a 내지 도 169c는 서구 식이요법으로 사육되고 TGFRt15-TGFRs 또는 2t2로 치료된 ApoE-/- 마우스에서 Tregs, NK 세포, 및 CD8+ T 세포의 생체내 자극을 도시하는 한 세트의 그래프이다.
도 170a 및 도 170b는 C57BL/6 마우스에서 2t2에 의한 비장세포 증식의 유도를 도시하는 한 세트의 그래프이다.
도 171a 내지 도 171c는 TGFRt15-TGFRs로 치료 후, C57BL/6 마우스에서 면역자극을 도시하는 한 세트의 그래프이다.
도 172a 및 도 172b는 서구 식이요법으로 사육되고 TGFRt15-TGFRs 또는 2t2로 치료된 ApoE-/- 마우스에서 NK 세포 및 CD8+ T 세포의 생체내 증식 유도를 도시하는 한 세트의 그래프이다.
도 173은 7t15-21, TGFRt15-TGFRs 또는 2t2로 치료 후, NSG 마우스에서 7t15-21s 및 항-TF 항체-확장 NK 세포의 지속성을 도시하는 개략도 및 한 세트의 그래프이다.
도 174a 및 도 174b는 NK 세포를 TGFRt15-TGFRs로 처리한 후, NK 세포의 세포독성의 증강을 도시하는 한 세트의 그래프이다.
도 175a 및 도 175b는 NK 세포를 TGFRt15-TGFRs로 처리한 후, NK 세포의 ADCC 활성의 증강을 도시하는 한 세트의 그래프이다.
도 176은 TGFRt15-TGFRs/2t2-활성화된 마우스 NK 세포에 의한 노쇠 B16F10 흑색종 세포의 시험관내 사멸의 그래프이다.
도 177a 내지 도 177h는 흑색종 마우스 모델에서 화학치료법과 병용된 TGFRt15-TGFRs + 항-TRP1 항체(TA99)의 항종양 활성을 도시하는 한 세트의 그래프이다.
도 178a 내지 도 178c는 ApoE-/- 마우스에서 2t2에 의한 서구 식이요법-유도 고혈당의 개선을 도시하는 한 세트의 그래프이다.
도 179는 18t15-12s를 이용하여 자극되고 rhIL-15에서 배양된 후, NK 세포로부터 사이토카인-유도 기억 유사 NK 세포(CIML-NK 세포)로의 분화를 요약하는 세포 표면 염색을 도시하는 한 세트의 그래프이다.
도 180은 CD44 기억 T 세포의 상향조절을 도시한다. 상부 패널은 TGFRt15-TGFRs로 치료 시 CD44 기억 T 세포의 상향조절을 도시한다. 하부 패널은 2t2로 치료 시 CD44 기억 T 세포의 상향조절을 도시한다.
도 181a 및 도 181b는 2t2 또는 IL-2로 치료된 마우스에서 제모 후 모발 재성장의 향상을 도시한다. 도 181a는 PBS-치료, 2t2-치료, 또는 IL-2-치료 마우스에서 제모 후 10일째의 피부 색소침착을 도시한다. 도 181b는 ImageJ 소프트웨어를 사용하여 분석된 바와 같은 PBS-치료, 2t2-치료, 또는 IL-2-치료 마우스에서 색소침착 백분율을 도시한다.
도 182는 PBS-치료, 2t2-치료, 또는 IL-2-치료 마우스에서 제모 후 14일째의 피부 색소침착을 도시한다.
도 183은 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드에 의한 치료 후 인자 X(FX) 활성화의 그래프를 도시한다.
도 184는 프로트롬빈 시간(PT) 시험에서 다양한 농도의 인노빈을 포함하는 완충액에 대한 응고 시간을 도시한다.
도 185는 PT 검정법에서 다중-사슬 키메라 폴리펩타이드에 대한 응고 시간을 도시한다.
도 186은 32DB 세포와 혼합될 때 PT 검정법에서 다중-사슬 키메라 폴리펩타이드의 응고 시간을 도시한다.
도 187은 인간 PBMC와 혼합될 때 PT 검정법에서 다중-사슬 키메라 폴리펩타이드의 응고 시간을 도시한다.
도 188은 CD137(4.1BB)에의 7t15-21s137L(롱 버전) 및 7t15-21s137L(쇼트 버전)의 결합을 도시한다.
도 189a 내지 도 189d는 ELISA를 사용하여 7t15-21s137L(롱 버전)에서 각각의 항체에 의한 IL7, IL21, IL15, 및 4.1BBL의 검출을 도시한다.
도 190은 IL2Rαβγ-함유 CTLL2 세포 증식 검정법에 의해 평가된 바와 같이 7t15-21s137L(롱 버전) 및 7t15-21s137L(쇼트 버전)의 IL-15 활성을 도시한다.
도 191a 내지 도 191c는 2t2 또는 IL2 치료에 반응하여 CD4+CD25hiTreg 세포, CD4+CD25-Tcon 세포, 또는 CD8+ Tcon 세포에서 인간 혈액 림프구 pStat5a 반응을 도시한다. 도 191a는 CD4+CD25hiTreg 세포에서 pSTAT5 반응을 도시한다. 도 C191b는 CD4+CD25-Tcon 세포에서 pSTAT5 반응을 도시한다. 도 191c는 CD8+ Tcon 세포에서 pSTAT5 반응을 도시한다.
도 192a 내지 도 192e는 IL-2 기초 분자(2t2)를 이용한 치료가 마우스 모델에서 제모 후 모낭의 형성을 유도할 수 있음을 도시하는 한 세트의 이미지이다. 도 192a는 대조군 마우스로부터의 이미지이며 - 털이 면도된 후 수행된 제모 단독, 도 192b는 제모에 뒤이어 저용량의 IL-2(1 mg/kg) 투여가 이어진 마우스로부터의 이미지이고, 도 192c 내지 도 192e는 제모에 뒤이어 0.3 mg/kg(도 192c), 1 mg/kg(도 192d), 및 (도 192e) 3 mg/kg에서의 2t2가 이어진 마우스로부터의 이미지를 도시한다. 검정색 화살표는 이후에 피부 내로 연장되고 모발 성장을 용이하게 할 생장기 모낭을 나타낸다.
도 193은 각각의 치료군에 대해 10개 필드당 카운팅된 생장기 모낭의 총 수를 도시한다.
도 194는 7t15-21s+ 항-조직 인자(TF)-항체(IgG1)(50 nM)를 이용한 확장 후 2명의 상이한 공여자로부터의 NK 세포(비노출된 NK 세포에 비해)에서의 DNA 탈메틸화에서 상이한 백분율을 도시하는 그래프이다.
도 195는 TGFRt15-TGFRs를 이용한 단회 용량 치료 후 4일 후의 말초 혈액 분석으로부터의 면역-표현형을 도시하는 한 세트의 그래프이다.
도 196은 TGFRt15-TGFRs를 이용한 단회 용량 치료 후 4일 후의 말초 혈액 분석으로부터의 면역-표현형을 도시하는 한 세트의 그래프이다.
도 197은 TGFRt15-TGFRs를 이용한 제2 투여 후 7일째에 FACS에 의한 β-Gal 염색 분석을 도시하는 그래프이다.
도 198은 TGFRt15-TGFRs를 이용한 제2 투여 후 7일째에 qPCR을 사용하여 결정된 간 조직에서의 노쇠 마커의 수준을 도시하는 한 세트의 그래프이다.
도 199는 TGFRt15-TGFRs를 이용한 제2 투여 후 7일째에 qPCR을 사용하여 결정된 신장 조직에서의 노쇠 마커의 수준을 도시하는 한 세트의 그래프이다.
도 200은 TGFRt15-TGFRs를 이용한 제2 투여 후 7일째에 qPCR을 사용하여 결정된 피부 조직에서의 노쇠 마커의 수준을 도시하는 한 세트의 그래프이다.
도 201은 TGFRt15-TGFRs를 이용한 제2 투여 후 7일째에 qPCR을 사용하여 결정된 폐 조직에서의 노쇠 마커의 수준을 도시하는 한 세트의 그래프이다.
도 202는 TGFRt15-TGFRs를 이용한 제2 치료 후 7일째에 신장 조직 상에서의 β-Gal 염색을 도시하는 한 세트의 조직학적 이미지이다.
도 203a 내지 도 203c는 화학요법이 C57BL/6 마우스에서 p21CIP1p21 노쇠-관련 유전자 발현을 유도함을 도시한다. 도 203a는 실험 치료 계획을 도시하는 예시적인 개략도이다. 도 203b 및 도 203c는 폐(b) 및 간(c) 조직 각각에서 p21CIP1p21의 발현을 도시하는 그래프이다.
도 204는 치료 후 3일차에 IL-15-기초 제제를 이용한 치료 후 면역-표현형 및 세포 증식을 도시하는 한 세트의 그래프이다.
도 205a 내지 도 205c는 TGFRt15-TGFRs 치료가 C57BL/6 마우스에서 노쇠-관련 유전자 발현을 감소시킴을 도시하는 그래프이다. 그래프는 폐에서의 p21CIP1p21과 CD26(a와 b) 및 간(c) 조직에서의 p21CIP1p21의 발현을 도시한다.
도 206은 CD4+, CD8+, 및 Treg 세포 백분율 및 증식을 도시하는 한 세트의 그래프이다.
도 207은 NK, CD19+ 및 단핵구 세포 백분율 및 증식을 도시하는 한 세트의 그래프이다.
도 208a 내지 도 208c는 폐 및 간 조직에서 노쇠 마커 p21CIP1p21 및 CD26의 평가를 도시하는 그래프이다. 도 208a 및 도 208b는 폐 p21CIP1p21(a) 및 폐 CD26(b) 노쇠 마커를 도시한다. 도 208c는 간 p21CIP1p21 노쇠 마커를 도시한다.
도 209는 TGFRt15*-TGFRs 복합체를 초래하는 예시적인 TGFβRII/IL-15RαSu와 TGFβRII/TF/IL-15Mut 단백질 사이의 상호작용의 도식적 다이어그램을 도시한다.
도 210은 예시적인 TGFβRII/IL-15RαSu와 TGFβRII/TF/IL-15Mut 단백질 사이의 상호작용의 도식적 다이어그램을 도시한다.
도 211a는 TGF-β1 및 LAP에의 TGFRt15-TGFRs의 결합 활성을 도시하는 그래프이다.
도 211b는 TGF-β1 및 LAP에의 TGFRII/Fc의 결합 활성을 도시하는 그래프이다.
도 211c는 TGF-β1 및 LAP에의 TGFRt15-TGFRs의 결합 활성을 도시하는 그래프이다.
도 211d는 TGF-β1 및 LAP에의 TGFRt15*-TGFRs의 결합 활성을 도시하는 그래프이다.
도 211e는 CTLL-2에의 TGFRt15-TGFRs, TGFRt15*-TGFRs, 및 7t15-21s의 결합 활성을 도시하는 그래프이다.
도 212a는 TGFRt15-TGFRs 및 TGFRt15*-TGFRs의 TGF- β 1 차단 활성의 그래프이다.
도 212b는 TGFRt15-TGFRs 및 TGFRt15*-TGFRs의 IL-15 생물학적 활성의 그래프이다.
도 212c는 TGF-β1, TGF-β2, 및 TGF-β3이 각각 TGFRt15*-TGFRs의 부재 하에 IL-4-유도 CTLL-2 성장을 유사하게 저해함을 도시하는 그래프이다.
도 212d는 TGFRt15*-TGFRs가 IL-4-유도 CTLL-2 세포 성장의 TGF-β1 및 TGF-β3의 저해를 유의하게 역전시켰음을 도시하는 그래프이다.
도 213a는 4°C, 25°C, 또는 37°C에서의 10-일 인큐베이션 후 TGFRt15-TGFRs의 IL-15 도메인에 대해 어떠한 유의한 손상도 없음을 도시한다.
도 213b는 4°C, 25°C, 또는 37°C에서의 10-일 인큐베이션 후 TGFRt15-TGFRs의 TGFβ-RII 도메인에 대해 어떠한 유의한 손상도 없음을 도시한다.
도 213c는 4°C, 25°C, 또는 37°C에서 10일 동안 인간 혈청에서의 인큐베이션 후 TGFRt15-TGFRs의 TGF-β1 중화 활성을 도시하는 그래프이다.
도 213d는 4°C, 25°C, 또는 37°C에서 10일 동안 인간 혈청에서의 인큐베이션 후 TGFRt15-TGFRs의 IL-15 활성을 도시하는 그래프이다.
도 214a는 도시된 NK 세포 및 작제물을 사용한 검정에서 세포-매개 세포의 세포독성을 도시하는 그래프이다.
도 214b는 도시된 PBMC 및 작제물을 사용한 검정에서 세포-매개 세포의 세포독성을 도시하는 그래프이다.
도 214c는 도시된 NK 세포 및 작제물을 사용한 검정에서 세포내 그랜자임 B 생성을 도시하는 그래프이다.
도 214d는 도시된 PBMC 및 작제물을 사용한 검정에서 세포내 그랜자임 B 생성을 도시하는 그래프이다.
도 214e는 도시된 NK 세포 및 작제물을 사용한 검정에서 인터페론-감마 생성을 도시하는 그래프이다.
도 214f는 도시된 PBMC 및 작제물을 사용한 검정에서 인터페론-감마 생성을 도시하는 그래프이다.
도 215는 암컷 C57BL/6 마우스에서 평가된 TGFRt15-TGFRs의 약물동력학(반감기, t1/2)을 도시하는 그래프이다.
도 216은 C57BL/6 마우스에서 TGFRt15-TGFRs의 독성을 도시하는 그래프이다.
도 217은 C57BL/6 뮤린 흑색종 모델에서 TGFRt15-TGFRs의 항종양 활성을 도시하는 그래프이다.
도 218은 9주령의 C57BL6/j 수컷 마우스에서 TGFRt15-TGFRs의 활성을 도시하며, 마우스는 구강인두 경로를 통해 50 μl의 블레오마이신(2.5 mg/kg, 단회 용량)을 받은 다음, 블레오마이신 치료 후 17일차에 TGFRt15-TGFRs를 피하(3 mg/kg)로 받았다.
도 219는 TGFRt15-TGFRs 또는 TGFRt15*-TGFRs를 이용한 치료 후 4일째에 db/db 마우스에서의 공복 혈장 포도당 수준을 도시한다.
도 220a 내지 도 220c는 TGFRt15-TGFRs 또는 TGFRt15*-TGFRs를 이용한 치료 후 4일째에 db/db 마우스에서의 TGFβ1-3 수준을 도시한다: TGFβ1(도 220a), TGFβ2(도 220b), 및 TGFβ3(도 220c).
도 221a 내지 도 221e는 TGFRt15-TGFRs 또는 TGFRt15*-TGFRs를 이용한 치료 후 4일째에 db/db 마우스에서의 림프구 하위세트를 도시한다: 혈액 NK 세포(도 221a), 혈액 Ki67+ NK 세포(도 221b), 혈액 그랜자임 B+(GzmB+)(도 221c), 혈액 CD8+(도 221d), 및 혈액 CD8+Ki67+ T 세포(도 221e).
도 222a는 TGFRt15*-TGFRs 또는 TGFRt15-TGFRs와 잠복(latent) TGFβ1(SLC)와의 또는 CD39(대조군)와의 상호작용을 도시한다.
도 222b는 TGFRt15*-TGFRs 및 TGFRII-Fc와 잠복 TGFβ1와의 상호작용을 도시한다.
도 223은 PT 검정에서 인노빈의 응고 시간을 도시하는 그래프이다.
도 224는 PT 검정에서 TGFRt15-TGFRs의 응고 시간을 도시하는 그래프이다.
도 225는 신장에서의 노쇠 마커 PAI-1, IL-1α, IL6, 및 IL-1β의 유전자 발현을 도시하고 젊은 vs PBS 또는 TGFRt15-TGFRs 치료된 노화 마우스를 단기간 vs 장기간 추적 관찰로 비교하는 그래프이다.
도 226은 간에서 노쇠 마커 IL-1α 및 IL6의 유전자 발현을 도시하는 그래프이다.
도 227은 신장에서 노쇠 마커 PAI-1의 단백질 발현을 도시한다.
도 228은 IL15SA(양성 대조군) 또는 TGFRt15*-TGFRs + IL15SA가 혈액에서 CD3+CD8+, CD3-NK1.1+, 및 CD3+CD45+ 면역 세포의 백분율의 증가를 매개한 반면, TGFRt15*-TGFRs를 이용한 치료가 이들 세포 집단의 백분율에 거의 효과를 갖지 않거나 전혀 갖지 않았음을 도시하는 그래프이다.
도 229는 IL15SA(양성 대조군) 또는 TGFRt15*-TGFRs + IL15SA가 비장에서 CD3+CD8+, CD3-NK1.1+, 및 CD3+CD45+ 면역 세포의 백분율의 증가를 매개한 반면, TGFRt15*-TGFRs를 이용한 치료가 이들 세포 집단의 백분율에 거의 효과를 갖지 않거나 전혀 갖지 않았음을 도시하는 그래프이다.
도 230a는 시험 물품 치료 후 신장 및 간 조직에서 노쇠 마커 p21의 유전자 발현을 도시한다.
도 230b는 연구 치료 후 신장 및 간 조직에서 노쇠 마커 PAI1의 유전자 발현을 도시한다.
도 230c는 연구 치료 후 신장 및 간 조직에서 노쇠 마커 IL-1α의 유전자 발현을 도시한다.
도 230d는 연구 치료 후 신장 및 간 조직에서 노쇠 마커 IL-6의 유전자 발현을 도시한다.
도 231a는 제시된 제제를 이용한 치료 후 CD4+, CD8+, 및 Treg 세포 백분율 및 증식을 도시한다. 도 231b는 제시된 제제를 이용한 치료 후 NK, CD19+, 및 단핵구 세포 백분율 및 증식을 도시한다.
도 232a는 화학요법 및 제시된 제제를 이용한 치료 후 마우스의 폐 조직에서 노쇠 마커 p21의 유전자 발현의 평가를 도시한다.
도 232b는 화학요법 및 제시된 제제를 이용한 치료 후 마우스의 폐 조직에서 노쇠 마커 CD26의 유전자 발현의 평가를 도시한다.
도 232c는 화학요법 및 제시된 제제를 이용한 치료 후 마우스의 간 조직에서 노쇠 마커 p21의 유전자 발현의 평가를 도시한다.
도 233a 내지 도 233b는 TGFRt15-TGFRs 치료가 B16F10 종양 보유 마우스의 말초 혈액에서 면역 세포 증식, 확장 및 활성화를 증강시킴을 도시하는 그래프이다.
도 234는 TGFRt15-TGFRs 치료가 B16F10 종양 보유 마우스의 혈장에서 TGFβ의 수준을 저하시킴을 도시하는 그래프이다.
도 235는 TGFRt15-TGFRs 치료가 B16F10 종양 보유 마우스의 혈장에서 전염증성 사이토카인의 수준을 감소시킴을 도시하는 그래프이다.
도 236은 TGFRt15-TGFRs 치료가 B16F10 종양 보유 마우스의 비장에서 NK 및 CD8 확장을 증강시킴을 도시한다.
도 237a 내지 도 237b는 TGFRt15-TGFRs 치료가 B16F10 종양 보유 마우스에서 비장세포의 해당 활성을 증강시킴을 도시한다.
도 238a 내지 도 238b는 TGFRt15-TGFRs 치료가 B16F10 종양 보유 마우스에서 비장세포의 미토콘드리아 호흡을 증강시킴을 도시한다.
도 239a 내지 도 293b는 TGFRt15-TGFRs 치료가 B16F10 종양 보유 마우스의 종양 내로의 NK 및 CD8 면역 세포 침윤(TIL)을 증강시킴을 도시한다.
도 240은 TGFRt15-TGFRs 치료 후 종양의 조직병리학적 분석을 도시하며, TGFRt15-TGFRs+TA99 항체 치료 후, 종양은 유사분열 및 괴사 활성을 거의 나타내지 않았다. 유사분열 지수는 분열 세포와 상관관계가 있고, 괴사의 존재는 더 공격적인 특질 및 불량한 예후의 측정치이다.
도 241은 B16F10 흑색종 마우스 모델에서 TGFRt15-TGFRs+TA99 항체 및 화학요법과 병용된 항-PD-L1 항체를 도시하는 그래프이다.
도 242는 B16F10 흑색종 마우스 모델에서 TGFRt15-TGFRs의 항종양 효능이 NK 세포 및 CD8 T 세포에 의존적임을 도시하는 그래프이다.
도 243a 내지 도 243b는 화학요법 후 종양 보유 마우스의 간 및 폐 조직에서 노쇠 마커 p21, IL-1α 및 IL6의 유전자 발현을 도시하는 그래프이다.
도 244는 B16F10 GFP 세포의 도세탁셀 처리에 의한 노쇠 마커 p21, IL6, H2AX, 및 NK 세포 리간드, Rae1e 및 ULBP1의 유전자 발현의 유도를 도시하는 그래프이다.
도 245는 종양 보유 마우스에서 치료 후 4일 후에 일일당 종양 침윤 림프구를 도시한다.
도 246a 내지 도 246b는 면역요법 치료를 받은 마우스가 PBS 대조군과 비교하여 4일 및 10일의 치료 후 더 낮은 수의 GFP 양성 노쇠 종양 세포(도 246a), 및 형광 현미경에 의해 평가된 24웰 플레이트에 평판배양된 종양 세포(도 246b)를 보여주었음을 나타내는 종양 세포 상에서의 유세포 분석을 도시한다.
도 247은 시스플라틴으로 신장 손상을 유도하고 TGFRt15-TGFRs로 치료 후 마우스의 신장에서의 TGFβ 수준을 도시한다.
도 248a 내지 도 248c는 C57BL/6 마우스에서 TGFRt15-TGFRs의 반복 용량 피하 투여의 독성학적 효과를 도시한다. 체중 변화는 SD21을 통해 제시된다(도 248a). 비장 중량(도 248b) 및 혈액 세포 카운트 및 차등(differential)(도 248c)은 TGFRt15-TGFRs의 1개 용량 후 SD7 및 2개 용량 후 SD21에서 마우스에 대해 표시된다.
도 249는 PBS, TGFRt15-TGFRs(3 mg/kg) 또는 TGFRt15*-TGFRs(3 mg/kg)를 이용한 생체내 치료 후 마우스에서의 TGF-β 이소형의 혈장 수준을 도시한다.
도 250a 내지 도 250b는 PBS, TGFRt15-TGFRs, TGFRt15*-TGFRs 또는 IL15SA를 이용한 생체내 치료 후 마우스의 비장세포에서 해당 용량의 속도(ECAR)(도 250a) 및 미토콘드리아 호흡 용량(OCR)(도 250b)의 변화를 도시한다.
도 251a 내지 도 251b는 PBS, TGFRt15-TGFRs, 또는 TGFRt15*-TGFRs를 이용한 시험관내 처리 후 마우스 비장세포에서 해당 용량의 속도(ECAR)(도 251a) 및 미토콘드리아 호흡 용량(OCR)(도 251b)의 변화를 도시한다.
도 252a 내지 도 252b는 PBS, TGFRt15-TGFRs, 또는 TGFRt15*-TGFRs를 이용한 시험관내 처리 후 C57BL/6 마우스에서 B16F10 흑색종 종양의 종양 성장 및 생존율의 변화를 도시한다. 종양 부피(도 252a) 및 마우스 생존율(종양 부피 < 4000 mm3에 기초함)(도 252b)이 평가되었다. 마우스는 도 252a에서와 같이 B16F10 흑색종 종양 세포의 주사 전에 면역 세포를 고갈시키기 위해 항-CD8, 항-NK, 또는 항-CD8 및 항-NK Ab로 1주일 동안 복강내 치료되었다. 그 후에, 종양 보유 마우스는 종양 세포 접종 후 1일차 및 4일차에 PBS 또는 20 mg/kg TGFRt15-TGFRs로 치료되었다. 동물의 종양 부피(도 252c) 및 마우스 생존율(도 252d)이 평가되었다. B16F10 종양 보유 마우스는 종양 접종 후 1일차 및 7일차에 PBS 또는 20 mg/kg TGFRt15-TGFRs로 치료되었다(도 252e). 종양 접종 후 11일차에, 종양이 수집되었고, 종양-침윤성 NK1.1+ 세포 및 CD8+ T 세포가 유세포측정법에 의해 정량화되었다.
도 253a 내지 도 253b는 PBS(대조군) 또는 TGFRt15-TGFRs를 받는 db/db 마우스에서 공복 혈장 포도당(도 253a) 및 인슐린(도 253b) 수준에 미치는 치료 효과를 도시한다.
도 254a는 PBS 대조군과 비교하여 TGFRt15-TGFRs를 받는 db/db 마우스의 췌장에서 유전자 발현 수준의 배수 변화를 도시한다.
도 254b 내지 도 254d는 PBS 대조군과 비교하여 TGFRt15-TGFRs를 받는 db/db 마우스에 대해 SASP, 노화 및 베타 세포 지수의 유전자에 대한 췌장 발현 수준의 평균 배수 변화를 각각 도시한다.
도 255a 내지 도 255b는 PBS(대조군)(도 255a) 또는 TGFRt15-TGFRs(도 255b)로 치료된 db/db 마우스로부터의 췌장 조직 절편의 다중스펙트럼 이미지화를 도시한다. 대표적인 췌장도(pancreatic islet)가 제시되며, OPAL-520으로서의 인슐린+ 췌도 베타 세포, OPAL-570(회색-척도 이미지에서 백색 세포로서 표시됨)으로서의 인슐린+p21+ 베타 세포는 PBS 치료군(도 255a)과 비교하여 TGRt15-TGFRs 치료군(도 255b)에서 감소되었다. 도 255c 및 도 255d는 PBS(대조군) 또는 TGFRt15-TGFRs로 치료된 db/db 마우스로부터의 췌장 조직 절편에서 췌도 인슐린+(도 255c) 및 췌도 인슐린+ p21+(도 255d) 세포의 수준을 도시한다.
도 256a 내지 도 256c는 PBS(대조군) 또는 TGFRt15-TGFRs를 받는 db/db 마우스에서 혈액 면역 세포 하위세트의 백분율에 미치는 치료 효과를 도시한다.
도 257은 PBS(비히클)와 비교하여 TGFRt15-TGFRs를 이용한 시노몰구스 원숭이의 피하 치료 후 혈액에서 유도된 Ki67 양성 면역 세포의 백분율을 도시한다.
도 258은 PBS, TGFRt15-TGFRs(3 mg/kg) 또는 TGFRt15*-TGFRs(3 mg/kg)를 이용한 생체내 치료 후 4일째에 젊은(6주령) 및 노화(72주령) 마우스로부터 단리된 비장세포의 해당 기능을 나타내는 세포외 산성화율(ECAR)을 도시한다.
도 259는 PBS, TGFRt15-TGFRs(3 mg/kg) 또는 TGFRt15*-TGFRs(3 mg/kg)를 이용한 생체내 치료 후 4일째에 젊은(6주령) 및 노화(72주령) 마우스로부터 단리된 비장세포의 미토콘드리아 호흡을 나타내는 산소 소모율(OCR)을 도시한다.
도 260은 PBS, TGFRt15-TGFRs(3 mg/kg) 또는 TGFRt15*-TGFRs(3 mg/kg)를 이용한 생체내 치료 후 4일째에 젊은(6주령) 및 노화(72주령) 마우스의 혈액 내 면역 세포 하위세트의 백분율을 도시한다.
도 261은 PBS, TGFRt15-TGFRs 또는 TGFRt15*-TGFRs를 이용한 생체내 치료 후 4일째에 젊은(6주령) 및 노화(72주령) 마우스의 비장 내 면역 세포 하위세트의 백분율을 도시한다.
도 262는 1개 또는 2개 용량의 TGFRt15-TGFRs 치료 후 노화 마우스의 간에서 IL1-α, IL1-β, IL-6, p21 및 PAI-1에 대한 유전자 발현 수준을 도시한다.
도 263은 1개 또는 2개 용량의 TGFRt15-TGFRs 치료 후 노화 마우스의 간 조직의 염증 점수를 도시한다.
도 264는 1개 또는 2개 용량의 TGFRt15-TGFRs 치료 후 노화 마우스의 간에서 IL1-α, IL1-β, IL-6, IL-8, TGF-β, PAI-1, 콜라겐 및 피브로넥틴 단백질의 발현 수준을 도시한다.
도 265는 PBS 또는 TGFRt15-TGFRs를 이용한 생체내 치료 후 4일째에 노화 마우스의 간 조직에서 β-갈락토시다제의 수준을 도시한다.
도 266은 PBS 또는 1개 용량의 TGFRt15-TGFRs(3 mg/kg)를 이용한 피하 치료 후 72주령 C57BL/6 마우스의 생존율 곡선을 도시한다.
도 267은 화학요법 및 TGFRt15-TGFRs + TA99 요법 후 B16F10 종양-보유 마우스의 간에서 SASP 인자의 단백질 수준을 도시한다.
도 268a 내지 도 268b는 화학요법 및 TGFRt15-TGFRs + TA99 요법 후 마우스의 종양에서 TIS B16F10-GFP 세포(도 268a)와 NK 및 CD8+ T 세포(도 268b)의 수준에 미치는 CD8+ T 세포(dpCD8) 및 NK 세포(dpNK) 항체 고갈의 효과를 도시한다.
도 269a 내지 도 269e는 B16F10 종양-보유 마우스에서 면역 관문 저해제와 병용된 TGFRt15-TGFRs + TA99의 항종양 활성 및 작용 기전을 도시한다. 도 269a는 마우스 모델에서 B16F10 흑색종을 치료하기 위한 예시적인 개략도를 도시한다. 도 269b는 PBS 또는 화학요법 치료 단독과 비교하여 도세탁셀 후 TGFRt15-TGFRs+TA99+항-PD-L1 항체를 포함한 병용 치료 후 시간 경과에 걸쳐 그리고 18일차에 종양 부피의 변화를 도시한다. 도 269c 및 도 269d는 18일차에 종양 침윤성 CD28+CD8+ T 세포 및 비장 IFNγ+CD8+ T 세포의 백분율에 미치는 치료 효과를 도시한다. 도 269e는 18일차에 종양 침윤성 CD8+ 및 CD8+CD44hi T 세포의 NKG2D의 수준(MFI)에 미치는 치료 효과를 도시한다.
도 270a 내지 도 270d는 PBS, 겜시타빈 및 nab-파클리탁셀 화학요법, TGFRt15-TGFRs, 또는 TGFRt15-TGFRs+화학요법을 이용한 시험관내 처리 후 C57BL/6 scid 마우스에서 SW1990 인간 췌장 종양의 종양 성장 및 생존율의 변화를 도시한다. 도 270a는 이종이식 마우스 모델에서 SW1990 인간 췌장 종양을 치료하기 위한 예시적인 개략도를 도시한다. 도 270b 및 도 270c는 PBS 또는 화학요법 치료 단독과 비교하여 TGFRt15-TGFRs + 화학요법을 포함한 병용 치료 후 시간 경과에 걸쳐 그리고 38일차 각각에서의 종양 부피의 변화를 도시한다. 도 270d는 SW1990 인간 췌장 종양을 보유하는 마우스의 생존율에 미치는 치료 효과를 도시한다.
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포를 사멸시키거나 이의 수를 감소시키는 방법이 본원에 제공되며, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다. 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 축적을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다. 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 마커의 수준을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다. 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 활성을 감소시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다. 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포로부터 유래된 SASP 인자의 수준 또는 활성을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다.
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포를 사멸시키거나 이의 수를 감소시키는 방법이 추가로 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함한다. 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 축적을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함한다. 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 마커의 수준을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함한다. 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 활성을 감소시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함한다. 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포로부터 유래된 하나 이상의 SASP 인자(들)의 수준 및/또는 활성을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함한다.
치료를 필요로 하는 대상체에서 노화-관련 질환 또는 병태를 치료하는 방법이 본원에 제공되며, 노화-관련 질환 또는 병태를 갖는 것으로 식별된 대상체에게 치료적 유효량의 하나 이상의 자연 살해(NK) 세포 활성화제(들) 및/또는 치료적 유효수의 활성화된 NK 세포를 투여하는 단계를 포함한다. 노쇠 세포의 사멸 또는 수의 감소를 필요로 하는 대상체에서 노쇠 세포를 사멸시키거나 이의 수를 감소시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 NK 세포 활성화제(들) 및/또는 치료적 유효수의 활성화된 NK 세포를 투여하는 단계를 포함한다. 기간에 걸쳐 향상을 필요로 하는 대상체에서 피부 및/또는 모발의 질감 및/또는 외양을 향상시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 자연 살해(NK) 세포 활성화제(들) 및/또는 치료적 유효수의 활성화된 NK 세포를 투여하는 단계를 포함한다. 기간에 걸쳐 보조를 필요로 하는 대상체에서 비만 치료를 보조하는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 자연 살해(NK) 세포 활성화제(들) 및/또는 치료적 유효수의 활성화된 NK 세포를 투여하는 단계를 포함한다.
활성화된 NK 세포
본원에 기재된 임의의 방법의 일부 구현예는 대상체(예를 들어, 본원에 기재된 임의의 예시적인 대상체)에게 치료적 유효수의 활성화된 NK 세포(예를 들어, 인간 활성화된 NK 세포)를 투여하는 단계를 포함할 수 있다. 활성화된 NK 세포는 예를 들어, 휴지기 NK 세포(예를 들어, 인간 휴지기 NK 세포)와 비교하여, CD25, CD69, MTOR-C1, SREBP1, IFN-γ, 및 그랜자임(예를 들어, 그랜자임 B) 중 2개 이상(예를 들어, 3개, 4개, 5개, 또는 6개)의 증가된 발현 수준을 갖는 NK 세포(예를 들어, 인간 NK 세포)이다. 예를 들어, 활성화된 NK 세포는 예를 들어, 휴지기 NK 세포(예를 들어, 인간 활성화된 NK 세포)와 비교하여, CD25, CD69, MTOR-C1, SREBP1, IFN-γ, 및 그랜자임(예를 들어, 그랜자임 B) 중 2개 이상(예를 들어, 3개, 4개, 5개, 또는 6개)의 발현 수준에서 적어도 10% 증가(예를 들어, 적어도 15% 증가, 적어도 20% 증가, 적어도 25% 증가, 적어도 30% 증가, 적어도 35% 증가, 적어도 40% 증가, 적어도 45% 증가, 적어도 50% 증가, 적어도 55% 증가, 적어도 60% 증가, 적어도 65% 증가, 적어도 70% 증가, 적어도 75% 증가, 적어도 80% 증가, 적어도 85% 증가, 적어도 90% 증가, 적어도 95% 증가, 적어도 100% 증가, 적어도 120% 증가, 적어도 140% 증가, 적어도 160% 증가, 적어도 180% 증가, 적어도 200% 증가, 적어도 220% 증가, 적어도 240% 증가, 적어도 260% 증가, 적어도 280% 증가, 또는 적어도 300% 증가)를 가질 수 있다.
일부 구현예에서, 활성화된 NK 세포는 선택적으로 예를 들어, 휴지기 NK 세포(예를 들어, 인간 활성화된 NK 세포)와 비교하여, CD25, CD59, CD352, NKp80, DNAM-1, 2B4, NKp30, NKp44, NKp46, NKG2D, CD16, KIR2DS1, KIR2Ds2/3, KIR2DL4, KIR2DS4, KIR2DS5, KIR3DS1, NKG2C, CCR7, CXCR3, L-셀렉틴, CXCR1, CXCR2, CX3CR1, ChemR23, CXCR4, CCR5, S1P5, c-Kit, mTORC1 중 2개 이상(예를 들어, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 또는 29개)의 발현 수준에서 적어도 10% 증가(예를 들어, 적어도 15% 증가, 적어도 20% 증가, 적어도 25% 증가, 적어도 30% 증가, 적어도 35% 증가, 적어도 40% 증가, 적어도 45% 증가, 적어도 50% 증가, 적어도 55% 증가, 적어도 60% 증가, 적어도 65% 증가, 적어도 70% 증가, 적어도 75% 증가, 적어도 80% 증가, 적어도 85% 증가, 적어도 90% 증가, 적어도 95% 증가, 적어도 100% 증가, 적어도 120% 증가, 적어도 140% 증가, 적어도 160% 증가, 적어도 180% 증가, 적어도 200% 증가, 적어도 220% 증가, 적어도 240% 증가, 적어도 260% 증가, 적어도 280% 증가, 또는 적어도 300% 증가)를 추가로 가질 수 있다.
예를 들어, 활성화된 NK 세포(예를 들어, 인간 활성화된 NK 세포)는 예를 들어, 휴지기 NK 세포(예를 들어, 인간 휴지기 NK 세포)와 비교하여, CD25, CD69, mTORC1, SREBP1, IFN-γ, 및 그랜자임(예를 들어, 그랜자임 B) 중 2개 이상(예를 들어, 3개, 4개, 5개, 또는 6개)의 발현 수준에서 약 10% 증가 내지 약 500% 증가, 약 10% 증가 내지 약 450% 증가, 약 10% 증가 내지 약 400% 증가, 약 10% 증가 내지 약 350% 증가, 약 10% 증가 내지 약 300% 증가, 약 10% 증가 내지 약 280% 증가, 약 10% 증가 내지 약 260% 증가, 약 10% 증가 내지 약 240% 증가, 약 10% 증가 내지 약 220% 증가, 약 10% 증가 내지 약 200% 증가, 약 10% 증가 내지 약 180% 증가, 약 10% 증가 내지 약 160% 증가, 약 10% 증가 내지 약 140% 증가, 약 10% 증가 내지 약 120% 증가, 약 10% 증가 내지 약 100% 증가, 약 10% 증가 내지 약 80% 증가, 약 10% 증가 내지 약 60% 증가, 약 10% 증가 내지 약 40% 증가, 약 10% 증가 내지 약 20% 증가, 20% 증가 내지 약 500% 증가, 약 20% 증가 내지 약 450% 증가, 약 20% 증가 내지 약 400% 증가, 약 20% 증가 내지 약 350% 증가, 약 20% 증가 내지 약 300% 증가, 약 20% 증가 내지 약 280% 증가, 약 20% 증가 내지 약 260% 증가, 약 20% 증가 내지 약 240% 증가, 약 20% 증가 내지 약 220% 증가, 약 20% 증가 내지 약 200% 증가, 약 20% 증가 내지 약 180% 증가, 약 20% 증가 내지 약 160% 증가, 약 20% 증가 내지 약 140% 증가, 약 20% 증가 내지 약 120% 증가, 약 20% 증가 내지 약 100% 증가, 약 20% 증가 내지 약 80% 증가, 약 20% 증가 내지 약 60% 증가, 약 20% 증가 내지 약 40% 증가, 40% 증가 내지 약 500% 증가, 약 40% 증가 내지 약 450% 증가, 약 40% 증가 내지 약 400% 증가, 약 40% 증가 내지 약 350% 증가, 약 40% 증가 내지 약 300% 증가, 약 40% 증가 내지 약 280% 증가, 약 40% 증가 내지 약 260% 증가, 약 40% 증가 내지 약 240% 증가, 약 40% 증가 내지 약 220% 증가, 약 40% 증가 내지 약 200% 증가, 약 40% 증가 내지 약 180% 증가, 약 40% 증가 내지 약 160% 증가, 약 40% 증가 내지 약 140% 증가, 약 40% 증가 내지 약 120% 증가, 약 40% 증가 내지 약 100% 증가, 약 40% 증가 내지 약 80% 증가, 약 40% 증가 내지 약 60% 증가, 60% 증가 내지 약 500% 증가, 약 60% 증가 내지 약 450% 증가, 약 60% 증가 내지 약 400% 증가, 약 60% 증가 내지 약 350% 증가, 약 60% 증가 내지 약 300% 증가, 약 60% 증가 내지 약 280% 증가, 약 60% 증가 내지 약 260% 증가, 약 60% 증가 내지 약 240% 증가, 약 60% 증가 내지 약 220% 증가, 약 60% 증가 내지 약 200% 증가, 약 60% 증가 내지 약 180% 증가, 약 60% 증가 내지 약 160% 증가, 약 60% 증가 내지 약 140% 증가, 약 60% 증가 내지 약 120% 증가, 약 60% 증가 내지 약 100% 증가, 약 60% 증가 내지 약 80% 증가, 80% 증가 내지 약 500% 증가, 약 80% 증가 내지 약 450% 증가, 약 80% 증가 내지 약 400% 증가, 약 80% 증가 내지 약 350% 증가, 약 80% 증가 내지 약 300% 증가, 약 80% 증가 내지 약 280% 증가, 약 80% 증가 내지 약 260% 증가, 약 80% 증가 내지 약 240% 증가, 약 80% 증가 내지 약 220% 증가, 약 80% 증가 내지 약 200% 증가, 약 80% 증가 내지 약 180% 증가, 약 80% 증가 내지 약 160% 증가, 약 80% 증가 내지 약 140% 증가, 약 80% 증가 내지 약 120% 증가, 약 80% 증가 내지 약 100% 증가, 약 100% 증가 내지 약 500% 증가, 약 100% 증가 내지 약 450% 증가, 약 100% 증가 내지 약 400% 증가, 약 100% 증가 내지 약 350% 증가, 약 100% 증가 내지 약 300% 증가, 약 100% 증가 내지 약 280% 증가, 약 100% 증가 내지 약 260% 증가, 약 100% 증가 내지 약 240% 증가, 약 100% 증가 내지 약 220% 증가, 약 100% 증가 내지 약 200% 증가, 약 100% 증가 내지 약 180% 증가, 약 100% 증가 내지 약 160% 증가, 약 100% 증가 내지 약 140% 증가, 약 100% 증가 내지 약 120% 증가, 약 120% 증가 내지 약 500% 증가, 약 120% 증가 내지 약 450% 증가, 약 120% 증가 내지 약 400% 증가, 약 120% 증가 내지 약 350% 증가, 약 120% 증가 내지 약 300% 증가, 약 120% 증가 내지 약 280% 증가, 약 120% 증가 내지 약 260% 증가, 약 120% 증가 내지 약 240% 증가, 약 120% 증가 내지 약 220% 증가, 약 120% 증가 내지 약 200% 증가, 약 120% 증가 내지 약 180% 증가, 약 120% 증가 내지 약 160% 증가, 약 120% 증가 내지 약 140% 증가, 약 140% 증가 내지 약 500% 증가, 약 140% 증가 내지 약 450% 증가, 약 140% 증가 내지 약 400% 증가, 약 140% 증가 내지 약 350% 증가, 약 140% 증가 내지 약 300% 증가, 약 140% 증가 내지 약 280% 증가, 약 140% 증가 내지 약 260% 증가, 약 140% 증가 내지 약 240% 증가, 약 140% 증가 내지 약 220% 증가, 약 140% 증가 내지 약 200% 증가, 약 140% 증가 내지 약 180% 증가, 약 140% 증가 내지 약 160% 증가, 약 160% 증가 내지 약 500% 증가, 약 160% 증가 내지 약 450% 증가, 약 160% 증가 내지 약 400% 증가, 약 160% 증가 내지 약 350% 증가, 약 160% 증가 내지 약 300% 증가, 약 160% 증가 내지 약 280% 증가, 약 160% 증가 내지 약 260% 증가, 약 160% 증가 내지 약 240% 증가, 약 160% 증가 내지 약 220% 증가, 약 160% 증가 내지 약 200% 증가, 약 160% 증가 내지 약 180% 증가, 약 180% 증가 내지 약 500% 증가, 약 180% 증가 내지 약 450% 증가, 약 180% 증가 내지 약 400% 증가, 약 180% 증가 내지 약 350% 증가, 약 180% 증가 내지 약 300% 증가, 약 180% 증가 내지 약 280% 증가, 약 180% 증가 내지 약 260% 증가, 약 180% 증가 내지 약 240% 증가, 약 180% 증가 내지 약 220% 증가, 약 180% 증가 내지 약 200% 증가, 약 200% 증가 내지 약 500% 증가, 약 200% 증가 내지 약 450% 증가, 약 200% 증가 내지 약 400% 증가, 약 200% 증가 내지 약 350% 증가, 약 200% 증가 내지 약 300% 증가, 약 200% 증가 내지 약 280% 증가, 약 200% 증가 내지 약 260% 증가, 약 200% 증가 내지 약 240% 증가, 약 200% 증가 내지 약 220% 증가, 약 220% 증가 내지 약 500% 증가, 약 220% 증가 내지 약 450% 증가, 약 220% 증가 내지 약 400% 증가, 약 220% 증가 내지 약 350% 증가, 약 220% 증가 내지 약 300% 증가, 약 220% 증가 내지 약 280% 증가, 약 220% 증가 내지 약 260% 증가, 약 220% 증가 내지 약 240% 증가, 약 240% 증가 내지 약 500% 증가, 약 240% 증가 내지 약 450% 증가, 약 240% 증가 내지 약 400% 증가, 약 240% 증가 내지 약 350% 증가, 약 240% 증가 내지 약 300% 증가, 약 240% 증가 내지 약 280% 증가, 약 240% 증가 내지 약 260% 증가, 약 260% 증가 내지 약 500% 증가, 약 260% 증가 내지 약 450% 증가, 약 260% 증가 내지 약 400% 증가, 약 260% 증가 내지 약 350% 증가, 약 260% 증가 내지 약 300% 증가, 약 260% 증가 내지 약 280% 증가, 약 280% 증가 내지 약 500% 증가, 약 280% 증가 내지 약 450% 증가, 약 280% 증가 내지 약 400% 증가, 약 280% 증가 내지 약 350% 증가, 약 280% 증가 내지 약 300% 증가, 약 300% 증가 내지 약 500% 증가, 약 300% 증가 내지 약 450% 증가, 약 300% 증가 내지 약 400% 증가, 약 300% 증가 내지 약 350% 증가, 약 350% 증가 내지 약 500% 증가, 약 350% 증가 내지 약 450% 증가, 약 350% 증가 내지 약 400% 증가, 약 400% 증가 내지 약 500% 증가, 약 400% 증가 내지 약 450% 증가, 또는 약 400% 증가 내지 약 500% 증가를 가질 수 있다.
일부 구현예에서, 활성화된 NK 세포는 예를 들어, 휴지기 NK 세포(예를 들어, 인간 활성화된 NK 세포)와 비교하여, CD25, CD59, CD352, NKp80, DNAM-1, 2B4, NKp30, NKp44, NKp46, NKG2D, CD16, KIR2DS1, KIR2Ds2/3, KIR2DL4, KIR2DS4, KIR2DS5, KIR3DS1, NKG2C, CCR7, CXCR3, L-셀렉틴, CXCR1, CXCR2, CX3CR1, ChemR23, CXCR4, CCR5, S1P5, c-Kit, mTORC1 중 2개 이상(예를 들어, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 또는 29개)의 발현 수준에서 약 10% 증가 내지 약 500% 증가(예를 들어, 또는 본원에 기재된 이 범위의 임의의 하위범위)를 추가로 가질 수 있다.
CD25, CD69, CD59, CD352, NKp80, DNAM-1, 2B4, NKp30, NKp44, NKp46, NKG2D, CD16, KIR2DS1, KIR2Ds2/3, KIR2DL4, KIR2DS4, KIR2DS5, KIR3DS1, NKG2C, CCR7, CXCR3, L-셀렉틴, CXCR1, CXCR2, CX3CR1, ChemR23, CXCR4, CCR5, S1P5, c-Kit, mTORC1, MYC, SREBP1, IFN-γ, 및 그랜자임(예를 들어, 그랜자임 B)의 발현 수준을 결정하는 데 사용될 수 있는 검정의 비제한적인 예는 예를 들어, 면역블로팅, 형광-보조 세포 분류, 효소-연결 면역흡착 검정, 및 RT-PCR을 포함한다.
CD25의 발현 수준을 결정하는 데 사용될 수 있는 상업적인 ELISA 검정의 비제한적인 예는 Diaclone, Covalab Biotechnology, 및 Caltag Medsystems로부터 입수 가능하다. 성숙한 인간 CD25에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 CD25 단백질 (SEQ ID NO: 1)
elcdddppe iphatfkama ykegtmlnce ckrgfrriks gslymlctgn sshsswdnqc qctssatrnt tkqvtpqpee qkerkttemq spmqpvdqas lpghcreppp weneateriy hfvvgqmvyy qcvqgyralh rgpaesvckm thgktrwtqp qlictgemet sqfpgeekpq aspegrpese tsclvtttdf qiqtemaatm etsiftteyq vavagcvfll isvlllsglt wqrrqrksrr ti
인간 CD25 cDNA (SEQ ID NO: 2)
gagctctg tgacgatgac ccgccagaga tcccacacgc cacattcaaa gccatggcct acaaggaagg aaccatgttg aactgtgaat gcaagagagg tttccgcaga ataaaaagcg ggtcactcta tatgctctgt acaggaaact ctagccactc gtcctgggac aaccaatgtc aatgcacaag ctctgccact cggaacacaa cgaaacaagt gacacctcaa cctgaagaac agaaagaaag gaaaaccaca gaaatgcaaa gtccaatgca gccagtggac caagcgagcc ttccaggtca ctgcagggaa cctccaccat gggaaaatga agccacagag agaatttatc atttcgtggt ggggcagatg gtttattatc agtgcgtcca gggatacagg gctctacaca gaggtcctgc tgagagcgtc tgcaaaatga cccacgggaa gacaaggtgg acccagcccc agctcatatg cacaggtgaa atggagacca gtcagtttcc aggtgaagag aagcctcagg caagccccga aggccgtcct gagagtgaga cttcctgcct cgtcacaaca acagattttc aaatacagac agaaatggct gcaaccatgg agacgtccat atttacaaca gagtaccagg tagcagtggc cggctgtgtt ttcctgctga tcagcgtcct cctcctgagt gggctcacct ggcagcggag acagaggaag agtagaagaa caatc
CD69의 발현 수준을 결정하는 데 사용될 수 있는 상업적인 ELISA 검정의 비제한적인 예는 RayBiotech, Novus Biologicals, 및 Aviscera Bioscience로부터 입수 가능하다. 성숙한 인간 CD69에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 CD69 단백질 (SEQ ID NO: 3)
mssencfvae nsslhpesgq endatsphfs trhegsfqvp vlcavmnvvf itiliialia
lsvgqyncpg qytfsmpsds hvsscsedwv gyqrkcyfis tvkrswtsaq nacsehgatl
avidsekdmn flkryagree hwvglkkepg hpwkwsngke fnnwfnvtgs dkcvflknte
vssmeceknl ywicnkpyk
인간 CD69 cDNA (SEQ ID NO: 4)
atgagctctg aaaattgttt cgtagcagag aacagctctt tgcatccgga gagtggacaa
gaaaatgatg ccaccagtcc ccatttctca acacgtcatg aagggtcctt ccaagttcct
gtcctgtgtg ctgtaatgaa tgtggtcttc atcaccattt taatcatagc tctcattgcc
ttatcagtgg gccaatacaa ttgtccaggc caatacacat tctcaatgcc atcagacagc
catgtttctt catgctctga ggactgggtt ggctaccaga ggaaatgcta ctttatttct
actgtgaaga ggagctggac ttcagcccaa aatgcttgtt ctgaacatgg tgctactctt
gctgtcattg attctgaaaa ggacatgaac tttctaaaac gatacgcagg tagagaggaa
cactgggttg gactgaaaaa ggaacctggt cacccatgga agtggtcaaa tggcaaagaa
tttaacaact ggttcaacgt tacagggtct gacaagtgtg tttttctgaa aaacacagag
gtcagcagca tggaatgtga gaagaattta tactggatat gtaacaaacc ttacaaataa
성숙한 인간 CD59에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 CD59 단백질 (SEQ ID NO: 5)
lqcyncpnptadckt avncssdfda clitkaglqv ynkcwkfehc nfndvttrlr eneltyycck kdlcnfneql en
인간 CD59 cDNA (SEQ ID NO: 6)
atgggaatcc aaggagggtc tgtcctgttc gggctgctgc tcgtcctggc tgtcttctgc cattcaggtc atagcctgca gtgctacaac tgtcctaacc caactgctga ctgcaaaaca gccgtcaatt gttcatctga ttttgatgcg tgtctcatta ccaaagctgg gttacaagtg tataacaagt gttggaagtt tgagcattgc aatttcaacg acgtcacaac ccgcttgagg gaaaatgagc taacgtacta ctgctgcaag aaggacctgt gtaactttaa cgaacagctt gaaaatggtg ggacatcctt atcagagaaa acagttcttc tgctggtgac tccatttctg gcagcagcct ggagccttca tccctaa
성숙한 인간 CD352에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 CD352 단백질 (SEQ ID NO: 7)
qssltplmv ngilgesvtl plefpagekv nfitwlfnet slafivphet kspeihvtnp kqgkrlnftq syslqlsnlk medtgsyraq istktsakls sytlrilrql rniqvtnhsq lfqnmtcelh ltcsvedadd nvsfrwealg ntlssqpnlt vswdprisse qdytciaena vsnlsfsvsa qklcedvkiq ytdtkmilfm vsgicivfgf iillllvlrk rrdslslstq rtqgpaesar nleyvsvspt nntvyasvth snreteiwtp rendtitiys tinhskeskp tfsrataldn vv
인간 CD352 cDNA (SEQ ID NO: 8)
atgttgtggc tgttccaatc gctcctgttt gtcttctgct ttggcccagg gaatgtagtt tcacaaagca gcttaacccc attgatggtg aacgggattc tgggggagtc agtaactctt cccctggagt ttcctgcagg agagaaggtc aacttcatca cttggctttt caatgaaaca tctcttgcct tcatagtacc ccatgaaacc aaaagtccag aaatccacgt gactaatccg aaacagggaa agcgactgaa cttcacccag tcctactccc tgcaactcag caacctgaag atggaagaca caggctctta cagagcccag atatccacaa agacctctgc aaagctgtcc agttacactc tgaggatatt aagacaactg aggaacatac aagttaccaa tcacagtcag ctatttcaga atatgacctg tgagctccat ctgacttgct ctgtggagga tgcagatgac aatgtctcat tcagatggga ggccttggga aacacacttt caagtcagcc aaacctcact gtctcctggg accccaggat ttccagtgaa caggactaca cctgcatagc agagaatgct gtcagtaatt tatccttctc tgtctctgcc cagaagcttt gcgaagatgt taaaattcaa tatacagata ccaaaatgat tctgtttatg gtttctggga tatgcatagt cttcggtttc atcatactgc tgttacttgt tttgaggaaa agaagagatt ccctatcttt gtctactcag cgaacacagg gccccgagtc cgcaaggaac ctagagtatg tttcagtgtc tccaacgaac aacactgtgt atgcttcagt cactcattca aacagggaaa cagaaatctg gacacctaga gaaaatgata ctatcacaat ttactccaca attaatcatt ccaaagagag taaacccact ttttccaggg caactgccct tgacaatgtc gtgtaa
성숙한 인간 NKp80에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 NKp80 단백질 (SEQ ID NO: 9)
mqdeerymtl nvqskkrssa qtsqltfkdy svtlhwykil lgisgtvngi ltltlislil
lvsqgvllkc qkgscsnatq yedtgdlkvn ngtrrnisnk dlcasrsadq tvlcqsewlk
yqgkcywfsn emkswsdsyv yclerkshll iihdqlemaf iqknlrqlny vwiglnftsl
kmtwtwvdgs pidskiffik gpakenscaa ikeskifset cssvfkwicq y
인간 NKp80 cDNA (SEQ ID NO: 10)
atgcaagatg aagaaagata catgacattg aatgtacagt caaagaaaag gagttctgcc caaacatctc aacttacatt taaagattat tcagtgacgt tgcactggta taaaatctta ctgggaatat ctggaaccgt gaatggtatt ctcactttga ctttgatctc cttgatcctg ttggtactat gccaatcaga atggctcaaa taccaaggga agtgttattg gttctctaat gagatgaaaa gctggagtga cagttatgtg tattgtttgg aaagaaaatc tcatctacta atcatacatg accaacttga aatggctttt atacagaaaa acctaagaca attaaactac gtatggattg ggcttaactt tacctccttg aaaatgacat ggacttgggt ggatggttct ccaatagatt caaagatatt cttcataaag ggaccagcta aagaaaacag ctgtgctgcc attaaggaaa gcaaaatttt ctctgaaacc tgcagcagtg ttttcaaatg gatttgtcag tattag
성숙한 인간 DNAM-1에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 DNAM-1 단백질 (SEQ ID NO: 11)
ee vlwhtsvpfa enmslecvyp smgiltqvew fkigtqqdsi aifspthgmv irkpyaervy flnstmasnn mtlffrnase ddvgyyscsl ytypqgtwqk viqvvqsdsf eaavpsnshi vsepgknvtl tcqpqmtwpv qavrwekiqp rqidlltycn lvhgrnftsk fprqivsncs hgrwsvivip dvtvsdsgly rcylqasage netfvmrltv aegktdnqyt lfvaggtvll llfvisitti iviflnrrrr rerrdlftes wdtqkapnny rspistsqpt nqsmddtred iyvnyptfsr rpktrv
인간 DNAM-1 cDNA (SEQ ID NO: 12)
atggattatc ctactttact tttggctctt cttcatgtat acagagctct atgtgaagag gtgctttggc atacatcagt tccctttgcc gagaacatgt ctctagaatg tgtgtatcca tcaatgggca tcttaacaca ggtggagtgg ttcaagatcg ggacccagca ggattccata gccattttca gccctactca tggcatggtc ataaggaagc cctatgctga gagggtttac tttttgaatt caacgatggc ttccaataac atgactcttt tctttcggaa tgcctctgaa gatgatgttg gctactattc ctgctctctt tacacttacc cacagggaac ttggcagaag gtgatacagg tggttcagtc agatagtttt gaggcagctg tgccatcaaa tagccacatt gtttcggaac ctggaaagaa tgtcacactc acttgtcagc ctcagatgac gtggcctgtg caggcagtga ggtgggaaaa gatccagccc cgtcagatcg acctcttaac ttactgcaac ttggtccatg gcagaaattt cacctccaag ttcccaagac aaatagtgag caactgcagc cacggaaggt ggagcgtcat cgtcatcccc gatgtcacag tctcagactc ggggctttac cgctgctact tgcaggccag cgcaggagaa aacgaaacct tcgtgatgag attgactgta gccgagggta aaaccgataa ccaatatacc ctctttgtgg ctggagggac agttttattg ttgttgtttg ttatctcaat taccaccatc attgtcattt tccttaacag aaggagaagg agagagagaa gagatctatt tacagagtcc tgggatacac agaaggcacc caataactat agaagtccca tctctaccag tcaacctacc aatcaatcca tggatgatac aagagaggat atttatgtca actatccaac cttctctcgc agaccaaaga ctagagttta a
성숙한 인간 2B4에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 2B4 단백질 (SEQ ID NO: 13)
gk gcqgsadhvv sisgvplqlq pnsiqtkvds iawkkllpsq ngfhhilkwe ngslpsntsn drfsfivknl sllikaaqqq dsglyclevt sisgkvqtat fqvfvfdkve kprlqgqgki ldrgrcqval sclvsrdgnv syawyrgskl iqtagnltyl deevdingth tytcnvsnpv sweshtlnlt qdcqnahqef rfwpflviiv ilsalflgtl acfcvwrrkr kekqsetspk efltiyedvk dlktrrnheq eqtfpgggst iysmiqsqss aptsqepayt lysliqpsrk sgsrkrnhsp sfnstiyevi gksqpkaqnp arlsrkelen fdvys
인간 2B4 cDNA (SEQ ID NO: 14)
atgctggggc aagtggtcac cctcatactc ctcctgctcc tcaaggtgta tcagggcaaa ggatgccagg gatcagctga ccatgtggtt agcatctcgg gagtgcctct tcagttacaa ccaaacagca tacagacgaa ggttgacagc attgcatgga agaagttgct gccctcacaa aatggatttc atcacatatt gaagtgggag aatggctctt tgccttccaa tacttccaat gatagattca gttttatagt caagaacttg agtcttctca tcaaggcagc tcagcagcag gacagtggcc tctactgcct ggaggtcacc agtatatctg gaaaagttca gacagccacg ttccaggttt ttgtatttga taaagttgag aaaccccgcc tacaggggca ggggaagatc ctggacagag ggagatgcca agtggctctg tcttgcttgg tctccaggga tggcaatgtg tcctatgctt ggtacagagg gagcaagctg atccagacag cagggaacct cacctacctg gacgaggagg ttgacattaa tggcactcac acatatacct gcaatgtcag caatcctgtt agctgggaaa gccacaccct gaatctcact caggactgtc agaatgccca tcaggaattc agattttggc cgtttttggt gatcatcgtg attctaagcg cactgttcct tggcaccctt gcctgcttct gtgtgtggag gagaaagagg aaggagaagc agtcagagac cagtcccaag gaatttttga caatttacga agatgtcaag gatctgaaaa ccaggagaaa tcacgagcag gagcagactt ttcctggagg ggggagcacc atctactcta tgatccagtc ccagtcttct gctcccacgt cacaagaacc tgcatataca ttatattcat taattcagcc ttccaggaag tctggatcca ggaagaggaa ccacagccct tccttcaata gcactatcta tgaagtgatt ggaaagagtc aacctaaagc ccagaaccct gctcgattga gccgcaaaga gctggagaac tttgatgttt attcctag
성숙한 인간 NKp30에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 NKp30 단백질 (SEQ ID NO: 15)
lw vsqppeirtl egssaflpcs fnasqgrlai gsvtwfrdev vpgkevrngt pefrgrlapl assrflhdhq aelhirdvrg hdasiyvcrv evlglgvgtg ngtrlvveke hpqlgagtvl llragfyavs flsvavgstv yyqgkcltwk gprrqlpavv paplpppcgs sahllppvpg g
인간 NKp30 cDNA (SEQ ID NO: 16)
atggcctgga tgctgttgct catcttgatc atggtccatc caggatcctg tgctctctgg gtgtcccagc cccctgagat tcgtaccctg gaaggatcct ctgccttcct gccctgctcc ttcaatgcca gccaagggag actggccatt ggctccgtca cgtggttccg agatgaggtg gttccaggga aggaggtgag gaatggaacc ccagagttca ggggccgcct ggccccactt gcttcttccc gtttcctcca tgaccaccag gctgagctgc acatccggga cgtgcgaggc catgacgcca gcatctacgt gtgcagagtg gaggtgctgg gccttggtgt cgggacaggg aatgggactc ggctggtggt ggagaaagaa catcctcagc taggggctgg tacagtcctc ctccttcggg ctggattcta tgctgtcagc tttctctctg tggccgtggg cagcaccgtc tattaccagg gcaaatgcca ctgtcacatg ggaacacact gccactcctc agatgggccc cgaggagtga ttccagagcc cagatgtccc tag
성숙한 인간 NKp44에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 NKp44 단백질 (SEQ ID NO: 17)
qskaqvlqs vagqtltvrc qypptgslye kkgwckeasa lvcirlvtss kprtmawtsr ftiwddpdag fftvtmtdlr eedsghywcr iyrpsdnsvs ksvrfylvvs pasastqtsw tprdlvssqt qtqscvppta garqapesps tipvpsqpqn stlrpgpaap ialvpvfcgl lvakslvlsa llvwwgdiww ktmmelrsld tqkatchlqq vtdlpwtsvs spvereilyh tvartkisdd ddehtl
인간 NKp44 cDNA (SEQ ID NO: 18)
atggcctggc gagccctaca cccactgcta ctgctgctgc tgctgttccc aggctctcag gcacaatcca aggctcaggt acttcaaagt gtggcagggc agacgctaac cgtgagatgc cagtacccgc ccacgggcag tctctacgag aagaaaggct ggtgtaagga ggcttcagca cttgtgtgca tcaggttagt caccagctcc aagcccagga cgatggcttg gacctctcga ttcacaatct gggacgaccc tgatgctggc ttcttcactg tcaccatgac tgatctgaga gaggaagact caggacatta ctggtgtaga atctaccgcc cttctgacaa ctctgtctct aagtccgtca gattctatct ggtggtatct ccagcctctg cctccacaca gacctcctgg actccccgcg acctggtctc ttcacagacc cagacccaga gctgtgtgcc tcccactgca ggagccagac aagcccctga gtctccatct accatccctg tcccttcaca gccacagaac tccacgctcc gccctggccc tgcagccccc attgccctgg tgcctgtgtt ctgtggactc ctcgtagcca agagcctggt gctgtcagcc ctgctcgtct ggtgggtttt aaggaatcgg cacatgcagc atcaagggag gtctctgctg cacccagctc agcccaggcc ccaggcccat agacacttcc cactgagcca cagggcacca ggggggacat atggtggaaa accatga
성숙한 인간 NKp46에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 NKp46 단백질 (SEQ ID NO: 19)
qqqtlpkpf iwaephfmvp kekqvticcq gnygaveyql hfegslfavd rpkpperink vqfyipdmns rmagqysciy rvgelwseps nlldlvvtem ydtptlsvhp gpevisgekv tfycrldtat smflllkegr sshvqrgygk vqaefplgpv ttahrgtyrc fgsynnhaws fpsepvkllv tgdientsla pedptfpadt wgtyllttet glqkdhalwd htaqnllrmg laflvlvalv wflvedwlsr krtrerasra stwegrrrln tqtl
인간 NKp46 cDNA (SEQ ID NO: 20)
atggcctggc gagccctaca cccactgcta ctgctgctgc tgctgttccc aggctctcag gcacaatcca aggctcaggt acttcaaagt gtggcagggc agacgctaac cgtgagatgc cagtacccgc ccacgggcag tctctacgag aagaaaggct ggtgtaagga ggcttcagca cttgtgtgca tcaggttagt caccagctcc aagcccagga cgatggcttg gacctctcga ttcacaatct gggacgaccc tgatgctggc ttcttcactg tcaccatgac tgatctgaga gaggaagact caggacatta ctggtgtaga atctaccgcc cttctgacaa ctctgtctct aagtccgtca gattctatct ggtggtatct ccagcctctg cctccacaca gacctcctgg actccccgcg acctggtctc ttcacagacc cagacccaga gctgtgtgcc tcccactgca ggagccagac aagcccctga gtctccatct accatccctg tcccttcaca gccacagaac tccacgctcc gccctggccc tgcagccccc attgccctgg tgcctgtgtt ctgtggactc ctcgtagcca agagcctggt gctgtcagcc ctgctcgtct ggtgggtttt aaggaatcgg cacatgcagc atcaagggag gtctctgctg cacccagctc agcccaggcc ccaggcccat agacacttcc cactgagcca cagggcacca ggggggacat atggtggaaa accatga
성숙한 인간 NKG2D에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 NKG2D 단백질 (SEQ ID NO: 21)
mgwirgrrsr hswemsefhn ynldlkksdf strwqkqrcp vvkskcrena spfffccfia
vamgirfiim vaiwsavfln slfnqevqip ltesycgpcp knwicyknnc yqffdesknw
yesqascmsq nasllkvysk edqdllklvk syhwmglvhi ptngswqwed gsilspnllt
iiemqkgdca lyassfkgyi encstpntyi cmqrtv
인간 NKG2D cDNA (SEQ ID NO: 22)
atggggtgga ttcgtggtcg gaggtctcga cacagctggg agatgagtga atttcataat tataacttgg atctgaagaa gagtgatttt tcaacacgat ggcaaaagca aagatgtcca gtagtcaaaa gcaaatgtag agaaaatgca tctccatttt ttttctgctg cttcatcgct gtagccatgg gaatccgttt cattattatg gtaacaatat ggagtgctgt attcctaaac tcattattca accaagaagt tcaaattccc ttgaccgaaa gttactgtgg cccatgtcct aaaaactgga tatgttacaa aaataactgc taccaatttt ttgatgagag taaaaactgg tatgagagcc aggcttcttg tatgtctcaa aatgccagcc ttctgaaagt atacagcaaa gaggaccagg atttacttaa actggtgaag tcatatcatt ggatgggact agtacacatt ccaacaaatg gatcttggca gtgggaagat ggctccattc tctcacccaa cctactaaca ataattgaaa tgcagaaggg agactgtgca ctctatgcct cgagctttaa aggctatata gaaaactgtt caactccaaa tacgtacatc tgcatgcaaa ggactgtgta a
성숙한 인간 CD16a에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 CD16a 단백질 (SEQ ID NO: 23)
maegtlwqil cvssdaqpqt fegvkgadpp tlppgsflpg pvlwwgslar lqteksdevs
rkgnwwvtem gggagerlft ssclvglvpl glrislvtcp lqcgimwqll lptallllvs
agmrtedlpk avvflepqwy rvlekdsvtl kcqgaysped nstqwfhnes lissqassyf
idaatvddsg eyrcqtnlst lsdpvqlevh igwlllqapr wvfkeedpih lrchswknta
lhkvtylqng kgrkyfhhns dfyipkatlk dsgsyfcrgl fgsknvsset vnititqgla
vstissffpp gyqvsfclvm vllfavdtgl yfsvktnirs strdwkdhkf kwrkdpqdk
인간 CD16a cDNA (SEQ ID NO: 24)
atggctgagggcacactctggcagattctgtgtgtgtcctcagatgctca
gccacagacctttgagggagtaaagggggcagacccacccaccttgcctc
caggctctttccttcctggtcctgttctatggtggggctcccttgccaga
cttcagactgagaagtcagatgaagtttcaagaaaaggaaattggtgggt
gacagagatgggtggaggggctggggaaaggctgtttacttcctcctgtc
tagtcggtttggtccctttagggctccggatatctttggtgacttgtcca
ctccagtgtggcatcatgtggcagctgctcctcccaactgctctgctact
tctagtttcagctggcatgcggactgaagatctcccaaaggctgtggtgt
tcctggagcctcaatggtacagggtgctcgagaaggacagtgtgactctg
aagtgccagggagcctactcccctgaggacaattccacacagtggtttca
caatgagagcctcatctcaagccaggcctcgagctacttcattgacgctg
ccacagtcgacgacagtggagagtacaggtgccagacaaacctctccacc
ctcagtgacccggtgcagctagaagtccatatcggctggctgttgctcca
ggcccctcggtgggtgttcaaggaggaagaccctattcacctgaggtgtc
acagctggaagaacactgctctgcataaggtcacatatttacagaatggc
aaaggcaggaagtattttcatcataattctgacttctacattccaaaagc
cacactcaaagacagcggctcctacttctgcagggggctttttgggagta
aaaatgtgtcttcagagactgtgaacatcaccatcactcaaggtttggca
gtgtcaaccatctcatcattctttccacctgggtaccaagtctctttctg
cttggtgatggtactcctttttgcagtggacacaggactatatttctctg
tgaagacaaacattcgaagctcaacaagagactggaaggaccataaattt
aaatggagaaaggaccctcaagacaaatga
성숙한 인간 CD16b에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 CD16b 단백질 (SEQ ID NO: 25)
mwqlllptal lllvsagmrt edlpkavvfl epqwysvlek dsvtlkcqga yspednstqw fhneslissq assyfidaat vndsgeyrcq tnlstlsdpv qlevhigwll lqaprwvfke edpihlrchs wkntalhkvt ylqngkdrky fhhnsdfhip katlkdsgsy fcrglvgskn vssetvniti tqglavstis sfsppgyqvs fclvmvllfa vdtglyfsvk tni
인간 CD16b cDNA (SEQ ID NO: 26)
atgtggcagctgctcctcccaactgctctgctacttctagtttcagctgg
catgcggactgaagatctcccaaaggctgtggtgttcctggagcctcaat
ggtacagcgtgcttgagaaggacagtgtgactctgaagtgccagggagcc
tactcccctgaggacaattccacacagtggtttcacaatgagaacctcat
ctcaagccaggcctcgagctacttcattgacgctgccacagtcaacgaca
gtggagagtacaggtgccagacaaacctctccaccctcagtgacccggtg
cagctagaagtccatatcggctggctgttgctccaggcccctcggtgggt
gttcaaggaggaagaccctattcacctgaggtgtcacagctggaagaaca
ctgctctgcataaggtcacatatttacagaatggcaaagacaggaagtat
tttcatcataattctgacttccacattccaaaagccacactcaaagatag
cggctcctacttctgcagggggcttgttgggagtaaaaatgtgtcttcag
agactgtgaacatcaccatcactcaaggtttggcagtgtcaaccatctca
tcattctctccacctgggtaccaagtctctttctgcttggtgatggtact
cctttttgcagtggacacaggactatatttctctgtgaagacaaacattt
ga
성숙한 인간 KIR2DS1에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
인간 KIR2DS1 단백질 (SEQ ID NO: 27)
msltvvsmac vgffllqgaw phegvhrkps llahpgrlvk seetvilqcw sdvmfehfll
hregmfndtl rligehhdgv skanfsisrm kqdlagtyrc ygsvthspyq vsapsdpldi
viiglyekps lsaqpgptvl agesvtlscs srssydmyhl sregeaherr lpagtkvngt
fqanfplgpa thggtyrcfg sfrdspyews kssdpllvsv tgnpsnswps ptepssetgn
prhlhvligt svvkipftil lffllhrwcs dkknaavmdq epagnrtvns edsdeqdhqe
vsya
인간 KIR2DS1 cDNA (SEQ ID NO: 28)
atgtcgctcacggtcgtcagcatggcgtgtgttgggttcttcttgctgca
gggggcctggccacatgagggagtccacagaaaaccttccctcctggccc
acccaggtcgcctggtgaaatcagaagagacagtcatcctgcaatgttgg
tcagatgtcatgtttgaacacttccttctgcacagagaggggatgtttaa
cgacactttgcgcctcattggagaacaccatgatggggtctccaaggcca
acttctccatcagtcgcatgaagcaagacctggcagggacctacagatgc
tacggttctgttactcactccccctatcagttgtcagctcccagtgaccc
tctggacatcgtgatcataggtctatatgagaaaccttctctctcagccc
agccgggccccacggttctggcaggagagaatgtgaccttgtcctgcagc
tcccggagctcctatgacatgtaccatctatccagggaaggggaggccca
tgaacgtaggctccctgcagggaccaaggtcaacggaacattccaggcca
actttcctctgggccctgccacccatggagggacctacagatgcttcggc
tctttccgtgactctccatacgagtggtcaaagtcaagtgacccactgct
tgtttctgtcacaggaaacccttcaaatagttggccttcacccactgaac
caagctccgaaaccggtaaccccagacacctacatgttctgattgggacc
tcagtggtcaaaatccctttcaccatcctcctcttctttctccttcatcg
ctggtgctccgacaaaaaaaatgctgctgtaatggaccaagagcctgcag
ggaacagaacagtgaacagcgaggattctgatgaacaagaccatcaggag
gtgtcatacgcataa
성숙한 인간 KIR2DS2에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
인간 KIR2DS2 단백질 (SEQ ID NO: 29)
mslmvvsmvc vgffllqgaw phegvhrkps llahpgplvk seetvilqcw sdvrfehfll
hregkykdtl hligehhdgv skanfsigpm mqdlagtyrc ygsvthspyq lsapsdpldi
vitglyekps lsaqpgptvl agesvtlscs srssydmyhl sregeaherr fsagpkvngt
fqadfplgpa thggtyrcfg sfrdspyews nssdpllvsv tgnpsnswps ptepssktgn
prhlhvligt svvkipftil lffllhrwcs nkknaavmdq epagnrtvns edsdeqdhqe
vsya
인간 KIR2DS2 cDNA (SEQ ID NO: 30)
atgtcgctcatggtcgtcagcatggcgtgtgttgggttcttcttgctgca
gggggcctggccacatgagggagtccacagaaaaccttccctcctggccc
acccaggtcccctggtgaaatcagaagagacagtcatcctgcaatgttgg
tcagatgtcaggtttgagcacttccttctgcacagagaggggaagtataa
ggacactttgcacctcattggagagcaccatgatggggtctccaaggcca
acttctccatcggtcccatgatgcaagaccttgcagggacctacagatgc
tacggttctgttactcactccccctatcagttgtcagctcccagtgaccc
tctggacatcgtcatcacaggtctatatgagaaaccttctctctcagccc
agccgggccccacggttttggcaggagagagcgtgaccttgtcctgcagc
tcccggagctcctatgacatgtaccatctatccagggagggggaggccca
tgaacgtaggttctctgcagggcccaaggtcaacggaacattccaggccg
actttcctctgggccctgccacccacggaggaacctacagatgcttcggc
tctttccgtgactctccctatgagtggtcaaactcgagtgacccactgct
tgtttctgtcacaggaaacccttcaaatagttggccttcacccactgaac
caagctccaaaaccggtaaccccagacacctgcatgttctgattgggacc
tcagtggtcaaaatccctttcaccatcctcctcttctttctccttcatcg
ctggtgctccaacaaaaaaaatgctgctgtaatggaccaagagcctgcag
ggaacagaacagtgaacagcgaggactctgatgaacaagaccctcaggag
gtgacatacacacagttgaatcactgcgttttcacacagagaaaaatcac
tcgcccttctcagaggcccaagacacccccaacagatatcatcgtgtaca
cggaacttccaaatgctgagtccaga
성숙한 인간 KIR2DS3에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 KIR2DS3 단백질 (SEQ ID NO: 31)
mslmvismac vgffwlqgaw phegfrrkps llahpgrlvk seetvilqcw sdvmfehfll
hregtfndtl rligehidgv skanfsigrm rqdlagtyrc ygsvphspyq fsapsdpldi
vitglyekps lsaqpgptvl agesvtlscs swssydmyhl stegeaherr fsagpkvngt
fqadfplgpa tqggtyrcfg sfhdspyews kssdpllvsv tgnpsnswps ptepssktgn
prhlhvligt svvklpftil lffllhrwcs dkknasvmdq gpagnrtvnr edsdeqdhqe
vsya
인간 KIR2DS3 cDNA (SEQ ID NO: 32)
atgtcgctcatggtcatcagcatggcatgtgttgggttcttctggctgca
gggggcctggccacatgagggattccgcagaaaaccttccctcctggccc
acccaggtcgcctggtgaaatcagaagagacagtcatcctgcaatgttgg
tcagatgtcatgtttgagcacttccttctgcacagagaggggacgtttaa
cgacactttgcgcctcattggagagcacattgatggggtctccaaggcca
acttctccatcggtcgcatgaggcaagacctggcagggacctacagatgc
tacggttctgttcctcactccccctatcagttttcagctcccagtgaccc
tctggacatcgtgatcacaggtctatatgagaaaccttctctctcagccc
agccgggccccacggttctggcaggagagagcgtgaccttgtcctgcagc
tcctggagctcctatgacatgtaccatctatccacggagggggaggccca
tgaacgtaggttctctgcagggcccaaggtcaacggaacattccaggccg
actttcctctgggccctgccacccaaggaggaacctacagatgcttcggc
tctttccatgactctccctacgagtggtcaaagtcaagtgacccactgct
tgtttctgtcacaggaaacccttcaaatagttggccttcacccactgaac
caagctccaaaaccggtaaccccagacacctacacgttctgattgggacc
tcagtggtcaaactccctttcaccatcctcctcttctttctccttcatcg
ctggtgctccgacaaaaaaaatgcatctgtaatggaccaagggcctgcgg
ggaacagaacagtgaacagggaggattctgatgaacaggaccatcaggag
gtgtcatacgcataa
성숙한 인간 KIR2DL4에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 KIR2DL4 단백질 (SEQ ID NO: 33)
hvggqdk pfcsawpsav vpqgghatlr chcrrgfnif tlykkdgvpv pelynrifwn sflispvtpa hagtyrcrgf hphsptewsa psnplvimvt glyekpslta rpgptvrage nvtlscssqs sfdiyhlsre geahelrlpa vpsingtfqa dfplgpathg etyrcfgsfh gspyewsdps dplpvsvtgn pssswpspte psfktgiarh lhavirysva iilftilpff llhrwcskkk naavmnqepa ghrtvnreds deqdpqevty aqldhciftq rkitgpsqrs krpstdtsvc ielpnaepra lspahehhsq almgssrett alsqtqlass nvpaagi
인간 KIR2DL4 cDNA (SEQ ID NO: 34)
atgtccccttcacatgttgtggtcaatgtgtcaactgcacgatccgggcc
cctcaccacatcctctgcaccggtcagtcgagccgagtcactgcgtcctg
gcagcagaagctgcaccatgtccatgtcacccacggtcatcatcctggca
tgtcttgggttcttcttggaccagagtgtgtgggcacacgtgggtggtca
ggacaagcccttctgctctgcctggcccagcgctgtggtgcctcaaggag
gacacgtgactcttcggtgtcactatcgtcgtgggtttaacatcttcacg
ctgtacaagaaagatggggtccctgtccctgagctctacaacagaatatt
ctggaacagtttcctcattagccctgtgaccccagcacacgcagggacct
acagatgtcgaggttttcacccgcactcccccactgagtggtcggcaccc
agcaaccccctggtgatcatggtcacaggtctatatgagaaaccttcgct
tacagcccggccgggccccacggttcgcgcaggagagaacgtgaccttgt
cctgcagctcccagagctcctttgacatctaccatctatccagggagggg
gaagcccatgaacttaggctccctgcagtgcccagcatcaatggaacatt
ccaggccgacttccctctgggtcctgccacccacggagagacctacagat
gcttcggctctttccatggatctccctacgagtggtcagacccgagtgac
ccactgcctgtttctgtcacaggaaacccttctagtagttggccttcacc
cactgaaccaagcttcaaaactggtatcgccagacacctgcatgctgtga
ttaggtactcagtggccatcatcctctttaccatccttcccttctttctc
cttcatcgctggtgctccaaaaaaaaagatgctgctgtaatgaaccaaga
gcctgcgggacacagaacagtgaacagggaggactctgatgaacaagacc
ctcaggaggtgacatacgcacagttggatcactgcattttcacacagaga
aaaatcactggcccttctcagaggagcaagagaccctcaacagataccag
cgtgtgtatagaacttccaaatgctgagcccagagcgttgtctcctgccc
atgagcaccacagtcaggccttgatgggatcttctagggagacaacagcc
ctgtctcaaacccagcttgccagctctaatgtaccagcagctggaatctg
a
성숙한 인간 KIR2DS4에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 KIR2DS4 단백질 (SEQ ID NO: 35)
qegvhrkps flalpghlvk seetvilqcw sdvmfehfll hregkfnntl hligehhdgv skanfsigpm mpvlagtyrc yssvphspyq lsapsdpldm viiglyekps lsaqpgptvq agenvslscs siypgrgrpm nvgslqcaas tehsrptflw alpptegptd asalsvtlpt sgqtrvihcl fpsqetlqiv glhplnqapk pvtpdtymf
인간 KIR2DS4 cDNA (SEQ ID NO: 36)
atgtcgctcatggtcatcatcatggcgtgtgttgggttcttcttgctgca
gggggcctggccacaggagggagtccacagaaaaccttccttcctggccc
tcccaggtcacctggtgaaatcagaagagacagtcatcctgcaatgttgg
tcggatgtcatgtttgagcacttccttctgcacagagaggggaagtttaa
caacactttgcacctcattggagagcaccatgatggggtttccaaggcca
acttctccattggtcccatgatgcctgtccttgcaggaacctacagatgc
tacggttctgttcctcactccccctatcagttgtcagctcccagtgaccc
tctggacatggtgatcataggtctatatgagaaaccttctctctcagccc
agccgggccccacggttcaggcaggagagaatgtgaccttgtcctgcagc
tccatctatccagggaaggggaggcccatgaacgtaggctccctgcagtg
cgcagcatcaacggaacattccaggccgactttcctctgggccctgccac
ccacggagggacctacagatgcttcggctctttccgtgacgctccctacg
agtggtcaaactcgagtgatccactgcttgtttccgtcacaggaaaccct
tcaaatagttggccttcacccactgaaccaagctccaaaaccggtaaccc
cagacacctacatgttctgattgggacctcagtggtcaaaatccctttca
ccatcctcctcttctttctccttcatcgctggtgctccgacaaaaaaaat
gctgctgtaatggaccaagagcctgcagggaacagaacagtgaacagcga
ggattctgatgaacaagaccatcaggaggtgtcatacgcataa
성숙한 인간 KIR2DS5에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 KIR2DS5 (SEQ ID NO: 37)
hegfrrkps llahpgplvk seetvilqcw sdvmfehfll hregtfnhtl rligehidgv skgnfsigrm tqdlagtyrc ygsvthspyq lsapsdpldi vitglyekps lsaqpgptvl agesvtlscs srssydmyhl sregeaherr lpagtkvngt fqadfpldpa thggtyrcfg sfrdspyews kssdpllvsv tgntsnswps ptepssktgn prhlhvligt svvklpftil lffllhrwcs nkknasvmdq gpagnrtvnr edsdeqdhqe vsya
인간 KIR2DS5 cDNA (SEQ ID NO: 38)
atgtcgctcatggtcatcagcatggcgtgtgttgcgttcttcttgctgca
gggggcctggccacatgagggattccgcagaaaaccttccctcctggccc
acccaggtcccctggtgaaatcagaagagacagtcatcctgcaatgttgg
tcagatgtcatgtttgagcacttccttctgcacagagaggggacgtttaa
ccacactttgcgcctcattggagagcacattgatggggtctccaagggca
acttctccatcggtcgcatgacacaagacctggcagggacctacagatgc
tacggttctgttactcactccccctatcagttgtcagcgcccagtgaccc
tctggacatcgtgatcacaggtctatatgagaaaccttctctctcagccc
agccgggccccacggttctggcaggagagagcgtgaccttgtcctgcagc
tcccggagctcctatgacatgtaccatctatccagggaaggggaggccca
tgaacgtaggctccctgcagggcccaaggtcaacagaacattccaggccg
actttcctctggaccctgccacccacggagggacctacagatgcttcggc
tctttccgtgactctccatacgagtggtcaaagtcaagtgacccactgct
tgtttctgtcacaggaaactcttcaaatagttggccttcacccactgaac
caagctccgaaaccggtaaccccagacacctacacgttctgattgggacc
tcagtggtcaaactccctttcaccatcctcctcttctttctccttcatcg
ctggtgctccaacaaaaaaaatgcatctgtaatggaccaagggcctgcgg
ggaacagaacagtgaacagggaggattctgatgaacaggaccatcaggag
gtgtcatacgcataa
성숙한 인간 KIR3DS1에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 KIR3DS1 cDNA (SEQ ID NO: 39)
hmggqdkpf lsawpsavvp rgghvtlrch yrhrfnnfml ykedrihvpi fhgrifqegf nmspvttaha gnytcrgshp hsptgwsaps npmvimvtgn hrkpsllahp gplvksgerv ilqcwsdimf ehfflhkegi skdpsrlvgq ihdgvskanf sigsmmrala gtyrcygsvt htpyqlsaps dpldivvtgl yekpslsaqp gpkvqagesv tlscssrssy dmyhlsregg aherrlpavr kvnrtfqadf plgpathggt yrcfgsfrhs pyewsdpsdp llvsvtgnps sswpspteps sksgnlrhlh iligtsvvki pftillffll hrwcsnkkkc ccngpracre qk
인간 KIR3DS1 cDNA (SEQ ID NO: 40)
atgttgctcatggtcgtcagcatggcgtgtgttgggttgttcttggtcca
gagggccggtccacacatgggtggtcaggacaagcccttcctgtctgcct
ggcccagcgctgtggtgcctcgcggaggacacgtgactcttcggtgtcac
tatcgtcataggtttaacaatttcatgctatacaaagaagacagaatcca
cgttcccatcttccatggcagaatattccaggagggcttcaacatgagcc
ctgtgaccacagcacatgcagggaactacacatgtcggggttcacaccca
cactcccccactgggtggtcggcacccagcaaccccatggtgatcatggt
cacaggaaaccacagaaaaccttccctcctggcccacccaggtcccctgg
tgaaatcaggagagagagtcatcctgcaatgttggtcagatatcatgttt
gagcacttctttctgcacaaagagtggatctctaaggacccctcacgcct
cgttggacagatccatgatggggtctccaaggccaatttctccatcggtt
ccatgatgcgtgcccttgcagggacctacagatgctacggttctgttact
cacaccccctatcagttgtcagctcccagtgatcccctggacatcgtggt
cacaggtctatatgagaaaccttctctctcagcccagccgggccccaagg
ttcaggcaggagagagcgtgaccttgtcctgtagctcccggagctcctat
gacatgtaccatctatccagggaggggggagcccatgaacgtaggctccc
tgcagtgcgcaaggtcaacagaacattccaggcagatttccctctgggcc
ctgccacccacggagggacctacagatgcttcggctctttccgtcactct
ccctacgagtggtcagacccgagtgacccactgcttgtttctgtcacagg
aaacccttcaagtagttggccttcacccacagaaccaagctccaaatctg
gtaacctcagacacctgcacattctgattgggacctcagtggtcaaaatc
cctttcaccatcctcctcttctttctccttcatcgctggtgctccaacaa
aaaaaaatgctgctgtaatggaccaagagcctgcagggaacagaagtga
성숙한 인간 NKG2C에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 NKG2C 단백질 (SEQ ID NO: 41)
mskqrgtfse vslaqdpkrq qrkpkgnkss isgteqeifq velnlqnpsl nhqgidkiyd
cqgllpppek ltaevlgiic ivlmatvlkt ivlipfleqn nsspntrtqk arhcghcpee
witysnscyy igkerrtwee sllactskns sllsidneee mkflasilps swigvfrnss
hhpwvtingl afkhkikdsd naelncavlq vnrlksaqcg ssmiyhckhk l
인간 NKG2C cDNA (SEQ ID NO: 42)
atgaataaacaaagaggaaccttctcagaagtgagtctggcccaggaccc
aaagcggcagcaaaggaaacctaaaggcaataaaagctccatttcaggaa
ccgaacaggaaatattccaagtagaattaaatcttcaaaatccttccctg
aatcatcaagggattgataaaatatatgactgccaaggtttactgccacc
tccagagaagctcactgccgaggtcctaggaatcatttgcattgtcctga
tggccactgtgttaaaaacaatagttcttattcctttcctggagcagaac
aatttttccccgaatacaagaacgcagaaagcacgtcattgtggccattg
tcctgaggagtggattacatattccaacagttgttattacattggtaagg
aaagaagaacttgggaagagagtttgctggcctgtacttcgaagaactcc
agtctgctttctatagataatgaagaagaaatgaaatttctggccagcat
tttaccttcctcatggattggtgtgtttcgtaacagcagtcatcatccat
gggtgacaataaatggtttggctttcaaacataagataaaagactcagat
aatgctgaacttaactgtgcagtgctacaagtaaatcgacttaaatcagc
ccagtgtggatcttcaatgatatatcattgtaagcataagctttag
성숙한 인간 CCR7에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 CCR7 단백질 (SEQ ID NO: 43)
qdevtd dyigdnttvd ytlfeslcsk kdvrnfkawf lpimysiicf vgllgnglvv ltyiyfkrlk tmtdtyllnl avadilfllt lpfwaysaak swvfgvhfck lifaiykmsf fsgmllllci sidryvaivq avsahrhrar vllisklscv giwilatvls ipellysdlq rssseqamrc slitehveaf itiqvaqmvi gflvpllams fcylviirtl lqarnfernk aikviiavvv vfivfqlpyn gvvlaqtvan fnitsstcel skqlniaydv tyslacvrcc vnpflyafig vkfrndlfkl fkdlgclsqe qlrqwsscrh irrssmsvea ettttfsp
인간 CCR7 cDNA (SEQ ID NO: 44)
atggacctggggaaaccaatgaaaagcgtgctggtggtggctctccttgt
cattttccaggtatgcctgtgtcaagatgaggtcacggacgattacatcg
gagacaacaccacagtggactacactttgttcgagtctttgtgctccaag
aaggacgtgcggaactttaaagcctggttcctccctatcatgtactccat
catttgtttcgtgggcctactgggcaatgggctggtcgtgttgacctata
tctatttcaagaggctcaagaccatgaccgatacctacctgctcaacctg
gcggtggcagacatcctcttcctcctgacccttcccttctgggcctacag
cgcggccaagtcctgggtcttcggtgtccacttttgcaagctcatctttg
ccatctacaagatgagcttcttcagtggcatgctcctacttctttgcatc
agcattgaccgctacgtggccatcgtccaggctgtctcagctcaccgcca
ccgtgcccgcgtccttctcatcagcaagctgtcctgtgtgggcatctgga
tactagccacagtgctctccatcccagagctcctgtacagtgacctccag
aggagcagcagtgagcaagcgatgcgatgctctctcatcacagagcatgt
ggaggcctttatcaccatccaggtggcccagatggtgatcggctttctgg
tccccctgctggccatgagcttctgttaccttgtcatcatccgcaccctg
ctccaggcacgcaactttgagcgcaacaaggccatcaaggtgatcatcgc
tgtggtcgtggtcttcatagtcttccagctgccctacaatggggtggtcc
tggcccagacggtggccaacttcaacatcaccagtagcacctgtgagctc
agtaagcaactcaacatcgcctacgacgtcacctacagcctggcctgcgt
ccgctgctgcgtcaaccctttcttgtacgccttcatcggcgtcaagttcc
gcaacgatctcttcaagctcttcaaggacctgggctgcctcagccaggag
cagctccggcagtggtcttcctgtcggcacatccggcgctcctccatgag
tgtggaggccgagaccaccaccaccttctccccatag
성숙한 인간 CXCR3에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 CXCR3 단백질 (SEQ ID NO: 45)
mvlevsdhqv lndaevaall enfsssydyg enesdsccts ppcpqdfsln fdraflpaly
sllfllgllg ngavaavlls rrtalsstdt fllhlavadt llvltlplwa vdaavqwvfg
sglckvagal fninfyagal llacisfdry lnivhatqly rrgpparvtl tclavwglcl
lfalpdfifl sahhderlna thcqynfpqv grtalrvlql vagfllpllv maycyahila
vllvsrgqrr lramrlvvvv vvafalcwtp yhlvvlvdil mdlgalarnc gresrvdvak
svtsglgymh cclnpllyaf vgvkfrermw mlllrlgcpn qrglqrqpss srrdsswset
seasysgl
인간 CXCR3 cDNA (SEQ ID NO: 46)
atggagttgaggaagtacggccctggaagactggcggggacagttatagg
aggagctgctcagagtaaatcacagactaaatcagactcaatcacaaaag
agttcctgccaggcctttacacagccccttcctccccgttcccgccctca
caggtgagtgaccaccaagtgctaaatgacgccgaggttgccgccctcct
ggagaacttcagctcttcctatgactatggagaaaacgagagtgactcgt
gctgtacctccccgccctgcccacaggacttcagcctgaacttcgaccgg
gccttcctgccagccctctacagcctcctctttctgctggggctgctggg
caacggcgcggtggcagccgtgctgctgagccggcggacagccctgagca
gcaccgacaccttcctgctccacctagctgtagcagacacgctgctggtg
ctgacactgccgctctgggcagtggacgctgccgtccagtgggtctttgg
ctctggcctctgcaaagtggcaggtgccctcttcaacatcaacttctacg
caggagccctcctgctggcctgcatcagctttgaccgctacctgaacata
gttcatgccacccagctctaccgccgggggcccccggcccgcgtgaccct
cacctgcctggctgtctgggggctctgcctgcttttcgccctcccagact
tcatcttcctgtcggcccaccacgacgagcgcctcaacgccacccactgc
caatacaacttcccacaggtgggccgcacggctctgcgggtgctgcagct
ggtggctggctttctgctgcccctgctggtcatggcctactgctatgccc
acatcctggccgtgctgctggtttccaggggccagcggcgcctgcgggcc
atgcggctggtggtggtggtcgtggtggcctttgccctctgctggacccc
ctatcacctggtggtgctggtggacatcctcatggacctgggcgctttgg
cccgcaactgtggccgagaaagcagggtagacgtggccaagtcggtcacc
tcaggcctgggctacatgcactgctgcctcaacccgctgctctatgcctt
tgtaggggtcaagttccgggagcggatgtggatgctgctcttgcgcctgg
gctgccccaaccagagagggctccagaggcagccatcgtcttcccgccgg
gattcatcctggtctgagacctcagaggcctcctactcgggcttgtga
성숙한 인간 L-셀렉틴에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 L-셀렉틴 단백질 (SEQ ID NO: 47)
df lahhgtdcwt yhysekpmnw qrarrfcrdn ytdlvaiqnk aeieylektl pfsrsyywig irkiggiwtw vgtnksltee aenwgdgepn nkknkedcve iyikrnkdag kwnddachkl kaalcytasc qpwscsghge cveiinnytc ncdvgyygpq cqfviqcepl eapelgtmdc thplgnfsfs sqcafscseg tnltgieett cgpfgnwssp eptcqviqce plsapdlgim ncshplasfs ftsactfics egteligkkk ticessgiws npspicqkld ksfsmikegd ynplfipvav mvtafsglaf iiwlarrlkk gkkskrsmnd py
인간 L-셀렉틴 cDNA (SEQ ID NO: 48)
atgggctgcagaagaactagagaaggaccaagcaaagccatgatatttcc
atggaaatgtcagagcacccagagggacttatggaacatcttcaagttgt
gggggtggacaatgctctgttgtgatttcctggcacatcatggaaccgac
tgctggacttaccattattctgaaaaacccatgaactggcaaagggctag
aagattctgccgagacaattacacagatttagttgccatacaaaacaagg
cggaaattgagtatctggagaagactctgcctttcagtcgttcttactac
tggataggaatccggaagataggaggaatatggacgtgggtgggaaccaa
caaatctcttactgaagaagcagagaactggggagatggtgagcccaaca
acaagaagaacaaggaggactgcgtggagatctatatcaagagaaacaaa
gatgcaggcaaatggaacgatgacgcctgccacaaactaaaggcagccct
ctgttacacagcttcttgccagccctggtcatgcagtggccatggagaat
gtgtagaaatcatcaataattacacctgcaactgtgatgtggggtactat
gggccccagtgtcagtttgtgattcagtgtgagcctttggaggccccaga
gctgggtaccatggactgtactcaccctttgggaaacttcagcttcagct
cacagtgtgccttcagctgctctgaaggaacaaacttaactgggattgaa
gaaaccacctgtggaccatttggaaactggtcatctccagaaccaacctg
tcaagtgattcagtgtgagcctctatcagcaccagatttggggatcatga
actgtagccatcccctggccagcttcagctttacctctgcatgtaccttc
atctgctcagaaggaactgagttaattgggaagaagaaaaccatttgtga
atcatctggaatctggtcaaatcctagtccaatatgtcaaaaattggaca
aaagtttctcaatgattaaggagggtgattataaccccctcttcattcca
gtggcagtcatggttactgcattctctgggttggcatttatcatttggct
ggcaaggagattaaaaaaaggcaagaaatccaagagaagtatgaatgacc
catattaa
성숙한 인간 CXCR1에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 CXCR1 단백질 (SEQ ID NO: 49)
msnitdpqmw dfddlnftgm ppadedyspc xletetlnky vviiayalvf llsllgnslv
mlvilysrvg rsvtdvylln laladllfal tlpiwaaskv ngwifgtflc kvvsllkevn
fysgilllac isvdrylaiv hatrtltqkr hlvkfvclgc wglsmnlslp fflfrqayhp
nnsspvcyev lgndtakwrm vlrilphtfg fivplfvmlf cygftlrtlf kahmgqkhra
mrvifavvli fllcwlpynl vlladtlmrt qviqescerr nnigraldat eilgflhscl
npiiyafigq nfrhgflkil amhglvskef larhrvtsyt sssvnvssnl
인간 CXCR1 cDNA (SEQ ID NO: 50)
atgtcaaatattacagatccacagatgtgggattttgatgatctaaattt
cactggcatgccacctgcagatgaagattacagcccctgtatgctagaaa
ctgagacactcaacaagtatgttgtgatcatcgcctatgccctagtgttc
ctgctgagcctgctgggaaactccctggtgatgctggtcatcttatacag
cagggtcggccgctccgtcactgatgtctacctgctgaacctggccttgg
ccgacctactctttgccctgaccttgcccatctgggccgcctccaaggtg
aatggctggatttttggcacattcctgtgcaaggtggtctcactcctgaa
ggaagtcaacttctacagtggcatcctgctgttggcctgcatcagtgtgg
accgttacctggccattgtccatgccacacgcacactgacccagaagcgt
cacttggtcaagtttgtttgtcttggctgctggggactgtctatgaatct
gtccctgcccttcttccttttccgccaggcttaccatccaaacaattcca
gtccagtttgctatgaggtcctgggaaatgacacagcaaaatggcggatg
gtgttgcggatcctgcctcacacctttggcttcatcgtgccgctgtttgt
catgctgttctgctatggattcaccctgcgtacactgtttaaggcccaca
tggggcagaagcaccgagccatgagggtcatctttgctgtcgtcctcatc
ttcctgctttgctggctgccctacaacctggtcctgctggcagacaccct
catgaggacccaggtgatccaggagagctgtgagcgccgcaacaacatcg
gccgggccctggatgccactgagattctgggatttctccatagctgcctc
aaccccatcatctacgccttcatcggccaaaattttcgccatggattcct
caagatcctggctatgcatggcctggtcagcaaggagttcttggcacgtc
atcgtgttacctcctacacttcttcgtctgtcaatgtctcttccaacctc
tga
성숙한 인간 CXCR2에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 CXCR2 단백질 (SEQ ID NO: 51)
medfnmesds fedfwkgedl snysysstlp pflldaapce pesleinkyf vviiyalvfl
lsllgnslvm lvilysrvgr svtdvyllnl aladllfalt lpiwaaskvn gwifgtflck
vvsllkevnf ysgilllaci svdrylaivh atrtltqkry lvkficlsiw glslllalpv
llfrrtvyss nvspacyedm gnntanwrml lrilpqsfgf ivpllimlfc ygftlrtlfk
ahmgqkhram rvifavvlif llcwlpynlv lladtlmrtq viqetcerrn hidraldate
ilgilhscln pliyafigqk frhgllkila ihgliskdsl pkdsrpsfvg sssghtsttl
인간 CXCR2 cDNA (SEQ ID NO: 52)
atggaagattttaacatggagagtgacagctttgaagatttctggaaagg
tgaagatcttagtaattacagttacagctctaccctgcccccttttctac
tagatgccgccccatgtgaaccagaatccctggaaatcaacaagtatttt
gtggtcattatctatgccctggtattcctgctgagcctgctgggaaactc
cctcgtgatgctggtcatcttatacagcagggtcggccgctccgtcactg
atgtctacctgctgaacctagccttggccgacctactctttgccctgacc
ttgcccatctgggccgcctccaaggtgaatggctggatttttggcacatt
cctgtgcaaggtggtctcactcctgaaggaagtcaacttctatagtggca
tcctgctactggcctgcatcagtgtggaccgttacctggccattgtccat
gccacacgcacactgacccagaagcgctacttggtcaaattcatatgtct
cagcatctggggtctgtccttgctcctggccctgcctgtcttacttttcc
gaaggaccgtctactcatccaatgttagcccagcctgctatgaggacatg
ggcaacaatacagcaaactggcggatgctgttacggatcctgccccagtc
ctttggcttcatcgtgccactgctgatcatgctgttctgctacggattca
ccctgcgtacgctgtttaaggcccacatggggcagaagcaccgggccatg
cgggtcatctttgctgtcgtcctcatcttcctgctctgctggctgcccta
caacctggtcctgctggcagacaccctcatgaggacccaggtgatccagg
agacctgtgagcgccgcaatcacatcgaccgggctctggatgccaccgag
attctgggcatccttcacagctgcctcaaccccctcatctacgccttcat
tggccagaagtttcgccatggactcctcaagattctagctatacatggct
tgatcagcaaggactccctgcccaaagacagcaggccttcctttgttggc
tcttcttcagggcacacttccactactctctaa
성숙한 인간 CX3CR1에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 CX3CR1 단백질 (SEQ ID NO: 53)
mdqfpesvte nfeyddlaea cyigdivvfg tvflsifysv ifaiglvgnl lvvfaltnsk
kpksvtdiyl lnlalsdllf vatlpfwthy linekglhna mckfttafff igffgsiffi
tvisidryla ivlaansmnn rtvqhgvtis lgvwaaailv aapqfmftkq keneclgdyp
evlqeiwpvl rnvetnflgf llpllimsyc yfriiqtlfs cknhkkakai klillvvivf
flfwtpynvm ifletlklyd ffpscdmrkd lrlalsvtet vafshcclnp liyafagekf
rrylyhlygk clavlcgrsv hvdfsssesq rsrhgsvlss nftyhtsdgd allll
인간 CX3CR1 cDNA (SEQ ID NO: 54)
atggatcagttccctgaatcagtgacagaaaactttgagtacgatgattt
ggctgaggcctgttatattggggacatcgtggtctttgggactgtgttcc
tgtccatattctactccgtcatctttgccattggcctggtgggaaatttg
ttggtagtgtttgccctcaccaacagcaagaagcccaagagtgtcaccga
catttacctcctgaacctggccttgtctgatctgctgtttgtagccactt
tgcccttctggactcactatttgataaatgaaaagggcctccacaatgcc
atgtgcaaattcactaccgccttcttcttcatcggcttttttggaagcat
attcttcatcaccgtcatcagcattgataggtacctggccatcgtcctgg
ccgccaactccatgaacaaccggaccgtgcagcatggcgtcaccatcagc
ctaggcgtctgggcagcagccattttggtggcagcaccccagttcatgtt
cacaaagcagaaagaaaatgaatgccttggtgactaccccgaggtcctcc
aggaaatctggcccgtgctccgcaatgtggaaacaaattttcttggcttc
ctactccccctgctcattatgagttattgctacttcagaatcatccagac
gctgttttcctgcaagaaccacaagaaagccaaagccattaaactgatcc
ttctggtggtcatcgtgtttttcctcttctggacaccctacaacgttatg
attttcctggagacgcttaagctctatgacttctttcccagttgtgacat
gaggaaggatctgaggctggccctcagtgtgactgagacggttgcattta
gccattgttgcctgaatcctctcatctatgcatttgctggggagaagttc
agaagatacctttaccacctgtatgggaaatgcctggctgtcctgtgtgg
gcgctcagtccacgttgatttctcctcatctgaatcacaaaggagcaggc
atggaagtgttctgagcagcaattttacttaccacacgagtgatggagat
gcattgctccttctctga
성숙한 인간 ChemR23에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 ChemR23 단백질 (SEQ ID NO: 55)
mrmededynt sisygdeypd yldsivvled lsplearvtr iflvvvysiv cflgilgngl
viiiatfkmk ktvnmvwfln lavadflfnv flpihityaa mdyhwvfgta mckisnflli
hnmftsvfll tiissdrcis vllpvwsqnh rsvrlaymac mviwvlaffl sspslvfrdt
anlhgkiscf nnfslstpgs sswpthsqmd pvgysrhmvv tvtrflcgfl vpvliitacy
ltivcklqrn rlaktkkpfk iivtiiitff lcwcpyhtln llelhhtamp gsvfslglpl
atalaiansc mnpilyvfmg qdfkkfkval fsrlvnalse dtghssypsh rsftkmssmn
ertsmneret gml
인간 ChemR23 cDNA (SEQ ID NO: 56)
atgagaatggaggatgaagattacaacacttccatcagttacggtgatga
ataccctgattatttagactccattgtggttttggaggacttatccccct
tggaagccagggtgaccaggatcttcctggtggtggtctacagcatcgtc
tgcttcctcgggattctgggcaatggtctggtgatcatcattgccacctt
caagatgaagaagacagtgaacatggtctggttcctcaacctggcagtgg
cagatttcctgttcaacgtcttcctcccaatccatatcacctatgccgcc
atggactaccactgggttttcgggacagccatgtgcaagatcagcaactt
ccttctcatccacaacatgttcaccagcgtcttcctgctgaccatcatca
gctctgaccgctgcatctctgtgctcctccctgtctggtcccagaaccac
cgcagcgttcgcctggcttacatggcctgcatggtcatctgggtcctggc
tttcttcttgagttccccatctctcgtcttccgggacacagccaacctgc
atgggaaaatatcctgcttcaacaacttcagcctgtccacacctgggtct
tcctcgtggcccactcactcccaaatggaccctgtggggtatagccggca
catggtggtgactgtcacccgcttcctctgtggcttcctggtcccagtcc
tcatcatcacagcttgctacctcaccatcgtgtgcaaactgcagcgcaac
cgcctggccaagaccaagaagcccttcaagattattgtgaccatcatcat
taccttcttcctctgctggtgcccctaccacacactcaacctcctagagc
tccaccacactgccatgcctggctctgtcttcagcctgggtttgcccctg
gccactgcccttgccattgccaacagctgcatgaaccccattctgtatgt
tttcatgggtcaggacttcaagaagttcaaggtggccctcttctctcgcc
tggtcaatgctctaagtgaagatacaggccactcttcctaccccagccat
agaagctttaccaagatgtcatcaatgaatgagaggacttctatgaatga
gagggagaccggcatgctttga
성숙한 인간 CXCR4에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 CXCR4 단백질 (SEQ ID NO: 57)
megisiytsd nyteemgsgd ydsmkepcfr eenanfnkif lptiysiifl tgivgnglvi
lvmgyqkklr smtdkyrlhl svadllfvit lpfwavdava nwyfgnflck avhviytvnl
yssvlilafi sldrylaivh atnsqrprkl laekvvyvgv wipallltip dfifanvsea
ddryicdrfy pndlwvvvfq fqhimvglil pgivilscyc iiisklshsk ghqkrkalkt
tvililaffa cwlpyyigis idsfilleii kqgcefentv hkwisiteal affhcclnpi
lyaflgakfk tsaqhaltsv srgsslkils kgkrgghssv stesesssfh ss
인간 CXCR4 cDNA (SEQ ID NO: 58)
atgtccattcctttgcctcttttgcagatatacacttcagataactacac
cgaggaaatgggctcaggggactatgactccatgaaggaaccctgtttcc
gtgaagaaaatgctaatttcaataaaatcttcctgcccaccatctactcc
atcatcttcttaactggcattgtgggcaatggattggtcatcctggtcat
gggttaccagaagaaactgagaagcatgacggacaagtacaggctgcacc
tgtcagtggccgacctcctctttgtcatcacgcttcccttctgggcagtt
gatgccgtggcaaactggtactttgggaacttcctatgcaaggcagtcca
tgtcatctacacagtcaacctctacagcagtgtcctcatcctggccttca
tcagtctggaccgctacctggccatcgtccacgccaccaacagtcagagg
ccaaggaagctgttggctgaaaaggtggtctatgttggcgtctggatccc
tgccctcctgctgactattcccgacttcatctttgccaacgtcagtgagg
cagatgacagatatatctgtgaccgcttctaccccaatgacttgtgggtg
gttgtgttccagtttcagcacatcatggttggccttatcctgcctggtat
tgtcatcctgtcctgctattgcattatcatctccaagctgtcacactcca
agggccaccagaagcgcaaggccctcaagaccacagtcatcctcatcctg
gctttcttcgcctgttggctgccttactacattgggatcagcatcgactc
cttcatcctcctggaaatcatcaagcaagggtgtgagtttgagaacactg
tgcacaagtggatttccatcaccgaggccctagctttcttccactgttgt
ctgaaccccatcctctatgctttccttggagccaaatttaaaacctctgc
ccagcacgcactcacctctgtgagcagagggtccagcctcaagatcctct
ccaaaggaaagcgaggtggacattcatctgtttccactgagtctgagtct
tcaagttttcactccagctaa
성숙한 인간 CCR5에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 CCR5 단백질 (SEQ ID NO: 59)
mdyqvsspiy dinyytsepc qkinvkqiaa rllpplyslv fifgfvgnml vililinckr
lksmtdiyll nlaisdlffl ltvpfwahya aaqwdfgntm cqlltglyfi gffsgiffii
lltidrylav vhavfalkar tvtfgvvtsv itwvvavfas lpgiiftrsq keglhytcss
hfpysqyqfw knfqtlkivi lglvlpllvm vicysgilkt llrcrnekkr hravrlifti
mivyflfwap ynivlllntf qeffglnncs ssnrldqamq vtetlgmthc cinpiiyafv
gekfrnyllv ffqkhiakrf ckccsifqqe aperassvyt rstgeqeisv gl
인간 CCR5 cDNA (SEQ ID NO: 60)
atggattatcaagtgtcaagtccaatctatgacatcaattattatacatc
ggagccctgccaaaaaatcaatgtgaagcaaatcgcagcccgcctcctgc
ctccgctctactcactggtgttcatctttggttttgtgggcaacatgctg
gtcatcctcatcctgataaactgcaaaaggctgaagagcatgactgacat
ctacctgctcaacctggccatctctgacctgtttttccttcttactgtcc
ccttctgggctcactatgctgccgcccagtgggactttggaaatacaatg
tgtcaactcttgacagggctctattttataggcttcttctctggaatctt
cttcatcatcctcctgacaatcgataggtacctggctgtcgtccatgctg
tgtttgctttaaaagccaggacggtcacctttggggtggtgacaagtgtg
atcacttgggtggtggctgtgtttgcgtctctcccaggaatcatctttac
cagatctcaaaaagaaggtcttcattacacctgcagctctcattttccat
acagtcagtatcaattctggaagaatttccagacattaaagatagtcatc
ttggggctggtcctgccgctgcttgtcatggtcatctgctactcgggaat
cctaaaaactctgcttcggtgtcgaaatgagaagaagaggcacagggctg
tgaggcttatcttcaccatcatgattgtttattttctcttctgggctccc
tacaacattgtccttctcctgaacaccttccaggaattctttggcctgaa
taattgcagtagctctaacaggttggaccaagctatgcaggtgacagaga
ctcttgggatgacgcactgctgcatcaaccccatcatctatgcctttgtc
ggggagaagttcagaaactacctcttagtcttcttccaaaagcacattgc
caaacgcttctgcaaatgctgttctattttccagcaagaggctcccgagc
gagcaagctcagtttacacccgatccactggggagcaggaaatatctgtg
ggcttgtga
성숙한 인간 S1P5에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 S1P5 단백질 (SEQ ID NO: 61)
mesgllrpap vsevivlhyn ytgklrgary qpgaglrada vvclavcafi vlenlavllv
lgrhprfhap mflllgsltl sdllagaaya anillsgplt lklspalwfa reggvfvalt
asvlsllaia lersltmarr gpapvssrgr tlamaaaawg vslllgllpa lgwnclgrld
acstvlplya kayvlfcvla fvgilaaica lyariycqvr anarrlparp gtagttstra
rrkprslall rtlsvvllaf vacwgplfll llldvacpar tcpvllqadp flglamansl
lnpiiytltn rdlrhallrl vccgrhscgr dpsgsqqsas aaeasgglrr clppgldgsf
sgsersspqr dgldtsgstg spgaptaart lvsepaad
인간 S1P5 cDNA (SEQ ID NO: 62)
atggagtcggggctgctgcggccggcgccggtgagcgaggtcatcgtcct
gcattacaactacaccggcaagctccgcggtgcgcgctaccagccgggtg
ccggcctgcgcgccgacgccgtggtgtgcctggcggtgtgcgccttcatc
gtgctagagaatctagccgtgttgttggtgctcggacgccacccgcgctt
ccacgctcccatgttcctgctcctgggcagcctcacgttgtcggatctgc
tggcaggcgccgcctacgccgccaacatcctactgtcggggccgctcacg
ctgaaactgtcccccgcgctctggttcgcacgggagggaggcgtcttcgt
ggcactcactgcgtccgtgctgagcctcctggccatcgcgctggagcgca
gcctcaccatggcgcgcagggggcccgcgcccgtctccagtcgggggcgc
acgctggcgatggcagccgcggcctggggcgtgtcgctgctcctcgggct
cctgccagcgctgggctggaattgcctgggtcgcctggacgcttgctcca
ctgtcttgccgctctacgccaaggcctacgtgctcttctgcgtgctcgcc
ttcgtgggcatcctggccgctatctgtgcactctacgcgcgcatctactg
ccaggtacgcgccaacgcgcggcgcctgccggcacggcccgggactgcgg
ggaccacctcgacccgggcgcgtcgcaagccgcgctcgctggccttgctg
cgcacgctcagcgtggtgctcctggcctttgtggcatgttggggccccct
cttcctgctgctgttgctcgacgtggcgtgcccggcgcgcacctgtcctg
tactcctgcaggccgatcccttcctgggactggccatggccaactcactt
ctgaaccccatcatctacacgctcaccaaccgcgacctgcgccacgcgct
cctgcgcctggtctgctgcggacgccactcctgcggcagagacccgagtg
gctcccagcagtcggcgagcgcggctgaggcttccgggggcctgcgccgc
tgcctgcccccgggccttgatgggagcttcagcggctcggagcgctcatc
gccccagcgcgacgggctggacaccagcggctccacaggcagccccggtg
cacccacagccgcccggactctggtatcagaaccggctgcagactga
성숙한 인간 C-kit에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 C-kit 단백질 (SEQ ID NO: 63)
qpsvs pgepsppsih pgksdlivrv gdeirllctd pgfvkwtfei ldetnenkqn ewitekaeat ntgkytctnk hglsnsiyvf vrdpaklflv drslygkedn dtlvrcpltd pevtnyslkg cqgkplpkdl rfipdpkagi miksvkrayh rlclhcsvdq egksvlsekf ilkvrpafka vpvvsvskas yllregeeft vtctikdvss svystwkren sqtklqekyn swhhgdfnye rqatltissa rvndsgvfmc yanntfgsan vtttlevvdk gfinifpmin ttvfvndgen vdliveyeaf pkpehqqwiy mnrtftdkwe dypksenesn iryvselhlt rlkgteggty tflvsnsdvn aaiafnvyvn tkpeiltydr lvngmlqcva agfpeptidw yfcpgteqrc sasvlpvdvq tlnssgppfg klvvqssids safkhngtve ckayndvgkt sayfnfafkg nnkeqihpht lftplligfv ivagmmciiv miltykylqk pmyevqwkvv eeingnnyvy idptqlpydh kwefprnrls fgktlgagaf gkvveatayg liksdaamtv avkmlkpsah lterealmse lkvlsylgnh mnivnllgac tiggptlvit eyccygdlln flrrkrdsfi cskqedhaea alyknllhsk esscsdstne ymdmkpgvsy vvptkadkrr svrigsyier dvtpaimedd elaldledll sfsyqvakgm aflaskncih rdlaarnill thgritkicd fglardiknd snyvvkgnar lpvkwmapes ifncvytfes dvwsygiflw elfslgsspy pgmpvdskfy kmikegfrml spehapaemy dimktcwdad plkrptfkqi vqliekqise stnhiysnla ncspnrqkpv vdhsvrinsv gstasssqpl lvhddv
인간 C-kit cDNA (SEQ ID NO: 64)
atgagaggcgctcgcggcgcctgggattttctctgcgttctgctcctact
gcttcgcgtccagacaggctcttctcaaccatctgtgagtccaggggaac
cgtctccaccatccatccatccaggaaaatcagacttaatagtccgcgtg
ggcgacgagattaggctgttatgcactgatccgggctttgtcaaatggac
ttttgagatcctggatgaaacgaatgagaataagcagaatgaatggatca
cggaaaaggcagaagccaccaacaccggcaaatacacgtgcaccaacaaa
cacggcttaagcaattccatttatgtgtttgttagagatcctgccaagct
tttccttgttgaccgctccttgtatgggaaagaagacaacgacacgctgg
tccgctgtcctctcacagacccagaagtgaccaattattccctcaagggg
tgccaggggaagcctcttcccaaggacttgaggtttattcctgaccccaa
ggcgggcatcatgatcaaaagtgtgaaacgcgcctaccatcggctctgtc
tgcattgttctgtggaccaggagggcaagtcagtgctgtcggaaaaattc
atcctgaaagtgaggccagccttcaaagctgtgcctgttgtgtctgtgtc
caaagcaagctatcttcttagggaaggggaagaattcacagtgacgtgca
caataaaagatgtgtctagttctgtgtactcaacgtggaaaagagaaaac
agtcagactaaactacaggagaaatataatagctggcatcacggtgactt
caattatgaacgtcaggcaacgttgactatcagttcagcgagagttaatg
attctggagtgttcatgtgttatgccaataatacttttggatcagcaaat
gtcacaacaaccttggaagtagtagataaaggattcattaatatcttccc
catgataaacactacagtatttgtaaacgatggagaaaatgtagatttga
ttgttgaatatgaagcattccccaaacctgaacaccagcagtggatctat
atgaacagaaccttcactgataaatgggaagattatcccaagtctgagaa
tgaaagtaatatcagatacgtaagtgaacttcatctaacgagattaaaag
gcaccgaaggaggcacttacacattcctagtgtccaattctgacgtcaat
gctgccatagcatttaatgtttatgtgaatacaaaaccagaaatcctgac
ttacgacaggctcgtgaatggcatgctccaatgtgtggcagcaggattcc
cagagcccacaatagattggtatttttgtccaggaactgagcagagatgc
tctgcttctgtactgccagtggatgtgcagacactaaactcatctgggcc
accgtttggaaagctagtggttcagagttctatagattctagtgcattca
agcacaatggcacggttgaatgtaaggcttacaacgatgtgggcaagact
tctgcctattttaactttgcatttaaaggtaacaacaaagagcaaatcca
tccccacaccctgttcactcctttgctgattggtttcgtaatcgtagctg
gcatgatgtgcattattgtgatgattctgacctacaaatatttacagaaa
cccatgtatgaagtacagtggaaggttgttgaggagataaatggaaacaa
ttatgtttacatagacccaacacaacttccttatgatcacaaatgggagt
ttcccagaaacaggctgagttttgggaaaaccctgggtgctggagctttc
gggaaggttgttgaggcaactgcttatggcttaattaagtcagatgcggc
catgactgtcgctgtaaagatgctcaagccgagtgcccatttgacagaac
gggaagccctcatgtctgaactcaaagtcctgagttaccttggtaatcac
atgaatattgtgaatctacttggagcctgcaccattggagggcccaccct
ggtcattacagaatattgttgctatggtgatcttttgaattttttgagaa
gaaaacgtgattcatttatttgttcaaagcaggaagatcatgcagaagct
gcactttataagaatcttctgcattcaaaggagtcttcctgcagcgatag
tactaatgagtacatggacatgaaacctggagtttcttatgttgtcccaa
ccaaggccgacaaaaggagatctgtgagaataggctcatacatagaaaga
gatgtgactcccgccatcatggaggatgacgagttggccctagacttaga
agacttgctgagcttttcttaccaggtggcaaagggcatggctttcctcg
cctccaagaattgtattcacagagacttggcagccagaaatatcctcctt
actcatggtcggatcacaaagatttgtgattttggtctagccagagacat
caagaatgattctaattatgtggttaaaggaaacgctcgactacctgtga
agtggatggcacctgaaagcattttcaactgtgtatacacgtttgaaagt
gacgtctggtcctatgggatttttctttgggagctgttctctttaggaag
cagcccctatcctggaatgccggtcgattctaagttctacaagatgatca
aggaaggcttccggatgctcagccctgaacacgcacctgctgaaatgtat
gacataatgaagacttgctgggatgcagatcccctaaaaagaccaacatt
caagcaaattgttcagctaattgagaagcagatttcagagagcaccaatc
atatttactccaacttagcaaactgcagccccaaccgacagaagcccgtg
gtagaccattctgtgcggatcaattctgtcggcagcaccgcttcctcctc
ccagcctctgcttgtgcacgacgatgtctga
성숙한 인간 mTOR에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 mTOR 단백질 (SEQ ID NO: 65)
mlgtgpaaat taattssnvs vlqqfasglk srneetraka akelqhyvtm elremsqees
trfydqlnhh ifelvsssda nerkggilai asligveggn atrigrfany lrnllpsndp
vvmemaskai grlamagdtf taeyvefevk ralewlgadr negrrhaavl vlrelaisvp
tfffqqvqpf fdnifvavwd pkqairegav aalraclilt tqrepkemqk pqwyrhtfee
aekgfdetla kekgmnrddr ihgallilne lvrissmege rlreemeeit qqqlvhdkyc
kdlmgfgtkp rhitpftsfq avqpqqsnal vgllgysshq glmgfgtsps pakstlvesr
ccrdlmeekf dqvcqwvlkc rnsknsliqm tilnllprla afrpsaftdt qylqdtmnhv
lscvkkeker taafqalgll svavrsefkv ylprvldiir aalppkdfah krqkamqvda
tvftcismla ramgpgiqqd ikellepmla vglspaltav lydlsrqipq lkkdiqdgll
kmlslvlmhk plrhpgmpkg lahqlaspgl ttlpeasdvg sitlalrtlg sfefeghslt
qfvrhcadhf lnsehkeirm eaartcsrll tpsihlisgh ahvvsqtavq vvadvlskll
vvgitdpdpd irycvlasld erfdahlaqa enlqalfval ndqvfeirel aictvgrlss
mnpafvmpfl rkmliqilte lehsgigrik eqsarmlghl vsnaprlirp ymepilkali
lklkdpdpdp npgvinnvla tigelaqvsg lemrkwvdel fiiimdmlqd ssllakrqva
lwtlgqlvas tgyvvepyrk yptllevlln flkteqnqgt rreairvlgl lgaldpykhk
vnigmidqsr dasavslses kssqdssdys tsemlvnmgn lpldefypav smvalmrifr
dqslshhhtm vvqaitfifk slglkcvqfl pqvmptflnv irvcdgaire flfqqlgmlv
sfvkshirpy mdeivtlmre fwvmntsiqs tiillieqiv valggefkly lpqliphmlr
vfmhdnspgr ivsikllaai qlfganlddy lhlllppivk lfdapeaplp srkaaletvd
rltesldftd yasriihpiv rtldqspelr stamdtlssl vfqlgkkyqi fipmvnkvlv
rhrinhqryd vlicrivkgy tladeeedpl iyqhrmlrsg qgdalasgpv etgpmkklhv
stinlqkawg aarrvskddw lewlrrlsle llkdssspsl rscwalaqay npmardlfna
afvscwseln edqqdelirs ielaltsqdi aevtqtllnl aefmehsdkg plplrddngi
vllgeraakc rayakalhyk elefqkgptp aileslisin nklqqpeaaa gvleyamkhf
geleiqatwy eklhewedal vaydkkmdtn kddpelmlgr mrclealgew gqlhqqccek
wtlvndetqa kmarmaaaaa wglgqwdsme eytcmiprdt hdgafyravl alhqdlfsla
qqcidkardl ldaeltamag esysraygam vschmlsele eviqyklvpe rreiirqiww
erlqgcqriv edwqkilmvr slvvsphedm rtwlkyaslc gksgrlalah ktlvlllgvd
psrqldhplp tvhpqvtyay mknmwksark idafqhmqhf vqtmqqqaqh aiatedqqhk
qelhklmarc flklgewqln lqginestip kvlqyysaat ehdrswykaw hawavmnfea
vlhykhqnqa rdekkklrha sganitnatt aattaatatt tastegsnse seaestensp
tpsplqkkvt edlsktllmy tvpavqgffr sislsrgnnl qdtlrvltlw fdyghwpdvn
ealvegvkai qidtwlqvip qliaridtpr plvgrlihql ltdigryhpq aliypltvas
kstttarhna ankilknmce hsntlvqqam mvseelirva ilwhemwheg leeasrlyfg
ernvkgmfev leplhammer gpqtlketsf nqaygrdlme aqewcrkymk sgnvkdltqa
wdlyyhvfrr iskqlpqlts lelqyvspkl lmcrdlelav pgtydpnqpi iriqsiapsl
qvitskqrpr kltlmgsngh efvfllkghe dlrqdervmq lfglvntlla ndptslrknl
siqryavipl stnsgligwv phcdtlhali rdyrekkkil lniehrimlr mapdydhltl
mqkvevfeha vnntagddla kllwlkspss evwfdrrtny trslavmsmv gyilglgdrh
psnlmldrls gkilhidfgd cfevamtrek fpekipfrlt rmltnamevt gldgnyritc
htvmevlreh kdsvmavlea fvydpllnwr lmdtntkgnk rsrtrtdsys agqsveildg
velgepahkk tgttvpesih sfigdglvkp ealnkkaiqi inrvrdkltg rdfshddtld
vptqvellik qatshenlcq cyigwcpfw
인간 mTOR cDNA (SEQ ID NO: 66)
atgcttgga accggacctg ccgccgccac caccgctgcc accacatcta gcaatgtgag
cgtcctgcag cagtttgcca gtggcctaaa gagccggaat gaggaaacca gggccaaagc
cgccaaggag ctccagcact atgtcaccat ggaactccga gagatgagtc aagaggagtc
tactcgcttc tatgaccaac tgaaccatca catttttgaa ttggtttcca gctcagatgc
caatgagagg aaaggtggca tcttggccat agctagcctc ataggagtgg aaggtgggaa
tgccacccga attggcagat ttgccaacta tcttcggaac ctcctcccct ccaatgaccc
agttgtcatg gaaatggcat ccaaggccat tggccgtctt gccatggcag gggacacttt
taccgctgag tacgtggaat ttgaggtgaa gcgagccctg gaatggctgg gtgctgaccg
caatgagggc cggagacatg cagctgtcct ggttctccgt gagctggcca tcagcgtccc
taccttcttc ttccagcaag tgcaaccctt ctttgacaac atttttgtgg ccgtgtggga
ccccaaacag gccatccgtg agggagctgt agccgccctt cgtgcctgtc tgattctcac
aacccagcgt gagccgaagg agatgcagaa gcctcagtgg tacaggcaca catttgaaga
agcagagaag ggatttgatg agaccttggc caaagagaag ggcatgaatc gggatgatcg
gatccatgga gccttgttga tccttaacga gctggtccga atcagcagca tggagggaga
gcgtctgaga gaagaaatgg aagaaatcac acagcagcag ctggtacacg acaagtactg
caaagatctc atgggcttcg gaacaaaacc tcgtcacatt acccccttca ccagtttcca
ggctgtacag ccccagcagt caaatgcctt ggtggggctg ctggggtaca gctctcacca
aggcctcatg ggatttggga cctcccccag tccagctaag tccaccctgg tggagagccg
gtgttgcaga gacttgatgg aggagaaatt tgatcaggtg tgccagtggg tgctgaaatg
caggaatagc aagaactcgc tgatccaaat gacaatcctt aatttgttgc cccgcttggc
tgcattccga ccttctgcct tcacagatac ccagtatctc caagatacca tgaaccatgt
cctaagctgt gtcaagaagg agaaggaacg tacagcggcc ttccaagccc tggggctact
ttctgtggct gtgaggtctg agtttaaggt ctatttgcct cgcgtgctgg acatcatccg
agcggccctg cccccaaagg acttcgccca taagaggcag aaggcaatgc aggtggatgc
cacagtcttc acttgcatca gcatgctggc tcgagcaatg gggccaggca tccagcagga
tatcaaggag ctgctggagc ccatgctggc agtgggacta agccctgccc tcactgcagt
gctctacgac ctgagccgtc agattccaca gctaaagaag gacattcaag atgggctact
gaaaatgctg tccctggtcc ttatgcacaa accccttcgc cacccaggca tgcccaaggg
cctggcccat cagctggcct ctcctggcct cacgaccctc cctgaggcca gcgatgtggg
cagcatcact cttgccctcc gaacgcttgg cagctttgaa tttgaaggcc actctctgac
ccaatttgtt cgccactgtg cggatcattt cctgaacagt gagcacaagg agatccgcat
ggaggctgcc cgcacctgct cccgcctgct cacaccctcc atccacctca tcagtggcca
tgctcatgtg gttagccaga ccgcagtgca agtggtggca gatgtgctta gcaaactgct
cgtagttggg ataacagatc ctgaccctga cattcgctac tgtgtcttgg cgtccctgga
cgagcgcttt gatgcacacc tggcccaggc ggagaacttg caggccttgt ttgtggctct
gaatgaccag gtgtttgaga tccgggagct ggccatctgc actgtgggcc gactcagtag
catgaaccct gcctttgtca tgcctttcct gcgcaagatg ctcatccaga ttttgacaga
gttggagcac agtgggattg gaagaatcaa agagcagagt gcccgcatgc tggggcacct
ggtctccaat gccccccgac tcatccgccc ctacatggag cctattctga aggcattaat
tttgaaactg aaagatccag accctgatcc aaacccaggt gtgatcaata atgtcctggc
aacaatagga gaattggcac aggttagtgg cctggaaatg aggaaatggg ttgatgaact
ttttattatc atcatggaca tgctccagga ttcctctttg ttggccaaaa ggcaggtggc
tctgtggacc ctgggacagt tggtggccag cactggctat gtagtagagc cctacaggaa
gtaccctact ttgcttgagg tgctactgaa ttttctgaag actgagcaga accagggtac
acgcagagag gccatccgtg tgttagggct tttaggggct ttggatcctt acaagcacaa
agtgaacatt ggcatgatag accagtcccg ggatgcctct gctgtcagcc tgtcagaatc
caagtcaagt caggattcct ctgactatag cactagtgaa atgctggtca acatgggaaa
cttgcctctg gatgagttct acccagctgt gtccatggtg gccctgatgc ggatcttccg
agaccagtca ctctctcatc atcacaccat ggttgtccag gccatcacct tcatcttcaa
gtccctggga ctcaaatgtg tgcagttcct gccccaggtc atgcccacgt tccttaacgt
cattcgagtc tgtgatgggg ccatccggga atttttgttc cagcagctgg gaatgttggt
gtcctttgtg aagagccaca tcagacctta tatggatgaa atagtcaccc tcatgagaga
attctgggtc atgaacacct caattcagag cacgatcatt cttctcattg agcaaattgt
ggtagctctt gggggtgaat ttaagctcta cctgccccag ctgatcccac acatgctgcg
tgtcttcatg catgacaaca gcccaggccg cattgtctct atcaagttac tggctgcaat
ccagctgttt ggcgccaacc tggatgacta cctgcattta ctgctgcctc ctattgttaa
gttgtttgat gcccctgaag ctccactgcc atctcgaaag gcagcgctag agactgtgga
ccgcctgacg gagtccctgg atttcactga ctatgcctcc cggatcattc accctattgt
tcgaacactg gaccagagcc cagaactgcg ctccacagcc atggacacgc tgtcttcact
tgtttttcag ctggggaaga agtaccaaat tttcattcca atggtgaata aagttctggt
gcgacaccga atcaatcatc agcgctatga tgtgctcatc tgcagaattg tcaagggata
cacacttgct gatgaagagg aggatccttt gatttaccag catcggatgc ttaggagtgg
ccaaggggat gcattggcta gtggaccagt ggaaacagga cccatgaaga aactgcacgt
cagcaccatc aacctccaaa aggcctgggg cgctgccagg agggtctcca aagatgactg
gctggaatgg ctgagacggc tgagcctgga gctgctgaag gactcatcat cgccctccct
gcgctcctgc tgggccctgg cacaggccta caacccgatg gccagggatc tcttcaatgc
tgcatttgtg tcctgctggt ctgaactgaa tgaagatcaa caggatgagc tcatcagaag
catcgagttg gccctcacct cacaagacat cgctgaagtc acacagaccc tcttaaactt
ggctgaattc atggaacaca gtgacaaggg ccccctgcca ctgagagatg acaatggcat
tgttctgctg ggtgagagag ctgccaagtg ccgagcatat gccaaagcac tacactacaa
agaactggag ttccagaaag gccccacccc tgccattcta gaatctctca tcagcattaa
taataagcta cagcagccgg aggcagcggc cggagtgtta gaatatgcca tgaaacactt
tggagagctg gagatccagg ctacctggta tgagaaactg cacgagtggg aggatgccct
tgtggcctat gacaagaaaa tggacaccaa caaggacgac ccagagctga tgctgggccg
catgcgctgc ctcgaggcct tgggggaatg gggtcaactc caccagcagt gctgtgaaaa
gtggaccctg gttaatgatg agacccaagc caagatggcc cggatggctg ctgcagctgc
atggggttta ggtcagtggg acagcatgga agaatacacc tgtatgatcc ctcgggacac
ccatgatggg gcattttata gagctgtgct ggcactgcat caggacctct tctccttggc
acaacagtgc attgacaagg ccagggacct gctggatgct gaattaactg cgatggcagg
agagagttac agtcgggcat atggggccat ggtttcttgc cacatgctgt ccgagctgga
ggaggttatc cagtacaaac ttgtccccga gcgacgagag atcatccgcc agatctggtg
ggagagactg cagggctgcc agcgtatcgt agaggactgg cagaaaatcc ttatggtgcg
gtcccttgtg gtcagccctc atgaagacat gagaacctgg ctcaagtatg caagcctgtg
cggcaagagt ggcaggctgg ctcttgctca taaaacttta gtgttgctcc tgggagttga
tccgtctcgg caacttgacc atcctctgcc aacagttcac cctcaggtga cctatgccta
catgaaaaac atgtggaaga gtgcccgcaa gatcgatgcc ttccagcaca tgcagcattt
tgtccagacc atgcagcaac aggcccagca tgccatcgct actgaggacc agcagcataa
gcaggaactg cacaagctca tggcccgatg cttcctgaaa cttggagagt ggcagctgaa
tctacagggc atcaatgaga gcacaatccc caaagtgctg cagtactaca gcgccgccac
agagcacgac cgcagctggt acaaggcctg gcatgcgtgg gcagtgatga acttcgaagc
tgtgctacac tacaaacatc agaaccaagc ccgcgatgag aagaagaaac tgcgtcatgc
cagcggggcc aacatcacca acgccaccac tgccgccacc acggccgcca ctgccaccac
cactgccagc accgagggca gcaacagtga gagcgaggcc gagagcaccg agaacagccc
caccccatcg ccgctgcaga agaaggtcac tgaggatctg tccaaaaccc tcctgatgta
cacggtgcct gccgtccagg gcttcttccg ttccatctcc ttgtcacgag gcaacaacct
ccaggataca ctcagagttc tcaccttatg gtttgattat ggtcactggc cagatgtcaa
tgaggcctta gtggaggggg tgaaagccat ccagattgat acctggctac aggttatacc
tcagctcatt gcaagaattg atacgcccag acccttggtg ggacgtctca ttcaccagct
tctcacagac attggtcggt accaccccca ggccctcatc tacccactga cagtggcttc
taagtctacc acgacagccc ggcacaatgc agccaacaag attctgaaga acatgtgtga
gcacagcaac accctggtcc agcaggccat gatggtgagc gaggagctga tccgagtggc
catcctctgg catgagatgt ggcatgaagg cctggaagag gcatctcgtt tgtactttgg
ggaaaggaac gtgaaaggca tgtttgaggt gctggagccc ttgcatgcta tgatggaacg
gggcccccag actctgaagg aaacatcctt taatcaggcc tatggtcgag atttaatgga
ggcccaagag tggtgcagga agtacatgaa atcagggaat gtcaaggacc tcacccaagc
ctgggacctc tattatcatg tgttccgacg aatctcaaag cagctgcctc agctcacatc
cttagagctg caatatgttt ccccaaaact tctgatgtgc cgggaccttg aattggctgt
gccaggaaca tatgacccca accagccaat cattcgcatt cagtccatag caccgtcttt
gcaagtcatc acatccaagc agaggccccg gaaattgaca cttatgggca gcaacggaca
tgagtttgtt ttccttctaa aaggccatga agatctgcgc caggatgagc gtgtgatgca
gctcttcggc ctggttaaca cccttctggc caatgaccca acatctcttc ggaaaaacct
cagcatccag agatacgctg tcatcccttt atcgaccaac tcgggcctca ttggctgggt
tccccactgt gacacactgc acgccctcat ccgggactac agggagaaga agaagatcct
tctcaacatc gagcatcgca tcatgttgcg gatggctccg gactatgacc acttgactct
gatgcagaag gtggaggtgt ttgagcatgc cgtcaataat acagctgggg acgacctggc
caagctgctg tggctgaaaa gccccagctc cgaggtgtgg tttgaccgaa gaaccaatta
tacccgttct ttagcggtca tgtcaatggt tgggtatatt ttaggcctgg gagatagaca
cccatccaac ctgatgctgg accgtctgag tgggaagatc ctgcacattg actttgggga
ctgctttgag gttgctatga cccgagagaa gtttccagag aagattccat ttagactaac
aagaatgttg accaatgcta tggaggttac aggcctggat ggcaactaca gaatcacatg
ccacacagtg atggaggtgc tgcgagagca caaggacagt gtcatggccg tgctggaagc
ctttgtctat gaccccttgc tgaactggag gctgatggac acaaatacca aaggcaacaa
gcgatcccga acgaggacgg attcctactc tgctggccag tcagtcgaaa ttttggacgg
tgtggaactt ggagagccag cccataagaa aacggggacc acagtgccag aatctattca
ttctttcatt ggagacggtt tggtgaaacc agaggcccta aataagaaag ctatccagat
tattaacagg gttcgagata agctcactgg tcgggacttc tctcatgatg acactttgga
tgttccaacg caagttgagc tgctcatcaa acaagcgaca tcccatgaaa acctctgcca
gtgctatatt ggctggtgcc ctttctggta a
SREBP1의 발현 수준을 결정하는 데 사용될 수 있는 상업적인 ELISA 검정의 비제한적인 예는 Novus Biologicals 및 Abcam으로부터 입수 가능하다. 성숙한 인간 SREBP1에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 SREBP1 단백질 (SEQ ID NO: 67)
MDEPPFSEAALEQALGEPCDLDAALLTDIEDMLQLINNQDSDFPGLFDPPYAGSGAGGTDPASPDTSSPGSLSPPPATLSSSLEAFLSGPQAAPSPLSPPQPAPTPLKMYPSMPAFSPGPGIKEESVPLSILQTPTPQPLPGALLPQSFPAPAPPQFSSTPVLGYPSPPGGFSTGSPPGNTQQPLPGLPLASPPGVPPVSLHTQVQSVVPQQLLTVTAAPTAAPVTTTVTSQIQQVPVLLQPHFIKADSLLLTAMKTDGATVKAAGLSPLVSGTTVQTGPLPTLVSGGTILATVPLVVDAEKLPINRLAAGSKAPASAQSRGEKRTAHNAIEKRYRSSINDKIIELKDLVVGTEAKLNKSAVLRKAIDYIRFLQHSNQKLKQENLSLRTAVHKSKSLKDLVSACGSGGNTDVLMEGVKTEVEDTLTPPPSDAGSPFQSSPLSLGSRGSGSGGSGSDSEPDSPVFEDSKAKPEQRPSLHSRGMLDRSRLALCTLVFLCLSCNPLASLLGARGLPSPSDTTSVYHSPGRNVLGTESRDGPGWAQWLLPPVVWLLNGLLVLVSLVLLFVYGEPVTRPHSGPAVYFWRHRKQADLDLARGDFAQAAQQLWLALRALGRPLPTSHLDLACSLLWNLIRHLLQRLWVGRWLAGRAGGLQQDCALRVDASASARDAALVYHKLHQLHTMGKHTGGHLTATNLALSALNLAECAGDAVSVATLAEIYVAAALRVKTSLPRALHFLTRFFLSSARQACLAQSGSVPPAMQWLCHPVGHRFFVDGDWSVLSTPWESLYSLAGNPVDPLAQVTQLFREHLLERALNCVTQPNPSPGSADGDKEFSDALGYLQLLNSCSDAAGAPAYSFSISSSMATTTGVDPVAKWWASLTAVVIHWLRRDEEAAERLCPLVEHLPRVLQESERPLPRAALHSFKAARALLGCAKAESGPASLTICEKASGYLQDSLATTPASSSIDKAVQLFLCDLLLVVRTSLWRQQQPPAPAPAAQGTSSRPQASALELRGFQRDLSSLRRLAQSFRPAMRRVFLHEATARLMAGASPTRTHQLLDRSLRRRAGPGGKGGAVAELEPRPTRREHAEALLLASCYLPPGFLSAPGQRVGMLAEAARTLEKLGDRRLLHDCQQMLMRLGGGTTVTSS
인간 SREBP1 cDNA (SEQ ID NO: 68)
atggacgagccacccttcagcgaggcggctttggagcaggcgctgggcga
gccgtgcgatctggacgcggcgctgctgaccgacatcgaagacatgcttc
agcttatcaacaaccaagacagtgacttccctggcctatttgacccaccc
tatgctgggagtggggcagggggcacagaccctgccagccccgataccag
ctccccaggcagcttgtctccacctcctgccacattgagctcctctcttg
aagccttcctgagcgggccgcaggcagcgccctcacccctgtcccctccc
cagcctgcacccactccattgaagatgtacccgtccatgcccgctttctc
ccctgggcctggtatcaaggaagagtcagtgccactgagcatcctgcaga
cccccaccccacagcccctgccaggggccctcctgccacagagcttccca
gccccagccccaccgcagttcagctccacccctgtgttaggctaccccag
ccctccgggaggcttctctacaggaagccctcccgggaacacccagcagc
cgctgcctggcctgccactggcttccccgccaggggtcccgcccgtctcc
ttgcacacccaggtccagagtgtggtcccccagcagctactgacagtcac
agctgcccccacggcagcccctgtaacgaccactgtgacctcgcagatcc
agcaggtcccggtcctgctgcagccccacttcatcaaggcagactcgctg
cttctgacagccatgaagacagacggagccactgtgaaggcggcaggtct
cagtcccctggtctctggcaccactgtgcagacagggcctttgccgaccc
tggtgagtggcggaaccatcttggcaacagtcccactggtcgtagatgcg
gagaagctgcctatcaaccggctcgcagctggcagcaaggccccggcctc
tgcccagagccgtggagagaagcgcacagcccacaacgccattgagaagc
gctaccgctcctccatcaatgacaaaatcattgagctcaaggatctggtg
gtgggcactgaggcaaagctgaataaatctgctgtcttgcgcaaggccat
cgactacattcgctttctgcaacacagcaaccagaaactcaagcaggaga
acctaagtctgcgcactgctgtccacaaaagcaaatctctgaaggatctg
gtgtcggcctgtggcagtggagggaacacagacgtgctcatggagggcgt
gaagactgaggtggaggacacactgaccccacccccctcggatgctggct
cacctttccagagcagccccttgtcccttggcagcaggggcagtggcagc
ggtggcagtggcagtgactcggagcctgacagcccagtctttgaggacag
caaggcaaagccagagcagcggccgtctctgcacagccggggcatgctgg
accgctcccgcctggccctgtgcacgctcgtcttcctctgcctgtcctgc
aaccccttggcctccttgctgggggcccgggggcttcccagcccctcaga
taccaccagcgtctaccatagccctgggcgcaacgtgctgggcaccgaga
gcagagatggccctggctgggcccagtggctgctgcccccagtggtctgg
ctgctcaatgggctgttggtgctcgtctccttggtgcttctctttgtcta
cggtgagccagtcacacggccccactcaggccccgccgtgtacttctgga
ggcatcgcaagcaggctgacctggacctggcccggggagactttgcccag
gctgcccagcagctgtggctggccctgcgggcactgggccggcccctgcc
cacctcccacctggacctggcttgtagcctcctctggaacctcatccgtc
acctgctgcagcgtctctgggtgggccgctggctggcaggccgggcaggg
ggcctgcagcaggactgtgctctgcgagtggatgctagcgccagcgcccg
agacgcagccctggtctaccataagctgcaccagctgcacaccatgggga
agcacacaggcgggcacctcactgccaccaacctggcgctgagtgccctg
aacctggcagagtgtgcaggggatgccgtgtctgtggcgacgctggccga
gatctatgtggcggctgcattgagagtgaagaccagtctcccacgggcct
tgcattttctgacacgcttcttcctgagcagtgcccgccaggcctgcctg
gcacagagtggctcagtgcctcctgccatgcagtggctctgccaccccgt
gggccaccgtttcttcgtggatggggactggtccgtgctcagtaccccat
gggagagcctgtacagcttggccgggaacccagtggaccccctggcccag
gtgactcagctattccgggaacatctcttagagcgagcactgaactgtgt
gacccagcccaaccccagccctgggtcagctgatggggacaaggaattct
cggatgccctcgggtacctgcagctgctgaacagctgttctgatgctgcg
ggggctcctgcctacagcttctccatcagttccagcatggccaccaccac
cggcgtagacccggtggccaagtggtgggcctctctgacagctgtggtga
tccactggctgcggcgggatgaggaggcggctgagcggctgtgcccgctg
gtggagcacctgccccgggtgctgcaggagtctgagagacccctgcccag
ggcagctctgcactccttcaaggctgcccgggccctgctgggctgtgcca
aggcagagtctggtccagccagcctgaccatctgtgagaaggccagtggg
tacctgcaggacagcctggctaccacaccagccagcagctccattgacaa
ggccgtgcagctgttcctgtgtgacctgcttcttgtggtgcgcaccagcc
tgtggcggcagcagcagcccccggccccggccccagcagcccagggcacc
agcagcaggccccaggcttccgcccttgagctgcgtggcttccaacggga
cctgagcagcctgaggcggctggcacagagcttccggcccgccatgcgga
gggtgttcctacatgaggccacggcccggctgatggcgggggccagcccc
acacggacacaccagctcctcgaccgcagtctgaggcggcgggcaggccc
cggtggcaaaggaggcgcggtggcggagctggagccgcggcccacgcggc
gggagcacgcggaggccttgctgctggcctcctgctacctgccccccggc
ttcctgtcggcgcccgggcagcgcgtgggcatgctggctgaggcggcgcg
cacactcgagaagcttggcgatcgccggctgctgcacgactgtcagcaga
tgctcatgcgcctgggcggtgggaccactgtcacttccagctag
IFN-γ의 발현 수준을 결정하는 데 사용될 수 있는 상업적인 ELISA 검정의 비제한적인 예는 R&D Systems, Thermo Fisher Scientific, Abcam, Enzo Life Sciences, 및 RayBiotech으로부터 입수 가능하다. 성숙한 인간 IFN-γ에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 IFN-γ (SEQ ID NO: 69)
qdpyvke aenlkkyfna ghsdvadngt lflgilknwk eesdrkimqs qivsfyfklf knfkddqsiq ksvetikedm nvkffnsnkk krddfekltn ysvtdlnvqr kaiheliqvm aelspaaktg krkrsqmlfr g
인간 IFN-γ cDNA (SEQ ID NO: 70)
caggac ccatatgtaa aagaagcaga aaaccttaag aaatatttta atgcaggtca ttcagatgta gcggataatg gaactctttt cttaggcatt ttgaagaatt ggaaagagga gagtgacaga aaaataatgc agagccaaat tgtctccttt tacttcaaac tttttaaaaa ctttaaagat gaccagagca tccaaaagag tgtggagacc atcaaggaag acatgaatgt caagtttttc aatagcaaca aaaagaaacg agatgacttc gaaaagctga ctaattattc ggtaactgac ttgaatgtcc aacgcaaagc aatacatgaa ctcatccaag tgatggctga actgtcgcca gcagctaaaa cagggaagcg aaaaaggagt cagatgctgt ttcgaggt
그랜자임 B의 발현 수준을 결정하는 데 사용될 수 있는 상업적인 ELISA 검정의 비제한적인 예는 RayBiotech, Thermo Fisher Scientific, 및 R&D Systems으로부터 입수 가능하다. 성숙한 인간 그랜자임 B에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
성숙한 인간 그랜자임 B (SEQ ID NO: 71)
iiggheakph srpymaylmi wdqkslkrcg gflirddfvl taahcwgssi nvtlgahnik eqeptqqfip vkrpiphpay npknfsndim llqlerkakr travqplrlp snkaqvkpgq tcsvagwgqt aplgkhshtl qevkmtvqed rkcesdlrhy ydstielcvg dpeikktsfk gdsggplvcn kvaqgivsyg rnngmpprac tkvssfvhwi kktmkry
인간 그랜자임 B cDNA (SEQ ID NO: 72)
atcatcgggg gacatgaggc caagccccac tcccgcccct acatggctta tcttatgatc tgggatcaga agtctctgaa gaggtgcggt ggcttcctga tacgagacga cttcgtgctg acagctgctc actgttgggg aagctccata aatgtcacct tgggggccca caatatcaaa gaacaggagc cgacccagca gtttatccct gtgaaaagac ccatccccca tccagcctat aatcctaaga acttctccaa cgacatcatg ctactgcagc tggagagaaa ggccaagcgg accagagctg tgcagcccct caggctacct agcaacaagg cccaggtgaa gccagggcag acatgcagtg tggccggctg ggggcagacg gcccccctgg gaaaacactc acacacacta caagaggtga agatgacagt gcaggaagat cgaaagtgcg aatctgactt acgccattat tacgacagta ccattgagtt gtgcgtgggg gacccagaga ttaaaaagac ttcctttaag ggggactctg gaggccctct tgtgtgtaac aaggtggccc agggcattgt ctcctatgga cgaaacaatg gcatgcctcc acgagcctgc accaaagtct caagctttgt acactggata aagaaaacca tgaaacgcta c
MYC의 발현 수준을 결정하는 데 사용될 수 있는 상업적인 ELISA 검정의 비제한적인 예는 Invitrogen, LSBio, Biocodon Technologies, 및 Elisa Genie로부터 입수 가능하다. 성숙한 인간 MYC에 대한 단백질 및 cDNA 서열은 아래에 제시된다.
인간 Myc 단백질 (SEQ ID NO: 329)
mdffrvvenq qppatmplnv sftnrnydld ydsvqpyfyc deeenfyqqq qqselqppap sediwkkfel lptpplspsr rsglcspsyv avtpfslrgd ndggggsfst adqlemvtel lggdmvnqsf icdpddetfi kniiiqdcmw sgfsaaaklv seklasyqaa rkdsgspnpa rghsvcstss lylqdlsaaa secidpsvvf pyplndsssp kscasqdssa fspssdslls stesspqgsp eplvlheetp pttssdseee qedeeeidvv svekrqapgk rsesgspsag ghskpphspl vlkrchvsth qhnyaappst rkdypaakrv kldsvrvlrq isnnrkctsp rssdteenvk rrthnvlerq rrnelkrsff alrdqipele nnekapkvvi lkkatayils vqaeeqklis eedllrkrre qlkhkleqlr nsca
인간 Myc cDNA (SEQ ID NO: 330)
ctggatt tttttcgggt agtggaaaac cagcagcctc ccgcgacgat gcccctcaac gttagcttca ccaacaggaa ctatgacctc gactacgact cggtgcagcc gtatttctac tgcgacgagg aggagaactt ctaccagcag cagcagcaga gcgagctgca gcccccggcg cccagcgagg atatctggaa gaaattcgag ctgctgccca ccccgcccct gtcccctagc cgccgctccg ggctctgctc gccctcctac gttgcggtca cacccttctc ccttcgggga gacaacgacg gcggtggcgg gagcttctcc acggccgacc agctggagat ggtgaccgag ctgctgggag gagacatggt gaaccagagt ttcatctgcg acccggacga cgagaccttc atcaaaaaca tcatcatcca ggactgtatg tggagcggct tctcggccgc cgccaagctc gtctcagaga agctggcctc ctaccaggct gcgcgcaaag acagcggcag cccgaacccc gcccgcggcc acagcgtctg ctccacctcc agcttgtacc tgcaggatct gagcgccgcc gcctcagagt gcatcgaccc ctcggtggtc ttcccctacc ctctcaacga cagcagctcg cccaagtcct gcgcctcgca agactccagc gccttctctc cgtcctcgga ttctctgctc tcctcgacgg agtcctcccc gcagggcagc cccgagcccc tggtgctcca tgaggagaca ccgcccacca ccagcagcga ctctgaggag gaacaagaag atgaggaaga aatcgatgtt gtttctgtgg aaaagaggca ggctcctggc aaaaggtcag agtctggatc accttctgct ggaggccaca gcaaacctcc tcacagccca ctggtcctca agaggtgcca cgtctccaca catcagcaca actacgcagc gcctccctcc actcggaagg actatcctgc tgccaagagg gtcaagttgg acagtgtcag agtcctgaga cagatcagca acaaccgaaa atgcaccagc cccaggtcct cggacaccga ggagaatgtc aagaggcgaa cacacaacgt cttggagcgc cagaggagga acgagctaaa acggagcttt tttgccctgc gtgaccagat cccggagttg gaaaacaatg aaaaggcccc caaggtagtt atccttaaaa aagccacagc atacatcctg tccgtccaag cagaggagca aaagctcatt tctgaagagg acttgttgcg gaaacgacga gaacagttga aacacaaact tgaacagcta cggaactctt gtgcgtaa
일부 구현예에서, 활성화된 NK 세포(예를 들어, 인간 활성화된 NK 세포)는 휴지기 NK 세포(예를 들어, 인간 휴지기 NK 세포)와 비교하여, 대상체(예를 들어, 본원에 기재된 임의의 대상체)에서 또는 시험관내에서 노쇠 세포(예를 들어, 본원에 기재된 임의의 노쇠 세포)를 사멸시키는 증가된(예를 들어, 적어도 10% 증가, 적어도 20% 증가, 적어도 30% 증가, 적어도 40% 증가, 적어도 50% 증가, 적어도 60% 증가, 적어도 70% 증가, 적어도 80% 증가, 적어도 90% 증가, 적어도 100% 증가, 적어도 120% 증가, 적어도 140% 증가, 적어도 160% 증가, 적어도 180% 증가, 적어도 200% 증가, 적어도 220% 증가, 적어도 240% 증가, 적어도 260% 증가, 적어도 280% 증가, 또는 적어도 300% 증가) 능력을 보여줄 수 있다.
일부 구현예에서, 활성화된 NK 세포(예를 들어, 인간 활성화된 NK 세포)는 휴지기 NK 세포(예를 들어, 인간 휴지기 NK 세포)와 비교하여, 대상체(예를 들어, 본원에 기재된 임의의 대상체)에서 또는 생체내에서 노쇠 세포(예를 들어, 본원에 기재된 임의의 노쇠 세포)를 사멸시키는 능력의 약 10% 내지 약 500% 증가(또는 본원에 기재된 이 범위의 임의의 하위범위)를 보여줄 수 있다.
일부 구현예에서, 활성화된 NK 세포(예를 들어, 인간 활성화된 NK 세포)는 예를 들어, 휴지기 NK 세포(예를 들어, 인간 휴지기 NK 세포)와 비교하여, 노쇠 또는 표적 세포 상에 존재하는 항원에 특이적으로 결합하는 항체의 존재 하에 접촉-세포독성 검정에서 증가된(예를 들어, 적어도 10% 증가, 적어도 20% 증가, 적어도 30% 증가, 적어도 40% 증가, 적어도 50% 증가, 적어도 60% 증가, 적어도 70% 증가, 적어도 80% 증가, 적어도 90% 증가, 적어도 100% 증가, 적어도 120% 증가, 적어도 140% 증가, 적어도 160% 증가, 적어도 180% 증가, 적어도 200% 증가, 적어도 220% 증가, 적어도 240% 증가, 적어도 260% 증가, 적어도 280% 증가, 또는 적어도 300% 증가) 세포독성 활성을 보여줄 수 있다.
일부 구현예에서, 활성화된 NK 세포(예를 들어, 인간 활성화된 NK 세포)는 예를 들어, 휴지기 NK 세포(예를 들어, 인간 휴지기 NK 세포)와 비교하여, 노쇠 또는 표적 세포 상에 존재하는 항원에 특이적으로 결합하는 항체의 존재 하에 접촉-세포독성 검정에서 증가된(예를 들어, 약 10% 증가 내지 약 500% 증가, 또는 본원에 기재된 이 범위 내의 임의의 하위범위) 세포독성 활성을 보여줄 수 있다.
일부 구현예에서, 활성화된 NK 세포는 휴지기 NK 세포를 수득하는 단계; 및 상기 휴지기 NK 세포를 시험관내에서 하나 이상의 NK 세포 활성화제(들)를 포함하는 액체 배양 배지에서 접촉시키는 단계를 포함하는 방법에 의해 생성될 수 있으며, 상기 접촉은 후속적으로 대상체에게 투여되는 활성화된 NK 세포의 생성을 초래한다. 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 대상체로부터 수득된 자가 NK 세포이다. 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 대상체로부터 수득된 자가 NK 세포이다. 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 반일치 휴지기 NK 세포이다. 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 동종이계 휴지기 NK 세포이다. 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 인공 NK 세포이다. 임의의 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 키메라 항원 수용체 또는 재조합 T 세포 수용체를 갖고 있는 유전자-조작된 NK 세포이다.
이들 방법의 일부 예에서, 액체 배양 배지는 무혈청 액체 배양 배지이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 액체 배양 배지는 화학적으로-한정된 액체 배양 배지이다. 이들 방법의 일부 구현예는 활성화된 NK 세포를 단리하는 단계(및 선택적으로 추가로 치료적 유효량의 활성화된 NK 세포를 대상체, 예를 들어, 본원에 기재된 임의의 대상체에게 투여하는 단계)를 추가로 포함한다.
이들 방법의 일부 구현예에서, 접촉 단계는 약 2시간 내지 약 20일(예를 들어, 약 2시간 내지 약 18일, 약 2시간 내지 약 16일, 약 2시간 내지 약 14일, 약 2시간 내지 약 12일, 약 2시간 내지 약 10일, 약 2시간 내지 약 8일, 약 2시간 내지 약 7일, 약 2시간 내지 약 6일, 약 2시간 내지 약 5일, 약 2시간 내지 약 4일, 약 2시간 내지 약 3일, 약 2시간 내지 약 2일, 약 2시간 내지 약 1일, 약 6시간 내지 약 18일, 약 6시간 내지 약 16일, 약 6시간 내지 약 14일, 약 6시간 내지 약 12일, 약 6시간 내지 약 10일, 약 6시간 내지 약 8일, 약 6시간 내지 약 7일, 약 6시간 내지 약 6일, 약 6시간 내지 약 5일, 약 6시간 내지 약 4일, 약 6시간 내지 약 3일, 약 6시간 내지 약 2일, 약 6시간 내지 약 1일, 약 12시간 내지 약 18일, 약 12시간 내지 약 16일, 약 12시간 내지 약 14일, 약 12시간 내지 약 12일, 약 12시간 내지 약 10일, 약 12시간 내지 약 8일, 약 12시간 내지 약 7일, 약 12시간 내지 약 6일, 약 12시간 내지 약 5일, 약 12시간 내지 약 4일, 약 12시간 내지 약 3일, 약 12시간 내지 약 2일, 약 12시간 내지 약 1일, 약 1일 내지 약 18일, 약 1일 내지 약 16일, 약 1일 내지 약 15일, 약 1일 내지 약 14일, 약 1일 내지 약 12일, 약 1일 내지 약 10일, 약 1일 내지 약 8일, 약 1일 내지 약 7일, 약 1일 내지 약 6일, 약 1일 내지 약 5일, 약 1일 내지 약 4일, 약 1일 내지 약 3일, 약 1일 내지 약 2일, 약 2일 내지 약 18일, 약 2일 내지 약 16일, 약 2일 내지 약 14일, 약 2일 내지 약 12일, 약 2일 내지 약 10일, 약 2일 내지 약 8일, 약 2일 내지 약 7일, 약 2일 내지 약 6일, 약 2일 내지 약 5일, 약 2일 내지 약 4일, 약 2일 내지 약 3일, 약 3일 내지 약 18일, 약 3일 내지 약 16일, 약 3일 내지 약 14일, 약 3일 내지 약 12일, 약 3일 내지 약 10일, 약 3일 내지 약 8일, 약 3일 내지 약 7일, 약 3일 내지 약 6일, 약 3일 내지 약 5일, 약 3일 내지 약 4일, 약 4일 내지 약 18일, 약 4일 내지 약 16일, 약 4일 내지 약 14일, 약 4일 내지 약 12일, 약 4일 내지 약 10일, 약 4일 내지 약 8일, 약 4일 내지 약 7일, 약 4일 내지 약 6일, 약 4일 내지 약 5일, 약 5일 내지 약 18일, 약 5일 내지 약 16일, 약 5일 내지 약 14일, 약 5일 내지 약 12일, 약 5일 내지 약 10일, 약 5일 내지 약 8일, 약 5일 내지 약 7일, 약 5일 내지 약 6일, 약 6일 내지 약 18일, 약 6일 내지 약 16일, 약 6일 내지 약 14일, 약 6일 내지 약 12일, 약 6일 내지 약 10일, 약 6일 내지 약 8일, 약 6일 내지 약 7일, 약 7일 내지 약 18일, 약 7일 내지 약 16일, 약 7일 내지 약 14일, 약 7일 내지 약 12일, 약 7일 내지 약 10일, 약 7일 내지 약 8일, 약 8일 내지 약 18일, 약 8일 내지 약 16일, 약 8일 내지 약 14일, 약 8일 내지 약 12일, 약 8일 내지 약 10일, 약 9일 내지 약 18일, 약 9일 내지 약 16일, 약 9일 내지 약 14일, 약 9일 내지 약 12일, 약 12일 내지 약 18일, 약 12일 내지 약 16일, 약 12일 내지 약 14일, 약 14일 내지 약 18일, 약 14일 내지 약 16일, 또는 약 16일 내지 약 18일)의 기간 동안 수행된다.
NK 세포 활성화제
하나 이상의 NK 세포 활성화제의 사용 또는 투여를 포함하는 방법이 본원에 제공된다. 일부 구현예에서, NK 세포 활성화제는 단백질일 수 있다. 일부 구현예에서, NK 세포 활성화제는 단일-사슬 키메라 폴리펩타이드(예를 들어 본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드), 다중-사슬 키메라 폴리펩타이드(예를 들어 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드, 예를 들어, 본원에 기재된 예시적인 A형 및 B형 다중-사슬 키메라 폴리펩타이드), 항체, 재조합 사이토카인 또는 인터류킨(예를 들어 본원에 기재된 임의의 재조합 사이토카인 또는 인터류킨), 및 가용성 인터류킨 또는 사이토카인 수용체(예를 들어 본원에 기재된 임의의 가용성 인터류킨 또는 사이토카인 수용체)일 수 있다. 일부 구현예에서, NK 세포 활성화제는 저분자(예를 들어, 글리코겐 신타제 키나제-3(GSK3: glycogen synthase kinase-3) 저해제, 예를 들어, 문헌[Cichocki et al., Cancer Res. 77:5664-5675, 2017]에 기재된 바와 같은 CHIR99021) 또는 앱타머일 수 있다.
본원에 제공된 임의의 하나 이상의 NK 세포 활성화제의 일부 구현예에서, 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 하나 이상의 NK 세포 활성화제(들)의 부재 하에서의 활성화 수준과 비교하여 하기 중 하나 이상(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 또는 8개)의 활성화를 초래한다: IL-2에 대한 수용체, IL-7에 대한 수용체, IL-12에 대한 수용체, IL-15에 대한 수용체, IL-18에 대한 수용체, IL-21에 대한 수용체, IL-33, CD16, CD69, CD25, CD59, CD352, NKp80, DNAM-1, 2B4, NKp30, NKp44, NKp46, NKG2D, KIR2DS1, KIR2Ds2/3, KIR2DL4, KIR2DS4, KIR2DS5, 및 KIR3DS1(예를 들어, 면역 세포, 예를 들어, 인간 면역 세포, 예를 들어, 인간 NK 세포에서).
일부 구현예에서, IL-2에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 가용성 IL-2 또는 IL-2 수용체에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, IL-7에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 가용성 IL-7 또는 IL-7 수용체에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, IL-12에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 가용성 IL-12 또는 IL-12 수용체에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, IL-15에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 가용성 IL-15 또는 IL-15 수용체에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, IL-21에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 가용성 IL-21 또는 IL-21 수용체에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, IL-33에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 가용성 IL-33 또는 IL-33 수용체에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, CD16의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 CD16에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, CD69의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 CD69에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, CD25, CD59의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 CD25, CD59에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, CD352의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 CD352에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, NKp80의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 NKp80에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, DNAM-1의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 DNAM-1에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, 2B4의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 2B4에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, NKp30의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 NKp30에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, NKp44의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 NKp44에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, NKp46의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 NKp46에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, NKG2D의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 NKG2D에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, KIR2DS1의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIT2DS1에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, KIR2DS2/3의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIT2DS2/3에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, KIR2DL4의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIT2DL4에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, KIR2DS4의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIT2DS4에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, KIR2DS5의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIT2DS5에 특이적으로 결합하는 작용제성 항체이다.
일부 구현예에서, KIR3DS1의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIT3DS1에 특이적으로 결합하는 작용제성 항체이다.
본원에 제공된 임의의 하나 이상의 NK 세포 활성화제의 일부 구현예에서, 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나(예를 들어, 2개, 3개, 4개, 또는 5개)는 하나 이상의 NK 세포 활성화제(들)의 부재 하에서의 활성화 수준과 비교하여 하기 중 하나 이상의 활성화의 저하를 초래한다: PD-1, TGF-β 수용체, TIGIT, CD1, TIM-3, Siglec-7, IRP60, Tactile, IL1R8, NKG2A/KLRD1, KIR2DL1, KIR2DL2/3, KIR2DL5, KIR3DL1, KIR3DL2, ILT2/LIR-1, 및 LAG-2(예를 들어, 면역 세포, 예를 들어, 인간 면역 세포, 예를 들어, 인간 NK 세포에서).
일부 구현예에서, TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 가용성 TGF-β 수용체, TGF-β에 특이적으로 결합하는 항체, 또는 TGF-β 수용체에 특이적으로 결합하는 길항제성 항체이다.
일부 구현예에서, TIGIT의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 TIGIT에 특이적으로 결합하는 길항제성 항체, 가용성 TIGIT, 또는 TIGIT의 리간드에 특이적으로 결합하는 항체이다.
일부 구현예에서, CD1의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 CD1에 특이적으로 결합하는 길항제성 항체, 가용성 CD1, 또는 CD1의 리간드에 특이적으로 결합하는 항체이다.
일부 구현예에서, TIM-3의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 TIM-3에 특이적으로 결합하는 길항제성 항체, 가용성 TIM-3, 또는 TIM-3의 리간드에 특이적으로 결합하는 항체이다.
일부 구현예에서, Siglec-7의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 Siglec-7에 특이적으로 결합하는 길항제성 항체, 가용성 Siglec-7, 또는 Siglec-7의 리간드에 특이적으로 결합하는 항체이다.
일부 구현예에서, IRP-60의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 IRP-60에 특이적으로 결합하는 길항제성 항체, 가용성 IRP-60, 또는 IRP-60의 리간드에 특이적으로 결합하는 항체이다.
일부 구현예에서, Tactile의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 Tactile에 특이적으로 결합하는 길항제성 항체, 가용성 Tactile, 또는 Tactile의 리간드에 특이적으로 결합하는 항체이다.
일부 구현예에서, IL1R8의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 IL1R8에 특이적으로 결합하는 길항제성 항체, 가용성 IL1R8, 또는 IL1R8의 리간드에 특이적으로 결합하는 항체이다.
일부 구현예에서, NKG2A/KLRD1의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 NKG2A/KLRD1에 특이적으로 결합하는 길항제성 항체, 가용성 NKG2A/KLRD1, 또는 NKG2A/KLRD1의 리간드에 특이적으로 결합하는 항체이다.
일부 구현예에서, KIR2DL1의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR2DL1에 특이적으로 결합하는 길항제성 항체, 가용성 KIR2DL1, 또는 KIR2DL1의 리간드에 특이적으로 결합하는 항체이다.
일부 구현예에서, KIR2DL2/3의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR2DL2/3에 특이적으로 결합하는 길항제성 항체, 가용성 KIR2DL2/3, 또는 KIR2DL2/3의 리간드에 특이적으로 결합하는 항체이다.
일부 구현예에서, KIR2DL5의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR2DL5에 특이적으로 결합하는 길항제성 항체, 가용성 KIR2DL5, 또는 KIR2DL5의 리간드에 특이적으로 결합하는 항체이다.
일부 구현예에서, KIR3DL1의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR3DL1에 특이적으로 결합하는 길항제성 항체, 가용성 KIR3DL1, 또는 KIR3DL1의 리간드에 특이적으로 결합하는 항체이다.
일부 구현예에서, KIR3DL2의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR3DL2에 특이적으로 결합하는 길항제성 항체, 가용성 KIR3DL2, 또는 KIR3DL2의 리간드에 특이적으로 결합하는 항체이다.
일부 구현예에서, ILT2/LIR-1의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 ILT2/LIR-1에 특이적으로 결합하는 길항제성 항체, 가용성 ILT2/LIR-1, 또는 ILT2/LIR-1의 리간드에 특이적으로 결합하는 항체이다.
일부 구현예에서, LAG2의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 LAG2에 특이적으로 결합하는 길항제성 항체, 가용성 LAG2, 또는 LAG2의 리간드에 특이적으로 결합하는 항체이다.
NK 세포 활성화제의 비제한적인 예는 아래에 기재되어 있고 임의의 조합으로 사용될 수 있다.
일부 예에서, NK 세포 활성화제는 가용성 PD-1, 가용성 PD-L1, 가용성 TIGIT, 가용성 CD1, 또는 가용성 TIM-3일 수 있다. 가용성 PD-1, PD-L1, TIGIT, CD1, 및 TIM-3의 비제한적인 예는 아래에 제공된다.
인간 가용성 PD-1 (SEQ ID NO: 73)
pgwfldspdr pwnpptfspa llvvtegdna tftcsfsnts esfvlnwyrm spsnqtdkla afpedrsqpg qdcrfrvtql pngrdfhmsv vrarrndsgt ylcgaislap kaqikeslra elrvterrae vptahpspsp rpagqfqtlv vgvvggllgs lvllvwvlav icsraargti garrtgqplk edpsavpvfs vdygeldfqw rektpeppvp cvpeqteyat ivfpsgmgts sparrgsadg prsaqplrpe dghcswpl
인간 가용성 PD-L1 (SEQ ID NO: 74)
ftvtvpkdlyvv eygsnmtiec kfpvekqldl aalivyweme dkniiqfvhg eedlkvqhss yrqrarllkd qlslgnaalq itdvklqdag vyrcmisygg adykritvkv napynkinqr ilvvdpvtse heltcqaegy pkaeviwtss dhqvlsgktt ttnskreekl fnvtstlrin tttneifyct frrldpeenh taelvipelp lahppnerth lvilgaillc lgvaltfifr lrkgrmmdvk kcgiqdtnsk kqsdthleet
인간 가용성 TIGIT (SEQ ID NO: 75)
mmtgtiett gnisaekggs iilqchlsst taqvtqvnwe qqdqllaicn adlgwhisps fkdrvapgpg lgltlqsltv ndtgeyfciy htypdgtytg riflevless vaehgarfqi pllgamaatl vvictavivv valtrkkkal rihsvegdlr rksagqeews psapsppgsc vqaeaapagl cgeqrgedca elhdyfnvls yrslgncsff tetg
인간 가용성 CD1A(SEQ ID NO: 76)
nadglkeplsfhvt wiasfynhsw kqnlvsgwls dlqthtwdsn sstivflcpw srgnfsneew keletlfrir tirsfegirr yahelqfeyp feiqvtggce lhsgkvsgsf lqlayqgsdf vsfqnnswlp ypvagnmakh fckvlnqnqh endithnlls dtcprfilgl ldagkahlqr qvkpeawlsh gpspgpghlq lvchvsgfyp kpvwvmwmrg eqeqqgtqrg dilpsadgtw ylratlevaa geaadlscrv khsslegqdi vlywehhssv gfiilavivp lllliglalw frkrcfc
인간 가용성 TIM3(SEQ ID NO: 77)
seveyraev gqnaylpcfy tpaapgnlvp vcwgkgacpv fecgnvvlrt derdvnywts rywlngdfrk gdvsltienv tladsgiycc riqipgimnd ekfnlklvik pakvtpaptr qrdftaafpr mlttrghgpa etqtlgslpd inltqistla nelrdsrlan dlrdsgatir igiyigagic aglalalifg alifkwyshs kekiqnlsli slanlppsgl anavaegirs eeniytieen vyeveepney ycyvssrqqp sqplgcrfam
일부 구현예에서, 가용성 PD-1 단백질은 SEQ ID NO: 73과 적어도 80% 동일한, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한 서열을 포함할 수 있다.
일부 구현예에서, 가용성 PD-L1 단백질은 SEQ ID NO: 74와 적어도 80% 동일한, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한 서열을 포함할 수 있다.
일부 구현예에서, 가용성 TIGIT 단백질은 SEQ ID NO: 75와 적어도 80% 동일한, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한 서열을 포함할 수 있다.
일부 구현예에서, 가용성 CD1A 단백질은 SEQ ID NO: 76과 적어도 80% 동일한, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한 서열을 포함할 수 있다.
일부 구현예에서, 가용성 TIM3 단백질은 SEQ ID NO: 77과 적어도 80% 동일한, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한 서열을 포함할 수 있다.
재조합 항체
일부 예에서, NK 활성화제는 하기일 수 있다: IL-2 수용체에 특이적으로 결합하는 작용제성 항체(예를 들어, 문헌[Gaulton et al., Clinical Immunology and Immunopathology 36(1):18-29, 1985]에 기재된 것들 참조), IL-7 수용체에 특이적으로 결합하는 작용제성 항체, IL-12 수용체에 특이적으로 결합하는 작용제성 항체(예를 들어, 문헌[Rogge et al., J. Immunol. 162(7): 3926-3932, 1999]에 기재된 것들 참조), IL-15 수용체에 특이적으로 결합하는 작용제성 항체, IL-21 수용체에 특이적으로 결합하는 작용제성 항체(예를 들어, 미국 특허 출원 공개 제2006/159655호에 기재된 것들 참조), IL-33 수용체에 특이적으로 결합하는 작용제성 항체(예를 들어, 미국 특허 출원 공개 제2007/160579호에 기재된 것들 참조), PD-1에 특이적으로 결합하는 길항제성 항체(예를 들어, 미국 특허 제7,521,051호에 기재된 것들 참조), PD-L1에 특이적으로 결합하는 항체(예를 들어, 미국 특허 제8,217,149호에 기재된 것들 참조), TGF-β에 특이적으로 결합하는 항체, TGF-β 수용체에 특이적으로 결합하는 길항제성 항체(예를 들어, 유럽 특허 출원 공개 제1245676 A1호에 기재된 것들 참조), TIGIT에 특이적으로 결합하는 길항제성 항체(예를 들어, WO 제2017/053748호에 기재된 것들 참조), TIGIT의 리간드에 특이적으로 결합하는 항체(예를 들어, WO 제2011/127324호에 기재된 것들 참조), CD1에 특이적으로 결합하는 길항제성 항체(예를 들어, 문헌[Szalay et al., J. Immunol. 162(12):6955-6958, 1999]에 기재된 것들 참조), CD1의 리간드에 특이적으로 결합하는 항체(예를 들어, 문헌[Kain et al., Immunity 41(4):543-554, 2014]에 기재된 것들 참조), TIM-3에 특이적으로 결합하는 길항제성 항체(예를 들어, 미국 특허 출원 공개 제2015/218274호에 기재된 것들 참조), TIM-3의 리간드에 특이적으로 결합하는 항체(예를 들어, 미국 특허 출원 공개 제2017/283499호에 기재된 것들 참조), CD69에 특이적으로 결합하는 작용제성 항체(예를 들어, 문헌[Moretta et al., Journal of Experimental Medicine 174:1393, 1991]에 기재된 것들 참조), CD25, CD59에 특이적으로 결합하는 작용제성 항체, CD352에 특이적으로 결합하는 작용제성 항체(예를 들어, 문헌[Yigit et al., Oncotarget 7:26346-26360, 2016]에 기재된 것들 참조), NKp80에 특이적으로 결합하는 작용제성 항체(예를 들어, 문헌[Peipp et al., Oncotarget 6:32075-32088, 2015]에 기재된 것들 참조), DNAM-1에 특이적으로 결합하는 작용제성 항체, 2B4에 특이적으로 결합하는 작용제성 항체(예를 들어, 문헌[Sandusky et al., European J. Immunol. 36:3268-3276, 2006]에 기재된 것들 참조), NKp30에 특이적으로 결합하는 작용제성 항체(예를 들어, 문헌[Kellner et al., OncoImmunology 5:1-12, 2016]에 기재된 것들 참조), NKp44에 특이적으로 결합하는 작용제성 항체, NKp46에 특이적으로 결합하는 작용제성 항체(예를 들어, 문헌[Xiong et al., J. Clin. Invest. 123:4264-4272, 2013]에 기재된 것들 참조), NKG2D에 특이적으로 결합하는 작용제성 항체(예를 들어, 문헌[Kellner et al., OncoImmunology 5:1-12, 2016]에 기재된 것들 참조), KIR2DS1에 특이적으로 결합하는 작용제성 항체(예를 들어, 문헌[Xiong et al., J. Clin. Invest. 123:4264-4272, 2013]에 기재된 것들 참조), KIR2Ds2/3에 특이적으로 결합하는 작용제성 항체(예를 들어, 문헌[Borgerding et al., Exp. Hematology 38:213-221, 2010]에 기재된 것들 참조), KIR2DL4에 특이적으로 결합하는 작용제성 항체(예를 들어, 문헌[Miah et al., J. Immunol. 180:2922-32, 2008]에 기재된 것들 참조), KIR2DS4에 특이적으로 결합하는 작용제성 항체(예를 들어, 문헌[Czaja et al., Genes and Immunity 15:33-37, 2014]에 기재된 것들 참조), KIR2DS5에 특이적으로 결합하는 작용제성 항체(예를 들어, 문헌[Czaja et al., Genes and Immunity 15:33-37, 2014]에 기재된 것들 참조), KIR3DS1에 특이적으로 결합하는 작용제성 항체(예를 들어, 문헌[Czaja et al., Genes and Immunity 15:33-37, 2014]에 기재된 것들 참조), Siglec-7에 특이적으로 결합하는 길항제성 항체(예를 들어, 문헌[Hudak et al., Nature Chemical Biology 10:69-75, 2014]에 기재된 것들 참조), IRP60에 특이적으로 결합하는 길항제성 항체(예를 들어, 문헌[Bachelet et al., J. Biol. Chem. 281:27190-27196, 2006]에 기재된 것들 참조), Tactile에 특이적으로 결합하는 길항제성 항체(예를 들어, 문헌[Brooks et al., Eur. J. Cancer 61(Suppl. 1):S189, 2016]에 기재된 것들 참조), IL1R8에 특이적으로 결합하는 길항제성 항체(예를 들어, 문헌[Molgora et al., Frontiers Immunol. 7:1, 2016]에 기재된 것들 참조), NKG2A/KLRD1에 특이적으로 결합하는 길항제성 항체(예를 들어, 문헌[Kim et al., Infection Immunity 76:5873-5882, 2008]에 기재된 것들 참조), KIR2DL1에 특이적으로 결합하는 길항제성 항체(예를 들어, 문헌[Weiner et al., Cell 148:1081-1084, 2012]에 기재된 것들 참조), KIR2DL2/3에 특이적으로 결합하는 길항제성 항체(예를 들어, 문헌[Weiner et al., Cell 148:1081-1084, 2012]에 기재된 것들 참조), KIR2DL5에 특이적으로 결합하는 길항제성 항체(예를 들어, US 제9,067,997호에 기재된 것들 참조), 및 KIR3DL1에 특이적으로 결합하는 길항제성 항체(예를 들어, US 제9,067,997호에 기재된 것들 참조), KIR3DL2에 특이적으로 결합하는 길항제성 항체(예를 들어, US 제9,067,997호에 기재된 것들 참조), ILT2/LIR-1에 특이적으로 결합하는 길항제성 항체(예를 들어, US 제8,133,485호에 기재된 것들 참조), 및 LAG-2에 특이적으로 결합하는 길항제성 항체.
NK 세포 활성화제인 재조합 항체는 본원에 기재된 임의의 예시적인 유형의 항체(예를 들어, 인간 또는 인간화 항체) 또는 임의의 예시적인 항체 단편일 수 있다. NK 세포 활성화제인 재조합 항체는 예를 들어, 본원에 기재된 임의의 항원-결합 도메인을 포함할 수 있다.
재조합 인터류킨 또는 사이토카인
일부 예에서, NK 활성화제는 예를 들어, 가용성 IL-2, 가용성 IL-7, 가용성 IL-12, 가용성 IL-15, 가용성 IL-21, 및 가용성 IL-33일 수 있다. 가용성 IL-12, IL-15, IL-21, 및 IL-33의 비제한적인 예는 아래에 제공된다.
인간 가용성 IL-2(SEQ ID NO: 78)
aptssstkkt qlqlehllld lqmilnginn yknpkltrml tfkfympkka telkhlqcle eelkpleevl nlaqsknfhl rprdlisnin vivlelkgse ttfmceyade tativeflnr witfcqsiis tlt
인간 가용성 IL-7(SEQ ID NO: 79)
dcdiegkdgkqyesv lmvsidqlld smkeigsncl nnefnffkrh icdankegmf lfraarklrq flkmnstgdf dlhllkvseg ttillnctgq vkgrkpaalg eaqptkslee nkslkeqkkl ndlcflkrll qeiktcwnki lmgtkeh
인간 가용성 IL-12 하위단위 알파 (SEQ ID NO: 80)
rnlpvatp dpgmfpclhh sqnllravsn mlqkarqtle fypctseeid heditkdkts tveaclplel tknesclnsr etsfitngsc lasrktsfmm alclssiyed lkmyqvefkt mnakllmdpk rqifldqnml avidelmqal nfnsetvpqk ssleepdfyk tkiklcillh afriravtid rvmsylnas
인간 가용성 IL-12 하위단위 베타 (SEQ ID NO: 81)
iwelkkdv yvveldwypd apgemvvltc dtpeedgitw tldqssevlg sgktltiqvk efgdagqytc hkggevlshs llllhkkedg iwstdilkdq kepknktflr ceaknysgrf tcwwlttist dltfsvkssr gssdpqgvtc gaatlsaerv rgdnkeyeys vecqedsacp aaeeslpiev mvdavhklky enytssffir diikpdppkn lqlkplknsr qvevsweypd twstphsyfs ltfcvqvqgk skrekkdrvf tdktsatvic rknasisvra qdryysssws ewasvpcs
인간 가용성 IL-15(SEQ ID NO: 82)
Nwvnvisdlkki edliqsmhid atlytesdvh psckvtamkc fllelqvisl esgdasihdt venliilann slssngnvte sgckeceele eknikeflqs fvhivqmfin ts
인간 가용성 IL-21(SEQ ID NO: 83)
qgqdrhmi rmrqlidivd qlknyvndlv peflpapedv etncewsafs cfqkaqlksa ntgnneriin vsikklkrkp pstnagrrqk hrltcpscds yekkppkefl erfksllqkm ihqhlssrth gseds
인간 가용성 IL-33 (SEQ ID NO: 84)
mkpkmkystn kistakwknt askalcfklg ksqqkakevc pmyfmklrsg
lmikkeacyf rrettkrpsl ktgrkhkrhl vlaacqqqst vecfafgisg
vqkytralhd ssitgispit eylaslstyn dqsitfaled esyeiyvedl
kkdekkdkvl lsyyesqhps nesgdgvdgk mlmvtlsptk dfwlhannke
hsvelhkcek plpdqaffvl hnmhsncvsf ecktdpgvfi gvkdnhlali
kvdssenlct enilfklset
일부 구현예에서, 가용성 IL-2 단백질은 SEQ ID NO: 78과 적어도 80% 동일한, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한 서열을 포함할 수 있다.
일부 구현예에서, 가용성 IL-7 단백질은 SEQ ID NO: 79와 적어도 80% 동일한, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한 서열을 포함할 수 있다.
일부 구현예에서, 가용성 IL-2 단백질은 SEQ ID NO: 80과 적어도 80% 동일한, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한 서열 및 SEQ ID NO: 81과 적어도 80% 동일한, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한 서열을 포함한다.
일부 구현예에서, 가용성 IL-15 단백질은 SEQ ID NO: 82와 적어도 80% 동일한, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한 서열을 포함할 수 있다.
일부 구현예에서, 가용성 IL-21 단백질은 SEQ ID NO: 83과 적어도 80% 동일한, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한 서열을 포함할 수 있다.
일부 구현예에서, 가용성 IL-33 단백질은 SEQ ID NO: 84와 적어도 80% 동일한, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한 서열을 포함할 수 있다.
가용성 사이토카인 또는 인터류킨 수용체
본원에 기재된 임의의 가용성 사이토카인 또는 인터류킨 수용체의 일부 예에서, 가용성 사이토카인 또는 인터류킨 수용체는 가용성 TGF-β 수용체일 수 있다. 일부 예에서, 가용성 TGF-β 수용체는 가용성 TGF-β 수용체 I(TGF-βRI)(예를 들어, 문헌[Docagne et al., Journal of Biological Chemistry 276(49):46243-46250, 2001]에 기재된 것들 참조), 가용성 TGF-β 수용체 II(TGF-βRII)(예를 들어, 문헌[Yung et al., Am. J. Resp. Crit. Care Med. 194(9):1140-1151, 2016]에 기재된 것들 참조), 가용성 TGF-βRIII(예를 들어, 문헌[Heng et al., Placenta 57:320, 2017]에 기재된 것들 참조)이다. 일부 예에서, 가용성 TGF-β 수용체는 TGF-β에 대한 수용체 "트랩(trap)"이다(예를 들어, 문헌[Zwaagstra et al., Mol. Cancer Ther. 11(7):1477-1487, 2012]에 기재된 것들, 및 문헌[De Crescenzo et al. Transforming Growth Factor-β in Cancer Therapy, Volume II, pp 671-684]에 기재된 것들 참조).
가용성 사이토카인 또는 가용성 인터류킨 수용체의 추가 예는 당업계에 알려져 있다.
단일 사슬 키메라 폴리펩타이드
NK 세포 활성화제의 비제한적인 예는 하기를 포함하는 단일-사슬 키메라 폴리펩타이드이다: (i) 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 표적-결합 도메인), (ii) 가용성 조직 인자 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 가용성 조직 인자 도메인), 및 (iii) 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 표적-결합 도메인).
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 예에서, 단일-사슬 키메라 폴리펩타이드는 약 50개 아미노산 내지 약 3000개 아미노산, 약 50개 아미노산 내지 약 2500개 아미노산, 약 50개 아미노산 내지 약 2000개 아미노산, 약 50개 아미노산 내지 약 1500개 아미노산, 약 50개 아미노산 내지 약 1000개 아미노산, 약 50개 아미노산 내지 약 950개 아미노산, 약 50개 아미노산 내지 약 900개 아미노산, 약 50개 아미노산 내지 약 850개 아미노산, 약 50개 아미노산 내지 약 800개 아미노산, 약 50개 아미노산 내지 약 750개 아미노산, 약 50개 아미노산 내지 약 700개 아미노산, 약 50개 아미노산 내지 약 650개 아미노산, 약 50개 아미노산 내지 약 600개 아미노산, 약 50개 아미노산 내지 약 550개 아미노산, 약 50개 아미노산 내지 약 500개 아미노산, 약 50개 아미노산 내지 약 480개 아미노산, 약 50개 아미노산 내지 약 460개 아미노산, 약 50개 아미노산 내지 약 440개 아미노산, 약 50개 아미노산 내지 약 420개 아미노산, 약 50개 아미노산 내지 약 400개 아미노산, 약 50개 아미노산 내지 약 380개 아미노산, 약 50개 아미노산 내지 약 360개 아미노산, 약 50개 아미노산 내지 약 340개 아미노산, 약 50개 아미노산 내지 약 320개 아미노산, 약 50개 아미노산 내지 약 300개 아미노산, 약 50개 아미노산 내지 약 280개 아미노산, 약 50개 아미노산 내지 약 260개 아미노산, 약 50개 아미노산 내지 약 240개 아미노산, 약 50개 아미노산 내지 약 220개 아미노산, 약 50개 아미노산 내지 약 200개 아미노산, 약 50개 아미노산 내지 약 150개 아미노산, 약 50개 아미노산 내지 약 100개 아미노산, 약 100개 아미노산 내지 약 3000개 아미노산, 약 100개 아미노산 내지 약 2500개 아미노산, 약 100개 아미노산 내지 약 2000개 아미노산, 약 100개 아미노산 내지 약 1500개 아미노산, 약 100개 아미노산 내지 약 1000개 아미노산, 약 100개 아미노산 내지 약 950개 아미노산, 약 100개 아미노산 내지 약 900개 아미노산, 약 100개 아미노산 내지 약 850개 아미노산, 약 100개 아미노산 내지 약 800개 아미노산, 약 100개 아미노산 내지 약 750개 아미노산, 약 100개 아미노산 내지 약 700개 아미노산, 약 100개 아미노산 내지 약 650개 아미노산, 약 100개 아미노산 내지 약 600개 아미노산, 약 100개 아미노산 내지 약 550개 아미노산, 약 100개 아미노산 내지 약 500개 아미노산, 약 100개 아미노산 내지 약 480개 아미노산, 약 100개 아미노산 내지 약 460개 아미노산, 약 100개 아미노산 내지 약 440개 아미노산, 약 100개 아미노산 내지 약 420개 아미노산, 약 100개 아미노산 내지 약 400개 아미노산, 약 100개 아미노산 내지 약 380개 아미노산, 약 100개 아미노산 내지 약 360개 아미노산, 약 100개 아미노산 내지 약 340개 아미노산, 약 100개 아미노산 내지 약 320개 아미노산, 약 100개 아미노산 내지 약 300개 아미노산, 약 100개 아미노산 내지 약 280개 아미노산, 약 100개 아미노산 내지 약 260개 아미노산, 약 100개 아미노산 내지 약 240개 아미노산, 약 100개 아미노산 내지 약 220개 아미노산, 약 100개 아미노산 내지 약 200개 아미노산, 약 100개 아미노산 내지 약 150개 아미노산, 약 150개 아미노산 내지 약 3000개 아미노산, 약 150개 아미노산 내지 약 2500개 아미노산, 약 150개 아미노산 내지 약 2000개 아미노산, 약 150개 아미노산 내지 약 1500개 아미노산, 약 150개 아미노산 내지 약 1000개 아미노산, 약 150개 아미노산 내지 약 950개 아미노산, 약 150개 아미노산 내지 약 900개 아미노산, 약 150개 아미노산 내지 약 850개 아미노산, 약 150개 아미노산 내지 약 800개 아미노산, 약 150개 아미노산 내지 약 750개 아미노산, 약 150개 아미노산 내지 약 700개 아미노산, 약 150개 아미노산 내지 약 650개 아미노산, 약 150개 아미노산 내지 약 600개 아미노산, 약 150개 아미노산 내지 약 550개 아미노산, 약 150개 아미노산 내지 약 500개 아미노산, 약 150개 아미노산 내지 약 480개 아미노산, 약 150개 아미노산 내지 약 460개 아미노산, 약 150개 아미노산 내지 약 440개 아미노산, 약 150개 아미노산 내지 약 420개 아미노산, 약 150개 아미노산 내지 약 400개 아미노산, 약 150개 아미노산 내지 약 380개 아미노산, 약 150개 아미노산 내지 약 360개 아미노산, 약 150개 아미노산 내지 약 340개 아미노산, 약 150개 아미노산 내지 약 320개 아미노산, 약 150개 아미노산 내지 약 300개 아미노산, 약 150개 아미노산 내지 약 280개 아미노산, 약 150개 아미노산 내지 약 260개 아미노산, 약 150개 아미노산 내지 약 240개 아미노산, 약 150개 아미노산 내지 약 220개 아미노산, 약 150개 아미노산 내지 약 200개 아미노산, 약 200개 아미노산 내지 약 3000개 아미노산, 약 200개 아미노산 내지 약 2500개 아미노산, 약 200개 아미노산 내지 약 2000개 아미노산, 약 200개 아미노산 내지 약 1500개 아미노산, 약 200개 아미노산 내지 약 1000개 아미노산, 약 200개 아미노산 내지 약 950개 아미노산, 약 200개 아미노산 내지 약 900개 아미노산, 약 200개 아미노산 내지 약 850개 아미노산, 약 200개 아미노산 내지 약 800개 아미노산, 약 200개 아미노산 내지 약 750개 아미노산, 약 200개 아미노산 내지 약 700개 아미노산, 약 200개 아미노산 내지 약 650개 아미노산, 약 200개 아미노산 내지 약 600개 아미노산, 약 200개 아미노산 내지 약 550개 아미노산, 약 200개 아미노산 내지 약 500개 아미노산, 약 200개 아미노산 내지 약 480개 아미노산, 약 200개 아미노산 내지 약 460개 아미노산, 약 200개 아미노산 내지 약 440개 아미노산, 약 200개 아미노산 내지 약 420개 아미노산, 약 200개 아미노산 내지 약 400개 아미노산, 약 200개 아미노산 내지 약 380개 아미노산, 약 200개 아미노산 내지 약 360개 아미노산, 약 200개 아미노산 내지 약 340개 아미노산, 약 200개 아미노산 내지 약 320개 아미노산, 약 200개 아미노산 내지 약 300개 아미노산, 약 200개 아미노산 내지 약 280개 아미노산, 약 200개 아미노산 내지 약 260개 아미노산, 약 200개 아미노산 내지 약 240개 아미노산, 약 200개 아미노산 내지 약 220개 아미노산, 약 220개 아미노산 내지 약 3000개 아미노산, 약 220개 아미노산 내지 약 2500개 아미노산, 약 220개 아미노산 내지 약 2000개 아미노산, 약 220개 아미노산 내지 약 1500개 아미노산, 약 220개 아미노산 내지 약 1000개 아미노산, 약 220개 아미노산 내지 약 950개 아미노산, 약 220개 아미노산 내지 약 900개 아미노산, 약 220개 아미노산 내지 약 850개 아미노산, 약 220개 아미노산 내지 약 800개 아미노산, 약 220개 아미노산 내지 약 750개 아미노산, 약 220개 아미노산 내지 약 700개 아미노산, 약 220개 아미노산 내지 약 650개 아미노산, 약 220개 아미노산 내지 약 600개 아미노산, 약 220개 아미노산 내지 약 550개 아미노산, 약 220개 아미노산 내지 약 500개 아미노산, 약 220개 아미노산 내지 약 480개 아미노산, 약 220개 아미노산 내지 약 460개 아미노산, 약 220개 아미노산 내지 약 440개 아미노산, 약 220개 아미노산 내지 약 420개 아미노산, 약 220개 아미노산 내지 약 400개 아미노산, 약 220개 아미노산 내지 약 380개 아미노산, 약 220개 아미노산 내지 약 360개 아미노산, 약 220개 아미노산 내지 약 340개 아미노산, 약 220개 아미노산 내지 약 320개 아미노산, 약 220개 아미노산 내지 약 300개 아미노산, 약 220개 아미노산 내지 약 280개 아미노산, 약 220개 아미노산 내지 약 260개 아미노산, 약 220개 아미노산 내지 약 240개 아미노산, 약 240개 아미노산 내지 약 3000개 아미노산, 약 240개 아미노산 내지 약 2500개 아미노산, 약 240개 아미노산 내지 약 2000개 아미노산, 약 240개 아미노산 내지 약 1500개 아미노산, 약 240개 아미노산 내지 약 1000개 아미노산, 약 240개 아미노산 내지 약 950개 아미노산, 약 240개 아미노산 내지 약 900개 아미노산, 약 240개 아미노산 내지 약 850개 아미노산, 약 240개 아미노산 내지 약 800개 아미노산, 약 240개 아미노산 내지 약 750개 아미노산, 약 240개 아미노산 내지 약 700개 아미노산, 약 240개 아미노산 내지 약 650개 아미노산, 약 240개 아미노산 내지 약 600개 아미노산, 약 240개 아미노산 내지 약 550개 아미노산, 약 240개 아미노산 내지 약 500개 아미노산, 약 240개 아미노산 내지 약 480개 아미노산, 약 240개 아미노산 내지 약 460개 아미노산, 약 240개 아미노산 내지 약 440개 아미노산, 약 240개 아미노산 내지 약 420개 아미노산, 약 240개 아미노산 내지 약 400개 아미노산, 약 240개 아미노산 내지 약 380개 아미노산, 약 240개 아미노산 내지 약 360개 아미노산, 약 240개 아미노산 내지 약 340개 아미노산, 약 240개 아미노산 내지 약 320개 아미노산, 약 240개 아미노산 내지 약 300개 아미노산, 약 240개 아미노산 내지 약 280개 아미노산, 약 240개 아미노산 내지 약 260개 아미노산, 약 260개 아미노산 내지 약 3000개 아미노산, 약 260개 아미노산 내지 약 2500개 아미노산, 약 260개 아미노산 내지 약 2000개 아미노산, 약 260개 아미노산 내지 약 1500개 아미노산, 약 260개 아미노산 내지 약 1000개 아미노산, 약 260개 아미노산 내지 약 950개 아미노산, 약 260개 아미노산 내지 약 900개 아미노산, 약 260개 아미노산 내지 약 850개 아미노산, 약 260개 아미노산 내지 약 800개 아미노산, 약 260개 아미노산 내지 약 750개 아미노산, 약 260개 아미노산 내지 약 700개 아미노산, 약 260개 아미노산 내지 약 650개 아미노산, 약 260개 아미노산 내지 약 600개 아미노산, 약 260개 아미노산 내지 약 550개 아미노산, 약 260개 아미노산 내지 약 500개 아미노산, 약 260개 아미노산 내지 약 480개 아미노산, 약 260개 아미노산 내지 약 460개 아미노산, 약 260개 아미노산 내지 약 440개 아미노산, 약 260개 아미노산 내지 약 420개 아미노산, 약 260개 아미노산 내지 약 400개 아미노산, 약 260개 아미노산 내지 약 380개 아미노산, 약 260개 아미노산 내지 약 360개 아미노산, 약 260개 아미노산 내지 약 340개 아미노산, 약 260개 아미노산 내지 약 320개 아미노산, 약 260개 아미노산 내지 약 300개 아미노산, 약 260개 아미노산 내지 약 280개 아미노산, 약 280개 아미노산 내지 약 3000개 아미노산, 약 280개 아미노산 내지 약 2500개 아미노산, 약 280개 아미노산 내지 약 2000개 아미노산, 약 280개 아미노산 내지 약 1500개 아미노산, 약 280개 아미노산 내지 약 1000개 아미노산, 약 280개 아미노산 내지 약 950개 아미노산, 약 280개 아미노산 내지 약 900개 아미노산, 약 280개 아미노산 내지 약 850개 아미노산, 약 280개 아미노산 내지 약 800개 아미노산, 약 280개 아미노산 내지 약 750개 아미노산, 약 280개 아미노산 내지 약 700개 아미노산, 약 280개 아미노산 내지 약 650개 아미노산, 약 280개 아미노산 내지 약 600개 아미노산, 약 280개 아미노산 내지 약 550개 아미노산, 약 280개 아미노산 내지 약 500개 아미노산, 약 280개 아미노산 내지 약 480개 아미노산, 약 280개 아미노산 내지 약 460개 아미노산, 약 280개 아미노산 내지 약 440개 아미노산, 약 280개 아미노산 내지 약 420개 아미노산, 약 280개 아미노산 내지 약 400개 아미노산, 약 280개 아미노산 내지 약 380개 아미노산, 약 280개 아미노산 내지 약 360개 아미노산, 약 280개 아미노산 내지 약 340개 아미노산, 약 280개 아미노산 내지 약 320개 아미노산, 약 280개 아미노산 내지 약 300개 아미노산, 약 300개 아미노산 내지 약 3000개 아미노산, 약 300개 아미노산 내지 약 2500개 아미노산, 약 300개 아미노산 내지 약 2000개 아미노산, 약 300개 아미노산 내지 약 1500개 아미노산, 약 300개 아미노산 내지 약 1000개 아미노산, 약 300개 아미노산 내지 약 950개 아미노산, 약 300개 아미노산 내지 약 900개 아미노산, 약 300개 아미노산 내지 약 850개 아미노산, 약 300개 아미노산 내지 약 800개 아미노산, 약 300개 아미노산 내지 약 750개 아미노산, 약 300개 아미노산 내지 약 700개 아미노산, 약 300개 아미노산 내지 약 650개 아미노산, 약 300개 아미노산 내지 약 600개 아미노산, 약 300개 아미노산 내지 약 550개 아미노산, 약 300개 아미노산 내지 약 500개 아미노산, 약 300개 아미노산 내지 약 480개 아미노산, 약 300개 아미노산 내지 약 460개 아미노산, 약 300개 아미노산 내지 약 440개 아미노산, 약 300개 아미노산 내지 약 420개 아미노산, 약 300개 아미노산 내지 약 400개 아미노산, 약 300개 아미노산 내지 약 380개 아미노산, 약 300개 아미노산 내지 약 360개 아미노산, 약 300개 아미노산 내지 약 340개 아미노산, 약 300개 아미노산 내지 약 320개 아미노산, 약 320개 아미노산 내지 약 3000개 아미노산, 약 320개 아미노산 내지 약 2500개 아미노산, 약 320개 아미노산 내지 약 2000개 아미노산, 약 320개 아미노산 내지 약 1500개 아미노산, 약 320개 아미노산 내지 약 1000개 아미노산, 약 320개 아미노산 내지 약 950개 아미노산, 약 320개 아미노산 내지 약 900개 아미노산, 약 320개 아미노산 내지 약 850개 아미노산, 약 320개 아미노산 내지 약 800개 아미노산, 약 320개 아미노산 내지 약 750개 아미노산, 약 320개 아미노산 내지 약 700개 아미노산, 약 320개 아미노산 내지 약 650개 아미노산, 약 320개 아미노산 내지 약 600개 아미노산, 약 320개 아미노산 내지 약 550개 아미노산, 약 320개 아미노산 내지 약 500개 아미노산, 약 320개 아미노산 내지 약 480개 아미노산, 약 320개 아미노산 내지 약 460개 아미노산, 약 320개 아미노산 내지 약 440개 아미노산, 약 320개 아미노산 내지 약 420개 아미노산, 약 320개 아미노산 내지 약 400개 아미노산, 약 320개 아미노산 내지 약 380개 아미노산, 약 320개 아미노산 내지 약 360개 아미노산, 약 320개 아미노산 내지 약 340개 아미노산, 약 340개 아미노산 내지 약 3000개 아미노산, 약 340개 아미노산 내지 약 2500개 아미노산, 약 340개 아미노산 내지 약 2000개 아미노산, 약 340개 아미노산 내지 약 1500개 아미노산, 약 340개 아미노산 내지 약 1000개 아미노산, 약 340개 아미노산 내지 약 950개 아미노산, 약 340개 아미노산 내지 약 900개 아미노산, 약 340개 아미노산 내지 약 850개 아미노산, 약 340개 아미노산 내지 약 800개 아미노산, 약 340개 아미노산 내지 약 750개 아미노산, 약 340개 아미노산 내지 약 700개 아미노산, 약 340개 아미노산 내지 약 650개 아미노산, 약 340개 아미노산 내지 약 600개 아미노산, 약 340개 아미노산 내지 약 550개 아미노산, 약 340개 아미노산 내지 약 500개 아미노산, 약 340개 아미노산 내지 약 480개 아미노산, 약 340개 아미노산 내지 약 460개 아미노산, 약 340개 아미노산 내지 약 440개 아미노산, 약 340개 아미노산 내지 약 420개 아미노산, 약 340개 아미노산 내지 약 400개 아미노산, 약 340개 아미노산 내지 약 380개 아미노산, 약 340개 아미노산 내지 약 360개 아미노산, 약 360개 아미노산 내지 약 3000개 아미노산, 약 360개 아미노산 내지 약 2500개 아미노산, 약 360개 아미노산 내지 약 2000개 아미노산, 약 360개 아미노산 내지 약 1500개 아미노산, 약 360개 아미노산 내지 약 1000개 아미노산, 약 360개 아미노산 내지 약 950개 아미노산, 약 360개 아미노산 내지 약 900개 아미노산, 약 360개 아미노산 내지 약 850개 아미노산, 약 360개 아미노산 내지 약 800개 아미노산, 약 360개 아미노산 내지 약 750개 아미노산, 약 360개 아미노산 내지 약 700개 아미노산, 약 360개 아미노산 내지 약 650개 아미노산, 약 360개 아미노산 내지 약 600개 아미노산, 약 360개 아미노산 내지 약 550개 아미노산, 약 360개 아미노산 내지 약 500개 아미노산, 약 360개 아미노산 내지 약 480개 아미노산, 약 360개 아미노산 내지 약 460개 아미노산, 약 360개 아미노산 내지 약 440개 아미노산, 약 360개 아미노산 내지 약 420개 아미노산, 약 360개 아미노산 내지 약 400개 아미노산, 약 360개 아미노산 내지 약 380개 아미노산, 약 380개 아미노산 내지 약 3000개 아미노산, 약 380개 아미노산 내지 약 2500개 아미노산, 약 380개 아미노산 내지 약 2000개 아미노산, 약 380개 아미노산 내지 약 1500개 아미노산, 약 380개 아미노산 내지 약 1000개 아미노산, 약 380개 아미노산 내지 약 950개 아미노산, 약 380개 아미노산 내지 약 900개 아미노산, 약 380개 아미노산 내지 약 850개 아미노산, 약 380개 아미노산 내지 약 800개 아미노산, 약 380개 아미노산 내지 약 750개 아미노산, 약 380개 아미노산 내지 약 700개 아미노산, 약 380개 아미노산 내지 약 650개 아미노산, 약 380개 아미노산 내지 약 600개 아미노산, 약 380개 아미노산 내지 약 550개 아미노산, 약 380개 아미노산 내지 약 500개 아미노산, 약 380개 아미노산 내지 약 480개 아미노산, 약 380개 아미노산 내지 약 460개 아미노산, 약 380개 아미노산 내지 약 440개 아미노산, 약 380개 아미노산 내지 약 420개 아미노산, 약 380개 아미노산 내지 약 400개 아미노산, 약 400개 아미노산 내지 약 3000개 아미노산, 약 400개 아미노산 내지 약 2500개 아미노산, 약 400개 아미노산 내지 약 2000개 아미노산, 약 400개 아미노산 내지 약 1500개 아미노산, 약 400개 아미노산 내지 약 1000개 아미노산, 약 400개 아미노산 내지 약 950개 아미노산, 약 400개 아미노산 내지 약 900개 아미노산, 약 400개 아미노산 내지 약 850개 아미노산, 약 400개 아미노산 내지 약 800개 아미노산, 약 400개 아미노산 내지 약 750개 아미노산, 약 400개 아미노산 내지 약 700개 아미노산, 약 400개 아미노산 내지 약 650개 아미노산, 약 400개 아미노산 내지 약 600개 아미노산, 약 400개 아미노산 내지 약 550개 아미노산, 약 400개 아미노산 내지 약 500개 아미노산, 약 400개 아미노산 내지 약 480개 아미노산, 약 400개 아미노산 내지 약 460개 아미노산, 약 400개 아미노산 내지 약 440개 아미노산, 약 400개 아미노산 내지 약 420개 아미노산, 약 420개 아미노산 내지 약 3000개 아미노산, 약 420개 아미노산 내지 약 2500개 아미노산, 약 420개 아미노산 내지 약 2000개 아미노산, 약 420개 아미노산 내지 약 1500개 아미노산, 약 420개 아미노산 내지 약 1000개 아미노산, 약 420개 아미노산 내지 약 950개 아미노산, 약 420개 아미노산 내지 약 900개 아미노산, 약 420개 아미노산 내지 약 850개 아미노산, 약 420개 아미노산 내지 약 800개 아미노산, 약 420개 아미노산 내지 약 750개 아미노산, 약 420개 아미노산 내지 약 700개 아미노산, 약 420개 아미노산 내지 약 650개 아미노산, 약 420개 아미노산 내지 약 600개 아미노산, 약 420개 아미노산 내지 약 550개 아미노산, 약 420개 아미노산 내지 약 500개 아미노산, 약 420개 아미노산 내지 약 480개 아미노산, 약 420개 아미노산 내지 약 460개 아미노산, 약 420개 아미노산 내지 약 440개 아미노산, 약 440개 아미노산 내지 약 3000개 아미노산, 약 440개 아미노산 내지 약 2500개 아미노산, 약 440개 아미노산 내지 약 2000개 아미노산, 약 440개 아미노산 내지 약 1500개 아미노산, 약 440개 아미노산 내지 약 1000개 아미노산, 약 440개 아미노산 내지 약 950개 아미노산, 약 440개 아미노산 내지 약 900개 아미노산, 약 440개 아미노산 내지 약 850개 아미노산, 약 440개 아미노산 내지 약 800개 아미노산, 약 440개 아미노산 내지 약 750개 아미노산, 약 440개 아미노산 내지 약 700개 아미노산, 약 440개 아미노산 내지 약 650개 아미노산, 약 440개 아미노산 내지 약 600개 아미노산, 약 440개 아미노산 내지 약 550개 아미노산, 약 440개 아미노산 내지 약 500개 아미노산, 약 440개 아미노산 내지 약 480개 아미노산, 약 440개 아미노산 내지 약 460개 아미노산, 약 460개 아미노산 내지 약 3000개 아미노산, 약 460개 아미노산 내지 약 2500개 아미노산, 약 460개 아미노산 내지 약 2000개 아미노산, 약 460개 아미노산 내지 약 1500개 아미노산, 약 460개 아미노산 내지 약 1000개 아미노산, 약 460개 아미노산 내지 약 950개 아미노산, 약 460개 아미노산 내지 약 900개 아미노산, 약 460개 아미노산 내지 약 850개 아미노산, 약 460개 아미노산 내지 약 800개 아미노산, 약 460개 아미노산 내지 약 750개 아미노산, 약 460개 아미노산 내지 약 700개 아미노산, 약 460개 아미노산 내지 약 650개 아미노산, 약 460개 아미노산 내지 약 600개 아미노산, 약 460개 아미노산 내지 약 550개 아미노산, 약 460개 아미노산 내지 약 500개 아미노산, 약 460개 아미노산 내지 약 480개 아미노산, 약 480개 아미노산 내지 약 3000개 아미노산, 약 480개 아미노산 내지 약 2500개 아미노산, 약 480개 아미노산 내지 약 2000개 아미노산, 약 480개 아미노산 내지 약 1500개 아미노산, 약 480개 아미노산 내지 약 1000개 아미노산, 약 480개 아미노산 내지 약 950개 아미노산, 약 480개 아미노산 내지 약 900개 아미노산, 약 480개 아미노산 내지 약 850개 아미노산, 약 480개 아미노산 내지 약 800개 아미노산, 약 480개 아미노산 내지 약 750개 아미노산, 약 480개 아미노산 내지 약 700개 아미노산, 약 480개 아미노산 내지 약 650개 아미노산, 약 480개 아미노산 내지 약 600개 아미노산, 약 480개 아미노산 내지 약 550개 아미노산, 약 480개 아미노산 내지 약 500개 아미노산, 약 500개 아미노산 내지 약 3000개 아미노산, 약 500개 아미노산 내지 약 2500개 아미노산, 약 500개 아미노산 내지 약 2000개 아미노산, 약 500개 아미노산 내지 약 1500개 아미노산, 약 500개 아미노산 내지 약 1000개 아미노산, 약 500개 아미노산 내지 약 950개 아미노산, 약 500개 아미노산 내지 약 900개 아미노산, 약 500개 아미노산 내지 약 850개 아미노산, 약 500개 아미노산 내지 약 800개 아미노산, 약 500개 아미노산 내지 약 750개 아미노산, 약 500개 아미노산 내지 약 700개 아미노산, 약 500개 아미노산 내지 약 650개 아미노산, 약 500개 아미노산 내지 약 600개 아미노산, 약 500개 아미노산 내지 약 550개 아미노산, 약 550개 아미노산 내지 약 3000개 아미노산, 약 550개 아미노산 내지 약 2500개 아미노산, 약 550개 아미노산 내지 약 2000개 아미노산, 약 550개 아미노산 내지 약 1500개 아미노산, 약 550개 아미노산 내지 약 1000개 아미노산, 약 550개 아미노산 내지 약 950개 아미노산, 약 550개 아미노산 내지 약 900개 아미노산, 약 550개 아미노산 내지 약 850개 아미노산, 약 550개 아미노산 내지 약 800개 아미노산, 약 550개 아미노산 내지 약 750개 아미노산, 약 550개 아미노산 내지 약 700개 아미노산, 약 550개 아미노산 내지 약 650개 아미노산, 약 550개 아미노산 내지 약 600개 아미노산, 약 600개 아미노산 내지 약 3000개 아미노산, 약 600개 아미노산 내지 약 2500개 아미노산, 약 600개 아미노산 내지 약 2000개 아미노산, 약 600개 아미노산 내지 약 1500개 아미노산, 약 600개 아미노산 내지 약 1000개 아미노산, 약 600개 아미노산 내지 약 950개 아미노산, 약 600개 아미노산 내지 약 900개 아미노산, 약 600개 아미노산 내지 약 850개 아미노산, 약 600개 아미노산 내지 약 800개 아미노산, 약 600개 아미노산 내지 약 750개 아미노산, 약 600개 아미노산 내지 약 700개 아미노산, 약 600개 아미노산 내지 약 650개 아미노산, 약 650개 아미노산 내지 약 3000개 아미노산, 약 650개 아미노산 내지 약 2500개 아미노산, 약 650개 아미노산 내지 약 2000개 아미노산, 약 650개 아미노산 내지 약 1500개 아미노산, 약 650개 아미노산 내지 약 1000개 아미노산, 약 650개 아미노산 내지 약 950개 아미노산, 약 650개 아미노산 내지 약 900개 아미노산, 약 650개 아미노산 내지 약 850개 아미노산, 약 650개 아미노산 내지 약 800개 아미노산, 약 650개 아미노산 내지 약 750개 아미노산, 약 650개 아미노산 내지 약 700개 아미노산, 약 700개 아미노산 내지 약 3000개 아미노산, 약 700개 아미노산 내지 약 2500개 아미노산, 약 700개 아미노산 내지 약 2000개 아미노산, 약 700개 아미노산 내지 약 1500개 아미노산, 약 700개 아미노산 내지 약 1000개 아미노산, 약 700개 아미노산 내지 약 950개 아미노산, 약 700개 아미노산 내지 약 900개 아미노산, 약 700개 아미노산 내지 약 850개 아미노산, 약 700개 아미노산 내지 약 800개 아미노산, 약 700개 아미노산 내지 약 750개 아미노산, 약 750개 아미노산 내지 약 3000개 아미노산, 약 750개 아미노산 내지 약 2500개 아미노산, 약 750개 아미노산 내지 약 2000개 아미노산, 약 750개 아미노산 내지 약 1500개 아미노산, 약 750개 아미노산 내지 약 1000개 아미노산, 약 750개 아미노산 내지 약 950개 아미노산, 약 750개 아미노산 내지 약 900개 아미노산, 약 750개 아미노산 내지 약 850개 아미노산, 약 750개 아미노산 내지 약 800개 아미노산, 약 800개 아미노산 내지 약 3000개 아미노산, 약 800개 아미노산 내지 약 2500개 아미노산, 약 800개 아미노산 내지 약 2000개 아미노산, 약 800개 아미노산 내지 약 1500개 아미노산, 약 800개 아미노산 내지 약 1000개 아미노산, 약 800개 아미노산 내지 약 950개 아미노산, 약 800개 아미노산 내지 약 900개 아미노산, 약 800개 아미노산 내지 약 850개 아미노산, 약 850개 아미노산 내지 약 3000개 아미노산, 약 850개 아미노산 내지 약 2500개 아미노산, 약 850개 아미노산 내지 약 2000개 아미노산, 약 850개 아미노산 내지 약 1500개 아미노산, 약 850개 아미노산 내지 약 1000개 아미노산, 약 850개 아미노산 내지 약 950개 아미노산, 약 850개 아미노산 내지 약 900개 아미노산, 약 900개 아미노산 내지 약 3000개 아미노산, 약 900개 아미노산 내지 약 2500개 아미노산, 약 900개 아미노산 내지 약 2000개 아미노산, 약 900개 아미노산 내지 약 1500개 아미노산, 약 900개 아미노산 내지 약 1000개 아미노산, 약 900개 아미노산 내지 약 950개 아미노산, 약 950개 아미노산 내지 약 3000개 아미노산, 약 950개 아미노산 내지 약 2500개 아미노산, 약 950개 아미노산 내지 약 2000개 아미노산, 약 950개 아미노산 내지 약 1500개 아미노산, 약 950개 아미노산 내지 약 1000개 아미노산, 약 1000개 아미노산 내지 약 3000개 아미노산, 약 1000개 아미노산 내지 약 2500개 아미노산, 약 1000개 아미노산 내지 약 2000개 아미노산, 약 1000개 아미노산 내지 약 1500개 아미노산, 약 1500개 아미노산 내지 약 3000개 아미노산, 약 1500개 아미노산 내지 약 2500개 아미노산, 약 1500개 아미노산 내지 약 2000개 아미노산, 약 2000개 아미노산 내지 약 3000개 아미노산, 약 2000개 아미노산 내지 약 2500개 아미노산, 또는 약 2500개 아미노산 내지 약 3000개 아미노산의 총 길이를 가질 수 있다.
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)과 가용성 조직 인자 도메인(예를 들어, 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인)은 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)과 가용성 조직 인자 도메인(예를 들어, 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인) 사이에 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 링커 서열)을 추가로 포함한다. 본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인(예를 들어, 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인)과 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 가용성 조직 인자 도메인(예를 들어, 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인)과 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인) 사이에 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 링커 서열)을 추가로 포함한다.
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)과 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)과 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인) 사이에 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 링커 서열)을 추가로 포함한다. 본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)과 가용성 조직 인자 도메인(예를 들어, 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인)은 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)과 가용성 조직 인자 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 가용성 조직 인자 도메인) 사이에 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 링커 서열)을 추가로 포함한다.
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 하기와 적어도 70% 동일한(예를 들어, 적어도 75% 동일한, 적어도 80% 동일한, 적어도 85% 동일한, 적어도 90% 동일한, 적어도 95% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
QIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINRGGGGSGGGGSGGGGSQVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTDKSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREVQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSSGGGGSGGGGSGGGGSDIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKR (SEQ ID NO: 85).
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 하기와 적어도 70% 동일한(예를 들어, 적어도 75% 동일한, 적어도 80% 동일한, 적어도 85% 동일한, 적어도 90% 동일한, 적어도 95% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함하는 핵산에 의해 인코딩된다:
CAGATCGTGCTGACCCAAAGCCCCGCCATCATGAGCGCTAGCCCCGGTGAGAAGGTGACCATGACATGCTCCGCTTCCAGCTCCGTGTCCTACATGAACTGGTATCAGCAGAAAAGCGGAACCAGCCCCAAAAGGTGGATCTACGACACCAGCAAGCTGGCCTCCGGAGTGCCCGCTCATTTCCGGGGCTCTGGATCCGGCACCAGCTACTCTTTAACCATTTCCGGCATGGAAGCTGAAGACGCTGCCACCTACTATTGCCAGCAATGGAGCAGCAACCCCTTCACATTCGGATCTGGCACCAAGCTCGAAATCAATCGTGGAGGAGGTGGCAGCGGCGGCGGTGGATCCGGCGGAGGAGGAAGCCAAGTTCAACTCCAGCAGAGCGGCGCTGAACTGGCCCGGCCCGGCGCCTCCGTCAAGATGAGCTGCAAGGCTTCCGGCTATACATTTACTCGTTACACAATGCATTGGGTCAAGCAGAGGCCCGGTCAAGGTTTAGAGTGGATCGGATATATCAACCCTTCCCGGGGCTACACCAACTATAACCAAAAGTTCAAGGATAAAGCCACTTTAACCACTGACAAGAGCTCCTCCACCGCCTACATGCAGCTGTCCTCTTTAACCAGCGAGGACTCCGCTGTTTACTACTGCGCTAGGTATTACGACGACCACTACTGTTTAGACTATTGGGGACAAGGTACCACTTTAACCGTCAGCAGCTCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGGTCCAGCTGCAGCAGAGCGGACCCGAACTCGTGAAACCCGGTGCTTCCGTGAAAATGTCTTGTAAGGCCAGCGGATACACCTTCACCTCCTATGTGATCCAGTGGGTCAAACAGAAGCCCGGACAAGGTCTCGAGTGGATCGGCAGCATCAACCCTTACAACGACTATACCAAATACAACGAGAAGTTTAAGGGAAAGGCTACTTTAACCTCCGACAAAAGCTCCATCACAGCCTACATGGAGTTCAGCTCTTTAACATCCGAGGACAGCGCTCTGTACTATTGCGCCCGGTGGGGCGACGGCAATTACTGGGGACGGGGCACAACACTGACCGTGAGCAGCGGAGGCGGAGGCTCCGGCGGAGGCGGATCTGGCGGTGGCGGCTCCGACATCGAGATGACCCAGTCCCCCGCTATCATGTCCGCCTCTTTAGGCGAGCGGGTCACAATGACTTGTACAGCCTCCTCCAGCGTCTCCTCCTCCTACTTCCATTGGTACCAACAGAAACCCGGAAGCTCCCCTAAACTGTGCATCTACAGCACCAGCAATCTCGCCAGCGGCGTGCCCCCTAGGTTTTCCGGAAGCGGAAGCACCAGCTACTCTTTAACCATCTCCTCCATGGAGGCTGAGGATGCCGCCACCTACTTTTGTCACCAGTACCACCGGTCCCCCACCTTCGGAGGCGGCACCAAACTGGAGACAAAGAGG (SEQ ID NO: 86).
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 하기와 적어도 70% 동일한(예를 들어, 적어도 75% 동일한, 적어도 80% 동일한, 적어도 85% 동일한, 적어도 90% 동일한, 적어도 95% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSQIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINRGGGGSGGGGSGGGGSQVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTDKSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREVQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSSGGGGSGGGGSGGGGSDIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKR (SEQ ID NO: 87).
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 하기와 적어도 70% 동일한(예를 들어, 적어도 75% 동일한, 적어도 80% 동일한, 적어도 85% 동일한, 적어도 90% 동일한, 적어도 95% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함하는 핵산에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCTTATTATTTTTATTCAGCTCCGCCTATTCCCAGATCGTGCTGACCCAAAGCCCCGCCATCATGAGCGCTAGCCCCGGTGAGAAGGTGACCATGACATGCTCCGCTTCCAGCTCCGTGTCCTACATGAACTGGTATCAGCAGAAAAGCGGAACCAGCCCCAAAAGGTGGATCTACGACACCAGCAAGCTGGCCTCCGGAGTGCCCGCTCATTTCCGGGGCTCTGGATCCGGCACCAGCTACTCTTTAACCATTTCCGGCATGGAAGCTGAAGACGCTGCCACCTACTATTGCCAGCAATGGAGCAGCAACCCCTTCACATTCGGATCTGGCACCAAGCTCGAAATCAATCGTGGAGGAGGTGGCAGCGGCGGCGGTGGATCCGGCGGAGGAGGAAGCCAAGTTCAACTCCAGCAGAGCGGCGCTGAACTGGCCCGGCCCGGCGCCTCCGTCAAGATGAGCTGCAAGGCTTCCGGCTATACATTTACTCGTTACACAATGCATTGGGTCAAGCAGAGGCCCGGTCAAGGTTTAGAGTGGATCGGATATATCAACCCTTCCCGGGGCTACACCAACTATAACCAAAAGTTCAAGGATAAAGCCACTTTAACCACTGACAAGAGCTCCTCCACCGCCTACATGCAGCTGTCCTCTTTAACCAGCGAGGACTCCGCTGTTTACTACTGCGCTAGGTATTACGACGACCACTACTGTTTAGACTATTGGGGACAAGGTACCACTTTAACCGTCAGCAGCTCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGGTCCAGCTGCAGCAGAGCGGACCCGAACTCGTGAAACCCGGTGCTTCCGTGAAAATGTCTTGTAAGGCCAGCGGATACACCTTCACCTCCTATGTGATCCAGTGGGTCAAACAGAAGCCCGGACAAGGTCTCGAGTGGATCGGCAGCATCAACCCTTACAACGACTATACCAAATACAACGAGAAGTTTAAGGGAAAGGCTACTTTAACCTCCGACAAAAGCTCCATCACAGCCTACATGGAGTTCAGCTCTTTAACATCCGAGGACAGCGCTCTGTACTATTGCGCCCGGTGGGGCGACGGCAATTACTGGGGACGGGGCACAACACTGACCGTGAGCAGCGGAGGCGGAGGCTCCGGCGGAGGCGGATCTGGCGGTGGCGGCTCCGACATCGAGATGACCCAGTCCCCCGCTATCATGTCCGCCTCTTTAGGCGAGCGGGTCACAATGACTTGTACAGCCTCCTCCAGCGTCTCCTCCTCCTACTTCCATTGGTACCAACAGAAACCCGGAAGCTCCCCTAAACTGTGCATCTACAGCACCAGCAATCTCGCCAGCGGCGTGCCCCCTAGGTTTTCCGGAAGCGGAAGCACCAGCTACTCTTTAACCATCTCCTCCATGGAGGCTGAGGATGCCGCCACCTACTTTTGTCACCAGTACCACCGGTCCCCCACCTTCGGAGGCGGCACCAAACTGGAGACAAAGAGG (SEQ ID NO: 88).
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 하기와 적어도 70% 동일한(예를 들어, 적어도 75% 동일한, 적어도 80% 동일한, 적어도 85% 동일한, 적어도 90% 동일한, 적어도 95% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
VQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSSGGGGSGGGGSGGGGSDIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKRSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREQIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINRGGGGSGGGGSGGGGSQVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTDKSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSS (SEQ ID NO: 89).
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 하기와 적어도 70% 동일한(예를 들어, 적어도 75% 동일한, 적어도 80% 동일한, 적어도 85% 동일한, 적어도 90% 동일한, 적어도 95% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함하는 핵산에 의해 인코딩된다:
GTGCAGCTGCAGCAGTCCGGACCCGAACTGGTCAAGCCCGGTGCCTCCGTGAAAATGTCTTGTAAGGCTTCTGGCTACACCTTTACCTCCTACGTCATCCAATGGGTGAAGCAGAAGCCCGGTCAAGGTCTCGAGTGGATCGGCAGCATCAATCCCTACAACGATTACACCAAGTATAACGAAAAGTTTAAGGGCAAGGCCACTCTGACAAGCGACAAGAGCTCCATTACCGCCTACATGGAGTTTTCCTCTTTAACTTCTGAGGACTCCGCTTTATACTATTGCGCTCGTTGGGGCGATGGCAATTATTGGGGCCGGGGAACTACTTTAACAGTGAGCTCCGGCGGCGGCGGAAGCGGAGGTGGAGGATCTGGCGGTGGAGGCAGCGACATCGAGATGACACAGTCCCCCGCTATCATGAGCGCCTCTTTAGGAGAACGTGTGACCATGACTTGTACAGCTTCCTCCAGCGTGAGCAGCTCCTATTTCCACTGGTACCAGCAGAAACCCGGCTCCTCCCCTAAACTGTGTATCTACTCCACAAGCAATTTAGCTAGCGGCGTGCCTCCTCGTTTTAGCGGCTCCGGCAGCACCTCTTACTCTTTAACCATTAGCTCTATGGAGGCCGAAGATGCCGCCACATACTTTTGCCATCAGTACCACCGGTCCCCTACCTTTGGCGGAGGCACAAAGCTGGAGACCAAGCGGAGCGGCACCACCAACACAGTGGCCGCCTACAATCTGACTTGGAAATCCACCAACTTCAAGACCATCCTCGAGTGGGAGCCCAAGCCCGTTAATCAAGTTTATACCGTGCAGATTTCCACCAAGAGCGGCGACTGGAAATCCAAGTGCTTCTATACCACAGACACCGAGTGCGATCTCACCGACGAGATCGTCAAAGACGTGAAGCAGACATATTTAGCTAGGGTGTTCTCCTACCCCGCTGGAAACGTGGAGAGCACCGGATCCGCTGGAGAGCCTTTATACGAGAACTCCCCCGAATTCACCCCCTATCTGGAAACCAATTTAGGCCAGCCCACCATCCAGAGCTTCGAACAAGTTGGCACAAAGGTGAACGTCACCGTCGAAGATGAGAGGACTTTAGTGCGGAGGAACAATACATTTTTATCCTTACGTGACGTCTTCGGCAAGGATTTAATCTACACACTGTATTACTGGAAGTCTAGCTCCTCCGGCAAGAAGACCGCCAAGACCAATACCAACGAATTTTTAATTGACGTGGACAAGGGCGAGAACTACTGCTTCTCCGTGCAAGCTGTGATCCCCTCCCGGACAGTGAACCGGAAGTCCACCGACTCCCCCGTGGAGTGCATGGGCCAAGAGAAGGGAGAGTTTCGTGAGCAGATCGTGCTGACCCAGTCCCCCGCTATTATGAGCGCTAGCCCCGGTGAAAAGGTGACTATGACATGCAGCGCCAGCTCTTCCGTGAGCTACATGAACTGGTATCAGCAGAAGTCCGGCACCAGCCCTAAAAGGTGGATCTACGACACCAGCAAGCTGGCCAGCGGCGTCCCCGCTCACTTTCGGGGCTCCGGCTCCGGAACAAGCTACTCTCTGACCATCAGCGGCATGGAAGCCGAGGATGCCGCTACCTATTACTGTCAGCAGTGGAGCTCCAACCCCTTCACCTTTGGATCCGGCACCAAGCTCGAGATTAATCGTGGAGGCGGAGGTAGCGGAGGAGGCGGATCCGGCGGTGGAGGTAGCCAAGTTCAGCTCCAGCAAAGCGGCGCCGAACTCGCTCGGCCCGGCGCTTCCGTGAAGATGTCTTGTAAGGCCTCCGGCTATACCTTCACCCGGTACACAATGCACTGGGTCAAGCAACGGCCCGGTCAAGGTTTAGAGTGGATTGGCTATATCAACCCCTCCCGGGGCTATACCAACTACAACCAGAAGTTCAAGGACAAAGCCACCCTCACCACCGACAAGTCCAGCAGCACCGCTTACATGCAGCTGAGCTCTTTAACATCCGAGGATTCCGCCGTGTACTACTGCGCTCGGTACTACGACGATCATTACTGCCTCGATTACTGGGGCCAAGGTACCACCTTAACAGTCTCCTCC (SEQ ID NO: 90).
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 하기와 적어도 70% 동일한(예를 들어, 적어도 75% 동일한, 적어도 80% 동일한, 적어도 85% 동일한, 적어도 90% 동일한, 적어도 95% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSVQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSSGGGGSGGGGSGGGGSDIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKRSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREQIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINRGGGGSGGGGSGGGGSQVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTDKSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSS (SEQ ID NO: 91).
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 하기와 적어도 70% 동일한(예를 들어, 적어도 75% 동일한, 적어도 80% 동일한, 적어도 85% 동일한, 적어도 90% 동일한, 적어도 95% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함하는 핵산에 의해 인코딩된다:
ATGAAATGGGTCACCTTCATCTCTTTACTGTTTTTATTTAGCAGCGCCTACAGCGTGCAGCTGCAGCAGTCCGGACCCGAACTGGTCAAGCCCGGTGCCTCCGTGAAAATGTCTTGTAAGGCTTCTGGCTACACCTTTACCTCCTACGTCATCCAATGGGTGAAGCAGAAGCCCGGTCAAGGTCTCGAGTGGATCGGCAGCATCAATCCCTACAACGATTACACCAAGTATAACGAAAAGTTTAAGGGCAAGGCCACTCTGACAAGCGACAAGAGCTCCATTACCGCCTACATGGAGTTTTCCTCTTTAACTTCTGAGGACTCCGCTTTATACTATTGCGCTCGTTGGGGCGATGGCAATTATTGGGGCCGGGGAACTACTTTAACAGTGAGCTCCGGCGGCGGCGGAAGCGGAGGTGGAGGATCTGGCGGTGGAGGCAGCGACATCGAGATGACACAGTCCCCCGCTATCATGAGCGCCTCTTTAGGAGAACGTGTGACCATGACTTGTACAGCTTCCTCCAGCGTGAGCAGCTCCTATTTCCACTGGTACCAGCAGAAACCCGGCTCCTCCCCTAAACTGTGTATCTACTCCACAAGCAATTTAGCTAGCGGCGTGCCTCCTCGTTTTAGCGGCTCCGGCAGCACCTCTTACTCTTTAACCATTAGCTCTATGGAGGCCGAAGATGCCGCCACATACTTTTGCCATCAGTACCACCGGTCCCCTACCTTTGGCGGAGGCACAAAGCTGGAGACCAAGCGGAGCGGCACCACCAACACAGTGGCCGCCTACAATCTGACTTGGAAATCCACCAACTTCAAGACCATCCTCGAGTGGGAGCCCAAGCCCGTTAATCAAGTTTATACCGTGCAGATTTCCACCAAGAGCGGCGACTGGAAATCCAAGTGCTTCTATACCACAGACACCGAGTGCGATCTCACCGACGAGATCGTCAAAGACGTGAAGCAGACATATTTAGCTAGGGTGTTCTCCTACCCCGCTGGAAACGTGGAGAGCACCGGATCCGCTGGAGAGCCTTTATACGAGAACTCCCCCGAATTCACCCCCTATCTGGAAACCAATTTAGGCCAGCCCACCATCCAGAGCTTCGAACAAGTTGGCACAAAGGTGAACGTCACCGTCGAAGATGAGAGGACTTTAGTGCGGAGGAACAATACATTTTTATCCTTACGTGACGTCTTCGGCAAGGATTTAATCTACACACTGTATTACTGGAAGTCTAGCTCCTCCGGCAAGAAGACCGCCAAGACCAATACCAACGAATTTTTAATTGACGTGGACAAGGGCGAGAACTACTGCTTCTCCGTGCAAGCTGTGATCCCCTCCCGGACAGTGAACCGGAAGTCCACCGACTCCCCCGTGGAGTGCATGGGCCAAGAGAAGGGAGAGTTTCGTGAGCAGATCGTGCTGACCCAGTCCCCCGCTATTATGAGCGCTAGCCCCGGTGAAAAGGTGACTATGACATGCAGCGCCAGCTCTTCCGTGAGCTACATGAACTGGTATCAGCAGAAGTCCGGCACCAGCCCTAAAAGGTGGATCTACGACACCAGCAAGCTGGCCAGCGGCGTCCCCGCTCACTTTCGGGGCTCCGGCTCCGGAACAAGCTACTCTCTGACCATCAGCGGCATGGAAGCCGAGGATGCCGCTACCTATTACTGTCAGCAGTGGAGCTCCAACCCCTTCACCTTTGGATCCGGCACCAAGCTCGAGATTAATCGTGGAGGCGGAGGTAGCGGAGGAGGCGGATCCGGCGGTGGAGGTAGCCAAGTTCAGCTCCAGCAAAGCGGCGCCGAACTCGCTCGGCCCGGCGCTTCCGTGAAGATGTCTTGTAAGGCCTCCGGCTATACCTTCACCCGGTACACAATGCACTGGGTCAAGCAACGGCCCGGTCAAGGTTTAGAGTGGATTGGCTATATCAACCCCTCCCGGGGCTATACCAACTACAACCAGAAGTTCAAGGACAAAGCCACCCTCACCACCGACAAGTCCAGCAGCACCGCTTACATGCAGCTGAGCTCTTTAACATCCGAGGATTCCGCCGTGTACTACTGCGCTCGGTACTACGACGATCATTACTGCCTCGATTACTGGGGCCAAGGTACCACCTTAACAGTCTCCTCC (SEQ ID NO: 92).
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예는 이의 N-말단 및/또는 C-말단에 하나 이상의(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개의) 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)을 추가로 포함할 수 있다.
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 이의 N-말단에 하나 이상의(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개의) 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)을 포함할 수 있다. 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드의 N-말단에서 하나 이상의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인) 중 하나는 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 또는 가용성 조직 인자 도메인(예를 들어, 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인)에 직접적으로 인접해 있을 수 있다. 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 상기 단일-사슬 키메라 폴리펩타이드의 N-말단에서 적어도 하나의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)과 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 또는 가용성 조직 인자 도메인(예를 들어, 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인) 사이에 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 링커 서열)을 추가로 포함한다.
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 이의 C-말단에 하나 이상의(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개의) 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)을 추가로 포함할 수 있다. 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드의 C-말단에서 하나 이상의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인) 중 하나는 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 또는 가용성 조직 인자 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 가용성 조직 인자 도메인)에 직접적으로 인접해 있다. 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 상기 단일-사슬 키메라 폴리펩타이드의 C-말단에서 적어도 하나의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)과 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 또는 가용성 조직 인자 도메인(예를 들어, 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인) 사이에 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 링커 서열)을 추가로 포함한다.
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 이의 N-말단 및 이의 C-말단에 하나 이상의(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개의) 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)을 추가로 포함할 수 있다. 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드의 N-말단에서 하나 이상의 추가 항원-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인) 중 하나는 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 또는 가용성 조직 인자 도메인(예를 들어, 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인)에 직접적으로 인접해 있다. 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 N-말단에서 하나 이상의 추가 항원-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)과 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 또는 가용성 조직 인자 도메인(예를 들어, 임의의 예시적인 가용성 조직 인자 도메인) 사이에 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 링커 서열)을 추가로 포함한다. 일부 구현예에서, C-말단에서 하나 이상의 추가 항원-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인) 중 하나는 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 또는 가용성 조직 인자 도메인(예를 들어, 임의의 예시적인 가용성 조직 인자 도메인)에 직접적으로 인접해 있다. 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 C-말단에서 하나 이상의 추가 항원-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)과 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 또는 가용성 조직 인자 도메인(예를 들어, 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인) 사이에 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 링커 서열)을 추가로 포함한다.
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 2개 이상(예를 들어, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개)의 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 및 하나 이상의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 동일한 항원에 특이적으로 결합한다. 일부 구현예에서, 2개 이상(예를 들어, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개)의 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 및 하나 이상의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 동일한 에피토프에 특이적으로 결합한다. 일부 구현예에서, 2개 이상(예를 들어, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개)의 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 및 하나 이상의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 동일한 아미노산 서열을 포함한다.
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 및 하나 이상(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개)의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 각각 동일한 항원에 특이적으로 결합한다. 일부 구현예에서, 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 및 하나 이상(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개)의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 각각 동일한 에피토프에 특이적으로 결합한다. 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개)의 추가 표적-결합 도메인은 각각 동일한 아미노산 서열을 포함한다.
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 및 하나 이상(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개)의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 상이한 항원에 특이적으로 결합한다.
임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 하나 이상의 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 표적-결합 도메인은 항원-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 항원-결합 도메인)이다. 본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인은 각각 항원-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 항원-결합 도메인)이다. 일부 구현예에서, 항원-결합 도메인은 scFv 또는 단일 도메인 항체를 포함할 수 있다.
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 하나 이상(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개)의 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인), 및 하나 이상의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 하기의 군으로부터 선택되는 표적에 특이적으로 결합한다: CD16a, CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL-1, VEGF, IL-6R, IL-4, IL-10, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKp30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, IL-1에 대한 수용체, IL-2에 대한 수용체, IL-3에 대한 수용체, IL-7에 대한 수용체, IL-8에 대한 수용체, IL-10에 대한 수용체, IL-12에 대한 수용체, IL-15에 대한 수용체, IL-17에 대한 수용체, IL-18에 대한 수용체, IL-21에 대한 수용체, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, CD122에 대한 수용체, 및 CD28에 대한 수용체.
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 하나 이상의 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 및 하나 이상의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 가용성 인터류킨 또는 사이토카인 단백질이다. 가용성 인터류킨 단백질 및 가용성 사이토카인 단백질의 비제한적인 예는 하기를 포함한다: IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, 및 SCF.
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 하나 이상의 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 및 하나 이상의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 가용성 인터류킨 또는 사이토카인 수용체이다. 가용성 인터류킨 수용체 및 가용성 사이토카인 수용체의 비제한적인 예는 하기를 포함한다: 가용성 TGF-β 수용체 II(TGF-βRII), 가용성 TGF-βRIII, 가용성 NKG2D, 가용성 NKP30, 가용성 NKp44, 가용성 NKp46, 가용성 DNAM1, scMHCI, scMHCII, scTCR, 가용성 CD155, 가용성 CD122, 가용성 CD3, 또는 가용성 CD28.
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인(예를 들어, 본원에 기재된 임의의 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재된 임의의 표적-결합 도메인), 및 하나 이상의 추가 표적-결합 도메인(예를 들어, 본원에 기재된 임의의 표적-결합 도메인)은 각각 독립적으로 하기의 군으로부터 선택되는 표적에 특이적으로 결합할 수 있다: CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKP30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, 및 CD122에 대한 수용체.
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 하나 이상의 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 및 하나 이상의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 가용성 인터류킨 또는 사이토카인 단백질이다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인터류킨 또는 사이토카인 단백질은 하기의 군으로부터 선택된다: IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, 및 SCF.
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 하나 이상의 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 및 하나 이상의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 가용성 인터류킨 또는 사이토카인 수용체이다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 수용체는 가용성 TGF-β 수용체 II(TGF-βRII), 가용성 TGF-βRIII, TNFα에 대한 가용성 수용체, IL-4에 대한 가용성 수용체, 또는 IL-10에 대한 가용성 수용체.
다중-사슬 키메라 폴리펩타이드- A형
NK 세포 활성화제의 비제한적인 예는 (a) (i) 제1 표적-결합 도메인; (ii) 가용성 조직 인자 도메인; 및 (iii) 친화도 도메인 쌍의 제1 도메인을 포함하는 제1 키메라 폴리펩타이드; 및 (b) (i) 친화도 도메인 쌍의 제2 도메인; 및 (ii) 제2 표적-결합 도메인을 포함하는 제2 키메라 폴리펩타이드를 포함하는 다중-사슬 키메라 폴리펩타이드이며, 이때, 제1 키메라 폴리펩타이드 및 제2 키메라 폴리펩타이드는 친화도 도메인 쌍의 제1 도메인과 제2 도메인의 결합을 통해 회합된다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 키메라 폴리펩타이드 및/또는 제2 키메라 폴리펩타이드의 총 길이는 각각 독립적으로 약 50개 아미노산 내지 약 3000개 아미노산, 약 50개 아미노산 내지 약 2500개 아미노산, 약 50개 아미노산 내지 약 2000개 아미노산, 약 50개 아미노산 내지 약 1500개 아미노산, 약 50개 아미노산 내지 약 1000개 아미노산, 약 50개 아미노산 내지 약 950개 아미노산, 약 50개 아미노산 내지 약 900개 아미노산, 약 50개 아미노산 내지 약 850개 아미노산, 약 50개 아미노산 내지 약 800개 아미노산, 약 50개 아미노산 내지 약 750개 아미노산, 약 50개 아미노산 내지 약 700개 아미노산, 약 50개 아미노산 내지 약 650개 아미노산, 약 50개 아미노산 내지 약 600개 아미노산, 약 50개 아미노산 내지 약 550개 아미노산, 약 50개 아미노산 내지 약 500개 아미노산, 약 50개 아미노산 내지 약 480개 아미노산, 약 50개 아미노산 내지 약 460개 아미노산, 약 50개 아미노산 내지 약 440개 아미노산, 약 50개 아미노산 내지 약 420개 아미노산, 약 50개 아미노산 내지 약 400개 아미노산, 약 50개 아미노산 내지 약 380개 아미노산, 약 50개 아미노산 내지 약 360개 아미노산, 약 50개 아미노산 내지 약 340개 아미노산, 약 50개 아미노산 내지 약 320개 아미노산, 약 50개 아미노산 내지 약 300개 아미노산, 약 50개 아미노산 내지 약 280개 아미노산, 약 50개 아미노산 내지 약 260개 아미노산, 약 50개 아미노산 내지 약 240개 아미노산, 약 50개 아미노산 내지 약 220개 아미노산, 약 50개 아미노산 내지 약 200개 아미노산, 약 50개 아미노산 내지 약 150개 아미노산, 약 50개 아미노산 내지 약 100개 아미노산, 약 100개 아미노산 내지 약 3000개 아미노산, 약 100개 아미노산 내지 약 2500개 아미노산, 약 100개 아미노산 내지 약 2000개 아미노산, 약 100개 아미노산 내지 약 1500개 아미노산, 약 100개 아미노산 내지 약 1000개 아미노산, 약 100개 아미노산 내지 약 950개 아미노산, 약 100개 아미노산 내지 약 900개 아미노산, 약 100개 아미노산 내지 약 850개 아미노산, 약 100개 아미노산 내지 약 800개 아미노산, 약 100개 아미노산 내지 약 750개 아미노산, 약 100개 아미노산 내지 약 700개 아미노산, 약 100개 아미노산 내지 약 650개 아미노산, 약 100개 아미노산 내지 약 600개 아미노산, 약 100개 아미노산 내지 약 550개 아미노산, 약 100개 아미노산 내지 약 500개 아미노산, 약 100개 아미노산 내지 약 480개 아미노산, 약 100개 아미노산 내지 약 460개 아미노산, 약 100개 아미노산 내지 약 440개 아미노산, 약 100개 아미노산 내지 약 420개 아미노산, 약 100개 아미노산 내지 약 400개 아미노산, 약 100개 아미노산 내지 약 380개 아미노산, 약 100개 아미노산 내지 약 360개 아미노산, 약 100개 아미노산 내지 약 340개 아미노산, 약 100개 아미노산 내지 약 320개 아미노산, 약 100개 아미노산 내지 약 300개 아미노산, 약 100개 아미노산 내지 약 280개 아미노산, 약 100개 아미노산 내지 약 260개 아미노산, 약 100개 아미노산 내지 약 240개 아미노산, 약 100개 아미노산 내지 약 220개 아미노산, 약 100개 아미노산 내지 약 200개 아미노산, 약 100개 아미노산 내지 약 150개 아미노산, 약 150개 아미노산 내지 약 3000개 아미노산, 약 150개 아미노산 내지 약 2500개 아미노산, 약 150개 아미노산 내지 약 2000개 아미노산, 약 150개 아미노산 내지 약 1500개 아미노산, 약 150개 아미노산 내지 약 1000개 아미노산, 약 150개 아미노산 내지 약 950개 아미노산, 약 150개 아미노산 내지 약 900개 아미노산, 약 150개 아미노산 내지 약 850개 아미노산, 약 150개 아미노산 내지 약 800개 아미노산, 약 150개 아미노산 내지 약 750개 아미노산, 약 150개 아미노산 내지 약 700개 아미노산, 약 150개 아미노산 내지 약 650개 아미노산, 약 150개 아미노산 내지 약 600개 아미노산, 약 150개 아미노산 내지 약 550개 아미노산, 약 150개 아미노산 내지 약 500개 아미노산, 약 150개 아미노산 내지 약 480개 아미노산, 약 150개 아미노산 내지 약 460개 아미노산, 약 150개 아미노산 내지 약 440개 아미노산, 약 150개 아미노산 내지 약 420개 아미노산, 약 150개 아미노산 내지 약 400개 아미노산, 약 150개 아미노산 내지 약 380개 아미노산, 약 150개 아미노산 내지 약 360개 아미노산, 약 150개 아미노산 내지 약 340개 아미노산, 약 150개 아미노산 내지 약 320개 아미노산, 약 150개 아미노산 내지 약 300개 아미노산, 약 150개 아미노산 내지 약 280개 아미노산, 약 150개 아미노산 내지 약 260개 아미노산, 약 150개 아미노산 내지 약 240개 아미노산, 약 150개 아미노산 내지 약 220개 아미노산, 약 150개 아미노산 내지 약 200개 아미노산, 약 200개 아미노산 내지 약 3000개 아미노산, 약 200개 아미노산 내지 약 2500개 아미노산, 약 200개 아미노산 내지 약 2000개 아미노산, 약 200개 아미노산 내지 약 1500개 아미노산, 약 200개 아미노산 내지 약 1000개 아미노산, 약 200개 아미노산 내지 약 950개 아미노산, 약 200개 아미노산 내지 약 900개 아미노산, 약 200개 아미노산 내지 약 850개 아미노산, 약 200개 아미노산 내지 약 800개 아미노산, 약 200개 아미노산 내지 약 750개 아미노산, 약 200개 아미노산 내지 약 700개 아미노산, 약 200개 아미노산 내지 약 650개 아미노산, 약 200개 아미노산 내지 약 600개 아미노산, 약 200개 아미노산 내지 약 550개 아미노산, 약 200개 아미노산 내지 약 500개 아미노산, 약 200개 아미노산 내지 약 480개 아미노산, 약 200개 아미노산 내지 약 460개 아미노산, 약 200개 아미노산 내지 약 440개 아미노산, 약 200개 아미노산 내지 약 420개 아미노산, 약 200개 아미노산 내지 약 400개 아미노산, 약 200개 아미노산 내지 약 380개 아미노산, 약 200개 아미노산 내지 약 360개 아미노산, 약 200개 아미노산 내지 약 340개 아미노산, 약 200개 아미노산 내지 약 320개 아미노산, 약 200개 아미노산 내지 약 300개 아미노산, 약 200개 아미노산 내지 약 280개 아미노산, 약 200개 아미노산 내지 약 260개 아미노산, 약 200개 아미노산 내지 약 240개 아미노산, 약 200개 아미노산 내지 약 220개 아미노산, 약 220개 아미노산 내지 약 3000개 아미노산, 약 220개 아미노산 내지 약 2500개 아미노산, 약 220개 아미노산 내지 약 2000개 아미노산, 약 220개 아미노산 내지 약 1500개 아미노산, 약 220개 아미노산 내지 약 1000개 아미노산, 약 220개 아미노산 내지 약 950개 아미노산, 약 220개 아미노산 내지 약 900개 아미노산, 약 220개 아미노산 내지 약 850개 아미노산, 약 220개 아미노산 내지 약 800개 아미노산, 약 220개 아미노산 내지 약 750개 아미노산, 약 220개 아미노산 내지 약 700개 아미노산, 약 220개 아미노산 내지 약 650개 아미노산, 약 220개 아미노산 내지 약 600개 아미노산, 약 220개 아미노산 내지 약 550개 아미노산, 약 220개 아미노산 내지 약 500개 아미노산, 약 220개 아미노산 내지 약 480개 아미노산, 약 220개 아미노산 내지 약 460개 아미노산, 약 220개 아미노산 내지 약 440개 아미노산, 약 220개 아미노산 내지 약 420개 아미노산, 약 220개 아미노산 내지 약 400개 아미노산, 약 220개 아미노산 내지 약 380개 아미노산, 약 220개 아미노산 내지 약 360개 아미노산, 약 220개 아미노산 내지 약 340개 아미노산, 약 220개 아미노산 내지 약 320개 아미노산, 약 220개 아미노산 내지 약 300개 아미노산, 약 220개 아미노산 내지 약 280개 아미노산, 약 220개 아미노산 내지 약 260개 아미노산, 약 220개 아미노산 내지 약 240개 아미노산, 약 240개 아미노산 내지 약 3000개 아미노산, 약 240개 아미노산 내지 약 2500개 아미노산, 약 240개 아미노산 내지 약 2000개 아미노산, 약 240개 아미노산 내지 약 1500개 아미노산, 약 240개 아미노산 내지 약 1000개 아미노산, 약 240개 아미노산 내지 약 950개 아미노산, 약 240개 아미노산 내지 약 900개 아미노산, 약 240개 아미노산 내지 약 850개 아미노산, 약 240개 아미노산 내지 약 800개 아미노산, 약 240개 아미노산 내지 약 750개 아미노산, 약 240개 아미노산 내지 약 700개 아미노산, 약 240개 아미노산 내지 약 650개 아미노산, 약 240개 아미노산 내지 약 600개 아미노산, 약 240개 아미노산 내지 약 550개 아미노산, 약 240개 아미노산 내지 약 500개 아미노산, 약 240개 아미노산 내지 약 480개 아미노산, 약 240개 아미노산 내지 약 460개 아미노산, 약 240개 아미노산 내지 약 440개 아미노산, 약 240개 아미노산 내지 약 420개 아미노산, 약 240개 아미노산 내지 약 400개 아미노산, 약 240개 아미노산 내지 약 380개 아미노산, 약 240개 아미노산 내지 약 360개 아미노산, 약 240개 아미노산 내지 약 340개 아미노산, 약 240개 아미노산 내지 약 320개 아미노산, 약 240개 아미노산 내지 약 300개 아미노산, 약 240개 아미노산 내지 약 280개 아미노산, 약 240개 아미노산 내지 약 260개 아미노산, 약 260개 아미노산 내지 약 3000개 아미노산, 약 260개 아미노산 내지 약 2500개 아미노산, 약 260개 아미노산 내지 약 2000개 아미노산, 약 260개 아미노산 내지 약 1500개 아미노산, 약 260개 아미노산 내지 약 1000개 아미노산, 약 260개 아미노산 내지 약 950개 아미노산, 약 260개 아미노산 내지 약 900개 아미노산, 약 260개 아미노산 내지 약 850개 아미노산, 약 260개 아미노산 내지 약 800개 아미노산, 약 260개 아미노산 내지 약 750개 아미노산, 약 260개 아미노산 내지 약 700개 아미노산, 약 260개 아미노산 내지 약 650개 아미노산, 약 260개 아미노산 내지 약 600개 아미노산, 약 260개 아미노산 내지 약 550개 아미노산, 약 260개 아미노산 내지 약 500개 아미노산, 약 260개 아미노산 내지 약 480개 아미노산, 약 260개 아미노산 내지 약 460개 아미노산, 약 260개 아미노산 내지 약 440개 아미노산, 약 260개 아미노산 내지 약 420개 아미노산, 약 260개 아미노산 내지 약 400개 아미노산, 약 260개 아미노산 내지 약 380개 아미노산, 약 260개 아미노산 내지 약 360개 아미노산, 약 260개 아미노산 내지 약 340개 아미노산, 약 260개 아미노산 내지 약 320개 아미노산, 약 260개 아미노산 내지 약 300개 아미노산, 약 260개 아미노산 내지 약 280개 아미노산, 약 280개 아미노산 내지 약 3000개 아미노산, 약 280개 아미노산 내지 약 2500개 아미노산, 약 280개 아미노산 내지 약 2000개 아미노산, 약 280개 아미노산 내지 약 1500개 아미노산, 약 280개 아미노산 내지 약 1000개 아미노산, 약 280개 아미노산 내지 약 950개 아미노산, 약 280개 아미노산 내지 약 900개 아미노산, 약 280개 아미노산 내지 약 850개 아미노산, 약 280개 아미노산 내지 약 800개 아미노산, 약 280개 아미노산 내지 약 750개 아미노산, 약 280개 아미노산 내지 약 700개 아미노산, 약 280개 아미노산 내지 약 650개 아미노산, 약 280개 아미노산 내지 약 600개 아미노산, 약 280개 아미노산 내지 약 550개 아미노산, 약 280개 아미노산 내지 약 500개 아미노산, 약 280개 아미노산 내지 약 480개 아미노산, 약 280개 아미노산 내지 약 460개 아미노산, 약 280개 아미노산 내지 약 440개 아미노산, 약 280개 아미노산 내지 약 420개 아미노산, 약 280개 아미노산 내지 약 400개 아미노산, 약 280개 아미노산 내지 약 380개 아미노산, 약 280개 아미노산 내지 약 360개 아미노산, 약 280개 아미노산 내지 약 340개 아미노산, 약 280개 아미노산 내지 약 320개 아미노산, 약 280개 아미노산 내지 약 300개 아미노산, 약 300개 아미노산 내지 약 3000개 아미노산, 약 300개 아미노산 내지 약 2500개 아미노산, 약 300개 아미노산 내지 약 2000개 아미노산, 약 300개 아미노산 내지 약 1500개 아미노산, 약 300개 아미노산 내지 약 1000개 아미노산, 약 300개 아미노산 내지 약 950개 아미노산, 약 300개 아미노산 내지 약 900개 아미노산, 약 300개 아미노산 내지 약 850개 아미노산, 약 300개 아미노산 내지 약 800개 아미노산, 약 300개 아미노산 내지 약 750개 아미노산, 약 300개 아미노산 내지 약 700개 아미노산, 약 300개 아미노산 내지 약 650개 아미노산, 약 300개 아미노산 내지 약 600개 아미노산, 약 300개 아미노산 내지 약 550개 아미노산, 약 300개 아미노산 내지 약 500개 아미노산, 약 300개 아미노산 내지 약 480개 아미노산, 약 300개 아미노산 내지 약 460개 아미노산, 약 300개 아미노산 내지 약 440개 아미노산, 약 300개 아미노산 내지 약 420개 아미노산, 약 300개 아미노산 내지 약 400개 아미노산, 약 300개 아미노산 내지 약 380개 아미노산, 약 300개 아미노산 내지 약 360개 아미노산, 약 300개 아미노산 내지 약 340개 아미노산, 약 300개 아미노산 내지 약 320개 아미노산, 약 320개 아미노산 내지 약 3000개 아미노산, 약 320개 아미노산 내지 약 2500개 아미노산, 약 320개 아미노산 내지 약 2000개 아미노산, 약 320개 아미노산 내지 약 1500개 아미노산, 약 320개 아미노산 내지 약 1000개 아미노산, 약 320개 아미노산 내지 약 950개 아미노산, 약 320개 아미노산 내지 약 900개 아미노산, 약 320개 아미노산 내지 약 850개 아미노산, 약 320개 아미노산 내지 약 800개 아미노산, 약 320개 아미노산 내지 약 750개 아미노산, 약 320개 아미노산 내지 약 700개 아미노산, 약 320개 아미노산 내지 약 650개 아미노산, 약 320개 아미노산 내지 약 600개 아미노산, 약 320개 아미노산 내지 약 550개 아미노산, 약 320개 아미노산 내지 약 500개 아미노산, 약 320개 아미노산 내지 약 480개 아미노산, 약 320개 아미노산 내지 약 460개 아미노산, 약 320개 아미노산 내지 약 440개 아미노산, 약 320개 아미노산 내지 약 420개 아미노산, 약 320개 아미노산 내지 약 400개 아미노산, 약 320개 아미노산 내지 약 380개 아미노산, 약 320개 아미노산 내지 약 360개 아미노산, 약 320개 아미노산 내지 약 340개 아미노산, 약 340개 아미노산 내지 약 3000개 아미노산, 약 340개 아미노산 내지 약 2500개 아미노산, 약 340개 아미노산 내지 약 2000개 아미노산, 약 340개 아미노산 내지 약 1500개 아미노산, 약 340개 아미노산 내지 약 1000개 아미노산, 약 340개 아미노산 내지 약 950개 아미노산, 약 340개 아미노산 내지 약 900개 아미노산, 약 340개 아미노산 내지 약 850개 아미노산, 약 340개 아미노산 내지 약 800개 아미노산, 약 340개 아미노산 내지 약 750개 아미노산, 약 340개 아미노산 내지 약 700개 아미노산, 약 340개 아미노산 내지 약 650개 아미노산, 약 340개 아미노산 내지 약 600개 아미노산, 약 340개 아미노산 내지 약 550개 아미노산, 약 340개 아미노산 내지 약 500개 아미노산, 약 340개 아미노산 내지 약 480개 아미노산, 약 340개 아미노산 내지 약 460개 아미노산, 약 340개 아미노산 내지 약 440개 아미노산, 약 340개 아미노산 내지 약 420개 아미노산, 약 340개 아미노산 내지 약 400개 아미노산, 약 340개 아미노산 내지 약 380개 아미노산, 약 340개 아미노산 내지 약 360개 아미노산, 약 360개 아미노산 내지 약 3000개 아미노산, 약 360개 아미노산 내지 약 2500개 아미노산, 약 360개 아미노산 내지 약 2000개 아미노산, 약 360개 아미노산 내지 약 1500개 아미노산, 약 360개 아미노산 내지 약 1000개 아미노산, 약 360개 아미노산 내지 약 950개 아미노산, 약 360개 아미노산 내지 약 900개 아미노산, 약 360개 아미노산 내지 약 850개 아미노산, 약 360개 아미노산 내지 약 800개 아미노산, 약 360개 아미노산 내지 약 750개 아미노산, 약 360개 아미노산 내지 약 700개 아미노산, 약 360개 아미노산 내지 약 650개 아미노산, 약 360개 아미노산 내지 약 600개 아미노산, 약 360개 아미노산 내지 약 550개 아미노산, 약 360개 아미노산 내지 약 500개 아미노산, 약 360개 아미노산 내지 약 480개 아미노산, 약 360개 아미노산 내지 약 460개 아미노산, 약 360개 아미노산 내지 약 440개 아미노산, 약 360개 아미노산 내지 약 420개 아미노산, 약 360개 아미노산 내지 약 400개 아미노산, 약 360개 아미노산 내지 약 380개 아미노산, 약 380개 아미노산 내지 약 3000개 아미노산, 약 380개 아미노산 내지 약 2500개 아미노산, 약 380개 아미노산 내지 약 2000개 아미노산, 약 380개 아미노산 내지 약 1500개 아미노산, 약 380개 아미노산 내지 약 1000개 아미노산, 약 380개 아미노산 내지 약 950개 아미노산, 약 380개 아미노산 내지 약 900개 아미노산, 약 380개 아미노산 내지 약 850개 아미노산, 약 380개 아미노산 내지 약 800개 아미노산, 약 380개 아미노산 내지 약 750개 아미노산, 약 380개 아미노산 내지 약 700개 아미노산, 약 380개 아미노산 내지 약 650개 아미노산, 약 380개 아미노산 내지 약 600개 아미노산, 약 380개 아미노산 내지 약 550개 아미노산, 약 380개 아미노산 내지 약 500개 아미노산, 약 380개 아미노산 내지 약 480개 아미노산, 약 380개 아미노산 내지 약 460개 아미노산, 약 380개 아미노산 내지 약 440개 아미노산, 약 380개 아미노산 내지 약 420개 아미노산, 약 380개 아미노산 내지 약 400개 아미노산, 약 400개 아미노산 내지 약 3000개 아미노산, 약 400개 아미노산 내지 약 2500개 아미노산, 약 400개 아미노산 내지 약 2000개 아미노산, 약 400개 아미노산 내지 약 1500개 아미노산, 약 400개 아미노산 내지 약 1000개 아미노산, 약 400개 아미노산 내지 약 950개 아미노산, 약 400개 아미노산 내지 약 900개 아미노산, 약 400개 아미노산 내지 약 850개 아미노산, 약 400개 아미노산 내지 약 800개 아미노산, 약 400개 아미노산 내지 약 750개 아미노산, 약 400개 아미노산 내지 약 700개 아미노산, 약 400개 아미노산 내지 약 650개 아미노산, 약 400개 아미노산 내지 약 600개 아미노산, 약 400개 아미노산 내지 약 550개 아미노산, 약 400개 아미노산 내지 약 500개 아미노산, 약 400개 아미노산 내지 약 480개 아미노산, 약 400개 아미노산 내지 약 460개 아미노산, 약 400개 아미노산 내지 약 440개 아미노산, 약 400개 아미노산 내지 약 420개 아미노산, 약 420개 아미노산 내지 약 3000개 아미노산, 약 420개 아미노산 내지 약 2500개 아미노산, 약 420개 아미노산 내지 약 2000개 아미노산, 약 420개 아미노산 내지 약 1500개 아미노산, 약 420개 아미노산 내지 약 1000개 아미노산, 약 420개 아미노산 내지 약 950개 아미노산, 약 420개 아미노산 내지 약 900개 아미노산, 약 420개 아미노산 내지 약 850개 아미노산, 약 420개 아미노산 내지 약 800개 아미노산, 약 420개 아미노산 내지 약 750개 아미노산, 약 420개 아미노산 내지 약 700개 아미노산, 약 420개 아미노산 내지 약 650개 아미노산, 약 420개 아미노산 내지 약 600개 아미노산, 약 420개 아미노산 내지 약 550개 아미노산, 약 420개 아미노산 내지 약 500개 아미노산, 약 420개 아미노산 내지 약 480개 아미노산, 약 420개 아미노산 내지 약 460개 아미노산, 약 420개 아미노산 내지 약 440개 아미노산, 약 440개 아미노산 내지 약 3000개 아미노산, 약 440개 아미노산 내지 약 2500개 아미노산, 약 440개 아미노산 내지 약 2000개 아미노산, 약 440개 아미노산 내지 약 1500개 아미노산, 약 440개 아미노산 내지 약 1000개 아미노산, 약 440개 아미노산 내지 약 950개 아미노산, 약 440개 아미노산 내지 약 900개 아미노산, 약 440개 아미노산 내지 약 850개 아미노산, 약 440개 아미노산 내지 약 800개 아미노산, 약 440개 아미노산 내지 약 750개 아미노산, 약 440개 아미노산 내지 약 700개 아미노산, 약 440개 아미노산 내지 약 650개 아미노산, 약 440개 아미노산 내지 약 600개 아미노산, 약 440개 아미노산 내지 약 550개 아미노산, 약 440개 아미노산 내지 약 500개 아미노산, 약 440개 아미노산 내지 약 480개 아미노산, 약 440개 아미노산 내지 약 460개 아미노산, 약 460개 아미노산 내지 약 3000개 아미노산, 약 460개 아미노산 내지 약 2500개 아미노산, 약 460개 아미노산 내지 약 2000개 아미노산, 약 460개 아미노산 내지 약 1500개 아미노산, 약 460개 아미노산 내지 약 1000개 아미노산, 약 460개 아미노산 내지 약 950개 아미노산, 약 460개 아미노산 내지 약 900개 아미노산, 약 460개 아미노산 내지 약 850개 아미노산, 약 460개 아미노산 내지 약 800개 아미노산, 약 460개 아미노산 내지 약 750개 아미노산, 약 460개 아미노산 내지 약 700개 아미노산, 약 460개 아미노산 내지 약 650개 아미노산, 약 460개 아미노산 내지 약 600개 아미노산, 약 460개 아미노산 내지 약 550개 아미노산, 약 460개 아미노산 내지 약 500개 아미노산, 약 460개 아미노산 내지 약 480개 아미노산, 약 480개 아미노산 내지 약 3000개 아미노산, 약 480개 아미노산 내지 약 2500개 아미노산, 약 480개 아미노산 내지 약 2000개 아미노산, 약 480개 아미노산 내지 약 1500개 아미노산, 약 480개 아미노산 내지 약 1000개 아미노산, 약 480개 아미노산 내지 약 950개 아미노산, 약 480개 아미노산 내지 약 900개 아미노산, 약 480개 아미노산 내지 약 850개 아미노산, 약 480개 아미노산 내지 약 800개 아미노산, 약 480개 아미노산 내지 약 750개 아미노산, 약 480개 아미노산 내지 약 700개 아미노산, 약 480개 아미노산 내지 약 650개 아미노산, 약 480개 아미노산 내지 약 600개 아미노산, 약 480개 아미노산 내지 약 550개 아미노산, 약 480개 아미노산 내지 약 500개 아미노산, 약 500개 아미노산 내지 약 3000개 아미노산, 약 500개 아미노산 내지 약 2500개 아미노산, 약 500개 아미노산 내지 약 2000개 아미노산, 약 500개 아미노산 내지 약 1500개 아미노산, 약 500개 아미노산 내지 약 1000개 아미노산, 약 500개 아미노산 내지 약 950개 아미노산, 약 500개 아미노산 내지 약 900개 아미노산, 약 500개 아미노산 내지 약 850개 아미노산, 약 500개 아미노산 내지 약 800개 아미노산, 약 500개 아미노산 내지 약 750개 아미노산, 약 500개 아미노산 내지 약 700개 아미노산, 약 500개 아미노산 내지 약 650개 아미노산, 약 500개 아미노산 내지 약 600개 아미노산, 약 500개 아미노산 내지 약 550개 아미노산, 약 550개 아미노산 내지 약 3000개 아미노산, 약 550개 아미노산 내지 약 2500개 아미노산, 약 550개 아미노산 내지 약 2000개 아미노산, 약 550개 아미노산 내지 약 1500개 아미노산, 약 550개 아미노산 내지 약 1000개 아미노산, 약 550개 아미노산 내지 약 950개 아미노산, 약 550개 아미노산 내지 약 900개 아미노산, 약 550개 아미노산 내지 약 850개 아미노산, 약 550개 아미노산 내지 약 800개 아미노산, 약 550개 아미노산 내지 약 750개 아미노산, 약 550개 아미노산 내지 약 700개 아미노산, 약 550개 아미노산 내지 약 650개 아미노산, 약 550개 아미노산 내지 약 600개 아미노산, 약 600개 아미노산 내지 약 3000개 아미노산, 약 600개 아미노산 내지 약 2500개 아미노산, 약 600개 아미노산 내지 약 2000개 아미노산, 약 600개 아미노산 내지 약 1500개 아미노산, 약 600개 아미노산 내지 약 1000개 아미노산, 약 600개 아미노산 내지 약 950개 아미노산, 약 600개 아미노산 내지 약 900개 아미노산, 약 600개 아미노산 내지 약 850개 아미노산, 약 600개 아미노산 내지 약 800개 아미노산, 약 600개 아미노산 내지 약 750개 아미노산, 약 600개 아미노산 내지 약 700개 아미노산, 약 600개 아미노산 내지 약 650개 아미노산, 약 650개 아미노산 내지 약 3000개 아미노산, 약 650개 아미노산 내지 약 2500개 아미노산, 약 650개 아미노산 내지 약 2000개 아미노산, 약 650개 아미노산 내지 약 1500개 아미노산, 약 650개 아미노산 내지 약 1000개 아미노산, 약 650개 아미노산 내지 약 950개 아미노산, 약 650개 아미노산 내지 약 900개 아미노산, 약 650개 아미노산 내지 약 850개 아미노산, 약 650개 아미노산 내지 약 800개 아미노산, 약 650개 아미노산 내지 약 750개 아미노산, 약 650개 아미노산 내지 약 700개 아미노산, 약 700개 아미노산 내지 약 3000개 아미노산, 약 700개 아미노산 내지 약 2500개 아미노산, 약 700개 아미노산 내지 약 2000개 아미노산, 약 700개 아미노산 내지 약 1500개 아미노산, 약 700개 아미노산 내지 약 1000개 아미노산, 약 700개 아미노산 내지 약 950개 아미노산, 약 700개 아미노산 내지 약 900개 아미노산, 약 700개 아미노산 내지 약 850개 아미노산, 약 700개 아미노산 내지 약 800개 아미노산, 약 700개 아미노산 내지 약 750개 아미노산, 약 750개 아미노산 내지 약 3000개 아미노산, 약 750개 아미노산 내지 약 2500개 아미노산, 약 750개 아미노산 내지 약 2000개 아미노산, 약 750개 아미노산 내지 약 1500개 아미노산, 약 750개 아미노산 내지 약 1000개 아미노산, 약 750개 아미노산 내지 약 950개 아미노산, 약 750개 아미노산 내지 약 900개 아미노산, 약 750개 아미노산 내지 약 850개 아미노산, 약 750개 아미노산 내지 약 800개 아미노산, 약 800개 아미노산 내지 약 3000개 아미노산, 약 800개 아미노산 내지 약 2500개 아미노산, 약 800개 아미노산 내지 약 2000개 아미노산, 약 800개 아미노산 내지 약 1500개 아미노산, 약 800개 아미노산 내지 약 1000개 아미노산, 약 800개 아미노산 내지 약 950개 아미노산, 약 800개 아미노산 내지 약 900개 아미노산, 약 800개 아미노산 내지 약 850개 아미노산, 약 850개 아미노산 내지 약 3000개 아미노산, 약 850개 아미노산 내지 약 2500개 아미노산, 약 850개 아미노산 내지 약 2000개 아미노산, 약 850개 아미노산 내지 약 1500개 아미노산, 약 850개 아미노산 내지 약 1000개 아미노산, 약 850개 아미노산 내지 약 950개 아미노산, 약 850개 아미노산 내지 약 900개 아미노산, 약 900개 아미노산 내지 약 3000개 아미노산, 약 900개 아미노산 내지 약 2500개 아미노산, 약 900개 아미노산 내지 약 2000개 아미노산, 약 900개 아미노산 내지 약 1500개 아미노산, 약 900개 아미노산 내지 약 1000개 아미노산, 약 900개 아미노산 내지 약 950개 아미노산, 약 950개 아미노산 내지 약 3000개 아미노산, 약 950개 아미노산 내지 약 2500개 아미노산, 약 950개 아미노산 내지 약 2000개 아미노산, 약 950개 아미노산 내지 약 1500개 아미노산, 약 950개 아미노산 내지 약 1000개 아미노산, 약 1000개 아미노산 내지 약 3000개 아미노산, 약 1000개 아미노산 내지 약 2500개 아미노산, 약 1000개 아미노산 내지 약 2000개 아미노산, 약 1000개 아미노산 내지 약 1500개 아미노산, 약 1500개 아미노산 내지 약 3000개 아미노산, 약 1500개 아미노산 내지 약 2500개 아미노산, 약 1500개 아미노산 내지 약 2000개 아미노산, 약 2000개 아미노산 내지 약 3000개 아미노산, 약 2000개 아미노산 내지 약 2500개 아미노산, 또는 약 2500개 아미노산 내지 약 3000개 아미노산일 수 있다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인(예를 들어, 본원에 기재된 임의의 제1 표적-결합 도메인)과 가용성 조직 인자 도메인(예를 들어, 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인)은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인(예를 들어, 본원에 기재된 임의의 예시적인 제1 표적-결합 도메인)과 가용성 조직 인자 도메인(예를 들어, 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인) 사이에 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 링커 서열)을 추가로 포함한다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인(예를 들어, 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인)과 친화도 도메인의 쌍의 제1 도메인(예를 들어, 본원에 기재된 임의의 예시적인 친화도 도메인의 쌍의 임의의 예시적인 제1 도메인)은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인(예를 들어, 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인)과 친화도 도메인의 쌍의 제1 도메인(예를 들어, 본원에 기재된 임의의 예시적인 친화도 도메인의 쌍의 임의의 예시적인 제1 도메인) 사이에 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 링커 서열)을 추가로 포함한다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인의 쌍의 제2 도메인(예를 들어, 본원에 기재된 임의의 예시적인 친화도 도메인의 쌍의 임의의 예시적인 제2 도메인)과 제2 표적-결합 도메인(예를 들어, 본원에 기재된 임의의 예시적인 제2 표적-결합 도메인)은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인의 쌍의 제2 도메인(예를 들어, 본원에 기재된 임의의 예시적인 친화도 도메인의 쌍의 임의의 예시적인 제2 도메인)과 제2 표적-결합 도메인(예를 들어, 본원에 기재된 임의의 예시적인 제2 표적-결합 도메인) 사이에 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 링커 서열)을 추가로 포함한다.
임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 하나 이상의(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개의) 추가 표적-결합 도메인(들)(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)을 추가로 포함하며, 이때, 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나는 가용성 조직 인자 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 가용성 조직 인자 도메인)과 친화도 도메인의 쌍의 제1 도메인(예를 들어, 본원에 기재된 임의의 예시적인 친화도 도메인의 쌍의 임의의 예시적인 제1 도메인) 사이에 위치한다. 일부 구현예에서, 제1 키메라 폴리펩타이드는 가용성 조직 인자 도메인(예를 들어, 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인)과 하나 이상의 추가 표적-결합 도메인 중 적어도 하나(들)(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인) 사이에 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 링커 서열), 및/또는 하나 이상의 추가 표적-결합 도메인 중 적어도 하나(들)(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)와 친화도 도메인의 쌍의 제1 도메인(예를 들어, 본원에 기재된 임의의 예시적인 친화도 도메인의 쌍의 본원에 기재된 임의의 예시적인 제1 도메인) 사이에 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 링커 서열)을 추가로 포함할 수 있다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 제1 키메라 폴리펩타이드의 N-말단 및/또는 C-말단 단부에 하나 이상의(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개의) 추가 표적-결합 도메인을 추가로 포함한다. 일부 구현예에서, 하나 이상의 추가 표적-결합 도메인 중 적어도 하나(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)는 제1 키메라 폴리펩타이드 내의 친화도 도메인의 쌍의 제1 도메인(예를 들어, 본원에 기재된 임의의 예시적인 친화도 도메인의 쌍의 본원에 기재된 임의의 예시적인 제1 도메인)에 직접적으로 인접해 있다. 일부 구현예에서, 제1 키메라 폴리펩타이드는 하나 이상의 추가 표적-결합 도메인 중 적어도 하나(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)와 친화도 도메인의 쌍의 제1 도메인(예를 들어, 본원에 기재된 임의의 예시적인 친화도 도메인의 쌍의 본원에 기재된 임의의 예시적인 제1 도메인) 사이에 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 링커 서열)을 추가로 포함한다. 일부 구현예에서, 하나 이상의 추가 표적-결합 도메인 중 적어도 하나(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)는 제1 키메라 폴리펩타이드 내의 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)에 직접적으로 인접해 있다. 일부 구현예에서, 제1 키메라 폴리펩타이드는 하나 이상의 추가 표적-결합 도메인 중 적어도 하나(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)와 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인) 사이에 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 링커 서열)을 추가로 포함한다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 하나 이상의 추가 표적-결합 도메인 중 적어도 하나(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)는 제1 키메라 폴리펩타이드의 N-말단 및/또는 C-말단에 배치되고, 하나 이상의 추가 표적-결합 도메인 중 적어도 하나(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)는 제1 키메라 폴리펩타이드 내의 가용성 조직 인자 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 가용성 조직 인자 도메인)과 친화도 도메인의 쌍의 제1 도메인(예를 들어, 본원에 기재된 임의의 예시적인 친화도 도메인의 쌍의 임의의 예시적인 제1 도메인) 사이에 위치한다. 일부 구현예에서, N-말단에 배치된 하나 이상의 추가 표적-결합 도메인의 적어도 하나의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)은 제1 키메라 폴리펩타이드 내의 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인) 또는 친화도 도메인의 쌍의 제1 도메인(예를 들어, 본원에 기재된 임의의 예시적인 친화도 도메인의 쌍의 본원에 기재된 임의의 예시적인 제1 도메인)에 직접적으로 인접해 있다. 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드 내의 적어도 하나의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)과 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인) 또는 친화도 도메인의 쌍의 제1 도메인(예를 들어, 본원에 기재된 임의의 예시적인 친화도 도메인의 쌍의 본원에 기재된 임의의 예시적인 제1 도메인) 사이에 배치된 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 링커 서열)을 추가로 포함한다. 일부 구현예에서, C-말단에 배치된 하나 이상의 추가 표적-결합 도메인의 적어도 하나의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)은 제1 키메라 폴리펩타이드 내의 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인) 또는 친화도 도메인의 쌍의 제1 도메인(예를 들어, 본원에 기재된 임의의 예시적인 친화도 도메인의 쌍의 임의의 예시적인 제1 도메인)에 직접적으로 인접해 있다. 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드 내의 적어도 하나의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)과 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인) 또는 친화도 도메인의 쌍의 제1 도메인(예를 들어, 본원에 기재된 임의의 예시적인 친화도 도메인의 쌍의 본원에 기재된 임의의 예시적인 제1 도메인) 사이에 배치된 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 링커 서열)을 추가로 포함한다. 일부 구현예에서, 가용성 조직 인자 도메인(예를 들어, 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인)과 친화도 도메인의 쌍의 제1 도메인(예를 들어, 본원에 기재된 임의의 제1 도메인 또는 본원에 기재된 임의의 예시적인 친화도 도메인의 쌍) 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)는 가용성 조직 인자 도메인 및/또는 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있다. 일부 구현예에서, 제1 키메라 폴리펩타이드는 (i) 가용성 조직 인자 도메인(예를 들어, 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인)과, 상기 가용성 조직 인자 도메인(예를 들어, 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인)과 친화도 도메인의 쌍의 제1 도메인(예를 들어, 본원에 기재된 임의의 예시적인 친화도 도메인의 쌍의 임의의 예시적인 제1 도메인) 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인) 사이에, 및/또는 (ii) 친화도 도메인의 쌍의 제1 도메인과, 가용성 조직 인자 도메인과 상기 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나 위치 사이에 배치된 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 링커 서열)을 추가로 포함한다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드의 N-말단 단부 및/또는 C-말단 단부에 하나 이상의(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개의) 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)을 추가로 포함한다. 일부 구현예에서, 하나 이상의 추가 표적-결합 도메인 중 적어도 하나(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)는 제2 키메라 폴리펩타이드 내의 친화도 도메인의 쌍의 제2 도메인(예를 들어, 본원에 기재된 임의의 예시적인 친화도 도메인의 쌍의 임의의 예시적인 제2 도메인)에 직접적으로 인접해 있다. 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드 내의 하나 이상의 추가 표적-결합 도메인 중 적어도 하나(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)와 친화도 도메인 쌍의 제2 도메인(예를 들어, 본원에 기재된 임의의 예시적인 친화도 도메인 쌍의 본원에 기재된 임의의 제2 도메인) 사이에 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 링커 서열)을 추가로 포함한다. 일부 구현예에서, 하나 이상의 추가 표적-결합 도메인 중 적어도 하나(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)는 제2 키메라 폴리펩타이드 내의 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 표적-결합 도메인)에 직접적으로 인접해 있다. 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드 내에 하나 이상의 추가 표적-결합 도메인 중 적어도 하나(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)와 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인) 사이에 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 링커 서열)을 추가로 포함한다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 2개 이상(예를 들어, 3개 이상, 4개 이상, 5개 이상, 6개 이상, 7개 이상, 8개 이상, 9개 이상, 또는 10개 이상)의 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인은 동일한 항원에 특이적으로 결합한다. 일부 구현예에서, 2개 이상(예를 들어, 3개 이상, 4개 이상, 5개 이상, 6개 이상, 7개 이상, 8개 이상, 9개 이상, 또는 10개 이상)의 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합한다. 일부 구현예에서, 2개 이상(예를 들어, 3개 이상, 4개 이상, 5개 이상, 6개 이상, 7개 이상, 8개 이상, 9개 이상, 또는 10개 이상)의 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인은 동일한 아미노산 서열을 포함한다. 일부 구현예에서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 각각 동일한 항원에 특이적으로 결합한다. 일부 구현예에서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 각각 동일한 에피토프에 특이적으로 결합한다. 일부 구현예에서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 각각 동일한 아미노산 서열을 포함한다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인은 상이한 항원에 특이적으로 결합한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인 중 하나 이상(예를 들어, 2개 이상, 3개 이상, 4개 이상, 5개 이상, 6개 이상, 7개 이상, 8개 이상, 9개 이상, 또는 10개 이상)은 항원-결합 도메인이다. 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 추가 표적-결합 도메인은 각각 항원-결합 도메인(예를 들어, scFv 또는 단일-도메인 항체)이다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 하나 이상(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개)의 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인), 및 하나 이상의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 하기의 군으로부터 선택되는 표적에 특이적으로 결합한다: CD16a, CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL-1, VEGF, IL-6R, IL-4, IL-10, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKP30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, IL-1에 대한 수용체, IL-2에 대한 수용체, IL-3에 대한 수용체, IL-7에 대한 수용체, IL-8에 대한 수용체, IL-10에 대한 수용체, IL-12에 대한 수용체, IL-15에 대한 수용체, IL-17에 대한 수용체, IL-18에 대한 수용체, IL-21에 대한 수용체, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, CD122에 대한 수용체, 및 CD28에 대한 수용체.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 하나 이상의 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 및 하나 이상의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 가용성 인터류킨 또는 사이토카인 단백질이다. 가용성 인터류킨 단백질 및 가용성 사이토카인 단백질의 비제한적인 예는 하기를 포함한다: IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, 및 SCF.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 하나 이상의 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 및 하나 이상의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 가용성 인터류킨 또는 사이토카인 수용체이다. 가용성 인터류킨 수용체 및 가용성 사이토카인 수용체의 비제한적인 예는 하기를 포함한다: 가용성 TGF-β 수용체 II(TGF-βRII), 가용성 TGF-βRIII, 가용성 NKG2D, 가용성 NKP30, 가용성 NKp44, 가용성 NKp46, 가용성 DNAM1, scMHCI, scMHCII, scTCR, 가용성 CD155, 가용성 CD122, 가용성 CD3, 또는 가용성 CD28.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인(예를 들어, 본원에 기재된 임의의 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재된 임의의 표적-결합 도메인), 및 하나 이상의 추가 표적-결합 도메인(예를 들어, 본원에 기재된 임의의 표적-결합 도메인)은 각각 독립적으로 하기의 군으로부터 선택되는 표적에 특이적으로 결합할 수 있다: CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKp30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, 및 CD122에 대한 수용체.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인(예를 들어, 본원에 기재된 임의의 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재된 임의의 표적-결합 도메인), 및 하나 이상의 추가 결합 도메인(예를 들어, 본원에 기재된 임의의 표적-결합) 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 단백질이다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인터류킨 또는 사이토카인 단백질은 하기의 군으로부터 선택된다: IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, 및 SCF.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 수용체이다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 수용체는 가용성 TGF-β 수용체 II(TGF-βRII), 가용성 TGF-βRIII, TNFα에 대한 가용성 수용체, IL-4에 대한 가용성 수용체, 또는 IL-10에 대한 가용성 수용체.
다중-사슬 키메라 폴리펩타이드- B형
NK 세포 활성화제의 비제한적인 예는 다중-사슬 키메라 폴리펩타이드로서, (a) 각각 (i) 제1 표적-결합 도메인; (ii) Fc 도메인; 및 (iii) 친화도 도메인 쌍의 제1 도메인을 포함하는 제1 및 제2 키메라 폴리펩타이드; 및 (b) 각각 (i) 친화도 도메인 쌍의 제2 도메인; 및 (ii) 제2 표적-결합 도메인을 포함하는 제3 및 제4 키메라 폴리펩타이드를 포함하며, 상기 제1 및 제2 키메라 폴리펩타이드와 제3 및 제4 키메라 폴리펩타이드는 친화도 도메인 쌍의 제1 도메인과 제2 도메인의 결합을 통해 회합되고, 제1 키메라 폴리펩타이드와 제2 키메라 폴리펩타이드는 이들의 Fc 도메인을 통해 회합된다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인(예를 들어, 본원에 기재된 임의의 제1 표적-결합 도메인)과 Fc 도메인(예를 들어, 본원에 기재된 임의의 예시적인 Fc 도메인)은 제1 및 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 및 제2 키메라 폴리펩타이드는 상기 제1 및 제2 키메라 폴리펩타이드에서 제1 표적-결합 도메인(예를 들어, 본원에 기재된 임의의 예시적인 제1 표적-결합 도메인)과 Fc 도메인(예를 들어, 본원에 기재된 임의의 예시적인 Fc 도메인) 사이에 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 링커 서열)을 추가로 포함한다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, Fc 도메인(예를 들어, 본원에 기재된 임의의 예시적인 Fc 도메인)과 친화도 도메인 쌍의 제1 도메인(예를 들어, 본원에 기재된 임의의 예시적인 친화도 도메인 쌍의 임의의 예시적인 제1 도메인)은 제1 및 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 및 제2 키메라 폴리펩타이드는 상기 제1 및 제2 키메라 폴리펩타이드에서 Fc 도메인(예를 들어, 본원에 기재된 임의의 예시적인 Fc 도메인)과 친화도 도메인 쌍의 제1 도메인(예를 들어, 본원에 기재된 임의의 예시적인 친화도 도메인 쌍의 임의의 예시적인 제1 도메인) 사이에 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 링커 서열)을 추가로 포함한다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인 쌍의 제2 도메인(예를 들어, 본원에 기재된 임의의 예시적인 친화도 도메인 쌍의 임의의 예시적인 제2 도메인)과 제2 표적-결합 도메인(예를 들어, 본원에 기재된 임의의 예시적인 제2 표적-결합 도메인)은 제3 및 제4 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제3 및 제4 키메라 폴리펩타이드는 상기 제3 및 제4 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인(예를 들어, 본원에 기재된 임의의 예시적인 친화도 도메인 쌍의 임의의 예시적인 제2 도메인)과 제2 표적-결합 도메인(예를 들어, 본원에 기재된 임의의 예시적인 제2 표적-결합 도메인) 사이에 링커 서열(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 링커 서열)을 추가로 포함한다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 항원에 특이적으로 결합한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 상이한 항원에 특이적으로 결합한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 항원-결합 도메인(예를 들어, 본원에 기재된 임의의 예시적인 제2 표적-결합 도메인)이다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 항원-결합 도메인(예를 들어, 본원에 기재된 임의의 예시적인 제2 표적-결합 도메인)이다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 항원-결합 도메인(예를 들어, 본원에 기재된 임의의 예시적인 제2 표적-결합 도메인)은 scFv 또는 단일 도메인 항체를 포함한다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)과 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인) 중 하나 또는 둘 다는 하기의 군으로부터 선택되는 표적에 특이적으로 결합한다: CD16a, CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL-1, VEGF, IL-6R, IL-4, IL-10, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKp30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, IL-1에 대한 수용체, IL-2에 대한 수용체, IL-3에 대한 수용체, IL-7에 대한 수용체, IL-8에 대한 수용체, IL-10에 대한 수용체, IL-12에 대한 수용체, IL-15에 대한 수용체, IL-17에 대한 수용체, IL-18에 대한 수용체, IL-21에 대한 수용체, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, CD122에 대한 수용체, 및 CD28에 대한 수용체.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)과 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인) 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 단백질이다. 가용성 인터류킨 단백질 및 가용성 사이토카인 단백질의 비제한적인 예는 하기를 포함한다: IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, 및 SCF.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인과 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인) 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 단백질이다. 가용성 인터류킨 수용체 및 가용성 사이토카인 수용체의 비제한적인 예는 하기를 포함한다: 가용성 TGF-β 수용체 II(TGF-βRII), 가용성 TGF-βRIII, 가용성 NKG2D, 가용성 NKp30, 가용성 NKp44, 가용성 NKp46, 가용성 DNAM1, scMHCI, scMHCII, scTCR, 가용성 CD155, 가용성 CD122, 가용성 CD3, 또는 가용성 CD28.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로 하기의 군으로부터 선택되는 표적에 특이적으로 결합할 수 있다: CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKp30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, 및 CD122에 대한 수용체.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 단백질이다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인터류킨 또는 사이토카인 단백질은 하기의 군으로부터 선택된다: IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, 및 SCF.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 수용체이다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 수용체는 가용성 TGF-β 수용체 II(TGF-βRII), 가용성 TGF-βRIII, TNFα에 대한 가용성 수용체, IL-4에 대한 가용성 수용체, 또는 IL-10에 대한 가용성 수용체.
조직 인자
인간 조직 인자는 3개의 도메인을 함유하는 263개-아미노산 막관통 단백질이다: (1) 219-아미노산 N-말단 세포외 도메인(잔기 1-219); (2) 22-아미노산 막관통 도메인(잔기 220-242); 및 (3) 21-아미노산 세포질 C-말단 테일(tail)(잔기 242-263)((UniProtKB 식별 번호: P13726). 세포질 테일은 Ser253 및 Ser258에서 2개의 인산화 부위 및 Cys245에서 하나의 S-팔미토일화 부위를 함유한다. 세포질 도메인의 결실 또는 돌연변이는 조직 인자 응고 활성에 영향을 미치는 것으로 밝혀지지 않았다. 조직 인자는 Cys245에서 단백질의 세포내 도메인에 하나의 S-팔미토일화 부위를 갖는다. Cys245는 세포내 도메인의 아미노산 말단에 그리고 막 표면에 근접하게 위치한다. 조직 인자 막관통 도메인은 단일-경유(단일-spanning) α-나선으로 이루어진다.
2개의 피브로넥틴 III형 도메인으로 이루어진 조직 인자의 세포외 도메인은 6-아미노산 링커를 통해 막관통 도메인에 연결된다. 이 링커는 조직 인자 세포외 도메인을 이의 막관통 도메인 및 세포질 도메인으로부터 디커플링시키기 위해 형태적 가요성(flexibility)을 제공한다. 각각의 조직 인자 피브로넥틴 III형 모듈(module)은 3개의 역평행 β-가닥을 함유하는 상단(top) 시트 도메인 및 4개의 β-가닥을 함유하는 하단(bottom) 시트를 갖는 2개의 중첩 β 시트로 이루어진다. β-가닥은 가닥 βA와 βB, βC와 βD, 및 βE와 βF 사이에서 β-루프에 의해 연결되며, 이들은 모두 2개의 모듈에서 형태가 보존된다. β-가닥을 연결하는 3개의 짧은 α-나선 세그먼트(segment)가 존재한다. 조직 인자의 독특한 특질은 가닥 β10과 가닥 β11 사이의 17-아미노산 β-헤어핀이고, 이는 피브로넥틴 슈퍼패밀리의 공통 요소가 아니다. N-말단 도메인은 또한, C-말단 도메인에 존재하지 않고 조직 인자에 독특한 β6F와 β7G 사이에 12-아미노산 루프를 함유한다. 이러한 피브로넥틴 III형 도메인 구조는 단백질 폴드(fold)의 면역글로불린-유사 패밀리의 특질이고, 광범위하게 다양한 세포외 단백질 중에서 보존된다.
자이모겐 FVII은 제한된 단백질분해에 의해 FVIIa로 신속하게 전환되어, 일단 이것이 조직에 결합하면 활성 조직 인자-FVIIa 복합체를 형성한다. 대략 0.1 nM(1%의 혈장 FVII)의 농도에서 효소로서 순환되는 FVIIa는 또한, 조직 인자에 직접적으로 결합할 수 있다. 조직 인자-FVIIa 복합체 상에서 조직 인자와 FVIIa 사이의 알로스테릭(allosteric) 상호작용은 FVIIa의 효소적 활성을 크게 증가시킨다: 작은 발색성(chromogenic) 펩티딜 기질의 가수분해 속도에서 대략 20-배 내지 100-배 증가, 및 천연 거대분자 기질 FIX 및 FX의 활성화 속도에서 거의 100만-배 증가. 조직 인자에의 결합 시 FVIIa의 활성 부위의 알로스테릭 활성화와 협력하여, 인지질 이중층 상에서 조직 인자-FVIIa 복합체의 형성(즉, 막 표면 상에서 포스파티딜-L-세린의 노출 시)은 FIX 또는 FX 활성화 속도를 Ca2+-의존적 방식으로 추가 1,000-배 증가시킨다. 자유 FVIIa와 비교하여 조직 인자-FVIIa-인지질 복합체에 의한 FX 활성화의 대략 100만-배 전체적 증가는 응고 캐스케이드에 대한 중요한 조절 포인트이다.
FVII는 N-말단 γ-카르복시글루타메이트-풍부(GLA) 도메인, 2개의 표피 성장 인자-유사 도메인(EGF1 및 EFG2), 및 C-말단 세린 프로테아제 도메인과 함께 406개 아미노산 잔기로 구성된 약 50 kDa, 단일-사슬 폴리펩타이드이다. FVII는 EGF2와 프로테아제 도메인 사이의 짧은 링커 영역에서 Ile-154-Arg152 결합의 특이적인 단백질분해 절단에 의해 FVIIa로 활성화된다. 이러한 절단은 Cys135 및 Cys262의 단일 이황화 결합에 의해 함께 보유되는 경쇄 및 중쇄를 초래한다. FVIIa는 이의 N-말단 GLA-도메인을 통해 Ca2+-의존적 방식으로 인지질 막에 결합한다. GLA 도메인에 대해 바로 C-말단에 방향족 스택(stack) 및 2개의 EGF 도메인이 있다. 방향족 스택은 단일 Ca2+ 이온에 결합하는 EGF1 도메인에 GLA를 연결한다. 이 Ca2+-결합 부위의 점유(occupancy)는 FVIIa 아미도분해(amidolytic) 활성 및 조직 인자 회합을 증가시킨다. 촉매적 트리아드(triad)는 His193, Asp242, 및 Ser344로 구성되고, FVIIa 프로테아제 도메인 내에서 단일 Ca2+ 이온의 결합은 이의 촉매적 활성에 중요하다. FVII 내지 FVIIa의 단백질분해 활성화는 Ile153에서 새로 형성된 아미노 말단을 유리시켜(free) 다시 접히게 하고, Asp343의 카르복실레이트와 염 브릿지를 형성하는 활성화 포켓 내로 삽입되어 옥시음이온 정공(oxyanion hole)을 형성한다. 이 염 브릿지의 형성은 FVIIa 활성에 중요하다. 그러나, 옥시음이온 정공 형성은 단백질분해 활성화 시 자유(free) FVIIa에서 발생하지 않는다. 그 결과, FVIIa는 혈장 프로테아제 저해제에 의해 불량하게 인식되는 자이모겐-유사 상태로 순환되어, 이것이 대략 90분의 반감기로 순환할 수 있게 한다.
막 표면 위에서 FVIIa 활성 부위의 조직 인자-매개 위치화는 FVIIa가 동족 기질로 향하게 하는 데 중요하다. 자유 FVIIa는 막 표면 위의 약 80 Å에 위치한 이의 활성 부위와 함께 막에 결합될 때 안정하고 연장된 구조를 채택한다. FVIIa가 조직 인자에 결합할 때, FVa 활성 부위는 막에 약 6 Å 더 근접하게 재위치된다. 이러한 조절은 표적 기질 절단 부위와 함께 FVIIa 촉매적 트리아드의 적절한 정렬에 일조할 수 있다. GLA-도메인리스(domainless) FVIIa를 사용하여, 활성 부위는 막 위의 유사한 거리에서 여전히 위치해 있는 것으로 나타났으며, 이는 조직 인자가 심지어 FVIIa-막 상호작용의 부재 하에 FVIIa 활성 부위 위치화를 완전히 지지할 수 있음을 실증한다. 추가 데이터는, 조직 인자 세포외 도메인이 일부 방식으로 막 표면에 부착되는(tethered) 한, 완전 FVIIa 단백질분해 활성을 뒷받침하였음을 나타내었다. 그러나, FVIIa의 활성 부위를 막 표면 위에서 80 Å보다 더 크게 상승시키는 것은, 조직 인자-FVIIa 복합체가 FX를 활성화시키는 능력을 크게 감소시켰으나, 조직 인자-FVIIa 아미도분해 활성은 저하시키지 않았다.
알라닌 스캐닝 돌연변이형성(mutagenesis)은 FVIIa와의 상호작용을 위한 조직 인자 세포외 도메인에서 특이적인 아미노산 측쇄의 역할을 평가하는 데 사용되어 왔다(문헌[Gibbs et al., Biochemistry 33(47): 14003-14010, 1994]; 문헌[Schullek et al., J Biol Chem 269(30): 19399-19403, 1994]). 알라닌 치환은, 알라닌 대체가 FVIIa 결합에 대해 5-배 내지 10-배 더 낮은 친화도를 야기하는 제한된 수의 잔기 위치를 식별하였다. 대부분의 이들 잔기 측쇄는 거대분자 리간드 상호작용과 화합하는 결정 구조 내 용매에 잘-노출되는 것으로 밝혀졌다. FVIIa 리간드-결합 부위는 2개의 모듈 사이의 경계에서 광범위한 영역에 걸쳐 위치한다. C-모듈에서, 돌출형(protruding) B-C 루프 상에 위치한 잔기 Arg135 및 Phe140은 FVIIa와 독립적인 접촉을 제공한다. Leu133은 핑거유사(fingerlike) 구조의 기부(base)에 위치하고, 2개의 모듈 사이의 틈(cleft) 내로 패킹(packed)된다. 이는 Lys20, Thr60, Asp58, 및 Ile22로 구성된 중요한 결합 잔기의 주요 클러스터(cluster)에 연속성(continuity)을 제공한다. Thr60은 단지 부분적으로 용매-노출되고, 리간드와 유의한 접촉을 형성하기보다는 국소적인 구조적 역할을 할 수 있다. 결합 부위는 Glu24 및 Gln110, 그리고 잠재적으로는 더 원거리의 잔기 Val207을 수반하는 모듈간(intermodule) 각도의 오목한(concave) 측면 상으로 연장된다. 결합 영역은 Asp58로부터 Lys48, Lys46, Gln37, Asp44, 및 Trp45에 의해 형성된 볼록한(convex) 표면적 상으로 연장된다. Trp45 및 Asp44은 FVIIa와 독립적으로 상호작용하며, 이는 Trp45 위치에서의 돌연변이 효과가 인접한 Asp44 및 Gln37 측쇄의 국소적인 패킹을 위한 이 측쇄의 구조적 중요성을 반영할 수 있음을 나타낸다. 상호적인 영역은 2개의 표면-노출된 방향족 잔기인 Phe76 및 Tyr78을 추가로 포함하고, 이들 잔기는 N-모듈에서 소수성 클러스터의 일부를 형성한다.
조직 인자-FVIIa의 기지의 생리학적 기질은 FVII, FIX, 및 FX 및 소정의 프로테이나제-활성화된 수용체이다. 돌연변이 분석은, 돌연변이화되었을 때 작은 펩티딜 기질에 대한 완전 FVIIa 아미도분해 활성을 뒷받침하지만 거대분자 기질(즉, FVII, FIX, 및 FX) 활성화를 뒷받침하는 이들의 능력이 부족한 많은 잔기를 식별하였다(문헌[Ruf et al., J Biol Chem 267(31): 22206-22210, 1992]; 문헌[Rufet al., J Biol Chem 267(9): 6375-6381, 1992]; 문헌[Huanget al., J Biol Chem 271(36): 21752-21757, 1996]; 문헌[Kirchhoferet al., Biochemistry 39(25): 7380-7387, 2000]). 잔기 159-165에서의 조직 인자 루프 영역, 및 이러한 가요성 루프 내의 또는 루프에 인접한 잔기는 조직 인자-FVIIa 복합체의 단백질분해 활성에 중요한 것으로 나타났다. 이는, FVIIa 활성 부위로부터 꽤 원거리에 있는 조직 인자의 제안된 기질-결합 부위외(exosite) 영역을 한정한다(define). 미미하게 더 벌키한 잔기 알라닌에 의한 글리신 잔기의 치환은 조직 인자-FVIIa 단백질분해 활성을 유의하게 손상시킨다. 이는, 글리신에 의해 부여되는 가요성이 조직 인자 거대분자 기질 인식을 위해 잔기 159-165의 루프에 중요함을 시사한다.
잔기 Lys165 및 Lys166은 또한, 기질 인식 및 결합에 중요한 것으로 실증되었다. 이들 잔기로부터 알라닌으로의 돌연변이는 조직 인자 보조-인자 기능에서 유의한 저하를 초래한다. Lys165 및 Lys166은 서로로부터 멀리 향하며, 이때 Lys165은 대부분의 조직 인자-FVIIa 구조에서 FVIIa로 향하고, Lys166은 결정 구조에서 기질 결합 부위외 영역으로 향한다. FVIIa의 Lys165과 Gla35 사이의 추정상(putative) 염 브릿지 형성은, FVIIa의 GLA 도메인과의 조직 인자 상호작용이 기질 인식을 조절한다는 개념을 뒷받침할 것이다. 이들 결과는, 조직 인자 엑토도메인의 C-말단 부분이 FIX 및 FX의 GLA-도메인, 가능한 인접한 EGF1 도메인과 직접적으로 상호작용하며, FVIIa GLA-도메인의 존재는 이들 상호작용을 직접적으로 또는 간접적으로 조절할 수 있음을 시사한다.
가용성 조직 인자 도메인
본원에 기재된 임의의 폴리펩타이드, 조성물, 또는 방법의 일부 구현예에서, 가용성 조직 인자 도메인은 신호 서열, 막관통 도메인, 및 세포내 도메인이 결여된 야생형 조직 인자 폴리펩타이드일 수 있다. 일부 예에서, 가용성 조직 인자 도메인은 조직 인자 돌연변이체일 수 있으며, 여기서, 야생형 조직 인자 폴리펩타이드는 신호 서열, 막관통 도메인, 및 세포내 도메인이 결여되어 있고, 선택된 아미노산에서 추가로 변형되었다. 일부 예에서, 가용성 조직 인자 도메인은 가용성 인간 조직 인자 도메인일 수 있다. 일부 예에서, 가용성 조직 인자 도메인은 가용성 마우스 조직 인자 도메인일 수 있다. 일부 예에서, 가용성 조직 인자 도메인은 가용성 래트 조직 인자 도메인일 수 있다. 가용성 인간 조직 인자 도메인, 마우스 가용성 조직 인자 도메인, 래트 가용성 조직 인자 도메인, 및 돌연변이체 가용성 조직 인자 도메인의 비제한적인 예는 하기에 나타나 있다.
예시적인 가용성 인간 조직 인자 도메인(SEQ ID NO: 93)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
가용성 인간 조직 인자 도메인을 인코딩하는 예시적인 핵산(SEQ ID NO: 94)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
예시적인 가용성 마우스 조직 인자 도메인(SEQ ID NO: 95)
agipekafnltwistdfktilewqpkptnytytvqisdrsrnwknkcfsttdtecdltdeivkdvtwayeakvlsvprrnsvhgdgdqlvihgeeppftnapkflpyrdtnlgqpviqqfeqdgrklnvvvkdsltlvrkngtfltlrqvfgkdlgyiityrkgsstgkktnitntnefsidveegvsycffvqamifsrktnqnspgsstvcteqwksflge
예시적인 가용성 래트 조직 인자 도메인(SEQ ID NO: 96)
Agtppgkafnltwistdfktilewqpkptnytytvqisdrsrnwkykctgttdtecdltdeivkdvnwtyearvlsvpwrnsthgketlfgthgeeppftnarkflpyrdtkigqpviqkyeqggtklkvtvkdsftlvrkngtfltlrqvfgndlgyiltyrkdsstgrktntthtneflidvekgvsycffaqavifsrktnhkspesitkcteqwksvlge
예시적인 돌연변이체 가용성 인간 조직 인자 도메인(SEQ ID NO: 97)
SGTTNTVAAYNLTWKSTNFATALEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECALTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVARNNTALSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
예시적인 돌연변이체 가용성 인간 조직 인자 도메인(SEQ ID NO: 98)
SGTTNTVAAYNLTWKSTNFATALEWEPKPVNQVYTVQISTKSGDAKSKCFYTTDTECALTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLAENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVARNNTALSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
일부 구현예에서, 가용성 조직 인자 도메인은 SEQ ID NO: 93, 95, 96, 97, 또는 98과 적어도 70% 동일한, 적어도 72% 동일한, 적어도 74% 동일한, 적어도 76% 동일한, 적어도 78% 동일한, 적어도 80% 동일한, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한 서열을 포함할 수 있다. 일부 구현예에서, 가용성 조직 인자 도메인은 SEQ ID NO: 93, 95, 96, 97, 또는 98의 서열을 포함할 수 있고, 1개 내지 12개의 아미노산(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 10개, 11개, 12개, 13개, 14개, 15개, 16개, 17개, 18개, 19개, 또는 20개의 아미노산)은 이의 N 말단으로부터 제거되고/되거나, 1개 내지 12개의 아미노산(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 10개, 11개, 12개, 13개, 14개, 15개, 16개, 17개, 18개, 19개, 또는 20개의 아미노산)은 이의 C 말단으로부터 제거된다.
당업계에서 이해될 수 있는 바와 같이, 당업자는, 상이한 포유류 종들 사이에서 보존되는 아미노산의 돌연변이는 단백질의 활성 및/또는 구조적 안정성을 저하시킬 가능성이 더 큰 한편, 상이한 포유류 종들 사이에서 보존되지 않는 아미노산의 돌연변이는 단백질의 활성 및/또는 구조적 안정성을 저하시킬 가능성이 더 작음을 이해할 것이다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 가용성 조직 인자 도메인은 인자 VIIa에 결합할 수 없다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 가용성 조직 인자 도메인은 불활성 인자 X를 인자 Xa로 전환시키지 않는다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 다중-사슬 키메라 폴리펩타이드는 포유류에서 혈액 응고를 자극시키지 않는다.
일부 예에서, 가용성 조직 인자 도메인은 가용성 인간 조직 인자 도메인일 수 있다. 일부 구현예에서, 가용성 조직 인자 도메인은 가용성 마우스 조직 인자 도메인일 수 있다. 일부 구현예에서, 가용성 조직 인자 도메인은 가용성 래트 조직 인자 도메인일 수 있다.
일부 예에서, 가용성 조직 인자 도메인은, 성숙한 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서 라이신; 성숙한 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서 이소류신; 성숙한 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서 트립토판; 성숙한 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서 아스파르트산; 성숙한 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서 티로신; 성숙한 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서 아르기닌; 및 성숙한 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서 페닐알라닌 중 하나 이상(예를 들어, 2개, 3개, 4개, 5개, 6개, 또는 7개)을 포함하지 않는다. 일부 구현예에서, 돌연변이체 가용성 조직 인자는 SEQ ID NO: 97 또는 SEQ ID NO: 98의 아미노산 서열을 보유한다.
일부 예에서, 가용성 조직 인자 도메인은 SEQ ID NO: 94와 적어도 70% 동일한, 적어도 72% 동일한, 적어도 74% 동일한, 적어도 76% 동일한, 적어도 78% 동일한, 적어도 80% 동일한, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한 또는 100% 동일한 서열을 포함하는 핵산에 의해 인코딩될 수 있다.
일부 구현예에서, 가용성 조직 인자 도메인은 약 20개 아미노산 내지 약 220개 아미노산, 약 20개 아미노산 내지 약 215개 아미노산, 약 20개 아미노산 내지 약 210개 아미노산, 약 20개 아미노산 내지 약 205개 아미노산, 약 20개 아미노산 내지 약 200개 아미노산, 약 20개 아미노산 내지 약 195개 아미노산, 약 20개 아미노산 내지 약 190개 아미노산, 약 20개 아미노산 내지 약 185개 아미노산, 약 20개 아미노산 내지 약 180개 아미노산, 약 20개 아미노산 내지 약 175개 아미노산, 약 20개 아미노산 내지 약 170개 아미노산, 약 20개 아미노산 내지 약 165개 아미노산, 약 20개 아미노산 내지 약 160개 아미노산, 약 20개 아미노산 내지 약 155개 아미노산, 약 20개 아미노산 내지 약 150개 아미노산, 약 20개 아미노산 내지 약 145개 아미노산, 약 20개 아미노산 내지 약 140개 아미노산, 약 20개 아미노산 내지 약 135개 아미노산, 약 20개 아미노산 내지 약 130개 아미노산, 약 20개 아미노산 내지 약 125개 아미노산, 약 20개 아미노산 내지 약 120개 아미노산, 약 20개 아미노산 내지 약 115개 아미노산, 약 20개 아미노산 내지 약 110개 아미노산, 약 20개 아미노산 내지 약 105개 아미노산, 약 20개 아미노산 내지 약 100개 아미노산, 약 20개 아미노산 내지 약 95개 아미노산, 약 20개 아미노산 내지 약 90개 아미노산, 약 20개 아미노산 내지 약 85개 아미노산, 약 20개 아미노산 내지 약 80개 아미노산, 약 20개 아미노산 내지 약 75개 아미노산, 약 20개 아미노산 내지 약 70개 아미노산, 약 20개 아미노산 내지 약 60개 아미노산, 약 20개 아미노산 내지 약 50개 아미노산, 약 20개 아미노산 내지 약 40개 아미노산, 약 20개 아미노산 내지 약 30개 아미노산, 약 30개 아미노산 내지 약 220개 아미노산, 약 30개 아미노산 내지 약 215개 아미노산, 약 30개 아미노산 내지 약 210개 아미노산, 약 30개 아미노산 내지 약 205개 아미노산, 약 30개 아미노산 내지 약 200개 아미노산, 약 30개 아미노산 내지 약 195개 아미노산, 약 30개 아미노산 내지 약 190개 아미노산, 약 30개 아미노산 내지 약 185개 아미노산, 약 30개 아미노산 내지 약 180개 아미노산, 약 30개 아미노산 내지 약 175개 아미노산, 약 30개 아미노산 내지 약 170개 아미노산, 약 30개 아미노산 내지 약 165개 아미노산, 약 30개 아미노산 내지 약 160개 아미노산, 약 30개 아미노산 내지 약 155개 아미노산, 약 30개 아미노산 내지 약 150개 아미노산, 약 30개 아미노산 내지 약 145개 아미노산, 약 30개 아미노산 내지 약 140개 아미노산, 약 30개 아미노산 내지 약 135개 아미노산, 약 30개 아미노산 내지 약 130개 아미노산, 약 30개 아미노산 내지 약 125개 아미노산, 약 30개 아미노산 내지 약 120개 아미노산, 약 30개 아미노산 내지 약 115개 아미노산, 약 30개 아미노산 내지 약 110개 아미노산, 약 30개 아미노산 내지 약 105개 아미노산, 약 30개 아미노산 내지 약 100개 아미노산, 약 30개 아미노산 내지 약 95개 아미노산, 약 30개 아미노산 내지 약 90개 아미노산, 약 30개 아미노산 내지 약 85개 아미노산, 약 30개 아미노산 내지 약 80개 아미노산, 약 30개 아미노산 내지 약 75개 아미노산, 약 30개 아미노산 내지 약 70개 아미노산, 약 30개 아미노산 내지 약 60개 아미노산, 약 30개 아미노산 내지 약 50개 아미노산, 약 30개 아미노산 내지 약 40개 아미노산, 약 40개 아미노산 내지 약 220개 아미노산, 약 40개 아미노산 내지 약 215개 아미노산, 약 40개 아미노산 내지 약 210개 아미노산, 약 40개 아미노산 내지 약 205개 아미노산, 약 40개 아미노산 내지 약 200개 아미노산, 약 40개 아미노산 내지 약 195개 아미노산, 약 40개 아미노산 내지 약 190개 아미노산, 약 40개 아미노산 내지 약 185개 아미노산, 약 40개 아미노산 내지 약 180개 아미노산, 약 40개 아미노산 내지 약 175개 아미노산, 약 40개 아미노산 내지 약 170개 아미노산, 약 40개 아미노산 내지 약 165개 아미노산, 약 40개 아미노산 내지 약 160개 아미노산, 약 40개 아미노산 내지 약 155개 아미노산, 약 40개 아미노산 내지 약 150개 아미노산, 약 40개 아미노산 내지 약 145개 아미노산, 약 40개 아미노산 내지 약 140개 아미노산, 약 40개 아미노산 내지 약 135개 아미노산, 약 40개 아미노산 내지 약 130개 아미노산, 약 40개 아미노산 내지 약 125개 아미노산, 약 40개 아미노산 내지 약 120개 아미노산, 약 40개 아미노산 내지 약 115개 아미노산, 약 40개 아미노산 내지 약 110개 아미노산, 약 40개 아미노산 내지 약 105개 아미노산, 약 40개 아미노산 내지 약 100개 아미노산, 약 40개 아미노산 내지 약 95개 아미노산, 약 40개 아미노산 내지 약 90개 아미노산, 약 40개 아미노산 내지 약 85개 아미노산, 약 40개 아미노산 내지 약 80개 아미노산, 약 40개 아미노산 내지 약 75개 아미노산, 약 40개 아미노산 내지 약 70개 아미노산, 약 40개 아미노산 내지 약 60개 아미노산, 약 40개 아미노산 내지 약 50개 아미노산, 약 50개 아미노산 내지 약 220개 아미노산, 약 50개 아미노산 내지 약 215개 아미노산, 약 50개 아미노산 내지 약 210개 아미노산, 약 50개 아미노산 내지 약 205개 아미노산, 약 50개 아미노산 내지 약 200개 아미노산, 약 50개 아미노산 내지 약 195개 아미노산, 약 50개 아미노산 내지 약 190개 아미노산, 약 50개 아미노산 내지 약 185개 아미노산, 약 50개 아미노산 내지 약 180개 아미노산, 약 50개 아미노산 내지 약 175개 아미노산, 약 50개 아미노산 내지 약 170개 아미노산, 약 50개 아미노산 내지 약 165개 아미노산, 약 50개 아미노산 내지 약 160개 아미노산, 약 50개 아미노산 내지 약 155개 아미노산, 약 50개 아미노산 내지 약 150개 아미노산, 약 50개 아미노산 내지 약 145개 아미노산, 약 50개 아미노산 내지 약 140개 아미노산, 약 50개 아미노산 내지 약 135개 아미노산, 약 50개 아미노산 내지 약 130개 아미노산, 약 50개 아미노산 내지 약 125개 아미노산, 약 50개 아미노산 내지 약 120개 아미노산, 약 50개 아미노산 내지 약 115개 아미노산, 약 50개 아미노산 내지 약 110개 아미노산, 약 50개 아미노산 내지 약 105개 아미노산, 약 50개 아미노산 내지 약 100개 아미노산, 약 50개 아미노산 내지 약 95개 아미노산, 약 50개 아미노산 내지 약 90개 아미노산, 약 50개 아미노산 내지 약 85개 아미노산, 약 50개 아미노산 내지 약 80개 아미노산, 약 50개 아미노산 내지 약 75개 아미노산, 약 50개 아미노산 내지 약 70개 아미노산, 약 50개 아미노산 내지 약 60개 아미노산, 약 60개 아미노산 내지 약 220개 아미노산, 약 60개 아미노산 내지 약 215개 아미노산, 약 60개 아미노산 내지 약 210개 아미노산, 약 60개 아미노산 내지 약 205개 아미노산, 약 60개 아미노산 내지 약 200개 아미노산, 약 60개 아미노산 내지 약 195개 아미노산, 약 60개 아미노산 내지 약 190개 아미노산, 약 60개 아미노산 내지 약 185개 아미노산, 약 60개 아미노산 내지 약 180개 아미노산, 약 60개 아미노산 내지 약 175개 아미노산, 약 60개 아미노산 내지 약 170개 아미노산, 약 60개 아미노산 내지 약 165개 아미노산, 약 60개 아미노산 내지 약 160개 아미노산, 약 60개 아미노산 내지 약 155개 아미노산, 약 60개 아미노산 내지 약 150개 아미노산, 약 60개 아미노산 내지 약 145개 아미노산, 약 60개 아미노산 내지 약 140개 아미노산, 약 60개 아미노산 내지 약 135개 아미노산, 약 60개 아미노산 내지 약 130개 아미노산, 약 60개 아미노산 내지 약 125개 아미노산, 약 60개 아미노산 내지 약 120개 아미노산, 약 60개 아미노산 내지 약 115개 아미노산, 약 60개 아미노산 내지 약 110개 아미노산, 약 60개 아미노산 내지 약 105개 아미노산, 약 60개 아미노산 내지 약 100개 아미노산, 약 60개 아미노산 내지 약 95개 아미노산, 약 60개 아미노산 내지 약 90개 아미노산, 약 60개 아미노산 내지 약 85개 아미노산, 약 60개 아미노산 내지 약 80개 아미노산, 약 60개 아미노산 내지 약 75개 아미노산, 약 60개 아미노산 내지 약 70개 아미노산, 약 70개 아미노산 내지 약 220개 아미노산, 약 70개 아미노산 내지 약 215개 아미노산, 약 70개 아미노산 내지 약 210개 아미노산, 약 70개 아미노산 내지 약 205개 아미노산, 약 70개 아미노산 내지 약 200개 아미노산, 약 70개 아미노산 내지 약 195개 아미노산, 약 70개 아미노산 내지 약 190개 아미노산, 약 70개 아미노산 내지 약 185개 아미노산, 약 70개 아미노산 내지 약 180개 아미노산, 약 70개 아미노산 내지 약 175개 아미노산, 약 70개 아미노산 내지 약 170개 아미노산, 약 70개 아미노산 내지 약 165개 아미노산, 약 70개 아미노산 내지 약 160개 아미노산, 약 70개 아미노산 내지 약 155개 아미노산, 약 70개 아미노산 내지 약 150개 아미노산, 약 70개 아미노산 내지 약 145개 아미노산, 약 70개 아미노산 내지 약 140개 아미노산, 약 70개 아미노산 내지 약 135개 아미노산, 약 70개 아미노산 내지 약 130개 아미노산, 약 70개 아미노산 내지 약 125개 아미노산, 약 70개 아미노산 내지 약 120개 아미노산, 약 70개 아미노산 내지 약 115개 아미노산, 약 70개 아미노산 내지 약 110개 아미노산, 약 70개 아미노산 내지 약 105개 아미노산, 약 70개 아미노산 내지 약 100개 아미노산, 약 70개 아미노산 내지 약 95개 아미노산, 약 70개 아미노산 내지 약 90개 아미노산, 약 70개 아미노산 내지 약 85개 아미노산, 약 70개 아미노산 내지 약 80개 아미노산, 약 80개 아미노산 내지 약 220개 아미노산, 약 80개 아미노산 내지 약 215개 아미노산, 약 80개 아미노산 내지 약 210개 아미노산, 약 80개 아미노산 내지 약 205개 아미노산, 약 80개 아미노산 내지 약 200개 아미노산, 약 80개 아미노산 내지 약 195개 아미노산, 약 80개 아미노산 내지 약 190개 아미노산, 약 80개 아미노산 내지 약 185개 아미노산, 약 80개 아미노산 내지 약 180개 아미노산, 약 80개 아미노산 내지 약 175개 아미노산, 약 80개 아미노산 내지 약 170개 아미노산, 약 80개 아미노산 내지 약 165개 아미노산, 약 80개 아미노산 내지 약 160개 아미노산, 약 80개 아미노산 내지 약 155개 아미노산, 약 80개 아미노산 내지 약 150개 아미노산, 약 80개 아미노산 내지 약 145개 아미노산, 약 80개 아미노산 내지 약 140개 아미노산, 약 80개 아미노산 내지 약 135개 아미노산, 약 80개 아미노산 내지 약 130개 아미노산, 약 80개 아미노산 내지 약 125개 아미노산, 약 80개 아미노산 내지 약 120개 아미노산, 약 80개 아미노산 내지 약 115개 아미노산, 약 80개 아미노산 내지 약 110개 아미노산, 약 80개 아미노산 내지 약 105개 아미노산, 약 80개 아미노산 내지 약 100개 아미노산, 약 80개 아미노산 내지 약 95개 아미노산, 약 80개 아미노산 내지 약 90개 아미노산, 약 90개 아미노산 내지 약 220개 아미노산, 약 90개 아미노산 내지 약 215개 아미노산, 약 90개 아미노산 내지 약 210개 아미노산, 약 90개 아미노산 내지 약 205개 아미노산, 약 90개 아미노산 내지 약 200개 아미노산, 약 90개 아미노산 내지 약 195개 아미노산, 약 90개 아미노산 내지 약 190개 아미노산, 약 90개 아미노산 내지 약 185개 아미노산, 약 90개 아미노산 내지 약 180개 아미노산, 약 90개 아미노산 내지 약 175개 아미노산, 약 90개 아미노산 내지 약 170개 아미노산, 약 90개 아미노산 내지 약 165개 아미노산, 약 90개 아미노산 내지 약 160개 아미노산, 약 90개 아미노산 내지 약 155개 아미노산, 약 90개 아미노산 내지 약 150개 아미노산, 약 90개 아미노산 내지 약 145개 아미노산, 약 90개 아미노산 내지 약 140개 아미노산, 약 90개 아미노산 내지 약 135개 아미노산, 약 90개 아미노산 내지 약 130개 아미노산, 약 90개 아미노산 내지 약 125개 아미노산, 약 90개 아미노산 내지 약 120개 아미노산, 약 90개 아미노산 내지 약 115개 아미노산, 약 90개 아미노산 내지 약 110개 아미노산, 약 90개 아미노산 내지 약 105개 아미노산, 약 90개 아미노산 내지 약 100개 아미노산, 약 100개 아미노산 내지 약 220개 아미노산, 약 100개 아미노산 내지 약 215개 아미노산, 약 100개 아미노산 내지 약 210개 아미노산, 약 100개 아미노산 내지 약 205개 아미노산, 약 100개 아미노산 내지 약 200개 아미노산, 약 100개 아미노산 내지 약 195개 아미노산, 약 100개 아미노산 내지 약 190개 아미노산, 약 100개 아미노산 내지 약 185개 아미노산, 약 100개 아미노산 내지 약 180개 아미노산, 약 100개 아미노산 내지 약 175개 아미노산, 약 100개 아미노산 내지 약 170개 아미노산, 약 100개 아미노산 내지 약 165개 아미노산, 약 100개 아미노산 내지 약 160개 아미노산, 약 100개 아미노산 내지 약 155개 아미노산, 약 100개 아미노산 내지 약 150개 아미노산, 약 100개 아미노산 내지 약 145개 아미노산, 약 100개 아미노산 내지 약 140개 아미노산, 약 100개 아미노산 내지 약 135개 아미노산, 약 100개 아미노산 내지 약 130개 아미노산, 약 100개 아미노산 내지 약 125개 아미노산, 약 100개 아미노산 내지 약 120개 아미노산, 약 100개 아미노산 내지 약 115개 아미노산, 약 100개 아미노산 내지 약 110개 아미노산, 약 110개 아미노산 내지 약 220개 아미노산, 약 110개 아미노산 내지 약 215개 아미노산, 약 110개 아미노산 내지 약 210개 아미노산, 약 110개 아미노산 내지 약 205개 아미노산, 약 110개 아미노산 내지 약 200개 아미노산, 약 110개 아미노산 내지 약 195개 아미노산, 약 110개 아미노산 내지 약 190개 아미노산, 약 110개 아미노산 내지 약 185개 아미노산, 약 110개 아미노산 내지 약 180개 아미노산, 약 110개 아미노산 내지 약 175개 아미노산, 약 110개 아미노산 내지 약 170개 아미노산, 약 110개 아미노산 내지 약 165개 아미노산, 약 110개 아미노산 내지 약 160개 아미노산, 약 110개 아미노산 내지 약 155개 아미노산, 약 110개 아미노산 내지 약 150개 아미노산, 약 110개 아미노산 내지 약 145개 아미노산, 약 110개 아미노산 내지 약 140개 아미노산, 약 110개 아미노산 내지 약 135개 아미노산, 약 110개 아미노산 내지 약 130개 아미노산, 약 110개 아미노산 내지 약 125개 아미노산, 약 110개 아미노산 내지 약 120개 아미노산, 약 110개 아미노산 내지 약 115개 아미노산, 약 115개 아미노산 내지 약 220개 아미노산, 약 115개 아미노산 내지 약 215개 아미노산, 약 115개 아미노산 내지 약 210개 아미노산, 약 115개 아미노산 내지 약 205개 아미노산, 약 115개 아미노산 내지 약 200개 아미노산, 약 115개 아미노산 내지 약 195개 아미노산, 약 115개 아미노산 내지 약 190개 아미노산, 약 115개 아미노산 내지 약 185개 아미노산, 약 115개 아미노산 내지 약 180개 아미노산, 약 115개 아미노산 내지 약 175개 아미노산, 약 115개 아미노산 내지 약 170개 아미노산, 약 115개 아미노산 내지 약 165개 아미노산, 약 115개 아미노산 내지 약 160개 아미노산, 약 115개 아미노산 내지 약 155개 아미노산, 약 115개 아미노산 내지 약 150개 아미노산, 약 115개 아미노산 내지 약 145개 아미노산, 약 115개 아미노산 내지 약 140개 아미노산, 약 115개 아미노산 내지 약 135개 아미노산, 약 115개 아미노산 내지 약 130개 아미노산, 약 115개 아미노산 내지 약 125개 아미노산, 약 115개 아미노산 내지 약 120개 아미노산, 약 120개 아미노산 내지 약 220개 아미노산, 약 120개 아미노산 내지 약 215개 아미노산, 약 120개 아미노산 내지 약 210개 아미노산, 약 120개 아미노산 내지 약 205개 아미노산, 약 120개 아미노산 내지 약 200개 아미노산, 약 120개 아미노산 내지 약 195개 아미노산, 약 120개 아미노산 내지 약 190개 아미노산, 약 120개 아미노산 내지 약 185개 아미노산, 약 120개 아미노산 내지 약 180개 아미노산, 약 120개 아미노산 내지 약 175개 아미노산, 약 120개 아미노산 내지 약 170개 아미노산, 약 120개 아미노산 내지 약 165개 아미노산, 약 120개 아미노산 내지 약 160개 아미노산, 약 120개 아미노산 내지 약 155개 아미노산, 약 120개 아미노산 내지 약 150개 아미노산, 약 120개 아미노산 내지 약 145개 아미노산, 약 120개 아미노산 내지 약 140개 아미노산, 약 120개 아미노산 내지 약 135개 아미노산, 약 120개 아미노산 내지 약 130개 아미노산, 약 120개 아미노산 내지 약 125개 아미노산, 약 125개 아미노산 내지 약 220개 아미노산, 약 125개 아미노산 내지 약 215개 아미노산, 약 125개 아미노산 내지 약 210개 아미노산, 약 125개 아미노산 내지 약 205개 아미노산, 약 125개 아미노산 내지 약 200개 아미노산, 약 125개 아미노산 내지 약 195개 아미노산, 약 125개 아미노산 내지 약 190개 아미노산, 약 125개 아미노산 내지 약 185개 아미노산, 약 125개 아미노산 내지 약 180개 아미노산, 약 125개 아미노산 내지 약 175개 아미노산, 약 125개 아미노산 내지 약 170개 아미노산, 약 125개 아미노산 내지 약 165개 아미노산, 약 125개 아미노산 내지 약 160개 아미노산, 약 125개 아미노산 내지 약 155개 아미노산, 약 125개 아미노산 내지 약 150개 아미노산, 약 125개 아미노산 내지 약 145개 아미노산, 약 125개 아미노산 내지 약 140개 아미노산, 약 125개 아미노산 내지 약 135개 아미노산, 약 125개 아미노산 내지 약 130개 아미노산, 약 130개 아미노산 내지 약 220개 아미노산, 약 130개 아미노산 내지 약 215개 아미노산, 약 130개 아미노산 내지 약 210개 아미노산, 약 130개 아미노산 내지 약 205개 아미노산, 약 130개 아미노산 내지 약 200개 아미노산, 약 130개 아미노산 내지 약 195개 아미노산, 약 130개 아미노산 내지 약 190개 아미노산, 약 130개 아미노산 내지 약 185개 아미노산, 약 130개 아미노산 내지 약 180개 아미노산, 약 130개 아미노산 내지 약 175개 아미노산, 약 130개 아미노산 내지 약 170개 아미노산, 약 130개 아미노산 내지 약 165개 아미노산, 약 130개 아미노산 내지 약 160개 아미노산, 약 130개 아미노산 내지 약 155개 아미노산, 약 130개 아미노산 내지 약 150개 아미노산, 약 130개 아미노산 내지 약 145개 아미노산, 약 130개 아미노산 내지 약 140개 아미노산, 약 130개 아미노산 내지 약 135개 아미노산, 약 135개 아미노산 내지 약 220개 아미노산, 약 135개 아미노산 내지 약 215개 아미노산, 약 135개 아미노산 내지 약 210개 아미노산, 약 135개 아미노산 내지 약 205개 아미노산, 약 135개 아미노산 내지 약 200개 아미노산, 약 135개 아미노산 내지 약 195개 아미노산, 약 135개 아미노산 내지 약 190개 아미노산, 약 135개 아미노산 내지 약 185개 아미노산, 약 135개 아미노산 내지 약 180개 아미노산, 약 135개 아미노산 내지 약 175개 아미노산, 약 135개 아미노산 내지 약 170개 아미노산, 약 135개 아미노산 내지 약 165개 아미노산, 약 135개 아미노산 내지 약 160개 아미노산, 약 135개 아미노산 내지 약 155개 아미노산, 약 135개 아미노산 내지 약 150개 아미노산, 약 135개 아미노산 내지 약 145개 아미노산, 약 135개 아미노산 내지 약 140개 아미노산, 약 140개 아미노산 내지 약 220개 아미노산, 약 140개 아미노산 내지 약 215개 아미노산, 약 140개 아미노산 내지 약 210개 아미노산, 약 140개 아미노산 내지 약 205개 아미노산, 약 140개 아미노산 내지 약 200개 아미노산, 약 140개 아미노산 내지 약 195개 아미노산, 약 140개 아미노산 내지 약 190개 아미노산, 약 140개 아미노산 내지 약 185개 아미노산, 약 140개 아미노산 내지 약 180개 아미노산, 약 140개 아미노산 내지 약 175개 아미노산, 약 140개 아미노산 내지 약 170개 아미노산, 약 140개 아미노산 내지 약 165개 아미노산, 약 140개 아미노산 내지 약 160개 아미노산, 약 140개 아미노산 내지 약 155개 아미노산, 약 140개 아미노산 내지 약 150개 아미노산, 약 140개 아미노산 내지 약 145개 아미노산, 약 145개 아미노산 내지 약 220개 아미노산, 약 145개 아미노산 내지 약 215개 아미노산, 약 145개 아미노산 내지 약 210개 아미노산, 약 145개 아미노산 내지 약 205개 아미노산, 약 145개 아미노산 내지 약 200개 아미노산, 약 145개 아미노산 내지 약 195개 아미노산, 약 145개 아미노산 내지 약 190개 아미노산, 약 145개 아미노산 내지 약 185개 아미노산, 약 145개 아미노산 내지 약 180개 아미노산, 약 145개 아미노산 내지 약 175개 아미노산, 약 145개 아미노산 내지 약 170개 아미노산, 약 145개 아미노산 내지 약 165개 아미노산, 약 145개 아미노산 내지 약 160개 아미노산, 약 145개 아미노산 내지 약 155개 아미노산, 약 145개 아미노산 내지 약 150개 아미노산, 약 150개 아미노산 내지 약 220개 아미노산, 약 150개 아미노산 내지 약 215개 아미노산, 약 150개 아미노산 내지 약 210개 아미노산, 약 150개 아미노산 내지 약 205개 아미노산, 약 150개 아미노산 내지 약 200개 아미노산, 약 150개 아미노산 내지 약 195개 아미노산, 약 150개 아미노산 내지 약 190개 아미노산, 약 150개 아미노산 내지 약 185개 아미노산, 약 150개 아미노산 내지 약 180개 아미노산, 약 150개 아미노산 내지 약 175개 아미노산, 약 150개 아미노산 내지 약 170개 아미노산, 약 150개 아미노산 내지 약 165개 아미노산, 약 150개 아미노산 내지 약 160개 아미노산, 약 150개 아미노산 내지 약 155개 아미노산, 약 155개 아미노산 내지 약 220개 아미노산, 약 155개 아미노산 내지 약 215개 아미노산, 약 155개 아미노산 내지 약 210개 아미노산, 약 155개 아미노산 내지 약 205개 아미노산, 약 155개 아미노산 내지 약 200개 아미노산, 약 155개 아미노산 내지 약 195개 아미노산, 약 155개 아미노산 내지 약 190개 아미노산, 약 155개 아미노산 내지 약 185개 아미노산, 약 155개 아미노산 내지 약 180개 아미노산, 약 155개 아미노산 내지 약 175개 아미노산, 약 155개 아미노산 내지 약 170개 아미노산, 약 155개 아미노산 내지 약 165개 아미노산, 약 155개 아미노산 내지 약 160개 아미노산, 약 160개 아미노산 내지 약 220개 아미노산, 약 160개 아미노산 내지 약 215개 아미노산, 약 160개 아미노산 내지 약 210개 아미노산, 약 160개 아미노산 내지 약 205개 아미노산, 약 160개 아미노산 내지 약 200개 아미노산, 약 160개 아미노산 내지 약 195개 아미노산, 약 160개 아미노산 내지 약 190개 아미노산, 약 160개 아미노산 내지 약 185개 아미노산, 약 160개 아미노산 내지 약 180개 아미노산, 약 160개 아미노산 내지 약 175개 아미노산, 약 160개 아미노산 내지 약 170개 아미노산, 약 160개 아미노산 내지 약 165개 아미노산, 약 165개 아미노산 내지 약 220개 아미노산, 약 165개 아미노산 내지 약 215개 아미노산, 약 165개 아미노산 내지 약 210개 아미노산, 약 165개 아미노산 내지 약 205개 아미노산, 약 165개 아미노산 내지 약 200개 아미노산, 약 165개 아미노산 내지 약 195개 아미노산, 약 165개 아미노산 내지 약 190개 아미노산, 약 165개 아미노산 내지 약 185개 아미노산, 약 165개 아미노산 내지 약 180개 아미노산, 약 165개 아미노산 내지 약 175개 아미노산, 약 165개 아미노산 내지 약 170개 아미노산, 약 170개 아미노산 내지 약 220개 아미노산, 약 170개 아미노산 내지 약 215개 아미노산, 약 170개 아미노산 내지 약 210개 아미노산, 약 170개 아미노산 내지 약 205개 아미노산, 약 170개 아미노산 내지 약 200개 아미노산, 약 170개 아미노산 내지 약 195개 아미노산, 약 170개 아미노산 내지 약 190개 아미노산, 약 170개 아미노산 내지 약 185개 아미노산, 약 170개 아미노산 내지 약 180개 아미노산, 약 170개 아미노산 내지 약 175개 아미노산, 약 175개 아미노산 내지 약 220개 아미노산, 약 175개 아미노산 내지 약 215개 아미노산, 약 175개 아미노산 내지 약 210개 아미노산, 약 175개 아미노산 내지 약 205개 아미노산, 약 175개 아미노산 내지 약 200개 아미노산, 약 175개 아미노산 내지 약 195개 아미노산, 약 175개 아미노산 내지 약 190개 아미노산, 약 175개 아미노산 내지 약 185개 아미노산, 약 175개 아미노산 내지 약 180개 아미노산, 약 180개 아미노산 내지 약 220개 아미노산, 약 180개 아미노산 내지 약 215개 아미노산, 약 180개 아미노산 내지 약 210개 아미노산, 약 180개 아미노산 내지 약 205개 아미노산, 약 180개 아미노산 내지 약 200개 아미노산, 약 180개 아미노산 내지 약 195개 아미노산, 약 180개 아미노산 내지 약 190개 아미노산, 약 180개 아미노산 내지 약 185개 아미노산, 약 185개 아미노산 내지 약 220개 아미노산, 약 185개 아미노산 내지 약 215개 아미노산, 약 185개 아미노산 내지 약 210개 아미노산, 약 185개 아미노산 내지 약 205개 아미노산, 약 185개 아미노산 내지 약 200개 아미노산, 약 185개 아미노산 내지 약 195개 아미노산, 약 185개 아미노산 내지 약 190개 아미노산, 약 190개 아미노산 내지 약 220개 아미노산, 약 190개 아미노산 내지 약 215개 아미노산, 약 190개 아미노산 내지 약 210개 아미노산, 약 190개 아미노산 내지 약 205개 아미노산, 약 190개 아미노산 내지 약 200개 아미노산, 약 190개 아미노산 내지 약 195개 아미노산, 약 195개 아미노산 내지 약 220개 아미노산, 약 195개 아미노산 내지 약 215개 아미노산, 약 195개 아미노산 내지 약 210개 아미노산, 약 195개 아미노산 내지 약 205개 아미노산, 약 195개 아미노산 내지 약 200개 아미노산, 약 200개 아미노산 내지 약 220개 아미노산, 약 200개 아미노산 내지 약 215개 아미노산, 약 200개 아미노산 내지 약 210개 아미노산, 약 200개 아미노산 내지 약 205개 아미노산, 약 205개 아미노산 내지 약 220개 아미노산, 약 205개 아미노산 내지 약 215개 아미노산, 약 205개 아미노산 내지 약 210개 아미노산, 약 210개 아미노산 내지 약 220개 아미노산, 약 210개 아미노산 내지 약 215개 아미노산, 또는 약 215개 아미노산 내지 약 220개 아미노산의 총 길이를 가질 수 있다.
링커 서열
일부 구현예에서, 링커 서열은 가요성 링커 서열일 수 있다. 사용될 수 있는 링커 서열의 비제한적인 예는 문헌[Kleinet al., Protein Engineering, Design & Selection 27(10):325-330, 2014]; 문헌[Priyankaet al., Protein Sci. 22(2):153-167, 2013]에 기재되어 있다. 일부 예에서, 링커 서열은 합성 링커 서열이다.
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개의 링커 서열(들)(예를 들어, 동일하거나 상이한 링커 서열, 예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 링커 서열)을 포함할 수 있다. 본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개의 링커 서열(들)(예를 들어, 동일하거나 상이한 링커 서열, 예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 링커 서열)을 포함할 수 있다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개의 링커 서열(들)(예를 들어, 동일하거나 상이한 링커 서열, 예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 링커 서열)을 포함할 수 있다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개의 링커 서열(들)(예를 들어, 동일하거나 상이한 링커 서열, 예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 링커 서열)을 포함할 수 있다.
일부 구현예에서, 링커 서열은 1개 아미노산 내지 약 100개 아미노산, 1개 아미노산 내지 약 90개 아미노산, 1개 아미노산 내지 약 80개 아미노산, 1개 아미노산 내지 약 70개 아미노산, 1개 아미노산 내지 약 60개 아미노산, 1개 아미노산 내지 약 50개 아미노산, 1개 아미노산 내지 약 45개 아미노산, 1개 아미노산 내지 약 40개 아미노산, 1개 아미노산 내지 약 35개 아미노산, 1개 아미노산 내지 약 30개 아미노산, 1개 아미노산 내지 약 25개 아미노산, 1개 아미노산 내지 약 24개 아미노산, 1개 아미노산 내지 약 22개 아미노산, 1개 아미노산 내지 약 20개 아미노산, 1개 아미노산 내지 약 18개 아미노산, 1개 아미노산 내지 약 16개 아미노산, 1개 아미노산 내지 약 14개 아미노산, 1개 아미노산 내지 약 12개 아미노산, 1개 아미노산 내지 약 10개 아미노산, 1개 아미노산 내지 약 8개 아미노산, 1개 아미노산 내지 약 6개 아미노산, 1개 아미노산 내지 약 4개 아미노산, 약 2개 아미노산 내지 약 100개 아미노산, 약 2개 아미노산 내지 약 90개 아미노산, 약 2개 아미노산 내지 약 80개 아미노산, 약 2개 아미노산 내지 약 70개 아미노산, 약 2개 아미노산 내지 약 60개 아미노산, 약 2개 아미노산 내지 약 50개 아미노산, 약 2개 아미노산 내지 약 45개 아미노산, 약 2개 아미노산 내지 약 40개 아미노산, 약 2개 아미노산 내지 약 35개 아미노산, 약 2개 아미노산 내지 약 30개 아미노산, 약 2개 아미노산 내지 약 25개 아미노산, 약 2개 아미노산 내지 약 24개 아미노산, 약 2개 아미노산 내지 약 22개 아미노산, 약 2개 아미노산 내지 약 20개 아미노산, 약 2개 아미노산 내지 약 18개 아미노산, 약 2개 아미노산 내지 약 16개 아미노산, 약 2개 아미노산 내지 약 14개 아미노산, 약 2개 아미노산 내지 약 12개 아미노산, 약 2개 아미노산 내지 약 10개 아미노산, 약 2개 아미노산 내지 약 8개 아미노산, 약 2개 아미노산 내지 약 6개 아미노산, 약 2개 아미노산 내지 약 4개 아미노산, 약 4개 아미노산 내지 약 100개 아미노산, 약 4개 아미노산 내지 약 90개 아미노산, 약 4개 아미노산 내지 약 80개 아미노산, 약 4개 아미노산 내지 약 70개 아미노산, 약 4개 아미노산 내지 약 60개 아미노산, 약 4개 아미노산 내지 약 50개 아미노산, 약 4개 아미노산 내지 약 45개 아미노산, 약 4개 아미노산 내지 약 40개 아미노산, 약 4개 아미노산 내지 약 35개 아미노산, 약 4개 아미노산 내지 약 30개 아미노산, 약 4개 아미노산 내지 약 25개 아미노산, 약 4개 아미노산 내지 약 24개 아미노산, 약 4개 아미노산 내지 약 22개 아미노산, 약 4개 아미노산 내지 약 20개 아미노산, 약 4개 아미노산 내지 약 18개 아미노산, 약 4개 아미노산 내지 약 16개 아미노산, 약 4개 아미노산 내지 약 14개 아미노산, 약 4개 아미노산 내지 약 12개 아미노산, 약 4개 아미노산 내지 약 10개 아미노산, 약 4개 아미노산 내지 약 8개 아미노산, 약 4개 아미노산 내지 약 6개 아미노산, 약 6개 아미노산 내지 약 100개 아미노산, 약 6개 아미노산 내지 약 90개 아미노산, 약 6개 아미노산 내지 약 80개 아미노산, 약 6개 아미노산 내지 약 70개 아미노산, 약 6개 아미노산 내지 약 60개 아미노산, 약 6개 아미노산 내지 약 50개 아미노산, 약 6개 아미노산 내지 약 45개 아미노산, 약 6개 아미노산 내지 약 40개 아미노산, 약 6개 아미노산 내지 약 35개 아미노산, 약 6개 아미노산 내지 약 30개 아미노산, 약 6개 아미노산 내지 약 25개 아미노산, 약 6개 아미노산 내지 약 24개 아미노산, 약 6개 아미노산 내지 약 22개 아미노산, 약 6개 아미노산 내지 약 20개 아미노산, 약 6개 아미노산 내지 약 18개 아미노산, 약 6개 아미노산 내지 약 16개 아미노산, 약 6개 아미노산 내지 약 14개 아미노산, 약 6개 아미노산 내지 약 12개 아미노산, 약 6개 아미노산 내지 약 10개 아미노산, 약 6개 아미노산 내지 약 8개 아미노산, 약 8개 아미노산 내지 약 100개 아미노산, 약 8개 아미노산 내지 약 90개 아미노산, 약 8개 아미노산 내지 약 80개 아미노산, 약 8개 아미노산 내지 약 70개 아미노산, 약 8개 아미노산 내지 약 60개 아미노산, 약 8개 아미노산 내지 약 50개 아미노산, 약 8개 아미노산 내지 약 45개 아미노산, 약 8개 아미노산 내지 약 40개 아미노산, 약 8개 아미노산 내지 약 35개 아미노산, 약 8개 아미노산 내지 약 30개 아미노산, 약 8개 아미노산 내지 약 25개 아미노산, 약 8개 아미노산 내지 약 24개 아미노산, 약 8개 아미노산 내지 약 22개 아미노산, 약 8개 아미노산 내지 약 20개 아미노산, 약 8개 아미노산 내지 약 18개 아미노산, 약 8개 아미노산 내지 약 16개 아미노산, 약 8개 아미노산 내지 약 14개 아미노산, 약 8개 아미노산 내지 약 12개 아미노산, 약 8개 아미노산 내지 약 10개 아미노산, 약 10개 아미노산 내지 약 100개 아미노산, 약 10개 아미노산 내지 약 90개 아미노산, 약 10개 아미노산 내지 약 80개 아미노산, 약 10개 아미노산 내지 약 70개 아미노산, 약 10개 아미노산 내지 약 60개 아미노산, 약 10개 아미노산 내지 약 50개 아미노산, 약 10개 아미노산 내지 약 45개 아미노산, 약 10개 아미노산 내지 약 40개 아미노산, 약 10개 아미노산 내지 약 35개 아미노산, 약 10개 아미노산 내지 약 30개 아미노산, 약 10개 아미노산 내지 약 25개 아미노산, 약 10개 아미노산 내지 약 24개 아미노산, 약 10개 아미노산 내지 약 22개 아미노산, 약 10개 아미노산 내지 약 20개 아미노산, 약 10개 아미노산 내지 약 18개 아미노산, 약 10개 아미노산 내지 약 16개 아미노산, 약 10개 아미노산 내지 약 14개 아미노산, 약 10개 아미노산 내지 약 12개 아미노산, 약 12개 아미노산 내지 약 100개 아미노산, 약 12개 아미노산 내지 약 90개 아미노산, 약 12개 아미노산 내지 약 80개 아미노산, 약 12개 아미노산 내지 약 70개 아미노산, 약 12개 아미노산 내지 약 60개 아미노산, 약 12개 아미노산 내지 약 50개 아미노산, 약 12개 아미노산 내지 약 45개 아미노산, 약 12개 아미노산 내지 약 40개 아미노산, 약 12개 아미노산 내지 약 35개 아미노산, 약 12개 아미노산 내지 약 30개 아미노산, 약 12개 아미노산 내지 약 25개 아미노산, 약 12개 아미노산 내지 약 24개 아미노산, 약 12개 아미노산 내지 약 22개 아미노산, 약 12개 아미노산 내지 약 20개 아미노산, 약 12개 아미노산 내지 약 18개 아미노산, 약 12개 아미노산 내지 약 16개 아미노산, 약 12개 아미노산 내지 약 14개 아미노산, 약 14개 아미노산 내지 약 100개 아미노산, 약 14개 아미노산 내지 약 90개 아미노산, 약 14개 아미노산 내지 약 80개 아미노산, 약 14개 아미노산 내지 약 70개 아미노산, 약 14개 아미노산 내지 약 60개 아미노산, 약 14개 아미노산 내지 약 50개 아미노산, 약 14개 아미노산 내지 약 45개 아미노산, 약 14개 아미노산 내지 약 40개 아미노산, 약 14개 아미노산 내지 약 35개 아미노산, 약 14개 아미노산 내지 약 30개 아미노산, 약 14개 아미노산 내지 약 25개 아미노산, 약 14개 아미노산 내지 약 24개 아미노산, 약 14개 아미노산 내지 약 22개 아미노산, 약 14개 아미노산 내지 약 20개 아미노산, 약 14개 아미노산 내지 약 18개 아미노산, 약 14개 아미노산 내지 약 16개 아미노산, 약 16개 아미노산 내지 약 100개 아미노산, 약 16개 아미노산 내지 약 90개 아미노산, 약 16개 아미노산 내지 약 80개 아미노산, 약 16개 아미노산 내지 약 70개 아미노산, 약 16개 아미노산 내지 약 60개 아미노산, 약 16개 아미노산 내지 약 50개 아미노산, 약 16개 아미노산 내지 약 45개 아미노산, 약 16개 아미노산 내지 약 40개 아미노산, 약 16개 아미노산 내지 약 35개 아미노산, 약 16개 아미노산 내지 약 30개 아미노산, 약 16개 아미노산 내지 약 25개 아미노산, 약 16개 아미노산 내지 약 24개 아미노산, 약 16개 아미노산 내지 약 22개 아미노산, 약 16개 아미노산 내지 약 20개 아미노산, 약 16개 아미노산 내지 약 18개 아미노산, 약 18개 아미노산 내지 약 100개 아미노산, 약 18개 아미노산 내지 약 90개 아미노산, 약 18개 아미노산 내지 약 80개 아미노산, 약 18개 아미노산 내지 약 70개 아미노산, 약 18개 아미노산 내지 약 60개 아미노산, 약 18개 아미노산 내지 약 50개 아미노산, 약 18개 아미노산 내지 약 45개 아미노산, 약 18개 아미노산 내지 약 40개 아미노산, 약 18개 아미노산 내지 약 35개 아미노산, 약 18개 아미노산 내지 약 30개 아미노산, 약 18개 아미노산 내지 약 25개 아미노산, 약 18개 아미노산 내지 약 24개 아미노산, 약 18개 아미노산 내지 약 22개 아미노산, 약 18개 아미노산 내지 약 20개 아미노산, 약 20개 아미노산 내지 약 100개 아미노산, 약 20개 아미노산 내지 약 90개 아미노산, 약 20개 아미노산 내지 약 80개 아미노산, 약 20개 아미노산 내지 약 70개 아미노산, 약 20개 아미노산 내지 약 60개 아미노산, 약 20개 아미노산 내지 약 50개 아미노산, 약 20개 아미노산 내지 약 45개 아미노산, 약 20개 아미노산 내지 약 40개 아미노산, 약 20개 아미노산 내지 약 35개 아미노산, 약 20개 아미노산 내지 약 30개 아미노산, 약 20개 아미노산 내지 약 25개 아미노산, 약 20개 아미노산 내지 약 24개 아미노산, 약 20개 아미노산 내지 약 22개 아미노산, 약 22개 아미노산 내지 약 100개 아미노산, 약 22개 아미노산 내지 약 90개 아미노산, 약 22개 아미노산 내지 약 80개 아미노산, 약 22개 아미노산 내지 약 70개 아미노산, 약 22개 아미노산 내지 약 60개 아미노산, 약 22개 아미노산 내지 약 50개 아미노산, 약 22개 아미노산 내지 약 45개 아미노산, 약 22개 아미노산 내지 약 40개 아미노산, 약 22개 아미노산 내지 약 35개 아미노산, 약 22개 아미노산 내지 약 30개 아미노산, 약 22개 아미노산 내지 약 25개 아미노산, 약 22개 아미노산 내지 약 24개 아미노산, 약 25개 아미노산 내지 약 100개 아미노산, 약 25개 아미노산 내지 약 90개 아미노산, 약 25개 아미노산 내지 약 80개 아미노산, 약 25개 아미노산 내지 약 70개 아미노산, 약 25개 아미노산 내지 약 60개 아미노산, 약 25개 아미노산 내지 약 50개 아미노산, 약 25개 아미노산 내지 약 45개 아미노산, 약 25개 아미노산 내지 약 40개 아미노산, 약 25개 아미노산 내지 약 35개 아미노산, 약 25개 아미노산 내지 약 30개 아미노산, 약 30개 아미노산 내지 약 100개 아미노산, 약 30개 아미노산 내지 약 90개 아미노산, 약 30개 아미노산 내지 약 80개 아미노산, 약 30개 아미노산 내지 약 70개 아미노산, 약 30개 아미노산 내지 약 60개 아미노산, 약 30개 아미노산 내지 약 50개 아미노산, 약 30개 아미노산 내지 약 45개 아미노산, 약 30개 아미노산 내지 약 40개 아미노산, 약 30개 아미노산 내지 약 35개 아미노산, 약 35개 아미노산 내지 약 100개 아미노산, 약 35개 아미노산 내지 약 90개 아미노산, 약 35개 아미노산 내지 약 80개 아미노산, 약 35개 아미노산 내지 약 70개 아미노산, 약 35개 아미노산 내지 약 60개 아미노산, 약 35개 아미노산 내지 약 50개 아미노산, 약 35개 아미노산 내지 약 45개 아미노산, 약 35개 아미노산 내지 약 40개 아미노산, 약 40개 아미노산 내지 약 100개 아미노산, 약 40개 아미노산 내지 약 90개 아미노산, 약 40개 아미노산 내지 약 80개 아미노산, 약 40개 아미노산 내지 약 70개 아미노산, 약 40개 아미노산 내지 약 60개 아미노산, 약 40개 아미노산 내지 약 50개 아미노산, 약 40개 아미노산 내지 약 45개 아미노산, 약 45개 아미노산 내지 약 100개 아미노산, 약 45개 아미노산 내지 약 90개 아미노산, 약 45개 아미노산 내지 약 80개 아미노산, 약 45개 아미노산 내지 약 70개 아미노산, 약 45개 아미노산 내지 약 60개 아미노산, 약 45개 아미노산 내지 약 50개 아미노산, 약 50개 아미노산 내지 약 100개 아미노산, 약 50개 아미노산 내지 약 90개 아미노산, 약 50개 아미노산 내지 약 80개 아미노산, 약 50개 아미노산 내지 약 70개 아미노산, 약 50개 아미노산 내지 약 60개 아미노산, 약 60개 아미노산 내지 약 100개 아미노산, 약 60개 아미노산 내지 약 90개 아미노산, 약 60개 아미노산 내지 약 80개 아미노산, 약 60개 아미노산 내지 약 70개 아미노산, 약 70개 아미노산 내지 약 100개 아미노산, 약 70개 아미노산 내지 약 90개 아미노산, 약 70개 아미노산 내지 약 80개 아미노산, 약 80개 아미노산 내지 약 100개 아미노산, 약 80개 아미노산 내지 약 90개 아미노산, 또는 약 90개 아미노산 내지 약 100개 아미노산의 총 길이를 가질 수 있다.
일부 구현예에서, 링커는 글리신(Gly 또는 G) 잔기가 풍부하다. 일부 구현예에서, 링커는 세린(Ser 또는 S) 잔기가 풍부하다. 일부 구현예에서, 링커는 글리신 및 세린 잔기가 풍부하다. 일부 구현예에서, 링커는 하나 이상의 글리신-세린 잔기 쌍(GS), 예를 들어, 1, 2, 3, 4, 5, 6, 7, 8, 9, 또는 10개 이상의 GS 쌍을 갖는다. 일부 구현예에서, 링커는 하나 이상의 Gly-Gly-Gly-Ser(GGGS)(SEQ ID NO: 99) 서열, 예를 들어, 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개 이상의 GGGS(SEQ ID NO: 99) 서열을 갖는다. 일부 구현예에서, 링커는 하나 이상의 Gly-Gly-Gly-Gly-Ser(GGGGS) 서열, 예를 들어, 1, 2, 3, 4, 5, 6, 7, 8, 9, 또는 10개 이상의 GGGGS(SEQ ID NO: 100) 서열을 갖는다. 일부 구현예에서, 링커는 하나 이상의 Gly-Gly-Ser-Gly(GGSG)(SEQ ID NO: 101) 서열, 예를 들어, 1개, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개 이상의 GGSG(SEQ ID NO: 101) 서열을 갖는다. 일부 구현예에서, 링커는 ggssrssssggggsgggg(SEQ ID NO: 222)를 포함한다.
일부 구현예에서, 링커 서열은 GGGGSGGGGSGGGGS(SEQ ID NO: 102)를 포함하거나 이로 구성될 수 있다. 일부 구현예에서, 링커 서열은 GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT(SEQ ID NO: 103)를 포함하거나 이로 구성된 핵산에 의해 인코딩될 수 있다. 일부 구현예에서, 링커 서열은 GGGSGGGS(SEQ ID NO: 104)를 포함하거나 이로 구성될 수 있다.
표적-결합 도메인
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및/또는 추가 하나 이상의 표적-결합 도메인은 항원-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 항원-결합 도메인), 가용성 인터류킨 또는 사이토카인 단백질(예를 들어, 본원에 기재된 임의의 예시적인 가용성 인터류킨 단백질 또는 가용성 사이토카인 단백질), 및 가용성 인터류킨 또는 사이토카인 수용체(예를 들어, 본원에 기재된 임의의 예시적인 가용성 인터류킨 수용체 또는 가용성 사이토카인 수용체)일 수 있다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및/또는 하나 이상의 추가 표적-결합 도메인은 서로 독립적으로 약 5개 아미노산 내지 약 1000개 아미노산, 약 5개 아미노산 내지 약 950개 아미노산, 약 5개 아미노산 내지 약 900개 아미노산, 약 5개 아미노산 내지 약 850개 아미노산, 약 5개 아미노산 내지 약 800개 아미노산, 약 5개 아미노산 내지 약 750개 아미노산, 약 5개 아미노산 내지 약 700개 아미노산, 약 5개 아미노산 내지 약 650개 아미노산, 약 5개 아미노산 내지 약 600개 아미노산, 약 5개 아미노산 내지 약 550개 아미노산, 약 5개 아미노산 내지 약 500개 아미노산, 약 5개 아미노산 내지 약 450개 아미노산, 약 5개 아미노산 내지 약 400개 아미노산, 약 5개 아미노산 내지 약 350개 아미노산, 약 5개 아미노산 내지 약 300개 아미노산, 약 5개 아미노산 내지 약 280개 아미노산, 약 5개 아미노산 내지 약 260개 아미노산, 약 5개 아미노산 내지 약 240개 아미노산, 약 5개 아미노산 내지 약 220개 아미노산, 약 5개 아미노산 내지 약 200개 아미노산, 약 5개 아미노산 내지 약 195개 아미노산, 약 5개 아미노산 내지 약 190개 아미노산, 약 5개 아미노산 내지 약 185개 아미노산, 약 5개 아미노산 내지 약 180개 아미노산, 약 5개 아미노산 내지 약 175개 아미노산, 약 5개 아미노산 내지 약 170개 아미노산, 약 5개 아미노산 내지 약 165개 아미노산, 약 5개 아미노산 내지 약 160개 아미노산, 약 5개 아미노산 내지 약 155개 아미노산, 약 5개 아미노산 내지 약 150개 아미노산, 약 5개 아미노산 내지 약 145개 아미노산, 약 5개 아미노산 내지 약 140개 아미노산, 약 5개 아미노산 내지 약 135개 아미노산, 약 5개 아미노산 내지 약 130개 아미노산, 약 5개 아미노산 내지 약 125개 아미노산, 약 5개 아미노산 내지 약 120개 아미노산, 약 5개 아미노산 내지 약 115개 아미노산, 약 5개 아미노산 내지 약 110개 아미노산, 약 5개 아미노산 내지 약 105개 아미노산, 약 5개 아미노산 내지 약 100개 아미노산, 약 5개 아미노산 내지 약 95개 아미노산, 약 5개 아미노산 내지 약 90개 아미노산, 약 5개 아미노산 내지 약 85개 아미노산, 약 5개 아미노산 내지 약 80개 아미노산, 약 5개 아미노산 내지 약 75개 아미노산, 약 5개 아미노산 내지 약 70개 아미노산, 약 5개 아미노산 내지 약 65개 아미노산, 약 5개 아미노산 내지 약 60개 아미노산, 약 5개 아미노산 내지 약 55개 아미노산, 약 5개 아미노산 내지 약 50개 아미노산, 약 5개 아미노산 내지 약 45개 아미노산, 약 5개 아미노산 내지 약 40개 아미노산, 약 5개 아미노산 내지 약 35개 아미노산, 약 5개 아미노산 내지 약 30개 아미노산, 약 5개 아미노산 내지 약 25개 아미노산, 약 5개 아미노산 내지 약 20개 아미노산, 약 5개 아미노산 내지 약 15개 아미노산, 약 5개 아미노산 내지 약 10개 아미노산, 약 10개 아미노산 내지 약 1000개 아미노산, 약 10개 아미노산 내지 약 950개 아미노산, 약 10개 아미노산 내지 약 900개 아미노산, 약 10개 아미노산 내지 약 850개 아미노산, 약 10개 아미노산 내지 약 800개 아미노산, 약 10개 아미노산 내지 약 750개 아미노산, 약 10개 아미노산 내지 약 700개 아미노산, 약 10개 아미노산 내지 약 650개 아미노산, 약 10개 아미노산 내지 약 600개 아미노산, 약 10개 아미노산 내지 약 550개 아미노산, 약 10개 아미노산 내지 약 500개 아미노산, 약 10개 아미노산 내지 약 450개 아미노산, 약 10개 아미노산 내지 약 400개 아미노산, 약 10개 아미노산 내지 약 350개 아미노산, 약 10개 아미노산 내지 약 300개 아미노산, 약 10개 아미노산 내지 약 280개 아미노산, 약 10개 아미노산 내지 약 260개 아미노산, 약 10개 아미노산 내지 약 240개 아미노산, 약 10개 아미노산 내지 약 220개 아미노산, 약 10개 아미노산 내지 약 200개 아미노산, 약 10개 아미노산 내지 약 195개 아미노산, 약 10개 아미노산 내지 약 190개 아미노산, 약 10개 아미노산 내지 약 185개 아미노산, 약 10개 아미노산 내지 약 180개 아미노산, 약 10개 아미노산 내지 약 175개 아미노산, 약 10개 아미노산 내지 약 170개 아미노산, 약 10개 아미노산 내지 약 165개 아미노산, 약 10개 아미노산 내지 약 160개 아미노산, 약 10개 아미노산 내지 약 155개 아미노산, 약 10개 아미노산 내지 약 150개 아미노산, 약 10개 아미노산 내지 약 145개 아미노산, 약 10개 아미노산 내지 약 140개 아미노산, 약 10개 아미노산 내지 약 135개 아미노산, 약 10개 아미노산 내지 약 130개 아미노산, 약 10개 아미노산 내지 약 125개 아미노산, 약 10개 아미노산 내지 약 120개 아미노산, 약 10개 아미노산 내지 약 115개 아미노산, 약 10개 아미노산 내지 약 110개 아미노산, 약 10개 아미노산 내지 약 105개 아미노산, 약 10개 아미노산 내지 약 100개 아미노산, 약 10개 아미노산 내지 약 95개 아미노산, 약 10개 아미노산 내지 약 90개 아미노산, 약 10개 아미노산 내지 약 85개 아미노산, 약 10개 아미노산 내지 약 80개 아미노산, 약 10개 아미노산 내지 약 75개 아미노산, 약 10개 아미노산 내지 약 70개 아미노산, 약 10개 아미노산 내지 약 65개 아미노산, 약 10개 아미노산 내지 약 60개 아미노산, 약 10개 아미노산 내지 약 55개 아미노산, 약 10개 아미노산 내지 약 50개 아미노산, 약 10개 아미노산 내지 약 45개 아미노산, 약 10개 아미노산 내지 약 40개 아미노산, 약 10개 아미노산 내지 약 35개 아미노산, 약 10개 아미노산 내지 약 30개 아미노산, 약 10개 아미노산 내지 약 25개 아미노산, 약 10개 아미노산 내지 약 20개 아미노산, 약 10개 아미노산 내지 약 15개 아미노산, 약 15개 아미노산 내지 약 1000개 아미노산, 약 15개 아미노산 내지 약 950개 아미노산, 약 15개 아미노산 내지 약 900개 아미노산, 약 15개 아미노산 내지 약 850개 아미노산, 약 15개 아미노산 내지 약 800개 아미노산, 약 15개 아미노산 내지 약 750개 아미노산, 약 15개 아미노산 내지 약 700개 아미노산, 약 15개 아미노산 내지 약 650개 아미노산, 약 15개 아미노산 내지 약 600개 아미노산, 약 15개 아미노산 내지 약 550개 아미노산, 약 15개 아미노산 내지 약 500개 아미노산, 약 15개 아미노산 내지 약 450개 아미노산, 약 15개 아미노산 내지 약 400개 아미노산, 약 15개 아미노산 내지 약 350개 아미노산, 약 15개 아미노산 내지 약 300개 아미노산, 약 15개 아미노산 내지 약 280개 아미노산, 약 15개 아미노산 내지 약 260개 아미노산, 약 15개 아미노산 내지 약 240개 아미노산, 약 15개 아미노산 내지 약 220개 아미노산, 약 15개 아미노산 내지 약 200개 아미노산, 약 15개 아미노산 내지 약 195개 아미노산, 약 15개 아미노산 내지 약 190개 아미노산, 약 15개 아미노산 내지 약 185개 아미노산, 약 15개 아미노산 내지 약 180개 아미노산, 약 15개 아미노산 내지 약 175개 아미노산, 약 15개 아미노산 내지 약 170개 아미노산, 약 15개 아미노산 내지 약 165개 아미노산, 약 15개 아미노산 내지 약 160개 아미노산, 약 15개 아미노산 내지 약 155개 아미노산, 약 15개 아미노산 내지 약 150개 아미노산, 약 15개 아미노산 내지 약 145개 아미노산, 약 15개 아미노산 내지 약 140개 아미노산, 약 15개 아미노산 내지 약 135개 아미노산, 약 15개 아미노산 내지 약 130개 아미노산, 약 15개 아미노산 내지 약 125개 아미노산, 약 15개 아미노산 내지 약 120개 아미노산, 약 15개 아미노산 내지 약 115개 아미노산, 약 15개 아미노산 내지 약 110개 아미노산, 약 15개 아미노산 내지 약 105개 아미노산, 약 15개 아미노산 내지 약 100개 아미노산, 약 15개 아미노산 내지 약 95개 아미노산, 약 15개 아미노산 내지 약 90개 아미노산, 약 15개 아미노산 내지 약 85개 아미노산, 약 15개 아미노산 내지 약 80개 아미노산, 약 15개 아미노산 내지 약 75개 아미노산, 약 15개 아미노산 내지 약 70개 아미노산, 약 15개 아미노산 내지 약 65개 아미노산, 약 15개 아미노산 내지 약 60개 아미노산, 약 15개 아미노산 내지 약 55개 아미노산, 약 15개 아미노산 내지 약 50개 아미노산, 약 15개 아미노산 내지 약 45개 아미노산, 약 15개 아미노산 내지 약 40개 아미노산, 약 15개 아미노산 내지 약 35개 아미노산, 약 15개 아미노산 내지 약 30개 아미노산, 약 15개 아미노산 내지 약 25개 아미노산, 약 15개 아미노산 내지 약 20개 아미노산, 약 20개 아미노산 내지 약 1000개 아미노산, 약 20개 아미노산 내지 약 950개 아미노산, 약 20개 아미노산 내지 약 900개 아미노산, 약 20개 아미노산 내지 약 850개 아미노산, 약 20개 아미노산 내지 약 800개 아미노산, 약 20개 아미노산 내지 약 750개 아미노산, 약 20개 아미노산 내지 약 700개 아미노산, 약 20개 아미노산 내지 약 650개 아미노산, 약 20개 아미노산 내지 약 600개 아미노산, 약 20개 아미노산 내지 약 550개 아미노산, 약 20개 아미노산 내지 약 500개 아미노산, 약 20개 아미노산 내지 약 450개 아미노산, 약 20개 아미노산 내지 약 400개 아미노산, 약 20개 아미노산 내지 약 350개 아미노산, 약 20개 아미노산 내지 약 300개 아미노산, 약 20개 아미노산 내지 약 280개 아미노산, 약 20개 아미노산 내지 약 260개 아미노산, 약 20개 아미노산 내지 약 240개 아미노산, 약 20개 아미노산 내지 약 220개 아미노산, 약 20개 아미노산 내지 약 200개 아미노산, 약 20개 아미노산 내지 약 195개 아미노산, 약 20개 아미노산 내지 약 190개 아미노산, 약 20개 아미노산 내지 약 185개 아미노산, 약 20개 아미노산 내지 약 180개 아미노산, 약 20개 아미노산 내지 약 175개 아미노산, 약 20개 아미노산 내지 약 170개 아미노산, 약 20개 아미노산 내지 약 165개 아미노산, 약 20개 아미노산 내지 약 160개 아미노산, 약 20개 아미노산 내지 약 155개 아미노산, 약 20개 아미노산 내지 약 150개 아미노산, 약 20개 아미노산 내지 약 145개 아미노산, 약 20개 아미노산 내지 약 140개 아미노산, 약 20개 아미노산 내지 약 135개 아미노산, 약 20개 아미노산 내지 약 130개 아미노산, 약 20개 아미노산 내지 약 125개 아미노산, 약 20개 아미노산 내지 약 120개 아미노산, 약 20개 아미노산 내지 약 115개 아미노산, 약 20개 아미노산 내지 약 110개 아미노산, 약 20개 아미노산 내지 약 105개 아미노산, 약 20개 아미노산 내지 약 100개 아미노산, 약 20개 아미노산 내지 약 95개 아미노산, 약 20개 아미노산 내지 약 90개 아미노산, 약 20개 아미노산 내지 약 85개 아미노산, 약 20개 아미노산 내지 약 80개 아미노산, 약 20개 아미노산 내지 약 75개 아미노산, 약 20개 아미노산 내지 약 70개 아미노산, 약 20개 아미노산 내지 약 65개 아미노산, 약 20개 아미노산 내지 약 60개 아미노산, 약 20개 아미노산 내지 약 55개 아미노산, 약 20개 아미노산 내지 약 50개 아미노산, 약 20개 아미노산 내지 약 45개 아미노산, 약 20개 아미노산 내지 약 40개 아미노산, 약 20개 아미노산 내지 약 35개 아미노산, 약 20개 아미노산 내지 약 30개 아미노산, 약 20개 아미노산 내지 약 25개 아미노산, 약 25개 아미노산 내지 약 1000개 아미노산, 약 25개 아미노산 내지 약 950개 아미노산, 약 25개 아미노산 내지 약 900개 아미노산, 약 25개 아미노산 내지 약 850개 아미노산, 약 25개 아미노산 내지 약 800개 아미노산, 약 25개 아미노산 내지 약 750개 아미노산, 약 25개 아미노산 내지 약 700개 아미노산, 약 25개 아미노산 내지 약 650개 아미노산, 약 25개 아미노산 내지 약 600개 아미노산, 약 25개 아미노산 내지 약 550개 아미노산, 약 25개 아미노산 내지 약 500개 아미노산, 약 25개 아미노산 내지 약 450개 아미노산, 약 25개 아미노산 내지 약 400개 아미노산, 약 25개 아미노산 내지 약 350개 아미노산, 약 25개 아미노산 내지 약 300개 아미노산, 약 25개 아미노산 내지 약 280개 아미노산, 약 25개 아미노산 내지 약 260개 아미노산, 약 25개 아미노산 내지 약 240개 아미노산, 약 25개 아미노산 내지 약 220개 아미노산, 약 25개 아미노산 내지 약 200개 아미노산, 약 25개 아미노산 내지 약 195개 아미노산, 약 25개 아미노산 내지 약 190개 아미노산, 약 25개 아미노산 내지 약 185개 아미노산, 약 25개 아미노산 내지 약 180개 아미노산, 약 25개 아미노산 내지 약 175개 아미노산, 약 25개 아미노산 내지 약 170개 아미노산, 약 25개 아미노산 내지 약 165개 아미노산, 약 25개 아미노산 내지 약 160개 아미노산, 약 25개 아미노산 내지 약 155개 아미노산, 약 25개 아미노산 내지 약 150개 아미노산, 약 25개 아미노산 내지 약 145개 아미노산, 약 25개 아미노산 내지 약 140개 아미노산, 약 25개 아미노산 내지 약 135개 아미노산, 약 25개 아미노산 내지 약 130개 아미노산, 약 25개 아미노산 내지 약 125개 아미노산, 약 25개 아미노산 내지 약 120개 아미노산, 약 25개 아미노산 내지 약 115개 아미노산, 약 25개 아미노산 내지 약 110개 아미노산, 약 25개 아미노산 내지 약 105개 아미노산, 약 25개 아미노산 내지 약 100개 아미노산, 약 25개 아미노산 내지 약 95개 아미노산, 약 25개 아미노산 내지 약 90개 아미노산, 약 25개 아미노산 내지 약 85개 아미노산, 약 25개 아미노산 내지 약 80개 아미노산, 약 25개 아미노산 내지 약 75개 아미노산, 약 25개 아미노산 내지 약 70개 아미노산, 약 25개 아미노산 내지 약 65개 아미노산, 약 25개 아미노산 내지 약 60개 아미노산, 약 25개 아미노산 내지 약 55개 아미노산, 약 25개 아미노산 내지 약 50개 아미노산, 약 25개 아미노산 내지 약 45개 아미노산, 약 25개 아미노산 내지 약 40개 아미노산, 약 25개 아미노산 내지 약 35개 아미노산, 약 25개 아미노산 내지 약 30개 아미노산, 약 30개 아미노산 내지 약 1000개 아미노산, 약 30개 아미노산 내지 약 950개 아미노산, 약 30개 아미노산 내지 약 900개 아미노산, 약 30개 아미노산 내지 약 850개 아미노산, 약 30개 아미노산 내지 약 800개 아미노산, 약 30개 아미노산 내지 약 750개 아미노산, 약 30개 아미노산 내지 약 700개 아미노산, 약 30개 아미노산 내지 약 650개 아미노산, 약 30개 아미노산 내지 약 600개 아미노산, 약 30개 아미노산 내지 약 550개 아미노산, 약 30개 아미노산 내지 약 500개 아미노산, 약 30개 아미노산 내지 약 450개 아미노산, 약 30개 아미노산 내지 약 400개 아미노산, 약 30개 아미노산 내지 약 350개 아미노산, 약 30개 아미노산 내지 약 300개 아미노산, 약 30개 아미노산 내지 약 280개 아미노산, 약 30개 아미노산 내지 약 260개 아미노산, 약 30개 아미노산 내지 약 240개 아미노산, 약 30개 아미노산 내지 약 220개 아미노산, 약 30개 아미노산 내지 약 200개 아미노산, 약 30개 아미노산 내지 약 195개 아미노산, 약 30개 아미노산 내지 약 190개 아미노산, 약 30개 아미노산 내지 약 185개 아미노산, 약 30개 아미노산 내지 약 180개 아미노산, 약 30개 아미노산 내지 약 175개 아미노산, 약 30개 아미노산 내지 약 170개 아미노산, 약 30개 아미노산 내지 약 165개 아미노산, 약 30개 아미노산 내지 약 160개 아미노산, 약 30개 아미노산 내지 약 155개 아미노산, 약 30개 아미노산 내지 약 150개 아미노산, 약 30개 아미노산 내지 약 145개 아미노산, 약 30개 아미노산 내지 약 140개 아미노산, 약 30개 아미노산 내지 약 135개 아미노산, 약 30개 아미노산 내지 약 130개 아미노산, 약 30개 아미노산 내지 약 125개 아미노산, 약 30개 아미노산 내지 약 120개 아미노산, 약 30개 아미노산 내지 약 115개 아미노산, 약 30개 아미노산 내지 약 110개 아미노산, 약 30개 아미노산 내지 약 105개 아미노산, 약 30개 아미노산 내지 약 100개 아미노산, 약 30개 아미노산 내지 약 95개 아미노산, 약 30개 아미노산 내지 약 90개 아미노산, 약 30개 아미노산 내지 약 85개 아미노산, 약 30개 아미노산 내지 약 80개 아미노산, 약 30개 아미노산 내지 약 75개 아미노산, 약 30개 아미노산 내지 약 70개 아미노산, 약 30개 아미노산 내지 약 65개 아미노산, 약 30개 아미노산 내지 약 60개 아미노산, 약 30개 아미노산 내지 약 55개 아미노산, 약 30개 아미노산 내지 약 50개 아미노산, 약 30개 아미노산 내지 약 45개 아미노산, 약 30개 아미노산 내지 약 40개 아미노산, 약 30개 아미노산 내지 약 35개 아미노산, 약 35개 아미노산 내지 약 1000개 아미노산, 약 35개 아미노산 내지 약 950개 아미노산, 약 35개 아미노산 내지 약 900개 아미노산, 약 35개 아미노산 내지 약 850개 아미노산, 약 35개 아미노산 내지 약 800개 아미노산, 약 35개 아미노산 내지 약 750개 아미노산, 약 35개 아미노산 내지 약 700개 아미노산, 약 35개 아미노산 내지 약 650개 아미노산, 약 35개 아미노산 내지 약 600개 아미노산, 약 35개 아미노산 내지 약 550개 아미노산, 약 35개 아미노산 내지 약 500개 아미노산, 약 35개 아미노산 내지 약 450개 아미노산, 약 35개 아미노산 내지 약 400개 아미노산, 약 35개 아미노산 내지 약 350개 아미노산, 약 35개 아미노산 내지 약 300개 아미노산, 약 35개 아미노산 내지 약 280개 아미노산, 약 35개 아미노산 내지 약 260개 아미노산, 약 35개 아미노산 내지 약 240개 아미노산, 약 35개 아미노산 내지 약 220개 아미노산, 약 35개 아미노산 내지 약 200개 아미노산, 약 35개 아미노산 내지 약 195개 아미노산, 약 35개 아미노산 내지 약 190개 아미노산, 약 35개 아미노산 내지 약 185개 아미노산, 약 35개 아미노산 내지 약 180개 아미노산, 약 35개 아미노산 내지 약 175개 아미노산, 약 35개 아미노산 내지 약 170개 아미노산, 약 35개 아미노산 내지 약 165개 아미노산, 약 35개 아미노산 내지 약 160개 아미노산, 약 35개 아미노산 내지 약 155개 아미노산, 약 35개 아미노산 내지 약 150개 아미노산, 약 35개 아미노산 내지 약 145개 아미노산, 약 35개 아미노산 내지 약 140개 아미노산, 약 35개 아미노산 내지 약 135개 아미노산, 약 35개 아미노산 내지 약 130개 아미노산, 약 35개 아미노산 내지 약 125개 아미노산, 약 35개 아미노산 내지 약 120개 아미노산, 약 35개 아미노산 내지 약 115개 아미노산, 약 35개 아미노산 내지 약 110개 아미노산, 약 35개 아미노산 내지 약 105개 아미노산, 약 35개 아미노산 내지 약 100개 아미노산, 약 35개 아미노산 내지 약 95개 아미노산, 약 35개 아미노산 내지 약 90개 아미노산, 약 35개 아미노산 내지 약 85개 아미노산, 약 35개 아미노산 내지 약 80개 아미노산, 약 35개 아미노산 내지 약 75개 아미노산, 약 35개 아미노산 내지 약 70개 아미노산, 약 35개 아미노산 내지 약 65개 아미노산, 약 35개 아미노산 내지 약 60개 아미노산, 약 35개 아미노산 내지 약 55개 아미노산, 약 35개 아미노산 내지 약 50개 아미노산, 약 35개 아미노산 내지 약 45개 아미노산, 약 35개 아미노산 내지 약 40개 아미노산, 약 40개 아미노산 내지 약 1000개 아미노산, 약 40개 아미노산 내지 약 950개 아미노산, 약 40개 아미노산 내지 약 900개 아미노산, 약 40개 아미노산 내지 약 850개 아미노산, 약 40개 아미노산 내지 약 800개 아미노산, 약 40개 아미노산 내지 약 750개 아미노산, 약 40개 아미노산 내지 약 700개 아미노산, 약 40개 아미노산 내지 약 650개 아미노산, 약 40개 아미노산 내지 약 600개 아미노산, 약 40개 아미노산 내지 약 550개 아미노산, 약 40개 아미노산 내지 약 500개 아미노산, 약 40개 아미노산 내지 약 450개 아미노산, 약 40개 아미노산 내지 약 400개 아미노산, 약 40개 아미노산 내지 약 350개 아미노산, 약 40개 아미노산 내지 약 300개 아미노산, 약 40개 아미노산 내지 약 280개 아미노산, 약 40개 아미노산 내지 약 260개 아미노산, 약 40개 아미노산 내지 약 240개 아미노산, 약 40개 아미노산 내지 약 220개 아미노산, 약 40개 아미노산 내지 약 200개 아미노산, 약 40개 아미노산 내지 약 195개 아미노산, 약 40개 아미노산 내지 약 190개 아미노산, 약 40개 아미노산 내지 약 185개 아미노산, 약 40개 아미노산 내지 약 180개 아미노산, 약 40개 아미노산 내지 약 175개 아미노산, 약 40개 아미노산 내지 약 170개 아미노산, 약 40개 아미노산 내지 약 165개 아미노산, 약 40개 아미노산 내지 약 160개 아미노산, 약 40개 아미노산 내지 약 155개 아미노산, 약 40개 아미노산 내지 약 150개 아미노산, 약 40개 아미노산 내지 약 145개 아미노산, 약 40개 아미노산 내지 약 140개 아미노산, 약 40개 아미노산 내지 약 135개 아미노산, 약 40개 아미노산 내지 약 130개 아미노산, 약 40개 아미노산 내지 약 125개 아미노산, 약 40개 아미노산 내지 약 120개 아미노산, 약 40개 아미노산 내지 약 115개 아미노산, 약 40개 아미노산 내지 약 110개 아미노산, 약 40개 아미노산 내지 약 105개 아미노산, 약 40개 아미노산 내지 약 100개 아미노산, 약 40개 아미노산 내지 약 95개 아미노산, 약 40개 아미노산 내지 약 90개 아미노산, 약 40개 아미노산 내지 약 85개 아미노산, 약 40개 아미노산 내지 약 80개 아미노산, 약 40개 아미노산 내지 약 75개 아미노산, 약 40개 아미노산 내지 약 70개 아미노산, 약 40개 아미노산 내지 약 65개 아미노산, 약 40개 아미노산 내지 약 60개 아미노산, 약 40개 아미노산 내지 약 55개 아미노산, 약 40개 아미노산 내지 약 50개 아미노산, 약 40개 아미노산 내지 약 45개 아미노산, 약 45개 아미노산 내지 약 1000개 아미노산, 약 45개 아미노산 내지 약 950개 아미노산, 약 45개 아미노산 내지 약 900개 아미노산, 약 45개 아미노산 내지 약 850개 아미노산, 약 45개 아미노산 내지 약 800개 아미노산, 약 45개 아미노산 내지 약 750개 아미노산, 약 45개 아미노산 내지 약 700개 아미노산, 약 45개 아미노산 내지 약 650개 아미노산, 약 45개 아미노산 내지 약 600개 아미노산, 약 45개 아미노산 내지 약 550개 아미노산, 약 45개 아미노산 내지 약 500개 아미노산, 약 45개 아미노산 내지 약 450개 아미노산, 약 45개 아미노산 내지 약 400개 아미노산, 약 45개 아미노산 내지 약 350개 아미노산, 약 45개 아미노산 내지 약 300개 아미노산, 약 45개 아미노산 내지 약 280개 아미노산, 약 45개 아미노산 내지 약 260개 아미노산, 약 45개 아미노산 내지 약 240개 아미노산, 약 45개 아미노산 내지 약 220개 아미노산, 약 45개 아미노산 내지 약 200개 아미노산, 약 45개 아미노산 내지 약 195개 아미노산, 약 45개 아미노산 내지 약 190개 아미노산, 약 45개 아미노산 내지 약 185개 아미노산, 약 45개 아미노산 내지 약 180개 아미노산, 약 45개 아미노산 내지 약 175개 아미노산, 약 45개 아미노산 내지 약 170개 아미노산, 약 45개 아미노산 내지 약 165개 아미노산, 약 45개 아미노산 내지 약 160개 아미노산, 약 45개 아미노산 내지 약 155개 아미노산, 약 45개 아미노산 내지 약 150개 아미노산, 약 45개 아미노산 내지 약 145개 아미노산, 약 45개 아미노산 내지 약 140개 아미노산, 약 45개 아미노산 내지 약 135개 아미노산, 약 45개 아미노산 내지 약 130개 아미노산, 약 45개 아미노산 내지 약 125개 아미노산, 약 45개 아미노산 내지 약 120개 아미노산, 약 45개 아미노산 내지 약 115개 아미노산, 약 45개 아미노산 내지 약 110개 아미노산, 약 45개 아미노산 내지 약 105개 아미노산, 약 45개 아미노산 내지 약 100개 아미노산, 약 45개 아미노산 내지 약 95개 아미노산, 약 45개 아미노산 내지 약 90개 아미노산, 약 45개 아미노산 내지 약 85개 아미노산, 약 45개 아미노산 내지 약 80개 아미노산, 약 45개 아미노산 내지 약 75개 아미노산, 약 45개 아미노산 내지 약 70개 아미노산, 약 45개 아미노산 내지 약 65개 아미노산, 약 45개 아미노산 내지 약 60개 아미노산, 약 45개 아미노산 내지 약 55개 아미노산, 약 45개 아미노산 내지 약 50개 아미노산, 약 50개 아미노산 내지 약 1000개 아미노산, 약 50개 아미노산 내지 약 950개 아미노산, 약 50개 아미노산 내지 약 900개 아미노산, 약 50개 아미노산 내지 약 850개 아미노산, 약 50개 아미노산 내지 약 800개 아미노산, 약 50개 아미노산 내지 약 750개 아미노산, 약 50개 아미노산 내지 약 700개 아미노산, 약 50개 아미노산 내지 약 650개 아미노산, 약 50개 아미노산 내지 약 600개 아미노산, 약 50개 아미노산 내지 약 550개 아미노산, 약 50개 아미노산 내지 약 500개 아미노산, 약 50개 아미노산 내지 약 450개 아미노산, 약 50개 아미노산 내지 약 400개 아미노산, 약 50개 아미노산 내지 약 350개 아미노산, 약 50개 아미노산 내지 약 300개 아미노산, 약 50개 아미노산 내지 약 280개 아미노산, 약 50개 아미노산 내지 약 260개 아미노산, 약 50개 아미노산 내지 약 240개 아미노산, 약 50개 아미노산 내지 약 220개 아미노산, 약 50개 아미노산 내지 약 200개 아미노산, 약 50개 아미노산 내지 약 195개 아미노산, 약 50개 아미노산 내지 약 190개 아미노산, 약 50개 아미노산 내지 약 185개 아미노산, 약 50개 아미노산 내지 약 180개 아미노산, 약 50개 아미노산 내지 약 175개 아미노산, 약 50개 아미노산 내지 약 170개 아미노산, 약 50개 아미노산 내지 약 165개 아미노산, 약 50개 아미노산 내지 약 160개 아미노산, 약 50개 아미노산 내지 약 155개 아미노산, 약 50개 아미노산 내지 약 150개 아미노산, 약 50개 아미노산 내지 약 145개 아미노산, 약 50개 아미노산 내지 약 140개 아미노산, 약 50개 아미노산 내지 약 135개 아미노산, 약 50개 아미노산 내지 약 130개 아미노산, 약 50개 아미노산 내지 약 125개 아미노산, 약 50개 아미노산 내지 약 120개 아미노산, 약 50개 아미노산 내지 약 115개 아미노산, 약 50개 아미노산 내지 약 110개 아미노산, 약 50개 아미노산 내지 약 105개 아미노산, 약 50개 아미노산 내지 약 100개 아미노산, 약 50개 아미노산 내지 약 95개 아미노산, 약 50개 아미노산 내지 약 90개 아미노산, 약 50개 아미노산 내지 약 85개 아미노산, 약 50개 아미노산 내지 약 80개 아미노산, 약 50개 아미노산 내지 약 75개 아미노산, 약 50개 아미노산 내지 약 70개 아미노산, 약 50개 아미노산 내지 약 65개 아미노산, 약 50개 아미노산 내지 약 60개 아미노산, 약 50개 아미노산 내지 약 55개 아미노산, 약 55개 아미노산 내지 약 1000개 아미노산, 약 55개 아미노산 내지 약 950개 아미노산, 약 55개 아미노산 내지 약 900개 아미노산, 약 55개 아미노산 내지 약 850개 아미노산, 약 55개 아미노산 내지 약 800개 아미노산, 약 55개 아미노산 내지 약 750개 아미노산, 약 55개 아미노산 내지 약 700개 아미노산, 약 55개 아미노산 내지 약 650개 아미노산, 약 55개 아미노산 내지 약 600개 아미노산, 약 55개 아미노산 내지 약 550개 아미노산, 약 55개 아미노산 내지 약 500개 아미노산, 약 55개 아미노산 내지 약 450개 아미노산, 약 55개 아미노산 내지 약 400개 아미노산, 약 55개 아미노산 내지 약 350개 아미노산, 약 55개 아미노산 내지 약 300개 아미노산, 약 55개 아미노산 내지 약 280개 아미노산, 약 55개 아미노산 내지 약 260개 아미노산, 약 55개 아미노산 내지 약 240개 아미노산, 약 55개 아미노산 내지 약 220개 아미노산, 약 55개 아미노산 내지 약 200개 아미노산, 약 55개 아미노산 내지 약 195개 아미노산, 약 55개 아미노산 내지 약 190개 아미노산, 약 55개 아미노산 내지 약 185개 아미노산, 약 55개 아미노산 내지 약 180개 아미노산, 약 55개 아미노산 내지 약 175개 아미노산, 약 55개 아미노산 내지 약 170개 아미노산, 약 55개 아미노산 내지 약 165개 아미노산, 약 55개 아미노산 내지 약 160개 아미노산, 약 55개 아미노산 내지 약 155개 아미노산, 약 55개 아미노산 내지 약 150개 아미노산, 약 55개 아미노산 내지 약 145개 아미노산, 약 55개 아미노산 내지 약 140개 아미노산, 약 55개 아미노산 내지 약 135개 아미노산, 약 55개 아미노산 내지 약 130개 아미노산, 약 55개 아미노산 내지 약 125개 아미노산, 약 55개 아미노산 내지 약 120개 아미노산, 약 55개 아미노산 내지 약 115개 아미노산, 약 55개 아미노산 내지 약 110개 아미노산, 약 55개 아미노산 내지 약 105개 아미노산, 약 55개 아미노산 내지 약 100개 아미노산, 약 55개 아미노산 내지 약 95개 아미노산, 약 55개 아미노산 내지 약 90개 아미노산, 약 55개 아미노산 내지 약 85개 아미노산, 약 55개 아미노산 내지 약 80개 아미노산, 약 55개 아미노산 내지 약 75개 아미노산, 약 55개 아미노산 내지 약 70개 아미노산, 약 55개 아미노산 내지 약 65개 아미노산, 약 55개 아미노산 내지 약 60개 아미노산, 약 60개 아미노산 내지 약 1000개 아미노산, 약 60개 아미노산 내지 약 950개 아미노산, 약 60개 아미노산 내지 약 900개 아미노산, 약 60개 아미노산 내지 약 850개 아미노산, 약 60개 아미노산 내지 약 800개 아미노산, 약 60개 아미노산 내지 약 750개 아미노산, 약 60개 아미노산 내지 약 700개 아미노산, 약 60개 아미노산 내지 약 650개 아미노산, 약 60개 아미노산 내지 약 600개 아미노산, 약 60개 아미노산 내지 약 550개 아미노산, 약 60개 아미노산 내지 약 500개 아미노산, 약 60개 아미노산 내지 약 450개 아미노산, 약 60개 아미노산 내지 약 400개 아미노산, 약 60개 아미노산 내지 약 350개 아미노산, 약 60개 아미노산 내지 약 300개 아미노산, 약 60개 아미노산 내지 약 280개 아미노산, 약 60개 아미노산 내지 약 260개 아미노산, 약 60개 아미노산 내지 약 240개 아미노산, 약 60개 아미노산 내지 약 220개 아미노산, 약 60개 아미노산 내지 약 200개 아미노산, 약 60개 아미노산 내지 약 195개 아미노산, 약 60개 아미노산 내지 약 190개 아미노산, 약 60개 아미노산 내지 약 185개 아미노산, 약 60개 아미노산 내지 약 180개 아미노산, 약 60개 아미노산 내지 약 175개 아미노산, 약 60개 아미노산 내지 약 170개 아미노산, 약 60개 아미노산 내지 약 165개 아미노산, 약 60개 아미노산 내지 약 160개 아미노산, 약 60개 아미노산 내지 약 155개 아미노산, 약 60개 아미노산 내지 약 150개 아미노산, 약 60개 아미노산 내지 약 145개 아미노산, 약 60개 아미노산 내지 약 140개 아미노산, 약 60개 아미노산 내지 약 135개 아미노산, 약 60개 아미노산 내지 약 130개 아미노산, 약 60개 아미노산 내지 약 125개 아미노산, 약 60개 아미노산 내지 약 120개 아미노산, 약 60개 아미노산 내지 약 115개 아미노산, 약 60개 아미노산 내지 약 110개 아미노산, 약 60개 아미노산 내지 약 105개 아미노산, 약 60개 아미노산 내지 약 100개 아미노산, 약 60개 아미노산 내지 약 95개 아미노산, 약 60개 아미노산 내지 약 90개 아미노산, 약 60개 아미노산 내지 약 85개 아미노산, 약 60개 아미노산 내지 약 80개 아미노산, 약 60개 아미노산 내지 약 75개 아미노산, 약 60개 아미노산 내지 약 70개 아미노산, 약 60개 아미노산 내지 약 65개 아미노산, 약 65개 아미노산 내지 약 1000개 아미노산, 약 65개 아미노산 내지 약 950개 아미노산, 약 65개 아미노산 내지 약 900개 아미노산, 약 65개 아미노산 내지 약 850개 아미노산, 약 65개 아미노산 내지 약 800개 아미노산, 약 65개 아미노산 내지 약 750개 아미노산, 약 65개 아미노산 내지 약 700개 아미노산, 약 65개 아미노산 내지 약 650개 아미노산, 약 65개 아미노산 내지 약 600개 아미노산, 약 65개 아미노산 내지 약 550개 아미노산, 약 65개 아미노산 내지 약 500개 아미노산, 약 65개 아미노산 내지 약 450개 아미노산, 약 65개 아미노산 내지 약 400개 아미노산, 약 65개 아미노산 내지 약 350개 아미노산, 약 65개 아미노산 내지 약 300개 아미노산, 약 65개 아미노산 내지 약 280개 아미노산, 약 65개 아미노산 내지 약 260개 아미노산, 약 65개 아미노산 내지 약 240개 아미노산, 약 65개 아미노산 내지 약 220개 아미노산, 약 65개 아미노산 내지 약 200개 아미노산, 약 65개 아미노산 내지 약 195개 아미노산, 약 65개 아미노산 내지 약 190개 아미노산, 약 65개 아미노산 내지 약 185개 아미노산, 약 65개 아미노산 내지 약 180개 아미노산, 약 65개 아미노산 내지 약 175개 아미노산, 약 65개 아미노산 내지 약 170개 아미노산, 약 65개 아미노산 내지 약 165개 아미노산, 약 65개 아미노산 내지 약 160개 아미노산, 약 65개 아미노산 내지 약 155개 아미노산, 약 65개 아미노산 내지 약 150개 아미노산, 약 65개 아미노산 내지 약 145개 아미노산, 약 65개 아미노산 내지 약 140개 아미노산, 약 65개 아미노산 내지 약 135개 아미노산, 약 65개 아미노산 내지 약 130개 아미노산, 약 65개 아미노산 내지 약 125개 아미노산, 약 65개 아미노산 내지 약 120개 아미노산, 약 65개 아미노산 내지 약 115개 아미노산, 약 65개 아미노산 내지 약 110개 아미노산, 약 65개 아미노산 내지 약 105개 아미노산, 약 65개 아미노산 내지 약 100개 아미노산, 약 65개 아미노산 내지 약 95개 아미노산, 약 65개 아미노산 내지 약 90개 아미노산, 약 65개 아미노산 내지 약 85개 아미노산, 약 65개 아미노산 내지 약 80개 아미노산, 약 65개 아미노산 내지 약 75개 아미노산, 약 65개 아미노산 내지 약 70개 아미노산, 약 70개 아미노산 내지 약 1000개 아미노산, 약 70개 아미노산 내지 약 950개 아미노산, 약 70개 아미노산 내지 약 900개 아미노산, 약 70개 아미노산 내지 약 850개 아미노산, 약 70개 아미노산 내지 약 800개 아미노산, 약 70개 아미노산 내지 약 750개 아미노산, 약 70개 아미노산 내지 약 700개 아미노산, 약 70개 아미노산 내지 약 650개 아미노산, 약 70개 아미노산 내지 약 600개 아미노산, 약 70개 아미노산 내지 약 550개 아미노산, 약 70개 아미노산 내지 약 500개 아미노산, 약 70개 아미노산 내지 약 450개 아미노산, 약 70개 아미노산 내지 약 400개 아미노산, 약 70개 아미노산 내지 약 350개 아미노산, 약 70개 아미노산 내지 약 300개 아미노산, 약 70개 아미노산 내지 약 280개 아미노산, 약 70개 아미노산 내지 약 260개 아미노산, 약 70개 아미노산 내지 약 240개 아미노산, 약 70개 아미노산 내지 약 220개 아미노산, 약 70개 아미노산 내지 약 200개 아미노산, 약 70개 아미노산 내지 약 195개 아미노산, 약 70개 아미노산 내지 약 190개 아미노산, 약 70개 아미노산 내지 약 185개 아미노산, 약 70개 아미노산 내지 약 180개 아미노산, 약 70개 아미노산 내지 약 175개 아미노산, 약 70개 아미노산 내지 약 170개 아미노산, 약 70개 아미노산 내지 약 165개 아미노산, 약 70개 아미노산 내지 약 160개 아미노산, 약 70개 아미노산 내지 약 155개 아미노산, 약 70개 아미노산 내지 약 150개 아미노산, 약 70개 아미노산 내지 약 145개 아미노산, 약 70개 아미노산 내지 약 140개 아미노산, 약 70개 아미노산 내지 약 135개 아미노산, 약 70개 아미노산 내지 약 130개 아미노산, 약 70개 아미노산 내지 약 125개 아미노산, 약 70개 아미노산 내지 약 120개 아미노산, 약 70개 아미노산 내지 약 115개 아미노산, 약 70개 아미노산 내지 약 110개 아미노산, 약 70개 아미노산 내지 약 105개 아미노산, 약 70개 아미노산 내지 약 100개 아미노산, 약 70개 아미노산 내지 약 95개 아미노산, 약 70개 아미노산 내지 약 90개 아미노산, 약 70개 아미노산 내지 약 85개 아미노산, 약 70개 아미노산 내지 약 80개 아미노산, 약 70개 아미노산 내지 약 75개 아미노산, 약 75개 아미노산 내지 약 1000개 아미노산, 약 75개 아미노산 내지 약 950개 아미노산, 약 75개 아미노산 내지 약 900개 아미노산, 약 75개 아미노산 내지 약 850개 아미노산, 약 75개 아미노산 내지 약 800개 아미노산, 약 75개 아미노산 내지 약 750개 아미노산, 약 75개 아미노산 내지 약 700개 아미노산, 약 75개 아미노산 내지 약 650개 아미노산, 약 75개 아미노산 내지 약 600개 아미노산, 약 75개 아미노산 내지 약 550개 아미노산, 약 75개 아미노산 내지 약 500개 아미노산, 약 75개 아미노산 내지 약 450개 아미노산, 약 75개 아미노산 내지 약 400개 아미노산, 약 75개 아미노산 내지 약 350개 아미노산, 약 75개 아미노산 내지 약 300개 아미노산, 약 75개 아미노산 내지 약 280개 아미노산, 약 75개 아미노산 내지 약 260개 아미노산, 약 75개 아미노산 내지 약 240개 아미노산, 약 75개 아미노산 내지 약 220개 아미노산, 약 75개 아미노산 내지 약 200개 아미노산, 약 75개 아미노산 내지 약 195개 아미노산, 약 75개 아미노산 내지 약 190개 아미노산, 약 75개 아미노산 내지 약 185개 아미노산, 약 75개 아미노산 내지 약 180개 아미노산, 약 75개 아미노산 내지 약 175개 아미노산, 약 75개 아미노산 내지 약 170개 아미노산, 약 75개 아미노산 내지 약 165개 아미노산, 약 75개 아미노산 내지 약 160개 아미노산, 약 75개 아미노산 내지 약 155개 아미노산, 약 75개 아미노산 내지 약 150개 아미노산, 약 75개 아미노산 내지 약 145개 아미노산, 약 75개 아미노산 내지 약 140개 아미노산, 약 75개 아미노산 내지 약 135개 아미노산, 약 75개 아미노산 내지 약 130개 아미노산, 약 75개 아미노산 내지 약 125개 아미노산, 약 75개 아미노산 내지 약 120개 아미노산, 약 75개 아미노산 내지 약 115개 아미노산, 약 75개 아미노산 내지 약 110개 아미노산, 약 75개 아미노산 내지 약 105개 아미노산, 약 75개 아미노산 내지 약 100개 아미노산, 약 75개 아미노산 내지 약 95개 아미노산, 약 75개 아미노산 내지 약 90개 아미노산, 약 75개 아미노산 내지 약 85개 아미노산, 약 75개 아미노산 내지 약 80개 아미노산, 약 80개 아미노산 내지 약 1000개 아미노산, 약 80개 아미노산 내지 약 950개 아미노산, 약 80개 아미노산 내지 약 900개 아미노산, 약 80개 아미노산 내지 약 850개 아미노산, 약 80개 아미노산 내지 약 800개 아미노산, 약 80개 아미노산 내지 약 750개 아미노산, 약 80개 아미노산 내지 약 700개 아미노산, 약 80개 아미노산 내지 약 650개 아미노산, 약 80개 아미노산 내지 약 600개 아미노산, 약 80개 아미노산 내지 약 550개 아미노산, 약 80개 아미노산 내지 약 500개 아미노산, 약 80개 아미노산 내지 약 450개 아미노산, 약 80개 아미노산 내지 약 400개 아미노산, 약 80개 아미노산 내지 약 350개 아미노산, 약 80개 아미노산 내지 약 300개 아미노산, 약 80개 아미노산 내지 약 280개 아미노산, 약 80개 아미노산 내지 약 260개 아미노산, 약 80개 아미노산 내지 약 240개 아미노산, 약 80개 아미노산 내지 약 220개 아미노산, 약 80개 아미노산 내지 약 200개 아미노산, 약 80개 아미노산 내지 약 195개 아미노산, 약 80개 아미노산 내지 약 190개 아미노산, 약 80개 아미노산 내지 약 185개 아미노산, 약 80개 아미노산 내지 약 180개 아미노산, 약 80개 아미노산 내지 약 175개 아미노산, 약 80개 아미노산 내지 약 170개 아미노산, 약 80개 아미노산 내지 약 165개 아미노산, 약 80개 아미노산 내지 약 160개 아미노산, 약 80개 아미노산 내지 약 155개 아미노산, 약 80개 아미노산 내지 약 150개 아미노산, 약 80개 아미노산 내지 약 145개 아미노산, 약 80개 아미노산 내지 약 140개 아미노산, 약 80개 아미노산 내지 약 135개 아미노산, 약 80개 아미노산 내지 약 130개 아미노산, 약 80개 아미노산 내지 약 125개 아미노산, 약 80개 아미노산 내지 약 120개 아미노산, 약 80개 아미노산 내지 약 115개 아미노산, 약 80개 아미노산 내지 약 110개 아미노산, 약 80개 아미노산 내지 약 105개 아미노산, 약 80개 아미노산 내지 약 100개 아미노산, 약 80개 아미노산 내지 약 95개 아미노산, 약 80개 아미노산 내지 약 90개 아미노산, 약 80개 아미노산 내지 약 85개 아미노산, 약 85개 아미노산 내지 약 1000개 아미노산, 약 85개 아미노산 내지 약 950개 아미노산, 약 85개 아미노산 내지 약 900개 아미노산, 약 85개 아미노산 내지 약 850개 아미노산, 약 85개 아미노산 내지 약 800개 아미노산, 약 85개 아미노산 내지 약 750개 아미노산, 약 85개 아미노산 내지 약 700개 아미노산, 약 85개 아미노산 내지 약 650개 아미노산, 약 85개 아미노산 내지 약 600개 아미노산, 약 85개 아미노산 내지 약 550개 아미노산, 약 85개 아미노산 내지 약 500개 아미노산, 약 85개 아미노산 내지 약 450개 아미노산, 약 85개 아미노산 내지 약 400개 아미노산, 약 85개 아미노산 내지 약 350개 아미노산, 약 85개 아미노산 내지 약 300개 아미노산, 약 85개 아미노산 내지 약 280개 아미노산, 약 85개 아미노산 내지 약 260개 아미노산, 약 85개 아미노산 내지 약 240개 아미노산, 약 85개 아미노산 내지 약 220개 아미노산, 약 85개 아미노산 내지 약 200개 아미노산, 약 85개 아미노산 내지 약 195개 아미노산, 약 85개 아미노산 내지 약 190개 아미노산, 약 85개 아미노산 내지 약 185개 아미노산, 약 85개 아미노산 내지 약 180개 아미노산, 약 85개 아미노산 내지 약 175개 아미노산, 약 85개 아미노산 내지 약 170개 아미노산, 약 85개 아미노산 내지 약 165개 아미노산, 약 85개 아미노산 내지 약 160개 아미노산, 약 85개 아미노산 내지 약 155개 아미노산, 약 85개 아미노산 내지 약 150개 아미노산, 약 85개 아미노산 내지 약 145개 아미노산, 약 85개 아미노산 내지 약 140개 아미노산, 약 85개 아미노산 내지 약 135개 아미노산, 약 85개 아미노산 내지 약 130개 아미노산, 약 85개 아미노산 내지 약 125개 아미노산, 약 85개 아미노산 내지 약 120개 아미노산, 약 85개 아미노산 내지 약 115개 아미노산, 약 85개 아미노산 내지 약 110개 아미노산, 약 85개 아미노산 내지 약 105개 아미노산, 약 85개 아미노산 내지 약 100개 아미노산, 약 85개 아미노산 내지 약 95개 아미노산, 약 85개 아미노산 내지 약 90개 아미노산, 약 90개 아미노산 내지 약 1000개 아미노산, 약 90개 아미노산 내지 약 950개 아미노산, 약 90개 아미노산 내지 약 900개 아미노산, 약 90개 아미노산 내지 약 850개 아미노산, 약 90개 아미노산 내지 약 800개 아미노산, 약 90개 아미노산 내지 약 750개 아미노산, 약 90개 아미노산 내지 약 700개 아미노산, 약 90개 아미노산 내지 약 650개 아미노산, 약 90개 아미노산 내지 약 600개 아미노산, 약 90개 아미노산 내지 약 550개 아미노산, 약 90개 아미노산 내지 약 500개 아미노산, 약 90개 아미노산 내지 약 450개 아미노산, 약 90개 아미노산 내지 약 400개 아미노산, 약 90개 아미노산 내지 약 350개 아미노산, 약 90개 아미노산 내지 약 300개 아미노산, 약 90개 아미노산 내지 약 280개 아미노산, 약 90개 아미노산 내지 약 260개 아미노산, 약 90개 아미노산 내지 약 240개 아미노산, 약 90개 아미노산 내지 약 220개 아미노산, 약 90개 아미노산 내지 약 200개 아미노산, 약 90개 아미노산 내지 약 195개 아미노산, 약 90개 아미노산 내지 약 190개 아미노산, 약 90개 아미노산 내지 약 185개 아미노산, 약 90개 아미노산 내지 약 180개 아미노산, 약 90개 아미노산 내지 약 175개 아미노산, 약 90개 아미노산 내지 약 170개 아미노산, 약 90개 아미노산 내지 약 165개 아미노산, 약 90개 아미노산 내지 약 160개 아미노산, 약 90개 아미노산 내지 약 155개 아미노산, 약 90개 아미노산 내지 약 150개 아미노산, 약 90개 아미노산 내지 약 145개 아미노산, 약 90개 아미노산 내지 약 140개 아미노산, 약 90개 아미노산 내지 약 135개 아미노산, 약 90개 아미노산 내지 약 130개 아미노산, 약 90개 아미노산 내지 약 125개 아미노산, 약 90개 아미노산 내지 약 120개 아미노산, 약 90개 아미노산 내지 약 115개 아미노산, 약 90개 아미노산 내지 약 110개 아미노산, 약 90개 아미노산 내지 약 105개 아미노산, 약 90개 아미노산 내지 약 100개 아미노산, 약 90개 아미노산 내지 약 95개 아미노산, 약 95개 아미노산 내지 약 1000개 아미노산, 약 95개 아미노산 내지 약 950개 아미노산, 약 95개 아미노산 내지 약 900개 아미노산, 약 95개 아미노산 내지 약 850개 아미노산, 약 95개 아미노산 내지 약 800개 아미노산, 약 95개 아미노산 내지 약 750개 아미노산, 약 95개 아미노산 내지 약 700개 아미노산, 약 95개 아미노산 내지 약 650개 아미노산, 약 95개 아미노산 내지 약 600개 아미노산, 약 95개 아미노산 내지 약 550개 아미노산, 약 95개 아미노산 내지 약 500개 아미노산, 약 95개 아미노산 내지 약 450개 아미노산, 약 95개 아미노산 내지 약 400개 아미노산, 약 95개 아미노산 내지 약 350개 아미노산, 약 95개 아미노산 내지 약 300개 아미노산, 약 95개 아미노산 내지 약 280개 아미노산, 약 95개 아미노산 내지 약 260개 아미노산, 약 95개 아미노산 내지 약 240개 아미노산, 약 95개 아미노산 내지 약 220개 아미노산, 약 95개 아미노산 내지 약 200개 아미노산, 약 95개 아미노산 내지 약 195개 아미노산, 약 95개 아미노산 내지 약 190개 아미노산, 약 95개 아미노산 내지 약 185개 아미노산, 약 95개 아미노산 내지 약 180개 아미노산, 약 95개 아미노산 내지 약 175개 아미노산, 약 95개 아미노산 내지 약 170개 아미노산, 약 95개 아미노산 내지 약 165개 아미노산, 약 95개 아미노산 내지 약 160개 아미노산, 약 95개 아미노산 내지 약 155개 아미노산, 약 95개 아미노산 내지 약 150개 아미노산, 약 95개 아미노산 내지 약 145개 아미노산, 약 95개 아미노산 내지 약 140개 아미노산, 약 95개 아미노산 내지 약 135개 아미노산, 약 95개 아미노산 내지 약 130개 아미노산, 약 95개 아미노산 내지 약 125개 아미노산, 약 95개 아미노산 내지 약 120개 아미노산, 약 95개 아미노산 내지 약 115개 아미노산, 약 95개 아미노산 내지 약 110개 아미노산, 약 95개 아미노산 내지 약 105개 아미노산, 약 95개 아미노산 내지 약 100개 아미노산, 약 100개 아미노산 내지 약 1000개 아미노산, 약 100개 아미노산 내지 약 950개 아미노산, 약 100개 아미노산 내지 약 900개 아미노산, 약 100개 아미노산 내지 약 850개 아미노산, 약 100개 아미노산 내지 약 800개 아미노산, 약 100개 아미노산 내지 약 750개 아미노산, 약 100개 아미노산 내지 약 700개 아미노산, 약 100개 아미노산 내지 약 650개 아미노산, 약 100개 아미노산 내지 약 600개 아미노산, 약 100개 아미노산 내지 약 550개 아미노산, 약 100개 아미노산 내지 약 500개 아미노산, 약 100개 아미노산 내지 약 450개 아미노산, 약 100개 아미노산 내지 약 400개 아미노산, 약 100개 아미노산 내지 약 350개 아미노산, 약 100개 아미노산 내지 약 300개 아미노산, 약 100개 아미노산 내지 약 280개 아미노산, 약 100개 아미노산 내지 약 260개 아미노산, 약 100개 아미노산 내지 약 240개 아미노산, 약 100개 아미노산 내지 약 220개 아미노산, 약 100개 아미노산 내지 약 200개 아미노산, 약 100개 아미노산 내지 약 195개 아미노산, 약 100개 아미노산 내지 약 190개 아미노산, 약 100개 아미노산 내지 약 185개 아미노산, 약 100개 아미노산 내지 약 180개 아미노산, 약 100개 아미노산 내지 약 175개 아미노산, 약 100개 아미노산 내지 약 170개 아미노산, 약 100개 아미노산 내지 약 165개 아미노산, 약 100개 아미노산 내지 약 160개 아미노산, 약 100개 아미노산 내지 약 155개 아미노산, 약 100개 아미노산 내지 약 150개 아미노산, 약 100개 아미노산 내지 약 145개 아미노산, 약 100개 아미노산 내지 약 140개 아미노산, 약 100개 아미노산 내지 약 135개 아미노산, 약 100개 아미노산 내지 약 130개 아미노산, 약 100개 아미노산 내지 약 125개 아미노산, 약 100개 아미노산 내지 약 120개 아미노산, 약 100개 아미노산 내지 약 115개 아미노산, 약 100개 아미노산 내지 약 110개 아미노산, 약 100개 아미노산 내지 약 105개 아미노산, 약 105개 아미노산 내지 약 1000개 아미노산, 약 105개 아미노산 내지 약 950개 아미노산, 약 105개 아미노산 내지 약 900개 아미노산, 약 105개 아미노산 내지 약 850개 아미노산, 약 105개 아미노산 내지 약 800개 아미노산, 약 105개 아미노산 내지 약 750개 아미노산, 약 105개 아미노산 내지 약 700개 아미노산, 약 105개 아미노산 내지 약 650개 아미노산, 약 105개 아미노산 내지 약 600개 아미노산, 약 105개 아미노산 내지 약 550개 아미노산, 약 105개 아미노산 내지 약 500개 아미노산, 약 105개 아미노산 내지 약 450개 아미노산, 약 105개 아미노산 내지 약 400개 아미노산, 약 105개 아미노산 내지 약 350개 아미노산, 약 105개 아미노산 내지 약 300개 아미노산, 약 105개 아미노산 내지 약 280개 아미노산, 약 105개 아미노산 내지 약 260개 아미노산, 약 105개 아미노산 내지 약 240개 아미노산, 약 105개 아미노산 내지 약 220개 아미노산, 약 105개 아미노산 내지 약 200개 아미노산, 약 105개 아미노산 내지 약 195개 아미노산, 약 105개 아미노산 내지 약 190개 아미노산, 약 105개 아미노산 내지 약 185개 아미노산, 약 105개 아미노산 내지 약 180개 아미노산, 약 105개 아미노산 내지 약 175개 아미노산, 약 105개 아미노산 내지 약 170개 아미노산, 약 105개 아미노산 내지 약 165개 아미노산, 약 105개 아미노산 내지 약 160개 아미노산, 약 105개 아미노산 내지 약 155개 아미노산, 약 105개 아미노산 내지 약 150개 아미노산, 약 105개 아미노산 내지 약 145개 아미노산, 약 105개 아미노산 내지 약 140개 아미노산, 약 105개 아미노산 내지 약 135개 아미노산, 약 105개 아미노산 내지 약 130개 아미노산, 약 105개 아미노산 내지 약 125개 아미노산, 약 105개 아미노산 내지 약 120개 아미노산, 약 105개 아미노산 내지 약 115개 아미노산, 약 105개 아미노산 내지 약 110개 아미노산, 약 110개 아미노산 내지 약 1000개 아미노산, 약 110개 아미노산 내지 약 950개 아미노산, 약 110개 아미노산 내지 약 900개 아미노산, 약 110개 아미노산 내지 약 850개 아미노산, 약 110개 아미노산 내지 약 800개 아미노산, 약 110개 아미노산 내지 약 750개 아미노산, 약 110개 아미노산 내지 약 700개 아미노산, 약 110개 아미노산 내지 약 650개 아미노산, 약 110개 아미노산 내지 약 600개 아미노산, 약 110개 아미노산 내지 약 550개 아미노산, 약 110개 아미노산 내지 약 500개 아미노산, 약 110개 아미노산 내지 약 450개 아미노산, 약 110개 아미노산 내지 약 400개 아미노산, 약 110개 아미노산 내지 약 350개 아미노산, 약 110개 아미노산 내지 약 300개 아미노산, 약 110개 아미노산 내지 약 280개 아미노산, 약 110개 아미노산 내지 약 260개 아미노산, 약 110개 아미노산 내지 약 240개 아미노산, 약 110개 아미노산 내지 약 220개 아미노산, 약 110개 아미노산 내지 약 200개 아미노산, 약 110개 아미노산 내지 약 195개 아미노산, 약 110개 아미노산 내지 약 190개 아미노산, 약 110개 아미노산 내지 약 185개 아미노산, 약 110개 아미노산 내지 약 180개 아미노산, 약 110개 아미노산 내지 약 175개 아미노산, 약 110개 아미노산 내지 약 170개 아미노산, 약 110개 아미노산 내지 약 165개 아미노산, 약 110개 아미노산 내지 약 160개 아미노산, 약 110개 아미노산 내지 약 155개 아미노산, 약 110개 아미노산 내지 약 150개 아미노산, 약 110개 아미노산 내지 약 145개 아미노산, 약 110개 아미노산 내지 약 140개 아미노산, 약 110개 아미노산 내지 약 135개 아미노산, 약 110개 아미노산 내지 약 130개 아미노산, 약 110개 아미노산 내지 약 125개 아미노산, 약 110개 아미노산 내지 약 120개 아미노산, 약 110개 아미노산 내지 약 115개 아미노산, 약 115개 아미노산 내지 약 1000개 아미노산, 약 115개 아미노산 내지 약 950개 아미노산, 약 115개 아미노산 내지 약 900개 아미노산, 약 115개 아미노산 내지 약 850개 아미노산, 약 115개 아미노산 내지 약 800개 아미노산, 약 115개 아미노산 내지 약 750개 아미노산, 약 115개 아미노산 내지 약 700개 아미노산, 약 115개 아미노산 내지 약 650개 아미노산, 약 115개 아미노산 내지 약 600개 아미노산, 약 115개 아미노산 내지 약 550개 아미노산, 약 115개 아미노산 내지 약 500개 아미노산, 약 115개 아미노산 내지 약 450개 아미노산, 약 115개 아미노산 내지 약 400개 아미노산, 약 115개 아미노산 내지 약 350개 아미노산, 약 115개 아미노산 내지 약 300개 아미노산, 약 115개 아미노산 내지 약 280개 아미노산, 약 115개 아미노산 내지 약 260개 아미노산, 약 115개 아미노산 내지 약 240개 아미노산, 약 115개 아미노산 내지 약 220개 아미노산, 약 115개 아미노산 내지 약 200개 아미노산, 약 115개 아미노산 내지 약 195개 아미노산, 약 115개 아미노산 내지 약 190개 아미노산, 약 115개 아미노산 내지 약 185개 아미노산, 약 115개 아미노산 내지 약 180개 아미노산, 약 115개 아미노산 내지 약 175개 아미노산, 약 115개 아미노산 내지 약 170개 아미노산, 약 115개 아미노산 내지 약 165개 아미노산, 약 115개 아미노산 내지 약 160개 아미노산, 약 115개 아미노산 내지 약 155개 아미노산, 약 115개 아미노산 내지 약 150개 아미노산, 약 115개 아미노산 내지 약 145개 아미노산, 약 115개 아미노산 내지 약 140개 아미노산, 약 115개 아미노산 내지 약 135개 아미노산, 약 115개 아미노산 내지 약 130개 아미노산, 약 115개 아미노산 내지 약 125개 아미노산, 약 115개 아미노산 내지 약 120개 아미노산, 약 120개 아미노산 내지 약 1000개 아미노산, 약 120개 아미노산 내지 약 950개 아미노산, 약 120개 아미노산 내지 약 900개 아미노산, 약 120개 아미노산 내지 약 850개 아미노산, 약 120개 아미노산 내지 약 800개 아미노산, 약 120개 아미노산 내지 약 750개 아미노산, 약 120개 아미노산 내지 약 700개 아미노산, 약 120개 아미노산 내지 약 650개 아미노산, 약 120개 아미노산 내지 약 600개 아미노산, 약 120개 아미노산 내지 약 550개 아미노산, 약 120개 아미노산 내지 약 500개 아미노산, 약 120개 아미노산 내지 약 450개 아미노산, 약 120개 아미노산 내지 약 400개 아미노산, 약 120개 아미노산 내지 약 350개 아미노산, 약 120개 아미노산 내지 약 300개 아미노산, 약 120개 아미노산 내지 약 280개 아미노산, 약 120개 아미노산 내지 약 260개 아미노산, 약 120개 아미노산 내지 약 240개 아미노산, 약 120개 아미노산 내지 약 220개 아미노산, 약 120개 아미노산 내지 약 200개 아미노산, 약 120개 아미노산 내지 약 195개 아미노산, 약 120개 아미노산 내지 약 190개 아미노산, 약 120개 아미노산 내지 약 185개 아미노산, 약 120개 아미노산 내지 약 180개 아미노산, 약 120개 아미노산 내지 약 175개 아미노산, 약 120개 아미노산 내지 약 170개 아미노산, 약 120개 아미노산 내지 약 165개 아미노산, 약 120개 아미노산 내지 약 160개 아미노산, 약 120개 아미노산 내지 약 155개 아미노산, 약 120개 아미노산 내지 약 150개 아미노산, 약 120개 아미노산 내지 약 145개 아미노산, 약 120개 아미노산 내지 약 140개 아미노산, 약 120개 아미노산 내지 약 135개 아미노산, 약 120개 아미노산 내지 약 130개 아미노산, 약 120개 아미노산 내지 약 125개 아미노산, 약 125개 아미노산 내지 약 1000개 아미노산, 약 125개 아미노산 내지 약 950개 아미노산, 약 125개 아미노산 내지 약 900개 아미노산, 약 125개 아미노산 내지 약 850개 아미노산, 약 125개 아미노산 내지 약 800개 아미노산, 약 125개 아미노산 내지 약 750개 아미노산, 약 125개 아미노산 내지 약 700개 아미노산, 약 125개 아미노산 내지 약 650개 아미노산, 약 125개 아미노산 내지 약 600개 아미노산, 약 125개 아미노산 내지 약 550개 아미노산, 약 125개 아미노산 내지 약 500개 아미노산, 약 125개 아미노산 내지 약 450개 아미노산, 약 125개 아미노산 내지 약 400개 아미노산, 약 125개 아미노산 내지 약 350개 아미노산, 약 125개 아미노산 내지 약 300개 아미노산, 약 125개 아미노산 내지 약 280개 아미노산, 약 125개 아미노산 내지 약 260개 아미노산, 약 125개 아미노산 내지 약 240개 아미노산, 약 125개 아미노산 내지 약 220개 아미노산, 약 125개 아미노산 내지 약 200개 아미노산, 약 125개 아미노산 내지 약 195개 아미노산, 약 125개 아미노산 내지 약 190개 아미노산, 약 125개 아미노산 내지 약 185개 아미노산, 약 125개 아미노산 내지 약 180개 아미노산, 약 125개 아미노산 내지 약 175개 아미노산, 약 125개 아미노산 내지 약 170개 아미노산, 약 125개 아미노산 내지 약 165개 아미노산, 약 125개 아미노산 내지 약 160개 아미노산, 약 125개 아미노산 내지 약 155개 아미노산, 약 125개 아미노산 내지 약 150개 아미노산, 약 125개 아미노산 내지 약 145개 아미노산, 약 125개 아미노산 내지 약 140개 아미노산, 약 125개 아미노산 내지 약 135개 아미노산, 약 125개 아미노산 내지 약 130개 아미노산, 약 130개 아미노산 내지 약 1000개 아미노산, 약 130개 아미노산 내지 약 950개 아미노산, 약 130개 아미노산 내지 약 900개 아미노산, 약 130개 아미노산 내지 약 850개 아미노산, 약 130개 아미노산 내지 약 800개 아미노산, 약 130개 아미노산 내지 약 750개 아미노산, 약 130개 아미노산 내지 약 700개 아미노산, 약 130개 아미노산 내지 약 650개 아미노산, 약 130개 아미노산 내지 약 600개 아미노산, 약 130개 아미노산 내지 약 550개 아미노산, 약 130개 아미노산 내지 약 500개 아미노산, 약 130개 아미노산 내지 약 450개 아미노산, 약 130개 아미노산 내지 약 400개 아미노산, 약 130개 아미노산 내지 약 350개 아미노산, 약 130개 아미노산 내지 약 300개 아미노산, 약 130개 아미노산 내지 약 280개 아미노산, 약 130개 아미노산 내지 약 260개 아미노산, 약 130개 아미노산 내지 약 240개 아미노산, 약 130개 아미노산 내지 약 220개 아미노산, 약 130개 아미노산 내지 약 200개 아미노산, 약 130개 아미노산 내지 약 195개 아미노산, 약 130개 아미노산 내지 약 190개 아미노산, 약 130개 아미노산 내지 약 185개 아미노산, 약 130개 아미노산 내지 약 180개 아미노산, 약 130개 아미노산 내지 약 175개 아미노산, 약 130개 아미노산 내지 약 170개 아미노산, 약 130개 아미노산 내지 약 165개 아미노산, 약 130개 아미노산 내지 약 160개 아미노산, 약 130개 아미노산 내지 약 155개 아미노산, 약 130개 아미노산 내지 약 150개 아미노산, 약 130개 아미노산 내지 약 145개 아미노산, 약 130개 아미노산 내지 약 140개 아미노산, 약 130개 아미노산 내지 약 135개 아미노산, 약 135개 아미노산 내지 약 1000개 아미노산, 약 135개 아미노산 내지 약 950개 아미노산, 약 135개 아미노산 내지 약 900개 아미노산, 약 135개 아미노산 내지 약 850개 아미노산, 약 135개 아미노산 내지 약 800개 아미노산, 약 135개 아미노산 내지 약 750개 아미노산, 약 135개 아미노산 내지 약 700개 아미노산, 약 135개 아미노산 내지 약 650개 아미노산, 약 135개 아미노산 내지 약 600개 아미노산, 약 135개 아미노산 내지 약 550개 아미노산, 약 135개 아미노산 내지 약 500개 아미노산, 약 135개 아미노산 내지 약 450개 아미노산, 약 135개 아미노산 내지 약 400개 아미노산, 약 135개 아미노산 내지 약 350개 아미노산, 약 135개 아미노산 내지 약 300개 아미노산, 약 135개 아미노산 내지 약 280개 아미노산, 약 135개 아미노산 내지 약 260개 아미노산, 약 135개 아미노산 내지 약 240개 아미노산, 약 135개 아미노산 내지 약 220개 아미노산, 약 135개 아미노산 내지 약 200개 아미노산, 약 135개 아미노산 내지 약 195개 아미노산, 약 135개 아미노산 내지 약 190개 아미노산, 약 135개 아미노산 내지 약 185개 아미노산, 약 135개 아미노산 내지 약 180개 아미노산, 약 135개 아미노산 내지 약 175개 아미노산, 약 135개 아미노산 내지 약 170개 아미노산, 약 135개 아미노산 내지 약 165개 아미노산, 약 135개 아미노산 내지 약 160개 아미노산, 약 135개 아미노산 내지 약 155개 아미노산, 약 135개 아미노산 내지 약 150개 아미노산, 약 135개 아미노산 내지 약 145개 아미노산, 약 135개 아미노산 내지 약 140개 아미노산, 약 140개 아미노산 내지 약 1000개 아미노산, 약 140개 아미노산 내지 약 950개 아미노산, 약 140개 아미노산 내지 약 900개 아미노산, 약 140개 아미노산 내지 약 850개 아미노산, 약 140개 아미노산 내지 약 800개 아미노산, 약 140개 아미노산 내지 약 750개 아미노산, 약 140개 아미노산 내지 약 700개 아미노산, 약 140개 아미노산 내지 약 650개 아미노산, 약 140개 아미노산 내지 약 600개 아미노산, 약 140개 아미노산 내지 약 550개 아미노산, 약 140개 아미노산 내지 약 500개 아미노산, 약 140개 아미노산 내지 약 450개 아미노산, 약 140개 아미노산 내지 약 400개 아미노산, 약 140개 아미노산 내지 약 350개 아미노산, 약 140개 아미노산 내지 약 300개 아미노산, 약 140개 아미노산 내지 약 280개 아미노산, 약 140개 아미노산 내지 약 260개 아미노산, 약 140개 아미노산 내지 약 240개 아미노산, 약 140개 아미노산 내지 약 220개 아미노산, 약 140개 아미노산 내지 약 200개 아미노산, 약 140개 아미노산 내지 약 195개 아미노산, 약 140개 아미노산 내지 약 190개 아미노산, 약 140개 아미노산 내지 약 185개 아미노산, 약 140개 아미노산 내지 약 180개 아미노산, 약 140개 아미노산 내지 약 175개 아미노산, 약 140개 아미노산 내지 약 170개 아미노산, 약 140개 아미노산 내지 약 165개 아미노산, 약 140개 아미노산 내지 약 160개 아미노산, 약 140개 아미노산 내지 약 155개 아미노산, 약 140개 아미노산 내지 약 150개 아미노산, 약 140개 아미노산 내지 약 145개 아미노산, 약 145개 아미노산 내지 약 1000개 아미노산, 약 145개 아미노산 내지 약 950개 아미노산, 약 145개 아미노산 내지 약 900개 아미노산, 약 145개 아미노산 내지 약 850개 아미노산, 약 145개 아미노산 내지 약 800개 아미노산, 약 145개 아미노산 내지 약 750개 아미노산, 약 145개 아미노산 내지 약 700개 아미노산, 약 145개 아미노산 내지 약 650개 아미노산, 약 145개 아미노산 내지 약 600개 아미노산, 약 145개 아미노산 내지 약 550개 아미노산, 약 145개 아미노산 내지 약 500개 아미노산, 약 145개 아미노산 내지 약 450개 아미노산, 약 145개 아미노산 내지 약 400개 아미노산, 약 145개 아미노산 내지 약 350개 아미노산, 약 145개 아미노산 내지 약 300개 아미노산, 약 145개 아미노산 내지 약 280개 아미노산, 약 145개 아미노산 내지 약 260개 아미노산, 약 145개 아미노산 내지 약 240개 아미노산, 약 145개 아미노산 내지 약 220개 아미노산, 약 145개 아미노산 내지 약 200개 아미노산, 약 145개 아미노산 내지 약 195개 아미노산, 약 145개 아미노산 내지 약 190개 아미노산, 약 145개 아미노산 내지 약 185개 아미노산, 약 145개 아미노산 내지 약 180개 아미노산, 약 145개 아미노산 내지 약 175개 아미노산, 약 145개 아미노산 내지 약 170개 아미노산, 약 145개 아미노산 내지 약 165개 아미노산, 약 145개 아미노산 내지 약 160개 아미노산, 약 145개 아미노산 내지 약 155개 아미노산, 약 145개 아미노산 내지 약 150개 아미노산, 약 150개 아미노산 내지 약 1000개 아미노산, 약 150개 아미노산 내지 약 950개 아미노산, 약 150개 아미노산 내지 약 900개 아미노산, 약 150개 아미노산 내지 약 850개 아미노산, 약 150개 아미노산 내지 약 800개 아미노산, 약 150개 아미노산 내지 약 750개 아미노산, 약 150개 아미노산 내지 약 700개 아미노산, 약 150개 아미노산 내지 약 650개 아미노산, 약 150개 아미노산 내지 약 600개 아미노산, 약 150개 아미노산 내지 약 550개 아미노산, 약 150개 아미노산 내지 약 500개 아미노산, 약 150개 아미노산 내지 약 450개 아미노산, 약 150개 아미노산 내지 약 400개 아미노산, 약 150개 아미노산 내지 약 350개 아미노산, 약 150개 아미노산 내지 약 300개 아미노산, 약 150개 아미노산 내지 약 280개 아미노산, 약 150개 아미노산 내지 약 260개 아미노산, 약 150개 아미노산 내지 약 240개 아미노산, 약 150개 아미노산 내지 약 220개 아미노산, 약 150개 아미노산 내지 약 200개 아미노산, 약 150개 아미노산 내지 약 195개 아미노산, 약 150개 아미노산 내지 약 190개 아미노산, 약 150개 아미노산 내지 약 185개 아미노산, 약 150개 아미노산 내지 약 180개 아미노산, 약 150개 아미노산 내지 약 175개 아미노산, 약 150개 아미노산 내지 약 170개 아미노산, 약 150개 아미노산 내지 약 165개 아미노산, 약 150개 아미노산 내지 약 160개 아미노산, 약 150개 아미노산 내지 약 155개 아미노산, 약 155개 아미노산 내지 약 1000개 아미노산, 약 155개 아미노산 내지 약 950개 아미노산, 약 155개 아미노산 내지 약 900개 아미노산, 약 155개 아미노산 내지 약 850개 아미노산, 약 155개 아미노산 내지 약 800개 아미노산, 약 155개 아미노산 내지 약 750개 아미노산, 약 155개 아미노산 내지 약 700개 아미노산, 약 155개 아미노산 내지 약 650개 아미노산, 약 155개 아미노산 내지 약 600개 아미노산, 약 155개 아미노산 내지 약 550개 아미노산, 약 155개 아미노산 내지 약 500개 아미노산, 약 155개 아미노산 내지 약 450개 아미노산, 약 155개 아미노산 내지 약 400개 아미노산, 약 155개 아미노산 내지 약 350개 아미노산, 약 155개 아미노산 내지 약 300개 아미노산, 약 155개 아미노산 내지 약 280개 아미노산, 약 155개 아미노산 내지 약 260개 아미노산, 약 155개 아미노산 내지 약 240개 아미노산, 약 155개 아미노산 내지 약 220개 아미노산, 약 155개 아미노산 내지 약 200개 아미노산, 약 155개 아미노산 내지 약 195개 아미노산, 약 155개 아미노산 내지 약 190개 아미노산, 약 155개 아미노산 내지 약 185개 아미노산, 약 155개 아미노산 내지 약 180개 아미노산, 약 155개 아미노산 내지 약 175개 아미노산, 약 155개 아미노산 내지 약 170개 아미노산, 약 155개 아미노산 내지 약 165개 아미노산, 약 155개 아미노산 내지 약 160개 아미노산, 약 160개 아미노산 내지 약 1000개 아미노산, 약 160개 아미노산 내지 약 950개 아미노산, 약 160개 아미노산 내지 약 900개 아미노산, 약 160개 아미노산 내지 약 850개 아미노산, 약 160개 아미노산 내지 약 800개 아미노산, 약 160개 아미노산 내지 약 750개 아미노산, 약 160개 아미노산 내지 약 700개 아미노산, 약 160개 아미노산 내지 약 650개 아미노산, 약 160개 아미노산 내지 약 600개 아미노산, 약 160개 아미노산 내지 약 550개 아미노산, 약 160개 아미노산 내지 약 500개 아미노산, 약 160개 아미노산 내지 약 450개 아미노산, 약 160개 아미노산 내지 약 400개 아미노산, 약 160개 아미노산 내지 약 350개 아미노산, 약 160개 아미노산 내지 약 300개 아미노산, 약 160개 아미노산 내지 약 280개 아미노산, 약 160개 아미노산 내지 약 260개 아미노산, 약 160개 아미노산 내지 약 240개 아미노산, 약 160개 아미노산 내지 약 220개 아미노산, 약 160개 아미노산 내지 약 200개 아미노산, 약 160개 아미노산 내지 약 195개 아미노산, 약 160개 아미노산 내지 약 190개 아미노산, 약 160개 아미노산 내지 약 185개 아미노산, 약 160개 아미노산 내지 약 180개 아미노산, 약 160개 아미노산 내지 약 175개 아미노산, 약 160개 아미노산 내지 약 170개 아미노산, 약 160개 아미노산 내지 약 165개 아미노산, 약 165개 아미노산 내지 약 1000개 아미노산, 약 165개 아미노산 내지 약 950개 아미노산, 약 165개 아미노산 내지 약 900개 아미노산, 약 165개 아미노산 내지 약 850개 아미노산, 약 165개 아미노산 내지 약 800개 아미노산, 약 165개 아미노산 내지 약 750개 아미노산, 약 165개 아미노산 내지 약 700개 아미노산, 약 165개 아미노산 내지 약 650개 아미노산, 약 165개 아미노산 내지 약 600개 아미노산, 약 165개 아미노산 내지 약 550개 아미노산, 약 165개 아미노산 내지 약 500개 아미노산, 약 165개 아미노산 내지 약 450개 아미노산, 약 165개 아미노산 내지 약 400개 아미노산, 약 165개 아미노산 내지 약 350개 아미노산, 약 165개 아미노산 내지 약 300개 아미노산, 약 165개 아미노산 내지 약 280개 아미노산, 약 165개 아미노산 내지 약 260개 아미노산, 약 165개 아미노산 내지 약 240개 아미노산, 약 165개 아미노산 내지 약 220개 아미노산, 약 165개 아미노산 내지 약 200개 아미노산, 약 165개 아미노산 내지 약 195개 아미노산, 약 165개 아미노산 내지 약 190개 아미노산, 약 165개 아미노산 내지 약 185개 아미노산, 약 165개 아미노산 내지 약 180개 아미노산, 약 165개 아미노산 내지 약 175개 아미노산, 약 165개 아미노산 내지 약 170개 아미노산, 약 170개 아미노산 내지 약 1000개 아미노산, 약 170개 아미노산 내지 약 950개 아미노산, 약 170개 아미노산 내지 약 900개 아미노산, 약 170개 아미노산 내지 약 850개 아미노산, 약 170개 아미노산 내지 약 800개 아미노산, 약 170개 아미노산 내지 약 750개 아미노산, 약 170개 아미노산 내지 약 700개 아미노산, 약 170개 아미노산 내지 약 650개 아미노산, 약 170개 아미노산 내지 약 600개 아미노산, 약 170개 아미노산 내지 약 550개 아미노산, 약 170개 아미노산 내지 약 500개 아미노산, 약 170개 아미노산 내지 약 450개 아미노산, 약 170개 아미노산 내지 약 400개 아미노산, 약 170개 아미노산 내지 약 350개 아미노산, 약 170개 아미노산 내지 약 300개 아미노산, 약 170개 아미노산 내지 약 280개 아미노산, 약 170개 아미노산 내지 약 260개 아미노산, 약 170개 아미노산 내지 약 240개 아미노산, 약 170개 아미노산 내지 약 220개 아미노산, 약 170개 아미노산 내지 약 200개 아미노산, 약 170개 아미노산 내지 약 195개 아미노산, 약 170개 아미노산 내지 약 190개 아미노산, 약 170개 아미노산 내지 약 185개 아미노산, 약 170개 아미노산 내지 약 180개 아미노산, 약 170개 아미노산 내지 약 175개 아미노산, 약 175개 아미노산 내지 약 1000개 아미노산, 약 175개 아미노산 내지 약 950개 아미노산, 약 175개 아미노산 내지 약 900개 아미노산, 약 175개 아미노산 내지 약 850개 아미노산, 약 175개 아미노산 내지 약 800개 아미노산, 약 175개 아미노산 내지 약 750개 아미노산, 약 175개 아미노산 내지 약 700개 아미노산, 약 175개 아미노산 내지 약 650개 아미노산, 약 175개 아미노산 내지 약 600개 아미노산, 약 175개 아미노산 내지 약 550개 아미노산, 약 175개 아미노산 내지 약 500개 아미노산, 약 175개 아미노산 내지 약 450개 아미노산, 약 175개 아미노산 내지 약 400개 아미노산, 약 175개 아미노산 내지 약 350개 아미노산, 약 175개 아미노산 내지 약 300개 아미노산, 약 175개 아미노산 내지 약 280개 아미노산, 약 175개 아미노산 내지 약 260개 아미노산, 약 175개 아미노산 내지 약 240개 아미노산, 약 175개 아미노산 내지 약 220개 아미노산, 약 175개 아미노산 내지 약 200개 아미노산, 약 175개 아미노산 내지 약 195개 아미노산, 약 175개 아미노산 내지 약 190개 아미노산, 약 175개 아미노산 내지 약 185개 아미노산, 약 175개 아미노산 내지 약 180개 아미노산, 약 180개 아미노산 내지 약 1000개 아미노산, 약 180개 아미노산 내지 약 950개 아미노산, 약 180개 아미노산 내지 약 900개 아미노산, 약 180개 아미노산 내지 약 850개 아미노산, 약 180개 아미노산 내지 약 800개 아미노산, 약 180개 아미노산 내지 약 750개 아미노산, 약 180개 아미노산 내지 약 700개 아미노산, 약 180개 아미노산 내지 약 650개 아미노산, 약 180개 아미노산 내지 약 600개 아미노산, 약 180개 아미노산 내지 약 550개 아미노산, 약 180개 아미노산 내지 약 500개 아미노산, 약 180개 아미노산 내지 약 450개 아미노산, 약 180개 아미노산 내지 약 400개 아미노산, 약 180개 아미노산 내지 약 350개 아미노산, 약 180개 아미노산 내지 약 300개 아미노산, 약 180개 아미노산 내지 약 280개 아미노산, 약 180개 아미노산 내지 약 260개 아미노산, 약 180개 아미노산 내지 약 240개 아미노산, 약 180개 아미노산 내지 약 220개 아미노산, 약 180개 아미노산 내지 약 200개 아미노산, 약 180개 아미노산 내지 약 195개 아미노산, 약 180개 아미노산 내지 약 190개 아미노산, 약 180개 아미노산 내지 약 185개 아미노산, 약 185개 아미노산 내지 약 1000개 아미노산, 약 185개 아미노산 내지 약 950개 아미노산, 약 185개 아미노산 내지 약 900개 아미노산, 약 185개 아미노산 내지 약 850개 아미노산, 약 185개 아미노산 내지 약 800개 아미노산, 약 185개 아미노산 내지 약 750개 아미노산, 약 185개 아미노산 내지 약 700개 아미노산, 약 185개 아미노산 내지 약 650개 아미노산, 약 185개 아미노산 내지 약 600개 아미노산, 약 185개 아미노산 내지 약 550개 아미노산, 약 185개 아미노산 내지 약 500개 아미노산, 약 185개 아미노산 내지 약 450개 아미노산, 약 185개 아미노산 내지 약 400개 아미노산, 약 185개 아미노산 내지 약 350개 아미노산, 약 185개 아미노산 내지 약 300개 아미노산, 약 185개 아미노산 내지 약 280개 아미노산, 약 185개 아미노산 내지 약 260개 아미노산, 약 185개 아미노산 내지 약 240개 아미노산, 약 185개 아미노산 내지 약 220개 아미노산, 약 185개 아미노산 내지 약 200개 아미노산, 약 185개 아미노산 내지 약 195개 아미노산, 약 185개 아미노산 내지 약 190개 아미노산, 약 190개 아미노산 내지 약 1000개 아미노산, 약 190개 아미노산 내지 약 950개 아미노산, 약 190개 아미노산 내지 약 900개 아미노산, 약 190개 아미노산 내지 약 850개 아미노산, 약 190개 아미노산 내지 약 800개 아미노산, 약 190개 아미노산 내지 약 750개 아미노산, 약 190개 아미노산 내지 약 700개 아미노산, 약 190개 아미노산 내지 약 650개 아미노산, 약 190개 아미노산 내지 약 600개 아미노산, 약 190개 아미노산 내지 약 550개 아미노산, 약 190개 아미노산 내지 약 500개 아미노산, 약 190개 아미노산 내지 약 450개 아미노산, 약 190개 아미노산 내지 약 400개 아미노산, 약 190개 아미노산 내지 약 350개 아미노산, 약 190개 아미노산 내지 약 300개 아미노산, 약 190개 아미노산 내지 약 280개 아미노산, 약 190개 아미노산 내지 약 260개 아미노산, 약 190개 아미노산 내지 약 240개 아미노산, 약 190개 아미노산 내지 약 220개 아미노산, 약 190개 아미노산 내지 약 200개 아미노산, 약 190개 아미노산 내지 약 195개 아미노산, 약 195개 아미노산 내지 약 1000개 아미노산, 약 195개 아미노산 내지 약 950개 아미노산, 약 195개 아미노산 내지 약 900개 아미노산, 약 195개 아미노산 내지 약 850개 아미노산, 약 195개 아미노산 내지 약 800개 아미노산, 약 195개 아미노산 내지 약 750개 아미노산, 약 195개 아미노산 내지 약 700개 아미노산, 약 195개 아미노산 내지 약 650개 아미노산, 약 195개 아미노산 내지 약 600개 아미노산, 약 195개 아미노산 내지 약 550개 아미노산, 약 195개 아미노산 내지 약 500개 아미노산, 약 195개 아미노산 내지 약 450개 아미노산, 약 195개 아미노산 내지 약 400개 아미노산, 약 195개 아미노산 내지 약 350개 아미노산, 약 195개 아미노산 내지 약 300개 아미노산, 약 195개 아미노산 내지 약 280개 아미노산, 약 195개 아미노산 내지 약 260개 아미노산, 약 195개 아미노산 내지 약 240개 아미노산, 약 195개 아미노산 내지 약 220개 아미노산, 약 195개 아미노산 내지 약 200개 아미노산, 약 200개 아미노산 내지 약 1000개 아미노산, 약 200개 아미노산 내지 약 950개 아미노산, 약 200개 아미노산 내지 약 900개 아미노산, 약 200개 아미노산 내지 약 850개 아미노산, 약 200개 아미노산 내지 약 800개 아미노산, 약 200개 아미노산 내지 약 750개 아미노산, 약 200개 아미노산 내지 약 700개 아미노산, 약 200개 아미노산 내지 약 650개 아미노산, 약 200개 아미노산 내지 약 600개 아미노산, 약 200개 아미노산 내지 약 550개 아미노산, 약 200개 아미노산 내지 약 500개 아미노산, 약 200개 아미노산 내지 약 450개 아미노산, 약 200개 아미노산 내지 약 400개 아미노산, 약 200개 아미노산 내지 약 350개 아미노산, 약 200개 아미노산 내지 약 300개 아미노산, 약 200개 아미노산 내지 약 280개 아미노산, 약 200개 아미노산 내지 약 260개 아미노산, 약 200개 아미노산 내지 약 240개 아미노산, 약 200개 아미노산 내지 약 220개 아미노산, 약 220개 아미노산 내지 약 1000개 아미노산, 약 220개 아미노산 내지 약 950개 아미노산, 약 220개 아미노산 내지 약 900개 아미노산, 약 220개 아미노산 내지 약 850개 아미노산, 약 220개 아미노산 내지 약 800개 아미노산, 약 220개 아미노산 내지 약 750개 아미노산, 약 220개 아미노산 내지 약 700개 아미노산, 약 220개 아미노산 내지 약 650개 아미노산, 약 220개 아미노산 내지 약 600개 아미노산, 약 220개 아미노산 내지 약 550개 아미노산, 약 220개 아미노산 내지 약 500개 아미노산, 약 220개 아미노산 내지 약 450개 아미노산, 약 220개 아미노산 내지 약 400개 아미노산, 약 220개 아미노산 내지 약 350개 아미노산, 약 220개 아미노산 내지 약 300개 아미노산, 약 220개 아미노산 내지 약 280개 아미노산, 약 220개 아미노산 내지 약 260개 아미노산, 약 220개 아미노산 내지 약 240개 아미노산, 약 240개 아미노산 내지 약 1000개 아미노산, 약 240개 아미노산 내지 약 950개 아미노산, 약 240개 아미노산 내지 약 900개 아미노산, 약 240개 아미노산 내지 약 850개 아미노산, 약 240개 아미노산 내지 약 800개 아미노산, 약 240개 아미노산 내지 약 750개 아미노산, 약 240개 아미노산 내지 약 700개 아미노산, 약 240개 아미노산 내지 약 650개 아미노산, 약 240개 아미노산 내지 약 600개 아미노산, 약 240개 아미노산 내지 약 550개 아미노산, 약 240개 아미노산 내지 약 500개 아미노산, 약 240개 아미노산 내지 약 450개 아미노산, 약 240개 아미노산 내지 약 400개 아미노산, 약 240개 아미노산 내지 약 350개 아미노산, 약 240개 아미노산 내지 약 300개 아미노산, 약 240개 아미노산 내지 약 280개 아미노산, 약 240개 아미노산 내지 약 260개 아미노산, 약 260개 아미노산 내지 약 1000개 아미노산, 약 260개 아미노산 내지 약 950개 아미노산, 약 260개 아미노산 내지 약 900개 아미노산, 약 260개 아미노산 내지 약 850개 아미노산, 약 260개 아미노산 내지 약 800개 아미노산, 약 260개 아미노산 내지 약 750개 아미노산, 약 260개 아미노산 내지 약 700개 아미노산, 약 260개 아미노산 내지 약 650개 아미노산, 약 260개 아미노산 내지 약 600개 아미노산, 약 260개 아미노산 내지 약 550개 아미노산, 약 260개 아미노산 내지 약 500개 아미노산, 약 260개 아미노산 내지 약 450개 아미노산, 약 260개 아미노산 내지 약 400개 아미노산, 약 260개 아미노산 내지 약 350개 아미노산, 약 260개 아미노산 내지 약 300개 아미노산, 약 260개 아미노산 내지 약 280개 아미노산, 약 280개 아미노산 내지 약 1000개 아미노산, 약 280개 아미노산 내지 약 950개 아미노산, 약 280개 아미노산 내지 약 900개 아미노산, 약 280개 아미노산 내지 약 850개 아미노산, 약 280개 아미노산 내지 약 800개 아미노산, 약 280개 아미노산 내지 약 750개 아미노산, 약 280개 아미노산 내지 약 700개 아미노산, 약 280개 아미노산 내지 약 650개 아미노산, 약 280개 아미노산 내지 약 600개 아미노산, 약 280개 아미노산 내지 약 550개 아미노산, 약 280개 아미노산 내지 약 500개 아미노산, 약 280개 아미노산 내지 약 450개 아미노산, 약 280개 아미노산 내지 약 400개 아미노산, 약 280개 아미노산 내지 약 350개 아미노산, 약 280개 아미노산 내지 약 300개 아미노산, 약 300개 아미노산 내지 약 1000개 아미노산, 약 300개 아미노산 내지 약 950개 아미노산, 약 300개 아미노산 내지 약 900개 아미노산, 약 300개 아미노산 내지 약 850개 아미노산, 약 300개 아미노산 내지 약 800개 아미노산, 약 300개 아미노산 내지 약 750개 아미노산, 약 300개 아미노산 내지 약 700개 아미노산, 약 300개 아미노산 내지 약 650개 아미노산, 약 300개 아미노산 내지 약 600개 아미노산, 약 300개 아미노산 내지 약 550개 아미노산, 약 300개 아미노산 내지 약 500개 아미노산, 약 300개 아미노산 내지 약 450개 아미노산, 약 300개 아미노산 내지 약 400개 아미노산, 약 300개 아미노산 내지 약 350개 아미노산, 약 350개 아미노산 내지 약 1000개 아미노산, 약 350개 아미노산 내지 약 950개 아미노산, 약 350개 아미노산 내지 약 900개 아미노산, 약 350개 아미노산 내지 약 850개 아미노산, 약 350개 아미노산 내지 약 800개 아미노산, 약 350개 아미노산 내지 약 750개 아미노산, 약 350개 아미노산 내지 약 700개 아미노산, 약 350개 아미노산 내지 약 650개 아미노산, 약 350개 아미노산 내지 약 600개 아미노산, 약 350개 아미노산 내지 약 550개 아미노산, 약 350개 아미노산 내지 약 500개 아미노산, 약 350개 아미노산 내지 약 450개 아미노산, 약 350개 아미노산 내지 약 400개 아미노산, 약 400개 아미노산 내지 약 1000개 아미노산, 약 400개 아미노산 내지 약 950개 아미노산, 약 400개 아미노산 내지 약 900개 아미노산, 약 400개 아미노산 내지 약 850개 아미노산, 약 400개 아미노산 내지 약 800개 아미노산, 약 400개 아미노산 내지 약 750개 아미노산, 약 400개 아미노산 내지 약 700개 아미노산, 약 400개 아미노산 내지 약 650개 아미노산, 약 400개 아미노산 내지 약 600개 아미노산, 약 400개 아미노산 내지 약 550개 아미노산, 약 400개 아미노산 내지 약 500개 아미노산, 약 400개 아미노산 내지 약 450개 아미노산, 약 450개 아미노산 내지 약 1000개 아미노산, 약 450개 아미노산 내지 약 950개 아미노산, 약 450개 아미노산 내지 약 900개 아미노산, 약 450개 아미노산 내지 약 850개 아미노산, 약 450개 아미노산 내지 약 800개 아미노산, 약 450개 아미노산 내지 약 750개 아미노산, 약 450개 아미노산 내지 약 700개 아미노산, 약 450개 아미노산 내지 약 650개 아미노산, 약 450개 아미노산 내지 약 600개 아미노산, 약 450개 아미노산 내지 약 550개 아미노산, 약 450개 아미노산 내지 약 500개 아미노산, 약 500개 아미노산 내지 약 1000개 아미노산, 약 500개 아미노산 내지 약 950개 아미노산, 약 500개 아미노산 내지 약 900개 아미노산, 약 500개 아미노산 내지 약 850개 아미노산, 약 500개 아미노산 내지 약 800개 아미노산, 약 500개 아미노산 내지 약 750개 아미노산, 약 500개 아미노산 내지 약 700개 아미노산, 약 500개 아미노산 내지 약 650개 아미노산, 약 500개 아미노산 내지 약 600개 아미노산, 약 500개 아미노산 내지 약 550개 아미노산, 약 550개 아미노산 내지 약 1000개 아미노산, 약 550개 아미노산 내지 약 950개 아미노산, 약 550개 아미노산 내지 약 900개 아미노산, 약 550개 아미노산 내지 약 850개 아미노산, 약 550개 아미노산 내지 약 800개 아미노산, 약 550개 아미노산 내지 약 750개 아미노산, 약 550개 아미노산 내지 약 700개 아미노산, 약 550개 아미노산 내지 약 650개 아미노산, 약 550개 아미노산 내지 약 600개 아미노산, 약 600개 아미노산 내지 약 1000개 아미노산, 약 600개 아미노산 내지 약 950개 아미노산, 약 600개 아미노산 내지 약 900개 아미노산, 약 600개 아미노산 내지 약 850개 아미노산, 약 600개 아미노산 내지 약 800개 아미노산, 약 600개 아미노산 내지 약 750개 아미노산, 약 600개 아미노산 내지 약 700개 아미노산, 약 600개 아미노산 내지 약 650개 아미노산, 약 650개 아미노산 내지 약 1000개 아미노산, 약 650개 아미노산 내지 약 950개 아미노산, 약 650개 아미노산 내지 약 900개 아미노산, 약 650개 아미노산 내지 약 850개 아미노산, 약 650개 아미노산 내지 약 800개 아미노산, 약 650개 아미노산 내지 약 750개 아미노산, 약 650개 아미노산 내지 약 700개 아미노산, 약 700개 아미노산 내지 약 1000개 아미노산, 약 700개 아미노산 내지 약 950개 아미노산, 약 700개 아미노산 내지 약 900개 아미노산, 약 700개 아미노산 내지 약 850개 아미노산, 약 700개 아미노산 내지 약 800개 아미노산, 약 700개 아미노산 내지 약 750개 아미노산, 약 750개 아미노산 내지 약 1000개 아미노산, 약 750개 아미노산 내지 약 950개 아미노산, 약 750개 아미노산 내지 약 900개 아미노산, 약 750개 아미노산 내지 약 850개 아미노산, 약 750개 아미노산 내지 약 800개 아미노산, 약 800개 아미노산 내지 약 1000개 아미노산, 약 800개 아미노산 내지 약 950개 아미노산, 약 800개 아미노산 내지 약 900개 아미노산, 약 800개 아미노산 내지 약 850개 아미노산, 약 850개 아미노산 내지 약 1000개 아미노산, 약 850개 아미노산 내지 약 950개 아미노산, 약 850개 아미노산 내지 약 900개 아미노산, 약 900개 아미노산 내지 약 1000개 아미노산, 약 900개 아미노산 내지 약 950개 아미노산, 또는 약 950개 아미노산 내지 약 1000개 아미노산의, 아미노산의 총 수를 가질 수 있다.
본원에 기재된 임의의 표적-결합 도메인은 1 x 10-7 M 미만, 1 x 10-8 M 미만, 1 x 10-9 M 미만, 1 x 10-10 M 미만, 1 x 10-11 M 미만, 1 x 10-12 M 미만, 또는 1 x 10-13 M 미만의 해리 평형 상수(KD)로 이의 표적에 결합할 수 있다. 일부 구현예에서, 본원에 제공된 항원-결합 단백질 작제물은 약 1 x 10-3 M 내지 약 1 x 10-5 M, 약 1 x 10-4 M 내지 약 1 x 10-6 M, 약 1 x 10-5 M 내지 약 1 x 10-7 M, 약 1 x 10-6 M 내지 약 1 x 10-8 M, 약 1 x 10-7 M 내지 약 1 x 10-9 M, 약 1 x 10-8 M 내지 약 1 x 10-10 M, 또는 약 1 x 10-9 M 내지 약 1 x 10-11 M(포함)의 KD로 식별 항원에 결합할 수 있다.
본원에 기재된 임의의 표적-결합 도메인의 약 1 pM 내지 약 30 nM(예를 들어, 약 1 pM 내지 약 25 nM, 약 1 pM 내지 약 20 nM, 약 1 pM 내지 약 15 nM, 약 1 pM 내지 약 10 nM, 약 1 pM 내지 약 5 nM, 약 1 pM 내지 약 2 nM, 약 1 pM 내지 약 1 nM, 약 1 pM 내지 약 950 pM, 약 1 pM 내지 약 900 pM, 약 1 pM 내지 약 850 pM, 약 1 pM 내지 약 800 pM, 약 1 pM 내지 약 750 pM, 약 1 pM 내지 약 700 pM, 약 1 pM 내지 약 650 pM, 약 1 pM 내지 약 600 pM, 약 1 pM 내지 약 550 pM, 약 1 pM 내지 약 500 pM, 약 1 pM 내지 약 450 pM, 약 1 pM 내지 약 400 pM, 약 1 pM 내지 약 350 pM, 약 1 pM 내지 약 300 pM, 약 1 pM 내지 약 250 pM, 약 1 pM 내지 약 200 pM, 약 1 pM 내지 약 150 pM, 약 1 pM 내지 약 100 pM, 약 1 pM 내지 약 90 pM, 약 1 pM 내지 약 80 pM, 약 1 pM 내지 약 70 pM, 약 1 pM 내지 약 60 pM, 약 1 pM 내지 약 50 pM, 약 1 pM 내지 약 40 pM, 약 1 pM 내지 약 30 pM, 약 1 pM 내지 약 20 pM, 약 1 pM 내지 약 10 pM, 약 1 pM 내지 약 5 pM, 약 1 pM 내지 약 4 pM, 약 1 pM 내지 약 3 pM, 약 1 pM 내지 약 2 pM, 약 2 pM 내지 약 30 nM, 약 2 pM 내지 약 25 nM, 약 2 pM 내지 약 20 nM, 약 2 pM 내지 약 15 nM, 약 2 pM 내지 약 10 nM, 약 2 pM 내지 약 5 nM, 약 2 pM 내지 약 2 nM, 약 2 pM 내지 약 1 nM, 약 2 pM 내지 약 950 pM, 약 2 pM 내지 약 900 pM, 약 2 pM 내지 약 850 pM, 약 2 pM 내지 약 800 pM, 약 2 pM 내지 약 750 pM, 약 2 pM 내지 약 700 pM, 약 2 pM 내지 약 650 pM, 약 2 pM 내지 약 600 pM, 약 2 pM 내지 약 550 pM, 약 2 pM 내지 약 500 pM, 약 2 pM 내지 약 450 pM, 약 2 pM 내지 약 400 pM, 약 2 pM 내지 약 350 pM, 약 2 pM 내지 약 300 pM, 약 2 pM 내지 약 250 pM, 약 2 pM 내지 약 200 pM, 약 2 pM 내지 약 150 pM, 약 2 pM 내지 약 100 pM, 약 2 pM 내지 약 90 pM, 약 2 pM 내지 약 80 pM, 약 2 pM 내지 약 70 pM, 약 2 pM 내지 약 60 pM, 약 2 pM 내지 약 50 pM, 약 2 pM 내지 약 40 pM, 약 2 pM 내지 약 30 pM, 약 2 pM 내지 약 20 pM, 약 2 pM 내지 약 10 pM, 약 2 pM 내지 약 5 pM, 약 2 pM 내지 약 4 pM, 약 2 pM 내지 약 3 pM, 약 5 pM 내지 약 30 nM, 약 5 pM 내지 약 25 nM, 약 5 pM 내지 약 20 nM, 약 5 pM 내지 약 15 nM, 약 5 pM 내지 약 10 nM, 약 5 pM 내지 약 5 nM, 약 5 pM 내지 약 2 nM, 약 5 pM 내지 약 1 nM, 약 5 pM 내지 약 950 pM, 약 5 pM 내지 약 900 pM, 약 5 pM 내지 약 850 pM, 약 5 pM 내지 약 800 pM, 약 5 pM 내지 약 750 pM, 약 5 pM 내지 약 700 pM, 약 5 pM 내지 약 650 pM, 약 5 pM 내지 약 600 pM, 약 5 pM 내지 약 550 pM, 약 5 pM 내지 약 500 pM, 약 5 pM 내지 약 450 pM, 약 5 pM 내지 약 400 pM, 약 5 pM 내지 약 350 pM, 약 5 pM 내지 약 300 pM, 약 5 pM 내지 약 250 pM, 약 5 pM 내지 약 200 pM, 약 5 pM 내지 약 150 pM, 약 5 pM 내지 약 100 pM, 약 5 pM 내지 약 90 pM, 약 5 pM 내지 약 80 pM, 약 5 pM 내지 약 70 pM, 약 5 pM 내지 약 60 pM, 약 5 pM 내지 약 50 pM, 약 5 pM 내지 약 40 pM, 약 5 pM 내지 약 30 pM, 약 5 pM 내지 약 20 pM, 약 5 pM 내지 약 10 pM, 약 10 pM 내지 약 30 nM, 약 10 pM 내지 약 25 nM, 약 10 pM 내지 약 20 nM, 약 10 pM 내지 약 15 nM, 약 10 pM 내지 약 10 nM, 약 10 pM 내지 약 5 nM, 약 10 pM 내지 약 2 nM, 약 10 pM 내지 약 1 nM, 약 10 pM 내지 약 950 pM, 약 10 pM 내지 약 900 pM, 약 10 pM 내지 약 850 pM, 약 10 pM 내지 약 800 pM, 약 10 pM 내지 약 750 pM, 약 10 pM 내지 약 700 pM, 약 10 pM 내지 약 650 pM, 약 10 pM 내지 약 600 pM, 약 10 pM 내지 약 550 pM, 약 10 pM 내지 약 500 pM, 약 10 pM 내지 약 450 pM, 약 10 pM 내지 약 400 pM, 약 10 pM 내지 약 350 pM, 약 10 pM 내지 약 300 pM, 약 10 pM 내지 약 250 pM, 약 10 pM 내지 약 200 pM, 약 10 pM 내지 약 150 pM, 약 10 pM 내지 약 100 pM, 약 10 pM 내지 약 90 pM, 약 10 pM 내지 약 80 pM, 약 10 pM 내지 약 70 pM, 약 10 pM 내지 약 60 pM, 약 10 pM 내지 약 50 pM, 약 10 pM 내지 약 40 pM, 약 10 pM 내지 약 30 pM, 약 10 pM 내지 약 20 pM, 약 15 pM 내지 약 30 nM, 약 15 pM 내지 약 25 nM, 약 15 pM 내지 약 20 nM, 약 15 pM 내지 약 15 nM, 약 15 pM 내지 약 10 nM, 약 15 pM 내지 약 5 nM, 약 15 pM 내지 약 2 nM, 약 15 pM 내지 약 1 nM, 약 15 pM 내지 약 950 pM, 약 15 pM 내지 약 900 pM, 약 15 pM 내지 약 850 pM, 약 15 pM 내지 약 800 pM, 약 15 pM 내지 약 750 pM, 약 15 pM 내지 약 700 pM, 약 15 pM 내지 약 650 pM, 약 15 pM 내지 약 600 pM, 약 15 pM 내지 약 550 pM, 약 15 pM 내지 약 500 pM, 약 15 pM 내지 약 450 pM, 약 15 pM 내지 약 400 pM, 약 15 pM 내지 약 350 pM, 약 15 pM 내지 약 300 pM, 약 15 pM 내지 약 250 pM, 약 15 pM 내지 약 200 pM, 약 15 pM 내지 약 150 pM, 약 15 pM 내지 약 100 pM, 약 15 pM 내지 약 90 pM, 약 15 pM 내지 약 80 pM, 약 15 pM 내지 약 70 pM, 약 15 pM 내지 약 60 pM, 약 15 pM 내지 약 50 pM, 약 15 pM 내지 약 40 pM, 약 15 pM 내지 약 30 pM, 약 15 pM 내지 약 20 pM, 약 20 pM 내지 약 30 nM, 약 20 pM 내지 약 25 nM, 약 20 pM 내지 약 20 nM, 약 20 pM 내지 약 15 nM, 약 20 pM 내지 약 10 nM, 약 20 pM 내지 약 5 nM, 약 20 pM 내지 약 2 nM, 약 20 pM 내지 약 1 nM, 약 20 pM 내지 약 950 pM, 약 20 pM 내지 약 900 pM, 약 20 pM 내지 약 850 pM, 약 20 pM 내지 약 800 pM, 약 20 pM 내지 약 750 pM, 약 20 pM 내지 약 700 pM, 약 20 pM 내지 약 650 pM, 약 20 pM 내지 약 600 pM, 약 20 pM 내지 약 550 pM, 약 20 pM 내지 약 500 pM, 약 20 pM 내지 약 450 pM, 약 20 pM 내지 약 400 pM, 약 20 pM 내지 약 350 pM, 약 20 pM 내지 약 300 pM, 약 20 pM 내지 약 250 pM, 약 20 pM 내지 약 20 pM, 약 200 pM 내지 약 150 pM, 약 20 pM 내지 약 100 pM, 약 20 pM 내지 약 90 pM, 약 20 pM 내지 약 80 pM, 약 20 pM 내지 약 70 pM, 약 20 pM 내지 약 60 pM, 약 20 pM 내지 약 50 pM, 약 20 pM 내지 약 40 pM, 약 20 pM 내지 약 30 pM, 약 30 pM 내지 약 30 nM, 약 30 pM 내지 약 25 nM, 약 30 pM 내지 약 30 nM, 약 30 pM 내지 약 15 nM, 약 30 pM 내지 약 10 nM, 약 30 pM 내지 약 5 nM, 약 30 pM 내지 약 2 nM, 약 30 pM 내지 약 1 nM, 약 30 pM 내지 약 950 pM, 약 30 pM 내지 약 900 pM, 약 30 pM 내지 약 850 pM, 약 30 pM 내지 약 800 pM, 약 30 pM 내지 약 750 pM, 약 30 pM 내지 약 700 pM, 약 30 pM 내지 약 650 pM, 약 30 pM 내지 약 600 pM, 약 30 pM 내지 약 550 pM, 약 30 pM 내지 약 500 pM, 약 30 pM 내지 약 450 pM, 약 30 pM 내지 약 400 pM, 약 30 pM 내지 약 350 pM, 약 30 pM 내지 약 300 pM, 약 30 pM 내지 약 250 pM, 약 30 pM 내지 약 200 pM, 약 30 pM 내지 약 150 pM, 약 30 pM 내지 약 100 pM, 약 30 pM 내지 약 90 pM, 약 30 pM 내지 약 80 pM, 약 30 pM 내지 약 70 pM, 약 30 pM 내지 약 60 pM, 약 30 pM 내지 약 50 pM, 약 30 pM 내지 약 40 pM, 약 40 pM 내지 약 30 nM, 약 40 pM 내지 약 25 nM, 약 40 pM 내지 약 30 nM, 약 40 pM 내지 약 15 nM, 약 40 pM 내지 약 10 nM, 약 40 pM 내지 약 5 nM, 약 40 pM 내지 약 2 nM, 약 40 pM 내지 약 1 nM, 약 40 pM 내지 약 950 pM, 약 40 pM 내지 약 900 pM, 약 40 pM 내지 약 850 pM, 약 40 pM 내지 약 800 pM, 약 40 pM 내지 약 750 pM, 약 40 pM 내지 약 700 pM, 약 40 pM 내지 약 650 pM, 약 40 pM 내지 약 600 pM, 약 40 pM 내지 약 550 pM, 약 40 pM 내지 약 500 pM, 약 40 pM 내지 약 450 pM, 약 40 pM 내지 약 400 pM, 약 40 pM 내지 약 350 pM, 약 40 pM 내지 약 300 pM, 약 40 pM 내지 약 250 pM, 약 40 pM 내지 약 200 pM, 약 40 pM 내지 약 150 pM, 약 40 pM 내지 약 100 pM, 약 40 pM 내지 약 90 pM, 약 40 pM 내지 약 80 pM, 약 40 pM 내지 약 70 pM, 약 40 pM 내지 약 60 pM, 약 40 pM 내지 약 50 pM, 약 50 pM 내지 약 30 nM, 약 50 pM 내지 약 25 nM, 약 50 pM 내지 약 30 nM, 약 50 pM 내지 약 15 nM, 약 50 pM 내지 약 10 nM, 약 50 pM 내지 약 5 nM, 약 50 pM 내지 약 2 nM, 약 50 pM 내지 약 1 nM, 약 50 pM 내지 약 950 pM, 약 50 pM 내지 약 900 pM, 약 50 pM 내지 약 850 pM, 약 50 pM 내지 약 800 pM, 약 50 pM 내지 약 750 pM, 약 50 pM 내지 약 700 pM, 약 50 pM 내지 약 650 pM, 약 50 pM 내지 약 600 pM, 약 50 pM 내지 약 550 pM, 약 50 pM 내지 약 500 pM, 약 50 pM 내지 약 450 pM, 약 50 pM 내지 약 400 pM, 약 50 pM 내지 약 350 pM, 약 50 pM 내지 약 300 pM, 약 50 pM 내지 약 250 pM, 약 50 pM 내지 약 200 pM, 약 50 pM 내지 약 150 pM, 약 50 pM 내지 약 100 pM, 약 50 pM 내지 약 90 pM, 약 50 pM 내지 약 80 pM, 약 50 pM 내지 약 70 pM, 약 50 pM 내지 약 60 pM, 약 60 pM 내지 약 30 nM, 약 60 pM 내지 약 25 nM, 약 60 pM 내지 약 30 nM, 약 60 pM 내지 약 15 nM, 약 60 pM 내지 약 10 nM, 약 60 pM 내지 약 5 nM, 약 60 pM 내지 약 2 nM, 약 60 pM 내지 약 1 nM, 약 60 pM 내지 약 950 pM, 약 60 pM 내지 약 900 pM, 약 60 pM 내지 약 850 pM, 약 60 pM 내지 약 800 pM, 약 60 pM 내지 약 750 pM, 약 60 pM 내지 약 700 pM, 약 60 pM 내지 약 650 pM, 약 60 pM 내지 약 600 pM, 약 60 pM 내지 약 550 pM, 약 60 pM 내지 약 500 pM, 약 60 pM 내지 약 450 pM, 약 60 pM 내지 약 400 pM, 약 60 pM 내지 약 350 pM, 약 60 pM 내지 약 300 pM, 약 60 pM 내지 약 250 pM, 약 60 pM 내지 약 200 pM, 약 60 pM 내지 약 150 pM, 약 60 pM 내지 약 100 pM, 약 60 pM 내지 약 90 pM, 약 60 pM 내지 약 80 pM, 약 60 pM 내지 약 70 pM, 약 70 pM 내지 약 30 nM, 약 70 pM 내지 약 25 nM, 약 70 pM 내지 약 30 nM, 약 70 pM 내지 약 15 nM, 약 70 pM 내지 약 10 nM, 약 70 pM 내지 약 5 nM, 약 70 pM 내지 약 2 nM, 약 70 pM 내지 약 1 nM, 약 70 pM 내지 약 950 pM, 약 70 pM 내지 약 900 pM, 약 70 pM 내지 약 850 pM, 약 70 pM 내지 약 800 pM, 약 70 pM 내지 약 750 pM, 약 70 pM 내지 약 700 pM, 약 70 pM 내지 약 650 pM, 약 70 pM 내지 약 600 pM, 약 70 pM 내지 약 550 pM, 약 70 pM 내지 약 500 pM, 약 70 pM 내지 약 450 pM, 약 70 pM 내지 약 400 pM, 약 70 pM 내지 약 350 pM, 약 70 pM 내지 약 300 pM, 약 70 pM 내지 약 250 pM, 약 70 pM 내지 약 200 pM, 약 70 pM 내지 약 150 pM, 약 70 pM 내지 약 100 pM, 약 70 pM 내지 약 90 pM, 약 70 pM 내지 약 80 pM, 약 80 pM 내지 약 30 nM, 약 80 pM 내지 약 25 nM, 약 80 pM 내지 약 30 nM, 약 80 pM 내지 약 15 nM, 약 80 pM 내지 약 10 nM, 약 80 pM 내지 약 5 nM, 약 80 pM 내지 약 2 nM, 약 80 pM 내지 약 1 nM, 약 80 pM 내지 약 950 pM, 약 80 pM 내지 약 900 pM, 약 80 pM 내지 약 850 pM, 약 80 pM 내지 약 800 pM, 약 80 pM 내지 약 750 pM, 약 80 pM 내지 약 700 pM, 약 80 pM 내지 약 650 pM, 약 80 pM 내지 약 600 pM, 약 80 pM 내지 약 550 pM, 약 80 pM 내지 약 500 pM, 약 80 pM 내지 약 450 pM, 약 80 pM 내지 약 400 pM, 약 80 pM 내지 약 350 pM, 약 80 pM 내지 약 300 pM, 약 80 pM 내지 약 250 pM, 약 80 pM 내지 약 200 pM, 약 80 pM 내지 약 150 pM, 약 80 pM 내지 약 100 pM, 약 80 pM 내지 약 90 pM, 약 90 pM 내지 약 30 nM, 약 90 pM 내지 약 25 nM, 약 90 pM 내지 약 30 nM, 약 90 pM 내지 약 15 nM, 약 90 pM 내지 약 10 nM, 약 90 pM 내지 약 5 nM, 약 90 pM 내지 약 2 nM, 약 90 pM 내지 약 1 nM, 약 90 pM 내지 약 950 pM, 약 90 pM 내지 약 900 pM, 약 90 pM 내지 약 850 pM, 약 90 pM 내지 약 800 pM, 약 90 pM 내지 약 750 pM, 약 90 pM 내지 약 700 pM, 약 90 pM 내지 약 650 pM, 약 90 pM 내지 약 600 pM, 약 90 pM 내지 약 550 pM, 약 90 pM 내지 약 500 pM, 약 90 pM 내지 약 450 pM, 약 90 pM 내지 약 400 pM, 약 90 pM 내지 약 350 pM, 약 90 pM 내지 약 300 pM, 약 90 pM 내지 약 250 pM, 약 90 pM 내지 약 200 pM, 약 90 pM 내지 약 150 pM, 약 90 pM 내지 약 100 pM, 약 100 pM 내지 약 30 nM, 약 100 pM 내지 약 25 nM, 약 100 pM 내지 약 30 nM, 약 100 pM 내지 약 15 nM, 약 100 pM 내지 약 10 nM, 약 100 pM 내지 약 5 nM, 약 100 pM 내지 약 2 nM, 약 100 pM 내지 약 1 nM, 약 100 pM 내지 약 950 pM, 약 100 pM 내지 약 900 pM, 약 100 pM 내지 약 850 pM, 약 100 pM 내지 약 800 pM, 약 100 pM 내지 약 750 pM, 약 100 pM 내지 약 700 pM, 약 100 pM 내지 약 650 pM, 약 100 pM 내지 약 600 pM, 약 100 pM 내지 약 550 pM, 약 100 pM 내지 약 500 pM, 약 100 pM 내지 약 450 pM, 약 100 pM 내지 약 400 pM, 약 100 pM 내지 약 350 pM, 약 100 pM 내지 약 300 pM, 약 100 pM 내지 약 250 pM, 약 100 pM 내지 약 200 pM, 약 100 pM 내지 약 150 pM, 약 150 pM 내지 약 30 nM, 약 150 pM 내지 약 25 nM, 약 150 pM 내지 약 30 nM, 약 150 pM 내지 약 15 nM, 약 150 pM 내지 약 10 nM, 약 150 pM 내지 약 5 nM, 약 150 pM 내지 약 2 nM, 약 150 pM 내지 약 1 nM, 약 150 pM 내지 약 950 pM, 약 150 pM 내지 약 900 pM, 약 150 pM 내지 약 850 pM, 약 150 pM 내지 약 800 pM, 약 150 pM 내지 약 750 pM, 약 150 pM 내지 약 700 pM, 약 150 pM 내지 약 650 pM, 약 150 pM 내지 약 600 pM, 약 150 pM 내지 약 550 pM, 약 150 pM 내지 약 500 pM, 약 150 pM 내지 약 450 pM, 약 150 pM 내지 약 400 pM, 약 150 pM 내지 약 350 pM, 약 150 pM 내지 약 300 pM, 약 150 pM 내지 약 250 pM, 약 150 pM 내지 약 200 pM, 약 200 pM 내지 약 30 nM, 약 200 pM 내지 약 25 nM, 약 200 pM 내지 약 30 nM, 약 200 pM 내지 약 15 nM, 약 200 pM 내지 약 10 nM, 약 200 pM 내지 약 5 nM, 약 200 pM 내지 약 2 nM, 약 200 pM 내지 약 1 nM, 약 200 pM 내지 약 950 pM, 약 200 pM 내지 약 900 pM, 약 200 pM 내지 약 850 pM, 약 200 pM 내지 약 800 pM, 약 200 pM 내지 약 750 pM, 약 200 pM 내지 약 700 pM, 약 200 pM 내지 약 650 pM, 약 200 pM 내지 약 600 pM, 약 200 pM 내지 약 550 pM, 약 200 pM 내지 약 500 pM, 약 200 pM 내지 약 450 pM, 약 200 pM 내지 약 400 pM, 약 200 pM 내지 약 350 pM, 약 200 pM 내지 약 300 pM, 약 200 pM 내지 약 250 pM, 약 300 pM 내지 약 30 nM, 약 300 pM 내지 약 25 nM, 약 300 pM 내지 약 30 nM, 약 300 pM 내지 약 15 nM, 약 300 pM 내지 약 10 nM, 약 300 pM 내지 약 5 nM, 약 300 pM 내지 약 2 nM, 약 300 pM 내지 약 1 nM, 약 300 pM 내지 약 950 pM, 약 300 pM 내지 약 900 pM, 약 300 pM 내지 약 850 pM, 약 300 pM 내지 약 800 pM, 약 300 pM 내지 약 750 pM, 약 300 pM 내지 약 700 pM, 약 300 pM 내지 약 650 pM, 약 300 pM 내지 약 600 pM, 약 300 pM 내지 약 550 pM, 약 300 pM 내지 약 500 pM, 약 300 pM 내지 약 450 pM, 약 300 pM 내지 약 400 pM, 약 300 pM 내지 약 350 pM, 약 400 pM 내지 약 30 nM, 약 400 pM 내지 약 25 nM, 약 400 pM 내지 약 30 nM, 약 400 pM 내지 약 15 nM, 약 400 pM 내지 약 10 nM, 약 400 pM 내지 약 5 nM, 약 400 pM 내지 약 2 nM, 약 400 pM 내지 약 1 nM, 약 400 pM 내지 약 950 pM, 약 400 pM 내지 약 900 pM, 약 400 pM 내지 약 850 pM, 약 400 pM 내지 약 800 pM, 약 400 pM 내지 약 750 pM, 약 400 pM 내지 약 700 pM, 약 400 pM 내지 약 650 pM, 약 400 pM 내지 약 600 pM, 약 400 pM 내지 약 550 pM, 약 400 pM 내지 약 500 pM, 약 500 pM 내지 약 30 nM, 약 500 pM 내지 약 25 nM, 약 500 pM 내지 약 30 nM, 약 500 pM 내지 약 15 nM, 약 500 pM 내지 약 10 nM, 약 500 pM 내지 약 5 nM, 약 500 pM 내지 약 2 nM, 약 500 pM 내지 약 1 nM, 약 500 pM 내지 약 950 pM, 약 500 pM 내지 약 900 pM, 약 500 pM 내지 약 850 pM, 약 500 pM 내지 약 800 pM, 약 500 pM 내지 약 750 pM, 약 500 pM 내지 약 700 pM, 약 500 pM 내지 약 650 pM, 약 500 pM 내지 약 600 pM, 약 500 pM 내지 약 550 pM, 약 600 pM 내지 약 30 nM, 약 600 pM 내지 약 25 nM, 약 600 pM 내지 약 30 nM, 약 600 pM 내지 약 15 nM, 약 600 pM 내지 약 10 nM, 약 600 pM 내지 약 5 nM, 약 600 pM 내지 약 2 nM, 약 600 pM 내지 약 1 nM, 약 600 pM 내지 약 950 pM, 약 600 pM 내지 약 900 pM, 약 600 pM 내지 약 850 pM, 약 600 pM 내지 약 800 pM, 약 600 pM 내지 약 750 pM, 약 600 pM 내지 약 700 pM, 약 600 pM 내지 약 650 pM, 약 700 pM 내지 약 30 nM, 약 700 pM 내지 약 25 nM, 약 700 pM 내지 약 30 nM, 약 700 pM 내지 약 15 nM, 약 700 pM 내지 약 10 nM, 약 700 pM 내지 약 5 nM, 약 700 pM 내지 약 2 nM, 약 700 pM 내지 약 1 nM, 약 700 pM 내지 약 950 pM, 약 700 pM 내지 약 900 pM, 약 700 pM 내지 약 850 pM, 약 700 pM 내지 약 800 pM, 약 700 pM 내지 약 750 pM, 약 800 pM 내지 약 30 nM, 약 800 pM 내지 약 25 nM, 약 800 pM 내지 약 30 nM, 약 800 pM 내지 약 15 nM, 약 800 pM 내지 약 10 nM, 약 800 pM 내지 약 5 nM, 약 800 pM 내지 약 2 nM, 약 800 pM 내지 약 1 nM, 약 800 pM 내지 약 950 pM, 약 800 pM 내지 약 900 pM, 약 800 pM 내지 약 850 pM, 약 900 pM 내지 약 30 nM, 약 900 pM 내지 약 25 nM, 약 900 pM 내지 약 30 nM, 약 900 pM 내지 약 15 nM, 약 900 pM 내지 약 10 nM, 약 900 pM 내지 약 5 nM, 약 900 pM 내지 약 2 nM, 약 900 pM 내지 약 1 nM, 약 900 pM 내지 약 950 pM, 약 1 nM 내지 약 30 nM, 약 1 nM 내지 약 25 nM, 약 1 nM 내지 약 20 nM, 약 1 nM 내지 약 15 nM, 약 1 nM 내지 약 10 nM, 약 1 nM 내지 약 5 nM, 약 2 nM 내지 약 30 nM, 약 2 nM 내지 약 25 nM, 약 2 nM 내지 약 20 nM, 약 2 nM 내지 약 15 nM, 약 2 nM 내지 약 10 nM, 약 2 nM 내지 약 5 nM, 약 4 nM 내지 약 30 nM, 약 4 nM 내지 약 25 nM, 약 4 nM 내지 약 20 nM, 약 4 nM 내지 약 15 nM, 약 4 nM 내지 약 10 nM, 약 4 nM 내지 약 5 nM, 약 5 nM 내지 약 30 nM, 약 5 nM 내지 약 25 nM, 약 5 nM 내지 약 20 nM, 약 5 nM 내지 약 15 nM, 약 5 nM 내지 약 10 nM, 약 10 nM 내지 약 30 nM, 약 10 nM 내지 약 25 nM, 약 10 nM 내지 약 20 nM, 약 10 nM 내지 약 15 nM, 약 15 nM 내지 약 30 nM, 약 15 nM 내지 약 25 nM, 약 15 nM 내지 약 20 nM, 약 20 nM 내지 약 30 nM, 및 약 20 nM 내지 약 25 nM)의 KD로 이의 표적에 결합할 수 있다.
본원에 기재된 임의의 표적 결합 도메인은 약 1 nM 내지 약 10 nM(예를 들어, 약 1 nM 내지 약 9 nM, 약 1 nM 내지 약 8 nM, 약 1 nM 내지 약 7 nM, 약 1 nM 내지 약 6 nM, 약 1 nM 내지 약 5 nM, 약 1 nM 내지 약 4 nM, 약 1 nM 내지 약 3 nM, 약 1 nM 내지 약 2 nM, 약 2 nM 내지 약 10 nM, 약 2 nM 내지 약 9 nM, 약 2 nM 내지 약 8 nM, 약 2 nM 내지 약 7 nM, 약 2 nM 내지 약 6 nM, 약 2 nM 내지 약 5 nM, 약 2 nM 내지 약 4 nM, 약 2 nM 내지 약 3 nM, 약 3 nM 내지 약 10 nM, 약 3 nM 내지 약 9 nM, 약 3 nM 내지 약 8 nM, 약 3 nM 내지 약 7 nM, 약 3 nM 내지 약 6 nM, 약 3 nM 내지 약 5 nM, 약 3 nM 내지 약 4 nM, 약 4 nM 내지 약 10 nM, 약 4 nM 내지 약 9 nM, 약 4 nM 내지 약 8 nM, 약 4 nM 내지 약 7 nM, 약 4 nM 내지 약 6 nM, 약 4 nM 내지 약 5 nM, 약 5 nM 내지 약 10 nM, 약 5 nM 내지 약 9 nM, 약 5 nM 내지 약 8 nM, 약 5 nM 내지 약 7 nM, 약 5 nM 내지 약 6 nM, 약 6 nM 내지 약 10 nM, 약 6 nM 내지 약 9 nM, 약 6 nM 내지 약 8 nM, 약 6 nM 내지 약 7 nM, 약 7 nM 내지 약 10 nM, 약 7 nM 내지 약 9 nM, 약 7 nM 내지 약 8 nM, 약 8 nM 내지 약 10 nM, 약 8 nM 내지 약 9 nM, 및 약 9 nM 내지 약 10 nM)의 KD로 이의 표적에 결합할 수 있다.
당업계에 알려진 여러 가지 상이한 방법들(예를 들어, 전기영동 이동성 시프트 검정법(electrophoretic mobility shift assay) 필터 결합 검정법, 표면 플라즈몬 공명, 및 생물분자 결합 동역학 검정법(biomolecular binding kinetics assay) 등)은 본원에 기재된 임의의 항원-결합 단백질 작제물의 KD 값을 결정하는 데 사용될 수 있다.
항원-결합 도메인
본원에 기재된 임의의 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 항원에 특이적으로 결합한다. 이들 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합한다. 이들 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함한다.
본원에 기재된 임의의 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 상이한 항원에 특이적으로 결합한다.
본원에 기재된 임의의 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 항원-결합 도메인이다. 본원에 기재된 임의의 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 항원-결합 도메인이다. 본원에 기재된 임의의 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 항원-결합 도메인은 scFv 또는 단일 도메인 항체(예를 들어, VaHH 또는 VNAR 도메인)를 포함하거나 이것이다.
일부 예에서, 항원-결합 도메인(예를 들어, 본원에 기재된 임의의 항원-결합 도메인)은 CD16a(예를 들어, 미국 특허 제9,035,026호에 기재된 것들 참조), CD28(예를 들어, 미국 특허 제7,723,482호에 기재된 것들 참조), CD3(예를 들어, 미국 특허 제9,226,962호에 기재된 것들 참조), CD33(예를 들어, 미국 특허 제8,759,494호에 기재된 것들 참조), CD20(예를 들어, WO 2014/026054호에 기재된 것들 참조), CD19(예를 들어, 미국 특허 제9,701,758호에 기재된 것들 참조), CD22(예를 들어, WO 2003/104425호에 기재된 것들 참조), CD123(예를 들어, WO 2014/130635호에 기재된 것들 참조), IL-1R(예를 들어, 미국 특허 제8,741,604호에 기재된 것들 참조), IL-1(예를 들어, WO 2014/095808호에 기재된 것들 참조), VEGF(예를 들어, 미국 특허 제9,090,684호에 기재된 것들 참조), IL-6R(예를 들어, 미국 특허 제7,482,436호에 기재된 것들 참조), IL-4(예를 들어, 미국 특허출원공개 2012/0171197호에 기재된 것들 참조), IL-10(예를 들어, 미국 특허출원공개 2016/0340413호에 기재된 것들 참조), PDL-1(예를 들어, 문헌[Drees et al., Protein Express. Purif. 94:60-66, 2014]에 기재된 것들 참조), TIGIT(예를 들어, 미국 특허출원공개 2017/0198042호에 기재된 것들 참조), PD-1(예를 들어, 미국 특허 제7,488,802호에 기재된 것들 참조), TIM3(예를 들어, 미국 특허 제8,552,156호에 기재된 것들 참조), CTLA4(예를 들어, WO 2012/120125호에 기재된 것들 참조), MICA(예를 들어, WO 2016/154585호에 기재된 것들 참조), MICB(예를 들어, 미국 특허 제8,753,640호에 기재된 것들 참조), IL-6(예를 들어, 문헌[Gejima et al., Human Antibodies 11(4):121-129, 2002]에 기재된 것들 참조), IL-8(예를 들어, 미국 특허 제6,117,980호에 기재된 것들 참조), TNFα(예를 들어, 문헌[Geng et al., Immunol. Res. 62(3):377-385, 2015]에 기재된 것들 참조), CD26(예를 들어, WO 2017/189526호에 기재된 것들 참조), CD36(예를 들어, 미국 특허출원공개 2015/0259429호에 기재된 것들 참조), ULBP2(예를 들어, 미국 특허 제9,273,136호에 기재된 것들 참조), CD30(예를 들어, 문헌[Homach et al., Scand. J. Immunol. 48(5):497-501, 1998]에 기재된 것들 참조), CD200(예를 들어, 미국 특허 제9,085,623호에 기재된 것들 참조), IGF-1R(예를 들어, 미국 특허출원공개 2017/0051063호에 기재된 것들 참조), MUC4AC(예를 들어, WO 2012/170470호에 기재된 것들 참조), MUC5AC(예를 들어, 미국 특허 제9,238,084호에 기재된 것들 참조), Trop-2(예를 들어, WO 2013/068946호에 기재된 것들 참조), CMET(예를 들어, 문헌[Edwardraja et al., Biotechnol. Bioeng. 106(3):367-375, 2010]에 기재된 것들 참조), EGFR(예를 들어, 문헌[Akbari et al., Protein Expr. Purif. 127:8-15, 2016]에 기재된 것들 참조), HER1(예를 들어, 미국 특허출원공개 2013/0274446호에 기재된 것들 참조), HER2(예를 들어, 문헌[Cao et al., Biotechnol. Lett. 37(7):1347-1354, 2015]에 기재된 것들 참조), HER3(예를 들어, 미국 특허 제9,505,843호에 기재된 것들 참조), PSMA(예를 들어, 문헌[Parker et al., Protein Expr. Purif. 89(2):136-145, 2013]에 기재된 것들 참조), CEA(예를 들어, WO 1995/015341호에 기재된 것들 참조), B7H3(예를 들어, 미국 특허 제9,371,395호에 기재된 것들 참조), EPCAM(예를 들어, WO 2014/159531호에 기재된 것들 참조), BCMA(예를 들어, 문헌[Smith et al., Mol. Ther. 26(6):1447-1456, 2018]에 기재된 것들 참조), P-카드헤린(예를 들어, 미국 특허 제7,452,537호에 기재된 것들 참조), CEACAM5(예를 들어, 미국 특허 제9,617,345호에 기재된 것들 참조), UL16-결합 단백질(예를 들어, WO 2017/083612호에 기재된 것들 참조), HLA-DR(예를 들어, 문헌[Pistillo et al., Exp. Clin. Immunogenet. 14(2):123-130, 1997]에 기재된 것들 참조), DLL4(예를 들어, WO 2014/007513호에 기재된 것들 참조), TYRO3(예를 들어, WO 2016/166348호에 기재된 것들 참조), AXL(예를 들어, WO 2012/175692호에 기재된 것들 참조), MER(예를 들어, WO 2016/106221호에 기재된 것들 참조), CD122(예를 들어, 미국 특허출원공개 2016/0367664호에 기재된 것들 참조), CD155(예를 들어, WO 2017/149538호에 기재된 것들 참조), 또는 PDGF-DD(예를 들어, 미국 특허 제9,441,034호에 기재된 것들 참조) 중 임의의 하나에 특이적으로 결합할 수 있다.
본원에 기재된 임의의 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드에 존재하는 항원-결합 도메인은 각각 독립적으로, VHH 도메인, VNAR 도메인, 및 scFv로 이루어진 군으로부터 선택된다. 일부 구현예에서, 본원에 기재된 임의의 항원-결합 도메인은 BiTe, (scFv)2, 나노바디, 나노바디-HSA, DART, TandAb, sc디아바디, sc디아바디-CH3, scFv-CH-CL-scFv, HSA바디, sc디아바디-HAS, 또는 탠덤-scFv이다. 임의의 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드에 사용될 수 있는 항원-결합 도메인의 추가 예는 당업계에 알려져 있다.
VHH 도메인은 낙타과(camelid)에서 발견될 수 있는 단일 단량체성 가변 항체 도메인이다. VNAR 도메인은 연골 어류(cartilaginous fish)에서 발견될 수 있는 단일 단량체성 가변 항체 도메인이다. VHH 도메인 및 VNAR 도메인의 비제한적인 양태는 예를 들어 문헌[Cromieet al., Curr. Top. Med. Chem. 15:2543-2557, 2016]; 문헌[De Genstet al., Dev. Comp. Immunol. 30:187-198, 2006]; 문헌[De Meyeret al., Trends Biotechnol. 32:263-270, 2014]; 문헌[Kijankaet al., Nanomedicine 10:161-174, 2015]; 문헌[Kovalevaet al., Expert. Opin. Biol. Ther. 14:1527-1539, 2014]; 문헌[Krahet al., Immunopharmacol. Immunotoxicol. 38:21-28, 2016]; 문헌[Mujic-Delicet al., Trends Pharmacol. Sci. 35:247-255, 2014]; 문헌[Muyldermans, J. Biotechnol. 74:277-302, 2001]; 문헌[Muyldermanset al., Trends Biochem. Sci. 26:230-235, 2001]; 문헌[Muyldermans, Ann. Rev. Biochem. 82:775-797, 2013]; 문헌[Rahbarizadehet al., Immunol. Invest. 40:299-338, 2011]; 문헌[Van Audenhoveet al., EBioMedicine 8:40-48, 2016]; 문헌[Van Bockstaeleet al., Curr. Opin. Investig. Drugs 10:1212-1224, 2009]; 문헌[Vinckeet al., Methods Mol. Biol. 911:15-26, 2012]; 및 문헌[Wesolowskiet al., Med. Microbiol. Immunol. 198:157-174, 2009]에 기재되어 있다.
일부 구현예에서, 본원에 기재된 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 각각의 항원-결합 도메인은 둘 다 VHH 도메인이거나, 적어도 하나의 항원-결합 도메인은 VHH 도메인이다. 일부 구현예에서, 본원에 기재된 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 각각의 항원-결합 도메인은 둘 다 VNAR 도메인이거나, 적어도 하나의 항원-결합 도메인은 VNAR 도메인이다. 일부 구현예에서, 본원에 기재된 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 각각의 항원-결합 도메인은 둘 다 scFv 도메인이거나, 적어도 하나의 항원-결합 도메인은 scFv 도메인이다.
일부 구현예에서, 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드에 존재하는 2개 이상의 폴리펩타이드는 조립되어(예를 들어, 비-공유적으로 조립되어), 본원에 기재된 임의의 항원-결합 도메인, 예를 들어, 항체의 항원-결합 단편(예를 들어, 본원에 기재된 항체의 임의의 항원-결합 단편), VHH-scAb, VHH-Fab, 이중 scFab, F(ab')2, 디아바디, crossMab, DAF(투-인-원), DAF(포-인-원), DutaMab, DT-IgG, 놉스-인 홀(knobs-in-holes) 공통 경쇄, 놉스-인-홀 조립체, 전하쌍(charge pair), Fab-아암 교환, SEED바디, LUZ-Y, Fcab, κλ-바디, 오르토고날(orthogonal) Fab, DVD-IgG, IgG(H)-scFv, scFv-(H)IgG, IgG(L)-scFv, scFv-(L)IgG, IgG(L,H)-Fv, IgG(H)-V, V(H)-IgG, IgG(L)-V, V(L)-IgG, KIH IgG-scFab, 2scFv-IgG, IgG-2scFv, scFv4-Ig, Zybody, DVI-IgG, 디아바디-CH3, 트리플바디(triple body), 미니항체, 미니바디, TriBi 미니바디, scFv-CH3 KIH, Fab-scFv, F(ab')2-scFv2, scFv-KIH, Fab-scFv-Fc, 4가 HCAb, sc디아바디-Fc, 디아바디-Fc, 탠덤 scFv-Fc, 인트라체(intrabody), 도크 앤드 록(dock and lock), lmmTAC, IgG-IgG 접합체, Cov-X-바디, 및 scFv1-PEG-scFv2를 형성할 수 있다. 예를 들어, 이들 요소의 설명에 대해 그 전체가 본원에 포함된 문헌[Spiesset al., Mol. Immunol. 67:95-106, 2015]를 참조한다. 항체의 항원-결합 단편의 비제한적인 예는 Fv 단편, Fab 단편, F(ab')2 단편, 및 Fab' 단편을 포함한다. 항체의 항원-결합 단편의 추가 예는 IgG의 항원-결합 단편(예를 들어, IgG1, IgG2, IgG3, 또는 IgG4의 항원-결합 단편)(예를 들어, 인간 또는 인간화 IgG, 예를 들어, 인간 또는 인간화 IgG1, IgG2, IgG3, 또는 IgG4의 항원-결합 단편); IgA의 항원-결합 단편(예를 들어, IgA1 또는 IgA2의 항원-결합 단편)(예를 들어, 인간 또는 인간화 IgA, 예를 들어, 인간 또는 인간화 IgA1 또는 IgA2의 항원-결합 단편); IgD의 항원-결합 단편(예를 들어, 인간 또는 인간화 IgD의 항원-결합 단편); IgE의 항원-결합 단편(예를 들어, 인간 또는 인간화 IgE의 항원-결합 단편); 또는 IgM의 항원-결합 단편의 항원-결합 단편(예를 들어, 인간 또는 인간화 IgM의 항원-결합 단편)이다.
"Fv" 단편은 하나의 중쇄 가변 도메인 및 하나의 경쇄 가변 도메인의 비-공유-연결된 이량체를 포함한다.
"Fab" 단편은 Fv 단편의 중쇄 및 경쇄 가변 도메인 외에도, 경쇄의 불변 도메인 및 중쇄의 제1 불변 도메인(CH1)을 포함한다.
"F(ab')2" 단편은 힌지 영역 부근에서, 이황화 결합에 의해 결합된 2개의 Fab 단편을 포함한다.
"이중 가변 도메인 면역글로불린" 또는 "DVD-Ig"은 예를 들어, 문헌[DiGiammarinoet al., Methods Mol. Biol. 899:145-156, 2012]; 문헌[Jakobet al., MABs 5:358-363, 2013]; 및 미국 특허 제7,612,181호; 제8,258,268호; 제8,586,714호; 제8,716,450호; 제8,722,855호; 제8,735,546호; 및 제8,822,645호에 기재된 바와 같은 다가(multivalent) 및 다중특이적 결합 단백질을 지칭하며, 이들은 각각 그 전체가 참조로서 포함된다.
DARTs는 예를 들어, 문헌[Garber, Nature Reviews Drug Discovery 13:799-801, 2014]에 기재되어 있다.
일부 구현예에서, 본원에 기재된 임의의 항원-결합 도메인은 단백질, 탄수화물, 지질, 및 이들의 조합으로 이루어진 군으로부터 선택되는 항원에 결합할 수 있다.
항원-결합 도메인의 추가 예 및 양태는 당업계에 알려져 있다.
가용성 인터류킨 또는 사이토카인 단백질
본원에 기재된 임의의 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 단백질 또는 가용성 사이토카인 단백질일 수 있다. 일부 구현예에서, 가용성 인터류킨 또는 가용성 사이토카인 단백질은 하기의 군으로부터 선택된다: IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, 및 SCF. 가용성 IL-2, IL-3, IL-7, IL-8, IL-10, IL-15, IL-17, IL-18, IL-21, PDGF-DD, 및 SCF의 비제한적인 예는 하기에 제공된다.
인간 가용성 IL-3(SEQ ID NO: 105)
apmtqttplkt swvncsnmid eiithlkqpp lplldfnnln gedqdilmen nlrrpnleaf nravkslqna saiesilknl lpclplataa ptrhpihikd
gdwnefrrkl tfylktlena qaqqttlsla if
인간 가용성 IL-8(SEQ ID NO: 106)
egavlprsak elrcqcikty skpfhpkfik elrviesgph canteiivkl sdgrelcldp kenwvqrvve kflkraens
인간 가용성 IL-10(SEQ ID NO: 107)
spgqgtqsensc thfpgnlpnm lrdlrdafsr vktffqmkdq ldnlllkesl ledfkgylgc qalsemiqfy leevmpqaen qdpdikahvn slgenlktlr
lrlrrchrfl pcenkskave qvknafnklq ekgiykamse fdifinyiea ymtmkirn
인간 가용성 IL-17(SEQ ID NO: 108)
gitiprn pgcpnsedkn fprtvmvnln ihnrntntnp krssdyynrs tspwnlhrne dperypsviw eakcrhlgci nadgnvdyhm nsvpiqqeil
vlrrepphcp nsfrlekilv svgctcvtpi vhhva
인간 가용성 IL-18(SEQ ID NO: 109)
yfgklesklsvirn lndqvlfidq gnrplfedmt dsdcrdnapr tifiismykd sqprgmavti svkcekistl scenkiisfk emnppdnikd tksdiiffqr svpghdnkmq fesssyegyf lacekerdlf klilkkedel gdrsimftvq ned
인간 가용성 PDGF-DD(SEQ ID NO: 110)
rdtsatpqsasi kalrnanlrr desnhltdly rrdetiqvkg ngyvqsprfp nsyprnlllt wrlhsqentr iqlvfdnqfg leeaendicr ydfvevedis etstiirgrw cghkevppri ksrtnqikit fksddyfvak pgfkiyysll edfqpaaase tnwesvtssi sgvsynspsv tdptliadal dkkiaefdtv edllkyfnpe swqedlenmy ldtpryrgrs yhdrkskvdl drlnddakry sctprnysvn ireelklanv vffprcllvq rcggncgcgt vnwrsctcns gktvkkyhev lqfepghikr rgraktmalv diqldhherc dcicssrppr
인간 가용성 SCF(SEQ ID NO: 111)
egicrnrvtnnvkdv tklvanlpkd ymitlkyvpg mdvlpshcwi semvvqlsds ltdlldkfsn iseglsnysi idklvnivdd lvecvkenss kdlkksfksp eprlftpeef frifnrsida fkdfvvaset sdcvvsstls pekdsrvsvt kpfmlppvaa sslrndssss nrkaknppgd sslhwaamal palfsliigf afgalywkkr qpsltraven iqineednei smlqekeref qev
인간 가용성 FLT3L(SEQ ID NO: 112)
tqdcsfqhspissd favkirelsd yllqdypvtv asnlqdeelc gglwrlvlaq rwmerlktva gskmqgller vnteihfvtk cafqpppscl rfvqtnisrl lqetseqlva lkpwitrqnf srclelqcqp dsstlpppws prpleatapt apqpplllll llpvglllla aawclhwqrt rrrtprpgeq vppvpspqdl llveh
가용성 인터류킨 단백질 및 가용성 사이토카인 단백질의 추가 예는 당업계에 알려져 있다.
가용성 수용체
본원에 기재된 임의의 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 수용체 또는 가용성 사이토카인 수용체이다. 일부 구현예에서, 가용성 수용체는 가용성 TGF-β 수용체 II(TGF-β RII)(예를 들어, 문헌[Yunget al., Am. J. Resp. Crit. Care Med. 194(9):1140-1151, 2016]에 기재된 것들 참조), 가용성 TGF-βRIII(예를 들어, 문헌[Henget al., Placenta 57:320, 2017]에 기재된 것들 참조), 가용성 NKG2D(예를 들어, 문헌[Cosmanet al., Immunity 14(2):123-133, 2001]; 문헌[Costaet al., Front. Immunol., Vol. 9, Article 1150, May 29, 2018; doi: 10.3389/fimmu.2018.01150] 참조), 가용성 NKp30(예를 들어, 문헌[Costaet al., Front. Immunol., Vol. 9, Article 1150, May 29, 2018; doi: 10.3389/fimmu.2018.01150] 참조), 가용성 NKp44(예를 들어, 문헌[Costaet al., Front. Immunol., Vol. 9, Article 1150, May 29, 2018; doi: 10.3389/fimmu.2018.01150]에 기재된 것들 참조), 가용성 NKp46(예를 들어, 문헌[Mandelboimet al., Nature 409:1055-1060, 2001]; 문헌[Costaet al., Front. Immunol., Vol. 9, Article 1150, May 29, 2018; doi: 10.3389/fimmu.2018.01150] 참조), 가용성 DNAM1(예를 들어, 문헌[Costaet al., Front. Immunol., Vol. 9, Article 1150, May 29, 2018; doi: 10.3389/fimmu.2018.01150]에 기재된 것들 참조), scMHCI(예를 들어, 문헌[Washburnet al., PLoS One 6(3):e18439, 2011]에 기재된 것들 참조), scMHCII(예를 들어, 문헌[Bishwajitet al., Cellular Immunol. 170(1):25-33, 1996]에 기재된 것들 참조), scTCR(예를 들어, 문헌[Weberet al., Nature 356(6372):793-796, 1992]에 기재된 것들 참조), 가용성 CD155(예를 들어, 문헌[Tahara-Hanaokaet al., Int. Immunol. 16(4):533-538, 2004]에 기재된 것들 참조), 또는 가용성 CD28(예를 들어, 문헌[Hebbaret al., Clin. Exp. Immunol. 136:388-392, 2004] 참조)이다.
가용성 인터류킨 수용체 및 가용성 사이토카인 수용체의 추가 예는 당업계에 알려져 있다.
친화도 도메인의 쌍
일부 구현예에서, 다중-사슬 키메라 폴리펩타이드는 1) 친화도 도메인 쌍의 제1 도메인을 포함하는 제1 키메라 폴리펩타이드, 및 2) 친화도 도메인 쌍의 제2 도메인을 포함하는 제2 키메라 폴리펩타이드를, 상기 제1 키메라 폴리펩타이드 및 상기 제2 키메라 폴리펩타이드가 제1 도메인 및 친화도 도메인의 쌍의 제2 도메인의 결합을 통해 회합되도록 포함한다. 일부 구현예에서, 상기 친화도 도메인의 쌍은 인간 IL-15 수용체의 알파 사슬(IL-15Rα) 및 가용성 IL-15로부터의 sushi 도메인이다. 짧은 컨센서스(consensus) 반복부 또는 1형 당단백질 모티프로도 알려져 있는 sushi 도메인은 단백질-단백질 상호작용에서 공통 모티프이다. Sushi 도메인은 보체 구성요소 C1r, C1s, 인자 H, 및 C2m, 뿐만 아니라 비면역학적 분자 인자 XIII 및 β2-당단백질을 포함하여 많은 단백질-결합 분자들 상에서 식별되어 왔다. 전형적인 Sushi 도메인은 대략 60개 아미노산 잔기를 갖고 4개의 시스테인을 함유한다(문헌[Ranganathan, Pac. Symp Biocomput. 2000:155-67]). 제1 시스테인은 제3 시스테인과 이황화 결합을 형성할 수 있고, 제2 시스테인은 제4 시스테인과 이황화 브릿지를 형성할 수 있다. 친화도 도메인 쌍의 하나의 구성원이 가용성 IL-15인 일부 구현예에서, 가용성 IL-15는 D8N 또는 D8A 아미노산 치환을 갖는다. 친화도 도메인의 쌍의 하나의 구성원이 인간 IL-15 수용체의 알파 사슬(IL-15Rα)인 일부 구현예에서, 인간 IL-15Rα는 성숙한 전장 IL-15Rα이다. 일부 구현예에서, 친화도 도메인의 쌍은 바르나제와 바른스타이다. 일부 구현예에서, 친화도 도메인의 쌍은 PKA 및 AKAP이다. 일부 구현예에서, 친화도 도메인의 쌍은 돌연변이화된 RNase I 단편에 기초한 어댑터/도킹 태그 모듈(문헌[Rossi, Proc Natl Acad Sci USA. 103:6841-6846, 2006]; 문헌[Sharkeyet al., Cancer Res. 68:5282-5290, 2008]; 문헌[Rossiet al., Trends Pharmacol Sci. 33:474-481, 2012]) 또는 단백질 신택신, 시냅토태그민, 시냅토브레빈, 및 SNAP25의 상호작용에 기초한 SNARE 모듈(문헌[Deyevet al., Nat Biotechnol. 1486-1492, 2003])이다.
일부 구현예에서, 다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드는 친화도 도메인 쌍의 제1 도메인을 포함하고, 다중-사슬 키메라 폴리펩타이드의 제2 키메라 폴리펩타이드는 친화도 도메인 쌍의 제2 도메인을 포함하며, 여기서 친화도 도메인의 쌍의 제1 도메인 및 친화도 도메인의 쌍의 제2 도메인은 1 x 10-7 M 미만, 1 x 10-8 M 미만, 1 x 10-9 M 미만, 1 x 10-10 M 미만, 1 x 10-11 M 미만, 1 x 10-12 M 미만, 또는 1 x 10-13 M 미만의 해리 평형 상수(KD)로 서로 결합한다. 일부 구현예에서, 친화성 도메인의 쌍의 제1 도메인과 친화성 도메인의 쌍의 제2 도메인은 약 1 x 10-4 M 내지 약 1 x 10-6 M, 약 1 x 10-5 M 내지 약 1 x 10-7 M, 약 1 x 10-6 M 내지 약 1 x 10-8 M, 약 1 x 10-7 M 내지 약 1 x 10-9 M, 약 1 x 10-8 M 내지 약 1 x 10-10 M, 약 1 x 10-9 M 내지 약 1 x 10-11 M, 약 1 x 10-10 M 내지 약 1 x 10-12 M, 약 1 x 10-11 M 내지 약 1 x 10-13 M, 약 1 x 10-4 M 내지 약 1 x 10-5 M, 약 1 x 10-5 M 내지 약 1 x 10-6 M, 약 1 x 10-6 M 내지 약 1 x 10-7 M, 약 1 x 10-7 M 내지 약 1 x 10-8 M, 약 1 x 10-8 M 내지 약 1 x 10-9 M, 약 1 x 10-9 M 내지 약 1 x 10-10 M, 약 1 x 10-10 M 내지 약 1 x 10-11 M, 약 1 x 10-11 M 내지 약 1 x 10-12 M, 또는 약 1 x 10-12 M 내지 약 1 x 10-13 M(포함)의 KD로 서로에 결합한다. 당업계에 알려진 임의의 여러 가지 상이한 방법들(예를 들어, 전기영동 이동성 시프트 검정법, 필터 결합 검정법, 표면 플라즈몬 공명, 및 생물분자 결합 동역학 검정법 등)은 친화도 도메인의 쌍의 제1 도메인 및 친화도 도메인의 쌍의 제2 도메인의 결합의 KD 값을 결정하는 데 사용될 수 있다.
일부 구현예에서, 다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드는 친화도 도메인 쌍의 제1 도메인을 포함하고, 다중-사슬 키메라 폴리펩타이드의 제2 키메라 폴리펩타이드는 친화도 도메인 쌍의 제2 도메인을 포함하며, 상기 친화도 도메인 쌍의 제1 도메인, 친화도 도메인 쌍의 제2 도메인, 또는 둘 다는 약 10개 내지 100개 아미노산 길이이다. 예를 들어, 친화성 도메인 쌍의 제1 도메인, 친화성 도메인 쌍의 제2 도메인, 또는 둘 다는 약 10개 내지 100개 아미노산 길이, 약 15개 내지 100개 아미노산 길이, 약 20개 내지 100개 아미노산 길이, 약 25개 내지 100개 아미노산 길이, 약 30개 내지 100개 아미노산 길이, 약 35개 내지 100개 아미노산 길이, 약 40개 내지 100개 아미노산 길이, 약 45개 내지 100개 아미노산 길이, 약 50개 내지 100개 아미노산 길이, 약 55개 내지 100개 아미노산 길이, 약 60개 내지 100개 아미노산 길이, 약 65개 내지 100개 아미노산 길이, 약 70개 내지 100개 아미노산 길이, 약 75개 내지 100개 아미노산 길이, 약 80개 내지 100개 아미노산 길이, 약 85개 내지 100개 아미노산 길이, 약 90개 내지 100개 아미노산 길이, 약 95개 내지 100개 아미노산 길이, 약 10개 내지 95개 아미노산 길이, 약 10개 내지 90개 아미노산 길이, 약 10개 내지 85개 아미노산 길이, 약 10개 내지 80개 아미노산 길이, 약 10개 내지 75개 아미노산 길이, 약 10개 내지 70개 아미노산 길이, 약 10개 내지 65개 아미노산 길이, 약 10개 내지 60개 아미노산 길이, 약 10개 내지 55개 아미노산 길이, 약 10개 내지 50개 아미노산 길이, 약 10개 내지 45개 아미노산 길이, 약 10개 내지 40개 아미노산 길이, 약 10개 내지 35개 아미노산 길이, 약 10개 내지 30개 아미노산 길이, 약 10개 내지 25개 아미노산 길이, 약 10개 내지 20개 아미노산 길이, 약 10개 내지 15개 아미노산 길이, 약 20개 내지 30개 아미노산 길이, 약 30개 내지 40개 아미노산 길이, 약 40개 내지 50개 아미노산 길이, 약 50개 내지 60개 아미노산 길이, 약 60개 내지 70개 아미노산 길이, 약 70개 내지 80개 아미노산 길이, 약 80개 내지 90개 아미노산 길이, 약 90개 내지 100개 아미노산 길이, 약 20개 내지 90개 아미노산 길이, 약 30개 내지 80개 아미노산 길이, 약 40개 내지 70개 아미노산 길이, 약 50개 내지 60개 아미노산 길이, 또는 이들 사이의 임의의 범위일 수 있다. 일부 구현예에서, 친화성 도메인 쌍의 제1 도메인, 친화성 도메인 쌍의 제2 도메인, 또는 둘 다는 약 10개, 15개, 20개, 25개, 30개, 35개, 40개, 45개, 50개, 55개, 60개, 65개, 70개, 75개, 80개, 85개, 90개, 95개 또는 100개 아미노산 길이이다.
일부 구현예에서, 본원에 개시된 임의의 친화도 도메인 쌍의 제1 도메인 및/또는 제2 도메인은 친화도 도메인 쌍의 제1 도메인 및/또는 제2 도메인의 기능이 무손상으로 유지되는 한, 이의 N-말단 및/또는 C-말단에 하나 이상의 추가 아미노산(예를 들어, 1, 2, 3, 5, 6, 7, 8, 9, 10개 이상의 아미노산)을 포함할 수 있다. 예를 들어, 인간 IL-15 수용체의 알파 사슬(IL-15Rα)로부터의 sushi 도메인은 가용성 IL-15에 결합하는 능력을 여전히 보유하면서도 N-말단 및/또는 C-말단에 하나 이상의 추가 아미노산을 포함할 수 있다. 추가로 또는 대안적으로, 가용성 IL-15는 인간 IL-15 수용체의 알파 사슬(IL-15Rα)로부터의 sushi 도메인에 결합하는 능력을 여전히 보유하면서도 N-말단 및/또는 C-말단에 하나 이상의 추가 아미노산을 포함할 수 있다.
IL-15 수용체 알파(IL-15Rα)의 알파 사슬로부터의 sushi 도메인의 비제한적인 예는 ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR(SEQ ID NO: 113)과 적어도 70% 동일한, 적어도 75% 동일한, 적어도 80% 동일한, 적어도 85% 동일한, 적어도 90% 동일한, 적어도 95% 동일한, 적어도 99% 동일한 또는 100% 동일한 서열을 포함할 수 있다. 일부 구현예에서, IL-15Rα의 알파 사슬로부터의 sushi 도메인은 ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG(SEQ ID NO: 114)를 포함하는 핵산에 의해 인코딩될 수 있다.
일부 구현예에서, 가용성 IL-15는 NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS(SEQ ID NO: 115)와 적어도 70% 동일한, 적어도 75% 동일한, 적어도 80% 동일한, 적어도 85% 동일한, 적어도 90% 동일한, 적어도 95% 동일한, 적어도 99% 동일한 또는 100% 동일한 서열을 포함할 수 있다. 일부 구현예에서, 가용성 IL-15는 AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC(SEQ ID NO: 116)의 서열을 포함하는 핵산에 의해 인코딩될 수 있다.
신호 서열
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 이의 N-말단 단부에 신호 서열을 포함한다. 일부 구현예에서, 다중-사슬 키메라 폴리펩타이드는 이의 N-말단 단부에 신호 서열을 포함하는 제1 키메라 폴리펩타이드를 포함한다. 일부 구현예에서, 다중-사슬 키메라 폴리펩타이드는 이의 N-말단 단부에 신호 서열을 포함하는 제2 키메라 폴리펩타이드를 포함한다. 일부 구현예에서, 다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드와 다중-사슬 키메라 폴리펩타이드의 제2 키메라 폴리펩타이드 둘 다 신호 서열을 포함한다. 당업자가 이해할 바와 같이, 신호 서열은, 많은 내인성적으로 생성된 단백질의 N-말단에 존재하고 상기 단백질을 분비 경로로 안내하는 아미노산 서열이다(예를 들어, 단백질은 소정의 세포내 소기관에 체류하도록, 세포막에 체류하도록, 또는 세포로부터 분비되도록 안내됨). 신호 서열은 이종성이고, 이의 1차 아미노산 서열에서 크게 차이가 난다. 그러나, 신호 서열은 전형적으로 16개 내지 30개 아미노산 길이이고, 친수성의 통상 양으로 하전된 N-말단 영역, 중심의 소수성 도메인, 및 신호 펩티다제에 대한 절단 부위를 함유하는 C-말단 영역을 포함한다.
일부 구현예에서, 다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드, 다중-사슬 키메라 폴리펩타이드의 제2 키메라 폴리펩타이드, 또는 둘 다, 또는 단일-사슬 키메라 폴리펩타이드는 아미노산 서열 MKWVTFISLLFLFSSAYS(SEQ ID NO: 117)를 갖는 신호 서열을 포함한다. 일부 구현예에서, 다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드, 다중-사슬 키메라 폴리펩타이드의 제2 키메라 폴리펩타이드, 또는 둘 다, 또는 단일-사슬 키메라 폴리펩타이드는 핵산 서열 ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCC (SEQ ID NO: 118), ATGAAGTGGGTCACATTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGC (SEQ ID NO: 119), 또는 ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCC (SEQ ID NO: 120)에 의해 인코딩되는 신호 서열을 포함한다.
일부 구현예에서, 다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드, 다중-사슬 키메라 폴리펩타이드의 제2 키메라 폴리펩타이드, 또는 둘 다, 또는 단일-사슬 키메라 폴리펩타이드는 아미노산 서열 MKCLLYLAFLFLGVNC(SEQ ID NO: 121)를 갖는 신호 서열을 포함한다. 일부 구현예에서, 다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드, 다중-사슬 키메라 폴리펩타이드의 제2 키메라 폴리펩타이드, 또는 둘 다, 또는 단일-사슬 키메라 폴리펩타이드는 아미노산 서열 MGQIVTMFEALPHIIDEVINIVIIVLIIITSIKAVYNFATCGILALVSFLFLAGRSCG(SEQ ID NO: 122)를 갖는 신호 서열을 포함한다. 일부 구현예에서, 다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드, 다중-사슬 키메라 폴리펩타이드의 제2 키메라 폴리펩타이드, 또는 둘 다, 또는 단일-사슬 키메라 폴리펩타이드는 아미노산 서열: MPNHQSGSPTGSSDLLLSGKKQRPHLALRRKRRREMRKINRKVRRMNLAPIKEKTAWQHLQALISEAEEVLKTSQTPQNSLTLFLALLSVLGPPVTG(SEQ ID NO: 123)를 갖는 신호 서열을 포함한다. 일부 구현예에서, 다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드, 다중-사슬 키메라 폴리펩타이드의 제2 키메라 폴리펩타이드, 또는 둘 다, 또는 단일-사슬 키메라 폴리펩타이드는 아미노산 서열 MDSKGSSQKGSRLLLLLVVSNLLLCQGVVS(SEQ ID NO: 124)를 갖는 신호 서열을 포함한다. 당업자는 본원에 기재된 다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드 및/또는 제2 키메라 폴리펩타이드, 또는 단일-사슬 키메라 폴리펩타이드에 사용되기에 적절한 다른 신호 서열을 알고 있을 것이다.
일부 구현예에서, 다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드, 다중-사슬 키메라 폴리펩타이드의 제2 키메라 폴리펩타이드, 또는 둘 다, 또는 단일-사슬 키메라 폴리펩타이드는 약 10개 내지 100개 아미노산 길이인 신호 서열을 포함한다. 예를 들어, 신호 서열은 약 10개 내지 100개 아미노산 길이, 약 15개 내지 100개 아미노산 길이, 약 20개 내지 100개 아미노산 길이, 약 25개 내지 100개 아미노산 길이, 약 30개 내지 100개 아미노산 길이, 약 35개 내지 100개 아미노산 길이, 약 40개 내지 100개 아미노산 길이, 약 45개 내지 100개 아미노산 길이, 약 50개 내지 100개 아미노산 길이, 약 55개 내지 100개 아미노산 길이, 약 60개 내지 100개 아미노산 길이, 약 65개 내지 100개 아미노산 길이, 약 70개 내지 100개 아미노산 길이, 약 75개 내지 100개 아미노산 길이, 약 80개 내지 100개 아미노산 길이, 약 85개 내지 100개 아미노산 길이, 약 90개 내지 100개 아미노산 길이, 약 95개 내지 100개 아미노산 길이, 약 10개 내지 95개 아미노산 길이, 약 10개 내지 90개 아미노산 길이, 약 10개 내지 85개 아미노산 길이, 약 10개 내지 80개 아미노산 길이, 약 10개 내지 75개 아미노산 길이, 약 10개 내지 70개 아미노산 길이, 약 10개 내지 65개 아미노산 길이, 약 10개 내지 60개 아미노산 길이, 약 10개 내지 55개 아미노산 길이, 약 10개 내지 50개 아미노산 길이, 약 10개 내지 45개 아미노산 길이, 약 10개 내지 40개 아미노산 길이, 약 10개 내지 35개 아미노산 길이, 약 10개 내지 30개 아미노산 길이, 약 10개 내지 25개 아미노산 길이, 약 10개 내지 20개 아미노산 길이, 약 10개 내지 15개 아미노산 길이, 약 20개 내지 30개 아미노산 길이, 약 30개 내지 40개 아미노산 길이, 약 40개 내지 50개 아미노산 길이, 약 50개 내지 60개 아미노산 길이, 약 60개 내지 70개 아미노산 길이, 약 70개 내지 80개 아미노산 길이, 약 80개 내지 90개 아미노산 길이, 약 90개 내지 100개 아미노산 길이, 약 20개 내지 90개 아미노산 길이, 약 30개 내지 80개 아미노산 길이, 약 40개 내지 70개 아미노산 길이, 약 50개 내지 60개 아미노산 길이, 또는 이들 사이의 임의의 범위일 수 있다. 일부 구현예에서, 신호 서열은 약 10개, 15개, 20개, 25개, 30개, 35개, 40개, 45개, 50개, 55개, 60개, 65개, 70개, 75개, 80개, 85개, 90개, 95개 또는 100개 아미노산 길이이다.
일부 구현예에서, 본원에 개시된 임의의 신호 서열은 상기 신호 서열의 기능이 무손상으로 유지되는 한, 이의 N-말단 및/또는 C-말단에 하나 이상의 추가 아미노산(예를 들어, 1, 2, 3, 5, 6, 7, 8, 9, 10개 이상의 아미노산)을 포함할 수 있다. 예를 들어, 아미노산 서열 MKCLLYLAFLFLGVNC(SEQ ID NO: 125)를 갖는 신호 서열은 다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드, 다중-사슬 키메라 폴리펩타이드의 제2 키메라 폴리펩타이드, 또는 둘 다, 또는 단일-사슬 키메라 폴리펩타이드를 분비 경로로 안내하는 능력을 여전히 보유하면서도, N-말단 또는 C-말단에 하나 이상의 추가 아미노산을 포함할 수 있다.
일부 구현예에서, 다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드, 다중-사슬 키메라 폴리펩타이드의 제2 키메라 폴리펩타이드, 또는 둘 다, 다중-사슬 키메라 폴리펩타이드, 또는 단일-사슬 키메라 폴리펩타이드를 세포외 공간 내로 안내하는 신호 서열을 포함한다. 이러한 구현예는 단리되고/거나 정제되기에 상대적으로 용이한 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드를 생성하는 데 유용하다.
펩타이드 태그
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 펩타이드 태그를 (예를 들어, 키메라 폴리펩타이드의 N-말단 단부 또는 C-말단 단부에서) 포함한다. 일부 구현예에서, 다중-사슬 키메라 폴리펩타이드는 펩타이드 태그를(예를 들어, 제1 키메라 폴리펩타이드의 N-말단 단부 또는 C-말단 단부에서) 포함하는 제1 키메라 폴리펩타이드를 포함한다. 일부 구현예에서, 다중-사슬 키메라 폴리펩타이드는 펩타이드 태그를(예를 들어, 제2 키메라 폴리펩타이드의 N-말단 단부 또는 C-말단 단부에서) 포함하는 제2 키메라 폴리펩타이드를 포함한다. 일부 구현예에서, 다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드와 다중-사슬 키메라 폴리펩타이드의 제2 키메라 폴리펩타이드 둘 다 펩타이드 태그를 포함한다. 일부 구현예에서, 다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드, 다중-사슬 키메라 폴리펩타이드의 제2 키메라 폴리펩타이드, 또는 둘 다, 또는 단일-사슬 키메라 폴리펩타이드는 2개 이상의 펩타이드 태그를 포함한다.
다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드, 다중-사슬 키메라 폴리펩타이드의 제2 키메라 폴리펩타이드, 또는 둘 다, 또는 단일-사슬 키메라 폴리펩타이드에 포함될 수 있는 예시적인 펩타이드 태그는 제한 없이, AviTag(GLNDIFEAQKIEWHE; SEQ ID NO: 126), 칼모듈린(calmodulin)-태그(KRRWKKNFIAVSAANRFKKISSSGAL; SEQ ID NO: 127), 폴리글루타메이트 태그(EEEEEE; SEQ ID NO: 128), E-태그(GAPVPYPDPLEPR; SEQ ID NO: 129), FLAG-태그(DYKDDDDK; SEQ ID NO: 130), HA-태그, 헤마글루티닌으로부터의 펩타이드(YPYDVPDYA; SEQ ID NO: 131), his-태그(HHHHH(SEQ ID NO: 132); HHHHHH(SEQ ID NO: ); HHHHHHH(SEQ ID NO: 133); HHHHHHHH(SEQ ID NO: 134); HHHHHHHHH(SEQ ID NO: 135); 또는 HHHHHHHHHH(SEQ ID NO: 136), HHHHHHHHHH(SEQ ID NO: 137)), myc-태그(EQKLISEEDL; SEQ ID NO: 138), NE-태그(TKENPRSNQEESYDDNES; SEQ ID NO: 139), S-태그, (KETAAAKFERQHMDS; SEQ ID NO: 140), SBP-태그(MDEKTTGWRGGHVVEGLAGELEQLRARLEHHPQGQREP; SEQ ID NO: 141), Softag 1(SLAELLNAGLGGS; SEQ ID NO: 142), Softag 3(TQDPSRVG; SEQ ID NO: 143), Spot-태그(PDRVRAVSHWSS; SEQ ID NO: 144), Strep-태그(WSHPQFEK; SEQ ID NO: 145), TC 태그(CCPGCC; SEQ ID NO: 146), Ty 태그(EVHTNQDPLD; SEQ ID NO: 147), V5 태그(GKPIPNPLLGLDST; SEQ ID NO: 148), VSV-태그(YTDIEMNRLGK; SEQ ID NO: 149), 및 Xpress 태그(DLYDDDDK; SEQ ID NO: 150)를 포함한다. 일부 구현예에서, 조직 인자 단백질은 펩타이드 태그이다.
다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드, 다중-사슬 키메라 폴리펩타이드의 제2 키메라 폴리펩타이드, 또는 둘 다, 또는 단일-사슬 키메라 폴리펩타이드에 포함될 수 있는 펩타이드 태그는 다중-사슬 또는 단일-사슬 키메라 폴리펩타이드와 각각 관련된 임의의 여러 가지 적용에 사용될 수 있다. 예를 들어, 펩타이드 태그는 다중-사슬 또는 단일-사슬 키메라 폴리펩타이드의 정제에 사용될 수 있다. 하나의 비제한적인 예로서, 다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드(예를 들어, 재조합적으로 발현된 제1 키메라 폴리펩타이드), 다중-사슬 키메라 폴리펩타이드의 제2 키메라 폴리펩타이드(예를 들어, 재조합적으로 발현된 제2 키메라 폴리펩타이드), 또는 둘 다, 또는 단일-사슬 키메라 폴리펩타이드는 myc 태그를 포함할 수 있으며; myc-태깅된 제1 키메라 폴리펩타이드, myc-태깅된 제2 키메라 폴리펩타이드, 또는 둘 다를 포함하는 다중-사슬 키메라 폴리펩타이드, 또는 myc-태깅된 또는 단일-사슬 키메라 폴리펩타이드는 myc 태그(들)를 인식하는 항체를 사용하여 정제될 수 있다. Myc 태그를 인식하는 항체의 하나의 비제한적인 예는 비-상업적인 Developmental Studies Hybridoma Bank로부터 입수 가능한 9E10이다. 또 다른 비제한적인 예로서, 다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드(예를 들어, 재조합적으로 발현된 제1 키메라 폴리펩타이드), 다중-사슬 키메라 폴리펩타이드의 제2 키메라 폴리펩타이드(예를 들어, 재조합적으로 발현된 제2 키메라 폴리펩타이드), 또는 둘 다, 또는 단일-사슬 키메라 폴리펩타이드는 히스티딘 태그를 포함할 수 있으며; 히스티딘-태깅된 제1 키메라 폴리펩타이드, 히스티딘-태깅된 제2 키메라 폴리펩타이드, 또는 둘 다 포함하는 다중-사슬 키메라 폴리펩타이드, 또는 히스티딘-태깅된 단일-사슬 키메라 폴리펩타이드는 니켈 또는 코발트 킬레이트를 사용하여 정제될 수 있다. 당업자는 다른 적합한 태그 및 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드를 정제하는 데 사용되기 위한 태그에 결합하는 제제를 알고 있을 것이다. 일부 구현예에서, 펩타이드 태그는 정제 후 다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드 및/또는 제2 키메라 폴리펩타이드, 또는 단일-사슬 키메라 폴리펩타이드로부터 제거된다. 일부 구현예에서, 펩타이드 태그는 정제 후 다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드 및/또는 제2 키메라 폴리펩타이드, 또는 단일-사슬 키메라 폴리펩타이드로부터 제거되지 않는다.
다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드, 다중-사슬 키메라 폴리펩타이드의 제2 키메라 폴리펩타이드, 또는 둘 다, 또는 단일-사슬 키메라 폴리펩타이드에 포함될 수 있는 펩타이드 태그는 예를 들어, 다중-사슬 키메라 폴리펩타이드 또는 단일-사슬 키메라 폴리펩타이드 각각의 면역침전, 다중-사슬 키메라 폴리펩타이드 또는 단일-사슬 키메라 폴리펩타이드 각각의(예를 들어, 웨스턴 블로팅, ELISA, 유세포측정법, 및/또는 면역세포화학을 통한) 이미지화, 및/또는 다중-사슬 키메라 폴리펩타이드 또는 단일-사슬 키메라 폴리펩타이드 각각의 용해에 사용될 수 있다.
일부 구현예에서, 다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드, 다중-사슬 키메라 폴리펩타이드의 제2 키메라 폴리펩타이드, 또는 둘 다, 또는 단일-사슬 키메라 폴리펩타이드는 약 10개 내지 100개 아미노산 길이인 펩타이드 태그를 포함한다. 예를 들어, 펩타이드 태그는 약 10개 내지 100개 아미노산 길이, 약 15개 내지 100개 아미노산 길이, 약 20개 내지 100개 아미노산 길이, 약 25개 내지 100개 아미노산 길이, 약 30개 내지 100개 아미노산 길이, 약 35개 내지 100개 아미노산 길이, 약 40개 내지 100개 아미노산 길이, 약 45개 내지 100개 아미노산 길이, 약 50개 내지 100개 아미노산 길이, 약 55개 내지 100개 아미노산 길이, 약 60개 내지 100개 아미노산 길이, 약 65개 내지 100개 아미노산 길이, 약 70개 내지 100개 아미노산 길이, 약 75개 내지 100개 아미노산 길이, 약 80개 내지 100개 아미노산 길이, 약 85개 내지 100개 아미노산 길이, 약 90개 내지 100개 아미노산 길이, 약 95개 내지 100개 아미노산 길이, 약 10개 내지 95개 아미노산 길이, 약 10개 내지 90개 아미노산 길이, 약 10개 내지 85개 아미노산 길이, 약 10개 내지 80개 아미노산 길이, 약 10개 내지 75개 아미노산 길이, 약 10개 내지 70개 아미노산 길이, 약 10개 내지 65개 아미노산 길이, 약 10개 내지 60개 아미노산 길이, 약 10개 내지 55개 아미노산 길이, 약 10개 내지 50개 아미노산 길이, 약 10개 내지 45개 아미노산 길이, 약 10개 내지 40개 아미노산 길이, 약 10개 내지 35개 아미노산 길이, 약 10개 내지 30개 아미노산 길이, 약 10개 내지 25개 아미노산 길이, 약 10개 내지 20개 아미노산 길이, 약 10개 내지 15개 아미노산 길이, 약 20개 내지 30개 아미노산 길이, 약 30개 내지 40개 아미노산 길이, 약 40개 내지 50개 아미노산 길이, 약 50개 내지 60개 아미노산 길이, 약 60개 내지 70개 아미노산 길이, 약 70개 내지 80개 아미노산 길이, 약 80개 내지 90개 아미노산 길이, 약 90개 내지 100개 아미노산 길이, 약 20개 내지 90개 아미노산 길이, 약 30개 내지 80개 아미노산 길이, 약 40개 내지 70개 아미노산 길이, 약 50개 내지 60개 아미노산 길이, 또는 이들 사이의 임의의 범위일 수 있다. 일부 구현예에서, 펩타이드 태그는 약 10개, 15개, 20개, 25개, 30개, 35개, 40개, 45개, 50개, 55개, 60개, 65개, 70개, 75개, 80개, 85개, 90개, 95개 또는 100개 아미노산 길이이다.
다중-사슬 키메라 폴리펩타이드의 제1 키메라 폴리펩타이드, 다중-사슬 키메라 폴리펩타이드의 제2 키메라 폴리펩타이드, 또는 둘 다, 또는 단일-사슬 키메라 폴리펩타이드에 포함된 펩타이드 태그는 임의의 적합한 길이일 수 있다. 예를 들어, 펩타이드 태그는 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20개 이상의 아미노산 길이일 수 있다. 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드가 2개 이상 펩타이드 태그를 포함하는 구현예에서, 2개 이상 펩타이드 태그는 동일하거나 상이한 길이일 수 있다. 일부 구현예에서, 본원에 개시된 임의의 펩타이드 태그는 상기 펩타이드 태그의 기능이 무손상으로 유지되는 한, 이의 N-말단 및/또는 C-말단에 하나 이상의 추가 아미노산(예를 들어, 1, 2, 3, 5, 6, 7, 8, 9, 10개 이상의 아미노산)을 포함할 수 있다. 예를 들어, 아미노산 서열 EQKLISEEDL(SEQ ID NO: 138)을 갖는 myc 태그는 항체(예를 들어, 9E10)에 의해 결합되는 능력을 여전히 보유하면서 하나 이상의 추가 아미노산을(예를 들어, 펩타이드 태그의 N 말단 및/또는 C 말단에) 포함할 수 있다.
단일-사슬 키메라 폴리펩타이드- A형의 예시적인 구현예
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및/또는 제2 표적-결합 도메인은 독립적으로, CD3(예를 들어, 인간 CD3) 또는 CD28(예를 들어, 인간 CD28)에 특이적으로 결합할 수 있다. 일부 구현예에서, 제1 표적-결합 도메인은 CD3(예를 들어, 인간 CD3)에 특이적으로 결합하고, 제2 표적-결합 도메인은 CD28(예를 들어, 인간 CD28)에 특이적으로 결합한다. 일부 구현예에서, 제1 표적-결합 도메인은 CD28(예를 들어, 인간 CD28)에 특이적으로 결합하고, 제2 표적-결합 도메인은 CD3(예를 들어, 인간 CD3)에 특이적으로 결합한다.
이들 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 가용성 조직 인자 도메인은 서로 직접적으로 인접해 있다. 이들 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 추가로 포함한다.
이들 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인 및 제2 표적-결합 도메인은 서로 직접적으로 인접해 있다. 이들 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 가용성 조직 인자 도메인과 제2 표적-결합 도메인 사이에 추가로 포함한다.
이들 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 항원-결합 도메인이다. 이들 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 서로 항원-결합 도메인(예를 들어, 본원에 기재된 임의의 예시적인 항원-결합 도메인)이다. 이들 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 항원-결합 도메인은 scFv 또는 단일 도메인 항체를 포함한다.
CD3에 특이적으로 결합하는 scFv의 비제한적인 예는, 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
QIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINRGGGGSGGGGSGGGGSQVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTDKSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSS (SEQ ID NO: 151).
일부 구현예에서, CD3에 특이적으로 결합하는 scFv는, 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩될 수 있다:
CAGATCGTGCTGACCCAAAGCCCCGCCATCATGAGCGCTAGCCCCGGTGAGAAGGTGACCATGACATGCTCCGCTTCCAGCTCCGTGTCCTACATGAACTGGTATCAGCAGAAAAGCGGAACCAGCCCCAAAAGGTGGATCTACGACACCAGCAAGCTGGCCTCCGGAGTGCCCGCTCATTTCCGGGGCTCTGGATCCGGCACCAGCTACTCTTTAACCATTTCCGGCATGGAAGCTGAAGACGCTGCCACCTACTATTGCCAGCAATGGAGCAGCAACCCCTTCACATTCGGATCTGGCACCAAGCTCGAAATCAATCGTGGAGGAGGTGGCAGCGGCGGCGGTGGATCCGGCGGAGGAGGAAGCCAAGTTCAACTCCAGCAGAGCGGCGCTGAACTGGCCCGGCCCGGCGCCTCCGTCAAGATGAGCTGCAAGGCTTCCGGCTATACATTTACTCGTTACACAATGCATTGGGTCAAGCAGAGGCCCGGTCAAGGTTTAGAGTGGATCGGATATATCAACCCTTCCCGGGGCTACACCAACTATAACCAAAAGTTCAAGGATAAAGCCACTTTAACCACTGACAAGAGCTCCTCCACCGCCTACATGCAGCTGTCCTCTTTAACCAGCGAGGACTCCGCTGTTTACTACTGCGCTAGGTATTACGACGACCACTACTGTTTAGACTATTGGGGACAAGGTACCACTTTAACCGTCAGCAGC (SEQ ID NO: 152).
CD28에 특이적으로 결합하는 scFv의 비제한적인 예는, 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
VQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSSGGGGSGGGGSGGGGSDIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKR (SEQ ID NO: 153).
일부 구현예에서, CD28에 특이적으로 결합하는 scFv는, 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩될 수 있다:
GTCCAGCTGCAGCAGAGCGGACCCGAACTCGTGAAACCCGGTGCTTCCGTGAAAATGTCTTGTAAGGCCAGCGGATACACCTTCACCTCCTATGTGATCCAGTGGGTCAAACAGAAGCCCGGACAAGGTCTCGAGTGGATCGGCAGCATCAACCCTTACAACGACTATACCAAATACAACGAGAAGTTTAAGGGAAAGGCTACTTTAACCTCCGACAAAAGCTCCATCACAGCCTACATGGAGTTCAGCTCTTTAACATCCGAGGACAGCGCTCTGTACTATTGCGCCCGGTGGGGCGACGGCAATTACTGGGGACGGGGCACAACACTGACCGTGAGCAGCGGAGGCGGAGGCTCCGGCGGAGGCGGATCTGGCGGTGGCGGCTCCGACATCGAGATGACCCAGTCCCCCGCTATCATGTCCGCCTCTTTAGGCGAGCGGGTCACAATGACTTGTACAGCCTCCTCCAGCGTCTCCTCCTCCTACTTCCATTGGTACCAACAGAAACCCGGAAGCTCCCCTAAACTGTGCATCTACAGCACCAGCAATCTCGCCAGCGGCGTGCCCCCTAGGTTTTCCGGAAGCGGAAGCACCAGCTACTCTTTAACCATCTCCTCCATGGAGGCTGAGGATGCCGCCACCTACTTTTGTCACCAGTACCACCGGTCCCCCACCTTCGGAGGCGGCACCAAACTGGAGACAAAGAGG (SEQ ID NO: 154).
이들 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및/또는 제2 표적-결합 도메인은 가용성 수용체(예를 들어, 가용성 CD28 수용체 또는 가용성 CD3 수용체)이다. 이들 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인은 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인일 수 있다.
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
QIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINRGGGGSGGGGSGGGGSQVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTDKSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREVQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSSGGGGSGGGGSGGGGSDIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKR (SEQ ID NO: 155).
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CAGATCGTGCTGACCCAAAGCCCCGCCATCATGAGCGCTAGCCCCGGTGAGAAGGTGACCATGACATGCTCCGCTTCCAGCTCCGTGTCCTACATGAACTGGTATCAGCAGAAAAGCGGAACCAGCCCCAAAAGGTGGATCTACGACACCAGCAAGCTGGCCTCCGGAGTGCCCGCTCATTTCCGGGGCTCTGGATCCGGCACCAGCTACTCTTTAACCATTTCCGGCATGGAAGCTGAAGACGCTGCCACCTACTATTGCCAGCAATGGAGCAGCAACCCCTTCACATTCGGATCTGGCACCAAGCTCGAAATCAATCGTGGAGGAGGTGGCAGCGGCGGCGGTGGATCCGGCGGAGGAGGAAGCCAAGTTCAACTCCAGCAGAGCGGCGCTGAACTGGCCCGGCCCGGCGCCTCCGTCAAGATGAGCTGCAAGGCTTCCGGCTATACATTTACTCGTTACACAATGCATTGGGTCAAGCAGAGGCCCGGTCAAGGTTTAGAGTGGATCGGATATATCAACCCTTCCCGGGGCTACACCAACTATAACCAAAAGTTCAAGGATAAAGCCACTTTAACCACTGACAAGAGCTCCTCCACCGCCTACATGCAGCTGTCCTCTTTAACCAGCGAGGACTCCGCTGTTTACTACTGCGCTAGGTATTACGACGACCACTACTGTTTAGACTATTGGGGACAAGGTACCACTTTAACCGTCAGCAGCTCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGGTCCAGCTGCAGCAGAGCGGACCCGAACTCGTGAAACCCGGTGCTTCCGTGAAAATGTCTTGTAAGGCCAGCGGATACACCTTCACCTCCTATGTGATCCAGTGGGTCAAACAGAAGCCCGGACAAGGTCTCGAGTGGATCGGCAGCATCAACCCTTACAACGACTATACCAAATACAACGAGAAGTTTAAGGGAAAGGCTACTTTAACCTCCGACAAAAGCTCCATCACAGCCTACATGGAGTTCAGCTCTTTAACATCCGAGGACAGCGCTCTGTACTATTGCGCCCGGTGGGGCGACGGCAATTACTGGGGACGGGGCACAACACTGACCGTGAGCAGCGGAGGCGGAGGCTCCGGCGGAGGCGGATCTGGCGGTGGCGGCTCCGACATCGAGATGACCCAGTCCCCCGCTATCATGTCCGCCTCTTTAGGCGAGCGGGTCACAATGACTTGTACAGCCTCCTCCAGCGTCTCCTCCTCCTACTTCCATTGGTACCAACAGAAACCCGGAAGCTCCCCTAAACTGTGCATCTACAGCACCAGCAATCTCGCCAGCGGCGTGCCCCCTAGGTTTTCCGGAAGCGGAAGCACCAGCTACTCTTTAACCATCTCCTCCATGGAGGCTGAGGATGCCGCCACCTACTTTTGTCACCAGTACCACCGGTCCCCCACCTTCGGAGGCGGCACCAAACTGGAGACAAAGAGG (SEQ ID NO: 156).
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSQIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINRGGGGSGGGGSGGGGSQVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTDKSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREVQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSSGGGGSGGGGSGGGGSDIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKR (SEQ ID NO: 157).
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCTTATTATTTTTATTCAGCTCCGCCTATTCCCAGATCGTGCTGACCCAAAGCCCCGCCATCATGAGCGCTAGCCCCGGTGAGAAGGTGACCATGACATGCTCCGCTTCCAGCTCCGTGTCCTACATGAACTGGTATCAGCAGAAAAGCGGAACCAGCCCCAAAAGGTGGATCTACGACACCAGCAAGCTGGCCTCCGGAGTGCCCGCTCATTTCCGGGGCTCTGGATCCGGCACCAGCTACTCTTTAACCATTTCCGGCATGGAAGCTGAAGACGCTGCCACCTACTATTGCCAGCAATGGAGCAGCAACCCCTTCACATTCGGATCTGGCACCAAGCTCGAAATCAATCGTGGAGGAGGTGGCAGCGGCGGCGGTGGATCCGGCGGAGGAGGAAGCCAAGTTCAACTCCAGCAGAGCGGCGCTGAACTGGCCCGGCCCGGCGCCTCCGTCAAGATGAGCTGCAAGGCTTCCGGCTATACATTTACTCGTTACACAATGCATTGGGTCAAGCAGAGGCCCGGTCAAGGTTTAGAGTGGATCGGATATATCAACCCTTCCCGGGGCTACACCAACTATAACCAAAAGTTCAAGGATAAAGCCACTTTAACCACTGACAAGAGCTCCTCCACCGCCTACATGCAGCTGTCCTCTTTAACCAGCGAGGACTCCGCTGTTTACTACTGCGCTAGGTATTACGACGACCACTACTGTTTAGACTATTGGGGACAAGGTACCACTTTAACCGTCAGCAGCTCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGGTCCAGCTGCAGCAGAGCGGACCCGAACTCGTGAAACCCGGTGCTTCCGTGAAAATGTCTTGTAAGGCCAGCGGATACACCTTCACCTCCTATGTGATCCAGTGGGTCAAACAGAAGCCCGGACAAGGTCTCGAGTGGATCGGCAGCATCAACCCTTACAACGACTATACCAAATACAACGAGAAGTTTAAGGGAAAGGCTACTTTAACCTCCGACAAAAGCTCCATCACAGCCTACATGGAGTTCAGCTCTTTAACATCCGAGGACAGCGCTCTGTACTATTGCGCCCGGTGGGGCGACGGCAATTACTGGGGACGGGGCACAACACTGACCGTGAGCAGCGGAGGCGGAGGCTCCGGCGGAGGCGGATCTGGCGGTGGCGGCTCCGACATCGAGATGACCCAGTCCCCCGCTATCATGTCCGCCTCTTTAGGCGAGCGGGTCACAATGACTTGTACAGCCTCCTCCAGCGTCTCCTCCTCCTACTTCCATTGGTACCAACAGAAACCCGGAAGCTCCCCTAAACTGTGCATCTACAGCACCAGCAATCTCGCCAGCGGCGTGCCCCCTAGGTTTTCCGGAAGCGGAAGCACCAGCTACTCTTTAACCATCTCCTCCATGGAGGCTGAGGATGCCGCCACCTACTTTTGTCACCAGTACCACCGGTCCCCCACCTTCGGAGGCGGCACCAAACTGGAGACAAAGAGG (SEQ ID NO: 158).
단일-사슬 키메라 폴리펩타이드- B형의 예시적인 구현예
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및/또는 제2 표적-결합 도메인은 독립적으로, IL-2 수용체(예를 들어, 인간 IL-2 수용체)에 특이적으로 결합할 수 있다.
이들 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 가용성 조직 인자 도메인은 서로 직접적으로 인접해 있다. 이들 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 추가로 포함한다.
이들 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인 및 제2 표적-결합 도메인은 서로 직접적으로 인접해 있다. 이들 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 가용성 조직 인자 도메인과 제2 표적-결합 도메인 사이에 추가로 포함한다.
이들 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 가용성 인간 IL-2 단백질이다. IL-2 수용체에 특이적으로 결합하는 IL-2 단백질의 비제한적인 예는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
APTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLELKGSETTFMCEYADETATIVEFLNRWITFCQSIISTLT (SEQ ID NO: 78).
일부 구현예에서, IL-2 수용체에 특이적으로 결합하는 IL-2 단백질은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩될 수 있다:
GCACCTACTTCAAGTTCTACAAAGAAAACACAGCTACAACTGGAGCATTTACTGCTGGATTTACAGATGATTTTGAATGGAATTAATAATTACAAGAATCCCAAACTCACCAGGATGCTCACATTTAAGTTTTACATGCCCAAGAAGGCCACAGAACTGAAACATCTTCAGTGTCTAGAAGAAGAACTCAAACCTCTGGAGGAAGTGCTAAATTTAGCTCAAAGCAAAAACTTTCACTTAAGACCCAGGGACTTAATCAGCAATATCAACGTAATAGTTCTGGAACTAAAGGGATCTGAAACAACATTCATGTGTGAATATGCTGATGAGACAGCAACCATTGTAGAATTTCTGAACAGATGGATTACCTTTTGTCAAAGCATCATCTCAACACTAACT (SEQ ID NO: 159).
일부 구현예에서, IL-2 수용체에 특이적으로 결합하는 IL-2 단백질은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩될 수 있다:
GCCCCCACCTCCTCCTCCACCAAGAAGACCCAGCTGCAGCTGGAGCATTTACTGCTGGATTTACAGATGATTTTAAACGGCATCAACAACTACAAGAACCCCAAGCTGACTCGTATGCTGACCTTCAAGTTCTACATGCCCAAGAAGGCCACCGAGCTGAAGCATTTACAGTGTTTAGAGGAGGAGCTGAAGCCCCTCGAGGAGGTGCTGAATTTAGCCCAGTCCAAGAATTTCCATTTAAGGCCCCGGGATTTAATCAGCAACATCAACGTGATCGTTTTAGAGCTGAAGGGCTCCGAGACCACCTTCATGTGCGAGTACGCCGACGAGACCGCCACCATCGTGGAGTTTTTAAATCGTTGGATCACCTTCTGCCAGTCCATCATCTCCACTTTAACC (SEQ ID NO: 160).
이들 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인은 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인일 수 있다.
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
APTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLELKGSETTFMCEYADETATIVEFLNRWITFCQSIISTLTSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREAPTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLELKGSETTFMCEYADETATIVEFLNRWITFCQSIISTLT (SEQ ID NO: 161).
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
GCCCCCACCTCCTCCTCCACCAAGAAGACCCAGCTGCAGCTGGAGCATTTACTGCTGGATTTACAGATGATTTTAAACGGCATCAACAACTACAAGAACCCCAAGCTGACTCGTATGCTGACCTTCAAGTTCTACATGCCCAAGAAGGCCACCGAGCTGAAGCATTTACAGTGTTTAGAGGAGGAGCTGAAGCCCCTCGAGGAGGTGCTGAATTTAGCCCAGTCCAAGAATTTCCATTTAAGGCCCCGGGATTTAATCAGCAACATCAACGTGATCGTTTTAGAGCTGAAGGGCTCCGAGACCACCTTCATGTGCGAGTACGCCGACGAGACCGCCACCATCGTGGAGTTTTTAAATCGTTGGATCACCTTCTGCCAGTCCATCATCTCCACTTTAACCAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGGCACCTACTTCAAGTTCTACAAAGAAAACACAGCTACAACTGGAGCATTTACTGCTGGATTTACAGATGATTTTGAATGGAATTAATAATTACAAGAATCCCAAACTCACCAGGATGCTCACATTTAAGTTTTACATGCCCAAGAAGGCCACAGAACTGAAACATCTTCAGTGTCTAGAAGAAGAACTCAAACCTCTGGAGGAAGTGCTAAATTTAGCTCAAAGCAAAAACTTTCACTTAAGACCCAGGGACTTAATCAGCAATATCAACGTAATAGTTCTGGAACTAAAGGGATCTGAAACAACATTCATGTGTGAATATGCTGATGAGACAGCAACCATTGTAGAATTTCTGAACAGATGGATTACCTTTTGTCAAAGCATCATCTCAACACTAACT (SEQ ID NO: 162).
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSAPTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLELKGSETTFMCEYADETATIVEFLNRWITFCQSIISTLTSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFREAPTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLELKGSETTFMCEYADETATIVEFLNRWITFCQSIISTLT (SEQ ID NO: 163).
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCGCCCCCACCTCCTCCTCCACCAAGAAGACCCAGCTGCAGCTGGAGCATTTACTGCTGGATTTACAGATGATTTTAAACGGCATCAACAACTACAAGAACCCCAAGCTGACTCGTATGCTGACCTTCAAGTTCTACATGCCCAAGAAGGCCACCGAGCTGAAGCATTTACAGTGTTTAGAGGAGGAGCTGAAGCCCCTCGAGGAGGTGCTGAATTTAGCCCAGTCCAAGAATTTCCATTTAAGGCCCCGGGATTTAATCAGCAACATCAACGTGATCGTTTTAGAGCTGAAGGGCTCCGAGACCACCTTCATGTGCGAGTACGCCGACGAGACCGCCACCATCGTGGAGTTTTTAAATCGTTGGATCACCTTCTGCCAGTCCATCATCTCCACTTTAACCAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGGCACCTACTTCAAGTTCTACAAAGAAAACACAGCTACAACTGGAGCATTTACTGCTGGATTTACAGATGATTTTGAATGGAATTAATAATTACAAGAATCCCAAACTCACCAGGATGCTCACATTTAAGTTTTACATGCCCAAGAAGGCCACAGAACTGAAACATCTTCAGTGTCTAGAAGAAGAACTCAAACCTCTGGAGGAAGTGCTAAATTTAGCTCAAAGCAAAAACTTTCACTTAAGACCCAGGGACTTAATCAGCAATATCAACGTAATAGTTCTGGAACTAAAGGGATCTGAAACAACATTCATGTGTGAATATGCTGATGAGACAGCAACCATTGTAGAATTTCTGAACAGATGGATTACCTTTTGTCAAAGCATCATCTCAACACTAACT (SEQ ID NO: 164).
단일-사슬 키메라 폴리펩타이드- C형의 예시적인 구현예
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및/또는 제2 표적-결합 도메인은 독립적으로, IL-15 수용체(예를 들어, 인간 IL-15 수용체)에 특이적으로 결합할 수 있다.
이들 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 가용성 조직 인자 도메인은 서로 직접적으로 인접해 있다. 이들 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 추가로 포함한다.
이들 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인 및 제2 표적-결합 도메인은 서로 직접적으로 인접해 있다. 이들 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 가용성 조직 인자 도메인과 제2 표적-결합 도메인 사이에 추가로 포함한다.
이들 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 가용성 인간 IL-15 단백질이다. IL-15 수용체에 특이적으로 결합하는 IL-15 단백질의 비제한적인 예는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 82).
일부 구현예에서, IL-15 수용체에 특이적으로 결합하는 IL-15 단백질은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩될 수 있다:
AACTGGGTGAACGTGATCAGCGATTTAAAGAAGATCGAGGATTTAATCCAGAGCATGCACATCGACGCCACTCTGTACACTGAGAGCGACGTGCACCCTAGCTGCAAGGTGACTGCCATGAAGTGCTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGCGATGCCAGCATCCACGACACTGTGGAGAATTTAATCATTTTAGCCAACAACTCTTTAAGCAGCAACGGCAACGTGACAGAGAGCGGCTGCAAGGAGTGCGAGGAGCTGGAGGAGAAGAACATCAAGGAGTTTTTACAGAGCTTCGTGCACATCGTGCAGATGTTCATCAACACTAGC (SEQ ID NO: 165).
일부 구현예에서, IL-15 수용체에 특이적으로 결합하는 IL-15 단백질은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩될 수 있다:
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 166).
이들 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인은 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인일 수 있다.
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 167).
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
AACTGGGTGAACGTGATCAGCGATTTAAAGAAGATCGAGGATTTAATCCAGAGCATGCACATCGACGCCACTCTGTACACTGAGAGCGACGTGCACCCTAGCTGCAAGGTGACTGCCATGAAGTGCTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGCGATGCCAGCATCCACGACACTGTGGAGAATTTAATCATTTTAGCCAACAACTCTTTAAGCAGCAACGGCAACGTGACAGAGAGCGGCTGCAAGGAGTGCGAGGAGCTGGAGGAGAAGAACATCAAGGAGTTTTTACAGAGCTTCGTGCACATCGTGCAGATGTTCATCAACACTAGCAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 168).
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSNWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 169).
일부 구현예에서, 단일-사슬 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCAACTGGGTGAACGTGATCAGCGATTTAAAGAAGATCGAGGATTTAATCCAGAGCATGCACATCGACGCCACTCTGTACACTGAGAGCGACGTGCACCCTAGCTGCAAGGTGACTGCCATGAAGTGCTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGCGATGCCAGCATCCACGACACTGTGGAGAATTTAATCATTTTAGCCAACAACTCTTTAAGCAGCAACGGCAACGTGACAGAGAGCGGCTGCAAGGAGTGCGAGGAGCTGGAGGAGAAGAACATCAAGGAGTTTTTACAGAGCTTCGTGCACATCGTGCAGATGTTCATCAACACTAGCAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 170).
예시적인 다중-사슬 키메라 폴리펩타이드- A형
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, IL-18의 수용체 또는 IL-12의 수용체에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 표적-결합 도메인과 가용성 조직 인자 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 상기 친화도 도메인 쌍의 제2 도메인과 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인은 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인일 수 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인 쌍은 본원에 기재된 임의의 예시적인 친화도 도메인 쌍일 수 있다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 작용제성 항원-결합 도메인이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 작용제성 항원-결합 도메인이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 항원-결합 도메인은 scFv 또는 단일-도메인 항체를 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다 가용성 IL-15 또는 가용성 IL-18이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, 가용성 IL-15 또는 가용성 IL-18이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인과 제2 표적-결합 도메인 둘 다 IL-18의 수용체 또는 IL-12의 수용체에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 IL-12에 대한 수용체에 특이적으로 결합하고, 제2 표적-결합 도메인은 IL-18에 대한 수용체에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 IL-18에 대한 수용체에 특이적으로 결합하고, 제2 표적-결합 도메인은 IL-12에 대한 수용체에 특이적으로 결합한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 가용성 IL-18(예를 들어, 가용성 인간 IL-18)을 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-18은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNED (SEQ ID NO: 109).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-18은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
TACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGAT (SEQ ID NO: 171).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인은 가용성 IL-12(예를 들어, 가용성 인간 IL-12)를 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-15는 가용성 인간 IL-12β(p40)의 서열 및 가용성 인간 IL-12α(p35)의 서열을 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 IL-15 인간 IL-15는 가용성 IL-12β(p40)의 서열과 가용성 인간 IL-12α(p35)의 서열 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커 서열)을 추가로 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 링커 서열은 GGGGSGGGGSGGGGS(SEQ ID NO: 102)를 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-12β(p40)의 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCS (SEQ ID NO: 81).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-12β(p40)는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCC (SEQ ID NO: 172).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-12α(p35)는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
RNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNAS (SEQ ID NO: 80).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-12α(p35)는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGC (SEQ ID NO: 173).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNEDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 174).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
TACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 175).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSYFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNEDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 176).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTCACATTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGCTACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 177).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCSGGGGSGGGGSGGGGSRNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNASITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR (SEQ ID NO: 178).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCCGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG (SEQ ID NO: 179).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSIWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCSGGGGSGGGGSGGGGSRNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNASITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR (SEQ ID NO: 180).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCCATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCCGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG (SEQ ID NO: 181).
예시적인 다중-사슬 키메라 폴리펩타이드- B형
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, IL-21의 수용체 또는 TGF-β에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 표적-결합 도메인과 가용성 조직 인자 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 상기 친화도 도메인 쌍의 제2 도메인과 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인은 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인일 수 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인 쌍은 본원에 기재된 임의의 예시적인 친화도 도메인 쌍일 수 있다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다 가용성 IL-21(예를 들어, 가용성 인간 IL-21 폴리펩타이드) 또는 가용성 TGF-β 수용체(예를 들어, 가용성 TGFRβRII 수용체)이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, 가용성 IL-21 또는 가용성 TGF-β 수용체(예를 들어, 가용성 TGFRβRII 수용체)이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인과 제2 표적-결합 도메인 둘 다 IL-21의 수용체 또는 TGF-β에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 IL-21에 대한 수용체에 특이적으로 결합하고, 제2 표적-결합 도메인은 TGF-β에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 TGF-β에 특이적으로 결합하고, 제2 표적-결합 도메인은 IL-21에 대한 수용체에 특이적으로 결합한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 가용성 IL-21(예를 들어, 가용성 인간 IL-21)을 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-21은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 83).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-21은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 182).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인은 가용성 TGF-β 수용체(예를 들어, 가용성 TGFRβRII 수용체(예를 들어, 가용성 인간 TGFRβRII 수용체))를 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII는 가용성 인간 TGFRβRII의 제1 서열 및 가용성 인간 TGFRβRII의 제2 서열을 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII는 가용성 인간 TGFRβRII의 제1 서열과 가용성 인간 TGFRβRII의 제2 서열 사이에 배치된 링커를 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 링커는 서열 GGGGSGGGGSGGGGS(SEQ ID NO: 102)를 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제1 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 183).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제2 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 184).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제1 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT (SEQ ID NO: 185).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제2 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC (SEQ ID NO: 186).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC (SEQ ID NO: 187).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 인간 TGFβRII 수용체는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 188).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 189).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCTCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 190).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 191).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCTCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 192).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR (SEQ ID NO: 193).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATCACGTGTCCTCCTCCTATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGTATTAGA (SEQ ID NO: 194).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR (SEQ ID NO: 195).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATCACGTGTCCTCCTCCTATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGTATTAGA (SEQ ID NO: 196).
예시적인 다중-사슬 키메라 폴리펩타이드- C형
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, IL-7의 수용체 또는 IL-21의 수용체에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 표적-결합 도메인과 가용성 조직 인자 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 상기 친화도 도메인 쌍의 제2 도메인과 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인은 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인일 수 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인 쌍은 본원에 기재된 임의의 예시적인 친화도 도메인 쌍일 수 있다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다 가용성 IL-21(예를 들어, 가용성 인간 IL-21 폴리펩타이드) 또는 가용성 IL-7(예를 들어, 가용성 인간 IL-7 폴리펩타이드)이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, 가용성 IL-21 또는 가용성 IL-7이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인과 제2 표적-결합 도메인 둘 다 IL-21의 수용체 또는 IL-7의 수용체에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 IL-21에 대한 수용체에 특이적으로 결합하고, 제2 표적-결합 도메인은 IL-7에 대한 수용체에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 IL-7에 대한 수용체에 특이적으로 결합하고, 제2 표적-결합 도메인은 IL-21에 대한 수용체에 특이적으로 결합한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 가용성 IL-21(예를 들어, 가용성 인간 IL-21)을 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-21은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 83).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-21은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCC (SEQ ID NO: 197).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-21은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 182).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-7의 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH (SEQ ID NO: 79).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-7은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACAC (SEQ ID NO: 198).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 199).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCCTCAGGCACTACAAATACTGTGGCAGCATATAATTTAACTTGGAAATCAACTAATTTCAAGACAATTTTGGAGTGGGAACCCAAACCCGTCAATCAAGTCTACACTGTTCAAATAAGCACTAAGTCAGGAGATTGGAAAAGCAAATGCTTTTACACAACAGACACAGAGTGTGACCTCACCGACGAGATTGTGAAGGATGTGAAGCAGACGTACTTGGCACGGGTCTTCTCCTACCCGGCAGGGAATGTGGAGAGCACCGGTTCTGCTGGGGAGCCTCTGTATGAGAACTCCCCAGAGTTCACACCTTACCTGGAGACAAACCTCGGACAGCCAACAATTCAGAGTTTTGAACAGGTGGGAACAAAAGTGAATGTGACCGTAGAAGATGAACGGACTTTAGTCAGAAGGAACAACACTTTCCTAAGCCTCCGGGATGTTTTTGGCAAGGACTTAATTTATACACTTTATTATTGGAAATCTTCAAGTTCAGGAAAGAAAACAGCCAAAACAAACACTAATGAGTTTTTGATTGATGTGGATAAAGGAGAAAACTACTGTTTCAGTGTTCAAGCAGTGATTCCCTCCCGAACAGTTAACCGGAAGAGTACAGACAGCCCGGTAGAGTGTATGGGCCAGGAGAAAGGGGAATTCAGAGAAAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 200).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MGVKVLFALICIAVAEAQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 201).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGGGAGTGAAAGTTCTTTTTGCCCTTATTTGTATTGCTGTGGCCGAGGCCCAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCCTCAGGCACTACAAATACTGTGGCAGCATATAATTTAACTTGGAAATCAACTAATTTCAAGACAATTTTGGAGTGGGAACCCAAACCCGTCAATCAAGTCTACACTGTTCAAATAAGCACTAAGTCAGGAGATTGGAAAAGCAAATGCTTTTACACAACAGACACAGAGTGTGACCTCACCGACGAGATTGTGAAGGATGTGAAGCAGACGTACTTGGCACGGGTCTTCTCCTACCCGGCAGGGAATGTGGAGAGCACCGGTTCTGCTGGGGAGCCTCTGTATGAGAACTCCCCAGAGTTCACACCTTACCTGGAGACAAACCTCGGACAGCCAACAATTCAGAGTTTTGAACAGGTGGGAACAAAAGTGAATGTGACCGTAGAAGATGAACGGACTTTAGTCAGAAGGAACAACACTTTCCTAAGCCTCCGGGATGTTTTTGGCAAGGACTTAATTTATACACTTTATTATTGGAAATCTTCAAGTTCAGGAAAGAAAACAGCCAAAACAAACACTAATGAGTTTTTGATTGATGTGGATAAAGGAGAAAACTACTGTTTCAGTGTTCAAGCAGTGATTCCCTCCCGAACAGTTAACCGGAAGAGTACAGACAGCCCGGTAGAGTGTATGGGCCAGGAGAAAGGGGAATTCAGAGAAAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 202)
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR (SEQ ID NO: 203)
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACACATCACGTGCCCTCCCCCCATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGCATTAGA (SEQ ID NO: 204).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MGVKVLFALICIAVAEADCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR (SEQ ID NO: 205).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGGGAGTGAAAGTTCTTTTTGCCCTTATTTGTATTGCTGTGGCCGAGGCCGATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACACATCACGTGCCCTCCCCCCATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGCATTAGA (SEQ ID NO: 206).
예시적인 다중-사슬 키메라 폴리펩타이드- D형
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, IL-7의 수용체 또는 IL-21의 수용체에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 표적-결합 도메인과 가용성 조직 인자 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 상기 친화도 도메인 쌍의 제2 도메인과 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인은 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인일 수 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인 쌍은 본원에 기재된 임의의 예시적인 친화도 도메인 쌍일 수 있다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다 가용성 IL-21(예를 들어, 가용성 인간 IL-21 폴리펩타이드) 또는 가용성 IL-7(예를 들어, 가용성 인간 IL-7 폴리펩타이드)이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, 가용성 IL-21 또는 가용성 IL-7이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인과 제2 표적-결합 도메인 둘 다 IL-21의 수용체 또는 IL-7의 수용체에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 IL-21에 대한 수용체에 특이적으로 결합하고, 제2 표적-결합 도메인은 IL-7에 대한 수용체에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 IL-7에 대한 수용체에 특이적으로 결합하고, 제2 표적-결합 도메인은 IL-21에 대한 수용체에 특이적으로 결합한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-21은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 83).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-21은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCC (SEQ ID NO: 197).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-21은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 182).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-7의 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH (SEQ ID NO: 79).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-7은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACAC (SEQ ID NO: 198).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 207).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 208).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 209).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 210).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR (SEQ ID NO: 211).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG (SEQ ID NO: 212).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR (SEQ ID NO: 213).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG (SEQ ID NO: 214).
예시적인 다중-사슬 키메라 폴리펩타이드- E형
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, IL-18(예를 들어, 가용성 인간 IL-18)에 대한 수용체, IL-12(예를 들어, 가용성 인간 IL-12)에 대한 수용체, 또는 CD16(예를 들어, 항-CD16 scFv)에 특이적으로 결합한다. 본원에 기재된 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 추가 표적-결합 도메인을 추가로 포함한다. 본원에 기재된 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 추가 표적-결합 도메인을 추가로 포함한다. 본원에 기재된 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인은 CD16 또는 IL-12에 대한 수용체에 특이적으로 결합한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 표적-결합 도메인과 가용성 조직 인자 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 상기 친화도 도메인 쌍의 제2 도메인과 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드의 N-말단 또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인과 친화도 도메인 쌍의 제2 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 추가 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인과 제2 표적-결합 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 제2 표적-결합 도메인과 추가 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인은 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인일 수 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인 쌍은 본원에 기재된 임의의 예시적인 친화도 도메인 쌍일 수 있다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 하나 이상의 제1 표적-결합 도메인, 제2 표적-결합 도메인 및 추가 항원-결합 도메인은 작용제성 항원-결합 도메인이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 추가 항원-결합 도메인은 각각 작용제성 항원-결합 도메인이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 항원-결합 도메인은 scFv 또는 단일-도메인 항체를 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다 가용성 IL-15 또는 가용성 IL-18이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, 가용성 IL-15 또는 가용성 IL-18이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인과 제2 표적-결합 도메인 둘 다 IL-18의 수용체 또는 IL-12의 수용체에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 IL-12에 대한 수용체에 특이적으로 결합하고, 제2 표적-결합 도메인은 IL-18에 대한 수용체에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 IL-18에 대한 수용체에 특이적으로 결합하고, 제2 표적-결합 도메인은 IL-12에 대한 수용체에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 CD16에 특이적으로 결합하고, 제2 표적-결합 도메인은 IL-18에 대한 수용체에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 IL-18에 대한 수용체에 특이적으로 결합하고, 제2 표적-결합 도메인은 CD16에 특이적으로 결합한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 항원에 특이적으로 결합한다. 일부 구현예에서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 에피토프에 특이적으로 결합한다. 일부 구현예에서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 아미노산 서열을 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 가용성 IL-18(예를 들어, 가용성 인간 IL-18)을 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-18은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNED (SEQ ID NO: 109).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-18은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
TACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGAT (SEQ ID NO: 171).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인은 가용성 IL-12(예를 들어, 가용성 인간 IL-12)를 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-15는 가용성 인간 IL-12β(p40)의 서열 및 가용성 인간 IL-12α(p35)의 서열을 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 IL-15(예를 들어, 가용성 인간 IL-15)는 가용성 IL-12β(p40)의 서열과 가용성 인간 IL-12α(p35)의 서열 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커 서열)을 추가로 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 링커 서열은 GGGGSGGGGSGGGGS(SEQ ID NO: 102)를 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-12β(p40)의 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCS (SEQ ID NO: 81).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-12β(p40)는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCC (SEQ ID NO: 172).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-12α(p35)는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
RNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNAS (SEQ ID NO: 80).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-12α(p35)는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGC (SEQ ID NO: 173).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인은 CD16에 특이적으로 결합하는 scFv(예를 들어, 항-CD16 scFv)를 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, CD16에 특이적으로 결합하는 scFv는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함하는 경쇄 가변 도메인을 포함한다:
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGH (SEQ ID NO: 215).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, CD16에 특이적으로 결합하는 scFv는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 경쇄 가변 도메인 서열에 의해 인코딩된다:
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCAT (SEQ ID NO: 216).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, CD16에 특이적으로 결합하는 scFv는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함하는 중쇄 가변 도메인을 포함한다:
EVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR (SEQ ID NO: 217).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, CD16에 특이적으로 결합하는 scFv는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 중쇄 가변 도메인 서열에 의해 인코딩된다:
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG (SEQ ID NO: 218).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNEDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 174).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
TACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 175).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSYFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNEDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 176).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTCACATTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGCTACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 177).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCSGGGGSGGGGSGGGGSRNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNASITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR (SEQ ID NO: 223).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCCGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGTCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG (SEQ ID NO: 224).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSIWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCSGGGGSGGGGSGGGGSRNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNASITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR (SEQ ID NO: 225).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCCATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCCGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGTCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG (SEQ ID NO: 226).
예시적인 다중-사슬 키메라 폴리펩타이드- F형
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, IL-7(예를 들어, 가용성 인간 IL-7)에 대한 수용체, CD16(예를 들어, 항-CD16 scFv), 또는 IL-21(예를 들어, 가용성 인간 IL-21)에 대한 수용체에 특이적으로 결합한다. 본원에 기재된 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 추가 표적-결합 도메인을 추가로 포함한다. 본원에 기재된 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 추가 표적-결합 도메인을 추가로 포함한다. 본원에 기재된 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인은 CD16 또는 IL-21에 대한 수용체에 특이적으로 결합한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 표적-결합 도메인과 가용성 조직 인자 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 상기 친화도 도메인 쌍의 제2 도메인과 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드의 N-말단 또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인과 친화도 도메인 쌍의 제2 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 추가 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인과 제2 표적-결합 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 제2 표적-결합 도메인과 추가 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인은 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인일 수 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인 쌍은 본원에 기재된 임의의 예시적인 친화도 도메인 쌍일 수 있다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 하나 이상의 제1 표적-결합 도메인, 제2 표적-결합 도메인 및 추가 항원-결합 도메인은 작용제성 항원-결합 도메인이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 추가 항원-결합 도메인은 각각 작용제성 항원-결합 도메인이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 항원-결합 도메인은 scFv 또는 단일-도메인 항체를 포함한다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 상기 제1 표적-결합 도메인은 IL-7에 대한 수용체에 특이적으로 결합하고, 상기 제2 표적-결합 도메인은 CD16, 또는 IL-21에 대한 수용체에 특이적으로 결합한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 가용성 IL-7 단백질을 포함한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 IL-7 단백질은 가용성 인간 IL-7이다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 항원-결합 도메인은 CD16에 특이적으로 결합하는 표적-결합 도메인을 포함한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인은 CD16에 특이적으로 결합하는 scFv를 포함한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인은 IL-21에 대한 수용체에 특이적으로 결합한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인은 가용성 IL-21을 포함한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 IL-21은 가용성 인간 IL-21이다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 IL-21에 대한 수용체에 특이적으로 결합하는 추가 표적-결합 도메인을 추가로 포함한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인은 가용성 IL-21을 포함한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 IL-21은 가용성 인간 IL-21이다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 CD16에 특이적으로 결합하는 추가 표적-결합 도메인을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 항원에 특이적으로 결합한다. 일부 구현예에서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 에피토프에 특이적으로 결합한다. 일부 구현예에서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 아미노산 서열을 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 가용성 IL-7(예를 들어, 가용성 인간 IL-7)을 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-7은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH (SEQ ID NO: 79).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-7은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACAC (SEQ ID NO: 198).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-7은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT (SEQ ID NO: 227).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-21의 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 83).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-21은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCC (SEQ ID NO: 197).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-21은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 182)
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인은 CD16에 특이적으로 결합하는 scFv(예를 들어, 항-CD16 scFv)를 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, CD16에 특이적으로 결합하는 scFv는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함하는 경쇄 가변 도메인을 포함한다:
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGH (SEQ ID NO: 215).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, CD16에 특이적으로 결합하는 scFv는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 경쇄 가변 도메인 서열에 의해 인코딩된다:
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCAT (SEQ ID NO: 216).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, CD16에 특이적으로 결합하는 scFv는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함하는 중쇄 가변 도메인을 포함한다:
EVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR (SEQ ID NO: 217).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, CD16에 특이적으로 결합하는 scFv는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 중쇄 가변 도메인 서열에 의해 인코딩된다:
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG (SEQ ID NO: 218).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 207).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 208).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 209).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 210).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSRITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 232).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGGATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 233).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSRITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 234).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCTCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGGATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 235).
예시적인 다중-사슬 키메라 폴리펩타이드- G형
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, TGFβ(예를 들어, 인간 TGFβRII 수용체), CD16(예를 들어, 항-CD16 scFv), 또는 IL-21(예를 들어, 가용성 인간 IL-21)에 대한 수용체에 특이적으로 결합한다. 본원에 기재된 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 추가 표적-결합 도메인을 추가로 포함한다. 본원에 기재된 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 추가 표적-결합 도메인을 추가로 포함한다. 본원에 기재된 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인은 CD16 또는 IL-21에 대한 수용체에 특이적으로 결합한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 표적-결합 도메인과 가용성 조직 인자 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 상기 친화도 도메인 쌍의 제2 도메인과 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드의 N-말단 또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인과 친화도 도메인 쌍의 제2 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 추가 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인과 제2 표적-결합 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 제2 표적-결합 도메인과 추가 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인은 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인일 수 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인 쌍은 본원에 기재된 임의의 예시적인 친화도 도메인 쌍일 수 있다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 하나 이상의 제1 표적-결합 도메인, 제2 표적-결합 도메인 및 추가 항원-결합 도메인은 작용제성 항원-결합 도메인이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 추가 항원-결합 도메인은 각각 작용제성 항원-결합 도메인이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 항원-결합 도메인은 scFv 또는 단일-도메인 항체를 포함한다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, TGF-β, CD16, 또는 IL-21에 대한 수용체에 특이적으로 결합한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 TGF-β에 특이적으로 결합하고, 제2 표적-결합 도메인은 CD16 또는 IL-21의 수용체에 특이적으로 결합한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 가용성 TGF-β 수용체이다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 TGF-β 수용체는 가용성 TGFβRII 수용체이다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인은 CD16에 특이적으로 결합한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 항원-결합 도메인은 CD16에 특이적으로 결합하는 항원-결합 도메인을 포함한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 항원-결합 도메인은 CD16에 특이적으로 결합하는 scFv를 포함한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인은 IL-21에 대한 수용체에 특이적으로 결합한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인은 가용성 IL-21을 포함한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인은 가용성 인간 IL-21을 포함한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 IL-21에 대한 수용체에 특이적으로 결합하는 추가 표적-결합 도메인을 추가로 포함한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인은 가용성 IL-21을 포함한다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 IL-21은 가용성 인간 IL-21이다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 CD16에 특이적으로 결합하는 추가 표적-결합 도메인을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 항원에 특이적으로 결합한다. 일부 구현예에서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 에피토프에 특이적으로 결합한다. 일부 구현예에서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 아미노산 서열을 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 TGFβRII 수용체(예를 들어, 가용성 인간 TGFβRII 수용체)를 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII는 가용성 인간 TGFRβRII의 제1 서열 및 가용성 인간 TGFRβRII의 제2 서열을 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII는 가용성 인간 TGFRβRII의 제1 서열과 가용성 인간 TGFRβRII의 제2 서열 사이에 배치된 링커를 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 링커는 서열 GGGGSGGGGSGGGGS(SEQ ID NO: 102)를 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제1 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 183).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제2 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 184).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제1 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT (SEQ ID NO: 185)
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제2 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC (SEQ ID NO: 186).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 TGF-β 수용체는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 188).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFβRII 수용체는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC (SEQ ID NO: 187).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-21의 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 83).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-21은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCC (SEQ ID NO: 197).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-21은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 182).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, CD16에 특이적으로 결합하는 scFv는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함하는 경쇄 가변 도메인을 포함한다:
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGH (SEQ ID NO: 215).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, CD16에 특이적으로 결합하는 scFv는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 경쇄 가변 도메인 서열에 의해 인코딩된다:
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCAT (SEQ ID NO: 216).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, CD16에 특이적으로 결합하는 scFv는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함하는 중쇄 가변 도메인을 포함한다:
EVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR (SEQ ID NO: 217).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, CD16에 특이적으로 결합하는 scFv는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 중쇄 가변 도메인 서열에 의해 인코딩된다:
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG (SEQ ID NO: 218).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 236).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 237).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 238).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 239).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSRITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 232).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGGATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 233).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSRITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 234).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCTCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGGATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 235).
예시적인 다중-사슬 키메라 폴리펩타이드- H형
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, IL-7의 수용체에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 표적-결합 도메인과 가용성 조직 인자 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 상기 친화도 도메인 쌍의 제2 도메인과 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인은 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인일 수 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인 쌍은 본원에 기재된 임의의 예시적인 친화도 도메인 쌍일 수 있다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, IL-7에 대한 수용체에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 가용성 IL-7(예를 들어, 가용성 인간 IL-7)을 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-7은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH (SEQ ID NO: 79).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-7은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT (SEQ ID NO: 227).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 207).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 208).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 209).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 210).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR (SEQ ID NO: 203).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACACATCACGTGCCCTCCCCCCATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGCATTAGA (SEQ ID NO: 204).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR (SEQ ID NO: 250).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG (SEQ ID NO: 251).
예시적인 다중-사슬 키메라 폴리펩타이드- I형
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, TGF-β에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 표적-결합 도메인과 가용성 조직 인자 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 상기 친화도 도메인 쌍의 제2 도메인과 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인은 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인일 수 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인 쌍은 본원에 기재된 임의의 예시적인 친화도 도메인 쌍일 수 있다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, TGF-β에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 가용성 TGF-β 수용체(예를 들어, 가용성 TGFβRII 수용체, 예를 들어, 가용성 인간 TGFβRII)이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII는 가용성 인간 TGFRβRII의 제1 서열 및 가용성 인간 TGFRβRII의 제2 서열을 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII는 가용성 인간 TGFRβRII의 제1 서열과 가용성 인간 TGFRβRII의 제2 서열 사이에 배치된 링커를 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 링커는 서열 GGGGSGGGGSGGGGS(SEQ ID NO: 102)를 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제1 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 183).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제2 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 184).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제1 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT (SEQ ID NO: 185).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제2 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC (SEQ ID NO: 186).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 TGF-β 수용체는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 188).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 TGF-β 수용체는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC (SEQ ID NO: 187).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 236).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 237).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 238).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 239).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR (SEQ ID NO: 193).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG (SEQ ID NO: 257).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR (SEQ ID NO: 195).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG (SEQ ID NO: 259).
예시적인 다중-사슬 키메라 폴리펩타이드- J형
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, IL-7의 수용체, IL-21의 수용체, 또는 CD137L의 수용체에 특이적으로 결합한다. 본원에 기재된 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 추가 표적-결합 도메인을 추가로 포함한다. 본원에 기재된 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인은 IL-21(예를 들어, 가용성 IL-21, 예를 들어, 가용성 인간 IL-21)에 대한 수용체 또는 CD137L(예를 들어, 가용성 CD137L, 예를 들어, 가용성 인간 CD137L)에 대한 수용체에 특이적으로 결합한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 표적-결합 도메인과 가용성 조직 인자 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 상기 친화도 도메인 쌍의 제2 도메인과 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드의 N-말단 또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인과 친화도 도메인 쌍의 제2 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 추가 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인과 제2 표적-결합 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 제2 표적-결합 도메인과 추가 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인은 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인일 수 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인 쌍은 본원에 기재된 임의의 예시적인 친화도 도메인 쌍일 수 있다.
일부 구현예에서, 제2 키메라 폴리펩타이드는 추가 표적-결합 도메인을 포함할 수 있다. 일부 구현예에서, 추가 표적-결합 도메인 및
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 하나 이상의 제1 표적-결합 도메인, 제2 표적-결합 도메인 및 추가 표적-결합 도메인은 작용제성 항원-결합 도메인이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 추가 표적-결합 도메인은 각각 작용제성 항원-결합 도메인이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 항원-결합 도메인은 scFv 또는 단일-도메인 항체를 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 IL-7에 대한 수용체에 특이적으로 결합하고, 제2 표적-결합 도메인은 IL-21에 대한 수용체 또는 CD137L에 대한 수용체에 특이적으로 결합한다. 일부 구현예에서, 추가 표적-결합 도메인은 IL-21에 대한 수용체 또는 CD137L에 대한 수용체에 특이적으로 결합한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 가용성 IL-7(예를 들어, 가용성 인간 IL-7)이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-7은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH (SEQ ID NO: 79).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-7은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT (SEQ ID NO: 227).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인 또는 추가 표적-결합 도메인은 IL-21에 대한 수용체에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인 또는 추가 표적-결합 도메인은 가용성 IL-21(예를 들어, 가용성 인간 IL-21)이다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-21은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 83).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-21은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 182).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인은 CD137L에 대한 수용체에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 CD137L에 대한 수용체에 특이적으로 결합하는 추가 표적-결합 도메인을 추가로 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인 및/또는 추가 표적-결합 도메인은 가용성 CD137L(예를 들어, 가용성 인간 CD137L)이다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 CD137L은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
REGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE (SEQ ID NO: 260).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 CD137L은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA (SEQ ID NO: 261).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 CD137L은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
DPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI (SEQ ID NO: 262).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 CD137L은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
GATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC (SEQ ID NO: 263).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 207).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 208).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 209).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 210).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE (SEQ ID NO: 268).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA (SEQ ID NO: 269).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE (SEQ ID NO: 270).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA (SEQ ID NO: 271).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI (SEQ ID NO: 272).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC (SEQ ID NO: 273).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI (SEQ ID NO: 274).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC (SEQ ID NO: 275).
예시적인 다중-사슬 키메라 폴리펩타이드- K형
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, IL-7의 수용체 또는 TGF-β에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 표적-결합 도메인과 가용성 조직 인자 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 상기 친화도 도메인 쌍의 제2 도메인과 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인은 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인일 수 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인 쌍은 본원에 기재된 임의의 예시적인 친화도 도메인 쌍일 수 있다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 IL-7에 대한 수용체에 특이적으로 결합하고, 제2 표적-결합 도메인은 TGF-β에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 TGF-β에 특이적으로 결합하고, 제2 표적-결합 도메인은 IL-7에 대한 수용체에 특이적으로 결합한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 가용성 IL-7 단백질(예를 들어, 가용성 인간 IL-7 단백질)을 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-7 단백질은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH (SEQ ID NO: 79).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-7은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT (SEQ ID NO: 227).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인은 TGF-β에 특이적으로 결합하는 표적-결합 도메인을 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인은 가용성 TGF-β 수용체(예를 들어, 가용성 TGFβRII 수용체, 예를 들어, 가용성 인간 TGFβRII 수용체)이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII는 가용성 인간 TGFRβRII의 제1 서열 및 가용성 인간 TGFRβRII의 제2 서열을 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII는 가용성 인간 TGFRβRII의 제1 서열과 가용성 인간 TGFRβRII의 제2 서열 사이에 배치된 링커를 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 링커는 서열 GGGGSGGGGSGGGGS(SEQ ID NO: 102)를 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제1 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 183).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제2 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 184).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제1 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT (SEQ ID NO: 185).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제2 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC (SEQ ID NO: 186).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 TGF-β 수용체는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 188).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 TGF-β 수용체는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC (SEQ ID NO: 187).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 207).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 208).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSDCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEHSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 209).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCGATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCATAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 210).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR (SEQ ID NO: 193).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG (SEQ ID NO: 257).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR (SEQ ID NO: 195).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG (SEQ ID NO: 259).
예시적인 다중-사슬 키메라 폴리펩타이드- L형
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, TGF-β, IL-21의 수용체, 또는 CD137L의 수용체에 특이적으로 결합한다. 본원에 기재된 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 추가 표적-결합 도메인을 추가로 포함한다. 본원에 기재된 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인은 IL-21(예를 들어, 가용성 IL-21, 예를 들어, 가용성 인간 IL-21)에 대한 수용체 또는 CD137L(예를 들어, 가용성 CD137L, 예를 들어, 가용성 인간 CD137L)에 대한 수용체에 특이적으로 결합한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 표적-결합 도메인과 가용성 조직 인자 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 상기 친화도 도메인 쌍의 제2 도메인과 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드의 N-말단 또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인과 친화도 도메인 쌍의 제2 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 추가 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인과 제2 표적-결합 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 제2 표적-결합 도메인과 추가 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인은 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인일 수 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인 쌍은 본원에 기재된 임의의 예시적인 친화도 도메인 쌍일 수 있다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 하나 이상의 제1 표적-결합 도메인, 제2 표적-결합 도메인 및 추가 표적-결합 도메인은 작용제성 항원-결합 도메인이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 추가 표적-결합 도메인은 각각 작용제성 항원-결합 도메인이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 항원-결합 도메인은 scFv 또는 단일-도메인 항체를 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 TGF-β에 특이적으로 결합하고, 제2 표적-결합 도메인은 IL-21에 대한 수용체 또는 CD137L에 대한 수용체에 특이적으로 결합한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 가용성 TGF-β 수용체(예를 들어, 가용성 TGFβRII 수용체, 예를 들어, 가용성 인간 TGFβRII 수용체)이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII는 가용성 인간 TGFRβRII의 제1 서열 및 가용성 인간 TGFRβRII의 제2 서열을 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII는 가용성 인간 TGFRβRII의 제1 서열과 가용성 인간 TGFRβRII의 제2 서열 사이에 배치된 링커를 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 링커는 서열 GGGGSGGGGSGGGGS(SEQ ID NO: 102)를 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제1 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 183).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제2 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 184).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제1 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT (SEQ ID NO: 185).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제2 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC (SEQ ID NO: 186).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 TGF-β 수용체는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 188).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 TGF-β 수용체는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC (SEQ ID NO: 187).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인 또는 추가 표적-결합 도메인은 IL-21에 대한 수용체에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인 또는 추가 표적-결합 도메인은 가용성 IL-21(예를 들어, 가용성 인간 IL-21)을 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-21은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 83).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 IL-21은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 182).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인 또는 추가 표적-결합 도메인은 CD137L에 대한 수용체에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인 및/또는 추가 표적-결합 도메인은 가용성 CD137L(예를 들어, 가용성 인간 CD137L)을 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 CD137L은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
REGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE (SEQ ID NO: 260).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 CD137L은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA (SEQ ID NO: 261).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 CD137L은 하기와 적어도 80% 동일한(예를 들어, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 또는 100% 동일한) 서열을 포함한다:
DPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI (SEQ ID NO: 262).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 CD137L은 하기와 적어도 80% 동일한(예를 들어, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 또는 100% 동일한) 서열에 의해 인코딩된다:
GATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC (SEQ ID NO: 263).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 236).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 237).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 238).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 239).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE (SEQ ID NO: 268).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA (SEQ ID NO: 269)
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE (SEQ ID NO: 270).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA (SEQ ID NO: 271).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI (SEQ ID NO: 272).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC (SEQ ID NO: 273).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDSITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI (SEQ ID NO: 274).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCCATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC (SEQ ID NO: 275).
예시적인 다중-사슬 키메라 폴리펩타이드- M형
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, TGF-β 또는 IL-21의 수용체에 특이적으로 결합한다. 본원에 기재된 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 추가 표적-결합 도메인을 추가로 포함한다. 본원에 기재된 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인은 IL-21(예를 들어, 가용성 IL-21, 예를 들어, 가용성 인간 IL-21)에 대한 수용체 또는 TGF-β(예를 들어, 가용성 TGF-β 수용체, 예를 들어, 가용성 TGFβRII 수용체)에 특이적으로 결합한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 표적-결합 도메인과 가용성 조직 인자 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 상기 친화도 도메인 쌍의 제2 도메인과 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드의 N-말단 또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인과 친화도 도메인 쌍의 제2 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 추가 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인과 제2 표적-결합 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 제2 표적-결합 도메인과 추가 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인은 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인일 수 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인 쌍은 본원에 기재된 임의의 예시적인 친화도 도메인 쌍일 수 있다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 TGF-β에 특이적으로 결합하고, 제2 표적-결합 도메인은 TGF-β 또는 IL-21에 대한 수용체에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 가용성 TGF-β 수용체(예를 들어, 가용성 TGFβRII 수용체, 예를 들어, 가용성 인간 TGFβRII 수용체)이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII는 가용성 인간 TGFRβRII의 제1 서열 및 가용성 인간 TGFRβRII의 제2 서열을 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII는 가용성 인간 TGFRβRII의 제1 서열과 가용성 인간 TGFRβRII의 제2 서열 사이에 배치된 링커를 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 링커는 서열 GGGGSGGGGSGGGGS(SEQ ID NO: 102)를 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제1 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 183).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제2 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 184).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제1 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT (SEQ ID NO: 185).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제2 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC (SEQ ID NO: 186).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 TGF-β 수용체는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 188).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 TGF-β 수용체는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC (SEQ ID NO: 187).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인은 IL-21에 대한 수용체에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인은 가용성 IL-21(예를 들어, 인간 가용성 IL-21)을 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 IL-21은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 83).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 IL-21은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 182).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 236).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 237).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 238).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 239).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 300).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 301).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRQGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS (SEQ ID NO: 302).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGCAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC (SEQ ID NO: 303).
예시적인 다중-사슬 키메라 폴리펩타이드- N형
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, TGF-β 또는 CD16에 특이적으로 결합한다. 본원에 기재된 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 추가 표적-결합 도메인을 추가로 포함한다. 본원에 기재된 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인은 CD16(예를 들어, 항-CD16 scFv) 또는 TGF-β(예를 들어, 가용성 TGF-β 수용체, 예를 들어, 가용성 TGFβRII 수용체)에 특이적으로 결합한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 표적-결합 도메인과 가용성 조직 인자 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 상기 친화도 도메인 쌍의 제2 도메인과 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드의 N-말단 또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인과 친화도 도메인 쌍의 제2 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 추가 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인과 제2 표적-결합 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 제2 표적-결합 도메인과 추가 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인은 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인일 수 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인 쌍은 본원에 기재된 임의의 예시적인 친화도 도메인 쌍일 수 있다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 TGF-β에 특이적으로 결합하고, 제2 표적-결합 도메인은 TGF-β 또는 CD16에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 가용성 TGF-β 수용체(예를 들어, 가용성 TGFβRII 수용체, 예를 들어, 가용성 인간 TGFβRII 수용체)이다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII는 가용성 인간 TGFRβRII의 제1 서열 및 가용성 인간 TGFRβRII의 제2 서열을 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII는 가용성 인간 TGFRβRII의 제1 서열과 가용성 인간 TGFRβRII의 제2 서열 사이에 배치된 링커를 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 링커는 서열 GGGGSGGGGSGGGGS(SEQ ID NO: 102)를 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제1 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 183).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제2 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 184).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제1 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT (SEQ ID NO: 185).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제2 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC (SEQ ID NO: 186).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 TGF-β 수용체는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 188).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 TGF-β 수용체는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC (SEQ ID NO: 187).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인은 CD16에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인은 항-CD16 scFv를 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, CD16에 특이적으로 결합하는 scFv는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함하는 경쇄 가변 도메인을 포함한다:
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGH (SEQ ID NO: 215).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, CD16에 특이적으로 결합하는 scFv는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 경쇄 가변 도메인 서열에 의해 인코딩된다:
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCAT (SEQ ID NO: 216).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, CD16에 특이적으로 결합하는 scFv는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함하는 중쇄 가변 도메인을 포함한다:
EVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR (SEQ ID NO: 217).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, CD16에 특이적으로 결합하는 scFv는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 중쇄 가변 도메인 서열에 의해 인코딩된다:
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG (SEQ ID NO: 218).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 236).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 237).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 238).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 239).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR (SEQ ID NO: 308).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGTCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG (SEQ ID NO: 309).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRSELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR (SEQ ID NO: 310).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGTCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG (SEQ ID NO: 311).
예시적인 다중-사슬 키메라 폴리펩타이드- O형
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, TGF-β 또는 CD137L의 수용체에 특이적으로 결합한다. 본원에 기재된 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 추가 표적-결합 도메인을 추가로 포함한다. 본원에 기재된 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인은 TGF-β에 대한 수용체(예를 들어, 가용성 TGF-β 수용체, 예를 들어, 가용성 TGFβRII 수용체) 또는 CD137L에 특이적으로 결합한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 표적-결합 도메인과 가용성 조직 인자 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 상기 친화도 도메인 쌍의 제2 도메인과 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드의 N-말단 또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인과 친화도 도메인 쌍의 제2 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 추가 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인과 제2 표적-결합 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 제2 표적-결합 도메인과 추가 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인은 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인일 수 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인 쌍은 본원에 기재된 임의의 예시적인 친화도 도메인 쌍일 수 있다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 TGF-β에 특이적으로 결합하고, 제2 표적-결합 도메인은 CD137L에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 또는 추가 표적-결합 도메인은 가용성 TGF-β 수용체(예를 들어, 가용성 TGFβRII 수용체, 예를 들어, 가용성 인간 TGFβRII 수용체)이다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII는 가용성 인간 TGFRβRII의 제1 서열 및 가용성 인간 TGFRβRII의 제2 서열을 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII는 가용성 인간 TGFRβRII의 제1 서열과 가용성 인간 TGFRβRII의 제2 서열 사이에 배치된 링커를 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 링커는 서열 GGGGSGGGGSGGGGS(SEQ ID NO: 102)를 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제1 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 183).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제2 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 184).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제1 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT (SEQ ID NO: 185).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제2 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC (SEQ ID NO: 186).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 TGF-β 수용체는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 188).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 TGF-β 수용체는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC (SEQ ID NO: 187).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 표적-결합 도메인은 가용성 CD137L 단백질(예를 들어, 가용성 인간 CD137L 단백질)을 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 CD137L은 하기와 적어도 80% 동일한(예를 들어, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 또는 100% 동일한) 서열을 포함한다:
REGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE (SEQ ID NO: 260).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 CD137L은 하기와 적어도 80% 동일한(예를 들어, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 또는 100% 동일한) 서열에 의해 인코딩된다:
CGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA (SEQ ID NO: 261).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 CD137L은 하기와 적어도 80% 동일한(예를 들어, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 또는 100% 동일한) 서열을 포함한다:
DPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI (SEQ ID NO: 262).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 CD137L은 하기와 적어도 80% 동일한(예를 들어, 적어도 85%, 적어도 90%, 적어도 95%, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 또는 100% 동일한) 서열에 의해 인코딩된다:
GATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC (SEQ ID NO: 263).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 236).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 237).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 238).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACAGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAGAACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC (SEQ ID NO: 239).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE (SEQ ID NO: 316).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA (SEQ ID NO: 317).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIRGGGGSGGGGSGGGGSREGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE (SEQ ID NO: 318).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGGGGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCTCGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA (SEQ ID NO: 319).
예시적인 다중-사슬 키메라 폴리펩타이드- P형
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 TGF-β에 특이적으로 결합한다. 본원에 기재된 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 추가 표적-결합 도메인을 추가로 포함한다. 이러한 유형의 다중-사슬 키메라 폴리펩타이드의 비제한적인 예는 도 209 및 도 210에 도시된다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 표적-결합 도메인과 가용성 조직 인자 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 상기 친화도 도메인 쌍의 제2 도메인과 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드의 N-말단 또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인과 친화도 도메인 쌍의 제2 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 추가 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 추가 표적-결합 도메인과 제2 표적-결합 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 제2 표적-결합 도메인과 추가 표적-결합 도메인 사이에 링커 서열(예를 들어, 본원에 기재된 임의의 예시적인 링커)을 추가로 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 조직 인자 도메인은 본원에 기재된 임의의 예시적인 가용성 조직 인자 도메인일 수 있다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인 쌍은 본원에 기재된 임의의 예시적인 친화도 도메인 쌍일 수 있다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인은 TGF-β에 특이적으로 결합하고, 제2 표적-결합 도메인은 TGF-β에 특이적으로 결합한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및/또는 제2 표적-결합 도메인은 가용성 TGF-β 수용체(예를 들어, 가용성 TGFβRII 수용체, 예를 들어, 가용성 인간 TGFβRII 수용체)이다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII는 가용성 인간 TGFRβRII의 제1 서열 및 가용성 인간 TGFRβRII의 제2 서열을 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII는 가용성 인간 TGFRβRII의 제1 서열과 가용성 인간 TGFRβRII의 제2 서열 사이에 배치된 링커를 포함한다. 이들 다중-사슬 키메라 폴리펩타이드의 일부 예에서, 링커는 서열 GGGGSGGGGSGGGGS(SEQ ID NO: 102)를 포함한다.
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제1 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 183).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제2 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 184).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제1 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT (SEQ ID NO: 185).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 인간 TGFRβRII 수용체의 제2 서열은 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC (SEQ ID NO: 186).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 TGF-β 수용체는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함한다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD (SEQ ID NO: 188).
이들 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 TGF-β 수용체는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC (SEQ ID NO: 187).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDSGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRENWVNVISNLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS (SEQ ID NO: 238).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCACCGCACGTTCAGAAGTCGGTGAATAACGACATGATAGTCACTGACAACAACGGTGCAGTCAAGTTTCCACAACTGTGTAAATTTTGTGATGTGAGATTTTCCACCTGTGACAACCAGAAATCCTGCATGAGCAACTGCAGCATCACCTCCATCTGTGAGAAGCCACAGGAAGTCTGTGTGGCTGTATGGAGAAAGAATGACGAGAACATAACACTAGAGACAGTTTGCCATGACCCCAAGCTCCCCTACCATGACTTTATTCTGGAAGATGCTGCTTCTCCAAAGTGCATTATGAAGGAAAAAAAAAAGCCTGGTGAGACTTTCTTCATGTGTTCCTGTAGCTCTGATGAGTGCAATGACAACATCATCTTCTCAGAAGAATATAACACCAGCAATCCTGACGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACTCAGGCACTACAAATACTGTGGCAGCATATAATTTAACTTGGAAATCAACTAATTTCAAGACAATTTTGGAGTGGGAACCCAAACCCGTCAATCAAGTCTACACTGTTCAAATAAGCACTAAGTCAGGAGATTGGAAAAGCAAATGCTTTTACACAACAGACACAGAGTGTGACCTCACCGACGAGATTGTGAAGGATGTGAAGCAGACGTACTTGGCACGGGTCTTCTCCTACCCGGCAGGGAATGTGGAGAGCACCGGTTCTGCTGGGGAGCCTCTGTATGAGAACTCCCCAGAGTTCACACCTTACCTGGAGACAAACCTCGGACAGCCAACAATTCAGAGTTTTGAACAGGTGGGAACAAAAGTGAATGTGACCGTAGAAGATGAACGGACTTTAGTCAGAAGGAACAACACTTTCCTAAGCCTCCGGGATGTTTTTGGCAAGGACTTAATTTATACACTTTATTATTGGAAATCTTCAAGTTCAGGAAAGAAAACAGCCAAAACAAACACTAATGAGTTTTTGATTGATGTGGATAAAGGAGAAAACTACTGTTTCAGTGTTCAAGCAGTGATTCCCTCCCGAACAGTTAACCGGAAGAGTACAGACAGCCCGGTAGAGTGTATGGGCCAGGAGAAAGGGGAATTCAGAGAAAACTGGGTGAATGTAATAAGTAATTTGAAAAAAATTGAAGATCTTATTCAATCTATGCATATTGATGCTACTTTATATACGGAAAGTGATGTTCACCCCAGTTGCAAAGTAACAGCAATGAAGTGCTTTCTCTTGGAGTTACAAGTTATTTCACTTGAGTCCGGAGATGCAAGTATTCATGATACAGTAGAAAATCTGATCATCCTAGCAAACAACAGTTTGTCTTCTAATGGGAATGTAACAGAATCTGGATGCAAAGAATGTGAGGAACTGGAGGAAAAAAATATTAAAGAATTTTTGCAGAGTTTTGTACATATTGTCCAAATGTTCATCAACACTTCT (SEQ ID NO: 239).
일부 구현예에서, 제1 키메라 폴리펩타이드는 D8N 아미노산 치환을 포함하는 가용성 IL-15를 포함하고, 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 가질 수 있다:
(신호 펩타이드)
MGVKVLFALICIAVAEA
(단일 사슬 인간 TGF-베타 수용체 II 동종이량체)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(조직 인자)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(IL-15D8N)
NWVNVISNLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
(SEQ ID NO: 238).
일부 구현예에서, 제1 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
(신호 펩타이드)
ATGGGAGTGAAAGTTCTTTTTGCCCTTATTTGTATTGCTGTGGCCGAGGCC
(단일 사슬 인간 TGF-베타 수용체 II 동종이량체)
ATCCCACCGCACGTTCAGAAGTCGGTGAATAACGACATGATAGTCACTGACAACAACGGTGCAGTCAAGTTTCCACAACTGTGTAAATTTTGTGATGTGAGATTTTCCACCTGTGACAACCAGAAATCCTGCATGAGCAACTGCAGCATCACCTCCATCTGTGAGAAGCCACAGGAAGTCTGTGTGGCTGTATGGAGAAAGAATGACGAGAACATAACACTAGAGACAGTTTGCCATGACCCCAAGCTCCCCTACCATGACTTTATTCTGGAAGATGCTGCTTCTCCAAAGTGCATTATGAAGGAAAAAAAAAAGCCTGGTGAGACTTTCTTCATGTGTTCCTGTAGCTCTGATGAGTGCAATGACAACATCATCTTCTCAGAAGAATATAACACCAGCAATCCTGACGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(인간 조직 인자 219)
TCAGGCACTACAAATACTGTGGCAGCATATAATTTAACTTGGAAATCAACTAATTTCAAGACAATTTTGGAGTGGGAACCCAAACCCGTCAATCAAGTCTACACTGTTCAAATAAGCACTAAGTCAGGAGATTGGAAAAGCAAATGCTTTTACACAACAGACACAGAGTGTGACCTCACCGACGAGATTGTGAAGGATGTGAAGCAGACGTACTTGGCACGGGTCTTCTCCTACCCGGCAGGGAATGTGGAGAGCACCGGTTCTGCTGGGGAGCCTCTGTATGAGAACTCCCCAGAGTTCACACCTTACCTGGAGACAAACCTCGGACAGCCAACAATTCAGAGTTTTGAACAGGTGGGAACAAAAGTGAATGTGACCGTAGAAGATGAACGGACTTTAGTCAGAAGGAACAACACTTTCCTAAGCCTCCGGGATGTTTTTGGCAAGGACTTAATTTATACACTTTATTATTGGAAATCTTCAAGTTCAGGAAAGAAAACAGCCAAAACAAACACTAATGAGTTTTTGATTGATGTGGATAAAGGAGAAAACTACTGTTTCAGTGTTCAAGCAGTGATTCCCTCCCGAACAGTTAACCGGAAGAGTACAGACAGCCCGGTAGAGTGTATGGGCCAGGAGAAAGGGGAATTCAGAGAA
(인간 IL-15D8N)
AACTGGGTGAATGTAATAAGTAATTTGAAAAAAATTGAAGATCTTATTCAATCTATGCATATTGATGCTACTTTATATACGGAAAGTGATGTTCACCCCAGTTGCAAAGTAACAGCAATGAAGTGCTTTCTCTTGGAGTTACAAGTTATTTCACTTGAGTCCGGAGATGCAAGTATTCATGATACAGTAGAAAATCTGATCATCCTAGCAAACAACAGTTTGTCTTCTAATGGGAATGTAACAGAATCTGGATGCAAAGAATGTGAGGAACTGGAGGAAAAAAATATTAAAGAATTTTTGCAGAGTTTTGTACATATTGTCCAAATGTTCATCAACACTTCT (SEQ ID NO: 244).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR (SEQ ID NO: 240).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다:
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG (SEQ ID NO: 241).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열을 포함할 수 있다:
MKWVTFISLLFLFSSAYSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR (SEQ ID NO: 242).
일부 구현예에서, 제2 키메라 폴리펩타이드는 하기와 적어도 80% 동일한(예를 들어, 적어도 82% 동일한, 적어도 84% 동일한, 적어도 86% 동일한, 적어도 88% 동일한, 적어도 90% 동일한, 적어도 92% 동일한, 적어도 94% 동일한, 적어도 96% 동일한, 적어도 98% 동일한, 적어도 99% 동일한, 또는 100% 동일한) 서열에 의해 인코딩된다: ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCCATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGACATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG (SEQ ID NO: 243).
노화-관련 질환 또는 병태를 치료하는 방법
치료를 필요로 하는 대상체에서 노화-관련 질환 또는 병태(예를 들어 본원에 기재되거나 당업계에 알려진 임의의 예시적인 유형의 노화-관련 질환 또는 병태)를 치료하는 방법이 본원에 제공되며, 노화-관련 질환 또는 병태(예를 들어 본원에 기재되거나 당업계에 알려진 임의의 예시적인 유형의 노화-관련 질환 또는 병태)를 갖는 것으로 식별된 대상체에게 치료적 유효량의 하나 이상의 자연 살해(NK) 세포 활성화제(들)(예를 들어 본원에 기재되거나 당업계에 알려진 임의의 자연 살해(NK) 세포 활성화제(들))를 투여하는 단계를 포함한다.
치료를 필요로 하는 대상체에서 노화-관련 질환 또는 병태(예를 들어 본원에 기재되거나 당업계에 알려진 임의의 예시적인 유형의 노화-관련 질환 또는 병태)를 치료하는 방법이 본원에 제공되며, 노화-관련 질환 또는 병태(예를 들어 본원에 기재되거나 당업계에 알려진 임의의 예시적인 유형의 노화-관련 질환 또는 병태)를 갖는 것으로 식별된 대상체에게 치료적 유효량의 활성화된 NK 세포(예를 들어 본원에 기재되거나 당업계에 알려진 임의의 활성화된 NK 세포)를 투여하는 단계를 포함한다.
이들 방법의 일부 구현예는 휴지기 NK 세포를 수득하는 단계; 및 상기 휴지기 NK 세포를 시험관내에서 하나 이상의 NK 세포 활성화제(들)를 포함하는 액체 배양 배지에서 접촉시키는 단계를 추가로 포함하며, 상기 접촉은 후속적으로 대상체에게 투여되는 활성화된 NK 세포의 생성을 초래한다. 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 대상체로부터 수득된 자가 NK 세포이다. 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 대상체로부터 수득된 반일치 NK 세포이다. 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 동종이계 휴지기 NK 세포이다. 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 인공 NK 세포이다. 임의의 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 키메라 항원 수용체 또는 재조합 T 세포 수용체를 갖고 있는 유전자-조작된 NK 세포이다.
이들 방법의 일부 예에서, 액체 배양 배지는 무혈청 액체 배양 배지이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 액체 배양 배지는 화학적으로-한정된 액체 배양 배지이다. 이들 방법의 일부 구현예는 활성화된 NK 세포를 단리하는 단계(및 선택적으로 추가로 치료적 유효량의 활성화된 NK 세포를 대상체, 예를 들어, 본원에 기재된 임의의 대상체에게 투여하는 단계)를 추가로 포함한다. 이들 방법의 일부 구현예에서, 접촉 단계는 약 2시간 내지 약 20일(또는 본원에 기재된 이 범위의 임의의 하위범위)의 기간 동안 수행된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 노화-관련 질환 또는 병태는 암, 자가면역 질환, 대사 질환, 신경퇴행성 질환, 심혈관 질환, 피부 질환, 조로증 질환, 및 유약 질환의 군으로부터 선택된다.
암의 비제한적인 예는 고형 종양, 혈액학적 종양, 육종, 골육종, 교모세포종, 신경모세포종, 흑색종, 횡문근육종, 유잉 육종, 골육종, B-세포 신생물, 다발성 골수종, B-세포 림프종, B-세포 비-호지킨 림프종, 호지킨 림프종, 만성 림프구성 백혈병(CLL), 급성 골수성 백혈병(AML), 만성 골수성 백혈병(CML), 급성 림프구성 백혈병(ALL), 골수이형성 증후군(MDS), 피부 T-세포 림프종, 망막모세포종, 위암, 요로상피세포암종, 폐암, 신세포 암종, 위 및 식도 암, 췌장암, 전립선암, 유방암, 결장직장암, 난소암, 비-소세포 폐 암종, 편평 세포 두경부 암종, 자궁내막암, 자궁경부암, 간암, 및 간세포 암종을 포함한다.
자가면역 질환의 비제한적인 예는 1형 당뇨병이다.
대사 질환의 비제한적인 예는 비만, 지방이영양증, 및 2형 진성 당뇨병을 포함한다.
신경퇴행성 질환의 비제한적인 예는 알츠하이머 질환, 파킨슨 질환, 및 치매를 포함한다.
심혈관 질환의 비제한적인 예는 관상 동맥 질환, 죽상동맥경화증, 및 폐동맥 고혈압을 포함한다.
피부 질환의 비제한적인 예는 상처 치유, 탈모증, 주름, 노인성 흑점, 피부 얇아짐, 색소성 건피증, 및 선천성 각화이상증을 포함한다.
조로증 질환의 비제한적인 예는 조로증 및 허친슨-길포트 조로증 증후군을 포함한다.
유약 질환의 비제한적인 예는 유약, 백신화에 대한 민감도, 골다공증, 및 사르코페니아를 포함한다.
본원에 기재된 임의의 노화-관련 질환 또는 병태의 일부 구현예에서, 노화-관련 질환 또는 병태는 하기의 군으로부터 선택된다: 노화-관련 황반 변성, 골관절염, 지방세포 위축, 만성 폐쇄성 폐 질환, 특발성 폐 섬유증, 신장 이식 실패, 간 섬유증, 골질량 손실, 사르코페니아, 연령-연관 폐 조직 탄성 손실, 골다공증, 노화-연관 신장 기능장애, 및 화학-유도 신장 기능장애.
본원에 기재된 임의의 노화-관련 질환 또는 병태의 일부 구현예에서, 노화-관련 질환 또는 병태는 2형 당뇨병 또는 죽상동맥경화증이다.
본원에 기재된 임의의 방법의 일부 구현예에서, 대상체는 노화-관련 질환 또는 병태(예를 들어, 본원에 기재된 임의의 예시적인 노화-관련 질환 또는 병태)를 갖는 것으로 진단되거나 식별되었다. 본원에 기재된 임의의 방법의 일부 구현예는 노화-관련 질환 또는 병태(예를 들어, 본원에 기재된 임의의 예시적인 노화-관련 질환 또는 병태)를 갖는 것으로 진단되거나 식별된 대상체를 선택하는 단계를 포함할 수 있다.
이들 방법의 일부 구현예에서, 투여는 예를 들어, 치료 전 대상체의 표적 조직에서의 노쇠 세포의 수와 비교하여, 대상체의 표적 조직에서의 노쇠 세포의 수의 저하(예를 들어, 적어도 5% 저하, 적어도 10% 저하, 적어도 15% 저하, 적어도 20% 저하, 적어도 25% 저하, 적어도 30% 저하, 적어도 35% 저하, 적어도 40% 저하, 적어도 45% 저하, 적어도 50% 저하, 적어도 55% 저하, 적어도 60% 저하, 적어도 65% 저하, 적어도 70% 저하, 적어도 75% 저하, 적어도 80% 저하, 적어도 85% 저하, 적어도 90% 저하, 또는 적어도 95% 저하, 또는 약 10% 저하 내지 약 99% 저하, 약 10% 저하 내지 약 95% 저하, 약 10% 저하 내지 약 90% 저하, 약 10% 저하 내지 약 85% 저하, 약 10% 저하 내지 약 80% 저하, 약 10% 저하 내지 약 75% 저하, 약 10% 저하 내지 약 70% 저하, 약 10% 저하 내지 약 65% 저하, 약 10% 저하 내지 약 60% 저하, 약 10% 저하 내지 약 55% 저하, 약 10% 저하 내지 약 50% 저하, 약 10% 저하 내지 약 45% 저하, 약 10% 저하 내지 약 40% 저하, 약 10% 저하 내지 약 35% 저하, 약 10% 저하 내지 약 30% 저하, 약 10% 저하 내지 약 25% 저하, 약 10% 저하 내지 약 20% 저하, 약 10% 저하 내지 약 15% 저하, 약 15% 저하 내지 약 99% 저하, 약 15% 저하 내지 약 95% 저하, 약 15% 저하 내지 약 90% 저하, 약 15% 저하 내지 약 85% 저하, 약 15% 저하 내지 약 80% 저하, 약 15% 저하 내지 약 75% 저하, 약 15% 저하 내지 약 70% 저하, 약 15% 저하 내지 약 65% 저하, 약 15% 저하 내지 약 60% 저하, 약 15% 저하 내지 약 55% 저하, 약 15% 저하 내지 약 50% 저하, 약 15% 저하 내지 약 45% 저하, 약 15% 저하 내지 약 40% 저하, 약 15% 저하 내지 약 35% 저하, 약 15% 저하 내지 약 30% 저하, 약 15% 저하 내지 약 25% 저하, 약 15% 저하 내지 약 20% 저하, 약 20% 저하 내지 약 99% 저하, 약 20% 저하 내지 약 95% 저하, 약 20% 저하 내지 약 90% 저하, 약 20% 저하 내지 약 85% 저하, 약 20% 저하 내지 약 80% 저하, 약 20% 저하 내지 약 75% 저하, 약 20% 저하 내지 약 70% 저하, 약 20% 저하 내지 약 65% 저하, 약 20% 저하 내지 약 60% 저하, 약 20% 저하 내지 약 55% 저하, 약 20% 저하 내지 약 50% 저하, 약 20% 저하 내지 약 45% 저하, 약 20% 저하 내지 약 40% 저하, 약 20% 저하 내지 약 35% 저하, 약 20% 저하 내지 약 30% 저하, 약 20% 저하 내지 약 25% 저하, 약 25% 저하 내지 약 99% 저하, 약 25% 저하 내지 약 95% 저하, 약 25% 저하 내지 약 90% 저하, 약 25% 저하 내지 약 85% 저하, 약 25% 저하 내지 약 80% 저하, 약 25% 저하 내지 약 75% 저하, 약 25% 저하 내지 약 70% 저하, 약 25% 저하 내지 약 65% 저하, 약 25% 저하 내지 약 60% 저하, 약 25% 저하 내지 약 55% 저하, 약 25% 저하 내지 약 50% 저하, 약 25% 저하 내지 약 45% 저하, 약 25% 저하 내지 약 40% 저하, 약 25% 저하 내지 약 35% 저하, 약 25% 저하 내지 약 30% 저하, 약 30% 저하 내지 약 99% 저하, 약 30% 저하 내지 약 95% 저하, 약 30% 저하 내지 약 90% 저하, 약 30% 저하 내지 약 85% 저하, 약 30% 저하 내지 약 80% 저하, 약 30% 저하 내지 약 75% 저하, 약 30% 저하 내지 약 70% 저하, 약 30% 저하 내지 약 65% 저하, 약 30% 저하 내지 약 60% 저하, 약 30% 저하 내지 약 55% 저하, 약 30% 저하 내지 약 50% 저하, 약 30% 저하 내지 약 45% 저하, 약 30% 저하 내지 약 40% 저하, 약 30% 저하 내지 약 35% 저하, 약 35% 저하 내지 약 99% 저하, 약 35% 저하 내지 약 95% 저하, 약 35% 저하 내지 약 90% 저하, 약 35% 저하 내지 약 85% 저하, 약 35% 저하 내지 약 80% 저하, 약 35% 저하 내지 약 75% 저하, 약 35% 저하 내지 약 70% 저하, 약 35% 저하 내지 약 65% 저하, 약 35% 저하 내지 약 60% 저하, 약 35% 저하 내지 약 55% 저하, 약 35% 저하 내지 약 50% 저하, 약 35% 저하 내지 약 45% 저하, 약 35% 저하 내지 약 40% 저하, 약 40% 저하 내지 약 99% 저하, 약 40% 저하 내지 약 95% 저하, 약 40% 저하 내지 약 90% 저하, 약 40% 저하 내지 약 85% 저하, 약 40% 저하 내지 약 80% 저하, 약 40% 저하 내지 약 75% 저하, 약 40% 저하 내지 약 70% 저하, 약 40% 저하 내지 약 65% 저하, 약 40% 저하 내지 약 60% 저하, 약 40% 저하 내지 약 55% 저하, 약 40% 저하 내지 약 50% 저하, 약 40% 저하 내지 약 45% 저하, 약 45% 저하 내지 약 99% 저하, 약 45% 저하 내지 약 95% 저하, 약 45% 저하 내지 약 90% 저하, 약 45% 저하 내지 약 85% 저하, 약 45% 저하 내지 약 80% 저하, 약 45% 저하 내지 약 75% 저하, 약 45% 저하 내지 약 70% 저하, 약 45% 저하 내지 약 65% 저하, 약 45% 저하 내지 약 60% 저하, 약 45% 저하 내지 약 55% 저하, 약 45% 저하 내지 약 50% 저하, 약 50% 저하 내지 약 99% 저하, 약 50% 저하 내지 약 95% 저하, 약 50% 저하 내지 약 90% 저하, 약 50% 저하 내지 약 85% 저하, 약 50% 저하 내지 약 80% 저하, 약 50% 저하 내지 약 75% 저하, 약 50% 저하 내지 약 70% 저하, 약 50% 저하 내지 약 65% 저하, 약 50% 저하 내지 약 60% 저하, 약 50% 저하 내지 약 55% 저하, 약 55% 저하 내지 약 99% 저하, 약 55% 저하 내지 약 95% 저하, 약 55% 저하 내지 약 90% 저하, 약 55% 저하 내지 약 85% 저하, 약 55% 저하 내지 약 80% 저하, 약 55% 저하 내지 약 75% 저하, 약 55% 저하 내지 약 70% 저하, 약 55% 저하 내지 약 65% 저하, 약 55% 저하 내지 약 60% 저하, 약 60% 저하 내지 약 99% 저하, 약 60% 저하 내지 약 95% 저하, 약 60% 저하 내지 약 90% 저하, 약 60% 저하 내지 약 85% 저하, 약 60% 저하 내지 약 80% 저하, 약 60% 저하 내지 약 75% 저하, 약 60% 저하 내지 약 70% 저하, 약 60% 저하 내지 약 65% 저하, 약 65% 저하 내지 약 99% 저하, 약 65% 저하 내지 약 95% 저하, 약 65% 저하 내지 약 90% 저하, 약 65% 저하 내지 약 85% 저하, 약 65% 저하 내지 약 80% 저하, 약 65% 저하 내지 약 75% 저하, 약 65% 저하 내지 약 70% 저하, 약 70% 저하 내지 약 99% 저하, 약 70% 저하 내지 약 95% 저하, 약 70% 저하 내지 약 90% 저하, 약 70% 저하 내지 약 85% 저하, 약 70% 저하 내지 약 80% 저하, 약 70% 저하 내지 약 75% 저하, 약 75% 저하 내지 약 99% 저하, 약 75% 저하 내지 약 95% 저하, 약 75% 저하 내지 약 90% 저하, 약 75% 저하 내지 약 85% 저하, 약 75% 저하 내지 약 80% 저하, 약 80% 저하 내지 약 99% 저하, 약 80% 저하 내지 약 95% 저하, 약 80% 저하 내지 약 90% 저하, 약 80% 저하 내지 약 85% 저하, 약 85% 저하 내지 약 99% 저하, 약 85% 저하 내지 약 95% 저하, 약 85% 저하 내지 약 90% 저하, 약 90% 저하 내지 약 99% 저하, 약 90% 저하 내지 약 95% 저하, 또는 약 95% 저하 내지 약 99% 저하)를 초래한다.
이들 방법의 일부 구현예에서, 투여는 치료 전의 대상체 또는 치료를 받은 적이 없는 유사한 대조군 대상체에서의 수준과 비교하여, 대상체에서의 IFN-γ, 세포독성 과립 그랜자임, 및/또는 퍼포린의 수준의 증가(예를 들어, 적어도 5% 증가, 적어도 10% 증가, 적어도 15% 증가, 적어도 20% 증가, 적어도 25% 증가, 적어도 30% 증가, 적어도 35% 증가, 적어도 40% 증가, 적어도 45% 증가, 적어도 50% 증가, 적어도 55% 증가, 적어도 60% 증가, 적어도 65% 증가, 적어도 70% 증가, 적어도 75% 증가, 적어도 80% 증가, 적어도 85% 증가, 적어도 90% 증가, 적어도 95% 증가, 또는 적어도 99% 증가, 또는 약 10% 증가 내지 약 500% 증가(또는 본원에 기재된 이 범위의 임의의 하위범위)를 초래한다.
일부 구현예에서, 이들 방법은 대상체에서 암의 하나 이상의 증상의 수, 중증도, 또는 빈도의 감소를(예를 들어, 치료 전 대상체에서의 암의 하나 이상의 증상의 수, 중증도, 또는 빈도와 비교하여) 초래할 수 있다. 일부 구현예에서, 이들 방법은 대상체의 하나 이상의 고형 종양의 부피에서(예를 들어, 치료 전에 또는 치료 시작 시 하나 이상의 고형 종양의 부피와 비교하여) 감소(예를 들어, 약 1% 감소 내지 약 99% 감소, 약 1% 감소 내지 약 95% 감소, 약 1% 감소 내지 약 90% 감소, 약 1% 감소 내지 약 85% 감소, 약 1% 감소 내지 약 80% 감소, 약 1% 감소 내지 약 75% 감소, 약 1% 감소 내지 약 70% 감소, 약 1% 감소 내지 약 65% 감소, 약 1% 감소 내지 약 60% 감소, 약 1% 감소 내지 약 55% 감소, 약 1% 감소 내지 약 50% 감소, 약 1% 감소 내지 약 45% 감소, 약 1% 감소 내지 약 40% 감소, 약 1% 감소 내지 약 35% 감소, 약 1% 감소 내지 약 30% 감소, 약 1% 감소 내지 약 25% 감소, 약 1% 감소 내지 약 20% 감소, 약 1% 감소 내지 약 15% 감소, 약 1% 감소 내지 약 10% 감소, 약 1% 감소 내지 약 5% 감소, 약 5% 감소 내지 약 99% 감소, 약 5% 감소 내지 약 95% 감소, 약 5% 감소 내지 약 90% 감소, 약 5% 감소 내지 약 85% 감소, 약 5% 감소 내지 약 80% 감소, 약 5% 감소 내지 약 75% 감소, 약 5% 감소 내지 약 70% 감소, 약 5% 감소 내지 약 65% 감소, 약 5% 감소 내지 약 60% 감소, 약 5% 감소 내지 약 55% 감소, 약 5% 감소 내지 약 50% 감소, 약 5% 감소 내지 약 45% 감소, 약 5% 감소 내지 약 40% 감소, 약 5% 감소 내지 약 35% 감소, 약 5% 감소 내지 약 30% 감소, 약 5% 감소 내지 약 25% 감소, 약 5% 감소 내지 약 20% 감소, 약 5% 감소 내지 약 15% 감소, 약 5% 감소 내지 약 10% 감소, 약 10% 감소 내지 약 99% 감소, 약 10% 감소 내지 약 95% 감소, 약 10% 감소 내지 약 90% 감소, 약 10% 감소 내지 약 85% 감소, 약 10% 감소 내지 약 80% 감소, 약 10% 감소 내지 약 75% 감소, 약 10% 감소 내지 약 70% 감소, 약 10% 감소 내지 약 65% 감소, 약 10% 감소 내지 약 60% 감소, 약 10% 감소 내지 약 55% 감소, 약 10% 감소 내지 약 50% 감소, 약 10% 감소 내지 약 45% 감소, 약 10% 감소 내지 약 40% 감소, 약 10% 감소 내지 약 35% 감소, 약 10% 감소 내지 약 30% 감소, 약 10% 감소 내지 약 25% 감소, 약 10% 감소 내지 약 20% 감소, 약 10% 감소 내지 약 15% 감소, 약 15% 감소 내지 약 99% 감소, 약 15% 감소 내지 약 95% 감소, 약 15% 감소 내지 약 90% 감소, 약 15% 감소 내지 약 85% 감소, 약 15% 감소 내지 약 80% 감소, 약 15% 감소 내지 약 75% 감소, 약 15% 감소 내지 약 70% 감소, 약 15% 감소 내지 약 65% 감소, 약 15% 감소 내지 약 60% 감소, 약 15% 감소 내지 약 55% 감소, 약 15% 감소 내지 약 50% 감소, 약 15% 감소 내지 약 45% 감소, 약 15% 감소 내지 약 40% 감소, 약 15% 감소 내지 약 35% 감소, 약 15% 감소 내지 약 30% 감소, 약 15% 감소 내지 약 25% 감소, 약 15% 감소 내지 약 20% 감소, 약 20% 감소 내지 약 99% 감소, 약 20% 감소 내지 약 95% 감소, 약 20% 감소 내지 약 90% 감소, 약 20% 감소 내지 약 85% 감소, 약 20% 감소 내지 약 80% 감소, 약 20% 감소 내지 약 75% 감소, 약 20% 감소 내지 약 70% 감소, 약 20% 감소 내지 약 65% 감소, 약 20% 감소 내지 약 60% 감소, 약 20% 감소 내지 약 55% 감소, 약 20% 감소 내지 약 50% 감소, 약 20% 감소 내지 약 45% 감소, 약 20% 감소 내지 약 40% 감소, 약 20% 감소 내지 약 35% 감소, 약 20% 감소 내지 약 30% 감소, 약 20% 감소 내지 약 25% 감소, 약 25% 감소 내지 약 99% 감소, 약 25% 감소 내지 약 95% 감소, 약 25% 감소 내지 약 90% 감소, 약 25% 감소 내지 약 85% 감소, 약 25% 감소 내지 약 80% 감소, 약 25% 감소 내지 약 75% 감소, 약 25% 감소 내지 약 70% 감소, 약 25% 감소 내지 약 65% 감소, 약 25% 감소 내지 약 60% 감소, 약 25% 감소 내지 약 55% 감소, 약 25% 감소 내지 약 50% 감소, 약 25% 감소 내지 약 45% 감소, 약 25% 감소 내지 약 40% 감소, 약 25% 감소 내지 약 35% 감소, 약 25% 감소 내지 약 30% 감소, 약 30% 감소 내지 약 99% 감소, 약 30% 감소 내지 약 95% 감소, 약 30% 감소 내지 약 90% 감소, 약 30% 감소 내지 약 85% 감소, 약 30% 감소 내지 약 80% 감소, 약 30% 감소 내지 약 75% 감소, 약 30% 감소 내지 약 70% 감소, 약 30% 감소 내지 약 65% 감소, 약 30% 감소 내지 약 60% 감소, 약 30% 감소 내지 약 55% 감소, 약 30% 감소 내지 약 50% 감소, 약 30% 감소 내지 약 45% 감소, 약 30% 감소 내지 약 40% 감소, 약 30% 감소 내지 약 35% 감소, 약 35% 감소 내지 약 99% 감소, 약 35% 감소 내지 약 95% 감소, 약 35% 감소 내지 약 90% 감소, 약 35% 감소 내지 약 85% 감소, 약 35% 감소 내지 약 80% 감소, 약 35% 감소 내지 약 75% 감소, 약 35% 감소 내지 약 70% 감소, 약 35% 감소 내지 약 65% 감소, 약 35% 감소 내지 약 60% 감소, 약 35% 감소 내지 약 55% 감소, 약 35% 감소 내지 약 50% 감소, 약 35% 감소 내지 약 45% 감소, 약 35% 감소 내지 약 40% 감소, 약 40% 감소 내지 약 99% 감소, 약 40% 감소 내지 약 95% 감소, 약 40% 감소 내지 약 90% 감소, 약 40% 감소 내지 약 85% 감소, 약 40% 감소 내지 약 80% 감소, 약 40% 감소 내지 약 75% 감소, 약 40% 감소 내지 약 70% 감소, 약 40% 감소 내지 약 65% 감소, 약 40% 감소 내지 약 60% 감소, 약 40% 감소 내지 약 55% 감소, 약 40% 감소 내지 약 50% 감소, 약 40% 감소 내지 약 45% 감소, 약 45% 감소 내지 약 99% 감소, 약 45% 감소 내지 약 95% 감소, 약 45% 감소 내지 약 90% 감소, 약 45% 감소 내지 약 85% 감소, 약 45% 감소 내지 약 80% 감소, 약 45% 감소 내지 약 75% 감소, 약 45% 감소 내지 약 70% 감소, 약 45% 감소 내지 약 65% 감소, 약 45% 감소 내지 약 60% 감소, 약 45% 감소 내지 약 55% 감소, 약 45% 감소 내지 약 50% 감소, 약 50% 감소 내지 약 99% 감소, 약 50% 감소 내지 약 95% 감소, 약 50% 감소 내지 약 90% 감소, 약 50% 감소 내지 약 85% 감소, 약 50% 감소 내지 약 80% 감소, 약 50% 감소 내지 약 75% 감소, 약 50% 감소 내지 약 70% 감소, 약 50% 감소 내지 약 65% 감소, 약 50% 감소 내지 약 60% 감소, 약 50% 감소 내지 약 55% 감소, 약 55% 감소 내지 약 99% 감소, 약 55% 감소 내지 약 95% 감소, 약 55% 감소 내지 약 90% 감소, 약 55% 감소 내지 약 85% 감소, 약 55% 감소 내지 약 80% 감소, 약 55% 감소 내지 약 75% 감소, 약 55% 감소 내지 약 70% 감소, 약 55% 감소 내지 약 65% 감소, 약 55% 감소 내지 약 60% 감소, 약 60% 감소 내지 약 99% 감소, 약 60% 감소 내지 약 95% 감소, 약 60% 감소 내지 약 90% 감소, 약 60% 감소 내지 약 85% 감소, 약 60% 감소 내지 약 80% 감소, 약 60% 감소 내지 약 75% 감소, 약 60% 감소 내지 약 70% 감소, 약 60% 감소 내지 약 65% 감소, 약 65% 감소 내지 약 99% 감소, 약 65% 감소 내지 약 95% 감소, 약 65% 감소 내지 약 90% 감소, 약 65% 감소 내지 약 85% 감소, 약 65% 감소 내지 약 80% 감소, 약 65% 감소 내지 약 75% 감소, 약 65% 감소 내지 약 70% 감소, 약 70% 감소 내지 약 99% 감소, 약 70% 감소 내지 약 95% 감소, 약 70% 감소 내지 약 90% 감소, 약 70% 감소 내지 약 85% 감소, 약 70% 감소 내지 약 80% 감소, 약 70% 감소 내지 약 75% 감소, 약 75% 감소 내지 약 99% 감소, 약 75% 감소 내지 약 95% 감소, 약 75% 감소 내지 약 90% 감소, 약 75% 감소 내지 약 85% 감소, 약 75% 감소 내지 약 80% 감소, 약 80% 감소 내지 약 99% 감소, 약 80% 감소 내지 약 95% 감소, 약 80% 감소 내지 약 90% 감소, 약 80% 감소 내지 약 85% 감소, 약 85% 감소 내지 약 99% 감소, 약 85% 감소 내지 약 95% 감소, 약 85% 감소 내지 약 90% 감소, 약 90% 감소 내지 약 99% 감소, 약 90% 감소 내지 약 95% 감소, 또는 약 95% 감소 내지 약 99% 감소)를 초래할 수 있다. 일부 구현예에서, 이들 방법은 대상체에서 전이를 발증시키거나 하나 이상의 추가 전이를 발증시킬 위험을(예를 들어, 치료 전의 대상체에서 또는 상이한 치료가 투여된 유사한 대상체 또는 대상체들의 집단에서 전이를 발증시키거나 하나 이상의 추가 전이를 발증시킬 위험과 비교하여) 감소(예를 들어, 약 1% 감소 내지 약 99% 감소, 또는 본원에 기재된 이 범위의 임의의 서브범위)시킬 수 있다.
일부 구현예에서, 이들 방법은 대상체에서 대사 질환의 치료를 초래할 수 있다. 일부 구현예에서, 대사 질환의 치료는 예를 들어, 향상된 내당성, 향상된 포도당 이용성, 당뇨병성 골관절증의 저하된 중증도 또는 진행, 피부 병변의 저하된 중증도 또는 진행, 케톤증의 저하된 중증도 또는 진행, 췌도 세포에 대한 자가항체의 저하된 생성, 증가된 인슐린 감수성, 저하된 질량, 및 저하된 체질량 지수 중 하나 이상(예를 들어, 2개, 3개, 4개, 5개, 또는 6개)을 초래할 수 있다. 치료에 대한 대상체의 반응은 공복 포도당 또는 내당성을 표준 기법에 따라 결정함으로써 모니터링될 수 있다. 전형적으로, 방법에 따르면, 혈당은 저하되어, 100 mg/dL 미만의 공복 혈당 또는 140 mg/dL 미만의 2시간 75-g 경구 내당성 시험 값을 특징으로 하는 혈당 수준을 달성한다. 일부 구현예에서, 치료에 대한 반응은 혈압, 체질량 지수, PPAR-γ 기능, 지질 대사, 당화된 헤모글로빈(H1c), 및 신장 기능을 포함하여 전당뇨병, 신규-발생 당뇨병, 또는 활성 당뇨병과 관련된 다른 인자를 결정하는 단계를 포함할 수 있다.
일부 구현예에서, 이들 방법은 질환의 발증 동안 제시되는 질환, 이의 합병증 및 중간 병리학적 표현형의 생화학적, 조직학적 및/또는 행동학적 증상을 포함하여 신경퇴행성 질환의 위험을 제거하거나 감소시키거나, 중증도를 약화시키거나, 발생을 지연시킬 수 있다.
일부 구현예에서, 피부 질환의 효과적인 치료는 치료 전의 피부 상태와 비교하여, 피부 색상, 수분, 온도, 질감, 운동성과 팽압, 및 피부 병변을 포함하는 피부 조건을 조사하는 단계를 포함하여 본원에 기재되거나 당업계에 알려진 임의의 방법에 의해 평가될 수 있다.
일부 구현예에서, 자가면역 질환의 효과적인 치료는 신선하게 단리된 PBMC에 대한 전혈 카운트 분석, 총 Ig 수준, 및 혈청 자가항체 역가의 분석을 모니터링하는 단계를 포함하여 본원에 기재되거나 당업계에 알려진 임의의 방법에 의해 평가될 수 있다.
일부 구현예에서, 유약 질환의 효과적인 치료는 골밀도, 골 구조와 기하학, 골 전환율의 생물의학적 마커, 비타민 D 측정, 카르노프스키 수행 상태(Karnofsky performance status)와 ECOG 점수, 및 백신화에 대한 민감도를 모니터링하는 단계를 포함하여 본원에 기재되거나 당업계에 알려진 임의의 방법에 의해 평가될 수 있다.
대상체에서 노쇠 세포를 사멸시키거나 이의 수를 감소시키는 방법
노쇠 세포의 사멸 또는 수의 감소를 필요로 하는 대상체에서 노쇠 세포(예를 들어, 본원에 기재되거나 당업계에 알려진 임의의 예시적인 유형의 노쇠 세포)를 사멸시키거나 이의 수를 감소시키는 방법이 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 NK 세포 활성화제(들)(예를 들어 본원에 기재되거나 당업계에 알려진 임의의 NK 세포 활성화제(들))를 투여하는 단계를 포함한다.
노쇠 세포의 사멸 또는 수의 감소를 필요로 하는 대상체에서 노쇠 세포(예를 들어, 본원에 기재되거나 당업계에 알려진 임의의 예시적인 유형의 노쇠 세포)를 사멸시키거나 이의 수를 감소시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 활성화된 NK 세포(예를 들어 본원에 기재되거나 당업계에 알려진 임의의 활성화된 NK 세포)를 투여하는 단계를 포함한다.
이들 방법의 일부 구현예는 휴지기 NK 세포를 수득하는 단계; 및 상기 휴지기 NK 세포를 시험관내에서 하나 이상의 NK 세포 활성화제(들)를 포함하는 액체 배양 배지에서 접촉시키는 단계를 추가로 포함하며, 상기 접촉은 후속적으로 대상체에게 투여되는 활성화된 NK 세포의 생성을 초래한다. 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 대상체로부터 수득된 자가 NK 세포이다. 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 대상체로부터 수득된 반일치 NK 세포이다. 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 동종이계 휴지기 NK 세포이다. 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 인공 NK 세포이다. 임의의 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 키메라 항원 수용체 또는 재조합 T 세포 수용체를 갖고 있는 유전자-조작된 NK 세포이다.
이들 방법의 일부 예에서, 액체 배양 배지는 무혈청 액체 배양 배지이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 액체 배양 배지는 화학적으로-한정된 액체 배양 배지이다. 이들 방법의 일부 구현예는 활성화된 NK 세포를 단리하는 단계(및 추가로 치료적 유효량의 활성화된 NK 세포를 대상체, 예를 들어, 본원에 기재된 임의의 대상체에게 투여하는 단계)를 추가로 포함한다. 이들 방법의 일부 구현예에서, 접촉 단계는 약 2시간 내지 약 20일(또는 본원에 기재된 이 범위의 임의의 하위범위)의 기간 동안 수행된다.
이들 방법의 일부 구현예에서, 노쇠 세포는 노쇠 암세포, 노쇠 단핵구, 노쇠 림프구, 노쇠 성상세포, 노쇠 소교세포, 노쇠 뉴런, 노쇠 조직 섬유아세포, 노쇠 피부 섬유아세포, 노쇠 케라틴세포, 또는 다른 분화된 조직-특이적 분열 기능 세포이다. 이들 방법의 일부 구현예에서, 노쇠 암세포는 화학요법-유도 노쇠 세포 또는 방사선-유도 노쇠 세포이다.
이들 방법의 일부 구현예에서, 대상체는 노화-관련 질환 또는 병태를 갖는 것으로 식별되거나 진단되었다(예를 들어, 본원에 기재되거나 당업계에 알려진 임의의 노화-관련 질환 또는 병태). 본원에 기재된 임의의 노화-관련 질환 또는 병태의 일부 구현예에서, 노화-관련 질환 또는 병태는 하기의 군으로부터 선택된다: 암, 자가면역 질환, 대사 질환, 신경퇴행성 질환, 심혈관 질환, 피부 질환, 조로증 질환, 및 유약 질환.
암의 비제한적인 예는 고형 종양, 혈액학적 종양, 육종, 골육종, 교모세포종, 신경모세포종, 흑색종, 횡문근육종, 유잉 육종, 골육종, B-세포 신생물, 다발성 골수종, B-세포 림프종, B-세포 비-호지킨 림프종, 호지킨 림프종, 만성 림프구성 백혈병(CLL), 급성 골수성 백혈병(AML), 만성 골수성 백혈병(CML), 급성 림프구성 백혈병(ALL), 골수이형성 증후군(MDS), 피부 T-세포 림프종, 망막모세포종, 위암, 요로상피세포암종, 폐암, 신세포 암종, 위 및 식도 암, 췌장암, 전립선암, 유방암, 결장직장암, 난소암, 비-소세포 폐 암종, 편평 세포 두경부 암종, 자궁내막암, 자궁경부암, 간암, 및 간세포 암종을 포함한다.
자가면역 질환의 비제한적인 예는 1형 당뇨병이다.
대사 질환의 비제한적인 예는 비만, 지방이영양증, 및 2형 진성 당뇨병을 포함한다.
신경퇴행성 질환의 비제한적인 예는 알츠하이머 질환, 파킨슨 질환, 및 치매를 포함한다.
심혈관 질환의 비제한적인 예는 관상 동맥 질환, 죽상동맥경화증, 및 폐동맥 고혈압을 포함한다.
피부 질환의 비제한적인 예는 상처 치유, 탈모증, 주름, 노인성 흑점, 피부 얇아짐, 색소성 건피증, 및 선천성 각화이상증을 포함한다.
조로증 질환의 비제한적인 예는 조로증 및 허친슨-길포트 조로증 증후군을 포함한다.
유약 질환의 비제한적인 예는 유약, 백신화에 대한 민감도, 골다공증, 및 사르코페니아를 포함한다.
본원에 기재된 임의의 노화-관련 질환 또는 병태의 일부 구현예에서, 노화-관련 질환 또는 병태는 하기의 군으로부터 선택된다: 노화-관련 황반 변성, 골관절염, 지방세포 위축, 만성 폐쇄성 폐 질환, 특발성 폐 섬유증, 신장 이식 실패, 간 섬유증, 골질량 손실, 사르코페니아, 연령-연관 폐 조직 탄성 손실, 골다공증, 노화-연관 신장 기능장애, 및 화학-유도 신장 기능장애.
본원에 기재된 임의의 노화-관련 질환 또는 병태의 일부 구현예에서, 노화-관련 질환 또는 병태는 2형 당뇨병 또는 죽상동맥경화증이다.
이들 방법의 일부 구현예에서, 투여는 예를 들어, 치료 전 대상체의 표적 조직에서의 노쇠 세포의 수와 비교하여, 대상체의 표적 조직에서의 노쇠 세포의 수의 저하(예를 들어, 적어도 5% 저하, 적어도 10% 저하, 적어도 15% 저하, 적어도 20% 저하, 적어도 25% 저하, 적어도 30% 저하, 적어도 35% 저하, 적어도 40% 저하, 적어도 45% 저하, 적어도 50% 저하, 적어도 55% 저하, 적어도 60% 저하, 적어도 65% 저하, 적어도 70% 저하, 적어도 75% 저하, 적어도 80% 저하, 적어도 85% 저하, 적어도 90% 저하, 또는 적어도 95% 저하, 또는 약 10% 저하 내지 약 99% 저하(또는 본원에 기재된 이 범위의 임의의 하위범위))를 초래한다. 이들 방법의 일부 구현예에서, 대상체에서의 표적 조직은 지방 조직, 췌장 조직, 간 조직, 폐 조직, 혈관 구조, 뼈 조직, 중추신경계(CNS) 조직, 안구 조직, 피부 조직, 근육 조직, 및 2차 림프-기관 조직 중 하나 이상일 수 있다.
이들 방법의 일부 구현예에서, 투여는 치료 전의 대상체 또는 치료를 받은 적이 없는 유사한 대조군 대상체에서의 수준과 비교하여, 대상체에서의 IFN-γ, 세포독성 과립 그랜자임, 및/또는 퍼포린의 수준의 증가(예를 들어, 적어도 5% 증가, 적어도 10% 증가, 적어도 15% 증가, 적어도 20% 증가, 적어도 25% 증가, 적어도 30% 증가, 적어도 35% 증가, 적어도 40% 증가, 적어도 45% 증가, 적어도 50% 증가, 적어도 55% 증가, 적어도 60% 증가, 적어도 65% 증가, 적어도 70% 증가, 적어도 75% 증가, 적어도 80% 증가, 적어도 85% 증가, 적어도 90% 증가, 적어도 95% 증가, 또는 적어도 99% 증가, 또는 약 10% 증가 내지 약 500% 증가(또는 본원에 기재된 이 범위의 임의의 하위범위))를 초래한다.
이들 방법의 일부 구현예에서, 표적 조직(예를 들어 본원에 기재된 임의의 표적 조직)에서의 노쇠 세포의 수는 생검 시료 상에서 면역염색을 수행함으로써 결정될 수 있다. 이들 방법의 일부 구현예에서, 표적 조직(예를 들어 본원에 기재된 임의의 표적 조직)에서 노쇠 세포의 수는 대상체에서 노화-관련 질환 또는 병태(예를 들어 본원에 기재된 노화-관련 질환 또는 병태의 임의의 증상)의 하나 이상의 증상의 향상을 통해 간접적으로 관찰될 수 있다.
노화 세포
노쇠 세포는 형태, 염색질 구조화, 유전자 발현, 및 대사에서의 변화를 포함하는 중요하고 독특한 특성을 나타낸다. 세포적 노쇠와 관련된 생화학적 특성 및 기능적 특성, 예컨대 (i) 사이클린-의존적 키나제의 저해제인 p16INK4a 및 p21CIP1의 증가된 발현, (ii) 리소좀 활성의 마커인 노화-관련 β-갈락토시다제의 존재, (iii) 노화-관련 이질염색질 병소의 출현 및 라민 B1 수준의 하향조절, (iv) 항-세포자멸사 BCL-패밀리 단백질의 증가된 발현에 의해 야기되는 세포자멸사에 대한 내성, 및 (v) CD26(DPP4), CD36(스캐빈저 수용체), 포크헤드 박스 4(FOXO4), 및 분비형 담체 막 단백질 4(SCAMP4)의 상향조절이 존재한다. 노쇠 세포는 또한, 소위 노쇠-관련 분비 표현형(SASP)인 염증 시그너처를 발현한다. SASP를 통해, 노쇠 세포는, 노쇠를 보강하고(자가분비(autocrine) 효과) 미세환경과 소통하며 이를 변형시키는(측분비(paracrine) 효과) 세포-자율 방식으로 작동하는 광범위한 염증성 사이토카인(IL-6, IL-8), 성장 인자(TGF-β), 케모카인(CCL-2), 및 매트릭스 메탈로프로테이나제(MMP-3, MMP-9)를 생성한다. SASP 인자는 노쇠 세포의 면역-매개 청소인 노쇠 감시를 촉발함으로써 종양 억제에 기여할 수 있다. 그러나, 만성 염증 또한 종양발생의 기지의 유발자이고, 누적되고 있는 증거는 만성 SASP가 또한 암 전이 및 노화-관련 질환을 증강시킬 수 있음을 나타낸다.
노쇠 세포의 분비 프로파일은 컨텍스트(context) 의존적이다. 예를 들어, 인간 섬유모세포에서 상이한 미토콘드리아 기능장애에 의해 유도되는 미토콘드리아 기능장애-관련 노쇠(MiDAS)는 IL-1-의존적 염증 인자가 부족한 SASP의 출현을 유발하였다. NAD+/NADH 비의 저하는 AMPK 신호화를 활성화시켰으며, 이는 p53의 활성화를 통해 MiDAS를 유도하였다. 그 결과, p53은 전-염증성 SASP의 중요한 유도인자인 NF-κB 신호화를 저해하였다. 대조적으로, 인간 세포에서 지속적인 DNA 손상에 의해 야기되는 세포 노쇠는 염증성 SASP를 유도하였으며, 이는 p53이 아니라 운동실조-모세혈관확장증 돌연변이화된(ATM: ataxia-telangiectasia mutated) 키나제의 활성화에 의존하였다. 특히, IL-6 및 IL-8의 발현 및 분비 수준은 증가되었다. 이소성(ectopic) 발현 p16INK4a 및 p21CIP1에 의해 야기된 세포 노쇠는 염증성 SASP 없이 인간 섬유모세포에서 노쇠 표현형을 유도하였으며, 이는 성장 억제 자체가 SASP를 자극시키지 않았음을 나타내는 것이 또한 실증되었다.
노쇠의 가장 규정적인(defining) 특징 중 하나는 안정한 성장 억제이다. 이는 2개의 중요한 경로인 p16INK4a/Rb 및 p53/p21CIP1에 의해 달성되며, 둘 다 종양 억제에서 중심적이다. DNA 손상은 (1) 염색질에서 γH2Ax(히스톤 코딩 유전자) 및 53BP1(DNA 손상 반응에 관여함)의 높은 침착을 초래하며: 이는 키나제 캐스케이드의 활성화를 유발하여 결국 p53 활성화를 초래하고, (2) p16INK4a 및 ARF(둘 다 CDKN2A에 의해 인코딩됨) 및 P15INK4b(CDKN2B에 의해 인코딩됨)의 활성화를 초래하며: p53은 사이클린-의존적 키나제 저해제(p21CIP1)의 전사를 유도하고, p16INK4a와 p15INK4b 둘 다와 함께 세포 주기 진행을 위한 유전자(CDK4 및 CDK6)를 차단시킨다. 이는 결국 망막모세포종 단백질(Rb)의 과소인산화(hypophosphorylation) 및 G1 기에서 세포 주기 억제를 유발한다.
노쇠 세포의 선택적인 사멸는 정상적인 노화의 맥락에서 마우스의 건강 수명(health span)을 유의하게 향상시키고 노화-관련 질환 또는 암 요법의 결과를 호전시키는 것으로 나타났다(문헌[Ovadya, J Clin Invest. 128(4):1247-1254, 2018]). 자연상에서, 노쇠 세포는 내재 면역(innate immune) 세포에 의해 정상적으로 제거된다. 노쇠의 유도는 손상된/변경된 세포의 잠재적인 증식 및 형질전환을 방지할 뿐만 아니라, 주로 자연 살해(NK) 세포(예컨대 IL-15 및 CCL2) 및 대식세포(예컨대 CFS-1 및 CCL2)에 대해 화학주성인자(chemoattractant)로서 작용하는 SASP 인자의 생성을 통한 조직 복구를 선호한다. 이들 내재 면역 세포는 스트레스를 받은 세포를 제거하기 위한 면역감시 기전을 매개한다. 노쇠 세포는 통상, NK-세포 활성화 수용체 NKG2D 및 DNAM1 리간드를 상향조절하며, 상기 리간드는 스트레스-유도성 리간드: 감염성 질환 및 악성물에 대한 최전방 면역 방어의 중요한 구성요소의 패밀리에 속한다. 수용체 활성화 시, NK 세포는 그 후에 노쇠 세포의 사멸을 이들 세포의 세포용해 기구를 통해 특이적으로 유도할 수 있다. 노쇠 세포의 면역 감시에서 NK 세포의 역할은 간 섬유증(문헌[Sagiv, Oncogene 32(15): 1971-1977, 2013]), 간세포 암종(문헌[Iannello, J Exp Med 210(10): 2057-2069, 2013]), 다발성 골수종(문헌[Soriani, Blood 113(15): 3503-3511, 2009]), 및 메발로네이트(mevalonate) 경로의 기능장애에 의해 스트레스를 받는 신경교종 세포(문헌[Ciaglia, Int J Cancer 142(1): 176-190, 2018])에서 주목되었다. 자궁내막 세포는 급성 세포 노쇠를 겪고, 탈락막(decidual) 세포로 분화되지 않는다. 분화된 탈락막 세포는 IL-15를 분비하여, 자궁 NK 세포를 표적으로 동원시키고 미분화된 노쇠 세포를 제거하므로, 자궁내막의 재건(re-model) 및 회춘을 돕는다(문헌[Brighton, Elife 6: e31274, 2017]). 유사한 기전을 이용하여, 간 섬유증 동안, p53-발현 노쇠 간 위성 세포(satellite cell)는, 전-염증성 M1 표현형으로 향하는 체류하는 쿠퍼 대식세포 및 새로 침윤된 대식세포의 분극화를 회피하였으며(skew), 이는 노화세포용해(senolytic) 활성을 나타낸다. F4/80+ 대식세포는 분만후 자궁 기능을 유지시키기 위해 마우스 자궁 노쇠 세포의 청소에서 주요 역할을 하는 것으로 나타났다.
노쇠 세포는 NKG2D(NK 세포 상에서 발현됨), 케모카인, 및 다른 SASP 인자에 대한 리간드를 주로 상향조절함으로써 NK 세포를 동원한다. 간 섬유증의 생체내 모델은 활성화된 NK 세포에 의한 노쇠 세포의 효과적인 청소를 나타내었다(문헌[Krizhanovsky, Cell 134(4): 657-667, 2008]). 연구는 간 섬유증(문헌[Krizhanovsky, Cell 134(4): 657-667, 2008]), 골관절염(문헌[Xu, J Gerontol A Biol Sci Med Sci 72(6): 780-785, 2017]), 및 파킨슨 질환(문헌[Chinta, Cell Rep 22(4): 930-940, 2018])을 포함하여 노쇠를 연구하기 위한 다양한 모델을 기재하였다. 노쇠 세포를 연구하기 위한 동물 모델은 문헌[Krizhanovsky, Cell 134(4): 657-667, 2008]; 문헌[Baker, Nature 479(7372): 232-236, 2011]; 문헌[Farr, Nat Med 23(9): 1072-1079, 2017]; 문헌[Bourgeois, FEBS Lett 592(12): 2083-2097, 2018]; 문헌[Xu, Nat Med 24(8): 1246-1256, 2018)]에 기재되어 있다.
노쇠는 표현형 변화, 세포자멸사에 대한 저항성 및 손상-감지 신호화 경로의 활성화에 의해 동반되는 비가역적인 성장 억제 형태이다. 이의 증식 능력을 소실하여 약 50개 집단 배가(Hayflick 한계라고 칭함) 후 영구적인 정지에 도달하는 배양된 인간 섬유아세포 세포에서 세포 노쇠가 처음에 기재되었다(문헌[Hayflick et al., Exp. Cell Res. 25:585-621, 1961]). 그는 각각의 세포 분열 시 점진적인 텔로미어 단축에 의해 야기되고 게놈 불안정성 및 따라서 DNA 손상의 축적을 예방하기 위한 생리학적 반응을 나타내는 비-불멸화된 인간 섬유아세포의 배양물에서 "복제성 노쇠" 현상을 관찰하였다(문헌[He et al., Cell 169(6):1000-1011, 2017]).
노쇠는 산화적 및 유전자독성(genotoxic) 스트레스, DNA 손상, 텔로미어 마모, 또는 종양원성 활성화, 미토콘드리아 기능장애, 또는 화학요법제를 포함하여 광범위한 내인성 공격 및 외인성 공격에 의해 유도될 수 있는 스트레스 반응으로 간주된다(문헌[McHugh et al., J. Cell Biol. 217(1):65-77, 2018]). 텔로미어 단축과 독립적인 이러한 가속화된 노쇠 반응은 조기 노쇠로 알려져 있다. 노쇠는 당뇨병, 골다공증, 심혈관 질환, 치매, 신경퇴행성 장애, 신부전, 및 사르코페니아와 같은 다양한 연령-관련 합병증과 연관이 있어 왔다. 노화가 암에 대한 가장 큰 단일 위험 인자임을 유념하는 것이 또한 흥미롭다(문헌[McHugh et al., J. Cell Biol. 217(1):65-77, 2018]; 문헌[Childs et al., Nat. Rev. Drug Discov. 16(10):718-735, 2017]).
노쇠 세포는 대사적으로 활성적으로 남아 있고, 이들 세포의 분비 표현형을 통해 조직 항상성, 질환 및 노화에 영향을 미칠 수 있다(문헌[He et al., Cell 169(6):1000-1011, 2017]). 노쇠는 생리학적 과정으로서 간주되고, 상처 치유, 조직 항상성(문헌[Brighton et al., Elife 6, 2017]), 재생, 배아발생, 및 섬유증 조절 등(문헌[von Kobbe, Cell Mol. Life Sci. 2018])을 촉진하는 데 중요하다. 예를 들어, 노쇠 세포의 일시적인 유도는 상처 치유 동안 관찰되고, 상처 해소(resolution)에 기여한다. 아마도 노쇠의 가장 중요한 역할 중 하나는 종양형성 억제에서의 노화의 역할이다(문헌[von Kobbe, Cell Mol. Life Sci. 2018]). 그러나, 노쇠 세포의 축적은 또한, 나이- 및 노화-관련 질환을 유발한다. 노화 표현형은 또한, 만성 염증 반응을 촉발하고 결과적으로 만성 염증 병태를 악화시켜(augment) 종양 성장을 촉진할 수 있다. 노쇠와 노화(aging) 사이의 연관성은 처음에, 노쇠 세포가 노화 조직에서 축적된다는 관찰에 기초하였다. 지난 10년 이내에, 노화 및 연령-관련 병증에 있어서 노쇠의 유해한 결과에 대한 본 발명자들의 이해는 유의하게 확장되었다. 유전자이식(trasngenic) 모델의 사용은 많은 노화-관련 병상(pathology)에서 노쇠 세포를 전신적으로 검출할 수 있게 하였다. 노쇠 세포를 선택적으로 제거하기 위한 유전적 및 노쇠용해성 약물 전략의 개발은, 노쇠 세포가 사실상 노화 및 관련 병상에서 인과 관계 역할을 할 수 있음을 실증하였다.
노쇠 세포는 형태, 염색질 구조화, 유전자 발현, 및 대사에서의 변화를 포함하는 중요하고 독특한 특성을 나타낸다. 세포적 노쇠와 관련된 생화학적 특성 및 기능적 특성, 예컨대 (i) 사이클린-의존적 키나제의 저해제인 p16INK4a 및 p21CIP1의 증가된 발현, (ii) 리소좀 활성의 마커인 노화-관련 β-갈락토시다제의 존재, (iii) 노화-관련 이질염색질 병소의 출현 및 라민 B1 수준의 하향조절, (iv) 항-세포자멸사 BCL-패밀리 단백질의 증가된 발현에 의해 야기되는 세포자멸사에 대한 내성, (v) CD26(DPP4)(문헌[Kim et al., Genes Dev. 31(15):1529-1534, 2017]), CD36(스캐빈저 수용체)(문헌[Chong et al., EMBO Rep. 19(6), 2018]), 포크헤드 박스 4(FOXO4)(문헌[Bourgeois et al., FEBS Lett. 592(12): 2083-2097, 2018]), 및 분비형 담체 막 단백질 4(SCAMP4)(문헌[Kim et al., Genes Dev. 32(13-14): 909-914, 2018])의 상향조절, (vi) 리포퓨신(lipofuscin)의 축적, 및 (vii) 배아 연골세포-발현 1 및 유인(decoy) 사멸 수용체 2의 발현이 존재한다. 노쇠 세포는 또한, 소위 SASP인 염증 시그너처를 발현한다. SASP를 통해, 노쇠 세포는, 노쇠를 보강하고(자가분비 효과) 미세환경과 소통하며 이를 변형시키는(측분비 효과) 세포-자율 방식으로 작동하는 광범위한 염증성 사이토카인(IL-1α, IL-1β, IL-6, IL-8, TNF-α), 성장 인자(TGF-β, PDGF-AA, 인슐린-유사 성장 인자-결합 단백질(IGFBP)), 케모카인(CCL-2, CCL-20, CCL-7, CXCL-4, CXCL1, 및 CXCL-12), 및 매트릭스 메탈로프로테이나제(MMP-3, MMP-9)를 생성한다(문헌[Milanovic et al., Nature 553(7686):96-100, 2018]). IL-1α는 SASP의 마스터 조절자 중 하나인 것으로 여겨진다. 노쇠 세포에 의한 IL-1α의 방출은 노쇠를 정상 세포에 전달한다. IFN은 표적 세포에서 DNA 손상을 촉발함으로써 노쇠를 유도할 수 있다. IGFBs는 인슐린-유사 성장 인자(IGF) 경로를 조절할 수 있고, IGF는 노쇠의 강력한 유도자로서 작용할 수 있다. SASP 인자 중 하나로서 분비되는 TGF-β는 노쇠 표현형 및 연령-관련 병리학적 병태를 자가분비/측분비 방식으로 유도하고 유지시킬 수 있다. 폴리콤(polycom) 단백질 CBX7에 의해 조절되는 인테그린 β3은 인간 섬유아세포에서 노쇠 동안 상향조절되었으며, TGF-β 신호전달을 자가분비/측분비 방식으로 활성화시킴으로써 노쇠를 촉진하였고, SASP를 강화시켰다. 이에 더하여, 노쇠 세포의 TGF-β-매개 축적은 특발성 폐 섬유증에서 시사되었다. 최근의 보고는 TGF-β 신호전달이 H4K20me3 풍부도의 감소를 유도하였고, 이는 섬유아세포에서 miR-29a/c를 상향조절하고 Suv4-20h 내 이의 표적을 하향조절함으로써 DNA 손상 수선을 저하시켰고 노쇠를 복구하고 촉진하였음을 보여주었다. 이러한 경로는 생체내에서 심장 노화에 기여하였고, TGF-β 신호전달의 저해는 더 노화된 마우스에서 H4K20me3를 복구하였고 심장 기능을 향상시켰다.
매트릭스 메탈로프로테이나제(MMP)는 MMP-1 및 MMP-3을 포함하여 SASP의 중요한 요소이며, 이는 노쇠의 조절 요소로서 작용할 수 있다. 이들은 IL-8, IL-1, VEGF, 및 다른 CXCL/CCL 계열 케모카인을 절단할 수 있다. 이에 더하여, 노쇠 세포는 유로키나제-유형 또는 조직-유형 플라스미노겐 활성자와 같은 세린 프로테아제를 분비한다.
SASP는 또한 이웃 세포의 표현형에 영향을 미칠 수 있는 산화질소 및 반응성 산소종과 같은 비-거대분자 요소로 이루어진다.
노쇠 세포의 분비 프로파일은 컨텍스트(context) 의존적이다. 예를 들어, 인간 섬유모세포에서 상이한 미토콘드리아 기능장애에 의해 유도되는 미토콘드리아 기능장애-관련 노쇠(MiDAS)는 IL-1-의존적 염증 인자가 부족한 SASP의 출현을 유발하였다(문헌[Wiley et al., Cell Metab. 23(2):303-314, 2016]). NAD+/NADH 비의 저하는 AMPK 신호화를 활성화시켰으며, 이는 p53의 활성화를 통해 MiDAS를 유도하였다. 그 결과, p53은 전-염증성 SASP의 중요한 유도인자인 NF-κB 신호화를 저해하였다(문헌[Salminen et al., Cell Signal. 24(4):835-845, 2012]). 대조적으로, 인간 세포에서 지속적인 DNA 손상에 의해 야기되는 세포 노쇠는 염증성 SASP를 유도하였으며, 이는 p53이 아니라 운동실조-모세혈관확장증 돌연변이화된(ATM) 키나제의 활성화에 의존하였다(문헌[Rodier et al., Nat. Cell Biol. 11(8): 973-979, 2009]). 특히, IL-6 및 IL-8의 발현 및 분비 수준은 증가되었다. 이소성 발현 p16INK4a 및 p21CIP1에 의해 야기된 세포 노쇠는 염증성 SASP 없이 인간 섬유모세포에서 노쇠 표현형을 유도하였으며, 이는 성장 억제 자체가 SASP를 자극시키지 않았음을 나타내는 것이 또한 실증되었다(문헌[Coppe et al., J. Biol. Chem. 286(42): 36396-36403, 2011]). 이들은 노쇠 표현형이 SASP의 성질의 제어 및 이의 생리학적 및 병리학적 결과에서 중대한 역할을 가짐을 나타낸다.
그러므로, SASP의 다수의 구성요소는 근처의 비-노쇠 세포에서 노쇠를 측분비 방식으로 구동하는 능력을 가져서 노쇠 세포의 전체 수를 증가시킨다. SASP에 의해, 노쇠 세포는 또한 측분비 기전을 통해 조직 미세환경에 영향을 미쳐서, 노화 조직 및 종양에서 면역 세포의 모집과 활성화 및 이웃의 증식중인 세포에 영향을 미칠 수 있다.
SASP 인자는 노쇠 세포의 면역-매개 청소인 노쇠 감시를 촉발함으로써 종양 억제에 기여할 수 있다. 그러나, 만성 염증 또한 종양발생의 기지의 유발자이고, 누적되고 있는 증거는 만성 SASP가 또한 암 및 노화-관련 질환을 증강시킬 수 있음을 나타낸다. 최근, 노쇠 세포는 직접적인 세포내 단백질 전달을 통해 이웃 세포에 영향을 미친다는 것이 또한 제시되었다(문헌[Biran et al., Genes Dev. 29(8):791-802, 2015]). 노쇠 세포로부터 수혜자 이웃 세포로 전달된 단백질은 이들 세포에서 신호전달 경로의 활성화를 촉발하였고, 이는 이들의 세포 거동의 변화를 유발하였다. 최근의 연구는 화학요법-유도 노쇠 암세포가 이웃의 노쇠 또는 비-노쇠 암세포를 포식하였음을 보여주었다. 포식은 심지어 세포-사멸 저해제 p53의 존재 하에서도 발생하였다. 섭취된 세포는 리소좀에서 분해된다. 이들의 이웃을 포식한 노쇠 세포는 그렇지 않은 세포보다 시험관내에서 더 오래 생존하였다. 이는, 이웃 세포의 리소좀 분해로부터 회수되는 대사 구성(building) 블록은 노쇠 세포에 의해 사용되어 이의 생존율을 촉진하였음을 시사하였다. 포식은 주로 엔토시스(entosis) 작용 기전보다는 식세포작용을 통한 것이었다. 세포 카니발리즘(cell cannibalism)은 SASP 반응을 지지함으로써 암 진행에 영향을 미칠 것으로 제안되었다. 그러나, 화학요법-유도 노쇠 암 세포의 이러한 새로 획득된 능력은 특정 세포를 종양 환경으로부터 제거함으로써 암-세포 전이를 직접적으로 촉진하거나 용이하게 할 수 있었다. 정상 세포가 또한 노화된 조직에서 노쇠 세포에 의해 제거되는 것으로 발견된다면, 이는 조직 분해를 직접적으로 야기할 것이다.
요약하자면, SASP의 모든 구성요소는 국소 염증 환경에 기여하고, 염증화(inflammaging) 현상에 기여할 수 있다.
대부분의 SASP 구성요소는 활성화된 B 세포의 핵 인자 카파 경쇄-증강제(NF-κB), CCAAT/결합 단백질 베타(CEBP/β)에 의해 그리고 mTOR에 의해 조절된다. NF-κB의 업스트림에서 작용하는 전사 인자 GATA4가 또한 노쇠 확립 및 SASP 유도에 필요하다. SASP의 또 다른 조절자는 노쇠 세크레톰(secretome)을 긍정적으로 조절하고 노쇠 면역 청소를 촉진하는 브로모도메인 및 엑스트라터미널 도메인(BET: bromodomain and extraterminal domain) 계열 구성원 브로모도메인-함유 단백질 4(BRD4)이다. SASP는 또한 특정한 조직에서 전사의 신호 전달자 및 활성자 3(STAT3)에 의해 조절된다. 이에 더하여, 혼합-직계성 백혈병 1(MLL1: mixed-lineage leukemia 1)이 또한, 주로 DNA 복제 및 DDR 활성화에 필요한 유전자를 유도함으로써 SASP를 가능하게 하는 것으로 보고되었다. 다른 SASP 조절자는 NOTCH1 및 고 운동성 군 B 단백질(HMGB1 및 HMGB2)을 포함한다. 최근의 데이터는 또한, SASP가 cGAS/STING 경로에 의해 제어될 수 있음을 실증한다. cGAS는 어댑터 단백질 STING을 통해 SASP를 제어하는 유전자의 전사 및 세포 노쇠를 촉발하는 DNA 센서이다.
노쇠의 가장 규정적인(defining) 특징 중 하나는 안정한 성장 억제이다. 이는 p53/p21CIP1p21cip1 및 p16INK4a/Rb 경로에 의해 달성된다(문헌[McHugh et al., J. Cell Biol. 217(1):65-77, 2018]). DNA 손상 및/또는 DNA 손상 반응(DDR)은 이들 2개 경로를 결정적으로 제어한다.
(1) p53/p21CIP1p21cip1: p53은 세포 노쇠에서 중추적인 역할을 하고, 이의 활성화는 DDR-의존적 또는 DDR-독립적일 수 있다. 텔로미어 DDR-의존적 경우, 반복되는 스트레스로부터 비롯되는 텔로미어 소모, DNA 손상, 뿐만 아니라 종양유전자의 과다활성화 및 종양-억제자의 비활성화(종양유전자 유도 노쇠, OIS)는 DNA 손상 수선 캐스케이드를 활성화시킨다. DDR은 스트레스 센서의 모세혈관확장성-운동실조증 돌연변이화된 키나제(ATM: ataxia-telangiectasia mutated) 또는 모세혈관확장성-운동실조증 및 Rad3-관련(ATR: ataxia telangiectasia and Rad3-related) 키나제를 활성화시킨다. ATM/ATR은 다시, p53과 이의 유비퀴틴 리가제 Mdm2를 둘 다 인산화시켜 p53의 안정화를 유발함으로써 p53/p21CIP1p21cip1 축을 안정화시킨다. P53은 Ser-15에서 직접적으로 인산화되고, Ser-20에서는 Chk1/2를 통해 간접적으로 인산화된다. 많은 최근의 연구는 또한, 몇몇 OIS 경로가 DDR을 우회하는 p53p35를 실제로 활성화시킬 수 있음을 실증하였다. 이들은 제1 돌연변이의 발생 후 종양형성의 억제를 위한 p53 및 p53-촉발 노쇠의 중대한 역할을 다시 한번 더 실증하였다.
p53 단백질의 안정화는 p21CIP1을 상향조절한다. p21CIP1p21cip1. 포유류 사이클린-의존적 키나제(CDK) 저해제 계열의 구성원인 p21cip1은 G1/S 또는 G2/M 검문에서 p53-유도 세포 주기 억제에 필요하다. 인간에서 염색체 6 상에 위치한 CDKN1A 유전자에 의해 인코딩되는 p21CIP1p21cip1은 강력한 사이클린-의존적 키나제 저해제(CKI)이다. 이는 사이클린-CDK2, -CDK1, 및 -CDK4/6 복합체에 결합하고 이의 활성을 저해하며, 그러므로 G1 및 S 기에서 세포 주기 진행의 조절자로서 기능한다. p21CIP1p21cip1은 또한 주로 E4F4 복합체 모집을 통해 CDC25C, CDC25B와 같은 많은 p53 표적의 유전자 발현 조절 및 생존을 매개한다. p21CIP1p21cip1은 또한 세포자멸사의 저해를 통해 노쇠를 촉진한다. 이는 많은 카스파제를 포함한 많은 세포자멸사 제제에 결합한다. 노쇠 세포에서 P21CIP1P21cip1 넉아웃은 카스파제 활성화 캐스케이드를 통해 프로그래밍된 세포 사멸을 촉진한다. p21CIP1p21cip1은 또한 p53 활성과 독립적으로 노쇠를 유도할 수 있다. Chk2는 p53-결함 세포주에서 p21cip1 발현을 유도하여 Chk2-매개 노쇠에 기여할 수 있는 것으로 제시되었다.
(2) p16 INK4a /Rb: 3개의 종양 억제자는 INK4/ARF 좌위에 체류한다: 둘 다 CNDN2A 유전자에 의해 인코딩되는 p16INK4a와 ARF, 및 CDKN2B 유전자에 의해 인코딩되는 p15INK4b. p15INK4b 및 p16INK4a는 CDK4 및 CDK6에 결합하고 이를 저해함으로써 세포 주기에 영향을 미치는 p21CIP1과 같은 CDKIs이다. 대조적으로, ARF는 MDM2를 저해하여, 이로써 p53/p21CIP1 경로와의 혼선(cross talk)을 가능하게 한다. INK4/ARF 좌위는 노쇠 센서로서 거동한다. 젊은 정상 세포에서, INK4/ARF 좌위는 억제성 H3K27me3 마크의 침착을 통해 후생적으로 침묵화된다. H3K27 메틸화는 폴리콤 억제성 복합체, PRC2 및 PRC3에 의해 제어된다. PRC1 또는 PRC2의 구성요소 중 일부의 발현을 결실시킴으로써 이들 PRC1 또는 PRC2의 활성을 방해하는 것은 p16INK4a를 저하시키고 노쇠를 유도한다. 노쇠 동안, H3K27 히스톤 탈메틸화제 JMJD3은 INK4/ARF 좌위 주변에서 억제성 마크를 제거하여, 이의 유도를 용이하게 하는 역할을 한다. INK4/ARF 유도는 자연 노화 동안 조직에서 관찰될 수 있다. 특히, p16INK4a는 노화 생체표지자인 것으로 여겨진다.
요약하자면, p53은 사이클린-의존적 키나제 저해제 p21CIP1의 전사를 유도하고, p16INK4a와 p15INK4b 둘 다와 함께 세포 주기 진행을 위한 유전자(CDK4 및 CDK6)를 차단시킨다. 이는 결국 망막모세포종 단백질(Rb)의 과소인산화(hypophosphorylation) 및 G1 기에서 세포 주기 억제를 유발한다(문헌[McHugh et al., J. Cell Biol. 217(1):65-77, 2018]).
p53/p21CIP1 경로는 노쇠의 개시에서 핵심 역할을 하는 것으로 보이며, 상기 경로는 p16INK4a를 수반하고, RB 계열은 노쇠의 유지에서 중심적인 역할을 갖는 것으로 보인다. 이는 노쇠의 유도 후 p53 수준의 저하의 관찰에 의해 시사된 한편, p16INK4a 수준은 꾸준히 높게 유지된다. 또한, 노쇠 세포에서 p53의 하향조절은 p16 활성에 따라 상이한 효과를 갖는 것으로 제시되었다. p53은 낮은 수준의 p16INK4a를 갖는 세포에서 복제 및 세포 성장을 유도하는 데 성공하는 한편, 이는 높은 p16INK4a 활성을 갖는 세포에서는 그렇지 않다. 이들 발견은 p16INK4a/Rb 경로의 활성화가 노쇠의 2개의 상이한 단계 사이에서 선을 긋는 데 책임이 있음을 시사한다: 초기 및 가역 단계는 p53 활성에 의해 지배되고, 비가역 단계는 p16INK4a/Rb 경로에 의해 유도된다.
최근, cGAS-cGAMP-STING 경로는 DNA 손상으로부터 염증, 세포 노쇠, 및 암까지의 중요한 연관성으로서 출현하였다(문헌[Tuo et al., J. Exp. Med. 215(5):1287-1299, 2018]). 이러한 경로는 DNA 손상 후 세포질 DNA를 검출하고, I형 IFN 및 다른 사이토카인을 활성화시킨다. DNase2와 TREX1이 둘 다 노쇠-전 세포 내 핵으로부터 나오는 세포질 DNA 단편을 신속하게 제거하지만, 이러한 DNase의 발현은 노쇠 세포에서 하향조절되어, 핵 DNA의 세포질 축적을 초래한다. 이는 cGAS-STING 세포질 DNA 센서의 비정상적인 활성화를 야기하여, IFN-β의 유도를 통해 SASP를 촉발한다(문헌[Takahashi et al., Nature Comm. 9:1249, 2018])
형질전환 성장 인자-β(TGF-β)는 세포 분화 및 증식의 조직-특이적 제어를 제공하기 위해 다양한 범위의 신호전달 기능을 매개하는 진화적으로 보존된 사이토카인의 슈퍼계열이다. 이들은 또한, 세포 사멸을 촉진하거나 이에 대해 보호하며, 세포외 매트릭스 단백질 발현, 세포 운동성 및 침범을 촉진하고, 세포 대사를 제어한다.
인간 TGF-β 계열은 동종이량체성 또는 헤테로이량체성 분비된 사이토카인을 인코딩하는 33개의 유전자를 포함한다. 계열 구성원은 액티빈, 골 형태형성 단백질, 성장 분화 인자, 뮬러리안 저해 성분, 노달(nodal) 및 TGF-β를 포함한다. TGF-β 계열 단백질은 신호 펩타이드, 프로도메인(TGF-β에 대해, 잠복기-관련 펩타이드(LAP)), 및 성숙한 폴리펩타이드로 구성된 전구체 분자로서 합성된다. 짧은 N-말단 신호 펩타이드의 제거는 소포체로부터 골지체로의 수송 동안 단백질 접힘, 당화 및 후속적인 생합성 단계에서의 가공을 가능하게 한다. 이황화 결합을 통한 이량체화는 N-말단 긴 이량체 및 이황화-연결된 LAP, 및 C-말단 짧은 이량체 이황화-연결된 성숙 TGF-β의 형성을 초래하는 푸린 계열 프로테아제에 의한 폴리펩타이드의 단백질 분해 절단으로 이어진다. LAP와 성숙 TGF-β는 서로 회합된 상태를 유지하고 작은 잠복 복합체(SLC: small latency complex)라는 리간드의 잠복 형태를 형성하며, 이러한 잠복 형태의 TGF-β에 대한 구조 분석은 LAP가 직접적으로 C-말단 이량체의 중요한 아미노산을 덮고, 이는 이후에 신호전달 수용체와의 상호작용에 사용되어 성숙 TGF-β 이량체의 불활성화를 부여함을 보여준다. TGF-β 폴리펩타이드의 가공에 수반되어, 다른 분비형 단백질인 잠복 TGF-β 결합 단백질(LTBP)에의 이황화 결합을 통한 N-말단 LAP의 가교가 발생하여, 큰 잠복 복합체(LLC)를 형성한다. LTBP는 세포외 단백질이며, 분비 시 피브로넥틴 및 피브릴린과 같은 ECM의 다른 단백질과 가교하는 능력을 통해 세포외 기질(EMC)에 대한 LLC의 침착을 매개한다. 그러므로, LTBP는 잠복 TGF-β를 ECM에 묶는 스캐폴딩 단위를 제공한다. 3개의 TGF-β의 잠복 복합체는 성숙 리간드를 방출시키기 위해 활성화 메커니즘을 필요로 하지만; TGF-β1 복합체의 활성화만이 잘 특징화되어 있다. 단백질 분해, 낮은 pH, 반응성 산소종, 다른 단백질에의 결합, 및 전단 또는 인테그린-매개 세포 당김에 의한 기계적 변형을 포함하는 생리학적으로 관련된 설정에서 잠복 세포외 잠복 TGF-β 활성화의 다양한 모드는 신호전달 맥락에 의존할 수 있는 조직-선택적 메커니즘의 세포 유형-선택적임을 시사한다. 다양한 맥락에서, SLC에서 LAP의 한쪽은 Cys33 잔기를 통해 LTBP의 8-Cys 도메인에 공유적으로 가교되며, 이는 다시 ECM에 연결된다. 이러한 저항으로, 인테그린, 특히 αvβ1, αvβ6 및 αvβ8을 통해 LAP의 다른 쪽 끝을 당기는 것은 LLC로부터 활성 TGF-β1의 방출을 초래하는 잠복 TGF-β 복합체의 입체배열에서 변화를 가능하게 한다. 다양한 프로테아제는 또한, 잠복 TGF-β의 활성화를 부여한다. 많은 연구는 잠복 TGF-β1의 생리학적 활성화가 인테그린과 프로테아제의 조합된 활성을 필요로 함을 강하게 시사한다. LTBP와 회합하는 대신, 잠복 TGF-β 복합체는 또한, LRRC32, 또는 밀접하게 관련된 LRRC33으로도 알려진 GARP라는 막 회합 단백질에 이황화-결합된 것으로 밝혀졌다. GARP는 조절 T 세포(Tregs)와 같은 면역 세포에서 주로 발현된다. GARP의 기능은 Treg에서 광범위하게 연구되어 왔으며, 여기서 이는 αvβ8 인테그린과 복합체화하여 세포 표면으로부터 활성 TGF-β를 방출한다. GARP는 Tregs-매개 말초 내약성을 증강시키는 데 관여하는 것으로 제시되었다. 혈소판에서, 트롬빈은 GARP를 절단하여 GARP-LAP-TGF-β1 복합체로부터 활성 TGF-β1의 유리를 초래하는 것으로 또한 제시되었다.
일단 LAP로부터 활성화되면, 모든 3개의 TGF-β 이소형은 이량체성 TGF-β I형 수용체(RI) alk5(일명 TβR1) 및 이량체성 TGF-β II형 수용체(RII) TGFβRII에 의해 형성된 동일한 이량체성 막관통 TGF-β 수용체 복합체를 통해 작용한다. TGF-β는 먼저 동종이량체성 TGFβRII와 회합한다. 이러한 상호작용은 리간드와 TGFβRII의 계면에서 TGFβRI에 대해 새로운 고-친화도 결합 부위가 형성되는 방식으로 리간드와 TGFβRII 사이의 구조적 적응을 야기한다. TGFβRI의 2개 단위의 모집 시, II형 수용체 키나제는 짧은 글리신 및 세린이 풍부한 모티프(GS)를 특징으로 하는 TGFβRI의 막-인접 하위도메인에 존재하는 세린 및 트레오닌 잔기를 인산화하며, 이는 그 후에 GS 도메인으로부터 면역친화성 FKBP12를 방출하는 입체배열 변화를 유도한다. 이러한 해리는 키나제 도메인과 GS 도메인의 저해성 상호작용을 경감시키고, I형 수용체에서 키나제를 활성화시킨다. 그 후에 리간드-유도 수용체 활성화 시, TGFβRI은 이펙터 SMAD를 이들의 2개의 C-말단 세린 잔기의 인산화를 통해 활성화시킨다. 구체적으로, I형 수용체는 TGF-β의 경우 2개의 상이한 SMAD 단백질(및 액티빈 및 노달과 같은 다른 계열 구성원), SMAD2 및 SMAD3, 또는 BMP의 경우 3개의 상이한 SMAD 단백질(또한 일부 GDF 및 다른 리간드 구성원), SMAD1, SMAD5 및 SMAD8을 인산화시킨다. 이들 "수용체-활성화 SMADs"(R-SMADs)는 그 후에 수용체로부터 해리되고, SMAD4와 조합되어 핵으로 전좌하는 복합체를 형성하고, 여기서 이들은 고-친화도 DNA 결합 전사 인자 및 공동조절자와 협력하여 표적 유전자를 활성화시키거나 억제시킨다. SMAD 복합체는 2차 유전자 발현 변화를 유발하는 유전자 전사를 지시할 뿐만 아니라 mRNA 스플라이싱, miRNA 발현과 가공, 및 후생유전학적 변화를 제어한다. SMAD 복합체 형성이 더욱 다양해짐에 따라, SMAD 신호전달 경로는 유전자 발현을 제어하는 고도로 다재다능하며 상황-의존적이고 미묘한 차이가 있는 경로이다.
정규 SMAD 신호전달에 더하여, TGF-β는 상황에 따라 다른 신호 변환기를 통해서도 다운스트림 세포 반응을 조절할 수 있다. 이들은 ERK MAP 키나제 경로, JNK 및 p38 MAP 키나제 경로(TAK1을 통해), PI3-AKT 경로, JAK-STAT 경로, Rho-(유사) GTPase 경로, 및 TGF-β I형 수용체 세포내 도메인 신호전달 경로를 포함한다. SMADS의 광범위한 기능적 다양성 및 의존성은 이들 비정규 경로에 있다는 것은 이제 잘 알려져 있다.
TGF-β는 전부는 아니더라도 대부분의 세포 계열의 분화를 제어하고 세포 및 조직 항상성의 많은 양태를 조절하기 때문에, TGF-β 신호전달의 하향조절은 발달 이상 및 질환을 유발한다. 축적된 증거는, 특정 세포 유형의 TGF-β 신호전달 장애 및 TGF-β 리간드의 조절이 세포 노쇠, 세포 변성, 조직 섬유증, 염증, 저하된 재생 능력, 및 대사 기능장애에 기여함을 나타내었다.
SASP 인자 중 하나로서 분비되는 TGF-β1는 섬유아세포, 기관지 상피 세포, 및 암을 포함한 다양한 세포 유형에서 노쇠 표현형을 자가분비/측분비 방식으로 유도하거나 가속화시키고, 유지시킬 수 있다. 폴리콤 단백질 CBX7에 의해 조절되는 인테그린 β3은 인간 섬유아세포에서 노쇠 동안 상향조절되었으며, TGF-β 신호전달을 자가분비/측분비 방식으로 활성화시킴으로써 노쇠를 촉진하였고, SASP를 강화시켰다. 이에 더하여, 노쇠 세포의 TGF-β1-매개 축적은 특발성 폐 섬유증에서 시사되었다. 최근의 보고는 TGF-β1 신호전달이 H4K20me3 풍부도의 감소를 유도하였고, 이는 섬유아세포에서 miR-29a/c를 상향조절하고 Suv4-20h 내 이의 표적을 하향조절함으로써 DNA 손상 수선을 저하시켰고 노쇠를 복구하고 촉진하였음을 보여주었다. 이러한 경로는 생체내에서 심장 노화에 기여하였고, TGF-β 신호전달의 저해는 더 노화된 마우스에서 H4K20me3를 복구하였고 심장 기능을 향상시켰다.
TGF-β1은 노쇠 구동자로서 기능하고, 플라스미노겐 활성자 저해제 1형(PAI -1, 세르핀 1)을 포함한 SASP 인자의 발현 및 NF-κB 신호전달 경로의 활성 산소종(ROS)-자극 활성화를 통해 혈관 평활근 세포(VSMC) 노쇠를 유도한다. PAI-1은 세포 노쇠의 바이오마커일 뿐만 아니라 p53의 복제 노쇠 다운스트림에 필요하고 충분하며 노쇠 프로그램의 핵심 유도자이다. PAI-1/TGF-β1 양성 피드-포워드 메커니즘의 존재를 시사하는 증거가 있으며, 노쇠 표현형의 출현 동안 TGF-β1의 상승된 조직 수준이 PAI-1의 발현을 자극하는 모델을 제공하고, 이는 다시 지속적인 TGF-β1 합성을 강화하여 노쇠 VSMC 집단의 유지 및 아마도 확장을 촉진한다(문헌[Seo et al., Am. J. Nephrol. 30:481-490, 2009]).
노쇠는 화학요법 후 임상 진행을 지연시키는 종양 억제 효과를 갖는 것으로 잘 알려져 있다. 지난 10년은 노쇠의 생물학에 대한 이해에서 큰 진전, 특히 종양 미세환경에서 종양-억제성 특성을 갖는 것으로부터 인접한 암세포, 간질, 및 혈관구조에 미치는 프로-발암성(pro-oncogenic) 효과를 유발할 수 있는 복잡하며 역동적이고 상호활성인 것으로의 진전을 목격하였다(문헌[Hoare et al., Ann. Rev. Cancer Biol. 2:175-194, 2018]). Milanovic의 매우 정교한 연구는 원발성 B-세포 만성 백혈병 환자의 시료에서 노쇠 세포가 중요한 줄기세포 관련 전사물을 상향조절하였음을 보여주었다(문헌[Milanovic et al., Nature 553(7686):96-100, 2018]). 노쇠 세포는 급성 골수성 백혈병(AML) 환자에서 나타났으며, AML 아세포는 간질 세포에서 노쇠 표현형을 유도하고 이들 간질 세포가 차례로 피드백되어 SASP를 통해 AML 아세포 생존 및 증식을 촉진하는 것으로 나타났다(문헌[Abdul-Aziz et al., Blood 133(5):446-456, 2019]). 종양은 기관 발달 또는 조직 수선에 참여하는 것으로 의도되는 성장 조절의 병태생리학적 프로그램을 포착하고 종양 진행을 위한 신규 메커니즘을 만드는 대신 발암성 성능을 위해 이러한 과정을 '도용'하는 것으로 생각된다(문헌[Milanovic et al., Trends Cell Biol. 28(12):1049-1061, 2018]). 후생학적 메커니즘은 노쇠 유도(H3K9 탈메틸화제) 및 후속적인 줄기(H3K9 탈메틸화제 저해) 획득에 책임이 있는 것으로 기재되었다(문헌[Yu et al., Cancer Cell 33(2):322-336, 2018]).
TGF-β1은 특정 전사인 Snail 및 Zeb1/2의 발현 유도를 통해 상피-간엽 전이(EMT)를 촉발한다. EMT는 세포 접착 변형으로 인해 세포에 운동성 및 침범성 거동을 제공한다. 이러한 과정은 운동성 및 침범성 특성을 유발하는 상피 특질 및 획득 특질의 손실을 수반한다. EMT는 암세포의 진행 및 전이를 유발하는 중요한 과정을 나타낸다.
TGF-β1은 면역억제성 사이토카인으로서 대식세포, 자연 살해 세포, 수지상 세포 및 T 세포를 포함한 내재성 및 후천적 면역계의 기능 및 발달을 저해한다. 최근의 생체내 연구는 조직-유래 또는 단백질-유래 TGF-β1에의 노출이 순환중인 NK 세포로부터 내재성 림프 세포 I(ILC-I)-유사 표현형으로의 전환을 구동할 수 있으며, 이는 몇몇 ILC1-관련 표면 마커의 세포독성 역량 및 획득의 감소를 특징으로 한다. 흥미롭게도, TGF-β1은 또한 MAPK 경로를 통해 IL-15와 상승작용하여, 인간 NK 세포로부터 ILC-1-유사 표현형으로의 전환을 구동한다. TGF-β는 또한, 인간 NK 세포대사를 이의 정규 신호전달 경로를 통해 억제시켜, NK-세포 세포독성을 억제시킨다. TGF-β1은 또한 다른 림프구의 기능을 억제시키는 조절 T 세포를 자극시킨다. 이들 억제성 기능은 면역 파괴를 피하는 것과 함께 많은 암 특징 중 하나를 TGF-β1에 부여한다.
췌장 도관 선암종(PDAC)은 5년 생존율이 7%이고 생존 중앙값이 11개월 미만인 극도로 불량한 예후를 가진 췌장의 가장 흔한 악성물이다. PDAC는 모든 이용 가능한 항종양 약리학적 옵션에 대해 고도로 불응성이다. 이는 PDAC 진행과 관련된 강한 섬유조직형성 반응의 결과이며, 췌장 성상 세포의 강한 활성화와 조밀한 세포외 기질의 형성을 나타내며, 이는 정맥내로 주입된 항암 약물 또는 화학요법제에 대한 불투과성 장벽 및 불충분한 종양 관류를 초래한다. TGF-β1은 섬유아세포 또는 내피 세포의 암-관련 섬유아세포(CAF)라고도 알려진 근섬유아세포로의 전환을 증강시킴으로써 PDAC 섬유조직형성에 기여한다. 공격성은 높은 수준의 TGF-β를 생성할 수 있는 종양 미세환경에서 침윤된 면역 세포 및 섬유아세포에 의해 추가로 증폭된다. TGF-β는 PDAC 진행, 침범, 및 전이를 가능하게 하는 혈관 내피 성장 인자와 같은 전구혈관신생(proangiogenic) 인자를 유도한다. 아실-CoA 신타제 장쇄 3(ACSL3)은 PDAC에서 상향조절되는 것으로 발견되었고, 증가된 섬유증과 상관관계가 있다. Acsl3 넉아웃에 의한 종양 세포로부터의 저하된 PAI-1 분비는 종양 섬유증 및 종양-침윤성 면역억제 세포를 현저하게 감소시키고, 마우스에서 세포독성 T 세포 침윤을 증가시킨다. 이 연구는 또한 PDAC에서 PAI-1 발현이 섬유증 및 면역억제의 마커와 양의 상관관계가 있으며 환자의 불량한 생존을 예측함을 발견하였다. PAI-1이 SASP의 핵심 구성요소 및 세포 노쇠의 매개자이고 TGF-β1에 의해 조절되기 때문에, TGF-β1이 이러한 ACSL3-PAI-1 신호전달 축에서 췌장암 진행을 촉진하는 종양-간질 혼선을 매개하는 역할을 한다고 여겨질 만하다.
섬유증 질환에서, 세포외 기질(EMC)의 과도한 침착은 조직 무결성을 손상시키고 정상적인 기관 기능을 방해한다. 섬유증은 만성 손상을 입은 임의의 조직에서 발생할 수 있지만, 신장, 간, 폐, 및 심장에서 가장 빈번하게 관찰된다. 섬유증은 주로 인터류킨 및 TGF-β 슈퍼계열의 구성원을 포함하는 염증성 사이토카인에 의해 구동된다. 이들 리간드 중 많은 것들은 손상된 조직으로 이끌려지는 침윤성 염증 세포에 의해 발현된다. TGF-β1의 과발현은 정규(SMAD-기초) 신호전달 경로와 비정규(비 SMAD-기초) 신호전달 경로 둘 다의 활성화를 통해 섬유증을 유도하며, 이는 근섬유아세포의 활성화, ECM의 과도한 생성 및 ECM 분해의 저해를 초래한다. SMAD 2/3의 활성화는 콜라겐(COL1A1, COL3A1, COL5A2, COL6A1, COL6A3, 및 COL7A1), PAI-1, 다양한 프로테오글리칸, 인테그린, 결합 조직 성장 인자, 및 매트릭스 메탈로프로테아제를 포함한 몇몇 전섬유성 유전자의 발현을 조절한다. 이는 국소 조직 구조를 저하시키는 ECM의 과도한 침착물을 초래한다.
SMAD 경로를 통한 신호전달이 TGF-β의 섬유형성에서 중심적인 역할을 하는 것으로 여겨지긴 하지만, 출현하는 증거는 반응성 산소종(ROS)이 또한 SMAD 경로를 포함한 상이한 경로를 통해 TGF-β의 신호전달을 조절하는 데 관여함을 나타낸다. TGF-β1은 상이한 유형의 세포에서 미토콘드리아 ROS 생성을 증가시키며, 이는 TGF-β-유도 세포의 세포자멸사, 노쇠, EMT, 섬유증 유전자 발현 및 근섬유아세포 분화를 매개한다. TGF-β는 몇몇 NADPH 옥시다제(Nox) 효소(상이한 유형의 세포에서 Nox1, Nox2 및 Nox 4 포함)의 발현을 유도하는 것으로 제시되었으며, 이는 식세포와 비-식세포 둘 다에 대해 ROS 생성에 중요한 헴-함유 막관통 단백질의 군이다. Nox4-유래 ROS는 섬유아세포 활성화/근섬유아세포 분화, 상피 및 내피 세포 세포자멸사, EMT, 및 섬유아세포/전섬유증성 유전자의 발현을 포함한 TGF-β의 섬유원성 효과를 매개한다. Nox4 발현의 증가 또한 IPF를 포함한 섬유증 질환에서 검출되었으며, 이는 근섬유아세포 마커인 α-SMA의 증가된 발현과 상관관계가 있고, 섬유증 질환에서 Nox4의 역할을 추가로 지지한다. 몇몇 경로는 TGF-β에 의한 Nox4의 유도에 관여하는 것으로 제시되었다. 이들은 SMAD 경로, PI3K 경로, MAPK 경로, 및 RHOA/ROCK 경로를 포함한다.
출현중인 증거는 미토콘드리아와 NADPH 옥시다제 사이에 혼선이 있음을 시사한다. 미토콘드리아-유래 ROS는 TGF-β에 반응하여 NOX 발현 증가에 기여하는 반면, NOX-생성 ROS는 미토콘드리아 기능장애를 야기하고 미토콘드리아 ROS 생성을 증가시킨다. 미토콘드리아와 Nox 효소 사이의 혼선은 또한 TGF-β의 전섬유원성 효과를 매개하는 것으로 나타났다. TGF-β-유도 ROS 생성에서 미토콘드리아와 Nox4 사이의 피드-포워드 상호작용이 관련되어 있다(문헌[Jain et al., Journal of Biological Chemistry. 288:770-777, 2013]).
2030년까지 인구 중 20% 초과가 65세 이상이 될 것이며(census.gov/content/dam/Census/library/publications/2014/demo/p23-212.pdf 참조) 대략 40%가 비만이 될 것이다(문헌[Finkelstein et al., Am. J. Prev. Med. 42(6):563-570, 2012]). 대사 질환은 단백질, 탄수화물 및 지질의 수송 또는 가공을 수반하는 중요한 과정을 수행하는 세포의 능력에 영향을 미친다. 노화 및 비만은 당뇨병, 심혈관 질환 및 간 지방증을 포함한 병태의 소인이 있는 만성 병태에 대한 주요 위험 인자이며, 이들은 모두 사망의 주된 원인이므로 유의한 공중 보건 문제를 제기한다(문헌[Must et al., "The Disease Burden Associated with Overweight and Obesity," In: Feingold KR, Anawalt B., Boyce A., et al., eds., Endotext, South Dartmouth (MA), 2000]; 문헌[Martin et al., Nat. Rev. Cardiol. 14(3):132, 2017]).
과도한 열량 섭취는 마우스에서 지방 조직의 산화적 스트레스를 촉진시켰고, 그 결과 마우스에서 2형 당뇨병의 특징과 더불어 p53, 베타갈락토시다제와 같은 노쇠 마커의 발현을 동반하였다(문헌[Minamino et al., Nat. Med. 15(9):1082-1087, 2009]). 노쇠는 또한 지방원성 분화를 방지함으로써 지방 조직에서 생물학적 저하를 촉진하였다(문헌[Mitterberger et al., Gerontol. A Biol. Sci. 69(1):13-24, 2014]). 최근의 또 다른 연구는, 비만-유도 노쇠가 뇌에서 지방 침착을 증가시킴으로써 불안 및 신경 발생 장애를 유발할 수 있으며, 이들 노쇠 세포의 청소는 마우스에서 비만-유도 불안-유사 행동에서 향상을 유발하였음을 보여주었다(문헌[Ogrodnik et al., Cell Metab. 29(5):1061-1077, 2019]). 다른 연구는 비만이 또한 면역 세포의 기능을 손상시킴을 제시하였다. NK 세포 이펙터 기능은 이들 세포에서 지질 축적으로 인해 손상된 것으로 나타났고 이 과정의 역전은 기능을 회복하였다(문헌[Michelet et al., Nat. Immunol. 19(12):1330-1340, 2018]). 추가적인 연구는 젊고 나이든 비만 개체에서 유사한 결함이 관찰되었기 때문에 비만에서 NK 세포의 손상은 연령에 독립적임을 보여주었다(문헌[Tobin et al., JCI Insight 2(24):e94939, 2017]; 문헌[Michelet et al., Nat. Immunol. 19(12):1330-1340, 2018]).
마우스에서, 증가된 열량 섭취는 혈관에서 지방 침착을 유발하고, 이는 차례로 이들 지질을 삼키고 거품형 대식세포로 변하는 단핵구를 모집하여 결국 죽상동맥경화성 플라크를 유발하는 내피하 공간에 축적된다(문헌[Bennett et al., Nat. Rev. Cardiol. 14(3):132, 2017]; 문헌[Katsuumi et al., Front. Cardiovasc. Med. 5:18, 2018]). 서부 고지방 식이요법(42%의 열량이 지방으로 구성된 식이요법)으로 사육된 마우스 또한 노쇠 세포의 부담이 플라크(지질이 가득한 대식세포) 형성에 정비례하는 것으로 나타났다. 유전자이식 마우스에서 이들 노쇠 세포의 성공적인 제거는 플라크 형성에서 유의한 감소를 유발하였다(문헌[Childs et al., Science 354(6311):472-477, 2016]).
포도당 수준, 성장 호르몬(IGF)의 변경과 연관된 연령, 비만 및 다른 인자는 당뇨병을 유발할 수 있다(문헌[Palmer et al., Diabetes 64(7):2289-2298, 2015]). 고지방 식이요법으로 사육된 마우스에서 p53과 같은 노쇠 마커의 상향조절은 인슐린 내성과 상관관계가 있는 반면, 지방 조직에서 p53 활성의 저해는 마우스 모델에서 노쇠 마커의 저하를 유발하고 향상된 인슐린 내성과 상관관계가 있었다(문헌[Minamino et al., Nat. Med. 15(9):1082-1087, 2009]). 수반적으로, 췌장 β-세포 노쇠는 비만 마우스에서 2형 당뇨병에 대한 기여인자인 것으로 제시되었다(문헌[Sone et al., Diabetologia 48(1):58-67, 2005]).
TGF-β의 시상하부 생성은 고지방 식이요법 조건 하에 과도하다. 이는 시상하부 염증, 고혈당증, 및 포도당 과민증을 유발한다. 데이터는 과도한 양의 TGF-β가 시상하부 RNA 스트레스 반응을 유도하여 IκBα의 가속화된 mRNA 붕괴를 유발함을 시사한다. IκBα는 NF-κB의 저해제이다(문헌[Yan et al., Nature Medicine 20:1001-1008, 2014]). 그러므로, TGF-β 신호전달은 말초 신경계 및 중추 신경계에서의 작용을 통해 비만 및 당뇨병을 악화시킨다.
노화는 많은 신경퇴행성 질환을 발증시키기 위한 주요한 위험 인자이다. 신경계에서 노쇠 세포의 축적은 노화 및 신경퇴행성 질환과 함께 나타났으며, 사람이 신경퇴행성 병태의 외양의 소인이 있을 수 있거나 이의 경과를 악화시킬 수 있다(문헌[Kritsilis et al., Int. J. Mol. Sci. 19(10:2937, 2018]). 세포 노쇠는 하기에 의한 세포 기능을 지연시킬 수 있다: 1. 만성 염증의 촉진(문헌[Huell et al., Acta Neuropathol. 89(6):544-551, 1995]; 문헌[Nelson et al., Aging Cell 11(2):345-349, 2012]), 2. 뉴런 재생의 고갈(문헌[Cipriani et al., Cereb. Cortex 28(7):2458-2478, 2018]), 3. 기능 소실(문헌[De Stefano et al., J. Neurol. Neurosurg. Psychiatry 87(1):93-99, 2016]) 및 4. 혈액 뇌 장벽 기능장애(문헌[Yamazaki et al., Stroke 47(4):1068-1077, 2016]). 연구는 인간에서 가장 우세한 신경퇴행성 질환인 알츠하이머 질환(AD)에서 아밀로이드 플라크 및 잘못 접힌 타우 단백질을 함유하는 Aβ 펩타이드의 축적을 보여주었다(문헌[Musi et al., Aging Cell 17(6):e12840, 2018]). 이들 변화는 결국 뉴런에 영향을 미쳐 인지 장애 및 신경퇴행을 유발한다. AD 환자로부터 배양된 성상세포는 잘 알려진 노쇠 마커 CDKi p16INK4A 및 MMP-1 및 IL-6의 높은 발현을 보여주었다(문헌[Bhat et al., PLoS One 7(9):e45069, 2012]; 문헌[Myung et al., Age 30(4):209-215, 2008]). 아밀로이드 단백질을 표적화하는 임상 시험은 실망을 주고 있었다(문헌[Mehta et al., Expert Opin. Invest. Drugs 26(6):735-739, 2017]). 최근의 연구는 노쇠 세포의 존재가 동물 모델에서 신경 장애에 책임이 있음을 제시하였다(문헌[Crews et al., Hum. Mol. Genet. 19(R1):R12-R20, 2010]; 문헌[Chinta et al., Cell Rep. 22(4):930-940, 2018]). 인간 AD를 반영하는 동물 모델에서의 연구는 고무적인 결과를 제시하였다. 유전자이식 마우스에서 노쇠 세포의 청소는 뉴런 내부에서 타우 단백질의 비정상적인 축적 및 신경섬유성 꼬임을 방지하였으며, 따라서 인지 기능을 보존하였다(문헌[Bussian et al., Nature 562(7728):578-582, 2018]). 두 번째로 가장 흔한 신경퇴행성 질환인 파킨슨 질환(PD)을 갖는 환자는 흑색질에서 도파민-생성 뉴런의 손실로 인한 운동 제어의 소실을 실증한다. CNS 내의 가장 풍부한 세포 유형인 성상세포는 뉴런에 구조적 대사 지지체를 제공하는 데 중요하고, 혈액 뇌 장벽 및 혈액 유동의 제어에서 역할을 한다. 최근의 획기적인 연구는 PD 환자로부터의 사후 뇌 시료에서 성상세포의 노쇠 표현형을 보여주었다(문헌[Chinta et al., Cell Rep. 22(4):930-940, 2018]). 이 연구는 또한 환경 신경독소(산화 스트레스를 통해 노쇠를 유도하는 파르콰트(Parquat))에 의해 유도된 PD의 동물 모델을 개발하였고, 이는 PD와 연관된 신경병리를 보여주었다. 저자는 유전자이식 마우스에서 노쇠 세포의 제거가 파라콰트-유도 신경병리의 제거를 유발함을 보여주었다.
인간 피부의 노화는 하기 중 임의의 것일 수 있다: 1. 내인성(연대순(chronological))으로서, 이는 시간 경과에 걸친 생리학적 및 유전적 변화의 결과임 또는 2. 외인성; 자외선(UV) 조사, 환경 독소 및 DNA 손상을 유도할 수 있는 다른 제제와 같은 외부 인자에의 노출에 의해 야기됨(문헌[Cavinato et al., Exp. Gerontol. 94:78-82, 2017]). 나이가 들어감에 따라 피부 조직에 영향을 미치는 변화 중에서, 엘라스틴 생성의 변화, 증가된 분해 및/또는 가공에 의해 야기되는 탄력성 손실은 조직의 심미성과 건강에 실질적인 영향을 미친다(문헌[Wang et al., Front. Genet. 9:247, 2018]). 급성 UV 노출은 일광 화상, 비정상적인 색소 침착, 피부 아래 혈관의 가시적인 외양(모세혈관확장증) 및 면역억제를 유발하는 한편, 장기간 노출은 조기 피부 노화 및 심지어 악성물 발병 위험을 유발할 수 있다(문헌[Rittie et al., Cold Spring Harb. Perspective 5(1):a015370, 2015]). 의학의 발전과 인구 증가 사이에 직접적인 상관관계가 있으며, 이는 중간-연령 및 노인 개체의 수의 증가 및 따라서 항노화 치료에 대한 유의한 수요를 특징으로 한다(문헌[Weihermann et al., Int. J. Cosmet. Sci. 39(3):241-247, 2017]). 태양광으로부터의 UVB는 돌연변이생성적이고 DNA 복제 동안 DNA 손상을 직접적으로 유도한다. 광손상된 피부의 특질은 탈구조화된 피부 콜라겐과 더불어 비정질 탄성 섬유의 축적이다. 연구는 이것이 탄성 및 피브릴린 생성 장애 또는 DNA 손상을 입은 노쇠 세포에 의해 분비되는 매트릭스 메탈로프로테이나제(MMP)의 분해 증가로부터 비롯될 수 있음을 보여주었다(문헌[Pittayapruek et al., Int. J. Mol. Sci. 17(6):868, 2016]). UVB 조사 후의 반응성 산소종(ROS) 생성은 노쇠에 중심적인 인자, 예컨대 핵 인자-카파(NF-κB) 및 미토겐-활성화된 단백질 키나제(MAPK)의 활성화를 유발한다(문헌[Pittayapruek et al., Int. J. Mol. Sci. 17(6):868, 2016]). UVB 조사는 주로 형질전환 성장 인자-β 수용체 II(TβRII)의 합성을 저하시킴으로써 인간 피부 섬유아세포에서 TGF-β 신호전달 경로를 변경시킬 수 있다(문헌[Purohit et al., J. Dermatol. 83(1):80-83, 2016]). 몇몇 연구는 시험관내와 생체내 둘 다에서 UV에 노출된 피부뿐만 아니라 노화된 피부에서 노쇠 세포의 존재를 제시하였다. 케라틴세포 및 피부 섬유아세포는 p16INK4asd, 베타 갈락토시다제, 라민 B1 및 노쇠 관련 분비 표현형(SASP)과 같은 노쇠 마커를 발현하는 광노화 모델로서 광범위하게 연구되어 왔다(문헌[Waaijer et al., Aging 10(2):278-289, 2018]; 문헌[Dimri et al., Proc. Natl. Acad. Sci. U.S.A. 92(20):9363-9367, 1995]; 문헌[Wang et al., Sci. Rep. 7(1):15678, 2017]; 문헌[Ghosh et al., J. Invest. Dermatol. 136(11):2133-2139, 2016]). 노쇠 세포는 NK 리간드를 발현하는 것으로 알려져 있으므로, 다른 면역 세포(T 조절 세포)의 활성화와 더불어 NK 세포의 유도는 노쇠 세포를 청소하고 건강한 피부를 유지시키기 위한 매력적인 전략을 나타낼 것이다(문헌[Carr et al., Clin. Immunol. 105(2):126-140, 2002]; 문헌[Ali et al., Immunology 152(3):372-381, 2017]).
노쇠 세포의 선택적인 사멸가 정상적인 노화의 맥락에서 마우스의 건강 수명을 유의하게 향상시키고 노화-관련 질환 또는 암 요법의 결과를 호전시킨다는 확인은 노쇠 세포를 청소할 수 있는 화합물의 식별에 관심을 불러 일으켰다. 자연상에서, 노쇠 세포는 내재 면역(innate immune) 세포에 의해 정상적으로 제거된다. 노쇠의 유도는 손상된/변경된 세포의 잠재적인 증식 및 형질전환을 방지할 뿐만 아니라, 주로 자연 살해(NK) 세포(예컨대 IL-15 및 CCL2) 및 대식세포(예컨대 CFS-1 및 CCL2)에 대해 화학주성인자로서 작용하는 SASP 인자(문헌[Munoz-Espin et al., Nat. Rev. Mol. Cell Biol. 15(7):482-496, 2014])의 생성을 통한 조직 복구를 선호한다. 이들 내재 면역 세포는 스트레스를 받은 세포를 제거하기 위한 면역감시 기전을 매개한다. 노쇠 세포는 통상, NK-세포 활성화 수용체 NKG2D 및 DNAM1 리간드를 상향조절하며, 상기 리간드는 감염성 질환 및 악성물에 대한 최전방 면역 방어의 중요한 구성요소인 스트레스-유도성 리간드의 패밀리에 속한다. 수용체 활성화 시, NK 세포는 그 후에 노쇠 세포의 사멸을 이들 세포의 세포용해 기구를 통해 특이적으로 유도할 수 있다. 노쇠 세포의 면역 감시에서 NK 세포의 역할은 간 섬유증(문헌[Sagiv et al., Oncogene 32(15):1971-1977, 2013]), 간세포 암종(문헌[Iannello et al., J. Exp. Med. 210(10):2057-2069, 2013]), 다발성 골수종(문헌[Soriani et al., Blood 113(15):3503-3511, 2009]), 및 메발로네이트 경로의 기능장애에 의해 스트레스를 받는 신경교종 세포(문헌[Ciaglia et al., Int. J. Cancer 142(1):176-190, 2018])에서 주목되었다. 암에서, 병용 화학요법은 KRAS-돌연변이체 폐 종양에서 NK 리간드 및 노쇠의 마커를 상향조절하는 것으로 제시되었으며, 이는 NK 세포가 이들 세포를 표적화하기 위해 필요함을 시사한다(문헌[Ruscetti et al., Science 362(6421):1416-1422, 2018]). 자궁내막 세포는 급성 세포 노쇠를 겪고, 탈락막(decidual) 세포로 분화되지 않는다. 분화된 탈락막 세포는 IL-15를 분비하여, 자궁 NK 세포를 표적으로 동원시키고 미분화된 노쇠 세포를 제거하므로, 자궁내막의 재건(re-model) 및 회춘을 돕는다(문헌[Brighton et al., Elife 6, 2017]). 유사한 기전을 이용하여, 간 섬유증 동안, p53-발현 노쇠 간 위성 세포(satellite cell)는, 전-염증성 M1 표현형으로 향하는 체류하는 쿠퍼 대식세포 및 새로 침윤된 대식세포의 분극화를 회피하였으며(skew), 이는 노화세포용해(senolytic) 활성을 나타낸다. F4/80+ 대식세포는 분만후 자궁 기능을 유지시키기 위해 마우스 자궁 노쇠 세포의 청소에서 주요 역할을 하는 것으로 나타났다(문헌[Lujambio et al., Cell 153(2):449-460, 2013]).
노쇠 세포 청소의 전략은 주로 3개 범주에 속한다: 노쇠용해, 면역요법 및 SASP 저해(문헌[He et al., Cell 169(6):1000-1011, 2017]). 노쇠 세포를 청소하기 위한 노쇠용해제의 효능을 시사하는 신체 증거가 증가하고 있다. 일반적으로 노쇠용해제는 BCL-2 단백질 계열, p53/ p21CIP1p21 축, PI3K/AKT, 수용체 티로신 키나제, 및 HSP90 단백질과 같은 노쇠 세포 항-세포자멸사 경로(SCAP)를 표적화함으로써 작용한다. 마우스에서, 노쇠용해는 노쇠 세포의 효과와 관련되어 온 광범위한 병태를 경감시킨다. 현재까지 몇몇 동물 모델에서 심장, 혈관, 대사, 신경계, 방사선-유도, 화학요법-유도, 신장, 및 폐 기능뿐만 아니라 운동성 및 유약성에 미치는 효과를 포함한다(문헌[Kirkland et al., EBioMedicine 21:21-28, 2017). 다수의 추가 노쇠용해성 약물이 현재 개발되고 있다. 최근, PI3K/AKT/p53/p21 경로를 저해하는 FOXO4-관련 펩타이드가 기재되었고, 시험관내 인간 섬유아세포 모델과 마우스 모델 둘 다에서 고무적인 결과를 보여주었다. 다른 노쇠용해제는 BCL-2 단백질에 작용하는 ABT-737과 ABT-263(문헌[Tse et al., Cancer Res. 68(9):3421-3428, 2008]) 및 BCL-XL 경로를 표적화하는 A1331852와 A1155463(문헌[Zhu et al., Aging (Albany NY) 9(3):955-963, 2017]), 티로신 키나제를 표적화하는 다사티닙 및 퀘르시틴을 포함하고, 노쇠 세포 청소를 실증하였다(문헌[Farr et al., Nat. Med. 23(9):1072-1079, 2017]). BCL-2 계열 저해제는 호중구감소증 및 혈소판감소증과 같은 부작용을 잠재적으로 야기할 수 있다. 많은 노쇠용해제가 전임상단계에 불과하므로, 임상단계 시험으로 이동하기 전에 가능한 부작용에 대한 연구가 보증된다.
SASP 인자의 차단은 노쇠 세포의 유해 역할을 방지하기 위한 대안적인 전략이다. 이들 인자는 염증성 케모카인 및 사이토카인, 성장 인자, 및 매트릭스-리모델링 프로테아제를 포함한다. 이들 효과에 관여된 중심적인 경로는 NF-κB 및 C/EBPβ 경로이다. mTOR 저해제, 예컨대 라파마이신 및 이의 유사체는 막-결합 IL-1α의 발현을 감소시킴으로써 SASP를 무효화시킬 수 있다. 생체내 마우스 모델에서 NF-κB 및 C/EBPβ 경로를 저해하는 데 사용되는 2개의 주목할 만한 약물은 각각 메토포르민(Metformin) 및 룩솔리티닙(Ruxolitinib)이다(문헌[Moiseeva et al., Aging Cell 12(3):489-498, 2013]; 문헌[Xu et al., Proc. Natl. Acad. Sci. U.S.A. 112(46):E6301-6310, 2015]). 실툭시맙(siltuximab) 또는 토실리주맙(tocilizumab)과 같은 다른 약물은 또 다른 SASP 인자인 IL-6과 같은 사이토카인을 차단한다. 또한, 일부 노쇠용해제의 사용으로, 항염증성 약물을 이용한 처리는 잠재적인 부작용을 야기할 수 있다(문헌[Karkera et al., Prostate 71(13):1455-1465, 2011]). 폐 섬유증을 갖는 환자에서 노쇠용해제(다사티닙 + 퀘르세틴)를 사용하는 최근의 I상 임상 시험은 임의의 결론적인 결과를 유발하지 않았다(문헌[Justice et al., EBioMedicine 40:554-563, 2019]).
위에서 기재된 것보다 잠재적으로 우수한 세 번째 전략은 면역-매개 개입이다. 상기 언급된 바와 같이, 노쇠 세포를 청소하기 위해 모집되는 세포는 NK 세포, 대식세포 및 호중구를 포함한다. 노쇠 세포는 NKG2D(NK 세포 상에서 발현됨), 케모카인 및 다른 SASP 인자에 대한 리간드를 주로 상향조절함으로써 NK 세포를 동원한다. 간 섬유증의 생체내 모델은 활성화된 NK 세포에 의한 노쇠 세포의 효과적인 청소를 나타내었다(문헌[Krizhanovsky et al., Cell 134(4):657-667, 2008]). 노쇠 세포는 주로 그랜자임 및 퍼포린 매개 경로에 의해 세포자멸사를 저해하고 이의 청소를 제한하는 미끼 수용체 DCR2를 상향조절함으로써 NK 세포 매개 청소에 저항한다(문헌[Sagiv et al., Oncogene 32(15):1971-1977, 2013]). 최근 데이터는, 비만 개체에서 관찰되는 NK 세포에서의 지질 축적이 이의 빈도와 이펙터 세포독성 기능 둘 다에서 감소를 유발하고, 이는 연령에 독립적이었음을 보여주었다(문헌[Michelet et al., Nat. Immunol. 19(12):1330-1340, 2018]; 문헌[Tobin et al., JCI Insight 2(24):e94939, 2017]). NK 세포-매개 항체-의존적 세포의 세포독성(ADCC)은 시험관내에서 최근에 기재된 노쇠 마커인 디펩티딜 펩티다제 4(DPP4/CD26)에 대한 인간 노쇠 세포에서 실증되었다(문헌[Kim et al., Genes Dev. 31(15):1529-1534, 2017]). 다른 전략은 노쇠 세포에 대한 면역 반응을 전용(redirect)하기 위해 CAR-T 세포를 사용하는 것을 포함한다(문헌[Grupp et al., N. Engl. J. Med. 368(16):1509-1518, 2013]; 문헌[Yousefzadeh et al., Nature, published online on May 12, 2021]).
연구는 간 섬유증(문헌[Krizhanovsky et al., Cell 134(4):657-667, 2008]), 골관절염(문헌[Xu et al., J. Gerontol. A Biol. Sci. Med. Sci. 72(6):780-785, 2017]), 파킨슨(문헌[Chinta et al., Cell Rep. 22(4):930-940, 2018]), 비만 유도 불안(문헌[Ogrodnik et al., Cell Metab. 29(5):1061-1077, 2019]), 죽상동맥경화증(문헌[Childs et al., Science 354(6311):472-477, 2016]), 및 당뇨병(문헌[Sone et al., Diabetologia 48(1):58-67, 2005])을 포함하여 노쇠를 연구하기 위한 다양한 모델을 기재하였다. 최근의 한 연구는, 시험관내 노쇠-유도 세포를 젊은 마우스에게 이식하는 것이 신체적 기능장애를 유발하였음을 보여주었다(문헌[Xu et al., Nat. Med. 24(8):1246-1256, 2018]). 남아 있는 질문은 어떤 유형의 요법이 상이한 조직에서 노쇠 세포를 청소하는 데 효과적이냐 하는 것이다. 이용 가능한 데이터 대부분은 시험관내 실험 및 소수의 마우스 연구에 기초한다(문헌[Krizhanovsky et al., Cell 134(4):657-667, 2008]; 문헌[Xu et al., Nat. Med. 24(8):1246-1256, 2018]; 문헌[Baker et al., Nature 479(7372):232-236, 2011]; 문헌[Farr et al., Nat. Med. 23(9):1072-1079, 2017]; 문헌[Xu et al., J. Gerontol. A Biol. Sci. Med. Sci. 72(6):780-785, 2017]; 문헌[Bourgeois et al., FEBS Lett. 592(12):2083-2097, 2018]). NK 세포는 노쇠 세포 축적에 대항하기 위한 매력적인 전략이다. 그러나, 노쇠 모델에서 매우 소수의 연구가 이 전략을 이용하였다(문헌[Krizhanovsky et al., Cell 134(4):657-667, 2008]). 다양한 임상 시험은 다양한 유형의 암을 치료하기 위해 NK 세포의 입양 전달을 활용하는 것의 성공을 제시하였다(문헌[Sakamoto et al., J. Transl. Med. 13:277, 2015]; 문헌[Miller et al., Blood 105(8):3051-3057, 2005]; 문헌[Cifaldi et al., Trends Mol. Med. 23(12):1156-1175, 2017]; 문헌[Li et al., Cytotherapy 20(1):134-148, 2018]). 중요한 것은 결장암 환자에서 자가 생체외 확장된 NK 세포를 활용하는 최근의 임상 시험이다(문헌[Li et al., Cytotherapy 20(1):134-148, 2018]). 저자들은 화학요법과 병용된 NK 세포 요법이 허용 가능한 부작용과 함께 재발을 예방하고 생존을 연장시켰음을 보여주었다(문헌[Li et al., Cytotherapy 20(1):134-148, 2018]). IL-15, IL-12, IL-18 및 IL-21과 같은 사이토카인에 의한 사이토카인 활성화된-NK 세포의 전달은 최소의 부작용으로 노쇠 세포를 청소하기 위한 잠재적인 면역치료적 전략으로서 사용될 수 있다(문헌[Romee et al., Blood 120(24): 4751-4760, 2012]; 문헌[Song et al., Eur. J. Immunol. 48(4):670-682, 2018]). 더욱이, NK 세포 사용의 안전성은 급성 골수성 백혈병에서 제시되었다(문헌[Romee et al., Blood 120(24): 4751-4760, 2012]; 문헌[Fehniger et al., Biol. Blood Marrow Transplant 2018]). 다른 접근법은 TGF-β, IL-8 및 IL-6과 같은 순환형 SASP 인자를 차단하는 것일 것이다(문헌[Ganesh et al., Immunity 48(4):626-628, 2018]; 문헌[Georgilis et al., Cancer Cell 34(1):85-102, 2018]). 위에서 언급된 노쇠 모델은 이들 접근법을 시험하는 데 이상적일 것이다. 따라서, 연령-관련 병증에 대한 해결방안으로서 외래 화합물 및 약물을 사용하는 것으로부터의 원치 않는 부작용을 피하는 이러한 전략에 더 많은 고려사항이 주어져야 한다.
세포 노쇠는 초기 성장 억제 후 획득되는 일련의 점진적이고 표현형적으로 다양한 세포 상태이다(문헌[Van Deursen, Nature 509(7501): 439-446, 2014]). 그러므로, 노쇠 세포는 몇몇 공유된 핵심 특성을 갖는 세포의 불균질한 집단이다(문헌[Dou et al., Nature 550(7676):402-406, 2017]). 따라서, 공통의 노쇠용해 약물 표적을 식별하는 것은 어렵다. 이는 추가로, 전신 투여 시 노쇠 세포를 선택적으로, 안전하게, 그리고 효과적으로 제거하는 노쇠용해제를 개발하는 목표의 달성을 방해한다. 위에 기재된 바와 같이, 면역 세포는 노쇠-세포 생리학적 역할의 이행 후 노쇠 세포를 천연적으로 제거하기 위한 이펙터 세포이다(문헌[Brighton et al., Elife 6, 2017]). 노화 과정 동안 면역계의 약화는 노쇠 세포의 축적을 가능하게 한다(문헌[Karin et al., Nat Commun 10(1):5495, 2019]; 문헌[Chambers et al., Allergy Clin Immunol 145(5): 1323-1331, 2020]). 이에 더하여, 노쇠 세포의 SASP의 구성요소인 TGF-β는 이것이 조직에서 과도한 양으로 생성될 때 세포 노쇠 및 노화-관련 병증에서 원인적인 역할을 한다(문헌[Tominaga et al., Int. J. Mol. Sci. 20(20), 2019]). 면역 세포를 촉진하고 활성화시키기 위해 공통 감마-사슬 사이토카인과 이의 동족 수용체의 복합체, 및 노화 조직 및 종양 미세환경에서 활성 형태의 TGF-β의 양을 감소시키기 위해 TGF-βRII를 피하 투여를 통해 사용하여, 생체내에서 효과적으로, 선택적으로, 그리고 안전하게 노쇠 세포를 감소시키는 이들의 능력을 재획득하고 만성 염증을 낮추는 방법이 본원에 제공된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 대상체에서 노화 면역 세포의 회춘(예를 들어, 치료 전 대상체에서의 수준(들)과 비교하여 하기 중 하나 이상을 초래한다: 대상체에서 노화 면역 세포의 증가된 대사 활성(예를 들어, 증가된 산화적 인산화, 증가된 해당작용, 및 증가된 산소 소모); 대상체의 노화 면역 세포에서 p16, p21, 및 SASP 인자 중 하나 이상의 저하된 수준(들); 및 대상체에서 노화 면역 세포의 증가된 세포용해 활성). 본원에 사용된 용어 "노화 면역 세포"는 예를 들어, 연령이 대상체 집단의 평균 수명의 절반 미만인 건강한 대상체(비-면역 저하 대상체)로부터 수득된 대조군 면역 세포와 비교하여, 하기 중 하나 이상을 갖는 면역 세포를 의미한다: 감소된 대사 활성(예를 들어, 감소된 산화적 인산화, 감소된 해당작용, 및 감소된 산소 소모); p16, p21, 및 SASP 인자 중 하나 이상의 증가된 수준(들); 및 저하된 세포용해 활성. 노화 면역 세포의 비제한적인 예는 노화 NK 세포, 노화 NKT 세포, 노화 T 세포, 노화 B 세포, 노화 단핵구, 노화 대식세포, 노화 호중구, 노화 호염기구, 노화 호산구, 쿠퍼 세포, 및 노화 소교 세포를 포함한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 대상체에서 기억 T 세포에 대한 무경험(naive) T 세포의 비의 증가를 초래한다. 본원에 기재된 임의의 방법의 일부 구현예에서, 방법은 대상체에서 CD8+ T 세포에 대한 CD4+ T 세포의 비의 저하를 초래한다.
일부 구현예에서, 노화 면역 세포의 회춘은 대상체에서 유병 세포 또는 병원성 감염체의 수의 감소를 초래한다. 일부 구현예에서, 노화 면역 세포는 노화 NK 세포, 노화 NKT 세포, 노화 T 세포, 노화 B 세포, 노화 단핵구, 노화 대식세포, 노화 호중구, 노화 호염기구, 노화 호산구, 노화 쿠퍼 세포, 및 노화 소교 세포 중 하나 이상을 포함한다. 일부 구현예에서, 유병 세포는 암세포, 바이러스-감염 세포, 및 세포내-박테리아-감염 세포를 포함한다. 일부 구현예에서, 감염성 병원체는 바이러스, 박테리아, 진균류, 및 기생충을 포함한다.
TGF-β 수용체의 활성화의 저하를 초래하여 면역계를 회춘시키는 공통 감마-사슬 사이토카인과 이의 동족 수용체 및/또는 제제의 복합체를 사용하는 방법이 또한 본원에 제공된다.
피부 및/또는 모발의 질감 및/또는 외양을 향상시키는 방법
기간(예를 들어 본원에 기재된 임의의 기간)에 걸쳐 향상을 필요로 하는 대상체에서 피부 및/또는 모발의 질감 및/또는 외양을 향상시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 자연 살해(NK) 세포 활성화제(들)(예를 들어 본원에 기재되거나 당업계에 알려진 임의의 NK 세포 활성화제(들))를 투여하는 단계를 포함한다.
기간(예를 들어 본원에 기재된 임의의 기간)에 걸쳐 향상을 필요로 하는 대상체에서 피부 및/또는 모발의 질감 및/또는 외양을 향상시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효수의 활성화된 NK 세포(예를 들어 본원에 기재되거나 당업계에 알려진 임의의 활성화된 NK 세포)를 투여하는 단계를 포함한다.
이들 방법의 일부 구현예는 휴지기 NK 세포를 수득하는 단계; 및 상기 휴지기 NK 세포를 시험관내에서 하나 이상의 NK 세포 활성화제(들)를 포함하는 액체 배양 배지에서 접촉시키는 단계를 추가로 포함하며, 상기 접촉은 후속적으로 대상체에게 투여되는 활성화된 NK 세포의 생성을 초래한다. 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 대상체로부터 수득된 자가 NK 세포이다. 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 대상체로부터 수득된 반일치 NK 세포이다. 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 동종이계 휴지기 NK 세포이다. 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 인공 NK 세포이다. 임의의 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 키메라 항원 수용체 또는 재조합 T 세포 수용체를 갖고 있는 유전자-조작된 NK 세포이다.
이들 방법의 일부 예에서, 액체 배양 배지는 무혈청 액체 배양 배지이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 액체 배양 배지는 화학적으로-한정된 액체 배양 배지이다. 이들 방법의 일부 구현예는 활성화된 NK 세포를 단리하는 단계(및 추가로 치료적 유효량의 활성화된 NK 세포를 대상체, 예를 들어, 본원에 기재된 임의의 대상체에게 투여하는 단계)를 추가로 포함한다. 이들 방법의 일부 구현예에서, 접촉 단계는 약 2시간 내지 약 20일(또는 본원에 기재된 이 범위의 임의의 하위범위)의 기간 동안 수행된다.
이들 방법의 일부 구현예에서, 방법은 기간(예를 들어 본원에 기재된 임의의 기간)에 걸쳐 대상체의 피부의 질감 및/또는 외양의 향상을 제공한다.
이들 방법의 일부 구현예에서, 방법은 예를 들어, 치료 전 대상체에서의 주름 형성 속도 또는 치료를 받지 않는 유사한 대상체에서의 주름 형성 속도와 비교하여 기간(예를 들어, 본원에 기재된 임의의 기간)에 걸쳐 대상체의 피부에서 주름 형성 속도의 저하(예를 들어, 적어도 5% 저하, 적어도 10% 저하, 적어도 15% 저하, 적어도 20% 저하, 적어도 25% 저하, 적어도 30% 저하, 적어도 35% 저하, 적어도 40% 저하, 적어도 45% 저하, 적어도 50% 저하, 적어도 55% 저하, 적어도 60% 저하, 적어도 65% 저하, 적어도 70% 저하, 적어도 75% 저하, 적어도 80% 저하, 적어도 85% 저하, 적어도 90% 저하, 또는 적어도 95% 저하, 또는 약 5% 저하 내지 약 99% 저하(또는 본원에 기재된 이 범위의 임의의 하위범위))를 초래한다.
이들 방법의 일부 구현예에서, 방법은 기간(예를 들어 본원에 기재된 임의의 기간)에 걸쳐 대상체의 피부의 착색의 향상을 초래한다.
이들 방법의 일부 구현예에서, 방법은 기간(예를 들어 본원에 기재된 임의의 기간)에 걸쳐 대상체의 피부의 질감의 향상을 초래한다.
이들 방법의 일부 구현예에서, 방법은 기간(예를 들어 본원에 기재된 임의의 기간)에 걸쳐 대상체의 모발의 질감 및/또는 외양의 향상을 제공한다.
이들 방법의 일부 구현예에서, 방법은 예를 들어, 치료 전 대상체에서의 흰머리 형성 속도 또는 치료를 받지 않는 유사한 대상체에서의 흰머리 형성 속도와 비교하여 기간(예를 들어, 본원에 기재된 임의의 기간)에 걸쳐 대상체에서의 흰머리 형성 속도의 저하(예를 들어, 적어도 5% 저하, 적어도 10% 저하, 적어도 15% 저하, 적어도 20% 저하, 적어도 25% 저하, 적어도 30% 저하, 적어도 35% 저하, 적어도 40% 저하, 적어도 45% 저하, 적어도 50% 저하, 적어도 55% 저하, 적어도 60% 저하, 적어도 65% 저하, 적어도 70% 저하, 적어도 75% 저하, 적어도 80% 저하, 적어도 85% 저하, 적어도 90% 저하, 또는 적어도 95% 저하, 또는 약 5% 저하 내지 약 99% 저하(또는 본원에 기재된 이 범위의 임의의 하위범위))를 초래한다.
이들 방법의 일부 구현예에서, 방법은 예를 들어, 치료 전 대상체에서의 흰머리 수 또는 치료를 받지 않는 유사한 대상체에서의 흰머리 형성 속도와 비교하여 기간(예를 들어, 본원에 기재된 임의의 기간)에 걸쳐 대상체에서의 흰머리 수의 저하(예를 들어, 적어도 5% 저하, 적어도 10% 저하, 적어도 15% 저하, 적어도 20% 저하, 적어도 25% 저하, 적어도 30% 저하, 적어도 35% 저하, 적어도 40% 저하, 적어도 45% 저하, 적어도 50% 저하, 적어도 55% 저하, 적어도 60% 저하, 적어도 65% 저하, 적어도 70% 저하, 적어도 75% 저하, 적어도 80% 저하, 적어도 85% 저하, 적어도 90% 저하, 또는 적어도 95% 저하, 또는 약 5% 저하 내지 약 99% 저하(또는 본원에 기재된 이 범위의 임의의 하위범위))를 초래한다.
이들 방법의 일부 구현예에서, 방법은 예를 들어, 치료 전 대상체에서의 모발 손실 속도 또는 치료를 받지 않는 유사한 대상체에서의 모발 손실 속도와 비교하여 기간(예를 들어, 본원에 기재된 임의의 기간)에 걸쳐 대상체에서 모발 손실 속도의 저하(예를 들어, 적어도 5% 저하, 적어도 10% 저하, 적어도 15% 저하, 적어도 20% 저하, 적어도 25% 저하, 적어도 30% 저하, 적어도 35% 저하, 적어도 40% 저하, 적어도 45% 저하, 적어도 50% 저하, 적어도 55% 저하, 적어도 60% 저하, 적어도 65% 저하, 적어도 70% 저하, 적어도 75% 저하, 적어도 80% 저하, 적어도 85% 저하, 적어도 90% 저하, 또는 적어도 95% 저하, 또는 약 5% 저하 내지 약 99% 저하(또는 본원에 기재된 이 범위의 임의의 하위범위))를 초래한다.
이들 방법의 일부 구현예에서, 방법은 기간(예를 들어 본원에 기재된 임의의 기간)에 걸쳐 대상체의 모발의 질감의 향상을 초래한다.
이들 방법의 일부 구현예에서, 방법은 예를 들어, 치료 전 대상체에서의 노쇠 피부 세포의 수 또는 치료를 받지 않는 유사한 대상체에서의 노쇠 피부 세포의 수와 비교하여 기간(예를 들어, 본원에 기재된 임의의 기간)에 걸쳐 대상체의 피부에서 노쇠 피부 섬유아세포의 수의 저하(예를 들어, 적어도 5% 저하, 적어도 10% 저하, 적어도 15% 저하, 적어도 20% 저하, 적어도 25% 저하, 적어도 30% 저하, 적어도 35% 저하, 적어도 40% 저하, 적어도 45% 저하, 적어도 50% 저하, 적어도 55% 저하, 적어도 60% 저하, 적어도 65% 저하, 적어도 70% 저하, 적어도 75% 저하, 적어도 80% 저하, 적어도 85% 저하, 적어도 90% 저하, 또는 적어도 95% 저하, 또는 약 5% 저하 내지 약 99% 저하(또는 본원에 기재된 이 범위의 임의의 하위범위))를 초래한다.
이들 방법의 일부 구현예에서, 기간(예를 들어 본원에 기재된 임의의 기간)에 걸쳐 대상체의 피부의 질감 및/또는 외양의 향상은 피부 병변, 피부 색상 및 착색, 피부 수분, 온도, 탄성, 및 혈관구조의 존재, 크기 및 모양을 조사하는 것을 포함하여 본원에 기재되거나 당업계에 알려진 임의의 방법에 의해 평가될 수 있다.
이들 방법의 일부 구현예에서, 기간(예를 들어 본원에 기재된 임의의 기간)에 걸쳐 대상체의 모발의 질감 및/또는 외양의 향상은 본원에 기재되거나 당업계에 알려진 임의의 방법에 의해 평가될 수 있다.
이들 방법의 일부 구현예에서, 기간은 예를 들어, 1개월 내지 10년, 1개월 내지 9년, 1개월 내지 8년, 1개월 내지 7년, 1개월 내지 6년, 1개월 내지 5년, 1개월 내지 4년, 1개월 내지 3년, 1개월 내지 2년, 1개월 내지 18개월, 1개월 내지 12개월, 1개월 내지 10개월, 1개월 내지 8개월, 1개월 내지 6개월, 1개월 내지 4개월, 1개월 내지 2개월, 1개월 내지 6주, 6주 내지 10년, 6주 내지 9년, 6주 내지 8년, 6주 내지 7년, 6주 내지 6년, 6주 내지 5년, 6주 내지 4년, 6주 내지 3년, 6주 내지 2년, 6주 내지 18개월, 6주 내지 12개월, 6주 내지 10개월, 6주 내지 8개월, 6주 내지 6개월, 6주 내지 4개월, 6주 내지 2개월, 2개월 내지 10년, 2개월 내지 9년, 2개월 내지 8년, 2개월 내지 7년, 2개월 내지 6년, 2개월 내지 5년, 2개월 내지 4년, 2개월 내지 3년, 2개월 내지 2년, 2개월 내지 18개월, 2개월 내지 12개월, 2개월 내지 10개월, 2개월 내지 8개월, 2개월 내지 6개월, 2개월 내지 4개월, 4개월 내지 10년, 4개월 내지 9년, 4개월 내지 8년, 4개월 내지 7년, 4개월 내지 6년, 4개월 내지 5년, 4개월 내지 4년, 4개월 내지 3년, 4개월 내지 2년, 4개월 내지 18개월, 4개월 내지 12개월, 4개월 내지 10개월, 4개월 내지 8개월, 4개월 내지 6개월, 6개월 내지 10년, 6개월 내지 9년, 6개월 내지 8년, 6개월 내지 7년, 6개월 내지 6년, 6개월 내지 5년, 6개월 내지 4년, 6개월 내지 3년, 6개월 내지 2년, 6개월 내지 18개월, 6개월 내지 12개월, 6개월 내지 10개월, 6개월 내지 8개월, 8개월 내지 10년, 8개월 내지 9년, 8개월 내지 8년, 8개월 내지 7년, 8개월 내지 6년, 8개월 내지 5년, 8개월 내지 4년, 8개월 내지 3년, 8개월 내지 2년,개월 내지 18개월, 8개월 내지 12개월, 8개월 내지 10개월, 10개월 내지 10년, 10개월 내지 9년, 10개월 내지 8년, 10개월 내지 7년, 10개월 내지 6년, 10개월 내지 5년, 10개월 내지 4년, 10개월 내지 3년, 10개월 내지 2년, 10개월 내지 18개월, 10개월 내지 12개월, 12개월 내지 10년, 12개월 내지 9년, 12개월 내지 8년, 12개월 내지 7년, 12개월 내지 6년, 12개월 내지 5년, 12개월 내지 4년, 12개월 내지 3년, 12개월 내지 2년, 12개월 내지 18개월, 18개월 내지 10년, 18개월 내지 9년, 18개월 내지 8년, 18개월 내지 7년, 18개월 내지 6년, 18개월 내지 5년, 18개월 내지 4년, 18개월 내지 3년, 18개월 내지 2년, 2년 내지 10년, 2년 내지 9년, 2년 내지 8년, 2년 내지 7년, 2년 내지 6년, 2년 내지 5년, 2년 내지 4년, 2년 내지 3년, 3년 내지 10년, 3년 내지 9년, 3년 내지 8년, 3년 내지 7년, 3년 내지 6년, 3년 내지 5년, 3년 내지 4년, 4년 내지 10년, 4년 내지 9년, 4년 내지 8년, 4년 내지 7년, 4년 내지 6년, 4년 내지 5년, 5년 내지 10년, 5년 내지 9년, 5년 내지 8년, 5년 내지 7년, 5년 내지 6년, 6년 내지 10년, 6년 내지 9년, 6년 내지 8년, 6년 내지 7년, 7년 내지 10년, 7년 내지 9년, 7년 내지 8년, 8년 내지 10년, 8년 내지 9년, 또는 9년 내지 10년이다.
이들 방법의 일부 구현예에서, 대상체의 연령은 약 30세 내지 35세, 약 35세 내지 40세, 약 40세 내지 45세, 약 45세 내지 50세, 약 50세 내지 55세, 약 55세 내지 60세, 약 60세 내지 65세, 약 65세 내지 70세, 약 70세 내지 75세, 약 75세 내지 80세, 약 80세 내지 85세, 약 85세 내지 90세, 약 90세 내지 95세, 약 95세 내지 100세, 약 100세 내지 105세, 약 105세 내지 110세, 약 110세 내지 115세, 또는 약 115세 내지 120세이다.
대상체에서 비만의 치료를 돕는 방법
기간(예를 들어 본원에 기재된 임의의 범위의 기간)에 걸쳐 치료의 도움을 필요로 하는 대상체에서 비만의 치료를 돕는 방법이 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 자연 살해(NK) 세포 활성화제(들)(예를 들어 본원에 기재되거나 당업계에 알려진 임의의 NK 세포 활성화제(들))를 투여하는 단계를 포함한다.
기간(예를 들어 본원에 기재된 임의의 범위의 기간)에 걸쳐 치료의 도움을 필요로 하는 대상체에서 비만의 치료를 돕는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효수의 활성화된 NK 세포(예를 들어 본원에 기재되거나 당업계에 알려진 임의의 활성화된 NK 세포)를 투여하는 단계를 포함한다.
이들 방법의 일부 구현예는 휴지기 NK 세포를 수득하는 단계; 및 상기 휴지기 NK 세포를 시험관내에서 하나 이상의 NK 세포 활성화제(들)를 포함하는 액체 배양 배지에서 접촉시키는 단계를 추가로 포함하며, 상기 접촉은 후속적으로 대상체에게 투여되는 활성화된 NK 세포의 생성을 초래한다. 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 대상체로부터 수득된 자가 NK 세포이다. 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 대상체로부터 수득된 반일치 NK 세포이다. 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 동종이계 휴지기 NK 세포이다. 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 인공 NK 세포이다. 임의의 이들 방법의 일부 구현예에서, 휴지기 NK 세포는 키메라 항원 수용체 또는 재조합 T 세포 수용체를 갖고 있는 유전자-조작된 NK 세포이다.
이들 방법의 일부 예에서, 액체 배양 배지는 무혈청 액체 배양 배지이다. 본원에 기재된 임의의 방법의 일부 구현예에서, 액체 배양 배지는 화학적으로-한정된 액체 배양 배지이다. 이들 방법의 일부 구현예는 활성화된 NK 세포를 단리하는 단계(및 추가로 치료적 유효량의 활성화된 NK 세포를 대상체, 예를 들어, 본원에 기재된 임의의 대상체에게 투여하는 단계)를 추가로 포함한다. 이들 방법의 일부 구현예에서, 접촉 단계는 약 2시간 내지 약 20일(또는 본원에 기재된 이 범위의 임의의 하위범위)의 기간 동안 수행된다.
이들 방법의 일부 구현예에서, 방법은 예를 들어, 치료 전 대상체의 질량과 비교하여 기간(예를 들어, 본원에 기재된 임의의 기간)에 걸쳐 대상체의 질량의 저하(예를 들어, 적어도 5% 저하, 적어도 10% 저하, 적어도 15% 저하, 적어도 20% 저하, 적어도 25% 저하, 적어도 30% 저하, 적어도 35% 저하, 적어도 40% 저하, 적어도 45% 저하, 적어도 50% 저하, 적어도 55% 저하, 적어도 60% 저하, 적어도 65% 저하, 적어도 70% 저하, 적어도 75% 저하, 적어도 80% 저하, 적어도 85% 저하, 적어도 90% 저하, 또는 적어도 95% 저하, 또는 약 5% 저하 내지 약 99% 저하(또는 본원에 기재된 이 범위의 임의의 하위범위))를 초래한다.
이들 방법의 일부 구현예에서, 방법은 예를 들어, 치료 전 대상체의 체질량 지수(BMI)와 비교하여 기간(예를 들어, 본원에 기재된 임의의 기간)에 걸쳐 대상체의 BMI의 저하(예를 들어, 적어도 5% 저하, 적어도 10% 저하, 적어도 15% 저하, 적어도 20% 저하, 적어도 25% 저하, 적어도 30% 저하, 적어도 35% 저하, 적어도 40% 저하, 적어도 45% 저하, 적어도 50% 저하, 적어도 55% 저하, 적어도 60% 저하, 적어도 65% 저하, 적어도 70% 저하, 적어도 75% 저하, 적어도 80% 저하, 적어도 85% 저하, 적어도 90% 저하, 또는 적어도 95% 저하, 또는 약 5% 저하 내지 약 99% 저하(또는 본원에 기재된 이 범위의 임의의 하위범위))를 초래한다.
이들 방법의 일부 구현예에서, 방법은 대상체에서의 전당뇨병으로부터 2형 당뇨병으로의 진행 속도에서, 예를 들어, 치료 전 대상체에서의 전당뇨병으로부터 2형 당뇨병으로의 진행 속도 또는 치료를 받지 않는 유사한 대상체에서의 전당뇨병으로부터 2형 당뇨병으로의 진행 속도와 비교하여 저하(예를 들어, 적어도 5% 저하, 적어도 10% 저하, 적어도 15% 저하, 적어도 20% 저하, 적어도 25% 저하, 적어도 30% 저하, 적어도 35% 저하, 적어도 40% 저하, 적어도 45% 저하, 적어도 50% 저하, 적어도 55% 저하, 적어도 60% 저하, 적어도 65% 저하, 적어도 70% 저하, 적어도 75% 저하, 적어도 80% 저하, 적어도 85% 저하, 적어도 90% 저하, 또는 적어도 95% 저하, 또는 약 5% 저하 내지 약 99% 저하(또는 본원에 기재된 이 범위의 임의의 하위범위))를 초래한다.
이들 방법의 일부 구현예에서, 방법은 예를 들어, 치료 전 대상체에서의 공복 혈청 포도당 수준과 비교하여, 대상체에서의 공복 혈청 포도당 수준의 저하(예를 들어, 적어도 5% 저하, 적어도 10% 저하, 적어도 15% 저하, 적어도 20% 저하, 적어도 25% 저하, 적어도 30% 저하, 적어도 35% 저하, 적어도 40% 저하, 적어도 45% 저하, 적어도 50% 저하, 적어도 55% 저하, 적어도 60% 저하, 적어도 65% 저하, 적어도 70% 저하, 적어도 75% 저하, 적어도 80% 저하, 적어도 85% 저하, 적어도 90% 저하, 또는 적어도 95% 저하, 또는 약 5% 저하 내지 약 99% 저하(또는 본원에 기재된 이 범위의 임의의 하위범위))를 초래한다.
이들 방법의 일부 구현예에서, 방법은 치료 전 대상체에서의 인슐린 감수성과 비교하여, 대상체에서의 인슐린 감수성의 수준의 증가(예를 들어, 적어도 5% 증가, 적어도 10% 증가, 적어도 15% 증가, 적어도 20% 증가, 적어도 25% 증가, 적어도 30% 증가, 적어도 35% 증가, 적어도 40% 증가, 적어도 45% 증가, 적어도 50% 증가, 적어도 55% 증가, 적어도 60% 증가, 적어도 65% 증가, 적어도 70% 증가, 적어도 75% 증가, 적어도 80% 증가, 적어도 85% 증가, 적어도 90% 증가, 적어도 95% 증가, 또는 적어도 99% 증가, 또는 약 10% 증가 내지 약 500% 증가(또는 본원에 기재된 이 범위의 임의의 하위범위)를 초래한다.
이들 방법의 일부 구현예에서, 방법은 예를 들어, 치료 전 대상체에서의 죽상동맥경화증의 중증도와 비교하여, 대상체에서의 죽상동맥경화증의 중증도의 저하(예를 들어, 적어도 5% 저하, 적어도 10% 저하, 적어도 15% 저하, 적어도 20% 저하, 적어도 25% 저하, 적어도 30% 저하, 적어도 35% 저하, 적어도 40% 저하, 적어도 45% 저하, 적어도 50% 저하, 적어도 55% 저하, 적어도 60% 저하, 적어도 65% 저하, 적어도 70% 저하, 적어도 75% 저하, 적어도 80% 저하, 적어도 85% 저하, 적어도 90% 저하, 또는 적어도 95% 저하, 또는 약 5% 저하 내지 약 99% 저하(또는 본원에 기재된 이 범위의 임의의 하위범위))를 초래한다.
이들 방법의 일부 구현예에서, 기간(예를 들어 본원에 기재된 임의의 기간)에 걸친 대상체에서의 비만 치료는 예를 들어, 체중 및/또는 신체 치수, 총 체지방, 총 또는 지역 지방과다증, 및 체질량 지수(BMI)의 측정을 포함하여 본원에 기재되거나 당업계에 알려진 임의의 방법에 의해 평가될 수 있다.
이들 방법의 일부 구현예에서, 치료에 대한 대상체의 반응은 공복 혈청 포도당 수준 또는 내당성을 표준 기법에 따라 결정함으로써 모니터링될 수 있다. 이들 방법의 일부 구현예에서, 인슐린 감수성은 고인슐린혈증 정상혈당 클램프법(hyperinsulinemic euglycemic clamp) 및 정맥내 내당성 시험, 항상성 모델 평가(HOMA: homeostasis model assessment), 및 정량적 인슐린 감수성 점검 지수(QUICKI: quantitative insulin sensitivity check index)를 포함하여 본원에 기재되거나 당업계에 알려진 임의의 방법을 사용하여 측정될 수 있다.
이들 방법의 일부 구현예에서, 대상체에서 죽상동맥경화증의 중증도는 심도자법(cardiac catheterization), 도플러 초음파, 혈압 비교, MUGA/방사성핵종 혈관조영술, 탈륨/심근경색 관류 스캔, 및 컴퓨터 단층촬영을 포함하여 본원에 기재되거나 당업계에 알려진 임의의 방법을 사용하여 측정될 수 있다.
이들 방법의 일부 구현예에서, 기간은 1개월 내지 10년(또는 본원에 기재된 이 범위의 임의의 하위범위)이다.
이들 방법의 일부 구현예에서, 대상체에 대한 연령 범위는 약 1세 내지 5세, 약 5세 내지 10세, 약 10세 내지 15세, 약 15세 내지 20세, 약 20세 내지 25세, 약 25세 내지 30세, 약 30세 내지 35세, 약 35세 내지 40세, 약 40세 내지 45세, 약 45세 내지 50세, 약 50세 내지 55세, 약 55세 내지 60세, 약 60세 내지 65세, 약 65세 내지 70세, 약 70세 내지 75세, 약 75세 내지 80세, 약 80세 내지 85세, 약 85세 내지 90세, 약 90세 내지 95세, 약 95세 내지 100세, 약 100세 내지 105세, 약 105세 내지 110세, 약 110세 내지 115세, 또는 약 115세 내지 120세이다.
추가 치료제
본원에 기재된 임의의 방법의 일부 구현예는 치료적 유효량의 하나 이상의 추가 치료제를 대상체(예를 들어, 본원에 기재된 임의의 대상체)에게 투여하는 단계를 추가로 포함할 수 있다. 하나 이상의 추가 치료제는 NK 세포 활성화제(들) 또는 활성화된 NK 세포와 실질적으로 동일한 시간에 대상체에게 투여(예를 들어, 대상체에게 단일 제형 또는 2개 이상의 제형으로서 투여)될 수 있다. 일부 구현예에서, 하나 이상의 추가 치료제는 NK 세포 활성화제(들) 또는 활성화된 NK 세포의 투여 전에 대상체에게 투여될 수 있다. 일부 구현예에서, 하나 이상의 추가 치료제는 대상체에게의 NK 세포 활성화제(들) 또는 활성화된 NK 세포의 투여 후에 대상체에게 투여될 수 있다.
추가 치료제의 비제한적인 예는 항암 약물, 활성화 수용체 작용제, 면역 체크포인트 저해제, HLA-특이적 저해 수용체를 차단하기 위한 제제, 글루코겐 신타제 키나제(GSK) 3 저해제, 및 항체를 포함한다.
항암 약물의 비제한적인 예는 항대사 약물(예를 들어, 5-플루오로우라실(5-FU: 5-fluorouracil), 6-머캅토퓨린(6-MP: 6-mercaptopurine), 카페시타빈(capecitabine), 시타라빈(cytarabine), 플록수리딘(floxuridine), 플루다라빈(fludarabine), 겜시타빈(gemcitabine), 하이드록시카르바마이드(hydroxycarbamide), 메토트렉세이트(methotrexate), 6-티오구아닌(6-thioguanine), 클라드리빈(cladribine), 넬라라빈(nelarabine), 펜토스타틴(pentostatin), 또는 페메트렉세드(pemetrexed)), 식물 알칼로이드(예를 들어, 빈블라스틴(vinblastine), 빈크리스틴(vincristine), 빈데신(vindesine), 캄토테신(camptothecin), 9-메톡시캄토테신, 코로나리딘(coronaridine), 택솔(taxol), 나우클레아오랄스(naucleaorals), 디프레닐화된 인돌 알칼로이드(diprenylated indole alkaloid), 몬타민(montamine), 쉬시키니인(schischkiniin), 프로토베르베린(protoberberine), 베르베린, 산귀나린(sanguinarine), 켈레리트린(chelerythrine), 켈리도닌(chelidonine), 리리오데닌(liriodenine), 클리보린(clivorine), β-카르볼린(carboline), 안토핀(antofine), 틸로포린(tylophorine), 크립톨레핀(cryptolepine), 네오크립톨레핀, 코리놀린(corynoline), 삼판긴(sampangine), 카르바졸(carbazole), 크리나민(crinamine), 몬타닌(montanine), 엘립티신(ellipticine), 파클리탁셀(paclitaxel), 도세탁셀(docetaxel), 에토포사이드(etoposide), 테니소파이드(tenisopide), 이리노테칸(irinotecan), 토포테칸(topotecan), 또는 아크리돈 알칼로이드), 프로테아좀 저해제(예를 들어, 락타시스틴(lactacystin), 디설피람(disulfiram), 에피갈로카테킨-3-갈레이트(epigallocatechin-3-gallate), 마리조밉(marizomib)(살리노스포라마이드 A(salinosporamide A)), 오프로조밉(oprozomib)(ONX-0912), 델란조밉(delanzomib)(CEP-18770), 에폭소미신(epoxomicin), MG132, 베타-하이드록시 베타-메틸부티레이트, 보르테조밉(bortezomib), 카르필조밉(carfilzomib), 또는 익사조밉(ixazomib)), 항종양 항생제(예를 들어, 독소루비신(doxorubicin), 다우노루비신(daunorubicin), 에피루비신(epirubicin), 미톡산트론(mitoxantrone), 이다루비신(idarubicin), 액티노마이신(actinomycin), 플리카마이신(plicamycin), 미토마이신(mitomycin), 또는 블레오마이신(bleomycin)), 히스톤 데아세틸라제 저해제(예를 들어, 보리노스탓(vorinostat), 파노비노스탓(panobinostat), 벨리노스탓(belinostat), 기비노스탓(givinostat), 아벡시노스탓(abexinostat), 뎁시펩타이드(depsipeptide), 엔티노스탓(entinostat), 페닐 부티레이트, 발프로산(valproic acid), 트리코스타틴 A(trichostatin A), 다시노스탓(dacinostat), 모세티노스탓(mocetinostat), 프라시노스탓(pracinostat), 니코틴아미드(nicotinamide), 캄비놀(cambinol), 테노빈 1(tenovin 1), 테노빈 6, 시르티놀(sirtinol), 리콜리노스탓(ricolinostat), 테피노스탓(tefinostat), 케베트린(kevetrin), 퀴시노스탓(quisinostat), 레스미노스탓(resminostat), 타세디날린(tacedinaline), 키다마이드(chidamide), 또는 셀리시스탓(selisistat)), 티로신 키나제 저해제(예를 들어, 악시티닙(axitinib), 다사티닙(dasatinib), 엔코라피닙(encorafinib), 에를로티닙(erlotinib), 이마티닙(imatinib), 닐로티닙(nilotinib), 파조파닙(pazopanib), 및 수니티닙(sunitinib)), 및 화학요법제(예를 들어, 올-트랜스(all-trans) 레티노산, 아자시티딘(azacitidine), 아자티오프린(azathioprine), 독시플루리딘(doxifluridine), 에포틸론(epothilone), 하이드록시우레아, 이마티닙(imatinib), 테니포사이드(teniposide), 티오구아닌(tioguanine), 발루비신(valrubicin), 베무라페닙(vemurafenib), 및 레날리도마이드(lenalidomide))을 포함한다. 화학요법제의 추가 예는 알킬화제, 예를 들어, 메클로레타민(mechlorethamine), 사이클로포스파미드(cyclophosphamide), 클로람부실(chlorambucil), 멜팔란(melphalan), 이포스파미드(ifosfamide), 티오테파(thiotepa), 헥사메틸멜라민, 부설판(busulfan), 알트레타민(altretamine), 프로카르바진(procarbazine), 다카바진(dacarbazine), 테모졸로마이드(temozolomide), 카르무스틴(carmustine), 루무스틴(lumustine), 스트렙토조신(streptozocin), 카르보플라틴(carboplatin), 시스플라틴(cisplatin), 및 옥살리플라틴(oxaliplatin)을 포함한다.
활성화 수용체 작용제의 비제한적인 예는 항-CD16 항체(예를 들어, 항-CD16/CD30 이중특이적 모노클로날 항체(BiMAb)) 및 Fc-기초 융합 단백질을 포함하여 NK 세포의 세포독성을 활성화시키고 증강시키는 활성화 수용체에 대한 임의의 작용제를 포함한다. 체크포인트 저해제의 비제한적인 예는 항-PD-1 항체(예를 들어, MEDI0680), 항-PD-L1 항체(예를 들어, BCD-135, BGB-A333, CBT-502, CK-301, CS1001, FAZ053, KN035, MDX-1105, MSB2311, SHR-1316, 항-PD-L1/CTLA-4 이중특이적 항체 KN046, 항-PD-L1/TGFβRII 융합 단백질 M7824, 항-PD-L1/TIM-3 이중특이적 항체 LY3415244, 아테졸리주맙(atezolizumab), 또는 아벨루맙(avelumab)), 항-TIM3 항체(예를 들어, TSR-022, Sym023, 또는 MBG453) 및 항-CTLA-4 항체(예를 들어, AGEN1884, MK-1308, 또는 항-CTLA-4/OX40 이중특이적 항체 ATOR-1015)를 포함한다. HLA-특이적 저해 수용체를 차단하기 위한 제제의 비제한적인 예는 모날리주맙(monalizumab)(예를 들어, 항-HLA-E NKG2A 저해 수용체 모노클로날 항체)을 포함한다. GSK3 저해제의 비제한적인 예는 티데글루십(tideglusib) 또는 CHIR99021을 포함한다. 추가 치료제로서 사용될 수 있는 항체의 비제한적인 예는 항-CD26 항체(예를 들어, YS110), 항-CD36 항체, 및 NK 세포 상의 Fc 수용체(예를 들어, CD16)에 결합하고 이를 활성화시킬 수 있는 임의의 다른 항체 또는 항체 작제물을 포함한다. 일부 구현예에서, 추가 치료제는 인슐린 또는 메트포르민(metformin)일 수 있다.
하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)의 투여를 포함하는 예시적인 방법
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포를 사멸시키거나 이의 수를 감소시키는 방법이 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함한다.
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 축적을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함한다.
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 마커의 수준을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함한다. 일부 구현예에서, 천연-발생 및/또는 치료-유도 노쇠 세포의 마커는 p21CIP1p21 및 CD26이다. 천연-발생 및/또는 치료-유도 노쇠 세포의 추가 마커는 본원에 기재되어 있다. 천연-발생 및/또는 치료-유도 노쇠 세포의 추가 마커는 당업계에 알려져 있다.
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 활성을 감소시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함한다.
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포로부터 유래된 하나 이상의 노쇠-관련 분비 표현형(SASP) 인자(들)의 수준 및/또는 활성을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함한다. 일부 구현예에서, 노쇠 세포는 염증성 시그너처를 발현하고, 상기 염증성 시그너처는 aSASP 인자이다. 일부 구현예에서, 노쇠-관련 분비 표현형(SASP) 인자는, 노쇠를 보강하고(자가분비 효과) 미세환경과 소통하며 이를 변형시키는(측분비 효과) 세포-자율 방식으로 작동하는 염증성 사이토카인(예를 들어, IL-1α, IL-1β, IL-6, IL-8, TNF-α), 성장 인자(예를 들어, TGF-β, PDGF-AA, 및 인슐린-유사 성장 인자-결합 단백질(IGFBP)), 케모카인(예를 들어, CCL-2, CCL-20, CCL-7, CXCL-4, CXCL1, 및 CXCL-12), 및 매트릭스 메탈로프로테이나제(예를 들어, MMP-3, MMP-9)를 포함하지만 이로 제한되지 않는다. 일부 구현예에서, 방법은 노쇠-관련 분비 표현형 (SASP) 인자(들) 중 하나 이상(예를 들어, 2개, 3개, 4개, 또는 5개)의 발현 수준 및/또는 활성을 저하시킨다. 일부 구현예에서, SASP 인자의 발현 수준 또는 활성은 효소-연결 면역흡착 검정(ELISA)을 사용하여 결정된다. 일부 구현예에서, SASP 인자의 발현 수준 또는 활성은 면역블로팅을 사용하여 결정된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 대상체는 노화-관련 질환(예를 들어, 본원에 기재되거나 당업계에 알려진 임의의 예시적인 유형의 노화-관련 질환 또는 병태) 또는 노화-관련 질환 또는 병태(예를 들어, 본원에 기재되거나 당업계에 알려진 임의의 예시적인 유형의 염증성 질환)를 갖는 것으로 진단되거나 식별되었다.
일부 구현예에서, 노화-관련 질환은 염증-노화와 관련이 있다.
일부 구현예에서, 노화-관련 질환은 암(예를 들어 본원에 기재되거나 당업계에 알려진 임의의 예시적인 유형의 암)이다.
본원에 기재된 임의의 방법의 일부 구현예에서, 염증성 질환은 하기로 이루어진 군으로부터 선택된다: 류마티스 관절염, 염증성 장 질환, 홍반성 루푸스, 루푸스 신염, 당뇨병성 신증, CNS 손상, 알츠하이머 질환, 파킨슨 질환, 근위축성 측삭 경화증, 크론 질환, 다발성 경화증, 길랑-바레 증후군, 건선, 그레이브스 질환, 궤양성 대장염, 비알코올성 지방간염, 기분 장애 및 암 치료-관련 인지 장애.
이들 방법의 일부 구현예에서, 치료-유도 노쇠 세포는 화학요법-유도 노쇠 세포이다.
이들 방법의 일부 구현예에서, 투여는 예를 들어, 치료 전 대상체의 표적 조직(예를 들어, 본원에 기재되거나 당업계에 알려진 임의의 예시적인 유형의 표적 조직)에서의 천연-발생 및/또는 치료-유도 노쇠 세포의 수와 비교하여, 대상체의 표적 조직에서의 천연-발생 및/또는 치료-유도 노쇠 세포의 수의 저하(예를 들어, 적어도 5% 저하, 적어도 10% 저하, 적어도 15% 저하, 적어도 20% 저하, 적어도 25% 저하, 적어도 30% 저하, 적어도 35% 저하, 적어도 40% 저하, 적어도 45% 저하, 적어도 50% 저하, 적어도 55% 저하, 적어도 60% 저하, 적어도 65% 저하, 적어도 70% 저하, 적어도 75% 저하, 적어도 80% 저하, 적어도 85% 저하, 적어도 90% 저하, 또는 적어도 95% 저하, 또는 약 5% 저하 내지 약 99% 저하(또는 본원에 기재된 이 범위의 임의의 하위범위))를 초래한다.
이들 방법의 일부 구현예에서, 투여는 예를 들어, 치료 전 대상체에서의 천연-발생 및/또는 치료-유도 노쇠 세포의 축적 또는 치료를 받지 않는 유사한 대상체에서의 천연-발생 및/또는 치료-유도 노쇠 세포의 축적과 비교하여, 대상체(예를 들어, 본원에 기재된 임의의 기간)에서의 천연-발생 및/또는 치료-유도 노쇠 세포의 저하(예를 들어, 적어도 5% 저하, 적어도 10% 저하, 적어도 15% 저하, 적어도 20% 저하, 적어도 25% 저하, 적어도 30% 저하, 적어도 35% 저하, 적어도 40% 저하, 적어도 45% 저하, 적어도 50% 저하, 적어도 55% 저하, 적어도 60% 저하, 적어도 65% 저하, 적어도 70% 저하, 적어도 75% 저하, 적어도 80% 저하, 적어도 85% 저하, 적어도 90% 저하, 또는 적어도 95% 저하, 또는 약 5% 저하 내지 약 99% 저하(또는 본원에 기재된 이 범위의 임의의 하위범위))를 초래한다.
이들 방법의 일부 구현예에서, 투여는 예를 들어, 치료 전 대상체에서의 천연-발생 및/또는 치료-유도 노쇠 세포의 하나 이상의 마커(들)의 수준과 비교하여, 대상체에서의 천연-발생 및/또는 치료-유도 노쇠 세포의 하나 이상(예를 들어, 2개, 3개, 또는 4개)의 마커(들)의 수준에서 저하(예를 들어, 적어도 5% 저하, 적어도 10% 저하, 적어도 15% 저하, 적어도 20% 저하, 적어도 25% 저하, 적어도 30% 저하, 적어도 35% 저하, 적어도 40% 저하, 적어도 45% 저하, 적어도 50% 저하, 적어도 55% 저하, 적어도 60% 저하, 적어도 65% 저하, 적어도 70% 저하, 적어도 75% 저하, 적어도 80% 저하, 적어도 85% 저하, 적어도 90% 저하, 또는 적어도 95% 저하, 또는 약 5% 저하 내지 약 99% 저하(또는 본원에 기재된 이 범위의 임의의 하위범위))를 초래한다.
본원에 기재된 바와 같이 "천연-발생 노쇠 세포"는 정상적인 노화 또는 염증성 과정의 결과 생성되는 노쇠 세포이다. 천연-발생 노쇠 세포는 시간 경과에 따라 개체의 다양한 조직 및 기관에 축적될 수 있다. 천연-발생 노쇠 세포는 치료적 치료(예를 들어, 화학요법 또는 방사선)에 의해 유도되지 않는 본원에 기재된 임의의 예시적인 유형의 노쇠 세포일 수 있다.
본원에 기재된 바와 같이 "치료-유도 노쇠 세포"는 치료적 치료(예를 들어, 화학요법 또는 방사선)의 결과 생성되는 노쇠 세포이다.
공통 감마-사슬 계열 사이토카인 수용체 활성화제
하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)의 사용 또는 투여를 포함하는 방법이 본원에 제공된다. 일부 구현예에서, 공통 감마-사슬 계열 사이토카인 수용체 활성화제는 단일-사슬 키메라 폴리펩타이드(예를 들어 본원에 기재된 임의의 예시적인 단일-사슬 키메라 폴리펩타이드), 다중-사슬 키메라 폴리펩타이드(예를 들어 본원에 기재된 임의의 예시적인 다중-사슬 키메라 폴리펩타이드), 가용성 IL-15 또는 IL-15 작용제(예를 들어, 본원에 기재된 임의의 가용성 IL-15 또는 IL-15 작용제), 가용성 IL-2 또는 IL-2 작용제(예를 들어, 본원에 기재된 임의의 가용성 IL-2 또는 IL-2 작용제), 공통 감마-사슬 계열 사이토카인(또는 이의 기능성 단편)과 공통 감마-사슬 계열 사이토카인 또는 이의 기능성 단편에 특이적으로 결합하는 항체(또는 항체 단편)의 복합체, 공통 감마-사슬 계열 사이토카인에 특이적으로 결합하는 항체 또는 항원-결합 항체 단편이다.
예시적인 단일-사슬 키메라 폴리펩타이드
공통 감마-사슬 계열 사이토카인 수용체 활성화제의 비제한적인 예는, (i) 제1 표적-결합 도메인; (ii) 가용성 조직 인자 도메인(예를 들어, 본원에 기재되거나 당업계에 알려진 임의의 예시적인 가용성 조직 인자 도메인); 및 (iii) 제2 표적-결합 도메인을 포함하는 단일-사슬 키메라 폴리펩타이드이며, 상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 공통 감마-사슬 계열 사이토카인, 공통 감마-사슬 계열 사이토카인 수용체에 특이적으로 결합하는 작용제성 항원-결합 도메인, 가용성 공통 감마-사슬 계열 사이토카인 수용체, 또는 공통 감마-사슬 계열 사이토카인에 특이적으로 결합하는 항원-결합 도메인이다.
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예는 이의 N-말단 및/또는 C-말단에 하나 이상의(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개의) 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)을 추가로 포함할 수 있다.
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 하나 이상의 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 및 하나 이상의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 가용성 공통 감마-사슬 계열 사이토카인이다. 가용성 공통 감마-사슬 계열 사이토카인의 비제한적인 예는 가용성 IL-2, 가용성 IL-4, 가용성 IL-7, 가용성 IL-9, 가용성 IL-15, 및 가용성 IL-21을 포함한다.
일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 공통 감마-사슬 계열 사이토카인 수용체(예를 들어, IL-2, IL-4, IL-7, IL-9, IL-15, 및 IL-21에 대한 가용성 수용체)를 포함한다.
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 하나 이상의 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 및 하나 이상의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 공통 감마-사슬 계열 사이토카인 수용체에 특이적으로 결합하는 작용제성 항원-결합 도메인이다. 공통 감마-사슬 계열 사이토카인 수용체의 비제한적인 예는 IL-2, IL-4, IL-7, IL-9, IL-15, 및 IL-21 중 하나 이상에 대한 수용체를 포함한다.
다중-사슬 키메라 폴리펩타이드
공통 감마-사슬 계열 사이토카인 수용체 활성화제의 비제한적인 예는 (a) (i) 제1 표적-결합 도메인; (ii) 가용성 조직 인자 도메인; 및 (iii) 친화도 도메인 쌍의 제1 도메인을 포함하는 제1 키메라 폴리펩타이드; 및 (b) (i) 친화도 도메인 쌍의 제2 도메인; 및 (ii) 제2 표적-결합 도메인을 포함하는 제2 키메라 폴리펩타이드를 포함하는 다중-사슬 키메라 폴리펩타이드이며, 상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 공통 감마-사슬 계열 사이토카인, 공통 감마-사슬 계열 사이토카인 수용체에 특이적으로 결합하는 작용제성 항원-결합 도메인, 가용성 공통 감마-사슬 계열 사이토카인 수용체, 또는 공통 감마-사슬 계열 사이토카인에 특이적으로 결합하는 항원-결합 도메인이다.
임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 하나 이상의(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개의) 추가 표적-결합 도메인(들)(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)을 추가로 포함한다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 하나 이상(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개)의 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 및 하나 이상의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 가용성 공통 감마-사슬 계열 사이토카인이다. 가용성 공통 감마-사슬 계열 사이토카인의 비제한적인 예는 가용성 IL-2, 가용성 IL-4, 가용성 IL-7, 가용성 IL-9, 가용성 IL-15, 및 가용성 IL-21을 포함한다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 하나 이상의 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 및 하나 이상의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 공통 감마-사슬 계열 사이토카인 수용체에 특이적으로 결합하는 작용제성 항원-결합 도메인이다. 공통 감마-사슬 계열 사이토카인 수용체의 비제한적인 예는 IL-2, IL-4, IL-7, IL-9, IL-15, 및 IL-21 중 하나 이상에 대한 수용체를 포함한다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 하나 이상(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개)의 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인), 및 하나 이상의 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 가용성 공통 감마-사슬 계열 사이토카인 수용체이다.
본원에 기재된 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인 쌍의 제1 도메인 또는 제2 도메인은 공통 감마-사슬 계열 사이토카인 수용체에 특이적으로 결합하는 가용성 공통 감마-사슬 계열 사이토카인 또는 항원-결합 도메인이다.
가용성 공통 감마-사슬 계열 사이토카인
본원에 기재된 임의의 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 공통 감마-사슬 계열 사이토카인일 수 있다. 일부 구현예에서, 공통 감마-사슬 계열 사이토카인 수용체 활성화제는 가용성 공통 감마-사슬 계열 사이토카인일 수 있다. 가용성 공통 감마-사슬 계열 사이토카인의 비제한적인 예는 가용성 IL-2, 가용성 IL-4, 가용성 IL-7, 가용성 IL-9, 가용성 IL-15, 및 가용성 IL-21을 포함한다. 가용성 IL-2, 가용성 IL-7, 가용성 IL-15, 및 가용성 IL-21에 대한 서열의 비제한적인 예는 본원에 기재되어 있다. 가용성 IL-4 및 IL-9 서열의 비제한적인 예는 아래에 제시된다.
인간 가용성 IL-4 (SEQ ID NO: 335)
HKCDITLQEIIKTLNS LTEQKTLCTE LTVTDIFAAS KNTTEKETFC RAATVLRQFY SHHEKDTRCL GATAQQFHRH KQLIRFLKRL DRNLWGLAGL NSCPVKEANQ STLENFLERL KTIMREKYSK CSS
인간 가용성 IL-9 (SEQ ID NO: 336)
QGCPTLAGILDI NFLINKMQED PASKCHCSAN VTSCLCLGIP SDNCTRPCFS ERLSQMTNTT MQTRYPLIFS RVKKSVEVLK NNKCPYFSCE QPCNQTTAGN ALTFLKSLLE IFQKEKMRGM RGKI
항원-결합 도메인
본원에 기재된 임의의 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 항원-결합 도메인이다. 본원에 기재된 임의의 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 항원-결합 도메인이다. 본원에 기재된 임의의 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 항원-결합 도메인은 scFv 또는 단일 도메인 항체(예를 들어, VaHH 또는 VNAR 도메인)를 포함하거나 이것이다.
본원에 기재된 임의의 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 공통 감마-사슬 계열 사이토카인 수용체에 특이적으로 결합하는 작용제성 항원-결합 도메인이다. 일부 예에서, 작용제성 항원-결합 도메인(예를 들어, 본원에 기재된 임의의 항원-결합 도메인)은 IL-2, IL-4, IL-7, IL-9, IL-15, 또는 IL-21에 대한 수용체에 특이적으로 결합할 수 있다.
본원에 기재된 임의의 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드에 존재하는 항원-결합 도메인은 각각 독립적으로, VHH 도메인, VNAR 도메인, 및 scFv로 이루어진 군으로부터 선택된다. 일부 구현예에서, 본원에 기재된 임의의 항원-결합 도메인은 BiTe, (scFv)2, 나노바디, 나노바디-HSA, DART, TandAb, sc디아바디, sc디아바디-CH3, scFv-CH-CL-scFv, HSA바디, sc디아바디-HAS, 또는 탠덤-scFv이다. 임의의 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드에 사용될 수 있는 항원-결합 도메인의 추가 예는 당업계에 알려져 있다.
일부 구현예에서, 본원에 기재된 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 각각의 항원-결합 도메인은 둘 다 VHH 도메인이거나, 적어도 하나의 항원-결합 도메인은 VHH 도메인이다. 일부 구현예에서, 본원에 기재된 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 각각의 항원-결합 도메인은 둘 다 VNAR 도메인이거나, 적어도 하나의 항원-결합 도메인은 VNAR 도메인이다. 일부 구현예에서, 본원에 기재된 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 각각의 항원-결합 도메인은 둘 다 scFv 도메인이거나, 적어도 하나의 항원-결합 도메인은 scFv 도메인이다.
일부 구현예에서, 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드에 존재하는 2개 이상의 폴리펩타이드는 조립되어(예를 들어, 비-공유적으로 조립되어), 본원에 기재된 임의의 항원-결합 도메인, 예를 들어, 항체의 항원-결합 단편(예를 들어, 본원에 기재된 항체의 임의의 항원-결합 단편), VHH-scAb, VHH-Fab, 이중 scFab, F(ab')2, 디아바디, crossMab, DAF(투-인-원), DAF(포-인-원), DutaMab, DT-IgG, 놉스-인 홀 공통 경쇄, 놉스-인-홀 조립체, 전하쌍, Fab-아암 교환, SEED바디, LUZ-Y, Fcab, κλ-바디, 오르토고날 Fab, DVD-IgG, IgG(H)-scFv, scFv-(H)IgG, IgG(L)-scFv, scFv-(L)IgG, IgG(L,H)-Fv, IgG(H)-V, V(H)-IgG, IgG(L)-V, V(L)-IgG, KIH IgG-scFab, 2scFv-IgG, IgG-2scFv, scFv4-Ig, Zybody, DVI-IgG, 디아바디-CH3, 트리플바디, 미니항체, 미니바디, TriBi 미니바디, scFv-CH3 KIH, Fab-scFv, F(ab')2-scFv2, scFv-KIH, Fab-scFv-Fc, 4가 HCAb, sc디아바디-Fc, 디아바디-Fc, 탠덤 scFv-Fc, 인트라체, 도크 앤드 록, lmmTAC, IgG-IgG 접합체, Cov-X-바디, 및 scFv1-PEG-scFv2를 형성할 수 있다. 예를 들어, 이들 요소의 설명에 대해 그 전체가 본원에 포함된 문헌[Spiesset al., Mol. Immunol. 67:95-106, 2015]를 참조한다. 항체의 항원-결합 단편의 비제한적인 예는 Fv 단편, Fab 단편, F(ab')2 단편, 및 Fab' 단편을 포함한다. 항체의 항원-결합 단편의 추가 예는 IgG의 항원-결합 단편(예를 들어, IgG1, IgG2, IgG3, 또는 IgG4의 항원-결합 단편)(예를 들어, 인간 또는 인간화 IgG, 예를 들어, 인간 또는 인간화 IgG1, IgG2, IgG3, 또는 IgG4의 항원-결합 단편); IgA의 항원-결합 단편(예를 들어, IgA1 또는 IgA2의 항원-결합 단편)(예를 들어, 인간 또는 인간화 IgA, 예를 들어, 인간 또는 인간화 IgA1 또는 IgA2의 항원-결합 단편); IgD의 항원-결합 단편(예를 들어, 인간 또는 인간화 IgD의 항원-결합 단편); IgE의 항원-결합 단편(예를 들어, 인간 또는 인간화 IgE의 항원-결합 단편); 또는 IgM의 항원-결합 단편의 항원-결합 단편(예를 들어, 인간 또는 인간화 IgM의 항원-결합 단편)이다.
가용성 IL-15 및 IL-15 작용제
공통 감마-사슬 계열 사이토카인 수용체 활성화제의 비제한적인 예는 가용성 IL-15 또는 IL-15 작용제이다. IL-15는 삼량체성 IL-15 수용체 복합체를 통해 기능하며, 이러한 복합체는 IL-2와 공유되는 γ-사슬과 공통 IL-15Rβ(IL-2Rβ/γ로도 알려져 있음) 및 IL-15에 대한 수용체 특이성을 부여하는 높은 친화도의 독특한 결합 IL-15Rα 사슬로 구성된다.
일부 구현예에서, 가용성 IL-15는 SEQ ID NO: 82와 적어도 90%(예를 들어, 적어도 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 또는 99%) 동일하다. 일부 구현예에서, 가용성 IL-15는 재조합 가용성 인간 IL-15이다. 일부 구현예에서, 가용성 IL-15는 야생형 IL-15(예를 들어, SEQ ID NO: 82)와 비교하여 하나 이상의 아미노산 치환을 갖는 돌연변이체 IL-15이다. 돌연변이체 IL-15는 예를 들어, 야생형 IL-15와 비교하여 D8N 또는 D8A 아미노산 치환을 포함할 수 있다. 일부 구현예에서, 가용성 IL-15는 중합체에 접합될 수 있다(예를 들어 문헌[Miyazaki et al., Proceed. Annual Meeting AACR, 2019, Abstract 3265] 참조).
본원에 기재된 IL-15 작용제의 일부 예는 IL-15와 가용성 IL-15 수용체(IL-15R)의 전부 또는 일부의 복합체를 포함할 수 있다. IL-15와 가용성 IL-15R의 전부 또는 일부의 복합체는 유리 IL-15와 비교하여 연장된 반감기 및/또는 더 높은 약효를 가질 수 있다. 일부 구현예에서, 본원에 기재된 IL-15 작용제는 Fc 도메인(예를 들어, 본원에 기재된 임의의 예시적인 Fc 도메인)을 추가로 포함한다.
일부 구현예에서, 가용성 IL-15R의 일부는 IL-15Rα이다. 예를 들어, IL-15는 IL-15Rα-Fc 융합과 회합되어, IL-15:IL-15Rα-Fc 복합체를 형성할 수 있다(예를 들어, 문헌[Stoklasek et al., J. Immunology 177:6072-80, 2006]; 문헌[Dubios et al., J. Immunol. 180:2099-106, 2008]; 문헌[Epardaud et al., Cancer Res. 68:2972-83, 2008]; 문헌[Rubinstein et al., Proc. Natl. Acad. Sci. U.S.A. 103:9166-71, 2006]에 기재된 것들 참조). 일부 구현예에서, 가용성 IL-15와 IL-15Rα는 헤테로이량체를 형성한다(예를 들어 문헌[Colon et al., Cancer Res. 79(13 Supplement):CT082, July 1, 2019] 참조).
일부 구현예에서, 가용성 IL-15R의 일부는 IL-15Rα의 일부(예를 들어, IL-15Rα의 sushi 도메인)이다.
복합체 내 IL-15는 야생형 IL-15 또는 돌연변이체 IL-15일 수 있다. 예를 들어, N72D 돌연변이를 함유하는 돌연변이체 IL-15는 가용성 IL-15R의 전부 또는 일부(예를 들어, IL-15Rα의 sushi 도메인)와 복합체화하는 데 사용될 수 있다. 일부 구현예에서, 복합체는 IL-15Rα sushi-Fc 융합과 복합체화된 인간 IL-15 돌연변이체 IL-15N72D를 포함하는 ALT-803이다(예를 들어 문헌[Zhu et al., J. Immunol. 183(6):3598-607, 2009] 참조).
IL-15 작용제의 비제한적인 예는 ALT-803/N-803 (Altor Bioscience/ImmunityBio), BNZ-1 (Bioniz Therapeutics), NIZ985 (Novartis), RTX-212 (Rubius Therapeutics), AM0015 (rhIL-15) (Lilly), IGM-7354 (IGM), XmAb24306 (Roche/Xencor), KD033 (srKD033) (Kadmon), OXS-C3550 (GT Biopharma), 및 NKTR-255 (Nektar Therapeutics)를 포함한다.
가용성 IL-2 및 IL-2 작용제
공통 감마-사슬 계열 사이토카인 수용체 활성화제의 비제한적인 예는 가용성 IL-2 또는 IL-2 작용제이다. IL-2는 CD4+ T 조절 세포 및 세포독성 이펙터 림프구, 예컨대 CD8+ T 세포 및 NK 세포에 미치는 이의 효과에 의해 면역 내약성 및 면역 활성화에 중심적으로 관여하는 사이토카인이다. IL-2는 IL-2Rβ 사슬 및 γ 사슬로 구성된 이량체성 IL-2 수용체(IL-2R) 또는 삼량체성 αβγ 수용체(IL-2Rαβγ)를 발현하는 세포에 작용하며, 상기 삼량체성 수용체는 이량체성 IL-2R과 비교하여 IL-2에 대해 10배 내지 100배 더 높은 친화도를 나타낸다. CD4+ T 조절 세포는 IL-2Rα의 강한 항시적 발현을 특징으로 하며, 이는 세포가 IL-2Rαβγ를 발현시키고 이에 의해 낮은 수준의 IL-2를 사용할 수 있게 한다. 이량체성 IL-2R은 항원-경험(기억) CD8+ T 세포 및 NK 세포 상에서 가장 현저하다. 따라서, 높은 수준의 IL-2는 Treg 세포를 활성화시키는 것에 더하여 CD8+ T 세포 및 NK 세포를 강하게 자극시킨다.
일부 구현예에서, 가용성 IL-2는 SEQ ID NO: 78과 적어도 90%(예를 들어, 적어도 95% 동일한, 적어도 96%, 적어도 97%, 적어도 98%, 적어도 99%, 또는 100%) 동일하다. 일부 구현예에서, 가용성 IL-2는 재조합 인간 IL-2이다. 가용성 IL-2는 IL-2 변이체일 수 있다. 예를 들어, IL-2 변이체는 IL-2Rα보다 IL-2Rβ에 더 효과적으로(예를 들어, 적어도 50배, 100배, 150배 또는 200배 더 효과적으로) 결합할 수 있다. 예시적인 IL-2 변이체는 MDNA109이다(예를 들어, 문헌[Rafei et al., J. Clin. Oncol. 37(15 Suppl.), 2019] 참조). 일부 구현예에서, IL-2 변이체는 CD25 결합을 무효화시켰다. 예를 들어, CD25 결합에 관여하는 잔기 F42, Y45, 및 L72는 돌연변이화될 수 있다(예를 들어, 문헌[Klein et al., Oncoimmunology 6(3):e1277306, 2017] 참조).
일부 구현예에서, IL-2 작용제는 IL2Rα 하위단위에 대한 제한된 결합을 갖는 PEG화된 IL-2이고, 이량체성 IL2Rβγ에 우선적으로 결합한다(예를 들어, 문헌[Bentebibel et al., Cancer Discov. 9(6):711-721, 2019] 참조).
본원에 기재된 IL-2 작용제의 일부 예는 IL-2를 포함하는 융합 단백질이다. 일부 구현예에서, 융합 단백질은 가용성 IL-2R의 전부 또는 일부에 연결된 IL-2 또는 이의 변이체를 포함한다. 일부 구현예에서, 가용성 IL-2R의 일부는 IL-2Rα이다(예를 들어, 문헌[Vaishampayan et al., J. Clin. Oncol. 35 (15 Suppl.), 2017] 참조). 융합 단백질은 예를 들어, 이량체성 IL-2Rβγ를 선택적으로 활성화시킬 수 있다. IL-2 융합 단백질의 추가 예는 독소(예를 들어, 디프테리아 독소)에 융합된 것들을 포함한다.
일부 구현예에서, 융합 단백질은 항체(예를 들어, 단일클론 항체 또는 scFv)에 연결된 IL-2 또는 이의 변이체(예를 들어, 본원에 기재된 임의의 IL-2 변이체)를 포함한다. IL-2 또는 이의 변이체에 연결될 수 있는 항체의 비제한적인 예는 섬유아세포 활성화 단백질-알파(FAP)에 대한 인간 단일클론 항체(예를 들어, 문헌[Soerensen et al., J. Clin. Oncol. 36, No. 15 Suppl.] 참조), 항-CD20 단일클론 항체(예를 들어, 문헌[Lansigan et al., Blood 128(22):620, 2016] 참조), 테나신-C의 A1 도메인에 대한 scFv(예를 들어 문헌[Catania et al., Cell Adh. Migr. 9(1-2):14-21, 2015] 참조); 및 항-CEA 항체(예를 들어 문헌[Klein et al., Oncoimmunol. 6(3):e1277306, 2017] 참조)를 포함한다.
IL-2 작용제의 추가 예는 프로류킨(Proleukin)(Clinigen), 풀모류킨(pulmoleukin)(Immunservice), NKTR-214(Nektar Therapeutics), DI-Leu16-IL2(Alopexx/Provenance Biopharmaceuticals), RG7461(Roche), 텔류킨(Teleukin)(Philogen), ALT-801803(Altor Bioscience), ALT-801(Altor Bioscience), ALKS 4230(Alkermes), 세르구투주맙 아뮤날류킨(cergutuzumab amunaleukin)(RG7813)(Roche), 카미단루맙 테리신(Camidanlumab tesirine)(ADC Therapeutics/Genbmab), NHS-IL2-LT/EMD 521873(Merck KGaA), NIZ985(Novartis), MDNA109(Medicenna Therapeutics), 안겔록신(Angeloxin)(Angelica Therapeutics), PB101(Pivotal Biosciences), 항-IL-2 프로그램(Xoma), NKTR-255(Nektar Therapeutics), NKTR-358/LY3471851(Nektar Therapeutics/Lilly), CYP 0150(Cytunepharma), NL-201(Neoleukin), THOR-809(Sanofi/Synthorx), BNT151/153(BioNTech), TransCon IL-2 β/γ(Ascendis Pharma), ILT-101(Servier/ILT-101) 및 AM0015(Lilly)를 포함한다. IL-2 작용제의 추가 예는 당업계에 알려져 있다.
공통 감마-사슬 계열 사이토카인과 항체 또는 항체 단편의 복합체
공통 감마-사슬 계열 사이토카인 수용체 활성화제의 비제한적인 예는 공통 감마-사슬 계열 사이토카인(예를 들어, 본원에 기재된 임의의 공통 감마-사슬 계열 사이토카인)과 공통 감마-사슬 계열 사이토카인에 특이적으로 결합하는 항체 또는 항원-결합 항체 단편을 포함하는 복합체이다.
일부 구현예에서, 공통 감마-사슬 계열 사이토카인과 이러한 공통 감마-사슬 계열 사이토카인에 특이적으로 결합하는 항체 또는 항원-결합 항체 단편의 복합체는 공통 감마-사슬 계열 사이토카인의 활성을 증강시키고, CD8+ T 세포 및/또는 NK 세포의 확장을 유발할 수 있다. 일부 구현예에서, 복합체는 자유 공통 감마-사슬 계열 사이토카인보다 순환 시 더 긴 반감기를 갖는다.
일부 구현예에서, 복합체는 가용성 IL-2(예를 들어, 재조합 가용성 인간 IL-2) 또는 이의 기능성 단편, 및 항-IL-2 항체 또는 이의 항원-결합 항체 단편을 포함할 수 있다. 가용성 IL-2와 항-IL-2 항체의 복합체의 비제한적인 예는 항-IL-2 항체 S4B6, JES6-5, 또는 MAB602와 각각 복합체화된 가용성 IL-2를 포함한다(예를 들어, 문헌[Tomala et al., J. Immunol. 183:4904-4912, 2009]; 및 문헌[Boyman et al., Science 311, 2006] 참조).
일부 구현예에서, 복합체는 가용성 IL-4(예를 들어, 재조합 가용성 인간 IL-4) 및 항-IL-4 항체 또는 이의 항원-결합 항체 단편을 포함할 수 있다. 항-IL-4 항체의 비제한적인 예는 예를 들어, 문헌[Sato et al., J. Immunol. 150:2717-2723, 1993], 및 문헌[Finkelman et al., J. Immunol. 151:1235-1244, 1993]에 기재된 것들을 포함한다.
일부 구현예에서, 복합체는 가용성 IL-7(예를 들어, 재조합 가용성 인간 IL-7) 및 항-IL-7 항체 또는 이의 항원-결합 항체 단편을 포함할 수 있다. 항-IL-7 항체의 비제한적인 예는 예를 들어, 문헌[Finkelman et al., J. Immunol. 151:1235-1244, 1993], 및 문헌[Boyman et al., J. Immunol. 180:7265-75, 2008]에 기재된 것들을 포함한다.
복합체의 일부 예에서, 공통 감마-사슬 계열 사이토카인(또는 이의 기능성 단편) 및 항체(또는 이의 항원-결합 항체 단편)는 별개로 투여될 수 있고, 공통 감마-사슬 계열 사이토카인과 항체 또는 항원-결합 항체 단편 사이의 복합체는 생체내에서 형성될 수 있다.
공통 감마-사슬 계열 사이토카인 및 이에 결합하는 상응하는 항체 또는 항원-결합 항체 단편의 추가 예는 당업계에 알려져 있다.
TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)의 투여를 포함하는 예시적인 방법
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포를 사멸시키거나 이의 수를 감소시키는 방법이 본원에 제공되며, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다.
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 축적을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다.
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 마커의 수준을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다. 일부 구현예에서, 천연-발생 및/또는 치료-유도 노쇠 세포의 마커는 p21CIP1p21 및 CD26이다. 천연-발생 및/또는 치료-유도 노쇠 세포의 추가 마커는 본원에 기재되어 있다. 천연-발생 및/또는 치료-유도 노쇠 세포의 추가 마커는 당업계에 알려져 있다.
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 활성을 감소시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다.
대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포로부터 유래된 하나 이상의 SASP 인자(들)의 수준 및/또는 활성을 저하시키는 방법이 또한 본원에 제공되며, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다. 일부 구현예에서, 노쇠 세포는 염증성 시그너처를 발현하고, 상기 염증성 시그너처는 SASP 인자이다. 일부 구현예에서, SASP 인자는, 노쇠를 보강하고(자가분비 효과) 미세환경과 소통하며 이를 변형시키는(측분비 효과) 세포-자율 방식으로 작동하는 염증성 사이토카인(예를 들어, IL-1α, IL-1β, IL-6, IL-8, TNF-α), 성장 인자(예를 들어, TGF-β, PDGF-AA, 및 인슐린-유사 성장 인자-결합 단백질(IGFBP)), 케모카인(예를 들어, CCL-2, CCL-20, CCL-7, CXCL-4, CXCL1, 및 CXCL-12), 및 매트릭스 메탈로프로테이나제(예를 들어, MMP-3, 및 MMP-9)를 포함하지만 이로 제한되지 않는다. 일부 구현예에서, 방법은 SASP 인자(들) 중 하나 이상의 발현 수준 및/또는 활성을 저하시킨다. 일부 구현예에서, SASP 인자의 발현 수준 또는 활성은 효소-연결 면역흡착 검정(ELISA)을 사용하여 결정된다. 일부 구현예에서, SASP 인자의 발현 수준 또는 활성은 면역블로팅을 사용하여 결정된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 대상체는 노화-관련 질환(예를 들어, 본원에 기재되거나 당업계에 알려진 임의의 예시적인 유형의 노화-관련 질환 또는 병태) 또는 노화-관련 질환 또는 병태(예를 들어, 본원에 기재되거나 당업계에 알려진 임의의 예시적인 유형의 염증성 질환)를 갖는 것으로 진단되거나 식별되었다.
일부 구현예에서, 노화-관련 질환은 염증-노화와 관련이 있다.
일부 구현예에서, 노화-관련 질환은 암(예를 들어 본원에 기재되거나 당업계에 알려진 임의의 예시적인 유형의 암)이다.
본원에 기재된 임의의 방법의 일부 구현예에서, 염증성 질환은 하기로 이루어진 군으로부터 선택된다: 류마티스 관절염, 염증성 장 질환, 홍반성 루푸스, 루푸스 신염, 당뇨병성 신증, CNS 손상, 알츠하이머 질환, 파킨슨 질환, 근위축성 측삭 경화증, 크론 질환, 다발성 경화증, 길랑-바레 증후군, 건선, 그레이브스 질환, 궤양성 대장염, 비알코올성 지방간염, 기분 장애 및 암 치료-관련 인지 장애.
이들 방법의 일부 구현예에서, 치료-유도 노쇠 세포는 화학요법-유도 노쇠 세포이다.
이들 방법의 일부 구현예에서, 투여는 예를 들어, 치료 전 대상체의 표적 조직(예를 들어, 본원에 기재되거나 당업계에 알려진 임의의 예시적인 유형의 표적 조직)에서의 천연-발생 및/또는 치료-유도 노쇠 세포의 수와 비교하여, 대상체의 표적 조직에서의 천연-발생 및/또는 치료-유도 노쇠 세포의 수의 저하(예를 들어, 적어도 5% 저하, 적어도 10% 저하, 적어도 15% 저하, 적어도 20% 저하, 적어도 25% 저하, 적어도 30% 저하, 적어도 35% 저하, 적어도 40% 저하, 적어도 45% 저하, 적어도 50% 저하, 적어도 55% 저하, 적어도 60% 저하, 적어도 65% 저하, 적어도 70% 저하, 적어도 75% 저하, 적어도 80% 저하, 적어도 85% 저하, 적어도 90% 저하, 또는 적어도 95% 저하, 또는 약 5% 저하 내지 약 99% 저하(또는 본원에 기재된 이 범위의 임의의 하위범위))를 초래한다.
이들 방법의 일부 구현예에서, 투여는 예를 들어, 치료 전 대상체에서의 천연-발생 및/또는 치료-유도 노쇠 세포의 축적 또는 치료를 받지 않는 유사한 대상체에서의 천연-발생 및/또는 치료-유도 노쇠 세포의 축적과 비교하여, 대상체(예를 들어, 본원에 기재된 임의의 기간)에서의 천연-발생 및/또는 치료-유도 노쇠 세포의 저하(예를 들어, 적어도 5% 저하, 적어도 10% 저하, 적어도 15% 저하, 적어도 20% 저하, 적어도 25% 저하, 적어도 30% 저하, 적어도 35% 저하, 적어도 40% 저하, 적어도 45% 저하, 적어도 50% 저하, 적어도 55% 저하, 적어도 60% 저하, 적어도 65% 저하, 적어도 70% 저하, 적어도 75% 저하, 적어도 80% 저하, 적어도 85% 저하, 적어도 90% 저하, 또는 적어도 95% 저하, 또는 약 5% 저하 내지 약 99% 저하(또는 본원에 기재된 이 범위의 임의의 하위범위))를 초래한다.
이들 방법의 일부 구현예에서, 투여는 예를 들어, 치료 전 대상체에서의 천연-발생 및/또는 치료-유도 노쇠 세포의 하나 이상의 마커(들)의 수준과 비교하여, 대상체에서의 천연-발생 및/또는 치료-유도 노쇠 세포의 하나 이상(예를 들어, 2개, 3개, 또는 4개)의 마커(들)의 수준에서 저하(예를 들어, 적어도 5% 저하, 적어도 10% 저하, 적어도 15% 저하, 적어도 20% 저하, 적어도 25% 저하, 적어도 30% 저하, 적어도 35% 저하, 적어도 40% 저하, 적어도 45% 저하, 적어도 50% 저하, 적어도 55% 저하, 적어도 60% 저하, 적어도 65% 저하, 적어도 70% 저하, 적어도 75% 저하, 적어도 80% 저하, 적어도 85% 저하, 적어도 90% 저하, 또는 적어도 95% 저하, 또는 약 5% 저하 내지 약 99% 저하(또는 본원에 기재된 이 범위의 임의의 하위범위))를 초래한다.
일부 구현예에서, TGF-β 수용체는 TGF-β 수용체 II(TGF-βRII)이다.
일부 구현예에서, TGF-β 수용체는 TGF-βRIII이다.
일부 구현예에서, TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들) 중 적어도 하나는 가용성 TGF-β 수용체, TGF-β 수용체의 세포외 도메인, TGF-β에 특이적으로 결합하는 항체, TGF-β 수용체에 결합하는 길항제성 항체, LAP에 결합하는 제제, 또는 TGF-β/LAP 복합체에 결합하는 제제이다. 일부 구현예에서, TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)는 LAP에의 또는 TGF-β/LAP 복합체에의 결합을 통해 TGF-β 수용체의 활성화를 저하시킨다. TGF-β 수용체의 활성화의 저하를 초래하는 제제의 비제한적인 예는 아래에 기재되어 있다.
TGF-β 수용체의 활성화의 저하를 초래하는 제제(들)
TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)의 사용 또는 투여를 포함하는 방법이 본원에 제공된다. 일부 구현예에서, TGF-β 수용체의 활성화의 저하를 초래하는 제제는 단일-사슬 키메라 폴리펩타이드(예를 들어 본원에 기재된 임의의 예시적인 단일-사슬 키메라 폴리펩타이드), 다중-사슬 키메라 폴리펩타이드(예를 들어 본원에 기재된 임의의 예시적인 다중-사슬 키메라 폴리펩타이드), 가용성 TGF-β 수용체, TGF-β 수용체의 세포외 도메인, TGF-β에 특이적으로 결합하는 항체(또는 항체 단편), TGF-β 수용체에 결합하는 길항제성 항체, LAP에 결합하는 제제, 또는 TGF-β/LAP 복합체에 결합하는 제제이다.
예시적인 단일-사슬 키메라 폴리펩타이드
TGF-β 수용체의 활성화의 저하를 초래하는 제제의 비제한적인 예는, (i) 제1 표적-결합 도메인; (ii) 가용성 조직 인자 도메인(예를 들어, 본원에 기재되거나 당업계에 알려진 임의의 예시적인 가용성 조직 인자 도메인); 및 (iii) 제2 표적-결합 도메인을 포함하는 단일-사슬 키메라 폴리펩타이드이며, 상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 TGF-β 수용체의 리간드에 특이적으로 결합하거나; 상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 TGF-β 수용체에 특이적으로 결합하는 길항제성 항원-결합 도메인이다. 일부 구현예에서, TGF-β 수용체는 TGF-βRII이다. 일부 구현예에서, TGF-β 수용체는 TGF-βRIII이다.
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예는 이의 N-말단 및/또는 C-말단에 하나 이상의(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개의) 추가 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려진 임의의 예시적인 표적-결합 도메인)을 추가로 포함할 수 있다.
본원에 기재된 임의의 단일-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인) 및/또는 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 가용성 TGF-β 수용체이다. 가용성 TGF-β 수용체의 비제한적인 예는 가용성 TGFβRI, 가용성 TGFβRII, 가용성 TGFβRIII, 및 가용성 엔도글린(endoglin)을 포함한다. 예시적인 가용성 TGFβRII에 대한 비제한적인 서열은 본원에 기재되어 있다.
예시적인 다중-사슬 키메라 폴리펩타이드
TGF-β 수용체의 활성화의 저하를 초래하는 제제의 비제한적인 예는 (a) (i) 제1 표적-결합 도메인; (ii) 가용성 조직 인자 도메인; 및 (iii) 친화도 도메인 쌍의 제1 도메인을 포함하는 제1 키메라 폴리펩타이드; 및 (b) (i) 친화도 도메인 쌍의 제2 도메인; 및 (ii) 제2 표적-결합 도메인을 포함하는 제2 키메라 폴리펩타이드를 포함하는 다중-사슬 키메라 폴리펩타이드이며, 상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 TGF-β 수용체의 리간드에 특이적으로 결합하거나; 상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 TGF-β 수용체에 특이적으로 결합하는 길항제성 항원-결합 도메인이다.
임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 키메라 폴리펩타이드는 하나 이상의(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개의) 추가 표적-결합 도메인(들)(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)을 추가로 포함한다.
임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제2 키메라 폴리펩타이드는 하나 이상의(예를 들어, 2개, 3개, 4개, 5개, 6개, 7개, 8개, 9개, 또는 10개의) 추가 표적-결합 도메인(들)(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)을 추가로 포함한다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인) 및/또는 제2 표적-결합 도메인(예를 들어, 본원에 기재되어 있거나 당업계에 알려져 있는 임의의 예시적인 표적-결합 도메인)은 가용성 TGF-β 수용체이다. 가용성 TGF-β 수용체의 비제한적인 예는 가용성 TGFβRI, 가용성 TGFβRII, 가용성 TGFβRIII, 및 가용성 엔도글린을 포함한다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인 쌍은 인간 IL-15 수용체의 알파 사슬(IL15Rα) 및 가용성 IL-15로부터의 sushi 도메인이다. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 가용성 IL-15는 D8N 또는 D8A 아미노산 치환을 갖는다. 일부 구현예에서, 가용성 IL-15는 IL-15 활성을 감소시키거나 제거하기 위한 돌연변이를 포함한다.
본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인 쌍은 하기로 이루어진 군으로부터 선택된다: 바르나제와 바른스타, PKA와 AKAP, 돌연변이화된 RNase I 단편에 기초한 어댑터/도킹 태그 모듈, 및 단백질 신택신, 시냅토태그민, 시냅토브레빈, 및 SNAP25의 상호작용에 기초한 SNARE 모듈. 본원에 기재된 임의의 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 친화도 도메인 쌍의 제1 도메인 또는 제2 도메인은 공통 감마-사슬 계열 사이토카인 수용체에 특이적으로 결합하는 가용성 공통 감마-사슬 계열 사이토카인 또는 항원-결합 도메인이다.
TGF-β 수용체의 활성화의 저하를 초래하는 제제인 다중-사슬 키메라 폴리펩타이드의 비제한적인 예는 본원에서 "예시적인 다중-사슬 키메라 폴리펩타이드- 유형 B, G, I, K, L, M, N, O, 및 P"라는 명칭의 하위단락에 기재된 것들이다.
가용성 TGF-β 수용체
일부 구현예에서, TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)는 가용성 TGF-β 수용체이다. 일부 구현예에서, TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)는 가용성 TGF-β 수용체이다. 가용성 TGF-β 수용체의 비제한적인 예는 가용성 TGFβRI, 가용성 TGFβRII, 가용성 TGFβRIII, 및 가용성 엔도글린을 포함한다.
일부 구현예에서, TGF-β 수용체는 TGF-β 수용체 II(TGFβRII)이다. 일부 구현예에서, TGFβ 수용체는 TGFβRIII이다.
I형 수용체인 TGFβRI은 TGF-β에 결합하기 위해 TGFβRII의 존재를 필요로 하는 막-결합 세린/트레오닌 키나제이다. II 수용체인 TGFβRII는 TGF-β 1 및 TGF-β 3에 높은 친화도로 그리고 TGF-β2에 훨씬 더 낮은 친화도로 결합하는 막-결합 세린/트레오닌 키나제이다. 일부 구현예에서, 신호 전달은 TGFβRI과 TGFβRII 둘 다의 세포질 도메인을 필요로 한다. III형 수용체인 TGF-βRIII은 막-결합 형태 및 가용성 형태로 존재하는 프로테오글리칸이고, TGF-β1, TGF-β2, 및 TGF-β3에 결합하지만, 신호 전달에 관여하는 것으로 보이지 않는다. 가용성 TGFβRII에 대한 서열의 비제한적인 예는 본원에 기재되어 있다.
항원-결합 도메인
본원에 기재된 임의의 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 항원-결합 도메인이다. 본원에 기재된 임의의 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 항원-결합 도메인이다. 본원에 기재된 임의의 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 항원-결합 도메인은 scFv 또는 단일 도메인 항체(예를 들어, VHH 또는 VNAR 도메인)를 포함하거나 이것이다.
본원에 기재된 임의의 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드의 일부 구현예에서, 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 TGF-β 수용체에 특이적으로 결합하는 길항제성 항원-결합 도메인이다. 일부 예에서, 길항제성 항원-결합 도메인(예를 들어, 본원에 기재된 임의의 항원-결합 도메인)은 가용성 TGFβRI, 가용성 TGFβRII, 가용성 TGFβRIII, 또는 가용성 엔도글린에 특이적으로 결합할 수 있다.
일부 구현예에서, 본원에 기재된 임의의 항원-결합 도메인은 BiTe, (scFv)2, 나노바디, 나노바디-HSA, DART, TandAb, sc디아바디, sc디아바디-CH3, scFv-CH-CL-scFv, HSA바디, sc디아바디-HSA, 또는 탠덤-scFv이다. 임의의 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드에 사용될 수 있는 항원-결합 도메인의 추가 예는 당업계에 알려져 있다.
일부 구현예에서, 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드에 존재하는 2개 이상의 폴리펩타이드는 조립되어(예를 들어, 비-공유적으로 조립되어), 본원에 기재된 임의의 항원-결합 도메인, 예를 들어, 항체의 항원-결합 단편(예를 들어, 본원에 기재된 항체의 임의의 항원-결합 단편), VHH-scAb, VHH-Fab, 이중 scFab, F(ab')2, 디아바디, crossMab, DAF(투-인-원), DAF(포-인-원), DutaMab, DT-IgG, 놉스-인 홀 공통 경쇄, 놉스-인-홀 조립체, 전하쌍, Fab-아암 교환, SEED바디, LUZ-Y, Fcab, κλ-바디, 오르토고날 Fab, DVD-IgG, IgG(H)-scFv, scFv-(H)IgG, IgG(L)-scFv, scFv-(L)IgG, IgG(L,H)-Fv, IgG(H)-V, V(H)-IgG, IgG(L)-V, V(L)-IgG, KIH IgG-scFab, 2scFv-IgG, IgG-2scFv, scFv4-Ig, Zybody, DVI-IgG, 디아바디-CH3, 트리플바디, 미니항체, 미니바디, TriBi 미니바디, scFv-CH3 KIH, Fab-scFv, F(ab')2-scFv2, scFv-KIH, Fab-scFv-Fc, 4가 HCAb, sc디아바디-Fc, 디아바디-Fc, 탠덤 scFv-Fc, 인트라체, 도크 앤드 록, lmmTAC, IgG-IgG 접합체, Cov-X-바디, 및 scFv1-PEG-scFv2를 형성할 수 있다. 예를 들어, 이들 요소의 설명에 대해 그 전체가 본원에 포함된 문헌[Spiesset al., Mol. Immunol. 67:95-106, 2015]를 참조한다. 항체의 항원-결합 단편의 비제한적인 예는 Fv 단편, Fab 단편, F(ab')2 단편, 및 Fab' 단편을 포함한다. 항체의 항원-결합 단편의 추가 예는 IgG의 항원-결합 단편(예를 들어, IgG1, IgG2, IgG3, 또는 IgG4의 항원-결합 단편)(예를 들어, 인간 또는 인간화 IgG, 예를 들어, 인간 또는 인간화 IgG1, IgG2, IgG3, 또는 IgG4의 항원-결합 단편); IgA의 항원-결합 단편(예를 들어, IgA1 또는 IgA2의 항원-결합 단편)(예를 들어, 인간 또는 인간화 IgA, 예를 들어, 인간 또는 인간화 IgA1 또는 IgA2의 항원-결합 단편); IgD의 항원-결합 단편(예를 들어, 인간 또는 인간화 IgD의 항원-결합 단편); IgE의 항원-결합 단편(예를 들어, 인간 또는 인간화 IgE의 항원-결합 단편); 또는 IgM의 항원-결합 단편의 항원-결합 단편(예를 들어, 인간 또는 인간화 IgM의 항원-결합 단편)이다.
잠복기-관련 펩타이드(LAP)에 결합하는 제제
잠복기-관련 펩타이드(LAP)에 결합하는 제제의 비제한적인 예는 TGF-β1, 트롬보스폰딘-1(TSP-1), 인테그린 αvβ6, 또는 KRFK 펩타이드이다. 일부 구현예에서, LAP는 TGF-β1에 결합하여 잠복 복합체를 형성하고, 상기 LAP는 활성 TGF-β1에 대한 격리제로서 기능을 하는 것으로 추정된다. 일부 구현예에서, 잠복 TGF-β 복합체의 LAP는 또한 생물학적 활성 복합체의 부분으로서 트롬보스폰딘-1(TSP-1)과 상호작용한다. TSP-1/LAP 복합체 형성은 TGF- β1-5에 보존되는 LAP의 아미노 말단 부근에 TPS-1의 활성화 서열(KRFK) 및 서열(LSKL)을 수반한다. LSKL 및 KRFK 서열을 통한 LAP와 TSP-1의 상호작용은, LSKL 펩타이드가 TSP-1 또는 KRFK-함유 펩타이드에 의해 잠복 TGF-β 활성화를 경쟁적으로 저해할 수 있기 때문에 잠복 TGF-β의 트롬보스폰딘-매개 활성화에 중요하다. 일부 구현예에서, 인테그린 αvβ6은 TGF-β1 LAP에 대해 높은 친화도를 갖고 TGF-β1 잠복 복합체의 활성화에 참여하는 것으로 제시되었다.
TGF-β/LAP 복합체에 결합하는 제제
TFG-β/LAP 복합체에 결합하는 제제의 비제한적인 예는 잠복 TGF-β 결합 단백질(LTBP)이다. 일부 구현예에서, 잠복 TGF-β 결합 단백질(LTBP)은 TFG-β/LAP 복합체에 결합하여, 큰 잠복 복합체(LLC)라고 하는 더 큰 복합체를 형성한다. 일부 구현예에서, LTBP는 LTBP-1, LTBP-2, LTBP-3 및 LTBP-4를 포함한다. 일부 구현예에서, LTBP-1은 소포체에서 TGFβ 프로펩타이드(예를 들어, LAP)와 이황화 연결 복합체를 형성한다. 일부 구현예에서, LTBP-4는 TGF-β1에만 결합하므로, LTBP-4에서의 돌연변이는 TGF-β1을 대체로 수반하는 조직에 특이적인 TGF-β 관련 합병증을 유발할 수 있다.
투여 방법
본원에 기재된 방법의 일부 구현예는 대상체에게 1개 또는 2개 이상(예를 들어, 3개 이상, 4개 이상, 5개 이상, 6개 이상, 7개 이상, 8개 이상, 9개 이상, 또는 10개 이상)의 용량의, TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함한다. 이들 방법의 일부 구현예에서, 2개 이상의 용량 중 임의의 2개의 연속 용량은 약 1주 내지 약 1년 간격을 두고(예를 들어, 약 1주 내지 약 11개월, 약 1주 내지 약 10개월, 약 1주 내지 약 9개월, 약 1주 내지 약 8개월, 약 1주 내지 약 7개월, 약 1주 내지 약 6개월, 약 1주 내지 약 5개월, 약 1주 내지 약 4개월, 약 1주 내지 약 3개월, 약 1주 내지 약 2개월, 약 1주 내지 약 1개월, 약 1주 내지 약 3주, 약 1주 내지 약 2주, 약 2주 내지 약 12개월, 약 2주 내지 약 11개월, 약 2주 내지 약 10개월, 약 2주 내지 약 9개월, 약 2주 내지 약 8개월, 약 2주 내지 약 7개월, 약 2주 내지 약 6개월, 약 2주 내지 약 5개월, 약 2주 내지 약 4개월, 약 2주 내지 약 3개월, 약 2주 내지 약 2개월, 약 2주 내지 약 1개월, 약 2주 내지 약 3주, 약 3주 내지 약 12개월, 약 3주 내지 약 11개월, 약 3주 내지 약 10개월, 약 3주 내지 약 9개월, 약 3주 내지 약 8개월, 약 3주 내지 약 7개월, 약 3주 내지 약 6개월, 약 3주 내지 약 5개월, 약 3주 내지 약 4개월, 약 3주 내지 약 3개월, 약 3주 내지 약 2개월, 약 3주 내지 약 1개월, 약 1개월 내지 약 12개월, 약 1개월 내지 약 11개월, 약 1개월 내지 약 10개월, 약 1개월 내지 약 9개월, 약 1개월 내지 약 8개월, 약 1개월 내지 약 7개월, 약 1개월 내지 약 6개월, 약 1개월 내지 약 5개월, 약 1개월 내지 약 4개월, 약 1개월 내지 약 3개월, 약 1개월 내지 약 2개월, 약 2개월 내지 약 12개월, 약 2개월 내지 약 11개월, 약 2개월 내지 약 10개월, 약 2개월 내지 약 9개월, 약 2개월 내지 약 8개월, 약 2개월 내지 약 7개월, 약 2개월 내지 약 6개월, 약 2개월 내지 약 5개월, 약 2개월 내지 약 4개월, 약 2개월 내지 약 3개월, 약 3개월 내지 약 12개월, 약 3개월 내지 약 11개월, 약 3개월 내지 약 10개월, 약 3개월 내지 약 9개월, 약 3개월 내지 약 8개월, 약 3개월 내지 약 7개월, 약 3개월 내지 약 6개월, 약 3개월 내지 약 5개월, 약 3개월 내지 약 4개월, 약 4개월 내지 약 12개월, 약 4개월 내지 약 11개월, 약 4개월 내지 약 10개월, 약 4개월 내지 약 9개월, 약 4개월 내지 약 8개월, 약 4개월 내지 약 7개월, 약 4개월 내지 약 6개월, 약 4개월 내지 약 5개월, 약 4개월 내지 약 4개월, 약 5개월 내지 약 12개월, 약 5개월 내지 약 11개월, 약 5개월 내지 약 10개월, 약 5개월 내지 약 9개월, 약 5개월 내지 약 8개월, 약 5개월 내지 약 7개월, 약 5개월 내지 약 6개월, 약 6개월 내지 약 12개월, 약 6개월 내지 약 11개월, 약 6개월 내지 약 10개월, 약 6개월 내지 약 9개월, 약 6개월 내지 약 8개월, 약 6개월 내지 약 7개월, 약 7개월 내지 약 12개월, 약 7개월 내지 약 11개월, 약 7개월 내지 약 10개월, 약 7개월 내지 약 9개월, 약 7개월 내지 약 8개월, 약 8개월 내지 약 12개월, 약 8개월 내지 약 11개월, 약 8개월 내지 약 10개월, 약 8개월 내지 약 9개월, 약 9개월 내지 약 12개월, 약 9개월 내지 약 11개월, 약 9개월 내지 약 10개월, 약 10개월 내지 약 12개월, 약 10개월 내지 약 11개월, 또는 약 11개월 내지 약 12개월 간격을 두고) 투여된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 1개 또는 2개 이상의 용량은 피하 투여에 의해 투여된다. 본원에 기재된 임의의 방법의 일부 구현예에서, 1개 또는 2개 이상의 용량은 근육내 투여에 의해 투여된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 2개 이상의 용량은 약 1년 내지 약 60년(예를 들어, 약 1년 내지 약 55년, 약 1년 내지 약 50년, 약 1년 내지 약 45년, 약 1년 내지 약 40년, 약 1년 내지 약 35년, 약 1년 내지 약 30년, 약 1년 내지 약 25년, 약 1년 내지 약 20년, 약 1년 내지 약 15년, 약 1년 내지 약 10년, 약 1년 내지 약 5년, 약 5년 내지 약 60년, 약 5년 내지 약 55년, 약 5년 내지 약 50년, 약 5년 내지 약 45년, 약 5년 내지 약 40년, 약 5년 내지 약 35년, 약 5년 내지 약 30년, 약 5년 내지 약 25년, 약 5년 내지 약 20년, 약 5년 내지 약 15년, 약 5년 내지 약 10년, 약 10년 내지 약 60년, 약 10년 내지 약 55년, 약 10년 내지 약 50년, 약 10년 내지 약 45년, 약 10년 내지 약 40년, 약 10년 내지 약 35년, 약 10년 내지 약 30년, 약 10년 내지 약 25년, 약 10년 내지 약 20년, 약 10년 내지 약 15년, 약 15년 내지 약 60년, 약 15년 내지 약 55년, 약 15년 내지 약 50년, 약 15년 내지 약 45년, 약 15년 내지 약 40년, 약 15년 내지 약 35년, 약 15년 내지 약 30년, 약 15년 내지 약 25년, 약 15년 내지 약 20년, 약 20년 내지 약 60년, 약 20년 내지 약 55년, 약 20년 내지 약 50년, 약 20년 내지 약 45년, 약 20년 내지 약 40년, 약 20년 내지 약 35년, 약 20년 내지 약 30년, 약 20년 내지 약 25년, 약 25년 내지 약 60년, 약 25년 내지 약 55년, 약 25년 내지 약 50년, 약 25년 내지 약 45년, 약 25년 내지 약 40년, 약 25년 내지 약 35년, 약 25년 내지 약 30년, 약 30년 내지 약 60년, 약 30년 내지 약 55년, 약 30년 내지 약 50년, 약 30년 내지 약 45년, 약 30년 내지 약 40년, 약 30년 내지 약 35년, 약 35년 내지 약 60년, 약 35년 내지 약 55년, 약 35년 내지 약 50년, 약 35년 내지 약 45년, 약 35년 내지 약 40년, 약 40년 내지 약 60년, 약 40년 내지 약 55년, 약 40년 내지 약 50년, 약 40년 내지 약 45년, 약 45년 내지 약 60년, 약 45년 내지 약 55년, 약 45년 내지 약 50년, 약 50년 내지 약 60년, 약 50년 내지 약 55년, 또는 약 55년 내지 약 60년)의 시간의 기간에 걸쳐 투여된다.
이들 방법의 일부 구현예에서, 1개 또는 2개 이상의 용량 각각은, kg당 약 0.01 mg의 TGF-β 수용체의 활성화의 저하를 초래하는 각각의 제제 내지 kg당 약 10 mg의 TGF-β 수용체의 활성화의 저하를 초래하는 각각의 제제(예를 들어, 약 0.01 mg/kg 내지 약 9 mg/kg, 약 0.01 mg/kg 내지 약 8 mg/kg, 약 0.01 mg/kg 내지 약 7 mg/kg, 약 0.01 mg/kg 내지 약 6 mg/kg, 약 0.01 mg/kg 내지 약 5 mg/kg, 약 0.01 mg/kg 내지 약 4 mg/kg, 약 0.01 mg/kg 내지 약 3 mg/kg, 약 0.01 mg/kg 내지 약 2 mg/kg, 약 0.01 mg/kg 내지 약 1 mg/kg, 약 0.01 mg/kg 내지 약 0.5 mg/kg, 약 0.01 mg/kg 내지 약 0.1 mg/kg, 약 0.01 mg/kg 내지 약 0.05 mg/kg, 약 0.05 mg/kg 내지 약 10 mg/kg, 약 0.05 mg/kg 내지 약 9 mg/kg, 약 0.05 mg/kg 내지 약 8 mg/kg, 약 0.05 mg/kg 내지 약 7 mg/kg, 약 0.05 mg/kg 내지 약 6 mg/kg, 약 0.05 mg/kg 내지 약 5 mg/kg, 약 0.05 mg/kg 내지 약 4 mg/kg, 약 0.05 mg/kg 내지 약 3 mg/kg, 약 0.05 mg/kg 내지 약 2 mg/kg, 약 0.05 mg/kg 내지 약 1 mg/kg, 약 0.05 mg/kg 내지 약 0.5 mg/kg, 약 0.05 mg/kg 내지 약 0.1 mg/kg, 약 0.1 mg/kg 내지 약 10 mg/kg, 약 0.1 mg/kg 내지 약 9 mg/kg, 약 0.1 mg/kg 내지 약 8 mg/kg, 약 0.1 mg/kg 내지 약 7 mg/kg, 약 0.1 mg/kg 내지 약 6 mg/kg, 약 0.1 mg/kg 내지 약 5 mg/kg, 약 0.1 mg/kg 내지 약 4 mg/kg, 약 0.1 mg/kg 내지 약 3 mg/kg, 약 0.1 mg/kg 내지 약 2 mg/kg, 약 0.1 mg/kg 내지 약 1 mg/kg, 약 0.1 mg/kg 내지 약 0.5 mg/kg, 약 0.5 mg/kg 내지 약 10 mg/kg, 약 0.5 mg/kg 내지 약 9 mg/kg, 약 0.5 mg/kg 내지 약 8 mg/kg, 약 0.5 mg/kg 내지 약 7 mg/kg, 약 0.5 mg/kg 내지 약 6 mg/kg, 약 0.5 mg/kg 내지 약 5 mg/kg, 약 0.5 mg/kg 내지 약 4 mg/kg, 약 0.5 mg/kg 내지 약 3 mg/kg, 약 0.5 mg/kg 내지 약 2 mg/kg, 약 0.5 mg/kg 내지 약 1 mg/kg, 약 1 mg/kg 내지 약 10 mg/kg, 약 1 mg/kg 내지 약 9 mg/kg, 약 1 mg/kg 내지 약 8 mg/kg, 약 1 mg/kg 내지 약 7 mg/kg, 약 1 mg/kg 내지 약 6 mg/kg, 약 1 mg/kg 내지 약 5 mg/kg, 약 1 mg/kg 내지 약 4 mg/kg, 약 1 mg/kg 내지 약 3 mg/kg, 약 1 mg/kg 내지 약 2 mg/kg, 약 2 mg/kg 내지 약 10 mg/kg, 약 2 mg/kg 내지 약 9 mg/kg, 약 2 mg/kg 내지 약 8 mg/kg, 약 2 mg/kg 내지 약 7 mg/kg, 약 2 mg/kg 내지 약 6 mg/kg, 약 2 mg/kg 내지 약 5 mg/kg, 약 2 mg/kg 내지 약 4 mg/kg, 약 2 mg/kg 내지 약 3 mg/kg, 약 3 mg/kg 내지 약 10 mg/kg, 약 3 mg/kg 내지 약 9 mg/kg, 약 3 mg/kg 내지 약 8 mg/kg, 약 3 mg/kg 내지 약 7 mg/kg, 약 3 mg/kg 내지 약 6 mg/kg, 약 3 mg/kg 내지 약 5 mg/kg, 약 3 mg/kg 내지 약 4 mg/kg, 약 4 mg/kg 내지 약 10 mg/kg, 약 4 mg/kg 내지 약 9 mg/kg, 약 4 mg/kg 내지 약 8 mg/kg, 약 4 mg/kg 내지 약 7 mg/kg, 약 4 mg/kg 내지 약 6 mg/kg, 약 4 mg/kg 내지 약 5 mg/kg, 약 5 mg/kg 내지 약 10 mg/kg, 약 5 mg/kg 내지 약 9 mg/kg, 약 5 mg/kg 내지 약 8 mg/kg, 약 5 mg/kg 내지 약 7 mg/kg, 약 5 mg/kg 내지 약 6 mg/kg, 약 6 mg/kg 내지 약 10 mg/kg, 약 6 mg/kg 내지 약 9 mg/kg, 약 6 mg/kg 내지 약 8 mg/kg, 약 6 mg/kg 내지 약 7 mg/kg, 약 7 mg/kg 내지 약 10 mg/kg, 약 7 mg/kg 내지 약 9 mg/kg, 약 7 mg/kg 내지 약 8 mg/kg, 약 8 mg/kg 내지 약 10 mg/kg, 약 8 mg/kg 내지 약 9 mg/kg, 또는 약 8 mg/kg 내지 약 10 mg/kg의, TGF-β 수용체의 활성화의 저하를 초래하는 각각의 제제)의 투여량으로 투여된다.
이들 방법의 일부 구현예에서, TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)의 단일 또는 최초 용량은 대상체가 적어도 30세(예를 들어, 적어도 32세, 34세, 36세, 38세, 40세, 42세, 44세, 46세, 48세, 50세, 52세, 54세, 56세, 58세, 60세, 62세, 65세, 70세, 75세, 또는 80세)의 연령에 도달할 때 시작한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 대상체는 노화-관련 질환(예를 들어, 본원에 기재되거나 당업계에 알려진 임의의 노화-관련 질환 또는 병태) 또는 염증성 질환(예를 들어, 본원에 기재되거나 당업계에 알려진 임의의 염증성 질환)을 갖는 것으로 진단되거나 식별되지 않는다. 본원에 기재된 임의의 방법의 일부 구현예에서, 대상체는 이전에 화학요법제(예를 들어, 본원에 기재되거나 당업계에 알려진 임의의 화학요법제)로 치료된 적이 없다. 본원에 기재된 임의의 방법의 일부 구현예에서, 대상체는 이전에 세포 노쇠를 유도하는 치료제(예를 들어 본원에 기재된 세포 노쇠를 유도하는 임의의 추가 치료제)로 치료된 적이 없다.
본원에 기재된 방법의 일부 구현예는 대상체에게 1개 또는 2개 이상(예를 들어, 3개 이상, 4개 이상, 5개 이상, 6개 이상, 7개 이상, 8개 이상, 9개 이상, 또는 10개 이상)의 용량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함한다. 이들 방법의 일부 구현예에서, 2개 이상의 용량 중 임의의 2개의 연속 용량은 약 1주 내지 약 1년 간격을 두고(예를 들어, 약 1주 내지 약 11개월, 약 1주 내지 약 10개월, 약 1주 내지 약 9개월, 약 1주 내지 약 8개월, 약 1주 내지 약 7개월, 약 1주 내지 약 6개월, 약 1주 내지 약 5개월, 약 1주 내지 약 4개월, 약 1주 내지 약 3개월, 약 1주 내지 약 2개월, 약 1주 내지 약 1개월, 약 1주 내지 약 3주, 약 1주 내지 약 2주, 약 2주 내지 약 12개월, 약 2주 내지 약 11개월, 약 2주 내지 약 10개월, 약 2주 내지 약 9개월, 약 2주 내지 약 8개월, 약 2주 내지 약 7개월, 약 2주 내지 약 6개월, 약 2주 내지 약 5개월, 약 2주 내지 약 4개월, 약 2주 내지 약 3개월, 약 2주 내지 약 2개월, 약 2주 내지 약 1개월, 약 2주 내지 약 3주, 약 3주 내지 약 12개월, 약 3주 내지 약 11개월, 약 3주 내지 약 10개월, 약 3주 내지 약 9개월, 약 3주 내지 약 8개월, 약 3주 내지 약 7개월, 약 3주 내지 약 6개월, 약 3주 내지 약 5개월, 약 3주 내지 약 4개월, 약 3주 내지 약 3개월, 약 3주 내지 약 2개월, 약 3주 내지 약 1개월, 약 1개월 내지 약 12개월, 약 1개월 내지 약 11개월, 약 1개월 내지 약 10개월, 약 1개월 내지 약 9개월, 약 1개월 내지 약 8개월, 약 1개월 내지 약 7개월, 약 1개월 내지 약 6개월, 약 1개월 내지 약 5개월, 약 1개월 내지 약 4개월, 약 1개월 내지 약 3개월, 약 1개월 내지 약 2개월, 약 2개월 내지 약 12개월, 약 2개월 내지 약 11개월, 약 2개월 내지 약 10개월, 약 2개월 내지 약 9개월, 약 2개월 내지 약 8개월, 약 2개월 내지 약 7개월, 약 2개월 내지 약 6개월, 약 2개월 내지 약 5개월, 약 2개월 내지 약 4개월, 약 2개월 내지 약 3개월, 약 3개월 내지 약 12개월, 약 3개월 내지 약 11개월, 약 3개월 내지 약 10개월, 약 3개월 내지 약 9개월, 약 3개월 내지 약 8개월, 약 3개월 내지 약 7개월, 약 3개월 내지 약 6개월, 약 3개월 내지 약 5개월, 약 3개월 내지 약 4개월, 약 4개월 내지 약 12개월, 약 4개월 내지 약 11개월, 약 4개월 내지 약 10개월, 약 4개월 내지 약 9개월, 약 4개월 내지 약 8개월, 약 4개월 내지 약 7개월, 약 4개월 내지 약 6개월, 약 4개월 내지 약 5개월, 약 4개월 내지 약 4개월, 약 5개월 내지 약 12개월, 약 5개월 내지 약 11개월, 약 5개월 내지 약 10개월, 약 5개월 내지 약 9개월, 약 5개월 내지 약 8개월, 약 5개월 내지 약 7개월, 약 5개월 내지 약 6개월, 약 6개월 내지 약 12개월, 약 6개월 내지 약 11개월, 약 6개월 내지 약 10개월, 약 6개월 내지 약 9개월, 약 6개월 내지 약 8개월, 약 6개월 내지 약 7개월, 약 7개월 내지 약 12개월, 약 7개월 내지 약 11개월, 약 7개월 내지 약 10개월, 약 7개월 내지 약 9개월, 약 7개월 내지 약 8개월, 약 8개월 내지 약 12개월, 약 8개월 내지 약 11개월, 약 8개월 내지 약 10개월, 약 8개월 내지 약 9개월, 약 9개월 내지 약 12개월, 약 9개월 내지 약 11개월, 약 9개월 내지 약 10개월, 약 10개월 내지 약 12개월, 약 10개월 내지 약 11개월, 또는 약 11개월 내지 약 12개월 간격을 두고) 투여된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 1개 또는 2개 이상의 용량은 피하 투여에 의해 투여된다. 본원에 기재된 임의의 방법의 일부 구현예에서, 1개 또는 2개 이상의 용량은 근육내 투여에 의해 투여된다.
본원에 기재된 임의의 방법의 일부 구현예에서, 2개 이상의 용량은 약 1년 내지 약 60년(예를 들어, 약 1년 내지 약 55년, 약 1년 내지 약 50년, 약 1년 내지 약 45년, 약 1년 내지 약 40년, 약 1년 내지 약 35년, 약 1년 내지 약 30년, 약 1년 내지 약 25년, 약 1년 내지 약 20년, 약 1년 내지 약 15년, 약 1년 내지 약 10년, 약 1년 내지 약 5년, 약 5년 내지 약 60년, 약 5년 내지 약 55년, 약 5년 내지 약 50년, 약 5년 내지 약 45년, 약 5년 내지 약 40년, 약 5년 내지 약 35년, 약 5년 내지 약 30년, 약 5년 내지 약 25년, 약 5년 내지 약 20년, 약 5년 내지 약 15년, 약 5년 내지 약 10년, 약 10년 내지 약 60년, 약 10년 내지 약 55년, 약 10년 내지 약 50년, 약 10년 내지 약 45년, 약 10년 내지 약 40년, 약 10년 내지 약 35년, 약 10년 내지 약 30년, 약 10년 내지 약 25년, 약 10년 내지 약 20년, 약 10년 내지 약 15년, 약 15년 내지 약 60년, 약 15년 내지 약 55년, 약 15년 내지 약 50년, 약 15년 내지 약 45년, 약 15년 내지 약 40년, 약 15년 내지 약 35년, 약 15년 내지 약 30년, 약 15년 내지 약 25년, 약 15년 내지 약 20년, 약 20년 내지 약 60년, 약 20년 내지 약 55년, 약 20년 내지 약 50년, 약 20년 내지 약 45년, 약 20년 내지 약 40년, 약 20년 내지 약 35년, 약 20년 내지 약 30년, 약 20년 내지 약 25년, 약 25년 내지 약 60년, 약 25년 내지 약 55년, 약 25년 내지 약 50년, 약 25년 내지 약 45년, 약 25년 내지 약 40년, 약 25년 내지 약 35년, 약 25년 내지 약 30년, 약 30년 내지 약 60년, 약 30년 내지 약 55년, 약 30년 내지 약 50년, 약 30년 내지 약 45년, 약 30년 내지 약 40년, 약 30년 내지 약 35년, 약 35년 내지 약 60년, 약 35년 내지 약 55년, 약 35년 내지 약 50년, 약 35년 내지 약 45년, 약 35년 내지 약 40년, 약 40년 내지 약 60년, 약 40년 내지 약 55년, 약 40년 내지 약 50년, 약 40년 내지 약 45년, 약 45년 내지 약 60년, 약 45년 내지 약 55년, 약 45년 내지 약 50년, 약 50년 내지 약 60년, 약 50년 내지 약 55년, 또는 약 55년 내지 약 60년)의 시간의 기간에 걸쳐 투여된다.
이들 방법의 일부 구현예에서, 1개 또는 2개 이상의 용량 각각은, kg당 약 0.01 mg의 각각의 공통 감마-사슬 계열 사이토카인 수용체 활성화제 내지 kg당 약 10 mg의 각각의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(예를 들어, 약 0.01 mg/kg 내지 약 9 mg/kg, 약 0.01 mg/kg 내지 약 8 mg/kg, 약 0.01 mg/kg 내지 약 7 mg/kg, 약 0.01 mg/kg 내지 약 6 mg/kg, 약 0.01 mg/kg 내지 약 5 mg/kg, 약 0.01 mg/kg 내지 약 4 mg/kg, 약 0.01 mg/kg 내지 약 3 mg/kg, 약 0.01 mg/kg 내지 약 2 mg/kg, 약 0.01 mg/kg 내지 약 1 mg/kg, 약 0.01 mg/kg 내지 약 0.5 mg/kg, 약 0.01 mg/kg 내지 약 0.1 mg/kg, 약 0.01 mg/kg 내지 약 0.05 mg/kg, 약 0.05 mg/kg 내지 약 10 mg/kg, 약 0.05 mg/kg 내지 약 9 mg/kg, 약 0.05 mg/kg 내지 약 8 mg/kg, 약 0.05 mg/kg 내지 약 7 mg/kg, 약 0.05 mg/kg 내지 약 6 mg/kg, 약 0.05 mg/kg 내지 약 5 mg/kg, 약 0.05 mg/kg 내지 약 4 mg/kg, 약 0.05 mg/kg 내지 약 3 mg/kg, 약 0.05 mg/kg 내지 약 2 mg/kg, 약 0.05 mg/kg 내지 약 1 mg/kg, 약 0.05 mg/kg 내지 약 0.5 mg/kg, 약 0.05 mg/kg 내지 약 0.1 mg/kg, 약 0.1 mg/kg 내지 약 10 mg/kg, 약 0.1 mg/kg 내지 약 9 mg/kg, 약 0.1 mg/kg 내지 약 8 mg/kg, 약 0.1 mg/kg 내지 약 7 mg/kg, 약 0.1 mg/kg 내지 약 6 mg/kg, 약 0.1 mg/kg 내지 약 5 mg/kg, 약 0.1 mg/kg 내지 약 4 mg/kg, 약 0.1 mg/kg 내지 약 3 mg/kg, 약 0.1 mg/kg 내지 약 2 mg/kg, 약 0.1 mg/kg 내지 약 1 mg/kg, 약 0.1 mg/kg 내지 약 0.5 mg/kg, 약 0.5 mg/kg 내지 약 10 mg/kg, 약 0.5 mg/kg 내지 약 9 mg/kg, 약 0.5 mg/kg 내지 약 8 mg/kg, 약 0.5 mg/kg 내지 약 7 mg/kg, 약 0.5 mg/kg 내지 약 6 mg/kg, 약 0.5 mg/kg 내지 약 5 mg/kg, 약 0.5 mg/kg 내지 약 4 mg/kg, 약 0.5 mg/kg 내지 약 3 mg/kg, 약 0.5 mg/kg 내지 약 2 mg/kg, 약 0.5 mg/kg 내지 약 1 mg/kg, 약 1 mg/kg 내지 약 10 mg/kg, 약 1 mg/kg 내지 약 9 mg/kg, 약 1 mg/kg 내지 약 8 mg/kg, 약 1 mg/kg 내지 약 7 mg/kg, 약 1 mg/kg 내지 약 6 mg/kg, 약 1 mg/kg 내지 약 5 mg/kg, 약 1 mg/kg 내지 약 4 mg/kg, 약 1 mg/kg 내지 약 3 mg/kg, 약 1 mg/kg 내지 약 2 mg/kg, 약 2 mg/kg 내지 약 10 mg/kg, 약 2 mg/kg 내지 약 9 mg/kg, 약 2 mg/kg 내지 약 8 mg/kg, 약 2 mg/kg 내지 약 7 mg/kg, 약 2 mg/kg 내지 약 6 mg/kg, 약 2 mg/kg 내지 약 5 mg/kg, 약 2 mg/kg 내지 약 4 mg/kg, 약 2 mg/kg 내지 약 3 mg/kg, 약 3 mg/kg 내지 약 10 mg/kg, 약 3 mg/kg 내지 약 9 mg/kg, 약 3 mg/kg 내지 약 8 mg/kg, 약 3 mg/kg 내지 약 7 mg/kg, 약 3 mg/kg 내지 약 6 mg/kg, 약 3 mg/kg 내지 약 5 mg/kg, 약 3 mg/kg 내지 약 4 mg/kg, 약 4 mg/kg 내지 약 10 mg/kg, 약 4 mg/kg 내지 약 9 mg/kg, 약 4 mg/kg 내지 약 8 mg/kg, 약 4 mg/kg 내지 약 7 mg/kg, 약 4 mg/kg 내지 약 6 mg/kg, 약 4 mg/kg 내지 약 5 mg/kg, 약 5 mg/kg 내지 약 10 mg/kg, 약 5 mg/kg 내지 약 9 mg/kg, 약 5 mg/kg 내지 약 8 mg/kg, 약 5 mg/kg 내지 약 7 mg/kg, 약 5 mg/kg 내지 약 6 mg/kg, 약 6 mg/kg 내지 약 10 mg/kg, 약 6 mg/kg 내지 약 9 mg/kg, 약 6 mg/kg 내지 약 8 mg/kg, 약 6 mg/kg 내지 약 7 mg/kg, 약 7 mg/kg 내지 약 10 mg/kg, 약 7 mg/kg 내지 약 9 mg/kg, 약 7 mg/kg 내지 약 8 mg/kg, 약 8 mg/kg 내지 약 10 mg/kg, 약 8 mg/kg 내지 약 9 mg/kg, 또는 약 8 mg/kg 내지 약 10 mg/kg의 각각의 공통 감마-사슬 계열 사이토카인 수용체 활성화제)의 투여량으로 투여된다.
이들 방법의 일부 구현예에서, 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)의 단일 또는 최초 용량은 대상체가 적어도 30세(예를 들어, 적어도 32세, 34세, 36세, 38세, 40세, 42세, 44세, 46세, 48세, 50세, 52세, 54세, 56세, 58세, 60세, 62세, 65세, 70세, 75세, 또는 80세)의 연령에 도달할 때 시작한다.
본원에 기재된 임의의 방법의 일부 구현예에서, 대상체는 노화-관련 질환(예를 들어, 본원에 기재되거나 당업계에 알려진 임의의 노화-관련 질환 또는 병태) 또는 염증성 질환(예를 들어, 본원에 기재되거나 당업계에 알려진 임의의 염증성 질환)을 갖는 것으로 진단되거나 식별되지 않는다. 본원에 기재된 임의의 방법의 일부 구현예에서, 대상체는 이전에 화학요법제(예를 들어, 본원에 기재되거나 당업계에 알려진 임의의 화학요법제)로 치료된 적이 없다. 본원에 기재된 임의의 방법의 일부 구현예에서, 대상체는 이전에 세포 노쇠를 유도하는 치료제(예를 들어 본원에 기재된 세포 노쇠를 유도하는 임의의 추가 치료제)로 치료된 적이 없다.
실시예
본 발명은 하기 실시예에서 추가로 기재되며, 이 실시예는 청구항에 기재된 본 발명의 범위를 제한하지 않는다.
실시예 1: C57BL/6 마우스에서 다중-사슬 폴리펩타이드를 사용한 면역자극
재료 및 방법
제1 폴리펩타이드 및 제2 폴리펩타이드를 포함하는 예시적인 다중-사슬 폴리펩타이드(본원에 기재된 A형 다중-사슬 폴리펩타이드)를 생성하였고, 상기 제1 폴리펩타이드는 2개의 TGFβRII 도메인, 인간 조직 인자 219 단편, 및 인간 IL-15의 가용성 융합이고, 제2 폴리펩타이드는 2개의 TGFβRII 도메인과 인간 IL-15Rα 사슬의 sushi 도메인의 가용성 융합이다.
결과
C57BL/6 마우스에서의 면역자극
야생형 C57BL/6 마우스를 대조군 PBS 용액으로 또는 0.3 mg/kg, 1 mg/kg, 3 mg/kg, 또는 10 mg/kg의 투약량에서 다중-사슬 폴리펩타이드로 피하 치료하였다. 치료 후 4일째에, 비장 중량 및 비장에 존재하는 다양한 면역 세포 유형의 백분율을 평가하였다. 구체적으로, 단일 비장세포 현탁액을 생성하였고, 항-CD4, 항-CD8, 항-NK1.1, 및 항-CD19를 포함하는 형광단-접합 항체로 염색하였다. 대조군 용액 또는 다중-사슬 폴리펩타이드로 치료된 마우스의 비장에 존재하는 CD4+ T 세포, CD8+ T 세포, 자연 살해(NK) 세포, 및 CD19+ B 세포의 백분율을 유세포측정법을 사용하여 평가하였다. 도 1a에 도시된 바와 같이, 다중-사슬 폴리펩타이드로 치료된 마우스에서 비장 중량은 다중-사슬 폴리펩타이드의 증가하는 투약량에 따라 증가하였다. 더욱이, 1 mg/kg, 3 mg/kg, 및 10 mg/kg의 다중-사슬 폴리펩타이드로 치료된 마우스에서 비장 중량은 대조군 용액으로 치료된 마우스와 비교하여 각각 유의하게 더 무거웠다. 도 1b에 도시된 바와 같이, 다중-사슬 폴리펩타이드로 치료된 마우스의 비장에서, CD8+ T 세포와 NK 세포 둘 다의 백분율은 다중-사슬 폴리펩타이드의 증가하는 투약량에 따라 증가하였다. 구체적으로, CD8+ T 세포의 백분율은 대조군-치료 마우스와 비교하여 0.3 mg/kg, 3 mg/kg, 및 10 mg/kg의 다중-사슬 폴리펩타이드로 치료된 마우스에서 더 높았고, NK 세포의 백분율은 대조군-치료 마우스와 비교하여 0.3 mg/kg, 1 mg/kg, 3 mg/kg, 및 10 mg/kg의 다중-사슬 폴리펩타이드로 치료된 마우스에서 더 높았다. 이들 결과는, 예시적인 다중-사슬 폴리펩타이드가 비장에서 면역 세포, 특히 CD8+ T 세포 및 NK 세포를 자극시킬 수 있음을 실증한다.
약물동력학
예시적인 다중-사슬 폴리펩타이드의 약물동력학을 야생형 C57BL/6 마우스에서 평가하였다. 상기 마우스를 3 mg/kg의 투약량에서 다중-사슬 폴리펩타이드로 피하 치료하였다. 혈액을 다양한 시점에서 꼬리 정맥을 통해 채혈하고, 혈청을 제조하였다. 혈청 내 다중-사슬 폴리펩타이드의 농도를 ELISA로 결정하였다. 간략하게는, 다중-사슬 폴리펩타이드를 항-인간 조직 인자 항체를 사용하여 포착하고, 비오틴화된 항-인간 TGFβ 수용체, 퍼옥시다제 접합 스트렙타비딘, 및 ABTS 기질을 사용하여 검출하였다. 결과는 예시적인 다중-사슬 폴리펩타이드의 반감기가 12.66시간이었음을 보여주었다.
C57BL/6 마우스에서 시간 경과에 따른 면역자극
시간 경과에 따른 다중-사슬 폴리펩타이드에 의한 면역자극의 효과를 평가하기 위해, 마우스를 3 mg/kg에서 단회 용량의 다중-사슬 폴리펩타이드로 치료하였고, 비장 중량 및 비장에 존재하는 면역 세포 유형의 백분율을 위에 기재된 기법을 사용하여 치료 즉시 그리고 치료 후 16시간, 24시간, 48시간, 72시간, 및 92시간째에 평가하였다. 도 2a에 도시된 바와 같이, 다중-사슬 폴리펩타이드로 치료된 마우스에서 비장 중량은 치료 후 48시간째에 증가하였고, 다음 44시간에 걸쳐 계속 증가하였다. 더욱이, 도 2b에 도시된 바와 같이, 다중-사슬 폴리펩타이드로 치료된 마우스의 비장에서 CD8+ T 세포와 NK 세포 둘 다의 백분율은 치료 후 48시간째에 증가하였고, 다음 44시간에 걸쳐 계속 증가하였다. 이들 결과는, 예시적인 다중-사슬 폴리펩타이드가 시간 경과에 걸쳐 비장에서 면역 세포, 특히 CD8+ T 세포 및 NK 세포를 자극시킬 수 있음을 추가로 실증한다.
CD8
+
T 세포 및 NK 세포에 의한 증가된 증식 및 그랜자임 B 발현
다중-사슬 폴리펩타이드에 의해 유도되는 면역 세포의 증식 및 세포독성 잠재력을 평가하기 위해, 마우스를 3 mg/kg에서 단회 용량의 다중-사슬 폴리펩타이드로 치료하였고, 이들 마우스의 비장을 치료 즉시 그리고 치료 후 16시간, 24시간, 48시간, 72시간, 및 92시간째에 평가하였다. 간략하게는, 단일 비장세포 현탁액을 생성하였고, 항-CD4, 항-CD8, 항-NK1.1, 및 항-CD19를 포함하는 다양한 세포 유형에 대한 형광단-접합 항체로, 그리고 항-Ki67 항체(즉, 세포 증식 마커) 및 항-그랜자임 B 항체(즉, 세포독성 마커)로 염색하였다. 각각의 면역 세포 유형에 대한 Ki67 및 그랜자임 B의 평균치 형광 강도(MFI)를 유세포측정법에 의해 분석하였다. 도 3a 및 도 3b에 도시된 바와 같이, NK 세포에 의한 Ki67 및 그랜자임 B의 발현은 치료 후 즉시(0시간)와 비교하여 이후에 평가된 각각의 시점뿐만 아니라 24시간째에 증가를 보여주었다. 더욱이, CD8+ T 세포에 의한 Ki67 및 그랜자임 B의 발현은 치료 후 즉시(0시간)와 비교하여 이후에 평가된 각각의 시점뿐만 아니라 48시간째에 증가를 보여주었다. 이와 같이, 단회 용량의 다중-사슬 폴리펩타이드는 치료-후 최대 적어도 4일 동안 CD8+ T 세포 및 NK 세포의 증식을 초래하였다.
이들 결과는, 다중-사슬 폴리펩타이드가 비장 내 CD8+ T 세포 및 NK 세포의 수를 증가시켰을 뿐만 아니라, 이들 세포의 증식 및 세포독성을 증강시켰음을 실증한다.
종양 세포에 대한 세포독성
다음, 종양 세포에 대한 다중-사슬 폴리펩타이드에 의해 활성화된 비장세포의 세포독성은 C57BL/6 마우스에서 평가되었다. 마우스 몰로니 백혈병(Moloney leukemia) 세포(Yac-1)를 CellTrace 바이올렛으로 표지하고, 종양 표적 세포로서 사용하였다. C57BL/6 마우스를 3 mg/kg에서 단회 용량의 다중-사슬 폴리펩타이드로 치료하고, 비장세포를 이후 다양한 시점에서 준비하고 이펙터 세포로서 사용하였다. 표적 종양 세포를 이펙터 세포와 이펙터:표적(E:T) 비 = 10:1로 혼합하고, 37℃에서 20시간 동안 인큐베이션하였다. 유세포측정법을 사용하는 프로피디움 요오다이드(PI)-양성, 바이올렛-표지 Yac-1 세포를 분석함으로써 표적 세포 생존력을 평가하였다. Yac-1 종양 저해의 백분율은 하기 식을 사용하여 계산되었다:
Yac-1 종양 저해의 백분율 = (1-실험 시료 내 생존 Yac-1 세포의 수/비장세포가 없는 시료 내 생존 Yac-1 세포의 수) x 100.
도 4에 도시된 바와 같이, 다중-사슬 폴리펩타이드에 의한 24시간 이상의 치료 후 마우스로부터의 비장세포는 비치료된 마우스로부터의 비장세포와 비교하여 Yac-1 세포에 대해 증가된 세포독성을 보여주었다.
실시예 2: C57BL/6 마우스에서 고지방 식이요법-기초 2형 당뇨병 마우스 모델을 사용한 면역자극
재료 및 방법
TGFRt15-TGFRs는 가용성 인간 TGFβRII 이량체(aa24-159)인 2개의 TGFβ-결합 도메인을 포함하는 다중-사슬 키메라 폴리펩타이드(본원에 기재된 A형 다중-사슬 키메라 폴리펩타이드)이다. 21t15-TGFRs는 IL-21 및 TGFβ-결합 도메인을 포함하는 다중-사슬 키메라 폴리펩타이드(본원에 기재된 A형 다중-사슬 키메라 폴리펩타이드)이다. 2t2는 2개의 IL-2 폴리펩타이드를 포함하는 키메라 폴리펩타이드(본원에 기재된 B형 키메라 폴리펩타이드)이다.
결과
2형 당뇨병을 치료하는 데 있어서 TGFRt15-TGFRs, 2t2, 및 21t15-TGFRs의 효과를 평가하기 위해, 고지방 식이요법-기초 2형 당뇨병 마우스 모델(The Jackson Laboratory로부터의 B6.129P2-ApoEtm1Unc/J)을 사용하였다. 마우스를 대조군 식이요법 또는 고지방 식이요법으로 11주 동안 사육하였다. 고지방 식이요법으로 사육된 마우스 하위세트를 또한 TGFRt15-TGFRs, 2t2, 또는 21t15-TGFRs로 치료하였다. 대조군 식이요법, 고지방 식이요법으로 사육된 마우스, 및 고지방 식이요법으로 사육되고 TGFRt15-TGFRs, 2t2, 또는 21t15-TGFRs로 치료된 마우스를 치료-후 4일째에 평가하였다. 간략하게는, 단일 비장세포 현탁액을 생성하였고, 항-CD4, 항-CD8, 항-NK1.1, 및 항-CD19를 포함하는 형광단-접합 항체로 염색하였다. 각각의 군의 마우스의 비장에 존재하는 CD4+ T 세포, CD8+ T 세포, 자연 살해(NK) 세포, 및 CD19+ B 세포의 백분율을 유세포측정법을 사용하여 평가하였다.
도 5a에 도시된 바와 같이, 고지방 식이요법으로 사육된 마우스에서, PBMC 내 NK 세포의 백분율은 비치료 마우스와 비교하여 21t15-TGFRs를 이용한 치료 후가 아니라 TGFRt15-TGFRs 또는 2t2를 이용한 치료 후 유의하게 증가되었다. 더욱이, PBMC 내 CD8+ T 세포의 백분율은 비치료 마우스와 비교하여 TGFRt15-TGFRs, 2t2, 또는 21t15-TGFRs를 이용한 치료 후 유의하게 증가되었다. 더욱이, PBMC에서의 CD4+ T 세포, CD8+ T 세포, 자연 살해(NK) 세포, 및 CD19+ B 세포의 증식을 또한 항-Ki67 항체를 사용하여 평가하였다. 도 5b에 도시된 바와 같이, 증식중인 NK 세포, CD4+ T 세포, 및 CD8+ T 세포의 수는 2t2 또는 21t15-TGFRs를 이용한 치료 후가 아니라 TGFRt15-TGFRs를 이용한 치료 후 유의하게 증가되었다.
동물에서 피부의 외양 및 질감에 미치는 TGFRt15-TGFRs, 2t2 및 21t15-TGFRs의 효과를 검사하기 위해, 마우스를 대조군 또는 고지방 식이요법으로 7일 동안 사육하고, 고지방 식이요법으로 사육된 마우스의 하위세트를 또한 TGFRt15-TGFRs, 2t2 또는 21t15-TGFRs로 치료하였다. 치료-후 1주째에, 마우스의 외양을 평가하였다. 고지방 식이요법으로 사육되고 비치료된 마우스, 또는 고지방 식이요법으로 사육되고 21t15-TGFRs로 치료된 마우스는 정리되지 않고 주름진 것으로 보였고, 대조군 식이요법으로 사육된 마우스와 비교하여 증가된 흰머리/모발 손실을 가졌다(도 6의 A, B 및 C). 놀랍게도, 고지방 식이요법으로 사육되고 TGFRt15-TGFRs 또는 2t2 치료를 받은 마우스는 고지방 식이요법으로 사육되고 TGFRt15-TGFRs 또는 2t2 치료를 받지 않은 마우스(도 6의 B)와 비교하여 정돈되고 더 건강한 것으로 보였다(더 적은 흰머리/모발 손실)(도 6의 C 및 D). 구체적으로, TGFRt15-TGFRs 또는 2t2-치료 마우스는 대조군 마우스와 비교하여 우수한 피부 및 모발 외양과 질감을 보여주었다. 이들 결과는 TGFRt15-TGFRs 또는 2t2를 이용한 치료가 포유류에서 피부 및 모발의 외양과 질감을 향상시킴을 실증한다.
다음, 마우스를 대조군 또는 고지방 식이요법으로 9일 동안 사육하고, 고지방 식이요법으로 사육된 마우스의 하위세트를 TGFRt15-TGFRs, 2t2 또는 21t15-TGFRs로 치료하였다. 치료-후 4일째에, 각각의 군에서 마우스의 공복 체중을 측정하였다. 고지방 식이요법으로 사육되고 비치료된 마우스, 뿐만 아니라 고지방 식이요법으로 사육되고 21t15-TGFRs로 치료된 마우스의 공복 체중은 대조군 식이요법으로 사육된 마우스와 비교하여 유의하게 증가되었다. 그러나, 고지방 식이요법으로 사육되고 TGFRt15-TGFRs 또는 2t2로 치료된 마우스의 공복 체중은 위에서 언급된 다른 2개의 고지방 식이요법 군과 비교하여 저하되었다. 연구 종료(9주) 시 마우스의 공복 체중을 도 7에 도시한다.
각각의 군의 마우스에서 공복 포도당 수준을 평가하기 위해, 마우스는 대조군 또는 고지방 식이요법을 공급받았고, 44일차, 59일차 및 73일차에 비치료되거나 TGFRt15-TGFRs, 2t2, 또는 21t15-TGFRs로 치료되었다. 각각의 군의 마우스에서 공복 혈당을 치료-후 4일째에 측정하였다. 도 8에 도시된 바와 같이, 제2 용량 및 제3 용량(59일차 및 73일차) 후, 공복 혈당 수준은 고지방 식이요법으로 사육되지만 비치료된 마우스(황색 선)와 비교하여 고지방 식이요법으로 사육되고 2t2로 치료된 마우스(적색 선)에 대해 유의하게 감소되었다. 공복 혈당 수준은 고지방 식이요법으로 사육되고 TGFRt15-TGFRs로 치료된 마우스(녹색 선)에 대해 일정하게 유지된 반면, 공복 혈당 수준은 고지방 식이요법으로 사육되고 21t15-TGFRs로 치료된 마우스(청색 선)에 대해 증가되었다.
실시예 3: 화학요법-유도 노쇠 B16F10 흑색종 세포는 NK 리간드를 발현한다
재료 및 방법
세포를 도세탁셀(7.5 μM, Sigma)로 3일 동안 처리하고, 뒤이어 완전 배지에서 4일 동안 회복시킴으로써 B16F10 흑색종 세포에서 세포 노쇠를 유도하였다. 세포를 노쇠-관련 β-갈락토시다제(SA β-gal)로 염색함으로써 세포 노쇠를 평가하였다. 간략하게는, B16F10 대조군 및 노쇠 세포(B16F10-SNC)를 PBS로 1회 세척하고, 0.5% 글루타르알데하이드(PBS(pH 7.2))로 30분 동안 고정시켰다. 세포를 X-gal 용액(PBS 중 1 mg/mL X-gal, 0.12 mM K3Fe [CN]6, 0.12 mM K4Fe[CN]6, 및 1 mM MgCl2, pH 6.0)에서 37°C에서 밤새 염색시키고, Nikon 광학 광 현미경을 사용하여 이미지화하였다.
결과
B16F10 흑색종 세포에서의 세포 노쇠를 위에 기재된 바와 같이 화학요법을 사용하여 유도하였다. 도 9a에 도시된 바와 같이, 화학요법-유도 노쇠 B16F10 세포(B16F10-SNC)는 SA β-gal 염색에 대해 양성인 한편, 대조군 B16F10 세포는 염색되지 않았다. 다음, 0일차에 단리되거나 4일차, 8일차, 12일차 및 16일차에 각각 노쇠 유도된 RNA와 함께 RT-qPCR을 사용하여 노쇠 유전자의 발현을 분석하였다. 발현 수준을 대조군 B16F10 세포에 대해 정규화하였다. 도 9b 내지 도 9d에 도시된 바와 같이, p21, IL6 및 DPP4의 발현은 실험 연속기간에 걸쳐 노쇠 세포로부터 단리된 RNA에서 상향조절되었다. 더욱이, 도 9e 및 도 9f에 도시된 바와 같이, RATE1E 및 ULBP1(NK 활성화 수용체 NKG2D 리간드)의 발현이 또한 노쇠 세포에서 유도되었으며, 최고 발현 수준은 16일차였다. 이들 결과는, 화학요법-유도 노쇠 B16F10 세포가 대조군 B16F10 세포보다 활성화된 NK 세포의 더 강한 세포독성을 받음을 실증한다.
화학요법-유도 노쇠 B16F10 흑색종 세포에서 줄기세포 특성의 획득
화학요법-유도 노쇠 B16F10 흑색종 세포가 줄기세포 특성을 획득하였는지의 여부를 검사하기 위해, 콜로니 형성 검정을 수행하였다. 간략하게는, 1000개 세포/웰을 6웰 플레이트 상에 시딩하고, 배지를 3일마다 교환하였다. 도 10a(100x 배율로 촬영된 이미지)에 도시된 바와 같이, 배양물에서 5주 후 노쇠 세포는 콜로니를 형성할 수 있었다. 콜로니에 의한 줄기세포 마커 발현을 평가하기 위해, RNA를 콜로니로부터 단리하고, Oct4 및 Notch4 mRNA의 발현을 RT-qPCR에 의해 결정하였다. 대조군 B16F10 세포와 비교하여, 화학요법-유도 노쇠 B16F10 흑색종 세포는 Oct4 및 Notch 4의 상향조절을 보여주었고, 이는 암 줄기세포 마커이다(도 10b 및 도 10c). 더욱이, 줄기세포 마커 CD44, CD24 및 CD133의 세포 표면 발현을 CD44, CD24 및 CD133에 대한 항체로 염색하고, 뒤이어 유세포측정법에 의해 평가하였다. 도 10d 내지 도 10f에 도시된 바와 같이, 이중 양성 집단(CD44+CD24+, CD44+CD133+, 및 CD24+CD133+)은 대조군 B16F10과 비교하여 화학요법 유도 노쇠 줄기세포(B16F10-SNC-CSC)에서 증가되었다.
줄기세포 특성을 갖는 화학요법-유도 노쇠(CIS) 흑색종 세포는 대조군 B16F10 세포보다 더 "이동성"이고 "침범성"이다
줄기세포 특성(B16F10-SNC-CSC)을 갖는 화학요법-유도 노쇠(CIS) 흑색종 세포의 이동 특성을 이동 검정을 사용하여 분석하였다. 간략하게는, 대조군 B16F10 세포 및 B16F10-SNC-CSC 세포를 6웰 플레이트 상에 평판배양하고, p20 피펫 팁으로 상처를 내었다. 0시간, 12시간, 및 24시간 후에 세포의 운동을 이미지화하였다. 도 11a에 도시된 바와 같이, 줄기세포 특성(B16F10-SNC-CSC)을 갖는 화학요법-유도 노쇠(CIS) 세포는 대조군 B16F10 세포와 비교하여 시험관내 이동 검정에서 더 이동성이었다.
다음, 줄기세포 특성(B16F10-SNC-CSC)을 갖는 화학요법-유도 노쇠 세포의 침습 특성을 침습 검정을 사용하여 분석하였다. 침습 검정을 Matrigel로 코팅된 24-웰 트랜스웰 인서트 상에서 실시하였다. 간략하게는, 0.5x106 대조군 B16F10 세포 및 B16F10-SNC-CSC 세포를 혈청-무함유 배지에서 상부 챔버 상으로 시딩하고, 하부 챔버를 10% FBS가 보충된 배지로 충전시켰다. 16시간의 인큐베이션 후, 필터의 상부 표면 상의 세포를 제거하고, 필터 아래의 세포를 고정시키고 0.02% 크리스탈 바이올렛 용액으로 염색하였다. 세포의 수를 100× 배율에서 3개 필드에서 카운티하였다. 도 11b 및 도 11c에 도시된 바와 같이, 줄기세포 특성을 갖는 화학요법-유도 노쇠 세포는 대조군 B16F10 세포와 비교하여 Matrigel 코팅된 막을 침습하는 데 있어서 더 공격적이었다. 이들 결과는 화학요법-유도 노쇠 B16F10 종양 세포가 이의 증식 능력을 다시 얻고, 줄기-세포 특질을 수득할 수 있고, 전이에 대한 증가된 이동 능력 및 침범성을 가짐을 실증한다.
줄기세포 특성을 갖는 화학요법-유도 노쇠 세포에 대한 마우스 NK 세포의 세포독성 활성
생체내에서 NK 세포를 확장시키기 위해, C57BL/6 마우스에게 TGFRt15-TGFRs(10 mg/kg)를 4일 동안 피하 주사하였다. 이들 마우스로부터의 비장을 수득하고, MACS Miltenyi 컬럼을 사용하여 NK 세포를 정제하였다. 그 후에, 정제된 NK 세포를 시험관내에서 2t2와 함께 확장시켰다(도 12a).
확장된 NK 세포의 세포독성을 평가하기 위해, 화학요법-유도 노쇠 줄기세포(B16F10-SNC-CSC) 또는 대조군 B16F10 세포를 CellTrace 바이올렛으로 표지하고, 시험관내에서 활성화된 2t2 마우스 NK 세포(4일 동안 10 mg/kg TGFRt15-TGFRs가 주사된 C57BL/6 마우스의 비장으로부터 단리됨)와 함께 다양한 E:T 비로 16시간 동안 인큐베이션하였다. B16F10-SNC-CSC 및 대조군 B16F10 세포를 트립신처리하고, 세척하고, 프로피디움 요오다이드(PI) 용액을 함유하는 완전 배지에 재현탁시키고, 세포독성을 유세포측정법에 의해 평가하였다. 도 12b에 도시된 바와 같이, NK 세포는 대조군 B16F10 세포와 비교하여 줄기세포 특성(B16F10-SNC-CSC)을 갖는 화학요법-유도 노쇠 세포를 사멸시키는 데 있어서 더 효과적이었다.
흑색종 마우스 모델에서의 병용 치료
흑색종을 치료하는 데 있어서 TGFRt15-TGFRs의 효과를 마우스 흑색종 모델에서 평가하였다. 간략하게는, 5x105 B16F10 세포를 C57BL/6 마우스 내로 피하 주사하였다. 종양 부피가 대략 100 mm3에 도달하였을 때, 마우스를 도세탁셀(화학요법)(5 mg/kg) 또는 TA99(200 μg)로 단일 제제로서 또는 병용하여 3일마다 치료하고, TGFRt15-TGFRs(3 mg/kg)를 1주일에 1회 주었다(도 13a). 식염수, 도세탁셀(화학요법)/TA99 단독, 또는 TGFRt15-TGFRs 단독을 받은 마우스를 대조군으로서 사용하였다. 5 마리의 마우스를 각각의 실험군 및 대조군에서 시험하였다. 종양 부피를 3일차마다 측정하였다. 도 13b 및 도 13c에 도시된 바와 같이, TGFRt15-TGFR과 화학요법 또는 TA99의 병용은 동계 흑색종 마우스 모델에서 식염수로 치료된 마우스 또는 화학요법 또는 TA99 단독으로 치료된 마우스와 비교하여 종양 진행을 느리게 하였다.
실시예 4: 인간 췌장 세포주 SW1990에서 노쇠의 화학요법적 유도
재료 및 방법
β-갈락토시다제 염색: 화학요법 유도 노쇠의 확인을 pH 6.0에서 상업적으로 입수 가능한 키트(Cell Signaling Technology)를 제조업체의 설명서에 따라 사용하여 표준 β-갈락토시다제 염색에 의해 실시하였다. 이튿날, 염색 용액을 제거하고, 세포를 포스페이트 완충 식염수로 세척하고, 70% 글리세롤을 웰에 첨가하였다. β-갈락토시다제 양성 세포는 청색으로 염색될 것이며, 한편 대조군 비처리 세포는 염색되지 않을 것이다.
유세포측정법: 1백만개의 대조군 및 노쇠 세포를 수득하고, 항-CD44 항체 및 항-CD24 항체(Biolegend)와 같은 줄기세포의 표면 마커에 대한 상업적으로 입수 가능한 항체를 제조업체의 설명서에 따라 사용하여 염색하였다. 그 후에, 세포를 세척하고, BD Celesta 유세포측정기를 사용하여 분석하였다. 줄기세포-유사 특성을 보여주는 세포는 CD44와 CD24 둘 다에 대해 이중 양성일 것이다.
유전자 발현 검정: 100만개의 대조군 및 노쇠 세포를 수득하고, 트리졸(Thermofisher)을 사용하여 용해시키고, 뒤이어 RNA 단리 키트(Qiagen)를 사용하여 RNA 정제하였다. RNA를 정량화하고, Qiagen cDNA Quantitect 키트를 사용하여 cDNA로 전환시켰다. 그 후에, cDNA를 표준 Taqman 유전자 발현 검정(Thermofisher)을 위한 주형으로서 사용하여, 노쇠, 줄기세포 마커뿐만 아니라 NK 리간드의 상대 존재비를 정량화하였다.
NK 세포 세포독성 검정: NK 세포를 건강한 인간 공여자(n=2)로부터 상업적으로 입수 가능한 NK 단리 키트(Stem Cell)를 사용하여 단리하고, 사이토카인 융합 분자 18t15-12s(100 nM)를 사용하여 밤새 활성화시켰다. 다음날, NK 세포를 세척하여 사이토카인 분자를 제거하고, CellTrace Violet 표지된 대조군 비처리 종양 세포 또는 화학요법-유도 노쇠 종양 세포와 함께 4:1의 E:T 비로 20시간 동안 혼합하였다. 다음날, 세포를 트립신처리하고, 각각의 웰의 완전한 내용물을 유세포측정법을 사용하여 분석하고, 세포의 저해 백분율을 분석하였다.
결과
인간 췌장 종양 세포주 SW1990에서의 노쇠를 화학요법 약물 아브락산(Celgene) 및 겜시타빈(Sigma Aldrich)을 이용한 2.5 μM 및 6.25 μM에서 3일 동안의 처리를 통해 유도하였다. 비처리된 SW1990 세포를 대조군으로서 사용하였다. 배지를 3일 후에 교환하고, 세포를 배양 배지에서 4일 동안 휴지기에 있게 하였다. 도 14에 도시된 바와 같이, 화학요법 약물로 처리된 노쇠 세포는 β-갈락토시다제 염색(청색)에 대해 양성인 한편, 대조군 세포는 염색되지 않았다. 노쇠 세포 및 대조군 세포를 처리-후 4일, 11일, 및 22일째에 노쇠 및 줄기세포 마커의 발현에 대해 평가하였다. 도 14에 도시된 바와 같이, 노쇠 세포는 대조군 세포와 비교하여 시간 경과에 걸쳐 CD44 및 CD24에 대해 증가된 이중 양성 염색을 보여주었다. 더욱이, 화학요법-유도 노쇠 SW1990 세포를 또한 0일차, 및 처리-후 2일차, 4일차, 및 24일차에 위에서 기재된 유전자 발현 검정을 사용하여 DPP4, IL6, 및 p21을 포함한 노쇠 마커, Oct3/4, CD24, 및 CD44를 포함한 줄기세포 마커, 및 넥틴 및 MICA를 포함한 NK 리간드의 발현에 대해 분석하였다. 도 15에 도시된 바와 같이, 언급된 모든 마커의 발현은 시간 경과에 걸쳐 증가를 보여주었다.
시험관내 활성화된 인간 NK 세포의 세포독성
시험관내 활성화된 인간 NK 세포(18t15-12s로 처리됨)의 세포독성을 평가하기 위해, 인간 췌장 종양 세포주 SW1990에서의 노쇠를 화학요법 약물 아브락산(Celgene) 및 겜시타빈(Sigma Aldrich)을 이용한 2.5 μM 및 6.25 μM에서 3일 동안의 처리를 통해 유도하였다. 비처리된 SW1990 세포를 대조군으로서 사용하였다. 배지를 3일 후에 교환하고, 세포를 배양 배지에서 30일 동안 휴지기에 있게 하였다. 베양 배지를 4일마다 교환하였다. 활성화된 NK 세포를 수득하고, 화학요법-유도 노쇠 종양 세포 및 비처리 대조군 종양 세포에 대한 이의 세포독성을 위에서 기재된 NK 세포 세포독성 검정을 사용하여 평가하였다. 도 16에 도시된 바와 같이, 활성화된 NK 세포는 대조군 SW1990 세포(SW1990)와 노쇠 SW1990 세포(SW1990s) 둘 다에 대해 증가된 세포독성을 보여주었다.
실시예 5: IL-12/IL-15RαSu DNA 작제물의 생성
비제한적인 예에서, IL-12/IL-15RαSu DNA 작제물을 생성시켰다(도 17). 인간 IL-12 서브유닛 서열, 인간 IL-15RαSu 서열, 인간 IL-15 서열, 인간 조직 인자 219 서열, 및 인간 IL-18 서열을 UniProt 웹사이트로부터 수득하였고, 이들 서열에 대한 DNA를 게네위즈(Genewiz)에 의해 합성하였다. GS(3) 링커를 이용하여 IL-12 서브유닛 베타(p40)를 IL-12 서브유닛 알파(p35)에 연결하는 DNA 작제물을 만들어서, IL-12의 단일 사슬 버전을 생성시키고, 그 후에 IL-12 서열을 IL-15RαSu 서열에 직접적으로 연결하였다. 최종 IL-12/IL-15RαSu DNA 작제물 서열을 게네위즈에 의해 합성하였다.
IL12/IL-15RαSu 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다(SEQ ID NO: 181):
(신호 펩타이드)
ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCC
(인간 IL-12 서브유닛 베타(p40))
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCC
(링커)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(인간 IL-12 서브유닛 알파(p35))
CGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGC
(인간 IL-15R α sushi 도메인)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
실시예 6: IL-18/TF/IL-15 DNA 작제물의 생성
비제한적인 예에서, IL-18 서열을 조직 인자 219의 N-말단 코딩 영역에 연결하고, IL-18/TF 작제물을 IL-15의 N-말단 코딩 영역과 추가로 연결하는 IL-18/TF/IL-15 작제물을 만들었다(도 18). 게네위즈에 의해 합성된 IL-18/TF/IL-15 작제물의 핵산 서열(리더 서열 포함)은 하기와 같다(SEQ ID NO: 177):
(신호 펩타이드)
ATGAAGTGGGTCACATTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGC
(인간 IL-18)
TACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGAT
(인간 조직 인자 219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(인간 IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
실시예 7: IL-12/IL-15RαSu 및 IL-18/TF/IL-15 융합 단백질의 분비
IL-12/IL-15RαSu 및 IL-18/TF/IL-15 DNA 작제물을 pMSGV-1 변형된 레트로바이러스 발현 벡터 내로 클로닝하고(참조로서 본원에 포함된 문헌[Hughes, Hum Gene Ther 16:457-72, 2005]에 기재된 바와 같음), 상기 발현 벡터를 CHO-K1 세포 내로 형질주입하였다. CHO-K1 세포에서 2개 작제물의 공동-발현은 가용성 IL-18/TF/IL-15:IL-12/IL-15RαSu 단백질 복합체(18t15-12s로 지칭됨; 도 19 및 도 20)의 형성 및 분비를 가능하게 하였다. 항-TF 항체 친화도 크로마토그래피 및 크기 배제 크로마토그래피를 사용하여 CHO-K1 세포 배양 상청액으로부터 18t15-12s 단백질을 정제하여, IL-12/IL-15RαSu 및 IL-18/TF/IL-15 융합 단백질로 구성된 가용성(비-응집된) 단백질 복합체를 초래하였다.
IL12/IL-15RαSu 융합 단백질의 아미노산 서열(신호 펩타이드 서열 포함)은 하기와 같다(SEQ ID NO: 180):
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL-12 서브유닛 베타(p40))
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCS
(링커)
GGGGSGGGGSGGGGS
(인간 IL-12 서브유닛 알파(p35))
RNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNAS
(인간 IL-15R α sushi 도메인)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
IL-18/TF/IL-15 융합 단백질의 아미노산 서열(신호 펩타이드 서열 포함)은 하기와 같다(SEQ ID NO: 176):
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL-18)
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNED
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
일부 경우, 리더(신호 서열) 펩타이드를 무손상 폴리펩타이드로부터 절단하여, 가용성이거나 분비될 수 있는 성숙한 형태를 생성시킨다.
실시예 8: 면역친화도 크로마토그래피에 의한
18t15-12s
의 정제
항-TF 항체 친화도 컬럼을 GE Healthcare™ AKTA Avant 단백질 정제 시스템에 연결하였다. 유속이 2 mL/분인 용리 단계를 제외하고는, 모든 단계에 대해 유속은 4 mL/분이었다.
18t15-12s의 세포 배양 수합물을 1 M Tris 염기를 이용하여 pH 7.4로 조정하고, 5 컬럼 부피의 PBS로 평형화된 항-TF 항체 친화도 컬럼 상으로 로딩하였다. 시료를 로딩한 후, 컬럼을 5 컬럼 부피의 PBS로 세척하고, 뒤이어 6 컬럼 부피의 0.1 M 아세트산, pH 2.9로 용리하였다. 280 nm에서의 흡광도를 수집한 다음, 1 M Tris 염기를 첨가함으로써 시료를 pH 7.5 내지 8.0으로 중화시켰다. 그 후에, 30 KDa 분자량 컷오프와 함께 Amicon® 원심분리 필터를 사용하여, 중화된 시료를 PBS로 완충액 교환하였다. 도 21은, 18t15-12s 복합체가 항-TF 항체 친화도 컬럼에 결합함을 도시하며, 여기서, TF는 18t15-12s 결합 파트너이다. 완충액-교환된 단백질 시료를 추가의 생화학적 분석 및 생물학적 활성 시험을 위해 2℃ 내지 8℃에 보관한다.
그 후에, 각각의 용리 후, 6 컬럼 부피의 0.1 M 글리신, pH 2.5를 사용하여 항-TF 항체 친화도 컬럼을 박리(strip)시켰다. 그 후에, 컬럼을 10 컬럼 부피의 PBS, 0.05% 소듐 아자이드를 사용하여 중화시키고, 2℃ 내지 8℃에 보관하였다.
실시예 9: 18t15-12s의 크기 배제 크로마토그래피
GE Healthcare Superdex® 200 Increase 10/300 GL 겔 여과 컬럼을 GE Healthcare AKTA™ Avant 단백질 정제 시스템에 연결하였다. 상기 컬럼을 2 컬럼 부피의 PBS로 평형화시켰다. 유속은 0.8 mL/분이었다. 모세관 루프를 사용하여, 200 μL의 1 mg/mL 18t15-12s 복합체를 컬럼 상에 주사하였다. 1.25 컬럼 부피의 PBS를 주사하였다. SEC 크로마토그래프를 도 22에 도시한다. 아마도 18t15-12s 이량체 또는 응집물의 상이한 글리코실화도(degree of glycosylation)로 인해, 미미한 고분자량 피크와 함께 주요 18t15-12s 단백질 피크가 존재한다.
실시예 10: 18t15-12s의 SDS-PAGE
순도 및 단백질 분자량을 결정하기 위해, 4-12% NuPage Bis-Tris 단백질 겔 SDS-PAGE를 사용하여, 정제된 18t15-12s 단백질 시료를 분석하였다. 상기 겔을 InstantBlue™로 약 30분 동안 염색시키고, 뒤이어 정제수에서 밤새 탈색시켰다. 도 23은 항-TF 항체 친화도 정제된 18t15-12s의 SDS 겔의 일례를 도시하며, 이때 밴드는 예상된 분자량(66 kDa 및 56 kDa)에 존재하였다.
실시예 11: CHO-K1 세포에서 18t15-12s의 글리코실화
단백질 탈글리코실화 믹스 II 키트(New England Biolabs)를 제조업체의 설명서에 따라 사용하여 CHO-K1 세포에서의 18t15-12s의 글리코실화를 확인하였다. 도 24는 탈글리코실화된 및 비-탈글리코실화된 18t15-12s의 SDS PAGE 분석의 일례를 도시한다. 탈글리코실화는 도 24, 레인 4에 도시된 바와 같이 18t15-12s의 분자량을 감소시킨다.
실시예 12: 18t15-12s 복합체의 재조합 단백질 정량화
표준 샌드위치 ELISA 방법(도 25-28)을 사용하여 18t15-12s 복합체를 검출하고 정량화하였다. 항-인간 조직 인자 항체는 포착 항체로서 역할을 하였고, 비오틴화된 항-인간 IL-12, IL-15, 또는 IL-18 항체(BAF 219, BAM 247, D045-6, 모두 R&D Systems)는 검출 항체로서 역할을 하였다. 항-인간 조직 인자 포착 항체(I43), 및 항-인간 조직 인자 항체 검출을 사용하여, 정제된 18t15-12s 단백질 복합체 내의 조직 인자를 또한 검출하였다. I43/항-TF 항체 ELISA를 유사한 농도에서 정제된 조직 인자와 비교하였다.
실시예 13: 18t15-12s 복합체의 면역자극 역량
18t15-12s 복합체의 IL-15 면역자극 활성을 평가하기 위해, 증가하는 농도의 18t15-12s를 200 μL IMDM:10% FBS 배지 중 32Dβ 세포(104개 세포/웰)에 첨가하였다. 32Dβ 세포를 37℃에서 3일 동안 인큐베이션하였다. 제4일에, WST-1 증식 시약(10 μL/웰)을 첨가하고, 4시간 후에 흡광도를 450 nm에서 측정하여, 가용성 포르마잔 염료로의 WST-1의 절단에 기초하여 세포 증식을 결정하였다. 인간 재조합 IL-15의 생물활성을 양성 대조군으로서 평가하였다. 도 29에 도시된 바와 같이, 18t15-12s는 32Dβ 세포의 IL-15-의존적 세포 증식을 실증하였다. 18t15-12s 복합체는, 아마도 IL-18 및 조직 인자와 IL-15 도메인의 연결로 인해, 인간 재조합 IL-15와 비교하여 감소된 활성을 실증하였다.
18t15-12s 복합체에서 IL-12 및 IL-18의 개별 활성을 평가하기 위해, 18t15-12s를 200 μL IMDM:10% 가열-불활성화된 FBS 배지 중 HEK-Blue IL-12 및 HEK-Blue IL-18 리포터 세포(5x104개 세포/웰; hkb-il12 및 hkb-hmil18, InvivoGen)에 첨가하였다. 세포를 37℃에서 밤새 인큐베이션하였다. 20 μl의 유도된 HEK-Blue IL-12 및 HEK-Blue IL-18 리포터 세포 상청액을 180 μl의 QUANTI-Blue(InvivoGen)에 첨가하고, 37℃에서 1시간 내지 3시간 동안 인큐베이션하였다. 620 nm에서 흡광도를 측정함으로써 IL-12 또는 IL-18 활성을 평가하였다. 인간 재조합 IL-12 또는 IL-18을 양성 또는 음성 대조군으로서 평가하였다. 도 30 및 도 31에 도시된 바와 같이, 18t15-12s 복합체의 각각의 사이토카인 도메인은 특이적인 생물학적 활성을 보유한다. 18t15-12s의 활성은, 아마도 IL-15 및 조직 인자와 IL-18 도메인의 연결 및 IL-12와 IL-15Rα sushi 도메인의 연결로 인해, 인간 재조합 IL-18 또는 IL-12의 활성과 비교하여 감소되었다.
실시예 14: 18t15-12s 복합체에 의한 사이토카인-유도 기억-유사 NK 세포의 유도
사이토카인-유도 기억-유사 NK 세포는, 정제된 NK 세포를 포화량의 IL-12(10 ng/mL), IL-15(50 ng/mL), 및 IL-18(50 ng/mL)로 밤새 자극시킨 후, 생체외에서 유도될 수 있다. 이들 기억-유사 특성을 IL-2 수용체 α(IL-2Rα, CD25), CD69(및 다른 활성화 마커)의 발현, 및 증가된 IFN-γ 생성을 통해 측정되어 왔다. 18t15-12s 복합체가 사이토카인-유도 기억-유사 NK 세포의 생성을 촉진하는 능력을 평가하기 위해, 정제된 인간 NK 세포(>95% CD56+)를 0.01 nM 내지 10000 nM의 18t15-12s 복합체 또는 개별 사이토카인(재조합 IL-12(10 ng/ml), IL-18(50 ng/ml), 및 IL-15(50 ng/ml))의 조합으로 14시간 내지 18시간 동안 자극시켰다. 세포-표면 CD25 및 CD 69 발현 및 세포내 IFN-γ 수준을 항체-염색 및 유세포측정법에 의해 평가하였다.
새로운 인간 백혈구를 혈액 은행으로부터 수득하였고, CD56+ NK 세포를 RosetteSep/인간 NK 세포 시약(StemCell Technologies)으로 단리시켰다. NK 세포의 순도는 >70%였고, CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750에 특이적인 항체(BioLegend)로 염색함으로써 확인되었다. 세포를 96웰 편평 바닥 플레이트에서 0.2 mL의 완전 배지(2 mM L-글루타민(Thermo Life Technologies), 페니실린(Thermo Life Technologies), 스트렙토마이신(Thermo Life Technologies), 및 10% FBS(Hyclone)가 보충된 RPMI 1640(Gibco))에서 0.2 x 106/mL에서 카운팅하고 재현탁시켰다. 세포를 사이토카인 hIL-12(10 ng/mL)(Biolegend), hIL-18(50 ng/mL)(R&D Systems) 및 hIL-15(50 ng/mL)(NCI)의 혼합물과 함께 또는 0.01 nM 내지 10000 nM의 18t15-12s와 함께 37℃, 5% CO2에서 14시간 내지 18시간 동안 자극시켰다. 그 후에, 세포를 수합하고, CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750에 특이적인 항체(BioLegend)로 30분 동안 표면 염색시켰다. 염색 후, 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다(실온에서 1500 RPM에서 5분 동안). 2회의 세척 후, BD FACSCelesta™ 유세포측정기(플롯화된 데이터-평균치 형광 강도(Plotted Data-Mean Fluorescence Intensity); 도 32a 및 도 32b)를 사용하여 세포를 분석하였다.
새로운 인간 백혈구를 혈액 은행으로부터 수득하였고, CD56+ NK 세포를 RosetteSep/인간 NK 세포 시약(StemCell Technologies)으로 단리시켰다. NK 세포의 순도는 >70%였고, CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750에 특이적인 항체(BioLegend)로 염색함으로써 확인되었다. 세포를 96웰 편평 바닥 플레이트에서 0.2 mL의 완전 배지(2 mM L-글루타민(Thermo Life Technologies), 페니실린(Thermo Life Technologies), 스트렙토마이신(Thermo Life Technologies), 및 10% FBS(Hyclone)가 보충된 RPMI 1640(Gibco))에서 0.2 x 106/mL에서 카운팅하고 재현탁시켰다. 세포를 hIL-12(10 ng/mL)(Biolegend), hIL-18(50 ng/mL)(R&D) 및 hIL-15(50 ng/mL)(NCI)의 사이토카인 혼합물과 함께 또는 0.01 nM 내지 10000 nM의 18t15-12s 복합체와 함께 37℃, 5% CO2에서 14시간 내지 18시간 동안 자극시켰다. 그 후에, 세포를 10 μg/mL의 Brefeldin A(Sigma) 및 1X의 Monensin(eBioscience)으로 4시간 동안 처리한 후, 수합하고, CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750 특이적 항체로 30분 동안 염색시켰다. 염색 후, 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하고(실온에서 1500 RPM에서 5분 동안), 실온에서 10분 동안 고정시켰다. 고정 후, 세포를 1x 투과 완충액(eBioscience)에서 세척하고(실온에서 1500 RPM에서 5분 동안), 실온에서 IFN-γ-PE(Biolegend)로 30분 동안 염색하였다. 세포를 1x 투과 완충액으로 1회 더 세척한 다음, FACS 완충액으로 세척하였다. 세포 펠렛을 300 μl의 FACS 완충액에 재현탁시키고, BD FACSCelesta™ 유세포측정기를 사용하여 분석하였다(IFN-γ 양성 세포의 플롯화된(plotted) %; 도 33).
실시예 15: 인간 종양 세포에 대한 NK 세포의 시험관내 세포독성
인간 골수원성 백혈병 세포, K562(CellTrace 바이올렛 표지)를, 증가하는 농도의 18t15-12s 복합체 또는 대조군으로서 사이토카인의 혼합물의 존재 하에, 정제된 인간 NK 세포와 함께 인큐베이션하였다. 20시간 후, 배양물을 수합하며, 프로피디움 요오다이드(PI)로 염색하고, 유세포측정법에 의해 평가하였다. 도 34에 도시된 바와 같이, 18t15-12s 복합체는 K562에 대해 인간 NK 세포독성을 사이토카인 혼합물과 유사하거나 그보다 큰 수준으로 유도하였으며, 여기서, 18t15-12s 복합체와 사이토카인 혼합물 둘 다 배지 대조군보다 더 큰 세포독성을 유도하였다.
실시예 16: IL-12/IL-15RαSu/αCD16scFv 및 IL-18/TF/IL-15 DNA 작제물의 생성
비제한적인 예에서, IL-12/IL-15RαSu/αCD16scFv 및 IL-18/TF/IL-15 DNA 작제물을 생성시켰다(도 35 및 도 36). 인간 IL-12 서브유닛 서열, 인간 IL-15RαSu 서열, 인간 IL-15 서열, 인간 조직 인자 219 서열, 및 인간 IL-18 서열을 게네위즈에 의해 합성하였다. GS(3) 링커를 이용하여 IL-12 서브유닛 베타(p40)를 IL-12 서브유닛 알파(p35)에 연결하는 DNA 작제물을 만들어서, IL-12의 단일 사슬 버전을 생성시키고, 그 후에 IL-12 서열을 IL-15RαSu 서열에 직접적으로 연결하고, IL-12/ IL-15RαSu 작제물을 αCD16scFv의 N-말단 코딩 영역에 직접적으로 연결하였다.
IL-12/IL-15RαSu/αCD16scFv 작제물의 핵산 서열은 하기와 같다(SEQ ID NO: 226):
(신호 펩타이드)
ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCC
(인간 IL-12 서브유닛 베타(p40))
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCC
(링커)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(인간 IL-12 서브유닛 알파(p35))
CGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGC
(인간 IL-15R α sushi 도메인)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
(항-인간 CD16 경쇄 가변 도메인)
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCAT
(링커)
GGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCC
(항-인간 CD16 중쇄 가변 도메인)
GAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG
또한, IL-18 서열을 조직 인자 219의 N-말단 코딩 영역에 연결하고, IL-18/TF 작제물을 IL-15의 N-말단 코딩 영역과 연결하여 작제물을 만들었다(도 36). IL-18/TF/IL-15 작제물의 핵산 서열(리더 서열 포함)은 하기와 같다(SEQ ID NO: 177):
(신호 펩타이드)
ATGAAGTGGGTCACATTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGC
(인간 IL-18)
TACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGAT
(인간 조직 인자 219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(인간 IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
실시예 17: IL-12/IL-15RαSu/αCD16scFv 및 IL-18/TF/IL-15 융합 단백질의 분비
IL-12/IL-15RαSu/αCD16scFv 및 IL-18/TF/IL-15 작제물을 pMSGV-1 변형된 레트로바이러스 발현 벡터 내로 클로닝하고(참조로서 본원에 포함된 문헌[Hughes, Hum Gene Ther 16:457-72, 2005]), 상기 발현 벡터를 CHO-K1 세포 내로 형질주입하였다. CHO-K1 세포에서 2개 작제물의 공동-발현은 가용성 IL-18/TF/IL-15:IL-12/IL-15RαSu/αCD16scFv 단백질 복합체(18t15-12s/αCD16로 지칭됨; 도 37 및 도 38)의 분비를 초래하였다. CHO-K1 세포에서 2개 작제물의 공동-발현은 가용성 IL-18/TF/IL-15:IL-12/IL-15RαSu/αCD16scFv 단백질 복합체(18t15-12s/αCD16로 지칭됨; 도 37 및 도 38)의 분비를 초래하였으며, 이는 항-TF Ab 친화도 및 다른 크로마토그래피 방법에 의해 정제될 수 있다. 일부 경우, 신호 펩타이드는 무손상 폴리펩타이드로부터 절단되어, 성숙한 형태를 생성시킨다.
IL-12/IL-15RαSu/αCD16scFv 융합 단백질의 아미노산 서열(신호 펩타이드 서열 포함)은 하기와 같다(SEQ ID NO: 225):
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL-12 서브유닛 베타(p40))
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCS
(링커)
GGGGSGGGGSGGGGS
(인간 IL-12 서브유닛 알파(p35))
RNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNAS
(인간 IL-15R α sushi 도메인)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
(항-인간 CD16 경쇄 가변 도메인)
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGH
(링커)
GGGGSGGGGSGGGGS
(항-인간 CD16 중쇄 가변 도메인)
EVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR
IL-18/TF/IL-15 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다(SEQ ID NO: 221):
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL-18)
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNED
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
실시예 18: IL-18/IL-15RαSu 및 IL-12/TF/IL-15 DNA 작제물의 생성
비제한적인 예에서, IL-18/IL-15RαSu 및 IL-12/TF/IL-15 DNA 작제물을 생성시켰다. 인간 IL-18 서브유닛 서열, 인간 IL-15RαSu 서열, 인간 IL-12 서열, 인간 조직 인자 219 서열, 및 인간 IL-15 서열을 게네위즈에 의해 합성하였다. IL-18을 IL-15RαSu에 직접적으로 연결하여 DNA 작제물을 만들었다. 또한, IL-12 서열을 인간 조직 인자 219 형태의 N-말단 코딩 영역에 연결하고, IL-12/TF 작제물을 IL-15의 N-말단 코딩 영역과 추가로 연결하여 추가 작제물을 만들었다. 상기 기재된 바와 같이, IL-12의 단일-사슬 버전(p40-링커-p35)을 사용하였다.
IL-18/IL-15RαSu 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다(SEQ ID NO: 320):
(신호 펩타이드)
ATGAAGTGGGTCACATTTATCTCTTTACTGTTCCTCTTCTCCAGCGCCTACAGC
(인간 IL-18)
TACTTCGGCAAACTGGAATCCAAGCTGAGCGTGATCCGGAATTTAAACGACCAAGTTCTGTTTATCGATCAAGGTAACCGGCCTCTGTTCGAGGACATGACCGACTCCGATTGCCGGGACAATGCCCCCCGGACCATCTTCATTATCTCCATGTACAAGGACAGCCAGCCCCGGGGCATGGCTGTGACAATTAGCGTGAAGTGTGAGAAAATCAGCACTTTATCTTGTGAGAACAAGATCATCTCCTTTAAGGAAATGAACCCCCCCGATAACATCAAGGACACCAAGTCCGATATCATCTTCTTCCAGCGGTCCGTGCCCGGTCACGATAACAAGATGCAGTTCGAATCCTCCTCCTACGAGGGCTACTTTTTAGCTTGTGAAAAGGAGAGGGATTTATTCAAGCTGATCCTCAAGAAGGAGGACGAGCTGGGCGATCGTTCCATCATGTTCACCGTCCAAAACGAGGAT
(인간 IL-15R α sushi 도메인)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
IL-12/TF/IL-15 작제물의 핵산 서열(리더 서열 포함)은 하기와 같다(SEQ ID NO: 321):
(신호 펩타이드)
ATGAAATGGGTGACCTTTATTTCTTTACTGTTCCTCTTTAGCAGCGCCTACTCC
(인간 IL-12 서브유닛 베타(p40))
ATTTGGGAACTGAAGAAGGACGTCTACGTGGTCGAACTGGACTGGTATCCCGATGCTCCCGGCGAAATGGTGGTGCTCACTTGTGACACCCCCGAAGAAGACGGCATCACTTGGACCCTCGATCAGAGCAGCGAGGTGCTGGGCTCCGGAAAGACCCTCACAATCCAAGTTAAGGAGTTCGGAGACGCTGGCCAATACACATGCCACAAGGGAGGCGAGGTGCTCAGCCATTCCTTATTATTATTACACAAGAAGGAAGACGGAATCTGGTCCACCGACATTTTAAAAGATCAGAAGGAGCCCAAGAATAAGACCTTTTTAAGGTGTGAGGCCAAAAACTACAGCGGTCGTTTCACTTGTTGGTGGCTGACCACCATTTCCACCGATTTAACCTTCTCCGTGAAAAGCAGCCGGGGAAGCTCCGACCCTCAAGGTGTGACATGTGGAGCCGCTACCCTCAGCGCTGAGAGGGTTCGTGGCGATAACAAGGAATACGAGTACAGCGTGGAGTGCCAAGAAGATAGCGCTTGTCCCGCTGCCGAAGAATCTTTACCCATTGAGGTGATGGTGGACGCCGTGCACAAACTCAAGTACGAGAACTACACCTCCTCCTTCTTTATCCGGGACATCATTAAGCCCGATCCTCCTAAGAATTTACAGCTGAAGCCTCTCAAAAATAGCCGGCAAGTTGAGGTCTCTTGGGAATATCCCGACACTTGGAGCACACCCCACAGCTACTTCTCTTTAACCTTTTGTGTGCAAGTTCAAGGTAAAAGCAAGCGGGAGAAGAAAGACCGGGTGTTTACCGACAAAACCAGCGCCACCGTCATCTGTCGGAAGAACGCCTCCATCAGCGTGAGGGCTCAAGATCGTTATTACTCCAGCAGCTGGTCCGAGTGGGCCAGCGTGCCTTGTTCC
(링커)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(인간 IL-12 서브유닛 알파(p35))
CGTAACCTCCCCGTGGCTACCCCCGATCCCGGAATGTTCCCTTGTTTACACCACAGCCAGAATTTACTGAGGGCCGTGAGCAACATGCTGCAGAAAGCTAGGCAGACTTTAGAATTTTACCCTTGCACCAGCGAGGAGATCGACCATGAAGATATCACCAAGGACAAGACATCCACCGTGGAGGCTTGTTTACCTCTGGAGCTGACAAAGAACGAGTCTTGTCTCAACTCTCGTGAAACCAGCTTCATCACAAATGGCTCTTGTTTAGCTTCCCGGAAGACCTCCTTTATGATGGCTTTATGCCTCAGCTCCATCTACGAGGATTTAAAGATGTACCAAGTGGAGTTCAAGACCATGAACGCCAAGCTGCTCATGGACCCTAAACGGCAGATCTTTTTAGACCAGAACATGCTGGCTGTGATTGATGAGCTGATGCAAGCTTTAAACTTCAACTCCGAGACCGTCCCTCAGAAGTCCTCCCTCGAGGAGCCCGATTTTTACAAGACAAAGATCAAACTGTGCATTTTACTCCACGCCTTTAGGATCCGGGCCGTGACCATTGACCGGGTCATGAGCTATTTAAACGCCAGC
(인간 조직 인자 219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(인간 IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
실시예 19: IL-18/IL-15RαSu 및 IL-12/TF/IL-15 융합 단백질의 분비
IL-18/IL-15RαSu 및 IL-12/TF/IL-15 작제물을 pMSGV-1 변형된 레트로바이러스 발현 벡터 내로 클로닝하고(참조로서 본원에 포함된 문헌[Hughes, Hum Gene Ther 16:457-72, 2005]), 상기 발현 벡터를 CHO-K1 세포 내로 형질주입하였다. CHO-K1 세포에서 2개 작제물의 공동-발현은 가용성 IL-12/TF/IL-15:IL-18/IL-15RαSu 단백질 복합체(12t15/s18로 지칭됨)의 분비를 초래하였으며, 이는 항-TF Ab 친화도 및 다른 크로마토그래피 방법에 의해 정제될 수 있다.
IL-18/IL-15RαSu 융합 단백질의 아미노산 서열(신호 펩타이드 서열 포함)은 하기와 같다(SEQ ID NO: 322):
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL-18)
YFGKLESKLSVIRNLNDQVLFIDQGNRPLFEDMTDSDCRDNAPRTIFIISMYKDSQPRGMAVTISVKCEKISTLSCENKIISFKEMNPPDNIKDTKSDIIFFQRSVPGHDNKMQFESSSYEGYFLACEKERDLFKLILKKEDELGDRSIMFTVQNED
(인간 IL-15R α sushi 도메인)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
IL-12/TF/IL-15 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다(SEQ ID NO: 323):
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL-12 서브유닛 베타(p40))
IWELKKDVYVVELDWYPDAPGEMVVLTCDTPEEDGITWTLDQSSEVLGSGKTLTIQVKEFGDAGQYTCHKGGEVLSHSLLLLHKKEDGIWSTDILKDQKEPKNKTFLRCEAKNYSGRFTCWWLTTISTDLTFSVKSSRGSSDPQGVTCGAATLSAERVRGDNKEYEYSVECQEDSACPAAEESLPIEVMVDAVHKLKYENYTSSFFIRDIIKPDPPKNLQLKPLKNSRQVEVSWEYPDTWSTPHSYFSLTFCVQVQGKSKREKKDRVFTDKTSATVICRKNASISVRAQDRYYSSSWSEWASVPCS
(링커)
GGGGSGGGGSGGGGS
(인간 IL-12 서브유닛 알파(p35))
RNLPVATPDPGMFPCLHHSQNLLRAVSNMLQKARQTLEFYPCTSEEIDHEDITKDKTSTVEACLPLELTKNESCLNSRETSFITNGSCLASRKTSFMMALCLSSIYEDLKMYQVEFKTMNAKLLMDPKRQIFLDQNMLAVIDELMQALNFNSETVPQKSSLEEPDFYKTKIKLCILLHAFRIRAVTIDRVMSYLNAS
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
일부 경우, 리더 펩타이드를 무손상 폴리펩타이드로부터 절단하여, 가용성이거나 분비될 수 있는 성숙한 형태를 생성시킨다.
실시예 20: 18t15-12s16 복합체의 재조합 단백질 정량화
표준 샌드위치 ELISA 방법(도 39)을 사용하여 18t15-12s16 복합체(IL-12/IL-15RαSu/αCD16scFv;IL-18/TF/IL-15를 포함함)를 검출하고 정량화하였다. 항-인간 조직 인자 항체/IL-2 또는 항-TF Ab/IL-18은 포착 항체로서 역할을 하였고, 비오틴화된 항-인간 IL-12 또는 IL-18 항체(BAF 219, D045-6, 둘 다 R&D Systems)는 검출 항체로서 역할을 하였다. 항-인간 조직 인자 항체(I43), 및 항-인간 조직 인자 항체 검출을 사용하여, 조직 인자를 또한 검출하였다.
실시예 21: TGFβRII/IL-15RαSu 및 IL-21/TF/IL-15 DNA 작제물의 생성
비제한적인 예에서, TGFβRII/IL-15RαSu DNA 작제물을 생성시켰다(도 40). 인간 TGFβRII 이량체 및 인간 IL-21 서열을 UniProt 웹사이트로부터 수득하였고, 이들 서열에 대한 DNA를 게네위즈에 의해 합성하였다. 링커를 이용하여 TGFβRII를 또 다른 TGFβRII에 연결하는 DNA 작제물을 만들어서, TGFβRII의 단일 사슬 버전을 생성시키고, 그 후에 TGFβRII 단일 사슬 이량체 서열을 IL-15RαSu의 N-말단 코딩 영역에 직접적으로 연결하였다.
TGFβRII/IL-15RαSu 작제물의 핵산 서열(신호 서열 포함)은 하기와 같다(SEQ ID NO: 196):
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 TGFβRII-제1 단편)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT
(링커)
GGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGT
(인간 TGFβRII-제2 단편)
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(인간 IL-15R α sushi 도메인)
ATCACGTGTCCTCCTCCTATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGTATTAGA
추가로, IL-21 서열을 조직 인자 219의 N-말단 코딩 영역에 연결하고, IL-21/TF 작제물을 IL-15의 N-말단 코딩 영역과 연결하여 IL-21/TF/IL-15 작제물을 만들었다(도 41). IL-21/TF/IL-15 작제물의 핵산 서열(리더 서열 포함)은 하기와 같다(SEQ ID NO: 192):
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(인간 조직 인자 219)
TCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(인간 IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
실시예 22: TGFβRII/IL-15RαSu 및 IL-21/TF/IL-15 융합 단백질의 분비
TGFβRII/IL-15RαSu 및 IL-21/TF/IL-15 DNA 작제물을 pMSGV-1 변형된 레트로바이러스 발현 벡터 내로 클로닝하고(참조로서 본원에 포함된 문헌[Hughes et al., Hum Gene Ther 16:457-72, 2005]에 기재된 바와 같음), 상기 발현 벡터를 CHO-K1 세포 내로 형질주입하였다. CHO-K1 세포에서 2개 작제물의 공동-발현은 가용성 IL-21/TF/IL-15:TGFβRII/IL-15RαSu 단백질 복합체(21t15-TGFRs로 지칭됨; 도 42 및 도 43)의 분비를 초래하였다. 항-TF 항체 친화도 크로마토그래피 및 다른 크로마토그래피 방법을 사용하여 CHO-K1 세포 배양 상청액으로부터 21t15-TGFRs 단백질을 정제하였다.
TGFβRII/IL-15RαSu 작제물의 아미노산 서열(신호 펩타이드 서열 포함)은 하기와 같다(SEQ ID NO: 195):
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 TGFβRII-제1 단편)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(링커)
GGGGSGGGGSGGGGS
(인간 TGFβRII-제2 단편)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(인간 IL-15R α sushi 도메인)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
성숙한 IL-21/TF/IL-15 융합 단백질의 아미노산 서열(신호 펩타이드 서열 포함)은 하기와 같다(SEQ ID NO: 191):
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
일부 경우, 리더 펩타이드를 무손상 폴리펩타이드로부터 절단하여, 가용성이거나 분비될 수 있는 성숙한 형태를 생성시킨다.
실시예 23: 면역친화도 크로마토그래피에 의한 21t15-TGFRs의 정제
항-TF 항체 친화도 컬럼을 GE Healthcare AKTA™ Avant 단백질 정제 시스템에 연결하였다. 유속이 2 mL/분인 용리 단계를 제외하고는, 모든 단계에 대해 유속은 4 mL/분이었다.
21t15-TGFRs의 세포 배양 수합물을 1 M Tris 염기를 이용하여 pH 7.4로 조정하고, 5 컬럼 부피의 PBS로 평형화된 항-TF 항체 친화도 컬럼 상으로 로딩하였다. 시료를 로딩한 후, 컬럼을 5 컬럼 부피의 PBS로 세척하고, 뒤이어 6 컬럼 부피의 0.1 M 아세트산, pH 2.9로 용리하였다. 280 nm에서의 흡광도를 수집한 다음, 1 M Tris 염기를 첨가함으로써 시료를 pH 7.5 내지 8.0으로 중화시켰다. 그 후에, 30 KDa 분자량 컷오프와 함께 Amicon® 원심분리 필터를 사용하여, 중화된 시료를 PBS로 완충액 교환하였다. 도 44는, 21t15-TGFRs 복합체가 항-TF 항체 친화도 컬럼에 결합함을 도시하며, 여기서, TF는 21t15-TGFRs 결합 파트너이다. 완충액-교환된 단백질 시료를 추가의 생화학적 분석 및 생물학적 활성 시험을 위해 2℃ 내지 8℃에 보관한다.
그 후에, 각각의 용리 후, 6 컬럼 부피의 0.1 M 글리신, pH 2.5를 사용하여 항-TF 항체 친화도 컬럼을 박리시켰다. 그 후에, 컬럼을 10 컬럼 부피의 PBS, 0.05% 소듐 아자이드를 사용하여 중화시키고, 2℃ 내지 8℃에 보관하였다.
실시예 24: 21t15-TGFRs의 크기 배제 크로마토그래피
GE Healthcare Superdex® 200 Increase 10/300 GL 겔 여과 컬럼을 GE Healthcare AKTA™ Avant 단백질 정제 시스템에 연결하였다. 상기 컬럼을 2 컬럼 부피의 PBS로 평형화시켰다. 유속은 0.8 mL/분이었다. 모세관 루프를 사용하여, 200 μL의 1 mg/mL 21t15-TGFRs 복합체를 컬럼 상에 주사하였다. 뒤이어, 1.25 컬럼 부피의 PBS를 주사하였다. SEC 크로마토그래프를 도 45에 도시하였다. 21t15-TGFRs의 단량체 형태 및 이량체 형태를 나타내는 것 같은 2개의 단백질 피크가 존재하였다.
실시예 25: 21t15-TGFRs의 SDS-PAGE
순도 및 단백질 분자량을 결정하기 위해, 환원된 조건 하에 4-12% NuPage Bis-Tris 단백질 겔 SDS-PAGE를 사용하여, 정제된 21t15-TGFRs 복합체 단백질 시료를 분석하였다. 상기 겔을 InstantBlue™로 약 30분 동안 염색시키고, 뒤이어 정제수에서 밤새 탈색시켰다. 도 46은 항-TF 항체 친화도 정제된 21t15-TGFRs의 SDS 겔의 일례를 도시하며, 이때 밴드는 39.08 kDa 및 53 kDa에 존재하였다.
단백질 탈글리코실화 믹스 II 키트(New England Biolabs)를 제조업체의 설명서에 따라 사용하여 CHO 세포에서의 21t15-TGFRs의 글리코실화를 확인하였다. 탈글리코실화는 도 46의 레인 4에 도시된 바와 같이 21t15-TGFRs의 분자량을 감소시킨다.
실시예 26: 21t15-TGFRs 복합체의 재조합 단백질 정량화
표준 샌드위치 ELISA 방법(도 47 내지 도 50)을 사용하여 21t15-TGFRs 복합체를 검출하고 정량화하였다. 항-인간 조직 인자 항체는 포착 항체로서 역할을 하였고, 비오틴화된 항-인간 IL-21, IL-15, 또는 TGFβRII는 검출 항체로서 역할을 하였다. 항-인간 조직 인자 포착 항체(I43), 및 항-인간 조직 인자 항체 검출을 사용하여, 조직 인자를 또한 검출하였다. I43/ 항-TF 항체 ELISA를 유사한 농도에서 정제된 조직 인자와 비교하였다.
실시예 27: 21t15-TGFRs 복합체의 면역자극 역량
21t15-TGFRs 복합체의 IL-15 면역자극 활성을 평가하기 위해, 증가하는 농도의 21t15-TGFRs를 200 μL IMDM:10% FBS 배지 중 32Dβ 세포(104개 세포/웰)에 첨가하고, 37℃에서 3일 동안 인큐베이션하였다. 그 후에, 제4일에, WST-1 증식 시약(10 μL/웰)을 첨가하고, 4시간 후에 흡광도를 450 nm에서 측정하여, 가용성 포르마잔 염료로의 WST-1의 절단에 기초하여 세포 증식을 결정하였다. 인간 재조합 IL-15의 생물활성을 양성 대조군으로서 평가하였다. 도 51에 도시된 바와 같이, 21t15-TGFRs는 IL-15-의존적 32Dβ 세포 증식을 실증하였다. 21t15-TGFRs 복합체는, 아마도 IL-21 및 조직 인자와 IL-15 도메인의 연결로 인해, 인간 재조합 IL-15와 비교하여 감소되었다.
추가로, HEK-Blue TGFβ 리포터 세포(hkb-tgfb, InvivoGen)를 사용하여, 21t15-TGFRs이 TGFβ1 활성을 차단하는 능력을 측정하였다(도 52). 증가하는 농도의 21t15-TGFRs을 0.1 nM의 TGFβ1과 혼합하고, 200 μL IMDM:10% 가열-불활성화된 FBS 배지 중 HEK-Blue TGFβ 리포터 세포(2.5x104 세포/웰)에 첨가하였다. 세포를 37℃에서 밤새 인큐베이션하였다. 다음날, 20 μl의 유도된 HEK-Blue TGFβ 리포터 세포 상청액을 180 μl의 QUANTI-Blue(InvivoGen)에 첨가하고, 37℃에서 1시간 내지 3시간 동안 인큐베이션하였다. 620 nm에서 흡광도를 측정함으로써 21t15-TGFRs 활성을 평가하였다. 인간 재조합 TGFβRII/Fc 활성을 양성 대조군으로서 평가하였다.
이들 결과는, 21t15-TGFRs 복합체의 TGFβRII 도메인이 TGFβ1을 잡는(trap) 능력을 보유함을 실증한다. 21t15-TGFRs가 TGFβ1 활성을 차단하는 능력은, 아마도 TGFβRII와 IL-15Rα sushi 도메인의 연결로 인해, 인간 재조합 TGFβRII/Fc와 비교하여 감소되었다.
실시예 28: 21t15-TGFRs 복합체에 의한 사이토카인-유도 기억-유사 NK 세포의 유도
사이토카인-유도 기억-유사 NK 세포는, 정제된 NK 세포를 포화량의 사이토카인으로 밤새 자극시킨 후, 생체외에서 유도될 수 있다. 이들 기억-유사 특성을 IL-2 수용체 α(IL-2Rα, CD25), CD69(및 다른 활성화 마커)의 발현, 및 증가된 IFN-γ 생성을 통해 측정될 수 있다. 21t15-TGFRs 복합체가 사이토카인-유도 기억-유사 NK 세포의 생성을 촉진하는 능력을 평가하기 위해, 정제된 인간 NK 세포(>95% CD56+)를 1 nM 내지 100 nM의 21t15-TGFRs 복합체로 14시간 내지 18시간 동안 자극시켰다. 세포-표면 CD25 및 CD 69 발현 및 세포내 IFN-γ 수준을 항체-염색 및 유세포측정법에 의해 평가하였다.
새로운 인간 백혈구를 혈액 은행으로부터 수득하였고, CD56+ NK 세포를 RosetteSep/인간 NK 세포 시약(StemCell Technologies)으로 단리시켰다. NK 세포의 순도는 >70%였고, CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750에 특이적인 항체(BioLegend)로 염색함으로써 확인되었다. 세포를 96웰 편평 바닥 플레이트에서 0.2 mL의 완전 배지(2 mM L-글루타민(Thermo Life Technologies), 페니실린(Thermo Life Technologies), 스트렙토마이신(Thermo Life Technologies), 및 10% FBS(Hyclone)가 보충된 RPMI 1640(Gibco))에서 0.2 x 106/mL에서 카운팅하고 재현탁시켰다. 세포를 믹스-사이토카인 hIL-21(50 ng/ml)(Biolegend) 및 hIL-15(50 ng/ml)(NCI)와 함께 또는 1 nM, 10 nM, 또는 100 nM의 21t15-TGFRs 복합체와 함께 밤새 37℃, 5% CO2에서 14시간 내지 18시간 동안 자극시켰다. 그 후에, 세포를 수합하고, CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750에 특이적인 항체로 30분 동안 표면 염색시켰다. 염색 후, 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다(실온에서 1500 RPM에서 5분 동안). 2회의 세척 후, BD FACSCelesta™ 유세포측정기를 사용하여 세포를 분석하였다. (플롯화된 데이터-평균치 형광 강도; 도 53 및 도 54).
새로운 인간 백혈구를 혈액 은행으로부터 수득하였고, CD56+ NK 세포를 RosetteSep/인간 NK 세포 시약(StemCell Technologies)으로 단리시켰다. NK 세포의 순도는 >70%였고, CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750에 특이적인 항체(BioLegend)로 염색함으로써 확인되었다. 세포를 96웰 편평 바닥 플레이트에서 0.2 mL의 완전 배지(2 mM L-글루타민(Thermo Life Technologies), 페니실린(Thermo Life Technologies), 스트렙토마이신(Thermo Life Technologies), 및 10% FBS(Hyclone)가 보충된 RPMI 1640(Gibco))에서 0.2 x 106/ml에서 카운팅하고 재현탁시켰다. 세포를 믹스-사이토카인 hIL-21(50 ng/ml)(Biolegend) 및 hIL-15(50 ng/ml)(NCI)와 함께 또는 1 nM, 10 nM, 또는 100 nM의 21t15-TGFRs 복합체와 함께 밤새 37℃, 5% CO2에서 14시간 내지 18시간 동안 자극시켰다. 그 후에, 세포를 10 μg/ml의 Brefeldin A(Sigma) 및 1X의 Monensin(eBioscience)으로 4시간 동안 처리하였다. 세포를 수합하고, CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750에 특이적인 항체로 30분 동안 표면 염색시켰다. 염색 후, 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하고(실온에서 1500 RPM에서 5분 동안), 실온에서 10분 동안 고정시켰다. 고정 후, 세포를 1x 투과 완충액(eBioscience)에서 세척하고(실온에서 1500 RPM에서 5분 동안), 실온에서 세포내 IFN-γ-PE(Biolegend)로 30분 동안 염색하였다. 세포를 1x 투과 완충액으로 1회 더 세척한 다음, FACS 완충액으로 세척하였다. 세포 펠렛을 300 μl의 FACS 완충액에 재현탁시키고, BD FACSCelesta™ 유세포측정기를 사용하여 분석하였다. (IFN-γ 양성 세포의 플롯화된 %; 도 55).
실시예 29: 인간 종양 세포에 대한 NK 세포의 시험관내 세포독성
K562(CellTrace 바이올렛 표지), 인간 골수원성 백혈병 세포를 증가하는 농도의 21t15-TGFRs 복합체의 존재 하에, 정제된 인간 NK 세포(StemCell 인간 NK 세포 정제 키트를 사용함(E:T 비; 2:1))와 함께 인큐베이션하였다. 20시간 후, 배양물을 수합하며, 프로피디움 요오다이드(PI)로 염색하고, 유세포측정법에 의해 평가하였다. 도 56에 도시된 바와 같이, 21t15-TGFRs 복합체는 대조군과 비교하여, K562에 대한 인간 NK 세포독성을 유도하였다.
실시예 30: IL-21/TF 돌연변이체/IL-15 DNA 작제물의 생성 및 TGFβRII /IL-15RαSu를 갖는 생성된 융합 단백질 복합체
비제한적인 예에서, IL-21을 조직 인자 219 돌연변이체의 N-말단 코딩 영역에 직접적으로 연결하고, IL-21/TF 돌연변이체를 IL-15의 N-말단 코딩 영역에 추가로 연결함으로써 IL-21/TF 돌연변이체/IL-15 DNA 작제물을 만들었다.
IL-21/TF 돌연변이체/IL-15 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다(SEQ ID NO: 324, 음영처리된 뉴클레오타이드는 돌연변이체이고 돌연변이체 코돈은 밑줄처리되어 있음):
(신호 서열)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(인간 조직 인자 219 돌연변이체)

(인간 IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
IL-21/TF 돌연변이체/IL-15 작제물의 아미노산 서열(신호 펩타이드 서열 포함)은 하기와 같다(SEQ ID NO: 325, 치환된 잔기는 음영처리되어 있음):
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(인간 조직 인자 219)

(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
일부 경우, 리더 펩타이드를 무손상 폴리펩타이드로부터 절단하여, 가용성이거나 분비될 수 있는 성숙한 형태를 생성시킨다.
일부 구현예에서, IL-21/TF 돌연변이체/IL-15 DNA 작제물을 TGFβRII /IL-15RαSu DNA 작제물과 조합하며, 상기 기재된 바와 같이 레트로바이러스 벡터를 사용하여 세포 내로 형질주입하고, IL-21/TF 돌연변이체/IL-15 및 TGFβRII/IL-15RαSu 융합 단백질로서 발현시킬 수 있다. TGFβRII/IL-15RαSu 융합 단백질의 IL-15RαSu 도메인은 IL-21/TF 돌연변이체/IL-15 융합 단백질의 IL-15 도메인에 결합하여, IL-21/TF 돌연변이체/IL-15:TGFβRII /IL-15RαSu 복합체를 생성시킨다.
실시예 31: IL-21/IL-15RαSu 및 TGFβRII/TF/IL-15 DNA 작제물의 생성 및 생성된 융합 단백질 복합체
비제한적인 예에서, IL-21을 IL-15RαSu 서브유닛 서열에 직접적으로 연결함으로써 IL-21/IL-15RαSu DNA 작제물을 만들었다. IL-21/IL-15RαSu 작제물의 핵산 서열(신호 서열 포함)은 하기와 같다(SEQ ID NO: 214):
(신호 서열)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(인간 IL-15R α sushi 도메인)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
IL-21/IL-15RαSu 작제물의 아미노산 서열(신호 펩타이드 서열 포함)은 하기와 같다(SEQ ID NO: 213):
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(인간 IL-15R α sushi 도메인)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
일부 경우, 리더 펩타이드를 무손상 폴리펩타이드로부터 절단하여, 가용성이거나 분비될 수 있는 성숙한 형태를 생성시킨다.
일부 구현예에서, IL-21/IL-15RαSu DNA 작제물을 TGFβRII/TF/IL-15 DNA 작제물과 조합하며, 상기 기재된 바와 같이 레트로바이러스 벡터를 사용하여 세포 내로 형질주입하고, IL-21/IL-15RαSu 및 TGFβRII/TF/IL-15 융합 단백질로서 발현시킬 수 있다. IL-21/IL-15RαSu 융합 단백질의 IL-15RαSu 도메인은 TGFβRII/TF/IL-15 융합 단백질의 IL-15 도메인에 결합하여, TGFβRII/TF/IL-15:IL-21/IL-15RαSu 복합체를 생성시킨다.
또한, TGFβRII 서열을 인간 조직 인자 219 형태의 N-말단 코딩 영역에 연결한 다음, TGFβRII/TF 작제물을 IL-15의 N-말단 코딩 영역에 연결함으로써 TGFβRII/TF/IL-15RαSu DNA 작제물을 생성시켰다. 상기 기재된 바와 같이, TGFβRII(TGFβRII-링커-TGFβRII)의 단일-사슬을 사용하였다. TGFβRII/TF/IL-15 작제물의 핵산 서열(리더 서열 포함)은 하기와 같다(SEQ ID NO: 239):
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 TGFβRII-제1 단편)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCACGATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGAT
(링커)
GGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGT
(인간 TGFβRII-제2 단편)
ATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCACAATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(인간 조직 인자 219)
TCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(인간 IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
TGFβRII/TF/IL-15 융합 단백질의 아미노산 서열(신호 펩타이드 포함)은 하기와 같다(SEQ ID NO: 238):
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 TGFβRII-제1 단편)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(링커)
GGGGSGGGGSGGGGS
(인간 TGFβRII-제2 단편)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
실시예 32. 예시적인 단일-사슬 키메라 폴리펩타이드의 생성
항-CD3 scFv인 제1 표적-결합 도메인, 가용성 인간 조직 인자 도메인, 및 항-CD28 scFv인 제2 표적-결합 도메인을 포함하는 예시적인 단일-사슬 키메라 폴리펩타이드가 생성되었다(αCD3scFv/TF/αCD28scFv)(도 57). 이 단일-사슬 키메라 폴리펩타이드의 핵산 및 아미노산 서열은 하기에 제시된다.
예시적인 단일-사슬 키메라 폴리펩타이드를 인코딩하는 핵산(αCD3scFv/TF/αCD28scFv)(SEQ ID NO: 158)
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCTTATTATTTTTATTCAGCTCCGCCTATTCC
(αCD3 경쇄 가변 영역)
CAGATCGTGCTGACCCAAAGCCCCGCCATCATGAGCGCTAGCCCCGGTGAGAAGGTGACCATGACATGCTCCGCTTCCAGCTCCGTGTCCTACATGAACTGGTATCAGCAGAAAAGCGGAACCAGCCCCAAAAGGTGGATCTACGACACCAGCAAGCTGGCCTCCGGAGTGCCCGCTCATTTCCGGGGCTCTGGATCCGGCACCAGCTACTCTTTAACCATTTCCGGCATGGAAGCTGAAGACGCTGCCACCTACTATTGCCAGCAATGGAGCAGCAACCCCTTCACATTCGGATCTGGCACCAAGCTCGAAATCAATCGT
(링커)
GGAGGAGGTGGCAGCGGCGGCGGTGGATCCGGCGGAGGAGGAAGC
(αCD3 중쇄 가변 영역)
CAAGTTCAACTCCAGCAGAGCGGCGCTGAACTGGCCCGGCCCGGCGCCTCCGTCAAGATGAGCTGCAAGGCTTCCGGCTATACATTTACTCGTTACACAATGCATTGGGTCAAGCAGAGGCCCGGTCAAGGTTTAGAGTGGATCGGATATATCAACCCTTCCCGGGGCTACACCAACTATAACCAAAAGTTCAAGGATAAAGCCACTTTAACCACTGACAAGAGCTCCTCCACCGCCTACATGCAGCTGTCCTCTTTAACCAGCGAGGACTCCGCTGTTTACTACTGCGCTAGGTATTACGACGACCACTACTGTTTAGACTATTGGGGACAAGGTACCACTTTAACCGTCAGCAGC
(인간 조직 인자 219 형태)
TCCGGCACCACCAATACCGTGGCCGCTTATAACCTCACATGGAAGAGCACCAACTTCAAGACAATTCTGGAATGGGAACCCAAGCCCGTCAATCAAGTTTACACCGTGCAGATCTCCACCAAATCCGGAGACTGGAAGAGCAAGTGCTTCTACACAACAGACACCGAGTGTGATTTAACCGACGAAATCGTCAAGGACGTCAAGCAAACCTATCTGGCTCGGGTCTTTTCCTACCCCGCTGGCAATGTCGAGTCCACCGGCTCCGCTGGCGAGCCTCTCTACGAGAATTCCCCCGAATTCACCCCTTATTTAGAGACCAATTTAGGCCAGCCTACCATCCAGAGCTTCGAGCAAGTTGGCACCAAGGTGAACGTCACCGTCGAGGATGAAAGGACTTTAGTGCGGCGGAATAACACATTTTTATCCCTCCGGGATGTGTTCGGCAAAGACCTCATCTACACACTGTACTATTGGAAGTCCAGCTCCTCCGGCAAAAAGACCGCTAAGACCAACACCAACGAGTTTTTAATTGACGTGGACAAAGGCGAGAACTACTGCTTCAGCGTGCAAGCCGTGATCCCTTCTCGTACCGTCAACCGGAAGAGCACAGATTCCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(αCD28 경쇄 가변 영역)
GTCCAGCTGCAGCAGAGCGGACCCGAACTCGTGAAACCCGGTGCTTCCGTGAAAATGTCTTGTAAGGCCAGCGGATACACCTTCACCTCCTATGTGATCCAGTGGGTCAAACAGAAGCCCGGACAAGGTCTCGAGTGGATCGGCAGCATCAACCCTTACAACGACTATACCAAATACAACGAGAAGTTTAAGGGAAAGGCTACTTTAACCTCCGACAAAAGCTCCATCACAGCCTACATGGAGTTCAGCTCTTTAACATCCGAGGACAGCGCTCTGTACTATTGCGCCCGGTGGGGCGACGGCAATTACTGGGGACGGGGCACAACACTGACCGTGAGCAGC
(링커)
GGAGGCGGAGGCTCCGGCGGAGGCGGATCTGGCGGTGGCGGCTCC
(αCD28 경쇄 가변 영역)
GACATCGAGATGACCCAGTCCCCCGCTATCATGTCCGCCTCTTTAGGCGAGCGGGTCACAATGACTTGTACAGCCTCCTCCAGCGTCTCCTCCTCCTACTTCCATTGGTACCAACAGAAACCCGGAAGCTCCCCTAAACTGTGCATCTACAGCACCAGCAATCTCGCCAGCGGCGTGCCCCCTAGGTTTTCCGGAAGCGGAAGCACCAGCTACTCTTTAACCATCTCCTCCATGGAGGCTGAGGATGCCGCCACCTACTTTTGTCACCAGTACCACCGGTCCCCCACCTTCGGAGGCGGCACCAAACTGGAGACAAAGAGG
예시적인 단일-사슬 키메라 폴리펩타이드(αCD3scFv/TF/αCD28scFv)(SEQ ID NO: 157)
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(αCD3 경쇄 가변 영역)
QIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINR
(링커)
GGGGSGGGGSGGGGS
(αCD3 중쇄 가변 영역)
QVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTDKSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSS
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(αCD28 경쇄 가변 영역)
VQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSS
(링커)
GGGGSGGGGSGGGGS
(αCD28 중쇄 가변 영역)
DIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKR
항-CD28 scFv인 제1 표적-결합 도메인, 가용성 인간 조직 인자 도메인, 및 항-CD3 scFv인 제2 표적-결합 도메인을 포함하는 제2 예시적인 단일-사슬 키메라 폴리펩타이드가 생성되었다(αCD28scFv/TF/αCD3scFv)(도 57). 이 단일-사슬 키메라 폴리펩타이드의 핵산 및 아미노산 서열은 하기에 제시된다.
예시적인 단일-사슬 키메라 폴리펩타이드를 인코딩하는 핵산(αCD28scFv/TF/αCD3scFv)(SEQ ID NO: 326)
(신호 펩타이드)
ATGAAATGGGTCACCTTCATCTCTTTACTGTTTTTATTTAGCAGCGCCTACAGC
(αCD28 경쇄 가변 영역)
GTGCAGCTGCAGCAGTCCGGACCCGAACTGGTCAAGCCCGGTGCCTCCGTGAAAATGTCTTGTAAGGCTTCTGGCTACACCTTTACCTCCTACGTCATCCAATGGGTGAAGCAGAAGCCCGGTCAAGGTCTCGAGTGGATCGGCAGCATCAATCCCTACAACGATTACACCAAGTATAACGAAAAGTTTAAGGGCAAGGCCACTCTGACAAGCGACAAGAGCTCCATTACCGCCTACATGGAGTTTTCCTCTTTAACTTCTGAGGACTCCGCTTTATACTATTGCGCTCGTTGGGGCGATGGCAATTATTGGGGCCGGGGAACTACTTTAACAGTGAGCTCC
(링커)
GGCGGCGGCGGAAGCGGAGGTGGAGGATCTGGCGGTGGAGGCAGC
(αCD28 중쇄 가변 영역)
GACATCGAGATGACACAGTCCCCCGCTATCATGAGCGCCTCTTTAGGAGAACGTGTGACCATGACTTGTACAGCTTCCTCCAGCGTGAGCAGCTCCTATTTCCACTGGTACCAGCAGAAACCCGGCTCCTCCCCTAAACTGTGTATCTACTCCACAAGCAATTTAGCTAGCGGCGTGCCTCCTCGTTTTAGCGGCTCCGGCAGCACCTCTTACTCTTTAACCATTAGCTCTATGGAGGCCGAAGATGCCGCCACATACTTTTGCCATCAGTACCACCGGTCCCCTACCTTTGGCGGAGGCACAAAGCTGGAGACCAAGCGG
(인간 조직 인자 219 형태)
AGCGGCACCACCAACACAGTGGCCGCCTACAATCTGACTTGGAAATCCACCAACTTCAAGACCATCCTCGAGTGGGAGCCCAAGCCCGTTAATCAAGTTTATACCGTGCAGATTTCCACCAAGAGCGGCGACTGGAAATCCAAGTGCTTCTATACCACAGACACCGAGTGCGATCTCACCGACGAGATCGTCAAAGACGTGAAGCAGACATATTTAGCTAGGGTGTTCTCCTACCCCGCTGGAAACGTGGAGAGCACCGGATCCGCTGGAGAGCCTTTATACGAGAACTCCCCCGAATTCACCCCCTATCTGGAAACCAATTTAGGCCAGCCCACCATCCAGAGCTTCGAACAAGTTGGCACAAAGGTGAACGTCACCGTCGAAGATGAGAGGACTTTAGTGCGGAGGAACAATACATTTTTATCCTTACGTGACGTCTTCGGCAAGGATTTAATCTACACACTGTATTACTGGAAGTCTAGCTCCTCCGGCAAGAAGACCGCCAAGACCAATACCAACGAATTTTTAATTGACGTGGACAAGGGCGAGAACTACTGCTTCTCCGTGCAAGCTGTGATCCCCTCCCGGACAGTGAACCGGAAGTCCACCGACTCCCCCGTGGAGTGCATGGGCCAAGAGAAGGGAGAGTTTCGTGAG
(αCD3 경쇄 가변 영역)
CAGATCGTGCTGACCCAGTCCCCCGCTATTATGAGCGCTAGCCCCGGTGAAAAGGTGACTATGACATGCAGCGCCAGCTCTTCCGTGAGCTACATGAACTGGTATCAGCAGAAGTCCGGCACCAGCCCTAAAAGGTGGATCTACGACACCAGCAAGCTGGCCAGCGGCGTCCCCGCTCACTTTCGGGGCTCCGGCTCCGGAACAAGCTACTCTCTGACCATCAGCGGCATGGAAGCCGAGGATGCCGCTACCTATTACTGTCAGCAGTGGAGCTCCAACCCCTTCACCTTTGGATCCGGCACCAAGCTCGAGATTAATCGT
(링커)
GGAGGCGGAGGTAGCGGAGGAGGCGGATCCGGCGGTGGAGGTAGC
(αCD3 중쇄 가변 영역)
CAAGTTCAGCTCCAGCAAAGCGGCGCCGAACTCGCTCGGCCCGGCGCTTCCGTGAAGATGTCTTGTAAGGCCTCCGGCTATACCTTCACCCGGTACACAATGCACTGGGTCAAGCAACGGCCCGGTCAAGGTTTAGAGTGGATTGGCTATATCAACCCCTCCCGGGGCTATACCAACTACAACCAGAAGTTCAAGGACAAAGCCACCCTCACCACCGACAAGTCCAGCAGCACCGCTTACATGCAGCTGAGCTCTTTAACATCCGAGGATTCCGCCGTGTACTACTGCGCTCGGTACTACGACGATCATTACTGCCTCGATTACTGGGGCCAAGGTACCACCTTAACAGTCTCCTCC
예시적인 단일-사슬 키메라 폴리펩타이드(αCD28scFv/TF/αCD3scFv)(SEQ ID NO: 327)
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(αCD28 경쇄 가변 영역)
VQLQQSGPELVKPGASVKMSCKASGYTFTSYVIQWVKQKPGQGLEWIGSINPYNDYTKYNEKFKGKATLTSDKSSITAYMEFSSLTSEDSALYYCARWGDGNYWGRGTTLTVSS
(링커)
GGGGSGGGGSGGGGS
(αCD28 중쇄 가변 영역)
DIEMTQSPAIMSASLGERVTMTCTASSSVSSSYFHWYQQKPGSSPKLCIYSTSNLASGVPPRFSGSGSTSYSLTISSMEAEDAATYFCHQYHRSPTFGGGTKLETKR
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(αCD3 경쇄 가변 영역)
QIVLTQSPAIMSASPGEKVTMTCSASSSVSYMNWYQQKSGTSPKRWIYDTSKLASGVPAHFRGSGSGTSYSLTISGMEAEDAATYYCQQWSSNPFTFGSGTKLEINR
(링커)
GGGGSGGGGSGGGGS
(αCD3 중쇄 가변 영역)
QVQLQQSGAELARPGASVKMSCKASGYTFTRYTMHWVKQRPGQGLEWIGYINPSRGYTNYNQKFKDKATLTTDKSSSTAYMQLSSLTSEDSAVYYCARYYDDHYCLDYWGQGTTLTVSS
αCD3scFv/TF/αCD28scFv를 인코딩하는 핵산을 이전에 기재된 바와 같이 변형된 레트로바이러스 발현 벡터 내로 클로닝하였다(문헌[Hugheset al., Hum Gene Ther 16:457-72, 2005]). αCD3scFv/TF/αCD28scFv를 인코딩하는 발현 벡터를 CHO-K1 세포 내로 형질주입하였다. CHO-K1 세포에서 발현 벡터의 발현은 가용성 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드(3t28로 지칭됨)의 분비를 가능하게 하였으며, 이는 항-TF Ab 친화도 및 다른 크로마토그래피 방법에 의해 정제될 수 있다.
항-조직 인자 친화도 컬럼을 사용하여, αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드를 정제하였다. 항-조직 인자 친화도 컬럼을 GE Healthcar AKTA Avant 시스템에 연결하였다. 유속이 2 mL/분인 용리 단계를 제외하고는, 모든 단계에 대해 4 mL/분의 유속을 사용하였다.
αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드를 포함하는 세포 배양 수합물을 1 M Tris 염기를 이용하여 pH 7.4로 조정하고, 5 컬럼 부피의 PBS로 평형화된 항-TF 항체 친화도 컬럼(상기 기재됨) 상으로 로딩하였다. 시료를 로딩한 후, 컬럼을 5 컬럼 부피의 PBS로 세척하고, 뒤이어 6 컬럼 부피의 0.1 M 아세트산, pH 2.9로 용리하였다. A280 용리 피크를 수집한 다음, 1 M Tris 염기를 첨가함으로써 pH 7.5 내지 8.0으로 중화시켰다. 그 후에, 30 kDa 분자량 컷오프와 함께 Amicon 원심분리 필터를 사용하여, 중화된 시료를 PBS로 완충액 교환하였다. 도 58의 데이터는, 항-조직 인자 친화도 컬럼이, 인간 가용성 조직 인자 도메인을 함유하는 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드에 결합할 수 있음을 나타낸다. 완충액-교환된 단백질 시료를 추가의 생화학적 분석 및 생물학적 활성 시험을 위해 2℃ 내지 8℃에 보관하였다.
각각의 용리 후, 6 컬럼 부피의 0.1 M 글리신, pH 2.5를 사용하여 항-조직 인자 친화도 컬럼을 박리시켰다. 그 후에, 컬럼을 10 컬럼 부피의 PBS, 0.05% NaN3를 사용하여 중화시키고, 2℃ 내지 8℃에 보관하였다.
αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드 상에서, AKTA Avant 단백질 정제 시스템(GE Healthcare)에 연결된 Superdex 200 Increase 10/300 GL 겔 여과 컬럼(GE Healthcare)을 사용하여 분석적 크기 배제 크로마토그래피(SEC)를 수행하였다. 상기 컬럼을 2 컬럼 부피의 PBS로 평형화시켰다. 0.8 mL/분의 유속을 사용하였다. 200 μL의 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드(1 mg/mL)를 모세관 루프를 사용하여 컬럼 상으로 주사하였다. 단일-사슬 키메라 폴리펩타이드의 주사 후, 1.25 컬럼 부피의 PBS를 컬럼 내로 유동시켰다. SEC 크로마토그래프를 도 59에 도시한다. 데이터는, αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드의 단량체 형태 및 이량체 형태 또는 다른 상이한 형태를 나타내는 것 같은 3개의 단백질 피크가 존재함을 나타낸다.
αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드의 순도 및 단백질 분자량을 결정하기 위해, 항-조직 인자 친화도 컬럼으로부터의 정제된 αCD3scFv/TF/αCD28scFv 단백질 시료를, 환원된 조건 하에 표준 소듐 도데실 설페이트 폴리아크릴아미드 겔(4% 내지 12% NuPage Bis-Tris 겔) 전기영동(SDS-PAGE) 방법에 의해 분석하였다. 상기 겔을 InstantBlue로 약 30분 동안 염색시키고, 뒤이어 정제수에서 밤새 탈색시켰다. 도 60은 항-조직 인자 친화도 컬럼을 사용하여 정제된 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드의 SDS 겔을 도시한다. 결과는, 정제된 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드가 환원된 SDS 겔에서 예상된 분자량(72 kDa)을 가짐을 나타낸다.
실시예 33. αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드의 기능적 특징화
ELISA-기초 방법은 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드의 형성을 확인시켜 주었다. αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드를, 포착 항체, 항-인간 조직 인자 항체(I43), 및 검출 항체, 항-TF 항체를 이용하는 항-TF 항체(I43)/항-TF 항체-특이적 ELISA를 사용하여 검출하였다(도 61). 유사한 농도의 정제된 조직 인자 단백질을 대조군으로서 사용하였다.
추가의 시험관내 방법을 수행하여, αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드가 인간 말초 혈액 단핵 세포(PBMC)를 활성화시킬 수 있는지의 여부를 결정하였다. 신선한 인간 림프구를 혈액 은행으로부터 수득하고, 밀도 구배 Histopaque(Sigma)를 사용하여 말초 혈액 단핵 세포(PBMC)를 단리하였다. 세포를 96웰 편평 바닥 플레이트에서 0.2 mL의 완전 배지(2 mM L-글루타민(Thermo Life Technologies), 페니실린(Thermo Life Technologies), 스트렙토마이신(Thermo Life Technologies), 및 10% FBS(Hyclone)가 보충된 RPMI 1640(Gibco))에서 0.2 x 106/mL에서 카운팅하고 재현탁시켰다. 세포를 37℃, 5% CO2에서 3일 동안 0.01 nM 내지 1000 nM의 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드로 자극시켰다. 72시간 후, 세포를 수합하고, CD4-488, CD8-PerCP Cy5.5, CD25-BV421,CD69-APCFire750, CD62L-PE Cy7, 및 CD44-PE 특이적 항체(Biolegend)에 대해 30분 동안 표면 염색하였다. 표면 염색 후, 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다(실온에서 1500 RPM에서 5분 동안). 2회의 세척 후, 세포를 300 μL의 FACS 완충액에 재현탁시키고, 유세포측정법(Celesta-BD Bioscience)에 의해 분석하였다. 도 62 및 도 63의 데이터는, αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드가 CD8+ T-세포와 CD4+ T-세포 둘 다를 자극시킬 수 있음을 나타낸다.
추가의 실험을 수행하였으며, 이 실험에서 Histopaque(Sigma)를 사용하여 혈액으로부터 단리된 PBMC를 96웰 편평 바닥 플레이트에서 0.2 mL의 완전 배지(2 mM L-글루타민(Thermo Life Technologies), 페니실린(Thermo Life Technologies), 스트렙토마이신(Thermo Life Technologies), 및 10% FBS(Hyclone)가 보충된 RPMI 1640(Gibco))에서 0.2 x 106/mL에서 카운팅하고 재현탁시켰다. 그 후에, 세포를 37℃, 5% CO2에서 3일 동안 0.01 nM 내지 1000 nM의 αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드로 자극시켰다. 72시간 후, 세포를 수합하고, CD4-488, CD8-PerCP Cy5.5, CD25-BV421, CD69-APCFire750, CD62L-PE Cy7, 및 CD44-PE(Biolegend)에 대해 30분 동안 표면 염색하였다. 표면 염색 후, 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다(실온에서 1500 RPM에서 5분 동안). 2회의 세척 후, 세포를 300 μL의 FACS 완충액에 재현탁시키고, 유세포측정법(Celesta-BD Bioscience)에 의해 분석하였다. 데이터는 다시, αCD3scFv/TF/αCD28scFv 단일-사슬 키메라 폴리펩타이드가 CD4+ T-세포의 활성화를 자극시킬 수 있었음을 나타낸다(도 64).
실시예 34: IL-7/IL-15RαSu DNA 작제물의 생성
비제한적인 예에서, IL-7/IL-15RαSu DNA 작제물을 생성시켰다(도 65 참조). 인간 IL-7 서열, 인간 IL-15RαSu 서열, 인간 IL-15 서열, 및 인간 조직 인자 219 서열을 UniProt 웹사이트로부터 수득하였고, 이들 서열에 대한 DNA를 게네위즈에 의해 합성하였다. IL-7 서열을 IL-15RαSu 서열에 연결하여 DNA 작제물을 만들었다. 최종 IL-7/IL-15RαSu DNA 작제물 서열을 게네위즈에 의해 합성하였다.
IL-7/IL-15RαSu 작제물의 제2 키메라 폴리펩타이드를 인코딩하는 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다(SEQ ID NO: 206):
(신호 펩타이드)
ATGGGAGTGAAAGTTCTTTTTGCCCTTATTTGTATTGCTGTGGCCGAGGCC
(인간 IL-7)
GATTGTGATATTGAAGGTAAAGATGGCAAACAATATGAGAGTGTTCTAATGGTCAGCATCGATCAATTATTGGACAGCATGAAAGAAATTGGTAGCAATTGCCTGAATAATGAATTTAACTTTTTTAAAAGACATATCTGTGATGCTAATAAGGAAGGTATGTTTTTATTCCGTGCTGCTCGCAAGTTGAGGCAATTTCTTAAAATGAATAGCACTGGTGATTTTGATCTCCACTTATTAAAAGTTTCAGAAGGCACAACAATACTGTTGAACTGCACTGGCCAGGTTAAAGGAAGAAAACCAGCTGCCCTGGGTGAAGCCCAACCAACAAAGAGTTTGGAAGAAAATAAATCTTTAAAGGAACAGAAAAAACTGAATGACTTGTGTTTCCTAAAGAGACTATTACAAGAGATAAAAACTTGTTGGAATAAAATTTTGATGGGCACTAAAGAACAC
(인간 IL-15R α sushi 도메인)
ATCACGTGCCCTCCCCCCATGTCCGTGGAACACGCAGACATCTGGGTCAAGAGCTACAGCTTGTACTCCAGGGAGCGGTACATTTGTAACTCTGGTTTCAAGCGTAAAGCCGGCACGTCCAGCCTGACGGAGTGCGTGTTGAACAAGGCCACGAATGTCGCCCACTGGACAACCCCCAGTCTCAAATGCATTAGA
IL-7/IL-15RαSu 작제물의 제2 키메라 폴리펩타이드(신호 펩타이드 서열 포함)는 하기와 같다(SEQ ID NO: 205):
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL-7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
실시예 35: IL-21/TF/IL-15 DNA 작제물의 생성
비제한적인 예에서, IL-21 서열을 조직 인자 219의 N-말단 코딩 영역에 연결하고, IL-21/TF 작제물을 IL-15의 N-말단 코딩 영역과 연결하여 IL-21/TF/IL-15 작제물을 만들었다(도 66).
게네위즈에 의해 합성된 IL-21/TF/IL-15 작제물의 제1 키메라 폴리펩타이드를 인코딩하는 핵산 서열(리더 서열 포함)은 하기와 같다(SEQ ID NO: 202):
(신호 펩타이드)
ATGGGAGTGAAAGTTCTTTTTGCCCTTATTTGTATTGCTGTGGCCGAGGCC
(인간 IL-21 단편)
CAAGGTCAAGATCGCCACATGATTAGAATGCGTCAACTTATAGATATTGTTGATCAGCTGAAAAATTATGTGAATGACTTGGTCCCTGAATTTCTGCCAGCTCCAGAAGATGTAGAGACAAACTGTGAGTGGTCAGCTTTTTCCTGTTTTCAGAAGGCCCAACTAAAGTCAGCAAATACAGGAAACAATGAAAGGATAATCAATGTATCAATTAAAAAGCTGAAGAGGAAACCACCTTCCACAAATGCAGGGAGAAGACAGAAACACAGACTAACATGCCCTTCATGTGATTCTTATGAGAAAAAACCACCCAAAGAATTCCTAGAAAGATTCAAATCACTTCTCCAAAAGATGATTCATCAGCATCTGTCCTCTAGAACACACGGAAGTGAAGATTCC
(인간 조직 인자 219)
TCAGGCACTACAAATACTGTGGCAGCATATAATTTAACTTGGAAATCAACTAATTTCAAGACAATTTTGGAGTGGGAACCCAAACCCGTCAATCAAGTCTACACTGTTCAAATAAGCACTAAGTCAGGAGATTGGAAAAGCAAATGCTTTTACACAACAGACACAGAGTGTGACCTCACCGACGAGATTGTGAAGGATGTGAAGCAGACGTACTTGGCACGGGTCTTCTCCTACCCGGCAGGGAATGTGGAGAGCACCGGTTCTGCTGGGGAGCCTCTGTATGAGAACTCCCCAGAGTTCACACCTTACCTGGAGACAAACCTCGGACAGCCAACAATTCAGAGTTTTGAACAGGTGGGAACAAAAGTGAATGTGACCGTAGAAGATGAACGGACTTTAGTCAGAAGGAACAACACTTTCCTAAGCCTCCGGGATGTTTTTGGCAAGGACTTAATTTATACACTTTATTATTGGAAATCTTCAAGTTCAGGAAAGAAAACAGCCAAAACAAACACTAATGAGTTTTTGATTGATGTGGATAAAGGAGAAAACTACTGTTTCAGTGTTCAAGCAGTGATTCCCTCCCGAACAGTTAACCGGAAGAGTACAGACAGCCCGGTAGAGTGTATGGGCCAGGAGAAAGGGGAATTCAGAGAA
(인간 IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
리더 서열을 포함하는 IL-21/TF/IL-15 작제물의 제1 키메라 폴리펩타이드는 SEQ ID NO: 201이다:
(신호 펩타이드)
MGVKVLFALICIAVAEA (SEQ ID NO: 328)
(인간 IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
실시예 36: IL-7/IL-15RαSu 및 IL-21/TF/IL-15 융합 단백질의 분비
IL-7/IL-15RαSu 및 IL-21/TF/IL-15 DNA 작제물을 pMSGV-1 변형된 레트로바이러스 발현 벡터 내로 클로닝하고(참조로서 본원에 포함된 문헌[Hughes, Hum Gene Ther 16:457-72, 2005]에 기재된 바와 같음), 상기 발현 벡터를 CHO-K1 세포 내로 형질주입하였다. CHO-K1 세포에서 2개 작제물의 공동-발현은 가용성 IL-21/TF/IL-15:IL-7/IL-15RαSu 단백질 복합체(21t15-7s로 지칭됨; 도 67 및 도 68)의 형성 및 분비를 가능하게 하였다. 항-TF 항체 친화도 크로마토그래피 및 크기 배제 크로마토그래피를 사용하여 CHO-K1 세포 배양 상청액으로부터 21t15-7s 단백질을 정제하여, IL-7/IL-15RαSu 및 IL-21/TF/IL-15 융합 단백질로 구성된 가용성(비-응집된) 단백질 복합체를 초래하였다.
일부 경우, 리더(신호 서열) 펩타이드를 무손상 폴리펩타이드로부터 절단하여, 가용성이거나 분비될 수 있는 성숙한 형태를 생성시킨다.
실시예 37: 면역친화도 크로마토그래피에 의한 21t15-7s의 정제
항-TF 항체 친화도 컬럼을 GE Healthcare™ AKTA Avant 단백질 정제 시스템에 연결하였다. 유속이 2 mL/분인 용리 단계를 제외하고는, 모든 단계에 대해 유속은 4 mL/분이었다.
21t15-7s의 세포 배양 수합물을 1 M Tris 염기를 이용하여 pH 7.4로 조정하고, 5 컬럼 부피의 PBS로 평형화된 항-TF 항체 친화도 컬럼 상으로 로딩하였다. 시료를 로딩한 후, 컬럼을 5 컬럼 부피의 PBS로 세척하고, 뒤이어 6 컬럼 부피의 0.1 M 아세트산, pH 2.9로 용리하였다. 280 nm에서의 흡광도를 수집한 다음, 1 M Tris 염기를 첨가함으로써 시료를 pH 7.5 내지 8.0으로 중화시켰다. 그 후에, 30 KDa 분자량 컷오프와 함께 Amicon® 원심분리 필터를 사용하여, 중화된 시료를 PBS로 완충액 교환하였다. 완충액-교환된 단백질 시료를 추가의 생화학적 분석 및 생물학적 활성 시험을 위해 2℃ 내지 8℃에 보관하였다.
그 후에, 각각의 용리 후, 6 컬럼 부피의 0.1 M 글리신, pH 2.5를 사용하여 항-TF 항체 친화도 컬럼을 박리시켰다. 그 후에, 컬럼을 10 컬럼 부피의 PBS, 0.05% 소듐 아자이드를 사용하여 중화시키고, 2℃ 내지 8℃에 보관하였다.
실시예 38: 크기 배제 크로마토그래피
GE Healthcare Superdex® 200 Increase 10/300 GL 겔 여과 컬럼을 GE Healthcare AKTA™ Avant 단백질 정제 시스템에 연결하였다. 상기 컬럼을 2 컬럼 부피의 PBS로 평형화시켰다. 유속은 0.7 mL/분이었다. 모세관 루프를 사용하여, 200 μL의 1 mg/mL 7t15-21s 복합체를 컬럼 상에 주사하였다. 1.25 컬럼 부피의 PBS를 주사하였다.
실시예 39: 21t15-7s 및 21t15-TGFRs의 SDS-PAGE
순도 및 단백질 분자량을 결정하기 위해, 4-12% NuPage Bis-Tris 단백질 겔 SDS-PAGE를 사용하여, 정제된 21t15-7s 또는 21t15-TGFRs 단백질 시료를 분석하였다. 상기 겔을 InstantBlue™로 약 30분 동안 염색시키고, 뒤이어 정제수에서 밤새 탈색시킬 것이다.
실시예 40: CHO-K1 세포에서 21t15-7s 및 21t15-TGFRs의 글리코실화
단백질 탈글리코실화 믹스 II 키트(New England Biolabs)를 제조업체의 설명서에 따라 사용하여 CHO-K1 세포에서의 21t15-7s 또는 CHO-K1 세포에서의 21t15-TGFRs의 글리코실화를 확인하였다.
실시예 41: 21t15-7s 및 21t15-TGFRs 복합체의 재조합 단백질 정량화
표준 샌드위치 ELISA 방법을 사용하여 21t15-7s 복합체 또는 21t15-TGFRs 복합체를 검출하고 정량화하였다. 항-인간 조직 인자 항체(IgG1)는 포착 항체로서 역할을 하였고, 비오틴화된 항-인간 IL-21, IL-15, 또는 IL-7 항체(21t15-7s) 또는 비오틴화된 항-인간 IL-21, IL-15, 또는 TGF-βRII 항체(21t15-TGFRs)는 검출 항체로서 역할을 하였다. 항-인간 조직 인자 포착 항체, 및 항-인간 조직 인자 항체(IgG1) 검출 항체를 사용하여, 정제된 21t15-7s 또는 21t15-TGFRs 단백질 복합체 내의 조직 인자를 또한 검출하였다. 항-TF 항체 ELISA를 유사한 농도에서 정제된 조직 인자와 비교할 것이다.
실시예 42: IL-21/IL-15RαSu DNA 작제물의 생성
비제한적인 예에서, IL-21/IL-15RαSu DNA 작제물을 생성시켰다. 인간 IL-21 서열 및 인간 IL-15RαSu 서열을 UniProt 웹사이트로부터 수득하였고, 이들 서열에 대한 DNA를 게네위즈에 의해 합성하였다. IL-21 서열을 IL-15RαSu 서열에 연결하여 DNA 작제물을 만들었다. 최종 IL-21/IL-15RαSu DNA 작제물 서열을 게네위즈에 의해 합성하였다. 도 69를 참조한다.
실시예 43: IL-7/TF/IL-15 DNA 작제물의 생성
비제한적인 예에서, IL-7 서열을 조직 인자 219의 N-말단 코딩 영역에 연결하고, IL-7/TF 작제물을 IL-15의 N-말단 코딩 영역과 추가로 연결하는 IL-7/TF/IL-15 작제물을 만들었다. 도 70을 참조한다.
실시예 44: IL-21/IL-15Rα Sushi DNA 작제물의 생성
비제한적인 예에서, IL-21/IL-15RαSu의 제2 키메라 폴리펩타이드를 생성시켰다. 인간 IL-21 서열 및 인간 IL-15Rα sushi 서열을 UniProt 웹사이트로부터 수득하였고, 이들 서열에 대한 DNA를 게네위즈에 의해 합성하였다. IL-21 서열을 IL-15Rα sushi 서열에 연결하여 DNA 작제물을 만들었다. 최종 IL-21/IL-15RαSu DNA 작제물 서열을 게네위즈에 의해 합성하였다.
게네위즈에 의해 합성된 IL-21/IL-15RαSu 도메인의 제2 키메라 폴리펩타이드를 인코딩하는 핵산 서열(리더 서열 포함)은 하기와 같다(SEQ ID NO: 214):
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(인간 IL-15R α sushi 도메인)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
IL-21/IL-15Rα sushi 도메인의 제2 키메라 폴리펩타이드(리더 서열 포함)는 하기와 같다(SEQ ID NO: 213):
(신호 서열)
MKWVTFISLLFLFSSAYS
(인간 IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(인간 IL-15Rα sushi 도메인)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
실시예 45: IL-7/TF/IL-15 DNA 작제물의 생성
비제한적인 예에서, IL-7 서열을 조직 인자 219의 N-말단 코딩 영역에 연결하고, IL-7/TF 작제물을 IL-15의 N-말단 코딩 영역과 추가로 연결하는 IL-7/TF/IL-15의 예시적인 제1 키메라 폴리펩타이드를 만들었다. 게네위즈에 의해 합성된 IL-7/TF/IL-15 작제물의 제1 키메라 폴리펩타이드를 인코딩하는 핵산 서열(리더 서열 포함)은 하기와 같다(SEQ ID NO: 210):
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 IL-7 단편)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(인간 조직 인자 219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(인간 IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
IL-7/TF/IL-15의 제1 키메라 폴리펩타이드(리더 서열 포함)는 하기와 같다(SEQ ID NO: 209):
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL-7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
실시예 46: IL-21/IL-15RαSu 및 IL-7/TF/IL-15 융합 단백질의 분비
IL-21/IL-15RαSu 및 IL-7/TF/IL-15 DNA 작제물을 pMSGV-1 변형된 레트로바이러스 발현 벡터 내로 클로닝하고(참조로서 본원에 포함된 문헌[Hughes, Hum Gene Ther 16:457-72, 2005]에 기재된 바와 같음), 상기 발현 벡터를 CHO-K1 세포 내로 형질주입하였다. CHO-K1 세포에서 2개 작제물의 공동-발현은 가용성 IL-7/TF/IL-15:IL-21/IL-15RαSu 단백질 복합체(7t15-21s로 지칭됨)의 형성 및 분비를 가능하게 하였다. 항-TF 항체(IgG1) 친화도 크로마토그래피 및 크기 배제 크로마토그래피를 사용하여 CHO-K1 세포 배양 상청액으로부터 7t15-21s 단백질을 정제하여, IL-21/IL-15RαSu 및 IL-7/TF/IL-15 융합 단백질로 구성된 가용성(비-응집된) 단백질 복합체를 초래하였다. 도 71 및 도 72를 참조한다.
실시예 47: 7t15-21s 복합체 + 항-TF IgG1 항체에 의한 1차 자연 살해(NK) 세포의 확장 역량
1차 자연 살해(NK) 세포를 확장시키는 7t15-21s 복합체의 능력을 평가하기 위해, 7t15-21s 복합체 및 7t15-21s 복합체 + 항-TF IgG1 항체를 새로운 인간 백혈구 시료로부터 수득된 NK 세포에 첨가한다. 세포를 37° 및 5% CO2에서 25 nM의 항-TF IgG1 항체 또는 항-TF IgG4 항체와 함께 또는 상기 항체 없이 50 nM의 7t15-21s 복합체로 자극시킨다. 48시간 내지 72시간마다 카운팅함으로써 2.0 x 106/mL를 초과하지 않는 0.5 x 106/mL 농도에서 세포를 유지시키고, 배지에 새로운 자극인자를 보충한다. 7t15-21s 복합체 또는 항-TF IgG1 항체 또는 항-TFIgG4 항체, 또는 항-TF IgG4 + 7t15-21s 복합체로 자극시킨 세포를 제5일까지 유지시킨다. 21t15-7s 복합체 + 항-TF IgG1 항체와 함께 인큐베이션 시 1차 NK 세포의 확장이 관찰된다.
실시예 48: 7t15-21s 복합체 + 항-TF IgG1 항체에 의한 확장된 NK 세포의 활성화
1차 NK 세포는, 정제된 NK 세포를 7t15-21s 복합체 + 항-TF IgG1 항체로 밤새 자극시킨 후, 생체외에서 유도된다. 새로운 인간 백혈구를 혈액 은행으로부터 수득하고, CD56+ NK 세포를 RosetteSep/인간 NK 세포 시약(StemCell Technologies)으로 단리시킨다. NK 세포의 순도는 >80%이고, CD56-BV421 및 CD16-BV510에 특이적인 항체(BioLegend)로 염색함으로써 확인된다. 세포를 24웰 편평 바닥 플레이트에서 1 mL의 완전 배지(4 mM L-글루타민(Thermo Life Technologies), 페니실린(Thermo Life Technologies), 스트렙토마이신(Thermo Life Technologies), 비-필수 아미노산(Thermo Life Technologies), 소듐 피루베이트(Thermo Life Technologies), 및 10% FBS(Hyclone)가 보충된 RPMI 1640(Gibco))에서 1 x 106/mL에서 카운팅하고 재현탁시킨다. 세포를 37° 및 5% CO2에서 25 nM의 항-TF IgG1 항체와 함께 또는 상기 항체 없이 50 nM의 7t15-21s로 자극시킨다. 세포를 48시간 내지 72시간마다 카운팅하고, 제14일까지 0.5 x 106/mL 내지 2.0 x 106/mL의 농도에서 유지시킨다. 배지에 새로운 자극인자를 주기적으로 보충한다. 세포를 수합하고, 제3일에 CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750에 특이적인 항체(Biolegend)로 표면 염색하고 유세포측정법-Celeste-BD Bioscience)로 분석하였다. 활성화 마커 CD25 MFI는 7t15-21s 복합체 + 항-TF IgG1 항체 자극에 의해 증가하였으나, 7t15-21s 복합체 자극에 의해서는 증가하는 것으로 관찰된다. 활성화 마커 CD69 MFI는 7t15-21s 복합체 + 항-TF IgG1 항체와 7t15-21s 복합체 단독 둘 다에 의해 증가하는 것으로 관찰된다.
실시예 49: NK 세포에서 18t15-12s를 사용한 포도당 대사의 증가
한 세트의 실험을 수행하여, 인간 혈액으로부터 단리된 NK 세포 상에서 산소 소모율 및 세포외 산성화율(ECAR)에 미치는 18t15-12s의 효과를 결정하였다.
이들 실험에서, 새로운 인간 백혈구를 혈액 은행으로부터 2명의 상이한 인간 공여자로부터 수득하였고, NK 세포를 RosetteSep/인간 NK 세포 시약(StemCell Technologies)을 사용한 음성 선별을 통해 단리시켰다. NK 세포의 순도는 >80%였고, CD56-BV421 및 CD16-BV510에 특이적인 항체(BioLegend)로 염색함으로써 확인되었다. 세포를 24웰 편평 바닥 플레이트에서 1 mL의 완전 배지(4 mM L-글루타민(Thermo Life Technologies), 페니실린(Thermo Life Technologies), 스트렙토마이신(Thermo Life Technologies), 비-필수 아미노산(Thermo Life Technologies), 소듐 피루베이트(Thermo Life Technologies), 및 10% FBS(Hyclone)가 보충된 RPMI 1640(Gibco))에서 2 x 106/mL에서 카운팅하고 재현탁시켰다. 세포를 (1) 배지 단독, (2) 100 nM 18t15-12s, 또는 (3) 단일 사이토카인 재조합 인간 IL-12(0.25 μg), 재조합 인간 IL-15(1.25 μg), 및 재조합 인간 IL-18(1.25 μg)의 혼합물로 37℃, 5% CO2에서 밤새 자극시켰다. 다음날, 세포를 수합하고, 확장된 NK 세포 상에서 세포외 흐름(flux) 검정법을 XFp Analyzer(Seahorse Bioscience)를 사용하여 수행하였다. 수합된 세포를 세척하고, OCR(산소 소모율) 및 ECAR(세포외 산성화율)의 세포외 흐름 분석을 위해 적어도 2벌로 2.0 x 105 세포/웰로 평판배양하였다. 해당(glycolysis) 스트레스 시험을 2 mM의 글루타민을 함유하는 Seahorse 배지에서 수행하였다. 하기 성분을 검정법 동안 사용하였다: 10 mM 포도당; 100 nM 올리고마이신; 및 100 mM 2-데옥시-D-글리코스(2DG).
데이터는, 18t15-12s는, 재조합 인간 IL-12, 재조합 인간 IL-15, 및 재조합 인간 IL-18의 조합으로 활성화된 동일한 세포와 비교하여(도 74), 유의하게 증가된 산소 소모율(도 73) 및 세포외 산성화율(ECAR)을 초래한다.
실시예 50: 7t15-16s21 융합 단백질 발생 및 특징화
항-CD16scFv/IL-15RαSu/IL-21 및 IL-7/TF/IL-15 융합 단백질을 포함하는 융합 단백질 복합체를 생성시켰다. 인간 IL-7 서열 및 IL-21 서열을 UniProt 웹사이트로부터 수득하였고, 이들 서열에 대한 DNA를 게네위즈에 의해 합성하였다. 구체적으로, IL-7 서열을 조직 인자 219의 N-말단 코딩 영역에 연결하고, 뒤이어 IL-15의 N-말단 코딩 영역과 연결하는 작제물을 만들었다.
조직 인자 219의 N-말단, 뒤이어 IL-15의 N-말단에 연결된 IL-7을 포함하는 작제물의 핵산 서열 및 단백질 서열은 하기에 제시된다.
IL-7/TF/IL-15 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 IL-7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(인간 조직 인자 219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(인간 IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
IL-7/TF/IL-15 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL-7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
항-CD16scFv 서열을 IL-15RαSu 사슬의 N-말단 코딩 영역에 연결하고, 뒤이어 게네위즈에 의해 합성된 IL-21의 N-말단 코딩 영역과 연결하는 작제물을 또한 만들었다. IL-15RαSu 사슬의 N-말단, 뒤이어 IL-21의 N-말단 코딩 영역에 연결된 항-CD16scFv를 포함하는 작제물의 핵산 서열 및 단백질 서열은 하기에 제시된다.
항-CD16SscFv/IL-15 RαSu/IL-21 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
((항-인간 CD16scFv)
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG
(인간 IL-15R α sushi 도메인)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
(인간 IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
항-CD16scFv/IL-15RαSu/IL-21 작제물의 아미노산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(항-인간 CD16scFv)
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR
(인간 IL-15R α sushi 도메인)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
(인간 IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
일부 경우, 리더 펩타이드를 무손상 폴리펩타이드로부터 절단하여, 가용성이거나 분비될 수 있는 성숙한 형태를 생성시킨다.
항-CD16scFv/IL-15RαSu/IL-21 및 IL-7/TF/IL-15 작제물을 이전에 기재된 바와 같이 변형된 레트로바이러스 발현 벡터 내로 클로닝하였고(문헌[Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y, et al. Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions. Hum Gene Ther 2005;16:457-72]), 발현 벡터를 CHO-K1 세포 내로 형질주입하였다. CHO-K1 세포에서 2개 작제물의 공동-발현은 가용성 IL-7/TF/IL-15:항-CD16scFv/IL-15RαSu/IL-21 단백질 복합체(7t15-16s21로 지칭됨; 도 75 및 도 76)의 형성 및 분비를 가능하게 하였으며, 이는 항-TF IgG1 항체-기초 친화도 및 다른 크로마토그래피 방법에 의해 정제될 수 있다.
인간 CD16b를 발현하는 CHO 세포에의 7t15-16s21의 결합
CHO 세포를 pMC 플라스미드에서 인간 CD16b로 형질주입하고, 10 μg/mL의 블라스티시딘(blasticidin)으로 10일 동안 선별하였다. CD16b를 안정하게 발현하는 CHO 세포를, 음성 대조군으로서 항-인간 CD16 scFv를 함유하지 않으며 항-인간 CD16 scFv 또는 18t15-12s를 함유하는 1.2 μg/mL의 7t15-16s21로 염색한 다음, 비오틴화된 항-인간 조직 인자 및 PE 접합 스트렙타비딘으로 염색하였다. 7t15-16s21를 함유하는 항-인간 CD16scFv는 도 77a에 도시된 바와 같이 세포를 염색시켰다. 18t15-12s는 도 77b에 도시된 바와 같이 인간 CD16b를 발현하는 CHO 세포를 염색시키지 않았다.
ELISA를 사용한 7t15-16s21 내 IL-15, IL-21, 및 IL-7의 검출
96-웰 플레이트를 R5(코팅 완충액) 중 100 μL(8 μg/mL)의 항-TF IgG1로 코팅시키고, 실온(RT)에서 2시간 동안 인큐베이션하였다. 상기 플레이트를 3회 세척하고, 100 μL의, PBS 중 1% BSA로 블라킹시켰다. 7t15-16s21의 단계 희석물(1:3 비)을 웰에 첨가하고, RT에서 60분 동안 인큐베이션하였다. 3회 세척 후, 50 ng/mL의 비오틴화된-항-IL-15 항체(BAM247, R&D Systems), 500 ng/mL의 비오틴화된-항-IL-21 항체(13-7218-81, R&D Systems), 또는 500 ng/mL의 비오틴화된-항-IL-7 항체(506602, R&D Systems)를 웰에 첨가하고, RT에서 60분 동안 인큐베이션하였다. 플레이트를 3회 세척하고, 0.25 μg/mL의 HRP-SA(Jackson ImmunoResearch)와 함께 웰당 100 μL에서 RT에서 30분 동안 인큐베이션하고, 뒤이어 4회 세척하고 100 μl의 ABTS와 함께 RT에서 2분 동안 인큐베이션하였다. 흡광도를 405 nm에서 판독하였다. 도 78a 내지 도 78c에 도시된 바와 같이, 7t15-16s21에서 IL-15, IL-21, 및 IL-7 도메인은 개별 항체에 의해 검출되었다.
7t15-16s21 내 IL-15는 IL-2Rβ 및 공통 γ 사슬 함유 32Dβ 세포 증식을 촉진한다
7t15-16s21에서 IL-15의 활성을 분석하기 위해, 7t15-16s21의 IL-15 활성을, IL2Rβ 및 공통 γ 사슬을 발현하는 32Dβ 세포를 사용하고, 세포 증식을 촉진하는 데 있어서 이들의 효과를 평가하여 재조합 IL-15와 비교하였다. IL-15 의존적 32Dβ 세포를 IMDM-10% FBS로 5회 세척하고, 웰에 2 x 104 세포/웰로 접종하였다. 단계 희석된 7t15-16s21 또는 IL-15를 세포에 첨가하였다(도 79). 세포를 CO2 인큐베이터에서 37℃에서 3일 동안 인큐베이션하였다. 제3일에 10 μl의 WST1을 각각의 웰에 첨가하고 CO2 인큐베이터에서 37℃에서 추가 3시간 동안 인큐베이션함으로써 세포 증식을 검출하였다. 생성된 포르마잔 염료의 양을 분석함으로써 450 nm의 흡광도를 측정하였다. 도 79에 도시된 바와 같이, 7t15-16s21 및 IL-15는 32Dβ 세포 증식을 촉진하였으며, 이때 7t15-16s21 및 IL-15의 EC50은 각각 172.2 pM 및 16.63 pM이었다.
항-TF 항체 친화도 컬럼으로부터의 7t15-16s21의 정제 용리 크로마토그래프
세포 배양물로부터 수합된 7t15-16s21을 5 컬럼 부피의 PBS로 평형화된 항-TF 항체 친화도 컬럼 상으로 로딩하였다. 그 후에, 컬럼을 5 컬럼 부피의 PBS로 세척하고, 뒤이어 6 컬럼 부피의 0.1 M 아세트산(pH 2.9)으로 용리하였다. A280 용리 피크를 수집하고, 1 M Tris 염기를 첨가함으로써 pH 7.5 내지 8.0으로 중화시켰다. 30 KDa 분자량 컷오프와 함께 Amicon 원심분리 필터를 사용하여, 중화된 시료를 PBS로 완충액 교환하였다. 도 80은 항-TF 항체 수지 상에서 결합 및 용리 후 7t15-16s21 단백질-함유 세포 배양물 상청액의 크로마토그래프 프로파일을 도시하는 선 그래프이다. 도 80에 도시된 바와 같이, 항-TF 항체 친화도 컬럼은 TF를 함유하는 7t15-16s21에 결합하였다. 완충액-교환된 단백질 시료를 추가의 생화학적 분석 및 생물학적 활성 시험을 위해 2℃ 내지 8℃에 보관하였다. 각각의 용리 후, 6 컬럼 부피의 0.1 M 글리신(pH 2.5)를 사용하여 항-TF 항체 친화도 컬럼을 박리시켰다. 그 후에, 보관을 위해 상기 컬럼을 5 컬럼 부피의 PBS, 및 7 컬럼 부피의 20% 에탄올을 사용하여 중화시켰다. 항-TF 항체 친화도 컬럼을 GE Healthcar AKTA Avant 시스템에 연결하였다. 유속이 2 mL/분인 용리 단계를 제외하고는, 모든 단계에 대해 유속은 4 mL/분이었다.
7t15-16s21의 분석적 크기 배제 크로마토그래피(SEC) 분석
7t15-16s21에 대한 크기 배제 크로마토그래피(SEC) 분석을 수행하기 위해, AKTA Avant 단백질 정제 시스템(GE Healthcare)에 연결된 Superdex 200 Increase 10/300 GL 겔 여과 컬럼(GE Healthcare)을 사용하였다. 상기 컬럼을 2 컬럼 부피의 PBS로 평형화시켰다. 유속은 0.7 mL/분이었다. 7t15-16s21을 PBS에 함유하는 시료를 모세관 루프를 사용하여 Superdex 200 컬럼 내로 주사하고, SEC에 의해 분석하였다. 도 81에 도시된 바와 같이, SEC 결과는 7t15-16s21에 대한 2개의 단백질 피크를 나타내었다.
실시예 51: TGFRt15-16s21 융합 단백질 발생 및 특징화
항-인간 CD16scFv/IL-15RαSu/IL21 및 TGFβ 수용체 II/TF/IL-15 융합 단백질을 포함하는 융합 단백질 복합체를 생성시켰다(도 82 및 도 83). 인간 TGFβ 수용체 II(Ile24-Asp159), 조직 인자 219, 및 IL-15 서열을 UniProt 웹사이트로부터 수득하였고, 이들 서열에 대한 DNA를 게네위즈에 의해 합성하였다. 구체적으로, G4S(3) 링커를 이용하여 2개의 TGFβ 수용체 II 서열을 연결하여 TGFβ 수용체 II의 단일 사슬 버전을 생성시킨 다음, 조직 인자 219의 N-말단 코딩 영역에 연결하고, 뒤이어 IL-15의 N-말단 코딩 영역과 연결하는 작제물을 만들었다.
조직 인자 219의 N-말단, 뒤이어 IL-15의 N-말단에 연결된 2개의 TGFβ 수용체 II를 포함하는 작제물의 핵산 서열 및 단백질 서열은 하기에 제시된다.
2개의 TGFβ 수용체 II/TF/IL-15 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(2개의 인간 TGFβ 수용체 II 단편)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(인간 조직 인자 219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(인간 IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
TGFβ 수용체 II/TF/IL-15 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 TGFβ 수용체 II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
IL-15RαSu 사슬의 N-말단 코딩 영역에 직접적으로 연결하고, 뒤이어 게네위즈에 의해 합성된 IL-21의 N-말단 코딩 영역과 연결하는 항-CD16scFv 서열을 부착시킴으로써 작제물을 또한 만들었다. IL-15RαSu 사슬의 N-말단, 뒤이어 IL-21의 N-말단 코딩 영역에 연결된 항-인간 CD16scFv를 포함하는 작제물의 핵산 서열 및 단백질 서열은 하기에 제시된다.
항-CD16scFv/IL-15 RαSu/IL-21 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(항-인간 CD16scFv)
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG
(인간 IL-15R α sushi 도메인)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
(인간 IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
항-CD16scFv/IL-15RαSu/IL-21 작제물의 아미노산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(항-인간 CD16scFv)
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR
(인간 IL-15R α sushi 도메인)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
(인간 IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
일부 경우, 리더 펩타이드를 무손상 폴리펩타이드로부터 절단하여, 가용성이거나 분비될 수 있는 성숙한 형태를 생성시킨다.
항-CD16scFv/IL-15RαSu/IL-21 및 TGFR/TF/IL-15 작제물을 이전에 기재된 바와 같이 변형된 레트로바이러스 발현 벡터 내로 클로닝하고(문헌[Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y, et al. Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions. Hum Gene Ther 2005;16:457-72]), 발현 벡터를 CHO-K1 세포 내로 형질주입하였다. CHO-K1 세포에서 2개 작제물의 공동-발현은 가용성 TGFR/TF/IL-15:CD16scFv/IL-15RαSu/IL-21 단백질 복합체(TGFRt15-16s21로 지칭됨)의 형성 및 분비를 가능하게 하였으며, 이는 항-TF IgG1-기초 친화도 및 다른 크로마토그래피 방법에 의해 정제될 수 있다.
TGFRt15-16s21과 인간 CD16b를 발현하는 CHO 세포 사이의 상호작용
CHO 세포를 pMC 플라스미드에서 인간 CD16b로 형질주입하고, 10 μg/mL의 블라스티시딘으로 10일 동안 선별하였다. CD16b를 안정하게 발현하는 세포를, 음성 대조군으로서 항-인간 CD16 scFv를 함유하지 않으며 항-인간 CD16 scFv 또는 7t15-21s를 함유하는 1.2 μg/mL의 TGFRt15-16s21로 염색한 다음, 비오틴화된 항-인간 조직 인자 항체 및 PE 접합 스트렙타비딘으로 염색하였다. 도 84a 및 도 84b에 도시된 바와 같이, 항-인간 CD16scFv를 함유하는 TGFRt15-16s21은 양의(positive) 결합을 나타낸 한편, 7t15-21s는 결합을 나타내지 않았다.
HEK-Blue TGFβ 세포에서 TGFβ1 활성에 미치는 TGFRt15-16s21의 효과
TGFRt15-16s21에서 TGFβRII의 활성을 평가하기 위해, HEK-Blue TGFβ 세포에서 TGFβ1의 활성에 미치는 TGFRt15-16s21의 효과를 분석하였다. HEK-Blue TGFβ 세포(Invivogen)를 예열된 PBS로 2회 세척하고, 시험 배지(DMEM, 10% 가열-불활성화된 FCS, 1x 글루타민, 1x 항-항, 및 2x 글루타민)에 5 x 105 세포/mL로 재현탁시켰다. 편평-바닥 96-웰 플레이트에서, 50 μl 세포를 각각의 웰(2.5 x 104 세포/웰)에 첨가하고, 뒤이어 50 μL 0.1 nM TGFβ1(R&D systems)을 첨가하였다. 그 후에, 1:3 단계 희석물로 제조된 TGFRt15-16s21 또는 TGFR-Fc(R&D Systems)를 플레이트에 첨가하여, 200 μL의 총 부피에 도달하였다. 37℃에서 24시간 동안 인큐베이션한 후, 40 μL의 유도된 HEK-Blue TGFβ 세포 상청액을 편평-바닥 96-웰 플레이트에서 160 μL의 예열된 QUANTI-Blue(Invivogen)에 첨가하고, 37℃에서 1시간 내지 3시간 동안 인큐베이션하였다. 그 후에, 플레이트 판독기(Multiscan Sky)를 620 nM 내지 655 nM에서 사용하여 OD 값을 결정하였다. 각각의 단백질 시료의 IC50을 GraphPad Prism 7.04를 이용하여 계산하였다. TGFRt15-16s21 및 TGFR-Fc의 IC50은 각각 9127 pM 및 460.6 pM이었다. 이들 결과는, TGFRt15-16s21에서 TGFβRII 도메인이 HEK-Blue TGFβ 세포에서 TGFβ-1의 활성을 차단할 수 있었음을 나타내었다.
TGFRt15-16s21 내 IL-15는 IL-2Rβ 및 공통 γ 사슬 함유 32Dβ 세포 증식을 촉진한다
TGFRt15-16s21에서 IL-15의 활성을 분석하기 위해, TGFRt15-16s21의 IL-15 활성을, IL2Rβ 및 공통 γ 사슬을 발현하는 32Dβ 세포를 사용하고, 세포 증식을 촉진하는 데 있어서 이들의 효과를 평가하여 재조합 IL-15와 비교하였다. IL-15 의존적 32Dβ 세포를 IMDM-10% FBS로 5회 세척하고, 웰에 2 x 104 세포/웰로 접종하였다. 단계 희석된 TGFRt15-16s21 또는 IL-15를 세포에 첨가하였다(도 86). 세포를 CO2 인큐베이터에서 37℃에서 3일 동안 인큐베이션하였다. 제3일에 10 μL의 WST1을 각각의 웰에 첨가하고 CO2 인큐베이터에서 37℃에서 추가 3시간 동안 인큐베이션함으로써 세포 증식을 검출하였다. 생성된 포르마잔 염료의 양을 분석함으로써 450 nm의 흡광도를 측정하였다. 데이터를 도 85에 도시한다. 도 86에 도시된 바와 같이, TGFRt15-16s21 및 IL-15는 32Dβ 세포 증식을 촉진하였으며, 이때 TGFRt15-16s21 및 IL-15의 EC50은 각각 51298 pM 및 10.63 pM이었다.
ELISA를 사용한 TGFRt15-16s21 내 IL-15, IL-21, 및 TGFβRII의 검출
96-웰 플레이트를 R5(코팅 완충액) 중 100 μL(8 μg/mL)의 항-TF IgG1로 코팅시키고, 실온(RT)에서 2시간 동안 인큐베이션하였다. 상기 플레이트를 3회 세척하고, 100 μL의, PBS 중 1% BSA로 블라킹시켰다. 1:3 비로 단계 희석된 TGFRt15-16s21을 첨가하고, RT에서 60분 동안 인큐베이션하였다. 3회 세척 후, 50 ng/mL의 비오틴화된-항-IL-15 항체(BAM247, R&D Systems), 500 ng/mL의 비오틴화된-항-IL-21 항체(13-7218-81, R&D Systems), 또는 200 ng/mL의 비오틴화된-항-TGFβRII 항체(BAF241, R&D Systems)를 웰당 적용하고, RT에서 60분 동안 인큐베이션하였다. 3회 세척 후, 0.25 μg/mL의 HRP-SA(Jackson ImmunoResearch)와 함께 웰당 100 μL에서 RT에서 30분 동안 인큐베이션하고, 뒤이어 4회 세척하고 100 μL의 ABTS와 함께 RT에서 2분 동안 인큐베이션하였다. 흡광도를 405 nm에서 판독하였다. 도 87a 내지 도 87c에 도시된 바와 같이, TGFRt15-16s21에서 IL-15, IL-21, 및 TGFβRII 도메인은 각각의 항체에 의해 검출되었다.
항-TF 항체 친화도 컬럼을 사용한 TGFRt15-16s21의 정제 용리 크로마토그래프
세포 배양물로부터 수합된 TGFRt15-16s21을 5 컬럼 부피의 PBS로 평형화된 항-TF 항체 친화도 컬럼 상으로 로딩하였다. 시료를 로딩한 후, 컬럼을 5 컬럼 부피의 PBS로 세척하고, 뒤이어 6 컬럼 부피의 0.1 M 아세트산(pH 2.9)으로 용리하였다. A280 용리 피크를 수집한 다음, 1 M Tris 염기로 pH 7.5 내지 8.0으로 중화시켰다. 그 후에, 30 KDa 분자량 컷오프와 함께 Amicon 원심분리 필터를 사용하여, 중화된 시료를 PBS로 완충액 교환하였다. 도 88에 도시된 바와 같이, 항-TF 항체 친화도 컬럼은, 조직 인자를 융합 파트너로서 함유하는 TGFRt15-16s21에 결합하였다. 완충액-교환된 단백질 시료를 추가의 생화학적 분석 및 생물학적 활성 시험을 위해 2℃ 내지 8℃에 보관하였다. 각각의 용리 후, 6 컬럼 부피의 0.1 M 글리신(pH 2.5)를 사용하여 항-TF 항체 친화도 컬럼을 박리시켰다. 그 후에, 보관을 위해 상기 컬럼을 5 컬럼 부피의 PBS, 및 7 컬럼 부피의 20% 에탄올을 사용하여 중화시켰다. 항-TF 항체 친화도 컬럼을 GE Healthcar AKTA Avant 시스템에 연결하였다. 유속이 2 mL/분인 용리 단계를 제외하고는, 모든 단계에 대해 유속은 4 mL/분이었다.
TGFRt15-16s21의 환원된 SDS-PAGE
TGFRt15-16s21 단백질의 순도 및 분자량을 결정하기 위해, 항-TF 항체 친화도 컬럼으로 정제된 단백질 시료를, 환원된 조건 하에 소듐 도데실 설페이트 폴리아크릴아미드 겔(4% 내지 12% NuPage Bis-Tris 겔) 전기영동(SDS-PAGE)에 의해 분석하였다. 전기영동 후, 상기 겔을 InstantBlue로 약 30분 동안 염색시키고, 뒤이어 정제수에서 밤새 탈색시켰다.
TGFRt15-16s21 단백질이 CHO 세포에서 번역 후 글리코실화를 겪음을 확증하기 위해, New England Biolabs로부터의 단백질 탈글리코실화 믹스 II 키트를 제조업체의 설명서에 따라 사용하여 탈글리코실화 실험을 수행하였다. 도 89는 비-탈글리코실화된 상태(붉은 윤곽선에서 레인 1) 및 탈글리코실화된 상태(황색 윤곽선에서 레인 2)에서 시료의 환원된 SDS-PAGE 분석으로부터의 결과를 도시한다. 그 결과는, TGFRt15-16s21 단백질이 CHO 세포에서 발현되었을 때 글리코실화됨을 나타내었다. 탈글리코실화 후, 정제된 시료는 환원된 SDS 겔에서 예상된 분자량(69 kDa 및 48 kDa)을 나타내었다. 레인 M에는 10 μL의 SeeBlue Plus2 예비염색된 표준을 로딩하였다.
실시예 52: 7t15-7s 융합 단백질 발생 및 특징화
IL-7/TF/IL-15 및 IL-7/IL-15RαSu 융합 단백질을 포함하는 융합 단백질 복합체를 생성시켰다(도 90 및 도 91). 인간 IL-7, 조직 인자 219, 및 IL-15 서열을 UniProt 웹사이트로부터 수득하였고, 이들 서열에 대한 DNA를 게네위즈에 의해 합성하였다. 구체적으로, IL-7 서열을 조직 인자 219의 N-말단 코딩 영역에 연결하고, 뒤이어 IL-15의 N-말단 코딩 영역과 연결하는 작제물을 만들었다.
조직 인자 219의 N-말단, 뒤이어 IL-15의 N-말단에 연결된 IL-7을 포함하는 작제물의 핵산 서열 및 단백질 서열은 하기에 제시된다.
7t15 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 IL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(인간 조직 인자 219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(인간 IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
7t15 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
IL-7 서열을 게네위즈에 의해 합성된 IL-15RαSu 사슬의 N-말단 코딩 영역에 연결함으로써 작제물을 또한 만들었다. IL-15RαSu 사슬의 N-말단에 연결된 IL-7을 포함하는 작제물의 핵산 서열 및 단백질 서열은 하기에 제시된다.
7s 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 IL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(인간 IL-15R α sushi 도메인)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
7s 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(인간 IL-15R α sushi 도메인)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
IL-7/TF/IL-15 및 IL-7/IL-15RαSu 작제물을 이전에 기재된 바와 같이 변형된 레트로바이러스 발현 벡터 내로 클로닝하고(문헌[Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y, et al. Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions. Hum Gene Ther 2005;16:457-72]), 발현 벡터를 CHO-K1 세포 내로 형질주입하였다. CHO-K1 세포에서 2개 작제물의 공동-발현은 7t15-7s로 지칭되는 가용성 IL-7/TF/IL-15:IL-7/IL-15RαSu 단백질 복합체의 형성 및 분비를 가능하게 하였으며, 이는 항-TF 항체 IgG1 친화도 및 다른 크로마토그래피 방법에 의해 정제될 수 있다.
항-TF 항체 친화도 컬럼을 사용한 7t15-7s의 정제 용리 크로마토그래프
세포 배양물로부터 수합된 7t15-7s를 5 컬럼 부피의 PBS로 평형화된 항-TF 항체 친화도 컬럼 상으로 로딩하였다. 시료를 로딩한 후, 컬럼을 5 컬럼 부피의 PBS로 세척하고, 뒤이어 6 컬럼 부피의 0.1 M 아세트산(pH 2.9)으로 용리하였다. A280 용리 피크를 수집한 다음, 1 M Tris 염기로 pH 7.5 내지 8.0으로 중화시켰다. 그 후에, 30 KDa 분자량 컷오프와 함께 Amicon 원심분리 필터를 사용하여, 중화된 시료를 PBS로 완충액 교환하였다. 도 92에 도시된 바와 같이, 항-TF 항체 친화도 컬럼은, 조직 인자(TF)를 융합 파트너로서 함유하는 7t15-7s에 결합하였다. 완충액-교환된 단백질 시료를 추가의 생화학적 분석 및 생물학적 활성 시험을 위해 2℃ 내지 8℃에 보관하였다. 각각의 용리 후, 6 컬럼 부피의 0.1 M 글리신(pH 2.5)를 사용하여 항-TF 항체 친화도 컬럼을 박리시켰다. 그 후에, 보관을 위해 상기 컬럼을 5 컬럼 부피의 PBS, 및 7 컬럼 부피의 20% 에탄올을 사용하여 중화시켰다. 항-TF 항체 친화도 컬럼을 GE Healthcar AKTA Avant 시스템에 연결하였다. 유속이 2 mL/분인 용리 단계를 제외하고는, 모든 단계에 대해 유속은 4 mL/분이었다.
C57BL/6 마우스에서 7t15-7s의 면역자극
7t15-7s는, 인간 IL-7, 인간 조직 인자 219 단편 및 인간 IL-15의 가용성 융합인 제1 폴리펩타이드(7t15), 및 인간 IL-7 및 인간 IL-15 수용체 알파 사슬의 sushi 도메인의 가용성 융합인 제2 폴리펩타이드(7s)를 포함하는 다중-사슬 폴리펩타이드(A형 다중-사슬 폴리펩타이드 본원에 기재된)이다.
CHO 세포를 IL7-TF-IL-15(7t15) 및 IL7-IL-15Ra sushi 도메인(7s) 벡터로 공동-형질주입하였다. 7t15-7s 복합체를 형질주입된 CHO 세포 배양 상청액으로부터 정제하였다. IL-7, IL-15 및 조직 인자(TF) 구성요소는 도 93에 도시된 바와 같이 ELISA에 의해 복합체에서 실증되었다. 인간화 항-TF 항체 모노클로날 항체(항-TF IgG1)를 포착 항체로서 사용하여 7t15-7s에서 TF를 결정하였고, 비오틴화된 항-인간 IL-15 항체(R&D systems) 및 비오틴화된 항-인간 IL-7 항체(R&D Systems)를 검출 항체로서 사용하여, 7t15-7s에서 IL-15 및 IL-7을 검출하고, 뒤이어 퍼옥시다제 접합 스트렙타비딘(Jackson ImmunoResearch Lab) 및 ABTS 기질(Surmodics IVD, Inc.)을 사용하였다.
7t15-7s를 C57BL/6 마우스 내로 10 mg/kg으로 피하 주사하여, 생체내에서 7t15-7s의 면역자극 활성을 결정하였다. PBS로 피하 치료된 C57BL/6 마우스를 대조군으로서 사용하였다. 치료 후 제4일에 마우스의 비장을 수집하고 칭량하였다. 단일 비장세포 현탁액을 제조하며, 형광색소-접합 항-CD4, 항-CD8, 및 항-NK1.1 항체로 염색하고, CD4+ T 세포, CD8+ T 세포, 및 NK 세포의 백분율을 유세포분석에 의해 분석하였다. 결과는, 7t15-7s가 비장 중량에 기초하여 비장세포를 확장시키는 데 효과적이었고(도 94a), 구체적으로 CD8+ T 세포 및 NK 세포의 백분율이 대조군-치료 마우스와 비교하여 더 높았음(도 94b)을 보여주었다.
실시예 53: TGFRt15-TGFRs 융합 단백질 발생 및 특징화
TGFβ 수용체 II/IL-15RαSu 및 TGFβ 수용체 II/TF/IL-15 융합 단백질을 포함하는 융합 단백질 복합체를 생성시켰다(도 95 및 도 96). 인간 TGFβ 수용체 II(Ile24-Asp159), 조직 인자 219, 및 IL-15 서열을 UniProt 웹사이트로부터 수득하였고, 이들 서열에 대한 DNA를 게네위즈에 의해 합성하였다. 구체적으로, G4S(3) 링커를 이용하여 2개의 TGFβ 수용체 II 서열을 연결하여 TGFβ 수용체 II의 단일 사슬 버전을 생성시킨 다음, 조직 인자 219의 N-말단 코딩 영역에 연결하고, 뒤이어 IL-15의 N-말단 코딩 영역과 연결하는 작제물을 만들었다.
조직 인자 219의 N-말단, 뒤이어 IL-15의 N-말단에 연결된 2개의 TGFβ 수용체 II를 포함하는 작제물의 핵산 서열 및 단백질 서열은 하기에 제시된다.
2개의 TGFβ 수용체 II/TF/IL-15 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(2개의 인간 TGFβ 수용체 II 단편)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(인간 조직 인자 219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(인간 IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
TGFβ 수용체 II/TF/IL-15 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 TGFβ 수용체 II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
2개의 TGFβ 수용체 II를 게네위즈에 의해 합성된 IL-15RαSu 사슬에 직접적으로 부착함으로써 작제물을 또한 만들었다. IL-15RαSu의 N-말단에 연결된 TGFβ 수용체 II를 포함하는 작제물의 핵산 서열 및 단백질 서열은 하기에 제시된다.
TGFβ 수용체 II/IL-15 RαSu 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(2개의 인간 TGFβ 수용체 II 단편)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(인간 IL-15R α sushi 도메인)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
2개의 TGFβ 수용체 II/IL-15RαSu 작제물의 아미노산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(2개의 인간 TGFβ 수용체 II 세포외 도메인)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(인간 IL-15R α sushi 도메인)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
일부 경우, 리더 펩타이드를 무손상 폴리펩타이드로부터 절단하여, 가용성이거나 분비될 수 있는 성숙한 형태를 생성시킨다.
TGFβR/IL-15RαSu 및 TGFβR/TF/IL-15 작제물을 이전에 기재된 바와 같이 변형된 레트로바이러스 발현 벡터 내로 클로닝하고(문헌[Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y, et al. Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions. Hum Gene Ther 2005;16:457-72]), 발현 벡터를 CHO-K1 세포 내로 형질주입하였다. CHO-K1 세포에서 2개 작제물의 공동-발현은 가용성 TGFβR/TF/IL-15:TGFβR/IL-15RαSu 단백질 복합체(TGFRt15-TGFRs로 지칭됨)의 형성 및 분비를 가능하게 하였으며, 이는 항-TF IgG1 친화도 및 다른 크로마토그래피 방법에 의해 정제될 수 있다.
HEK-Blue TGFβ 세포에서 TGFβ1 활성에 미치는 TGFRt15-TGFRs의 효과
TGFRt15-TGFRs에서 TGFβRII의 활성을 평가하기 위해, HEK-Blue TGFβ 세포에서 TGFβ1의 활성에 미치는 TGFRt15-16s21의 효과를 분석하였다. HEK-Blue TGFβ 세포(Invivogen)를 예열된 PBS로 2회 세척하고, 시험 배지(DMEM, 10% 가열-불활성화된 FCS, 1x 글루타민, 1x 항-항, 및 2x 글루타민)에 5 x 105 세포/mL로 재현탁시켰다. 편평-바닥 96-웰 플레이트에서, 50 μL 세포를 각각의 웰(2.5 x 104 세포/웰)에 첨가하고, 뒤이어 50 μL 0.1 nM TGFβ1(R&D systems)을 첨가하였다. 그 후에, 1:3 단계 희석물로 제조된 TGFRt15-16s21 또는 TGFR-Fc(R&D Systems)를 플레이트에 첨가하여, 200 μL의 총 부피에 도달하였다. 37℃에서 24시간 동안 인큐베이션한 후, 40 μL의 유도된 HEK-Blue TGFβ 세포 상청액을 편평-바닥 96-웰 플레이트에서 160 μL의 예열된 QUANTI-Blue(Invivogen)에 첨가하고, 37℃에서 1시간 내지 3시간 동안 인큐베이션하였다. 그 후에, 플레이트 판독기(Multiscan Sky)를 620 nM 내지 655 nM에서 사용하여 OD 값을 결정하였다(도 97). 각각의 단백질 시료의 IC50을 GraphPad Prism 7.04를 이용하여 계산하였다. TGFRt15-TGFRs 및 TGFR-Fc의 IC50은 각각 216.9 pM 및 460.6 pM이었다. 이들 결과는, TGFRt15-TGFRs에서 TGFβRII 도메인이 HEK-Blue TGFβ 세포에서 TGFβ1의 활성을 차단할 수 있었음을 나타내었다.
TGFRt15-TGFRs 내 IL-15는 IL-2Rβ 및 공통 γ 사슬 함유 32Dβ 세포 증식을 촉진한다
TGFRt15-TGFRs에서 IL-15의 활성을 평가하기 위해, TGFRt15-TGFRs의 IL-15 활성을, IL2Rβ 및 공통 γ 사슬을 발현하는 32Dβ 세포를 사용하고, 세포 증식을 촉진하는 데 있어서 이들의 효과를 평가하여 재조합 IL-15와 비교하였다. IL-15 의존적 32Dβ 세포를 IMDM-10% FBS로 5회 세척하고, 웰에 2 x 104 세포/웰로 접종하였다. 단계 희석된 TGFRt15-TGFRs 또는 IL-15를 세포에 첨가하였다(도 98). 세포를 CO2 인큐베이터에서 37℃에서 3일 동안 인큐베이션하였다. 제3일에 10 μL의 WST1을 각각의 웰에 첨가하고 CO2 인큐베이터에서 37℃에서 추가 3시간 동안 인큐베이션함으로써 세포 증식을 검출하였다. 생성된 포르마잔 염료의 양을 분석함으로써 450 nm의 흡광도를 측정하였다. 도 98에 도시된 바와 같이, TGFRt15-TGFRs 및 IL-15는 32Dβ 세포 증식을 촉진하였으며, 이때 TGFRt15-16s21 및 IL-15의 EC50은 각각 1901 pM 및 10.63 pM이었다.
ELISA를 사용하여 TGFRt15-TGFRs에서 IL-15 및 TGFβRII 도메인을 상응하는 항체로 검출
96-웰 플레이트를 R5(코팅 완충액) 중 100 μL(8 μg/mL)의 항-TF IgG1로 코팅시키고, 실온(RT)에서 2시간 동안 인큐베이션하였다. 상기 플레이트를 3회 세척하고, 100 μL의, PBS 중 1% BSA로 블라킹시켰다. TGFRt15-TGFRs를 1:3 비로 단계 희석으로 첨가하고, RT에서 60분 동안 인큐베이션하였다. 3회 세척 후, 50 ng/mL의 비오틴화된-항-IL-15 항체(BAM247, R&D Systems), 또는 200 ng/mL의 비오틴화된-항-TGFbRII 항체(BAF241, R&D Systems)를 웰에 첨가하고, RT에서 60분 동안 인큐베이션하였다. 다음, 플레이트를 3회 세척하고, 0.25 μg/mL의 HRP-SA(Jackson ImmunoResearch)를 웰당 100 μL로 첨가하며, RT에서 30분 동안 인큐베이션하고, 뒤이어 4회 세척하고 100 μL의 ABTS와 함께 RT에서 2분 동안 인큐베이션하였다. 405 nm에서의 흡광도를 판독하였다. 도 99a 내지 도 99b에 도시된 바와 같이, TGFRt15-TGFRs에서 IL-15 및 TGFβRII 도메인은 개별 항체에 의해 검출되었다.
항-TF 항체 친화도 컬럼으로부터의 TGFRt15-TGFRs의 정제 용리 크로마토그래프
세포 배양물로부터 수합된 TGFRt15-TGFRs를 5 컬럼 부피의 PBS로 평형화된 항-TF 항체 친화도 컬럼 상으로 로딩하였다. 시료를 로딩한 후, 컬럼을 5 컬럼 부피의 PBS로 세척하고, 뒤이어 6 컬럼 부피의 0.1 M 아세트산(pH 2.9)으로 용리하였다. A280 용리 피크를 수집한 다음, 1 M Tris 염기로 pH 7.5 내지 8.0으로 중화시켰다. 그 후에, 30 KDa 분자량 컷오프와 함께 Amicon 원심분리 필터를 사용하여, 중화된 시료를 PBS로 완충액 교환하였다. 도 100에 도시된 바와 같이, 항-TF 항체 친화도 컬럼은, TF를 융합 파트너로서 함유하는 TGFRt15-TGFRs에 결합하였다. 완충액-교환된 단백질 시료를 추가의 생화학적 분석 및 생물학적 활성 시험을 위해 2℃ 내지 8℃에 보관하였다. 각각의 용리 후, 6 컬럼 부피의 0.1 M 글리신(pH 2.5)를 사용하여 항-TF 항체 친화도 컬럼을 박리시켰다. 그 후에, 보관을 위해 상기 컬럼을 5 컬럼 부피의 PBS, 및 7 컬럼 부피의 20% 에탄올을 사용하여 중화시켰다. 항-TF 항체 친화도 컬럼을 GE Healthcar AKTA Avant 시스템에 연결하였다. 유속이 2 mL/분인 용리 단계를 제외하고는, 모든 단계에 대해 유속은 4 mL/분이었다.
TGFRt15-TGFRs의 분석적 크기 배제 크로마토그래피(SEC) 분석
Superdex 200 Increase 10/300 GL 겔 여과 컬럼(GE Healthcare)을 AKTA Avant 단백질 정제 시스템(GE Healthcare)에 연결하였다. 상기 컬럼을 2 컬럼 부피의 PBS로 평형화시켰다. 유속은 0.7 mL/분이었다. TGFRt15-TGFRs를 PBS에 함유하는 시료를 모세관 루프를 사용하여 Superdex 200 컬럼 내로 주사하고, SEC에 의해 분석하였다. 시료의 SEC 크로마토그래프를 도 101에 도시한다. SEC 결과는 TGFRt15-TGFRs에 대한 4개의 단백질 피크를 나타내었다.
TGFRt15-TGFRs의 환원된 SDS-PAGE 분석
TGFRt15-TGFRs 단백질의 순도 및 분자량을 결정하기 위해, 항-TF 항체 친화도 컬럼으로 정제된 단백질 시료를, 환원된 조건 하에 소듐 도데실 설페이트 폴리아크릴아미드 겔(4% 내지 12% NuPage Bis-Tris 겔) 전기영동(SDS-PAGE) 방법에 의해 분석하였다. 전기영동 후, 상기 겔을 InstantBlue로 약 30분 동안 염색시키고, 뒤이어 정제수에서 밤새 탈색시켰다.
TGFRt15-TGFRs 단백질이 CHO 세포에서 번역 후 글리코실화를 겪음을 확증하기 위해, New England Biolabs로부터의 단백질 탈글리코실화 믹스 II 키트를 제조업체의 설명서에 따라 사용하여 탈글리코실화 실험을 수행하였다. 도 102는 비-탈글리코실화된 상태(붉은 윤곽선에서 레인 1) 및 탈글리코실화된 상태(황색 윤곽선에서 레인 2)에서 시료의 환원된 SDS-PAGE 분석을 도시한다. 그 결과는, TGFRt15-TGFRs 단백질이 CHO 세포에서 발현되었을 때 글리코실화됨을 나타내었다. 탈글리코실화 후, 정제된 시료는 환원된 SDS 겔에서 예상된 분자량(69 kDa 및 39 kDa)을 나타내었다. 레인 M에는 10 μl의 SeeBlue Plus2 예비염색된 표준을 로딩하였다.
C57BL/6 마우스에서 TGFRt15-TGFRs의 면역자극 활성
TGFRt15-TGFRs는, 2개의 TGFβRII 도메인, 인간 조직 인자 219 단편 및 인간 IL-15의 가용성 융합인 제1 폴리펩타이드, 및 2개의 TGFβRII 도메인 및 인간 IL-15 수용체 알파 사슬의 sushi 도메인의 가용성 융합인 제2 폴리펩타이드를 포함하는 다중-사슬 폴리펩타이드(A형 다중-사슬 폴리펩타이드 본원에 기재된)이다.
야생형 C57BL/6 마우스를 대조군 용액으로 또는 0.3 mg/kg, 1 mg/kg, 3 mg/kg, 또는 10 mg/kg의 투약량에서 TGFRt15-TGFRs로 피하 치료하였다. 치료 후 4일째에, 비장 중량 및 비장에 존재하는 다양한 면역 세포 유형의 백분율을 평가하였다. 도 103a에 도시된 바와 같이, TGFRt15-TGFRs로 치료된 마우스에서 비장 중량은 TGFRt15-TGFRs의 증가하는 투약량에 따라 증가하였다. 더욱이, 1 mg/kg, 3 mg/kg, 및 10 mg/kg의 TGFRt15-TGFRs로 치료된 마우스에서 비장 중량은 대조군 용액으로 치료된 마우스와 비교하여 각각 더 무거웠다. 게다가, 대조군-치료 마우스 및 TGFRt15-TGFRs-치료 마우스의 비장에 존재하는 CD4+ T 세포, CD8+ T 세포, NK 세포, 및 CD19+ B 세포의 백분율을 평가하였다. 도 103b에 도시된 바와 같이, TGFRt15-TGFRs로 치료된 마우스의 비장에서, CD8+ T 세포와 NK 세포 둘 다의 백분율은 TGFRt15-TGFRs의 증가하는 투약량에 따라 증가하였다. 구체적으로, CD8+ T 세포의 백분율은 대조군-치료 마우스와 비교하여 0.3 mg/kg, 3 mg/kg, 및 10 mg/kg의 TGFRt15-TGFRs로 치료된 마우스에서 더 높았고, NK 세포의 백분율은 대조군-치료 마우스와 비교하여 0.3 mg/kg, 1 mg/kg, 3 mg/kg, 및 10 mg/kg의 TGFRt15-TGFRs로 치료된 마우스에서 더 높았다. 이들 결과는, TGFRt15-TGFRs가 비장에서 면역 세포, 특히 CD8+ T 세포 및 NK 세포를 자극시킬 수 있음을 실증한다.
TGFRt15-TGFRs 분자의 약물동력학을 야생형 C57BL/6 마우스에서 평가하였다. 상기 마우스를 3 mg/kg의 투약량에서 TGFRt15-TGFRs로 피하 치료하였다. 마우스 혈액을 다양한 시점에서 꼬리 정맥으로부터 채혈하고, 혈청을 제조하였다. 마우스 혈청에서 TGFRt15-TGFRs 농도를 ELISA(포착: 항-인간 조직 인자 항체; 검출: 비오틴화된 항-인간 TGFβ 수용체 항체, 뒤이어 퍼옥시다제 접합 스트렙타비딘 및 ABTS 기질)로 결정하였다. 결과는, TGFRt15-TGFRs의 반감기가 C57BL/6 마우스에서 12.66시간이었음을 나타내었다.
마우스에서 시간 경과에 따른 TGFRt15-TGFRs의 면역자극 활성을 평가하기 위해 마우스 비장세포를 제조하였다. 도 104a에 도시된 바와 같이, TGFRt15-TGFRs로 치료된 마우스에서 비장 중량은 치료 후 48시간째에 증가하였고, 시간 경과에 따라 계속 증가하였다. 게다가, 대조군-치료 마우스 및 TGFRt15-TGFRs-치료 마우스의 비장에 존재하는 CD4+ T 세포, CD8+ T 세포, NK 세포, 및 CD19+ B 세포의 백분율을 평가하였다. 도 104b에 도시된 바와 같이, TGFRt15-TGFRs로 치료된 마우스의 비장에서, CD8+ T 세포와 NK 세포 둘 다의 백분율은 치료 후 48시간째에 증가하였고, 단회 용량 치료 후 시간 경과에 따라 더욱 더 높았다. 이들 결과는, TGFRt15-TGFRs가 비장에서 면역 세포, 특히 CD8+ T 세포 및 NK 세포를 자극시킬 수 있음을 추가로 실증한다.
더욱이, 비장세포의 Ki67 발현에 기초한 면역 세포의 역학적(dynamic) 증식 및 그랜자임 B 발현에 기초한 세포독성 잠재력을 단회 용량(3 mg/kg)의 TGFRt15-TGFRs 후 마우스로부터 단리된 비장세포에서 평가하였다. 도 105a 및 도 105b에 도시된 바와 같이, TGFRt15-TGFRs로 치료된 마우스의 비장에서, NK 세포에 의한 Ki67 및 그랜자임 B의 발현은 치료 후 24시간째에 증가하였고, CD8+ T 세포와 NK 세포의 이의 발현은 둘 다 단회 용량 치료 후 48시간째 및 이후의 시점에서 증가하였다. 이들 결과는, TGFRt15-TGFRs는 CD8+ T 세포 및 NK 세포의 수를 증가시킬 뿐만 아니라 이들 세포의 세포독성을 증강시킴을 실증한다. TGFRt15-TGFRs의 단회 용량 치료는 CD8+ T 세포 및 NK 세포가 적어도 4일 동안 증식하도록 유발하였다.
종양 세포에 대한 TGFRt15-TGFRs-치료 마우스로부터의 비장 세포의 세포독성을 또한 평가하였다. 마우스 몰로니 백혈병(Moloney leukemia) 세포(Yac-1)를 CellTrace 바이올렛으로 표지하고, 종양 표적 세포로서 사용하였다. 비장세포를 치료 후 다양한 시점에서 TGFRt15-TGFRs(3 mg/kg)-치료 마우스 비장으로부터 제조하고, 이펙터 세포로서 사용하였다. 표적 세포를 이펙터 세포와 E:T 비 = 10:1로 혼합하고, 37℃에서 20시간 동안 인큐베이션하였다. 유세포측정법을 사용하는 프로피디움 요오다이드 양성, 바이올렛-표지 Yac-1 세포의 분석에 의해 표적 세포 생존력을 평가하였다. 식 (1-[실험 시료 내 생존 Yac-1 세포의 수]/[비장세포가 없는 시료 내 생존 Yac-1 세포의 수]) x 100을 사용하여 Yac-1 종양 저해의 백분율을 계산하였다. 도 106에 도시된 바와 같이, TGFRt15-TGFRs-치료 마우스로부터의 비장세포는 Yac-1 세포에 대해 대조군 마우스 비장세포보다 더 강한 세포독성을 가졌다.
화학치료법 및/또는 TGFRt15-TGFRs에 반응한 종양 크기 분석
췌장암 세포(SW1990, ATCC® CRL-2172)를 C57BL/6 scid 마우스(The Jackson Laboratory, 001913, 2x106 세포/마우스, 100 μL HBSS 중)에 피하(s.c.) 주사하여, 췌장암 마우스 모델을 확립하였다. 종양 세포 주사 후 2주째에, 이들 마우스에서 복강내로 아브락산(Abraxane)(Celgene, 68817-134, 5 mg/kg, i.p.)과 겜시타빈(Sigma Aldrich, G6423, 40 mg/kg, i.p.)의 조합을, 뒤이어 2일 이내에 TGFRt15-TGFRs(3 mg/kg, s.c.)에 의한 면역치료법을 개시하였다. 상기 절차는 하나의 치료 주기인 것으로 간주되었고, 또 다른 3개 사이클(1개 사이클/주) 동안 반복되었다. 대조군은 PBS, 화학치료법(겜시타빈 및 아브락산), 또는 TGFRt15-TGFRs 단독을 받는 SW1990-주사 마우스로서 설정되었다. 치료 주기에 따라, SW1990 세포를 주사한 후 2개월째에 실험을 종료할 때까지 각각의 동물의 종양 크기를 격일로 측정하고 기록하였다. 종양 부피의 측정을 군(group)에 의해 분석하였고, 그 결과는, 화학치료법과 TGFRt15-TGFRs의 조합을 받는 동물이 PBS 군과 비교하여 유의하게 더 작은 종양을 가진 반면, 화학치료법 또는 TGFRt15-TGFRs 치료법 단독 중 어느 것도 조합처럼 충분히 작동하지 않음을 나타낸다(도 107).
시험관내 노화 B16F10 흑색종 모델
다음, 활성화된 마우스 NK 세포에 의한 노화 B16F10 흑색종 세포의 시험관내 사멸을 평가하였다. B16F10 노화 세포(B16F10-SNC) 세포를 CellTrace 바이올렛으로 표지하고, 상이한 E:T 비의 시험관내 2t2-활성화된 마우스 NK 세포(TGFRt15-TGFRs10 mg/kg을 4일 동안 주사한 C57BL/6 마우스의 비장으로부터 단리됨)와 함께 16시간 동안 인큐베이션하였다. 세포를 트립신처리하며, 세척하고, 프로피디움 요오다이드(PI) 용액을 함유하는 완전 배지에 재현탁시켰다. 세포독성을 유세포측정법에 의해 평가하였다(도 108).
실시예 54: 7t15-21s137L(롱 버전) 융합 단백질 생성 및 특징화
IL-21/IL-15RαSu/CD137L 및 IL-7/TF/IL-15 융합 단백질을 포함하는 융합 단백질 복합체를 생성시켰다(도 109 및 도 110). 구체적으로, IL-7 서열을 조직 인자 219의 N-말단 코딩 영역에 연결하고, 뒤이어 IL-15의 N-말단 코딩 영역과 연결하는 작제물을 만들었다. 조직 인자 219의 N-말단, 뒤이어 IL-15의 N-말단에 연결된 IL-7을 포함하는 작제물의 핵산 서열 및 단백질 서열은 하기에 제시된다.
7t15 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 IL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(인간 조직 인자 219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(인간 IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
7t15 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
21s137L의 핵산 및 단백질 서열은 하기에 제시된다. 21s137L 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(인간 IL-15R α sushi 도메인)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
((G4S)3 링커)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(인간 CD137L)
CGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA
21s137L 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(인간 IL-15R α sushi 도메인)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
((G4S)3 링커)
GGGGSGGGGSGGGGS
(인간 CD137L)
REGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE
일부 경우, 리더 펩타이드를 무손상 폴리펩타이드로부터 절단하여, 가용성이거나 분비될 수 있는 성숙한 형태를 생성시킨다.
IL-21/IL-15RαSu/CD137L 및 IL-7/TF/IL-15 작제물을 이전에 기재된 바와 같이 변형된 레트로바이러스 발현 벡터 내로 클로닝하고(문헌[Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y, et al. Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions. Hum Gene Ther 2005;16:457-72]), 발현 벡터를 CHO-K1 세포 내로 형질주입하였다. CHO-K1 세포에서 2개 작제물의 공동-발현은 가용성 IL-7/TF/IL-15: IL-21/IL-15RαSu/CD137L 단백질 복합체(7t15-21s137L로 지칭됨)의 형성 및 분비를 가능하게 하였으며, 이는 항-TF 항체 IgG1 친화도 및 다른 크로마토그래피 방법에 의해 정제될 수 있다.
항-TF 항체 친화도 컬럼을 사용한 7t15-21s137L의 정제 용리 크로마토그래프
세포 배양물로부터 수합된 7t15-21s137L을 5 컬럼 부피의 PBS로 평형화된 항-TF 항체 친화도 컬럼 상으로 로딩하였다. 시료를 로딩한 후, 컬럼을 5 컬럼 부피의 PBS로 세척하고, 뒤이어 6 컬럼 부피의 0.1 M 아세트산(pH 2.9)으로 용리하였다. A280 용리 피크를 수집한 다음, 1 M Tris 염기로 pH 7.5 내지 8.0으로 중화시켰다. 그 후에, 30 KDa 분자량 컷오프와 함께 Amicon 원심분리 필터를 사용하여, 중화된 시료를 PBS로 완충액 교환하였다. 도 111에 도시된 바와 같이, 항-TF 항체 친화도 컬럼은, TF를 융합 파트너로서 함유하는 7t15-21s137L에 결합하였다. 완충액-교환된 단백질 시료를 추가의 생화학적 분석 및 생물학적 활성 시험을 위해 2℃ 내지 8℃에 보관하였다. 각각의 용리 후, 6 컬럼 부피의 0.1 M 글리신(pH 2.5)를 사용하여 항-TF 항체 친화도 컬럼을 박리시켰다. 그 후에, 보관을 위해 상기 컬럼을 5 컬럼 부피의 PBS, 및 7 컬럼 부피의 20% 에탄올을 사용하여 중화시켰다. 항-TF 항체 친화도 컬럼을 GE Healthcar AKTA Avant 시스템에 연결하였다. 유속이 2 mL/분인 용리 단계를 제외하고는, 모든 단계에 대해 유속은 4 mL/분이었다. 도 112는 7t15-21s137L의 분석적 SEC 프로파일을 도시한다.
실시예 55: 7t15-21s137L(쇼트 버전) 융합 단백질 발생 및 특징화
IL-21/IL-15RαSu/CD137L 및 IL-7/TF/IL-15 융합 단백질을 포함하는 융합 단백질 복합체를 생성시켰다. 구체적으로, IL-7 서열을 조직 인자 219의 N-말단 코딩 영역에 연결하고, 뒤이어 IL-15의 N-말단 코딩 영역과 연결하는 작제물을 만들었다. 조직 인자 219의 N-말단, 뒤이어 IL-15의 N-말단에 연결된 IL-7을 포함하는 작제물의 핵산 서열 및 단백질 서열은 하기에 제시된다.
7t15 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 IL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(인간 조직 인자 219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(인간 IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
7t15 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
21s137L(쇼트 버전)의 핵산 및 단백질 서열은 하기에 제시된다. 21s137L(쇼트 버전) 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(인간 IL-15R α sushi 도메인)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
((G4S)3 링커)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(인간 CD137 리간드 쇼트 버전)
GATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATC
21s137L(쇼트 버전) 작제물의 아미노산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(인간 IL-15R α sushi 도메인)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
((G4S)3 링커)
GGGGSGGGGSGGGGS
(인간 CD137 리간드 쇼트 버전)
DPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEI
IL-21/IL-15RαSu/CD137L(쇼트 버전) 및 IL-7/TF/IL-15 작제물을 이전에 기재된 바와 같이 변형된 레트로바이러스 발현 벡터 내로 클로닝하고(문헌[Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y, et al. Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions. Hum Gene Ther 2005;16:457-72]), 발현 벡터를 CHO-K1 세포 내로 형질주입하였다. CHO-K1 세포에서 2개 작제물의 공동-발현은 가용성 IL-7/TF/IL-15: IL-21/IL-15RαSu/CD137L 단백질 복합체(7t15-21s137L(쇼트 버전)로 지칭됨)의 형성 및 분비를 가능하게 하였으며, 이는 항-TF 항체 IgG1 친화도 및 다른 크로마토그래피 방법에 의해 정제될 수 있다.
CD137(4.1BB)에의 7t15-21s137L(쇼트 버전)의 결합
제1일에, 96-웰 플레이트를 100 μL(2.5 μg/mL)의, R5(코팅 완충액) 중 GAH IgG Fc(G-102-C, R&D Systems) 또는 R5 단독으로 코팅시키고, 4℃에서 밤새 인큐베이션하였다. 제2일에, 상기 플레이트를 3회 세척하고, 300 μL의, PBS 중 1% BSA로 37℃에서 2시간 동안 블라킹시켰다. 10 ng/mL의 4.1BB/Fc(838-4B, R&D Systems)를 100 μL/웰로 첨가하고, RT에서 2시간 동안 인큐베이션하였다. 3회 세척 후, 7t15-21s137L 또는 7t15-21s를 1/3 비(10 nM에서 출발함)로 단계 희석하고, 4℃에서 밤새 인큐베이션하였다. 제3일에, 3회 세척 후, 300 ng/mL의 비오틴화된-항-hTF 항체(BAF2339, R&D Systems)를 100 μL/웰로 첨가하고, RT에서 2시간 동안 인큐베이션하였다. 그 후에, 플레이트를 3회 세척하고, 0.25 μg/mL의 HRP-SA(Jackson ImmuneResearch)와 함께 웰당 100 μL에서 30분 동안 인큐베이션하고, 뒤이어 3회 세척하고 100 μL의 ABTS와 함께 RT에서 2분 동안 인큐베이션하였다. 흡광도를 405 nm에서 판독하였다. 도 113에 도시된 바와 같이, 7t15-21s137L(쇼트 버전)은 7t15-21s와 비교하여 4.1BB/Fc(청색선)와 유의한 상호작용을 나타내었다.
ELISA를 사용한 7t15-21s137L(쇼트 버전) 내 IL-15, IL-21, 및 IL-7의 검출
96-웰 플레이트를 R5(코팅 완충액) 중 100 μL(8 μg/mL)의 항-TF 항체 IgG1로 코팅시키고, RT에서 2시간 동안 인큐베이션하였다. 상기 플레이트를 3회 세척하고, 100 μL의, PBS 중 1% BSA로 블라킹시켰다. 1:3 비로 단계 희석된 7t15-21s137L(쇼트 버전)을 첨가하고, RT에서 60분 동안 인큐베이션하였다. 3회 세척 후, 50 ng/mL의 비오틴화된-항-IL-15 항체(BAM247, R&D Systems), 500 ng/mL의 비오틴화된-항-IL21 항체(13-7218-81, R&D Systems), 또는 500 ng/mL의 비오틴화된-항-IL7 항체(506602, R&D Systems)를 웰에 첨가하고, RT에서 60분 동안 인큐베이션하였다. 3회 세척 및 0.25 μg/mL의 HRP-SA(Jackson ImmunoResearch)와 함께 웰당 100 μL에서의 인큐베이션을 RT에서 30분 동안 인큐베이션한 후, 뒤이어 4회 세척하고 100 μL의 ABTS와 함께 RT에서 2분 동안 인큐베이션하였다. 흡광도를 405 nm에서 판독하였다. 도 114a 내지 도 114c에 도시된 바와 같이, 7t15-21s137L(쇼트 버전)에서 IL-15, IL-21, 및 IL-7 도메인은 각각의 항체에 의해 검출되었다.
7t15-1s137L(쇼트 버전) 중 IL-15는 IL2Rαβγ-함유 CTLL2 세포 증식을 촉진한다
7t15-21s137L(쇼트 버전)의 IL-15 활성을 평가하기 위해, IL2Rαβγ 발현 CTLL2 세포의 증식을 촉진하는 데 있어서 7t15-21s137L(쇼트 버전)을 재조합 IL-15와 비교하였다. IL-15-의존적 CTLL2 세포를 IMDM-10% FBS로 5회 세척하고, 웰에 2 x 104 세포/웰로 접종하였다. 단계 희석된 7t15-21s137L(쇼트 버전) 또는 IL-15를 세포에 첨가하였다(도 115). 세포를 CO2 인큐베이터에서 37℃에서 3일 동안 인큐베이션하였다. 제3일에 10 μL의 WST1을 각각의 웰에 첨가하고 CO2 인큐베이터에서 37℃에서 추가 3시간 동안 인큐베이션함으로써 세포 증식을 검출하였다. 450 nm에서 흡광도를 측정함으로써, 생성된 포르마잔 염료의 양을 분석하였다. 도 115에 도시된 바와 같이, 7t15-21s137L(쇼트 버전) 및 IL-15는 CTLL2 세포 증식을 촉진하였다. 7t15-21s137L(쇼트 버전) 및 IL-15의 EC50은 각각 55.91 pM 및 6.22 pM이었다.
7t15-1s137L(쇼트 버전) 중 IL-21은 IL21R-함유 B9 세포 증식을 촉진한다
7t15-21s137L(쇼트 버전)의 IL-21 활성을 평가하기 위해, IL-21R 발현 B9 세포의 증식을 촉진하는 데 있어서 7t15-21s137L(쇼트 버전)을 재조합 IL-21과 비교하였다. IL-21R 함유 B9 세포를 RPMI-10% FBS로 5회 세척하고, 웰에 1 x 104 세포/웰로 접종하였다. 단계 희석된 7t15-21s137L(쇼트 버전) 또는 IL-21을 세포에 첨가하였다(도 116). 세포를 CO2 인큐베이터에서 37℃에서 5일 동안 인큐베이션하였다. 제5일에 10 μL의 WST1을 각각의 웰에 첨가하고 CO2 인큐베이터에서 37℃에서 추가 4시간 동안 인큐베이션함으로써 세포 증식을 검출하였다. 450 nm에서 흡광도를 측정함으로써, 생성된 포르마잔 염료의 양을 분석하였다. 도 116에 도시된 바와 같이, 7t15-21s137L(쇼트 버전) 및 IL-21은 B9 세포 증식을 촉진하였다. 7t15-21s137L(쇼트 버전) 및 IL-21의 EC50은 각각 104.1 nM 및 72.55 nM이었다.
실시예 56: 7t15-TGFRs 융합 단백질 발생 및 특징화
TGFβ 수용체 II/IL-15RαSu 및 IL-7/TF/IL-15 융합 단백질을 포함하는 융합 단백질 복합체를 생성시켰다(도 117 및 도 118). 인간 TGFβ 수용체 II(Ile24-Asp159), 조직 인자 219, IL-15, 및 IL-7 서열을 UniProt 웹사이트로부터 수득하였고, 이들 서열에 대한 DNA를 게네위즈에 의해 합성하였다. 구체적으로, IL-7 서열을 조직 인자 219의 N-말단 코딩 영역에 연결하고, 뒤이어 IL-15의 N-말단 코딩 영역과 연결하는 작제물을 만들었다. 조직 인자 219의 N-말단, 뒤이어 IL-15의 N-말단에 연결된 IL-7을 포함하는 작제물의 핵산 서열 및 단백질 서열은 하기에 제시된다.
7t15 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 IL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(인간 조직 인자 219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(인간 IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
7t15 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
2개의 TGFβ 수용체 II를 게네위즈에 의해 합성된 IL-15RαSu 사슬에 직접적으로 부착함으로써 작제물을 또한 만들었다. IL-15RαSu의 N-말단에 연결된 TGFβ 수용체 II를 포함하는 작제물의 핵산 서열 및 단백질 서열은 하기에 제시된다.
TGFRs 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 TGFβ 수용체 II 단편)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(인간 IL-15R α sushi 도메인)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
TGFRs 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 TGFβ 수용체 II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(인간 IL-15R α sushi 도메인)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
HEK-Blue TGFβ 세포에서 TGFβ1 활성에 미치는 7t15-TGFRs의 효과
7t15-TGFRs에서 TGFβR의 활성을 평가하기 위해, HEK-Blue TGFβ 세포에서 TGFβ1의 활성에 미치는 7t15-TGFRs의 효과를 분석하였다. HEK-Blue TGFβ 세포(Invivogen)를 예열된 PBS로 2회 세척하고, 시험 배지(DMEM, 10% 가열-불활성화된 FCS, 1x 글루타민, 1x 항-항, 및 2x 글루타민)에 5 x 105 세포/mL로 재현탁시켰다. 편평-바닥 96-웰 플레이트에서, 50 μL 세포를 각각의 웰(2.5 x 104 세포/웰)에 첨가하고, 뒤이어 50 μL 0.1 nM TGFβ1(R&D systems)을 첨가하였다. 그 후에, 1:3 단계 희석물로 제조된 7t15-TGFRs 또는 TGFR-Fc(R&D Systems)를 플레이트에 첨가하여, 200 μL의 총 부피에 도달하였다. 37℃에서 24시간 동안 인큐베이션한 후, 40 μL의 유도된 HEK-Blue TGFβ 세포 상청액을 편평-바닥 96-웰 플레이트에서 160 μL의 예열된 QUANTI-Blue(Invivogen)에 첨가하고, 37℃에서 1시간 내지 3시간 동안 인큐베이션하였다. 그 후에, 플레이트 판독기(Multiscan Sky)를 620 nM 내지 655 nM에서 사용하여 OD 값을 결정하였다. 데이터를 도 119에 도시한다. 각각의 단백질 시료의 IC50을 GraphPad Prism 7.04를 이용하여 계산하였다. 7t15-TGFRs 및 TGFR-Fc의 IC50은 각각 1142 pM 및 558.6 pM이었다. 이들 결과는, 7t15-TGFRs에서 TGFβR이 HEK-Blue TGFβ 세포에서 TGFβ1의 활성을 차단할 수 있었음을 나타내었다.
7t15-TGFRs에서 ELISA를 이용한 IL-15, TGFβRII, 및 IL-7의 검출
96-웰 플레이트를 R5(코팅 완충액) 중 100 μL(8 μg/mL)의 항-TF 항체 IgG1로 코팅시키고, 실온(RT)에서 2시간 동안 인큐베이션하였다. 상기 플레이트를 3회 세척하고, 100 μL의, PBS 중 1% BSA로 블라킹시켰다. 7t15-TGFRs의 단계 희석물(1:3 비)을 첨가하고, RT에서 60분 동안 인큐베이션하였다. 3회 세척 후, 50 ng/mL의 비오틴화된-항-IL-15 항체(BAM247, R&D Systems), 200 ng/mL의 비오틴화된-항-TGFbRII 항체(BAF241, R&D Systems), 또는 500 ng/mL의 비오틴화된-항-IL-7 항체(506602, R&D Systems)를 첨가하고, RT에서 60분 동안 인큐베이션하였다. 3회 세척 후, 0.25 μg/mL의 HRP-SA(Jackson ImmunoResearch)와 함께 웰당 100 μL에서 RT에서 30분 동안 인큐베이션하고, 뒤이어 4회 세척하고 100 μL의 ABTS와 함께 RT에서 2분 동안 인큐베이션하였다. 흡광도를 405 nm에서 판독하였다. 도 120a 내지 도 120c에 도시된 바와 같이, 7t15-TGFRs에서 IL-15, TGFR, 및 IL-7은 각각의 항체에 의해 검출되었다.
7t15-TGFRs 내 IL-15는 IL-2Rβ 및 공통 γ 사슬 함유 32Dβ 세포 증식을 촉진한다
7t15-TGFRs에서 IL-15의 활성을 평가하기 위해, 7t15-TGFRs을, IL2Rβ 및 공통 γ 사슬을 발현하는 32Dβ 세포를 사용하고, 세포 증식을 촉진하는 데 있어서 이들의 효과를 평가하여 재조합 IL-15와 비교하였다. IL-15 의존적 32Dβ 세포를 IMDM-10% FBS로 5회 세척하고, 웰에 2 x 104 세포/웰로 접종하였다. 단계 희석된 7t15-TGFRs 또는 IL-15를 세포에 첨가하였다(도 121). 세포를 CO2 인큐베이터에서 37℃에서 3일 동안 인큐베이션하였다. 제3일에 10 μL의 WST1을 각각의 웰에 첨가하고 CO2 인큐베이터에서 37℃에서 추가 3시간 동안 인큐베이션함으로써 세포 증식을 검출하였다. 450 nm에서 흡광도를 측정함으로써, 생성된 포르마잔 염료의 양을 분석하였다. 도 121에 도시된 바와 같이, 7t15-TGFRs 및 IL-15는 32Dβ 세포 증식을 촉진하였으며, 이때 7t15-TGFRs 및 IL-15의 EC50은 각각 126 nM 및 16.63 pM이었다.
항-TF 항체 친화도 컬럼을 사용한 7t15-TGFRs의 정제 용리 크로마토그래프
세포 배양물로부터 수합된 7t15-TGFRs를 5 컬럼 부피의 PBS로 평형화된 항-TF 항체 친화도 컬럼 상으로 로딩하였다. 시료를 로딩한 후, 컬럼을 5 컬럼 부피의 PBS로 세척하고, 뒤이어 6 컬럼 부피의 0.1 M 아세트산(pH 2.9)으로 용리하였다. A280 용리 피크를 수집한 다음, 1 M Tris 염기로 pH 7.5 내지 8.0으로 중화시켰다. 그 후에, 30 KDa 분자량 컷오프와 함께 Amicon 원심분리 필터를 사용하여, 중화된 시료를 PBS로 완충액 교환하였다. 도 122에 도시된 바와 같이, 항-TF 항체 친화도 컬럼은, TF를 7t15-TGFRs의 융합 파트너로서 함유하는 7t15-TGFRs에 결합할 수 있다. 완충액-교환된 단백질 시료를 추가의 생화학적 분석 및 생물학적 활성 시험을 위해 2℃ 내지 8℃에 보관하였다. 각각의 용리 후, 6 컬럼 부피의 0.1 M 글리신(pH 2.5)를 사용하여 항-TF 항체 친화도 컬럼을 박리시켰다. 그 후에, 보관을 위해 상기 컬럼을 5 컬럼 부피의 PBS, 및 7 컬럼 부피의 20% 에탄올을 사용하여 중화시켰다. 항-TF 항체 친화도 컬럼을 GE Healthcar AKTA Avant 시스템에 연결하였다. 유속이 2 mL/분인 용리 단계를 제외하고는, 모든 단계에 대해 유속은 4 mL/분이었다.
7t15-TGFRs의 환원된 SDS-PAGE 분석
7t15-TGFRs 단백질의 순도 및 분자량을 결정하기 위해, 항-TF 항체 친화도 컬럼으로 정제된 단백질 시료를, 환원된 조건 하에 소듐 도데실 설페이트 폴리아크릴아미드 겔(4% 내지 12% NuPage Bis-Tris 겔) 전기영동(SDS-PAGE) 방법에 의해 분석하였다. 전기영동 후, 상기 겔을 InstantBlue로 약 30분 동안 염색시키고, 뒤이어 정제수에서 밤새 탈색시켰다.
7t15-TGFRs 단백질이 CHO 세포에서 번역 후 글리코실화를 겪음을 확증하기 위해, New England Biolabs로부터의 단백질 탈글리코실화 믹스 II 키트를 제조업체의 설명서에 따라 사용하여 탈글리코실화 실험을 수행하였다. 도 123은 비-탈글리코실화된 상태(붉은 윤곽선에서 레인 1) 및 탈글리코실화된 상태(황색 윤곽선에서 레인 2)에서 시료의 환원된 SDS-PAGE 분석을 도시한다. 이들 결과는, 상기 단백질은 이것이 CHO 세포에서 발현될 때 글리코실화됨을 나타내었다. 탈글리코실화 후, 정제된 시료는 환원된 SDS 겔에서 예상된 분자량(55 kDa 및 39 kDa)을 나타내었다. 레인 M에는 10 μl의 SeeBlue Plus2 예비염색된 표준을 로딩하였다.
7t15-TGFRs의 특징화
7t15-TGFRs는, 인간 IL-7, 인간 조직 인자 219 단편 및 인간 IL-15의 가용성 융합인 제1 폴리펩타이드(7t15), 및 단일 사슬 2개 TGFβRII 도메인 및 인간 IL-15 수용체 알파 사슬의 sushi 도메인의 가용성 융합인 제2 폴리펩타이드(TGFRs)를 포함하는 다중-사슬 폴리펩타이드(A형 다중-사슬 폴리펩타이드 본원에 기재된)이다.
CHO 세포를 7t15및 TGFRs 벡터로 공동-형질주입하였다. 7t15-TGFRs 복합체를 형질주입된 CHO 세포 배양 상청액으로부터 정제하였다. IL-7, IL-15, TGFβ 수용체 및 조직 인자(TF) 구성요소는 도 124에 도시된 바와 같이 ELISA에 의해 복합체에서 실증되었다. 인간화 항-TF 항체 모노클로날 항체(항-TF 항체 IgG1)를 포착 항체로서 사용하여 7t15-TGFRs에서 TF를 결정하였고, IL-15(R&D systems), 인간 IL-7(Biolegend), 항-TGFβ 수용체(R&D Systems)에 대한 비오틴화된 항체를 검출 항체로서 사용하여 7t15-TGFRs에서 IL-7, IL-15 및 TGFβ 수용체를 각각 결정하였다. 그 후에, 퍼옥시다제 접합 스트렙타비딘(Jackson ImmunoResearch Lab) 및 ABTS 기질(Surmodics IVD, Inc.)을 사용하여, 결합된 비오틴화된 항체를 검출하였다. 그 결과를 ELISA에 의해 분석하였다(도 124).
C57BL/6 마우스에서 7t15-TGFRs의 생체내 특징화
생체내에서 7t15-TGFRs의 면역자극 활성을 결정하기 위해, C57BL/6 마우스를 대조군 용액(PBS) 또는 0.3, 1, 3 및 10 mg/kg에서 7t15-TGFRs로 피하 치료하였다. 치료된 마우스를 안락사시켰다. 치료 후 제4일에 마우스의 비장을 수집하고 칭량하였다. 단일 비장세포 현탁액을 제조하며, 형광색소-접합 항-CD4, 항-CD8, 및 항-NK1.1 항체로 염색하고, CD4+ T 세포, CD8+ T 세포, 및 NK 세포의 백분율을 유세포측정법에 의해 분석하였다. 그 결과는, 7t15-TGFRs가 특히 1 내지 10 mg/kg에서 비장 중량(도 125a)에 기초하여 비장세포를 확장시키는 데 효과적이었다. CD8+ T 세포 및 NK 세포의 백분율을 시험된 모든 용량에서 대조군-치료 마우스(도 125b)와 비교하여 더 높았다.
CD4
+
세포 및CD8
+
T 세포의 CD44 발현
IL-15는 T 세포 상에서 CD44 발현 및 기억 T 세포의 발달을 유도하는 것으로 알려져 왔다. 7t15-TGFRs 치료 마우스에서 CD4+ T 세포 및 CD8+ T 세포의 CD44 발현을 평가하였다. C57BL/6 마우스를 7t15-TGFRs로 피하 치료하였다. 비장세포를 면역세포 서브세트에 대한 형광색소-접합 항-CD4, 항-CD8 및 항-CD44 모노클로날 항체로 염색하였다. 총 CD4+ T 세포 중 CD4+CD44고 T 세포 및 총 CD8+ T 세포 중 CD8+CD44고 T 세포의 백분율을 유세포측정법에 의해 분석하였다. 도 126a 및 도 126b에 도시된 바와 같이, 7t15-TGFRs는 CD4+ T 세포 및 CD8+ T 세포를 유의하게 활성화시켜 기억 T 세포로 분화시켰다.
더욱이, 마우스의 단회 용량 치료 후 7t15-TGFRs에 의해 유도된 비장세포의 Ki67 발현에 기초한 면역 세포의 역학적 증식 및 비장세포의 그랜자임 B 발현에 기초한 세포독성 잠재력을 평가하였다. C57BL/6 마우스를 3 mg/kg에서 7t15-TGFRs로 피하 치료하였다. 치료된 마우스를 안락사시키고, 비장세포를 제조하였다. 제조된 비장세포를 면역세포 서브세트에 대한 형광색소-접합 항-CD4, 항-CD8 및 항-NK1.1(NK) 항체로 염색한 다음, 세포 증식에 대한 항-Ki67 항체 및 세포독성 마커에 대한 항-그랜자임 B 항체로 세포내 염색하였다. 상응하는 면역세포 서브세트의 Ki67 및 그랜자임 B의 평균치 형광 강도(MFI)를 유세포측정법에 의해 분석하였다. 도 127a 및 도 127b에 도시된 바와 같이, 7t15-TGFRs로 치료된 마우스의 비장에서, CD8+ T 세포 및 NK 세포에 의한 Ki67 및 그랜자임 B의 발현은 PBS 대조군 치료와 비교하여 증가하였다. 이들 결과는, 7t15-TGFRs는 CD8+ T 세포 및 NK 세포의 수를 증가시킬 뿐만 아니라 이들 세포의 잠재적인 세포독성을 증강시킴을 실증한다.
추가로, 종양 세포에 대한 마우스 비장 세포의 세포독성을 또한 평가하였다. 마우스 Yac-1 세포를 CellTrace 바이올렛으로 표지하고, 종양 표적 세포로서 사용하였다. 비장세포를 7t15-TGFRs-치료 마우스로부터 제조하고, 이펙터 세포로서 사용하였다. 표적 세포를 100 nM에서 7t15-TGFRs와 함께 또는 7t15-TGFRs 없이 RPMI-10 배지에서 이펙터 세포와 E:T 비 = 10:1로 혼합하고, 37℃에서 20시간 동안 인큐베이션하였다. 유세포측정법을 사용하는 생존 바이올렛-표지 Yac-1 세포의 분석에 의해 표적 Yac-1 세포 저해를 평가하였다. 식 (1-실험 시료 내 생존 Yac-1 세포의 수/비장세포가 없는 시료 내 생존 Yac-1 세포의 수) x 100을 사용하여 Yac-1 저해의 백분율을 계산하였다. 도 128에 도시된 바와 같이, 7t15-TGFRs-치료 마우스 비장세포는 Yac-1 세포에 대해 대조군 마우스 비장세포보다 더 강한 세포독성을 가졌고, 세포독성 검정법 동안 7t15-TGFRs의 첨가는 Yac-1 표적 세포에 대한 비장세포의 세포독성을 추가로 증강시켰다.
실시예 57: TGFRt15-21s137L 융합 단백질 발생 및 특징화
IL-21/IL-15RαSu/CD137L 및 TGFβ 수용체 II/TF/IL-15 융합 단백질을 포함하는 융합 단백질 복합체를 생성시켰다(도 129 및 도 130). 인간 TGFβ 수용체 II(Ile24-Asp159), 조직 인자 219, 및 IL-15 서열을 UniProt 웹사이트로부터 수득하였고, 이들 서열에 대한 DNA를 게네위즈에 의해 합성하였다. 구체적으로, G4S(3) 링커를 이용하여 2개의 TGFβ 수용체 II 서열을 연결하여 TGFβ 수용체 II의 단일 사슬 버전을 생성시킨 다음, 조직 인자 219의 N-말단 코딩 영역에 연결하고, 뒤이어 IL-15의 N-말단 코딩 영역과 연결하는 작제물을 만들었다.
TGFRt15 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 TGFβ 수용체 II 단편)
atccccccccatgtgcaaaagagcgtgaacaacgatatgatcgtgaccgacaacaacggcgccgtgaagtttccccagctctgcaagttctgcgatgtcaggttcagcacctgcgataatcagaagtcctgcatgtccaactgcagcatcacctccatctgcgagaagccccaagaagtgtgcgtggccgtgtggcggaaaaatgacgagaacatcaccctggagaccgtgtgtcacgaccccaagctcccttatcacgacttcattctggaggacgctgcctcccccaaatgcatcatgaaggagaagaagaagcccggagagaccttctttatgtgttcctgtagcagcgacgagtgtaacgacaacatcatcttcagcgaagagtacaacaccagcaaccctgatggaggtggcggatccggaggtggaggttctggtggaggtgggagtattcctccccacgtgcagaagagcgtgaataatgacatgatcgtgaccgataacaatggcgccgtgaaatttccccagctgtgcaaattctgcgatgtgaggttttccacctgcgacaaccagaagtcctgtatgagcaactgctccatcacctccatctgtgagaagcctcaggaggtgtgcgtggctgtctggcggaagaatgacgagaatatcaccctggaaaccgtctgccacgatcccaagctgccctaccacgatttcatcctggaagacgccgccagccctaagtgcatcatgaaagagaaaaagaagcctggcgagacctttttcatgtgctcctgcagcagcgacgaatgcaacgacaatatcatctttagcgaggaatacaataccagcaaccccgac
(인간 조직 인자 219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(인간 IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
TGFRt15 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 TGFβ 수용체 II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
21s137L의 핵산 및 단백질 서열은 하기에 제시된다. 21s137L 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(인간 IL-15R α sushi 도메인)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
((G4S)3 링커)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(인간 CD137L)
CGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA
21s137L 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(인간 IL-15R α sushi 도메인)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
((G4S)3 링커)
GGGGSGGGGSGGGGS
(인간 CD137L)
REGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE
일부 경우, 리더 펩타이드를 무손상 폴리펩타이드로부터 절단하여, 가용성이거나 분비될 수 있는 성숙한 형태를 생성시킨다.
IL-21/IL-15RαSu/CD137L 및 TGFR/TF/IL-15 작제물을 이전에 기재된 바와 같이 변형된 레트로바이러스 발현 벡터 내로 클로닝하고(문헌[Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y, et al. Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions. Hum Gene Ther 2005;16:457-72]), 발현 벡터를 CHO-K1 세포 내로 형질주입하였다. CHO-K1 세포에서 2개 작제물의 공동-발현은 가용성 TGFR/TF/IL-15: IL-21/IL-15RαSu/CD137L 단백질 복합체(TGFRt15-21s137L로 지칭됨)의 형성 및 분비를 가능하게 하였으며, 이는 항-TF 항체 IgG1 친화도 및 다른 크로마토그래피 방법에 의해 정제될 수 있다.
항-TF 항체 친화도 컬럼을 사용한 TGFRt15-21s137L의 정제 용리 크로마토그래프
세포 배양물로부터 수합된 TGFRt15-21s137L을 5 컬럼 부피의 PBS로 평형화된 항-TF 항체 친화도 컬럼 상으로 로딩하였다. 시료를 로딩한 후, 컬럼을 5 컬럼 부피의 PBS로 세척하고, 뒤이어 6 컬럼 부피의 0.1 M 아세트산(pH 2.9)으로 용리하였다. A280 용리 피크를 수집한 다음, 1 M Tris 염기로 pH 7.5 내지 8.0으로 중화시켰다. 그 후에, 30 KDa 분자량 컷오프와 함께 Amicon 원심분리 필터를 사용하여, 중화된 시료를 PBS로 완충액 교환하였다. 도 131에 도시된 바와 같이, 항-TF 항체 친화도 컬럼은, TF를 TGFRt15-21s137L의 융합 파트너로서 함유하는 TGFRt15-21s137L에 결합하였다. 완충액-교환된 단백질 시료를 추가의 생화학적 분석 및 생물학적 활성 시험을 위해 2℃ 내지 8℃에 보관하였다. 각각의 용리 후, 6 컬럼 부피의 0.1 M 글리신(pH 2.5)를 사용하여 항-TF 항체 친화도 컬럼을 박리시켰다. 그 후에, 보관을 위해 상기 컬럼을 5 컬럼 부피의 PBS, 및 7 컬럼 부피의 20% 에탄올을 사용하여 중화시켰다. 항-TF 항체 친화도 컬럼을 GE Healthcar AKTA Avant 시스템에 연결하였다. 유속이 2 mL/분인 용리 단계를 제외하고는, 모든 단계에 대해 유속은 4 mL/분이었다.
실시예 58: TGFRt15-TGFRs21 융합 단백질 발생 및 특징화
TGFβ 수용체 II/IL-15RαSu/IL-21 및 TGFβ 수용체 II/TF/IL-15 융합 단백질을 포함하는 융합 단백질 복합체를 생성시켰다(도 132 및 도 133). 인간 TGFβ 수용체 II(Ile24-Asp159), 조직 인자 219, IL-21, 및 IL-15 서열을 UniProt 웹사이트로부터 수득하였고, 이들 서열에 대한 DNA를 게네위즈에 의해 합성하였다. 구체적으로, G4S(3) 링커를 이용하여 2개의 TGFβ 수용체 II 서열을 연결하여 TGFβ 수용체 II의 단일 사슬 버전을 생성시킨 다음, 조직 인자 219의 N-말단 코딩 영역에 연결하고, 뒤이어 IL-15의 N-말단 코딩 영역과 연결하는 작제물을 만들었다.
조직 인자 219의 N-말단, 뒤이어 IL-15의 N-말단에 연결된 2개의 TGFβ 수용체 II를 포함하는 작제물의 핵산 서열 및 단백질 서열은 하기에 제시된다.
TGFRt15 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 TGFβ 수용체 II 단편)
atccccccccatgtgcaaaagagcgtgaacaacgatatgatcgtgaccgacaacaacggcgccgtgaagtttccccagctctgcaagttctgcgatgtcaggttcagcacctgcgataatcagaagtcctgcatgtccaactgcagcatcacctccatctgcgagaagccccaagaagtgtgcgtggccgtgtggcggaaaaatgacgagaacatcaccctggagaccgtgtgtcacgaccccaagctcccttatcacgacttcattctggaggacgctgcctcccccaaatgcatcatgaaggagaagaagaagcccggagagaccttctttatgtgttcctgtagcagcgacgagtgtaacgacaacatcatcttcagcgaagagtacaacaccagcaaccctgatggaggtggcggatccggaggtggaggttctggtggaggtgggagtattcctccccacgtgcagaagagcgtgaataatgacatgatcgtgaccgataacaatggcgccgtgaaatttccccagctgtgcaaattctgcgatgtgaggttttccacctgcgacaaccagaagtcctgtatgagcaactgctccatcacctccatctgtgagaagcctcaggaggtgtgcgtggctgtctggcggaagaatgacgagaatatcaccctggaaaccgtctgccacgatcccaagctgccctaccacgatttcatcctggaagacgccgccagccctaagtgcatcatgaaagagaaaaagaagcctggcgagacctttttcatgtgctcctgcagcagcgacgaatgcaacgacaatatcatctttagcgaggaatacaataccagcaaccccgac
(인간 조직 인자 219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(인간 IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
TGFRt15 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 TGFβ 수용체 II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
2개의 TGFβ 수용체 II를 IL-15RαSu 사슬에 직접적으로 부착하고, 뒤이어 게네위즈에 의해 합성된 IL-21의 N-말단 코딩 영역에 부착함으로써 작제물을 또한 만들었다. IL-15RαSu의 N-말단, 뒤이어 IL-21의 N-말단에 연결된 TGFβ 수용체 II를 포함하는 작제물의 핵산 서열 및 단백질 서열은 하기에 제시된다.
TGFRs21 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 TGFβ 수용체 II 단편)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(인간 IL-15R α sushi 도메인)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
(인간 IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
TGFRs21 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 TGFβ 수용체 II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(인간 IL-15R α sushi 도메인)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
(인간 IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
일부 경우, 리더 펩타이드를 무손상 폴리펩타이드로부터 절단하여, 가용성이거나 분비될 수 있는 성숙한 형태를 생성시킨다.
TGFR/IL-15RαSu/IL-21 및 TGFR/TF/IL-15 작제물을 이전에 기재된 바와 같이 변형된 레트로바이러스 발현 벡터 내로 클로닝하고(문헌[Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y, et al. Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions. Hum Gene Ther 2005;16:457-72]), 발현 벡터를 CHO-K1 세포 내로 형질주입하였다. CHO-K1 세포에서 2개 작제물의 공동-발현은 가용성 TGFR/TF/IL-15:TGFR/IL-15RαSu/IL-21 단백질 복합체(TGFRt15-TGFRs21로 지칭됨)의 형성 및 분비를 가능하게 하였으며, 이는 항-TF 항체 IgG1 친화도 및 다른 크로마토그래피 방법에 의해 정제될 수 있다.
항-TF 항체 친화도 컬럼을 사용한 TGFRt15-TGFRs21의 정제 용리 크로마토그래프
세포 배양물로부터 수합된 TGFRt15-TGFRs21을 5 컬럼 부피의 PBS로 평형화된 항-TF 항체 친화도 컬럼 상으로 로딩하였다. 시료를 로딩한 후, 컬럼을 5 컬럼 부피의 PBS로 세척하고, 뒤이어 6 컬럼 부피의 0.1 M 아세트산(pH 2.9)으로 용리하였다. A280 용리 피크를 수집한 다음, 1 M Tris 염기로 pH 7.5 내지 8.0으로 중화시켰다. 그 후에, 30 KDa 분자량 컷오프와 함께 Amicon 원심분리 필터를 사용하여, 중화된 시료를 PBS로 완충액 교환하였다. 도 134에 도시된 바와 같이, 항-TF 항체 친화도 컬럼은, TF를 융합 파트너로서 함유하는 TGFRt15-TGFRs21에 결합하였다. 완충액-교환된 단백질 시료를 추가의 생화학적 분석 및 생물학적 활성 시험을 위해 2℃ 내지 8℃에 보관하였다. 각각의 용리 후, 6 컬럼 부피의 0.1 M 글리신(pH 2.5)를 사용하여 항-TF 항체 친화도 컬럼을 박리시켰다. 그 후에, 보관을 위해 상기 컬럼을 5 컬럼 부피의 PBS, 및 7 컬럼 부피의 20% 에탄올을 사용하여 중화시켰다. 항-TF 항체 친화도 컬럼을 GE Healthcar AKTA Avant 시스템에 연결하였다. 유속이 2 mL/분인 용리 단계를 제외하고는, 모든 단계에 대해 유속은 4 mL/분이었다.
TGFRt15-TGFRs21의 환원된 SDS-PAGE 분석
TGFRt15-TGFRs21 단백질의 순도 및 분자량을 결정하기 위해, 항-TF 항체 친화도 컬럼으로 정제된 단백질 시료를, 환원된 조건 하에 소듐 도데실 설페이트 폴리아크릴아미드 겔(4% 내지 12% NuPage Bis-Tris 겔) 전기영동(SDS-PAGE) 방법에 의해 분석하였다. 전기영동 후, 상기 겔을 InstantBlue로 약 30분 동안 염색시키고, 뒤이어 정제수에서 밤새 탈색시켰다.
TGFRt15-TGFRs21 단백질이 CHO 세포에서 번역 후 글리코실화를 겪음을 확증하기 위해, New England Biolabs로부터의 단백질 탈글리코실화 믹스 II 키트를 제조업체의 설명서에 따라 사용하여 탈글리코실화 실험을 수행하였다. 도 135는 비-탈글리코실화된 상태(붉은 윤곽선에서 레인 1) 및 탈글리코실화된 상태(황색 윤곽선에서 레인 2)에서 시료의 환원된 SDS-PAGE 분석을 도시한다. 상기 단백질은 이것이 CHO 세포에서 발현될 때 글리코실화된다는 것이 명백하다. 탈글리코실화 후, 정제된 시료는 환원된 SDS 겔에서 예상된 분자량(69 kDa 및 55 kDa)을 나타내었다. 레인 M에는 10 μl의 SeeBlue Plus2 예비염색된 표준을 로딩하였다.
C57BL/6 마우스에서 TGFRt15-TGFRs21의 면역자극
TGFRt15-TGFRs21은, 단일 사슬 2개의 TGFβRII 도메인, 인간 조직 인자 219 단편 및 인간 IL-15의 가용성 융합인 제1 폴리펩타이드(TGFRt15), 및 단일 사슬 2개 TGFβRII 도메인, 인간 IL-15 수용체 알파 사슬의 sushi 도메인 및 인간 IL-21의 가용성 융합인 제2 폴리펩타이드(TGFRs21)를 포함하는 다중-사슬 폴리펩타이드(A형 다중-사슬 폴리펩타이드 본원에 기재된)이다.
CHO 세포를 TGFRt15및 TGFRs21 벡터로 공동-형질주입하였다. TGFRt15-TGFRs21 복합체를 형질주입된 CHO 세포 배양 상청액으로부터 정제하였다. TGFβ 수용체, IL-15, IL-21 및 조직 인자(TF) 구성요소는 도 136에 도시된 바와 같이 ELISA에 의해 복합체에서 실증되었다. 인간화 항-TF 모노클로날 항체(항-TF IgG1)를 포착 항체로서 사용하여 TGFRt15-TGFRs21에서 TF를 결정하였고, 비오틴화된 항-인간 IL-15 항체(R&D systems), 비오틴화된 항-인간 TGFβ 수용체 항체(R&D systems), 및 비오틴화된 항-인간 IL-21 항체(R&D Systems)를 검출 항체로서 사용하여 TGFRt15-TGFRs21에서 IL-15, TGFβ 수용체, 및 IL-21을 각각 결정하였다. 검출을 위해, 퍼옥시다제 접합 스트렙타비딘(Jackson ImmunoResearch Lab) 및 ABTS를 사용하였다.
야생형 C57BL/6 마우스를 대조군 용액(PBS)으로 또는 3 mg/kg에서 TGFRt15-TGFRs21로 피하 치료하였다. 치료 후 4일째에, 비장 중량 및 비장에 존재하는 다양한 면역 세포 유형의 백분율을 평가하였다. 도 137a에 도시된 바와 같이, 대조군-치료 마우스 및 TGFRt15-TGFRs21-치료 마우스의 비장에 존재하는 CD4+ T 세포, CD8+ T 세포, 및 NK 세포의 백분율을 평가하였다. TGFRt15-TGFRs21 치료 후 Ki67 발현에 기초한 면역 세포의 역학적 증식을 또한 평가하였다. 비장세포를 형광색소-접합 항-CD4, 항-CD8 및 항-NK1.1(NK) 항체로 염색한 다음, 항-Ki67 항체로 세포내 염색하였다. CD4+ T 세포, CD8+ T 세포, 및 NK 세포의 백분율 및 상응하는 면역세포 서브세트의 Ki67의 평균치 형광 강도(MFI)를 유세포측정법에 의해 분석하였다(도 137a 및 도 137b). 더욱이, 마우스의 단회 용량 치료 후 TGFRt15-TGFRs21에 의해 유도된 비장세포의 그랜자임 B 발현에 기초한 세포독성 잠재력을 또한 평가하였다. 도 138에 도시된 바와 같이, TGFRt15-TGFRs21로 치료된 마우스의 비장에서, NK 세포에 의한 그랜자임 B의 발현은 치료 후 증가하였다. TGFRt15-TGFRs21-치료 마우스로부터의 비장세포를 형광색소-접합 항-CD4, 항-CD8 및 항-NK1.1(NK) 항체로 염색한 다음, 항-그랜자임 B 항체로 세포내 염색하였다. 상응하는 면역세포 서브세트의 그랜자임 B의 평균치 형광 강도(MFI)를 유세포측정법에 의해 분석하였다(도 138).
도 137a에 도시된 바와 같이, TGFRt15-TGFRs21로 치료된 마우스의 비장에서, CD8+ T 세포와 NK 세포 둘 다의 백분율은 단일 TGFRt15-TGFRs21 치료 후 제4일에 증가하였다. 이들 결과는, TGFRt15-TGFRs21이 마우스 비장에서 면역 세포, 특히 CD8+ T 세포 및 NK 세포의 증식을 유도할 수 있음을 실증한다.
추가로, 종양 세포에 대한 마우스 비장 세포의 세포독성을 또한 평가하였다. 마우스 Yac-1 세포를 CellTrace 바이올렛으로 표지하고, 종양 표적 세포로서 사용하였다. 비장세포를 TGFRt15-TGFRs21-치료 마우스로부터 제조하고, 이펙터 세포로서 사용하였다. 표적 세포를 100 nM에서 TGFRt15-TGFRs21과 함께 또는 TGFRt15-TGFRs21 없이 RPMI-10 배지에서 이펙터 세포와 E:T 비 = 10:1로 혼합하고, 37℃에서 24시간 동안 인큐베이션하였다. 유세포측정법을 사용하는 생존 바이올렛-표지 Yac-1 세포의 분석에 의해 표적 Yac-1 세포 저해를 평가하였다. 식 (1-[실험 시료 내 생존 Yac-1 세포의 수]/[비장세포가 없는 시료 내 생존 Yac-1 세포의 수]) x 100을 사용하여 Yac-1 저해의 백분율을 계산하였다. 도 139에 도시된 바와 같이, TGFRt15-TGFRs21-치료 마우스 비장세포는 세포독성 검정법 동안 TGFRt15-TGFRs21의 존재 하에 Yac-1 세포에 대해 대조군 마우스 세포보다 더 강한 세포독성을 가졌다(도 139).
실시예 59: TGFRt15-TGFRs16 융합 단백질 발생
TGFβ 수용체 II/IL-15RαSu/ 항-CD16scFv 및 TGFβ 수용체 II/TF/IL-15 융합 단백질을 포함하는 융합 단백질 복합체를 생성시켰다(도 140 및 도 141). 인간 TGFβ 수용체 II(Ile24-Asp159), 조직 인자 219, 및 IL-15 서열을 UniProt 웹사이트로부터 수득하였고, 이들 서열에 대한 DNA를 게네위즈에 의해 합성하였다. 구체적으로, G4S(3) 링커를 이용하여 2개의 TGFβ 수용체 II 서열을 연결하여 TGFβ 수용체 II의 단일 사슬 버전을 생성시킨 다음, 조직 인자 219의 N-말단 코딩 영역에 연결하고, 뒤이어 IL-15의 N-말단 코딩 영역과 연결하는 작제물을 만들었다.
조직 인자 219의 N-말단, 뒤이어 IL-15의 N-말단에 연결된 2개의 TGFβ 수용체 II를 포함하는 작제물의 핵산 서열 및 단백질 서열은 하기에 제시된다.
TGFRt15 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 TGFβ 수용체 II 단편)
atccccccccatgtgcaaaagagcgtgaacaacgatatgatcgtgaccgacaacaacggcgccgtgaagtttccccagctctgcaagttctgcgatgtcaggttcagcacctgcgataatcagaagtcctgcatgtccaactgcagcatcacctccatctgcgagaagccccaagaagtgtgcgtggccgtgtggcggaaaaatgacgagaacatcaccctggagaccgtgtgtcacgaccccaagctcccttatcacgacttcattctggaggacgctgcctcccccaaatgcatcatgaaggagaagaagaagcccggagagaccttctttatgtgttcctgtagcagcgacgagtgtaacgacaacatcatcttcagcgaagagtacaacaccagcaaccctgatggaggtggcggatccggaggtggaggttctggtggaggtgggagtattcctccccacgtgcagaagagcgtgaataatgacatgatcgtgaccgataacaatggcgccgtgaaatttccccagctgtgcaaattctgcgatgtgaggttttccacctgcgacaaccagaagtcctgtatgagcaactgctccatcacctccatctgtgagaagcctcaggaggtgtgcgtggctgtctggcggaagaatgacgagaatatcaccctggaaaccgtctgccacgatcccaagctgccctaccacgatttcatcctggaagacgccgccagccctaagtgcatcatgaaagagaaaaagaagcctggcgagacctttttcatgtgctcctgcagcagcgacgaatgcaacgacaatatcatctttagcgaggaatacaataccagcaaccccgac
(인간 조직 인자 219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(인간 IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
TGFRt15 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 TGFβ 수용체 II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
2개의 TGFβ 수용체 II를 IL-15RαSu 사슬에 직접적으로 부착하고, 뒤이어 게네위즈에 의해 합성된 항-CD16scFv 서열에 부착함으로써 작제물을 또한 만들었다. IL-15RαSu의 N-말단, 뒤이어 항-CD16scFv 서열에 연결된 TGFβ 수용체 II를 포함하는 작제물의 핵산 서열 및 단백질 서열은 하기에 제시된다.
TGFRs16 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 TGFβ 수용체 II 단편)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(인간 IL-15R α sushi 도메인)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
(항-인간 CD16scFv)
TCCGAGCTGACCCAGGACCCTGCTGTGTCCGTGGCTCTGGGCCAGACCGTGAGGATCACCTGCCAGGGCGACTCCCTGAGGTCCTACTACGCCTCCTGGTACCAGCAGAAGCCCGGCCAGGCTCCTGTGCTGGTGATCTACGGCAAGAACAACAGGCCCTCCGGCATCCCTGACAGGTTCTCCGGATCCTCCTCCGGCAACACCGCCTCCCTGACCATCACAGGCGCTCAGGCCGAGGACGAGGCTGACTACTACTGCAACTCCAGGGACTCCTCCGGCAACCATGTGGTGTTCGGCGGCGGCACCAAGCTGACCGTGGGCCATGGCGGCGGCGGCTCCGGAGGCGGCGGCAGCGGCGGAGGAGGATCCGAGGTGCAGCTGGTGGAGTCCGGAGGAGGAGTGGTGAGGCCTGGAGGCTCCCTGAGGCTGAGCTGTGCTGCCTCCGGCTTCACCTTCGACGACTACGGCATGTCCTGGGTGAGGCAGGCTCCTGGAAAGGGCCTGGAGTGGGTGTCCGGCATCAACTGGAACGGCGGATCCACCGGCTACGCCGATTCCGTGAAGGGCAGGTTCACCATCAGCAGGGACAACGCCAAGAACTCCCTGTACCTGCAGATGAACTCCCTGAGGGCCGAGGACACCGCCGTGTACTACTGCGCCAGGGGCAGGTCCCTGCTGTTCGACTACTGGGGACAGGGCACCCTGGTGACCGTGTCCAGG
TGFRs16 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 TGFβ 수용체 II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(인간 IL-15R α sushi 도메인)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
(항-인간 CD16scFv)
SELTQDPAVSVALGQTVRITCQGDSLRSYYASWYQQKPGQAPVLVIYGKNNRPSGIPDRFSGSSSGNTASLTITGAQAEDEADYYCNSRDSSGNHVVFGGGTKLTVGHGGGGSGGGGSGGGGSEVQLVESGGGVVRPGGSLRLSCAASGFTFDDYGMSWVRQAPGKGLEWVSGINWNGGSTGYADSVKGRFTISRDNAKNSLYLQMNSLRAEDTAVYYCARGRSLLFDYWGQGTLVTVSR
일부 경우, 리더 펩타이드를 무손상 폴리펩타이드로부터 절단하여, 가용성이거나 분비될 수 있는 성숙한 형태를 생성시킨다.
TGFR/IL-15RαSu/항-CD16scFv 및 TGFR/TF/IL-15 작제물을 이전에 기재된 바와 같이 변형된 레트로바이러스 발현 벡터 내로 클로닝하고(문헌[Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y, et al. Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions. Hum Gene Ther 2005;16:457-72]), 발현 벡터를 CHO-K1 세포 내로 형질주입하였다. CHO-K1 세포에서 2개 작제물의 공동-발현은 가용성 TGFR/TF/IL-15:TGFR/IL-15RαSu/항-CD16scFv 단백질 복합체(TGFRt15-TGFRs16로 지칭됨)의 형성 및 분비를 가능하게 하였으며, 이는 항-TF IgG1 친화도 및 다른 크로마토그래피 방법에 의해 정제될 수 있다.
실시예 60: TGFRt15-TGFRs137L 융합 단백질 발생
TGFβ 수용체 II/IL-15RαSu/ CD137L 및 TGFβ 수용체 II/TF/IL-15 융합 단백질을 포함하는 융합 단백질 복합체를 생성시켰다(도 142 및 도 143). 인간 TGFβ 수용체 II(Ile24-Asp159), 조직 인자 219, CD137L, 및 IL-15 서열을 UniProt 웹사이트로부터 수득하였고, 이들 서열에 대한 DNA를 게네위즈에 의해 합성하였다. 구체적으로, G4S(3) 링커를 이용하여 2개의 TGFβ 수용체 II 서열을 연결하여 TGFβ 수용체 II의 단일 사슬 버전을 생성시킨 다음, 조직 인자 219의 N-말단 코딩 영역에 연결하고, 뒤이어 IL-15의 N-말단 코딩 영역과 연결하는 작제물을 만들었다.
조직 인자 219의 N-말단, 뒤이어 IL-15의 N-말단에 연결된 2개의 TGFβ 수용체 II를 포함하는 작제물의 핵산 서열 및 단백질 서열은 하기에 제시된다.
TGFRt15 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 TGFβ 수용체 II 단편)
atccccccccatgtgcaaaagagcgtgaacaacgatatgatcgtgaccgacaacaacggcgccgtgaagtttccccagctctgcaagttctgcgatgtcaggttcagcacctgcgataatcagaagtcctgcatgtccaactgcagcatcacctccatctgcgagaagccccaagaagtgtgcgtggccgtgtggcggaaaaatgacgagaacatcaccctggagaccgtgtgtcacgaccccaagctcccttatcacgacttcattctggaggacgctgcctcccccaaatgcatcatgaaggagaagaagaagcccggagagaccttctttatgtgttcctgtagcagcgacgagtgtaacgacaacatcatcttcagcgaagagtacaacaccagcaaccctgatggaggtggcggatccggaggtggaggttctggtggaggtgggagtattcctccccacgtgcagaagagcgtgaataatgacatgatcgtgaccgataacaatggcgccgtgaaatttccccagctgtgcaaattctgcgatgtgaggttttccacctgcgacaaccagaagtcctgtatgagcaactgctccatcacctccatctgtgagaagcctcaggaggtgtgcgtggctgtctggcggaagaatgacgagaatatcaccctggaaaccgtctgccacgatcccaagctgccctaccacgatttcatcctggaagacgccgccagccctaagtgcatcatgaaagagaaaaagaagcctggcgagacctttttcatgtgctcctgcagcagcgacgaatgcaacgacaatatcatctttagcgaggaatacaataccagcaaccccgac
(인간 조직 인자 219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(인간 IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
TGFRt15 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 TGFβ 수용체 II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
2개의 TGFβ 수용체 II를 IL-15RαSu 사슬에 직접적으로 부착하고, 뒤이어 (G4S)3 링커 및 게네위즈에 의해 합성된 CD137L 서열에 부착함으로써 작제물을 또한 만들었다. IL-15RαSu의 N-말단, 뒤이어 (G4S)3 링커 및 CD137L 서열에 연결된 TGFβ 수용체 II를 포함하는 작제물의 핵산 서열 및 단백질 서열은 하기에 제시된다.
TGFRs137L 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 TGFβ 수용체 II 단편)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(인간 IL-15R α sushi 도메인)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
((G4S)3 링커)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(인간 CD137L)
CGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA
TGFRs137L 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 TGFβ 수용체 II)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(인간 IL-15R α sushi 도메인)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
((G4S)3 링커)
GGGGSGGGGSGGGGS
(인간 CD137L)
REGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE
일부 경우, 리더 펩타이드를 무손상 폴리펩타이드로부터 절단하여, 가용성이거나 분비될 수 있는 성숙한 형태를 생성시킨다.
TGFR/IL-15RαSu/CD137L 및 TGFR/TF/IL-15 작제물을 이전에 기재된 바와 같이 변형된 레트로바이러스 발현 벡터 내로 클로닝하였고(문헌[Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y, et al. Transfer of a TCR gene derived from a patient with a marked antitumor response conveys highly active T-cell effector functions. Hum Gene Ther 2005;16:457-72]), 발현 벡터를 CHO-K1 세포 내로 형질주입하였다. CHO-K1 세포에서 2개 작제물의 공동-발현은 가용성 TGFR/TF/IL-15:TGFR/IL-15RαSu/CD137L 단백질 복합체(TGFRt15-TGFRs137L로 지칭됨)의 형성 및 분비를 가능하게 하였으며, 이는 항-TF IgG1 친화도 및 다른 크로마토그래피 방법에 의해 정제될 수 있다.
실시예 61. 예시적인 단일-사슬 키메라 폴리펩타이드 2t2의 생성 및 특징화
IL-2 수용체에 결합하는 제1 표적-결합 도메인, 가용성 인간 조직 인자 도메인, 및 IL-2 수용체에 결합하는 제2 표적-결합 도메인을 포함하는 예시적인 단일-사슬 키메라 폴리펩타이드가 생성되었다(IL-2/TF/IL-2; 2t2로 지칭됨)(도 144). 이 단일-사슬 키메라 폴리펩타이드의 핵산 및 아미노산 서열은 하기에 제시된다.
예시적인 단일-사슬 키메라 폴리펩타이드를 인코딩하는 핵산(IL-2/TF/IL-2)(SEQ ID NO: 164)
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(제1 IL-2 단편)
GCCCCCACCTCCTCCTCCACCAAGAAGACCCAGCTGCAGCTGGAGCATTTACTGCTGGATTTACAGATGATTTTAAACGGCATCAACAACTACAAGAACCCCAAGCTGACTCGTATGCTGACCTTCAAGTTCTACATGCCCAAGAAGGCCACCGAGCTGAAGCATTTACAGTGTTTAGAGGAGGAGCTGAAGCCCCTCGAGGAGGTGCTGAATTTAGCCCAGTCCAAGAATTTCCATTTAAGGCCCCGGGATTTAATCAGCAACATCAACGTGATCGTTTTAGAGCTGAAGGGCTCCGAGACCACCTTCATGTGCGAGTACGCCGACGAGACCGCCACCATCGTGGAGTTTTTAAATCGTTGGATCACCTTCTGCCAGTCCATCATCTCCACTTTAACC
(인간 조직 인자 219 형태)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(제2 IL-2 단편)
GCACCTACTTCAAGTTCTACAAAGAAAACACAGCTACAACTGGAGCATTTACTGCTGGATTTACAGATGATTTTGAATGGAATTAATAATTACAAGAATCCCAAACTCACCAGGATGCTCACATTTAAGTTTTACATGCCCAAGAAGGCCACAGAACTGAAACATCTTCAGTGTCTAGAAGAAGAACTCAAACCTCTGGAGGAAGTGCTAAATTTAGCTCAAAGCAAAAACTTTCACTTAAGACCCAGGGACTTAATCAGCAATATCAACGTAATAGTTCTGGAACTAAAGGGATCTGAAACAACATTCATGTGTGAATATGCTGATGAGACAGCAACCATTGTAGAATTTCTGAACAGATGGATTACCTTTTGTCAAAGCATCATCTCAACACTAACT
예시적인 단일-사슬 키메라 폴리펩타이드(IL-2/TF/IL-2)(SEQ ID NO: 163)
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL-2)
APTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLELKGSETTFMCEYADETATIVEFLNRWITFCQSIISTLT
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-2)
APTSSSTKKTQLQLEHLLLDLQMILNGINNYKNPKLTRMLTFKFYMPKKATELKHLQCLEEELKPLEEVLNLAQSKNFHLRPRDLISNINVIVLELKGSETTFMCEYADETATIVEFLNRWITFCQSIISTLT
IL-2/TF/IL-2를 인코딩하는 핵산을 이전에 기재된 바와 같이 변형된 레트로바이러스 발현 벡터 내로 클로닝하였다(문헌[Hugheset al., Hum Gene Ther 16:457-72, 2005]). IL-2/TF/IL-2를 인코딩하는 발현 벡터를 CHO-K1 세포 내로 형질주입하였다. CHO-K1 세포에서 발현 벡터의 공동-발현은 가용성 IL-2/TF/IL-2 단일-사슬 키메라 폴리펩타이드(2t2로 지칭됨)의 분비를 가능하게 하였으며, 이는 항-TF 항체 친화도 및 다른 크로마토그래피 방법에 의해 정제될 수 있다.
IL-2 및 2t2는 IL-2Rβ 및 공통 γ 사슬 함유 32Dβ 세포 증식을 유사한 방식으로 촉진하였다
2t2의 IL-2 활성을 평가하기 위해, 2t2를, IL-2Rβ 및 공통 γ 사슬을 발현하는 32Dβ 세포의 증식을 촉진하는 데 대해 재조합 IL-2와 비교하였다. IL-2 의존적 32Dβ 세포를 IMDM-10% FBS로 5회 세척하고, 웰에 2 x 104 세포/웰로 접종하였다. 2t2 또는 IL-2의 단계 희석물을 세포에 첨가하였다(도 145). 세포를 CO2 인큐베이터에서 37℃에서 3일 동안 인큐베이션하였다. 제3일에 10 μl의 WST1을 각각의 웰에 첨가하고 CO2 인큐베이터에서 37℃에서 추가 3시간 동안 인큐베이션함으로써 세포 증식을 검출하였다. 450 nm에서 흡광도를 측정함으로써, 생성된 포르마잔 염료의 양을 분석하였다. 도 145에 도시된 바와 같이, 2t2 및 IL-2는 32Dβ 세포를 유사한 방식으로 활성화시켰다. 2t2 및 IL-2의 EC50은 각각 158.1 pM 및 140 pM이었다.
2t2는 IL-2와 비교하여 IL-2Rαβγ 함유 CTLL-2 세포 증식을 촉진하는 향상된 능력을 나타내었다
2t2의 IL-2 활성을 평가하기 위해, 2t2를, IL-2Rα, IL-2Rβ 및 공통 γ 사슬을 발현하는 CTLL-2 세포의 증식을 촉진하는 데 대해 재조합 IL-2와 비교하였다. IL-2 의존적 CTLL-2 세포를 IMDM-10% FBS로 5회 세척하고, 웰에 2 x 104 세포/웰로 접종하였다. 2t2 또는 IL-2의 단계 희석물을 세포에 첨가하였다(도 146). 세포를 CO2 인큐베이터에서 37℃에서 3일 동안 인큐베이션하였다. 제3일에 10 μl의 WST1을 각각의 웰에 첨가하고 CO2 인큐베이터에서 37℃에서 추가 3시간 동안 인큐베이션함으로써 세포 증식을 검출하였다. 450 nm에서 흡광도를 측정함으로써, 생성된 포르마잔 염료의 양을 분석하였다. 도 146에 도시된 바와 같이, 2t2는 IL-2보다 CTLL-2 세포 증식을 4배 내지 5배 더 강하게 촉진하였다. 2t2의 EC50은 123.2 pM이었고, IL-2는 548.2 pM이었다.
2t2는 ApoE
-/-
마우스에서 고지방-유도 고혈당증의 증가를 억제시켰다
6-주령 암컷 ApoE-/- 마우스(Jackson Lab)를 표준 사료 식이요법 또는 고지방 식이요법(21% 지방, 0.15% 콜레스테롤, 34.1% 수크로스, 19.5% 카제인, 및 15% 전분을 함유함)(TD88137, Envigo Laboratories)으로 사육하고, 표준 조건에서 유지시켰다. 제7주 후, 고지방 식이요법으로 사육된 마우스를 대조군 및 치료군으로 무작위로 할당하였다. 그 후에, 마우스는 피하 주사당 3 mg/kg의 투약량에서 2t2(치료군) 또는 PBS(사료 식이요법 군 및 대조군)를 받았다. 투약 후 3일째에, 마우스를 밤새 단식시키고, 혈액 시료를 안와 정맥총 천자(retro-orbital venous plexus puncture)를 통해 수집하였다. OneTouch 포도당 측정기(Glucometer)를 사용하여, 밤새 공복 포도당 수준을 측정하였다. 도 147에 도시된 바와 같이, 결과는, 2t2 주사가 ApoE-/- 마우스에서 포도당 수준의 증가를 효과적으로 억제시킴을 나타내었다.
2t2는 혈액 림프구에서 CD4
+
CD25
+
FoxP3
+
T 조절(Treg) 세포의 비를 유의하게 상향조절한다
6-주령 암컷 ApoE-/- 마우스(Jackson Lab)를 표준 사료 식이요법 또는 고지방 식이요법(21% 지방, 0.15% 콜레스테롤, 34.1% 수크로스, 19.5% 카제인, 및 15% 전분을 함유함)(TD88137, Envigo Laboratories)으로 사육하고, 표준 조건에서 유지시켰다. 제7주 후, 고지방 식이요법으로 사육된 마우스를 대조군 및 치료군으로 무작위로 할당하였다. 그 후에, 마우스는 피하 주사당 3 mg/kg의 투약량에서 2t2(치료군) 또는 PBS(사료 식이요법 군 및 대조군)를 받았다. 투약 후 3일째에, 밤새 공복 혈액 시료를 안와 정맥총 천자(retro-orbital venous plexus puncture)를 통해 수집하고 ACK 용해 완충액(Thermo Fisher Scientific)과 함께 37℃에서 5분 동안 인큐베이션하였다. 그 후에, 시료를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1 X PBS(Hyclone))에 재현탁시키고, FITC-항-CD4 및 APC-항-CD25 항체(BioLegend)로 30분 동안 표면 염색하였다. 표면-염색된 시료를 추가로 고정시키며, Fix/Perm 완충액(BioLegend)으로 투과시키고 PE-항-Foxp3 항체(BioLegend)로 세포내 염색시켰다. 염색 후, 세포를 FACs 완충액으로 2회 세척하고, 뒤이어 실온에서 1500 RPM에서 5분 동안 원심분리하였다. 유세포측정기(Celesta-BD Bioscience)에 의해 세포를 분석하였다. 도 148에 도시된 바와 같이, 2t2 처리는 비처리군(먹이 식이요법 군에 대해 0.4%±0.16 및 고지방 식이요법 군에 대해 0.46%±0.09)과 비교하여 혈액 림프구(3.5%±0.32)에서 Treg 집단을 유의하게 증가시켰다.
항-TF 항체 친화도 컬럼으로부터의 2t2의 정제 용리 크로마토그래프
세포 배양물로부터 수합된 2t2를 5 컬럼 부피의 PBS로 평형화된 항-TF 항체 친화도 컬럼 상으로 로딩하였다. 시료를 로딩한 후, 컬럼을 5 컬럼 부피의 PBS로 세척하고, 뒤이어 6 컬럼 부피의 0.1 M 아세트산, pH 2.9로 용리하였다. A280 용리 피크를 수집한 다음, 1 M Tris 염기로 pH 7.5 내지 8.0으로 중화시켰다. 그 후에, 30 kDa 분자량 컷오프와 함께 Amicon 원심분리 필터를 사용하여, 중화된 시료를 PBS로 완충액 교환하였다. 도 149에 도시된 바와 같이, 항-TF 항체 친화도 컬럼은, TF를 융합 파트너로서 함유하는 2t2에 결합하였다. 완충액-교환된 단백질 시료를 추가의 생화학적 분석 및 생물학적 활성 시험을 위해 2℃ 내지 8℃에 보관하였다. 각각의 용리 후, 6 컬럼 부피의 0.1 M 글리신, pH 2.5를 사용하여 항-TF 항체 친화도 컬럼을 박리시켰다. 그 후에, 보관을 위해 상기 컬럼을 5 컬럼 부피의 PBS, 및 7 컬럼 부피의 20% 에탄올을 사용하여 중화시켰다. 항-TF 항체 친화도 컬럼을 GE Healthcar AKTA Avant 시스템에 연결하였다. 유속이 2 mL/분인 용리 단계를 제외하고는, 모든 단계에 대해 유속은 4 mL/분이었다.
2t2의 분석적 크기 배제 크로마토그래피(SEC) 분석
분석적 크기 배제 크로마토그래피(SEC)를 사용하여 2t2를 분석하기 위해, Superdex 200 Increase 10/300 GL 겔 여과 컬럼(GE Healthcare)을 AKTA Avant 단백질 정제 시스템(GE Healthcare)에 연결하였다. 상기 컬럼을 2 컬럼 부피의 PBS로 평형화시켰다. 유속은 0.7 mL/분이었다. 2t2를 PBS에 함유하는 시료를 모세관 루프를 사용하여 Superdex 200 컬럼 내로 주사하고, SEC에 의해 분석하였다. 시료의 SEC 크로마토그래프를 도 150에 도시한다. SEC 결과는 2t2에 대한 2개의 단백질 피크를 나타내었다.
2t2의 환원된 SDS-PAGE
단백질의 순도 및 분자량을 결정하기 위해, 항-TF 항체 친화도 컬럼으로 정제된 2t2 단백질 시료를, 환원된 조건 하에 소듐 도데실 설페이트 폴리아크릴아미드 겔(4% 내지 12% NuPage Bis-Tris gel) 전기영동(SDS-PAGE) 방법에 의해 분석하였다. 전기영동 후, 상기 겔을 InstantBlue로 약 30분 동안 염색시키고, 뒤이어 정제수에서 밤새 탈색시켰다.
2t2 단백질이 CHO 세포에서 번역 후 글리코실화를 겪음을 확증하기 위해, New England Biolabs로부터의 단백질 탈글리코실화 믹스 II 키트를 제조업체의 설명서에 따라 사용하여 탈글리코실화 실험을 수행하였다. 도 151a 및 도 151b는 비-탈글리코실화된 상태(붉은 윤곽선에서 레인 1) 및 탈글리코실화된 상태(황색 윤곽선에서 레인 2)에서 시료의 환원된 SDS-PAGE 분석을 도시한다. 그 결과는, 2t2 단백질이 CHO 세포에서 발현되었을 때 글리코실화됨을 나타내다. 탈글리코실화 후, 정제된 시료는 환원된 SDS 겔에서 예상된 분자량(56 kDa)으로 진행되었다. 레인 M에는 10 μL의 SeeBlue Plus2 예비염색된 표준을 로딩하였다.
2t2의 생체내 특징화
2t2를 C57BL/6 마우스 내로 다양한 용량으로 피하 주사하여, 생체내에서 2t2의 면역자극 활성을 결정하였다. 마우스를 대조군 용액(PBS) 또는 0.1, 0.4, 2 및 10 mg/kg에서 2t2로 피하 치료하였다. 치료 후 3일째에, 치료된 마우스를 안락사시켰다. 치료 후 제3일에 마우스의 비장을 수집하고 칭량하였다. 단일 비장세포 현탁액을 제조하며, 제조된 비장세포를 CD4+ T 세포, CD8+ T 세포, 및 NK 세포(형광색소-접합 항-CD4, 항-CD8, 및 항-NK1.1 항체를 이용)에 대해 염색시키고 유세포측정법에 의해 분석하였다. 그 결과는, 2t2가 특히 0.1 내지 10 mg/kg에서 비장 중량(도 152a)에 기초하여 비장세포를 확장시키는 데 효과적이었다. CD8+ T 세포의 백분율은 2 mg/kg 및 10 mg/kg에서 대조군-치료 마우스(도 152b)와 비교하여 더 높았다. NK 세포의 백분율은 시험된 모든 용량에서 대조군-치료 마우스(도 152b)와 비교하여 더 높았다.
IL-2는 면역세포에 의한 CD25 발현을 상향조절하는 것으로 알려져 왔다. 따라서, 본 발명자들은 2t2 치료 마우스에서 CD4+ T 세포, CD8+ T 세포 및 NK 세포의 CD25 발현을 평가하였다. C57BL/6 마우스를 상기 단락에 기재된 바와 같이 2t2로 피하 치료하였다. 비장세포를 형광색소-접합 항-CD4, 항-CD8, CD25 및 NK1.1 모노클로날 항체로 염색하였다. 비장세포 서브세트의 CD25 발현(MFI)을 유세포측정법에 의해 분석하였다. 도 153에 도시된 바와 같이, 시험된 용량 및 시점에서, 2t2는 CD8+ T 세포 및 NK 세포가 아니라 CD4+ T 세포에 의한 CD25 발현을 유의하게 상향조절하였다.
C57BL/6 마우스에서 2t2의 약물동력학을 또한 조사하였다. 2t2를 C57BL/6 마우스 내로 1 mg/kg으로 피하 주사하였다. 마우스 혈액을 도 154에 도시된 바와 같이 다양한 시점에서 꼬리 정맥으로부터 채혈하고, 혈청을 제조하였다. 2t2 농도를 ELISA(포착: 항-조직 인자 항체; 검출: 비오틴화된 항-인간 IL-2 항체, 뒤이어 SA-HRP 및 ABTS 기질)로 결정하였다. 2t2의 반감기는 PK Solutions 2.0(Summit Research Services)으로 계산 시 1.83시간이었다.
2t2는 ApoE
-/-
마우스에서 고지방-유도 아테롬성 동맥경화증 플라크(plaque)의 형성을 감쇠시켰다
6-주령 암컷 ApoE-/- 마우스(The Jackson Laboratory)를 표준 사료 식이요법 또는 고지방 식이요법(21% 지방, 0.15% 콜레스테롤, 34.1% 수크로스, 19.5% 카제인, 및 15% 전분)(TD88137, Envigo Laboratories)으로 사육하고, 표준 조건에서 유지시켰다. 제7주 후, 고지방 식이요법(HFD)으로 사육된 마우스를 대조군 및 치료군으로 무작위로 할당하였다. 그 후에, 마우스에게 2t2(치료군) 또는 PBS(사료 식이요법 군 및 대조군)를 4주 동안 매주 3 mg/kg의 투약량에서 피하 투여하였다. 제12주에, 모든 마우스를 이소플루란에 의해 안락사시켰다. 대동맥을 수집하며, 세로방향으로 개방하고, 인 페이스(en face) 방법을 사용하여 수단(Sudan) IV 용액(0.5%)으로 염색하였다. 그 후에, 총 대동맥 면적과 비교하여 플라크 면적의 백분율(도 155a에 도시된 바와 같이 적색)을 Image J 소프트웨어로 정량화하였다. 도 155a는 각각의 군으로부터의 아테롬성 동맥경화증 플라크의 대표도를 도시한다. 도 155b는 각각의 군의 아테롬성 동맥경화증 플라크의 정량적 분석의 결과를 도시한다. 대조군(HF 식이요법)에서 플라크 면적의 백분율은 10.28% 대 4.68%로 치료군(HFD+2t2)보다 훨씬 더 높았다.
2t2는 2형 당뇨병의 진행을 억제시킨다.
수컷 BKS.Cg-Dock7m +/+ Leprdb/J(db/db(Jackson Lab)) 마우스를 표준 사료 식이요법으로 사육하고, 식수(drinking water)를 마음대로 제공받았다. 6주령에서, 마우스를 대조군 및 치료군으로 무작위로 할당하였다. 치료군은 2t2를 3 mg/kg에서 격주로 피하 주사에 의해 받은 한편, 대조군은 비히클(PBS) 단독을 받았다. OneTouch 포도당 측정기(Glucometer)를 사용하여, 밤새 공복 포도당 수준을 매주 측정하였다. 결과는, 2t2가 BKS.Cg-Dock7m +/+ Leprdb/J 마우스에서 포도당 수준의 증가를 효과적으로 억제시켰음을 나타내었다(도 156).
2t2는 제1 주사 후 혈액 림프구에서 CD4
+
CD25
+
FoxP3
+
T 조절 세포의 비를 유의하게 상향조절한다
수컷 BKS.Cg-Dock7m +/+ Leprdb/J(db/db)(The Jackson Laboratory) 마우스를 표준 사료 식이요법으로 사육하고, 식수를 마음대로 제공받았다. 6주령에서, 마우스를 대조군 및 치료군으로 무작위로 할당하였다. 치료군은 2t2를 3 mg/kg에서 격주로 피하 주사에 의해 받은 한편, 대조군은 비히클(PBS) 단독을 받았다. 제1 약물 주사 후 4일째에, 밤새 공복 혈액 시료를 수집하고 ACK 용해 완충액(Thermo Fisher Scientific)과 함께 37℃에서 5분 동안 인큐베이션하였다. 그 후에, 시료를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에 재현탁시키고, FITC-항-CD4 및 APC-항-CD25 항체(BioLegend)로 30분 동안 표면 염색하였다. 표면-염색된 시료를 추가로 고정시키며, Fix/Perm 완충액(BioLegend)으로 투과시키고 PE-항-Foxp3 항체(BioLegend)로 세포내 염색시켰다. 염색 후, 세포를 FACs 완충액으로 2회 세척하고, 유세포측정기(Celesta-BD Bioscience)에 의해 분석하였다. 혈액 림프구 내 CD4+CD25+FoxP3+ Tregs의 백분율을 측정하였다. 도 157에 도시된 바와 같이, 결과는, 2t2가 혈액 림프구에서 Tregs의 비를 유의하게 상향조절하였음을 나타내었다(* p<0.05).
실시예 62. 예시적인 단일-사슬 키메라 폴리펩타이드 15t15의 생성 및 특징화
IL-15 수용체에 결합하는 제1 표적-결합 도메인, 가용성 인간 조직 인자 도메인, 및 IL-15 수용체에 결합하는 제2 표적-결합 도메인을 포함하는 제2 예시적인 단일-사슬 키메라 폴리펩타이드가 생성되었다(IL-15/TF/IL-15; 15t15로 지칭됨)(도 158). 이 단일-사슬 키메라 폴리펩타이드의 핵산 및 아미노산 서열은 하기에 제시된다.
예시적인 단일-사슬 키메라 폴리펩타이드를 인코딩하는 핵산(IL-15/TF/IL-15)(SEQ ID NO: 170)
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(제1 IL-15 단편)
AACTGGGTGAACGTGATCAGCGATTTAAAGAAGATCGAGGATTTAATCCAGAGCATGCACATCGACGCCACTCTGTACACTGAGAGCGACGTGCACCCTAGCTGCAAGGTGACTGCCATGAAGTGCTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGCGATGCCAGCATCCACGACACTGTGGAGAATTTAATCATTTTAGCCAACAACTCTTTAAGCAGCAACGGCAACGTGACAGAGAGCGGCTGCAAGGAGTGCGAGGAGCTGGAGGAGAAGAACATCAAGGAGTTTTTACAGAGCTTCGTGCACATCGTGCAGATGTTCATCAACACTAGC
(인간 조직 인자 219 형태)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(제2 IL-15 단편)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
예시적인 단일-사슬 키메라 폴리펩타이드(IL-15/TF/IL-15)(SEQ ID NO: 169)
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
IL-15/TF/IL-15를 인코딩하는 핵산을 이전에 기재된 바와 같이 변형된 레트로바이러스 발현 벡터 내로 클로닝하였다(문헌[Hugheset al., Hum Gene Ther 16:457-72, 2005]). IL-15/TF/IL-15를 인코딩하는 발현 벡터를 CHO-K1 세포 내로 형질주입하였다. CHO-K1 세포에서 발현 벡터의 공동-발현은 가용성 IL-15/TF/IL-15 단일-사슬 키메라 폴리펩타이드(15t15로 지칭됨)의 분비를 가능하게 하였으며, 이는 항-TF 항체 친화도 및 다른 크로마토그래피 방법에 의해 정제될 수 있다.
15t15는 IL-2Rβ 및 공통 γ 사슬 함유 32Dβ 세포 증식을 촉진한다
15t15의 IL-15 활성을 IL2Rβ 및 공통 γ 사슬 발현된 32Dβ 세포에서 재조합 IL-15와 비교하였다. IL-15 의존적 32Dβ 세포를 IMDM-10% FBS로 5회 세척하고, 웰에 2 x 104 세포/웰로 접종하였다. 15t15 또는 IL-15의 단계 희석물을 세포에 첨가하였다(도 159). 세포를 CO2 인큐베이터에서 37℃에서 3일 동안 인큐베이션하였다. 제3일에 10 μl의 WST1을 각각의 웰에 첨가하고 CO2 인큐베이터에서 37℃에서 추가 3시간 동안 인큐베이션함으로써 세포 증식을 검출하였다. 450 nm에서 흡광도를 측정함으로써, 생성된 포르마잔 염료의 양을 분석하였다. 도 159에 도시된 바와 같이, 15t15는 IL-15와 비교하여 32Dβ 세포 증식을 덜 효율적으로 촉진하였다. 15t15 및 IL-15의 EC50은 각각 161.4 pM 및 1.6 pM이었다.
항-TF 항체 친화도 컬럼으로부터의 15t15의 정제 용리 크로마토그래프
세포 배양물로부터 수합된 15t15를 5 컬럼 부피의 PBS로 평형화된 항-TF 항체 친화도 컬럼 상으로 로딩하였다. 시료를 로딩한 후, 컬럼을 5 컬럼 부피의 PBS로 세척하고, 뒤이어 6 컬럼 부피의 0.1 M 아세트산, pH 2.9로 용리하였다. A280 용리 피크를 수집한 다음, 1 M Tris 염기로 pH 7.5 내지 8.0으로 중화시켰다. 그 후에, 30 kDa 분자량 컷오프와 함께 Amicon 원심분리 필터를 사용하여, 중화된 시료를 PBS로 완충액 교환하였다. 도 160에 도시된 바와 같이, 항-TF 항체 친화도 컬럼은, TF를 융합 파트너로서 함유하는 15t15에 결합하였다. 완충액-교환된 단백질 시료를 추가의 생화학적 분석 및 생물학적 활성 시험을 위해 2℃ 내지 8℃에 보관하였다. 각각의 용리 후, 6 컬럼 부피의 0.1 M 글리신, pH 2.5를 사용하여 항-TF 항체 친화도 컬럼을 박리시켰다. 그 후에, 보관을 위해 상기 컬럼을 5 컬럼 부피의 PBS, 및 7 컬럼 부피의 20% 에탄올을 사용하여 중화시켰다. 항-TF 항체 친화도 컬럼을 GE Healthcar AKTA Avant 시스템에 연결하였다. 유속이 2 mL/분인 용리 단계를 제외하고는, 모든 단계에 대해 유속은 4 mL/분이었다.
15t15의 환원된 SDS-PAGE
단백질의 순도 및 분자량을 결정하기 위해, 항-TF 항체 친화도 컬럼으로 정제된 15t15 단백질 시료를, 환원된 조건 하에 소듐 도데실 설페이트 폴리아크릴아미드 겔(4% 내지 12% NuPage Bis-Tris gel) 전기영동(SDS-PAGE) 방법에 의해 분석하였다. 전기영동 후, 상기 겔을 InstantBlue로 약 30분 동안 염색시키고, 뒤이어 정제수에서 밤새 탈색시켰다.
15t15 단백질이 CHO 세포에서 번역 후 글리코실화를 겪음을 확증하기 위해, New England Biolabs로부터의 단백질 탈글리코실화 믹스 II 키트를 제조업체의 설명서에 따라 사용하여 탈글리코실화 실험을 수행하였다. 도 161a 및 도 161b는 비-탈글리코실화된 상태(붉은 윤곽선에서 레인 1) 및 탈글리코실화된 상태(황색 윤곽선에서 레인 2)에서 시료의 환원된 SDS-PAGE 분석을 도시한다. 그 결과는, 15t15 단백질이 CHO 세포에서 발현되었을 때 글리코실화됨을 나타내었다. 탈글리코실화 후, 정제된 시료는 환원된 SDS 겔에서 예상된 분자량(50 kDa)으로 진행되었다. 레인 M에는 10 μL의 SeeBlue Plus2 예비염색된 표준을 로딩하였다.
실시예 63:
시험관내에서
NK 세포의 자극
한 세트의 실험을 수행하여, 18t15-12s, 18t15-12s16, 및 7t15-21s + 항-TF 항체로 자극 후의 NK 세포의 표면 표현형의 변화를 평가하였다. 이들 실험에서, 새로운 인간 백혈구를 혈액 은행으로부터 수득하였고, CD56+ NK 세포를 RosetteSep/인간 NK 세포 시약(StemCell Technologies)으로 단리시켰다. NK 세포의 순도는 >90%였고, CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750에 항체(BioLegend)로 염색함으로써 확인되었다. 세포를 96웰 편평 바닥 플레이트에서 0.2 mL의 완전 배지(2 mM L-글루타민(Thermo Life Technologies), 페니실린(Thermo Life Technologies), 스트렙토마이신(Thermo Life Technologies), 및 10% FBS(Hyclone)가 보충된 RPMI 1640(Gibco))에서 0.2 x 106/mL에서 카운팅하고 재현탁시켰다. 세포를 18t15-12s(100 nM); 18t15-12s16(100 nM), 단일 사이토카인 rhIL-15(50 ng/mL)(Miltenyi), rhIL18(50 ng/mL)(Invivogen), 및 rhIL-12(10 ng/mL)(Peprotech)의 혼합물; 7t15-21s + 항-TF 항체(100 nM 내지 50 nM); 7t15-21s(100 nM); 또는 항-TF 항체(50 nM)로 37℃ 및 5% CO2에서 16시간 동안 자극시켰다. 다음날, 세포를 수합하고, CD56, CD16, CD25, CD69, CD27, CD62L, NKp30, 및 NKp44 특이적 항체로 30분 동안 표면 염색하였다. 표면 염색 후, 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다(실온에서 1500 RPM에서 5분 동안). 2회의 세척 후, 유세포측정기(Celesta-BD Bioscience)에 의해 세포를 분석하였다. 도 162a 및 도 162b는, 정제된 NK 세포와 18t15-12s, 18t15-12s16, 및 7t15-21s + 항-TF 항체의 밤새 인큐베이션이, CD25, CD69, NKp44, 및 NKp30 활성화 마커를 발현하는 세포의 백분율의 증가 및 CD62L을 발현하는 세포의 백분율의 저하를 초래하였음을 도시한다. 모든 활성화 마커 데이터는 CD56+ 게이팅된 림프구로부터의 것이다.
한 세트의 실험을 수행하여, 18t15-12s, 18t15-12s16, 및 7t15-21s로 자극 후의 림프구 집단의 표면 표현형의 변화를 평가하였다. 이들 실험에서, 새로운 인간 백혈구를 혈액 은행으로부터 수득하였다. Ficoll-PAQUE Plus(GE Healthcare) 밀도 구배 배지를 이용하여 말초 혈액 림프구를 단리하였다. 세포를 96웰 편평 바닥 플레이트에서 0.2 mL의 완전 배지(2 mM L-글루타민(Thermo Life Technologies), 페니실린(Thermo Life Technologies), 스트렙토마이신(Thermo Life Technologies), 및 10% FBS(Hyclone)가 보충된 RPMI 1640(Gibco))에서 0.2 x 106/mL에서 카운팅하고 재현탁시켰다. 세포를 18t15-12s(100 nM); 18t15-12s16(100 nM), 단일 사이토카인 rhIL-15(50 ng/mL)(Miltenyi), rhIL18(50 ng/mL)(Invivogen), 및 rhIL-12(10 ng/mL)(Peprotech)의 혼합물; 7t15-21s(100 nM) + 항-TF 항체(50 nM); 7t15-21s(100 nM); 또는 항-TF 항체(50 nM)로 37℃ 및 5% CO2에서 16시간 동안 자극시켰다. 다음날, 세포를 수합하고, CD4 또는 CD8, CD62L, 및 CD69 특이적 항체로 30분 동안 표면 염색하였다. 표면 염색 후, 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다(실온에서 1500 RPM에서 5분 동안). 2회의 세척 후, 유세포측정기(Celesta-BD Bioscience)에 의해 세포를 분석하였다. 도 163은, 정제된 림프구 집단(CD4 T 세포 및 CD8 T 세포)과 18t15-12s, 18t15-12s16, 또는 7t15-21s + 항-TF 항체의 밤새 인큐베이션이, CD69를 발현하는 CD8 T 세포 및 CD4 T 세포의 백분율의 증가를 초래하였음을 도시한다. 추가로, 7t15-21s + 항-TF 항체의 인큐베이션은 CD62L을 발현하는 CD8 T 세포 및 CD4 T 세포의 백분율의 증가를 초래하였다(도 163).
한 세트의 실험을 수행하여, 인간 혈액으로부터 정제된 NK 세포의 세포외 산성화율(ECAR)에 미치는 18t15-12s의 효과를 결정하였다. ECAR를 사용하여, 해당작용을 측정할 수 있다. 해당작용은 2개 분자의 ATP의 동시적인 생성과 함께 1개 분자로부터 2개 분자의 피루베이트로의 세포내 생화학적 전환이다. 해당작용에서의 증가는 Seahorse XF96 분석기에 의해 측정된 ECAR의 증가에 의해 제시되었다. 이들 실험에서, 새로운 인간 백혈구를 혈액 은행으로부터 수득하였고, CD56+ NK 세포를 RosetteSep/인간 NK 세포 시약(StemCell Technologies)으로 단리시켰다. NK 세포의 순도는 >70%였고, CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750 항체(BioLegend)에 대해 염색함으로써 확인되었다. 세포를 96웰 편평 바닥 플레이트에서 0.2 mL의 완전 배지(2 mM L-글루타민(Thermo Life Technologies), 페니실린(Thermo Life Technologies), 스트렙토마이신(Thermo Life Technologies), 및 10% FBS(Hyclone)가 보충된 RPMI 1640(Gibco))에서 0.2 x 106/mL에서 카운팅하고 재현탁시켰다. 세포를 단일 사이토카인 hIL-12(10 ng/mL)(Biolegend), hIL-18(50 ng/mL)(R&D), 및 hIL-15(50 ng/mL)(NCI) 또는 18t15-12s(100 nM)의 혼합물로 37℃ 및 5% CO2에서 14시간 내지 18시간 동안 자극시켰다. 다음날, 세포를 수합하고, Seahorse 배지로 2회 세척하였다. 세포(2 × 105 세포/웰)를 10 μL의 폴리-L-리신(Sigma)으로 코팅된 96-웰 플럭스 플레이트에 시딩하였다. 검정 전 30분 동안 NK 세포를 플레이트에 부착시켰다. 포도당, 올리고마이신, 및 2DG 용액을 완충 Seahorse 배지에서 10x 농도로 제조하고, 보정 플레이트의 포트 A, B, 및 C에 주사하였다. ECAR 판독을 6.5분 내지 7분마다 취하고, ECAR 결과는 80분에 걸친 평균 판독 또는 각각의 시점에서의 평균 판독을 나타낸다. 도 164는 18t15-12s를 이용한 NK 세포의 밤새 자극이 증가된 기저 ECAR 수준을 초래하였음을 도시한다. 포도당 및 올리고마이신의 첨가는 18t15-12s로 밤새 자극된 NK 세포의 증강된 해당작용 및 해당 용량을 각각 추가로 보여주었다(도 164). 배지 단독 또는 IL12, IL18, 및 IL-15의 혼합물로 밤새 처리된 NK 세포를 비교를 위해 사용하였다(도 164).
한 세트의 실험을 수행하여, 18t15-12s로 자극 후, NK 세포에서의 포스포-STAT4 및 포스포-STAT5 수준의 증가를 결정하였다. 이들 실험에서, 새로운 인간 백혈구를 혈액 은행으로부터 수득하였고, CD56+ NK 세포를 RosetteSep/인간 NK 세포 시약(StemCell Technologies)으로 단리시켰다. NK 세포의 순도는 >70%였고, CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750에 특이적인 항체(BioLegend)로 염색함으로써 확인되었다. 세포를 96웰 편평 바닥 플레이트에서 0.1 mL의 완전 배지(2 mM L-글루타민(Thermo Life Technologies), 페니실린(Thermo Life Technologies), 스트렙토마이신(Thermo Life Technologies), 및 10% FBS(Hyclone)가 보충된 RPMI 1640(Gibco))에서 0.05 x 106/mL에서 카운팅하고 재현탁시켰다. 세포를 hIL-12(10 ng/mL)(Biolegend) 또는 hIL-15(50 ng/mL)(NCI)(단일 사이토카인), 또는 18t15-12s(100 nM)로 37℃ 및 5% CO2에서 90분 동안 자극시켰다. 비자극된 NK 세포(US)를 대조군으로서 사용하였다. 세포를 수합하고 파라포름알데하이드(Sigma)에서 1.6%의 최종 농도로 고정시켰다. 플레이트를 암실에서 실온에서 10분 동안 인큐베이션하였다. FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))(100 μL)을 첨가하고, 세포를 96-웰 "V" 바닥 플레이트로 이전시켰다. 세포를 실온에서 1500 RPM에서 5분 동안 세척하였다. 피펫팅을 위아래로 부드럽게 함으로써 세포 펠렛을 100 μL 냉각 메탄올과 함께 혼합하고, 세포를 4℃에서 30분 동안 인큐베이션하였다. 세포를 100 mL의 FACS 완충액과 혼합하고, 실온에서 1500 RPM에서 5분 동안 세척하였다. 세포 펠렛을 4 mL의 pSTAT4(BD Bioscience) 및 pSTAT5 항체(BD Bioscience)를 함유하는 50 mL의 FACS 완충액과 함께 혼합하고, 뒤이어 암실에서 실온에서 30분 동안 인큐베이션하였다. 세포를 100 mL의 FACS 완충액과 혼합하고, 실온에서 1500 RPM에서 5분 동안 세척하였다. 세포 펠렛을 50 mL의 FACS 완충액과 혼합하고, 유세포측정기(Celesta-BD Bioscience)에 의해 세포를 분석하였다. 도 165는, NK 세포와 18t15-12s와의 인큐베이션이 pSTAT4 및 pSTAT5에서 증가를 유도하였음을 도시한다(플롯화된 데이터, 정규화된 배수-변화).
한 세트의 실험을 수행하여, 인간 혈액으로부터 정제된 NK 세포 상에서 산소 소모율(OCR) 및 세포외 산성화율(ECAR)에 미치는 18t15-12s 또는 사이토카인(예를 들어, IL12, IL18, 및 IL-15)의 효과를 결정하였다. OCR 및 ECAR을 Seahorse XF96 분석기에 의해 측정하였다. 이들 실험에서, 신선한 인간 NK 세포를 RosetteSep/인간 NK 세포 시약(StemCell Technologies)을 사용한 음성 선별을 통해 인간 림프구로부터 단리시켰다. 신선하게 정제된 NK 세포를 18t15-12s(100 nM) 또는 rhIL12(10 ng/mL), rhIL18(50 ng/mL), 및 rhIL-15(50 ng/mL) 사이토카인의 혼합물로 대조군으로서 밤새(16시간) 자극시켰다. 다음날, 세포를 세척하고, 카운팅하고, 동일한 수의 세포를 완충된 Seahorse 배지에 평판배양하였다. 포도당, 올리고마이신, 및 2DG 용액을 완충 Seahorse 배지에서 10x 농도로 제조하고, 보정 플레이트의 포트 A, B, 및 C에 주사하였다. 도 166은 2개의 개별 공여자로부터의 OCR(좌측) 및 ECAR(우측) 데이터를 도시한다. 18t15-12s를 이용한 NK 세포의 밤새 자극은 기저 ECAR 및 OCR 수준의 증가를 초래하였다. 포도당 및 올리고마이신의 첨가는 18t15-12s로 밤새 자극된 NK 세포의 증강된 해당작용 및 해당 용량을 각각 추가로 보여주었다. 배지 단독 또는 IL12, IL18, 및 IL-15의 혼합물로 밤새 처리된 NK 세포를 비교를 위해 사용하였다.
실시예 64:
생체내에서
2t2 및/또는 TGFRt15-TGFRs에 의한 NK 세포의 자극
한 세트의 실험을 수행하여, C57BL/6 마우스에서 면역 자극에 미치는 2t2 작제물의 효과를 결정하였다. 이들 실험에서, C57BL/6 마우스를 대조군 용액(PBS) 또는 0.1, 0.4, 2 및 10 mg/kg에서 2t2로 피하 치료하였다. 치료-후 3일째에 치료된 마우스를 안락사시켰다. 비장 중량을 측정하고, 단일 비장세포 현탁액을 제조하였다. 비장세포 현탁액을 접합된 항-CD4, 항-CD8, 및 항-NK1.1(NK) 항체로 염색하였다. CD4+ T 세포, CD8+ T 세포, 및 NK 세포의 백분율, 및 림프구 서브세트 상에서 CD25 발현을 유세포측정법에 의해 분석하였다. 도 167a는, 2t2가 특히 0.1 내지 10 mg/kg의 용량 수준에서 비장 중량에 기초하여 비장세포를 확장시키는 데 효과적이었음을 도시한다. 치료 후, CD8+ T 세포의 백분율을 2 mg/kg 및 10 mg/kg에서 대조군-치료 마우스(도 167b)와 비교하여 2t2-치료 마우스에서 더 높았다. NK 세포의 백분율 또한, 시험된 모든 용량의 2t2에서 대조군-치료 마우스(도 167b)와 비교하여 2t2-치료 마우스에서 더 높았다. 추가로, 2t2는 0.4 mg/kg 내지 10 mg/kg에서 치료 후, CD8+ T 세포 및 NK 세포가 아니라 CD4+ T 세포에 의한 CD25 발현을 유의하게 상향조절하였다(도 167c).
한 세트의 실험을 수행하여, C57BL/6 마우스에서 면역 자극에 미치는 TGFRt15-TGFRs 작제물의 효과를 결정하였다. 이들 실험에서, C57BL/6 마우스를 대조군 용액(PBS) 또는 0.3, 1, 3, 및 10 mg/kg에서 TGFRt15-TGFRs로 피하 치료하였다. 치료-후 4일째에 치료된 마우스를 안락사시켰다. 비장 중량을 측정하고, 단일 비장세포 현탁액을 제조하였다. 비장세포 현탁액을 접합된 항-CD4, 항-CD8, 및 항-NK1.1(NK) 항체로 염색하였다. CD4+ T 세포, CD8+ T 세포, 및 NK 세포의 백분율을 유세포측정법에 의해 분석하였다. 도 168a는 TGFRt15-TGFRs로 치료된 마우스에서 비장 중량은 TGFRt15-TGFRs의 증가하는 투약량에 따라 증가하였음을 도시한다. 추가로, 1 mg/kg, 3 mg/kg, 및 10 mg/kg의 TGFRt15-TGFRs로 치료된 마우스에서 비장 중량은 대조군 용액으로 치료된 마우스와 비교하여 더 무거웠다. 도 168b는 CD8+ T 세포와 NK 세포 둘 다의 백분율이 TGFRt15-TGFRs의 증가하는 투약량에 따라 증가하였음을 보여준다. 구체적으로, CD8+ T 세포의 백분율은 대조군-치료 마우스와 비교하여 0.3 mg/kg, 3 mg/kg, 및 10 mg/kg의 TGFRt15-TGFRs로 치료된 마우스에서 더 높았고, NK 세포의 백분율은 대조군-치료 마우스와 비교하여 0.3 mg/kg, 1 mg/kg, 3 mg/kg, 및 10 mg/kg의 TGFRt15-TGFRs로 치료된 마우스에서 더 높았다.
실험 세트를 수행하여, 서구 식이요법으로 사육된 ApoE-/- 마우스에서 면역 자극에 미치는 TGFRt15-TGFRs 작제물 또는 2t2 작제물의 효과를 결정하였다. 이들 실험에서, 21% 지방, 0.15% 콜레스테롤, 34.1% 수크로스, 19.5% 카제인, 및 15% 전분(TD88137, Envigo Laboratories)을 함유하는 서구 식이요법으로 6-주령 암컷 B6.129P2-ApoEtm1Unc/J 마우스(Jackson Laboratory)를 사육하였다. 8-주의 서구 식이요법 후, 상기 마우스에게 3 mg/kg에서 TGFRt15-TGFRs 또는 2t2를 피하 주사하였다. 치료 후 3일째에, 마우스를 16시간 동안 단식시킨 다음, 혈액 시료를 안와 정맥총 천자를 통해 수집하였다. 혈액을 10 μL 0.5 M EDTA와 혼합하고, 림프구 서브세트 분석을 위해 20 μL 혈액을 얻었다. 적혈구 세포를 ACK(0.15 M NH4Cl, 1.0 mM KHCO3, 0.1 mM Na2EDTA, pH 7.4)로 용해시키고, 림프구를 FACS 염색 완충액(PBS 중 1% BSA)에서 항-마우스 CD8a 항체 및 항-마우스 NK1.1 항체로 4℃에서 30분 동안 염색하였다. 세포를 1회 세척하고, BD FACS Celesta로 분석하였다. Treg 염색을 위해, ACK 처리된 혈액 림프구를 FACS 염색 완충액에서 항-마우스 CD4 항체 및 항-마우스 CD25 항체로 4℃에서 30분 동안 염색하였다. 세포를 1회 세척하며, 고정/투과 작업 용액에 재현탁시키고, 실온에서 60분 동안 인큐베이션하였다. 세포를 1회 세척하고, 투과 용액에 재현탁시켰다. 시료를 300 내지 400 x g에서 실온에서 5분 동안 원심분리한 다음, 상청액을 폐기하였다. 세포 펠렛을 잔여 부피에 재현탁시키고, 1 x 투과 완충액을 이용하여 부피를 약 100 μL로 조정하였다. 항-Foxp3 항체를 세포에 첨가하고, 상기 세포를 실온에서 30분 동안 인큐베이션하였다. 투과 완충액(200 μL)을 세포에 첨가하고, 상기 세포를 300 내지 400 x g에서 실온에서 5분 동안 원심분리하였다. 세포를 유세포측정법 염색 완충액에 재현탁시키고, 유세포측정기 상에서 분석하였다. 도 169b 내지 도 169c는, TGFRt15-TGFRs 및 2t2에 의한 치료가 서구 식이요법으로 사육된 ApoE-/- 마우스에서 NK 세포 및 CD8+ T 세포의 백분율을 증가시켰음을 도시한다. 도 169a는 2t2에 의한 치료가 또한 Treg 세포의 백분율을 증가시켰음을 도시한다.
실시예 65:
생체내에서
면역 세포의 증식 유도
한 세트의 실험을 수행하여, C57BL/6 마우스에서 면역 세포 자극에 미치는 2t2 작제물의 효과를 결정하였다. 이들 실험에서, C57BL/6 마우스를 대조군 용액(PBS) 또는 0.1, 0.4, 2 및 10 mg/kg에서 2t2로 피하 치료하였다. 치료-후 3일째에 치료된 마우스를 안락사시켰다. 비장 중량을 측정하고, 단일 비장세포 현탁액을 제조하였다. 비장세포 현탁액을 접합된 항-CD4, 항-CD8, 및 항-NK1.1(NK) 항체로 염색하였다. CD4+ T 세포, CD8+ T 세포, 및 NK 세포의 백분율을 유세포측정법에 의해 분석하였다. 도 170a는, 2t2 치료가 특히 0.1 내지 10 mg/kg에서 비장 중량에 기초하여 비장세포를 확장시키는 데 효과적이었음을 도시한다. CD8+ T 세포의 백분율은 2 mg/kg 및 10 mg/kg에서 대조군-치료 마우스와 비교하여 더 높았다(도 170b). 추가로, NK 세포의 백분율은, 시험된 모든 용량의 2t2에서 대조군-치료 마우스(도 170b)와 비교하여 더 높았다. 이들 결과는, 2t2 치료가 C57BL/6 마우스에서 CD8+ T 세포와 NK 세포 둘 다의 증식을 유도할 수 있었음을 실증한다.
한 세트의 실험을 수행하여, C57BL/6 마우스에서 면역 자극에 미치는 TGFRt15-TGFRs 작제물의 효과를 결정하였다. 이들 실험에서, C57BL/6 마우스를 대조군 용액(PBS) 또는 0.1, 0.3, 1, 3 및 10 mg/kg에서 TGFRt15-TGFRs로 피하 치료하였다. 치료-후 4일째에 치료된 마우스를 안락사시켰다. 비장 중량을 측정하고, 비장세포 현탁액을 제조하였다. 비장세포 현탁액을 접합된 항-CD4, 항-CD8, 및 항-NK1.1(NK) 항체로 염색하였다. 세포를 증식 마커 Ki67에 대해 추가로 염색하였다. 도 171a는 TGFRt15-TGFRs로 치료된 마우스에서 비장 중량은 TGFRt15-TGFRs의 증가하는 투약량에 따라 증가하였음을 도시한다. 추가로, 1 mg/kg, 3 mg/kg, 및 10 mg/kg의 TGFRt15-TGFRs로 치료된 마우스에서 비장 중량은 단지 대조군 용액으로 치료된 마우스와 비교하여 더 무거웠다. CD8+ T 세포와 NK 세포 둘 다의 백분율은 TGFRt15-TGFRs의 증가하는 투약량에 따라 증가하였다(도 171b). 마지막으로, TGFRt15-TGFRs는 시험된 모든 용량의 TGFRt15-TGFRs에서 CD8+ T 세포와 NK 세포 둘 다에서 세포 증식 마커 Ki67의 발현을 유의하게 상향조절하였다. 이들 결과는, TGFRt15-TGFRs가 C57BL/6 마우스에서 CD8+ T 세포와 NK 세포 둘 다의 증식을 유도하였음을 실증한다.
실험 세트를 수행하여, 서구 식이요법으로 사육된 ApoE-/- 마우스에서 면역 자극에 미치는 TGFRt15-TGFRs 작제물 또는 2t2 작제물의 효과를 결정하였다. 이들 실험에서, 21% 지방, 0.15% 콜레스테롤, 34.1% 수크로스, 19.5% 카제인, 및 15% 전분(TD88137, Envigo Laboratories)을 함유하는 서구 식이요법으로 6-주령 암컷 B6.129P2-ApoEtm1Unc/J 마우스(Jackson Laboratory)를 사육하였다. 8-주의 서구 식이요법 후, 상기 마우스에게 3 mg/kg에서 TGFRt15-TGFRs 또는 2t2를 피하 주사하였다. 치료 후 3일째에, 마우스를 16시간 동안 단식시킨 다음, 혈액 시료를 안와 정맥총 천자를 통해 수집하였다. 혈액을 10 μL 0.5 M EDTA와 혼합하고, 림프구 서브세트 분석을 위해 20 μL 혈액을 얻었다. 적혈구 세포를 ACK(0.15 M NH4Cl, 1.0 mM KHCO3, 0.1 mM Na2EDTA, pH 7.4)로 용해시키고, 림프구를 FACS 염색 완충액(PBS 중 1% BSA)에서 항-마우스 CD8a 항체 및 항-마우스 NK1.1 항체로 4℃에서 30분 동안 염색하였다. 세포를 1회 세척하며, 고정 완충액(BioLegend Cat# 420801)에 실온에서 20분 동안 재현탁시켰다. 세포를 350 x g에서 5분 동안 원심분리하고, 고정된 세포를 세포내 염색 투과 세척 완충액(BioLegend Cat# 421002)에 재현탁시킨 다음, 350 x g에서 5분 동안 원심분리하였다. 그 후에, 세포를 항-Ki67 항체로 RT에서 20분 동안 염색하였다. 세포를 세포내 염색 투과 세척 완충액으로 2회 세척하고, 350 x g에서 5분 동안 원심분리하였다. 그 후에, 세포를 FACS 염색 완충액에 재현탁시켰다. 림프구 서브세트를 BD FACS Celesta로 분석하였다. 도 172a에 기재된 바와 같이, TGFRt15-TGFRs에 의한 ApoE-/- 마우스의 치료는 NK 세포 및 CD8+ T 세포에서 증식(Ki67-양성 염색)을 유도하였다. 추가로, 도 172b는, 2t2에 의한 ApoE-/- 마우스의 치료는 NK 세포 및 CD8+ T 세포에서 증식(Ki67-양성 염색)을 유도하였음을 도시한다.
한 세트의 실험을 수행하여, NSG 마우스에서 7t15-21s, TGFRt15-TGFRs, 및 2t2를 이용한 치료 후 7t15-21s + 항-TF 항체-확장 NK 세포의 효과를 결정하였다. 이들 실험에서, 새로운 인간 백혈구를 혈액 은행으로부터 수득하였고, CD56+ NK 세포를 RosetteSep/인간 NK 세포 시약(StemCell Technologies)으로 단리시켰다. NK 세포의 순도는 >90%였고, CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750에 항체(BioLegend)로 염색함으로써 확인되었다. 세포를 24-웰 편평 바닥 플레이트에서 2 mL의 완전 배지(2 mM L-글루타민(Thermo Life Technologies), 페니실린(Thermo Life Technologies), 스트렙토마이신(Thermo Life Technologies), 및 10% FBS(Hyclone)가 보충된 RPMI 1640(Gibco))에서 2 x 106/mL에서 카운팅하고 재현탁시켰다. 세포를 하기로 15일 동안 자극시켰다: 7t15-21s(100 nM) 및 항-TF 항체(50 nM). 2일마다 후에, 100 nM 7t15-21s 및 50 nM의 항-TF 항체를 함유하는 신선한 배지로 세포를 2 x 106/mL로 재현탁시켰다. 배양물의 부피가 증가함에 따라, 세포를 더 높은 부피의 플라스크로 옮겼다. 트립판 블루를 사용하여 세포를 카운팅하여, 배수-확장을 평가하였다. 7t15-21s + 항-TF 항체-확장된 NK 세포를 가온 HBSS 완충액(Hyclone)에서 실온에서 1000 RPM에서 10분 동안 3회 세척하였다. 7t15-21s + 항-TF 항체-확장-NK 세포를 10 x 106/0.2 mL HBSS 완충액에 재현탁시키고, NSG 마우스(NOD scid 공통 감마 마우스)(Jackson Laboratories)의 꼬리 정맥 내로 정맥내 주사하였다. 전달된 NK 세포는 최대 21일 동안 48시간마다 7t15-21s(10 ng/용량, i.p.), TGFRt15-TGFRs(10 ng/용량, i.p.) 또는 2t2(10 ng/용량, i.p.)로 지지되었다. 인간 7t15-21s + 항-TF 항체-확장 NK 세포의 접목 및 지속성을 hCD45, mCD45, hCD56, hCD3, 및 hCD16 항체에 대한 혈액 염색에서 1주일마다 유세포측정법(Celesta-BD Bioscience)에 의해 측정하였다(데이터는 군당 3 마리의 마우스를 나타냄). 도 173은 입양-전달된 7t15-21s + 항-TF 항체-확장된 NK 세포를 보유하는 마우스를 7t15-21s-, TGFRt15-TGFRs-, 또는 2t2-유도 확장 및 입양 전달된 NK 세포의 지속성의 처리를 대조군 치료된 마우스와 비교하여 나타낸다.
실시예 66: 단일-사슬 작제물 또는 다중-사슬 작제물에 의한 처리 후 NK-매개 세포독성
한 세트의 실험을 수행하여, TGFRt15-TGFRs에 의한 NK 세포의 처리가 NK 세포의 세포독성을 증강시켰는지 결정하였다. 이들 실험에서, 인간 Daudi B 림프종 세포를 CellTrace 바이올렛(CTV)으로 표지하고, 종양 표적 세포로서 사용하였다. 3 mg/kg에서 TGFRt15-TGFRs 피하 치료 후 4일째에 C57BL/6 암컷 마우스 비장의 자기 세포 분류 방법(Miltenyi Biotec)을 사용한 NK1.1-양성 선별을 이용하여 마우스 NK 이펙터 세포를 단리하였다. 인간 혈액 연막으로부터 유래된 말초 혈액 단핵 세포로부터 인간 NK 이펙터 세포를, RosetteSep/인간 NK 세포 시약(Stemcell Technologies)을 이용하여 단리하였다. 표적 세포(인간 Daudi B 림프종 세포)를 50 nM TGFRt15-TGFRs의 존재 하에 또는 TGFRt15-TGFRs의 부재 하에(대조군) 이펙터 세포(마우스 NK 이펙터 세포 또는 인간 NK 이펙터 세포)와 혼합하고, 37℃에서 마우스 NK 세포에 대해 44시간 동안 그리고 인간 NK 세포에 대해 20시간 동안 인큐베이션하였다. 유세포측정법을 사용하는 프로피디움 요오다이드-양성, CTV-표지 세포의 분석에 의해 표적 세포(Daudi) 생존력을 평가하였다. 식 (1-실험 시료 내 생존 종양 세포의 수/NK 세포가 없는 시료 내 생존 종양 세포의 수) x 100을 사용하여 Daudi 저해의 백분율을 계산하였다. 도 174는, 마우스(도 174a) 및 인간(도 174b) NK 세포는 TGFRt15-TGFRs 활성화의 부재 하에서보다 TGFRt15-TGFRs에 의한 NK 세포 활성화 후 Daudi B 세포에 대해 유의하게 더 강한 세포독성을 가졌음을 도시한다.
한 세트의 실험을 수행하여, TGFRt15-TGFRs에 의한 처리 후 마우스 NK 세포 및 인간 NK 세포의 항체-의존적 세포적 세포독성(ADCC)을 결정하였다. 이들 실험에서, 인간 Daudi B 림프종 세포를 CellTrace 바이올렛(CTV)으로 표지하고, 종양 표적 세포로서 사용하였다. 3 mg/kg에서 TGFRt15-TGFRs 피하 치료 후 4일째에 C57BL/6 암컷 마우스 비장의 자기 세포 분류 방법(Miltenyi Biotec)을 사용한 NK1.1-양성 선별을 이용하여 마우스 NK 이펙터 세포를 단리하였다. 인간 혈액 연막으로부터 유래된 말초 혈액 단핵 세포로부터 인간 NK 이펙터 세포를, RosetteSep/인간 NK 세포 시약(Stemcell Technologies)을 이용하여 단리하였다. 표적 세포(Daudi B 세포)를 항-CD20 항체(10 nM 리툭시맙, Genentech)의 존재 하에 그리고 50 nM TGFRt15-TGFRs의 존재 하에, 또는 TGFRt15-TGFRs의 부재 하에(대조군) 이펙터 세포(마우스 NK 이펙터 세포 또는 인간 NK 이펙터 세포)와 혼합하고, 37℃에서 마우스 NK 세포에 대해 44시간 동안 그리고 인간 NK 세포에 대해 20시간 동안 인큐베이션하였다. Daudi B 세포는 항-CD20 항체에 대한 CD20 표적을 발현한다. 인큐베이션 후, 유세포측정법을 사용하는 프로피디움 요오다이드-양성, CTV-표지 표적 세포의 분석에 의해 표적 세포 생존력을 평가하였다. 식 (1-실험 시료 내 생존 종양 세포의 수/NK 세포가 없는 시료 내 생존 종양 세포의 수) x 100을 사용하여 Daudi 저해의 백분율을 계산하였다. 도 175는, 마우스 NK 세포(도 175a) 및 인간 NK 세포(도 175b)는 TGFRt15-TGFRs 활성화의 부재 하에서보다 TGFRt15-TGFRs에 의한 NK 세포 활성화 후 Daudi B 세포에 대해 더 강한 ADCC 활성을 가졌음을 도시한다.
한 세트의 실험을 수행하여, 노쇠 B16F10 흑색종 세포에 대한 TGFRt15-TGFRs-활성화 마우스 NK 세포의 세포독성을 결정하였다. 이들 실험에서, C57BL/6 마우스에게 10 mg/kg의 TGFRt15-TGFRs를 4일 동안 주사하고 뒤이어 비장 NK 세포를 단리함으로써 마우스 NK 세포를 생체내에서 활성화시켰다. 그 후에, NK 세포를 시험관내에서 100 nM 2t2의 존재 하에 7일 동안 확장시켰다. B16F10 노쇠 표적 세포(B16F10-SNC)를 CellTrace Violet(CTV)으로 표지화시키고, 활성화된 마우스 NK 이펙터 세포와 함께 상이한 이펙터:표적(E:T) 비에서 16시간 동안 인큐베이션하였다. 세포를 트립신처리하며, 세척하고, 프로피디움 요오다이드(PI) 용액을 함유하는 완전 배지에 재현탁시켰다. 노쇠 세포 표적에 대한 TGFRt15-TGFRs/2t2-활성화된 NK 세포의 세포독성을 CTV-표지 세포의 PI 염색에 기초한 유세포측정법에 의해 평가하였다. 이러한 발견은, TGFRt15-TGFRs를 이용한 NK 세포의 생체내 활성화, 뒤이어 2t2를 이용한 시험관내 확장 및 활성화가 NK 세포에 의한 노쇠 흑색종 종양 세포의 증가된 사멸을 초래하였음을 실증한다(도 176).
실시예 67: 암, 당뇨병, 및 죽상동맥경화증의 치료
한 세트의 실험을 수행하여, 흑색종 마우스 모델에서 화학치료법과 병용된 TGFRt15-TGFRs + 항-TRP1 항체(TA99)의 항종양 활성을 평가하였다. 이들 실험에서, C57BL/6 마우스에게 0.5 x 106 B16F10 흑색종 세포를 피하 주사하였다. 마우스를 제1일, 제4일, 및 제7일에 3개 용량의 화학치료법 도세탁셀(10 mg/kg)(DTX), 뒤이어 제9일에 단회 용량의 병용 면역치료법 TGFRt15-TGFRs(3 mg/kg) + 항-TRP1 항체 TA99(200 μg)에 의한 치료로 마우스를 치료하였다. 도 177a는 치료 요법의 도식을 도시한다. 종양 성장을 캘리퍼 측정에 의해 모니터링하였고, 종양 부피를 식 V = (L × W2)/2를 사용하여 계산하였으며, 상기 식에서, L은 최대 종양 직경이고 W는 수직(perpendicular) 종양 직경이다. 도 177b는, DTX + TGFRt15-TGFRs + TA99에 의한 치료가 식염수 대조군 및 DTX 치료군과 비교하여 종양 성장을 유의하게 감소시켰음을 도시한다(N=10, ****p <0.001, 다중 t 검정 분석(Multiple t test analysis)).
B16F10 종양 모델에서 면역 세포 서브세트를 평가하기 위해, 말초 혈액 분석을 수행하였다. 이들 실험에서, C57BL/6 마우스에게 B16F10 세포를 주사하고, DTX, DTX + TGFRt15-TGFRs + TA99, 또는 식염수로 치료하였다. DTX + TGFRt15-TGFRs + TA99 군에 대해 면역치료법 후 제2일, 제5일, 및 제8일에 그리고 DTX 및 식염수 군에 대해 종양 주사 후 제11일에, B16F10 종양-보유 마우스의 하악하 정맥(submandibular vein)으로부터 혈액을 채혈하였다. RBC를 ACK 용해 완충액에서 용해시키며, 림프구를 세척하고 항-NK1.1, 항-CD8, 및 항-CD4 항체로 염색하였다. 유세포측정기(Celesta-BD Bioscience)에 의해 세포를 분석하였다. 도 177c 내지 도 177e는, DTX + TGFRt15-TGFRs + TA99 치료가 식염수 및 DTX 치료군과 비교하여 종양에서 NK 세포 및 CD8+ T 세포의 백분율의 증가를 유도하였음을 도시한다.
제17일에, 식염수, DTX 또는 DTX + TGFRt15-TGFRs + TA99로 치료한 마우스의 종양으로부터 총 RNA를, 트리졸(Trizol)을 사용하여 추출하였다. QuantiTect 역전사 키트(Qiagen)를 사용하는 cDNA 합성에 총 RNA(1 μg)를 사용하였다. 노화 세포 마커, (f) p21 (g) DPP4 및 (h) IL6에 대해 FAM-표지 예비설계된 프라이머를 사용하여 CFX96 검출 시스템(Bio-Rad)으로 실시간 PCR을 수행하였다. 하우스킵핑 유전자 18S 리보솜 RNA를 내부 대조군으로서 사용하여, 발현 수준에서의 가변성을 정규화하였다. 18S rRNA와 비교하여 각각의 표적 mRNA의 발현을 Ct에 기초하여 2-Δ(ΔCt)로서 계산하였으며, 여기서, ΔCt = Ct표적 - Ct18S이다. 데이터를 식염수 대조군과 비교하여 배수-변화로서 제시한다. 도 177f 내지 도 177h는, DTX 치료가 노화 종양 세포에서 증가를 유도하였으며, 이는 후속적으로 TGFRt15-TGFRs + TA99 면역치료법에 의한 치료 후 감소되었음을 도시한다.
한 세트의 실험을 수행하여, ApoE-/- 마우스에서 2t2에 의한 서구 식이요법-유도 고혈당의 개선을 조사하였다. 이들 실험에서, 21% 지방, 0.15% 콜레스테롤, 34.1% 수크로스, 19.5% 카제인, 및 15% 전분(TD88137, Envigo Laboratories)을 함유하는 서구 식이요법으로 6-주령 암컷 B6.129P2-ApoEtm1Unc/J 마우스(Jackson Laboratory)를 사육하였다. 8-주의 서구 식이요법 후, 상기 마우스에게 3 mg/kg에서 TGFRt15-TGFRs 또는 2t2를 피하 주사하였다. 치료 후 3일째에, 마우스를 16시간 동안 단식시킨 다음, 혈액 시료를 안와 정맥총 천자를 통해 수집하였다. 신선한 혈액 한방울을 사용하여 포도당 미터(OneTouch UltraMini) 및 GenUltimated 시험 스트립에 의해 혈중 포도당을 검출하였다. 도 178a에 도시된 바와 같이, 2t2 치료는 서구 식이요법에 의해 유도된 고혈당증을 감소시켰다(p<0.04). Eve Technologies에 의한 마우스 래트 대사 어레이를 이용하여 혈장 인슐린 및 레지스틴 수준을 분석하였다. HOMA-IR을 하기 식을 사용하여 계산하였다: 항상성 모델 평가-인슐린 내성 = 포도당(mg/dL) * 인슐린(mU/mL)/405. 도 178b에 도시된 바와 같이, 2t2와 TGFRt15-TGFRs 둘 다의 치료는 비치료군과 비교하여 인슐린 내성을 감소시켰다. 2t2(p<0.02)와 TGFRt15-TGFRs(p<0.05)는 도 178c에 도시된 바와 같이 비치료군과 비교하여 레지스틴 수준을 유의하게 감소시켰으며, 이는 2t2 및 TGFRt15-TGFRs에 의해 유도되는 감소된 인슐린 내성과 관련이 있을 수 있다(도 F3b).
실시예 68: NK 세포로부터 사이토카인-유도 기억 유사 NK 세포로의 분화의 유도
한 세트의 실험을 수행하여, 18t15-12s에 의한 자극 후, NK 세포로부터 사이토카인-유도 기억 유사 NK 세포(CIMK-NK 세포)로의 분화를 평가하였다. 이들 실험에서, 새로운 인간 백혈구를 혈액 은행으로부터 수득하였고, CD56+ NK 세포를 RosetteSep/인간 NK 세포 시약(StemCell Technologies)으로 단리시켰다. NK 세포의 순도는 >90%였고, CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750에 항체(BioLegend)로 염색함으로써 확인되었다. 세포를 24-웰 편평 바닥 플레이트에서 2 mL의 완전 배지(2 mM L-글루타민(Thermo Life Technologies), 페니실린(Thermo Life Technologies), 스트렙토마이신(Thermo Life Technologies), 및 10% FBS(Hyclone)가 보충된 RPMI 1640(Gibco))에서 2 x 106/mL에서 카운팅하고 재현탁시켰다. 세포를 자극시키지 않거나("노 스파이크(No Spike)"), 18t15-12s(100 nM) 또는 rhIL-15(50 ng/mL)(Miltenyi), rhIL18(50 ng/mL)(Invivogen), 및 rhIL-12(10 ng/mL)(Peprotech)를 포함한 단일 사이토카인의 혼합물("단일 사이토카인")로 37℃ 및 5% CO2에서 16시간 동안 자극시켰다. 다음날, 세포를 수합하고, 실온에서 1000 RPM에서 10분 동안 가온(warm) 완전 배지로 2회 세척하였다. 세포를 24-웰 편평 바닥 플레이트에서 rhIL-15(1 ng/mL)를 포함하는 2 mL의 완전 배지에서 2 x 106/mL로 재현탁시켰다. 2일마다 후, 배지 중 절반을, rhIL-15를 함유하는 새로운 완전 배지로 대체하였다.
제7일에 NK 세포의 기억 표현형의 변화를 평가하기 위해, 세포를 세포-표면 CD56, CD16, CD27, CD62L, NKp30, 및 NKp44(BioLegend)에 대한 항체로 염색하였다. 표면 염색 후, 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다(실온에서 1500 RPM에서 5분 동안). 2회의 세척 후, 유세포측정기(Celesta-BD Bioscience)에 의해 세포를 분석하였다. 도 179는, NK 세포와 18t15-12s의 인큐베이션이, CD27, CD62L, 및 NKp44를 발현하는 CD16+CD56+ NK 세포의 백분율의 증가, 및 CD16+CD56+ NK 세포에서 NKp30의 수준(MFI)의 증가를 초래하였음을 도시한다.
실시예 69. CD44 기억 T 세포의 상향조절
C57BL/6 마우스를 TGFRt15-TGFRs 또는 2t2로 피하 치료하였다. 치료된 마우스를 안락사시키고, 치료 후 4일째에(TGFRt15-TGFRs) 단일 비장세포 현탁액을 제조하거나 3일째에(2t2) 제조하였다. 제조된 비장세포를 형광색소-접합 항-CD4, 항-CD8 및 항-CD44 항체로 염색하고, CD4+ T 세포 또는 CD8+ T 세포 내 CD44고 T 세포의 백분율을 유세포측정법에 의해 분석하였다. 결과는, TGFRt15-TGFRs 및 2t2가 CD4+ T 세포 및 CD8+ T 세포 상에서 기억 마커 CD44의 발현을 상향조절하였음을 나타낸다(도 180). 이들 발견은, TGFRt15-TGFRs 및 2t2 분자가 마우스 T 세포를 기억 T 세포로 분화되도록 유도할 수 있었음을 나타낸다.
실시예 70: 질감 및/또는 외양 및/또는 모발의 향상
모발 재성장에 미치는 2t2의 효과를 검사하기 위해, C57BL6/J 마우스(Jackson Laboratory)의 등쪽 모발을 우선 가위로 짧게 하고, 뒤이어 제모 크림(Nair)을 면도된 영역에 30초의 기간 동안 적용한 후 깨끗하게 닦아내었다. 4시간 후, 2t2(3 mg/kg, 단회 용량), 저용량 재조합 IL-2(25000 IU, 5 연속일, 1 용량/일), 또는 PBS를 피하 투여하였다. 마우스를 모발 재성장과 관련된 피부 색소침착에 대해 모니터링하고, 사진을 촬영하고 Image J 소프트웨어를 사용하여 분석하였다. 도 181a는 PBS-치료, 2t2-치료, 또는 IL-2-치료 마우스에서 제모 후 10일째의 피부 색소침착을 도시한다. 도 181b는 Image J 소프트웨어를 사용하여 분석된 바와 같이 치료-후 10일째에 각각의 마우스 군에서의 색소침착 백분율을 도시한다. 결과는 2t2 또는 IL-2를 이용한 마우스의 치료가 PBS-치료 마우스와 비교하여 제모 후 모발 재성장을 촉진시켰음을 보여주었다.
C57BL6/J 마우스(Jackson Laboratory)의 등쪽 모발을 우선 가위로 짧게 한 후, 제모 크림(Nair)을 면도된 영역에 30초의 기간 동안 적용한 후 깨끗하게 닦아내었다. 4시간 후, 2t2(3 mg/kg, 단회 용량), 저용량 재조합 IL-2(25000 IU, 5 연속일, 1 용량/일), 또는 PBS를 피하 투여하였다. 마우스를 모발 재성장과 관련된 피부 색소침착에 대해 모니터링하고, 사진을 촬영하고 Image J 소프트웨어를 사용하여 분석하였다. 도 182는 PBS-치료, 2t2-치료, 또는 IL-2-치료 마우스에서 제모 후 14일째의 피부 색소침착을 도시한다. 결과는 2t2 또는 IL-2를 이용한 마우스의 치료가 PBS-치료 마우스와 비교하여 제모 후 모발 재성장을 촉진시켰음을 보여주었다.
실시예 71:
단일-사슬 또는 다중-사슬 키메라 폴리펩타이드에 의한 치료 후 조직 인자 응고 검정법
한 세트의 실험을 수행하여, 단일-사슬 또는 다중-사슬 키메라 폴리펩타이드에 의한 치료 후 혈액 응고를 평가하였다. 혈액 응고 캐스케이드 경로를 개시하기 위해, 조직 인자(TF)는 인자 VIIa(FVIIa)에 결합하여 TF/FVIIa 복합체를 형성한다. 그 후에, TF/FVIIa 복합체는 인자 X(FX)에 결합하고, FX를 FXa로 전환시킨다.
인자 VIIa(FVIIa) 활성 검정법
혈액 응고를 측정하는 하나의 검정법은 인자 VIIa(FVIIa) 활성을 측정하는 단계를 수반한다. 이러한 유형의 검정법은 조직 인자 및 칼슘의 존재를 필요로 한다. TF/FVIIa 복합체 활성은 작은 기질에 의해 또는 천연 단백질 기질, 예를 들어, 인자 X(FX)에 의해 측정될 수 있다. FX가 기질로서 사용될 때, 인지질 또한 TF/FVIIa 활성에 필요하다. 이 검정법에서, FVIIa 활성을 FVIIa-특이적 발색성 기질 S-2288(Diapharma, West Chester, OH)을 이용하여 결정한다. S-2288 기질의 색상 변화는 분광광도법으로 측정될 수 있고, FVIIa(예를 들어, TF/FVIIa 복합체)의 단백질분해 활성에 비례한다.
이들 실험에서, 하기 군의 FVIIa 활성을 비교하였다: 조직 인자 도메인의 219-아미노산 세포외 도메인(TF219), 야생형 조직 인자 도메인을 갖는 다중-사슬 키메라 폴리펩타이드, 및 돌연변이체 조직 인자 도메인을 갖는 다중-사슬 키메라 폴리펩타이드. 아미노산 부위: Lys20, Ile22, Asp58, Arg135, 및 Phe140에서 TF 도메인에 돌연변이를 갖는, 돌연변이체 조직 인자 분자를 함유하는 키메라 폴리펩타이드를 작제하였다.
FVIIa의 활성을 평가하기 위해, FVIIa, 및 TF219 또는 TF219 -함유 다중-사슬 키메라 폴리펩타이드를 96-웰 ELISA 플레이트의 모든 웰에서 70 μL의 총 부피에서 동일한 몰 농도(10 nM)로 혼합하였다. 37℃에서 10분 동안 인큐베이션 후, 10 μL의 8 mM S-2288 기질을 첨가하여 반응을 시작하였다. 다음, 인큐베이션을 37℃에서 20분 동안 유지시켰다. 마지막으로, 405 nm에서 흡광도를 판독함으로써 색상 변화를 모니터링하였다. 상이한 TF/VIIa 복합체의 OD 값을 표 1 및 표 2에 제시한다. 표 1은 TF219, 21t15-21s 야생형(WT)과 21t15-21s 돌연변이체(Mut)의 비교를 나타낸다. 표 2는 TF219, 21t15-TGFRs 야생형(WT)과 21t15-TGFRs 돌연변이체(Mut)의 비교를 나타낸다. 이들 데이터는, 발색성(chromogenic) S-2288을 기질로서 사용하였을 때, TF219-함유 다중-사슬 키메라 폴리펩타이드(예를 들어, 21t15-21s-WT, 21t15-21s-Mut, 21t15-TGFRS-WT, 및 21t15-TGFRS-Mut)가 TF219보다 더 낮은 FVIIa 활성을 가짐을 나타낸다. 주목할 만하게도, 야생형 TF219를 함유하는 다중-사슬 키메라 폴리펩타이드와 비교할 때, TF219 돌연변이를 함유하는 다중-사슬 키메라 폴리펩타이드가 훨씬 더 낮은 FVIIa 활성을 나타내었다.


인자 X(FX) 활성화 검정법
혈액 응고를 측정하기 위한 추가 검정법은 인자 X(FX)의 활성화를 측정하는 단계를 수반한다. 간략하게는, TF/VIIa는 칼슘 및 인지질의 존재 하에 혈액 응고 인자 X(FX)를 인자 Xa(FXa)로 활성화시킨다. TF의 막관통 도메인을 함유하는 TF243은, 막관통 도메인을 함유하지 않는 TF219보다 FX를 FXa로 활성화시키는 데 있어서 훨씬 더 높은 활성을 가진다. FXa-특이적 발색성 기질 S-2765(Diapharma, West Chester, OH)를 사용하여 FXa 활성을 측정함으로써 FX의 TF/VIIa 의존적 활성화를 결정한다. S-2765의 색상 변화는 분광광도법으로 측정될 수 있고, FXa의 단백질분해 활성에 비례한다.
이들 실험에서, 다중-사슬 키메라 폴리펩타이드(18t15-12s, 마우스 (m)21t15, 21t15-TGFRs, 및 21t15-7s)에 의한 FX 활성화를 양성 대조군(인노빈) 또는 TF219와 비교하였다. TF219(또는 TF219-함유 다중-사슬 키메라 폴리펩타이드)/FVIIa 복합체를 96-웰 ELISA 플레이트의 둥근 바닥 웰에서 50 μL의 부피에서 동일한 몰 농도(각각 0.1 nM)로 혼합하고, 이후에 10 μL의 180 nM FX를 첨가하였다. 37℃에서 15분 동안 인큐베이션한 후, 8 μL의 0.5 M EDTA(칼슘을 킬레이트화시켜 TF/VIIa에 의한 FX 활성화를 종결시킴)를 각각의 웰에 첨가하여 FX 활성화를 중단시켰으며, 상기 인큐베이션 동안 FX를 FXa로 전환되었다. 다음, 10 μL의 3.2 mM S-2765 기질을 반응 혼합물에 첨가하였다. 즉시, 플레이트 흡광도를 405 nm에서 측정하고, 제0시간에서 흡광도로서 기록하였다. 그 후에, 플레이트를 37℃에서 10분 내지 20분 동안 인큐베이션하였다. 인큐베이션 후, 405 nm에서 흡광도를 판독함으로써 색상 변화를 모니터링하였다. 발색성 기질 S-2765를 사용하여 FXa 활성에 의해 측정된 바와 같은 FX 활성화의 결과를 도 183에 도시한다. 이 실험에서, 지질화된 재조합 인간 TF243을 함유하는 상업적인 프로트롬빈 시약인 인노빈을 FX 활성화에 대한 양성 대조군으로서 사용하였다. 정제수를 이용하여 인노빈을 약 10 nM의 TF243으로 재구성하였다. 다음, 동일한 부피의 0.2 nM의 FVIIa를 0.2 nM의 인노빈과 혼합함으로써 0.1 nM TF/VIIa 복합체를 만들었다. 인노빈은 매우 강력한 FX 활성화 활성을 실증한 한편, TF219 및 TF219-함유 다중-사슬 키메라 폴리펩타이드는 매우 낮은 FX 활성화 활성을 가졌고, 이는 TF219가 생체내에서 천연 기질 FX를 활성화시키기 위한 TF/FVIIa 복합체에서 활성이지 않음을 확인시켜 준다.
프로트롬빈 시간 시험
혈액 응고를 측정하기 위한 제3 검정법은 혈액 응고 활성을 측정하는 프로트롬빈 시간(PT) 시험이다. 본원에서, 상업적으로 입수 가능한 정상 인간 혈장(Ci-Trol 응고 대조군, 수준 I)을 사용하여 PT 시험을 수행하였다. 표준 PT 시험을 위해, 칼슘의 존재 하에, 지질화된 재조합 인간 TF243인 인노빈의 첨가에 의해 응고 반응을 개시하였다. STart PT 분석기(Diagnostica Stago, Parsippany, N.J.)에 의해 응고 시간을 모니터링하고 기록하였다. 0.2 mL의, PT 검정법 완충액(50 mM Tris-HCl, pH 7.5, 14.6 mM CaCl2, 0.1% BSA)에 희석된 인노빈의 다양한 희석물을, 37℃에서 예열된 0.1 mL의 정상 인간 혈장을 함유하는 큐벳 내로 주사함으로써 PT 검정법을 시작하였다. PT 검정법에서, 더 짧은 PT 시간(응고 시간)은 더 높은 TF-의존적 응고 활성을 나타내는 한편, 더 긴 PT(응고 시간)는 더 낮은 TF-의존적 응고 활성을 의미한다.
도 184에 도시된 바와 같이, PT 검정법에의 상이한 양의 인노빈(예를 들어, 10 nM의 지질화된 재조합 인간 TF243과 동등한 정제수로 재구성된 인노빈은 100% 인노빈인 것으로 간주되었음)의 첨가는 용량-반응 관계를 실증하였으며, 이때, 더 낮은 농도의 TF243은 더 긴 PT 시간(더 낮은 응고 활성)을 초래하였다. 예를 들어, 0.001% 인노빈은 110초보다 더 긴 PT 시간을 가졌으며, 이는 완충액 단독과 거의 동일하였다.
또 다른 실험에서, TF219, 및 18t15-12s, 7t15-21s, 21t15-TGFRs-WT, 및 21t15-TGFRs-Mut를 포함하는 다중-사슬 키메라 폴리펩타이드 상에서 PT 시험을 수행하였다. 도 185는, TF219 및 TF219-함유 다중-사슬 키메라 폴리펩타이드(100 nM의 농도에서)가 연장된 PT 시간을 가졌으며, 이는 매우 낮은 응고 활성을 나타내거나 응고 활성이 없음을 나타낸다.
연구를 또한 수행하여, 다중-사슬 키메라 폴리펩타이드(32Dβ 또는 인간 PBMC)의 사이토카인 구성요소에 대한 수용체를 갖는 다른 세포의 존재 하에 다중-사슬 키메라 폴리펩타이드를 인큐베이션하는 것이 PT 검정법에서 응고 시간에 영향을 미칠 것인지의 여부를 평가하였다. IL-15 수용체를 발현하는 세포(32Dβ 세포) 또는 IL-15 및 IL-21 수용체를 발현하는 세포(PBMC)가 IL-15-함유 다중-사슬 키메라 폴리펩타이드에 결합하여 세포성 FVIIa 수용체로서 천연 TF를 모방할 것인지의 여부를 검사하기 위해, TF219-함유 다중-사슬 키메라 폴리펩타이드(각각의 분자에 대해 100 nM의 농도)를 PT 검정법 완충액에 희석하고, 32Dβ 세포(2 x 105 세포/mL) 또는 PBMC(1 x 105 세포/mL)와 함께 실온에서 20분 내지 30분 동안 예비인큐베이션하였다. 그 후에, PT 검정법을 상기 기재된 바와 같이 수행하였다. 도 186 및 도 187은, 100 nM의 최종 농도에서 32Dβ 세포(도 186) 또는 PBMC(도 187)와 혼합된 TF219 및 TF219-함유 다중-사슬 키메라 폴리펩타이드가 0.001% 내지 0.01% 인노빈(0.1 pM 내지 1.0 pM의 TF243과 동등함)과 유사하게 PT 시간을 연장시켰음을 도시한다. 상대 TF243 활성의 백분율로서 표현하면, TF219-함유 다중-사슬 키메라 폴리펩타이드는 인노빈과 비교할 때 100,000배 내지 1,000,000배 더 낮은 TF 의존적 응고 활성을 가졌다. 이는, 심지어 분자가 무손상 세포막 표면, 예컨대 32Dβ 또는 PBMC에 결합된 한편, TF219-함유 다중-사슬 키메라 폴리펩타이드가 매우 낮은 TF-의존적 응고 활성을 갖거나 TF-의존적 응고 활성을 갖지 않았음을 실증하였다.
실시예 72: 7t15-21s137L(롱 버전)의 특징화
7t15 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다(SEQ ID NO: 210):
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 IL7)
GATTGCGACATCGAGGGCAAGGACGGCAAGCAGTACGAGAGCGTGCTGATGGTGTCCATCGACCAGCTGCTGGACAGCATGAAGGAGATCGGCTCCAACTGCCTCAACAACGAGTTCAACTTCTTCAAGCGGCACATCTGCGACGCCAACAAGGAGGGCATGTTCCTGTTCAGGGCCGCCAGGAAACTGCGGCAGTTCCTGAAGATGAACTCCACCGGCGACTTCGACCTGCACCTGCTGAAGGTGTCCGAGGGCACCACCATCCTGCTGAACTGCACCGGACAGGTGAAGGGCCGGAAACCTGCTGCTCTGGGAGAGGCCCAACCCACCAAGAGCCTGGAGGAGAACAAGTCCCTGAAGGAGCAGAAGAAGCTGAACGACCTGTGCTTCCTGAAGAGGCTGCTGCAGGAGATCAAGACCTGCTGGAACAAGATCCTGATGGGCACCAAGGAGCAT
(인간 조직 인자 219)
AGCGGCACAACCAACACAGTCGCTGCCTATAACCTCACTTGGAAGAGCACCAACTTCAAAACCATCCTCGAATGGGAACCCAAACCCGTTAACCAAGTTTACACCGTGCAGATCAGCACCAAGTCCGGCGACTGGAAGTCCAAATGTTTCTATACCACCGACACCGAGTGCGATCTCACCGATGAGATCGTGAAAGATGTGAAACAGACCTACCTCGCCCGGGTGTTTAGCTACCCCGCCGGCAATGTGGAGAGCACTGGTTCCGCTGGCGAGCCTTTATACGAGAACAGCCCCGAATTTACCCCTTACCTCGAGACCAATTTAGGACAGCCCACCATCCAAAGCTTTGAGCAAGTTGGCACAAAGGTGAATGTGACAGTGGAGGACGAGCGGACTTTAGTGCGGCGGAACAACACCTTTCTCAGCCTCCGGGATGTGTTCGGCAAAGATTTAATCTACACACTGTATTACTGGAAGTCCTCTTCCTCCGGCAAGAAGACAGCTAAAACCAACACAAACGAGTTTTTAATCGACGTGGATAAAGGCGAAAACTACTGTTTCAGCGTGCAAGCTGTGATCCCCTCCCGGACCGTGAATAGGAAAAGCACCGATAGCCCCGTTGAGTGCATGGGCCAAGAAAAGGGCGAGTTCCGGGAG
(인간 IL-15)
AACTGGGTGAACGTCATCAGCGATTTAAAGAAGATCGAAGATTTAATTCAGTCCATGCATATCGACGCCACTTTATACACAGAATCCGACGTGCACCCCTCTTGTAAGGTGACCGCCATGAAATGTTTTTTACTGGAGCTGCAAGTTATCTCTTTAGAGAGCGGAGACGCTAGCATCCACGACACCGTGGAGAATTTAATCATTTTAGCCAATAACTCTTTATCCAGCAACGGCAACGTGACAGAGTCCGGCTGCAAGGAGTGCGAAGAGCTGGAGGAGAAGAACATCAAGGAGTTTCTGCAATCCTTTGTGCACATTGTCCAGATGTTCATCAATACCTCC
7t15 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다(SEQ ID NO: 209):
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL7)
DCDIEGKDGKQYESVLMVSIDQLLDSMKEIGSNCLNNEFNFFKRHICDANKEGMFLFRAARKLRQFLKMNSTGDFDLHLLKVSEGTTILLNCTGQVKGRKPAALGEAQPTKSLEENKSLKEQKKLNDLCFLKRLLQEIKTCWNKILMGTKEH
(인간 조직 인자 219)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(인간 IL-15)
NWVNVISDLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
21s137L 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다(SEQ ID NO: 331):
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(인간 IL-21)
CAGGGCCAGGACAGGCACATGATCCGGATGAGGCAGCTCATCGACATCGTCGACCAGCTGAAGAACTACGTGAACGACCTGGTGCCCGAGTTTCTGCCTGCCCCCGAGGACGTGGAGACCAACTGCGAGTGGTCCGCCTTCTCCTGCTTTCAGAAGGCCCAGCTGAAGTCCGCCAACACCGGCAACAACGAGCGGATCATCAACGTGAGCATCAAGAAGCTGAAGCGGAAGCCTCCCTCCACAAACGCCGGCAGGAGGCAGAAGCACAGGCTGACCTGCCCCAGCTGTGACTCCTACGAGAAGAAGCCCCCCAAGGAGTTCCTGGAGAGGTTCAAGTCCCTGCTGCAGAAGATGATCCATCAGCACCTGTCCTCCAGGACCCACGGCTCCGAGGACTCC
(인간 IL-15R α sushi 도메인)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
((G4S)3 링커)
GGCGGTGGAGGATCCGGAGGAGGTGGCTCCGGCGGCGGAGGATCT
(인간 CD137L)
CGCGAGGGTCCCGAGCTTTCGCCCGACGATCCCGCCGGCCTCTTGGACCTGCGGCAGGGCATGTTTGCGCAGCTGGTGGCCCAAAATGTTCTGCTGATCGATGGGCCCCTGAGCTGGTACAGTGACCCAGGCCTGGCAGGCGTGTCCCTGACGGGGGGCCTGAGCTACAAAGAGGACACGAAGGAGCTGGTGGTGGCCAAGGCTGGAGTCTACTATGTCTTCTTTCAACTAGAGCTGCGGCGCGTGGTGGCCGGCGAGGGCTCAGGCTCCGTTTCACTTGCGCTGCACCTGCAGCCACTGCGCTCTGCTGCTGGGGCCGCCGCCCTGGCTTTGACCGTGGACCTGCCACCCGCCTCCTCCGAGGCTCGGAACTCGGCCTTCGGTTTCCAGGGCCGCTTGCTGCACCTGAGTGCCGGCCAGCGCCTGGGCGTCCATCTTCACACTGAGGCCAGGGCACGCCATGCCTGGCAGCTTACCCAGGGCGCCACAGTCTTGGGACTCTTCCGGGTGACCCCCGAAATCCCAGCCGGACTCCCTTCACCGAGGTCGGAA
21s137L 융합 단백질의 아미노산 서열(리더 서열 포함)은 하기와 같다(SEQ ID NO: 332):
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(인간 IL-21)
QGQDRHMIRMRQLIDIVDQLKNYVNDLVPEFLPAPEDVETNCEWSAFSCFQKAQLKSANTGNNERIINVSIKKLKRKPPSTNAGRRQKHRLTCPSCDSYEKKPPKEFLERFKSLLQKMIHQHLSSRTHGSEDS
(인간 IL-15R α sushi 도메인)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
((G4S)3 링커)
GGGGSGGGGSGGGGS
(인간 CD137L)
REGPELSPDDPAGLLDLRQGMFAQLVAQNVLLIDGPLSWYSDPGLAGVSLTGGLSYKEDTKELVVAKAGVYYVFFQLELRRVVAGEGSGSVSLALHLQPLRSAAGAAALALTVDLPPASSEARNSAFGFQGRLLHLSAGQRLGVHLHTEARARHAWQLTQGATVLGLFRVTPEIPAGLPSPRSE
하기 실험을 수행하여, 7t15-21s137L 내 CD137L 부분이 무손상이어서 CD137(4.1BB)에 결합하였는지의 여부를 평가하였다. 제1일에, 96-웰 플레이트를 100 μL(2.5 μg/mL)의, R5(코팅 완충액) 중 GAH IgG Fc(G-102-C, R&D Systems)로 밤새 코팅시켰다. 제2일에, 상기 플레이트를 3회 세척하고, 300 μL의, PBS 중 1% BSA로 37℃에서 2시간 동안 블라킹시켰다. 10 ng/mL의 4.1BB/Fc(838-4B, R&D Systems)를 실온에서 2시간 동안 100 μl/웰로 첨가하였다. 3회 세척 후, 7t15-21s137L(롱 버전) 또는 7t15-21s137Ls(쇼트 버전)를 1/3 희석으로 10 nM에서 출발하여 첨가하거나 재조합 인간 4.1BBL을 180 ng/mL에서 출발하여 첨가하고, 뒤이어 4℃에서 밤새 인큐베이션하였다. 제3일에, 플레이트를 3회 세척하고, 500 ng/mL의 비오틴화된-염소 항-인간 4.1BBL(BAF2295, R&D Systems)을 웰당 100 μL로 적용하고, 뒤이어 RT에서 2시간 동안 인큐베이션하였다. 플레이트를 3회 세척하고, 0.25 μg/mL의 HRP-SA(Jackson ImmuneResearch)와 함께 웰당 100 μL에서 30분 동안 인큐베이션하였다. 그 후에, 플레이트를 3회 세척하고, 100 μL의 ABTS와 함께 RT에서 2분 동안 인큐베이션하였다. 그 결과를 405 nm에서 판독하였다. 도 188에 도시된 바와 같이, 7t15-21s137L(롱 버전)과 7t15-21s137L(쇼트 버전) 둘 다 재조합 인간 4.1BB 리간드(rhCD137L, 연회색 별표)와 비교하여 4.1BB/Fc(진한 다이아몬드 및 회색 정사각형)와 상호작용할 수 있었다. 7t15-21s137L(롱 버전)(진한 다이아몬드)은 7t15-21s137L(쇼트 버전)(회색 정사각형)과 비교하여 4.1BB/Fc와 더 양호하게 상호작용하였다.
하기 실험을 수행하여, 7t15-21s137L(롱 버전)에서 구성요소 IL7, IL21, IL15, 및 4.1BBL이 ELISA를 사용한 개별 항체에 의해 검출되기에 무손상이었는지의 여부를 평가하였다. 96-웰 플레이트를 R5(코팅 완충액) 중 100 μL(4 μg/mL)의 항-TF(인간 IgG1)로 코팅시키고, RT에서 2시간 동안 인큐베이션하였다. 상기 플레이트를 3회 세척하고, 100 μL의, PBS 중 1% BSA로 블라킹시켰다. 정제된 7t15-21s137L(롱 버전)을 10 nM에서 출발하여 첨가하고, 1/3 희석에서, 뒤이어 RT에서 60분 동안 인큐베이션하였다. 플레이트를 3회 세척하고, 500 ng/mL의 비오틴화된-항-IL7(506602, R&D Systems), 500 ng/mL의 비오틴화된-항-IL21(13-7218-81, R&D Systems), 50 ng/mL의 비오틴화된-항-IL15(BAM247, R&D Systems), 또는 500 ng/ml의 비오틴화된-염소 항-인간 4.1BBL(BAF2295, R&D Systems)을 웰당 첨가하고, 실온에서 60분 동안 인큐베이션하였다. 플레이트를 3회 세척하고, 0.25 μg/mL의 HRP-SA(Jackson ImmunoResearch)와 함께 웰당 100 μL에서 RT에서 30분 동안 인큐베이션하였다. 그 후에, 플레이트를 4회 세척하고, 100 μL의 ABTS와 함께 실온에서 2분 동안 인큐베이션하였다. 흡광도 결과를 405 nm에서 판독하였다. 도 189a 내지 도 189d에 도시된 바와 같이, 7t15-21s137L(롱 버전)에서 IL7, IL21, IL15, 및 4.1BBL을 포함한 구성요소를 개별 항체에 의해 검출하였다.
하기 실험을 수행하여, 7t15-21s137L(롱 버전) 및 7t15-21s137L(쇼트 버전)에서 IL15의 활성을 평가하였다. 7t15-21s137L(롱 버전) 및 7t15-21s137L(쇼트 버전)이 IL2Rαβγ-발현 CTLL2 세포의 증식을 촉진하는 능력을 재조합 IL15의 능력과 비교하였다. IL15 의존적 CTLL2 세포를 IMDM-10% FBS로 5회 세척하고, 웰에 2 x 104 세포/웰로 접종하였다. 단계 희석된 7t15-21s137L(롱 버전), 7t15-21s137L(쇼트 버전), 또는 IL15를 세포에 첨가하였다. 세포를 CO2 인큐베이터에서 37℃에서 3일 동안 인큐베이션하였다. 제3일에 20 μL의 PrestoBlue(A13261, ThermoFisher)를 각각의 웰에 첨가하고 CO2 인큐베이터에서 37℃에서 추가 4시간 동안 인큐베이션함으로써 세포 증식을 검출하였다. 마이크로-역가 플레이트 판독기에서 570 nm 내지 610 nm에서의 원(raw) 흡광도를 판독하였다. 도 190에 도시된 바와 같이, 7t15-21s137L(롱 버전), 7t15-21s137L(쇼트 버전) 및 IL15은 모두 CTLL2 세포 증식을 촉진하였다. 7t15-21s137L(롱 버전), 7t15-21s137L(쇼트 버전), 및 IL15의 EC50은 각각 51.19 pM, 55.75 pM, 및 4.947 pM이다.
실시예 73: 2t2에 의한 Treg 세포의 유도
건강한 공여자(공여자 163)의 말초 혈액 단핵 세포(PBMC)를 Ficoll Paque Plus(GE17144003)에 의해 5 mL의 전혈 연막으로부터 단리하였다. 그 후에, PBMC를 ACK로 용해시켜, 적혈구를 제거하였다. 세포를 IMDM-10% FBS로 세척하고, 카운팅하였다. 1.8 x106 세포(100 μL/튜브)를 유동 튜브에 접종하고, 50 μL의 디센딩(descending) 2t2 또는 IL2(15000, 1500, 150, 15, 1.5, 0.15, 또는 0 pM) 및 50 μL의 예비-염색 항체(항-CD8-BV605 및 항-CD127-AF647)와 함께 인큐베이션하였다. 세포를 37℃에서 수조에서 30분 동안 인큐베이션하였다. 200 μL의 예열된 BD Phosflow Fix 완충액 I(Cat# 557870, Becton Dickinson Biosciences)을 37℃에서 수조에서 10분 동안 첨가하여, 자극을 중단시켰다. 세포(4.5 x105 세포/100 μL)를 V-모양 96-웰 플레이트로 이전시키며, 회전시키고, 뒤이어 100 μL의, -20℃의 예비냉각된 BD Phosflow Perm 완충액 III(Cat# BD Biosciences)을 얼음 상에서 30분 동안 이용하여 투과시켰다. 그 후에, 세포를 200 μL의 FACS 완충액으로 2회 광범위하게 세척하고, 형광 항체 패널(항-CD25-PE, CD4-PerCP-Cy5.5, CD56-BV421, CD45RA-PE-Cy7 및 pSTAT5a-AF488)로 염색하여, 상이한 림프구 서브집단들 사이를 구별하고 pSTAT5a 상태를 평가하였다. 세포를 FACSCelesta 분석을 위해 200 μL의 FACS 완충액에 재현탁시켰다. 도 191a에 도시된 바와 같이, 6 pM의 2t2는 CD4+CD25hi Treg 세포에서 Stat5a의 인산화를 유도하기에 충분한 한편, 43.11 pM의 IL-2를 동일한 림프구 집단에서 Stat5a의 인산화를 유도하는 데 필요하였다. 대조적으로, 2t2는 CD4+CD25-Tcon 및 CD8+Tcon 세포에서 Stat5a의 인산화를 유도하는 데 있어서 IL2와 비교하여 덜 활성이었거나(도 191b) 동등하게 활성이었다(도 191c). 이들 결과는, 인간 PBMC에서 Treg를 증가시키는 데 있어서 IL2와 비교하여 2t2는 우수하고, 2t2는 인간 혈액 림프구 pStat5a 반응에서 IL-2와 비교하여 증가된 Treg 선택성을 실증한다.
실시예 74. 단일-사슬 키메라 폴리펩타이드를 사용한 모발 성장의 향상
7주령 C57BL6/J 마우스의 등쪽 모발을 면도하고, 상업적인 제모 크림을 사용하여 제모하였다. 마우스를 동일한 일자에 단회 용량의 2t2 또는 저용량의 상업적으로 입수 가능한 재조합 IL-2로 피하 주사하고, 뒤이어 4 추가일 동안 매일 투약하였다. 비치료된 마우스는 대조군으로서 역할을 하였다. 10일차에, 마우스를 희생시키고, 제모된 영역의 피부 구획을 준비하였다. 제모 후 10일차에 C57BL6J 마우스로부터의 피부 절편의 대표적인 H&E 염색을 도 192a 내지 도 192e에 도시한다. 도 192a는 대조군 마우스 - 털이 면도된 후 수행된 제모 단독을 도시하며, 도 192b는 제모에 뒤이어 저용량의 IL-2(1 mg/kg) 투여가 이어진 마우스를 도시하고, 도 192c 내지 도 192e는 제모에 뒤이어 0.3 mg/kg(도 192c), 1 mg/kg(도 192d), 및 3 mg/kg(도 192e)에서의 2t2 투여가 이어진 마우스를 도시한다. 검정색 화살표는 이후에 피부 내로 연장되고 모발 성장을 용이하게 할 생장기 모낭을 나타낸다. 도 194는 각각의 치료군에 대해 10개 필드당 카운팅된 생장기 모낭의 총 수를 도시한다. 요약하자면, 데이터는 2t2 분자가 탈모 단독과 비교하여 증가된 수의 생장기 모낭을 초래하였음을 보여준다. 이러한 효과는 또한 용량-의존적이었다.
실시예 75: 면역 세포로부터 기억-유사 면역 세포로의 분화
새로운 인간 백혈구를 혈액 은행으로부터 수득하였고, CD56+ NK 세포를 RosetteSep/인간 NK 세포 시약(StemCell Technologies)으로 단리시켰다. NK 세포의 순도는 >70%였고, CD56-BV421, CD16-BV510, CD25-PE, CD69-APCFire750(BioLegend)으로 염색함으로써 확인되었다. 세포를 카운팅하고, 2 mM L-글루타민(Thermo Life Technologies), 항생제(페니실린, 10,000 단위/mL; 스트렙토마이신, 10,000 μg/mL; Thermo Life Technologies) 및 10% FBS(Hyclone)가 보충된 RPMI 1640 배지(Gibco)에 2 x 106 세포/mL의 밀도로 재현탁하였다. 세포(1 mL)를 24-웰 편평 바닥 플레이트 내로 전달하고, 하기 중 어느 하나를 받게 하였다: 비처리, 또는 배지와 함께 14일 동안 7t15-21s + 항-조직 인자(TF)-항체(IgG1)(50 nM)로 확장됨. 세포를 신선한 7t15-21s + 항-TF-항체(IgG1)(50 nM)로 보충하여, 세포 밀도를 대략 1 x 106 세포/mL로 유지시켰다.
치료군에 대한 비확장된 NK 세포를 완전 DNA 메틸화 수준에 대한 양성 대조군으로서 사용하였다(데이터는 제시되지 않음). NK 세포를 펠렛화하고(1 x 106), 게놈 DNA(nDNA)를 QIAamp UCP DNA Micro Kit(Qiagen)를 사용하여 단리하였다. 500 ng의 정제된 nDNA를 EZ DNA Methylation-Direct 키트(Zymo Research)를 제조업체의 프로토콜에 따라 사용하여 소듐 비설파이트 처리를 받게 하였다. 비설파이트 처리는 DNA에서 메틸화-의존적 변화를 도입하고, 탈메틸화된 시토신은 우라실로 전환되는 반면, 메틸화된 시토신은 변하지 않은 채로 남아 있다. 비설파이트(bisulfite)-치료 nDNA(10 ng 내지 50 ng)를 주형으로서 사용하여, 포워드 프라이머 IFNG127F(5'-ATGGTATAGGTGGGTATAATGG-3') 및 비오틴화된 리버스 프라이머 IFNG355R-bio(비오틴-5'-CAATATACTACACCTCCTCTAACTAC-3')(GENEWIZ)와 함께 Pyromark PCR 키트(Qiagen)를 사용하여 T 세포에서의 DNA 메틸화에 의해 과도하게 조절되는 것으로 알려진 2개의 CpG 부위(전사 시작 부위, TSS에 비해 CpG -186 및 CpG-54 위치)를 함유하는 IFNγ 프로모터의 228 bp 영역을 PCR 증폭시켰다. PCR 조건은 95°C에서 15분, 95°C에서 30초, 56°C에서 30초, 72°C에서 60초의 48 주기, 뒤이어 72°C에서 10분이었다. PCR 증폭된 생성물의 무결성 및 품질을 1.2% TAE 아가로스 겔 상에서 시각화하였다. 이들 2개 CpG 부위의 DNA 메틸화 상태를 피로시퀀싱에 의해 결정하였고, 이는 단일 CpG-부위에서 DNA 메틸화를 정량적으로 측정하기 위한 골드 표준 기법이다. 피로시퀀싱 반응을 CpG 부위 -186 및 -54에 각각 특이적인 DNA 시퀀싱 프라이머 C186-IFNG135F(5'-GGTGGGTATAATGGG-3')(SEQ ID NO: 333) 및 C54-IFNG261F(5'-ATTATTTTATTTTAAAAAATTTGTG-3')(SEQ ID NO: 334)를 사용하여 Johns Hopkins University Genetic Resources Core Facility에서 수행하였다. 상업적으로 입수 가능한 비-메틸화된 DNA 및 메틸화된 DNA(Zymo Research)를 DNA 메틸화에 대한 대조군으로서 사용하였다. 2개 CpG 부위(-186 및 -54)의 메틸화 백분율을 각각의 치료에 대해 풀링하였다. DNA 메틸화에서의 차이 백분율을 비노출된 NK 세포에서 관찰된 2개의 CpG 부위에서 DNA 메틸화 수준에 비해 계산하였다.
이들 2개의 IFNγ CpG 부위의 DNA 메틸화 상태의 분석은 비노출된 NK 세포와 비교하여 7t15-21s + 항-TF-항체에 의해 지지되는 NK 세포에서 더 높은 수준의 DNA 탈메틸화를 드러내었다(도 194). 이들 7t15-21s + 항-TF-항체는 NK 세포가 비노출된 NK 세포와 비교하여 DNA 메틸화(즉, 탈메틸화)에서 47.70% ± 11.76 차이를 나타내었음을 지지하였다. 이들 2개의 IFNγ CpG 부위의 DNA 메틸화 수준은 7t15-21s + 항-TF-항체를 이용한 처리 후 IFNγ의 증가된 발현과 상관관계가 있었다. 이들 데이터는, 7t15-21s + 항-TF-항체의 병용 계획을 이용한 NK 세포의 장기간 노출(배양물에서의 14일 확장)이 2개의 저메틸화된 IFNγ CpG 부위(-186 및 -54)의 DNA 탈메틸화를 유도할 수 있고, 7t15-21s + 항-TF-항체(IgG1)가 CpG 부위의 DNA 탈메틸화를 통해 IFNγ의 유전자 발현을 후생적으로 재프로그래밍하여 NK 세포로부터 내재성 면역 기억 NK 세포로의 상호전환을 유발할 수 있음을 시사한다.
실시예 76: 화학요법은 C57BL/6 마우스에서 p21
CIP1
p21 노쇠-관련 유전자 발현을 유도한다
화학요법은 C57BL/6 마우스에서 p21CIP1p21 노쇠-관련 유전자 발현을 유도한다. 도 203a는 치료 계획을 도시하는 개략도이다. C57BL/6 마우스를 제1일, 제4일, 및 제7일에 3개 용량의 화학요법 도세탁셀(DTX)(10 mg/kg)로 치료하였다. 9일차에 마우스를 희생시키고, 폐 및 간 조직을 수합하여 노쇠 마커를 평가하였다. 도 203b 및 도 203c는 폐(b) 및 간(c) 조직 각각에서 p21CIP1p21의 발현을 도시한다. 폐 및 간 조직을 막자 및 사발을 사용하여 액체 질소에서 균질화하였다. 균질화된 조직을, 1 mL의 트리졸(Thermo Fischer)을 함유하는 신선한 Eppendorf 튜브에 옮겼다. RNeasy Mini 키트(Qiagen #74106)를 제조업체의 설명서에 따라 사용하여 총 RNA를 추출하였다. QuantiTect 역전사 키트(Qiagen)를 사용하는 cDNA 합성에 1 μg의 총 RNA를 사용하였다. Thermo Scientific으로부터 구매된 FAM-표지 예비설계된 프라이머 p21CIP1p21을 사용하여 CFX96 검출 시스템(Bio-Rad)으로 실시간 PCR을 수행하였다. 반응을 검사된 모든 유전자에 대해 3벌로 진행시켰다. 하우스킵핑 유전자 18S 리보솜 RNA를 내부 대조군으로서 사용하여, 발현 수준에서의 가변성을 정규화하였다. 18S rRNA와 비교하여 각각의 표적 mRNA의 발현을 Ct에 기초하여 2-Δ(ΔCt)로서 계산하였으며, 여기서, ΔCt = Ct표적 - Ct18S이다.
도 203a 내지 도 203c에 도시된 바와 같이, 노쇠 마커 p21CIP1p21을 도세탁셀로 치료된 마우스의 폐 및 간 조직에서 유도하였다.
실시예 77: IL-15-기초 제제를 이용한 치료 후(치료 후 3일차) 면역-표현형 및 세포 증식
마우스 혈액을 준비하여, TGFRt15-TGFRs를 이용한 치료 후 면역 세포의 상이한 하위세트를 평가하였다. C57BL/6, 6주령 마우스를 The Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 사육시켰다. 마우스를 하기와 같이 군으로 나누었다: 식염수 대조군(n =6), 도세탁셀군(n =6), TGFRt15-TGFRs와 함께 도세탁셀군(n =6) 및 IL-15SA와 함께 도세탁셀군(n =6). IL-15 슈퍼작용제(IL-15SA)를 이전에 기재된 바와 같이 작제하고 투여하였다(문헌[Zhu et al., J. Immunol. 183(6):3598-3607, 2009]). 1일차, 4일차 및 7일차에 마우스에서 3개 용량의 도세탁셀(10 mg/kg)로 노쇠를 유도하였다. 8일차에, 마우스를 PBS로 또는 TGFRt15-TGFRs(3 mg/kg) 또는 IL-15SA(0.2 mg/kg)로 피하 치료하였다. 치료 후 3일차에 하악하 정맥으로부터 마우스 혈액을 EDTA 함유 튜브에 채혈하였다. 전혈을 원심분리하여, 혈장을 마이크로 원심분리기에서 3000 RPM에서 10분 동안 수집하였다. 혈장을 -80°C에 저장하고, 유세포측정법에 의한 면역 세포 표현형 분석을 위해 전혈을 가공하였다. 전혈을 ACK 완충액에서 실온에서 5분 동안 용해시켰다. 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다. 혈액 내 상이한 유형의 면역 세포를 평가하기 위해, 세포를 세포-표면 CD4, CD45, CD8 및 NK1.1(BioLegend)에 대해 RT에서 30분 동안 염색하였다. 표면 염색 후, 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다(실온에서 1500 RPM에서 5분 동안). 고정 후, 세포를 세척하고, 4°C에서 20분 동안 투과 용액(Invitrogen)으로 처리하고, 뒤이어 Perm 완충액(Invitrogen)으로 세척하였다. 그 후에, 세포를 세포내 마커(Ki67) 및 FoxP3에 대해 실온에서 30분 동안 염색하였다. 2회의 세척 후, 세포를 고정 완충액에 재현탁시키고, 유세포측정법(Celesta-BD Bioscience)에 의해 분석하였다. 이들 데이터는 IL-15-기초 제제 TGFRt15-TGFRs 및 IL-15SA가 도세탁셀 처리 후 NK 및 CD8+ T 세포의 확장 및 증식을 자극시키고 촉진할 수 있음을 보여준다(도 204).
실시예 78: TGFRt15-TGFRs 치료는 C57BL/6 마우스에서 노쇠-관련 유전자 발현을 감소시킨다
화학요법 유도 노쇠-관련 유전자 발현은 C57BL/6 마우스의 폐 및 간에서 TGFRt15-TGFRs에 의해 유의하게 감소되었다. C57BL/6 마우스를 제1일, 제4일, 및 제7일에 3개 용량의 화학요법 도세탁셀(10 mg/kg)로 치료하였다. 8일차에, 도세탁셀 치료 마우스를 3개 군으로 나누었다. 제1 군은 치료를 받지 않았고, 제2 군은 TGFRt15-TGFRs를 받았고, 제3 군은 IL-15SA를 받았다. 식염수 치료된 마우스를 대조군으로서 사용하였다. TGFRt15-TGFRs를 3 mg/kg의 투여량으로 투여하고, IL-15SA를 0.2 mg/kg의 투여량으로 투여하였다. 시험약 치료 후 3일차에, 마우스를 희생시키고, 폐 및 간 조직을 수집하였다. 도 205a 내지 도 205c는 폐에서의 p21CIP1p21과 CD26(a와 b) 및 간(c) 조직에서의 p21CIP1p21의 발현을 도시한다. 폐 및 간 조직을 막자 및 사발을 사용하여 액체 질소에서 균질화하였다. 균질화된 조직을, 1 mL의 트리졸(Thermo Fischer)을 함유하는 신선한 Eppendorf 튜브에 옮겼다. RNeasy Mini 키트(Qiagen #74106)를 제조업체의 설명서에 따라 사용하여 총 RNA를 추출하였다. QuantiTect 역전사 키트(Qiagen)를 사용하는 cDNA 합성에 1 μg의 총 RNA를 사용하였다. Thermo Scientific으로부터 구매된 FAM-표지 예비설계된 프라이머 p21CIP1p21 및 CD26을 사용하여 CFX96 검출 시스템(Bio-Rad)으로 실시간 PCR을 수행하였다. 반응을 검사된 모든 유전자에 대해 3벌로 진행시켰다. 하우스킵핑 유전자 18S 리보솜 RNA를 내부 대조군으로서 사용하여, 발현 수준에서의 가변성을 정규화하였다. 18S rRNA와 비교하여 각각의 표적 mRNA의 발현을 Ct에 기초하여 2-Δ(ΔCt)로서 계산하였으며, 여기서, ΔCt = Ct표적 - Ct18S이다.
도 205a 내지 도 205c에 도시된 바와 같이, 요법-유도 노쇠 마커 p21CIP1p21은 TGFRt15-TGFRs로 치료된 마우스의 폐 및 간 조직에서 유의하게 감소되었다. 요법-유도 노쇠 마커 CD26 또한 TGFRt15-TGFRs로 치료된 마우스의 폐 조직에서 유의하게 감소되었다.
실시예 79: IL-15-기초 제제를 이용한 치료 후 면역-표현형
마우스 혈액을 준비하여, IL-15-기초 제제를 이용한 치료 후 면역 세포의 상이한 하위세트를 평가하였다: TGFRt15-TGFRs, IL-15 슈퍼작용제(IL-15SA) 및 IL-15 활성을 넉아웃시킨 D8N 돌연변이체와의 IL-15 융합(TGFRt15*-TGFRs). C57BL/6, 6주령 마우스를 The Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 사육시켰다. 마우스를 군(n =6/군)으로 나누고, 하기와 같이 치료하였다: 1) PBS(식염수) 대조군, 2) 도세탁셀, 3) 도세탁셀과 TGFRt15-TGFRs, 4) 도세탁셀과 IL-15SA, 5) 도세탁셀과 IL-15 돌연변이체(TGFRt15*-TGFRs) 및 6) 도세탁셀과 IL-15 슈퍼작용제(IL-15SA) + TGFRt15*-TGFRs. 1일차, 4일차 및 7일차에 마우스에서 3개 용량의 도세탁셀(10 mg/kg)로 노쇠를 유도하였다. 8일차에, 마우스를 위에서 논의된 바와 같이 PBS, TGFRt15-TGFRs, TGFRt15*-TGFRs, IL-15SA 또는 병용으로 피하 치료하였다. TGFRt15-TGFRs 및 TGFRt15*-TGFRs를 3 mg/kg의 투여량으로 투여하고, IL-15SA를 0.05 mg/kg의 투여량으로 투여하였다. 시험약 치료 후 3일차에 하악하 정맥으로부터 마우스 혈액을 EDTA 함유 튜브에 채혈하였다. 전혈을 원심분리하여, 혈장을 마이크로 원심분리기에서 3000 RPM에서 10분 동안 수집하였다. 혈장을 -80°C에 저장하고, 유세포측정법에 의한 면역 세포 표현형 분석을 위해 전혈을 가공하였다. 전혈을 ACK 완충액에서 37°C에서 5분 동안 용해시켰다. 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다. 혈액 내 상이한 유형의 면역 세포를 평가하기 위해, 세포를 세포-표면 CD4, CD45, CD19 CD8 및 NK1.1(BioLegend)에 대해 실온(RT)에서 30분 동안 염색하였다. 표면 염색 후, 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다(실온에서 1500 RPM에서 5분 동안). 고정 후, 세포를 세척하고, 4°C에서 20분 동안 투과 용액(Invitrogen)으로 처리하고, 뒤이어 Perm 완충액(Invitrogen)으로 세척하였다. 그 후에, 세포를 세포내 마커(Ki67)에 대해 RT에서 30분 동안 염색하였다. 2회의 세척 후, 세포를 고정 완충액에 재현탁시키고, 유세포측정법(Celesta-BD Bioscience)에 의해 분석하였다(도 206 및 도 207).
이들 데이터는 IL-15-기초 제제 TGFRt15-TGFRs 및 IL-15SA가 도세탁셀 처리 후 NK 및 CD8+ T 세포의 확장 및 증식을 자극시키고 촉진할 수 있음을 보여준다. 증가된 NK 및 CD8+ T 세포 확장 및 증식은 IL-15 활성이 결여된 융합 단백질(즉, TGFRt15*-TGFRs)에서는 관찰되지 않았다.
실시예 80: 폐 및 간 조직에서 노쇠 마커 p21
CIP1
p21 및 CD26의 평가
세포 노쇠에 대한 마커를 화학요법 및 연구 치료의 투여 후 정상 마우스의 조직에서 평가하였다. C57BL/6, 6주령 마우스를 The Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 사육시켰다. 마우스를 6개의 군으로 나누고, 하기와 같이 치료하였다: 1) PBS(식염수) 대조군(n =5), 2) 도세탁셀(n =8), 3) 도세탁셀과 TGFRt15-TGFRs(n =8), 4) 도세탁셀과 IL15SA(n =8), 5) 도세탁셀과 IL-15 돌연변이체(TGFRt15*-TGFRs)(n =8) 및 6) 도세탁셀과 IL-15 슈퍼작용제(IL-15SA) + TGFRt15*-TGFRs(n =6). 1일차, 4일차 및 7일차에 마우스에서 3개 용량의 도세탁셀(10 mg/kg)로 노쇠를 유도하였다. 8일차에, 마우스를 아래에서 논의된 바와 같이 PBS, TGFRt15-TGFRs, TGFRt15*-TGFRs, IL-15SA 또는 병용으로 피하 치료하였다. TGFRt15-TGFRs 및 TGFRt15*-TGFRs를 3 mg/kg의 투여량으로 투여하고, IL-15SA를 0.05 mg/kg의 투여량으로 투여하였다. 마우스 조직을 준비하여, 상이한 노쇠 마커를 평가하였다. 시험약 치료 후 7일차에 마우스를 안락사시키고, 간 및 폐 조직을 수합하고 1.7 mL Eppendorf 튜브에서 액체 질소에 저장하였다. 시료를 막자 및 사발을 사용하여 액체 질소에서 균질화하였다. 균질화된 조직을, 1 mL의 트리졸(Thermo Fischer)을 함유하는 신선한 Eppendorf 튜브에 옮겼다. RNeasy Mini Kit(Qiagen #74106)를 제조업체의 설명서에 따라 사용하여 총 RNA를 추출하고, QuantiTect 역전사 키트(Qiagen)를 사용하는 cDNA 합성에 1 μg의 총 RNA를 사용하였다. Thermo Scientific으로부터 구매된 FAM-표지 예비설계된 프라이머를 사용하여 CFX96 검출 시스템(Bio-Rad)으로 실시간 PCR을 수행하였다. 반응을 검사된 모든 유전자에 대해 3벌로 진행시켰다. 하우스킵핑 유전자 18S 리보솜 RNA를 내부 대조군으로서 사용하여, 발현 수준에서의 가변성을 정규화하였다. 18S rRNA와 비교하여 각각의 표적 mRNA의 발현을 Ct에 기초하여 2-Δ(ΔCt)로서 계산하였으며, 여기서, ΔCt = Ct표적 - Ct18S이다.
도 208a 내지 도 208c에 도시된 바와 같이, 노쇠 마커 p21 및 CD26은 도세탁셀로 치료된 마우스의 폐[각각 (a) 및 (b)]에서 유도되었고 p21CIP1p21은 간(c) 조직에서 유도되었다. 폐에서의 노쇠 마커 p21CIP1p21과 CD26 및 간에서의 p21CIP1p21은 TGFRt15-TGFRs, IL-15SA 및 IL-15SA와 TGFRt15*-TGFRs 돌연변이체의 조합으로 치료된 마우스에서 감소되었다. 그러나, TGFRt15*-TGFRs 돌연변이체 치료된 마우스 폐는 이들 조직에서 노쇠 마커를 제거하는 데 실패하였다. 이들 결과는, IL-15 활성이 TIS 노쇠 세포의 청소에 중요함을 보여준다.
실시예 81: TGFRt15-TGFRs를 이용한 치료 후 면역-표현형
마우스 혈액을 준비하여, TGFRt15-TGFRs를 이용한 치료 후 면역 세포의 상이한 하위세트를 평가하였다. C57BL/6, 76주령 마우스를 The Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 사육시켰다. 마우스를 하기와 같이 2개 군으로 나누었다: PBS 대조군(n =6) 및 TGFRt15-TGFRs 군(n =6). 상기 마우스를 0일차에 PBS 또는 3 mg/kg의 투약량에서 TGFRt15-TGFRs로 피하 치료하였다. 제1 용량의 시험 치료 후 4일차에, 하악하 정맥으로부터 마우스 혈액을 EDTA 함유 튜브에 채혈하였다. 전혈을 원심분리하여, 혈장을 마이크로 원심분리기에서 3000 RPM에서 10분 동안 수집하였다. 혈장을 -80°C에 저장하고, 유세포측정법에 의한 면역 세포 표현형 분석을 위해 혈액을 가공하였다. 전혈을 ACK 완충액에서 실온에서 5분 동안 용해시켰다. 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다. 혈액 내 상이한 유형의 면역 세포를 평가하기 위해, 세포를 세포-표면 CD4, CD45, CD19 CD8 및 NK1.1(BioLegend)에 대해 실온(RT)에서 30분 동안 염색하였다. 표면 염색 후, 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다(RT에서 1500 RPM에서 5분 동안). 고정 후, 세포를 세척하고, 4°C에서 20분 동안 투과 용액(Invitrogen)으로 처리하고, 뒤이어 Perm 완충액(Invitrogen)으로 세척하였다. 그 후에, 세포를 세포내 마커(Ki67)에 대해 RT에서 30분 동안 염색하였다. 2회의 세척 후, 세포를 고정 완충액에 재현탁시키고, 유세포측정법(Celesta-BD Bioscience)에 의해 분석하였다.
도 195에 도시된 바와 같이, Ki67에 의해 측정된 CD8+ T 세포의 백분율 및 CD8+ T 세포의 증식은 제1 용량의 TGFRt15-TGFRs 후 4일째에 유의하게 증가되었다. 본 발명자들은 또한 도 196에 도시된 바와 같이 NK 세포의 증가 및 NK 세포의 증식을 관찰하였다. 본 발명자들은 제1 용량의 TGFRt15-TGFRs 후에 CD19+ 세포에서 유의한 저하를 관찰하였다. 이들 결과는 피하 투여된 단일 용량의 TGFRt15-TGFRs가 CD8+ T 세포 및 NK 세포와 같은 면역 세포를 자극시켜, 노화 마우스의 혈액에서 증식할 있음을 실증한다.
실시예 82: TGFRt15-TGFRs는 간 및 폐 조직으로부터 노쇠-관련 β-Gal을 감소시킨다
마우스 간 및 폐를 준비하여, TGFRt15-TGFRs에 의한 치료 후 조직에서 노쇠-관련 β-gal을 평가하였다. C57BL/6, 76주령 마우스를 The Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 사육시켰다. 마우스를 하기와 같이 2개 군으로 나누었다: PBS 대조군(n =6) 및 TGFRt15-TGFRs 군(n =6). 상기 마우스를 0일차 및 10일차에 PBS 또는 3 mg/kg의 투약량에서 TGFRt15-TGFRs로 피하 치료하였다. 제2 용량의 연구 치료 후 7일차에, 마우스를 안락사시키고, 간 및 폐를 수합하고, 2% PBS를 함유하는 PBS에서 균질화시키고, 70-미크론 필터에서 여과하여, 단일 세포 현탁액을 수득하였다. 세포를 회전 침강시킨 다음, 14 mL 둥근 바닥 튜브에서 0.5 mg/mL 콜라게나제 IV 및 0.02 mg/mL DNAse를 함유하는 5 mL RPMI에 재현탁시켰다. 그 후에, 세포를 오비탈 진탕기 상에서 37°C에서 1시간 동안 진탕시켰다. 세포를 RPMI로 2회 세척하였다. 세포를 24웰 편평 바닥 플레이트에서 2 mL의 완전 배지(2 mM L-글루타민(Thermo Life Technologies), 페니실린(Thermo Life Technologies), 스트렙토마이신(Thermo Life Technologies), 및 10% FBS(Hyclone)가 보충된 RPMI 1640(Gibco))에서 2 x 106/mL에서 재현탁시키고, 37°C, 5% CO2에서 48시간 동안 배양하였다. 세포를 수합하고, 실온에서 1000 RPM에서 10분 동안 가온 완전 배지로 1회 세척하였다. 세포 펠렛을 튜브당 1.5 μL의 노쇠 염료를 함유하는 500 μL의 신선한 배지에 재현탁시켰다. 그 후에, 세포를 37°C, 5% CO2에서 1시간 내지 2시간 동안 추가로 인큐베이션하고, 500 μL 세척 완충액으로 2X 세척하였다. 세포 펠렛을 500 μL의 세척 완충액에서 세포를 재현탁시키고, 유세포측정법(Celesta-BD Bioscience)에 의해 즉시 분석하였다.
도 197에 도시된 바와 같이, 노쇠-관련 β-gal+ 세포의 백분율은 제2 용량의 TGFRt15-TGFRs 후 7일째에 저하되었다. 이들 결과는 TGFRt15-TGFRs가 노화 마우스의 조직에서 노쇠-관련 β-gal을 감소시킬 수 있음을 추가로 실증한다.
실시예 83: 신장, 피부, 간 및 폐 조직에서의 노쇠 마커 CD26, IL-1α, p16INK4 및 p21
CIP1
마우스 신장, 피부, 간 및 폐를 수합하여, TGFRt15-TGFRs 또는 PBS 대조군을 이용한 치료 후 조직에서의 정량적 PCR에 의해 노쇠 마커 CD26, IL-1α, p16 및 p21을 평가하였다. C57BL/6, 76주령 마우스를 The Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 1주일 동안 사육시킨 후, 임의의 연구를 수행하였다. 마우스를 하기와 같이 2개 군으로 나누었다: PBS 대조군(n =6) 및 TGFRt15-TGFRs 군(n =6). 상기 마우스를 0일차 및 10일차에 PBS 또는 3 mg/kg의 투약량에서 TGFRt15-TGFRs로 피하 치료하였다. 제2 용량의 연구 치료 후 7일차에, 마우스를 안락사시키고, 신장, 피부, 간 및 폐를 수합하고 1.7 mL Eppendorf 튜브에서 액체 질소에 저장하였다. 시료를 막자 및 사발을 사용하여 액체 질소에서 균질화하였다. 균질화된 조직을, 1 mL의 트리졸(Thermo Fischer)을 함유하는 신선한 Eppendorf 튜브에 옮겼다. RNeasy Mini Kit(Qiagen #74106)를 제조업체의 설명서에 따라 사용하여 총 RNA를 추출하고, QuantiTect 역전사 키트(Qiagen)를 사용하는 cDNA 합성에 1 μg의 총 RNA를 사용하였다. Thermo Scientific으로부터 구매된 FAM-표지 예비설계된 프라이머를 사용하여 CFX96 검출 시스템(Bio-Rad)으로 실시간 PCR을 수행하였다. 반응을 검사된 모든 유전자에 대해 3벌로 진행시켰다. 하우스킵핑 유전자 18S 리보솜 RNA를 내부 대조군으로서 사용하여, 발현 수준에서의 가변성을 정규화하였다. 18S rRNA와 비교하여 각각의 표적 mRNA의 발현을 Ct에 기초하여 2-Δ(ΔCt)로서 계산하였으며, 여기서, ΔCt = Ct표적 - Ct18S이다.
도 198 내지 도 201에 도시된 바와 같이, 노쇠 마커 CD26 및 IL-1α에서 어떠한 차이도 없었으나, p21CIP1은 TGFRt15-TGFRs-치료-마우스의 간(도 198), 폐(도 201) 및 피부(도 200)에서 저하된 발현을 보여주었다. 신장(도 199)에서, p21CIP1과 IL1α 마커는 둘 다 제2 용량의 TGFRt15-TGFRs 후 7일째에 노화 마우스에서 유의하게 저하되었다.
실시예 84: 조직학에 의한 신장 조직 상에서의 β-Gal 염색
마우스 신장을 준비하여, TGFRt15-TGFRs에 의한 치료 후 신장 조직에서 노쇠 마커 β-gal을 평가하였다. C57BL/6, 76주령 마우스를 The Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 사육시켰다. 마우스를 하기와 같이 2개 군으로 나누었다: PBS 대조군(n =6) 및 TGFRt15-TGFRs 군(n =6). 상기 마우스를 0일차 및 10일차에 PBS 또는 3 mg/kg의 투약량에서 TGFRt15-TGFRs로 피하 치료하였다. 제2 용량의 연구 치료 후 7일차에, 마우스를 안락사시키고, 신장을 수합하고, 신장 조직 중 절반을 OCT 화합물을 함유하는 조직-tek cyromolds에 포매시켰다. 조직-tek cyromolds 함유 조직을 액체 질소의 증기상에서 즉시 냉동시켰다. 시료를 추가로 가공하여 4 내지 8 um 두께의 크리오스타트(cryostat) 절편을 절단하고(Lecia Cm 1800 Cryostat), 슈퍼프로스트 플러스 슬라이드 상에 마운팅하였다. 절편을 갖는 슬라이드를 노쇠 b-갈락토시다제 염색 키트(Cell Signaling)를 위해 제조업체의 프로토콜에 따라 가공하였다. 조직 절편을 현미경 하에 관찰하였다.
도 202에 도시된 바와 같이, 저하된 수의 노쇠-관련 β-gal+ 세포는 대조군 마우스(n=3)와 비교하여 TGFRt15-TGFRs 치료 마우스에서 관찰되었다. 이들 결과는 TGFRt15-TGFRs 치료가 노화 마우스의 조직에서 노쇠-관련 β-gal을 감소시킬 수 있음을 추가로 실증한다.
실시예 85: TGFRt15*-TGFRs 융합 단백질 발생
TGFR/IL15RαSu 및 TGFR/TF/IL-15D8N 융합 단백질을 포함하는 융합 단백질 복합체를 생성시켰다(도 209 및 도 210). 인간 TGF-β 수용체(TGFR), IL-15 알파 수용체 sushi 도메인(IL15RaSu), 조직 인자(TF) 및 D8N 돌연변이체를 갖는 IL-15(IL15D8N) 서열을 GenBank 웹사이트로부터 수득하고, 이들 서열에 대한 DNA 단편을 Genewiz에 의해 합성하였다. 구체적으로, TGFR 서열을 IL15RaSu의 N-말단 코딩 영역에 연결하고 TGFR 서열을 조직 인자 219의 N-말단 코딩 영역에 연결하고, 뒤이어 IL-15D8N의 N-말단 코딩 영역에 연결하는 작제물을 만들었다.
TGFR/IL15RaSu 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGAAGTGGGTGACCTTCATCAGCCTGCTGTTCCTGTTCTCCAGCGCCTACTCC
(단일 사슬 인간 TGF-베타 수용체 II 동종이량체)
ATCCCCCCCCATGTGCAAAAGAGCGTGAACAACGATATGATCGTGACCGACAACAACGGCGCCGTGAAGTTTCCCCAGCTCTGCAAGTTCTGCGATGTCAGGTTCAGCACCTGCGATAATCAGAAGTCCTGCATGTCCAACTGCAGCATCACCTCCATCTGCGAGAAGCCCCAAGAAGTGTGCGTGGCCGTGTGGCGGAAAAATGACGAGAACATCACCCTGGAGACCGTGTGTCACGACCCCAAGCTCCCTTATCACGACTTCATTCTGGAGGACGCTGCCTCCCCCAAATGCATCATGAAGGAGAAGAAGAAGCCCGGAGAGACCTTCTTTATGTGTTCCTGTAGCAGCGACGAGTGTAACGACAACATCATCTTCAGCGAAGAGTACAACACCAGCAACCCTGATGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(IL15 수용체 알파 사슬의 Sushi 도메인)
ATTACATGCCCCCCTCCCATGAGCGTGGAGCACGCCGACATCTGGGTGAAGAGCTATAGCCTCTACAGCCGGGAGAGGTATATCTGTAACAGCGGCTTCAAGAGGAAGGCCGGCACCAGCAGCCTCACCGAGTGCGTGCTGAATAAGGCTACCAACGTGGCTCACTGGACAACACCCTCTTTAAAGTGCATCCGG
TGFR/TF/IL15D8N 작제물의 핵산 서열(신호 펩타이드 서열 포함)은 하기와 같다:
(신호 펩타이드)
ATGGGAGTGAAAGTTCTTTTTGCCCTTATTTGTATTGCTGTGGCCGAGGCC (단일 사슬 인간 TGF-베타 수용체 II 동종이량체)
ATCCCACCGCACGTTCAGAAGTCGGTGAATAACGACATGATAGTCACTGACAACAACGGTGCAGTCAAGTTTCCACAACTGTGTAAATTTTGTGATGTGAGATTTTCCACCTGTGACAACCAGAAATCCTGCATGAGCAACTGCAGCATCACCTCCATCTGTGAGAAGCCACAGGAAGTCTGTGTGGCTGTATGGAGAAAGAATGACGAGAACATAACACTAGAGACAGTTTGCCATGACCCCAAGCTCCCCTACCATGACTTTATTCTGGAAGATGCTGCTTCTCCAAAGTGCATTATGAAGGAAAAAAAAAAGCCTGGTGAGACTTTCTTCATGTGTTCCTGTAGCTCTGATGAGTGCAATGACAACATCATCTTCTCAGAAGAATATAACACCAGCAATCCTGACGGAGGTGGCGGATCCGGAGGTGGAGGTTCTGGTGGAGGTGGGAGTATTCCTCCCCACGTGCAGAAGAGCGTGAATAATGACATGATCGTGACCGATAACAATGGCGCCGTGAAATTTCCCCAGCTGTGCAAATTCTGCGATGTGAGGTTTTCCACCTGCGACAACCAGAAGTCCTGTATGAGCAACTGCTCCATCACCTCCATCTGTGAGAAGCCTCAGGAGGTGTGCGTGGCTGTCTGGCGGAAGAATGACGAGAATATCACCCTGGAAACCGTCTGCCACGATCCCAAGCTGCCCTACCACGATTTCATCCTGGAAGACGCCGCCAGCCCTAAGTGCATCATGAAAGAGAAAAAGAAGCCTGGCGAGACCTTTTTCATGTGCTCCTGCAGCAGCGACGAATGCAACGACAATATCATCTTTAGCGAGGAATACAATACCAGCAACCCCGAC
(인간 조직 인자 219)
TCAGGCACTACAAATACTGTGGCAGCATATAATTTAACTTGGAAATCAACTAATTTCAAGACAATTTTGGAGTGGGAACCCAAACCCGTCAATCAAGTCTACACTGTTCAAATAAGCACTAAGTCAGGAGATTGGAAAAGCAAATGCTTTTACACAACAGACACAGAGTGTGACCTCACCGACGAGATTGTGAAGGATGTGAAGCAGACGTACTTGGCACGGGTCTTCTCCTACCCGGCAGGGAATGTGGAGAGCACCGGTTCTGCTGGGGAGCCTCTGTATGAGAACTCCCCAGAGTTCACACCTTACCTGGAGACAAACCTCGGACAGCCAACAATTCAGAGTTTTGAACAGGTGGGAACAAAAGTGAATGTGACCGTAGAAGATGAACGGACTTTAGTCAGAAGGAACAACACTTTCCTAAGCCTCCGGGATGTTTTTGGCAAGGACTTAATTTATACACTTTATTATTGGAAATCTTCAAGTTCAGGAAAGAAAACAGCCAAAACAAACACTAATGAGTTTTTGATTGATGTGGATAAAGGAGAAAACTACTGTTTCAGTGTTCAAGCAGTGATTCCCTCCCGAACAGTTAACCGGAAGAGTACAGACAGCCCGGTAGAGTGTATGGGCCAGGAGAAAGGGGAATTCAGAGAA
(인간 IL-15D8N)
AACTGGGTGAATGTAATAAGTAATTTGAAAAAAATTGAAGATCTTATTCAATCTATGCATATTGATGCTACTTTATATACGGAAAGTGATGTTCACCCCAGTTGCAAAGTAACAGCAATGAAGTGCTTTCTCTTGGAGTTACAAGTTATTTCACTTGAGTCCGGAGATGCAAGTATTCATGATACAGTAGAAAATCTGATCATCCTAGCAAACAACAGTTTGTCTTCTAATGGGAATGTAACAGAATCTGGATGCAAAGAATGTGAGGAACTGGAGGAAAAAAATATTAAAGAATTTTTGCAGAGTTTTGTACATATTGTCCAAATGTTCATCAACACTTCT
TGFR/IL15RaSu 융합 단백질의 아미노산 서열(신호 펩타이드 서열포함)은 하기와 같다:
(신호 펩타이드)
MKWVTFISLLFLFSSAYS
(단일 사슬 인간 TGF-베타 수용체 II 동종이량체)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(인간 IL-15 수용체 α sushi 도메인)
ITCPPPMSVEHADIWVKSYSLYSRERYICNSGFKRKAGTSSLTECVLNKATNVAHWTTPSLKCIR
TGFR/TF/IL15D8N 융합 단백질의 아미노산 서열(신호 펩타이드 서열포함)은 하기와 같다:
(신호 펩타이드)
MGVKVLFALICIAVAEA
(단일 사슬 인간 TGF-베타 수용체 II 동종이량체)
IPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPDGGGGSGGGGSGGGGSIPPHVQKSVNNDMIVTDNNGAVKFPQLCKFCDVRFSTCDNQKSCMSNCSITSICEKPQEVCVAVWRKNDENITLETVCHDPKLPYHDFILEDAASPKCIMKEKKKPGETFFMCSCSSDECNDNIIFSEEYNTSNPD
(조직 인자)
SGTTNTVAAYNLTWKSTNFKTILEWEPKPVNQVYTVQISTKSGDWKSKCFYTTDTECDLTDEIVKDVKQTYLARVFSYPAGNVESTGSAGEPLYENSPEFTPYLETNLGQPTIQSFEQVGTKVNVTVEDERTLVRRNNTFLSLRDVFGKDLIYTLYYWKSSSSGKKTAKTNTNEFLIDVDKGENYCFSVQAVIPSRTVNRKSTDSPVECMGQEKGEFRE
(IL-15D8N)
NWVNVISNLKKIEDLIQSMHIDATLYTESDVHPSCKVTAMKCFLLELQVISLESGDASIHDTVENLIILANNSLSSNGNVTESGCKECEELEEKNIKEFLQSFVHIVQMFINTS
TGFR/IL15RαSu 및 TGFR/TF/IL-15D8N 작제물을 이전에 기재된 바와 같이 변형된 레트로바이러스 발현 벡터 내로 클로닝하였다(Hughes MS, Yu YY, Dudley ME, Zheng Z, Robbins PF, Li Y, et al). 발현 벡터를 CHO-K1 세포 내로 형질주입하였다. CHO-K1 세포에서 2개 작제물의 공동-발현은 가용성 TGFR/IL15RαSu - TGFR/TF/IL-15D8N 단백질 복합체(TGFRt15*-TGFRs로 지칭됨)의 형성 및 분비를 가능하게 하였으며, 이는 항-TF 항체 친화도에 의해 정제될 수 있다.
실시예 86: TGF-β1 및 LAP에 대한 TGFRt15-TGFRs 및 TGFRt15*-TGFRs의 결합 활성
TGF-β1 및 LAP에 대한 TGFRt15-TGFRs의 결합 활성을 ELISA에 의해 결정하였다. TGFRt15-TGFRs(5 mg/mL)를 사용하여, 적정된 TGF-β1(TGFβ1로서 표지됨, BioLegend) 및 TGF-β1의 잠복 관련 펩타이드(LAP, R&D Systems)를 포착하였다. TGF-β1을 비오틴화된 항-TGF-β1(0.2 mg/mL, R&D Systems)에 의해, 그리고 LAP를 비오틴화된 항-LAP(0.2 mg/mL, R&D Systems)에 의해, 뒤이어 퍼옥시다제 접합 스트렙타비딘(Jackson ImmunoResearch Lab)에 의해 검출하였다. 2,2'-아지노-비스(3-에틸벤조티아졸린-6-설폰산)(ABTS, Surmodics IVD)을 기질로서 사용하고, 플레이트 판독기에 의해 측정하였다. 도 211a에 도시된 바와 같이, 결과는 TGFRt15-TGFRs가 TGF-β1 및 LAP에 유사하게 결합하고, Fc 융합보다 더 강하게 결합함을 실증한다.
TGF-β1 및 LAP에 대한 TGF-β1 수용체/Fc 융합의 결합 활성을 ELISA에 의해 결정하였다. 상업적인 TGF-β1 수용체 II - Fc 융합(TGFRII/Fc)을 사용하여, TGF-β1 및 LAP에 대한 TGFRt15-TGFRs의 결합 활성을 비교하였다. TGFRII/Fc(5 mg/mL, R&D Systems)를 사용하여, 적정된 TGF-β1 및 LAP를 포착하였다. 다른 절차는 상기 기재된 바와 동일하였다. 도 211b에 도시된 바와 같이, 결과는 TGFRII/Fc가 TGF-β1 및 LAP에 유사하게 결합하고 이의 결합은 TGFRt15-TGFRs와 대등하며 Fc 융합보다 더 강함을 실증한다.
TGF-β1 및 LAP에 대한 TGFRt15-TGFRs 및 TGFRt15*-TGFRs의 결합 활성
TGFRt15-TGFRs 및 TGFRt15*-TGFRs(10 mg/mL)를 사용하여, 적정된 TGF-β1 LAP를 포착하였다. 다른 절차는 상기 기재된 바와 동일하였다. 도 211c 및 도 211d에 도시된 바와 같이, 결과는 TGFRt15*-TGFRs가 TGF-β1 및 LAP에 유사하게 결합하고 이의 결합은 TGFRt15-TGFRs와 대등하며 Fc 융합보다 더 강함을 실증한다.
CTLL-2 세포에 대한 TGFRt15-TGFRs 및 TGFRt15*-TGFRs의 결합
IL-2-의존적 CTLL-2 세포를 TGFRt15-TGFRs(50 nM), TGFRt15*-TGFRs(50 nM), 7t15-21s(50 nM, IL-7-TF-IL15 및 IL-21-IL-15RaSu)(TGF-β1 수용체 II를 함유하지 않는 대조군 융합 분자로서), 및 PBS(음성 대조군으로서)로 60분 동안 염색하고, 비오틴화된 제2 염색 항체(항-TF: 항-인간 조직 인자, HCW Biologics 및 항-TGFR: 항-TGF-β 수용체 II: R&D Systems), 그 후에 뒤이어 R-피코에리트린-스트렙타비딘(Jackson ImmunoResearch Lab)에 의해 프로브하였다. 염색의 평균치 형광 강도(MFI)를 유세포측정법에 의해 측정하였다. 도 211e에 도시된 바와 같이, 결과는 CTLL-2 세포에 결합된 TGFRt15-TGFRs가, IL-15 돌연변이체때문에 TGFRt15-TGFRs보다 TGFRt15*-TGFRs에 덜, 다른 분자보다 유의하게 더 양호하게 CTLL-2 세포에 결합하였음을 보여준다. 그러나, CTLL-2 세포에 대한 7t15-21s 결합은 항-TGFR이 아니라 항-TF로 검출될 수 없었다.
실시예 87: 세포-기초 검정을 이용한 TGFRt15-TGFRs 및 TGFRt15*-TGFRs의 생물학적 활성
TGFRt15-TGFRs 및 TGFRt15*-TGFRs의 TGF- β1 차단 활성.
HEK-Blue TGF-β 세포(InvivoGen)를 TGF-β1(0.1 nM, BioLegend)의 존재 하에 대조군으로서 적정된 TGFRt15-TGFRs, TGFRt15*-TGFRs 및 TGFRII/Fc와 함께 IMDM-10에서 인큐베이션하였다. TGFRII/Fc는 상업적인 TGF-β1 수용체 II - Fc 융합(R&D Systems)이다. 24시간의 인큐베이션 후, 배양 상청액을 QUANTI-Blue(InvivoGen)와 혼합하고 1시간 내지 3시간 동안 인큐베이션하였다. OD620 값을 플레이트 판독기에 의해 측정하였다. 도 212a에 도시된 바와 같이, TGFRt15-TGFRs 및 TGFRt15*-TGFRs는 동일한 TGF-β1 차단 활성을 가졌다. 대조적으로, TGFRII/Fc(IC50=470.2 pM)는 TGFRt15-TGFRs(IC50=43.2 pM) 또는 TGFRt15*-TGFRs(45.2 pM)보다 10배 더 낮은 TGF-β1 차단 활성을 가졌다. 차단 활성을 GraphPad Prism 7.04를 이용하여 계산하였다.
TGFRt15-TGFRs 및 TGFRt15*-TGFRs의 IL-15 활성
IL-15 의존적 32Dβ 세포를 적정된 TGFRt15-TGFRs, TGFRt15*-TGFRs 및 IL15가 있는 IMDM-10에서 대조군으로서 배양하였다. WST-1(Fisher Scientific)을 2일 후에 첨가하고, OD450 값을 플레이트 판독기에 의해 측정하였다. 도 212b에 도시된 바와 같이, TGFRt15-TGFRs(EC50=1641 pM)는 IL-15 자체(IC50=81.8 pM)보다 약 20배 더 낮은 IL-15 생물학적 활성을 가졌다. 예상된 바와 같이, TGFRt15*-TGFRs는 어떠한 검출 가능한 IL-15 활성도 갖지 않았다. IL-15 활성을 GraphPad Prism 7.04를 이용하여 계산하였다.
TGFRt15*-TGFRs에 의한 CTLL-2의 TGF-β 성장 억제의 역전
TGF- β는 3개의 이소형(TGF-β1, TGF-β2 및 TGF-β3)을 포함하고, 이들은 유사한 생물학적 기능을 갖는다. CTLL-2 세포를 사용하여, 이 연구에서 TGFRt15*-TGFRs의 생물학적 차단 활성을 비교하였다. TGFRt15*-TGFRs는 TGFRt15-TGFRs와 구조적으로 매우 유사하고, 이는 TGFRt15-TGFRs의 IL-15 활성으로 인해 그렇게 사용될 수 없다. CTLL-2 세포를 적정된 마우스 IL-4(Biolegend), TGF-β(5 ng/ml, TGF-β1(Biolegend), TGF-β2, β3(R&D Systems)) 및 TGFRt15*-TGFRs(21 nM; TGFRt15*-TGFRs:TGF-β 몰비=100:1)와 함께 RPMI-10에서 5일 동안 배양하였다. PrestoBlue(Fisher Scientific)를 마지막 날 배양에서 첨가한 후 플레이트 판독기에 의해 세포 증식(OD570-600 값)을 결정하였다. 도 212c는 모든 3개의 TGF-β가 TGFRt15*-TGFRs의 부재 하에 IL-4 유도 CTLL-2 성장을 유사하게 저해하였음을 도시한다. 도 212d는 TGFRt15*-TGFRs(21 nM; TGF-β:TGFRt15*-TGFRs 몰비=1:100)가 IL-4-유도 CTLL-2 세포 성장의 TGF-β1 및 TGF-β3의 저해를 유의하게 역전시켰음을 보여준다. 대조적으로, TGFRt15*-TGFRs는 최소의 가역적인 TGF-β2 저해 활성을 가졌다.
실시예 88: TGFRt15-TGFRs의 안정성
ELISA에 의한 TGFRt15-TGFRs의 안정성. TGFRt15-TGFRs를 50% 인간 혈청과 함께 RPMI 배지에서 4°C, 실온(RT) 또는 37°C에서 10일 동안 예비인큐베이션하였다. TGFRt15-TGFRs의 TGFβRII 도메인 및 IL-15 도메인을 ELISA에 의해 평가하였다. 항-TF 항체(HCW Biologics)를 사용하여 TGFRt15-TGFRs 분자를 포착하고, 비오틴화된 항-IL-15(R&D Systems)를 사용하여 IL-15 도메인을 검출하고, 비오틴화된 항-TGFβRII(R&D Systems)를 사용하여 TGFβRII 도메인을 검출하였다. 비오틴화된 검출 항체를 퍼옥시다제-스트렙타비딘(Jackson ImmunoResearch Lab)에 의해 프로브하였다. 2,2'-아지노-비스(3-에틸벤조티아졸린-6-설폰산)(ABTS, Surmodics IVD)을 기질로서 사용하고, 플레이트 판독기에 의해 OD405 값을 측정하였다. 도 213a 및 도 213b에 도시된 바와 같이, 결과는 4°C, RT, 또는 37°C에서 10일 동안 인큐베이션 후 TGFRt15-TGFRs의 도메인에서 어떠한 유의한 변화도 없었음을 보여준다. 이들 발견은 TGFRt15-TGFRs의 TGFβRII 도메인 및 IL-15 도메인이 평가된 조건 하에 인간 혈청과 함께 인큐베이션될 때 무결한 채로 남아 있음을 실증한다.
세포-기초 검정을 이용한 TGFRt15-TGFRs 생물학적 활성의 안정성
TGFRt15-TGFRs를 50% 인간 혈청과 함께 RPMI-10에서 4°C, 실온(RT) 또는 37°C에서 10일 동안 예비인큐베이션하였다. TGFRt15-TGFRs의 TGF-β1 중화 활성을 HEK-Blue TGF-β 세포(TGF-β1 활성 보고 세포주, InvivoGen)와 함께 평가하였다. HEK-Blue TGF-β 세포를 TGF-β1(0.1 nM)의 존재 하에 적정된 TGFRt15-TGFRs와 함께 IMDM-10에서 인큐베이션하였다. 24시간의 인큐베이션 후, 배양 상청액을 QUANTI-Blue(InvivoGen)와 혼합하고 1시간 내지 3시간 동안 인큐베이션하였다. OD620 값을 플레이트 판독기에 의해 측정하였다. 도 213c에 도시된 바와 같이, 결과는 4°C, RT, 또는 37°C에서 10일 동안 인간 혈청에서의 인큐베이션 후 TGFRt15-TGFRs의 TGF-β1 중화 활성에서 어떠한 변화도 없었음을 보여준다. TGFRt15-TGFRs의 IL-15 활성을 IL-15 의존적 32Dβ 세포를 이용하여 평가하였다. 32Dβ 세포를 적정된 TGFRt15-TGFRs가 있는 IMDM-10에서 배양하였다. WST-1(InvitroGen)을 2일 후에 첨가하고, OD450 값을 플레이트 판독기에 의해 측정하였다. 도 213d에 도시된 바와 같이, 결과는 4°C, RT, 또는 37°C에서 10일 동안 인간 혈청에서의 인큐베이션 후 TGFRt15-TGFRs의 IL-15 활성에서 어떠한 변화도 없었음을 보여준다.
실시예 89: TGFRt15-TGFRs 및 TGFRt15*-TGFRs에 의한 인간 NK 세포 및 PBMC에 대한 TGF-β1 면역억제의 역전
인간 NK 세포를 혈액 연막(4명의 공여자, 하나의 혈액)으로부터 RosetteSep™ 인간 NK 세포 농화 칵테일(StemCell)을 StemCell 설명서에 따라 이용하여 정제하고, PBMC를 Ficoll-Paque(Sigma-Aldrich) 밀도 원심분리를 이용하여 혈액 연막(6명의 공여자)으로부터 단리하였다. NK 세포 및 PBMC를 RPMI-10에서 IL-15(10 ng/mL, PeproTech) 및/또는 TGF-β1(10 ng/mL, Biolegend), TGFRt15-TGFRs(42 nM 또는 4.2 nM) 또는 TGFRt15*-TGFRs(42 nM 또는 4.2 nM)와 함께 3일 동안 배양하였다. 배양물을 수합하고, 하기 검정에 사용하였다: 세포 매개 세포독성 검정(도 214a 및 도 214b) 및 세포내 그랜자임 B(도 214c 및 도 214d)와 인터페론 감마(IFNγ, 도 214e 및 도 214f)에 대한 유세포측정법 분석.
배양된 NK 세포 및 PBMC를 세포 매개 세포독성 검정에서 이펙터 세포로서 사용하고 K562 종양 세포(ATCC)를 표적 세포로서 사용하였다. 이펙터 세포와 K562 종양 세포의 혼합물을 NK 세포에 대해 RPMI-10에서 E:T 비=4:1(도 214a) 또는 PBMC에 대해 20:1(도 214b)에서 37°C에서 4시간 동안 인큐베이션하였다. 사멸된 K562 세포의 수준을 유세포측정법에 의해 결정하였다. 도 214a 및 도 214b에 도시된 바와 같이, 결과는 배지 대조군 배양물에서 관찰된 것보다 TGF-β1의 존재 하에 유의하게 더 적은 사멸된 K562 표적 세포가 존재하였음을 보여주었고, 이는 TGF-β1이 면역 세포의 세포독성을 저해함을 나타낸다. 그러나, TGF-β1 단독 조건으로 인큐베이션된 배양물에서 관찰된 것보다 TGF-β1 및 TGFRt15-TGFRs 또는 TGFRt15*-TGFRs의 존재 하에 유의하게 더 많은 사멸된 K562 표적 세포가 존재하였다. 이들 발견은 TGFRt15-TGFRs 및 TGFRt15*-TGFRs가 TGF-β1 면역억제를 유의하게 감소시켰고 K562 표적 세포에 대한 인간 NK 세포 및 PBMC의 세포독성을 농도 의존적 방식으로 증강시켰음을 실증한다. 추가로, TGFRt15-TGFRs의 IL-15 활성은 TGFRt15*-TGFRs의 활성과 비교할 때 인간 NK 세포 및 PBMC의 세포독성을 추가로 증강시킨다.
배양된 NK 세포 및 PBMC를 형광 색소 표지된 항-CD56 및 항-CD16 인간 NK 세포 표면 마커로, 그 다음에 형광 색소 표지된 그랜자임 B 및 IFNγ 세포내 분자(BioLegend)로 염색하였다. PBMC 배양물의 정제된 NK 세포 및 게이팅된 NK 세포(CD56+ 및/또는 CD16+)에서의 그랜자임 B 및 IFNγ 발현(MFI: 평균치 형광 강도)을 유세포측정법에 의해 분석하였다. 도 214c 및 도 214d에 도시된 바와 같이, 배지 단독에서 배양된 세포에서 관찰된 것보다 TGF-β1의 존재 하에 배양된 NK 세포에서 유의하게 더 적은 그랜자임 B(도 214c 및 도 214d) 및 IFNγ(도 214e 및 도 214f) 발현이 존재하였으며, 이는 TGF-β1이 면역 세포 활성화를 저해함을 나타낸다. 그러나, TGF-β1 단독에서 배양된 세포에서 관찰된 것보다 TGF-β1 및 TGFRt15-TGFRs 또는 TGFRt15*-TGFRs의 존재 하에 유의하게 더 높은 그랜자임 B 및 IFNγ 발현 NK 세포 배양물이 존재하였다. TGFRt15*-TGFRs는 4.2 nM 농도에서 그랜자임 B 및 IFNγ 발현에 대해 최소의 효과를 가졌다. 이들 발견은 TGFRt15-TGFRs 및 TGFRt15*-TGFRs가 IL-15 및 TGFβRII 도메인의 활성을 통해 농도-의존적 방식으로 인간 NK 세포의 그랜자임 B 및 IFNγ 발현을 유의하게 증강시켰음을 실증한다.
실시예 90: C57BL/6 마우스에서 TGFRt15-TGFRs의 반감기
TGFRt15-TGFRs의 약물동력학(반감기, t1/2)을 암컷 C57BL/6 마우스에서 평가하였다. 상기 마우스를 3 mg/kg의 투약량에서 TGFRt15-TGFRs로 피하 치료하였다. 마우스 혈액을 다양한 시점에서 꼬리 정맥으로부터 수집하고, 혈청을 제조하였다. 마우스 혈청 내 TGFRt15-TGFRs 농도를 ELISA로 결정하였다. 항-TF 항체(HCW Biologics에서 생성된 항-인간 조직 인자 항체)를 사용하여 TGFRt15-TGFRs 분자를 포착하고, 비오틴화된 항-TGFβRII(R&D Systems)를 사용하여 TGFβRII 도메인을 검출하였다. 비오틴화된 검출 항체를 퍼옥시다제-스트렙타비딘(Jackson ImmunoResearch Lab)에 의해 프로브하였다. 2,2'-아지노-비스(3-에틸벤조티아졸린-6-설폰산)(ABTS, Surmodics IVD)을 기질로서 사용하고, 플레이트 판독기에 의해 OD405 값을 측정하였다. 도 215에 도시된 바와 같이, TGFRt15-TGFRs의 반감기는 GraphPad Prism 7.04로 계산 시 C57BL/6 마우스에서 18.22시간이었다.
실시예 91: C57BL/6 마우스에서 TGFRt15-TGFRs의 독성
단회 용량의 TGFRt15-TGFRs(50-400 mg/kg)를 C57BL/6 암컷 마우스(7주령, n=4) 내로 피하 주사하였다. 마우스 체중을 도 216에 도시된 바와 같이 측정하고, 임상 징후(사망율, 이환율, 헝크러진 털, 구부정한 자세, 무기력 등)를 실험 기간 동안 평가하였다. 200 mg/kg 또는 400 mg/kg의 TGFRt15-TGFRs를 받은 마우스는 치료-후 6일 내지 8일째에 더 적은 활성을 보여주었고 다른 유의한 임상 징후는 없었다. 200 mg/kg 또는 400 mg/kg에서의 TGFRt15-TGFRs는 특히 치료 후 7일차에 PBS 군과 비교하여 마우스 체중의 손실을 야기하였다(p<0.05). 영향은 받는 마우스는 사망률 또는 이환율 없이 10일 후에 점차적으로 회복하였다. 도 216에 도시된 바와 같이, 이들 발견은 C57BL/6 마우스가 최대 100 mg/kg에서 단회 용량 TGFRt15-TGFRs에 대해 내약성이 있을 수 있음을 나타낸다.
실시예 92: C57BL/6 뮤린 흑색종 모델에서 TGFRt15-TGFRs의 항종양 활성
마우스 B16F10 흑색종 세포를 C57BL/6 마우스(The Jackson Laboratory) 내로 피하 주사하여, 마우스 흑색종 모델을 확립하였다. 종양 세포 주사 후 4일째에, 마우스를 4개의 군으로 나누어 하기 면역요법을 받게 하였다: 1군: PBS 비히클 대조군; 2군: 항종양 항체 TA99(10 mg/kg) 단독 대조군; 3군: IL-15SA(0.05 mg/kg)와 조합된 TA99; 4군: TGFRt15-TGFRs(4.93 mg/kg, 0.05 mg/kg IL-15SA의 동등한 IL-15 활성)와 조합된 TA99; 및 5군: TGFRt15*-TGFRs(4.93 mg/kg. IL-15 활성이 없는 IL-15D8N 돌연변이체)와 조합된 TA99. 종양 부피를 측정하고, 식을 사용하여 계산하였다: 길이 x 폭 x 폭/2 식/ 도 217에 도시된 바와 같이, 결과는 TGFRt15-TGFRs 또는 IL15SA와 병용된 항종양 항체 TA99를 받는 마우스가 PBS, TA99 항체 단독, 및 TGFRt15*-TGFRs와 함께 TA99 군과 비교하여 종양 접종 후 11일차에 유의하게 더 작은 종양을 가졌음을 나타내었다(p<0.05). 1군, 2군, 및 5군 중에서 그리고 3군과 4군 사이에 어떠한 유의한 차이도 없었다. 이들 발견은 TGFRt15-TGFRs의 IL-15 활성이 TGFRt15-TGFRs의 항종양 활성에 중요하였음을 실증하였다.
실시예 93: 폐 섬유증의 모델 - TGFRt15-TGFRs에 의한 치료
염증성 및 섬유성 폐 질환(특발성 폐 섬유증, 만성 폐쇄성 폐 질환 및 낭포성 섬유증 포함)은 제한된 치료 옵션을 갖는 사망의 주요 원인이다. 추가로, 다양한 요법은 폐 섬유증을 유발하는 폐 손상 부작용을 초래한다. 예를 들어, 폐 독성은 블레오마이신 화학요법을 받는 암 환자 중 약 10%에서 발증한다. 이들 효과는 섬유원증에 관여하는 메커니즘의 연구를 위한 그리고 잠재적인 요법의 평가를 위한 폐 섬유증을 모델링하기 위해 설치류에서 블레오마이신 치료의 사용을 유발하였다. 이 모델에서 TGFRt15-TGFRs의 활성을 평가하기 위해, 9주령의 C57Bl6/j 수컷 마우스에게 구강인두 경로를 통해 50 μl의 블레오마이신(2.5 mg/kg, 단회 용량)을 주었다. 마우스는 블레오마이신 치료 후 17일차에 TGFRt15-TGFRs를 피하(3 mg/kg)로 받았다. 블레오마이신-후 28일차에 마우스를 희생시켰다. 폐를 단리하고, 좌측 폐를 균질화하고, 100 μL의 균질물을 상업적으로 입수 가능한 키트를 제조업체의 설명서에 따라 사용하여 콜라겐 침착의 측정치로서 하이드록시프롤린 함량에 대해 검정하였다. 데이터를 폐 그램당 하이드록시프롤린 함량 μg으로서 표현하였다. 도 218에 도시된 바와 같이, 결과는 TGFRt15-TGFRs 요법이 블레오마이신-치료 마우스의 폐에서 콜라겐 침착(즉, 섬유증)을 유의하게 감소시켰음을 나타낸다.
실시예 94: TGFRt15-TGFRs 및 TGFRt15*-TGFRs의 활성의 생체내 특징화
렙틴 결핍 ob/ob 마우스에서 비만 및 당뇨병으로부터의 보호가 TGF-β/Smad3 신호전달의 차단에 의해 달성될 수 있다는 것이 제시되었다. TGFRt15-TGFRs 또는 TGFRt15*-TGFRs가 TGF-β/Smad3 신호전달의 차단에 의해 비만 및 당뇨병으로부터 마우스를 보호할 수 있는지의 여부를 평가하기 위해, 렙틴 수용체 결핍 db/db 마우스 계통(BKS.Cg Dock7m+/+ Leprdb/J)을 연구에 사용하였다. 6주령의 db/db 마우스를 3개 군(군당 N=8)으로 나누었다. 마우스에게 3 mg/kg에서 TGFRt15-TGFRs, TGFRt15*-TGFRs, 또는 PBS를 피하 주사하였다. 마우스를 20일 동안 공복시키고 난 후 혈액을 주사-후 4일차에 하악하 정맥을 통해 채혈하였다. 혈액을 채혈한 후 즉시 공복 혈당을 OneTouch UltraMini 측정기로 측정하였다. 도 219에 도시된 바와 같이, TGFRt15-TGFRs와 TGFRt15*-TGFRs는 둘 다 공복 혈장 포도당 수준을 유의하게 감소시킬 수 있다.
혈장 TGFβ1-3 수준을 평가하여, db/db 마우스에서 공복 혈장 포도당의 치료-관련 감소의 원인을 식별하였다. 치료 후 4일째에, 혈장을 단리하고, 30 μL의 혈장을 EVE Technologies(Calgary, AB Canada)에 보내어, TGF-β 3-Plex(TGFB1-3) 검정에 의해 TGFβ1-3 수준을 평가하였다. 도 220a 내지 도 220c에 도시된 바와 같이, TGFRt15-TGFRs와 TGFRt15*-TGFRs는 둘 다 혈장 TGFβ1을 완전히 결핍시켰고(도 220a), TGFβ2를 부분적으로 감소시켰고(도 220b), TGFβ3에는 어떠한 효과도 갖지 않았다(도 220c).
림프구 하위세트를 평가하여, db/db 마우스에서 공복 혈장 포도당의 치료-관련 감소의 원인을 식별하였다. 치료 후 4일째에, 전혈 세포(50 μl)를 ACK(암모늄-클로라이드-포타슘) 용해 완충액으로 처리하여 적혈구 세포를 용해시켰다. 그 후에, 림프구를 PE-Cy7-항-CD3, BV605-항-CD45, PerCP-Cy5.5-항-CD8a, BV510-항-CD4, 및 APC-항-NKp46(모두 BioLegend로부터의 항체)로 염색하여, T 세포 및 NK 세포의 집단을 평가하였다. 세포를 추가로 투과시키고, eBioscience Foxp3/전사 인자 염색 완충액 세트(Cat# 00-5523-00, ThermoFisher)로 고정시키고, eBioscience 투과 완충액(Cat# 00-8333-56, ThermoFisher) 중 AF700-항-Ki67 및 FITC-항-그랜자임 B로 염색하여, T 세포 및 NK 세포의 증식 및 활성화를 평가하였다. 또 다른 림프구 세트를 우선 PE-Cy7-항-CD3, BV605-항-CD45, BV510-항-CD4 및 apc-Cy7-항-CD25로 염색한 다음, 투과시키고, eBioscience Foxp3/전사 인자 염색 완충액 세트(Cat# 00-5523-00, ThermoFisher)로 고정시키고, eBioscience 투과 완충액(Cat# 00-8333-56, ThermoFisher) 중 PE-항-Foxp3로 염색하여, Treg 세포의 집단을 평가하였다.
TGFRt15-TGFRs는 NK 세포(도 221a) 및 CD8+ T 세포(도 221d)의 집단을 증가시켰고, NK 세포(도 221b) 및 CD8+ T 세포(도 221e), 및 활성화된 NK 세포(도 221c)의 증식을 자극시켰다. TGFRt15*-TGFRs는 어떤 세포 집단에서 어떠한 효과도 갖지 않았다(도 221a 내지 도 221e). TGFRt15-TGFRs와 TGFRt15*-TGFRs는 둘 다 CD4+ T 세포, CD19+ B 세포, 및 CD4+CD25+Foxp3+ Treg 세포에 어떠한 효과도 갖지 않았다.
결론적으로, db/db 마우스에서, TGFRt15-TGFRs와 TGFRt15*-TGFRs는 둘 다 공복 혈장 포도당 수준을 감소시켰고, TGFRt15-TGFRs와 TGFRt15*-TGFRs는 둘 다 혈장 TGFβ1을 완전히 결실시켰다. 그러나, TGFRt15-TGFRs만 NK 세포를 활성화시켰고, CD8+ T 세포 및 NK 세포 증식을 증강시켰다. 이들 결과에 기초하여, TGFβ1의 결핍은 공복 혈장 포도당의 감소에 관여하는 경향이 있었으며, 이는 TGF-β/Smad3 신호전달의 차단이 ob/ob 마우스에서 비만 및 당뇨병의 예방에서 역할을 하였음을 보여준다.
실시예 95: TGFRt15-TGFRs 및 TGFRt15*-TGFRs의 활성의 시험관내 특징화
TGFRII는 TGFβ1-3과 상호작용하는 것으로 실증되었다. TGFRII와 잠복 TGFβ 사이에서의 상호작용을 실증하는 어떠한 보고도 문헌에 존재하지 않는다. TGFRt15-TGFRs, TGFRt15*-TGFRs, 및 TGFRII-Fc가 잠복 TGFβ와 상호작용하는지의 여부를 평가하기 위해, 본 발명자들은 50 mM 카르보네이트 완충액 pH 9.4(100 μl/웰) 중 2.5 nM의 인간 잠복 TGFβ1-his 태그(Cat# TG1-H524x, Acro Biosystems) 또는 대조군 단백질 CD39-his 태그(Lot# 58-49/51, HCW Biologics)를 적용하여 ELISA 플레이트(Cat# 80040LE 0910, ThermoFisher)를 4°C에서 밤새 코팅시켰다. 이튿날, 플레이트를 ELISA 세척 완충액(0.05% Tween 20과 함께 포스페이트-완충 식염수)으로 3회 세척하고, 플레이트를 차단 완충액(1% BSA-PBS)으로 1시간 동안 차단시킨 다음, 차단 완충액 중 200 nM로부터 0.09 nM까지의 감소하는 농도의 TGFRt15-TGFRs, TGFRt15*-TGFRs, 또는 TGFRII-Fc를 플레이트에 첨가하고, 플레이트를 25°C에서 1시간 동안 인큐베이션하였다. 플레이트를 ELISA 세척 완충액으로 3회 세척하였다. 검출 항체인 비오틴화된 항-TGFRII 항체(Cat# BAF241, R&D Systems)를 0.1 μg/mL에서 플레이트에 첨가하고, 25°C에서 1시간 동안 인큐베이션하였다. 플레이트를 세척하고, 0.25 μg/mL에서 호스래디쉬 퍼옥시다제-스트렙타비딘(code#016-030-084, Jackson ImmunoResearch)을 플레이트에 첨가하고, 25°C에서 30분 동안 인큐베이션하였다. 플레이트를 세척하고, HRP의 기질인 ABTS(Cat# ABTS-1000-01, Surmodics)를 플레이트에 첨가하고, 25℃에서 20분 동안 인큐베이션하였다. 플레이트를 마이크로플레이트 판독기(Multiscan Sky, Thermo Scientific)로 OD405 nm에서 판독하였다. 도 222a에 도시된 바와 같이, TGFRt15-TGFRs와 TGFRt15*-TGFRs는 둘 다 잠복 TGFβ1과 유사하게 상호작용하였다. 그러나, TGFRII-Fc는 TGFRt15*-TGFRs로 관찰된 것보다 더 낮은 친화도로 잠복 TGFβ1과 상호작용하였다(도 222b). 결과는 TGFRt15-TGFRs, TGFRt15*-TGFRs, 및 TGFRII-Fc가 잠복 TGFβ1과 상호작용할 수 있으며, TGFRt15-TGFRs, TGFRt15*-TGFRs가 놀랍게도 TGFRII-Fc보다 더 높은 친화도 상호작용을 보여줌을 실증하였다.
실시예 96: 프로트롬빈 시간 시험
프로트롬빈 시간(PT) 시험을 설계하여, 조직 인자 및 최적 농도의 칼슘과 혼합 후 혈장이 응고하는 데 소요되는 시간을 측정한다. 인지질(트롬빈프라스틴이라고 함)과의 조직 인자 혼합물은 효소로서 작용하여, 프로트롬빈을 트롬빈으로 전환시키며, 이는 차례로 피브리노겐을 피브린으로 전환시킴으로써 혈액 응고를 야기한다. 인노빈은 지질화된 재조합 인간 TF243이고, 본 발명자들의 실험에서 표준으로서 사용된다. PT 검정법에서, 더 짧은 PT 시간(응고 시간)은 더 높은 TF-의존적 응고 활성을 나타내는 한편, 더 긴 PT(응고 시간)는 더 낮은 TF-의존적 응고 활성을 의미한다.
간략하게는, 0.1 mL의 정상 인간 혈장(Ci-Trol 응고 대조군, 수준 I)을 37°C에서 3분 동안 예열시켰다. 0.2 mL의, PT 검정법 완충액(50 mM Tris-HCl, pH 7.5, 14.6 mM CaCl2, 0.1% BSA)에 희석된 인노빈 또는 시험 시료(TGFRt15-TGFRs)의 다양한 희석물을 혈장 내에 첨가함으로써 혈장 응고 반응을 개시하였다. STart PT 분석기(미국 뉴저지주 파시패니 소재의 Diagnostica Stago)에 의해 응고 시간을 모니터링하고 기록하였다.
도 223에 도시된 바와 같이, PT 검정에 첨가된 상이한 양의 인노빈(10 nM의 지질화된 재조합 인간 TF243과 동등한 정제수로 재구성된 인노빈은 100% 인노빈인 것으로 간주되었음)은 사실상 PT 시간과 PT 검정에 첨가된 TF243의 양 사이에서 역의 관계를 실증하였다. 예를 들어, 1% 인노빈은 약 25.0초의 PT 시간을 가졌으며, 한편 100% 인노빈은 8.5초의 PT 시간을 가졌다.
도 224는 TGFRt15-TGFRs 상에서의 PT 시험 결과를 도시한다. 인노빈과 대조적으로, TGFRt15-TGFRs는 연장된 PT 시간을 나타내었고, 이는 완충액과 거의 동일하였고, 이는 매우 낮은 응고 활성 또는 응고 활성이 없음을 나타낸다.
CTLL 세포의 존재 하에 TGFRt15-TGFRs의 응고 효과를 또한 평가하였다. 실시된 결합 실험은 TGFRt15-TGFRs가 CTLL 세포에 결합할 수 있음을 확인시켜 주었다. CTLL 세포의 존재 하에 TGFRt15-TGFRs 응고 시험은 생체내에서의 강력한 응고 활성과 더 근접하게 반영할 것이다. TGFRt15-TGFRs를 PT 검정 완충액에서 37°C에서 CTLL 세포와 함께 20분 내지 30분 동안 예비인큐베이션하였다. 그 후에, 본 발명자들은 위에 기재된 바와 같이 PT 검정을 진행시켰다. 도 224는 TGFRt15-TGFRs와 CTLL 세포의 혼합물이 TGFRt15-TGFRs 단독(167.6초) 또는 CTLL 세포 단독(161.9초)보다 약간 더 짧은 응고 시간(154.6초)를 가졌음을 보여준다. 그러나, 154.6초의 응고 시간은 8.5초의 인노빈 응고 시간보다 더욱 유의하게 더 길다.
요약하자면, TGFRt15-TGFRs는 TGFRt15-TGFRs에 결합할 수 있는 세포의 존재 하에서도 매우 낮거나 전혀 없는 TF-의존적 응고 활성(즉, 인간 혈장 내 생리학적 범위의 응고 인자에서)을 갖는다.
실시예 97: TGFRt15-TGFRs 또는 PBS에 의한 치료 및 단기간(10일) 또는 장기간(60일) 추적 관찰 후 젊은 마우스 및 노화 마우스의 조직에서의 노쇠 마커의 유전자 발현
C57BL/6, 72주령 마우스를 Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 사육시켰다. 마우스를 2개 군으로 나누고, PBS(PBS 대조군) 또는 3 mg/kg의 투약량에서 TGFRt15-TGFRs(TGFRt15-TGFRs 군)로 피하 치료하였다. 치료-후 10일차 또는 60일차에, 마우스를 안락사시키고, 신장을 수합하여 노쇠 마커 PAI1, IL-1α, IL6, 및 TNFα의 발현 수준을 정량적-PCR에 의해 평가하였다. 수합된 신장을 1.7 mL Eppendorf 튜브에서 액체 질소에 저장하였다. 시료를, 균질화기를 사용하여 1 mL의 트리졸(Thermo Fischer)에서 균질화하였다. 균질화된 조직을 신선한 Eppendorf 튜브에 옮겼다. RNeasy Mini 키트(Qiagen #74106)를 제조업체의 설명서에 따라 사용하여 총 RNA를 추출하였다. QuantiTect 역전사 키트(Qiagen)를 사용하는 cDNA 합성에 1 μg의 총 RNA를 사용하였다. Thermo Scientific으로부터 구매된 FAM-표지 예비설계된 프라이머를 사용하여 CFX96 검출 시스템(Bio-Rad)으로 실시간 PCR을 수행하였다. 반응을 검사된 모든 유전자에 대해 3벌로 진행시켰다. 하우스킵핑 유전자 18S 리보솜 RNA를 내부 대조군으로서 사용하여, 발현 수준에서의 가변성을 정규화하였다. 18S rRNA와 비교하여 각각의 표적 mRNA의 발현을 Ct에 기초하여 2-Δ(ΔCt)로서 계산하였으며, 여기서, ΔCt = Ct 표적 - Ct18S이다. 비치료된 6주령 마우스(젊음)를 대조군으로서 사용하여, 유전자 발현 수준을 노화된 마우스와 비교하였다.
도 225에 도시된 바와 같이, 결과는 신장에서의 PAI-1, IL-1α, IL6, 및 IL-1β의 유전자 발현이 세포 노쇠에서의 연령-의존적 증가로 예상된 바와 같이 마우스의 연령에 따라 증가하였음을 보여준다. 단회 용량의 TGFRt15-TGFRs를 이용한 72월령 마우스의 치료는 신장에서 노쇠 마커의 유전자 발현을 감소시키는 데 있어서 유의하고 장기간 지속되는 효과를 초래하였으며, 이는 노화 마우스의 신장에서 천연-발생 노쇠 세포의 치료 관련 저하를 시사한다.
도 226에 도시된 바와 같이, 결과는 단회 용량의 TGFRt15-TGFRs를 이용한 72월령 마우스의 치료가 간에서 IL-1α 및 IL6 유전자 발현을 감소시키는 데 있어서 유의하고 장기간 지속되는 효과를 매개하였으며, 이는 노화 마우스의 간에서 천연-발생 노쇠 세포의 치료 관련 저하를 시사함을 보여주었다.
C57BL/6, 72주령 마우스를 Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 사육시켰다. 마우스를 2개 군으로 나누고, PBS(PBS 대조군) 또는 3 mg/kg의 투약량에서 TGFRt15-TGFRs(TGFRt15-TGFRs 군)로 피하 치료하였다. 치료-후 10일차 또는 60일차에, 마우스를 안락사시키고, 신장을 수합하여 노쇠 마커 PAI-1 단백질 수준을 조직 ELISA에 의해 평가하였다. 수합된 신장을 1.7 mL Eppendorf 튜브에서 액체 질소에 저장하였다. 시료를, 균질화기를 사용하여 0.3 mL의 추출 완충액(Abcam)에서 균질화하였다. 균질화된 조직을 신선한 Eppendorf 튜브에 옮겼다. 균질화된 조직 내 단백질 수준을 BCA 단백질 검정 키트(Pierce)를 사용하여 정량화하였다. 마우스 PAI-1 ELISA(R&D System)를 200 mg의 조직 균질화물을 이용하여 수행하였다. 표준 곡선에 기초하여, PAI-1의 농도를 조직 밀리그램당 피코그램으로서 계산하였다.
도 227에 도시된 바와 같이, 노쇠 마커 PAI-1의 단백질 수준은 치료-후 60일째에 PBS 군과 비교하여 TGFRt15-TGFRs 치료 노화 마우스의 신장에서 저하되었다. 이들 결과는 노화 마우스의 신장에서 PAI-1 유전자 발현에 미치는 TGFRt15-TGFRs 치료의 효과와 일관된다. 종합하자면, 이들 결과는 TGFRt15-TGFRs의 단회 치료가 노화 마우스의 조직에서 천연-발생 노쇠 세포(노쇠 마커의 감소된 유전자 및 단백질 발현에 의해 측정된 바와 같음)의 유의하고 장기간 지속되는 효과를 초래하였음을 나타낸다.
실시예 98: 노화 마우스의 조직에서 노쇠 마커의 유전자 발현을 감소시키는 데 있어서 TGFRt15-TGFRs 및 TGFRt15*-TGFRs(IL-15 돌연변이체) 치료의 비교
C57BL/6, 72주령 마우스를 Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 사육시켰다. 마우스를 하기와 같이 5개 군으로 나누었다: 식염수 대조군(n =8); TGFRt15-TGFRs 군(n =8); IL15SA 군(n =8); TGFRt15*-TGFRs 군(n =8); 및 IL15SA + TGFRt15*-TGFRs 군(n =8). 마우스를 PBS, TGFRt15-TGFRs(3 mg/kg), TGFRt15*-TGFRs(3 mg/kg), IL15SA(0.5 mg/kg), 또는 TGFRt15*-TGFRs(3 mg/kg) + IL15SA(0.5 mg/kg)로 피하 치료하였다. 마우스 혈액을 준비하여, TGFRt15-TGFRs 및 다른 제제를 이용한 치료 후 면역 세포의 상이한 하위세트에서 변화를 평가하였다. 치료 후 17일차에 하악하 정맥으로부터 마우스 혈액을 EDTA 함유 튜브에 채혈하였다. 전혈을 원심분리하여, 혈장을 마이크로 원심분리기에서 3000 RPM에서 10분 동안 수집하였다. 혈장을 -80°C에 저장하고, 유세포측정법에 의한 면역 세포 표현형 분석을 위해 전혈을 가공하였다. 전혈 RBC를 ACK 완충액에서 실온에서 5분 동안 용해시켰다. 잔여 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다. 혈액 내 상이한 유형의 면역 세포를 평가하기 위해, 세포를 세포-표면 CD3, CD45, CD8 및 NK1.1에 특이적인 항체(BioLegend)로 실온(RT)에서 30분 동안 염색하였다. 표면 염색 후, 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다(실온에서 1500 RPM에서 5분 동안). 2회의 세척 후, 세포를 고정 완충액에 재현탁시키고, 유세포측정법(Celesta-BD Bioscience)에 의해 분석하였다.
도 228에 도시된 바와 같이, 결과는 TGFRt15-TGFRs를 이용한 노화 마우스의 치료를 나타낸다. IL15SA(양성 대조군) 또는 TGFRt15*-TGFRs + IL15SA가 혈액에서 CD3+CD8+, CD3-NK1.1+, 및 CD3+CD45+ 면역 세포의 백분율의 증가를 매개한 반면, TGFRt15*-TGFRs를 이용한 치료가 이들 세포 집단의 백분율에 거의 효과를 갖지 않거나 전혀 갖지 않았다. 이들 결과는 TGFRt15-TGFRs의 IL-15 활성이 노화 마우스의 혈액에서 CD8+ T 세포 및 NK 세포를 증가시키는 데 역할을 함을 시사한다.
도 229에 도시된 바와 같이, 결과는 TGFRt15-TGFRs를 이용한 노화 마우스의 치료를 나타낸다. IL15SA(양성 대조군) 또는 TGFRt15*-TGFRs + IL15SA가 비장에서 CD3+CD8+, CD3-NK1.1+, 및 CD3+CD45+ 면역 세포의 백분율의 증가를 매개한 반면, TGFRt15*-TGFRs를 이용한 치료가 이들 세포 집단의 백분율에 거의 효과를 갖지 않거나 전혀 갖지 않았다. 이들 결과는 TGFRt15-TGFRs의 IL-15 활성이 노화 마우스의 비장에서 CD8+ T 세포 및 NK 세포를 증가시키는 데 역할을 함을 시사한다.
C57BL/6, 72주령 마우스를 Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 사육시켰다. 마우스를 하기와 같이 5개 군으로 나누었다: 식염수 대조군(n =8); TGFRt15-TGFRs 군(n =8); IL15SA 군(n =8); TGFRt15*-TGFRs 군(n =8); 및 IL15SA + TGFRt15*-TGFRs 군(n =8). 마우스를 PBS, TGFRt15-TGFRs(3 mg/kg), TGFRt15*-TGFRs(3 mg/kg), IL15SA(0.5 mg/kg), 또는 TGFRt15*-TGFRs(3 mg/kg) + IL15SA(0.5 mg/kg)로 피하 치료하였다. 마우스 신장, 간, 및 폐를 수합하여, TGFRt15-TGFRs, TGFRt15*-TGFRs, 또는 PBS 대조군을 이용한 치료 후 조직에서의 정량적-PCR에 의해 노쇠 마커 p21, PAI1, IL-1α, 및 IL6의 유전자 발현을 평가하였다. 치료 후 7일차에 마우스를 안락사시키고, 신장, 간, 및 폐를 수합하고 1.7 mL Eppendorf 튜브에서 액체 질소에 저장하였다. 시료를, 균질화기를 사용하여 1 mL의 트리졸(Thermo Fischer)에서 균질화하였다. 균질화된 조직을 신선한 Eppendorf 튜브에 옮겼다. RNeasy Mini 키트(Qiagen #74106)를 제조업체의 설명서에 따라 사용하여 총 RNA를 추출하였다. QuantiTect 역전사 키트(Qiagen)를 사용하는 cDNA 합성에 1 μg의 총 RNA를 사용하였다. Thermo Scientific으로부터 구매된 FAM-표지 예비설계된 프라이머를 사용하여 CFX96 검출 시스템(Bio-Rad)으로 실시간 PCR을 수행하였다. 반응을 검사된 모든 유전자에 대해 3벌로 진행시켰다. 하우스킵핑 유전자 18S 리보솜 RNA를 내부 대조군으로서 사용하여, 발현 수준에서의 가변성을 정규화하였다. 18S rRNA와 비교하여 각각의 표적 mRNA의 발현을 Ct에 기초하여 2-Δ(ΔCt)로서 계산하였으며, 여기서, ΔCt = Ct 표적 - Ct18S이다.
도 230a 내지 도 230d에 도시된 바와 같이, 단회 용량의 TGFRt15-TGFRs 또는 TGFRt15*-TGFRs를 이용한 72월령 마우스의 치료는 신장 및 간에서 p21, PAI1, IL-1α, 및 IL6 유전자 발현에서 유의한 저하를 매개하였으며, 이는 노화 마우스의 신장 및 간에서 천연-발생 노쇠 세포의 치료 관련 저하를 시사하였다. 이 연구의 결과는 TGFRt15-TGFRs의 IL-15와 TGF-β 포착 활성이 둘 다 노화 마우스의 조직에서 천연-발생 노쇠 세포를 감소시킬 수 있음을 시사한다.
실시예 99: IL-15-기초 제제를 이용한 치료 후 면역-표현형
마우스 혈액을 준비하여, IL-15-기초 제제를 이용한 치료 후 면역 세포의 상이한 하위세트에서의 변화를 평가하였다: TGFRt15-TGFRs, IL-15 슈퍼작용제(IL-15SA) 및 IL-15 활성을 넉아웃시킨 D8N 돌연변이체와의 IL-15 융합(TGFRt15*-TGFRs). C57BL/6, 6주령 마우스를 Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 사육시켰다. 마우스를 군(n =6/군)으로 나누고, 하기와 같이 치료하였다: 1) PBS(식염수) 대조군, 2) 도세탁셀, 3) 도세탁셀과 TGFRt15-TGFRs, 4) 도세탁셀과 IL15SA, 5) 도세탁셀과 IL-15 돌연변이체(TGFRt15*-TGFRs) 및 6) 도세탁셀과 IL-15 슈퍼작용제(IL-15SA) + TGFRt15*-TGFRs. 1일차, 4일차 및 7일차에 마우스에서 3개 용량의 도세탁셀(10 mg/kg)로 노쇠를 유도하였다. 8일차에, 마우스를 위에서 논의된 바와 같이 PBS, TGFRt15-TGFRs, TGFRt15*-TGFRs, IL-15SA 또는 병용으로 피하 치료하였다. TGFRt15-TGFRs 및 TGFRt15*-TGFRs를 3 mg/kg의 투여량으로 투여하고, IL-15SA를 0.05 mg/kg의 투여량으로 투여하였다. 시험약 치료 후 3일차에 하악하 정맥으로부터 마우스 혈액을 EDTA 함유 튜브에 채혈하였다. 전혈을 원심분리하여, 혈장을 마이크로 원심분리기에서 3000 RPM에서 10분 동안 수집하였다. 혈장을 -80°C에 저장하고, 유세포측정법에 의한 면역 세포 표현형 분석을 위해 전혈을 가공하였다. RBC를 ACK 완충액에서 37°C에서 5분 동안 용해시켰다. 잔여 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다. 혈액 내 상이한 유형의 면역 세포를 평가하기 위해, 세포를 세포-표면 CD4, CD45, CD19 CD8 및 NK1.1에 대한 항체(BioLegend)로 실온(RT)에서 30분 동안 염색하였다. 표면 염색 후, 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다(실온에서 1500 RPM에서 5분 동안). 세포를 40°C에서 20분 동안 투과 용액(Invitrogen)으로 처리하고, 뒤이어 투과 완충액(Invitrogen)으로 세척하였다. 그 후에, 세포를 증식에 대한 세포내 마커(Ki67)에 대해 RT에서 30분 동안 염색하였다. 2회의 세척 후, 세포를 고정 완충액에 재현탁시키고, 유세포측정법(Celesta-BD Bioscience)에 의해 분석하였다.
도 231a 및 도 231b에 도시된 바와 같이, 결과는 TGFRt15-TGFRs, IL15SA(양성 대조군), 또는 TGFRt15*-TGFRs + IL15SA를 이용한 마우스의 치료가 혈액에서 CD8+ T 세포 및 NK1.1+ 세포의 백분율 및 증식(Ki67에 의해 측정된 바와 같음)의 증가를 매개한 반면, TGFRt15*-TGFRs를 이용한 치료가 이들 세포 집단의 백분율에 거의 효과를 갖지 않거나 전혀 갖지 않았음을 나타낸다. 이들 결과는 TGFRt15-TGFRs의 IL-15 활성이 화학요법 후 마우스의 혈액에서 CD8+ T 세포 및 NK 세포를 증가시키는 데 역할을 함을 시사한다.
실시예 100: 화학요법 및 IL-15-기초 제제를 이용한 치료 후 마우스의 폐 및 간 조직에서 노쇠 마커 p21 및 CD26의 유전자 발현의 평가
세포 노쇠에 대한 마커의 유전자 발현을 화학요법 및 연구 치료의 투여 후 정상 마우스의 조직에서 평가하였다. C57BL/6, 6주령 마우스를 Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 사육시켰다. 마우스를 6개의 군으로 나누고, 하기와 같이 치료하였다: 1) PBS(식염수) 대조군(n =5), 2) 도세탁셀(n =8), 3) 도세탁셀과 TGFRt15-TGFRs(n =8), 4) 도세탁셀과 IL15SA(n =8), 5) 도세탁셀과 IL-15 돌연변이체(TGFRt15*-TGFRs)(n =8) 및 6) 도세탁셀과 IL-15 슈퍼작용제(IL-15SA) + TGFRt15*-TGFRs(n =6). 1일차, 4일차 및 7일차에 마우스에서 3개 용량의 도세탁셀(10 mg/kg)로 노쇠를 유도하였다. 8일차에, 마우스를 아래에서 논의된 바와 같이 PBS, TGFRt15-TGFRs, TGFRt15*-TGFRs, IL-15SA 또는 병용으로 피하 치료하였다. TGFRt15-TGFRs 및 TGFRt15*-TGFRs를 3 mg/kg의 투여량으로 투여하고, IL-15SA를 0.5 mg/kg의 투여량으로 투여하였다. 마우스 조직을 준비하여, 노쇠 마커의 상이한 유전자 발현을 평가하였다. 시험약 치료 후 7일차에 마우스를 안락사시키고, 간 및 폐 조직을 수합하고 1.7 mL Eppendorf 튜브에서 액체 질소에 저장하였다. 시료를 막자 및 사발을 사용하여 액체 질소에서 균질화하였다. 균질화된 조직을, 1 mL의 트리졸(Thermo Fischer)을 함유하는 신선한 Eppendorf 튜브에 옮겼다. RNeasy Mini Kit(Qiagen #74106)를 제조업체의 설명서에 따라 사용하여 총 RNA를 추출하고, QuantiTect 역전사 키트(Qiagen)를 사용하는 cDNA 합성에 1 μg의 총 RNA를 사용하였다. Thermo Scientific으로부터 구매된 FAM-표지 예비설계된 프라이머를 사용하여 CFX96 검출 시스템(Bio-Rad)으로 실시간 PCR을 수행하였다. 반응을 검사된 모든 유전자에 대해 3벌로 진행시켰다. 하우스킵핑 유전자 18S 리보솜 RNA를 내부 대조군으로서 사용하여, 발현 수준에서의 가변성을 정규화하였다. 18S rRNA와 비교하여 각각의 표적 mRNA의 발현을 Ct에 기초하여 2-Δ(ΔCt)로서 계산하였으며, 여기서, ΔCt = Ct 표적 - Ct18S이다.
도 232에 도시된 바와 같이, 노쇠 마커 p21 및 CD26의 유전자 발현은 식염수-치료 마우스의 조직에서의 유전자 발현과 비교하여 도세탁셀로 치료된 마우스의 폐(도 232a) 및 (도 232b)에서 유도되었고, p21은 간(도 232c) 조직에서 유도되었다. 폐에서의 노쇠 마커 p21과 CD26 및 간에서의 p21의 유전자 발현은 화학요법-치료 대조군과 비교하여 TGFRt15-TGFRs, IL-15SA, 및 IL-15SA와 TGFRt15*-TGFRs 돌연변이체의 조합을 이용한 후속 치료 후 화학요법-치료 마우스에서 감소되었다. 그러나, TGFRt15*-TGFRs 돌연변이체 치료는 이들 조직에서 화학요법-유도 노쇠 마커 유전자 발현에 영향을 미치는 데 실패하였다. 이들 결과는, IL-15 활성이 마우스의 정상 조직에서 TIS 노쇠 세포의 청소에 중요함을 보여준다.
실시예 101: TGFRt15-TGFRs 치료는 B16F10 종양 보유 마우스의 말초 혈액에서 면역 세포 증식, 확장, 및 활성화를 증강시킨다
C57BL/6 마우스에게 0.5x106 B16F10 세포를 피하 주사하였다. 종양 접종(0일차) 후, 마우스에게 1일차, 4일차, 및 7일차에 3개 용량의 도세탁셀 화학요법(10 mg/kg) 및 8일차에 종양 항원을 표적화하는 단일클론 항체 항-TYRP-1 항체 TA99(200 μg)와 병용된 단회 용량의 TGFRt15-TGFRs(3 mg/kg)를 주었다. 1일차, 4일차, 및 7일차에 식염수 또는 도세탁셀 화학요법(10 mg/kg)으로 치료된 종양-보유 마우스는 대조군으로서 역할을 하였다. 면역요법 치료(8일차) 후 3일차, 5일차, 및 10일차에 하악하 정맥으로부터 혈액을 채혈하였다. RBC를 ACK 용해 완충액에 용해시키고, 림프구를 세척하고 실온(RT)에서 30분 동안 NK, CD8, CD25, 및 그랜자임 B(GzB)의 세포 표면 발현에 특이적인 항체(BioLegend)로 염색하였다. 표면 염색 후, 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다(RT에서 1500 RPM에서 5분 동안). 2회의 세척 후, 세포를 고정 완충액에 재현탁시켰다. 고정 후, 세포를 세척하고, 4°C에서 20분 동안 투과 용액(Invitrogen)으로 처리하고, 뒤이어 투과 완충액(Invitrogen)으로 세척하였다. 그 후에, 세포를 증식에 대한 세포내 마커(Ki67)에 대해 RT에서 30분 동안 염색하였다. 2회의 세척 후, 세포를 고정 완충액에 재현탁시키고, 유세포측정법(Celesta-BD Bioscience)에 의해 분석하였다.
도 233a 및 도 233b에 도시된 바와 같이, 말초 혈액 분석은 증식적 Ki67-양성 NK 및 CD8+ 세포가 식염수 또는 화학요법 치료군과 비교할 때 TGFRt15-TGFRs+TA99 화학요법 후 3일차에 우세하게 존재하였음을 보여주었다. NK 및 CD8+ 세포의 확장은 면역요법-후 3일차 및 5일차에 발견되었다. NK 세포는 여전히 확장하고 있는 한편, CD8+ 세포는 면역요법-후 10일차에 혈액에서 확장하고 있는 것으로 발견되지 않았다. 이들 세포는 또한 식염수 또는 화학요법 치료군의 면역 세포와 비교할 때 TGFRt15-TGFRs+TA99 요법 후 활성화 마커 CD25 및 그랜자임 B를 발현하였다. 이들 효과는 TGFRt15-TGFRs의 면역자극성 활성과 일관된다.
실시예 102: TGFRt15-TGFRs 치료는 B16F10 종양 보유 마우스의 혈장에서 TGFβ의 수준을 저하시킨다
C57BL/6 마우스에게 0.5x106 B16F10 세포를 피하 주사하였다. 종양 접종(0일차) 후, 마우스에게 1일차, 4일차, 및 7일차에 3개 용량의 도세탁셀 화학요법(10 mg/kg) 및 8일차에 종양 항원을 표적화하는 단일클론 항체 항-TYRP-1 항체 TA99(200 μg)와 병용된 단회 용량의 TGFRt15-TGFRs(3 mg/kg)를 주었다. 1일차, 4일차, 및 7일차에 식염수 또는 도세탁셀 화학요법(10 mg/kg)으로 치료된 종양-보유 마우스는 대조군으로서 역할을 하였다. 면역요법 치료 후 1일차, 3일차, 5일차, 및 10일차에 하악하 정맥으로부터 혈액을, EDTA를 함유하는 튜브에 수집하고, 즉시 얼음 위에 두었다. 혈액을 실온에서 3,000 rpm에서 15분 동안 원심분리하여, 혈장을 분리하였다. 혈장 시료를 분취하고, -80°C에 저장하였다. 혈장 TGFβ 수준을 캐나다 앨버타 캘거리 소재의 Eve Technologies로부터의 사이토카인 검정, TGFβ 3-플렉스(TGFβ 1-3)를 사용함으로써 분석하였다.
도 234에 도시된 바와 같이, 결과는 TGFRt15-TGFRs+TA99의 투여가 식염수 또는 화학요법 치료군과 비교할 때 치료-후 3일 내지 5일 동안 종양-보유 마우스에서 TGF-β1, TGF-β2, 및 TGF-β3의 혈장 수준의 감소를 유발하였음을 보여준다. 이러한 효과는 TGFRt15-TGFRs의 TGF-β 작용제성 활성과 일관된다.
실시예 103: TGFRt15-TGFRs 치료는 B16F10 종양 보유 마우스의 혈장에서 전염증성 사이토카인의 수준을 감소시킨다
C57BL/6 마우스에게 0.5x106 B16F10 세포를 피하 주사하였다. 종양 접종(0일차) 후, 마우스에게 1일차, 4일차, 및 7일차에 3개 용량의 도세탁셀 화학요법(10 mg/kg) 및 8일차에 종양 항원을 표적화하는 단일클론 항체 항-TYRP-1 항체 TA99(200 μg)와 병용된 단회 용량의 TGFRt15-TGFRs(3 mg/kg)를 주었다. 1일차, 4일차, 및 7일차에 식염수 또는 도세탁셀 화학요법(10 mg/kg)으로 치료된 종양-보유 마우스는 대조군으로서 역할을 하였다. 면역요법 치료(8일차) 후 1일차, 3일차, 5일차, 및 10일차에 하악하 정맥으로부터 혈액을, EDTA를 함유하는 튜브에 채혈하고, 즉시 얼음 위에 두었다. 혈액을 실온에서 3,000 rpm에서 15분 동안 원심분리하여, 혈장을 분리하였다. 혈장 시료를 분취하고, -80°C에 저장하였다. 분취량을 PBS에서 2배 희석하고, 마우스 사이토카인 어레이 전염증성 집중 10-플렉스(MDF10: Mouse Cytokine Array Proinflammatory Focused 10-plex) 검정을 사용하여 분석하였다.
도 235에 도시된 바와 같이, 결과는 TGFRt15-TGFRs+TA99의 투여가 화학요법 치료군과 비교할 때 치료-후 10일차에 종양-보유 마우스에서 IL2, IL-1β, IL6, MCP-1, 및 GM-CSF의 혈장 수준을 감소시켰음을 보여준다. 이러한 효과는 TGFRt15-TGFRs의 면역자극성 활성과 일관된다.
실시예 104: TGFRt15-TGFRs 치료는 B16F10 종양 보유 마우스의 비장에서 NK 및 CD8
+
확장을 증강시킨다
C57BL/6 마우스에게 0.5x106 B16F10 세포를 피하 주사하였다. 종양 접종(0일차) 후, 마우스에게 1일차, 4일차, 및 7일차에 3개 용량의 도세탁셀 화학요법(10 mg/kg) 및 8일차에 종양 항원을 표적화하는 단일클론 항체 항-TYRP-1 항체 TA99(200 μg)와 병용된 단회 용량의 TGFRt15-TGFRs(3 mg/kg)를 주었다. 1일차, 4일차, 및 7일차에 식염수 또는 도세탁셀 화학요법(10 mg/kg)으로 치료된 종양-보유 마우스는 대조군으로서 역할을 하였다. 마우스를 희생시키고, 비장을 면역요법-후 3일차, 5일차, 및 10일차에 수합하였다(8일차). 3 cc 주사기의 멸균 피스톤/플런저의 편평한 후단(back end)으로 비장을 분쇄하여 비장 세포를 방출하였다. 비장세포를 70-μM 세포 스트레이너를 통해 통과시키고, 단일 세포 현탁액으로 균질화하였다. RBC를 ACK 용해 완충액에 용해시키고, 비장세포를 세척하고 실온에서 30분 동안 NK 및 CD8의 세포 표면 발현을 위한 항체(BioLegend)로 염색하였다. 2회의 세척 후, 세포를 고정 완충액에 재현탁시키고, 유세포측정법(Celesta-BD Bioscience)에 의해 분석하였다.
도 236에 도시된 바와 같이, NK 세포 및 CD8+ 세포의 확장은 식염수 또는 화학요법 치료군과 비교할 때 TGFRt15-TGFRs+TA99 요법 후 3일차 및 5일차에 비장에서 관찰되었다. NK 세포(CD8+ 세포가 아닌)의 수준은 화학요법 치료군의 비장에서의 수준과 비교할 때 종양-보유 마우스의 비장에서 면역요법-후 10일차에 상승되는 것으로 여전히 발견되었다. 이들 효과는 TGFRt15-TGFRs의 면역자극성 활성과 일관된다.
실시예 105: TGFRt15-TGFRs 치료는 B16F10 종양 보유 마우스에서 비장세포의 해당 활성을 증강시킨다
C57BL/6 마우스에게 0.5x106 B16F10 세포를 피하 주사하였다. 종양 접종(0일차) 후, 마우스에게 1일차, 4일차, 및 7일차에 3개 용량의 도세탁셀 화학요법(10 mg/kg) 및 8일차에 종양 항원을 표적화하는 단일클론 항체 항-TYRP-1 항체 TA99(200 μg)와 병용된 단회 용량의 TGFRt15-TGFRs(3 mg/kg)를 주었다. 1일차, 4일차, 및 7일차에 식염수 또는 도세탁셀 화학요법(10 mg/kg)으로 치료된 종양-보유 마우스는 대조군으로서 역할을 하였다. 마우스를 희생시키고, 비장을 면역요법-후 3일차, 5일차, 및 10일차에 수합하였다(8일차). 3 cc 주사기의 멸균 피스톤/플런저의 편평한 후단으로 비장을 분쇄하여 비장 세포를 방출하였다. 비장세포를 70-μM 세포 스트레이너를 통해 통과시키고, 단일 세포 현탁액으로 균질화하였다. RBC를 ACK 용해 완충액에서 용해시키고, 비장세포를 세척하고 카운팅하였다. 비장세포의 해당 활성을 측정하기 위해, 세포를 세척하고, seahorse 배지에 재현탁시키고, 4 x 106 세포/mL로 재현탁시켰다. 세포를 해당 스트레스 시험을 위해 Cell-Tak-코팅된 Seahorse Bioanalyzer XFe96 배양 플레이트에서 2 mM L-글루타민이 보충된 Seahorse XF RPMI 배지, pH 7.4에서 50 μL/웰로 시딩하였다. 세포를 37℃에서 30분 동안 플레이트에 부착하게 하였다. 추가로, 130 μL의 검정 배지를 플레이트의 각각의 웰(또한 배경 웰)에 첨가하였다. 플레이트를 1시간 동안 37℃, 비-CO2 인큐베이터에서 인큐베이션하였다. 해당작용 스트레스 시험을 위해 보정 플레이트는 Seahorse 검정 배지에서 제조된 포도당/올리고마이신/2DG의 10x 용액을 함유하였고, 20 μL의 포도당/올리고마이신/2DG를 밤새 보정된 세포외 플럭스 플레이트의 각각의 포트에 첨가하였다. 해당작용 스트레스 시험은 세포외 산성화율(ECAR)에 기초하고, 해당작용, 해당 용량, 및 해당 비축량(glycolytic reserve)을 포함한 해당 기능의 3개의 핵심 파라미터를 측정한다. 완전 ECAR 분석은 4개 단계로 구성되었다: 비-해당작용 산성화(약물 없음), 해당작용(10 mM 포도당), 최대 해당작용 유도/해당작용 용량(2 μM 올리고마이신), 및 해당작용 비축량(100 mM 2-DG). 실험 종료 시, 데이터를 Graph Pad Prism 파일로서 내보내기하였다. XF 해당작용 스트레스 시험 보고 생성기(generator)는 Wave 데이터로부터의 XF 세포 해당작용 스트레스 시험 파라미터를 자동적으로 계산하였다. Wave 소프트웨어(Agilent)를 사용하여 데이터를 분석하였다.
도 237a 및 도 237b에 도시된 바와 같이, TGFRt15-TGFRs+TA99 요법 후 3일차 및 5일차에 종양-보유 마우스로부터 단리된 비장세포는 식염수 또는 화학요법 치료군의 비장세포와 비교할 때 증강된 기저 해당작용, 용량 및 비축율을 보여주었다. 그러나, 비장세포 해당 활성에서의 어떠한 유의한 차이도 면역요법-후 10일차에 관찰되지 않았다. 이들 효과는 TGFRt15-TGFRs의 면역자극성 활성과 일관된다.
실시예 106: TGFRt15-TGFRs 치료는 B16F10 종양 보유 마우스에서 비장세포의 미토콘드리아 호흡을 증강시킨다
C57BL/6 마우스에게 0.5x106 B16F10 세포를 피하 주사하였다. 종양 접종(0일차) 후, 마우스에게 1일차, 4일차, 및 7일차에 3개 용량의 도세탁셀 화학요법(10 mg/kg) 및 8일차에 종양 항원을 표적화하는 단일클론 항체 항-TYRP-1 항체 TA99(200 μg)와 병용된 단회 용량의 TGFRt15-TGFRs(3 mg/kg)를 주었다. 1일차, 4일차, 및 7일차에 식염수 또는 도세탁셀 화학요법(10 mg/kg)으로 치료된 종양-보유 마우스는 대조군으로서 역할을 하였다. 마우스를 희생시키고, 비장을 면역요법-후 3일차, 5일차, 및 10일차에 수합하였다(8일차). 3 cc 주사기의 멸균 피스톤/플런저의 편평한 후단으로 비장을 분쇄하여 비장 세포를 방출하였다. 비장세포를 70 μM 세포 스트레이너를 통해 통과시키고, 단일 세포 현탁액으로 균질화하였다. RBC를 ACK 용해 완충액에서 용해시키고, 비장세포를 세척하고 카운팅하였다. 비장세포의 미토콘드리아 호흡율을 측정하기 위해, 세포를 세척하고, seahorse 배지에 재현탁시키고, 4 x 106 세포/mL로 재현탁시켰다. 세포를 해당 스트레스 시험을 위해 Cell-Tak-코팅된 Seahorse Bioanalyzer XFe96 배양 플레이트에서 2 mM L-글루타민이 보충된 Seahorse XF RPMI 배지, pH 7.4에서 50 μL/웰로 시딩하였다. 미토콘드리아 스트레스 시험을 위해, 세포를 10 mM 포도당 및 2 mM L-글루타민이 보충된 Seahorse XF RPMI 배지, pH 7.4에서 시딩하였다. 세포를 37℃에서 30분 동안 플레이트에 부착하게 하였다. 추가로, 130 μL의 검정 배지를 플레이트의 각각의 웰(또한 배경 웰)에 첨가하였다. 플레이트를 1시간 동안 37℃, 비-CO2 인큐베이터에서 인큐베이션하였다. 미토콘드리아 스트레스 시험을 위해, 보정 플레이트는 Seahorse 검정 배지에서 제조된 올리고마이신/FCCP/로테논의 10x 용액을 함유하였고, 20 μL의 올리고마이신, FCCP, 및 로테논을 밤새 보정된 세포외 플럭스 플레이트의 각각의 포트에 첨가하였다. XFe96 Extracellular Flux Analyzer를 사용하여 산소 소모율(OCR)을 측정하였다. 완전 OCR 분석은 4개 단계로 구성되었다: 기저 호흡율(약물 없음), ATP-연결 호흡율/양성자 피크(1.5 μM mM 올리고마이신), 최대 호흡율(2 μM FCCP), 및 여분 호흡율(0.5 μM 로테논). 실험 종료 시, 데이터를 Graph Pad Prism 파일로서 내보내기하였다. XF 미토콘드리아 스트레스 시험 보고 생성기는 엑셀로 내보내기된 Wave 데이터로부터의 XF 미토콘드리아 스트레스 시험 파라미터를 자동적으로 계산한다. Wave 소프트웨어(Agilent)를 사용하여 데이터를 분석하였다.
도 238a 및 도 238b에 도시된 바와 같이, TGFRt15-TGFRs+TA99 요법 후 3일차 및 5일차에 종양-보유 마우스로부터 단리된 비장세포는 식염수 또는 화학요법 치료군의 비장세포와 비교할 때 증강된 기저 호흡율, 미토콘드리아 호흡율, 용량 및 ATP 생성을 보여주었다. 그러나, 비장세포 미토코드리아 호합율에서의 어떠한 유의한 차이도 면역요법-후 10일차에 관찰되지 않았다. 이들 효과는 TGFRt15-TGFRs의 면역자극성 활성과 일관된다. 산화적 대사 및 해당작용과 같은 대사 경로는 세포 운명 결정 및 면역 세포의 이펙터 기능을 우선적으로 북돋는 것으로 알려져 있다. 따라서, TGFRt15-TGFRs 매개 증가된 해당 활성 및 미토콘드리아 호흡율은 마우스의 혈액, 비장, 및 종양에서 NK 및 CD8+ 면역 세포의 활성화와 관련이 있을 것이다.
실시예 107: TGFRt15-TGFRs 치료는 B16F10 종양 보유 마우스의 종양 내로의 NK 및 CD8 면역 세포 침윤(TIL)을 증강시킨다
C57BL/6 마우스에게 0.5x106 B16F10 세포를 피하 주사하였다. 종양 접종(0일차) 후, 마우스에게 1일차, 4일차, 및 7일차에 3개 용량의 도세탁셀 화학요법(10 mg/kg) 및 8일차에 종양 항원을 표적화하는 단일클론 항체 항-TYRP-1 항체 TA99(200 μg)와 병용된 단회 용량의 TGFRt15-TGFRs(3 mg/kg)를 주었다. 1일차, 4일차, 및 7일차에 식염수 또는 도세탁셀 화학요법(10 mg/kg)으로 치료된 종양-보유 마우스는 대조군으로서 역할을 하였다. 마우스를 희생시키고, 종양을 면역요법-후 3일차, 5일차, 및 10일차에 수합하였다. 종양 조직을 콜라게나제 분해에 의해 단일 세포 현탁액으로 해리시켜, 종양-침윤성 면역 세포를 결정하였다. 단일 세포 현탁액을 Ficoll-Paque 배지 상에 적층하고, 뒤이어 밀도 구배 원심분리하여 림프구 및 종양 세포를 분리하였다. 세포를 20°C에서 1000 g에서 20분 동안 원심분리하고, 천천히 가속하고, 브레이크를 껐다. 원심분리 후, Ficoll-Paque는 2개 층 사이에서 명백한 분리를 초래한다. TIL은 배지와 Ficoll-Paque 사이의 계면에서 발견되는 한편, 펠렛은 종양 세포로 구성된다. TIL을 계면으로부터 조심스럽게 제거하고, 완전 PRMI 배지로 세척하였다. 세척 후, RBC를 ACK 완충액에서 실온에서 5분 동안 용해시켰다. 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다. 종양 내 상이한 유형의 면역 세포를 평가하기 위해, 세포를 세포-표면 CD8, NK1.1, CD25, 및 GzB(BioLegend)에 대한 항체로 RT에서 30분 동안 염색하였다. 표면 염색 후, 잔여 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다(실온에서 1500 RPM에서 5분 동안). 2회의 세척 후, 세포를 고정 완충액에 재현탁시켰다. 고정 후, 세포를 세척하고, 4°C에서 20분 동안 투과 용액(Invitrogen)으로 처리하고, 뒤이어 투과 완충액(Invitrogen)으로 세척하였다. 그 후에, 세포를 증식에 대한 세포내 마커(Ki67)에 대해 RT에서 30분 동안 염색하였다. 2회의 세척 후, 세포를 고정 완충액에 재현탁시키고, 유세포측정법(Celesta-BD Bioscience)에 의해 분석하였다.
도 239a 및 도 239b에 도시된 바와 같이, 종양 분석은 요법 후 3일째에 높은 수준의 Ki67-양성 NK 세포 및 CD8 세포를 보여주었다. NK 및 CD8+ 세포(종양 내 림프구의 %에 기초함)의 확장은 화학요법 치료군과 비교할 때 TGFRt15-TGFRs+TA99 요법 후 3일차 및 5일차에 발견되었다. 종양 CD8+ 세포가 면역요법-후 10일차에서도 상승되었다. NK와 CD8+는 둘 다 화학요법 치료군의 면역 세포와 비교할 때 TGFRt15-TGFRs+TA99 요법 후 3일차에 활성화 마커 CD25 및 그랜자임 B의 발현을 보여주었다. 이들 효과는 TGFRt15-TGFRs의 면역자극성 활성과 일관되고, 종양-보유 마우스의 혈액 및 비장세포에서 관찰된 변화와 대등하다.
실시예 108: TGFRt15-TGFRs 치료 후 종양의 조직병리학적 분석
C57BL/6 마우스에게 0.5x106 B16F10 세포를 피하 주사하였다. 종양 접종(0일차) 후, 마우스에게 1일차, 4일차, 및 7일차에 3개 용량의 도세탁셀 화학요법(10 mg/kg) 및 8일차에 종양 항원을 표적화하는 단일클론 항체 항-TYRP-1 항체 TA99(200 μg)와 병용된 단회 용량의 TGFRt15-TGFRs(3 mg/kg)를 주었다. 1일차, 4일차, 및 7일차에 식염수 또는 도세탁셀 화학요법(10 mg/kg)으로 치료된 종양-보유 마우스는 대조군으로서 역할을 하였다. 면역요법 치료(8일차) 후 1일차, 3일차, 5일차, 및 10일차에 하악하 정맥으로부터 혈액을 채혈하였다. 면역요법-후 10일차에, 마우스를 희생시키고, 종양을 단리하였다. 조직학적 분석을 위해, 종양 시료를 10% 포르말린 용액에서 고정시키고, 파라핀에 포매시키고, 5 μm로 절단하였다. 절편을 H & E로 염색하여, 조직 및 세포 형태를 평가하였다. 슬라이드를 종양의 유사분열 및 괴사 활성에 기초하여 채점하였다. 종양에서의 괴사 백분율을 +1(0-20%), +2(20-40%), 및 +3(40-60%)로서 채점하였다. 종양의 유사분열 지수를 +1=중간(고출력장당 1 내지 5) 및 +2= 광범위(고출력장당 >5)로서 채점하였다.
도 240에 도시된 바와 같이, TGFRt15-TGFRs+TA99 치료 후, 종양은 유사분열 및 괴사 활성을 거의 나타내지 않았다. 유사분열 지수는 분열 세포와 상관관계가 있고, 괴사의 존재는 더 공격적인 특질 및 불량한 예후의 측정치이다. 그러므로, TGFRt15-TGFRs는 병용 종양 면역요법의 시험을 위한 전임상 뮤린 모델에서 유망한 요법이다.
실시예 109: B16F10 흑색종 마우스 모델에서 TGFRt15-TGFRs+TA99 및 화학요법과 병용된 항-PD-L1 항체
C57BL/6 마우스에게 0.5x106 B16F10 세포를 피하 주사하였다. 종양 접종(0일차) 후, 마우스에게 1일차, 4일차, 및 7일차에 3개 용량의 도세탁셀 화학요법(10 mg/kg)을 주었다. 1일차, 4일차, 및 7일차에 식염수 또는 도세탁셀 화학요법(10 mg/kg) 단독으로 치료된 종양-보유 마우스는 대조군으로서 역할을 하였다. 잔여 마우스를 2개 군으로 무작위화하고, 1개 군을 항-mPD-L1 항체(2 x 10 mg/kg)로 치료하고 다른 군을 8일차에 TA99(200 μg)와 함께 TGFRt15-TGFRs(3 mg/kg)로 치료하였다. 6일 후에, TA99와 함께 TGFRt15-TGFRs를 받은 마우스에게 항-mPD-L1 항체(2 x 10 mg/kg)를 주었고, 항-mPD-L1 항체를 받은 마우스를 TA99(200 μg)와 함께 TGFRt15-TGFRs(3 mg/kg)로 치료하였다. 항-mPD-L1 항체를 8일차와 10일차 또는 14일차와 16일차에 2개 용량으로 주었다. 종양 성장을 캘리퍼 측정에 의해 모니터링하였고, 종양 부피를 식 V= (LxW2)/2를 사용하여 계산하였으며, 상기 식에서, L은 최대 종양 직경이고 W는 수직 종양 직경이다. N=6-8 마우스/군.
도 241에 도시된 바와 같이, TGFRt15-TGFRs+TA99 투여, 뒤이어 항-PD-L1 항체 치료는 항-PD-L1 항체와 그 다음에 TGFRt15-TGFRs+TA99를 이용한 치료와 비교하여 B16F10 종양-보유 마우스에서 더 양호한 항종양 활성을 초래하였다. 따라서, TGFRt15-TGFRs와 항-PD-L1 항체의 병용은 항-PD-L1 항체 요법에 내성인 종양을 치료하는 데 유리할 수 있다.
실시예 110: B16F10 흑색종 마우스 모델에서 TGFRt15-TGFRs의 항종양 효능은 NK 및 CD8+ T 세포에 의존한다
C57BL/6 마우스 군(N=6-8 마우스/군)을 3일마다 3개 용량의 NK1.1 Ab(500 μg) 또는 CD8+a(500 μg) 항체로 복강내로 치료하여, NK 세포 및 CD8 세포를 결실시켰다. 혈액을 채혈하고, B16F10 종양 이식 전에 NK 및 CD8+ 림프구 수준에 대해 분석하였다. 비치료된 마우스는 면역적격 대조군으로서 역할을 하였다. C57BL/6 마우스에게 0.5x106 B16F10 세포를 피하 주사하였다. 종양 접종(0일차) 후, 마우스에게 1일차, 4일차, 및 7일차에 3개 용량의 도세탁셀(10 mg/kg) 및 8일차에 단회 용량의 TGFRt15-TGFRs(3 mg/kg) + TA99(200 μg)를 주었다. 종양 성장을 캘리퍼 측정에 의해 모니터링하였고, 종양 부피를 식 V = (L × W2)/2를 사용하여 계산하였으며, 상기 식에서, L은 최대 종양 직경이고 W는 수직 종양 직경이다.
도 242에 도시된 바와 같이, TA99 및 화학요법과 병용된 TGFRt15-TGFRs로 치료된 B16F10 종양 보유 마우스는 식염수 또는 화학요법 치료군의 종양과 비교할 때 B16F10 종양 부피에서 유의한 감소를 보여주었다. 그러나, 마우스가 NK 및 CD8+ 세포 하위세트에 대해 결실되었을 때, 항-항종양 활성에 미치는 면역요법의 어떠한 효과도 존재하지 않았다. 이 실험은 NK 면역 세포와 CD8+ 면역 세포가 둘 다 TGFRt15-TGFRs 매개 항종양 활성에서 중요한 역할을 함을 보여준다.
실시예 111: 화학요법 후 B16F10 종양-보유 마우스의 간 및 폐 조직에서 노쇠 마커를 감소시키는 데 있어서 TGFRt15-TGFRs 및 TGFRt15*-TGFRs 치료의 비교
C57BL/6, 6-8주령 마우스를 Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 사육시켰다. 마우스를 하기와 같이 5개 군으로 나누었다: 식염수 대조군(n =7), 도세탁셀군(DTX)(n =7), DTX + TGFRt15-TGFRs 군(n =7), DTX + TGFRt15*-TGFRs 군(n =7), 및 DTX + IL15SA 군(n =7). B16F10 종양 세포(1 x107 세포/마우스)를 0일차에 이식하였다. 마우스를 1일차, 4일차, 및 7일차에 10 mg/kg 도세탁셀로 피하 치료하였다. 8일차에, 마우스를 PBS, TGFRt15-TGFRs(3 mg/kg), TGFRt15*-TGFRs(3 mg/kg), 또는 IL15SA(0.5 mg/kg)로 피하 치료하였다. 마우스를 치료-후 17일차에 안락사시키고, 간 및 폐를 수합하여, TGFRt15-TGFRs 또는 TGFRt15*-TGFRs 및 대조군을 이용한 치료 후 조직에서의 정량적-PCR에 의해 간에 대한 노쇠 마커 p21, IL-1α, 및 IL6과 폐에 대한 p21 및 IL-1α의 유전자 발현을 평가하였다. 수합된 기관을 1.7 mL Eppendorf 튜브에서 액체 질소에 저장하였다. 시료를, 균질화기를 사용하여 1 mL의 트리졸(Thermo Fischer)에서 균질화하였다. 균질화된 조직을 신선한 Eppendorf 튜브에 옮겼다. RNeasy Mini 키트(Qiagen #74106)를 제조업체의 설명서에 따라 사용하여 총 RNA를 추출하였다. QuantiTect 역전사 키트(Qiagen)를 사용하는 cDNA 합성에 1 μg의 총 RNA를 사용하였다. Thermo Scientific으로부터 구매된 FAM-표지 예비설계된 프라이머를 사용하여 CFX96 검출 시스템(Bio-Rad)으로 실시간 PCR을 수행하였다. 반응을 검사된 모든 유전자에 대해 3벌로 진행시켰다. 하우스킵핑 유전자 18S 리보솜 RNA를 내부 대조군으로서 사용하여, 발현 수준에서의 가변성을 정규화하였다. 18S rRNA와 비교하여 각각의 표적 mRNA의 발현을 Ct에 기초하여 2-Δ(ΔCt)로서 계산하였으며, 여기서, ΔCt = Ct 표적 - Ct18S이다.
도 243에 도시된 바와 같이, 노쇠 마커 p21, IL-1α, 및 IL6은 화학요법 치료 마우스의 조직에서의 유전자 발현과 비교할 때 TGFRt15-TGFRs와 TGFRt15*-TGFRs-치료 종양 보유 마우스 둘 다에서 간(a) 및 폐(b) 조직에서 저하된 유전자 발현을 보여주었다.
실시예 112: 생체내에서 화학요법-유도 노쇠 종양 세포를 감소시키는 데 있어서 TGFRt15-TGFRs 치료
B16F10 흑색종 세포를 GFP 렌티바이러스 플라스미드로 안정하게 형질도입하고, GFP-발현 종양 세포(B16F10-GFP)를 퓨로마이신 함유 배지에서의 성장에 의해 선택하였다. 대략 95% B16F10 흑색종 세포는 FACS에 의해 분석된 바와 같이 GFP-양성이었다. 노쇠를 유도하기 위해, B16F10-GFP 세포를 7.5 μM 도세탁셀(DTX)로 3일 동안 처리하고, 뒤이어 정상 성장 배지에서 4일 회복시켰다. 노쇠 마커 및 NK 세포 리간드의 유전자 발현을 정량화하기 위해, 1 mL의 트리졸(Thermo Fischer)에서 균질화기를 사용함으로써 도세탁셀-처리 B16F10 GFP 세포(B16F10-GFP-SNC)를 균질화하였다. 균질화된 세포를 신선한 Eppendorf 튜브에 옮겼다. RNeasy Mini 키트(Qiagen #74106)를 제조업체의 설명서에 따라 사용하여 총 RNA를 추출하였다. QuantiTect 역전사 키트(Qiagen)를 사용하는 cDNA 합성에 1 μg의 총 RNA를 사용하였다. Thermo Scientific으로부터 구매된 FAM-표지 예비설계된 프라이머를 사용하여 CFX96 검출 시스템(Bio-Rad)으로 실시간 PCR을 수행하였다. 반응을 검사된 모든 유전자에 대해 3벌로 진행시켰다. 하우스킵핑 유전자 18S 리보솜 RNA를 내부 대조군으로서 사용하여, 발현 수준에서의 가변성을 정규화하였다. 18S rRNA와 비교하여 각각의 표적 mRNA의 발현을 Ct에 기초하여 2-Δ(ΔCt)로서 계산하였으며, 여기서, ΔCt = Ct 표적 - Ct18S이다. 상이한 유전자의 발현을 비처리 B16F10-GFP 세포와 비교하여 B16F10-GFP-SNC 세포에서 배수-변화로서 플롯화한다.
도 244에 도시된 바와 같이, 실시간 PCR 분석은 시험관내에서 도세탁셀로 처리된 B16F10-GFP 세포가 비처리된 B16F10-GFP 세포와 비교할 때 노쇠 마커, p21, H2AX, 및 IL6과 NK 세포 리간드, Rae-1e 및 ULBP-1의 유전자 발현을 상향조절하였음을 보여주었다.
화학요법-유도 노쇠 종양 세포가 생체내에서 면역요법에 의해 감소되는지의 여부를 결정하기 위해, B16F10 모 흑색종 세포(0.75 x 106)를 B16F10-GFP-SNC 세포(0.75 x 106)와 혼합하고, 세포 혼합물을 C57BL/6 마우스에서 피하 주사하였다. 마우스에게 B16F10 및 B16F10-GFP 세포를 또한 대조군으로서 주사하였다. B16F10 모(parent) 세포는 성장하여 종양을 형성할 것이고, B16F10-GFP-SNC 세포는 종양 미세환경의 부분이 될 것이다. 종양이 대략 350 mm3에 도달하였을 때, 혼합 종양을 보유한 마우스를 2개 군으로 나누었다. 하나의 군은 PBS를 대조군으로서 받았고, 다른 군은 TA99(200 μg)와 함께 TGFRt15-TGFRs(3 mg/kg)를 피하로 받았다. 면역요법 치료 후 4일차에 마우스를 희생시켰다. 종양 조직을 콜라게나제 분해에 의해 단일 세포 현탁액으로 해리시켜, 종양-침윤성 면역 세포를 결정하였다. 단일 세포 현탁액을 Ficoll-Paque 배지 상에 적층하고, 뒤이어 밀도 구배 원심분리하여 림프구 및 종양 세포를 분리하였다. 세포를 20°C에서 1000 g에서 20분 동안 원심분리하고, 천천히 가속하고, 브레이크를 껐다. 원심분리 후, Ficoll-Paque는 2개 층 사이에서 명백한 분리를 초래한다. TIL은 배지와 Ficoll-Paque 사이의 계면에서 발견되는 한편, 펠렛은 종양 세포로 구성된다. TIL을 계면으로부터 조심스럽게 제거하고, 완전 PRMI 배지로 세척하였다. 세척 후, RBC를 ACK 완충액에서 실온에서 5분 동안 용해시켰다. 잔여 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다. 종양 내 상이한 유형의 면역 세포를 평가하기 위해, 세포를 세포-표면 CD3, CD45, CD8 및 NK1.1(BioLegend)에 특이적인 항체로 RT에서 30분 동안 염색하였다. 표면 염색 후, 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다(실온에서 1500 RPM에서 5분 동안). 2회의 세척 후, 세포를 고정 완충액에 재현탁시켰다. 고정 후, 세포를 세척하고, 4°C에서 20분 동안 투과 용액(Invitrogen)으로 처리하고, 뒤이어 투과 완충액(Invitrogen)으로 세척하였다. 그 후에, 세포를 증식에 대한 세포내 마커(Ki67)에 대해 RT에서 30분 동안 염색하였다. 2회의 세척 후, 세포를 고정 완충액에 재현탁시키고, 유세포측정법(Celesta-BD Bioscience)에 의해 분석하였다.
도 245에 도시된 바와 같이, CD8+ T 세포 및 자연 살해(NK) 세포의 백분율은 대조군과 비교하여 TGFRt15-TGFRs+TA99 치료 후 종양에서 처리-후 4일 후에 증가되었다. 이들 결과는, TGFRt15-TGFRs가 종양에서 CD8+ T 세포 및 NK 세포의 침윤을 자극시킬 수 있음을 실증한다. CD8+ T 세포와 NK 면역 세포는 둘 다 또한 Ki67 마커에 의해 측정된 바와 같이 종양에서 증식할 수 있었다.
화학요법-유도 노쇠 종양 세포가 생체내에서 면역요법에 의해 감소되는지의 여부를 결정하기 위해, B16F10 모 흑색종 세포(0.75 x 106)를 B16F10-GFP-SNC 세포(0.75 x 106)와 혼합하고, 세포 혼합물을 C57BL/6 마우스에서 피하 주사하였다. 마우스에게 B16F10 및 B16F10-GFP 세포를 또한 대조군으로서 주사하였다. B16F10 모 세포는 성장하여 종양을 형성할 것이고, B16F10-GFP-SNC 세포는 종양 미세환경의 부분이 될 것이다. 종양이 대략 350 mm3에 도달하였을 때, 혼합 종양을 보유한 마우스를 2개 군으로 나누었다. 하나의 군은 PBS를 대조군으로서 받았고, 다른 군은 TA99(200 μg)와 함께 TGFRt15-TGFRs(3 mg/kg)를 피하로 받았다. 면역요법 치료 후 4일차 및 10일차에 마우스를 희생시켰다. 종양 조직을 콜라게나제 분해에 의해 단일 세포 현탁액으로 해리시켜, 종양에서 종양-침윤성 면역 세포 및 GFP-양성 세포를 결정하였다. 종양 세포 상에서의 유세포측정법 분석(도 246a)은 면역요법 치료를 받은 마우스가 PBS 대조군과 비교하여 치료-후 4일 및 10일째에 더 낮은 수의 GFP-양성 세포를 나타내었음을 보여주었다. 종양 세포를 24-웰 플레이트에 평판배양하여, 형광 현미경에 의해 평가하였다(도 246b).
현미경 이미지는 또한, 대조군 PBS-치료군과 비교하여 면역요법-치료 마우스의 종양에서 더 적은 수의 GFP-양성 세포를 보여주었다. 종양에서의 GFP 발현은 화학요법-유도 B16F10-GFP 노쇠 세포와 관련이 있으며, 따라서 면역요법 치료 후 GFP 발현에서의 감소는 종양 보유 마우스에서 노쇠 종양 세포의 성공적인 제거를 보여준다.
실시예 113: 시스플라틴에 의해 신장 손상을 유도하고 TGFRt15-TGFRs를 이용한 치료 후 조직 ELISA에 의한 신장에서의 TGFβ 수준
마우스 신장을 수합하여, 시스플라틴에 의한 신장 손상을 유도하고 TGFRt15-TGFRs를 이용한 치료 후 노쇠 마커 TGFβ의 단백질 수준의 변화를 평가하였다. C57BL/6, 8주령 마우스를 Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 사육시켰다. 마우스에게 3주 동안 매주 시스플라틴(5 mg/kg, 복강내)을 주사하여, 신장 손상을 유도하였다. 시스플라틴 후 1주일째에, 마우스를 PBS 또는 TGFRt15-TGFRs(3 mg/kg)(n =8/군)로 치료하였다. 마우스를 30일의 면역요법 치료 후 안락사시키고, 신장을 수합하고 1.7 mL-Eppendorf 튜브에서 액체 질소에 저장하였다. 시료를, 균질화기를 사용하여 0.3 mL의 추출 완충액(Abcam)에서 균질화하였다. 균질화된 조직을 신선한 Eppendorf 튜브에 옮겼다. 균질화된 조직 내 단백질 수준을 BCA 단백질 검정 키트(Pierce)를 사용하여 정량화하였다. 마우스 TGFβ ELISA(R&D System)를 200 μg의 조직에서 수행하였다. TGFβ의 농도를 조직 밀리그램당 계산하였다.
도 247에 도시된 바와 같이, TGFβ 수준은 PBS 대조군과 비교하여 TGFRt15-TGFRs 치료 마우스 신장에서 저하되었다. 이들 결과는 TGFRt15-TGFRs 치료가 화학요법-치료 마우스의 조직에서 TGFβ 수준을 감소시키는 데 있어서 장기간 지속되는 활성을 제공할 수 있음을 나타낸다.
실시예 114: 마우스에서 TGFRt15-TGFRs의 피하 투여의 독성
TGFRt15-TGFRs의 용량-의존적 독성학적 효과를 추가로 평가하기 위해, 암컷 C57BL/6 마우스(N=3/군)에게 1개 또는 2개(2주마다)의 피하 용량의 PBS 또는 TGFRt15-TGFRs를 3, 10, 50, 및 200 mg/kg에서 투여하였다. 동물을 시험 약물-관련 독성의 징후, 연구 기간 동안의 체중 변화 및 혈액학과 혈청 화학 파라미터에 대해 투약-후 7일차에 모니터링하였다. 200 mg/kg TGFRt15-TGFRs를 받는 마우스는 제1 주사(연구일(SD) 0) 후 4일째에 시작하고 SD6-9 사이에 최하점에 도달한 후 SD11에 의해 용량-전 수준으로 되돌아가는 유의한 체중 손실을 나타내었다(도 248a). 사망율은 SD9에서 200 mg/kg 군 중 1 마리의 마우스에서 관찰되었다. 임의의 다른 용량군에서 또는 200 mg/kg에서의 제2 TGFRt15-TGFRs 용량 후 체중 또는 다른 임상 징후에 미치는 어떠한 분명한 치료-매개 효과도 없었다. 비장 중량은 1개 또는 2개 용량의 TGFRt15-TGFRs 후 용량 의존적 방식으로 증가되었다(도 248b). PBS 군과 비교하여, 마우스는 또한 단회 200 mg/kg 용량의 TGFRt15-TGFRs 후 7일째에 WBC 카운트에서 25배 증가를 나타내었고, 이는 제2의 200 mg/kg 용량 후 7일째에 5배 더 높은 채로 유지되었다(도 248c, 표 3 및 표 4). WBC 하위세트 분석은 200 mg/kg 군에서 SD7에서 호중구, 단핵구, 호산구, 및 호염기구 카운트에서 >50배 증가 및 절대 림프구 카운트에서 16배 증가를 보여주었다. 이들 변화는 더 낮은 TGFRt15-TGFRs 용량 수준에서는 관찰되지 않았으나, IL-15/IL-15Rα 복합체를 이용한 피하 치료로 치료된 C57BL/6 마우스에 대해 보고된 것과 유사하였다(문헌[Liu et al., Cytokine 107: 105-112, 2018]). 다른 혈액학 및 혈청 화학 파라미터는 TGFRt15-TGFRs 및 PBS 치료 동물에서 유사하였고, C57BL/6 마우스에 대해서는 일반적으로 예상된 범위 내에 있었다(표 3 및 표 4). TGFRt15-TGFRs-매개 효과는 제1 용량 후 7일째에 최대였고, 제2 용량 후 감소되었으며, 이는 IL-15/IL-15Rα를 이용한 반복 투약 후 마우스에서 저하된 면역 반응을 보여주는 이전의 연구와 일관되었다(문헌[Elpek et al., PNAS 107: 21647-21652, 2010; Frutoso et al., J Immunol 201: 493-506, 2018]). 전반적으로, TGFRt15-TGFRs는 최대 50 mg/kg의 용량 수준에서 C57BL/6 마우스에 의해 내약성이 좋았다.


실시예 115: 마우스에서 TGFRt15-TGFRs 및 TGFRt15*-TGFRs에 의한 TGF-β의 격리
암컷 C57BL/6 마우스에게 PBS 또는 3 mg/kg의 TGFRt15-TGFRs 또는 TGFRt15*-TGFRs를 피하 주사하고, 혈장을 치료-후 다양한 시점에서 수집하였다. TGF-β1 및 TGF-β2의 혈장 수준을 TGFβ 3-플렉스 검정을 사용하여 결정하였다(Eve Technologies, Calgary, AL, Canada). TGFRt15-TGFRs 및 TGFRt15*-TGFRs는 치료 후 2일째에 C57BL/6 마우스에서 혈장 TGF-β1 및 TGF-β2 수준을 유의하게 저하시키는 것으로 발견되었고(도 249), 이는 이들 융합 단백질의 TGFβRII 도메인의 활성과 일관되었다.
실시예 116: 생체내에서 그리고 시험관내에서 면역 세포에 미치는 TGFRt15-TGFRs 및 TGFRt15*-TGFRs의 효과
면역 세포 대사에 미치는 치료 매개 효과를 평가하기 위해, 세포외 흐름 검정을 PBS, TGFRt15-TGFRs, TGFRt15*-TGFRs 또는 IL-15/IL-15R(IL15SA) 투여 후 4일째에 마우스로부터 단리된 비장세포 상에서 수행하였다. 마우스 비장세포 상에서 세포외 흐름 검정을 XFp Analyzer(Seahorse Bioscience)를 사용하여 수행하였다. 예상된 바와 같이, TGFRt15-TGFRs 및 IL-15는 단리된 비장세포의 해당 용량의 속도(ECAR)(도 250a) 및 미토콘드리아 호흡 용량(OCR)(도 250b)을 용량-수준-의존적 방식으로 증가시켰다. 생체내 TGFRt15*-TGFRs 치료는 또한 비장세포의 ECAR 및 OCR을 증가시켰다. 이러한 현상은 비치료된 C57BL/6 마우스로부터의 비장세포를 시험관내에서 TGFRt15*-TGFRs로 4일 인큐베이션하였을 때 관찰되지 않았다. TGFRt15-TGFRs(TGFRt15*-TGFRs가 아니라)만 시험관내에서 생리학적으로 관련된 농도에서 비장세포 ECAR 및 OCR을 증가시킬 수 있었다(도 251a 내지 도 251b). 이는 TGFRt15-TGFRs의 TGFβRII 도메인 및 IL-15 도메인이 생체내에서 면역 세포 대사를 자극시키는 데 있어서 역할을 가짐을 시사한다.
실시예 117: C57BL/6 마우스에서 B16F10 흑색종에 대한 TGFRt15-TGFRs 및 TGFRt15*-TGFRs의 항종양 효능
TGFRt15-TGFRs 및 TGFRt15*-TGFRs 항종양 효능을 평가하기 위해, 뮤린 B16F10 약한 모델을 선택하였는데, 그 이유는 이것이 매우 공격적이고, 면역원성이 불량하고, 면역 침윤물이 없고, 성장에서 역할을 하는 TGF-β를 발현하고, 사이토카인과 검문 차단 면역요법에 내성이기 때문이다. B16F10 흑색종 세포(5 x 105 세포)(CRL-6475, ATCC)를 C57BL/6 마우스 내로 피하 주사하고, 뒤이어 종양 이식 후 1일차 및 4일차에 PBS, TGFRt15-TGFRs(3 또는 20 mg/kg) 또는 TGFRt15*-TGFRs(3 또는 20 mg/kg)를 피하 주사하였다. 종양 부피를 격일로 측정하고, ≥4000 mm3인 종양을 갖는 마우스를 IACUC 규제에 따라 희생시켰다. 마우스 생존율을 또한 연구 기간 전반에 걸쳐 평가하였다. SD15(즉, 동물 사망률 전)를 통해 비교할 때, 20 mg/kg에서 TGFRt15-TGFRs 또는 TGFRt15*-TGFRs를 이용한 치료는 PBS 치료 마우스에서 관찰된 것보다 유의하게 더 느린 종양 성장을 초래하였다(도 252a). 20 mg/kg TGFRt15-TGFRs로 치료된 종양-보유 마우스는 또한 3 mg/kg TGFRt15-TGFRs 및 PBS 치료군과 비교할 때 연장된 생존율을 보여주었다(도 252b). 이들 결과는 TGFRt15-TGFRs 및 TGFRt15*-TGFRs가 고형 B16F10 흑색종 종양에 대해 항종양 활성을 가짐을 나타내며, 이작용성 TGFRt15-TGFRs 복합체가 더 큰 효능을 나타낸다. 그러므로, TGFβRII 도메인과 IL-15/IL-15RαSu 도메인은 둘 다 B16F10 종양에 대한 TGFRt15-TGFRs-매개 활성에서 역할을 한다.
TGFRt15-TGFRs 치료는 생체내에서 NK 세포 및 T 세포의 수를 유의하게 증가시킬 수 있다. 이들 면역 세포가 TGFRt15-TGFRs-매개 항종양 효능에 책임이 있는지의 여부를 결정하기 위해, CD8+ T 세포 및 NK1.1+ 세포의 Ab 면역고갈을 TGFRt15-TGFRs 치료 전에 종양-보유 마우스에서 실시하였다. NK1.1+ 세포 결핍(단독으로 또는 CD8+ T 세포 결핍과 조합됨)은 제1의 2주 치료-후 동안 B16F10 종양-보유 마우스에서 TGFRt15-TGFRs의 항종양 효과를 제거한 반면(도 252c), NK1.1+ 세포 결핍 또는 CD8+ T 세포 결핍은 TGFRt15-TGFRs로 관찰된 생존 이익을 감소시킨 것으로(도 252d) 발견되었다. 이들 발견과 일관되게, TGFRt15-TGFRs 치료는 또한 B16F10 종양 내로의 NK 세포 및 CD8+ T 세포 침윤의 증가를 촉진하였다(도 252e). 이들 결과는 CD8+ T 세포와 NK 세포가 둘 다 C57BL/6 마우스에서 흑색종 종양 세포에 대한 TGFRt15-TGFRs-매개 활성에서 주요한 역할을 한다는 결론을 지지한다.
실시예 118: TGFRt15-TGFRs는 db/db 마우스에서 포도당 제어를 향상시켰다
5주령의 수컷 BKS.Cg-Dock7m +/+ Leprdb/J(db/db) 마우스(Jackson Lab)를 표준 사료 식이요법으로 사육하고, 표준 조건에서 유지시켰다. 마우스(n = 5/군)는 연구 시작으로부터 6주차 및 12주차에 PBS(대조군) 또는 TGFRt15-TGFRs(3 mg/kg)(치료군)의 피하 주사를 받았다. 공복 혈당 및 인슐린을 제1 용량 후 3주째에 체크하였다. 공복 포도당은 대조군과 비교하여 TGFRt15-TFGRs 치료 후 유의하게 감소되었으나(도 253a), 혈액 인슐린 수준은 변하지 않았다(도 253b).
실시예 119: TGFRt15-TGFRs는 노화 지수 및 SASP 지수를 유의하게 하향조절하였다
5주령의 수컷 BKS.Cg-Dock7m +/+ Leprdb/J(db/db) 마우스를 표준 사료 식이요법으로 사육하고, 식수를 마음대로 제공받았다. 6주령에서, 마우스를 대조군 및 치료군(n = 5/군)으로 무작위로 할당하였다. 치료군은 TGFRt15-TGFRs를 3 mg/kg에서 연구 시작으로부터 6주차 및 12주차에 피하 주사에 의해 받은 한편, 대조군은 비히클(PBS) 단독을 받았다. 연구 종료(제2 용량 후 4주째) 시, 마우스를 안락사시키고, 췌장을 수집하였다. 췌장의 절반을 TRIzol 시약(Invitrogen)으로 균질화하고, 전체 조직 RNA를 RNeasy Mini 키트(Qiagen)로 정제하였다. cDNA 합성을 QuantiTect Reverse Transcription 키트(Qiagen)를 사용하여 수행하고, 정량적 PCR을 SsoAdvanced™ Universal SYBR® Green Supermix(BioRad)와 QuantiStudio 3 Real-Time PCR System(Applied Biosystems)을 제조업체의 설명서에 따라 대등한 역치 주기에 따라 사용하여 수행하였다. 증폭 반응을 2벌로 수행하였고, 형광 곡선을 QuantiStudio 3 Real-Time PCR 시스템에 포함된 소프트웨어로 분석하였다. 하우스킵핑 유전자 18s 리보솜 RNA를 내인성 대조 참조로서 사용하였다. 18s rRNA와 비교하여 각각의 표적 mRNA의 발현을 Ct에 기초하여 2-Δ(ΔCt)로서 계산하였으며, 여기서, ΔCt = Ct표적 - Ct18S이다. 도 254a에 도시된 바와 같이, db/db 마우스의 TGFRt15-TGFRs 치료는 대조군과 비교할 때 노화 유전자 지수의 p16, p21, Igfr1, 및 Bamb1 및 SASP 유전자 지수의 IL-1α, IL-6, MCP-1, 및 TNFα에 대한 췌장 유전자 발현의 감소를 초래하였다. 일반적으로, SASP 지수 및 노화 지수의 유전자의 췌장 발현은 대조군과 비교하여 TGFRt15-TGFRs 치료 후 유의하게 감소된 반면, 베타 세포 지수의 췌장 유전자 발현은 TGFRt15-TGFRs 및 PBS-치료 db/db 마우스에서 유의하게 변하지 않았다(도 254b, 도 254c 및 도 254d). 데이터는 TGFRt15-TGFRs가 db/db 마우스의 췌장에서 노쇠 세포 및 SASP 인자를 감소시키는 강력한 노쇠용해 및 노쇠형태 활성을 가짐을 시사하였다.
실시예 120: TGFRt15-TGFRs는 췌장 베타 세포의 노쇠 세포를 감소시켰다
5주령의 수컷 BKS.Cg-Dock7m +/+ Leprdb/J(db/db) 마우스(Jackson Lab)를 표준 사료 식이요법(방사선 조사된 2018 Teklad 글로벌 18% 단백질 설치류 식이요법, Envigo)으로 사육하고, 식수를 마음대로 제공받았다. 6주령에서, 마우스를 대조군 및 치료군(n = 5/군)으로 무작위로 할당하였다. 치료군은 TGFRt15-TGFRs를 3 mg/kg에서 연구 시작으로부터 6주차 및 12주차에 피하 주사에 의해 받은 한편, 대조군은 비히클(PBS) 단독을 받았다. 연구 종료 시(제2 용량 후 4주째), 마우스를 안락사시키고, 췌장을 일괄 제거하고, 4% 포름알데하이드(0.1 M 포스페이트 완충액 중 4% 포름알데하이드; PBS pH 7.4)에 침지-고정시키고, 4°C에서 추가 가공 시까지 저장하였다. 해부된 췌장을 파라핀 처리하고, 포매하고, 절편화하고, 각각의 블록으로부터 3개의 10 mm 절편(150 mm 간격)을 절단하였으며, 이는 각각의 동물의 전체 췌장의 체계적이고 균일한 무작위 시료를 전체적으로 나타낸다.
Akoya Vectra Polaris 기기를 사용하여 다중스펙트럼 이미징을 수행하였다. 이 계측은 포르말린-고정 파라핀-내장 생검 절편에서 조직 침윤물의 표현형 분석, 정량화, 및 공간 관계 분석을 가능하게 한다. 췌장의 인슐린+ 췌도 영역에서 p21의 수준을 정량화하기 위해, 포르말린-고정 파라핀-내장 조직 절편을 Akoya에 의해 제공되고 HIMSR에 의해 일상적으로 수행되는 표준 프로토콜에 따라 특정 1차 항체로 연속적으로 염색하였다. 간략하게는, 슬라이드를 탈파라핀화하고, 항원 제거 완충액에서 열 처리하고, 차단하고, 인슐린(#4590, Cell Signaling Technology) 및 p21(EPR362, Abcam)에 대한 토끼 1차 항체, 뒤이어 호스래디쉬 퍼옥시다제(HRP)-접합 2차 항체 중합체(항-토끼), 및 각각의 HRP 분자 바로 옆을 둘러싸고 있는 조직 상에 염료를 침착시키기 위해 TSA 화학을 사용하는 HRP-반응성 OPAL 형광 시약(인슐린에 대해 OPAL-520, 및 p21에 대해 OPAL-570, Akoya)과 함께 인큐베이션하였다. 후속적인 염색 단계에서 형광 염료의 추가 침착을 방지하기 위해, 슬라이드를 항원 검색 완충액(인슐린에 대해서는 시트레이트 완충액 및 p21에 대해서는 EDTA 완충액)에서의 열 처리로 각각의 염색 사이에서 스트리핑하였다. 전체 슬라이드 스캔을 0.5 미크론 해상도의 20x 대물렌즈를 사용하는 Akoya Vectra Polaris 장비로 수집하였다. 3색 이미지를 inForm 소프트웨어(Akoya)로 분석하여, 인접한 형광색소를 혼합 해제하고, 자가형광을 빼고, 세그먼트 인슐린+ 영역을 구분하고, 세포의 빈도와 위치를 비교하고, 세포의 세포질과 핵 영역을 구분하고, 세포 마커 발현에 따라 침윤성 세포를 포현형분석하였다.
도 255a 내지 도 255d에 도시된 바와 같이, p21 양성 노쇠 세포(OPAL-570)는 대조군의 췌장 내 인슐린 양성 췌도 베타 세포(OPAL-520)에서 더 많이 축적되었고(도 255a), 이들 노쇠 세포는 TGFRt15-TGFRs 치료군의 췌장에서 감소되었다(도 255b). 인슐린 양성 췌도 세포는 대조군과 비교하여 TGFRt15-TGFRs 치료군에서 유의하게 증가되었다(p=0.0278, 도 255c). p21 양성 노쇠 베타 세포(인슐린 양성)는 대조군과 비교하여 TGFRt15-TGFRs 치료군에서 감소되었지만, 차이는 통계학적으로 유의하지 않았다(도 255d). 전반적으로, 데이터는 TGFR15-TGFRs가 노쇠 세포를 제거하는 노쇠용해 활성을 갖고 db/db 마우스의 췌장에서 정상적인 기능적 췌도 베타 세포의 회수를 촉진함을 시사하였다.
실시예 121: TGFRt15-TGFRs는 NK, NKT, 및 CD8
+
T 세포를 증가시킴으로써 췌장 베타 세포의 노쇠 세포를 감소시켰다
5주령의 수컷 BKS.Cg-Dock7m +/+ Leprdb/J(db/db) 마우스(Jackson Lab)를 표준 사료 식이요법(방사선 조사된 2018 Teklad 글로벌 18% 단백질 설치류 식이요법, Envigo)으로 사육하고, 식수를 마음대로 제공받았다. 6주령에서, 마우스를 대조군 및 치료군(n = 5/군)으로 무작위로 할당하였다. 치료군은 TGFRt15-TGFRs를 3 mg/kg에서 연구 시작으로부터 6주차 및 12주차에 피하 주사에 의해 받은 한편, 대조군은 비히클(PBS) 단독을 받았다.
제1 용량 치료 후 4일째에, 혈액을 채혈하고, 전혈 세포(50 mL)를 ACK(암모늄-클로라이드-포타슘) 용해 완충액으로 처리하여 적혈구 세포를 용해시켰다. 그 후에, 림프구를 PE-Cy7-항-CD3, BV605-항-CD45, PerCP-Cy5.5-항-CD8a, BV510-항-CD4, 및 APC-항-NKp46 항체(모두 BioLegend로부터의 항체)로 염색하여, T 세포, NKT 세포, 및 NK 세포의 집단을 평가하였다. 도 256a 내지 도 256c에 도시된 바와 같이, CD8+ T 세포, CD3+NKP46+ NKT 세포, 및 CD3-NKP46+ NK 세포의 백분율은 PBS-치료 마우스와 비교하여 TGFRt15-TGFRs를 이용한 치료 후 db/db 마우스의 혈액에서 증가하였다.
실시예 122: TGFRt15-TGFRs의 투여 후 시노몰구스 원숭이의 말초 혈액에서 면역 세포 하위세트의 표현형 분석
시노몰구스 원숭이(군당 5M:5F)를 연구 1일차 및 15일차에 PBS(비히클) 또는 TGFRt15-TGFRs로 1, 3 또는 10 mg/kg으로 피하 치료하였다. 혈액을 예비일(1일차) 및 치료-후 5일차, 22일차, 및 29일차에 채혈하였다. PBMC를 준비하고 플루오르-접합 항체 패널로 염색하여, B 세포, NK 세포, NK-T 세포, Treg 세포 및 CD4+ T 세포와 CD8+ T 세포의 표현형을 유세포측정법에 의해 평가하였다. 도 257은 TGFRt15-TGFRs 투여가 치료-후 5일차에 Ki67+ NK 세포, NK-T 세포, Treg 세포 및 CD4+ T 세포와 CD8+ T 세포의 백분율의 유의한 증가를 초래하였음을 도시한다. 이들 발견은 TGFRt15-TGFRs 치료가 비-인간 영장류에서 이들 림프구 하위세트의 증식을 유도하였음을 나타낸다. 어떠한 치료 효과도 B 세포에서의 Ki67 발현에서 관찰되지 않았다.
실시예 123: TGFRt15-TGFRs의 IL-15 면역자극 및 TGF-β 길항제성 활성
6주령(젊음) 및 72주령(노화) C57BL/6 마우스에게 단회 용량의 PBS, TGFRt15-TGFRs(3 mg/kg) 또는 TGFRt15*-TGFRs(3 mg/kg)를 피하 주사하였다. 치료 후 4일차에, 마우스를 희생시키고, 비장을 수합하였다. 3 cc 주사기의 멸균 피스톤/플런저의 편평한 후단으로 비장을 분쇄하여 비장 세포를 방출하였다. 비장세포를 70 μM 세포 스트레이너를 통해 통과시키고, 단일 세포 현탁액으로 균질화하였다. RBC를 ACK 용해 완충액에서 용해시키고, 비장세포를 세척하고 카운팅하였다. 비장세포의 해당 활성을 측정하기 위해, 세포를 세척하고, Seahorse 배지에 재현탁시키고, 4 x 106 세포/mL로 재현탁시켰다. 세포를 해당 스트레스 시험을 위해 Cell-Tak-코팅된 Seahorse Bioanalyzer XFe96 배양 플레이트에서 2 mM L-글루타민이 보충된 Seahorse XF RPMI 배지, pH 7.4에서 50 μL/웰로 시딩하였다. 세포를 37℃에서 30분 동안 플레이트에 부착하게 하였다. 추가로, 130 μL의 검정 배지를 플레이트의 각각의 웰(또한 배경 웰)에 첨가하였다. 플레이트를 1시간 동안 37℃, 비-CO2 인큐베이터에서 인큐베이션하였다. 해당작용 스트레스 시험을 위해 보정 플레이트는 Seahorse 검정 배지에서 제조된 포도당/올리고마이신/2DG의 10x 용액을 함유하였고, 20 μL의 포도당/올리고마이신/2DG를 밤새 보정된 세포외 플럭스 플레이트의 각각의 포트에 첨가하였다. 해당작용 스트레스 시험은 세포외 산성화율(ECAR)에 기초하고, 해당작용, 해당 용량, 및 해당 비축량을 포함한 해당 기능의 3개의 핵심 파라미터를 측정한다. 완전 ECAR 분석은 4개 단계로 구성되었다: 비-해당작용 산성화(약물 없음), 해당작용(10 mM 포도당), 최대 해당작용 유도/해당작용 용량(2 μM 올리고마이신), 및 해당작용 비축량(100 mM 2-DG). 실험 종료 시, 데이터를 Graph Pad Prism 파일로서 내보내기하였다. XF 해당작용 스트레스 시험 보고 생성기는 Wave 데이터로부터의 XF 세포 해당작용 스트레스 시험 파라미터를 자동적으로 계산하였다. Wave 소프트웨어(Agilent)를 사용하여 데이터를 분석하였다.
도 258에 도시된 바와 같이, TGFRt15-TGFRs 치료 후 4일차에 노화 마우스로부터 단리된 비장세포는 PBS 또는 TGFRt15*-TGFRs 치료군의 비장세포와 비교할 때 증강된 기저 해당작용, 해당 용량, 및 해당 비축율을 보여주었다. 노화 대조군 마우스의 비장세포의 해당 기능은 젊은 대조군 마우스보다 더 작았다. TGFRt15*-TGFRs에 의한 젊은 마우스 및 노화 마우스의 치료는 비장세포 해당 기능을 증가시킬 수 있었다. 그러나, 노화 마우스의 TGFRt15-TGFRs 치료는 비장세포 기저 해당작용 속도, 해당 용량, 및 해당 비축량을 TGFRt15-TGFRs 치료된 젊은 마우스로부터의 비장세포에서 관찰된 것과 동등한 수준까지 증가시킬 수 있었다. 이들 발견은 TGFRt15-TGFRs의 TGF-β 길항제 활성 및 IL-15 면역자극 활성이 노화 마우스로부터의 면역 세포의 약화된 대사 활성을 효과적으로 자극하고 회춘시킴을 시사한다.
6주령(젊음) 및 72주령(노화) C57BL/6 마우스에게 단회 용량의 PBS, TGFRt15-TGFRs(3 mg/kg) 또는 TGFRt15*-TGFRs(3 mg/kg)를 피하 주사하였다. 치료 후 4일차에, 마우스를 희생시키고, 비장을 수합하였다. 3 cc 주사기의 멸균 피스톤/플런저의 편평한 후단으로 비장을 분쇄하여 비장 세포를 방출하였다. 비장세포를 70 μM 세포 스트레이너를 통해 통과시키고, 단일 세포 현탁액으로 균질화하였다. RBC를 ACK 용해 완충액에서 용해시키고, 비장세포를 세척하고 카운팅하였다. 비장세포의 미토콘드리아 호흡율을 측정하기 위해, 세포를 세척하고, Seahorse 배지에 재현탁시키고, 4 x 106 세포/mL로 재현탁시켰다. 세포를 해당 스트레스 시험을 위해 Cell-Tak-코팅된 Seahorse Bioanalyzer XFe96 배양 플레이트에서 2 mM L-글루타민이 보충된 Seahorse XF RPMI 배지, pH 7.4에서 50 μL/웰로 시딩하였다. 미토콘드리아 스트레스 시험을 위해, 세포를 10 mM 포도당 및 2 mM L-글루타민이 보충된 Seahorse XF RPMI 배지, pH 7.4에서 시딩하였다. 세포를 37℃에서 30분 동안 플레이트에 부착하게 하였다. 추가로, 130 μL의 검정 배지를 플레이트의 각각의 웰(또한 배경 웰)에 첨가하였다. 플레이트를 1시간 동안 37℃, 비-CO2 인큐베이터에서 인큐베이션하였다. 미토콘드리아 스트레스 시험을 위해, 보정 플레이트는 Seahorse 검정 배지에서 제조된 올리고마이신/FCCP/로테논의 10x 용액을 함유하였고, 20 μL의 올리고마이신, FCCP, 및 로테논을 밤새 보정된 세포외 플럭스 플레이트의 각각의 포트에 첨가하였다. XFe96 Extracellular Flux Analyzer를 사용하여 산소 소모율(OCR)을 측정하였다. 완전 OCR 분석은 4개 단계로 구성되었다: 기저 호흡율(약물 없음), ATP-연결 호흡율/양성자 피크(1.5 μM 올리고마이신), 최대 호흡율(2 μM FCCP), 및 여분 호흡율(0.5 μM 로테논). 실험 종료 시, 데이터를 Graph Pad Prism 파일로서 내보내기하였다. XF 미토콘드리아 스트레스 시험 보고 생성기는 엑셀로 내보내기된 Wave 데이터로부터의 XF 미토콘드리아 스트레스 시험 파라미터를 자동적으로 계산한다. Wave 소프트웨어(Agilent)를 사용하여 데이터를 분석하였다.
도 259에 도시된 바와 같이, TGFRt15-TGFRs 요법 후 4일차에 노화 마우스로부터 단리된 비장세포는 PBS 또는 TGFRt15*-TGFRs 치료군의 비장세포와 비교할 때 증강된 기저 호흡율, ATP-연관 호흡율, 최대 호흡율, 및 비축 용량을 보여주었다. TGFRt15*-TGFRs에 의한 젊은 마우스 및 노화 마우스의 치료는 비장세포 미토콘드리아 호흡율을 증가시킬 수 있었다. 그러나, 노화 마우스의 TGFRt15-TGFRs 치료는 기저 호흡율 속도, ATP-연관 호흡율, 최대 호흡율, 및 비축 용량을 TGFRt15-TGFRs 치료된 젊은 마우스로부터의 지방세포에서 관찰된 것과 동등하거나 더 높은 수준까지 증가시킬 수 있다. 이들 발견은 TGFRt15-TGFRs의 TGF-β 길항제 활성 및 IL-15 면역자극 활성이 노화 마우스로부터의 면역 세포의 약화된 대사 활성을 효과적으로 자극하고 회춘시킴을 시사한다.
실시예 124: TGFRt15-TGFRs의 IL-15 활성은 CD8
+
T 세포 및 NK 세포를 증가시키는 역할을 한다
6주령(젊은) 및 72주령(노화) C57BL/6 마우스를 The Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 사육시켰다. 마우스(n =6/군)를 PBS, TGFRt15-TGFRs(3 mg/kg), 및 TGFRt15*-TGFRs(3 mg/kg)로 피하 치료하였다. 마우스 혈액을 치료 후 4일차에 하악하 정맥으로부터 EDTA를 함유하는 튜브에 채혈하여, 면역 세포의 상이한 하위세트에서의 변화를 평가하였다. 전혈 RBC를 ACK 완충액에서 실온에서 5분 동안 용해시켰다. 잔여 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다. 혈액 내 상이한 유형의 면역 세포를 평가하기 위해, 세포를 세포-표면 CD3, CD4, CD45, CD8 및 NK1.1에 특이적인 항체(BioLegend)로 실온(RT)에서 30분 동안 염색하였다. 표면 염색 후, 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다(RT에서 1500 RPM에서 5분 동안). 2회의 세척 후, 세포를 고정 완충액에 재현탁시키고, 유세포측정법(Celesta-BD Bioscience)에 의해 분석하였다.
도 260에 도시된 바와 같이, 결과는 TGFRt15-TGFRs를 이용한 노화 마우스의 치료가 혈액에서 CD3+CD45+, CD3+CD8+, 및 CD3-NK1.1+ 면역 세포의 백분율의 증가를 유도한 반면, TGFRt15*-TGFRs를 이용한 노화 마우스의 치료가 이들 혈액 세포 집단의 백분율에 어떠한 효과도 갖지 않았음을 나타낸다. 이들 결과는 TGFRt15-TGFRs의 IL-15 활성이 노화 마우스의 혈액에서 CD8+ T 세포 및 NK 세포를 증가시키는 데 역할을 함을 시사한다. 노화 대조군 마우스에서 혈액 T 세포 및 NK 세포의 백분율은 젊은 대조군 마우스보다 더 작았다. 그러나, TGFRt15-TGFRs를 이용한 노화 마우스의 치료는 혈액 내 CD3+CD45+, CD3+CD8+, 및 CD3-NK1.1+ 면역 세포의 백분율을 TGFRt15-TGFRs 치료된 젊은 마우스의 혈액에서 관찰된 것과 유사한 수준까지 증가시켰다.
6주령(젊은) 및 72주령(노화) C57BL/6 마우스를 The Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 사육시켰다. 마우스(n =6/군)를 PBS, TGFRt15-TGFRs(3 mg/kg), 및 TGFRt15*-TGFRs(3 mg/kg)로 피하 치료하였다. 치료 후 4일째에, 마우스를 안락사시키고, 비장을 수합하고 단일 세포 현탁액으로 가공하였다. 단일 세포 현탁액을 준비하여, 면역 세포의 상이한 하위세트를 평가하였다. RBC를 ACK 완충액에서 실온에서 5분 동안 용해시켰다. 잔여 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다. 비장 내 상이한 유형의 면역 세포를 평가하기 위해, 세포를 세포-표면 CD3, CD45, CD8 및 NK1.1(BioLegend)에 특이적인 항체로 RT에서 30분 동안 염색하였다. 표면 염색 후, 세포를 FACS 완충액(0.5% BSA(EMD Millipore) 및 0.001% 소듐 아자이드(Sigma)를 포함하는 1X PBS(Hyclone))에서 세척하였다(실온에서 1500 RPM에서 5분 동안). 2회의 세척 후, 세포를 고정 완충액에 재현탁시키고, 유세포측정법(Celesta-BD Bioscience)에 의해 분석하였다.
도 261에 도시된 바와 같이, 결과는 TGFRt15-TGFRs를 이용한 노화 마우스의 치료가 비장에서 CD3+CD45+, CD3+CD8+, 및 CD3-NK1.1+ 면역 세포의 백분율의 증가를 유도한 반면, TGFRt15*-TGFRs를 이용한 노화 마우스의 치료가 이들 비장세포 집단의 백분율에 어떠한 효과도 갖지 않았음을 나타낸다. 이들 결과는 TGFRt15-TGFRs의 IL-15 활성이 노화 마우스의 혈액에서 CD8+ T 세포 및 NK 세포를 증가시키는 데 역할을 함을 시사한다. 노화 대조군 마우스에서 비장 T 세포 및 NK 세포의 백분율은 젊은 대조군 마우스보다 더 작았다. 그러나, TGFRt15-TGFRs를 이용한 노화 마우스의 치료는 비장 내 CD3+CD45+, CD3+CD8+, 및 CD3-NK1.1+ 면역 세포의 백분율을 TGFRt15-TGFRs 치료된 젊은 마우스의 비장에서 관찰된 것과 유사한 수준까지 증가시켰다.
실시예 125: 간에서 천연-발생 노쇠 세포에서의 TGFRt15-TGFRs-관련 저하
72주령(노화) C57BL/6 마우스를 The Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 사육시켰다. 마우스(n =8/군)를 PBS 또는 1개 용량 또는 2개 용량의 TGFRt15-TGFRs(3 mg/kg)로 (0일차 및 60일차에서) 피하 치료하였다. 치료 후 71일차에, 마우스를 안락사시키고, 간을 1.7 mL Eppendorf 튜브에서 액체 질소에 저장하였다. 조직 시료를, 균질화기를 사용하여 1 mL의 트리졸(Thermo Fischer)에서 균질화하였다. 균질화된 조직을 신선한 Eppendorf 튜브에 옮기고, RNeasy Mini 키트(Qiagen #74106)를 제조업체의 설명서에 따라 사용하여 총 RNA를 추출하였다. QuantiTect 역전사 키트(Qiagen)를 사용하는 cDNA 합성에 1 μg의 총 RNA를 사용하였다. Thermo Scientific으로부터 구매된 FAM-표지 예비설계된 프라이머를 사용하여 CFX96 검출 시스템(Bio-Rad)으로 실시간 PCR을 수행하였다. 반응을 검사된 모든 유전자에 대해 3벌로 진행시켰다. 하우스킵핑 유전자 18S 리보솜 RNA를 내부 대조군으로서 사용하여, 유전자 발현 수준에서의 가변성을 정규화하였다. 18S rRNA와 비교하여 각각의 표적 mRNA의 발현을 Ct에 기초하여 2-Δ(ΔCt)로서 계산하였으며, 여기서, ΔCt = Ct표적 - Ct18S이다. 비치료된 6주령 마우스를 대조군으로서 사용하여, 유전자 발현 수준을 노화된 마우스와 비교하였다. 결과는 간에서의 IL-1α, IL-1β, IL-6, p21 및 PAI-1의 유전자 발현이 세포 노쇠-관련 전사물에서의 연령-의존적 증가로 예상된 바와 같이 마우스의 연령에 따라 증가하였음을 보여주었다. 단회 용량 또는 2개 용량의 TGFRt15-TGFRs를 이용한 72주령 마우스의 치료는 PBS 대조군과 비교할 때 간에서 노쇠 마커 IL-1α, IL-1β, IL-6, p21 및 PAI-1의 유전자 발현의 유의한 감소를 초래하였다(도 262). 이들 발견은 노화 마우스의 간 내 천연-발생 노쇠 세포에서 TGFRt15-TGFRs-관련 저하를 시사한다.
실시예 126: TGFRt15-TGFRs 치료는 간 조직에서 염증을 감소시킬 수 있다
72주령(노화) C57BL/6 마우스를 The Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 사육시켰다. 마우스(n =10/군)를 PBS 또는 1개 또는 2개 용량의 TGFRt15-TGFRs(3 mg/kg)로 피하 치료하였다. 치료 후 120일차에, 마우스를 안락사시키고, 마우스 간을 준비하여 조직화학에 대해 평가하였다. 간 조직 표본을 10% 포름알데하이드에 고정시키고, 파라핀 차단 절차 후, 단면을 헤마톡실린-에오신으로 염색하였다. 간 손상의 정도를 맹검 방식으로 조직학적으로 평가하였다. 전체 간 영역의 조직학적 절편을 0 내지 4(0, 부재 및 정상인 것으로 보임; 1, 약함; 2, 중간; 3, 강함; 및 4, 집약적임)의 척도를 사용하여 염증에 대해 채점하였다. 도 263에 도시된 바와 같이, 2개 용량의 TGFRt15-TGFRs는 단회 용량의 TGFRt15-TGFRs 또는 PBS 대조군과 비교하여 노화 마우스의 간에서 간 염증 채점을 저하시킨다. 이들 결과는 TGFRt15-TGFRs 치료가 노화 마우스의 간 조직에서 염증을 감소시킬 수 있음을 시사한다.
실시예 127: TGFRt15-TGFRs 치료는 IL1-α, IL-6, IL-8, PAI-1 및 피브로넥틴 단백질 수준을 감소시킬 수 있다
72주령(노화) C57BL/6 마우스를 The Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 사육시켰다. 마우스(n =10/군)를 PBS 또는 1개 용량 또는 2개 용량의 TGFRt15-TGFRs(3 mg/kg)로 (0일차 및 60일차에서) 치료하였다. 치료 후 120일차에, 마우스를 안락사시키고, 간을 1.7 mL Eppendorf 튜브에서 액체 질소에 저장하였다. 조직 시료를, 균질화기를 사용하여 0.3 mL의 추출 완충액(Abcam)에서 균질화하였다. 균질화된 조직을 신선한 Eppendorf 튜브에 옮겼다. 균질화된 조직 내 단백질 수준을 BCA 단백질 검정 키트(Pierce)를 사용하여 정량화하였다. IL-1α, IL-1β, IL-6, IL-8, TGF-β, PAI-1, 콜라겐 및 피브로넥틴(R&D System)을 검출하기 위한 ELISA를 25 μg의 조직 균질물을 사용하여 수행하였다. 도 264에 도시된 바와 같이, IL-1α, IL-6, IL-8, PAI-1 및 피브로넥틴의 단백질 수준은 PBS 대조군 또는 1개 용량의 TGFRt15-TGFRs 치료군과 비교하여 2개 용량의 TGFRt15-TGFRs로 치료된 마우스의 간에서 감소되었다. 이들 결과는 2개 용량의 TGFRt15-TGFRs 치료가 노화 마우스의 간에서 IL-1α, IL-6, IL-8, PAI-1 및 피브로넥틴 단백질 수준을 감소시킬 수 있음을 나타낸다. IL-1β, TGF-β 및 콜라겐의 단백질 수준은 또한 PBS 대조군과 비교하여 2개 용량의 TGFRt15-TGFRs로 치료된 마우스의 간에서 더 낮았으며; 그러나, 이들 변화는 통계학적 유의성에 도달하지 않았다.
실시예 128: TGFRt15-TGFRs는 노쇠 세포를 감소시킨다
72주령(노화) C57BL/6 마우스를 The Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 사육시켰다. 마우스(n =5/군)를 PBS 또는 TGFRt15-TGFRs(3 mg/kg)로 피하 치료하였다. 치료 후 4일차에, 마우스를 안락사시키고, 간을 수합하고, 2% PBS를 함유하는 PBS에서 균질화시키고, 70-미크론 필터에서 여과하여, 단일 세포 현탁액을 수득하였다. 세포를 회전 침강시킨 다음, 14 mL 둥근 바닥 튜브에서 0.5 mg/mL 콜라게나제 IV 및 0.02 mg/mL DNAse를 함유하는 5 mL RPMI에 재현탁시켰다. 그 후에, 세포를 오비탈 진탕기 상에서 37°C에서 1시간 동안 진탕시키고, RPMI로 2회 세척하였다. 세포를 24웰 편평 바닥 플레이트에서 2 mL의 완전 배지(2 mM L-글루타민(Thermo Life Technologies), 페니실린(Thermo Life Technologies), 스트렙토마이신(Thermo Life Technologies), 및 10% FBS(Hyclone)가 보충된 RPMI 1640(Gibco))에서 2 x 106/mL에서 재현탁시키고, 37°C, 5% CO2에서 48시간 동안 배양하였다. 세포를 수합하고, 실온에서 1000 RPM에서 10분 동안 가온 완전 배지로 1회 세척하였다. 세포 펠렛을 튜브(Abcam)당 1.5 μL의 노쇠 염료를 함유하는 500 μL의 신선한 배지에 재현탁시켰다. 세포를 37°C, 5% CO2에서 1시간 내지 2시간 동안 추가로 인큐베이션하고, 500 μL 세척 완충액으로 2회 세척하였다. 세포 펠렛을 500 μL의 세척 완충액에서 재현탁시키고, 유세포측정법(Celesta-BD Bioscience)에 의해 즉시 분석하였다. 도 265에 도시된 바와 같이, 노쇠 마커 β-gal+ 세포의 백분율은 생체내에서 TGFRt15-TGFR로 치료 후 4일째에 저하되었다. 이들 결과는 TGFRt15-TGFRs가 노화 마우스의 간에서 노쇠 세포를 감소시킬 수 있음을 시사한다(β-gal 마커에 기초함).
실시예 129: 노화 마우스의 생존율에 미치는 TGFRt15-TGFRs의 효과
72주령 C57BL/6 마우스를 The Jackson Laboratory로부터 구매하였다. 마우스를 온도 및 빛 제어된 환경에서 사육시켰다. 마우스를 PBS 또는 1개 용량의 TGFRt15-TGFRs(3 mg/kg)(n =20/군)로 피하 치료하였다. 마우스를 치료 후 최대 120주 동안 생존율에 대해 매일 모니터링하였다. 만텔-콕스 로그-순위 검정(Mantel-Cox log-rank test)에 기초하여 치료군의 생존율 가능성을 도 266에 도시한다. TGFRt15-TGFRs와 비교하여, 더 높은 사망률은 대조군에서 발견되었고, 이는 마우스의 생존율에서의 하락으로 나타났다. 치료 후 120주차까지, TGFRt15-TGFRs-치료 마우스에서의 45% 사망률과 비교하여 PBS 대조군에서 70% 사망률이 존재하였다.
실시예 130: 화학요법 후 B16F10 종양-보유 마우스의 간에서 SASP 인자를 감소시키는 데 있어서 TGFRt15-TGFRs의 효과
화학요법 후 B16F10 종양-보유 마우스에서 SASP 인자의 단백질 수준을 감소시키는 데 있어서 TGFRt15-TGFRs 치료의 효과를 추가로 평가하였다. B16F10 종양 세포(1 x107 세포/마우스)를 0일차에 이식하였다. 마우스를 1일차, 4일차, 및 7일차에 10 mg/kg 도세탁셀로 피하 치료하였다. 8일차에, 마우스를 PBS 또는 TGFRt15-TGFRs(3 mg/kg)로 피하 치료하였다. 마우스를 종양 접종 후 17일차에 안락사시키고, 간을 수집하고 균질화하였다. 간 균질화물에서 SASP 인자의 단백질 수준을 ELISA에 의해 결정하였다. 도 267에 도시된 바와 같이, TGFRt15-TGFRs에 의한 생체내 치료는 화학요법 후 B16F10 종양 보유 마우스에서 간 IL-1α, IL-6, TNFα 및 IL-8 SASP 인자의 수준에서 유의한 감소를 초래하였다.
실시예 131: B16F10 흑색종 마우스 모델에서 노쇠 종양 세포의 TGFRt15-TGFRs-매개 제거에 있어서 면역 세포 하위세트의 역할
TGFRt15-TGFRs-매개 노쇠-종양-세포 제거에서 면역세포 하위세트의 역할을 평가하기 위해, 시험관내-도세탁셀 유도 노쇠 B16F10-GFP 종양 세포를 모 B16F10 세포와 혼합하고, 항-NK1.1 또는 항-CD8a 항체로 치료 후 마우스에 피하 이식하였다. 종양이 대략 350 mm3에 도달하였을 때, 마우스를 무작위화하여 PBS 또는 TGFRt15-TGFRs(3 mg/kg) + TA99(200 μg)로 피하 치료받게 하였다. 요법 후 4일차에 마우스를 희생시키고, 종양을 수집하고 분석하였다. 종양에서 GFP-양성 B16F10-GFP TIS 세포 및 NK와 CD8+ T 세포의 수준을 유세포측정법에 의해 평가하였다. 도 268a에 도시된 바와 같이, 면역고갈이 없거나 CD8+ T 면역 세포에 대해 결손된 TGFRt15-TGFRs-치료 혼합 종양은 대조군 치료 마우스보다 유의하게 더 적은 수의 GFP-발현 노쇠 종양 세포를 함유하였다. 또한, CD8+ 결손 마우스의 종양은 NK 세포로 유의하게 침윤되었고 NK 결손 마우스의 종양은 CD8+ T 세포로 유의하게 침윤된 것으로 관찰되었다(도 268b). 이들 결과는 NK 세포와 CD8+ T 세포가 둘 다 종양 성장을 제어하는 데 있어서 역할을 하고, NK 세포가 TIS 종양 세포를 결손시키기 위해 TGFRt15-TGFRs의 활성을 우세적으로 매개함을 시사하였다.
실시예 132: B16F10 흑색종 마우스 모델에서 TGFRt15-TGFRs+TA99 및 화학요법과 병용된 항-PD-L1 항체
순차적인 TGFRt15-TGFRs-면역 관문 저해제 치료 계획(실시예 109에 기재됨)을 추가로 평가하기 위해, B16F10 종양-보유 마우스를 우선 도세탁셀(DTX)로 치료한 다음, TGFRt15-TGFRs+TA99로 치료하고, 뒤이어 항-PD-L1 항체 또는 항-PD-L1 항체, 뒤이어 TGFRt15-TGFRs+TA99로 치료하였다(도 269a). 18일차에서의 종양 성장 곡선 및 평가 변수 종양 부피는, 병용 요법(TGFRt15-TGFRs+TA99, 뒤이어 항-PD-L1 및 그 반대)이 둘 다 개별적인 면역요법(TGFRt15-TGFRs+TA99 또는 항-PD-L1 단독) 또는 DTX 단독과 비교하여 유의한 종양 부피 감소를 보여주었음을 나타내었다(도 269b). 흥미롭게도, TGFRt15-TGFRs +TA99-치료 종양은 항-PD-L1-치료 종양과 비교하여 병용 치료의 시작 전 13일차에 유의하게 더 낮은 종양 부피를 보여주었으며, 이는 종양 성장의 초기 제어에서 TGFRt15-TGFRs+TA99의 효과를 보여주었다. 평가 변수 분석은 또한, TGFRt15-TGFRs+TA99와 항-PD-L1 항체의 병용으로 치료된 종양이 단일 치료군과 비교하여 종양 침윤성 CD8+ T 세포 및 NK 세포의 유의하게 증가된 수준을 유발하였음을 보여주었다. 병용 치료는 단일 치료와 비교하여 CD8+ TIL 상에서의 공동자극성 수용체 CD28의 발현을 증가시켰으며, 이는 검문 차단이 종양 미세환경 내에서 TGFRt15-TGFRs의 IL-15 활성에 의해 추가로 활성화되는 기능장애성 CD8+ TIL을 구제할 수 있었음을 시사한다(도 269c). 이는 PMA/이오노마이신을 이용한 자극 후 병용 치료군으로부터의 비장 CD8+ T 세포의 증강된 활성화 표현형(IFNγ 분비)과 수반되었다(도 269d). 병용 치료는 또한, 개별 면역요법 치료와 비교하여 종양에서 총 CD8+ T 세포 및 CD44hi CD8+ T 세포 상에서 증가된 NKG2D 발현을 보여주었다(도 269e). 이들 데이터는 종합하여, TGFRt15-TGFRs+TA99와 항-PD-L1 항체의 병용 요법이 효과적인 종양 제어에 기여될 수 있는 CD8+ T 세포의 활성화 및 침윤을 유발하였음을 보여준다.
실시예 133: C57BL/6 SCID 마우스에서 SW1990 인간 췌장 종양에 대한 화학요법과 병용된 TGFRt15-TGFRs의 항종양 효능
화학요법과의 병용에서 TGFRt15-TGFRs의 항종양 활성을 추가로 평가하기 위해, SW1990 인간 췌장 암세포(2x106 세포/마우스)를 C57BL/6 scid 마우스 내로 피하(s.c.) 주사하였다. 종양 세포 이식 후 9일째에, 겜시타빈(40 mg/kg, i.p.) 및 나브-파클리탁셀(nab-paclitaxel)(아브락산)(5 mg/kg, i.p.) 화학요법을 개시하고, 2일 후에 TGFRt15-TGFRs(3 mg/kg, s.c.)를 개시하였다. 이는 하나의 치료 주기인 것으로 간주되었고, 또 다른 3개 사이클(1개 사이클/주) 동안 반복되었다(도 270a). 종양-보유 대조군은 PBS, 화학요법, 또는 TGFRt15-TGFRs 치료 단독을 받았다. 연구 치료 동안 그리고 후에, 종양 부피를 측정하고, 종양 부피 < 4000 mm3에 기초하여 동물 생존율을 평가하였다. 결과는 TGFRt15-TGFRs와 화학요법의 병용을 받는 동물이 PBS 군과 비교하여 유의하게 더 느린 SW1990 종양 성장을 가졌음을 나타내었다(도 270b 내지 도 270c). TGFRt15-TGFRs + 화학요법은 SW1990 종양-보유 마우스의 생존율을 연장시켰다(도 270d). 이들 결과는 TGFRt15-TGFRs가 마우스 이종이식 종양 모델에서 인간 췌장 종양에 대한 표준 치유 화학요법의 효능을 증강시켰음을 확인시켜 준다.
다른 구현예
본 발명이 이의 상세한 설명과 함께 기재되긴 하였지만, 상기 설명은 본 발명의 범위를 예시하는 것이고 이를 제한하려는 것이 아니며, 본 발명의 범위는 첨부된 청구항의 범위에 의해 정의된다. 다른 양태, 이점 및 변형은 하기 청구항의 범위 내에 있다.
예시적인 구현예
구현예 A1. 단일-사슬 키메라 폴리펩타이드로서, 상기 단일-사슬 키메라 폴리펩타이드는
(i) 제1 표적-결합 도메인;
(ii) 가용성 조직 인자 도메인; 및
(iii) 제2 표적-결합 도메인을 포함하는, 방법.
구현예 A2. 구현예 A1에 있어서, 상기 제1 표적-결합 도메인 및 상기 가용성 조직 인자 도메인은 서로 직접적으로 인접해 있는, 단일-사슬 키메라 폴리펩타이드.
구현예 A3. 구현예 A1에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A4. 구현예 A1 내지 구현예 A3 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인 및 상기 제2 표적-결합 도메인은 서로 직접적으로 인접해 있는, 단일-사슬 키메라 폴리펩타이드.
구현예 A5. 구현예 A1 내지 구현예 A3 중 어느 한 구현예에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 가용성 조직 인자 도메인과 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A6. 구현예 A1에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 서로 직접적으로 인접해 있는, 단일-사슬 키메라 폴리펩타이드.
구현예 A7. 구현예 A1에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 제1 표적-결합 도메인과 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A8. 구현예 A6 또는 구현예 A7에 있어서, 상기 제2 표적-결합 도메인 및 상기 가용성 조직 인자 도메인은 서로 직접적으로 인접해 있는, 단일-사슬 키메라 폴리펩타이드.
구현예 A9. 구현예 A6 또는 구현예 A7에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 제2 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A10. 구현예 A1 내지 구현예 A9 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 항원에 특이적으로 결합하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A11. 구현예 A10에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A12. 구현예 A11에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A13. 구현예 A1 내지 구현예 A9 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 상이한 항원에 특이적으로 결합하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A14. 구현예 A1 내지 구현예 A13 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 항원-결합 도메인인, 단일-사슬 키메라 폴리펩타이드.
구현예 A15. 구현예 A14에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 각각 항원-결합 도메인인, 단일-사슬 키메라 폴리펩타이드.
구현예 A16. 구현예 A13에 있어서, 상기 항원-결합 도메인은 scFv 또는 단일 도메인 항체를 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A17. 구현예 A1 내지 구현예 A16 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인과 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는, CD16a, CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL-1, VEGF, IL-6R, IL-4, IL-10, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKp30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, IL-1에 대한 수용체, IL-2에 대한 수용체, IL-3에 대한 수용체, IL-7에 대한 수용체, IL-8에 대한 수용체, IL-10에 대한 수용체, IL-12에 대한 수용체, IL-15에 대한 수용체, IL-17에 대한 수용체, IL-18에 대한 수용체, IL-21에 대한 수용체, PDGF-D에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, CD122에 대한 수용체, 및 CD28에 대한 수용체로 이루어진 군으로부터 선택되는 표적에 결합하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A18. 구현예 A1 내지 구현예 A16 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 단백질인, 단일-사슬 키메라 폴리펩타이드.
구현예 A19. 구현예 A18에 있어서, 상기 가용성 인터류킨, 사이토카인, 또는 리간드 단백질은 IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-D, 및 SCF, FLT3L, MICA, MICB, 및 ULP16-결합 단백질로 이루어진 군으로부터 선택되는, 단일-사슬 키메라 폴리펩타이드.
구현예 A20. 구현예 A1 내지 구현예 A16 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 수용체인, 단일-사슬 키메라 폴리펩타이드.
구현예 A21. 구현예 A20에 있어서, 상기 인터류킨 또는 사이토카인 수용체는 가용성 TGF-β 수용체 II(TGF-βRII), 가용성 TGF-βRIII, 가용성 NKG2D, 가용성 NKp30, 가용성 NKp44, 가용성 NKp46, 가용성 DNAM1, scMHCI, scMHCII, scTCR, 가용성 CD155, 또는 가용성 CD28인, 단일-사슬 키메라 폴리펩타이드.
구현예 A22. 구현예 A1 내지 구현예 A21 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 가용성 인간 조직 인자 도메인인, 단일-사슬 키메라 폴리펩타이드.
구현예 A23. 구현예 A22에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 80% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A24. 구현예 A23에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 90% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A25. 구현예 A24에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 95% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A26. 구현예 A22 내지 구현예 A25 중 어느 한 구현예에 있어서, 상기 가용성 인간 조직 인자 도메인은
성숙 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 리신;
성숙 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신;
성숙 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판;
성숙 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산;
성숙 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신;
성숙 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및
성숙 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
구현예 A27. 구현예 A26에 있어서, 상기 가용성 인간 조직 인자 도메인은
성숙 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 리신;
성숙 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신;
성숙 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판;
성숙 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산;
성숙 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신;
성숙 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및
성숙 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
구현예 A28. 구현예 A1 내지 구현예 A27 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 인자 VIIa에 결합할 수 없는, 단일-사슬 키메라 폴리펩타이드.
구현예 A29. 구현예 A1 내지 구현예 A28 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 불활성 인자 X를 인자 Xa로 전환시키지 않는, 단일-사슬 키메라 폴리펩타이드.
구현예 A30. 구현예 A1 내지 구현예 A29 중 어느 한 구현예에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 포유류에서 혈액 응고를 자극시키지 않는, 단일-사슬 키메라 폴리펩타이드.
구현예 A31. 구현예 A1 내지 구현예 A30 중 어느 한 구현예에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 이의 N-말단 및/또는 C-말단에 하나 이상의 추가 표적-결합 도메인을 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A32. 구현예 A31에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 이의 N-말단에 하나 이상의 추가 표적-결합 도메인을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A33. 구현예 A32에 있어서, 상기 하나 이상의 추가 표적-결합 도메인은 상기 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인에 직접적으로 인접해 있는, 단일-사슬 키메라 폴리펩타이드.
구현예 A34. 구현예 A33에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 적어도 하나의 추가 표적-결합 도메인과 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A35. 구현예 A31에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 이의 C-말단에 하나 이상의 추가 표적-결합 도메인을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A36. 구현예 A35에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 하나는 상기 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인에 직접적으로 인접해 있는, 단일-사슬 키메라 폴리펩타이드.
구현예 A37. 구현예 A35에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 적어도 하나의 추가 표적-결합 도메인과 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A38. 구현예 A31에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 이의 N-말단 및 C-말단에 하나 이상의 추가 표적-결합 도메인을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A39. 구현예 A38에 있어서, 상기 하나 이상의 추가 항원-결합 도메인 중 하나는 N-말단에서 상기 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인에 직접적으로 인접해 있는, 단일-사슬 키메라 폴리펩타이드.
구현예 A40. 구현예 A38에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 N-말단에서 하나 이상의 추가 항원-결합 도메인 중 하나와 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A41. 구현예 A38에 있어서, 상기 하나 이상의 추가 항원-결합 도메인 중 하나는 C-말단에서 상기 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인에 직접적으로 인접해 있는, 단일-사슬 키메라 폴리펩타이드.
구현예 A42. 구현예 A38에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 C-말단에서 하나 이상의 추가 항원-결합 도메인 중 하나와 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A43. 구현예 A31 내지 구현예 A42 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 항원에 특이적으로 결합하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A44. 구현예 A43에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 에피토프에 특이적으로 결합하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A45. 구현예 A44에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 아미노산 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A46. 구현예 A43에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 각각 동일한 항원에 특이적으로 결합하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A47. 구현예 A46에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 각각 동일한 에피토프에 특이적으로 결합하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A48. 구현예 A47에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 각각 동일한 아미노산 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A49. 구현예 A31 내지 구현예 A42 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 상이한 항원에 특이적으로 결합하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A50. 구현예 A31 내지 구현예 A49 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 표적-결합 도메인 중 하나 이상은 항원-결합 도메인인, 단일-사슬 키메라 폴리펩타이드.
구현예 A51. 구현예 A50에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 각각 항원-결합 도메인인, 단일-사슬 키메라 폴리펩타이드.
구현예 A52. 구현예 A51에 있어서, 상기 항원-결합 도메인은 scFv 또는 단일 도메인 항체를 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A53. 구현예 A31 내지 구현예 A52 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 표적-결합 도메인 중 하나 이상은, CD16a, CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL-1, VEGF, IL-6R, IL-4, IL-10, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKp30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, IL-1에 대한 수용체, IL-2에 대한 수용체, IL-3에 대한 수용체, IL-7에 대한 수용체, IL-8에 대한 수용체, IL-10에 대한 수용체, IL-12에 대한 수용체, IL-15에 대한 수용체, IL-17에 대한 수용체, IL-18에 대한 수용체, IL-21에 대한 수용체, PDGF-D에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, CD122에 대한 수용체, 및 CD28에 대한 수용체로 이루어진 군으로부터 선택되는 표적에 특이적으로 결합하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A54. 구현예 A31 내지 구현예 A52 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 하나 이상은 가용성 인터류킨 또는 사이토카인 단백질인, 단일-사슬 키메라 폴리펩타이드.
구현예 A55. 구현예 A54에 있어서, 상기 가용성 인터류킨, 사이토카인, 또는 리간드 단백질은 IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-D, 및 SCF, FLT3L, MICA, MICB, 및 ULP16-결합 단백질로 이루어진 군으로부터 선택되는, 단일-사슬 키메라 폴리펩타이드.
구현예 A56. 구현예 A31 내지 구현예 A52 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 하나 이상은 가용성 인터류킨 또는 사이토카인 수용체인, 단일-사슬 키메라 폴리펩타이드.
구현예 A57. 구현예 A56에 있어서, 상기 가용성 수용체는 가용성 TGF-β 수용체 II(TGF-βRII), 가용성 TGF-βRIII, 가용성 NKG2D, 가용성 NKp30, 가용성 NKp44, 가용성 NKp46, 가용성 DNAM1, scMHCI, scMHCII, scTCR, 가용성 CD155, 가용성 CD122, 가용성 CD3, 또는 가용성 CD28인, 단일-사슬 키메라 폴리펩타이드.
구현예 A58. 구현예 A1 내지 구현예 A57 중 어느 한 구현예에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 이의 N-말단 단부에 신호 서열을 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A59. 구현예 A1 내지 구현예 A58 중 어느 한 구현예에 있어서, 단일-사슬 키메라 폴리펩타이드는 상기 단일-사슬 키메라 폴리펩타이드의 N-말단 단부 또는 C-말단 단부에 위치한 펩타이드 태그를 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A60. 구현예 A1 내지 구현예 A59의 임의의 단일-사슬 키메라 폴리펩타이드를 포함하는 조성물.
구현예 A61. 구현예 A60에 있어서, 상기 조성물은 약학적 조성물인, 조성물.
구현예 A62. 구현예 A60 또는 구현예 A61의 조성물의 적어도 하나의 용량을 포함하는 키트.
구현예 A63. 구현예 A1 내지 구현예 A59 중 임의의 한 구현예의 임의의 단일-사슬 키메라 폴리펩타이드를 인코딩하는 핵산.
구현예 A64. 구현예 A63의 핵산을 포함하는 벡터.
구현예 A65. 구현예 A64에 있어서, 상기 벡터는 발현 벡터인, 벡터.
구현예 A66. 구현예 A63의 핵산 또는 구현예 A64 또는 구현예 A65의 벡터를 포함하는 세포.
구현예 A67. 단일-사슬 키메라 폴리펩타이드를 생성하는 방법으로서, 상기 방법은
단일-사슬 키메라 폴리펩타이드의 생성을 초래하기에 충분한 조건 하에 구현예 A66의 세포를 배양 배지에서 배양하는 단계; 및
상기 단일-사슬 키메라 폴리펩타이드를 상기 세포 및/또는 상기 배양 배지로부터 회수하는 단계를 포함하는, 방법.
구현예 A68. 구현예 A67의 방법에 의해 생성되는 단일-사슬 키메라 폴리펩타이드.
구현예 A69. 구현예 A26에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 적어도 80% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A70. 구현예 A69에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 적어도 90% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A71. 구현예 A70에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 적어도 95% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A72. 구현예 A71에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 100% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A73. 구현예 A26에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 적어도 80% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A74. 구현예 A73에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 적어도 90% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A75. 구현예 A74에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 적어도 95% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 A76. 구현예 A75에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 100% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B1. 단일-사슬 키메라 폴리펩타이드로서, 상기 단일-사슬 키메라 폴리펩타이드는
(i) 제1 표적-결합 도메인;
(ii) 가용성 조직 인자 도메인; 및
(ii) 제2 표적-결합 도메인
을 포함하고,
제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 IL-2 수용체에 특이적으로 결합하거나;
제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 IL-15 수용체에 특이적으로 결합하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B2. 구현예 B1에 있어서, 상기 제1 표적-결합 도메인 및 상기 가용성 조직 인자 도메인은 서로 직접적으로 인접해 있는, 단일-사슬 키메라 폴리펩타이드.
구현예 B3. 구현예 B1에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B4. 구현예 B1 내지 구현예 B3 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인 및 상기 제2 표적-결합 도메인은 서로 직접적으로 인접해 있는, 단일-사슬 키메라 폴리펩타이드.
구현예 B5. 구현예 B1 내지 구현예 B3 중 어느 한 구현예에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 가용성 조직 인자 도메인과 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B6. 구현예 B1에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 서로 직접적으로 인접해 있는, 단일-사슬 키메라 폴리펩타이드.
구현예 B7. 구현예 B1에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 제1 표적-결합 도메인과 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B8. 구현예 B6 또는 구현예 B7에 있어서, 상기 제2 표적-결합 도메인 및 상기 가용성 조직 인자 도메인은 서로 직접적으로 인접해 있는, 단일-사슬 키메라 폴리펩타이드.
구현예 B9. 구현예 B6 또는 구현예 B7에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 제2 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B10. 구현예 B1 내지 구현예 B9 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인과 상기 제2 표적-결합 도메인은 둘 다 가용성 인터류킨 단백질인, 단일-사슬 키메라 폴리펩타이드.
구현예 B11. 구현예 B10에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 가용성 IL-2 단백질인, 단일-사슬 키메라 폴리펩타이드.
구현예 B12. 구현예 B11에 있어서, 상기 가용성 IL-2 단백질은 가용성 인간 IL-2 단백질인, 단일-사슬 키메라 폴리펩타이드.
구현예 B13. 구현예 B12에 있어서, 상기 가용성 인간 IL-2 단백질은 SEQ ID NO: 78을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B14. 구현예 B10에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 가용성 IL-15 단백질인, 단일-사슬 키메라 폴리펩타이드.
구현예 B15. 구현예 B14에 있어서, 상기 가용성 IL-15 단백질은 가용성 인간 IL-15 단백질인, 단일-사슬 키메라 폴리펩타이드.
구현예 B16. 구현예 B15에 있어서, 상기 가용성 인간 IL-15 단백질은 SEQ ID NO: 82를 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B17. 구현예 B1 내지 구현예 B16 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 가용성 인간 조직 인자 도메인인, 단일-사슬 키메라 폴리펩타이드.
구현예 B18. 구현예 B17에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 80% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B19. 구현예 B18에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 90% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B20. 구현예 B19에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 95% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B21. 구현예 B17 내지 구현예 B20 중 어느 한 구현예에 있어서, 상기 가용성 인간 조직 인자 도메인은
성숙 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 리신;
성숙 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신;
성숙 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판;
성숙 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산;
성숙 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신;
성숙 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및
성숙 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
구현예 B22. 구현예 B21에 있어서, 상기 가용성 인간 조직 인자 도메인은
성숙 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 리신;
성숙 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신;
성숙 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판;
성숙 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산;
성숙 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신;
성숙 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및
성숙 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
구현예 B23. 구현예 B1 내지 구현예 B22 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 인자 VIIa에 결합할 수 없는, 단일-사슬 키메라 폴리펩타이드.
구현예 B24. 구현예 B1 내지 구현예 B23 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 불활성 인자 X를 인자 Xa로 전환시키지 않는, 단일-사슬 키메라 폴리펩타이드.
구현예 B25. 구현예 B1 내지 구현예 B24 중 어느 한 구현예에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 포유류에서 혈액 응고를 자극시키지 않는, 단일-사슬 키메라 폴리펩타이드.
구현예 B26. 구현예 B1 내지 구현예 B25 중 어느 한 구현예에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 이의 N-말단 및/또는 C-말단에 하나 이상의 추가 표적-결합 도메인을 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B27. 구현예 B26에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 이의 N-말단에 하나 이상의 추가 표적-결합 도메인을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B28. 구현예 B27에 있어서, 상기 하나 이상의 추가 표적-결합 도메인은 상기 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인에 직접적으로 인접해 있는, 단일-사슬 키메라 폴리펩타이드.
구현예 B29. 구현예 B28에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 적어도 하나의 추가 표적-결합 도메인과 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B30. 구현예 B26에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 이의 C-말단에 하나 이상의 추가 표적-결합 도메인을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B31. 구현예 B30에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 하나는 상기 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인에 직접적으로 인접해 있는, 단일-사슬 키메라 폴리펩타이드.
구현예 B32. 구현예 B30에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 적어도 하나의 추가 표적-결합 도메인과 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B33. 구현예 B26에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 이의 N-말단 및 C-말단에 하나 이상의 추가 표적-결합 도메인을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B34. 구현예 B33에 있어서, 상기 하나 이상의 추가 항원-결합 도메인 중 하나는 N-말단에서 상기 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인에 직접적으로 인접해 있는, 단일-사슬 키메라 폴리펩타이드.
구현예 B35. 구현예 B33에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 N-말단에서 하나 이상의 추가 항원-결합 도메인 중 하나와 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B36. 구현예 B33에 있어서, 상기 하나 이상의 추가 항원-결합 도메인 중 하나는 C-말단에서 상기 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인에 직접적으로 인접해 있는, 단일-사슬 키메라 폴리펩타이드.
구현예 B37. 구현예 B33에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 C-말단에서 하나 이상의 추가 항원-결합 도메인 중 하나와 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B38. 구현예 B26 내지 구현예 B37 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 각각 IL-2 수용체 또는 IL-15 수용체에 특이적으로 결합하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B39. 구현예 B38에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 각각 동일한 아미노산 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B40. 구현예 B26 내지 구현예 B37 중 어느 한 구현예에 있어서, 상기 하나 이상의 표적-결합 도메인은 항원-결합 도메인인, 단일-사슬 키메라 폴리펩타이드.
구현예 B41. 구현예 B40에 있어서, 상기 항원-결합 도메인은 scFv 또는 단일 도메인 항체를 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B42. 구현예 B26 내지 구현예 B37, 구현예 B40, 및 구현예 B41 중 어느 한 구현예에 있어서, 상기 하나 이상의 추가 표적-결합 도메인은 CD16a, CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL-1, VEGF, IL-6R, IL-4, IL-10, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKp30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, IL-1에 대한 수용체, IL-2에 대한 수용체, IL-3에 대한 수용체, IL-7에 대한 수용체, IL-8에 대한 수용체, IL-10에 대한 수용체, IL-12에 대한 수용체, IL-15에 대한 수용체, IL-17에 대한 수용체, IL-18에 대한 수용체, IL-21에 대한 수용체, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, CD122에 대한 수용체, 및 CD28에 대한 수용체로 이루어진 군으로부터 선택되는 표적에 특이적으로 결합하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B43. 구현예 B6 내지 구현예 B37, 구현예 B40, 및 구현예 B41 중 어느 한 구현예에 있어서, 상기 하나 이상의 추가 표적-결합 도메인은 가용성 인터류킨 또는 사이토카인 단백질인, 단일-사슬 키메라 폴리펩타이드.
구현예 B44. 구현예 B43에 있어서, 상기 가용성 인터류킨 또는 사이토카인 단백질은 IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, 및 SCF로 이루어진 군으로부터 선택되는, 단일-사슬 키메라 폴리펩타이드.
구현예 B45. 구현예 B6 내지 구현예 B37, 구현예 B40, 및 구현예 B41 중 어느 한 구현예에 있어서, 상기 하나 이상의 추가 표적-결합 도메인은 가용성 인터류킨 또는 사이토카인 수용체인, 단일-사슬 키메라 폴리펩타이드.
구현예 B46. 구현예 B45에 있어서, 상기 가용성 수용체는 가용성 TGF-β 수용체 II(TGF-βRII) 및 가용성 TGF-βRIII인, 단일-사슬 키메라 폴리펩타이드.
구현예 B47. 구현예 B1 내지 구현예 B46 중 어느 한 구현예에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 이의 N-말단 단부에 신호 서열을 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B48. 구현예 B1 내지 구현예 B47 중 어느 한 구현예에 있어서, 단일-사슬 키메라 폴리펩타이드는 상기 단일-사슬 키메라 폴리펩타이드의 N-말단 단부 또는 C-말단 단부에 위치한 펩타이드 태그를 추가로 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B49. 구현예 B1 내지 구현예 B48의 임의의 단일-사슬 키메라 폴리펩타이드를 포함하는 조성물.
구현예 B50. 구현예 B49에 있어서, 상기 조성물은 약학적 조성물인, 조성물.
구현예 B51. 구현예 B49 또는 구현예 B50의 조성물의 적어도 하나의 용량을 포함하는 키트.
구현예 B52. 구현예 B1 내지 구현예 B48 중 임의의 한 구현예의 임의의 단일-사슬 키메라 폴리펩타이드를 인코딩하는 핵산.
구현예 B53. 구현예 B52의 핵산을 포함하는 벡터.
구현예 B54. 구현예 B53에 있어서, 상기 벡터는 발현 벡터인, 벡터.
구현예 B55. 구현예 B52의 핵산 또는 구현예 B53 또는 구현예 B54의 벡터를 포함하는 세포.
구현예 B56. 단일-사슬 키메라 폴리펩타이드를 생성하는 방법으로서, 상기 방법은
단일-사슬 키메라 폴리펩타이드의 생성을 초래하기에 충분한 조건 하에 구현예 B55의 세포를 배양 배지에서 배양하는 단계; 및
상기 단일-사슬 키메라 폴리펩타이드를 상기 세포 및/또는 상기 배양 배지로부터 회수하는 단계를 포함하는, 방법.
구현예 B57. 구현예 B56의 방법에 의해 생성되는 단일-사슬 키메라 폴리펩타이드.
구현예 B58. 구현예 B21에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 적어도 80% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B59. 구현예 B58에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 적어도 90% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B60. 구현예 B59에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 적어도 95% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B61. 구현예 B60에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 100% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B62. 구현예 B21에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 적어도 80% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B63. 구현예 B62에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 적어도 90% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B64. 구현예 B63에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 적어도 95% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 B65. 구현예 B64에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 100% 동일한 서열을 포함하는, 단일-사슬 키메라 폴리펩타이드.
구현예 C1. 다중-사슬 키메라 폴리펩타이드로서, 상기 다중-사슬 키메라 폴리펩타이드는
(a) 제1 키메라 폴리펩타이드로서,
(i) 제1 표적-결합 도메인;
(ii) 가용성 조직 인자 도메인; 및
(iii) 친화도 도메인 쌍의 제1 도메인을 포함하는, 제1 키메라 폴리펩타이드; 및
(b) 제2 키메라 폴리펩타이드로서,
(i) 친화도 도메인 쌍의 제2 도메인; 및
(ii) 제2 표적-결합 도메인을 포함하는, 제2 키메라 폴리펩타이드를 포함하고,
상기 제1 키메라 폴리펩타이드 및 상기 제2 키메라 폴리펩타이드는 친화도 도메인 쌍의 제1 도메인과 제2 도메인의 결합을 통해 회합되는, 방법.
구현예 C2. 구현예 C1에 있어서, 상기 제1 표적-결합 도메인 및 상기 가용성 조직 인자 도메인은 상기 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 C3. 구현예 C1에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C4. 구현예 C1 내지 구현예 C3 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인 및 상기 친화도 도메인의 쌍의 제1 도메인은 상기 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 C5. 구현예 C1 내지 구현예 C3 중 어느 한 구현예에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C6. 구현예 C1 내지 구현예 C5 중 어느 한 구현예에 있어서, 상기 친화도 도메인의 쌍의 제2 도메인 및 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 C7. 구현예 C1 내지 구현예 C5 중 어느 한 구현예에 있어서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 상기 친화도 도메인의 쌍의 제2 도메인과 상기 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C8. 구현예 C1 내지 구현예 C7 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 항원에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C9. 구현예 C8에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C10. 구현예 C9에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C11. 구현예 C1 내지 구현예 C7 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 상이한 항원에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C12. 구현예 C1 내지 구현예 C11 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 항원-결합 도메인인, 다중-사슬 키메라 폴리펩타이드.
구현예 C13. 구현예 C12에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 각각 항원-결합 도메인인, 다중-사슬 키메라 폴리펩타이드.
구현예 C14. 구현예 C12 또는 구현예 C13에 있어서, 상기 항원-결합 도메인은 scFv 또는 단일 도메인 항체를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C15. 구현예 C1 내지 구현예 C14 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인과 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는, CD16a, CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL-1, VEGF, IL-6R, IL-4, IL-10, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKp30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, IL-1에 대한 수용체, IL-2에 대한 수용체, IL-3에 대한 수용체, IL-7에 대한 수용체, IL-8에 대한 수용체, IL-10에 대한 수용체, IL-12에 대한 수용체, IL-15에 대한 수용체, IL-17에 대한 수용체, IL-18에 대한 수용체, IL-21에 대한 수용체, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, CD122에 대한 수용체, 및 CD28에 대한 수용체로 이루어진 군으로부터 선택되는 표적에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C16. 구현예 C1 내지 구현예 C14 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 단백질인, 다중-사슬 키메라 폴리펩타이드.
구현예 C17. 구현예 C16에 있어서, 상기 가용성 인터류킨 또는 사이토카인 단백질은 IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, SCF, FLT3L, MICA, MICB, 및 ULP16-결합 단백질로 이루어진 군으로부터 선택되는, 다중-사슬 키메라 폴리펩타이드.
구현예 C18. 구현예 C1 내지 구현예 C14 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 수용체인, 다중-사슬 키메라 폴리펩타이드.
구현예 C19. 구현예 C18에 있어서, 상기 가용성 수용체는 가용성 TGF-β 수용체 II(TGF-β RII), 가용성 TGF-βRIII, 가용성 NKG2D, 가용성 NKp30, 가용성 NKp44, 가용성 NKp46, 가용성 DNAM1, scMHCI, scMHCII, scTCR, 가용성 CD155, 또는 가용성 CD28인, 다중-사슬 키메라 폴리펩타이드.
구현예 C20. 구현예 C1 내지 구현예 C19 중 어느 한 구현예에 있어서, 상기 제1 키메라 폴리펩타이드는 하나 이상의 추가 표적-결합 도메인(들)을 추가로 포함하며, 이때, 상기 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나는 상기 가용성 조직 인자 도메인과 상기 친화도 도메인의 쌍의 제1 도메인 사이에 위치하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C21. 구현예 C20에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 가용성 조직 인자 도메인과 상기 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나 사이에 링커 서열, 및/또는 상기 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나와 상기 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C22. 구현예 C1 내지 구현예 C19 중 어느 한 구현예에 있어서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드의 N-말단 및/또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C23. 구현예 C22에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드에서 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 C24. 구현예 C22에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C25. 구현예 C22에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 C26. 구현예 C22에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 제1 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C27. 구현예 C22에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드의 N-말단 및/또는 C-말단에 배치되고, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C28. 구현예 C27에 있어서, N-말단에 배치된 하나 이상의 추가 표적-결합 도메인의 적어도 하나의 추가 표적-결합 도메인은 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 C29. 구현예 C27에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 적어도 하나의 추가 표적-결합 도메인과 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인 사이에 배치된 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C30. 구현예 C27에 있어서, C-말단에 배치된 하나 이상의 추가 표적-결합 도메인의 적어도 하나의 추가 표적-결합 도메인은 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 C31. 구현예 C27에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 적어도 하나의 추가 표적-결합 도메인과 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인 사이에 배치된 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C32. 구현예 C27에 있어서, 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 가용성 조직 인자 도메인 및/또는 상기 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 C33. 구현예 C27에 있어서, 상기 제1 키메라 폴리펩타이드는 (i) 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 가용성 조직 인자 도메인 사이에, 및/또는 (ii) 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 친화도 도메인의 쌍의 제1 도메인 사이에 배치된 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C34. 구현예 C1 내지 구현예 C33 중 어느 한 구현예에 있어서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드의 N-말단 또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C35. 구현예 C34에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인의 쌍의 제2 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 C36. 구현예 C34에 있어서, 상기 제2 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 제2 키메라 폴리펩타이드 내 친화도 도메인의 쌍의 제2 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C37. 구현예 C34에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제2 키메라 폴리펩타이드에서 제2 표적-결합 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 C38. 구현예 C34에 있어서, 상기 제2 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 제2 키메라 폴리펩타이드 내 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C39. 구현예 C20 내지 구현예 C38 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 항원에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C40. 구현예 C39에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 에피토프에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C41. 구현예 C40에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 아미노산 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C42. 구현예 C39에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 각각 동일한 항원에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C43. 구현예 C42에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 각각 동일한 에피토프에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C44. 구현예 C43에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 각각 동일한 아미노산 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C45. 구현예 C20 내지 구현예 C38 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 상이한 항원에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C46. 구현예 C20 내지 구현예 C45 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 표적-결합 도메인 중 하나 이상은 항원-결합 도메인인, 다중-사슬 키메라 폴리펩타이드.
구현예 C47. 구현예 C46에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 각각 항원-결합 도메인인, 다중-사슬 키메라 폴리펩타이드.
구현예 C48. 구현예 C47에 있어서, 상기 항원-결합 도메인은 scFv를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C49. 구현예 C20 내지 구현예 C48 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 하나 이상의 표적-결합 도메인 중 하나 이상은, CD16a, CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL-1, VEGF, IL-6R, IL-4, IL-10, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKp30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, IL-1에 대한 수용체, IL-2에 대한 수용체, IL-3에 대한 수용체, IL-7에 대한 수용체, IL-8에 대한 수용체, IL-10에 대한 수용체, IL-12에 대한 수용체, IL-15에 대한 수용체, IL-17에 대한 수용체, IL-18에 대한 수용체, IL-21에 대한 수용체, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, CD122에 대한 수용체, CD3에 대한 수용체, 및 CD28에 대한 수용체로 이루어진 군으로부터 선택되는 표적에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C50. 구현예 C20 내지 구현예 C48 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 하나 이상은 가용성 인터류킨 또는 사이토카인 단백질인, 다중-사슬 키메라 폴리펩타이드.
구현예 C51. 구현예 C50에 있어서, 상기 가용성 인터류킨, 사이토카인, 또는 리간드 단백질은 IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, 및 SCF, FLT3L, MICA, MICB, 및 ULP16-결합 단백질로 이루어진 군으로부터 선택되는, 다중-사슬 키메라 폴리펩타이드.
구현예 C52. 구현예 C20 내지 구현예 C48 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 하나 이상은 가용성 인터류킨 또는 사이토카인 수용체인, 다중-사슬 키메라 폴리펩타이드.
구현예 C53. 구현예 C52에 있어서, 상기 가용성 수용체는 가용성 TGF-β 수용체 II(TGF-β RII), 가용성 TGF-βRIII, 가용성 NKG2D, 가용성 NKp30, 가용성 NKp44, 가용성 NKp46, 가용성 DNAM1, scMHCI, scMHCII, scTCR, 가용성 CD155, 가용성 CD122, 가용성 CD3, 또는 가용성 CD28인, 다중-사슬 키메라 폴리펩타이드.
구현예 C54. 구현예 C1 내지 구현예 C53 중 어느 한 구현예에 있어서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드의 N-말단 단부 또는 C-말단 단부에 펩타이드 태그를 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C55. 구현예 C1 내지 구현예 C53 중 어느 한 구현예에 있어서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드의 N-말단 단부 또는 C-말단 단부에 펩타이드 태그를 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C56. 구현예 C1 내지 구현예 C55 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 가용성 인간 조직 인자 도메인인, 다중-사슬 키메라 폴리펩타이드.
구현예 C57. 구현예 C56에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C58. 구현예 C57에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C59. 구현예 C58에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C60. 구현예 C56 내지 구현예 C59 중 어느 한 구현예에 있어서, 상기 가용성 인간 조직 인자 도메인은
성숙 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 리신;
성숙 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신;
성숙 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판;
성숙 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산;
성숙 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신;
성숙 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및
성숙 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
구현예 C61. 구현예 C60에 있어서, 상기 가용성 인간 조직 인자 도메인은
성숙 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 리신;
성숙 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신;
성숙 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판;
성숙 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산;
성숙 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신;
성숙 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및
성숙 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
구현예 C62. 구현예 C1 내지 구현예 C61 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 인자 VIIa에 결합할 수 없는, 다중-사슬 키메라 폴리펩타이드.
구현예 C63. 구현예 C1 내지 구현예 C62 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 불활성 인자 X를 인자 Xa로 전환시키지 않는, 다중-사슬 키메라 폴리펩타이드.
구현예 C64. 구현예 C1 내지 구현예 C63 중 어느 한 구현예에 있어서, 상기 다중-사슬 키메라 폴리펩타이드는 포유류에서 혈액 응고를 자극시키지 않는, 다중-사슬 키메라 폴리펩타이드.
구현예 C65. 구현예 C1 내지 구현예 C64 중 어느 한 구현예에 있어서, 상기 친화도 도메인의 쌍은 인간 IL-15 수용체의 알파 사슬(IL-15Rα) 및 가용성 IL-15로부터의 sushi 도메인인, 다중-사슬 키메라 폴리펩타이드.
구현예 C66. 구현예 C65에 있어서, 상기 가용성 IL-15는 D8N 또는 D8A 아미노산 치환을 갖는, 다중-사슬 키메라 폴리펩타이드.
구현예 C67. 구현예 C65 또는 C66에 있어서, 상기 인간 IL-15Rα는 성숙한 전장 IL-15Rα인, 다중-사슬 키메라 폴리펩타이드.
구현예 C68. 구현예 C1 내지 구현예 C64 중 어느 한 구현예에 있어서, 상기 친화도 도메인의 쌍은 바르나제 및 바른스타, PKA와 AKAP, 돌연변이화된 RNase I 단편에 기초한 어댑터/도킹 태그 모듈, 및 단백질 신택신, 시냅토태그민, 시냅토브레빈, 및 SNAP25의 상호작용에 기초한 SNARE로 이루어진 군으로부터 선택되는, 다중-사슬 키메라 폴리펩타이드.
구현예 C69. 구현예 C1 내지 구현예 C68 중 어느 한 구현예에 있어서, 상기 제1 키메라 폴리펩타이드 및/또는 상기 제2 키메라 폴리펩타이드는 이의 N-말단 단부에 신호 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C70. 구현예 C1 내지 구현예 C69의 임의의 다중-사슬 키메라 폴리펩타이드를 포함하는 조성물.
구현예 C71. 구현예 C70에 있어서, 상기 조성물은 약학적 조성물인, 조성물.
구현예 C72. 구현예 C70 또는 구현예 C71의 조성물의 적어도 하나의 용량을 포함하는 키트.
구현예 C73. 구현예 C1 내지 구현예 C69 중 임의의 한 구현예의 임의의 다중-사슬 키메라 폴리펩타이드를 인코딩하는 핵산.
구현예 C74. 구현예 C73의 핵산을 포함하는 벡터.
구현예 C75. 구현예 C74에 있어서, 상기 벡터는 발현 벡터인, 벡터.
구현예 C76. 구현예 C73의 핵산 또는 구현예 C74 또는 구현예 C75의 벡터를 포함하는 세포.
구현예 C77. 다중-사슬 키메라 폴리펩타이드를 생성하는 방법으로서, 상기 방법은
다중-사슬 키메라 폴리펩타이드의 생성을 초래하기에 충분한 조건 하에 구현예 C76의 세포를 배양 배지에서 배양하는 단계; 및
상기 다중-사슬 키메라 폴리펩타이드를 상기 세포 및/또는 상기 배양 배지로부터 회수하는 단계를 포함하는, 방법.
구현예 C78. 구현예 C77의 방법에 의해 생성되는 다중-사슬 키메라 폴리펩타이드.
구현예 C79. 구현예 A56에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C80. 구현예 C79에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C81. 구현예 C80에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C82. 구현예 C81에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 100% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C83. 구현예 C56에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C84. 구현예 C83에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C85. 구현예 C84에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 C86. 구현예 C85에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 100% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D1. 다중-사슬 키메라 폴리펩타이드로서, 상기 다중-사슬 키메라 폴리펩타이드는
(a) 제1 키메라 폴리펩타이드로서,
(i) 제1 표적-결합 도메인;
(ii) 가용성 조직 인자 도메인; 및
(iii) 친화도 도메인 쌍의 제1 도메인을 포함하는, 제1 키메라 폴리펩타이드; 및
(b) 제2 키메라 폴리펩타이드로서,
(i) 친화도 도메인 쌍의 제2 도메인; 및
(ii) 제2 표적-결합 도메인을 포함하는, 제2 키메라 폴리펩타이드
를 포함하고,
제1 키메라 폴리펩타이드 및 제2 키메라 폴리펩타이드는 친화도 도메인의 쌍의 제1 도메인 및 제2 도메인의 결합을 통해 회합되고;
제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, IL-18의 수용체 또는 IL-12의 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D2. 구현예 D1에 있어서, 상기 제1 표적-결합 도메인 및 상기 가용성 조직 인자 도메인은 상기 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 D3. 구현예 D1에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D4. 구현예 D1 내지 구현예 D3 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인 및 상기 친화도 도메인의 쌍의 제1 도메인은 상기 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 D5. 구현예 D1 내지 구현예 D3 중 어느 한 구현예에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D6. 구현예 D1 내지 구현예 D5 중 어느 한 구현예에 있어서, 상기 친화도 도메인의 쌍의 제2 도메인 및 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 D7. 구현예 D1 내지 구현예 D5 중 어느 한 구현예에 있어서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 상기 친화도 도메인의 쌍의 제2 도메인과 상기 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D8. 구현예 D1 내지 구현예 D7 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 가용성 인간 조직 인자 도메인인, 다중-사슬 키메라 폴리펩타이드.
구현예 D9. 구현예 D8에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D10. 구현예 D9에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D11. 구현예 D10에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D12. 구현예 D8 내지 구현예 D11 중 어느 한 구현예에 있어서, 상기 가용성 인간 조직 인자 도메인은
성숙 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 리신;
성숙 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신;
성숙 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판;
성숙 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산;
성숙 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신;
성숙 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및
성숙 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
구현예 D13. 구현예 D12에 있어서, 상기 가용성 인간 조직 인자 도메인은
성숙 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 리신;
성숙 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신;
성숙 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판;
성숙 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산;
성숙 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신;
성숙 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및
성숙 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
구현예 D14. 구현예 D1 내지 구현예 D13 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 인자 VIIa에 결합할 수 없는, 다중-사슬 키메라 폴리펩타이드.
구현예 D15. 구현예 D1 내지 구현예 D14 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 불활성 인자 X를 인자 Xa로 전환시키지 않는, 다중-사슬 키메라 폴리펩타이드.
구현예 D16. 구현예 D1 내지 구현예 D15 중 어느 한 구현예에 있어서, 상기 다중-사슬 키메라 폴리펩타이드는 포유류에서 혈액 응고를 자극시키지 않는, 다중-사슬 키메라 폴리펩타이드.
구현예 D17. 구현예 D1 내지 구현예 D16 중 어느 한 구현예에 있어서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드의 N-말단 단부 또는 C-말단 단부에 펩타이드 태그를 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D18. 구현예 D1 내지 구현예 D17 중 어느 한 구현예에 있어서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드의 N-말단 단부 또는 C-말단 단부에 펩타이드 태그를 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D19. 구현예 D1 내지 구현예 D18 중 어느 한 구현예에 있어서, 상기 제1 키메라 폴리펩타이드 및/또는 상기 제2 키메라 폴리펩타이드는 이의 N-말단 단부에 신호 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D20. 구현예 D19에 있어서, 상기 신호 서열은 SEQ ID NO: 117을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D21. 구현예 D20에 있어서, 상기 신호 서열은 SEQ ID NO: 117인, 다중-사슬 키메라 폴리펩타이드.
구현예 D22. 구현예 D1 내지 구현예 D21 중 어느 한 구현예에 있어서, 상기 친화도 도메인의 쌍은 인간 IL-15 수용체의 알파 사슬(IL-15Rα) 및 가용성 IL-15로부터의 sushi 도메인인, 다중-사슬 키메라 폴리펩타이드.
구현예 D23. 구현예 D22에 있어서, 상기 가용성 IL-15는 D8N 또는 D8A 아미노산 치환을 갖는, 다중-사슬 키메라 폴리펩타이드.
구현예 D24. 구현예 D22에 있어서, 상기 가용성 IL-15는 SEQ ID NO: 82와 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D25. 구현예 D24에 있어서, 상기 가용성 IL-15는 SEQ ID NO: 82와 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D26. 구현예 D25에 있어서, 상기 가용성 IL-15는 SEQ ID NO: 82와 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D27. 구현예 D26에 있어서, 상기 가용성 IL-15는 SEQ ID NO: 82를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D28. 구현예 D22 내지 구현예 D27 중 어느 한 구현예에 있어서, IL-15Rα의 sushi 도메인은 인간 IL-15Rα로부터의 sushi 도메인을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D29. 구현예 D28에 있어서, 상기 인간 IL-15Rα로부터의 sushi 도메인은 SEQ ID NO: 113과 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D30. 구현예 D29에 있어서, 상기 인간 IL-15Rα로부터의 sushi 도메인은 SEQ ID NO: 113과 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D31. 구현예 D30에 있어서, 상기 인간 IL-15Rα로부터의 sushi 도메인은 SEQ ID NO: 113과 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D32. 구현예 D31에 있어서, 상기 인간 IL-15Rα로부터의 sushi 도메인은 SEQ ID NO: 113을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D33. 구현예 D28에 있어서, 상기 인간 IL-15Rα로부터의 sushi 도메인은 성숙한 전장 IL-15Rα인, 다중-사슬 키메라 폴리펩타이드.
구현예 D34. 구현예 D1 내지 구현예 D21 중 어느 한 구현예에 있어서, 상기 친화도 도메인의 쌍은 바르나제 및 바른스타, PKA와 AKAP, 돌연변이화된 RNase I 단편에 기초한 어댑터/도킹 태그 모듈, 및 단백질 신택신, 시냅토태그민, 시냅토브레빈, 및 SNAP25의 상호작용에 기초한 SNARE로 이루어진 군으로부터 선택되는, 다중-사슬 키메라 폴리펩타이드.
구현예 D35. 구현예 D1 내지 구현예 D34 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 작용제성 항원-결합 도메인인, 다중-사슬 키메라 폴리펩타이드.
구현예 D36. 구현예 D35에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 각각 작용제성 항원-결합 도메인인, 다중-사슬 키메라 폴리펩타이드.
구현예 D37. 구현예 D35 또는 구현예 D36에 있어서, 상기 항원-결합 도메인은 scFv 또는 단일 도메인 항체를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D38. 구현예 D1 내지 구현예 D34 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 IL-15 또는 가용성 IL-18인, 다중-사슬 키메라 폴리펩타이드.
구현예 D39. 구현예 D38에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 각각 독립적으로, 가용성 IL-15 또는 가용성 IL-18인, 다중-사슬 키메라 폴리펩타이드.
구현예 D40. 구현예 D1 내지 구현예 D39 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인과 상기 제2 표적-결합 도메인은 둘 다 IL-18의 수용체 또는 IL-12의 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D41. 구현예 B40에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D42. 구현예 D41에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D43. 구현예 D1 내지 구현예 D39 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인은 IL-12에 대한 수용체에 특이적으로 결합하고, 상기 제2 표적-결합 도메인은 IL-18에 대한 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D44. 구현예 D1 내지 구현예 D39 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인은 IL-18에 대한 수용체에 특이적으로 결합하고, 상기 제2 표적-결합 도메인은 IL-12에 대한 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D45. 구현예 D44에 있어서, 상기 제1 표적-결합 도메인은 가용성 IL-18을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D46. 구현예 D45에 있어서, 상기 가용성 IL-18은 가용성 인간 IL-18인, 다중-사슬 키메라 폴리펩타이드.
구현예 D47. 구현예 D46에 있어서, 상기 가용성 인간 IL-18은 SEQ ID NO: 109와 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D48. 구현예 D47에 있어서, 상기 가용성 인간 IL-18은 SEQ ID NO: 109와 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D49. 구현예 D48에 있어서, 상기 가용성 인간 IL-18은 SEQ ID NO: 109와 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D50. 구현예 D49에 있어서, 상기 가용성 인간 IL-18은 SEQ ID NO: 109의 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D51. 구현예 D44 내지 구현예 D50 중 어느 한 구현예에 있어서, 상기 제2 표적-결합 도메인은 가용성 IL-12를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D52. 구현예 D51에 있어서, 상기 가용성 IL-18은 가용성 인간 IL-12인, 다중-사슬 키메라 폴리펩타이드.
구현예 D53. 구현예 D52에 있어서, 상기 가용성 인간 IL-15는 가용성 인간 IL-12β(p40)의 서열 및 가용성 인간 IL-12α(p35)의 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D54. 구현예 D53에 있어서, 상기 가용성 인간 IL-15는 가용성 IL-12β(p40)의 서열과 가용성 인간 IL-12α(p35)의 서열 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D55. 구현예 D54에 있어서, 상기 링커 서열은 SEQ ID NO: 102를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D56. 구현예 D53 내지 구현예 D55 중 어느 한 구현예에 있어서, 상기 가용성 인간 IL-12β(p40)의 서열은 SEQ ID NO: 81과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D57. 구현예 D56에 있어서, 상기 가용성 인간 IL-12β(p40)의 서열은 SEQ ID NO: 81과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D58. 구현예 D57에 있어서, 상기 가용성 인간 IL-12β(p40)의 서열은 SEQ ID NO: 81과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D59. 구현예 D58에 있어서, 상기 가용성 인간 IL-12β(p40)의 서열은 SEQ ID NO: 81을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D60. 구현예 D53 내지 구현예 D59 중 어느 한 구현예에 있어서, 상기 가용성 인간 IL-12α(p35)의 서열은 SEQ ID NO: 80과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D61. 구현예 D60에 있어서, 상기 가용성 인간 IL-12α(p35)의 서열은 SEQ ID NO: 80과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D62. 구현예 D61에 있어서, 상기 가용성 인간 IL-12α(p35)의 서열은 SEQ ID NO: 80과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D63. 구현예 D62에 있어서, 상기 가용성 인간 IL-12α(p35)의 서열은 SEQ ID NO: 80을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D64. 구현예 D1에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 174와 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D65. 구현예 D64에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 174와 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D66. 구현예 D65에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 174와 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D67. 구현예 D66에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 174를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D68. 구현예 D67에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 176을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D69. 구현예 D1 및 구현예 D64 내지 구현예 D68 중 어느 한 구현예에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 178과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D70. 구현예 D69에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 178과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D71. 구현예 D70에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 178과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D72. 구현예 D71에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 178을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D73. 구현예 D72에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 180을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D74. 구현예 D1 내지 구현예 D63 중 어느 한 구현예에 있어서, 상기 제1 키메라 폴리펩타이드는 하나 이상의 추가 표적-결합 도메인(들)을 추가로 포함하며, 이때, 상기 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나는 상기 가용성 조직 인자 도메인과 상기 친화도 도메인의 쌍의 제1 도메인 사이에 위치하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D75. 구현예 D74에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 가용성 조직 인자 도메인과 상기 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나 사이에 링커 서열, 및/또는 상기 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나와 상기 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D76. 구현예 D1 내지 구현예 D63 중 어느 한 구현예에 있어서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드의 N-말단 및/또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D77. 구현예 D76에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드에서 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 D78. 구현예 D76에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D79. 구현예 D76에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 D80. 구현예 D76에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 제1 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D81. 구현예 D76에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드의 N-말단 및/또는 C-말단에 배치되고, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D82. 구현예 D81에 있어서, N-말단에 배치된 하나 이상의 추가 표적-결합 도메인의 적어도 하나의 추가 표적-결합 도메인은 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 D83. 구현예 D81에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 적어도 하나의 추가 표적-결합 도메인과 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인 사이에 배치된 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D84. 구현예 D81에 있어서, C-말단에 배치된 하나 이상의 추가 표적-결합 도메인의 적어도 하나의 추가 표적-결합 도메인은 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 D85. 구현예 D81에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 적어도 하나의 추가 표적-결합 도메인과 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인 사이에 배치된 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D86. 구현예 D81에 있어서, 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 가용성 조직 인자 도메인 및/또는 상기 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 D87. 구현예 D81에 있어서, 상기 제1 키메라 폴리펩타이드는 (i) 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 가용성 조직 인자 도메인 사이에, 및/또는 (ii) 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 친화도 도메인의 쌍의 제1 도메인 사이에 배치된 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D88. 구현예 D1 내지 구현예 D63 및 구현예 D74 내지 구현예 D87 중 어느 한 구현예에 있어서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드의 N-말단 또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D89. 구현예 D88에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인의 쌍의 제2 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 D90. 구현예 D88에 있어서, 상기 제2 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 제2 키메라 폴리펩타이드 내 친화도 도메인의 쌍의 제2 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D91. 구현예 D88에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제2 키메라 폴리펩타이드에서 제2 표적-결합 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 D92. 구현예 B88에 있어서, 상기 제2 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 제2 키메라 폴리펩타이드 내 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D93. 구현예 D74 내지 구현예 D92 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 항원에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D94. 구현예 B93에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 에피토프에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D95. 구현예 B94에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 아미노산 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D96. 구현예 D74 내지 구현예 D92 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 상이한 항원에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D97. 구현예 D74 내지 구현예 D96 중 어느 한 구현예에 있어서, 상기 하나 이상의 추가 항원-결합 도메인은 CD16a, CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL-1, VEGF, IL-6R, IL-4, IL-10, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKp30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, IL-1에 대한 수용체, IL-2에 대한 수용체, IL-3에 대한 수용체, IL-7에 대한 수용체, IL-8에 대한 수용체, IL-10에 대한 수용체, IL-12에 대한 수용체, IL-15에 대한 수용체, IL-17에 대한 수용체, IL-18에 대한 수용체, IL-21에 대한 수용체, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, 및 CD28에 대한 수용체로 이루어진 군으로부터 선택되는 표적에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D98. 구현예 D74 내지 구현예 D96 중 어느 한 구현예에 있어서, 상기 하나 이상의 추가 표적-결합 도메인은 가용성 인터류킨 또는 사이토카인 단백질인, 다중-사슬 키메라 폴리펩타이드.
구현예 D99. 구현예 B98에 있어서, 상기 가용성 인터류킨, 사이토카인, 또는 리간드 단백질은 IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, SCF, FLT3L, MICA, MICB, 및 ULP16-결합 단백질로 이루어진 군으로부터 선택되는, 다중-사슬 키메라 폴리펩타이드.
구현예 D100. 구현예 D74 내지 구현예 D96 중 어느 한 구현예에 있어서, 상기 하나 이상의 추가 표적-결합 도메인은 가용성 인터류킨 또는 사이토카인 수용체인, 다중-사슬 키메라 폴리펩타이드.
구현예 D101. 구현예 B100에 있어서, 상기 가용성 수용체는 가용성 TGF-β 수용체 II(TGF-β RII), 가용성 TGF-βRIII, 가용성 NKG2D, 가용성 NKp30, 가용성 NKp44, 가용성 NKp46, 가용성 DNAM1, scMHCI, scMHCII, scTCR, 가용성 CD155, 가용성 CD122, 또는 가용성 CD28인, 다중-사슬 키메라 폴리펩타이드.
구현예 D102. 구현예 D1 내지 구현예 D101의 임의의 다중-사슬 키메라 폴리펩타이드를 포함하는 조성물.
구현예 D103. 구현예 D102에 있어서, 상기 조성물은 약학적 조성물인, 조성물.
구현예 D104. 구현예 D102 또는 구현예 D103의 조성물의 적어도 하나의 용량을 포함하는 키트.
구현예 D105. 구현예 D1 내지 구현예 D101 중 임의의 한 구현예의 임의의 다중-사슬 키메라 폴리펩타이드를 인코딩하는 핵산.
구현예 D106. 구현예 D105의 핵산을 포함하는 벡터.
구현예 D107. 구현예 D106에 있어서, 상기 벡터는 발현 벡터인, 벡터.
구현예 D108. 구현예 D105의 핵산 또는 구현예 D106 또는 구현예 D107의 벡터를 포함하는 세포.
구현예 D109. 다중-사슬 키메라 폴리펩타이드를 생성하는 방법으로서, 상기 방법은
다중-사슬 키메라 폴리펩타이드의 생성을 초래하기에 충분한 조건 하에 구현예 D108의 세포를 배양 배지에서 배양하는 단계; 및
상기 다중-사슬 키메라 폴리펩타이드를 상기 세포 및/또는 상기 배양 배지로부터 회수하는 단계를 포함하는, 방법.
구현예 D110. 구현예 D109의 방법에 의해 생성되는 다중-사슬 키메라 폴리펩타이드.
구현예 D111. 구현예 D8에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D112. 구현예 D111에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D113. 구현예 D112에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D114. 구현예 D113에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 100% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D115. 구현예 D8에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D116. 구현예 D115에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D117. 구현예 D116에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 D118. 구현예 D117에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 100% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E1. 다중-사슬 키메라 폴리펩타이드로서, 상기 다중-사슬 키메라 폴리펩타이드는
(a) 제1 키메라 폴리펩타이드로서,
(i) 제1 표적-결합 도메인;
(ii) 가용성 조직 인자 도메인; 및
(iii) 친화도 도메인 쌍의 제1 도메인을 포함하는, 제1 키메라 폴리펩타이드; 및
(b) 제2 키메라 폴리펩타이드로서,
(i) 친화도 도메인 쌍의 제2 도메인; 및
(ii) 제2 표적-결합 도메인을 포함하는, 제2 키메라 폴리펩타이드
를 포함하고,
상기 제1 키메라 폴리펩타이드 및 상기 제2 키메라 폴리펩타이드는 친화도 도메인 쌍의 제1 도메인과 제2 도메인의 결합을 통해 회합되고;
제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, IL-21의 수용체 또는 종양 성장 인자 수용체 β II(TGFβRII)의 리간드에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E2. 구현예 E1에 있어서, 상기 제1 표적-결합 도메인 및 상기 가용성 조직 인자 도메인은 상기 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 E3. 구현예 E1에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E4. 구현예 E1 내지 구현예 E3 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인 및 상기 친화도 도메인의 쌍의 제1 도메인은 상기 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 E5. 구현예 E1 내지 구현예 E3 중 어느 한 구현예에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E6. 구현예 E1 내지 구현예 E5 중 어느 한 구현예에 있어서, 상기 친화도 도메인의 쌍의 제2 도메인 및 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 E7. 구현예 E1 내지 구현예 E5 중 어느 한 구현예에 있어서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 상기 친화도 도메인의 쌍의 제2 도메인과 상기 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E8. 구현예 E1 내지 구현예 E7 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 가용성 인간 조직 인자 도메인인, 다중-사슬 키메라 폴리펩타이드.
구현예 E9. 구현예 E8에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E10. 구현예 E9에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E11. 구현예 E10에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E12. 구현예 E8 내지 구현예 E11 중 어느 한 구현예에 있어서, 상기 가용성 인간 조직 인자 도메인은
성숙 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 리신;
성숙 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신;
성숙 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판;
성숙 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산;
성숙 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신;
성숙 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및
성숙 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
구현예 E13. 구현예 E12에 있어서, 상기 가용성 인간 조직 인자 도메인은
성숙 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 리신;
성숙 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신;
성숙 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판;
성숙 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산;
성숙 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신;
성숙 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및
성숙 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
구현예 E14. 구현예 E1 내지 구현예 E13 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 인자 VIIa에 결합할 수 없는, 다중-사슬 키메라 폴리펩타이드.
구현예 E15. 구현예 E1 내지 구현예 E14 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 불활성 인자 X를 인자 Xa로 전환시키지 않는, 다중-사슬 키메라 폴리펩타이드.
구현예 E16. 구현예 E1 내지 구현예 E15 중 어느 한 구현예에 있어서, 상기 다중-사슬 키메라 폴리펩타이드는 포유류에서 혈액 응고를 자극시키지 않는, 다중-사슬 키메라 폴리펩타이드.
구현예 E17. 구현예 E1 내지 구현예 E16 중 어느 한 구현예에 있어서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드의 N-말단 단부 또는 C-말단 단부에 펩타이드 태그를 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E18. 구현예 E1 내지 구현예 E17 중 어느 한 구현예에 있어서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드의 N-말단 단부 또는 C-말단 단부에 펩타이드 태그를 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E19. 구현예 E1 내지 구현예 E18 중 어느 한 구현예에 있어서, 상기 제1 키메라 폴리펩타이드 및/또는 상기 제2 키메라 폴리펩타이드는 이의 N-말단 단부에 신호 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E20. 구현예 E19에 있어서, 상기 신호 서열은 SEQ ID NO: 117을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E21. 구현예 E20에 있어서, 상기 신호 서열은 SEQ ID NO: 117인, 다중-사슬 키메라 폴리펩타이드.
구현예 E22. 구현예 E1 내지 구현예 E21 중 어느 한 구현예에 있어서, 상기 친화도 도메인의 쌍은 인간 IL-15 수용체의 알파 사슬(IL-15Rα) 및 가용성 IL-15로부터의 sushi 도메인인, 다중-사슬 키메라 폴리펩타이드.
구현예 E23. 구현예 E22에 있어서, 상기 가용성 IL-15는 D8N 또는 D8A 아미노산 치환을 갖는, 다중-사슬 키메라 폴리펩타이드.
구현예 E24. 구현예 E22에 있어서, 상기 가용성 IL-15는 SEQ ID NO: 82와 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E25. 구현예 E24에 있어서, 상기 가용성 IL-15는 SEQ ID NO: 82와 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E26. 구현예 E25에 있어서, 상기 가용성 IL-15는 SEQ ID NO: 82와 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E27. 구현예 E26에 있어서, 상기 가용성 IL-15는 SEQ ID NO: 82를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E28. 구현예 E22 내지 구현예 E27 중 어느 한 구현예에 있어서, IL-15Rα의 sushi 도메인은 인간 IL-15Rα로부터의 sushi 도메인을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E29. 구현예 E28에 있어서, 상기 인간 IL-15Rα로부터의 sushi 도메인은 SEQ ID NO: 113과 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E30. 구현예 E29에 있어서, 상기 인간 IL-15Rα로부터의 sushi 도메인은 SEQ ID NO: 113과 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E31. 구현예 E30에 있어서, 상기 인간 IL-15Rα로부터의 sushi 도메인은 SEQ ID NO: 113과 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E32. 구현예 E31에 있어서, 상기 인간 IL-15Rα로부터의 sushi 도메인은 SEQ ID NO: 113을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E33. 구현예 E28에 있어서, 상기 인간 IL-15Rα로부터의 sushi 도메인은 성숙한 전장 IL-15Rα인, 다중-사슬 키메라 폴리펩타이드.
구현예 E34. 구현예 E1 내지 구현예 E21 중 어느 한 구현예에 있어서, 상기 친화도 도메인의 쌍은 바르나제 및 바른스타, PKA와 AKAP, 돌연변이화된 RNase I 단편에 기초한 어댑터/도킹 태그 모듈, 및 단백질 신택신, 시냅토태그민, 시냅토브레빈, 및 SNAP25의 상호작용에 기초한 SNARE로 이루어진 군으로부터 선택되는, 다중-사슬 키메라 폴리펩타이드.
구현예 E35. 구현예 E1 내지 구현예 E34 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 항원-결합 도메인인, 다중-사슬 키메라 폴리펩타이드.
구현예 E36. 구현예 E35에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 항원-결합 도메인인, 다중-사슬 키메라 폴리펩타이드.
구현예 E37. 구현예 E35 또는 구현예 E36에 있어서, 상기 항원-결합 도메인은 scFv 또는 단일 도메인 항체를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E38. 구현예 E1 내지 구현예 E34 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 IL-21 또는 가용성 TGFβRII인, 다중-사슬 키메라 폴리펩타이드.
구현예 E39. 구현예 E1 내지 구현예 E38 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인과 상기 제2 표적-결합 도메인은 둘 다 IL-21의 수용체 또는 TGFβRII의 리간드에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E40. 구현예 E39에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E41. 구현예 E40에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E42. 구현예 E1 내지 구현예 E38 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인은 TGFβRII의 리간드에 특이적으로 결합하고, 상기 제2 표적-결합 도메인은 IL-21에 대한 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E43. 구현예 E1 내지 구현예 E38 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인은 IL-21에 대한 수용체에 특이적으로 결합하고, 상기 제2 표적-결합 도메인은 TGFβRII의 리간드에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E44. 구현예 E43에 있어서, 상기 제1 표적-결합 도메인은 가용성 IL-21을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E45. 구현예 E44에 있어서, 상기 가용성 IL-21은 가용성 인간 IL-21인, 다중-사슬 키메라 폴리펩타이드.
구현예 E46. 구현예 E45에 있어서, 상기 가용성 인간 IL-21은 SEQ ID NO: 83과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E47. 구현예 E46에 있어서, 상기 가용성 인간 IL-21은 SEQ ID NO: 83과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E48. 구현예 E47에 있어서, 상기 가용성 인간 IL-21은 SEQ ID NO: 83과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E49. 구현예 E48에 있어서, 상기 가용성 인간 IL-21은 SEQ ID NO: 83의 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E50. 구현예 E43 내지 구현예 E49 중 어느 한 구현예에 있어서, 상기 제2 표적-결합 도메인은 가용성 TGFβRII를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E51. 구현예 E50에 있어서, 상기 가용성 TGFβRII는 가용성 인간 TGFβRII인, 다중-사슬 키메라 폴리펩타이드.
구현예 E52. 구현예 E51에 있어서, 상기 가용성 인간 TGFβRII는 가용성 인간 TGFβRII의 제1 서열 및 가용성 인간 TGFβRII의 제2 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E53. 구현예 E52에 있어서, 상기 가용성 인간 TGFβRII는 가용성 인간 TGFβRII의 제1 서열과 가용성 인간 TGFβRII의 제2 서열 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E54. 구현예 E53에 있어서, 상기 링커 서열은 SEQ ID NO: 102를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E55. 구현예 E52 내지 구현예 E54 중 어느 한 구현예에 있어서, 상기 가용성 인간 TGFβRII의 제1 서열은 SEQ ID NO: 183과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E56. 구현예 E55에 있어서, 상기 가용성 인간 TGFβRII의 제1 서열은 SEQ ID NO: 183과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E57. 구현예 E56에 있어서, 상기 가용성 인간 TGFβRII의 제1 서열은 SEQ ID NO: 183과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E58. 구현예 E57에 있어서, 상기 가용성 인간 TGFβRII의 제1 서열은 SEQ ID NO: 183을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E59. 구현예 E52 내지 구현예 E58 중 어느 한 구현예에 있어서, 상기 가용성 인간 TGFβRII의 제2 서열은 SEQ ID NO: 184와 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E60. 구현예 E59에 있어서, 상기 가용성 인간 TGFβRII의 제2 서열은 SEQ ID NO: 184와 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E61. 구현예 E60에 있어서, 상기 가용성 인간 TGFβRII의 제2 서열은 SEQ ID NO: 184와 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E62. 구현예 E61에 있어서, 상기 가용성 인간 TGFβRII의 제2 서열은 SEQ ID NO: 184를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E63. 구현예 E1에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 189와 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E64. 구현예 E63에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 189와 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E65. 구현예 E64에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 189와 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E66. 구현예 E65에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 189를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E67. 구현예 E66에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 191을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E68. 구현예 E1 및 구현예 E63 내지 구현예 E67 중 어느 한 구현예에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 193과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E69. 구현예 E68에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 193과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E70. 구현예 E69에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 193과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E71. 구현예 E70에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 193을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E72. 구현예 E71에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 195를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E73. 구현예 E1 내지 구현예 E62 중 어느 한 구현예에 있어서, 상기 제1 키메라 폴리펩타이드는 하나 이상의 추가 표적-결합 도메인(들)을 추가로 포함하며, 이때, 상기 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나는 상기 가용성 조직 인자 도메인과 상기 친화도 도메인의 쌍의 제1 도메인 사이에 위치하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E74. 구현예 E73에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 가용성 조직 인자 도메인과 상기 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나 사이에 링커 서열, 및/또는 상기 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나와 상기 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E75. 구현예 E1 내지 구현예 E62 중 어느 한 구현예에 있어서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드의 N-말단 및/또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E76. 구현예 E75에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드에서 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 E77. 구현예 E75에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E78. 구현예 E75에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 E79. 구현예 E75에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 제1 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E80. 구현예 E75에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드의 N-말단 및/또는 C-말단에 배치되고, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E81. 구현예 E80에 있어서, N-말단에 배치된 하나 이상의 추가 표적-결합 도메인의 적어도 하나의 추가 표적-결합 도메인은 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 E82. 구현예 E80에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 적어도 하나의 추가 표적-결합 도메인과 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인 사이에 배치된 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E83. 구현예 E80에 있어서, C-말단에 배치된 하나 이상의 추가 표적-결합 도메인의 적어도 하나의 추가 표적-결합 도메인은 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 E84. 구현예 E80에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 적어도 하나의 추가 표적-결합 도메인과 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인 사이에 배치된 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E85. 구현예 E80에 있어서, 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 가용성 조직 인자 도메인 및/또는 상기 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 E86. 구현예 E80에 있어서, 상기 제1 키메라 폴리펩타이드는 (i) 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 가용성 조직 인자 도메인 사이에, 및/또는 (ii) 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 친화도 도메인의 쌍의 제1 도메인 사이에 배치된 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E87. 구현예 E1 내지 구현예 E62 및 구현예 E73 내지 구현예 E86 중 어느 한 구현예에 있어서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드의 N-말단 또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E88. 구현예 E87에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인의 쌍의 제2 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 E89. 구현예 E87에 있어서, 상기 제2 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 제2 키메라 폴리펩타이드 내 친화도 도메인의 쌍의 제2 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E90. 구현예 E87에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제2 키메라 폴리펩타이드에서 제2 표적-결합 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 E91. 구현예 E87에 있어서, 상기 제2 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 제2 키메라 폴리펩타이드 내 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E92. 구현예 E73 내지 구현예 E91 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 항원에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E93. 구현예 E92에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 에피토프에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E94. 구현예 E93에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 아미노산 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E95. 구현예 E73 내지 구현예 E91 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 상이한 항원에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E96. 구현예 E73 내지 구현예 E95 중 어느 한 구현예에 있어서, 상기 하나 이상의 추가 항원-결합 도메인은 CD16a, CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL-1, VEGF, IL-6R, IL-4, IL-10, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-D, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKp30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, IL-1에 대한 수용체, IL-2에 대한 수용체, IL-3에 대한 수용체, IL-7에 대한 수용체, IL-8에 대한 수용체, IL-10에 대한 수용체, IL-12에 대한 수용체, IL-15에 대한 수용체, IL-17에 대한 수용체, IL-18에 대한 수용체, IL-21에 대한 수용체, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, 및 CD28에 대한 수용체로 이루어진 군으로부터 선택되는 표적에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E97. 구현예 E73 내지 구현예 E95 중 어느 한 구현예에 있어서, 상기 하나 이상의 추가 표적-결합 도메인은 가용성 인터류킨 또는 사이토카인 단백질인, 다중-사슬 키메라 폴리펩타이드.
구현예 E98. 구현예 E97에 있어서, 상기 가용성 인터류킨, 사이토카인, 또는 리간드 단백질은 IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, SCF, FLT3L, MICA, MICB, 및 ULP16-결합 단백질로 이루어진 군으로부터 선택되는, 다중-사슬 키메라 폴리펩타이드.
구현예 E99. 구현예 E73 내지 구현예 E95 중 어느 한 구현예에 있어서, 상기 하나 이상의 추가 표적-결합 도메인은 가용성 인터류킨 또는 사이토카인 수용체인, 다중-사슬 키메라 폴리펩타이드.
구현예 E100. 구현예 E99에 있어서, 상기 가용성 수용체는 가용성 TGF-β 수용체 II(TGF-β RII), 가용성 TGF-βRIII, 가용성 NKG2D, 가용성 NKp30, 가용성 NKp44, 가용성 NKp46, 가용성 DNAM1, scMHCI, scMHCII, scTCR, 가용성 CD155, , 또는 가용성 CD28인, 다중-사슬 키메라 폴리펩타이드.
구현예 E101. 구현예 E1 내지 구현예 E100의 임의의 다중-사슬 키메라 폴리펩타이드를 포함하는 조성물.
구현예 E102. 구현예 E101에 있어서, 상기 조성물은 약학적 조성물인, 조성물.
구현예 E103. 구현예 E101 또는 구현예 E102의 조성물의 적어도 하나의 용량을 포함하는 키트.
구현예 E104. 구현예 E1 내지 구현예 E100 중 임의의 한 구현예의 임의의 다중-사슬 키메라 폴리펩타이드를 인코딩하는 핵산.
구현예 E105. 구현예 E104의 핵산을 포함하는 벡터.
구현예 E106. 구현예 E105에 있어서, 상기 벡터는 발현 벡터인, 벡터.
구현예 E107. 구현예 C104의 핵산 또는 구현예 E105 또는 구현예 E106의 벡터를 포함하는 세포.
구현예 E108. 다중-사슬 키메라 폴리펩타이드를 생성하는 방법으로서, 상기 방법은
다중-사슬 키메라 폴리펩타이드의 생성을 초래하기에 충분한 조건 하에 구현예 E107의 세포를 배양 배지에서 배양하는 단계; 및
상기 다중-사슬 키메라 폴리펩타이드를 상기 세포 및/또는 상기 배양 배지로부터 회수하는 단계를 포함하는, 방법.
구현예 E109. 구현예 E108의 방법에 의해 생성되는 다중-사슬 키메라 폴리펩타이드.
구현예 E110. 구현예 E12에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E111. 구현예 E110에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E112. 구현예 E111에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E113. 구현예 E112에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 100% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E114. 구현예 E12에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E115. 구현예 E114에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E116. 구현예 E115에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 E117. 구현예 E116에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 100% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F1. 다중-사슬 키메라 폴리펩타이드로서, 상기 다중-사슬 키메라 폴리펩타이드는
(c) 제1 키메라 폴리펩타이드로서,
(i) 제1 표적-결합 도메인;
(ii) 가용성 조직 인자 도메인; 및
(iii) 친화도 도메인 쌍의 제1 도메인을 포함하는, 제1 키메라 폴리펩타이드; 및
(d) 제2 키메라 폴리펩타이드로서,
(i) 친화도 도메인 쌍의 제2 도메인; 및
(ii) 제2 표적-결합 도메인을 포함하는, 제2 키메라 폴리펩타이드
를 포함하고,
제1 키메라 폴리펩타이드 및 제2 키메라 폴리펩타이드는 친화도 도메인의 쌍의 제1 도메인 및 제2 도메인의 결합을 통해 회합되고;
제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, IL-21의 수용체 또는 IL-7의 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F2. 구현예 F1에 있어서, 상기 제1 표적-결합 도메인 및 상기 가용성 조직 인자 도메인은 상기 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 F3. 구현예 F1에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F4. 구현예 F1 내지 구현예 F3 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인 및 상기 친화도 도메인의 쌍의 제1 도메인은 상기 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 F5. 구현예 F1 내지 구현예 F3 중 어느 한 구현예에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F6. 구현예 F1 내지 구현예 F5 중 어느 한 구현예에 있어서, 상기 친화도 도메인의 쌍의 제2 도메인 및 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 F7. 구현예 F1 내지 구현예 F5 중 어느 한 구현예에 있어서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 상기 친화도 도메인의 쌍의 제2 도메인과 상기 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F8. 구현예 F1 내지 구현예 F7 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 가용성 인간 조직 인자 도메인인, 다중-사슬 키메라 폴리펩타이드.
구현예 F9. 구현예 F8에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F10. 구현예 F9에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F11. 구현예 F10에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F12. 구현예 F11에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F13. 구현예 F8에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F14. 구현예 F13에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F15. 구현예 F14에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F16. 구현예 F15에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F17. 구현예 F8에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F18. 구현예 F17에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F19. 구현예 F18에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F20. 구현예 F19에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F21. 구현예 F8 내지 구현예 F11, 구현예 F13 내지 구현예 F15, 및 구현예 F17 내지 구현예 F19 중 어느 한 구현예에 있어서, 상기 가용성 인간 조직 인자 도메인은
성숙 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 리신;
성숙 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신;
성숙 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판;
성숙 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산;
성숙 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신;
성숙 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및
성숙 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
구현예 F22. 구현예 F21에 있어서, 상기 가용성 인간 조직 인자 도메인은
성숙 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 리신;
성숙 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신;
성숙 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판;
성숙 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산;
성숙 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신;
성숙 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및
성숙 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
구현예 F23. 구현예 F1 내지 구현예 F22 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 인자 VIIa에 결합할 수 없는, 다중-사슬 키메라 폴리펩타이드.
구현예 F24. 구현예 F1 내지 구현예 F23 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 불활성 인자 X를 인자 Xa로 전환시키지 않는, 다중-사슬 키메라 폴리펩타이드.
구현예 F25. 구현예 F1 내지 구현예 F24 중 어느 한 구현예에 있어서, 상기 다중-사슬 키메라 폴리펩타이드는 포유류에서 혈액 응고를 자극시키지 않는, 다중-사슬 키메라 폴리펩타이드.
구현예 F26. 구현예 F1 내지 구현예 F25 중 어느 한 구현예에 있어서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드의 N-말단 단부 또는 C-말단 단부에 펩타이드 태그를 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F27. 구현예 F1 내지 구현예 F26 중 어느 한 구현예에 있어서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드의 N-말단 단부 또는 C-말단 단부에 펩타이드 태그를 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F28. 구현예 F1 내지 구현예 F27 중 어느 한 구현예에 있어서, 상기 제1 키메라 폴리펩타이드 및/또는 상기 제2 키메라 폴리펩타이드는 이의 N-말단 단부에 신호 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F29. 구현예 F28에 있어서, 상기 신호 서열은 SEQ ID NO: 117을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F30. 구현예 F28에 있어서, 상기 신호 서열은 SEQ ID NO: 328인, 다중-사슬 키메라 폴리펩타이드.
구현예 F31. 구현예 F1 내지 구현예 F30 중 어느 한 구현예에 있어서, 상기 친화도 도메인의 쌍은 인간 IL-15 수용체의 알파 사슬(IL-15Rα) 및 가용성 IL-15로부터의 sushi 도메인인, 다중-사슬 키메라 폴리펩타이드.
구현예 F32. 구현예 F31에 있어서, 상기 가용성 IL-15는 D8N 또는 D8A 아미노산 치환을 갖는, 다중-사슬 키메라 폴리펩타이드.
구현예 F33. 구현예 F31에 있어서, 상기 가용성 IL-15는 SEQ ID NO: 82와 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F34. 구현예 F33에 있어서, 상기 가용성 IL-15는 SEQ ID NO: 82와 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F35. 구현예 F34에 있어서, 상기 가용성 IL-15는 SEQ ID NO: 82와 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F36. 구현예 F35에 있어서, 상기 가용성 IL-15는 SEQ ID NO: 82를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F37. 구현예 F31 내지 구현예 F36 중 어느 한 구현예에 있어서, IL-15Rα의 sushi 도메인은 인간 IL-15Rα로부터의 sushi 도메인을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F38. 구현예 F37에 있어서, 상기 인간 IL-15Rα로부터의 sushi 도메인은 SEQ ID NO: 113과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F39. 구현예 F38에 있어서, 상기 인간 IL-15Rα로부터의 sushi 도메인은 SEQ ID NO: 113과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F40. 구현예 F39에 있어서, 상기 인간 IL-15Rα로부터의 sushi 도메인은 SEQ ID NO: 113과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F41. 구현예 F40에 있어서, 상기 인간 IL-15Rα로부터의 sushi 도메인은 SEQ ID NO: 113을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F42. 구현예 F37에 있어서, 상기 인간 IL-15Rα로부터의 sushi 도메인은 성숙한 전장 IL-15Rα인, 다중-사슬 키메라 폴리펩타이드.
구현예 F43. 구현예 F1 내지 구현예 F30 중 어느 한 구현예에 있어서, 상기 친화도 도메인의 쌍은 바르나제 및 바른스타, PKA와 AKAP, 돌연변이화된 RNase I 단편에 기초한 어댑터/도킹 태그 모듈, 및 단백질 신택신, 시냅토태그민, 시냅토브레빈, 및 SNAP25의 상호작용에 기초한 SNARE로 이루어진 군으로부터 선택되는, 다중-사슬 키메라 폴리펩타이드.
구현예 F44. 구현예 F1 내지 구현예 F43 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 작용제성 항원-결합 도메인인, 다중-사슬 키메라 폴리펩타이드.
구현예 F45. 구현예 F44에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 각각 작용제성 항원-결합 도메인인, 다중-사슬 키메라 폴리펩타이드.
구현예 F46. 구현예 F44 또는 구현예 F45에 있어서, 상기 항원-결합 도메인은 scFv 또는 단일 도메인 항체를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F47. 구현예 F1 내지 구현예 F43 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 IL-21 또는 가용성 IL-7인, 다중-사슬 키메라 폴리펩타이드.
구현예 F48. 구현예 F47에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 각각 독립적으로, 가용성 IL-21 또는 가용성 IL-7인, 다중-사슬 키메라 폴리펩타이드.
구현예 F49. 구현예 F1 내지 구현예 F48 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인과 상기 제2 표적-결합 도메인은 둘 다 IL-21의 수용체 또는 IL-7의 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F50. 구현예 F49에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F51. 구현예 F50에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F52. 구현예 F1 내지 구현예 F48 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인은 IL-21에 대한 수용체에 특이적으로 결합하고, 상기 제2 표적-결합 도메인은 IL-7에 대한 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F53. 구현예 F1 내지 구현예 F48 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인은 IL-7에 대한 수용체에 특이적으로 결합하고, 상기 제2 표적-결합 도메인은 IL-21에 대한 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F54. 구현예 F53에 있어서, 상기 제1 표적-결합 도메인은 가용성 IL-21을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F55. 구현예 F54에 있어서, 상기 가용성 IL-21은 가용성 인간 IL-21인, 다중-사슬 키메라 폴리펩타이드.
구현예 F56. 구현예 F55에 있어서, 상기 가용성 인간 IL-21은 SEQ ID NO: 83과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F57. 구현예 F56에 있어서, 상기 가용성 인간 IL-21은 SEQ ID NO: 83과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F58. 구현예 F57에 있어서, 상기 가용성 인간 IL-21은 SEQ ID NO: 83과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F59. 구현예 F58에 있어서, 상기 가용성 인간 IL-21은 SEQ ID NO: 83의 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F60. 구현예 F53 내지 구현예 F59 중 어느 한 구현예에 있어서, 상기 제2 표적-결합 도메인은 가용성 IL-7을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F61. 구현예 D60에 있어서, 상기 가용성 IL-7은 가용성 인간 IL-7인, 다중-사슬 키메라 폴리펩타이드.
구현예 F62. 구현예 F61에 있어서, 상기 가용성 인간 IL-7은 SEQ ID NO: 79와 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F63. 구현예 F62에 있어서, 상기 가용성 인간 IL-7은 SEQ ID NO: 79와 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F64. 구현예 F63에 있어서, 상기 가용성 인간 IL-7은 SEQ ID NO: 79와 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F65. 구현예 F64에 있어서, 상기 가용성 인간 IL-7은 SEQ ID NO: 79의 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F66. 구현예 F1에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F67. 구현예 F66에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F68. 구현예 F67에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F69. 구현예 F68에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F70. 구현예 F69에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 209를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F71. 구현예 F1 및 구현예 F66 내지 구현예 F70 중 어느 한 구현예에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 211과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F72. 구현예 F71에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 211과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F73. 구현예 F72에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 211과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F74. 구현예 F73에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 211을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F75. 구현예 F74에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 213을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F76. 구현예 F1에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 199과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F77. 구현예 F76에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 199와 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F78. 구현예 F77에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 199와 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F79. 구현예 F68에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 199를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F80. 구현예 F69에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 201을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F81. 구현예 F1 및 구현예 F76 내지 구현예 F80 중 어느 한 구현예에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 203과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F82. 구현예 F81에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 203과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F83. 구현예 F82에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 203과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F84. 구현예 F83에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 203을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F85. 구현예 F84에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 209를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F86. 구현예 F1 내지 구현예 F65 중 어느 한 구현예에 있어서, 상기 제1 키메라 폴리펩타이드는 하나 이상의 추가 표적-결합 도메인(들)을 추가로 포함하며, 이때, 상기 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나는 상기 가용성 조직 인자 도메인과 상기 친화도 도메인의 쌍의 제1 도메인 사이에 위치하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F87. 구현예 F86에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 가용성 조직 인자 도메인과 상기 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나 사이에 링커 서열, 및/또는 상기 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나와 상기 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F88. 구현예 F1 내지 구현예 F65 중 어느 한 구현예에 있어서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드의 N-말단 및/또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F89. 구현예 F88에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드에서 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 F90. 구현예 F88에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F91. 구현예 F88에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 F92. 구현예 F88에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 제1 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F93. 구현예 F88에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드의 N-말단 및/또는 C-말단에 배치되고, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F94. 구현예 F93에 있어서, N-말단에 배치된 하나 이상의 추가 표적-결합 도메인의 적어도 하나의 추가 표적-결합 도메인은 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 F95. 구현예 F93에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 적어도 하나의 추가 표적-결합 도메인과 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인 사이에 배치된 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F96. 구현예 F93에 있어서, C-말단에 배치된 하나 이상의 추가 표적-결합 도메인의 적어도 하나의 추가 표적-결합 도메인은 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 F97. 구현예 F93에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 적어도 하나의 추가 표적-결합 도메인과 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인 사이에 배치된 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F98. 구현예 F93에 있어서, 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 가용성 조직 인자 도메인 및/또는 상기 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 F99. 구현예 F93에 있어서, 상기 제1 키메라 폴리펩타이드는 (i) 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 가용성 조직 인자 도메인 사이에, 및/또는 (ii) 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 친화도 도메인의 쌍의 제1 도메인 사이에 배치된 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F100. 구현예 F1 내지 구현예 F65 및 구현예 F86 내지 구현예 F99 중 어느 한 구현예에 있어서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드의 N-말단 또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F101. 구현예 F100에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인의 쌍의 제2 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 F102. 구현예 F100에 있어서, 상기 제2 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 제2 키메라 폴리펩타이드 내 친화도 도메인의 쌍의 제2 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F103. 구현예 F100에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제2 키메라 폴리펩타이드에서 제2 표적-결합 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 F104. 구현예 F100에 있어서, 상기 제2 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 제2 키메라 폴리펩타이드 내 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F105. 구현예 F86 내지 구현예 F104 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 항원에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F106. 구현예 F105에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 에피토프에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F107. 구현예 F106에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 아미노산 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F108. 구현예 F86 내지 구현예 F104 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 상이한 항원에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F109. 구현예 F86 내지 구현예 F108 중 어느 한 구현예에 있어서, 상기 하나 이상의 추가 항원-결합 도메인은 CD16a, CD28, CD3, CD33, CD20, CD19, CD22, CD123, IL-1R, IL-1, VEGF, IL-6R, IL-4, IL-10, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKp30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, IL-1에 대한 수용체, IL-2에 대한 수용체, IL-3에 대한 수용체, IL-7에 대한 수용체, IL-8에 대한 수용체, IL-10에 대한 수용체, IL-12에 대한 수용체, IL-15에 대한 수용체, IL-17에 대한 수용체, IL-18에 대한 수용체, IL-21에 대한 수용체, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, 및 CD28에 대한 수용체로 이루어진 군으로부터 선택되는 표적에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 F110. 구현예 F86 내지 구현예 F108 중 어느 한 구현예에 있어서, 상기 하나 이상의 추가 표적-결합 도메인은 가용성 인터류킨 또는 사이토카인 단백질인, 다중-사슬 키메라 폴리펩타이드.
구현예 F111. 구현예 F110에 있어서, 상기 가용성 인터류킨, 사이토카인, 또는 리간드 단백질은 IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, SCF, FLT3L, MICA, MICB, 및 ULP16-결합 단백질로 이루어진 군으로부터 선택되는, 다중-사슬 키메라 폴리펩타이드.
구현예 F112. 구현예 F86 내지 구현예 F108 중 어느 한 구현예에 있어서, 상기 하나 이상의 추가 표적-결합 도메인은 가용성 인터류킨 또는 사이토카인 수용체인, 다중-사슬 키메라 폴리펩타이드.
구현예 F113. 구현예 F112에 있어서, 상기 가용성 수용체는 가용성 TGF-β 수용체 II(TGF-βRII), 가용성 TGF-βRIII, 가용성 NKG2D, 가용성 NKp30, 가용성 NKp44, 가용성 NKp46, 가용성 DNAM1, scMHCI, scMHCII, scTCR, 가용성 CD155, 가용성 CD122, 또는 가용성 CD28인, 다중-사슬 키메라 폴리펩타이드.
구현예 F114. 구현예 F1 내지 구현예 F113의 임의의 다중-사슬 키메라 폴리펩타이드를 포함하는 조성물.
구현예 F115. 구현예 F114에 있어서, 상기 조성물은 약학적 조성물인, 조성물.
구현예 F116. 구현예 F114 또는 구현예 F115의 조성물의 적어도 하나의 용량을 포함하는 키트.
구현예 F117. 구현예 F1 내지 구현예 F113 중 임의의 한 구현예의 임의의 다중-사슬 키메라 폴리펩타이드를 인코딩하는 핵산.
구현예 F118. 구현예 F117의 핵산을 포함하는 벡터.
구현예 F119. 구현예 F118에 있어서, 상기 벡터는 발현 벡터인, 벡터.
구현예 F120. 구현예 F117의 핵산 또는 구현예 F118 또는 구현예 F119의 벡터를 포함하는 세포.
구현예 F121. 다중-사슬 키메라 폴리펩타이드를 생성하는 방법으로서, 상기 방법은
다중-사슬 키메라 폴리펩타이드의 생성을 초래하기에 충분한 조건 하에 구현예 F120의 세포를 배양 배지에서 배양하는 단계; 및
상기 다중-사슬 키메라 폴리펩타이드를 상기 세포 및/또는 상기 배양 배지로부터 회수하는 단계를 포함하는, 방법.
구현예 F122. 구현예 F121의 방법에 의해 생성되는 다중-사슬 키메라 폴리펩타이드.
구현예 G1. 다중-사슬 키메라 폴리펩타이드로서, 상기 다중-사슬 키메라 폴리펩타이드는
(e) 제1 키메라 폴리펩타이드로서,
(i) 제1 표적-결합 도메인;
(ii) 가용성 조직 인자 도메인; 및
(iii) 친화도 도메인 쌍의 제1 도메인을 포함하는, 제1 키메라 폴리펩타이드; 및
(f) 제2 키메라 폴리펩타이드로서,
(i) 친화도 도메인 쌍의 제2 도메인; 및
(ii) 제2 표적-결합 도메인을 포함하는, 제2 키메라 폴리펩타이드
를 포함하고,
상기 제1 키메라 폴리펩타이드 및 상기 제2 키메라 폴리펩타이드는 친화도 도메인 쌍의 제1 도메인과 제2 도메인의 결합을 통해 회합되고;
제1 표적-결합 도메인 및 제2 표적-결합 도메인은 각각 독립적으로, IL-7에 대한 수용체, CD16, IL-21에 대한 수용체, TGF-β, 또는 CD137L에 대한 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G2. 구현예 G1에 있어서, 상기 제1 표적-결합 도메인 및 상기 가용성 조직 인자 도메인은 상기 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 G3. 구현예 G1에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G4. 구현예 G1 내지 구현예 G3 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인 및 상기 친화도 도메인의 쌍의 제1 도메인은 상기 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 G5. 구현예 G1 내지 구현예 G3 중 어느 한 구현예에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G6. 구현예 G1 내지 구현예 G5 중 어느 한 구현예에 있어서, 상기 친화도 도메인의 쌍의 제2 도메인 및 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 G7. 구현예 G1 내지 구현예 G5 중 어느 한 구현예에 있어서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 상기 친화도 도메인의 쌍의 제2 도메인과 상기 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G8. 구현예 G1 내지 구현예 G7 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 가용성 인간 조직 인자 도메인인, 다중-사슬 키메라 폴리펩타이드.
구현예 G9. 구현예 G8에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G10. 구현예 G9에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G11. 구현예 G10에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G12. 구현예 G8 내지 구현예 G11 중 어느 한 구현예에 있어서, 상기 가용성 인간 조직 인자 도메인은
성숙 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 리신;
성숙 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신;
성숙 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판;
성숙 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산;
성숙 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신;
성숙 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및
성숙 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
구현예 G13. 구현예 G12에 있어서, 상기 가용성 인간 조직 인자 도메인은
성숙 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 리신;
성숙 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신;
성숙 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판;
성숙 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산;
성숙 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신;
성숙 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및
성숙 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
구현예 G14. 구현예 G1 내지 구현예 G13 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 인자 VIIa에 결합할 수 없는, 다중-사슬 키메라 폴리펩타이드.
구현예 G15. 구현예 G1 내지 구현예 G14 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 불활성 인자 X를 인자 Xa로 전환시키지 않는, 다중-사슬 키메라 폴리펩타이드.
구현예 G16. 구현예 G1 내지 구현예 G15 중 어느 한 구현예에 있어서, 상기 다중-사슬 키메라 폴리펩타이드는 포유류에서 혈액 응고를 자극시키지 않는, 다중-사슬 키메라 폴리펩타이드.
구현예 G17. 구현예 G1 내지 구현예 G16 중 어느 한 구현예에 있어서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드의 N-말단 단부 또는 C-말단 단부에 펩타이드 태그를 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G18. 구현예 G1 내지 구현예 G17 중 어느 한 구현예에 있어서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드의 N-말단 단부 또는 C-말단 단부에 펩타이드 태그를 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G19. 구현예 G1 내지 구현예 G18 중 어느 한 구현예에 있어서, 상기 제1 키메라 폴리펩타이드 및/또는 상기 제2 키메라 폴리펩타이드는 이의 N-말단 단부에 신호 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G20. 구현예 G19에 있어서, 상기 신호 서열은 SEQ ID NO: 117을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G21. 구현예 G20에 있어서, 상기 신호 서열은 SEQ ID NO: 117인, 다중-사슬 키메라 폴리펩타이드.
구현예 G22. 구현예 G1 내지 구현예 G21 중 어느 한 구현예에 있어서, 상기 친화도 도메인의 쌍은 인간 IL-15 수용체의 알파 사슬(IL-15Rα) 및 가용성 IL-15로부터의 sushi 도메인인, 다중-사슬 키메라 폴리펩타이드.
구현예 G23. 구현예 G22에 있어서, 상기 가용성 IL-15는 D8N 또는 D8A 아미노산 치환을 갖는, 다중-사슬 키메라 폴리펩타이드.
구현예 G24. 구현예 G22에 있어서, 상기 가용성 IL-15는 SEQ ID NO: 82와 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G25. 구현예 G24에 있어서, 상기 가용성 IL-15는 SEQ ID NO: 82와 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G26. 구현예 G25에 있어서, 상기 가용성 IL-15는 SEQ ID NO: 82와 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G27. 구현예 G26에 있어서, 상기 가용성 IL-15는 SEQ ID NO: 82를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G28. 구현예 G22 내지 구현예 G27 중 어느 한 구현예에 있어서, IL-15Rα의 sushi 도메인은 인간 IL-15Rα로부터의 sushi 도메인을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G29. 구현예 G28에 있어서, 상기 인간 IL-15Rα로부터의 sushi 도메인은 SEQ ID NO: 113과 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G30. 구현예 G29에 있어서, 상기 인간 IL-15Rα로부터의 sushi 도메인은 SEQ ID NO: 113과 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G31. 구현예 G30에 있어서, 상기 인간 IL-15Rα로부터의 sushi 도메인은 SEQ ID NO: 113과 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G32. 구현예 G31에 있어서, 상기 인간 IL-15Rα로부터의 sushi 도메인은 SEQ ID NO: 113을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G33. 구현예 G28에 있어서, 상기 인간 IL-15Rα로부터의 sushi 도메인은 성숙한 전장 IL-15Rα인, 다중-사슬 키메라 폴리펩타이드.
구현예 G34. 구현예 G1 내지 구현예 G21 중 어느 한 구현예에 있어서, 상기 친화도 도메인의 쌍은 바르나제 및 바른스타, PKA와 AKAP, 돌연변이화된 RNase I 단편에 기초한 어댑터/도킹 태그 모듈, 및 단백질 신택신, 시냅토태그민, 시냅토브레빈, 및 SNAP25의 상호작용에 기초한 SNARE로 이루어진 군으로부터 선택되는, 다중-사슬 키메라 폴리펩타이드.
구현예 G35. 구현예 G1 내지 구현예 G34 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 각각 독립적으로, IL-7에 대한 수용체, CD16, 또는 IL-21에 대한 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G36. 구현예 G35에 있어서, 상기 제1 표적-결합 도메인은 IL-7에 대한 수용체에 특이적으로 결합하고, 상기 제2 표적-결합 도메인은 CD16, 또는 IL-21에 대한 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G37. 구현예 G36에 있어서, 상기 제1 표적-결합 도메인은 가용성 IL-7 단백질을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G38. 구현예 G37에 있어서, 상기 가용성 IL-7 단백질은 가용성 인간 IL-7인, 다중-사슬 키메라 폴리펩타이드.
구현예 G39. 구현예 G36 내지 구현예 G38 중 어느 한 구현예에 있어서, 상기 제2 항원-결합 도메인은 CD16에 특이적으로 결합하는 항원-결합 도메인을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G40. 구현예 G39에 있어서, 상기 제2 항원-결합 도메인은 CD16에 특이적으로 결합하는 scFv를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G41. 구현예 G36 내지 구현예 G38 중 어느 한 구현예에 있어서, 상기 제2 항원-결합 도메인은 IL-21에 대한 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G42. 구현예 G41에 있어서, 상기 제2 항원-결합 도메인은 가용성 IL-21을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G43. 구현예 G42에 있어서, 상기 가용성 IL-21은 가용성 인간 IL-21인, 다중-사슬 키메라 폴리펩타이드.
구현예 G44. 구현예 G36 내지 구현예 G40 중 어느 한 구현예에 있어서, 상기 제2 키메라 폴리펩타이드는 IL-21에 대한 수용체에 특이적으로 결합하는 추가 표적-결합 도메인을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G45. 구현예 G44에 있어서, 상기 추가 표적-결합 도메인은 가용성 IL-21을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G46. 구현예 G45에 있어서, 상기 가용성 IL-21은 가용성 인간 IL-12인, 다중-사슬 키메라 폴리펩타이드.
구현예 G47. 구현예 G1 내지 구현예 G34 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 각각 독립적으로, TGF-β, CD16, 또는 IL-21에 대한 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G48. 구현예 G47에 있어서, 상기 제1 표적-결합 도메인은 TGF-β에 특이적으로 결합하고, 상기 제2 표적-결합 도메인은 CD16, 또는 IL-21의 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G49. 구현예 G48에 있어서, 상기 제1 표적-결합 도메인은 가용성 TGF-β 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G50. 구현예 G49에 있어서, 상기 가용성 TGF-β 수용체는 가용성 TGFβRII 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G51. 구현예 G48 내지 구현예 G50 중 어느 한 구현예에 있어서, 상기 제2 표적-결합 도메인은 CD16에 특이적으로 결합하는, 다중-특이적 키메라 폴리펩타이드.
구현예 G52. 구현예 G51에 있어서, 상기 제2 항원-결합 도메인은 CD16에 특이적으로 결합하는 항원-결합 도메인을 포함하는, 다중-특이적 키메라 폴리펩타이드.
구현예 G53. 구현예 G52에 있어서, 상기 제2 항원-결합 도메인은 CD16에 특이적으로 결합하는 scFv를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G54. 구현예 G48 내지 구현예 G50 중 어느 한 구현예에 있어서, 상기 제2 표적-결합 도메인은 IL-21에 대한 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G55. 구현예 G54에 있어서, 상기 제2 표적-결합 도메인은 가용성 IL-21을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G56. 구현예 G55에 있어서, 상기 제2 표적-결합 도메인은 가용성 인간 IL-21을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G57. 구현예 G48 내지 구현예 G53 중 어느 한 구현예에 있어서, 상기 제2 키메라 폴리펩타이드는 IL-21에 대한 수용체에 특이적으로 결합하는 추가 표적-결합 도메인을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G58. 구현예 G57에 있어서, 상기 추가 표적-결합 도메인은 가용성 IL-21을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G59. 구현예 G58에 있어서, 상기 가용성 IL-21은 가용성 인간 IL-21인, 다중-사슬 키메라 폴리펩타이드.
구현예 G60. 구현예 G1 내지 구현예 G34 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 각각 독립적으로, IL-7에 대한 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G61. 구현예 G60에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 가용성 IL-7을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G62. 구현예 G61에 있어서, 상기 가용성 IL-7은 가용성 인간 IL-7인, 다중-사슬 키메라 폴리펩타이드.
구현예 G63. 구현예 G1 내지 구현예 G34 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 각각 독립적으로, TGF-β에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G64. 구현예 G63에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 가용성 TGF-β 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G65. 구현예 G64에 있어서, 상기 가용성 TGF-β 수용체는 가용성 TGFβRII 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G66. 구현예 G1 내지 구현예 G34 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 각각 독립적으로, IL-7에 대한 수용체, IL-21에 대한 수용체, 또는 CD137L에 대한 수용체에 특이적으로 결합하는, 다중-특이적 키메라 폴리펩타이드.
구현예 G67. 구현예 G66에 있어서, 상기 제1 표적-결합 도메인은 IL-7에 대한 수용체에 특이적으로 결합하고, 상기 제2 표적-결합 도메인은 IL-21에 대한 수용체 또는 CD137L에 대한 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G68. 구현예 G67에 있어서, 상기 제1 표적-결합 도메인은 가용성 IL-7인, 다중-특이적 키메라 폴리펩타이드.
구현예 G69. 구현예 G68에 있어서, 상기 가용성 IL-7은 가용성 인간 IL-7인, 다중-특이적 키메라 폴리펩타이드.
구현예 G70. 구현예 G67 내지 구현예 G69 중 어느 한 구현예에 있어서, 상기 제2 표적-결합 도메인은 IL-21에 대한 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G71. 구현예 G70에 있어서, 상기 제2 표적-결합 도메인은 가용성 IL-21인, 다중-사슬 키메라 폴리펩타이드.
구현예 G72. 구현예 G71에 있어서, 상기 가용성 IL-21은 가용성 인간 IL-21인, 다중-사슬 키메라 폴리펩타이드.
구현예 G73. 구현예 G67 내지 구현예 G69 중 어느 한 구현예에 있어서, 상기 제2 항원-결합 도메인은 CD137L에 대한 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G74. 구현예 G73에 있어서, 상기 제2 항원-결합 도메인은 가용성 CD137L인, 다중-사슬 키메라 폴리펩타이드.
구현예 G75. 구현예 G74에 있어서, 상기 가용성 CD137L은 가용성 인간 CD137L인, 다중-사슬 키메라 폴리펩타이드.
구현예 G76. 구현예 G67 내지 구현예 G72 중 어느 한 구현예에 있어서, 상기 제2 키메라 폴리펩타이드는 CD137L에 대한 수용체에 특이적으로 결합하는 추가 표적-결합 도메인을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G77. 구현예 G76에 있어서, 상기 추가 표적-결합 도메인은 가용성 CD137L을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G78. 구현예 G77에 있어서, 상기 가용성 CD137L은 가용성 인간 CD137L인, 다중-사슬 키메라 폴리펩타이드.
구현예 G79. 구현예 G1 내지 구현예 G34 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 각각 독립적으로, IL-7에 대한 수용체 또는 TGF-β에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G80. 구현예 G79에 있어서, 상기 제1 표적-결합 도메인은 수용체 IL-7에 특이적으로 결합하고, 상기 제2 표적-결합 도메인은 TGF-β에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G81. 구현예 G80에 있어서, 상기 제1 표적-결합 도메인은 가용성 IL-7 단백질을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G82. 구현예 G81에 있어서, 상기 가용성 IL-7 단백질은 가용성 인간 IL-7인, 다중-사슬 키메라 폴리펩타이드.
구현예 G83. 구현예 G80 내지 구현예 G82 중 어느 한 구현예에 있어서, 상기 제2 항원-결합 도메인은 TGF-β에 특이적으로 결합하는 항원-결합 도메인을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G84. 구현예 G83에 있어서, 상기 제2 표적-결합 도메인은 가용성 TGF-β 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G85. 구현예 G84에 있어서, 상기 가용성 TGF-β 수용체는 가용성 TGFβRII 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G86. 구현예 G1 내지 구현예 G34 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 각각 독립적으로, TGF-β, IL-21에 대한 수용체, 또는 CD137L에 대한 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G87. 구현예 G86에 있어서, 상기 제1 표적-결합 도메인은 TGF-β에 특이적으로 결합하고, 상기 제2 표적-결합 도메인은 IL-21에 대한 수용체 또는 CD137L에 대한 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G88. 구현예 G87에 있어서, 상기 제1 표적-결합 도메인은 가용성 TGF-β 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G89. 구현예 G88에 있어서, 상기 가용성 TGF-β 수용체는 가용성 TGFβRII 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G90. 구현예 G87 내지 구현예 G89 중 어느 한 구현예에 있어서, 상기 제2 표적-결합 도메인은 IL-21에 대한 수용체에 특이적으로 결합하는, 다중-특이적 키메라 폴리펩타이드.
구현예 G91. 구현예 G90에 있어서, 상기 제2 표적-결합 도메인은 가용성 IL-21을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G92. 구현예 G91에 있어서, 상기 제2 표적-결합 도메인은 가용성 인간 IL-21을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G93. 구현예 G87 내지 구현예 G89 중 어느 한 구현예에 있어서, 상기 제2 표적-결합 도메인은 CD137L에 대한 수용체에 특이적으로 결합하는, 다중-특이적 키메라 폴리펩타이드.
구현예 G94. 구현예 G93에 있어서, 상기 제2 표적-결합 도메인은 가용성 CD137L을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G95. 구현예 G94에 있어서, 상기 제2 표적-결합 도메인은 가용성 인간 CD137L을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G96. 구현예 G87 내지 구현예 G92 중 어느 한 구현예에 있어서, 상기 제2 키메라 폴리펩타이드는 CD137L에 대한 수용체에 특이적으로 결합하는 추가 표적-결합 도메인을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G97. 구현예 G96에 있어서, 상기 추가 표적-결합 도메인은 가용성 CD137L을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G98. 구현예 G97에 있어서, 상기 가용성 CD137L은 가용성 인간 CD137L인, 다중-사슬 키메라 폴리펩타이드.
구현예 G99. 구현예 G1 내지 구현예 G34 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 각각 독립적으로, TGF-β 또는 IL-21에 대한 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G100. 구현예 G99에 있어서, 상기 제1 표적-결합 도메인은 TGF-β에 특이적으로 결합하고, 상기 제2 표적-결합 도메인은 TGF-β 또는 IL-21에 대한 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G101. 구현예 G100에 있어서, 상기 제1 표적-결합 도메인은 가용성 TGF-β 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G102. 구현예 G101에 있어서, 상기 가용성 TGF-β 수용체는 가용성 TGFβRII 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G103. 구현예 G100 내지 구현예 G102 중 어느 한 구현예에 있어서, 상기 제2 표적-결합 도메인은 IL-21에 대한 수용체에 특이적으로 결합하는, 다중-특이적 키메라 폴리펩타이드.
구현예 G104. 구현예 G103에 있어서, 상기 제2 표적-결합 도메인은 가용성 IL-21을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G105. 구현예 G104에 있어서, 상기 제2 표적-결합 도메인은 가용성 인간 IL-21을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G106. 구현예 G100 내지 구현예 G102 중 어느 한 구현예에 있어서, 상기 제2 표적-결합 도메인은 TGF-β에 특이적으로 결합하는, 다중-특이적 키메라 폴리펩타이드.
구현예 G107. 구현예 G106에 있어서, 상기 제1 표적-결합 도메인은 가용성 TGF-β 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G108. 구현예 G107에 있어서, 상기 가용성 TGF-β 수용체는 가용성 TGFβRII 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G109. 구현예 G100 내지 구현예 G105 중 어느 한 구현예에 있어서, 상기 제2 폴리펩타이드는 TGF-β에 특이적으로 결합하는 추가 표적-결합 도메인을 추가로 포함하는, 다중-특이적 키메라 폴리펩타이드.
구현예 G110. 구현예 G109에 있어서, 상기 제1 표적-결합 도메인은 가용성 TGF-β 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G111. 구현예 G110에 있어서, 상기 가용성 TGF-β 수용체는 가용성 TGFβRII 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G112. 구현예 G1 내지 구현예 G34 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 각각 독립적으로, TGF-β 또는 IL-16에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G113. 구현예 G112에 있어서, 상기 제1 표적-결합 도메인은 TGF-β에 특이적으로 결합하고, 상기 제2 표적-결합 도메인은 TGF-β 또는 IL-16에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G114. 구현예 G113에 있어서, 상기 제1 표적-결합 도메인은 가용성 TGF-β 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G115. 구현예 G114에 있어서, 상기 가용성 TGF-β 수용체는 가용성 TGFβRII 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G116. 구현예 G113 내지 구현예 G115 중 어느 한 구현예에 있어서, 상기 제2 표적-결합 도메인은 IL-16에 특이적으로 결합하는, 다중-특이적 키메라 폴리펩타이드.
구현예 G117. 구현예 G116에 있어서, 상기 제2 항원-결합 도메인은 CD16에 특이적으로 결합하는 항원-결합 도메인을 포함하는, 다중-특이적 키메라 폴리펩타이드.
구현예 G118. 구현예 G117에 있어서, 상기 제2 항원-결합 도메인은 CD16에 특이적으로 결합하는 scFv를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G119. 구현예 G113 내지 구현예 G115 중 어느 한 구현예에 있어서, 상기 제2 표적-결합 도메인은 TGF-β에 특이적으로 결합하는, 다중-특이적 키메라 폴리펩타이드.
구현예 G120. 구현예 G119에 있어서, 상기 제1 표적-결합 도메인은 가용성 TGF-β 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G121. 구현예 G120에 있어서, 상기 가용성 TGF-β 수용체는 가용성 TGFβRII 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G122. 구현예 G113 내지 구현예 G118 중 어느 한 구현예에 있어서, 상기 제2 키메라 폴리펩타이드는 TGF-β에 특이적으로 결합하는 추가 표적-결합 도메인을 추가로 포함하는, 다중-특이적 키메라 폴리펩타이드.
구현예 G123. 구현예 G122에 있어서, 상기 제1 표적-결합 도메인은 가용성 TGF-β 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G124. 구현예 G123에 있어서, 상기 가용성 TGF-β 수용체는 가용성 TGFβRII 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G125. 구현예 G1 내지 구현예 G34 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 각각 독립적으로, TGF-β, 또는 CD137L에 대한 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G126. 구현예 G125에 있어서, 상기 제1 표적-결합 도메인은 TGF-β에 특이적으로 결합하고, 상기 제2 표적-결합 도메인은 CD137L에 대한 수용체에 특이적으로 결합하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G127. 구현예 G126에 있어서, 상기 제1 표적-결합 도메인은 가용성 TGF-β 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G128. 구현예 G127에 있어서, 상기 가용성 TGF-β 수용체는 가용성 TGFβRII 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G129. 구현예 G128에 있어서, 상기 제2 표적-결합 도메인은 가용성 CD137L 단백질을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G130. 구현예 G129에 있어서, 상기 가용성 CD137L 단백질은 가용성 인간 CD137L인, 다중-사슬 키메라 폴리펩타이드.
구현예 G131. 구현예 G126 내지 구현예 G130 중 어느 한 구현예에 있어서, 상기 제2 키메라 폴리펩타이드는 TGF-β에 특이적으로 결합하는 추가 표적-결합 도메인을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G132. 구현예 G131에 있어서, 상기 추가 표적-결합 도메인은 가용성 TGF-β 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G133. 구현예 G132에 있어서, 상기 가용성 TGF-β 수용체는 가용성 TGFβRII 수용체인, 다중-특이적 키메라 폴리펩타이드.
구현예 G134. 구현예 G1에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G135. 구현예 G134에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G136. 구현예 G135에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G137. 구현예 G136에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G138. 구현예 G137에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 209를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G139. 구현예 G1 및 구현예 G134 내지 구현예 G138 중 어느 한 구현예에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 232와 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G140. 구현예 G139에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 232와 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G141. 구현예 G140에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 232와 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G142. 구현예 G141에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 232를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G143. 구현예 G142에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 234를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G144. 구현예 G1에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G145. 구현예 G144에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G146. 구현예 G145에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G147. 구현예 G146에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G148. 구현예 G147에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 238을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G149. 구현예 G1 및 구현예 G144 내지 구현예 G148 중 어느 한 구현예에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 232와 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G150. 구현예 G149에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 232와 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G151. 구현예 G150에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 232와 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G152. 구현예 G151에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 232를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G153. 구현예 G152에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 234를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G154. 구현예 G1에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G155. 구현예 G154에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G156. 구현예 G155에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G157. 구현예 G156에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G158. 구현예 G157에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 209를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G159. 구현예 G1 및 구현예 G154 내지 구현예 G158 중 어느 한 구현예에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 203과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G160. 구현예 G159에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 203과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G161. 구현예 G160에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 203과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G162. 구현예 G161에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 203을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G163. 구현예 G162에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 250을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G164. 구현예 G1에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G165. 구현예 G164에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G166. 구현예 G165에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G167. 구현예 G166에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G168. 구현예 G167에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 238을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G169. 구현예 G1 및 구현예 G164 내지 구현예 G168 중 어느 한 구현예에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 193과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G170. 구현예 G169에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 193과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G171. 구현예 G170에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 193과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G172. 구현예 G171에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 193을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G173. 구현예 G172에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 195를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G174. 구현예 G1에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G175. 구현예 G174에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G176. 구현예 G175에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G177. 구현예 G176에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G178. 구현예 G177에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 209를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G179. 구현예 G1 및 구현예 G174 내지 구현예 G178 중 어느 한 구현예에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 268과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G180. 구현예 G179에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 268과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G181. 구현예 G180에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 268과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G182. 구현예 G181에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 268을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G183. 구현예 G182에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 270을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G184. 구현예 G1에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G185. 구현예 G184에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G186. 구현예 G185에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G187. 구현예 G186에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G188. 구현예 G187에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 209를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G189. 구현예 G1 및 구현예 G184 내지 구현예 G188 중 어느 한 구현예에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 272와 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G190. 구현예 G189에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 272와 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G191. 구현예 G190에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 272와 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G192. 구현예 G191에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 272를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G193. 구현예 G192에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 272를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G194. 구현예 G1에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G195. 구현예 G194에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G196. 구현예 G195에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G197. 구현예 G196에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 207을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G198. 구현예 G197에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 209를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G199. 구현예 G1 및 구현예 G194 내지 구현예 G198 중 어느 한 구현예에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 193과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G200. 구현예 G199에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 193과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G201. 구현예 G200에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 193과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G202. 구현예 G201에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 193을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G203. 구현예 G202에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 195를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G204. 구현예 G1에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G205. 구현예 G204에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G206. 구현예 G205에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G207. 구현예 G206에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G208. 구현예 G207에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 238을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G209. 구현예 G1 및 구현예 G204 내지 구현예 G208 중 어느 한 구현예에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 268과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G210. 구현예 G209에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 268과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G211. 구현예 G210에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 268과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G212. 구현예 G211에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 268을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G213. 구현예 G212에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 270을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G214. 구현예 G1에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G215. 구현예 G214에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G216. 구현예 G215에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G217. 구현예 G216에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G218. 구현예 G217에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 238을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G219. 구현예 G1 및 구현예 G214 내지 구현예 G218 중 어느 한 구현예에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 300과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G220. 구현예 G219에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 300과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G221. 구현예 G220에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 300과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G222. 구현예 G221에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 300을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G223. 구현예 G222에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 302를 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G224. 구현예 G1에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G225. 구현예 G224에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G226. 구현예 G225에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G227. 구현예 G226에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G228. 구현예 G227에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 238을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G229. 구현예 G1 및 구현예 G224 내지 구현예 G228 중 어느 한 구현예에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 308과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G230. 구현예 G229에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 308과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G231. 구현예 G230에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 308과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G232. 구현예 G231에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 308을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G233. 구현예 G232에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 310을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G234. 구현예 G1에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G235. 구현예 G234에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G236. 구현예 G235에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G237. 구현예 G236에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G238. 구현예 G237에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 238을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G239. 구현예 G1 및 구현예 G234 내지 구현예 G238 중 어느 한 구현예에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 316과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G240. 구현예 G239에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 316과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G241. 구현예 G240에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 316과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G242. 구현예 G241에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 316을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G243. 구현예 G242에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 318을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G244. 구현예 G1 내지 구현예 G133 중 어느 한 구현예에 있어서, 상기 제1 키메라 폴리펩타이드는 하나 이상의 추가 표적-결합 도메인(들)을 추가로 포함하며, 이때, 상기 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나는 상기 가용성 조직 인자 도메인과 상기 친화도 도메인의 쌍의 제1 도메인 사이에 위치하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G245. 구현예 G244에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 가용성 조직 인자 도메인과 상기 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나 사이에 링커 서열, 및/또는 상기 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나와 상기 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G246. 구현예 G1 내지 구현예 G133 중 어느 한 구현예에 있어서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드의 N-말단 및/또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G247. 구현예 G246에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드에서 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 G248. 구현예 G246에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G249. 구현예 G246에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 G250. 구현예 G246에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 제1 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G251. 구현예 G246에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드의 N-말단 및/또는 C-말단에 배치되고, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G252. 구현예 G251에 있어서, N-말단에 배치된 하나 이상의 추가 표적-결합 도메인의 적어도 하나의 추가 표적-결합 도메인은 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 G253. 구현예 G251에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 적어도 하나의 추가 표적-결합 도메인과 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인 사이에 배치된 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G254. 구현예 G251에 있어서, C-말단에 배치된 하나 이상의 추가 표적-결합 도메인의 적어도 하나의 추가 표적-결합 도메인은 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 G255. 구현예 G251에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 적어도 하나의 추가 표적-결합 도메인과 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인 사이에 배치된 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G256. 구현예 G251에 있어서, 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 가용성 조직 인자 도메인 및/또는 상기 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 G257. 구현예 G251에 있어서, 상기 제1 키메라 폴리펩타이드는 (i) 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 가용성 조직 인자 도메인 사이에, 및/또는 (ii) 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 친화도 도메인의 쌍의 제1 도메인 사이에 배치된 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G258. 구현예 G44-G46, G57-G59, G76-G78, G96-G98, G109-G111, G122-G124, 및 G131-G133 중 어느 한 구현예에 있어서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드의 N-말단 또는 C-말단 단부에 추가 표적-결합 도메인을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G259. 구현예 G258에 있어서, 상기 추가 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 친화도 도메인의 쌍의 제2 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 G260. 구현예 G258에 있어서, 상기 제2 키메라 폴리펩타이드는 상기 추가 표적-결합 도메인과 상기 제2 키메라 폴리펩타이드 내 친화도 도메인의 쌍의 제2 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G261. 구현예 G258에 있어서, 상기 추가 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드 내 제2 표적-결합 도메인에 직접적으로 인접해 있는, 다중-사슬 키메라 폴리펩타이드.
구현예 G262. 구현예 G258에 있어서, 상기 제2 키메라 폴리펩타이드는 상기 추가 표적-결합 도메인과 상기 제2 키메라 폴리펩타이드 내 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G263. 구현예 G1 내지 구현예 G262의 임의의 다중-사슬 키메라 폴리펩타이드를 포함하는 조성물.
구현예 G264. 구현예 G263에 있어서, 상기 조성물은 약학적 조성물인, 조성물.
구현예 G265. 구현예 G263 또는 구현예 G264의 조성물의 적어도 하나의 용량을 포함하는 키트.
구현예 G266. 구현예 G1 내지 구현예 G262 중 임의의 한 구현예의 임의의 다중-사슬 키메라 폴리펩타이드를 인코딩하는 핵산.
구현예 G267. 구현예 G266의 핵산을 포함하는 벡터.
구현예 G268. 구현예 G267에 있어서, 상기 벡터는 발현 벡터인, 벡터.
구현예 G269. 구현예 G323의 핵산 또는 구현예 G267 또는 구현예 G268의 벡터를 포함하는 세포.
구현예 G270. 다중-사슬 키메라 폴리펩타이드를 생성하는 방법으로서, 상기 방법은
다중-사슬 키메라 폴리펩타이드의 생성을 초래하기에 충분한 조건 하에 구현예 G269의 세포를 배양 배지에서 배양하는 단계; 및
상기 다중-사슬 키메라 폴리펩타이드를 상기 세포 및/또는 상기 배양 배지로부터 회수하는 단계를 포함하는, 방법.
구현예 G271. 구현예 G270의 방법에 의해 생성되는 다중-사슬 키메라 폴리펩타이드.
구현예 G272. 구현예 G8에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G273. 구현예 G272에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G274. 구현예 G273에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G275. 구현예 G274에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 97과 100% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G276. 구현예 G8에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 적어도 80% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G277. 구현예 G276에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 적어도 90% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G278. 구현예 G277에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 적어도 95% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 G279. 구현예 G278에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 98과 100% 동일한 서열을 포함하는, 다중-사슬 키메라 폴리펩타이드.
구현예 H1. 치료를 필요로 하는 대상체에서 노화-관련 질환 또는 병태를 치료하는 방법으로서, 노화-관련 질환 또는 병태를 갖는 것으로 식별된 대상체에게 치료적 유효량의 하나 이상의 자연 살해(NK) 세포 활성화제(들)를 투여하는 단계를 포함하는, 방법.
구현예 H2. 노쇠 세포의 사멸 또는 수의 감소를 필요로 하는 대상체에서 노쇠 세포를 사멸시키거나 이의 수를 감소시키는 방법으로서, 대상체에게 치료적 유효량의 하나 이상의 NK 세포 활성화제(들)를 투여하는 단계를 포함하는, 방법.
구현예 H3. 구현예 H2에 있어서, 상기 노쇠 세포는 노쇠 암세포, 노쇠 단핵구, 노쇠 림프구, 노쇠 성상세포, 노쇠 소교세포, 노쇠 뉴런, 노쇠 조직 섬유아세포, 노쇠 피부 섬유아세포, 노쇠 케라틴세포, 또는 다른 분화된 조직-특이적 분열 기능 세포인, 방법.
구현예 H4. 구현예 H3에 있어서, 상기 노쇠 암세포는 화학요법-유도 노쇠 세포 또는 방사선-유도 노쇠 세포인, 방법.
구현예 H5. 구현예 H2에 있어서, 상기 대상체는 나이-관련 질환 또는 병태를 갖는 것으로 식별되거나 진단된 적이 있는, 방법.
구현예 H6. 구현예 H1 또는 H5에 있어서, 상기 노화-관련 질환 또는 병태는 암, 자가면역 질환, 대사 질환, 신경퇴행성 질환, 심혈관 질환, 피부 질환, 조로증 질환, 및 유약 질환으로 이루어진 군으로부터 선택되는, 방법.
구현예 H7. 구현예 H6에 있어서, 상기 암은 고형 종양, 혈액학적 종양, 육종, 골육종, 교모세포종, 신경모세포종, 흑색종, 횡문근육종, 유잉 육종, 골육종, B-세포 신생물, 다발성 골수종, B-세포 림프종, B-세포 비-호지킨 림프종, 호지킨 림프종, 만성 림프구성 백혈병(CLL), 급성 골수성 백혈병(AML), 만성 골수성 백혈병(CML), 급성 림프구성 백혈병(ALL), 골수이형성 증후군(MDS), 피부 T-세포 림프종, 망막모세포종, 위암, 요로상피세포암종, 폐암, 신세포 암종, 위 및 식도 암, 췌장암, 전립선암, 유방암, 결장직장암, 난소암, 비-소세포 폐 암종, 편평 세포 두경부 암종, 자궁내막암, 자궁경부암, 간암, 및 간세포 암종으로 이루어진 군으로부터 선택되는, 방법.
구현예 H8. 구현예 H6에 있어서, 상기 자가면역 질환은 1형 당뇨병인, 방법.
구현예 H9. 구현예 H6에 있어서, 상기 대사 질환은 비만, 지방이영양증, 및 2형 진성 당뇨병으로 이루어진 군으로부터 선택되는, 방법.
구현예 H10. 구현예 H6에 있어서, 상기 신경퇴행성 질환은 알츠하이머 질환, 파킨슨 질환, 및 치매로 이루어진 군으로부터 선택되는, 방법.
구현예 H11. 구현예 H6에 있어서, 상기 심혈관 질환은 관상 동맥 질환, 죽상동맥경화증, 및 폐동맥 고혈압으로 이루어진 군으로부터 선택되는, 방법.
구현예 H12. 구현예 H6에 있어서, 상기 피부 질환은 상처 치유, 탈모증, 주름, 노인성 흑점, 피부 얇아짐, 색소성 건피증, 및 선천성 각화이상증으로 이루어진 군으로부터 선택되는, 방법.
구현예 H13. 구현예 H6에 있어서, 상기 조로증 질환은 조로증 및 허친슨-길포트 조로증 증후군으로 이루어진 군으로부터 선택되는, 방법.
구현예 H14. 구현예 H6에 있어서, 상기 유약 질환은 유약, 백신화에 대한 민감도, 골다공증, 및 사르코페니아로 이루어진 군으로부터 선택되는, 방법.
구현예 H15. 구현예 H1 또는 H5에 있어서, 상기 노화-관련 질환 또는 병태는 노화-관련 황반 변성, 골관절염, 지방세포 위축, 만성 폐쇄성 폐 질환, 특발성 폐 섬유증, 신장 이식 실패, 간 섬유증, 골질량 손실, 사르코페니아, 연령-연관 폐 조직 탄성 손실, 골다공증, 노화-연관 신장 기능장애, 및 화학-유도 신장 기능장애로 이루어진 군으로부터 선택되는, 방법.
구현예 H16. 구현예 H1 또는 H5에 있어서, 상기 노화-관련 질환 또는 병태는 2형 당뇨병 또는 죽상동맥경화증인, 방법.
구현예 H17. 구현예 H1 내지 H16 중 어느 한 구현예에 있어서, 상기 투여는 대상체에서 표적 조직 내 노쇠 세포의 수의 저하를 초래하는, 방법.
구현예 H18. 구현예 H17에 있어서, 상기 표적 조직은 지방 조직, 췌장 조직, 간 조직, 폐 조직, 혈관 구조, 뼈 조직, 중추신경계(CNS) 조직, 안구 조직, 피부 조직, 근육 조직, 및 2차 림프-기관 조직으로 이루어진 군으로부터 선택되는, 방법.
구현예 H19. 구현예 H1 내지 H18 중 어느 한 구현예에 있어서, 상기 투여는 활성화된 NK 세포에서 CD25, CD69, MTOR-C1, SREBP1, IFN-γ, 및 그랜자임 B의 발현 수준의 증가를 초래하는, 방법.
구현예 H20. 치료를 필요로 하는 대상체에서 노화-관련 질환 또는 병태를 치료하는 방법으로서, 노화-관련 질환 또는 병태를 갖는 것으로 식별된 대상체에게 치료적 유효수의 활성화된 NK 세포를 투여하는 단계를 포함하는, 방법.
구현예 H21. 노쇠 세포의 사멸 또는 수의 감소를 필요로 하는 대상체에서 노쇠 세포를 사멸시키거나 이의 수를 감소시키는 방법으로서, 대상체에게 치료적 유효수의 활성화된 NK 세포를 투여하는 단계를 포함하는, 방법.
구현예 H22. 구현예 H21에 있어서, 상기 노쇠 세포는 노쇠 암세포, 노쇠 단핵구, 노쇠 림프구, 노쇠 성상세포, 노쇠 소교세포, 노쇠 뉴런, 노쇠 조직 섬유아세포, 노쇠 피부 섬유아세포, 노쇠 케라틴세포, 또는 다른 분화된 조직-특이적 분열 기능 세포인, 방법.
구현예 H23. 구현예 H22에 있어서, 상기 노쇠 암세포는 화학요법-유도 노쇠 세포 또는 방사선-유도 노쇠 세포인, 방법.
구현예 H24. 구현예 H21에 있어서, 상기 대상체는 나이-관련 질환 또는 병태를 갖는 것으로 식별되거나 진단된 적이 있는, 방법.
구현예 H25. 구현예 H20 또는 H24에 있어서, 상기 노화-관련 질환 또는 병태는 암, 자가면역 질환, 대사 질환, 신경퇴행성 질환, 심혈관 질환, 피부 질환, 조로증 질환, 및 유약 질환으로 이루어진 군으로부터 선택되는, 방법.
구현예 H26. 구현예 H25에 있어서, 상기 암은 고형 종양, 혈액학적 종양, 육종, 골육종, 교모세포종, 신경모세포종, 흑색종, 횡문근육종, 유잉 육종, 골육종, B-세포 신생물, 다발성 골수종, B-세포 림프종, B-세포 비-호지킨 림프종, 호지킨 림프종, 만성 림프구성 백혈병(CLL), 급성 골수성 백혈병(AML), 만성 골수성 백혈병(CML), 급성 림프구성 백혈병(ALL), 골수이형성 증후군(MDS), 피부 T-세포 림프종, 망막모세포종, 위암, 요로상피세포암종, 폐암, 신세포 암종, 위 및 식도 암, 췌장암, 전립선암, 유방암, 결장직장암, 난소암, 비-소세포 폐 암종, 편평 세포 두경부 암종, 자궁내막암, 자궁경부암, 간암, 및 간세포 암종으로 이루어진 군으로부터 선택되는, 방법.
구현예 H27. 구현예 H25에 있어서, 상기 자가면역 질환은 1형 당뇨병인, 방법.
구현예 H28. 구현예 H25에 있어서, 상기 대사 질환은 비만, 지방이영양증, 및 2형 진성 당뇨병으로 이루어진 군으로부터 선택되는, 방법.
구현예 H29. 구현예 H25에 있어서, 상기 신경퇴행성 질환은 알츠하이머 질환, 파킨슨 질환, 및 치매로 이루어진 군으로부터 선택되는, 방법.
구현예 H30. 구현예 H25에 있어서, 상기 심혈관 질환은 관상 동맥 질환, 죽상동맥경화증, 및 폐동맥 고혈압으로 이루어진 군으로부터 선택되는, 방법.
구현예 H31. 구현예 H25에 있어서, 상기 피부 질환은 상처 치유, 탈모증, 주름, 노인성 흑점, 피부 얇아짐, 색소성 건피증, 및 선천성 각화이상증으로 이루어진 군으로부터 선택되는, 방법.
구현예 H32. 구현예 H25에 있어서, 상기 조로증 질환은 조로증 및 허친슨-길포트 조로증 증후군으로 이루어진 군으로부터 선택되는, 방법.
구현예 H33. 구현예 H25에 있어서, 상기 유약 질환은 유약, 백신화에 대한 민감도, 골다공증, 및 사르코페니아로 이루어진 군으로부터 선택되는, 방법.
구현예 H34. 구현예 H20 또는 H24에 있어서, 상기 노화-관련 질환 또는 병태는 노화-관련 황반 변성, 골관절염, 지방세포 위축, 만성 폐쇄성 폐 질환, 특발성 폐 섬유증, 신장 이식 실패, 간 섬유증, 골질량 손실, 사르코페니아, 연령-연관 폐 조직 탄성 손실, 골다공증, 노화-연관 신장 기능장애, 및 화학-유도 신장 기능장애로 이루어진 군으로부터 선택되는, 방법.
구현예 H35. 구현예 H20 내지 H34 중 어느 한 구현예에 있어서,
휴지기 NK 세포를 수득하는 단계; 및
상기 휴지기 NK 세포를 시험관내에서 하나 이상의 NK 세포 활성화제(들)를 포함하는 액체 배양 배지에서 접촉시키는 단계를 추가로 포함하며, 상기 접촉은 후속적으로 대상체에게 투여되는 활성화된 NK 세포의 생성을 초래하는, 방법.
구현예 H36. 구현예 H35에 있어서, 상기 휴지기 NK 세포는 대상체로부터 수득된 자가 NK 세포인, 방법.
구현예 H37. 구현예 H35에 있어서, 상기 휴지기 NK 세포는 동종이계 휴지기 NK 세포인, 방법.
구현예 H38. 구현예 H35에 있어서, 상기 휴지기 NK 세포는 인공 NK 세포인, 방법.
구현예 H39. 구현예 H35에 있어서, 상기 휴지기 NK 세포는 반일치 휴지기 NK 세포인, 방법.
구현예 H40. 구현예 H35 내지 H39 중 어느 한 구현예에 있어서, 휴지기 NK 세포는 키메라 항원 수용체 또는 재조합 T 세포 수용체를 갖고 있는 유전자-조작된 NK 세포인, 방법.
구현예 H41. 구현예 H35 내지 H40 중 어느 한 구현예에 있어서, 활성화된 NK 세포가 대상체에게 투여되기 전에 상기 활성화된 NK 세포를 단리하는 단계를 추가로 포함하는, 방법.
구현예 H42. 기간에 걸쳐 향상을 필요로 하는 대상체에서 피부 및/또는 모발의 질감 및/또는 외양을 향상시키는 방법으로서, 대상체에게 치료적 유효량의 하나 이상의 자연 살해(NK) 세포 활성화제(들)를 투여하는 단계를 포함하는, 방법.
구현예 H43. 기간에 걸쳐 향상을 필요로 하는 대상체에서 피부 및/또는 모발의 질감 및/또는 외양을 향상시키는 방법으로서, 대상체에게 치료적 유효수의 활성화된 NK 세포를 투여하는 단계를 포함하는, 방법.
구현예 H44. 구현예 H43에 있어서,
휴지기 NK 세포를 수득하는 단계; 및
상기 휴지기 NK 세포를 시험관내에서 하나 이상의 NK 세포 활성화제(들)를 포함하는 액체 배양 배지에서 접촉시키는 단계를 추가로 포함하며, 상기 접촉은 후속적으로 대상체에게 투여되는 활성화된 NK 세포의 생성을 초래하는, 방법.
구현예 H45. 구현예 H44에 있어서, 상기 휴지기 NK 세포는 대상체로부터 수득된 자가 NK 세포인, 방법.
구현예 H46. 구현예 H44에 있어서, 상기 휴지기 NK 세포는 동종이계 휴지기 NK 세포인, 방법.
구현예 H47. 구현예 H44에 있어서, 상기 휴지기 NK 세포는 인공 NK 세포인, 방법.
구현예 H48. 구현예 H44에 있어서, 상기 휴지기 NK 세포는 반일치 휴지기 NK 세포인, 방법.
구현예 H49. 구현예 H44 내지 H48 중 어느 한 구현예에 있어서, 휴지기 NK 세포는 키메라 항원 수용체 또는 재조합 T 세포 수용체를 갖고 있는 유전자-조작된 NK 세포인, 방법.
구현예 H50. 구현예 H44 내지 H49 중 어느 한 구현예에 있어서, 활성화된 NK 세포가 대상체에게 투여되기 전에 상기 활성화된 NK 세포를 단리하는 단계를 추가로 포함하는, 방법.
구현예 H51. 구현예 H42 내지 H50 중 어느 한 구현예에 있어서, 기간에 걸쳐 대상체의 피부의 질감 및/또는 외양의 향상을 제공하는, 방법.
구현예 H52. 구현예 H51에 있어서, 기간에 걸쳐 대상체의 피부에서 주름 형성 속도의 저하를 초래하는, 방법.
구현예 H53. 구현예 H51 또는 H52에 있어서, 기간에 걸쳐 대상체의 피부의 착색의 향상을 초래하는, 방법.
구현예 H54. 구현예 H51 내지 H53 중 어느 한 구현예에 있어서, 기간에 걸쳐 대상체의 피부의 질감의 향상을 초래하는, 방법.
구현예 H55. 구현예 H42 내지 H50 중 어느 한 구현예에 있어서, 기간에 걸쳐 대상체의 모발의 질감 및/또는 외양의 향상을 제공하는, 방법.
구현예 H56. 구현예 H55에 있어서, 기간에 걸쳐 대상체에서 흰머리 형성 속도의 저하를 초래하는, 방법.
구현예 H57. 구현예 H55 또는 H56에 있어서, 기간에 걸쳐 대상체에서 흰머리 수의 저하를 초래하는, 방법.
구현예 H58. 구현예 H55 내지 H57 중 어느 한 구현예에 있어서, 기간에 걸쳐 대상체에서 모발 손실 속도의 저하를 초래하는, 방법.
구현예 H59. 구현예 H55 내지 H58 중 어느 한 구현예에 있어서, 기간에 걸쳐 대상체의 모발의 질감의 향상을 초래하는, 방법.
구현예 H60. 구현예 H42 내지 H59 중 어느 한 구현예에 있어서, 기간은 약 1개월 내지 약 10년인, 방법.
구현예 H61. 구현예 H42 내지 H60 중 어느 한 구현예에 있어서, 기간에 걸쳐 대상체의 피부에서 노쇠 피부 섬유아세포 수의 저하를 초래하는, 방법.
구현예 H62. 기간에 걸쳐 보조를 필요로 하는 대상체에서 비만 치료를 보조하는 방법으로서, 대상체에게 치료적 유효량의 하나 이상의 자연 살해(NK) 세포 활성화제(들)를 투여하는 단계를 포함하는, 방법.
구현예 H63. 기간에 걸쳐 보조를 필요로 하는 대상체에서 비만 치료를 보조하는 방법으로서, 대상체에게 치료적 유효수의 활성화된 NK 세포를 투여하는 단계를 포함하는, 방법.
구현예 H64. 구현예 H63에 있어서,
휴지기 NK 세포를 수득하는 단계; 및
상기 휴지기 NK 세포를 시험관내에서 하나 이상의 NK 세포 활성화제(들)를 포함하는 액체 배양 배지에서 접촉시키는 단계를 추가로 포함하며, 상기 접촉은 후속적으로 대상체에게 투여되는 활성화된 NK 세포의 생성을 초래하는, 방법.
구현예 H65. 구현예 H64에 있어서, 상기 휴지기 NK 세포는 대상체로부터 수득된 자가 NK 세포인, 방법.
구현예 H66. 구현예 H64에 있어서, 상기 휴지기 NK 세포는 동종이계 휴지기 NK 세포인, 방법.
구현예 H67. 구현예 H64에 있어서, 상기 휴지기 NK 세포는 인공 NK 세포인, 방법.
구현예 H68. 구현예 H64에 있어서, 상기 휴지기 NK 세포는 반일치 휴지기 NK 세포인, 방법.
구현예 H69. 구현예 H64 내지 H68 중 어느 한 구현예에 있어서, 휴지기 NK 세포는 키메라 항원 수용체 또는 재조합 T 세포 수용체를 갖고 있는 유전자-조작된 NK 세포인, 방법.
구현예 H70. 구현예 H64 내지 H69 중 어느 한 구현예에 있어서, 활성화된 NK 세포가 대상체에게 투여되기 전에 상기 활성화된 NK 세포를 단리하는 단계를 추가로 포함하는, 방법.
구현예 H71. 구현예 H62 내지 H70 중 어느 한 구현예에 있어서, 기간에 걸쳐 대상체의 질량의 저하를 초래하는, 방법.
구현예 H72. 구현예 H62 내지 H71 중 어느 한 구현예에 있어서, 기간에 걸쳐 대상체의 체질량 지수(BMI)의 저하를 초래하는, 방법.
구현예 H73. 구현예 H62 내지 H70 중 어느 한 구현예에 있어서, 기간에 걸쳐 전당뇨병으로부터 2형 당뇨병으로의 진행 속도의 저하를 초래하는, 방법.
구현예 H74. 구현예 H62 내지 H70 중 어느 한 구현예에 있어서, 대상체에서 공복 혈청 포도당 수준의 저하를 초래하는, 방법.
구현예 H75. 구현예 H62 내지 H70 중 어느 한 구현예에 있어서, 대상체에서 인슐린 감수성의 증가를 초래하는, 방법.
구현예 H76. 구현예 H62 내지 H70 중 어느 한 구현예에 있어서, 대상체에서 죽상동맥경화증의 중증도의 저하를 초래하는, 방법.
구현예 H77. 구현예 H62 내지 H76 중 어느 한 구현예에 있어서, 기간은 약 2주 내지 약 10년인, 방법.
구현예 H78. H1-H19, H35-H42, H44-H62, 및 H64-H77 중 어느 한 구현예에 있어서, 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 IL-2에 대한 수용체, IL-7에 대한 수용체, IL-12에 대한 수용체, IL-15에 대한 수용체, IL-18에 대한 수용체, IL-21에 대한 수용체, IL-33, CD16, CD69, CD25, CD36, CD59, CD352, NKp80, DNAM-1, 2B4, NKp30, NKp44, NKp46, NKG2D, KIR2DS1, KIR2Ds2/3, KIR2DL4, KIR2DS4, KIR2DS5, 및 KIR3DS1에 대한 수용체 중 하나 이상의 활성화를 초래하는, 방법.
구현예 H79. 구현예 H78에 있어서, IL-2에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 가용성 IL-2 또는 IL-2 수용체에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H80. 구현예 H78에 있어서, IL-7에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 가용성 IL-7 또는 IL-7 수용체에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H81. 구현예 H78에 있어서, IL-12에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 가용성 IL-12 또는 IL-12 수용체에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H82. 구현예 H78에 있어서, IL-15에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 가용성 IL-15 또는 IL-15 수용체에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H83. 구현예 H78에 있어서, IL-21에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 가용성 IL-21 또는 IL-21 수용체에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H84. 구현예 H78에 있어서, IL-33에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 가용성 IL-33 또는 IL-33 수용체에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H85. 구현예 H78에 있어서, CD16에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 CD16에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H86. 구현예 H78에 있어서, CD69에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 CD69에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H87. 구현예 H78에 있어서, CD25, CD36, CD59에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 CD25, CD6, CD59에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H88. 구현예 H78에 있어서, CD352에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 CD352에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H89. 구현예 H78에 있어서, NKp80에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 NKp80에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H90. 구현예 H78에 있어서, DNAM-1에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 DNAM-1에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H91. 구현예 H78에 있어서, 2B4에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 2B4에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H92. 구현예 H78에 있어서, NKp30에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 NKp30에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H93. 구현예 H78에 있어서, NKp44에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 NKp44에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H94. 구현예 H78에 있어서, NKp46에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 NKp46에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H95. 구현예 H78에 있어서, NKG2D에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 NKG2D에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H96. 구현예 H78에 있어서, KIR2DS1에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR2DS1에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H97. 구현예 H78에 있어서, KIR2DS2/3에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR2DS2/3에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H98. 구현예 H78에 있어서, KIR2DL4에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR2DL4에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H99. 구현예 H78에 있어서, KIR2DS4에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR2DS4에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H100. 구현예 H78에 있어서, KIR2DS5에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR2DS5에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H101. 구현예 H78에 있어서, KIR3DS1에 대한 수용체의 활성화를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR3DS1에 특이적으로 결합하는 작용제성 항체인, 방법.
구현예 H102. 구현예 H1-H19, H35-H42, H44-H62, 및 H64-H101 중 어느 한 구현예에 있어서, 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 PD-1, TGF-β 수용체, TIGIT, CD1, TIM-3, Siglec-7, IRP60, Tactile, IL1R8, NKG2A/KLRD1, KIR2DL1, KIR2DL2/3, KIR2DL5, KIR3DL1, KIR3DL2, ILT2/LIR-1, 및 LAG-2 중 하나 이상의 활성화의 저하를 초래하는, 방법.
구현예 H103. 구현예 H102에 있어서, PD-1의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 PD-1에 특이적으로 결합하는 길항제성 항체, 가용성 PD-1, 가용성 PD-L1, 또는 PD-L1에 특이적으로 결합하는 항체인, 방법.
구현예 H104. 구현예 H102에 있어서, TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 가용성 TGF-β 수용체, TGF-β에 특이적으로 결합하는 항체, 또는 TGF-β 수용체에 특이적으로 결합하는 길항제성 항체인, 방법.
구현예 H105. 구현예 H102에 있어서, TIGIT의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 TIGIT에 특이적으로 결합하는 길항제성 항체, 가용성 TIGIT, 또는 TIGIT의 리간드에 특이적으로 결합하는 항체인, 방법.
구현예 H106. 구현예 H102에 있어서, CD1의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 CD1에 특이적으로 결합하는 길항제성 항체, 가용성 CD1, 또는 CD1의 리간드에 특이적으로 결합하는 항체인, 방법.
구현예 H107. 구현예 H102에 있어서, TIM-3의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 TIM-3에 특이적으로 결합하는 길항제성 항체, 가용성 TIM-3, 또는 TIM-3의 리간드에 특이적으로 결합하는 항체인, 방법.
구현예 H108. 구현예 H102에 있어서, Siglec-7의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 Siglec-7에 특이적으로 결합하는 길항제성 항체 또는 Siglec-7의 리간드에 특이적으로 결합하는 항체인, 방법.
구현예 H109. 구현예 H102에 있어서, IRP60의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 IRP60에 특이적으로 결합하는 길항제성 항체 또는 IRP60의 리간드에 특이적으로 결합하는 항체인, 방법.
구현예 H110. 구현예 H102에 있어서, Tactile의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 Tactile에 특이적으로 결합하는 길항제성 항체 또는 Tactile의 리간드에 특이적으로 결합하는 항체인, 방법.
구현예 H111. 구현예 H102에 있어서, IL1R8의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 IL1R8에 특이적으로 결합하는 길항제성 항체 또는 IL1R8의 리간드에 특이적으로 결합하는 항체인, 방법.
구현예 H112. 구현예 H102에 있어서, NKG2A/KLRD1의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 NKG2A/KLRD1에 특이적으로 결합하는 길항제성 항체 또는 NKG2A/KLRD1의 리간드에 특이적으로 결합하는 항체인, 방법.
구현예 H113. 구현예 H102에 있어서, KIR2DL1의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR2DL1에 특이적으로 결합하는 길항제성 항체 또는 KIR2DL1의 리간드에 특이적으로 결합하는 항체인, 방법.
구현예 H114. 구현예 H102에 있어서, KIR2DL2/3의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR2DL2/3에 특이적으로 결합하는 길항제성 항체 또는 KIR2DL2/3의 리간드에 특이적으로 결합하는 항체인, 방법.
구현예 H115. 구현예 H102에 있어서, KIR2DL5의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR2DL5에 특이적으로 결합하는 길항제성 항체 또는 KIR2DL5의 리간드에 특이적으로 결합하는 항체인, 방법.
구현예 H116. 구현예 H102에 있어서, KIR3DL1의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR3DL1에 특이적으로 결합하는 길항제성 항체 또는 KIR3DL1의 리간드에 특이적으로 결합하는 항체인, 방법.
구현예 H117. 구현예 H102에 있어서, KIR3DL2의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 KIR3DL2에 특이적으로 결합하는 길항제성 항체 또는 KIR3DL2의 리간드에 특이적으로 결합하는 항체인, 방법.
구현예 H118. 구현예 H102에 있어서, ILT2/LIR-1의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 ILT2/LIR-1에 특이적으로 결합하는 길항제성 항체 또는 ILT2/LIR-1의 리간드에 특이적으로 결합하는 항체인, 방법.
구현예 H119. 구현예 H102에 있어서, LAG-2의 활성화의 저하를 초래하는 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 LAG-2에 특이적으로 결합하는 길항제성 항체 또는 LAG-2의 리간드에 특이적으로 결합하는 항체인, 방법.
구현예 H120. 구현예 H1-H19, H35-H42, H44-H62, 및 H64-H77 중 어느 한 구현예에 있어서, 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 하기를 포함하는 단일-사슬 키메라 폴리펩타이드인, 방법:
(i) 제1 표적-결합 도메인;
(ii) 가용성 조직 인자 도메인; 및
(iii) 제2 표적-결합 도메인.
구현예 H121. 구현예 H120에 있어서, 상기 제1 표적-결합 도메인 및 상기 가용성 조직 인자 도메인은 서로 직접적으로 인접해 있는, 방법.
구현예 H122. 구현예 H120에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 H123. 구현예 H120 내지 구현예 H122 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인 및 상기 제2 표적-결합 도메인은 서로 직접적으로 인접해 있는, 방법.
구현예 H124. 구현예 H120 내지 H122 중 어느 한 구현예에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 가용성 조직 인자 도메인과 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 H125. 구현예 H120에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 서로 직접적으로 인접해 있는, 방법.
구현예 H126. 구현예 H120에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 제1 표적-결합 도메인과 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 H127. 구현예 H125 또는 구현예 H126에 있어서, 상기 제2 표적-결합 도메인 및 상기 가용성 조직 인자 도메인은 서로 직접적으로 인접해 있는, 방법.
구현예 H128. 구현예 H125 또는 구현예 H126에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 제2 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 H129. 구현예 H120 내지 H128 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 항원에 특이적으로 결합하는, 방법.
구현예 H130. 구현예 H129에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합하는, 방법.
구현예 H131. 구현예 H130에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함하는, 방법.
구현예 H132. 구현예 H120 내지 H128 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 상이한 항원에 특이적으로 결합하는, 방법.
구현예 H133. 구현예 H120 내지 구현예 H132 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 항원-결합 도메인인, 방법.
구현예 H134. 구현예 H133에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 각각 항원-결합 도메인인, 방법.
구현예 H135. 구현예 H134에 있어서, 상기 항원-결합 도메인은 scFv 또는 단일 도메인 항체를 포함하는, 방법.
구현예 H136. 구현예 H120 내지 H135 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKP30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, 및 CD122에 대한 수용체로 이루어진 군으로부터 선택되는 표적에 결합하는, 방법.
구현예 H137. 구현예 H120 내지 구현예 H128 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 단백질인, 방법.
구현예 H138. 구현예 H137에 있어서, 상기 가용성 인터류킨 또는 사이토카인 단백질은 IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, 및 SCF로 이루어진 군으로부터 선택되는, 방법.
구현예 H139. 구현예 H120 내지 구현예 H128 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 수용체인, 방법.
구현예 H140. 구현예 H139에 있어서, 상기 가용성 인터류킨 또는 사이토카인 수용체는 가용성 TGF-β 수용체 II(TGF-βRII), 가용성 TGF-βRIII, TNFα에 대한 가용성 수용체, IL-4에 대한 가용성 수용체, 또는 IL-10에 대한 가용성 수용체인, 방법.
구현예 H141. 구현예 H120 내지 구현예 H140 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 가용성 인간 조직 인자 도메인인, 방법.
구현예 H142. 구현예 H141에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 80% 동일한 서열을 포함하는, 방법.
구현예 H143. 구현예 H142에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 90% 동일한 서열을 포함하는, 방법.
구현예 H144. 구현예 H143에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 95% 동일한 서열을 포함하는, 방법.
구현예 H145. 구현예 H141 내지 구현예 H144 중 어느 한 구현예에 있어서, 상기 가용성 인간 조직 인자 도메인은 하기 중 하나 이상을 포함하지 않는, 방법:
성숙 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 리신;
성숙 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신;
성숙 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판;
성숙 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산;
성숙 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신;
성숙 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및
성숙 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
구현예 H146. 구현예 H145에 있어서, 상기 가용성 인간 조직 인자 도메인은 하기 중 임의의 것을 포함하지 않는, 방법:
성숙 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 리신;
성숙 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신;
성숙 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판;
성숙 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산;
성숙 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신;
성숙 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및
성숙 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
구현예 H147. 구현예 H120 내지 구현예 H146 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 인자 VIIa에 결합할 수 없는, 방법.
구현예 H148. 구현예 H120 내지 구현예 H147 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 불활성 인자 X를 인자 Xa로 전환시키지 않는, 방법.
구현예 H149. 구현예 H120 내지 구현예 H148 중 어느 한 구현예에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 포유류에서 혈액 응고를 자극시키지 않는, 방법.
구현예 H150. 구현예 H120 내지 구현예 H149 중 어느 한 구현예에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 이의 N-말단 및/또는 C-말단에 하나 이상의 추가 표적-결합 도메인을 추가로 포함하는, 방법.
구현예 H151. 구현예 H150에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 이의 N-말단에 하나 이상의 추가 표적-결합 도메인을 포함하는, 방법.
구현예 H152. 구현예 H151에 있어서, 상기 하나 이상의 추가 표적-결합 도메인은 상기 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인에 직접적으로 인접해 있는, 방법.
구현예 H153. 구현예 H152에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 적어도 하나의 추가 표적-결합 도메인과 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 H154. 구현예 H150에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 이의 C-말단에 하나 이상의 추가 표적-결합 도메인을 포함하는, 방법.
구현예 H155. 구현예 H154에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 하나는 상기 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인에 직접적으로 인접해 있는, 방법.
구현예 H156. 구현예 H154에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 적어도 하나의 추가 표적-결합 도메인과 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 H157. 구현예 H150에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 이의 N-말단 및 C-말단에 하나 이상의 추가 표적-결합 도메인을 포함하는, 방법.
구현예 H158. 구현예 H157에 있어서, 상기 하나 이상의 추가 항원-결합 도메인 중 하나는 N-말단에서 상기 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인에 직접적으로 인접해 있는, 방법.
구현예 H159. 구현예 H157에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 N-말단에서 하나 이상의 추가 항원-결합 도메인 중 하나와 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 H160. 구현예 H157에 있어서, 상기 하나 이상의 추가 항원-결합 도메인 중 하나는 C-말단에서 상기 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인에 직접적으로 인접해 있는, 방법.
구현예 H161. 구현예 H157에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 C-말단에서 하나 이상의 추가 항원-결합 도메인 중 하나와 제1 표적-결합 도메인, 제2 표적-결합 도메인, 또는 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 H162. 구현예 H150 내지 구현예 H161 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 에피토프에 특이적으로 결합하는, 방법.
구현예 H163. 구현예 H162에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 에피토프에 특이적으로 결합하는, 방법.
구현예 H164. 구현예 H163에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 아미노산 서열을 포함하는, 방법.
구현예 H165. 구현예 H162에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 각각 동일한 항원에 특이적으로 결합하는, 방법.
구현예 H166. 구현예 H165에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 각각 동일한 에피토프에 특이적으로 결합하는, 방법.
구현예 H167. 구현예 H166에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 각각 동일한 아미노산 서열을 포함하는, 방법.
구현예 H168. 구현예 H150 내지 구현예 H161 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 상이한 항원에 특이적으로 결합하는, 방법.
구현예 H169. 구현예 H150 내지 구현예 H168 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 표적-결합 도메인 중 하나 이상은 항원-결합 도메인인, 방법.
구현예 H170. 구현예 H169에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 각각 항원-결합 도메인인, 방법.
구현예 H171. 구현예 H170에 있어서, 상기 항원-결합 도메인은 scFv 또는 단일 도메인 항체를 포함하는, 방법.
구현예 H172. 구현예 H150 내지 구현예 H171 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 하나 이상의 표적-결합 도메인 중 하나 이상은 CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKP30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, 및 CD122에 대한 수용체로 이루어진 군으로부터 선택되는 표적에 특이적으로 결합하는, 방법.
구현예 H173. 구현예 H150 내지 구현예 H161 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 하나 이상은 가용성 인터류킨 또는 사이토카인 단백질인, 방법.
구현예 H174. 구현예 H173에 있어서, 상기 가용성 인터류킨 또는 사이토카인 단백질은 IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, 및 SCF로 이루어진 군으로부터 선택되는, 방법.
구현예 H175. 구현예 H150 내지 구현예 H161 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 하나 이상은 가용성 인터류킨 또는 사이토카인 수용체인, 방법.
구현예 H176. 구현예 H175에 있어서, 상기 가용성 수용체는 가용성 TGF-β 수용체 II(TGF-βRII), 가용성 TGF-βRIII, TNFα에 대한 가용성 수용체, IL-4에 대한 가용성 수용체, 또는 IL-10에 대한 가용성 수용체인, 방법.
구현예 H177. 구현예 H1-H19, H35-H42, H44-H62, 및 H64-H77 중 어느 한 구현예에 있어서, 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 하기를 포함하는 다중-사슬 키메라 폴리펩타이드인, 방법:
(c) 제1 키메라 폴리펩타이드로서,
(i) 제1 표적-결합 도메인;
(ii) 가용성 조직 인자 도메인; 및
(iii) 친화도 도메인 쌍의 제1 도메인을 포함하는, 제1 키메라 폴리펩타이드; 및
(d) 제2 키메라 폴리펩타이드로서,
(i) 친화도 도메인 쌍의 제2 도메인; 및
(ii) 제2 표적-결합 도메인을 포함하는, 제2 키메라 폴리펩타이드를 포함하고,
상기 제1 키메라 폴리펩타이드 및 상기 제2 키메라 폴리펩타이드는 친화도 도메인 쌍의 제1 도메인과 제2 도메인의 결합을 통해 회합되는, 방법.
구현예 H178. 구현예 H177에 있어서, 상기 제1 표적-결합 도메인 및 상기 가용성 조직 인자 도메인은 상기 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 방법.
구현예 H179. 구현예 H177에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 H180. 구현예 H177 내지 구현예 H179 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인 및 상기 친화도 도메인의 쌍의 제1 도메인은 상기 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 방법.
구현예 H181. 구현예 H177 내지 구현예 H179 중 어느 한 구현예에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 H182. 구현예 H177 내지 구현예 H181 중 어느 한 구현예에 있어서, 상기 친화도 도메인의 쌍의 제2 도메인 및 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 방법.
구현예 H183. 구현예 H177 내지 구현예 H181 중 어느 한 구현예에 있어서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 상기 친화도 도메인의 쌍의 제2 도메인과 상기 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 H184. 구현예 H177 내지 H183 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 항원에 특이적으로 결합하는, 방법.
구현예 H185. 구현예 H184에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합하는, 방법.
구현예 H186. 구현예 H185에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함하는, 방법.
구현예 H187. 구현예 H177 내지 H183 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 상이한 항원에 특이적으로 결합하는, 방법.
구현예 H188. 구현예 H177 내지 구현예 H187 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 항원-결합 도메인인, 방법.
구현예 H189. 구현예 H188에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 각각 항원-결합 도메인인, 방법.
구현예 H190. 구현예 H188 또는 H189에 있어서, 상기 항원-결합 도메인은 scFv 또는 단일 도메인 항체를 포함하는, 방법.
구현예 H191. 구현예 H177 내지 H190 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKP30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, 및 CD122에 대한 수용체로 이루어진 군으로부터 선택되는 표적에 특이적으로 결합하는, 방법.
구현예 H192. 구현예 H177 내지 구현예 H183 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 단백질인, 방법.
구현예 H193. 구현예 H192에 있어서, 상기 가용성 인터류킨 또는 사이토카인 단백질은 IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, 및 SCF로 이루어진 군으로부터 선택되는, 방법.
구현예 H194. 구현예 H177 내지 구현예 H183 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 수용체인, 방법.
구현예 H195. 구현예 H194에 있어서, 상기 가용성 수용체는 가용성 TGF-β 수용체 II(TGF-βRII), 가용성 TGF-βRIII, TNFα에 대한 가용성 수용체, IL-4에 대한 가용성 수용체, 또는 IL-10에 대한 가용성 수용체인, 방법.
구현예 H196. 구현예 H177 내지 구현예 H195 중 어느 한 구현예에 있어서, 상기 제1 키메라 폴리펩타이드는 하나 이상의 추가 표적-결합 도메인(들)을 추가로 포함하며, 이때, 상기 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나는 상기 가용성 조직 인자 도메인과 상기 친화도 도메인의 쌍의 제1 도메인 사이에 위치하는, 방법.
구현예 H197. 구현예 H196에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 가용성 조직 인자 도메인과 상기 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나 사이에 링커 서열, 및/또는 상기 하나 이상의 추가 항원-결합 도메인(들) 중 적어도 하나와 상기 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 H198. 구현예 H177 내지 구현예 H195 중 어느 한 구현예에 있어서, 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드의 N-말단 및/또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함하는, 방법.
구현예 H199. 구현예 H198에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드에서 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 방법.
구현예 H200. 구현예 H198에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 H201. 구현예 H198에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인에 직접적으로 인접해 있는, 방법.
구현예 H202. 구현예 H198에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 제1 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 H203. 구현예 H198에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드의 N-말단 및/또는 C-말단에 배치되고, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치하는, 방법.
구현예 H204. 구현예 H203에 있어서, N-말단에 배치된 하나 이상의 추가 표적-결합 도메인의 적어도 하나의 추가 표적-결합 도메인은 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 방법.
구현예 H205. 구현예 H203에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 적어도 하나의 추가 표적-결합 도메인과 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인 사이에 배치된 링커 서열을 추가로 포함하는, 방법.
구현예 H206. 구현예 H203에 있어서, C-말단에 배치된 하나 이상의 추가 표적-결합 도메인의 적어도 하나의 추가 표적-결합 도메인은 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 방법.
구현예 H207. 구현예 H203에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 적어도 하나의 추가 표적-결합 도메인과 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인 또는 친화도 도메인의 쌍의 제1 도메인 사이에 배치된 링커 서열을 추가로 포함하는, 방법.
구현예 H208. 구현예 H203에 있어서, 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 가용성 조직 인자 도메인 및/또는 상기 친화도 도메인의 쌍의 제1 도메인에 직접적으로 인접해 있는, 방법.
구현예 H209. 구현예 H203에 있어서, 상기 제1 키메라 폴리펩타이드는 (i) 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 가용성 조직 인자 도메인 사이에, 및/또는 (ii) 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 위치한 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 친화도 도메인의 쌍의 제1 도메인 사이에 배치된 링커 서열을 추가로 포함하는, 방법.
구현예 H210. 구현예 H177 내지 구현예 H209 중 어느 한 구현예에 있어서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드의 N-말단 또는 C-말단 단부에 하나 이상의 추가 표적-결합 도메인을 추가로 포함하는, 방법.
구현예 H211. 구현예 H210에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제2 키메라 폴리펩타이드에서 친화도 도메인의 쌍의 제2 도메인에 직접적으로 인접해 있는, 방법.
구현예 H212. 구현예 H210에 있어서, 상기 제2 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 제2 키메라 폴리펩타이드 내 친화도 도메인의 쌍의 제2 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 H213. 구현예 H210에 있어서, 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나는 상기 제2 키메라 폴리펩타이드에서 제2 표적-결합 도메인에 직접적으로 인접해 있는, 방법.
구현예 H214. 구현예 H210에 있어서, 상기 제2 키메라 폴리펩타이드는 상기 하나 이상의 추가 표적-결합 도메인 중 적어도 하나와 상기 제2 키메라 폴리펩타이드 내 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 H215. 구현예 H196 내지 구현예 H214 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 에피토프에 특이적으로 결합하는, 방법.
구현예 H216. 구현예 H215에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 에피토프에 특이적으로 결합하는, 방법.
구현예 H217. 구현예 H216에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 2개 이상은 동일한 아미노산 서열을 포함하는, 방법.
구현예 H218. 구현예 H215에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 각각 동일한 항원에 특이적으로 결합하는, 방법.
구현예 H219. 구현예 H218에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 각각 동일한 에피토프에 특이적으로 결합하는, 방법.
구현예 H220. 구현예 H219에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 각각 동일한 아미노산 서열을 포함하는, 방법.
구현예 H221. 구현예 H196 내지 구현예 H214 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 상이한 항원에 특이적으로 결합하는, 방법.
구현예 H222. 구현예 H196 내지 구현예 H221 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 표적-결합 도메인 중 하나 이상은 항원-결합 도메인인, 방법.
구현예 H223. 구현예 H222에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인은 각각 항원-결합 도메인인, 방법.
구현예 H224. 구현예 H223에 있어서, 상기 항원-결합 도메인은 scFv를 포함하는, 방법.
구현예 H225. 구현예 H196 내지 구현예 H224 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 제2 표적-결합 도메인, 및 하나 이상의 하나 이상의 표적-결합 도메인 중 하나 이상은 CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKp30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, 및 CD122에 대한 수용체로 이루어진 군으로부터 선택되는 표적에 특이적으로 결합하는, 방법.
구현예 H226. 구현예 H196 내지 구현예 H214 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 하나 이상은 가용성 인터류킨 또는 사이토카인 단백질인, 방법.
구현예 H227. 구현예 H226에 있어서, 상기 가용성 인터류킨 또는 사이토카인 단백질은 IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, 및 SCF로 이루어진 군으로부터 선택되는, 방법.
구현예 H228. 구현예 H196 내지 구현예 H214 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인, 상기 제2 표적-결합 도메인, 및 상기 하나 이상의 추가 표적-결합 도메인 중 하나 이상은 가용성 인터류킨 또는 사이토카인 수용체인, 방법.
구현예 H229. 구현예 H228에 있어서, 상기 가용성 수용체는 가용성 TGF-β 수용체 II(TGF-βRII), 가용성 TGF-βRIII, TNFα에 대한 가용성 수용체, IL-4에 대한 가용성 수용체, 또는 IL-10에 대한 가용성 수용체인, 방법.
구현예 H230. 구현예 H196 내지 구현예 H229 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 가용성 인간 조직 인자 도메인인, 방법.
구현예 H231. 구현예 H230에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 80% 동일한 서열을 포함하는, 방법.
구현예 H232. 구현예 H231에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 90% 동일한 서열을 포함하는, 방법.
구현예 H233. 구현예 H232에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 95% 동일한 서열을 포함하는, 방법.
구현예 H234. 구현예 H230 내지 구현예 H233 중 어느 한 구현예에 있어서, 상기 가용성 인간 조직 인자 도메인은 하기 중 하나 이상을 포함하지 않는, 방법:
성숙 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 리신;
성숙 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신;
성숙 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판;
성숙 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산;
성숙 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신;
성숙 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및
성숙 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
구현예 H235. 구현예 H234에 있어서, 상기 가용성 인간 조직 인자 도메인은 하기 중 임의의 것을 포함하지 않는, 방법:
성숙 야생형 인간 조직 인자 단백질의 20번 아미노산 위치에 상응하는 아미노산 위치에서의 리신;
성숙 야생형 인간 조직 인자 단백질의 22번 아미노산 위치에 상응하는 아미노산 위치에서의 이소류신;
성숙 야생형 인간 조직 인자 단백질의 45번 아미노산 위치에 상응하는 아미노산 위치에서의 트립토판;
성숙 야생형 인간 조직 인자 단백질의 58번 아미노산 위치에 상응하는 아미노산 위치에서의 아스파르트산;
성숙 야생형 인간 조직 인자 단백질의 94번 아미노산 위치에 상응하는 아미노산 위치에서의 티로신;
성숙 야생형 인간 조직 인자 단백질의 135번 아미노산 위치에 상응하는 아미노산 위치에서의 아르기닌; 및
성숙 야생형 인간 조직 인자 단백질의 140번 아미노산 위치에 상응하는 아미노산 위치에서의 페닐알라닌.
구현예 H236. 구현예 H196 내지 구현예 H235 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 인자 VIIa에 결합할 수 없는, 방법.
구현예 H237. 구현예 H196 내지 구현예 H236 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 불활성 인자 X를 인자 Xa로 전환시키지 않는, 방법.
구현예 H238. 구현예 H196 내지 구현예 H237 중 어느 한 구현예에 있어서, 상기 다중-사슬 키메라 폴리펩타이드는 포유류에서 혈액 응고를 자극시키지 않는, 방법.
구현예 H239. 구현예 H196 내지 구현예 H238 중 어느 한 구현예에 있어서, 상기 친화도 도메인의 쌍은 인간 IL-15 수용체의 알파 사슬(IL-15Rα) 및 가용성 IL-15로부터의 sushi 도메인인, 방법.
구현예 H240. 구현예 H239에 있어서, 상기 가용성 IL-15는 D8N 또는 D8A 아미노산 치환을 갖는, 방법.
구현예 H241. 구현예 H239 또는 H240에 있어서, 상기 인간 IL-15Rα는 성숙한 전장 IL-15Rα인, 방법.
구현예 H242. 구현예 H196 내지 구현예 H238 중 어느 한 구현예에 있어서, 상기 친화도 도메인의 쌍은 바르나제 및 바른스타, PKA와 AKAP, 돌연변이화된 RNase I 단편에 기초한 어댑터/도킹 태그 모듈, 및 단백질 신택신, 시냅토태그민, 시냅토브레빈, 및 SNAP25의 상호작용에 기초한 SNARE로 이루어진 군으로부터 선택되는, 방법.
구현예 H243. 구현예 H1-H19, H35-H42, H44-H62, 및 H64-H77 중 어느 한 구현예에 있어서, 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는
(a) 제1 키메라 폴리펩타이드 및 제2 키메라 폴리펩타이드로서, 각각은
(i) 제1 표적-결합 도메인;
(ii) Fc 도메인; 및
(iii) 친화도 도메인 쌍의 제1 도메인을 포함하는, 제1 키메라 폴리펩타이드 및 제2 키메라 폴리펩타이드;
(b) 제3 키메라 폴리펩타이드 및 제4 키메라 폴리펩타이드로서, 각각은
(i) 친화도 도메인 쌍의 제2 도메인; 및
(ii) 제2 표적-결합 도메인을 포함하는, 제3 키메라 폴리펩타이드 및 제4 키메라 폴리펩타이드를 포함하는 다중-사슬 키메라 폴리펩타이드이고,
상기 제1 및 제2 키메라 폴리펩타이드와 상기 제3 및 제4 키메라 폴리펩타이드는 친화도 도메인 쌍의 제1 도메인과 제2 도메인의 결합을 통해 회합되고, 상기 제1 및 제2 키메라 폴리펩타이드는 이들의 Fc 도메인을 통해 회합되는, 방법.
구현예 H244. 구현예 H243에 있어서, 상기 제1 표적-결합 도메인 및 Fc 도메인은 상기 제1 및 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 방법.
구현예 H245. 구현예 H243에 있어서, 상기 제1 및 제2 키메라 폴리펩타이드는 상기 제1 및 제2 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 Fc 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 H246. 구현예 H243 내지 구현예 H245 중 어느 한 구현예에 있어서, 상기 Fc 도메인과 친화도 도메인 쌍의 제1 도메인은 제1 및 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 방법.
구현예 H247. 구현예 H243 내지 구현예 H245 중 어느 한 구현예에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 제1 및 제2 키메라 폴리펩타이드에서 Fc 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 H248. 구현예 H243 내지 구현예 H247 중 어느 한 구현예에 있어서, 상기 친화도 도메인의 쌍의 제2 도메인 및 상기 제2 표적-결합 도메인은 상기 제3 및 제4 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 방법.
구현예 H249. 구현예 H243 내지 구현예 H247 중 어느 한 구현예에 있어서, 제3 및 제4 키메라 폴리펩타이드는 상기 제3 및 제4 키메라 폴리펩타이드에서 상기 친화도 도메인의 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 H250. 구현예 H243 내지 H249 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 항원에 특이적으로 결합하는, 방법.
구현예 H251. 구현예 H250에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합하는, 방법.
구현예 H252. 구현예 H251에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함하는, 방법.
구현예 H253. 구현예 H243 내지 H249 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 상이한 항원에 특이적으로 결합하는, 방법.
구현예 H254. 구현예 H243 내지 구현예 H253 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 항원-결합 도메인인, 방법.
구현예 H255. 구현예 H254에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 각각 항원-결합 도메인인, 방법.
구현예 H256. 구현예 H254 또는 H255에 있어서, 상기 항원-결합 도메인은 scFv 또는 단일 도메인 항체를 포함하는, 방법.
구현예 H257. 구현예 H243 내지 H256 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKp30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, 및 CD122에 대한 수용체로 이루어진 군으로부터 선택되는 표적에 특이적으로 결합하는, 방법.
구현예 H258. 구현예 H243 내지 구현예 H256 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 단백질인, 방법.
구현예 H259. 구현예 H258에 있어서, 상기 가용성 인터류킨 또는 사이토카인 단백질은 IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, 및 SCF로 이루어진 군으로부터 선택되는, 방법.
구현예 H260. 구현예 H243 내지 구현예 H256 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 수용체인, 방법.
구현예 H261. 구현예 H260에 있어서, 상기 가용성 수용체는 가용성 TGF-β 수용체 II(TGF-βRII), 가용성 TGF-βRIII, TNFα에 대한 가용성 수용체, IL-4에 대한 가용성 수용체, 또는 IL-10에 대한 가용성 수용체인, 방법.
구현예 I1. 치료를 필요로 하는 대상체에서 노화-관련 질환 또는 병태를 치료하는 방법으로서, 노화-관련 질환 또는 병태를 갖는 것으로 식별된 대상체에게 치료적 유효량의 하나 이상의 자연 살해(NK) 세포 활성화제(들)를 투여하는 단계를 포함하는, 방법.
구현예 I2. 노쇠 세포의 사멸 또는 수의 감소를 필요로 하는 대상체에서 노쇠 세포를 사멸시키거나 이의 수를 감소시키는 방법으로서, 대상체에게 치료적 유효량의 하나 이상의 NK 세포 활성화제(들)를 투여하는 단계를 포함하는, 방법.
구현예 I3. 구현예 I1 또는 I2에 있어서, 상기 투여는 대상체에서 표적 조직 내 노쇠 세포의 수의 저하를 초래하는, 방법.
구현예 I4. 구현예 I3에 있어서, 상기 표적 조직은 지방 조직, 췌장 조직, 간 조직, 폐 조직, 혈관 구조, 뼈 조직, 중추신경계(CNS) 조직, 안구 조직, 피부 조직, 근육 조직, 및 2차 림프-기관 조직으로 이루어진 군으로부터 선택되는, 방법.
구현예 I5. 치료를 필요로 하는 대상체에서 노화-관련 질환 또는 병태를 치료하는 방법으로서, 노화-관련 질환 또는 병태를 갖는 것으로 식별된 대상체에게 치료적 유효수의 활성화된 NK 세포를 투여하는 단계를 포함하는, 방법.
구현예 I6. 노쇠 세포의 사멸 또는 수의 감소를 필요로 하는 대상체에서 노쇠 세포를 사멸시키거나 이의 수를 감소시키는 방법으로서, 대상체에게 치료적 유효수의 활성화된 NK 세포를 투여하는 단계를 포함하는, 방법.
구현예 I7. 구현예 I1 내지 구현예 I6 중 어느 한 구현예에 있어서, 상기 대상체는 나이-관련 질환 또는 병태를 갖는 것으로 식별되거나 진단된 적이 있는, 방법.
구현예 I8. 구현예 I7에 있어서, 상기 노화-관련 질환 또는 병태는 암, 자가면역 질환, 대사 질환, 신경퇴행성 질환, 심혈관 질환, 피부 질환, 조로증 질환, 및 유약 질환으로 이루어진 군으로부터 선택되는, 방법.
구현예 I9. 구현예 I8에 있어서, 상기 암은 고형 종양, 혈액학적 종양, 육종, 골육종, 교모세포종, 신경모세포종, 흑색종, 횡문근육종, 유잉 육종, 골육종, B-세포 신생물, 다발성 골수종, B-세포 림프종, B-세포 비-호지킨 림프종, 호지킨 림프종, 만성 림프구성 백혈병(CLL), 급성 골수성 백혈병(AML), 만성 골수성 백혈병(CML), 급성 림프구성 백혈병(ALL), 골수이형성 증후군(MDS), 피부 T-세포 림프종, 망막모세포종, 위암, 요로상피세포암종, 폐암, 신세포 암종, 위 및 식도 암, 췌장암, 전립선암, 유방암, 결장직장암, 난소암, 비-소세포 폐 암종, 편평 세포 두경부 암종, 자궁내막암, 자궁경부암, 간암, 및 간세포 암종으로 이루어진 군으로부터 선택되는, 방법.
구현예 I10. 구현예 I8에 있어서, 상기 자가면역 질환은 1형 당뇨병인, 방법.
구현예 I11. 구현예 I8에 있어서, 상기 대사 질환은 비만, 지방이영양증, 및 2형 진성 당뇨병으로 이루어진 군으로부터 선택되는, 방법.
구현예 I12. 구현예 I8에 있어서, 상기 신경퇴행성 질환은 알츠하이머 질환, 파킨슨 질환, 근위축성 측삭 경화증, 및 치매로 이루어진 군으로부터 선택되는, 방법.
구현예 I13. 구현예 8에 있어서, 상기 심혈관 질환은 관상 동맥 질환, 죽상동맥경화증, 및 폐동맥 고혈압으로 이루어진 군으로부터 선택되는, 방법.
구현예 I14. 구현예 I8에 있어서, 상기 피부 질환은 상처 치유, 탈모증, 주름, 노인성 흑점, 피부 얇아짐, 색소성 건피증, 및 선천성 각화이상증으로 이루어진 군으로부터 선택되는, 방법.
구현예 I15. 구현예 I8에 있어서, 상기 조로증 질환은 조로증 및 허친슨-길포트 조로증 증후군으로 이루어진 군으로부터 선택되는, 방법.
구현예 I16. 구현예 I8에 있어서, 상기 유약 질환은 유약, 백신화에 대한 민감도, 골다공증, 및 사르코페니아로 이루어진 군으로부터 선택되는, 방법.
구현예 I17. 구현예 I1 내지 구현예 I6 중 어느 한 구현예에 있어서, 상기 노화-관련 질환 또는 병태는 골관절염, 지방세포 위축, 만성 폐쇄성 폐 질환, 특발성 폐 섬유증, 신장 이식 실패, 간 섬유증, 골질량 손실, 사르코페니아, 연령-연관 폐 조직 탄성 손실, 골다공증, 노화-연관 신장 기능장애, 및 화학-유도 신장 기능장애로 이루어진 군으로부터 선택되는, 방법.
구현예 I18. 구현예 I1 내지 구현예 I6 중 어느 한 구현예에 있어서, 상기 노화-관련 질환 또는 병태는 2형 당뇨병 또는 죽상동맥경화증인, 방법.
구현예 I19. 기간에 걸쳐 향상을 필요로 하는 대상체에서 피부 및/또는 모발의 질감 및/또는 외양을 향상시키는 방법으로서, 대상체에게 치료적 유효량의 하나 이상의 자연 살해(NK) 세포 활성화제(들)를 투여하는 단계를 포함하는, 방법.
구현예 I20. 기간에 걸쳐 향상을 필요로 하는 대상체에서 피부 및/또는 모발의 질감 및/또는 외양을 향상시키는 방법으로서, 대상체에게 치료적 유효수의 활성화된 NK 세포를 투여하는 단계를 포함하는, 방법.
구현예 I21. 구현예 I19 또는 I20에 있어서, 기간에 걸쳐 대상체의 피부의 질감 및/또는 외양의 향상을 제공하는, 방법.
구현예 I22. 구현예 I21에 있어서, 기간에 걸쳐 대상체의 피부에서 주름 형성 속도의 저하를 초래하는, 방법.
구현예 I23. 구현예 I21 또는 I22에 있어서, 기간에 걸쳐 대상체의 피부의 착색의 향상을 초래하는, 방법.
구현예 I24. 구현예 I21 내지 I23 중 어느 한 구현예에 있어서, 기간에 걸쳐 대상체의 피부의 질감의 향상을 초래하는, 방법.
구현예 I25. 구현예 I20 내지 I24 중 어느 한 구현예에 있어서, 기간에 걸쳐 대상체의 모발의 질감 및/또는 외양의 향상을 제공하는, 방법.
구현예 I26. 구현예 I25에 있어서, 기간에 걸쳐 대상체에서 흰머리 형성 속도의 저하를 초래하는, 방법.
구현예 I27. 구현예 I25 또는 I26에 있어서, 기간에 걸쳐 대상체에서 흰머리 수의 저하를 초래하는, 방법.
구현예 I28. 구현예 I25 내지 I27 중 어느 한 구현예에 있어서, 기간에 걸쳐 대상체에서 모발 손실 속도의 저하를 초래하는, 방법.
구현예 I29. 구현예 I25 내지 I28 중 어느 한 구현예에 있어서, 기간에 걸쳐 대상체의 모발의 질감의 향상을 초래하는, 방법.
구현예 I30. 구현예 I19 내지 I29 중 어느 한 구현예에 있어서, 기간에 걸쳐 대상체의 피부에서 노쇠 피부 섬유아세포 수의 저하를 초래하는, 방법.
구현예 I31. 기간에 걸쳐 보조를 필요로 하는 대상체에서 비만 치료를 보조하는 방법으로서, 대상체에게 치료적 유효량의 하나 이상의 자연 살해(NK) 세포 활성화제(들)를 투여하는 단계를 포함하는, 방법.
구현예 I32. 기간에 걸쳐 보조를 필요로 하는 대상체에서 비만 치료를 보조하는 방법으로서, 대상체에게 치료적 유효수의 활성화된 NK 세포를 투여하는 단계를 포함하는, 방법.
구현예 I33. 구현예 I1 내지 구현예 I32 중 어느 한 구현예에 있어서,
휴지기 NK 세포를 수득하는 단계; 및
상기 휴지기 NK 세포를 시험관내에서 하나 이상의 NK 세포 활성화제(들)를 포함하는 액체 배양 배지에서 접촉시키는 단계를 추가로 포함하며, 상기 접촉은 후속적으로 대상체에게 투여되는 활성화된 NK 세포의 생성을 초래하는, 방법.
구현예 I34. 구현예 I33에 있어서, 휴지기 NK 세포는 키메라 항원 수용체 또는 재조합 T 세포 수용체를 갖고 있는 유전자-조작된 NK 세포인, 방법.
구현예 I35. 구현예 I33에 있어서, 키메라 항원 수용체 또는 재조합 T 세포 수용체를 인코딩하는 핵산을 휴지기 NK 세포 또는 활성화된 NK 세포 내로 도입한 후 대상체에게 투여하는 단계를 추가로 포함하는, 방법.
구현예 I36. 구현예 I31 내지 I35 중 어느 한 구현예에 있어서, 기간에 걸쳐 대상체의 질량의 저하를 초래하는, 방법.
구현예 I37. 구현예 I31 내지 I36 중 어느 한 구현예에 있어서, 기간에 걸쳐 대상체의 체질량 지수(BMI)의 저하를 초래하는, 방법.
구현예 I38. 구현예 I31 내지 I35 중 어느 한 구현예에 있어서, 기간에 걸쳐 전당뇨병으로부터 2형 당뇨병으로의 진행 속도의 저하를 초래하는, 방법.
구현예 I39. 구현예 I31 내지 I35 중 어느 한 구현예에 있어서, 대상체에서 공복 혈청 포도당 수준의 저하를 초래하는, 방법.
구현예 I40. 구현예 I31 내지 I35 중 어느 한 구현예에 있어서, 대상체에서 인슐린 감수성의 증가를 초래하는, 방법.
구현예 I41. 구현예 I31 내지 I35 중 어느 한 구현예에 있어서, 대상체에서 죽상동맥경화증의 중증도의 저하를 초래하는, 방법.
구현예 I42. 구현예 I1 내지 구현예 I41 중 어느 한 구현예에 있어서, 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 IL-2에 대한 수용체, IL-7에 대한 수용체, IL-12에 대한 수용체, IL-15에 대한 수용체, IL-18에 대한 수용체, IL-21에 대한 수용체, IL-33, CD16, CD69, CD25, CD36, CD59, CD352, NKp80, DNAM-1, 2B4, NKp30, NKp44, NKp46, NKG2D, KIR2DS1, KIR2Ds2/3, KIR2DL4, KIR2DS4, KIR2DS5, 및 KIR3DS1에 대한 수용체 중 하나 이상의 활성화를 초래하는, 방법.
구현예 I43. 구현예 I1 내지 구현예 I42 중 어느 한 구현예에 있어서, 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 PD-1, TGF-β 수용체, TIGIT, CD1, TIM-3, Siglec-7, IRP60, Tactile, IL1R8, NKG2A/KLRD1, KIR2DL1, KIR2DL2/3, KIR2DL5, KIR3DL1, KIR3DL2, ILT2/LIR-1, 및 LAG-2 중 하나 이상의 활성화의 저하를 초래하는, 방법.
구현예 I44. 구현예 I1 내지 구현예 I41 중 어느 한 구현예에 있어서, 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 하기를 포함하는 단일-사슬 키메라 폴리펩타이드인, 방법:
(i) 제1 표적-결합 도메인;
(ii) 가용성 조직 인자 도메인; 및
(iii) 제2 표적-결합 도메인.
구현예 I45. 구현예 I44에 있어서, 상기 제1 표적-결합 도메인 및 상기 가용성 조직 인자 도메인은 서로 직접적으로 인접해 있는, 방법.
구현예 I46. 구현예 I44에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 I47. 구현예 I44 내지 구현예 I46 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인 및 상기 제2 표적-결합 도메인은 서로 직접적으로 인접해 있는, 방법.
구현예 I48. 구현예 I44 내지 구현예 I46 중 어느 한 구현예에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 가용성 조직 인자 도메인과 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 I49. 구현예 I1 내지 구현예 I41 중 어느 한 구현예에 있어서, 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는 하기를 포함하는 다중-사슬 키메라 폴리펩타이드인, 방법:
(a) 제1 키메라 폴리펩타이드로서,
(i) 제1 표적-결합 도메인;
(ii) 가용성 조직 인자 도메인; 및
(iii) 친화도 도메인 쌍의 제1 도메인을 포함하는, 제1 키메라 폴리펩타이드; 및
(b) 제2 키메라 폴리펩타이드로서,
(i) 친화도 도메인 쌍의 제2 도메인; 및
(ii) 제2 표적-결합 도메인을 포함하는, 제2 키메라 폴리펩타이드를 포함하고,
상기 제1 키메라 폴리펩타이드 및 상기 제2 키메라 폴리펩타이드는 친화도 도메인 쌍의 제1 도메인과 제2 도메인의 결합을 통해 회합되는, 방법.
구현예 I50. 구현예 I49에 있어서, 상기 제1 표적-결합 도메인 및 상기 가용성 조직 인자 도메인은 상기 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 방법.
구현예 I51. 구현예 I49에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 I52. 구현예 I49 내지 구현예 I51 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인 및 상기 친화도 도메인의 쌍의 제1 도메인은 상기 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 방법.
구현예 I53. 구현예 I49 내지 구현예 I51 중 어느 한 구현예에 있어서, 상기 제1 키메라 폴리펩타이드는 상기 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인의 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 I54. 구현예 I49 내지 구현예 I53 중 어느 한 구현예에 있어서, 상기 친화도 도메인의 쌍의 제2 도메인 및 상기 제2 표적-결합 도메인은 상기 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 방법.
구현예 I55. 구현예 I49 내지 구현예 I53 중 어느 한 구현예에 있어서, 제2 키메라 폴리펩타이드는 상기 제2 키메라 폴리펩타이드에서 상기 친화도 도메인의 쌍의 제2 도메인과 상기 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
구현예 I56. 구현예 I1 내지 구현예 I41 중 어느 한 구현예에 있어서, 하나 이상의 NK 세포 활성화제(들) 중 적어도 하나는
(a) 제1 키메라 폴리펩타이드 및 제2 키메라 폴리펩타이드로서, 각각은
(i) 제1 표적-결합 도메인;
(ii) Fc 도메인; 및
(iii) 친화도 도메인 쌍의 제1 도메인을 포함하는, 제1 키메라 폴리펩타이드 및 제2 키메라 폴리펩타이드;
(b) 제3 키메라 폴리펩타이드 및 제4 키메라 폴리펩타이드로서, 각각은
(i) 친화도 도메인 쌍의 제2 도메인; 및
(ii) 제2 표적-결합 도메인을 포함하는, 제3 키메라 폴리펩타이드 및 제4 키메라 폴리펩타이드를 포함하는 다중-사슬 키메라 폴리펩타이드이고,
상기 제1 및 제2 키메라 폴리펩타이드와 상기 제3 및 제4 키메라 폴리펩타이드는 친화도 도메인 쌍의 제1 도메인과 제2 도메인의 결합을 통해 회합되고, 상기 제1 및 제2 키메라 폴리펩타이드는 이들의 Fc 도메인을 통해 회합되는, 방법.
구현예 I57. 구현예 I44 내지 I56 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 CD16a, CD33, CD20, CD19, CD22, CD123, PDL-1, TIGIT, PD-1, TIM3, CTLA4, MICA, MICB, IL-6, IL-8, TNFα, CD26, CD36, ULBP2, CD30, CD200, IGF-1R, MUC4AC, MUC5AC, Trop-2, CMET, EGFR, HER1, HER2, HER3, PSMA, CEA, B7H3, EPCAM, BCMA, P-카드헤린, CEACAM5, UL16-결합 단백질, HLA-DR, DLL4, TYRO3, AXL, MER, CD122, CD155, PDGF-DD, TGF-β 수용체 II(TGF-βRII)의 리간드, TGF-βRIII의 리간드, DNAM1의 리간드, NKp46의 리간드, NKp44의 리간드, NKG2D의 리간드, NKp30의 리간드, scMHCI에 대한 리간드, scMHCII에 대한 리간드, scTCR에 대한 리간드, PDGF-DD에 대한 수용체, 줄기세포 인자(SCF)에 대한 수용체, 줄기세포-유사 티로신 키나제 3 리간드(FLT3L)에 대한 수용체, MICA에 대한 수용체, MICB에 대한 수용체, ULP16-결합 단백질에 대한 수용체, CD155에 대한 수용체, 및 CD122에 대한 수용체로 이루어진 군으로부터 선택되는 표적에 특이적으로 결합하는, 방법.
구현예 I58. 구현예 I44 내지 구현예 I56 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 단백질인, 방법.
구현예 I59. 구현예 I58에 있어서, 상기 가용성 인터류킨 또는 사이토카인 단백질은 IL-1, IL-2, IL-3, IL-7, IL-8, IL-10, IL-12, IL-15, IL-17, IL-18, IL-21, PDGF-DD, 및 SCF로 이루어진 군으로부터 선택되는, 방법.
구현예 I60. 구현예 I44 내지 구현예 I56 중 어느 한 구현예에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 인터류킨 또는 사이토카인 수용체인, 방법.
구현예 I61. 구현예 I60에 있어서, 상기 가용성 수용체는 가용성 TGF-β 수용체 II(TGF-βRII), 가용성 TGF-βRIII, TNFα에 대한 가용성 수용체, IL-4에 대한 가용성 수용체, 또는 IL-10에 대한 가용성 수용체인, 방법.
구현예 I62. 구현예 I44 내지 구현예 I55 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 혈액 응고를 자극시키지 않는 가용성 인간 조직 인자 도메인인, 방법.
구현예 I63. 구현예 I43 내지 구현예 I55 중 어느 한 구현예에 있어서, 상기 가용성 조직 인자 도메인은 야생형 가용성 인간 조직 인자 도메인으로부터의 서열을 포함하거나 이로 구성되는, 방법.
SEQUENCE LISTING
<110> HCW BIOLOGICS, INC.
<120> METHODS OF TREATING AGING-RELATED DISORDERS
<130> 47039-0022WO2
<140>
<141>
<150> 63/118,536
<151> 2020-11-25
<150> 63/032,933
<151> 2020-06-01
<150> PCT/US2020/035598
<151> 2020-06-01
<160> 336
<170> PatentIn version 3.5
<210> 1
<211> 251
<212> PRT
<213> Homo sapiens
<400> 1
Glu Leu Cys Asp Asp Asp Pro Pro Glu Ile Pro His Ala Thr Phe Lys
1 5 10 15
Ala Met Ala Tyr Lys Glu Gly Thr Met Leu Asn Cys Glu Cys Lys Arg
20 25 30
Gly Phe Arg Arg Ile Lys Ser Gly Ser Leu Tyr Met Leu Cys Thr Gly
35 40 45
Asn Ser Ser His Ser Ser Trp Asp Asn Gln Cys Gln Cys Thr Ser Ser
50 55 60
Ala Thr Arg Asn Thr Thr Lys Gln Val Thr Pro Gln Pro Glu Glu Gln
65 70 75 80
Lys Glu Arg Lys Thr Thr Glu Met Gln Ser Pro Met Gln Pro Val Asp
85 90 95
Gln Ala Ser Leu Pro Gly His Cys Arg Glu Pro Pro Pro Trp Glu Asn
100 105 110
Glu Ala Thr Glu Arg Ile Tyr His Phe Val Val Gly Gln Met Val Tyr
115 120 125
Tyr Gln Cys Val Gln Gly Tyr Arg Ala Leu His Arg Gly Pro Ala Glu
130 135 140
Ser Val Cys Lys Met Thr His Gly Lys Thr Arg Trp Thr Gln Pro Gln
145 150 155 160
Leu Ile Cys Thr Gly Glu Met Glu Thr Ser Gln Phe Pro Gly Glu Glu
165 170 175
Lys Pro Gln Ala Ser Pro Glu Gly Arg Pro Glu Ser Glu Thr Ser Cys
180 185 190
Leu Val Thr Thr Thr Asp Phe Gln Ile Gln Thr Glu Met Ala Ala Thr
195 200 205
Met Glu Thr Ser Ile Phe Thr Thr Glu Tyr Gln Val Ala Val Ala Gly
210 215 220
Cys Val Phe Leu Leu Ile Ser Val Leu Leu Leu Ser Gly Leu Thr Trp
225 230 235 240
Gln Arg Arg Gln Arg Lys Ser Arg Arg Thr Ile
245 250
<210> 2
<211> 753
<212> DNA
<213> Homo sapiens
<400> 2
gagctctgtg acgatgaccc gccagagatc ccacacgcca cattcaaagc catggcctac 60
aaggaaggaa ccatgttgaa ctgtgaatgc aagagaggtt tccgcagaat aaaaagcggg 120
tcactctata tgctctgtac aggaaactct agccactcgt cctgggacaa ccaatgtcaa 180
tgcacaagct ctgccactcg gaacacaacg aaacaagtga cacctcaacc tgaagaacag 240
aaagaaagga aaaccacaga aatgcaaagt ccaatgcagc cagtggacca agcgagcctt 300
ccaggtcact gcagggaacc tccaccatgg gaaaatgaag ccacagagag aatttatcat 360
ttcgtggtgg ggcagatggt ttattatcag tgcgtccagg gatacagggc tctacacaga 420
ggtcctgctg agagcgtctg caaaatgacc cacgggaaga caaggtggac ccagccccag 480
ctcatatgca caggtgaaat ggagaccagt cagtttccag gtgaagagaa gcctcaggca 540
agccccgaag gccgtcctga gagtgagact tcctgcctcg tcacaacaac agattttcaa 600
atacagacag aaatggctgc aaccatggag acgtccatat ttacaacaga gtaccaggta 660
gcagtggccg gctgtgtttt cctgctgatc agcgtcctcc tcctgagtgg gctcacctgg 720
cagcggagac agaggaagag tagaagaaca atc 753
<210> 3
<211> 199
<212> PRT
<213> Homo sapiens
<400> 3
Met Ser Ser Glu Asn Cys Phe Val Ala Glu Asn Ser Ser Leu His Pro
1 5 10 15
Glu Ser Gly Gln Glu Asn Asp Ala Thr Ser Pro His Phe Ser Thr Arg
20 25 30
His Glu Gly Ser Phe Gln Val Pro Val Leu Cys Ala Val Met Asn Val
35 40 45
Val Phe Ile Thr Ile Leu Ile Ile Ala Leu Ile Ala Leu Ser Val Gly
50 55 60
Gln Tyr Asn Cys Pro Gly Gln Tyr Thr Phe Ser Met Pro Ser Asp Ser
65 70 75 80
His Val Ser Ser Cys Ser Glu Asp Trp Val Gly Tyr Gln Arg Lys Cys
85 90 95
Tyr Phe Ile Ser Thr Val Lys Arg Ser Trp Thr Ser Ala Gln Asn Ala
100 105 110
Cys Ser Glu His Gly Ala Thr Leu Ala Val Ile Asp Ser Glu Lys Asp
115 120 125
Met Asn Phe Leu Lys Arg Tyr Ala Gly Arg Glu Glu His Trp Val Gly
130 135 140
Leu Lys Lys Glu Pro Gly His Pro Trp Lys Trp Ser Asn Gly Lys Glu
145 150 155 160
Phe Asn Asn Trp Phe Asn Val Thr Gly Ser Asp Lys Cys Val Phe Leu
165 170 175
Lys Asn Thr Glu Val Ser Ser Met Glu Cys Glu Lys Asn Leu Tyr Trp
180 185 190
Ile Cys Asn Lys Pro Tyr Lys
195
<210> 4
<211> 600
<212> DNA
<213> Homo sapiens
<400> 4
atgagctctg aaaattgttt cgtagcagag aacagctctt tgcatccgga gagtggacaa 60
gaaaatgatg ccaccagtcc ccatttctca acacgtcatg aagggtcctt ccaagttcct 120
gtcctgtgtg ctgtaatgaa tgtggtcttc atcaccattt taatcatagc tctcattgcc 180
ttatcagtgg gccaatacaa ttgtccaggc caatacacat tctcaatgcc atcagacagc 240
catgtttctt catgctctga ggactgggtt ggctaccaga ggaaatgcta ctttatttct 300
actgtgaaga ggagctggac ttcagcccaa aatgcttgtt ctgaacatgg tgctactctt 360
gctgtcattg attctgaaaa ggacatgaac tttctaaaac gatacgcagg tagagaggaa 420
cactgggttg gactgaaaaa ggaacctggt cacccatgga agtggtcaaa tggcaaagaa 480
tttaacaact ggttcaacgt tacagggtct gacaagtgtg tttttctgaa aaacacagag 540
gtcagcagca tggaatgtga gaagaattta tactggatat gtaacaaacc ttacaaataa 600
<210> 5
<211> 77
<212> PRT
<213> Homo sapiens
<400> 5
Leu Gln Cys Tyr Asn Cys Pro Asn Pro Thr Ala Asp Cys Lys Thr Ala
1 5 10 15
Val Asn Cys Ser Ser Asp Phe Asp Ala Cys Leu Ile Thr Lys Ala Gly
20 25 30
Leu Gln Val Tyr Asn Lys Cys Trp Lys Phe Glu His Cys Asn Phe Asn
35 40 45
Asp Val Thr Thr Arg Leu Arg Glu Asn Glu Leu Thr Tyr Tyr Cys Cys
50 55 60
Lys Lys Asp Leu Cys Asn Phe Asn Glu Gln Leu Glu Asn
65 70 75
<210> 6
<211> 387
<212> DNA
<213> Homo sapiens
<400> 6
atgggaatcc aaggagggtc tgtcctgttc gggctgctgc tcgtcctggc tgtcttctgc 60
cattcaggtc atagcctgca gtgctacaac tgtcctaacc caactgctga ctgcaaaaca 120
gccgtcaatt gttcatctga ttttgatgcg tgtctcatta ccaaagctgg gttacaagtg 180
tataacaagt gttggaagtt tgagcattgc aatttcaacg acgtcacaac ccgcttgagg 240
gaaaatgagc taacgtacta ctgctgcaag aaggacctgt gtaactttaa cgaacagctt 300
gaaaatggtg ggacatcctt atcagagaaa acagttcttc tgctggtgac tccatttctg 360
gcagcagcct ggagccttca tccctaa 387
<210> 7
<211> 311
<212> PRT
<213> Homo sapiens
<400> 7
Gln Ser Ser Leu Thr Pro Leu Met Val Asn Gly Ile Leu Gly Glu Ser
1 5 10 15
Val Thr Leu Pro Leu Glu Phe Pro Ala Gly Glu Lys Val Asn Phe Ile
20 25 30
Thr Trp Leu Phe Asn Glu Thr Ser Leu Ala Phe Ile Val Pro His Glu
35 40 45
Thr Lys Ser Pro Glu Ile His Val Thr Asn Pro Lys Gln Gly Lys Arg
50 55 60
Leu Asn Phe Thr Gln Ser Tyr Ser Leu Gln Leu Ser Asn Leu Lys Met
65 70 75 80
Glu Asp Thr Gly Ser Tyr Arg Ala Gln Ile Ser Thr Lys Thr Ser Ala
85 90 95
Lys Leu Ser Ser Tyr Thr Leu Arg Ile Leu Arg Gln Leu Arg Asn Ile
100 105 110
Gln Val Thr Asn His Ser Gln Leu Phe Gln Asn Met Thr Cys Glu Leu
115 120 125
His Leu Thr Cys Ser Val Glu Asp Ala Asp Asp Asn Val Ser Phe Arg
130 135 140
Trp Glu Ala Leu Gly Asn Thr Leu Ser Ser Gln Pro Asn Leu Thr Val
145 150 155 160
Ser Trp Asp Pro Arg Ile Ser Ser Glu Gln Asp Tyr Thr Cys Ile Ala
165 170 175
Glu Asn Ala Val Ser Asn Leu Ser Phe Ser Val Ser Ala Gln Lys Leu
180 185 190
Cys Glu Asp Val Lys Ile Gln Tyr Thr Asp Thr Lys Met Ile Leu Phe
195 200 205
Met Val Ser Gly Ile Cys Ile Val Phe Gly Phe Ile Ile Leu Leu Leu
210 215 220
Leu Val Leu Arg Lys Arg Arg Asp Ser Leu Ser Leu Ser Thr Gln Arg
225 230 235 240
Thr Gln Gly Pro Ala Glu Ser Ala Arg Asn Leu Glu Tyr Val Ser Val
245 250 255
Ser Pro Thr Asn Asn Thr Val Tyr Ala Ser Val Thr His Ser Asn Arg
260 265 270
Glu Thr Glu Ile Trp Thr Pro Arg Glu Asn Asp Thr Ile Thr Ile Tyr
275 280 285
Ser Thr Ile Asn His Ser Lys Glu Ser Lys Pro Thr Phe Ser Arg Ala
290 295 300
Thr Ala Leu Asp Asn Val Val
305 310
<210> 8
<211> 996
<212> DNA
<213> Homo sapiens
<400> 8
atgttgtggc tgttccaatc gctcctgttt gtcttctgct ttggcccagg gaatgtagtt 60
tcacaaagca gcttaacccc attgatggtg aacgggattc tgggggagtc agtaactctt 120
cccctggagt ttcctgcagg agagaaggtc aacttcatca cttggctttt caatgaaaca 180
tctcttgcct tcatagtacc ccatgaaacc aaaagtccag aaatccacgt gactaatccg 240
aaacagggaa agcgactgaa cttcacccag tcctactccc tgcaactcag caacctgaag 300
atggaagaca caggctctta cagagcccag atatccacaa agacctctgc aaagctgtcc 360
agttacactc tgaggatatt aagacaactg aggaacatac aagttaccaa tcacagtcag 420
ctatttcaga atatgacctg tgagctccat ctgacttgct ctgtggagga tgcagatgac 480
aatgtctcat tcagatggga ggccttggga aacacacttt caagtcagcc aaacctcact 540
gtctcctggg accccaggat ttccagtgaa caggactaca cctgcatagc agagaatgct 600
gtcagtaatt tatccttctc tgtctctgcc cagaagcttt gcgaagatgt taaaattcaa 660
tatacagata ccaaaatgat tctgtttatg gtttctggga tatgcatagt cttcggtttc 720
atcatactgc tgttacttgt tttgaggaaa agaagagatt ccctatcttt gtctactcag 780
cgaacacagg gccccgagtc cgcaaggaac ctagagtatg tttcagtgtc tccaacgaac 840
aacactgtgt atgcttcagt cactcattca aacagggaaa cagaaatctg gacacctaga 900
gaaaatgata ctatcacaat ttactccaca attaatcatt ccaaagagag taaacccact 960
ttttccaggg caactgccct tgacaatgtc gtgtaa 996
<210> 9
<211> 231
<212> PRT
<213> Homo sapiens
<400> 9
Met Gln Asp Glu Glu Arg Tyr Met Thr Leu Asn Val Gln Ser Lys Lys
1 5 10 15
Arg Ser Ser Ala Gln Thr Ser Gln Leu Thr Phe Lys Asp Tyr Ser Val
20 25 30
Thr Leu His Trp Tyr Lys Ile Leu Leu Gly Ile Ser Gly Thr Val Asn
35 40 45
Gly Ile Leu Thr Leu Thr Leu Ile Ser Leu Ile Leu Leu Val Ser Gln
50 55 60
Gly Val Leu Leu Lys Cys Gln Lys Gly Ser Cys Ser Asn Ala Thr Gln
65 70 75 80
Tyr Glu Asp Thr Gly Asp Leu Lys Val Asn Asn Gly Thr Arg Arg Asn
85 90 95
Ile Ser Asn Lys Asp Leu Cys Ala Ser Arg Ser Ala Asp Gln Thr Val
100 105 110
Leu Cys Gln Ser Glu Trp Leu Lys Tyr Gln Gly Lys Cys Tyr Trp Phe
115 120 125
Ser Asn Glu Met Lys Ser Trp Ser Asp Ser Tyr Val Tyr Cys Leu Glu
130 135 140
Arg Lys Ser His Leu Leu Ile Ile His Asp Gln Leu Glu Met Ala Phe
145 150 155 160
Ile Gln Lys Asn Leu Arg Gln Leu Asn Tyr Val Trp Ile Gly Leu Asn
165 170 175
Phe Thr Ser Leu Lys Met Thr Trp Thr Trp Val Asp Gly Ser Pro Ile
180 185 190
Asp Ser Lys Ile Phe Phe Ile Lys Gly Pro Ala Lys Glu Asn Ser Cys
195 200 205
Ala Ala Ile Lys Glu Ser Lys Ile Phe Ser Glu Thr Cys Ser Ser Val
210 215 220
Phe Lys Trp Ile Cys Gln Tyr
225 230
<210> 10
<211> 546
<212> DNA
<213> Homo sapiens
<400> 10
atgcaagatg aagaaagata catgacattg aatgtacagt caaagaaaag gagttctgcc 60
caaacatctc aacttacatt taaagattat tcagtgacgt tgcactggta taaaatctta 120
ctgggaatat ctggaaccgt gaatggtatt ctcactttga ctttgatctc cttgatcctg 180
ttggtactat gccaatcaga atggctcaaa taccaaggga agtgttattg gttctctaat 240
gagatgaaaa gctggagtga cagttatgtg tattgtttgg aaagaaaatc tcatctacta 300
atcatacatg accaacttga aatggctttt atacagaaaa acctaagaca attaaactac 360
gtatggattg ggcttaactt tacctccttg aaaatgacat ggacttgggt ggatggttct 420
ccaatagatt caaagatatt cttcataaag ggaccagcta aagaaaacag ctgtgctgcc 480
attaaggaaa gcaaaatttt ctctgaaacc tgcagcagtg ttttcaaatg gatttgtcag 540
tattag 546
<210> 11
<211> 318
<212> PRT
<213> Homo sapiens
<400> 11
Glu Glu Val Leu Trp His Thr Ser Val Pro Phe Ala Glu Asn Met Ser
1 5 10 15
Leu Glu Cys Val Tyr Pro Ser Met Gly Ile Leu Thr Gln Val Glu Trp
20 25 30
Phe Lys Ile Gly Thr Gln Gln Asp Ser Ile Ala Ile Phe Ser Pro Thr
35 40 45
His Gly Met Val Ile Arg Lys Pro Tyr Ala Glu Arg Val Tyr Phe Leu
50 55 60
Asn Ser Thr Met Ala Ser Asn Asn Met Thr Leu Phe Phe Arg Asn Ala
65 70 75 80
Ser Glu Asp Asp Val Gly Tyr Tyr Ser Cys Ser Leu Tyr Thr Tyr Pro
85 90 95
Gln Gly Thr Trp Gln Lys Val Ile Gln Val Val Gln Ser Asp Ser Phe
100 105 110
Glu Ala Ala Val Pro Ser Asn Ser His Ile Val Ser Glu Pro Gly Lys
115 120 125
Asn Val Thr Leu Thr Cys Gln Pro Gln Met Thr Trp Pro Val Gln Ala
130 135 140
Val Arg Trp Glu Lys Ile Gln Pro Arg Gln Ile Asp Leu Leu Thr Tyr
145 150 155 160
Cys Asn Leu Val His Gly Arg Asn Phe Thr Ser Lys Phe Pro Arg Gln
165 170 175
Ile Val Ser Asn Cys Ser His Gly Arg Trp Ser Val Ile Val Ile Pro
180 185 190
Asp Val Thr Val Ser Asp Ser Gly Leu Tyr Arg Cys Tyr Leu Gln Ala
195 200 205
Ser Ala Gly Glu Asn Glu Thr Phe Val Met Arg Leu Thr Val Ala Glu
210 215 220
Gly Lys Thr Asp Asn Gln Tyr Thr Leu Phe Val Ala Gly Gly Thr Val
225 230 235 240
Leu Leu Leu Leu Phe Val Ile Ser Ile Thr Thr Ile Ile Val Ile Phe
245 250 255
Leu Asn Arg Arg Arg Arg Arg Glu Arg Arg Asp Leu Phe Thr Glu Ser
260 265 270
Trp Asp Thr Gln Lys Ala Pro Asn Asn Tyr Arg Ser Pro Ile Ser Thr
275 280 285
Ser Gln Pro Thr Asn Gln Ser Met Asp Asp Thr Arg Glu Asp Ile Tyr
290 295 300
Val Asn Tyr Pro Thr Phe Ser Arg Arg Pro Lys Thr Arg Val
305 310 315
<210> 12
<211> 1011
<212> DNA
<213> Homo sapiens
<400> 12
atggattatc ctactttact tttggctctt cttcatgtat acagagctct atgtgaagag 60
gtgctttggc atacatcagt tccctttgcc gagaacatgt ctctagaatg tgtgtatcca 120
tcaatgggca tcttaacaca ggtggagtgg ttcaagatcg ggacccagca ggattccata 180
gccattttca gccctactca tggcatggtc ataaggaagc cctatgctga gagggtttac 240
tttttgaatt caacgatggc ttccaataac atgactcttt tctttcggaa tgcctctgaa 300
gatgatgttg gctactattc ctgctctctt tacacttacc cacagggaac ttggcagaag 360
gtgatacagg tggttcagtc agatagtttt gaggcagctg tgccatcaaa tagccacatt 420
gtttcggaac ctggaaagaa tgtcacactc acttgtcagc ctcagatgac gtggcctgtg 480
caggcagtga ggtgggaaaa gatccagccc cgtcagatcg acctcttaac ttactgcaac 540
ttggtccatg gcagaaattt cacctccaag ttcccaagac aaatagtgag caactgcagc 600
cacggaaggt ggagcgtcat cgtcatcccc gatgtcacag tctcagactc ggggctttac 660
cgctgctact tgcaggccag cgcaggagaa aacgaaacct tcgtgatgag attgactgta 720
gccgagggta aaaccgataa ccaatatacc ctctttgtgg ctggagggac agttttattg 780
ttgttgtttg ttatctcaat taccaccatc attgtcattt tccttaacag aaggagaagg 840
agagagagaa gagatctatt tacagagtcc tgggatacac agaaggcacc caataactat 900
agaagtccca tctctaccag tcaacctacc aatcaatcca tggatgatac aagagaggat 960
atttatgtca actatccaac cttctctcgc agaccaaaga ctagagttta a 1011
<210> 13
<211> 347
<212> PRT
<213> Homo sapiens
<400> 13
Gly Lys Gly Cys Gln Gly Ser Ala Asp His Val Val Ser Ile Ser Gly
1 5 10 15
Val Pro Leu Gln Leu Gln Pro Asn Ser Ile Gln Thr Lys Val Asp Ser
20 25 30
Ile Ala Trp Lys Lys Leu Leu Pro Ser Gln Asn Gly Phe His His Ile
35 40 45
Leu Lys Trp Glu Asn Gly Ser Leu Pro Ser Asn Thr Ser Asn Asp Arg
50 55 60
Phe Ser Phe Ile Val Lys Asn Leu Ser Leu Leu Ile Lys Ala Ala Gln
65 70 75 80
Gln Gln Asp Ser Gly Leu Tyr Cys Leu Glu Val Thr Ser Ile Ser Gly
85 90 95
Lys Val Gln Thr Ala Thr Phe Gln Val Phe Val Phe Asp Lys Val Glu
100 105 110
Lys Pro Arg Leu Gln Gly Gln Gly Lys Ile Leu Asp Arg Gly Arg Cys
115 120 125
Gln Val Ala Leu Ser Cys Leu Val Ser Arg Asp Gly Asn Val Ser Tyr
130 135 140
Ala Trp Tyr Arg Gly Ser Lys Leu Ile Gln Thr Ala Gly Asn Leu Thr
145 150 155 160
Tyr Leu Asp Glu Glu Val Asp Ile Asn Gly Thr His Thr Tyr Thr Cys
165 170 175
Asn Val Ser Asn Pro Val Ser Trp Glu Ser His Thr Leu Asn Leu Thr
180 185 190
Gln Asp Cys Gln Asn Ala His Gln Glu Phe Arg Phe Trp Pro Phe Leu
195 200 205
Val Ile Ile Val Ile Leu Ser Ala Leu Phe Leu Gly Thr Leu Ala Cys
210 215 220
Phe Cys Val Trp Arg Arg Lys Arg Lys Glu Lys Gln Ser Glu Thr Ser
225 230 235 240
Pro Lys Glu Phe Leu Thr Ile Tyr Glu Asp Val Lys Asp Leu Lys Thr
245 250 255
Arg Arg Asn His Glu Gln Glu Gln Thr Phe Pro Gly Gly Gly Ser Thr
260 265 270
Ile Tyr Ser Met Ile Gln Ser Gln Ser Ser Ala Pro Thr Ser Gln Glu
275 280 285
Pro Ala Tyr Thr Leu Tyr Ser Leu Ile Gln Pro Ser Arg Lys Ser Gly
290 295 300
Ser Arg Lys Arg Asn His Ser Pro Ser Phe Asn Ser Thr Ile Tyr Glu
305 310 315 320
Val Ile Gly Lys Ser Gln Pro Lys Ala Gln Asn Pro Ala Arg Leu Ser
325 330 335
Arg Lys Glu Leu Glu Asn Phe Asp Val Tyr Ser
340 345
<210> 14
<211> 1098
<212> DNA
<213> Homo sapiens
<400> 14
atgctggggc aagtggtcac cctcatactc ctcctgctcc tcaaggtgta tcagggcaaa 60
ggatgccagg gatcagctga ccatgtggtt agcatctcgg gagtgcctct tcagttacaa 120
ccaaacagca tacagacgaa ggttgacagc attgcatgga agaagttgct gccctcacaa 180
aatggatttc atcacatatt gaagtgggag aatggctctt tgccttccaa tacttccaat 240
gatagattca gttttatagt caagaacttg agtcttctca tcaaggcagc tcagcagcag 300
gacagtggcc tctactgcct ggaggtcacc agtatatctg gaaaagttca gacagccacg 360
ttccaggttt ttgtatttga taaagttgag aaaccccgcc tacaggggca ggggaagatc 420
ctggacagag ggagatgcca agtggctctg tcttgcttgg tctccaggga tggcaatgtg 480
tcctatgctt ggtacagagg gagcaagctg atccagacag cagggaacct cacctacctg 540
gacgaggagg ttgacattaa tggcactcac acatatacct gcaatgtcag caatcctgtt 600
agctgggaaa gccacaccct gaatctcact caggactgtc agaatgccca tcaggaattc 660
agattttggc cgtttttggt gatcatcgtg attctaagcg cactgttcct tggcaccctt 720
gcctgcttct gtgtgtggag gagaaagagg aaggagaagc agtcagagac cagtcccaag 780
gaatttttga caatttacga agatgtcaag gatctgaaaa ccaggagaaa tcacgagcag 840
gagcagactt ttcctggagg ggggagcacc atctactcta tgatccagtc ccagtcttct 900
gctcccacgt cacaagaacc tgcatataca ttatattcat taattcagcc ttccaggaag 960
tctggatcca ggaagaggaa ccacagccct tccttcaata gcactatcta tgaagtgatt 1020
ggaaagagtc aacctaaagc ccagaaccct gctcgattga gccgcaaaga gctggagaac 1080
tttgatgttt attcctag 1098
<210> 15
<211> 183
<212> PRT
<213> Homo sapiens
<400> 15
Leu Trp Val Ser Gln Pro Pro Glu Ile Arg Thr Leu Glu Gly Ser Ser
1 5 10 15
Ala Phe Leu Pro Cys Ser Phe Asn Ala Ser Gln Gly Arg Leu Ala Ile
20 25 30
Gly Ser Val Thr Trp Phe Arg Asp Glu Val Val Pro Gly Lys Glu Val
35 40 45
Arg Asn Gly Thr Pro Glu Phe Arg Gly Arg Leu Ala Pro Leu Ala Ser
50 55 60
Ser Arg Phe Leu His Asp His Gln Ala Glu Leu His Ile Arg Asp Val
65 70 75 80
Arg Gly His Asp Ala Ser Ile Tyr Val Cys Arg Val Glu Val Leu Gly
85 90 95
Leu Gly Val Gly Thr Gly Asn Gly Thr Arg Leu Val Val Glu Lys Glu
100 105 110
His Pro Gln Leu Gly Ala Gly Thr Val Leu Leu Leu Arg Ala Gly Phe
115 120 125
Tyr Ala Val Ser Phe Leu Ser Val Ala Val Gly Ser Thr Val Tyr Tyr
130 135 140
Gln Gly Lys Cys Leu Thr Trp Lys Gly Pro Arg Arg Gln Leu Pro Ala
145 150 155 160
Val Val Pro Ala Pro Leu Pro Pro Pro Cys Gly Ser Ser Ala His Leu
165 170 175
Leu Pro Pro Val Pro Gly Gly
180
<210> 16
<211> 573
<212> DNA
<213> Homo sapiens
<400> 16
atggcctgga tgctgttgct catcttgatc atggtccatc caggatcctg tgctctctgg 60
gtgtcccagc cccctgagat tcgtaccctg gaaggatcct ctgccttcct gccctgctcc 120
ttcaatgcca gccaagggag actggccatt ggctccgtca cgtggttccg agatgaggtg 180
gttccaggga aggaggtgag gaatggaacc ccagagttca ggggccgcct ggccccactt 240
gcttcttccc gtttcctcca tgaccaccag gctgagctgc acatccggga cgtgcgaggc 300
catgacgcca gcatctacgt gtgcagagtg gaggtgctgg gccttggtgt cgggacaggg 360
aatgggactc ggctggtggt ggagaaagaa catcctcagc taggggctgg tacagtcctc 420
ctccttcggg ctggattcta tgctgtcagc tttctctctg tggccgtggg cagcaccgtc 480
tattaccagg gcaaatgcca ctgtcacatg ggaacacact gccactcctc agatgggccc 540
cgaggagtga ttccagagcc cagatgtccc tag 573
<210> 17
<211> 255
<212> PRT
<213> Homo sapiens
<400> 17
Gln Ser Lys Ala Gln Val Leu Gln Ser Val Ala Gly Gln Thr Leu Thr
1 5 10 15
Val Arg Cys Gln Tyr Pro Pro Thr Gly Ser Leu Tyr Glu Lys Lys Gly
20 25 30
Trp Cys Lys Glu Ala Ser Ala Leu Val Cys Ile Arg Leu Val Thr Ser
35 40 45
Ser Lys Pro Arg Thr Met Ala Trp Thr Ser Arg Phe Thr Ile Trp Asp
50 55 60
Asp Pro Asp Ala Gly Phe Phe Thr Val Thr Met Thr Asp Leu Arg Glu
65 70 75 80
Glu Asp Ser Gly His Tyr Trp Cys Arg Ile Tyr Arg Pro Ser Asp Asn
85 90 95
Ser Val Ser Lys Ser Val Arg Phe Tyr Leu Val Val Ser Pro Ala Ser
100 105 110
Ala Ser Thr Gln Thr Ser Trp Thr Pro Arg Asp Leu Val Ser Ser Gln
115 120 125
Thr Gln Thr Gln Ser Cys Val Pro Pro Thr Ala Gly Ala Arg Gln Ala
130 135 140
Pro Glu Ser Pro Ser Thr Ile Pro Val Pro Ser Gln Pro Gln Asn Ser
145 150 155 160
Thr Leu Arg Pro Gly Pro Ala Ala Pro Ile Ala Leu Val Pro Val Phe
165 170 175
Cys Gly Leu Leu Val Ala Lys Ser Leu Val Leu Ser Ala Leu Leu Val
180 185 190
Trp Trp Gly Asp Ile Trp Trp Lys Thr Met Met Glu Leu Arg Ser Leu
195 200 205
Asp Thr Gln Lys Ala Thr Cys His Leu Gln Gln Val Thr Asp Leu Pro
210 215 220
Trp Thr Ser Val Ser Ser Pro Val Glu Arg Glu Ile Leu Tyr His Thr
225 230 235 240
Val Ala Arg Thr Lys Ile Ser Asp Asp Asp Asp Glu His Thr Leu
245 250 255
<210> 18
<211> 777
<212> DNA
<213> Homo sapiens
<400> 18
atggcctggc gagccctaca cccactgcta ctgctgctgc tgctgttccc aggctctcag 60
gcacaatcca aggctcaggt acttcaaagt gtggcagggc agacgctaac cgtgagatgc 120
cagtacccgc ccacgggcag tctctacgag aagaaaggct ggtgtaagga ggcttcagca 180
cttgtgtgca tcaggttagt caccagctcc aagcccagga cgatggcttg gacctctcga 240
ttcacaatct gggacgaccc tgatgctggc ttcttcactg tcaccatgac tgatctgaga 300
gaggaagact caggacatta ctggtgtaga atctaccgcc cttctgacaa ctctgtctct 360
aagtccgtca gattctatct ggtggtatct ccagcctctg cctccacaca gacctcctgg 420
actccccgcg acctggtctc ttcacagacc cagacccaga gctgtgtgcc tcccactgca 480
ggagccagac aagcccctga gtctccatct accatccctg tcccttcaca gccacagaac 540
tccacgctcc gccctggccc tgcagccccc attgccctgg tgcctgtgtt ctgtggactc 600
ctcgtagcca agagcctggt gctgtcagcc ctgctcgtct ggtgggtttt aaggaatcgg 660
cacatgcagc atcaagggag gtctctgctg cacccagctc agcccaggcc ccaggcccat 720
agacacttcc cactgagcca cagggcacca ggggggacat atggtggaaa accatga 777
<210> 19
<211> 283
<212> PRT
<213> Homo sapiens
<400> 19
Gln Gln Gln Thr Leu Pro Lys Pro Phe Ile Trp Ala Glu Pro His Phe
1 5 10 15
Met Val Pro Lys Glu Lys Gln Val Thr Ile Cys Cys Gln Gly Asn Tyr
20 25 30
Gly Ala Val Glu Tyr Gln Leu His Phe Glu Gly Ser Leu Phe Ala Val
35 40 45
Asp Arg Pro Lys Pro Pro Glu Arg Ile Asn Lys Val Gln Phe Tyr Ile
50 55 60
Pro Asp Met Asn Ser Arg Met Ala Gly Gln Tyr Ser Cys Ile Tyr Arg
65 70 75 80
Val Gly Glu Leu Trp Ser Glu Pro Ser Asn Leu Leu Asp Leu Val Val
85 90 95
Thr Glu Met Tyr Asp Thr Pro Thr Leu Ser Val His Pro Gly Pro Glu
100 105 110
Val Ile Ser Gly Glu Lys Val Thr Phe Tyr Cys Arg Leu Asp Thr Ala
115 120 125
Thr Ser Met Phe Leu Leu Leu Lys Glu Gly Arg Ser Ser His Val Gln
130 135 140
Arg Gly Tyr Gly Lys Val Gln Ala Glu Phe Pro Leu Gly Pro Val Thr
145 150 155 160
Thr Ala His Arg Gly Thr Tyr Arg Cys Phe Gly Ser Tyr Asn Asn His
165 170 175
Ala Trp Ser Phe Pro Ser Glu Pro Val Lys Leu Leu Val Thr Gly Asp
180 185 190
Ile Glu Asn Thr Ser Leu Ala Pro Glu Asp Pro Thr Phe Pro Ala Asp
195 200 205
Thr Trp Gly Thr Tyr Leu Leu Thr Thr Glu Thr Gly Leu Gln Lys Asp
210 215 220
His Ala Leu Trp Asp His Thr Ala Gln Asn Leu Leu Arg Met Gly Leu
225 230 235 240
Ala Phe Leu Val Leu Val Ala Leu Val Trp Phe Leu Val Glu Asp Trp
245 250 255
Leu Ser Arg Lys Arg Thr Arg Glu Arg Ala Ser Arg Ala Ser Thr Trp
260 265 270
Glu Gly Arg Arg Arg Leu Asn Thr Gln Thr Leu
275 280
<210> 20
<211> 777
<212> DNA
<213> Homo sapiens
<400> 20
atggcctggc gagccctaca cccactgcta ctgctgctgc tgctgttccc aggctctcag 60
gcacaatcca aggctcaggt acttcaaagt gtggcagggc agacgctaac cgtgagatgc 120
cagtacccgc ccacgggcag tctctacgag aagaaaggct ggtgtaagga ggcttcagca 180
cttgtgtgca tcaggttagt caccagctcc aagcccagga cgatggcttg gacctctcga 240
ttcacaatct gggacgaccc tgatgctggc ttcttcactg tcaccatgac tgatctgaga 300
gaggaagact caggacatta ctggtgtaga atctaccgcc cttctgacaa ctctgtctct 360
aagtccgtca gattctatct ggtggtatct ccagcctctg cctccacaca gacctcctgg 420
actccccgcg acctggtctc ttcacagacc cagacccaga gctgtgtgcc tcccactgca 480
ggagccagac aagcccctga gtctccatct accatccctg tcccttcaca gccacagaac 540
tccacgctcc gccctggccc tgcagccccc attgccctgg tgcctgtgtt ctgtggactc 600
ctcgtagcca agagcctggt gctgtcagcc ctgctcgtct ggtgggtttt aaggaatcgg 660
cacatgcagc atcaagggag gtctctgctg cacccagctc agcccaggcc ccaggcccat 720
agacacttcc cactgagcca cagggcacca ggggggacat atggtggaaa accatga 777
<210> 21
<211> 216
<212> PRT
<213> Homo sapiens
<400> 21
Met Gly Trp Ile Arg Gly Arg Arg Ser Arg His Ser Trp Glu Met Ser
1 5 10 15
Glu Phe His Asn Tyr Asn Leu Asp Leu Lys Lys Ser Asp Phe Ser Thr
20 25 30
Arg Trp Gln Lys Gln Arg Cys Pro Val Val Lys Ser Lys Cys Arg Glu
35 40 45
Asn Ala Ser Pro Phe Phe Phe Cys Cys Phe Ile Ala Val Ala Met Gly
50 55 60
Ile Arg Phe Ile Ile Met Val Ala Ile Trp Ser Ala Val Phe Leu Asn
65 70 75 80
Ser Leu Phe Asn Gln Glu Val Gln Ile Pro Leu Thr Glu Ser Tyr Cys
85 90 95
Gly Pro Cys Pro Lys Asn Trp Ile Cys Tyr Lys Asn Asn Cys Tyr Gln
100 105 110
Phe Phe Asp Glu Ser Lys Asn Trp Tyr Glu Ser Gln Ala Ser Cys Met
115 120 125
Ser Gln Asn Ala Ser Leu Leu Lys Val Tyr Ser Lys Glu Asp Gln Asp
130 135 140
Leu Leu Lys Leu Val Lys Ser Tyr His Trp Met Gly Leu Val His Ile
145 150 155 160
Pro Thr Asn Gly Ser Trp Gln Trp Glu Asp Gly Ser Ile Leu Ser Pro
165 170 175
Asn Leu Leu Thr Ile Ile Glu Met Gln Lys Gly Asp Cys Ala Leu Tyr
180 185 190
Ala Ser Ser Phe Lys Gly Tyr Ile Glu Asn Cys Ser Thr Pro Asn Thr
195 200 205
Tyr Ile Cys Met Gln Arg Thr Val
210 215
<210> 22
<211> 651
<212> DNA
<213> Homo sapiens
<400> 22
atggggtgga ttcgtggtcg gaggtctcga cacagctggg agatgagtga atttcataat 60
tataacttgg atctgaagaa gagtgatttt tcaacacgat ggcaaaagca aagatgtcca 120
gtagtcaaaa gcaaatgtag agaaaatgca tctccatttt ttttctgctg cttcatcgct 180
gtagccatgg gaatccgttt cattattatg gtaacaatat ggagtgctgt attcctaaac 240
tcattattca accaagaagt tcaaattccc ttgaccgaaa gttactgtgg cccatgtcct 300
aaaaactgga tatgttacaa aaataactgc taccaatttt ttgatgagag taaaaactgg 360
tatgagagcc aggcttcttg tatgtctcaa aatgccagcc ttctgaaagt atacagcaaa 420
gaggaccagg atttacttaa actggtgaag tcatatcatt ggatgggact agtacacatt 480
ccaacaaatg gatcttggca gtgggaagat ggctccattc tctcacccaa cctactaaca 540
ataattgaaa tgcagaaggg agactgtgca ctctatgcct cgagctttaa aggctatata 600
gaaaactgtt caactccaaa tacgtacatc tgcatgcaaa ggactgtgta a 651
<210> 23
<211> 359
<212> PRT
<213> Homo sapiens
<400> 23
Met Ala Glu Gly Thr Leu Trp Gln Ile Leu Cys Val Ser Ser Asp Ala
1 5 10 15
Gln Pro Gln Thr Phe Glu Gly Val Lys Gly Ala Asp Pro Pro Thr Leu
20 25 30
Pro Pro Gly Ser Phe Leu Pro Gly Pro Val Leu Trp Trp Gly Ser Leu
35 40 45
Ala Arg Leu Gln Thr Glu Lys Ser Asp Glu Val Ser Arg Lys Gly Asn
50 55 60
Trp Trp Val Thr Glu Met Gly Gly Gly Ala Gly Glu Arg Leu Phe Thr
65 70 75 80
Ser Ser Cys Leu Val Gly Leu Val Pro Leu Gly Leu Arg Ile Ser Leu
85 90 95
Val Thr Cys Pro Leu Gln Cys Gly Ile Met Trp Gln Leu Leu Leu Pro
100 105 110
Thr Ala Leu Leu Leu Leu Val Ser Ala Gly Met Arg Thr Glu Asp Leu
115 120 125
Pro Lys Ala Val Val Phe Leu Glu Pro Gln Trp Tyr Arg Val Leu Glu
130 135 140
Lys Asp Ser Val Thr Leu Lys Cys Gln Gly Ala Tyr Ser Pro Glu Asp
145 150 155 160
Asn Ser Thr Gln Trp Phe His Asn Glu Ser Leu Ile Ser Ser Gln Ala
165 170 175
Ser Ser Tyr Phe Ile Asp Ala Ala Thr Val Asp Asp Ser Gly Glu Tyr
180 185 190
Arg Cys Gln Thr Asn Leu Ser Thr Leu Ser Asp Pro Val Gln Leu Glu
195 200 205
Val His Ile Gly Trp Leu Leu Leu Gln Ala Pro Arg Trp Val Phe Lys
210 215 220
Glu Glu Asp Pro Ile His Leu Arg Cys His Ser Trp Lys Asn Thr Ala
225 230 235 240
Leu His Lys Val Thr Tyr Leu Gln Asn Gly Lys Gly Arg Lys Tyr Phe
245 250 255
His His Asn Ser Asp Phe Tyr Ile Pro Lys Ala Thr Leu Lys Asp Ser
260 265 270
Gly Ser Tyr Phe Cys Arg Gly Leu Phe Gly Ser Lys Asn Val Ser Ser
275 280 285
Glu Thr Val Asn Ile Thr Ile Thr Gln Gly Leu Ala Val Ser Thr Ile
290 295 300
Ser Ser Phe Phe Pro Pro Gly Tyr Gln Val Ser Phe Cys Leu Val Met
305 310 315 320
Val Leu Leu Phe Ala Val Asp Thr Gly Leu Tyr Phe Ser Val Lys Thr
325 330 335
Asn Ile Arg Ser Ser Thr Arg Asp Trp Lys Asp His Lys Phe Lys Trp
340 345 350
Arg Lys Asp Pro Gln Asp Lys
355
<210> 24
<211> 1080
<212> DNA
<213> Homo sapiens
<400> 24
atggctgagg gcacactctg gcagattctg tgtgtgtcct cagatgctca gccacagacc 60
tttgagggag taaagggggc agacccaccc accttgcctc caggctcttt ccttcctggt 120
cctgttctat ggtggggctc ccttgccaga cttcagactg agaagtcaga tgaagtttca 180
agaaaaggaa attggtgggt gacagagatg ggtggagggg ctggggaaag gctgtttact 240
tcctcctgtc tagtcggttt ggtcccttta gggctccgga tatctttggt gacttgtcca 300
ctccagtgtg gcatcatgtg gcagctgctc ctcccaactg ctctgctact tctagtttca 360
gctggcatgc ggactgaaga tctcccaaag gctgtggtgt tcctggagcc tcaatggtac 420
agggtgctcg agaaggacag tgtgactctg aagtgccagg gagcctactc ccctgaggac 480
aattccacac agtggtttca caatgagagc ctcatctcaa gccaggcctc gagctacttc 540
attgacgctg ccacagtcga cgacagtgga gagtacaggt gccagacaaa cctctccacc 600
ctcagtgacc cggtgcagct agaagtccat atcggctggc tgttgctcca ggcccctcgg 660
tgggtgttca aggaggaaga ccctattcac ctgaggtgtc acagctggaa gaacactgct 720
ctgcataagg tcacatattt acagaatggc aaaggcagga agtattttca tcataattct 780
gacttctaca ttccaaaagc cacactcaaa gacagcggct cctacttctg cagggggctt 840
tttgggagta aaaatgtgtc ttcagagact gtgaacatca ccatcactca aggtttggca 900
gtgtcaacca tctcatcatt ctttccacct gggtaccaag tctctttctg cttggtgatg 960
gtactccttt ttgcagtgga cacaggacta tatttctctg tgaagacaaa cattcgaagc 1020
tcaacaagag actggaagga ccataaattt aaatggagaa aggaccctca agacaaatga 1080
<210> 25
<211> 233
<212> PRT
<213> Homo sapiens
<400> 25
Met Trp Gln Leu Leu Leu Pro Thr Ala Leu Leu Leu Leu Val Ser Ala
1 5 10 15
Gly Met Arg Thr Glu Asp Leu Pro Lys Ala Val Val Phe Leu Glu Pro
20 25 30
Gln Trp Tyr Ser Val Leu Glu Lys Asp Ser Val Thr Leu Lys Cys Gln
35 40 45
Gly Ala Tyr Ser Pro Glu Asp Asn Ser Thr Gln Trp Phe His Asn Glu
50 55 60
Ser Leu Ile Ser Ser Gln Ala Ser Ser Tyr Phe Ile Asp Ala Ala Thr
65 70 75 80
Val Asn Asp Ser Gly Glu Tyr Arg Cys Gln Thr Asn Leu Ser Thr Leu
85 90 95
Ser Asp Pro Val Gln Leu Glu Val His Ile Gly Trp Leu Leu Leu Gln
100 105 110
Ala Pro Arg Trp Val Phe Lys Glu Glu Asp Pro Ile His Leu Arg Cys
115 120 125
His Ser Trp Lys Asn Thr Ala Leu His Lys Val Thr Tyr Leu Gln Asn
130 135 140
Gly Lys Asp Arg Lys Tyr Phe His His Asn Ser Asp Phe His Ile Pro
145 150 155 160
Lys Ala Thr Leu Lys Asp Ser Gly Ser Tyr Phe Cys Arg Gly Leu Val
165 170 175
Gly Ser Lys Asn Val Ser Ser Glu Thr Val Asn Ile Thr Ile Thr Gln
180 185 190
Gly Leu Ala Val Ser Thr Ile Ser Ser Phe Ser Pro Pro Gly Tyr Gln
195 200 205
Val Ser Phe Cys Leu Val Met Val Leu Leu Phe Ala Val Asp Thr Gly
210 215 220
Leu Tyr Phe Ser Val Lys Thr Asn Ile
225 230
<210> 26
<211> 702
<212> DNA
<213> Homo sapiens
<400> 26
atgtggcagc tgctcctccc aactgctctg ctacttctag tttcagctgg catgcggact 60
gaagatctcc caaaggctgt ggtgttcctg gagcctcaat ggtacagcgt gcttgagaag 120
gacagtgtga ctctgaagtg ccagggagcc tactcccctg aggacaattc cacacagtgg 180
tttcacaatg agaacctcat ctcaagccag gcctcgagct acttcattga cgctgccaca 240
gtcaacgaca gtggagagta caggtgccag acaaacctct ccaccctcag tgacccggtg 300
cagctagaag tccatatcgg ctggctgttg ctccaggccc ctcggtgggt gttcaaggag 360
gaagacccta ttcacctgag gtgtcacagc tggaagaaca ctgctctgca taaggtcaca 420
tatttacaga atggcaaaga caggaagtat tttcatcata attctgactt ccacattcca 480
aaagccacac tcaaagatag cggctcctac ttctgcaggg ggcttgttgg gagtaaaaat 540
gtgtcttcag agactgtgaa catcaccatc actcaaggtt tggcagtgtc aaccatctca 600
tcattctctc cacctgggta ccaagtctct ttctgcttgg tgatggtact cctttttgca 660
gtggacacag gactatattt ctctgtgaag acaaacattt ga 702
<210> 27
<211> 304
<212> PRT
<213> Homo sapiens
<400> 27
Met Ser Leu Thr Val Val Ser Met Ala Cys Val Gly Phe Phe Leu Leu
1 5 10 15
Gln Gly Ala Trp Pro His Glu Gly Val His Arg Lys Pro Ser Leu Leu
20 25 30
Ala His Pro Gly Arg Leu Val Lys Ser Glu Glu Thr Val Ile Leu Gln
35 40 45
Cys Trp Ser Asp Val Met Phe Glu His Phe Leu Leu His Arg Glu Gly
50 55 60
Met Phe Asn Asp Thr Leu Arg Leu Ile Gly Glu His His Asp Gly Val
65 70 75 80
Ser Lys Ala Asn Phe Ser Ile Ser Arg Met Lys Gln Asp Leu Ala Gly
85 90 95
Thr Tyr Arg Cys Tyr Gly Ser Val Thr His Ser Pro Tyr Gln Val Ser
100 105 110
Ala Pro Ser Asp Pro Leu Asp Ile Val Ile Ile Gly Leu Tyr Glu Lys
115 120 125
Pro Ser Leu Ser Ala Gln Pro Gly Pro Thr Val Leu Ala Gly Glu Ser
130 135 140
Val Thr Leu Ser Cys Ser Ser Arg Ser Ser Tyr Asp Met Tyr His Leu
145 150 155 160
Ser Arg Glu Gly Glu Ala His Glu Arg Arg Leu Pro Ala Gly Thr Lys
165 170 175
Val Asn Gly Thr Phe Gln Ala Asn Phe Pro Leu Gly Pro Ala Thr His
180 185 190
Gly Gly Thr Tyr Arg Cys Phe Gly Ser Phe Arg Asp Ser Pro Tyr Glu
195 200 205
Trp Ser Lys Ser Ser Asp Pro Leu Leu Val Ser Val Thr Gly Asn Pro
210 215 220
Ser Asn Ser Trp Pro Ser Pro Thr Glu Pro Ser Ser Glu Thr Gly Asn
225 230 235 240
Pro Arg His Leu His Val Leu Ile Gly Thr Ser Val Val Lys Ile Pro
245 250 255
Phe Thr Ile Leu Leu Phe Phe Leu Leu His Arg Trp Cys Ser Asp Lys
260 265 270
Lys Asn Ala Ala Val Met Asp Gln Glu Pro Ala Gly Asn Arg Thr Val
275 280 285
Asn Ser Glu Asp Ser Asp Glu Gln Asp His Gln Glu Val Ser Tyr Ala
290 295 300
<210> 28
<211> 915
<212> DNA
<213> Homo sapiens
<400> 28
atgtcgctca cggtcgtcag catggcgtgt gttgggttct tcttgctgca gggggcctgg 60
ccacatgagg gagtccacag aaaaccttcc ctcctggccc acccaggtcg cctggtgaaa 120
tcagaagaga cagtcatcct gcaatgttgg tcagatgtca tgtttgaaca cttccttctg 180
cacagagagg ggatgtttaa cgacactttg cgcctcattg gagaacacca tgatggggtc 240
tccaaggcca acttctccat cagtcgcatg aagcaagacc tggcagggac ctacagatgc 300
tacggttctg ttactcactc cccctatcag ttgtcagctc ccagtgaccc tctggacatc 360
gtgatcatag gtctatatga gaaaccttct ctctcagccc agccgggccc cacggttctg 420
gcaggagaga atgtgacctt gtcctgcagc tcccggagct cctatgacat gtaccatcta 480
tccagggaag gggaggccca tgaacgtagg ctccctgcag ggaccaaggt caacggaaca 540
ttccaggcca actttcctct gggccctgcc acccatggag ggacctacag atgcttcggc 600
tctttccgtg actctccata cgagtggtca aagtcaagtg acccactgct tgtttctgtc 660
acaggaaacc cttcaaatag ttggccttca cccactgaac caagctccga aaccggtaac 720
cccagacacc tacatgttct gattgggacc tcagtggtca aaatcccttt caccatcctc 780
ctcttctttc tccttcatcg ctggtgctcc gacaaaaaaa atgctgctgt aatggaccaa 840
gagcctgcag ggaacagaac agtgaacagc gaggattctg atgaacaaga ccatcaggag 900
gtgtcatacg cataa 915
<210> 29
<211> 304
<212> PRT
<213> Homo sapiens
<400> 29
Met Ser Leu Met Val Val Ser Met Val Cys Val Gly Phe Phe Leu Leu
1 5 10 15
Gln Gly Ala Trp Pro His Glu Gly Val His Arg Lys Pro Ser Leu Leu
20 25 30
Ala His Pro Gly Pro Leu Val Lys Ser Glu Glu Thr Val Ile Leu Gln
35 40 45
Cys Trp Ser Asp Val Arg Phe Glu His Phe Leu Leu His Arg Glu Gly
50 55 60
Lys Tyr Lys Asp Thr Leu His Leu Ile Gly Glu His His Asp Gly Val
65 70 75 80
Ser Lys Ala Asn Phe Ser Ile Gly Pro Met Met Gln Asp Leu Ala Gly
85 90 95
Thr Tyr Arg Cys Tyr Gly Ser Val Thr His Ser Pro Tyr Gln Leu Ser
100 105 110
Ala Pro Ser Asp Pro Leu Asp Ile Val Ile Thr Gly Leu Tyr Glu Lys
115 120 125
Pro Ser Leu Ser Ala Gln Pro Gly Pro Thr Val Leu Ala Gly Glu Ser
130 135 140
Val Thr Leu Ser Cys Ser Ser Arg Ser Ser Tyr Asp Met Tyr His Leu
145 150 155 160
Ser Arg Glu Gly Glu Ala His Glu Arg Arg Phe Ser Ala Gly Pro Lys
165 170 175
Val Asn Gly Thr Phe Gln Ala Asp Phe Pro Leu Gly Pro Ala Thr His
180 185 190
Gly Gly Thr Tyr Arg Cys Phe Gly Ser Phe Arg Asp Ser Pro Tyr Glu
195 200 205
Trp Ser Asn Ser Ser Asp Pro Leu Leu Val Ser Val Thr Gly Asn Pro
210 215 220
Ser Asn Ser Trp Pro Ser Pro Thr Glu Pro Ser Ser Lys Thr Gly Asn
225 230 235 240
Pro Arg His Leu His Val Leu Ile Gly Thr Ser Val Val Lys Ile Pro
245 250 255
Phe Thr Ile Leu Leu Phe Phe Leu Leu His Arg Trp Cys Ser Asn Lys
260 265 270
Lys Asn Ala Ala Val Met Asp Gln Glu Pro Ala Gly Asn Arg Thr Val
275 280 285
Asn Ser Glu Asp Ser Asp Glu Gln Asp His Gln Glu Val Ser Tyr Ala
290 295 300
<210> 30
<211> 1026
<212> DNA
<213> Homo sapiens
<400> 30
atgtcgctca tggtcgtcag catggcgtgt gttgggttct tcttgctgca gggggcctgg 60
ccacatgagg gagtccacag aaaaccttcc ctcctggccc acccaggtcc cctggtgaaa 120
tcagaagaga cagtcatcct gcaatgttgg tcagatgtca ggtttgagca cttccttctg 180
cacagagagg ggaagtataa ggacactttg cacctcattg gagagcacca tgatggggtc 240
tccaaggcca acttctccat cggtcccatg atgcaagacc ttgcagggac ctacagatgc 300
tacggttctg ttactcactc cccctatcag ttgtcagctc ccagtgaccc tctggacatc 360
gtcatcacag gtctatatga gaaaccttct ctctcagccc agccgggccc cacggttttg 420
gcaggagaga gcgtgacctt gtcctgcagc tcccggagct cctatgacat gtaccatcta 480
tccagggagg gggaggccca tgaacgtagg ttctctgcag ggcccaaggt caacggaaca 540
ttccaggccg actttcctct gggccctgcc acccacggag gaacctacag atgcttcggc 600
tctttccgtg actctcccta tgagtggtca aactcgagtg acccactgct tgtttctgtc 660
acaggaaacc cttcaaatag ttggccttca cccactgaac caagctccaa aaccggtaac 720
cccagacacc tgcatgttct gattgggacc tcagtggtca aaatcccttt caccatcctc 780
ctcttctttc tccttcatcg ctggtgctcc aacaaaaaaa atgctgctgt aatggaccaa 840
gagcctgcag ggaacagaac agtgaacagc gaggactctg atgaacaaga ccctcaggag 900
gtgacataca cacagttgaa tcactgcgtt ttcacacaga gaaaaatcac tcgcccttct 960
cagaggccca agacaccccc aacagatatc atcgtgtaca cggaacttcc aaatgctgag 1020
tccaga 1026
<210> 31
<211> 304
<212> PRT
<213> Homo sapiens
<400> 31
Met Ser Leu Met Val Ile Ser Met Ala Cys Val Gly Phe Phe Trp Leu
1 5 10 15
Gln Gly Ala Trp Pro His Glu Gly Phe Arg Arg Lys Pro Ser Leu Leu
20 25 30
Ala His Pro Gly Arg Leu Val Lys Ser Glu Glu Thr Val Ile Leu Gln
35 40 45
Cys Trp Ser Asp Val Met Phe Glu His Phe Leu Leu His Arg Glu Gly
50 55 60
Thr Phe Asn Asp Thr Leu Arg Leu Ile Gly Glu His Ile Asp Gly Val
65 70 75 80
Ser Lys Ala Asn Phe Ser Ile Gly Arg Met Arg Gln Asp Leu Ala Gly
85 90 95
Thr Tyr Arg Cys Tyr Gly Ser Val Pro His Ser Pro Tyr Gln Phe Ser
100 105 110
Ala Pro Ser Asp Pro Leu Asp Ile Val Ile Thr Gly Leu Tyr Glu Lys
115 120 125
Pro Ser Leu Ser Ala Gln Pro Gly Pro Thr Val Leu Ala Gly Glu Ser
130 135 140
Val Thr Leu Ser Cys Ser Ser Trp Ser Ser Tyr Asp Met Tyr His Leu
145 150 155 160
Ser Thr Glu Gly Glu Ala His Glu Arg Arg Phe Ser Ala Gly Pro Lys
165 170 175
Val Asn Gly Thr Phe Gln Ala Asp Phe Pro Leu Gly Pro Ala Thr Gln
180 185 190
Gly Gly Thr Tyr Arg Cys Phe Gly Ser Phe His Asp Ser Pro Tyr Glu
195 200 205
Trp Ser Lys Ser Ser Asp Pro Leu Leu Val Ser Val Thr Gly Asn Pro
210 215 220
Ser Asn Ser Trp Pro Ser Pro Thr Glu Pro Ser Ser Lys Thr Gly Asn
225 230 235 240
Pro Arg His Leu His Val Leu Ile Gly Thr Ser Val Val Lys Leu Pro
245 250 255
Phe Thr Ile Leu Leu Phe Phe Leu Leu His Arg Trp Cys Ser Asp Lys
260 265 270
Lys Asn Ala Ser Val Met Asp Gln Gly Pro Ala Gly Asn Arg Thr Val
275 280 285
Asn Arg Glu Asp Ser Asp Glu Gln Asp His Gln Glu Val Ser Tyr Ala
290 295 300
<210> 32
<211> 915
<212> DNA
<213> Homo sapiens
<400> 32
atgtcgctca tggtcatcag catggcatgt gttgggttct tctggctgca gggggcctgg 60
ccacatgagg gattccgcag aaaaccttcc ctcctggccc acccaggtcg cctggtgaaa 120
tcagaagaga cagtcatcct gcaatgttgg tcagatgtca tgtttgagca cttccttctg 180
cacagagagg ggacgtttaa cgacactttg cgcctcattg gagagcacat tgatggggtc 240
tccaaggcca acttctccat cggtcgcatg aggcaagacc tggcagggac ctacagatgc 300
tacggttctg ttcctcactc cccctatcag ttttcagctc ccagtgaccc tctggacatc 360
gtgatcacag gtctatatga gaaaccttct ctctcagccc agccgggccc cacggttctg 420
gcaggagaga gcgtgacctt gtcctgcagc tcctggagct cctatgacat gtaccatcta 480
tccacggagg gggaggccca tgaacgtagg ttctctgcag ggcccaaggt caacggaaca 540
ttccaggccg actttcctct gggccctgcc acccaaggag gaacctacag atgcttcggc 600
tctttccatg actctcccta cgagtggtca aagtcaagtg acccactgct tgtttctgtc 660
acaggaaacc cttcaaatag ttggccttca cccactgaac caagctccaa aaccggtaac 720
cccagacacc tacacgttct gattgggacc tcagtggtca aactcccttt caccatcctc 780
ctcttctttc tccttcatcg ctggtgctcc gacaaaaaaa atgcatctgt aatggaccaa 840
gggcctgcgg ggaacagaac agtgaacagg gaggattctg atgaacagga ccatcaggag 900
gtgtcatacg cataa 915
<210> 33
<211> 354
<212> PRT
<213> Homo sapiens
<400> 33
His Val Gly Gly Gln Asp Lys Pro Phe Cys Ser Ala Trp Pro Ser Ala
1 5 10 15
Val Val Pro Gln Gly Gly His Ala Thr Leu Arg Cys His Cys Arg Arg
20 25 30
Gly Phe Asn Ile Phe Thr Leu Tyr Lys Lys Asp Gly Val Pro Val Pro
35 40 45
Glu Leu Tyr Asn Arg Ile Phe Trp Asn Ser Phe Leu Ile Ser Pro Val
50 55 60
Thr Pro Ala His Ala Gly Thr Tyr Arg Cys Arg Gly Phe His Pro His
65 70 75 80
Ser Pro Thr Glu Trp Ser Ala Pro Ser Asn Pro Leu Val Ile Met Val
85 90 95
Thr Gly Leu Tyr Glu Lys Pro Ser Leu Thr Ala Arg Pro Gly Pro Thr
100 105 110
Val Arg Ala Gly Glu Asn Val Thr Leu Ser Cys Ser Ser Gln Ser Ser
115 120 125
Phe Asp Ile Tyr His Leu Ser Arg Glu Gly Glu Ala His Glu Leu Arg
130 135 140
Leu Pro Ala Val Pro Ser Ile Asn Gly Thr Phe Gln Ala Asp Phe Pro
145 150 155 160
Leu Gly Pro Ala Thr His Gly Glu Thr Tyr Arg Cys Phe Gly Ser Phe
165 170 175
His Gly Ser Pro Tyr Glu Trp Ser Asp Pro Ser Asp Pro Leu Pro Val
180 185 190
Ser Val Thr Gly Asn Pro Ser Ser Ser Trp Pro Ser Pro Thr Glu Pro
195 200 205
Ser Phe Lys Thr Gly Ile Ala Arg His Leu His Ala Val Ile Arg Tyr
210 215 220
Ser Val Ala Ile Ile Leu Phe Thr Ile Leu Pro Phe Phe Leu Leu His
225 230 235 240
Arg Trp Cys Ser Lys Lys Lys Asn Ala Ala Val Met Asn Gln Glu Pro
245 250 255
Ala Gly His Arg Thr Val Asn Arg Glu Asp Ser Asp Glu Gln Asp Pro
260 265 270
Gln Glu Val Thr Tyr Ala Gln Leu Asp His Cys Ile Phe Thr Gln Arg
275 280 285
Lys Ile Thr Gly Pro Ser Gln Arg Ser Lys Arg Pro Ser Thr Asp Thr
290 295 300
Ser Val Cys Ile Glu Leu Pro Asn Ala Glu Pro Arg Ala Leu Ser Pro
305 310 315 320
Ala His Glu His His Ser Gln Ala Leu Met Gly Ser Ser Arg Glu Thr
325 330 335
Thr Ala Leu Ser Gln Thr Gln Leu Ala Ser Ser Asn Val Pro Ala Ala
340 345 350
Gly Ile
<210> 34
<211> 1251
<212> DNA
<213> Homo sapiens
<400> 34
atgtcccctt cacatgttgt ggtcaatgtg tcaactgcac gatccgggcc cctcaccaca 60
tcctctgcac cggtcagtcg agccgagtca ctgcgtcctg gcagcagaag ctgcaccatg 120
tccatgtcac ccacggtcat catcctggca tgtcttgggt tcttcttgga ccagagtgtg 180
tgggcacacg tgggtggtca ggacaagccc ttctgctctg cctggcccag cgctgtggtg 240
cctcaaggag gacacgtgac tcttcggtgt cactatcgtc gtgggtttaa catcttcacg 300
ctgtacaaga aagatggggt ccctgtccct gagctctaca acagaatatt ctggaacagt 360
ttcctcatta gccctgtgac cccagcacac gcagggacct acagatgtcg aggttttcac 420
ccgcactccc ccactgagtg gtcggcaccc agcaaccccc tggtgatcat ggtcacaggt 480
ctatatgaga aaccttcgct tacagcccgg ccgggcccca cggttcgcgc aggagagaac 540
gtgaccttgt cctgcagctc ccagagctcc tttgacatct accatctatc cagggagggg 600
gaagcccatg aacttaggct ccctgcagtg cccagcatca atggaacatt ccaggccgac 660
ttccctctgg gtcctgccac ccacggagag acctacagat gcttcggctc tttccatgga 720
tctccctacg agtggtcaga cccgagtgac ccactgcctg tttctgtcac aggaaaccct 780
tctagtagtt ggccttcacc cactgaacca agcttcaaaa ctggtatcgc cagacacctg 840
catgctgtga ttaggtactc agtggccatc atcctcttta ccatccttcc cttctttctc 900
cttcatcgct ggtgctccaa aaaaaaagat gctgctgtaa tgaaccaaga gcctgcggga 960
cacagaacag tgaacaggga ggactctgat gaacaagacc ctcaggaggt gacatacgca 1020
cagttggatc actgcatttt cacacagaga aaaatcactg gcccttctca gaggagcaag 1080
agaccctcaa cagataccag cgtgtgtata gaacttccaa atgctgagcc cagagcgttg 1140
tctcctgccc atgagcacca cagtcaggcc ttgatgggat cttctaggga gacaacagcc 1200
ctgtctcaaa cccagcttgc cagctctaat gtaccagcag ctggaatctg a 1251
<210> 35
<211> 218
<212> PRT
<213> Homo sapiens
<400> 35
Gln Glu Gly Val His Arg Lys Pro Ser Phe Leu Ala Leu Pro Gly His
1 5 10 15
Leu Val Lys Ser Glu Glu Thr Val Ile Leu Gln Cys Trp Ser Asp Val
20 25 30
Met Phe Glu His Phe Leu Leu His Arg Glu Gly Lys Phe Asn Asn Thr
35 40 45
Leu His Leu Ile Gly Glu His His Asp Gly Val Ser Lys Ala Asn Phe
50 55 60
Ser Ile Gly Pro Met Met Pro Val Leu Ala Gly Thr Tyr Arg Cys Tyr
65 70 75 80
Ser Ser Val Pro His Ser Pro Tyr Gln Leu Ser Ala Pro Ser Asp Pro
85 90 95
Leu Asp Met Val Ile Ile Gly Leu Tyr Glu Lys Pro Ser Leu Ser Ala
100 105 110
Gln Pro Gly Pro Thr Val Gln Ala Gly Glu Asn Val Ser Leu Ser Cys
115 120 125
Ser Ser Ile Tyr Pro Gly Arg Gly Arg Pro Met Asn Val Gly Ser Leu
130 135 140
Gln Cys Ala Ala Ser Thr Glu His Ser Arg Pro Thr Phe Leu Trp Ala
145 150 155 160
Leu Pro Pro Thr Glu Gly Pro Thr Asp Ala Ser Ala Leu Ser Val Thr
165 170 175
Leu Pro Thr Ser Gly Gln Thr Arg Val Ile His Cys Leu Phe Pro Ser
180 185 190
Gln Glu Thr Leu Gln Ile Val Gly Leu His Pro Leu Asn Gln Ala Pro
195 200 205
Lys Pro Val Thr Pro Asp Thr Tyr Met Phe
210 215
<210> 36
<211> 893
<212> DNA
<213> Homo sapiens
<400> 36
atgtcgctca tggtcatcat catggcgtgt gttgggttct tcttgctgca gggggcctgg 60
ccacaggagg gagtccacag aaaaccttcc ttcctggccc tcccaggtca cctggtgaaa 120
tcagaagaga cagtcatcct gcaatgttgg tcggatgtca tgtttgagca cttccttctg 180
cacagagagg ggaagtttaa caacactttg cacctcattg gagagcacca tgatggggtt 240
tccaaggcca acttctccat tggtcccatg atgcctgtcc ttgcaggaac ctacagatgc 300
tacggttctg ttcctcactc cccctatcag ttgtcagctc ccagtgaccc tctggacatg 360
gtgatcatag gtctatatga gaaaccttct ctctcagccc agccgggccc cacggttcag 420
gcaggagaga atgtgacctt gtcctgcagc tccatctatc cagggaaggg gaggcccatg 480
aacgtaggct ccctgcagtg cgcagcatca acggaacatt ccaggccgac tttcctctgg 540
gccctgccac ccacggaggg acctacagat gcttcggctc tttccgtgac gctccctacg 600
agtggtcaaa ctcgagtgat ccactgcttg tttccgtcac aggaaaccct tcaaatagtt 660
ggccttcacc cactgaacca agctccaaaa ccggtaaccc cagacaccta catgttctga 720
ttgggacctc agtggtcaaa atccctttca ccatcctcct cttctttctc cttcatcgct 780
ggtgctccga caaaaaaaat gctgctgtaa tggaccaaga gcctgcaggg aacagaacag 840
tgaacagcga ggattctgat gaacaagacc atcaggaggt gtcatacgca taa 893
<210> 37
<211> 283
<212> PRT
<213> Homo sapiens
<400> 37
His Glu Gly Phe Arg Arg Lys Pro Ser Leu Leu Ala His Pro Gly Pro
1 5 10 15
Leu Val Lys Ser Glu Glu Thr Val Ile Leu Gln Cys Trp Ser Asp Val
20 25 30
Met Phe Glu His Phe Leu Leu His Arg Glu Gly Thr Phe Asn His Thr
35 40 45
Leu Arg Leu Ile Gly Glu His Ile Asp Gly Val Ser Lys Gly Asn Phe
50 55 60
Ser Ile Gly Arg Met Thr Gln Asp Leu Ala Gly Thr Tyr Arg Cys Tyr
65 70 75 80
Gly Ser Val Thr His Ser Pro Tyr Gln Leu Ser Ala Pro Ser Asp Pro
85 90 95
Leu Asp Ile Val Ile Thr Gly Leu Tyr Glu Lys Pro Ser Leu Ser Ala
100 105 110
Gln Pro Gly Pro Thr Val Leu Ala Gly Glu Ser Val Thr Leu Ser Cys
115 120 125
Ser Ser Arg Ser Ser Tyr Asp Met Tyr His Leu Ser Arg Glu Gly Glu
130 135 140
Ala His Glu Arg Arg Leu Pro Ala Gly Thr Lys Val Asn Gly Thr Phe
145 150 155 160
Gln Ala Asp Phe Pro Leu Asp Pro Ala Thr His Gly Gly Thr Tyr Arg
165 170 175
Cys Phe Gly Ser Phe Arg Asp Ser Pro Tyr Glu Trp Ser Lys Ser Ser
180 185 190
Asp Pro Leu Leu Val Ser Val Thr Gly Asn Thr Ser Asn Ser Trp Pro
195 200 205
Ser Pro Thr Glu Pro Ser Ser Lys Thr Gly Asn Pro Arg His Leu His
210 215 220
Val Leu Ile Gly Thr Ser Val Val Lys Leu Pro Phe Thr Ile Leu Leu
225 230 235 240
Phe Phe Leu Leu His Arg Trp Cys Ser Asn Lys Lys Asn Ala Ser Val
245 250 255
Met Asp Gln Gly Pro Ala Gly Asn Arg Thr Val Asn Arg Glu Asp Ser
260 265 270
Asp Glu Gln Asp His Gln Glu Val Ser Tyr Ala
275 280
<210> 38
<211> 915
<212> DNA
<213> Homo sapiens
<400> 38
atgtcgctca tggtcatcag catggcgtgt gttgcgttct tcttgctgca gggggcctgg 60
ccacatgagg gattccgcag aaaaccttcc ctcctggccc acccaggtcc cctggtgaaa 120
tcagaagaga cagtcatcct gcaatgttgg tcagatgtca tgtttgagca cttccttctg 180
cacagagagg ggacgtttaa ccacactttg cgcctcattg gagagcacat tgatggggtc 240
tccaagggca acttctccat cggtcgcatg acacaagacc tggcagggac ctacagatgc 300
tacggttctg ttactcactc cccctatcag ttgtcagcgc ccagtgaccc tctggacatc 360
gtgatcacag gtctatatga gaaaccttct ctctcagccc agccgggccc cacggttctg 420
gcaggagaga gcgtgacctt gtcctgcagc tcccggagct cctatgacat gtaccatcta 480
tccagggaag gggaggccca tgaacgtagg ctccctgcag ggcccaaggt caacagaaca 540
ttccaggccg actttcctct ggaccctgcc acccacggag ggacctacag atgcttcggc 600
tctttccgtg actctccata cgagtggtca aagtcaagtg acccactgct tgtttctgtc 660
acaggaaact cttcaaatag ttggccttca cccactgaac caagctccga aaccggtaac 720
cccagacacc tacacgttct gattgggacc tcagtggtca aactcccttt caccatcctc 780
ctcttctttc tccttcatcg ctggtgctcc aacaaaaaaa atgcatctgt aatggaccaa 840
gggcctgcgg ggaacagaac agtgaacagg gaggattctg atgaacagga ccatcaggag 900
gtgtcatacg cataa 915
<210> 39
<211> 361
<212> PRT
<213> Homo sapiens
<400> 39
His Met Gly Gly Gln Asp Lys Pro Phe Leu Ser Ala Trp Pro Ser Ala
1 5 10 15
Val Val Pro Arg Gly Gly His Val Thr Leu Arg Cys His Tyr Arg His
20 25 30
Arg Phe Asn Asn Phe Met Leu Tyr Lys Glu Asp Arg Ile His Val Pro
35 40 45
Ile Phe His Gly Arg Ile Phe Gln Glu Gly Phe Asn Met Ser Pro Val
50 55 60
Thr Thr Ala His Ala Gly Asn Tyr Thr Cys Arg Gly Ser His Pro His
65 70 75 80
Ser Pro Thr Gly Trp Ser Ala Pro Ser Asn Pro Met Val Ile Met Val
85 90 95
Thr Gly Asn His Arg Lys Pro Ser Leu Leu Ala His Pro Gly Pro Leu
100 105 110
Val Lys Ser Gly Glu Arg Val Ile Leu Gln Cys Trp Ser Asp Ile Met
115 120 125
Phe Glu His Phe Phe Leu His Lys Glu Gly Ile Ser Lys Asp Pro Ser
130 135 140
Arg Leu Val Gly Gln Ile His Asp Gly Val Ser Lys Ala Asn Phe Ser
145 150 155 160
Ile Gly Ser Met Met Arg Ala Leu Ala Gly Thr Tyr Arg Cys Tyr Gly
165 170 175
Ser Val Thr His Thr Pro Tyr Gln Leu Ser Ala Pro Ser Asp Pro Leu
180 185 190
Asp Ile Val Val Thr Gly Leu Tyr Glu Lys Pro Ser Leu Ser Ala Gln
195 200 205
Pro Gly Pro Lys Val Gln Ala Gly Glu Ser Val Thr Leu Ser Cys Ser
210 215 220
Ser Arg Ser Ser Tyr Asp Met Tyr His Leu Ser Arg Glu Gly Gly Ala
225 230 235 240
His Glu Arg Arg Leu Pro Ala Val Arg Lys Val Asn Arg Thr Phe Gln
245 250 255
Ala Asp Phe Pro Leu Gly Pro Ala Thr His Gly Gly Thr Tyr Arg Cys
260 265 270
Phe Gly Ser Phe Arg His Ser Pro Tyr Glu Trp Ser Asp Pro Ser Asp
275 280 285
Pro Leu Leu Val Ser Val Thr Gly Asn Pro Ser Ser Ser Trp Pro Ser
290 295 300
Pro Thr Glu Pro Ser Ser Lys Ser Gly Asn Leu Arg His Leu His Ile
305 310 315 320
Leu Ile Gly Thr Ser Val Val Lys Ile Pro Phe Thr Ile Leu Leu Phe
325 330 335
Phe Leu Leu His Arg Trp Cys Ser Asn Lys Lys Lys Cys Cys Cys Asn
340 345 350
Gly Pro Arg Ala Cys Arg Glu Gln Lys
355 360
<210> 40
<211> 1149
<212> DNA
<213> Homo sapiens
<400> 40
atgttgctca tggtcgtcag catggcgtgt gttgggttgt tcttggtcca gagggccggt 60
ccacacatgg gtggtcagga caagcccttc ctgtctgcct ggcccagcgc tgtggtgcct 120
cgcggaggac acgtgactct tcggtgtcac tatcgtcata ggtttaacaa tttcatgcta 180
tacaaagaag acagaatcca cgttcccatc ttccatggca gaatattcca ggagggcttc 240
aacatgagcc ctgtgaccac agcacatgca gggaactaca catgtcgggg ttcacaccca 300
cactccccca ctgggtggtc ggcacccagc aaccccatgg tgatcatggt cacaggaaac 360
cacagaaaac cttccctcct ggcccaccca ggtcccctgg tgaaatcagg agagagagtc 420
atcctgcaat gttggtcaga tatcatgttt gagcacttct ttctgcacaa agagtggatc 480
tctaaggacc cctcacgcct cgttggacag atccatgatg gggtctccaa ggccaatttc 540
tccatcggtt ccatgatgcg tgcccttgca gggacctaca gatgctacgg ttctgttact 600
cacaccccct atcagttgtc agctcccagt gatcccctgg acatcgtggt cacaggtcta 660
tatgagaaac cttctctctc agcccagccg ggccccaagg ttcaggcagg agagagcgtg 720
accttgtcct gtagctcccg gagctcctat gacatgtacc atctatccag ggagggggga 780
gcccatgaac gtaggctccc tgcagtgcgc aaggtcaaca gaacattcca ggcagatttc 840
cctctgggcc ctgccaccca cggagggacc tacagatgct tcggctcttt ccgtcactct 900
ccctacgagt ggtcagaccc gagtgaccca ctgcttgttt ctgtcacagg aaacccttca 960
agtagttggc cttcacccac agaaccaagc tccaaatctg gtaacctcag acacctgcac 1020
attctgattg ggacctcagt ggtcaaaatc cctttcacca tcctcctctt ctttctcctt 1080
catcgctggt gctccaacaa aaaaaaatgc tgctgtaatg gaccaagagc ctgcagggaa 1140
cagaagtga 1149
<210> 41
<211> 231
<212> PRT
<213> Homo sapiens
<400> 41
Met Ser Lys Gln Arg Gly Thr Phe Ser Glu Val Ser Leu Ala Gln Asp
1 5 10 15
Pro Lys Arg Gln Gln Arg Lys Pro Lys Gly Asn Lys Ser Ser Ile Ser
20 25 30
Gly Thr Glu Gln Glu Ile Phe Gln Val Glu Leu Asn Leu Gln Asn Pro
35 40 45
Ser Leu Asn His Gln Gly Ile Asp Lys Ile Tyr Asp Cys Gln Gly Leu
50 55 60
Leu Pro Pro Pro Glu Lys Leu Thr Ala Glu Val Leu Gly Ile Ile Cys
65 70 75 80
Ile Val Leu Met Ala Thr Val Leu Lys Thr Ile Val Leu Ile Pro Phe
85 90 95
Leu Glu Gln Asn Asn Ser Ser Pro Asn Thr Arg Thr Gln Lys Ala Arg
100 105 110
His Cys Gly His Cys Pro Glu Glu Trp Ile Thr Tyr Ser Asn Ser Cys
115 120 125
Tyr Tyr Ile Gly Lys Glu Arg Arg Thr Trp Glu Glu Ser Leu Leu Ala
130 135 140
Cys Thr Ser Lys Asn Ser Ser Leu Leu Ser Ile Asp Asn Glu Glu Glu
145 150 155 160
Met Lys Phe Leu Ala Ser Ile Leu Pro Ser Ser Trp Ile Gly Val Phe
165 170 175
Arg Asn Ser Ser His His Pro Trp Val Thr Ile Asn Gly Leu Ala Phe
180 185 190
Lys His Lys Ile Lys Asp Ser Asp Asn Ala Glu Leu Asn Cys Ala Val
195 200 205
Leu Gln Val Asn Arg Leu Lys Ser Ala Gln Cys Gly Ser Ser Met Ile
210 215 220
Tyr His Cys Lys His Lys Leu
225 230
<210> 42
<211> 696
<212> DNA
<213> Homo sapiens
<400> 42
atgaataaac aaagaggaac cttctcagaa gtgagtctgg cccaggaccc aaagcggcag 60
caaaggaaac ctaaaggcaa taaaagctcc atttcaggaa ccgaacagga aatattccaa 120
gtagaattaa atcttcaaaa tccttccctg aatcatcaag ggattgataa aatatatgac 180
tgccaaggtt tactgccacc tccagagaag ctcactgccg aggtcctagg aatcatttgc 240
attgtcctga tggccactgt gttaaaaaca atagttctta ttcctttcct ggagcagaac 300
aatttttccc cgaatacaag aacgcagaaa gcacgtcatt gtggccattg tcctgaggag 360
tggattacat attccaacag ttgttattac attggtaagg aaagaagaac ttgggaagag 420
agtttgctgg cctgtacttc gaagaactcc agtctgcttt ctatagataa tgaagaagaa 480
atgaaatttc tggccagcat tttaccttcc tcatggattg gtgtgtttcg taacagcagt 540
catcatccat gggtgacaat aaatggtttg gctttcaaac ataagataaa agactcagat 600
aatgctgaac ttaactgtgc agtgctacaa gtaaatcgac ttaaatcagc ccagtgtgga 660
tcttcaatga tatatcattg taagcataag ctttag 696
<210> 43
<211> 354
<212> PRT
<213> Homo sapiens
<400> 43
Gln Asp Glu Val Thr Asp Asp Tyr Ile Gly Asp Asn Thr Thr Val Asp
1 5 10 15
Tyr Thr Leu Phe Glu Ser Leu Cys Ser Lys Lys Asp Val Arg Asn Phe
20 25 30
Lys Ala Trp Phe Leu Pro Ile Met Tyr Ser Ile Ile Cys Phe Val Gly
35 40 45
Leu Leu Gly Asn Gly Leu Val Val Leu Thr Tyr Ile Tyr Phe Lys Arg
50 55 60
Leu Lys Thr Met Thr Asp Thr Tyr Leu Leu Asn Leu Ala Val Ala Asp
65 70 75 80
Ile Leu Phe Leu Leu Thr Leu Pro Phe Trp Ala Tyr Ser Ala Ala Lys
85 90 95
Ser Trp Val Phe Gly Val His Phe Cys Lys Leu Ile Phe Ala Ile Tyr
100 105 110
Lys Met Ser Phe Phe Ser Gly Met Leu Leu Leu Leu Cys Ile Ser Ile
115 120 125
Asp Arg Tyr Val Ala Ile Val Gln Ala Val Ser Ala His Arg His Arg
130 135 140
Ala Arg Val Leu Leu Ile Ser Lys Leu Ser Cys Val Gly Ile Trp Ile
145 150 155 160
Leu Ala Thr Val Leu Ser Ile Pro Glu Leu Leu Tyr Ser Asp Leu Gln
165 170 175
Arg Ser Ser Ser Glu Gln Ala Met Arg Cys Ser Leu Ile Thr Glu His
180 185 190
Val Glu Ala Phe Ile Thr Ile Gln Val Ala Gln Met Val Ile Gly Phe
195 200 205
Leu Val Pro Leu Leu Ala Met Ser Phe Cys Tyr Leu Val Ile Ile Arg
210 215 220
Thr Leu Leu Gln Ala Arg Asn Phe Glu Arg Asn Lys Ala Ile Lys Val
225 230 235 240
Ile Ile Ala Val Val Val Val Phe Ile Val Phe Gln Leu Pro Tyr Asn
245 250 255
Gly Val Val Leu Ala Gln Thr Val Ala Asn Phe Asn Ile Thr Ser Ser
260 265 270
Thr Cys Glu Leu Ser Lys Gln Leu Asn Ile Ala Tyr Asp Val Thr Tyr
275 280 285
Ser Leu Ala Cys Val Arg Cys Cys Val Asn Pro Phe Leu Tyr Ala Phe
290 295 300
Ile Gly Val Lys Phe Arg Asn Asp Leu Phe Lys Leu Phe Lys Asp Leu
305 310 315 320
Gly Cys Leu Ser Gln Glu Gln Leu Arg Gln Trp Ser Ser Cys Arg His
325 330 335
Ile Arg Arg Ser Ser Met Ser Val Glu Ala Glu Thr Thr Thr Thr Phe
340 345 350
Ser Pro
<210> 44
<211> 1137
<212> DNA
<213> Homo sapiens
<400> 44
atggacctgg ggaaaccaat gaaaagcgtg ctggtggtgg ctctccttgt cattttccag 60
gtatgcctgt gtcaagatga ggtcacggac gattacatcg gagacaacac cacagtggac 120
tacactttgt tcgagtcttt gtgctccaag aaggacgtgc ggaactttaa agcctggttc 180
ctccctatca tgtactccat catttgtttc gtgggcctac tgggcaatgg gctggtcgtg 240
ttgacctata tctatttcaa gaggctcaag accatgaccg atacctacct gctcaacctg 300
gcggtggcag acatcctctt cctcctgacc cttcccttct gggcctacag cgcggccaag 360
tcctgggtct tcggtgtcca cttttgcaag ctcatctttg ccatctacaa gatgagcttc 420
ttcagtggca tgctcctact tctttgcatc agcattgacc gctacgtggc catcgtccag 480
gctgtctcag ctcaccgcca ccgtgcccgc gtccttctca tcagcaagct gtcctgtgtg 540
ggcatctgga tactagccac agtgctctcc atcccagagc tcctgtacag tgacctccag 600
aggagcagca gtgagcaagc gatgcgatgc tctctcatca cagagcatgt ggaggccttt 660
atcaccatcc aggtggccca gatggtgatc ggctttctgg tccccctgct ggccatgagc 720
ttctgttacc ttgtcatcat ccgcaccctg ctccaggcac gcaactttga gcgcaacaag 780
gccatcaagg tgatcatcgc tgtggtcgtg gtcttcatag tcttccagct gccctacaat 840
ggggtggtcc tggcccagac ggtggccaac ttcaacatca ccagtagcac ctgtgagctc 900
agtaagcaac tcaacatcgc ctacgacgtc acctacagcc tggcctgcgt ccgctgctgc 960
gtcaaccctt tcttgtacgc cttcatcggc gtcaagttcc gcaacgatct cttcaagctc 1020
ttcaaggacc tgggctgcct cagccaggag cagctccggc agtggtcttc ctgtcggcac 1080
atccggcgct cctccatgag tgtggaggcc gagaccacca ccaccttctc cccatag 1137
<210> 45
<211> 368
<212> PRT
<213> Homo sapiens
<400> 45
Met Val Leu Glu Val Ser Asp His Gln Val Leu Asn Asp Ala Glu Val
1 5 10 15
Ala Ala Leu Leu Glu Asn Phe Ser Ser Ser Tyr Asp Tyr Gly Glu Asn
20 25 30
Glu Ser Asp Ser Cys Cys Thr Ser Pro Pro Cys Pro Gln Asp Phe Ser
35 40 45
Leu Asn Phe Asp Arg Ala Phe Leu Pro Ala Leu Tyr Ser Leu Leu Phe
50 55 60
Leu Leu Gly Leu Leu Gly Asn Gly Ala Val Ala Ala Val Leu Leu Ser
65 70 75 80
Arg Arg Thr Ala Leu Ser Ser Thr Asp Thr Phe Leu Leu His Leu Ala
85 90 95
Val Ala Asp Thr Leu Leu Val Leu Thr Leu Pro Leu Trp Ala Val Asp
100 105 110
Ala Ala Val Gln Trp Val Phe Gly Ser Gly Leu Cys Lys Val Ala Gly
115 120 125
Ala Leu Phe Asn Ile Asn Phe Tyr Ala Gly Ala Leu Leu Leu Ala Cys
130 135 140
Ile Ser Phe Asp Arg Tyr Leu Asn Ile Val His Ala Thr Gln Leu Tyr
145 150 155 160
Arg Arg Gly Pro Pro Ala Arg Val Thr Leu Thr Cys Leu Ala Val Trp
165 170 175
Gly Leu Cys Leu Leu Phe Ala Leu Pro Asp Phe Ile Phe Leu Ser Ala
180 185 190
His His Asp Glu Arg Leu Asn Ala Thr His Cys Gln Tyr Asn Phe Pro
195 200 205
Gln Val Gly Arg Thr Ala Leu Arg Val Leu Gln Leu Val Ala Gly Phe
210 215 220
Leu Leu Pro Leu Leu Val Met Ala Tyr Cys Tyr Ala His Ile Leu Ala
225 230 235 240
Val Leu Leu Val Ser Arg Gly Gln Arg Arg Leu Arg Ala Met Arg Leu
245 250 255
Val Val Val Val Val Val Ala Phe Ala Leu Cys Trp Thr Pro Tyr His
260 265 270
Leu Val Val Leu Val Asp Ile Leu Met Asp Leu Gly Ala Leu Ala Arg
275 280 285
Asn Cys Gly Arg Glu Ser Arg Val Asp Val Ala Lys Ser Val Thr Ser
290 295 300
Gly Leu Gly Tyr Met His Cys Cys Leu Asn Pro Leu Leu Tyr Ala Phe
305 310 315 320
Val Gly Val Lys Phe Arg Glu Arg Met Trp Met Leu Leu Leu Arg Leu
325 330 335
Gly Cys Pro Asn Gln Arg Gly Leu Gln Arg Gln Pro Ser Ser Ser Arg
340 345 350
Arg Asp Ser Ser Trp Ser Glu Thr Ser Glu Ala Ser Tyr Ser Gly Leu
355 360 365
<210> 46
<211> 1248
<212> DNA
<213> Homo sapiens
<400> 46
atggagttga ggaagtacgg ccctggaaga ctggcgggga cagttatagg aggagctgct 60
cagagtaaat cacagactaa atcagactca atcacaaaag agttcctgcc aggcctttac 120
acagcccctt cctccccgtt cccgccctca caggtgagtg accaccaagt gctaaatgac 180
gccgaggttg ccgccctcct ggagaacttc agctcttcct atgactatgg agaaaacgag 240
agtgactcgt gctgtacctc cccgccctgc ccacaggact tcagcctgaa cttcgaccgg 300
gccttcctgc cagccctcta cagcctcctc tttctgctgg ggctgctggg caacggcgcg 360
gtggcagccg tgctgctgag ccggcggaca gccctgagca gcaccgacac cttcctgctc 420
cacctagctg tagcagacac gctgctggtg ctgacactgc cgctctgggc agtggacgct 480
gccgtccagt gggtctttgg ctctggcctc tgcaaagtgg caggtgccct cttcaacatc 540
aacttctacg caggagccct cctgctggcc tgcatcagct ttgaccgcta cctgaacata 600
gttcatgcca cccagctcta ccgccggggg cccccggccc gcgtgaccct cacctgcctg 660
gctgtctggg ggctctgcct gcttttcgcc ctcccagact tcatcttcct gtcggcccac 720
cacgacgagc gcctcaacgc cacccactgc caatacaact tcccacaggt gggccgcacg 780
gctctgcggg tgctgcagct ggtggctggc tttctgctgc ccctgctggt catggcctac 840
tgctatgccc acatcctggc cgtgctgctg gtttccaggg gccagcggcg cctgcgggcc 900
atgcggctgg tggtggtggt cgtggtggcc tttgccctct gctggacccc ctatcacctg 960
gtggtgctgg tggacatcct catggacctg ggcgctttgg cccgcaactg tggccgagaa 1020
agcagggtag acgtggccaa gtcggtcacc tcaggcctgg gctacatgca ctgctgcctc 1080
aacccgctgc tctatgcctt tgtaggggtc aagttccggg agcggatgtg gatgctgctc 1140
ttgcgcctgg gctgccccaa ccagagaggg ctccagaggc agccatcgtc ttcccgccgg 1200
gattcatcct ggtctgagac ctcagaggcc tcctactcgg gcttgtga 1248
<210> 47
<211> 344
<212> PRT
<213> Homo sapiens
<400> 47
Asp Phe Leu Ala His His Gly Thr Asp Cys Trp Thr Tyr His Tyr Ser
1 5 10 15
Glu Lys Pro Met Asn Trp Gln Arg Ala Arg Arg Phe Cys Arg Asp Asn
20 25 30
Tyr Thr Asp Leu Val Ala Ile Gln Asn Lys Ala Glu Ile Glu Tyr Leu
35 40 45
Glu Lys Thr Leu Pro Phe Ser Arg Ser Tyr Tyr Trp Ile Gly Ile Arg
50 55 60
Lys Ile Gly Gly Ile Trp Thr Trp Val Gly Thr Asn Lys Ser Leu Thr
65 70 75 80
Glu Glu Ala Glu Asn Trp Gly Asp Gly Glu Pro Asn Asn Lys Lys Asn
85 90 95
Lys Glu Asp Cys Val Glu Ile Tyr Ile Lys Arg Asn Lys Asp Ala Gly
100 105 110
Lys Trp Asn Asp Asp Ala Cys His Lys Leu Lys Ala Ala Leu Cys Tyr
115 120 125
Thr Ala Ser Cys Gln Pro Trp Ser Cys Ser Gly His Gly Glu Cys Val
130 135 140
Glu Ile Ile Asn Asn Tyr Thr Cys Asn Cys Asp Val Gly Tyr Tyr Gly
145 150 155 160
Pro Gln Cys Gln Phe Val Ile Gln Cys Glu Pro Leu Glu Ala Pro Glu
165 170 175
Leu Gly Thr Met Asp Cys Thr His Pro Leu Gly Asn Phe Ser Phe Ser
180 185 190
Ser Gln Cys Ala Phe Ser Cys Ser Glu Gly Thr Asn Leu Thr Gly Ile
195 200 205
Glu Glu Thr Thr Cys Gly Pro Phe Gly Asn Trp Ser Ser Pro Glu Pro
210 215 220
Thr Cys Gln Val Ile Gln Cys Glu Pro Leu Ser Ala Pro Asp Leu Gly
225 230 235 240
Ile Met Asn Cys Ser His Pro Leu Ala Ser Phe Ser Phe Thr Ser Ala
245 250 255
Cys Thr Phe Ile Cys Ser Glu Gly Thr Glu Leu Ile Gly Lys Lys Lys
260 265 270
Thr Ile Cys Glu Ser Ser Gly Ile Trp Ser Asn Pro Ser Pro Ile Cys
275 280 285
Gln Lys Leu Asp Lys Ser Phe Ser Met Ile Lys Glu Gly Asp Tyr Asn
290 295 300
Pro Leu Phe Ile Pro Val Ala Val Met Val Thr Ala Phe Ser Gly Leu
305 310 315 320
Ala Phe Ile Ile Trp Leu Ala Arg Arg Leu Lys Lys Gly Lys Lys Ser
325 330 335
Lys Arg Ser Met Asn Asp Pro Tyr
340
<210> 48
<211> 1158
<212> DNA
<213> Homo sapiens
<400> 48
atgggctgca gaagaactag agaaggacca agcaaagcca tgatatttcc atggaaatgt 60
cagagcaccc agagggactt atggaacatc ttcaagttgt gggggtggac aatgctctgt 120
tgtgatttcc tggcacatca tggaaccgac tgctggactt accattattc tgaaaaaccc 180
atgaactggc aaagggctag aagattctgc cgagacaatt acacagattt agttgccata 240
caaaacaagg cggaaattga gtatctggag aagactctgc ctttcagtcg ttcttactac 300
tggataggaa tccggaagat aggaggaata tggacgtggg tgggaaccaa caaatctctt 360
actgaagaag cagagaactg gggagatggt gagcccaaca acaagaagaa caaggaggac 420
tgcgtggaga tctatatcaa gagaaacaaa gatgcaggca aatggaacga tgacgcctgc 480
cacaaactaa aggcagccct ctgttacaca gcttcttgcc agccctggtc atgcagtggc 540
catggagaat gtgtagaaat catcaataat tacacctgca actgtgatgt ggggtactat 600
gggccccagt gtcagtttgt gattcagtgt gagcctttgg aggccccaga gctgggtacc 660
atggactgta ctcacccttt gggaaacttc agcttcagct cacagtgtgc cttcagctgc 720
tctgaaggaa caaacttaac tgggattgaa gaaaccacct gtggaccatt tggaaactgg 780
tcatctccag aaccaacctg tcaagtgatt cagtgtgagc ctctatcagc accagatttg 840
gggatcatga actgtagcca tcccctggcc agcttcagct ttacctctgc atgtaccttc 900
atctgctcag aaggaactga gttaattggg aagaagaaaa ccatttgtga atcatctgga 960
atctggtcaa atcctagtcc aatatgtcaa aaattggaca aaagtttctc aatgattaag 1020
gagggtgatt ataaccccct cttcattcca gtggcagtca tggttactgc attctctggg 1080
ttggcattta tcatttggct ggcaaggaga ttaaaaaaag gcaagaaatc caagagaagt 1140
atgaatgacc catattaa 1158
<210> 49
<211> 350
<212> PRT
<213> Homo sapiens
<220>
<221> MOD_RES
<222> (31)..(31)
<223> Any amino acid
<400> 49
Met Ser Asn Ile Thr Asp Pro Gln Met Trp Asp Phe Asp Asp Leu Asn
1 5 10 15
Phe Thr Gly Met Pro Pro Ala Asp Glu Asp Tyr Ser Pro Cys Xaa Leu
20 25 30
Glu Thr Glu Thr Leu Asn Lys Tyr Val Val Ile Ile Ala Tyr Ala Leu
35 40 45
Val Phe Leu Leu Ser Leu Leu Gly Asn Ser Leu Val Met Leu Val Ile
50 55 60
Leu Tyr Ser Arg Val Gly Arg Ser Val Thr Asp Val Tyr Leu Leu Asn
65 70 75 80
Leu Ala Leu Ala Asp Leu Leu Phe Ala Leu Thr Leu Pro Ile Trp Ala
85 90 95
Ala Ser Lys Val Asn Gly Trp Ile Phe Gly Thr Phe Leu Cys Lys Val
100 105 110
Val Ser Leu Leu Lys Glu Val Asn Phe Tyr Ser Gly Ile Leu Leu Leu
115 120 125
Ala Cys Ile Ser Val Asp Arg Tyr Leu Ala Ile Val His Ala Thr Arg
130 135 140
Thr Leu Thr Gln Lys Arg His Leu Val Lys Phe Val Cys Leu Gly Cys
145 150 155 160
Trp Gly Leu Ser Met Asn Leu Ser Leu Pro Phe Phe Leu Phe Arg Gln
165 170 175
Ala Tyr His Pro Asn Asn Ser Ser Pro Val Cys Tyr Glu Val Leu Gly
180 185 190
Asn Asp Thr Ala Lys Trp Arg Met Val Leu Arg Ile Leu Pro His Thr
195 200 205
Phe Gly Phe Ile Val Pro Leu Phe Val Met Leu Phe Cys Tyr Gly Phe
210 215 220
Thr Leu Arg Thr Leu Phe Lys Ala His Met Gly Gln Lys His Arg Ala
225 230 235 240
Met Arg Val Ile Phe Ala Val Val Leu Ile Phe Leu Leu Cys Trp Leu
245 250 255
Pro Tyr Asn Leu Val Leu Leu Ala Asp Thr Leu Met Arg Thr Gln Val
260 265 270
Ile Gln Glu Ser Cys Glu Arg Arg Asn Asn Ile Gly Arg Ala Leu Asp
275 280 285
Ala Thr Glu Ile Leu Gly Phe Leu His Ser Cys Leu Asn Pro Ile Ile
290 295 300
Tyr Ala Phe Ile Gly Gln Asn Phe Arg His Gly Phe Leu Lys Ile Leu
305 310 315 320
Ala Met His Gly Leu Val Ser Lys Glu Phe Leu Ala Arg His Arg Val
325 330 335
Thr Ser Tyr Thr Ser Ser Ser Val Asn Val Ser Ser Asn Leu
340 345 350
<210> 50
<211> 1053
<212> DNA
<213> Homo sapiens
<400> 50
atgtcaaata ttacagatcc acagatgtgg gattttgatg atctaaattt cactggcatg 60
ccacctgcag atgaagatta cagcccctgt atgctagaaa ctgagacact caacaagtat 120
gttgtgatca tcgcctatgc cctagtgttc ctgctgagcc tgctgggaaa ctccctggtg 180
atgctggtca tcttatacag cagggtcggc cgctccgtca ctgatgtcta cctgctgaac 240
ctggccttgg ccgacctact ctttgccctg accttgccca tctgggccgc ctccaaggtg 300
aatggctgga tttttggcac attcctgtgc aaggtggtct cactcctgaa ggaagtcaac 360
ttctacagtg gcatcctgct gttggcctgc atcagtgtgg accgttacct ggccattgtc 420
catgccacac gcacactgac ccagaagcgt cacttggtca agtttgtttg tcttggctgc 480
tggggactgt ctatgaatct gtccctgccc ttcttccttt tccgccaggc ttaccatcca 540
aacaattcca gtccagtttg ctatgaggtc ctgggaaatg acacagcaaa atggcggatg 600
gtgttgcgga tcctgcctca cacctttggc ttcatcgtgc cgctgtttgt catgctgttc 660
tgctatggat tcaccctgcg tacactgttt aaggcccaca tggggcagaa gcaccgagcc 720
atgagggtca tctttgctgt cgtcctcatc ttcctgcttt gctggctgcc ctacaacctg 780
gtcctgctgg cagacaccct catgaggacc caggtgatcc aggagagctg tgagcgccgc 840
aacaacatcg gccgggccct ggatgccact gagattctgg gatttctcca tagctgcctc 900
aaccccatca tctacgcctt catcggccaa aattttcgcc atggattcct caagatcctg 960
gctatgcatg gcctggtcag caaggagttc ttggcacgtc atcgtgttac ctcctacact 1020
tcttcgtctg tcaatgtctc ttccaacctc tga 1053
<210> 51
<211> 360
<212> PRT
<213> Homo sapiens
<400> 51
Met Glu Asp Phe Asn Met Glu Ser Asp Ser Phe Glu Asp Phe Trp Lys
1 5 10 15
Gly Glu Asp Leu Ser Asn Tyr Ser Tyr Ser Ser Thr Leu Pro Pro Phe
20 25 30
Leu Leu Asp Ala Ala Pro Cys Glu Pro Glu Ser Leu Glu Ile Asn Lys
35 40 45
Tyr Phe Val Val Ile Ile Tyr Ala Leu Val Phe Leu Leu Ser Leu Leu
50 55 60
Gly Asn Ser Leu Val Met Leu Val Ile Leu Tyr Ser Arg Val Gly Arg
65 70 75 80
Ser Val Thr Asp Val Tyr Leu Leu Asn Leu Ala Leu Ala Asp Leu Leu
85 90 95
Phe Ala Leu Thr Leu Pro Ile Trp Ala Ala Ser Lys Val Asn Gly Trp
100 105 110
Ile Phe Gly Thr Phe Leu Cys Lys Val Val Ser Leu Leu Lys Glu Val
115 120 125
Asn Phe Tyr Ser Gly Ile Leu Leu Leu Ala Cys Ile Ser Val Asp Arg
130 135 140
Tyr Leu Ala Ile Val His Ala Thr Arg Thr Leu Thr Gln Lys Arg Tyr
145 150 155 160
Leu Val Lys Phe Ile Cys Leu Ser Ile Trp Gly Leu Ser Leu Leu Leu
165 170 175
Ala Leu Pro Val Leu Leu Phe Arg Arg Thr Val Tyr Ser Ser Asn Val
180 185 190
Ser Pro Ala Cys Tyr Glu Asp Met Gly Asn Asn Thr Ala Asn Trp Arg
195 200 205
Met Leu Leu Arg Ile Leu Pro Gln Ser Phe Gly Phe Ile Val Pro Leu
210 215 220
Leu Ile Met Leu Phe Cys Tyr Gly Phe Thr Leu Arg Thr Leu Phe Lys
225 230 235 240
Ala His Met Gly Gln Lys His Arg Ala Met Arg Val Ile Phe Ala Val
245 250 255
Val Leu Ile Phe Leu Leu Cys Trp Leu Pro Tyr Asn Leu Val Leu Leu
260 265 270
Ala Asp Thr Leu Met Arg Thr Gln Val Ile Gln Glu Thr Cys Glu Arg
275 280 285
Arg Asn His Ile Asp Arg Ala Leu Asp Ala Thr Glu Ile Leu Gly Ile
290 295 300
Leu His Ser Cys Leu Asn Pro Leu Ile Tyr Ala Phe Ile Gly Gln Lys
305 310 315 320
Phe Arg His Gly Leu Leu Lys Ile Leu Ala Ile His Gly Leu Ile Ser
325 330 335
Lys Asp Ser Leu Pro Lys Asp Ser Arg Pro Ser Phe Val Gly Ser Ser
340 345 350
Ser Gly His Thr Ser Thr Thr Leu
355 360
<210> 52
<211> 1083
<212> DNA
<213> Homo sapiens
<400> 52
atggaagatt ttaacatgga gagtgacagc tttgaagatt tctggaaagg tgaagatctt 60
agtaattaca gttacagctc taccctgccc ccttttctac tagatgccgc cccatgtgaa 120
ccagaatccc tggaaatcaa caagtatttt gtggtcatta tctatgccct ggtattcctg 180
ctgagcctgc tgggaaactc cctcgtgatg ctggtcatct tatacagcag ggtcggccgc 240
tccgtcactg atgtctacct gctgaaccta gccttggccg acctactctt tgccctgacc 300
ttgcccatct gggccgcctc caaggtgaat ggctggattt ttggcacatt cctgtgcaag 360
gtggtctcac tcctgaagga agtcaacttc tatagtggca tcctgctact ggcctgcatc 420
agtgtggacc gttacctggc cattgtccat gccacacgca cactgaccca gaagcgctac 480
ttggtcaaat tcatatgtct cagcatctgg ggtctgtcct tgctcctggc cctgcctgtc 540
ttacttttcc gaaggaccgt ctactcatcc aatgttagcc cagcctgcta tgaggacatg 600
ggcaacaata cagcaaactg gcggatgctg ttacggatcc tgccccagtc ctttggcttc 660
atcgtgccac tgctgatcat gctgttctgc tacggattca ccctgcgtac gctgtttaag 720
gcccacatgg ggcagaagca ccgggccatg cgggtcatct ttgctgtcgt cctcatcttc 780
ctgctctgct ggctgcccta caacctggtc ctgctggcag acaccctcat gaggacccag 840
gtgatccagg agacctgtga gcgccgcaat cacatcgacc gggctctgga tgccaccgag 900
attctgggca tccttcacag ctgcctcaac cccctcatct acgccttcat tggccagaag 960
tttcgccatg gactcctcaa gattctagct atacatggct tgatcagcaa ggactccctg 1020
cccaaagaca gcaggccttc ctttgttggc tcttcttcag ggcacacttc cactactctc 1080
taa 1083
<210> 53
<211> 355
<212> PRT
<213> Homo sapiens
<400> 53
Met Asp Gln Phe Pro Glu Ser Val Thr Glu Asn Phe Glu Tyr Asp Asp
1 5 10 15
Leu Ala Glu Ala Cys Tyr Ile Gly Asp Ile Val Val Phe Gly Thr Val
20 25 30
Phe Leu Ser Ile Phe Tyr Ser Val Ile Phe Ala Ile Gly Leu Val Gly
35 40 45
Asn Leu Leu Val Val Phe Ala Leu Thr Asn Ser Lys Lys Pro Lys Ser
50 55 60
Val Thr Asp Ile Tyr Leu Leu Asn Leu Ala Leu Ser Asp Leu Leu Phe
65 70 75 80
Val Ala Thr Leu Pro Phe Trp Thr His Tyr Leu Ile Asn Glu Lys Gly
85 90 95
Leu His Asn Ala Met Cys Lys Phe Thr Thr Ala Phe Phe Phe Ile Gly
100 105 110
Phe Phe Gly Ser Ile Phe Phe Ile Thr Val Ile Ser Ile Asp Arg Tyr
115 120 125
Leu Ala Ile Val Leu Ala Ala Asn Ser Met Asn Asn Arg Thr Val Gln
130 135 140
His Gly Val Thr Ile Ser Leu Gly Val Trp Ala Ala Ala Ile Leu Val
145 150 155 160
Ala Ala Pro Gln Phe Met Phe Thr Lys Gln Lys Glu Asn Glu Cys Leu
165 170 175
Gly Asp Tyr Pro Glu Val Leu Gln Glu Ile Trp Pro Val Leu Arg Asn
180 185 190
Val Glu Thr Asn Phe Leu Gly Phe Leu Leu Pro Leu Leu Ile Met Ser
195 200 205
Tyr Cys Tyr Phe Arg Ile Ile Gln Thr Leu Phe Ser Cys Lys Asn His
210 215 220
Lys Lys Ala Lys Ala Ile Lys Leu Ile Leu Leu Val Val Ile Val Phe
225 230 235 240
Phe Leu Phe Trp Thr Pro Tyr Asn Val Met Ile Phe Leu Glu Thr Leu
245 250 255
Lys Leu Tyr Asp Phe Phe Pro Ser Cys Asp Met Arg Lys Asp Leu Arg
260 265 270
Leu Ala Leu Ser Val Thr Glu Thr Val Ala Phe Ser His Cys Cys Leu
275 280 285
Asn Pro Leu Ile Tyr Ala Phe Ala Gly Glu Lys Phe Arg Arg Tyr Leu
290 295 300
Tyr His Leu Tyr Gly Lys Cys Leu Ala Val Leu Cys Gly Arg Ser Val
305 310 315 320
His Val Asp Phe Ser Ser Ser Glu Ser Gln Arg Ser Arg His Gly Ser
325 330 335
Val Leu Ser Ser Asn Phe Thr Tyr His Thr Ser Asp Gly Asp Ala Leu
340 345 350
Leu Leu Leu
355
<210> 54
<211> 1068
<212> DNA
<213> Homo sapiens
<400> 54
atggatcagt tccctgaatc agtgacagaa aactttgagt acgatgattt ggctgaggcc 60
tgttatattg gggacatcgt ggtctttggg actgtgttcc tgtccatatt ctactccgtc 120
atctttgcca ttggcctggt gggaaatttg ttggtagtgt ttgccctcac caacagcaag 180
aagcccaaga gtgtcaccga catttacctc ctgaacctgg ccttgtctga tctgctgttt 240
gtagccactt tgcccttctg gactcactat ttgataaatg aaaagggcct ccacaatgcc 300
atgtgcaaat tcactaccgc cttcttcttc atcggctttt ttggaagcat attcttcatc 360
accgtcatca gcattgatag gtacctggcc atcgtcctgg ccgccaactc catgaacaac 420
cggaccgtgc agcatggcgt caccatcagc ctaggcgtct gggcagcagc cattttggtg 480
gcagcacccc agttcatgtt cacaaagcag aaagaaaatg aatgccttgg tgactacccc 540
gaggtcctcc aggaaatctg gcccgtgctc cgcaatgtgg aaacaaattt tcttggcttc 600
ctactccccc tgctcattat gagttattgc tacttcagaa tcatccagac gctgttttcc 660
tgcaagaacc acaagaaagc caaagccatt aaactgatcc ttctggtggt catcgtgttt 720
ttcctcttct ggacacccta caacgttatg attttcctgg agacgcttaa gctctatgac 780
ttctttccca gttgtgacat gaggaaggat ctgaggctgg ccctcagtgt gactgagacg 840
gttgcattta gccattgttg cctgaatcct ctcatctatg catttgctgg ggagaagttc 900
agaagatacc tttaccacct gtatgggaaa tgcctggctg tcctgtgtgg gcgctcagtc 960
cacgttgatt tctcctcatc tgaatcacaa aggagcaggc atggaagtgt tctgagcagc 1020
aattttactt accacacgag tgatggagat gcattgctcc ttctctga 1068
<210> 55
<211> 373
<212> PRT
<213> Homo sapiens
<400> 55
Met Arg Met Glu Asp Glu Asp Tyr Asn Thr Ser Ile Ser Tyr Gly Asp
1 5 10 15
Glu Tyr Pro Asp Tyr Leu Asp Ser Ile Val Val Leu Glu Asp Leu Ser
20 25 30
Pro Leu Glu Ala Arg Val Thr Arg Ile Phe Leu Val Val Val Tyr Ser
35 40 45
Ile Val Cys Phe Leu Gly Ile Leu Gly Asn Gly Leu Val Ile Ile Ile
50 55 60
Ala Thr Phe Lys Met Lys Lys Thr Val Asn Met Val Trp Phe Leu Asn
65 70 75 80
Leu Ala Val Ala Asp Phe Leu Phe Asn Val Phe Leu Pro Ile His Ile
85 90 95
Thr Tyr Ala Ala Met Asp Tyr His Trp Val Phe Gly Thr Ala Met Cys
100 105 110
Lys Ile Ser Asn Phe Leu Leu Ile His Asn Met Phe Thr Ser Val Phe
115 120 125
Leu Leu Thr Ile Ile Ser Ser Asp Arg Cys Ile Ser Val Leu Leu Pro
130 135 140
Val Trp Ser Gln Asn His Arg Ser Val Arg Leu Ala Tyr Met Ala Cys
145 150 155 160
Met Val Ile Trp Val Leu Ala Phe Phe Leu Ser Ser Pro Ser Leu Val
165 170 175
Phe Arg Asp Thr Ala Asn Leu His Gly Lys Ile Ser Cys Phe Asn Asn
180 185 190
Phe Ser Leu Ser Thr Pro Gly Ser Ser Ser Trp Pro Thr His Ser Gln
195 200 205
Met Asp Pro Val Gly Tyr Ser Arg His Met Val Val Thr Val Thr Arg
210 215 220
Phe Leu Cys Gly Phe Leu Val Pro Val Leu Ile Ile Thr Ala Cys Tyr
225 230 235 240
Leu Thr Ile Val Cys Lys Leu Gln Arg Asn Arg Leu Ala Lys Thr Lys
245 250 255
Lys Pro Phe Lys Ile Ile Val Thr Ile Ile Ile Thr Phe Phe Leu Cys
260 265 270
Trp Cys Pro Tyr His Thr Leu Asn Leu Leu Glu Leu His His Thr Ala
275 280 285
Met Pro Gly Ser Val Phe Ser Leu Gly Leu Pro Leu Ala Thr Ala Leu
290 295 300
Ala Ile Ala Asn Ser Cys Met Asn Pro Ile Leu Tyr Val Phe Met Gly
305 310 315 320
Gln Asp Phe Lys Lys Phe Lys Val Ala Leu Phe Ser Arg Leu Val Asn
325 330 335
Ala Leu Ser Glu Asp Thr Gly His Ser Ser Tyr Pro Ser His Arg Ser
340 345 350
Phe Thr Lys Met Ser Ser Met Asn Glu Arg Thr Ser Met Asn Glu Arg
355 360 365
Glu Thr Gly Met Leu
370
<210> 56
<211> 1122
<212> DNA
<213> Homo sapiens
<400> 56
atgagaatgg aggatgaaga ttacaacact tccatcagtt acggtgatga ataccctgat 60
tatttagact ccattgtggt tttggaggac ttatccccct tggaagccag ggtgaccagg 120
atcttcctgg tggtggtcta cagcatcgtc tgcttcctcg ggattctggg caatggtctg 180
gtgatcatca ttgccacctt caagatgaag aagacagtga acatggtctg gttcctcaac 240
ctggcagtgg cagatttcct gttcaacgtc ttcctcccaa tccatatcac ctatgccgcc 300
atggactacc actgggtttt cgggacagcc atgtgcaaga tcagcaactt ccttctcatc 360
cacaacatgt tcaccagcgt cttcctgctg accatcatca gctctgaccg ctgcatctct 420
gtgctcctcc ctgtctggtc ccagaaccac cgcagcgttc gcctggctta catggcctgc 480
atggtcatct gggtcctggc tttcttcttg agttccccat ctctcgtctt ccgggacaca 540
gccaacctgc atgggaaaat atcctgcttc aacaacttca gcctgtccac acctgggtct 600
tcctcgtggc ccactcactc ccaaatggac cctgtggggt atagccggca catggtggtg 660
actgtcaccc gcttcctctg tggcttcctg gtcccagtcc tcatcatcac agcttgctac 720
ctcaccatcg tgtgcaaact gcagcgcaac cgcctggcca agaccaagaa gcccttcaag 780
attattgtga ccatcatcat taccttcttc ctctgctggt gcccctacca cacactcaac 840
ctcctagagc tccaccacac tgccatgcct ggctctgtct tcagcctggg tttgcccctg 900
gccactgccc ttgccattgc caacagctgc atgaacccca ttctgtatgt tttcatgggt 960
caggacttca agaagttcaa ggtggccctc ttctctcgcc tggtcaatgc tctaagtgaa 1020
gatacaggcc actcttccta ccccagccat agaagcttta ccaagatgtc atcaatgaat 1080
gagaggactt ctatgaatga gagggagacc ggcatgcttt ga 1122
<210> 57
<211> 352
<212> PRT
<213> Homo sapiens
<400> 57
Met Glu Gly Ile Ser Ile Tyr Thr Ser Asp Asn Tyr Thr Glu Glu Met
1 5 10 15
Gly Ser Gly Asp Tyr Asp Ser Met Lys Glu Pro Cys Phe Arg Glu Glu
20 25 30
Asn Ala Asn Phe Asn Lys Ile Phe Leu Pro Thr Ile Tyr Ser Ile Ile
35 40 45
Phe Leu Thr Gly Ile Val Gly Asn Gly Leu Val Ile Leu Val Met Gly
50 55 60
Tyr Gln Lys Lys Leu Arg Ser Met Thr Asp Lys Tyr Arg Leu His Leu
65 70 75 80
Ser Val Ala Asp Leu Leu Phe Val Ile Thr Leu Pro Phe Trp Ala Val
85 90 95
Asp Ala Val Ala Asn Trp Tyr Phe Gly Asn Phe Leu Cys Lys Ala Val
100 105 110
His Val Ile Tyr Thr Val Asn Leu Tyr Ser Ser Val Leu Ile Leu Ala
115 120 125
Phe Ile Ser Leu Asp Arg Tyr Leu Ala Ile Val His Ala Thr Asn Ser
130 135 140
Gln Arg Pro Arg Lys Leu Leu Ala Glu Lys Val Val Tyr Val Gly Val
145 150 155 160
Trp Ile Pro Ala Leu Leu Leu Thr Ile Pro Asp Phe Ile Phe Ala Asn
165 170 175
Val Ser Glu Ala Asp Asp Arg Tyr Ile Cys Asp Arg Phe Tyr Pro Asn
180 185 190
Asp Leu Trp Val Val Val Phe Gln Phe Gln His Ile Met Val Gly Leu
195 200 205
Ile Leu Pro Gly Ile Val Ile Leu Ser Cys Tyr Cys Ile Ile Ile Ser
210 215 220
Lys Leu Ser His Ser Lys Gly His Gln Lys Arg Lys Ala Leu Lys Thr
225 230 235 240
Thr Val Ile Leu Ile Leu Ala Phe Phe Ala Cys Trp Leu Pro Tyr Tyr
245 250 255
Ile Gly Ile Ser Ile Asp Ser Phe Ile Leu Leu Glu Ile Ile Lys Gln
260 265 270
Gly Cys Glu Phe Glu Asn Thr Val His Lys Trp Ile Ser Ile Thr Glu
275 280 285
Ala Leu Ala Phe Phe His Cys Cys Leu Asn Pro Ile Leu Tyr Ala Phe
290 295 300
Leu Gly Ala Lys Phe Lys Thr Ser Ala Gln His Ala Leu Thr Ser Val
305 310 315 320
Ser Arg Gly Ser Ser Leu Lys Ile Leu Ser Lys Gly Lys Arg Gly Gly
325 330 335
His Ser Ser Val Ser Thr Glu Ser Glu Ser Ser Ser Phe His Ser Ser
340 345 350
<210> 58
<211> 1071
<212> DNA
<213> Homo sapiens
<400> 58
atgtccattc ctttgcctct tttgcagata tacacttcag ataactacac cgaggaaatg 60
ggctcagggg actatgactc catgaaggaa ccctgtttcc gtgaagaaaa tgctaatttc 120
aataaaatct tcctgcccac catctactcc atcatcttct taactggcat tgtgggcaat 180
ggattggtca tcctggtcat gggttaccag aagaaactga gaagcatgac ggacaagtac 240
aggctgcacc tgtcagtggc cgacctcctc tttgtcatca cgcttccctt ctgggcagtt 300
gatgccgtgg caaactggta ctttgggaac ttcctatgca aggcagtcca tgtcatctac 360
acagtcaacc tctacagcag tgtcctcatc ctggccttca tcagtctgga ccgctacctg 420
gccatcgtcc acgccaccaa cagtcagagg ccaaggaagc tgttggctga aaaggtggtc 480
tatgttggcg tctggatccc tgccctcctg ctgactattc ccgacttcat ctttgccaac 540
gtcagtgagg cagatgacag atatatctgt gaccgcttct accccaatga cttgtgggtg 600
gttgtgttcc agtttcagca catcatggtt ggccttatcc tgcctggtat tgtcatcctg 660
tcctgctatt gcattatcat ctccaagctg tcacactcca agggccacca gaagcgcaag 720
gccctcaaga ccacagtcat cctcatcctg gctttcttcg cctgttggct gccttactac 780
attgggatca gcatcgactc cttcatcctc ctggaaatca tcaagcaagg gtgtgagttt 840
gagaacactg tgcacaagtg gatttccatc accgaggccc tagctttctt ccactgttgt 900
ctgaacccca tcctctatgc tttccttgga gccaaattta aaacctctgc ccagcacgca 960
ctcacctctg tgagcagagg gtccagcctc aagatcctct ccaaaggaaa gcgaggtgga 1020
cattcatctg tttccactga gtctgagtct tcaagttttc actccagcta a 1071
<210> 59
<211> 352
<212> PRT
<213> Homo sapiens
<400> 59
Met Asp Tyr Gln Val Ser Ser Pro Ile Tyr Asp Ile Asn Tyr Tyr Thr
1 5 10 15
Ser Glu Pro Cys Gln Lys Ile Asn Val Lys Gln Ile Ala Ala Arg Leu
20 25 30
Leu Pro Pro Leu Tyr Ser Leu Val Phe Ile Phe Gly Phe Val Gly Asn
35 40 45
Met Leu Val Ile Leu Ile Leu Ile Asn Cys Lys Arg Leu Lys Ser Met
50 55 60
Thr Asp Ile Tyr Leu Leu Asn Leu Ala Ile Ser Asp Leu Phe Phe Leu
65 70 75 80
Leu Thr Val Pro Phe Trp Ala His Tyr Ala Ala Ala Gln Trp Asp Phe
85 90 95
Gly Asn Thr Met Cys Gln Leu Leu Thr Gly Leu Tyr Phe Ile Gly Phe
100 105 110
Phe Ser Gly Ile Phe Phe Ile Ile Leu Leu Thr Ile Asp Arg Tyr Leu
115 120 125
Ala Val Val His Ala Val Phe Ala Leu Lys Ala Arg Thr Val Thr Phe
130 135 140
Gly Val Val Thr Ser Val Ile Thr Trp Val Val Ala Val Phe Ala Ser
145 150 155 160
Leu Pro Gly Ile Ile Phe Thr Arg Ser Gln Lys Glu Gly Leu His Tyr
165 170 175
Thr Cys Ser Ser His Phe Pro Tyr Ser Gln Tyr Gln Phe Trp Lys Asn
180 185 190
Phe Gln Thr Leu Lys Ile Val Ile Leu Gly Leu Val Leu Pro Leu Leu
195 200 205
Val Met Val Ile Cys Tyr Ser Gly Ile Leu Lys Thr Leu Leu Arg Cys
210 215 220
Arg Asn Glu Lys Lys Arg His Arg Ala Val Arg Leu Ile Phe Thr Ile
225 230 235 240
Met Ile Val Tyr Phe Leu Phe Trp Ala Pro Tyr Asn Ile Val Leu Leu
245 250 255
Leu Asn Thr Phe Gln Glu Phe Phe Gly Leu Asn Asn Cys Ser Ser Ser
260 265 270
Asn Arg Leu Asp Gln Ala Met Gln Val Thr Glu Thr Leu Gly Met Thr
275 280 285
His Cys Cys Ile Asn Pro Ile Ile Tyr Ala Phe Val Gly Glu Lys Phe
290 295 300
Arg Asn Tyr Leu Leu Val Phe Phe Gln Lys His Ile Ala Lys Arg Phe
305 310 315 320
Cys Lys Cys Cys Ser Ile Phe Gln Gln Glu Ala Pro Glu Arg Ala Ser
325 330 335
Ser Val Tyr Thr Arg Ser Thr Gly Glu Gln Glu Ile Ser Val Gly Leu
340 345 350
<210> 60
<211> 1059
<212> DNA
<213> Homo sapiens
<400> 60
atggattatc aagtgtcaag tccaatctat gacatcaatt attatacatc ggagccctgc 60
caaaaaatca atgtgaagca aatcgcagcc cgcctcctgc ctccgctcta ctcactggtg 120
ttcatctttg gttttgtggg caacatgctg gtcatcctca tcctgataaa ctgcaaaagg 180
ctgaagagca tgactgacat ctacctgctc aacctggcca tctctgacct gtttttcctt 240
cttactgtcc ccttctgggc tcactatgct gccgcccagt gggactttgg aaatacaatg 300
tgtcaactct tgacagggct ctattttata ggcttcttct ctggaatctt cttcatcatc 360
ctcctgacaa tcgataggta cctggctgtc gtccatgctg tgtttgcttt aaaagccagg 420
acggtcacct ttggggtggt gacaagtgtg atcacttggg tggtggctgt gtttgcgtct 480
ctcccaggaa tcatctttac cagatctcaa aaagaaggtc ttcattacac ctgcagctct 540
cattttccat acagtcagta tcaattctgg aagaatttcc agacattaaa gatagtcatc 600
ttggggctgg tcctgccgct gcttgtcatg gtcatctgct actcgggaat cctaaaaact 660
ctgcttcggt gtcgaaatga gaagaagagg cacagggctg tgaggcttat cttcaccatc 720
atgattgttt attttctctt ctgggctccc tacaacattg tccttctcct gaacaccttc 780
caggaattct ttggcctgaa taattgcagt agctctaaca ggttggacca agctatgcag 840
gtgacagaga ctcttgggat gacgcactgc tgcatcaacc ccatcatcta tgcctttgtc 900
ggggagaagt tcagaaacta cctcttagtc ttcttccaaa agcacattgc caaacgcttc 960
tgcaaatgct gttctatttt ccagcaagag gctcccgagc gagcaagctc agtttacacc 1020
cgatccactg gggagcagga aatatctgtg ggcttgtga 1059
<210> 61
<211> 398
<212> PRT
<213> Homo sapiens
<400> 61
Met Glu Ser Gly Leu Leu Arg Pro Ala Pro Val Ser Glu Val Ile Val
1 5 10 15
Leu His Tyr Asn Tyr Thr Gly Lys Leu Arg Gly Ala Arg Tyr Gln Pro
20 25 30
Gly Ala Gly Leu Arg Ala Asp Ala Val Val Cys Leu Ala Val Cys Ala
35 40 45
Phe Ile Val Leu Glu Asn Leu Ala Val Leu Leu Val Leu Gly Arg His
50 55 60
Pro Arg Phe His Ala Pro Met Phe Leu Leu Leu Gly Ser Leu Thr Leu
65 70 75 80
Ser Asp Leu Leu Ala Gly Ala Ala Tyr Ala Ala Asn Ile Leu Leu Ser
85 90 95
Gly Pro Leu Thr Leu Lys Leu Ser Pro Ala Leu Trp Phe Ala Arg Glu
100 105 110
Gly Gly Val Phe Val Ala Leu Thr Ala Ser Val Leu Ser Leu Leu Ala
115 120 125
Ile Ala Leu Glu Arg Ser Leu Thr Met Ala Arg Arg Gly Pro Ala Pro
130 135 140
Val Ser Ser Arg Gly Arg Thr Leu Ala Met Ala Ala Ala Ala Trp Gly
145 150 155 160
Val Ser Leu Leu Leu Gly Leu Leu Pro Ala Leu Gly Trp Asn Cys Leu
165 170 175
Gly Arg Leu Asp Ala Cys Ser Thr Val Leu Pro Leu Tyr Ala Lys Ala
180 185 190
Tyr Val Leu Phe Cys Val Leu Ala Phe Val Gly Ile Leu Ala Ala Ile
195 200 205
Cys Ala Leu Tyr Ala Arg Ile Tyr Cys Gln Val Arg Ala Asn Ala Arg
210 215 220
Arg Leu Pro Ala Arg Pro Gly Thr Ala Gly Thr Thr Ser Thr Arg Ala
225 230 235 240
Arg Arg Lys Pro Arg Ser Leu Ala Leu Leu Arg Thr Leu Ser Val Val
245 250 255
Leu Leu Ala Phe Val Ala Cys Trp Gly Pro Leu Phe Leu Leu Leu Leu
260 265 270
Leu Asp Val Ala Cys Pro Ala Arg Thr Cys Pro Val Leu Leu Gln Ala
275 280 285
Asp Pro Phe Leu Gly Leu Ala Met Ala Asn Ser Leu Leu Asn Pro Ile
290 295 300
Ile Tyr Thr Leu Thr Asn Arg Asp Leu Arg His Ala Leu Leu Arg Leu
305 310 315 320
Val Cys Cys Gly Arg His Ser Cys Gly Arg Asp Pro Ser Gly Ser Gln
325 330 335
Gln Ser Ala Ser Ala Ala Glu Ala Ser Gly Gly Leu Arg Arg Cys Leu
340 345 350
Pro Pro Gly Leu Asp Gly Ser Phe Ser Gly Ser Glu Arg Ser Ser Pro
355 360 365
Gln Arg Asp Gly Leu Asp Thr Ser Gly Ser Thr Gly Ser Pro Gly Ala
370 375 380
Pro Thr Ala Ala Arg Thr Leu Val Ser Glu Pro Ala Ala Asp
385 390 395
<210> 62
<211> 1197
<212> DNA
<213> Homo sapiens
<400> 62
atggagtcgg ggctgctgcg gccggcgccg gtgagcgagg tcatcgtcct gcattacaac 60
tacaccggca agctccgcgg tgcgcgctac cagccgggtg ccggcctgcg cgccgacgcc 120
gtggtgtgcc tggcggtgtg cgccttcatc gtgctagaga atctagccgt gttgttggtg 180
ctcggacgcc acccgcgctt ccacgctccc atgttcctgc tcctgggcag cctcacgttg 240
tcggatctgc tggcaggcgc cgcctacgcc gccaacatcc tactgtcggg gccgctcacg 300
ctgaaactgt cccccgcgct ctggttcgca cgggagggag gcgtcttcgt ggcactcact 360
gcgtccgtgc tgagcctcct ggccatcgcg ctggagcgca gcctcaccat ggcgcgcagg 420
gggcccgcgc ccgtctccag tcgggggcgc acgctggcga tggcagccgc ggcctggggc 480
gtgtcgctgc tcctcgggct cctgccagcg ctgggctgga attgcctggg tcgcctggac 540
gcttgctcca ctgtcttgcc gctctacgcc aaggcctacg tgctcttctg cgtgctcgcc 600
ttcgtgggca tcctggccgc tatctgtgca ctctacgcgc gcatctactg ccaggtacgc 660
gccaacgcgc ggcgcctgcc ggcacggccc gggactgcgg ggaccacctc gacccgggcg 720
cgtcgcaagc cgcgctcgct ggccttgctg cgcacgctca gcgtggtgct cctggccttt 780
gtggcatgtt ggggccccct cttcctgctg ctgttgctcg acgtggcgtg cccggcgcgc 840
acctgtcctg tactcctgca ggccgatccc ttcctgggac tggccatggc caactcactt 900
ctgaacccca tcatctacac gctcaccaac cgcgacctgc gccacgcgct cctgcgcctg 960
gtctgctgcg gacgccactc ctgcggcaga gacccgagtg gctcccagca gtcggcgagc 1020
gcggctgagg cttccggggg cctgcgccgc tgcctgcccc cgggccttga tgggagcttc 1080
agcggctcgg agcgctcatc gccccagcgc gacgggctgg acaccagcgg ctccacaggc 1140
agccccggtg cacccacagc cgcccggact ctggtatcag aaccggctgc agactga 1197
<210> 63
<211> 951
<212> PRT
<213> Homo sapiens
<400> 63
Gln Pro Ser Val Ser Pro Gly Glu Pro Ser Pro Pro Ser Ile His Pro
1 5 10 15
Gly Lys Ser Asp Leu Ile Val Arg Val Gly Asp Glu Ile Arg Leu Leu
20 25 30
Cys Thr Asp Pro Gly Phe Val Lys Trp Thr Phe Glu Ile Leu Asp Glu
35 40 45
Thr Asn Glu Asn Lys Gln Asn Glu Trp Ile Thr Glu Lys Ala Glu Ala
50 55 60
Thr Asn Thr Gly Lys Tyr Thr Cys Thr Asn Lys His Gly Leu Ser Asn
65 70 75 80
Ser Ile Tyr Val Phe Val Arg Asp Pro Ala Lys Leu Phe Leu Val Asp
85 90 95
Arg Ser Leu Tyr Gly Lys Glu Asp Asn Asp Thr Leu Val Arg Cys Pro
100 105 110
Leu Thr Asp Pro Glu Val Thr Asn Tyr Ser Leu Lys Gly Cys Gln Gly
115 120 125
Lys Pro Leu Pro Lys Asp Leu Arg Phe Ile Pro Asp Pro Lys Ala Gly
130 135 140
Ile Met Ile Lys Ser Val Lys Arg Ala Tyr His Arg Leu Cys Leu His
145 150 155 160
Cys Ser Val Asp Gln Glu Gly Lys Ser Val Leu Ser Glu Lys Phe Ile
165 170 175
Leu Lys Val Arg Pro Ala Phe Lys Ala Val Pro Val Val Ser Val Ser
180 185 190
Lys Ala Ser Tyr Leu Leu Arg Glu Gly Glu Glu Phe Thr Val Thr Cys
195 200 205
Thr Ile Lys Asp Val Ser Ser Ser Val Tyr Ser Thr Trp Lys Arg Glu
210 215 220
Asn Ser Gln Thr Lys Leu Gln Glu Lys Tyr Asn Ser Trp His His Gly
225 230 235 240
Asp Phe Asn Tyr Glu Arg Gln Ala Thr Leu Thr Ile Ser Ser Ala Arg
245 250 255
Val Asn Asp Ser Gly Val Phe Met Cys Tyr Ala Asn Asn Thr Phe Gly
260 265 270
Ser Ala Asn Val Thr Thr Thr Leu Glu Val Val Asp Lys Gly Phe Ile
275 280 285
Asn Ile Phe Pro Met Ile Asn Thr Thr Val Phe Val Asn Asp Gly Glu
290 295 300
Asn Val Asp Leu Ile Val Glu Tyr Glu Ala Phe Pro Lys Pro Glu His
305 310 315 320
Gln Gln Trp Ile Tyr Met Asn Arg Thr Phe Thr Asp Lys Trp Glu Asp
325 330 335
Tyr Pro Lys Ser Glu Asn Glu Ser Asn Ile Arg Tyr Val Ser Glu Leu
340 345 350
His Leu Thr Arg Leu Lys Gly Thr Glu Gly Gly Thr Tyr Thr Phe Leu
355 360 365
Val Ser Asn Ser Asp Val Asn Ala Ala Ile Ala Phe Asn Val Tyr Val
370 375 380
Asn Thr Lys Pro Glu Ile Leu Thr Tyr Asp Arg Leu Val Asn Gly Met
385 390 395 400
Leu Gln Cys Val Ala Ala Gly Phe Pro Glu Pro Thr Ile Asp Trp Tyr
405 410 415
Phe Cys Pro Gly Thr Glu Gln Arg Cys Ser Ala Ser Val Leu Pro Val
420 425 430
Asp Val Gln Thr Leu Asn Ser Ser Gly Pro Pro Phe Gly Lys Leu Val
435 440 445
Val Gln Ser Ser Ile Asp Ser Ser Ala Phe Lys His Asn Gly Thr Val
450 455 460
Glu Cys Lys Ala Tyr Asn Asp Val Gly Lys Thr Ser Ala Tyr Phe Asn
465 470 475 480
Phe Ala Phe Lys Gly Asn Asn Lys Glu Gln Ile His Pro His Thr Leu
485 490 495
Phe Thr Pro Leu Leu Ile Gly Phe Val Ile Val Ala Gly Met Met Cys
500 505 510
Ile Ile Val Met Ile Leu Thr Tyr Lys Tyr Leu Gln Lys Pro Met Tyr
515 520 525
Glu Val Gln Trp Lys Val Val Glu Glu Ile Asn Gly Asn Asn Tyr Val
530 535 540
Tyr Ile Asp Pro Thr Gln Leu Pro Tyr Asp His Lys Trp Glu Phe Pro
545 550 555 560
Arg Asn Arg Leu Ser Phe Gly Lys Thr Leu Gly Ala Gly Ala Phe Gly
565 570 575
Lys Val Val Glu Ala Thr Ala Tyr Gly Leu Ile Lys Ser Asp Ala Ala
580 585 590
Met Thr Val Ala Val Lys Met Leu Lys Pro Ser Ala His Leu Thr Glu
595 600 605
Arg Glu Ala Leu Met Ser Glu Leu Lys Val Leu Ser Tyr Leu Gly Asn
610 615 620
His Met Asn Ile Val Asn Leu Leu Gly Ala Cys Thr Ile Gly Gly Pro
625 630 635 640
Thr Leu Val Ile Thr Glu Tyr Cys Cys Tyr Gly Asp Leu Leu Asn Phe
645 650 655
Leu Arg Arg Lys Arg Asp Ser Phe Ile Cys Ser Lys Gln Glu Asp His
660 665 670
Ala Glu Ala Ala Leu Tyr Lys Asn Leu Leu His Ser Lys Glu Ser Ser
675 680 685
Cys Ser Asp Ser Thr Asn Glu Tyr Met Asp Met Lys Pro Gly Val Ser
690 695 700
Tyr Val Val Pro Thr Lys Ala Asp Lys Arg Arg Ser Val Arg Ile Gly
705 710 715 720
Ser Tyr Ile Glu Arg Asp Val Thr Pro Ala Ile Met Glu Asp Asp Glu
725 730 735
Leu Ala Leu Asp Leu Glu Asp Leu Leu Ser Phe Ser Tyr Gln Val Ala
740 745 750
Lys Gly Met Ala Phe Leu Ala Ser Lys Asn Cys Ile His Arg Asp Leu
755 760 765
Ala Ala Arg Asn Ile Leu Leu Thr His Gly Arg Ile Thr Lys Ile Cys
770 775 780
Asp Phe Gly Leu Ala Arg Asp Ile Lys Asn Asp Ser Asn Tyr Val Val
785 790 795 800
Lys Gly Asn Ala Arg Leu Pro Val Lys Trp Met Ala Pro Glu Ser Ile
805 810 815
Phe Asn Cys Val Tyr Thr Phe Glu Ser Asp Val Trp Ser Tyr Gly Ile
820 825 830
Phe Leu Trp Glu Leu Phe Ser Leu Gly Ser Ser Pro Tyr Pro Gly Met
835 840 845
Pro Val Asp Ser Lys Phe Tyr Lys Met Ile Lys Glu Gly Phe Arg Met
850 855 860
Leu Ser Pro Glu His Ala Pro Ala Glu Met Tyr Asp Ile Met Lys Thr
865 870 875 880
Cys Trp Asp Ala Asp Pro Leu Lys Arg Pro Thr Phe Lys Gln Ile Val
885 890 895
Gln Leu Ile Glu Lys Gln Ile Ser Glu Ser Thr Asn His Ile Tyr Ser
900 905 910
Asn Leu Ala Asn Cys Ser Pro Asn Arg Gln Lys Pro Val Val Asp His
915 920 925
Ser Val Arg Ile Asn Ser Val Gly Ser Thr Ala Ser Ser Ser Gln Pro
930 935 940
Leu Leu Val His Asp Asp Val
945 950
<210> 64
<211> 2931
<212> DNA
<213> Homo sapiens
<400> 64
atgagaggcg ctcgcggcgc ctgggatttt ctctgcgttc tgctcctact gcttcgcgtc 60
cagacaggct cttctcaacc atctgtgagt ccaggggaac cgtctccacc atccatccat 120
ccaggaaaat cagacttaat agtccgcgtg ggcgacgaga ttaggctgtt atgcactgat 180
ccgggctttg tcaaatggac ttttgagatc ctggatgaaa cgaatgagaa taagcagaat 240
gaatggatca cggaaaaggc agaagccacc aacaccggca aatacacgtg caccaacaaa 300
cacggcttaa gcaattccat ttatgtgttt gttagagatc ctgccaagct tttccttgtt 360
gaccgctcct tgtatgggaa agaagacaac gacacgctgg tccgctgtcc tctcacagac 420
ccagaagtga ccaattattc cctcaagggg tgccagggga agcctcttcc caaggacttg 480
aggtttattc ctgaccccaa ggcgggcatc atgatcaaaa gtgtgaaacg cgcctaccat 540
cggctctgtc tgcattgttc tgtggaccag gagggcaagt cagtgctgtc ggaaaaattc 600
atcctgaaag tgaggccagc cttcaaagct gtgcctgttg tgtctgtgtc caaagcaagc 660
tatcttctta gggaagggga agaattcaca gtgacgtgca caataaaaga tgtgtctagt 720
tctgtgtact caacgtggaa aagagaaaac agtcagacta aactacagga gaaatataat 780
agctggcatc acggtgactt caattatgaa cgtcaggcaa cgttgactat cagttcagcg 840
agagttaatg attctggagt gttcatgtgt tatgccaata atacttttgg atcagcaaat 900
gtcacaacaa ccttggaagt agtagataaa ggattcatta atatcttccc catgataaac 960
actacagtat ttgtaaacga tggagaaaat gtagatttga ttgttgaata tgaagcattc 1020
cccaaacctg aacaccagca gtggatctat atgaacagaa ccttcactga taaatgggaa 1080
gattatccca agtctgagaa tgaaagtaat atcagatacg taagtgaact tcatctaacg 1140
agattaaaag gcaccgaagg aggcacttac acattcctag tgtccaattc tgacgtcaat 1200
gctgccatag catttaatgt ttatgtgaat acaaaaccag aaatcctgac ttacgacagg 1260
ctcgtgaatg gcatgctcca atgtgtggca gcaggattcc cagagcccac aatagattgg 1320
tatttttgtc caggaactga gcagagatgc tctgcttctg tactgccagt ggatgtgcag 1380
acactaaact catctgggcc accgtttgga aagctagtgg ttcagagttc tatagattct 1440
agtgcattca agcacaatgg cacggttgaa tgtaaggctt acaacgatgt gggcaagact 1500
tctgcctatt ttaactttgc atttaaaggt aacaacaaag agcaaatcca tccccacacc 1560
ctgttcactc ctttgctgat tggtttcgta atcgtagctg gcatgatgtg cattattgtg 1620
atgattctga cctacaaata tttacagaaa cccatgtatg aagtacagtg gaaggttgtt 1680
gaggagataa atggaaacaa ttatgtttac atagacccaa cacaacttcc ttatgatcac 1740
aaatgggagt ttcccagaaa caggctgagt tttgggaaaa ccctgggtgc tggagctttc 1800
gggaaggttg ttgaggcaac tgcttatggc ttaattaagt cagatgcggc catgactgtc 1860
gctgtaaaga tgctcaagcc gagtgcccat ttgacagaac gggaagccct catgtctgaa 1920
ctcaaagtcc tgagttacct tggtaatcac atgaatattg tgaatctact tggagcctgc 1980
accattggag ggcccaccct ggtcattaca gaatattgtt gctatggtga tcttttgaat 2040
tttttgagaa gaaaacgtga ttcatttatt tgttcaaagc aggaagatca tgcagaagct 2100
gcactttata agaatcttct gcattcaaag gagtcttcct gcagcgatag tactaatgag 2160
tacatggaca tgaaacctgg agtttcttat gttgtcccaa ccaaggccga caaaaggaga 2220
tctgtgagaa taggctcata catagaaaga gatgtgactc ccgccatcat ggaggatgac 2280
gagttggccc tagacttaga agacttgctg agcttttctt accaggtggc aaagggcatg 2340
gctttcctcg cctccaagaa ttgtattcac agagacttgg cagccagaaa tatcctcctt 2400
actcatggtc ggatcacaaa gatttgtgat tttggtctag ccagagacat caagaatgat 2460
tctaattatg tggttaaagg aaacgctcga ctacctgtga agtggatggc acctgaaagc 2520
attttcaact gtgtatacac gtttgaaagt gacgtctggt cctatgggat ttttctttgg 2580
gagctgttct ctttaggaag cagcccctat cctggaatgc cggtcgattc taagttctac 2640
aagatgatca aggaaggctt ccggatgctc agccctgaac acgcacctgc tgaaatgtat 2700
gacataatga agacttgctg ggatgcagat cccctaaaaa gaccaacatt caagcaaatt 2760
gttcagctaa ttgagaagca gatttcagag agcaccaatc atatttactc caacttagca 2820
aactgcagcc ccaaccgaca gaagcccgtg gtagaccatt ctgtgcggat caattctgtc 2880
ggcagcaccg cttcctcctc ccagcctctg cttgtgcacg acgatgtctg a 2931
<210> 65
<211> 2549
<212> PRT
<213> Homo sapiens
<400> 65
Met Leu Gly Thr Gly Pro Ala Ala Ala Thr Thr Ala Ala Thr Thr Ser
1 5 10 15
Ser Asn Val Ser Val Leu Gln Gln Phe Ala Ser Gly Leu Lys Ser Arg
20 25 30
Asn Glu Glu Thr Arg Ala Lys Ala Ala Lys Glu Leu Gln His Tyr Val
35 40 45
Thr Met Glu Leu Arg Glu Met Ser Gln Glu Glu Ser Thr Arg Phe Tyr
50 55 60
Asp Gln Leu Asn His His Ile Phe Glu Leu Val Ser Ser Ser Asp Ala
65 70 75 80
Asn Glu Arg Lys Gly Gly Ile Leu Ala Ile Ala Ser Leu Ile Gly Val
85 90 95
Glu Gly Gly Asn Ala Thr Arg Ile Gly Arg Phe Ala Asn Tyr Leu Arg
100 105 110
Asn Leu Leu Pro Ser Asn Asp Pro Val Val Met Glu Met Ala Ser Lys
115 120 125
Ala Ile Gly Arg Leu Ala Met Ala Gly Asp Thr Phe Thr Ala Glu Tyr
130 135 140
Val Glu Phe Glu Val Lys Arg Ala Leu Glu Trp Leu Gly Ala Asp Arg
145 150 155 160
Asn Glu Gly Arg Arg His Ala Ala Val Leu Val Leu Arg Glu Leu Ala
165 170 175
Ile Ser Val Pro Thr Phe Phe Phe Gln Gln Val Gln Pro Phe Phe Asp
180 185 190
Asn Ile Phe Val Ala Val Trp Asp Pro Lys Gln Ala Ile Arg Glu Gly
195 200 205
Ala Val Ala Ala Leu Arg Ala Cys Leu Ile Leu Thr Thr Gln Arg Glu
210 215 220
Pro Lys Glu Met Gln Lys Pro Gln Trp Tyr Arg His Thr Phe Glu Glu
225 230 235 240
Ala Glu Lys Gly Phe Asp Glu Thr Leu Ala Lys Glu Lys Gly Met Asn
245 250 255
Arg Asp Asp Arg Ile His Gly Ala Leu Leu Ile Leu Asn Glu Leu Val
260 265 270
Arg Ile Ser Ser Met Glu Gly Glu Arg Leu Arg Glu Glu Met Glu Glu
275 280 285
Ile Thr Gln Gln Gln Leu Val His Asp Lys Tyr Cys Lys Asp Leu Met
290 295 300
Gly Phe Gly Thr Lys Pro Arg His Ile Thr Pro Phe Thr Ser Phe Gln
305 310 315 320
Ala Val Gln Pro Gln Gln Ser Asn Ala Leu Val Gly Leu Leu Gly Tyr
325 330 335
Ser Ser His Gln Gly Leu Met Gly Phe Gly Thr Ser Pro Ser Pro Ala
340 345 350
Lys Ser Thr Leu Val Glu Ser Arg Cys Cys Arg Asp Leu Met Glu Glu
355 360 365
Lys Phe Asp Gln Val Cys Gln Trp Val Leu Lys Cys Arg Asn Ser Lys
370 375 380
Asn Ser Leu Ile Gln Met Thr Ile Leu Asn Leu Leu Pro Arg Leu Ala
385 390 395 400
Ala Phe Arg Pro Ser Ala Phe Thr Asp Thr Gln Tyr Leu Gln Asp Thr
405 410 415
Met Asn His Val Leu Ser Cys Val Lys Lys Glu Lys Glu Arg Thr Ala
420 425 430
Ala Phe Gln Ala Leu Gly Leu Leu Ser Val Ala Val Arg Ser Glu Phe
435 440 445
Lys Val Tyr Leu Pro Arg Val Leu Asp Ile Ile Arg Ala Ala Leu Pro
450 455 460
Pro Lys Asp Phe Ala His Lys Arg Gln Lys Ala Met Gln Val Asp Ala
465 470 475 480
Thr Val Phe Thr Cys Ile Ser Met Leu Ala Arg Ala Met Gly Pro Gly
485 490 495
Ile Gln Gln Asp Ile Lys Glu Leu Leu Glu Pro Met Leu Ala Val Gly
500 505 510
Leu Ser Pro Ala Leu Thr Ala Val Leu Tyr Asp Leu Ser Arg Gln Ile
515 520 525
Pro Gln Leu Lys Lys Asp Ile Gln Asp Gly Leu Leu Lys Met Leu Ser
530 535 540
Leu Val Leu Met His Lys Pro Leu Arg His Pro Gly Met Pro Lys Gly
545 550 555 560
Leu Ala His Gln Leu Ala Ser Pro Gly Leu Thr Thr Leu Pro Glu Ala
565 570 575
Ser Asp Val Gly Ser Ile Thr Leu Ala Leu Arg Thr Leu Gly Ser Phe
580 585 590
Glu Phe Glu Gly His Ser Leu Thr Gln Phe Val Arg His Cys Ala Asp
595 600 605
His Phe Leu Asn Ser Glu His Lys Glu Ile Arg Met Glu Ala Ala Arg
610 615 620
Thr Cys Ser Arg Leu Leu Thr Pro Ser Ile His Leu Ile Ser Gly His
625 630 635 640
Ala His Val Val Ser Gln Thr Ala Val Gln Val Val Ala Asp Val Leu
645 650 655
Ser Lys Leu Leu Val Val Gly Ile Thr Asp Pro Asp Pro Asp Ile Arg
660 665 670
Tyr Cys Val Leu Ala Ser Leu Asp Glu Arg Phe Asp Ala His Leu Ala
675 680 685
Gln Ala Glu Asn Leu Gln Ala Leu Phe Val Ala Leu Asn Asp Gln Val
690 695 700
Phe Glu Ile Arg Glu Leu Ala Ile Cys Thr Val Gly Arg Leu Ser Ser
705 710 715 720
Met Asn Pro Ala Phe Val Met Pro Phe Leu Arg Lys Met Leu Ile Gln
725 730 735
Ile Leu Thr Glu Leu Glu His Ser Gly Ile Gly Arg Ile Lys Glu Gln
740 745 750
Ser Ala Arg Met Leu Gly His Leu Val Ser Asn Ala Pro Arg Leu Ile
755 760 765
Arg Pro Tyr Met Glu Pro Ile Leu Lys Ala Leu Ile Leu Lys Leu Lys
770 775 780
Asp Pro Asp Pro Asp Pro Asn Pro Gly Val Ile Asn Asn Val Leu Ala
785 790 795 800
Thr Ile Gly Glu Leu Ala Gln Val Ser Gly Leu Glu Met Arg Lys Trp
805 810 815
Val Asp Glu Leu Phe Ile Ile Ile Met Asp Met Leu Gln Asp Ser Ser
820 825 830
Leu Leu Ala Lys Arg Gln Val Ala Leu Trp Thr Leu Gly Gln Leu Val
835 840 845
Ala Ser Thr Gly Tyr Val Val Glu Pro Tyr Arg Lys Tyr Pro Thr Leu
850 855 860
Leu Glu Val Leu Leu Asn Phe Leu Lys Thr Glu Gln Asn Gln Gly Thr
865 870 875 880
Arg Arg Glu Ala Ile Arg Val Leu Gly Leu Leu Gly Ala Leu Asp Pro
885 890 895
Tyr Lys His Lys Val Asn Ile Gly Met Ile Asp Gln Ser Arg Asp Ala
900 905 910
Ser Ala Val Ser Leu Ser Glu Ser Lys Ser Ser Gln Asp Ser Ser Asp
915 920 925
Tyr Ser Thr Ser Glu Met Leu Val Asn Met Gly Asn Leu Pro Leu Asp
930 935 940
Glu Phe Tyr Pro Ala Val Ser Met Val Ala Leu Met Arg Ile Phe Arg
945 950 955 960
Asp Gln Ser Leu Ser His His His Thr Met Val Val Gln Ala Ile Thr
965 970 975
Phe Ile Phe Lys Ser Leu Gly Leu Lys Cys Val Gln Phe Leu Pro Gln
980 985 990
Val Met Pro Thr Phe Leu Asn Val Ile Arg Val Cys Asp Gly Ala Ile
995 1000 1005
Arg Glu Phe Leu Phe Gln Gln Leu Gly Met Leu Val Ser Phe Val
1010 1015 1020
Lys Ser His Ile Arg Pro Tyr Met Asp Glu Ile Val Thr Leu Met
1025 1030 1035
Arg Glu Phe Trp Val Met Asn Thr Ser Ile Gln Ser Thr Ile Ile
1040 1045 1050
Leu Leu Ile Glu Gln Ile Val Val Ala Leu Gly Gly Glu Phe Lys
1055 1060 1065
Leu Tyr Leu Pro Gln Leu Ile Pro His Met Leu Arg Val Phe Met
1070 1075 1080
His Asp Asn Ser Pro Gly Arg Ile Val Ser Ile Lys Leu Leu Ala
1085 1090 1095
Ala Ile Gln Leu Phe Gly Ala Asn Leu Asp Asp Tyr Leu His Leu
1100 1105 1110
Leu Leu Pro Pro Ile Val Lys Leu Phe Asp Ala Pro Glu Ala Pro
1115 1120 1125
Leu Pro Ser Arg Lys Ala Ala Leu Glu Thr Val Asp Arg Leu Thr
1130 1135 1140
Glu Ser Leu Asp Phe Thr Asp Tyr Ala Ser Arg Ile Ile His Pro
1145 1150 1155
Ile Val Arg Thr Leu Asp Gln Ser Pro Glu Leu Arg Ser Thr Ala
1160 1165 1170
Met Asp Thr Leu Ser Ser Leu Val Phe Gln Leu Gly Lys Lys Tyr
1175 1180 1185
Gln Ile Phe Ile Pro Met Val Asn Lys Val Leu Val Arg His Arg
1190 1195 1200
Ile Asn His Gln Arg Tyr Asp Val Leu Ile Cys Arg Ile Val Lys
1205 1210 1215
Gly Tyr Thr Leu Ala Asp Glu Glu Glu Asp Pro Leu Ile Tyr Gln
1220 1225 1230
His Arg Met Leu Arg Ser Gly Gln Gly Asp Ala Leu Ala Ser Gly
1235 1240 1245
Pro Val Glu Thr Gly Pro Met Lys Lys Leu His Val Ser Thr Ile
1250 1255 1260
Asn Leu Gln Lys Ala Trp Gly Ala Ala Arg Arg Val Ser Lys Asp
1265 1270 1275
Asp Trp Leu Glu Trp Leu Arg Arg Leu Ser Leu Glu Leu Leu Lys
1280 1285 1290
Asp Ser Ser Ser Pro Ser Leu Arg Ser Cys Trp Ala Leu Ala Gln
1295 1300 1305
Ala Tyr Asn Pro Met Ala Arg Asp Leu Phe Asn Ala Ala Phe Val
1310 1315 1320
Ser Cys Trp Ser Glu Leu Asn Glu Asp Gln Gln Asp Glu Leu Ile
1325 1330 1335
Arg Ser Ile Glu Leu Ala Leu Thr Ser Gln Asp Ile Ala Glu Val
1340 1345 1350
Thr Gln Thr Leu Leu Asn Leu Ala Glu Phe Met Glu His Ser Asp
1355 1360 1365
Lys Gly Pro Leu Pro Leu Arg Asp Asp Asn Gly Ile Val Leu Leu
1370 1375 1380
Gly Glu Arg Ala Ala Lys Cys Arg Ala Tyr Ala Lys Ala Leu His
1385 1390 1395
Tyr Lys Glu Leu Glu Phe Gln Lys Gly Pro Thr Pro Ala Ile Leu
1400 1405 1410
Glu Ser Leu Ile Ser Ile Asn Asn Lys Leu Gln Gln Pro Glu Ala
1415 1420 1425
Ala Ala Gly Val Leu Glu Tyr Ala Met Lys His Phe Gly Glu Leu
1430 1435 1440
Glu Ile Gln Ala Thr Trp Tyr Glu Lys Leu His Glu Trp Glu Asp
1445 1450 1455
Ala Leu Val Ala Tyr Asp Lys Lys Met Asp Thr Asn Lys Asp Asp
1460 1465 1470
Pro Glu Leu Met Leu Gly Arg Met Arg Cys Leu Glu Ala Leu Gly
1475 1480 1485
Glu Trp Gly Gln Leu His Gln Gln Cys Cys Glu Lys Trp Thr Leu
1490 1495 1500
Val Asn Asp Glu Thr Gln Ala Lys Met Ala Arg Met Ala Ala Ala
1505 1510 1515
Ala Ala Trp Gly Leu Gly Gln Trp Asp Ser Met Glu Glu Tyr Thr
1520 1525 1530
Cys Met Ile Pro Arg Asp Thr His Asp Gly Ala Phe Tyr Arg Ala
1535 1540 1545
Val Leu Ala Leu His Gln Asp Leu Phe Ser Leu Ala Gln Gln Cys
1550 1555 1560
Ile Asp Lys Ala Arg Asp Leu Leu Asp Ala Glu Leu Thr Ala Met
1565 1570 1575
Ala Gly Glu Ser Tyr Ser Arg Ala Tyr Gly Ala Met Val Ser Cys
1580 1585 1590
His Met Leu Ser Glu Leu Glu Glu Val Ile Gln Tyr Lys Leu Val
1595 1600 1605
Pro Glu Arg Arg Glu Ile Ile Arg Gln Ile Trp Trp Glu Arg Leu
1610 1615 1620
Gln Gly Cys Gln Arg Ile Val Glu Asp Trp Gln Lys Ile Leu Met
1625 1630 1635
Val Arg Ser Leu Val Val Ser Pro His Glu Asp Met Arg Thr Trp
1640 1645 1650
Leu Lys Tyr Ala Ser Leu Cys Gly Lys Ser Gly Arg Leu Ala Leu
1655 1660 1665
Ala His Lys Thr Leu Val Leu Leu Leu Gly Val Asp Pro Ser Arg
1670 1675 1680
Gln Leu Asp His Pro Leu Pro Thr Val His Pro Gln Val Thr Tyr
1685 1690 1695
Ala Tyr Met Lys Asn Met Trp Lys Ser Ala Arg Lys Ile Asp Ala
1700 1705 1710
Phe Gln His Met Gln His Phe Val Gln Thr Met Gln Gln Gln Ala
1715 1720 1725
Gln His Ala Ile Ala Thr Glu Asp Gln Gln His Lys Gln Glu Leu
1730 1735 1740
His Lys Leu Met Ala Arg Cys Phe Leu Lys Leu Gly Glu Trp Gln
1745 1750 1755
Leu Asn Leu Gln Gly Ile Asn Glu Ser Thr Ile Pro Lys Val Leu
1760 1765 1770
Gln Tyr Tyr Ser Ala Ala Thr Glu His Asp Arg Ser Trp Tyr Lys
1775 1780 1785
Ala Trp His Ala Trp Ala Val Met Asn Phe Glu Ala Val Leu His
1790 1795 1800
Tyr Lys His Gln Asn Gln Ala Arg Asp Glu Lys Lys Lys Leu Arg
1805 1810 1815
His Ala Ser Gly Ala Asn Ile Thr Asn Ala Thr Thr Ala Ala Thr
1820 1825 1830
Thr Ala Ala Thr Ala Thr Thr Thr Ala Ser Thr Glu Gly Ser Asn
1835 1840 1845
Ser Glu Ser Glu Ala Glu Ser Thr Glu Asn Ser Pro Thr Pro Ser
1850 1855 1860
Pro Leu Gln Lys Lys Val Thr Glu Asp Leu Ser Lys Thr Leu Leu
1865 1870 1875
Met Tyr Thr Val Pro Ala Val Gln Gly Phe Phe Arg Ser Ile Ser
1880 1885 1890
Leu Ser Arg Gly Asn Asn Leu Gln Asp Thr Leu Arg Val Leu Thr
1895 1900 1905
Leu Trp Phe Asp Tyr Gly His Trp Pro Asp Val Asn Glu Ala Leu
1910 1915 1920
Val Glu Gly Val Lys Ala Ile Gln Ile Asp Thr Trp Leu Gln Val
1925 1930 1935
Ile Pro Gln Leu Ile Ala Arg Ile Asp Thr Pro Arg Pro Leu Val
1940 1945 1950
Gly Arg Leu Ile His Gln Leu Leu Thr Asp Ile Gly Arg Tyr His
1955 1960 1965
Pro Gln Ala Leu Ile Tyr Pro Leu Thr Val Ala Ser Lys Ser Thr
1970 1975 1980
Thr Thr Ala Arg His Asn Ala Ala Asn Lys Ile Leu Lys Asn Met
1985 1990 1995
Cys Glu His Ser Asn Thr Leu Val Gln Gln Ala Met Met Val Ser
2000 2005 2010
Glu Glu Leu Ile Arg Val Ala Ile Leu Trp His Glu Met Trp His
2015 2020 2025
Glu Gly Leu Glu Glu Ala Ser Arg Leu Tyr Phe Gly Glu Arg Asn
2030 2035 2040
Val Lys Gly Met Phe Glu Val Leu Glu Pro Leu His Ala Met Met
2045 2050 2055
Glu Arg Gly Pro Gln Thr Leu Lys Glu Thr Ser Phe Asn Gln Ala
2060 2065 2070
Tyr Gly Arg Asp Leu Met Glu Ala Gln Glu Trp Cys Arg Lys Tyr
2075 2080 2085
Met Lys Ser Gly Asn Val Lys Asp Leu Thr Gln Ala Trp Asp Leu
2090 2095 2100
Tyr Tyr His Val Phe Arg Arg Ile Ser Lys Gln Leu Pro Gln Leu
2105 2110 2115
Thr Ser Leu Glu Leu Gln Tyr Val Ser Pro Lys Leu Leu Met Cys
2120 2125 2130
Arg Asp Leu Glu Leu Ala Val Pro Gly Thr Tyr Asp Pro Asn Gln
2135 2140 2145
Pro Ile Ile Arg Ile Gln Ser Ile Ala Pro Ser Leu Gln Val Ile
2150 2155 2160
Thr Ser Lys Gln Arg Pro Arg Lys Leu Thr Leu Met Gly Ser Asn
2165 2170 2175
Gly His Glu Phe Val Phe Leu Leu Lys Gly His Glu Asp Leu Arg
2180 2185 2190
Gln Asp Glu Arg Val Met Gln Leu Phe Gly Leu Val Asn Thr Leu
2195 2200 2205
Leu Ala Asn Asp Pro Thr Ser Leu Arg Lys Asn Leu Ser Ile Gln
2210 2215 2220
Arg Tyr Ala Val Ile Pro Leu Ser Thr Asn Ser Gly Leu Ile Gly
2225 2230 2235
Trp Val Pro His Cys Asp Thr Leu His Ala Leu Ile Arg Asp Tyr
2240 2245 2250
Arg Glu Lys Lys Lys Ile Leu Leu Asn Ile Glu His Arg Ile Met
2255 2260 2265
Leu Arg Met Ala Pro Asp Tyr Asp His Leu Thr Leu Met Gln Lys
2270 2275 2280
Val Glu Val Phe Glu His Ala Val Asn Asn Thr Ala Gly Asp Asp
2285 2290 2295
Leu Ala Lys Leu Leu Trp Leu Lys Ser Pro Ser Ser Glu Val Trp
2300 2305 2310
Phe Asp Arg Arg Thr Asn Tyr Thr Arg Ser Leu Ala Val Met Ser
2315 2320 2325
Met Val Gly Tyr Ile Leu Gly Leu Gly Asp Arg His Pro Ser Asn
2330 2335 2340
Leu Met Leu Asp Arg Leu Ser Gly Lys Ile Leu His Ile Asp Phe
2345 2350 2355
Gly Asp Cys Phe Glu Val Ala Met Thr Arg Glu Lys Phe Pro Glu
2360 2365 2370
Lys Ile Pro Phe Arg Leu Thr Arg Met Leu Thr Asn Ala Met Glu
2375 2380 2385
Val Thr Gly Leu Asp Gly Asn Tyr Arg Ile Thr Cys His Thr Val
2390 2395 2400
Met Glu Val Leu Arg Glu His Lys Asp Ser Val Met Ala Val Leu
2405 2410 2415
Glu Ala Phe Val Tyr Asp Pro Leu Leu Asn Trp Arg Leu Met Asp
2420 2425 2430
Thr Asn Thr Lys Gly Asn Lys Arg Ser Arg Thr Arg Thr Asp Ser
2435 2440 2445
Tyr Ser Ala Gly Gln Ser Val Glu Ile Leu Asp Gly Val Glu Leu
2450 2455 2460
Gly Glu Pro Ala His Lys Lys Thr Gly Thr Thr Val Pro Glu Ser
2465 2470 2475
Ile His Ser Phe Ile Gly Asp Gly Leu Val Lys Pro Glu Ala Leu
2480 2485 2490
Asn Lys Lys Ala Ile Gln Ile Ile Asn Arg Val Arg Asp Lys Leu
2495 2500 2505
Thr Gly Arg Asp Phe Ser His Asp Asp Thr Leu Asp Val Pro Thr
2510 2515 2520
Gln Val Glu Leu Leu Ile Lys Gln Ala Thr Ser His Glu Asn Leu
2525 2530 2535
Cys Gln Cys Tyr Ile Gly Trp Cys Pro Phe Trp
2540 2545
<210> 66
<211> 7650
<212> DNA
<213> Homo sapiens
<400> 66
atgcttggaa ccggacctgc cgccgccacc accgctgcca ccacatctag caatgtgagc 60
gtcctgcagc agtttgccag tggcctaaag agccggaatg aggaaaccag ggccaaagcc 120
gccaaggagc tccagcacta tgtcaccatg gaactccgag agatgagtca agaggagtct 180
actcgcttct atgaccaact gaaccatcac atttttgaat tggtttccag ctcagatgcc 240
aatgagagga aaggtggcat cttggccata gctagcctca taggagtgga aggtgggaat 300
gccacccgaa ttggcagatt tgccaactat cttcggaacc tcctcccctc caatgaccca 360
gttgtcatgg aaatggcatc caaggccatt ggccgtcttg ccatggcagg ggacactttt 420
accgctgagt acgtggaatt tgaggtgaag cgagccctgg aatggctggg tgctgaccgc 480
aatgagggcc ggagacatgc agctgtcctg gttctccgtg agctggccat cagcgtccct 540
accttcttct tccagcaagt gcaacccttc tttgacaaca tttttgtggc cgtgtgggac 600
cccaaacagg ccatccgtga gggagctgta gccgcccttc gtgcctgtct gattctcaca 660
acccagcgtg agccgaagga gatgcagaag cctcagtggt acaggcacac atttgaagaa 720
gcagagaagg gatttgatga gaccttggcc aaagagaagg gcatgaatcg ggatgatcgg 780
atccatggag ccttgttgat ccttaacgag ctggtccgaa tcagcagcat ggagggagag 840
cgtctgagag aagaaatgga agaaatcaca cagcagcagc tggtacacga caagtactgc 900
aaagatctca tgggcttcgg aacaaaacct cgtcacatta cccccttcac cagtttccag 960
gctgtacagc cccagcagtc aaatgccttg gtggggctgc tggggtacag ctctcaccaa 1020
ggcctcatgg gatttgggac ctcccccagt ccagctaagt ccaccctggt ggagagccgg 1080
tgttgcagag acttgatgga ggagaaattt gatcaggtgt gccagtgggt gctgaaatgc 1140
aggaatagca agaactcgct gatccaaatg acaatcctta atttgttgcc ccgcttggct 1200
gcattccgac cttctgcctt cacagatacc cagtatctcc aagataccat gaaccatgtc 1260
ctaagctgtg tcaagaagga gaaggaacgt acagcggcct tccaagccct ggggctactt 1320
tctgtggctg tgaggtctga gtttaaggtc tatttgcctc gcgtgctgga catcatccga 1380
gcggccctgc ccccaaagga cttcgcccat aagaggcaga aggcaatgca ggtggatgcc 1440
acagtcttca cttgcatcag catgctggct cgagcaatgg ggccaggcat ccagcaggat 1500
atcaaggagc tgctggagcc catgctggca gtgggactaa gccctgccct cactgcagtg 1560
ctctacgacc tgagccgtca gattccacag ctaaagaagg acattcaaga tgggctactg 1620
aaaatgctgt ccctggtcct tatgcacaaa ccccttcgcc acccaggcat gcccaagggc 1680
ctggcccatc agctggcctc tcctggcctc acgaccctcc ctgaggccag cgatgtgggc 1740
agcatcactc ttgccctccg aacgcttggc agctttgaat ttgaaggcca ctctctgacc 1800
caatttgttc gccactgtgc ggatcatttc ctgaacagtg agcacaagga gatccgcatg 1860
gaggctgccc gcacctgctc ccgcctgctc acaccctcca tccacctcat cagtggccat 1920
gctcatgtgg ttagccagac cgcagtgcaa gtggtggcag atgtgcttag caaactgctc 1980
gtagttggga taacagatcc tgaccctgac attcgctact gtgtcttggc gtccctggac 2040
gagcgctttg atgcacacct ggcccaggcg gagaacttgc aggccttgtt tgtggctctg 2100
aatgaccagg tgtttgagat ccgggagctg gccatctgca ctgtgggccg actcagtagc 2160
atgaaccctg cctttgtcat gcctttcctg cgcaagatgc tcatccagat tttgacagag 2220
ttggagcaca gtgggattgg aagaatcaaa gagcagagtg cccgcatgct ggggcacctg 2280
gtctccaatg ccccccgact catccgcccc tacatggagc ctattctgaa ggcattaatt 2340
ttgaaactga aagatccaga ccctgatcca aacccaggtg tgatcaataa tgtcctggca 2400
acaataggag aattggcaca ggttagtggc ctggaaatga ggaaatgggt tgatgaactt 2460
tttattatca tcatggacat gctccaggat tcctctttgt tggccaaaag gcaggtggct 2520
ctgtggaccc tgggacagtt ggtggccagc actggctatg tagtagagcc ctacaggaag 2580
taccctactt tgcttgaggt gctactgaat tttctgaaga ctgagcagaa ccagggtaca 2640
cgcagagagg ccatccgtgt gttagggctt ttaggggctt tggatcctta caagcacaaa 2700
gtgaacattg gcatgataga ccagtcccgg gatgcctctg ctgtcagcct gtcagaatcc 2760
aagtcaagtc aggattcctc tgactatagc actagtgaaa tgctggtcaa catgggaaac 2820
ttgcctctgg atgagttcta cccagctgtg tccatggtgg ccctgatgcg gatcttccga 2880
gaccagtcac tctctcatca tcacaccatg gttgtccagg ccatcacctt catcttcaag 2940
tccctgggac tcaaatgtgt gcagttcctg ccccaggtca tgcccacgtt ccttaacgtc 3000
attcgagtct gtgatggggc catccgggaa tttttgttcc agcagctggg aatgttggtg 3060
tcctttgtga agagccacat cagaccttat atggatgaaa tagtcaccct catgagagaa 3120
ttctgggtca tgaacacctc aattcagagc acgatcattc ttctcattga gcaaattgtg 3180
gtagctcttg ggggtgaatt taagctctac ctgccccagc tgatcccaca catgctgcgt 3240
gtcttcatgc atgacaacag cccaggccgc attgtctcta tcaagttact ggctgcaatc 3300
cagctgtttg gcgccaacct ggatgactac ctgcatttac tgctgcctcc tattgttaag 3360
ttgtttgatg cccctgaagc tccactgcca tctcgaaagg cagcgctaga gactgtggac 3420
cgcctgacgg agtccctgga tttcactgac tatgcctccc ggatcattca ccctattgtt 3480
cgaacactgg accagagccc agaactgcgc tccacagcca tggacacgct gtcttcactt 3540
gtttttcagc tggggaagaa gtaccaaatt ttcattccaa tggtgaataa agttctggtg 3600
cgacaccgaa tcaatcatca gcgctatgat gtgctcatct gcagaattgt caagggatac 3660
acacttgctg atgaagagga ggatcctttg atttaccagc atcggatgct taggagtggc 3720
caaggggatg cattggctag tggaccagtg gaaacaggac ccatgaagaa actgcacgtc 3780
agcaccatca acctccaaaa ggcctggggc gctgccagga gggtctccaa agatgactgg 3840
ctggaatggc tgagacggct gagcctggag ctgctgaagg actcatcatc gccctccctg 3900
cgctcctgct gggccctggc acaggcctac aacccgatgg ccagggatct cttcaatgct 3960
gcatttgtgt cctgctggtc tgaactgaat gaagatcaac aggatgagct catcagaagc 4020
atcgagttgg ccctcacctc acaagacatc gctgaagtca cacagaccct cttaaacttg 4080
gctgaattca tggaacacag tgacaagggc cccctgccac tgagagatga caatggcatt 4140
gttctgctgg gtgagagagc tgccaagtgc cgagcatatg ccaaagcact acactacaaa 4200
gaactggagt tccagaaagg ccccacccct gccattctag aatctctcat cagcattaat 4260
aataagctac agcagccgga ggcagcggcc ggagtgttag aatatgccat gaaacacttt 4320
ggagagctgg agatccaggc tacctggtat gagaaactgc acgagtggga ggatgccctt 4380
gtggcctatg acaagaaaat ggacaccaac aaggacgacc cagagctgat gctgggccgc 4440
atgcgctgcc tcgaggcctt gggggaatgg ggtcaactcc accagcagtg ctgtgaaaag 4500
tggaccctgg ttaatgatga gacccaagcc aagatggccc ggatggctgc tgcagctgca 4560
tggggtttag gtcagtggga cagcatggaa gaatacacct gtatgatccc tcgggacacc 4620
catgatgggg cattttatag agctgtgctg gcactgcatc aggacctctt ctccttggca 4680
caacagtgca ttgacaaggc cagggacctg ctggatgctg aattaactgc gatggcagga 4740
gagagttaca gtcgggcata tggggccatg gtttcttgcc acatgctgtc cgagctggag 4800
gaggttatcc agtacaaact tgtccccgag cgacgagaga tcatccgcca gatctggtgg 4860
gagagactgc agggctgcca gcgtatcgta gaggactggc agaaaatcct tatggtgcgg 4920
tcccttgtgg tcagccctca tgaagacatg agaacctggc tcaagtatgc aagcctgtgc 4980
ggcaagagtg gcaggctggc tcttgctcat aaaactttag tgttgctcct gggagttgat 5040
ccgtctcggc aacttgacca tcctctgcca acagttcacc ctcaggtgac ctatgcctac 5100
atgaaaaaca tgtggaagag tgcccgcaag atcgatgcct tccagcacat gcagcatttt 5160
gtccagacca tgcagcaaca ggcccagcat gccatcgcta ctgaggacca gcagcataag 5220
caggaactgc acaagctcat ggcccgatgc ttcctgaaac ttggagagtg gcagctgaat 5280
ctacagggca tcaatgagag cacaatcccc aaagtgctgc agtactacag cgccgccaca 5340
gagcacgacc gcagctggta caaggcctgg catgcgtggg cagtgatgaa cttcgaagct 5400
gtgctacact acaaacatca gaaccaagcc cgcgatgaga agaagaaact gcgtcatgcc 5460
agcggggcca acatcaccaa cgccaccact gccgccacca cggccgccac tgccaccacc 5520
actgccagca ccgagggcag caacagtgag agcgaggccg agagcaccga gaacagcccc 5580
accccatcgc cgctgcagaa gaaggtcact gaggatctgt ccaaaaccct cctgatgtac 5640
acggtgcctg ccgtccaggg cttcttccgt tccatctcct tgtcacgagg caacaacctc 5700
caggatacac tcagagttct caccttatgg tttgattatg gtcactggcc agatgtcaat 5760
gaggccttag tggagggggt gaaagccatc cagattgata cctggctaca ggttatacct 5820
cagctcattg caagaattga tacgcccaga cccttggtgg gacgtctcat tcaccagctt 5880
ctcacagaca ttggtcggta ccacccccag gccctcatct acccactgac agtggcttct 5940
aagtctacca cgacagcccg gcacaatgca gccaacaaga ttctgaagaa catgtgtgag 6000
cacagcaaca ccctggtcca gcaggccatg atggtgagcg aggagctgat ccgagtggcc 6060
atcctctggc atgagatgtg gcatgaaggc ctggaagagg catctcgttt gtactttggg 6120
gaaaggaacg tgaaaggcat gtttgaggtg ctggagccct tgcatgctat gatggaacgg 6180
ggcccccaga ctctgaagga aacatccttt aatcaggcct atggtcgaga tttaatggag 6240
gcccaagagt ggtgcaggaa gtacatgaaa tcagggaatg tcaaggacct cacccaagcc 6300
tgggacctct attatcatgt gttccgacga atctcaaagc agctgcctca gctcacatcc 6360
ttagagctgc aatatgtttc cccaaaactt ctgatgtgcc gggaccttga attggctgtg 6420
ccaggaacat atgaccccaa ccagccaatc attcgcattc agtccatagc accgtctttg 6480
caagtcatca catccaagca gaggccccgg aaattgacac ttatgggcag caacggacat 6540
gagtttgttt tccttctaaa aggccatgaa gatctgcgcc aggatgagcg tgtgatgcag 6600
ctcttcggcc tggttaacac ccttctggcc aatgacccaa catctcttcg gaaaaacctc 6660
agcatccaga gatacgctgt catcccttta tcgaccaact cgggcctcat tggctgggtt 6720
ccccactgtg acacactgca cgccctcatc cgggactaca gggagaagaa gaagatcctt 6780
ctcaacatcg agcatcgcat catgttgcgg atggctccgg actatgacca cttgactctg 6840
atgcagaagg tggaggtgtt tgagcatgcc gtcaataata cagctgggga cgacctggcc 6900
aagctgctgt ggctgaaaag ccccagctcc gaggtgtggt ttgaccgaag aaccaattat 6960
acccgttctt tagcggtcat gtcaatggtt gggtatattt taggcctggg agatagacac 7020
ccatccaacc tgatgctgga ccgtctgagt gggaagatcc tgcacattga ctttggggac 7080
tgctttgagg ttgctatgac ccgagagaag tttccagaga agattccatt tagactaaca 7140
agaatgttga ccaatgctat ggaggttaca ggcctggatg gcaactacag aatcacatgc 7200
cacacagtga tggaggtgct gcgagagcac aaggacagtg tcatggccgt gctggaagcc 7260
tttgtctatg accccttgct gaactggagg ctgatggaca caaataccaa aggcaacaag 7320
cgatcccgaa cgaggacgga ttcctactct gctggccagt cagtcgaaat tttggacggt 7380
gtggaacttg gagagccagc ccataagaaa acggggacca cagtgccaga atctattcat 7440
tctttcattg gagacggttt ggtgaaacca gaggccctaa ataagaaagc tatccagatt 7500
attaacaggg ttcgagataa gctcactggt cgggacttct ctcatgatga cactttggat 7560
gttccaacgc aagttgagct gctcatcaaa caagcgacat cccatgaaaa cctctgccag 7620
tgctatattg gctggtgccc tttctggtaa 7650
<210> 67
<211> 1147
<212> PRT
<213> Homo sapiens
<400> 67
Met Asp Glu Pro Pro Phe Ser Glu Ala Ala Leu Glu Gln Ala Leu Gly
1 5 10 15
Glu Pro Cys Asp Leu Asp Ala Ala Leu Leu Thr Asp Ile Glu Asp Met
20 25 30
Leu Gln Leu Ile Asn Asn Gln Asp Ser Asp Phe Pro Gly Leu Phe Asp
35 40 45
Pro Pro Tyr Ala Gly Ser Gly Ala Gly Gly Thr Asp Pro Ala Ser Pro
50 55 60
Asp Thr Ser Ser Pro Gly Ser Leu Ser Pro Pro Pro Ala Thr Leu Ser
65 70 75 80
Ser Ser Leu Glu Ala Phe Leu Ser Gly Pro Gln Ala Ala Pro Ser Pro
85 90 95
Leu Ser Pro Pro Gln Pro Ala Pro Thr Pro Leu Lys Met Tyr Pro Ser
100 105 110
Met Pro Ala Phe Ser Pro Gly Pro Gly Ile Lys Glu Glu Ser Val Pro
115 120 125
Leu Ser Ile Leu Gln Thr Pro Thr Pro Gln Pro Leu Pro Gly Ala Leu
130 135 140
Leu Pro Gln Ser Phe Pro Ala Pro Ala Pro Pro Gln Phe Ser Ser Thr
145 150 155 160
Pro Val Leu Gly Tyr Pro Ser Pro Pro Gly Gly Phe Ser Thr Gly Ser
165 170 175
Pro Pro Gly Asn Thr Gln Gln Pro Leu Pro Gly Leu Pro Leu Ala Ser
180 185 190
Pro Pro Gly Val Pro Pro Val Ser Leu His Thr Gln Val Gln Ser Val
195 200 205
Val Pro Gln Gln Leu Leu Thr Val Thr Ala Ala Pro Thr Ala Ala Pro
210 215 220
Val Thr Thr Thr Val Thr Ser Gln Ile Gln Gln Val Pro Val Leu Leu
225 230 235 240
Gln Pro His Phe Ile Lys Ala Asp Ser Leu Leu Leu Thr Ala Met Lys
245 250 255
Thr Asp Gly Ala Thr Val Lys Ala Ala Gly Leu Ser Pro Leu Val Ser
260 265 270
Gly Thr Thr Val Gln Thr Gly Pro Leu Pro Thr Leu Val Ser Gly Gly
275 280 285
Thr Ile Leu Ala Thr Val Pro Leu Val Val Asp Ala Glu Lys Leu Pro
290 295 300
Ile Asn Arg Leu Ala Ala Gly Ser Lys Ala Pro Ala Ser Ala Gln Ser
305 310 315 320
Arg Gly Glu Lys Arg Thr Ala His Asn Ala Ile Glu Lys Arg Tyr Arg
325 330 335
Ser Ser Ile Asn Asp Lys Ile Ile Glu Leu Lys Asp Leu Val Val Gly
340 345 350
Thr Glu Ala Lys Leu Asn Lys Ser Ala Val Leu Arg Lys Ala Ile Asp
355 360 365
Tyr Ile Arg Phe Leu Gln His Ser Asn Gln Lys Leu Lys Gln Glu Asn
370 375 380
Leu Ser Leu Arg Thr Ala Val His Lys Ser Lys Ser Leu Lys Asp Leu
385 390 395 400
Val Ser Ala Cys Gly Ser Gly Gly Asn Thr Asp Val Leu Met Glu Gly
405 410 415
Val Lys Thr Glu Val Glu Asp Thr Leu Thr Pro Pro Pro Ser Asp Ala
420 425 430
Gly Ser Pro Phe Gln Ser Ser Pro Leu Ser Leu Gly Ser Arg Gly Ser
435 440 445
Gly Ser Gly Gly Ser Gly Ser Asp Ser Glu Pro Asp Ser Pro Val Phe
450 455 460
Glu Asp Ser Lys Ala Lys Pro Glu Gln Arg Pro Ser Leu His Ser Arg
465 470 475 480
Gly Met Leu Asp Arg Ser Arg Leu Ala Leu Cys Thr Leu Val Phe Leu
485 490 495
Cys Leu Ser Cys Asn Pro Leu Ala Ser Leu Leu Gly Ala Arg Gly Leu
500 505 510
Pro Ser Pro Ser Asp Thr Thr Ser Val Tyr His Ser Pro Gly Arg Asn
515 520 525
Val Leu Gly Thr Glu Ser Arg Asp Gly Pro Gly Trp Ala Gln Trp Leu
530 535 540
Leu Pro Pro Val Val Trp Leu Leu Asn Gly Leu Leu Val Leu Val Ser
545 550 555 560
Leu Val Leu Leu Phe Val Tyr Gly Glu Pro Val Thr Arg Pro His Ser
565 570 575
Gly Pro Ala Val Tyr Phe Trp Arg His Arg Lys Gln Ala Asp Leu Asp
580 585 590
Leu Ala Arg Gly Asp Phe Ala Gln Ala Ala Gln Gln Leu Trp Leu Ala
595 600 605
Leu Arg Ala Leu Gly Arg Pro Leu Pro Thr Ser His Leu Asp Leu Ala
610 615 620
Cys Ser Leu Leu Trp Asn Leu Ile Arg His Leu Leu Gln Arg Leu Trp
625 630 635 640
Val Gly Arg Trp Leu Ala Gly Arg Ala Gly Gly Leu Gln Gln Asp Cys
645 650 655
Ala Leu Arg Val Asp Ala Ser Ala Ser Ala Arg Asp Ala Ala Leu Val
660 665 670
Tyr His Lys Leu His Gln Leu His Thr Met Gly Lys His Thr Gly Gly
675 680 685
His Leu Thr Ala Thr Asn Leu Ala Leu Ser Ala Leu Asn Leu Ala Glu
690 695 700
Cys Ala Gly Asp Ala Val Ser Val Ala Thr Leu Ala Glu Ile Tyr Val
705 710 715 720
Ala Ala Ala Leu Arg Val Lys Thr Ser Leu Pro Arg Ala Leu His Phe
725 730 735
Leu Thr Arg Phe Phe Leu Ser Ser Ala Arg Gln Ala Cys Leu Ala Gln
740 745 750
Ser Gly Ser Val Pro Pro Ala Met Gln Trp Leu Cys His Pro Val Gly
755 760 765
His Arg Phe Phe Val Asp Gly Asp Trp Ser Val Leu Ser Thr Pro Trp
770 775 780
Glu Ser Leu Tyr Ser Leu Ala Gly Asn Pro Val Asp Pro Leu Ala Gln
785 790 795 800
Val Thr Gln Leu Phe Arg Glu His Leu Leu Glu Arg Ala Leu Asn Cys
805 810 815
Val Thr Gln Pro Asn Pro Ser Pro Gly Ser Ala Asp Gly Asp Lys Glu
820 825 830
Phe Ser Asp Ala Leu Gly Tyr Leu Gln Leu Leu Asn Ser Cys Ser Asp
835 840 845
Ala Ala Gly Ala Pro Ala Tyr Ser Phe Ser Ile Ser Ser Ser Met Ala
850 855 860
Thr Thr Thr Gly Val Asp Pro Val Ala Lys Trp Trp Ala Ser Leu Thr
865 870 875 880
Ala Val Val Ile His Trp Leu Arg Arg Asp Glu Glu Ala Ala Glu Arg
885 890 895
Leu Cys Pro Leu Val Glu His Leu Pro Arg Val Leu Gln Glu Ser Glu
900 905 910
Arg Pro Leu Pro Arg Ala Ala Leu His Ser Phe Lys Ala Ala Arg Ala
915 920 925
Leu Leu Gly Cys Ala Lys Ala Glu Ser Gly Pro Ala Ser Leu Thr Ile
930 935 940
Cys Glu Lys Ala Ser Gly Tyr Leu Gln Asp Ser Leu Ala Thr Thr Pro
945 950 955 960
Ala Ser Ser Ser Ile Asp Lys Ala Val Gln Leu Phe Leu Cys Asp Leu
965 970 975
Leu Leu Val Val Arg Thr Ser Leu Trp Arg Gln Gln Gln Pro Pro Ala
980 985 990
Pro Ala Pro Ala Ala Gln Gly Thr Ser Ser Arg Pro Gln Ala Ser Ala
995 1000 1005
Leu Glu Leu Arg Gly Phe Gln Arg Asp Leu Ser Ser Leu Arg Arg
1010 1015 1020
Leu Ala Gln Ser Phe Arg Pro Ala Met Arg Arg Val Phe Leu His
1025 1030 1035
Glu Ala Thr Ala Arg Leu Met Ala Gly Ala Ser Pro Thr Arg Thr
1040 1045 1050
His Gln Leu Leu Asp Arg Ser Leu Arg Arg Arg Ala Gly Pro Gly
1055 1060 1065
Gly Lys Gly Gly Ala Val Ala Glu Leu Glu Pro Arg Pro Thr Arg
1070 1075 1080
Arg Glu His Ala Glu Ala Leu Leu Leu Ala Ser Cys Tyr Leu Pro
1085 1090 1095
Pro Gly Phe Leu Ser Ala Pro Gly Gln Arg Val Gly Met Leu Ala
1100 1105 1110
Glu Ala Ala Arg Thr Leu Glu Lys Leu Gly Asp Arg Arg Leu Leu
1115 1120 1125
His Asp Cys Gln Gln Met Leu Met Arg Leu Gly Gly Gly Thr Thr
1130 1135 1140
Val Thr Ser Ser
1145
<210> 68
<211> 3444
<212> DNA
<213> Homo sapiens
<400> 68
atggacgagc cacccttcag cgaggcggct ttggagcagg cgctgggcga gccgtgcgat 60
ctggacgcgg cgctgctgac cgacatcgaa gacatgcttc agcttatcaa caaccaagac 120
agtgacttcc ctggcctatt tgacccaccc tatgctggga gtggggcagg gggcacagac 180
cctgccagcc ccgataccag ctccccaggc agcttgtctc cacctcctgc cacattgagc 240
tcctctcttg aagccttcct gagcgggccg caggcagcgc cctcacccct gtcccctccc 300
cagcctgcac ccactccatt gaagatgtac ccgtccatgc ccgctttctc ccctgggcct 360
ggtatcaagg aagagtcagt gccactgagc atcctgcaga cccccacccc acagcccctg 420
ccaggggccc tcctgccaca gagcttccca gccccagccc caccgcagtt cagctccacc 480
cctgtgttag gctaccccag ccctccggga ggcttctcta caggaagccc tcccgggaac 540
acccagcagc cgctgcctgg cctgccactg gcttccccgc caggggtccc gcccgtctcc 600
ttgcacaccc aggtccagag tgtggtcccc cagcagctac tgacagtcac agctgccccc 660
acggcagccc ctgtaacgac cactgtgacc tcgcagatcc agcaggtccc ggtcctgctg 720
cagccccact tcatcaaggc agactcgctg cttctgacag ccatgaagac agacggagcc 780
actgtgaagg cggcaggtct cagtcccctg gtctctggca ccactgtgca gacagggcct 840
ttgccgaccc tggtgagtgg cggaaccatc ttggcaacag tcccactggt cgtagatgcg 900
gagaagctgc ctatcaaccg gctcgcagct ggcagcaagg ccccggcctc tgcccagagc 960
cgtggagaga agcgcacagc ccacaacgcc attgagaagc gctaccgctc ctccatcaat 1020
gacaaaatca ttgagctcaa ggatctggtg gtgggcactg aggcaaagct gaataaatct 1080
gctgtcttgc gcaaggccat cgactacatt cgctttctgc aacacagcaa ccagaaactc 1140
aagcaggaga acctaagtct gcgcactgct gtccacaaaa gcaaatctct gaaggatctg 1200
gtgtcggcct gtggcagtgg agggaacaca gacgtgctca tggagggcgt gaagactgag 1260
gtggaggaca cactgacccc acccccctcg gatgctggct cacctttcca gagcagcccc 1320
ttgtcccttg gcagcagggg cagtggcagc ggtggcagtg gcagtgactc ggagcctgac 1380
agcccagtct ttgaggacag caaggcaaag ccagagcagc ggccgtctct gcacagccgg 1440
ggcatgctgg accgctcccg cctggccctg tgcacgctcg tcttcctctg cctgtcctgc 1500
aaccccttgg cctccttgct gggggcccgg gggcttccca gcccctcaga taccaccagc 1560
gtctaccata gccctgggcg caacgtgctg ggcaccgaga gcagagatgg ccctggctgg 1620
gcccagtggc tgctgccccc agtggtctgg ctgctcaatg ggctgttggt gctcgtctcc 1680
ttggtgcttc tctttgtcta cggtgagcca gtcacacggc cccactcagg ccccgccgtg 1740
tacttctgga ggcatcgcaa gcaggctgac ctggacctgg cccggggaga ctttgcccag 1800
gctgcccagc agctgtggct ggccctgcgg gcactgggcc ggcccctgcc cacctcccac 1860
ctggacctgg cttgtagcct cctctggaac ctcatccgtc acctgctgca gcgtctctgg 1920
gtgggccgct ggctggcagg ccgggcaggg ggcctgcagc aggactgtgc tctgcgagtg 1980
gatgctagcg ccagcgcccg agacgcagcc ctggtctacc ataagctgca ccagctgcac 2040
accatgggga agcacacagg cgggcacctc actgccacca acctggcgct gagtgccctg 2100
aacctggcag agtgtgcagg ggatgccgtg tctgtggcga cgctggccga gatctatgtg 2160
gcggctgcat tgagagtgaa gaccagtctc ccacgggcct tgcattttct gacacgcttc 2220
ttcctgagca gtgcccgcca ggcctgcctg gcacagagtg gctcagtgcc tcctgccatg 2280
cagtggctct gccaccccgt gggccaccgt ttcttcgtgg atggggactg gtccgtgctc 2340
agtaccccat gggagagcct gtacagcttg gccgggaacc cagtggaccc cctggcccag 2400
gtgactcagc tattccggga acatctctta gagcgagcac tgaactgtgt gacccagccc 2460
aaccccagcc ctgggtcagc tgatggggac aaggaattct cggatgccct cgggtacctg 2520
cagctgctga acagctgttc tgatgctgcg ggggctcctg cctacagctt ctccatcagt 2580
tccagcatgg ccaccaccac cggcgtagac ccggtggcca agtggtgggc ctctctgaca 2640
gctgtggtga tccactggct gcggcgggat gaggaggcgg ctgagcggct gtgcccgctg 2700
gtggagcacc tgccccgggt gctgcaggag tctgagagac ccctgcccag ggcagctctg 2760
cactccttca aggctgcccg ggccctgctg ggctgtgcca aggcagagtc tggtccagcc 2820
agcctgacca tctgtgagaa ggccagtggg tacctgcagg acagcctggc taccacacca 2880
gccagcagct ccattgacaa ggccgtgcag ctgttcctgt gtgacctgct tcttgtggtg 2940
cgcaccagcc tgtggcggca gcagcagccc ccggccccgg ccccagcagc ccagggcacc 3000
agcagcaggc cccaggcttc cgcccttgag ctgcgtggct tccaacggga cctgagcagc 3060
ctgaggcggc tggcacagag cttccggccc gccatgcgga gggtgttcct acatgaggcc 3120
acggcccggc tgatggcggg ggccagcccc acacggacac accagctcct cgaccgcagt 3180
ctgaggcggc gggcaggccc cggtggcaaa ggaggcgcgg tggcggagct ggagccgcgg 3240
cccacgcggc gggagcacgc ggaggccttg ctgctggcct cctgctacct gccccccggc 3300
ttcctgtcgg cgcccgggca gcgcgtgggc atgctggctg aggcggcgcg cacactcgag 3360
aagcttggcg atcgccggct gctgcacgac tgtcagcaga tgctcatgcg cctgggcggt 3420
gggaccactg tcacttccag ctag 3444
<210> 69
<211> 138
<212> PRT
<213> Homo sapiens
<400> 69
Gln Asp Pro Tyr Val Lys Glu Ala Glu Asn Leu Lys Lys Tyr Phe Asn
1 5 10 15
Ala Gly His Ser Asp Val Ala Asp Asn Gly Thr Leu Phe Leu Gly Ile
20 25 30
Leu Lys Asn Trp Lys Glu Glu Ser Asp Arg Lys Ile Met Gln Ser Gln
35 40 45
Ile Val Ser Phe Tyr Phe Lys Leu Phe Lys Asn Phe Lys Asp Asp Gln
50 55 60
Ser Ile Gln Lys Ser Val Glu Thr Ile Lys Glu Asp Met Asn Val Lys
65 70 75 80
Phe Phe Asn Ser Asn Lys Lys Lys Arg Asp Asp Phe Glu Lys Leu Thr
85 90 95
Asn Tyr Ser Val Thr Asp Leu Asn Val Gln Arg Lys Ala Ile His Glu
100 105 110
Leu Ile Gln Val Met Ala Glu Leu Ser Pro Ala Ala Lys Thr Gly Lys
115 120 125
Arg Lys Arg Ser Gln Met Leu Phe Arg Gly
130 135
<210> 70
<211> 414
<212> DNA
<213> Homo sapiens
<400> 70
caggacccat atgtaaaaga agcagaaaac cttaagaaat attttaatgc aggtcattca 60
gatgtagcgg ataatggaac tcttttctta ggcattttga agaattggaa agaggagagt 120
gacagaaaaa taatgcagag ccaaattgtc tccttttact tcaaactttt taaaaacttt 180
aaagatgacc agagcatcca aaagagtgtg gagaccatca aggaagacat gaatgtcaag 240
tttttcaata gcaacaaaaa gaaacgagat gacttcgaaa agctgactaa ttattcggta 300
actgacttga atgtccaacg caaagcaata catgaactca tccaagtgat ggctgaactg 360
tcgccagcag ctaaaacagg gaagcgaaaa aggagtcaga tgctgtttcg aggt 414
<210> 71
<211> 227
<212> PRT
<213> Homo sapiens
<400> 71
Ile Ile Gly Gly His Glu Ala Lys Pro His Ser Arg Pro Tyr Met Ala
1 5 10 15
Tyr Leu Met Ile Trp Asp Gln Lys Ser Leu Lys Arg Cys Gly Gly Phe
20 25 30
Leu Ile Arg Asp Asp Phe Val Leu Thr Ala Ala His Cys Trp Gly Ser
35 40 45
Ser Ile Asn Val Thr Leu Gly Ala His Asn Ile Lys Glu Gln Glu Pro
50 55 60
Thr Gln Gln Phe Ile Pro Val Lys Arg Pro Ile Pro His Pro Ala Tyr
65 70 75 80
Asn Pro Lys Asn Phe Ser Asn Asp Ile Met Leu Leu Gln Leu Glu Arg
85 90 95
Lys Ala Lys Arg Thr Arg Ala Val Gln Pro Leu Arg Leu Pro Ser Asn
100 105 110
Lys Ala Gln Val Lys Pro Gly Gln Thr Cys Ser Val Ala Gly Trp Gly
115 120 125
Gln Thr Ala Pro Leu Gly Lys His Ser His Thr Leu Gln Glu Val Lys
130 135 140
Met Thr Val Gln Glu Asp Arg Lys Cys Glu Ser Asp Leu Arg His Tyr
145 150 155 160
Tyr Asp Ser Thr Ile Glu Leu Cys Val Gly Asp Pro Glu Ile Lys Lys
165 170 175
Thr Ser Phe Lys Gly Asp Ser Gly Gly Pro Leu Val Cys Asn Lys Val
180 185 190
Ala Gln Gly Ile Val Ser Tyr Gly Arg Asn Asn Gly Met Pro Pro Arg
195 200 205
Ala Cys Thr Lys Val Ser Ser Phe Val His Trp Ile Lys Lys Thr Met
210 215 220
Lys Arg Tyr
225
<210> 72
<211> 681
<212> DNA
<213> Homo sapiens
<400> 72
atcatcgggg gacatgaggc caagccccac tcccgcccct acatggctta tcttatgatc 60
tgggatcaga agtctctgaa gaggtgcggt ggcttcctga tacgagacga cttcgtgctg 120
acagctgctc actgttgggg aagctccata aatgtcacct tgggggccca caatatcaaa 180
gaacaggagc cgacccagca gtttatccct gtgaaaagac ccatccccca tccagcctat 240
aatcctaaga acttctccaa cgacatcatg ctactgcagc tggagagaaa ggccaagcgg 300
accagagctg tgcagcccct caggctacct agcaacaagg cccaggtgaa gccagggcag 360
acatgcagtg tggccggctg ggggcagacg gcccccctgg gaaaacactc acacacacta 420
caagaggtga agatgacagt gcaggaagat cgaaagtgcg aatctgactt acgccattat 480
tacgacagta ccattgagtt gtgcgtgggg gacccagaga ttaaaaagac ttcctttaag 540
ggggactctg gaggccctct tgtgtgtaac aaggtggccc agggcattgt ctcctatgga 600
cgaaacaatg gcatgcctcc acgagcctgc accaaagtct caagctttgt acactggata 660
aagaaaacca tgaaacgcta c 681
<210> 73
<211> 268
<212> PRT
<213> Homo sapiens
<400> 73
Pro Gly Trp Phe Leu Asp Ser Pro Asp Arg Pro Trp Asn Pro Pro Thr
1 5 10 15
Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp Asn Ala Thr Phe
20 25 30
Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe Val Leu Asn Trp Tyr
35 40 45
Arg Met Ser Pro Ser Asn Gln Thr Asp Lys Leu Ala Ala Phe Pro Glu
50 55 60
Asp Arg Ser Gln Pro Gly Gln Asp Cys Arg Phe Arg Val Thr Gln Leu
65 70 75 80
Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg Ala Arg Arg Asn
85 90 95
Asp Ser Gly Thr Tyr Leu Cys Gly Ala Ile Ser Leu Ala Pro Lys Ala
100 105 110
Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val Thr Glu Arg Arg
115 120 125
Ala Glu Val Pro Thr Ala His Pro Ser Pro Ser Pro Arg Pro Ala Gly
130 135 140
Gln Phe Gln Thr Leu Val Val Gly Val Val Gly Gly Leu Leu Gly Ser
145 150 155 160
Leu Val Leu Leu Val Trp Val Leu Ala Val Ile Cys Ser Arg Ala Ala
165 170 175
Arg Gly Thr Ile Gly Ala Arg Arg Thr Gly Gln Pro Leu Lys Glu Asp
180 185 190
Pro Ser Ala Val Pro Val Phe Ser Val Asp Tyr Gly Glu Leu Asp Phe
195 200 205
Gln Trp Arg Glu Lys Thr Pro Glu Pro Pro Val Pro Cys Val Pro Glu
210 215 220
Gln Thr Glu Tyr Ala Thr Ile Val Phe Pro Ser Gly Met Gly Thr Ser
225 230 235 240
Ser Pro Ala Arg Arg Gly Ser Ala Asp Gly Pro Arg Ser Ala Gln Pro
245 250 255
Leu Arg Pro Glu Asp Gly His Cys Ser Trp Pro Leu
260 265
<210> 74
<211> 272
<212> PRT
<213> Homo sapiens
<400> 74
Phe Thr Val Thr Val Pro Lys Asp Leu Tyr Val Val Glu Tyr Gly Ser
1 5 10 15
Asn Met Thr Ile Glu Cys Lys Phe Pro Val Glu Lys Gln Leu Asp Leu
20 25 30
Ala Ala Leu Ile Val Tyr Trp Glu Met Glu Asp Lys Asn Ile Ile Gln
35 40 45
Phe Val His Gly Glu Glu Asp Leu Lys Val Gln His Ser Ser Tyr Arg
50 55 60
Gln Arg Ala Arg Leu Leu Lys Asp Gln Leu Ser Leu Gly Asn Ala Ala
65 70 75 80
Leu Gln Ile Thr Asp Val Lys Leu Gln Asp Ala Gly Val Tyr Arg Cys
85 90 95
Met Ile Ser Tyr Gly Gly Ala Asp Tyr Lys Arg Ile Thr Val Lys Val
100 105 110
Asn Ala Pro Tyr Asn Lys Ile Asn Gln Arg Ile Leu Val Val Asp Pro
115 120 125
Val Thr Ser Glu His Glu Leu Thr Cys Gln Ala Glu Gly Tyr Pro Lys
130 135 140
Ala Glu Val Ile Trp Thr Ser Ser Asp His Gln Val Leu Ser Gly Lys
145 150 155 160
Thr Thr Thr Thr Asn Ser Lys Arg Glu Glu Lys Leu Phe Asn Val Thr
165 170 175
Ser Thr Leu Arg Ile Asn Thr Thr Thr Asn Glu Ile Phe Tyr Cys Thr
180 185 190
Phe Arg Arg Leu Asp Pro Glu Glu Asn His Thr Ala Glu Leu Val Ile
195 200 205
Pro Glu Leu Pro Leu Ala His Pro Pro Asn Glu Arg Thr His Leu Val
210 215 220
Ile Leu Gly Ala Ile Leu Leu Cys Leu Gly Val Ala Leu Thr Phe Ile
225 230 235 240
Phe Arg Leu Arg Lys Gly Arg Met Met Asp Val Lys Lys Cys Gly Ile
245 250 255
Gln Asp Thr Asn Ser Lys Lys Gln Ser Asp Thr His Leu Glu Glu Thr
260 265 270
<210> 75
<211> 223
<212> PRT
<213> Homo sapiens
<400> 75
Met Met Thr Gly Thr Ile Glu Thr Thr Gly Asn Ile Ser Ala Glu Lys
1 5 10 15
Gly Gly Ser Ile Ile Leu Gln Cys His Leu Ser Ser Thr Thr Ala Gln
20 25 30
Val Thr Gln Val Asn Trp Glu Gln Gln Asp Gln Leu Leu Ala Ile Cys
35 40 45
Asn Ala Asp Leu Gly Trp His Ile Ser Pro Ser Phe Lys Asp Arg Val
50 55 60
Ala Pro Gly Pro Gly Leu Gly Leu Thr Leu Gln Ser Leu Thr Val Asn
65 70 75 80
Asp Thr Gly Glu Tyr Phe Cys Ile Tyr His Thr Tyr Pro Asp Gly Thr
85 90 95
Tyr Thr Gly Arg Ile Phe Leu Glu Val Leu Glu Ser Ser Val Ala Glu
100 105 110
His Gly Ala Arg Phe Gln Ile Pro Leu Leu Gly Ala Met Ala Ala Thr
115 120 125
Leu Val Val Ile Cys Thr Ala Val Ile Val Val Val Ala Leu Thr Arg
130 135 140
Lys Lys Lys Ala Leu Arg Ile His Ser Val Glu Gly Asp Leu Arg Arg
145 150 155 160
Lys Ser Ala Gly Gln Glu Glu Trp Ser Pro Ser Ala Pro Ser Pro Pro
165 170 175
Gly Ser Cys Val Gln Ala Glu Ala Ala Pro Ala Gly Leu Cys Gly Glu
180 185 190
Gln Arg Gly Glu Asp Cys Ala Glu Leu His Asp Tyr Phe Asn Val Leu
195 200 205
Ser Tyr Arg Ser Leu Gly Asn Cys Ser Phe Phe Thr Glu Thr Gly
210 215 220
<210> 76
<211> 311
<212> PRT
<213> Homo sapiens
<400> 76
Asn Ala Asp Gly Leu Lys Glu Pro Leu Ser Phe His Val Thr Trp Ile
1 5 10 15
Ala Ser Phe Tyr Asn His Ser Trp Lys Gln Asn Leu Val Ser Gly Trp
20 25 30
Leu Ser Asp Leu Gln Thr His Thr Trp Asp Ser Asn Ser Ser Thr Ile
35 40 45
Val Phe Leu Cys Pro Trp Ser Arg Gly Asn Phe Ser Asn Glu Glu Trp
50 55 60
Lys Glu Leu Glu Thr Leu Phe Arg Ile Arg Thr Ile Arg Ser Phe Glu
65 70 75 80
Gly Ile Arg Arg Tyr Ala His Glu Leu Gln Phe Glu Tyr Pro Phe Glu
85 90 95
Ile Gln Val Thr Gly Gly Cys Glu Leu His Ser Gly Lys Val Ser Gly
100 105 110
Ser Phe Leu Gln Leu Ala Tyr Gln Gly Ser Asp Phe Val Ser Phe Gln
115 120 125
Asn Asn Ser Trp Leu Pro Tyr Pro Val Ala Gly Asn Met Ala Lys His
130 135 140
Phe Cys Lys Val Leu Asn Gln Asn Gln His Glu Asn Asp Ile Thr His
145 150 155 160
Asn Leu Leu Ser Asp Thr Cys Pro Arg Phe Ile Leu Gly Leu Leu Asp
165 170 175
Ala Gly Lys Ala His Leu Gln Arg Gln Val Lys Pro Glu Ala Trp Leu
180 185 190
Ser His Gly Pro Ser Pro Gly Pro Gly His Leu Gln Leu Val Cys His
195 200 205
Val Ser Gly Phe Tyr Pro Lys Pro Val Trp Val Met Trp Met Arg Gly
210 215 220
Glu Gln Glu Gln Gln Gly Thr Gln Arg Gly Asp Ile Leu Pro Ser Ala
225 230 235 240
Asp Gly Thr Trp Tyr Leu Arg Ala Thr Leu Glu Val Ala Ala Gly Glu
245 250 255
Ala Ala Asp Leu Ser Cys Arg Val Lys His Ser Ser Leu Glu Gly Gln
260 265 270
Asp Ile Val Leu Tyr Trp Glu His His Ser Ser Val Gly Phe Ile Ile
275 280 285
Leu Ala Val Ile Val Pro Leu Leu Leu Leu Ile Gly Leu Ala Leu Trp
290 295 300
Phe Arg Lys Arg Cys Phe Cys
305 310
<210> 77
<211> 279
<212> PRT
<213> Homo sapiens
<400> 77
Ser Glu Val Glu Tyr Arg Ala Glu Val Gly Gln Asn Ala Tyr Leu Pro
1 5 10 15
Cys Phe Tyr Thr Pro Ala Ala Pro Gly Asn Leu Val Pro Val Cys Trp
20 25 30
Gly Lys Gly Ala Cys Pro Val Phe Glu Cys Gly Asn Val Val Leu Arg
35 40 45
Thr Asp Glu Arg Asp Val Asn Tyr Trp Thr Ser Arg Tyr Trp Leu Asn
50 55 60
Gly Asp Phe Arg Lys Gly Asp Val Ser Leu Thr Ile Glu Asn Val Thr
65 70 75 80
Leu Ala Asp Ser Gly Ile Tyr Cys Cys Arg Ile Gln Ile Pro Gly Ile
85 90 95
Met Asn Asp Glu Lys Phe Asn Leu Lys Leu Val Ile Lys Pro Ala Lys
100 105 110
Val Thr Pro Ala Pro Thr Arg Gln Arg Asp Phe Thr Ala Ala Phe Pro
115 120 125
Arg Met Leu Thr Thr Arg Gly His Gly Pro Ala Glu Thr Gln Thr Leu
130 135 140
Gly Ser Leu Pro Asp Ile Asn Leu Thr Gln Ile Ser Thr Leu Ala Asn
145 150 155 160
Glu Leu Arg Asp Ser Arg Leu Ala Asn Asp Leu Arg Asp Ser Gly Ala
165 170 175
Thr Ile Arg Ile Gly Ile Tyr Ile Gly Ala Gly Ile Cys Ala Gly Leu
180 185 190
Ala Leu Ala Leu Ile Phe Gly Ala Leu Ile Phe Lys Trp Tyr Ser His
195 200 205
Ser Lys Glu Lys Ile Gln Asn Leu Ser Leu Ile Ser Leu Ala Asn Leu
210 215 220
Pro Pro Ser Gly Leu Ala Asn Ala Val Ala Glu Gly Ile Arg Ser Glu
225 230 235 240
Glu Asn Ile Tyr Thr Ile Glu Glu Asn Val Tyr Glu Val Glu Glu Pro
245 250 255
Asn Glu Tyr Tyr Cys Tyr Val Ser Ser Arg Gln Gln Pro Ser Gln Pro
260 265 270
Leu Gly Cys Arg Phe Ala Met
275
<210> 78
<211> 133
<212> PRT
<213> Homo sapiens
<400> 78
Ala Pro Thr Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His
1 5 10 15
Leu Leu Leu Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys
20 25 30
Asn Pro Lys Leu Thr Arg Met Leu Thr Phe Lys Phe Tyr Met Pro Lys
35 40 45
Lys Ala Thr Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys
50 55 60
Pro Leu Glu Glu Val Leu Asn Leu Ala Gln Ser Lys Asn Phe His Leu
65 70 75 80
Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu
85 90 95
Lys Gly Ser Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala
100 105 110
Thr Ile Val Glu Phe Leu Asn Arg Trp Ile Thr Phe Cys Gln Ser Ile
115 120 125
Ile Ser Thr Leu Thr
130
<210> 79
<211> 152
<212> PRT
<213> Homo sapiens
<400> 79
Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser Val Leu
1 5 10 15
Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile Gly Ser
20 25 30
Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile Cys Asp
35 40 45
Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys Leu Arg
50 55 60
Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His Leu Leu
65 70 75 80
Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly Gln Val
85 90 95
Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr Lys Ser
100 105 110
Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn Asp Leu
115 120 125
Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp Asn Lys
130 135 140
Ile Leu Met Gly Thr Lys Glu His
145 150
<210> 80
<211> 197
<212> PRT
<213> Homo sapiens
<400> 80
Arg Asn Leu Pro Val Ala Thr Pro Asp Pro Gly Met Phe Pro Cys Leu
1 5 10 15
His His Ser Gln Asn Leu Leu Arg Ala Val Ser Asn Met Leu Gln Lys
20 25 30
Ala Arg Gln Thr Leu Glu Phe Tyr Pro Cys Thr Ser Glu Glu Ile Asp
35 40 45
His Glu Asp Ile Thr Lys Asp Lys Thr Ser Thr Val Glu Ala Cys Leu
50 55 60
Pro Leu Glu Leu Thr Lys Asn Glu Ser Cys Leu Asn Ser Arg Glu Thr
65 70 75 80
Ser Phe Ile Thr Asn Gly Ser Cys Leu Ala Ser Arg Lys Thr Ser Phe
85 90 95
Met Met Ala Leu Cys Leu Ser Ser Ile Tyr Glu Asp Leu Lys Met Tyr
100 105 110
Gln Val Glu Phe Lys Thr Met Asn Ala Lys Leu Leu Met Asp Pro Lys
115 120 125
Arg Gln Ile Phe Leu Asp Gln Asn Met Leu Ala Val Ile Asp Glu Leu
130 135 140
Met Gln Ala Leu Asn Phe Asn Ser Glu Thr Val Pro Gln Lys Ser Ser
145 150 155 160
Leu Glu Glu Pro Asp Phe Tyr Lys Thr Lys Ile Lys Leu Cys Ile Leu
165 170 175
Leu His Ala Phe Arg Ile Arg Ala Val Thr Ile Asp Arg Val Met Ser
180 185 190
Tyr Leu Asn Ala Ser
195
<210> 81
<211> 306
<212> PRT
<213> Homo sapiens
<400> 81
Ile Trp Glu Leu Lys Lys Asp Val Tyr Val Val Glu Leu Asp Trp Tyr
1 5 10 15
Pro Asp Ala Pro Gly Glu Met Val Val Leu Thr Cys Asp Thr Pro Glu
20 25 30
Glu Asp Gly Ile Thr Trp Thr Leu Asp Gln Ser Ser Glu Val Leu Gly
35 40 45
Ser Gly Lys Thr Leu Thr Ile Gln Val Lys Glu Phe Gly Asp Ala Gly
50 55 60
Gln Tyr Thr Cys His Lys Gly Gly Glu Val Leu Ser His Ser Leu Leu
65 70 75 80
Leu Leu His Lys Lys Glu Asp Gly Ile Trp Ser Thr Asp Ile Leu Lys
85 90 95
Asp Gln Lys Glu Pro Lys Asn Lys Thr Phe Leu Arg Cys Glu Ala Lys
100 105 110
Asn Tyr Ser Gly Arg Phe Thr Cys Trp Trp Leu Thr Thr Ile Ser Thr
115 120 125
Asp Leu Thr Phe Ser Val Lys Ser Ser Arg Gly Ser Ser Asp Pro Gln
130 135 140
Gly Val Thr Cys Gly Ala Ala Thr Leu Ser Ala Glu Arg Val Arg Gly
145 150 155 160
Asp Asn Lys Glu Tyr Glu Tyr Ser Val Glu Cys Gln Glu Asp Ser Ala
165 170 175
Cys Pro Ala Ala Glu Glu Ser Leu Pro Ile Glu Val Met Val Asp Ala
180 185 190
Val His Lys Leu Lys Tyr Glu Asn Tyr Thr Ser Ser Phe Phe Ile Arg
195 200 205
Asp Ile Ile Lys Pro Asp Pro Pro Lys Asn Leu Gln Leu Lys Pro Leu
210 215 220
Lys Asn Ser Arg Gln Val Glu Val Ser Trp Glu Tyr Pro Asp Thr Trp
225 230 235 240
Ser Thr Pro His Ser Tyr Phe Ser Leu Thr Phe Cys Val Gln Val Gln
245 250 255
Gly Lys Ser Lys Arg Glu Lys Lys Asp Arg Val Phe Thr Asp Lys Thr
260 265 270
Ser Ala Thr Val Ile Cys Arg Lys Asn Ala Ser Ile Ser Val Arg Ala
275 280 285
Gln Asp Arg Tyr Tyr Ser Ser Ser Trp Ser Glu Trp Ala Ser Val Pro
290 295 300
Cys Ser
305
<210> 82
<211> 114
<212> PRT
<213> Homo sapiens
<400> 82
Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile
1 5 10 15
Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp Val His
20 25 30
Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu Glu Leu Gln
35 40 45
Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp Thr Val Glu
50 55 60
Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly Asn Val
65 70 75 80
Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile
85 90 95
Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met Phe Ile Asn
100 105 110
Thr Ser
<210> 83
<211> 133
<212> PRT
<213> Homo sapiens
<400> 83
Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp Ile
1 5 10 15
Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe Leu
20 25 30
Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe Ser
35 40 45
Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn Glu
50 55 60
Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro Ser
65 70 75 80
Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser Cys
85 90 95
Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe Lys
100 105 110
Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr His
115 120 125
Gly Ser Glu Asp Ser
130
<210> 84
<211> 270
<212> PRT
<213> Homo sapiens
<400> 84
Met Lys Pro Lys Met Lys Tyr Ser Thr Asn Lys Ile Ser Thr Ala Lys
1 5 10 15
Trp Lys Asn Thr Ala Ser Lys Ala Leu Cys Phe Lys Leu Gly Lys Ser
20 25 30
Gln Gln Lys Ala Lys Glu Val Cys Pro Met Tyr Phe Met Lys Leu Arg
35 40 45
Ser Gly Leu Met Ile Lys Lys Glu Ala Cys Tyr Phe Arg Arg Glu Thr
50 55 60
Thr Lys Arg Pro Ser Leu Lys Thr Gly Arg Lys His Lys Arg His Leu
65 70 75 80
Val Leu Ala Ala Cys Gln Gln Gln Ser Thr Val Glu Cys Phe Ala Phe
85 90 95
Gly Ile Ser Gly Val Gln Lys Tyr Thr Arg Ala Leu His Asp Ser Ser
100 105 110
Ile Thr Gly Ile Ser Pro Ile Thr Glu Tyr Leu Ala Ser Leu Ser Thr
115 120 125
Tyr Asn Asp Gln Ser Ile Thr Phe Ala Leu Glu Asp Glu Ser Tyr Glu
130 135 140
Ile Tyr Val Glu Asp Leu Lys Lys Asp Glu Lys Lys Asp Lys Val Leu
145 150 155 160
Leu Ser Tyr Tyr Glu Ser Gln His Pro Ser Asn Glu Ser Gly Asp Gly
165 170 175
Val Asp Gly Lys Met Leu Met Val Thr Leu Ser Pro Thr Lys Asp Phe
180 185 190
Trp Leu His Ala Asn Asn Lys Glu His Ser Val Glu Leu His Lys Cys
195 200 205
Glu Lys Pro Leu Pro Asp Gln Ala Phe Phe Val Leu His Asn Met His
210 215 220
Ser Asn Cys Val Ser Phe Glu Cys Lys Thr Asp Pro Gly Val Phe Ile
225 230 235 240
Gly Val Lys Asp Asn His Leu Ala Leu Ile Lys Val Asp Ser Ser Glu
245 250 255
Asn Leu Cys Thr Glu Asn Ile Leu Phe Lys Leu Ser Glu Thr
260 265 270
<210> 85
<211> 696
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 85
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Leu Ala Ser Gly Val Pro Ala His Phe Arg Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Gly Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Asn Pro Phe Thr
85 90 95
Phe Gly Ser Gly Thr Lys Leu Glu Ile Asn Arg Gly Gly Gly Gly Ser
100 105 110
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln
115 120 125
Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala Ser Val Lys Met Ser Cys
130 135 140
Lys Ala Ser Gly Tyr Thr Phe Thr Arg Tyr Thr Met His Trp Val Lys
145 150 155 160
Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile Gly Tyr Ile Asn Pro Ser
165 170 175
Arg Gly Tyr Thr Asn Tyr Asn Gln Lys Phe Lys Asp Lys Ala Thr Leu
180 185 190
Thr Thr Asp Lys Ser Ser Ser Thr Ala Tyr Met Gln Leu Ser Ser Leu
195 200 205
Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala Arg Tyr Tyr Asp Asp
210 215 220
His Tyr Cys Leu Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser
225 230 235 240
Ser Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys
245 250 255
Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn
260 265 270
Gln Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser
275 280 285
Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile
290 295 300
Val Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro
305 310 315 320
Ala Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu
325 330 335
Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro
340 345 350
Thr Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val
355 360 365
Glu Asp Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu
370 375 380
Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys
385 390 395 400
Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe
405 410 415
Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala
420 425 430
Val Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val
435 440 445
Glu Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Val Gln Leu Gln
450 455 460
Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala Ser Val Lys Met Ser
465 470 475 480
Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr Val Ile Gln Trp Val
485 490 495
Lys Gln Lys Pro Gly Gln Gly Leu Glu Trp Ile Gly Ser Ile Asn Pro
500 505 510
Tyr Asn Asp Tyr Thr Lys Tyr Asn Glu Lys Phe Lys Gly Lys Ala Thr
515 520 525
Leu Thr Ser Asp Lys Ser Ser Ile Thr Ala Tyr Met Glu Phe Ser Ser
530 535 540
Leu Thr Ser Glu Asp Ser Ala Leu Tyr Tyr Cys Ala Arg Trp Gly Asp
545 550 555 560
Gly Asn Tyr Trp Gly Arg Gly Thr Thr Leu Thr Val Ser Ser Gly Gly
565 570 575
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Ile Glu
580 585 590
Met Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Leu Gly Glu Arg Val
595 600 605
Thr Met Thr Cys Thr Ala Ser Ser Ser Val Ser Ser Ser Tyr Phe His
610 615 620
Trp Tyr Gln Gln Lys Pro Gly Ser Ser Pro Lys Leu Cys Ile Tyr Ser
625 630 635 640
Thr Ser Asn Leu Ala Ser Gly Val Pro Pro Arg Phe Ser Gly Ser Gly
645 650 655
Ser Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu Asp Ala
660 665 670
Ala Thr Tyr Phe Cys His Gln Tyr His Arg Ser Pro Thr Phe Gly Gly
675 680 685
Gly Thr Lys Leu Glu Thr Lys Arg
690 695
<210> 86
<211> 2088
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 86
cagatcgtgc tgacccaaag ccccgccatc atgagcgcta gccccggtga gaaggtgacc 60
atgacatgct ccgcttccag ctccgtgtcc tacatgaact ggtatcagca gaaaagcgga 120
accagcccca aaaggtggat ctacgacacc agcaagctgg cctccggagt gcccgctcat 180
ttccggggct ctggatccgg caccagctac tctttaacca tttccggcat ggaagctgaa 240
gacgctgcca cctactattg ccagcaatgg agcagcaacc ccttcacatt cggatctggc 300
accaagctcg aaatcaatcg tggaggaggt ggcagcggcg gcggtggatc cggcggagga 360
ggaagccaag ttcaactcca gcagagcggc gctgaactgg cccggcccgg cgcctccgtc 420
aagatgagct gcaaggcttc cggctataca tttactcgtt acacaatgca ttgggtcaag 480
cagaggcccg gtcaaggttt agagtggatc ggatatatca acccttcccg gggctacacc 540
aactataacc aaaagttcaa ggataaagcc actttaacca ctgacaagag ctcctccacc 600
gcctacatgc agctgtcctc tttaaccagc gaggactccg ctgtttacta ctgcgctagg 660
tattacgacg accactactg tttagactat tggggacaag gtaccacttt aaccgtcagc 720
agctccggca ccaccaatac cgtggccgct tataacctca catggaagag caccaacttc 780
aagacaattc tggaatggga acccaagccc gtcaatcaag tttacaccgt gcagatctcc 840
accaaatccg gagactggaa gagcaagtgc ttctacacaa cagacaccga gtgtgattta 900
accgacgaaa tcgtcaagga cgtcaagcaa acctatctgg ctcgggtctt ttcctacccc 960
gctggcaatg tcgagtccac cggctccgct ggcgagcctc tctacgagaa ttcccccgaa 1020
ttcacccctt atttagagac caatttaggc cagcctacca tccagagctt cgagcaagtt 1080
ggcaccaagg tgaacgtcac cgtcgaggat gaaaggactt tagtgcggcg gaataacaca 1140
tttttatccc tccgggatgt gttcggcaaa gacctcatct acacactgta ctattggaag 1200
tccagctcct ccggcaaaaa gaccgctaag accaacacca acgagttttt aattgacgtg 1260
gacaaaggcg agaactactg cttcagcgtg caagccgtga tcccttctcg taccgtcaac 1320
cggaagagca cagattcccc cgttgagtgc atgggccaag aaaagggcga gttccgggag 1380
gtccagctgc agcagagcgg acccgaactc gtgaaacccg gtgcttccgt gaaaatgtct 1440
tgtaaggcca gcggatacac cttcacctcc tatgtgatcc agtgggtcaa acagaagccc 1500
ggacaaggtc tcgagtggat cggcagcatc aacccttaca acgactatac caaatacaac 1560
gagaagttta agggaaaggc tactttaacc tccgacaaaa gctccatcac agcctacatg 1620
gagttcagct ctttaacatc cgaggacagc gctctgtact attgcgcccg gtggggcgac 1680
ggcaattact ggggacgggg cacaacactg accgtgagca gcggaggcgg aggctccggc 1740
ggaggcggat ctggcggtgg cggctccgac atcgagatga cccagtcccc cgctatcatg 1800
tccgcctctt taggcgagcg ggtcacaatg acttgtacag cctcctccag cgtctcctcc 1860
tcctacttcc attggtacca acagaaaccc ggaagctccc ctaaactgtg catctacagc 1920
accagcaatc tcgccagcgg cgtgccccct aggttttccg gaagcggaag caccagctac 1980
tctttaacca tctcctccat ggaggctgag gatgccgcca cctacttttg tcaccagtac 2040
caccggtccc ccaccttcgg aggcggcacc aaactggaga caaagagg 2088
<210> 87
<211> 714
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 87
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser
20 25 30
Pro Gly Glu Lys Val Thr Met Thr Cys Ser Ala Ser Ser Ser Val Ser
35 40 45
Tyr Met Asn Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp
50 55 60
Ile Tyr Asp Thr Ser Lys Leu Ala Ser Gly Val Pro Ala His Phe Arg
65 70 75 80
Gly Ser Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Gly Met Glu
85 90 95
Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Asn Pro
100 105 110
Phe Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Asn Arg Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Val Gln Leu
130 135 140
Gln Gln Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala Ser Val Lys Met
145 150 155 160
Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Arg Tyr Thr Met His Trp
165 170 175
Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile Gly Tyr Ile Asn
180 185 190
Pro Ser Arg Gly Tyr Thr Asn Tyr Asn Gln Lys Phe Lys Asp Lys Ala
195 200 205
Thr Leu Thr Thr Asp Lys Ser Ser Ser Thr Ala Tyr Met Gln Leu Ser
210 215 220
Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala Arg Tyr Tyr
225 230 235 240
Asp Asp His Tyr Cys Leu Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr
245 250 255
Val Ser Ser Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr
260 265 270
Trp Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro
275 280 285
Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp
290 295 300
Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp
305 310 315 320
Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser
325 330 335
Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu
340 345 350
Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly
355 360 365
Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val
370 375 380
Thr Val Glu Asp Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu
385 390 395 400
Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr
405 410 415
Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn
420 425 430
Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val
435 440 445
Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser
450 455 460
Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Val Gln
465 470 475 480
Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala Ser Val Lys
485 490 495
Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr Val Ile Gln
500 505 510
Trp Val Lys Gln Lys Pro Gly Gln Gly Leu Glu Trp Ile Gly Ser Ile
515 520 525
Asn Pro Tyr Asn Asp Tyr Thr Lys Tyr Asn Glu Lys Phe Lys Gly Lys
530 535 540
Ala Thr Leu Thr Ser Asp Lys Ser Ser Ile Thr Ala Tyr Met Glu Phe
545 550 555 560
Ser Ser Leu Thr Ser Glu Asp Ser Ala Leu Tyr Tyr Cys Ala Arg Trp
565 570 575
Gly Asp Gly Asn Tyr Trp Gly Arg Gly Thr Thr Leu Thr Val Ser Ser
580 585 590
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp
595 600 605
Ile Glu Met Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Leu Gly Glu
610 615 620
Arg Val Thr Met Thr Cys Thr Ala Ser Ser Ser Val Ser Ser Ser Tyr
625 630 635 640
Phe His Trp Tyr Gln Gln Lys Pro Gly Ser Ser Pro Lys Leu Cys Ile
645 650 655
Tyr Ser Thr Ser Asn Leu Ala Ser Gly Val Pro Pro Arg Phe Ser Gly
660 665 670
Ser Gly Ser Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
675 680 685
Asp Ala Ala Thr Tyr Phe Cys His Gln Tyr His Arg Ser Pro Thr Phe
690 695 700
Gly Gly Gly Thr Lys Leu Glu Thr Lys Arg
705 710
<210> 88
<211> 2142
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 88
atgaagtggg tgaccttcat cagcttatta tttttattca gctccgccta ttcccagatc 60
gtgctgaccc aaagccccgc catcatgagc gctagccccg gtgagaaggt gaccatgaca 120
tgctccgctt ccagctccgt gtcctacatg aactggtatc agcagaaaag cggaaccagc 180
cccaaaaggt ggatctacga caccagcaag ctggcctccg gagtgcccgc tcatttccgg 240
ggctctggat ccggcaccag ctactcttta accatttccg gcatggaagc tgaagacgct 300
gccacctact attgccagca atggagcagc aaccccttca cattcggatc tggcaccaag 360
ctcgaaatca atcgtggagg aggtggcagc ggcggcggtg gatccggcgg aggaggaagc 420
caagttcaac tccagcagag cggcgctgaa ctggcccggc ccggcgcctc cgtcaagatg 480
agctgcaagg cttccggcta tacatttact cgttacacaa tgcattgggt caagcagagg 540
cccggtcaag gtttagagtg gatcggatat atcaaccctt cccggggcta caccaactat 600
aaccaaaagt tcaaggataa agccacttta accactgaca agagctcctc caccgcctac 660
atgcagctgt cctctttaac cagcgaggac tccgctgttt actactgcgc taggtattac 720
gacgaccact actgtttaga ctattgggga caaggtacca ctttaaccgt cagcagctcc 780
ggcaccacca ataccgtggc cgcttataac ctcacatgga agagcaccaa cttcaagaca 840
attctggaat gggaacccaa gcccgtcaat caagtttaca ccgtgcagat ctccaccaaa 900
tccggagact ggaagagcaa gtgcttctac acaacagaca ccgagtgtga tttaaccgac 960
gaaatcgtca aggacgtcaa gcaaacctat ctggctcggg tcttttccta ccccgctggc 1020
aatgtcgagt ccaccggctc cgctggcgag cctctctacg agaattcccc cgaattcacc 1080
ccttatttag agaccaattt aggccagcct accatccaga gcttcgagca agttggcacc 1140
aaggtgaacg tcaccgtcga ggatgaaagg actttagtgc ggcggaataa cacattttta 1200
tccctccggg atgtgttcgg caaagacctc atctacacac tgtactattg gaagtccagc 1260
tcctccggca aaaagaccgc taagaccaac accaacgagt ttttaattga cgtggacaaa 1320
ggcgagaact actgcttcag cgtgcaagcc gtgatccctt ctcgtaccgt caaccggaag 1380
agcacagatt cccccgttga gtgcatgggc caagaaaagg gcgagttccg ggaggtccag 1440
ctgcagcaga gcggacccga actcgtgaaa cccggtgctt ccgtgaaaat gtcttgtaag 1500
gccagcggat acaccttcac ctcctatgtg atccagtggg tcaaacagaa gcccggacaa 1560
ggtctcgagt ggatcggcag catcaaccct tacaacgact ataccaaata caacgagaag 1620
tttaagggaa aggctacttt aacctccgac aaaagctcca tcacagccta catggagttc 1680
agctctttaa catccgagga cagcgctctg tactattgcg cccggtgggg cgacggcaat 1740
tactggggac ggggcacaac actgaccgtg agcagcggag gcggaggctc cggcggaggc 1800
ggatctggcg gtggcggctc cgacatcgag atgacccagt cccccgctat catgtccgcc 1860
tctttaggcg agcgggtcac aatgacttgt acagcctcct ccagcgtctc ctcctcctac 1920
ttccattggt accaacagaa acccggaagc tcccctaaac tgtgcatcta cagcaccagc 1980
aatctcgcca gcggcgtgcc ccctaggttt tccggaagcg gaagcaccag ctactcttta 2040
accatctcct ccatggaggc tgaggatgcc gccacctact tttgtcacca gtaccaccgg 2100
tcccccacct tcggaggcgg caccaaactg gagacaaaga gg 2142
<210> 89
<211> 696
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 89
Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala Ser
1 5 10 15
Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr Val
20 25 30
Ile Gln Trp Val Lys Gln Lys Pro Gly Gln Gly Leu Glu Trp Ile Gly
35 40 45
Ser Ile Asn Pro Tyr Asn Asp Tyr Thr Lys Tyr Asn Glu Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Ser Asp Lys Ser Ser Ile Thr Ala Tyr Met
65 70 75 80
Glu Phe Ser Ser Leu Thr Ser Glu Asp Ser Ala Leu Tyr Tyr Cys Ala
85 90 95
Arg Trp Gly Asp Gly Asn Tyr Trp Gly Arg Gly Thr Thr Leu Thr Val
100 105 110
Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Asp Ile Glu Met Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Leu
130 135 140
Gly Glu Arg Val Thr Met Thr Cys Thr Ala Ser Ser Ser Val Ser Ser
145 150 155 160
Ser Tyr Phe His Trp Tyr Gln Gln Lys Pro Gly Ser Ser Pro Lys Leu
165 170 175
Cys Ile Tyr Ser Thr Ser Asn Leu Ala Ser Gly Val Pro Pro Arg Phe
180 185 190
Ser Gly Ser Gly Ser Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu
195 200 205
Ala Glu Asp Ala Ala Thr Tyr Phe Cys His Gln Tyr His Arg Ser Pro
210 215 220
Thr Phe Gly Gly Gly Thr Lys Leu Glu Thr Lys Arg Ser Gly Thr Thr
225 230 235 240
Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe Lys
245 250 255
Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val Tyr Thr Val
260 265 270
Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr
275 280 285
Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys Asp Val Lys
290 295 300
Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly Asn Val Glu
305 310 315 320
Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe
325 330 335
Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe
340 345 350
Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu Asp Glu Arg Thr
355 360 365
Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp Val Phe Gly
370 375 380
Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly
385 390 395 400
Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile Asp Val Asp
405 410 415
Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile Pro Ser Arg
420 425 430
Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys Met Gly Gln
435 440 445
Glu Lys Gly Glu Phe Arg Glu Gln Ile Val Leu Thr Gln Ser Pro Ala
450 455 460
Ile Met Ser Ala Ser Pro Gly Glu Lys Val Thr Met Thr Cys Ser Ala
465 470 475 480
Ser Ser Ser Val Ser Tyr Met Asn Trp Tyr Gln Gln Lys Ser Gly Thr
485 490 495
Ser Pro Lys Arg Trp Ile Tyr Asp Thr Ser Lys Leu Ala Ser Gly Val
500 505 510
Pro Ala His Phe Arg Gly Ser Gly Ser Gly Thr Ser Tyr Ser Leu Thr
515 520 525
Ile Ser Gly Met Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Gln
530 535 540
Trp Ser Ser Asn Pro Phe Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile
545 550 555 560
Asn Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
565 570 575
Ser Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Ala Arg Pro Gly
580 585 590
Ala Ser Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Arg
595 600 605
Tyr Thr Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp
610 615 620
Ile Gly Tyr Ile Asn Pro Ser Arg Gly Tyr Thr Asn Tyr Asn Gln Lys
625 630 635 640
Phe Lys Asp Lys Ala Thr Leu Thr Thr Asp Lys Ser Ser Ser Thr Ala
645 650 655
Tyr Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr
660 665 670
Cys Ala Arg Tyr Tyr Asp Asp His Tyr Cys Leu Asp Tyr Trp Gly Gln
675 680 685
Gly Thr Thr Leu Thr Val Ser Ser
690 695
<210> 90
<211> 2088
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 90
gtgcagctgc agcagtccgg acccgaactg gtcaagcccg gtgcctccgt gaaaatgtct 60
tgtaaggctt ctggctacac ctttacctcc tacgtcatcc aatgggtgaa gcagaagccc 120
ggtcaaggtc tcgagtggat cggcagcatc aatccctaca acgattacac caagtataac 180
gaaaagttta agggcaaggc cactctgaca agcgacaaga gctccattac cgcctacatg 240
gagttttcct ctttaacttc tgaggactcc gctttatact attgcgctcg ttggggcgat 300
ggcaattatt ggggccgggg aactacttta acagtgagct ccggcggcgg cggaagcgga 360
ggtggaggat ctggcggtgg aggcagcgac atcgagatga cacagtcccc cgctatcatg 420
agcgcctctt taggagaacg tgtgaccatg acttgtacag cttcctccag cgtgagcagc 480
tcctatttcc actggtacca gcagaaaccc ggctcctccc ctaaactgtg tatctactcc 540
acaagcaatt tagctagcgg cgtgcctcct cgttttagcg gctccggcag cacctcttac 600
tctttaacca ttagctctat ggaggccgaa gatgccgcca catacttttg ccatcagtac 660
caccggtccc ctacctttgg cggaggcaca aagctggaga ccaagcggag cggcaccacc 720
aacacagtgg ccgcctacaa tctgacttgg aaatccacca acttcaagac catcctcgag 780
tgggagccca agcccgttaa tcaagtttat accgtgcaga tttccaccaa gagcggcgac 840
tggaaatcca agtgcttcta taccacagac accgagtgcg atctcaccga cgagatcgtc 900
aaagacgtga agcagacata tttagctagg gtgttctcct accccgctgg aaacgtggag 960
agcaccggat ccgctggaga gcctttatac gagaactccc ccgaattcac cccctatctg 1020
gaaaccaatt taggccagcc caccatccag agcttcgaac aagttggcac aaaggtgaac 1080
gtcaccgtcg aagatgagag gactttagtg cggaggaaca atacattttt atccttacgt 1140
gacgtcttcg gcaaggattt aatctacaca ctgtattact ggaagtctag ctcctccggc 1200
aagaagaccg ccaagaccaa taccaacgaa tttttaattg acgtggacaa gggcgagaac 1260
tactgcttct ccgtgcaagc tgtgatcccc tcccggacag tgaaccggaa gtccaccgac 1320
tcccccgtgg agtgcatggg ccaagagaag ggagagtttc gtgagcagat cgtgctgacc 1380
cagtcccccg ctattatgag cgctagcccc ggtgaaaagg tgactatgac atgcagcgcc 1440
agctcttccg tgagctacat gaactggtat cagcagaagt ccggcaccag ccctaaaagg 1500
tggatctacg acaccagcaa gctggccagc ggcgtccccg ctcactttcg gggctccggc 1560
tccggaacaa gctactctct gaccatcagc ggcatggaag ccgaggatgc cgctacctat 1620
tactgtcagc agtggagctc caaccccttc acctttggat ccggcaccaa gctcgagatt 1680
aatcgtggag gcggaggtag cggaggaggc ggatccggcg gtggaggtag ccaagttcag 1740
ctccagcaaa gcggcgccga actcgctcgg cccggcgctt ccgtgaagat gtcttgtaag 1800
gcctccggct ataccttcac ccggtacaca atgcactggg tcaagcaacg gcccggtcaa 1860
ggtttagagt ggattggcta tatcaacccc tcccggggct ataccaacta caaccagaag 1920
ttcaaggaca aagccaccct caccaccgac aagtccagca gcaccgctta catgcagctg 1980
agctctttaa catccgagga ttccgccgtg tactactgcg ctcggtacta cgacgatcat 2040
tactgcctcg attactgggg ccaaggtacc accttaacag tctcctcc 2088
<210> 91
<211> 714
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 91
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly
20 25 30
Ala Ser Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser
35 40 45
Tyr Val Ile Gln Trp Val Lys Gln Lys Pro Gly Gln Gly Leu Glu Trp
50 55 60
Ile Gly Ser Ile Asn Pro Tyr Asn Asp Tyr Thr Lys Tyr Asn Glu Lys
65 70 75 80
Phe Lys Gly Lys Ala Thr Leu Thr Ser Asp Lys Ser Ser Ile Thr Ala
85 90 95
Tyr Met Glu Phe Ser Ser Leu Thr Ser Glu Asp Ser Ala Leu Tyr Tyr
100 105 110
Cys Ala Arg Trp Gly Asp Gly Asn Tyr Trp Gly Arg Gly Thr Thr Leu
115 120 125
Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
130 135 140
Gly Gly Ser Asp Ile Glu Met Thr Gln Ser Pro Ala Ile Met Ser Ala
145 150 155 160
Ser Leu Gly Glu Arg Val Thr Met Thr Cys Thr Ala Ser Ser Ser Val
165 170 175
Ser Ser Ser Tyr Phe His Trp Tyr Gln Gln Lys Pro Gly Ser Ser Pro
180 185 190
Lys Leu Cys Ile Tyr Ser Thr Ser Asn Leu Ala Ser Gly Val Pro Pro
195 200 205
Arg Phe Ser Gly Ser Gly Ser Thr Ser Tyr Ser Leu Thr Ile Ser Ser
210 215 220
Met Glu Ala Glu Asp Ala Ala Thr Tyr Phe Cys His Gln Tyr His Arg
225 230 235 240
Ser Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu Thr Lys Arg Ser Gly
245 250 255
Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr Asn
260 265 270
Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val Tyr
275 280 285
Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys Phe
290 295 300
Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys Asp
305 310 315 320
Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly Asn
325 330 335
Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser Pro
340 345 350
Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile Gln
355 360 365
Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu Asp Glu
370 375 380
Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp Val
385 390 395 400
Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser Ser
405 410 415
Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile Asp
420 425 430
Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile Pro
435 440 445
Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys Met
450 455 460
Gly Gln Glu Lys Gly Glu Phe Arg Glu Gln Ile Val Leu Thr Gln Ser
465 470 475 480
Pro Ala Ile Met Ser Ala Ser Pro Gly Glu Lys Val Thr Met Thr Cys
485 490 495
Ser Ala Ser Ser Ser Val Ser Tyr Met Asn Trp Tyr Gln Gln Lys Ser
500 505 510
Gly Thr Ser Pro Lys Arg Trp Ile Tyr Asp Thr Ser Lys Leu Ala Ser
515 520 525
Gly Val Pro Ala His Phe Arg Gly Ser Gly Ser Gly Thr Ser Tyr Ser
530 535 540
Leu Thr Ile Ser Gly Met Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys
545 550 555 560
Gln Gln Trp Ser Ser Asn Pro Phe Thr Phe Gly Ser Gly Thr Lys Leu
565 570 575
Glu Ile Asn Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
580 585 590
Gly Gly Ser Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Ala Arg
595 600 605
Pro Gly Ala Ser Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe
610 615 620
Thr Arg Tyr Thr Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu
625 630 635 640
Glu Trp Ile Gly Tyr Ile Asn Pro Ser Arg Gly Tyr Thr Asn Tyr Asn
645 650 655
Gln Lys Phe Lys Asp Lys Ala Thr Leu Thr Thr Asp Lys Ser Ser Ser
660 665 670
Thr Ala Tyr Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val
675 680 685
Tyr Tyr Cys Ala Arg Tyr Tyr Asp Asp His Tyr Cys Leu Asp Tyr Trp
690 695 700
Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
705 710
<210> 92
<211> 2142
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 92
atgaaatggg tcaccttcat ctctttactg tttttattta gcagcgccta cagcgtgcag 60
ctgcagcagt ccggacccga actggtcaag cccggtgcct ccgtgaaaat gtcttgtaag 120
gcttctggct acacctttac ctcctacgtc atccaatggg tgaagcagaa gcccggtcaa 180
ggtctcgagt ggatcggcag catcaatccc tacaacgatt acaccaagta taacgaaaag 240
tttaagggca aggccactct gacaagcgac aagagctcca ttaccgccta catggagttt 300
tcctctttaa cttctgagga ctccgcttta tactattgcg ctcgttgggg cgatggcaat 360
tattggggcc ggggaactac tttaacagtg agctccggcg gcggcggaag cggaggtgga 420
ggatctggcg gtggaggcag cgacatcgag atgacacagt cccccgctat catgagcgcc 480
tctttaggag aacgtgtgac catgacttgt acagcttcct ccagcgtgag cagctcctat 540
ttccactggt accagcagaa acccggctcc tcccctaaac tgtgtatcta ctccacaagc 600
aatttagcta gcggcgtgcc tcctcgtttt agcggctccg gcagcacctc ttactcttta 660
accattagct ctatggaggc cgaagatgcc gccacatact tttgccatca gtaccaccgg 720
tcccctacct ttggcggagg cacaaagctg gagaccaagc ggagcggcac caccaacaca 780
gtggccgcct acaatctgac ttggaaatcc accaacttca agaccatcct cgagtgggag 840
cccaagcccg ttaatcaagt ttataccgtg cagatttcca ccaagagcgg cgactggaaa 900
tccaagtgct tctataccac agacaccgag tgcgatctca ccgacgagat cgtcaaagac 960
gtgaagcaga catatttagc tagggtgttc tcctaccccg ctggaaacgt ggagagcacc 1020
ggatccgctg gagagccttt atacgagaac tcccccgaat tcacccccta tctggaaacc 1080
aatttaggcc agcccaccat ccagagcttc gaacaagttg gcacaaaggt gaacgtcacc 1140
gtcgaagatg agaggacttt agtgcggagg aacaatacat ttttatcctt acgtgacgtc 1200
ttcggcaagg atttaatcta cacactgtat tactggaagt ctagctcctc cggcaagaag 1260
accgccaaga ccaataccaa cgaattttta attgacgtgg acaagggcga gaactactgc 1320
ttctccgtgc aagctgtgat cccctcccgg acagtgaacc ggaagtccac cgactccccc 1380
gtggagtgca tgggccaaga gaagggagag tttcgtgagc agatcgtgct gacccagtcc 1440
cccgctatta tgagcgctag ccccggtgaa aaggtgacta tgacatgcag cgccagctct 1500
tccgtgagct acatgaactg gtatcagcag aagtccggca ccagccctaa aaggtggatc 1560
tacgacacca gcaagctggc cagcggcgtc cccgctcact ttcggggctc cggctccgga 1620
acaagctact ctctgaccat cagcggcatg gaagccgagg atgccgctac ctattactgt 1680
cagcagtgga gctccaaccc cttcaccttt ggatccggca ccaagctcga gattaatcgt 1740
ggaggcggag gtagcggagg aggcggatcc ggcggtggag gtagccaagt tcagctccag 1800
caaagcggcg ccgaactcgc tcggcccggc gcttccgtga agatgtcttg taaggcctcc 1860
ggctatacct tcacccggta cacaatgcac tgggtcaagc aacggcccgg tcaaggttta 1920
gagtggattg gctatatcaa cccctcccgg ggctatacca actacaacca gaagttcaag 1980
gacaaagcca ccctcaccac cgacaagtcc agcagcaccg cttacatgca gctgagctct 2040
ttaacatccg aggattccgc cgtgtactac tgcgctcggt actacgacga tcattactgc 2100
ctcgattact ggggccaagg taccacctta acagtctcct cc 2142
<210> 93
<211> 219
<212> PRT
<213> Homo sapiens
<400> 93
Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser
1 5 10 15
Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn Gln
20 25 30
Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys
35 40 45
Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val
50 55 60
Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala
65 70 75 80
Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn
85 90 95
Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr
100 105 110
Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu
115 120 125
Asp Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg
130 135 140
Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser
145 150 155 160
Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu
165 170 175
Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val
180 185 190
Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu
195 200 205
Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu
210 215
<210> 94
<211> 657
<212> DNA
<213> Homo sapiens
<400> 94
agcggcacaa ccaacacagt cgctgcctat aacctcactt ggaagagcac caacttcaaa 60
accatcctcg aatgggaacc caaacccgtt aaccaagttt acaccgtgca gatcagcacc 120
aagtccggcg actggaagtc caaatgtttc tataccaccg acaccgagtg cgatctcacc 180
gatgagatcg tgaaagatgt gaaacagacc tacctcgccc gggtgtttag ctaccccgcc 240
ggcaatgtgg agagcactgg ttccgctggc gagcctttat acgagaacag ccccgaattt 300
accccttacc tcgagaccaa tttaggacag cccaccatcc aaagctttga gcaagttggc 360
acaaaggtga atgtgacagt ggaggacgag cggactttag tgcggcggaa caacaccttt 420
ctcagcctcc gggatgtgtt cggcaaagat ttaatctaca cactgtatta ctggaagtcc 480
tcttcctccg gcaagaagac agctaaaacc aacacaaacg agtttttaat cgacgtggat 540
aaaggcgaaa actactgttt cagcgtgcaa gctgtgatcc cctcccggac cgtgaatagg 600
aaaagcaccg atagccccgt tgagtgcatg ggccaagaaa agggcgagtt ccgggag 657
<210> 95
<211> 223
<212> PRT
<213> Mus sp.
<400> 95
Ala Gly Ile Pro Glu Lys Ala Phe Asn Leu Thr Trp Ile Ser Thr Asp
1 5 10 15
Phe Lys Thr Ile Leu Glu Trp Gln Pro Lys Pro Thr Asn Tyr Thr Tyr
20 25 30
Thr Val Gln Ile Ser Asp Arg Ser Arg Asn Trp Lys Asn Lys Cys Phe
35 40 45
Ser Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys Asp
50 55 60
Val Thr Trp Ala Tyr Glu Ala Lys Val Leu Ser Val Pro Arg Arg Asn
65 70 75 80
Ser Val His Gly Asp Gly Asp Gln Leu Val Ile His Gly Glu Glu Pro
85 90 95
Pro Phe Thr Asn Ala Pro Lys Phe Leu Pro Tyr Arg Asp Thr Asn Leu
100 105 110
Gly Gln Pro Val Ile Gln Gln Phe Glu Gln Asp Gly Arg Lys Leu Asn
115 120 125
Val Val Val Lys Asp Ser Leu Thr Leu Val Arg Lys Asn Gly Thr Phe
130 135 140
Leu Thr Leu Arg Gln Val Phe Gly Lys Asp Leu Gly Tyr Ile Ile Thr
145 150 155 160
Tyr Arg Lys Gly Ser Ser Thr Gly Lys Lys Thr Asn Ile Thr Asn Thr
165 170 175
Asn Glu Phe Ser Ile Asp Val Glu Glu Gly Val Ser Tyr Cys Phe Phe
180 185 190
Val Gln Ala Met Ile Phe Ser Arg Lys Thr Asn Gln Asn Ser Pro Gly
195 200 205
Ser Ser Thr Val Cys Thr Glu Gln Trp Lys Ser Phe Leu Gly Glu
210 215 220
<210> 96
<211> 224
<212> PRT
<213> Rattus sp.
<400> 96
Ala Gly Thr Pro Pro Gly Lys Ala Phe Asn Leu Thr Trp Ile Ser Thr
1 5 10 15
Asp Phe Lys Thr Ile Leu Glu Trp Gln Pro Lys Pro Thr Asn Tyr Thr
20 25 30
Tyr Thr Val Gln Ile Ser Asp Arg Ser Arg Asn Trp Lys Tyr Lys Cys
35 40 45
Thr Gly Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys
50 55 60
Asp Val Asn Trp Thr Tyr Glu Ala Arg Val Leu Ser Val Pro Trp Arg
65 70 75 80
Asn Ser Thr His Gly Lys Glu Thr Leu Phe Gly Thr His Gly Glu Glu
85 90 95
Pro Pro Phe Thr Asn Ala Arg Lys Phe Leu Pro Tyr Arg Asp Thr Lys
100 105 110
Ile Gly Gln Pro Val Ile Gln Lys Tyr Glu Gln Gly Gly Thr Lys Leu
115 120 125
Lys Val Thr Val Lys Asp Ser Phe Thr Leu Val Arg Lys Asn Gly Thr
130 135 140
Phe Leu Thr Leu Arg Gln Val Phe Gly Asn Asp Leu Gly Tyr Ile Leu
145 150 155 160
Thr Tyr Arg Lys Asp Ser Ser Thr Gly Arg Lys Thr Asn Thr Thr His
165 170 175
Thr Asn Glu Phe Leu Ile Asp Val Glu Lys Gly Val Ser Tyr Cys Phe
180 185 190
Phe Ala Gln Ala Val Ile Phe Ser Arg Lys Thr Asn His Lys Ser Pro
195 200 205
Glu Ser Ile Thr Lys Cys Thr Glu Gln Trp Lys Ser Val Leu Gly Glu
210 215 220
<210> 97
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 97
Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser
1 5 10 15
Thr Asn Phe Ala Thr Ala Leu Glu Trp Glu Pro Lys Pro Val Asn Gln
20 25 30
Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys
35 40 45
Cys Phe Tyr Thr Thr Asp Thr Glu Cys Ala Leu Thr Asp Glu Ile Val
50 55 60
Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala
65 70 75 80
Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn
85 90 95
Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr
100 105 110
Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu
115 120 125
Asp Glu Arg Thr Leu Val Ala Arg Asn Asn Thr Ala Leu Ser Leu Arg
130 135 140
Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser
145 150 155 160
Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu
165 170 175
Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val
180 185 190
Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu
195 200 205
Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu
210 215
<210> 98
<211> 219
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 98
Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser
1 5 10 15
Thr Asn Phe Ala Thr Ala Leu Glu Trp Glu Pro Lys Pro Val Asn Gln
20 25 30
Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Ala Lys Ser Lys
35 40 45
Cys Phe Tyr Thr Thr Asp Thr Glu Cys Ala Leu Thr Asp Glu Ile Val
50 55 60
Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala
65 70 75 80
Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Ala Glu Asn
85 90 95
Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr
100 105 110
Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu
115 120 125
Asp Glu Arg Thr Leu Val Ala Arg Asn Asn Thr Ala Leu Ser Leu Arg
130 135 140
Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser
145 150 155 160
Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu
165 170 175
Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val
180 185 190
Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu
195 200 205
Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu
210 215
<210> 99
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 99
Gly Gly Gly Ser
1
<210> 100
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 100
Gly Gly Gly Gly Ser
1 5
<210> 101
<211> 4
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 101
Gly Gly Ser Gly
1
<210> 102
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 102
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10 15
<210> 103
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 103
ggcggtggag gatccggagg aggtggctcc ggcggcggag gatct 45
<210> 104
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 104
Gly Gly Gly Ser Gly Gly Gly Ser
1 5
<210> 105
<211> 133
<212> PRT
<213> Homo sapiens
<400> 105
Ala Pro Met Thr Gln Thr Thr Pro Leu Lys Thr Ser Trp Val Asn Cys
1 5 10 15
Ser Asn Met Ile Asp Glu Ile Ile Thr His Leu Lys Gln Pro Pro Leu
20 25 30
Pro Leu Leu Asp Phe Asn Asn Leu Asn Gly Glu Asp Gln Asp Ile Leu
35 40 45
Met Glu Asn Asn Leu Arg Arg Pro Asn Leu Glu Ala Phe Asn Arg Ala
50 55 60
Val Lys Ser Leu Gln Asn Ala Ser Ala Ile Glu Ser Ile Leu Lys Asn
65 70 75 80
Leu Leu Pro Cys Leu Pro Leu Ala Thr Ala Ala Pro Thr Arg His Pro
85 90 95
Ile His Ile Lys Asp Gly Asp Trp Asn Glu Phe Arg Arg Lys Leu Thr
100 105 110
Phe Tyr Leu Lys Thr Leu Glu Asn Ala Gln Ala Gln Gln Thr Thr Leu
115 120 125
Ser Leu Ala Ile Phe
130
<210> 106
<211> 79
<212> PRT
<213> Homo sapiens
<400> 106
Glu Gly Ala Val Leu Pro Arg Ser Ala Lys Glu Leu Arg Cys Gln Cys
1 5 10 15
Ile Lys Thr Tyr Ser Lys Pro Phe His Pro Lys Phe Ile Lys Glu Leu
20 25 30
Arg Val Ile Glu Ser Gly Pro His Cys Ala Asn Thr Glu Ile Ile Val
35 40 45
Lys Leu Ser Asp Gly Arg Glu Leu Cys Leu Asp Pro Lys Glu Asn Trp
50 55 60
Val Gln Arg Val Val Glu Lys Phe Leu Lys Arg Ala Glu Asn Ser
65 70 75
<210> 107
<211> 160
<212> PRT
<213> Homo sapiens
<400> 107
Ser Pro Gly Gln Gly Thr Gln Ser Glu Asn Ser Cys Thr His Phe Pro
1 5 10 15
Gly Asn Leu Pro Asn Met Leu Arg Asp Leu Arg Asp Ala Phe Ser Arg
20 25 30
Val Lys Thr Phe Phe Gln Met Lys Asp Gln Leu Asp Asn Leu Leu Leu
35 40 45
Lys Glu Ser Leu Leu Glu Asp Phe Lys Gly Tyr Leu Gly Cys Gln Ala
50 55 60
Leu Ser Glu Met Ile Gln Phe Tyr Leu Glu Glu Val Met Pro Gln Ala
65 70 75 80
Glu Asn Gln Asp Pro Asp Ile Lys Ala His Val Asn Ser Leu Gly Glu
85 90 95
Asn Leu Lys Thr Leu Arg Leu Arg Leu Arg Arg Cys His Arg Phe Leu
100 105 110
Pro Cys Glu Asn Lys Ser Lys Ala Val Glu Gln Val Lys Asn Ala Phe
115 120 125
Asn Lys Leu Gln Glu Lys Gly Ile Tyr Lys Ala Met Ser Glu Phe Asp
130 135 140
Ile Phe Ile Asn Tyr Ile Glu Ala Tyr Met Thr Met Lys Ile Arg Asn
145 150 155 160
<210> 108
<211> 132
<212> PRT
<213> Homo sapiens
<400> 108
Gly Ile Thr Ile Pro Arg Asn Pro Gly Cys Pro Asn Ser Glu Asp Lys
1 5 10 15
Asn Phe Pro Arg Thr Val Met Val Asn Leu Asn Ile His Asn Arg Asn
20 25 30
Thr Asn Thr Asn Pro Lys Arg Ser Ser Asp Tyr Tyr Asn Arg Ser Thr
35 40 45
Ser Pro Trp Asn Leu His Arg Asn Glu Asp Pro Glu Arg Tyr Pro Ser
50 55 60
Val Ile Trp Glu Ala Lys Cys Arg His Leu Gly Cys Ile Asn Ala Asp
65 70 75 80
Gly Asn Val Asp Tyr His Met Asn Ser Val Pro Ile Gln Gln Glu Ile
85 90 95
Leu Val Leu Arg Arg Glu Pro Pro His Cys Pro Asn Ser Phe Arg Leu
100 105 110
Glu Lys Ile Leu Val Ser Val Gly Cys Thr Cys Val Thr Pro Ile Val
115 120 125
His His Val Ala
130
<210> 109
<211> 157
<212> PRT
<213> Homo sapiens
<400> 109
Tyr Phe Gly Lys Leu Glu Ser Lys Leu Ser Val Ile Arg Asn Leu Asn
1 5 10 15
Asp Gln Val Leu Phe Ile Asp Gln Gly Asn Arg Pro Leu Phe Glu Asp
20 25 30
Met Thr Asp Ser Asp Cys Arg Asp Asn Ala Pro Arg Thr Ile Phe Ile
35 40 45
Ile Ser Met Tyr Lys Asp Ser Gln Pro Arg Gly Met Ala Val Thr Ile
50 55 60
Ser Val Lys Cys Glu Lys Ile Ser Thr Leu Ser Cys Glu Asn Lys Ile
65 70 75 80
Ile Ser Phe Lys Glu Met Asn Pro Pro Asp Asn Ile Lys Asp Thr Lys
85 90 95
Ser Asp Ile Ile Phe Phe Gln Arg Ser Val Pro Gly His Asp Asn Lys
100 105 110
Met Gln Phe Glu Ser Ser Ser Tyr Glu Gly Tyr Phe Leu Ala Cys Glu
115 120 125
Lys Glu Arg Asp Leu Phe Lys Leu Ile Leu Lys Lys Glu Asp Glu Leu
130 135 140
Gly Asp Arg Ser Ile Met Phe Thr Val Gln Asn Glu Asp
145 150 155
<210> 110
<211> 352
<212> PRT
<213> Homo sapiens
<400> 110
Arg Asp Thr Ser Ala Thr Pro Gln Ser Ala Ser Ile Lys Ala Leu Arg
1 5 10 15
Asn Ala Asn Leu Arg Arg Asp Glu Ser Asn His Leu Thr Asp Leu Tyr
20 25 30
Arg Arg Asp Glu Thr Ile Gln Val Lys Gly Asn Gly Tyr Val Gln Ser
35 40 45
Pro Arg Phe Pro Asn Ser Tyr Pro Arg Asn Leu Leu Leu Thr Trp Arg
50 55 60
Leu His Ser Gln Glu Asn Thr Arg Ile Gln Leu Val Phe Asp Asn Gln
65 70 75 80
Phe Gly Leu Glu Glu Ala Glu Asn Asp Ile Cys Arg Tyr Asp Phe Val
85 90 95
Glu Val Glu Asp Ile Ser Glu Thr Ser Thr Ile Ile Arg Gly Arg Trp
100 105 110
Cys Gly His Lys Glu Val Pro Pro Arg Ile Lys Ser Arg Thr Asn Gln
115 120 125
Ile Lys Ile Thr Phe Lys Ser Asp Asp Tyr Phe Val Ala Lys Pro Gly
130 135 140
Phe Lys Ile Tyr Tyr Ser Leu Leu Glu Asp Phe Gln Pro Ala Ala Ala
145 150 155 160
Ser Glu Thr Asn Trp Glu Ser Val Thr Ser Ser Ile Ser Gly Val Ser
165 170 175
Tyr Asn Ser Pro Ser Val Thr Asp Pro Thr Leu Ile Ala Asp Ala Leu
180 185 190
Asp Lys Lys Ile Ala Glu Phe Asp Thr Val Glu Asp Leu Leu Lys Tyr
195 200 205
Phe Asn Pro Glu Ser Trp Gln Glu Asp Leu Glu Asn Met Tyr Leu Asp
210 215 220
Thr Pro Arg Tyr Arg Gly Arg Ser Tyr His Asp Arg Lys Ser Lys Val
225 230 235 240
Asp Leu Asp Arg Leu Asn Asp Asp Ala Lys Arg Tyr Ser Cys Thr Pro
245 250 255
Arg Asn Tyr Ser Val Asn Ile Arg Glu Glu Leu Lys Leu Ala Asn Val
260 265 270
Val Phe Phe Pro Arg Cys Leu Leu Val Gln Arg Cys Gly Gly Asn Cys
275 280 285
Gly Cys Gly Thr Val Asn Trp Arg Ser Cys Thr Cys Asn Ser Gly Lys
290 295 300
Thr Val Lys Lys Tyr His Glu Val Leu Gln Phe Glu Pro Gly His Ile
305 310 315 320
Lys Arg Arg Gly Arg Ala Lys Thr Met Ala Leu Val Asp Ile Gln Leu
325 330 335
Asp His His Glu Arg Cys Asp Cys Ile Cys Ser Ser Arg Pro Pro Arg
340 345 350
<210> 111
<211> 248
<212> PRT
<213> Homo sapiens
<400> 111
Glu Gly Ile Cys Arg Asn Arg Val Thr Asn Asn Val Lys Asp Val Thr
1 5 10 15
Lys Leu Val Ala Asn Leu Pro Lys Asp Tyr Met Ile Thr Leu Lys Tyr
20 25 30
Val Pro Gly Met Asp Val Leu Pro Ser His Cys Trp Ile Ser Glu Met
35 40 45
Val Val Gln Leu Ser Asp Ser Leu Thr Asp Leu Leu Asp Lys Phe Ser
50 55 60
Asn Ile Ser Glu Gly Leu Ser Asn Tyr Ser Ile Ile Asp Lys Leu Val
65 70 75 80
Asn Ile Val Asp Asp Leu Val Glu Cys Val Lys Glu Asn Ser Ser Lys
85 90 95
Asp Leu Lys Lys Ser Phe Lys Ser Pro Glu Pro Arg Leu Phe Thr Pro
100 105 110
Glu Glu Phe Phe Arg Ile Phe Asn Arg Ser Ile Asp Ala Phe Lys Asp
115 120 125
Phe Val Val Ala Ser Glu Thr Ser Asp Cys Val Val Ser Ser Thr Leu
130 135 140
Ser Pro Glu Lys Asp Ser Arg Val Ser Val Thr Lys Pro Phe Met Leu
145 150 155 160
Pro Pro Val Ala Ala Ser Ser Leu Arg Asn Asp Ser Ser Ser Ser Asn
165 170 175
Arg Lys Ala Lys Asn Pro Pro Gly Asp Ser Ser Leu His Trp Ala Ala
180 185 190
Met Ala Leu Pro Ala Leu Phe Ser Leu Ile Ile Gly Phe Ala Phe Gly
195 200 205
Ala Leu Tyr Trp Lys Lys Arg Gln Pro Ser Leu Thr Arg Ala Val Glu
210 215 220
Asn Ile Gln Ile Asn Glu Glu Asp Asn Glu Ile Ser Met Leu Gln Glu
225 230 235 240
Lys Glu Arg Glu Phe Gln Glu Val
245
<210> 112
<211> 209
<212> PRT
<213> Homo sapiens
<400> 112
Thr Gln Asp Cys Ser Phe Gln His Ser Pro Ile Ser Ser Asp Phe Ala
1 5 10 15
Val Lys Ile Arg Glu Leu Ser Asp Tyr Leu Leu Gln Asp Tyr Pro Val
20 25 30
Thr Val Ala Ser Asn Leu Gln Asp Glu Glu Leu Cys Gly Gly Leu Trp
35 40 45
Arg Leu Val Leu Ala Gln Arg Trp Met Glu Arg Leu Lys Thr Val Ala
50 55 60
Gly Ser Lys Met Gln Gly Leu Leu Glu Arg Val Asn Thr Glu Ile His
65 70 75 80
Phe Val Thr Lys Cys Ala Phe Gln Pro Pro Pro Ser Cys Leu Arg Phe
85 90 95
Val Gln Thr Asn Ile Ser Arg Leu Leu Gln Glu Thr Ser Glu Gln Leu
100 105 110
Val Ala Leu Lys Pro Trp Ile Thr Arg Gln Asn Phe Ser Arg Cys Leu
115 120 125
Glu Leu Gln Cys Gln Pro Asp Ser Ser Thr Leu Pro Pro Pro Trp Ser
130 135 140
Pro Arg Pro Leu Glu Ala Thr Ala Pro Thr Ala Pro Gln Pro Pro Leu
145 150 155 160
Leu Leu Leu Leu Leu Leu Pro Val Gly Leu Leu Leu Leu Ala Ala Ala
165 170 175
Trp Cys Leu His Trp Gln Arg Thr Arg Arg Arg Thr Pro Arg Pro Gly
180 185 190
Glu Gln Val Pro Pro Val Pro Ser Pro Gln Asp Leu Leu Leu Val Glu
195 200 205
His
<210> 113
<211> 65
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 113
Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp Val
1 5 10 15
Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly
20 25 30
Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu Asn
35 40 45
Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys Ile
50 55 60
Arg
65
<210> 114
<211> 195
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 114
attacatgcc cccctcccat gagcgtggag cacgccgaca tctgggtgaa gagctatagc 60
ctctacagcc gggagaggta tatctgtaac agcggcttca agaggaaggc cggcaccagc 120
agcctcaccg agtgcgtgct gaataaggct accaacgtgg ctcactggac aacaccctct 180
ttaaagtgca tccgg 195
<210> 115
<211> 114
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 115
Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile
1 5 10 15
Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp Val His
20 25 30
Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu Glu Leu Gln
35 40 45
Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp Thr Val Glu
50 55 60
Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly Asn Val
65 70 75 80
Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile
85 90 95
Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met Phe Ile Asn
100 105 110
Thr Ser
<210> 116
<211> 342
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 116
aactgggtga acgtcatcag cgatttaaag aagatcgaag atttaattca gtccatgcat 60
atcgacgcca ctttatacac agaatccgac gtgcacccct cttgtaaggt gaccgccatg 120
aaatgttttt tactggagct gcaagttatc tctttagaga gcggagacgc tagcatccac 180
gacaccgtgg agaatttaat cattttagcc aataactctt tatccagcaa cggcaacgtg 240
acagagtccg gctgcaagga gtgcgaagag ctggaggaga agaacatcaa ggagtttctg 300
caatcctttg tgcacattgt ccagatgttc atcaatacct cc 342
<210> 117
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 117
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser
<210> 118
<211> 54
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 118
atgaaatggg tgacctttat ttctttactg ttcctcttta gcagcgccta ctcc 54
<210> 119
<211> 54
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 119
atgaagtggg tcacatttat ctctttactg ttcctcttct ccagcgccta cagc 54
<210> 120
<211> 54
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 120
atgaaatggg tgacctttat ttctttactg ttcctcttta gcagcgccta ctcc 54
<210> 121
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 121
Met Lys Cys Leu Leu Tyr Leu Ala Phe Leu Phe Leu Gly Val Asn Cys
1 5 10 15
<210> 122
<211> 58
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 122
Met Gly Gln Ile Val Thr Met Phe Glu Ala Leu Pro His Ile Ile Asp
1 5 10 15
Glu Val Ile Asn Ile Val Ile Ile Val Leu Ile Ile Ile Thr Ser Ile
20 25 30
Lys Ala Val Tyr Asn Phe Ala Thr Cys Gly Ile Leu Ala Leu Val Ser
35 40 45
Phe Leu Phe Leu Ala Gly Arg Ser Cys Gly
50 55
<210> 123
<211> 97
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 123
Met Pro Asn His Gln Ser Gly Ser Pro Thr Gly Ser Ser Asp Leu Leu
1 5 10 15
Leu Ser Gly Lys Lys Gln Arg Pro His Leu Ala Leu Arg Arg Lys Arg
20 25 30
Arg Arg Glu Met Arg Lys Ile Asn Arg Lys Val Arg Arg Met Asn Leu
35 40 45
Ala Pro Ile Lys Glu Lys Thr Ala Trp Gln His Leu Gln Ala Leu Ile
50 55 60
Ser Glu Ala Glu Glu Val Leu Lys Thr Ser Gln Thr Pro Gln Asn Ser
65 70 75 80
Leu Thr Leu Phe Leu Ala Leu Leu Ser Val Leu Gly Pro Pro Val Thr
85 90 95
Gly
<210> 124
<211> 30
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 124
Met Asp Ser Lys Gly Ser Ser Gln Lys Gly Ser Arg Leu Leu Leu Leu
1 5 10 15
Leu Val Val Ser Asn Leu Leu Leu Cys Gln Gly Val Val Ser
20 25 30
<210> 125
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 125
Met Lys Cys Leu Leu Tyr Leu Ala Phe Leu Phe Leu Gly Val Asn Cys
1 5 10 15
<210> 126
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 126
Gly Leu Asn Asp Ile Phe Glu Ala Gln Lys Ile Glu Trp His Glu
1 5 10 15
<210> 127
<211> 26
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 127
Lys Arg Arg Trp Lys Lys Asn Phe Ile Ala Val Ser Ala Ala Asn Arg
1 5 10 15
Phe Lys Lys Ile Ser Ser Ser Gly Ala Leu
20 25
<210> 128
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 128
Glu Glu Glu Glu Glu Glu
1 5
<210> 129
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 129
Gly Ala Pro Val Pro Tyr Pro Asp Pro Leu Glu Pro Arg
1 5 10
<210> 130
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 130
Asp Tyr Lys Asp Asp Asp Asp Lys
1 5
<210> 131
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 131
Tyr Pro Tyr Asp Val Pro Asp Tyr Ala
1 5
<210> 132
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 132
His His His His His
1 5
<210> 133
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 133
His His His His His His
1 5
<210> 134
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 134
His His His His His His His
1 5
<210> 135
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 135
His His His His His His His His
1 5
<210> 136
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 136
His His His His His His His His His
1 5
<210> 137
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 137
His His His His His His His His His His
1 5 10
<210> 138
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 138
Glu Gln Lys Leu Ile Ser Glu Glu Asp Leu
1 5 10
<210> 139
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 139
Thr Lys Glu Asn Pro Arg Ser Asn Gln Glu Glu Ser Tyr Asp Asp Asn
1 5 10 15
Glu Ser
<210> 140
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 140
Lys Glu Thr Ala Ala Ala Lys Phe Glu Arg Gln His Met Asp Ser
1 5 10 15
<210> 141
<211> 38
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 141
Met Asp Glu Lys Thr Thr Gly Trp Arg Gly Gly His Val Val Glu Gly
1 5 10 15
Leu Ala Gly Glu Leu Glu Gln Leu Arg Ala Arg Leu Glu His His Pro
20 25 30
Gln Gly Gln Arg Glu Pro
35
<210> 142
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 142
Ser Leu Ala Glu Leu Leu Asn Ala Gly Leu Gly Gly Ser
1 5 10
<210> 143
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 143
Thr Gln Asp Pro Ser Arg Val Gly
1 5
<210> 144
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 144
Pro Asp Arg Val Arg Ala Val Ser His Trp Ser Ser
1 5 10
<210> 145
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 145
Trp Ser His Pro Gln Phe Glu Lys
1 5
<210> 146
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 146
Cys Cys Pro Gly Cys Cys
1 5
<210> 147
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 147
Glu Val His Thr Asn Gln Asp Pro Leu Asp
1 5 10
<210> 148
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 148
Gly Lys Pro Ile Pro Asn Pro Leu Leu Gly Leu Asp Ser Thr
1 5 10
<210> 149
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 149
Tyr Thr Asp Ile Glu Met Asn Arg Leu Gly Lys
1 5 10
<210> 150
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 150
Asp Leu Tyr Asp Asp Asp Asp Lys
1 5
<210> 151
<211> 241
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 151
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Leu Ala Ser Gly Val Pro Ala His Phe Arg Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Gly Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Asn Pro Phe Thr
85 90 95
Phe Gly Ser Gly Thr Lys Leu Glu Ile Asn Arg Gly Gly Gly Gly Ser
100 105 110
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln
115 120 125
Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala Ser Val Lys Met Ser Cys
130 135 140
Lys Ala Ser Gly Tyr Thr Phe Thr Arg Tyr Thr Met His Trp Val Lys
145 150 155 160
Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile Gly Tyr Ile Asn Pro Ser
165 170 175
Arg Gly Tyr Thr Asn Tyr Asn Gln Lys Phe Lys Asp Lys Ala Thr Leu
180 185 190
Thr Thr Asp Lys Ser Ser Ser Thr Ala Tyr Met Gln Leu Ser Ser Leu
195 200 205
Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala Arg Tyr Tyr Asp Asp
210 215 220
His Tyr Cys Leu Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser
225 230 235 240
Ser
<210> 152
<211> 723
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 152
cagatcgtgc tgacccaaag ccccgccatc atgagcgcta gccccggtga gaaggtgacc 60
atgacatgct ccgcttccag ctccgtgtcc tacatgaact ggtatcagca gaaaagcgga 120
accagcccca aaaggtggat ctacgacacc agcaagctgg cctccggagt gcccgctcat 180
ttccggggct ctggatccgg caccagctac tctttaacca tttccggcat ggaagctgaa 240
gacgctgcca cctactattg ccagcaatgg agcagcaacc ccttcacatt cggatctggc 300
accaagctcg aaatcaatcg tggaggaggt ggcagcggcg gcggtggatc cggcggagga 360
ggaagccaag ttcaactcca gcagagcggc gctgaactgg cccggcccgg cgcctccgtc 420
aagatgagct gcaaggcttc cggctataca tttactcgtt acacaatgca ttgggtcaag 480
cagaggcccg gtcaaggttt agagtggatc ggatatatca acccttcccg gggctacacc 540
aactataacc aaaagttcaa ggataaagcc actttaacca ctgacaagag ctcctccacc 600
gcctacatgc agctgtcctc tttaaccagc gaggactccg ctgtttacta ctgcgctagg 660
tattacgacg accactactg tttagactat tggggacaag gtaccacttt aaccgtcagc 720
agc 723
<210> 153
<211> 236
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 153
Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala Ser
1 5 10 15
Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr Val
20 25 30
Ile Gln Trp Val Lys Gln Lys Pro Gly Gln Gly Leu Glu Trp Ile Gly
35 40 45
Ser Ile Asn Pro Tyr Asn Asp Tyr Thr Lys Tyr Asn Glu Lys Phe Lys
50 55 60
Gly Lys Ala Thr Leu Thr Ser Asp Lys Ser Ser Ile Thr Ala Tyr Met
65 70 75 80
Glu Phe Ser Ser Leu Thr Ser Glu Asp Ser Ala Leu Tyr Tyr Cys Ala
85 90 95
Arg Trp Gly Asp Gly Asn Tyr Trp Gly Arg Gly Thr Thr Leu Thr Val
100 105 110
Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Asp Ile Glu Met Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Leu
130 135 140
Gly Glu Arg Val Thr Met Thr Cys Thr Ala Ser Ser Ser Val Ser Ser
145 150 155 160
Ser Tyr Phe His Trp Tyr Gln Gln Lys Pro Gly Ser Ser Pro Lys Leu
165 170 175
Cys Ile Tyr Ser Thr Ser Asn Leu Ala Ser Gly Val Pro Pro Arg Phe
180 185 190
Ser Gly Ser Gly Ser Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu
195 200 205
Ala Glu Asp Ala Ala Thr Tyr Phe Cys His Gln Tyr His Arg Ser Pro
210 215 220
Thr Phe Gly Gly Gly Thr Lys Leu Glu Thr Lys Arg
225 230 235
<210> 154
<211> 708
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 154
gtccagctgc agcagagcgg acccgaactc gtgaaacccg gtgcttccgt gaaaatgtct 60
tgtaaggcca gcggatacac cttcacctcc tatgtgatcc agtgggtcaa acagaagccc 120
ggacaaggtc tcgagtggat cggcagcatc aacccttaca acgactatac caaatacaac 180
gagaagttta agggaaaggc tactttaacc tccgacaaaa gctccatcac agcctacatg 240
gagttcagct ctttaacatc cgaggacagc gctctgtact attgcgcccg gtggggcgac 300
ggcaattact ggggacgggg cacaacactg accgtgagca gcggaggcgg aggctccggc 360
ggaggcggat ctggcggtgg cggctccgac atcgagatga cccagtcccc cgctatcatg 420
tccgcctctt taggcgagcg ggtcacaatg acttgtacag cctcctccag cgtctcctcc 480
tcctacttcc attggtacca acagaaaccc ggaagctccc ctaaactgtg catctacagc 540
accagcaatc tcgccagcgg cgtgccccct aggttttccg gaagcggaag caccagctac 600
tctttaacca tctcctccat ggaggctgag gatgccgcca cctacttttg tcaccagtac 660
caccggtccc ccaccttcgg aggcggcacc aaactggaga caaagagg 708
<210> 155
<211> 696
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 155
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Leu Ala Ser Gly Val Pro Ala His Phe Arg Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Gly Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Asn Pro Phe Thr
85 90 95
Phe Gly Ser Gly Thr Lys Leu Glu Ile Asn Arg Gly Gly Gly Gly Ser
100 105 110
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln
115 120 125
Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala Ser Val Lys Met Ser Cys
130 135 140
Lys Ala Ser Gly Tyr Thr Phe Thr Arg Tyr Thr Met His Trp Val Lys
145 150 155 160
Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile Gly Tyr Ile Asn Pro Ser
165 170 175
Arg Gly Tyr Thr Asn Tyr Asn Gln Lys Phe Lys Asp Lys Ala Thr Leu
180 185 190
Thr Thr Asp Lys Ser Ser Ser Thr Ala Tyr Met Gln Leu Ser Ser Leu
195 200 205
Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala Arg Tyr Tyr Asp Asp
210 215 220
His Tyr Cys Leu Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser
225 230 235 240
Ser Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys
245 250 255
Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn
260 265 270
Gln Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser
275 280 285
Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile
290 295 300
Val Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro
305 310 315 320
Ala Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu
325 330 335
Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro
340 345 350
Thr Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val
355 360 365
Glu Asp Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu
370 375 380
Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys
385 390 395 400
Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe
405 410 415
Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala
420 425 430
Val Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val
435 440 445
Glu Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Val Gln Leu Gln
450 455 460
Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala Ser Val Lys Met Ser
465 470 475 480
Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr Val Ile Gln Trp Val
485 490 495
Lys Gln Lys Pro Gly Gln Gly Leu Glu Trp Ile Gly Ser Ile Asn Pro
500 505 510
Tyr Asn Asp Tyr Thr Lys Tyr Asn Glu Lys Phe Lys Gly Lys Ala Thr
515 520 525
Leu Thr Ser Asp Lys Ser Ser Ile Thr Ala Tyr Met Glu Phe Ser Ser
530 535 540
Leu Thr Ser Glu Asp Ser Ala Leu Tyr Tyr Cys Ala Arg Trp Gly Asp
545 550 555 560
Gly Asn Tyr Trp Gly Arg Gly Thr Thr Leu Thr Val Ser Ser Gly Gly
565 570 575
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Ile Glu
580 585 590
Met Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Leu Gly Glu Arg Val
595 600 605
Thr Met Thr Cys Thr Ala Ser Ser Ser Val Ser Ser Ser Tyr Phe His
610 615 620
Trp Tyr Gln Gln Lys Pro Gly Ser Ser Pro Lys Leu Cys Ile Tyr Ser
625 630 635 640
Thr Ser Asn Leu Ala Ser Gly Val Pro Pro Arg Phe Ser Gly Ser Gly
645 650 655
Ser Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu Asp Ala
660 665 670
Ala Thr Tyr Phe Cys His Gln Tyr His Arg Ser Pro Thr Phe Gly Gly
675 680 685
Gly Thr Lys Leu Glu Thr Lys Arg
690 695
<210> 156
<211> 2088
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 156
cagatcgtgc tgacccaaag ccccgccatc atgagcgcta gccccggtga gaaggtgacc 60
atgacatgct ccgcttccag ctccgtgtcc tacatgaact ggtatcagca gaaaagcgga 120
accagcccca aaaggtggat ctacgacacc agcaagctgg cctccggagt gcccgctcat 180
ttccggggct ctggatccgg caccagctac tctttaacca tttccggcat ggaagctgaa 240
gacgctgcca cctactattg ccagcaatgg agcagcaacc ccttcacatt cggatctggc 300
accaagctcg aaatcaatcg tggaggaggt ggcagcggcg gcggtggatc cggcggagga 360
ggaagccaag ttcaactcca gcagagcggc gctgaactgg cccggcccgg cgcctccgtc 420
aagatgagct gcaaggcttc cggctataca tttactcgtt acacaatgca ttgggtcaag 480
cagaggcccg gtcaaggttt agagtggatc ggatatatca acccttcccg gggctacacc 540
aactataacc aaaagttcaa ggataaagcc actttaacca ctgacaagag ctcctccacc 600
gcctacatgc agctgtcctc tttaaccagc gaggactccg ctgtttacta ctgcgctagg 660
tattacgacg accactactg tttagactat tggggacaag gtaccacttt aaccgtcagc 720
agctccggca ccaccaatac cgtggccgct tataacctca catggaagag caccaacttc 780
aagacaattc tggaatggga acccaagccc gtcaatcaag tttacaccgt gcagatctcc 840
accaaatccg gagactggaa gagcaagtgc ttctacacaa cagacaccga gtgtgattta 900
accgacgaaa tcgtcaagga cgtcaagcaa acctatctgg ctcgggtctt ttcctacccc 960
gctggcaatg tcgagtccac cggctccgct ggcgagcctc tctacgagaa ttcccccgaa 1020
ttcacccctt atttagagac caatttaggc cagcctacca tccagagctt cgagcaagtt 1080
ggcaccaagg tgaacgtcac cgtcgaggat gaaaggactt tagtgcggcg gaataacaca 1140
tttttatccc tccgggatgt gttcggcaaa gacctcatct acacactgta ctattggaag 1200
tccagctcct ccggcaaaaa gaccgctaag accaacacca acgagttttt aattgacgtg 1260
gacaaaggcg agaactactg cttcagcgtg caagccgtga tcccttctcg taccgtcaac 1320
cggaagagca cagattcccc cgttgagtgc atgggccaag aaaagggcga gttccgggag 1380
gtccagctgc agcagagcgg acccgaactc gtgaaacccg gtgcttccgt gaaaatgtct 1440
tgtaaggcca gcggatacac cttcacctcc tatgtgatcc agtgggtcaa acagaagccc 1500
ggacaaggtc tcgagtggat cggcagcatc aacccttaca acgactatac caaatacaac 1560
gagaagttta agggaaaggc tactttaacc tccgacaaaa gctccatcac agcctacatg 1620
gagttcagct ctttaacatc cgaggacagc gctctgtact attgcgcccg gtggggcgac 1680
ggcaattact ggggacgggg cacaacactg accgtgagca gcggaggcgg aggctccggc 1740
ggaggcggat ctggcggtgg cggctccgac atcgagatga cccagtcccc cgctatcatg 1800
tccgcctctt taggcgagcg ggtcacaatg acttgtacag cctcctccag cgtctcctcc 1860
tcctacttcc attggtacca acagaaaccc ggaagctccc ctaaactgtg catctacagc 1920
accagcaatc tcgccagcgg cgtgccccct aggttttccg gaagcggaag caccagctac 1980
tctttaacca tctcctccat ggaggctgag gatgccgcca cctacttttg tcaccagtac 2040
caccggtccc ccaccttcgg aggcggcacc aaactggaga caaagagg 2088
<210> 157
<211> 714
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 157
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser
20 25 30
Pro Gly Glu Lys Val Thr Met Thr Cys Ser Ala Ser Ser Ser Val Ser
35 40 45
Tyr Met Asn Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp
50 55 60
Ile Tyr Asp Thr Ser Lys Leu Ala Ser Gly Val Pro Ala His Phe Arg
65 70 75 80
Gly Ser Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Gly Met Glu
85 90 95
Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Asn Pro
100 105 110
Phe Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Asn Arg Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Val Gln Leu
130 135 140
Gln Gln Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala Ser Val Lys Met
145 150 155 160
Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Arg Tyr Thr Met His Trp
165 170 175
Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile Gly Tyr Ile Asn
180 185 190
Pro Ser Arg Gly Tyr Thr Asn Tyr Asn Gln Lys Phe Lys Asp Lys Ala
195 200 205
Thr Leu Thr Thr Asp Lys Ser Ser Ser Thr Ala Tyr Met Gln Leu Ser
210 215 220
Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala Arg Tyr Tyr
225 230 235 240
Asp Asp His Tyr Cys Leu Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr
245 250 255
Val Ser Ser Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr
260 265 270
Trp Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro
275 280 285
Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp
290 295 300
Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp
305 310 315 320
Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser
325 330 335
Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu
340 345 350
Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly
355 360 365
Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val
370 375 380
Thr Val Glu Asp Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu
385 390 395 400
Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr
405 410 415
Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn
420 425 430
Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val
435 440 445
Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser
450 455 460
Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Val Gln
465 470 475 480
Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala Ser Val Lys
485 490 495
Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr Val Ile Gln
500 505 510
Trp Val Lys Gln Lys Pro Gly Gln Gly Leu Glu Trp Ile Gly Ser Ile
515 520 525
Asn Pro Tyr Asn Asp Tyr Thr Lys Tyr Asn Glu Lys Phe Lys Gly Lys
530 535 540
Ala Thr Leu Thr Ser Asp Lys Ser Ser Ile Thr Ala Tyr Met Glu Phe
545 550 555 560
Ser Ser Leu Thr Ser Glu Asp Ser Ala Leu Tyr Tyr Cys Ala Arg Trp
565 570 575
Gly Asp Gly Asn Tyr Trp Gly Arg Gly Thr Thr Leu Thr Val Ser Ser
580 585 590
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp
595 600 605
Ile Glu Met Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Leu Gly Glu
610 615 620
Arg Val Thr Met Thr Cys Thr Ala Ser Ser Ser Val Ser Ser Ser Tyr
625 630 635 640
Phe His Trp Tyr Gln Gln Lys Pro Gly Ser Ser Pro Lys Leu Cys Ile
645 650 655
Tyr Ser Thr Ser Asn Leu Ala Ser Gly Val Pro Pro Arg Phe Ser Gly
660 665 670
Ser Gly Ser Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
675 680 685
Asp Ala Ala Thr Tyr Phe Cys His Gln Tyr His Arg Ser Pro Thr Phe
690 695 700
Gly Gly Gly Thr Lys Leu Glu Thr Lys Arg
705 710
<210> 158
<211> 2142
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 158
atgaagtggg tgaccttcat cagcttatta tttttattca gctccgccta ttcccagatc 60
gtgctgaccc aaagccccgc catcatgagc gctagccccg gtgagaaggt gaccatgaca 120
tgctccgctt ccagctccgt gtcctacatg aactggtatc agcagaaaag cggaaccagc 180
cccaaaaggt ggatctacga caccagcaag ctggcctccg gagtgcccgc tcatttccgg 240
ggctctggat ccggcaccag ctactcttta accatttccg gcatggaagc tgaagacgct 300
gccacctact attgccagca atggagcagc aaccccttca cattcggatc tggcaccaag 360
ctcgaaatca atcgtggagg aggtggcagc ggcggcggtg gatccggcgg aggaggaagc 420
caagttcaac tccagcagag cggcgctgaa ctggcccggc ccggcgcctc cgtcaagatg 480
agctgcaagg cttccggcta tacatttact cgttacacaa tgcattgggt caagcagagg 540
cccggtcaag gtttagagtg gatcggatat atcaaccctt cccggggcta caccaactat 600
aaccaaaagt tcaaggataa agccacttta accactgaca agagctcctc caccgcctac 660
atgcagctgt cctctttaac cagcgaggac tccgctgttt actactgcgc taggtattac 720
gacgaccact actgtttaga ctattgggga caaggtacca ctttaaccgt cagcagctcc 780
ggcaccacca ataccgtggc cgcttataac ctcacatgga agagcaccaa cttcaagaca 840
attctggaat gggaacccaa gcccgtcaat caagtttaca ccgtgcagat ctccaccaaa 900
tccggagact ggaagagcaa gtgcttctac acaacagaca ccgagtgtga tttaaccgac 960
gaaatcgtca aggacgtcaa gcaaacctat ctggctcggg tcttttccta ccccgctggc 1020
aatgtcgagt ccaccggctc cgctggcgag cctctctacg agaattcccc cgaattcacc 1080
ccttatttag agaccaattt aggccagcct accatccaga gcttcgagca agttggcacc 1140
aaggtgaacg tcaccgtcga ggatgaaagg actttagtgc ggcggaataa cacattttta 1200
tccctccggg atgtgttcgg caaagacctc atctacacac tgtactattg gaagtccagc 1260
tcctccggca aaaagaccgc taagaccaac accaacgagt ttttaattga cgtggacaaa 1320
ggcgagaact actgcttcag cgtgcaagcc gtgatccctt ctcgtaccgt caaccggaag 1380
agcacagatt cccccgttga gtgcatgggc caagaaaagg gcgagttccg ggaggtccag 1440
ctgcagcaga gcggacccga actcgtgaaa cccggtgctt ccgtgaaaat gtcttgtaag 1500
gccagcggat acaccttcac ctcctatgtg atccagtggg tcaaacagaa gcccggacaa 1560
ggtctcgagt ggatcggcag catcaaccct tacaacgact ataccaaata caacgagaag 1620
tttaagggaa aggctacttt aacctccgac aaaagctcca tcacagccta catggagttc 1680
agctctttaa catccgagga cagcgctctg tactattgcg cccggtgggg cgacggcaat 1740
tactggggac ggggcacaac actgaccgtg agcagcggag gcggaggctc cggcggaggc 1800
ggatctggcg gtggcggctc cgacatcgag atgacccagt cccccgctat catgtccgcc 1860
tctttaggcg agcgggtcac aatgacttgt acagcctcct ccagcgtctc ctcctcctac 1920
ttccattggt accaacagaa acccggaagc tcccctaaac tgtgcatcta cagcaccagc 1980
aatctcgcca gcggcgtgcc ccctaggttt tccggaagcg gaagcaccag ctactcttta 2040
accatctcct ccatggaggc tgaggatgcc gccacctact tttgtcacca gtaccaccgg 2100
tcccccacct tcggaggcgg caccaaactg gagacaaaga gg 2142
<210> 159
<211> 399
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 159
gcacctactt caagttctac aaagaaaaca cagctacaac tggagcattt actgctggat 60
ttacagatga ttttgaatgg aattaataat tacaagaatc ccaaactcac caggatgctc 120
acatttaagt tttacatgcc caagaaggcc acagaactga aacatcttca gtgtctagaa 180
gaagaactca aacctctgga ggaagtgcta aatttagctc aaagcaaaaa ctttcactta 240
agacccaggg acttaatcag caatatcaac gtaatagttc tggaactaaa gggatctgaa 300
acaacattca tgtgtgaata tgctgatgag acagcaacca ttgtagaatt tctgaacaga 360
tggattacct tttgtcaaag catcatctca acactaact 399
<210> 160
<211> 399
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 160
gcccccacct cctcctccac caagaagacc cagctgcagc tggagcattt actgctggat 60
ttacagatga ttttaaacgg catcaacaac tacaagaacc ccaagctgac tcgtatgctg 120
accttcaagt tctacatgcc caagaaggcc accgagctga agcatttaca gtgtttagag 180
gaggagctga agcccctcga ggaggtgctg aatttagccc agtccaagaa tttccattta 240
aggccccggg atttaatcag caacatcaac gtgatcgttt tagagctgaa gggctccgag 300
accaccttca tgtgcgagta cgccgacgag accgccacca tcgtggagtt tttaaatcgt 360
tggatcacct tctgccagtc catcatctcc actttaacc 399
<210> 161
<211> 485
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 161
Ala Pro Thr Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His
1 5 10 15
Leu Leu Leu Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys
20 25 30
Asn Pro Lys Leu Thr Arg Met Leu Thr Phe Lys Phe Tyr Met Pro Lys
35 40 45
Lys Ala Thr Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys
50 55 60
Pro Leu Glu Glu Val Leu Asn Leu Ala Gln Ser Lys Asn Phe His Leu
65 70 75 80
Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu
85 90 95
Lys Gly Ser Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala
100 105 110
Thr Ile Val Glu Phe Leu Asn Arg Trp Ile Thr Phe Cys Gln Ser Ile
115 120 125
Ile Ser Thr Leu Thr Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn
130 135 140
Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro
145 150 155 160
Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly
165 170 175
Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu
180 185 190
Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val
195 200 205
Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu
210 215 220
Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn
225 230 235 240
Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val
245 250 255
Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val Arg Arg Asn Asn Thr
260 265 270
Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu
275 280 285
Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn
290 295 300
Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe
305 310 315 320
Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr
325 330 335
Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu
340 345 350
Ala Pro Thr Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu Glu His
355 360 365
Leu Leu Leu Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn Tyr Lys
370 375 380
Asn Pro Lys Leu Thr Arg Met Leu Thr Phe Lys Phe Tyr Met Pro Lys
385 390 395 400
Lys Ala Thr Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu Leu Lys
405 410 415
Pro Leu Glu Glu Val Leu Asn Leu Ala Gln Ser Lys Asn Phe His Leu
420 425 430
Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu Glu Leu
435 440 445
Lys Gly Ser Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu Thr Ala
450 455 460
Thr Ile Val Glu Phe Leu Asn Arg Trp Ile Thr Phe Cys Gln Ser Ile
465 470 475 480
Ile Ser Thr Leu Thr
485
<210> 162
<211> 1455
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 162
gcccccacct cctcctccac caagaagacc cagctgcagc tggagcattt actgctggat 60
ttacagatga ttttaaacgg catcaacaac tacaagaacc ccaagctgac tcgtatgctg 120
accttcaagt tctacatgcc caagaaggcc accgagctga agcatttaca gtgtttagag 180
gaggagctga agcccctcga ggaggtgctg aatttagccc agtccaagaa tttccattta 240
aggccccggg atttaatcag caacatcaac gtgatcgttt tagagctgaa gggctccgag 300
accaccttca tgtgcgagta cgccgacgag accgccacca tcgtggagtt tttaaatcgt 360
tggatcacct tctgccagtc catcatctcc actttaacca gcggcacaac caacacagtc 420
gctgcctata acctcacttg gaagagcacc aacttcaaaa ccatcctcga atgggaaccc 480
aaacccgtta accaagttta caccgtgcag atcagcacca agtccggcga ctggaagtcc 540
aaatgtttct ataccaccga caccgagtgc gatctcaccg atgagatcgt gaaagatgtg 600
aaacagacct acctcgcccg ggtgtttagc taccccgccg gcaatgtgga gagcactggt 660
tccgctggcg agcctttata cgagaacagc cccgaattta ccccttacct cgagaccaat 720
ttaggacagc ccaccatcca aagctttgag caagttggca caaaggtgaa tgtgacagtg 780
gaggacgagc ggactttagt gcggcggaac aacacctttc tcagcctccg ggatgtgttc 840
ggcaaagatt taatctacac actgtattac tggaagtcct cttcctccgg caagaagaca 900
gctaaaacca acacaaacga gtttttaatc gacgtggata aaggcgaaaa ctactgtttc 960
agcgtgcaag ctgtgatccc ctcccggacc gtgaatagga aaagcaccga tagccccgtt 1020
gagtgcatgg gccaagaaaa gggcgagttc cgggaggcac ctacttcaag ttctacaaag 1080
aaaacacagc tacaactgga gcatttactg ctggatttac agatgatttt gaatggaatt 1140
aataattaca agaatcccaa actcaccagg atgctcacat ttaagtttta catgcccaag 1200
aaggccacag aactgaaaca tcttcagtgt ctagaagaag aactcaaacc tctggaggaa 1260
gtgctaaatt tagctcaaag caaaaacttt cacttaagac ccagggactt aatcagcaat 1320
atcaacgtaa tagttctgga actaaaggga tctgaaacaa cattcatgtg tgaatatgct 1380
gatgagacag caaccattgt agaatttctg aacagatgga ttaccttttg tcaaagcatc 1440
atctcaacac taact 1455
<210> 163
<211> 503
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 163
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ala Pro Thr Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu
20 25 30
Glu His Leu Leu Leu Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn
35 40 45
Tyr Lys Asn Pro Lys Leu Thr Arg Met Leu Thr Phe Lys Phe Tyr Met
50 55 60
Pro Lys Lys Ala Thr Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu
65 70 75 80
Leu Lys Pro Leu Glu Glu Val Leu Asn Leu Ala Gln Ser Lys Asn Phe
85 90 95
His Leu Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu
100 105 110
Glu Leu Lys Gly Ser Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu
115 120 125
Thr Ala Thr Ile Val Glu Phe Leu Asn Arg Trp Ile Thr Phe Cys Gln
130 135 140
Ser Ile Ile Ser Thr Leu Thr Ser Gly Thr Thr Asn Thr Val Ala Ala
145 150 155 160
Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp
165 170 175
Glu Pro Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr Lys
180 185 190
Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys
195 200 205
Asp Leu Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu Ala
210 215 220
Arg Val Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser Ala
225 230 235 240
Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu
245 250 255
Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly Thr
260 265 270
Lys Val Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val Arg Arg Asn
275 280 285
Asn Thr Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr
290 295 300
Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys
305 310 315 320
Thr Asn Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr
325 330 335
Cys Phe Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg Lys
340 345 350
Ser Thr Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu Phe
355 360 365
Arg Glu Ala Pro Thr Ser Ser Ser Thr Lys Lys Thr Gln Leu Gln Leu
370 375 380
Glu His Leu Leu Leu Asp Leu Gln Met Ile Leu Asn Gly Ile Asn Asn
385 390 395 400
Tyr Lys Asn Pro Lys Leu Thr Arg Met Leu Thr Phe Lys Phe Tyr Met
405 410 415
Pro Lys Lys Ala Thr Glu Leu Lys His Leu Gln Cys Leu Glu Glu Glu
420 425 430
Leu Lys Pro Leu Glu Glu Val Leu Asn Leu Ala Gln Ser Lys Asn Phe
435 440 445
His Leu Arg Pro Arg Asp Leu Ile Ser Asn Ile Asn Val Ile Val Leu
450 455 460
Glu Leu Lys Gly Ser Glu Thr Thr Phe Met Cys Glu Tyr Ala Asp Glu
465 470 475 480
Thr Ala Thr Ile Val Glu Phe Leu Asn Arg Trp Ile Thr Phe Cys Gln
485 490 495
Ser Ile Ile Ser Thr Leu Thr
500
<210> 164
<211> 1509
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 164
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccgccccc 60
acctcctcct ccaccaagaa gacccagctg cagctggagc atttactgct ggatttacag 120
atgattttaa acggcatcaa caactacaag aaccccaagc tgactcgtat gctgaccttc 180
aagttctaca tgcccaagaa ggccaccgag ctgaagcatt tacagtgttt agaggaggag 240
ctgaagcccc tcgaggaggt gctgaattta gcccagtcca agaatttcca tttaaggccc 300
cgggatttaa tcagcaacat caacgtgatc gttttagagc tgaagggctc cgagaccacc 360
ttcatgtgcg agtacgccga cgagaccgcc accatcgtgg agtttttaaa tcgttggatc 420
accttctgcc agtccatcat ctccacttta accagcggca caaccaacac agtcgctgcc 480
tataacctca cttggaagag caccaacttc aaaaccatcc tcgaatggga acccaaaccc 540
gttaaccaag tttacaccgt gcagatcagc accaagtccg gcgactggaa gtccaaatgt 600
ttctatacca ccgacaccga gtgcgatctc accgatgaga tcgtgaaaga tgtgaaacag 660
acctacctcg cccgggtgtt tagctacccc gccggcaatg tggagagcac tggttccgct 720
ggcgagcctt tatacgagaa cagccccgaa tttacccctt acctcgagac caatttagga 780
cagcccacca tccaaagctt tgagcaagtt ggcacaaagg tgaatgtgac agtggaggac 840
gagcggactt tagtgcggcg gaacaacacc tttctcagcc tccgggatgt gttcggcaaa 900
gatttaatct acacactgta ttactggaag tcctcttcct ccggcaagaa gacagctaaa 960
accaacacaa acgagttttt aatcgacgtg gataaaggcg aaaactactg tttcagcgtg 1020
caagctgtga tcccctcccg gaccgtgaat aggaaaagca ccgatagccc cgttgagtgc 1080
atgggccaag aaaagggcga gttccgggag gcacctactt caagttctac aaagaaaaca 1140
cagctacaac tggagcattt actgctggat ttacagatga ttttgaatgg aattaataat 1200
tacaagaatc ccaaactcac caggatgctc acatttaagt tttacatgcc caagaaggcc 1260
acagaactga aacatcttca gtgtctagaa gaagaactca aacctctgga ggaagtgcta 1320
aatttagctc aaagcaaaaa ctttcactta agacccaggg acttaatcag caatatcaac 1380
gtaatagttc tggaactaaa gggatctgaa acaacattca tgtgtgaata tgctgatgag 1440
acagcaacca ttgtagaatt tctgaacaga tggattacct tttgtcaaag catcatctca 1500
acactaact 1509
<210> 165
<211> 342
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 165
aactgggtga acgtgatcag cgatttaaag aagatcgagg atttaatcca gagcatgcac 60
atcgacgcca ctctgtacac tgagagcgac gtgcacccta gctgcaaggt gactgccatg 120
aagtgctttt tactggagct gcaagttatc tctttagaga gcggcgatgc cagcatccac 180
gacactgtgg agaatttaat cattttagcc aacaactctt taagcagcaa cggcaacgtg 240
acagagagcg gctgcaagga gtgcgaggag ctggaggaga agaacatcaa ggagttttta 300
cagagcttcg tgcacatcgt gcagatgttc atcaacacta gc 342
<210> 166
<211> 342
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 166
aactgggtga acgtcatcag cgatttaaag aagatcgaag atttaattca gtccatgcat 60
atcgacgcca ctttatacac agaatccgac gtgcacccct cttgtaaggt gaccgccatg 120
aaatgttttt tactggagct gcaagttatc tctttagaga gcggagacgc tagcatccac 180
gacaccgtgg agaatttaat cattttagcc aataactctt tatccagcaa cggcaacgtg 240
acagagtccg gctgcaagga gtgcgaagag ctggaggaga agaacatcaa ggagtttctg 300
caatcctttg tgcacattgt ccagatgttc atcaatacct cc 342
<210> 167
<211> 447
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 167
Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile
1 5 10 15
Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp Val His
20 25 30
Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu Glu Leu Gln
35 40 45
Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp Thr Val Glu
50 55 60
Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly Asn Val
65 70 75 80
Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile
85 90 95
Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met Phe Ile Asn
100 105 110
Thr Ser Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp
115 120 125
Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val
130 135 140
Asn Gln Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys
145 150 155 160
Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu
165 170 175
Ile Val Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr
180 185 190
Pro Ala Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr
195 200 205
Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln
210 215 220
Pro Thr Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr
225 230 235 240
Val Glu Asp Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser
245 250 255
Leu Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp
260 265 270
Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu
275 280 285
Phe Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln
290 295 300
Ala Val Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro
305 310 315 320
Val Glu Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val
325 330 335
Asn Val Ile Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met
340 345 350
His Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys
355 360 365
Lys Val Thr Ala Met Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser
370 375 380
Leu Glu Ser Gly Asp Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile
385 390 395 400
Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser
405 410 415
Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe
420 425 430
Leu Gln Ser Phe Val His Ile Val Gln Met Phe Ile Asn Thr Ser
435 440 445
<210> 168
<211> 1341
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 168
aactgggtga acgtgatcag cgatttaaag aagatcgagg atttaatcca gagcatgcac 60
atcgacgcca ctctgtacac tgagagcgac gtgcacccta gctgcaaggt gactgccatg 120
aagtgctttt tactggagct gcaagttatc tctttagaga gcggcgatgc cagcatccac 180
gacactgtgg agaatttaat cattttagcc aacaactctt taagcagcaa cggcaacgtg 240
acagagagcg gctgcaagga gtgcgaggag ctggaggaga agaacatcaa ggagttttta 300
cagagcttcg tgcacatcgt gcagatgttc atcaacacta gcagcggcac aaccaacaca 360
gtcgctgcct ataacctcac ttggaagagc accaacttca aaaccatcct cgaatgggaa 420
cccaaacccg ttaaccaagt ttacaccgtg cagatcagca ccaagtccgg cgactggaag 480
tccaaatgtt tctataccac cgacaccgag tgcgatctca ccgatgagat cgtgaaagat 540
gtgaaacaga cctacctcgc ccgggtgttt agctaccccg ccggcaatgt ggagagcact 600
ggttccgctg gcgagccttt atacgagaac agccccgaat ttacccctta cctcgagacc 660
aatttaggac agcccaccat ccaaagcttt gagcaagttg gcacaaaggt gaatgtgaca 720
gtggaggacg agcggacttt agtgcggcgg aacaacacct ttctcagcct ccgggatgtg 780
ttcggcaaag atttaatcta cacactgtat tactggaagt cctcttcctc cggcaagaag 840
acagctaaaa ccaacacaaa cgagttttta atcgacgtgg ataaaggcga aaactactgt 900
ttcagcgtgc aagctgtgat cccctcccgg accgtgaata ggaaaagcac cgatagcccc 960
gttgagtgca tgggccaaga aaagggcgag ttccgggaga actgggtgaa cgtcatcagc 1020
gatttaaaga agatcgaaga tttaattcag tccatgcata tcgacgccac tttatacaca 1080
gaatccgacg tgcacccctc ttgtaaggtg accgccatga aatgtttttt actggagctg 1140
caagttatct ctttagagag cggagacgct agcatccacg acaccgtgga gaatttaatc 1200
attttagcca ataactcttt atccagcaac ggcaacgtga cagagtccgg ctgcaaggag 1260
tgcgaagagc tggaggagaa gaacatcaag gagtttctgc aatcctttgt gcacattgtc 1320
cagatgttca tcaatacctc c 1341
<210> 169
<211> 465
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 169
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu Asp
20 25 30
Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp
35 40 45
Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu Glu
50 55 60
Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp Thr
65 70 75 80
Val Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly
85 90 95
Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys
100 105 110
Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met Phe
115 120 125
Ile Asn Thr Ser Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu
130 135 140
Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys
145 150 155 160
Pro Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp
165 170 175
Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr
180 185 190
Asp Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe
195 200 205
Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro
210 215 220
Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu
225 230 235 240
Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn
245 250 255
Val Thr Val Glu Asp Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe
260 265 270
Leu Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr
275 280 285
Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr
290 295 300
Asn Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser
305 310 315 320
Val Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp
325 330 335
Ser Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Asn
340 345 350
Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile Gln
355 360 365
Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp Val His Pro
370 375 380
Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu Glu Leu Gln Val
385 390 395 400
Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp Thr Val Glu Asn
405 410 415
Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly Asn Val Thr
420 425 430
Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile Lys
435 440 445
Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met Phe Ile Asn Thr
450 455 460
Ser
465
<210> 170
<211> 1395
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 170
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccaactgg 60
gtgaacgtga tcagcgattt aaagaagatc gaggatttaa tccagagcat gcacatcgac 120
gccactctgt acactgagag cgacgtgcac cctagctgca aggtgactgc catgaagtgc 180
tttttactgg agctgcaagt tatctcttta gagagcggcg atgccagcat ccacgacact 240
gtggagaatt taatcatttt agccaacaac tctttaagca gcaacggcaa cgtgacagag 300
agcggctgca aggagtgcga ggagctggag gagaagaaca tcaaggagtt tttacagagc 360
ttcgtgcaca tcgtgcagat gttcatcaac actagcagcg gcacaaccaa cacagtcgct 420
gcctataacc tcacttggaa gagcaccaac ttcaaaacca tcctcgaatg ggaacccaaa 480
cccgttaacc aagtttacac cgtgcagatc agcaccaagt ccggcgactg gaagtccaaa 540
tgtttctata ccaccgacac cgagtgcgat ctcaccgatg agatcgtgaa agatgtgaaa 600
cagacctacc tcgcccgggt gtttagctac cccgccggca atgtggagag cactggttcc 660
gctggcgagc ctttatacga gaacagcccc gaatttaccc cttacctcga gaccaattta 720
ggacagccca ccatccaaag ctttgagcaa gttggcacaa aggtgaatgt gacagtggag 780
gacgagcgga ctttagtgcg gcggaacaac acctttctca gcctccggga tgtgttcggc 840
aaagatttaa tctacacact gtattactgg aagtcctctt cctccggcaa gaagacagct 900
aaaaccaaca caaacgagtt tttaatcgac gtggataaag gcgaaaacta ctgtttcagc 960
gtgcaagctg tgatcccctc ccggaccgtg aataggaaaa gcaccgatag ccccgttgag 1020
tgcatgggcc aagaaaaggg cgagttccgg gagaactggg tgaacgtcat cagcgattta 1080
aagaagatcg aagatttaat tcagtccatg catatcgacg ccactttata cacagaatcc 1140
gacgtgcacc cctcttgtaa ggtgaccgcc atgaaatgtt ttttactgga gctgcaagtt 1200
atctctttag agagcggaga cgctagcatc cacgacaccg tggagaattt aatcatttta 1260
gccaataact ctttatccag caacggcaac gtgacagagt ccggctgcaa ggagtgcgaa 1320
gagctggagg agaagaacat caaggagttt ctgcaatcct ttgtgcacat tgtccagatg 1380
ttcatcaata cctcc 1395
<210> 171
<211> 471
<212> DNA
<213> Homo sapiens
<400> 171
tacttcggca aactggaatc caagctgagc gtgatccgga atttaaacga ccaagttctg 60
tttatcgatc aaggtaaccg gcctctgttc gaggacatga ccgactccga ttgccgggac 120
aatgcccccc ggaccatctt cattatctcc atgtacaagg acagccagcc ccggggcatg 180
gctgtgacaa ttagcgtgaa gtgtgagaaa atcagcactt tatcttgtga gaacaagatc 240
atctccttta aggaaatgaa cccccccgat aacatcaagg acaccaagtc cgatatcatc 300
ttcttccagc ggtccgtgcc cggtcacgat aacaagatgc agttcgaatc ctcctcctac 360
gagggctact ttttagcttg tgaaaaggag agggatttat tcaagctgat cctcaagaag 420
gaggacgagc tgggcgatcg ttccatcatg ttcaccgtcc aaaacgagga t 471
<210> 172
<211> 918
<212> DNA
<213> Homo sapiens
<400> 172
atttgggaac tgaagaagga cgtctacgtg gtcgaactgg actggtatcc cgatgctccc 60
ggcgaaatgg tggtgctcac ttgtgacacc cccgaagaag acggcatcac ttggaccctc 120
gatcagagca gcgaggtgct gggctccgga aagaccctca caatccaagt taaggagttc 180
ggagacgctg gccaatacac atgccacaag ggaggcgagg tgctcagcca ttccttatta 240
ttattacaca agaaggaaga cggaatctgg tccaccgaca ttttaaaaga tcagaaggag 300
cccaagaata agaccttttt aaggtgtgag gccaaaaact acagcggtcg tttcacttgt 360
tggtggctga ccaccatttc caccgattta accttctccg tgaaaagcag ccggggaagc 420
tccgaccctc aaggtgtgac atgtggagcc gctaccctca gcgctgagag ggttcgtggc 480
gataacaagg aatacgagta cagcgtggag tgccaagaag atagcgcttg tcccgctgcc 540
gaagaatctt tacccattga ggtgatggtg gacgccgtgc acaaactcaa gtacgagaac 600
tacacctcct ccttctttat ccgggacatc attaagcccg atcctcctaa gaatttacag 660
ctgaagcctc tcaaaaatag ccggcaagtt gaggtctctt gggaatatcc cgacacttgg 720
agcacacccc acagctactt ctctttaacc ttttgtgtgc aagttcaagg taaaagcaag 780
cgggagaaga aagaccgggt gtttaccgac aaaaccagcg ccaccgtcat ctgtcggaag 840
aacgcctcca tcagcgtgag ggctcaagat cgttattact ccagcagctg gtccgagtgg 900
gccagcgtgc cttgttcc 918
<210> 173
<211> 591
<212> DNA
<213> Homo sapiens
<400> 173
cgtaacctcc ccgtggctac ccccgatccc ggaatgttcc cttgtttaca ccacagccag 60
aatttactga gggccgtgag caacatgctg cagaaagcta ggcagacttt agaattttac 120
ccttgcacca gcgaggagat cgaccatgaa gatatcacca aggacaagac atccaccgtg 180
gaggcttgtt tacctctgga gctgacaaag aacgagtctt gtctcaactc tcgtgaaacc 240
agcttcatca caaatggctc ttgtttagct tcccggaaga cctcctttat gatggcttta 300
tgcctcagct ccatctacga ggatttaaag atgtaccaag tggagttcaa gaccatgaac 360
gccaagctgc tcatggaccc taaacggcag atctttttag accagaacat gctggctgtg 420
attgatgagc tgatgcaagc tttaaacttc aactccgaga ccgtccctca gaagtcctcc 480
ctcgaggagc ccgattttta caagacaaag atcaaactgt gcattttact ccacgccttt 540
aggatccggg ccgtgaccat tgaccgggtc atgagctatt taaacgccag c 591
<210> 174
<211> 490
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 174
Tyr Phe Gly Lys Leu Glu Ser Lys Leu Ser Val Ile Arg Asn Leu Asn
1 5 10 15
Asp Gln Val Leu Phe Ile Asp Gln Gly Asn Arg Pro Leu Phe Glu Asp
20 25 30
Met Thr Asp Ser Asp Cys Arg Asp Asn Ala Pro Arg Thr Ile Phe Ile
35 40 45
Ile Ser Met Tyr Lys Asp Ser Gln Pro Arg Gly Met Ala Val Thr Ile
50 55 60
Ser Val Lys Cys Glu Lys Ile Ser Thr Leu Ser Cys Glu Asn Lys Ile
65 70 75 80
Ile Ser Phe Lys Glu Met Asn Pro Pro Asp Asn Ile Lys Asp Thr Lys
85 90 95
Ser Asp Ile Ile Phe Phe Gln Arg Ser Val Pro Gly His Asp Asn Lys
100 105 110
Met Gln Phe Glu Ser Ser Ser Tyr Glu Gly Tyr Phe Leu Ala Cys Glu
115 120 125
Lys Glu Arg Asp Leu Phe Lys Leu Ile Leu Lys Lys Glu Asp Glu Leu
130 135 140
Gly Asp Arg Ser Ile Met Phe Thr Val Gln Asn Glu Asp Ser Gly Thr
145 150 155 160
Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe
165 170 175
Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val Tyr Thr
180 185 190
Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr
195 200 205
Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys Asp Val
210 215 220
Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly Asn Val
225 230 235 240
Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu
245 250 255
Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser
260 265 270
Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu Asp Glu Arg
275 280 285
Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp Val Phe
290 295 300
Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser
305 310 315 320
Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile Asp Val
325 330 335
Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile Pro Ser
340 345 350
Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys Met Gly
355 360 365
Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val Asn Val Ile Ser Asp
370 375 380
Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr
385 390 395 400
Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys Val Thr Ala Met
405 410 415
Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp
420 425 430
Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asn
435 440 445
Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys
450 455 460
Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val
465 470 475 480
His Ile Val Gln Met Phe Ile Asn Thr Ser
485 490
<210> 175
<211> 1470
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 175
tacttcggca aactggaatc caagctgagc gtgatccgga atttaaacga ccaagttctg 60
tttatcgatc aaggtaaccg gcctctgttc gaggacatga ccgactccga ttgccgggac 120
aatgcccccc ggaccatctt cattatctcc atgtacaagg acagccagcc ccggggcatg 180
gctgtgacaa ttagcgtgaa gtgtgagaaa atcagcactt tatcttgtga gaacaagatc 240
atctccttta aggaaatgaa cccccccgat aacatcaagg acaccaagtc cgatatcatc 300
ttcttccagc ggtccgtgcc cggtcacgat aacaagatgc agttcgaatc ctcctcctac 360
gagggctact ttttagcttg tgaaaaggag agggatttat tcaagctgat cctcaagaag 420
gaggacgagc tgggcgatcg ttccatcatg ttcaccgtcc aaaacgagga tagcggcaca 480
accaacacag tcgctgccta taacctcact tggaagagca ccaacttcaa aaccatcctc 540
gaatgggaac ccaaacccgt taaccaagtt tacaccgtgc agatcagcac caagtccggc 600
gactggaagt ccaaatgttt ctataccacc gacaccgagt gcgatctcac cgatgagatc 660
gtgaaagatg tgaaacagac ctacctcgcc cgggtgttta gctaccccgc cggcaatgtg 720
gagagcactg gttccgctgg cgagccttta tacgagaaca gccccgaatt taccccttac 780
ctcgagacca atttaggaca gcccaccatc caaagctttg agcaagttgg cacaaaggtg 840
aatgtgacag tggaggacga gcggacttta gtgcggcgga acaacacctt tctcagcctc 900
cgggatgtgt tcggcaaaga tttaatctac acactgtatt actggaagtc ctcttcctcc 960
ggcaagaaga cagctaaaac caacacaaac gagtttttaa tcgacgtgga taaaggcgaa 1020
aactactgtt tcagcgtgca agctgtgatc ccctcccgga ccgtgaatag gaaaagcacc 1080
gatagccccg ttgagtgcat gggccaagaa aagggcgagt tccgggagaa ctgggtgaac 1140
gtcatcagcg atttaaagaa gatcgaagat ttaattcagt ccatgcatat cgacgccact 1200
ttatacacag aatccgacgt gcacccctct tgtaaggtga ccgccatgaa atgtttttta 1260
ctggagctgc aagttatctc tttagagagc ggagacgcta gcatccacga caccgtggag 1320
aatttaatca ttttagccaa taactcttta tccagcaacg gcaacgtgac agagtccggc 1380
tgcaaggagt gcgaagagct ggaggagaag aacatcaagg agtttctgca atcctttgtg 1440
cacattgtcc agatgttcat caatacctcc 1470
<210> 176
<211> 508
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 176
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Tyr Phe Gly Lys Leu Glu Ser Lys Leu Ser Val Ile Arg Asn
20 25 30
Leu Asn Asp Gln Val Leu Phe Ile Asp Gln Gly Asn Arg Pro Leu Phe
35 40 45
Glu Asp Met Thr Asp Ser Asp Cys Arg Asp Asn Ala Pro Arg Thr Ile
50 55 60
Phe Ile Ile Ser Met Tyr Lys Asp Ser Gln Pro Arg Gly Met Ala Val
65 70 75 80
Thr Ile Ser Val Lys Cys Glu Lys Ile Ser Thr Leu Ser Cys Glu Asn
85 90 95
Lys Ile Ile Ser Phe Lys Glu Met Asn Pro Pro Asp Asn Ile Lys Asp
100 105 110
Thr Lys Ser Asp Ile Ile Phe Phe Gln Arg Ser Val Pro Gly His Asp
115 120 125
Asn Lys Met Gln Phe Glu Ser Ser Ser Tyr Glu Gly Tyr Phe Leu Ala
130 135 140
Cys Glu Lys Glu Arg Asp Leu Phe Lys Leu Ile Leu Lys Lys Glu Asp
145 150 155 160
Glu Leu Gly Asp Arg Ser Ile Met Phe Thr Val Gln Asn Glu Asp Ser
165 170 175
Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr
180 185 190
Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val
195 200 205
Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys
210 215 220
Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys
225 230 235 240
Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly
245 250 255
Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser
260 265 270
Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile
275 280 285
Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu Asp
290 295 300
Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp
305 310 315 320
Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser
325 330 335
Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile
340 345 350
Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile
355 360 365
Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys
370 375 380
Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val Asn Val Ile
385 390 395 400
Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp
405 410 415
Ala Thr Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys Val Thr
420 425 430
Ala Met Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser
435 440 445
Gly Asp Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala
450 455 460
Asn Asn Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys
465 470 475 480
Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser
485 490 495
Phe Val His Ile Val Gln Met Phe Ile Asn Thr Ser
500 505
<210> 177
<211> 1524
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 177
atgaagtggg tcacatttat ctctttactg ttcctcttct ccagcgccta cagctacttc 60
ggcaaactgg aatccaagct gagcgtgatc cggaatttaa acgaccaagt tctgtttatc 120
gatcaaggta accggcctct gttcgaggac atgaccgact ccgattgccg ggacaatgcc 180
ccccggacca tcttcattat ctccatgtac aaggacagcc agccccgggg catggctgtg 240
acaattagcg tgaagtgtga gaaaatcagc actttatctt gtgagaacaa gatcatctcc 300
tttaaggaaa tgaacccccc cgataacatc aaggacacca agtccgatat catcttcttc 360
cagcggtccg tgcccggtca cgataacaag atgcagttcg aatcctcctc ctacgagggc 420
tactttttag cttgtgaaaa ggagagggat ttattcaagc tgatcctcaa gaaggaggac 480
gagctgggcg atcgttccat catgttcacc gtccaaaacg aggatagcgg cacaaccaac 540
acagtcgctg cctataacct cacttggaag agcaccaact tcaaaaccat cctcgaatgg 600
gaacccaaac ccgttaacca agtttacacc gtgcagatca gcaccaagtc cggcgactgg 660
aagtccaaat gtttctatac caccgacacc gagtgcgatc tcaccgatga gatcgtgaaa 720
gatgtgaaac agacctacct cgcccgggtg tttagctacc ccgccggcaa tgtggagagc 780
actggttccg ctggcgagcc tttatacgag aacagccccg aatttacccc ttacctcgag 840
accaatttag gacagcccac catccaaagc tttgagcaag ttggcacaaa ggtgaatgtg 900
acagtggagg acgagcggac tttagtgcgg cggaacaaca cctttctcag cctccgggat 960
gtgttcggca aagatttaat ctacacactg tattactgga agtcctcttc ctccggcaag 1020
aagacagcta aaaccaacac aaacgagttt ttaatcgacg tggataaagg cgaaaactac 1080
tgtttcagcg tgcaagctgt gatcccctcc cggaccgtga ataggaaaag caccgatagc 1140
cccgttgagt gcatgggcca agaaaagggc gagttccggg agaactgggt gaacgtcatc 1200
agcgatttaa agaagatcga agatttaatt cagtccatgc atatcgacgc cactttatac 1260
acagaatccg acgtgcaccc ctcttgtaag gtgaccgcca tgaaatgttt tttactggag 1320
ctgcaagtta tctctttaga gagcggagac gctagcatcc acgacaccgt ggagaattta 1380
atcattttag ccaataactc tttatccagc aacggcaacg tgacagagtc cggctgcaag 1440
gagtgcgaag agctggagga gaagaacatc aaggagtttc tgcaatcctt tgtgcacatt 1500
gtccagatgt tcatcaatac ctcc 1524
<210> 178
<211> 583
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 178
Ile Trp Glu Leu Lys Lys Asp Val Tyr Val Val Glu Leu Asp Trp Tyr
1 5 10 15
Pro Asp Ala Pro Gly Glu Met Val Val Leu Thr Cys Asp Thr Pro Glu
20 25 30
Glu Asp Gly Ile Thr Trp Thr Leu Asp Gln Ser Ser Glu Val Leu Gly
35 40 45
Ser Gly Lys Thr Leu Thr Ile Gln Val Lys Glu Phe Gly Asp Ala Gly
50 55 60
Gln Tyr Thr Cys His Lys Gly Gly Glu Val Leu Ser His Ser Leu Leu
65 70 75 80
Leu Leu His Lys Lys Glu Asp Gly Ile Trp Ser Thr Asp Ile Leu Lys
85 90 95
Asp Gln Lys Glu Pro Lys Asn Lys Thr Phe Leu Arg Cys Glu Ala Lys
100 105 110
Asn Tyr Ser Gly Arg Phe Thr Cys Trp Trp Leu Thr Thr Ile Ser Thr
115 120 125
Asp Leu Thr Phe Ser Val Lys Ser Ser Arg Gly Ser Ser Asp Pro Gln
130 135 140
Gly Val Thr Cys Gly Ala Ala Thr Leu Ser Ala Glu Arg Val Arg Gly
145 150 155 160
Asp Asn Lys Glu Tyr Glu Tyr Ser Val Glu Cys Gln Glu Asp Ser Ala
165 170 175
Cys Pro Ala Ala Glu Glu Ser Leu Pro Ile Glu Val Met Val Asp Ala
180 185 190
Val His Lys Leu Lys Tyr Glu Asn Tyr Thr Ser Ser Phe Phe Ile Arg
195 200 205
Asp Ile Ile Lys Pro Asp Pro Pro Lys Asn Leu Gln Leu Lys Pro Leu
210 215 220
Lys Asn Ser Arg Gln Val Glu Val Ser Trp Glu Tyr Pro Asp Thr Trp
225 230 235 240
Ser Thr Pro His Ser Tyr Phe Ser Leu Thr Phe Cys Val Gln Val Gln
245 250 255
Gly Lys Ser Lys Arg Glu Lys Lys Asp Arg Val Phe Thr Asp Lys Thr
260 265 270
Ser Ala Thr Val Ile Cys Arg Lys Asn Ala Ser Ile Ser Val Arg Ala
275 280 285
Gln Asp Arg Tyr Tyr Ser Ser Ser Trp Ser Glu Trp Ala Ser Val Pro
290 295 300
Cys Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
305 310 315 320
Ser Arg Asn Leu Pro Val Ala Thr Pro Asp Pro Gly Met Phe Pro Cys
325 330 335
Leu His His Ser Gln Asn Leu Leu Arg Ala Val Ser Asn Met Leu Gln
340 345 350
Lys Ala Arg Gln Thr Leu Glu Phe Tyr Pro Cys Thr Ser Glu Glu Ile
355 360 365
Asp His Glu Asp Ile Thr Lys Asp Lys Thr Ser Thr Val Glu Ala Cys
370 375 380
Leu Pro Leu Glu Leu Thr Lys Asn Glu Ser Cys Leu Asn Ser Arg Glu
385 390 395 400
Thr Ser Phe Ile Thr Asn Gly Ser Cys Leu Ala Ser Arg Lys Thr Ser
405 410 415
Phe Met Met Ala Leu Cys Leu Ser Ser Ile Tyr Glu Asp Leu Lys Met
420 425 430
Tyr Gln Val Glu Phe Lys Thr Met Asn Ala Lys Leu Leu Met Asp Pro
435 440 445
Lys Arg Gln Ile Phe Leu Asp Gln Asn Met Leu Ala Val Ile Asp Glu
450 455 460
Leu Met Gln Ala Leu Asn Phe Asn Ser Glu Thr Val Pro Gln Lys Ser
465 470 475 480
Ser Leu Glu Glu Pro Asp Phe Tyr Lys Thr Lys Ile Lys Leu Cys Ile
485 490 495
Leu Leu His Ala Phe Arg Ile Arg Ala Val Thr Ile Asp Arg Val Met
500 505 510
Ser Tyr Leu Asn Ala Ser Ile Thr Cys Pro Pro Pro Met Ser Val Glu
515 520 525
His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg
530 535 540
Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu
545 550 555 560
Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr
565 570 575
Pro Ser Leu Lys Cys Ile Arg
580
<210> 179
<211> 1749
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 179
atttgggaac tgaagaagga cgtctacgtg gtcgaactgg actggtatcc cgatgctccc 60
ggcgaaatgg tggtgctcac ttgtgacacc cccgaagaag acggcatcac ttggaccctc 120
gatcagagca gcgaggtgct gggctccgga aagaccctca caatccaagt taaggagttc 180
ggagacgctg gccaatacac atgccacaag ggaggcgagg tgctcagcca ttccttatta 240
ttattacaca agaaggaaga cggaatctgg tccaccgaca ttttaaaaga tcagaaggag 300
cccaagaata agaccttttt aaggtgtgag gccaaaaact acagcggtcg tttcacttgt 360
tggtggctga ccaccatttc caccgattta accttctccg tgaaaagcag ccggggaagc 420
tccgaccctc aaggtgtgac atgtggagcc gctaccctca gcgctgagag ggttcgtggc 480
gataacaagg aatacgagta cagcgtggag tgccaagaag atagcgcttg tcccgctgcc 540
gaagaatctt tacccattga ggtgatggtg gacgccgtgc acaaactcaa gtacgagaac 600
tacacctcct ccttctttat ccgggacatc attaagcccg atcctcctaa gaatttacag 660
ctgaagcctc tcaaaaatag ccggcaagtt gaggtctctt gggaatatcc cgacacttgg 720
agcacacccc acagctactt ctctttaacc ttttgtgtgc aagttcaagg taaaagcaag 780
cgggagaaga aagaccgggt gtttaccgac aaaaccagcg ccaccgtcat ctgtcggaag 840
aacgcctcca tcagcgtgag ggctcaagat cgttattact ccagcagctg gtccgagtgg 900
gccagcgtgc cttgttccgg cggtggagga tccggaggag gtggctccgg cggcggagga 960
tctcgtaacc tccccgtggc tacccccgat cccggaatgt tcccttgttt acaccacagc 1020
cagaatttac tgagggccgt gagcaacatg ctgcagaaag ctaggcagac tttagaattt 1080
tacccttgca ccagcgagga gatcgaccat gaagatatca ccaaggacaa gacatccacc 1140
gtggaggctt gtttacctct ggagctgaca aagaacgagt cttgtctcaa ctctcgtgaa 1200
accagcttca tcacaaatgg ctcttgttta gcttcccgga agacctcctt tatgatggct 1260
ttatgcctca gctccatcta cgaggattta aagatgtacc aagtggagtt caagaccatg 1320
aacgccaagc tgctcatgga ccctaaacgg cagatctttt tagaccagaa catgctggct 1380
gtgattgatg agctgatgca agctttaaac ttcaactccg agaccgtccc tcagaagtcc 1440
tccctcgagg agcccgattt ttacaagaca aagatcaaac tgtgcatttt actccacgcc 1500
tttaggatcc gggccgtgac cattgaccgg gtcatgagct atttaaacgc cagcattaca 1560
tgcccccctc ccatgagcgt ggagcacgcc gacatctggg tgaagagcta tagcctctac 1620
agccgggaga ggtatatctg taacagcggc ttcaagagga aggccggcac cagcagcctc 1680
accgagtgcg tgctgaataa ggctaccaac gtggctcact ggacaacacc ctctttaaag 1740
tgcatccgg 1749
<210> 180
<211> 601
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 180
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Trp Glu Leu Lys Lys Asp Val Tyr Val Val Glu Leu Asp
20 25 30
Trp Tyr Pro Asp Ala Pro Gly Glu Met Val Val Leu Thr Cys Asp Thr
35 40 45
Pro Glu Glu Asp Gly Ile Thr Trp Thr Leu Asp Gln Ser Ser Glu Val
50 55 60
Leu Gly Ser Gly Lys Thr Leu Thr Ile Gln Val Lys Glu Phe Gly Asp
65 70 75 80
Ala Gly Gln Tyr Thr Cys His Lys Gly Gly Glu Val Leu Ser His Ser
85 90 95
Leu Leu Leu Leu His Lys Lys Glu Asp Gly Ile Trp Ser Thr Asp Ile
100 105 110
Leu Lys Asp Gln Lys Glu Pro Lys Asn Lys Thr Phe Leu Arg Cys Glu
115 120 125
Ala Lys Asn Tyr Ser Gly Arg Phe Thr Cys Trp Trp Leu Thr Thr Ile
130 135 140
Ser Thr Asp Leu Thr Phe Ser Val Lys Ser Ser Arg Gly Ser Ser Asp
145 150 155 160
Pro Gln Gly Val Thr Cys Gly Ala Ala Thr Leu Ser Ala Glu Arg Val
165 170 175
Arg Gly Asp Asn Lys Glu Tyr Glu Tyr Ser Val Glu Cys Gln Glu Asp
180 185 190
Ser Ala Cys Pro Ala Ala Glu Glu Ser Leu Pro Ile Glu Val Met Val
195 200 205
Asp Ala Val His Lys Leu Lys Tyr Glu Asn Tyr Thr Ser Ser Phe Phe
210 215 220
Ile Arg Asp Ile Ile Lys Pro Asp Pro Pro Lys Asn Leu Gln Leu Lys
225 230 235 240
Pro Leu Lys Asn Ser Arg Gln Val Glu Val Ser Trp Glu Tyr Pro Asp
245 250 255
Thr Trp Ser Thr Pro His Ser Tyr Phe Ser Leu Thr Phe Cys Val Gln
260 265 270
Val Gln Gly Lys Ser Lys Arg Glu Lys Lys Asp Arg Val Phe Thr Asp
275 280 285
Lys Thr Ser Ala Thr Val Ile Cys Arg Lys Asn Ala Ser Ile Ser Val
290 295 300
Arg Ala Gln Asp Arg Tyr Tyr Ser Ser Ser Trp Ser Glu Trp Ala Ser
305 310 315 320
Val Pro Cys Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
325 330 335
Gly Gly Ser Arg Asn Leu Pro Val Ala Thr Pro Asp Pro Gly Met Phe
340 345 350
Pro Cys Leu His His Ser Gln Asn Leu Leu Arg Ala Val Ser Asn Met
355 360 365
Leu Gln Lys Ala Arg Gln Thr Leu Glu Phe Tyr Pro Cys Thr Ser Glu
370 375 380
Glu Ile Asp His Glu Asp Ile Thr Lys Asp Lys Thr Ser Thr Val Glu
385 390 395 400
Ala Cys Leu Pro Leu Glu Leu Thr Lys Asn Glu Ser Cys Leu Asn Ser
405 410 415
Arg Glu Thr Ser Phe Ile Thr Asn Gly Ser Cys Leu Ala Ser Arg Lys
420 425 430
Thr Ser Phe Met Met Ala Leu Cys Leu Ser Ser Ile Tyr Glu Asp Leu
435 440 445
Lys Met Tyr Gln Val Glu Phe Lys Thr Met Asn Ala Lys Leu Leu Met
450 455 460
Asp Pro Lys Arg Gln Ile Phe Leu Asp Gln Asn Met Leu Ala Val Ile
465 470 475 480
Asp Glu Leu Met Gln Ala Leu Asn Phe Asn Ser Glu Thr Val Pro Gln
485 490 495
Lys Ser Ser Leu Glu Glu Pro Asp Phe Tyr Lys Thr Lys Ile Lys Leu
500 505 510
Cys Ile Leu Leu His Ala Phe Arg Ile Arg Ala Val Thr Ile Asp Arg
515 520 525
Val Met Ser Tyr Leu Asn Ala Ser Ile Thr Cys Pro Pro Pro Met Ser
530 535 540
Val Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg
545 550 555 560
Glu Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser
565 570 575
Ser Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp
580 585 590
Thr Thr Pro Ser Leu Lys Cys Ile Arg
595 600
<210> 181
<211> 1803
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 181
atgaaatggg tgacctttat ttctttactg ttcctcttta gcagcgccta ctccatttgg 60
gaactgaaga aggacgtcta cgtggtcgaa ctggactggt atcccgatgc tcccggcgaa 120
atggtggtgc tcacttgtga cacccccgaa gaagacggca tcacttggac cctcgatcag 180
agcagcgagg tgctgggctc cggaaagacc ctcacaatcc aagttaagga gttcggagac 240
gctggccaat acacatgcca caagggaggc gaggtgctca gccattcctt attattatta 300
cacaagaagg aagacggaat ctggtccacc gacattttaa aagatcagaa ggagcccaag 360
aataagacct ttttaaggtg tgaggccaaa aactacagcg gtcgtttcac ttgttggtgg 420
ctgaccacca tttccaccga tttaaccttc tccgtgaaaa gcagccgggg aagctccgac 480
cctcaaggtg tgacatgtgg agccgctacc ctcagcgctg agagggttcg tggcgataac 540
aaggaatacg agtacagcgt ggagtgccaa gaagatagcg cttgtcccgc tgccgaagaa 600
tctttaccca ttgaggtgat ggtggacgcc gtgcacaaac tcaagtacga gaactacacc 660
tcctccttct ttatccggga catcattaag cccgatcctc ctaagaattt acagctgaag 720
cctctcaaaa atagccggca agttgaggtc tcttgggaat atcccgacac ttggagcaca 780
ccccacagct acttctcttt aaccttttgt gtgcaagttc aaggtaaaag caagcgggag 840
aagaaagacc gggtgtttac cgacaaaacc agcgccaccg tcatctgtcg gaagaacgcc 900
tccatcagcg tgagggctca agatcgttat tactccagca gctggtccga gtgggccagc 960
gtgccttgtt ccggcggtgg aggatccgga ggaggtggct ccggcggcgg aggatctcgt 1020
aacctccccg tggctacccc cgatcccgga atgttccctt gtttacacca cagccagaat 1080
ttactgaggg ccgtgagcaa catgctgcag aaagctaggc agactttaga attttaccct 1140
tgcaccagcg aggagatcga ccatgaagat atcaccaagg acaagacatc caccgtggag 1200
gcttgtttac ctctggagct gacaaagaac gagtcttgtc tcaactctcg tgaaaccagc 1260
ttcatcacaa atggctcttg tttagcttcc cggaagacct cctttatgat ggctttatgc 1320
ctcagctcca tctacgagga tttaaagatg taccaagtgg agttcaagac catgaacgcc 1380
aagctgctca tggaccctaa acggcagatc tttttagacc agaacatgct ggctgtgatt 1440
gatgagctga tgcaagcttt aaacttcaac tccgagaccg tccctcagaa gtcctccctc 1500
gaggagcccg atttttacaa gacaaagatc aaactgtgca ttttactcca cgcctttagg 1560
atccgggccg tgaccattga ccgggtcatg agctatttaa acgccagcat tacatgcccc 1620
cctcccatga gcgtggagca cgccgacatc tgggtgaaga gctatagcct ctacagccgg 1680
gagaggtata tctgtaacag cggcttcaag aggaaggccg gcaccagcag cctcaccgag 1740
tgcgtgctga ataaggctac caacgtggct cactggacaa caccctcttt aaagtgcatc 1800
cgg 1803
<210> 182
<211> 399
<212> DNA
<213> Homo sapiens
<400> 182
cagggccagg acaggcacat gatccggatg aggcagctca tcgacatcgt cgaccagctg 60
aagaactacg tgaacgacct ggtgcccgag tttctgcctg cccccgagga cgtggagacc 120
aactgcgagt ggtccgcctt ctcctgcttt cagaaggccc agctgaagtc cgccaacacc 180
ggcaacaacg agcggatcat caacgtgagc atcaagaagc tgaagcggaa gcctccctcc 240
acaaacgccg gcaggaggca gaagcacagg ctgacctgcc ccagctgtga ctcctacgag 300
aagaagcccc ccaaggagtt cctggagagg ttcaagtccc tgctgcagaa gatgatccat 360
cagcacctgt cctccaggac ccacggctcc gaggactcc 399
<210> 183
<211> 136
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 183
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp
130 135
<210> 184
<211> 136
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 184
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp
130 135
<210> 185
<211> 408
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 185
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcacgatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgat 408
<210> 186
<211> 408
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 186
attcctcccc acgtgcagaa gagcgtgaat aatgacatga tcgtgaccga taacaatggc 60
gccgtgaaat ttccccagct gtgcaaattc tgcgatgtga ggttttccac ctgcgacaac 120
cagaagtcct gtatgagcaa ctgcacaatc acctccatct gtgagaagcc tcaggaggtg 180
tgcgtggctg tctggcggaa gaatgacgag aatatcaccc tggaaaccgt ctgccacgat 240
cccaagctgc cctaccacga tttcatcctg gaagacgccg ccagccctaa gtgcatcatg 300
aaagagaaaa agaagcctgg cgagaccttt ttcatgtgct cctgcagcag cgacgaatgc 360
aacgacaata tcatctttag cgaggaatac aataccagca accccgac 408
<210> 187
<211> 861
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 187
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcacgatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgatgg aggtggcgga 420
tccggaggtg gaggttctgg tggaggtggg agtattcctc cccacgtgca gaagagcgtg 480
aataatgaca tgatcgtgac cgataacaat ggcgccgtga aatttcccca gctgtgcaaa 540
ttctgcgatg tgaggttttc cacctgcgac aaccagaagt cctgtatgag caactgcaca 600
atcacctcca tctgtgagaa gcctcaggag gtgtgcgtgg ctgtctggcg gaagaatgac 660
gagaatatca ccctggaaac cgtctgccac gatcccaagc tgccctacca cgatttcatc 720
ctggaagacg ccgccagccc taagtgcatc atgaaagaga aaaagaagcc tggcgagacc 780
tttttcatgt gctcctgcag cagcgacgaa tgcaacgaca atatcatctt tagcgaggaa 840
tacaatacca gcaaccccga c 861
<210> 188
<211> 287
<212> PRT
<213> Homo sapiens
<400> 188
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys Ser Val
145 150 155 160
Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro
165 170 175
Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln
180 185 190
Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro
195 200 205
Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr
210 215 220
Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile
225 230 235 240
Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys
245 250 255
Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn
260 265 270
Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp
275 280 285
<210> 189
<211> 466
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 189
Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp Ile
1 5 10 15
Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe Leu
20 25 30
Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe Ser
35 40 45
Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn Glu
50 55 60
Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro Ser
65 70 75 80
Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser Cys
85 90 95
Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe Lys
100 105 110
Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr His
115 120 125
Gly Ser Glu Asp Ser Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn
130 135 140
Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro
145 150 155 160
Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly
165 170 175
Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu
180 185 190
Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val
195 200 205
Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu
210 215 220
Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn
225 230 235 240
Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val
245 250 255
Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val Arg Arg Asn Asn Thr
260 265 270
Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu
275 280 285
Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn
290 295 300
Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe
305 310 315 320
Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr
325 330 335
Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu
340 345 350
Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile
355 360 365
Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp Val His
370 375 380
Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu Glu Leu Gln
385 390 395 400
Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp Thr Val Glu
405 410 415
Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly Asn Val
420 425 430
Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile
435 440 445
Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met Phe Ile Asn
450 455 460
Thr Ser
465
<210> 190
<211> 1398
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 190
cagggccagg acaggcacat gatccggatg aggcagctca tcgacatcgt cgaccagctg 60
aagaactacg tgaacgacct ggtgcccgag tttctgcctg cccccgagga cgtggagacc 120
aactgcgagt ggtccgcctt ctcctgcttt cagaaggccc agctgaagtc cgccaacacc 180
ggcaacaacg agcggatcat caacgtgagc atcaagaagc tgaagcggaa gcctccctcc 240
acaaacgccg gcaggaggca gaagcacagg ctgacctgcc ccagctgtga ctcctacgag 300
aagaagcccc ccaaggagtt cctggagagg ttcaagtccc tgctgcagaa gatgatccat 360
cagcacctgt cctccaggac ccacggctcc gaggactcct ccggcaccac caataccgtg 420
gccgcttata acctcacatg gaagagcacc aacttcaaga caattctgga atgggaaccc 480
aagcccgtca atcaagttta caccgtgcag atctccacca aatccggaga ctggaagagc 540
aagtgcttct acacaacaga caccgagtgt gatttaaccg acgaaatcgt caaggacgtc 600
aagcaaacct atctggctcg ggtcttttcc taccccgctg gcaatgtcga gtccaccggc 660
tccgctggcg agcctctcta cgagaattcc cccgaattca ccccttattt agagaccaat 720
ttaggccagc ctaccatcca gagcttcgag caagttggca ccaaggtgaa cgtcaccgtc 780
gaggatgaaa ggactttagt gcggcggaat aacacatttt tatccctccg ggatgtgttc 840
ggcaaagacc tcatctacac actgtactat tggaagtcca gctcctccgg caaaaagacc 900
gctaagacca acaccaacga gtttttaatt gacgtggaca aaggcgagaa ctactgcttc 960
agcgtgcaag ccgtgatccc ttctcgtacc gtcaaccgga agagcacaga ttcccccgtt 1020
gagtgcatgg gccaagaaaa gggcgagttc cgggagaact gggtgaacgt catcagcgat 1080
ttaaagaaga tcgaagattt aattcagtcc atgcatatcg acgccacttt atacacagaa 1140
tccgacgtgc acccctcttg taaggtgacc gccatgaaat gttttttact ggagctgcaa 1200
gttatctctt tagagagcgg agacgctagc atccacgaca ccgtggagaa tttaatcatt 1260
ttagccaata actctttatc cagcaacggc aacgtgacag agtccggctg caaggagtgc 1320
gaagagctgg aggagaagaa catcaaggag tttctgcaat cctttgtgca cattgtccag 1380
atgttcatca atacctcc 1398
<210> 191
<211> 484
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 191
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile
20 25 30
Asp Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu
35 40 45
Phe Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala
50 55 60
Phe Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn
65 70 75 80
Asn Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro
85 90 95
Pro Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro
100 105 110
Ser Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg
115 120 125
Phe Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg
130 135 140
Thr His Gly Ser Glu Asp Ser Ser Gly Thr Thr Asn Thr Val Ala Ala
145 150 155 160
Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp
165 170 175
Glu Pro Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr Lys
180 185 190
Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys
195 200 205
Asp Leu Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu Ala
210 215 220
Arg Val Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser Ala
225 230 235 240
Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu
245 250 255
Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly Thr
260 265 270
Lys Val Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val Arg Arg Asn
275 280 285
Asn Thr Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr
290 295 300
Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys
305 310 315 320
Thr Asn Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr
325 330 335
Cys Phe Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg Lys
340 345 350
Ser Thr Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu Phe
355 360 365
Arg Glu Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu Asp
370 375 380
Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp
385 390 395 400
Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu Glu
405 410 415
Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp Thr
420 425 430
Val Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly
435 440 445
Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys
450 455 460
Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met Phe
465 470 475 480
Ile Asn Thr Ser
<210> 192
<211> 1452
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 192
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcccagggc 60
caggacaggc acatgatccg gatgaggcag ctcatcgaca tcgtcgacca gctgaagaac 120
tacgtgaacg acctggtgcc cgagtttctg cctgcccccg aggacgtgga gaccaactgc 180
gagtggtccg ccttctcctg ctttcagaag gcccagctga agtccgccaa caccggcaac 240
aacgagcgga tcatcaacgt gagcatcaag aagctgaagc ggaagcctcc ctccacaaac 300
gccggcagga ggcagaagca caggctgacc tgccccagct gtgactccta cgagaagaag 360
ccccccaagg agttcctgga gaggttcaag tccctgctgc agaagatgat ccatcagcac 420
ctgtcctcca ggacccacgg ctccgaggac tcctccggca ccaccaatac cgtggccgct 480
tataacctca catggaagag caccaacttc aagacaattc tggaatggga acccaagccc 540
gtcaatcaag tttacaccgt gcagatctcc accaaatccg gagactggaa gagcaagtgc 600
ttctacacaa cagacaccga gtgtgattta accgacgaaa tcgtcaagga cgtcaagcaa 660
acctatctgg ctcgggtctt ttcctacccc gctggcaatg tcgagtccac cggctccgct 720
ggcgagcctc tctacgagaa ttcccccgaa ttcacccctt atttagagac caatttaggc 780
cagcctacca tccagagctt cgagcaagtt ggcaccaagg tgaacgtcac cgtcgaggat 840
gaaaggactt tagtgcggcg gaataacaca tttttatccc tccgggatgt gttcggcaaa 900
gacctcatct acacactgta ctattggaag tccagctcct ccggcaaaaa gaccgctaag 960
accaacacca acgagttttt aattgacgtg gacaaaggcg agaactactg cttcagcgtg 1020
caagccgtga tcccttctcg taccgtcaac cggaagagca cagattcccc cgttgagtgc 1080
atgggccaag aaaagggcga gttccgggag aactgggtga acgtcatcag cgatttaaag 1140
aagatcgaag atttaattca gtccatgcat atcgacgcca ctttatacac agaatccgac 1200
gtgcacccct cttgtaaggt gaccgccatg aaatgttttt tactggagct gcaagttatc 1260
tctttagaga gcggagacgc tagcatccac gacaccgtgg agaatttaat cattttagcc 1320
aataactctt tatccagcaa cggcaacgtg acagagtccg gctgcaagga gtgcgaagag 1380
ctggaggaga agaacatcaa ggagtttctg caatcctttg tgcacattgt ccagatgttc 1440
atcaatacct cc 1452
<210> 193
<211> 352
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 193
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys Ser Val
145 150 155 160
Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro
165 170 175
Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln
180 185 190
Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro
195 200 205
Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr
210 215 220
Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile
225 230 235 240
Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys
245 250 255
Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn
260 265 270
Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Ile
275 280 285
Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp Val Lys
290 295 300
Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly Phe
305 310 315 320
Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu Asn Lys
325 330 335
Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys Ile Arg
340 345 350
<210> 194
<211> 1056
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 194
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcacgatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgatgg aggtggcgga 420
tccggaggtg gaggttctgg tggaggtggg agtattcctc cccacgtgca gaagagcgtg 480
aataatgaca tgatcgtgac cgataacaat ggcgccgtga aatttcccca gctgtgcaaa 540
ttctgcgatg tgaggttttc cacctgcgac aaccagaagt cctgtatgag caactgcaca 600
atcacctcca tctgtgagaa gcctcaggag gtgtgcgtgg ctgtctggcg gaagaatgac 660
gagaatatca ccctggaaac cgtctgccac gatcccaagc tgccctacca cgatttcatc 720
ctggaagacg ccgccagccc taagtgcatc atgaaagaga aaaagaagcc tggcgagacc 780
tttttcatgt gctcctgcag cagcgacgaa tgcaacgaca atatcatctt tagcgaggaa 840
tacaatacca gcaaccccga catcacgtgt cctcctccta tgtccgtgga acacgcagac 900
atctgggtca agagctacag cttgtactcc agggagcggt acatttgtaa ctctggtttc 960
aagcgtaaag ccggcacgtc cagcctgacg gagtgcgtgt tgaacaaggc cacgaatgtc 1020
gcccactgga caacccccag tctcaaatgt attaga 1056
<210> 195
<211> 370
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 195
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile
20 25 30
Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe
35 40 45
Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser
50 55 60
Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val
65 70 75 80
Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys
85 90 95
His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala
100 105 110
Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe
115 120 125
Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe
130 135 140
Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys
165 170 175
Ser Val Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys
180 185 190
Phe Pro Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp
195 200 205
Asn Gln Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu
210 215 220
Lys Pro Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn
225 230 235 240
Ile Thr Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp
245 250 255
Phe Ile Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys
260 265 270
Lys Lys Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu
275 280 285
Cys Asn Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro
290 295 300
Asp Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp
305 310 315 320
Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser
325 330 335
Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu
340 345 350
Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys
355 360 365
Ile Arg
370
<210> 196
<211> 1110
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 196
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccatcccc 60
ccccatgtgc aaaagagcgt gaacaacgat atgatcgtga ccgacaacaa cggcgccgtg 120
aagtttcccc agctctgcaa gttctgcgat gtcaggttca gcacctgcga taatcagaag 180
tcctgcatgt ccaactgcac gatcacctcc atctgcgaga agccccaaga agtgtgcgtg 240
gccgtgtggc ggaaaaatga cgagaacatc accctggaga ccgtgtgtca cgaccccaag 300
ctcccttatc acgacttcat tctggaggac gctgcctccc ccaaatgcat catgaaggag 360
aagaagaagc ccggagagac cttctttatg tgttcctgta gcagcgacga gtgtaacgac 420
aacatcatct tcagcgaaga gtacaacacc agcaaccctg atggaggtgg cggatccgga 480
ggtggaggtt ctggtggagg tgggagtatt cctccccacg tgcagaagag cgtgaataat 540
gacatgatcg tgaccgataa caatggcgcc gtgaaatttc cccagctgtg caaattctgc 600
gatgtgaggt tttccacctg cgacaaccag aagtcctgta tgagcaactg cacaatcacc 660
tccatctgtg agaagcctca ggaggtgtgc gtggctgtct ggcggaagaa tgacgagaat 720
atcaccctgg aaaccgtctg ccacgatccc aagctgccct accacgattt catcctggaa 780
gacgccgcca gccctaagtg catcatgaaa gagaaaaaga agcctggcga gacctttttc 840
atgtgctcct gcagcagcga cgaatgcaac gacaatatca tctttagcga ggaatacaat 900
accagcaacc ccgacatcac gtgtcctcct cctatgtccg tggaacacgc agacatctgg 960
gtcaagagct acagcttgta ctccagggag cggtacattt gtaactctgg tttcaagcgt 1020
aaagccggca cgtccagcct gacggagtgc gtgttgaaca aggccacgaa tgtcgcccac 1080
tggacaaccc ccagtctcaa atgtattaga 1110
<210> 197
<211> 399
<212> DNA
<213> Homo sapiens
<400> 197
caaggtcaag atcgccacat gattagaatg cgtcaactta tagatattgt tgatcagctg 60
aaaaattatg tgaatgactt ggtccctgaa tttctgccag ctccagaaga tgtagagaca 120
aactgtgagt ggtcagcttt ttcctgtttt cagaaggccc aactaaagtc agcaaataca 180
ggaaacaatg aaaggataat caatgtatca attaaaaagc tgaagaggaa accaccttcc 240
acaaatgcag ggagaagaca gaaacacaga ctaacatgcc cttcatgtga ttcttatgag 300
aaaaaaccac ccaaagaatt cctagaaaga ttcaaatcac ttctccaaaa gatgattcat 360
cagcatctgt cctctagaac acacggaagt gaagattcc 399
<210> 198
<211> 456
<212> DNA
<213> Homo sapiens
<400> 198
gattgtgata ttgaaggtaa agatggcaaa caatatgaga gtgttctaat ggtcagcatc 60
gatcaattat tggacagcat gaaagaaatt ggtagcaatt gcctgaataa tgaatttaac 120
ttttttaaaa gacatatctg tgatgctaat aaggaaggta tgtttttatt ccgtgctgct 180
cgcaagttga ggcaatttct taaaatgaat agcactggtg attttgatct ccacttatta 240
aaagtttcag aaggcacaac aatactgttg aactgcactg gccaggttaa aggaagaaaa 300
ccagctgccc tgggtgaagc ccaaccaaca aagagtttgg aagaaaataa atctttaaag 360
gaacagaaaa aactgaatga cttgtgtttc ctaaagagac tattacaaga gataaaaact 420
tgttggaata aaattttgat gggcactaaa gaacac 456
<210> 199
<211> 466
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 199
Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp Ile
1 5 10 15
Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe Leu
20 25 30
Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe Ser
35 40 45
Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn Glu
50 55 60
Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro Ser
65 70 75 80
Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser Cys
85 90 95
Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe Lys
100 105 110
Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr His
115 120 125
Gly Ser Glu Asp Ser Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn
130 135 140
Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro
145 150 155 160
Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly
165 170 175
Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu
180 185 190
Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val
195 200 205
Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu
210 215 220
Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn
225 230 235 240
Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val
245 250 255
Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val Arg Arg Asn Asn Thr
260 265 270
Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu
275 280 285
Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn
290 295 300
Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe
305 310 315 320
Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr
325 330 335
Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu
340 345 350
Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile
355 360 365
Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp Val His
370 375 380
Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu Glu Leu Gln
385 390 395 400
Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp Thr Val Glu
405 410 415
Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly Asn Val
420 425 430
Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile
435 440 445
Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met Phe Ile Asn
450 455 460
Thr Ser
465
<210> 200
<211> 1398
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 200
caaggtcaag atcgccacat gattagaatg cgtcaactta tagatattgt tgatcagctg 60
aaaaattatg tgaatgactt ggtccctgaa tttctgccag ctccagaaga tgtagagaca 120
aactgtgagt ggtcagcttt ttcctgtttt cagaaggccc aactaaagtc agcaaataca 180
ggaaacaatg aaaggataat caatgtatca attaaaaagc tgaagaggaa accaccttcc 240
acaaatgcag ggagaagaca gaaacacaga ctaacatgcc cttcatgtga ttcttatgag 300
aaaaaaccac ccaaagaatt cctagaaaga ttcaaatcac ttctccaaaa gatgattcat 360
cagcatctgt cctctagaac acacggaagt gaagattcct caggcactac aaatactgtg 420
gcagcatata atttaacttg gaaatcaact aatttcaaga caattttgga gtgggaaccc 480
aaacccgtca atcaagtcta cactgttcaa ataagcacta agtcaggaga ttggaaaagc 540
aaatgctttt acacaacaga cacagagtgt gacctcaccg acgagattgt gaaggatgtg 600
aagcagacgt acttggcacg ggtcttctcc tacccggcag ggaatgtgga gagcaccggt 660
tctgctgggg agcctctgta tgagaactcc ccagagttca caccttacct ggagacaaac 720
ctcggacagc caacaattca gagttttgaa caggtgggaa caaaagtgaa tgtgaccgta 780
gaagatgaac ggactttagt cagaaggaac aacactttcc taagcctccg ggatgttttt 840
ggcaaggact taatttatac actttattat tggaaatctt caagttcagg aaagaaaaca 900
gccaaaacaa acactaatga gtttttgatt gatgtggata aaggagaaaa ctactgtttc 960
agtgttcaag cagtgattcc ctcccgaaca gttaaccgga agagtacaga cagcccggta 1020
gagtgtatgg gccaggagaa aggggaattc agagaaaact gggtgaacgt catcagcgat 1080
ttaaagaaga tcgaagattt aattcagtcc atgcatatcg acgccacttt atacacagaa 1140
tccgacgtgc acccctcttg taaggtgacc gccatgaaat gttttttact ggagctgcaa 1200
gttatctctt tagagagcgg agacgctagc atccacgaca ccgtggagaa tttaatcatt 1260
ttagccaata actctttatc cagcaacggc aacgtgacag agtccggctg caaggagtgc 1320
gaagagctgg aggagaagaa catcaaggag tttctgcaat cctttgtgca cattgtccag 1380
atgttcatca atacctcc 1398
<210> 201
<211> 483
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 201
Met Gly Val Lys Val Leu Phe Ala Leu Ile Cys Ile Ala Val Ala Glu
1 5 10 15
Ala Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp
20 25 30
Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe
35 40 45
Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe
50 55 60
Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn
65 70 75 80
Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro
85 90 95
Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser
100 105 110
Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe
115 120 125
Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr
130 135 140
His Gly Ser Glu Asp Ser Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr
145 150 155 160
Asn Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu
165 170 175
Pro Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr Lys Ser
180 185 190
Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp
195 200 205
Leu Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg
210 215 220
Val Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser Ala Gly
225 230 235 240
Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr
245 250 255
Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly Thr Lys
260 265 270
Val Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val Arg Arg Asn Asn
275 280 285
Thr Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr
290 295 300
Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr
305 310 315 320
Asn Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys
325 330 335
Phe Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg Lys Ser
340 345 350
Thr Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu Phe Arg
355 360 365
Glu Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu Asp Leu
370 375 380
Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp Val
385 390 395 400
His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu Glu Leu
405 410 415
Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp Thr Val
420 425 430
Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly Asn
435 440 445
Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys Asn
450 455 460
Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met Phe Ile
465 470 475 480
Asn Thr Ser
<210> 202
<211> 1449
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 202
atgggagtga aagttctttt tgcccttatt tgtattgctg tggccgaggc ccaaggtcaa 60
gatcgccaca tgattagaat gcgtcaactt atagatattg ttgatcagct gaaaaattat 120
gtgaatgact tggtccctga atttctgcca gctccagaag atgtagagac aaactgtgag 180
tggtcagctt tttcctgttt tcagaaggcc caactaaagt cagcaaatac aggaaacaat 240
gaaaggataa tcaatgtatc aattaaaaag ctgaagagga aaccaccttc cacaaatgca 300
gggagaagac agaaacacag actaacatgc ccttcatgtg attcttatga gaaaaaacca 360
cccaaagaat tcctagaaag attcaaatca cttctccaaa agatgattca tcagcatctg 420
tcctctagaa cacacggaag tgaagattcc tcaggcacta caaatactgt ggcagcatat 480
aatttaactt ggaaatcaac taatttcaag acaattttgg agtgggaacc caaacccgtc 540
aatcaagtct acactgttca aataagcact aagtcaggag attggaaaag caaatgcttt 600
tacacaacag acacagagtg tgacctcacc gacgagattg tgaaggatgt gaagcagacg 660
tacttggcac gggtcttctc ctacccggca gggaatgtgg agagcaccgg ttctgctggg 720
gagcctctgt atgagaactc cccagagttc acaccttacc tggagacaaa cctcggacag 780
ccaacaattc agagttttga acaggtggga acaaaagtga atgtgaccgt agaagatgaa 840
cggactttag tcagaaggaa caacactttc ctaagcctcc gggatgtttt tggcaaggac 900
ttaatttata cactttatta ttggaaatct tcaagttcag gaaagaaaac agccaaaaca 960
aacactaatg agtttttgat tgatgtggat aaaggagaaa actactgttt cagtgttcaa 1020
gcagtgattc cctcccgaac agttaaccgg aagagtacag acagcccggt agagtgtatg 1080
ggccaggaga aaggggaatt cagagaaaac tgggtgaacg tcatcagcga tttaaagaag 1140
atcgaagatt taattcagtc catgcatatc gacgccactt tatacacaga atccgacgtg 1200
cacccctctt gtaaggtgac cgccatgaaa tgttttttac tggagctgca agttatctct 1260
ttagagagcg gagacgctag catccacgac accgtggaga atttaatcat tttagccaat 1320
aactctttat ccagcaacgg caacgtgaca gagtccggct gcaaggagtg cgaagagctg 1380
gaggagaaga acatcaagga gtttctgcaa tcctttgtgc acattgtcca gatgttcatc 1440
aatacctcc 1449
<210> 203
<211> 217
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 203
Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser Val Leu
1 5 10 15
Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile Gly Ser
20 25 30
Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile Cys Asp
35 40 45
Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys Leu Arg
50 55 60
Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His Leu Leu
65 70 75 80
Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly Gln Val
85 90 95
Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr Lys Ser
100 105 110
Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn Asp Leu
115 120 125
Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp Asn Lys
130 135 140
Ile Leu Met Gly Thr Lys Glu His Ile Thr Cys Pro Pro Pro Met Ser
145 150 155 160
Val Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg
165 170 175
Glu Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser
180 185 190
Ser Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp
195 200 205
Thr Thr Pro Ser Leu Lys Cys Ile Arg
210 215
<210> 204
<211> 651
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 204
gattgtgata ttgaaggtaa agatggcaaa caatatgaga gtgttctaat ggtcagcatc 60
gatcaattat tggacagcat gaaagaaatt ggtagcaatt gcctgaataa tgaatttaac 120
ttttttaaaa gacatatctg tgatgctaat aaggaaggta tgtttttatt ccgtgctgct 180
cgcaagttga ggcaatttct taaaatgaat agcactggtg attttgatct ccacttatta 240
aaagtttcag aaggcacaac aatactgttg aactgcactg gccaggttaa aggaagaaaa 300
ccagctgccc tgggtgaagc ccaaccaaca aagagtttgg aagaaaataa atctttaaag 360
gaacagaaaa aactgaatga cttgtgtttc ctaaagagac tattacaaga gataaaaact 420
tgttggaata aaattttgat gggcactaaa gaacacatca cgtgccctcc ccccatgtcc 480
gtggaacacg cagacatctg ggtcaagagc tacagcttgt actccaggga gcggtacatt 540
tgtaactctg gtttcaagcg taaagccggc acgtccagcc tgacggagtg cgtgttgaac 600
aaggccacga atgtcgccca ctggacaacc cccagtctca aatgcattag a 651
<210> 205
<211> 234
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 205
Met Gly Val Lys Val Leu Phe Ala Leu Ile Cys Ile Ala Val Ala Glu
1 5 10 15
Ala Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser Val
20 25 30
Leu Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile Gly
35 40 45
Ser Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile Cys
50 55 60
Asp Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys Leu
65 70 75 80
Arg Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His Leu
85 90 95
Leu Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly Gln
100 105 110
Val Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr Lys
115 120 125
Ser Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn Asp
130 135 140
Leu Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp Asn
145 150 155 160
Lys Ile Leu Met Gly Thr Lys Glu His Ile Thr Cys Pro Pro Pro Met
165 170 175
Ser Val Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser
180 185 190
Arg Glu Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr
195 200 205
Ser Ser Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His
210 215 220
Trp Thr Thr Pro Ser Leu Lys Cys Ile Arg
225 230
<210> 206
<211> 702
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 206
atgggagtga aagttctttt tgcccttatt tgtattgctg tggccgaggc cgattgtgat 60
attgaaggta aagatggcaa acaatatgag agtgttctaa tggtcagcat cgatcaatta 120
ttggacagca tgaaagaaat tggtagcaat tgcctgaata atgaatttaa cttttttaaa 180
agacatatct gtgatgctaa taaggaaggt atgtttttat tccgtgctgc tcgcaagttg 240
aggcaatttc ttaaaatgaa tagcactggt gattttgatc tccacttatt aaaagtttca 300
gaaggcacaa caatactgtt gaactgcact ggccaggtta aaggaagaaa accagctgcc 360
ctgggtgaag cccaaccaac aaagagtttg gaagaaaata aatctttaaa ggaacagaaa 420
aaactgaatg acttgtgttt cctaaagaga ctattacaag agataaaaac ttgttggaat 480
aaaattttga tgggcactaa agaacacatc acgtgccctc cccccatgtc cgtggaacac 540
gcagacatct gggtcaagag ctacagcttg tactccaggg agcggtacat ttgtaactct 600
ggtttcaagc gtaaagccgg cacgtccagc ctgacggagt gcgtgttgaa caaggccacg 660
aatgtcgccc actggacaac ccccagtctc aaatgcatta ga 702
<210> 207
<211> 485
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 207
Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser Val Leu
1 5 10 15
Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile Gly Ser
20 25 30
Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile Cys Asp
35 40 45
Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys Leu Arg
50 55 60
Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His Leu Leu
65 70 75 80
Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly Gln Val
85 90 95
Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr Lys Ser
100 105 110
Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn Asp Leu
115 120 125
Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp Asn Lys
130 135 140
Ile Leu Met Gly Thr Lys Glu His Ser Gly Thr Thr Asn Thr Val Ala
145 150 155 160
Ala Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu
165 170 175
Trp Glu Pro Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr
180 185 190
Lys Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu
195 200 205
Cys Asp Leu Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu
210 215 220
Ala Arg Val Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser
225 230 235 240
Ala Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu
245 250 255
Glu Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly
260 265 270
Thr Lys Val Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val Arg Arg
275 280 285
Asn Asn Thr Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile
290 295 300
Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala
305 310 315 320
Lys Thr Asn Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn
325 330 335
Tyr Cys Phe Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg
340 345 350
Lys Ser Thr Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu
355 360 365
Phe Arg Glu Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu
370 375 380
Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser
385 390 395 400
Asp Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu
405 410 415
Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp
420 425 430
Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn
435 440 445
Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu
450 455 460
Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met
465 470 475 480
Phe Ile Asn Thr Ser
485
<210> 208
<211> 1455
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 208
gattgcgaca tcgagggcaa ggacggcaag cagtacgaga gcgtgctgat ggtgtccatc 60
gaccagctgc tggacagcat gaaggagatc ggctccaact gcctcaacaa cgagttcaac 120
ttcttcaagc ggcacatctg cgacgccaac aaggagggca tgttcctgtt cagggccgcc 180
aggaaactgc ggcagttcct gaagatgaac tccaccggcg acttcgacct gcacctgctg 240
aaggtgtccg agggcaccac catcctgctg aactgcaccg gacaggtgaa gggccggaaa 300
cctgctgctc tgggagaggc ccaacccacc aagagcctgg aggagaacaa gtccctgaag 360
gagcagaaga agctgaacga cctgtgcttc ctgaagaggc tgctgcagga gatcaagacc 420
tgctggaaca agatcctgat gggcaccaag gagcatagcg gcacaaccaa cacagtcgct 480
gcctataacc tcacttggaa gagcaccaac ttcaaaacca tcctcgaatg ggaacccaaa 540
cccgttaacc aagtttacac cgtgcagatc agcaccaagt ccggcgactg gaagtccaaa 600
tgtttctata ccaccgacac cgagtgcgat ctcaccgatg agatcgtgaa agatgtgaaa 660
cagacctacc tcgcccgggt gtttagctac cccgccggca atgtggagag cactggttcc 720
gctggcgagc ctttatacga gaacagcccc gaatttaccc cttacctcga gaccaattta 780
ggacagccca ccatccaaag ctttgagcaa gttggcacaa aggtgaatgt gacagtggag 840
gacgagcgga ctttagtgcg gcggaacaac acctttctca gcctccggga tgtgttcggc 900
aaagatttaa tctacacact gtattactgg aagtcctctt cctccggcaa gaagacagct 960
aaaaccaaca caaacgagtt tttaatcgac gtggataaag gcgaaaacta ctgtttcagc 1020
gtgcaagctg tgatcccctc ccggaccgtg aataggaaaa gcaccgatag ccccgttgag 1080
tgcatgggcc aagaaaaggg cgagttccgg gagaactggg tgaacgtcat cagcgattta 1140
aagaagatcg aagatttaat tcagtccatg catatcgacg ccactttata cacagaatcc 1200
gacgtgcacc cctcttgtaa ggtgaccgcc atgaaatgtt ttttactgga gctgcaagtt 1260
atctctttag agagcggaga cgctagcatc cacgacaccg tggagaattt aatcatttta 1320
gccaataact ctttatccag caacggcaac gtgacagagt ccggctgcaa ggagtgcgaa 1380
gagctggagg agaagaacat caaggagttt ctgcaatcct ttgtgcacat tgtccagatg 1440
ttcatcaata cctcc 1455
<210> 209
<211> 503
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 209
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser
20 25 30
Val Leu Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile
35 40 45
Gly Ser Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile
50 55 60
Cys Asp Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys
65 70 75 80
Leu Arg Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His
85 90 95
Leu Leu Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly
100 105 110
Gln Val Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr
115 120 125
Lys Ser Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn
130 135 140
Asp Leu Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp
145 150 155 160
Asn Lys Ile Leu Met Gly Thr Lys Glu His Ser Gly Thr Thr Asn Thr
165 170 175
Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile
180 185 190
Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile
195 200 205
Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp
210 215 220
Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr
225 230 235 240
Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr
245 250 255
Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro
260 265 270
Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln
275 280 285
Val Gly Thr Lys Val Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val
290 295 300
Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp
305 310 315 320
Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys
325 330 335
Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly
340 345 350
Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val
355 360 365
Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys
370 375 380
Gly Glu Phe Arg Glu Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys
385 390 395 400
Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr
405 410 415
Glu Ser Asp Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe
420 425 430
Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile
435 440 445
His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser
450 455 460
Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu
465 470 475 480
Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val
485 490 495
Gln Met Phe Ile Asn Thr Ser
500
<210> 210
<211> 1509
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 210
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccgattgc 60
gacatcgagg gcaaggacgg caagcagtac gagagcgtgc tgatggtgtc catcgaccag 120
ctgctggaca gcatgaagga gatcggctcc aactgcctca acaacgagtt caacttcttc 180
aagcggcaca tctgcgacgc caacaaggag ggcatgttcc tgttcagggc cgccaggaaa 240
ctgcggcagt tcctgaagat gaactccacc ggcgacttcg acctgcacct gctgaaggtg 300
tccgagggca ccaccatcct gctgaactgc accggacagg tgaagggccg gaaacctgct 360
gctctgggag aggcccaacc caccaagagc ctggaggaga acaagtccct gaaggagcag 420
aagaagctga acgacctgtg cttcctgaag aggctgctgc aggagatcaa gacctgctgg 480
aacaagatcc tgatgggcac caaggagcat agcggcacaa ccaacacagt cgctgcctat 540
aacctcactt ggaagagcac caacttcaaa accatcctcg aatgggaacc caaacccgtt 600
aaccaagttt acaccgtgca gatcagcacc aagtccggcg actggaagtc caaatgtttc 660
tataccaccg acaccgagtg cgatctcacc gatgagatcg tgaaagatgt gaaacagacc 720
tacctcgccc gggtgtttag ctaccccgcc ggcaatgtgg agagcactgg ttccgctggc 780
gagcctttat acgagaacag ccccgaattt accccttacc tcgagaccaa tttaggacag 840
cccaccatcc aaagctttga gcaagttggc acaaaggtga atgtgacagt ggaggacgag 900
cggactttag tgcggcggaa caacaccttt ctcagcctcc gggatgtgtt cggcaaagat 960
ttaatctaca cactgtatta ctggaagtcc tcttcctccg gcaagaagac agctaaaacc 1020
aacacaaacg agtttttaat cgacgtggat aaaggcgaaa actactgttt cagcgtgcaa 1080
gctgtgatcc cctcccggac cgtgaatagg aaaagcaccg atagccccgt tgagtgcatg 1140
ggccaagaaa agggcgagtt ccgggagaac tgggtgaacg tcatcagcga tttaaagaag 1200
atcgaagatt taattcagtc catgcatatc gacgccactt tatacacaga atccgacgtg 1260
cacccctctt gtaaggtgac cgccatgaaa tgttttttac tggagctgca agttatctct 1320
ttagagagcg gagacgctag catccacgac accgtggaga atttaatcat tttagccaat 1380
aactctttat ccagcaacgg caacgtgaca gagtccggct gcaaggagtg cgaagagctg 1440
gaggagaaga acatcaagga gtttctgcaa tcctttgtgc acattgtcca gatgttcatc 1500
aatacctcc 1509
<210> 211
<211> 198
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 211
Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp Ile
1 5 10 15
Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe Leu
20 25 30
Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe Ser
35 40 45
Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn Glu
50 55 60
Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro Ser
65 70 75 80
Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser Cys
85 90 95
Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe Lys
100 105 110
Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr His
115 120 125
Gly Ser Glu Asp Ser Ile Thr Cys Pro Pro Pro Met Ser Val Glu His
130 135 140
Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr
145 150 155 160
Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr
165 170 175
Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro
180 185 190
Ser Leu Lys Cys Ile Arg
195
<210> 212
<211> 594
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 212
cagggccagg acaggcacat gatccggatg aggcagctca tcgacatcgt cgaccagctg 60
aagaactacg tgaacgacct ggtgcccgag tttctgcctg cccccgagga cgtggagacc 120
aactgcgagt ggtccgcctt ctcctgcttt cagaaggccc agctgaagtc cgccaacacc 180
ggcaacaacg agcggatcat caacgtgagc atcaagaagc tgaagcggaa gcctccctcc 240
acaaacgccg gcaggaggca gaagcacagg ctgacctgcc ccagctgtga ctcctacgag 300
aagaagcccc ccaaggagtt cctggagagg ttcaagtccc tgctgcagaa gatgatccat 360
cagcacctgt cctccaggac ccacggctcc gaggactcca ttacatgccc ccctcccatg 420
agcgtggagc acgccgacat ctgggtgaag agctatagcc tctacagccg ggagaggtat 480
atctgtaaca gcggcttcaa gaggaaggcc ggcaccagca gcctcaccga gtgcgtgctg 540
aataaggcta ccaacgtggc tcactggaca acaccctctt taaagtgcat ccgg 594
<210> 213
<211> 216
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 213
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile
20 25 30
Asp Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu
35 40 45
Phe Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala
50 55 60
Phe Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn
65 70 75 80
Asn Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro
85 90 95
Pro Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro
100 105 110
Ser Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg
115 120 125
Phe Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg
130 135 140
Thr His Gly Ser Glu Asp Ser Ile Thr Cys Pro Pro Pro Met Ser Val
145 150 155 160
Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu
165 170 175
Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser
180 185 190
Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr
195 200 205
Thr Pro Ser Leu Lys Cys Ile Arg
210 215
<210> 214
<211> 648
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 214
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcccagggc 60
caggacaggc acatgatccg gatgaggcag ctcatcgaca tcgtcgacca gctgaagaac 120
tacgtgaacg acctggtgcc cgagtttctg cctgcccccg aggacgtgga gaccaactgc 180
gagtggtccg ccttctcctg ctttcagaag gcccagctga agtccgccaa caccggcaac 240
aacgagcgga tcatcaacgt gagcatcaag aagctgaagc ggaagcctcc ctccacaaac 300
gccggcagga ggcagaagca caggctgacc tgccccagct gtgactccta cgagaagaag 360
ccccccaagg agttcctgga gaggttcaag tccctgctgc agaagatgat ccatcagcac 420
ctgtcctcca ggacccacgg ctccgaggac tccattacat gcccccctcc catgagcgtg 480
gagcacgccg acatctgggt gaagagctat agcctctaca gccgggagag gtatatctgt 540
aacagcggct tcaagaggaa ggccggcacc agcagcctca ccgagtgcgt gctgaataag 600
gctaccaacg tggctcactg gacaacaccc tctttaaagt gcatccgg 648
<210> 215
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 215
Ser Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu Gly Gln Thr
1 5 10 15
Val Arg Ile Thr Cys Gln Gly Asp Ser Leu Arg Ser Tyr Tyr Ala Ser
20 25 30
Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val Ile Tyr Gly
35 40 45
Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser Gly Ser Ser
50 55 60
Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln Ala Glu Asp
65 70 75 80
Glu Ala Asp Tyr Tyr Cys Asn Ser Arg Asp Ser Ser Gly Asn His Val
85 90 95
Val Phe Gly Gly Gly Thr Lys Leu Thr Val Gly His
100 105
<210> 216
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 216
tccgagctga cccaggaccc tgctgtgtcc gtggctctgg gccagaccgt gaggatcacc 60
tgccagggcg actccctgag gtcctactac gcctcctggt accagcagaa gcccggccag 120
gctcctgtgc tggtgatcta cggcaagaac aacaggccct ccggcatccc tgacaggttc 180
tccggatcct cctccggcaa caccgcctcc ctgaccatca caggcgctca ggccgaggac 240
gaggctgact actactgcaa ctccagggac tcctccggca accatgtggt gttcggcggc 300
ggcaccaagc tgaccgtggg ccat 324
<210> 217
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 217
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Arg Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Asn Trp Asn Gly Gly Ser Thr Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Gly Arg Ser Leu Leu Phe Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Arg
115
<210> 218
<211> 351
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 218
gaggtgcagc tggtggagtc cggaggagga gtggtgaggc ctggaggctc cctgaggctg 60
agctgtgctg cctccggctt caccttcgac gactacggca tgtcctgggt gaggcaggct 120
cctggaaagg gcctggagtg ggtgtccggc atcaactgga acggcggatc caccggctac 180
gccgattccg tgaagggcag gttcaccatc agcagggaca acgccaagaa ctccctgtac 240
ctgcagatga actccctgag ggccgaggac accgccgtgt actactgcgc caggggcagg 300
tccctgctgt tcgactactg gggacagggc accctggtga ccgtgtccag g 351
<210> 219
<400> 219
000
<210> 220
<400> 220
000
<210> 221
<211> 508
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 221
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Tyr Phe Gly Lys Leu Glu Ser Lys Leu Ser Val Ile Arg Asn
20 25 30
Leu Asn Asp Gln Val Leu Phe Ile Asp Gln Gly Asn Arg Pro Leu Phe
35 40 45
Glu Asp Met Thr Asp Ser Asp Cys Arg Asp Asn Ala Pro Arg Thr Ile
50 55 60
Phe Ile Ile Ser Met Tyr Lys Asp Ser Gln Pro Arg Gly Met Ala Val
65 70 75 80
Thr Ile Ser Val Lys Cys Glu Lys Ile Ser Thr Leu Ser Cys Glu Asn
85 90 95
Lys Ile Ile Ser Phe Lys Glu Met Asn Pro Pro Asp Asn Ile Lys Asp
100 105 110
Thr Lys Ser Asp Ile Ile Phe Phe Gln Arg Ser Val Pro Gly His Asp
115 120 125
Asn Lys Met Gln Phe Glu Ser Ser Ser Tyr Glu Gly Tyr Phe Leu Ala
130 135 140
Cys Glu Lys Glu Arg Asp Leu Phe Lys Leu Ile Leu Lys Lys Glu Asp
145 150 155 160
Glu Leu Gly Asp Arg Ser Ile Met Phe Thr Val Gln Asn Glu Asp Ser
165 170 175
Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr
180 185 190
Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val
195 200 205
Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys
210 215 220
Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys
225 230 235 240
Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly
245 250 255
Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser
260 265 270
Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile
275 280 285
Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu Asp
290 295 300
Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp
305 310 315 320
Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser
325 330 335
Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile
340 345 350
Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile
355 360 365
Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys
370 375 380
Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val Asn Val Ile
385 390 395 400
Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp
405 410 415
Ala Thr Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys Val Thr
420 425 430
Ala Met Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser
435 440 445
Gly Asp Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala
450 455 460
Asn Asn Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys
465 470 475 480
Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser
485 490 495
Phe Val His Ile Val Gln Met Phe Ile Asn Thr Ser
500 505
<210> 222
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 222
Gly Gly Ser Ser Arg Ser Ser Ser Ser Gly Gly Gly Gly Ser Gly Gly
1 5 10 15
Gly Gly
<210> 223
<211> 823
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 223
Ile Trp Glu Leu Lys Lys Asp Val Tyr Val Val Glu Leu Asp Trp Tyr
1 5 10 15
Pro Asp Ala Pro Gly Glu Met Val Val Leu Thr Cys Asp Thr Pro Glu
20 25 30
Glu Asp Gly Ile Thr Trp Thr Leu Asp Gln Ser Ser Glu Val Leu Gly
35 40 45
Ser Gly Lys Thr Leu Thr Ile Gln Val Lys Glu Phe Gly Asp Ala Gly
50 55 60
Gln Tyr Thr Cys His Lys Gly Gly Glu Val Leu Ser His Ser Leu Leu
65 70 75 80
Leu Leu His Lys Lys Glu Asp Gly Ile Trp Ser Thr Asp Ile Leu Lys
85 90 95
Asp Gln Lys Glu Pro Lys Asn Lys Thr Phe Leu Arg Cys Glu Ala Lys
100 105 110
Asn Tyr Ser Gly Arg Phe Thr Cys Trp Trp Leu Thr Thr Ile Ser Thr
115 120 125
Asp Leu Thr Phe Ser Val Lys Ser Ser Arg Gly Ser Ser Asp Pro Gln
130 135 140
Gly Val Thr Cys Gly Ala Ala Thr Leu Ser Ala Glu Arg Val Arg Gly
145 150 155 160
Asp Asn Lys Glu Tyr Glu Tyr Ser Val Glu Cys Gln Glu Asp Ser Ala
165 170 175
Cys Pro Ala Ala Glu Glu Ser Leu Pro Ile Glu Val Met Val Asp Ala
180 185 190
Val His Lys Leu Lys Tyr Glu Asn Tyr Thr Ser Ser Phe Phe Ile Arg
195 200 205
Asp Ile Ile Lys Pro Asp Pro Pro Lys Asn Leu Gln Leu Lys Pro Leu
210 215 220
Lys Asn Ser Arg Gln Val Glu Val Ser Trp Glu Tyr Pro Asp Thr Trp
225 230 235 240
Ser Thr Pro His Ser Tyr Phe Ser Leu Thr Phe Cys Val Gln Val Gln
245 250 255
Gly Lys Ser Lys Arg Glu Lys Lys Asp Arg Val Phe Thr Asp Lys Thr
260 265 270
Ser Ala Thr Val Ile Cys Arg Lys Asn Ala Ser Ile Ser Val Arg Ala
275 280 285
Gln Asp Arg Tyr Tyr Ser Ser Ser Trp Ser Glu Trp Ala Ser Val Pro
290 295 300
Cys Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
305 310 315 320
Ser Arg Asn Leu Pro Val Ala Thr Pro Asp Pro Gly Met Phe Pro Cys
325 330 335
Leu His His Ser Gln Asn Leu Leu Arg Ala Val Ser Asn Met Leu Gln
340 345 350
Lys Ala Arg Gln Thr Leu Glu Phe Tyr Pro Cys Thr Ser Glu Glu Ile
355 360 365
Asp His Glu Asp Ile Thr Lys Asp Lys Thr Ser Thr Val Glu Ala Cys
370 375 380
Leu Pro Leu Glu Leu Thr Lys Asn Glu Ser Cys Leu Asn Ser Arg Glu
385 390 395 400
Thr Ser Phe Ile Thr Asn Gly Ser Cys Leu Ala Ser Arg Lys Thr Ser
405 410 415
Phe Met Met Ala Leu Cys Leu Ser Ser Ile Tyr Glu Asp Leu Lys Met
420 425 430
Tyr Gln Val Glu Phe Lys Thr Met Asn Ala Lys Leu Leu Met Asp Pro
435 440 445
Lys Arg Gln Ile Phe Leu Asp Gln Asn Met Leu Ala Val Ile Asp Glu
450 455 460
Leu Met Gln Ala Leu Asn Phe Asn Ser Glu Thr Val Pro Gln Lys Ser
465 470 475 480
Ser Leu Glu Glu Pro Asp Phe Tyr Lys Thr Lys Ile Lys Leu Cys Ile
485 490 495
Leu Leu His Ala Phe Arg Ile Arg Ala Val Thr Ile Asp Arg Val Met
500 505 510
Ser Tyr Leu Asn Ala Ser Ile Thr Cys Pro Pro Pro Met Ser Val Glu
515 520 525
His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg
530 535 540
Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu
545 550 555 560
Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr
565 570 575
Pro Ser Leu Lys Cys Ile Arg Ser Glu Leu Thr Gln Asp Pro Ala Val
580 585 590
Ser Val Ala Leu Gly Gln Thr Val Arg Ile Thr Cys Gln Gly Asp Ser
595 600 605
Leu Arg Ser Tyr Tyr Ala Ser Trp Tyr Gln Gln Lys Pro Gly Gln Ala
610 615 620
Pro Val Leu Val Ile Tyr Gly Lys Asn Asn Arg Pro Ser Gly Ile Pro
625 630 635 640
Asp Arg Phe Ser Gly Ser Ser Ser Gly Asn Thr Ala Ser Leu Thr Ile
645 650 655
Thr Gly Ala Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Asn Ser Arg
660 665 670
Asp Ser Ser Gly Asn His Val Val Phe Gly Gly Gly Thr Lys Leu Thr
675 680 685
Val Gly His Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
690 695 700
Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Arg Pro
705 710 715 720
Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp
725 730 735
Asp Tyr Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu
740 745 750
Trp Val Ser Gly Ile Asn Trp Asn Gly Gly Ser Thr Gly Tyr Ala Asp
755 760 765
Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser
770 775 780
Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr
785 790 795 800
Tyr Cys Ala Arg Gly Arg Ser Leu Leu Phe Asp Tyr Trp Gly Gln Gly
805 810 815
Thr Leu Val Thr Val Ser Arg
820
<210> 224
<211> 2469
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 224
atttgggaac tgaagaagga cgtctacgtg gtcgaactgg actggtatcc cgatgctccc 60
ggcgaaatgg tggtgctcac ttgtgacacc cccgaagaag acggcatcac ttggaccctc 120
gatcagagca gcgaggtgct gggctccgga aagaccctca caatccaagt taaggagttc 180
ggagacgctg gccaatacac atgccacaag ggaggcgagg tgctcagcca ttccttatta 240
ttattacaca agaaggaaga cggaatctgg tccaccgaca ttttaaaaga tcagaaggag 300
cccaagaata agaccttttt aaggtgtgag gccaaaaact acagcggtcg tttcacttgt 360
tggtggctga ccaccatttc caccgattta accttctccg tgaaaagcag ccggggaagc 420
tccgaccctc aaggtgtgac atgtggagcc gctaccctca gcgctgagag ggttcgtggc 480
gataacaagg aatacgagta cagcgtggag tgccaagaag atagcgcttg tcccgctgcc 540
gaagaatctt tacccattga ggtgatggtg gacgccgtgc acaaactcaa gtacgagaac 600
tacacctcct ccttctttat ccgggacatc attaagcccg atcctcctaa gaatttacag 660
ctgaagcctc tcaaaaatag ccggcaagtt gaggtctctt gggaatatcc cgacacttgg 720
agcacacccc acagctactt ctctttaacc ttttgtgtgc aagttcaagg taaaagcaag 780
cgggagaaga aagaccgggt gtttaccgac aaaaccagcg ccaccgtcat ctgtcggaag 840
aacgcctcca tcagcgtgag ggctcaagat cgttattact ccagcagctg gtccgagtgg 900
gccagcgtgc cttgttccgg cggtggagga tccggaggag gtggctccgg cggcggagga 960
tctcgtaacc tccccgtggc tacccccgat cccggaatgt tcccttgttt acaccacagc 1020
cagaatttac tgagggccgt gagcaacatg ctgcagaaag ctaggcagac tttagaattt 1080
tacccttgca ccagcgagga gatcgaccat gaagatatca ccaaggacaa gacatccacc 1140
gtggaggctt gtttacctct ggagctgaca aagaacgagt cttgtctcaa ctctcgtgaa 1200
accagcttca tcacaaatgg ctcttgttta gcttcccgga agacctcctt tatgatggct 1260
ttatgcctca gctccatcta cgaggattta aagatgtacc aagtggagtt caagaccatg 1320
aacgccaagc tgctcatgga ccctaaacgg cagatctttt tagaccagaa catgctggct 1380
gtgattgatg agctgatgca agctttaaac ttcaactccg agaccgtccc tcagaagtcc 1440
tccctcgagg agcccgattt ttacaagaca aagatcaaac tgtgcatttt actccacgcc 1500
tttaggatcc gggccgtgac cattgaccgg gtcatgagct atttaaacgc cagcattaca 1560
tgcccccctc ccatgagcgt ggagcacgcc gacatctggg tgaagagcta tagcctctac 1620
agccgggaga ggtatatctg taacagcggc ttcaagagga aggccggcac cagcagcctc 1680
accgagtgcg tgctgaataa ggctaccaac gtggctcact ggacaacacc ctctttaaag 1740
tgcatccggt ccgagctgac ccaggaccct gctgtgtccg tggctctggg ccagaccgtg 1800
aggatcacct gccagggcga ctccctgagg tcctactacg cctcctggta ccagcagaag 1860
cccggccagg ctcctgtgct ggtgatctac ggcaagaaca acaggccctc cggcatccct 1920
gacaggttct ccggatcctc ctccggcaac accgcctccc tgaccatcac aggcgctcag 1980
gccgaggacg aggctgacta ctactgcaac tccagggact cctccggcaa ccatgtggtg 2040
ttcggcggcg gcaccaagct gaccgtgggc catggcggcg gcggctccgg aggcggcggc 2100
agcggcggag gaggatccga ggtgcagctg gtggagtccg gaggaggagt ggtgaggcct 2160
ggaggctccc tgaggctgag ctgtgctgcc tccggcttca ccttcgacga ctacggcatg 2220
tcctgggtga ggcaggctcc tggaaagggc ctggagtggg tgtccggcat caactggaac 2280
ggcggatcca ccggctacgc cgattccgtg aagggcaggt tcaccatcag cagggacaac 2340
gccaagaact ccctgtacct gcagatgaac tccctgaggg ccgaggacac cgccgtgtac 2400
tactgcgcca ggggcaggtc cctgctgttc gactactggg gacagggcac cctggtgacc 2460
gtgtccagg 2469
<210> 225
<211> 841
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 225
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Trp Glu Leu Lys Lys Asp Val Tyr Val Val Glu Leu Asp
20 25 30
Trp Tyr Pro Asp Ala Pro Gly Glu Met Val Val Leu Thr Cys Asp Thr
35 40 45
Pro Glu Glu Asp Gly Ile Thr Trp Thr Leu Asp Gln Ser Ser Glu Val
50 55 60
Leu Gly Ser Gly Lys Thr Leu Thr Ile Gln Val Lys Glu Phe Gly Asp
65 70 75 80
Ala Gly Gln Tyr Thr Cys His Lys Gly Gly Glu Val Leu Ser His Ser
85 90 95
Leu Leu Leu Leu His Lys Lys Glu Asp Gly Ile Trp Ser Thr Asp Ile
100 105 110
Leu Lys Asp Gln Lys Glu Pro Lys Asn Lys Thr Phe Leu Arg Cys Glu
115 120 125
Ala Lys Asn Tyr Ser Gly Arg Phe Thr Cys Trp Trp Leu Thr Thr Ile
130 135 140
Ser Thr Asp Leu Thr Phe Ser Val Lys Ser Ser Arg Gly Ser Ser Asp
145 150 155 160
Pro Gln Gly Val Thr Cys Gly Ala Ala Thr Leu Ser Ala Glu Arg Val
165 170 175
Arg Gly Asp Asn Lys Glu Tyr Glu Tyr Ser Val Glu Cys Gln Glu Asp
180 185 190
Ser Ala Cys Pro Ala Ala Glu Glu Ser Leu Pro Ile Glu Val Met Val
195 200 205
Asp Ala Val His Lys Leu Lys Tyr Glu Asn Tyr Thr Ser Ser Phe Phe
210 215 220
Ile Arg Asp Ile Ile Lys Pro Asp Pro Pro Lys Asn Leu Gln Leu Lys
225 230 235 240
Pro Leu Lys Asn Ser Arg Gln Val Glu Val Ser Trp Glu Tyr Pro Asp
245 250 255
Thr Trp Ser Thr Pro His Ser Tyr Phe Ser Leu Thr Phe Cys Val Gln
260 265 270
Val Gln Gly Lys Ser Lys Arg Glu Lys Lys Asp Arg Val Phe Thr Asp
275 280 285
Lys Thr Ser Ala Thr Val Ile Cys Arg Lys Asn Ala Ser Ile Ser Val
290 295 300
Arg Ala Gln Asp Arg Tyr Tyr Ser Ser Ser Trp Ser Glu Trp Ala Ser
305 310 315 320
Val Pro Cys Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
325 330 335
Gly Gly Ser Arg Asn Leu Pro Val Ala Thr Pro Asp Pro Gly Met Phe
340 345 350
Pro Cys Leu His His Ser Gln Asn Leu Leu Arg Ala Val Ser Asn Met
355 360 365
Leu Gln Lys Ala Arg Gln Thr Leu Glu Phe Tyr Pro Cys Thr Ser Glu
370 375 380
Glu Ile Asp His Glu Asp Ile Thr Lys Asp Lys Thr Ser Thr Val Glu
385 390 395 400
Ala Cys Leu Pro Leu Glu Leu Thr Lys Asn Glu Ser Cys Leu Asn Ser
405 410 415
Arg Glu Thr Ser Phe Ile Thr Asn Gly Ser Cys Leu Ala Ser Arg Lys
420 425 430
Thr Ser Phe Met Met Ala Leu Cys Leu Ser Ser Ile Tyr Glu Asp Leu
435 440 445
Lys Met Tyr Gln Val Glu Phe Lys Thr Met Asn Ala Lys Leu Leu Met
450 455 460
Asp Pro Lys Arg Gln Ile Phe Leu Asp Gln Asn Met Leu Ala Val Ile
465 470 475 480
Asp Glu Leu Met Gln Ala Leu Asn Phe Asn Ser Glu Thr Val Pro Gln
485 490 495
Lys Ser Ser Leu Glu Glu Pro Asp Phe Tyr Lys Thr Lys Ile Lys Leu
500 505 510
Cys Ile Leu Leu His Ala Phe Arg Ile Arg Ala Val Thr Ile Asp Arg
515 520 525
Val Met Ser Tyr Leu Asn Ala Ser Ile Thr Cys Pro Pro Pro Met Ser
530 535 540
Val Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg
545 550 555 560
Glu Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser
565 570 575
Ser Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp
580 585 590
Thr Thr Pro Ser Leu Lys Cys Ile Arg Ser Glu Leu Thr Gln Asp Pro
595 600 605
Ala Val Ser Val Ala Leu Gly Gln Thr Val Arg Ile Thr Cys Gln Gly
610 615 620
Asp Ser Leu Arg Ser Tyr Tyr Ala Ser Trp Tyr Gln Gln Lys Pro Gly
625 630 635 640
Gln Ala Pro Val Leu Val Ile Tyr Gly Lys Asn Asn Arg Pro Ser Gly
645 650 655
Ile Pro Asp Arg Phe Ser Gly Ser Ser Ser Gly Asn Thr Ala Ser Leu
660 665 670
Thr Ile Thr Gly Ala Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Asn
675 680 685
Ser Arg Asp Ser Ser Gly Asn His Val Val Phe Gly Gly Gly Thr Lys
690 695 700
Leu Thr Val Gly His Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
705 710 715 720
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
725 730 735
Arg Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr
740 745 750
Phe Asp Asp Tyr Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly
755 760 765
Leu Glu Trp Val Ser Gly Ile Asn Trp Asn Gly Gly Ser Thr Gly Tyr
770 775 780
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys
785 790 795 800
Asn Ser Leu Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala
805 810 815
Val Tyr Tyr Cys Ala Arg Gly Arg Ser Leu Leu Phe Asp Tyr Trp Gly
820 825 830
Gln Gly Thr Leu Val Thr Val Ser Arg
835 840
<210> 226
<211> 2523
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 226
atgaaatggg tgacctttat ttctttactg ttcctcttta gcagcgccta ctccatttgg 60
gaactgaaga aggacgtcta cgtggtcgaa ctggactggt atcccgatgc tcccggcgaa 120
atggtggtgc tcacttgtga cacccccgaa gaagacggca tcacttggac cctcgatcag 180
agcagcgagg tgctgggctc cggaaagacc ctcacaatcc aagttaagga gttcggagac 240
gctggccaat acacatgcca caagggaggc gaggtgctca gccattcctt attattatta 300
cacaagaagg aagacggaat ctggtccacc gacattttaa aagatcagaa ggagcccaag 360
aataagacct ttttaaggtg tgaggccaaa aactacagcg gtcgtttcac ttgttggtgg 420
ctgaccacca tttccaccga tttaaccttc tccgtgaaaa gcagccgggg aagctccgac 480
cctcaaggtg tgacatgtgg agccgctacc ctcagcgctg agagggttcg tggcgataac 540
aaggaatacg agtacagcgt ggagtgccaa gaagatagcg cttgtcccgc tgccgaagaa 600
tctttaccca ttgaggtgat ggtggacgcc gtgcacaaac tcaagtacga gaactacacc 660
tcctccttct ttatccggga catcattaag cccgatcctc ctaagaattt acagctgaag 720
cctctcaaaa atagccggca agttgaggtc tcttgggaat atcccgacac ttggagcaca 780
ccccacagct acttctcttt aaccttttgt gtgcaagttc aaggtaaaag caagcgggag 840
aagaaagacc gggtgtttac cgacaaaacc agcgccaccg tcatctgtcg gaagaacgcc 900
tccatcagcg tgagggctca agatcgttat tactccagca gctggtccga gtgggccagc 960
gtgccttgtt ccggcggtgg aggatccgga ggaggtggct ccggcggcgg aggatctcgt 1020
aacctccccg tggctacccc cgatcccgga atgttccctt gtttacacca cagccagaat 1080
ttactgaggg ccgtgagcaa catgctgcag aaagctaggc agactttaga attttaccct 1140
tgcaccagcg aggagatcga ccatgaagat atcaccaagg acaagacatc caccgtggag 1200
gcttgtttac ctctggagct gacaaagaac gagtcttgtc tcaactctcg tgaaaccagc 1260
ttcatcacaa atggctcttg tttagcttcc cggaagacct cctttatgat ggctttatgc 1320
ctcagctcca tctacgagga tttaaagatg taccaagtgg agttcaagac catgaacgcc 1380
aagctgctca tggaccctaa acggcagatc tttttagacc agaacatgct ggctgtgatt 1440
gatgagctga tgcaagcttt aaacttcaac tccgagaccg tccctcagaa gtcctccctc 1500
gaggagcccg atttttacaa gacaaagatc aaactgtgca ttttactcca cgcctttagg 1560
atccgggccg tgaccattga ccgggtcatg agctatttaa acgccagcat tacatgcccc 1620
cctcccatga gcgtggagca cgccgacatc tgggtgaaga gctatagcct ctacagccgg 1680
gagaggtata tctgtaacag cggcttcaag aggaaggccg gcaccagcag cctcaccgag 1740
tgcgtgctga ataaggctac caacgtggct cactggacaa caccctcttt aaagtgcatc 1800
cggtccgagc tgacccagga ccctgctgtg tccgtggctc tgggccagac cgtgaggatc 1860
acctgccagg gcgactccct gaggtcctac tacgcctcct ggtaccagca gaagcccggc 1920
caggctcctg tgctggtgat ctacggcaag aacaacaggc cctccggcat ccctgacagg 1980
ttctccggat cctcctccgg caacaccgcc tccctgacca tcacaggcgc tcaggccgag 2040
gacgaggctg actactactg caactccagg gactcctccg gcaaccatgt ggtgttcggc 2100
ggcggcacca agctgaccgt gggccatggc ggcggcggct ccggaggcgg cggcagcggc 2160
ggaggaggat ccgaggtgca gctggtggag tccggaggag gagtggtgag gcctggaggc 2220
tccctgaggc tgagctgtgc tgcctccggc ttcaccttcg acgactacgg catgtcctgg 2280
gtgaggcagg ctcctggaaa gggcctggag tgggtgtccg gcatcaactg gaacggcgga 2340
tccaccggct acgccgattc cgtgaagggc aggttcacca tcagcaggga caacgccaag 2400
aactccctgt acctgcagat gaactccctg agggccgagg acaccgccgt gtactactgc 2460
gccaggggca ggtccctgct gttcgactac tggggacagg gcaccctggt gaccgtgtcc 2520
agg 2523
<210> 227
<211> 456
<212> DNA
<213> Homo sapiens
<400> 227
gattgcgaca tcgagggcaa ggacggcaag cagtacgaga gcgtgctgat ggtgtccatc 60
gaccagctgc tggacagcat gaaggagatc ggctccaact gcctcaacaa cgagttcaac 120
ttcttcaagc ggcacatctg cgacgccaac aaggagggca tgttcctgtt cagggccgcc 180
aggaaactgc ggcagttcct gaagatgaac tccaccggcg acttcgacct gcacctgctg 240
aaggtgtccg agggcaccac catcctgctg aactgcaccg gacaggtgaa gggccggaaa 300
cctgctgctc tgggagaggc ccaacccacc aagagcctgg aggagaacaa gtccctgaag 360
gagcagaaga agctgaacga cctgtgcttc ctgaagaggc tgctgcagga gatcaagacc 420
tgctggaaca agatcctgat gggcaccaag gagcat 456
<210> 228
<400> 228
000
<210> 229
<400> 229
000
<210> 230
<400> 230
000
<210> 231
<400> 231
000
<210> 232
<211> 438
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 232
Ser Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu Gly Gln Thr
1 5 10 15
Val Arg Ile Thr Cys Gln Gly Asp Ser Leu Arg Ser Tyr Tyr Ala Ser
20 25 30
Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val Ile Tyr Gly
35 40 45
Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser Gly Ser Ser
50 55 60
Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln Ala Glu Asp
65 70 75 80
Glu Ala Asp Tyr Tyr Cys Asn Ser Arg Asp Ser Ser Gly Asn His Val
85 90 95
Val Phe Gly Gly Gly Thr Lys Leu Thr Val Gly His Gly Gly Gly Gly
100 105 110
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val
115 120 125
Glu Ser Gly Gly Gly Val Val Arg Pro Gly Gly Ser Leu Arg Leu Ser
130 135 140
Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr Gly Met Ser Trp Val
145 150 155 160
Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Gly Ile Asn Trp
165 170 175
Asn Gly Gly Ser Thr Gly Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr
180 185 190
Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu Gln Met Asn Ser
195 200 205
Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Gly Arg Ser
210 215 220
Leu Leu Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Arg
225 230 235 240
Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp Val
245 250 255
Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly
260 265 270
Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu Asn
275 280 285
Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys Ile
290 295 300
Arg Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp
305 310 315 320
Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe
325 330 335
Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe
340 345 350
Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn
355 360 365
Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro
370 375 380
Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser
385 390 395 400
Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe
405 410 415
Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr
420 425 430
His Gly Ser Glu Asp Ser
435
<210> 233
<211> 1314
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 233
tccgagctga cccaggaccc tgctgtgtcc gtggctctgg gccagaccgt gaggatcacc 60
tgccagggcg actccctgag gtcctactac gcctcctggt accagcagaa gcccggccag 120
gctcctgtgc tggtgatcta cggcaagaac aacaggccct ccggcatccc tgacaggttc 180
tccggatcct cctccggcaa caccgcctcc ctgaccatca caggcgctca ggccgaggac 240
gaggctgact actactgcaa ctccagggac tcctccggca accatgtggt gttcggcggc 300
ggcaccaagc tgaccgtggg ccatggcggc ggcggctccg gaggcggcgg cagcggcgga 360
ggaggatccg aggtgcagct ggtggagtcc ggaggaggag tggtgaggcc tggaggctcc 420
ctgaggctga gctgtgctgc ctccggcttc accttcgacg actacggcat gtcctgggtg 480
aggcaggctc ctggaaaggg cctggagtgg gtgtccggca tcaactggaa cggcggatcc 540
accggctacg ccgattccgt gaagggcagg ttcaccatca gcagggacaa cgccaagaac 600
tccctgtacc tgcagatgaa ctccctgagg gccgaggaca ccgccgtgta ctactgcgcc 660
aggggcaggt ccctgctgtt cgactactgg ggacagggca ccctggtgac cgtgtccagg 720
attacatgcc cccctcccat gagcgtggag cacgccgaca tctgggtgaa gagctatagc 780
ctctacagcc gggagaggta tatctgtaac agcggcttca agaggaaggc cggcaccagc 840
agcctcaccg agtgcgtgct gaataaggct accaacgtgg ctcactggac aacaccctct 900
ttaaagtgca tccggcaggg ccaggacagg cacatgatcc ggatgaggca gctcatcgac 960
atcgtcgacc agctgaagaa ctacgtgaac gacctggtgc ccgagtttct gcctgccccc 1020
gaggacgtgg agaccaactg cgagtggtcc gccttctcct gctttcagaa ggcccagctg 1080
aagtccgcca acaccggcaa caacgagcgg atcatcaacg tgagcatcaa gaagctgaag 1140
cggaagcctc cctccacaaa cgccggcagg aggcagaagc acaggctgac ctgccccagc 1200
tgtgactcct acgagaagaa gccccccaag gagttcctgg agaggttcaa gtccctgctg 1260
cagaagatga tccatcagca cctgtcctcc aggacccacg gctccgagga ctcc 1314
<210> 234
<211> 456
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 234
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ser Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu Gly
20 25 30
Gln Thr Val Arg Ile Thr Cys Gln Gly Asp Ser Leu Arg Ser Tyr Tyr
35 40 45
Ala Ser Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val Ile
50 55 60
Tyr Gly Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser Gly
65 70 75 80
Ser Ser Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln Ala
85 90 95
Glu Asp Glu Ala Asp Tyr Tyr Cys Asn Ser Arg Asp Ser Ser Gly Asn
100 105 110
His Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Gly His Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln
130 135 140
Leu Val Glu Ser Gly Gly Gly Val Val Arg Pro Gly Gly Ser Leu Arg
145 150 155 160
Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr Gly Met Ser
165 170 175
Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Gly Ile
180 185 190
Asn Trp Asn Gly Gly Ser Thr Gly Tyr Ala Asp Ser Val Lys Gly Arg
195 200 205
Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu Gln Met
210 215 220
Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Gly
225 230 235 240
Arg Ser Leu Leu Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val
245 250 255
Ser Arg Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile
260 265 270
Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn
275 280 285
Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val
290 295 300
Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys
305 310 315 320
Cys Ile Arg Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu
325 330 335
Ile Asp Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro
340 345 350
Glu Phe Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser
355 360 365
Ala Phe Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly
370 375 380
Asn Asn Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys
385 390 395 400
Pro Pro Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys
405 410 415
Pro Ser Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu
420 425 430
Arg Phe Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser
435 440 445
Arg Thr His Gly Ser Glu Asp Ser
450 455
<210> 235
<211> 1368
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 235
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcctccgag 60
ctgacccagg accctgctgt gtccgtggct ctgggccaga ccgtgaggat cacctgccag 120
ggcgactccc tgaggtccta ctacgcctcc tggtaccagc agaagcccgg ccaggctcct 180
gtgctggtga tctacggcaa gaacaacagg ccctccggca tccctgacag gttctccgga 240
tcctcctccg gcaacaccgc ctccctgacc atcacaggcg ctcaggccga ggacgaggct 300
gactactact gcaactccag ggactcctcc ggcaaccatg tggtgttcgg cggcggcacc 360
aagctgaccg tgggccatgg cggcggcggc tccggaggcg gcggcagcgg cggaggagga 420
tccgaggtgc agctggtgga gtccggagga ggagtggtga ggcctggagg ctccctgagg 480
ctgagctgtg ctgcctccgg cttcaccttc gacgactacg gcatgtcctg ggtgaggcag 540
gctcctggaa agggcctgga gtgggtgtcc ggcatcaact ggaacggcgg atccaccggc 600
tacgccgatt ccgtgaaggg caggttcacc atcagcaggg acaacgccaa gaactccctg 660
tacctgcaga tgaactccct gagggccgag gacaccgccg tgtactactg cgccaggggc 720
aggtccctgc tgttcgacta ctggggacag ggcaccctgg tgaccgtgtc caggattaca 780
tgcccccctc ccatgagcgt ggagcacgcc gacatctggg tgaagagcta tagcctctac 840
agccgggaga ggtatatctg taacagcggc ttcaagagga aggccggcac cagcagcctc 900
accgagtgcg tgctgaataa ggctaccaac gtggctcact ggacaacacc ctctttaaag 960
tgcatccggc agggccagga caggcacatg atccggatga ggcagctcat cgacatcgtc 1020
gaccagctga agaactacgt gaacgacctg gtgcccgagt ttctgcctgc ccccgaggac 1080
gtggagacca actgcgagtg gtccgccttc tcctgctttc agaaggccca gctgaagtcc 1140
gccaacaccg gcaacaacga gcggatcatc aacgtgagca tcaagaagct gaagcggaag 1200
cctccctcca caaacgccgg caggaggcag aagcacaggc tgacctgccc cagctgtgac 1260
tcctacgaga agaagccccc caaggagttc ctggagaggt tcaagtccct gctgcagaag 1320
atgatccatc agcacctgtc ctccaggacc cacggctccg aggactcc 1368
<210> 236
<211> 620
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 236
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys Ser Val
145 150 155 160
Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro
165 170 175
Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln
180 185 190
Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro
195 200 205
Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr
210 215 220
Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile
225 230 235 240
Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys
245 250 255
Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn
260 265 270
Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Ser
275 280 285
Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr
290 295 300
Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val
305 310 315 320
Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys
325 330 335
Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys
340 345 350
Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly
355 360 365
Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser
370 375 380
Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile
385 390 395 400
Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu Asp
405 410 415
Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp
420 425 430
Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser
435 440 445
Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile
450 455 460
Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile
465 470 475 480
Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys
485 490 495
Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val Asn Val Ile
500 505 510
Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His Ile Asp
515 520 525
Ala Thr Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys Val Thr
530 535 540
Ala Met Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu Glu Ser
545 550 555 560
Gly Asp Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile Leu Ala
565 570 575
Asn Asn Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly Cys Lys
580 585 590
Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu Gln Ser
595 600 605
Phe Val His Ile Val Gln Met Phe Ile Asn Thr Ser
610 615 620
<210> 237
<211> 1860
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 237
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcagcatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgatgg aggtggcgga 420
tccggaggtg gaggttctgg tggaggtggg agtattcctc cccacgtgca gaagagcgtg 480
aataatgaca tgatcgtgac cgataacaat ggcgccgtga aatttcccca gctgtgcaaa 540
ttctgcgatg tgaggttttc cacctgcgac aaccagaagt cctgtatgag caactgctcc 600
atcacctcca tctgtgagaa gcctcaggag gtgtgcgtgg ctgtctggcg gaagaatgac 660
gagaatatca ccctggaaac cgtctgccac gatcccaagc tgccctacca cgatttcatc 720
ctggaagacg ccgccagccc taagtgcatc atgaaagaga aaaagaagcc tggcgagacc 780
tttttcatgt gctcctgcag cagcgacgaa tgcaacgaca atatcatctt tagcgaggaa 840
tacaatacca gcaaccccga cagcggcaca accaacacag tcgctgccta taacctcact 900
tggaagagca ccaacttcaa aaccatcctc gaatgggaac ccaaacccgt taaccaagtt 960
tacaccgtgc agatcagcac caagtccggc gactggaagt ccaaatgttt ctataccacc 1020
gacaccgagt gcgatctcac cgatgagatc gtgaaagatg tgaaacagac ctacctcgcc 1080
cgggtgttta gctaccccgc cggcaatgtg gagagcactg gttccgctgg cgagccttta 1140
tacgagaaca gccccgaatt taccccttac ctcgagacca atttaggaca gcccaccatc 1200
caaagctttg agcaagttgg cacaaaggtg aatgtgacag tggaggacga gcggacttta 1260
gtgcggcgga acaacacctt tctcagcctc cgggatgtgt tcggcaaaga tttaatctac 1320
acactgtatt actggaagtc ctcttcctcc ggcaagaaga cagctaaaac caacacaaac 1380
gagtttttaa tcgacgtgga taaaggcgaa aactactgtt tcagcgtgca agctgtgatc 1440
ccctcccgga ccgtgaatag gaaaagcacc gatagccccg ttgagtgcat gggccaagaa 1500
aagggcgagt tccgggagaa ctgggtgaac gtcatcagcg atttaaagaa gatcgaagat 1560
ttaattcagt ccatgcatat cgacgccact ttatacacag aatccgacgt gcacccctct 1620
tgtaaggtga ccgccatgaa atgtttttta ctggagctgc aagttatctc tttagagagc 1680
ggagacgcta gcatccacga caccgtggag aatttaatca ttttagccaa taactcttta 1740
tccagcaacg gcaacgtgac agagtccggc tgcaaggagt gcgaagagct ggaggagaag 1800
aacatcaagg agtttctgca atcctttgtg cacattgtcc agatgttcat caatacctcc 1860
<210> 238
<211> 638
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 238
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile
20 25 30
Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe
35 40 45
Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser
50 55 60
Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val
65 70 75 80
Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys
85 90 95
His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala
100 105 110
Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe
115 120 125
Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe
130 135 140
Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys
165 170 175
Ser Val Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys
180 185 190
Phe Pro Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp
195 200 205
Asn Gln Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu
210 215 220
Lys Pro Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn
225 230 235 240
Ile Thr Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp
245 250 255
Phe Ile Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys
260 265 270
Lys Lys Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu
275 280 285
Cys Asn Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro
290 295 300
Asp Ser Gly Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys
305 310 315 320
Ser Thr Asn Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn
325 330 335
Gln Val Tyr Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser
340 345 350
Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile
355 360 365
Val Lys Asp Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro
370 375 380
Ala Gly Asn Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu
385 390 395 400
Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro
405 410 415
Thr Ile Gln Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val
420 425 430
Glu Asp Glu Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu
435 440 445
Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys
450 455 460
Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe
465 470 475 480
Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala
485 490 495
Val Ile Pro Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val
500 505 510
Glu Cys Met Gly Gln Glu Lys Gly Glu Phe Arg Glu Asn Trp Val Asn
515 520 525
Val Ile Ser Asp Leu Lys Lys Ile Glu Asp Leu Ile Gln Ser Met His
530 535 540
Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp Val His Pro Ser Cys Lys
545 550 555 560
Val Thr Ala Met Lys Cys Phe Leu Leu Glu Leu Gln Val Ile Ser Leu
565 570 575
Glu Ser Gly Asp Ala Ser Ile His Asp Thr Val Glu Asn Leu Ile Ile
580 585 590
Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly Asn Val Thr Glu Ser Gly
595 600 605
Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys Asn Ile Lys Glu Phe Leu
610 615 620
Gln Ser Phe Val His Ile Val Gln Met Phe Ile Asn Thr Ser
625 630 635
<210> 239
<211> 1914
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 239
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccatcccc 60
ccccatgtgc aaaagagcgt gaacaacgat atgatcgtga ccgacaacaa cggcgccgtg 120
aagtttcccc agctctgcaa gttctgcgat gtcaggttca gcacctgcga taatcagaag 180
tcctgcatgt ccaactgcag catcacctcc atctgcgaga agccccaaga agtgtgcgtg 240
gccgtgtggc ggaaaaatga cgagaacatc accctggaga ccgtgtgtca cgaccccaag 300
ctcccttatc acgacttcat tctggaggac gctgcctccc ccaaatgcat catgaaggag 360
aagaagaagc ccggagagac cttctttatg tgttcctgta gcagcgacga gtgtaacgac 420
aacatcatct tcagcgaaga gtacaacacc agcaaccctg atggaggtgg cggatccgga 480
ggtggaggtt ctggtggagg tgggagtatt cctccccacg tgcagaagag cgtgaataat 540
gacatgatcg tgaccgataa caatggcgcc gtgaaatttc cccagctgtg caaattctgc 600
gatgtgaggt tttccacctg cgacaaccag aagtcctgta tgagcaactg ctccatcacc 660
tccatctgtg agaagcctca ggaggtgtgc gtggctgtct ggcggaagaa tgacgagaat 720
atcaccctgg aaaccgtctg ccacgatccc aagctgccct accacgattt catcctggaa 780
gacgccgcca gccctaagtg catcatgaaa gagaaaaaga agcctggcga gacctttttc 840
atgtgctcct gcagcagcga cgaatgcaac gacaatatca tctttagcga ggaatacaat 900
accagcaacc ccgacagcgg cacaaccaac acagtcgctg cctataacct cacttggaag 960
agcaccaact tcaaaaccat cctcgaatgg gaacccaaac ccgttaacca agtttacacc 1020
gtgcagatca gcaccaagtc cggcgactgg aagtccaaat gtttctatac caccgacacc 1080
gagtgcgatc tcaccgatga gatcgtgaaa gatgtgaaac agacctacct cgcccgggtg 1140
tttagctacc ccgccggcaa tgtggagagc actggttccg ctggcgagcc tttatacgag 1200
aacagccccg aatttacccc ttacctcgag accaatttag gacagcccac catccaaagc 1260
tttgagcaag ttggcacaaa ggtgaatgtg acagtggagg acgagcggac tttagtgcgg 1320
cggaacaaca cctttctcag cctccgggat gtgttcggca aagatttaat ctacacactg 1380
tattactgga agtcctcttc ctccggcaag aagacagcta aaaccaacac aaacgagttt 1440
ttaatcgacg tggataaagg cgaaaactac tgtttcagcg tgcaagctgt gatcccctcc 1500
cggaccgtga ataggaaaag caccgatagc cccgttgagt gcatgggcca agaaaagggc 1560
gagttccggg agaactgggt gaacgtcatc agcgatttaa agaagatcga agatttaatt 1620
cagtccatgc atatcgacgc cactttatac acagaatccg acgtgcaccc ctcttgtaag 1680
gtgaccgcca tgaaatgttt tttactggag ctgcaagtta tctctttaga gagcggagac 1740
gctagcatcc acgacaccgt ggagaattta atcattttag ccaataactc tttatccagc 1800
aacggcaacg tgacagagtc cggctgcaag gagtgcgaag agctggagga gaagaacatc 1860
aaggagtttc tgcaatcctt tgtgcacatt gtccagatgt tcatcaatac ctcc 1914
<210> 240
<211> 352
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 240
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys Ser Val
145 150 155 160
Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro
165 170 175
Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln
180 185 190
Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro
195 200 205
Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr
210 215 220
Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile
225 230 235 240
Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys
245 250 255
Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn
260 265 270
Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Ile
275 280 285
Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp Val Lys
290 295 300
Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly Phe
305 310 315 320
Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu Asn Lys
325 330 335
Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys Ile Arg
340 345 350
<210> 241
<211> 1056
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 241
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcagcatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgatgg aggtggcgga 420
tccggaggtg gaggttctgg tggaggtggg agtattcctc cccacgtgca gaagagcgtg 480
aataatgaca tgatcgtgac cgataacaat ggcgccgtga aatttcccca gctgtgcaaa 540
ttctgcgatg tgaggttttc cacctgcgac aaccagaagt cctgtatgag caactgctcc 600
atcacctcca tctgtgagaa gcctcaggag gtgtgcgtgg ctgtctggcg gaagaatgac 660
gagaatatca ccctggaaac cgtctgccac gatcccaagc tgccctacca cgatttcatc 720
ctggaagacg ccgccagccc taagtgcatc atgaaagaga aaaagaagcc tggcgagacc 780
tttttcatgt gctcctgcag cagcgacgaa tgcaacgaca atatcatctt tagcgaggaa 840
tacaatacca gcaaccccga cattacatgc ccccctccca tgagcgtgga gcacgccgac 900
atctgggtga agagctatag cctctacagc cgggagaggt atatctgtaa cagcggcttc 960
aagaggaagg ccggcaccag cagcctcacc gagtgcgtgc tgaataaggc taccaacgtg 1020
gctcactgga caacaccctc tttaaagtgc atccgg 1056
<210> 242
<211> 370
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 242
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile
20 25 30
Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe
35 40 45
Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser
50 55 60
Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val
65 70 75 80
Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys
85 90 95
His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala
100 105 110
Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe
115 120 125
Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe
130 135 140
Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys
165 170 175
Ser Val Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys
180 185 190
Phe Pro Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp
195 200 205
Asn Gln Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu
210 215 220
Lys Pro Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn
225 230 235 240
Ile Thr Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp
245 250 255
Phe Ile Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys
260 265 270
Lys Lys Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu
275 280 285
Cys Asn Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro
290 295 300
Asp Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp
305 310 315 320
Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser
325 330 335
Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu
340 345 350
Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys
355 360 365
Ile Arg
370
<210> 243
<211> 1110
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 243
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccatcccc 60
ccccatgtgc aaaagagcgt gaacaacgat atgatcgtga ccgacaacaa cggcgccgtg 120
aagtttcccc agctctgcaa gttctgcgat gtcaggttca gcacctgcga taatcagaag 180
tcctgcatgt ccaactgcag catcacctcc atctgcgaga agccccaaga agtgtgcgtg 240
gccgtgtggc ggaaaaatga cgagaacatc accctggaga ccgtgtgtca cgaccccaag 300
ctcccttatc acgacttcat tctggaggac gctgcctccc ccaaatgcat catgaaggag 360
aagaagaagc ccggagagac cttctttatg tgttcctgta gcagcgacga gtgtaacgac 420
aacatcatct tcagcgaaga gtacaacacc agcaaccctg atggaggtgg cggatccgga 480
ggtggaggtt ctggtggagg tgggagtatt cctccccacg tgcagaagag cgtgaataat 540
gacatgatcg tgaccgataa caatggcgcc gtgaaatttc cccagctgtg caaattctgc 600
gatgtgaggt tttccacctg cgacaaccag aagtcctgta tgagcaactg ctccatcacc 660
tccatctgtg agaagcctca ggaggtgtgc gtggctgtct ggcggaagaa tgacgagaat 720
atcaccctgg aaaccgtctg ccacgatccc aagctgccct accacgattt catcctggaa 780
gacgccgcca gccctaagtg catcatgaaa gagaaaaaga agcctggcga gacctttttc 840
atgtgctcct gcagcagcga cgaatgcaac gacaatatca tctttagcga ggaatacaat 900
accagcaacc ccgacattac atgcccccct cccatgagcg tggagcacgc cgacatctgg 960
gtgaagagct atagcctcta cagccgggag aggtatatct gtaacagcgg cttcaagagg 1020
aaggccggca ccagcagcct caccgagtgc gtgctgaata aggctaccaa cgtggctcac 1080
tggacaacac cctctttaaa gtgcatccgg 1110
<210> 244
<211> 1911
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 244
atgggagtga aagttctttt tgcccttatt tgtattgctg tggccgaggc catcccaccg 60
cacgttcaga agtcggtgaa taacgacatg atagtcactg acaacaacgg tgcagtcaag 120
tttccacaac tgtgtaaatt ttgtgatgtg agattttcca cctgtgacaa ccagaaatcc 180
tgcatgagca actgcagcat cacctccatc tgtgagaagc cacaggaagt ctgtgtggct 240
gtatggagaa agaatgacga gaacataaca ctagagacag tttgccatga ccccaagctc 300
ccctaccatg actttattct ggaagatgct gcttctccaa agtgcattat gaaggaaaaa 360
aaaaagcctg gtgagacttt cttcatgtgt tcctgtagct ctgatgagtg caatgacaac 420
atcatcttct cagaagaata taacaccagc aatcctgacg gaggtggcgg atccggaggt 480
ggaggttctg gtggaggtgg gagtattcct ccccacgtgc agaagagcgt gaataatgac 540
atgatcgtga ccgataacaa tggcgccgtg aaatttcccc agctgtgcaa attctgcgat 600
gtgaggtttt ccacctgcga caaccagaag tcctgtatga gcaactgctc catcacctcc 660
atctgtgaga agcctcagga ggtgtgcgtg gctgtctggc ggaagaatga cgagaatatc 720
accctggaaa ccgtctgcca cgatcccaag ctgccctacc acgatttcat cctggaagac 780
gccgccagcc ctaagtgcat catgaaagag aaaaagaagc ctggcgagac ctttttcatg 840
tgctcctgca gcagcgacga atgcaacgac aatatcatct ttagcgagga atacaatacc 900
agcaaccccg actcaggcac tacaaatact gtggcagcat ataatttaac ttggaaatca 960
actaatttca agacaatttt ggagtgggaa cccaaacccg tcaatcaagt ctacactgtt 1020
caaataagca ctaagtcagg agattggaaa agcaaatgct tttacacaac agacacagag 1080
tgtgacctca ccgacgagat tgtgaaggat gtgaagcaga cgtacttggc acgggtcttc 1140
tcctacccgg cagggaatgt ggagagcacc ggttctgctg gggagcctct gtatgagaac 1200
tccccagagt tcacacctta cctggagaca aacctcggac agccaacaat tcagagtttt 1260
gaacaggtgg gaacaaaagt gaatgtgacc gtagaagatg aacggacttt agtcagaagg 1320
aacaacactt tcctaagcct ccgggatgtt tttggcaagg acttaattta tacactttat 1380
tattggaaat cttcaagttc aggaaagaaa acagccaaaa caaacactaa tgagtttttg 1440
attgatgtgg ataaaggaga aaactactgt ttcagtgttc aagcagtgat tccctcccga 1500
acagttaacc ggaagagtac agacagcccg gtagagtgta tgggccagga gaaaggggaa 1560
ttcagagaaa actgggtgaa tgtaataagt aatttgaaaa aaattgaaga tcttattcaa 1620
tctatgcata ttgatgctac tttatatacg gaaagtgatg ttcaccccag ttgcaaagta 1680
acagcaatga agtgctttct cttggagtta caagttattt cacttgagtc cggagatgca 1740
agtattcatg atacagtaga aaatctgatc atcctagcaa acaacagttt gtcttctaat 1800
gggaatgtaa cagaatctgg atgcaaagaa tgtgaggaac tggaggaaaa aaatattaaa 1860
gaatttttgc agagttttgt acatattgtc caaatgttca tcaacacttc t 1911
<210> 245
<400> 245
000
<210> 246
<400> 246
000
<210> 247
<400> 247
000
<210> 248
<400> 248
000
<210> 249
<400> 249
000
<210> 250
<211> 235
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 250
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Asp Cys Asp Ile Glu Gly Lys Asp Gly Lys Gln Tyr Glu Ser
20 25 30
Val Leu Met Val Ser Ile Asp Gln Leu Leu Asp Ser Met Lys Glu Ile
35 40 45
Gly Ser Asn Cys Leu Asn Asn Glu Phe Asn Phe Phe Lys Arg His Ile
50 55 60
Cys Asp Ala Asn Lys Glu Gly Met Phe Leu Phe Arg Ala Ala Arg Lys
65 70 75 80
Leu Arg Gln Phe Leu Lys Met Asn Ser Thr Gly Asp Phe Asp Leu His
85 90 95
Leu Leu Lys Val Ser Glu Gly Thr Thr Ile Leu Leu Asn Cys Thr Gly
100 105 110
Gln Val Lys Gly Arg Lys Pro Ala Ala Leu Gly Glu Ala Gln Pro Thr
115 120 125
Lys Ser Leu Glu Glu Asn Lys Ser Leu Lys Glu Gln Lys Lys Leu Asn
130 135 140
Asp Leu Cys Phe Leu Lys Arg Leu Leu Gln Glu Ile Lys Thr Cys Trp
145 150 155 160
Asn Lys Ile Leu Met Gly Thr Lys Glu His Ile Thr Cys Pro Pro Pro
165 170 175
Met Ser Val Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr
180 185 190
Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly
195 200 205
Thr Ser Ser Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala
210 215 220
His Trp Thr Thr Pro Ser Leu Lys Cys Ile Arg
225 230 235
<210> 251
<211> 705
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 251
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccgattgc 60
gacatcgagg gcaaggacgg caagcagtac gagagcgtgc tgatggtgtc catcgaccag 120
ctgctggaca gcatgaagga gatcggctcc aactgcctca acaacgagtt caacttcttc 180
aagcggcaca tctgcgacgc caacaaggag ggcatgttcc tgttcagggc cgccaggaaa 240
ctgcggcagt tcctgaagat gaactccacc ggcgacttcg acctgcacct gctgaaggtg 300
tccgagggca ccaccatcct gctgaactgc accggacagg tgaagggccg gaaacctgct 360
gctctgggag aggcccaacc caccaagagc ctggaggaga acaagtccct gaaggagcag 420
aagaagctga acgacctgtg cttcctgaag aggctgctgc aggagatcaa gacctgctgg 480
aacaagatcc tgatgggcac caaggagcat attacatgcc cccctcccat gagcgtggag 540
cacgccgaca tctgggtgaa gagctatagc ctctacagcc gggagaggta tatctgtaac 600
agcggcttca agaggaaggc cggcaccagc agcctcaccg agtgcgtgct gaataaggct 660
accaacgtgg ctcactggac aacaccctct ttaaagtgca tccgg 705
<210> 252
<400> 252
000
<210> 253
<400> 253
000
<210> 254
<400> 254
000
<210> 255
<400> 255
000
<210> 256
<400> 256
000
<210> 257
<211> 1056
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 257
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcagcatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgatgg aggtggcgga 420
tccggaggtg gaggttctgg tggaggtggg agtattcctc cccacgtgca gaagagcgtg 480
aataatgaca tgatcgtgac cgataacaat ggcgccgtga aatttcccca gctgtgcaaa 540
ttctgcgatg tgaggttttc cacctgcgac aaccagaagt cctgtatgag caactgctcc 600
atcacctcca tctgtgagaa gcctcaggag gtgtgcgtgg ctgtctggcg gaagaatgac 660
gagaatatca ccctggaaac cgtctgccac gatcccaagc tgccctacca cgatttcatc 720
ctggaagacg ccgccagccc taagtgcatc atgaaagaga aaaagaagcc tggcgagacc 780
tttttcatgt gctcctgcag cagcgacgaa tgcaacgaca atatcatctt tagcgaggaa 840
tacaatacca gcaaccccga cattacatgc ccccctccca tgagcgtgga gcacgccgac 900
atctgggtga agagctatag cctctacagc cgggagaggt atatctgtaa cagcggcttc 960
aagaggaagg ccggcaccag cagcctcacc gagtgcgtgc tgaataaggc taccaacgtg 1020
gctcactgga caacaccctc tttaaagtgc atccgg 1056
<210> 258
<400> 258
000
<210> 259
<211> 1110
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 259
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccatcccc 60
ccccatgtgc aaaagagcgt gaacaacgat atgatcgtga ccgacaacaa cggcgccgtg 120
aagtttcccc agctctgcaa gttctgcgat gtcaggttca gcacctgcga taatcagaag 180
tcctgcatgt ccaactgcag catcacctcc atctgcgaga agccccaaga agtgtgcgtg 240
gccgtgtggc ggaaaaatga cgagaacatc accctggaga ccgtgtgtca cgaccccaag 300
ctcccttatc acgacttcat tctggaggac gctgcctccc ccaaatgcat catgaaggag 360
aagaagaagc ccggagagac cttctttatg tgttcctgta gcagcgacga gtgtaacgac 420
aacatcatct tcagcgaaga gtacaacacc agcaaccctg atggaggtgg cggatccgga 480
ggtggaggtt ctggtggagg tgggagtatt cctccccacg tgcagaagag cgtgaataat 540
gacatgatcg tgaccgataa caatggcgcc gtgaaatttc cccagctgtg caaattctgc 600
gatgtgaggt tttccacctg cgacaaccag aagtcctgta tgagcaactg ctccatcacc 660
tccatctgtg agaagcctca ggaggtgtgc gtggctgtct ggcggaagaa tgacgagaat 720
atcaccctgg aaaccgtctg ccacgatccc aagctgccct accacgattt catcctggaa 780
gacgccgcca gccctaagtg catcatgaaa gagaaaaaga agcctggcga gacctttttc 840
atgtgctcct gcagcagcga cgaatgcaac gacaatatca tctttagcga ggaatacaat 900
accagcaacc ccgacattac atgcccccct cccatgagcg tggagcacgc cgacatctgg 960
gtgaagagct atagcctcta cagccgggag aggtatatct gtaacagcgg cttcaagagg 1020
aaggccggca ccagcagcct caccgagtgc gtgctgaata aggctaccaa cgtggctcac 1080
tggacaacac cctctttaaa gtgcatccgg 1110
<210> 260
<211> 184
<212> PRT
<213> Homo sapiens
<400> 260
Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly Leu Leu Asp
1 5 10 15
Leu Arg Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu
20 25 30
Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val
35 40 45
Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val
50 55 60
Val Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg
65 70 75 80
Arg Val Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His
85 90 95
Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr
100 105 110
Val Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly
115 120 125
Phe Gln Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val
130 135 140
His Leu His Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln
145 150 155 160
Gly Ala Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile Pro Ala
165 170 175
Gly Leu Pro Ser Pro Arg Ser Glu
180
<210> 261
<211> 552
<212> DNA
<213> Homo sapiens
<400> 261
cgcgagggtc ccgagctttc gcccgacgat cccgccggcc tcttggacct gcggcagggc 60
atgtttgcgc agctggtggc ccaaaatgtt ctgctgatcg atgggcccct gagctggtac 120
agtgacccag gcctggcagg cgtgtccctg acggggggcc tgagctacaa agaggacacg 180
aaggagctgg tggtggccaa ggctggagtc tactatgtct tctttcaact agagctgcgg 240
cgcgtggtgg ccggcgaggg ctcaggctcc gtttcacttg cgctgcacct gcagccactg 300
cgctctgctg ctggggccgc cgccctggct ttgaccgtgg acctgccacc cgcctcctcc 360
gaggctcgga actcggcctt cggtttccag ggccgcttgc tgcacctgag tgccggccag 420
cgcctgggcg tccatcttca cactgaggcc agggcacgcc atgcctggca gcttacccag 480
ggcgccacag tcttgggact cttccgggtg acccccgaaa tcccagccgg actcccttca 540
ccgaggtcgg aa 552
<210> 262
<211> 165
<212> PRT
<213> Homo sapiens
<400> 262
Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu
1 5 10 15
Val Ala Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser
20 25 30
Asp Pro Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys
35 40 45
Glu Asp Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val
50 55 60
Phe Phe Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly
65 70 75 80
Ser Val Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly
85 90 95
Ala Ala Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu
100 105 110
Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser
115 120 125
Ala Gly Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg
130 135 140
His Ala Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg
145 150 155 160
Val Thr Pro Glu Ile
165
<210> 263
<211> 495
<212> DNA
<213> Homo sapiens
<400> 263
gatcccgccg gcctcttgga cctgcggcag ggcatgtttg cgcagctggt ggcccaaaat 60
gttctgctga tcgatgggcc cctgagctgg tacagtgacc caggcctggc aggcgtgtcc 120
ctgacggggg gcctgagcta caaagaggac acgaaggagc tggtggtggc caaggctgga 180
gtctactatg tcttctttca actagagctg cggcgcgtgg tggccggcga gggctcaggc 240
tccgtttcac ttgcgctgca cctgcagcca ctgcgctctg ctgctggggc cgccgccctg 300
gctttgaccg tggacctgcc acccgcctcc tccgaggctc ggaactcggc cttcggtttc 360
cagggccgct tgctgcacct gagtgccggc cagcgcctgg gcgtccatct tcacactgag 420
gccagggcac gccatgcctg gcagcttacc cagggcgcca cagtcttggg actcttccgg 480
gtgacccccg aaatc 495
<210> 264
<400> 264
000
<210> 265
<400> 265
000
<210> 266
<400> 266
000
<210> 267
<400> 267
000
<210> 268
<211> 397
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 268
Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp Ile
1 5 10 15
Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe Leu
20 25 30
Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe Ser
35 40 45
Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn Glu
50 55 60
Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro Ser
65 70 75 80
Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser Cys
85 90 95
Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe Lys
100 105 110
Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr His
115 120 125
Gly Ser Glu Asp Ser Ile Thr Cys Pro Pro Pro Met Ser Val Glu His
130 135 140
Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr
145 150 155 160
Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr
165 170 175
Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro
180 185 190
Ser Leu Lys Cys Ile Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
195 200 205
Gly Gly Gly Gly Ser Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro
210 215 220
Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu Val Ala
225 230 235 240
Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro
245 250 255
Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp
260 265 270
Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe
275 280 285
Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly Ser Val
290 295 300
Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala
305 310 315 320
Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg
325 330 335
Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser Ala Gly
340 345 350
Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg His Ala
355 360 365
Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg Val Thr
370 375 380
Pro Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu
385 390 395
<210> 269
<211> 1191
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 269
cagggccagg acaggcacat gatccggatg aggcagctca tcgacatcgt cgaccagctg 60
aagaactacg tgaacgacct ggtgcccgag tttctgcctg cccccgagga cgtggagacc 120
aactgcgagt ggtccgcctt ctcctgcttt cagaaggccc agctgaagtc cgccaacacc 180
ggcaacaacg agcggatcat caacgtgagc atcaagaagc tgaagcggaa gcctccctcc 240
acaaacgccg gcaggaggca gaagcacagg ctgacctgcc ccagctgtga ctcctacgag 300
aagaagcccc ccaaggagtt cctggagagg ttcaagtccc tgctgcagaa gatgatccat 360
cagcacctgt cctccaggac ccacggctcc gaggactcca ttacatgccc ccctcccatg 420
agcgtggagc acgccgacat ctgggtgaag agctatagcc tctacagccg ggagaggtat 480
atctgtaaca gcggcttcaa gaggaaggcc ggcaccagca gcctcaccga gtgcgtgctg 540
aataaggcta ccaacgtggc tcactggaca acaccctctt taaagtgcat ccggggcggt 600
ggaggatccg gaggaggtgg ctccggcggc ggaggatctc gcgagggtcc cgagctttcg 660
cccgacgatc ccgccggcct cttggacctg cggcagggca tgtttgcgca gctggtggcc 720
caaaatgttc tgctgatcga tgggcccctg agctggtaca gtgacccagg cctggcaggc 780
gtgtccctga cggggggcct gagctacaaa gaggacacga aggagctggt ggtggccaag 840
gctggagtct actatgtctt ctttcaacta gagctgcggc gcgtggtggc cggcgagggc 900
tcaggctccg tttcacttgc gctgcacctg cagccactgc gctctgctgc tggggccgcc 960
gccctggctt tgaccgtgga cctgccaccc gcctcctccg aggctcggaa ctcggccttc 1020
ggtttccagg gccgcttgct gcacctgagt gccggccagc gcctgggcgt ccatcttcac 1080
actgaggcca gggcacgcca tgcctggcag cttacccagg gcgccacagt cttgggactc 1140
ttccgggtga cccccgaaat cccagccgga ctcccttcac cgaggtcgga a 1191
<210> 270
<211> 415
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 270
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile
20 25 30
Asp Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu
35 40 45
Phe Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala
50 55 60
Phe Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn
65 70 75 80
Asn Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro
85 90 95
Pro Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro
100 105 110
Ser Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg
115 120 125
Phe Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg
130 135 140
Thr His Gly Ser Glu Asp Ser Ile Thr Cys Pro Pro Pro Met Ser Val
145 150 155 160
Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu
165 170 175
Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser
180 185 190
Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr
195 200 205
Thr Pro Ser Leu Lys Cys Ile Arg Gly Gly Gly Gly Ser Gly Gly Gly
210 215 220
Gly Ser Gly Gly Gly Gly Ser Arg Glu Gly Pro Glu Leu Ser Pro Asp
225 230 235 240
Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu
245 250 255
Val Ala Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser
260 265 270
Asp Pro Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys
275 280 285
Glu Asp Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val
290 295 300
Phe Phe Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly
305 310 315 320
Ser Val Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly
325 330 335
Ala Ala Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu
340 345 350
Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser
355 360 365
Ala Gly Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg
370 375 380
His Ala Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg
385 390 395 400
Val Thr Pro Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu
405 410 415
<210> 271
<211> 1245
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 271
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcccagggc 60
caggacaggc acatgatccg gatgaggcag ctcatcgaca tcgtcgacca gctgaagaac 120
tacgtgaacg acctggtgcc cgagtttctg cctgcccccg aggacgtgga gaccaactgc 180
gagtggtccg ccttctcctg ctttcagaag gcccagctga agtccgccaa caccggcaac 240
aacgagcgga tcatcaacgt gagcatcaag aagctgaagc ggaagcctcc ctccacaaac 300
gccggcagga ggcagaagca caggctgacc tgccccagct gtgactccta cgagaagaag 360
ccccccaagg agttcctgga gaggttcaag tccctgctgc agaagatgat ccatcagcac 420
ctgtcctcca ggacccacgg ctccgaggac tccattacat gcccccctcc catgagcgtg 480
gagcacgccg acatctgggt gaagagctat agcctctaca gccgggagag gtatatctgt 540
aacagcggct tcaagaggaa ggccggcacc agcagcctca ccgagtgcgt gctgaataag 600
gctaccaacg tggctcactg gacaacaccc tctttaaagt gcatccgggg cggtggagga 660
tccggaggag gtggctccgg cggcggagga tctcgcgagg gtcccgagct ttcgcccgac 720
gatcccgccg gcctcttgga cctgcggcag ggcatgtttg cgcagctggt ggcccaaaat 780
gttctgctga tcgatgggcc cctgagctgg tacagtgacc caggcctggc aggcgtgtcc 840
ctgacggggg gcctgagcta caaagaggac acgaaggagc tggtggtggc caaggctgga 900
gtctactatg tcttctttca actagagctg cggcgcgtgg tggccggcga gggctcaggc 960
tccgtttcac ttgcgctgca cctgcagcca ctgcgctctg ctgctggggc cgccgccctg 1020
gctttgaccg tggacctgcc acccgcctcc tccgaggctc ggaactcggc cttcggtttc 1080
cagggccgct tgctgcacct gagtgccggc cagcgcctgg gcgtccatct tcacactgag 1140
gccagggcac gccatgcctg gcagcttacc cagggcgcca cagtcttggg actcttccgg 1200
gtgacccccg aaatcccagc cggactccct tcaccgaggt cggaa 1245
<210> 272
<211> 378
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 272
Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp Ile
1 5 10 15
Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe Leu
20 25 30
Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe Ser
35 40 45
Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn Glu
50 55 60
Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro Ser
65 70 75 80
Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser Cys
85 90 95
Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe Lys
100 105 110
Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr His
115 120 125
Gly Ser Glu Asp Ser Ile Thr Cys Pro Pro Pro Met Ser Val Glu His
130 135 140
Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr
145 150 155 160
Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr
165 170 175
Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro
180 185 190
Ser Leu Lys Cys Ile Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
195 200 205
Gly Gly Gly Gly Ser Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly
210 215 220
Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu Ile Asp Gly Pro
225 230 235 240
Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val Ser Leu Thr Gly
245 250 255
Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val Val Ala Lys Ala
260 265 270
Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg Arg Val Val Ala
275 280 285
Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His Leu Gln Pro Leu
290 295 300
Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr Val Asp Leu Pro
305 310 315 320
Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg
325 330 335
Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val His Leu His Thr
340 345 350
Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln Gly Ala Thr Val
355 360 365
Leu Gly Leu Phe Arg Val Thr Pro Glu Ile
370 375
<210> 273
<211> 1134
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 273
cagggccagg acaggcacat gatccggatg aggcagctca tcgacatcgt cgaccagctg 60
aagaactacg tgaacgacct ggtgcccgag tttctgcctg cccccgagga cgtggagacc 120
aactgcgagt ggtccgcctt ctcctgcttt cagaaggccc agctgaagtc cgccaacacc 180
ggcaacaacg agcggatcat caacgtgagc atcaagaagc tgaagcggaa gcctccctcc 240
acaaacgccg gcaggaggca gaagcacagg ctgacctgcc ccagctgtga ctcctacgag 300
aagaagcccc ccaaggagtt cctggagagg ttcaagtccc tgctgcagaa gatgatccat 360
cagcacctgt cctccaggac ccacggctcc gaggactcca ttacatgccc ccctcccatg 420
agcgtggagc acgccgacat ctgggtgaag agctatagcc tctacagccg ggagaggtat 480
atctgtaaca gcggcttcaa gaggaaggcc ggcaccagca gcctcaccga gtgcgtgctg 540
aataaggcta ccaacgtggc tcactggaca acaccctctt taaagtgcat ccggggcggt 600
ggaggatccg gaggaggtgg ctccggcggc ggaggatctg atcccgccgg cctcttggac 660
ctgcggcagg gcatgtttgc gcagctggtg gcccaaaatg ttctgctgat cgatgggccc 720
ctgagctggt acagtgaccc aggcctggca ggcgtgtccc tgacgggggg cctgagctac 780
aaagaggaca cgaaggagct ggtggtggcc aaggctggag tctactatgt cttctttcaa 840
ctagagctgc ggcgcgtggt ggccggcgag ggctcaggct ccgtttcact tgcgctgcac 900
ctgcagccac tgcgctctgc tgctggggcc gccgccctgg ctttgaccgt ggacctgcca 960
cccgcctcct ccgaggctcg gaactcggcc ttcggtttcc agggccgctt gctgcacctg 1020
agtgccggcc agcgcctggg cgtccatctt cacactgagg ccagggcacg ccatgcctgg 1080
cagcttaccc agggcgccac agtcttggga ctcttccggg tgacccccga aatc 1134
<210> 274
<211> 396
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 274
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile
20 25 30
Asp Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu
35 40 45
Phe Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala
50 55 60
Phe Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn
65 70 75 80
Asn Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro
85 90 95
Pro Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro
100 105 110
Ser Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg
115 120 125
Phe Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg
130 135 140
Thr His Gly Ser Glu Asp Ser Ile Thr Cys Pro Pro Pro Met Ser Val
145 150 155 160
Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu
165 170 175
Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser
180 185 190
Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr
195 200 205
Thr Pro Ser Leu Lys Cys Ile Arg Gly Gly Gly Gly Ser Gly Gly Gly
210 215 220
Gly Ser Gly Gly Gly Gly Ser Asp Pro Ala Gly Leu Leu Asp Leu Arg
225 230 235 240
Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu Ile Asp
245 250 255
Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val Ser Leu
260 265 270
Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val Val Ala
275 280 285
Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg Arg Val
290 295 300
Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His Leu Gln
305 310 315 320
Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr Val Asp
325 330 335
Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly Phe Gln
340 345 350
Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val His Leu
355 360 365
His Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln Gly Ala
370 375 380
Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile
385 390 395
<210> 275
<211> 1188
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 275
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcccagggc 60
caggacaggc acatgatccg gatgaggcag ctcatcgaca tcgtcgacca gctgaagaac 120
tacgtgaacg acctggtgcc cgagtttctg cctgcccccg aggacgtgga gaccaactgc 180
gagtggtccg ccttctcctg ctttcagaag gcccagctga agtccgccaa caccggcaac 240
aacgagcgga tcatcaacgt gagcatcaag aagctgaagc ggaagcctcc ctccacaaac 300
gccggcagga ggcagaagca caggctgacc tgccccagct gtgactccta cgagaagaag 360
ccccccaagg agttcctgga gaggttcaag tccctgctgc agaagatgat ccatcagcac 420
ctgtcctcca ggacccacgg ctccgaggac tccattacat gcccccctcc catgagcgtg 480
gagcacgccg acatctgggt gaagagctat agcctctaca gccgggagag gtatatctgt 540
aacagcggct tcaagaggaa ggccggcacc agcagcctca ccgagtgcgt gctgaataag 600
gctaccaacg tggctcactg gacaacaccc tctttaaagt gcatccgggg cggtggagga 660
tccggaggag gtggctccgg cggcggagga tctgatcccg ccggcctctt ggacctgcgg 720
cagggcatgt ttgcgcagct ggtggcccaa aatgttctgc tgatcgatgg gcccctgagc 780
tggtacagtg acccaggcct ggcaggcgtg tccctgacgg ggggcctgag ctacaaagag 840
gacacgaagg agctggtggt ggccaaggct ggagtctact atgtcttctt tcaactagag 900
ctgcggcgcg tggtggccgg cgagggctca ggctccgttt cacttgcgct gcacctgcag 960
ccactgcgct ctgctgctgg ggccgccgcc ctggctttga ccgtggacct gccacccgcc 1020
tcctccgagg ctcggaactc ggccttcggt ttccagggcc gcttgctgca cctgagtgcc 1080
ggccagcgcc tgggcgtcca tcttcacact gaggccaggg cacgccatgc ctggcagctt 1140
acccagggcg ccacagtctt gggactcttc cgggtgaccc ccgaaatc 1188
<210> 276
<400> 276
000
<210> 277
<400> 277
000
<210> 278
<400> 278
000
<210> 279
<400> 279
000
<210> 280
<400> 280
000
<210> 281
<400> 281
000
<210> 282
<400> 282
000
<210> 283
<400> 283
000
<210> 284
<400> 284
000
<210> 285
<400> 285
000
<210> 286
<400> 286
000
<210> 287
<400> 287
000
<210> 288
<400> 288
000
<210> 289
<400> 289
000
<210> 290
<400> 290
000
<210> 291
<400> 291
000
<210> 292
<400> 292
000
<210> 293
<400> 293
000
<210> 294
<400> 294
000
<210> 295
<400> 295
000
<210> 296
<400> 296
000
<210> 297
<400> 297
000
<210> 298
<400> 298
000
<210> 299
<400> 299
000
<210> 300
<211> 485
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 300
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys Ser Val
145 150 155 160
Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro
165 170 175
Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln
180 185 190
Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro
195 200 205
Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr
210 215 220
Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile
225 230 235 240
Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys
245 250 255
Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn
260 265 270
Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Ile
275 280 285
Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp Val Lys
290 295 300
Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly Phe
305 310 315 320
Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu Asn Lys
325 330 335
Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys Ile Arg
340 345 350
Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile Asp Ile
355 360 365
Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu Phe Leu
370 375 380
Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala Phe Ser
385 390 395 400
Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn Asn Glu
405 410 415
Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro Pro Ser
420 425 430
Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro Ser Cys
435 440 445
Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg Phe Lys
450 455 460
Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg Thr His
465 470 475 480
Gly Ser Glu Asp Ser
485
<210> 301
<211> 1455
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 301
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcagcatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgatgg aggtggcgga 420
tccggaggtg gaggttctgg tggaggtggg agtattcctc cccacgtgca gaagagcgtg 480
aataatgaca tgatcgtgac cgataacaat ggcgccgtga aatttcccca gctgtgcaaa 540
ttctgcgatg tgaggttttc cacctgcgac aaccagaagt cctgtatgag caactgctcc 600
atcacctcca tctgtgagaa gcctcaggag gtgtgcgtgg ctgtctggcg gaagaatgac 660
gagaatatca ccctggaaac cgtctgccac gatcccaagc tgccctacca cgatttcatc 720
ctggaagacg ccgccagccc taagtgcatc atgaaagaga aaaagaagcc tggcgagacc 780
tttttcatgt gctcctgcag cagcgacgaa tgcaacgaca atatcatctt tagcgaggaa 840
tacaatacca gcaaccccga cattacatgc ccccctccca tgagcgtgga gcacgccgac 900
atctgggtga agagctatag cctctacagc cgggagaggt atatctgtaa cagcggcttc 960
aagaggaagg ccggcaccag cagcctcacc gagtgcgtgc tgaataaggc taccaacgtg 1020
gctcactgga caacaccctc tttaaagtgc atccggcagg gccaggacag gcacatgatc 1080
cggatgaggc agctcatcga catcgtcgac cagctgaaga actacgtgaa cgacctggtg 1140
cccgagtttc tgcctgcccc cgaggacgtg gagaccaact gcgagtggtc cgccttctcc 1200
tgctttcaga aggcccagct gaagtccgcc aacaccggca acaacgagcg gatcatcaac 1260
gtgagcatca agaagctgaa gcggaagcct ccctccacaa acgccggcag gaggcagaag 1320
cacaggctga cctgccccag ctgtgactcc tacgagaaga agccccccaa ggagttcctg 1380
gagaggttca agtccctgct gcagaagatg atccatcagc acctgtcctc caggacccac 1440
ggctccgagg actcc 1455
<210> 302
<211> 503
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 302
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile
20 25 30
Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe
35 40 45
Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser
50 55 60
Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val
65 70 75 80
Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys
85 90 95
His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala
100 105 110
Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe
115 120 125
Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe
130 135 140
Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys
165 170 175
Ser Val Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys
180 185 190
Phe Pro Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp
195 200 205
Asn Gln Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu
210 215 220
Lys Pro Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn
225 230 235 240
Ile Thr Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp
245 250 255
Phe Ile Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys
260 265 270
Lys Lys Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu
275 280 285
Cys Asn Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro
290 295 300
Asp Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp
305 310 315 320
Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser
325 330 335
Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu
340 345 350
Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys
355 360 365
Ile Arg Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile
370 375 380
Asp Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu
385 390 395 400
Phe Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala
405 410 415
Phe Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn
420 425 430
Asn Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro
435 440 445
Pro Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro
450 455 460
Ser Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg
465 470 475 480
Phe Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg
485 490 495
Thr His Gly Ser Glu Asp Ser
500
<210> 303
<211> 1509
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 303
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccatcccc 60
ccccatgtgc aaaagagcgt gaacaacgat atgatcgtga ccgacaacaa cggcgccgtg 120
aagtttcccc agctctgcaa gttctgcgat gtcaggttca gcacctgcga taatcagaag 180
tcctgcatgt ccaactgcag catcacctcc atctgcgaga agccccaaga agtgtgcgtg 240
gccgtgtggc ggaaaaatga cgagaacatc accctggaga ccgtgtgtca cgaccccaag 300
ctcccttatc acgacttcat tctggaggac gctgcctccc ccaaatgcat catgaaggag 360
aagaagaagc ccggagagac cttctttatg tgttcctgta gcagcgacga gtgtaacgac 420
aacatcatct tcagcgaaga gtacaacacc agcaaccctg atggaggtgg cggatccgga 480
ggtggaggtt ctggtggagg tgggagtatt cctccccacg tgcagaagag cgtgaataat 540
gacatgatcg tgaccgataa caatggcgcc gtgaaatttc cccagctgtg caaattctgc 600
gatgtgaggt tttccacctg cgacaaccag aagtcctgta tgagcaactg ctccatcacc 660
tccatctgtg agaagcctca ggaggtgtgc gtggctgtct ggcggaagaa tgacgagaat 720
atcaccctgg aaaccgtctg ccacgatccc aagctgccct accacgattt catcctggaa 780
gacgccgcca gccctaagtg catcatgaaa gagaaaaaga agcctggcga gacctttttc 840
atgtgctcct gcagcagcga cgaatgcaac gacaatatca tctttagcga ggaatacaat 900
accagcaacc ccgacattac atgcccccct cccatgagcg tggagcacgc cgacatctgg 960
gtgaagagct atagcctcta cagccgggag aggtatatct gtaacagcgg cttcaagagg 1020
aaggccggca ccagcagcct caccgagtgc gtgctgaata aggctaccaa cgtggctcac 1080
tggacaacac cctctttaaa gtgcatccgg cagggccagg acaggcacat gatccggatg 1140
aggcagctca tcgacatcgt cgaccagctg aagaactacg tgaacgacct ggtgcccgag 1200
tttctgcctg cccccgagga cgtggagacc aactgcgagt ggtccgcctt ctcctgcttt 1260
cagaaggccc agctgaagtc cgccaacacc ggcaacaacg agcggatcat caacgtgagc 1320
atcaagaagc tgaagcggaa gcctccctcc acaaacgccg gcaggaggca gaagcacagg 1380
ctgacctgcc ccagctgtga ctcctacgag aagaagcccc ccaaggagtt cctggagagg 1440
ttcaagtccc tgctgcagaa gatgatccat cagcacctgt cctccaggac ccacggctcc 1500
gaggactcc 1509
<210> 304
<400> 304
000
<210> 305
<400> 305
000
<210> 306
<400> 306
000
<210> 307
<400> 307
000
<210> 308
<211> 592
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 308
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys Ser Val
145 150 155 160
Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro
165 170 175
Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln
180 185 190
Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro
195 200 205
Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr
210 215 220
Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile
225 230 235 240
Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys
245 250 255
Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn
260 265 270
Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Ile
275 280 285
Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp Val Lys
290 295 300
Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly Phe
305 310 315 320
Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu Asn Lys
325 330 335
Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys Ile Arg
340 345 350
Ser Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu Gly Gln Thr
355 360 365
Val Arg Ile Thr Cys Gln Gly Asp Ser Leu Arg Ser Tyr Tyr Ala Ser
370 375 380
Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val Ile Tyr Gly
385 390 395 400
Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser Gly Ser Ser
405 410 415
Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln Ala Glu Asp
420 425 430
Glu Ala Asp Tyr Tyr Cys Asn Ser Arg Asp Ser Ser Gly Asn His Val
435 440 445
Val Phe Gly Gly Gly Thr Lys Leu Thr Val Gly His Gly Gly Gly Gly
450 455 460
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val
465 470 475 480
Glu Ser Gly Gly Gly Val Val Arg Pro Gly Gly Ser Leu Arg Leu Ser
485 490 495
Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr Gly Met Ser Trp Val
500 505 510
Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Gly Ile Asn Trp
515 520 525
Asn Gly Gly Ser Thr Gly Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr
530 535 540
Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu Gln Met Asn Ser
545 550 555 560
Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Gly Arg Ser
565 570 575
Leu Leu Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Arg
580 585 590
<210> 309
<211> 1776
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 309
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcagcatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgatgg aggtggcgga 420
tccggaggtg gaggttctgg tggaggtggg agtattcctc cccacgtgca gaagagcgtg 480
aataatgaca tgatcgtgac cgataacaat ggcgccgtga aatttcccca gctgtgcaaa 540
ttctgcgatg tgaggttttc cacctgcgac aaccagaagt cctgtatgag caactgctcc 600
atcacctcca tctgtgagaa gcctcaggag gtgtgcgtgg ctgtctggcg gaagaatgac 660
gagaatatca ccctggaaac cgtctgccac gatcccaagc tgccctacca cgatttcatc 720
ctggaagacg ccgccagccc taagtgcatc atgaaagaga aaaagaagcc tggcgagacc 780
tttttcatgt gctcctgcag cagcgacgaa tgcaacgaca atatcatctt tagcgaggaa 840
tacaatacca gcaaccccga cattacatgc ccccctccca tgagcgtgga gcacgccgac 900
atctgggtga agagctatag cctctacagc cgggagaggt atatctgtaa cagcggcttc 960
aagaggaagg ccggcaccag cagcctcacc gagtgcgtgc tgaataaggc taccaacgtg 1020
gctcactgga caacaccctc tttaaagtgc atccggtccg agctgaccca ggaccctgct 1080
gtgtccgtgg ctctgggcca gaccgtgagg atcacctgcc agggcgactc cctgaggtcc 1140
tactacgcct cctggtacca gcagaagccc ggccaggctc ctgtgctggt gatctacggc 1200
aagaacaaca ggccctccgg catccctgac aggttctccg gatcctcctc cggcaacacc 1260
gcctccctga ccatcacagg cgctcaggcc gaggacgagg ctgactacta ctgcaactcc 1320
agggactcct ccggcaacca tgtggtgttc ggcggcggca ccaagctgac cgtgggccat 1380
ggcggcggcg gctccggagg cggcggcagc ggcggaggag gatccgaggt gcagctggtg 1440
gagtccggag gaggagtggt gaggcctgga ggctccctga ggctgagctg tgctgcctcc 1500
ggcttcacct tcgacgacta cggcatgtcc tgggtgaggc aggctcctgg aaagggcctg 1560
gagtgggtgt ccggcatcaa ctggaacggc ggatccaccg gctacgccga ttccgtgaag 1620
ggcaggttca ccatcagcag ggacaacgcc aagaactccc tgtacctgca gatgaactcc 1680
ctgagggccg aggacaccgc cgtgtactac tgcgccaggg gcaggtccct gctgttcgac 1740
tactggggac agggcaccct ggtgaccgtg tccagg 1776
<210> 310
<211> 610
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 310
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile
20 25 30
Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe
35 40 45
Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser
50 55 60
Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val
65 70 75 80
Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys
85 90 95
His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala
100 105 110
Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe
115 120 125
Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe
130 135 140
Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys
165 170 175
Ser Val Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys
180 185 190
Phe Pro Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp
195 200 205
Asn Gln Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu
210 215 220
Lys Pro Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn
225 230 235 240
Ile Thr Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp
245 250 255
Phe Ile Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys
260 265 270
Lys Lys Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu
275 280 285
Cys Asn Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro
290 295 300
Asp Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp
305 310 315 320
Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser
325 330 335
Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu
340 345 350
Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys
355 360 365
Ile Arg Ser Glu Leu Thr Gln Asp Pro Ala Val Ser Val Ala Leu Gly
370 375 380
Gln Thr Val Arg Ile Thr Cys Gln Gly Asp Ser Leu Arg Ser Tyr Tyr
385 390 395 400
Ala Ser Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val Ile
405 410 415
Tyr Gly Lys Asn Asn Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser Gly
420 425 430
Ser Ser Ser Gly Asn Thr Ala Ser Leu Thr Ile Thr Gly Ala Gln Ala
435 440 445
Glu Asp Glu Ala Asp Tyr Tyr Cys Asn Ser Arg Asp Ser Ser Gly Asn
450 455 460
His Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Gly His Gly Gly
465 470 475 480
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln
485 490 495
Leu Val Glu Ser Gly Gly Gly Val Val Arg Pro Gly Gly Ser Leu Arg
500 505 510
Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr Gly Met Ser
515 520 525
Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Gly Ile
530 535 540
Asn Trp Asn Gly Gly Ser Thr Gly Tyr Ala Asp Ser Val Lys Gly Arg
545 550 555 560
Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr Leu Gln Met
565 570 575
Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg Gly
580 585 590
Arg Ser Leu Leu Phe Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val
595 600 605
Ser Arg
610
<210> 311
<211> 1830
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 311
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccatcccc 60
ccccatgtgc aaaagagcgt gaacaacgat atgatcgtga ccgacaacaa cggcgccgtg 120
aagtttcccc agctctgcaa gttctgcgat gtcaggttca gcacctgcga taatcagaag 180
tcctgcatgt ccaactgcag catcacctcc atctgcgaga agccccaaga agtgtgcgtg 240
gccgtgtggc ggaaaaatga cgagaacatc accctggaga ccgtgtgtca cgaccccaag 300
ctcccttatc acgacttcat tctggaggac gctgcctccc ccaaatgcat catgaaggag 360
aagaagaagc ccggagagac cttctttatg tgttcctgta gcagcgacga gtgtaacgac 420
aacatcatct tcagcgaaga gtacaacacc agcaaccctg atggaggtgg cggatccgga 480
ggtggaggtt ctggtggagg tgggagtatt cctccccacg tgcagaagag cgtgaataat 540
gacatgatcg tgaccgataa caatggcgcc gtgaaatttc cccagctgtg caaattctgc 600
gatgtgaggt tttccacctg cgacaaccag aagtcctgta tgagcaactg ctccatcacc 660
tccatctgtg agaagcctca ggaggtgtgc gtggctgtct ggcggaagaa tgacgagaat 720
atcaccctgg aaaccgtctg ccacgatccc aagctgccct accacgattt catcctggaa 780
gacgccgcca gccctaagtg catcatgaaa gagaaaaaga agcctggcga gacctttttc 840
atgtgctcct gcagcagcga cgaatgcaac gacaatatca tctttagcga ggaatacaat 900
accagcaacc ccgacattac atgcccccct cccatgagcg tggagcacgc cgacatctgg 960
gtgaagagct atagcctcta cagccgggag aggtatatct gtaacagcgg cttcaagagg 1020
aaggccggca ccagcagcct caccgagtgc gtgctgaata aggctaccaa cgtggctcac 1080
tggacaacac cctctttaaa gtgcatccgg tccgagctga cccaggaccc tgctgtgtcc 1140
gtggctctgg gccagaccgt gaggatcacc tgccagggcg actccctgag gtcctactac 1200
gcctcctggt accagcagaa gcccggccag gctcctgtgc tggtgatcta cggcaagaac 1260
aacaggccct ccggcatccc tgacaggttc tccggatcct cctccggcaa caccgcctcc 1320
ctgaccatca caggcgctca ggccgaggac gaggctgact actactgcaa ctccagggac 1380
tcctccggca accatgtggt gttcggcggc ggcaccaagc tgaccgtggg ccatggcggc 1440
ggcggctccg gaggcggcgg cagcggcgga ggaggatccg aggtgcagct ggtggagtcc 1500
ggaggaggag tggtgaggcc tggaggctcc ctgaggctga gctgtgctgc ctccggcttc 1560
accttcgacg actacggcat gtcctgggtg aggcaggctc ctggaaaggg cctggagtgg 1620
gtgtccggca tcaactggaa cggcggatcc accggctacg ccgattccgt gaagggcagg 1680
ttcaccatca gcagggacaa cgccaagaac tccctgtacc tgcagatgaa ctccctgagg 1740
gccgaggaca ccgccgtgta ctactgcgcc aggggcaggt ccctgctgtt cgactactgg 1800
ggacagggca ccctggtgac cgtgtccagg 1830
<210> 312
<400> 312
000
<210> 313
<400> 313
000
<210> 314
<400> 314
000
<210> 315
<400> 315
000
<210> 316
<211> 551
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 316
Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile Val Thr
1 5 10 15
Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe Cys Asp
20 25 30
Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser Asn Cys
35 40 45
Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val Ala Val
50 55 60
Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys His Asp
65 70 75 80
Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala Ser Pro
85 90 95
Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe Phe Met
100 105 110
Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe Ser Glu
115 120 125
Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys Ser Val
145 150 155 160
Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro
165 170 175
Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln
180 185 190
Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro
195 200 205
Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr
210 215 220
Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile
225 230 235 240
Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys
245 250 255
Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn
260 265 270
Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Ile
275 280 285
Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp Val Lys
290 295 300
Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly Phe
305 310 315 320
Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu Asn Lys
325 330 335
Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys Ile Arg
340 345 350
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Arg
355 360 365
Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly Leu Leu Asp Leu
370 375 380
Arg Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu Ile
385 390 395 400
Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val Ser
405 410 415
Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val Val
420 425 430
Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg Arg
435 440 445
Val Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His Leu
450 455 460
Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr Val
465 470 475 480
Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly Phe
485 490 495
Gln Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val His
500 505 510
Leu His Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln Gly
515 520 525
Ala Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile Pro Ala Gly
530 535 540
Leu Pro Ser Pro Arg Ser Glu
545 550
<210> 317
<211> 1653
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 317
atcccccccc atgtgcaaaa gagcgtgaac aacgatatga tcgtgaccga caacaacggc 60
gccgtgaagt ttccccagct ctgcaagttc tgcgatgtca ggttcagcac ctgcgataat 120
cagaagtcct gcatgtccaa ctgcagcatc acctccatct gcgagaagcc ccaagaagtg 180
tgcgtggccg tgtggcggaa aaatgacgag aacatcaccc tggagaccgt gtgtcacgac 240
cccaagctcc cttatcacga cttcattctg gaggacgctg cctcccccaa atgcatcatg 300
aaggagaaga agaagcccgg agagaccttc tttatgtgtt cctgtagcag cgacgagtgt 360
aacgacaaca tcatcttcag cgaagagtac aacaccagca accctgatgg aggtggcgga 420
tccggaggtg gaggttctgg tggaggtggg agtattcctc cccacgtgca gaagagcgtg 480
aataatgaca tgatcgtgac cgataacaat ggcgccgtga aatttcccca gctgtgcaaa 540
ttctgcgatg tgaggttttc cacctgcgac aaccagaagt cctgtatgag caactgctcc 600
atcacctcca tctgtgagaa gcctcaggag gtgtgcgtgg ctgtctggcg gaagaatgac 660
gagaatatca ccctggaaac cgtctgccac gatcccaagc tgccctacca cgatttcatc 720
ctggaagacg ccgccagccc taagtgcatc atgaaagaga aaaagaagcc tggcgagacc 780
tttttcatgt gctcctgcag cagcgacgaa tgcaacgaca atatcatctt tagcgaggaa 840
tacaatacca gcaaccccga cattacatgc ccccctccca tgagcgtgga gcacgccgac 900
atctgggtga agagctatag cctctacagc cgggagaggt atatctgtaa cagcggcttc 960
aagaggaagg ccggcaccag cagcctcacc gagtgcgtgc tgaataaggc taccaacgtg 1020
gctcactgga caacaccctc tttaaagtgc atccggggcg gtggaggatc cggaggaggt 1080
ggctccggcg gcggaggatc tcgcgagggt cccgagcttt cgcccgacga tcccgccggc 1140
ctcttggacc tgcggcaggg catgtttgcg cagctggtgg cccaaaatgt tctgctgatc 1200
gatgggcccc tgagctggta cagtgaccca ggcctggcag gcgtgtccct gacggggggc 1260
ctgagctaca aagaggacac gaaggagctg gtggtggcca aggctggagt ctactatgtc 1320
ttctttcaac tagagctgcg gcgcgtggtg gccggcgagg gctcaggctc cgtttcactt 1380
gcgctgcacc tgcagccact gcgctctgct gctggggccg ccgccctggc tttgaccgtg 1440
gacctgccac ccgcctcctc cgaggctcgg aactcggcct tcggtttcca gggccgcttg 1500
ctgcacctga gtgccggcca gcgcctgggc gtccatcttc acactgaggc cagggcacgc 1560
catgcctggc agcttaccca gggcgccaca gtcttgggac tcttccgggt gacccccgaa 1620
atcccagccg gactcccttc accgaggtcg gaa 1653
<210> 318
<211> 569
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 318
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Pro Pro His Val Gln Lys Ser Val Asn Asn Asp Met Ile
20 25 30
Val Thr Asp Asn Asn Gly Ala Val Lys Phe Pro Gln Leu Cys Lys Phe
35 40 45
Cys Asp Val Arg Phe Ser Thr Cys Asp Asn Gln Lys Ser Cys Met Ser
50 55 60
Asn Cys Ser Ile Thr Ser Ile Cys Glu Lys Pro Gln Glu Val Cys Val
65 70 75 80
Ala Val Trp Arg Lys Asn Asp Glu Asn Ile Thr Leu Glu Thr Val Cys
85 90 95
His Asp Pro Lys Leu Pro Tyr His Asp Phe Ile Leu Glu Asp Ala Ala
100 105 110
Ser Pro Lys Cys Ile Met Lys Glu Lys Lys Lys Pro Gly Glu Thr Phe
115 120 125
Phe Met Cys Ser Cys Ser Ser Asp Glu Cys Asn Asp Asn Ile Ile Phe
130 135 140
Ser Glu Glu Tyr Asn Thr Ser Asn Pro Asp Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Gly Gly Gly Gly Ser Ile Pro Pro His Val Gln Lys
165 170 175
Ser Val Asn Asn Asp Met Ile Val Thr Asp Asn Asn Gly Ala Val Lys
180 185 190
Phe Pro Gln Leu Cys Lys Phe Cys Asp Val Arg Phe Ser Thr Cys Asp
195 200 205
Asn Gln Lys Ser Cys Met Ser Asn Cys Ser Ile Thr Ser Ile Cys Glu
210 215 220
Lys Pro Gln Glu Val Cys Val Ala Val Trp Arg Lys Asn Asp Glu Asn
225 230 235 240
Ile Thr Leu Glu Thr Val Cys His Asp Pro Lys Leu Pro Tyr His Asp
245 250 255
Phe Ile Leu Glu Asp Ala Ala Ser Pro Lys Cys Ile Met Lys Glu Lys
260 265 270
Lys Lys Pro Gly Glu Thr Phe Phe Met Cys Ser Cys Ser Ser Asp Glu
275 280 285
Cys Asn Asp Asn Ile Ile Phe Ser Glu Glu Tyr Asn Thr Ser Asn Pro
290 295 300
Asp Ile Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp
305 310 315 320
Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser
325 330 335
Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu
340 345 350
Asn Lys Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys
355 360 365
Ile Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
370 375 380
Ser Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly Leu Leu
385 390 395 400
Asp Leu Arg Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu
405 410 415
Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly
420 425 430
Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu
435 440 445
Val Val Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu
450 455 460
Arg Arg Val Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu
465 470 475 480
His Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu
485 490 495
Thr Val Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe
500 505 510
Gly Phe Gln Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly
515 520 525
Val His Leu His Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr
530 535 540
Gln Gly Ala Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile Pro
545 550 555 560
Ala Gly Leu Pro Ser Pro Arg Ser Glu
565
<210> 319
<211> 1707
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 319
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctccatcccc 60
ccccatgtgc aaaagagcgt gaacaacgat atgatcgtga ccgacaacaa cggcgccgtg 120
aagtttcccc agctctgcaa gttctgcgat gtcaggttca gcacctgcga taatcagaag 180
tcctgcatgt ccaactgcag catcacctcc atctgcgaga agccccaaga agtgtgcgtg 240
gccgtgtggc ggaaaaatga cgagaacatc accctggaga ccgtgtgtca cgaccccaag 300
ctcccttatc acgacttcat tctggaggac gctgcctccc ccaaatgcat catgaaggag 360
aagaagaagc ccggagagac cttctttatg tgttcctgta gcagcgacga gtgtaacgac 420
aacatcatct tcagcgaaga gtacaacacc agcaaccctg atggaggtgg cggatccgga 480
ggtggaggtt ctggtggagg tgggagtatt cctccccacg tgcagaagag cgtgaataat 540
gacatgatcg tgaccgataa caatggcgcc gtgaaatttc cccagctgtg caaattctgc 600
gatgtgaggt tttccacctg cgacaaccag aagtcctgta tgagcaactg ctccatcacc 660
tccatctgtg agaagcctca ggaggtgtgc gtggctgtct ggcggaagaa tgacgagaat 720
atcaccctgg aaaccgtctg ccacgatccc aagctgccct accacgattt catcctggaa 780
gacgccgcca gccctaagtg catcatgaaa gagaaaaaga agcctggcga gacctttttc 840
atgtgctcct gcagcagcga cgaatgcaac gacaatatca tctttagcga ggaatacaat 900
accagcaacc ccgacattac atgcccccct cccatgagcg tggagcacgc cgacatctgg 960
gtgaagagct atagcctcta cagccgggag aggtatatct gtaacagcgg cttcaagagg 1020
aaggccggca ccagcagcct caccgagtgc gtgctgaata aggctaccaa cgtggctcac 1080
tggacaacac cctctttaaa gtgcatccgg ggcggtggag gatccggagg aggtggctcc 1140
ggcggcggag gatctcgcga gggtcccgag ctttcgcccg acgatcccgc cggcctcttg 1200
gacctgcggc agggcatgtt tgcgcagctg gtggcccaaa atgttctgct gatcgatggg 1260
cccctgagct ggtacagtga cccaggcctg gcaggcgtgt ccctgacggg gggcctgagc 1320
tacaaagagg acacgaagga gctggtggtg gccaaggctg gagtctacta tgtcttcttt 1380
caactagagc tgcggcgcgt ggtggccggc gagggctcag gctccgtttc acttgcgctg 1440
cacctgcagc cactgcgctc tgctgctggg gccgccgccc tggctttgac cgtggacctg 1500
ccacccgcct cctccgaggc tcggaactcg gccttcggtt tccagggccg cttgctgcac 1560
ctgagtgccg gccagcgcct gggcgtccat cttcacactg aggccagggc acgccatgcc 1620
tggcagctta cccagggcgc cacagtcttg ggactcttcc gggtgacccc cgaaatccca 1680
gccggactcc cttcaccgag gtcggaa 1707
<210> 320
<211> 720
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 320
atgaagtggg tcacatttat ctctttactg ttcctcttct ccagcgccta cagctacttc 60
ggcaaactgg aatccaagct gagcgtgatc cggaatttaa acgaccaagt tctgtttatc 120
gatcaaggta accggcctct gttcgaggac atgaccgact ccgattgccg ggacaatgcc 180
ccccggacca tcttcattat ctccatgtac aaggacagcc agccccgggg catggctgtg 240
acaattagcg tgaagtgtga gaaaatcagc actttatctt gtgagaacaa gatcatctcc 300
tttaaggaaa tgaacccccc cgataacatc aaggacacca agtccgatat catcttcttc 360
cagcggtccg tgcccggtca cgataacaag atgcagttcg aatcctcctc ctacgagggc 420
tactttttag cttgtgaaaa ggagagggat ttattcaagc tgatcctcaa gaaggaggac 480
gagctgggcg atcgttccat catgttcacc gtccaaaacg aggatattac atgcccccct 540
cccatgagcg tggagcacgc cgacatctgg gtgaagagct atagcctcta cagccgggag 600
aggtatatct gtaacagcgg cttcaagagg aaggccggca ccagcagcct caccgagtgc 660
gtgctgaata aggctaccaa cgtggctcac tggacaacac cctctttaaa gtgcatccgg 720
<210> 321
<211> 2607
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 321
atgaaatggg tgacctttat ttctttactg ttcctcttta gcagcgccta ctccatttgg 60
gaactgaaga aggacgtcta cgtggtcgaa ctggactggt atcccgatgc tcccggcgaa 120
atggtggtgc tcacttgtga cacccccgaa gaagacggca tcacttggac cctcgatcag 180
agcagcgagg tgctgggctc cggaaagacc ctcacaatcc aagttaagga gttcggagac 240
gctggccaat acacatgcca caagggaggc gaggtgctca gccattcctt attattatta 300
cacaagaagg aagacggaat ctggtccacc gacattttaa aagatcagaa ggagcccaag 360
aataagacct ttttaaggtg tgaggccaaa aactacagcg gtcgtttcac ttgttggtgg 420
ctgaccacca tttccaccga tttaaccttc tccgtgaaaa gcagccgggg aagctccgac 480
cctcaaggtg tgacatgtgg agccgctacc ctcagcgctg agagggttcg tggcgataac 540
aaggaatacg agtacagcgt ggagtgccaa gaagatagcg cttgtcccgc tgccgaagaa 600
tctttaccca ttgaggtgat ggtggacgcc gtgcacaaac tcaagtacga gaactacacc 660
tcctccttct ttatccggga catcattaag cccgatcctc ctaagaattt acagctgaag 720
cctctcaaaa atagccggca agttgaggtc tcttgggaat atcccgacac ttggagcaca 780
ccccacagct acttctcttt aaccttttgt gtgcaagttc aaggtaaaag caagcgggag 840
aagaaagacc gggtgtttac cgacaaaacc agcgccaccg tcatctgtcg gaagaacgcc 900
tccatcagcg tgagggctca agatcgttat tactccagca gctggtccga gtgggccagc 960
gtgccttgtt ccggcggtgg aggatccgga ggaggtggct ccggcggcgg aggatctcgt 1020
aacctccccg tggctacccc cgatcccgga atgttccctt gtttacacca cagccagaat 1080
ttactgaggg ccgtgagcaa catgctgcag aaagctaggc agactttaga attttaccct 1140
tgcaccagcg aggagatcga ccatgaagat atcaccaagg acaagacatc caccgtggag 1200
gcttgtttac ctctggagct gacaaagaac gagtcttgtc tcaactctcg tgaaaccagc 1260
ttcatcacaa atggctcttg tttagcttcc cggaagacct cctttatgat ggctttatgc 1320
ctcagctcca tctacgagga tttaaagatg taccaagtgg agttcaagac catgaacgcc 1380
aagctgctca tggaccctaa acggcagatc tttttagacc agaacatgct ggctgtgatt 1440
gatgagctga tgcaagcttt aaacttcaac tccgagaccg tccctcagaa gtcctccctc 1500
gaggagcccg atttttacaa gacaaagatc aaactgtgca ttttactcca cgcctttagg 1560
atccgggccg tgaccattga ccgggtcatg agctatttaa acgccagcag cggcacaacc 1620
aacacagtcg ctgcctataa cctcacttgg aagagcacca acttcaaaac catcctcgaa 1680
tgggaaccca aacccgttaa ccaagtttac accgtgcaga tcagcaccaa gtccggcgac 1740
tggaagtcca aatgtttcta taccaccgac accgagtgcg atctcaccga tgagatcgtg 1800
aaagatgtga aacagaccta cctcgcccgg gtgtttagct accccgccgg caatgtggag 1860
agcactggtt ccgctggcga gcctttatac gagaacagcc ccgaatttac cccttacctc 1920
gagaccaatt taggacagcc caccatccaa agctttgagc aagttggcac aaaggtgaat 1980
gtgacagtgg aggacgagcg gactttagtg cggcggaaca acacctttct cagcctccgg 2040
gatgtgttcg gcaaagattt aatctacaca ctgtattact ggaagtcctc ttcctccggc 2100
aagaagacag ctaaaaccaa cacaaacgag tttttaatcg acgtggataa aggcgaaaac 2160
tactgtttca gcgtgcaagc tgtgatcccc tcccggaccg tgaataggaa aagcaccgat 2220
agccccgttg agtgcatggg ccaagaaaag ggcgagttcc gggagaactg ggtgaacgtc 2280
atcagcgatt taaagaagat cgaagattta attcagtcca tgcatatcga cgccacttta 2340
tacacagaat ccgacgtgca cccctcttgt aaggtgaccg ccatgaaatg ttttttactg 2400
gagctgcaag ttatctcttt agagagcgga gacgctagca tccacgacac cgtggagaat 2460
ttaatcattt tagccaataa ctctttatcc agcaacggca acgtgacaga gtccggctgc 2520
aaggagtgcg aagagctgga ggagaagaac atcaaggagt ttctgcaatc ctttgtgcac 2580
attgtccaga tgttcatcaa tacctcc 2607
<210> 322
<211> 240
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 322
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Tyr Phe Gly Lys Leu Glu Ser Lys Leu Ser Val Ile Arg Asn
20 25 30
Leu Asn Asp Gln Val Leu Phe Ile Asp Gln Gly Asn Arg Pro Leu Phe
35 40 45
Glu Asp Met Thr Asp Ser Asp Cys Arg Asp Asn Ala Pro Arg Thr Ile
50 55 60
Phe Ile Ile Ser Met Tyr Lys Asp Ser Gln Pro Arg Gly Met Ala Val
65 70 75 80
Thr Ile Ser Val Lys Cys Glu Lys Ile Ser Thr Leu Ser Cys Glu Asn
85 90 95
Lys Ile Ile Ser Phe Lys Glu Met Asn Pro Pro Asp Asn Ile Lys Asp
100 105 110
Thr Lys Ser Asp Ile Ile Phe Phe Gln Arg Ser Val Pro Gly His Asp
115 120 125
Asn Lys Met Gln Phe Glu Ser Ser Ser Tyr Glu Gly Tyr Phe Leu Ala
130 135 140
Cys Glu Lys Glu Arg Asp Leu Phe Lys Leu Ile Leu Lys Lys Glu Asp
145 150 155 160
Glu Leu Gly Asp Arg Ser Ile Met Phe Thr Val Gln Asn Glu Asp Ile
165 170 175
Thr Cys Pro Pro Pro Met Ser Val Glu His Ala Asp Ile Trp Val Lys
180 185 190
Ser Tyr Ser Leu Tyr Ser Arg Glu Arg Tyr Ile Cys Asn Ser Gly Phe
195 200 205
Lys Arg Lys Ala Gly Thr Ser Ser Leu Thr Glu Cys Val Leu Asn Lys
210 215 220
Ala Thr Asn Val Ala His Trp Thr Thr Pro Ser Leu Lys Cys Ile Arg
225 230 235 240
<210> 323
<211> 869
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 323
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Ile Trp Glu Leu Lys Lys Asp Val Tyr Val Val Glu Leu Asp
20 25 30
Trp Tyr Pro Asp Ala Pro Gly Glu Met Val Val Leu Thr Cys Asp Thr
35 40 45
Pro Glu Glu Asp Gly Ile Thr Trp Thr Leu Asp Gln Ser Ser Glu Val
50 55 60
Leu Gly Ser Gly Lys Thr Leu Thr Ile Gln Val Lys Glu Phe Gly Asp
65 70 75 80
Ala Gly Gln Tyr Thr Cys His Lys Gly Gly Glu Val Leu Ser His Ser
85 90 95
Leu Leu Leu Leu His Lys Lys Glu Asp Gly Ile Trp Ser Thr Asp Ile
100 105 110
Leu Lys Asp Gln Lys Glu Pro Lys Asn Lys Thr Phe Leu Arg Cys Glu
115 120 125
Ala Lys Asn Tyr Ser Gly Arg Phe Thr Cys Trp Trp Leu Thr Thr Ile
130 135 140
Ser Thr Asp Leu Thr Phe Ser Val Lys Ser Ser Arg Gly Ser Ser Asp
145 150 155 160
Pro Gln Gly Val Thr Cys Gly Ala Ala Thr Leu Ser Ala Glu Arg Val
165 170 175
Arg Gly Asp Asn Lys Glu Tyr Glu Tyr Ser Val Glu Cys Gln Glu Asp
180 185 190
Ser Ala Cys Pro Ala Ala Glu Glu Ser Leu Pro Ile Glu Val Met Val
195 200 205
Asp Ala Val His Lys Leu Lys Tyr Glu Asn Tyr Thr Ser Ser Phe Phe
210 215 220
Ile Arg Asp Ile Ile Lys Pro Asp Pro Pro Lys Asn Leu Gln Leu Lys
225 230 235 240
Pro Leu Lys Asn Ser Arg Gln Val Glu Val Ser Trp Glu Tyr Pro Asp
245 250 255
Thr Trp Ser Thr Pro His Ser Tyr Phe Ser Leu Thr Phe Cys Val Gln
260 265 270
Val Gln Gly Lys Ser Lys Arg Glu Lys Lys Asp Arg Val Phe Thr Asp
275 280 285
Lys Thr Ser Ala Thr Val Ile Cys Arg Lys Asn Ala Ser Ile Ser Val
290 295 300
Arg Ala Gln Asp Arg Tyr Tyr Ser Ser Ser Trp Ser Glu Trp Ala Ser
305 310 315 320
Val Pro Cys Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
325 330 335
Gly Gly Ser Arg Asn Leu Pro Val Ala Thr Pro Asp Pro Gly Met Phe
340 345 350
Pro Cys Leu His His Ser Gln Asn Leu Leu Arg Ala Val Ser Asn Met
355 360 365
Leu Gln Lys Ala Arg Gln Thr Leu Glu Phe Tyr Pro Cys Thr Ser Glu
370 375 380
Glu Ile Asp His Glu Asp Ile Thr Lys Asp Lys Thr Ser Thr Val Glu
385 390 395 400
Ala Cys Leu Pro Leu Glu Leu Thr Lys Asn Glu Ser Cys Leu Asn Ser
405 410 415
Arg Glu Thr Ser Phe Ile Thr Asn Gly Ser Cys Leu Ala Ser Arg Lys
420 425 430
Thr Ser Phe Met Met Ala Leu Cys Leu Ser Ser Ile Tyr Glu Asp Leu
435 440 445
Lys Met Tyr Gln Val Glu Phe Lys Thr Met Asn Ala Lys Leu Leu Met
450 455 460
Asp Pro Lys Arg Gln Ile Phe Leu Asp Gln Asn Met Leu Ala Val Ile
465 470 475 480
Asp Glu Leu Met Gln Ala Leu Asn Phe Asn Ser Glu Thr Val Pro Gln
485 490 495
Lys Ser Ser Leu Glu Glu Pro Asp Phe Tyr Lys Thr Lys Ile Lys Leu
500 505 510
Cys Ile Leu Leu His Ala Phe Arg Ile Arg Ala Val Thr Ile Asp Arg
515 520 525
Val Met Ser Tyr Leu Asn Ala Ser Ser Gly Thr Thr Asn Thr Val Ala
530 535 540
Ala Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe Lys Thr Ile Leu Glu
545 550 555 560
Trp Glu Pro Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr
565 570 575
Lys Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu
580 585 590
Cys Asp Leu Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu
595 600 605
Ala Arg Val Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser
610 615 620
Ala Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu
625 630 635 640
Glu Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly
645 650 655
Thr Lys Val Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val Arg Arg
660 665 670
Asn Asn Thr Phe Leu Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile
675 680 685
Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala
690 695 700
Lys Thr Asn Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn
705 710 715 720
Tyr Cys Phe Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg
725 730 735
Lys Ser Thr Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu
740 745 750
Phe Arg Glu Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu
755 760 765
Asp Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser
770 775 780
Asp Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu
785 790 795 800
Glu Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp
805 810 815
Thr Val Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn
820 825 830
Gly Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu
835 840 845
Lys Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met
850 855 860
Phe Ile Asn Thr Ser
865
<210> 324
<211> 1452
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 324
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcccagggc 60
caggacaggc acatgatccg gatgaggcag ctcatcgaca tcgtcgacca gctgaagaac 120
tacgtgaacg acctggtgcc cgagtttctg cctgcccccg aggacgtgga gaccaactgc 180
gagtggtccg ccttctcctg ctttcagaag gcccagctga agtccgccaa caccggcaac 240
aacgagcgga tcatcaacgt gagcatcaag aagctgaagc ggaagcctcc ctccacaaac 300
gccggcagga ggcagaagca caggctgacc tgccccagct gtgactccta cgagaagaag 360
ccccccaagg agttcctgga gaggttcaag tccctgctgc agaagatgat ccatcagcac 420
ctgtcctcca ggacccacgg ctccgaggac tcctccggca ccaccaatac cgtggccgct 480
tataacctca catggaagag caccaacttc gcgacagctc tggaatggga acccaagccc 540
gtcaatcaag tttacaccgt gcagatctcc accaaatccg gagactggaa gagcaagtgc 600
ttctacacaa cagacaccga gtgtgcttta accgacgaaa tcgtcaagga cgtcaagcaa 660
acctatctgg ctcgggtctt ttcctacccc gctggcaatg tcgagtccac cggctccgct 720
ggcgagcctc tctacgagaa ttcccccgaa ttcacccctt atttagagac caatttaggc 780
cagcctacca tccagagctt cgagcaagtt ggcaccaagg tgaacgtcac cgtcgaggat 840
gaaaggactt tagtggcgcg gaataacaca gctttatccc tccgggatgt gttcggcaaa 900
gacctcatct acacactgta ctattggaag tccagctcct ccggcaaaaa gaccgctaag 960
accaacacca acgagttttt aattgacgtg gacaaaggcg agaactactg cttcagcgtg 1020
caagccgtga tcccttctcg taccgtcaac cggaagagca cagattcccc cgttgagtgc 1080
atgggccaag aaaagggcga gttccgggag aactgggtga acgtcatcag cgatttaaag 1140
aagatcgaag atttaattca gtccatgcat atcgacgcca ctttatacac agaatccgac 1200
gtgcacccct cttgtaaggt gaccgccatg aaatgttttt tactggagct gcaagttatc 1260
tctttagaga gcggagacgc tagcatccac gacaccgtgg agaatttaat cattttagcc 1320
aataactctt tatccagcaa cggcaacgtg acagagtccg gctgcaagga gtgcgaagag 1380
ctggaggaga agaacatcaa ggagtttctg caatcctttg tgcacattgt ccagatgttc 1440
atcaatacct cc 1452
<210> 325
<211> 484
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 325
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile
20 25 30
Asp Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu
35 40 45
Phe Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala
50 55 60
Phe Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn
65 70 75 80
Asn Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro
85 90 95
Pro Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro
100 105 110
Ser Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg
115 120 125
Phe Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg
130 135 140
Thr His Gly Ser Glu Asp Ser Ser Gly Thr Thr Asn Thr Val Ala Ala
145 150 155 160
Tyr Asn Leu Thr Trp Lys Ser Thr Asn Phe Ala Thr Ala Leu Glu Trp
165 170 175
Glu Pro Lys Pro Val Asn Gln Val Tyr Thr Val Gln Ile Ser Thr Lys
180 185 190
Ser Gly Asp Trp Lys Ser Lys Cys Phe Tyr Thr Thr Asp Thr Glu Cys
195 200 205
Ala Leu Thr Asp Glu Ile Val Lys Asp Val Lys Gln Thr Tyr Leu Ala
210 215 220
Arg Val Phe Ser Tyr Pro Ala Gly Asn Val Glu Ser Thr Gly Ser Ala
225 230 235 240
Gly Glu Pro Leu Tyr Glu Asn Ser Pro Glu Phe Thr Pro Tyr Leu Glu
245 250 255
Thr Asn Leu Gly Gln Pro Thr Ile Gln Ser Phe Glu Gln Val Gly Thr
260 265 270
Lys Val Asn Val Thr Val Glu Asp Glu Arg Thr Leu Val Ala Arg Asn
275 280 285
Asn Thr Ala Leu Ser Leu Arg Asp Val Phe Gly Lys Asp Leu Ile Tyr
290 295 300
Thr Leu Tyr Tyr Trp Lys Ser Ser Ser Ser Gly Lys Lys Thr Ala Lys
305 310 315 320
Thr Asn Thr Asn Glu Phe Leu Ile Asp Val Asp Lys Gly Glu Asn Tyr
325 330 335
Cys Phe Ser Val Gln Ala Val Ile Pro Ser Arg Thr Val Asn Arg Lys
340 345 350
Ser Thr Asp Ser Pro Val Glu Cys Met Gly Gln Glu Lys Gly Glu Phe
355 360 365
Arg Glu Asn Trp Val Asn Val Ile Ser Asp Leu Lys Lys Ile Glu Asp
370 375 380
Leu Ile Gln Ser Met His Ile Asp Ala Thr Leu Tyr Thr Glu Ser Asp
385 390 395 400
Val His Pro Ser Cys Lys Val Thr Ala Met Lys Cys Phe Leu Leu Glu
405 410 415
Leu Gln Val Ile Ser Leu Glu Ser Gly Asp Ala Ser Ile His Asp Thr
420 425 430
Val Glu Asn Leu Ile Ile Leu Ala Asn Asn Ser Leu Ser Ser Asn Gly
435 440 445
Asn Val Thr Glu Ser Gly Cys Lys Glu Cys Glu Glu Leu Glu Glu Lys
450 455 460
Asn Ile Lys Glu Phe Leu Gln Ser Phe Val His Ile Val Gln Met Phe
465 470 475 480
Ile Asn Thr Ser
<210> 326
<211> 2142
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 326
atgaaatggg tcaccttcat ctctttactg tttttattta gcagcgccta cagcgtgcag 60
ctgcagcagt ccggacccga actggtcaag cccggtgcct ccgtgaaaat gtcttgtaag 120
gcttctggct acacctttac ctcctacgtc atccaatggg tgaagcagaa gcccggtcaa 180
ggtctcgagt ggatcggcag catcaatccc tacaacgatt acaccaagta taacgaaaag 240
tttaagggca aggccactct gacaagcgac aagagctcca ttaccgccta catggagttt 300
tcctctttaa cttctgagga ctccgcttta tactattgcg ctcgttgggg cgatggcaat 360
tattggggcc ggggaactac tttaacagtg agctccggcg gcggcggaag cggaggtgga 420
ggatctggcg gtggaggcag cgacatcgag atgacacagt cccccgctat catgagcgcc 480
tctttaggag aacgtgtgac catgacttgt acagcttcct ccagcgtgag cagctcctat 540
ttccactggt accagcagaa acccggctcc tcccctaaac tgtgtatcta ctccacaagc 600
aatttagcta gcggcgtgcc tcctcgtttt agcggctccg gcagcacctc ttactcttta 660
accattagct ctatggaggc cgaagatgcc gccacatact tttgccatca gtaccaccgg 720
tcccctacct ttggcggagg cacaaagctg gagaccaagc ggagcggcac caccaacaca 780
gtggccgcct acaatctgac ttggaaatcc accaacttca agaccatcct cgagtgggag 840
cccaagcccg ttaatcaagt ttataccgtg cagatttcca ccaagagcgg cgactggaaa 900
tccaagtgct tctataccac agacaccgag tgcgatctca ccgacgagat cgtcaaagac 960
gtgaagcaga catatttagc tagggtgttc tcctaccccg ctggaaacgt ggagagcacc 1020
ggatccgctg gagagccttt atacgagaac tcccccgaat tcacccccta tctggaaacc 1080
aatttaggcc agcccaccat ccagagcttc gaacaagttg gcacaaaggt gaacgtcacc 1140
gtcgaagatg agaggacttt agtgcggagg aacaatacat ttttatcctt acgtgacgtc 1200
ttcggcaagg atttaatcta cacactgtat tactggaagt ctagctcctc cggcaagaag 1260
accgccaaga ccaataccaa cgaattttta attgacgtgg acaagggcga gaactactgc 1320
ttctccgtgc aagctgtgat cccctcccgg acagtgaacc ggaagtccac cgactccccc 1380
gtggagtgca tgggccaaga gaagggagag tttcgtgagc agatcgtgct gacccagtcc 1440
cccgctatta tgagcgctag ccccggtgaa aaggtgacta tgacatgcag cgccagctct 1500
tccgtgagct acatgaactg gtatcagcag aagtccggca ccagccctaa aaggtggatc 1560
tacgacacca gcaagctggc cagcggcgtc cccgctcact ttcggggctc cggctccgga 1620
acaagctact ctctgaccat cagcggcatg gaagccgagg atgccgctac ctattactgt 1680
cagcagtgga gctccaaccc cttcaccttt ggatccggca ccaagctcga gattaatcgt 1740
ggaggcggag gtagcggagg aggcggatcc ggcggtggag gtagccaagt tcagctccag 1800
caaagcggcg ccgaactcgc tcggcccggc gcttccgtga agatgtcttg taaggcctcc 1860
ggctatacct tcacccggta cacaatgcac tgggtcaagc aacggcccgg tcaaggttta 1920
gagtggattg gctatatcaa cccctcccgg ggctatacca actacaacca gaagttcaag 1980
gacaaagcca ccctcaccac cgacaagtcc agcagcaccg cttacatgca gctgagctct 2040
ttaacatccg aggattccgc cgtgtactac tgcgctcggt actacgacga tcattactgc 2100
ctcgattact ggggccaagg taccacctta acagtctcct cc 2142
<210> 327
<211> 714
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 327
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly
20 25 30
Ala Ser Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser
35 40 45
Tyr Val Ile Gln Trp Val Lys Gln Lys Pro Gly Gln Gly Leu Glu Trp
50 55 60
Ile Gly Ser Ile Asn Pro Tyr Asn Asp Tyr Thr Lys Tyr Asn Glu Lys
65 70 75 80
Phe Lys Gly Lys Ala Thr Leu Thr Ser Asp Lys Ser Ser Ile Thr Ala
85 90 95
Tyr Met Glu Phe Ser Ser Leu Thr Ser Glu Asp Ser Ala Leu Tyr Tyr
100 105 110
Cys Ala Arg Trp Gly Asp Gly Asn Tyr Trp Gly Arg Gly Thr Thr Leu
115 120 125
Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
130 135 140
Gly Gly Ser Asp Ile Glu Met Thr Gln Ser Pro Ala Ile Met Ser Ala
145 150 155 160
Ser Leu Gly Glu Arg Val Thr Met Thr Cys Thr Ala Ser Ser Ser Val
165 170 175
Ser Ser Ser Tyr Phe His Trp Tyr Gln Gln Lys Pro Gly Ser Ser Pro
180 185 190
Lys Leu Cys Ile Tyr Ser Thr Ser Asn Leu Ala Ser Gly Val Pro Pro
195 200 205
Arg Phe Ser Gly Ser Gly Ser Thr Ser Tyr Ser Leu Thr Ile Ser Ser
210 215 220
Met Glu Ala Glu Asp Ala Ala Thr Tyr Phe Cys His Gln Tyr His Arg
225 230 235 240
Ser Pro Thr Phe Gly Gly Gly Thr Lys Leu Glu Thr Lys Arg Ser Gly
245 250 255
Thr Thr Asn Thr Val Ala Ala Tyr Asn Leu Thr Trp Lys Ser Thr Asn
260 265 270
Phe Lys Thr Ile Leu Glu Trp Glu Pro Lys Pro Val Asn Gln Val Tyr
275 280 285
Thr Val Gln Ile Ser Thr Lys Ser Gly Asp Trp Lys Ser Lys Cys Phe
290 295 300
Tyr Thr Thr Asp Thr Glu Cys Asp Leu Thr Asp Glu Ile Val Lys Asp
305 310 315 320
Val Lys Gln Thr Tyr Leu Ala Arg Val Phe Ser Tyr Pro Ala Gly Asn
325 330 335
Val Glu Ser Thr Gly Ser Ala Gly Glu Pro Leu Tyr Glu Asn Ser Pro
340 345 350
Glu Phe Thr Pro Tyr Leu Glu Thr Asn Leu Gly Gln Pro Thr Ile Gln
355 360 365
Ser Phe Glu Gln Val Gly Thr Lys Val Asn Val Thr Val Glu Asp Glu
370 375 380
Arg Thr Leu Val Arg Arg Asn Asn Thr Phe Leu Ser Leu Arg Asp Val
385 390 395 400
Phe Gly Lys Asp Leu Ile Tyr Thr Leu Tyr Tyr Trp Lys Ser Ser Ser
405 410 415
Ser Gly Lys Lys Thr Ala Lys Thr Asn Thr Asn Glu Phe Leu Ile Asp
420 425 430
Val Asp Lys Gly Glu Asn Tyr Cys Phe Ser Val Gln Ala Val Ile Pro
435 440 445
Ser Arg Thr Val Asn Arg Lys Ser Thr Asp Ser Pro Val Glu Cys Met
450 455 460
Gly Gln Glu Lys Gly Glu Phe Arg Glu Gln Ile Val Leu Thr Gln Ser
465 470 475 480
Pro Ala Ile Met Ser Ala Ser Pro Gly Glu Lys Val Thr Met Thr Cys
485 490 495
Ser Ala Ser Ser Ser Val Ser Tyr Met Asn Trp Tyr Gln Gln Lys Ser
500 505 510
Gly Thr Ser Pro Lys Arg Trp Ile Tyr Asp Thr Ser Lys Leu Ala Ser
515 520 525
Gly Val Pro Ala His Phe Arg Gly Ser Gly Ser Gly Thr Ser Tyr Ser
530 535 540
Leu Thr Ile Ser Gly Met Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys
545 550 555 560
Gln Gln Trp Ser Ser Asn Pro Phe Thr Phe Gly Ser Gly Thr Lys Leu
565 570 575
Glu Ile Asn Arg Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
580 585 590
Gly Gly Ser Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Ala Arg
595 600 605
Pro Gly Ala Ser Val Lys Met Ser Cys Lys Ala Ser Gly Tyr Thr Phe
610 615 620
Thr Arg Tyr Thr Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu
625 630 635 640
Glu Trp Ile Gly Tyr Ile Asn Pro Ser Arg Gly Tyr Thr Asn Tyr Asn
645 650 655
Gln Lys Phe Lys Asp Lys Ala Thr Leu Thr Thr Asp Lys Ser Ser Ser
660 665 670
Thr Ala Tyr Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val
675 680 685
Tyr Tyr Cys Ala Arg Tyr Tyr Asp Asp His Tyr Cys Leu Asp Tyr Trp
690 695 700
Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
705 710
<210> 328
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 328
Met Gly Val Lys Val Leu Phe Ala Leu Ile Cys Ile Ala Val Ala Glu
1 5 10 15
Ala
<210> 329
<211> 454
<212> PRT
<213> Homo sapiens
<400> 329
Met Asp Phe Phe Arg Val Val Glu Asn Gln Gln Pro Pro Ala Thr Met
1 5 10 15
Pro Leu Asn Val Ser Phe Thr Asn Arg Asn Tyr Asp Leu Asp Tyr Asp
20 25 30
Ser Val Gln Pro Tyr Phe Tyr Cys Asp Glu Glu Glu Asn Phe Tyr Gln
35 40 45
Gln Gln Gln Gln Ser Glu Leu Gln Pro Pro Ala Pro Ser Glu Asp Ile
50 55 60
Trp Lys Lys Phe Glu Leu Leu Pro Thr Pro Pro Leu Ser Pro Ser Arg
65 70 75 80
Arg Ser Gly Leu Cys Ser Pro Ser Tyr Val Ala Val Thr Pro Phe Ser
85 90 95
Leu Arg Gly Asp Asn Asp Gly Gly Gly Gly Ser Phe Ser Thr Ala Asp
100 105 110
Gln Leu Glu Met Val Thr Glu Leu Leu Gly Gly Asp Met Val Asn Gln
115 120 125
Ser Phe Ile Cys Asp Pro Asp Asp Glu Thr Phe Ile Lys Asn Ile Ile
130 135 140
Ile Gln Asp Cys Met Trp Ser Gly Phe Ser Ala Ala Ala Lys Leu Val
145 150 155 160
Ser Glu Lys Leu Ala Ser Tyr Gln Ala Ala Arg Lys Asp Ser Gly Ser
165 170 175
Pro Asn Pro Ala Arg Gly His Ser Val Cys Ser Thr Ser Ser Leu Tyr
180 185 190
Leu Gln Asp Leu Ser Ala Ala Ala Ser Glu Cys Ile Asp Pro Ser Val
195 200 205
Val Phe Pro Tyr Pro Leu Asn Asp Ser Ser Ser Pro Lys Ser Cys Ala
210 215 220
Ser Gln Asp Ser Ser Ala Phe Ser Pro Ser Ser Asp Ser Leu Leu Ser
225 230 235 240
Ser Thr Glu Ser Ser Pro Gln Gly Ser Pro Glu Pro Leu Val Leu His
245 250 255
Glu Glu Thr Pro Pro Thr Thr Ser Ser Asp Ser Glu Glu Glu Gln Glu
260 265 270
Asp Glu Glu Glu Ile Asp Val Val Ser Val Glu Lys Arg Gln Ala Pro
275 280 285
Gly Lys Arg Ser Glu Ser Gly Ser Pro Ser Ala Gly Gly His Ser Lys
290 295 300
Pro Pro His Ser Pro Leu Val Leu Lys Arg Cys His Val Ser Thr His
305 310 315 320
Gln His Asn Tyr Ala Ala Pro Pro Ser Thr Arg Lys Asp Tyr Pro Ala
325 330 335
Ala Lys Arg Val Lys Leu Asp Ser Val Arg Val Leu Arg Gln Ile Ser
340 345 350
Asn Asn Arg Lys Cys Thr Ser Pro Arg Ser Ser Asp Thr Glu Glu Asn
355 360 365
Val Lys Arg Arg Thr His Asn Val Leu Glu Arg Gln Arg Arg Asn Glu
370 375 380
Leu Lys Arg Ser Phe Phe Ala Leu Arg Asp Gln Ile Pro Glu Leu Glu
385 390 395 400
Asn Asn Glu Lys Ala Pro Lys Val Val Ile Leu Lys Lys Ala Thr Ala
405 410 415
Tyr Ile Leu Ser Val Gln Ala Glu Glu Gln Lys Leu Ile Ser Glu Glu
420 425 430
Asp Leu Leu Arg Lys Arg Arg Glu Gln Leu Lys His Lys Leu Glu Gln
435 440 445
Leu Arg Asn Ser Cys Ala
450
<210> 330
<211> 1365
<212> DNA
<213> Homo sapiens
<400> 330
ctggattttt ttcgggtagt ggaaaaccag cagcctcccg cgacgatgcc cctcaacgtt 60
agcttcacca acaggaacta tgacctcgac tacgactcgg tgcagccgta tttctactgc 120
gacgaggagg agaacttcta ccagcagcag cagcagagcg agctgcagcc cccggcgccc 180
agcgaggata tctggaagaa attcgagctg ctgcccaccc cgcccctgtc ccctagccgc 240
cgctccgggc tctgctcgcc ctcctacgtt gcggtcacac ccttctccct tcggggagac 300
aacgacggcg gtggcgggag cttctccacg gccgaccagc tggagatggt gaccgagctg 360
ctgggaggag acatggtgaa ccagagtttc atctgcgacc cggacgacga gaccttcatc 420
aaaaacatca tcatccagga ctgtatgtgg agcggcttct cggccgccgc caagctcgtc 480
tcagagaagc tggcctccta ccaggctgcg cgcaaagaca gcggcagccc gaaccccgcc 540
cgcggccaca gcgtctgctc cacctccagc ttgtacctgc aggatctgag cgccgccgcc 600
tcagagtgca tcgacccctc ggtggtcttc ccctaccctc tcaacgacag cagctcgccc 660
aagtcctgcg cctcgcaaga ctccagcgcc ttctctccgt cctcggattc tctgctctcc 720
tcgacggagt cctccccgca gggcagcccc gagcccctgg tgctccatga ggagacaccg 780
cccaccacca gcagcgactc tgaggaggaa caagaagatg aggaagaaat cgatgttgtt 840
tctgtggaaa agaggcaggc tcctggcaaa aggtcagagt ctggatcacc ttctgctgga 900
ggccacagca aacctcctca cagcccactg gtcctcaaga ggtgccacgt ctccacacat 960
cagcacaact acgcagcgcc tccctccact cggaaggact atcctgctgc caagagggtc 1020
aagttggaca gtgtcagagt cctgagacag atcagcaaca accgaaaatg caccagcccc 1080
aggtcctcgg acaccgagga gaatgtcaag aggcgaacac acaacgtctt ggagcgccag 1140
aggaggaacg agctaaaacg gagctttttt gccctgcgtg accagatccc ggagttggaa 1200
aacaatgaaa aggcccccaa ggtagttatc cttaaaaaag ccacagcata catcctgtcc 1260
gtccaagcag aggagcaaaa gctcatttct gaagaggact tgttgcggaa acgacgagaa 1320
cagttgaaac acaaacttga acagctacgg aactcttgtg cgtaa 1365
<210> 331
<211> 1245
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 331
atgaagtggg tgaccttcat cagcctgctg ttcctgttct ccagcgccta ctcccagggc 60
caggacaggc acatgatccg gatgaggcag ctcatcgaca tcgtcgacca gctgaagaac 120
tacgtgaacg acctggtgcc cgagtttctg cctgcccccg aggacgtgga gaccaactgc 180
gagtggtccg ccttctcctg ctttcagaag gcccagctga agtccgccaa caccggcaac 240
aacgagcgga tcatcaacgt gagcatcaag aagctgaagc ggaagcctcc ctccacaaac 300
gccggcagga ggcagaagca caggctgacc tgccccagct gtgactccta cgagaagaag 360
ccccccaagg agttcctgga gaggttcaag tccctgctgc agaagatgat ccatcagcac 420
ctgtcctcca ggacccacgg ctccgaggac tccattacat gcccccctcc catgagcgtg 480
gagcacgccg acatctgggt gaagagctat agcctctaca gccgggagag gtatatctgt 540
aacagcggct tcaagaggaa ggccggcacc agcagcctca ccgagtgcgt gctgaataag 600
gctaccaacg tggctcactg gacaacaccc tctttaaagt gcatccgggg cggtggagga 660
tccggaggag gtggctccgg cggcggagga tctcgcgagg gtcccgagct ttcgcccgac 720
gatcccgccg gcctcttgga cctgcggcag ggcatgtttg cgcagctggt ggcccaaaat 780
gttctgctga tcgatgggcc cctgagctgg tacagtgacc caggcctggc aggcgtgtcc 840
ctgacggggg gcctgagcta caaagaggac acgaaggagc tggtggtggc caaggctgga 900
gtctactatg tcttctttca actagagctg cggcgcgtgg tggccggcga gggctcaggc 960
tccgtttcac ttgcgctgca cctgcagcca ctgcgctctg ctgctggggc cgccgccctg 1020
gctttgaccg tggacctgcc acccgcctcc tccgaggctc ggaactcggc cttcggtttc 1080
cagggccgct tgctgcacct gagtgccggc cagcgcctgg gcgtccatct tcacactgag 1140
gccagggcac gccatgcctg gcagcttacc cagggcgcca cagtcttggg actcttccgg 1200
gtgacccccg aaatcccagc cggactccct tcaccgaggt cggaa 1245
<210> 332
<211> 415
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 332
Met Lys Trp Val Thr Phe Ile Ser Leu Leu Phe Leu Phe Ser Ser Ala
1 5 10 15
Tyr Ser Gln Gly Gln Asp Arg His Met Ile Arg Met Arg Gln Leu Ile
20 25 30
Asp Ile Val Asp Gln Leu Lys Asn Tyr Val Asn Asp Leu Val Pro Glu
35 40 45
Phe Leu Pro Ala Pro Glu Asp Val Glu Thr Asn Cys Glu Trp Ser Ala
50 55 60
Phe Ser Cys Phe Gln Lys Ala Gln Leu Lys Ser Ala Asn Thr Gly Asn
65 70 75 80
Asn Glu Arg Ile Ile Asn Val Ser Ile Lys Lys Leu Lys Arg Lys Pro
85 90 95
Pro Ser Thr Asn Ala Gly Arg Arg Gln Lys His Arg Leu Thr Cys Pro
100 105 110
Ser Cys Asp Ser Tyr Glu Lys Lys Pro Pro Lys Glu Phe Leu Glu Arg
115 120 125
Phe Lys Ser Leu Leu Gln Lys Met Ile His Gln His Leu Ser Ser Arg
130 135 140
Thr His Gly Ser Glu Asp Ser Ile Thr Cys Pro Pro Pro Met Ser Val
145 150 155 160
Glu His Ala Asp Ile Trp Val Lys Ser Tyr Ser Leu Tyr Ser Arg Glu
165 170 175
Arg Tyr Ile Cys Asn Ser Gly Phe Lys Arg Lys Ala Gly Thr Ser Ser
180 185 190
Leu Thr Glu Cys Val Leu Asn Lys Ala Thr Asn Val Ala His Trp Thr
195 200 205
Thr Pro Ser Leu Lys Cys Ile Arg Gly Gly Gly Gly Ser Gly Gly Gly
210 215 220
Gly Ser Gly Gly Gly Gly Ser Arg Glu Gly Pro Glu Leu Ser Pro Asp
225 230 235 240
Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu
245 250 255
Val Ala Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser
260 265 270
Asp Pro Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys
275 280 285
Glu Asp Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val
290 295 300
Phe Phe Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly
305 310 315 320
Ser Val Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly
325 330 335
Ala Ala Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu
340 345 350
Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser
355 360 365
Ala Gly Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg
370 375 380
His Ala Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg
385 390 395 400
Val Thr Pro Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu
405 410 415
<210> 333
<211> 15
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 333
ggtgggtata atggg 15
<210> 334
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 334
attattttat tttaaaaaat ttgtg 25
<210> 335
<211> 129
<212> PRT
<213> Homo sapiens
<400> 335
His Lys Cys Asp Ile Thr Leu Gln Glu Ile Ile Lys Thr Leu Asn Ser
1 5 10 15
Leu Thr Glu Gln Lys Thr Leu Cys Thr Glu Leu Thr Val Thr Asp Ile
20 25 30
Phe Ala Ala Ser Lys Asn Thr Thr Glu Lys Glu Thr Phe Cys Arg Ala
35 40 45
Ala Thr Val Leu Arg Gln Phe Tyr Ser His His Glu Lys Asp Thr Arg
50 55 60
Cys Leu Gly Ala Thr Ala Gln Gln Phe His Arg His Lys Gln Leu Ile
65 70 75 80
Arg Phe Leu Lys Arg Leu Asp Arg Asn Leu Trp Gly Leu Ala Gly Leu
85 90 95
Asn Ser Cys Pro Val Lys Glu Ala Asn Gln Ser Thr Leu Glu Asn Phe
100 105 110
Leu Glu Arg Leu Lys Thr Ile Met Arg Glu Lys Tyr Ser Lys Cys Ser
115 120 125
Ser
<210> 336
<211> 126
<212> PRT
<213> Homo sapiens
<400> 336
Gln Gly Cys Pro Thr Leu Ala Gly Ile Leu Asp Ile Asn Phe Leu Ile
1 5 10 15
Asn Lys Met Gln Glu Asp Pro Ala Ser Lys Cys His Cys Ser Ala Asn
20 25 30
Val Thr Ser Cys Leu Cys Leu Gly Ile Pro Ser Asp Asn Cys Thr Arg
35 40 45
Pro Cys Phe Ser Glu Arg Leu Ser Gln Met Thr Asn Thr Thr Met Gln
50 55 60
Thr Arg Tyr Pro Leu Ile Phe Ser Arg Val Lys Lys Ser Val Glu Val
65 70 75 80
Leu Lys Asn Asn Lys Cys Pro Tyr Phe Ser Cys Glu Gln Pro Cys Asn
85 90 95
Gln Thr Thr Ala Gly Asn Ala Leu Thr Phe Leu Lys Ser Leu Leu Glu
100 105 110
Ile Phe Gln Lys Glu Lys Met Arg Gly Met Arg Gly Lys Ile
115 120 125
Claims (194)
- 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포를 사멸시키거나 이의 수를 감소시키는 방법으로서, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함하는, 방법.
- 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 축적을 저하시키는 방법으로서, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함하는, 방법.
- 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 마커의 수준을 저하시키는 방법으로서, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함하는, 방법.
- 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 활성을 감소시키는 방법으로서, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함하는, 방법.
- 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포로부터 유래된 하나 이상의 SASP 인자(들)의 수준 및/또는 활성을 저하시키는 방법으로서, 대상체에게 치료적 유효량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함하는, 방법.
- 제1항 내지 제5항 중 어느 한 항에 있어서, 상기 대상체는 노화-관련 질환 또는 염증성 질환을 갖는 것으로 이전에 진단되거나 식별되었던, 방법.
- 제6항에 있어서, 상기 노화-관련 질환은 염증-노화와 관련이 있는, 방법.
- 제6항에 있어서, 상기 노화-관련 질환은 알츠하이머 질환, 동맥류, 낭성 섬유증, 췌장염에서의 섬유증, 녹내장, 고혈압, 염증성 장 질환, 추간판 퇴행, 골관절염, 2형 진성 당뇨병, 지방세포 위축, 지방이영양증, 죽상동맥경화증, 백내장, COPD, 특발성 폐 섬유증, 신장 이식 실패, 간 섬유증, 골질량 손실, 심근 경색, 사르코페니아, 상처 치유, 탈모증, 심근세포 비대, 골관절염, 파킨슨 질환, 연령-연관 폐 조직 탄성 손실, 연령-관련 황반 변성, 악액질, 사구체경화증, 간 경변증, NAFLD, 골다공증, 근위축성 측삭 경화증, 헌팅턴 질환, 척수소뇌 실조증, 다발성 경화증, 신경퇴행, 뇌졸중, 암, 치매, 혈관 질환, 감염 감수성, 만성 염증, 및 신장 기능장애로 이루어진 군으로부터 선택되는, 방법.
- 제6항에 있어서, 상기 노화-관련 질환은 고형 종양, 혈액학적 종양, 육종, 골육종, 교모세포종, 신경모세포종, 흑색종, 횡문근육종, 유잉 육종, 골육종, B-세포 신생물, 다발성 골수종, B-세포 림프종, B-세포 비-호지킨 림프종, 호지킨 림프종, 만성 림프구성 백혈병(CLL), 급성 골수성 백혈병(AML), 만성 골수성 백혈병(CML), 급성 림프구성 백혈병(ALL), 골수이형성 증후군(MDS), 피부 T-세포 림프종, 망막모세포종, 위암, 요로상피세포암종, 폐암, 신세포 암종, 위 및 식도 암, 췌장암, 전립선암, 유방암, 결장직장암, 난소암, 비-소세포 폐 암종, 편평 세포 두경부 암종, 자궁내막암, 자궁경부암, 간암, 및 간세포 암종으로 이루어진 군으로부터 선택되는 암인, 방법.
- 제6항에 있어서, 상기 염증성 질환은 류마티스 관절염, 염증성 장 질환, 홍반성 루푸스, 루푸스 신염, 당뇨병성 신증, CNS 손상, 알츠하이머 질환, 파킨슨 질환, 근위축성 측삭 경화증, 크론 질환, 다발성 경화증, 길랑-바레 증후군, 건선, 그레이브스 질환, 궤양성 대장염, 비알코올성 지방간염, 기분 장애 및 암 치료-관련 인지 장애로 이루어진 군으로부터 선택되는, 방법.
- 제1항 내지 제10항 중 어느 한 항에 있어서, 상기 치료-유도 노쇠 세포는 화학요법-유도 노쇠 세포인, 방법.
- 제1항 내지 제11항 중 어느 한 항에 있어서, 상기 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)의 투여는 대상체의 표적 조직에서 천연-발생 노쇠 세포 및/또는 치료-유도 노쇠 세포의 수 또는 활성의 저하를 초래하는, 방법.
- 제12항에 있어서, 상기 표적 조직은 지방 조직, 췌장 조직, 간 조직, 신장 조직, 폐 조직, 심장 조직, 혈관 구조, 뼈 조직, 중추신경계(CNS) 조직, 안구 조직, 피부 조직, 근육 조직, 및 2차 림프-기관 조직으로 이루어진 군으로부터 선택되는, 방법.
- 제1항 내지 제13항 중 어느 한 항에 있어서, 상기 TGFβ 수용체는 TGF-β 수용체 II(TGF-βRII)인, 방법.
- 제1항 내지 제13항 중 어느 한 항에 있어서, 상기 TGFβ 수용체는 TGF-βRIII인, 방법.
- 제1항 내지 제15항 중 어느 한 항에 있어서, TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들) 중 적어도 하나는 가용성 TGF-β 수용체, TGF-β 수용체의 세포외 도메인, TGF-β에 특이적으로 결합하는 항체, TGF-β 수용체에 결합하는 길항제성 항체, LAP에 결합하는 제제, 또는 TGF-β/LAP 복합체에 결합하는 제제인, 방법.
- 제16항에 있어서, TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)는 LAP에의 또는 TGF-β/LAP 복합체에의 결합을 통해 TGF-β 수용체의 활성화를 저하시키는, 방법.
- 제1항 내지 제15항 중 어느 한 항에 있어서, TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들) 중 적어도 하나는
(e) 제1 키메라 폴리펩타이드로서,
(i) 제1 표적-결합 도메인;
(ii) 가용성 조직 인자 도메인; 및
(iii) 친화도 도메인 쌍의 제1 도메인을 포함하는, 제1 키메라 폴리펩타이드; 및
(f) 제2 키메라 폴리펩타이드로서,
(i) 친화도 도메인 쌍의 제2 도메인; 및
(ii) 제2 표적-결합 도메인을 포함하는, 제2 키메라 폴리펩타이드를 포함하는 다중-사슬 키메라 폴리펩타이드이고,
상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 TGF-β 수용체의 리간드에 특이적으로 결합하거나;
상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 TGF-β 수용체에 특이적으로 결합하는 길항제성 항원-결합 도메인인, 방법. - 제18항에 있어서, 상기 TGF-β 수용체는 TGF-βRII인, 방법.
- 제18항에 있어서, 상기 TGF-β 수용체는 TGF-βRIII인, 방법.
- 제18항 내지 제20항 중 어느 한 항에 있어서, 상기 제1 표적-결합 도메인과 상기 가용성 조직 인자 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 방법.
- 제18항 내지 제20항 중 어느 한 항에 있어서, 상기 제1 키메라 폴리펩타이드는 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
- 제18항 내지 제22항 중 어느 한 항에 있어서, 상기 가용성 조직 인자 도메인과 상기 친화도 도메인 쌍의 제1 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 방법.
- 제18항 내지 제22항 중 어느 한 항에 있어서, 상기 제1 키메라 폴리펩타이드는 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
- 제18항 내지 제24항 중 어느 한 항에 있어서, 상기 친화도 도메인 쌍의 제2 도메인과 상기 제2 표적-결합 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 방법.
- 제18항 내지 제24항 중 어느 한 항에 있어서, 상기 제2 키메라 폴리펩타이드는 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
- 제18항 내지 제26항 중 어느 한 항에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 항원에 특이적으로 결합하는, 방법.
- 제18항 내지 제26항 중 어느 한 항에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 상이한 항원에 특이적으로 결합하는, 방법.
- 제18항 내지 제28항 중 어느 한 항에 있어서, 상기 제1 키메라 폴리펩타이드는 하나 이상의 추가 표적-결합 도메인(들)을 추가로 포함하는, 방법.
- 제18항 내지 제29항 중 어느 한 항에 있어서, 상기 제2 키메라 폴리펩타이드는 하나 이상의 추가 표적-결합 도메인(들)을 추가로 포함하는, 방법.
- 제18항 내지 제30항 중 어느 한 항에 있어서, 상기 가용성 조직 인자 도메인은 가용성 인간 조직 인자 도메인인, 방법.
- 제31항에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 80% 동일한 서열을 포함하는, 방법.
- 제18항 내지 제32항 중 어느 한 항에 있어서, 상기 친화도 도메인 쌍은 인간 IL-15 수용체의 알파 사슬(IL15Rα) 및 가용성 IL-15로부터의 sushi 도메인인, 방법.
- 제33항에 있어서, 상기 가용성 IL-15는 D8N 또는 D8A 아미노산 치환을 갖는, 방법.
- 제33항 또는 제34항에 있어서, 상기 가용성 IL-15는 IL-15 활성을 감소시키거나 제거하기 위한 돌연변이를 포함하는, 방법.
- 제18항 내지 제32항 중 어느 한 항에 있어서, 상기 친화도 도메인 쌍은 하기로 이루어진 군으로부터 선택되는, 방법: 바르나제(barnase)와 바른스타(barnstar), PKA와 AKAP, 돌연변이화된 RNase I 단편에 기초한 어댑터/도킹 태그 모듈, 및 단백질 신택신(syntaxin), 시냅토태그민(synaptotagmin), 시냅토브레빈(synaptobrevin), 및 SNAP25의 상호작용에 기초한 SNARE 모듈.
- 제18항 내지 제32항 중 어느 한 항에 있어서, 상기 친화도 도메인 쌍의 제1 도메인 또는 제2 도메인은 공통 감마-사슬 계열 사이토카인 수용체에 특이적으로 결합하는 가용성 공통 감마-사슬 계열 사이토카인 또는 항원-결합 도메인인, 방법.
- 제18항 내지 제37항 중 어느 한 항에 있어서, 상기 제1 표적-결합 도메인 및/또는 제2 표적-결합 도메인은 가용성 TGF-β 수용체를 포함하는, 방법.
- 제38항에 있어서, 상기 가용성 TGF-β 수용체는 가용성 TGF-βRII인, 방법.
- 제39항에 있어서, 상기 가용성 TGF-βRII는 SEQ ID NO: 183과 적어도 80% 동일한 제1 서열, 및 SEQ ID NO: 183과 적어도 80% 동일한 제2 서열을 포함하고, 상기 제1 서열과 제2 서열은 링커에 의해 분리되는, 방법.
- 제40항에 있어서, 상기 가용성 TGF-βRII는 SEQ ID NO: 183과 적어도 90% 동일한 제1 서열, 및 SEQ ID NO: 183과 적어도 90% 동일한 제2 서열을 포함하는, 방법.
- 제41항에 있어서, 상기 가용성 TGF-βRII는 SEQ ID NO: 183의 제1 서열, 및 SEQ ID NO: 183의 제2 서열을 포함하는, 방법.
- 제40항에 있어서, 상기 링커는 SEQ ID NO: 102의 서열을 포함하는, 방법.
- 제39항에 있어서, 상기 가용성 TGF-βRII는 SEQ ID NO: 188과 적어도 80% 동일한 서열을 포함하는, 방법.
- 제44항에 있어서, 상기 가용성 TGF-βRII는 SEQ ID NO: 188과 적어도 90% 동일한 서열을 포함하는, 방법.
- 제45항에 있어서, 상기 가용성 TGF-βRII는 SEQ ID NO: 188의 서열을 포함하는, 방법.
- 제18항에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 80% 동일한 서열을 포함하는, 방법.
- 제47항에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 90% 동일한 서열을 포함하는, 방법.
- 제48항에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236의 서열을 포함하는, 방법.
- 제18항에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 193과 적어도 80% 동일한 서열을 포함하는, 방법.
- 제50항에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236과 적어도 80% 동일한 서열을 포함하는, 방법.
- 제51항에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 193과 적어도 90% 동일한 서열을 포함하는, 방법.
- 제52항에 있어서, 상기 제2 키메라 폴리펩타이드는 SEQ ID NO: 193의 서열을 포함하는, 방법.
- 제53항에 있어서, 상기 제1 키메라 폴리펩타이드는 SEQ ID NO: 236의 서열을 포함하는, 방법.
- 제1항 내지 제15항 중 어느 한 항에 있어서, TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들) 중 적어도 하나는
(i) 제1 표적-결합 도메인;
(ii) 가용성 조직 인자 도메인; 및
(iii) 제2 표적-결합 도메인을 포함하는 단일-사슬 키메라 폴리펩타이드이고,
상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 TGF-β 수용체의 리간드에 특이적으로 결합하거나;
상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 TGF-β 수용체에 특이적으로 결합하는 길항제성 항원-결합 도메인인, 방법. - 제55항에 있어서, 상기 TGF-β 수용체는 TGF-βRII인, 방법.
- 제55항에 있어서, 상기 TGF-β 수용체는 TGF-βRIII인, 방법.
- 제55항 내지 제57항 중 어느 한 항에 있어서, 상기 제1 표적-결합 도메인과 상기 가용성 조직 인자 도메인은 서로 직접적으로 인접해 있는, 방법.
- 제55항 내지 제57항 중 어느 한 항에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
- 제55항 내지 제59항 중 어느 한 항에 있어서, 상기 가용성 조직 인자 도메인과 상기 제2 표적-결합 도메인은 서로 직접적으로 인접해 있는, 방법.
- 제55항 내지 제59항 중 어느 한 항에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 가용성 조직 인자 도메인과 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
- 제55항 내지 제61항 중 어느 한 항에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 항원에 특이적으로 결합하는, 방법.
- 제55항 내지 제61항 중 어느 한 항에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 상이한 항원에 특이적으로 결합하는, 방법.
- 제55항 내지 제63항 중 어느 한 항에 있어서, 상기 가용성 조직 인자 도메인은 가용성 인간 조직 인자 도메인인, 방법.
- 제64항에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 80% 동일한 서열을 포함하는, 방법.
- 제55항 내지 제65항 중 어느 한 항에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 이의 N-말단 및/또는 C-말단에 하나 이상의 추가 표적-결합 도메인을 추가로 포함하는, 방법.
- 제55항 또는 제66항에 있어서, 상기 제1 표적-결합 도메인 및/또는 제2 표적-결합 도메인은 가용성 TGF-β 수용체를 포함하는, 방법.
- 제67항에 있어서, 상기 가용성 TGF-β 수용체는 가용성 TGF-βRII인, 방법.
- 제68항에 있어서, 상기 가용성 TGF-βRII는 SEQ ID NO: 183과 적어도 80% 동일한 제1 서열, 및 SEQ ID NO: 183과 적어도 80% 동일한 제2 서열을 포함하고, 상기 제1 서열과 제2 서열은 링커에 의해 분리되는, 방법.
- 제69항에 있어서, 상기 가용성 TGF-βRII는 SEQ ID NO: 183과 적어도 90% 동일한 제1 서열, 및 SEQ ID NO: 183과 적어도 90% 동일한 제2 서열을 포함하는, 방법.
- 제70항에 있어서, 상기 가용성 TGF-βRII는 SEQ ID NO: 183의 제1 서열, 및 SEQ ID NO: 183의 제2 서열을 포함하는, 방법.
- 제69항에 있어서, 상기 링커는 SEQ ID NO: 102의 서열을 포함하는, 방법.
- 제72항에 있어서, 상기 가용성 TGF-βRII는 SEQ ID NO: 188과 적어도 80% 동일한 서열을 포함하는, 방법.
- 제73항에 있어서, 상기 가용성 TGF-βRII는 SEQ ID NO: 188과 적어도 90% 동일한 서열을 포함하는, 방법.
- 제74항에 있어서, 상기 가용성 TGF-βRII는 SEQ ID NO: 188의 서열을 포함하는, 방법.
- 제1항 내지 제75항 중 어느 한 항에 있어서, 상기 대상체에게 2개 이상의 용량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)를 투여하는 단계를 포함하는, 방법.
- 제76항에 있어서, 상기 2개 이상의 용량 중 임의의 2개의 연속 용량은 약 1주 내지 약 1년의 간격을 두고 투여되는, 방법.
- 제77항에 있어서, 상기 2개 이상의 용량 중 임의의 2개의 연속 용량은 약 1주 내지 약 6개월의 간격을 두고 투여되는, 방법.
- 제78항에 있어서, 상기 2개 이상의 용량 중 임의의 2개의 연속 용량은 약 1주 내지 약 2개월의 간격을 두고 투여되는, 방법.
- 제79항에 있어서, 상기 2개 이상의 용량 중 임의의 2개의 연속 용량은 약 1주 내지 약 1개월의 간격을 두고 투여되는, 방법.
- 제76항 내지 제80항 중 어느 한 항에 있어서, 상기 2개 이상의 용량은 피하 투여에 의해 투여되는, 방법.
- 제76항 내지 제80항 중 어느 한 항에 있어서, 상기 2개 이상의 용량은 근육내 투여에 의해 투여되는, 방법.
- 제76항 내지 제82항 중 어느 한 항에 있어서, 상기 2개 이상의 용량은 약 1년 내지 약 60년의 기간에 걸쳐 투여되는, 방법.
- 제83항에 있어서, 상기 2개 이상의 용량은 약 1년 내지 약 50년의 기간에 걸쳐 투여되는, 방법.
- 제84항에 있어서, 상기 2개 이상의 용량은 약 1년 내지 약 40년의 기간에 걸쳐 투여되는, 방법.
- 제85항에 있어서, 상기 2개 이상의 용량은 약 1년 내지 약 30년의 기간에 걸쳐 투여되는, 방법.
- 제86항에 있어서, 상기 2개 이상의 용량은 약 1년 내지 약 20년의 기간에 걸쳐 투여되는, 방법.
- 제87항에 있어서, 상기 2개 이상의 용량은 약 1년 내지 약 10년의 기간에 걸쳐 투여되는, 방법.
- 제1항 내지 제88항 중 어느 한 항에 있어서, 제1 용량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)는 대상체가 적어도 30세의 연령에 도달할 때 시작하는, 방법.
- 제89항에 있어서, 제1 용량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)는 대상체가 적어도 40세의 연령에 도달할 때 시작하는, 방법.
- 제90항에 있어서, 제1 용량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)는 대상체가 적어도 50세의 연령에 도달할 때 시작하는, 방법.
- 제91항에 있어서, 제1 용량의 TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들)는 대상체가 적어도 60세의 연령에 도달할 때 시작하는, 방법.
- 제1항 내지 제92항 중 어느 한 항에 있어서, 상기 2개 이상의 용량은 각각 kg당 약 0.01 mg의 TGF-β 수용체의 활성화의 저하를 초래하는 각각의 제제 내지 kg당 약 10 mg의 TGF-β 수용체의 활성화의 저하를 초래하는 각각의 제제의 투여량으로 투여되는, 방법.
- 제93항에 있어서, 상기 2개 이상의 용량은 각각 kg당 약 0.02 mg의 TGF-β 수용체의 활성화의 저하를 초래하는 각각의 제제 내지 kg당 약 5 mg의 TGF-β 수용체의 활성화의 저하를 초래하는 각각의 제제의 투여량으로 투여되는, 방법.
- 제1항 내지 제3항 및 제9항 내지 제94항 중 어느 한 항에 있어서, 상기 대상체는 노화-관련 질환 또는 염증성 질환을 갖는 것으로 진단되거나 식별되지 않는, 방법.
- 제1항 내지 제3항 및 제9항 내지 제95항 중 어느 한 항에 있어서, 상기 대상체는 이전에 화학요법제로 치료된 적이 없는, 방법.
- 제1항 내지 제3항 및 제9항 내지 제95항 중 어느 한 항에 있어서, 상기 대상체는 이전에 세포 노쇠를 유도하는 치료제로 치료된 적이 없는, 방법.
- 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포를 사멸시키거나 이의 수를 감소시키는 방법으로서, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함하는, 방법.
- 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 축적을 저하시키는 방법으로서, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함하는, 방법.
- 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 마커의 수준을 저하시키는 방법으로서, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함하는, 방법.
- 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포의 활성을 감소시키는 방법으로서, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함하는, 방법.
- 대상체에서 천연-발생 및/또는 치료-유도 노쇠 세포로부터 유래된 SASP 인자의 수준 또는 활성을 저하시키는 방법으로서, 대상체에게 치료적 유효량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함하는, 방법.
- 제98항 내지 제102항 중 어느 한 항에 있어서, 상기 대상체는 노화-관련 질환 또는 염증성 질환을 갖는 것으로 이전에 진단되거나 식별되었던, 방법.
- 제103항에 있어서, 상기 노화-관련 질환은 염증-노화와 관련이 있는, 방법.
- 제103항에 있어서, 상기 노화-관련 질환은 알츠하이머 질환, 동맥류, 낭성 섬유증, 췌장염에서의 섬유증, 녹내장, 고혈압, 염증성 장 질환, 추간판 퇴행, 골관절염, 2형 진성 당뇨병, 지방세포 위축, 지방이영양증, 죽상동맥경화증, 백내장, COPD, 특발성 폐 섬유증, 신장 이식 실패, 간 섬유증, 골질량 손실, 심근 경색, 사르코페니아, 상처 치유, 탈모증, 심근세포 비대, 골관절염, 파킨슨 질환, 연령-연관 폐 조직 탄성 손실, 연령-관련 황반 변성, 악액질, 사구체경화증, 간 경변증, NAFLD, 골다공증, 근위축성 측삭 경화증, 헌팅턴 질환, 척수소뇌 실조증, 다발성 경화증, 신경퇴행, 뇌졸중, 혈관 뇌 장벽 장애, 암, 치매, 혈관 질환, 감염 감수성, 만성 염증, 및 신장 기능장애로 이루어진 군으로부터 선택되는, 방법.
- 제103항에 있어서, 상기 노화-관련 질환은 고형 종양, 혈액학적 종양, 육종, 골육종, 교모세포종, 신경모세포종, 흑색종, 횡문근육종, 유잉 육종, 골육종, B-세포 신생물, 다발성 골수종, B-세포 림프종, B-세포 비-호지킨 림프종, 호지킨 림프종, 만성 림프구성 백혈병(CLL), 급성 골수성 백혈병(AML), 만성 골수성 백혈병(CML), 급성 림프구성 백혈병(ALL), 골수이형성 증후군(MDS), 피부 T-세포 림프종, 망막모세포종, 위암, 요로상피세포암종, 폐암, 신세포 암종, 위 및 식도 암, 췌장암, 전립선암, 유방암, 결장직장암, 난소암, 비-소세포 폐 암종, 편평 세포 두경부 암종, 자궁내막암, 자궁경부암, 간암, 및 간세포 암종으로 이루어진 군으로부터 선택되는 암인, 방법.
- 제103항에 있어서, 상기 염증성 질환은 류마티스 관절염, 염증성 장 질환, 홍반성 루푸스, 루푸스 신염, 당뇨병성 신증, CNS 손상, 알츠하이머 질환, 파킨슨 질환, 근위축성 측삭 경화증, 크론 질환, 다발성 경화증, 길랑-바레 증후군, 건선, 그레이브스 질환, 궤양성 대장염, 비알코올성 지방간염, 기분 장애 및 암 치료-관련 인지 장애로 이루어진 군으로부터 선택되는, 방법.
- 제98항 내지 제107항 중 어느 한 항에 있어서, 상기 치료-유도 노쇠 세포는 화학요법-유도 노쇠 세포인, 방법.
- 제98항 내지 제108항 중 어느 한 항에 있어서, 상기 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)의 투여는 대상체의 표적 조직에서 천연-발생 노쇠 세포 및/또는 치료-유도 노쇠 세포의 수의 저하를 초래하는, 방법.
- 제109항에 있어서, 상기 표적 조직은 지방 조직, 췌장 조직, 간 조직, 신장 조직, 폐 조직, 심장 조직, 혈관 구조, 뼈 조직, 중추신경계(CNS) 조직, 안구 조직, 피부 조직, 근육 조직, 및 2차 림프-기관 조직으로 이루어진 군으로부터 선택되는, 방법.
- 제98항 내지 제110항 중 어느 한 항에 있어서, 상기 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들) 중 적어도 하나는 공통 감마-사슬 계열 사이토카인 또는 이의 기능성 단편과 상기 공통 감마-사슬 계열 사이토카인 또는 이의 기능성 단편에 특이적으로 결합하는 항체 또는 항체 단편의 복합체인, 방법.
- 제98항 내지 제110항 중 어느 한 항에 있어서, 상기 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들) 중 적어도 하나는
(i) 제1 표적-결합 도메인;
(ii) 가용성 조직 인자 도메인; 및
(iii) 제2 표적-결합 도메인을 포함하는 단일-사슬 키메라 폴리펩타이드이고,
상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 공통 감마-사슬 계열 사이토카인, 공통 감마-사슬 계열 사이토카인 수용체에 특이적으로 결합하는 작용제성 항원-결합 도메인, 가용성 공통 감마-사슬 계열 사이토카인 수용체, 또는 공통 감마-사슬 계열 사이토카인에 특이적으로 결합하는 항원-결합 도메인인, 방법. - 제112항에 있어서, 상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 공통 감마-사슬 계열 사이토카인을 포함하는, 방법.
- 제113항에 있어서, 상기 가용성 공통 감마-사슬 계열 사이토카인은 가용성 IL-2, 가용성 IL-4, 가용성 IL-7, 가용성 IL-9, 가용성 IL-15, 및 가용성 IL-21로 이루어진 군으로부터 선택되는, 방법.
- 제114항에 있어서, 상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 공통 감마-사슬 계열 사이토카인 수용체에 특이적으로 결합하는 작용제성 항원-결합 도메인을 포함하는, 방법.
- 제115항에 있어서, 상기 공통 감마-사슬 계열 사이토카인 수용체는 IL-2, IL-4, IL-7, IL-9, IL-15, 및 IL-21 중 하나 이상에 대한 수용체인, 방법.
- 제115항 또는 제116항에 있어서, 상기 작용제성 항원-결합 도메인은 scFv, VHH, 또는 VNAR인, 방법.
- 제112항 내지 제117항 중 어느 한 항에 있어서, 상기 제1 표적-결합 도메인과 상기 가용성 조직 인자 도메인은 서로 직접적으로 인접해 있는, 방법.
- 제112항 내지 제117항 중 어느 한 항에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
- 제112항 내지 제119항 중 어느 한 항에 있어서, 상기 가용성 조직 인자 도메인과 상기 제2 표적-결합 도메인은 서로 직접적으로 인접해 있는, 방법.
- 제112항 내지 제119항 중 어느 한 항에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 가용성 조직 인자 도메인과 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
- 제112항 내지 제121항 중 어느 한 항에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 항원에 특이적으로 결합하는, 방법.
- 제122항에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 에피토프에 특이적으로 결합하는, 방법.
- 제123항에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 아미노산 서열을 포함하는, 방법.
- 제112항 내지 제121항 중 어느 한 항에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 상이한 항원에 특이적으로 결합하는, 방법.
- 제112항 내지 제125항 중 어느 한 항에 있어서, 상기 가용성 조직 인자 도메인은 가용성 인간 조직 인자 도메인인, 방법.
- 제126항에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 80% 동일한 서열을 포함하는, 방법.
- 제112항 내지 제127항 중 어느 한 항에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 이의 N-말단 및/또는 C-말단에 하나 이상의 추가 표적-결합 도메인을 추가로 포함하는, 방법.
- 제98항 내지 제110항 중 어느 한 항에 있어서, 상기 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들) 중 적어도 하나는
(a) 제1 키메라 폴리펩타이드로서,
(i) 제1 표적-결합 도메인;
(ii) 가용성 조직 인자 도메인; 및
(iii) 친화도 도메인 쌍의 제1 도메인을 포함하는, 제1 키메라 폴리펩타이드; 및
(b) 제2 키메라 폴리펩타이드로서,
(i) 친화도 도메인 쌍의 제2 도메인; 및
(ii) 제2 표적-결합 도메인을 포함하는, 제2 키메라 폴리펩타이드를 포함하는 다중-사슬 키메라 폴리펩타이드이고,
상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 공통 감마-사슬 계열 사이토카인, 공통 감마-사슬 계열 사이토카인 수용체에 특이적으로 결합하는 작용제성 항원-결합 도메인, 가용성 공통 감마-사슬 계열 사이토카인 수용체, 또는 공통 감마-사슬 계열 사이토카인에 특이적으로 결합하는 항원-결합 도메인인, 방법. - 제129항에 있어서, 상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 가용성 공통 감마-사슬 계열 사이토카인을 포함하는, 방법.
- 제130항에 있어서, 상기 가용성 공통 감마-사슬 계열 사이토카인은 가용성 IL-2, 가용성 IL-4, 가용성 IL-7, 가용성 IL-9, 가용성 IL-15, 및 가용성 IL-21로 이루어진 군으로부터 선택되는, 방법.
- 제129항에 있어서, 상기 제1 표적-결합 도메인 및 제2 표적-결합 도메인 중 하나 또는 둘 다는 공통 감마-사슬 계열 사이토카인 수용체에 특이적으로 결합하는 작용제성 항원-결합 도메인을 포함하는, 방법.
- 제132항에 있어서, 상기 공통 감마-사슬 계열 사이토카인 수용체는 IL-2, IL-4, IL-7, IL-9, IL-15, 및 IL-21 중 하나 이상에 대한 수용체인, 방법.
- 제132항 또는 제133항에 있어서, 상기 작용제성 항원-결합 도메인은 scFv, VHH, 또는 VNAR인, 방법.
- 제129항 내지 제134항 중 어느 한 항에 있어서, 상기 제1 표적-결합 도메인과 상기 가용성 조직 인자 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 방법.
- 제129항 내지 제134항 중 어느 한 항에 있어서, 상기 제1 키메라 폴리펩타이드는 제1 키메라 폴리펩타이드에서 제1 표적-결합 도메인과 가용성 조직 인자 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
- 제129항 내지 제136항 중 어느 한 항에 있어서, 상기 가용성 조직 인자 도메인과 상기 친화도 도메인 쌍의 제1 도메인은 제1 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 방법.
- 제129항 내지 제136항 중 어느 한 항에 있어서, 상기 제1 키메라 폴리펩타이드는 제1 키메라 폴리펩타이드에서 가용성 조직 인자 도메인과 친화도 도메인 쌍의 제1 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
- 제129항 내지 제138항 중 어느 한 항에 있어서, 상기 친화도 도메인 쌍의 제2 도메인과 상기 제2 표적-결합 도메인은 제2 키메라 폴리펩타이드에서 서로 직접적으로 인접해 있는, 방법.
- 제129항 내지 제138항 중 어느 한 항에 있어서, 상기 제2 키메라 폴리펩타이드는 제2 키메라 폴리펩타이드에서 친화도 도메인 쌍의 제2 도메인과 제2 표적-결합 도메인 사이에 링커 서열을 추가로 포함하는, 방법.
- 제129항 내지 제140항 중 어느 한 항에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 동일한 항원에 특이적으로 결합하는, 방법.
- 제129항 내지 제140항 중 어느 한 항에 있어서, 상기 제1 표적-결합 도메인 및 상기 제2 표적-결합 도메인은 상이한 항원에 특이적으로 결합하는, 방법.
- 제129항 내지 제142항 중 어느 한 항에 있어서, 상기 제1 키메라 폴리펩타이드는 하나 이상의 추가 표적-결합 도메인(들)을 추가로 포함하는, 방법.
- 제129항 내지 제143항 중 어느 한 항에 있어서, 상기 제2 키메라 폴리펩타이드는 하나 이상의 추가 표적-결합 도메인을 추가로 포함하는, 방법.
- 제129항 내지 제144항 중 어느 한 항에 있어서, 상기 가용성 조직 인자 도메인은 가용성 인간 조직 인자 도메인인, 방법.
- 제145항에 있어서, 상기 가용성 인간 조직 인자 도메인은 SEQ ID NO: 93과 적어도 80% 동일한 서열을 포함하는, 방법.
- 제129항 내지 제146항 중 어느 한 항에 있어서, 상기 친화도 도메인 쌍은 인간 IL-15 수용체의 알파 사슬(IL15Rα) 및 가용성 IL-15로부터의 sushi 도메인인, 방법.
- 제129항 내지 제146항 중 어느 한 항에 있어서, 상기 친화도 도메인 쌍은 하기로 이루어진 군으로부터 선택되는, 방법: 바르나제와 바른스타, PKA와 AKAP, 돌연변이화된 RNase I 단편에 기초한 어댑터/도킹 태그 모듈, 및 단백질 신택신, 시냅토태그민, 시냅토브레빈, 및 SNAP25의 상호작용에 기초한 SNARE 모듈.
- 제129항 내지 제146항 중 어느 한 항에 있어서, 상기 친화도 도메인 쌍의 제1 도메인 또는 제2 도메인은 공통 감마-사슬 계열 사이토카인 수용체에 특이적으로 결합하는 가용성 공통 감마-사슬 계열 사이토카인 또는 항원-결합 도메인인, 방법.
- 제98항 내지 제110항 중 어느 한 항에 있어서, 상기 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들) 중 적어도 하나는 가용성 IL-15 또는 IL-15 작용제인, 방법.
- 제150항에 있어서, 상기 가용성 IL-15는 SEQ ID NO: 82와 적어도 90% 동일한, 방법.
- 제150항에 있어서, 상기 IL-15 작용제는 IL-15와 가용성 IL-15 수용체(IL-15R)의 전부 또는 일부의 복합체인, 방법.
- 제152항에 있어서, 상기 가용성 IL-15R의 일부는 IL-15Rα의 일부인, 방법.
- 제153항에 있어서, 상기 가용성 IL-15Rα의 일부는 IL-15Rα의 sushi 도메인인, 방법.
- 제152항 내지 제154항 중 어느 한 항에 있어서, 상기 IL-15 작용제는 Fc 도메인을 추가로 포함하는, 방법.
- 제150항에 있어서, 상기 IL-15 작용제는 IL-15와 IL-15Rα로부터의 sushi 도메인을 포함하는 융합 단백질을 포함하는, 방법.
- 제98항 내지 제110항 중 어느 한 항에 있어서, 상기 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들) 중 하나는 가용성 IL-2 또는 IL-2 작용제인, 방법.
- 제98항 내지 제110항 중 어느 한 항에 있어서, 상기 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들) 중 하나는 공통 감마-사슬 계열 사이토카인에 특이적으로 결합하는 항체 또는 항원-결합 단편인, 방법.
- 제98항 내지 제158항 중 어느 한 항에 있어서, 대상체에게 1개, 2개 또는 그 이상의 용량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)를 투여하는 단계를 포함하는, 방법.
- 제159항에 있어서, 상기 2개 이상의 용량 중 임의의 2개의 연속 용량은 약 1주 내지 약 1년의 간격을 두고 투여되는, 방법.
- 제160항에 있어서, 상기 2개 이상의 용량 중 임의의 2개의 연속 용량은 약 1주 내지 약 6개월의 간격을 두고 투여되는, 방법.
- 제161항에 있어서, 상기 2개 이상의 용량 중 임의의 2개의 연속 용량은 약 1주 내지 약 2개월의 간격을 두고 투여되는, 방법.
- 제162항에 있어서, 상기 2개 이상의 용량 중 임의의 2개의 연속 용량은 약 1주 내지 약 1개월의 간격을 두고 투여되는, 방법.
- 제159항 내지 제163항 중 어느 한 항에 있어서, 상기 1개, 2개 이상의 용량은 피하 투여에 의해 투여되는, 방법.
- 제159항 내지 제163항 중 어느 한 항에 있어서, 상기 2개 이상의 용량은 근육내 투여에 의해 투여되는, 방법.
- 제159항 내지 제165항 중 어느 한 항에 있어서, 상기 2개 이상의 용량은 약 1년 내지 약 60년의 기간에 걸쳐 투여되는, 방법.
- 제166항에 있어서, 상기 2개 이상의 용량은 약 1년 내지 약 50년의 기간에 걸쳐 투여되는, 방법.
- 제167항에 있어서, 상기 2개 이상의 용량은 약 1년 내지 약 40년의 기간에 걸쳐 투여되는, 방법.
- 제168항에 있어서, 상기 2개 이상의 용량은 약 1년 내지 약 30년의 기간에 걸쳐 투여되는, 방법.
- 제169항에 있어서, 상기 2개 이상의 용량은 약 1년 내지 약 20년의 기간에 걸쳐 투여되는, 방법.
- 제170항에 있어서, 상기 2개 이상의 용량은 약 1년 내지 약 10년의 기간에 걸쳐 투여되는, 방법.
- 제98항 내지 제171항 중 어느 한 항에 있어서, 상기 2개 이상의 용량은 각각 kg당 약 0.01 mg의 각각의 공통 감마-사슬 계열 사이토카인 수용체 활성화제 내지 kg당 약 10 mg의 각각의 공통 감마-사슬 계열 사이토카인 수용체 활성화제의 투여량으로 투여되는, 방법.
- 제172항에 있어서, 상기 2개 이상의 용량은 각각 kg당 약 0.02 mg의 각각의 공통 감마-사슬 계열 사이토카인 수용체 활성화제 내지 kg당 약 5 mg의 각각의 공통 감마-사슬 계열 사이토카인 수용체 활성화제의 투여량으로 투여되는, 방법.
- 제98항 내지 제173항 중 어느 한 항에 있어서, 제1 용량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)는 대상체가 적어도 30세의 연령에 도달할 때 시작하는, 방법.
- 제174항에 있어서, 제1 용량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)는 대상체가 적어도 40세의 연령에 도달할 때 시작하는, 방법.
- 제175항에 있어서, 제1 용량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)는 대상체가 적어도 50세의 연령에 도달할 때 시작하는, 방법.
- 제176항에 있어서, 제1 용량의 하나 이상의 공통 감마-사슬 계열 사이토카인 수용체 활성화제(들)는 대상체가 적어도 60세의 연령에 도달할 때 시작하는, 방법.
- 제98항 내지 제102항 및 제108항 내지 제177항 중 어느 한 항에 있어서, 상기 대상체는 노화-관련 질환 또는 염증성 질환을 갖는 것으로 진단되거나 식별되지 않는, 방법.
- 제98항 내지 제102항 및 제108항 내지 제178항 중 어느 한 항에 있어서, 상기 대상체는 이전에 화학요법제로 치료된 적이 없는, 방법.
- 제98항 내지 제102항 및 제108항 내지 제178항 중 어느 한 항에 있어서, 상기 대상체는 이전에 세포 노쇠를 유도하는 치료제로 치료된 적이 없는, 방법.
- 제98항 내지 제180항 중 어느 한 항에 있어서, 대상체에게 TGF-β 수용체의 활성화의 저하를 초래하는 적어도 하나 이상의 제제(들)를 투여하는 단계를 추가로 포함하는, 방법.
- 제181항에 있어서, TGF-β 수용체의 활성화의 저하를 초래하는 하나 이상의 제제(들) 중 적어도 하나는 가용성 TGF-β 수용체, TGF-β 수용체의 세포외 도메인, TGF-β에 특이적으로 결합하는 항체, TGF-β 수용체에 결합하는 길항제성 항체, LAP에 결합하는 제제, 또는 TGF-β/LAP 복합체에 결합하는 제제인, 방법.
- 제182항에 있어서, TGF-β의 활성화의 저하를 초래하는 하나 이상의 제제(들)는 LAP에의 또는 TGF-β/LAP 복합체에의 결합을 통해 TGF-β 수용체의 활성화를 저하시키는, 방법.
- 제31항, 제32항, 제64항, 제65항, 제126항, 제127항, 제145항, 및 제146항 중 어느 한 항에 있어서, 상기 가용성 인간 조직 인자 도메인은 혈액 응고를 개시하지 않는, 방법.
- 제1항 내지 제184항 중 어느 한 항에 있어서, 관문 저해제, 화학요법 약물, 및 치료 항체와 같은 제제들의 조합의 군으로부터 선택되는 추가 치료제를 투여하는 단계를 추가로 포함하는, 방법.
- 제55항 내지 제75항 중 어느 한 항에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 37°C에서 적어도 10일 동안 인간 혈청에서 안정한, 방법.
- 제18항 내지 제54항 중 어느 한 항에 있어서, 상기 다중-사슬 키메라 폴리펩타이드는 37°C에서 적어도 10일 동안 인간 혈청에서 안정한, 방법.
- 제112항 내지 제128항 중 어느 한 항에 있어서, 상기 단일-사슬 키메라 폴리펩타이드는 유의한 응고(clotting) 활성을 갖지 않는, 방법.
- 제129항 내지 제149항 중 어느 한 항에 있어서, 상기 다중-사슬 키메라 폴리펩타이드는 유의한 응고 활성을 갖지 않는, 방법.
- 제1항 내지 제189항 중 어느 한 항에 있어서, 상기 대상체에서 노화 면역 세포의 회춘(rejuvenation)을 초래하는, 방법.
- 제190항에 있어서, 상기 노화 면역 세포의 회춘은 대상체에서 유병 세포 또는 병원성 감염체의 수의 감소를 초래하는, 방법.
- 제190항 또는 제191항에 있어서, 상기 노화 면역 세포는 노화 NK 세포, 노화 NKT 세포, 노화 T 세포, 노화 B 세포, 노화 단핵구, 노화 대식세포, 노화 호중구, 노화 호염기구, 노화 호산구, 노화 쿠퍼 세포, 및 노화 소교 세포 중 하나 이상을 포함하는, 방법.
- 제191항에 있어서, 상기 유병 세포는 암세포, 바이러스-감염 세포, 및 세포내-박테리아-감염 세포를 포함하는, 방법.
- 제191항에 있어서, 상기 감염성 병원체는 바이러스, 박테리아, 진균류, 및 기생충을 포함하는, 방법.
Applications Claiming Priority (7)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US202063032933P | 2020-06-01 | 2020-06-01 | |
| PCT/US2020/035598 WO2021247003A1 (en) | 2020-06-01 | 2020-06-01 | Methods of treating aging-related disorders |
| USPCT/US2020/035598 | 2020-06-01 | ||
| US63/032,933 | 2020-06-01 | ||
| US202063118536P | 2020-11-25 | 2020-11-25 | |
| US63/118,536 | 2020-11-25 | ||
| PCT/US2021/035285 WO2021247604A1 (en) | 2020-06-01 | 2021-06-01 | Methods of treating aging-related disorders |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20230031280A true KR20230031280A (ko) | 2023-03-07 |
Family
ID=76523519
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020237000057A KR20230031280A (ko) | 2020-06-01 | 2021-06-01 | 노화 관련 장애의 치료 방법 |
Country Status (7)
| Country | Link |
|---|---|
| EP (1) | EP4157460A1 (ko) |
| JP (1) | JP2023527869A (ko) |
| KR (1) | KR20230031280A (ko) |
| AU (1) | AU2021283199A1 (ko) |
| CA (1) | CA3184756A1 (ko) |
| IL (1) | IL298608A (ko) |
| WO (1) | WO2021247604A1 (ko) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20240046887A (ko) * | 2021-08-11 | 2024-04-11 | 에이치씨더블유 바이올로직스, 인크. | 다중-사슬 키메라 폴리펩타이드 및 간 질환의 치료에 있어서 이의 용도 |
| WO2023168363A1 (en) * | 2022-03-02 | 2023-09-07 | HCW Biologics, Inc. | Method of treating pancreatic cancer |
Family Cites Families (65)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB9324807D0 (en) | 1993-12-03 | 1994-01-19 | Cancer Res Campaign Tech | Tumour antibody |
| US6117980A (en) | 1997-02-21 | 2000-09-12 | Genentech, Inc. | Humanized anti-IL-8 monoclonal antibodies |
| JP2001206899A (ja) | 1999-11-18 | 2001-07-31 | Japan Tobacco Inc | TGF−βII型受容体に対するヒトモノクローナル抗体及びその医薬用途 |
| US7723482B2 (en) | 2000-12-26 | 2010-05-25 | Institut National De La Sante Et De La Recherche Medicale (Inserm) | Anti-CD28 antibody |
| AU2003239197A1 (en) | 2002-06-07 | 2003-12-22 | The Government Of The United States Of America, As Represented By The Secretary Of The Department Of | Novel stable anti-cd22 antibodies |
| EP1536012A4 (en) | 2002-08-30 | 2006-03-08 | Chemo Sero Therapeut Res Inst | HUMAN-TYPE ANTIHUMAN INTERLEUKIN-6 ANTIBODY ANTIBODY ANTIBODY FRAGMENT |
| EP1400534B1 (en) | 2002-09-10 | 2015-10-28 | Affimed GmbH | Human CD3-specific antibody with immunosuppressive properties |
| CN1753912B (zh) | 2002-12-23 | 2011-11-02 | 惠氏公司 | 抗pd-1抗体及其用途 |
| KR20060015482A (ko) | 2003-03-21 | 2006-02-17 | 와이어쓰 | 인터루킨-21/인터루킨-21 수용체의 작용제를 이용한면역장애의 치료 |
| US9005613B2 (en) | 2003-06-16 | 2015-04-14 | Immunomedics, Inc. | Anti-mucin antibodies for early detection and treatment of pancreatic cancer |
| NZ549040A (en) | 2004-02-17 | 2009-07-31 | Schering Corp | Use for interleukin-33 (IL33) and the IL-33 receptor complex |
| ES2375481T3 (es) | 2004-03-30 | 2012-03-01 | Yissum Research Development Company Of The Hebrew University Of Jerusalem | Anticuerpos biespecíficos para elegir como diana células que participan en reacciones de tipo alérgico, composiciones y usos de los mismos. |
| BRPI0608096A2 (pt) | 2005-04-26 | 2009-11-10 | Pfizer | anticorpos p-caderina |
| GB0510790D0 (en) | 2005-05-26 | 2005-06-29 | Syngenta Crop Protection Ag | Anti-CD16 binding molecules |
| US7612181B2 (en) | 2005-08-19 | 2009-11-03 | Abbott Laboratories | Dual variable domain immunoglobulin and uses thereof |
| US8092804B2 (en) | 2007-12-21 | 2012-01-10 | Medimmune Limited | Binding members for interleukin-4 receptor alpha (IL-4Rα)-173 |
| WO2009120922A2 (en) | 2008-03-27 | 2009-10-01 | Zymogenetics, Inc. | Compositions and methods for inhibiting pdgfrbeta and vegf-a |
| KR101671886B1 (ko) | 2008-06-25 | 2016-11-04 | 에스바테크 - 어 노바티스 컴파니 엘엘씨 | Vegf를 억제하는 안정하고 가용성인 항체 |
| WO2010006060A2 (en) | 2008-07-08 | 2010-01-14 | Abbott Laboratories | Prostaglandin e2 dual variable domain immunoglobulins and uses thereof |
| US9273136B2 (en) | 2008-08-04 | 2016-03-01 | The United States Of America, As Represented By The Secretary, Department Of Health And Human Services | Fully human anti-human NKG2D monoclonal antibodies |
| US8298533B2 (en) | 2008-11-07 | 2012-10-30 | Medimmune Limited | Antibodies to IL-1R1 |
| BRPI0917592B1 (pt) | 2008-12-09 | 2021-08-17 | Genentech, Inc | Anticorpo anti-pd-l1, composição, artigos manufaturados e usos de uma composição |
| EP2473524A4 (en) | 2009-09-01 | 2013-05-22 | Abbott Lab | IMMUNOGLOBULINE WITH DOUBLE VARIABLE DOMAIN AND ITS USE |
| DE102009045006A1 (de) | 2009-09-25 | 2011-04-14 | Technische Universität Dresden | Anti-CD33 Antikörper und ihre Anwendung zum Immunotargeting bei der Behandlung von CD33-assoziierten Erkrankungen |
| EP2488658A4 (en) | 2009-10-15 | 2013-06-19 | Abbvie Inc | IMMUNOGLOBULINE WITH DOUBLE VARIABLE DOMAIN AND ITS USE |
| UY32979A (es) | 2009-10-28 | 2011-02-28 | Abbott Lab | Inmunoglobulinas con dominio variable dual y usos de las mismas |
| AU2011215750A1 (en) | 2010-02-11 | 2012-08-23 | Alexion Pharmaceuticals, Inc. | Therapeutic methods using an ti-CD200 antibodies |
| CN102939305B (zh) | 2010-04-08 | 2016-08-17 | Jn生物科学有限责任公司 | 对cd122的抗体 |
| PL2581113T3 (pl) | 2010-06-11 | 2018-11-30 | Kyowa Hakko Kirin Co., Ltd. | Przeciwciało anty-tim-3 |
| EP3252072A3 (en) | 2010-08-03 | 2018-03-14 | AbbVie Inc. | Dual variable domain immunoglobulins and uses thereof |
| JP2012034668A (ja) | 2010-08-12 | 2012-02-23 | Tohoku Univ | ヒト型化抗egfr抗体リジン置換可変領域断片及びその利用 |
| GB201103955D0 (en) | 2011-03-09 | 2011-04-20 | Antitope Ltd | Antibodies |
| KR101517320B1 (ko) | 2011-04-19 | 2015-05-28 | 메리맥 파마슈티컬즈, 인크. | 단일특이적 및 이중특이적 항-igf-1r 및 항 erbb3 항체 |
| RU2668170C2 (ru) | 2011-04-25 | 2018-09-26 | Дайити Санкио Компани, Лимитед | Анти-в7-н3-антитело |
| CA2837184C (en) | 2011-05-25 | 2021-09-21 | Innate Pharma, S.A. | Anti-kir antibodies for the treatment of inflammatory and autoimmune disorders |
| US8753640B2 (en) | 2011-05-31 | 2014-06-17 | University Of Washington Through Its Center For Commercialization | MIC-binding antibodies and methods of use thereof |
| WO2012170470A1 (en) | 2011-06-06 | 2012-12-13 | Board Of Regents Of The University Of Nebraska | Compositions and methods for detection and treatment of cancer |
| JP6120833B2 (ja) | 2011-06-22 | 2017-04-26 | インサーム(インスティテュ ナシオナル ドゥ ラ サンテ エ ドゥ ラ ルシェルシェ メディカル)Inserm(Institut National Dela Sante Et De La Recherche Medicale) | 抗Axl抗体及びその使用 |
| EP2776470A2 (en) | 2011-11-11 | 2014-09-17 | Rinat Neuroscience Corporation | Antibodies specific for trop-2 and their uses |
| KR101535341B1 (ko) | 2012-07-02 | 2015-07-13 | 한화케미칼 주식회사 | Dll4에 특이적으로 결합하는 신규한 단일클론항체 및 이의 용도 |
| BR112015002085A2 (pt) | 2012-08-08 | 2017-12-19 | Roche Glycart Ag | proteína, polinucleotídeo, vetor, célula hospedeira, método para produzir a proteína, composição farmacêutica, uso da proteína, método de tratamento e invenção |
| WO2014026054A2 (en) | 2012-08-10 | 2014-02-13 | University Of Southern California | CD20 scFv-ELPs METHODS AND THERAPEUTICS |
| EP2890713A1 (en) | 2012-08-28 | 2015-07-08 | Institut Curie | Cluster of differentiation 36 (cd36) as a therapeutic target for hiv infection |
| JP6324399B2 (ja) | 2012-11-20 | 2018-05-16 | サノフイ | 抗ceacam5抗体およびその使用 |
| ES2895848T3 (es) | 2012-12-17 | 2022-02-22 | Cell Medica Inc | Anticuerpos contra IL-1 beta |
| WO2014130635A1 (en) | 2013-02-20 | 2014-08-28 | Novartis Ag | Effective targeting of primary human leukemia using anti-cd123 chimeric antigen receptor engineered t cells |
| US9790274B2 (en) | 2013-03-14 | 2017-10-17 | The Board Of Regents Of The University Of Texas System | Monoclonal antibodies targeting EpCAM for detection of prostate cancer lymph node metastases |
| SG11201509609SA (en) | 2013-05-24 | 2015-12-30 | Univ Texas | Chimeric antigen receptor-targeting monoclonal antibodies |
| KR102127408B1 (ko) | 2014-01-29 | 2020-06-29 | 삼성전자주식회사 | 항 Her3 scFv 단편 및 이를 포함하는 항 c-Met/항 Her3 이중 특이 항체 |
| JOP20200096A1 (ar) | 2014-01-31 | 2017-06-16 | Children’S Medical Center Corp | جزيئات جسم مضاد لـ tim-3 واستخداماتها |
| FR3021970B1 (fr) | 2014-06-06 | 2018-01-26 | Universite Sciences Technologies Lille | Anticorps dirige contre la galectine 9 et inhibiteur de l'activite suppressive des lymphocytes t regulateurs |
| AP2017009765A0 (en) | 2014-08-19 | 2017-02-28 | Merck Sharp & Dohme | Anti-tigit antibodies |
| ES2862701T3 (es) | 2014-12-22 | 2021-10-07 | Univ Rockefeller | Anticuerpos agonistas anti-MERTK y usos de los mismos |
| US10744157B2 (en) | 2015-03-26 | 2020-08-18 | The Trustees Of Dartmouth College | Anti-MICA antigen binding fragments, fusion molecules, cells which express and methods of using |
| CN108064245A (zh) | 2015-04-17 | 2018-05-22 | 埃尔萨里斯生物技术公司 | 抗Tyro3抗体及其用途 |
| CN115925939A (zh) | 2015-08-06 | 2023-04-07 | 新加坡科技研究局 | IL2Rβ/通用γ链抗体 |
| CN108290946B (zh) | 2015-09-25 | 2021-09-28 | 豪夫迈·罗氏有限公司 | 抗tigit抗体和使用方法 |
| CA3004148A1 (en) | 2015-11-13 | 2017-05-18 | Dana-Farber Cancer Institute, Inc. | An nkg2d-ig fusion protein for cancer immunotherapy |
| EP4043492A1 (en) | 2016-03-01 | 2022-08-17 | Yissum Research Development Company of the Hebrew University of Jerusalem Ltd. | Antibodies specific to human poliovirus receptor (pvr) |
| WO2017189526A1 (en) | 2016-04-25 | 2017-11-02 | Musc Foundation For Research Development | Activated cd26-high immune cells and cd26-negative immune cells and uses thereof |
| CA3048660A1 (en) * | 2017-01-03 | 2018-07-12 | Bioatla, Llc | Protein therapeutics for treatment of senescent cells |
| EP3676289A4 (en) * | 2017-08-28 | 2021-05-05 | Altor Bioscience LLC | IL-15 BASED FUSIONS TO IL-7 AND IL-21 |
| WO2020047462A2 (en) * | 2018-08-30 | 2020-03-05 | HCW Biologics, Inc. | Methods of treating aging-related disorders |
| AU2019328313A1 (en) * | 2018-08-30 | 2021-02-25 | HCW Biologics, Inc. | Single-chain chimeric polypeptides and uses thereof |
| JP7397874B2 (ja) * | 2018-08-30 | 2023-12-13 | エイチシーダブリュー バイオロジックス インコーポレイテッド | 多鎖キメラポリペプチドおよびその使用 |
-
2021
- 2021-06-01 CA CA3184756A patent/CA3184756A1/en active Pending
- 2021-06-01 WO PCT/US2021/035285 patent/WO2021247604A1/en unknown
- 2021-06-01 KR KR1020237000057A patent/KR20230031280A/ko unknown
- 2021-06-01 AU AU2021283199A patent/AU2021283199A1/en active Pending
- 2021-06-01 JP JP2022573633A patent/JP2023527869A/ja active Pending
- 2021-06-01 EP EP21733685.8A patent/EP4157460A1/en active Pending
- 2021-06-01 IL IL298608A patent/IL298608A/en unknown
Also Published As
| Publication number | Publication date |
|---|---|
| WO2021247604A1 (en) | 2021-12-09 |
| IL298608A (en) | 2023-01-01 |
| EP4157460A1 (en) | 2023-04-05 |
| AU2021283199A1 (en) | 2023-01-05 |
| CA3184756A1 (en) | 2021-12-09 |
| JP2023527869A (ja) | 2023-06-30 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11672826B2 (en) | Methods of treating aging-related disorders | |
| JP7189860B2 (ja) | ヒト化抗EGFRvIIIキメラ抗原受容体を用いたがんの処置 | |
| KR20200086278A (ko) | 선택적 단백질 분해를 위한 조성물 및 방법 | |
| RU2724999C2 (ru) | Химерный антигенный рецептор (car) против cd123 для использования в лечении злокачественных опухолей | |
| US20200283729A1 (en) | Treatment of cancer using chimeric antigen receptor | |
| KR20200096253A (ko) | Bcma-표적화 키메라 항원 수용체, 및 이의 용도 | |
| KR102612313B1 (ko) | 인간화 항-bcma 키메라 항원 수용체를 사용한 암의 치료 | |
| KR20200089285A (ko) | Bcma-표적화 키메라 항원 수용체, cd19-표적화 키메라 항원 수용체, 및 병용 요법 | |
| KR20210020932A (ko) | Bcma 키메라 항원 수용체 및 이의 용도 | |
| US20220073578A1 (en) | Methods of treating aging-related disorders | |
| TW202340473A (zh) | 利用嵌合抗原受體之癌症治療 | |
| CN113365660A (zh) | 对受体酪氨酸激酶样孤儿受体1(ror1)具特异性的抗体及嵌合抗原受体 | |
| JP2021522786A (ja) | インターロイキン15融合タンパク質、およびその組成物ならびに治療方法 | |
| KR20170132859A (ko) | 암 치료를 위한 fgfr/pd-1 조합 요법 | |
| US20230131056A1 (en) | sPD-1 VARIANT – FC FUSION PROTEINS | |
| KR20230031280A (ko) | 노화 관련 장애의 치료 방법 | |
| KR20210132668A (ko) | 인공 면역감시 키메라 항원 수용체(ai-car) 및 이를 발현하는 세포 | |
| CN113710697A (zh) | 嵌合衔接子和激酶信号传导蛋白及其在免疫疗法中的用途 | |
| KR20230160242A (ko) | 림프구 표적화된 렌티바이러스 벡터 | |
| KR20230024967A (ko) | Zbtb32 억제제 및 이의 용도 | |
| CN114729026A (zh) | 用于稳定免疫突触的嵌合抗原受体(car)t细胞 | |
| Giordano Attianese et al. | Coengineering specificity, safety, and function into T cells for cancer immunotherapy | |
| CN112204048A (zh) | 抗cct5结合分子及其使用方法 | |
| TWI819352B (zh) | 包含il-12及抗fap抗體的融合蛋白及其用途 | |
| WO2021247003A1 (en) | Methods of treating aging-related disorders |